Spaces:
Sleeping

Sleeping

modify app version
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- data/image_classification/class_accuracies.pkl +3 -0
- data/image_classification/diagonal.npy +3 -0
- data/image_classification/diagonal.pkl +3 -0
- data/image_classification/images/image1.jpg +0 -0
- data/image_classification/images/image2.jpg +0 -0
- data/image_classification/images/image3.jpg +0 -0
- data/image_classification/images/image4.jpg +0 -0
- data/image_classification/images/image5.jpg +0 -0
- data/image_classification/images/image6.jpg +0 -0
- data/image_classification/images/image7.jpg +0 -0
- data/image_classification/images/image8.jpg +0 -0
- data/image_classification/images/image9.jpg +0 -0
- data/image_classification/results.pkl +3 -0
- data/pinterest/image1.jpg +0 -0
- data/pinterest/image2.jpg +0 -0
- data/pinterest/image3.jpg +0 -0
- data/pinterest/image4.jpg +0 -0
- data/topic-modeling/data-tm-view.pkl +3 -0
- data/topic-modeling/similarity_topic_df.pkl +3 -0
- data/topic-modeling/similarity_topic_scores.npy +3 -0
- data/topic-modeling/topic_info.pkl +3 -0
- data/topic-modeling/topics_top_words.json +1 -0
- images/ML_domains.png +0 -0
- images/ML_header.jpg +0 -0
- images/brain_tumor.jpg +0 -0
- images/cnn_example.png +0 -0
- images/customer-churn.webp +0 -0
- images/e-commerce.jpg +0 -0
- images/fashion_ai.jpg +0 -0
- images/fashion_od.jpg +0 -0
- images/meningioma_tumor.png +0 -0
- images/no_tumor.png +0 -0
- images/od_header.jpg +0 -0
- images/pituitary.png +0 -0
- images/reviews.jpg +0 -0
- images/reviews.png +0 -0
- images/topic_modeling.gif +0 -0
- images/tumor_image.jpg +0 -0
- images/tumor_types_class.png +0 -0
- images/tumors_types_class.png +0 -0
- images/unsupervised_learner.webp +0 -0
- main_page.py +71 -20
- notebooks/Supervised-Unsupervised/supply_chain.ipynb +0 -55
- notebooks/energy_consumption.ipynb +11 -2
- notebooks/topic_modeling.ipynb +101 -0
- pages/image_classification.py +330 -0
- pages/object_detection.py +44 -18
- pages/recommendation_system.py +11 -5
- pages/sentiment_analysis.py +8 -5
- pages/supervised_unsupervised_page.py +13 -10
data/image_classification/class_accuracies.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b404d7c242ec04dea8a73b950670aee544791c4eafe19376888d0c21b78ecf6d
|
| 3 |
+
size 206
|
data/image_classification/diagonal.npy
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:092072623a33151cd67b60123fd4e5f8e81d464e772721c17e4fbf307e800be5
|
| 3 |
+
size 152
|
data/image_classification/diagonal.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:58b090912ec24da229e09882bfd7b13deef11eb1431b92ac0e9b4f2fab697a25
|
| 3 |
+
size 171
|
data/image_classification/images/image1.jpg
ADDED

|
data/image_classification/images/image2.jpg
ADDED

|
data/image_classification/images/image3.jpg
ADDED

|
data/image_classification/images/image4.jpg
ADDED
|
data/image_classification/images/image5.jpg
ADDED

|
data/image_classification/images/image6.jpg
ADDED

|
data/image_classification/images/image7.jpg
ADDED

|
data/image_classification/images/image8.jpg
ADDED

|
data/image_classification/images/image9.jpg
ADDED
|
data/image_classification/results.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0147d470ee6854e29a4d66577e820a3d76910c659c6c19ba09996d165385f2fb
|
| 3 |
+
size 796
|
data/pinterest/image1.jpg
DELETED
|
Binary file (82.5 kB)
|
|
|
data/pinterest/image2.jpg
DELETED
|
Binary file (84.4 kB)
|
|
|
data/pinterest/image3.jpg
DELETED
|
Binary file (113 kB)
|
|
|
data/pinterest/image4.jpg
DELETED
|
Binary file (13.9 kB)
|
|
|
data/topic-modeling/data-tm-view.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fcdfe682dc519405f991deb929d2e7bd197711ebd39d366204dc31540088bfe7
|
| 3 |
+
size 25643
|
data/topic-modeling/similarity_topic_df.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:56ffc20bf88f4794175504142c145f009c30882cc8f9a4a2bd6685565d7b1031
|
| 3 |
+
size 5702
|
data/topic-modeling/similarity_topic_scores.npy
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a0eae3be2576e7314e8972be092e5c983857b8630f72452656d5511161925ee0
|
| 3 |
+
size 1848
|
data/topic-modeling/topic_info.pkl
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b6641f3d3292ddf67301be1695a86d32dc1b4e50ce8300998a8f5ff4378006de
|
| 3 |
+
size 67773
|
data/topic-modeling/topics_top_words.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"Footwear": [["shoes", 0.38847787705376907], ["footwear", 0.35415016786395725], ["sole", 0.31010186887426383], ["heel", 0.3088388496929392], ["sandals", 0.3080144185111931]], "Stationery": [["poster", 0.4772449173738855], ["posters", 0.3532032467764592], ["paper", 0.33680800783349146], ["sticker", 0.32875394429105165], ["wall", 0.3267100065240568]], "Accessories": [["bag", 0.44865215755276705], ["bags", 0.34066237491127976], ["backpack", 0.32761906839012567], ["wallet", 0.3183404784655875], ["pouch", 0.3139648334711031]], "Casual Clothing": [["shirt", 0.4866213634648433], ["tshirt", 0.4388525801491516], ["cotton", 0.42030363825064176], ["hoodie", 0.3472116721637178], ["sweatshirt", 0.3252484971808718]], "Home Decor": [["bed", 0.3915837064596754], ["bedsheet", 0.3795293850199473], ["pillow", 0.3726331517956856], ["chair", 0.3620157706059908], ["cushion", 0.3371702503148896]], "Ethnic Wear": [["kurta", 0.5964118488674663], ["kurti", 0.46409279828742933], ["ethnic", 0.4271965752882015], ["lehenga", 0.35217693955328105], ["rayon", 0.32973478637750253]], "Kitchenware": [["food", 0.4053179773769792], ["baking", 0.36953324326216985], ["cooking", 0.33478563148016793], ["container", 0.33388107407524753], ["stainless", 0.328391980553913]], "Electronics": [["usb", 0.4370380638338913], ["remote", 0.3927290047743422], ["cable", 0.38592683873622896], ["battery", 0.37858979023970196], ["power", 0.35648534880129973]], "Mobile Accessories": [["multy", 0.8227986161311175], ["smartphone", 0.7174978731856773], ["sturdy", 0.614121692169791], ["designer", 0.6109682869843849], ["attractive", 0.6104716588340674]], "Toys and Games": [["toy", 0.49860348911927627], ["toys", 0.3988778432684865], ["kids", 0.3573877985545804], ["play", 0.32559893534296275], ["doll", 0.32138639583229955]], "Smartphone Cases": [["galaxy", 0.3735023765469636], ["samsung", 0.36692840942262006], ["tpu", 0.360454345644459], ["phone", 0.34470171090642315], ["case", 0.3323669244458833]], "Bathroom Essentials": [["towel", 0.47783909527995144], ["towels", 0.4756431172582276], ["bathroom", 0.45437940527046383], ["machine", 0.40002718019217415], ["washing", 0.39952622128733417]], "Fitness Apparel": [["shorts", 0.4030437177905839], ["yoga", 0.3508045282032731], ["fitness", 0.345809251125565], ["gym", 0.3372047840909218], ["exercise", 0.3255797401202898]], "Jewelry": [["beads", 0.5537295987387991], ["jewelry", 0.4715332431907011], ["necklace", 0.42530621186050926], ["sterling", 0.3859332057581718], ["jewellery", 0.37480366224575584]], "Tailoring": [["bust", 0.8067574906731596], ["length", 0.7507572954203788], ["hip", 0.7208533754339365], ["cuff", 0.6493257298350807], ["waist", 0.5680918306873547]], "Beauty Products": [["hair", 0.5233417349688945], ["skin", 0.49711579981104936], ["makeup", 0.4464886130813637], ["oil", 0.3695888525844108], ["powder", 0.33759452075830465]], "Automotive Parts": [["brake", 0.7679029085894177], ["ford", 0.538136002342594], ["caliper", 0.5149383886065275], ["rotors", 0.44156507901608216], ["remanufactured", 0.40996825453754265]], "Religious Items": [["pooja", 0.4592149148466313], ["puja", 0.440364978878493], ["ganesha", 0.4339401038570326], ["statue", 0.42572057559436643], ["lord", 0.4160582548834375]], "Rugs and Carpets": [["carpet", 0.7396822233119122], ["carpets", 0.6163891407029106], ["rug", 0.5466610489961798], ["pile", 0.4811751923719153], ["bedroomhall", 0.4774631207324265]], "Lighting": [["lamp", 0.572806507321936], ["lights", 0.5194199268441229], ["led", 0.4637118662205354], ["light", 0.42752197570640416], ["fog", 0.39030233935073244]], "Tools and Hardware": [["drill", 0.4090803554942639], ["wrench", 0.3887384996728029], ["brass", 0.37763561450770244], ["ratchet", 0.3576598563561437], ["welding", 0.34836291774213735]], "Gifts": [["gift", 0.49486738196492014], ["christmas", 0.4499909703416835], ["anniversary", 0.44211510176760416], ["birthday", 0.42329962363537077], ["holiday", 0.3769232700978505]], "Cups and Mugs": [["mug", 0.78550527496083], ["mugs", 0.6407372094776862], ["coffee", 0.5251853727580017], ["ceramic", 0.49068900003067073], ["microwave", 0.45930169018934874]], "Car Accessories": [["car", 0.5608807013030145], ["mats", 0.40243127224340647], ["vehicle", 0.32527312147968], ["mud", 0.3120217917532408], ["floor", 0.28639120838100274]], "Bicycles and Motorcycles": [["bike", 0.672669310609492], ["motorcycle", 0.45862702253497417], ["bicycle", 0.41604743198493005], ["wheeler", 0.4111806808042964], ["bikes", 0.40182534484285193]], "Eyewear": [["lens", 0.6347206656220337], ["sunglasses", 0.5827648990585392], ["lenses", 0.48591645135463507], ["glasses", 0.44000442658697553], ["vision", 0.35746121468648506]], "Gardening": [["plant", 0.5003258672377139], ["plants", 0.48132127991787405], ["flowers", 0.4775975182063175], ["pot", 0.45391275371608636], ["planter", 0.4432884490358204]], "Dining": [["table", 0.6153329443740811], ["dining", 0.37217834623751783], ["cutlery", 0.3139821236350345], ["tray", 0.3097030379964209], ["tablecloths", 0.3006277593090895]], "Lingerie": [["bra", 0.8965852601121921], ["cups", 0.5285363570485941], ["breast", 0.46345090588793064], ["nonpadded", 0.4551225849177485], ["straps", 0.4371461075717605]], "Apple Products": [["iphone", 0.7503862987601692], ["pro", 0.37695667339429706], ["apple", 0.37312380912718573], ["xr", 0.3582173040481931], ["max", 0.3526350702674551]], "Screen Protectors": [["screen", 0.6153666239172285], ["protector", 0.5651942935308064], ["protectors", 0.507626361439129], ["tempered", 0.4671540612427298], ["hardness", 0.4561645454021592]], "Women's Tops": [["sleeve", 0.49572716077806755], ["womens", 0.44013142956242973], ["sweatyrocks", 0.4203211398934657], ["crop", 0.41809175044803937], ["sleeveless", 0.41643008352599814]], "Gardening Supplies": [["hose", 0.7841372177474352], ["pipe", 0.6327301802335703], ["hoses", 0.5641588317324012], ["filter", 0.5118209249698248], ["fittings", 0.46796012979048174]], "Pet Supplies": [["dog", 0.6822708088198687], ["pet", 0.6400522687470505], ["dogs", 0.5160745818307858], ["collar", 0.42754412295633315], ["cats", 0.3647447770159879]], "Audio Equipment": [["sound", 0.7436954698780431], ["stereo", 0.6847399263959048], ["music", 0.6510439565263184], ["bluetooth", 0.6468335306088341], ["audio", 0.5323419441521797]], "Curtains": [["curtains", 0.7082112219740755], ["lxcm", 0.5903739907537208], ["curtain", 0.5406181796148612], ["sheer", 0.4277598568424003], ["panels", 0.419958307310006]], "Sarees": [["saree", 0.8783232110965399], ["sarees", 0.7321717143814415], ["sari", 0.5601859768503931], ["elegantly", 0.548955977226906], ["explore", 0.5321879512070764]], "Health and Wellness": [["coconut", 0.49630270118056097], ["dietary", 0.4819055711752624], ["ayurvedic", 0.46826858968976937], ["snack", 0.4369980524170574], ["supplement", 0.4248983967068878]], "Sportswear": [["hat", 0.7236122381999898], ["team", 0.5961027784061247], ["cap", 0.5198077659688286], ["jersey", 0.4724677801851194], ["nfl", 0.46235035258007345]], "Clocks and Alarms": [["clock", 0.9911350148825689], ["clocks", 0.5806141697627104], ["alarm", 0.4921721915993405], ["aa", 0.4199955227337318], ["wall", 0.41135071771777504]], "Watches": [["watch", 0.9877005762493802], ["watches", 0.6588330987551935], ["analogue", 0.6120074604752818], ["dial", 0.5425729098662936], ["band", 0.5008365915519408]], "Bar Accessories": [["wine", 0.7080736210501507], ["glasses", 0.6170645321866487], ["beer", 0.52017140239074], ["bottle", 0.5089754002398992], ["opener", 0.4765574582140716]], "Crafting Supplies": [["knitting", 0.7625115695769519], ["yarn", 0.624084654214461], ["needles", 0.6192608627071066], ["sewing", 0.5291732442509863], ["thread", 0.5207899838586767]]}
|
images/ML_domains.png
ADDED

