.
diff --git a/third_party/mmyolo/MANIFEST.in b/third_party/mmyolo/MANIFEST.in
new file mode 100644
index 0000000000000000000000000000000000000000..5bf1d9ebabcc5ca1f28207b62eab10141474db51
--- /dev/null
+++ b/third_party/mmyolo/MANIFEST.in
@@ -0,0 +1,6 @@
+include requirements/*.txt
+include mmyolo/VERSION
+include mmyolo/.mim/model-index.yml
+include mmyolo/.mim/demo/*/*
+recursive-include mmyolo/.mim/configs *.py *.yml
+recursive-include mmyolo/.mim/tools *.sh *.py
diff --git a/third_party/mmyolo/README.md b/third_party/mmyolo/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..b799a759c367938cbeea728b0763a36cda5b2544
--- /dev/null
+++ b/third_party/mmyolo/README.md
@@ -0,0 +1,428 @@
+
+

+
+
+
+
+[](https://pypi.org/project/mmyolo)
+[](https://mmyolo.readthedocs.io/en/latest/)
+[](https://github.com/open-mmlab/mmyolo/actions)
+[](https://codecov.io/gh/open-mmlab/mmyolo)
+[](https://github.com/open-mmlab/mmyolo/blob/main/LICENSE)
+[](https://github.com/open-mmlab/mmyolo/issues)
+[](https://github.com/open-mmlab/mmyolo/issues)
+
+[📘Documentation](https://mmyolo.readthedocs.io/en/latest/) |
+[🛠️Installation](https://mmyolo.readthedocs.io/en/latest/get_started/installation.html) |
+[👀Model Zoo](https://mmyolo.readthedocs.io/en/latest/model_zoo.html) |
+[🆕Update News](https://mmyolo.readthedocs.io/en/latest/notes/changelog.html) |
+[🤔Reporting Issues](https://github.com/open-mmlab/mmyolo/issues/new/choose)
+
+
+
+English | [简体中文](README_zh-CN.md)
+
+
+
+
+
+ 
+

+
+ 
+
+
+ 
+
+
+ 
+
+
+ 
+
+
+ 
+
+

+
 +
+
+
+
+Major features
+
+- 🕹️ **Unified and convenient benchmark**
+
+ MMYOLO unifies the implementation of modules in various YOLO algorithms and provides a unified benchmark. Users can compare and analyze in a fair and convenient way.
+
+- 📚 **Rich and detailed documentation**
+
+ MMYOLO provides rich documentation for getting started, model deployment, advanced usages, and algorithm analysis, making it easy for users at different levels to get started and make extensions quickly.
+
+- 🧩 **Modular Design**
+
+ MMYOLO decomposes the framework into different components where users can easily customize a model by combining different modules with various training and testing strategies.
+
+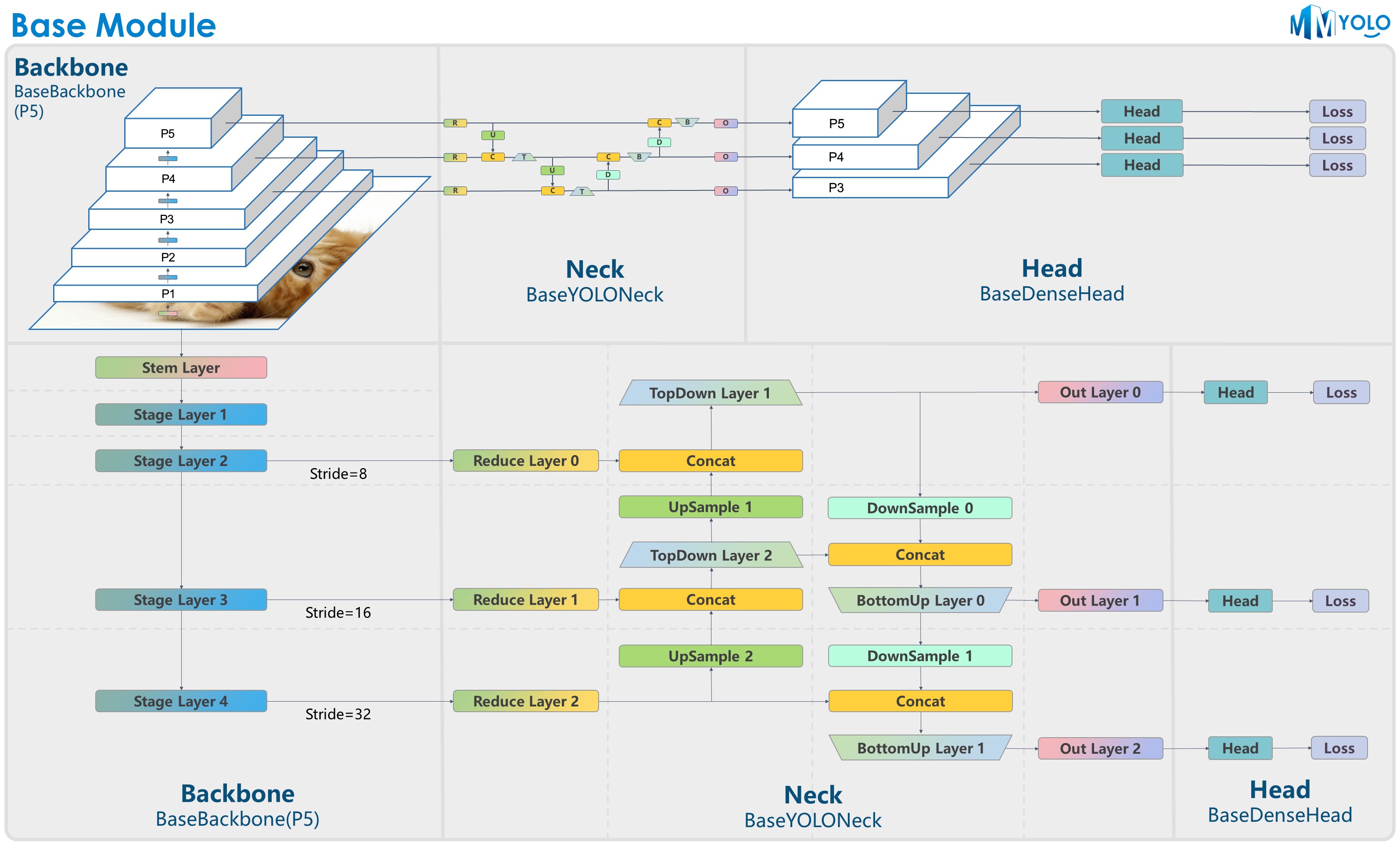 + The figure above is contributed by RangeKing@GitHub, thank you very much!
+
+And the figure of P6 model is in [model_design.md](docs/en/recommended_topics/model_design.md).
+
+
+ The figure above is contributed by RangeKing@GitHub, thank you very much!
+
+And the figure of P6 model is in [model_design.md](docs/en/recommended_topics/model_design.md).
+
+
+
+## 🛠️ Installation [🔝](#-table-of-contents)
+
+MMYOLO relies on PyTorch, MMCV, MMEngine, and MMDetection. Below are quick steps for installation. Please refer to the [Install Guide](docs/en/get_started/installation.md) for more detailed instructions.
+
+```shell
+conda create -n mmyolo python=3.8 pytorch==1.10.1 torchvision==0.11.2 cudatoolkit=11.3 -c pytorch -y
+conda activate mmyolo
+pip install openmim
+mim install "mmengine>=0.6.0"
+mim install "mmcv>=2.0.0rc4,<2.1.0"
+mim install "mmdet>=3.0.0,<4.0.0"
+git clone https://github.com/open-mmlab/mmyolo.git
+cd mmyolo
+# Install albumentations
+pip install -r requirements/albu.txt
+# Install MMYOLO
+mim install -v -e .
+```
+
+## 👨🏫 Tutorial [🔝](#-table-of-contents)
+
+MMYOLO is based on MMDetection and adopts the same code structure and design approach. To get better use of this, please read [MMDetection Overview](https://mmdetection.readthedocs.io/en/latest/get_started.html) for the first understanding of MMDetection.
+
+The usage of MMYOLO is almost identical to MMDetection and all tutorials are straightforward to use, you can also learn about [MMDetection User Guide and Advanced Guide](https://mmdetection.readthedocs.io/en/3.x/).
+
+For different parts from MMDetection, we have also prepared user guides and advanced guides, please read our [documentation](https://mmyolo.readthedocs.io/zenh_CN/latest/).
+
+
+Get Started
+
+- [Overview](docs/en/get_started/overview.md)
+- [Dependencies](docs/en/get_started/dependencies.md)
+- [Installation](docs/en/get_started/installation.md)
+- [15 minutes object detection](docs/en/get_started/15_minutes_object_detection.md)
+- [15 minutes rotated object detection](docs/en/get_started/15_minutes_rotated_object_detection.md)
+- [15 minutes instance segmentation](docs/en/get_started/15_minutes_instance_segmentation.md)
+- [Resources summary](docs/en/get_started/article.md)
+
+
+
+
+Recommended Topics
+
+- [How to contribute code to MMYOLO](docs/en/recommended_topics/contributing.md)
+- [Training testing tricks](docs/en/recommended_topics/training_testing_tricks.md)
+- [MMYOLO model design](docs/en/recommended_topics/model_design.md)
+- [Algorithm principles and implementation](docs/en/recommended_topics/algorithm_descriptions/)
+- [Replace the backbone network](docs/en/recommended_topics/replace_backbone.md)
+- [MMYOLO model complexity analysis](docs/en/recommended_topics/complexity_analysis.md)
+- [Annotation-to-deployment workflow for custom dataset](docs/en/recommended_topics/labeling_to_deployment_tutorials.md)
+- [Visualization](docs/en/recommended_topics/visualization.md)
+- [Model deployment](docs/en/recommended_topics/deploy/)
+- [Troubleshooting steps](docs/en/recommended_topics/troubleshooting_steps.md)
+- [MMYOLO application examples](docs/en/recommended_topics/application_examples/)
+- [MM series repo essential basics](docs/en/recommended_topics/mm_basics.md)
+- [Dataset preparation and description](docs/en/recommended_topics/dataset_preparation.md)
+
+
+
+
+Common Usage
+
+- [Resume training](docs/en/common_usage/resume_training.md)
+- [Enabling and disabling SyncBatchNorm](docs/en/common_usage/syncbn.md)
+- [Enabling AMP](docs/en/common_usage/amp_training.md)
+- [Multi-scale training and testing](docs/en/common_usage/ms_training_testing.md)
+- [TTA Related Notes](docs/en/common_usage/tta.md)
+- [Add plugins to the backbone network](docs/en/common_usage/plugins.md)
+- [Freeze layers](docs/en/common_usage/freeze_layers.md)
+- [Output model predictions](docs/en/common_usage/output_predictions.md)
+- [Set random seed](docs/en/common_usage/set_random_seed.md)
+- [Module combination](docs/en/common_usage/module_combination.md)
+- [Cross-library calls using mim](docs/en/common_usage/mim_usage.md)
+- [Apply multiple Necks](docs/en/common_usage/multi_necks.md)
+- [Specify specific device training or inference](docs/en/common_usage/specify_device.md)
+- [Single and multi-channel application examples](docs/en/common_usage/single_multi_channel_applications.md)
+
+
+
+
+Useful Tools
+
+- [Browse coco json](docs/en/useful_tools/browse_coco_json.md)
+- [Browse dataset](docs/en/useful_tools/browse_dataset.md)
+- [Print config](docs/en/useful_tools/print_config.md)
+- [Dataset analysis](docs/en/useful_tools/dataset_analysis.md)
+- [Optimize anchors](docs/en/useful_tools/optimize_anchors.md)
+- [Extract subcoco](docs/en/useful_tools/extract_subcoco.md)
+- [Visualization scheduler](docs/en/useful_tools/vis_scheduler.md)
+- [Dataset converters](docs/en/useful_tools/dataset_converters.md)
+- [Download dataset](docs/en/useful_tools/download_dataset.md)
+- [Log analysis](docs/en/useful_tools/log_analysis.md)
+- [Model converters](docs/en/useful_tools/model_converters.md)
+
+
+
+
+Basic Tutorials
+
+- [Learn about configs with YOLOv5](docs/en/tutorials/config.md)
+- [Data flow](docs/en/tutorials/data_flow.md)
+- [Rotated detection](docs/en/tutorials/rotated_detection.md)
+- [Custom Installation](docs/en/tutorials/custom_installation.md)
+- [Common Warning Notes](docs/zh_cn/tutorials/warning_notes.md)
+- [FAQ](docs/en/tutorials/faq.md)
+
+
+
+
+Advanced Tutorials
+
+- [MMYOLO cross-library application](docs/en/advanced_guides/cross-library_application.md)
+
+
+
+
+Descriptions
+
+- [Changelog](docs/en/notes/changelog.md)
+- [Compatibility](docs/en/notes/compatibility.md)
+- [Conventions](docs/en/notes/conventions.md)
+- [Code Style](docs/en/notes/code_style.md)
+
+
+
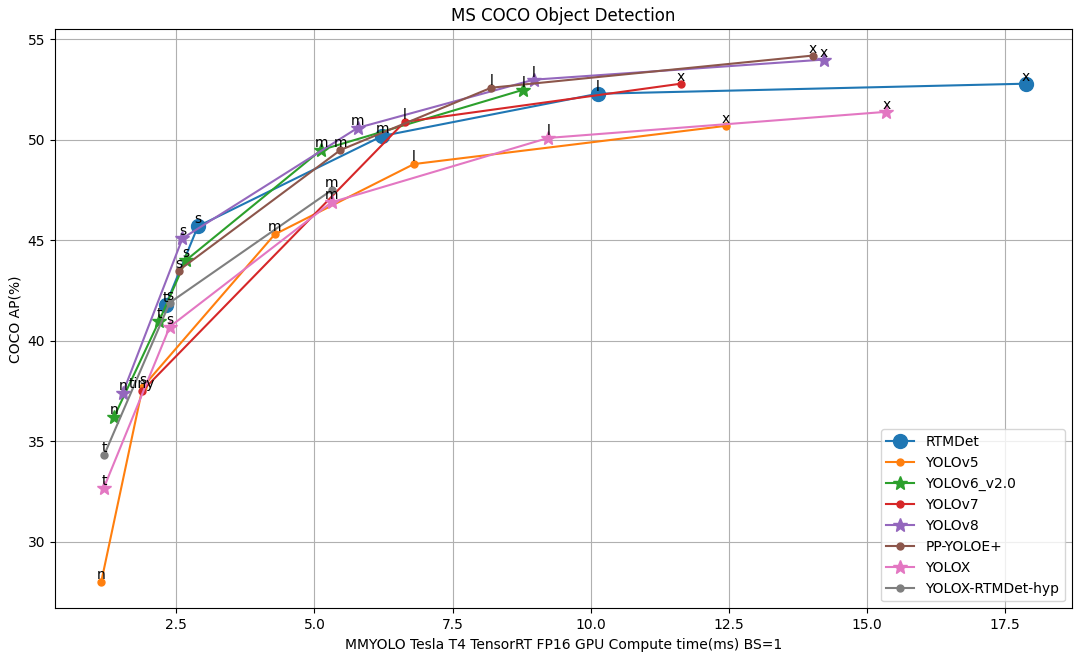
+## 📊 Overview of Benchmark and Model Zoo [🔝](#-table-of-contents)
+
+
+
+
+Supported Tasks
+
+- [x] Object detection
+- [x] Rotated object detection
+
+
+
+
+Supported Algorithms
+
+- [x] [YOLOv5](configs/yolov5)
+- [ ] [YOLOv5u](configs/yolov5/yolov5u) (Inference only)
+- [x] [YOLOX](configs/yolox)
+- [x] [RTMDet](configs/rtmdet)
+- [x] [RTMDet-Rotated](configs/rtmdet)
+- [x] [YOLOv6](configs/yolov6)
+- [x] [YOLOv7](configs/yolov7)
+- [x] [PPYOLOE](configs/ppyoloe)
+- [x] [YOLOv8](configs/yolov8)
+
+
+
+
+Supported Datasets
+
+- [x] COCO Dataset
+- [x] VOC Dataset
+- [x] CrowdHuman Dataset
+- [x] DOTA 1.0 Dataset
+
+
+
+
+
+ Module Components
+
+
+
+
+ |
+ Backbones
+ |
+
+ Necks
+ |
+
+ Loss
+ |
+
+ Common
+ |
+
+
+
+
+ - YOLOv5CSPDarknet
+ - YOLOv8CSPDarknet
+ - YOLOXCSPDarknet
+ - EfficientRep
+ - CSPNeXt
+ - YOLOv7Backbone
+ - PPYOLOECSPResNet
+ - mmdet backbone
+ - mmcls backbone
+ - timm
+
+ |
+
+
+ - YOLOv5PAFPN
+ - YOLOv8PAFPN
+ - YOLOv6RepPAFPN
+ - YOLOXPAFPN
+ - CSPNeXtPAFPN
+ - YOLOv7PAFPN
+ - PPYOLOECSPPAFPN
+
+ |
+
+
+ |
+
+
+ |
+
+
+
+
+
+
+
+
+## ❓ FAQ [🔝](#-table-of-contents)
+
+Please refer to the [FAQ](docs/en/tutorials/faq.md) for frequently asked questions.
+
+## 🙌 Contributing [🔝](#-table-of-contents)
+
+We appreciate all contributions to improving MMYOLO. Ongoing projects can be found in our [GitHub Projects](https://github.com/open-mmlab/mmyolo/projects). Welcome community users to participate in these projects. Please refer to [CONTRIBUTING.md](.github/CONTRIBUTING.md) for the contributing guideline.
+
+## 🤝 Acknowledgement [🔝](#-table-of-contents)
+
+MMYOLO is an open source project that is contributed by researchers and engineers from various colleges and companies. We appreciate all the contributors who implement their methods or add new features, as well as users who give valuable feedback.
+We wish that the toolbox and benchmark could serve the growing research community by providing a flexible toolkit to re-implement existing methods and develop their own new detectors.
+
+
+

+
+

+
+
+
+
+[](https://pypi.org/project/mmyolo)
+[](https://mmyolo.readthedocs.io/zh_CN/latest/)
+[](https://github.com/open-mmlab/mmyolo/actions)
+[](https://codecov.io/gh/open-mmlab/mmyolo)
+[](https://github.com/open-mmlab/mmyolo/blob/main/LICENSE)
+[](https://github.com/open-mmlab/mmyolo/issues)
+[](https://github.com/open-mmlab/mmyolo/issues)
+
+[📘使用文档](https://mmyolo.readthedocs.io/zh_CN/latest/) |
+[🛠️安装教程](https://mmyolo.readthedocs.io/zh_CN/latest/get_started/installation.html) |
+[👀模型库](https://mmyolo.readthedocs.io/zh_CN/latest/model_zoo.html) |
+[🆕更新日志](https://mmyolo.readthedocs.io/zh_CN/latest/notes/changelog.html) |
+[🤔报告问题](https://github.com/open-mmlab/mmyolo/issues/new/choose)
+
+
+
+[English](README.md) | 简体中文
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+

+
[10分钟换遍主干网络.ipynb](https://github.com/open-mmlab/OpenMMLabCourse/blob/main/codes/MMYOLO_tutorials/[实用类第二期]10分钟换遍主干网络.ipynb) |
+| 🌟 | 自定义数据集从标注到部署保姆级教程 | [](https://www.bilibili.com/video/BV1RG4y137i5) [](https://www.bilibili.com/video/BV1JG4y1d7GC) | [自定义数据集从标注到部署保姆级教程](https://github.com/open-mmlab/mmyolo/blob/dev/docs/zh_cn/user_guides/custom_dataset.md) |
+| 🌟 | 顶会第一步 · 模块自定义 | [](https://www.bilibili.com/video/BV1yd4y1j7VD) [](https://www.bilibili.com/video/BV1yd4y1j7VD) | [顶会第一步·模块自定义.ipynb](https://github.com/open-mmlab/OpenMMLabCourse/blob/main/codes/MMYOLO_tutorials/[实用类第四期]顶会第一步·模块自定义.ipynb) |
+
+完整视频列表请参考 [中文解读资源汇总 - 视频](https://mmyolo.readthedocs.io/zh_CN/latest/get_started/article.html)
+
+发布历史和更新细节请参考 [更新日志](https://mmyolo.readthedocs.io/zh_CN/latest/notes/changelog.html)
+
+### ✨ 亮点 [🔝](#-table-of-contents)
+
+我们很高兴向大家介绍我们在实时目标识别任务方面的最新成果 RTMDet,包含了一系列的全卷积单阶段检测模型。 RTMDet 不仅在从 tiny 到 extra-large 尺寸的目标检测模型上实现了最佳的参数量和精度的平衡,而且在实时实例分割和旋转目标检测任务上取得了最先进的成果。 更多细节请参阅[技术报告](https://arxiv.org/abs/2212.07784)。 预训练模型可以在[这里](configs/rtmdet)找到。
+
+[](https://paperswithcode.com/sota/real-time-instance-segmentation-on-mscoco?p=rtmdet-an-empirical-study-of-designing-real)
+[](https://paperswithcode.com/sota/object-detection-in-aerial-images-on-dota-1?p=rtmdet-an-empirical-study-of-designing-real)
+[](https://paperswithcode.com/sota/object-detection-in-aerial-images-on-hrsc2016?p=rtmdet-an-empirical-study-of-designing-real)
+
+| Task | Dataset | AP | FPS(TRT FP16 BS1 3090) |
+| ------------------------ | ------- | ------------------------------------ | ---------------------- |
+| Object Detection | COCO | 52.8 | 322 |
+| Instance Segmentation | COCO | 44.6 | 188 |
+| Rotated Object Detection | DOTA | 78.9(single-scale)/81.3(multi-scale) | 121 |
+
+
+
+
+主要特性
+
+- 🕹️ **统一便捷的算法评测**
+
+ MMYOLO 统一了各类 YOLO 算法模块的实现, 并提供了统一的评测流程,用户可以公平便捷地进行对比分析。
+
+- 📚 **丰富的入门和进阶文档**
+
+ MMYOLO 提供了从入门到部署到进阶和算法解析等一系列文档,方便不同用户快速上手和扩展。
+
+- 🧩 **模块化设计**
+
+ MMYOLO 将框架解耦成不同的模块组件,通过组合不同的模块和训练测试策略,用户可以便捷地构建自定义模型。
+
+
+ 图为 RangeKing@GitHub 提供,非常感谢!
+
+P6 模型图详见 [model_design.md](docs/zh_cn/recommended_topics/model_design.md)。
+
+
+
+## 🛠️ 安装 [🔝](#-table-of-contents)
+
+MMYOLO 依赖 PyTorch, MMCV, MMEngine 和 MMDetection,以下是安装的简要步骤。 更详细的安装指南请参考[安装文档](docs/zh_cn/get_started/installation.md)。
+
+```shell
+conda create -n mmyolo python=3.8 pytorch==1.10.1 torchvision==0.11.2 cudatoolkit=11.3 -c pytorch -y
+conda activate mmyolo
+pip install openmim
+mim install "mmengine>=0.6.0"
+mim install "mmcv>=2.0.0rc4,<2.1.0"
+mim install "mmdet>=3.0.0,<4.0.0"
+git clone https://github.com/open-mmlab/mmyolo.git
+cd mmyolo
+# Install albumentations
+pip install -r requirements/albu.txt
+# Install MMYOLO
+mim install -v -e .
+```
+
+## 👨🏫 教程 [🔝](#-table-of-contents)
+
+MMYOLO 基于 MMDetection 开源库,并且采用相同的代码组织和设计方式。为了更好的使用本开源库,请先阅读 [MMDetection 概述](https://mmdetection.readthedocs.io/zh_CN/latest/get_started.html) 对 MMDetection 进行初步地了解。
+
+MMYOLO 用法和 MMDetection 几乎一致,所有教程都是通用的,你也可以了解 [MMDetection 用户指南和进阶指南](https://mmdetection.readthedocs.io/zh_CN/3.x/) 。
+
+针对和 MMDetection 不同的部分,我们也准备了用户指南和进阶指南,请阅读我们的 [文档](https://mmyolo.readthedocs.io/zh_CN/latest/) 。
+
+
+开启 MMYOLO 之旅
+
+- [概述](docs/zh_cn/get_started/overview.md)
+- [依赖](docs/zh_cn/get_started/dependencies.md)
+- [安装和验证](docs/zh_cn/get_started/installation.md)
+- [15 分钟上手 MMYOLO 目标检测](docs/zh_cn/get_started/15_minutes_object_detection.md)
+- [15 分钟上手 MMYOLO 旋转框目标检测](docs/zh_cn/get_started/15_minutes_rotated_object_detection.md)
+- [15 分钟上手 MMYOLO 实例分割](docs/zh_cn/get_started/15_minutes_instance_segmentation.md)
+- [中文解读资源汇总](docs/zh_cn/get_started/article.md)
+
+
+
+
+推荐专题
+
+- [如何给 MMYOLO 贡献代码](docs/zh_cn/recommended_topics/contributing.md)
+- [训练和测试技巧](docs/zh_cn/recommended_topics/training_testing_tricks.md)
+- [MMYOLO 模型结构设计](docs/zh_cn/recommended_topics/model_design.md)
+- [原理和实现全解析](docs/zh_cn/recommended_topics/algorithm_descriptions/)
+- [轻松更换主干网络](docs/zh_cn/recommended_topics/replace_backbone.md)
+- [MMYOLO 模型复杂度分析](docs/zh_cn/recommended_topics/complexity_analysis.md)
+- [标注+训练+测试+部署全流程](docs/zh_cn/recommended_topics/labeling_to_deployment_tutorials.md)
+- [关于可视化的一切](docs/zh_cn/recommended_topics/visualization.md)
+- [模型部署流程](docs/zh_cn/recommended_topics/deploy/)
+- [常见错误排查步骤](docs/zh_cn/recommended_topics/troubleshooting_steps.md)
+- [MMYOLO 应用范例介绍](docs/zh_cn/recommended_topics/application_examples/)
+- [MM 系列 Repo 必备基础](docs/zh_cn/recommended_topics/mm_basics.md)
+- [数据集准备和说明](docs/zh_cn/recommended_topics/dataset_preparation.md)
+
+
+
+
+常用功能
+
+- [恢复训练](docs/zh_cn/common_usage/resume_training.md)
+- [开启和关闭 SyncBatchNorm](docs/zh_cn/common_usage/syncbn.md)
+- [开启混合精度训练](docs/zh_cn/common_usage/amp_training.md)
+- [多尺度训练和测试](docs/zh_cn/common_usage/ms_training_testing.md)
+- [测试时增强相关说明](docs/zh_cn/common_usage/tta.md)
+- [给主干网络增加插件](docs/zh_cn/common_usage/plugins.md)
+- [冻结指定网络层权重](docs/zh_cn/common_usage/freeze_layers.md)
+- [输出模型预测结果](docs/zh_cn/common_usage/output_predictions.md)
+- [设置随机种子](docs/zh_cn/common_usage/set_random_seed.md)
+- [算法组合替换教程](docs/zh_cn/common_usage/module_combination.md)
+- [使用 mim 跨库调用其他 OpenMMLab 仓库的脚本](docs/zh_cn/common_usage/mim_usage.md)
+- [应用多个 Neck](docs/zh_cn/common_usage/multi_necks.md)
+- [指定特定设备训练或推理](docs/zh_cn/common_usage/specify_device.md)
+- [单通道和多通道应用案例](docs/zh_cn/common_usage/single_multi_channel_applications.md)
+- [MM 系列开源库注册表](docs/zh_cn/common_usage/registries_info.md)
+
+
+
+
+实用工具
+
+- [可视化 COCO 标签](docs/zh_cn/useful_tools/browse_coco_json.md)
+- [可视化数据集](docs/zh_cn/useful_tools/browse_dataset.md)
+- [打印完整配置文件](docs/zh_cn/useful_tools/print_config.md)
+- [可视化数据集分析结果](docs/zh_cn/useful_tools/dataset_analysis.md)
+- [优化锚框尺寸](docs/zh_cn/useful_tools/optimize_anchors.md)
+- [提取 COCO 子集](docs/zh_cn/useful_tools/extract_subcoco.md)
+- [可视化优化器参数策略](docs/zh_cn/useful_tools/vis_scheduler.md)
+- [数据集转换](docs/zh_cn/useful_tools/dataset_converters.md)
+- [数据集下载](docs/zh_cn/useful_tools/download_dataset.md)
+- [日志分析](docs/zh_cn/useful_tools/log_analysis.md)
+- [模型转换](docs/zh_cn/useful_tools/model_converters.md)
+
+
+
+
+基础教程
+
+- [学习 YOLOv5 配置文件](docs/zh_cn/tutorials/config.md)
+- [数据流](docs/zh_cn/tutorials/data_flow.md)
+- [旋转目标检测](docs/zh_cn/tutorials/rotated_detection.md)
+- [自定义安装](docs/zh_cn/tutorials/custom_installation.md)
+- [常见警告说明](docs/zh_cn/tutorials/warning_notes.md)
+- [常见问题](docs/zh_cn/tutorials/faq.md)
+
+
+
+
+进阶教程
+
+- [MMYOLO 跨库应用解析](docs/zh_cn/advanced_guides/cross-library_application.md)
+
+
+
+
+说明
+
+- [更新日志](docs/zh_cn/notes/changelog.md)
+- [兼容性说明](docs/zh_cn/notes/compatibility.md)
+- [默认约定](docs/zh_cn/notes/conventions.md)
+- [代码规范](docs/zh_cn/notes/code_style.md)
+
+
+
+## 📊 基准测试和模型库 [🔝](#-table-of-contents)
+
+
+
+
+支持的任务
+
+- [x] 目标检测
+- [x] 旋转框目标检测
+
+
+
+
+支持的算法
+
+- [x] [YOLOv5](configs/yolov5)
+- [ ] [YOLOv5u](configs/yolov5/yolov5u) (仅推理)
+- [x] [YOLOX](configs/yolox)
+- [x] [RTMDet](configs/rtmdet)
+- [x] [RTMDet-Rotated](configs/rtmdet)
+- [x] [YOLOv6](configs/yolov6)
+- [x] [YOLOv7](configs/yolov7)
+- [x] [PPYOLOE](configs/ppyoloe)
+- [x] [YOLOv8](configs/yolov8)
+
+
+
+
+支持的数据集
+
+- [x] COCO Dataset
+- [x] VOC Dataset
+- [x] CrowdHuman Dataset
+- [x] DOTA 1.0 Dataset
+
+
+
+
+
+ 模块组件
+
+
+
+
+ |
+ Backbones
+ |
+
+ Necks
+ |
+
+ Loss
+ |
+
+ Common
+ |
+
+
+
+
+ - YOLOv5CSPDarknet
+ - YOLOv8CSPDarknet
+ - YOLOXCSPDarknet
+ - EfficientRep
+ - CSPNeXt
+ - YOLOv7Backbone
+ - PPYOLOECSPResNet
+ - mmdet backbone
+ - mmcls backbone
+ - timm
+
+ |
+
+
+ - YOLOv5PAFPN
+ - YOLOv8PAFPN
+ - YOLOv6RepPAFPN
+ - YOLOXPAFPN
+ - CSPNeXtPAFPN
+ - YOLOv7PAFPN
+ - PPYOLOECSPPAFPN
+
+ |
+
+
+ |
+
+
+ |
+
+
+
+
+
+
+
+
+## ❓ 常见问题 [🔝](#-table-of-contents)
+
+请参考 [FAQ](docs/zh_cn/tutorials/faq.md) 了解其他用户的常见问题。
+
+## 🙌 贡献指南 [🔝](#-table-of-contents)
+
+我们感谢所有的贡献者为改进和提升 MMYOLO 所作出的努力。我们将正在进行中的项目添加进了[GitHub Projects](https://github.com/open-mmlab/mmyolo/projects)页面,非常欢迎社区用户能参与进这些项目中来。请参考[贡献指南](.github/CONTRIBUTING.md)来了解参与项目贡献的相关指引。
+
+## 🤝 致谢 [🔝](#-table-of-contents)
+
+MMYOLO 是一款由来自不同高校和企业的研发人员共同参与贡献的开源项目。我们感谢所有为项目提供算法复现和新功能支持的贡献者,以及提供宝贵反馈的用户。 我们希望这个工具箱和基准测试可以为社区提供灵活的代码工具,供用户复现已有算法并开发自己的新模型,从而不断为开源社区提供贡献。
+
+
+
+
+


+
+

+
+

+PPYOLOE-PLUS-l model structure
+
+

+
+

+RTMDet-l model structure
+
+
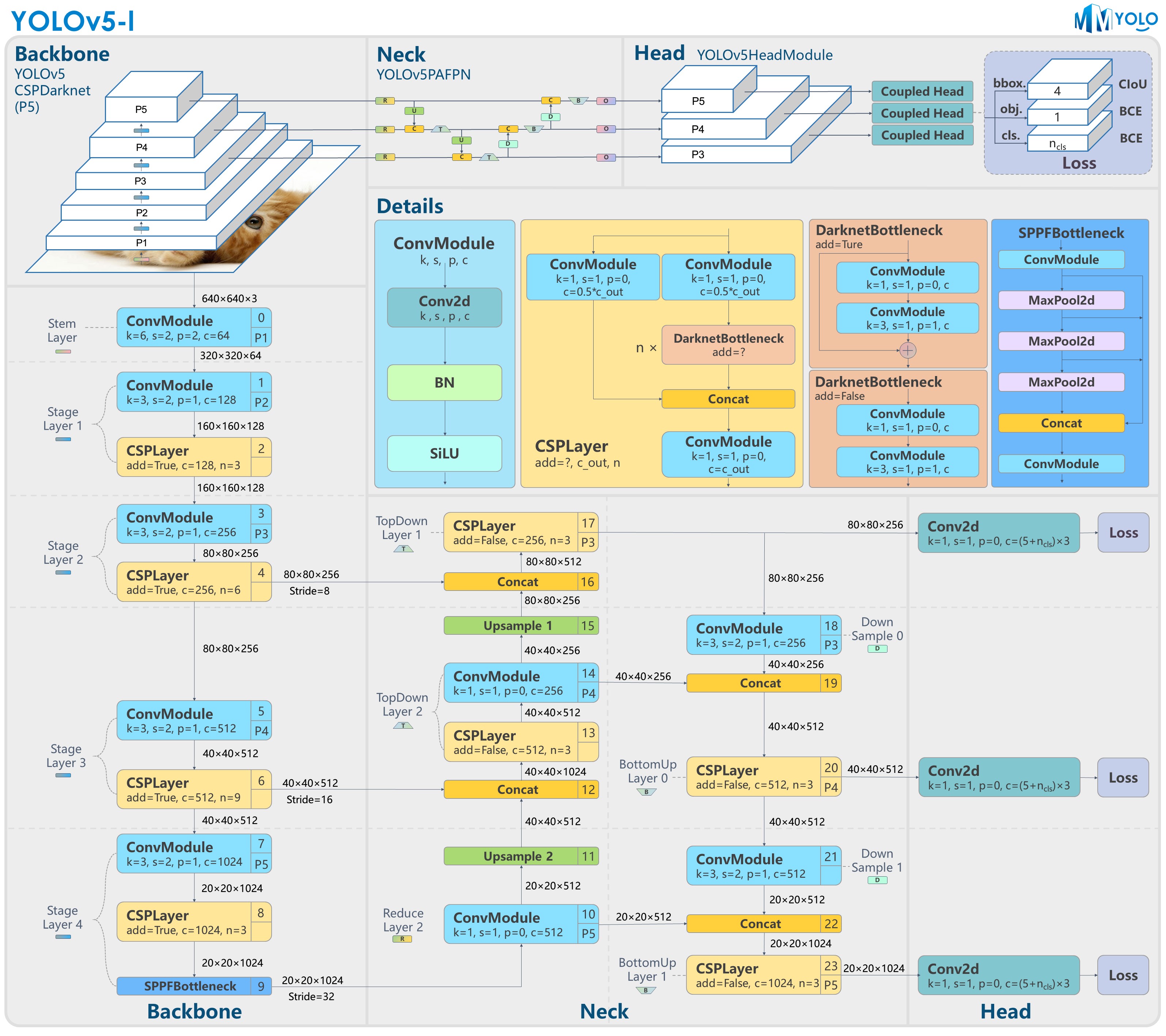
+YOLOv5-l-P5 model structure
+
+
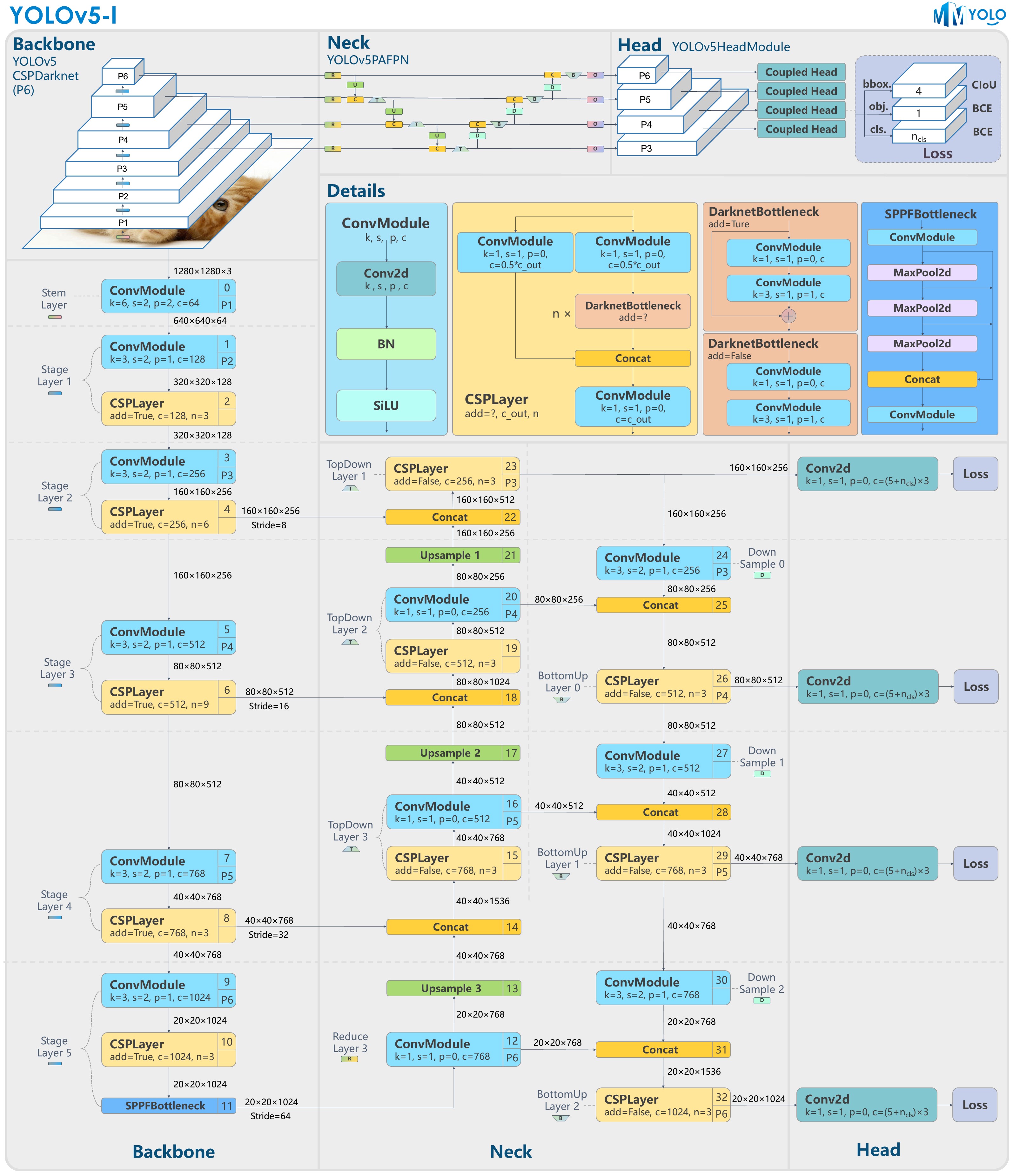
+YOLOv5-l-P6 model structure
+
+

+
+

+YOLOv6-s model structure
+
+

+YOLOv6-l model structure
+
+

+
+

+YOLOv7-l-P5 model structure
+
+

+YOLOv8 performance
+
+

+YOLOv8-P5 model structure
+
+
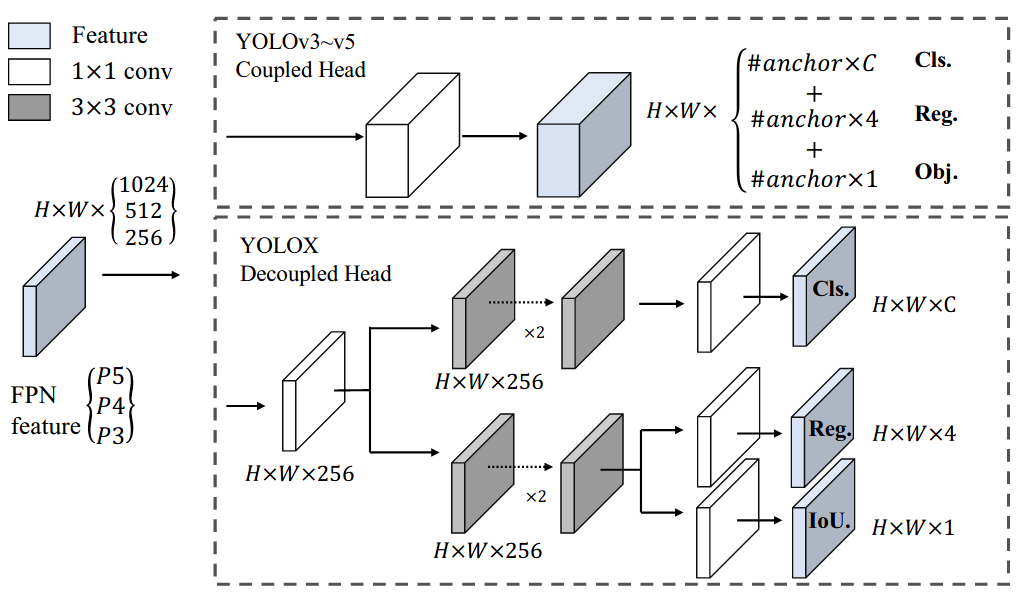
+
+
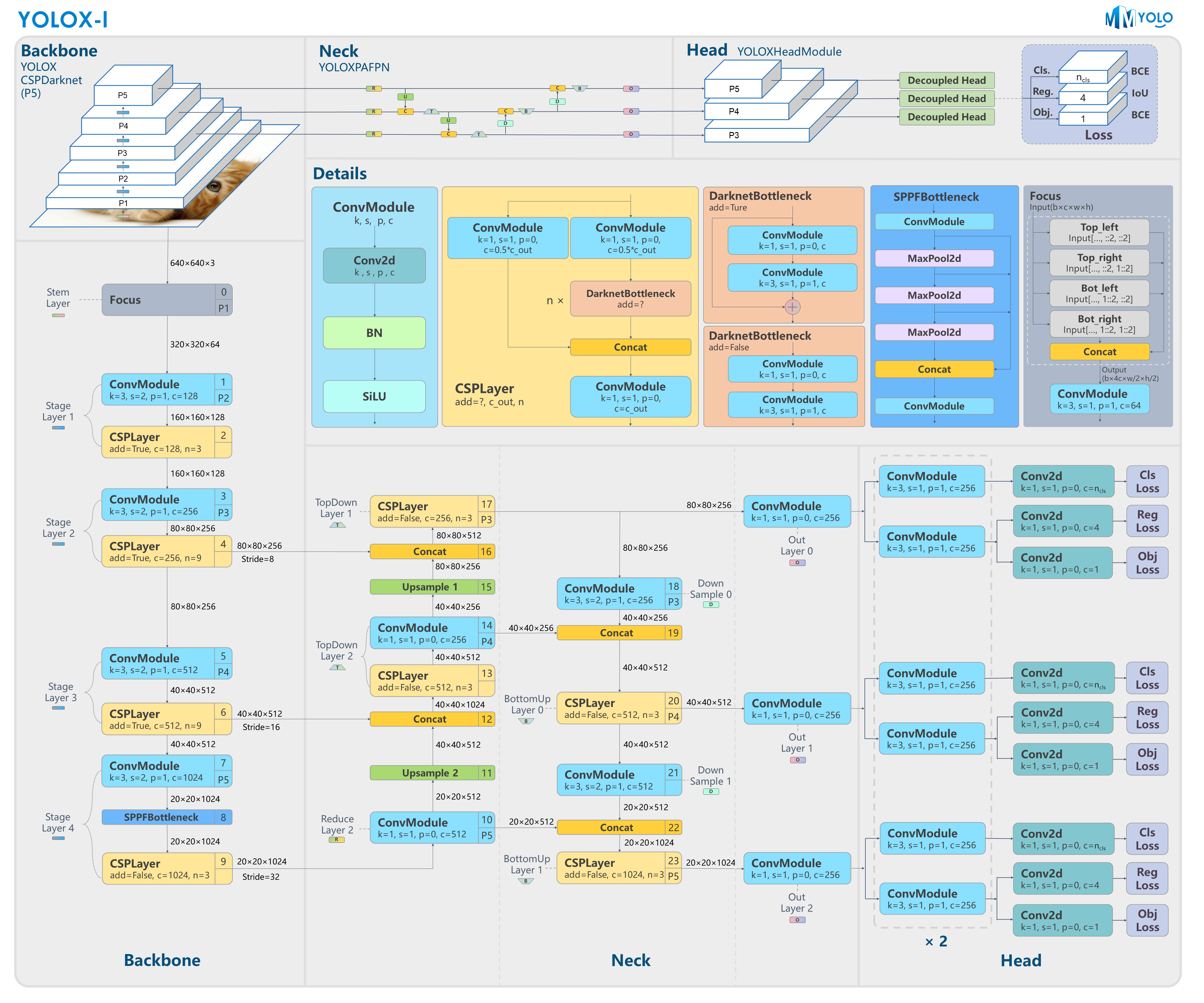
+YOLOX-l model structure
+
+

+
\n",
+ "

\n",
+ "
\n",
+ "
\n",
+ "
OpenMMLab website\n",
+ "
\n",
+ " \n",
+ " HOT\n",
+ " \n",
+ " \n",
+ " \n",
+ "
OpenMMLab platform\n",
+ "
\n",
+ " \n",
+ " TRY IT OUT\n",
+ " \n",
+ " \n",
+ "
\n",
+ "
\n",
+ "\n",
+ "

\n",
+ "\n",
+ "[](https://pypi.org/project/mmyolo)\n",
+ "[](https://mmyolo.readthedocs.io/en/latest/)\n",
+ "[](https://github.com/open-mmlab/mmyolo/actions)\n",
+ "[](https://codecov.io/gh/open-mmlab/mmyolo)\n",
+ "[](https://github.com/open-mmlab/mmyolo/blob/main/LICENSE)\n",
+ "[](https://github.com/open-mmlab/mmyolo/issues)\n",
+ "[](https://github.com/open-mmlab/mmyolo/issues)\n",
+ "\n",
+ "[📘Documentation](https://mmyolo.readthedocs.io/en/latest/) |\n",
+ "[🛠️Installation](https://mmyolo.readthedocs.io/en/latest/get_started/installation.html) |\n",
+ "[👀Model Zoo](https://mmyolo.readthedocs.io/en/latest/model_zoo.html) |\n",
+ "[🆕Update News](https://mmyolo.readthedocs.io/en/latest/notes/changelog.html) |\n",
+ "[🤔Reporting Issues](https://github.com/open-mmlab/mmyolo/issues/new/choose)\n",
+ "\n",
+ "
\n",
+ "
\n",
+ " 
\n",
+ "

\n",
+ "
\n",
+ " 
\n",
+ "
\n",
+ "
\n",
+ " 
\n",
+ "
\n",
+ "
\n",
+ " 
\n",
+ "
\n",
+ "
\n",
+ " 
\n",
+ "
\n",
+ "
\n",
+ " 
\n",
+ "
\n",
+ "

\n",
+ "
\n",
+ "

\n",
+ "
\n",
+ "

\n",
+ "
\n",
+ "

\n",
+ "
\n",
+ "

\n",
+ "
\n",
+ "

\n",
+ "
\n",
+ "

\n",
+ "
\n",
+ "

\n",
+ "
\n",
+ "

\n",
+ "
\n",
+ "
\n",
+ "
\n",
+ "
\n",
+ "
OpenMMLab website\n",
+ "
\n",
+ " \n",
+ " HOT\n",
+ " \n",
+ " \n",
+ " \n",
+ "
OpenMMLab platform\n",
+ "
\n",
+ " \n",
+ " TRY IT OUT\n",
+ " \n",
+ " \n",
+ "
\n",
+ "
\n",
+ "\n",
+ "
\n",
+ "\n",
+ "[](https://pypi.org/project/mmyolo)\n",
+ "[](https://mmyolo.readthedocs.io/en/latest/)\n",
+ "[](https://github.com/open-mmlab/mmyolo/actions)\n",
+ "[](https://codecov.io/gh/open-mmlab/mmyolo)\n",
+ "[](https://github.com/open-mmlab/mmyolo/blob/main/LICENSE)\n",
+ "[](https://github.com/open-mmlab/mmyolo/issues)\n",
+ "[](https://github.com/open-mmlab/mmyolo/issues)\n",
+ "\n",
+ "[📘Documentation](https://mmyolo.readthedocs.io/en/latest/) |\n",
+ "[🛠️Installation](https://mmyolo.readthedocs.io/en/latest/get_started/installation.html) |\n",
+ "[👀Model Zoo](https://mmyolo.readthedocs.io/en/latest/model_zoo.html) |\n",
+ "[🆕Update News](https://mmyolo.readthedocs.io/en/latest/notes/changelog.html) |\n",
+ "[🤔Reporting Issues](https://github.com/open-mmlab/mmyolo/issues/new/choose)\n",
+ "\n",
+ "
\n",
+ "
\n",
+ " \n",
+ "
\n",
+ "
\n",
+ " \n",
+ "
\n",
+ "
\n",
+ " \n",
+ "
\n",
+ "
\n",
+ " \n",
+ "
\n",
+ "
\n",
+ " \n",
+ "
\n",
+ "
\n",
+ " \n",
+ "
\n",
+ "

\n",
+ "
\n",
+ "

\n",
+ "
\n",
+ "

\n",
+ "
\n",
+ "

\n",
+ "
\n",
+ "
\n",
+ "
\n",
+ "
\n",
+ "
\n",
+ "
\n",
+ "
\n",
+ "

\n",
+ "
\n",
+ "

\n",
+ "
\n",
+ "

\n",
+ "
\n",
+ "

\n",
+ "
\n",
+ "

\n",
+ "
\n",
+ "

\n",
+ "
\n",
+ "

\n",
+ "
 +
+- Plot the classification and regression loss of some run, and save the figure to a pdf.
+
+ ```shell
+ mim run mmdet analyze_logs plot_curve \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
+ --keys loss_cls loss_bbox \
+ --legend loss_cls loss_bbox \
+ --out losses_yolov5_s.pdf
+ ```
+
+
+
+- Plot the classification and regression loss of some run, and save the figure to a pdf.
+
+ ```shell
+ mim run mmdet analyze_logs plot_curve \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
+ --keys loss_cls loss_bbox \
+ --legend loss_cls loss_bbox \
+ --out losses_yolov5_s.pdf
+ ```
+
+  +
+- Compare the bbox mAP of two runs in the same figure.
+
+ ```shell
+ mim run mmdet analyze_logs plot_curve \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
+ yolov5_n-v61_syncbn_fast_8xb16-300e_coco_20220919_090739.log.json \
+ --keys bbox_mAP \
+ --legend yolov5_s yolov5_n \
+ --eval-interval 10 # Note that the evaluation interval must be the same as during training. Otherwise, it will raise an error.
+ ```
+
+
+
+- Compare the bbox mAP of two runs in the same figure.
+
+ ```shell
+ mim run mmdet analyze_logs plot_curve \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
+ yolov5_n-v61_syncbn_fast_8xb16-300e_coco_20220919_090739.log.json \
+ --keys bbox_mAP \
+ --legend yolov5_s yolov5_n \
+ --eval-interval 10 # Note that the evaluation interval must be the same as during training. Otherwise, it will raise an error.
+ ```
+
+ +
+### Compute the average training speed
+
+```shell
+mim run mmdet analyze_logs cal_train_time \
+ ${LOG} \ # path of train log in json format
+ [--include-outliers] # include the first value of every epoch when computing the average time
+```
+
+Examples:
+
+```shell
+mim run mmdet analyze_logs cal_train_time \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json
+```
+
+The output is expected to be like the following.
+
+```text
+-----Analyze train time of yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json-----
+slowest epoch 278, average time is 0.1705 s/iter
+fastest epoch 300, average time is 0.1510 s/iter
+time std over epochs is 0.0026
+average iter time: 0.1556 s/iter
+```
diff --git a/third_party/mmyolo/docs/en/common_usage/module_combination.md b/third_party/mmyolo/docs/en/common_usage/module_combination.md
new file mode 100644
index 0000000000000000000000000000000000000000..3f9ffa4c38559fbcc806f3132dc2a91ae0f0dad7
--- /dev/null
+++ b/third_party/mmyolo/docs/en/common_usage/module_combination.md
@@ -0,0 +1 @@
+# Module combination
diff --git a/third_party/mmyolo/docs/en/common_usage/ms_training_testing.md b/third_party/mmyolo/docs/en/common_usage/ms_training_testing.md
new file mode 100644
index 0000000000000000000000000000000000000000..b7d88f63217343b7c9c3c3a512f9e2a9e822fe28
--- /dev/null
+++ b/third_party/mmyolo/docs/en/common_usage/ms_training_testing.md
@@ -0,0 +1,39 @@
+# Multi-scale training and testing
+
+## Multi-scale training
+
+The popular YOLOv5, YOLOv6, YOLOv7, YOLOv8 and RTMDet algorithms are supported in MMYOLO currently, and their default configuration is single-scale 640x640 training. There are two implementations of multi-scale training commonly used in the MM family of open source libraries
+
+1. Each image output in `train_pipeline` is at variable scale, and pad different scales of input images to the same scale by [stack_batch](https://github.com/open-mmlab/mmengine/blob/dbae83c52fa54d6dda08b6692b124217fe3b2135/mmengine/model/base_model/data_preprocessor.py#L260-L261) function in [DataPreprocessor](https://github.com/open-mmlab/mmdetection/blob/3.x/mmdet/models/data_preprocessors/data_preprocessor.py). Most of the algorithms in MMDet are implemented using this approach.
+2. Each image output in `train_pipeline` is at a fixed scale, and `DataPreprocessor` performs up- and down-sampling of image batches for multi-scale training directly.
+
+Both two multi-scale training approaches are supported in MMYOLO. Theoretically, the first implementation can generate richer scales, but its training efficiency is not as good as the second one due to its independent augmentation of a single image. Therefore, we recommend using the second approach.
+
+Take `configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py` configuration as an example, its default configuration is 640x640 fixed scale training, suppose you want to implement training in multiples of 32 and multi-scale range (480, 800), you can refer to YOLOX practice by [YOLOXBatchSyncRandomResize](https://github.com/open-mmlab/mmyolo/blob/dc85144fab20a970341550794857a2f2f9b11564/mmyolo/models/data_preprocessors/data_preprocessor.py#L20) in the DataPreprocessor.
+
+Create a new configuration under the `configs/yolov5` path named `configs/yolov5/yolov5_s-v61_fast_1xb12-ms-40e_cat.py` with the following contents.
+
+```python
+_base_ = 'yolov5_s-v61_fast_1xb12-40e_cat.py'
+
+model = dict(
+ data_preprocessor=dict(
+ type='YOLOv5DetDataPreprocessor',
+ pad_size_divisor=32,
+ batch_augments=[
+ dict(
+ type='YOLOXBatchSyncRandomResize',
+ # multi-scale range (480, 800)
+ random_size_range=(480, 800),
+ # The output scale needs to be divisible by 32
+ size_divisor=32,
+ interval=1)
+ ])
+)
+```
+
+The above configuration will enable multi-scale training. We have already provided this configuration under `configs/yolov5/` for convenience. The rest of the YOLO family of algorithms are similar.
+
+## Multi-scale testing
+
+MMYOLO multi-scale testing is equivalent to Test-Time Enhancement TTA and is currently supported, see [Test-Time Augmentation TTA](./tta.md).
diff --git a/third_party/mmyolo/docs/en/common_usage/multi_necks.md b/third_party/mmyolo/docs/en/common_usage/multi_necks.md
new file mode 100644
index 0000000000000000000000000000000000000000..b6f2bc252b2f151d80e0c500d3513651b09a704f
--- /dev/null
+++ b/third_party/mmyolo/docs/en/common_usage/multi_necks.md
@@ -0,0 +1,37 @@
+# Apply multiple Necks
+
+If you want to stack multiple Necks, you can directly set the Neck parameters in the config. MMYOLO supports concatenating multiple Necks in the form of `List`. You need to ensure that the output channel of the previous Neck matches the input channel of the next Neck. If you need to adjust the number of channels, you can insert the `mmdet.ChannelMapper` module to align the number of channels between multiple Necks. The specific configuration is as follows:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+deepen_factor = _base_.deepen_factor
+widen_factor = _base_.widen_factor
+model = dict(
+ type='YOLODetector',
+ neck=[
+ dict(
+ type='YOLOv5PAFPN',
+ deepen_factor=deepen_factor,
+ widen_factor=widen_factor,
+ in_channels=[256, 512, 1024],
+ out_channels=[256, 512, 1024], # The out_channels is controlled by widen_factor,so the YOLOv5PAFPN's out_channels equls to out_channels * widen_factor
+ num_csp_blocks=3,
+ norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
+ act_cfg=dict(type='SiLU', inplace=True)),
+ dict(
+ type='mmdet.ChannelMapper',
+ in_channels=[128, 256, 512],
+ out_channels=128,
+ ),
+ dict(
+ type='mmdet.DyHead',
+ in_channels=128,
+ out_channels=256,
+ num_blocks=2,
+ # disable zero_init_offset to follow official implementation
+ zero_init_offset=False)
+ ]
+ bbox_head=dict(head_module=dict(in_channels=[512,512,512])) # The out_channels is controlled by widen_factor,so the YOLOv5HeadModuled in_channels * widen_factor equals to the last neck's out_channels
+)
+```
diff --git a/third_party/mmyolo/docs/en/common_usage/output_predictions.md b/third_party/mmyolo/docs/en/common_usage/output_predictions.md
new file mode 100644
index 0000000000000000000000000000000000000000..571929900a1d516262cc17e0918c63a61f83c305
--- /dev/null
+++ b/third_party/mmyolo/docs/en/common_usage/output_predictions.md
@@ -0,0 +1,40 @@
+# Output prediction results
+
+If you want to save the prediction results as a specific file for offline evaluation, MMYOLO currently supports both json and pkl formats.
+
+```{note}
+The json file only save `image_id`, `bbox`, `score` and `category_id`. The json file can be read using the json library.
+The pkl file holds more content than the json file, and also holds information such as the file name and size of the predicted image; the pkl file can be read using the pickle library. The pkl file can be read using the pickle library.
+```
+
+## Output into json file
+
+If you want to output the prediction results as a json file, the command is as follows.
+
+```shell
+python tools/test.py {path_to_config} {path_to_checkpoint} --json-prefix {json_prefix}
+```
+
+The argument after `--json-prefix` should be a filename prefix (no need to enter the `.json` suffix) and can also contain a path. For a concrete example:
+
+```shell
+python tools/test.py configs\yolov5\yolov5_s-v61_syncbn_8xb16-300e_coco.py yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth --json-prefix work_dirs/demo/json_demo
+```
+
+Running the above command will output the `json_demo.bbox.json` file in the `work_dirs/demo` folder.
+
+## Output into pkl file
+
+If you want to output the prediction results as a pkl file, the command is as follows.
+
+```shell
+python tools/test.py {path_to_config} {path_to_checkpoint} --out {path_to_output_file}
+```
+
+The argument after `--out` should be a full filename (**must be** with a `.pkl` or `.pickle` suffix) and can also contain a path. For a concrete example:
+
+```shell
+python tools/test.py configs\yolov5\yolov5_s-v61_syncbn_8xb16-300e_coco.py yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth --out work_dirs/demo/pkl_demo.pkl
+```
+
+Running the above command will output the `pkl_demo.pkl` file in the `work_dirs/demo` folder.
diff --git a/third_party/mmyolo/docs/en/common_usage/plugins.md b/third_party/mmyolo/docs/en/common_usage/plugins.md
new file mode 100644
index 0000000000000000000000000000000000000000..5a0b32364308acf9f08eb369cccae183ad6cc121
--- /dev/null
+++ b/third_party/mmyolo/docs/en/common_usage/plugins.md
@@ -0,0 +1,34 @@
+# Plugins
+
+MMYOLO supports adding plugins such as `none_local` and `dropblock` after different stages of Backbone. Users can directly manage plugins by modifying the plugins parameter of the backbone in the config. For example, add `GeneralizedAttention` plugins for `YOLOv5`. The configuration files are as follows:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+model = dict(
+ backbone=dict(
+ plugins=[
+ dict(
+ cfg=dict(
+ type='GeneralizedAttention',
+ spatial_range=-1,
+ num_heads=8,
+ attention_type='0011',
+ kv_stride=2),
+ stages=(False, False, True, True))
+ ]))
+```
+
+`cfg` parameter indicates the specific configuration of the plugin. The `stages` parameter indicates whether to add plug-ins after the corresponding stage of the backbone. The length of the list `stages` must be the same as the number of backbone stages.
+
+MMYOLO currently supports the following plugins:
+
+
+
+### Compute the average training speed
+
+```shell
+mim run mmdet analyze_logs cal_train_time \
+ ${LOG} \ # path of train log in json format
+ [--include-outliers] # include the first value of every epoch when computing the average time
+```
+
+Examples:
+
+```shell
+mim run mmdet analyze_logs cal_train_time \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json
+```
+
+The output is expected to be like the following.
+
+```text
+-----Analyze train time of yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json-----
+slowest epoch 278, average time is 0.1705 s/iter
+fastest epoch 300, average time is 0.1510 s/iter
+time std over epochs is 0.0026
+average iter time: 0.1556 s/iter
+```
diff --git a/third_party/mmyolo/docs/en/common_usage/module_combination.md b/third_party/mmyolo/docs/en/common_usage/module_combination.md
new file mode 100644
index 0000000000000000000000000000000000000000..3f9ffa4c38559fbcc806f3132dc2a91ae0f0dad7
--- /dev/null
+++ b/third_party/mmyolo/docs/en/common_usage/module_combination.md
@@ -0,0 +1 @@
+# Module combination
diff --git a/third_party/mmyolo/docs/en/common_usage/ms_training_testing.md b/third_party/mmyolo/docs/en/common_usage/ms_training_testing.md
new file mode 100644
index 0000000000000000000000000000000000000000..b7d88f63217343b7c9c3c3a512f9e2a9e822fe28
--- /dev/null
+++ b/third_party/mmyolo/docs/en/common_usage/ms_training_testing.md
@@ -0,0 +1,39 @@
+# Multi-scale training and testing
+
+## Multi-scale training
+
+The popular YOLOv5, YOLOv6, YOLOv7, YOLOv8 and RTMDet algorithms are supported in MMYOLO currently, and their default configuration is single-scale 640x640 training. There are two implementations of multi-scale training commonly used in the MM family of open source libraries
+
+1. Each image output in `train_pipeline` is at variable scale, and pad different scales of input images to the same scale by [stack_batch](https://github.com/open-mmlab/mmengine/blob/dbae83c52fa54d6dda08b6692b124217fe3b2135/mmengine/model/base_model/data_preprocessor.py#L260-L261) function in [DataPreprocessor](https://github.com/open-mmlab/mmdetection/blob/3.x/mmdet/models/data_preprocessors/data_preprocessor.py). Most of the algorithms in MMDet are implemented using this approach.
+2. Each image output in `train_pipeline` is at a fixed scale, and `DataPreprocessor` performs up- and down-sampling of image batches for multi-scale training directly.
+
+Both two multi-scale training approaches are supported in MMYOLO. Theoretically, the first implementation can generate richer scales, but its training efficiency is not as good as the second one due to its independent augmentation of a single image. Therefore, we recommend using the second approach.
+
+Take `configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py` configuration as an example, its default configuration is 640x640 fixed scale training, suppose you want to implement training in multiples of 32 and multi-scale range (480, 800), you can refer to YOLOX practice by [YOLOXBatchSyncRandomResize](https://github.com/open-mmlab/mmyolo/blob/dc85144fab20a970341550794857a2f2f9b11564/mmyolo/models/data_preprocessors/data_preprocessor.py#L20) in the DataPreprocessor.
+
+Create a new configuration under the `configs/yolov5` path named `configs/yolov5/yolov5_s-v61_fast_1xb12-ms-40e_cat.py` with the following contents.
+
+```python
+_base_ = 'yolov5_s-v61_fast_1xb12-40e_cat.py'
+
+model = dict(
+ data_preprocessor=dict(
+ type='YOLOv5DetDataPreprocessor',
+ pad_size_divisor=32,
+ batch_augments=[
+ dict(
+ type='YOLOXBatchSyncRandomResize',
+ # multi-scale range (480, 800)
+ random_size_range=(480, 800),
+ # The output scale needs to be divisible by 32
+ size_divisor=32,
+ interval=1)
+ ])
+)
+```
+
+The above configuration will enable multi-scale training. We have already provided this configuration under `configs/yolov5/` for convenience. The rest of the YOLO family of algorithms are similar.
+
+## Multi-scale testing
+
+MMYOLO multi-scale testing is equivalent to Test-Time Enhancement TTA and is currently supported, see [Test-Time Augmentation TTA](./tta.md).
diff --git a/third_party/mmyolo/docs/en/common_usage/multi_necks.md b/third_party/mmyolo/docs/en/common_usage/multi_necks.md
new file mode 100644
index 0000000000000000000000000000000000000000..b6f2bc252b2f151d80e0c500d3513651b09a704f
--- /dev/null
+++ b/third_party/mmyolo/docs/en/common_usage/multi_necks.md
@@ -0,0 +1,37 @@
+# Apply multiple Necks
+
+If you want to stack multiple Necks, you can directly set the Neck parameters in the config. MMYOLO supports concatenating multiple Necks in the form of `List`. You need to ensure that the output channel of the previous Neck matches the input channel of the next Neck. If you need to adjust the number of channels, you can insert the `mmdet.ChannelMapper` module to align the number of channels between multiple Necks. The specific configuration is as follows:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+deepen_factor = _base_.deepen_factor
+widen_factor = _base_.widen_factor
+model = dict(
+ type='YOLODetector',
+ neck=[
+ dict(
+ type='YOLOv5PAFPN',
+ deepen_factor=deepen_factor,
+ widen_factor=widen_factor,
+ in_channels=[256, 512, 1024],
+ out_channels=[256, 512, 1024], # The out_channels is controlled by widen_factor,so the YOLOv5PAFPN's out_channels equls to out_channels * widen_factor
+ num_csp_blocks=3,
+ norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
+ act_cfg=dict(type='SiLU', inplace=True)),
+ dict(
+ type='mmdet.ChannelMapper',
+ in_channels=[128, 256, 512],
+ out_channels=128,
+ ),
+ dict(
+ type='mmdet.DyHead',
+ in_channels=128,
+ out_channels=256,
+ num_blocks=2,
+ # disable zero_init_offset to follow official implementation
+ zero_init_offset=False)
+ ]
+ bbox_head=dict(head_module=dict(in_channels=[512,512,512])) # The out_channels is controlled by widen_factor,so the YOLOv5HeadModuled in_channels * widen_factor equals to the last neck's out_channels
+)
+```
diff --git a/third_party/mmyolo/docs/en/common_usage/output_predictions.md b/third_party/mmyolo/docs/en/common_usage/output_predictions.md
new file mode 100644
index 0000000000000000000000000000000000000000..571929900a1d516262cc17e0918c63a61f83c305
--- /dev/null
+++ b/third_party/mmyolo/docs/en/common_usage/output_predictions.md
@@ -0,0 +1,40 @@
+# Output prediction results
+
+If you want to save the prediction results as a specific file for offline evaluation, MMYOLO currently supports both json and pkl formats.
+
+```{note}
+The json file only save `image_id`, `bbox`, `score` and `category_id`. The json file can be read using the json library.
+The pkl file holds more content than the json file, and also holds information such as the file name and size of the predicted image; the pkl file can be read using the pickle library. The pkl file can be read using the pickle library.
+```
+
+## Output into json file
+
+If you want to output the prediction results as a json file, the command is as follows.
+
+```shell
+python tools/test.py {path_to_config} {path_to_checkpoint} --json-prefix {json_prefix}
+```
+
+The argument after `--json-prefix` should be a filename prefix (no need to enter the `.json` suffix) and can also contain a path. For a concrete example:
+
+```shell
+python tools/test.py configs\yolov5\yolov5_s-v61_syncbn_8xb16-300e_coco.py yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth --json-prefix work_dirs/demo/json_demo
+```
+
+Running the above command will output the `json_demo.bbox.json` file in the `work_dirs/demo` folder.
+
+## Output into pkl file
+
+If you want to output the prediction results as a pkl file, the command is as follows.
+
+```shell
+python tools/test.py {path_to_config} {path_to_checkpoint} --out {path_to_output_file}
+```
+
+The argument after `--out` should be a full filename (**must be** with a `.pkl` or `.pickle` suffix) and can also contain a path. For a concrete example:
+
+```shell
+python tools/test.py configs\yolov5\yolov5_s-v61_syncbn_8xb16-300e_coco.py yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth --out work_dirs/demo/pkl_demo.pkl
+```
+
+Running the above command will output the `pkl_demo.pkl` file in the `work_dirs/demo` folder.
diff --git a/third_party/mmyolo/docs/en/common_usage/plugins.md b/third_party/mmyolo/docs/en/common_usage/plugins.md
new file mode 100644
index 0000000000000000000000000000000000000000..5a0b32364308acf9f08eb369cccae183ad6cc121
--- /dev/null
+++ b/third_party/mmyolo/docs/en/common_usage/plugins.md
@@ -0,0 +1,34 @@
+# Plugins
+
+MMYOLO supports adding plugins such as `none_local` and `dropblock` after different stages of Backbone. Users can directly manage plugins by modifying the plugins parameter of the backbone in the config. For example, add `GeneralizedAttention` plugins for `YOLOv5`. The configuration files are as follows:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+model = dict(
+ backbone=dict(
+ plugins=[
+ dict(
+ cfg=dict(
+ type='GeneralizedAttention',
+ spatial_range=-1,
+ num_heads=8,
+ attention_type='0011',
+ kv_stride=2),
+ stages=(False, False, True, True))
+ ]))
+```
+
+`cfg` parameter indicates the specific configuration of the plugin. The `stages` parameter indicates whether to add plug-ins after the corresponding stage of the backbone. The length of the list `stages` must be the same as the number of backbone stages.
+
+MMYOLO currently supports the following plugins:
+
+
+Supported Plugins
+
+1. [CBAM](https://github.com/open-mmlab/mmyolo/blob/dev/mmyolo/models/plugins/cbam.py#L86)
+2. [GeneralizedAttention](https://github.com/open-mmlab/mmcv/blob/2.x/mmcv/cnn/bricks/generalized_attention.py#L13)
+3. [NonLocal2d](https://github.com/open-mmlab/mmcv/blob/2.x/mmcv/cnn/bricks/non_local.py#L250)
+4. [ContextBlock](https://github.com/open-mmlab/mmcv/blob/2.x/mmcv/cnn/bricks/context_block.py#L18)
+
+
diff --git a/third_party/mmyolo/docs/en/common_usage/resume_training.md b/third_party/mmyolo/docs/en/common_usage/resume_training.md
new file mode 100644
index 0000000000000000000000000000000000000000..1e1184a728f2d22a71f52a2c2f9a1e3671bc3c41
--- /dev/null
+++ b/third_party/mmyolo/docs/en/common_usage/resume_training.md
@@ -0,0 +1,9 @@
+# Resume training
+
+Resume training means to continue training from the state saved from one of the previous trainings, where the state includes the model weights, the state of the optimizer and the optimizer parameter adjustment strategy.
+
+The user can add `--resume` at the end of the training command to resume training, and the program will automatically load the latest weight file from `work_dirs` to resume training. If there is an updated checkpoint in `work_dir` (e.g. the training was interrupted during the last training), the training will be resumed from that checkpoint, otherwise (e.g. the last training did not have time to save the checkpoint or a new training task was started) the training will be restarted. Here is an example of resuming training:
+
+```shell
+python tools/train.py configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py --resume
+```
diff --git a/third_party/mmyolo/docs/en/common_usage/set_random_seed.md b/third_party/mmyolo/docs/en/common_usage/set_random_seed.md
new file mode 100644
index 0000000000000000000000000000000000000000..c45c165f4323e5e522daccf0b1fbbb9bbf1f4b2a
--- /dev/null
+++ b/third_party/mmyolo/docs/en/common_usage/set_random_seed.md
@@ -0,0 +1,18 @@
+# Set the random seed
+
+If you want to set the random seed during training, you can use the following command.
+
+```shell
+python ./tools/train.py \
+ ${CONFIG} \ # path of the config file
+ --cfg-options randomness.seed=2023 \ # set seed to 2023
+ [randomness.diff_rank_seed=True] \ # set different seeds according to global rank
+ [randomness.deterministic=True] # set the deterministic option for CUDNN backend
+# [] stands for optional parameters, when actually entering the command line, you do not need to enter []
+```
+
+`randomness` has three parameters that can be set, with the following meanings.
+
+- `randomness.seed=2023`, set the random seed to 2023.
+- `randomness.diff_rank_seed=True`, set different seeds according to global rank. Defaults to False.
+- `randomness.deterministic=True`, set the deterministic option for cuDNN backend, i.e., set `torch.backends.cudnn.deterministic` to True and `torch.backends.cudnn.benchmark` to False. Defaults to False. See https://pytorch.org/docs/stable/notes/randomness.html for more details.
diff --git a/third_party/mmyolo/docs/en/common_usage/set_syncbn.md b/third_party/mmyolo/docs/en/common_usage/set_syncbn.md
new file mode 100644
index 0000000000000000000000000000000000000000..dba33be6e39b268c7a286b2c3d54469b5665d42c
--- /dev/null
+++ b/third_party/mmyolo/docs/en/common_usage/set_syncbn.md
@@ -0,0 +1 @@
+# Enabling and disabling SyncBatchNorm
diff --git a/third_party/mmyolo/docs/en/common_usage/single_multi_channel_applications.md b/third_party/mmyolo/docs/en/common_usage/single_multi_channel_applications.md
new file mode 100644
index 0000000000000000000000000000000000000000..30932708bb59ae226e1282ca70dbdca023f32a0f
--- /dev/null
+++ b/third_party/mmyolo/docs/en/common_usage/single_multi_channel_applications.md
@@ -0,0 +1,188 @@
+# Single and multi-channel application examples
+
+## Training example on a single-channel image dataset
+
+The default training images in MMYOLO are all color three-channel data. If you want to use a single-channel dataset for training and testing, it is expected that the following modifications are needed.
+
+1. All image processing pipelines have to support single channel operations
+2. The input channel of the first convolutional layer of the backbone network of the model needs to be changed from 3 to 1
+3. If you wish to load COCO pre-training weights, you need to handle the first convolutional layer weight size mismatch
+
+The following uses the `cat` dataset as an example to describe the entire modification process, if you are using a custom grayscale image dataset, you can skip the dataset preprocessing step.
+
+### 1 Dataset pre-processing
+
+The processing training of the custom dataset can be found in [Annotation-to-deployment workflow for custom dataset](../recommended_topics/labeling_to_deployment_tutorials.md)。
+
+`cat` is a three-channel color image dataset. For demonstration purpose, you can run the following code and commands to replace the dataset images with single-channel images for subsequent validation.
+
+**1. Download the `cat` dataset for decompression**
+
+```shell
+python tools/misc/download_dataset.py --dataset-name cat --save-dir ./data/cat --unzip --delete
+```
+
+**2. Convert datasets to grayscale maps**
+
+```python
+import argparse
+import imghdr
+import os
+from typing import List
+import cv2
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='data_path')
+ parser.add_argument('path', type=str, help='Original dataset path')
+ return parser.parse_args()
+
+def main():
+ args = parse_args()
+
+ path = args.path + '/images/'
+ save_path = path
+ file_list: List[str] = os.listdir(path)
+ # Grayscale conversion of each imager
+ for file in file_list:
+ if imghdr.what(path + '/' + file) != 'jpeg':
+ continue
+ img = cv2.imread(path + '/' + file)
+ img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
+ cv2.imwrite(save_path + '/' + file, img)
+
+if __name__ == '__main__':
+ main()
+```
+
+Name the above script as `cvt_single_channel.py`, and run the command as:
+
+```shell
+python cvt_single_channel.py data/cat
+```
+
+### 2 Modify the base configuration file
+
+**At present, some image processing functions of MMYOLO, such as color space transformation, are not compatible with single-channel images, so if we use single-channel data for training directly, we need to modify part of the pipeline, which is a large amount of work**. In order to solve the incompatibility problem, the recommended approach is to load the single-channel image as a three-channel image as a three-channel data, but convert it to single-channel format before input to the network. This approach will slightly increase the arithmetic burden, but the user basically does not need to modify the code to use.
+
+Take `projects/misc/custom_dataset/yolov5_s-v61_syncbn_fast_1xb32-100e_cat.py` as the `base` configuration, copy it to the `configs/yolov5` directory, and add `yolov5_s- v61_syncbn_fast_1xb32-100e_cat_single_channel.py` file. We can inherit `YOLOv5DetDataPreprocessor` from the `mmyolo/models/data_preprocessors/data_preprocessor.py` file and name the new class `YOLOv5SCDetDataPreprocessor`, in which convert the image to a single channel, add the dependency library and register the new class in `mmyolo/models/data_preprocessors/__init__.py`. The `YOLOv5SCDetDataPreprocessor` sample code is:
+
+```python
+@MODELS.register_module()
+class YOLOv5SCDetDataPreprocessor(YOLOv5DetDataPreprocessor):
+ """Rewrite collate_fn to get faster training speed.
+
+ Note: It must be used together with `mmyolo.datasets.utils.yolov5_collate`
+ """
+
+ def forward(self, data: dict, training: bool = False) -> dict:
+ """Perform normalization, padding, bgr2rgb conversion and convert to single channel image based on ``DetDataPreprocessor``.
+
+ Args:
+ data (dict): Data sampled from dataloader.
+ training (bool): Whether to enable training time augmentation.
+
+ Returns:
+ dict: Data in the same format as the model input.
+ """
+ if not training:
+ return super().forward(data, training)
+
+ data = self.cast_data(data)
+ inputs, data_samples = data['inputs'], data['data_samples']
+ assert isinstance(data['data_samples'], dict)
+
+ # TODO: Supports multi-scale training
+ if self._channel_conversion and inputs.shape[1] == 3:
+ inputs = inputs[:, [2, 1, 0], ...]
+
+ if self._enable_normalize:
+ inputs = (inputs - self.mean) / self.std
+
+ if self.batch_augments is not None:
+ for batch_aug in self.batch_augments:
+ inputs, data_samples = batch_aug(inputs, data_samples)
+
+ img_metas = [{'batch_input_shape': inputs.shape[2:]}] * len(inputs)
+ data_samples = {
+ 'bboxes_labels': data_samples['bboxes_labels'],
+ 'img_metas': img_metas
+ }
+
+ # Convert to single channel image
+ inputs = inputs.mean(dim=1, keepdim=True)
+
+ return {'inputs': inputs, 'data_samples': data_samples}
+```
+
+At this point, the `yolov5_s-v61_syncbn_fast_1xb32-100e_cat_single_channel.py` configuration file reads as follows.
+
+```python
+_base_ = 'yolov5_s-v61_syncbn_fast_1xb32-100e_cat.py'
+
+_base_.model.data_preprocessor.type = 'YOLOv5SCDetDataPreprocessor'
+```
+
+### 3 Pre-training model loading problem
+
+When using a pre-trained 3-channel model directly, it's theoretically possible to experience a decrease in accuracy, though this has not been experimentally verified. To mitigate this potential issue, there are several solutions, including adjusting the weight of each channel in the input layer. One approach is to set the weight of each channel in the input layer to the average of the weights of the original 3 channels. Alternatively, the weight of each channel could be set to one of the weights of the original 3 channels, or the input layer could be trained directly without modifying the weights, depending on the specific circumstances. In this work, we chose to adjust the weights of the 3 channels in the input layer to the average of the weights of the pre-trained 3 channels.
+
+```python
+import torch
+
+def main():
+ # Load weights file
+ state_dict = torch.load(
+ 'checkpoints/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth'
+ )
+
+ # Modify input layer weights
+ weights = state_dict['state_dict']['backbone.stem.conv.weight']
+ avg_weight = weights.mean(dim=1, keepdim=True)
+ state_dict['state_dict']['backbone.stem.conv.weight'] = avg_weight
+
+ # Save the modified weights to a new file
+ torch.save(
+ state_dict,
+ 'checkpoints/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187_single_channel.pth'
+ )
+
+if __name__ == '__main__':
+ main()
+```
+
+At this point, the `yolov5_s-v61_syncbn_fast_1xb32-100e_cat_single_channel.py` configuration file reads as follows:
+
+```python
+_base_ = 'yolov5_s-v61_syncbn_fast_1xb32-100e_cat.py'
+
+_base_.model.data_preprocessor.type = 'YOLOv5SCDetDataPreprocessor'
+
+load_from = './checkpoints/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187_single_channel.pth'
+```
+
+### 4 Model training effect
+
+ +
+The left figure shows the actual label and the right figure shows the target detection result.
+
+```shell
+ Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.958
+ Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 1.000
+ Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 1.000
+ Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
+ Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
+ Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.958
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.881
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.969
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.969
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
+ Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.969
+bbox_mAP_copypaste: 0.958 1.000 1.000 -1.000 -1.000 0.958
+Epoch(val) [100][116/116] coco/bbox_mAP: 0.9580 coco/bbox_mAP_50: 1.0000 coco/bbox_mAP_75: 1.0000 coco/bbox_mAP_s: -1.0000 coco/bbox_mAP_m: -1.0000 coco/bbox_mAP_l: 0.9580
+```
+
+## Training example on a multi-channel image dataset
+
+TODO
diff --git a/third_party/mmyolo/docs/en/common_usage/specify_device.md b/third_party/mmyolo/docs/en/common_usage/specify_device.md
new file mode 100644
index 0000000000000000000000000000000000000000..72c8017e552040413e118a85ad7785fb854a8d59
--- /dev/null
+++ b/third_party/mmyolo/docs/en/common_usage/specify_device.md
@@ -0,0 +1,23 @@
+# Specify specific GPUs during training or inference
+
+If you have multiple GPUs, such as 8 GPUs, numbered `0, 1, 2, 3, 4, 5, 6, 7`, GPU 0 will be used by default for training or inference. If you want to specify other GPUs for training or inference, you can use the following commands:
+
+```shell
+CUDA_VISIBLE_DEVICES=5 python ./tools/train.py ${CONFIG} #train
+CUDA_VISIBLE_DEVICES=5 python ./tools/test.py ${CONFIG} ${CHECKPOINT_FILE} #test
+```
+
+If you set `CUDA_VISIBLE_DEVICES` to -1 or a number greater than the maximum GPU number, such as 8, the CPU will be used for training or inference.
+
+If you want to use several of these GPUs to train in parallel, you can use the following command:
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 ./tools/dist_train.sh ${CONFIG} ${GPU_NUM}
+```
+
+Here the `GPU_NUM` is 4. In addition, if multiple tasks are trained in parallel on one machine and each task requires multiple GPUs, the PORT of each task need to be set differently to avoid communication conflict, like the following commands:
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 ./tools/dist_train.sh ${CONFIG} 4
+CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 ./tools/dist_train.sh ${CONFIG} 4
+```
diff --git a/third_party/mmyolo/docs/en/common_usage/tta.md b/third_party/mmyolo/docs/en/common_usage/tta.md
new file mode 100644
index 0000000000000000000000000000000000000000..517d34b8b67f4336c1e2acd93304c0e47af36571
--- /dev/null
+++ b/third_party/mmyolo/docs/en/common_usage/tta.md
@@ -0,0 +1,87 @@
+# TTA Related Notes
+
+## Test Time Augmentation (TTA)
+
+MMYOLO support for TTA in v0.5.0+, so that users can specify the `-tta` parameter to enable it during evaluation. Take `YOLOv5-s` as an example, its single GPU TTA test command is as follows
+
+```shell
+python tools/test.py configs/yolov5/yolov5_n-v61_syncbn_fast_8xb16-300e_coco.py https://download.openmmlab.com/mmyolo/v0/yolov5/yolov5_n-v61_syncbn_fast_8xb16-300e_coco/yolov5_n-v61_syncbn_fast_8xb16-300e_coco_20220919_090739-b804c1ad.pth --tta
+```
+
+For TTA to work properly, you must ensure that the variables `tta_model` and `tta_pipeline` are present in the configuration, see [det_p5_tta.py](https://github.com/open-mmlab/mmyolo/blob/dev/configs/_base_/det_p5_tta.py) for details.
+
+The default TTA in MMYOLO performs 3 multi-scale enhancements, followed by 2 horizontal flip enhancements, for a total of 6 parallel pipelines. take `YOLOv5-s` as an example, its TTA configuration is as follows
+
+```python
+img_scales = [(640, 640), (320, 320), (960, 960)]
+
+_multiscale_resize_transforms = [
+ dict(
+ type='Compose',
+ transforms=[
+ dict(type='YOLOv5KeepRatioResize', scale=s),
+ dict(
+ type='LetterResize',
+ scale=s,
+ allow_scale_up=False,
+ pad_val=dict(img=114))
+ ]) for s in img_scales
+]
+
+tta_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='TestTimeAug',
+ transforms=[
+ _multiscale_resize_transforms,
+ [
+ dict(type='mmdet.RandomFlip', prob=1.),
+ dict(type='mmdet.RandomFlip', prob=0.)
+ ], [dict(type='mmdet.LoadAnnotations', with_bbox=True)],
+ [
+ dict(
+ type='mmdet.PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'pad_param', 'flip',
+ 'flip_direction'))
+ ]
+ ])
+]
+```
+
+The schematic diagram is shown below.
+
+```text
+ LoadImageFromFile
+ / | \
+(RatioResize,LetterResize) (RatioResize,LetterResize) (RatioResize,LetterResize)
+ / \ / \ / \
+ RandomFlip RandomFlip RandomFlip RandomFlip RandomFlip RandomFlip
+ | | | | | |
+ LoadAnn LoadAnn LoadAnn LoadAnn LoadAnn LoadAnn
+ | | | | | |
+ PackDetIn PackDetIn PackDetIn PackDetIn PackDetIn PackDetIn
+```
+
+You can modify `img_scales` to support different multi-scale enhancements, or you can insert a new pipeline to implement custom TTA requirements. Assuming you only want to do horizontal flip enhancements, the configuration should be modified as follows.
+
+```python
+tta_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='TestTimeAug',
+ transforms=[
+ [
+ dict(type='mmdet.RandomFlip', prob=1.),
+ dict(type='mmdet.RandomFlip', prob=0.)
+ ], [dict(type='mmdet.LoadAnnotations', with_bbox=True)],
+ [
+ dict(
+ type='mmdet.PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'pad_param', 'flip',
+ 'flip_direction'))
+ ]
+ ])
+]
+```
diff --git a/third_party/mmyolo/docs/en/conf.py b/third_party/mmyolo/docs/en/conf.py
new file mode 100644
index 0000000000000000000000000000000000000000..437a257a34618f2d7022dbbe0b58928c671b800e
--- /dev/null
+++ b/third_party/mmyolo/docs/en/conf.py
@@ -0,0 +1,115 @@
+# Configuration file for the Sphinx documentation builder.
+#
+# This file only contains a selection of the most common options. For a full
+# list see the documentation:
+# https://www.sphinx-doc.org/en/master/usage/configuration.html
+
+# -- Path setup --------------------------------------------------------------
+
+# If extensions (or modules to document with autodoc) are in another directory,
+# add these directories to sys.path here. If the directory is relative to the
+# documentation root, use os.path.abspath to make it absolute, like shown here.
+#
+import os
+import subprocess
+import sys
+
+import pytorch_sphinx_theme
+
+sys.path.insert(0, os.path.abspath('../../'))
+
+# -- Project information -----------------------------------------------------
+
+project = 'MMYOLO'
+copyright = '2022, OpenMMLab'
+author = 'MMYOLO Authors'
+version_file = '../../mmyolo/version.py'
+
+
+def get_version():
+ with open(version_file) as f:
+ exec(compile(f.read(), version_file, 'exec'))
+ return locals()['__version__']
+
+
+# The full version, including alpha/beta/rc tags
+release = get_version()
+
+# -- General configuration ---------------------------------------------------
+
+# Add any Sphinx extension module names here, as strings. They can be
+# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
+# ones.
+extensions = [
+ 'sphinx.ext.autodoc',
+ 'sphinx.ext.napoleon',
+ 'sphinx.ext.viewcode',
+ 'myst_parser',
+ 'sphinx_markdown_tables',
+ 'sphinx_copybutton',
+]
+
+myst_enable_extensions = ['colon_fence']
+myst_heading_anchors = 3
+
+autodoc_mock_imports = [
+ 'matplotlib', 'pycocotools', 'terminaltables', 'mmyolo.version', 'mmcv.ops'
+]
+
+# Add any paths that contain templates here, relative to this directory.
+templates_path = ['_templates']
+
+# The suffix(es) of source filenames.
+# You can specify multiple suffix as a list of string:
+#
+source_suffix = {
+ '.rst': 'restructuredtext',
+ '.md': 'markdown',
+}
+
+# The master toctree document.
+master_doc = 'index'
+
+# List of patterns, relative to source directory, that match files and
+# directories to ignore when looking for source files.
+# This pattern also affects html_static_path and html_extra_path.
+exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
+
+# -- Options for HTML output -------------------------------------------------
+
+# The theme to use for HTML and HTML Help pages. See the documentation for
+# a list of builtin themes.
+#
+# html_theme = 'sphinx_rtd_theme'
+html_theme = 'pytorch_sphinx_theme'
+html_theme_path = [pytorch_sphinx_theme.get_html_theme_path()]
+
+html_theme_options = {
+ 'menu': [
+ {
+ 'name': 'GitHub',
+ 'url': 'https://github.com/open-mmlab/mmyolo'
+ },
+ ],
+ # Specify the language of shared menu
+ 'menu_lang': 'en',
+}
+
+# Add any paths that contain custom static files (such as style sheets) here,
+# relative to this directory. They are copied after the builtin static files,
+# so a file named "default.css" will overwrite the builtin "default.css".
+html_static_path = ['_static']
+html_css_files = ['css/readthedocs.css']
+
+# -- Extension configuration -------------------------------------------------
+# Ignore >>> when copying code
+copybutton_prompt_text = r'>>> |\.\.\. '
+copybutton_prompt_is_regexp = True
+
+
+def builder_inited_handler(app):
+ subprocess.run(['./stat.py'])
+
+
+def setup(app):
+ app.connect('builder-inited', builder_inited_handler)
diff --git a/third_party/mmyolo/docs/en/get_started/15_minutes_instance_segmentation.md b/third_party/mmyolo/docs/en/get_started/15_minutes_instance_segmentation.md
new file mode 100644
index 0000000000000000000000000000000000000000..b42e25f646f7adbc49f1b323e0016d62dd14a3ab
--- /dev/null
+++ b/third_party/mmyolo/docs/en/get_started/15_minutes_instance_segmentation.md
@@ -0,0 +1,332 @@
+# 15 minutes to get started with MMYOLO instance segmentation
+
+Instance segmentation is a task in computer vision that aims to segment each object in an image and assign each object a unique identifier.
+
+Unlike semantic segmentation, instance segmentation not only segments out different categories in an image, but also separates different instances of the same category.
+
+
+
+The left figure shows the actual label and the right figure shows the target detection result.
+
+```shell
+ Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.958
+ Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 1.000
+ Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 1.000
+ Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
+ Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
+ Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.958
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.881
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.969
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.969
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000
+ Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = -1.000
+ Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.969
+bbox_mAP_copypaste: 0.958 1.000 1.000 -1.000 -1.000 0.958
+Epoch(val) [100][116/116] coco/bbox_mAP: 0.9580 coco/bbox_mAP_50: 1.0000 coco/bbox_mAP_75: 1.0000 coco/bbox_mAP_s: -1.0000 coco/bbox_mAP_m: -1.0000 coco/bbox_mAP_l: 0.9580
+```
+
+## Training example on a multi-channel image dataset
+
+TODO
diff --git a/third_party/mmyolo/docs/en/common_usage/specify_device.md b/third_party/mmyolo/docs/en/common_usage/specify_device.md
new file mode 100644
index 0000000000000000000000000000000000000000..72c8017e552040413e118a85ad7785fb854a8d59
--- /dev/null
+++ b/third_party/mmyolo/docs/en/common_usage/specify_device.md
@@ -0,0 +1,23 @@
+# Specify specific GPUs during training or inference
+
+If you have multiple GPUs, such as 8 GPUs, numbered `0, 1, 2, 3, 4, 5, 6, 7`, GPU 0 will be used by default for training or inference. If you want to specify other GPUs for training or inference, you can use the following commands:
+
+```shell
+CUDA_VISIBLE_DEVICES=5 python ./tools/train.py ${CONFIG} #train
+CUDA_VISIBLE_DEVICES=5 python ./tools/test.py ${CONFIG} ${CHECKPOINT_FILE} #test
+```
+
+If you set `CUDA_VISIBLE_DEVICES` to -1 or a number greater than the maximum GPU number, such as 8, the CPU will be used for training or inference.
+
+If you want to use several of these GPUs to train in parallel, you can use the following command:
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 ./tools/dist_train.sh ${CONFIG} ${GPU_NUM}
+```
+
+Here the `GPU_NUM` is 4. In addition, if multiple tasks are trained in parallel on one machine and each task requires multiple GPUs, the PORT of each task need to be set differently to avoid communication conflict, like the following commands:
+
+```shell
+CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 ./tools/dist_train.sh ${CONFIG} 4
+CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 ./tools/dist_train.sh ${CONFIG} 4
+```
diff --git a/third_party/mmyolo/docs/en/common_usage/tta.md b/third_party/mmyolo/docs/en/common_usage/tta.md
new file mode 100644
index 0000000000000000000000000000000000000000..517d34b8b67f4336c1e2acd93304c0e47af36571
--- /dev/null
+++ b/third_party/mmyolo/docs/en/common_usage/tta.md
@@ -0,0 +1,87 @@
+# TTA Related Notes
+
+## Test Time Augmentation (TTA)
+
+MMYOLO support for TTA in v0.5.0+, so that users can specify the `-tta` parameter to enable it during evaluation. Take `YOLOv5-s` as an example, its single GPU TTA test command is as follows
+
+```shell
+python tools/test.py configs/yolov5/yolov5_n-v61_syncbn_fast_8xb16-300e_coco.py https://download.openmmlab.com/mmyolo/v0/yolov5/yolov5_n-v61_syncbn_fast_8xb16-300e_coco/yolov5_n-v61_syncbn_fast_8xb16-300e_coco_20220919_090739-b804c1ad.pth --tta
+```
+
+For TTA to work properly, you must ensure that the variables `tta_model` and `tta_pipeline` are present in the configuration, see [det_p5_tta.py](https://github.com/open-mmlab/mmyolo/blob/dev/configs/_base_/det_p5_tta.py) for details.
+
+The default TTA in MMYOLO performs 3 multi-scale enhancements, followed by 2 horizontal flip enhancements, for a total of 6 parallel pipelines. take `YOLOv5-s` as an example, its TTA configuration is as follows
+
+```python
+img_scales = [(640, 640), (320, 320), (960, 960)]
+
+_multiscale_resize_transforms = [
+ dict(
+ type='Compose',
+ transforms=[
+ dict(type='YOLOv5KeepRatioResize', scale=s),
+ dict(
+ type='LetterResize',
+ scale=s,
+ allow_scale_up=False,
+ pad_val=dict(img=114))
+ ]) for s in img_scales
+]
+
+tta_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='TestTimeAug',
+ transforms=[
+ _multiscale_resize_transforms,
+ [
+ dict(type='mmdet.RandomFlip', prob=1.),
+ dict(type='mmdet.RandomFlip', prob=0.)
+ ], [dict(type='mmdet.LoadAnnotations', with_bbox=True)],
+ [
+ dict(
+ type='mmdet.PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'pad_param', 'flip',
+ 'flip_direction'))
+ ]
+ ])
+]
+```
+
+The schematic diagram is shown below.
+
+```text
+ LoadImageFromFile
+ / | \
+(RatioResize,LetterResize) (RatioResize,LetterResize) (RatioResize,LetterResize)
+ / \ / \ / \
+ RandomFlip RandomFlip RandomFlip RandomFlip RandomFlip RandomFlip
+ | | | | | |
+ LoadAnn LoadAnn LoadAnn LoadAnn LoadAnn LoadAnn
+ | | | | | |
+ PackDetIn PackDetIn PackDetIn PackDetIn PackDetIn PackDetIn
+```
+
+You can modify `img_scales` to support different multi-scale enhancements, or you can insert a new pipeline to implement custom TTA requirements. Assuming you only want to do horizontal flip enhancements, the configuration should be modified as follows.
+
+```python
+tta_pipeline = [
+ dict(type='LoadImageFromFile'),
+ dict(
+ type='TestTimeAug',
+ transforms=[
+ [
+ dict(type='mmdet.RandomFlip', prob=1.),
+ dict(type='mmdet.RandomFlip', prob=0.)
+ ], [dict(type='mmdet.LoadAnnotations', with_bbox=True)],
+ [
+ dict(
+ type='mmdet.PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'pad_param', 'flip',
+ 'flip_direction'))
+ ]
+ ])
+]
+```
diff --git a/third_party/mmyolo/docs/en/conf.py b/third_party/mmyolo/docs/en/conf.py
new file mode 100644
index 0000000000000000000000000000000000000000..437a257a34618f2d7022dbbe0b58928c671b800e
--- /dev/null
+++ b/third_party/mmyolo/docs/en/conf.py
@@ -0,0 +1,115 @@
+# Configuration file for the Sphinx documentation builder.
+#
+# This file only contains a selection of the most common options. For a full
+# list see the documentation:
+# https://www.sphinx-doc.org/en/master/usage/configuration.html
+
+# -- Path setup --------------------------------------------------------------
+
+# If extensions (or modules to document with autodoc) are in another directory,
+# add these directories to sys.path here. If the directory is relative to the
+# documentation root, use os.path.abspath to make it absolute, like shown here.
+#
+import os
+import subprocess
+import sys
+
+import pytorch_sphinx_theme
+
+sys.path.insert(0, os.path.abspath('../../'))
+
+# -- Project information -----------------------------------------------------
+
+project = 'MMYOLO'
+copyright = '2022, OpenMMLab'
+author = 'MMYOLO Authors'
+version_file = '../../mmyolo/version.py'
+
+
+def get_version():
+ with open(version_file) as f:
+ exec(compile(f.read(), version_file, 'exec'))
+ return locals()['__version__']
+
+
+# The full version, including alpha/beta/rc tags
+release = get_version()
+
+# -- General configuration ---------------------------------------------------
+
+# Add any Sphinx extension module names here, as strings. They can be
+# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
+# ones.
+extensions = [
+ 'sphinx.ext.autodoc',
+ 'sphinx.ext.napoleon',
+ 'sphinx.ext.viewcode',
+ 'myst_parser',
+ 'sphinx_markdown_tables',
+ 'sphinx_copybutton',
+]
+
+myst_enable_extensions = ['colon_fence']
+myst_heading_anchors = 3
+
+autodoc_mock_imports = [
+ 'matplotlib', 'pycocotools', 'terminaltables', 'mmyolo.version', 'mmcv.ops'
+]
+
+# Add any paths that contain templates here, relative to this directory.
+templates_path = ['_templates']
+
+# The suffix(es) of source filenames.
+# You can specify multiple suffix as a list of string:
+#
+source_suffix = {
+ '.rst': 'restructuredtext',
+ '.md': 'markdown',
+}
+
+# The master toctree document.
+master_doc = 'index'
+
+# List of patterns, relative to source directory, that match files and
+# directories to ignore when looking for source files.
+# This pattern also affects html_static_path and html_extra_path.
+exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
+
+# -- Options for HTML output -------------------------------------------------
+
+# The theme to use for HTML and HTML Help pages. See the documentation for
+# a list of builtin themes.
+#
+# html_theme = 'sphinx_rtd_theme'
+html_theme = 'pytorch_sphinx_theme'
+html_theme_path = [pytorch_sphinx_theme.get_html_theme_path()]
+
+html_theme_options = {
+ 'menu': [
+ {
+ 'name': 'GitHub',
+ 'url': 'https://github.com/open-mmlab/mmyolo'
+ },
+ ],
+ # Specify the language of shared menu
+ 'menu_lang': 'en',
+}
+
+# Add any paths that contain custom static files (such as style sheets) here,
+# relative to this directory. They are copied after the builtin static files,
+# so a file named "default.css" will overwrite the builtin "default.css".
+html_static_path = ['_static']
+html_css_files = ['css/readthedocs.css']
+
+# -- Extension configuration -------------------------------------------------
+# Ignore >>> when copying code
+copybutton_prompt_text = r'>>> |\.\.\. '
+copybutton_prompt_is_regexp = True
+
+
+def builder_inited_handler(app):
+ subprocess.run(['./stat.py'])
+
+
+def setup(app):
+ app.connect('builder-inited', builder_inited_handler)
diff --git a/third_party/mmyolo/docs/en/get_started/15_minutes_instance_segmentation.md b/third_party/mmyolo/docs/en/get_started/15_minutes_instance_segmentation.md
new file mode 100644
index 0000000000000000000000000000000000000000..b42e25f646f7adbc49f1b323e0016d62dd14a3ab
--- /dev/null
+++ b/third_party/mmyolo/docs/en/get_started/15_minutes_instance_segmentation.md
@@ -0,0 +1,332 @@
+# 15 minutes to get started with MMYOLO instance segmentation
+
+Instance segmentation is a task in computer vision that aims to segment each object in an image and assign each object a unique identifier.
+
+Unlike semantic segmentation, instance segmentation not only segments out different categories in an image, but also separates different instances of the same category.
+
+
+
+
+

+
+

+
+
+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+
+
+

+
+
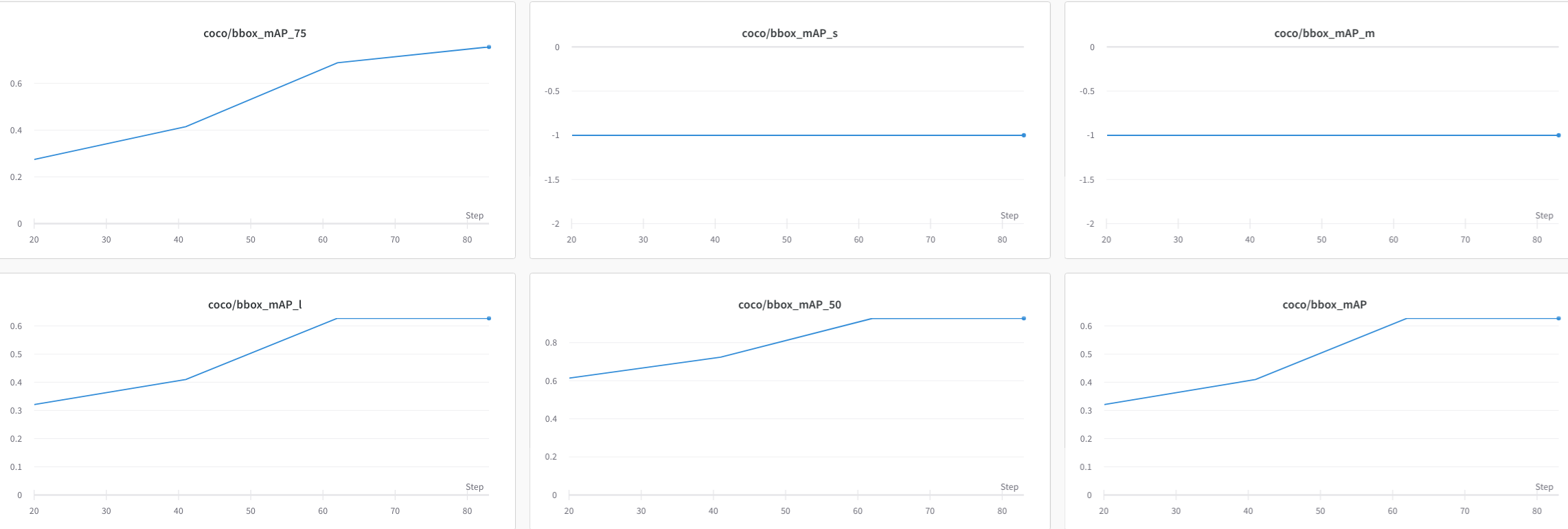
+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+
+
+

