
Upload 5 files
Browse files- CLIP.png +0 -0
- app.py +71 -0
- example_speed.txt +1 -0
- generate.py +25 -0
CLIP.png
ADDED
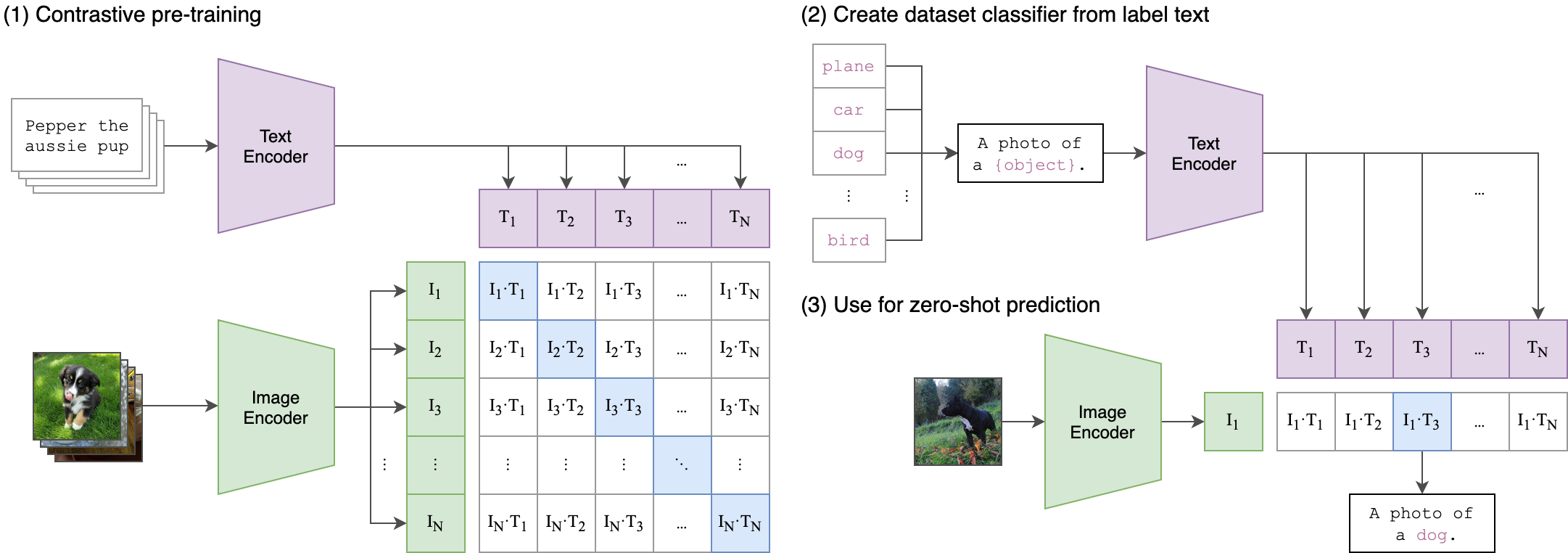
|
app.py
ADDED
|
@@ -0,0 +1,71 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import torch
|
| 3 |
+
import clip
|
| 4 |
+
from PIL import Image
|
| 5 |
+
import numpy as np
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
# Load CLIP model and preprocessing
|
| 9 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 10 |
+
model, preprocess = clip.load("ViT-B/32", device=device)
|
| 11 |
+
|
| 12 |
+
# Function to predict descriptions and probabilities
|
| 13 |
+
def predict(image, descriptions):
|
| 14 |
+
image = preprocess(image).unsqueeze(0).to(device)
|
| 15 |
+
text = clip.tokenize(descriptions).to(device)
|
| 16 |
+
|
| 17 |
+
with torch.no_grad():
|
| 18 |
+
image_features = model.encode_image(image)
|
| 19 |
+
text_features = model.encode_text(text)
|
| 20 |
+
|
| 21 |
+
logits_per_image, logits_per_text = model(image, text)
|
| 22 |
+
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
|
| 23 |
+
|
| 24 |
+
return descriptions[np.argmax(probs)], np.max(probs)
|
| 25 |
+
|
| 26 |
+
# Streamlit app
|
| 27 |
+
def main():
|
| 28 |
+
st.title("Image Understanding Model Test")
|
| 29 |
+
|
| 30 |
+
# Instructions for the user
|
| 31 |
+
st.markdown("---")
|
| 32 |
+
st.markdown("### Upload an Image to Test How Well the Model Understands It")
|
| 33 |
+
|
| 34 |
+
# Upload image through Streamlit with a unique key
|
| 35 |
+
uploaded_image = st.file_uploader("Upload an image...", type=["jpg", "png", "jpeg"], key="uploaded_image")
|
| 36 |
+
|
| 37 |
+
if uploaded_image is not None:
|
| 38 |
+
# Convert the uploaded image to PIL Image
|
| 39 |
+
pil_image = Image.open(uploaded_image)
|
| 40 |
+
|
| 41 |
+
# Limit the height of the displayed image to 400px
|
| 42 |
+
st.image(pil_image, caption="Uploaded Image.", use_column_width=True, width=200)
|
| 43 |
+
|
| 44 |
+
# Instructions for the user
|
| 45 |
+
st.markdown("### 2 Lies and 1 Truth")
|
| 46 |
+
st.markdown("Write 3 descriptions about the image, 1 must be true.")
|
| 47 |
+
|
| 48 |
+