|
images/ML_header.jpg
ADDED

|
images/brain_tumor.jpg
ADDED
|
images/cnn_example.png
ADDED

|
images/customer-churn.webp
DELETED
|
Binary file (22.5 kB)
|
|
|
images/e-commerce.jpg
ADDED

|
images/fashion_ai.jpg
DELETED
|
Binary file (128 kB)
|
|
|
images/fashion_od.jpg
DELETED
|
Binary file (101 kB)
|
|
|
images/meningioma_tumor.png
ADDED

|
images/no_tumor.png
ADDED

|
images/od_header.jpg
ADDED
|
images/pituitary.png
ADDED

|
images/reviews.jpg
DELETED
|
Binary file (41.4 kB)
|
|
|
images/reviews.png
ADDED

|
images/topic_modeling.gif
ADDED

|
images/tumor_image.jpg
ADDED
|
images/tumor_types_class.png
ADDED

|
images/tumors_types_class.png
ADDED

|
images/unsupervised_learner.webp
DELETED
|
Binary file (227 kB)
|
|
|
main_page.py
CHANGED
|
@@ -3,7 +3,7 @@ import streamlit as st
|
|
| 3 |
import pandas as pd
|
| 4 |
import numpy as np
|
| 5 |
|
| 6 |
-
from st_pages import Page, show_pages
|
| 7 |
from PIL import Image
|
| 8 |
#from utils import authenticate_drive
|
| 9 |
|
|
@@ -14,6 +14,7 @@ from PIL import Image
|
|
| 14 |
##################################################################################
|
| 15 |
|
| 16 |
st.set_page_config(layout="wide")
|
|
|
|
| 17 |
|
| 18 |
|
| 19 |
|
|
@@ -34,27 +35,41 @@ st.set_page_config(layout="wide")
|
|
| 34 |
# TITLE #
|
| 35 |
##################################################################################
|
| 36 |
|
|
|
|
| 37 |
st.image("images/AI.jpg")
|
| 38 |
-
st.
|
| 39 |
-
|
| 40 |
-
st.
|
| 41 |
-
|
| 42 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 43 |
#st.markdown("in collaboration with Hi! PARIS engineers: Laurène DAVID, Salma HOUIDI and Maeva N'GUESSAN")
|
| 44 |
|
| 45 |
-
|
| 46 |
-
|
| 47 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 48 |
|
|
|
|
| 49 |
st.divider()
|
| 50 |
|
| 51 |
|
| 52 |
-
#Hi! PARIS collaboration mention
|
| 53 |
-
st.markdown(" ")
|
| 54 |
-
image_hiparis = Image.open('images/hi-paris.png')
|
| 55 |
-
st.image(image_hiparis, width=150)
|
| 56 |
-
url = "https://www.hi-paris.fr/"
|
| 57 |
-
st.markdown("**The app was made in collaboration with [Hi! PARIS](%s)**" % url)
|
| 58 |
|
| 59 |
|
| 60 |
|
|
@@ -68,11 +83,21 @@ st.markdown("**The app was made in collaboration with [Hi! PARIS](%s)**" % url)
|
|
| 68 |
show_pages(
|
| 69 |
[
|
| 70 |
Page("main_page.py", "Home Page", "🏠"),
|
| 71 |
-
|
| 72 |
-
|
| 73 |
-
|
| 74 |
-
|
| 75 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 76 |
]
|
| 77 |
)
|
| 78 |
|
|
@@ -83,4 +108,30 @@ show_pages(
|
|
| 83 |
##################################################################################
|
| 84 |
|
| 85 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 86 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
import pandas as pd
|
| 4 |
import numpy as np
|
| 5 |
|
| 6 |
+
from st_pages import Page, show_pages, Section, add_indentation
|
| 7 |
from PIL import Image
|
| 8 |
#from utils import authenticate_drive
|
| 9 |
|
|
|
|
| 14 |
##################################################################################
|
| 15 |
|
| 16 |
st.set_page_config(layout="wide")
|
| 17 |
+
#add_indentation()
|
| 18 |
|
| 19 |
|
| 20 |
|
|
|
|
| 35 |
# TITLE #
|
| 36 |
##################################################################################
|
| 37 |
|
| 38 |
+
|
| 39 |
st.image("images/AI.jpg")
|
| 40 |
+
st.markdown(" ")
|
| 41 |
+
|
| 42 |
+
col1, col2 = st.columns([0.65,0.35], gap="medium")
|
| 43 |
+
|
| 44 |
+
with col1:
|
| 45 |
+
st.title("AI and Data Science Examples")
|
| 46 |
+
st.subheader("HEC Paris, 2023-2024")
|
| 47 |
+
st.markdown("""**Course provided by Shirish C. SRIVASTAVA** <br>
|
| 48 |
+
**Hi! PARIS Engineers**: Laurène DAVID, Salma HOUIDI and Maeva N'GUESSAN""", unsafe_allow_html=True)
|
| 49 |
#st.markdown("in collaboration with Hi! PARIS engineers: Laurène DAVID, Salma HOUIDI and Maeva N'GUESSAN")
|
| 50 |
|
| 51 |
+
with col2:
|
| 52 |
+
#Hi! PARIS collaboration mention
|
| 53 |
+
st.markdown(" ")
|
| 54 |
+
st.markdown(" ")
|
| 55 |
+
st.markdown(" ")
|
| 56 |
+
image_hiparis = Image.open('images/hi-paris.png')
|
| 57 |
+
st.image(image_hiparis, width=150)
|
| 58 |
+
|
| 59 |
+
url = "https://www.hi-paris.fr/"
|
| 60 |
+
st.markdown("""###### **Made in collaboration with [Hi! PARIS](%s)** """ % url, unsafe_allow_html=True)
|
| 61 |
+
|
| 62 |
|
| 63 |
+
st.markdown(" ")
|
| 64 |
st.divider()
|
| 65 |
|
| 66 |
|
| 67 |
+
# #Hi! PARIS collaboration mention
|
| 68 |
+
# st.markdown(" ")
|
| 69 |
+
# image_hiparis = Image.open('images/hi-paris.png')
|
| 70 |
+
# st.image(image_hiparis, width=150)
|
| 71 |
+
# url = "https://www.hi-paris.fr/"
|
| 72 |
+
# st.markdown("**The app was made in collaboration with [Hi! PARIS](%s)**" % url)
|
| 73 |
|
| 74 |
|
| 75 |
|
|
|
|
| 83 |
show_pages(
|
| 84 |
[
|
| 85 |
Page("main_page.py", "Home Page", "🏠"),
|
| 86 |
+
Section(name=" ", icon=""),
|
| 87 |
+
Section(name=" ", icon=""),
|
| 88 |
+
|
| 89 |
+
Section(name="Machine Learning", icon="1️⃣"),
|
| 90 |
+
Page("pages/supervised_unsupervised_page.py", "1| Supervised vs Unsupervised 🔍", ""),
|
| 91 |
+
Page("pages/timeseries_analysis.py", "2| Time Series Forecasting 📈", ""),
|
| 92 |
+
Page("pages/recommendation_system.py", "3| Recommendation systems 🛒", ""),
|
| 93 |
+
|
| 94 |
+
Section(name="Natural Language Processing", icon="2️⃣"),
|
| 95 |
+
Page("pages/topic_modeling.py", "1| Topic Modeling 📚", ""),
|
| 96 |
+
Page("pages/sentiment_analysis.py", "2| Sentiment Analysis 👍", ""),
|
| 97 |
+
|
| 98 |
+
Section(name="Computer Vision", icon="3️⃣"),
|
| 99 |
+
Page("pages/image_classification.py", "1| Image Classification 🖼️", ""),
|
| 100 |
+
Page("pages/object_detection.py", "2| Object Detection 📹", "")
|
| 101 |
]
|
| 102 |
)
|
| 103 |
|
|
|
|
| 108 |
##################################################################################
|
| 109 |
|
| 110 |
|
| 111 |
+
st.header("About the app")
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
st.info("""The **AI and Data Science Examples** app was created as a tool to introduce students to the field of Data Science by showcasing real-life applications of AI.
|
| 115 |
+
It includes use cases using traditional Machine Learning algorithms on structured data, as well as models that analyze unstructured data (text, images,...).""")
|
| 116 |
+
|
| 117 |
+
st.markdown(" ")
|
| 118 |
|
| 119 |
+
st.markdown("""The app is structured into three sections:
|
| 120 |
+
- 1️⃣ **Machine Learning**: This first section covers use cases where structured data (data in a tabular format) is fed to an AI model.
|
| 121 |
+
You will find pages on *Supervised/Unsupervised Learning*, *Time Series Forecasting* and AI powered *Recommendation Systems*.
|
| 122 |
+
- 2️�� **Natural Language Processing** (NLP): This second section showcases AI applications where large amounts of text data is analyzed using Deep Learning models.
|
| 123 |
+
Pages on *Topic Modeling* and *Sentiment Analysis*, which are types of NLP models, can be found in this section.
|
| 124 |
+
- 3️⃣ **Computer Vision**: This final section covers a sub-field of AI called Computer Vision which deals with image/video data.
|
| 125 |
+
The field of Computer Vision includes *Image classification* and *Object Detection*, which are both featured in this section.
|
| 126 |
+
""")
|
| 127 |
+
|
| 128 |
+
st.image("images/ML_domains.png",
|
| 129 |
+
caption="""This figure showcases a selection of sub-fields in Artificial Intelligence, such as traditional
|
| 130 |
+
Machine Learning, NLP, Computer Vision and Robotics.""")
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
# st.markdown(" ")
|
| 134 |
+
# st.markdown(" ")
|
| 135 |
+
# st.markdown("## Want to learn more about AI ?")
|
| 136 |
+
# st.markdown("""**Hi! PARIS**, a multidisciplinary center on Data Analysis and AI founded by Institut Polytechnique de Paris and HEC Paris,
|
| 137 |
+
# hosts every year a **Data Science Bootcamp** for students of all levels.""")
|
notebooks/Supervised-Unsupervised/supply_chain.ipynb
DELETED
|
@@ -1,55 +0,0 @@
|
|
| 1 |
-
{
|
| 2 |
-
"cells": [
|
| 3 |
-
{
|
| 4 |
-
"cell_type": "code",
|
| 5 |
-
"execution_count": 1,
|
| 6 |
-
"metadata": {},
|
| 7 |
-
"outputs": [],
|
| 8 |
-
"source": [
|
| 9 |
-
"import os\n",
|
| 10 |