+
+Tasks currently supported
+
+- Object detection
+- Rotated object detection
+
+
+
+The YOLO series of algorithms currently supported are as follows:
+
+
+Algorithms currently supported
+
+- YOLOv5
+- YOLOX
+- RTMDet
+- RTMDet-Rotated
+- YOLOv6
+- YOLOv7
+- PPYOLOE
+- YOLOv8
+
+
+
+The datasets currently supported are as follows:
+
+
+Datasets currently supported
+
+- COCO Dataset
+- VOC Dataset
+- CrowdHuman Dataset
+- DOTA 1.0 Dataset
+
+
+
+MMYOLO runs on Linux, Windows, macOS, and supports PyTorch 1.7 or later. It has the following three characteristics:
+
+- 🕹️ **Unified and convenient algorithm evaluation**
+
+ MMYOLO unifies various YOLO algorithm modules and provides a unified evaluation process, so that users can compare and analyze fairly and conveniently.
+
+- 📚 **Extensive documentation for started and advanced**
+
+ MMYOLO provides a series of documents, including getting started, deployment, advanced practice and algorithm analysis, which is convenient for different users to get started and expand.
+
+- 🧩 **Modular Design**
+
+ MMYOLO disentangled the framework into modular components, and users can easily build custom models by combining different modules and training and testing strategies.
+
+
+ This image is provided by RangeKing@GitHub, thanks very much!
+
+## User guide for this documentation
+
+MMYOLO divides the document structure into 6 parts, corresponding to different user needs.
+
+- **Get started with MMYOLO**. This part is must read for first-time MMYOLO users, so please read it carefully.
+- **Recommend Topics**. This part is the essence documentation provided in MMYOLO by topics, including lots of MMYOLO features, etc. Highly recommended reading for all MMYOLO users.
+- **Common functions**. This part provides a list of common features that you will use during the training and testing process, so you can refer back to them when you need.
+- **Useful tools**. This part is useful tools summary under `tools`, so that you can quickly and happily use the various scripts provided in MMYOLO.
+- **Basic and advanced tutorials**. This part introduces some basic concepts and advanced tutorials in MMYOLO. It is suitable for users who want to understand the design idea and structure design of MMYOLO in detail.
+- **Others**. The rest includes model repositories, specifications and interface documentation, etc.
+
+Users with different needs can choose your favorite content to read. If you have any questions about this documentation or a better idea to improve it, welcome to post a Pull Request to MMYOLO ~. Please refer to [How to Contribute to MMYOLO](../recommended_topics/contributing.md)
diff --git a/third_party/mmyolo/docs/en/index.rst b/third_party/mmyolo/docs/en/index.rst
new file mode 100644
index 0000000000000000000000000000000000000000..1a0ab6c3b3d170479f096487c21871a2e273beb4
--- /dev/null
+++ b/third_party/mmyolo/docs/en/index.rst
@@ -0,0 +1,120 @@
+Welcome to MMYOLO's documentation!
+=======================================
+You can switch between Chinese and English documents in the top-right corner of the layout.
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Get Started
+
+ get_started/overview.md
+ get_started/dependencies.md
+ get_started/installation.md
+ get_started/15_minutes_object_detection.md
+ get_started/15_minutes_rotated_object_detection.md
+ get_started/15_minutes_instance_segmentation.md
+ get_started/article.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Recommended Topics
+
+ recommended_topics/contributing.md
+ recommended_topics/training_testing_tricks.md
+ recommended_topics/model_design.md
+ recommended_topics/algorithm_descriptions/index.rst
+ recommended_topics/application_examples/index.rst
+ recommended_topics/replace_backbone.md
+ recommended_topics/complexity_analysis.md
+ recommended_topics/labeling_to_deployment_tutorials.md
+ recommended_topics/visualization.md
+ recommended_topics/deploy/index.rst
+ recommended_topics/troubleshooting_steps.md
+ recommended_topics/mm_basics.md
+ recommended_topics/dataset_preparation.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Common Usage
+
+ common_usage/resume_training.md
+ common_usage/syncbn.md
+ common_usage/amp_training.md
+ common_usage/ms_training_testing.md
+ common_usage/tta.md
+ common_usage/plugins.md
+ common_usage/freeze_layers.md
+ common_usage/output_predictions.md
+ common_usage/set_random_seed.md
+ common_usage/module_combination.md
+ common_usage/mim_usage.md
+ common_usage/multi_necks.md
+ common_usage/specify_device.md
+ common_usage/single_multi_channel_applications.md
+
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Useful Tools
+
+ useful_tools/browse_coco_json.md
+ useful_tools/browse_dataset.md
+ useful_tools/print_config.md
+ useful_tools/dataset_analysis.md
+ useful_tools/optimize_anchors.md
+ useful_tools/extract_subcoco.md
+ useful_tools/vis_scheduler.md
+ useful_tools/dataset_converters.md
+ useful_tools/download_dataset.md
+ useful_tools/log_analysis.md
+ useful_tools/model_converters.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Basic Tutorials
+
+ tutorials/config.md
+ tutorials/data_flow.md
+ tutorials/custom_installation.md
+ tutorials/warning_notes.md
+ tutorials/faq.md
+
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Advanced Tutorials
+
+ advanced_guides/cross-library_application.md
+
+
+.. toctree::
+ :maxdepth: 2
+ :caption: Model Zoo
+
+ model_zoo.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: Notes
+
+ notes/changelog.md
+ notes/compatibility.md
+ notes/conventions.md
+ notes/code_style.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: API Reference
+
+ api.rst
+
+.. toctree::
+ :caption: Switch Language
+
+ switch_language.md
+
+
+Indices and tables
+==================
+
+* :ref:`genindex`
+* :ref:`search`
diff --git a/third_party/mmyolo/docs/en/make.bat b/third_party/mmyolo/docs/en/make.bat
new file mode 100644
index 0000000000000000000000000000000000000000..922152e96a04a242e6fc40f124261d74890617d8
--- /dev/null
+++ b/third_party/mmyolo/docs/en/make.bat
@@ -0,0 +1,35 @@
+@ECHO OFF
+
+pushd %~dp0
+
+REM Command file for Sphinx documentation
+
+if "%SPHINXBUILD%" == "" (
+ set SPHINXBUILD=sphinx-build
+)
+set SOURCEDIR=.
+set BUILDDIR=_build
+
+if "%1" == "" goto help
+
+%SPHINXBUILD% >NUL 2>NUL
+if errorlevel 9009 (
+ echo.
+ echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
+ echo.installed, then set the SPHINXBUILD environment variable to point
+ echo.to the full path of the 'sphinx-build' executable. Alternatively you
+ echo.may add the Sphinx directory to PATH.
+ echo.
+ echo.If you don't have Sphinx installed, grab it from
+ echo.http://sphinx-doc.org/
+ exit /b 1
+)
+
+%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+goto end
+
+:help
+%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+
+:end
+popd
diff --git a/third_party/mmyolo/docs/en/model_zoo.md b/third_party/mmyolo/docs/en/model_zoo.md
new file mode 100644
index 0000000000000000000000000000000000000000..1547bb9d090c3f7aa65c2c1a39ae10fa096cb0f8
--- /dev/null
+++ b/third_party/mmyolo/docs/en/model_zoo.md
@@ -0,0 +1,94 @@
+# Model Zoo and Benchmark
+
+This page is used to summarize the performance and related evaluation metrics of various models supported in MMYOLO for users to compare and analyze.
+
+## COCO dataset
+
+
+
+
+
+
+
+
+

+
+
+
+
+Figure 1: YOLOv5-l-P5 model structure
+
+
+Figure 2: YOLOv5-l-P6 model structure
+
+
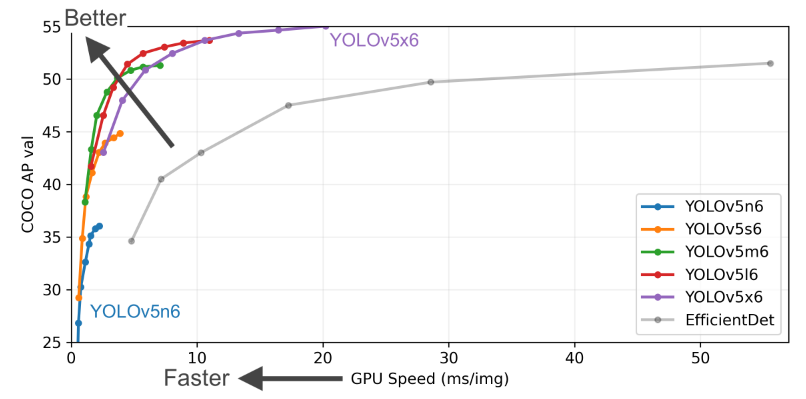
+
+
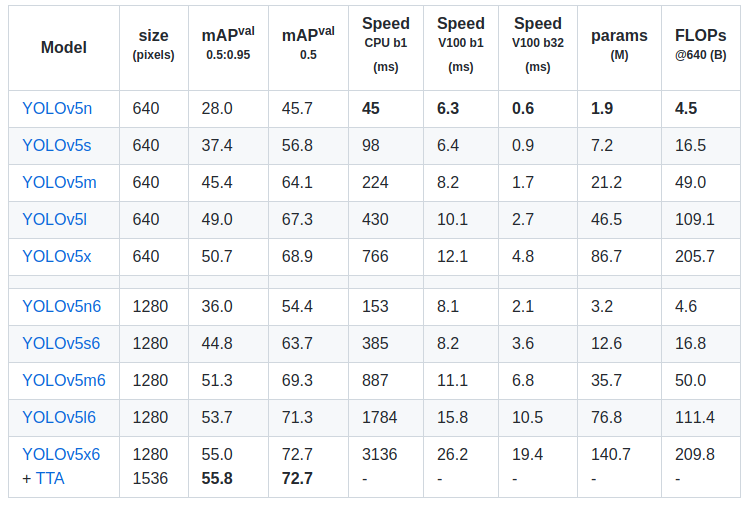
+
+
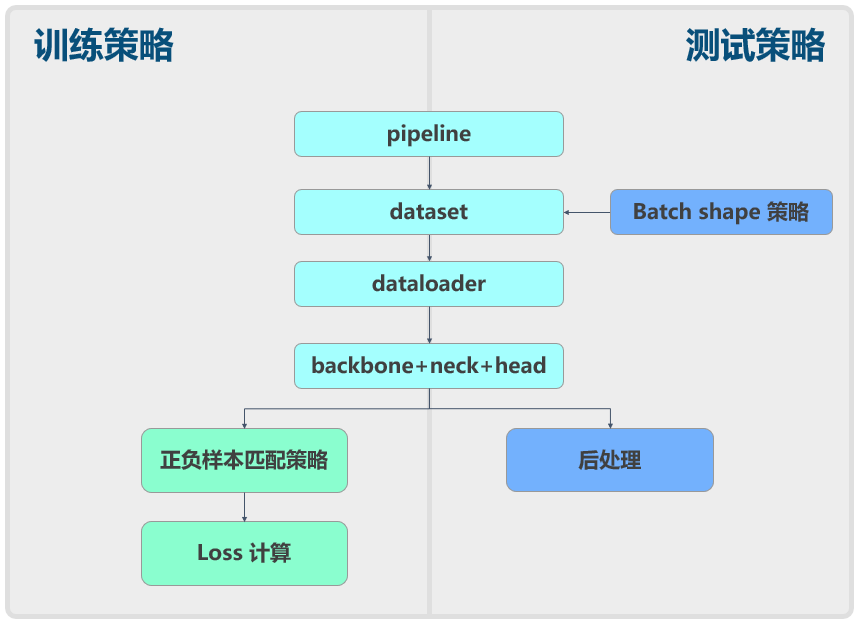
+
+
+
+

+
+

+
+
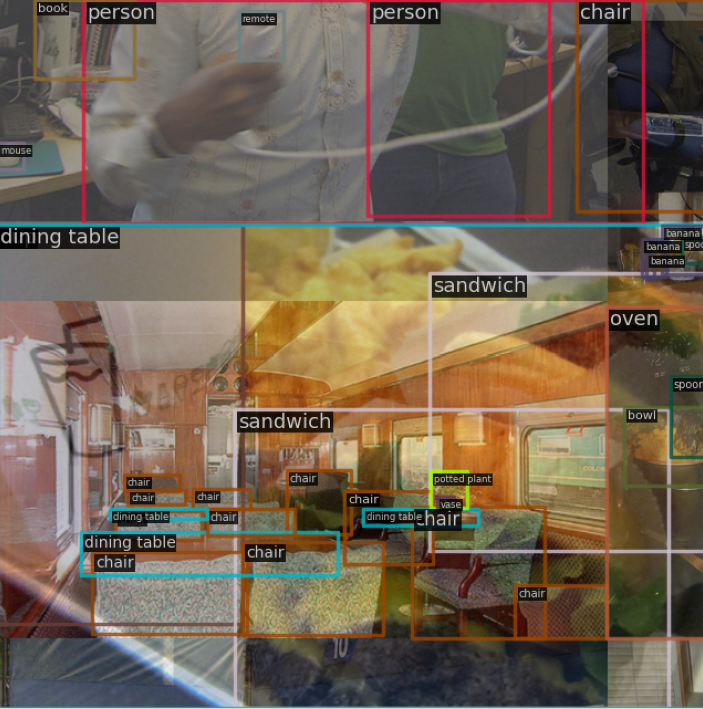
+
+

+
+
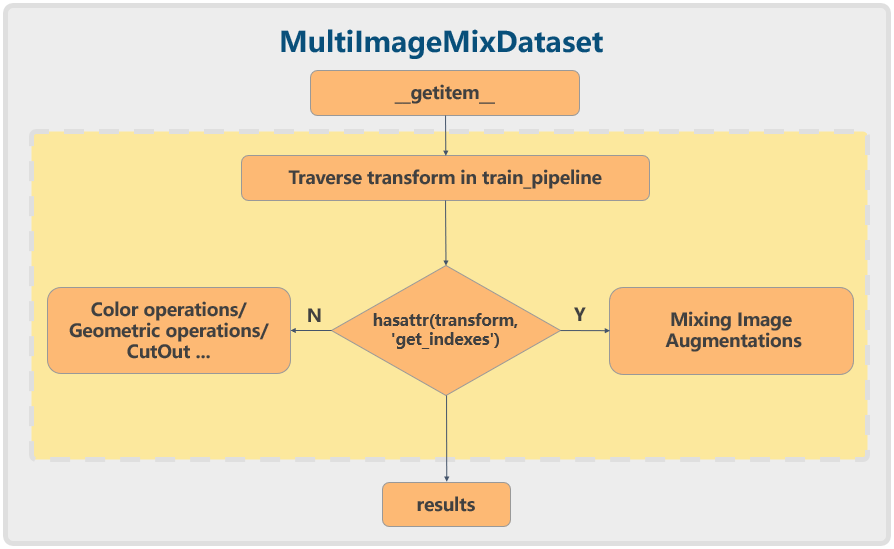
+
+
+
+
+
+
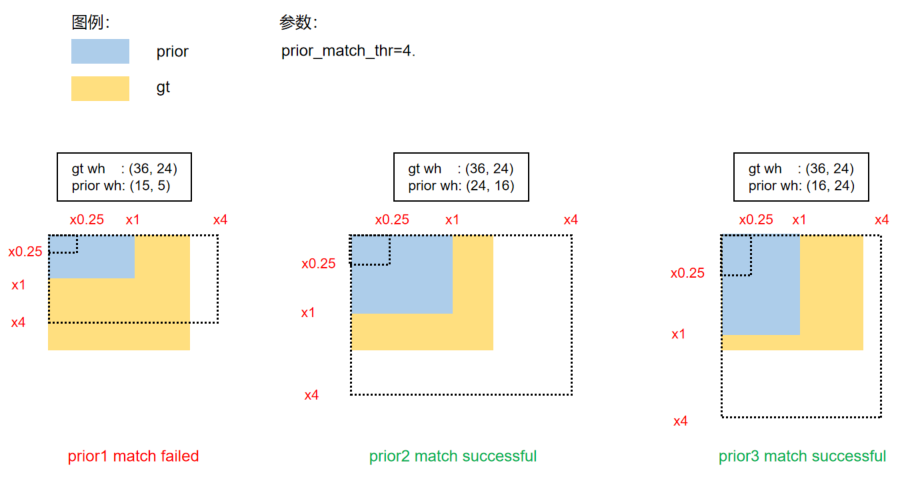
+
+
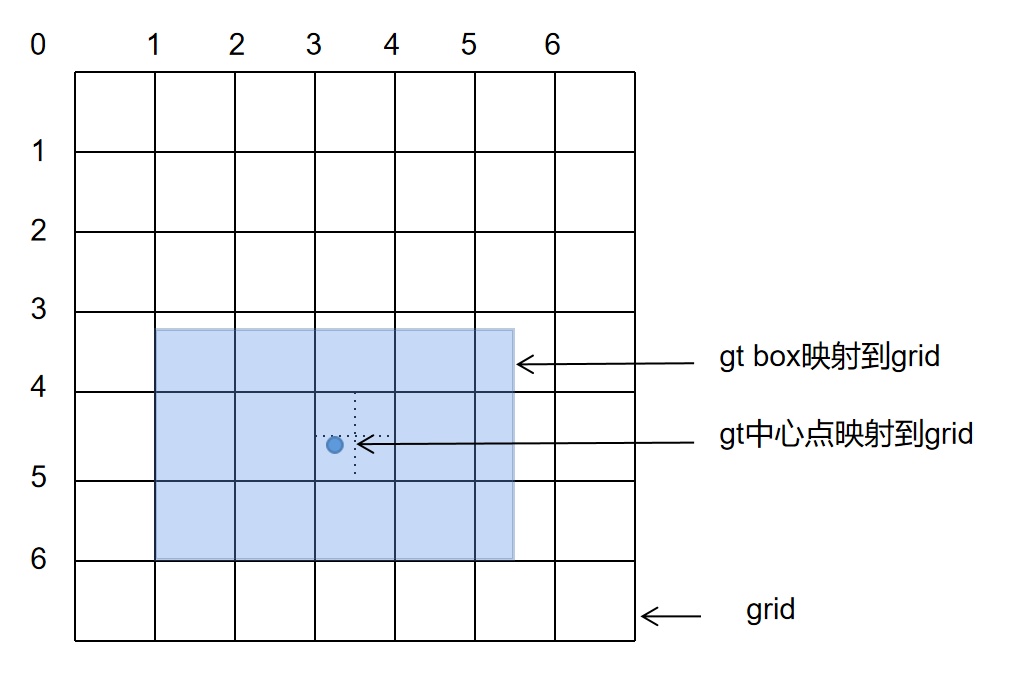
+
+
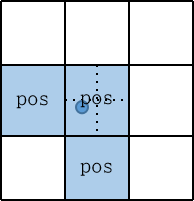
+
+
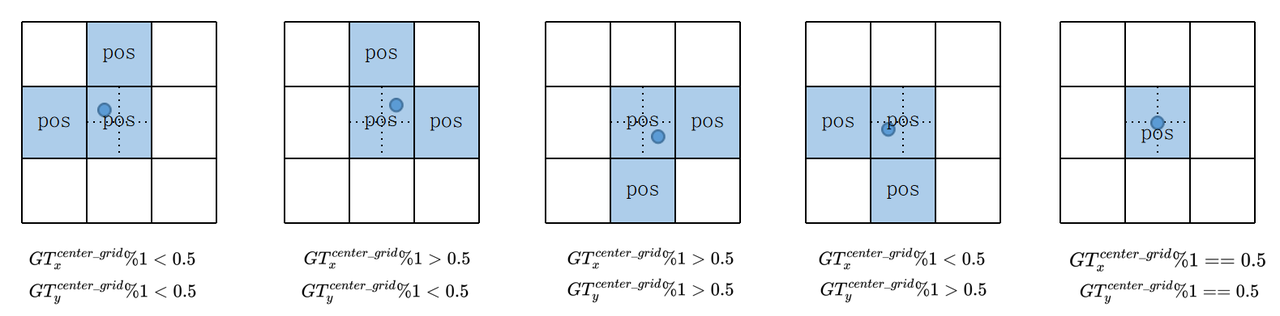
+
+
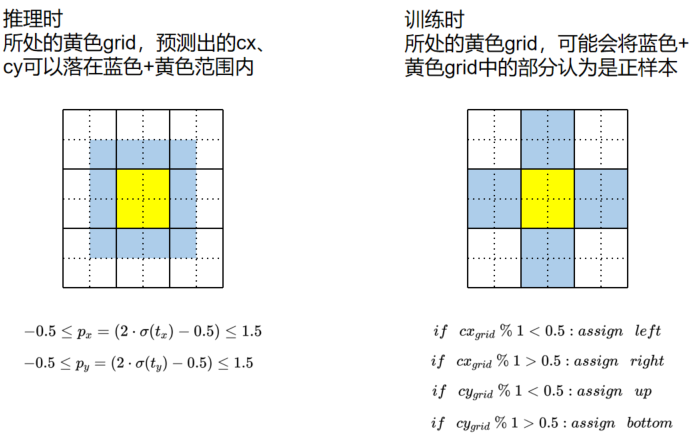
+
+
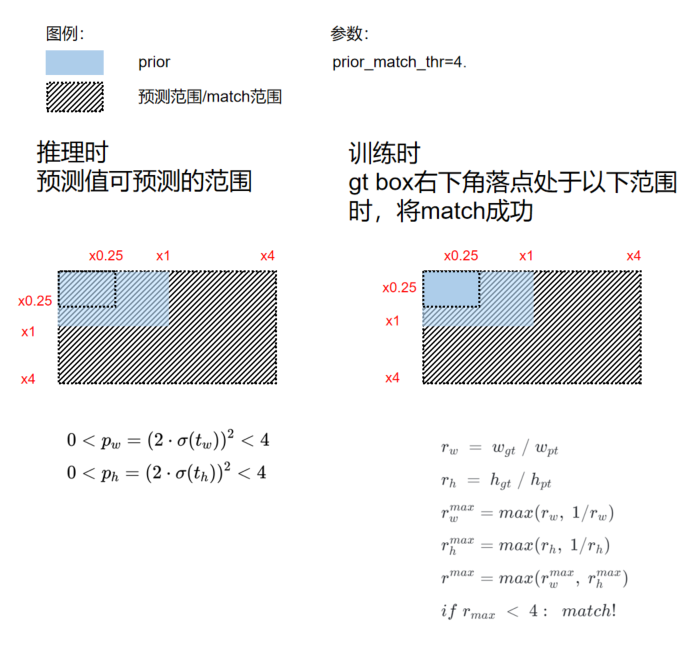
+
+
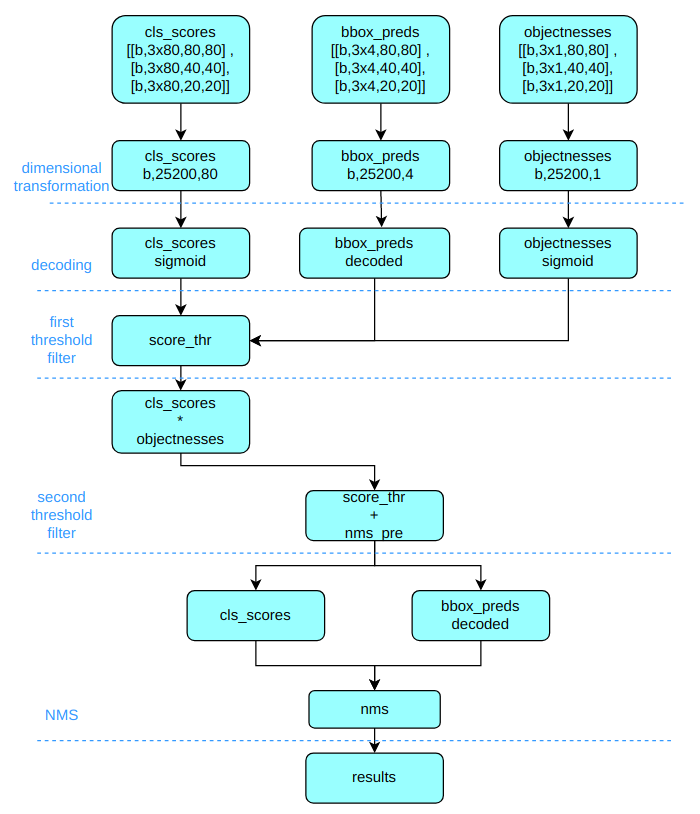
+
+
+Figure 1:YOLOv8-P5
+
+

+Figure 2:YOLOv8-logo
+
+

+Figure 3:YOLOv8-performance
+
+

+Figure 4:YOLOv5 and YOLOv8 YAML diff
+
+

+Figure 5:YOLOv5 and YOLOv8 module diff
+
+

+Figure 6:YOLOv8 Head
+
+

+Figure 7:pipeline
+
+

+Figure 8:results
+
+
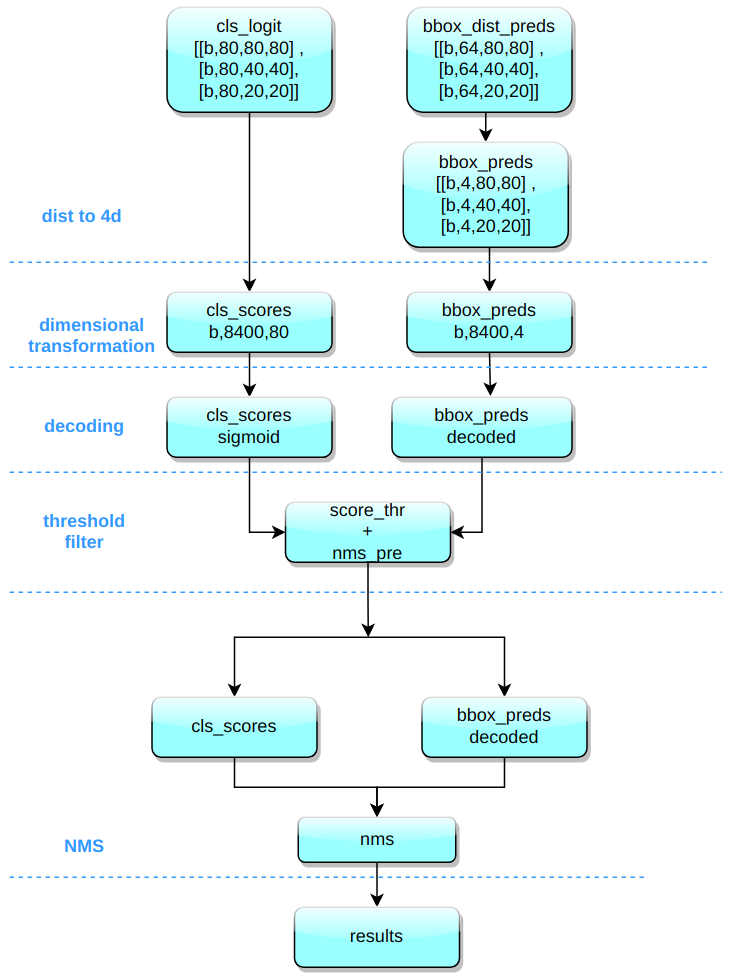
+Figure 9:results
+
+

+Figure 10:featmap
+
+

+Figure 11:featmap
+
+

+
+Preview of annotated images
+
+
+

+
+Statistics of object sizes for each category
+
+
+

+
+Visualization for intermediate images in the data pipeline
+
+
+

+
+The proportion of data loading time to the total time of each step.
+
+
+

+
+Comparison of loss reduction during training
+
+
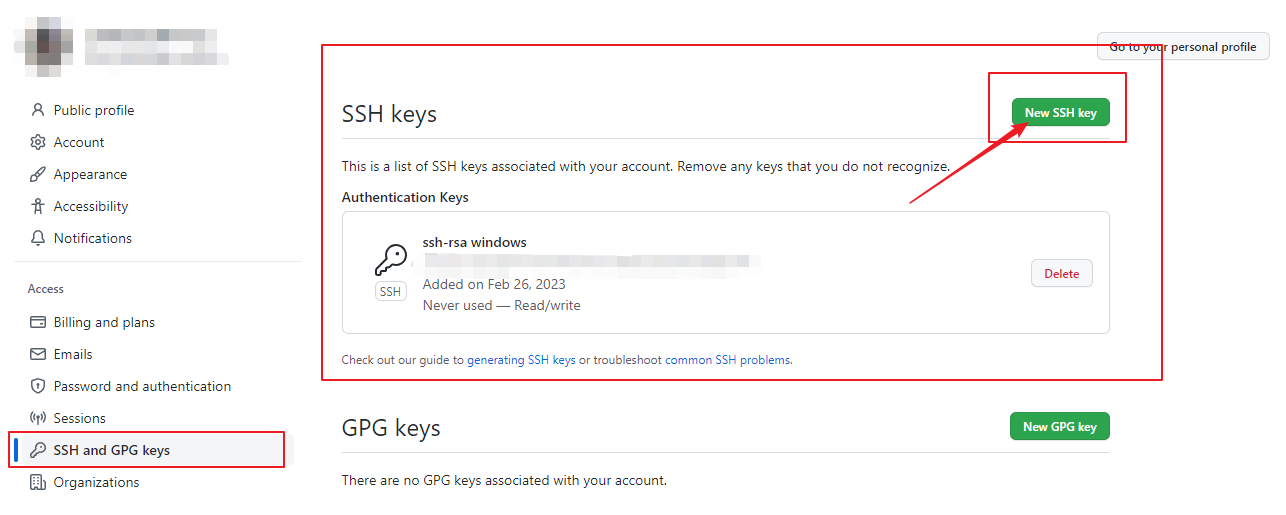 +
+Click `New SSH key` to add a new SSH keys, and paste the copied content into Key.
+
+
+
+Click `New SSH key` to add a new SSH keys, and paste the copied content into Key.
+
+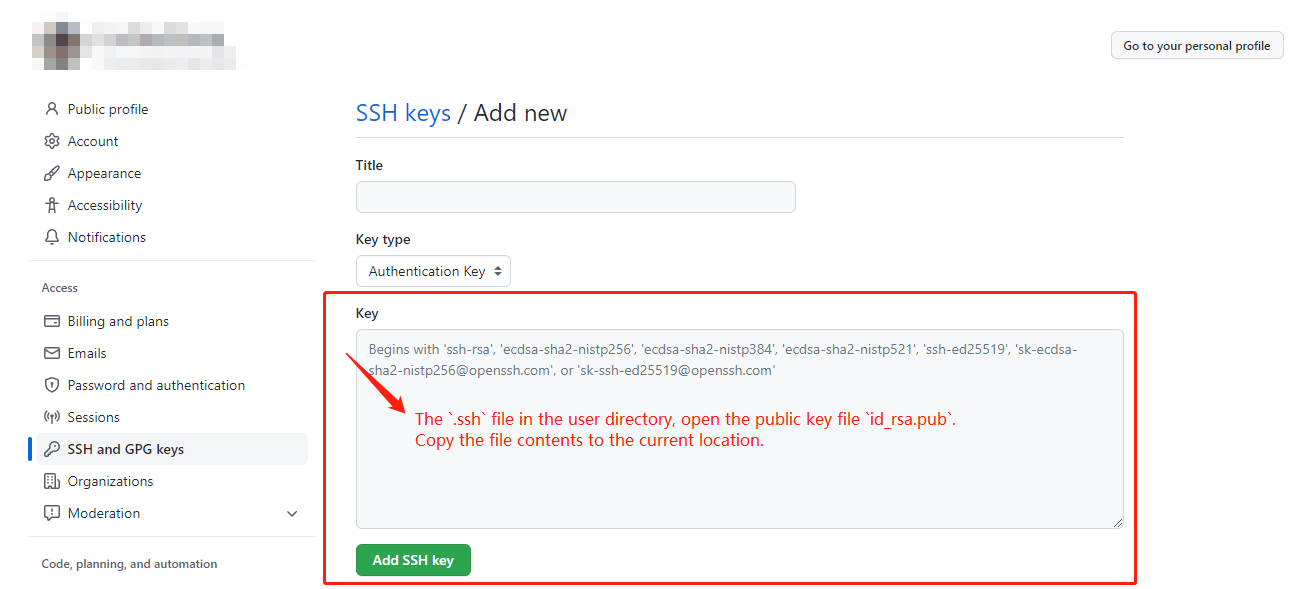 +
+Finally, verify that SSH matches the GitHub account by running the command in `git bash` or `terminal`. If it matches, enter `yes` to succeed.
+
+```shell
+ssh -T git@github.com
+```
+
+
+
+Finally, verify that SSH matches the GitHub account by running the command in `git bash` or `terminal`. If it matches, enter `yes` to succeed.
+
+```shell
+ssh -T git@github.com
+```
+
+ +
+## Pull Request Workflow
+
+If you're not familiar with Pull Request, don't worry! The following guidance will tell you how to create a Pull Request step by step. If you want to dive into the development mode of Pull Request, you can refer to the [official documents](https://docs.github.com/en/github/collaborating-with-issues-and-pull-requests/about-pull-requests)
+
+### 1. Fork and clone
+
+If you are posting a pull request for the first time, you should fork the OpenMMLab repositories by clicking the **Fork** button in the top right corner of the GitHub page, and the forked repositories will appear under your GitHub profile.
+
+
+
+## Pull Request Workflow
+
+If you're not familiar with Pull Request, don't worry! The following guidance will tell you how to create a Pull Request step by step. If you want to dive into the development mode of Pull Request, you can refer to the [official documents](https://docs.github.com/en/github/collaborating-with-issues-and-pull-requests/about-pull-requests)
+
+### 1. Fork and clone
+
+If you are posting a pull request for the first time, you should fork the OpenMMLab repositories by clicking the **Fork** button in the top right corner of the GitHub page, and the forked repositories will appear under your GitHub profile.
+
+ +
+Then, you can clone the repositories to local:
+
+```shell
+git clone git@github.com:{username}/mmyolo.git
+```
+
+After that, you should get into the project folder and add official repository as the upstream repository.
+
+```bash
+cd mmyolo
+git remote add upstream git@github.com:open-mmlab/mmyolo
+```
+
+Check whether the remote repository has been added successfully by `git remote -v`
+
+```bash
+origin git@github.com:{username}/mmyolo.git (fetch)
+origin git@github.com:{username}/mmyolo.git (push)
+upstream git@github.com:open-mmlab/mmyolo (fetch)
+upstream git@github.com:open-mmlab/mmyolo (push)
+```
+
+```{note}
+Here's a brief introduction to the origin and upstream. When we use "git clone", we create an "origin" remote by default, which points to the repository cloned from. As for "upstream", we add it ourselves to point to the target repository. Of course, if you don't like the name "upstream", you could name it as you wish. Usually, we'll push the code to "origin". If the pushed code conflicts with the latest code in official("upstream"), we should pull the latest code from upstream to resolve the conflicts, and then push to "origin" again. The posted Pull Request will be updated automatically.
+```
+
+### 2. Configure pre-commit
+
+You should configure [pre-commit](https://pre-commit.com/#intro) in the local development environment to make sure the code style matches that of OpenMMLab. **Note**: The following code should be executed under the MMYOLO directory.
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+Check that pre-commit is configured successfully, and install the hooks defined in `.pre-commit-config.yaml`.
+
+```shell
+pre-commit run --all-files
+```
+
+
+
+Then, you can clone the repositories to local:
+
+```shell
+git clone git@github.com:{username}/mmyolo.git
+```
+
+After that, you should get into the project folder and add official repository as the upstream repository.
+
+```bash
+cd mmyolo
+git remote add upstream git@github.com:open-mmlab/mmyolo
+```
+
+Check whether the remote repository has been added successfully by `git remote -v`
+
+```bash
+origin git@github.com:{username}/mmyolo.git (fetch)
+origin git@github.com:{username}/mmyolo.git (push)
+upstream git@github.com:open-mmlab/mmyolo (fetch)
+upstream git@github.com:open-mmlab/mmyolo (push)
+```
+
+```{note}
+Here's a brief introduction to the origin and upstream. When we use "git clone", we create an "origin" remote by default, which points to the repository cloned from. As for "upstream", we add it ourselves to point to the target repository. Of course, if you don't like the name "upstream", you could name it as you wish. Usually, we'll push the code to "origin". If the pushed code conflicts with the latest code in official("upstream"), we should pull the latest code from upstream to resolve the conflicts, and then push to "origin" again. The posted Pull Request will be updated automatically.
+```
+
+### 2. Configure pre-commit
+
+You should configure [pre-commit](https://pre-commit.com/#intro) in the local development environment to make sure the code style matches that of OpenMMLab. **Note**: The following code should be executed under the MMYOLO directory.
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+Check that pre-commit is configured successfully, and install the hooks defined in `.pre-commit-config.yaml`.
+
+```shell
+pre-commit run --all-files
+```
+
+ +
+
+
+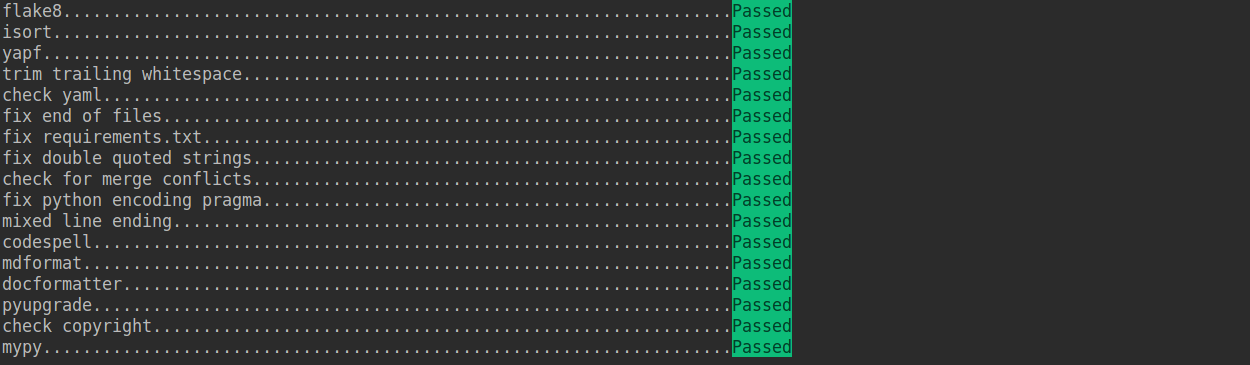 +
+```{note}
+Chinese users may fail to download the pre-commit hooks due to the network issue. In this case, you could download these hooks from gitee by setting the .pre-commit-config-zh-cn.yaml
+
+pre-commit install -c .pre-commit-config-zh-cn.yaml
+pre-commit run --all-files -c .pre-commit-config-zh-cn.yaml
+```
+
+If the installation process is interrupted, you can repeatedly run `pre-commit run ... ` to continue the installation.
+
+If the code does not conform to the code style specification, pre-commit will raise a warning and fixes some of the errors automatically.
+
+
+
+```{note}
+Chinese users may fail to download the pre-commit hooks due to the network issue. In this case, you could download these hooks from gitee by setting the .pre-commit-config-zh-cn.yaml
+
+pre-commit install -c .pre-commit-config-zh-cn.yaml
+pre-commit run --all-files -c .pre-commit-config-zh-cn.yaml
+```
+
+If the installation process is interrupted, you can repeatedly run `pre-commit run ... ` to continue the installation.
+
+If the code does not conform to the code style specification, pre-commit will raise a warning and fixes some of the errors automatically.
+
+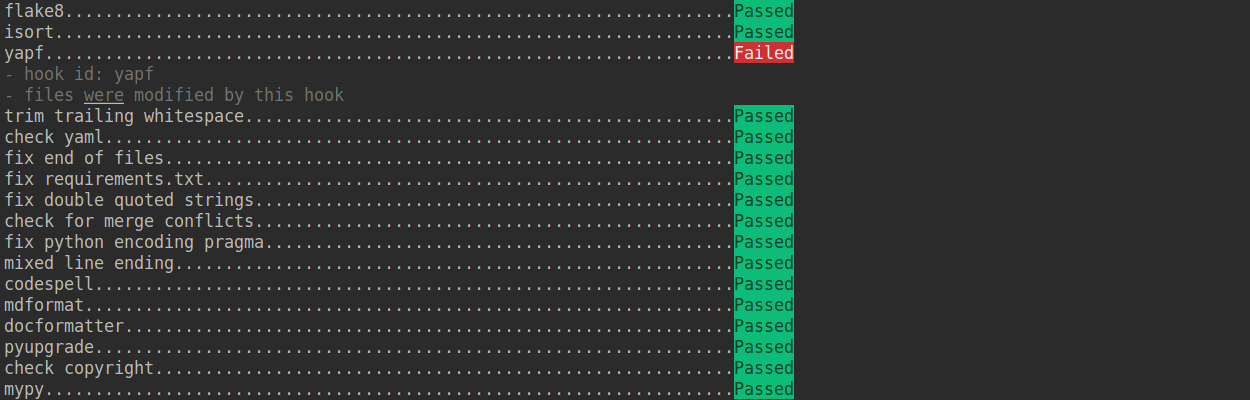 +
+If we want to commit our code bypassing the pre-commit hook, we can use the `--no-verify` option(**only for temporarily commit**).
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+### 3. Create a development branch
+
+After configuring the pre-commit, we should create a branch based on the dev branch to develop the new feature or fix the bug. The proposed branch name is `username/pr_name`
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+In subsequent development, if the dev branch of the local repository is behind the dev branch of "upstream", we need to pull the upstream for synchronization, and then execute the above command:
+
+```shell
+git pull upstream dev
+```
+
+### 4. Commit the code and pass the unit test
+
+- MMYOLO introduces mypy to do static type checking to increase the robustness of the code. Therefore, we need to add Type Hints to our code and pass the mypy check. If you are not familiar with Type Hints, you can refer to [this tutorial](https://docs.python.org/3/library/typing.html).
+
+- The committed code should pass through the unit test
+
+ ```shell
+ # Pass all unit tests
+ pytest tests
+
+ # Pass the unit test of yolov5_coco dataset
+ pytest tests/test_datasets/test_yolov5_coco.py
+ ```
+
+ If the unit test fails for lack of dependencies, you can install the dependencies referring to the [guidance](#unit-test)
+
+- If the documents are modified/added, we should check the rendering result referring to [guidance](#document-rendering)
+
+### 5. Push the code to remote
+
+We could push the local commits to remote after passing through the check of unit test and pre-commit. You can associate the local branch with remote branch by adding `-u` option.
+
+```shell
+git push -u origin {branch_name}
+```
+
+This will allow you to use the `git push` command to push code directly next time, without having to specify a branch or the remote repository.
+
+### 6. Create a Pull Request
+
+(1) Create a pull request in GitHub's Pull request interface
+
+
+
+If we want to commit our code bypassing the pre-commit hook, we can use the `--no-verify` option(**only for temporarily commit**).
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+### 3. Create a development branch
+
+After configuring the pre-commit, we should create a branch based on the dev branch to develop the new feature or fix the bug. The proposed branch name is `username/pr_name`
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+In subsequent development, if the dev branch of the local repository is behind the dev branch of "upstream", we need to pull the upstream for synchronization, and then execute the above command:
+
+```shell
+git pull upstream dev
+```
+
+### 4. Commit the code and pass the unit test
+
+- MMYOLO introduces mypy to do static type checking to increase the robustness of the code. Therefore, we need to add Type Hints to our code and pass the mypy check. If you are not familiar with Type Hints, you can refer to [this tutorial](https://docs.python.org/3/library/typing.html).
+
+- The committed code should pass through the unit test
+
+ ```shell
+ # Pass all unit tests
+ pytest tests
+
+ # Pass the unit test of yolov5_coco dataset
+ pytest tests/test_datasets/test_yolov5_coco.py
+ ```
+
+ If the unit test fails for lack of dependencies, you can install the dependencies referring to the [guidance](#unit-test)
+
+- If the documents are modified/added, we should check the rendering result referring to [guidance](#document-rendering)
+
+### 5. Push the code to remote
+
+We could push the local commits to remote after passing through the check of unit test and pre-commit. You can associate the local branch with remote branch by adding `-u` option.
+
+```shell
+git push -u origin {branch_name}
+```
+
+This will allow you to use the `git push` command to push code directly next time, without having to specify a branch or the remote repository.
+
+### 6. Create a Pull Request
+
+(1) Create a pull request in GitHub's Pull request interface
+
+ +
+(2) Modify the PR description according to the guidelines so that other developers can better understand your changes.
+
+```{note}
+The *base* branch should be modified to *dev* branch.
+```
+
+
+
+(2) Modify the PR description according to the guidelines so that other developers can better understand your changes.
+
+```{note}
+The *base* branch should be modified to *dev* branch.
+```
+
+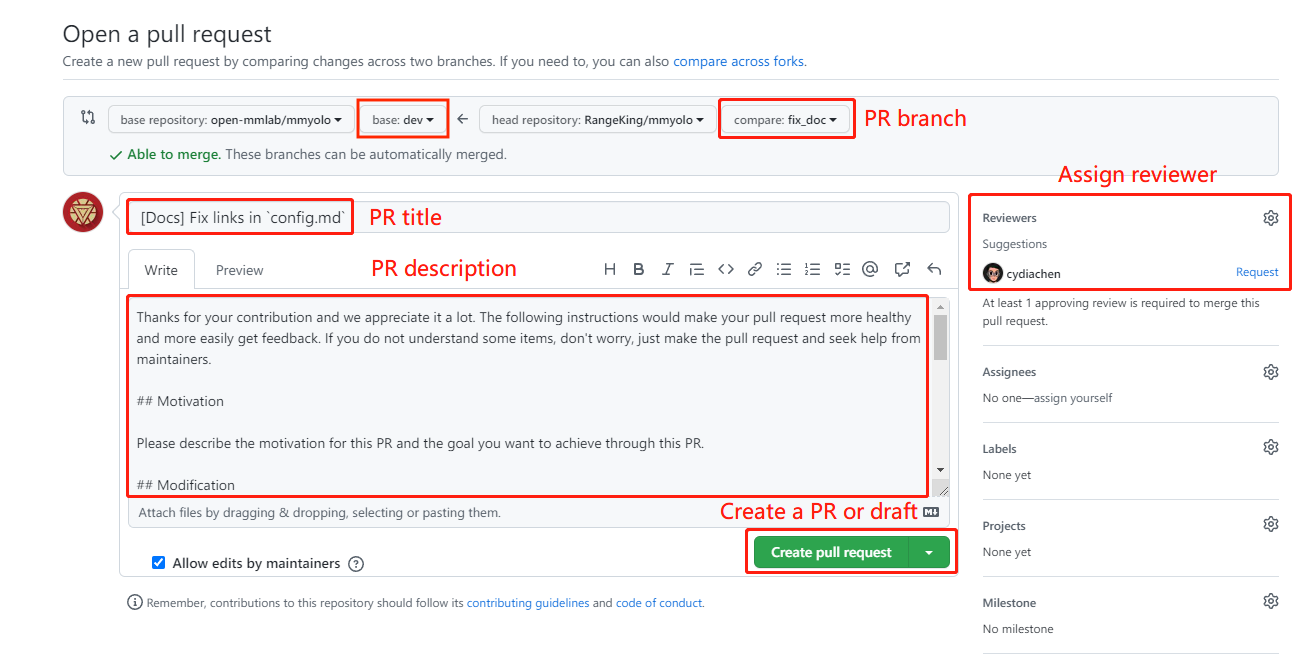 +
+Find more details about Pull Request description in [pull request guidelines](#pr-specs).
+
+**note**
+
+(a) The Pull Request description should contain the reason for the change, the content of the change, and the impact of the change, and be associated with the relevant Issue (see [documentation](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue))
+
+(b) If it is your first contribution, please sign the CLA
+
+
+
+Find more details about Pull Request description in [pull request guidelines](#pr-specs).
+
+**note**
+
+(a) The Pull Request description should contain the reason for the change, the content of the change, and the impact of the change, and be associated with the relevant Issue (see [documentation](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue))
+
+(b) If it is your first contribution, please sign the CLA
+
+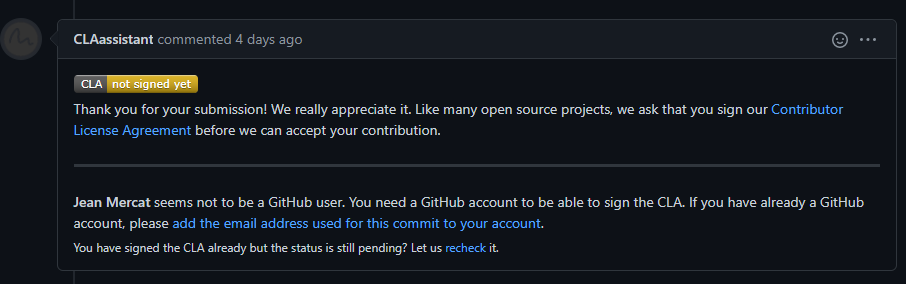 +
+(c) Check whether the Pull Request pass through the CI
+
+
+
+(c) Check whether the Pull Request pass through the CI
+
+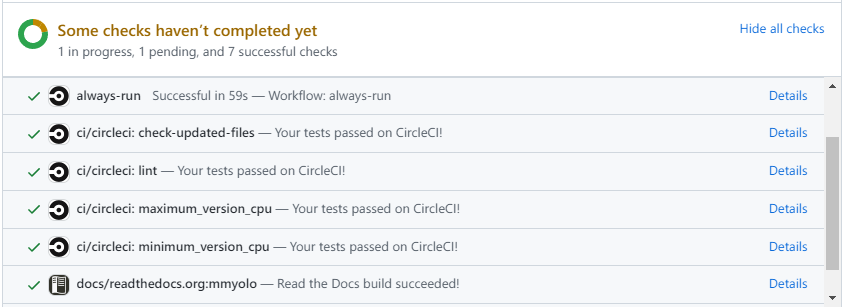 +
+MMYOLO will run unit test for the posted Pull Request on Linux, based on different versions of Python, and PyTorch to make sure the code is correct. We can see the specific test information by clicking `Details` in the above image so that we can modify the code.
+
+(3) If the Pull Request passes the CI, then you can wait for the review from other developers. You'll modify the code based on the reviewer's comments, and repeat the steps [4](#4-commit-the-code-and-pass-the-unit-test)-[5](#5-push-the-code-to-remote) until all reviewers approve it. Then, we will merge it ASAP.
+
+
+
+MMYOLO will run unit test for the posted Pull Request on Linux, based on different versions of Python, and PyTorch to make sure the code is correct. We can see the specific test information by clicking `Details` in the above image so that we can modify the code.
+
+(3) If the Pull Request passes the CI, then you can wait for the review from other developers. You'll modify the code based on the reviewer's comments, and repeat the steps [4](#4-commit-the-code-and-pass-the-unit-test)-[5](#5-push-the-code-to-remote) until all reviewers approve it. Then, we will merge it ASAP.
+
+ +
+### 7. Resolve conflicts
+
+If your local branch conflicts with the latest dev branch of "upstream", you'll need to resolove them. There are two ways to do this:
+
+```shell
+git fetch --all --prune
+git rebase upstream/dev
+```
+
+or
+
+```shell
+git fetch --all --prune
+git merge upstream/dev
+```
+
+If you are very good at handling conflicts, then you can use rebase to resolve conflicts, as this will keep your commit logs tidy. If you are unfamiliar with `rebase`, you can use `merge` to resolve conflicts.
+
+## Guidance
+
+### Unit test
+
+We should also make sure the committed code will not decrease the coverage of unit test, we could run the following command to check the coverage of unit test:
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+### Document rendering
+
+If the documents are modified/added, we should check the rendering result. We could install the dependencies and run the following command to render the documents and check the results:
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+## Code style
+
+### Python
+
+We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style.
+
+We use the following tools for linting and formatting:
+
+- [flake8](https://github.com/PyCQA/flake8): A wrapper around some linter tools.
+- [isort](https://github.com/timothycrosley/isort): A Python utility to sort imports.
+- [yapf](https://github.com/google/yapf): A formatter for Python files.
+- [codespell](https://github.com/codespell-project/codespell): A Python utility to fix common misspellings in text files.
+- [mdformat](https://github.com/executablebooks/mdformat): Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files.
+- [docformatter](https://github.com/myint/docformatter): A formatter to format docstring.
+
+Style configurations of yapf and isort can be found in [setup.cfg](../../../setup.cfg).
+
+We use [pre-commit hook](https://pre-commit.com/) that checks and formats for `flake8`, `yapf`, `isort`, `trailing whitespaces`, `markdown files`,
+fixes `end-of-files`, `double-quoted-strings`, `python-encoding-pragma`, `mixed-line-ending`, sorts `requirments.txt` automatically on every commit.
+The config for a pre-commit hook is stored in [.pre-commit-config](../../../.pre-commit-config.yaml).
+
+### C++ and CUDA
+
+We follow the [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html).
+
+## PR Specs
+
+1. Use [pre-commit](https://pre-commit.com) hook to avoid issues of code style
+
+2. One short-time branch should be matched with only one PR
+
+3. Accomplish a detailed change in one PR. Avoid large PR
+
+ - Bad: Support Faster R-CNN
+ - Acceptable: Add a box head to Faster R-CNN
+ - Good: Add a parameter to box head to support custom conv-layer number
+
+4. Provide clear and significant commit message
+
+5. Provide clear and meaningful PR description
+
+ - Task name should be clarified in title. The general format is: \[Prefix\] Short description of the PR (Suffix)
+ - Prefix: add new feature \[Feature\], fix bug \[Fix\], related to documents \[Docs\], in developing \[WIP\] (which will not be reviewed temporarily)
+ - Introduce main changes, results and influences on other modules in short description
+ - Associate related issues and pull requests with a milestone
diff --git a/third_party/mmyolo/docs/en/recommended_topics/dataset_preparation.md b/third_party/mmyolo/docs/en/recommended_topics/dataset_preparation.md
new file mode 100644
index 0000000000000000000000000000000000000000..af670d89a4214bd440bd39b4faf9fc37fe7d5286
--- /dev/null
+++ b/third_party/mmyolo/docs/en/recommended_topics/dataset_preparation.md
@@ -0,0 +1,145 @@
+# Dataset preparation and description
+
+## DOTA Dataset
+
+### Download dataset
+
+The DOTA dataset can be downloaded from [DOTA](https://captain-whu.github.io/DOTA/dataset.html)
+or [OpenDataLab](https://opendatalab.org.cn/DOTA_V1.0).
+
+We recommend using [OpenDataLab](https://opendatalab.org.cn/DOTA_V1.0) to download the dataset, as the folder structure has already been arranged as needed and can be directly extracted without the need to adjust the folder structure.
+
+Please unzip the file and place it in the following structure.
+
+```none
+${DATA_ROOT}
+├── train
+│ ├── images
+│ │ ├── P0000.png
+│ │ ├── ...
+│ ├── labelTxt-v1.0
+│ │ ├── labelTxt
+│ │ │ ├── P0000.txt
+│ │ │ ├── ...
+│ │ ├── trainset_reclabelTxt
+│ │ │ ├── P0000.txt
+│ │ │ ├── ...
+├── val
+│ ├── images
+│ │ ├── P0003.png
+│ │ ├── ...
+│ ├── labelTxt-v1.0
+│ │ ├── labelTxt
+│ │ │ ├── P0003.txt
+│ │ │ ├── ...
+│ │ ├── valset_reclabelTxt
+│ │ │ ├── P0003.txt
+│ │ │ ├── ...
+├── test
+│ ├── images
+│ │ ├── P0006.png
+│ │ ├── ...
+
+```
+
+The folder ending with reclabelTxt stores the labels for the horizontal boxes and is not used when slicing.
+
+### Split DOTA dataset
+
+Script `tools/dataset_converters/dota/dota_split.py` can split and prepare DOTA dataset.
+
+```shell
+python tools/dataset_converters/dota/dota_split.py \
+ [--splt-config ${SPLIT_CONFIG}] \
+ [--data-root ${DATA_ROOT}] \
+ [--out-dir ${OUT_DIR}] \
+ [--ann-subdir ${ANN_SUBDIR}] \
+ [--phase ${DATASET_PHASE}] \
+ [--nproc ${NPROC}] \
+ [--save-ext ${SAVE_EXT}] \
+ [--overwrite]
+```
+
+shapely is required, please install shapely first by `pip install shapely`.
+
+**Description of all parameters**:
+
+- `--split-config` : The split config for image slicing.
+- `--data-root`: Root dir of DOTA dataset.
+- `--out-dir`: Output dir for split result.
+- `--ann-subdir`: The subdir name for annotation. Defaults to `labelTxt-v1.0`.
+- `--phase`: Phase of the data set to be prepared. Defaults to `trainval test`
+- `--nproc`: Number of processes. Defaults to 8.
+- `--save-ext`: Extension of the saved image. Defaults to `png`
+- `--overwrite`: Whether to allow overwrite if annotation folder exist.
+
+Based on the configuration in the DOTA paper, we provide two commonly used split config.
+
+- `./split_config/single_scale.json` means single-scale split.
+- `./split_config/multi_scale.json` means multi-scale split.
+
+DOTA dataset usually uses the trainval set for training and the test set for online evaluation, since most papers
+provide the results of online evaluation. If you want to evaluate the model performance locally firstly, please split
+the train set and val set.
+
+Examples:
+
+Split DOTA trainval set and test set with single scale.
+
+```shell
+python tools/dataset_converters/dota/dota_split.py
+ --split-config 'tools/dataset_converters/dota/split_config/single_scale.json'
+ --data-root ${DATA_ROOT} \
+ --out-dir ${OUT_DIR}
+```
+
+If you want to split DOTA-v1.5 dataset, which have different annotation dir 'labelTxt-v1.5'.
+
+```shell
+python tools/dataset_converters/dota/dota_split.py
+ --split-config 'tools/dataset_converters/dota/split_config/single_scale.json'
+ --data-root ${DATA_ROOT} \
+ --out-dir ${OUT_DIR} \
+ --ann-subdir 'labelTxt-v1.5'
+```
+
+If you want to split DOTA train and val set with single scale.
+
+```shell
+python tools/dataset_converters/dota/dota_split.py
+ --split-config 'tools/dataset_converters/dota/split_config/single_scale.json'
+ --data-root ${DATA_ROOT} \
+ --phase train val \
+ --out-dir ${OUT_DIR}
+```
+
+For multi scale split:
+
+```shell
+python tools/dataset_converters/dota/dota_split.py
+ --split-config 'tools/dataset_converters/dota/split_config/multi_scale.json'
+ --data-root ${DATA_ROOT} \
+ --out-dir ${OUT_DIR}
+```
+
+The new data structure is as follows:
+
+```none
+${OUT_DIR}
+├── trainval
+│ ├── images
+│ │ ├── P0000__1024__0___0.png
+│ │ ├── ...
+│ ├── annfiles
+│ │ ├── P0000__1024__0___0.txt
+│ │ ├── ...
+├── test
+│ ├── images
+│ │ ├── P0006__1024__0___0.png
+│ │ ├── ...
+│ ├── annfiles
+│ │ ├── P0006__1024__0___0.txt
+│ │ ├── ...
+```
+
+Then change `data_root` to ${OUT_DIR}.
diff --git a/third_party/mmyolo/docs/en/recommended_topics/deploy/easydeploy_guide.md b/third_party/mmyolo/docs/en/recommended_topics/deploy/easydeploy_guide.md
new file mode 100644
index 0000000000000000000000000000000000000000..46fab865340f6db1eb52146de9459078b68f1319
--- /dev/null
+++ b/third_party/mmyolo/docs/en/recommended_topics/deploy/easydeploy_guide.md
@@ -0,0 +1 @@
+# EasyDeploy Deployment
diff --git a/third_party/mmyolo/docs/en/recommended_topics/deploy/index.rst b/third_party/mmyolo/docs/en/recommended_topics/deploy/index.rst
new file mode 100644
index 0000000000000000000000000000000000000000..f21f353c8c64d457e21c79b4af1c75eae9715174
--- /dev/null
+++ b/third_party/mmyolo/docs/en/recommended_topics/deploy/index.rst
@@ -0,0 +1,16 @@
+MMDeploy deployment tutorial
+********************************
+
+.. toctree::
+ :maxdepth: 1
+
+ mmdeploy_guide.md
+ mmdeploy_yolov5.md
+
+EasyDeploy deployment tutorial
+************************************
+
+.. toctree::
+ :maxdepth: 1
+
+ easydeploy_guide.md
diff --git a/third_party/mmyolo/docs/en/recommended_topics/deploy/mmdeploy_guide.md b/third_party/mmyolo/docs/en/recommended_topics/deploy/mmdeploy_guide.md
new file mode 100644
index 0000000000000000000000000000000000000000..096d39fbc9bd6ee46309332339cbcdca2009c098
--- /dev/null
+++ b/third_party/mmyolo/docs/en/recommended_topics/deploy/mmdeploy_guide.md
@@ -0,0 +1,414 @@
+# Basic Deployment Guide
+
+## Introduction of MMDeploy
+
+MMDeploy is an open-source deep learning model deployment toolset. It is a part of the [OpenMMLab](https://openmmlab.com/) project, and provides **a unified experience of exporting different models** to various platforms and devices of the OpenMMLab series libraries. Using MMDeploy, developers can easily export the specific compiled SDK they need from the training result, which saves a lot of effort.
+
+More detailed introduction and guides can be found [here](https://mmdeploy.readthedocs.io/en/latest/get_started.html)
+
+## Supported Algorithms
+
+Currently our deployment kit supports on the following models and backends:
+
+| Model | Task | OnnxRuntime | TensorRT | Model config |
+| :----- | :-------------- | :---------: | :------: | :---------------------------------------------------------------------: |
+| YOLOv5 | ObjectDetection | Y | Y | [config](https://github.com/open-mmlab/mmyolo/tree/main/configs/yolov5) |
+| YOLOv6 | ObjectDetection | Y | Y | [config](https://github.com/open-mmlab/mmyolo/tree/main/configs/yolov6) |
+| YOLOX | ObjectDetection | Y | Y | [config](https://github.com/open-mmlab/mmyolo/tree/main/configs/yolox) |
+| RTMDet | ObjectDetection | Y | Y | [config](https://github.com/open-mmlab/mmyolo/tree/main/configs/rtmdet) |
+
+Note: ncnn and other inference backends support are coming soon.
+
+## Installation
+
+Please install mmdeploy by following [this](https://mmdeploy.readthedocs.io/en/latest/get_started.html) guide.
+
+```{note}
+If you install mmdeploy prebuilt package, please also clone its repository by 'git clone https://github.com/open-mmlab/mmdeploy.git --depth=1' to get the 'tools' file for deployment.
+```
+
+## How to Write Config for MMYOLO
+
+All config files related to the deployment are located at [`configs/deploy`](../../../configs/deploy/).
+
+You only need to change the relative data processing part in the model config file to support either static or dynamic input for your model. Besides, MMDeploy integrates the post-processing parts as customized ops, you can modify the strategy in `post_processing` parameter in `codebase_config`.
+
+Here is the detail description:
+
+```python
+codebase_config = dict(
+ type='mmyolo',
+ task='ObjectDetection',
+ model_type='end2end',
+ post_processing=dict(
+ score_threshold=0.05,
+ confidence_threshold=0.005,
+ iou_threshold=0.5,
+ max_output_boxes_per_class=200,
+ pre_top_k=5000,
+ keep_top_k=100,
+ background_label_id=-1),
+ module=['mmyolo.deploy'])
+```
+
+- `score_threshold`: set the score threshold to filter candidate bboxes before `nms`
+- `confidence_threshold`: set the confidence threshold to filter candidate bboxes before `nms`
+- `iou_threshold`: set the `iou` threshold for removing duplicates in `nms`
+- `max_output_boxes_per_class`: set the maximum number of bboxes for each class
+- `pre_top_k`: set the number of fixedcandidate bboxes before `nms`, sorted by scores
+- `keep_top_k`: set the number of output candidate bboxs after `nms`
+- `background_label_id`: set to `-1` as MMYOLO has no background class information
+
+### Configuration for Static Inputs
+
+#### 1. Model Config
+
+Taking `YOLOv5` of MMYOLO as an example, here are the details:
+
+```python
+_base_ = '../../yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+test_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=_base_.backend_args),
+ dict(
+ type='LetterResize',
+ scale=_base_.img_scale,
+ allow_scale_up=False,
+ use_mini_pad=False,
+ ),
+ dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
+ dict(
+ type='mmdet.PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'pad_param'))
+]
+
+test_dataloader = dict(
+ dataset=dict(pipeline=test_pipeline, batch_shapes_cfg=None))
+```
+
+`_base_ = '../../yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'` inherits the model config in the training stage.
+
+`test_pipeline` adds the data processing piple for the deployment, `LetterResize` controls the size of the input images and the input for the converted model
+
+`test_dataloader` adds the dataloader config for the deployment, `batch_shapes_cfg` decides whether to use the `batch_shapes` strategy. More details can be found at [yolov5 configs](../user_guides/config.md)
+
+#### 2. Deployment Config
+
+Here we still use the `YOLOv5` in MMYOLO as the example. We can use [`detection_onnxruntime_static.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_onnxruntime_static.py) as the config to deploy `YOLOv5` to `ONNXRuntime` with static inputs.
+
+```python
+_base_ = ['./base_static.py']
+codebase_config = dict(
+ type='mmyolo',
+ task='ObjectDetection',
+ model_type='end2end',
+ post_processing=dict(
+ score_threshold=0.05,
+ confidence_threshold=0.005,
+ iou_threshold=0.5,
+ max_output_boxes_per_class=200,
+ pre_top_k=5000,
+ keep_top_k=100,
+ background_label_id=-1),
+ module=['mmyolo.deploy'])
+backend_config = dict(type='onnxruntime')
+```
+
+`backend_config` indicates the deployment backend with `type='onnxruntime'`, other information can be referred from the third section.
+
+To deploy the `YOLOv5` to `TensorRT`, please refer to the [`detection_tensorrt_static-640x640.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_tensorrt_static-640x640.py) as follows.
+
+```python
+_base_ = ['./base_static.py']
+onnx_config = dict(input_shape=(640, 640))
+backend_config = dict(
+ type='tensorrt',
+ common_config=dict(fp16_mode=False, max_workspace_size=1 << 30),
+ model_inputs=[
+ dict(
+ input_shapes=dict(
+ input=dict(
+ min_shape=[1, 3, 640, 640],
+ opt_shape=[1, 3, 640, 640],
+ max_shape=[1, 3, 640, 640])))
+ ])
+use_efficientnms = False
+```
+
+`backend_config` indices the backend with `type='tensorrt'`.
+
+Different from `ONNXRuntime` deployment configuration, `TensorRT` needs to specify the input image size and the parameters required to build the engine file, including:
+
+- `onnx_config` specifies the input shape as `input_shape=(640, 640)`
+- `fp16_mode=False` and `max_workspace_size=1 << 30` in `backend_config['common_config']` indicates whether to build the engine in the parameter format of `fp16`, and the maximum video memory for the current `gpu` device, respectively. The unit is in `GB`. For detailed configuration of `fp16`, please refer to the [`detection_tensorrt-fp16_static-640x640.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_tensorrt-fp16_static-640x640.py)
+- The `min_shape`/`opt_shape`/`max_shape` in `backend_config['model_inputs']['input_shapes']['input']` should remain the same under static input, the default is `[1, 3, 640, 640]`.
+
+`use_efficientnms` is a new configuration introduced by the `MMYOLO` series, indicating whether to enable `Efficient NMS Plugin` to replace `TRTBatchedNMS plugin` in `MMDeploy` when exporting `onnx`.
+
+You can refer to the official [efficient NMS plugins](https://github.com/NVIDIA/TensorRT/blob/main/plugin/efficientNMSPlugin/README.md) by `TensorRT` for more details.
+
+Note: this out-of-box feature is **only available in TensorRT>=8.0**, no need to compile it by yourself.
+
+### Configuration for Dynamic Inputs
+
+#### 1. Model Config
+
+When you deploy a dynamic input model, you don't need to modify any model configuration files but the deployment configuration files.
+
+#### 2. Deployment Config
+
+To deploy the `YOLOv5` in MMYOLO to `ONNXRuntime`, please refer to the [`detection_onnxruntime_dynamic.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_onnxruntime_dynamic.py).
+
+```python
+_base_ = ['./base_dynamic.py']
+codebase_config = dict(
+ type='mmyolo',
+ task='ObjectDetection',
+ model_type='end2end',
+ post_processing=dict(
+ score_threshold=0.05,
+ confidence_threshold=0.005,
+ iou_threshold=0.5,
+ max_output_boxes_per_class=200,
+ pre_top_k=5000,
+ keep_top_k=100,
+ background_label_id=-1),
+ module=['mmyolo.deploy'])
+backend_config = dict(type='onnxruntime')
+```
+
+`backend_config` indicates the backend with `type='onnxruntime'`. Other parameters stay the same as the static input section.
+
+To deploy the `YOLOv5` to `TensorRT`, please refer to the [`detection_tensorrt_dynamic-192x192-960x960.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_tensorrt_dynamic-192x192-960x960.py).
+
+```python
+_base_ = ['./base_dynamic.py']
+backend_config = dict(
+ type='tensorrt',
+ common_config=dict(fp16_mode=False, max_workspace_size=1 << 30),
+ model_inputs=[
+ dict(
+ input_shapes=dict(
+ input=dict(
+ min_shape=[1, 3, 192, 192],
+ opt_shape=[1, 3, 640, 640],
+ max_shape=[1, 3, 960, 960])))
+ ])
+use_efficientnms = False
+```
+
+`backend_config` indicates the backend with `type='tensorrt'`. Since the dynamic and static inputs are different in `TensorRT`, please check the details at [TensorRT dynamic input official introduction](https://docs.nvidia.com/deeplearning/tensorrt/archives/tensorrt-843/developer-guide/index.html#work_dynamic_shapes).
+
+`TensorRT` deployment requires you to specify `min_shape`, `opt_shape` , and `max_shape`. `TensorRT` limits the size of the input image between `min_shape` and `max_shape`.
+
+`min_shape` is the minimum size of the input image. `opt_shape` is the common size of the input image, inference performance is best under this size. `max_shape` is the maximum size of the input image.
+
+`use_efficientnms` configuration is the same as the `TensorRT` static input configuration in the previous section.
+
+### INT8 Quantization Support
+
+Note: Int8 quantization support will soon be released.
+
+## How to Convert Model
+
+### Usage
+
+#### Deploy with MMDeploy Tools
+
+Set the root directory of `MMDeploy` as an env parameter `MMDEPLOY_DIR` using `export MMDEPLOY_DIR=/the/root/path/of/MMDeploy` command.
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ ${DEPLOY_CFG_PATH} \
+ ${MODEL_CFG_PATH} \
+ ${MODEL_CHECKPOINT_PATH} \
+ ${INPUT_IMG} \
+ --test-img ${TEST_IMG} \
+ --work-dir ${WORK_DIR} \
+ --calib-dataset-cfg ${CALIB_DATA_CFG} \
+ --device ${DEVICE} \
+ --log-level INFO \
+ --show \
+ --dump-info
+```
+
+### Parameter Description
+
+- `deploy_cfg`: set the deployment config path of MMDeploy for the model, including the type of inference framework, whether quantize, whether the input shape is dynamic, etc. There may be a reference relationship between configuration files, e.g. `configs/deploy/detection_onnxruntime_static.py`
+- `model_cfg`: set the MMYOLO model config path, e.g. `configs/deploy/model/yolov5_s-deploy.py`, regardless of the path to MMDeploy
+- `checkpoint`: set the torch model path. It can start with `http/https`, more details are available in `mmengine.fileio` apis
+- `img`: set the path to the image or point cloud file used for testing during model conversion
+- `--test-img`: set the image file that used to test model. If not specified, it will be set to `None`
+- `--work-dir`: set the work directory that used to save logs and models
+- `--calib-dataset-cfg`: use for calibration only for INT8 mode. If not specified, it will be set to None and use “val” dataset in model config for calibration
+- `--device`: set the device used for model conversion. The default is `cpu`, for TensorRT used `cuda:0`
+- `--log-level`: set log level which in `'CRITICAL', 'FATAL', 'ERROR', 'WARN', 'WARNING', 'INFO', 'DEBUG', 'NOTSET'`. If not specified, it will be set to `INFO`
+- `--show`: show the result on screen or not
+- `--dump-info`: output SDK information or not
+
+#### Deploy with MMDeploy API
+
+Suppose the working directory is the root path of mmyolo. Take [YoloV5](https://github.com/open-mmlab/mmyolo/blob/main/configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py) model as an example. You can download its checkpoint from [here](https://download.openmmlab.com/mmyolo/v0/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth), and then convert it to onnx model as follows:
+
+```python
+from mmdeploy.apis import torch2onnx
+from mmdeploy.backend.sdk.export_info import export2SDK
+
+img = 'demo/demo.jpg'
+work_dir = 'mmdeploy_models/mmyolo/onnx'
+save_file = 'end2end.onnx'
+deploy_cfg = 'configs/deploy/detection_onnxruntime_dynamic.py'
+model_cfg = 'configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+model_checkpoint = 'checkpoints/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth'
+device = 'cpu'
+
+# 1. convert model to onnx
+torch2onnx(img, work_dir, save_file, deploy_cfg, model_cfg,
+ model_checkpoint, device)
+
+# 2. extract pipeline info for inference by MMDeploy SDK
+export2SDK(deploy_cfg, model_cfg, work_dir, pth=model_checkpoint,
+ device=device)
+```
+
+## Model specification
+
+Before moving on to model inference chapter, let's know more about the converted result structure which is very important for model inference. It is saved in the directory specified with `--wodk_dir`.
+
+The converted results are saved in the working directory `mmdeploy_models/mmyolo/onnx` in the previous example. It includes:
+
+```
+mmdeploy_models/mmyolo/onnx
+├── deploy.json
+├── detail.json
+├── end2end.onnx
+└── pipeline.json
+```
+
+in which,
+
+- **end2end.onnx**: backend model which can be inferred by ONNX Runtime
+- ***xxx*.json**: the necessary information for mmdeploy SDK
+
+The whole package **mmdeploy_models/mmyolo/onnx** is defined as **mmdeploy SDK model**, i.e., **mmdeploy SDK model** includes both backend model and inference meta information.
+
+## Model inference
+
+### Backend model inference
+
+Take the previous converted `end2end.onnx` model as an example, you can use the following code to inference the model and visualize the results.
+
+```python
+from mmdeploy.apis.utils import build_task_processor
+from mmdeploy.utils import get_input_shape, load_config
+import torch
+
+deploy_cfg = 'configs/deploy/detection_onnxruntime_dynamic.py'
+model_cfg = 'configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+device = 'cpu'
+backend_model = ['mmdeploy_models/mmyolo/onnx/end2end.onnx']
+image = 'demo/demo.jpg'
+
+# read deploy_cfg and model_cfg
+deploy_cfg, model_cfg = load_config(deploy_cfg, model_cfg)
+
+# build task and backend model
+task_processor = build_task_processor(model_cfg, deploy_cfg, device)
+model = task_processor.build_backend_model(backend_model)
+
+# process input image
+input_shape = get_input_shape(deploy_cfg)
+model_inputs, _ = task_processor.create_input(image, input_shape)
+
+# do model inference
+with torch.no_grad():
+ result = model.test_step(model_inputs)
+
+# visualize results
+task_processor.visualize(
+ image=image,
+ model=model,
+ result=result[0],
+ window_name='visualize',
+ output_file='work_dir/output_detection.png')
+```
+
+With the above code, you can find the inference result `output_detection.png` in `work_dir`.
+
+### SDK model inference
+
+You can also perform SDK model inference like following,
+
+```python
+from mmdeploy_runtime import Detector
+import cv2
+
+img = cv2.imread('demo/demo.jpg')
+
+# create a detector
+detector = Detector(model_path='mmdeploy_models/mmyolo/onnx',
+ device_name='cpu', device_id=0)
+# perform inference
+bboxes, labels, masks = detector(img)
+
+# visualize inference result
+indices = [i for i in range(len(bboxes))]
+for index, bbox, label_id in zip(indices, bboxes, labels):
+ [left, top, right, bottom], score = bbox[0:4].astype(int), bbox[4]
+ if score < 0.3:
+ continue
+
+ cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0))
+
+cv2.imwrite('work_dir/output_detection.png', img)
+```
+
+Besides python API, mmdeploy SDK also provides other FFI (Foreign Function Interface), such as C, C++, C#, Java and so on. You can learn their usage from [demos](https://github.com/open-mmlab/mmdeploy/tree/main/demo).
+
+## How to Evaluate Model
+
+### Usage
+
+After the model is converted to your backend, you can use `${MMDEPLOY_DIR}/tools/test.py` to evaluate the performance.
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/test.py \
+ ${DEPLOY_CFG} \
+ ${MODEL_CFG} \
+ --model ${BACKEND_MODEL_FILES} \
+ --device ${DEVICE} \
+ --work-dir ${WORK_DIR} \
+ [--cfg-options ${CFG_OPTIONS}] \
+ [--show] \
+ [--show-dir ${OUTPUT_IMAGE_DIR}] \
+ [--interval ${INTERVAL}] \
+ [--wait-time ${WAIT_TIME}] \
+ [--log2file work_dirs/output.txt]
+ [--speed-test] \
+ [--warmup ${WARM_UP}] \
+ [--log-interval ${LOG_INTERVERL}] \
+ [--batch-size ${BATCH_SIZE}] \
+ [--uri ${URI}]
+```
+
+### Parameter Description
+
+- `deploy_cfg`: set the deployment config file path.
+- `model_cfg`: set the MMYOLO model config file path.
+- `--model`: set the converted model. For example, if we exported a TensorRT model, we need to pass in the file path with the suffix ".engine".
+- `--device`: indicate the device to run the model. Note that some backends limit the running devices. For example, TensorRT must run on CUDA.
+- `--work-dir`: the directory to save the file containing evaluation metrics.
+- `--cfg-options`: pass in additional configs, which will override the current deployment configs.
+- `--show`: show the evaluation result on screen or not.
+- `--show-dir`: save the evaluation result to this directory, valid only when specified.
+- `--interval`: set the display interval between each two evaluation results.
+- `--wait-time`: set the display time of each window.
+- `--log2file`: log evaluation results and speed to file.
+- `--speed-test`: test the inference speed or not.
+- `--warmup`: warm up before speed test or not, works only when `speed-test` is specified.
+- `--log-interval`: the interval between each log, works only when `speed-test` is specified.
+- `--batch-size`: set the batch size for inference, which will override the `samples_per_gpu` in data config. The default value is `1`, however, not every model supports `batch_size > 1`.
+- `--uri`: Remote ipv4:port or ipv6:port for inference on edge device.
+
+Note: other parameters in `${MMDEPLOY_DIR}/tools/test.py` are used for speed test, they will not affect the evaluation results.
diff --git a/third_party/mmyolo/docs/en/recommended_topics/deploy/mmdeploy_yolov5.md b/third_party/mmyolo/docs/en/recommended_topics/deploy/mmdeploy_yolov5.md
new file mode 100644
index 0000000000000000000000000000000000000000..321a6734fe0a18f35e88b5f31e28be6b3abc7ee5
--- /dev/null
+++ b/third_party/mmyolo/docs/en/recommended_topics/deploy/mmdeploy_yolov5.md
@@ -0,0 +1,572 @@
+# YOLOv5 Deployment
+
+Please check the [basic_deployment_guide](mmdeploy_guide.md) to get familiar with the configurations.
+
+## Model Training and Validation
+
+TODO
+
+## MMDeploy Environment Setup
+
+Please check the installation document of `MMDeploy` at [build_from_source](https://github.com/open-mmlab/mmdeploy/blob/dev-1.x/docs/en/01-how-to-build/build_from_source.md). Please build both `MMDeploy` and the customized Ops to your specific platform.
+
+Note: please check at `MMDeploy` [FAQ](https://github.com/open-mmlab/mmdeploy/blob/dev-1.x/docs/en/faq.md) or create new issues in `MMDeploy` when you come across any problems.
+
+## How to Prepare Configuration File
+
+This deployment guide uses the `YOLOv5` model trained on `COCO` dataset in MMYOLO to illustrate the whole process, including both static and dynamic inputs and different procedures for `TensorRT` and `ONNXRuntime`.
+
+### For Static Input
+
+#### 1. Model Config
+
+To deploy the model with static inputs, you need to ensure that the model inputs are in fixed size, e.g. the input size is set to `640x640` while uploading data in the test pipeline and test dataloader.
+
+Here is a example in [`yolov5_s-static.py`](https://github.com/open-mmlab/mmyolo/tree/main/configs/deploy/model/yolov5_s-static.py)
+
+```python
+_base_ = '../../yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+test_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=_base_.backend_args),
+ dict(
+ type='LetterResize',
+ scale=_base_.img_scale,
+ allow_scale_up=False,
+ use_mini_pad=False,
+ ),
+ dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
+ dict(
+ type='mmdet.PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'pad_param'))
+]
+
+test_dataloader = dict(
+ dataset=dict(pipeline=test_pipeline, batch_shapes_cfg=None))
+```
+
+As the `YOLOv5` will turn on `allow_scale_up` and `use_mini_pad` during the test to change the size of the input image in order to achieve higher accuracy. However, it will cause the input size mismatch problem when deploying in the static input model.
+
+Compared with the original configuration file, this configuration has been modified as follows:
+
+- turn off the settings related to reshaping the image in `test_pipeline`, e.g. setting `allow_scale_up=False` and `use_mini_pad=False` in `LetterResize`
+- turn off the `batch_shapes` in `test_dataloader` as `batch_shapes_cfg=None`.
+
+#### 2. Deployment Cofnig
+
+To deploy the model to `ONNXRuntime`, please refer to the [`detection_onnxruntime_static.py`](https://github.com/open-mmlab/mmyolo/tree/main/configs/deploy/detection_onnxruntime_static.py) as follows:
+
+```python
+_base_ = ['./base_static.py']
+codebase_config = dict(
+ type='mmyolo',
+ task='ObjectDetection',
+ model_type='end2end',
+ post_processing=dict(
+ score_threshold=0.05,
+ confidence_threshold=0.005,
+ iou_threshold=0.5,
+ max_output_boxes_per_class=200,
+ pre_top_k=5000,
+ keep_top_k=100,
+ background_label_id=-1),
+ module=['mmyolo.deploy'])
+backend_config = dict(type='onnxruntime')
+```
+
+The `post_processing` in the default configuration aligns the accuracy of the current model with the trained `pytorch` model. If you need to modify the relevant parameters, you can refer to the detailed introduction of [dasic_deployment_guide](mmdeploy_guide.md).
+
+To deploy the model to `TensorRT`, please refer to the [`detection_tensorrt_static-640x640.py`](https://github.com/open-mmlab/mmyolo/tree/main/configs/deploy/detection_tensorrt_static-640x640.p).
+
+```python
+_base_ = ['./base_static.py']
+onnx_config = dict(input_shape=(640, 640))
+backend_config = dict(
+ type='tensorrt',
+ common_config=dict(fp16_mode=False, max_workspace_size=1 << 30),
+ model_inputs=[
+ dict(
+ input_shapes=dict(
+ input=dict(
+ min_shape=[1, 3, 640, 640],
+ opt_shape=[1, 3, 640, 640],
+ max_shape=[1, 3, 640, 640])))
+ ])
+use_efficientnms = False
+```
+
+In this guide, we use the default settings such as `input_shape=(640, 640)` and `fp16_mode=False` to build in network in `fp32` mode. Moreover, we set `max_workspace_size=1 << 30` for the gpu memory which allows `TensorRT` to build the engine with maximum `1GB` memory.
+
+### For Dynamic Input
+
+#### 1. Model Confige
+
+As `TensorRT` limits the minimum and maximum input size, we can use any size for the inputs when deploy the model in dynamic mode. In this way, we can keep the default settings in [`yolov5_s-v61_syncbn_8xb16-300e_coco.py`](https://github.com/open-mmlab/mmyolo/tree/main/configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py). The data processing and dataloader parts are as follows.
+
+```python
+batch_shapes_cfg = dict(
+ type='BatchShapePolicy',
+ batch_size=val_batch_size_per_gpu,
+ img_size=img_scale[0],
+ size_divisor=32,
+ extra_pad_ratio=0.5)
+
+test_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=_base_.backend_args),
+ dict(type='YOLOv5KeepRatioResize', scale=img_scale),
+ dict(
+ type='LetterResize',
+ scale=img_scale,
+ allow_scale_up=False,
+ pad_val=dict(img=114)),
+ dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
+ dict(
+ type='mmdet.PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'pad_param'))
+]
+
+val_dataloader = dict(
+ batch_size=val_batch_size_per_gpu,
+ num_workers=val_num_workers,
+ persistent_workers=persistent_workers,
+ pin_memory=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ test_mode=True,
+ data_prefix=dict(img='val2017/'),
+ ann_file='annotations/instances_val2017.json',
+ pipeline=test_pipeline,
+ batch_shapes_cfg=batch_shapes_cfg))
+```
+
+We use `allow_scale_up=False` to control when the input small images will be upsampled or not in the initialization of `LetterResize`. At the same time, the default `use_mini_pad=False` turns off the minimum padding strategy of the image, and `val_dataloader['dataset']` is passed in` batch_shapes_cfg=batch_shapes_cfg` to ensure that the minimum padding is performed according to the input size in `batch`. These configs will change the dimensions of the input image, so the converted model can support dynamic inputs according to the above dataset loader when testing.
+
+#### 2. Deployment Cofnig
+
+To deploy the model to `ONNXRuntime`, please refer to the [`detection_onnxruntime_dynamic.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_onnxruntime_dynamic.py) for more details.
+
+```python
+_base_ = ['./base_dynamic.py']
+codebase_config = dict(
+ type='mmyolo',
+ task='ObjectDetection',
+ model_type='end2end',
+ post_processing=dict(
+ score_threshold=0.05,
+ confidence_threshold=0.005,
+ iou_threshold=0.5,
+ max_output_boxes_per_class=200,
+ pre_top_k=5000,
+ keep_top_k=100,
+ background_label_id=-1),
+ module=['mmyolo.deploy'])
+backend_config = dict(type='onnxruntime')
+```
+
+Differs from the static input config we introduced in previous section, dynamic input config additionally inherits the `dynamic_axes`. The rest of the configuration stays the same as the static inputs.
+
+To deploy the model to `TensorRT`, please refer to the [`detection_tensorrt_dynamic-192x192-960x960.py`](https://github.com/open-mmlab/mmyolo/tree/main/configs/deploy/detection_tensorrt_dynamic-192x192-960x960.py) for more details.
+
+```python
+_base_ = ['./base_dynamic.py']
+backend_config = dict(
+ type='tensorrt',
+ common_config=dict(fp16_mode=False, max_workspace_size=1 << 30),
+ model_inputs=[
+ dict(
+ input_shapes=dict(
+ input=dict(
+ min_shape=[1, 3, 192, 192],
+ opt_shape=[1, 3, 640, 640],
+ max_shape=[1, 3, 960, 960])))
+ ])
+use_efficientnms = False
+```
+
+In our example, the network is built in `fp32` mode as `fp16_mode=False`, and the maximum graphic memory is `1GB` for building the `TensorRT` engine as `max_workspace_size=1 << 30`.
+
+At the same time, `min_shape=[1, 3, 192, 192]`, `opt_shape=[1, 3, 640, 640]`, and `max_shape=[1, 3, 960, 960]` in the default setting set the model with minimum input size to `192x192`, the maximum size to `960x960`, and the most common size to `640x640`.
+
+When you deploy the model, it can adopt to the input image dimensions automatically.
+
+## How to Convert Model
+
+Note: The `MMDeploy` root directory used in this guide is `/home/openmmlab/dev/mmdeploy`, please modify it to your `MMDeploy` directory.
+
+Use the following command to download the pretrained YOLOv5 weight and save it to your device:
+
+```shell
+wget https://download.openmmlab.com/mmyolo/v0/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth -O /home/openmmlab/dev/mmdeploy/yolov5s.pth
+```
+
+Set the relevant env parameters using the following command as well:
+
+```shell
+export MMDEPLOY_DIR=/home/openmmlab/dev/mmdeploy
+export PATH_TO_CHECKPOINTS=/home/openmmlab/dev/mmdeploy/yolov5s.pth
+```
+
+### YOLOv5 Static Model Deployment
+
+#### ONNXRuntime
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_onnxruntime_static.py \
+ configs/deploy/model/yolov5_s-static.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir \
+ --show \
+ --device cpu
+```
+
+#### TensorRT
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_tensorrt_static-640x640.py \
+ configs/deploy/model/yolov5_s-static.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir \
+ --show \
+ --device cuda:0
+```
+
+### YOLOv5 Dynamic Model Deployment
+
+#### ONNXRuntime
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_onnxruntime_dynamic.py \
+ configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir \
+ --show \
+ --device cpu
+ --dump-info
+```
+
+#### TensorRT
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_tensorrt_dynamic-192x192-960x960.py \
+ configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir \
+ --show \
+ --device cuda:0
+ --dump-info
+```
+
+When convert the model using the above commands, you will find the following files under the `work_dir` folder:
+
+
+
+or
+
+
+
+After exporting to `onnxruntime`, you will get six files as shown in Figure 1, where `end2end.onnx` represents the exported `onnxruntime` model. The `xxx.json` are the meta info for `MMDeploy SDK` inference.
+
+After exporting to `TensorRT`, you will get the seven files as shown in Figure 2, where `end2end.onnx` represents the exported intermediate model. `MMDeploy` uses this model to automatically continue to convert the `end2end.engine` model for `TensorRT `Deployment. The `xxx.json` are the meta info for `MMDeploy SDK` inference.
+
+## How to Evaluate Model
+
+After successfully convert the model, you can use `${MMDEPLOY_DIR}/tools/test.py` to evaluate the converted model. The following part shows how to evaluate the static models of `ONNXRuntime` and `TensorRT`. For dynamic model evaluation, please modify the configuration of the inputs.
+
+### ONNXRuntime
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/test.py \
+ configs/deploy/detection_onnxruntime_static.py \
+ configs/deploy/model/yolov5_s-static.py \
+ --model work_dir/end2end.onnx \
+ --device cpu \
+ --work-dir work_dir
+```
+
+Once the process is done, you can get the output results as this:
+
+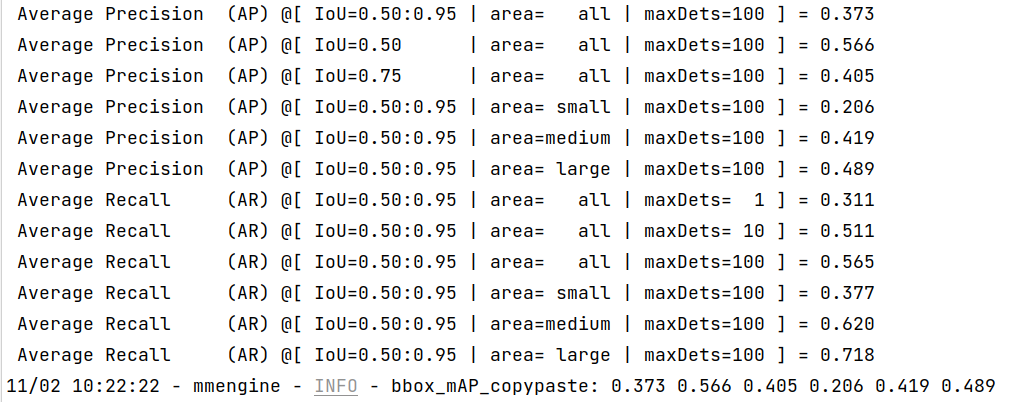
+
+### TensorRT
+
+Note: `TensorRT` must run on `CUDA` devices!
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/test.py \
+ configs/deploy/detection_tensorrt_static-640x640.py \
+ configs/deploy/model/yolov5_s-static.py \
+ --model work_dir/end2end.engine \
+ --device cuda:0 \
+ --work-dir work_dir
+```
+
+Once the process is done, you can get the output results as this:
+
+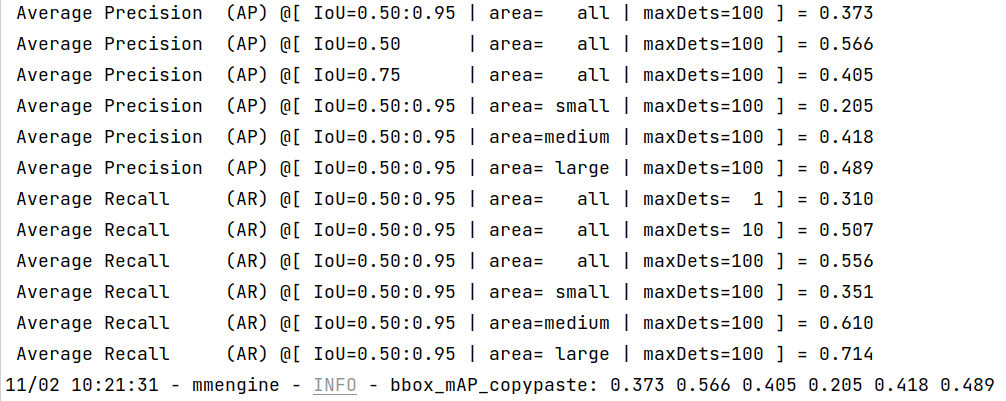
+
+More useful evaluation tools will be released in the future.
+
+# Deploy using Docker
+
+`MMYOLO` provides a deployment [`Dockerfile`](https://github.com/open-mmlab/mmyolo/blob/main/docker/Dockerfile_deployment) for deployment purpose. Please make sure your local docker version is greater than `19.03`.
+
+Note: users in mainland China can comment out the `Optional` part in the dockerfile for better experience.
+
+```dockerfile
+# (Optional)
+RUN sed -i 's/http:\/\/archive.ubuntu.com\/ubuntu\//http:\/\/mirrors.aliyun.com\/ubuntu\//g' /etc/apt/sources.list && \
+ pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
+```
+
+To build the docker image,
+
+```bash
+# build an image with PyTorch 1.12, CUDA 11.6, TensorRT 8.2.4 ONNXRuntime 1.8.1
+docker build -f docker/Dockerfile_deployment -t mmyolo:v1 .
+```
+
+To run the docker image,
+
+```bash
+export DATA_DIR=/path/to/your/dataset
+docker run --gpus all --shm-size=8g -it --name mmyolo -v ${DATA_DIR}:/openmmlab/mmyolo/data/coco mmyolo:v1
+```
+
+`DATA_DIR` is the path of your `COCO` dataset.
+
+We provide a `script.sh` file for you which runs the whole pipeline. Create the script under `/openmmlab/mmyolo` directory in your docker container using the following content.
+
+```bash
+#!/bin/bash
+wget -q https://download.openmmlab.com/mmyolo/v0/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth \
+ -O yolov5s.pth
+export MMDEPLOY_DIR=/openmmlab/mmdeploy
+export PATH_TO_CHECKPOINTS=/openmmlab/mmyolo/yolov5s.pth
+
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_tensorrt_static-640x640.py \
+ configs/deploy/model/yolov5_s-static.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir_trt \
+ --device cuda:0
+
+python3 ${MMDEPLOY_DIR}/tools/test.py \
+ configs/deploy/detection_tensorrt_static-640x640.py \
+ configs/deploy/model/yolov5_s-static.py \
+ --model work_dir_trt/end2end.engine \
+ --device cuda:0 \
+ --work-dir work_dir_trt
+
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_onnxruntime_static.py \
+ configs/deploy/model/yolov5_s-static.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir_ort \
+ --device cpu
+
+python3 ${MMDEPLOY_DIR}/tools/test.py \
+ configs/deploy/detection_onnxruntime_static.py \
+ configs/deploy/model/yolov5_s-static.py \
+ --model work_dir_ort/end2end.onnx \
+ --device cpu \
+ --work-dir work_dir_ort
+```
+
+Then run the script under `/openmmlab/mmyolo`.
+
+```bash
+sh script.sh
+```
+
+This script automatically downloads the `YOLOv5` pretrained weights in `MMYOLO` and convert the model using `MMDeploy`. You will get the output result as follows.
+
+- TensorRT:
+
+ 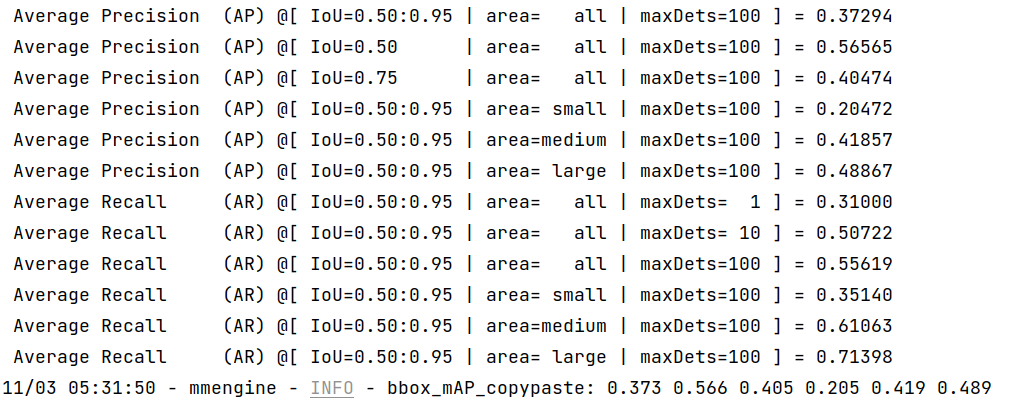
+
+- ONNXRuntime:
+
+ 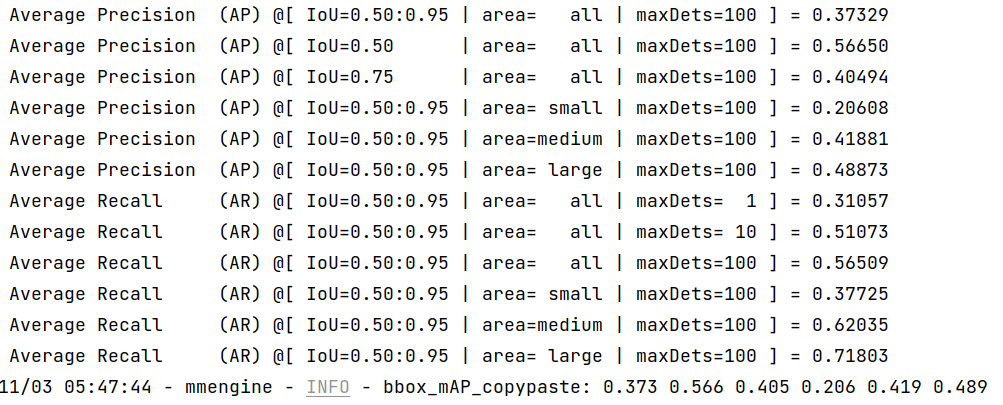
+
+We can see from the above images that the accuracy of converted models shrink within 1% compared with the pytorch [MMYOLO-YOLOv5](https://github.com/open-mmlab/mmyolo/tree/main/configs/yolov5#results-and-models) models.
+
+If you need to test the inference speed of the converted model, you can use the following commands.
+
+- TensorRT
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/profiler.py \
+ configs/deploy/detection_tensorrt_static-640x640.py \
+ configs/deploy/model/yolov5_s-static.py \
+ data/coco/val2017 \
+ --model work_dir_trt/end2end.engine \
+ --device cuda:0
+```
+
+- ONNXRuntime
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/profiler.py \
+ configs/deploy/detection_onnxruntime_static.py \
+ configs/deploy/model/yolov5_s-static.py \
+ data/coco/val2017 \
+ --model work_dir_ort/end2end.onnx \
+ --device cpu
+```
+
+## Model Inference
+
+### Backend Model Inference
+
+#### ONNXRuntime
+
+For the converted model `end2end.onnx`,you can do the inference with the following code:
+
+```python
+from mmdeploy.apis.utils import build_task_processor
+from mmdeploy.utils import get_input_shape, load_config
+import torch
+
+deploy_cfg = './configs/deploy/detection_onnxruntime_dynamic.py'
+model_cfg = '../mmyolo/configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+device = 'cpu'
+backend_model = ['./work_dir/end2end.onnx']
+image = '../mmyolo/demo/demo.jpg'
+
+# read deploy_cfg and model_cfg
+deploy_cfg, model_cfg = load_config(deploy_cfg, model_cfg)
+
+# build task and backend model
+task_processor = build_task_processor(model_cfg, deploy_cfg, device)
+model = task_processor.build_backend_model(backend_model)
+
+# process input image
+input_shape = get_input_shape(deploy_cfg)
+model_inputs, _ = task_processor.create_input(image, input_shape)
+
+# do model inference
+with torch.no_grad():
+ result = model.test_step(model_inputs)
+
+# visualize results
+task_processor.visualize(
+ image=image,
+ model=model,
+ result=result[0],
+ window_name='visualize',
+ output_file='work_dir/output_detection.png')
+```
+
+#### TensorRT
+
+For the converted model `end2end.engine`,you can do the inference with the following code:
+
+```python
+from mmdeploy.apis.utils import build_task_processor
+from mmdeploy.utils import get_input_shape, load_config
+import torch
+
+deploy_cfg = './configs/deploy/detection_tensorrt_dynamic-192x192-960x960.py'
+model_cfg = '../mmyolo/configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+device = 'cuda:0'
+backend_model = ['./work_dir/end2end.engine']
+image = '../mmyolo/demo/demo.jpg'
+
+# read deploy_cfg and model_cfg
+deploy_cfg, model_cfg = load_config(deploy_cfg, model_cfg)
+
+# build task and backend model
+task_processor = build_task_processor(model_cfg, deploy_cfg, device)
+model = task_processor.build_backend_model(backend_model)
+
+# process input image
+input_shape = get_input_shape(deploy_cfg)
+model_inputs, _ = task_processor.create_input(image, input_shape)
+
+# do model inference
+with torch.no_grad():
+ result = model.test_step(model_inputs)
+
+# visualize results
+task_processor.visualize(
+ image=image,
+ model=model,
+ result=result[0],
+ window_name='visualize',
+ output_file='work_dir/output_detection.png')
+```
+
+### SDK Model Inference
+
+#### ONNXRuntime
+
+For the converted model `end2end.onnx`,you can do the SDK inference with the following code:
+
+```python
+from mmdeploy_runtime import Detector
+import cv2
+
+img = cv2.imread('../mmyolo/demo/demo.jpg')
+
+# create a detector
+detector = Detector(model_path='work_dir',
+ device_name='cpu', device_id=0)
+# perform inference
+bboxes, labels, masks = detector(img)
+
+# visualize inference result
+indices = [i for i in range(len(bboxes))]
+for index, bbox, label_id in zip(indices, bboxes, labels):
+ [left, top, right, bottom], score = bbox[0:4].astype(int), bbox[4]
+ if score < 0.3:
+ continue
+
+ cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0))
+
+cv2.imwrite('work_dir/output_detection.png', img)
+```
+
+#### TensorRT
+
+For the converted model `end2end.engine`,you can do the SDK inference with the following code:
+
+```python
+from mmdeploy_runtime import Detector
+import cv2
+
+img = cv2.imread('../mmyolo/demo/demo.jpg')
+
+# create a detector
+detector = Detector(model_path='work_dir',
+ device_name='cuda', device_id=0)
+# perform inference
+bboxes, labels, masks = detector(img)
+
+# visualize inference result
+indices = [i for i in range(len(bboxes))]
+for index, bbox, label_id in zip(indices, bboxes, labels):
+ [left, top, right, bottom], score = bbox[0:4].astype(int), bbox[4]
+ if score < 0.3:
+ continue
+
+ cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0))
+
+cv2.imwrite('work_dir/output_detection.png', img)
+```
+
+Besides python API, mmdeploy SDK also provides other FFI (Foreign Function Interface), such as C, C++, C#, Java and so on. You can learn their usage from [demos](https://github.com/open-mmlab/mmdeploy/tree/main/demo).
diff --git a/third_party/mmyolo/docs/en/recommended_topics/labeling_to_deployment_tutorials.md b/third_party/mmyolo/docs/en/recommended_topics/labeling_to_deployment_tutorials.md
new file mode 100644
index 0000000000000000000000000000000000000000..bce5d53f57e6dad4baafc843ad6f86cb19540eb1
--- /dev/null
+++ b/third_party/mmyolo/docs/en/recommended_topics/labeling_to_deployment_tutorials.md
@@ -0,0 +1,1331 @@
+# Annotation-to-deployment workflow for custom dataset
+
+In our daily work and study, we often encounter some tasks that need to train custom dataset. There are few scenarios in which open-source datasets can be used as online models, so we need to carry out a series of operations on our custom datasets to ensure that the models can be put into production and serve users.
+
+```{SeeAlso}
+The video of this document has been posted on Bilibili: [A nanny level tutorials for custom datasets from annotationt to deployment](https://www.bilibili.com/video/BV1RG4y137i5)
+```
+
+```{Note}
+All instructions in this document are done on Linux and are fully available on Windows, only slightly different in commands and operations.
+```
+
+Default that you have completed the installation of MMYOLO, if not installed, please refer to the document [GET STARTED](https://mmyolo.readthedocs.io/en/latest/get_started.html) for installation.
+
+In this tutorial, we will introduce the whole process from annotating custom dataset to final training, testing and deployment. The overview steps are as below:
+
+01. Prepare dataset: `tools/misc/download_dataset.py`
+02. Use the software of [labelme](https://github.com/wkentaro/labelme) to annotate: `demo/image_demo.py` + labelme
+03. Convert the dataset into COCO format: `tools/dataset_converters/labelme2coco.py`
+04. Split dataset:`tools/misc/coco_split.py`
+05. Creat a config file based on dataset
+06. Dataset visualization analysis: `tools/analysis_tools/dataset_analysis.py`
+07. Optimize Anchor size: `tools/analysis_tools/optimize_anchors.py`
+08. Visualization the data processing part of config: `tools/analysis_tools/browse_dataset.py`
+09. Train: `tools/train.py`
+10. Inference: `demo/image_demo.py`
+11. Deployment
+
+```{Note}
+After obtaining the model weight and the mAP of validation set, users need to deep analyse the bad cases of incorrect predictions in order to optimize model. MMYOLO will add this function in the future. Expect.
+```
+
+Each step is described in detail below.
+
+## 1. Prepare custom dataset
+
+- If you don't have your own dataset, or want to use a small dataset to run the whole process, you can use the 144 images `cat` dataset provided with this tutorial (the raw picture of this dataset is supplied by @RangeKing, cleaned by @PeterH0323). This `cat` dataset will be used as an example for the rest tutorial.
+
+
+
+### 7. Resolve conflicts
+
+If your local branch conflicts with the latest dev branch of "upstream", you'll need to resolove them. There are two ways to do this:
+
+```shell
+git fetch --all --prune
+git rebase upstream/dev
+```
+
+or
+
+```shell
+git fetch --all --prune
+git merge upstream/dev
+```
+
+If you are very good at handling conflicts, then you can use rebase to resolve conflicts, as this will keep your commit logs tidy. If you are unfamiliar with `rebase`, you can use `merge` to resolve conflicts.
+
+## Guidance
+
+### Unit test
+
+We should also make sure the committed code will not decrease the coverage of unit test, we could run the following command to check the coverage of unit test:
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+### Document rendering
+
+If the documents are modified/added, we should check the rendering result. We could install the dependencies and run the following command to render the documents and check the results:
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+## Code style
+
+### Python
+
+We adopt [PEP8](https://www.python.org/dev/peps/pep-0008/) as the preferred code style.
+
+We use the following tools for linting and formatting:
+
+- [flake8](https://github.com/PyCQA/flake8): A wrapper around some linter tools.
+- [isort](https://github.com/timothycrosley/isort): A Python utility to sort imports.
+- [yapf](https://github.com/google/yapf): A formatter for Python files.
+- [codespell](https://github.com/codespell-project/codespell): A Python utility to fix common misspellings in text files.
+- [mdformat](https://github.com/executablebooks/mdformat): Mdformat is an opinionated Markdown formatter that can be used to enforce a consistent style in Markdown files.
+- [docformatter](https://github.com/myint/docformatter): A formatter to format docstring.
+
+Style configurations of yapf and isort can be found in [setup.cfg](../../../setup.cfg).
+
+We use [pre-commit hook](https://pre-commit.com/) that checks and formats for `flake8`, `yapf`, `isort`, `trailing whitespaces`, `markdown files`,
+fixes `end-of-files`, `double-quoted-strings`, `python-encoding-pragma`, `mixed-line-ending`, sorts `requirments.txt` automatically on every commit.
+The config for a pre-commit hook is stored in [.pre-commit-config](../../../.pre-commit-config.yaml).
+
+### C++ and CUDA
+
+We follow the [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html).
+
+## PR Specs
+
+1. Use [pre-commit](https://pre-commit.com) hook to avoid issues of code style
+
+2. One short-time branch should be matched with only one PR
+
+3. Accomplish a detailed change in one PR. Avoid large PR
+
+ - Bad: Support Faster R-CNN
+ - Acceptable: Add a box head to Faster R-CNN
+ - Good: Add a parameter to box head to support custom conv-layer number
+
+4. Provide clear and significant commit message
+
+5. Provide clear and meaningful PR description
+
+ - Task name should be clarified in title. The general format is: \[Prefix\] Short description of the PR (Suffix)
+ - Prefix: add new feature \[Feature\], fix bug \[Fix\], related to documents \[Docs\], in developing \[WIP\] (which will not be reviewed temporarily)
+ - Introduce main changes, results and influences on other modules in short description
+ - Associate related issues and pull requests with a milestone
diff --git a/third_party/mmyolo/docs/en/recommended_topics/dataset_preparation.md b/third_party/mmyolo/docs/en/recommended_topics/dataset_preparation.md
new file mode 100644
index 0000000000000000000000000000000000000000..af670d89a4214bd440bd39b4faf9fc37fe7d5286
--- /dev/null
+++ b/third_party/mmyolo/docs/en/recommended_topics/dataset_preparation.md
@@ -0,0 +1,145 @@
+# Dataset preparation and description
+
+## DOTA Dataset
+
+### Download dataset
+
+The DOTA dataset can be downloaded from [DOTA](https://captain-whu.github.io/DOTA/dataset.html)
+or [OpenDataLab](https://opendatalab.org.cn/DOTA_V1.0).
+
+We recommend using [OpenDataLab](https://opendatalab.org.cn/DOTA_V1.0) to download the dataset, as the folder structure has already been arranged as needed and can be directly extracted without the need to adjust the folder structure.
+
+Please unzip the file and place it in the following structure.
+
+```none
+${DATA_ROOT}
+├── train
+│ ├── images
+│ │ ├── P0000.png
+│ │ ├── ...
+│ ├── labelTxt-v1.0
+│ │ ├── labelTxt
+│ │ │ ├── P0000.txt
+│ │ │ ├── ...
+│ │ ├── trainset_reclabelTxt
+│ │ │ ├── P0000.txt
+│ │ │ ├── ...
+├── val
+│ ├── images
+│ │ ├── P0003.png
+│ │ ├── ...
+│ ├── labelTxt-v1.0
+│ │ ├── labelTxt
+│ │ │ ├── P0003.txt
+│ │ │ ├── ...
+│ │ ├── valset_reclabelTxt
+│ │ │ ├── P0003.txt
+│ │ │ ├── ...
+├── test
+│ ├── images
+│ │ ├── P0006.png
+│ │ ├── ...
+
+```
+
+The folder ending with reclabelTxt stores the labels for the horizontal boxes and is not used when slicing.
+
+### Split DOTA dataset
+
+Script `tools/dataset_converters/dota/dota_split.py` can split and prepare DOTA dataset.
+
+```shell
+python tools/dataset_converters/dota/dota_split.py \
+ [--splt-config ${SPLIT_CONFIG}] \
+ [--data-root ${DATA_ROOT}] \
+ [--out-dir ${OUT_DIR}] \
+ [--ann-subdir ${ANN_SUBDIR}] \
+ [--phase ${DATASET_PHASE}] \
+ [--nproc ${NPROC}] \
+ [--save-ext ${SAVE_EXT}] \
+ [--overwrite]
+```
+
+shapely is required, please install shapely first by `pip install shapely`.
+
+**Description of all parameters**:
+
+- `--split-config` : The split config for image slicing.
+- `--data-root`: Root dir of DOTA dataset.
+- `--out-dir`: Output dir for split result.
+- `--ann-subdir`: The subdir name for annotation. Defaults to `labelTxt-v1.0`.
+- `--phase`: Phase of the data set to be prepared. Defaults to `trainval test`
+- `--nproc`: Number of processes. Defaults to 8.
+- `--save-ext`: Extension of the saved image. Defaults to `png`
+- `--overwrite`: Whether to allow overwrite if annotation folder exist.
+
+Based on the configuration in the DOTA paper, we provide two commonly used split config.
+
+- `./split_config/single_scale.json` means single-scale split.
+- `./split_config/multi_scale.json` means multi-scale split.
+
+DOTA dataset usually uses the trainval set for training and the test set for online evaluation, since most papers
+provide the results of online evaluation. If you want to evaluate the model performance locally firstly, please split
+the train set and val set.
+
+Examples:
+
+Split DOTA trainval set and test set with single scale.
+
+```shell
+python tools/dataset_converters/dota/dota_split.py
+ --split-config 'tools/dataset_converters/dota/split_config/single_scale.json'
+ --data-root ${DATA_ROOT} \
+ --out-dir ${OUT_DIR}
+```
+
+If you want to split DOTA-v1.5 dataset, which have different annotation dir 'labelTxt-v1.5'.
+
+```shell
+python tools/dataset_converters/dota/dota_split.py
+ --split-config 'tools/dataset_converters/dota/split_config/single_scale.json'
+ --data-root ${DATA_ROOT} \
+ --out-dir ${OUT_DIR} \
+ --ann-subdir 'labelTxt-v1.5'
+```
+
+If you want to split DOTA train and val set with single scale.
+
+```shell
+python tools/dataset_converters/dota/dota_split.py
+ --split-config 'tools/dataset_converters/dota/split_config/single_scale.json'
+ --data-root ${DATA_ROOT} \
+ --phase train val \
+ --out-dir ${OUT_DIR}
+```
+
+For multi scale split:
+
+```shell
+python tools/dataset_converters/dota/dota_split.py
+ --split-config 'tools/dataset_converters/dota/split_config/multi_scale.json'
+ --data-root ${DATA_ROOT} \
+ --out-dir ${OUT_DIR}
+```
+
+The new data structure is as follows:
+
+```none
+${OUT_DIR}
+├── trainval
+│ ├── images
+│ │ ├── P0000__1024__0___0.png
+│ │ ├── ...
+│ ├── annfiles
+│ │ ├── P0000__1024__0___0.txt
+│ │ ├── ...
+├── test
+│ ├── images
+│ │ ├── P0006__1024__0___0.png
+│ │ ├── ...
+│ ├── annfiles
+│ │ ├── P0006__1024__0___0.txt
+│ │ ├── ...
+```
+
+Then change `data_root` to ${OUT_DIR}.
diff --git a/third_party/mmyolo/docs/en/recommended_topics/deploy/easydeploy_guide.md b/third_party/mmyolo/docs/en/recommended_topics/deploy/easydeploy_guide.md
new file mode 100644
index 0000000000000000000000000000000000000000..46fab865340f6db1eb52146de9459078b68f1319
--- /dev/null
+++ b/third_party/mmyolo/docs/en/recommended_topics/deploy/easydeploy_guide.md
@@ -0,0 +1 @@
+# EasyDeploy Deployment
diff --git a/third_party/mmyolo/docs/en/recommended_topics/deploy/index.rst b/third_party/mmyolo/docs/en/recommended_topics/deploy/index.rst
new file mode 100644
index 0000000000000000000000000000000000000000..f21f353c8c64d457e21c79b4af1c75eae9715174
--- /dev/null
+++ b/third_party/mmyolo/docs/en/recommended_topics/deploy/index.rst
@@ -0,0 +1,16 @@
+MMDeploy deployment tutorial
+********************************
+
+.. toctree::
+ :maxdepth: 1
+
+ mmdeploy_guide.md
+ mmdeploy_yolov5.md
+
+EasyDeploy deployment tutorial
+************************************
+
+.. toctree::
+ :maxdepth: 1
+
+ easydeploy_guide.md
diff --git a/third_party/mmyolo/docs/en/recommended_topics/deploy/mmdeploy_guide.md b/third_party/mmyolo/docs/en/recommended_topics/deploy/mmdeploy_guide.md
new file mode 100644
index 0000000000000000000000000000000000000000..096d39fbc9bd6ee46309332339cbcdca2009c098
--- /dev/null
+++ b/third_party/mmyolo/docs/en/recommended_topics/deploy/mmdeploy_guide.md
@@ -0,0 +1,414 @@
+# Basic Deployment Guide
+
+## Introduction of MMDeploy
+
+MMDeploy is an open-source deep learning model deployment toolset. It is a part of the [OpenMMLab](https://openmmlab.com/) project, and provides **a unified experience of exporting different models** to various platforms and devices of the OpenMMLab series libraries. Using MMDeploy, developers can easily export the specific compiled SDK they need from the training result, which saves a lot of effort.
+
+More detailed introduction and guides can be found [here](https://mmdeploy.readthedocs.io/en/latest/get_started.html)
+
+## Supported Algorithms
+
+Currently our deployment kit supports on the following models and backends:
+
+| Model | Task | OnnxRuntime | TensorRT | Model config |
+| :----- | :-------------- | :---------: | :------: | :---------------------------------------------------------------------: |
+| YOLOv5 | ObjectDetection | Y | Y | [config](https://github.com/open-mmlab/mmyolo/tree/main/configs/yolov5) |
+| YOLOv6 | ObjectDetection | Y | Y | [config](https://github.com/open-mmlab/mmyolo/tree/main/configs/yolov6) |
+| YOLOX | ObjectDetection | Y | Y | [config](https://github.com/open-mmlab/mmyolo/tree/main/configs/yolox) |
+| RTMDet | ObjectDetection | Y | Y | [config](https://github.com/open-mmlab/mmyolo/tree/main/configs/rtmdet) |
+
+Note: ncnn and other inference backends support are coming soon.
+
+## Installation
+
+Please install mmdeploy by following [this](https://mmdeploy.readthedocs.io/en/latest/get_started.html) guide.
+
+```{note}
+If you install mmdeploy prebuilt package, please also clone its repository by 'git clone https://github.com/open-mmlab/mmdeploy.git --depth=1' to get the 'tools' file for deployment.
+```
+
+## How to Write Config for MMYOLO
+
+All config files related to the deployment are located at [`configs/deploy`](../../../configs/deploy/).
+
+You only need to change the relative data processing part in the model config file to support either static or dynamic input for your model. Besides, MMDeploy integrates the post-processing parts as customized ops, you can modify the strategy in `post_processing` parameter in `codebase_config`.
+
+Here is the detail description:
+
+```python
+codebase_config = dict(
+ type='mmyolo',
+ task='ObjectDetection',
+ model_type='end2end',
+ post_processing=dict(
+ score_threshold=0.05,
+ confidence_threshold=0.005,
+ iou_threshold=0.5,
+ max_output_boxes_per_class=200,
+ pre_top_k=5000,
+ keep_top_k=100,
+ background_label_id=-1),
+ module=['mmyolo.deploy'])
+```
+
+- `score_threshold`: set the score threshold to filter candidate bboxes before `nms`
+- `confidence_threshold`: set the confidence threshold to filter candidate bboxes before `nms`
+- `iou_threshold`: set the `iou` threshold for removing duplicates in `nms`
+- `max_output_boxes_per_class`: set the maximum number of bboxes for each class
+- `pre_top_k`: set the number of fixedcandidate bboxes before `nms`, sorted by scores
+- `keep_top_k`: set the number of output candidate bboxs after `nms`
+- `background_label_id`: set to `-1` as MMYOLO has no background class information
+
+### Configuration for Static Inputs
+
+#### 1. Model Config
+
+Taking `YOLOv5` of MMYOLO as an example, here are the details:
+
+```python
+_base_ = '../../yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+test_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=_base_.backend_args),
+ dict(
+ type='LetterResize',
+ scale=_base_.img_scale,
+ allow_scale_up=False,
+ use_mini_pad=False,
+ ),
+ dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
+ dict(
+ type='mmdet.PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'pad_param'))
+]
+
+test_dataloader = dict(
+ dataset=dict(pipeline=test_pipeline, batch_shapes_cfg=None))
+```
+
+`_base_ = '../../yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'` inherits the model config in the training stage.
+
+`test_pipeline` adds the data processing piple for the deployment, `LetterResize` controls the size of the input images and the input for the converted model
+
+`test_dataloader` adds the dataloader config for the deployment, `batch_shapes_cfg` decides whether to use the `batch_shapes` strategy. More details can be found at [yolov5 configs](../user_guides/config.md)
+
+#### 2. Deployment Config
+
+Here we still use the `YOLOv5` in MMYOLO as the example. We can use [`detection_onnxruntime_static.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_onnxruntime_static.py) as the config to deploy `YOLOv5` to `ONNXRuntime` with static inputs.
+
+```python
+_base_ = ['./base_static.py']
+codebase_config = dict(
+ type='mmyolo',
+ task='ObjectDetection',
+ model_type='end2end',
+ post_processing=dict(
+ score_threshold=0.05,
+ confidence_threshold=0.005,
+ iou_threshold=0.5,
+ max_output_boxes_per_class=200,
+ pre_top_k=5000,
+ keep_top_k=100,
+ background_label_id=-1),
+ module=['mmyolo.deploy'])
+backend_config = dict(type='onnxruntime')
+```
+
+`backend_config` indicates the deployment backend with `type='onnxruntime'`, other information can be referred from the third section.
+
+To deploy the `YOLOv5` to `TensorRT`, please refer to the [`detection_tensorrt_static-640x640.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_tensorrt_static-640x640.py) as follows.
+
+```python
+_base_ = ['./base_static.py']
+onnx_config = dict(input_shape=(640, 640))
+backend_config = dict(
+ type='tensorrt',
+ common_config=dict(fp16_mode=False, max_workspace_size=1 << 30),
+ model_inputs=[
+ dict(
+ input_shapes=dict(
+ input=dict(
+ min_shape=[1, 3, 640, 640],
+ opt_shape=[1, 3, 640, 640],
+ max_shape=[1, 3, 640, 640])))
+ ])
+use_efficientnms = False
+```
+
+`backend_config` indices the backend with `type='tensorrt'`.
+
+Different from `ONNXRuntime` deployment configuration, `TensorRT` needs to specify the input image size and the parameters required to build the engine file, including:
+
+- `onnx_config` specifies the input shape as `input_shape=(640, 640)`
+- `fp16_mode=False` and `max_workspace_size=1 << 30` in `backend_config['common_config']` indicates whether to build the engine in the parameter format of `fp16`, and the maximum video memory for the current `gpu` device, respectively. The unit is in `GB`. For detailed configuration of `fp16`, please refer to the [`detection_tensorrt-fp16_static-640x640.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_tensorrt-fp16_static-640x640.py)
+- The `min_shape`/`opt_shape`/`max_shape` in `backend_config['model_inputs']['input_shapes']['input']` should remain the same under static input, the default is `[1, 3, 640, 640]`.
+
+`use_efficientnms` is a new configuration introduced by the `MMYOLO` series, indicating whether to enable `Efficient NMS Plugin` to replace `TRTBatchedNMS plugin` in `MMDeploy` when exporting `onnx`.
+
+You can refer to the official [efficient NMS plugins](https://github.com/NVIDIA/TensorRT/blob/main/plugin/efficientNMSPlugin/README.md) by `TensorRT` for more details.
+
+Note: this out-of-box feature is **only available in TensorRT>=8.0**, no need to compile it by yourself.
+
+### Configuration for Dynamic Inputs
+
+#### 1. Model Config
+
+When you deploy a dynamic input model, you don't need to modify any model configuration files but the deployment configuration files.
+
+#### 2. Deployment Config
+
+To deploy the `YOLOv5` in MMYOLO to `ONNXRuntime`, please refer to the [`detection_onnxruntime_dynamic.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_onnxruntime_dynamic.py).
+
+```python
+_base_ = ['./base_dynamic.py']
+codebase_config = dict(
+ type='mmyolo',
+ task='ObjectDetection',
+ model_type='end2end',
+ post_processing=dict(
+ score_threshold=0.05,
+ confidence_threshold=0.005,
+ iou_threshold=0.5,
+ max_output_boxes_per_class=200,
+ pre_top_k=5000,
+ keep_top_k=100,
+ background_label_id=-1),
+ module=['mmyolo.deploy'])
+backend_config = dict(type='onnxruntime')
+```
+
+`backend_config` indicates the backend with `type='onnxruntime'`. Other parameters stay the same as the static input section.
+
+To deploy the `YOLOv5` to `TensorRT`, please refer to the [`detection_tensorrt_dynamic-192x192-960x960.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_tensorrt_dynamic-192x192-960x960.py).
+
+```python
+_base_ = ['./base_dynamic.py']
+backend_config = dict(
+ type='tensorrt',
+ common_config=dict(fp16_mode=False, max_workspace_size=1 << 30),
+ model_inputs=[
+ dict(
+ input_shapes=dict(
+ input=dict(
+ min_shape=[1, 3, 192, 192],
+ opt_shape=[1, 3, 640, 640],
+ max_shape=[1, 3, 960, 960])))
+ ])
+use_efficientnms = False
+```
+
+`backend_config` indicates the backend with `type='tensorrt'`. Since the dynamic and static inputs are different in `TensorRT`, please check the details at [TensorRT dynamic input official introduction](https://docs.nvidia.com/deeplearning/tensorrt/archives/tensorrt-843/developer-guide/index.html#work_dynamic_shapes).
+
+`TensorRT` deployment requires you to specify `min_shape`, `opt_shape` , and `max_shape`. `TensorRT` limits the size of the input image between `min_shape` and `max_shape`.
+
+`min_shape` is the minimum size of the input image. `opt_shape` is the common size of the input image, inference performance is best under this size. `max_shape` is the maximum size of the input image.
+
+`use_efficientnms` configuration is the same as the `TensorRT` static input configuration in the previous section.
+
+### INT8 Quantization Support
+
+Note: Int8 quantization support will soon be released.
+
+## How to Convert Model
+
+### Usage
+
+#### Deploy with MMDeploy Tools
+
+Set the root directory of `MMDeploy` as an env parameter `MMDEPLOY_DIR` using `export MMDEPLOY_DIR=/the/root/path/of/MMDeploy` command.
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ ${DEPLOY_CFG_PATH} \
+ ${MODEL_CFG_PATH} \
+ ${MODEL_CHECKPOINT_PATH} \
+ ${INPUT_IMG} \
+ --test-img ${TEST_IMG} \
+ --work-dir ${WORK_DIR} \
+ --calib-dataset-cfg ${CALIB_DATA_CFG} \
+ --device ${DEVICE} \
+ --log-level INFO \
+ --show \
+ --dump-info
+```
+
+### Parameter Description
+
+- `deploy_cfg`: set the deployment config path of MMDeploy for the model, including the type of inference framework, whether quantize, whether the input shape is dynamic, etc. There may be a reference relationship between configuration files, e.g. `configs/deploy/detection_onnxruntime_static.py`
+- `model_cfg`: set the MMYOLO model config path, e.g. `configs/deploy/model/yolov5_s-deploy.py`, regardless of the path to MMDeploy
+- `checkpoint`: set the torch model path. It can start with `http/https`, more details are available in `mmengine.fileio` apis
+- `img`: set the path to the image or point cloud file used for testing during model conversion
+- `--test-img`: set the image file that used to test model. If not specified, it will be set to `None`
+- `--work-dir`: set the work directory that used to save logs and models
+- `--calib-dataset-cfg`: use for calibration only for INT8 mode. If not specified, it will be set to None and use “val” dataset in model config for calibration
+- `--device`: set the device used for model conversion. The default is `cpu`, for TensorRT used `cuda:0`
+- `--log-level`: set log level which in `'CRITICAL', 'FATAL', 'ERROR', 'WARN', 'WARNING', 'INFO', 'DEBUG', 'NOTSET'`. If not specified, it will be set to `INFO`
+- `--show`: show the result on screen or not
+- `--dump-info`: output SDK information or not
+
+#### Deploy with MMDeploy API
+
+Suppose the working directory is the root path of mmyolo. Take [YoloV5](https://github.com/open-mmlab/mmyolo/blob/main/configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py) model as an example. You can download its checkpoint from [here](https://download.openmmlab.com/mmyolo/v0/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth), and then convert it to onnx model as follows:
+
+```python
+from mmdeploy.apis import torch2onnx
+from mmdeploy.backend.sdk.export_info import export2SDK
+
+img = 'demo/demo.jpg'
+work_dir = 'mmdeploy_models/mmyolo/onnx'
+save_file = 'end2end.onnx'
+deploy_cfg = 'configs/deploy/detection_onnxruntime_dynamic.py'
+model_cfg = 'configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+model_checkpoint = 'checkpoints/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth'
+device = 'cpu'
+
+# 1. convert model to onnx
+torch2onnx(img, work_dir, save_file, deploy_cfg, model_cfg,
+ model_checkpoint, device)
+
+# 2. extract pipeline info for inference by MMDeploy SDK
+export2SDK(deploy_cfg, model_cfg, work_dir, pth=model_checkpoint,
+ device=device)
+```
+
+## Model specification
+
+Before moving on to model inference chapter, let's know more about the converted result structure which is very important for model inference. It is saved in the directory specified with `--wodk_dir`.
+
+The converted results are saved in the working directory `mmdeploy_models/mmyolo/onnx` in the previous example. It includes:
+
+```
+mmdeploy_models/mmyolo/onnx
+├── deploy.json
+├── detail.json
+├── end2end.onnx
+└── pipeline.json
+```
+
+in which,
+
+- **end2end.onnx**: backend model which can be inferred by ONNX Runtime
+- ***xxx*.json**: the necessary information for mmdeploy SDK
+
+The whole package **mmdeploy_models/mmyolo/onnx** is defined as **mmdeploy SDK model**, i.e., **mmdeploy SDK model** includes both backend model and inference meta information.
+
+## Model inference
+
+### Backend model inference
+
+Take the previous converted `end2end.onnx` model as an example, you can use the following code to inference the model and visualize the results.
+
+```python
+from mmdeploy.apis.utils import build_task_processor
+from mmdeploy.utils import get_input_shape, load_config
+import torch
+
+deploy_cfg = 'configs/deploy/detection_onnxruntime_dynamic.py'
+model_cfg = 'configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+device = 'cpu'
+backend_model = ['mmdeploy_models/mmyolo/onnx/end2end.onnx']
+image = 'demo/demo.jpg'
+
+# read deploy_cfg and model_cfg
+deploy_cfg, model_cfg = load_config(deploy_cfg, model_cfg)
+
+# build task and backend model
+task_processor = build_task_processor(model_cfg, deploy_cfg, device)
+model = task_processor.build_backend_model(backend_model)
+
+# process input image
+input_shape = get_input_shape(deploy_cfg)
+model_inputs, _ = task_processor.create_input(image, input_shape)
+
+# do model inference
+with torch.no_grad():
+ result = model.test_step(model_inputs)
+
+# visualize results
+task_processor.visualize(
+ image=image,
+ model=model,
+ result=result[0],
+ window_name='visualize',
+ output_file='work_dir/output_detection.png')
+```
+
+With the above code, you can find the inference result `output_detection.png` in `work_dir`.
+
+### SDK model inference
+
+You can also perform SDK model inference like following,
+
+```python
+from mmdeploy_runtime import Detector
+import cv2
+
+img = cv2.imread('demo/demo.jpg')
+
+# create a detector
+detector = Detector(model_path='mmdeploy_models/mmyolo/onnx',
+ device_name='cpu', device_id=0)
+# perform inference
+bboxes, labels, masks = detector(img)
+
+# visualize inference result
+indices = [i for i in range(len(bboxes))]
+for index, bbox, label_id in zip(indices, bboxes, labels):
+ [left, top, right, bottom], score = bbox[0:4].astype(int), bbox[4]
+ if score < 0.3:
+ continue
+
+ cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0))
+
+cv2.imwrite('work_dir/output_detection.png', img)
+```
+
+Besides python API, mmdeploy SDK also provides other FFI (Foreign Function Interface), such as C, C++, C#, Java and so on. You can learn their usage from [demos](https://github.com/open-mmlab/mmdeploy/tree/main/demo).
+
+## How to Evaluate Model
+
+### Usage
+
+After the model is converted to your backend, you can use `${MMDEPLOY_DIR}/tools/test.py` to evaluate the performance.
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/test.py \
+ ${DEPLOY_CFG} \
+ ${MODEL_CFG} \
+ --model ${BACKEND_MODEL_FILES} \
+ --device ${DEVICE} \
+ --work-dir ${WORK_DIR} \
+ [--cfg-options ${CFG_OPTIONS}] \
+ [--show] \
+ [--show-dir ${OUTPUT_IMAGE_DIR}] \
+ [--interval ${INTERVAL}] \
+ [--wait-time ${WAIT_TIME}] \
+ [--log2file work_dirs/output.txt]
+ [--speed-test] \
+ [--warmup ${WARM_UP}] \
+ [--log-interval ${LOG_INTERVERL}] \
+ [--batch-size ${BATCH_SIZE}] \
+ [--uri ${URI}]
+```
+
+### Parameter Description
+
+- `deploy_cfg`: set the deployment config file path.
+- `model_cfg`: set the MMYOLO model config file path.
+- `--model`: set the converted model. For example, if we exported a TensorRT model, we need to pass in the file path with the suffix ".engine".
+- `--device`: indicate the device to run the model. Note that some backends limit the running devices. For example, TensorRT must run on CUDA.
+- `--work-dir`: the directory to save the file containing evaluation metrics.
+- `--cfg-options`: pass in additional configs, which will override the current deployment configs.
+- `--show`: show the evaluation result on screen or not.
+- `--show-dir`: save the evaluation result to this directory, valid only when specified.
+- `--interval`: set the display interval between each two evaluation results.
+- `--wait-time`: set the display time of each window.
+- `--log2file`: log evaluation results and speed to file.
+- `--speed-test`: test the inference speed or not.
+- `--warmup`: warm up before speed test or not, works only when `speed-test` is specified.
+- `--log-interval`: the interval between each log, works only when `speed-test` is specified.
+- `--batch-size`: set the batch size for inference, which will override the `samples_per_gpu` in data config. The default value is `1`, however, not every model supports `batch_size > 1`.
+- `--uri`: Remote ipv4:port or ipv6:port for inference on edge device.
+
+Note: other parameters in `${MMDEPLOY_DIR}/tools/test.py` are used for speed test, they will not affect the evaluation results.
diff --git a/third_party/mmyolo/docs/en/recommended_topics/deploy/mmdeploy_yolov5.md b/third_party/mmyolo/docs/en/recommended_topics/deploy/mmdeploy_yolov5.md
new file mode 100644
index 0000000000000000000000000000000000000000..321a6734fe0a18f35e88b5f31e28be6b3abc7ee5
--- /dev/null
+++ b/third_party/mmyolo/docs/en/recommended_topics/deploy/mmdeploy_yolov5.md
@@ -0,0 +1,572 @@
+# YOLOv5 Deployment
+
+Please check the [basic_deployment_guide](mmdeploy_guide.md) to get familiar with the configurations.
+
+## Model Training and Validation
+
+TODO
+
+## MMDeploy Environment Setup
+
+Please check the installation document of `MMDeploy` at [build_from_source](https://github.com/open-mmlab/mmdeploy/blob/dev-1.x/docs/en/01-how-to-build/build_from_source.md). Please build both `MMDeploy` and the customized Ops to your specific platform.
+
+Note: please check at `MMDeploy` [FAQ](https://github.com/open-mmlab/mmdeploy/blob/dev-1.x/docs/en/faq.md) or create new issues in `MMDeploy` when you come across any problems.
+
+## How to Prepare Configuration File
+
+This deployment guide uses the `YOLOv5` model trained on `COCO` dataset in MMYOLO to illustrate the whole process, including both static and dynamic inputs and different procedures for `TensorRT` and `ONNXRuntime`.
+
+### For Static Input
+
+#### 1. Model Config
+
+To deploy the model with static inputs, you need to ensure that the model inputs are in fixed size, e.g. the input size is set to `640x640` while uploading data in the test pipeline and test dataloader.
+
+Here is a example in [`yolov5_s-static.py`](https://github.com/open-mmlab/mmyolo/tree/main/configs/deploy/model/yolov5_s-static.py)
+
+```python
+_base_ = '../../yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+test_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=_base_.backend_args),
+ dict(
+ type='LetterResize',
+ scale=_base_.img_scale,
+ allow_scale_up=False,
+ use_mini_pad=False,
+ ),
+ dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
+ dict(
+ type='mmdet.PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'pad_param'))
+]
+
+test_dataloader = dict(
+ dataset=dict(pipeline=test_pipeline, batch_shapes_cfg=None))
+```
+
+As the `YOLOv5` will turn on `allow_scale_up` and `use_mini_pad` during the test to change the size of the input image in order to achieve higher accuracy. However, it will cause the input size mismatch problem when deploying in the static input model.
+
+Compared with the original configuration file, this configuration has been modified as follows:
+
+- turn off the settings related to reshaping the image in `test_pipeline`, e.g. setting `allow_scale_up=False` and `use_mini_pad=False` in `LetterResize`
+- turn off the `batch_shapes` in `test_dataloader` as `batch_shapes_cfg=None`.
+
+#### 2. Deployment Cofnig
+
+To deploy the model to `ONNXRuntime`, please refer to the [`detection_onnxruntime_static.py`](https://github.com/open-mmlab/mmyolo/tree/main/configs/deploy/detection_onnxruntime_static.py) as follows:
+
+```python
+_base_ = ['./base_static.py']
+codebase_config = dict(
+ type='mmyolo',
+ task='ObjectDetection',
+ model_type='end2end',
+ post_processing=dict(
+ score_threshold=0.05,
+ confidence_threshold=0.005,
+ iou_threshold=0.5,
+ max_output_boxes_per_class=200,
+ pre_top_k=5000,
+ keep_top_k=100,
+ background_label_id=-1),
+ module=['mmyolo.deploy'])
+backend_config = dict(type='onnxruntime')
+```
+
+The `post_processing` in the default configuration aligns the accuracy of the current model with the trained `pytorch` model. If you need to modify the relevant parameters, you can refer to the detailed introduction of [dasic_deployment_guide](mmdeploy_guide.md).
+
+To deploy the model to `TensorRT`, please refer to the [`detection_tensorrt_static-640x640.py`](https://github.com/open-mmlab/mmyolo/tree/main/configs/deploy/detection_tensorrt_static-640x640.p).
+
+```python
+_base_ = ['./base_static.py']
+onnx_config = dict(input_shape=(640, 640))
+backend_config = dict(
+ type='tensorrt',
+ common_config=dict(fp16_mode=False, max_workspace_size=1 << 30),
+ model_inputs=[
+ dict(
+ input_shapes=dict(
+ input=dict(
+ min_shape=[1, 3, 640, 640],
+ opt_shape=[1, 3, 640, 640],
+ max_shape=[1, 3, 640, 640])))
+ ])
+use_efficientnms = False
+```
+
+In this guide, we use the default settings such as `input_shape=(640, 640)` and `fp16_mode=False` to build in network in `fp32` mode. Moreover, we set `max_workspace_size=1 << 30` for the gpu memory which allows `TensorRT` to build the engine with maximum `1GB` memory.
+
+### For Dynamic Input
+
+#### 1. Model Confige
+
+As `TensorRT` limits the minimum and maximum input size, we can use any size for the inputs when deploy the model in dynamic mode. In this way, we can keep the default settings in [`yolov5_s-v61_syncbn_8xb16-300e_coco.py`](https://github.com/open-mmlab/mmyolo/tree/main/configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py). The data processing and dataloader parts are as follows.
+
+```python
+batch_shapes_cfg = dict(
+ type='BatchShapePolicy',
+ batch_size=val_batch_size_per_gpu,
+ img_size=img_scale[0],
+ size_divisor=32,
+ extra_pad_ratio=0.5)
+
+test_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=_base_.backend_args),
+ dict(type='YOLOv5KeepRatioResize', scale=img_scale),
+ dict(
+ type='LetterResize',
+ scale=img_scale,
+ allow_scale_up=False,
+ pad_val=dict(img=114)),
+ dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
+ dict(
+ type='mmdet.PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'pad_param'))
+]
+
+val_dataloader = dict(
+ batch_size=val_batch_size_per_gpu,
+ num_workers=val_num_workers,
+ persistent_workers=persistent_workers,
+ pin_memory=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ test_mode=True,
+ data_prefix=dict(img='val2017/'),
+ ann_file='annotations/instances_val2017.json',
+ pipeline=test_pipeline,
+ batch_shapes_cfg=batch_shapes_cfg))
+```
+
+We use `allow_scale_up=False` to control when the input small images will be upsampled or not in the initialization of `LetterResize`. At the same time, the default `use_mini_pad=False` turns off the minimum padding strategy of the image, and `val_dataloader['dataset']` is passed in` batch_shapes_cfg=batch_shapes_cfg` to ensure that the minimum padding is performed according to the input size in `batch`. These configs will change the dimensions of the input image, so the converted model can support dynamic inputs according to the above dataset loader when testing.
+
+#### 2. Deployment Cofnig
+
+To deploy the model to `ONNXRuntime`, please refer to the [`detection_onnxruntime_dynamic.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_onnxruntime_dynamic.py) for more details.
+
+```python
+_base_ = ['./base_dynamic.py']
+codebase_config = dict(
+ type='mmyolo',
+ task='ObjectDetection',
+ model_type='end2end',
+ post_processing=dict(
+ score_threshold=0.05,
+ confidence_threshold=0.005,
+ iou_threshold=0.5,
+ max_output_boxes_per_class=200,
+ pre_top_k=5000,
+ keep_top_k=100,
+ background_label_id=-1),
+ module=['mmyolo.deploy'])
+backend_config = dict(type='onnxruntime')
+```
+
+Differs from the static input config we introduced in previous section, dynamic input config additionally inherits the `dynamic_axes`. The rest of the configuration stays the same as the static inputs.
+
+To deploy the model to `TensorRT`, please refer to the [`detection_tensorrt_dynamic-192x192-960x960.py`](https://github.com/open-mmlab/mmyolo/tree/main/configs/deploy/detection_tensorrt_dynamic-192x192-960x960.py) for more details.
+
+```python
+_base_ = ['./base_dynamic.py']
+backend_config = dict(
+ type='tensorrt',
+ common_config=dict(fp16_mode=False, max_workspace_size=1 << 30),
+ model_inputs=[
+ dict(
+ input_shapes=dict(
+ input=dict(
+ min_shape=[1, 3, 192, 192],
+ opt_shape=[1, 3, 640, 640],
+ max_shape=[1, 3, 960, 960])))
+ ])
+use_efficientnms = False
+```
+
+In our example, the network is built in `fp32` mode as `fp16_mode=False`, and the maximum graphic memory is `1GB` for building the `TensorRT` engine as `max_workspace_size=1 << 30`.
+
+At the same time, `min_shape=[1, 3, 192, 192]`, `opt_shape=[1, 3, 640, 640]`, and `max_shape=[1, 3, 960, 960]` in the default setting set the model with minimum input size to `192x192`, the maximum size to `960x960`, and the most common size to `640x640`.
+
+When you deploy the model, it can adopt to the input image dimensions automatically.
+
+## How to Convert Model
+
+Note: The `MMDeploy` root directory used in this guide is `/home/openmmlab/dev/mmdeploy`, please modify it to your `MMDeploy` directory.
+
+Use the following command to download the pretrained YOLOv5 weight and save it to your device:
+
+```shell
+wget https://download.openmmlab.com/mmyolo/v0/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth -O /home/openmmlab/dev/mmdeploy/yolov5s.pth
+```
+
+Set the relevant env parameters using the following command as well:
+
+```shell
+export MMDEPLOY_DIR=/home/openmmlab/dev/mmdeploy
+export PATH_TO_CHECKPOINTS=/home/openmmlab/dev/mmdeploy/yolov5s.pth
+```
+
+### YOLOv5 Static Model Deployment
+
+#### ONNXRuntime
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_onnxruntime_static.py \
+ configs/deploy/model/yolov5_s-static.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir \
+ --show \
+ --device cpu
+```
+
+#### TensorRT
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_tensorrt_static-640x640.py \
+ configs/deploy/model/yolov5_s-static.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir \
+ --show \
+ --device cuda:0
+```
+
+### YOLOv5 Dynamic Model Deployment
+
+#### ONNXRuntime
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_onnxruntime_dynamic.py \
+ configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir \
+ --show \
+ --device cpu
+ --dump-info
+```
+
+#### TensorRT
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_tensorrt_dynamic-192x192-960x960.py \
+ configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir \
+ --show \
+ --device cuda:0
+ --dump-info
+```
+
+When convert the model using the above commands, you will find the following files under the `work_dir` folder:
+
+
+
+or
+
+
+
+After exporting to `onnxruntime`, you will get six files as shown in Figure 1, where `end2end.onnx` represents the exported `onnxruntime` model. The `xxx.json` are the meta info for `MMDeploy SDK` inference.
+
+After exporting to `TensorRT`, you will get the seven files as shown in Figure 2, where `end2end.onnx` represents the exported intermediate model. `MMDeploy` uses this model to automatically continue to convert the `end2end.engine` model for `TensorRT `Deployment. The `xxx.json` are the meta info for `MMDeploy SDK` inference.
+
+## How to Evaluate Model
+
+After successfully convert the model, you can use `${MMDEPLOY_DIR}/tools/test.py` to evaluate the converted model. The following part shows how to evaluate the static models of `ONNXRuntime` and `TensorRT`. For dynamic model evaluation, please modify the configuration of the inputs.
+
+### ONNXRuntime
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/test.py \
+ configs/deploy/detection_onnxruntime_static.py \
+ configs/deploy/model/yolov5_s-static.py \
+ --model work_dir/end2end.onnx \
+ --device cpu \
+ --work-dir work_dir
+```
+
+Once the process is done, you can get the output results as this:
+
+
+
+### TensorRT
+
+Note: `TensorRT` must run on `CUDA` devices!
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/test.py \
+ configs/deploy/detection_tensorrt_static-640x640.py \
+ configs/deploy/model/yolov5_s-static.py \
+ --model work_dir/end2end.engine \
+ --device cuda:0 \
+ --work-dir work_dir
+```
+
+Once the process is done, you can get the output results as this:
+
+
+
+More useful evaluation tools will be released in the future.
+
+# Deploy using Docker
+
+`MMYOLO` provides a deployment [`Dockerfile`](https://github.com/open-mmlab/mmyolo/blob/main/docker/Dockerfile_deployment) for deployment purpose. Please make sure your local docker version is greater than `19.03`.
+
+Note: users in mainland China can comment out the `Optional` part in the dockerfile for better experience.
+
+```dockerfile
+# (Optional)
+RUN sed -i 's/http:\/\/archive.ubuntu.com\/ubuntu\//http:\/\/mirrors.aliyun.com\/ubuntu\//g' /etc/apt/sources.list && \
+ pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
+```
+
+To build the docker image,
+
+```bash
+# build an image with PyTorch 1.12, CUDA 11.6, TensorRT 8.2.4 ONNXRuntime 1.8.1
+docker build -f docker/Dockerfile_deployment -t mmyolo:v1 .
+```
+
+To run the docker image,
+
+```bash
+export DATA_DIR=/path/to/your/dataset
+docker run --gpus all --shm-size=8g -it --name mmyolo -v ${DATA_DIR}:/openmmlab/mmyolo/data/coco mmyolo:v1
+```
+
+`DATA_DIR` is the path of your `COCO` dataset.
+
+We provide a `script.sh` file for you which runs the whole pipeline. Create the script under `/openmmlab/mmyolo` directory in your docker container using the following content.
+
+```bash
+#!/bin/bash
+wget -q https://download.openmmlab.com/mmyolo/v0/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth \
+ -O yolov5s.pth
+export MMDEPLOY_DIR=/openmmlab/mmdeploy
+export PATH_TO_CHECKPOINTS=/openmmlab/mmyolo/yolov5s.pth
+
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_tensorrt_static-640x640.py \
+ configs/deploy/model/yolov5_s-static.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir_trt \
+ --device cuda:0
+
+python3 ${MMDEPLOY_DIR}/tools/test.py \
+ configs/deploy/detection_tensorrt_static-640x640.py \
+ configs/deploy/model/yolov5_s-static.py \
+ --model work_dir_trt/end2end.engine \
+ --device cuda:0 \
+ --work-dir work_dir_trt
+
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_onnxruntime_static.py \
+ configs/deploy/model/yolov5_s-static.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir_ort \
+ --device cpu
+
+python3 ${MMDEPLOY_DIR}/tools/test.py \
+ configs/deploy/detection_onnxruntime_static.py \
+ configs/deploy/model/yolov5_s-static.py \
+ --model work_dir_ort/end2end.onnx \
+ --device cpu \
+ --work-dir work_dir_ort
+```
+
+Then run the script under `/openmmlab/mmyolo`.
+
+```bash
+sh script.sh
+```
+
+This script automatically downloads the `YOLOv5` pretrained weights in `MMYOLO` and convert the model using `MMDeploy`. You will get the output result as follows.
+
+- TensorRT:
+
+ 
+
+- ONNXRuntime:
+
+ 
+
+We can see from the above images that the accuracy of converted models shrink within 1% compared with the pytorch [MMYOLO-YOLOv5](https://github.com/open-mmlab/mmyolo/tree/main/configs/yolov5#results-and-models) models.
+
+If you need to test the inference speed of the converted model, you can use the following commands.
+
+- TensorRT
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/profiler.py \
+ configs/deploy/detection_tensorrt_static-640x640.py \
+ configs/deploy/model/yolov5_s-static.py \
+ data/coco/val2017 \
+ --model work_dir_trt/end2end.engine \
+ --device cuda:0
+```
+
+- ONNXRuntime
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/profiler.py \
+ configs/deploy/detection_onnxruntime_static.py \
+ configs/deploy/model/yolov5_s-static.py \
+ data/coco/val2017 \
+ --model work_dir_ort/end2end.onnx \
+ --device cpu
+```
+
+## Model Inference
+
+### Backend Model Inference
+
+#### ONNXRuntime
+
+For the converted model `end2end.onnx`,you can do the inference with the following code:
+
+```python
+from mmdeploy.apis.utils import build_task_processor
+from mmdeploy.utils import get_input_shape, load_config
+import torch
+
+deploy_cfg = './configs/deploy/detection_onnxruntime_dynamic.py'
+model_cfg = '../mmyolo/configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+device = 'cpu'
+backend_model = ['./work_dir/end2end.onnx']
+image = '../mmyolo/demo/demo.jpg'
+
+# read deploy_cfg and model_cfg
+deploy_cfg, model_cfg = load_config(deploy_cfg, model_cfg)
+
+# build task and backend model
+task_processor = build_task_processor(model_cfg, deploy_cfg, device)
+model = task_processor.build_backend_model(backend_model)
+
+# process input image
+input_shape = get_input_shape(deploy_cfg)
+model_inputs, _ = task_processor.create_input(image, input_shape)
+
+# do model inference
+with torch.no_grad():
+ result = model.test_step(model_inputs)
+
+# visualize results
+task_processor.visualize(
+ image=image,
+ model=model,
+ result=result[0],
+ window_name='visualize',
+ output_file='work_dir/output_detection.png')
+```
+
+#### TensorRT
+
+For the converted model `end2end.engine`,you can do the inference with the following code:
+
+```python
+from mmdeploy.apis.utils import build_task_processor
+from mmdeploy.utils import get_input_shape, load_config
+import torch
+
+deploy_cfg = './configs/deploy/detection_tensorrt_dynamic-192x192-960x960.py'
+model_cfg = '../mmyolo/configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+device = 'cuda:0'
+backend_model = ['./work_dir/end2end.engine']
+image = '../mmyolo/demo/demo.jpg'
+
+# read deploy_cfg and model_cfg
+deploy_cfg, model_cfg = load_config(deploy_cfg, model_cfg)
+
+# build task and backend model
+task_processor = build_task_processor(model_cfg, deploy_cfg, device)
+model = task_processor.build_backend_model(backend_model)
+
+# process input image
+input_shape = get_input_shape(deploy_cfg)
+model_inputs, _ = task_processor.create_input(image, input_shape)
+
+# do model inference
+with torch.no_grad():
+ result = model.test_step(model_inputs)
+
+# visualize results
+task_processor.visualize(
+ image=image,
+ model=model,
+ result=result[0],
+ window_name='visualize',
+ output_file='work_dir/output_detection.png')
+```
+
+### SDK Model Inference
+
+#### ONNXRuntime
+
+For the converted model `end2end.onnx`,you can do the SDK inference with the following code:
+
+```python
+from mmdeploy_runtime import Detector
+import cv2
+
+img = cv2.imread('../mmyolo/demo/demo.jpg')
+
+# create a detector
+detector = Detector(model_path='work_dir',
+ device_name='cpu', device_id=0)
+# perform inference
+bboxes, labels, masks = detector(img)
+
+# visualize inference result
+indices = [i for i in range(len(bboxes))]
+for index, bbox, label_id in zip(indices, bboxes, labels):
+ [left, top, right, bottom], score = bbox[0:4].astype(int), bbox[4]
+ if score < 0.3:
+ continue
+
+ cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0))
+
+cv2.imwrite('work_dir/output_detection.png', img)
+```
+
+#### TensorRT
+
+For the converted model `end2end.engine`,you can do the SDK inference with the following code:
+
+```python
+from mmdeploy_runtime import Detector
+import cv2
+
+img = cv2.imread('../mmyolo/demo/demo.jpg')
+
+# create a detector
+detector = Detector(model_path='work_dir',
+ device_name='cuda', device_id=0)
+# perform inference
+bboxes, labels, masks = detector(img)
+
+# visualize inference result
+indices = [i for i in range(len(bboxes))]
+for index, bbox, label_id in zip(indices, bboxes, labels):
+ [left, top, right, bottom], score = bbox[0:4].astype(int), bbox[4]
+ if score < 0.3:
+ continue
+
+ cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0))
+
+cv2.imwrite('work_dir/output_detection.png', img)
+```
+
+Besides python API, mmdeploy SDK also provides other FFI (Foreign Function Interface), such as C, C++, C#, Java and so on. You can learn their usage from [demos](https://github.com/open-mmlab/mmdeploy/tree/main/demo).
diff --git a/third_party/mmyolo/docs/en/recommended_topics/labeling_to_deployment_tutorials.md b/third_party/mmyolo/docs/en/recommended_topics/labeling_to_deployment_tutorials.md
new file mode 100644
index 0000000000000000000000000000000000000000..bce5d53f57e6dad4baafc843ad6f86cb19540eb1
--- /dev/null
+++ b/third_party/mmyolo/docs/en/recommended_topics/labeling_to_deployment_tutorials.md
@@ -0,0 +1,1331 @@
+# Annotation-to-deployment workflow for custom dataset
+
+In our daily work and study, we often encounter some tasks that need to train custom dataset. There are few scenarios in which open-source datasets can be used as online models, so we need to carry out a series of operations on our custom datasets to ensure that the models can be put into production and serve users.
+
+```{SeeAlso}
+The video of this document has been posted on Bilibili: [A nanny level tutorials for custom datasets from annotationt to deployment](https://www.bilibili.com/video/BV1RG4y137i5)
+```
+
+```{Note}
+All instructions in this document are done on Linux and are fully available on Windows, only slightly different in commands and operations.
+```
+
+Default that you have completed the installation of MMYOLO, if not installed, please refer to the document [GET STARTED](https://mmyolo.readthedocs.io/en/latest/get_started.html) for installation.
+
+In this tutorial, we will introduce the whole process from annotating custom dataset to final training, testing and deployment. The overview steps are as below:
+
+01. Prepare dataset: `tools/misc/download_dataset.py`
+02. Use the software of [labelme](https://github.com/wkentaro/labelme) to annotate: `demo/image_demo.py` + labelme
+03. Convert the dataset into COCO format: `tools/dataset_converters/labelme2coco.py`
+04. Split dataset:`tools/misc/coco_split.py`
+05. Creat a config file based on dataset
+06. Dataset visualization analysis: `tools/analysis_tools/dataset_analysis.py`
+07. Optimize Anchor size: `tools/analysis_tools/optimize_anchors.py`
+08. Visualization the data processing part of config: `tools/analysis_tools/browse_dataset.py`
+09. Train: `tools/train.py`
+10. Inference: `demo/image_demo.py`
+11. Deployment
+
+```{Note}
+After obtaining the model weight and the mAP of validation set, users need to deep analyse the bad cases of incorrect predictions in order to optimize model. MMYOLO will add this function in the future. Expect.
+```
+
+Each step is described in detail below.
+
+## 1. Prepare custom dataset
+
+- If you don't have your own dataset, or want to use a small dataset to run the whole process, you can use the 144 images `cat` dataset provided with this tutorial (the raw picture of this dataset is supplied by @RangeKing, cleaned by @PeterH0323). This `cat` dataset will be used as an example for the rest tutorial.
+
+
+
+
+