# Get user input for descriptions
|
| 49 |
+
description1 = st.text_input("Description 1:", placeholder='A red apple')
|
| 50 |
+
description2 = st.text_input("Description 2:", placeholder='A car parked in a garage')
|
| 51 |
+
description3 = st.text_input("Description 3:", placeholder='An orange fruit on a tree')
|
| 52 |
+
|
| 53 |
+
descriptions = [description1, description2, description3]
|
| 54 |
+
|
| 55 |
+
# Button to trigger prediction
|
| 56 |
+
if st.button("Predict"):
|
| 57 |
+
if all(descriptions):
|
| 58 |
+
# Make predictions
|
| 59 |
+
best_description, best_prob = predict(pil_image, descriptions)
|
| 60 |
+
|
| 61 |
+
# Display the highest probability description and its probability
|
| 62 |
+
st.write(f"**Best Description:** {best_description}")
|
| 63 |
+
st.write(f"**Prediction Probability:** {best_prob:.2%}")
|
| 64 |
+
|
| 65 |
+
# Display progress bar for the highest probability
|
| 66 |
+
st.progress(float(best_prob))
|
| 67 |
+
else:
|
| 68 |
+
st.warning("Please provide all three descriptions.")
|
| 69 |
+
|
| 70 |
+
if __name__ == "__main__":
|
| 71 |
+
main()
|
example_speed.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
0.453
|
generate.py
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import time
|
| 3 |
+
import clip
|
| 4 |
+
from PIL import Image
|
| 5 |
+
|
| 6 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 7 |
+
model, preprocess = clip.load("ViT-B/32", device=device)
|
| 8 |
+
|
| 9 |
+
image = preprocess(Image.open("CLIP.png")).unsqueeze(0).to(device)
|
| 10 |
+
text = clip.tokenize(["a diagram", "a dog", "a cat"]).to(device)
|
| 11 |
+
|
| 12 |
+
start_time = time.time()
|
| 13 |
+
|
| 14 |
+
with torch.no_grad():
|
| 15 |
+
image_features = model.encode_image(image)
|
| 16 |
+
text_features = model.encode_text(text)
|
| 17 |
+
|
| 18 |
+
logits_per_image, logits_per_text = model(image, text)
|
| 19 |
+
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
|
| 20 |
+
|
| 21 |
+
end_time = time.time()
|
| 22 |
+
|
| 23 |
+
print("Label probs:", probs) # prints: [[0.9927937 0.00421068 0.00299572]]
|
| 24 |
+
|
| 25 |
+
print(f"Prediction time: {end_time - start_time} seconds")
|