-
"import pandas as pd\n",
|
| 11 |
-
"import numpy as np\n",
|
| 12 |
-
"import matplotlib.pyplot as plt \n",
|
| 13 |
-
"import seaborn as sns"
|
| 14 |
-
]
|
| 15 |
-
},
|
| 16 |
-
{
|
| 17 |
-
"cell_type": "code",
|
| 18 |
-
"execution_count": 2,
|
| 19 |
-
"metadata": {},
|
| 20 |
-
"outputs": [],
|
| 21 |
-
"source": [
|
| 22 |
-
"path_data = r\"C:\\Users\\LaurèneDAVID\\Documents\\Teaching\\Educational_apps\\app-hec-AI-DS\\data\\classification\\supply_chain_data.csv\"\n",
|
| 23 |
-
"supply_data = pd.read_csv(path_data)"
|
| 24 |
-
]
|
| 25 |
-
},
|
| 26 |
-
{
|
| 27 |
-
"cell_type": "code",
|
| 28 |
-
"execution_count": null,
|
| 29 |
-
"metadata": {},
|
| 30 |
-
"outputs": [],
|
| 31 |
-
"source": []
|
| 32 |
-
}
|
| 33 |
-
],
|
| 34 |
-
"metadata": {
|
| 35 |
-
"kernelspec": {
|
| 36 |
-
"display_name": "Python 3",
|
| 37 |
-
"language": "python",
|
| 38 |
-
"name": "python3"
|
| 39 |
-
},
|
| 40 |
-
"language_info": {
|
| 41 |
-
"codemirror_mode": {
|
| 42 |
-
"name": "ipython",
|
| 43 |
-
"version": 3
|
| 44 |
-
},
|
| 45 |
-
"file_extension": ".py",
|
| 46 |
-
"mimetype": "text/x-python",
|
| 47 |
-
"name": "python",
|
| 48 |
-
"nbconvert_exporter": "python",
|
| 49 |
-
"pygments_lexer": "ipython3",
|
| 50 |
-
"version": "3.9.0"
|
| 51 |
-
}
|
| 52 |
-
},
|
| 53 |
-
"nbformat": 4,
|
| 54 |
-
"nbformat_minor": 2
|
| 55 |
-
}
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
notebooks/energy_consumption.ipynb
CHANGED
|
@@ -9,9 +9,18 @@
|
|
| 9 |
},
|
| 10 |
{
|
| 11 |
"cell_type": "code",
|
| 12 |
-
"execution_count":
|
| 13 |
"metadata": {},
|
| 14 |
-
"outputs": [
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 15 |
"source": [
|
| 16 |
"import pandas as pd \n",
|
| 17 |
"import numpy as np\n",
|
|
|
|
| 9 |
},
|
| 10 |
{
|
| 11 |
"cell_type": "code",
|
| 12 |
+
"execution_count": 1,
|
| 13 |
"metadata": {},
|
| 14 |
+
"outputs": [
|
| 15 |
+
{
|
| 16 |
+
"name": "stderr",
|
| 17 |
+
"output_type": "stream",
|
| 18 |
+
"text": [
|
| 19 |
+
"c:\\Users\\LaurèneDAVID\\Documents\\Teaching\\Educational_apps\\app-ai-ds-hec\\venv\\lib\\site-packages\\tqdm\\auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html\n",
|
| 20 |
+
" from .autonotebook import tqdm as notebook_tqdm\n"
|
| 21 |
+
]
|
| 22 |
+
}
|
| 23 |
+
],
|
| 24 |
"source": [
|
| 25 |
"import pandas as pd \n",
|
| 26 |
"import numpy as np\n",
|
notebooks/topic_modeling.ipynb
ADDED
|
@@ -0,0 +1,101 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"metadata": {},
|
| 6 |
+
"source": [
|
| 7 |
+
"# Topic Modeling on product descriptions"
|
| 8 |
+
]
|
| 9 |
+
},
|
| 10 |
+
{
|
| 11 |
+
"cell_type": "code",
|
| 12 |
+
"execution_count": 2,
|
| 13 |
+
"metadata": {},
|
| 14 |
+
"outputs": [],
|
| 15 |
+
"source": [
|
| 16 |
+
"#py -m pip install bertopic"
|
| 17 |
+
]
|
| 18 |
+
},
|
| 19 |
+
{
|
| 20 |
+
"cell_type": "code",
|
| 21 |
+
"execution_count": 1,
|
| 22 |
+
"metadata": {},
|
| 23 |
+
"outputs": [
|
| 24 |
+
{
|
| 25 |
+
"name": "stderr",
|
| 26 |
+
"output_type": "stream",
|
| 27 |
+
"text": [
|
| 28 |
+
"c:\\Users\\LaurèneDAVID\\Documents\\Teaching\\Educational_apps\\app-ai-ds-hec\\venv\\lib\\site-packages\\tqdm\\auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html\n",
|
| 29 |
+
" from .autonotebook import tqdm as notebook_tqdm\n"
|
| 30 |
+
]
|
| 31 |
+
}
|
| 32 |
+
],
|
| 33 |
+
"source": [
|
| 34 |
+
"import os\n",
|
| 35 |
+
"import pickle\n",
|
| 36 |
+
"import pandas as pd\n",
|
| 37 |
+
"from bertopic import BERTopic"
|
| 38 |
+
]
|
| 39 |
+
},
|
| 40 |
+
{
|
| 41 |
+
"cell_type": "code",
|
| 42 |
+
"execution_count": 2,
|
| 43 |
+
"metadata": {},
|
| 44 |
+
"outputs": [],
|
| 45 |
+
"source": [
|
| 46 |
+
"path_model = r\"C:\\Users\\LaurèneDAVID\\Documents\\Teaching\\Educational_apps\\data-hec-AI-DS\\model_topicmodeling.pkl\"\n",
|
| 47 |
+
"path_data = r\"C:\\Users\\LaurèneDAVID\\Documents\\Teaching\\Educational_apps\\data-hec-AI-DS\\data-topicmodeling.csv\""
|
| 48 |
+
]
|
| 49 |
+
},
|
| 50 |
+
{
|
| 51 |
+
"cell_type": "code",
|
| 52 |
+
"execution_count": 3,
|
| 53 |
+
"metadata": {},
|
| 54 |
+
"outputs": [
|
| 55 |
+
{
|
| 56 |
+
"ename": "TypeError",
|
| 57 |
+
"evalue": "_rebuild() got an unexpected keyword argument 'impl_kind'",
|
| 58 |
+
"output_type": "error",
|
| 59 |
+
"traceback": [
|
| 60 |
+
"\u001b[1;31m---------------------------------------------------------------------------\u001b[0m",
|
| 61 |
+
"\u001b[1;31mTypeError\u001b[0m Traceback (most recent call last)",
|
| 62 |
+
"Cell \u001b[1;32mIn[3], line 1\u001b[0m\n\u001b[1;32m----> 1\u001b[0m model \u001b[38;5;241m=\u001b[39m \u001b[43mpickle\u001b[49m\u001b[38;5;241;43m.\u001b[39;49m\u001b[43mload\u001b[49m\u001b[43m(\u001b[49m\u001b[38;5;28;43mopen\u001b[39;49m\u001b[43m(\u001b[49m\u001b[43mpath_model\u001b[49m\u001b[43m,\u001b[49m\u001b[43m \u001b[49m\u001b[38;5;124;43m'\u001b[39;49m\u001b[38;5;124;43mrb\u001b[39;49m\u001b[38;5;124;43m'\u001b[39;49m\u001b[43m)\u001b[49m\u001b[43m)\u001b[49m\n",
|
| 63 |
+
"File \u001b[1;32mc:\\Users\\LaurèneDAVID\\Documents\\Teaching\\Educational_apps\\app-ai-ds-hec\\venv\\lib\\site-packages\\numba\\core\\serialize.py:152\u001b[0m, in \u001b[0;36mcustom_rebuild\u001b[1;34m(custom_pickled)\u001b[0m\n\u001b[0;32m 147\u001b[0m \u001b[38;5;250m\u001b[39m\u001b[38;5;124;03m\"\"\"Customized object deserialization.\u001b[39;00m\n\u001b[0;32m 148\u001b[0m \n\u001b[0;32m 149\u001b[0m \u001b[38;5;124;03mThis function is referenced internally by `custom_reduce()`.\u001b[39;00m\n\u001b[0;32m 150\u001b[0m \u001b[38;5;124;03m\"\"\"\u001b[39;00m\n\u001b[0;32m 151\u001b[0m \u001b[38;5;28mcls\u001b[39m, states \u001b[38;5;241m=\u001b[39m custom_pickled\u001b[38;5;241m.\u001b[39mctor, custom_pickled\u001b[38;5;241m.\u001b[39mstates\n\u001b[1;32m--> 152\u001b[0m \u001b[38;5;28;01mreturn\u001b[39;00m \u001b[38;5;28mcls\u001b[39m\u001b[38;5;241m.\u001b[39m_rebuild(\u001b[38;5;241m*\u001b[39m\u001b[38;5;241m*\u001b[39mstates)\n",
|
| 64 |
+
"\u001b[1;31mTypeError\u001b[0m: _rebuild() got an unexpected keyword argument 'impl_kind'"
|
| 65 |
+
]
|
| 66 |
+
}
|
| 67 |
+
],
|
| 68 |
+
"source": [
|
| 69 |
+
"model = pickle.load(open(path_model, 'rb'))"
|
| 70 |
+
]
|
| 71 |
+
},
|
| 72 |
+
{
|
| 73 |
+
"cell_type": "code",
|
| 74 |
+
"execution_count": null,
|
| 75 |
+
"metadata": {},
|
| 76 |
+
"outputs": [],
|
| 77 |
+
"source": []
|
| 78 |
+
}
|
| 79 |
+
],
|
| 80 |
+
"metadata": {
|
| 81 |
+
"kernelspec": {
|
| 82 |
+
"display_name": "venv",
|
| 83 |
+
"language": "python",
|
| 84 |
+
"name": "python3"
|
| 85 |
+
},
|
| 86 |
+
"language_info": {
|
| 87 |
+
"codemirror_mode": {
|
| 88 |
+
"name": "ipython",
|
| 89 |
+
"version": 3
|
| 90 |
+
},
|
| 91 |
+
"file_extension": ".py",
|
| 92 |
+
"mimetype": "text/x-python",
|
| 93 |
+
"name": "python",
|
| 94 |
+
"nbconvert_exporter": "python",
|
| 95 |
+
"pygments_lexer": "ipython3",
|
| 96 |
+
"version": "3.9.0"
|
| 97 |
+
}
|
| 98 |
+
},
|
| 99 |
+
"nbformat": 4,
|
| 100 |
+
"nbformat_minor": 2
|
| 101 |
+
}
|
pages/image_classification.py
ADDED
|
@@ -0,0 +1,330 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import pickle
|
| 3 |
+
import time
|
| 4 |
+
import os
|
| 5 |
+
import pandas as pd
|
| 6 |
+
import plotly.express as px
|
| 7 |
+
from PIL import Image
|
| 8 |
+
from utils import load_data_pickle
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
# import gradcam
|
| 12 |
+
# from gradcam.utils import visualize_cam
|
| 13 |
+
# from gradcam import GradCAM, GradCAMpp
|
| 14 |
+
|
| 15 |
+
#add_indentation()
|
| 16 |
+
st.set_page_config(layout="wide")
|
| 17 |
+
|
| 18 |
+
# Chemin vers le dossier contenant les images et le modèle pré-entraîné
|
| 19 |
+
DATA_DIR = r"data/image_classification/images"
|
| 20 |
+
MODEL_PATH = r"pretrained_models/image_classification/resnet18_braintumor.pt"
|
| 21 |
+
gradcam_images_paths = ["images/meningioma_tumor.png", "images/no_tumor.png", "images/pituitary.png"]
|
| 22 |
+
|
| 23 |
+
# PREPROCESSING
|
| 24 |
+
|
| 25 |
+
# def preprocess(image):
|
| 26 |
+
# # Il faut que l'image' est une image PIL. Si 'image' est un tableau numpy, on le convertit en image PIL.
|
| 27 |
+
# if isinstance(image, np.ndarray):
|
| 28 |
+
# image = Image.fromarray(image)
|
| 29 |
+
|
| 30 |
+