+

+
+

+
+

+
+

+
+

+
+

+
+
+
+ |
+ A distribution plot showing categories and the area of bbox instances based on the area rule
+ |
+
+ A distribution plot showing categories and the width and height of bbox instances
+ |
+
+
+
+  +
+ |
+
+  +
+ |
+
+
+ |
+ A distribution plot showing categories and the number of bbox instances
+ |
+
+ A distribution plot showing categories and the width/height ratio of bbox instances
+ |
+
+
+
+  +
+ |
+
+  +
+ |
+
+
+
+
+```{Note}
+Due to the cat dataset used in this tutorial is relatively small, we use RepeatDataset in config. The numbers shown are actually repeated five times. If you want a repeat-free analysis, you can change the `times` argument in RepeatDataset from `5` to `1` for now.
+```
+
+From the analysis output, we can conclude that the training set of the `cat` dataset used in this tutorial has the following characteristics:
+
+- The images are all `large object`;
+- The number of categories cat is `655`;
+- The width and height ratio of bbox is mostly concentrated in `1.0 ~ 1.11`, the minimum ratio is `0.36` and the maximum ratio is `2.9`;
+- The width of bbox is about `500 ~ 600` , and the height is about `500 ~ 600`.
+
+```{SeeAlso}
+See [Visualizing Dataset Analysis](https://mmyolo.readthedocs.io/en/latest/user_guides/useful_tools.html#id4) for more information on `tools/analysis_tools/dataset_analysis.py`
+```
+
+## 7. Optimize Anchor size
+
+```{Warning}
+This step only works for anchor-base models such as YOLOv5;
+
+This step can be skipped for Anchor-free models, such as YOLOv6, YOLOX.
+```
+
+The `tools/analysis_tools/optimize_anchors.py` script supports three anchor generation methods from YOLO series: `k-means`, `Differential Evolution` and `v5-k-means`.
+
+In this tutorial, we will use YOLOv5 for training, with an input size of `640 x 640`, and `v5-k-means` to optimize anchor:
+
+```shell
+python tools/analysis_tools/optimize_anchors.py configs/custom_dataset/yolov5_s-v61_syncbn_fast_1xb32-100e_cat.py \
+ --algorithm v5-k-means \
+ --input-shape 640 640 \
+ --prior-match-thr 4.0 \
+ --out-dir work_dirs/dataset_analysis_cat
+```
+
+```{Note}
+Because this command uses the k-means clustering algorithm, there is some randomness, which is related to the initialization. Therefore, the Anchor obtained by each execution will be somewhat different, but it is generated based on the dataset passed in, so it will not have any adverse effects.
+```
+
+The calculated anchors are as follows:
+
+
+

+
+

+
+

+
+
+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+

+
+
+Figure 1: P5 model structure
+
+
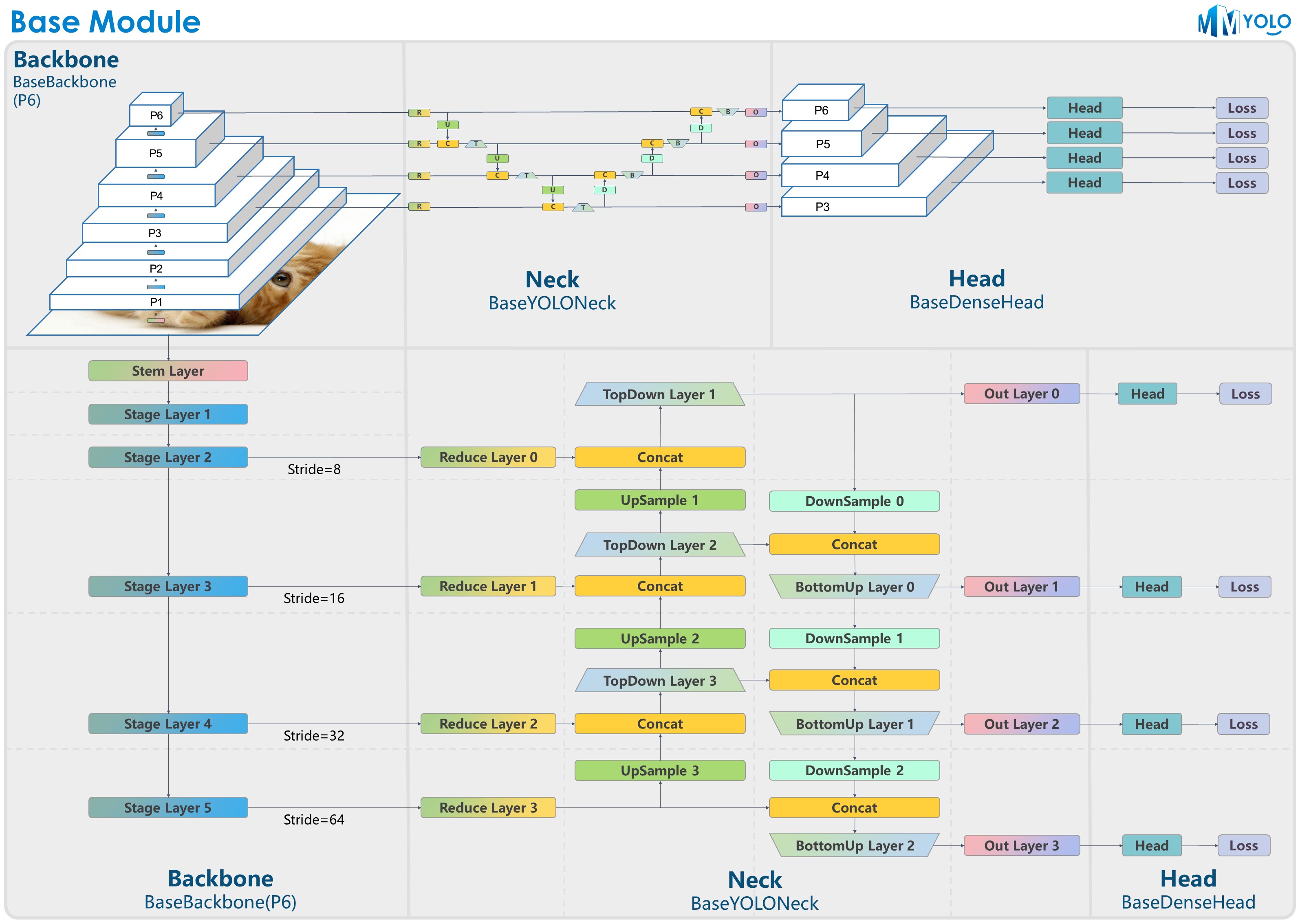
+Figure 2: P6 model structure
+
+
+
+

+
+
+
+

+
+

+
+

+
+
+
+

+
+

+
+

+
+
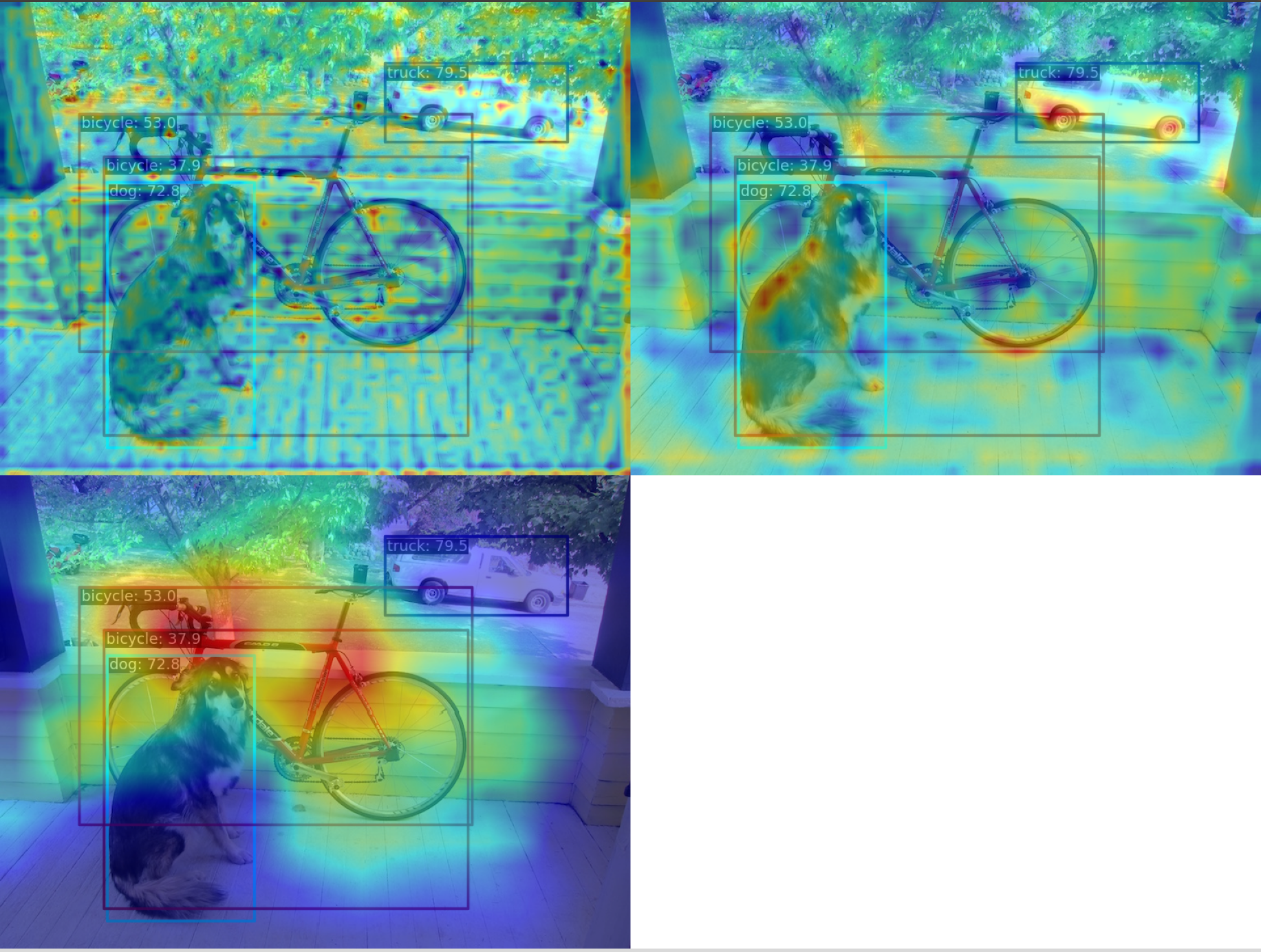
+
+
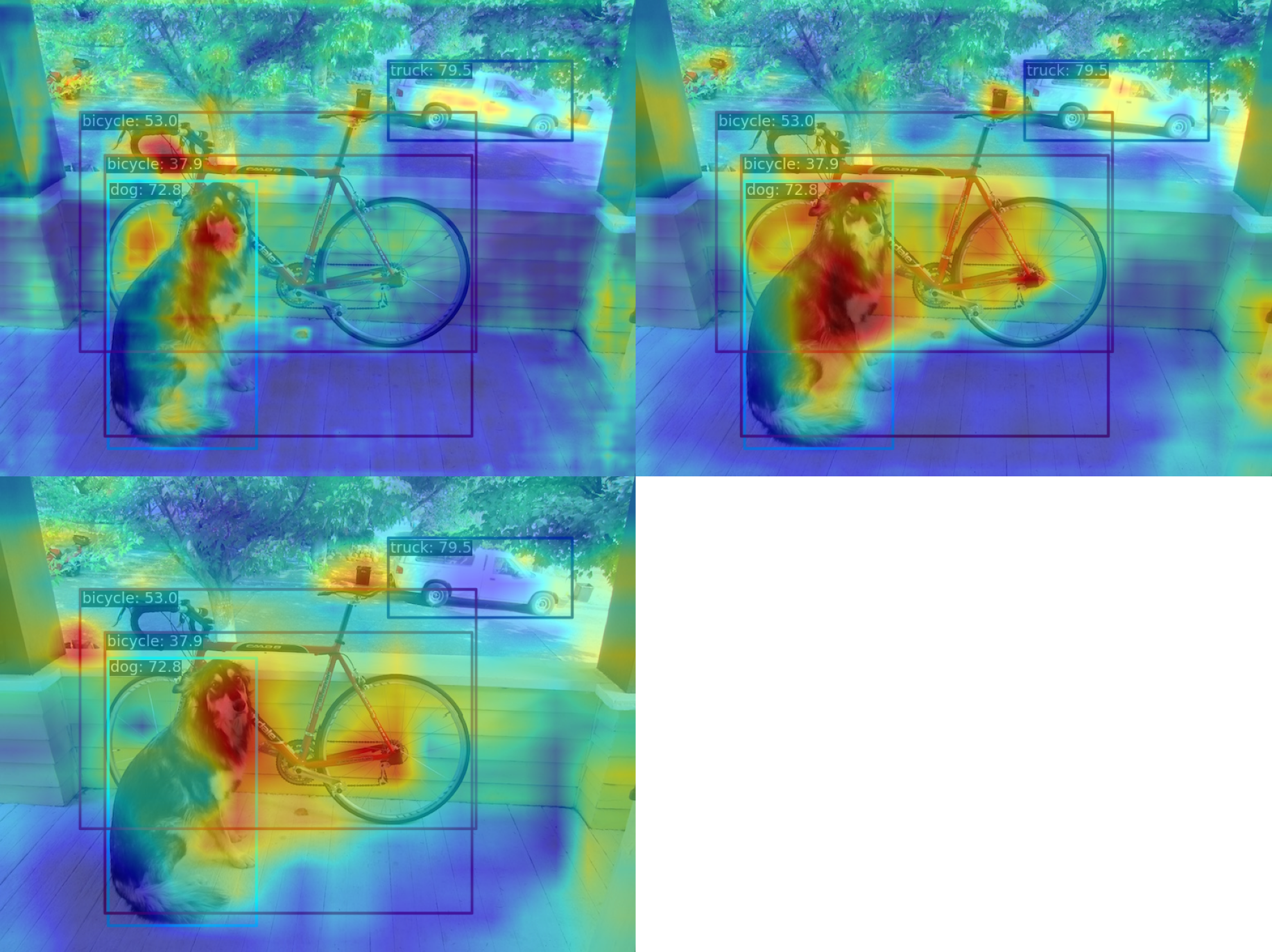
+
+