# transform = transforms.Compose([
|
| 31 |
+
# transforms.Resize((224, 224)),
|
| 32 |
+
# transforms.ToTensor(),
|
| 33 |
+
# transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # Normalisez l'image.
|
| 34 |
+
# ])
|
| 35 |
+
# # On applique les transformations définies sur l'image.
|
| 36 |
+
# image = transform(image)
|
| 37 |
+
# return image
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
# Chargement du modèle pré-entraîné
|
| 41 |
+
|
| 42 |
+
# def load_pretrained_model(num_classes=3):
|
| 43 |
+
# model = models.resnet18(pretrained=False)
|
| 44 |
+
# num_ftrs = model.fc.in_features
|
| 45 |
+
# model.fc = torch.nn.Linear(num_ftrs, num_classes)
|
| 46 |
+
|
| 47 |
+
# # Chargement des poids pré-entraînés tout en ignorant la dernière couche 'fc'
|
| 48 |
+
# state_dict = torch.load(MODEL_PATH, map_location=torch.device('cpu'))
|
| 49 |
+
# state_dict.pop('fc.weight', None)
|
| 50 |
+
# state_dict.pop('fc.bias', None)
|
| 51 |
+
# model.load_state_dict(state_dict, strict=False)
|
| 52 |
+
|
| 53 |
+
# model.eval()
|
| 54 |
+
# return model
|
| 55 |
+
|
| 56 |
+
# model = load_pretrained_model(num_classes=3) #On a supprimés une des classes
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
# # PREDICTION
|
| 60 |
+
# def predict(image_preprocessed, model):
|
| 61 |
+
# # Si image_preprocessed est déjà un tensor PyTorch, on doit s'assurer qu'il soit de dimension 3 : [batch_size, channels, height, width]
|
| 62 |
+
# # La fonction unsqueeze(0) ajoute une dimension de batch_size au début pour le faire correspondre à cette attente
|
| 63 |
+
# if image_preprocessed.dim() == 3:
|
| 64 |
+
# image_preprocessed = image_preprocessed.unsqueeze(0)
|
| 65 |
+
|
| 66 |
+
# with torch.no_grad():
|
| 67 |
+
# output = model(image_preprocessed)
|
| 68 |
+
# _, predicted = torch.max(output, 1)
|
| 69 |
+
# return predicted, output
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
###################################### TITLE ####################################
|
| 74 |
+
|
| 75 |
+
st.markdown("# Image Classification 🖼️")
|
| 76 |
+
|
| 77 |
+
st.markdown("### What is Image classification ?")
|
| 78 |
+
st.info("""**Image classification** is a process in Machine Learning and Computer Vision where an algorithm is trained to recognize and categorize images into predefined classes. It involves analyzing the visual content of an image and assigning it to a specific label based on its features.""")
|
| 79 |
+
#unsafe_allow_html=True)
|
| 80 |
+
st.markdown(" ")
|
| 81 |
+
st.markdown("""State-of-the-art image classification models use **neural networks** to predict whether an image belongs to a specific class.<br>
|
| 82 |
+
Each of the possible predicted classes are given a probability then the class with the highest value is assigned to the input image.""",
|
| 83 |
+
unsafe_allow_html=True)
|
| 84 |
+
|
| 85 |
+
image_ts = Image.open('images/cnn_example.png')
|
| 86 |
+
_, col, _ = st.columns([0.2,0.8,0.2])
|
| 87 |
+
with col:
|
| 88 |
+
st.image(image_ts,
|
| 89 |
+
caption="An example of an image classification model, with the 'backbone model' as the neural network.")
|
| 90 |
+
|
| 91 |
+
st.markdown(" ")
|
| 92 |
+
|
| 93 |
+
st.markdown("""Real-life applications of image classification includes:
|
| 94 |
+
- **Medical Imaging 👨⚕️**: Diagnose diseases and medical conditions from images such as X-rays, MRIs and CT scans to, for example, identify tumors and classify different types of cancers.
|
| 95 |
+
- **Autonomous Vehicules** 🏎️: Classify objects such as pedestrians, vehicles, traffic signs, lane markings, and obstacles, which is crucial for navigation and collision avoidance.
|
| 96 |
+
- **Satellite and Remote Sensing 🛰️**: Analyze satellite imagery to identify land use patterns, monitor vegetation health, assess environmental changes, and detect natural disasters such as wildfires and floods.
|
| 97 |
+
- **Quality Control 🛂**: Inspect products and identify defects to ensure compliance with quality standards during the manufacturying process.
|
| 98 |
+
""")
|
| 99 |
+
|
| 100 |
+
# st.markdown("""Real-life applications of Brain Tumor includes:
|
| 101 |
+
# - **Research and development💰**: The technologies and methodologies developed for brain tumor classification can advance research in neuroscience, oncology, and the development of new diagnostic tools and treatments.
|
| 102 |
+
# - **Healthcare👨⚕️**: Data derived from the classification and analysis of brain tumors can inform public health decisions, healthcare policies, and resource allocation, emphasizing areas with higher incidences of certain types of tumors.
|
| 103 |
+
# - **Insurance Industry 🏬**: Predict future demand for products to optimize inventory levels, reduce holding costs, and improve supply chain efficiency.
|
| 104 |
+
# """)
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
###################################### USE CASE #######################################
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
# BEGINNING OF USE CASE
|
| 111 |
+
st.divider()
|
| 112 |
+
st.markdown("# Brain Tumor Classification 🧠")
|
| 113 |
+
|
| 114 |
+
st.info("""In this use case, a **brain tumor classification** model is leveraged to accurately identify the presence of tumors in MRI scans of the brain.
|
| 115 |
+
This application can be a great resource for healthcare professionals to facilite early detection and consequently improve treatment outcomes for patients.""")
|
| 116 |
+
|
| 117 |
+
st.markdown(" ")
|
| 118 |
+
_, col, _ = st.columns([0.1,0.8,0.1])
|
| 119 |
+
with col:
|
| 120 |
+
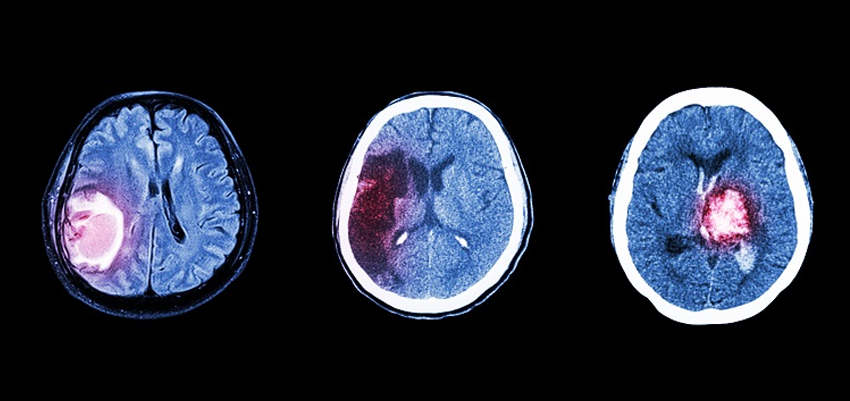
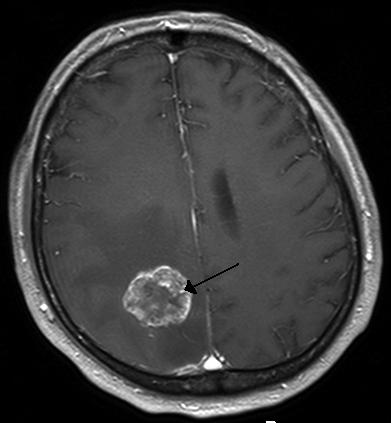
st.image("images/brain_tumor.jpg")
|
| 121 |
+
|
| 122 |
+
st.markdown(" ")
|
| 123 |
+
st.markdown(" ")
|
| 124 |
+
|
| 125 |
+
### WHAT ARE BRAIN TUMORS ?
|
| 126 |
+
st.markdown(" ### What is a Brain Tumor ?")
|
| 127 |
+
st.markdown("""Before introducing the use case, let's give a short description on what a brain tumor is.
|
| 128 |
+
A brain tumor occurs when **abnormal cells form within the brain**. Two main types of tumors exist: **cancerous (malignant) tumors** and **benign tumors**.
|
| 129 |
+
- **Cancerous tumors** are malignant tumors that have the ability to invade nearby tissues and spread to other parts of the body through a process called metastasis.
|
| 130 |
+
- **Benign tumors** can become quite large but will not invade nearby tissue or spread to other parts of the body. They can still cause serious health problems depending on their size, location and rate of growth.
|
| 131 |
+
""", unsafe_allow_html=True)
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
st.markdown(" ")
|
| 136 |
+
st.markdown(" ")
|
| 137 |
+
st.markdown("### About the data 📋")
|
| 138 |
+
|
| 139 |
+
st.markdown("""You were provided with a large dataset which contains **anonymized patient MRI scans** categorized into three distinct classes: **pituitary tumor** (in most cases benign), **meningioma tumor** (cancerous) and **no tumor**.
|
| 140 |
+
This dataset will serve as the foundation for training our classification model, offering a comprehensive view of varied tumor presentations within the brain.""")
|
| 141 |
+
|
| 142 |
+
_, col, _ = st.columns([0.15,0.7,0.15])
|
| 143 |
+
with col:
|
| 144 |
+
st.image("images/tumors_types_class.png")
|
| 145 |
+
|
| 146 |
+
# see_data = st.checkbox('**See the data**', key="image_class\seedata")
|
| 147 |
+
# if see_data:
|
| 148 |
+
# st.warning("You can view here a few examples of the MRI training data.")
|
| 149 |
+
# # image selection
|
| 150 |
+
# images = os.listdir(DATA_DIR)
|
| 151 |
+
# selected_image1 = st.selectbox("Choose an image to visualize 🔎 :", images, key="selectionbox_key_2")
|
| 152 |
+
|
| 153 |
+
# # show image
|
| 154 |
+
# image_path = os.path.join(DATA_DIR, selected_image1)
|
| 155 |
+
# image = Image.open(image_path)
|
| 156 |
+
# st.image(image, caption="Image selected", width=450)
|
| 157 |
+
|
| 158 |
+
# st.info("""**Note**: This dataset will serve as the foundation for training our classification model, offering a comprehensive view of varied tumor presentations within the brain.
|
| 159 |
+