+
+

+
+

+
+
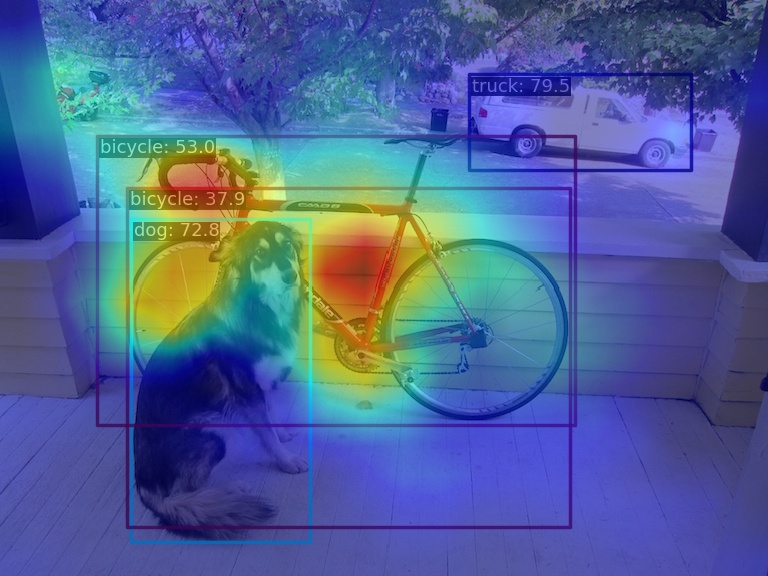
+
+

+
+
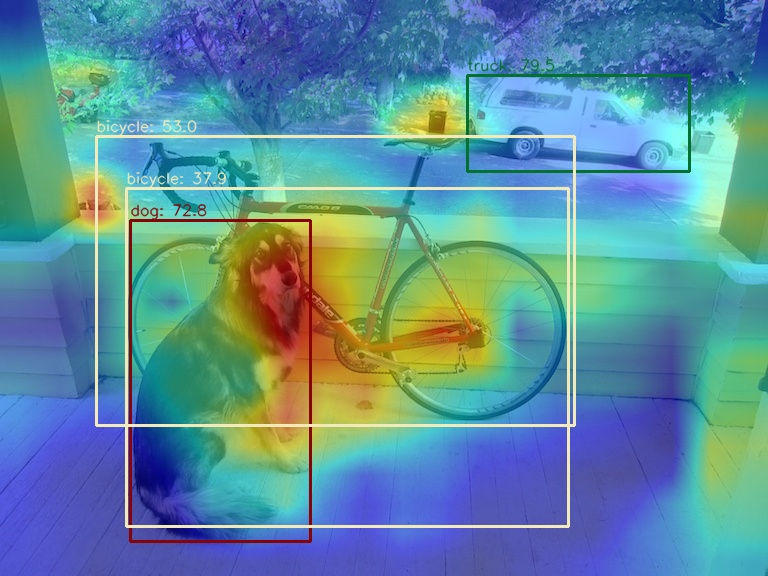
+
+
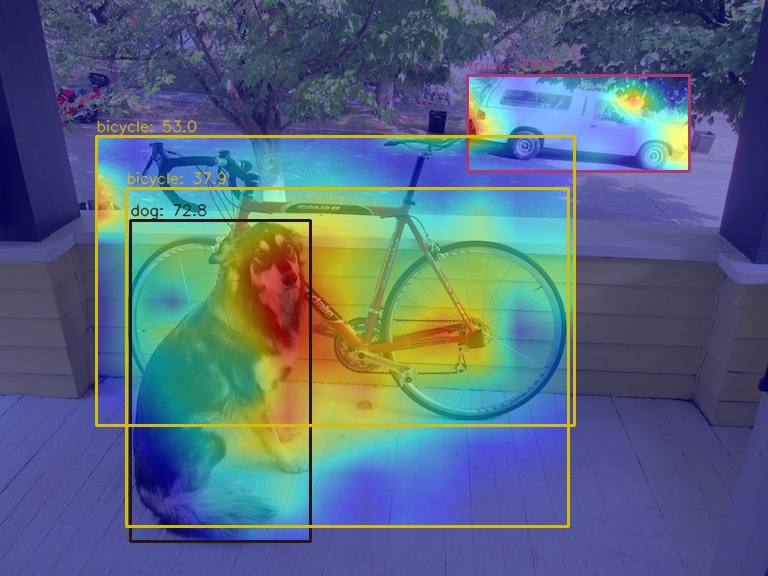
+
 +
+Function 2: Generated by the sub function `show_bbox_wh` to display the width and height distribution of categories and bbox instances.
+
+
+
+Function 2: Generated by the sub function `show_bbox_wh` to display the width and height distribution of categories and bbox instances.
+
+ +
+Function 3: Generated by the sub function `show_bbox_wh_ratio` to display the width to height ratio distribution of categories and bbox instances.
+
+
+
+Function 3: Generated by the sub function `show_bbox_wh_ratio` to display the width to height ratio distribution of categories and bbox instances.
+
+ +
+Function 3: Generated by the sub function `show_bbox_area` to display the distribution map of category and bbox instance area based on area rules.
+
+
+
+Function 3: Generated by the sub function `show_bbox_area` to display the distribution map of category and bbox instance area based on area rules.
+
+ +
+Print List: Generated by the sub function `show_class_list` and `show_data_list`.
+
+
+
+Print List: Generated by the sub function `show_class_list` and `show_data_list`.
+
+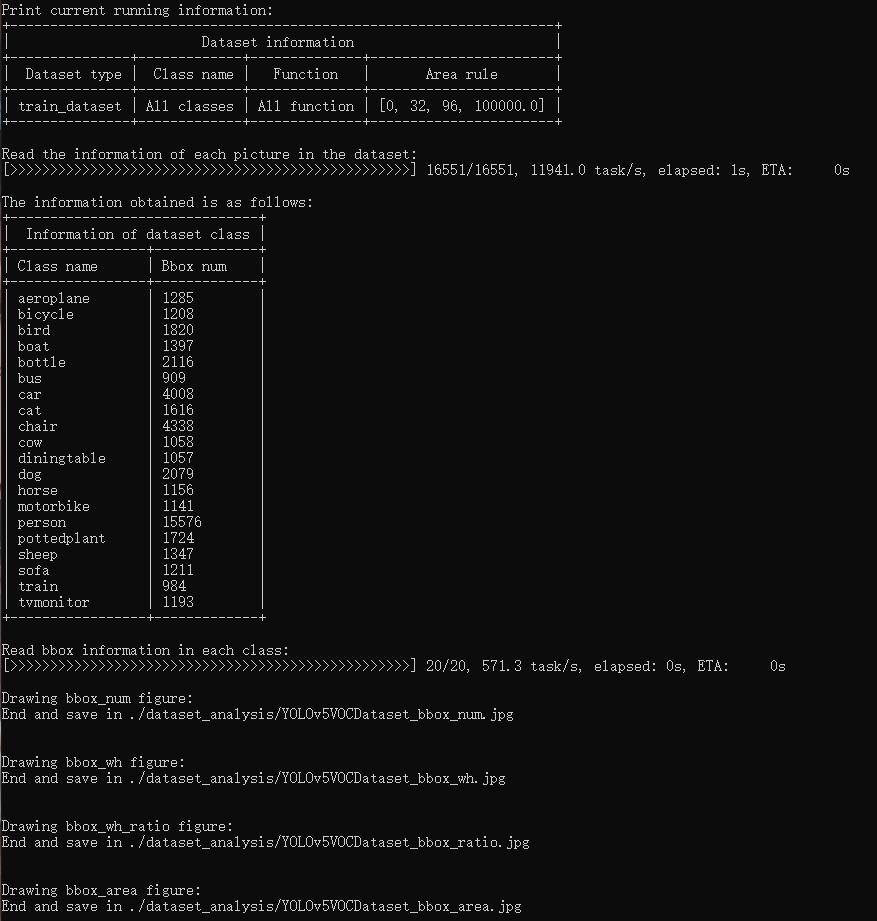 +
+```shell
+python tools/analysis_tools/dataset_analysis.py ${CONFIG} \
+ [--type ${TYPE}] \
+ [--class-name ${CLASS_NAME}] \
+ [--area-rule ${AREA_RULE}] \
+ [--func ${FUNC}] \
+ [--out-dir ${OUT_DIR}]
+```
+
+E,g:
+
+1.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, By default,the data loading type is `train_dataset`, the area rule is `[0,32,96,1e5]`, generate a result graph containing all functions and save the graph to the current running directory `./dataset_analysis` folder:
+
+```shell
+python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py
+```
+
+2.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, change the data loading type from the default `train_dataset` to `val_dataset` through the `--val-dataset` setting:
+
+```shell
+python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
+ --val-dataset
+```
+
+3.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, change the display of all generated classes to specific classes. Take the display of `person` classes as an example:
+
+```shell
+python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
+ --class-name person
+```
+
+4.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, redefine the area rule through `--area-rule` . Take `30 70 125` as an example, the area rule becomes `[0,30,70,125,1e5]`:
+
+```shell
+python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
+ --area-rule 30 70 125
+```
+
+5.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, change the display of four function renderings to only display `Function 1` as an example:
+
+```shell
+python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
+ --func show_bbox_num
+```
+
+6.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, modify the picture saving address to `work_dirs/dataset_analysis`:
+
+```shell
+python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
+ --out-dir work_dirs/dataset_analysis
+```
diff --git a/third_party/mmyolo/docs/en/useful_tools/dataset_converters.md b/third_party/mmyolo/docs/en/useful_tools/dataset_converters.md
new file mode 100644
index 0000000000000000000000000000000000000000..72ad968c14a0c4a8445b8fa57772903b823faa10
--- /dev/null
+++ b/third_party/mmyolo/docs/en/useful_tools/dataset_converters.md
@@ -0,0 +1,55 @@
+# Dataset Conversion
+
+The folder `tools/data_converters` currently contains `ballon2coco.py`, `yolo2coco.py`, and `labelme2coco.py` - three dataset conversion tools.
+
+- `ballon2coco.py` converts the `balloon` dataset (this small dataset is for starters only) to COCO format.
+
+```shell
+python tools/dataset_converters/balloon2coco.py
+```
+
+- `yolo2coco.py` converts a dataset from `yolo-style` **.txt** format to COCO format, please use it as follows:
+
+```shell
+python tools/dataset_converters/yolo2coco.py /path/to/the/root/dir/of/your_dataset
+```
+
+Instructions:
+
+1. `image_dir` is the root directory of the yolo-style dataset you need to pass to the script, which should contain `images`, `labels`, and `classes.txt`. `classes.txt` is the class declaration corresponding to the current dataset. One class a line. The structure of the root directory should be formatted as this example shows:
+
+```bash
+.
+└── $ROOT_PATH
+ ├── classes.txt
+ ├── labels
+ │ ├── a.txt
+ │ ├── b.txt
+ │ └── ...
+ ├── images
+ │ ├── a.jpg
+ │ ├── b.png
+ │ └── ...
+ └── ...
+```
+
+2. The script will automatically check if `train.txt`, `val.txt`, and `test.txt` have already existed under `image_dir`. If these files are located, the script will organize the dataset accordingly. Otherwise, the script will convert the dataset into one file. The image paths in these files must be **ABSOLUTE** paths.
+3. By default, the script will create a folder called `annotations` in the `image_dir` directory which stores the converted JSON file. If `train.txt`, `val.txt`, and `test.txt` are not found, the output file is `result.json`. Otherwise, the corresponding JSON file will be generated, named as `train.json`, `val.json`, and `test.json`. The `annotations` folder may look similar to this:
+
+```bash
+.
+└── $ROOT_PATH
+ ├── annotations
+ │ ├── result.json
+ │ └── ...
+ ├── classes.txt
+ ├── labels
+ │ ├── a.txt
+ │ ├── b.txt
+ │ └── ...
+ ├── images
+ │ ├── a.jpg
+ │ ├── b.png
+ │ └── ...
+ └── ...
+```
diff --git a/third_party/mmyolo/docs/en/useful_tools/download_dataset.md b/third_party/mmyolo/docs/en/useful_tools/download_dataset.md
new file mode 100644
index 0000000000000000000000000000000000000000..8a3e57ec6d14036813ccc7c9e586b99f939126d1
--- /dev/null
+++ b/third_party/mmyolo/docs/en/useful_tools/download_dataset.md
@@ -0,0 +1,11 @@
+# Download Dataset
+
+`tools/misc/download_dataset.py` supports downloading datasets such as `COCO`, `VOC`, `LVIS` and `Balloon`.
+
+```shell
+python tools/misc/download_dataset.py --dataset-name coco2017
+python tools/misc/download_dataset.py --dataset-name voc2007
+python tools/misc/download_dataset.py --dataset-name voc2012
+python tools/misc/download_dataset.py --dataset-name lvis
+python tools/misc/download_dataset.py --dataset-name balloon [--save-dir ${SAVE_DIR}] [--unzip]
+```
diff --git a/third_party/mmyolo/docs/en/useful_tools/extract_subcoco.md b/third_party/mmyolo/docs/en/useful_tools/extract_subcoco.md
new file mode 100644
index 0000000000000000000000000000000000000000..b2c7e06cf36c9b56d4aa91ec128601ef39674abc
--- /dev/null
+++ b/third_party/mmyolo/docs/en/useful_tools/extract_subcoco.md
@@ -0,0 +1,60 @@
+# Extracts a subset of COCO
+
+The training dataset of the COCO2017 dataset includes 118K images, and the validation set includes 5K images, which is a relatively large dataset. Loading JSON in debugging or quick verification scenarios will consume more resources and bring slower startup speed.
+
+The `extract_subcoco.py` script provides the ability to extract a specified number/classes/area-size of images. The user can use the `--num-img`, `--classes`, `--area-size` parameter to get a COCO subset of the specified condition of images.
+
+For example, extract images use scripts as follows:
+
+```shell
+python tools/misc/extract_subcoco.py \
+ ${ROOT} \
+ ${OUT_DIR} \
+ --num-img 20 \
+ --classes cat dog person \
+ --area-size small
+```
+
+It gone be extract 20 images, and only includes annotations which belongs to cat(or dog/person) and bbox area size is small, after filter by class and area size, the empty annotation images won't be chosen, guarantee the images be extracted definitely has annotation info.
+
+Currently, only support COCO2017. In the future will support user-defined datasets of standard coco JSON format.
+
+The root path folder format is as follows:
+
+```text
+├── root
+│ ├── annotations
+│ ├── train2017
+│ ├── val2017
+│ ├── test2017
+```
+
+1. Extract 10 training images and 10 validation images using only 5K validation sets.
+
+```shell
+python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --num-img 10
+```
+
+2. Extract 20 training images using the training set and 20 validation images using the validation set.
+
+```shell
+python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --num-img 20 --use-training-set
+```
+
+3. Set the global seed to 1. The default is no setting.
+
+```shell
+python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --num-img 20 --use-training-set --seed 1
+```
+
+4. Extract images by specify classes
+
+```shell
+python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --classes cat dog person
+```
+
+5. Extract images by specify anchor size
+
+```shell
+python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --area-size small
+```
diff --git a/third_party/mmyolo/docs/en/useful_tools/log_analysis.md b/third_party/mmyolo/docs/en/useful_tools/log_analysis.md
new file mode 100644
index 0000000000000000000000000000000000000000..c45170aaaadb97855c51e67819df52ce3868a141
--- /dev/null
+++ b/third_party/mmyolo/docs/en/useful_tools/log_analysis.md
@@ -0,0 +1,82 @@
+# Log Analysis
+
+## Curve plotting
+
+`tools/analysis_tools/analyze_logs.py` in MMDetection plots loss/mAP curves given a training log file. Run `pip install seaborn` first to install the dependency.
+
+```shell
+mim run mmdet analyze_logs plot_curve \
+ ${LOG} \ # path of train log in json format
+ [--keys ${KEYS}] \ # the metric that you want to plot, default to 'bbox_mAP'
+ [--start-epoch ${START_EPOCH}] # the epoch that you want to start, default to 1
+ [--eval-interval ${EVALUATION_INTERVAL}] \ # the evaluation interval when training, default to 1
+ [--title ${TITLE}] \ # title of figure
+ [--legend ${LEGEND}] \ # legend of each plot, default to None
+ [--backend ${BACKEND}] \ # backend of plt, default to None
+ [--style ${STYLE}] \ # style of plt, default to 'dark'
+ [--out ${OUT_FILE}] # the path of output file
+# [] stands for optional parameters, when actually entering the command line, you do not need to enter []
+```
+
+Examples:
+
+- Plot the classification loss of some run.
+
+ ```shell
+ mim run mmdet analyze_logs plot_curve \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
+ --keys loss_cls \
+ --legend loss_cls
+ ```
+
+
+
+- Plot the classification and regression loss of some run, and save the figure to a pdf.
+
+ ```shell
+ mim run mmdet analyze_logs plot_curve \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
+ --keys loss_cls loss_bbox \
+ --legend loss_cls loss_bbox \
+ --out losses_yolov5_s.pdf
+ ```
+
+
+
+- Compare the bbox mAP of two runs in the same figure.
+
+ ```shell
+ mim run mmdet analyze_logs plot_curve \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
+ yolov5_n-v61_syncbn_fast_8xb16-300e_coco_20220919_090739.log.json \
+ --keys bbox_mAP \
+ --legend yolov5_s yolov5_n \
+ --eval-interval 10 # Note that the evaluation interval must be the same as during training. Otherwise, it will raise an error.
+ ```
+
+
+
+## Compute the average training speed
+
+```shell
+mim run mmdet analyze_logs cal_train_time \
+ ${LOG} \ # path of train log in json format
+ [--include-outliers] # include the first value of every epoch when computing the average time
+```
+
+Examples:
+
+```shell
+mim run mmdet analyze_logs cal_train_time \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json
+```
+
+The output is expected to be like the following.
+
+```text
+-----Analyze train time of yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json-----
+slowest epoch 278, average time is 0.1705 s/iter
+fastest epoch 300, average time is 0.1510 s/iter
+time std over epochs is 0.0026
+average iter time: 0.1556 s/iter
+```
diff --git a/third_party/mmyolo/docs/en/useful_tools/model_converters.md b/third_party/mmyolo/docs/en/useful_tools/model_converters.md
new file mode 100644
index 0000000000000000000000000000000000000000..09fb52df13c2861f691672d7fe1d27e69af5d0e3
--- /dev/null
+++ b/third_party/mmyolo/docs/en/useful_tools/model_converters.md
@@ -0,0 +1,54 @@
+# Convert Model
+
+The six scripts under the `tools/model_converters` directory can help users convert the keys in the official pre-trained model of YOLO to the format of MMYOLO, and use MMYOLO to fine-tune the model.
+
+## YOLOv5
+
+Take conversion `yolov5s.pt` as an example:
+
+1. Clone the official YOLOv5 code to the local (currently the maximum supported version is `v6.1`):
+
+```shell
+git clone -b v6.1 https://github.com/ultralytics/yolov5.git
+cd yolov5
+```
+
+2. Download official weight file:
+
+```shell
+wget https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5s.pt
+```
+
+3. Copy file `tools/model_converters/yolov5_to_mmyolo.py` to the path of YOLOv5 official code clone:
+
+```shell
+cp ${MMDET_YOLO_PATH}/tools/model_converters/yolov5_to_mmyolo.py yolov5_to_mmyolo.py
+```
+
+4. Conversion
+
+```shell
+python yolov5_to_mmyolo.py --src ${WEIGHT_FILE_PATH} --dst mmyolov5.pt
+```
+
+The converted `mmyolov5.pt` can be used by MMYOLO. The official weight conversion of YOLOv6 is also used in the same way.
+
+## YOLOX
+
+The conversion of YOLOX model **does not need** to download the official YOLOX code, just download the weight.
+
+Take conversion `yolox_s.pth` as an example:
+
+1. Download official weight file:
+
+```shell
+wget https://github.com/Megvii-BaseDetection/YOLOX/releases/download/0.1.1rc0/yolox_s.pth
+```
+
+2. Conversion
+
+```shell
+python tools/model_converters/yolox_to_mmyolo.py --src yolox_s.pth --dst mmyolox.pt
+```
+
+The converted `mmyolox.pt` can be used by MMYOLO.
diff --git a/third_party/mmyolo/docs/en/useful_tools/optimize_anchors.md b/third_party/mmyolo/docs/en/useful_tools/optimize_anchors.md
new file mode 100644
index 0000000000000000000000000000000000000000..460bc6e2fa3f4bec41b39901f1e66c442802911c
--- /dev/null
+++ b/third_party/mmyolo/docs/en/useful_tools/optimize_anchors.md
@@ -0,0 +1,38 @@
+# Optimize anchors size
+
+Script `tools/analysis_tools/optimize_anchors.py` supports three methods to optimize YOLO anchors including `k-means`
+anchor cluster, `Differential Evolution` and `v5-k-means`.
+
+## k-means
+
+In k-means method, the distance criteria is based IoU, python shell as follow:
+
+```shell
+python tools/analysis_tools/optimize_anchors.py ${CONFIG} \
+ --algorithm k-means \
+ --input-shape ${INPUT_SHAPE [WIDTH HEIGHT]} \
+ --out-dir ${OUT_DIR}
+```
+
+## Differential Evolution
+
+In differential_evolution method, based differential evolution algorithm, use `avg_iou_cost` as minimum target function, python shell as follow:
+
+```shell
+python tools/analysis_tools/optimize_anchors.py ${CONFIG} \
+ --algorithm DE \
+ --input-shape ${INPUT_SHAPE [WIDTH HEIGHT]} \
+ --out-dir ${OUT_DIR}
+```
+
+## v5-k-means
+
+In v5-k-means method, clustering standard as same with YOLOv5 which use shape-match, python shell as follow:
+
+```shell
+python tools/analysis_tools/optimize_anchors.py ${CONFIG} \
+ --algorithm v5-k-means \
+ --input-shape ${INPUT_SHAPE [WIDTH HEIGHT]} \
+ --prior_match_thr ${PRIOR_MATCH_THR} \
+ --out-dir ${OUT_DIR}
+```
diff --git a/third_party/mmyolo/docs/en/useful_tools/print_config.md b/third_party/mmyolo/docs/en/useful_tools/print_config.md
new file mode 100644
index 0000000000000000000000000000000000000000..2a6ee79f36c749491a1b5095792b708755fca279
--- /dev/null
+++ b/third_party/mmyolo/docs/en/useful_tools/print_config.md
@@ -0,0 +1,20 @@
+# Print the whole config
+
+`print_config.py` in MMDetection prints the whole config verbatim, expanding all its imports. The command is as following.
+
+```shell
+mim run mmdet print_config \
+ ${CONFIG} \ # path of the config file
+ [--save-path] \ # save path of whole config, suffixed with .py, .json or .yml
+ [--cfg-options ${OPTIONS [OPTIONS...]}] # override some settings in the used config
+```
+
+Examples:
+
+```shell
+mim run mmdet print_config \
+ configs/yolov5/yolov5_s-v61_syncbn_fast_1xb4-300e_balloon.py \
+ --save-path ./work_dirs/yolov5_s-v61_syncbn_fast_1xb4-300e_balloon.py
+```
+
+Running the above command will save the `yolov5_s-v61_syncbn_fast_1xb4-300e_balloon.py` config file with the inheritance relationship expanded to \`\`yolov5_s-v61_syncbn_fast_1xb4-300e_balloon_whole.py`in the`./work_dirs\` folder.
diff --git a/third_party/mmyolo/docs/en/useful_tools/vis_scheduler.md b/third_party/mmyolo/docs/en/useful_tools/vis_scheduler.md
new file mode 100644
index 0000000000000000000000000000000000000000..f1526342c9ee80236f7c146231430818811e2a82
--- /dev/null
+++ b/third_party/mmyolo/docs/en/useful_tools/vis_scheduler.md
@@ -0,0 +1,44 @@
+# Hyper-parameter Scheduler Visualization
+
+`tools/analysis_tools/vis_scheduler` aims to help the user to check the hyper-parameter scheduler of the optimizer(without training), which support the "learning rate", "momentum", and "weight_decay".
+
+```bash
+python tools/analysis_tools/vis_scheduler.py \
+ ${CONFIG_FILE} \
+ [-p, --parameter ${PARAMETER_NAME}] \
+ [-d, --dataset-size ${DATASET_SIZE}] \
+ [-n, --ngpus ${NUM_GPUs}] \
+ [-o, --out-dir ${OUT_DIR}] \
+ [--title ${TITLE}] \
+ [--style ${STYLE}] \
+ [--window-size ${WINDOW_SIZE}] \
+ [--cfg-options]
+```
+
+**Description of all arguments**:
+
+- `config`: The path of a model config file.
+- **`-p, --parameter`**: The param to visualize its change curve, choose from "lr", "momentum" or "wd". Default to use "lr".
+- **`-d, --dataset-size`**: The size of the datasets. If set,`DATASETS.build` will be skipped and `${DATASET_SIZE}` will be used as the size. Default to use the function `DATASETS.build`.
+- **`-n, --ngpus`**: The number of GPUs used in training, default to be 1.
+- **`-o, --out-dir`**: The output path of the curve plot, default not to output.
+- `--title`: Title of figure. If not set, default to be config file name.
+- `--style`: Style of plt. If not set, default to be `whitegrid`.
+- `--window-size`: The shape of the display window. If not specified, it will be set to `12*7`. If used, it must be in the format `'W*H'`.
+- `--cfg-options`: Modifications to the configuration file, refer to [Learn about Configs](../tutorials/config.md).
+
+```{note}
+Loading annotations maybe consume much time, you can directly specify the size of the dataset with `-d, dataset-size` to save time.
+```
+
+You can use the following command to plot the step learning rate schedule used in the config `configs/rtmdet/rtmdet_s_syncbn_fast_8xb32-300e_coco.py`:
+
+```shell
+python tools/analysis_tools/vis_scheduler.py \
+ configs/rtmdet/rtmdet_s_syncbn_fast_8xb32-300e_coco.py \
+ --dataset-size 118287 \
+ --ngpus 8 \
+ --out-dir ./output
+```
+
+
diff --git a/third_party/mmyolo/docs/zh_cn/Makefile b/third_party/mmyolo/docs/zh_cn/Makefile
new file mode 100644
index 0000000000000000000000000000000000000000..d4bb2cbb9eddb1bb1b4f366623044af8e4830919
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/Makefile
@@ -0,0 +1,20 @@
+# Minimal makefile for Sphinx documentation
+#
+
+# You can set these variables from the command line, and also
+# from the environment for the first two.
+SPHINXOPTS ?=
+SPHINXBUILD ?= sphinx-build
+SOURCEDIR = .
+BUILDDIR = _build
+
+# Put it first so that "make" without argument is like "make help".
+help:
+ @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
+
+.PHONY: help Makefile
+
+# Catch-all target: route all unknown targets to Sphinx using the new
+# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
+%: Makefile
+ @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
diff --git a/third_party/mmyolo/docs/zh_cn/_static/css/readthedocs.css b/third_party/mmyolo/docs/zh_cn/_static/css/readthedocs.css
new file mode 100644
index 0000000000000000000000000000000000000000..353aa9e285a5639b0f34ecb3b16115cff1ad25ed
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/_static/css/readthedocs.css
@@ -0,0 +1,6 @@
+.header-logo {
+ background-image: url("../image/mmyolo-logo.png");
+ background-size: 115px 40px;
+ height: 40px;
+ width: 115px;
+}
diff --git a/third_party/mmyolo/docs/zh_cn/_static/image/mmyolo-logo.png b/third_party/mmyolo/docs/zh_cn/_static/image/mmyolo-logo.png
new file mode 100644
index 0000000000000000000000000000000000000000..41318aec92d86749d327bc5f9b9c689632ffc735
Binary files /dev/null and b/third_party/mmyolo/docs/zh_cn/_static/image/mmyolo-logo.png differ
diff --git a/third_party/mmyolo/docs/zh_cn/advanced_guides/cross-library_application.md b/third_party/mmyolo/docs/zh_cn/advanced_guides/cross-library_application.md
new file mode 100644
index 0000000000000000000000000000000000000000..d95f68cd22cdfc6218c24c7c02936f7fb04fd247
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/advanced_guides/cross-library_application.md
@@ -0,0 +1 @@
+# MMYOLO 跨库应用解析
diff --git a/third_party/mmyolo/docs/zh_cn/api.rst b/third_party/mmyolo/docs/zh_cn/api.rst
new file mode 100644
index 0000000000000000000000000000000000000000..39223a34f849b4b66dafea7fe9c9fdd34d06ecfe
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/api.rst
@@ -0,0 +1,80 @@
+mmyolo.datasets
+--------------------
+
+datasets
+^^^^^^^^^^
+.. automodule:: mmyolo.datasets
+ :members:
+
+transforms
+^^^^^^^^^^^^
+.. automodule:: mmyolo.datasets.transforms
+ :members:
+
+mmyolo.engine
+--------------
+
+hooks
+^^^^^^^^^^
+.. automodule:: mmyolo.engine.hooks
+ :members:
+
+optimizers
+^^^^^^^^^^
+.. automodule:: mmyolo.engine.optimizers
+ :members:
+
+mmyolo.models
+--------------
+
+backbones
+^^^^^^^^^^
+.. automodule:: mmyolo.models.backbones
+ :members:
+
+data_preprocessor
+^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmyolo.models.data_preprocessor
+ :members:
+
+dense_heads
+^^^^^^^^^^^^
+.. automodule:: mmyolo.models.dense_heads
+ :members:
+
+detectors
+^^^^^^^^^^
+.. automodule:: mmyolo.models.detectors
+ :members:
+
+layers
+^^^^^^^^^^
+.. automodule:: mmyolo.models.layers
+ :members:
+
+losses
+^^^^^^^^^^
+.. automodule:: mmyolo.models.losses
+ :members:
+
+necks
+^^^^^^^^^^^^
+.. automodule:: mmyolo.models.necks
+ :members:
+
+
+task_modules
+^^^^^^^^^^^^^^^
+.. automodule:: mmyolo.models.task_modules
+ :members:
+
+utils
+^^^^^^^^^^
+.. automodule:: mmyolo.models.utils
+ :members:
+
+
+mmyolo.utils
+--------------
+.. automodule:: mmyolo.utils
+ :members:
diff --git a/third_party/mmyolo/docs/zh_cn/common_usage/amp_training.md b/third_party/mmyolo/docs/zh_cn/common_usage/amp_training.md
new file mode 100644
index 0000000000000000000000000000000000000000..c7803abfea4487734b05de80705689d30c796e1a
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/common_usage/amp_training.md
@@ -0,0 +1,13 @@
+# 自动混合精度(AMP)训练
+
+如果要开启自动混合精度(AMP)训练,在训练命令最后加上 `--amp` 即可, 命令如下:
+
+```shell
+python tools/train.py python ./tools/train.py ${CONFIG} --amp
+```
+
+具体例子如下:
+
+```shell
+python tools/train.py configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py --amp
+```
diff --git a/third_party/mmyolo/docs/zh_cn/common_usage/freeze_layers.md b/third_party/mmyolo/docs/zh_cn/common_usage/freeze_layers.md
new file mode 100644
index 0000000000000000000000000000000000000000..ca0613903b65a6b2ba6986b3dea2830ee4465a2b
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/common_usage/freeze_layers.md
@@ -0,0 +1,28 @@
+# 冻结指定网络层权重
+
+## 冻结 backbone 权重
+
+在 MMYOLO 中我们可以通过设置 `frozen_stages` 参数去冻结主干网络的部分 `stage`, 使这些 `stage` 的参数不参与模型的更新。
+需要注意的是:`frozen_stages = i` 表示的意思是指从最开始的 `stage` 开始到第 `i` 层 `stage` 的所有参数都会被冻结。下面是 `YOLOv5` 的例子,其他算法也是同样的逻辑:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+model = dict(
+ backbone=dict(
+ frozen_stages=1 # 表示第一层 stage 以及它之前的所有 stage 中的参数都会被冻结
+ ))
+```
+
+## 冻结 neck 权重
+
+MMYOLO 中也可以通过参数 `freeze_all` 去冻结整个 `neck` 的参数。下面是 `YOLOv5` 的例子,其他算法也是同样的逻辑:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+model = dict(
+ neck=dict(
+ freeze_all=True # freeze_all=True 时表示整个 neck 的参数都会被冻结
+ ))
+```
diff --git a/third_party/mmyolo/docs/zh_cn/common_usage/mim_usage.md b/third_party/mmyolo/docs/zh_cn/common_usage/mim_usage.md
new file mode 100644
index 0000000000000000000000000000000000000000..aaf26920e15e0856c2f0fcb0a7fdd845766c44b7
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/common_usage/mim_usage.md
@@ -0,0 +1,89 @@
+# 使用 mim 跨库调用其他 OpenMMLab 仓库的脚本
+
+```{note}
+1. 目前暂不支持跨库调用所有脚本,正在修复中。等修复完成,本文档会添加更多的例子。
+2. 绘制 mAP 和 计算平均训练速度 两项功能在 MMDetection dev-3.x 分支中修复,目前需要通过源码安装该分支才能成功调用。
+```
+
+## 日志分析
+
+### 曲线图绘制
+
+MMDetection 中的 `tools/analysis_tools/analyze_logs.py` 可利用指定的训练 log 文件绘制 loss/mAP 曲线图, 第一次运行前请先运行 `pip install seaborn` 安装必要依赖。
+
+```shell
+mim run mmdet analyze_logs plot_curve \
+ ${LOG} \ # 日志文件路径
+ [--keys ${KEYS}] \ # 需要绘制的指标,默认为 'bbox_mAP'
+ [--start-epoch ${START_EPOCH}] # 起始的 epoch,默认为 1
+ [--eval-interval ${EVALUATION_INTERVAL}] \ # 评估间隔,默认为 1
+ [--title ${TITLE}] \ # 图片标题,无默认值
+ [--legend ${LEGEND}] \ # 图例,默认为 None
+ [--backend ${BACKEND}] \ # 绘制后端,默认为 None
+ [--style ${STYLE}] \ # 绘制风格,默认为 'dark'
+ [--out ${OUT_FILE}] # 输出文件路径
+# [] 代表可选参数,实际输入命令行时,不用输入 []
+```
+
+样例:
+
+- 绘制分类损失曲线图
+
+ ```shell
+ mim run mmdet analyze_logs plot_curve \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
+ --keys loss_cls \
+ --legend loss_cls
+ ```
+
+
+
+- 绘制分类损失、回归损失曲线图,保存图片为对应的 pdf 文件
+
+ ```shell
+ mim run mmdet analyze_logs plot_curve \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
+ --keys loss_cls loss_bbox \
+ --legend loss_cls loss_bbox \
+ --out losses_yolov5_s.pdf
+ ```
+
+
+
+- 在同一图像中比较两次运行结果的 bbox mAP
+
+ ```shell
+ mim run mmdet analyze_logs plot_curve \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
+ yolov5_n-v61_syncbn_fast_8xb16-300e_coco_20220919_090739.log.json \
+ --keys bbox_mAP \
+ --legend yolov5_s yolov5_n \
+ --eval-interval 10 # 注意评估间隔必须和训练时设置的一致,否则会报错
+ ```
+
+
+
+### 计算平均训练速度
+
+```shell
+mim run mmdet analyze_logs cal_train_time \
+ ${LOG} \ # 日志文件路径
+ [--include-outliers] # 计算时包含每个 epoch 的第一个数据
+```
+
+样例:
+
+```shell
+mim run mmdet analyze_logs cal_train_time \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json
+```
+
+输出以如下形式展示:
+
+```text
+-----Analyze train time of yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json-----
+slowest epoch 278, average time is 0.1705 s/iter
+fastest epoch 300, average time is 0.1510 s/iter
+time std over epochs is 0.0026
+average iter time: 0.1556 s/iter
+```
diff --git a/third_party/mmyolo/docs/zh_cn/common_usage/module_combination.md b/third_party/mmyolo/docs/zh_cn/common_usage/module_combination.md
new file mode 100644
index 0000000000000000000000000000000000000000..011836f68fb9b35434d7e823c382ce5357dd2f9f
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/common_usage/module_combination.md
@@ -0,0 +1,280 @@
+# 算法组合替换教程
+
+## Loss 组合替换教程
+
+OpenMMLab 2.0 体系中 MMYOLO、MMDetection、MMClassification 中的 loss 注册表都继承自 MMEngine 中的根注册表。 因此用户可以在 MMYOLO 中使用来自 MMDetection、MMClassification 中实现的 loss 而无需重新实现。
+
+### 替换 YOLOv5 Head 中的 loss_cls 函数
+
+1. 假设我们想使用 `LabelSmoothLoss` 作为 `loss_cls` 的损失函数。因为 `LabelSmoothLoss` 已经在 MMClassification 中实现了,所以可以直接在配置文件中进行替换。配置文件如下:
+
+```python
+# 请先使用命令: mim install "mmcls>=1.0.0rc2",安装 mmcls
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+model = dict(
+ bbox_head=dict(
+ loss_cls=dict(
+ _delete_=True,
+ _scope_='mmcls', # 临时替换 scope 为 mmcls
+ type='LabelSmoothLoss',
+ label_smooth_val=0.1,
+ mode='multi_label',
+ reduction='mean',
+ loss_weight=0.5)))
+```
+
+2. 假设我们想使用 `VarifocalLoss` 作为 `loss_cls` 的损失函数。因为 `VarifocalLoss` 在 MMDetection 已经实现好了,所以可以直接替换。配置文件如下:
+
+```python
+model = dict(
+ bbox_head=dict(
+ loss_cls=dict(
+ _delete_=True,
+ _scope_='mmdet',
+ type='VarifocalLoss',
+ loss_weight=1.0)))
+```
+
+3. 假设我们想使用 `FocalLoss` 作为 `loss_cls` 的损失函数。配置文件如下:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+model = dict(
+ bbox_head=dict(
+ loss_cls= dict(
+ _delete_=True,
+ _scope_='mmdet',
+ type='FocalLoss',
+ loss_weight=1.0)))
+```
+
+4. 假设我们想使用 `QualityFocalLoss` 作为 `loss_cls` 的损失函数。配置文件如下:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+model = dict(
+ bbox_head=dict(
+ loss_cls= dict(
+ _delete_=True,
+ _scope_='mmdet',
+ type='QualityFocalLoss',
+ loss_weight=1.0)))
+```
+
+### 替换 YOLOv5 Head 中的 loss_obj 函数
+
+`loss_obj` 的替换与 `loss_cls` 的替换类似,我们可以使用已经实现好的损失函数对 `loss_obj` 的损失函数进行替换
+
+1. 假设我们想使用 `VarifocalLoss` 作为 `loss_obj` 的损失函数
+
+```python
+model = dict(
+ bbox_head=dict(
+ loss_obj=dict(
+ _delete_=True,
+ _scope_='mmdet',
+ type='VarifocalLoss',
+ loss_weight=1.0)))
+```
+
+2. 假设我们想使用 `FocalLoss` 作为 `loss_obj` 的损失函数。
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+model = dict(
+ bbox_head=dict(
+ loss_cls= dict(
+ _delete_=True,
+ _scope_='mmdet',
+ type='FocalLoss',
+ loss_weight=1.0)))
+```
+
+3. 假设我们想使用 `QualityFocalLoss` 作为 `loss_obj` 的损失函数。
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+model = dict(
+ bbox_head=dict(
+ loss_cls= dict(
+ _delete_=True,
+ _scope_='mmdet',
+ type='QualityFocalLoss',
+ loss_weight=1.0)))
+```
+
+#### 注意
+
+1. 在本教程中损失函数的替换是运行不报错的,但无法保证性能一定会上升。
+2. 本次损失函数的替换都是以 YOLOv5 算法作为例子的,但是 MMYOLO 下的多个算法,如 YOLOv6,YOLOX 等算法都可以按照上述的例子进行替换。
+
+## Model 和 Loss 组合替换
+
+在 MMYOLO 中,model 即网络本身和 loss 是解耦的,用户可以简单的通过修改配置文件中 model 和 loss 来组合不同模块。下面给出两个具体例子。
+
+(1) YOLOv5 model 组合 YOLOv7 loss,配置文件如下:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+model = dict(
+ bbox_head=dict(
+ _delete_=True,
+ type='YOLOv7Head',
+ head_module=dict(
+ type='YOLOv5HeadModule',
+ num_classes=80,
+ in_channels=[256, 512, 1024],
+ widen_factor=0.5,
+ featmap_strides=[8, 16, 32],
+ num_base_priors=3)))
+```
+
+(2) RTMDet model 组合 YOLOv6 loss,配置文件如下:
+
+```python
+_base_ = './rtmdet_l_syncbn_8xb32-300e_coco.py'
+model = dict(
+ bbox_head=dict(
+ _delete_=True,
+ type='YOLOv6Head',
+ head_module=dict(
+ type='RTMDetSepBNHeadModule',
+ num_classes=80,
+ in_channels=256,
+ stacked_convs=2,
+ feat_channels=256,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='SiLU', inplace=True),
+ share_conv=True,
+ pred_kernel_size=1,
+ featmap_strides=[8, 16, 32]),
+ loss_bbox=dict(
+ type='IoULoss',
+ iou_mode='giou',
+ bbox_format='xyxy',
+ reduction='mean',
+ loss_weight=2.5,
+ return_iou=False)),
+ train_cfg=dict(
+ _delete_=True,
+ initial_epoch=4,
+ initial_assigner=dict(
+ type='BatchATSSAssigner',
+ num_classes=80,
+ topk=9,
+ iou_calculator=dict(type='mmdet.BboxOverlaps2D')),
+ assigner=dict(
+ type='BatchTaskAlignedAssigner',
+ num_classes=80,
+ topk=13,
+ alpha=1,
+ beta=6)
+ ))
+```
+
+## Backbone + Neck + HeadModule 的组合替换
+
+### 1. YOLOv5 Backbone 替换
+
+(1) 假设想将 `RTMDet backbone + yolov5 neck + yolov5 head` 作为 `YOLOv5` 的完整网络,则配置文件如下:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+widen_factor = 0.5
+deepen_factor = 0.33
+
+model = dict(
+ backbone=dict(
+ _delete_=True,
+ type='CSPNeXt',
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=deepen_factor,
+ widen_factor=widen_factor,
+ channel_attention=True,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='SiLU', inplace=True))
+)
+```
+
+(2) `YOLOv6EfficientRep backbone + yolov5 neck + yolov5 head` 作为 `YOLOv5` 的完整网络,则配置文件如下:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+model = dict(
+ backbone=dict(
+ type='YOLOv6EfficientRep',
+ norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
+ act_cfg=dict(type='ReLU', inplace=True))
+)
+```
+
+### 2. YOLOv5 Neck 替换
+
+(1) 假设想将 `yolov5 backbone + yolov6 neck + yolov5 head` 作为 `YOLOv5` 的完整网络,则配置文件如下:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+model = dict(
+ neck = dict(
+ type = 'YOLOv6RepPAFPN',
+ in_channels = [256, 512, 1024],
+ out_channels = [128, 256, 512], # 注意 YOLOv6RepPAFPN 的输出通道是[128, 256, 512]
+ num_csp_blocks = 12,
+ act_cfg = dict(type='ReLU', inplace = True),
+ ),
+ bbox_head = dict(
+ head_module = dict(
+ in_channels = [128, 256, 512])) # head 部分输入通道要做相应更改
+)
+```
+
+(2) 假设想将 `yolov5 backbone + yolov7 neck + yolov5 head` 作为 `YOLOv5` 的完整网络,则配置文件如下:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+deepen_factor = _base_.deepen_factor
+widen_factor = _base_.widen_factor
+
+model = dict(
+ neck = dict(
+ _delete_=True, # 将 _base_ 中关于 neck 的字段删除
+ type = 'YOLOv7PAFPN',
+ deepen_factor = deepen_factor,
+ widen_factor = widen_factor,
+ upsample_feats_cat_first = False,
+ in_channels = [256, 512, 1024],
+ out_channels = [128, 256, 512],
+ norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
+ act_cfg = dict(type='SiLU', inplace=True),
+ ),
+ bbox_head = dict(
+ head_module = dict(
+ in_channels = [256, 512, 1024])) # 注意使用 YOLOv7PAFPN 后 head 部分输入通道数是 neck 输出通道数的两倍
+)
+```
+
+### 3. YOLOv5 HeadModule 替换
+
+(1) 假设想将 `yolov5 backbone + yolov5 neck + yolo7 headmodule` 作为 `YOLOv5` 的完整网络,则配置文件如下:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+strides = [8, 16, 32]
+num_classes = 1 # 根据自己的数据集调整
+
+model = dict(
+ bbox_head=dict(
+ type='YOLOv7Head',
+ head_module=dict(
+ type='YOLOv7HeadModule',
+ num_classes=num_classes,
+ in_channels=[256, 512, 1024],
+ featmap_strides=strides,
+ num_base_priors=3)))
+```
diff --git a/third_party/mmyolo/docs/zh_cn/common_usage/ms_training_testing.md b/third_party/mmyolo/docs/zh_cn/common_usage/ms_training_testing.md
new file mode 100644
index 0000000000000000000000000000000000000000..1f271c54df6517bb515b4312ee7b921beeb7b6ba
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/common_usage/ms_training_testing.md
@@ -0,0 +1,41 @@
+# 多尺度训练和测试
+
+## 多尺度训练
+
+MMYOLO 中目前支持了主流的 YOLOv5、YOLOv6、YOLOv7、YOLOv8 和 RTMDet 等算法,其默认配置均为单尺度 640x640 训练。 在 MM 系列开源库中常用的多尺度训练有两种实现方式:
+
+1. 在 `train_pipeline` 中输出的每张图都是不定尺度的,然后在 [DataPreprocessor](https://github.com/open-mmlab/mmdetection/blob/3.x/mmdet/models/data_preprocessors/data_preprocessor.py) 中将不同尺度的输入图片
+ 通过 [stack_batch](https://github.com/open-mmlab/mmengine/blob/dbae83c52fa54d6dda08b6692b124217fe3b2135/mmengine/model/base_model/data_preprocessor.py#L260-L261) 函数填充到同一尺度,从而组成 batch 进行训练。MMDet 中大部分算法都是采用这个实现方式。
+2. 在 `train_pipeline` 中输出的每张图都是固定尺度的,然后直接在 `DataPreprocessor` 中进行 batch 张图片的上下采样,从而实现多尺度训练功能
+
+在 MMYOLO 中两种多尺度训练方式都是支持的。理论上第一种实现方式所生成的尺度会更加丰富,但是由于其对单张图进行独立增强,训练效率不如第二种方式。所以我们更推荐使用第二种方式。
+
+以 `configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py` 配置为例,其默认配置采用的是 640x640 固定尺度训练,假设想实现以 32 为倍数,且多尺度范围为 (480, 800) 的训练方式,则可以参考 YOLOX 做法通过 DataPreprocessor 中的 [YOLOXBatchSyncRandomResize](https://github.com/open-mmlab/mmyolo/blob/dc85144fab20a970341550794857a2f2f9b11564/mmyolo/models/data_preprocessors/data_preprocessor.py#L20) 实现。
+
+在 `configs/yolov5` 路径下新建配置,命名为 `configs/yolov5/yolov5_s-v61_fast_1xb12-ms-40e_cat.py`,其内容如下:
+
+```python
+_base_ = 'yolov5_s-v61_fast_1xb12-40e_cat.py'
+
+model = dict(
+ data_preprocessor=dict(
+ type='YOLOv5DetDataPreprocessor',
+ pad_size_divisor=32,
+ batch_augments=[
+ dict(
+ type='YOLOXBatchSyncRandomResize',
+ # 多尺度范围是 480~800
+ random_size_range=(480, 800),
+ # 输出尺度需要被 32 整除
+ size_divisor=32,
+ # 每隔 1 个迭代改变一次输出输出
+ interval=1)
+ ])
+)
+```
+
+上述配置就可以实现多尺度训练了。为了方便,我们已经在 `configs/yolov5/` 下已经提供了该配置。其余 YOLO 系列算法也是类似做法。
+
+## 多尺度测试
+
+MMYOLO 多尺度测试功能等同于测试时增强 TTA,目前已经支持,详情请查看 [测试时增强 TTA](./tta.md) 。
diff --git a/third_party/mmyolo/docs/zh_cn/common_usage/multi_necks.md b/third_party/mmyolo/docs/zh_cn/common_usage/multi_necks.md
new file mode 100644
index 0000000000000000000000000000000000000000..a4a17052729205884c6259b2087cd2a51044c7b0
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/common_usage/multi_necks.md
@@ -0,0 +1,40 @@
+# 应用多个 Neck
+
+如果你想堆叠多个 Neck,可以直接在配置文件中的 Neck 参数,MMYOLO 支持以 `List` 形式拼接多个 Neck 配置,你需要保证上一个 Neck 的输出通道与下一个 Neck
+的输入通道相匹配。如需要调整通道,可以插入 `mmdet.ChannelMapper` 模块用来对齐多个 Neck 之间的通道数量。具体配置如下:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+deepen_factor = _base_.deepen_factor
+widen_factor = _base_.widen_factor
+model = dict(
+ type='YOLODetector',
+ neck=[
+ dict(
+ type='YOLOv5PAFPN',
+ deepen_factor=deepen_factor,
+ widen_factor=widen_factor,
+ in_channels=[256, 512, 1024],
+ out_channels=[256, 512, 1024],
+ # 因为 out_channels 由 widen_factor 控制,YOLOv5PAFPN 的 out_channels = out_channels * widen_factor
+ num_csp_blocks=3,
+ norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
+ act_cfg=dict(type='SiLU', inplace=True)),
+ dict(
+ type='mmdet.ChannelMapper',
+ in_channels=[128, 256, 512],
+ out_channels=128,
+ ),
+ dict(
+ type='mmdet.DyHead',
+ in_channels=128,
+ out_channels=256,
+ num_blocks=2,
+ # disable zero_init_offset to follow official implementation
+ zero_init_offset=False)
+ ],
+ bbox_head=dict(head_module=dict(in_channels=[512, 512, 512]))
+ # 因为 out_channels 由 widen_factor 控制,YOLOv5HeadModuled 的 in_channels * widen_factor 才会等于最后一个 neck 的 out_channels
+)
+```
diff --git a/third_party/mmyolo/docs/zh_cn/common_usage/output_predictions.md b/third_party/mmyolo/docs/zh_cn/common_usage/output_predictions.md
new file mode 100644
index 0000000000000000000000000000000000000000..b11f856d674852582bbac3b50ac1d48148c366b8
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/common_usage/output_predictions.md
@@ -0,0 +1,40 @@
+# 输出模型预测结果
+
+如果想将预测结果保存为特定的文件,用于离线评估,目前 MMYOLO 支持 json 和 pkl 两种格式。
+
+```{note}
+json 文件仅保存 `image_id`、`bbox`、`score` 和 `category_id`; json 文件可以使用 json 库读取。
+pkl 保存内容比 json 文件更多,还会保存预测图片的文件名和尺寸等一系列信息; pkl 文件可以使用 pickle 库读取。
+```
+
+## 输出为 json 文件
+
+如果想将预测结果输出为 json 文件,则命令如下:
+
+```shell
+python tools/test.py ${CONFIG} ${CHECKPOINT} --json-prefix ${JSON_PREFIX}
+```
+
+`--json-prefix` 后的参数输入为文件名前缀(无需输入 `.json` 后缀),也可以包含路径。举一个具体例子:
+
+```shell
+python tools/test.py configs\yolov5\yolov5_s-v61_syncbn_8xb16-300e_coco.py yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth --json-prefix work_dirs/demo/json_demo
+```
+
+运行以上命令会在 `work_dirs/demo` 文件夹下,输出 `json_demo.bbox.json` 文件。
+
+## 输出为 pkl 文件
+
+如果想将预测结果输出为 pkl 文件,则命令如下:
+
+```shell
+python tools/test.py ${CONFIG} ${CHECKPOINT} --out ${OUTPUT_FILE} [--cfg-options ${OPTIONS [OPTIONS...]}]
+```
+
+`--out` 后的参数输入为完整文件名(**必须输入** `.pkl` 或 `.pickle` 后缀),也可以包含路径。举一个具体例子:
+
+```shell
+python tools/test.py configs\yolov5\yolov5_s-v61_syncbn_8xb16-300e_coco.py yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth --out work_dirs/demo/pkl_demo.pkl
+```
+
+运行以上命令会在 `work_dirs/demo` 文件夹下,输出 `pkl_demo.pkl` 文件。
diff --git a/third_party/mmyolo/docs/zh_cn/common_usage/plugins.md b/third_party/mmyolo/docs/zh_cn/common_usage/plugins.md
new file mode 100644
index 0000000000000000000000000000000000000000..337111f9975393bdc4804ebaf64860e40dfa9fc5
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/common_usage/plugins.md
@@ -0,0 +1,34 @@
+# 给主干网络增加插件
+
+MMYOLO 支持在 Backbone 的不同 Stage 后增加如 `none_local`、`dropblock` 等插件,用户可以直接通过修改 config 文件中 `backbone` 的 `plugins`参数来实现对插件的管理。例如为 `YOLOv5` 增加`GeneralizedAttention` 插件,其配置文件如下:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+model = dict(
+ backbone=dict(
+ plugins=[
+ dict(
+ cfg=dict(
+ type='GeneralizedAttention',
+ spatial_range=-1,
+ num_heads=8,
+ attention_type='0011',
+ kv_stride=2),
+ stages=(False, False, True, True))
+ ]))
+```
+
+`cfg` 参数表示插件的具体配置, `stages` 参数表示是否在 backbone 对应的 stage 后面增加插件,长度需要和 backbone 的 stage 数量相同。
+
+目前 `MMYOLO` 支持了如下插件:
+
+
+
+```shell
+python tools/analysis_tools/dataset_analysis.py ${CONFIG} \
+ [--type ${TYPE}] \
+ [--class-name ${CLASS_NAME}] \
+ [--area-rule ${AREA_RULE}] \
+ [--func ${FUNC}] \
+ [--out-dir ${OUT_DIR}]
+```
+
+E,g:
+
+1.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, By default,the data loading type is `train_dataset`, the area rule is `[0,32,96,1e5]`, generate a result graph containing all functions and save the graph to the current running directory `./dataset_analysis` folder:
+
+```shell
+python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py
+```
+
+2.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, change the data loading type from the default `train_dataset` to `val_dataset` through the `--val-dataset` setting:
+
+```shell
+python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
+ --val-dataset
+```
+
+3.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, change the display of all generated classes to specific classes. Take the display of `person` classes as an example:
+
+```shell
+python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
+ --class-name person
+```
+
+4.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, redefine the area rule through `--area-rule` . Take `30 70 125` as an example, the area rule becomes `[0,30,70,125,1e5]`:
+
+```shell
+python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
+ --area-rule 30 70 125
+```
+
+5.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, change the display of four function renderings to only display `Function 1` as an example:
+
+```shell
+python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
+ --func show_bbox_num
+```
+
+6.Use `config` file `configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py` analyze the dataset, modify the picture saving address to `work_dirs/dataset_analysis`:
+
+```shell
+python tools/analysis_tools/dataset_analysis.py configs/yolov5/voc/yolov5_s-v61_fast_1xb64-50e_voc.py \
+ --out-dir work_dirs/dataset_analysis
+```
diff --git a/third_party/mmyolo/docs/en/useful_tools/dataset_converters.md b/third_party/mmyolo/docs/en/useful_tools/dataset_converters.md
new file mode 100644
index 0000000000000000000000000000000000000000..72ad968c14a0c4a8445b8fa57772903b823faa10
--- /dev/null
+++ b/third_party/mmyolo/docs/en/useful_tools/dataset_converters.md
@@ -0,0 +1,55 @@
+# Dataset Conversion
+
+The folder `tools/data_converters` currently contains `ballon2coco.py`, `yolo2coco.py`, and `labelme2coco.py` - three dataset conversion tools.
+
+- `ballon2coco.py` converts the `balloon` dataset (this small dataset is for starters only) to COCO format.
+
+```shell
+python tools/dataset_converters/balloon2coco.py
+```
+
+- `yolo2coco.py` converts a dataset from `yolo-style` **.txt** format to COCO format, please use it as follows:
+
+```shell
+python tools/dataset_converters/yolo2coco.py /path/to/the/root/dir/of/your_dataset
+```
+
+Instructions:
+
+1. `image_dir` is the root directory of the yolo-style dataset you need to pass to the script, which should contain `images`, `labels`, and `classes.txt`. `classes.txt` is the class declaration corresponding to the current dataset. One class a line. The structure of the root directory should be formatted as this example shows:
+
+```bash
+.
+└── $ROOT_PATH
+ ├── classes.txt
+ ├── labels
+ │ ├── a.txt
+ │ ├── b.txt
+ │ └── ...
+ ├── images
+ │ ├── a.jpg
+ │ ├── b.png
+ │ └── ...
+ └── ...
+```
+
+2. The script will automatically check if `train.txt`, `val.txt`, and `test.txt` have already existed under `image_dir`. If these files are located, the script will organize the dataset accordingly. Otherwise, the script will convert the dataset into one file. The image paths in these files must be **ABSOLUTE** paths.
+3. By default, the script will create a folder called `annotations` in the `image_dir` directory which stores the converted JSON file. If `train.txt`, `val.txt`, and `test.txt` are not found, the output file is `result.json`. Otherwise, the corresponding JSON file will be generated, named as `train.json`, `val.json`, and `test.json`. The `annotations` folder may look similar to this:
+
+```bash
+.
+└── $ROOT_PATH
+ ├── annotations
+ │ ├── result.json
+ │ └── ...
+ ├── classes.txt
+ ├── labels
+ │ ├── a.txt
+ │ ├── b.txt
+ │ └── ...
+ ├── images
+ │ ├── a.jpg
+ │ ├── b.png
+ │ └── ...
+ └── ...
+```
diff --git a/third_party/mmyolo/docs/en/useful_tools/download_dataset.md b/third_party/mmyolo/docs/en/useful_tools/download_dataset.md
new file mode 100644
index 0000000000000000000000000000000000000000..8a3e57ec6d14036813ccc7c9e586b99f939126d1
--- /dev/null
+++ b/third_party/mmyolo/docs/en/useful_tools/download_dataset.md
@@ -0,0 +1,11 @@
+# Download Dataset
+
+`tools/misc/download_dataset.py` supports downloading datasets such as `COCO`, `VOC`, `LVIS` and `Balloon`.
+
+```shell
+python tools/misc/download_dataset.py --dataset-name coco2017
+python tools/misc/download_dataset.py --dataset-name voc2007
+python tools/misc/download_dataset.py --dataset-name voc2012
+python tools/misc/download_dataset.py --dataset-name lvis
+python tools/misc/download_dataset.py --dataset-name balloon [--save-dir ${SAVE_DIR}] [--unzip]
+```
diff --git a/third_party/mmyolo/docs/en/useful_tools/extract_subcoco.md b/third_party/mmyolo/docs/en/useful_tools/extract_subcoco.md
new file mode 100644
index 0000000000000000000000000000000000000000..b2c7e06cf36c9b56d4aa91ec128601ef39674abc
--- /dev/null
+++ b/third_party/mmyolo/docs/en/useful_tools/extract_subcoco.md
@@ -0,0 +1,60 @@
+# Extracts a subset of COCO
+
+The training dataset of the COCO2017 dataset includes 118K images, and the validation set includes 5K images, which is a relatively large dataset. Loading JSON in debugging or quick verification scenarios will consume more resources and bring slower startup speed.
+
+The `extract_subcoco.py` script provides the ability to extract a specified number/classes/area-size of images. The user can use the `--num-img`, `--classes`, `--area-size` parameter to get a COCO subset of the specified condition of images.
+
+For example, extract images use scripts as follows:
+
+```shell
+python tools/misc/extract_subcoco.py \
+ ${ROOT} \
+ ${OUT_DIR} \
+ --num-img 20 \
+ --classes cat dog person \
+ --area-size small
+```
+
+It gone be extract 20 images, and only includes annotations which belongs to cat(or dog/person) and bbox area size is small, after filter by class and area size, the empty annotation images won't be chosen, guarantee the images be extracted definitely has annotation info.
+
+Currently, only support COCO2017. In the future will support user-defined datasets of standard coco JSON format.
+
+The root path folder format is as follows:
+
+```text
+├── root
+│ ├── annotations
+│ ├── train2017
+│ ├── val2017
+│ ├── test2017
+```
+
+1. Extract 10 training images and 10 validation images using only 5K validation sets.
+
+```shell
+python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --num-img 10
+```
+
+2. Extract 20 training images using the training set and 20 validation images using the validation set.
+
+```shell
+python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --num-img 20 --use-training-set
+```
+
+3. Set the global seed to 1. The default is no setting.
+
+```shell
+python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --num-img 20 --use-training-set --seed 1
+```
+
+4. Extract images by specify classes
+
+```shell
+python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --classes cat dog person
+```
+
+5. Extract images by specify anchor size
+
+```shell
+python tools/misc/extract_subcoco.py ${ROOT} ${OUT_DIR} --area-size small
+```
diff --git a/third_party/mmyolo/docs/en/useful_tools/log_analysis.md b/third_party/mmyolo/docs/en/useful_tools/log_analysis.md
new file mode 100644
index 0000000000000000000000000000000000000000..c45170aaaadb97855c51e67819df52ce3868a141
--- /dev/null
+++ b/third_party/mmyolo/docs/en/useful_tools/log_analysis.md
@@ -0,0 +1,82 @@
+# Log Analysis
+
+## Curve plotting
+
+`tools/analysis_tools/analyze_logs.py` in MMDetection plots loss/mAP curves given a training log file. Run `pip install seaborn` first to install the dependency.
+
+```shell
+mim run mmdet analyze_logs plot_curve \
+ ${LOG} \ # path of train log in json format
+ [--keys ${KEYS}] \ # the metric that you want to plot, default to 'bbox_mAP'
+ [--start-epoch ${START_EPOCH}] # the epoch that you want to start, default to 1
+ [--eval-interval ${EVALUATION_INTERVAL}] \ # the evaluation interval when training, default to 1
+ [--title ${TITLE}] \ # title of figure
+ [--legend ${LEGEND}] \ # legend of each plot, default to None
+ [--backend ${BACKEND}] \ # backend of plt, default to None
+ [--style ${STYLE}] \ # style of plt, default to 'dark'
+ [--out ${OUT_FILE}] # the path of output file
+# [] stands for optional parameters, when actually entering the command line, you do not need to enter []
+```
+
+Examples:
+
+- Plot the classification loss of some run.
+
+ ```shell
+ mim run mmdet analyze_logs plot_curve \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
+ --keys loss_cls \
+ --legend loss_cls
+ ```
+
+
+
+- Plot the classification and regression loss of some run, and save the figure to a pdf.
+
+ ```shell
+ mim run mmdet analyze_logs plot_curve \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
+ --keys loss_cls loss_bbox \
+ --legend loss_cls loss_bbox \
+ --out losses_yolov5_s.pdf
+ ```
+
+
+
+- Compare the bbox mAP of two runs in the same figure.
+
+ ```shell
+ mim run mmdet analyze_logs plot_curve \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
+ yolov5_n-v61_syncbn_fast_8xb16-300e_coco_20220919_090739.log.json \
+ --keys bbox_mAP \
+ --legend yolov5_s yolov5_n \
+ --eval-interval 10 # Note that the evaluation interval must be the same as during training. Otherwise, it will raise an error.
+ ```
+
+
+
+## Compute the average training speed
+
+```shell
+mim run mmdet analyze_logs cal_train_time \
+ ${LOG} \ # path of train log in json format
+ [--include-outliers] # include the first value of every epoch when computing the average time
+```
+
+Examples:
+
+```shell
+mim run mmdet analyze_logs cal_train_time \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json
+```
+
+The output is expected to be like the following.
+
+```text
+-----Analyze train time of yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json-----
+slowest epoch 278, average time is 0.1705 s/iter
+fastest epoch 300, average time is 0.1510 s/iter
+time std over epochs is 0.0026
+average iter time: 0.1556 s/iter
+```
diff --git a/third_party/mmyolo/docs/en/useful_tools/model_converters.md b/third_party/mmyolo/docs/en/useful_tools/model_converters.md
new file mode 100644
index 0000000000000000000000000000000000000000..09fb52df13c2861f691672d7fe1d27e69af5d0e3
--- /dev/null
+++ b/third_party/mmyolo/docs/en/useful_tools/model_converters.md
@@ -0,0 +1,54 @@
+# Convert Model
+
+The six scripts under the `tools/model_converters` directory can help users convert the keys in the official pre-trained model of YOLO to the format of MMYOLO, and use MMYOLO to fine-tune the model.
+
+## YOLOv5
+
+Take conversion `yolov5s.pt` as an example:
+
+1. Clone the official YOLOv5 code to the local (currently the maximum supported version is `v6.1`):
+
+```shell
+git clone -b v6.1 https://github.com/ultralytics/yolov5.git
+cd yolov5
+```
+
+2. Download official weight file:
+
+```shell
+wget https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5s.pt
+```
+
+3. Copy file `tools/model_converters/yolov5_to_mmyolo.py` to the path of YOLOv5 official code clone:
+
+```shell
+cp ${MMDET_YOLO_PATH}/tools/model_converters/yolov5_to_mmyolo.py yolov5_to_mmyolo.py
+```
+
+4. Conversion
+
+```shell
+python yolov5_to_mmyolo.py --src ${WEIGHT_FILE_PATH} --dst mmyolov5.pt
+```
+
+The converted `mmyolov5.pt` can be used by MMYOLO. The official weight conversion of YOLOv6 is also used in the same way.
+
+## YOLOX
+
+The conversion of YOLOX model **does not need** to download the official YOLOX code, just download the weight.
+
+Take conversion `yolox_s.pth` as an example:
+
+1. Download official weight file:
+
+```shell
+wget https://github.com/Megvii-BaseDetection/YOLOX/releases/download/0.1.1rc0/yolox_s.pth
+```
+
+2. Conversion
+
+```shell
+python tools/model_converters/yolox_to_mmyolo.py --src yolox_s.pth --dst mmyolox.pt
+```
+
+The converted `mmyolox.pt` can be used by MMYOLO.
diff --git a/third_party/mmyolo/docs/en/useful_tools/optimize_anchors.md b/third_party/mmyolo/docs/en/useful_tools/optimize_anchors.md
new file mode 100644
index 0000000000000000000000000000000000000000..460bc6e2fa3f4bec41b39901f1e66c442802911c
--- /dev/null
+++ b/third_party/mmyolo/docs/en/useful_tools/optimize_anchors.md
@@ -0,0 +1,38 @@
+# Optimize anchors size
+
+Script `tools/analysis_tools/optimize_anchors.py` supports three methods to optimize YOLO anchors including `k-means`
+anchor cluster, `Differential Evolution` and `v5-k-means`.
+
+## k-means
+
+In k-means method, the distance criteria is based IoU, python shell as follow:
+
+```shell
+python tools/analysis_tools/optimize_anchors.py ${CONFIG} \
+ --algorithm k-means \
+ --input-shape ${INPUT_SHAPE [WIDTH HEIGHT]} \
+ --out-dir ${OUT_DIR}
+```
+
+## Differential Evolution
+
+In differential_evolution method, based differential evolution algorithm, use `avg_iou_cost` as minimum target function, python shell as follow:
+
+```shell
+python tools/analysis_tools/optimize_anchors.py ${CONFIG} \
+ --algorithm DE \
+ --input-shape ${INPUT_SHAPE [WIDTH HEIGHT]} \
+ --out-dir ${OUT_DIR}
+```
+
+## v5-k-means
+
+In v5-k-means method, clustering standard as same with YOLOv5 which use shape-match, python shell as follow:
+
+```shell
+python tools/analysis_tools/optimize_anchors.py ${CONFIG} \
+ --algorithm v5-k-means \
+ --input-shape ${INPUT_SHAPE [WIDTH HEIGHT]} \
+ --prior_match_thr ${PRIOR_MATCH_THR} \
+ --out-dir ${OUT_DIR}
+```
diff --git a/third_party/mmyolo/docs/en/useful_tools/print_config.md b/third_party/mmyolo/docs/en/useful_tools/print_config.md
new file mode 100644
index 0000000000000000000000000000000000000000..2a6ee79f36c749491a1b5095792b708755fca279
--- /dev/null
+++ b/third_party/mmyolo/docs/en/useful_tools/print_config.md
@@ -0,0 +1,20 @@
+# Print the whole config
+
+`print_config.py` in MMDetection prints the whole config verbatim, expanding all its imports. The command is as following.
+
+```shell
+mim run mmdet print_config \
+ ${CONFIG} \ # path of the config file
+ [--save-path] \ # save path of whole config, suffixed with .py, .json or .yml
+ [--cfg-options ${OPTIONS [OPTIONS...]}] # override some settings in the used config
+```
+
+Examples:
+
+```shell
+mim run mmdet print_config \
+ configs/yolov5/yolov5_s-v61_syncbn_fast_1xb4-300e_balloon.py \
+ --save-path ./work_dirs/yolov5_s-v61_syncbn_fast_1xb4-300e_balloon.py
+```
+
+Running the above command will save the `yolov5_s-v61_syncbn_fast_1xb4-300e_balloon.py` config file with the inheritance relationship expanded to \`\`yolov5_s-v61_syncbn_fast_1xb4-300e_balloon_whole.py`in the`./work_dirs\` folder.
diff --git a/third_party/mmyolo/docs/en/useful_tools/vis_scheduler.md b/third_party/mmyolo/docs/en/useful_tools/vis_scheduler.md
new file mode 100644
index 0000000000000000000000000000000000000000..f1526342c9ee80236f7c146231430818811e2a82
--- /dev/null
+++ b/third_party/mmyolo/docs/en/useful_tools/vis_scheduler.md
@@ -0,0 +1,44 @@
+# Hyper-parameter Scheduler Visualization
+
+`tools/analysis_tools/vis_scheduler` aims to help the user to check the hyper-parameter scheduler of the optimizer(without training), which support the "learning rate", "momentum", and "weight_decay".
+
+```bash
+python tools/analysis_tools/vis_scheduler.py \
+ ${CONFIG_FILE} \
+ [-p, --parameter ${PARAMETER_NAME}] \
+ [-d, --dataset-size ${DATASET_SIZE}] \
+ [-n, --ngpus ${NUM_GPUs}] \
+ [-o, --out-dir ${OUT_DIR}] \
+ [--title ${TITLE}] \
+ [--style ${STYLE}] \
+ [--window-size ${WINDOW_SIZE}] \
+ [--cfg-options]
+```
+
+**Description of all arguments**:
+
+- `config`: The path of a model config file.
+- **`-p, --parameter`**: The param to visualize its change curve, choose from "lr", "momentum" or "wd". Default to use "lr".
+- **`-d, --dataset-size`**: The size of the datasets. If set,`DATASETS.build` will be skipped and `${DATASET_SIZE}` will be used as the size. Default to use the function `DATASETS.build`.
+- **`-n, --ngpus`**: The number of GPUs used in training, default to be 1.
+- **`-o, --out-dir`**: The output path of the curve plot, default not to output.
+- `--title`: Title of figure. If not set, default to be config file name.
+- `--style`: Style of plt. If not set, default to be `whitegrid`.
+- `--window-size`: The shape of the display window. If not specified, it will be set to `12*7`. If used, it must be in the format `'W*H'`.
+- `--cfg-options`: Modifications to the configuration file, refer to [Learn about Configs](../tutorials/config.md).
+
+```{note}
+Loading annotations maybe consume much time, you can directly specify the size of the dataset with `-d, dataset-size` to save time.
+```
+
+You can use the following command to plot the step learning rate schedule used in the config `configs/rtmdet/rtmdet_s_syncbn_fast_8xb32-300e_coco.py`:
+
+```shell
+python tools/analysis_tools/vis_scheduler.py \
+ configs/rtmdet/rtmdet_s_syncbn_fast_8xb32-300e_coco.py \
+ --dataset-size 118287 \
+ --ngpus 8 \
+ --out-dir ./output
+```
+
+
diff --git a/third_party/mmyolo/docs/zh_cn/Makefile b/third_party/mmyolo/docs/zh_cn/Makefile
new file mode 100644
index 0000000000000000000000000000000000000000..d4bb2cbb9eddb1bb1b4f366623044af8e4830919
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/Makefile
@@ -0,0 +1,20 @@
+# Minimal makefile for Sphinx documentation
+#
+
+# You can set these variables from the command line, and also
+# from the environment for the first two.
+SPHINXOPTS ?=
+SPHINXBUILD ?= sphinx-build
+SOURCEDIR = .
+BUILDDIR = _build
+
+# Put it first so that "make" without argument is like "make help".
+help:
+ @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
+
+.PHONY: help Makefile
+
+# Catch-all target: route all unknown targets to Sphinx using the new
+# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
+%: Makefile
+ @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
diff --git a/third_party/mmyolo/docs/zh_cn/_static/css/readthedocs.css b/third_party/mmyolo/docs/zh_cn/_static/css/readthedocs.css
new file mode 100644
index 0000000000000000000000000000000000000000..353aa9e285a5639b0f34ecb3b16115cff1ad25ed
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/_static/css/readthedocs.css
@@ -0,0 +1,6 @@
+.header-logo {
+ background-image: url("../image/mmyolo-logo.png");
+ background-size: 115px 40px;
+ height: 40px;
+ width: 115px;
+}
diff --git a/third_party/mmyolo/docs/zh_cn/_static/image/mmyolo-logo.png b/third_party/mmyolo/docs/zh_cn/_static/image/mmyolo-logo.png
new file mode 100644
index 0000000000000000000000000000000000000000..41318aec92d86749d327bc5f9b9c689632ffc735
Binary files /dev/null and b/third_party/mmyolo/docs/zh_cn/_static/image/mmyolo-logo.png differ
diff --git a/third_party/mmyolo/docs/zh_cn/advanced_guides/cross-library_application.md b/third_party/mmyolo/docs/zh_cn/advanced_guides/cross-library_application.md
new file mode 100644
index 0000000000000000000000000000000000000000..d95f68cd22cdfc6218c24c7c02936f7fb04fd247
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/advanced_guides/cross-library_application.md
@@ -0,0 +1 @@
+# MMYOLO 跨库应用解析
diff --git a/third_party/mmyolo/docs/zh_cn/api.rst b/third_party/mmyolo/docs/zh_cn/api.rst
new file mode 100644
index 0000000000000000000000000000000000000000..39223a34f849b4b66dafea7fe9c9fdd34d06ecfe
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/api.rst
@@ -0,0 +1,80 @@
+mmyolo.datasets
+--------------------
+
+datasets
+^^^^^^^^^^
+.. automodule:: mmyolo.datasets
+ :members:
+
+transforms
+^^^^^^^^^^^^
+.. automodule:: mmyolo.datasets.transforms
+ :members:
+
+mmyolo.engine
+--------------
+
+hooks
+^^^^^^^^^^
+.. automodule:: mmyolo.engine.hooks
+ :members:
+
+optimizers
+^^^^^^^^^^
+.. automodule:: mmyolo.engine.optimizers
+ :members:
+
+mmyolo.models
+--------------
+
+backbones
+^^^^^^^^^^
+.. automodule:: mmyolo.models.backbones
+ :members:
+
+data_preprocessor
+^^^^^^^^^^^^^^^^^^^
+.. automodule:: mmyolo.models.data_preprocessor
+ :members:
+
+dense_heads
+^^^^^^^^^^^^
+.. automodule:: mmyolo.models.dense_heads
+ :members:
+
+detectors
+^^^^^^^^^^
+.. automodule:: mmyolo.models.detectors
+ :members:
+
+layers
+^^^^^^^^^^
+.. automodule:: mmyolo.models.layers
+ :members:
+
+losses
+^^^^^^^^^^
+.. automodule:: mmyolo.models.losses
+ :members:
+
+necks
+^^^^^^^^^^^^
+.. automodule:: mmyolo.models.necks
+ :members:
+
+
+task_modules
+^^^^^^^^^^^^^^^
+.. automodule:: mmyolo.models.task_modules
+ :members:
+
+utils
+^^^^^^^^^^
+.. automodule:: mmyolo.models.utils
+ :members:
+
+
+mmyolo.utils
+--------------
+.. automodule:: mmyolo.utils
+ :members:
diff --git a/third_party/mmyolo/docs/zh_cn/common_usage/amp_training.md b/third_party/mmyolo/docs/zh_cn/common_usage/amp_training.md
new file mode 100644
index 0000000000000000000000000000000000000000..c7803abfea4487734b05de80705689d30c796e1a
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/common_usage/amp_training.md
@@ -0,0 +1,13 @@
+# 自动混合精度(AMP)训练
+
+如果要开启自动混合精度(AMP)训练,在训练命令最后加上 `--amp` 即可, 命令如下:
+
+```shell
+python tools/train.py python ./tools/train.py ${CONFIG} --amp
+```
+
+具体例子如下:
+
+```shell
+python tools/train.py configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py --amp
+```
diff --git a/third_party/mmyolo/docs/zh_cn/common_usage/freeze_layers.md b/third_party/mmyolo/docs/zh_cn/common_usage/freeze_layers.md
new file mode 100644
index 0000000000000000000000000000000000000000..ca0613903b65a6b2ba6986b3dea2830ee4465a2b
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/common_usage/freeze_layers.md
@@ -0,0 +1,28 @@
+# 冻结指定网络层权重
+
+## 冻结 backbone 权重
+
+在 MMYOLO 中我们可以通过设置 `frozen_stages` 参数去冻结主干网络的部分 `stage`, 使这些 `stage` 的参数不参与模型的更新。
+需要注意的是:`frozen_stages = i` 表示的意思是指从最开始的 `stage` 开始到第 `i` 层 `stage` 的所有参数都会被冻结。下面是 `YOLOv5` 的例子,其他算法也是同样的逻辑:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+model = dict(
+ backbone=dict(
+ frozen_stages=1 # 表示第一层 stage 以及它之前的所有 stage 中的参数都会被冻结
+ ))
+```
+
+## 冻结 neck 权重
+
+MMYOLO 中也可以通过参数 `freeze_all` 去冻结整个 `neck` 的参数。下面是 `YOLOv5` 的例子,其他算法也是同样的逻辑:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+model = dict(
+ neck=dict(
+ freeze_all=True # freeze_all=True 时表示整个 neck 的参数都会被冻结
+ ))
+```
diff --git a/third_party/mmyolo/docs/zh_cn/common_usage/mim_usage.md b/third_party/mmyolo/docs/zh_cn/common_usage/mim_usage.md
new file mode 100644
index 0000000000000000000000000000000000000000..aaf26920e15e0856c2f0fcb0a7fdd845766c44b7
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/common_usage/mim_usage.md
@@ -0,0 +1,89 @@
+# 使用 mim 跨库调用其他 OpenMMLab 仓库的脚本
+
+```{note}
+1. 目前暂不支持跨库调用所有脚本,正在修复中。等修复完成,本文档会添加更多的例子。
+2. 绘制 mAP 和 计算平均训练速度 两项功能在 MMDetection dev-3.x 分支中修复,目前需要通过源码安装该分支才能成功调用。
+```
+
+## 日志分析
+
+### 曲线图绘制
+
+MMDetection 中的 `tools/analysis_tools/analyze_logs.py` 可利用指定的训练 log 文件绘制 loss/mAP 曲线图, 第一次运行前请先运行 `pip install seaborn` 安装必要依赖。
+
+```shell
+mim run mmdet analyze_logs plot_curve \
+ ${LOG} \ # 日志文件路径
+ [--keys ${KEYS}] \ # 需要绘制的指标,默认为 'bbox_mAP'
+ [--start-epoch ${START_EPOCH}] # 起始的 epoch,默认为 1
+ [--eval-interval ${EVALUATION_INTERVAL}] \ # 评估间隔,默认为 1
+ [--title ${TITLE}] \ # 图片标题,无默认值
+ [--legend ${LEGEND}] \ # 图例,默认为 None
+ [--backend ${BACKEND}] \ # 绘制后端,默认为 None
+ [--style ${STYLE}] \ # 绘制风格,默认为 'dark'
+ [--out ${OUT_FILE}] # 输出文件路径
+# [] 代表可选参数,实际输入命令行时,不用输入 []
+```
+
+样例:
+
+- 绘制分类损失曲线图
+
+ ```shell
+ mim run mmdet analyze_logs plot_curve \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
+ --keys loss_cls \
+ --legend loss_cls
+ ```
+
+
+
+- 绘制分类损失、回归损失曲线图,保存图片为对应的 pdf 文件
+
+ ```shell
+ mim run mmdet analyze_logs plot_curve \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
+ --keys loss_cls loss_bbox \
+ --legend loss_cls loss_bbox \
+ --out losses_yolov5_s.pdf
+ ```
+
+
+
+- 在同一图像中比较两次运行结果的 bbox mAP
+
+ ```shell
+ mim run mmdet analyze_logs plot_curve \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json \
+ yolov5_n-v61_syncbn_fast_8xb16-300e_coco_20220919_090739.log.json \
+ --keys bbox_mAP \
+ --legend yolov5_s yolov5_n \
+ --eval-interval 10 # 注意评估间隔必须和训练时设置的一致,否则会报错
+ ```
+
+
+
+### 计算平均训练速度
+
+```shell
+mim run mmdet analyze_logs cal_train_time \
+ ${LOG} \ # 日志文件路径
+ [--include-outliers] # 计算时包含每个 epoch 的第一个数据
+```
+
+样例:
+
+```shell
+mim run mmdet analyze_logs cal_train_time \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json
+```
+
+输出以如下形式展示:
+
+```text
+-----Analyze train time of yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700.log.json-----
+slowest epoch 278, average time is 0.1705 s/iter
+fastest epoch 300, average time is 0.1510 s/iter
+time std over epochs is 0.0026
+average iter time: 0.1556 s/iter
+```
diff --git a/third_party/mmyolo/docs/zh_cn/common_usage/module_combination.md b/third_party/mmyolo/docs/zh_cn/common_usage/module_combination.md
new file mode 100644
index 0000000000000000000000000000000000000000..011836f68fb9b35434d7e823c382ce5357dd2f9f
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/common_usage/module_combination.md
@@ -0,0 +1,280 @@
+# 算法组合替换教程
+
+## Loss 组合替换教程
+
+OpenMMLab 2.0 体系中 MMYOLO、MMDetection、MMClassification 中的 loss 注册表都继承自 MMEngine 中的根注册表。 因此用户可以在 MMYOLO 中使用来自 MMDetection、MMClassification 中实现的 loss 而无需重新实现。
+
+### 替换 YOLOv5 Head 中的 loss_cls 函数
+
+1. 假设我们想使用 `LabelSmoothLoss` 作为 `loss_cls` 的损失函数。因为 `LabelSmoothLoss` 已经在 MMClassification 中实现了,所以可以直接在配置文件中进行替换。配置文件如下:
+
+```python
+# 请先使用命令: mim install "mmcls>=1.0.0rc2",安装 mmcls
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+model = dict(
+ bbox_head=dict(
+ loss_cls=dict(
+ _delete_=True,
+ _scope_='mmcls', # 临时替换 scope 为 mmcls
+ type='LabelSmoothLoss',
+ label_smooth_val=0.1,
+ mode='multi_label',
+ reduction='mean',
+ loss_weight=0.5)))
+```
+
+2. 假设我们想使用 `VarifocalLoss` 作为 `loss_cls` 的损失函数。因为 `VarifocalLoss` 在 MMDetection 已经实现好了,所以可以直接替换。配置文件如下:
+
+```python
+model = dict(
+ bbox_head=dict(
+ loss_cls=dict(
+ _delete_=True,
+ _scope_='mmdet',
+ type='VarifocalLoss',
+ loss_weight=1.0)))
+```
+
+3. 假设我们想使用 `FocalLoss` 作为 `loss_cls` 的损失函数。配置文件如下:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+model = dict(
+ bbox_head=dict(
+ loss_cls= dict(
+ _delete_=True,
+ _scope_='mmdet',
+ type='FocalLoss',
+ loss_weight=1.0)))
+```
+
+4. 假设我们想使用 `QualityFocalLoss` 作为 `loss_cls` 的损失函数。配置文件如下:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+model = dict(
+ bbox_head=dict(
+ loss_cls= dict(
+ _delete_=True,
+ _scope_='mmdet',
+ type='QualityFocalLoss',
+ loss_weight=1.0)))
+```
+
+### 替换 YOLOv5 Head 中的 loss_obj 函数
+
+`loss_obj` 的替换与 `loss_cls` 的替换类似,我们可以使用已经实现好的损失函数对 `loss_obj` 的损失函数进行替换
+
+1. 假设我们想使用 `VarifocalLoss` 作为 `loss_obj` 的损失函数
+
+```python
+model = dict(
+ bbox_head=dict(
+ loss_obj=dict(
+ _delete_=True,
+ _scope_='mmdet',
+ type='VarifocalLoss',
+ loss_weight=1.0)))
+```
+
+2. 假设我们想使用 `FocalLoss` 作为 `loss_obj` 的损失函数。
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+model = dict(
+ bbox_head=dict(
+ loss_cls= dict(
+ _delete_=True,
+ _scope_='mmdet',
+ type='FocalLoss',
+ loss_weight=1.0)))
+```
+
+3. 假设我们想使用 `QualityFocalLoss` 作为 `loss_obj` 的损失函数。
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+model = dict(
+ bbox_head=dict(
+ loss_cls= dict(
+ _delete_=True,
+ _scope_='mmdet',
+ type='QualityFocalLoss',
+ loss_weight=1.0)))
+```
+
+#### 注意
+
+1. 在本教程中损失函数的替换是运行不报错的,但无法保证性能一定会上升。
+2. 本次损失函数的替换都是以 YOLOv5 算法作为例子的,但是 MMYOLO 下的多个算法,如 YOLOv6,YOLOX 等算法都可以按照上述的例子进行替换。
+
+## Model 和 Loss 组合替换
+
+在 MMYOLO 中,model 即网络本身和 loss 是解耦的,用户可以简单的通过修改配置文件中 model 和 loss 来组合不同模块。下面给出两个具体例子。
+
+(1) YOLOv5 model 组合 YOLOv7 loss,配置文件如下:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+model = dict(
+ bbox_head=dict(
+ _delete_=True,
+ type='YOLOv7Head',
+ head_module=dict(
+ type='YOLOv5HeadModule',
+ num_classes=80,
+ in_channels=[256, 512, 1024],
+ widen_factor=0.5,
+ featmap_strides=[8, 16, 32],
+ num_base_priors=3)))
+```
+
+(2) RTMDet model 组合 YOLOv6 loss,配置文件如下:
+
+```python
+_base_ = './rtmdet_l_syncbn_8xb32-300e_coco.py'
+model = dict(
+ bbox_head=dict(
+ _delete_=True,
+ type='YOLOv6Head',
+ head_module=dict(
+ type='RTMDetSepBNHeadModule',
+ num_classes=80,
+ in_channels=256,
+ stacked_convs=2,
+ feat_channels=256,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='SiLU', inplace=True),
+ share_conv=True,
+ pred_kernel_size=1,
+ featmap_strides=[8, 16, 32]),
+ loss_bbox=dict(
+ type='IoULoss',
+ iou_mode='giou',
+ bbox_format='xyxy',
+ reduction='mean',
+ loss_weight=2.5,
+ return_iou=False)),
+ train_cfg=dict(
+ _delete_=True,
+ initial_epoch=4,
+ initial_assigner=dict(
+ type='BatchATSSAssigner',
+ num_classes=80,
+ topk=9,
+ iou_calculator=dict(type='mmdet.BboxOverlaps2D')),
+ assigner=dict(
+ type='BatchTaskAlignedAssigner',
+ num_classes=80,
+ topk=13,
+ alpha=1,
+ beta=6)
+ ))
+```
+
+## Backbone + Neck + HeadModule 的组合替换
+
+### 1. YOLOv5 Backbone 替换
+
+(1) 假设想将 `RTMDet backbone + yolov5 neck + yolov5 head` 作为 `YOLOv5` 的完整网络,则配置文件如下:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+widen_factor = 0.5
+deepen_factor = 0.33
+
+model = dict(
+ backbone=dict(
+ _delete_=True,
+ type='CSPNeXt',
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=deepen_factor,
+ widen_factor=widen_factor,
+ channel_attention=True,
+ norm_cfg=dict(type='BN'),
+ act_cfg=dict(type='SiLU', inplace=True))
+)
+```
+
+(2) `YOLOv6EfficientRep backbone + yolov5 neck + yolov5 head` 作为 `YOLOv5` 的完整网络,则配置文件如下:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+model = dict(
+ backbone=dict(
+ type='YOLOv6EfficientRep',
+ norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
+ act_cfg=dict(type='ReLU', inplace=True))
+)
+```
+
+### 2. YOLOv5 Neck 替换
+
+(1) 假设想将 `yolov5 backbone + yolov6 neck + yolov5 head` 作为 `YOLOv5` 的完整网络,则配置文件如下:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+model = dict(
+ neck = dict(
+ type = 'YOLOv6RepPAFPN',
+ in_channels = [256, 512, 1024],
+ out_channels = [128, 256, 512], # 注意 YOLOv6RepPAFPN 的输出通道是[128, 256, 512]
+ num_csp_blocks = 12,
+ act_cfg = dict(type='ReLU', inplace = True),
+ ),
+ bbox_head = dict(
+ head_module = dict(
+ in_channels = [128, 256, 512])) # head 部分输入通道要做相应更改
+)
+```
+
+(2) 假设想将 `yolov5 backbone + yolov7 neck + yolov5 head` 作为 `YOLOv5` 的完整网络,则配置文件如下:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+deepen_factor = _base_.deepen_factor
+widen_factor = _base_.widen_factor
+
+model = dict(
+ neck = dict(
+ _delete_=True, # 将 _base_ 中关于 neck 的字段删除
+ type = 'YOLOv7PAFPN',
+ deepen_factor = deepen_factor,
+ widen_factor = widen_factor,
+ upsample_feats_cat_first = False,
+ in_channels = [256, 512, 1024],
+ out_channels = [128, 256, 512],
+ norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
+ act_cfg = dict(type='SiLU', inplace=True),
+ ),
+ bbox_head = dict(
+ head_module = dict(
+ in_channels = [256, 512, 1024])) # 注意使用 YOLOv7PAFPN 后 head 部分输入通道数是 neck 输出通道数的两倍
+)
+```
+
+### 3. YOLOv5 HeadModule 替换
+
+(1) 假设想将 `yolov5 backbone + yolov5 neck + yolo7 headmodule` 作为 `YOLOv5` 的完整网络,则配置文件如下:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+strides = [8, 16, 32]
+num_classes = 1 # 根据自己的数据集调整
+
+model = dict(
+ bbox_head=dict(
+ type='YOLOv7Head',
+ head_module=dict(
+ type='YOLOv7HeadModule',
+ num_classes=num_classes,
+ in_channels=[256, 512, 1024],
+ featmap_strides=strides,
+ num_base_priors=3)))
+```
diff --git a/third_party/mmyolo/docs/zh_cn/common_usage/ms_training_testing.md b/third_party/mmyolo/docs/zh_cn/common_usage/ms_training_testing.md
new file mode 100644
index 0000000000000000000000000000000000000000..1f271c54df6517bb515b4312ee7b921beeb7b6ba
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/common_usage/ms_training_testing.md
@@ -0,0 +1,41 @@
+# 多尺度训练和测试
+
+## 多尺度训练
+
+MMYOLO 中目前支持了主流的 YOLOv5、YOLOv6、YOLOv7、YOLOv8 和 RTMDet 等算法,其默认配置均为单尺度 640x640 训练。 在 MM 系列开源库中常用的多尺度训练有两种实现方式:
+
+1. 在 `train_pipeline` 中输出的每张图都是不定尺度的,然后在 [DataPreprocessor](https://github.com/open-mmlab/mmdetection/blob/3.x/mmdet/models/data_preprocessors/data_preprocessor.py) 中将不同尺度的输入图片
+ 通过 [stack_batch](https://github.com/open-mmlab/mmengine/blob/dbae83c52fa54d6dda08b6692b124217fe3b2135/mmengine/model/base_model/data_preprocessor.py#L260-L261) 函数填充到同一尺度,从而组成 batch 进行训练。MMDet 中大部分算法都是采用这个实现方式。
+2. 在 `train_pipeline` 中输出的每张图都是固定尺度的,然后直接在 `DataPreprocessor` 中进行 batch 张图片的上下采样,从而实现多尺度训练功能
+
+在 MMYOLO 中两种多尺度训练方式都是支持的。理论上第一种实现方式所生成的尺度会更加丰富,但是由于其对单张图进行独立增强,训练效率不如第二种方式。所以我们更推荐使用第二种方式。
+
+以 `configs/yolov5/yolov5_s-v61_fast_1xb12-40e_cat.py` 配置为例,其默认配置采用的是 640x640 固定尺度训练,假设想实现以 32 为倍数,且多尺度范围为 (480, 800) 的训练方式,则可以参考 YOLOX 做法通过 DataPreprocessor 中的 [YOLOXBatchSyncRandomResize](https://github.com/open-mmlab/mmyolo/blob/dc85144fab20a970341550794857a2f2f9b11564/mmyolo/models/data_preprocessors/data_preprocessor.py#L20) 实现。
+
+在 `configs/yolov5` 路径下新建配置,命名为 `configs/yolov5/yolov5_s-v61_fast_1xb12-ms-40e_cat.py`,其内容如下:
+
+```python
+_base_ = 'yolov5_s-v61_fast_1xb12-40e_cat.py'
+
+model = dict(
+ data_preprocessor=dict(
+ type='YOLOv5DetDataPreprocessor',
+ pad_size_divisor=32,
+ batch_augments=[
+ dict(
+ type='YOLOXBatchSyncRandomResize',
+ # 多尺度范围是 480~800
+ random_size_range=(480, 800),
+ # 输出尺度需要被 32 整除
+ size_divisor=32,
+ # 每隔 1 个迭代改变一次输出输出
+ interval=1)
+ ])
+)
+```
+
+上述配置就可以实现多尺度训练了。为了方便,我们已经在 `configs/yolov5/` 下已经提供了该配置。其余 YOLO 系列算法也是类似做法。
+
+## 多尺度测试
+
+MMYOLO 多尺度测试功能等同于测试时增强 TTA,目前已经支持,详情请查看 [测试时增强 TTA](./tta.md) 。
diff --git a/third_party/mmyolo/docs/zh_cn/common_usage/multi_necks.md b/third_party/mmyolo/docs/zh_cn/common_usage/multi_necks.md
new file mode 100644
index 0000000000000000000000000000000000000000..a4a17052729205884c6259b2087cd2a51044c7b0
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/common_usage/multi_necks.md
@@ -0,0 +1,40 @@
+# 应用多个 Neck
+
+如果你想堆叠多个 Neck,可以直接在配置文件中的 Neck 参数,MMYOLO 支持以 `List` 形式拼接多个 Neck 配置,你需要保证上一个 Neck 的输出通道与下一个 Neck
+的输入通道相匹配。如需要调整通道,可以插入 `mmdet.ChannelMapper` 模块用来对齐多个 Neck 之间的通道数量。具体配置如下:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+deepen_factor = _base_.deepen_factor
+widen_factor = _base_.widen_factor
+model = dict(
+ type='YOLODetector',
+ neck=[
+ dict(
+ type='YOLOv5PAFPN',
+ deepen_factor=deepen_factor,
+ widen_factor=widen_factor,
+ in_channels=[256, 512, 1024],
+ out_channels=[256, 512, 1024],
+ # 因为 out_channels 由 widen_factor 控制,YOLOv5PAFPN 的 out_channels = out_channels * widen_factor
+ num_csp_blocks=3,
+ norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
+ act_cfg=dict(type='SiLU', inplace=True)),
+ dict(
+ type='mmdet.ChannelMapper',
+ in_channels=[128, 256, 512],
+ out_channels=128,
+ ),
+ dict(
+ type='mmdet.DyHead',
+ in_channels=128,
+ out_channels=256,
+ num_blocks=2,
+ # disable zero_init_offset to follow official implementation
+ zero_init_offset=False)
+ ],
+ bbox_head=dict(head_module=dict(in_channels=[512, 512, 512]))
+ # 因为 out_channels 由 widen_factor 控制,YOLOv5HeadModuled 的 in_channels * widen_factor 才会等于最后一个 neck 的 out_channels
+)
+```
diff --git a/third_party/mmyolo/docs/zh_cn/common_usage/output_predictions.md b/third_party/mmyolo/docs/zh_cn/common_usage/output_predictions.md
new file mode 100644
index 0000000000000000000000000000000000000000..b11f856d674852582bbac3b50ac1d48148c366b8
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/common_usage/output_predictions.md
@@ -0,0 +1,40 @@
+# 输出模型预测结果
+
+如果想将预测结果保存为特定的文件,用于离线评估,目前 MMYOLO 支持 json 和 pkl 两种格式。
+
+```{note}
+json 文件仅保存 `image_id`、`bbox`、`score` 和 `category_id`; json 文件可以使用 json 库读取。
+pkl 保存内容比 json 文件更多,还会保存预测图片的文件名和尺寸等一系列信息; pkl 文件可以使用 pickle 库读取。
+```
+
+## 输出为 json 文件
+
+如果想将预测结果输出为 json 文件,则命令如下:
+
+```shell
+python tools/test.py ${CONFIG} ${CHECKPOINT} --json-prefix ${JSON_PREFIX}
+```
+
+`--json-prefix` 后的参数输入为文件名前缀(无需输入 `.json` 后缀),也可以包含路径。举一个具体例子:
+
+```shell
+python tools/test.py configs\yolov5\yolov5_s-v61_syncbn_8xb16-300e_coco.py yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth --json-prefix work_dirs/demo/json_demo
+```
+
+运行以上命令会在 `work_dirs/demo` 文件夹下,输出 `json_demo.bbox.json` 文件。
+
+## 输出为 pkl 文件
+
+如果想将预测结果输出为 pkl 文件,则命令如下:
+
+```shell
+python tools/test.py ${CONFIG} ${CHECKPOINT} --out ${OUTPUT_FILE} [--cfg-options ${OPTIONS [OPTIONS...]}]
+```
+
+`--out` 后的参数输入为完整文件名(**必须输入** `.pkl` 或 `.pickle` 后缀),也可以包含路径。举一个具体例子:
+
+```shell
+python tools/test.py configs\yolov5\yolov5_s-v61_syncbn_8xb16-300e_coco.py yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth --out work_dirs/demo/pkl_demo.pkl
+```
+
+运行以上命令会在 `work_dirs/demo` 文件夹下,输出 `pkl_demo.pkl` 文件。
diff --git a/third_party/mmyolo/docs/zh_cn/common_usage/plugins.md b/third_party/mmyolo/docs/zh_cn/common_usage/plugins.md
new file mode 100644
index 0000000000000000000000000000000000000000..337111f9975393bdc4804ebaf64860e40dfa9fc5
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/common_usage/plugins.md
@@ -0,0 +1,34 @@
+# 给主干网络增加插件
+
+MMYOLO 支持在 Backbone 的不同 Stage 后增加如 `none_local`、`dropblock` 等插件,用户可以直接通过修改 config 文件中 `backbone` 的 `plugins`参数来实现对插件的管理。例如为 `YOLOv5` 增加`GeneralizedAttention` 插件,其配置文件如下:
+
+```python
+_base_ = './yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+model = dict(
+ backbone=dict(
+ plugins=[
+ dict(
+ cfg=dict(
+ type='GeneralizedAttention',
+ spatial_range=-1,
+ num_heads=8,
+ attention_type='0011',
+ kv_stride=2),
+ stages=(False, False, True, True))
+ ]))
+```
+
+`cfg` 参数表示插件的具体配置, `stages` 参数表示是否在 backbone 对应的 stage 后面增加插件,长度需要和 backbone 的 stage 数量相同。
+
+目前 `MMYOLO` 支持了如下插件:
+
+
+支持的插件
+
+1. [CBAM](https://github.com/open-mmlab/mmyolo/blob/dev/mmyolo/models/plugins/cbam.py#L86)
+2. [GeneralizedAttention](https://github.com/open-mmlab/mmcv/blob/2.x/mmcv/cnn/bricks/generalized_attention.py#L13)
+3. [NonLocal2d](https://github.com/open-mmlab/mmcv/blob/2.x/mmcv/cnn/bricks/non_local.py#L250)
+4. [ContextBlock](https://github.com/open-mmlab/mmcv/blob/2.x/mmcv/cnn/bricks/context_block.py#L18)
+
+
diff --git a/third_party/mmyolo/docs/zh_cn/common_usage/registries_info.md b/third_party/mmyolo/docs/zh_cn/common_usage/registries_info.md
new file mode 100644
index 0000000000000000000000000000000000000000..4a9d184cd56b69262bf3831f0d175ab1ca52eb13
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/common_usage/registries_info.md
@@ -0,0 +1,788 @@
+# MM 系列开源库注册表
+
+(注意:本文档是通过 .dev_scripts/print_registers.py 脚本自动生成)
+
+## MMdetection (3.0.0rc6)
+
+MMdetection Module Components
+
+
+
+
+
+ | visualizer |
+ optimizer constructor |
+ loop |
+ parameter scheduler |
+ data sampler |
+
+
+
+
+ |
+ - LearningRateDecayOptimizerConstructor
|
+ |
+ - QuadraticWarmupParamScheduler
- QuadraticWarmupLR
- QuadraticWarmupMomentum
|
+ - AspectRatioBatchSampler
- ClassAwareSampler
- MultiSourceSampler
- GroupMultiSourceSampler
|
+
+
+
+
+
+
+
+
+ | metric |
+ hook |
+ dataset |
+ task util (part 1) |
+ task util (part 2) |
+
+
+
+
+ - CityScapesMetric
- CocoMetric
- CocoOccludedSeparatedMetric
- CocoPanopticMetric
- CrowdHumanMetric
- DumpDetResults
- DumpProposals
- LVISMetric
- OpenImagesMetric
- VOCMetric
|
+ - CheckInvalidLossHook
- MeanTeacherHook
- MemoryProfilerHook
- NumClassCheckHook
- PipelineSwitchHook
- SetEpochInfoHook
- SyncNormHook
- DetVisualizationHook
- YOLOXModeSwitchHook
- FastStopTrainingHook
|
+ - BaseDetDataset
- CocoDataset
- CityscapesDataset
- CocoPanopticDataset
- CrowdHumanDataset
- MultiImageMixDataset
- DeepFashionDataset
- LVISV05Dataset
- LVISDataset
- LVISV1Dataset
- Objects365V1Dataset
- Objects365V2Dataset
- OpenImagesDataset
- OpenImagesChallengeDataset
- XMLDataset
- VOCDataset
- WIDERFaceDataset
|
+ - MaxIoUAssigner
- ApproxMaxIoUAssigner
- ATSSAssigner
- CenterRegionAssigner
- DynamicSoftLabelAssigner
- GridAssigner
- HungarianAssigner
- BboxOverlaps2D
- BBoxL1Cost
- IoUCost
- ClassificationCost
- FocalLossCost
- DiceCost
- CrossEntropyLossCost
- MultiInstanceAssigner
|
+ - PointAssigner
- AnchorGenerator
- SSDAnchorGenerator
- LegacyAnchorGenerator
- LegacySSDAnchorGenerator
- YOLOAnchorGenerator
- PointGenerator
- MlvlPointGenerator
- RegionAssigner
- SimOTAAssigner
- TaskAlignedAssigner
- UniformAssigner
- BucketingBBoxCoder
- DeltaXYWHBBoxCoder
|
+
+
+
+
+
+
+
+
+ | task util (part 3) |
+ transform (part 1) |
+ transform (part 2) |
+ transform (part 3) |
+
+
+
+
+ - DistancePointBBoxCoder
- LegacyDeltaXYWHBBoxCoder
- PseudoBBoxCoder
- TBLRBBoxCoder
- YOLOBBoxCoder
- CombinedSampler
- RandomSampler
- InstanceBalancedPosSampler
- IoUBalancedNegSampler
- MaskPseudoSampler
- MultiInsRandomSampler
- OHEMSampler
- PseudoSampler
- ScoreHLRSampler
|
+ - AutoAugment
- RandAugment
- ColorTransform
- Color
- Brightness
- Contrast
- Sharpness
- Solarize
- SolarizeAdd
- Posterize
- Equalize
- AutoContrast
- Invert
- PackDetInputs
- ToTensor
- ImageToTensor
- Transpose
- WrapFieldsToLists
- GeomTransform
- ShearX
|
+ - ShearY
- Rotate
- TranslateX
- TranslateY
- InstaBoost
- LoadImageFromNDArray
- LoadMultiChannelImageFromFiles
- LoadAnnotations
- LoadPanopticAnnotations
- LoadProposals
- FilterAnnotations
- LoadEmptyAnnotations
- InferencerLoader
- Resize
- FixShapeResize
- RandomFlip
- RandomShift
- Pad
- RandomCrop
|
+ - SegRescale
- PhotoMetricDistortion
- Expand
- MinIoURandomCrop
- Corrupt
- Albu
- RandomCenterCropPad
- CutOut
- Mosaic
- MixUp
- RandomAffine
- YOLOXHSVRandomAug
- CopyPaste
- RandomErasing
- CachedMosaic
- CachedMixUp
- MultiBranch
- RandomOrder
- ProposalBroadcaster
|
+
+
+
+
+
+
+
+
+ | model (part 1) |
+ model (part 2) |
+ model (part 3) |
+ model (part 4) |
+
+
+
+
+ - SiLU
- DropBlock
- ExpMomentumEMA
- SinePositionalEncoding
- LearnedPositionalEncoding
- DynamicConv
- MSDeformAttnPixelDecoder
- Linear
- NormedLinear
- NormedConv2d
- PixelDecoder
- TransformerEncoderPixelDecoder
- CSPDarknet
- CSPNeXt
- Darknet
- ResNet
- ResNetV1d
- DetectoRS_ResNet
- DetectoRS_ResNeXt
- EfficientNet
|
+ - HourglassNet
- HRNet
- MobileNetV2
- PyramidVisionTransformer
- PyramidVisionTransformerV2
- ResNeXt
- RegNet
- Res2Net
- ResNeSt
- BFP
- ChannelMapper
- CSPNeXtPAFPN
- CTResNetNeck
- DilatedEncoder
- DyHead
- FPG
- FPN
- FPN_CARAFE
- HRFPN
- NASFPN
|
+ - NASFCOS_FPN
- PAFPN
- RFP
- SSDNeck
- SSH
- YOLOV3Neck
- YOLOXPAFPN
- SSDVGG
- SwinTransformer
- TridentResNet
- DetDataPreprocessor
- BatchSyncRandomResize
- BatchFixedSizePad
- MultiBranchDataPreprocessor
- BatchResize
- BoxInstDataPreprocessor
- AnchorFreeHead
- AnchorHead
- ATSSHead
- FCOSHead
|
+ - AutoAssignHead
- CondInstBboxHead
- CondInstMaskHead
- BoxInstBboxHead
- BoxInstMaskHead
- RPNHead
- StageCascadeRPNHead
- CascadeRPNHead
- CenterNetHead
- CenterNetUpdateHead
- CornerHead
- CentripetalHead
- DETRHead
- ConditionalDETRHead
- DABDETRHead
- DDODHead
- DeformableDETRHead
- DINOHead
- EmbeddingRPNHead
- FoveaHead
|
+
+
+
+
+
+
+
+
+ | model (part 5) |
+ model (part 6) |
+ model (part 7) |
+ model (part 8) |
+
+
+
+
+ - RetinaHead
- FreeAnchorRetinaHead
- AssociativeEmbeddingLoss
- BalancedL1Loss
- CrossEntropyLoss
- DiceLoss
- FocalLoss
- GaussianFocalLoss
- QualityFocalLoss
- DistributionFocalLoss
- GHMC
- GHMR
- IoULoss
- BoundedIoULoss
- GIoULoss
- DIoULoss
- CIoULoss
- EIoULoss
- KnowledgeDistillationKLDivLoss
- MSELoss
|
+ - SeesawLoss
- SmoothL1Loss
- L1Loss
- VarifocalLoss
- FSAFHead
- GuidedAnchorHead
- GARetinaHead
- GARPNHead
- GFLHead
- PAAHead
- LADHead
- LDHead
- MaskFormerHead
- Mask2FormerHead
- NASFCOSHead
- PISARetinaHead
- SSDHead
- PISASSDHead
- RepPointsHead
- RetinaSepBNHead
|
+ - RTMDetHead
- RTMDetSepBNHead
- RTMDetInsHead
- RTMDetInsSepBNHead
- SABLRetinaHead
- SOLOHead
- DecoupledSOLOHead
- DecoupledSOLOLightHead
- SOLOV2Head
- TOODHead
- VFNetHead
- YOLACTHead
- YOLACTProtonet
- YOLOV3Head
- YOLOFHead
- YOLOXHead
- SingleStageDetector
- ATSS
- AutoAssign
|
+ - DetectionTransformer
- SingleStageInstanceSegmentor
- BoxInst
- TwoStageDetector
- CascadeRCNN
- CenterNet
- CondInst
- DETR
- ConditionalDETR
- CornerNet
- CrowdDet
- Detectron2Wrapper
- DABDETR
- DDOD
- DeformableDETR
- DINO
- FastRCNN
- FasterRCNN
- FCOS
|
+
+
+
+
+
+
+
+
+ | model (part 9) |
+ model (part 10) |
+ model (part 11) |
+ model (part 12) |
+
+
+
+
+ - FOVEA
- FSAF
- GFL
- GridRCNN
- HybridTaskCascade
- KnowledgeDistillationSingleStageDetector
- LAD
- MaskFormer
- Mask2Former
- MaskRCNN
- MaskScoringRCNN
- NASFCOS
- PAA
- TwoStagePanopticSegmentor
- PanopticFPN
- PointRend
- SparseRCNN
- QueryInst
- RepPointsDetector
|
+ - RetinaNet
- RPN
- RTMDet
- SCNet
- SemiBaseDetector
- SoftTeacher
- SOLO
- SOLOv2
- TOOD
- TridentFasterRCNN
- VFNet
- YOLACT
- YOLOV3
- YOLOF
- YOLOX
- BBoxHead
- ConvFCBBoxHead
- Shared2FCBBoxHead
- Shared4Conv1FCBBoxHead
|
+ - DIIHead
- DoubleConvFCBBoxHead
- MultiInstanceBBoxHead
- SABLHead
- SCNetBBoxHead
- CascadeRoIHead
- StandardRoIHead
- DoubleHeadRoIHead
- DynamicRoIHead
- GridRoIHead
- HybridTaskCascadeRoIHead
- FCNMaskHead
- CoarseMaskHead
- DynamicMaskHead
- FeatureRelayHead
- FusedSemanticHead
- GlobalContextHead
- GridHead
- HTCMaskHead
|
+ - MaskPointHead
- MaskIoUHead
- SCNetMaskHead
- SCNetSemanticHead
- MaskScoringRoIHead
- MultiInstanceRoIHead
- PISARoIHead
- PointRendRoIHead
- GenericRoIExtractor
- SingleRoIExtractor
- SCNetRoIHead
- ResLayer
- SparseRoIHead
- TridentRoIHead
- BaseSemanticHead
- PanopticFPNHead
- BasePanopticFusionHead
- HeuristicFusionHead
- MaskFormerFusionHead
|
+
+
+
+
MMdetection Tools
+
+
+
+
+
+ | tools/dataset_converters |
+ tools/deployment |
+ tools |
+ tools/misc |
+
+
+
+
+ - pascal_voc.py
- images2coco.py
- cityscapes.py
|
+ - mmdet2torchserve.py
- test_torchserver.py
- mmdet_handler.py
|
+ - dist_test.sh
- slurm_test.sh
- test.py
- dist_train.sh
- train.py
- slurm_train.sh
|
+ - download_dataset.py
- get_image_metas.py
- gen_coco_panoptic_test_info.py
- split_coco.py
- get_crowdhuman_id_hw.py
- print_config.py
|
+
+
+
+
+
+
+
+
+ | tools/model_converters |
+ tools/analysis_tools |
+ .dev_scripts (part 1) |
+ .dev_scripts (part 2) |
+
+
+
+
+ - upgrade_model_version.py
- upgrade_ssd_version.py
- detectron2_to_mmdet.py
- selfsup2mmdet.py
- detectron2pytorch.py
- regnet2mmdet.py
- publish_model.py
|
+ - benchmark.py
- eval_metric.py
- robustness_eval.py
- confusion_matrix.py
- optimize_anchors.py
- browse_dataset.py
- test_robustness.py
- coco_error_analysis.py
- coco_occluded_separated_recall.py
- analyze_results.py
- analyze_logs.py
- get_flops.py
|
+ - convert_test_benchmark_script.py
- gather_test_benchmark_metric.py
- benchmark_valid_flops.py
- benchmark_train.py
- test_benchmark.sh
- download_checkpoints.py
- benchmark_test_image.py
- covignore.cfg
- benchmark_full_models.txt
- test_init_backbone.py
- batch_train_list.txt
- diff_coverage_test.sh
|
+ - batch_test_list.py
- linter.sh
- gather_train_benchmark_metric.py
- train_benchmark.sh
- benchmark_inference_fps.py
- benchmark_options.py
- check_links.py
- benchmark_test.py
- benchmark_train_models.txt
- convert_train_benchmark_script.py
- gather_models.py
- benchmark_filter.py
|
+
+
+
+
MMclassification Module Components
+
+
+
+
+
+ | visualizer |
+ data sampler |
+ optimizer |
+ batch augment |
+ metric |
+
+
+
+
+ |
+ |
+ |
+ |
+ - Accuracy
- SingleLabelMetric
- MultiLabelMetric
- AveragePrecision
- MultiTasksMetric
- VOCMultiLabelMetric
- VOCAveragePrecision
|
+
+
+
+
+
+
+
+
+ | hook |
+ dataset |
+ transform (part 1) |
+ transform (part 2) |
+
+
+
+
+ - ClassNumCheckHook
- EMAHook
- SetAdaptiveMarginsHook
- PreciseBNHook
- PrepareProtoBeforeValLoopHook
- SwitchRecipeHook
- VisualizationHook
|
+ - BaseDataset
- CIFAR10
- CIFAR100
- CUB
- CustomDataset
- KFoldDataset
- ImageNet
- ImageNet21k
- MNIST
- FashionMNIST
- MultiLabelDataset
- MultiTaskDataset
- VOC
|
+ - AutoAugment
- RandAugment
- Shear
- Translate
- Rotate
- AutoContrast
- Invert
- Equalize
- Solarize
- SolarizeAdd
- Posterize
- Contrast
- ColorTransform
- Brightness
- Sharpness
- Cutout
|
+ - PackClsInputs
- PackMultiTaskInputs
- Transpose
- ToPIL
- ToNumpy
- Collect
- RandomCrop
- RandomResizedCrop
- EfficientNetRandomCrop
- RandomErasing
- EfficientNetCenterCrop
- ResizeEdge
- ColorJitter
- Lighting
- Albumentations
- Albu
|
+
+
+
+
+
+
+
+
+ | model (part 1) |
+ model (part 2) |
+ model (part 3) |
+ model (part 4) |
+
+
+
+
+ - AlexNet
- ShiftWindowMSA
- ClsDataPreprocessor
- VisionTransformer
- BEiT
- Conformer
- ConvMixer
- ResNet
- ResNetV1c
- ResNetV1d
- ResNeXt
- CSPDarkNet
- CSPResNet
- CSPResNeXt
- DaViT
- DistilledVisionTransformer
- DeiT3
- DenseNet
- PoolFormer
- EfficientFormer
|
+ - EfficientNet
- EfficientNetV2
- HorNet
- HRNet
- InceptionV3
- LeNet5
- MixMIMTransformer
- MlpMixer
- MobileNetV2
- MobileNetV3
- MobileOne
- MViT
- RegNet
- RepLKNet
- RepMLPNet
- RepVGG
- Res2Net
- ResNeSt
- ResNet_CIFAR
- RevVisionTransformer
|
+ - SEResNet
- SEResNeXt
- ShuffleNetV1
- ShuffleNetV2
- SwinTransformer
- SwinTransformerV2
- T2T_ViT
- TIMMBackbone
- TNT
- PCPVT
- SVT
- VAN
- VGG
- HuggingFaceClassifier
- ImageClassifier
- TimmClassifier
- ClsHead
- ConformerHead
- VisionTransformerClsHead
- DeiTClsHead
|
+ - EfficientFormerClsHead
- LinearClsHead
- AsymmetricLoss
- CrossEntropyLoss
- FocalLoss
- LabelSmoothLoss
- SeesawLoss
- ArcFaceClsHead
- MultiLabelClsHead
- CSRAClsHead
- MultiLabelLinearClsHead
- MultiTaskHead
- StackedLinearClsHead
- GlobalAveragePooling
- GeneralizedMeanPooling
- HRFuseScales
- LinearReduction
- ImageToImageRetriever
- AverageClsScoreTTA
|
+
+
+
+
MMclassification Tools
+
+
+
+
+
+ | tools/misc |
+ tools/visualizations |
+ tools/torchserve |
+ .dev_scripts |
+ tools/analysis_tools |
+
+
+
+
+ - verify_dataset.py
- print_config.py
|
+ - browse_dataset.py
- vis_scheduler.py
- vis_cam.py
|
+ - mmcls_handler.py
- mmcls2torchserve.py
- test_torchserver.py
|
+ - compare_init.py
- ckpt_tree.py
- generate_readme.py
|
+ - eval_metric.py
- analyze_results.py
- analyze_logs.py
- get_flops.py
|
+
+
+
+
+
+
+
+
+ | .dev_scripts/benchmark_regression |
+ tools |
+ tools/model_converters (part 1) |
+ tools/model_converters (part 2) |
+
+
+
+
+ - bench_train.yml
- 4-benchmark_speed.py
- 3-benchmark_train.py
- 1-benchmark_valid.py
- 2-benchmark_test.py
|
+ - dist_test.sh
- slurm_test.sh
- test.py
- dist_train.sh
- train.py
- slurm_train.sh
- kfold-cross-valid.py
|
+ - efficientnet_to_mmcls.py
- repvgg_to_mmcls.py
- clip_to_mmcls.py
- reparameterize_model.py
- shufflenetv2_to_mmcls.py
- van2mmcls.py
- hornet2mmcls.py
- mixmimx_to_mmcls.py
- edgenext_to_mmcls.py
- torchvision_to_mmcls.py
- twins2mmcls.py
- revvit_to_mmcls.py
|
+ - convnext_to_mmcls.py
- replknet_to_mmcls.py
- efficientnetv2_to_mmcls.py
- mobilenetv2_to_mmcls.py
- mlpmixer_to_mmcls.py
- davit_to_mmcls.py
- vgg_to_mmcls.py
- deit3_to_mmcls.py
- eva_to_mmcls.py
- publish_model.py
- tinyvit_to_mmcls.py
|
+
+
+
+
MMsegmentation Module Components
+
+
+
+
+
+ | task util |
+ visualizer |
+ hook |
+ optimizer wrapper constructor |
+ metric |
+
+
+
+
+ |
+ |
+ |
+ - LearningRateDecayOptimizerConstructor
- LayerDecayOptimizerConstructor
|
+ |
+
+
+
+
+
+
+
+
+ | dataset (part 1) |
+ dataset (part 2) |
+ transform (part 1) |
+ transform (part 2) |
+
+
+
+
+ - BaseSegDataset
- ADE20KDataset
- ChaseDB1Dataset
- CityscapesDataset
- COCOStuffDataset
- DarkZurichDataset
- MultiImageMixDataset
- DecathlonDataset
- DRIVEDataset
- HRFDataset
- iSAIDDataset
|
+ - ISPRSDataset
- LIPDataset
- LoveDADataset
- NightDrivingDataset
- PascalContextDataset
- PascalContextDataset59
- PotsdamDataset
- STAREDataset
- SynapseDataset
- PascalVOCDataset
|
+ - PackSegInputs
- LoadAnnotations
- LoadImageFromNDArray
- LoadBiomedicalImageFromFile
- LoadBiomedicalAnnotation
- LoadBiomedicalData
- ResizeToMultiple
- Rerange
- CLAHE
- RandomCrop
- RandomRotate
- RGB2Gray
- AdjustGamma
|
+ - SegRescale
- PhotoMetricDistortion
- RandomCutOut
- RandomRotFlip
- RandomMosaic
- GenerateEdge
- ResizeShortestEdge
- BioMedical3DRandomCrop
- BioMedicalGaussianNoise
- BioMedicalGaussianBlur
- BioMedicalRandomGamma
- BioMedical3DPad
- BioMedical3DRandomFlip
|
+
+
+
+
+
+
+
+
+ | model (part 1) |
+ model (part 2) |
+ model (part 3) |
+ model (part 4) |
+
+
+
+
+ - VisionTransformer
- BEiT
- BiSeNetV1
- BiSeNetV2
- CGNet
- ERFNet
- CrossEntropyLoss
- DiceLoss
- FocalLoss
- LovaszLoss
- TverskyLoss
- ANNHead
- APCHead
- ASPPHead
- FCNHead
- CCHead
- DAHead
- DMHead
- DNLHead
|
+ - DPTHead
- EMAHead
- EncHead
- FPNHead
- GCHead
- ISAHead
- KernelUpdator
- KernelUpdateHead
- IterativeDecodeHead
- LRASPPHead
- Mask2FormerHead
- MaskFormerHead
- NLHead
- OCRHead
- PointHead
- PSAHead
- PSPHead
- SegformerHead
- SegmenterMaskTransformerHead
|
+ - DepthwiseSeparableASPPHead
- DepthwiseSeparableFCNHead
- SETRMLAHead
- SETRUPHead
- STDCHead
- UPerHead
- FastSCNN
- ResNet
- ResNetV1c
- ResNetV1d
- HRNet
- ICNet
- MAE
- MixVisionTransformer
- MobileNetV2
- MobileNetV3
- ResNeSt
- ResNeXt
- STDCNet
|
+ - STDCContextPathNet
- SwinTransformer
- TIMMBackbone
- PCPVT
- SVT
- DeconvModule
- InterpConv
- UNet
- SegDataPreProcessor
- Feature2Pyramid
- FPN
- ICNeck
- JPU
- MLANeck
- MultiLevelNeck
- EncoderDecoder
- CascadeEncoderDecoder
- SegTTAModel
|
+
+
+
+
MMsegmentation Tools
+
+
+
+
+
+ | tools/deployment |
+ tools/misc |
+ tools/torchserve |
+ tools/analysis_tools |
+
+
+
+
+ |
+ - browse_dataset.py
- publish_model.py
- print_config.py
|
+ - mmseg_handler.py
- mmseg2torchserve.py
- test_torchserve.py
|
+ - benchmark.py
- confusion_matrix.py
- analyze_logs.py
- get_flops.py
|
+
+
+
+
+
+
+
+
+ | tools |
+ tools/model_converters |
+ tools/dataset_converters |
+
+
+
+
+ - dist_test.sh
- slurm_test.sh
- test.py
- dist_train.sh
- train.py
- slurm_train.sh
|
+ - swin2mmseg.py
- vitjax2mmseg.py
- twins2mmseg.py
- stdc2mmseg.py
- vit2mmseg.py
- mit2mmseg.py
- beit2mmseg.py
|
+ - voc_aug.py
- hrf.py
- drive.py
- pascal_context.py
- vaihingen.py
- stare.py
- synapse.py
- isaid.py
- cityscapes.py
- loveda.py
- potsdam.py
- chase_db1.py
- coco_stuff164k.py
- coco_stuff10k.py
|
+
+
+
+
MMengine Module Components
+
+
+
+
+
+ | log_processor |
+ visualizer |
+ metric |
+ evaluator |
+ runner |
+
+
+
+
+ |
+ |
+ |
+ |
+ |
+
+
+
+
+
+
+
+
+ | optimizer wrapper constructor |
+ Collate Functions |
+ data sampler |
+ vis_backend |
+ dataset |
+
+
+
+
+ - DefaultOptimWrapperConstructor
|
+ - pseudo_collate
- default_collate
|
+ - DefaultSampler
- InfiniteSampler
|
+ - LocalVisBackend
- WandbVisBackend
- TensorboardVisBackend
|
+ - ConcatDataset
- RepeatDataset
- ClassBalancedDataset
|
+
+
+
+
+
+
+
+
+ | optim_wrapper |
+ loop |
+ model_wrapper |
+ model |
+ weight initializer |
+
+
+
+
+ - OptimWrapper
- AmpOptimWrapper
- ApexOptimWrapper
|
+ - EpochBasedTrainLoop
- IterBasedTrainLoop
- ValLoop
- TestLoop
|
+ - DistributedDataParallel
- DataParallel
- MMDistributedDataParallel
- MMSeparateDistributedDataParallel
|
+ - StochasticWeightAverage
- ExponentialMovingAverage
- MomentumAnnealingEMA
- BaseDataPreprocessor
- ImgDataPreprocessor
- BaseTTAModel
- ToyModel
|
+ - Constant
- Xavier
- Normal
- TruncNormal
- Uniform
- Kaiming
- Caffe2Xavier
- Pretrained
|
+
+
+
+
+
+
+
+
+ | hook |
+ optimizer |
+ parameter scheduler (part 1) |
+ parameter scheduler (part 2) |
+
+
+
+
+ - CheckpointHook
- EMAHook
- EmptyCacheHook
- IterTimerHook
- LoggerHook
- NaiveVisualizationHook
- ParamSchedulerHook
- ProfilerHook
- NPUProfilerHook
- RuntimeInfoHook
- DistSamplerSeedHook
- SyncBuffersHook
- PrepareTTAHook
|
+ - ASGD
- Adadelta
- Adagrad
- Adam
- AdamW
- Adamax
- LBFGS
- Optimizer
- RMSprop
- Rprop
- SGD
- SparseAdam
- ZeroRedundancyOptimizer
|
+ - StepParamScheduler
- MultiStepParamScheduler
- ConstantParamScheduler
- ExponentialParamScheduler
- CosineAnnealingParamScheduler
- LinearParamScheduler
- PolyParamScheduler
- OneCycleParamScheduler
- CosineRestartParamScheduler
- ReduceOnPlateauParamScheduler
- ConstantLR
- CosineAnnealingLR
- ExponentialLR
- LinearLR
- MultiStepLR
|
+ - StepLR
- PolyLR
- OneCycleLR
- CosineRestartLR
- ReduceOnPlateauLR
- ConstantMomentum
- CosineAnnealingMomentum
- ExponentialMomentum
- LinearMomentum
- MultiStepMomentum
- StepMomentum
- PolyMomentum
- CosineRestartMomentum
- ReduceOnPlateauMomentum
|
+
+
+
+
MMCV Module Components
+
+
+
+
+
+ | transform |
+ model (part 1) |
+ model (part 2) |
+ model (part 3) |
+
+
+
+
+ - LoadImageFromFile
- LoadAnnotations
- Compose
- KeyMapper
- TransformBroadcaster
- RandomChoice
- RandomApply
- Normalize
- Resize
- Pad
- CenterCrop
- RandomGrayscale
- MultiScaleFlipAug
- TestTimeAug
- RandomChoiceResize
- RandomFlip
- RandomResize
- ToTensor
- ImageToTensor
|
+ - ReLU
- LeakyReLU
- PReLU
- RReLU
- ReLU6
- ELU
- Sigmoid
- Tanh
- SiLU
- Clamp
- Clip
- GELU
- ContextBlock
- Conv1d
- Conv2d
- Conv3d
- Conv
- Conv2dAdaptivePadding
|
+ - BN
- BN1d
- BN2d
- BN3d
- SyncBN
- GN
- LN
- IN
- IN1d
- IN2d
- IN3d
- zero
- reflect
- replicate
- ConvModule
- ConvWS
- ConvAWS
- DropPath
|
+ - Dropout
- GeneralizedAttention
- HSigmoid
- HSwish
- NonLocal2d
- Swish
- nearest
- bilinear
- pixel_shuffle
- deconv
- ConvTranspose2d
- deconv3d
- ConvTranspose3d
- MultiheadAttention
- FFN
- BaseTransformerLayer
- TransformerLayerSequence
|
+
+
+
+
MMCV Tools
+
+
+
+
+
+ | .dev_scripts |
+
+
+
+
+ |
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
[特征图可视化.ipynb](https://github.com/open-mmlab/OpenMMLabCourse/blob/main/codes/MMYOLO_tutorials/%5B%E5%B7%A5%E5%85%B7%E7%B1%BB%E7%AC%AC%E4%B8%80%E6%9C%9F%5D%E7%89%B9%E5%BE%81%E5%9B%BE%E5%8F%AF%E8%A7%86%E5%8C%96.ipynb) |
+| 第2讲 | 基于 sahi 的大图推理 | [](https://www.bilibili.com/video/BV1EK411R7Ws/) [](https://www.bilibili.com/video/BV1EK411R7Ws/) | [10分钟轻松掌握大图推理.ipynb](https://github.com/open-mmlab/OpenMMLabCourse/blob/main/codes/MMYOLO_tutorials/[工具类第二期]10分钟轻松掌握大图推理.ipynb) |
+
+#### 基础类
+
+| | 内容 | 视频 | 课程中的代码/文档 |
+| :---: | :--------------: | :-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | :------------------------------------------------------------: |
+| 第1讲 | 配置全解读 | [](https://www.bilibili.com/video/BV1214y157ck) [](https://www.bilibili.com/video/BV1214y157ck) | [配置全解读文档](https://zhuanlan.zhihu.com/p/577715188) |
+| 第2讲 | 工程文件结构简析 | [](https://www.bilibili.com/video/BV1LP4y117jS)[](https://www.bilibili.com/video/BV1LP4y117jS) | [工程文件结构简析文档](https://zhuanlan.zhihu.com/p/584807195) |
+
+#### 实用类
+
+| | 内容 | 视频 | 课程中的代码/文档 |
+| :---: | :--------------------------------: | :-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+| 第1讲 | 源码阅读和调试「必备」技巧 | [](https://www.bilibili.com/video/BV1N14y1V7mB) [](https://www.bilibili.com/video/BV1N14y1V7mB) | [源码阅读和调试「必备」技巧文档](https://zhuanlan.zhihu.com/p/580885852) |
+| 第2讲 | 10分钟换遍主干网络 | [](https://www.bilibili.com/video/BV1JG4y1d7GC) [](https://www.bilibili.com/video/BV1JG4y1d7GC) | [10分钟换遍主干网络文档](https://zhuanlan.zhihu.com/p/585641598)
[10分钟换遍主干网络.ipynb](https://github.com/open-mmlab/OpenMMLabCourse/blob/main/codes/MMYOLO_tutorials/[实用类第二期]10分钟换遍主干网络.ipynb) |
+| 第3讲 | 自定义数据集从标注到部署保姆级教程 | [](https://www.bilibili.com/video/BV1RG4y137i5) [](https://www.bilibili.com/video/BV1RG4y137i5) | [自定义数据集从标注到部署保姆级教程](../recommended_topics/labeling_to_deployment_tutorials.md) |
+| 第4讲 | 顶会第一步 · 模块自定义 | [](https://www.bilibili.com/video/BV1yd4y1j7VD) [](https://www.bilibili.com/video/BV1yd4y1j7VD) | [顶会第一步·模块自定义.ipynb](https://github.com/open-mmlab/OpenMMLabCourse/blob/main/codes/MMYOLO_tutorials/[实用类第四期]顶会第一步·模块自定义.ipynb) |
+
+#### 源码解读类
+
+#### 演示类
+
+| | 内容 | 视频 |
+| :---: | :----------: | :-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+| 第1期 | 特征图可视化 | [](https://www.bilibili.com/video/BV1je4y1478R/) [](https://www.bilibili.com/video/BV1je4y1478R/) |
+
+## MMDetection 解读文章和资源
+
+### 文章
+
+- [MMDetection 3.0:目标检测新基准与前沿](https://zhuanlan.zhihu.com/p/575246786)
+- [目标检测、实例分割、旋转框样样精通!详解高性能检测算法 RTMDet](https://zhuanlan.zhihu.com/p/598846422)
+- [MMDetection 支持数据增强神器 Simple Copy Paste 全过程](https://zhuanlan.zhihu.com/p/559940982)
+
+### 知乎问答和资源
+
+- [深度学习科研,如何高效进行代码和实验管理?](https://www.zhihu.com/question/269707221/answer/2480772257)
+- [深度学习方面的科研工作中的实验代码有什么规范和写作技巧?如何妥善管理实验数据?](https://www.zhihu.com/question/268193800/answer/2586000037)
+- [COCO 数据集上 1x 模式下为什么不采用多尺度训练?](https://www.zhihu.com/question/462170786/answer/1915119662)
+- [MMDetection 中 SOTA 论文源码中将训练过程中 BN 层的 eval 打开?](https://www.zhihu.com/question/471189603/answer/2195540892)
+- [基于 PyTorch 的 MMDetection 中训练的随机性来自何处?](https://www.zhihu.com/question/453511684/answer/1839683634)
+
+## MMEngine 解读文章和资源
+
+- [从 MMCV 到 MMEngine,架构升级,体验升级!](https://zhuanlan.zhihu.com/p/571830155)
+
+## MMCV 解读文章和资源
+
+- [MMCV 全新升级,新增超全数据变换功能,还有两大变化](https://zhuanlan.zhihu.com/p/572550592)
+- [手把手教你如何高效地在 MMCV 中贡献算子](https://zhuanlan.zhihu.com/p/464492627)
+
+## PyTorch 解读文章和资源
+
+- [PyTorch1.11 亮点一览:TorchData、functorch、DDP 静态图](https://zhuanlan.zhihu.com/p/486222256)
+- [PyTorch1.12 亮点一览:DataPipe + TorchArrow 新的数据加载与处理范式](https://zhuanlan.zhihu.com/p/537868554)
+- [PyTorch 源码解读之 nn.Module:核心网络模块接口详解](https://zhuanlan.zhihu.com/p/340453841)
+- [PyTorch 源码解读之 torch.autograd:梯度计算详解](https://zhuanlan.zhihu.com/p/321449610)
+- [PyTorch 源码解读之 torch.utils.data:解析数据处理全流程](https://zhuanlan.zhihu.com/p/337850513)
+- [PyTorch 源码解读之 torch.optim:优化算法接口详解](https://zhuanlan.zhihu.com/p/346205754)
+- [PyTorch 源码解读之 DP & DDP:模型并行和分布式训练解析](https://zhuanlan.zhihu.com/p/343951042)
+- [PyTorch 源码解读之 BN & SyncBN:BN 与 多卡同步 BN 详解](https://zhuanlan.zhihu.com/p/337732517)
+- [PyTorch 源码解读之 torch.cuda.amp: 自动混合精度详解](https://zhuanlan.zhihu.com/p/348554267)
+- [PyTorch 源码解读之 cpp_extension:揭秘 C++/CUDA 算子实现和调用全流程](https://zhuanlan.zhihu.com/p/348555597)
+- [PyTorch 源码解读之即时编译篇](https://zhuanlan.zhihu.com/p/361101354)
+- [PyTorch 源码解读之分布式训练了解一下?](https://zhuanlan.zhihu.com/p/361314953)
+- [PyTorch 源码解读之 torch.serialization & torch.hub](https://zhuanlan.zhihu.com/p/364239544)
+
+## 其他
+
+- [Type Hints 入门教程,让代码更加规范整洁](https://zhuanlan.zhihu.com/p/519335398)
diff --git a/third_party/mmyolo/docs/zh_cn/get_started/dependencies.md b/third_party/mmyolo/docs/zh_cn/get_started/dependencies.md
new file mode 100644
index 0000000000000000000000000000000000000000..8713c139379e4a5103200af2ee66cf792c6a7887
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/get_started/dependencies.md
@@ -0,0 +1,60 @@
+# 依赖
+
+下表为 MMYOLO 和 MMEngine, MMCV, MMDetection 依赖库的版本要求,请安装正确的版本以避免安装问题。
+
+| MMYOLO version | MMDetection version | MMEngine version | MMCV version |
+| :------------: | :----------------------: | :----------------------: | :---------------------: |
+| main | mmdet>=3.0.0, \<3.1.0 | mmengine>=0.7.1, \<1.0.0 | mmcv>=2.0.0rc4, \<2.1.0 |
+| 0.6.0 | mmdet>=3.0.0, \<3.1.0 | mmengine>=0.7.1, \<1.0.0 | mmcv>=2.0.0rc4, \<2.1.0 |
+| 0.5.0 | mmdet>=3.0.0rc6, \<3.1.0 | mmengine>=0.6.0, \<1.0.0 | mmcv>=2.0.0rc4, \<2.1.0 |
+| 0.4.0 | mmdet>=3.0.0rc5, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
+| 0.3.0 | mmdet>=3.0.0rc5, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
+| 0.2.0 | mmdet>=3.0.0rc3, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
+| 0.1.3 | mmdet>=3.0.0rc3, \<3.1.0 | mmengine>=0.3.1, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
+| 0.1.2 | mmdet>=3.0.0rc2, \<3.1.0 | mmengine>=0.3.0, \<1.0.0 | mmcv>=2.0.0rc0, \<2.1.0 |
+| 0.1.1 | mmdet==3.0.0rc1 | mmengine>=0.1.0, \<0.2.0 | mmcv>=2.0.0rc0, \<2.1.0 |
+| 0.1.0 | mmdet==3.0.0rc0 | mmengine>=0.1.0, \<0.2.0 | mmcv>=2.0.0rc0, \<2.1.0 |
+
+本节中,我们将演示如何用 PyTorch 准备一个环境。
+
+MMYOLO 支持在 Linux,Windows 和 macOS 上运行。它的基本环境依赖为:
+
+- Python 3.7+
+- PyTorch 1.7+
+- CUDA 9.2+
+- GCC 5.4+
+
+```{note}
+如果你对 PyTorch 有经验并且已经安装了它,你可以直接跳转到下一小节。否则,你可以按照下述步骤进行准备
+```
+
+**步骤 0.** 从 [官方网站](https://docs.conda.io/en/latest/miniconda.html) 下载并安装 Miniconda。
+
+**步骤 1.** 创建并激活一个 conda 环境。
+
+```shell
+conda create -n mmyolo python=3.8 -y
+conda activate mmyolo
+```
+
+**步骤 2.** 基于 [PyTorch 官方说明](https://pytorch.org/get-started/locally/) 安装 PyTorch。
+
+在 GPU 平台上:
+
+```shell
+conda install pytorch torchvision -c pytorch
+```
+
+在 CPU 平台上:
+
+```shell
+conda install pytorch torchvision cpuonly -c pytorch
+```
+
+**步骤 3.** 验证 PyTorch 安装
+
+```shell
+python -c "import torch; print(torch.__version__); print(torch.cuda.is_available())"
+```
+
+如果是在 GPU 平台上,那么会打印版本信息和 True 字符,否则打印版本信息和 False 字符。
diff --git a/third_party/mmyolo/docs/zh_cn/get_started/installation.md b/third_party/mmyolo/docs/zh_cn/get_started/installation.md
new file mode 100644
index 0000000000000000000000000000000000000000..be77bccc961cfb21e49570d54df24c326c0b77ad
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/get_started/installation.md
@@ -0,0 +1,129 @@
+# 安装和验证
+
+## 最佳实践
+
+**步骤 0.** 使用 [MIM](https://github.com/open-mmlab/mim) 安装 [MMEngine](https://github.com/open-mmlab/mmengine)、 [MMCV](https://github.com/open-mmlab/mmcv) 和 [MMDetection](https://github.com/open-mmlab/mmdetection) 。
+
+```shell
+pip install -U openmim
+mim install "mmengine>=0.6.0"
+mim install "mmcv>=2.0.0rc4,<2.1.0"
+mim install "mmdet>=3.0.0,<4.0.0"
+```
+
+如果你当前已经处于 mmyolo 工程目录下,则可以采用如下简化写法
+
+```shell
+cd mmyolo
+pip install -U openmim
+mim install -r requirements/mminstall.txt
+```
+
+**注意:**
+
+a. 在 MMCV-v2.x 中,`mmcv-full` 改名为 `mmcv`,如果你想安装不包含 CUDA 算子精简版,可以通过 `mim install mmcv-lite>=2.0.0rc1` 来安装。
+
+b. 如果使用 `albumentations`,我们建议使用 `pip install -r requirements/albu.txt` 或者 `pip install -U albumentations --no-binary qudida,albumentations` 进行安装。 如果简单地使用 `pip install albumentations==1.0.1` 进行安装,则会同时安装 `opencv-python-headless`(即便已经安装了 `opencv-python` 也会再次安装)。我们建议在安装 albumentations 后检查环境,以确保没有同时安装 `opencv-python` 和 `opencv-python-headless`,因为同时安装可能会导致一些问题。更多细节请参考 [官方文档](https://albumentations.ai/docs/getting_started/installation/#note-on-opencv-dependencies) 。
+
+**步骤 1.** 安装 MMYOLO
+
+方案 1. 如果你基于 MMYOLO 框架开发自己的任务,建议从源码安装
+
+```shell
+git clone https://github.com/open-mmlab/mmyolo.git
+cd mmyolo
+# Install albumentations
+mim install -r requirements/albu.txt
+# Install MMYOLO
+mim install -v -e .
+# "-v" 指详细说明,或更多的输出
+# "-e" 表示在可编辑模式下安装项目,因此对代码所做的任何本地修改都会生效,从而无需重新安装。
+```
+
+方案 2. 如果你将 MMYOLO 作为依赖或第三方 Python 包,使用 MIM 安装
+
+```shell
+mim install "mmyolo"
+```
+
+## 验证安装
+
+为了验证 MMYOLO 是否安装正确,我们提供了一些示例代码来执行模型推理。
+
+**步骤 1.** 我们需要下载配置文件和模型权重文件。
+
+```shell
+mim download mmyolo --config yolov5_s-v61_syncbn_fast_8xb16-300e_coco --dest .
+```
+
+下载将需要几秒钟或更长时间,这取决于你的网络环境。完成后,你会在当前文件夹中发现两个文件 `yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py` 和 `yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth`。
+
+**步骤 2.** 推理验证
+
+方案 1. 如果你通过源码安装的 MMYOLO,那么直接运行以下命令进行验证:
+
+```shell
+python demo/image_demo.py demo/demo.jpg \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py \
+ yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth
+
+# 可选参数
+# --out-dir ./output *检测结果输出到指定目录下,默认为./output, 当--show参数存在时,不保存检测结果
+# --device cuda:0 *使用的计算资源,包括cuda, cpu等,默认为cuda:0
+# --show *使用该参数表示在屏幕上显示检测结果,默认为False
+# --score-thr 0.3 *置信度阈值,默认为0.3
+```
+
+运行结束后,在 `output` 文件夹中可以看到检测结果图像,图像中包含有网络预测的检测框。
+
+支持输入类型包括
+
+- 单张图片, 支持 `jpg`, `jpeg`, `png`, `ppm`, `bmp`, `pgm`, `tif`, `tiff`, `webp`。
+- 文件目录,会遍历文件目录下所有图片文件,并输出对应结果。
+- 网址,会自动从对应网址下载图片,并输出结果。
+
+方案 2. 如果你通过 MIM 安装的 MMYOLO, 那么可以打开你的 Python 解析器,复制并粘贴以下代码:
+
+```python
+from mmdet.apis import init_detector, inference_detector
+
+config_file = 'yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py'
+checkpoint_file = 'yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth'
+model = init_detector(config_file, checkpoint_file, device='cpu') # or device='cuda:0'
+inference_detector(model, 'demo/demo.jpg')
+```
+
+你将会看到一个包含 `DetDataSample` 的列表,预测结果在 `pred_instance` 里,包含有预测框、预测分数 和 预测类别。
+
+## 通过 Docker 使用 MMYOLO
+
+我们提供了一个 [Dockerfile](https://github.com/open-mmlab/mmyolo/blob/main/docker/Dockerfile) 来构建一个镜像。请确保你的 [docker 版本](https://docs.docker.com/engine/install/) >=`19.03`。
+
+温馨提示;国内用户建议取消掉 [Dockerfile](https://github.com/open-mmlab/mmyolo/blob/main/docker/Dockerfile#L19-L20) 里面 `Optional` 后两行的注释,可以获得火箭一般的下载提速:
+
+```dockerfile
+# (Optional)
+RUN sed -i 's/http:\/\/archive.ubuntu.com\/ubuntu\//http:\/\/mirrors.aliyun.com\/ubuntu\//g' /etc/apt/sources.list && \
+ pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
+```
+
+构建命令:
+
+```shell
+# build an image with PyTorch 1.9, CUDA 11.1
+# If you prefer other versions, just modified the Dockerfile
+docker build -t mmyolo docker/
+```
+
+用以下命令运行 Docker 镜像:
+
+```shell
+export DATA_DIR=/path/to/your/dataset
+docker run --gpus all --shm-size=8g -it -v ${DATA_DIR}:/mmyolo/data mmyolo
+```
+
+其余自定义安装流程请查看 [自定义安装](../tutorials/custom_installation.md)
+
+## 排除故障
+
+如果你在安装过程中遇到一些问题,你可以在 GitHub 上 [打开一个问题](https://github.com/open-mmlab/mmyolo/issues/new/choose)。
diff --git a/third_party/mmyolo/docs/zh_cn/get_started/overview.md b/third_party/mmyolo/docs/zh_cn/get_started/overview.md
new file mode 100644
index 0000000000000000000000000000000000000000..a6adc41748326cc9f9e34929b31a2abc07fc5a7c
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/get_started/overview.md
@@ -0,0 +1,81 @@
+# 概述
+
+## MMYOLO 介绍
+
+
+
+
+
+
+支持的任务
+
+- 目标检测
+- 旋转框目标检测
+
+
+
+目前支持的 YOLO 系列算法如下:
+
+
+支持的算法
+
+- YOLOv5
+- YOLOX
+- RTMDet
+- RTMDet-Rotated
+- YOLOv6
+- YOLOv7
+- PPYOLOE
+- YOLOv8
+
+
+
+目前支持的数据集如下:
+
+
+支持的数据集
+
+- COCO Dataset
+- VOC Dataset
+- CrowdHuman Dataset
+- DOTA 1.0 Dataset
+
+
+
+MMYOLO 支持在 Linux、Windows、macOS 上运行, 支持 PyTorch 1.7 及其以上版本运行。它具有如下三个特性:
+
+- 🕹️ **统一便捷的算法评测**
+
+ MMYOLO 统一了各类 YOLO 算法模块的实现,并提供了统一的评测流程,用户可以公平便捷地进行对比分析。
+
+- 📚 **丰富的入门和进阶文档**
+
+ MMYOLO 提供了从入门到部署到进阶和算法解析等一系列文档,方便不同用户快速上手和扩展。
+
+- 🧩 **模块化设计**
+
+ MMYOLO 将框架解耦成不同的模块组件,通过组合不同的模块和训练测试策略,用户可以便捷地构建自定义模型。
+
+
+ 图为 RangeKing@GitHub 提供,非常感谢!
+
+## 本文档使用指南
+
+MMYOLO 中将文档结构分成 6 个部分,对应不同需求的用户。
+
+- **开启 MMYOLO 之旅**。本部分是第一次使用 MMYOLO 用户的必读文档,请全文仔细阅读
+- **推荐专题**。本部分是 MMYOLO 中提供的以主题形式的精华文档,包括了 MMYOLO 中大量的特性等。强烈推荐使用 MMYOLO 的所有用户阅读
+- **常用功能**。本部分提供了训练测试过程中用户经常会用到的各类常用功能,用户可以在用到时候再次查阅
+- **实用工具**。本部分是 tools 下使用工具的汇总文档,便于大家能够快速的愉快使用 MMYOLO 中提供的各类脚本
+- **基础和进阶教程**。本部分涉及到 MMYOLO 中的一些基本概念和进阶教程等,适合想详细了解 MMYOLO 设计思想和结构设计的用户
+- **其他**。其余部分包括模型仓库、说明和接口文档等等
+
+不同需求的用户可以按需选择你心怡的内容阅读。如果你对本文档有异议或者更好的优化办法,欢迎给 MMYOLO 提 PR ~, 请参考 [如何给 MMYOLO 贡献代码](../recommended_topics/contributing.md)
diff --git a/third_party/mmyolo/docs/zh_cn/index.rst b/third_party/mmyolo/docs/zh_cn/index.rst
new file mode 100644
index 0000000000000000000000000000000000000000..9f150ac6c8d66e6c64603cff69e7d6be15b6ab01
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/index.rst
@@ -0,0 +1,122 @@
+欢迎来到 MMYOLO 中文文档!
+=======================================
+您可以在页面右上角切换中英文文档。
+
+.. toctree::
+ :maxdepth: 2
+ :caption: 开启 MMYOLO 之旅
+
+ get_started/overview.md
+ get_started/dependencies.md
+ get_started/installation.md
+ get_started/15_minutes_object_detection.md
+ get_started/15_minutes_rotated_object_detection.md
+ get_started/15_minutes_instance_segmentation.md
+ get_started/article.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: 推荐专题
+
+ recommended_topics/contributing.md
+ recommended_topics/training_testing_tricks.md
+ recommended_topics/model_design.md
+ recommended_topics/algorithm_descriptions/index.rst
+ recommended_topics/application_examples/index.rst
+ recommended_topics/replace_backbone.md
+ recommended_topics/complexity_analysis.md
+ recommended_topics/labeling_to_deployment_tutorials.md
+ recommended_topics/visualization.md
+ recommended_topics/deploy/index.rst
+ recommended_topics/troubleshooting_steps.md
+ recommended_topics/mm_basics.md
+ recommended_topics/dataset_preparation.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: 常用功能
+
+ common_usage/resume_training.md
+ common_usage/syncbn.md
+ common_usage/amp_training.md
+ common_usage/ms_training_testing.md
+ common_usage/tta.md
+ common_usage/plugins.md
+ common_usage/freeze_layers.md
+ common_usage/output_predictions.md
+ common_usage/set_random_seed.md
+ common_usage/module_combination.md
+ common_usage/mim_usage.md
+ common_usage/multi_necks.md
+ common_usage/specify_device.md
+ common_usage/single_multi_channel_applications.md
+ common_usage/registries_info.md
+
+
+.. toctree::
+ :maxdepth: 2
+ :caption: 实用工具
+
+ useful_tools/browse_coco_json.md
+ useful_tools/browse_dataset.md
+ useful_tools/print_config.md
+ useful_tools/dataset_analysis.md
+ useful_tools/optimize_anchors.md
+ useful_tools/extract_subcoco.md
+ useful_tools/vis_scheduler.md
+ useful_tools/dataset_converters.md
+ useful_tools/download_dataset.md
+ useful_tools/log_analysis.md
+ useful_tools/model_converters.md
+
+.. toctree::
+ :maxdepth: 2
+ :caption: 基础教程
+
+ tutorials/config.md
+ tutorials/data_flow.md
+ tutorials/rotated_detection.md
+ tutorials/custom_installation.md
+ tutorials/warning_notes.md
+ tutorials/faq.md
+
+
+.. toctree::
+ :maxdepth: 2
+ :caption: 进阶教程
+
+ advanced_guides/cross-library_application.md
+
+
+.. toctree::
+ :maxdepth: 2
+ :caption: 模型仓库
+
+ model_zoo.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: 说明
+
+ notes/changelog.md
+ notes/compatibility.md
+ notes/conventions.md
+ notes/code_style.md
+
+.. toctree::
+ :maxdepth: 1
+ :caption: 接口文档(英文)
+
+ api.rst
+
+.. toctree::
+ :caption: 语言切换
+
+ switch_language.md
+
+
+Indices and tables
+==================
+
+* :ref:`genindex`
+* :ref:`search`
diff --git a/third_party/mmyolo/docs/zh_cn/make.bat b/third_party/mmyolo/docs/zh_cn/make.bat
new file mode 100644
index 0000000000000000000000000000000000000000..922152e96a04a242e6fc40f124261d74890617d8
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/make.bat
@@ -0,0 +1,35 @@
+@ECHO OFF
+
+pushd %~dp0
+
+REM Command file for Sphinx documentation
+
+if "%SPHINXBUILD%" == "" (
+ set SPHINXBUILD=sphinx-build
+)
+set SOURCEDIR=.
+set BUILDDIR=_build
+
+if "%1" == "" goto help
+
+%SPHINXBUILD% >NUL 2>NUL
+if errorlevel 9009 (
+ echo.
+ echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
+ echo.installed, then set the SPHINXBUILD environment variable to point
+ echo.to the full path of the 'sphinx-build' executable. Alternatively you
+ echo.may add the Sphinx directory to PATH.
+ echo.
+ echo.If you don't have Sphinx installed, grab it from
+ echo.http://sphinx-doc.org/
+ exit /b 1
+)
+
+%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+goto end
+
+:help
+%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+
+:end
+popd
diff --git a/third_party/mmyolo/docs/zh_cn/model_zoo.md b/third_party/mmyolo/docs/zh_cn/model_zoo.md
new file mode 100644
index 0000000000000000000000000000000000000000..1091f9f5719f9b3e373cd7a04d32efd0097023f6
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/model_zoo.md
@@ -0,0 +1,94 @@
+# 模型库和评测
+
+本页面用于汇总 MMYOLO 中支持的各类模型性能和相关评测指标,方便用户对比分析。
+
+## COCO 数据集
+
+
+
+
+
+
+
+
+
+
+
+
+

+
+

+
+

+
+
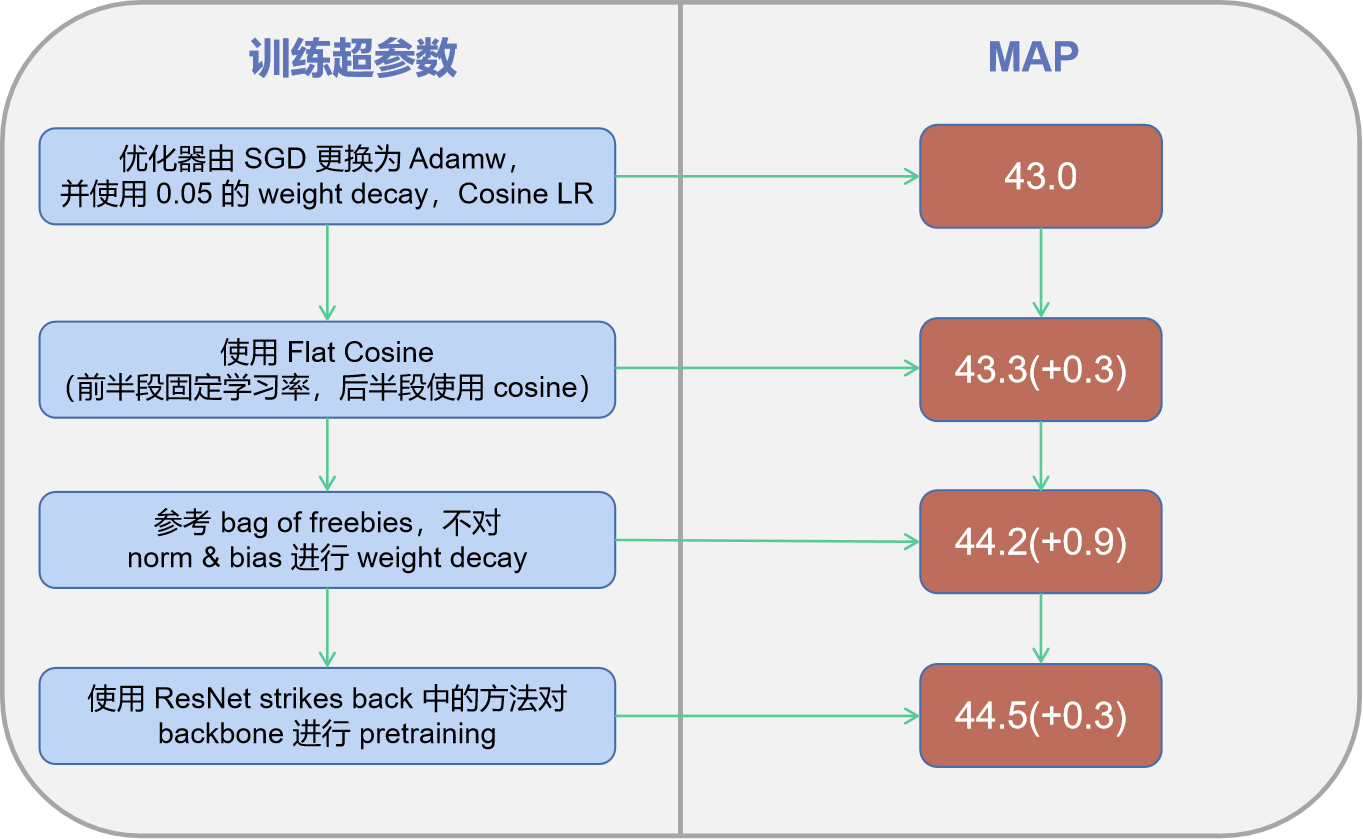
+
+

+
+
+图 1:YOLOv5-l-P5 模型结构
+
+
+图 2:YOLOv5-l-P6 模型结构
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+图 1:YOLOv6-S 模型结构
+
+
+图 2:YOLOv6-L 模型结构
+
+

+
+

+
+
+
 +
+在 N/T/S 模型中,YOLOv6 使用了 `EfficientRep` 作为骨干网络,其包含 1 个 `Stem Layer` 和 4 个 `Stage Layer`,具体细节如下:
+
+- `Stem Layer` 中采用 stride=2 的 `RepVGGBlock` 替换了 stride=2 的 6×6 `ConvModule`。
+- `Stage Layer` 结构与 YOLOv5 基本相似,将每个 `Stage layer` 的 1 个 `ConvModule` 和 1 个 `CSPLayer` 分别替换为 1 个 `RepVGGBlock` 和 1 个 `RepStageBlock`,如上图 Details 部分所示。其中,第一个 `RepVGGBlock` 会做下采样和 `Channel` 维度变换,而每个 `RepStageBlock` 则由 n 个 `RepVGGBlock` 组成。此外,仍然在第 4 个 `Stage Layer` 最后增加 `SPPF` 模块后输出。
+
+在 M/L 模型中,由于模型容量进一步增大,直接使用多个 `RepVGGBlock` 堆叠的 `RepStageBlock` 结构计算量和参数量呈现指数增长。因此,为了权衡计算负担和模型精度,在 M/L 模型中使用了 `CSPBep` 骨干网络,其采用 `BepC3StageBlock` 替换了小模型中的 `RepStageBlock` 。如下图所示,`BepC3StageBlock` 由 3 个 1×1 的 `ConvModule` 和多个子块(每个子块由两个 `RepVGGBlock` 残差连接)组成。
+
+
+
+在 N/T/S 模型中,YOLOv6 使用了 `EfficientRep` 作为骨干网络,其包含 1 个 `Stem Layer` 和 4 个 `Stage Layer`,具体细节如下:
+
+- `Stem Layer` 中采用 stride=2 的 `RepVGGBlock` 替换了 stride=2 的 6×6 `ConvModule`。
+- `Stage Layer` 结构与 YOLOv5 基本相似,将每个 `Stage layer` 的 1 个 `ConvModule` 和 1 个 `CSPLayer` 分别替换为 1 个 `RepVGGBlock` 和 1 个 `RepStageBlock`,如上图 Details 部分所示。其中,第一个 `RepVGGBlock` 会做下采样和 `Channel` 维度变换,而每个 `RepStageBlock` 则由 n 个 `RepVGGBlock` 组成。此外,仍然在第 4 个 `Stage Layer` 最后增加 `SPPF` 模块后输出。
+
+在 M/L 模型中,由于模型容量进一步增大,直接使用多个 `RepVGGBlock` 堆叠的 `RepStageBlock` 结构计算量和参数量呈现指数增长。因此,为了权衡计算负担和模型精度,在 M/L 模型中使用了 `CSPBep` 骨干网络,其采用 `BepC3StageBlock` 替换了小模型中的 `RepStageBlock` 。如下图所示,`BepC3StageBlock` 由 3 个 1×1 的 `ConvModule` 和多个子块(每个子块由两个 `RepVGGBlock` 残差连接)组成。
+
+ +
+#### 1.2.2 Neck
+
+Neck 部分结构仍然在 YOLOv5 基础上进行了模块的改动,同样采用 `RepStageBlock` 或 `BepC3StageBlock` 对原本的 `CSPLayer` 进行了替换,需要注意的是,Neck 中 `Down Sample` 部分仍然使用了 stride=2 的 3×3 `ConvModule`,而不是像 Backbone 一样替换为 `RepVGGBlock`。
+
+#### 1.2.3 Head
+
+不同于传统的 YOLO 系列检测头,YOLOv6 参考了 FCOS 和 YOLOX 中的做法,将分类和回归分支解耦成两个分支进行预测并且去掉了 obj 分支。同时,采用了 hybrid-channel 策略构建了更高效的解耦检测头,将中间 3×3 的 `ConvModule` 减少为 1 个,在维持精度的同时进一步减少了模型耗费,降低了推理延时。此外,需要说明的是,YOLOv6 在 Backobone 和 Neck 部分使用的激活函数是 `ReLU`,而在 Head 部分则使用的是 `SiLU`。
+
+由于 YOLOv6 是解耦输出,分类和 bbox 检测通过不同卷积完成。以 COCO 80 类为例:
+
+- P5 模型在输入为 640x640 分辨率情况下,其 Head 模块输出的 shape 分别为 `(B,4,80,80)`, `(B,80,80,80)`, `(B,4,40,40)`, `(B,80,40,40)`, `(B,4,20,20)`, `(B,80,20,20)`。
+
+### 1.3 正负样本匹配策略
+
+YOLOv6 采用的标签匹配策略与 [TOOD](https://arxiv.org/abs/2108.07755)
+相同, 前 4 个 epoch 采用 `ATSSAssigner` 作为标签匹配策略的 `warm-up` ,
+后续使用 `TaskAlignedAssigner` 算法选择正负样本, 基于官方开源代码, `MMYOLO` 中也对两个 assigner 算法进行了优化, 改进为 `Batch` 维度进行计算,
+能够一定程度的加快速度。 下面会对每个部分进行详细说明。
+
+#### 1.3.1 Anchor 设置
+
+YOLOv6 采用与 YOLOX 一样的 Anchor-free 无锚范式,省略了聚类和繁琐的 Anchor 超参设定,泛化能力强,解码逻辑简单。在训练的过程中会根据 feature size 去自动生成先验框。
+
+使用 `mmdet.MlvlPointGenerator` 生成 anchor points。
+
+```python
+prior_generator: ConfigType = dict(
+ type='mmdet.MlvlPointGenerator',
+ offset=0.5, # 网格中心点
+ strides=[8, 16, 32]) ,
+
+# 调用生成多层 anchor points: list[torch.Tensor]
+# 每一层都是 (featrue_h*feature_w,4), 4 表示 (x,y,stride_h,stride_w)
+self.mlvl_priors = self.prior_generator.grid_priors(
+ self.featmap_sizes,
+ with_stride=True)
+```
+
+#### 1.3.2 Bbox 编解码过程
+
+YOLOv6 的 BBox Coder 采用的是 `DistancePointBBoxCoder`。
+
+网络 bbox 预测的值为 (top, bottom, left, right),解码器将 `anchor point` 通过四个距离解码到坐标 (x1,y1,x2,y2)。
+
+MMYOLO 中解码的核心源码:
+
+```python
+def decode(points: torch.Tensor, pred_bboxes: torch.Tensor, stride: torch.Tensor) -> torch.Tensor:
+ """
+ 将预测值解码转化 bbox 的 xyxy
+ points (Tensor): 生成的 anchor point [x, y],Shape (B, N, 2) or (N, 2).
+ pred_bboxes (Tensor): 预测距离四边的距离。(left, top, right, bottom). Shape (B, N, 4) or (N, 4)
+ stride (Tensor): 特征图下采样倍率.
+ """
+ # 首先将预测值转化为原图尺度
+ distance = pred_bboxes * stride[None, :, None]
+ # 根据点以及到四条边距离转为 bbox 的 x1y1x2y2
+ x1 = points[..., 0] - distance[..., 0]
+ y1 = points[..., 1] - distance[..., 1]
+ x2 = points[..., 0] + distance[..., 2]
+ y2 = points[..., 1] + distance[..., 3]
+
+ bboxes = torch.stack([x1, y1, x2, y2], -1)
+
+ return bboxes
+```
+
+#### 1.3.3 匹配策略
+
+- 0 \<= epoch \< 4,使用 `BatchATSSAssigner`
+- epoch >= 4,使用 `BatchTaskAlignedAssigner`
+
+#### ATSSAssigner
+
+ATSSAssigner 是 [ATSS](https://arxiv.org/abs/1912.02424) 中提出的标签匹配策略。
+ATSS 的匹配策略简单总结为:**通过中心点距离先验对样本进行初筛,然后自适应生成 IoU 阈值筛选正样本。**
+YOLOv6 的实现种主要包括如下三个核心步骤:
+
+1. 因为 YOLOv6 是 Anchor-free,所以首先将 `anchor point` 转化为大小为 `5*strdie` 的 `anchor`。
+2. 对于每一个 `GT`,在 `FPN` 的每一个特征层上, 计算与该层所有 `anchor` 中心点距离(位置先验),
+ 然后优先选取距离 `topK` 近的样本,作为 **初筛样本**。
+3. 对于每一个 `GT`,计算其 **初筛样本** 的 `IoU` 的均值 `mean`与标准差 `std`,将 `mean + std`
+ 作为该 `GT` 的正样本的 **自适应 IoU 阈值** ,大于该 **自适应阈值** 且中心点在 `GT` 内部的 `anchor`
+ 才作为正样本,使得样本能够被 `assign` 到合适的 `FPN` 特征层上。
+
+下图中,(a) 所示中等大小物体被 assign 到 FPN 的中层,(b) 所示偏大的物体被 assign 到 FPN 中检测大物体和偏大物体的两个层。
+
+
+
+#### 1.2.2 Neck
+
+Neck 部分结构仍然在 YOLOv5 基础上进行了模块的改动,同样采用 `RepStageBlock` 或 `BepC3StageBlock` 对原本的 `CSPLayer` 进行了替换,需要注意的是,Neck 中 `Down Sample` 部分仍然使用了 stride=2 的 3×3 `ConvModule`,而不是像 Backbone 一样替换为 `RepVGGBlock`。
+
+#### 1.2.3 Head
+
+不同于传统的 YOLO 系列检测头,YOLOv6 参考了 FCOS 和 YOLOX 中的做法,将分类和回归分支解耦成两个分支进行预测并且去掉了 obj 分支。同时,采用了 hybrid-channel 策略构建了更高效的解耦检测头,将中间 3×3 的 `ConvModule` 减少为 1 个,在维持精度的同时进一步减少了模型耗费,降低了推理延时。此外,需要说明的是,YOLOv6 在 Backobone 和 Neck 部分使用的激活函数是 `ReLU`,而在 Head 部分则使用的是 `SiLU`。
+
+由于 YOLOv6 是解耦输出,分类和 bbox 检测通过不同卷积完成。以 COCO 80 类为例:
+
+- P5 模型在输入为 640x640 分辨率情况下,其 Head 模块输出的 shape 分别为 `(B,4,80,80)`, `(B,80,80,80)`, `(B,4,40,40)`, `(B,80,40,40)`, `(B,4,20,20)`, `(B,80,20,20)`。
+
+### 1.3 正负样本匹配策略
+
+YOLOv6 采用的标签匹配策略与 [TOOD](https://arxiv.org/abs/2108.07755)
+相同, 前 4 个 epoch 采用 `ATSSAssigner` 作为标签匹配策略的 `warm-up` ,
+后续使用 `TaskAlignedAssigner` 算法选择正负样本, 基于官方开源代码, `MMYOLO` 中也对两个 assigner 算法进行了优化, 改进为 `Batch` 维度进行计算,
+能够一定程度的加快速度。 下面会对每个部分进行详细说明。
+
+#### 1.3.1 Anchor 设置
+
+YOLOv6 采用与 YOLOX 一样的 Anchor-free 无锚范式,省略了聚类和繁琐的 Anchor 超参设定,泛化能力强,解码逻辑简单。在训练的过程中会根据 feature size 去自动生成先验框。
+
+使用 `mmdet.MlvlPointGenerator` 生成 anchor points。
+
+```python
+prior_generator: ConfigType = dict(
+ type='mmdet.MlvlPointGenerator',
+ offset=0.5, # 网格中心点
+ strides=[8, 16, 32]) ,
+
+# 调用生成多层 anchor points: list[torch.Tensor]
+# 每一层都是 (featrue_h*feature_w,4), 4 表示 (x,y,stride_h,stride_w)
+self.mlvl_priors = self.prior_generator.grid_priors(
+ self.featmap_sizes,
+ with_stride=True)
+```
+
+#### 1.3.2 Bbox 编解码过程
+
+YOLOv6 的 BBox Coder 采用的是 `DistancePointBBoxCoder`。
+
+网络 bbox 预测的值为 (top, bottom, left, right),解码器将 `anchor point` 通过四个距离解码到坐标 (x1,y1,x2,y2)。
+
+MMYOLO 中解码的核心源码:
+
+```python
+def decode(points: torch.Tensor, pred_bboxes: torch.Tensor, stride: torch.Tensor) -> torch.Tensor:
+ """
+ 将预测值解码转化 bbox 的 xyxy
+ points (Tensor): 生成的 anchor point [x, y],Shape (B, N, 2) or (N, 2).
+ pred_bboxes (Tensor): 预测距离四边的距离。(left, top, right, bottom). Shape (B, N, 4) or (N, 4)
+ stride (Tensor): 特征图下采样倍率.
+ """
+ # 首先将预测值转化为原图尺度
+ distance = pred_bboxes * stride[None, :, None]
+ # 根据点以及到四条边距离转为 bbox 的 x1y1x2y2
+ x1 = points[..., 0] - distance[..., 0]
+ y1 = points[..., 1] - distance[..., 1]
+ x2 = points[..., 0] + distance[..., 2]
+ y2 = points[..., 1] + distance[..., 3]
+
+ bboxes = torch.stack([x1, y1, x2, y2], -1)
+
+ return bboxes
+```
+
+#### 1.3.3 匹配策略
+
+- 0 \<= epoch \< 4,使用 `BatchATSSAssigner`
+- epoch >= 4,使用 `BatchTaskAlignedAssigner`
+
+#### ATSSAssigner
+
+ATSSAssigner 是 [ATSS](https://arxiv.org/abs/1912.02424) 中提出的标签匹配策略。
+ATSS 的匹配策略简单总结为:**通过中心点距离先验对样本进行初筛,然后自适应生成 IoU 阈值筛选正样本。**
+YOLOv6 的实现种主要包括如下三个核心步骤:
+
+1. 因为 YOLOv6 是 Anchor-free,所以首先将 `anchor point` 转化为大小为 `5*strdie` 的 `anchor`。
+2. 对于每一个 `GT`,在 `FPN` 的每一个特征层上, 计算与该层所有 `anchor` 中心点距离(位置先验),
+ 然后优先选取距离 `topK` 近的样本,作为 **初筛样本**。
+3. 对于每一个 `GT`,计算其 **初筛样本** 的 `IoU` 的均值 `mean`与标准差 `std`,将 `mean + std`
+ 作为该 `GT` 的正样本的 **自适应 IoU 阈值** ,大于该 **自适应阈值** 且中心点在 `GT` 内部的 `anchor`
+ 才作为正样本,使得样本能够被 `assign` 到合适的 `FPN` 特征层上。
+
+下图中,(a) 所示中等大小物体被 assign 到 FPN 的中层,(b) 所示偏大的物体被 assign 到 FPN 中检测大物体和偏大物体的两个层。
+
+
+

+
+

+
+

+
+
+图 1:YOLOv8-P5 模型结构
+
+
+图 2:YOLOv8 性能曲线
+
+
+图 3:YOLOv5 和 YOLOv8 YAML 文件对比
+
+
+图 4:YOLOv5 和 YOLOv8 模块对比
+
+
+图 5:YOLOv8 Head 结构
+
+
+图 6:pipeline
+
+
+图 7:results
+
+
+图 8:results
+
+
+图 9:featmap
+
+
+图 10:featmap
+
+
+
+使用 labelme 标注的图像预览
+
+
+
+
+各类别目标大小统计
+
+
+
+
+pipeline 输出可视化
+
+
+
+
+不同 batch size 的训练过程中,数据加载时间 `data_time` 占每步总时长的比例
+
+
+
+
+训练过程中的损失下降对比图
+
+
 +
+最后,在 `git bash` 或者 `终端` 中输入以下命令,验证 SSH 是否与 GitHub 账户匹配。如果匹配,输入 `yes` 就成功啦~
+
+```shell
+ssh -T git@github.com
+```
+
+
+
+## 拉取请求工作流
+
+如果你对拉取请求不了解,没关系,接下来的内容将会从零开始,一步一步地指引你如何创建一个拉取请求。如果你想深入了解拉取请求的开发模式,可以参考 github [官方文档](https://docs.github.com/en/github/collaborating-with-issues-and-pull-requests/about-pull-requests)
+
+### 1. 复刻仓库
+
+当你第一次提交拉取请求时,先复刻 OpenMMLab 原代码库,点击 GitHub 页面右上角的 **Fork** 按钮,复刻后的代码库将会出现在你的 GitHub 个人主页下。
+
+
+
+将代码克隆到本地
+
+```shell
+git clone git@github.com:{username}/mmyolo.git
+```
+
+进入项目并添加原代码库为上游代码库
+
+```bash
+cd mmyolo
+git remote add upstream git@github.com:open-mmlab/mmyolo
+```
+
+检查 remote 是否添加成功,在终端输入 `git remote -v`
+
+```bash
+origin git@github.com:{username}/mmyolo.git (fetch)
+origin git@github.com:{username}/mmyolo.git (push)
+upstream git@github.com:open-mmlab/mmyolo (fetch)
+upstream git@github.com:open-mmlab/mmyolo (push)
+```
+
+```{note}
+这里对 origin 和 upstream 进行一个简单的介绍,当我们使用 git clone 来克隆代码时,会默认创建一个 origin 的 remote,它指向我们克隆的代码库地址,而 upstream 则是我们自己添加的,用来指向原始代码库地址。当然如果你不喜欢他叫 upstream,也可以自己修改,比如叫 open-mmlab。我们通常向 origin 提交代码(即 fork 下来的远程仓库),然后向 upstream 提交一个 pull request。如果提交的代码和最新的代码发生冲突,再从 upstream 拉取最新的代码,和本地分支解决冲突,再提交到 origin。
+```
+
+### 2. 配置 pre-commit
+
+在本地开发环境中,我们使用 [pre-commit](https://pre-commit.com/#intro) 来检查代码风格,以确保代码风格的统一。在提交代码,需要先安装 pre-commit(需要在 MMYOLO 目录下执行):
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+检查 pre-commit 是否配置成功,并安装 `.pre-commit-config.yaml` 中的钩子:
+
+```shell
+pre-commit run --all-files
+```
+
+
+
+
+
+```{note}
+如果你是中国用户,由于网络原因,可能会出现安装失败的情况,这时可以使用国内源
+
+pre-commit install -c .pre-commit-config-zh-cn.yaml
+
+pre-commit run --all-files -c .pre-commit-config-zh-cn.yaml
+```
+
+如果安装过程被中断,可以重复执行 `pre-commit run ...` 继续安装。
+
+如果提交的代码不符合代码风格规范,pre-commit 会发出警告,并自动修复部分错误。
+
+
+
+如果我们想临时绕开 pre-commit 的检查提交一次代码,可以在 `git commit` 时加上 `--no-verify`(需要保证最后推送至远程仓库的代码能够通过 pre-commit 检查)。
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+### 3. 创建开发分支
+
+安装完 pre-commit 之后,我们需要基于 dev 创建开发分支,建议的分支命名规则为 `username/pr_name`。
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+在后续的开发中,如果本地仓库的 dev 分支落后于 upstream 的 dev 分支,我们需要先拉取 upstream 的代码进行同步,再执行上面的命令
+
+```shell
+git pull upstream dev
+```
+
+### 4. 提交代码并在本地通过单元测试
+
+- MMYOLO 引入了 mypy 来做静态类型检查,以增加代码的鲁棒性。因此我们在提交代码时,需要补充 Type Hints。具体规则可以参考[教程](https://zhuanlan.zhihu.com/p/519335398)。
+
+- 提交的代码同样需要通过单元测试
+
+ ```shell
+ # 通过全量单元测试
+ pytest tests
+
+ # 我们需要保证提交的代码能够通过修改模块的单元测试,以 yolov5_coco dataset 为例
+ pytest tests/test_datasets/test_yolov5_coco.py
+ ```
+
+ 如果你由于缺少依赖无法运行修改模块的单元测试,可以参考[指引-单元测试](#单元测试)
+
+- 如果修改/添加了文档,参考[指引](#文档渲染)确认文档渲染正常。
+
+### 5. 推送代码到远程
+
+代码通过单元测试和 pre-commit 检查后,将代码推送到远程仓库,如果是第一次推送,可以在 `git push` 后加上 `-u` 参数以关联远程分支
+
+```shell
+git push -u origin {branch_name}
+```
+
+这样下次就可以直接使用 `git push` 命令推送代码了,而无需指定分支和远程仓库。
+
+### 6. 提交拉取请求(PR)
+
+(1) 在 GitHub 的 Pull request 界面创建拉取请求
+
+
+(2) 根据指引修改 PR 描述,以便于其他开发者更好地理解你的修改
+
+```{note}
+注意在 PR branch 左侧的 base 需要修改为 dev 分支
+```
+
+
+
+描述规范详见[拉取请求规范](#拉取请求规范)
+
+
+
+**注意事项**
+
+(a) PR 描述应该包含修改理由、修改内容以及修改后带来的影响,并关联相关 Issue(具体方式见[文档](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue))
+
+(b) 如果是第一次为 OpenMMLab 做贡献,需要签署 CLA
+
+
+
+(c) 检查提交的 PR 是否通过 CI(集成测试)
+
+
+
+MMYOLO 会在 Linux 上,基于不同版本的 Python、PyTorch 对提交的代码进行单元测试,以保证代码的正确性,如果有任何一个没有通过,我们可点击上图中的 `Details` 来查看具体的测试信息,以便于我们修改代码。
+
+(3) 如果 PR 通过了 CI,那么就可以等待其他开发者的 review,并根据 reviewer 的意见,修改代码,并重复 [4](#4-提交代码并本地通过单元测试)-[5](#5-推送代码到远程) 步骤,直到 reviewer 同意合入 PR。
+
+
+
+所有 reviewer 同意合入 PR 后,我们会尽快将 PR 合并到 dev 分支。
+
+### 7. 解决冲突
+
+随着时间的推移,我们的代码库会不断更新,这时候,如果你的 PR 与 dev 分支存在冲突,你需要解决冲突,解决冲突的方式有两种:
+
+```shell
+git fetch --all --prune
+git rebase upstream/dev
+```
+
+或者
+
+```shell
+git fetch --all --prune
+git merge upstream/dev
+```
+
+如果你非常善于处理冲突,那么可以使用 rebase 的方式来解决冲突,因为这能够保证你的 commit log 的整洁。如果你不太熟悉 `rebase` 的使用,那么可以使用 `merge` 的方式来解决冲突。
+
+## 指引
+
+### 单元测试
+
+在提交修复代码错误或新增特性的拉取请求时,我们应该尽可能的让单元测试覆盖所有提交的代码,计算单元测试覆盖率的方法如下
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+### 文档渲染
+
+在提交修复代码错误或新增特性的拉取请求时,可能会需要修改/新增模块的 docstring。我们需要确认渲染后的文档样式是正确的。
+本地生成渲染后的文档的方法如下
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+## 代码风格
+
+### Python
+
+[PEP8](https://www.python.org/dev/peps/pep-0008/) 作为 OpenMMLab 算法库首选的代码规范,我们使用以下工具检查和格式化代码
+
+- [flake8](https://github.com/PyCQA/flake8):Python 官方发布的代码规范检查工具,是多个检查工具的封装
+- [isort](https://github.com/timothycrosley/isort):自动调整模块导入顺序的工具
+- [yapf](https://github.com/google/yapf):Google 发布的代码规范检查工具
+- [codespell](https://github.com/codespell-project/codespell):检查单词拼写是否有误
+- [mdformat](https://github.com/executablebooks/mdformat):检查 markdown 文件的工具
+- [docformatter](https://github.com/myint/docformatter):格式化 docstring 的工具
+
+yapf 和 isort 的配置可以在 [setup.cfg](../../../setup.cfg) 找到
+
+通过配置 [pre-commit hook](https://pre-commit.com/) ,我们可以在提交代码时自动检查和格式化 `flake8`、`yapf`、`isort`、`trailing whitespaces`、`markdown files`,
+修复 `end-of-files`、`double-quoted-strings`、`python-encoding-pragma`、`mixed-line-ending`,调整 `requirments.txt` 的包顺序。
+pre-commit 钩子的配置可以在 [.pre-commit-config](../../../.pre-commit-config.yaml) 找到。
+
+pre-commit 具体的安装使用方式见[拉取请求](#2-配置-pre-commit)。
+
+更具体的规范请参考 [OpenMMLab 代码规范](../notes/code_style.md)。
+
+### C++ and CUDA
+
+C++ 和 CUDA 的代码规范遵从 [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html)
+
+## 拉取请求规范
+
+1. 使用 [pre-commit hook](https://pre-commit.com),尽量减少代码风格相关问题
+
+2. 一个`拉取请求`对应一个短期分支
+
+3. 粒度要细,一个`拉取请求`只做一件事情,避免超大的`拉取请求`
+
+ - Bad:实现 Faster R-CNN
+ - Acceptable:给 Faster R-CNN 添加一个 box head
+ - Good:给 box head 增加一个参数来支持自定义的 conv 层数
+
+4. 每次 Commit 时需要提供清晰且有意义 commit 信息
+
+5. 提供清晰且有意义的`拉取请求`描述
+
+ - 标题写明白任务名称,一般格式:\[Prefix\] Short description of the pull request (Suffix)
+ - prefix:新增功能 \[Feature\], 修 bug \[Fix\], 文档相关 \[Docs\], 开发中 \[WIP\] (暂时不会被 review)
+ - 描述里介绍`拉取请求`的主要修改内容,结果,以及对其他部分的影响, 参考`拉取请求`模板
+ - 关联相关的`议题` (issue) 和其他`拉取请求`
+
+6. 如果引入了其他三方库,或借鉴了三方库的代码,请确认他们的许可证和 mmyolo 兼容,并在借鉴的代码上补充 `This code is inspired from http://`
diff --git a/third_party/mmyolo/docs/zh_cn/recommended_topics/dataset_preparation.md b/third_party/mmyolo/docs/zh_cn/recommended_topics/dataset_preparation.md
new file mode 100644
index 0000000000000000000000000000000000000000..25603a5c1859b736b6b0602607b3902db27f18d8
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/recommended_topics/dataset_preparation.md
@@ -0,0 +1,144 @@
+# 数据集格式准备和说明
+
+## DOTA 数据集
+
+### 下载 DOTA 数据集
+
+数据集可以从 DOTA 数据集的主页 [DOTA](https://captain-whu.github.io/DOTA/dataset.html)
+或 [OpenDataLab](https://opendatalab.org.cn/DOTA_V1.0) 下载。
+
+我们推荐使用 [OpenDataLab](https://opendatalab.org.cn/DOTA_V1.0) 下载,其中的文件夹结构已经按照需要排列好了,只需要解压即可,不需要费心去调整文件夹结构。
+
+下载后解压数据集,并按如下文件夹结构存放。
+
+```none
+${DATA_ROOT}
+├── train
+│ ├── images
+│ │ ├── P0000.png
+│ │ ├── ...
+│ ├── labelTxt-v1.0
+│ │ ├── labelTxt
+│ │ │ ├── P0000.txt
+│ │ │ ├── ...
+│ │ ├── trainset_reclabelTxt
+│ │ │ ├── P0000.txt
+│ │ │ ├── ...
+├── val
+│ ├── images
+│ │ ├── P0003.png
+│ │ ├── ...
+│ ├── labelTxt-v1.0
+│ │ ├── labelTxt
+│ │ │ ├── P0003.txt
+│ │ │ ├── ...
+│ │ ├── valset_reclabelTxt
+│ │ │ ├── P0003.txt
+│ │ │ ├── ...
+├── test
+│ ├── images
+│ │ ├── P0006.png
+│ │ ├── ...
+
+```
+
+其中,以 `reclabelTxt` 为结尾的文件夹存放了水平检测框的标注,目前仅使用了 `labelTxt-v1.0` 中旋转框的标注。
+
+### 数据集切片
+
+我们提供了 `tools/dataset_converters/dota/dota_split.py` 脚本用于 DOTA 数据集的准备和切片。
+
+```shell
+python tools/dataset_converters/dota/dota_split.py \
+ [--splt-config ${SPLIT_CONFIG}] \
+ [--data-root ${DATA_ROOT}] \
+ [--out-dir ${OUT_DIR}] \
+ [--ann-subdir ${ANN_SUBDIR}] \
+ [--phase ${DATASET_PHASE}] \
+ [--nproc ${NPROC}] \
+ [--save-ext ${SAVE_EXT}] \
+ [--overwrite]
+```
+
+脚本依赖于 shapely 包,请先通过 `pip install shapely` 安装 shapely。
+
+**参数说明**:
+
+- `--splt-config` : 切片参数的配置文件。
+- `--data-root`: DOTA 数据集的存放位置。
+- `--out-dir`: 切片后的输出位置。
+- `--ann-subdir`: 标注文件夹的名字。 默认为 `labelTxt-v1.0` 。
+- `--phase`: 数据集的阶段。默认为 `trainval test` 。
+- `--nproc`: 进程数量。 默认为 8 。
+- `--save-ext`: 输出图像的扩展名,如置空则与原图保持一致。 默认为 `None` 。
+- `--overwrite`: 如果目标文件夹已存在,是否允许覆盖。
+
+基于 DOTA 数据集论文中提供的配置,我们提供了两种切片配置。
+
+`./split_config/single_scale.json` 用于单尺度 `single-scale` 切片
+`./split_config/multi_scale.json` 用于多尺度 `multi-scale` 切片
+
+DOTA 数据集通常使用 `trainval` 集进行训练,然后使用 `test` 集进行在线验证,大多数论文提供的也是在线验证的精度。
+如果你需要进行本地验证,可以准备 `train` 集和 `val` 集进行训练和测试。
+
+示例:
+
+使用单尺度切片配置准备 `trainval` 和 `test` 集
+
+```shell
+python tools/dataset_converters/dota/dota_split.py
+ --split-config 'tools/dataset_converters/dota/split_config/single_scale.json'
+ --data-root ${DATA_ROOT} \
+ --out-dir ${OUT_DIR}
+```
+
+准备 DOTA-v1.5 数据集,它的标注文件夹名字是 `labelTxt-v1.5`
+
+```shell
+python tools/dataset_converters/dota/dota_split.py
+ --split-config 'tools/dataset_converters/dota/split_config/single_scale.json'
+ --data-root ${DATA_ROOT} \
+ --out-dir ${OUT_DIR} \
+ --ann-subdir 'labelTxt-v1.5'
+```
+
+使用单尺度切片配置准备 `train` 和 `val` 集
+
+```shell
+python tools/dataset_converters/dota/dota_split.py
+ --split-config 'tools/dataset_converters/dota/split_config/single_scale.json'
+ --data-root ${DATA_ROOT} \
+ --phase train val \
+ --out-dir ${OUT_DIR}
+```
+
+使用多尺度切片配置准备 `trainval` 和 `test` 集
+
+```shell
+python tools/dataset_converters/dota/dota_split.py
+ --split-config 'tools/dataset_converters/dota/split_config/multi_scale.json'
+ --data-root ${DATA_ROOT} \
+ --out-dir ${OUT_DIR}
+```
+
+在运行完成后,输出的结构如下:
+
+```none
+${OUT_DIR}
+├── trainval
+│ ├── images
+│ │ ├── P0000__1024__0___0.png
+│ │ ├── ...
+│ ├── annfiles
+│ │ ├── P0000__1024__0___0.txt
+│ │ ├── ...
+├── test
+│ ├── images
+│ │ ├── P0006__1024__0___0.png
+│ │ ├── ...
+│ ├── annfiles
+│ │ ├── P0006__1024__0___0.txt
+│ │ ├── ...
+```
+
+此时将配置文件中的 `data_root` 修改为 ${OUT_DIR} 即可开始使用 DOTA 数据集训练。
diff --git a/third_party/mmyolo/docs/zh_cn/recommended_topics/deploy/easydeploy_guide.md b/third_party/mmyolo/docs/zh_cn/recommended_topics/deploy/easydeploy_guide.md
new file mode 100644
index 0000000000000000000000000000000000000000..8f337e6cfc2ed719a4761d5fa58bc1f0af210028
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/recommended_topics/deploy/easydeploy_guide.md
@@ -0,0 +1,5 @@
+# EasyDeploy 部署
+
+本项目作为 MMYOLO 的部署 project 单独存在,意图剥离 MMDeploy 当前的体系,独自支持用户完成模型训练后的转换和部署功能,使用户的学习和工程成本下降。
+
+当前支持对 ONNX 格式和 TensorRT 格式的转换,后续对其他推理平台也会支持起来。
diff --git a/third_party/mmyolo/docs/zh_cn/recommended_topics/deploy/index.rst b/third_party/mmyolo/docs/zh_cn/recommended_topics/deploy/index.rst
new file mode 100644
index 0000000000000000000000000000000000000000..3d5f08bc92c0e7037932ecfcd91462fe2db9738c
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/recommended_topics/deploy/index.rst
@@ -0,0 +1,16 @@
+MMDeploy 部署必备教程
+************************
+
+.. toctree::
+ :maxdepth: 1
+
+ mmdeploy_guide.md
+ mmdeploy_yolov5.md
+
+EasyDeploy 部署必备教程
+************************
+
+.. toctree::
+ :maxdepth: 1
+
+ easydeploy_guide.md
diff --git a/third_party/mmyolo/docs/zh_cn/recommended_topics/deploy/mmdeploy_guide.md b/third_party/mmyolo/docs/zh_cn/recommended_topics/deploy/mmdeploy_guide.md
new file mode 100644
index 0000000000000000000000000000000000000000..e935d36e99ee38bb743a1efa5d275d04d0be320d
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/recommended_topics/deploy/mmdeploy_guide.md
@@ -0,0 +1,415 @@
+# MMDeploy 部署
+
+## MMDeploy 介绍
+
+MMDeploy 是 [OpenMMLab](https://openmmlab.com/) 模型部署工具箱,**为各算法库提供统一的部署体验**。基于 MMDeploy,开发者可以轻松从训练 repo 生成指定硬件所需 SDK,省去大量适配时间。
+
+更多介绍和使用指南见 https://mmdeploy.readthedocs.io/zh_CN/latest/get_started.html
+
+## 算法支持列表
+
+目前支持的 model-backend 组合:
+
+| Model | Task | OnnxRuntime | TensorRT | Model config |
+| :----- | :-------------- | :---------: | :------: | :---------------------------------------------------------------------: |
+| YOLOv5 | ObjectDetection | Y | Y | [config](https://github.com/open-mmlab/mmyolo/tree/main/configs/yolov5) |
+| YOLOv6 | ObjectDetection | Y | Y | [config](https://github.com/open-mmlab/mmyolo/tree/main/configs/yolov6) |
+| YOLOX | ObjectDetection | Y | Y | [config](https://github.com/open-mmlab/mmyolo/tree/main/configs/yolox) |
+| RTMDet | ObjectDetection | Y | Y | [config](https://github.com/open-mmlab/mmyolo/tree/main/configs/rtmdet) |
+
+ncnn 和其他后端的支持会在后续支持。
+
+## 安装
+
+按照[说明](https://mmdeploy.readthedocs.io/zh_CN/latest/get_started.html)安装 mmdeploy。
+
+```{note}
+如果安装的是 mmdeploy 预编译包,那么也请通过 ‘git clone https://github.com/open-mmlab/mmdeploy.git –depth=1’ 下载 mmdeploy 源码。因为它包含了部署时所需的 tools 文件夹。
+```
+
+## MMYOLO 中部署相关配置说明
+
+所有部署配置文件在 [`configs/deploy`](../../../configs/deploy/) 目录下。
+
+您可以部署静态输入或者动态输入的模型,因此您需要修改模型配置文件中与此相关的数据处理流程。
+
+MMDeploy 将后处理整合到自定义的算子中,因此您可以修改 `codebase_config` 中的 `post_processing` 参数来调整后处理策略,参数描述如下:
+
+```python
+codebase_config = dict(
+ type='mmyolo',
+ task='ObjectDetection',
+ model_type='end2end',
+ post_processing=dict(
+ score_threshold=0.05,
+ confidence_threshold=0.005,
+ iou_threshold=0.5,
+ max_output_boxes_per_class=200,
+ pre_top_k=5000,
+ keep_top_k=100,
+ background_label_id=-1),
+ module=['mmyolo.deploy'])
+```
+
+- `score_threshold`:在 `nms` 之前筛选候选框的类别分数阈值。
+- `confidence_threshold`:在 `nms` 之前筛选候选框的置信度分数阈值。
+- `iou_threshold`:在 `nms` 中去除重复框的 `iou` 阈值。
+- `max_output_boxes_per_class`:每个类别最大的输出框数量。
+- `pre_top_k`:在 `nms` 之前对候选框分数排序然后固定候选框的个数。
+- `keep_top_k`:`nms` 算法最终输出的候选框个数。
+- `background_label_id`:MMYOLO 算法中没有背景类别信息,置为 `-1` 即可。
+
+### 静态输入配置
+
+#### (1) 模型配置文件介绍
+
+以 MMYOLO 中的 `YOLOv5` 模型配置为例,下面是对部署时使用的模型配置文件参数说明介绍。
+
+```python
+_base_ = '../../yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+test_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=_base_.backend_args),
+ dict(
+ type='LetterResize',
+ scale=_base_.img_scale,
+ allow_scale_up=False,
+ use_mini_pad=False,
+ ),
+ dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
+ dict(
+ type='mmdet.PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'pad_param'))
+]
+
+test_dataloader = dict(
+ dataset=dict(pipeline=test_pipeline, batch_shapes_cfg=None))
+```
+
+`_base_ = '../../yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'` 继承了训练时构建模型的配置。
+
+`test_pipeline` 为部署时对输入图像进行处理的流程,`LetterResize` 控制了输入图像的尺寸,同时限制了导出模型所能接受的输入尺寸。
+
+`test_dataloader` 为部署时构建数据加载器配置,`batch_shapes_cfg` 控制了是否启用 `batch_shapes` 策略,详细内容可以参考 [yolov5 配置文件说明](../../tutorials/config.md) 。
+
+#### (2) 部署配置文件介绍
+
+以 `MMYOLO` 中的 `YOLOv5` 部署配置为例,下面是对配置文件参数说明介绍。
+
+`ONNXRuntime` 部署 `YOLOv5` 可以使用 [`detection_onnxruntime_static.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_onnxruntime_static.py) 配置。
+
+```python
+_base_ = ['./base_static.py']
+codebase_config = dict(
+ type='mmyolo',
+ task='ObjectDetection',
+ model_type='end2end',
+ post_processing=dict(
+ score_threshold=0.05,
+ confidence_threshold=0.005,
+ iou_threshold=0.5,
+ max_output_boxes_per_class=200,
+ pre_top_k=5000,
+ keep_top_k=100,
+ background_label_id=-1),
+ module=['mmyolo.deploy'])
+backend_config = dict(type='onnxruntime')
+```
+
+`backend_config` 中指定了部署后端 `type='onnxruntime'`,其他信息可参考第三小节。
+
+`TensorRT` 部署 `YOLOv5` 可以使用 [`detection_tensorrt_static-640x640.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_tensorrt_static-640x640.py) 配置。
+
+```python
+_base_ = ['./base_static.py']
+onnx_config = dict(input_shape=(640, 640))
+backend_config = dict(
+ type='tensorrt',
+ common_config=dict(fp16_mode=False, max_workspace_size=1 << 30),
+ model_inputs=[
+ dict(
+ input_shapes=dict(
+ input=dict(
+ min_shape=[1, 3, 640, 640],
+ opt_shape=[1, 3, 640, 640],
+ max_shape=[1, 3, 640, 640])))
+ ])
+use_efficientnms = False
+```
+
+`backend_config` 中指定了后端 `type=‘tensorrt’`。
+
+与 `ONNXRuntime` 部署配置不同的是,`TensorRT` 需要指定输入图片尺寸和构建引擎文件需要的参数,包括:
+
+- `onnx_config` 中指定 `input_shape=(640, 640)`
+- `backend_config['common_config']` 中包括 `fp16_mode=False` 和 `max_workspace_size=1 << 30`, `fp16_mode` 表示是否以 `fp16` 的参数格式构建引擎,`max_workspace_size` 表示当前 `gpu` 设备最大显存, 单位为 `GB`。`fp16` 的详细配置可以参考 [`detection_tensorrt-fp16_static-640x640.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_tensorrt-fp16_static-640x640.py)
+- `backend_config['model_inputs']['input_shapes']['input']` 中 `min_shape` /`opt_shape`/`max_shape` 对应的值在静态输入下应该保持相同,即默认均为 `[1, 3, 640, 640]`。
+
+`use_efficientnms` 是 `MMYOLO` 系列新引入的配置,表示在导出 `onnx` 时是否启用`Efficient NMS Plugin`来替换 `MMDeploy` 中的 `TRTBatchedNMS plugin` 。
+
+可以参考 `TensorRT` 官方实现的 [Efficient NMS Plugin](https://github.com/NVIDIA/TensorRT/blob/main/plugin/efficientNMSPlugin/README.md) 获取更多详细信息。
+
+**注意**,这个功能仅仅在 TensorRT >= 8.0 版本才能使用,无需编译开箱即用。
+
+### 动态输入配置
+
+#### (1) 模型配置文件介绍
+
+当您部署动态输入模型时,您无需修改任何模型配置文件,仅需要修改部署配置文件即可。
+
+#### (2) 部署配置文件介绍
+
+`ONNXRuntime` 部署 `YOLOv5` 可以使用 [`detection_onnxruntime_dynamic.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_onnxruntime_dynamic.py) 配置。
+
+```python
+_base_ = ['./base_dynamic.py']
+codebase_config = dict(
+ type='mmyolo',
+ task='ObjectDetection',
+ model_type='end2end',
+ post_processing=dict(
+ score_threshold=0.05,
+ confidence_threshold=0.005,
+ iou_threshold=0.5,
+ max_output_boxes_per_class=200,
+ pre_top_k=5000,
+ keep_top_k=100,
+ background_label_id=-1),
+ module=['mmyolo.deploy'])
+backend_config = dict(type='onnxruntime')
+```
+
+`backend_config` 中指定了后端 `type='onnxruntime'`,其他配置与上一节在 ONNXRuntime 部署静态输入模型相同。
+
+`TensorRT` 部署 `YOLOv5` 可以使用 [`detection_tensorrt_dynamic-192x192-960x960.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_tensorrt_dynamic-192x192-960x960.py) 配置。
+
+```python
+_base_ = ['./base_dynamic.py']
+backend_config = dict(
+ type='tensorrt',
+ common_config=dict(fp16_mode=False, max_workspace_size=1 << 30),
+ model_inputs=[
+ dict(
+ input_shapes=dict(
+ input=dict(
+ min_shape=[1, 3, 192, 192],
+ opt_shape=[1, 3, 640, 640],
+ max_shape=[1, 3, 960, 960])))
+ ])
+use_efficientnms = False
+```
+
+`backend_config` 中指定了后端 `type='tensorrt'`,由于 `TensorRT` 动态输入与静态输入有所不同,您可以了解更多动态输入相关信息通过访问 [TensorRT dynamic input official introduction](https://docs.nvidia.com/deeplearning/tensorrt/archives/tensorrt-843/developer-guide/index.html#work_dynamic_shapes)。
+
+`TensorRT` 部署需要配置 `min_shape`, `opt_shape`, `max_shape` ,`TensorRT` 限制输入图片的尺寸在 `min_shape` 和 ` max_shape` 之间。
+
+`min_shape` 为输入图片的最小尺寸,`opt_shape` 为输入图片常见尺寸, 在这个尺寸下推理性能最好,`max_shape` 为输入图片的最大尺寸。
+
+`use_efficientnms` 配置与上节 `TensorRT` 静态输入配置相同。
+
+### INT8 量化配置
+
+!!! 部署 TensorRT INT8 模型教程即将发布 !!!
+
+## 模型转换
+
+### 使用方法
+
+#### 从源码安装的 MMDeploy
+
+设置 `MMDeploy` 根目录为环境变量 `MMDEPLOY_DIR` ,例如 `export MMDEPLOY_DIR=/the/root/path/of/MMDeploy`
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ ${DEPLOY_CFG_PATH} \
+ ${MODEL_CFG_PATH} \
+ ${MODEL_CHECKPOINT_PATH} \
+ ${INPUT_IMG} \
+ --test-img ${TEST_IMG} \
+ --work-dir ${WORK_DIR} \
+ --calib-dataset-cfg ${CALIB_DATA_CFG} \
+ --device ${DEVICE} \
+ --log-level INFO \
+ --show \
+ --dump-info
+```
+
+### 参数描述
+
+- `deploy_cfg` : mmdeploy 针对此模型的部署配置,包含推理框架类型、是否量化、输入 shape 是否动态等。配置文件之间可能有引用关系,`configs/deploy/detection_onnxruntime_static.py` 是一个示例。
+- `model_cfg` : MMYOLO 算法库的模型配置,例如 `configs/deploy/model/yolov5_s-deploy.py`, 与 mmdeploy 的路径无关。
+- `checkpoint` : torch 模型路径。可以 http/https 开头,详见 `mmengine.fileio` 的实现。
+- `img` : 模型转换时,用做测试的图像文件路径。
+- `--test-img` : 用于测试模型的图像文件路径。默认设置成`None`。
+- `--work-dir` : 工作目录,用来保存日志和模型文件。
+- `--calib-dataset-cfg` : 此参数只有int8模式下生效,用于校准数据集配置文件。若在int8模式下未传入参数,则会自动使用模型配置文件中的'val'数据集进行校准。
+- `--device` : 用于模型转换的设备。 默认是`cpu`,对于 trt 可使用 `cuda:0` 这种形式。
+- `--log-level` : 设置日记的等级,选项包括`'CRITICAL', 'FATAL', 'ERROR', 'WARN', 'WARNING', 'INFO', 'DEBUG', 'NOTSET'`。 默认是`INFO`。
+- `--show` : 是否显示检测的结果。
+- `--dump-info` : 是否输出 SDK 信息。
+
+#### 通过 pip install 安装的 MMDeploy
+
+假设当前的工作目录为 mmyolo 的根目录, 那么以 [YoloV5](https://github.com/open-mmlab/mmyolo/blob/main/configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py) 模型为例,你可以从[此处](https://download.openmmlab.com/mmyolo/v0/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth)下载对应的 checkpoint,并使用以下代码将之转换为 onnx 模型:
+
+```python
+from mmdeploy.apis import torch2onnx
+from mmdeploy.backend.sdk.export_info import export2SDK
+
+img = 'demo/demo.jpg'
+work_dir = 'mmdeploy_models/mmyolo/onnx'
+save_file = 'end2end.onnx'
+deploy_cfg = 'configs/deploy/detection_onnxruntime_dynamic.py'
+model_cfg = 'configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+model_checkpoint = 'checkpoints/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth'
+device = 'cpu'
+
+# 1. convert model to onnx
+torch2onnx(img, work_dir, save_file, deploy_cfg, model_cfg,
+ model_checkpoint, device)
+
+# 2. extract pipeline info for inference by MMDeploy SDK
+export2SDK(deploy_cfg, model_cfg, work_dir, pth=model_checkpoint,
+ device=device)
+```
+
+## 模型规范
+
+在使用转换后的模型进行推理之前,有必要了解转换结果的结构。 它存放在 `--work-dir` 指定的路路径下。
+
+上例中的`mmdeploy_models/mmyolo/onnx`,结构如下:
+
+```
+mmdeploy_models/mmyolo/onnx
+├── deploy.json
+├── detail.json
+├── end2end.onnx
+└── pipeline.json
+```
+
+重要的是:
+
+- **end2end.onnx**: 推理引擎文件。可用 ONNX Runtime 推理
+- ***xxx*.json**: mmdeploy SDK 推理所需的 meta 信息
+
+整个文件夹被定义为**mmdeploy SDK model**。换言之,**mmdeploy SDK model**既包括推理引擎,也包括推理 meta 信息。
+
+## 模型推理
+
+### 后端模型推理
+
+以上述模型转换后的 `end2end.onnx` 为例,你可以使用如下代码进行推理:
+
+```python
+from mmdeploy.apis.utils import build_task_processor
+from mmdeploy.utils import get_input_shape, load_config
+import torch
+
+deploy_cfg = 'configs/deploy/detection_onnxruntime_dynamic.py'
+model_cfg = 'configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+device = 'cpu'
+backend_model = ['mmdeploy_models/mmyolo/onnx/end2end.onnx']
+image = 'demo/demo.jpg'
+
+# read deploy_cfg and model_cfg
+deploy_cfg, model_cfg = load_config(deploy_cfg, model_cfg)
+
+# build task and backend model
+task_processor = build_task_processor(model_cfg, deploy_cfg, device)
+model = task_processor.build_backend_model(backend_model)
+
+# process input image
+input_shape = get_input_shape(deploy_cfg)
+model_inputs, _ = task_processor.create_input(image, input_shape)
+
+# do model inference
+with torch.no_grad():
+ result = model.test_step(model_inputs)
+
+# visualize results
+task_processor.visualize(
+ image=image,
+ model=model,
+ result=result[0],
+ window_name='visualize',
+ output_file='work_dir/output_detection.png')
+```
+
+运行上述代码后,你可以在 `work_dir` 中看到推理的结果图片 `output_detection.png`。
+
+### SDK模型推理
+
+你也可以参考如下代码,对 SDK model 进行推理:
+
+```python
+from mmdeploy_runtime import Detector
+import cv2
+
+img = cv2.imread('demo/demo.jpg')
+
+# create a detector
+detector = Detector(model_path='mmdeploy_models/mmyolo/onnx',
+ device_name='cpu', device_id=0)
+# perform inference
+bboxes, labels, masks = detector(img)
+
+# visualize inference result
+indices = [i for i in range(len(bboxes))]
+for index, bbox, label_id in zip(indices, bboxes, labels):
+ [left, top, right, bottom], score = bbox[0:4].astype(int), bbox[4]
+ if score < 0.3:
+ continue
+
+ cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0))
+
+cv2.imwrite('work_dir/output_detection.png', img)
+```
+
+除了python API,mmdeploy SDK 还提供了诸如 C、C++、C#、Java等多语言接口。
+你可以参考[样例](https://github.com/open-mmlab/mmdeploy/tree/main/demo)学习其他语言接口的使用方法。
+
+## 模型评测
+
+当您将 PyTorch 模型转换为后端支持的模型后,您可能需要验证模型的精度,使用 `${MMDEPLOY_DIR}/tools/test.py`
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/test.py \
+ ${DEPLOY_CFG} \
+ ${MODEL_CFG} \
+ --model ${BACKEND_MODEL_FILES} \
+ --device ${DEVICE} \
+ --work-dir ${WORK_DIR} \
+ [--cfg-options ${CFG_OPTIONS}] \
+ [--show] \
+ [--show-dir ${OUTPUT_IMAGE_DIR}] \
+ [--interval ${INTERVAL}] \
+ [--wait-time ${WAIT_TIME}] \
+ [--log2file work_dirs/output.txt]
+ [--speed-test] \
+ [--warmup ${WARM_UP}] \
+ [--log-interval ${LOG_INTERVERL}] \
+ [--batch-size ${BATCH_SIZE}] \
+ [--uri ${URI}]
+```
+
+### 参数描述
+
+- `deploy_cfg`: 部署配置文件。
+- `model_cfg`: MMYOLO 模型配置文件。
+- `--model`: 导出的后端模型。 例如, 如果我们导出了 TensorRT 模型,我们需要传入后缀为 ".engine" 文件路径。
+- `--device`: 运行模型的设备。请注意,某些后端会限制设备。例如,TensorRT 必须在 cuda 上运行。
+- `--work-dir`: 模型转换、报告生成的路径。
+- `--cfg-options`: 传入额外的配置,将会覆盖当前部署配置。
+- `--show`: 是否在屏幕上显示评估结果。
+- `--show-dir`: 保存评估结果的目录。(只有给出这个参数才会保存结果)。
+- `--interval`: 屏幕上显示评估结果的间隔。
+- `--wait-time`: 每个窗口的显示时间
+- `--log2file`: 将评估结果(和速度)记录到文件中。
+- `--speed-test`: 是否开启速度测试。
+- `--warmup`: 在计算推理时间之前进行预热,需要先开启 `speed-test`。
+- `--log-interval`: 每个日志之间的间隔,需要先设置 `speed-test`。
+- `--batch-size`: 推理的批量大小,它将覆盖数据配置中的 `samples_per_gpu`。默认为 `1`。请注意,并非所有模型都支持 `batch_size > 1`。
+- `--uri`: 在边缘设备上推理时的 ipv4 或 ipv6 端口号。
+
+注意:`${MMDEPLOY_DIR}/tools/test.py` 中的其他参数用于速度测试。他们不影响评估。
diff --git a/third_party/mmyolo/docs/zh_cn/recommended_topics/deploy/mmdeploy_yolov5.md b/third_party/mmyolo/docs/zh_cn/recommended_topics/deploy/mmdeploy_yolov5.md
new file mode 100644
index 0000000000000000000000000000000000000000..e035e17641559853ae44c59b16c2c151f7073abd
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/recommended_topics/deploy/mmdeploy_yolov5.md
@@ -0,0 +1,572 @@
+# YOLOv5 部署全流程说明
+
+请先参考 [`部署必备指南`](./mmdeploy_guide.md) 了解部署配置文件等相关信息。
+
+## 模型训练和测试
+
+模型训练和测试请参考 [YOLOv5 从入门到部署全流程](./mmdeploy_yolov5.md) 。
+
+## 准备 MMDeploy 运行环境
+
+安装 `MMDeploy` 请参考 [`源码手动安装`](https://github.com/open-mmlab/mmdeploy/blob/dev-1.x/docs/zh_cn/01-how-to-build/build_from_source.md) ,选择您所使用的平台编译 `MMDeploy` 和自定义算子。
+
+*注意!* 如果环境安装有问题,可以查看 [`MMDeploy FAQ`](https://github.com/open-mmlab/mmdeploy/blob/dev-1.x/docs/zh_cn/faq.md) 或者在 `issuse` 中提出您的问题。
+
+## 准备模型配置文件
+
+本例将以基于 `coco` 数据集预训练的 `YOLOv5` 配置和权重进行部署的全流程讲解,包括静态/动态输入模型导出和推理,`TensorRT` / `ONNXRuntime` 两种后端部署和测试。
+
+### 静态输入配置
+
+#### (1) 模型配置文件
+
+当您需要部署静态输入模型时,您应该确保模型的输入尺寸是固定的,比如在测试流程或测试数据集加载时输入尺寸为 `640x640`。
+
+您可以查看 [`yolov5_s-static.py`](https://github.com/open-mmlab/mmyolo/tree/main/configs/deploy/model/yolov5_s-static.py) 中测试流程或测试数据集加载部分,如下所示:
+
+```python
+_base_ = '../../yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+test_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=_base_.backend_args),
+ dict(
+ type='LetterResize',
+ scale=_base_.img_scale,
+ allow_scale_up=False,
+ use_mini_pad=False,
+ ),
+ dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
+ dict(
+ type='mmdet.PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'pad_param'))
+]
+
+test_dataloader = dict(
+ dataset=dict(pipeline=test_pipeline, batch_shapes_cfg=None))
+```
+
+由于 `yolov5` 在测试时会开启 `allow_scale_up` 和 `use_mini_pad` 改变输入图像的尺寸来取得更高的精度,但是会给部署静态输入模型造成输入尺寸不匹配的问题。
+
+该配置相比与原始配置文件进行了如下修改:
+
+- 关闭 `test_pipline` 中改变尺寸相关的配置,如 `LetterResize` 中 `allow_scale_up=False` 和 `use_mini_pad=False` 。
+- 关闭 `test_dataloader` 中 `batch shapes` 策略,即 `batch_shapes_cfg=None` 。
+
+#### (2) 部署配置文件
+
+当您部署在 `ONNXRuntime` 时,您可以查看 [`detection_onnxruntime_static.py`](https://github.com/open-mmlab/mmyolo/tree/main/configs/deploy/detection_onnxruntime_static.py) ,如下所示:
+
+```python
+_base_ = ['./base_static.py']
+codebase_config = dict(
+ type='mmyolo',
+ task='ObjectDetection',
+ model_type='end2end',
+ post_processing=dict(
+ score_threshold=0.05,
+ confidence_threshold=0.005,
+ iou_threshold=0.5,
+ max_output_boxes_per_class=200,
+ pre_top_k=5000,
+ keep_top_k=100,
+ background_label_id=-1),
+ module=['mmyolo.deploy'])
+backend_config = dict(type='onnxruntime')
+```
+
+默认配置中的 `post_processing` 后处理参数是当前模型与 `pytorch` 模型精度对齐的配置,若您需要修改相关参数,可以参考 [`部署必备指南`](./mmdeploy_guide.md) 的详细介绍。
+
+当您部署在 `TensorRT` 时,您可以查看 [`detection_tensorrt_static-640x640.py`](https://github.com/open-mmlab/mmyolo/tree/main/configs/deploy/detection_tensorrt_static-640x640.py) ,如下所示:
+
+```python
+_base_ = ['./base_static.py']
+onnx_config = dict(input_shape=(640, 640))
+backend_config = dict(
+ type='tensorrt',
+ common_config=dict(fp16_mode=False, max_workspace_size=1 << 30),
+ model_inputs=[
+ dict(
+ input_shapes=dict(
+ input=dict(
+ min_shape=[1, 3, 640, 640],
+ opt_shape=[1, 3, 640, 640],
+ max_shape=[1, 3, 640, 640])))
+ ])
+use_efficientnms = False
+```
+
+本例使用了默认的输入尺寸 `input_shape=(640, 640)` ,构建网络以 `fp32` 模式即 `fp16_mode=False`,并且默认构建 `TensorRT` 构建引擎所使用的显存 `max_workspace_size=1 << 30` 即最大为 `1GB` 显存。
+
+### 动态输入配置
+
+#### (1) 模型配置文件
+
+当您需要部署动态输入模型时,模型的输入可以为任意尺寸(`TensorRT` 会限制最小和最大输入尺寸),因此使用默认的 [`yolov5_s-v61_syncbn_8xb16-300e_coco.py`](https://github.com/open-mmlab/mmyolo/tree/main/configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py) 模型配置文件即可,其中数据处理和数据集加载器部分如下所示:
+
+```python
+batch_shapes_cfg = dict(
+ type='BatchShapePolicy',
+ batch_size=val_batch_size_per_gpu,
+ img_size=img_scale[0],
+ size_divisor=32,
+ extra_pad_ratio=0.5)
+
+test_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=_base_.backend_args),
+ dict(type='YOLOv5KeepRatioResize', scale=img_scale),
+ dict(
+ type='LetterResize',
+ scale=img_scale,
+ allow_scale_up=False,
+ pad_val=dict(img=114)),
+ dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
+ dict(
+ type='mmdet.PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'pad_param'))
+]
+
+val_dataloader = dict(
+ batch_size=val_batch_size_per_gpu,
+ num_workers=val_num_workers,
+ persistent_workers=persistent_workers,
+ pin_memory=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ test_mode=True,
+ data_prefix=dict(img='val2017/'),
+ ann_file='annotations/instances_val2017.json',
+ pipeline=test_pipeline,
+ batch_shapes_cfg=batch_shapes_cfg))
+```
+
+其中 `LetterResize` 类初始化传入了 `allow_scale_up=False` 控制输入的小图像是否上采样,同时默认 `use_mini_pad=False` 关闭了图片最小填充策略,`val_dataloader['dataset']`中传入了 `batch_shapes_cfg=batch_shapes_cfg`,即按照 `batch` 内的输入尺寸进行最小填充。上述策略会改变输入图像的尺寸,因此动态输入模型在测试时会按照上述数据集加载器动态输入。
+
+#### (2) 部署配置文件
+
+当您部署在 `ONNXRuntime` 时,您可以查看 [`detection_onnxruntime_dynamic.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_onnxruntime_dynamic.py) ,如下所示:
+
+```python
+_base_ = ['./base_dynamic.py']
+codebase_config = dict(
+ type='mmyolo',
+ task='ObjectDetection',
+ model_type='end2end',
+ post_processing=dict(
+ score_threshold=0.05,
+ confidence_threshold=0.005,
+ iou_threshold=0.5,
+ max_output_boxes_per_class=200,
+ pre_top_k=5000,
+ keep_top_k=100,
+ background_label_id=-1),
+ module=['mmyolo.deploy'])
+backend_config = dict(type='onnxruntime')
+```
+
+与静态输入配置仅有 `_base_ = ['./base_dynamic.py']` 不同,动态输入会额外继承 `dynamic_axes` 属性。其他配置与静态输入配置相同。
+
+当您部署在 `TensorRT` 时,您可以查看 [`detection_tensorrt_dynamic-192x192-960x960.py`](https://github.com/open-mmlab/mmyolo/tree/main/configs/deploy/detection_tensorrt_dynamic-192x192-960x960.py) ,如下所示:
+
+```python
+_base_ = ['./base_dynamic.py']
+backend_config = dict(
+ type='tensorrt',
+ common_config=dict(fp16_mode=False, max_workspace_size=1 << 30),
+ model_inputs=[
+ dict(
+ input_shapes=dict(
+ input=dict(
+ min_shape=[1, 3, 192, 192],
+ opt_shape=[1, 3, 640, 640],
+ max_shape=[1, 3, 960, 960])))
+ ])
+use_efficientnms = False
+```
+
+本例构建网络以 `fp32` 模式即 `fp16_mode=False`,构建 `TensorRT` 构建引擎所使用的显存 `max_workspace_size=1 << 30` 即最大为 `1GB` 显存。
+
+同时默认配置 `min_shape=[1, 3, 192, 192]`,`opt_shape=[1, 3, 640, 640]` ,`max_shape=[1, 3, 960, 960]` ,意为该模型所能接受的输入尺寸最小为 `192x192` ,最大为 `960x960`,最常见尺寸为 `640x640`。
+
+当您部署自己的模型时,需要根据您的输入图像尺寸进行调整。
+
+## 模型转换
+
+本教程所使用的 `MMDeploy` 根目录为 `/home/openmmlab/dev/mmdeploy`,请注意修改为您的 `MMDeploy` 目录。
+预训练权重下载于 [yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth](https://download.openmmlab.com/mmyolo/v0/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth) ,保存在本地的 `/home/openmmlab/dev/mmdeploy/yolov5s.pth`。
+
+```shell
+wget https://download.openmmlab.com/mmyolo/v0/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth -O /home/openmmlab/dev/mmdeploy/yolov5s.pth
+```
+
+命令行执行以下命令配置相关路径:
+
+```shell
+export MMDEPLOY_DIR=/home/openmmlab/dev/mmdeploy
+export PATH_TO_CHECKPOINTS=/home/openmmlab/dev/mmdeploy/yolov5s.pth
+```
+
+### YOLOv5 静态输入模型导出
+
+#### ONNXRuntime
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_onnxruntime_static.py \
+ configs/deploy/model/yolov5_s-static.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir \
+ --show \
+ --device cpu
+```
+
+#### TensorRT
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_tensorrt_static-640x640.py \
+ configs/deploy/model/yolov5_s-static.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir \
+ --show \
+ --device cuda:0
+```
+
+### YOLOv5 动态输入模型导出
+
+#### ONNXRuntime
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_onnxruntime_dynamic.py \
+ configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir \
+ --show \
+ --device cpu
+ --dump-info
+```
+
+#### TensorRT
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_tensorrt_dynamic-192x192-960x960.py \
+ configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir \
+ --show \
+ --device cuda:0
+ --dump-info
+```
+
+当您使用上述命令转换模型时,您将会在 `work_dir` 文件夹下发现以下文件:
+
+
+
+或者
+
+
+
+在导出 `onnxruntime`模型后,您将得到图1的六个文件,其中 `end2end.onnx` 表示导出的`onnxruntime`模型,`xxx.json` 表示 `MMDeploy SDK` 推理所需要的 meta 信息。
+
+在导出 `TensorRT`模型后,您将得到图2的七个文件,其中 `end2end.onnx` 表示导出的中间模型,`MMDeploy`利用该模型自动继续转换获得 `end2end.engine` 模型用于 `TensorRT `部署,`xxx.json` 表示 `MMDeploy SDK` 推理所需要的 meta 信息。
+
+## 模型评测
+
+当您转换模型成功后,可以使用 `${MMDEPLOY_DIR}/tools/test.py` 工具对转换后的模型进行评测。下面是对 `ONNXRuntime` 和 `TensorRT` 静态模型的评测,动态模型评测修改传入模型配置即可。
+
+### ONNXRuntime
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/test.py \
+ configs/deploy/detection_onnxruntime_static.py \
+ configs/deploy/model/yolov5_s-static.py \
+ --model work_dir/end2end.onnx \
+ --device cpu \
+ --work-dir work_dir
+```
+
+执行完成您将看到命令行输出检测结果指标如下:
+
+
+
+### TensorRT
+
+**注意**: TensorRT 需要执行设备是 `cuda`
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/test.py \
+ configs/deploy/detection_tensorrt_static-640x640.py \
+ configs/deploy/model/yolov5_s-static.py \
+ --model work_dir/end2end.engine \
+ --device cuda:0 \
+ --work-dir work_dir
+```
+
+执行完成您将看到命令行输出检测结果指标如下:
+
+
+
+**未来我们将会支持模型测速等更加实用的脚本**
+
+# 使用 Docker 部署测试
+
+`MMYOLO` 提供了一个 [`Dockerfile`](https://github.com/open-mmlab/mmyolo/blob/main/docker/Dockerfile_deployment) 用于构建镜像。请确保您的 `docker` 版本大于等于 `19.03`。
+
+温馨提示;国内用户建议取消掉 [`Dockerfile`](https://github.com/open-mmlab/mmyolo/blob/main/docker/Dockerfile_deployment) 里面 `Optional` 后两行的注释,可以获得火箭一般的下载提速:
+
+```dockerfile
+# (Optional)
+RUN sed -i 's/http:\/\/archive.ubuntu.com\/ubuntu\//http:\/\/mirrors.aliyun.com\/ubuntu\//g' /etc/apt/sources.list && \
+ pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
+```
+
+构建命令:
+
+```bash
+# build an image with PyTorch 1.12, CUDA 11.6, TensorRT 8.2.4 ONNXRuntime 1.8.1
+docker build -f docker/Dockerfile_deployment -t mmyolo:v1 .
+```
+
+用以下命令运行 Docker 镜像:
+
+```bash
+export DATA_DIR=/path/to/your/dataset
+docker run --gpus all --shm-size=8g -it --name mmyolo -v ${DATA_DIR}:/openmmlab/mmyolo/data/coco mmyolo:v1
+```
+
+`DATA_DIR` 是 COCO 数据的路径。
+
+复制以下脚本到 `docker` 容器 `/openmmlab/mmyolo/script.sh`:
+
+```bash
+#!/bin/bash
+wget -q https://download.openmmlab.com/mmyolo/v0/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth \
+ -O yolov5s.pth
+export MMDEPLOY_DIR=/openmmlab/mmdeploy
+export PATH_TO_CHECKPOINTS=/openmmlab/mmyolo/yolov5s.pth
+
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_tensorrt_static-640x640.py \
+ configs/deploy/model/yolov5_s-static.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir_trt \
+ --device cuda:0
+
+python3 ${MMDEPLOY_DIR}/tools/test.py \
+ configs/deploy/detection_tensorrt_static-640x640.py \
+ configs/deploy/model/yolov5_s-static.py \
+ --model work_dir_trt/end2end.engine \
+ --device cuda:0 \
+ --work-dir work_dir_trt
+
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_onnxruntime_static.py \
+ configs/deploy/model/yolov5_s-static.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir_ort \
+ --device cpu
+
+python3 ${MMDEPLOY_DIR}/tools/test.py \
+ configs/deploy/detection_onnxruntime_static.py \
+ configs/deploy/model/yolov5_s-static.py \
+ --model work_dir_ort/end2end.onnx \
+ --device cpu \
+ --work-dir work_dir_ort
+```
+
+在 `/openmmlab/mmyolo` 下运行:
+
+```bash
+sh script.sh
+```
+
+脚本会自动下载 `MMYOLO` 的 `YOLOv5` 预训练权重并使用 `MMDeploy` 进行模型转换和测试。您将会看到以下输出:
+
+- TensorRT:
+
+ 
+
+- ONNXRuntime:
+
+ 
+
+可以看到,经过 `MMDeploy` 部署的模型与 [MMYOLO-YOLOv5](https://github.com/open-mmlab/mmyolo/tree/main/configs/yolov5#results-and-models) 的 mAP-37.7 差距在 1% 以内。
+
+如果您需要测试您的模型推理速度,可以使用以下命令:
+
+- TensorRT
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/profiler.py \
+ configs/deploy/detection_tensorrt_static-640x640.py \
+ configs/deploy/model/yolov5_s-static.py \
+ data/coco/val2017 \
+ --model work_dir_trt/end2end.engine \
+ --device cuda:0
+```
+
+- ONNXRuntime
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/profiler.py \
+ configs/deploy/detection_onnxruntime_static.py \
+ configs/deploy/model/yolov5_s-static.py \
+ data/coco/val2017 \
+ --model work_dir_ort/end2end.onnx \
+ --device cpu
+```
+
+## 模型推理
+
+### 后端模型推理
+
+#### ONNXRuntime
+
+以上述模型转换后的 `end2end.onnx` 为例,您可以使用如下代码进行推理:
+
+```python
+from mmdeploy.apis.utils import build_task_processor
+from mmdeploy.utils import get_input_shape, load_config
+import torch
+
+deploy_cfg = './configs/deploy/detection_onnxruntime_dynamic.py'
+model_cfg = '../mmyolo/configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+device = 'cpu'
+backend_model = ['./work_dir/end2end.onnx']
+image = '../mmyolo/demo/demo.jpg'
+
+# read deploy_cfg and model_cfg
+deploy_cfg, model_cfg = load_config(deploy_cfg, model_cfg)
+
+# build task and backend model
+task_processor = build_task_processor(model_cfg, deploy_cfg, device)
+model = task_processor.build_backend_model(backend_model)
+
+# process input image
+input_shape = get_input_shape(deploy_cfg)
+model_inputs, _ = task_processor.create_input(image, input_shape)
+
+# do model inference
+with torch.no_grad():
+ result = model.test_step(model_inputs)
+
+# visualize results
+task_processor.visualize(
+ image=image,
+ model=model,
+ result=result[0],
+ window_name='visualize',
+ output_file='work_dir/output_detection.png')
+```
+
+#### TensorRT
+
+以上述模型转换后的 `end2end.engine` 为例,您可以使用如下代码进行推理:
+
+```python
+from mmdeploy.apis.utils import build_task_processor
+from mmdeploy.utils import get_input_shape, load_config
+import torch
+
+deploy_cfg = './configs/deploy/detection_tensorrt_dynamic-192x192-960x960.py'
+model_cfg = '../mmyolo/configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+device = 'cuda:0'
+backend_model = ['./work_dir/end2end.engine']
+image = '../mmyolo/demo/demo.jpg'
+
+# read deploy_cfg and model_cfg
+deploy_cfg, model_cfg = load_config(deploy_cfg, model_cfg)
+
+# build task and backend model
+task_processor = build_task_processor(model_cfg, deploy_cfg, device)
+model = task_processor.build_backend_model(backend_model)
+
+# process input image
+input_shape = get_input_shape(deploy_cfg)
+model_inputs, _ = task_processor.create_input(image, input_shape)
+
+# do model inference
+with torch.no_grad():
+ result = model.test_step(model_inputs)
+
+# visualize results
+task_processor.visualize(
+ image=image,
+ model=model,
+ result=result[0],
+ window_name='visualize',
+ output_file='work_dir/output_detection.png')
+```
+
+### SDK 模型推理
+
+#### ONNXRuntime
+
+以上述模型转换后的 `end2end.onnx` 为例,您可以使用如下代码进行 `SDK` 推理:
+
+```python
+from mmdeploy_runtime import Detector
+import cv2
+
+img = cv2.imread('../mmyolo/demo/demo.jpg')
+
+# create a detector
+detector = Detector(model_path='work_dir',
+ device_name='cpu', device_id=0)
+# perform inference
+bboxes, labels, masks = detector(img)
+
+# visualize inference result
+indices = [i for i in range(len(bboxes))]
+for index, bbox, label_id in zip(indices, bboxes, labels):
+ [left, top, right, bottom], score = bbox[0:4].astype(int), bbox[4]
+ if score < 0.3:
+ continue
+
+ cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0))
+
+cv2.imwrite('work_dir/output_detection.png', img)
+```
+
+#### TensorRT
+
+以上述模型转换后的 `end2end.engine` 为例,您可以使用如下代码进行 `SDK` 推理:
+
+```python
+from mmdeploy_runtime import Detector
+import cv2
+
+img = cv2.imread('../mmyolo/demo/demo.jpg')
+
+# create a detector
+detector = Detector(model_path='work_dir',
+ device_name='cuda', device_id=0)
+# perform inference
+bboxes, labels, masks = detector(img)
+
+# visualize inference result
+indices = [i for i in range(len(bboxes))]
+for index, bbox, label_id in zip(indices, bboxes, labels):
+ [left, top, right, bottom], score = bbox[0:4].astype(int), bbox[4]
+ if score < 0.3:
+ continue
+
+ cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0))
+
+cv2.imwrite('work_dir/output_detection.png', img)
+```
+
+除了python API,mmdeploy SDK 还提供了诸如 C、C++、C#、Java等多语言接口。
+你可以参考[样例](https://github.com/open-mmlab/mmdeploy/tree/main/demo)学习其他语言接口的使用方法。
diff --git a/third_party/mmyolo/docs/zh_cn/recommended_topics/labeling_to_deployment_tutorials.md b/third_party/mmyolo/docs/zh_cn/recommended_topics/labeling_to_deployment_tutorials.md
new file mode 100644
index 0000000000000000000000000000000000000000..d4e3ddf8f6a107d19cf48f5677d75f47a7b7351c
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/recommended_topics/labeling_to_deployment_tutorials.md
@@ -0,0 +1,1326 @@
+# 标注+训练+测试+部署全流程
+
+在平时的工作学习中,我们经常会遇到一些任务需要训练自定义的私有数据集,开源数据集去作为上线模型的场景比较少,这就需要我们对自己的私有数据集进行一系列的操作,以确保模型能够上线生产服务于客户。
+
+```{SeeAlso}
+本文档配套的视频已发布在 B 站,可前去查看: [自定义数据集从标注到部署保姆级教程](https://www.bilibili.com/video/BV1RG4y137i5)
+```
+
+```{Note}
+本教程所有指令是在 Linux 上面完成,Windows 也是完全可用的,但是命令和操作稍有不同。
+```
+
+本教程默认您已经完成 MMYOLO 的安装,如果未安装,请参考文档 [开始你的第一步](https://mmyolo.readthedocs.io/zh_CN/latest/get_started.html#id1) 进行安装。
+
+本教程涵盖从 用户自定义图片数据集标注 到 最终进行训练和部署 的整体流程。步骤概览如下:
+
+01. 数据集准备:`tools/misc/download_dataset.py`
+02. 使用 [labelme](https://github.com/wkentaro/labelme) 和算法进行辅助和优化数据集标注:`demo/image_demo.py` + labelme
+03. 使用脚本转换成 COCO 数据集格式:`tools/dataset_converters/labelme2coco.py`
+04. 数据集划分为训练集、验证集和测试集:`tools/misc/coco_split.py`
+05. 根据数据集内容新建 config 文件
+06. 数据集可视化分析:`tools/analysis_tools/dataset_analysis.py`
+07. 优化 Anchor 尺寸:`tools/analysis_tools/optimize_anchors.py`
+08. 可视化 config 配置中数据处理部分: `tools/analysis_tools/browse_dataset.py`
+09. 训练:`tools/train.py`
+10. 推理:`demo/image_demo.py`
+11. 部署
+
+```{Note}
+在训练得到模型权重和验证集的 mAP 后,用户需要对预测错误的 bad case 进行深入分析,以便优化模型,MMYOLO 在后续会增加这个功能,敬请期待。
+```
+
+下面详细介绍每一步。
+
+## 1. 数据集准备
+
+- 如果您现在暂时没有自己的数据集,亦或者想尝试用一个小型数据集来跑通我们的整体流程,可以使用本教程提供的一个 144 张图片的 `cat` 数据集(本 `cat` 数据集由 @RangeKing 提供原始图片,由 @PeterH0323 进行数据清洗)。本教程的剩余部分都将以此 `cat` 数据集为例进行讲解。
+
+
+
+最后,在 `git bash` 或者 `终端` 中输入以下命令,验证 SSH 是否与 GitHub 账户匹配。如果匹配,输入 `yes` 就成功啦~
+
+```shell
+ssh -T git@github.com
+```
+
+
+
+## 拉取请求工作流
+
+如果你对拉取请求不了解,没关系,接下来的内容将会从零开始,一步一步地指引你如何创建一个拉取请求。如果你想深入了解拉取请求的开发模式,可以参考 github [官方文档](https://docs.github.com/en/github/collaborating-with-issues-and-pull-requests/about-pull-requests)
+
+### 1. 复刻仓库
+
+当你第一次提交拉取请求时,先复刻 OpenMMLab 原代码库,点击 GitHub 页面右上角的 **Fork** 按钮,复刻后的代码库将会出现在你的 GitHub 个人主页下。
+
+
+
+将代码克隆到本地
+
+```shell
+git clone git@github.com:{username}/mmyolo.git
+```
+
+进入项目并添加原代码库为上游代码库
+
+```bash
+cd mmyolo
+git remote add upstream git@github.com:open-mmlab/mmyolo
+```
+
+检查 remote 是否添加成功,在终端输入 `git remote -v`
+
+```bash
+origin git@github.com:{username}/mmyolo.git (fetch)
+origin git@github.com:{username}/mmyolo.git (push)
+upstream git@github.com:open-mmlab/mmyolo (fetch)
+upstream git@github.com:open-mmlab/mmyolo (push)
+```
+
+```{note}
+这里对 origin 和 upstream 进行一个简单的介绍,当我们使用 git clone 来克隆代码时,会默认创建一个 origin 的 remote,它指向我们克隆的代码库地址,而 upstream 则是我们自己添加的,用来指向原始代码库地址。当然如果你不喜欢他叫 upstream,也可以自己修改,比如叫 open-mmlab。我们通常向 origin 提交代码(即 fork 下来的远程仓库),然后向 upstream 提交一个 pull request。如果提交的代码和最新的代码发生冲突,再从 upstream 拉取最新的代码,和本地分支解决冲突,再提交到 origin。
+```
+
+### 2. 配置 pre-commit
+
+在本地开发环境中,我们使用 [pre-commit](https://pre-commit.com/#intro) 来检查代码风格,以确保代码风格的统一。在提交代码,需要先安装 pre-commit(需要在 MMYOLO 目录下执行):
+
+```shell
+pip install -U pre-commit
+pre-commit install
+```
+
+检查 pre-commit 是否配置成功,并安装 `.pre-commit-config.yaml` 中的钩子:
+
+```shell
+pre-commit run --all-files
+```
+
+
+
+
+
+```{note}
+如果你是中国用户,由于网络原因,可能会出现安装失败的情况,这时可以使用国内源
+
+pre-commit install -c .pre-commit-config-zh-cn.yaml
+
+pre-commit run --all-files -c .pre-commit-config-zh-cn.yaml
+```
+
+如果安装过程被中断,可以重复执行 `pre-commit run ...` 继续安装。
+
+如果提交的代码不符合代码风格规范,pre-commit 会发出警告,并自动修复部分错误。
+
+
+
+如果我们想临时绕开 pre-commit 的检查提交一次代码,可以在 `git commit` 时加上 `--no-verify`(需要保证最后推送至远程仓库的代码能够通过 pre-commit 检查)。
+
+```shell
+git commit -m "xxx" --no-verify
+```
+
+### 3. 创建开发分支
+
+安装完 pre-commit 之后,我们需要基于 dev 创建开发分支,建议的分支命名规则为 `username/pr_name`。
+
+```shell
+git checkout -b yhc/refactor_contributing_doc
+```
+
+在后续的开发中,如果本地仓库的 dev 分支落后于 upstream 的 dev 分支,我们需要先拉取 upstream 的代码进行同步,再执行上面的命令
+
+```shell
+git pull upstream dev
+```
+
+### 4. 提交代码并在本地通过单元测试
+
+- MMYOLO 引入了 mypy 来做静态类型检查,以增加代码的鲁棒性。因此我们在提交代码时,需要补充 Type Hints。具体规则可以参考[教程](https://zhuanlan.zhihu.com/p/519335398)。
+
+- 提交的代码同样需要通过单元测试
+
+ ```shell
+ # 通过全量单元测试
+ pytest tests
+
+ # 我们需要保证提交的代码能够通过修改模块的单元测试,以 yolov5_coco dataset 为例
+ pytest tests/test_datasets/test_yolov5_coco.py
+ ```
+
+ 如果你由于缺少依赖无法运行修改模块的单元测试,可以参考[指引-单元测试](#单元测试)
+
+- 如果修改/添加了文档,参考[指引](#文档渲染)确认文档渲染正常。
+
+### 5. 推送代码到远程
+
+代码通过单元测试和 pre-commit 检查后,将代码推送到远程仓库,如果是第一次推送,可以在 `git push` 后加上 `-u` 参数以关联远程分支
+
+```shell
+git push -u origin {branch_name}
+```
+
+这样下次就可以直接使用 `git push` 命令推送代码了,而无需指定分支和远程仓库。
+
+### 6. 提交拉取请求(PR)
+
+(1) 在 GitHub 的 Pull request 界面创建拉取请求
+
+
+(2) 根据指引修改 PR 描述,以便于其他开发者更好地理解你的修改
+
+```{note}
+注意在 PR branch 左侧的 base 需要修改为 dev 分支
+```
+
+
+
+描述规范详见[拉取请求规范](#拉取请求规范)
+
+
+
+**注意事项**
+
+(a) PR 描述应该包含修改理由、修改内容以及修改后带来的影响,并关联相关 Issue(具体方式见[文档](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue))
+
+(b) 如果是第一次为 OpenMMLab 做贡献,需要签署 CLA
+
+
+
+(c) 检查提交的 PR 是否通过 CI(集成测试)
+
+
+
+MMYOLO 会在 Linux 上,基于不同版本的 Python、PyTorch 对提交的代码进行单元测试,以保证代码的正确性,如果有任何一个没有通过,我们可点击上图中的 `Details` 来查看具体的测试信息,以便于我们修改代码。
+
+(3) 如果 PR 通过了 CI,那么就可以等待其他开发者的 review,并根据 reviewer 的意见,修改代码,并重复 [4](#4-提交代码并本地通过单元测试)-[5](#5-推送代码到远程) 步骤,直到 reviewer 同意合入 PR。
+
+
+
+所有 reviewer 同意合入 PR 后,我们会尽快将 PR 合并到 dev 分支。
+
+### 7. 解决冲突
+
+随着时间的推移,我们的代码库会不断更新,这时候,如果你的 PR 与 dev 分支存在冲突,你需要解决冲突,解决冲突的方式有两种:
+
+```shell
+git fetch --all --prune
+git rebase upstream/dev
+```
+
+或者
+
+```shell
+git fetch --all --prune
+git merge upstream/dev
+```
+
+如果你非常善于处理冲突,那么可以使用 rebase 的方式来解决冲突,因为这能够保证你的 commit log 的整洁。如果你不太熟悉 `rebase` 的使用,那么可以使用 `merge` 的方式来解决冲突。
+
+## 指引
+
+### 单元测试
+
+在提交修复代码错误或新增特性的拉取请求时,我们应该尽可能的让单元测试覆盖所有提交的代码,计算单元测试覆盖率的方法如下
+
+```shell
+python -m coverage run -m pytest /path/to/test_file
+python -m coverage html
+# check file in htmlcov/index.html
+```
+
+### 文档渲染
+
+在提交修复代码错误或新增特性的拉取请求时,可能会需要修改/新增模块的 docstring。我们需要确认渲染后的文档样式是正确的。
+本地生成渲染后的文档的方法如下
+
+```shell
+pip install -r requirements/docs.txt
+cd docs/zh_cn/
+# or docs/en
+make html
+# check file in ./docs/zh_cn/_build/html/index.html
+```
+
+## 代码风格
+
+### Python
+
+[PEP8](https://www.python.org/dev/peps/pep-0008/) 作为 OpenMMLab 算法库首选的代码规范,我们使用以下工具检查和格式化代码
+
+- [flake8](https://github.com/PyCQA/flake8):Python 官方发布的代码规范检查工具,是多个检查工具的封装
+- [isort](https://github.com/timothycrosley/isort):自动调整模块导入顺序的工具
+- [yapf](https://github.com/google/yapf):Google 发布的代码规范检查工具
+- [codespell](https://github.com/codespell-project/codespell):检查单词拼写是否有误
+- [mdformat](https://github.com/executablebooks/mdformat):检查 markdown 文件的工具
+- [docformatter](https://github.com/myint/docformatter):格式化 docstring 的工具
+
+yapf 和 isort 的配置可以在 [setup.cfg](../../../setup.cfg) 找到
+
+通过配置 [pre-commit hook](https://pre-commit.com/) ,我们可以在提交代码时自动检查和格式化 `flake8`、`yapf`、`isort`、`trailing whitespaces`、`markdown files`,
+修复 `end-of-files`、`double-quoted-strings`、`python-encoding-pragma`、`mixed-line-ending`,调整 `requirments.txt` 的包顺序。
+pre-commit 钩子的配置可以在 [.pre-commit-config](../../../.pre-commit-config.yaml) 找到。
+
+pre-commit 具体的安装使用方式见[拉取请求](#2-配置-pre-commit)。
+
+更具体的规范请参考 [OpenMMLab 代码规范](../notes/code_style.md)。
+
+### C++ and CUDA
+
+C++ 和 CUDA 的代码规范遵从 [Google C++ Style Guide](https://google.github.io/styleguide/cppguide.html)
+
+## 拉取请求规范
+
+1. 使用 [pre-commit hook](https://pre-commit.com),尽量减少代码风格相关问题
+
+2. 一个`拉取请求`对应一个短期分支
+
+3. 粒度要细,一个`拉取请求`只做一件事情,避免超大的`拉取请求`
+
+ - Bad:实现 Faster R-CNN
+ - Acceptable:给 Faster R-CNN 添加一个 box head
+ - Good:给 box head 增加一个参数来支持自定义的 conv 层数
+
+4. 每次 Commit 时需要提供清晰且有意义 commit 信息
+
+5. 提供清晰且有意义的`拉取请求`描述
+
+ - 标题写明白任务名称,一般格式:\[Prefix\] Short description of the pull request (Suffix)
+ - prefix:新增功能 \[Feature\], 修 bug \[Fix\], 文档相关 \[Docs\], 开发中 \[WIP\] (暂时不会被 review)
+ - 描述里介绍`拉取请求`的主要修改内容,结果,以及对其他部分的影响, 参考`拉取请求`模板
+ - 关联相关的`议题` (issue) 和其他`拉取请求`
+
+6. 如果引入了其他三方库,或借鉴了三方库的代码,请确认他们的许可证和 mmyolo 兼容,并在借鉴的代码上补充 `This code is inspired from http://`
diff --git a/third_party/mmyolo/docs/zh_cn/recommended_topics/dataset_preparation.md b/third_party/mmyolo/docs/zh_cn/recommended_topics/dataset_preparation.md
new file mode 100644
index 0000000000000000000000000000000000000000..25603a5c1859b736b6b0602607b3902db27f18d8
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/recommended_topics/dataset_preparation.md
@@ -0,0 +1,144 @@
+# 数据集格式准备和说明
+
+## DOTA 数据集
+
+### 下载 DOTA 数据集
+
+数据集可以从 DOTA 数据集的主页 [DOTA](https://captain-whu.github.io/DOTA/dataset.html)
+或 [OpenDataLab](https://opendatalab.org.cn/DOTA_V1.0) 下载。
+
+我们推荐使用 [OpenDataLab](https://opendatalab.org.cn/DOTA_V1.0) 下载,其中的文件夹结构已经按照需要排列好了,只需要解压即可,不需要费心去调整文件夹结构。
+
+下载后解压数据集,并按如下文件夹结构存放。
+
+```none
+${DATA_ROOT}
+├── train
+│ ├── images
+│ │ ├── P0000.png
+│ │ ├── ...
+│ ├── labelTxt-v1.0
+│ │ ├── labelTxt
+│ │ │ ├── P0000.txt
+│ │ │ ├── ...
+│ │ ├── trainset_reclabelTxt
+│ │ │ ├── P0000.txt
+│ │ │ ├── ...
+├── val
+│ ├── images
+│ │ ├── P0003.png
+│ │ ├── ...
+│ ├── labelTxt-v1.0
+│ │ ├── labelTxt
+│ │ │ ├── P0003.txt
+│ │ │ ├── ...
+│ │ ├── valset_reclabelTxt
+│ │ │ ├── P0003.txt
+│ │ │ ├── ...
+├── test
+│ ├── images
+│ │ ├── P0006.png
+│ │ ├── ...
+
+```
+
+其中,以 `reclabelTxt` 为结尾的文件夹存放了水平检测框的标注,目前仅使用了 `labelTxt-v1.0` 中旋转框的标注。
+
+### 数据集切片
+
+我们提供了 `tools/dataset_converters/dota/dota_split.py` 脚本用于 DOTA 数据集的准备和切片。
+
+```shell
+python tools/dataset_converters/dota/dota_split.py \
+ [--splt-config ${SPLIT_CONFIG}] \
+ [--data-root ${DATA_ROOT}] \
+ [--out-dir ${OUT_DIR}] \
+ [--ann-subdir ${ANN_SUBDIR}] \
+ [--phase ${DATASET_PHASE}] \
+ [--nproc ${NPROC}] \
+ [--save-ext ${SAVE_EXT}] \
+ [--overwrite]
+```
+
+脚本依赖于 shapely 包,请先通过 `pip install shapely` 安装 shapely。
+
+**参数说明**:
+
+- `--splt-config` : 切片参数的配置文件。
+- `--data-root`: DOTA 数据集的存放位置。
+- `--out-dir`: 切片后的输出位置。
+- `--ann-subdir`: 标注文件夹的名字。 默认为 `labelTxt-v1.0` 。
+- `--phase`: 数据集的阶段。默认为 `trainval test` 。
+- `--nproc`: 进程数量。 默认为 8 。
+- `--save-ext`: 输出图像的扩展名,如置空则与原图保持一致。 默认为 `None` 。
+- `--overwrite`: 如果目标文件夹已存在,是否允许覆盖。
+
+基于 DOTA 数据集论文中提供的配置,我们提供了两种切片配置。
+
+`./split_config/single_scale.json` 用于单尺度 `single-scale` 切片
+`./split_config/multi_scale.json` 用于多尺度 `multi-scale` 切片
+
+DOTA 数据集通常使用 `trainval` 集进行训练,然后使用 `test` 集进行在线验证,大多数论文提供的也是在线验证的精度。
+如果你需要进行本地验证,可以准备 `train` 集和 `val` 集进行训练和测试。
+
+示例:
+
+使用单尺度切片配置准备 `trainval` 和 `test` 集
+
+```shell
+python tools/dataset_converters/dota/dota_split.py
+ --split-config 'tools/dataset_converters/dota/split_config/single_scale.json'
+ --data-root ${DATA_ROOT} \
+ --out-dir ${OUT_DIR}
+```
+
+准备 DOTA-v1.5 数据集,它的标注文件夹名字是 `labelTxt-v1.5`
+
+```shell
+python tools/dataset_converters/dota/dota_split.py
+ --split-config 'tools/dataset_converters/dota/split_config/single_scale.json'
+ --data-root ${DATA_ROOT} \
+ --out-dir ${OUT_DIR} \
+ --ann-subdir 'labelTxt-v1.5'
+```
+
+使用单尺度切片配置准备 `train` 和 `val` 集
+
+```shell
+python tools/dataset_converters/dota/dota_split.py
+ --split-config 'tools/dataset_converters/dota/split_config/single_scale.json'
+ --data-root ${DATA_ROOT} \
+ --phase train val \
+ --out-dir ${OUT_DIR}
+```
+
+使用多尺度切片配置准备 `trainval` 和 `test` 集
+
+```shell
+python tools/dataset_converters/dota/dota_split.py
+ --split-config 'tools/dataset_converters/dota/split_config/multi_scale.json'
+ --data-root ${DATA_ROOT} \
+ --out-dir ${OUT_DIR}
+```
+
+在运行完成后,输出的结构如下:
+
+```none
+${OUT_DIR}
+├── trainval
+│ ├── images
+│ │ ├── P0000__1024__0___0.png
+│ │ ├── ...
+│ ├── annfiles
+│ │ ├── P0000__1024__0___0.txt
+│ │ ├── ...
+├── test
+│ ├── images
+│ │ ├── P0006__1024__0___0.png
+│ │ ├── ...
+│ ├── annfiles
+│ │ ├── P0006__1024__0___0.txt
+│ │ ├── ...
+```
+
+此时将配置文件中的 `data_root` 修改为 ${OUT_DIR} 即可开始使用 DOTA 数据集训练。
diff --git a/third_party/mmyolo/docs/zh_cn/recommended_topics/deploy/easydeploy_guide.md b/third_party/mmyolo/docs/zh_cn/recommended_topics/deploy/easydeploy_guide.md
new file mode 100644
index 0000000000000000000000000000000000000000..8f337e6cfc2ed719a4761d5fa58bc1f0af210028
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/recommended_topics/deploy/easydeploy_guide.md
@@ -0,0 +1,5 @@
+# EasyDeploy 部署
+
+本项目作为 MMYOLO 的部署 project 单独存在,意图剥离 MMDeploy 当前的体系,独自支持用户完成模型训练后的转换和部署功能,使用户的学习和工程成本下降。
+
+当前支持对 ONNX 格式和 TensorRT 格式的转换,后续对其他推理平台也会支持起来。
diff --git a/third_party/mmyolo/docs/zh_cn/recommended_topics/deploy/index.rst b/third_party/mmyolo/docs/zh_cn/recommended_topics/deploy/index.rst
new file mode 100644
index 0000000000000000000000000000000000000000..3d5f08bc92c0e7037932ecfcd91462fe2db9738c
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/recommended_topics/deploy/index.rst
@@ -0,0 +1,16 @@
+MMDeploy 部署必备教程
+************************
+
+.. toctree::
+ :maxdepth: 1
+
+ mmdeploy_guide.md
+ mmdeploy_yolov5.md
+
+EasyDeploy 部署必备教程
+************************
+
+.. toctree::
+ :maxdepth: 1
+
+ easydeploy_guide.md
diff --git a/third_party/mmyolo/docs/zh_cn/recommended_topics/deploy/mmdeploy_guide.md b/third_party/mmyolo/docs/zh_cn/recommended_topics/deploy/mmdeploy_guide.md
new file mode 100644
index 0000000000000000000000000000000000000000..e935d36e99ee38bb743a1efa5d275d04d0be320d
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/recommended_topics/deploy/mmdeploy_guide.md
@@ -0,0 +1,415 @@
+# MMDeploy 部署
+
+## MMDeploy 介绍
+
+MMDeploy 是 [OpenMMLab](https://openmmlab.com/) 模型部署工具箱,**为各算法库提供统一的部署体验**。基于 MMDeploy,开发者可以轻松从训练 repo 生成指定硬件所需 SDK,省去大量适配时间。
+
+更多介绍和使用指南见 https://mmdeploy.readthedocs.io/zh_CN/latest/get_started.html
+
+## 算法支持列表
+
+目前支持的 model-backend 组合:
+
+| Model | Task | OnnxRuntime | TensorRT | Model config |
+| :----- | :-------------- | :---------: | :------: | :---------------------------------------------------------------------: |
+| YOLOv5 | ObjectDetection | Y | Y | [config](https://github.com/open-mmlab/mmyolo/tree/main/configs/yolov5) |
+| YOLOv6 | ObjectDetection | Y | Y | [config](https://github.com/open-mmlab/mmyolo/tree/main/configs/yolov6) |
+| YOLOX | ObjectDetection | Y | Y | [config](https://github.com/open-mmlab/mmyolo/tree/main/configs/yolox) |
+| RTMDet | ObjectDetection | Y | Y | [config](https://github.com/open-mmlab/mmyolo/tree/main/configs/rtmdet) |
+
+ncnn 和其他后端的支持会在后续支持。
+
+## 安装
+
+按照[说明](https://mmdeploy.readthedocs.io/zh_CN/latest/get_started.html)安装 mmdeploy。
+
+```{note}
+如果安装的是 mmdeploy 预编译包,那么也请通过 ‘git clone https://github.com/open-mmlab/mmdeploy.git –depth=1’ 下载 mmdeploy 源码。因为它包含了部署时所需的 tools 文件夹。
+```
+
+## MMYOLO 中部署相关配置说明
+
+所有部署配置文件在 [`configs/deploy`](../../../configs/deploy/) 目录下。
+
+您可以部署静态输入或者动态输入的模型,因此您需要修改模型配置文件中与此相关的数据处理流程。
+
+MMDeploy 将后处理整合到自定义的算子中,因此您可以修改 `codebase_config` 中的 `post_processing` 参数来调整后处理策略,参数描述如下:
+
+```python
+codebase_config = dict(
+ type='mmyolo',
+ task='ObjectDetection',
+ model_type='end2end',
+ post_processing=dict(
+ score_threshold=0.05,
+ confidence_threshold=0.005,
+ iou_threshold=0.5,
+ max_output_boxes_per_class=200,
+ pre_top_k=5000,
+ keep_top_k=100,
+ background_label_id=-1),
+ module=['mmyolo.deploy'])
+```
+
+- `score_threshold`:在 `nms` 之前筛选候选框的类别分数阈值。
+- `confidence_threshold`:在 `nms` 之前筛选候选框的置信度分数阈值。
+- `iou_threshold`:在 `nms` 中去除重复框的 `iou` 阈值。
+- `max_output_boxes_per_class`:每个类别最大的输出框数量。
+- `pre_top_k`:在 `nms` 之前对候选框分数排序然后固定候选框的个数。
+- `keep_top_k`:`nms` 算法最终输出的候选框个数。
+- `background_label_id`:MMYOLO 算法中没有背景类别信息,置为 `-1` 即可。
+
+### 静态输入配置
+
+#### (1) 模型配置文件介绍
+
+以 MMYOLO 中的 `YOLOv5` 模型配置为例,下面是对部署时使用的模型配置文件参数说明介绍。
+
+```python
+_base_ = '../../yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+test_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=_base_.backend_args),
+ dict(
+ type='LetterResize',
+ scale=_base_.img_scale,
+ allow_scale_up=False,
+ use_mini_pad=False,
+ ),
+ dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
+ dict(
+ type='mmdet.PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'pad_param'))
+]
+
+test_dataloader = dict(
+ dataset=dict(pipeline=test_pipeline, batch_shapes_cfg=None))
+```
+
+`_base_ = '../../yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'` 继承了训练时构建模型的配置。
+
+`test_pipeline` 为部署时对输入图像进行处理的流程,`LetterResize` 控制了输入图像的尺寸,同时限制了导出模型所能接受的输入尺寸。
+
+`test_dataloader` 为部署时构建数据加载器配置,`batch_shapes_cfg` 控制了是否启用 `batch_shapes` 策略,详细内容可以参考 [yolov5 配置文件说明](../../tutorials/config.md) 。
+
+#### (2) 部署配置文件介绍
+
+以 `MMYOLO` 中的 `YOLOv5` 部署配置为例,下面是对配置文件参数说明介绍。
+
+`ONNXRuntime` 部署 `YOLOv5` 可以使用 [`detection_onnxruntime_static.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_onnxruntime_static.py) 配置。
+
+```python
+_base_ = ['./base_static.py']
+codebase_config = dict(
+ type='mmyolo',
+ task='ObjectDetection',
+ model_type='end2end',
+ post_processing=dict(
+ score_threshold=0.05,
+ confidence_threshold=0.005,
+ iou_threshold=0.5,
+ max_output_boxes_per_class=200,
+ pre_top_k=5000,
+ keep_top_k=100,
+ background_label_id=-1),
+ module=['mmyolo.deploy'])
+backend_config = dict(type='onnxruntime')
+```
+
+`backend_config` 中指定了部署后端 `type='onnxruntime'`,其他信息可参考第三小节。
+
+`TensorRT` 部署 `YOLOv5` 可以使用 [`detection_tensorrt_static-640x640.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_tensorrt_static-640x640.py) 配置。
+
+```python
+_base_ = ['./base_static.py']
+onnx_config = dict(input_shape=(640, 640))
+backend_config = dict(
+ type='tensorrt',
+ common_config=dict(fp16_mode=False, max_workspace_size=1 << 30),
+ model_inputs=[
+ dict(
+ input_shapes=dict(
+ input=dict(
+ min_shape=[1, 3, 640, 640],
+ opt_shape=[1, 3, 640, 640],
+ max_shape=[1, 3, 640, 640])))
+ ])
+use_efficientnms = False
+```
+
+`backend_config` 中指定了后端 `type=‘tensorrt’`。
+
+与 `ONNXRuntime` 部署配置不同的是,`TensorRT` 需要指定输入图片尺寸和构建引擎文件需要的参数,包括:
+
+- `onnx_config` 中指定 `input_shape=(640, 640)`
+- `backend_config['common_config']` 中包括 `fp16_mode=False` 和 `max_workspace_size=1 << 30`, `fp16_mode` 表示是否以 `fp16` 的参数格式构建引擎,`max_workspace_size` 表示当前 `gpu` 设备最大显存, 单位为 `GB`。`fp16` 的详细配置可以参考 [`detection_tensorrt-fp16_static-640x640.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_tensorrt-fp16_static-640x640.py)
+- `backend_config['model_inputs']['input_shapes']['input']` 中 `min_shape` /`opt_shape`/`max_shape` 对应的值在静态输入下应该保持相同,即默认均为 `[1, 3, 640, 640]`。
+
+`use_efficientnms` 是 `MMYOLO` 系列新引入的配置,表示在导出 `onnx` 时是否启用`Efficient NMS Plugin`来替换 `MMDeploy` 中的 `TRTBatchedNMS plugin` 。
+
+可以参考 `TensorRT` 官方实现的 [Efficient NMS Plugin](https://github.com/NVIDIA/TensorRT/blob/main/plugin/efficientNMSPlugin/README.md) 获取更多详细信息。
+
+**注意**,这个功能仅仅在 TensorRT >= 8.0 版本才能使用,无需编译开箱即用。
+
+### 动态输入配置
+
+#### (1) 模型配置文件介绍
+
+当您部署动态输入模型时,您无需修改任何模型配置文件,仅需要修改部署配置文件即可。
+
+#### (2) 部署配置文件介绍
+
+`ONNXRuntime` 部署 `YOLOv5` 可以使用 [`detection_onnxruntime_dynamic.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_onnxruntime_dynamic.py) 配置。
+
+```python
+_base_ = ['./base_dynamic.py']
+codebase_config = dict(
+ type='mmyolo',
+ task='ObjectDetection',
+ model_type='end2end',
+ post_processing=dict(
+ score_threshold=0.05,
+ confidence_threshold=0.005,
+ iou_threshold=0.5,
+ max_output_boxes_per_class=200,
+ pre_top_k=5000,
+ keep_top_k=100,
+ background_label_id=-1),
+ module=['mmyolo.deploy'])
+backend_config = dict(type='onnxruntime')
+```
+
+`backend_config` 中指定了后端 `type='onnxruntime'`,其他配置与上一节在 ONNXRuntime 部署静态输入模型相同。
+
+`TensorRT` 部署 `YOLOv5` 可以使用 [`detection_tensorrt_dynamic-192x192-960x960.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_tensorrt_dynamic-192x192-960x960.py) 配置。
+
+```python
+_base_ = ['./base_dynamic.py']
+backend_config = dict(
+ type='tensorrt',
+ common_config=dict(fp16_mode=False, max_workspace_size=1 << 30),
+ model_inputs=[
+ dict(
+ input_shapes=dict(
+ input=dict(
+ min_shape=[1, 3, 192, 192],
+ opt_shape=[1, 3, 640, 640],
+ max_shape=[1, 3, 960, 960])))
+ ])
+use_efficientnms = False
+```
+
+`backend_config` 中指定了后端 `type='tensorrt'`,由于 `TensorRT` 动态输入与静态输入有所不同,您可以了解更多动态输入相关信息通过访问 [TensorRT dynamic input official introduction](https://docs.nvidia.com/deeplearning/tensorrt/archives/tensorrt-843/developer-guide/index.html#work_dynamic_shapes)。
+
+`TensorRT` 部署需要配置 `min_shape`, `opt_shape`, `max_shape` ,`TensorRT` 限制输入图片的尺寸在 `min_shape` 和 ` max_shape` 之间。
+
+`min_shape` 为输入图片的最小尺寸,`opt_shape` 为输入图片常见尺寸, 在这个尺寸下推理性能最好,`max_shape` 为输入图片的最大尺寸。
+
+`use_efficientnms` 配置与上节 `TensorRT` 静态输入配置相同。
+
+### INT8 量化配置
+
+!!! 部署 TensorRT INT8 模型教程即将发布 !!!
+
+## 模型转换
+
+### 使用方法
+
+#### 从源码安装的 MMDeploy
+
+设置 `MMDeploy` 根目录为环境变量 `MMDEPLOY_DIR` ,例如 `export MMDEPLOY_DIR=/the/root/path/of/MMDeploy`
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ ${DEPLOY_CFG_PATH} \
+ ${MODEL_CFG_PATH} \
+ ${MODEL_CHECKPOINT_PATH} \
+ ${INPUT_IMG} \
+ --test-img ${TEST_IMG} \
+ --work-dir ${WORK_DIR} \
+ --calib-dataset-cfg ${CALIB_DATA_CFG} \
+ --device ${DEVICE} \
+ --log-level INFO \
+ --show \
+ --dump-info
+```
+
+### 参数描述
+
+- `deploy_cfg` : mmdeploy 针对此模型的部署配置,包含推理框架类型、是否量化、输入 shape 是否动态等。配置文件之间可能有引用关系,`configs/deploy/detection_onnxruntime_static.py` 是一个示例。
+- `model_cfg` : MMYOLO 算法库的模型配置,例如 `configs/deploy/model/yolov5_s-deploy.py`, 与 mmdeploy 的路径无关。
+- `checkpoint` : torch 模型路径。可以 http/https 开头,详见 `mmengine.fileio` 的实现。
+- `img` : 模型转换时,用做测试的图像文件路径。
+- `--test-img` : 用于测试模型的图像文件路径。默认设置成`None`。
+- `--work-dir` : 工作目录,用来保存日志和模型文件。
+- `--calib-dataset-cfg` : 此参数只有int8模式下生效,用于校准数据集配置文件。若在int8模式下未传入参数,则会自动使用模型配置文件中的'val'数据集进行校准。
+- `--device` : 用于模型转换的设备。 默认是`cpu`,对于 trt 可使用 `cuda:0` 这种形式。
+- `--log-level` : 设置日记的等级,选项包括`'CRITICAL', 'FATAL', 'ERROR', 'WARN', 'WARNING', 'INFO', 'DEBUG', 'NOTSET'`。 默认是`INFO`。
+- `--show` : 是否显示检测的结果。
+- `--dump-info` : 是否输出 SDK 信息。
+
+#### 通过 pip install 安装的 MMDeploy
+
+假设当前的工作目录为 mmyolo 的根目录, 那么以 [YoloV5](https://github.com/open-mmlab/mmyolo/blob/main/configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py) 模型为例,你可以从[此处](https://download.openmmlab.com/mmyolo/v0/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth)下载对应的 checkpoint,并使用以下代码将之转换为 onnx 模型:
+
+```python
+from mmdeploy.apis import torch2onnx
+from mmdeploy.backend.sdk.export_info import export2SDK
+
+img = 'demo/demo.jpg'
+work_dir = 'mmdeploy_models/mmyolo/onnx'
+save_file = 'end2end.onnx'
+deploy_cfg = 'configs/deploy/detection_onnxruntime_dynamic.py'
+model_cfg = 'configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+model_checkpoint = 'checkpoints/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth'
+device = 'cpu'
+
+# 1. convert model to onnx
+torch2onnx(img, work_dir, save_file, deploy_cfg, model_cfg,
+ model_checkpoint, device)
+
+# 2. extract pipeline info for inference by MMDeploy SDK
+export2SDK(deploy_cfg, model_cfg, work_dir, pth=model_checkpoint,
+ device=device)
+```
+
+## 模型规范
+
+在使用转换后的模型进行推理之前,有必要了解转换结果的结构。 它存放在 `--work-dir` 指定的路路径下。
+
+上例中的`mmdeploy_models/mmyolo/onnx`,结构如下:
+
+```
+mmdeploy_models/mmyolo/onnx
+├── deploy.json
+├── detail.json
+├── end2end.onnx
+└── pipeline.json
+```
+
+重要的是:
+
+- **end2end.onnx**: 推理引擎文件。可用 ONNX Runtime 推理
+- ***xxx*.json**: mmdeploy SDK 推理所需的 meta 信息
+
+整个文件夹被定义为**mmdeploy SDK model**。换言之,**mmdeploy SDK model**既包括推理引擎,也包括推理 meta 信息。
+
+## 模型推理
+
+### 后端模型推理
+
+以上述模型转换后的 `end2end.onnx` 为例,你可以使用如下代码进行推理:
+
+```python
+from mmdeploy.apis.utils import build_task_processor
+from mmdeploy.utils import get_input_shape, load_config
+import torch
+
+deploy_cfg = 'configs/deploy/detection_onnxruntime_dynamic.py'
+model_cfg = 'configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+device = 'cpu'
+backend_model = ['mmdeploy_models/mmyolo/onnx/end2end.onnx']
+image = 'demo/demo.jpg'
+
+# read deploy_cfg and model_cfg
+deploy_cfg, model_cfg = load_config(deploy_cfg, model_cfg)
+
+# build task and backend model
+task_processor = build_task_processor(model_cfg, deploy_cfg, device)
+model = task_processor.build_backend_model(backend_model)
+
+# process input image
+input_shape = get_input_shape(deploy_cfg)
+model_inputs, _ = task_processor.create_input(image, input_shape)
+
+# do model inference
+with torch.no_grad():
+ result = model.test_step(model_inputs)
+
+# visualize results
+task_processor.visualize(
+ image=image,
+ model=model,
+ result=result[0],
+ window_name='visualize',
+ output_file='work_dir/output_detection.png')
+```
+
+运行上述代码后,你可以在 `work_dir` 中看到推理的结果图片 `output_detection.png`。
+
+### SDK模型推理
+
+你也可以参考如下代码,对 SDK model 进行推理:
+
+```python
+from mmdeploy_runtime import Detector
+import cv2
+
+img = cv2.imread('demo/demo.jpg')
+
+# create a detector
+detector = Detector(model_path='mmdeploy_models/mmyolo/onnx',
+ device_name='cpu', device_id=0)
+# perform inference
+bboxes, labels, masks = detector(img)
+
+# visualize inference result
+indices = [i for i in range(len(bboxes))]
+for index, bbox, label_id in zip(indices, bboxes, labels):
+ [left, top, right, bottom], score = bbox[0:4].astype(int), bbox[4]
+ if score < 0.3:
+ continue
+
+ cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0))
+
+cv2.imwrite('work_dir/output_detection.png', img)
+```
+
+除了python API,mmdeploy SDK 还提供了诸如 C、C++、C#、Java等多语言接口。
+你可以参考[样例](https://github.com/open-mmlab/mmdeploy/tree/main/demo)学习其他语言接口的使用方法。
+
+## 模型评测
+
+当您将 PyTorch 模型转换为后端支持的模型后,您可能需要验证模型的精度,使用 `${MMDEPLOY_DIR}/tools/test.py`
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/test.py \
+ ${DEPLOY_CFG} \
+ ${MODEL_CFG} \
+ --model ${BACKEND_MODEL_FILES} \
+ --device ${DEVICE} \
+ --work-dir ${WORK_DIR} \
+ [--cfg-options ${CFG_OPTIONS}] \
+ [--show] \
+ [--show-dir ${OUTPUT_IMAGE_DIR}] \
+ [--interval ${INTERVAL}] \
+ [--wait-time ${WAIT_TIME}] \
+ [--log2file work_dirs/output.txt]
+ [--speed-test] \
+ [--warmup ${WARM_UP}] \
+ [--log-interval ${LOG_INTERVERL}] \
+ [--batch-size ${BATCH_SIZE}] \
+ [--uri ${URI}]
+```
+
+### 参数描述
+
+- `deploy_cfg`: 部署配置文件。
+- `model_cfg`: MMYOLO 模型配置文件。
+- `--model`: 导出的后端模型。 例如, 如果我们导出了 TensorRT 模型,我们需要传入后缀为 ".engine" 文件路径。
+- `--device`: 运行模型的设备。请注意,某些后端会限制设备。例如,TensorRT 必须在 cuda 上运行。
+- `--work-dir`: 模型转换、报告生成的路径。
+- `--cfg-options`: 传入额外的配置,将会覆盖当前部署配置。
+- `--show`: 是否在屏幕上显示评估结果。
+- `--show-dir`: 保存评估结果的目录。(只有给出这个参数才会保存结果)。
+- `--interval`: 屏幕上显示评估结果的间隔。
+- `--wait-time`: 每个窗口的显示时间
+- `--log2file`: 将评估结果(和速度)记录到文件中。
+- `--speed-test`: 是否开启速度测试。
+- `--warmup`: 在计算推理时间之前进行预热,需要先开启 `speed-test`。
+- `--log-interval`: 每个日志之间的间隔,需要先设置 `speed-test`。
+- `--batch-size`: 推理的批量大小,它将覆盖数据配置中的 `samples_per_gpu`。默认为 `1`。请注意,并非所有模型都支持 `batch_size > 1`。
+- `--uri`: 在边缘设备上推理时的 ipv4 或 ipv6 端口号。
+
+注意:`${MMDEPLOY_DIR}/tools/test.py` 中的其他参数用于速度测试。他们不影响评估。
diff --git a/third_party/mmyolo/docs/zh_cn/recommended_topics/deploy/mmdeploy_yolov5.md b/third_party/mmyolo/docs/zh_cn/recommended_topics/deploy/mmdeploy_yolov5.md
new file mode 100644
index 0000000000000000000000000000000000000000..e035e17641559853ae44c59b16c2c151f7073abd
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/recommended_topics/deploy/mmdeploy_yolov5.md
@@ -0,0 +1,572 @@
+# YOLOv5 部署全流程说明
+
+请先参考 [`部署必备指南`](./mmdeploy_guide.md) 了解部署配置文件等相关信息。
+
+## 模型训练和测试
+
+模型训练和测试请参考 [YOLOv5 从入门到部署全流程](./mmdeploy_yolov5.md) 。
+
+## 准备 MMDeploy 运行环境
+
+安装 `MMDeploy` 请参考 [`源码手动安装`](https://github.com/open-mmlab/mmdeploy/blob/dev-1.x/docs/zh_cn/01-how-to-build/build_from_source.md) ,选择您所使用的平台编译 `MMDeploy` 和自定义算子。
+
+*注意!* 如果环境安装有问题,可以查看 [`MMDeploy FAQ`](https://github.com/open-mmlab/mmdeploy/blob/dev-1.x/docs/zh_cn/faq.md) 或者在 `issuse` 中提出您的问题。
+
+## 准备模型配置文件
+
+本例将以基于 `coco` 数据集预训练的 `YOLOv5` 配置和权重进行部署的全流程讲解,包括静态/动态输入模型导出和推理,`TensorRT` / `ONNXRuntime` 两种后端部署和测试。
+
+### 静态输入配置
+
+#### (1) 模型配置文件
+
+当您需要部署静态输入模型时,您应该确保模型的输入尺寸是固定的,比如在测试流程或测试数据集加载时输入尺寸为 `640x640`。
+
+您可以查看 [`yolov5_s-static.py`](https://github.com/open-mmlab/mmyolo/tree/main/configs/deploy/model/yolov5_s-static.py) 中测试流程或测试数据集加载部分,如下所示:
+
+```python
+_base_ = '../../yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+
+test_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=_base_.backend_args),
+ dict(
+ type='LetterResize',
+ scale=_base_.img_scale,
+ allow_scale_up=False,
+ use_mini_pad=False,
+ ),
+ dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
+ dict(
+ type='mmdet.PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'pad_param'))
+]
+
+test_dataloader = dict(
+ dataset=dict(pipeline=test_pipeline, batch_shapes_cfg=None))
+```
+
+由于 `yolov5` 在测试时会开启 `allow_scale_up` 和 `use_mini_pad` 改变输入图像的尺寸来取得更高的精度,但是会给部署静态输入模型造成输入尺寸不匹配的问题。
+
+该配置相比与原始配置文件进行了如下修改:
+
+- 关闭 `test_pipline` 中改变尺寸相关的配置,如 `LetterResize` 中 `allow_scale_up=False` 和 `use_mini_pad=False` 。
+- 关闭 `test_dataloader` 中 `batch shapes` 策略,即 `batch_shapes_cfg=None` 。
+
+#### (2) 部署配置文件
+
+当您部署在 `ONNXRuntime` 时,您可以查看 [`detection_onnxruntime_static.py`](https://github.com/open-mmlab/mmyolo/tree/main/configs/deploy/detection_onnxruntime_static.py) ,如下所示:
+
+```python
+_base_ = ['./base_static.py']
+codebase_config = dict(
+ type='mmyolo',
+ task='ObjectDetection',
+ model_type='end2end',
+ post_processing=dict(
+ score_threshold=0.05,
+ confidence_threshold=0.005,
+ iou_threshold=0.5,
+ max_output_boxes_per_class=200,
+ pre_top_k=5000,
+ keep_top_k=100,
+ background_label_id=-1),
+ module=['mmyolo.deploy'])
+backend_config = dict(type='onnxruntime')
+```
+
+默认配置中的 `post_processing` 后处理参数是当前模型与 `pytorch` 模型精度对齐的配置,若您需要修改相关参数,可以参考 [`部署必备指南`](./mmdeploy_guide.md) 的详细介绍。
+
+当您部署在 `TensorRT` 时,您可以查看 [`detection_tensorrt_static-640x640.py`](https://github.com/open-mmlab/mmyolo/tree/main/configs/deploy/detection_tensorrt_static-640x640.py) ,如下所示:
+
+```python
+_base_ = ['./base_static.py']
+onnx_config = dict(input_shape=(640, 640))
+backend_config = dict(
+ type='tensorrt',
+ common_config=dict(fp16_mode=False, max_workspace_size=1 << 30),
+ model_inputs=[
+ dict(
+ input_shapes=dict(
+ input=dict(
+ min_shape=[1, 3, 640, 640],
+ opt_shape=[1, 3, 640, 640],
+ max_shape=[1, 3, 640, 640])))
+ ])
+use_efficientnms = False
+```
+
+本例使用了默认的输入尺寸 `input_shape=(640, 640)` ,构建网络以 `fp32` 模式即 `fp16_mode=False`,并且默认构建 `TensorRT` 构建引擎所使用的显存 `max_workspace_size=1 << 30` 即最大为 `1GB` 显存。
+
+### 动态输入配置
+
+#### (1) 模型配置文件
+
+当您需要部署动态输入模型时,模型的输入可以为任意尺寸(`TensorRT` 会限制最小和最大输入尺寸),因此使用默认的 [`yolov5_s-v61_syncbn_8xb16-300e_coco.py`](https://github.com/open-mmlab/mmyolo/tree/main/configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py) 模型配置文件即可,其中数据处理和数据集加载器部分如下所示:
+
+```python
+batch_shapes_cfg = dict(
+ type='BatchShapePolicy',
+ batch_size=val_batch_size_per_gpu,
+ img_size=img_scale[0],
+ size_divisor=32,
+ extra_pad_ratio=0.5)
+
+test_pipeline = [
+ dict(type='LoadImageFromFile', backend_args=_base_.backend_args),
+ dict(type='YOLOv5KeepRatioResize', scale=img_scale),
+ dict(
+ type='LetterResize',
+ scale=img_scale,
+ allow_scale_up=False,
+ pad_val=dict(img=114)),
+ dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
+ dict(
+ type='mmdet.PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor', 'pad_param'))
+]
+
+val_dataloader = dict(
+ batch_size=val_batch_size_per_gpu,
+ num_workers=val_num_workers,
+ persistent_workers=persistent_workers,
+ pin_memory=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ test_mode=True,
+ data_prefix=dict(img='val2017/'),
+ ann_file='annotations/instances_val2017.json',
+ pipeline=test_pipeline,
+ batch_shapes_cfg=batch_shapes_cfg))
+```
+
+其中 `LetterResize` 类初始化传入了 `allow_scale_up=False` 控制输入的小图像是否上采样,同时默认 `use_mini_pad=False` 关闭了图片最小填充策略,`val_dataloader['dataset']`中传入了 `batch_shapes_cfg=batch_shapes_cfg`,即按照 `batch` 内的输入尺寸进行最小填充。上述策略会改变输入图像的尺寸,因此动态输入模型在测试时会按照上述数据集加载器动态输入。
+
+#### (2) 部署配置文件
+
+当您部署在 `ONNXRuntime` 时,您可以查看 [`detection_onnxruntime_dynamic.py`](https://github.com/open-mmlab/mmyolo/blob/main/configs/deploy/detection_onnxruntime_dynamic.py) ,如下所示:
+
+```python
+_base_ = ['./base_dynamic.py']
+codebase_config = dict(
+ type='mmyolo',
+ task='ObjectDetection',
+ model_type='end2end',
+ post_processing=dict(
+ score_threshold=0.05,
+ confidence_threshold=0.005,
+ iou_threshold=0.5,
+ max_output_boxes_per_class=200,
+ pre_top_k=5000,
+ keep_top_k=100,
+ background_label_id=-1),
+ module=['mmyolo.deploy'])
+backend_config = dict(type='onnxruntime')
+```
+
+与静态输入配置仅有 `_base_ = ['./base_dynamic.py']` 不同,动态输入会额外继承 `dynamic_axes` 属性。其他配置与静态输入配置相同。
+
+当您部署在 `TensorRT` 时,您可以查看 [`detection_tensorrt_dynamic-192x192-960x960.py`](https://github.com/open-mmlab/mmyolo/tree/main/configs/deploy/detection_tensorrt_dynamic-192x192-960x960.py) ,如下所示:
+
+```python
+_base_ = ['./base_dynamic.py']
+backend_config = dict(
+ type='tensorrt',
+ common_config=dict(fp16_mode=False, max_workspace_size=1 << 30),
+ model_inputs=[
+ dict(
+ input_shapes=dict(
+ input=dict(
+ min_shape=[1, 3, 192, 192],
+ opt_shape=[1, 3, 640, 640],
+ max_shape=[1, 3, 960, 960])))
+ ])
+use_efficientnms = False
+```
+
+本例构建网络以 `fp32` 模式即 `fp16_mode=False`,构建 `TensorRT` 构建引擎所使用的显存 `max_workspace_size=1 << 30` 即最大为 `1GB` 显存。
+
+同时默认配置 `min_shape=[1, 3, 192, 192]`,`opt_shape=[1, 3, 640, 640]` ,`max_shape=[1, 3, 960, 960]` ,意为该模型所能接受的输入尺寸最小为 `192x192` ,最大为 `960x960`,最常见尺寸为 `640x640`。
+
+当您部署自己的模型时,需要根据您的输入图像尺寸进行调整。
+
+## 模型转换
+
+本教程所使用的 `MMDeploy` 根目录为 `/home/openmmlab/dev/mmdeploy`,请注意修改为您的 `MMDeploy` 目录。
+预训练权重下载于 [yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth](https://download.openmmlab.com/mmyolo/v0/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth) ,保存在本地的 `/home/openmmlab/dev/mmdeploy/yolov5s.pth`。
+
+```shell
+wget https://download.openmmlab.com/mmyolo/v0/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth -O /home/openmmlab/dev/mmdeploy/yolov5s.pth
+```
+
+命令行执行以下命令配置相关路径:
+
+```shell
+export MMDEPLOY_DIR=/home/openmmlab/dev/mmdeploy
+export PATH_TO_CHECKPOINTS=/home/openmmlab/dev/mmdeploy/yolov5s.pth
+```
+
+### YOLOv5 静态输入模型导出
+
+#### ONNXRuntime
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_onnxruntime_static.py \
+ configs/deploy/model/yolov5_s-static.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir \
+ --show \
+ --device cpu
+```
+
+#### TensorRT
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_tensorrt_static-640x640.py \
+ configs/deploy/model/yolov5_s-static.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir \
+ --show \
+ --device cuda:0
+```
+
+### YOLOv5 动态输入模型导出
+
+#### ONNXRuntime
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_onnxruntime_dynamic.py \
+ configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir \
+ --show \
+ --device cpu
+ --dump-info
+```
+
+#### TensorRT
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_tensorrt_dynamic-192x192-960x960.py \
+ configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir \
+ --show \
+ --device cuda:0
+ --dump-info
+```
+
+当您使用上述命令转换模型时,您将会在 `work_dir` 文件夹下发现以下文件:
+
+
+
+或者
+
+
+
+在导出 `onnxruntime`模型后,您将得到图1的六个文件,其中 `end2end.onnx` 表示导出的`onnxruntime`模型,`xxx.json` 表示 `MMDeploy SDK` 推理所需要的 meta 信息。
+
+在导出 `TensorRT`模型后,您将得到图2的七个文件,其中 `end2end.onnx` 表示导出的中间模型,`MMDeploy`利用该模型自动继续转换获得 `end2end.engine` 模型用于 `TensorRT `部署,`xxx.json` 表示 `MMDeploy SDK` 推理所需要的 meta 信息。
+
+## 模型评测
+
+当您转换模型成功后,可以使用 `${MMDEPLOY_DIR}/tools/test.py` 工具对转换后的模型进行评测。下面是对 `ONNXRuntime` 和 `TensorRT` 静态模型的评测,动态模型评测修改传入模型配置即可。
+
+### ONNXRuntime
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/test.py \
+ configs/deploy/detection_onnxruntime_static.py \
+ configs/deploy/model/yolov5_s-static.py \
+ --model work_dir/end2end.onnx \
+ --device cpu \
+ --work-dir work_dir
+```
+
+执行完成您将看到命令行输出检测结果指标如下:
+
+
+
+### TensorRT
+
+**注意**: TensorRT 需要执行设备是 `cuda`
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/test.py \
+ configs/deploy/detection_tensorrt_static-640x640.py \
+ configs/deploy/model/yolov5_s-static.py \
+ --model work_dir/end2end.engine \
+ --device cuda:0 \
+ --work-dir work_dir
+```
+
+执行完成您将看到命令行输出检测结果指标如下:
+
+
+
+**未来我们将会支持模型测速等更加实用的脚本**
+
+# 使用 Docker 部署测试
+
+`MMYOLO` 提供了一个 [`Dockerfile`](https://github.com/open-mmlab/mmyolo/blob/main/docker/Dockerfile_deployment) 用于构建镜像。请确保您的 `docker` 版本大于等于 `19.03`。
+
+温馨提示;国内用户建议取消掉 [`Dockerfile`](https://github.com/open-mmlab/mmyolo/blob/main/docker/Dockerfile_deployment) 里面 `Optional` 后两行的注释,可以获得火箭一般的下载提速:
+
+```dockerfile
+# (Optional)
+RUN sed -i 's/http:\/\/archive.ubuntu.com\/ubuntu\//http:\/\/mirrors.aliyun.com\/ubuntu\//g' /etc/apt/sources.list && \
+ pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
+```
+
+构建命令:
+
+```bash
+# build an image with PyTorch 1.12, CUDA 11.6, TensorRT 8.2.4 ONNXRuntime 1.8.1
+docker build -f docker/Dockerfile_deployment -t mmyolo:v1 .
+```
+
+用以下命令运行 Docker 镜像:
+
+```bash
+export DATA_DIR=/path/to/your/dataset
+docker run --gpus all --shm-size=8g -it --name mmyolo -v ${DATA_DIR}:/openmmlab/mmyolo/data/coco mmyolo:v1
+```
+
+`DATA_DIR` 是 COCO 数据的路径。
+
+复制以下脚本到 `docker` 容器 `/openmmlab/mmyolo/script.sh`:
+
+```bash
+#!/bin/bash
+wget -q https://download.openmmlab.com/mmyolo/v0/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_20220918_084700-86e02187.pth \
+ -O yolov5s.pth
+export MMDEPLOY_DIR=/openmmlab/mmdeploy
+export PATH_TO_CHECKPOINTS=/openmmlab/mmyolo/yolov5s.pth
+
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_tensorrt_static-640x640.py \
+ configs/deploy/model/yolov5_s-static.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir_trt \
+ --device cuda:0
+
+python3 ${MMDEPLOY_DIR}/tools/test.py \
+ configs/deploy/detection_tensorrt_static-640x640.py \
+ configs/deploy/model/yolov5_s-static.py \
+ --model work_dir_trt/end2end.engine \
+ --device cuda:0 \
+ --work-dir work_dir_trt
+
+python3 ${MMDEPLOY_DIR}/tools/deploy.py \
+ configs/deploy/detection_onnxruntime_static.py \
+ configs/deploy/model/yolov5_s-static.py \
+ ${PATH_TO_CHECKPOINTS} \
+ demo/demo.jpg \
+ --work-dir work_dir_ort \
+ --device cpu
+
+python3 ${MMDEPLOY_DIR}/tools/test.py \
+ configs/deploy/detection_onnxruntime_static.py \
+ configs/deploy/model/yolov5_s-static.py \
+ --model work_dir_ort/end2end.onnx \
+ --device cpu \
+ --work-dir work_dir_ort
+```
+
+在 `/openmmlab/mmyolo` 下运行:
+
+```bash
+sh script.sh
+```
+
+脚本会自动下载 `MMYOLO` 的 `YOLOv5` 预训练权重并使用 `MMDeploy` 进行模型转换和测试。您将会看到以下输出:
+
+- TensorRT:
+
+ 
+
+- ONNXRuntime:
+
+ 
+
+可以看到,经过 `MMDeploy` 部署的模型与 [MMYOLO-YOLOv5](https://github.com/open-mmlab/mmyolo/tree/main/configs/yolov5#results-and-models) 的 mAP-37.7 差距在 1% 以内。
+
+如果您需要测试您的模型推理速度,可以使用以下命令:
+
+- TensorRT
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/profiler.py \
+ configs/deploy/detection_tensorrt_static-640x640.py \
+ configs/deploy/model/yolov5_s-static.py \
+ data/coco/val2017 \
+ --model work_dir_trt/end2end.engine \
+ --device cuda:0
+```
+
+- ONNXRuntime
+
+```shell
+python3 ${MMDEPLOY_DIR}/tools/profiler.py \
+ configs/deploy/detection_onnxruntime_static.py \
+ configs/deploy/model/yolov5_s-static.py \
+ data/coco/val2017 \
+ --model work_dir_ort/end2end.onnx \
+ --device cpu
+```
+
+## 模型推理
+
+### 后端模型推理
+
+#### ONNXRuntime
+
+以上述模型转换后的 `end2end.onnx` 为例,您可以使用如下代码进行推理:
+
+```python
+from mmdeploy.apis.utils import build_task_processor
+from mmdeploy.utils import get_input_shape, load_config
+import torch
+
+deploy_cfg = './configs/deploy/detection_onnxruntime_dynamic.py'
+model_cfg = '../mmyolo/configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+device = 'cpu'
+backend_model = ['./work_dir/end2end.onnx']
+image = '../mmyolo/demo/demo.jpg'
+
+# read deploy_cfg and model_cfg
+deploy_cfg, model_cfg = load_config(deploy_cfg, model_cfg)
+
+# build task and backend model
+task_processor = build_task_processor(model_cfg, deploy_cfg, device)
+model = task_processor.build_backend_model(backend_model)
+
+# process input image
+input_shape = get_input_shape(deploy_cfg)
+model_inputs, _ = task_processor.create_input(image, input_shape)
+
+# do model inference
+with torch.no_grad():
+ result = model.test_step(model_inputs)
+
+# visualize results
+task_processor.visualize(
+ image=image,
+ model=model,
+ result=result[0],
+ window_name='visualize',
+ output_file='work_dir/output_detection.png')
+```
+
+#### TensorRT
+
+以上述模型转换后的 `end2end.engine` 为例,您可以使用如下代码进行推理:
+
+```python
+from mmdeploy.apis.utils import build_task_processor
+from mmdeploy.utils import get_input_shape, load_config
+import torch
+
+deploy_cfg = './configs/deploy/detection_tensorrt_dynamic-192x192-960x960.py'
+model_cfg = '../mmyolo/configs/yolov5/yolov5_s-v61_syncbn_8xb16-300e_coco.py'
+device = 'cuda:0'
+backend_model = ['./work_dir/end2end.engine']
+image = '../mmyolo/demo/demo.jpg'
+
+# read deploy_cfg and model_cfg
+deploy_cfg, model_cfg = load_config(deploy_cfg, model_cfg)
+
+# build task and backend model
+task_processor = build_task_processor(model_cfg, deploy_cfg, device)
+model = task_processor.build_backend_model(backend_model)
+
+# process input image
+input_shape = get_input_shape(deploy_cfg)
+model_inputs, _ = task_processor.create_input(image, input_shape)
+
+# do model inference
+with torch.no_grad():
+ result = model.test_step(model_inputs)
+
+# visualize results
+task_processor.visualize(
+ image=image,
+ model=model,
+ result=result[0],
+ window_name='visualize',
+ output_file='work_dir/output_detection.png')
+```
+
+### SDK 模型推理
+
+#### ONNXRuntime
+
+以上述模型转换后的 `end2end.onnx` 为例,您可以使用如下代码进行 `SDK` 推理:
+
+```python
+from mmdeploy_runtime import Detector
+import cv2
+
+img = cv2.imread('../mmyolo/demo/demo.jpg')
+
+# create a detector
+detector = Detector(model_path='work_dir',
+ device_name='cpu', device_id=0)
+# perform inference
+bboxes, labels, masks = detector(img)
+
+# visualize inference result
+indices = [i for i in range(len(bboxes))]
+for index, bbox, label_id in zip(indices, bboxes, labels):
+ [left, top, right, bottom], score = bbox[0:4].astype(int), bbox[4]
+ if score < 0.3:
+ continue
+
+ cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0))
+
+cv2.imwrite('work_dir/output_detection.png', img)
+```
+
+#### TensorRT
+
+以上述模型转换后的 `end2end.engine` 为例,您可以使用如下代码进行 `SDK` 推理:
+
+```python
+from mmdeploy_runtime import Detector
+import cv2
+
+img = cv2.imread('../mmyolo/demo/demo.jpg')
+
+# create a detector
+detector = Detector(model_path='work_dir',
+ device_name='cuda', device_id=0)
+# perform inference
+bboxes, labels, masks = detector(img)
+
+# visualize inference result
+indices = [i for i in range(len(bboxes))]
+for index, bbox, label_id in zip(indices, bboxes, labels):
+ [left, top, right, bottom], score = bbox[0:4].astype(int), bbox[4]
+ if score < 0.3:
+ continue
+
+ cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0))
+
+cv2.imwrite('work_dir/output_detection.png', img)
+```
+
+除了python API,mmdeploy SDK 还提供了诸如 C、C++、C#、Java等多语言接口。
+你可以参考[样例](https://github.com/open-mmlab/mmdeploy/tree/main/demo)学习其他语言接口的使用方法。
diff --git a/third_party/mmyolo/docs/zh_cn/recommended_topics/labeling_to_deployment_tutorials.md b/third_party/mmyolo/docs/zh_cn/recommended_topics/labeling_to_deployment_tutorials.md
new file mode 100644
index 0000000000000000000000000000000000000000..d4e3ddf8f6a107d19cf48f5677d75f47a7b7351c
--- /dev/null
+++ b/third_party/mmyolo/docs/zh_cn/recommended_topics/labeling_to_deployment_tutorials.md
@@ -0,0 +1,1326 @@
+# 标注+训练+测试+部署全流程
+
+在平时的工作学习中,我们经常会遇到一些任务需要训练自定义的私有数据集,开源数据集去作为上线模型的场景比较少,这就需要我们对自己的私有数据集进行一系列的操作,以确保模型能够上线生产服务于客户。
+
+```{SeeAlso}
+本文档配套的视频已发布在 B 站,可前去查看: [自定义数据集从标注到部署保姆级教程](https://www.bilibili.com/video/BV1RG4y137i5)
+```
+
+```{Note}
+本教程所有指令是在 Linux 上面完成,Windows 也是完全可用的,但是命令和操作稍有不同。
+```
+
+本教程默认您已经完成 MMYOLO 的安装,如果未安装,请参考文档 [开始你的第一步](https://mmyolo.readthedocs.io/zh_CN/latest/get_started.html#id1) 进行安装。
+
+本教程涵盖从 用户自定义图片数据集标注 到 最终进行训练和部署 的整体流程。步骤概览如下:
+
+01. 数据集准备:`tools/misc/download_dataset.py`
+02. 使用 [labelme](https://github.com/wkentaro/labelme) 和算法进行辅助和优化数据集标注:`demo/image_demo.py` + labelme
+03. 使用脚本转换成 COCO 数据集格式:`tools/dataset_converters/labelme2coco.py`
+04. 数据集划分为训练集、验证集和测试集:`tools/misc/coco_split.py`
+05. 根据数据集内容新建 config 文件
+06. 数据集可视化分析:`tools/analysis_tools/dataset_analysis.py`
+07. 优化 Anchor 尺寸:`tools/analysis_tools/optimize_anchors.py`
+08. 可视化 config 配置中数据处理部分: `tools/analysis_tools/browse_dataset.py`
+09. 训练:`tools/train.py`
+10. 推理:`demo/image_demo.py`
+11. 部署
+
+```{Note}
+在训练得到模型权重和验证集的 mAP 后,用户需要对预测错误的 bad case 进行深入分析,以便优化模型,MMYOLO 在后续会增加这个功能,敬请期待。
+```
+
+下面详细介绍每一步。
+
+## 1. 数据集准备
+
+- 如果您现在暂时没有自己的数据集,亦或者想尝试用一个小型数据集来跑通我们的整体流程,可以使用本教程提供的一个 144 张图片的 `cat` 数据集(本 `cat` 数据集由 @RangeKing 提供原始图片,由 @PeterH0323 进行数据清洗)。本教程的剩余部分都将以此 `cat` 数据集为例进行讲解。
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ |
+ 基于面积规则下,显示类别和 bbox 实例面积的分布图
+ |
+
+ 显示类别和 bbox 实例宽、高的分布图
+ |
+
+
+ |
+
+ |
+
+
+ |
+
+
+ |
+ 显示类别和 bbox 实例个数的分布图
+ |
+
+ 显示类别和 bbox 实例宽/高比例的分布图
+ |
+
+
+ |
+
+ |
+
+
+ |
+
+
+
+
+```{Note}
+因为本教程使用的 cat 数据集数量比较少,故 config 里面用了 RepeatDataset,显示的数目实际上都是重复了 5 次。如果您想得到无重复的分析结果,可以暂时将 RepeatDataset 下面的 `times` 参数从 `5` 改成 `1`。
+```
+
+经过输出的图片分析可以得出,本教程使用的 `cat` 数据集的训练集具有以下情况:
+
+- 图片全部是 `large object`;
+- 类别 cat 的数量是 `655`;
+- bbox 的宽高比例大部分集中在 `1.0 ~ 1.11`,比例最小值是 `0.36`,最大值是 `2.9`;
+- bbox 的宽大部分是 `500 ~ 600` 左右,高大部分是 `500 ~ 600` 左右。
+
+```{SeeAlso}
+关于 `tools/analysis_tools/dataset_analysis.py` 的更多用法请参考 [可视化数据集分析](https://mmyolo.readthedocs.io/zh_CN/latest/user_guides/useful_tools.html#id4)。
+```
+
+## 7. 优化 Anchor 尺寸
+
+```{Warning}
+该步骤仅适用于 anchor-base 的模型,例如 YOLOv5;
+
+Anchor-free 的模型可以跳过此步骤,例如 YOLOv6、YOLOX。
+```
+
+脚本 `tools/analysis_tools/optimize_anchors.py` 支持 YOLO 系列中三种锚框生成方式,分别是 `k-means`、`Differential Evolution`、`v5-k-means`.
+
+本示例使用的是 YOLOv5 进行训练,使用的是 `640 x 640` 的输入大小,使用 `v5-k-means` 进行描框的优化:
+
+```shell
+python tools/analysis_tools/optimize_anchors.py configs/custom_dataset/yolov5_s-v61_syncbn_fast_1xb32-100e_cat.py \
+ --algorithm v5-k-means \
+ --input-shape 640 640 \
+ --prior-match-thr 4.0 \
+ --out-dir work_dirs/dataset_analysis_cat
+```
+
+```{Note}
+因为该命令使用的是 k-means 聚类算法,存在一定的随机性,这与初始化有关。故每次执行得到的 Anchor 都会有些不一样,但是都是基于传递进去的数据集来进行生成的,故不会有什么不良影响。
+```
+
+经过计算的 Anchor 如下:
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+图 1:P5 模型结构
+
+
+图 2:P6 模型结构
+
+