# By analyzing these images, the model learns to discern the subtle differences between each class, thereby enabling the precise identification of tumor types.""")
|
| 160 |
+
|
| 161 |
+
st.markdown(" ")
|
| 162 |
+
st.markdown(" ")
|
| 163 |
+
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
st.markdown("### Train the algorithm ⚙️")
|
| 167 |
+
st.markdown("""**Training an AI model** means feeding it data that contains multiple examples/images each type of tumor to be detected.
|
| 168 |
+
By analyzing the provided MRI images, the model learns to discern the subtle differences between each classes, thereby enabling the precise identification of tumor types.""")
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
### CONDITION ##
|
| 172 |
+
|
| 173 |
+
# Initialisation de l'état du modèle
|
| 174 |
+
if 'model_train' not in st.session_state:
|
| 175 |
+
st.session_state['model_train'] = False
|
| 176 |
+
|
| 177 |
+
run_model = st.button("Train the model")
|
| 178 |
+
|
| 179 |
+
if run_model:
|
| 180 |
+
# Simuler l'entraînement du modèle
|
| 181 |
+
st.session_state.model_train = True
|
| 182 |
+
with st.spinner('Training the model...'):
|
| 183 |
+
time.sleep(2)
|
| 184 |
+
st.success("The model has been trained.")
|
| 185 |
+
else:
|
| 186 |
+
# Afficher le statut
|
| 187 |
+
st.info("The model hasn't been trained yet.")
|
| 188 |
+
|
| 189 |
+
# Afficher les résultats
|
| 190 |
+
if st.session_state.model_train:
|
| 191 |
+
st.markdown(" ")
|
| 192 |
+
st.markdown(" ")
|
| 193 |
+
st.markdown("### See the results ☑️")
|
| 194 |
+
tab1, tab2 = st.tabs(["Performance", "Explainability"])
|
| 195 |
+
|
| 196 |
+
with tab1:
|
| 197 |
+
#st.subheader("Performance")
|
| 198 |
+
st.info("""**Evaluating a model's performance** helps provide a quantitative measurement of it's ability to make accurate predictions.
|
| 199 |
+
In this use case, the performance of the brain tumor classification model was measured by comparing the patient's true diagnosis with the class predicted by the trained model.""")
|
| 200 |
+
|
| 201 |
+
class_accuracy_path = "data/image_classification/class_accuracies.pkl"
|
| 202 |
+
|
| 203 |
+
# Charger les données depuis le fichier Pickle
|
| 204 |
+
try:
|
| 205 |
+
with open(class_accuracy_path, 'rb') as file:
|
| 206 |
+
class_accuracy = pickle.load(file)
|
| 207 |
+
except Exception as e:
|
| 208 |
+
st.error(f"Erreur lors du chargement du fichier : {e}")
|
| 209 |
+
class_accuracy = {}
|
| 210 |
+
|
| 211 |
+
if not isinstance(class_accuracy, dict):
|
| 212 |
+
st.error(f"Expected a dictionary, but got: {type(class_accuracy)}")
|
| 213 |
+
else:
|
| 214 |
+
# Conversion des données en DataFrame
|
| 215 |
+
df_accuracy = pd.DataFrame(list(class_accuracy.items()), columns=['Tumor Type', 'Accuracy'])
|
| 216 |
+
df_accuracy['Accuracy'] = ((df_accuracy['Accuracy'] * 100).round()).astype(int)
|
| 217 |
+
|
| 218 |
+
# Générer le graphique à barres avec Plotly
|
| 219 |
+
fig = px.bar(df_accuracy, x='Tumor Type', y='Accuracy',
|
| 220 |
+
text='Accuracy', color='Tumor Type',
|
| 221 |
+
title="Model Performance",
|
| 222 |
+
labels={'Accuracy': 'Accuracy (%)', 'Tumor Type': 'Tumor Type'})
|
| 223 |
+
|
| 224 |
+
fig.update_traces(texttemplate='%{text}%', textposition='outside')
|
| 225 |
+
|
| 226 |
+
# Afficher le graphique dans Streamlit
|
| 227 |
+
st.plotly_chart(fig, use_container_width=True)
|
| 228 |
+
|
| 229 |
+
|
| 230 |
+
st.markdown("""<i>The model's accuracy was evaluated across two types of tumors (pituitary and meningioma) and no tumor type.</i>
|
| 231 |
+
<i>This evaluation is vital for determining if the model performs consistently across different tumor classifications, or if it encounters difficulties in accurately distinguishing between these two types of tumors.""",
|
| 232 |
+
unsafe_allow_html=True)
|
| 233 |
+
|
| 234 |
+
st.markdown(" ")
|
| 235 |
+
|
| 236 |
+
st.markdown("""**Interpretation**: <br>
|
| 237 |
+
Our model demonstrates high accuracy in predicting cancerous type tumors (meningioma) as well as 'healthy' brain scans (no tumor) with a 98% accuracy for both.
|
| 238 |
+
It is observed that the model's performance is lower for pituitary type tumors, as it is around 81%.
|
| 239 |
+
This discrepancy may indicate that the model finds it more challenging to distinguish pituitary tumors from other tumor
|
| 240 |
+
types, possibly due to their unique characteristics or lower representation in the training data.
|
| 241 |
+
""", unsafe_allow_html=True)
|
| 242 |
+
|
| 243 |
+
with tab2:
|
| 244 |
+
#st.subheader("Model Explainability with Grad-CAM")
|
| 245 |
+
st.info("""**Explainability in AI** refers to the ability to **understand and interpret how AI systems make predictions** and how to quantify the impact of the provided data on its results.
|
| 246 |
+
In the case of image classification, explainability can be measured by analyzing which of the image's pixel had the most impact on the model's output.""")
|
| 247 |
+
st.markdown(" ")
|
| 248 |
+
st.markdown("""The following images show the output of image classification explainability applied on three images used during training. <br>
|
| 249 |
+
Pixels that are colored in 'red' had a larger impact on the model's output and thus its ability to distinguish different tumor types (or none).
|
| 250 |
+
|
| 251 |
+
""", unsafe_allow_html=True)
|
| 252 |
+
|
| 253 |
+
st.markdown(" ")
|
| 254 |
+
gradcam_images_paths = ["images/meningioma_tumor.png", "images/no_tumor.png", "images/pituitary.png"]
|
| 255 |
+
class_names = ["Meningioma Tumor", "No Tumor", "Pituitary Tumor"]
|
| 256 |
+
|
| 257 |
+
for path, class_name in zip(gradcam_images_paths, class_names):
|
| 258 |
+
st.image(path, caption=f"Explainability for {class_name}")
|
| 259 |
+
|
| 260 |
+
# st.markdown("""
|
| 261 |
+
# <b>Interpretation</b>: <br>
|
| 262 |
+
|
| 263 |
+
# ### Meningioma Tumors <br>
|
| 264 |
+
# **Meningiomas** are tumors that originate from the meninges, the layers of tissue
|
| 265 |
+
# that envelop the brain and spinal cord. Although they are most often benign
|
| 266 |
+
# (noncancerous) and grow slowly, their location can cause significant issues by
|
| 267 |
+
# exerting pressure on the brain or spinal cord. Meningiomas can occur at various
|
| 268 |
+
# places around the brain and spinal cord and are more common in women than in men.
|
| 269 |
+
|
| 270 |
+
# ### Pituitary Tumors <br>
|
| 271 |
+
# **Pituitary** are growths that develop in the pituitary gland, a small gland located at the
|
| 272 |
+
# base of the brain, behind the nose, and between the ears. Despite their critical location,
|
| 273 |
+
# the majority of pituitary tumors are benign and grow slowly. This gland regulates many of the
|
| 274 |
+
# hormones that control various body functions, so even a small tumor can affect hormone production,
|
| 275 |
+
# leading to a variety of symptoms.""", unsafe_allow_html=True)
|
| 276 |
+
|
| 277 |
+
|
| 278 |
+
#################################################
|
| 279 |
+
|
| 280 |
+
st.markdown(" ")
|
| 281 |
+
st.markdown(" ")
|
| 282 |
+
st.markdown("### Classify MRI scans 🆕")
|
| 283 |
+
|
| 284 |
+
st.info("**Note**: The brain tumor classification model can classify new MRI images only if it has been previously trained.")
|
| 285 |
+
|
| 286 |
+
st.markdown("""Here, you are provided the MRI scans of nine new patients.
|
| 287 |
+
Select an image and press 'run the model' to classify the MRI as either a pituitary tumor, a meningioma tumor or no tumor.""")
|
| 288 |
+
|
| 289 |
+
|
| 290 |
+
# Définition des catégories de tumeurs
|
| 291 |
+
categories = ["pituitary tumor", "no tumor", "meningioma tumor"]
|
| 292 |
+
|
| 293 |
+
# Selection des images
|
| 294 |
+
images = os.listdir(DATA_DIR)
|
| 295 |
+
selected_image2 = st.selectbox("Choose an image", images, key="selectionbox_key_1")
|
| 296 |
+
|
| 297 |
+
# show image
|
| 298 |
+
image_path = os.path.join(DATA_DIR, selected_image2)
|
| 299 |
+
image = Image.open(image_path)
|
| 300 |
+
st.markdown("#### You've selected the following image.")
|
| 301 |
+
st.image(image, caption="Image selected", width=300)
|
| 302 |
+
|
| 303 |
+
|
| 304 |
+
if st.button('**Make predictions**', key='another_action_button'):
|
| 305 |
+
results_path = r"data/image_classification"
|
| 306 |
+
df_results = load_data_pickle(results_path, "results.pkl")
|
| 307 |
+
predicted_category = df_results.loc[df_results["image"]==selected_image2,"class"].to_numpy()
|
| 308 |
+
|
| 309 |
+
# # Prétraitement et prédiction
|
| 310 |
+
# image_preprocessed = preprocess(image)
|
| 311 |
+
# predicted_tensor, _ = predict(image_preprocessed, model)
|
| 312 |
+
|
| 313 |
+
# predicted_idx = predicted_tensor.item()
|
| 314 |
+
# predicted_category = categories[predicted_idx]
|
| 315 |
+
|
| 316 |
+
# Affichage de la prédiction avec la catégorie prédite
|
| 317 |
+
if predicted_category == "pituitary":
|
| 318 |
+
st.warning(f"**Results**: Pituitary tumor was detected. ")
|
| 319 |
+
elif predicted_category == "no tumor":
|
| 320 |
+
st.success(f"**Results**: No tumor was detected.")
|
| 321 |
+
elif predicted_category == "meningnoma":
|
| 322 |
+
st.error(f"**Results**: Meningioma was detected.")
|
| 323 |
+
|
| 324 |
+
|
| 325 |
+
# image_path = os.path.join(DATA_DIR, selected_image2)
|
| 326 |
+
# image = Image.open(image_path)
|
| 327 |
+
# st.image(image, caption="Image selected", width=450)
|
| 328 |
+
|
| 329 |
+
|
| 330 |
+
|
pages/object_detection.py
CHANGED
|
@@ -12,6 +12,9 @@ from PIL import Image
|
|
| 12 |
from transformers import YolosFeatureExtractor, YolosForObjectDetection
|
| 13 |
from torchvision.transforms import ToTensor, ToPILImage
|
| 14 |
from annotated_text import annotated_text
|
|
|
|
|
|
|
|
|
|
| 15 |
|
| 16 |
|
| 17 |
st.set_page_config(layout="wide")
|
|
@@ -134,7 +137,8 @@ cats = ['shirt, blouse', 'top, t-shirt, sweatshirt', 'sweater', 'cardigan', 'jac
|
|
| 134 |
|
| 135 |
######################################################################################################################################
|
| 136 |
|
| 137 |
-
st.
|
|
|
|
| 138 |
|
| 139 |
st.markdown("### What is Object Detection ?")
|
| 140 |
|
|
@@ -155,28 +159,38 @@ st.markdown("""Common applications of Object Detection include:
|
|
| 155 |
- **Retail** 🏬 : Implementing smart shelves and checkout systems that use object detection to track inventory and monitor stock levels.
|
| 156 |
- **Healthcare** 👨⚕️: Detecting and tracking anomalies in medical images, such as tumors or abnormalities, for diagnostic purposes or prevention.
|
| 157 |
- **Manufacturing** 🏭: Quality control on production lines by detecting defects or irregularities in manufactured products. Ensuring workplace safety by monitoring the movement of workers and equipment.
|
| 158 |
-
- **Fashion and E-commerce** 🛍️ : Improving virtual try-on experiences by accurately detecting and placing virtual clothing items on users.
|
| 159 |
""")
|
| 160 |
|
| 161 |
|
|
|
|
|
|
|
| 162 |
st.markdown(" ")
|
| 163 |
st.divider()
|
| 164 |
|
| 165 |
-
st.markdown("
|
| 166 |
# st.info("""This use case showcases the application of **Object detection** to detect clothing items/features on images. <br>
|
| 167 |
# The images used were gathered from Dior's""")
|
| 168 |
-
st.info("""
|
| 169 |
-
|
|
|
|
|
|
|
| 170 |
|
| 171 |
st.markdown(" ")
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 172 |
|
| 173 |
-
images_dior = [os.path.join("data/dior_show/images",url) for url in os.listdir("data/dior_show/images") if url != "results"]
|
| 174 |
-
columns_img = st.columns(4)
|
| 175 |
-
for img, col in zip(images_dior,columns_img):
|
| 176 |
-
with col:
|
| 177 |
-
st.image(img)
|
| 178 |
|
| 179 |
st.markdown(" ")
|
|
|
|
| 180 |
|
| 181 |
|
| 182 |
st.markdown("### About the model 📚")
|
|
@@ -204,12 +218,12 @@ st.markdown("")
|
|
| 204 |
############## SELECT AN IMAGE ###############
|
| 205 |
|
| 206 |
st.markdown("### Select an image 🖼️")
|
| 207 |
-
|
| 208 |
|
| 209 |
image_ = None
|
| 210 |
fashion_images_path = r"data/dior_show/images"
|
| 211 |
list_images = os.listdir(fashion_images_path)
|
| 212 |
-
image_name = st.selectbox("
|
| 213 |
image_ = os.path.join(fashion_images_path, image_name)
|
| 214 |
st.image(image_, width=300)
|
| 215 |
|
|
@@ -278,13 +292,19 @@ dict_cats_final = {key:value for (key,value) in dict_cats.items() if value in se
|
|
| 278 |
############## SELECT A THRESHOLD ###############
|
| 279 |
|
| 280 |
st.markdown("### Define a threshold for predictions 🔎")
|
| 281 |
-
st.markdown("""
|
| 282 |
-
Objects that are given a lower score than the chosen threshold will be ignored in the final results
|
| 283 |
-
|
| 284 |
-
|
|
|
|
| 285 |
|
|
|
|
|
|
|
| 286 |
|
| 287 |
-
st.
|
|
|
|
|
|
|
|
|
|
| 288 |
|
| 289 |
st.markdown(" ")
|
| 290 |
|
|
@@ -346,7 +366,8 @@ if run_model:
|
|
| 346 |
# PLOT BOUNDING BOX AND BARS/PROBA
|
| 347 |
col1, col2 = st.columns(2)
|
| 348 |
with col1:
|
| 349 |
-
|
|
|
|
| 350 |
bboxes_scaled = rescale_bboxes(outputs.pred_boxes[0, keep].cpu(), image.size)
|
| 351 |
colors_used = plot_results(image, probas[keep], bboxes_scaled)
|
| 352 |
|
|
@@ -356,7 +377,12 @@ if run_model:
|
|
| 356 |
st.error("""No objects were detected on the image.
|
| 357 |
Decrease your threshold or choose differents items to detect.""")
|
| 358 |
else:
|
|
|
|
|
|
|
|
|
|
|
|
|
| 359 |
visualize_probas(probas, threshold, colors_used)
|
|
|
|
| 360 |
|
| 361 |
|
| 362 |
else:
|
|
|
|
| 12 |
from transformers import YolosFeatureExtractor, YolosForObjectDetection
|
| 13 |
from torchvision.transforms import ToTensor, ToPILImage
|
| 14 |
from annotated_text import annotated_text
|
| 15 |
+
from st_pages import add_indentation
|
| 16 |
+
|
| 17 |
+
#add_indentation()
|
| 18 |
|
| 19 |
|
| 20 |
st.set_page_config(layout="wide")
|
|
|
|
| 137 |
|
| 138 |
######################################################################################################################################
|
| 139 |
|
| 140 |
+
#st.image("images/od_header.jpg")
|
| 141 |
+
st.markdown("# Object Detection 📹")
|
| 142 |
|
| 143 |
st.markdown("### What is Object Detection ?")
|
| 144 |
|
|
|
|
| 159 |
- **Retail** 🏬 : Implementing smart shelves and checkout systems that use object detection to track inventory and monitor stock levels.
|
| 160 |
- **Healthcare** 👨⚕️: Detecting and tracking anomalies in medical images, such as tumors or abnormalities, for diagnostic purposes or prevention.
|
| 161 |
- **Manufacturing** 🏭: Quality control on production lines by detecting defects or irregularities in manufactured products. Ensuring workplace safety by monitoring the movement of workers and equipment.
|
|
|
|
| 162 |
""")
|
| 163 |
|
| 164 |
|
| 165 |
+
|
| 166 |
+
############################# USE CASE #############################
|
| 167 |
st.markdown(" ")
|
| 168 |
st.divider()
|
| 169 |
|
| 170 |
+
st.markdown("# Fashion Object Detection 👗")
|
| 171 |
# st.info("""This use case showcases the application of **Object detection** to detect clothing items/features on images. <br>
|
| 172 |
# The images used were gathered from Dior's""")
|
| 173 |
+
st.info("""**Object detection models** can very valuable for fashion retailers wishing to improve customer experience by providing, for example, **product recognition**, **visual search**
|
| 174 |
+
and even **virtual try-ons**.
|
| 175 |
+
In this use case, we are going to show an object detection model that as able to identify and locate different articles of clothings on fashipn show images.
|
| 176 |
+
""")
|
| 177 |
|
| 178 |
st.markdown(" ")
|
| 179 |
+
st.markdown(" ")
|
| 180 |
+
|
| 181 |
+
# images_dior = [os.path.join("data/dior_show/images",url) for url in os.listdir("data/dior_show/images") if url != "results"]
|
| 182 |
+
# columns_img = st.columns(4)
|
| 183 |
+
# for img, col in zip(images_dior,columns_img):
|
| 184 |
+
# with col:
|
| 185 |
+
# st.image(img)
|
| 186 |
+
|
| 187 |
+
_, col, _ = st.columns([0.1,0.8,0.1])
|
| 188 |
+
with col:
|
| 189 |
+
st.image("images/fashion_od2.png")
|
| 190 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 191 |
|
| 192 |
st.markdown(" ")
|
| 193 |
+
st.markdown(" ")
|
| 194 |
|
| 195 |
|
| 196 |
st.markdown("### About the model 📚")
|
|
|
|
| 218 |
############## SELECT AN IMAGE ###############
|
| 219 |
|
| 220 |
st.markdown("### Select an image 🖼️")
|
| 221 |
+
st.markdown("""The images provided were taken from **Dior's 2020 Fall Women Fashion Show**""")
|
| 222 |
|
| 223 |
image_ = None
|
| 224 |