+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
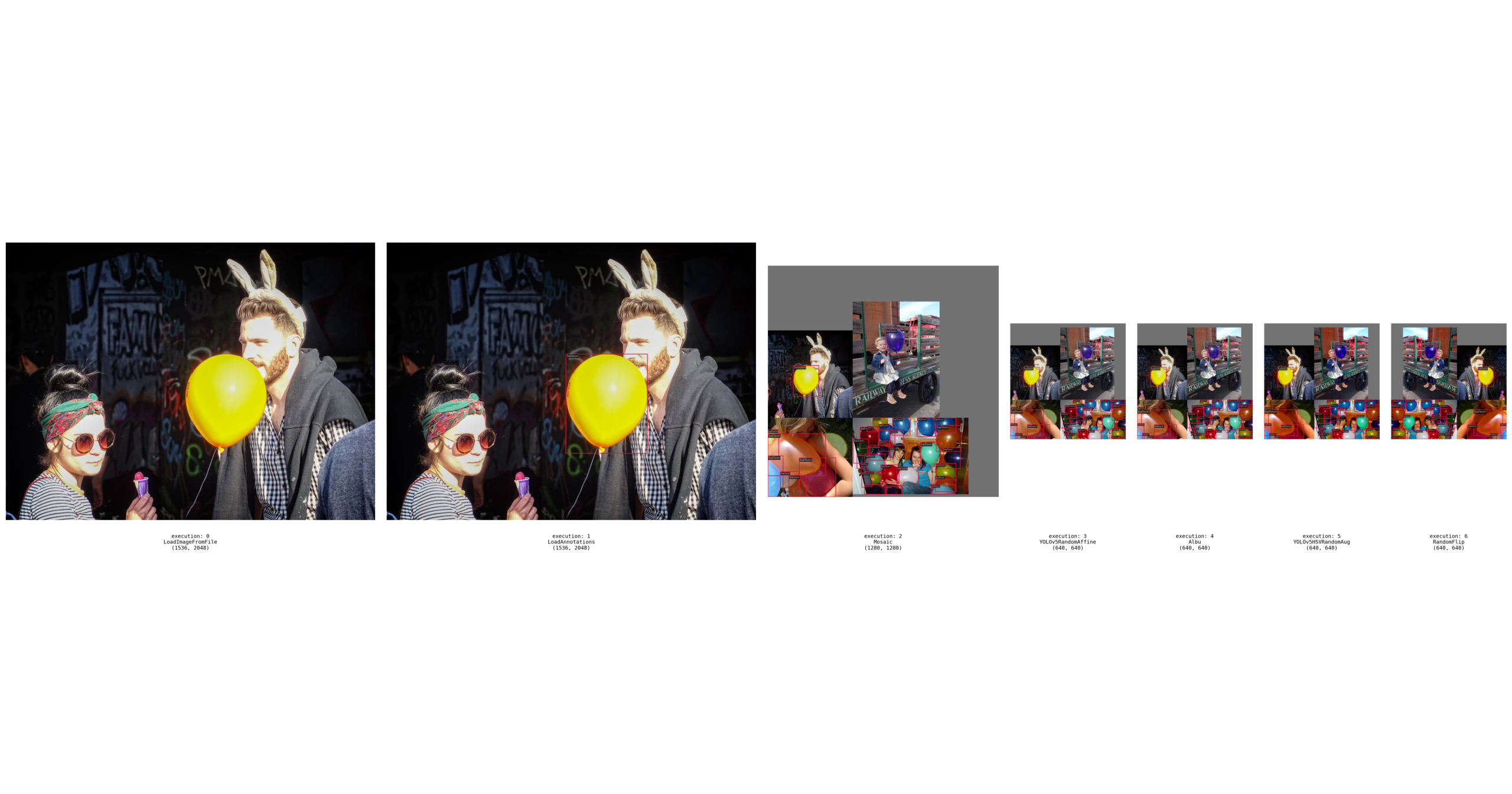
+
+
+
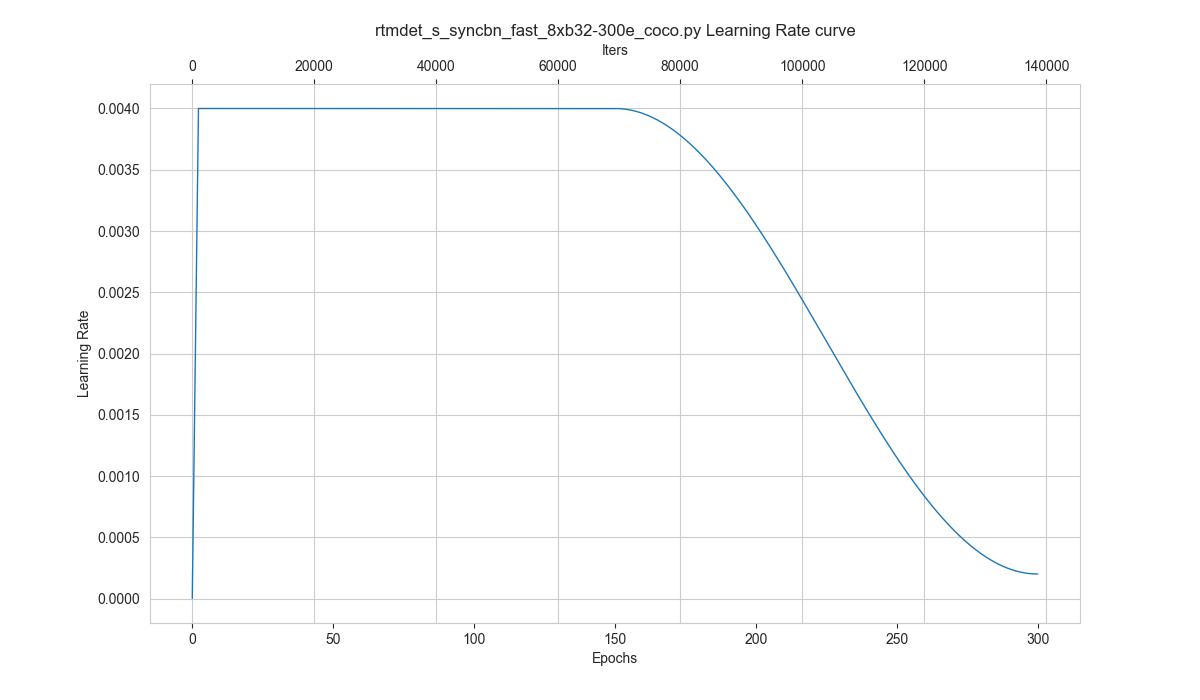
 +
+## Introduction
+
+This project is developed for easily showing assigning results. The script allows users to analyze where and how many positive samples each gt is assigned in the image.
+
+Now, the script supports `YOLOv5`, `YOLOv7`, `YOLOv8` and `RTMDet`.
+
+## Usage
+
+### Command
+
+YOLOv5 assigner visualization command:
+
+```shell
+python projects/assigner_visualization/assigner_visualization.py projects/assigner_visualization/configs/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_assignervisualization.py
+```
+
+Note: `YOLOv5` does not need to load the trained weights.
+
+YOLOv7 assigner visualization command:
+
+```shell
+python projects/assigner_visualization/assigner_visualization.py projects/assigner_visualization/configs/yolov7_tiny_syncbn_fast_8xb16-300e_coco_assignervisualization.py -c ${checkpont}
+```
+
+YOLOv8 assigner visualization command:
+
+```shell
+python projects/assigner_visualization/assigner_visualization.py projects/assigner_visualization/configs/yolov8_s_syncbn_fast_8xb16-500e_coco_assignervisualization.py -c ${checkpont}
+```
+
+RTMdet assigner visualization command:
+
+```shell
+python projects/assigner_visualization/assigner_visualization.py projects/assigner_visualization/configs/rtmdet_s_syncbn_fast_8xb32-300e_coco_assignervisualization.py -c ${checkpont}
+```
+
+${checkpont} is the checkpont file path. Dynamic label assignment is used in `YOLOv7`, `YOLOv8` and `RTMDet`, model weights will affect the positive sample allocation results, so it is recommended to load the trained model weights.
+
+If you want to know details about label assignment, you can check the [RTMDet](https://mmyolo.readthedocs.io/zh_CN/latest/algorithm_descriptions/rtmdet_description.html#id5).
diff --git a/third_party/mmyolo/projects/assigner_visualization/assigner_visualization.py b/third_party/mmyolo/projects/assigner_visualization/assigner_visualization.py
new file mode 100644
index 0000000000000000000000000000000000000000..e290d26b6d6fbb2f703faf3ebcd0474da871aea8
--- /dev/null
+++ b/third_party/mmyolo/projects/assigner_visualization/assigner_visualization.py
@@ -0,0 +1,177 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+import sys
+import warnings
+
+import mmcv
+import numpy as np
+import torch
+from mmengine import ProgressBar
+from mmengine.config import Config, DictAction
+from mmengine.dataset import COLLATE_FUNCTIONS
+from mmengine.runner.checkpoint import load_checkpoint
+from numpy import random
+
+from mmyolo.registry import DATASETS, MODELS
+from mmyolo.utils import register_all_modules
+from projects.assigner_visualization.dense_heads import (RTMHeadAssigner,
+ YOLOv5HeadAssigner,
+ YOLOv7HeadAssigner,
+ YOLOv8HeadAssigner)
+from projects.assigner_visualization.visualization import \
+ YOLOAssignerVisualizer
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='MMYOLO show the positive sample assigning'
+ ' results.')
+ parser.add_argument('config', help='config file path')
+ parser.add_argument('--checkpoint', '-c', type=str, help='checkpoint file')
+ parser.add_argument(
+ '--show-number',
+ '-n',
+ type=int,
+ default=sys.maxsize,
+ help='number of images selected to save, '
+ 'must bigger than 0. if the number is bigger than length '
+ 'of dataset, show all the images in dataset; '
+ 'default "sys.maxsize", show all images in dataset')
+ parser.add_argument(
+ '--output-dir',
+ default='assigned_results',
+ type=str,
+ help='The name of the folder where the image is saved.')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device used for inference.')
+ parser.add_argument(
+ '--show-prior',
+ default=False,
+ action='store_true',
+ help='Whether to show prior on image.')
+ parser.add_argument(
+ '--not-show-label',
+ default=False,
+ action='store_true',
+ help='Whether to show label on image.')
+ parser.add_argument('--seed', default=-1, type=int, help='random seed')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ register_all_modules()
+
+ # set random seed
+ seed = int(args.seed)
+ if seed != -1:
+ print(f'Set the global seed: {seed}')
+ random.seed(int(args.seed))
+
+ cfg = Config.fromfile(args.config)
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+ # build model
+ model = MODELS.build(cfg.model)
+ if args.checkpoint is not None:
+ load_checkpoint(model, args.checkpoint)
+ elif isinstance(model.bbox_head, (YOLOv7HeadAssigner, RTMHeadAssigner)):
+ warnings.warn(
+ 'if you use dynamic_assignment methods such as YOLOv7 or '
+ 'YOLOv8 or RTMDet assigner, please load the checkpoint.')
+ assert isinstance(model.bbox_head, (YOLOv5HeadAssigner,
+ YOLOv7HeadAssigner,
+ YOLOv8HeadAssigner,
+ RTMHeadAssigner)), \
+ 'Now, this script only support YOLOv5, YOLOv7, YOLOv8 and RTMdet, ' \
+ 'and bbox_head must use ' \
+ '`YOLOv5HeadAssigner or YOLOv7HeadAssigne or YOLOv8HeadAssigner ' \
+ 'or RTMHeadAssigner`. Please use `' \
+ 'yolov5_s-v61_syncbn_fast_8xb16-300e_coco_assignervisualization.py' \
+ 'or yolov7_tiny_syncbn_fast_8x16b-300e_coco_assignervisualization.py' \
+ 'or yolov8_s_syncbn_fast_8xb16-500e_coco_assignervisualization.py' \
+ 'or rtmdet_s_syncbn_fast_8xb32-300e_coco_assignervisualization.py' \
+ """` as config file."""
+ model.eval()
+ model.to(args.device)
+
+ # build dataset
+ dataset_cfg = cfg.get('train_dataloader').get('dataset')
+ dataset = DATASETS.build(dataset_cfg)
+
+ # get collate_fn
+ collate_fn_cfg = cfg.get('train_dataloader').pop(
+ 'collate_fn', dict(type='pseudo_collate'))
+ collate_fn_type = collate_fn_cfg.pop('type')
+ collate_fn = COLLATE_FUNCTIONS.get(collate_fn_type)
+
+ # init visualizer
+ visualizer = YOLOAssignerVisualizer(
+ vis_backends=[{
+ 'type': 'LocalVisBackend'
+ }], name='visualizer')
+ visualizer.dataset_meta = dataset.metainfo
+ # need priors size to draw priors
+
+ if hasattr(model.bbox_head.prior_generator, 'base_anchors'):
+ visualizer.priors_size = model.bbox_head.prior_generator.base_anchors
+
+ # make output dir
+ os.makedirs(args.output_dir, exist_ok=True)
+ print('Results will save to ', args.output_dir)
+
+ # init visualization image number
+ assert args.show_number > 0
+ display_number = min(args.show_number, len(dataset))
+
+ progress_bar = ProgressBar(display_number)
+ for ind_img in range(display_number):
+ data = dataset.prepare_data(ind_img)
+ if data is None:
+ print('Unable to visualize {} due to strong data augmentations'.
+ format(dataset[ind_img]['data_samples'].img_path))
+ continue
+ # convert data to batch format
+ batch_data = collate_fn([data])
+ with torch.no_grad():
+ assign_results = model.assign(batch_data)
+
+ img = data['inputs'].cpu().numpy().astype(np.uint8).transpose(
+ (1, 2, 0))
+ # bgr2rgb
+ img = mmcv.bgr2rgb(img)
+
+ gt_instances = data['data_samples'].gt_instances
+
+ img_show = visualizer.draw_assign(img, assign_results, gt_instances,
+ args.show_prior, args.not_show_label)
+
+ if hasattr(data['data_samples'], 'img_path'):
+ filename = osp.basename(data['data_samples'].img_path)
+ else:
+ # some dataset have not image path
+ filename = f'{ind_img}.jpg'
+ out_file = osp.join(args.output_dir, filename)
+
+ # convert rgb 2 bgr and save img
+ mmcv.imwrite(mmcv.rgb2bgr(img_show), out_file)
+ progress_bar.update()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/third_party/mmyolo/projects/assigner_visualization/configs/rtmdet_s_syncbn_fast_8xb32-300e_coco_assignervisualization.py b/third_party/mmyolo/projects/assigner_visualization/configs/rtmdet_s_syncbn_fast_8xb32-300e_coco_assignervisualization.py
new file mode 100644
index 0000000000000000000000000000000000000000..006502eb45af9ece927b68359525cc6c2de30788
--- /dev/null
+++ b/third_party/mmyolo/projects/assigner_visualization/configs/rtmdet_s_syncbn_fast_8xb32-300e_coco_assignervisualization.py
@@ -0,0 +1,9 @@
+_base_ = ['../../../configs/rtmdet/rtmdet_s_syncbn_fast_8xb32-300e_coco.py']
+
+custom_imports = dict(imports=[
+ 'projects.assigner_visualization.detectors',
+ 'projects.assigner_visualization.dense_heads'
+])
+
+model = dict(
+ type='YOLODetectorAssigner', bbox_head=dict(type='RTMHeadAssigner'))
diff --git a/third_party/mmyolo/projects/assigner_visualization/configs/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_assignervisualization.py b/third_party/mmyolo/projects/assigner_visualization/configs/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_assignervisualization.py
new file mode 100644
index 0000000000000000000000000000000000000000..1db799b5142375c86bd5a018764017c9d3170a07
--- /dev/null
+++ b/third_party/mmyolo/projects/assigner_visualization/configs/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_assignervisualization.py
@@ -0,0 +1,11 @@
+_base_ = [
+ '../../../configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py'
+]
+
+custom_imports = dict(imports=[
+ 'projects.assigner_visualization.detectors',
+ 'projects.assigner_visualization.dense_heads'
+])
+
+model = dict(
+ type='YOLODetectorAssigner', bbox_head=dict(type='YOLOv5HeadAssigner'))
diff --git a/third_party/mmyolo/projects/assigner_visualization/configs/yolov7_tiny_syncbn_fast_8xb16-300e_coco_assignervisualization.py b/third_party/mmyolo/projects/assigner_visualization/configs/yolov7_tiny_syncbn_fast_8xb16-300e_coco_assignervisualization.py
new file mode 100644
index 0000000000000000000000000000000000000000..626dc18b59df3b9ced0781347989b65f64de5042
--- /dev/null
+++ b/third_party/mmyolo/projects/assigner_visualization/configs/yolov7_tiny_syncbn_fast_8xb16-300e_coco_assignervisualization.py
@@ -0,0 +1,9 @@
+_base_ = ['../../../configs/yolov7/yolov7_tiny_syncbn_fast_8x16b-300e_coco.py']
+
+custom_imports = dict(imports=[
+ 'projects.assigner_visualization.detectors',
+ 'projects.assigner_visualization.dense_heads'
+])
+
+model = dict(
+ type='YOLODetectorAssigner', bbox_head=dict(type='YOLOv7HeadAssigner'))
diff --git a/third_party/mmyolo/projects/assigner_visualization/configs/yolov8_s_syncbn_fast_8xb16-500e_coco_assignervisualization.py b/third_party/mmyolo/projects/assigner_visualization/configs/yolov8_s_syncbn_fast_8xb16-500e_coco_assignervisualization.py
new file mode 100644
index 0000000000000000000000000000000000000000..03dcae8c39a09c0200dc52123efc1bc0a348dea3
--- /dev/null
+++ b/third_party/mmyolo/projects/assigner_visualization/configs/yolov8_s_syncbn_fast_8xb16-500e_coco_assignervisualization.py
@@ -0,0 +1,9 @@
+_base_ = ['../../../configs/yolov8/yolov8_s_syncbn_fast_8xb16-500e_coco.py']
+
+custom_imports = dict(imports=[
+ 'projects.assigner_visualization.detectors',
+ 'projects.assigner_visualization.dense_heads'
+])
+
+model = dict(
+ type='YOLODetectorAssigner', bbox_head=dict(type='YOLOv8HeadAssigner'))
diff --git a/third_party/mmyolo/projects/assigner_visualization/dense_heads/__init__.py b/third_party/mmyolo/projects/assigner_visualization/dense_heads/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..82adaaba8ebe3510895ebc3d5ed5ac7c573b41b2
--- /dev/null
+++ b/third_party/mmyolo/projects/assigner_visualization/dense_heads/__init__.py
@@ -0,0 +1,10 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .rtmdet_head_assigner import RTMHeadAssigner
+from .yolov5_head_assigner import YOLOv5HeadAssigner
+from .yolov7_head_assigner import YOLOv7HeadAssigner
+from .yolov8_head_assigner import YOLOv8HeadAssigner
+
+__all__ = [
+ 'YOLOv5HeadAssigner', 'YOLOv7HeadAssigner', 'YOLOv8HeadAssigner',
+ 'RTMHeadAssigner'
+]
diff --git a/third_party/mmyolo/projects/assigner_visualization/dense_heads/rtmdet_head_assigner.py b/third_party/mmyolo/projects/assigner_visualization/dense_heads/rtmdet_head_assigner.py
new file mode 100644
index 0000000000000000000000000000000000000000..d3ae1c86d054d02a7a8537ee91251c0cca39edc6
--- /dev/null
+++ b/third_party/mmyolo/projects/assigner_visualization/dense_heads/rtmdet_head_assigner.py
@@ -0,0 +1,175 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Union
+
+import torch
+from mmdet.structures.bbox import distance2bbox
+from mmdet.utils import InstanceList
+from torch import Tensor
+
+from mmyolo.models import RTMDetHead
+from mmyolo.models.utils import gt_instances_preprocess
+from mmyolo.registry import MODELS
+
+
+@MODELS.register_module()
+class RTMHeadAssigner(RTMDetHead):
+
+ def assign_by_gt_and_feat(
+ self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ inputs_hw: Union[Tensor, tuple] = (640, 640)
+ ) -> dict:
+ """Calculate the assigning results based on the gt and features
+ extracted by the detection head.
+
+ Args:
+ cls_scores (list[Tensor]): Box scores for each scale level
+ Has shape (N, num_anchors * num_classes, H, W)
+ bbox_preds (list[Tensor]): Decoded box for each scale
+ level with shape (N, num_anchors * 4, H, W) in
+ [tl_x, tl_y, br_x, br_y] format.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ inputs_hw (Union[Tensor, tuple]): Height and width of inputs size.
+ Returns:
+ dict[str, Tensor]: A dictionary of assigning results.
+ """
+ num_imgs = len(batch_img_metas)
+ featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
+ assert len(featmap_sizes) == self.prior_generator.num_levels
+ # rtmdet's prior offset differs from others
+ prior_offset = self.prior_generator.offset
+
+ gt_info = gt_instances_preprocess(batch_gt_instances, num_imgs)
+ gt_labels = gt_info[:, :, :1]
+ gt_bboxes = gt_info[:, :, 1:] # xyxy
+ pad_bbox_flag = (gt_bboxes.sum(-1, keepdim=True) > 0).float()
+
+ device = cls_scores[0].device
+
+ # If the shape does not equal, generate new one
+ if featmap_sizes != self.featmap_sizes_train:
+ self.featmap_sizes_train = featmap_sizes
+ mlvl_priors_with_stride = self.prior_generator.grid_priors(
+ featmap_sizes, device=device, with_stride=True)
+ self.flatten_priors_train = torch.cat(
+ mlvl_priors_with_stride, dim=0)
+
+ flatten_cls_scores = torch.cat([
+ cls_score.permute(0, 2, 3, 1).reshape(num_imgs, -1,
+ self.cls_out_channels)
+ for cls_score in cls_scores
+ ], 1).contiguous()
+
+ flatten_bboxes = torch.cat([
+ bbox_pred.permute(0, 2, 3, 1).reshape(num_imgs, -1, 4)
+ for bbox_pred in bbox_preds
+ ], 1)
+ flatten_bboxes = flatten_bboxes * self.flatten_priors_train[..., -1,
+ None]
+ flatten_bboxes = distance2bbox(self.flatten_priors_train[..., :2],
+ flatten_bboxes)
+
+ assigned_result = self.assigner(flatten_bboxes.detach(),
+ flatten_cls_scores.detach(),
+ self.flatten_priors_train, gt_labels,
+ gt_bboxes, pad_bbox_flag)
+
+ labels = assigned_result['assigned_labels'].reshape(-1)
+ bbox_targets = assigned_result['assigned_bboxes'].reshape(-1, 4)
+
+ # FG cat_id: [0, num_classes -1], BG cat_id: num_classes
+ bg_class_ind = self.num_classes
+ pos_inds = ((labels >= 0)
+ & (labels < bg_class_ind)).nonzero().squeeze(1)
+ targets = bbox_targets[pos_inds]
+ gt_bboxes = gt_bboxes.squeeze(0)
+ matched_gt_inds = torch.tensor(
+ [((t == gt_bboxes).sum(dim=1) == t.shape[0]).nonzero()[0]
+ for t in targets],
+ device=device)
+
+ level_inds = torch.zeros_like(labels)
+ img_inds = torch.zeros_like(labels)
+ level_nums = [0] + [f[0] * f[1] for f in featmap_sizes]
+ for i in range(len(level_nums) - 1):
+ level_nums[i + 1] = level_nums[i] + level_nums[i + 1]
+ level_inds[level_nums[i]:level_nums[i + 1]] = i
+ level_inds_pos = level_inds[pos_inds]
+
+ img_inds = img_inds[pos_inds]
+ labels = labels[pos_inds]
+
+ inputs_hw = batch_img_metas[0]['batch_input_shape']
+ assign_results = []
+ for i in range(self.num_levels):
+ retained_inds = level_inds_pos == i
+ if not retained_inds.any():
+ assign_results_prior = {
+ 'stride':
+ self.featmap_strides[i],
+ 'grid_x_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'grid_y_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'img_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'class_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'retained_gt_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'prior_ind':
+ 0,
+ 'offset':
+ prior_offset
+ }
+ else:
+ w = inputs_hw[1] // self.featmap_strides[i]
+
+ retained_pos_inds = pos_inds[retained_inds] - level_nums[i]
+ grid_y_inds = retained_pos_inds // w
+ grid_x_inds = retained_pos_inds - retained_pos_inds // w * w
+ assign_results_prior = {
+ 'stride': self.featmap_strides[i],
+ 'grid_x_inds': grid_x_inds,
+ 'grid_y_inds': grid_y_inds,
+ 'img_inds': img_inds[retained_inds],
+ 'class_inds': labels[retained_inds],
+ 'retained_gt_inds': matched_gt_inds[retained_inds],
+ 'prior_ind': 0,
+ 'offset': prior_offset
+ }
+ assign_results.append([assign_results_prior])
+ return assign_results
+
+ def assign(self, batch_data_samples: Union[list, dict],
+ inputs_hw: Union[tuple, torch.Size]) -> dict:
+ """Calculate assigning results. This function is provided to the
+ `assigner_visualization.py` script.
+
+ Args:
+ batch_data_samples (List[:obj:`DetDataSample`], dict): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ inputs_hw: Height and width of inputs size
+
+ Returns:
+ dict: A dictionary of assigning components.
+ """
+ if isinstance(batch_data_samples, list):
+ raise NotImplementedError(
+ 'assigning results_list is not implemented')
+ else:
+ # Fast version
+ cls_scores, bbox_preds = self(batch_data_samples['feats'])
+ assign_inputs = (cls_scores, bbox_preds,
+ batch_data_samples['bboxes_labels'],
+ batch_data_samples['img_metas'], inputs_hw)
+ assign_results = self.assign_by_gt_and_feat(*assign_inputs)
+ return assign_results
diff --git a/third_party/mmyolo/projects/assigner_visualization/dense_heads/yolov5_head_assigner.py b/third_party/mmyolo/projects/assigner_visualization/dense_heads/yolov5_head_assigner.py
new file mode 100644
index 0000000000000000000000000000000000000000..599963fede32fc02c73db8c744dfbc2946dd53fb
--- /dev/null
+++ b/third_party/mmyolo/projects/assigner_visualization/dense_heads/yolov5_head_assigner.py
@@ -0,0 +1,188 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Sequence, Union
+
+import torch
+from mmdet.models.utils import unpack_gt_instances
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmyolo.models import YOLOv5Head
+from mmyolo.registry import MODELS
+
+
+@MODELS.register_module()
+class YOLOv5HeadAssigner(YOLOv5Head):
+
+ def assign_by_gt_and_feat(
+ self,
+ batch_gt_instances: Sequence[InstanceData],
+ batch_img_metas: Sequence[dict],
+ inputs_hw: Union[Tensor, tuple] = (640, 640)
+ ) -> dict:
+ """Calculate the assigning results based on the gt and features
+ extracted by the detection head.
+
+ Args:
+ batch_gt_instances (Sequence[InstanceData]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (Sequence[dict]): Meta information of each image,
+ e.g., image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+ inputs_hw (Union[Tensor, tuple]): Height and width of inputs size.
+ Returns:
+ dict[str, Tensor]: A dictionary of assigning results.
+ """
+ # 1. Convert gt to norm format
+ batch_targets_normed = self._convert_gt_to_norm_format(
+ batch_gt_instances, batch_img_metas)
+
+ device = batch_targets_normed.device
+ scaled_factor = torch.ones(7, device=device)
+ gt_inds = torch.arange(
+ batch_targets_normed.shape[1],
+ dtype=torch.long,
+ device=device,
+ requires_grad=False).unsqueeze(0).repeat((self.num_base_priors, 1))
+
+ assign_results = []
+ for i in range(self.num_levels):
+ assign_results_feat = []
+ h = inputs_hw[0] // self.featmap_strides[i]
+ w = inputs_hw[1] // self.featmap_strides[i]
+
+ # empty gt bboxes
+ if batch_targets_normed.shape[1] == 0:
+ for k in range(self.num_base_priors):
+ assign_results_feat.append({
+ 'stride':
+ self.featmap_strides[i],
+ 'grid_x_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'grid_y_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'img_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'class_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'retained_gt_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'prior_ind':
+ k
+ })
+ assign_results.append(assign_results_feat)
+ continue
+
+ priors_base_sizes_i = self.priors_base_sizes[i]
+ # feature map scale whwh
+ scaled_factor[2:6] = torch.tensor([w, h, w, h])
+ # Scale batch_targets from range 0-1 to range 0-features_maps size.
+ # (num_base_priors, num_bboxes, 7)
+ batch_targets_scaled = batch_targets_normed * scaled_factor
+
+ # 2. Shape match
+ wh_ratio = batch_targets_scaled[...,
+ 4:6] / priors_base_sizes_i[:, None]
+ match_inds = torch.max(
+ wh_ratio, 1 / wh_ratio).max(2)[0] < self.prior_match_thr
+ batch_targets_scaled = batch_targets_scaled[match_inds]
+ match_gt_inds = gt_inds[match_inds]
+
+ # no gt bbox matches anchor
+ if batch_targets_scaled.shape[0] == 0:
+ for k in range(self.num_base_priors):
+ assign_results_feat.append({
+ 'stride':
+ self.featmap_strides[i],
+ 'grid_x_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'grid_y_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'img_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'class_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'retained_gt_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'prior_ind':
+ k
+ })
+ assign_results.append(assign_results_feat)
+ continue
+
+ # 3. Positive samples with additional neighbors
+
+ # check the left, up, right, bottom sides of the
+ # targets grid, and determine whether assigned
+ # them as positive samples as well.
+ batch_targets_cxcy = batch_targets_scaled[:, 2:4]
+ grid_xy = scaled_factor[[2, 3]] - batch_targets_cxcy
+ left, up = ((batch_targets_cxcy % 1 < self.near_neighbor_thr) &
+ (batch_targets_cxcy > 1)).T
+ right, bottom = ((grid_xy % 1 < self.near_neighbor_thr) &
+ (grid_xy > 1)).T
+ offset_inds = torch.stack(
+ (torch.ones_like(left), left, up, right, bottom))
+
+ batch_targets_scaled = batch_targets_scaled.repeat(
+ (5, 1, 1))[offset_inds]
+ retained_gt_inds = match_gt_inds.repeat((5, 1))[offset_inds]
+ retained_offsets = self.grid_offset.repeat(1, offset_inds.shape[1],
+ 1)[offset_inds]
+
+ # prepare pred results and positive sample indexes to
+ # calculate class loss and bbox lo
+ _chunk_targets = batch_targets_scaled.chunk(4, 1)
+ img_class_inds, grid_xy, grid_wh, priors_inds = _chunk_targets
+ priors_inds, (img_inds, class_inds) = priors_inds.long().view(
+ -1), img_class_inds.long().T
+
+ grid_xy_long = (grid_xy -
+ retained_offsets * self.near_neighbor_thr).long()
+ grid_x_inds, grid_y_inds = grid_xy_long.T
+ for k in range(self.num_base_priors):
+ retained_inds = priors_inds == k
+ assign_results_prior = {
+ 'stride': self.featmap_strides[i],
+ 'grid_x_inds': grid_x_inds[retained_inds],
+ 'grid_y_inds': grid_y_inds[retained_inds],
+ 'img_inds': img_inds[retained_inds],
+ 'class_inds': class_inds[retained_inds],
+ 'retained_gt_inds': retained_gt_inds[retained_inds],
+ 'prior_ind': k
+ }
+ assign_results_feat.append(assign_results_prior)
+ assign_results.append(assign_results_feat)
+ return assign_results
+
+ def assign(self, batch_data_samples: Union[list, dict],
+ inputs_hw: Union[tuple, torch.Size]) -> dict:
+ """Calculate assigning results. This function is provided to the
+ `assigner_visualization.py` script.
+
+ Args:
+ batch_data_samples (List[:obj:`DetDataSample`], dict): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ inputs_hw: Height and width of inputs size
+
+ Returns:
+ dict: A dictionary of assigning components.
+ """
+ if isinstance(batch_data_samples, list):
+ outputs = unpack_gt_instances(batch_data_samples)
+ (batch_gt_instances, batch_gt_instances_ignore,
+ batch_img_metas) = outputs
+
+ assign_inputs = (batch_gt_instances, batch_img_metas,
+ batch_gt_instances_ignore, inputs_hw)
+ else:
+ # Fast version
+ assign_inputs = (batch_data_samples['bboxes_labels'],
+ batch_data_samples['img_metas'], inputs_hw)
+ assign_results = self.assign_by_gt_and_feat(*assign_inputs)
+
+ return assign_results
diff --git a/third_party/mmyolo/projects/assigner_visualization/dense_heads/yolov7_head_assigner.py b/third_party/mmyolo/projects/assigner_visualization/dense_heads/yolov7_head_assigner.py
new file mode 100644
index 0000000000000000000000000000000000000000..de2a90e36b57f5ad54158ee546dac6cf513cd5a3
--- /dev/null
+++ b/third_party/mmyolo/projects/assigner_visualization/dense_heads/yolov7_head_assigner.py
@@ -0,0 +1,159 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Union
+
+import torch
+from mmdet.utils import InstanceList
+from torch import Tensor
+
+from mmyolo.models import YOLOv7Head
+from mmyolo.registry import MODELS
+
+
+@MODELS.register_module()
+class YOLOv7HeadAssigner(YOLOv7Head):
+
+ def assign_by_gt_and_feat(
+ self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ objectnesses: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ inputs_hw: Union[Tensor, tuple],
+ ) -> dict:
+ """Calculate the assigning results based on the gt and features
+ extracted by the detection head.
+ Args:
+ cls_scores (Sequence[Tensor]): Box scores for each scale level,
+ each is a 4D-tensor, the channel number is
+ num_priors * num_classes.
+ bbox_preds (Sequence[Tensor]): Box energies / deltas for each scale
+ level, each is a 4D-tensor, the channel number is
+ num_priors * 4.
+ objectnesses (Sequence[Tensor]): Score factor for
+ all scale level, each is a 4D-tensor, has shape
+ (batch_size, 1, H, W)
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ inputs_hw (Union[Tensor, tuple]): Height and width of inputs size.
+ Returns:
+ dict[str, Tensor]: A dictionary of assigning results.
+ """
+ device = cls_scores[0][0].device
+
+ head_preds = self._merge_predict_results(bbox_preds, objectnesses,
+ cls_scores)
+
+ batch_targets_normed = self._convert_gt_to_norm_format(
+ batch_gt_instances, batch_img_metas)
+
+ # yolov5_assign and simota_assign
+ assigner_results = self.assigner(
+ head_preds,
+ batch_targets_normed,
+ batch_img_metas[0]['batch_input_shape'],
+ self.priors_base_sizes,
+ self.grid_offset,
+ near_neighbor_thr=self.near_neighbor_thr)
+
+ # multi-level positive sample position.
+ mlvl_positive_infos = assigner_results['mlvl_positive_infos']
+ # assigned results with label and bboxes information.
+ mlvl_targets_normed = assigner_results['mlvl_targets_normed']
+
+ assign_results = []
+ for i in range(self.num_levels):
+ assign_results_feat = []
+ # no gt bbox matches anchor
+ if mlvl_positive_infos[i].shape[0] == 0:
+ for k in range(self.num_base_priors):
+ assign_results_feat.append({
+ 'stride':
+ self.featmap_strides[i],
+ 'grid_x_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'grid_y_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'img_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'class_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'retained_gt_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'prior_ind':
+ k
+ })
+ assign_results.append(assign_results_feat)
+ continue
+
+ # (batch_idx, prior_idx, x_scaled, y_scaled)
+ positive_info = mlvl_positive_infos[i]
+ targets_normed = mlvl_targets_normed[i]
+ priors_inds = positive_info[:, 1]
+ grid_x_inds = positive_info[:, 2]
+ grid_y_inds = positive_info[:, 3]
+ img_inds = targets_normed[:, 0]
+ class_inds = targets_normed[:, 1].long()
+ retained_gt_inds = self.get_gt_inds(
+ targets_normed, batch_targets_normed[0]).long()
+ for k in range(self.num_base_priors):
+ retained_inds = priors_inds == k
+ assign_results_prior = {
+ 'stride': self.featmap_strides[i],
+ 'grid_x_inds': grid_x_inds[retained_inds],
+ 'grid_y_inds': grid_y_inds[retained_inds],
+ 'img_inds': img_inds[retained_inds],
+ 'class_inds': class_inds[retained_inds],
+ 'retained_gt_inds': retained_gt_inds[retained_inds],
+ 'prior_ind': k
+ }
+ assign_results_feat.append(assign_results_prior)
+ assign_results.append(assign_results_feat)
+ return assign_results
+
+ def get_gt_inds(self, assigned_target, gt_instance):
+ """Judging which one gt_ind is assigned by comparing assign_target and
+ origin target.
+
+ Args:
+ assigned_target (Tensor(assign_nums,7)): YOLOv7 assigning results.
+ gt_instance (Tensor(gt_nums,7)): Normalized gt_instance, It
+ usually includes ``bboxes`` and ``labels`` attributes.
+ Returns:
+ gt_inds (Tensor): the index which one gt is assigned.
+ """
+ gt_inds = torch.zeros(assigned_target.shape[0])
+ for i in range(assigned_target.shape[0]):
+ gt_inds[i] = ((assigned_target[i] == gt_instance).sum(
+ dim=1) == 7).nonzero().squeeze()
+ return gt_inds
+
+ def assign(self, batch_data_samples: Union[list, dict],
+ inputs_hw: Union[tuple, torch.Size]) -> dict:
+ """Calculate assigning results.
+
+ This function is provided to the
+ `assigner_visualization.py` script.
+ Args:
+ batch_data_samples (List[:obj:`DetDataSample`], dict): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ inputs_hw: Height and width of inputs size
+ Returns:
+ dict: A dictionary of assigning components.
+ """
+ if isinstance(batch_data_samples, list):
+ raise NotImplementedError(
+ 'assigning results_list is not implemented')
+ else:
+ # Fast version
+ cls_scores, bbox_preds, objectnesses = self(
+ batch_data_samples['feats'])
+ assign_inputs = (cls_scores, bbox_preds, objectnesses,
+ batch_data_samples['bboxes_labels'],
+ batch_data_samples['img_metas'], inputs_hw)
+ assign_results = self.assign_by_gt_and_feat(*assign_inputs)
+ return assign_results
diff --git a/third_party/mmyolo/projects/assigner_visualization/dense_heads/yolov8_head_assigner.py b/third_party/mmyolo/projects/assigner_visualization/dense_heads/yolov8_head_assigner.py
new file mode 100644
index 0000000000000000000000000000000000000000..49d254fdf5ae1e941b5c9b906223ec47311439c3
--- /dev/null
+++ b/third_party/mmyolo/projects/assigner_visualization/dense_heads/yolov8_head_assigner.py
@@ -0,0 +1,180 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Union
+
+import torch
+from mmdet.utils import InstanceList
+from torch import Tensor
+
+from mmyolo.models import YOLOv8Head
+from mmyolo.models.utils import gt_instances_preprocess
+from mmyolo.registry import MODELS
+
+
+@MODELS.register_module()
+class YOLOv8HeadAssigner(YOLOv8Head):
+
+ def assign_by_gt_and_feat(
+ self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ inputs_hw: Union[Tensor, tuple] = (640, 640)
+ ) -> dict:
+ """Calculate the assigning results based on the gt and features
+ extracted by the detection head.
+ Args:
+ cls_scores (Sequence[Tensor]): Box scores for each scale level,
+ each is a 4D-tensor, the channel number is
+ num_priors * num_classes.
+ bbox_preds (Sequence[Tensor]): Box energies / deltas for each scale
+ level, each is a 4D-tensor, the channel number is
+ num_priors * 4.
+ bbox_dist_preds (Sequence[Tensor]): Box distribution logits for
+ each scale level with shape (bs, reg_max + 1, H*W, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ inputs_hw (Union[Tensor, tuple]): Height and width of inputs size.
+ Returns:
+ dict[str, Tensor]: A dictionary of assigning results.
+ """
+ num_imgs = len(batch_img_metas)
+ device = cls_scores[0].device
+
+ current_featmap_sizes = [
+ cls_score.shape[2:] for cls_score in cls_scores
+ ]
+ # If the shape does not equal, generate new one
+ if current_featmap_sizes != self.featmap_sizes_train:
+ self.featmap_sizes_train = current_featmap_sizes
+
+ mlvl_priors_with_stride = self.prior_generator.grid_priors(
+ self.featmap_sizes_train,
+ dtype=cls_scores[0].dtype,
+ device=device,
+ with_stride=True)
+
+ self.num_level_priors = [len(n) for n in mlvl_priors_with_stride]
+ self.flatten_priors_train = torch.cat(
+ mlvl_priors_with_stride, dim=0)
+ self.stride_tensor = self.flatten_priors_train[..., [2]]
+
+ # gt info
+ gt_info = gt_instances_preprocess(batch_gt_instances, num_imgs)
+ gt_labels = gt_info[:, :, :1]
+ gt_bboxes = gt_info[:, :, 1:] # xyxy
+ pad_bbox_flag = (gt_bboxes.sum(-1, keepdim=True) > 0).float()
+
+ # pred info
+ flatten_cls_preds = [
+ cls_pred.permute(0, 2, 3, 1).reshape(num_imgs, -1,
+ self.num_classes)
+ for cls_pred in cls_scores
+ ]
+ flatten_pred_bboxes = [
+ bbox_pred.permute(0, 2, 3, 1).reshape(num_imgs, -1, 4)
+ for bbox_pred in bbox_preds
+ ]
+ # (bs, n, 4 * reg_max)
+
+ flatten_cls_preds = torch.cat(flatten_cls_preds, dim=1)
+ flatten_pred_bboxes = torch.cat(flatten_pred_bboxes, dim=1)
+ flatten_pred_bboxes = self.bbox_coder.decode(
+ self.flatten_priors_train[..., :2], flatten_pred_bboxes,
+ self.stride_tensor[..., 0])
+
+ assigned_result = self.assigner(
+ (flatten_pred_bboxes.detach()).type(gt_bboxes.dtype),
+ flatten_cls_preds.detach().sigmoid(), self.flatten_priors_train,
+ gt_labels, gt_bboxes, pad_bbox_flag)
+
+ labels = assigned_result['assigned_labels'].reshape(-1)
+ bbox_targets = assigned_result['assigned_bboxes'].reshape(-1, 4)
+ fg_mask_pre_prior = assigned_result['fg_mask_pre_prior'].squeeze(0)
+
+ pos_inds = fg_mask_pre_prior.nonzero().squeeze(1)
+
+ targets = bbox_targets[pos_inds]
+ gt_bboxes = gt_bboxes.squeeze(0)
+ matched_gt_inds = torch.tensor(
+ [((t == gt_bboxes).sum(dim=1) == t.shape[0]).nonzero()[0]
+ for t in targets],
+ device=device)
+
+ level_inds = torch.zeros_like(labels)
+ img_inds = torch.zeros_like(labels)
+ level_nums = [0] + self.num_level_priors
+ for i in range(len(level_nums) - 1):
+ level_nums[i + 1] = level_nums[i] + level_nums[i + 1]
+ level_inds[level_nums[i]:level_nums[i + 1]] = i
+ level_inds_pos = level_inds[pos_inds]
+
+ img_inds = img_inds[pos_inds]
+ labels = labels[pos_inds]
+
+ assign_results = []
+ for i in range(self.num_levels):
+ retained_inds = level_inds_pos == i
+ if not retained_inds.any():
+ assign_results_prior = {
+ 'stride':
+ self.featmap_strides[i],
+ 'grid_x_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'grid_y_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'img_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'class_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'retained_gt_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'prior_ind':
+ 0
+ }
+ else:
+ w = inputs_hw[1] // self.featmap_strides[i]
+
+ retained_pos_inds = pos_inds[retained_inds] - level_nums[i]
+ grid_y_inds = retained_pos_inds // w
+ grid_x_inds = retained_pos_inds - retained_pos_inds // w * w
+ assign_results_prior = {
+ 'stride': self.featmap_strides[i],
+ 'grid_x_inds': grid_x_inds,
+ 'grid_y_inds': grid_y_inds,
+ 'img_inds': img_inds[retained_inds],
+ 'class_inds': labels[retained_inds],
+ 'retained_gt_inds': matched_gt_inds[retained_inds],
+ 'prior_ind': 0
+ }
+ assign_results.append([assign_results_prior])
+ return assign_results
+
+ def assign(self, batch_data_samples: Union[list, dict],
+ inputs_hw: Union[tuple, torch.Size]) -> dict:
+ """Calculate assigning results.
+
+ This function is provided to the
+ `assigner_visualization.py` script.
+ Args:
+ batch_data_samples (List[:obj:`DetDataSample`], dict): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ inputs_hw: Height and width of inputs size
+ Returns:
+ dict: A dictionary of assigning components.
+ """
+ if isinstance(batch_data_samples, list):
+ raise NotImplementedError(
+ 'assigning results_list is not implemented')
+ else:
+ # Fast version
+ cls_scores, bbox_preds = self(batch_data_samples['feats'])
+ assign_inputs = (cls_scores, bbox_preds,
+ batch_data_samples['bboxes_labels'],
+ batch_data_samples['img_metas'], inputs_hw)
+ assign_results = self.assign_by_gt_and_feat(*assign_inputs)
+ return assign_results
diff --git a/third_party/mmyolo/projects/assigner_visualization/detectors/__init__.py b/third_party/mmyolo/projects/assigner_visualization/detectors/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..155606a0136ef3e93d90347773af3eb7010b27ac
--- /dev/null
+++ b/third_party/mmyolo/projects/assigner_visualization/detectors/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from projects.assigner_visualization.detectors.yolo_detector_assigner import \
+ YOLODetectorAssigner
+
+__all__ = ['YOLODetectorAssigner']
diff --git a/third_party/mmyolo/projects/assigner_visualization/detectors/yolo_detector_assigner.py b/third_party/mmyolo/projects/assigner_visualization/detectors/yolo_detector_assigner.py
new file mode 100644
index 0000000000000000000000000000000000000000..5b723e01f65381155aaae962415d3c70040de06b
--- /dev/null
+++ b/third_party/mmyolo/projects/assigner_visualization/detectors/yolo_detector_assigner.py
@@ -0,0 +1,34 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Union
+
+from mmyolo.models import YOLODetector
+from mmyolo.registry import MODELS
+from projects.assigner_visualization.dense_heads import (RTMHeadAssigner,
+ YOLOv7HeadAssigner,
+ YOLOv8HeadAssigner)
+
+
+@MODELS.register_module()
+class YOLODetectorAssigner(YOLODetector):
+
+ def assign(self, data: dict) -> Union[dict, list]:
+ """Calculate assigning results from a batch of inputs and data
+ samples.This function is provided to the `assigner_visualization.py`
+ script.
+
+ Args:
+ data (dict or tuple or list): Data sampled from dataset.
+
+ Returns:
+ dict: A dictionary of assigning components.
+ """
+ assert isinstance(data, dict)
+ assert len(data['inputs']) == 1, 'Only support batchsize == 1'
+ data = self.data_preprocessor(data, True)
+ available_assigners = (YOLOv7HeadAssigner, YOLOv8HeadAssigner,
+ RTMHeadAssigner)
+ if isinstance(self.bbox_head, available_assigners):
+ data['data_samples']['feats'] = self.extract_feat(data['inputs'])
+ inputs_hw = data['inputs'].shape[-2:]
+ assign_results = self.bbox_head.assign(data['data_samples'], inputs_hw)
+ return assign_results
diff --git a/third_party/mmyolo/projects/assigner_visualization/visualization/__init__.py b/third_party/mmyolo/projects/assigner_visualization/visualization/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..521a25b8837cf084e78fffa9f84660a4c9ae02bb
--- /dev/null
+++ b/third_party/mmyolo/projects/assigner_visualization/visualization/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .assigner_visualizer import YOLOAssignerVisualizer
+
+__all__ = ['YOLOAssignerVisualizer']
diff --git a/third_party/mmyolo/projects/assigner_visualization/visualization/assigner_visualizer.py b/third_party/mmyolo/projects/assigner_visualization/visualization/assigner_visualizer.py
new file mode 100644
index 0000000000000000000000000000000000000000..fe1f4f0b90da2bbd683e3f9845efb66c9348459e
--- /dev/null
+++ b/third_party/mmyolo/projects/assigner_visualization/visualization/assigner_visualizer.py
@@ -0,0 +1,326 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import List, Union
+
+import mmcv
+import numpy as np
+import torch
+from mmdet.structures.bbox import HorizontalBoxes
+from mmdet.visualization import DetLocalVisualizer
+from mmdet.visualization.palette import _get_adaptive_scales, get_palette
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmyolo.registry import VISUALIZERS
+
+
+@VISUALIZERS.register_module()
+class YOLOAssignerVisualizer(DetLocalVisualizer):
+ """MMYOLO Detection Assigner Visualizer.
+
+ This class is provided to the `assigner_visualization.py` script.
+ Args:
+ name (str): Name of the instance. Defaults to 'visualizer'.
+ """
+
+ def __init__(self, name: str = 'visualizer', *args, **kwargs):
+ super().__init__(name=name, *args, **kwargs)
+ # need priors_size from config
+ self.priors_size = None
+
+ def draw_grid(self,
+ stride: int = 8,
+ line_styles: Union[str, List[str]] = ':',
+ colors: Union[str, tuple, List[str],
+ List[tuple]] = (180, 180, 180),
+ line_widths: Union[Union[int, float],
+ List[Union[int, float]]] = 1):
+ """Draw grids on image.
+
+ Args:
+ stride (int): Downsample factor of feature map.
+ line_styles (Union[str, List[str]]): The linestyle
+ of lines. ``line_styles`` can have the same length with
+ texts or just single value. If ``line_styles`` is single
+ value, all the lines will have the same linestyle.
+ Reference to
+ https://matplotlib.org/stable/api/collections_api.html?highlight=collection#matplotlib.collections.AsteriskPolygonCollection.set_linestyle
+ for more details. Defaults to ':'.
+ colors (Union[str, tuple, List[str], List[tuple]]): The colors of
+ lines. ``colors`` can have the same length with lines or just
+ single value. If ``colors`` is single value, all the lines
+ will have the same colors. Reference to
+ https://matplotlib.org/stable/gallery/color/named_colors.html
+ for more details. Defaults to (180, 180, 180).
+ line_widths (Union[Union[int, float], List[Union[int, float]]]):
+ The linewidth of lines. ``line_widths`` can have
+ the same length with lines or just single value.
+ If ``line_widths`` is single value, all the lines will
+ have the same linewidth. Defaults to 1.
+ """
+ assert self._image is not None, 'Please set image using `set_image`'
+ # draw vertical lines
+ x_datas_vertical = ((np.arange(self.width // stride - 1) + 1) *
+ stride).reshape((-1, 1)).repeat(
+ 2, axis=1)
+ y_datas_vertical = np.array([[0, self.height - 1]]).repeat(
+ self.width // stride - 1, axis=0)
+ self.draw_lines(
+ x_datas_vertical,
+ y_datas_vertical,
+ colors=colors,
+ line_styles=line_styles,
+ line_widths=line_widths)
+
+ # draw horizontal lines
+ x_datas_horizontal = np.array([[0, self.width - 1]]).repeat(
+ self.height // stride - 1, axis=0)
+ y_datas_horizontal = ((np.arange(self.height // stride - 1) + 1) *
+ stride).reshape((-1, 1)).repeat(
+ 2, axis=1)
+ self.draw_lines(
+ x_datas_horizontal,
+ y_datas_horizontal,
+ colors=colors,
+ line_styles=line_styles,
+ line_widths=line_widths)
+
+ def draw_instances_assign(self,
+ instances: InstanceData,
+ retained_gt_inds: Tensor,
+ not_show_label: bool = False):
+ """Draw instances of GT.
+
+ Args:
+ instances (:obj:`InstanceData`): gt_instance. It usually
+ includes ``bboxes`` and ``labels`` attributes.
+ retained_gt_inds (Tensor): The gt indexes assigned as the
+ positive sample in the current prior.
+ not_show_label (bool): Whether to show gt labels on images.
+ """
+ assert self.dataset_meta is not None
+ classes = self.dataset_meta['classes']
+ palette = self.dataset_meta['palette']
+ if len(retained_gt_inds) == 0:
+ return self.get_image()
+ draw_gt_inds = torch.from_numpy(
+ np.array(
+ list(set(retained_gt_inds.cpu().numpy())), dtype=np.int64))
+ bboxes = instances.bboxes[draw_gt_inds]
+ labels = instances.labels[draw_gt_inds]
+
+ if not isinstance(bboxes, Tensor):
+ bboxes = bboxes.tensor
+
+ edge_colors = [palette[i] for i in labels]
+
+ max_label = int(max(labels) if len(labels) > 0 else 0)
+ text_palette = get_palette(self.text_color, max_label + 1)
+ text_colors = [text_palette[label] for label in labels]
+
+ self.draw_bboxes(
+ bboxes,
+ edge_colors=edge_colors,
+ alpha=self.alpha,
+ line_widths=self.line_width)
+
+ if not not_show_label:
+ positions = bboxes[:, :2] + self.line_width
+ areas = (bboxes[:, 3] - bboxes[:, 1]) * (
+ bboxes[:, 2] - bboxes[:, 0])
+ scales = _get_adaptive_scales(areas)
+ for i, (pos, label) in enumerate(zip(positions, labels)):
+ label_text = classes[
+ label] if classes is not None else f'class {label}'
+
+ self.draw_texts(
+ label_text,
+ pos,
+ colors=text_colors[i],
+ font_sizes=int(13 * scales[i]),
+ bboxes=[{
+ 'facecolor': 'black',
+ 'alpha': 0.8,
+ 'pad': 0.7,
+ 'edgecolor': 'none'
+ }])
+
+ def draw_positive_assign(self,
+ grid_x_inds: Tensor,
+ grid_y_inds: Tensor,
+ class_inds: Tensor,
+ stride: int,
+ bboxes: Union[Tensor, HorizontalBoxes],
+ retained_gt_inds: Tensor,
+ offset: float = 0.5):
+ """
+
+ Args:
+ grid_x_inds (Tensor): The X-axis indexes of the positive sample
+ in current prior.
+ grid_y_inds (Tensor): The Y-axis indexes of the positive sample
+ in current prior.
+ class_inds (Tensor): The classes indexes of the positive sample
+ in current prior.
+ stride (int): Downsample factor of feature map.
+ bboxes (Union[Tensor, HorizontalBoxes]): Bounding boxes of GT.
+ retained_gt_inds (Tensor): The gt indexes assigned as the
+ positive sample in the current prior.
+ offset (float): The offset of points, the value is normalized
+ with corresponding stride. Defaults to 0.5.
+ """
+ if not isinstance(bboxes, Tensor):
+ # Convert HorizontalBoxes to Tensor
+ bboxes = bboxes.tensor
+
+ # The PALETTE in the dataset_meta is required
+ assert self.dataset_meta is not None
+ palette = self.dataset_meta['palette']
+ x = ((grid_x_inds + offset) * stride).long()
+ y = ((grid_y_inds + offset) * stride).long()
+ center = torch.stack((x, y), dim=-1)
+
+ retained_bboxes = bboxes[retained_gt_inds]
+ bbox_wh = retained_bboxes[:, 2:] - retained_bboxes[:, :2]
+ bbox_area = bbox_wh[:, 0] * bbox_wh[:, 1]
+ radius = _get_adaptive_scales(bbox_area) * 4
+ colors = [palette[i] for i in class_inds]
+
+ self.draw_circles(
+ center,
+ radius,
+ colors,
+ line_widths=0,
+ face_colors=colors,
+ alpha=1.0)
+
+ def draw_prior(self,
+ grid_x_inds: Tensor,
+ grid_y_inds: Tensor,
+ class_inds: Tensor,
+ stride: int,
+ feat_ind: int,
+ prior_ind: int,
+ offset: float = 0.5):
+ """Draw priors on image.
+
+ Args:
+ grid_x_inds (Tensor): The X-axis indexes of the positive sample
+ in current prior.
+ grid_y_inds (Tensor): The Y-axis indexes of the positive sample
+ in current prior.
+ class_inds (Tensor): The classes indexes of the positive sample
+ in current prior.
+ stride (int): Downsample factor of feature map.
+ feat_ind (int): Index of featmap.
+ prior_ind (int): Index of prior in current featmap.
+ offset (float): The offset of points, the value is normalized
+ with corresponding stride. Defaults to 0.5.
+ """
+
+ palette = self.dataset_meta['palette']
+ center_x = ((grid_x_inds + offset) * stride)
+ center_y = ((grid_y_inds + offset) * stride)
+ xyxy = torch.stack((center_x, center_y, center_x, center_y), dim=1)
+ device = xyxy.device
+ if self.priors_size is not None:
+ xyxy += self.priors_size[feat_ind][prior_ind].to(device)
+ else:
+ xyxy += torch.tensor(
+ [[-stride / 2, -stride / 2, stride / 2, stride / 2]],
+ device=device)
+
+ colors = [palette[i] for i in class_inds]
+ self.draw_bboxes(
+ xyxy,
+ edge_colors=colors,
+ alpha=self.alpha,
+ line_styles='--',
+ line_widths=math.ceil(self.line_width * 0.3))
+
+ def draw_assign(self,
+ image: np.ndarray,
+ assign_results: List[List[dict]],
+ gt_instances: InstanceData,
+ show_prior: bool = False,
+ not_show_label: bool = False) -> np.ndarray:
+ """Draw assigning results.
+
+ Args:
+ image (np.ndarray): The image to draw.
+ assign_results (list): The assigning results.
+ gt_instances (:obj:`InstanceData`): Data structure for
+ instance-level annotations or predictions.
+ show_prior (bool): Whether to show prior on image.
+ not_show_label (bool): Whether to show gt labels on images.
+
+ Returns:
+ np.ndarray: the drawn image which channel is RGB.
+ """
+ img_show_list = []
+ for feat_ind, assign_results_feat in enumerate(assign_results):
+ img_show_list_feat = []
+ for prior_ind, assign_results_prior in enumerate(
+ assign_results_feat):
+ self.set_image(image)
+ h, w = image.shape[:2]
+
+ # draw grid
+ stride = assign_results_prior['stride']
+ self.draw_grid(stride)
+
+ # draw prior on matched gt
+ grid_x_inds = assign_results_prior['grid_x_inds']
+ grid_y_inds = assign_results_prior['grid_y_inds']
+ class_inds = assign_results_prior['class_inds']
+ prior_ind = assign_results_prior['prior_ind']
+ offset = assign_results_prior.get('offset', 0.5)
+
+ if show_prior:
+ self.draw_prior(grid_x_inds, grid_y_inds, class_inds,
+ stride, feat_ind, prior_ind, offset)
+
+ # draw matched gt
+ retained_gt_inds = assign_results_prior['retained_gt_inds']
+ self.draw_instances_assign(gt_instances, retained_gt_inds,
+ not_show_label)
+
+ # draw positive
+ self.draw_positive_assign(grid_x_inds, grid_y_inds, class_inds,
+ stride, gt_instances.bboxes,
+ retained_gt_inds, offset)
+
+ # draw title
+ if self.priors_size is not None:
+ base_prior = self.priors_size[feat_ind][prior_ind]
+ else:
+ base_prior = [stride, stride, stride * 2, stride * 2]
+ prior_size = (base_prior[2] - base_prior[0],
+ base_prior[3] - base_prior[1])
+ pos = np.array((20, 20))
+ text = f'feat_ind: {feat_ind} ' \
+ f'prior_ind: {prior_ind} ' \
+ f'prior_size: ({prior_size[0]}, {prior_size[1]})'
+ scales = _get_adaptive_scales(np.array([h * w / 16]))
+ font_sizes = int(13 * scales)
+ self.draw_texts(
+ text,
+ pos,
+ colors=self.text_color,
+ font_sizes=font_sizes,
+ bboxes=[{
+ 'facecolor': 'black',
+ 'alpha': 0.8,
+ 'pad': 0.7,
+ 'edgecolor': 'none'
+ }])
+
+ img_show = self.get_image()
+ img_show = mmcv.impad(img_show, padding=(5, 5, 5, 5))
+ img_show_list_feat.append(img_show)
+ img_show_list.append(np.concatenate(img_show_list_feat, axis=1))
+
+ # Merge all images into one image
+ # setting axis is to beautify the merged image
+ axis = 0 if len(assign_results[0]) > 1 else 1
+ return np.concatenate(img_show_list, axis=axis)
diff --git a/third_party/mmyolo/projects/easydeploy/README.md b/third_party/mmyolo/projects/easydeploy/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..1816e7ed96ee34209c56af4a22eda5f1eb7e499b
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/README.md
@@ -0,0 +1,11 @@
+# MMYOLO Model Easy-Deployment
+
+## Introduction
+
+This project is developed for easily converting your MMYOLO models to other inference backends without the need of MMDeploy, which reduces the cost of both time and effort on getting familiar with MMDeploy.
+
+Currently we support converting to `ONNX` and `TensorRT` formats, other inference backends such `ncnn` will be added to this project as well.
+
+## Supported Backends
+
+- [Model Convert](docs/model_convert.md)
diff --git a/third_party/mmyolo/projects/easydeploy/README_zh-CN.md b/third_party/mmyolo/projects/easydeploy/README_zh-CN.md
new file mode 100644
index 0000000000000000000000000000000000000000..4c6bc0cf4ef91edeced04bdf15af08ae1f6f0dcd
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/README_zh-CN.md
@@ -0,0 +1,11 @@
+# MMYOLO 模型转换
+
+## 介绍
+
+本项目作为 MMYOLO 的部署 project 单独存在,意图剥离 MMDeploy 当前的体系,独自支持用户完成模型训练后的转换和部署功能,使用户的学习和工程成本下降。
+
+当前支持对 ONNX 格式和 TensorRT 格式的转换,后续对其他推理平台也会支持起来。
+
+## 转换教程
+
+- [Model Convert](docs/model_convert.md)
diff --git a/third_party/mmyolo/projects/easydeploy/backbone/__init__.py b/third_party/mmyolo/projects/easydeploy/backbone/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..dc167f8515c66a30d884ed9655a11d45e21481c0
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/backbone/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .common import DeployC2f
+from .focus import DeployFocus, GConvFocus, NcnnFocus
+
+__all__ = ['DeployFocus', 'NcnnFocus', 'GConvFocus', 'DeployC2f']
diff --git a/third_party/mmyolo/projects/easydeploy/backbone/common.py b/third_party/mmyolo/projects/easydeploy/backbone/common.py
new file mode 100644
index 0000000000000000000000000000000000000000..617875bd979a5b9150e476544090777118087a0b
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/backbone/common.py
@@ -0,0 +1,16 @@
+import torch
+import torch.nn as nn
+from torch import Tensor
+
+
+class DeployC2f(nn.Module):
+
+ def __init__(self, *args, **kwargs):
+ super().__init__()
+
+ def forward(self, x: Tensor) -> Tensor:
+ x_main = self.main_conv(x)
+ x_main = [x_main, x_main[:, self.mid_channels:, ...]]
+ x_main.extend(blocks(x_main[-1]) for blocks in self.blocks)
+ x_main.pop(1)
+ return self.final_conv(torch.cat(x_main, 1))
diff --git a/third_party/mmyolo/projects/easydeploy/backbone/focus.py b/third_party/mmyolo/projects/easydeploy/backbone/focus.py
new file mode 100644
index 0000000000000000000000000000000000000000..2a19afcca1d9c4e27109daeebd83907cd9b7b284
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/backbone/focus.py
@@ -0,0 +1,79 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from torch import Tensor
+
+
+class DeployFocus(nn.Module):
+
+ def __init__(self, orin_Focus: nn.Module):
+ super().__init__()
+ self.__dict__.update(orin_Focus.__dict__)
+
+ def forward(self, x: Tensor) -> Tensor:
+ batch_size, channel, height, width = x.shape
+ x = x.reshape(batch_size, channel, -1, 2, width)
+ x = x.reshape(batch_size, channel, x.shape[2], 2, -1, 2)
+ half_h = x.shape[2]
+ half_w = x.shape[4]
+ x = x.permute(0, 5, 3, 1, 2, 4)
+ x = x.reshape(batch_size, channel * 4, half_h, half_w)
+
+ return self.conv(x)
+
+
+class NcnnFocus(nn.Module):
+
+ def __init__(self, orin_Focus: nn.Module):
+ super().__init__()
+ self.__dict__.update(orin_Focus.__dict__)
+
+ def forward(self, x: Tensor) -> Tensor:
+ batch_size, c, h, w = x.shape
+ assert h % 2 == 0 and w % 2 == 0, f'focus for yolox needs even feature\
+ height and width, got {(h, w)}.'
+
+ x = x.reshape(batch_size, c * h, 1, w)
+ _b, _c, _h, _w = x.shape
+ g = _c // 2
+ # fuse to ncnn's shufflechannel
+ x = x.view(_b, g, 2, _h, _w)
+ x = torch.transpose(x, 1, 2).contiguous()
+ x = x.view(_b, -1, _h, _w)
+
+ x = x.reshape(_b, c * h * w, 1, 1)
+
+ _b, _c, _h, _w = x.shape
+ g = _c // 2
+ # fuse to ncnn's shufflechannel
+ x = x.view(_b, g, 2, _h, _w)
+ x = torch.transpose(x, 1, 2).contiguous()
+ x = x.view(_b, -1, _h, _w)
+
+ x = x.reshape(_b, c * 4, h // 2, w // 2)
+
+ return self.conv(x)
+
+
+class GConvFocus(nn.Module):
+
+ def __init__(self, orin_Focus: nn.Module):
+ super().__init__()
+ device = next(orin_Focus.parameters()).device
+ self.weight1 = torch.tensor([[1., 0], [0, 0]]).expand(3, 1, 2,
+ 2).to(device)
+ self.weight2 = torch.tensor([[0, 0], [1., 0]]).expand(3, 1, 2,
+ 2).to(device)
+ self.weight3 = torch.tensor([[0, 1.], [0, 0]]).expand(3, 1, 2,
+ 2).to(device)
+ self.weight4 = torch.tensor([[0, 0], [0, 1.]]).expand(3, 1, 2,
+ 2).to(device)
+ self.__dict__.update(orin_Focus.__dict__)
+
+ def forward(self, x: Tensor) -> Tensor:
+ conv1 = F.conv2d(x, self.weight1, stride=2, groups=3)
+ conv2 = F.conv2d(x, self.weight2, stride=2, groups=3)
+ conv3 = F.conv2d(x, self.weight3, stride=2, groups=3)
+ conv4 = F.conv2d(x, self.weight4, stride=2, groups=3)
+ return self.conv(torch.cat([conv1, conv2, conv3, conv4], dim=1))
diff --git a/third_party/mmyolo/projects/easydeploy/bbox_code/__init__.py b/third_party/mmyolo/projects/easydeploy/bbox_code/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..b85a815536a5749a15f0ad6aab2b028eb6a3fe0a
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/bbox_code/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .bbox_coder import (rtmdet_bbox_decoder, yolov5_bbox_decoder,
+ yolox_bbox_decoder)
+
+__all__ = ['yolov5_bbox_decoder', 'rtmdet_bbox_decoder', 'yolox_bbox_decoder']
diff --git a/third_party/mmyolo/projects/easydeploy/bbox_code/bbox_coder.py b/third_party/mmyolo/projects/easydeploy/bbox_code/bbox_coder.py
new file mode 100644
index 0000000000000000000000000000000000000000..6483cf8b0328aff3d61f1fa0788337ab536d347d
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/bbox_code/bbox_coder.py
@@ -0,0 +1,46 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional
+
+import torch
+from torch import Tensor
+
+
+def yolov5_bbox_decoder(priors: Tensor, bbox_preds: Tensor,
+ stride: Tensor) -> Tensor:
+ bbox_preds = bbox_preds.sigmoid()
+
+ x_center = (priors[..., 0] + priors[..., 2]) * 0.5
+ y_center = (priors[..., 1] + priors[..., 3]) * 0.5
+ w = priors[..., 2] - priors[..., 0]
+ h = priors[..., 3] - priors[..., 1]
+
+ x_center_pred = (bbox_preds[..., 0] - 0.5) * 2 * stride + x_center
+ y_center_pred = (bbox_preds[..., 1] - 0.5) * 2 * stride + y_center
+ w_pred = (bbox_preds[..., 2] * 2)**2 * w
+ h_pred = (bbox_preds[..., 3] * 2)**2 * h
+
+ decoded_bboxes = torch.stack(
+ [x_center_pred, y_center_pred, w_pred, h_pred], dim=-1)
+
+ return decoded_bboxes
+
+
+def rtmdet_bbox_decoder(priors: Tensor, bbox_preds: Tensor,
+ stride: Optional[Tensor]) -> Tensor:
+ stride = stride[None, :, None]
+ bbox_preds *= stride
+ tl_x = (priors[..., 0] - bbox_preds[..., 0])
+ tl_y = (priors[..., 1] - bbox_preds[..., 1])
+ br_x = (priors[..., 0] + bbox_preds[..., 2])
+ br_y = (priors[..., 1] + bbox_preds[..., 3])
+ decoded_bboxes = torch.stack([tl_x, tl_y, br_x, br_y], -1)
+ return decoded_bboxes
+
+
+def yolox_bbox_decoder(priors: Tensor, bbox_preds: Tensor,
+ stride: Optional[Tensor]) -> Tensor:
+ stride = stride[None, :, None]
+ xys = (bbox_preds[..., :2] * stride) + priors
+ whs = bbox_preds[..., 2:].exp() * stride
+ decoded_bboxes = torch.cat([xys, whs], -1)
+ return decoded_bboxes
diff --git a/third_party/mmyolo/projects/easydeploy/deepstream/CMakeLists.txt b/third_party/mmyolo/projects/easydeploy/deepstream/CMakeLists.txt
new file mode 100644
index 0000000000000000000000000000000000000000..f640bea13bacfc0f6cc2f33e598f65cf5ce0922e
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/deepstream/CMakeLists.txt
@@ -0,0 +1,35 @@
+cmake_minimum_required(VERSION 2.8.12)
+
+set(CMAKE_CUDA_ARCHITECTURES 60 61 62 70 72 75 86)
+set(CMAKE_CUDA_COMPILER /usr/local/cuda/bin/nvcc)
+
+project(nvdsparsebbox_mmyolo LANGUAGES CXX)
+
+set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++14 -O3 -g -Wall -Werror -shared -fPIC")
+set(CMAKE_CXX_STANDARD 14)
+set(CMAKE_BUILD_TYPE Release)
+option(CUDA_USE_STATIC_CUDA_RUNTIME OFF)
+
+# CUDA
+find_package(CUDA REQUIRED)
+
+# TensorRT
+set(TensorRT_INCLUDE_DIRS "/usr/include/x86_64-linux-gnu" CACHE STRING "TensorRT headers path")
+set(TensorRT_LIBRARIES "/usr/lib/x86_64-linux-gnu" CACHE STRING "TensorRT libs path")
+
+# DeepStream
+set(DEEPSTREAM "/opt/nvidia/deepstream/deepstream" CACHE STRING "DeepStream root path")
+set(DS_LIBRARIES ${DEEPSTREAM}/lib)
+set(DS_INCLUDE_DIRS ${DEEPSTREAM}/sources/includes)
+
+include_directories(
+ ${CUDA_INCLUDE_DIRS}
+ ${TensorRT_INCLUDE_DIRS}
+ ${DS_INCLUDE_DIRS})
+
+add_library(
+ ${PROJECT_NAME}
+ SHARED
+ custom_mmyolo_bbox_parser/nvdsparsebbox_mmyolo.cpp)
+
+target_link_libraries(${PROJECT_NAME} PRIVATE nvinfer nvinfer_plugin)
diff --git a/third_party/mmyolo/projects/easydeploy/deepstream/README.md b/third_party/mmyolo/projects/easydeploy/deepstream/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..111f3765e41d558b64097d8a25585bd9c14acf4f
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/deepstream/README.md
@@ -0,0 +1,48 @@
+# Inference MMYOLO Models with DeepStream
+
+This project demonstrates how to inference MMYOLO models with customized parsers in [DeepStream SDK](https://developer.nvidia.com/deepstream-sdk).
+
+## Pre-requisites
+
+### 1. Install Nvidia Driver and CUDA
+
+First, please follow the official documents and instructions to install dedicated Nvidia graphic driver and CUDA matched to your gpu and target Nvidia AIoT devices.
+
+### 2. Install DeepStream SDK
+
+Second, please follow the official instruction to download and install DeepStream SDK. Currently stable version of DeepStream is v6.2.
+
+### 3. Generate TensorRT Engine
+
+As DeepStream builds on top of several NVIDIA libraries, you need to first convert your trained MMYOLO models to TensorRT engine files. We strongly recommend you to try the supported TensorRT deployment solution in [EasyDeploy](../../easydeploy/).
+
+## Build and Run
+
+Please make sure that your converted TensorRT engine is already located in the `deepstream` folder as the config shows. Create your own model config files and change the `config-file` parameter in [deepstream_app_config.txt](deepstream_app_config.txt) to the model you want to run with.
+
+```bash
+mkdir build && cd build
+cmake ..
+make -j$(nproc) && make install
+```
+
+Then you can run the inference with this command.
+
+```bash
+deepstream-app -c deepstream_app_config.txt
+```
+
+## Code Structure
+
+```bash
+├── deepstream
+│ ├── configs # config file for MMYOLO models
+│ │ └── config_infer_rtmdet.txt
+│ ├── custom_mmyolo_bbox_parser # customized parser for MMYOLO models to DeepStream formats
+│ │ └── nvdsparsebbox_mmyolo.cpp
+| ├── CMakeLists.txt
+│ ├── coco_labels.txt # labels for coco detection
+│ ├── deepstream_app_config.txt # deepStream reference app configs for MMYOLO models
+│ ├── README_zh-CN.md
+│ └── README.md
+```
diff --git a/third_party/mmyolo/projects/easydeploy/deepstream/README_zh-CN.md b/third_party/mmyolo/projects/easydeploy/deepstream/README_zh-CN.md
new file mode 100644
index 0000000000000000000000000000000000000000..13a85d5bc90159c3ff9f1a32e93d01e82ed2faa4
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/deepstream/README_zh-CN.md
@@ -0,0 +1,48 @@
+# 使用 DeepStream SDK 推理 MMYOLO 模型
+
+本项目演示了如何使用 [DeepStream SDK](https://developer.nvidia.com/deepstream-sdk) 配合改写的 parser 来推理 MMYOLO 的模型。
+
+## 预先准备
+
+### 1. 安装 Nidia 驱动和 CUDA
+
+首先请根据当前的显卡驱动和目标使用设备的驱动完成显卡驱动和 CUDA 的安装。
+
+### 2. 安装 DeepStream SDK
+
+目前 DeepStream SDK 稳定版本已经更新到 v6.2,官方推荐使用这个版本。
+
+### 3. 将 MMYOLO 模型转换为 TensorRT Engine
+
+推荐使用 EasyDeploy 中的 TensorRT 方案完成目标模型的转换部署,具体可参考 [此文档](../../easydeploy/docs/model_convert.md) 。
+
+## 编译使用
+
+当前项目使用的是 MMYOLO 的 rtmdet 模型,若想使用其他的模型,请参照目录下的配置文件进行改写。然后将转换完的 TensorRT engine 放在当前目录下并执行如下命令:
+
+```bash
+mkdir build && cd build
+cmake ..
+make -j$(nproc) && make install
+```
+
+完成编译后可使用如下命令进行推理:
+
+```bash
+deepstream-app -c deepstream_app_config.txt
+```
+
+## 项目代码结构
+
+```bash
+├── deepstream
+│ ├── configs # MMYOLO 模型对应的 DeepStream 配置
+│ │ └── config_infer_rtmdet.txt
+│ ├── custom_mmyolo_bbox_parser # 适配 DeepStream formats 的 parser
+│ │ └── nvdsparsebbox_mmyolo.cpp
+| ├── CMakeLists.txt
+│ ├── coco_labels.txt # coco labels
+│ ├── deepstream_app_config.txt # DeepStream app 配置
+│ ├── README_zh-CN.md
+│ └── README.md
+```
diff --git a/third_party/mmyolo/projects/easydeploy/deepstream/coco_labels.txt b/third_party/mmyolo/projects/easydeploy/deepstream/coco_labels.txt
new file mode 100644
index 0000000000000000000000000000000000000000..ca76c80b5b2cd0b25047f75736656cfebc9da7aa
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/deepstream/coco_labels.txt
@@ -0,0 +1,80 @@
+person
+bicycle
+car
+motorbike
+aeroplane
+bus
+train
+truck
+boat
+traffic light
+fire hydrant
+stop sign
+parking meter
+bench
+bird
+cat
+dog
+horse
+sheep
+cow
+elephant
+bear
+zebra
+giraffe
+backpack
+umbrella
+handbag
+tie
+suitcase
+frisbee
+skis
+snowboard
+sports ball
+kite
+baseball bat
+baseball glove
+skateboard
+surfboard
+tennis racket
+bottle
+wine glass
+cup
+fork
+knife
+spoon
+bowl
+banana
+apple
+sandwich
+orange
+broccoli
+carrot
+hot dog
+pizza
+donut
+cake
+chair
+sofa
+pottedplant
+bed
+diningtable
+toilet
+tvmonitor
+laptop
+mouse
+remote
+keyboard
+cell phone
+microwave
+oven
+toaster
+sink
+refrigerator
+book
+clock
+vase
+scissors
+teddy bear
+hair drier
+toothbrush
diff --git a/third_party/mmyolo/projects/easydeploy/deepstream/configs/config_infer_rtmdet.txt b/third_party/mmyolo/projects/easydeploy/deepstream/configs/config_infer_rtmdet.txt
new file mode 100644
index 0000000000000000000000000000000000000000..a1e5efd2a3810730144e037ee96dfbd36124b0e6
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/deepstream/configs/config_infer_rtmdet.txt
@@ -0,0 +1,22 @@
+[property]
+gpu-id=0
+net-scale-factor=0.01735207357279195
+offsets=57.375;57.12;58.395
+model-color-format=1
+model-engine-file=../end2end.engine
+labelfile-path=../coco_labels.txt
+batch-size=1
+network-mode=0
+num-detected-classes=80
+interval=0
+gie-unique-id=1
+process-mode=1
+network-type=0
+cluster-mode=2
+maintain-aspect-ratio=1
+parse-bbox-func-name=NvDsInferParseCustomMMYOLO
+custom-lib-path=../build/libnvdsparsebbox_mmyolo.so
+
+[class-attrs-all]
+pre-cluster-threshold=0.45
+topk=100
diff --git a/third_party/mmyolo/projects/easydeploy/deepstream/configs/config_infer_yolov5.txt b/third_party/mmyolo/projects/easydeploy/deepstream/configs/config_infer_yolov5.txt
new file mode 100644
index 0000000000000000000000000000000000000000..6ad7d6429cacd0a6050821e5b2a41317478f5119
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/deepstream/configs/config_infer_yolov5.txt
@@ -0,0 +1,21 @@
+[property]
+gpu-id=0
+net-scale-factor=0.0039215697906911373
+model-color-format=0
+model-engine-file=../end2end.engine
+labelfile-path=../coco_labels.txt
+batch-size=1
+network-mode=0
+num-detected-classes=80
+interval=0
+gie-unique-id=1
+process-mode=1
+network-type=0
+cluster-mode=2
+maintain-aspect-ratio=1
+parse-bbox-func-name=NvDsInferParseCustomMMYOLO
+custom-lib-path=../build/libnvdsparsebbox_mmyolo.so
+
+[class-attrs-all]
+pre-cluster-threshold=0.45
+topk=100
diff --git a/third_party/mmyolo/projects/easydeploy/deepstream/configs/config_infer_yolov8.txt b/third_party/mmyolo/projects/easydeploy/deepstream/configs/config_infer_yolov8.txt
new file mode 100644
index 0000000000000000000000000000000000000000..6ad7d6429cacd0a6050821e5b2a41317478f5119
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/deepstream/configs/config_infer_yolov8.txt
@@ -0,0 +1,21 @@
+[property]
+gpu-id=0
+net-scale-factor=0.0039215697906911373
+model-color-format=0
+model-engine-file=../end2end.engine
+labelfile-path=../coco_labels.txt
+batch-size=1
+network-mode=0
+num-detected-classes=80
+interval=0
+gie-unique-id=1
+process-mode=1
+network-type=0
+cluster-mode=2
+maintain-aspect-ratio=1
+parse-bbox-func-name=NvDsInferParseCustomMMYOLO
+custom-lib-path=../build/libnvdsparsebbox_mmyolo.so
+
+[class-attrs-all]
+pre-cluster-threshold=0.45
+topk=100
diff --git a/third_party/mmyolo/projects/easydeploy/deepstream/custom_mmyolo_bbox_parser/nvdsparsebbox_mmyolo.cpp b/third_party/mmyolo/projects/easydeploy/deepstream/custom_mmyolo_bbox_parser/nvdsparsebbox_mmyolo.cpp
new file mode 100644
index 0000000000000000000000000000000000000000..eb780856cbd2b289cdf9dc8518438f946a2ab548
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/deepstream/custom_mmyolo_bbox_parser/nvdsparsebbox_mmyolo.cpp
@@ -0,0 +1,118 @@
+#include "nvdsinfer_custom_impl.h"
+#include
+#include
+
+/**
+ * Function expected by DeepStream for decoding the MMYOLO output.
+ *
+ * C-linkage [extern "C"] was written to prevent name-mangling. This function must return true after
+ * adding all bounding boxes to the objectList vector.
+ *
+ * @param [outputLayersInfo] std::vector of NvDsInferLayerInfo objects with information about the output layer.
+ * @param [networkInfo] NvDsInferNetworkInfo object with information about the MMYOLO network.
+ * @param [detectionParams] NvDsInferParseDetectionParams with information about some config params.
+ * @param [objectList] std::vector of NvDsInferParseObjectInfo objects to which bounding box information must
+ * be stored.
+ *
+ * @return true
+ */
+
+// This is just the function prototype. The definition is written at the end of the file.
+extern "C" bool NvDsInferParseCustomMMYOLO(
+ std::vector const& outputLayersInfo,
+ NvDsInferNetworkInfo const& networkInfo,
+ NvDsInferParseDetectionParams const& detectionParams,
+ std::vector& objectList);
+
+static __inline__ float clamp(float& val, float min, float max)
+{
+ return val > min ? (val < max ? val : max) : min;
+}
+
+static std::vector decodeMMYoloTensor(
+ const int* num_dets,
+ const float* bboxes,
+ const float* scores,
+ const int* labels,
+ const float& conf_thres,
+ const unsigned int& img_w,
+ const unsigned int& img_h
+)
+{
+ std::vector bboxInfo;
+ size_t nums = num_dets[0];
+ for (size_t i = 0; i < nums; i++)
+ {
+ float score = scores[i];
+ if (score < conf_thres)continue;
+ float x0 = (bboxes[i * 4]);
+ float y0 = (bboxes[i * 4 + 1]);
+ float x1 = (bboxes[i * 4 + 2]);
+ float y1 = (bboxes[i * 4 + 3]);
+ x0 = clamp(x0, 0.f, img_w);
+ y0 = clamp(y0, 0.f, img_h);
+ x1 = clamp(x1, 0.f, img_w);
+ y1 = clamp(y1, 0.f, img_h);
+ NvDsInferParseObjectInfo obj;
+ obj.left = x0;
+ obj.top = y0;
+ obj.width = x1 - x0;
+ obj.height = y1 - y0;
+ obj.detectionConfidence = score;
+ obj.classId = labels[i];
+ bboxInfo.push_back(obj);
+ }
+
+ return bboxInfo;
+}
+
+/* C-linkage to prevent name-mangling */
+extern "C" bool NvDsInferParseCustomMMYOLO(
+ std::vector const& outputLayersInfo,
+ NvDsInferNetworkInfo const& networkInfo,
+ NvDsInferParseDetectionParams const& detectionParams,
+ std::vector& objectList)
+{
+
+// Some assertions and error checking.
+ if (outputLayersInfo.empty() || outputLayersInfo.size() != 4)
+ {
+ std::cerr << "Could not find output layer in bbox parsing" << std::endl;
+ return false;
+ }
+
+// Score threshold of bboxes.
+ const float conf_thres = detectionParams.perClassThreshold[0];
+
+// Obtaining the output layer.
+ const NvDsInferLayerInfo& num_dets = outputLayersInfo[0];
+ const NvDsInferLayerInfo& bboxes = outputLayersInfo[1];
+ const NvDsInferLayerInfo& scores = outputLayersInfo[2];
+ const NvDsInferLayerInfo& labels = outputLayersInfo[3];
+
+// num_dets(int) bboxes(float) scores(float) labels(int)
+ assert (num_dets.dims.numDims == 2);
+ assert (bboxes.dims.numDims == 3);
+ assert (scores.dims.numDims == 2);
+ assert (labels.dims.numDims == 2);
+
+
+// Decoding the output tensor of MMYOLO to the NvDsInferParseObjectInfo format.
+ std::vector objects =
+ decodeMMYoloTensor(
+ (const int*)(num_dets.buffer),
+ (const float*)(bboxes.buffer),
+ (const float*)(scores.buffer),
+ (const int*)(labels.buffer),
+ conf_thres,
+ networkInfo.width,
+ networkInfo.height
+ );
+
+ objectList.clear();
+ objectList = objects;
+ return true;
+}
+
+/* Check that the custom function has been defined correctly */
+CHECK_CUSTOM_PARSE_FUNC_PROTOTYPE(NvDsInferParseCustomMMYOLO);
diff --git a/third_party/mmyolo/projects/easydeploy/deepstream/deepstream_app_config.txt b/third_party/mmyolo/projects/easydeploy/deepstream/deepstream_app_config.txt
new file mode 100644
index 0000000000000000000000000000000000000000..331776897a5e9109b9007ed1b7974f128287c4fc
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/deepstream/deepstream_app_config.txt
@@ -0,0 +1,62 @@
+[application]
+enable-perf-measurement=1
+perf-measurement-interval-sec=5
+
+[tiled-display]
+enable=1
+rows=1
+columns=1
+width=1280
+height=720
+gpu-id=0
+nvbuf-memory-type=0
+
+[source0]
+enable=1
+type=3
+uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
+num-sources=1
+gpu-id=0
+cudadec-memtype=0
+
+[sink0]
+enable=1
+type=2
+sync=0
+gpu-id=0
+nvbuf-memory-type=0
+
+[osd]
+enable=1
+gpu-id=0
+border-width=5
+text-size=15
+text-color=1;1;1;1;
+text-bg-color=0.3;0.3;0.3;1
+font=Serif
+show-clock=0
+clock-x-offset=800
+clock-y-offset=820
+clock-text-size=12
+clock-color=1;0;0;0
+nvbuf-memory-type=0
+
+[streammux]
+gpu-id=0
+live-source=0
+batch-size=1
+batched-push-timeout=40000
+width=1920
+height=1080
+enable-padding=0
+nvbuf-memory-type=0
+
+[primary-gie]
+enable=1
+gpu-id=0
+gie-unique-id=1
+nvbuf-memory-type=0
+config-file=configs/config_infer_rtmdet.txt
+
+[tests]
+file-loop=0
diff --git a/third_party/mmyolo/projects/easydeploy/docs/model_convert.md b/third_party/mmyolo/projects/easydeploy/docs/model_convert.md
new file mode 100644
index 0000000000000000000000000000000000000000..9af62599dd1b56648680fc315ca88c35c7b31cb9
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/docs/model_convert.md
@@ -0,0 +1,156 @@
+# MMYOLO 模型 ONNX 转换
+
+## 1. 导出后端支持的 ONNX
+
+## 环境依赖
+
+- [onnx](https://github.com/onnx/onnx)
+
+ ```shell
+ pip install onnx
+ ```
+
+ [onnx-simplifier](https://github.com/daquexian/onnx-simplifier) (可选,用于简化模型)
+
+ ```shell
+ pip install onnx-simplifier
+ ```
+
+\*\*\* 请确保您在 `MMYOLO` 根目录下运行相关脚本,避免无法找到相关依赖包。\*\*\*
+
+## 使用方法
+
+[模型导出脚本](./projects/easydeploy/tools/export_onnx.py)用于将 `MMYOLO` 模型转换为 `onnx` 。
+
+### 参数介绍:
+
+- `config` : 构建模型使用的配置文件,如 [`yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py`](./configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py) 。
+- `checkpoint` : 训练得到的权重文件,如 `yolov5s.pth` 。
+- `--work-dir` : 转换后的模型保存路径。
+- `--img-size`: 转换模型时输入的尺寸,如 `640 640`。
+- `--batch-size`: 转换后的模型输入 `batch size` 。
+- `--device`: 转换模型使用的设备,默认为 `cuda:0`。
+- `--simplify`: 是否简化导出的 `onnx` 模型,需要安装 [onnx-simplifier](https://github.com/daquexian/onnx-simplifier),默认关闭。
+- `--opset`: 指定导出 `onnx` 的 `opset`,默认为 `11` 。
+- `--backend`: 指定导出 `onnx` 用于的后端名称,`ONNXRuntime`: `onnxruntime`, `TensorRT8`: `tensorrt8`, `TensorRT7`: `tensorrt7`,默认为`onnxruntime`即 `ONNXRuntime`。
+- `--pre-topk`: 指定导出 `onnx` 的后处理筛选候选框个数阈值,默认为 `1000`。
+- `--keep-topk`: 指定导出 `onnx` 的非极大值抑制输出的候选框个数阈值,默认为 `100`。
+- `--iou-threshold`: 非极大值抑制中过滤重复候选框的 `iou` 阈值,默认为 `0.65`。
+- `--score-threshold`: 非极大值抑制中过滤候选框得分的阈值,默认为 `0.25`。
+- `--model-only`: 指定仅导出模型 backbone + neck, 不包含后处理,默认关闭。
+
+例子:
+
+```shell
+python ./projects/easydeploy/tools/export.py \
+ configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py \
+ yolov5s.pth \
+ --work-dir work_dir \
+ --img-size 640 640 \
+ --batch 1 \
+ --device cpu \
+ --simplify \
+ --opset 11 \
+ --backend 1 \
+ --pre-topk 1000 \
+ --keep-topk 100 \
+ --iou-threshold 0.65 \
+ --score-threshold 0.25
+```
+
+然后利用后端支持的工具如 `TensorRT` 读取 `onnx` 再次转换为后端支持的模型格式如 `.engine/.plan` 等。
+
+`MMYOLO` 目前支持 `TensorRT8`, `TensorRT7`, `ONNXRuntime` 后端的端到端模型转换,目前仅支持静态 shape 模型的导出和转换,动态 batch 或动态长宽的模型端到端转换会在未来继续支持。
+
+端到端转换得到的 `onnx` 模型输入输出如图:
+
+
+
+## Introduction
+
+This project is developed for easily showing assigning results. The script allows users to analyze where and how many positive samples each gt is assigned in the image.
+