fashion_images_path = r"data/dior_show/images"
|
| 225 |
list_images = os.listdir(fashion_images_path)
|
| 226 |
+
image_name = st.selectbox("Choose an image", list_images)
|
| 227 |
image_ = os.path.join(fashion_images_path, image_name)
|
| 228 |
st.image(image_, width=300)
|
| 229 |
|
|
|
|
| 292 |
############## SELECT A THRESHOLD ###############
|
| 293 |
|
| 294 |
st.markdown("### Define a threshold for predictions 🔎")
|
| 295 |
+
st.markdown("""In this section, you can select a threshold for the model's final predictions. <br>
|
| 296 |
+
Objects that are given a lower score than the chosen threshold will be ignored in the final results""", unsafe_allow_html=True)
|
| 297 |
+
st.info("""**Note**: Object detection models detect objects using bounding boxes as well as assign objects to specific classes.
|
| 298 |
+
Each object is given a class based on a probability score computed by the model. A high probability signals that the model is confident in its prediction.
|
| 299 |
+
On the contrary, a lower probability score signals a level of uncertainty.""")
|
| 300 |
|
| 301 |
+
st.markdown(" ")
|
| 302 |
+
#st.markdown("The images below are examples of probability scores given by object detection models for each element detected.")
|
| 303 |
|
| 304 |
+
_, col, _ = st.columns([0.2,0.6,0.2])
|
| 305 |
+
with col:
|
| 306 |
+
st.image("images/probability_od.png",
|
| 307 |
+
caption="Examples of object detection with bounding boses and probability scores")
|
| 308 |
|
| 309 |
st.markdown(" ")
|
| 310 |
|
|
|
|
| 366 |
# PLOT BOUNDING BOX AND BARS/PROBA
|
| 367 |
col1, col2 = st.columns(2)
|
| 368 |
with col1:
|
| 369 |
+
st.markdown(" ")
|
| 370 |
+
st.markdown("##### 1. Bounding box results")
|
| 371 |
bboxes_scaled = rescale_bboxes(outputs.pred_boxes[0, keep].cpu(), image.size)
|
| 372 |
colors_used = plot_results(image, probas[keep], bboxes_scaled)
|
| 373 |
|
|
|
|
| 377 |
st.error("""No objects were detected on the image.
|
| 378 |
Decrease your threshold or choose differents items to detect.""")
|
| 379 |
else:
|
| 380 |
+
st.markdown(" ")
|
| 381 |
+
st.markdown("##### 2. Probability score of each object")
|
| 382 |
+
st.info("""**Note**: Some items might have been detected more than once on the image.
|
| 383 |
+
For these items, we've computed the average probability score across all detections.""")
|
| 384 |
visualize_probas(probas, threshold, colors_used)
|
| 385 |
+
|
| 386 |
|
| 387 |
|
| 388 |
else:
|
pages/recommendation_system.py
CHANGED
|
@@ -6,21 +6,24 @@ import pickle
|
|
| 6 |
import os
|
| 7 |
import altair as alt
|
| 8 |
import plotly.express as px
|
|
|
|
| 9 |
from sklearn.preprocessing import MinMaxScaler
|
| 10 |
from sklearn.metrics.pairwise import cosine_similarity
|
| 11 |
from annotated_text import annotated_text
|
| 12 |
from utils import load_data_pickle, load_model_pickle, load_data_csv
|
|
|
|
| 13 |
|
|
|
|
| 14 |
|
| 15 |
|
| 16 |
st.set_page_config(layout="wide")
|
| 17 |
|
| 18 |
-
|
| 19 |
-
st.markdown("# Recommendation
|
| 20 |
|
| 21 |
st.markdown("### What is a Recommendation System ?")
|
| 22 |
|
| 23 |
-
st.info("""**Recommendation systems** are
|
| 24 |
They are very common in social media platforms such as TikTok, Youtube or Instagram or e-commerce websites as they help improve and personalize a consumer's experience.""")
|
| 25 |
|
| 26 |
st.markdown("""There are two methods to build recommendation systems:
|
|
@@ -123,7 +126,7 @@ if select_usecase == "Movie recommendation system 📽️":
|
|
| 123 |
|
| 124 |
|
| 125 |
# Description of the use case
|
| 126 |
-
st.markdown("""
|
| 127 |
|
| 128 |
#st.info(""" """)
|
| 129 |
|
|
@@ -349,7 +352,10 @@ From gleaming skyscrapers to vibrant neighborhoods, this cosmopolitan gem in Sou
|
|
| 349 |
if see_top_places:
|
| 350 |
st.markdown(top_places)
|
| 351 |
|
| 352 |
-
|
|
|
|
|
|
|
|
|
|
| 353 |
|
| 354 |
st.info("""This use case shows how you can create personalized hotel recommendations using a recommendation system with **content-based Filtering**.
|
| 355 |
Analyzing location, amenities, price, and reviews, the model suggests tailored hotel recommendation based on the user's preference.
|
|
|
|
| 6 |
import os
|
| 7 |
import altair as alt
|
| 8 |
import plotly.express as px
|
| 9 |
+
|
| 10 |
from sklearn.preprocessing import MinMaxScaler
|
| 11 |
from sklearn.metrics.pairwise import cosine_similarity
|
| 12 |
from annotated_text import annotated_text
|
| 13 |
from utils import load_data_pickle, load_model_pickle, load_data_csv
|
| 14 |
+
from st_pages import add_indentation
|
| 15 |
|
| 16 |
+
#add_indentation()
|
| 17 |
|
| 18 |
|
| 19 |
st.set_page_config(layout="wide")
|
| 20 |
|
| 21 |
+
#st.image("images/recom_system_header.png")
|
| 22 |
+
st.markdown("# Recommendation systems 🛒")
|
| 23 |
|
| 24 |
st.markdown("### What is a Recommendation System ?")
|
| 25 |
|
| 26 |
+
st.info("""**Recommendation systems** are algorithms built to **suggest** or **recommend** **products** to consumers.
|
| 27 |
They are very common in social media platforms such as TikTok, Youtube or Instagram or e-commerce websites as they help improve and personalize a consumer's experience.""")
|
| 28 |
|
| 29 |
st.markdown("""There are two methods to build recommendation systems:
|
|
|
|
| 126 |
|
| 127 |
|
| 128 |
# Description of the use case
|
| 129 |
+
st.markdown("""# Movie Recommendation System 📽️""")
|
| 130 |
|
| 131 |
#st.info(""" """)
|
| 132 |
|
|
|
|
| 352 |
if see_top_places:
|
| 353 |
st.markdown(top_places)
|
| 354 |
|
| 355 |
+
|
| 356 |
+
|
| 357 |
+
|
| 358 |
+
st.markdown("""# Hotel Recommendation System 🛎️""")
|
| 359 |
|
| 360 |
st.info("""This use case shows how you can create personalized hotel recommendations using a recommendation system with **content-based Filtering**.
|
| 361 |
Analyzing location, amenities, price, and reviews, the model suggests tailored hotel recommendation based on the user's preference.
|
pages/sentiment_analysis.py
CHANGED
|
@@ -7,11 +7,14 @@ import pandas as pd
|
|
| 7 |
import numpy as np
|
| 8 |
import altair as alt
|
| 9 |
import plotly.express as px
|
|
|
|
| 10 |
|
| 11 |
from pysentimiento import create_analyzer
|
| 12 |
from utils import load_data_pickle
|
| 13 |
|
| 14 |
st.set_page_config(layout="wide")
|
|
|
|
|
|
|
| 15 |
|
| 16 |
def clean_text(text):
|
| 17 |
pattern_punct = r"[^\w\s.',:/]"
|
|
@@ -30,8 +33,8 @@ def load_sa_model():
|
|
| 30 |
|
| 31 |
|
| 32 |
|
| 33 |
-
|
| 34 |
-
st.markdown("# Sentiment Analysis")
|
| 35 |
|
| 36 |
st.markdown("### What is Sentiment Analysis ?")
|
| 37 |
|
|
@@ -62,14 +65,14 @@ st.divider()
|
|
| 62 |
#use_case = st.selectbox("", sa_pages, label_visibility="collapsed")
|
| 63 |
|
| 64 |
|
| 65 |
-
st.markdown("
|
| 66 |
st.info("""In this use case, **sentiment analysis** is used to predict the **polarity** (negative, neutral, positive) of customer reviews.
|
| 67 |
You can try the application by using the provided starbucks customer reviews, or by writing your own.""")
|
| 68 |
st.markdown(" ")
|
| 69 |
|
| 70 |
-
_, col, _ = st.columns([0.
|
| 71 |
with col:
|
| 72 |
-
st.image("images/reviews.
|
| 73 |
|
| 74 |
st.markdown(" ")
|
| 75 |
|
|
|
|
| 7 |
import numpy as np
|
| 8 |
import altair as alt
|
| 9 |
import plotly.express as px
|
| 10 |
+
from st_pages import add_indentation
|
| 11 |
|
| 12 |
from pysentimiento import create_analyzer
|
| 13 |
from utils import load_data_pickle
|
| 14 |
|
| 15 |
st.set_page_config(layout="wide")
|
| 16 |
+
#add_indentation()
|
| 17 |
+
|
| 18 |
|
| 19 |
def clean_text(text):
|
| 20 |
pattern_punct = r"[^\w\s.',:/]"
|
|
|
|
| 33 |
|
| 34 |
|
| 35 |
|
| 36 |
+
#st.image("images/sa_header.jpg")
|
| 37 |
+
st.markdown("# Sentiment Analysis 👍")
|
| 38 |
|
| 39 |
st.markdown("### What is Sentiment Analysis ?")
|
| 40 |
|
|
|
|
| 65 |
#use_case = st.selectbox("", sa_pages, label_visibility="collapsed")
|
| 66 |
|
| 67 |
|
| 68 |
+
st.markdown("# Customer Review Analysis 📝")
|
| 69 |
st.info("""In this use case, **sentiment analysis** is used to predict the **polarity** (negative, neutral, positive) of customer reviews.
|
| 70 |
You can try the application by using the provided starbucks customer reviews, or by writing your own.""")
|
| 71 |
st.markdown(" ")
|
| 72 |
|
| 73 |
+
_, col, _ = st.columns([0.2,0.6,0.2])
|
| 74 |
with col:
|
| 75 |
+
st.image("images/reviews.png",use_column_width=True)
|
| 76 |
|
| 77 |
st.markdown(" ")
|
| 78 |
|
pages/supervised_unsupervised_page.py
CHANGED
|
@@ -7,12 +7,14 @@ import plotly.express as px
|
|
| 7 |
from PIL import Image
|
| 8 |
|
| 9 |
from utils import load_data_pickle, load_model_pickle
|
|
|
|
| 10 |
from annotated_text import annotated_text
|
| 11 |
|
| 12 |
#####################################################################################
|
| 13 |
# PAGE CONFIG
|
| 14 |
#####################################################################################
|
| 15 |
|
|
|
|
| 16 |
st.set_page_config(layout="wide")
|
| 17 |
|
| 18 |
|
|
@@ -21,20 +23,21 @@ st.set_page_config(layout="wide")
|
|
| 21 |
# INTRO
|
| 22 |
#####################################################################################
|
| 23 |
|
| 24 |
-
|
| 25 |
-
st.markdown("# Supervised vs Unsupervised Learning")
|
| 26 |
|
| 27 |
st.info("""There are two main types of models in the field of Data Science, **Supervised** and **Unsupervised learning** models.
|
| 28 |
Being able to distinguish which type of model fits your data is an essential step in building any AI project.""")
|
| 29 |
|
|
|
|
| 30 |
st.markdown(" ")
|
| 31 |
#st.markdown("## What are the differences between both ?")
|
| 32 |
|
| 33 |
col1, col2 = st.columns(2, gap="large")
|
| 34 |
|
| 35 |
with col1:
|
| 36 |
-
st.markdown("
|
| 37 |
-
st.markdown("""
|
| 38 |
Labeled data provides to the model the desired output, which it will then use to learn relevant patterns and make predictions.
|
| 39 |
- A model is first **trained** to make predictions using labeled data
|
| 40 |
- The trained model can then be used to **predict values** for new data.
|
|
@@ -43,15 +46,15 @@ with col1:
|
|
| 43 |
st.image("images/supervised_learner.png", caption="An example of supervised learning")
|
| 44 |
|
| 45 |
with col2:
|
| 46 |
-
st.markdown("
|
| 47 |
-
st.markdown("""
|
| 48 |
The algorithm will identify any naturally occurring patterns in the dataset using **unlabeled data**.
|
| 49 |
- They can be useful for applications where the goal is to discover **unknown groupings** in the data.
|
| 50 |
- They are also used to identify unusual patterns or **outliers**.
|
| 51 |
""", unsafe_allow_html=True)
|
| 52 |
st.markdown(" ")
|
| 53 |
st.image("images/unsupervised_learning.png", caption="An example of unsupervised Learning",
|
| 54 |
-
|
| 55 |
|
| 56 |
st.markdown(" ")
|
| 57 |
|
|
@@ -88,7 +91,7 @@ if learning_type == "Supervised Learning":
|
|
| 88 |
|
| 89 |
## Description of the use case
|
| 90 |
st.divider()
|
| 91 |
-
st.markdown("
|
| 92 |
st.info("""**Classification** is a type of supervised learning where the goal is to categorize input data into predefined classes or categories.
|
| 93 |
In this case, we will build a **credit score classification** model that predicts if a client will have a **'Bad'**, **'Standard'** or **'Good'** credit score.""")
|
| 94 |
st.markdown(" ")
|
|
@@ -347,7 +350,7 @@ if learning_type == "Supervised Learning":
|
|
| 347 |
|
| 348 |
## Description of the use case
|
| 349 |
st.divider()
|
| 350 |
-
st.markdown("
|
| 351 |
st.info(""" Classification is a type of supervised learning model whose goal is to categorize input data into predefined classes or categories.
|
| 352 |
In this example, we will build a **customer churn classification model** that can predict whether a customer is likely to leave a company's service in the future using historical data.
|
| 353 |
""")
|
|
@@ -670,7 +673,7 @@ if learning_type == "Unsupervised Learning":
|
|
| 670 |
|
| 671 |
# st.divider()
|
| 672 |
st.divider()
|
| 673 |
-
st.markdown("
|
| 674 |
|
| 675 |
st.info("""**Unsupervised learning** models are valulable tools for cases where you want your model to discover patterns by itself, without having to give it examples to learn from (especially if you don't have labeled data).
|
| 676 |
In this use case, we will show how they can be useful for **Customer Segmentation** to detect unknown groups of clients in a company's customer base.
|
|
|
|
| 7 |
from PIL import Image
|
| 8 |
|
| 9 |
from utils import load_data_pickle, load_model_pickle
|
| 10 |
+
from st_pages import add_indentation
|
| 11 |
from annotated_text import annotated_text
|
| 12 |
|
| 13 |
#####################################################################################
|
| 14 |
# PAGE CONFIG
|
| 15 |
#####################################################################################
|
| 16 |
|
| 17 |
+
#add_indentation()
|
| 18 |
st.set_page_config(layout="wide")
|
| 19 |
|
| 20 |
|
|
|
|
| 23 |
# INTRO
|
| 24 |
#####################################################################################
|
| 25 |
|
| 26 |
+
#st.image("images/ML_header.jpg", use_column_width=True)
|
| 27 |
+
st.markdown("# Supervised vs Unsupervised Learning 🔍")
|
| 28 |
|
| 29 |
st.info("""There are two main types of models in the field of Data Science, **Supervised** and **Unsupervised learning** models.
|
| 30 |
Being able to distinguish which type of model fits your data is an essential step in building any AI project.""")
|
| 31 |
|
| 32 |
+
st.markdown(" ")
|
| 33 |
st.markdown(" ")
|
| 34 |
#st.markdown("## What are the differences between both ?")
|
| 35 |
|
| 36 |
col1, col2 = st.columns(2, gap="large")
|
| 37 |
|
| 38 |
with col1:
|
| 39 |
+
st.markdown("## Supervised Learning")
|
| 40 |
+
st.markdown("""Supervised learning models are trained by learning from **labeled data**. <br>
|
| 41 |
Labeled data provides to the model the desired output, which it will then use to learn relevant patterns and make predictions.
|
| 42 |
- A model is first **trained** to make predictions using labeled data
|
| 43 |
- The trained model can then be used to **predict values** for new data.
|
|
|
|
| 46 |
st.image("images/supervised_learner.png", caption="An example of supervised learning")
|
| 47 |
|
| 48 |
with col2:
|
| 49 |
+
st.markdown("## Unsupervised Learning")
|
| 50 |
+
st.markdown("""Unsupervised learning models learn the data's inherent structure without any explicit guidance on what to look for.
|
| 51 |
The algorithm will identify any naturally occurring patterns in the dataset using **unlabeled data**.
|
| 52 |
- They can be useful for applications where the goal is to discover **unknown groupings** in the data.
|
| 53 |
- They are also used to identify unusual patterns or **outliers**.
|
| 54 |
""", unsafe_allow_html=True)
|
| 55 |
st.markdown(" ")
|
| 56 |
st.image("images/unsupervised_learning.png", caption="An example of unsupervised Learning",
|
| 57 |
+
use_column_width=True)
|
| 58 |
|
| 59 |
st.markdown(" ")
|
| 60 |
|
|
|
|
| 91 |
|
| 92 |
## Description of the use case
|
| 93 |
st.divider()
|
| 94 |
+
st.markdown("# Credit score classification 💯")
|
| 95 |
st.info("""**Classification** is a type of supervised learning where the goal is to categorize input data into predefined classes or categories.
|
| 96 |
In this case, we will build a **credit score classification** model that predicts if a client will have a **'Bad'**, **'Standard'** or **'Good'** credit score.""")
|
| 97 |
st.markdown(" ")
|
|
|
|
| 350 |
|
| 351 |
## Description of the use case
|
| 352 |
st.divider()
|
| 353 |
+
st.markdown("# Customer churn prediction ❌")
|
| 354 |
st.info(""" Classification is a type of supervised learning model whose goal is to categorize input data into predefined classes or categories.
|
| 355 |
In this example, we will build a **customer churn classification model** that can predict whether a customer is likely to leave a company's service in the future using historical data.
|
| 356 |
""")
|
|
|
|
| 673 |
|
| 674 |
# st.divider()
|
| 675 |
st.divider()
|
| 676 |
+
st.markdown("# Customer Segmentation 🧑🤝🧑")
|
| 677 |
|
| 678 |
st.info("""**Unsupervised learning** models are valulable tools for cases where you want your model to discover patterns by itself, without having to give it examples to learn from (especially if you don't have labeled data).
|
| 679 |
In this use case, we will show how they can be useful for **Customer Segmentation** to detect unknown groups of clients in a company's customer base.
|