+Now, the script supports `YOLOv5`, `YOLOv7`, `YOLOv8` and `RTMDet`.
+
+## Usage
+
+### Command
+
+YOLOv5 assigner visualization command:
+
+```shell
+python projects/assigner_visualization/assigner_visualization.py projects/assigner_visualization/configs/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_assignervisualization.py
+```
+
+Note: `YOLOv5` does not need to load the trained weights.
+
+YOLOv7 assigner visualization command:
+
+```shell
+python projects/assigner_visualization/assigner_visualization.py projects/assigner_visualization/configs/yolov7_tiny_syncbn_fast_8xb16-300e_coco_assignervisualization.py -c ${checkpont}
+```
+
+YOLOv8 assigner visualization command:
+
+```shell
+python projects/assigner_visualization/assigner_visualization.py projects/assigner_visualization/configs/yolov8_s_syncbn_fast_8xb16-500e_coco_assignervisualization.py -c ${checkpont}
+```
+
+RTMdet assigner visualization command:
+
+```shell
+python projects/assigner_visualization/assigner_visualization.py projects/assigner_visualization/configs/rtmdet_s_syncbn_fast_8xb32-300e_coco_assignervisualization.py -c ${checkpont}
+```
+
+${checkpont} is the checkpont file path. Dynamic label assignment is used in `YOLOv7`, `YOLOv8` and `RTMDet`, model weights will affect the positive sample allocation results, so it is recommended to load the trained model weights.
+
+If you want to know details about label assignment, you can check the [RTMDet](https://mmyolo.readthedocs.io/zh_CN/latest/algorithm_descriptions/rtmdet_description.html#id5).
diff --git a/third_party/mmyolo/projects/assigner_visualization/assigner_visualization.py b/third_party/mmyolo/projects/assigner_visualization/assigner_visualization.py
new file mode 100644
index 0000000000000000000000000000000000000000..e290d26b6d6fbb2f703faf3ebcd0474da871aea8
--- /dev/null
+++ b/third_party/mmyolo/projects/assigner_visualization/assigner_visualization.py
@@ -0,0 +1,177 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+import sys
+import warnings
+
+import mmcv
+import numpy as np
+import torch
+from mmengine import ProgressBar
+from mmengine.config import Config, DictAction
+from mmengine.dataset import COLLATE_FUNCTIONS
+from mmengine.runner.checkpoint import load_checkpoint
+from numpy import random
+
+from mmyolo.registry import DATASETS, MODELS
+from mmyolo.utils import register_all_modules
+from projects.assigner_visualization.dense_heads import (RTMHeadAssigner,
+ YOLOv5HeadAssigner,
+ YOLOv7HeadAssigner,
+ YOLOv8HeadAssigner)
+from projects.assigner_visualization.visualization import \
+ YOLOAssignerVisualizer
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='MMYOLO show the positive sample assigning'
+ ' results.')
+ parser.add_argument('config', help='config file path')
+ parser.add_argument('--checkpoint', '-c', type=str, help='checkpoint file')
+ parser.add_argument(
+ '--show-number',
+ '-n',
+ type=int,
+ default=sys.maxsize,
+ help='number of images selected to save, '
+ 'must bigger than 0. if the number is bigger than length '
+ 'of dataset, show all the images in dataset; '
+ 'default "sys.maxsize", show all images in dataset')
+ parser.add_argument(
+ '--output-dir',
+ default='assigned_results',
+ type=str,
+ help='The name of the folder where the image is saved.')
+ parser.add_argument(
+ '--device', default='cuda:0', help='Device used for inference.')
+ parser.add_argument(
+ '--show-prior',
+ default=False,
+ action='store_true',
+ help='Whether to show prior on image.')
+ parser.add_argument(
+ '--not-show-label',
+ default=False,
+ action='store_true',
+ help='Whether to show label on image.')
+ parser.add_argument('--seed', default=-1, type=int, help='random seed')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ register_all_modules()
+
+ # set random seed
+ seed = int(args.seed)
+ if seed != -1:
+ print(f'Set the global seed: {seed}')
+ random.seed(int(args.seed))
+
+ cfg = Config.fromfile(args.config)
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+ # build model
+ model = MODELS.build(cfg.model)
+ if args.checkpoint is not None:
+ load_checkpoint(model, args.checkpoint)
+ elif isinstance(model.bbox_head, (YOLOv7HeadAssigner, RTMHeadAssigner)):
+ warnings.warn(
+ 'if you use dynamic_assignment methods such as YOLOv7 or '
+ 'YOLOv8 or RTMDet assigner, please load the checkpoint.')
+ assert isinstance(model.bbox_head, (YOLOv5HeadAssigner,
+ YOLOv7HeadAssigner,
+ YOLOv8HeadAssigner,
+ RTMHeadAssigner)), \
+ 'Now, this script only support YOLOv5, YOLOv7, YOLOv8 and RTMdet, ' \
+ 'and bbox_head must use ' \
+ '`YOLOv5HeadAssigner or YOLOv7HeadAssigne or YOLOv8HeadAssigner ' \
+ 'or RTMHeadAssigner`. Please use `' \
+ 'yolov5_s-v61_syncbn_fast_8xb16-300e_coco_assignervisualization.py' \
+ 'or yolov7_tiny_syncbn_fast_8x16b-300e_coco_assignervisualization.py' \
+ 'or yolov8_s_syncbn_fast_8xb16-500e_coco_assignervisualization.py' \
+ 'or rtmdet_s_syncbn_fast_8xb32-300e_coco_assignervisualization.py' \
+ """` as config file."""
+ model.eval()
+ model.to(args.device)
+
+ # build dataset
+ dataset_cfg = cfg.get('train_dataloader').get('dataset')
+ dataset = DATASETS.build(dataset_cfg)
+
+ # get collate_fn
+ collate_fn_cfg = cfg.get('train_dataloader').pop(
+ 'collate_fn', dict(type='pseudo_collate'))
+ collate_fn_type = collate_fn_cfg.pop('type')
+ collate_fn = COLLATE_FUNCTIONS.get(collate_fn_type)
+
+ # init visualizer
+ visualizer = YOLOAssignerVisualizer(
+ vis_backends=[{
+ 'type': 'LocalVisBackend'
+ }], name='visualizer')
+ visualizer.dataset_meta = dataset.metainfo
+ # need priors size to draw priors
+
+ if hasattr(model.bbox_head.prior_generator, 'base_anchors'):
+ visualizer.priors_size = model.bbox_head.prior_generator.base_anchors
+
+ # make output dir
+ os.makedirs(args.output_dir, exist_ok=True)
+ print('Results will save to ', args.output_dir)
+
+ # init visualization image number
+ assert args.show_number > 0
+ display_number = min(args.show_number, len(dataset))
+
+ progress_bar = ProgressBar(display_number)
+ for ind_img in range(display_number):
+ data = dataset.prepare_data(ind_img)
+ if data is None:
+ print('Unable to visualize {} due to strong data augmentations'.
+ format(dataset[ind_img]['data_samples'].img_path))
+ continue
+ # convert data to batch format
+ batch_data = collate_fn([data])
+ with torch.no_grad():
+ assign_results = model.assign(batch_data)
+
+ img = data['inputs'].cpu().numpy().astype(np.uint8).transpose(
+ (1, 2, 0))
+ # bgr2rgb
+ img = mmcv.bgr2rgb(img)
+
+ gt_instances = data['data_samples'].gt_instances
+
+ img_show = visualizer.draw_assign(img, assign_results, gt_instances,
+ args.show_prior, args.not_show_label)
+
+ if hasattr(data['data_samples'], 'img_path'):
+ filename = osp.basename(data['data_samples'].img_path)
+ else:
+ # some dataset have not image path
+ filename = f'{ind_img}.jpg'
+ out_file = osp.join(args.output_dir, filename)
+
+ # convert rgb 2 bgr and save img
+ mmcv.imwrite(mmcv.rgb2bgr(img_show), out_file)
+ progress_bar.update()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/third_party/mmyolo/projects/assigner_visualization/configs/rtmdet_s_syncbn_fast_8xb32-300e_coco_assignervisualization.py b/third_party/mmyolo/projects/assigner_visualization/configs/rtmdet_s_syncbn_fast_8xb32-300e_coco_assignervisualization.py
new file mode 100644
index 0000000000000000000000000000000000000000..006502eb45af9ece927b68359525cc6c2de30788
--- /dev/null
+++ b/third_party/mmyolo/projects/assigner_visualization/configs/rtmdet_s_syncbn_fast_8xb32-300e_coco_assignervisualization.py
@@ -0,0 +1,9 @@
+_base_ = ['../../../configs/rtmdet/rtmdet_s_syncbn_fast_8xb32-300e_coco.py']
+
+custom_imports = dict(imports=[
+ 'projects.assigner_visualization.detectors',
+ 'projects.assigner_visualization.dense_heads'
+])
+
+model = dict(
+ type='YOLODetectorAssigner', bbox_head=dict(type='RTMHeadAssigner'))
diff --git a/third_party/mmyolo/projects/assigner_visualization/configs/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_assignervisualization.py b/third_party/mmyolo/projects/assigner_visualization/configs/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_assignervisualization.py
new file mode 100644
index 0000000000000000000000000000000000000000..1db799b5142375c86bd5a018764017c9d3170a07
--- /dev/null
+++ b/third_party/mmyolo/projects/assigner_visualization/configs/yolov5_s-v61_syncbn_fast_8xb16-300e_coco_assignervisualization.py
@@ -0,0 +1,11 @@
+_base_ = [
+ '../../../configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py'
+]
+
+custom_imports = dict(imports=[
+ 'projects.assigner_visualization.detectors',
+ 'projects.assigner_visualization.dense_heads'
+])
+
+model = dict(
+ type='YOLODetectorAssigner', bbox_head=dict(type='YOLOv5HeadAssigner'))
diff --git a/third_party/mmyolo/projects/assigner_visualization/configs/yolov7_tiny_syncbn_fast_8xb16-300e_coco_assignervisualization.py b/third_party/mmyolo/projects/assigner_visualization/configs/yolov7_tiny_syncbn_fast_8xb16-300e_coco_assignervisualization.py
new file mode 100644
index 0000000000000000000000000000000000000000..626dc18b59df3b9ced0781347989b65f64de5042
--- /dev/null
+++ b/third_party/mmyolo/projects/assigner_visualization/configs/yolov7_tiny_syncbn_fast_8xb16-300e_coco_assignervisualization.py
@@ -0,0 +1,9 @@
+_base_ = ['../../../configs/yolov7/yolov7_tiny_syncbn_fast_8x16b-300e_coco.py']
+
+custom_imports = dict(imports=[
+ 'projects.assigner_visualization.detectors',
+ 'projects.assigner_visualization.dense_heads'
+])
+
+model = dict(
+ type='YOLODetectorAssigner', bbox_head=dict(type='YOLOv7HeadAssigner'))
diff --git a/third_party/mmyolo/projects/assigner_visualization/configs/yolov8_s_syncbn_fast_8xb16-500e_coco_assignervisualization.py b/third_party/mmyolo/projects/assigner_visualization/configs/yolov8_s_syncbn_fast_8xb16-500e_coco_assignervisualization.py
new file mode 100644
index 0000000000000000000000000000000000000000..03dcae8c39a09c0200dc52123efc1bc0a348dea3
--- /dev/null
+++ b/third_party/mmyolo/projects/assigner_visualization/configs/yolov8_s_syncbn_fast_8xb16-500e_coco_assignervisualization.py
@@ -0,0 +1,9 @@
+_base_ = ['../../../configs/yolov8/yolov8_s_syncbn_fast_8xb16-500e_coco.py']
+
+custom_imports = dict(imports=[
+ 'projects.assigner_visualization.detectors',
+ 'projects.assigner_visualization.dense_heads'
+])
+
+model = dict(
+ type='YOLODetectorAssigner', bbox_head=dict(type='YOLOv8HeadAssigner'))
diff --git a/third_party/mmyolo/projects/assigner_visualization/dense_heads/__init__.py b/third_party/mmyolo/projects/assigner_visualization/dense_heads/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..82adaaba8ebe3510895ebc3d5ed5ac7c573b41b2
--- /dev/null
+++ b/third_party/mmyolo/projects/assigner_visualization/dense_heads/__init__.py
@@ -0,0 +1,10 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .rtmdet_head_assigner import RTMHeadAssigner
+from .yolov5_head_assigner import YOLOv5HeadAssigner
+from .yolov7_head_assigner import YOLOv7HeadAssigner
+from .yolov8_head_assigner import YOLOv8HeadAssigner
+
+__all__ = [
+ 'YOLOv5HeadAssigner', 'YOLOv7HeadAssigner', 'YOLOv8HeadAssigner',
+ 'RTMHeadAssigner'
+]
diff --git a/third_party/mmyolo/projects/assigner_visualization/dense_heads/rtmdet_head_assigner.py b/third_party/mmyolo/projects/assigner_visualization/dense_heads/rtmdet_head_assigner.py
new file mode 100644
index 0000000000000000000000000000000000000000..d3ae1c86d054d02a7a8537ee91251c0cca39edc6
--- /dev/null
+++ b/third_party/mmyolo/projects/assigner_visualization/dense_heads/rtmdet_head_assigner.py
@@ -0,0 +1,175 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Union
+
+import torch
+from mmdet.structures.bbox import distance2bbox
+from mmdet.utils import InstanceList
+from torch import Tensor
+
+from mmyolo.models import RTMDetHead
+from mmyolo.models.utils import gt_instances_preprocess
+from mmyolo.registry import MODELS
+
+
+@MODELS.register_module()
+class RTMHeadAssigner(RTMDetHead):
+
+ def assign_by_gt_and_feat(
+ self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ inputs_hw: Union[Tensor, tuple] = (640, 640)
+ ) -> dict:
+ """Calculate the assigning results based on the gt and features
+ extracted by the detection head.
+
+ Args:
+ cls_scores (list[Tensor]): Box scores for each scale level
+ Has shape (N, num_anchors * num_classes, H, W)
+ bbox_preds (list[Tensor]): Decoded box for each scale
+ level with shape (N, num_anchors * 4, H, W) in
+ [tl_x, tl_y, br_x, br_y] format.
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ inputs_hw (Union[Tensor, tuple]): Height and width of inputs size.
+ Returns:
+ dict[str, Tensor]: A dictionary of assigning results.
+ """
+ num_imgs = len(batch_img_metas)
+ featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
+ assert len(featmap_sizes) == self.prior_generator.num_levels
+ # rtmdet's prior offset differs from others
+ prior_offset = self.prior_generator.offset
+
+ gt_info = gt_instances_preprocess(batch_gt_instances, num_imgs)
+ gt_labels = gt_info[:, :, :1]
+ gt_bboxes = gt_info[:, :, 1:] # xyxy
+ pad_bbox_flag = (gt_bboxes.sum(-1, keepdim=True) > 0).float()
+
+ device = cls_scores[0].device
+
+ # If the shape does not equal, generate new one
+ if featmap_sizes != self.featmap_sizes_train:
+ self.featmap_sizes_train = featmap_sizes
+ mlvl_priors_with_stride = self.prior_generator.grid_priors(
+ featmap_sizes, device=device, with_stride=True)
+ self.flatten_priors_train = torch.cat(
+ mlvl_priors_with_stride, dim=0)
+
+ flatten_cls_scores = torch.cat([
+ cls_score.permute(0, 2, 3, 1).reshape(num_imgs, -1,
+ self.cls_out_channels)
+ for cls_score in cls_scores
+ ], 1).contiguous()
+
+ flatten_bboxes = torch.cat([
+ bbox_pred.permute(0, 2, 3, 1).reshape(num_imgs, -1, 4)
+ for bbox_pred in bbox_preds
+ ], 1)
+ flatten_bboxes = flatten_bboxes * self.flatten_priors_train[..., -1,
+ None]
+ flatten_bboxes = distance2bbox(self.flatten_priors_train[..., :2],
+ flatten_bboxes)
+
+ assigned_result = self.assigner(flatten_bboxes.detach(),
+ flatten_cls_scores.detach(),
+ self.flatten_priors_train, gt_labels,
+ gt_bboxes, pad_bbox_flag)
+
+ labels = assigned_result['assigned_labels'].reshape(-1)
+ bbox_targets = assigned_result['assigned_bboxes'].reshape(-1, 4)
+
+ # FG cat_id: [0, num_classes -1], BG cat_id: num_classes
+ bg_class_ind = self.num_classes
+ pos_inds = ((labels >= 0)
+ & (labels < bg_class_ind)).nonzero().squeeze(1)
+ targets = bbox_targets[pos_inds]
+ gt_bboxes = gt_bboxes.squeeze(0)
+ matched_gt_inds = torch.tensor(
+ [((t == gt_bboxes).sum(dim=1) == t.shape[0]).nonzero()[0]
+ for t in targets],
+ device=device)
+
+ level_inds = torch.zeros_like(labels)
+ img_inds = torch.zeros_like(labels)
+ level_nums = [0] + [f[0] * f[1] for f in featmap_sizes]
+ for i in range(len(level_nums) - 1):
+ level_nums[i + 1] = level_nums[i] + level_nums[i + 1]
+ level_inds[level_nums[i]:level_nums[i + 1]] = i
+ level_inds_pos = level_inds[pos_inds]
+
+ img_inds = img_inds[pos_inds]
+ labels = labels[pos_inds]
+
+ inputs_hw = batch_img_metas[0]['batch_input_shape']
+ assign_results = []
+ for i in range(self.num_levels):
+ retained_inds = level_inds_pos == i
+ if not retained_inds.any():
+ assign_results_prior = {
+ 'stride':
+ self.featmap_strides[i],
+ 'grid_x_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'grid_y_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'img_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'class_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'retained_gt_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'prior_ind':
+ 0,
+ 'offset':
+ prior_offset
+ }
+ else:
+ w = inputs_hw[1] // self.featmap_strides[i]
+
+ retained_pos_inds = pos_inds[retained_inds] - level_nums[i]
+ grid_y_inds = retained_pos_inds // w
+ grid_x_inds = retained_pos_inds - retained_pos_inds // w * w
+ assign_results_prior = {
+ 'stride': self.featmap_strides[i],
+ 'grid_x_inds': grid_x_inds,
+ 'grid_y_inds': grid_y_inds,
+ 'img_inds': img_inds[retained_inds],
+ 'class_inds': labels[retained_inds],
+ 'retained_gt_inds': matched_gt_inds[retained_inds],
+ 'prior_ind': 0,
+ 'offset': prior_offset
+ }
+ assign_results.append([assign_results_prior])
+ return assign_results
+
+ def assign(self, batch_data_samples: Union[list, dict],
+ inputs_hw: Union[tuple, torch.Size]) -> dict:
+ """Calculate assigning results. This function is provided to the
+ `assigner_visualization.py` script.
+
+ Args:
+ batch_data_samples (List[:obj:`DetDataSample`], dict): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ inputs_hw: Height and width of inputs size
+
+ Returns:
+ dict: A dictionary of assigning components.
+ """
+ if isinstance(batch_data_samples, list):
+ raise NotImplementedError(
+ 'assigning results_list is not implemented')
+ else:
+ # Fast version
+ cls_scores, bbox_preds = self(batch_data_samples['feats'])
+ assign_inputs = (cls_scores, bbox_preds,
+ batch_data_samples['bboxes_labels'],
+ batch_data_samples['img_metas'], inputs_hw)
+ assign_results = self.assign_by_gt_and_feat(*assign_inputs)
+ return assign_results
diff --git a/third_party/mmyolo/projects/assigner_visualization/dense_heads/yolov5_head_assigner.py b/third_party/mmyolo/projects/assigner_visualization/dense_heads/yolov5_head_assigner.py
new file mode 100644
index 0000000000000000000000000000000000000000..599963fede32fc02c73db8c744dfbc2946dd53fb
--- /dev/null
+++ b/third_party/mmyolo/projects/assigner_visualization/dense_heads/yolov5_head_assigner.py
@@ -0,0 +1,188 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Sequence, Union
+
+import torch
+from mmdet.models.utils import unpack_gt_instances
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmyolo.models import YOLOv5Head
+from mmyolo.registry import MODELS
+
+
+@MODELS.register_module()
+class YOLOv5HeadAssigner(YOLOv5Head):
+
+ def assign_by_gt_and_feat(
+ self,
+ batch_gt_instances: Sequence[InstanceData],
+ batch_img_metas: Sequence[dict],
+ inputs_hw: Union[Tensor, tuple] = (640, 640)
+ ) -> dict:
+ """Calculate the assigning results based on the gt and features
+ extracted by the detection head.
+
+ Args:
+ batch_gt_instances (Sequence[InstanceData]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (Sequence[dict]): Meta information of each image,
+ e.g., image size, scaling factor, etc.
+ batch_gt_instances_ignore (list[:obj:`InstanceData`], optional):
+ Batch of gt_instances_ignore. It includes ``bboxes`` attribute
+ data that is ignored during training and testing.
+ Defaults to None.
+ inputs_hw (Union[Tensor, tuple]): Height and width of inputs size.
+ Returns:
+ dict[str, Tensor]: A dictionary of assigning results.
+ """
+ # 1. Convert gt to norm format
+ batch_targets_normed = self._convert_gt_to_norm_format(
+ batch_gt_instances, batch_img_metas)
+
+ device = batch_targets_normed.device
+ scaled_factor = torch.ones(7, device=device)
+ gt_inds = torch.arange(
+ batch_targets_normed.shape[1],
+ dtype=torch.long,
+ device=device,
+ requires_grad=False).unsqueeze(0).repeat((self.num_base_priors, 1))
+
+ assign_results = []
+ for i in range(self.num_levels):
+ assign_results_feat = []
+ h = inputs_hw[0] // self.featmap_strides[i]
+ w = inputs_hw[1] // self.featmap_strides[i]
+
+ # empty gt bboxes
+ if batch_targets_normed.shape[1] == 0:
+ for k in range(self.num_base_priors):
+ assign_results_feat.append({
+ 'stride':
+ self.featmap_strides[i],
+ 'grid_x_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'grid_y_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'img_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'class_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'retained_gt_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'prior_ind':
+ k
+ })
+ assign_results.append(assign_results_feat)
+ continue
+
+ priors_base_sizes_i = self.priors_base_sizes[i]
+ # feature map scale whwh
+ scaled_factor[2:6] = torch.tensor([w, h, w, h])
+ # Scale batch_targets from range 0-1 to range 0-features_maps size.
+ # (num_base_priors, num_bboxes, 7)
+ batch_targets_scaled = batch_targets_normed * scaled_factor
+
+ # 2. Shape match
+ wh_ratio = batch_targets_scaled[...,
+ 4:6] / priors_base_sizes_i[:, None]
+ match_inds = torch.max(
+ wh_ratio, 1 / wh_ratio).max(2)[0] < self.prior_match_thr
+ batch_targets_scaled = batch_targets_scaled[match_inds]
+ match_gt_inds = gt_inds[match_inds]
+
+ # no gt bbox matches anchor
+ if batch_targets_scaled.shape[0] == 0:
+ for k in range(self.num_base_priors):
+ assign_results_feat.append({
+ 'stride':
+ self.featmap_strides[i],
+ 'grid_x_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'grid_y_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'img_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'class_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'retained_gt_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'prior_ind':
+ k
+ })
+ assign_results.append(assign_results_feat)
+ continue
+
+ # 3. Positive samples with additional neighbors
+
+ # check the left, up, right, bottom sides of the
+ # targets grid, and determine whether assigned
+ # them as positive samples as well.
+ batch_targets_cxcy = batch_targets_scaled[:, 2:4]
+ grid_xy = scaled_factor[[2, 3]] - batch_targets_cxcy
+ left, up = ((batch_targets_cxcy % 1 < self.near_neighbor_thr) &
+ (batch_targets_cxcy > 1)).T
+ right, bottom = ((grid_xy % 1 < self.near_neighbor_thr) &
+ (grid_xy > 1)).T
+ offset_inds = torch.stack(
+ (torch.ones_like(left), left, up, right, bottom))
+
+ batch_targets_scaled = batch_targets_scaled.repeat(
+ (5, 1, 1))[offset_inds]
+ retained_gt_inds = match_gt_inds.repeat((5, 1))[offset_inds]
+ retained_offsets = self.grid_offset.repeat(1, offset_inds.shape[1],
+ 1)[offset_inds]
+
+ # prepare pred results and positive sample indexes to
+ # calculate class loss and bbox lo
+ _chunk_targets = batch_targets_scaled.chunk(4, 1)
+ img_class_inds, grid_xy, grid_wh, priors_inds = _chunk_targets
+ priors_inds, (img_inds, class_inds) = priors_inds.long().view(
+ -1), img_class_inds.long().T
+
+ grid_xy_long = (grid_xy -
+ retained_offsets * self.near_neighbor_thr).long()
+ grid_x_inds, grid_y_inds = grid_xy_long.T
+ for k in range(self.num_base_priors):
+ retained_inds = priors_inds == k
+ assign_results_prior = {
+ 'stride': self.featmap_strides[i],
+ 'grid_x_inds': grid_x_inds[retained_inds],
+ 'grid_y_inds': grid_y_inds[retained_inds],
+ 'img_inds': img_inds[retained_inds],
+ 'class_inds': class_inds[retained_inds],
+ 'retained_gt_inds': retained_gt_inds[retained_inds],
+ 'prior_ind': k
+ }
+ assign_results_feat.append(assign_results_prior)
+ assign_results.append(assign_results_feat)
+ return assign_results
+
+ def assign(self, batch_data_samples: Union[list, dict],
+ inputs_hw: Union[tuple, torch.Size]) -> dict:
+ """Calculate assigning results. This function is provided to the
+ `assigner_visualization.py` script.
+
+ Args:
+ batch_data_samples (List[:obj:`DetDataSample`], dict): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ inputs_hw: Height and width of inputs size
+
+ Returns:
+ dict: A dictionary of assigning components.
+ """
+ if isinstance(batch_data_samples, list):
+ outputs = unpack_gt_instances(batch_data_samples)
+ (batch_gt_instances, batch_gt_instances_ignore,
+ batch_img_metas) = outputs
+
+ assign_inputs = (batch_gt_instances, batch_img_metas,
+ batch_gt_instances_ignore, inputs_hw)
+ else:
+ # Fast version
+ assign_inputs = (batch_data_samples['bboxes_labels'],
+ batch_data_samples['img_metas'], inputs_hw)
+ assign_results = self.assign_by_gt_and_feat(*assign_inputs)
+
+ return assign_results
diff --git a/third_party/mmyolo/projects/assigner_visualization/dense_heads/yolov7_head_assigner.py b/third_party/mmyolo/projects/assigner_visualization/dense_heads/yolov7_head_assigner.py
new file mode 100644
index 0000000000000000000000000000000000000000..de2a90e36b57f5ad54158ee546dac6cf513cd5a3
--- /dev/null
+++ b/third_party/mmyolo/projects/assigner_visualization/dense_heads/yolov7_head_assigner.py
@@ -0,0 +1,159 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Union
+
+import torch
+from mmdet.utils import InstanceList
+from torch import Tensor
+
+from mmyolo.models import YOLOv7Head
+from mmyolo.registry import MODELS
+
+
+@MODELS.register_module()
+class YOLOv7HeadAssigner(YOLOv7Head):
+
+ def assign_by_gt_and_feat(
+ self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ objectnesses: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ inputs_hw: Union[Tensor, tuple],
+ ) -> dict:
+ """Calculate the assigning results based on the gt and features
+ extracted by the detection head.
+ Args:
+ cls_scores (Sequence[Tensor]): Box scores for each scale level,
+ each is a 4D-tensor, the channel number is
+ num_priors * num_classes.
+ bbox_preds (Sequence[Tensor]): Box energies / deltas for each scale
+ level, each is a 4D-tensor, the channel number is
+ num_priors * 4.
+ objectnesses (Sequence[Tensor]): Score factor for
+ all scale level, each is a 4D-tensor, has shape
+ (batch_size, 1, H, W)
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ inputs_hw (Union[Tensor, tuple]): Height and width of inputs size.
+ Returns:
+ dict[str, Tensor]: A dictionary of assigning results.
+ """
+ device = cls_scores[0][0].device
+
+ head_preds = self._merge_predict_results(bbox_preds, objectnesses,
+ cls_scores)
+
+ batch_targets_normed = self._convert_gt_to_norm_format(
+ batch_gt_instances, batch_img_metas)
+
+ # yolov5_assign and simota_assign
+ assigner_results = self.assigner(
+ head_preds,
+ batch_targets_normed,
+ batch_img_metas[0]['batch_input_shape'],
+ self.priors_base_sizes,
+ self.grid_offset,
+ near_neighbor_thr=self.near_neighbor_thr)
+
+ # multi-level positive sample position.
+ mlvl_positive_infos = assigner_results['mlvl_positive_infos']
+ # assigned results with label and bboxes information.
+ mlvl_targets_normed = assigner_results['mlvl_targets_normed']
+
+ assign_results = []
+ for i in range(self.num_levels):
+ assign_results_feat = []
+ # no gt bbox matches anchor
+ if mlvl_positive_infos[i].shape[0] == 0:
+ for k in range(self.num_base_priors):
+ assign_results_feat.append({
+ 'stride':
+ self.featmap_strides[i],
+ 'grid_x_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'grid_y_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'img_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'class_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'retained_gt_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'prior_ind':
+ k
+ })
+ assign_results.append(assign_results_feat)
+ continue
+
+ # (batch_idx, prior_idx, x_scaled, y_scaled)
+ positive_info = mlvl_positive_infos[i]
+ targets_normed = mlvl_targets_normed[i]
+ priors_inds = positive_info[:, 1]
+ grid_x_inds = positive_info[:, 2]
+ grid_y_inds = positive_info[:, 3]
+ img_inds = targets_normed[:, 0]
+ class_inds = targets_normed[:, 1].long()
+ retained_gt_inds = self.get_gt_inds(
+ targets_normed, batch_targets_normed[0]).long()
+ for k in range(self.num_base_priors):
+ retained_inds = priors_inds == k
+ assign_results_prior = {
+ 'stride': self.featmap_strides[i],
+ 'grid_x_inds': grid_x_inds[retained_inds],
+ 'grid_y_inds': grid_y_inds[retained_inds],
+ 'img_inds': img_inds[retained_inds],
+ 'class_inds': class_inds[retained_inds],
+ 'retained_gt_inds': retained_gt_inds[retained_inds],
+ 'prior_ind': k
+ }
+ assign_results_feat.append(assign_results_prior)
+ assign_results.append(assign_results_feat)
+ return assign_results
+
+ def get_gt_inds(self, assigned_target, gt_instance):
+ """Judging which one gt_ind is assigned by comparing assign_target and
+ origin target.
+
+ Args:
+ assigned_target (Tensor(assign_nums,7)): YOLOv7 assigning results.
+ gt_instance (Tensor(gt_nums,7)): Normalized gt_instance, It
+ usually includes ``bboxes`` and ``labels`` attributes.
+ Returns:
+ gt_inds (Tensor): the index which one gt is assigned.
+ """
+ gt_inds = torch.zeros(assigned_target.shape[0])
+ for i in range(assigned_target.shape[0]):
+ gt_inds[i] = ((assigned_target[i] == gt_instance).sum(
+ dim=1) == 7).nonzero().squeeze()
+ return gt_inds
+
+ def assign(self, batch_data_samples: Union[list, dict],
+ inputs_hw: Union[tuple, torch.Size]) -> dict:
+ """Calculate assigning results.
+
+ This function is provided to the
+ `assigner_visualization.py` script.
+ Args:
+ batch_data_samples (List[:obj:`DetDataSample`], dict): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ inputs_hw: Height and width of inputs size
+ Returns:
+ dict: A dictionary of assigning components.
+ """
+ if isinstance(batch_data_samples, list):
+ raise NotImplementedError(
+ 'assigning results_list is not implemented')
+ else:
+ # Fast version
+ cls_scores, bbox_preds, objectnesses = self(
+ batch_data_samples['feats'])
+ assign_inputs = (cls_scores, bbox_preds, objectnesses,
+ batch_data_samples['bboxes_labels'],
+ batch_data_samples['img_metas'], inputs_hw)
+ assign_results = self.assign_by_gt_and_feat(*assign_inputs)
+ return assign_results
diff --git a/third_party/mmyolo/projects/assigner_visualization/dense_heads/yolov8_head_assigner.py b/third_party/mmyolo/projects/assigner_visualization/dense_heads/yolov8_head_assigner.py
new file mode 100644
index 0000000000000000000000000000000000000000..49d254fdf5ae1e941b5c9b906223ec47311439c3
--- /dev/null
+++ b/third_party/mmyolo/projects/assigner_visualization/dense_heads/yolov8_head_assigner.py
@@ -0,0 +1,180 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Union
+
+import torch
+from mmdet.utils import InstanceList
+from torch import Tensor
+
+from mmyolo.models import YOLOv8Head
+from mmyolo.models.utils import gt_instances_preprocess
+from mmyolo.registry import MODELS
+
+
+@MODELS.register_module()
+class YOLOv8HeadAssigner(YOLOv8Head):
+
+ def assign_by_gt_and_feat(
+ self,
+ cls_scores: List[Tensor],
+ bbox_preds: List[Tensor],
+ batch_gt_instances: InstanceList,
+ batch_img_metas: List[dict],
+ inputs_hw: Union[Tensor, tuple] = (640, 640)
+ ) -> dict:
+ """Calculate the assigning results based on the gt and features
+ extracted by the detection head.
+ Args:
+ cls_scores (Sequence[Tensor]): Box scores for each scale level,
+ each is a 4D-tensor, the channel number is
+ num_priors * num_classes.
+ bbox_preds (Sequence[Tensor]): Box energies / deltas for each scale
+ level, each is a 4D-tensor, the channel number is
+ num_priors * 4.
+ bbox_dist_preds (Sequence[Tensor]): Box distribution logits for
+ each scale level with shape (bs, reg_max + 1, H*W, 4).
+ batch_gt_instances (list[:obj:`InstanceData`]): Batch of
+ gt_instance. It usually includes ``bboxes`` and ``labels``
+ attributes.
+ batch_img_metas (list[dict]): Meta information of each image, e.g.,
+ image size, scaling factor, etc.
+ inputs_hw (Union[Tensor, tuple]): Height and width of inputs size.
+ Returns:
+ dict[str, Tensor]: A dictionary of assigning results.
+ """
+ num_imgs = len(batch_img_metas)
+ device = cls_scores[0].device
+
+ current_featmap_sizes = [
+ cls_score.shape[2:] for cls_score in cls_scores
+ ]
+ # If the shape does not equal, generate new one
+ if current_featmap_sizes != self.featmap_sizes_train:
+ self.featmap_sizes_train = current_featmap_sizes
+
+ mlvl_priors_with_stride = self.prior_generator.grid_priors(
+ self.featmap_sizes_train,
+ dtype=cls_scores[0].dtype,
+ device=device,
+ with_stride=True)
+
+ self.num_level_priors = [len(n) for n in mlvl_priors_with_stride]
+ self.flatten_priors_train = torch.cat(
+ mlvl_priors_with_stride, dim=0)
+ self.stride_tensor = self.flatten_priors_train[..., [2]]
+
+ # gt info
+ gt_info = gt_instances_preprocess(batch_gt_instances, num_imgs)
+ gt_labels = gt_info[:, :, :1]
+ gt_bboxes = gt_info[:, :, 1:] # xyxy
+ pad_bbox_flag = (gt_bboxes.sum(-1, keepdim=True) > 0).float()
+
+ # pred info
+ flatten_cls_preds = [
+ cls_pred.permute(0, 2, 3, 1).reshape(num_imgs, -1,
+ self.num_classes)
+ for cls_pred in cls_scores
+ ]
+ flatten_pred_bboxes = [
+ bbox_pred.permute(0, 2, 3, 1).reshape(num_imgs, -1, 4)
+ for bbox_pred in bbox_preds
+ ]
+ # (bs, n, 4 * reg_max)
+
+ flatten_cls_preds = torch.cat(flatten_cls_preds, dim=1)
+ flatten_pred_bboxes = torch.cat(flatten_pred_bboxes, dim=1)
+ flatten_pred_bboxes = self.bbox_coder.decode(
+ self.flatten_priors_train[..., :2], flatten_pred_bboxes,
+ self.stride_tensor[..., 0])
+
+ assigned_result = self.assigner(
+ (flatten_pred_bboxes.detach()).type(gt_bboxes.dtype),
+ flatten_cls_preds.detach().sigmoid(), self.flatten_priors_train,
+ gt_labels, gt_bboxes, pad_bbox_flag)
+
+ labels = assigned_result['assigned_labels'].reshape(-1)
+ bbox_targets = assigned_result['assigned_bboxes'].reshape(-1, 4)
+ fg_mask_pre_prior = assigned_result['fg_mask_pre_prior'].squeeze(0)
+
+ pos_inds = fg_mask_pre_prior.nonzero().squeeze(1)
+
+ targets = bbox_targets[pos_inds]
+ gt_bboxes = gt_bboxes.squeeze(0)
+ matched_gt_inds = torch.tensor(
+ [((t == gt_bboxes).sum(dim=1) == t.shape[0]).nonzero()[0]
+ for t in targets],
+ device=device)
+
+ level_inds = torch.zeros_like(labels)
+ img_inds = torch.zeros_like(labels)
+ level_nums = [0] + self.num_level_priors
+ for i in range(len(level_nums) - 1):
+ level_nums[i + 1] = level_nums[i] + level_nums[i + 1]
+ level_inds[level_nums[i]:level_nums[i + 1]] = i
+ level_inds_pos = level_inds[pos_inds]
+
+ img_inds = img_inds[pos_inds]
+ labels = labels[pos_inds]
+
+ assign_results = []
+ for i in range(self.num_levels):
+ retained_inds = level_inds_pos == i
+ if not retained_inds.any():
+ assign_results_prior = {
+ 'stride':
+ self.featmap_strides[i],
+ 'grid_x_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'grid_y_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'img_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'class_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'retained_gt_inds':
+ torch.zeros([0], dtype=torch.int64).to(device),
+ 'prior_ind':
+ 0
+ }
+ else:
+ w = inputs_hw[1] // self.featmap_strides[i]
+
+ retained_pos_inds = pos_inds[retained_inds] - level_nums[i]
+ grid_y_inds = retained_pos_inds // w
+ grid_x_inds = retained_pos_inds - retained_pos_inds // w * w
+ assign_results_prior = {
+ 'stride': self.featmap_strides[i],
+ 'grid_x_inds': grid_x_inds,
+ 'grid_y_inds': grid_y_inds,
+ 'img_inds': img_inds[retained_inds],
+ 'class_inds': labels[retained_inds],
+ 'retained_gt_inds': matched_gt_inds[retained_inds],
+ 'prior_ind': 0
+ }
+ assign_results.append([assign_results_prior])
+ return assign_results
+
+ def assign(self, batch_data_samples: Union[list, dict],
+ inputs_hw: Union[tuple, torch.Size]) -> dict:
+ """Calculate assigning results.
+
+ This function is provided to the
+ `assigner_visualization.py` script.
+ Args:
+ batch_data_samples (List[:obj:`DetDataSample`], dict): The Data
+ Samples. It usually includes information such as
+ `gt_instance`, `gt_panoptic_seg` and `gt_sem_seg`.
+ inputs_hw: Height and width of inputs size
+ Returns:
+ dict: A dictionary of assigning components.
+ """
+ if isinstance(batch_data_samples, list):
+ raise NotImplementedError(
+ 'assigning results_list is not implemented')
+ else:
+ # Fast version
+ cls_scores, bbox_preds = self(batch_data_samples['feats'])
+ assign_inputs = (cls_scores, bbox_preds,
+ batch_data_samples['bboxes_labels'],
+ batch_data_samples['img_metas'], inputs_hw)
+ assign_results = self.assign_by_gt_and_feat(*assign_inputs)
+ return assign_results
diff --git a/third_party/mmyolo/projects/assigner_visualization/detectors/__init__.py b/third_party/mmyolo/projects/assigner_visualization/detectors/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..155606a0136ef3e93d90347773af3eb7010b27ac
--- /dev/null
+++ b/third_party/mmyolo/projects/assigner_visualization/detectors/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from projects.assigner_visualization.detectors.yolo_detector_assigner import \
+ YOLODetectorAssigner
+
+__all__ = ['YOLODetectorAssigner']
diff --git a/third_party/mmyolo/projects/assigner_visualization/detectors/yolo_detector_assigner.py b/third_party/mmyolo/projects/assigner_visualization/detectors/yolo_detector_assigner.py
new file mode 100644
index 0000000000000000000000000000000000000000..5b723e01f65381155aaae962415d3c70040de06b
--- /dev/null
+++ b/third_party/mmyolo/projects/assigner_visualization/detectors/yolo_detector_assigner.py
@@ -0,0 +1,34 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Union
+
+from mmyolo.models import YOLODetector
+from mmyolo.registry import MODELS
+from projects.assigner_visualization.dense_heads import (RTMHeadAssigner,
+ YOLOv7HeadAssigner,
+ YOLOv8HeadAssigner)
+
+
+@MODELS.register_module()
+class YOLODetectorAssigner(YOLODetector):
+
+ def assign(self, data: dict) -> Union[dict, list]:
+ """Calculate assigning results from a batch of inputs and data
+ samples.This function is provided to the `assigner_visualization.py`
+ script.
+
+ Args:
+ data (dict or tuple or list): Data sampled from dataset.
+
+ Returns:
+ dict: A dictionary of assigning components.
+ """
+ assert isinstance(data, dict)
+ assert len(data['inputs']) == 1, 'Only support batchsize == 1'
+ data = self.data_preprocessor(data, True)
+ available_assigners = (YOLOv7HeadAssigner, YOLOv8HeadAssigner,
+ RTMHeadAssigner)
+ if isinstance(self.bbox_head, available_assigners):
+ data['data_samples']['feats'] = self.extract_feat(data['inputs'])
+ inputs_hw = data['inputs'].shape[-2:]
+ assign_results = self.bbox_head.assign(data['data_samples'], inputs_hw)
+ return assign_results
diff --git a/third_party/mmyolo/projects/assigner_visualization/visualization/__init__.py b/third_party/mmyolo/projects/assigner_visualization/visualization/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..521a25b8837cf084e78fffa9f84660a4c9ae02bb
--- /dev/null
+++ b/third_party/mmyolo/projects/assigner_visualization/visualization/__init__.py
@@ -0,0 +1,4 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .assigner_visualizer import YOLOAssignerVisualizer
+
+__all__ = ['YOLOAssignerVisualizer']
diff --git a/third_party/mmyolo/projects/assigner_visualization/visualization/assigner_visualizer.py b/third_party/mmyolo/projects/assigner_visualization/visualization/assigner_visualizer.py
new file mode 100644
index 0000000000000000000000000000000000000000..fe1f4f0b90da2bbd683e3f9845efb66c9348459e
--- /dev/null
+++ b/third_party/mmyolo/projects/assigner_visualization/visualization/assigner_visualizer.py
@@ -0,0 +1,326 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import math
+from typing import List, Union
+
+import mmcv
+import numpy as np
+import torch
+from mmdet.structures.bbox import HorizontalBoxes
+from mmdet.visualization import DetLocalVisualizer
+from mmdet.visualization.palette import _get_adaptive_scales, get_palette
+from mmengine.structures import InstanceData
+from torch import Tensor
+
+from mmyolo.registry import VISUALIZERS
+
+
+@VISUALIZERS.register_module()
+class YOLOAssignerVisualizer(DetLocalVisualizer):
+ """MMYOLO Detection Assigner Visualizer.
+
+ This class is provided to the `assigner_visualization.py` script.
+ Args:
+ name (str): Name of the instance. Defaults to 'visualizer'.
+ """
+
+ def __init__(self, name: str = 'visualizer', *args, **kwargs):
+ super().__init__(name=name, *args, **kwargs)
+ # need priors_size from config
+ self.priors_size = None
+
+ def draw_grid(self,
+ stride: int = 8,
+ line_styles: Union[str, List[str]] = ':',
+ colors: Union[str, tuple, List[str],
+ List[tuple]] = (180, 180, 180),
+ line_widths: Union[Union[int, float],
+ List[Union[int, float]]] = 1):
+ """Draw grids on image.
+
+ Args:
+ stride (int): Downsample factor of feature map.
+ line_styles (Union[str, List[str]]): The linestyle
+ of lines. ``line_styles`` can have the same length with
+ texts or just single value. If ``line_styles`` is single
+ value, all the lines will have the same linestyle.
+ Reference to
+ https://matplotlib.org/stable/api/collections_api.html?highlight=collection#matplotlib.collections.AsteriskPolygonCollection.set_linestyle
+ for more details. Defaults to ':'.
+ colors (Union[str, tuple, List[str], List[tuple]]): The colors of
+ lines. ``colors`` can have the same length with lines or just
+ single value. If ``colors`` is single value, all the lines
+ will have the same colors. Reference to
+ https://matplotlib.org/stable/gallery/color/named_colors.html
+ for more details. Defaults to (180, 180, 180).
+ line_widths (Union[Union[int, float], List[Union[int, float]]]):
+ The linewidth of lines. ``line_widths`` can have
+ the same length with lines or just single value.
+ If ``line_widths`` is single value, all the lines will
+ have the same linewidth. Defaults to 1.
+ """
+ assert self._image is not None, 'Please set image using `set_image`'
+ # draw vertical lines
+ x_datas_vertical = ((np.arange(self.width // stride - 1) + 1) *
+ stride).reshape((-1, 1)).repeat(
+ 2, axis=1)
+ y_datas_vertical = np.array([[0, self.height - 1]]).repeat(
+ self.width // stride - 1, axis=0)
+ self.draw_lines(
+ x_datas_vertical,
+ y_datas_vertical,
+ colors=colors,
+ line_styles=line_styles,
+ line_widths=line_widths)
+
+ # draw horizontal lines
+ x_datas_horizontal = np.array([[0, self.width - 1]]).repeat(
+ self.height // stride - 1, axis=0)
+ y_datas_horizontal = ((np.arange(self.height // stride - 1) + 1) *
+ stride).reshape((-1, 1)).repeat(
+ 2, axis=1)
+ self.draw_lines(
+ x_datas_horizontal,
+ y_datas_horizontal,
+ colors=colors,
+ line_styles=line_styles,
+ line_widths=line_widths)
+
+ def draw_instances_assign(self,
+ instances: InstanceData,
+ retained_gt_inds: Tensor,
+ not_show_label: bool = False):
+ """Draw instances of GT.
+
+ Args:
+ instances (:obj:`InstanceData`): gt_instance. It usually
+ includes ``bboxes`` and ``labels`` attributes.
+ retained_gt_inds (Tensor): The gt indexes assigned as the
+ positive sample in the current prior.
+ not_show_label (bool): Whether to show gt labels on images.
+ """
+ assert self.dataset_meta is not None
+ classes = self.dataset_meta['classes']
+ palette = self.dataset_meta['palette']
+ if len(retained_gt_inds) == 0:
+ return self.get_image()
+ draw_gt_inds = torch.from_numpy(
+ np.array(
+ list(set(retained_gt_inds.cpu().numpy())), dtype=np.int64))
+ bboxes = instances.bboxes[draw_gt_inds]
+ labels = instances.labels[draw_gt_inds]
+
+ if not isinstance(bboxes, Tensor):
+ bboxes = bboxes.tensor
+
+ edge_colors = [palette[i] for i in labels]
+
+ max_label = int(max(labels) if len(labels) > 0 else 0)
+ text_palette = get_palette(self.text_color, max_label + 1)
+ text_colors = [text_palette[label] for label in labels]
+
+ self.draw_bboxes(
+ bboxes,
+ edge_colors=edge_colors,
+ alpha=self.alpha,
+ line_widths=self.line_width)
+
+ if not not_show_label:
+ positions = bboxes[:, :2] + self.line_width
+ areas = (bboxes[:, 3] - bboxes[:, 1]) * (
+ bboxes[:, 2] - bboxes[:, 0])
+ scales = _get_adaptive_scales(areas)
+ for i, (pos, label) in enumerate(zip(positions, labels)):
+ label_text = classes[
+ label] if classes is not None else f'class {label}'
+
+ self.draw_texts(
+ label_text,
+ pos,
+ colors=text_colors[i],
+ font_sizes=int(13 * scales[i]),
+ bboxes=[{
+ 'facecolor': 'black',
+ 'alpha': 0.8,
+ 'pad': 0.7,
+ 'edgecolor': 'none'
+ }])
+
+ def draw_positive_assign(self,
+ grid_x_inds: Tensor,
+ grid_y_inds: Tensor,
+ class_inds: Tensor,
+ stride: int,
+ bboxes: Union[Tensor, HorizontalBoxes],
+ retained_gt_inds: Tensor,
+ offset: float = 0.5):
+ """
+
+ Args:
+ grid_x_inds (Tensor): The X-axis indexes of the positive sample
+ in current prior.
+ grid_y_inds (Tensor): The Y-axis indexes of the positive sample
+ in current prior.
+ class_inds (Tensor): The classes indexes of the positive sample
+ in current prior.
+ stride (int): Downsample factor of feature map.
+ bboxes (Union[Tensor, HorizontalBoxes]): Bounding boxes of GT.
+ retained_gt_inds (Tensor): The gt indexes assigned as the
+ positive sample in the current prior.
+ offset (float): The offset of points, the value is normalized
+ with corresponding stride. Defaults to 0.5.
+ """
+ if not isinstance(bboxes, Tensor):
+ # Convert HorizontalBoxes to Tensor
+ bboxes = bboxes.tensor
+
+ # The PALETTE in the dataset_meta is required
+ assert self.dataset_meta is not None
+ palette = self.dataset_meta['palette']
+ x = ((grid_x_inds + offset) * stride).long()
+ y = ((grid_y_inds + offset) * stride).long()
+ center = torch.stack((x, y), dim=-1)
+
+ retained_bboxes = bboxes[retained_gt_inds]
+ bbox_wh = retained_bboxes[:, 2:] - retained_bboxes[:, :2]
+ bbox_area = bbox_wh[:, 0] * bbox_wh[:, 1]
+ radius = _get_adaptive_scales(bbox_area) * 4
+ colors = [palette[i] for i in class_inds]
+
+ self.draw_circles(
+ center,
+ radius,
+ colors,
+ line_widths=0,
+ face_colors=colors,
+ alpha=1.0)
+
+ def draw_prior(self,
+ grid_x_inds: Tensor,
+ grid_y_inds: Tensor,
+ class_inds: Tensor,
+ stride: int,
+ feat_ind: int,
+ prior_ind: int,
+ offset: float = 0.5):
+ """Draw priors on image.
+
+ Args:
+ grid_x_inds (Tensor): The X-axis indexes of the positive sample
+ in current prior.
+ grid_y_inds (Tensor): The Y-axis indexes of the positive sample
+ in current prior.
+ class_inds (Tensor): The classes indexes of the positive sample
+ in current prior.
+ stride (int): Downsample factor of feature map.
+ feat_ind (int): Index of featmap.
+ prior_ind (int): Index of prior in current featmap.
+ offset (float): The offset of points, the value is normalized
+ with corresponding stride. Defaults to 0.5.
+ """
+
+ palette = self.dataset_meta['palette']
+ center_x = ((grid_x_inds + offset) * stride)
+ center_y = ((grid_y_inds + offset) * stride)
+ xyxy = torch.stack((center_x, center_y, center_x, center_y), dim=1)
+ device = xyxy.device
+ if self.priors_size is not None:
+ xyxy += self.priors_size[feat_ind][prior_ind].to(device)
+ else:
+ xyxy += torch.tensor(
+ [[-stride / 2, -stride / 2, stride / 2, stride / 2]],
+ device=device)
+
+ colors = [palette[i] for i in class_inds]
+ self.draw_bboxes(
+ xyxy,
+ edge_colors=colors,
+ alpha=self.alpha,
+ line_styles='--',
+ line_widths=math.ceil(self.line_width * 0.3))
+
+ def draw_assign(self,
+ image: np.ndarray,
+ assign_results: List[List[dict]],
+ gt_instances: InstanceData,
+ show_prior: bool = False,
+ not_show_label: bool = False) -> np.ndarray:
+ """Draw assigning results.
+
+ Args:
+ image (np.ndarray): The image to draw.
+ assign_results (list): The assigning results.
+ gt_instances (:obj:`InstanceData`): Data structure for
+ instance-level annotations or predictions.
+ show_prior (bool): Whether to show prior on image.
+ not_show_label (bool): Whether to show gt labels on images.
+
+ Returns:
+ np.ndarray: the drawn image which channel is RGB.
+ """
+ img_show_list = []
+ for feat_ind, assign_results_feat in enumerate(assign_results):
+ img_show_list_feat = []
+ for prior_ind, assign_results_prior in enumerate(
+ assign_results_feat):
+ self.set_image(image)
+ h, w = image.shape[:2]
+
+ # draw grid
+ stride = assign_results_prior['stride']
+ self.draw_grid(stride)
+
+ # draw prior on matched gt
+ grid_x_inds = assign_results_prior['grid_x_inds']
+ grid_y_inds = assign_results_prior['grid_y_inds']
+ class_inds = assign_results_prior['class_inds']
+ prior_ind = assign_results_prior['prior_ind']
+ offset = assign_results_prior.get('offset', 0.5)
+
+ if show_prior:
+ self.draw_prior(grid_x_inds, grid_y_inds, class_inds,
+ stride, feat_ind, prior_ind, offset)
+
+ # draw matched gt
+ retained_gt_inds = assign_results_prior['retained_gt_inds']
+ self.draw_instances_assign(gt_instances, retained_gt_inds,
+ not_show_label)
+
+ # draw positive
+ self.draw_positive_assign(grid_x_inds, grid_y_inds, class_inds,
+ stride, gt_instances.bboxes,
+ retained_gt_inds, offset)
+
+ # draw title
+ if self.priors_size is not None:
+ base_prior = self.priors_size[feat_ind][prior_ind]
+ else:
+ base_prior = [stride, stride, stride * 2, stride * 2]
+ prior_size = (base_prior[2] - base_prior[0],
+ base_prior[3] - base_prior[1])
+ pos = np.array((20, 20))
+ text = f'feat_ind: {feat_ind} ' \
+ f'prior_ind: {prior_ind} ' \
+ f'prior_size: ({prior_size[0]}, {prior_size[1]})'
+ scales = _get_adaptive_scales(np.array([h * w / 16]))
+ font_sizes = int(13 * scales)
+ self.draw_texts(
+ text,
+ pos,
+ colors=self.text_color,
+ font_sizes=font_sizes,
+ bboxes=[{
+ 'facecolor': 'black',
+ 'alpha': 0.8,
+ 'pad': 0.7,
+ 'edgecolor': 'none'
+ }])
+
+ img_show = self.get_image()
+ img_show = mmcv.impad(img_show, padding=(5, 5, 5, 5))
+ img_show_list_feat.append(img_show)
+ img_show_list.append(np.concatenate(img_show_list_feat, axis=1))
+
+ # Merge all images into one image
+ # setting axis is to beautify the merged image
+ axis = 0 if len(assign_results[0]) > 1 else 1
+ return np.concatenate(img_show_list, axis=axis)
diff --git a/third_party/mmyolo/projects/easydeploy/README.md b/third_party/mmyolo/projects/easydeploy/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..1816e7ed96ee34209c56af4a22eda5f1eb7e499b
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/README.md
@@ -0,0 +1,11 @@
+# MMYOLO Model Easy-Deployment
+
+## Introduction
+
+This project is developed for easily converting your MMYOLO models to other inference backends without the need of MMDeploy, which reduces the cost of both time and effort on getting familiar with MMDeploy.
+
+Currently we support converting to `ONNX` and `TensorRT` formats, other inference backends such `ncnn` will be added to this project as well.
+
+## Supported Backends
+
+- [Model Convert](docs/model_convert.md)
diff --git a/third_party/mmyolo/projects/easydeploy/README_zh-CN.md b/third_party/mmyolo/projects/easydeploy/README_zh-CN.md
new file mode 100644
index 0000000000000000000000000000000000000000..4c6bc0cf4ef91edeced04bdf15af08ae1f6f0dcd
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/README_zh-CN.md
@@ -0,0 +1,11 @@
+# MMYOLO 模型转换
+
+## 介绍
+
+本项目作为 MMYOLO 的部署 project 单独存在,意图剥离 MMDeploy 当前的体系,独自支持用户完成模型训练后的转换和部署功能,使用户的学习和工程成本下降。
+
+当前支持对 ONNX 格式和 TensorRT 格式的转换,后续对其他推理平台也会支持起来。
+
+## 转换教程
+
+- [Model Convert](docs/model_convert.md)
diff --git a/third_party/mmyolo/projects/easydeploy/backbone/__init__.py b/third_party/mmyolo/projects/easydeploy/backbone/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..dc167f8515c66a30d884ed9655a11d45e21481c0
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/backbone/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .common import DeployC2f
+from .focus import DeployFocus, GConvFocus, NcnnFocus
+
+__all__ = ['DeployFocus', 'NcnnFocus', 'GConvFocus', 'DeployC2f']
diff --git a/third_party/mmyolo/projects/easydeploy/backbone/common.py b/third_party/mmyolo/projects/easydeploy/backbone/common.py
new file mode 100644
index 0000000000000000000000000000000000000000..617875bd979a5b9150e476544090777118087a0b
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/backbone/common.py
@@ -0,0 +1,16 @@
+import torch
+import torch.nn as nn
+from torch import Tensor
+
+
+class DeployC2f(nn.Module):
+
+ def __init__(self, *args, **kwargs):
+ super().__init__()
+
+ def forward(self, x: Tensor) -> Tensor:
+ x_main = self.main_conv(x)
+ x_main = [x_main, x_main[:, self.mid_channels:, ...]]
+ x_main.extend(blocks(x_main[-1]) for blocks in self.blocks)
+ x_main.pop(1)
+ return self.final_conv(torch.cat(x_main, 1))
diff --git a/third_party/mmyolo/projects/easydeploy/backbone/focus.py b/third_party/mmyolo/projects/easydeploy/backbone/focus.py
new file mode 100644
index 0000000000000000000000000000000000000000..2a19afcca1d9c4e27109daeebd83907cd9b7b284
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/backbone/focus.py
@@ -0,0 +1,79 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from torch import Tensor
+
+
+class DeployFocus(nn.Module):
+
+ def __init__(self, orin_Focus: nn.Module):
+ super().__init__()
+ self.__dict__.update(orin_Focus.__dict__)
+
+ def forward(self, x: Tensor) -> Tensor:
+ batch_size, channel, height, width = x.shape
+ x = x.reshape(batch_size, channel, -1, 2, width)
+ x = x.reshape(batch_size, channel, x.shape[2], 2, -1, 2)
+ half_h = x.shape[2]
+ half_w = x.shape[4]
+ x = x.permute(0, 5, 3, 1, 2, 4)
+ x = x.reshape(batch_size, channel * 4, half_h, half_w)
+
+ return self.conv(x)
+
+
+class NcnnFocus(nn.Module):
+
+ def __init__(self, orin_Focus: nn.Module):
+ super().__init__()
+ self.__dict__.update(orin_Focus.__dict__)
+
+ def forward(self, x: Tensor) -> Tensor:
+ batch_size, c, h, w = x.shape
+ assert h % 2 == 0 and w % 2 == 0, f'focus for yolox needs even feature\
+ height and width, got {(h, w)}.'
+
+ x = x.reshape(batch_size, c * h, 1, w)
+ _b, _c, _h, _w = x.shape
+ g = _c // 2
+ # fuse to ncnn's shufflechannel
+ x = x.view(_b, g, 2, _h, _w)
+ x = torch.transpose(x, 1, 2).contiguous()
+ x = x.view(_b, -1, _h, _w)
+
+ x = x.reshape(_b, c * h * w, 1, 1)
+
+ _b, _c, _h, _w = x.shape
+ g = _c // 2
+ # fuse to ncnn's shufflechannel
+ x = x.view(_b, g, 2, _h, _w)
+ x = torch.transpose(x, 1, 2).contiguous()
+ x = x.view(_b, -1, _h, _w)
+
+ x = x.reshape(_b, c * 4, h // 2, w // 2)
+
+ return self.conv(x)
+
+
+class GConvFocus(nn.Module):
+
+ def __init__(self, orin_Focus: nn.Module):
+ super().__init__()
+ device = next(orin_Focus.parameters()).device
+ self.weight1 = torch.tensor([[1., 0], [0, 0]]).expand(3, 1, 2,
+ 2).to(device)
+ self.weight2 = torch.tensor([[0, 0], [1., 0]]).expand(3, 1, 2,
+ 2).to(device)
+ self.weight3 = torch.tensor([[0, 1.], [0, 0]]).expand(3, 1, 2,
+ 2).to(device)
+ self.weight4 = torch.tensor([[0, 0], [0, 1.]]).expand(3, 1, 2,
+ 2).to(device)
+ self.__dict__.update(orin_Focus.__dict__)
+
+ def forward(self, x: Tensor) -> Tensor:
+ conv1 = F.conv2d(x, self.weight1, stride=2, groups=3)
+ conv2 = F.conv2d(x, self.weight2, stride=2, groups=3)
+ conv3 = F.conv2d(x, self.weight3, stride=2, groups=3)
+ conv4 = F.conv2d(x, self.weight4, stride=2, groups=3)
+ return self.conv(torch.cat([conv1, conv2, conv3, conv4], dim=1))
diff --git a/third_party/mmyolo/projects/easydeploy/bbox_code/__init__.py b/third_party/mmyolo/projects/easydeploy/bbox_code/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..b85a815536a5749a15f0ad6aab2b028eb6a3fe0a
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/bbox_code/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .bbox_coder import (rtmdet_bbox_decoder, yolov5_bbox_decoder,
+ yolox_bbox_decoder)
+
+__all__ = ['yolov5_bbox_decoder', 'rtmdet_bbox_decoder', 'yolox_bbox_decoder']
diff --git a/third_party/mmyolo/projects/easydeploy/bbox_code/bbox_coder.py b/third_party/mmyolo/projects/easydeploy/bbox_code/bbox_coder.py
new file mode 100644
index 0000000000000000000000000000000000000000..6483cf8b0328aff3d61f1fa0788337ab536d347d
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/bbox_code/bbox_coder.py
@@ -0,0 +1,46 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional
+
+import torch
+from torch import Tensor
+
+
+def yolov5_bbox_decoder(priors: Tensor, bbox_preds: Tensor,
+ stride: Tensor) -> Tensor:
+ bbox_preds = bbox_preds.sigmoid()
+
+ x_center = (priors[..., 0] + priors[..., 2]) * 0.5
+ y_center = (priors[..., 1] + priors[..., 3]) * 0.5
+ w = priors[..., 2] - priors[..., 0]
+ h = priors[..., 3] - priors[..., 1]
+
+ x_center_pred = (bbox_preds[..., 0] - 0.5) * 2 * stride + x_center
+ y_center_pred = (bbox_preds[..., 1] - 0.5) * 2 * stride + y_center
+ w_pred = (bbox_preds[..., 2] * 2)**2 * w
+ h_pred = (bbox_preds[..., 3] * 2)**2 * h
+
+ decoded_bboxes = torch.stack(
+ [x_center_pred, y_center_pred, w_pred, h_pred], dim=-1)
+
+ return decoded_bboxes
+
+
+def rtmdet_bbox_decoder(priors: Tensor, bbox_preds: Tensor,
+ stride: Optional[Tensor]) -> Tensor:
+ stride = stride[None, :, None]
+ bbox_preds *= stride
+ tl_x = (priors[..., 0] - bbox_preds[..., 0])
+ tl_y = (priors[..., 1] - bbox_preds[..., 1])
+ br_x = (priors[..., 0] + bbox_preds[..., 2])
+ br_y = (priors[..., 1] + bbox_preds[..., 3])
+ decoded_bboxes = torch.stack([tl_x, tl_y, br_x, br_y], -1)
+ return decoded_bboxes
+
+
+def yolox_bbox_decoder(priors: Tensor, bbox_preds: Tensor,
+ stride: Optional[Tensor]) -> Tensor:
+ stride = stride[None, :, None]
+ xys = (bbox_preds[..., :2] * stride) + priors
+ whs = bbox_preds[..., 2:].exp() * stride
+ decoded_bboxes = torch.cat([xys, whs], -1)
+ return decoded_bboxes
diff --git a/third_party/mmyolo/projects/easydeploy/deepstream/CMakeLists.txt b/third_party/mmyolo/projects/easydeploy/deepstream/CMakeLists.txt
new file mode 100644
index 0000000000000000000000000000000000000000..f640bea13bacfc0f6cc2f33e598f65cf5ce0922e
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/deepstream/CMakeLists.txt
@@ -0,0 +1,35 @@
+cmake_minimum_required(VERSION 2.8.12)
+
+set(CMAKE_CUDA_ARCHITECTURES 60 61 62 70 72 75 86)
+set(CMAKE_CUDA_COMPILER /usr/local/cuda/bin/nvcc)
+
+project(nvdsparsebbox_mmyolo LANGUAGES CXX)
+
+set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++14 -O3 -g -Wall -Werror -shared -fPIC")
+set(CMAKE_CXX_STANDARD 14)
+set(CMAKE_BUILD_TYPE Release)
+option(CUDA_USE_STATIC_CUDA_RUNTIME OFF)
+
+# CUDA
+find_package(CUDA REQUIRED)
+
+# TensorRT
+set(TensorRT_INCLUDE_DIRS "/usr/include/x86_64-linux-gnu" CACHE STRING "TensorRT headers path")
+set(TensorRT_LIBRARIES "/usr/lib/x86_64-linux-gnu" CACHE STRING "TensorRT libs path")
+
+# DeepStream
+set(DEEPSTREAM "/opt/nvidia/deepstream/deepstream" CACHE STRING "DeepStream root path")
+set(DS_LIBRARIES ${DEEPSTREAM}/lib)
+set(DS_INCLUDE_DIRS ${DEEPSTREAM}/sources/includes)
+
+include_directories(
+ ${CUDA_INCLUDE_DIRS}
+ ${TensorRT_INCLUDE_DIRS}
+ ${DS_INCLUDE_DIRS})
+
+add_library(
+ ${PROJECT_NAME}
+ SHARED
+ custom_mmyolo_bbox_parser/nvdsparsebbox_mmyolo.cpp)
+
+target_link_libraries(${PROJECT_NAME} PRIVATE nvinfer nvinfer_plugin)
diff --git a/third_party/mmyolo/projects/easydeploy/deepstream/README.md b/third_party/mmyolo/projects/easydeploy/deepstream/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..111f3765e41d558b64097d8a25585bd9c14acf4f
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/deepstream/README.md
@@ -0,0 +1,48 @@
+# Inference MMYOLO Models with DeepStream
+
+This project demonstrates how to inference MMYOLO models with customized parsers in [DeepStream SDK](https://developer.nvidia.com/deepstream-sdk).
+
+## Pre-requisites
+
+### 1. Install Nvidia Driver and CUDA
+
+First, please follow the official documents and instructions to install dedicated Nvidia graphic driver and CUDA matched to your gpu and target Nvidia AIoT devices.
+
+### 2. Install DeepStream SDK
+
+Second, please follow the official instruction to download and install DeepStream SDK. Currently stable version of DeepStream is v6.2.
+
+### 3. Generate TensorRT Engine
+
+As DeepStream builds on top of several NVIDIA libraries, you need to first convert your trained MMYOLO models to TensorRT engine files. We strongly recommend you to try the supported TensorRT deployment solution in [EasyDeploy](../../easydeploy/).
+
+## Build and Run
+
+Please make sure that your converted TensorRT engine is already located in the `deepstream` folder as the config shows. Create your own model config files and change the `config-file` parameter in [deepstream_app_config.txt](deepstream_app_config.txt) to the model you want to run with.
+
+```bash
+mkdir build && cd build
+cmake ..
+make -j$(nproc) && make install
+```
+
+Then you can run the inference with this command.
+
+```bash
+deepstream-app -c deepstream_app_config.txt
+```
+
+## Code Structure
+
+```bash
+├── deepstream
+│ ├── configs # config file for MMYOLO models
+│ │ └── config_infer_rtmdet.txt
+│ ├── custom_mmyolo_bbox_parser # customized parser for MMYOLO models to DeepStream formats
+│ │ └── nvdsparsebbox_mmyolo.cpp
+| ├── CMakeLists.txt
+│ ├── coco_labels.txt # labels for coco detection
+│ ├── deepstream_app_config.txt # deepStream reference app configs for MMYOLO models
+│ ├── README_zh-CN.md
+│ └── README.md
+```
diff --git a/third_party/mmyolo/projects/easydeploy/deepstream/README_zh-CN.md b/third_party/mmyolo/projects/easydeploy/deepstream/README_zh-CN.md
new file mode 100644
index 0000000000000000000000000000000000000000..13a85d5bc90159c3ff9f1a32e93d01e82ed2faa4
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/deepstream/README_zh-CN.md
@@ -0,0 +1,48 @@
+# 使用 DeepStream SDK 推理 MMYOLO 模型
+
+本项目演示了如何使用 [DeepStream SDK](https://developer.nvidia.com/deepstream-sdk) 配合改写的 parser 来推理 MMYOLO 的模型。
+
+## 预先准备
+
+### 1. 安装 Nidia 驱动和 CUDA
+
+首先请根据当前的显卡驱动和目标使用设备的驱动完成显卡驱动和 CUDA 的安装。
+
+### 2. 安装 DeepStream SDK
+
+目前 DeepStream SDK 稳定版本已经更新到 v6.2,官方推荐使用这个版本。
+
+### 3. 将 MMYOLO 模型转换为 TensorRT Engine
+
+推荐使用 EasyDeploy 中的 TensorRT 方案完成目标模型的转换部署,具体可参考 [此文档](../../easydeploy/docs/model_convert.md) 。
+
+## 编译使用
+
+当前项目使用的是 MMYOLO 的 rtmdet 模型,若想使用其他的模型,请参照目录下的配置文件进行改写。然后将转换完的 TensorRT engine 放在当前目录下并执行如下命令:
+
+```bash
+mkdir build && cd build
+cmake ..
+make -j$(nproc) && make install
+```
+
+完成编译后可使用如下命令进行推理:
+
+```bash
+deepstream-app -c deepstream_app_config.txt
+```
+
+## 项目代码结构
+
+```bash
+├── deepstream
+│ ├── configs # MMYOLO 模型对应的 DeepStream 配置
+│ │ └── config_infer_rtmdet.txt
+│ ├── custom_mmyolo_bbox_parser # 适配 DeepStream formats 的 parser
+│ │ └── nvdsparsebbox_mmyolo.cpp
+| ├── CMakeLists.txt
+│ ├── coco_labels.txt # coco labels
+│ ├── deepstream_app_config.txt # DeepStream app 配置
+│ ├── README_zh-CN.md
+│ └── README.md
+```
diff --git a/third_party/mmyolo/projects/easydeploy/deepstream/coco_labels.txt b/third_party/mmyolo/projects/easydeploy/deepstream/coco_labels.txt
new file mode 100644
index 0000000000000000000000000000000000000000..ca76c80b5b2cd0b25047f75736656cfebc9da7aa
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/deepstream/coco_labels.txt
@@ -0,0 +1,80 @@
+person
+bicycle
+car
+motorbike
+aeroplane
+bus
+train
+truck
+boat
+traffic light
+fire hydrant
+stop sign
+parking meter
+bench
+bird
+cat
+dog
+horse
+sheep
+cow
+elephant
+bear
+zebra
+giraffe
+backpack
+umbrella
+handbag
+tie
+suitcase
+frisbee
+skis
+snowboard
+sports ball
+kite
+baseball bat
+baseball glove
+skateboard
+surfboard
+tennis racket
+bottle
+wine glass
+cup
+fork
+knife
+spoon
+bowl
+banana
+apple
+sandwich
+orange
+broccoli
+carrot
+hot dog
+pizza
+donut
+cake
+chair
+sofa
+pottedplant
+bed
+diningtable
+toilet
+tvmonitor
+laptop
+mouse
+remote
+keyboard
+cell phone
+microwave
+oven
+toaster
+sink
+refrigerator
+book
+clock
+vase
+scissors
+teddy bear
+hair drier
+toothbrush
diff --git a/third_party/mmyolo/projects/easydeploy/deepstream/configs/config_infer_rtmdet.txt b/third_party/mmyolo/projects/easydeploy/deepstream/configs/config_infer_rtmdet.txt
new file mode 100644
index 0000000000000000000000000000000000000000..a1e5efd2a3810730144e037ee96dfbd36124b0e6
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/deepstream/configs/config_infer_rtmdet.txt
@@ -0,0 +1,22 @@
+[property]
+gpu-id=0
+net-scale-factor=0.01735207357279195
+offsets=57.375;57.12;58.395
+model-color-format=1
+model-engine-file=../end2end.engine
+labelfile-path=../coco_labels.txt
+batch-size=1
+network-mode=0
+num-detected-classes=80
+interval=0
+gie-unique-id=1
+process-mode=1
+network-type=0
+cluster-mode=2
+maintain-aspect-ratio=1
+parse-bbox-func-name=NvDsInferParseCustomMMYOLO
+custom-lib-path=../build/libnvdsparsebbox_mmyolo.so
+
+[class-attrs-all]
+pre-cluster-threshold=0.45
+topk=100
diff --git a/third_party/mmyolo/projects/easydeploy/deepstream/configs/config_infer_yolov5.txt b/third_party/mmyolo/projects/easydeploy/deepstream/configs/config_infer_yolov5.txt
new file mode 100644
index 0000000000000000000000000000000000000000..6ad7d6429cacd0a6050821e5b2a41317478f5119
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/deepstream/configs/config_infer_yolov5.txt
@@ -0,0 +1,21 @@
+[property]
+gpu-id=0
+net-scale-factor=0.0039215697906911373
+model-color-format=0
+model-engine-file=../end2end.engine
+labelfile-path=../coco_labels.txt
+batch-size=1
+network-mode=0
+num-detected-classes=80
+interval=0
+gie-unique-id=1
+process-mode=1
+network-type=0
+cluster-mode=2
+maintain-aspect-ratio=1
+parse-bbox-func-name=NvDsInferParseCustomMMYOLO
+custom-lib-path=../build/libnvdsparsebbox_mmyolo.so
+
+[class-attrs-all]
+pre-cluster-threshold=0.45
+topk=100
diff --git a/third_party/mmyolo/projects/easydeploy/deepstream/configs/config_infer_yolov8.txt b/third_party/mmyolo/projects/easydeploy/deepstream/configs/config_infer_yolov8.txt
new file mode 100644
index 0000000000000000000000000000000000000000..6ad7d6429cacd0a6050821e5b2a41317478f5119
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/deepstream/configs/config_infer_yolov8.txt
@@ -0,0 +1,21 @@
+[property]
+gpu-id=0
+net-scale-factor=0.0039215697906911373
+model-color-format=0
+model-engine-file=../end2end.engine
+labelfile-path=../coco_labels.txt
+batch-size=1
+network-mode=0
+num-detected-classes=80
+interval=0
+gie-unique-id=1
+process-mode=1
+network-type=0
+cluster-mode=2
+maintain-aspect-ratio=1
+parse-bbox-func-name=NvDsInferParseCustomMMYOLO
+custom-lib-path=../build/libnvdsparsebbox_mmyolo.so
+
+[class-attrs-all]
+pre-cluster-threshold=0.45
+topk=100
diff --git a/third_party/mmyolo/projects/easydeploy/deepstream/custom_mmyolo_bbox_parser/nvdsparsebbox_mmyolo.cpp b/third_party/mmyolo/projects/easydeploy/deepstream/custom_mmyolo_bbox_parser/nvdsparsebbox_mmyolo.cpp
new file mode 100644
index 0000000000000000000000000000000000000000..eb780856cbd2b289cdf9dc8518438f946a2ab548
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/deepstream/custom_mmyolo_bbox_parser/nvdsparsebbox_mmyolo.cpp
@@ -0,0 +1,118 @@
+#include "nvdsinfer_custom_impl.h"
+#include
+#include
+
+/**
+ * Function expected by DeepStream for decoding the MMYOLO output.
+ *
+ * C-linkage [extern "C"] was written to prevent name-mangling. This function must return true after
+ * adding all bounding boxes to the objectList vector.
+ *
+ * @param [outputLayersInfo] std::vector of NvDsInferLayerInfo objects with information about the output layer.
+ * @param [networkInfo] NvDsInferNetworkInfo object with information about the MMYOLO network.
+ * @param [detectionParams] NvDsInferParseDetectionParams with information about some config params.
+ * @param [objectList] std::vector of NvDsInferParseObjectInfo objects to which bounding box information must
+ * be stored.
+ *
+ * @return true
+ */
+
+// This is just the function prototype. The definition is written at the end of the file.
+extern "C" bool NvDsInferParseCustomMMYOLO(
+ std::vector const& outputLayersInfo,
+ NvDsInferNetworkInfo const& networkInfo,
+ NvDsInferParseDetectionParams const& detectionParams,
+ std::vector& objectList);
+
+static __inline__ float clamp(float& val, float min, float max)
+{
+ return val > min ? (val < max ? val : max) : min;
+}
+
+static std::vector decodeMMYoloTensor(
+ const int* num_dets,
+ const float* bboxes,
+ const float* scores,
+ const int* labels,
+ const float& conf_thres,
+ const unsigned int& img_w,
+ const unsigned int& img_h
+)
+{
+ std::vector bboxInfo;
+ size_t nums = num_dets[0];
+ for (size_t i = 0; i < nums; i++)
+ {
+ float score = scores[i];
+ if (score < conf_thres)continue;
+ float x0 = (bboxes[i * 4]);
+ float y0 = (bboxes[i * 4 + 1]);
+ float x1 = (bboxes[i * 4 + 2]);
+ float y1 = (bboxes[i * 4 + 3]);
+ x0 = clamp(x0, 0.f, img_w);
+ y0 = clamp(y0, 0.f, img_h);
+ x1 = clamp(x1, 0.f, img_w);
+ y1 = clamp(y1, 0.f, img_h);
+ NvDsInferParseObjectInfo obj;
+ obj.left = x0;
+ obj.top = y0;
+ obj.width = x1 - x0;
+ obj.height = y1 - y0;
+ obj.detectionConfidence = score;
+ obj.classId = labels[i];
+ bboxInfo.push_back(obj);
+ }
+
+ return bboxInfo;
+}
+
+/* C-linkage to prevent name-mangling */
+extern "C" bool NvDsInferParseCustomMMYOLO(
+ std::vector const& outputLayersInfo,
+ NvDsInferNetworkInfo const& networkInfo,
+ NvDsInferParseDetectionParams const& detectionParams,
+ std::vector& objectList)
+{
+
+// Some assertions and error checking.
+ if (outputLayersInfo.empty() || outputLayersInfo.size() != 4)
+ {
+ std::cerr << "Could not find output layer in bbox parsing" << std::endl;
+ return false;
+ }
+
+// Score threshold of bboxes.
+ const float conf_thres = detectionParams.perClassThreshold[0];
+
+// Obtaining the output layer.
+ const NvDsInferLayerInfo& num_dets = outputLayersInfo[0];
+ const NvDsInferLayerInfo& bboxes = outputLayersInfo[1];
+ const NvDsInferLayerInfo& scores = outputLayersInfo[2];
+ const NvDsInferLayerInfo& labels = outputLayersInfo[3];
+
+// num_dets(int) bboxes(float) scores(float) labels(int)
+ assert (num_dets.dims.numDims == 2);
+ assert (bboxes.dims.numDims == 3);
+ assert (scores.dims.numDims == 2);
+ assert (labels.dims.numDims == 2);
+
+
+// Decoding the output tensor of MMYOLO to the NvDsInferParseObjectInfo format.
+ std::vector objects =
+ decodeMMYoloTensor(
+ (const int*)(num_dets.buffer),
+ (const float*)(bboxes.buffer),
+ (const float*)(scores.buffer),
+ (const int*)(labels.buffer),
+ conf_thres,
+ networkInfo.width,
+ networkInfo.height
+ );
+
+ objectList.clear();
+ objectList = objects;
+ return true;
+}
+
+/* Check that the custom function has been defined correctly */
+CHECK_CUSTOM_PARSE_FUNC_PROTOTYPE(NvDsInferParseCustomMMYOLO);
diff --git a/third_party/mmyolo/projects/easydeploy/deepstream/deepstream_app_config.txt b/third_party/mmyolo/projects/easydeploy/deepstream/deepstream_app_config.txt
new file mode 100644
index 0000000000000000000000000000000000000000..331776897a5e9109b9007ed1b7974f128287c4fc
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/deepstream/deepstream_app_config.txt
@@ -0,0 +1,62 @@
+[application]
+enable-perf-measurement=1
+perf-measurement-interval-sec=5
+
+[tiled-display]
+enable=1
+rows=1
+columns=1
+width=1280
+height=720
+gpu-id=0
+nvbuf-memory-type=0
+
+[source0]
+enable=1
+type=3
+uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
+num-sources=1
+gpu-id=0
+cudadec-memtype=0
+
+[sink0]
+enable=1
+type=2
+sync=0
+gpu-id=0
+nvbuf-memory-type=0
+
+[osd]
+enable=1
+gpu-id=0
+border-width=5
+text-size=15
+text-color=1;1;1;1;
+text-bg-color=0.3;0.3;0.3;1
+font=Serif
+show-clock=0
+clock-x-offset=800
+clock-y-offset=820
+clock-text-size=12
+clock-color=1;0;0;0
+nvbuf-memory-type=0
+
+[streammux]
+gpu-id=0
+live-source=0
+batch-size=1
+batched-push-timeout=40000
+width=1920
+height=1080
+enable-padding=0
+nvbuf-memory-type=0
+
+[primary-gie]
+enable=1
+gpu-id=0
+gie-unique-id=1
+nvbuf-memory-type=0
+config-file=configs/config_infer_rtmdet.txt
+
+[tests]
+file-loop=0
diff --git a/third_party/mmyolo/projects/easydeploy/docs/model_convert.md b/third_party/mmyolo/projects/easydeploy/docs/model_convert.md
new file mode 100644
index 0000000000000000000000000000000000000000..9af62599dd1b56648680fc315ca88c35c7b31cb9
--- /dev/null
+++ b/third_party/mmyolo/projects/easydeploy/docs/model_convert.md
@@ -0,0 +1,156 @@
+# MMYOLO 模型 ONNX 转换
+
+## 1. 导出后端支持的 ONNX
+
+## 环境依赖
+
+- [onnx](https://github.com/onnx/onnx)
+
+ ```shell
+ pip install onnx
+ ```
+
+ [onnx-simplifier](https://github.com/daquexian/onnx-simplifier) (可选,用于简化模型)
+
+ ```shell
+ pip install onnx-simplifier
+ ```
+
+\*\*\* 请确保您在 `MMYOLO` 根目录下运行相关脚本,避免无法找到相关依赖包。\*\*\*
+
+## 使用方法
+
+[模型导出脚本](./projects/easydeploy/tools/export_onnx.py)用于将 `MMYOLO` 模型转换为 `onnx` 。
+
+### 参数介绍:
+
+- `config` : 构建模型使用的配置文件,如 [`yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py`](./configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py) 。
+- `checkpoint` : 训练得到的权重文件,如 `yolov5s.pth` 。
+- `--work-dir` : 转换后的模型保存路径。
+- `--img-size`: 转换模型时输入的尺寸,如 `640 640`。
+- `--batch-size`: 转换后的模型输入 `batch size` 。
+- `--device`: 转换模型使用的设备,默认为 `cuda:0`。
+- `--simplify`: 是否简化导出的 `onnx` 模型,需要安装 [onnx-simplifier](https://github.com/daquexian/onnx-simplifier),默认关闭。
+- `--opset`: 指定导出 `onnx` 的 `opset`,默认为 `11` 。
+- `--backend`: 指定导出 `onnx` 用于的后端名称,`ONNXRuntime`: `onnxruntime`, `TensorRT8`: `tensorrt8`, `TensorRT7`: `tensorrt7`,默认为`onnxruntime`即 `ONNXRuntime`。
+- `--pre-topk`: 指定导出 `onnx` 的后处理筛选候选框个数阈值,默认为 `1000`。
+- `--keep-topk`: 指定导出 `onnx` 的非极大值抑制输出的候选框个数阈值,默认为 `100`。
+- `--iou-threshold`: 非极大值抑制中过滤重复候选框的 `iou` 阈值,默认为 `0.65`。
+- `--score-threshold`: 非极大值抑制中过滤候选框得分的阈值,默认为 `0.25`。
+- `--model-only`: 指定仅导出模型 backbone + neck, 不包含后处理,默认关闭。
+
+例子:
+
+```shell
+python ./projects/easydeploy/tools/export.py \
+ configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py \
+ yolov5s.pth \
+ --work-dir work_dir \
+ --img-size 640 640 \
+ --batch 1 \
+ --device cpu \
+ --simplify \
+ --opset 11 \
+ --backend 1 \
+ --pre-topk 1000 \
+ --keep-topk 100 \
+ --iou-threshold 0.65 \
+ --score-threshold 0.25
+```
+
+然后利用后端支持的工具如 `TensorRT` 读取 `onnx` 再次转换为后端支持的模型格式如 `.engine/.plan` 等。
+
+`MMYOLO` 目前支持 `TensorRT8`, `TensorRT7`, `ONNXRuntime` 后端的端到端模型转换,目前仅支持静态 shape 模型的导出和转换,动态 batch 或动态长宽的模型端到端转换会在未来继续支持。
+
+端到端转换得到的 `onnx` 模型输入输出如图:
+
+
+

+
+

+
YOLO-World: Real-Time Open-Vocabulary '
+ 'Object Detector
')
+ with gr.Row():
+ with gr.Column(scale=0.3):
+ with gr.Row():
+ image = gr.Image(type='pil', label='input image')
+ input_text = gr.Textbox(
+ lines=7,
+ label='Enter the classes to be detected, '
+ 'separated by comma',
+ value=', '.join(CocoDataset.METAINFO['classes']),
+ elem_id='textbox')
+ with gr.Row():
+ submit = gr.Button('Submit')
+ clear = gr.Button('Clear')
+ with gr.Row():
+ export = gr.Button('Deploy and Export ONNX Model')
+ out_download = gr.File(lines=1, visible=False)
+ max_num_boxes = gr.Slider(
+ minimum=1,
+ maximum=300,
+ value=100,
+ step=1,
+ interactive=True,
+ label='Maximum Number Boxes')
+ score_thr = gr.Slider(
+ minimum=0,
+ maximum=1,
+ value=0.05,
+ step=0.001,
+ interactive=True,
+ label='Score Threshold')
+ nms_thr = gr.Slider(
+ minimum=0,
+ maximum=1,
+ value=0.7,
+ step=0.001,
+ interactive=True,
+ label='NMS Threshold')
+ with gr.Column(scale=0.7):
+ output_image = gr.Image(
+ lines=20,
+ type='pil',
+ label='output image')
+
+ submit.click(partial(run_image, runner),
+ [image, input_text, max_num_boxes,
+ score_thr, nms_thr],
+ [output_image])
+ clear.click(lambda: [[], '', ''], None,
+ [image, input_text, output_image])
+ export.click(partial(export_model, runner, args.checkpoint),
+ [input_text, max_num_boxes, score_thr, nms_thr],
+ [out_download, out_download])
+ demo.launch(server_name='0.0.0.0', server_port=80)
+
+
+if __name__ == '__main__':
+ args = parse_args()
+
+ # load config
+ cfg = Config.fromfile(args.config)
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+ if args.work_dir is not None:
+ cfg.work_dir = args.work_dir
+ elif cfg.get('work_dir', None) is None:
+ cfg.work_dir = osp.join('./work_dirs',
+ osp.splitext(osp.basename(args.config))[0])
+
+ cfg.load_from = args.checkpoint
+
+ if 'runner_type' not in cfg:
+ runner = Runner.from_cfg(cfg)
+ else:
+ runner = RUNNERS.build(cfg)
+
+ runner.call_hook('before_run')
+ runner.load_or_resume()
+ pipeline = cfg.test_dataloader.dataset.pipeline
+ runner.pipeline = Compose(pipeline)
+ runner.model.eval()
+ demo(runner, args)
diff --git a/tools/deploy.py b/tools/deploy.py
new file mode 100644
index 0000000000000000000000000000000000000000..0e6c9c3d95589e7af3f72e89b41dc80cd6a76dd8
--- /dev/null
+++ b/tools/deploy.py
@@ -0,0 +1,335 @@
+# Copyright (c) Tencent Inc. All rights reserved.
+import argparse
+import logging
+import os
+import os.path as osp
+from functools import partial
+
+import mmengine
+import torch.multiprocessing as mp
+from torch.multiprocessing import Process, set_start_method
+
+from mmdeploy.apis import (create_calib_input_data, extract_model,
+ get_predefined_partition_cfg, torch2onnx,
+ torch2torchscript, visualize_model)
+from mmdeploy.apis.core import PIPELINE_MANAGER
+from mmdeploy.apis.utils import to_backend
+from mmdeploy.backend.sdk.export_info import export2SDK
+from mmdeploy.utils import (IR, Backend, get_backend, get_calib_filename,
+ get_ir_config, get_partition_config,
+ get_root_logger, load_config, target_wrapper)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Export model to backends.')
+ parser.add_argument('deploy_cfg', help='deploy config path')
+ parser.add_argument('model_cfg', help='model config path')
+ parser.add_argument('checkpoint', help='model checkpoint path')
+ parser.add_argument('img', help='image used to convert model model')
+ parser.add_argument(
+ '--test-img',
+ default=None,
+ type=str,
+ nargs='+',
+ help='image used to test model')
+ parser.add_argument(
+ '--work-dir',
+ default=os.getcwd(),
+ help='the dir to save logs and models')
+ parser.add_argument(
+ '--calib-dataset-cfg',
+ help='dataset config path used to calibrate in int8 mode. If not \
+ specified, it will use "val" dataset in model config instead.',
+ default=None)
+ parser.add_argument(
+ '--device', help='device used for conversion', default='cpu')
+ parser.add_argument(
+ '--log-level',
+ help='set log level',
+ default='INFO',
+ choices=list(logging._nameToLevel.keys()))
+ parser.add_argument(
+ '--show', action='store_true', help='Show detection outputs')
+ parser.add_argument(
+ '--dump-info', action='store_true', help='Output information for SDK')
+ parser.add_argument(
+ '--quant-image-dir',
+ default=None,
+ help='Image directory for quantize model.')
+ parser.add_argument(
+ '--quant', action='store_true', help='Quantize model to low bit.')
+ parser.add_argument(
+ '--uri',
+ default='192.168.1.1:60000',
+ help='Remote ipv4:port or ipv6:port for inference on edge device.')
+ args = parser.parse_args()
+ return args
+
+
+def create_process(name, target, args, kwargs, ret_value=None):
+ logger = get_root_logger()
+ logger.info(f'{name} start.')
+ log_level = logger.level
+
+ wrap_func = partial(target_wrapper, target, log_level, ret_value)
+
+ process = Process(target=wrap_func, args=args, kwargs=kwargs)
+ process.start()
+ process.join()
+
+ if ret_value is not None:
+ if ret_value.value != 0:
+ logger.error(f'{name} failed.')
+ exit(1)
+ else:
+ logger.info(f'{name} success.')
+
+
+def torch2ir(ir_type: IR):
+ """Return the conversion function from torch to the intermediate
+ representation.
+
+ Args:
+ ir_type (IR): The type of the intermediate representation.
+ """
+ if ir_type == IR.ONNX:
+ return torch2onnx
+ elif ir_type == IR.TORCHSCRIPT:
+ return torch2torchscript
+ else:
+ raise KeyError(f'Unexpected IR type {ir_type}')
+
+
+def main():
+ args = parse_args()
+ set_start_method('spawn', force=True)
+ logger = get_root_logger()
+ log_level = logging.getLevelName(args.log_level)
+ logger.setLevel(log_level)
+
+ pipeline_funcs = [
+ torch2onnx, torch2torchscript, extract_model, create_calib_input_data
+ ]
+ PIPELINE_MANAGER.enable_multiprocess(True, pipeline_funcs)
+ PIPELINE_MANAGER.set_log_level(log_level, pipeline_funcs)
+
+ deploy_cfg_path = args.deploy_cfg
+ model_cfg_path = args.model_cfg
+ checkpoint_path = args.checkpoint
+ quant = args.quant
+ quant_image_dir = args.quant_image_dir
+
+ # load deploy_cfg
+ deploy_cfg, model_cfg = load_config(deploy_cfg_path, model_cfg_path)
+
+ # create work_dir if not
+ mmengine.mkdir_or_exist(osp.abspath(args.work_dir))
+
+ if args.dump_info:
+ export2SDK(
+ deploy_cfg,
+ model_cfg,
+ args.work_dir,
+ pth=checkpoint_path,
+ device=args.device)
+
+ ret_value = mp.Value('d', 0, lock=False)
+
+ # convert to IR
+ ir_config = get_ir_config(deploy_cfg)
+ ir_save_file = ir_config['save_file']
+ ir_type = IR.get(ir_config['type'])
+ torch2ir(ir_type)(
+ args.img,
+ args.work_dir,
+ ir_save_file,
+ deploy_cfg_path,
+ model_cfg_path,
+ checkpoint_path,
+ device=args.device)
+
+ # convert backend
+ ir_files = [osp.join(args.work_dir, ir_save_file)]
+
+ # partition model
+ partition_cfgs = get_partition_config(deploy_cfg)
+
+ if partition_cfgs is not None:
+
+ if 'partition_cfg' in partition_cfgs:
+ partition_cfgs = partition_cfgs.get('partition_cfg', None)
+ else:
+ assert 'type' in partition_cfgs
+ partition_cfgs = get_predefined_partition_cfg(
+ deploy_cfg, partition_cfgs['type'])
+
+ origin_ir_file = ir_files[0]
+ ir_files = []
+ for partition_cfg in partition_cfgs:
+ save_file = partition_cfg['save_file']
+ save_path = osp.join(args.work_dir, save_file)
+ start = partition_cfg['start']
+ end = partition_cfg['end']
+ dynamic_axes = partition_cfg.get('dynamic_axes', None)
+
+ extract_model(
+ origin_ir_file,
+ start,
+ end,
+ dynamic_axes=dynamic_axes,
+ save_file=save_path)
+
+ ir_files.append(save_path)
+
+ # calib data
+ calib_filename = get_calib_filename(deploy_cfg)
+ if calib_filename is not None:
+ calib_path = osp.join(args.work_dir, calib_filename)
+ create_calib_input_data(
+ calib_path,
+ deploy_cfg_path,
+ model_cfg_path,
+ checkpoint_path,
+ dataset_cfg=args.calib_dataset_cfg,
+ dataset_type='val',
+ device=args.device)
+
+ backend_files = ir_files
+ # convert backend
+ backend = get_backend(deploy_cfg)
+
+ # preprocess deploy_cfg
+ if backend == Backend.RKNN:
+ # TODO: Add this to task_processor in the future
+ import tempfile
+
+ from mmdeploy.utils import (get_common_config, get_normalization,
+ get_quantization_config,
+ get_rknn_quantization)
+ quantization_cfg = get_quantization_config(deploy_cfg)
+ common_params = get_common_config(deploy_cfg)
+ if get_rknn_quantization(deploy_cfg) is True:
+ transform = get_normalization(model_cfg)
+ common_params.update(
+ dict(
+ mean_values=[transform['mean']],
+ std_values=[transform['std']]))
+
+ dataset_file = tempfile.NamedTemporaryFile(suffix='.txt').name
+ with open(dataset_file, 'w') as f:
+ f.writelines([osp.abspath(args.img)])
+ if quantization_cfg.get('dataset', None) is None:
+ quantization_cfg['dataset'] = dataset_file
+ if backend == Backend.ASCEND:
+ # TODO: Add this to backend manager in the future
+ if args.dump_info:
+ from mmdeploy.backend.ascend import update_sdk_pipeline
+ update_sdk_pipeline(args.work_dir)
+
+ if backend == Backend.VACC:
+ # TODO: Add this to task_processor in the future
+
+ from onnx2vacc_quant_dataset import get_quant
+
+ from mmdeploy.utils import get_model_inputs
+
+ deploy_cfg, model_cfg = load_config(deploy_cfg_path, model_cfg_path)
+ model_inputs = get_model_inputs(deploy_cfg)
+
+ for onnx_path, model_input in zip(ir_files, model_inputs):
+
+ quant_mode = model_input.get('qconfig', {}).get('dtype', 'fp16')
+ assert quant_mode in ['int8',
+ 'fp16'], quant_mode + ' not support now'
+ shape_dict = model_input.get('shape', {})
+
+ if quant_mode == 'int8':
+ create_process(
+ 'vacc quant dataset',
+ target=get_quant,
+ args=(deploy_cfg, model_cfg, shape_dict, checkpoint_path,
+ args.work_dir, args.device),
+ kwargs=dict(),
+ ret_value=ret_value)
+
+ # convert to backend
+ PIPELINE_MANAGER.set_log_level(log_level, [to_backend])
+ if backend == Backend.TENSORRT:
+ PIPELINE_MANAGER.enable_multiprocess(True, [to_backend])
+ backend_files = to_backend(
+ backend,
+ ir_files,
+ work_dir=args.work_dir,
+ deploy_cfg=deploy_cfg,
+ log_level=log_level,
+ device=args.device,
+ uri=args.uri)
+
+ # ncnn quantization
+ if backend == Backend.NCNN and quant:
+ from onnx2ncnn_quant_table import get_table
+
+ from mmdeploy.apis.ncnn import get_quant_model_file, ncnn2int8
+ model_param_paths = backend_files[::2]
+ model_bin_paths = backend_files[1::2]
+ backend_files = []
+ for onnx_path, model_param_path, model_bin_path in zip(
+ ir_files, model_param_paths, model_bin_paths):
+
+ deploy_cfg, model_cfg = load_config(deploy_cfg_path,
+ model_cfg_path)
+ quant_onnx, quant_table, quant_param, quant_bin = get_quant_model_file( # noqa: E501
+ onnx_path, args.work_dir)
+
+ create_process(
+ 'ncnn quant table',
+ target=get_table,
+ args=(onnx_path, deploy_cfg, model_cfg, quant_onnx,
+ quant_table, quant_image_dir, args.device),
+ kwargs=dict(),
+ ret_value=ret_value)
+
+ create_process(
+ 'ncnn_int8',
+ target=ncnn2int8,
+ args=(model_param_path, model_bin_path, quant_table,
+ quant_param, quant_bin),
+ kwargs=dict(),
+ ret_value=ret_value)
+ backend_files += [quant_param, quant_bin]
+
+ if args.test_img is None:
+ args.test_img = args.img
+
+ extra = dict(
+ backend=backend,
+ output_file=osp.join(args.work_dir, f'output_{backend.value}.jpg'),
+ show_result=args.show)
+ if backend == Backend.SNPE:
+ extra['uri'] = args.uri
+
+ # get backend inference result, try render
+ create_process(
+ f'visualize {backend.value} model',
+ target=visualize_model,
+ args=(model_cfg_path, deploy_cfg_path, backend_files, args.test_img,
+ args.device),
+ kwargs=extra,
+ ret_value=ret_value)
+
+ # get pytorch model inference result, try visualize if possible
+ create_process(
+ 'visualize pytorch model',
+ target=visualize_model,
+ args=(model_cfg_path, deploy_cfg_path, [checkpoint_path],
+ args.test_img, args.device),
+ kwargs=dict(
+ backend=Backend.PYTORCH,
+ output_file=osp.join(args.work_dir, 'output_pytorch.jpg'),
+ show_result=args.show),
+ ret_value=ret_value)
+ logger.info('All process success.')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/deploy_convert.py b/tools/deploy_convert.py
new file mode 100644
index 0000000000000000000000000000000000000000..5d5dbe95b347d553a0b913ca640c9c21455a6f57
--- /dev/null
+++ b/tools/deploy_convert.py
@@ -0,0 +1,118 @@
+# Copyright (c) Lin Song. All rights reserved.
+import os
+import json
+import argparse
+import os.path as osp
+
+import torch
+import torch.nn.functional as F
+from mmengine.config import Config, DictAction
+from mmengine.runner import Runner
+from mmengine.dataset import Compose
+from mmyolo.registry import RUNNERS
+
+
+def get_caption_embed(runner, caption, prompt_template):
+ captions = json.load(open(caption, 'r'))
+ captions = [[prompt_template.format(c[0])] for c in captions]
+ with torch.no_grad():
+ embed = runner.model.backbone.text_model(captions)
+ embed = F.normalize(embed[:, 0, :], dim=1, p=2)
+ embed = embed.detach().cpu()
+ embed = embed[:, :, None, None]
+ return embed
+
+
+def convert(runner, caption, checkpoint, prompt_template):
+ checkpoint = torch.load(checkpoint, map_location='cpu')
+ state_dict = checkpoint['state_dict']
+ embed = get_caption_embed(runner, caption, prompt_template)
+ import ipdb; ipdb.set_trace()
+
+ new_state_dict = {}
+ for key in list(state_dict.keys()):
+ if key.startswith('backbone.text_model'):
+ continue
+ elif key.startswith('backbone.image_model'):
+ new_key = key.replace('backbone.image_model', 'backbone')
+ new_state_dict[new_key] = state_dict[key].clone()
+ elif key.startswith('bbox_head.head_module.cls_contrasts'):
+ module_key = '.'.join(key.split('.')[:4])
+ logit_scale = state_dict[module_key + '.logit_scale']
+ bias = state_dict[module_key + '.bias']
+ conv_weight = embed * logit_scale.exp()
+ conv_bias = bias.repeat(conv_weight.shape[0])
+ new_state_dict[module_key + '.conv.weight'] = conv_weight
+ new_state_dict[module_key + '.conv.bias'] = conv_bias
+ else:
+ new_state_dict[key] = state_dict[key].clone()
+
+ new_checkpoint = {'state_dict': new_state_dict}
+ return new_checkpoint
+
+
+def parse_args():
+ parser = argparse.ArgumentParser()
+ parser.add_argument('config', type=str)
+ parser.add_argument('checkpoint', type=str)
+ parser.add_argument('caption', type=str)
+ parser.add_argument('output', type=str)
+ parser.add_argument('--prompt-template', type=str,
+ default='{}')
+ parser.add_argument(
+ '--work-dir',
+ help='the directory to save the file containing evaluation metrics')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ args = parser.parse_args()
+ return args
+
+
+if __name__ == '__main__':
+ args = parse_args()
+
+ # load config
+ cfg = Config.fromfile(args.config)
+ # replace the ${key} with the value of cfg.key
+ # cfg = replace_cfg_vals(cfg)
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+ # work_dir is determined in this priority: CLI > segment in file > filename
+ if args.work_dir is not None:
+ # update configs according to CLI args if args.work_dir is not None
+ cfg.work_dir = args.work_dir
+ elif cfg.get('work_dir', None) is None:
+ # use config filename as default work_dir if cfg.work_dir is None
+ cfg.work_dir = osp.join('./work_dirs',
+ osp.splitext(osp.basename(args.config))[0])
+
+ cfg.load_from = args.checkpoint
+
+ # build the runner from config
+ if 'runner_type' not in cfg:
+ # build the default runner
+ runner = Runner.from_cfg(cfg)
+ else:
+ # build customized runner from the registry
+ # if 'runner_type' is set in the cfg
+ runner = RUNNERS.build(cfg)
+
+ runner.call_hook('before_run')
+ runner.load_or_resume()
+ pipeline = cfg.test_dataloader.dataset.pipeline
+ runner.pipeline = Compose(pipeline)
+ runner.model.eval()
+
+ new_checkpoint = convert(runner, args.caption, args.checkpoint,
+ args.prompt_template)
+ os.makedirs(os.path.dirname(args.output), exist_ok=True)
+ torch.save(new_checkpoint, args.output)
diff --git a/tools/deploy_test.py b/tools/deploy_test.py
new file mode 100644
index 0000000000000000000000000000000000000000..4657d517b4b062e6ad098886bda16ca5552ca4ae
--- /dev/null
+++ b/tools/deploy_test.py
@@ -0,0 +1,159 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os.path as osp
+from copy import deepcopy
+
+from mmengine import DictAction
+
+from mmdeploy.apis import build_task_processor
+from mmdeploy.utils.config_utils import load_config
+from mmdeploy.utils.timer import TimeCounter
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='MMDeploy test (and eval) a backend.')
+ parser.add_argument('deploy_cfg', help='Deploy config path')
+ parser.add_argument('model_cfg', help='Model config path')
+ parser.add_argument(
+ '--model', type=str, nargs='+', help='Input model files.')
+ parser.add_argument(
+ '--device', help='device used for conversion', default='cpu')
+ parser.add_argument(
+ '--work-dir',
+ default='./work_dir',
+ help='the directory to save the file containing evaluation metrics')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ parser.add_argument('--show', action='store_true', help='show results')
+ parser.add_argument(
+ '--show-dir', help='directory where painted images will be saved')
+ parser.add_argument(
+ '--interval',
+ type=int,
+ default=1,
+ help='visualize per interval samples.')
+ parser.add_argument(
+ '--wait-time',
+ type=float,
+ default=2,
+ help='display time of every window. (second)')
+ parser.add_argument(
+ '--log2file',
+ type=str,
+ help='log evaluation results and speed to file',
+ default=None)
+ parser.add_argument(
+ '--speed-test', action='store_true', help='activate speed test')
+ parser.add_argument(
+ '--warmup',
+ type=int,
+ help='warmup before counting inference elapse, require setting '
+ 'speed-test first',
+ default=10)
+ parser.add_argument(
+ '--log-interval',
+ type=int,
+ help='the interval between each log, require setting '
+ 'speed-test first',
+ default=100)
+ parser.add_argument(
+ '--batch-size',
+ type=int,
+ default=1,
+ help='the batch size for test, would override `samples_per_gpu`'
+ 'in data config.')
+ parser.add_argument(
+ '--uri',
+ action='store_true',
+ default='192.168.1.1:60000',
+ help='Remote ipv4:port or ipv6:port for inference on edge device.')
+
+ args = parser.parse_args()
+ return args
+
+
+def main():
+ args = parse_args()
+ deploy_cfg_path = args.deploy_cfg
+ model_cfg_path = args.model_cfg
+
+ # load deploy_cfg
+ deploy_cfg, model_cfg = load_config(deploy_cfg_path, model_cfg_path)
+
+ # work_dir is determined in this priority: CLI > segment in file > filename
+ if args.work_dir is not None:
+ # update configs according to CLI args if args.work_dir is not None
+ work_dir = args.work_dir
+ elif model_cfg.get('work_dir', None) is None:
+ # use config filename as default work_dir if cfg.work_dir is None
+ work_dir = osp.join('./work_dirs',
+ osp.splitext(osp.basename(args.config))[0])
+
+ # merge options for model cfg
+ if args.cfg_options is not None:
+ model_cfg.merge_from_dict(args.cfg_options)
+
+ task_processor = build_task_processor(model_cfg, deploy_cfg, args.device)
+
+ # prepare the dataset loader
+ test_dataloader = deepcopy(model_cfg['test_dataloader'])
+ if isinstance(test_dataloader, list):
+ dataset = []
+ for loader in test_dataloader:
+ ds = task_processor.build_dataset(loader['dataset'])
+ dataset.append(ds)
+ loader['dataset'] = ds
+ loader['batch_size'] = args.batch_size
+ loader = task_processor.build_dataloader(loader)
+ dataloader = test_dataloader
+ else:
+ test_dataloader['batch_size'] = args.batch_size
+ dataset = task_processor.build_dataset(test_dataloader['dataset'])
+ test_dataloader['dataset'] = dataset
+ dataloader = task_processor.build_dataloader(test_dataloader)
+
+ # load the model of the backend
+ model = task_processor.build_backend_model(
+ args.model,
+ data_preprocessor_updater=task_processor.update_data_preprocessor)
+ destroy_model = model.destroy
+ is_device_cpu = (args.device == 'cpu')
+
+ runner = task_processor.build_test_runner(
+ model,
+ work_dir,
+ log_file=args.log2file,
+ show=args.show,
+ show_dir=args.show_dir,
+ wait_time=args.wait_time,
+ interval=args.interval,
+ dataloader=dataloader)
+
+ if args.speed_test:
+ with_sync = not is_device_cpu
+
+ with TimeCounter.activate(
+ warmup=args.warmup,
+ log_interval=args.log_interval,
+ with_sync=with_sync,
+ file=args.log2file,
+ batch_size=args.batch_size):
+ runner.test()
+
+ else:
+ runner.test()
+ # only effective when the backend requires explicit clean-up (e.g. Ascend)
+ destroy_model()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/dist_test.sh b/tools/dist_test.sh
new file mode 100755
index 0000000000000000000000000000000000000000..dea131b43ea8f1222661d20603d40c18ea7f28a1
--- /dev/null
+++ b/tools/dist_test.sh
@@ -0,0 +1,22 @@
+#!/usr/bin/env bash
+
+CONFIG=$1
+CHECKPOINT=$2
+GPUS=$3
+NNODES=${NNODES:-1}
+NODE_RANK=${NODE_RANK:-0}
+PORT=${PORT:-29500}
+MASTER_ADDR=${MASTER_ADDR:-"127.0.0.1"}
+
+PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
+python -m torch.distributed.launch \
+ --nnodes=$NNODES \
+ --node_rank=$NODE_RANK \
+ --master_addr=$MASTER_ADDR \
+ --nproc_per_node=$GPUS \
+ --master_port=$PORT \
+ $(dirname "$0")/test.py \
+ $CONFIG \
+ $CHECKPOINT \
+ --launcher pytorch \
+ ${@:4}
diff --git a/tools/dist_train.sh b/tools/dist_train.sh
new file mode 100755
index 0000000000000000000000000000000000000000..ea56f698d1f00b992eec8d481c75b273d202acf5
--- /dev/null
+++ b/tools/dist_train.sh
@@ -0,0 +1,19 @@
+#!/usr/bin/env bash
+
+CONFIG=$1
+GPUS=$2
+NNODES=${NNODES:-1}
+NODE_RANK=${NODE_RANK:-0}
+PORT=${MASTER_PORT:-29500}
+MASTER_ADDR=${MASTER_ADDR:-"127.0.0.1"}
+
+PYTHONPATH="$(dirname $0)/..":$PYTHONPATH \
+python -m torch.distributed.launch \
+ --nnodes=$NNODES \
+ --node_rank=$NODE_RANK \
+ --master_addr=$MASTER_ADDR \
+ --nproc_per_node=$GPUS \
+ --master_port=$PORT \
+ $(dirname "$0")/train.py \
+ $CONFIG \
+ --launcher pytorch ${@:3}
diff --git a/tools/dockerfiles/Dockerfile_deployment b/tools/dockerfiles/Dockerfile_deployment
new file mode 100644
index 0000000000000000000000000000000000000000..17a48cf05c8bd316d89ea602c3cfcd381bd00788
--- /dev/null
+++ b/tools/dockerfiles/Dockerfile_deployment
@@ -0,0 +1,64 @@
+FROM nvcr.io/nvidia/pytorch:22.04-py3
+
+WORKDIR /openmmlab
+ARG ONNXRUNTIME_VERSION=1.8.1
+ENV DEBIAN_FRONTEND=noninteractive \
+ APT_KEY_DONT_WARN_ON_DANGEROUS_USAGE=DontWarn \
+ FORCE_CUDA="1"
+
+# Install ZSH
+RUN apt-get update \
+ && apt-get install -y zsh \
+ && wget https://github.com/robbyrussell/oh-my-zsh/raw/master/tools/install.sh -O - | zsh || true
+
+# Install Prerequisites
+RUN apt-get update \
+ && apt-get install -y git vim wget
+RUN pip install -U ipdb pip
+
+# Install ONNXRUNTIME
+RUN wget -q https://github.com/microsoft/onnxruntime/releases/download/v${ONNXRUNTIME_VERSION}/onnxruntime-linux-x64-${ONNXRUNTIME_VERSION}.tgz \
+ && tar -zxvf onnxruntime-linux-x64-${ONNXRUNTIME_VERSION}.tgz \
+ && pip install --no-cache-dir onnxruntime-gpu==${ONNXRUNTIME_VERSION} \
+ && pip install pycuda
+
+# Install OpenMMLab
+RUN pip install --no-cache-dir openmim \
+ && mim install --no-cache-dir "mmengine>=0.6.0" "mmdet>=3.0.0,<4.0.0" \
+ && mim install --no-cache-dir opencv-python==4.5.5.64 opencv-python-headless==4.5.5.64
+
+# Install MMCV
+RUN git clone https://github.com/open-mmlab/mmcv.git -b 2.x mmcv \
+ && cd mmcv \
+ && mim install --no-cache-dir -r requirements/optional.txt \
+ && MMCV_WITH_OPS=1 mim install --no-cache-dir -e . -v \
+ && cd ..
+
+# Install MMYOLO
+RUN git clone https://github.com/open-mmlab/mmyolo.git -b dev mmyolo \
+ && cd mmyolo \
+ && mim install --no-cache-dir -e . \
+ && cd ..
+
+# Install MMDEPLOY
+ENV ONNXRUNTIME_DIR=/openmmlab/onnxruntime-linux-x64-${ONNXRUNTIME_VERSION} \
+ TENSORRT_DIR=/usr/lib/x86_64-linux-gnu \
+ CUDNN_DIR=/usr/lib/x86_64-linux-gnu
+
+RUN git clone https://github.com/open-mmlab/mmdeploy -b dev-1.x mmdeploy \
+ && cd mmdeploy \
+ && git submodule update --init --recursive \
+ && mkdir -p build \
+ && cd build \
+ && cmake -DMMDEPLOY_TARGET_BACKENDS="ort;trt" -DONNXRUNTIME_DIR=${ONNXRUNTIME_DIR} -DTENSORRT_DIR=${TENSORRT_DIR} -DCUDNN_DIR=${CUDNN_DIR} .. \
+ && make -j$(nproc) \
+ && make install \
+ && cd .. \
+ && mim install --no-cache-dir -e .
+
+# RUN apt-get install libopencv-dev -y
+
+# Fix undefined symbol bug
+RUN echo -e "\nexport LD_LIBRARY_PATH=${ONNXRUNTIME_DIR}/lib:${TENSORRT_DIR}/lib:${CUDNN_DIR}/lib64:${LD_LIBRARY_PATH}\nldconfig" >> /root/.bashrc
+# RUN apt-get update -y \
+# && apt-get install -y iputils-ping
\ No newline at end of file
diff --git a/tools/dockerfiles/Dockerfile_runtime b/tools/dockerfiles/Dockerfile_runtime
new file mode 100644
index 0000000000000000000000000000000000000000..3fc814bf78ae2344b867c8bb5197add9d3290c68
--- /dev/null
+++ b/tools/dockerfiles/Dockerfile_runtime
@@ -0,0 +1,33 @@
+ARG PYTORCH="1.9.0"
+ARG CUDA="11.1"
+ARG CUDNN="8"
+
+FROM pytorch/pytorch:${PYTORCH}-cuda${CUDA}-cudnn${CUDNN}-devel
+
+ENV TORCH_CUDA_ARCH_LIST="6.0 6.1 7.0 7.5 8.0 8.6+PTX" \
+ TORCH_NVCC_FLAGS="-Xfatbin -compress-all" \
+ CMAKE_PREFIX_PATH="$(dirname $(which conda))/../" \
+ FORCE_CUDA="1"
+
+RUN rm /etc/apt/sources.list.d/cuda.list \
+ && rm /etc/apt/sources.list.d/nvidia-ml.list \
+ && apt-key del 7fa2af80 \
+ && apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/3bf863cc.pub \
+ && apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64/7fa2af80.pub
+
+# (Optional)
+# RUN sed -i 's/http:\/\/archive.ubuntu.com\/ubuntu\//http:\/\/mirrors.aliyun.com\/ubuntu\//g' /etc/apt/sources.list && \
+# pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
+
+RUN apt-get update \
+ && apt-get install -y ffmpeg libsm6 libxext6 git ninja-build libglib2.0-0 libxrender-dev \
+ && apt-get clean \
+ && rm -rf /var/lib/apt/lists/*
+
+# Install MMEngine, MMCV, MMDet and MMYolo
+RUN pip install --no-cache-dir openmim && \
+ mim install --no-cache-dir "mmengine>=0.6.0" "mmcv>=2.0.0rc4,<2.1.0" "mmdet>=3.0.0,<4.0.0" \
+ mim install --no-cache-dir "mmyolo>=0.6.0"
+
+# Install other requirements
+RUN pip install --no-cache-dir transformers tokenizer gradio sentencepiece
diff --git a/tools/test.py b/tools/test.py
new file mode 100644
index 0000000000000000000000000000000000000000..c05defe3c70a4cf4b8775a98bb89a84b7faba63a
--- /dev/null
+++ b/tools/test.py
@@ -0,0 +1,150 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import os
+import os.path as osp
+
+from mmdet.engine.hooks.utils import trigger_visualization_hook
+from mmengine.config import Config, ConfigDict, DictAction
+from mmengine.evaluator import DumpResults
+from mmengine.runner import Runner
+
+from mmyolo.registry import RUNNERS
+from mmyolo.utils import is_metainfo_lower
+
+
+# TODO: support fuse_conv_bn
+def parse_args():
+ parser = argparse.ArgumentParser(
+ description='MMYOLO test (and eval) a model')
+ parser.add_argument('config', help='test config file path')
+ parser.add_argument('checkpoint', help='checkpoint file')
+ parser.add_argument(
+ '--work-dir',
+ help='the directory to save the file containing evaluation metrics')
+ parser.add_argument(
+ '--out',
+ type=str,
+ help='output result file (must be a .pkl file) in pickle format')
+ parser.add_argument(
+ '--json-prefix',
+ type=str,
+ help='the prefix of the output json file without perform evaluation, '
+ 'which is useful when you want to format the result to a specific '
+ 'format and submit it to the test server')
+ parser.add_argument(
+ '--tta',
+ action='store_true',
+ help='Whether to use test time augmentation')
+ parser.add_argument(
+ '--show', action='store_true', help='show prediction results')
+ parser.add_argument(
+ '--deploy',
+ action='store_true',
+ help='Switch model to deployment mode')
+ parser.add_argument(
+ '--show-dir',
+ help='directory where painted images will be saved. '
+ 'If specified, it will be automatically saved '
+ 'to the work_dir/timestamp/show_dir')
+ parser.add_argument(
+ '--wait-time', type=float, default=2, help='the interval of show (s)')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ parser.add_argument(
+ '--launcher',
+ choices=['none', 'pytorch', 'slurm', 'mpi'],
+ default='none',
+ help='job launcher')
+ parser.add_argument('--local_rank', type=int, default=0)
+ args = parser.parse_args()
+ if 'LOCAL_RANK' not in os.environ:
+ os.environ['LOCAL_RANK'] = str(args.local_rank)
+ return args
+
+
+def main():
+ args = parse_args()
+
+ # load config
+ cfg = Config.fromfile(args.config)
+ # replace the ${key} with the value of cfg.key
+ # cfg = replace_cfg_vals(cfg)
+ cfg.launcher = args.launcher
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+ # work_dir is determined in this priority: CLI > segment in file > filename
+ if args.work_dir is not None:
+ # update configs according to CLI args if args.work_dir is not None
+ cfg.work_dir = args.work_dir
+ elif cfg.get('work_dir', None) is None:
+ # use config filename as default work_dir if cfg.work_dir is None
+ cfg.work_dir = osp.join('./work_dirs',
+ osp.splitext(osp.basename(args.config))[0])
+
+ cfg.load_from = args.checkpoint
+
+ if args.show or args.show_dir:
+ cfg = trigger_visualization_hook(cfg, args)
+
+ if args.deploy:
+ cfg.custom_hooks.append(dict(type='SwitchToDeployHook'))
+
+ # add `format_only` and `outfile_prefix` into cfg
+ if args.json_prefix is not None:
+ cfg_json = {
+ 'test_evaluator.format_only': True,
+ 'test_evaluator.outfile_prefix': args.json_prefix
+ }
+ cfg.merge_from_dict(cfg_json)
+
+ # Determine whether the custom metainfo fields are all lowercase
+ is_metainfo_lower(cfg)
+
+ if args.tta:
+ assert 'tta_model' in cfg, 'Cannot find ``tta_model`` in config.' \
+ " Can't use tta !"
+ assert 'tta_pipeline' in cfg, 'Cannot find ``tta_pipeline`` ' \
+ "in config. Can't use tta !"
+
+ cfg.model = ConfigDict(**cfg.tta_model, module=cfg.model)
+ test_data_cfg = cfg.test_dataloader.dataset
+ while 'dataset' in test_data_cfg:
+ test_data_cfg = test_data_cfg['dataset']
+
+ # batch_shapes_cfg will force control the size of the output image,
+ # it is not compatible with tta.
+ if 'batch_shapes_cfg' in test_data_cfg:
+ test_data_cfg.batch_shapes_cfg = None
+ test_data_cfg.pipeline = cfg.tta_pipeline
+
+ # build the runner from config
+ if 'runner_type' not in cfg:
+ # build the default runner
+ runner = Runner.from_cfg(cfg)
+ else:
+ # build customized runner from the registry
+ # if 'runner_type' is set in the cfg
+ runner = RUNNERS.build(cfg)
+
+ # add `DumpResults` dummy metric
+ if args.out is not None:
+ assert args.out.endswith(('.pkl', '.pickle')), \
+ 'The dump file must be a pkl file.'
+ runner.test_evaluator.metrics.append(
+ DumpResults(out_file_path=args.out))
+
+ # start testing
+ runner.test()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/tools/train.py b/tools/train.py
new file mode 100644
index 0000000000000000000000000000000000000000..f634972af714badd6c501218e4774df58275d0d1
--- /dev/null
+++ b/tools/train.py
@@ -0,0 +1,120 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import argparse
+import logging
+import os
+import os.path as osp
+
+from mmengine.config import Config, DictAction
+from mmengine.logging import print_log
+from mmengine.runner import Runner
+
+from mmyolo.registry import RUNNERS
+from mmyolo.utils import is_metainfo_lower
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description='Train a detector')
+ parser.add_argument('config', help='train config file path')
+ parser.add_argument('--work-dir', help='the dir to save logs and models')
+ parser.add_argument(
+ '--amp',
+ action='store_true',
+ default=False,
+ help='enable automatic-mixed-precision training')
+ parser.add_argument(
+ '--resume',
+ nargs='?',
+ type=str,
+ const='auto',
+ help='If specify checkpoint path, resume from it, while if not '
+ 'specify, try to auto resume from the latest checkpoint '
+ 'in the work directory.')
+ parser.add_argument(
+ '--cfg-options',
+ nargs='+',
+ action=DictAction,
+ help='override some settings in the used config, the key-value pair '
+ 'in xxx=yyy format will be merged into config file. If the value to '
+ 'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
+ 'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
+ 'Note that the quotation marks are necessary and that no white space '
+ 'is allowed.')
+ parser.add_argument(
+ '--launcher',
+ choices=['none', 'pytorch', 'slurm', 'mpi'],
+ default='none',
+ help='job launcher')
+ parser.add_argument('--local_rank', type=int, default=0)
+ args = parser.parse_args()
+ if 'LOCAL_RANK' not in os.environ:
+ os.environ['LOCAL_RANK'] = str(args.local_rank)
+
+ return args
+
+
+def main():
+ args = parse_args()
+
+ # load config
+ cfg = Config.fromfile(args.config)
+ # replace the ${key} with the value of cfg.key
+ # cfg = replace_cfg_vals(cfg)
+ cfg.launcher = args.launcher
+ if args.cfg_options is not None:
+ cfg.merge_from_dict(args.cfg_options)
+
+ # work_dir is determined in this priority: CLI > segment in file > filename
+ if args.work_dir is not None:
+ # update configs according to CLI args if args.work_dir is not None
+ cfg.work_dir = args.work_dir
+ elif cfg.get('work_dir', None) is None:
+ # use config filename as default work_dir if cfg.work_dir is None
+ if args.config.startswith('projects/'):
+ config = args.config[len('projects/'):]
+ config = config.replace('/configs/', '/')
+ cfg.work_dir = osp.join('./work_dirs', osp.splitext(config)[0])
+ else:
+ cfg.work_dir = osp.join('./work_dirs',
+ osp.splitext(osp.basename(args.config))[0])
+
+ # enable automatic-mixed-precision training
+ if args.amp is True:
+ optim_wrapper = cfg.optim_wrapper.type
+ if optim_wrapper == 'AmpOptimWrapper':
+ print_log(
+ 'AMP training is already enabled in your config.',
+ logger='current',
+ level=logging.WARNING)
+ else:
+ assert optim_wrapper == 'OptimWrapper', (
+ '`--amp` is only supported when the optimizer wrapper type is '
+ f'`OptimWrapper` but got {optim_wrapper}.')
+ cfg.optim_wrapper.type = 'AmpOptimWrapper'
+ cfg.optim_wrapper.loss_scale = 'dynamic'
+
+ # resume is determined in this priority: resume from > auto_resume
+ if args.resume == 'auto':
+ cfg.resume = True
+ cfg.load_from = None
+ elif args.resume is not None:
+ cfg.resume = True
+ cfg.load_from = args.resume
+
+ # Determine whether the custom metainfo fields are all lowercase
+ is_metainfo_lower(cfg)
+
+ # build the runner from config
+ if 'runner_type' not in cfg:
+ # build the default runner
+ runner = Runner.from_cfg(cfg)
+ else:
+ # build customized runner from the registry
+ # if 'runner_type' is set in the cfg
+ runner = RUNNERS.build(cfg)
+
+ # start training
+ runner.train()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/yolo_world/__init__.py b/yolo_world/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..a975b032784f40f824c0fb55919e2f4782a42272
--- /dev/null
+++ b/yolo_world/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) Tencent Inc. All rights reserved.
+from .models import * # noqa
+from .datasets import * # noqa
+from .engine import * # noqa
+from .easydeploy import * # noqa
diff --git a/yolo_world/datasets/__init__.py b/yolo_world/datasets/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..3fbdad0ca10bca182c7323295d898afc03bd3913
--- /dev/null
+++ b/yolo_world/datasets/__init__.py
@@ -0,0 +1,17 @@
+# Copyright (c) Tencent Inc. All rights reserved.
+from .mm_dataset import (
+ MultiModalDataset, MultiModalMixedDataset)
+from .yolov5_obj365v1 import YOLOv5Objects365V1Dataset
+from .yolov5_obj365v2 import YOLOv5Objects365V2Dataset
+from .yolov5_mixed_grounding import YOLOv5MixedGroundingDataset
+from .utils import yolow_collate
+from .transformers import * # NOQA
+from .yolov5_v3det import YOLOv5V3DetDataset
+from .yolov5_lvis import YOLOv5LVISV1Dataset
+
+__all__ = [
+ 'MultiModalDataset', 'YOLOv5Objects365V1Dataset',
+ 'YOLOv5Objects365V2Dataset', 'YOLOv5MixedGroundingDataset',
+ 'YOLOv5V3DetDataset', 'yolow_collate',
+ 'YOLOv5LVISV1Dataset', 'MultiModalMixedDataset',
+]
diff --git a/yolo_world/datasets/mm_dataset.py b/yolo_world/datasets/mm_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..510e8b935fc85a570247b92b2459eaf160632199
--- /dev/null
+++ b/yolo_world/datasets/mm_dataset.py
@@ -0,0 +1,122 @@
+# Copyright (c) Tencent Inc. All rights reserved.
+import copy
+import json
+import logging
+from typing import Callable, List, Union
+
+from mmengine.logging import print_log
+from mmengine.dataset.base_dataset import (
+ BaseDataset, Compose, force_full_init)
+from mmyolo.registry import DATASETS
+
+
+@DATASETS.register_module()
+class MultiModalDataset:
+ """Multi-modal dataset."""
+
+ def __init__(self,
+ dataset: Union[BaseDataset, dict],
+ class_text_path: str = None,
+ test_mode: bool = True,
+ pipeline: List[Union[dict, Callable]] = [],
+ lazy_init: bool = False) -> None:
+ self.dataset: BaseDataset
+ if isinstance(dataset, dict):
+ self.dataset = DATASETS.build(dataset)
+ elif isinstance(dataset, BaseDataset):
+ self.dataset = dataset
+ else:
+ raise TypeError(
+ 'dataset must be a dict or a BaseDataset, '
+ f'but got {dataset}')
+
+ if class_text_path is not None:
+ self.class_texts = json.load(open(class_text_path, 'r'))
+ # ori_classes = self.dataset.metainfo['classes']
+ # assert len(ori_classes) == len(self.class_texts), \
+ # ('The number of classes in the dataset and the class text'
+ # 'file must be the same.')
+ else:
+ self.class_texts = None
+
+ self.test_mode = test_mode
+ self._metainfo = self.dataset.metainfo
+ self.pipeline = Compose(pipeline)
+
+ self._fully_initialized = False
+ if not lazy_init:
+ self.full_init()
+
+ @property
+ def metainfo(self) -> dict:
+ return copy.deepcopy(self._metainfo)
+
+ def full_init(self) -> None:
+ """``full_init`` dataset."""
+ if self._fully_initialized:
+ return
+
+ self.dataset.full_init()
+ self._ori_len = len(self.dataset)
+ self._fully_initialized = True
+
+ @force_full_init
+ def get_data_info(self, idx: int) -> dict:
+ """Get annotation by index."""
+ data_info = self.dataset.get_data_info(idx)
+ if self.class_texts is not None:
+ data_info.update({'texts': self.class_texts})
+ return data_info
+
+ def __getitem__(self, idx):
+ if not self._fully_initialized:
+ print_log(
+ 'Please call `full_init` method manually to '
+ 'accelerate the speed.',
+ logger='current',
+ level=logging.WARNING)
+ self.full_init()
+
+ data_info = self.get_data_info(idx)
+
+ if hasattr(self.dataset, 'test_mode') and not self.dataset.test_mode:
+ data_info['dataset'] = self
+ elif not self.test_mode:
+ data_info['dataset'] = self
+ return self.pipeline(data_info)
+
+ @force_full_init
+ def __len__(self) -> int:
+ return self._ori_len
+
+
+@DATASETS.register_module()
+class MultiModalMixedDataset(MultiModalDataset):
+ """Multi-modal Mixed dataset.
+ mix "detection dataset" and "caption dataset"
+ Args:
+ dataset_type (str): dataset type, 'detection' or 'caption'
+ """
+ def __init__(self,
+ dataset: Union[BaseDataset, dict],
+ class_text_path: str = None,
+ dataset_type: str = 'detection',
+ test_mode: bool = True,
+ pipeline: List[Union[dict, Callable]] = [],
+ lazy_init: bool = False) -> None:
+ self.dataset_type = dataset_type
+ super().__init__(dataset,
+ class_text_path,
+ test_mode,
+ pipeline,
+ lazy_init)
+
+ @force_full_init
+ def get_data_info(self, idx: int) -> dict:
+ """Get annotation by index."""
+ data_info = self.dataset.get_data_info(idx)
+ if self.class_texts is not None:
+ data_info.update({'texts': self.class_texts})
+ data_info['is_detection'] = 1 \
+ if self.dataset_type == 'detection' else 0
+ return data_info
diff --git a/yolo_world/datasets/transformers/__init__.py b/yolo_world/datasets/transformers/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..495e981551f7ae51761a97e4e41e141c43fbc536
--- /dev/null
+++ b/yolo_world/datasets/transformers/__init__.py
@@ -0,0 +1,9 @@
+# Copyright (c) Tencent Inc. All rights reserved.
+from .mm_transforms import RandomLoadText, LoadText
+from .mm_mix_img_transforms import (
+ MultiModalMosaic, MultiModalMosaic9, YOLOv5MultiModalMixUp,
+ YOLOXMultiModalMixUp)
+
+__all__ = ['RandomLoadText', 'LoadText', 'MultiModalMosaic',
+ 'MultiModalMosaic9', 'YOLOv5MultiModalMixUp',
+ 'YOLOXMultiModalMixUp']
diff --git a/yolo_world/datasets/transformers/mm_mix_img_transforms.py b/yolo_world/datasets/transformers/mm_mix_img_transforms.py
new file mode 100644
index 0000000000000000000000000000000000000000..0f4dfe084713a16438d13376ff36fd9265022a4e
--- /dev/null
+++ b/yolo_world/datasets/transformers/mm_mix_img_transforms.py
@@ -0,0 +1,1173 @@
+# Copyright (c) Tencent Inc. All rights reserved.
+import collections
+import copy
+from abc import ABCMeta, abstractmethod
+from typing import Optional, Sequence, Tuple, Union
+
+import mmcv
+import numpy as np
+from mmcv.transforms import BaseTransform
+from mmdet.structures.bbox import autocast_box_type
+from mmengine.dataset import BaseDataset
+from mmengine.dataset.base_dataset import Compose
+from numpy import random
+from mmyolo.registry import TRANSFORMS
+
+
+class BaseMultiModalMixImageTransform(BaseTransform, metaclass=ABCMeta):
+ """A Base Transform of Multimodal multiple images mixed.
+
+ Suitable for training on multiple images mixed data augmentation like
+ mosaic and mixup.
+
+ Cached mosaic transform will random select images from the cache
+ and combine them into one output image if use_cached is True.
+
+ Args:
+ pre_transform(Sequence[str]): Sequence of transform object or
+ config dict to be composed. Defaults to None.
+ prob(float): The transformation probability. Defaults to 1.0.
+ use_cached (bool): Whether to use cache. Defaults to False.
+ max_cached_images (int): The maximum length of the cache. The larger
+ the cache, the stronger the randomness of this transform. As a
+ rule of thumb, providing 10 caches for each image suffices for
+ randomness. Defaults to 40.
+ random_pop (bool): Whether to randomly pop a result from the cache
+ when the cache is full. If set to False, use FIFO popping method.
+ Defaults to True.
+ max_refetch (int): The maximum number of retry iterations for getting
+ valid results from the pipeline. If the number of iterations is
+ greater than `max_refetch`, but results is still None, then the
+ iteration is terminated and raise the error. Defaults to 15.
+ """
+
+ def __init__(self,
+ pre_transform: Optional[Sequence[str]] = None,
+ prob: float = 1.0,
+ use_cached: bool = False,
+ max_cached_images: int = 40,
+ random_pop: bool = True,
+ max_refetch: int = 15):
+
+ self.max_refetch = max_refetch
+ self.prob = prob
+
+ self.use_cached = use_cached
+ self.max_cached_images = max_cached_images
+ self.random_pop = random_pop
+ self.results_cache = []
+
+ if pre_transform is None:
+ self.pre_transform = None
+ else:
+ self.pre_transform = Compose(pre_transform)
+
+ @abstractmethod
+ def get_indexes(self, dataset: Union[BaseDataset,
+ list]) -> Union[list, int]:
+ """Call function to collect indexes.
+
+ Args:
+ dataset (:obj:`Dataset` or list): The dataset or cached list.
+
+ Returns:
+ list or int: indexes.
+ """
+ pass
+
+ @abstractmethod
+ def mix_img_transform(self, results: dict) -> dict:
+ """Mixed image data transformation.
+
+ Args:
+ results (dict): Result dict.
+
+ Returns:
+ results (dict): Updated result dict.
+ """
+ pass
+
+ def _update_label_text(self, results: dict) -> dict:
+ """Update label text."""
+ if 'texts' not in results:
+ return results
+
+ mix_texts = sum(
+ [results['texts']] +
+ [x['texts'] for x in results['mix_results']], [])
+ mix_texts = list({tuple(x) for x in mix_texts})
+ text2id = {text: i for i, text in enumerate(mix_texts)}
+
+ for res in [results] + results['mix_results']:
+ for i, label in enumerate(res['gt_bboxes_labels']):
+ text = res['texts'][label]
+ updated_id = text2id[tuple(text)]
+ res['gt_bboxes_labels'][i] = updated_id
+ res['texts'] = mix_texts
+ return results
+
+ @autocast_box_type()
+ def transform(self, results: dict) -> dict:
+ """Data augmentation function.
+
+ The transform steps are as follows:
+ 1. Randomly generate index list of other images.
+ 2. Before Mosaic or MixUp need to go through the necessary
+ pre_transform, such as MixUp' pre_transform pipeline
+ include: 'LoadImageFromFile','LoadAnnotations',
+ 'Mosaic' and 'RandomAffine'.
+ 3. Use mix_img_transform function to implement specific
+ mix operations.
+
+ Args:
+ results (dict): Result dict.
+
+ Returns:
+ results (dict): Updated result dict.
+ """
+
+ if random.uniform(0, 1) > self.prob:
+ return results
+
+ if self.use_cached:
+ # Be careful: deep copying can be very time-consuming
+ # if results includes dataset.
+ dataset = results.pop('dataset', None)
+ self.results_cache.append(copy.deepcopy(results))
+ if len(self.results_cache) > self.max_cached_images:
+ if self.random_pop:
+ index = random.randint(0, len(self.results_cache) - 1)
+ else:
+ index = 0
+ self.results_cache.pop(index)
+
+ if len(self.results_cache) <= 4:
+ return results
+ else:
+ assert 'dataset' in results
+ # Be careful: deep copying can be very time-consuming
+ # if results includes dataset.
+ dataset = results.pop('dataset', None)
+
+ for _ in range(self.max_refetch):
+ # get index of one or three other images
+ if self.use_cached:
+ indexes = self.get_indexes(self.results_cache)
+ else:
+ indexes = self.get_indexes(dataset)
+
+ if not isinstance(indexes, collections.abc.Sequence):
+ indexes = [indexes]
+
+ if self.use_cached:
+ mix_results = [
+ copy.deepcopy(self.results_cache[i]) for i in indexes
+ ]
+ else:
+ # get images information will be used for Mosaic or MixUp
+ mix_results = [
+ copy.deepcopy(dataset.get_data_info(index))
+ for index in indexes
+ ]
+
+ if self.pre_transform is not None:
+ for i, data in enumerate(mix_results):
+ # pre_transform may also require dataset
+ data.update({'dataset': dataset})
+ # before Mosaic or MixUp need to go through
+ # the necessary pre_transform
+ _results = self.pre_transform(data)
+ _results.pop('dataset')
+ mix_results[i] = _results
+
+ if None not in mix_results:
+ results['mix_results'] = mix_results
+ break
+ print('Repeated calculation')
+ else:
+ raise RuntimeError(
+ 'The loading pipeline of the original dataset'
+ ' always return None. Please check the correctness '
+ 'of the dataset and its pipeline.')
+
+ # update labels and texts
+ results = self._update_label_text(results)
+
+ # Mosaic or MixUp
+ results = self.mix_img_transform(results)
+
+ if 'mix_results' in results:
+ results.pop('mix_results')
+ results['dataset'] = dataset
+
+ return results
+
+
+@TRANSFORMS.register_module()
+class MultiModalMosaic(BaseMultiModalMixImageTransform):
+ """Mosaic augmentation.
+
+ Given 4 images, mosaic transform combines them into
+ one output image. The output image is composed of the parts from each sub-
+ image.
+
+ .. code:: text
+
+ mosaic transform
+ center_x
+ +------------------------------+
+ | pad | |
+ | +-----------+ pad |
+ | | | |
+ | | image1 +-----------+
+ | | | |
+ | | | image2 |
+ center_y |----+-+-----------+-----------+
+ | | cropped | |
+ |pad | image3 | image4 |
+ | | | |
+ +----|-------------+-----------+
+ | |
+ +-------------+
+
+ The mosaic transform steps are as follows:
+
+ 1. Choose the mosaic center as the intersections of 4 images
+ 2. Get the left top image according to the index, and randomly
+ sample another 3 images from the custom dataset.
+ 3. Sub image will be cropped if image is larger than mosaic patch
+
+ Required Keys:
+
+ - img
+ - gt_bboxes (BaseBoxes[torch.float32]) (optional)
+ - gt_bboxes_labels (np.int64) (optional)
+ - gt_ignore_flags (bool) (optional)
+ - mix_results (List[dict])
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - gt_bboxes (optional)
+ - gt_bboxes_labels (optional)
+ - gt_ignore_flags (optional)
+
+ Args:
+ img_scale (Sequence[int]): Image size after mosaic pipeline of single
+ image. The shape order should be (width, height).
+ Defaults to (640, 640).
+ center_ratio_range (Sequence[float]): Center ratio range of mosaic
+ output. Defaults to (0.5, 1.5).
+ bbox_clip_border (bool, optional): Whether to clip the objects outside
+ the border of the image. In some dataset like MOT17, the gt bboxes
+ are allowed to cross the border of images. Therefore, we don't
+ need to clip the gt bboxes in these cases. Defaults to True.
+ pad_val (int): Pad value. Defaults to 114.
+ pre_transform(Sequence[dict]): Sequence of transform object or
+ config dict to be composed.
+ prob (float): Probability of applying this transformation.
+ Defaults to 1.0.
+ use_cached (bool): Whether to use cache. Defaults to False.
+ max_cached_images (int): The maximum length of the cache. The larger
+ the cache, the stronger the randomness of this transform. As a
+ rule of thumb, providing 10 caches for each image suffices for
+ randomness. Defaults to 40.
+ random_pop (bool): Whether to randomly pop a result from the cache
+ when the cache is full. If set to False, use FIFO popping method.
+ Defaults to True.
+ max_refetch (int): The maximum number of retry iterations for getting
+ valid results from the pipeline. If the number of iterations is
+ greater than `max_refetch`, but results is still None, then the
+ iteration is terminated and raise the error. Defaults to 15.
+ """
+
+ def __init__(self,
+ img_scale: Tuple[int, int] = (640, 640),
+ center_ratio_range: Tuple[float, float] = (0.5, 1.5),
+ bbox_clip_border: bool = True,
+ pad_val: float = 114.0,
+ pre_transform: Sequence[dict] = None,
+ prob: float = 1.0,
+ use_cached: bool = False,
+ max_cached_images: int = 40,
+ random_pop: bool = True,
+ max_refetch: int = 15):
+ assert isinstance(img_scale, tuple)
+ assert 0 <= prob <= 1.0, 'The probability should be in range [0,1]. ' \
+ f'got {prob}.'
+ if use_cached:
+ assert max_cached_images >= 4, 'The length of cache must >= 4, ' \
+ f'but got {max_cached_images}.'
+
+ super().__init__(
+ pre_transform=pre_transform,
+ prob=prob,
+ use_cached=use_cached,
+ max_cached_images=max_cached_images,
+ random_pop=random_pop,
+ max_refetch=max_refetch)
+
+ self.img_scale = img_scale
+ self.center_ratio_range = center_ratio_range
+ self.bbox_clip_border = bbox_clip_border
+ self.pad_val = pad_val
+
+ def get_indexes(self, dataset: Union[BaseDataset, list]) -> list:
+ """Call function to collect indexes.
+
+ Args:
+ dataset (:obj:`Dataset` or list): The dataset or cached list.
+
+ Returns:
+ list: indexes.
+ """
+ indexes = [random.randint(0, len(dataset)) for _ in range(3)]
+ return indexes
+
+ def mix_img_transform(self, results: dict) -> dict:
+ """Mixed image data transformation.
+
+ Args:
+ results (dict): Result dict.
+
+ Returns:
+ results (dict): Updated result dict.
+ """
+ # print("use mosaic")
+ assert 'mix_results' in results
+ mosaic_bboxes = []
+ mosaic_bboxes_labels = []
+ mosaic_ignore_flags = []
+ mosaic_masks = []
+ with_mask = True if 'gt_masks' in results else False
+ # print("with_mask: ", with_mask)
+ # self.img_scale is wh format
+ img_scale_w, img_scale_h = self.img_scale
+
+ if len(results['img'].shape) == 3:
+ mosaic_img = np.full(
+ (int(img_scale_h * 2), int(img_scale_w * 2), 3),
+ self.pad_val,
+ dtype=results['img'].dtype)
+ else:
+ mosaic_img = np.full((int(img_scale_h * 2), int(img_scale_w * 2)),
+ self.pad_val,
+ dtype=results['img'].dtype)
+
+ # mosaic center x, y
+ center_x = int(random.uniform(*self.center_ratio_range) * img_scale_w)
+ center_y = int(random.uniform(*self.center_ratio_range) * img_scale_h)
+ center_position = (center_x, center_y)
+
+ loc_strs = ('top_left', 'top_right', 'bottom_left', 'bottom_right')
+ for i, loc in enumerate(loc_strs):
+ if loc == 'top_left':
+ results_patch = results
+ else:
+ results_patch = results['mix_results'][i - 1]
+
+ img_i = results_patch['img']
+ h_i, w_i = img_i.shape[:2]
+ # keep_ratio resize
+ scale_ratio_i = min(img_scale_h / h_i, img_scale_w / w_i)
+ img_i = mmcv.imresize(
+ img_i, (int(w_i * scale_ratio_i), int(h_i * scale_ratio_i)))
+
+ # compute the combine parameters
+ paste_coord, crop_coord = self._mosaic_combine(
+ loc, center_position, img_i.shape[:2][::-1])
+ x1_p, y1_p, x2_p, y2_p = paste_coord
+ x1_c, y1_c, x2_c, y2_c = crop_coord
+
+ # crop and paste image
+ mosaic_img[y1_p:y2_p, x1_p:x2_p] = img_i[y1_c:y2_c, x1_c:x2_c]
+
+ # adjust coordinate
+ gt_bboxes_i = results_patch['gt_bboxes']
+ gt_bboxes_labels_i = results_patch['gt_bboxes_labels']
+ gt_ignore_flags_i = results_patch['gt_ignore_flags']
+
+ padw = x1_p - x1_c
+ padh = y1_p - y1_c
+ gt_bboxes_i.rescale_([scale_ratio_i, scale_ratio_i])
+ gt_bboxes_i.translate_([padw, padh])
+ mosaic_bboxes.append(gt_bboxes_i)
+ mosaic_bboxes_labels.append(gt_bboxes_labels_i)
+ mosaic_ignore_flags.append(gt_ignore_flags_i)
+ if with_mask and results_patch.get('gt_masks', None) is not None:
+ gt_masks_i = results_patch['gt_masks']
+ gt_masks_i = gt_masks_i.rescale(float(scale_ratio_i))
+ gt_masks_i = gt_masks_i.translate(
+ out_shape=(int(self.img_scale[0] * 2),
+ int(self.img_scale[1] * 2)),
+ offset=padw,
+ direction='horizontal')
+ gt_masks_i = gt_masks_i.translate(
+ out_shape=(int(self.img_scale[0] * 2),
+ int(self.img_scale[1] * 2)),
+ offset=padh,
+ direction='vertical')
+ mosaic_masks.append(gt_masks_i)
+
+ mosaic_bboxes = mosaic_bboxes[0].cat(mosaic_bboxes, 0)
+ mosaic_bboxes_labels = np.concatenate(mosaic_bboxes_labels, 0)
+ mosaic_ignore_flags = np.concatenate(mosaic_ignore_flags, 0)
+
+ if self.bbox_clip_border:
+ mosaic_bboxes.clip_([2 * img_scale_h, 2 * img_scale_w])
+ if with_mask:
+ mosaic_masks = mosaic_masks[0].cat(mosaic_masks)
+ results['gt_masks'] = mosaic_masks
+ else:
+ # remove outside bboxes
+ inside_inds = mosaic_bboxes.is_inside(
+ [2 * img_scale_h, 2 * img_scale_w]).numpy()
+ mosaic_bboxes = mosaic_bboxes[inside_inds]
+ mosaic_bboxes_labels = mosaic_bboxes_labels[inside_inds]
+ mosaic_ignore_flags = mosaic_ignore_flags[inside_inds]
+ if with_mask:
+ mosaic_masks = mosaic_masks[0].cat(mosaic_masks)[inside_inds]
+ results['gt_masks'] = mosaic_masks
+
+ results['img'] = mosaic_img
+ results['img_shape'] = mosaic_img.shape
+ results['gt_bboxes'] = mosaic_bboxes
+ results['gt_bboxes_labels'] = mosaic_bboxes_labels
+ results['gt_ignore_flags'] = mosaic_ignore_flags
+
+ return results
+
+ def _mosaic_combine(
+ self, loc: str, center_position_xy: Sequence[float],
+ img_shape_wh: Sequence[int]) -> Tuple[Tuple[int], Tuple[int]]:
+ """Calculate global coordinate of mosaic image and local coordinate of
+ cropped sub-image.
+
+ Args:
+ loc (str): Index for the sub-image, loc in ('top_left',
+ 'top_right', 'bottom_left', 'bottom_right').
+ center_position_xy (Sequence[float]): Mixing center for 4 images,
+ (x, y).
+ img_shape_wh (Sequence[int]): Width and height of sub-image
+
+ Returns:
+ tuple[tuple[float]]: Corresponding coordinate of pasting and
+ cropping
+ - paste_coord (tuple): paste corner coordinate in mosaic image.
+ - crop_coord (tuple): crop corner coordinate in mosaic image.
+ """
+ assert loc in ('top_left', 'top_right', 'bottom_left', 'bottom_right')
+ if loc == 'top_left':
+ # index0 to top left part of image
+ x1, y1, x2, y2 = max(center_position_xy[0] - img_shape_wh[0], 0), \
+ max(center_position_xy[1] - img_shape_wh[1], 0), \
+ center_position_xy[0], \
+ center_position_xy[1]
+ crop_coord = img_shape_wh[0] - (x2 - x1), img_shape_wh[1] - (
+ y2 - y1), img_shape_wh[0], img_shape_wh[1]
+
+ elif loc == 'top_right':
+ # index1 to top right part of image
+ x1, y1, x2, y2 = center_position_xy[0], \
+ max(center_position_xy[1] - img_shape_wh[1], 0), \
+ min(center_position_xy[0] + img_shape_wh[0],
+ self.img_scale[0] * 2), \
+ center_position_xy[1]
+ crop_coord = 0, img_shape_wh[1] - (y2 - y1), min(
+ img_shape_wh[0], x2 - x1), img_shape_wh[1]
+
+ elif loc == 'bottom_left':
+ # index2 to bottom left part of image
+ x1, y1, x2, y2 = max(center_position_xy[0] - img_shape_wh[0], 0), \
+ center_position_xy[1], \
+ center_position_xy[0], \
+ min(self.img_scale[1] * 2, center_position_xy[1] +
+ img_shape_wh[1])
+ crop_coord = img_shape_wh[0] - (x2 - x1), 0, img_shape_wh[0], min(
+ y2 - y1, img_shape_wh[1])
+
+ else:
+ # index3 to bottom right part of image
+ x1, y1, x2, y2 = center_position_xy[0], \
+ center_position_xy[1], \
+ min(center_position_xy[0] + img_shape_wh[0],
+ self.img_scale[0] * 2), \
+ min(self.img_scale[1] * 2, center_position_xy[1] +
+ img_shape_wh[1])
+ crop_coord = 0, 0, min(img_shape_wh[0],
+ x2 - x1), min(y2 - y1, img_shape_wh[1])
+
+ paste_coord = x1, y1, x2, y2
+ return paste_coord, crop_coord
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(img_scale={self.img_scale}, '
+ repr_str += f'center_ratio_range={self.center_ratio_range}, '
+ repr_str += f'pad_val={self.pad_val}, '
+ repr_str += f'prob={self.prob})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class MultiModalMosaic9(BaseMultiModalMixImageTransform):
+ """Mosaic9 augmentation.
+
+ Given 9 images, mosaic transform combines them into
+ one output image. The output image is composed of the parts from each sub-
+ image.
+
+ .. code:: text
+
+ +-------------------------------+------------+
+ | pad | pad | |
+ | +----------+ | |
+ | | +---------------+ top_right |
+ | | | top | image2 |
+ | | top_left | image1 | |
+ | | image8 o--------+------+--------+---+
+ | | | | | |
+ +----+----------+ | right |pad|
+ | | center | image3 | |
+ | left | image0 +---------------+---|
+ | image7 | | | |
+ +---+-----------+---+--------+ | |
+ | | cropped | | bottom_right |pad|
+ | |bottom_left| | image4 | |
+ | | image6 | bottom | | |
+ +---|-----------+ image5 +---------------+---|
+ | pad | | pad |
+ +-----------+------------+-------------------+
+
+ The mosaic transform steps are as follows:
+
+ 1. Get the center image according to the index, and randomly
+ sample another 8 images from the custom dataset.
+ 2. Randomly offset the image after Mosaic
+
+ Required Keys:
+
+ - img
+ - gt_bboxes (BaseBoxes[torch.float32]) (optional)
+ - gt_bboxes_labels (np.int64) (optional)
+ - gt_ignore_flags (bool) (optional)
+ - mix_results (List[dict])
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - gt_bboxes (optional)
+ - gt_bboxes_labels (optional)
+ - gt_ignore_flags (optional)
+
+ Args:
+ img_scale (Sequence[int]): Image size after mosaic pipeline of single
+ image. The shape order should be (width, height).
+ Defaults to (640, 640).
+ bbox_clip_border (bool, optional): Whether to clip the objects outside
+ the border of the image. In some dataset like MOT17, the gt bboxes
+ are allowed to cross the border of images. Therefore, we don't
+ need to clip the gt bboxes in these cases. Defaults to True.
+ pad_val (int): Pad value. Defaults to 114.
+ pre_transform(Sequence[dict]): Sequence of transform object or
+ config dict to be composed.
+ prob (float): Probability of applying this transformation.
+ Defaults to 1.0.
+ use_cached (bool): Whether to use cache. Defaults to False.
+ max_cached_images (int): The maximum length of the cache. The larger
+ the cache, the stronger the randomness of this transform. As a
+ rule of thumb, providing 5 caches for each image suffices for
+ randomness. Defaults to 50.
+ random_pop (bool): Whether to randomly pop a result from the cache
+ when the cache is full. If set to False, use FIFO popping method.
+ Defaults to True.
+ max_refetch (int): The maximum number of retry iterations for getting
+ valid results from the pipeline. If the number of iterations is
+ greater than `max_refetch`, but results is still None, then the
+ iteration is terminated and raise the error. Defaults to 15.
+ """
+
+ def __init__(self,
+ img_scale: Tuple[int, int] = (640, 640),
+ bbox_clip_border: bool = True,
+ pad_val: Union[float, int] = 114.0,
+ pre_transform: Sequence[dict] = None,
+ prob: float = 1.0,
+ use_cached: bool = False,
+ max_cached_images: int = 50,
+ random_pop: bool = True,
+ max_refetch: int = 15):
+ assert isinstance(img_scale, tuple)
+ assert 0 <= prob <= 1.0, 'The probability should be in range [0,1]. ' \
+ f'got {prob}.'
+ if use_cached:
+ assert max_cached_images >= 9, 'The length of cache must >= 9, ' \
+ f'but got {max_cached_images}.'
+
+ super().__init__(
+ pre_transform=pre_transform,
+ prob=prob,
+ use_cached=use_cached,
+ max_cached_images=max_cached_images,
+ random_pop=random_pop,
+ max_refetch=max_refetch)
+
+ self.img_scale = img_scale
+ self.bbox_clip_border = bbox_clip_border
+ self.pad_val = pad_val
+
+ # intermediate variables
+ self._current_img_shape = [0, 0]
+ self._center_img_shape = [0, 0]
+ self._previous_img_shape = [0, 0]
+
+ def get_indexes(self, dataset: Union[BaseDataset, list]) -> list:
+ """Call function to collect indexes.
+
+ Args:
+ dataset (:obj:`Dataset` or list): The dataset or cached list.
+
+ Returns:
+ list: indexes.
+ """
+ indexes = [random.randint(0, len(dataset)) for _ in range(8)]
+ return indexes
+
+ def mix_img_transform(self, results: dict) -> dict:
+ """Mixed image data transformation.
+
+ Args:
+ results (dict): Result dict.
+
+ Returns:
+ results (dict): Updated result dict.
+ """
+ assert 'mix_results' in results
+
+ mosaic_bboxes = []
+ mosaic_bboxes_labels = []
+ mosaic_ignore_flags = []
+
+ img_scale_w, img_scale_h = self.img_scale
+
+ if len(results['img'].shape) == 3:
+ mosaic_img = np.full(
+ (int(img_scale_h * 3), int(img_scale_w * 3), 3),
+ self.pad_val,
+ dtype=results['img'].dtype)
+ else:
+ mosaic_img = np.full((int(img_scale_h * 3), int(img_scale_w * 3)),
+ self.pad_val,
+ dtype=results['img'].dtype)
+
+ # index = 0 is mean original image
+ # len(results['mix_results']) = 8
+ loc_strs = ('center', 'top', 'top_right', 'right', 'bottom_right',
+ 'bottom', 'bottom_left', 'left', 'top_left')
+
+ results_all = [results, *results['mix_results']]
+ for index, results_patch in enumerate(results_all):
+ img_i = results_patch['img']
+ # keep_ratio resize
+ img_i_h, img_i_w = img_i.shape[:2]
+ scale_ratio_i = min(img_scale_h / img_i_h, img_scale_w / img_i_w)
+ img_i = mmcv.imresize(
+ img_i,
+ (int(img_i_w * scale_ratio_i), int(img_i_h * scale_ratio_i)))
+
+ paste_coord = self._mosaic_combine(loc_strs[index],
+ img_i.shape[:2])
+
+ padw, padh = paste_coord[:2]
+ x1, y1, x2, y2 = (max(x, 0) for x in paste_coord)
+ mosaic_img[y1:y2, x1:x2] = img_i[y1 - padh:, x1 - padw:]
+
+ gt_bboxes_i = results_patch['gt_bboxes']
+ gt_bboxes_labels_i = results_patch['gt_bboxes_labels']
+ gt_ignore_flags_i = results_patch['gt_ignore_flags']
+ gt_bboxes_i.rescale_([scale_ratio_i, scale_ratio_i])
+ gt_bboxes_i.translate_([padw, padh])
+
+ mosaic_bboxes.append(gt_bboxes_i)
+ mosaic_bboxes_labels.append(gt_bboxes_labels_i)
+ mosaic_ignore_flags.append(gt_ignore_flags_i)
+
+ # Offset
+ offset_x = int(random.uniform(0, img_scale_w))
+ offset_y = int(random.uniform(0, img_scale_h))
+ mosaic_img = mosaic_img[offset_y:offset_y + 2 * img_scale_h,
+ offset_x:offset_x + 2 * img_scale_w]
+
+ mosaic_bboxes = mosaic_bboxes[0].cat(mosaic_bboxes, 0)
+ mosaic_bboxes.translate_([-offset_x, -offset_y])
+ mosaic_bboxes_labels = np.concatenate(mosaic_bboxes_labels, 0)
+ mosaic_ignore_flags = np.concatenate(mosaic_ignore_flags, 0)
+
+ if self.bbox_clip_border:
+ mosaic_bboxes.clip_([2 * img_scale_h, 2 * img_scale_w])
+ else:
+ # remove outside bboxes
+ inside_inds = mosaic_bboxes.is_inside(
+ [2 * img_scale_h, 2 * img_scale_w]).numpy()
+ mosaic_bboxes = mosaic_bboxes[inside_inds]
+ mosaic_bboxes_labels = mosaic_bboxes_labels[inside_inds]
+ mosaic_ignore_flags = mosaic_ignore_flags[inside_inds]
+
+ results['img'] = mosaic_img
+ results['img_shape'] = mosaic_img.shape
+ results['gt_bboxes'] = mosaic_bboxes
+ results['gt_bboxes_labels'] = mosaic_bboxes_labels
+ results['gt_ignore_flags'] = mosaic_ignore_flags
+ return results
+
+ def _mosaic_combine(self, loc: str,
+ img_shape_hw: Tuple[int, int]) -> Tuple[int, ...]:
+ """Calculate global coordinate of mosaic image.
+
+ Args:
+ loc (str): Index for the sub-image.
+ img_shape_hw (Sequence[int]): Height and width of sub-image
+
+ Returns:
+ paste_coord (tuple): paste corner coordinate in mosaic image.
+ """
+ assert loc in ('center', 'top', 'top_right', 'right', 'bottom_right',
+ 'bottom', 'bottom_left', 'left', 'top_left')
+
+ img_scale_w, img_scale_h = self.img_scale
+
+ self._current_img_shape = img_shape_hw
+ current_img_h, current_img_w = self._current_img_shape
+ previous_img_h, previous_img_w = self._previous_img_shape
+ center_img_h, center_img_w = self._center_img_shape
+
+ if loc == 'center':
+ self._center_img_shape = self._current_img_shape
+ # xmin, ymin, xmax, ymax
+ paste_coord = img_scale_w, \
+ img_scale_h, \
+ img_scale_w + current_img_w, \
+ img_scale_h + current_img_h
+ elif loc == 'top':
+ paste_coord = img_scale_w, \
+ img_scale_h - current_img_h, \
+ img_scale_w + current_img_w, \
+ img_scale_h
+ elif loc == 'top_right':
+ paste_coord = img_scale_w + previous_img_w, \
+ img_scale_h - current_img_h, \
+ img_scale_w + previous_img_w + current_img_w, \
+ img_scale_h
+ elif loc == 'right':
+ paste_coord = img_scale_w + center_img_w, \
+ img_scale_h, \
+ img_scale_w + center_img_w + current_img_w, \
+ img_scale_h + current_img_h
+ elif loc == 'bottom_right':
+ paste_coord = img_scale_w + center_img_w, \
+ img_scale_h + previous_img_h, \
+ img_scale_w + center_img_w + current_img_w, \
+ img_scale_h + previous_img_h + current_img_h
+ elif loc == 'bottom':
+ paste_coord = img_scale_w + center_img_w - current_img_w, \
+ img_scale_h + center_img_h, \
+ img_scale_w + center_img_w, \
+ img_scale_h + center_img_h + current_img_h
+ elif loc == 'bottom_left':
+ paste_coord = img_scale_w + center_img_w - \
+ previous_img_w - current_img_w, \
+ img_scale_h + center_img_h, \
+ img_scale_w + center_img_w - previous_img_w, \
+ img_scale_h + center_img_h + current_img_h
+ elif loc == 'left':
+ paste_coord = img_scale_w - current_img_w, \
+ img_scale_h + center_img_h - current_img_h, \
+ img_scale_w, \
+ img_scale_h + center_img_h
+ elif loc == 'top_left':
+ paste_coord = img_scale_w - current_img_w, \
+ img_scale_h + center_img_h - \
+ previous_img_h - current_img_h, \
+ img_scale_w, \
+ img_scale_h + center_img_h - previous_img_h
+
+ self._previous_img_shape = self._current_img_shape
+ # xmin, ymin, xmax, ymax
+ return paste_coord
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(img_scale={self.img_scale}, '
+ repr_str += f'pad_val={self.pad_val}, '
+ repr_str += f'prob={self.prob})'
+ return repr_str
+
+
+@TRANSFORMS.register_module()
+class YOLOv5MultiModalMixUp(BaseMultiModalMixImageTransform):
+ """MixUp data augmentation for YOLOv5.
+
+ .. code:: text
+
+ The mixup transform steps are as follows:
+
+ 1. Another random image is picked by dataset.
+ 2. Randomly obtain the fusion ratio from the beta distribution,
+ then fuse the target
+ of the original image and mixup image through this ratio.
+
+ Required Keys:
+
+ - img
+ - gt_bboxes (BaseBoxes[torch.float32]) (optional)
+ - gt_bboxes_labels (np.int64) (optional)
+ - gt_ignore_flags (bool) (optional)
+ - mix_results (List[dict])
+
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - gt_bboxes (optional)
+ - gt_bboxes_labels (optional)
+ - gt_ignore_flags (optional)
+
+
+ Args:
+ alpha (float): parameter of beta distribution to get mixup ratio.
+ Defaults to 32.
+ beta (float): parameter of beta distribution to get mixup ratio.
+ Defaults to 32.
+ pre_transform (Sequence[dict]): Sequence of transform object or
+ config dict to be composed.
+ prob (float): Probability of applying this transformation.
+ Defaults to 1.0.
+ use_cached (bool): Whether to use cache. Defaults to False.
+ max_cached_images (int): The maximum length of the cache. The larger
+ the cache, the stronger the randomness of this transform. As a
+ rule of thumb, providing 10 caches for each image suffices for
+ randomness. Defaults to 20.
+ random_pop (bool): Whether to randomly pop a result from the cache
+ when the cache is full. If set to False, use FIFO popping method.
+ Defaults to True.
+ max_refetch (int): The maximum number of iterations. If the number of
+ iterations is greater than `max_refetch`, but gt_bbox is still
+ empty, then the iteration is terminated. Defaults to 15.
+ """
+
+ def __init__(self,
+ alpha: float = 32.0,
+ beta: float = 32.0,
+ pre_transform: Sequence[dict] = None,
+ prob: float = 1.0,
+ use_cached: bool = False,
+ max_cached_images: int = 20,
+ random_pop: bool = True,
+ max_refetch: int = 15):
+ if use_cached:
+ assert max_cached_images >= 2, 'The length of cache must >= 2, ' \
+ f'but got {max_cached_images}.'
+ super().__init__(
+ pre_transform=pre_transform,
+ prob=prob,
+ use_cached=use_cached,
+ max_cached_images=max_cached_images,
+ random_pop=random_pop,
+ max_refetch=max_refetch)
+ self.alpha = alpha
+ self.beta = beta
+
+ def get_indexes(self, dataset: Union[BaseDataset, list]) -> int:
+ """Call function to collect indexes.
+
+ Args:
+ dataset (:obj:`Dataset` or list): The dataset or cached list.
+
+ Returns:
+ int: indexes.
+ """
+ return random.randint(0, len(dataset))
+
+ def mix_img_transform(self, results: dict) -> dict:
+ """YOLOv5 MixUp transform function.
+
+ Args:
+ results (dict): Result dict
+
+ Returns:
+ results (dict): Updated result dict.
+ """
+ assert 'mix_results' in results
+
+ retrieve_results = results['mix_results'][0]
+ retrieve_img = retrieve_results['img']
+ ori_img = results['img']
+ assert ori_img.shape == retrieve_img.shape
+
+ # Randomly obtain the fusion ratio from the beta distribution,
+ # which is around 0.5
+ ratio = np.random.beta(self.alpha, self.beta)
+ mixup_img = (ori_img * ratio + retrieve_img * (1 - ratio))
+
+ retrieve_gt_bboxes = retrieve_results['gt_bboxes']
+ retrieve_gt_bboxes_labels = retrieve_results['gt_bboxes_labels']
+ retrieve_gt_ignore_flags = retrieve_results['gt_ignore_flags']
+
+ mixup_gt_bboxes = retrieve_gt_bboxes.cat(
+ (results['gt_bboxes'], retrieve_gt_bboxes), dim=0)
+ mixup_gt_bboxes_labels = np.concatenate(
+ (results['gt_bboxes_labels'], retrieve_gt_bboxes_labels), axis=0)
+ mixup_gt_ignore_flags = np.concatenate(
+ (results['gt_ignore_flags'], retrieve_gt_ignore_flags), axis=0)
+ if 'gt_masks' in results:
+ assert 'gt_masks' in retrieve_results
+ mixup_gt_masks = results['gt_masks'].cat(
+ [results['gt_masks'], retrieve_results['gt_masks']])
+ results['gt_masks'] = mixup_gt_masks
+
+ results['img'] = mixup_img.astype(np.uint8)
+ results['img_shape'] = mixup_img.shape
+ results['gt_bboxes'] = mixup_gt_bboxes
+ results['gt_bboxes_labels'] = mixup_gt_bboxes_labels
+ results['gt_ignore_flags'] = mixup_gt_ignore_flags
+
+ return results
+
+
+@TRANSFORMS.register_module()
+class YOLOXMultiModalMixUp(BaseMultiModalMixImageTransform):
+ """MixUp data augmentation for YOLOX.
+
+ .. code:: text
+
+ mixup transform
+ +---------------+--------------+
+ | mixup image | |
+ | +--------|--------+ |
+ | | | | |
+ +---------------+ | |
+ | | | |
+ | | image | |
+ | | | |
+ | | | |
+ | +-----------------+ |
+ | pad |
+ +------------------------------+
+
+ The mixup transform steps are as follows:
+
+ 1. Another random image is picked by dataset and embedded in
+ the top left patch(after padding and resizing)
+ 2. The target of mixup transform is the weighted average of mixup
+ image and origin image.
+
+ Required Keys:
+
+ - img
+ - gt_bboxes (BaseBoxes[torch.float32]) (optional)
+ - gt_bboxes_labels (np.int64) (optional)
+ - gt_ignore_flags (bool) (optional)
+ - mix_results (List[dict])
+
+
+ Modified Keys:
+
+ - img
+ - img_shape
+ - gt_bboxes (optional)
+ - gt_bboxes_labels (optional)
+ - gt_ignore_flags (optional)
+
+
+ Args:
+ img_scale (Sequence[int]): Image output size after mixup pipeline.
+ The shape order should be (width, height). Defaults to (640, 640).
+ ratio_range (Sequence[float]): Scale ratio of mixup image.
+ Defaults to (0.5, 1.5).
+ flip_ratio (float): Horizontal flip ratio of mixup image.
+ Defaults to 0.5.
+ pad_val (int): Pad value. Defaults to 114.
+ bbox_clip_border (bool, optional): Whether to clip the objects outside
+ the border of the image. In some dataset like MOT17, the gt bboxes
+ are allowed to cross the border of images. Therefore, we don't
+ need to clip the gt bboxes in these cases. Defaults to True.
+ pre_transform(Sequence[dict]): Sequence of transform object or
+ config dict to be composed.
+ prob (float): Probability of applying this transformation.
+ Defaults to 1.0.
+ use_cached (bool): Whether to use cache. Defaults to False.
+ max_cached_images (int): The maximum length of the cache. The larger
+ the cache, the stronger the randomness of this transform. As a
+ rule of thumb, providing 10 caches for each image suffices for
+ randomness. Defaults to 20.
+ random_pop (bool): Whether to randomly pop a result from the cache
+ when the cache is full. If set to False, use FIFO popping method.
+ Defaults to True.
+ max_refetch (int): The maximum number of iterations. If the number of
+ iterations is greater than `max_refetch`, but gt_bbox is still
+ empty, then the iteration is terminated. Defaults to 15.
+ """
+
+ def __init__(self,
+ img_scale: Tuple[int, int] = (640, 640),
+ ratio_range: Tuple[float, float] = (0.5, 1.5),
+ flip_ratio: float = 0.5,
+ pad_val: float = 114.0,
+ bbox_clip_border: bool = True,
+ pre_transform: Sequence[dict] = None,
+ prob: float = 1.0,
+ use_cached: bool = False,
+ max_cached_images: int = 20,
+ random_pop: bool = True,
+ max_refetch: int = 15):
+ assert isinstance(img_scale, tuple)
+ if use_cached:
+ assert max_cached_images >= 2, 'The length of cache must >= 2, ' \
+ f'but got {max_cached_images}.'
+ super().__init__(
+ pre_transform=pre_transform,
+ prob=prob,
+ use_cached=use_cached,
+ max_cached_images=max_cached_images,
+ random_pop=random_pop,
+ max_refetch=max_refetch)
+ self.img_scale = img_scale
+ self.ratio_range = ratio_range
+ self.flip_ratio = flip_ratio
+ self.pad_val = pad_val
+ self.bbox_clip_border = bbox_clip_border
+
+ def get_indexes(self, dataset: Union[BaseDataset, list]) -> int:
+ """Call function to collect indexes.
+
+ Args:
+ dataset (:obj:`Dataset` or list): The dataset or cached list.
+
+ Returns:
+ int: indexes.
+ """
+ return random.randint(0, len(dataset))
+
+ def mix_img_transform(self, results: dict) -> dict:
+ """YOLOX MixUp transform function.
+
+ Args:
+ results (dict): Result dict.
+
+ Returns:
+ results (dict): Updated result dict.
+ """
+ assert 'mix_results' in results
+ assert len(
+ results['mix_results']) == 1, 'MixUp only support 2 images now !'
+
+ if results['mix_results'][0]['gt_bboxes'].shape[0] == 0:
+ # empty bbox
+ return results
+
+ retrieve_results = results['mix_results'][0]
+ retrieve_img = retrieve_results['img']
+
+ jit_factor = random.uniform(*self.ratio_range)
+ is_filp = random.uniform(0, 1) > self.flip_ratio
+
+ if len(retrieve_img.shape) == 3:
+ out_img = np.ones((self.img_scale[1], self.img_scale[0], 3),
+ dtype=retrieve_img.dtype) * self.pad_val
+ else:
+ out_img = np.ones(
+ self.img_scale[::-1], dtype=retrieve_img.dtype) * self.pad_val
+
+ # 1. keep_ratio resize
+ scale_ratio = min(self.img_scale[1] / retrieve_img.shape[0],
+ self.img_scale[0] / retrieve_img.shape[1])
+ retrieve_img = mmcv.imresize(
+ retrieve_img, (int(retrieve_img.shape[1] * scale_ratio),
+ int(retrieve_img.shape[0] * scale_ratio)))
+
+ # 2. paste
+ out_img[:retrieve_img.shape[0], :retrieve_img.shape[1]] = retrieve_img
+
+ # 3. scale jit
+ scale_ratio *= jit_factor
+ out_img = mmcv.imresize(out_img, (int(out_img.shape[1] * jit_factor),
+ int(out_img.shape[0] * jit_factor)))
+
+ # 4. flip
+ if is_filp:
+ out_img = out_img[:, ::-1, :]
+
+ # 5. random crop
+ ori_img = results['img']
+ origin_h, origin_w = out_img.shape[:2]
+ target_h, target_w = ori_img.shape[:2]
+ padded_img = np.ones((max(origin_h, target_h), max(
+ origin_w, target_w), 3)) * self.pad_val
+ padded_img = padded_img.astype(np.uint8)
+ padded_img[:origin_h, :origin_w] = out_img
+
+ x_offset, y_offset = 0, 0
+ if padded_img.shape[0] > target_h:
+ y_offset = random.randint(0, padded_img.shape[0] - target_h)
+ if padded_img.shape[1] > target_w:
+ x_offset = random.randint(0, padded_img.shape[1] - target_w)
+ padded_cropped_img = padded_img[y_offset:y_offset + target_h,
+ x_offset:x_offset + target_w]
+
+ # 6. adjust bbox
+ retrieve_gt_bboxes = retrieve_results['gt_bboxes']
+ retrieve_gt_bboxes.rescale_([scale_ratio, scale_ratio])
+ if self.bbox_clip_border:
+ retrieve_gt_bboxes.clip_([origin_h, origin_w])
+
+ if is_filp:
+ retrieve_gt_bboxes.flip_([origin_h, origin_w],
+ direction='horizontal')
+
+ # 7. filter
+ cp_retrieve_gt_bboxes = retrieve_gt_bboxes.clone()
+ cp_retrieve_gt_bboxes.translate_([-x_offset, -y_offset])
+ if self.bbox_clip_border:
+ cp_retrieve_gt_bboxes.clip_([target_h, target_w])
+
+ # 8. mix up
+ mixup_img = 0.5 * ori_img + 0.5 * padded_cropped_img
+
+ retrieve_gt_bboxes_labels = retrieve_results['gt_bboxes_labels']
+ retrieve_gt_ignore_flags = retrieve_results['gt_ignore_flags']
+
+ mixup_gt_bboxes = cp_retrieve_gt_bboxes.cat(
+ (results['gt_bboxes'], cp_retrieve_gt_bboxes), dim=0)
+ mixup_gt_bboxes_labels = np.concatenate(
+ (results['gt_bboxes_labels'], retrieve_gt_bboxes_labels), axis=0)
+ mixup_gt_ignore_flags = np.concatenate(
+ (results['gt_ignore_flags'], retrieve_gt_ignore_flags), axis=0)
+
+ if not self.bbox_clip_border:
+ # remove outside bbox
+ inside_inds = mixup_gt_bboxes.is_inside([target_h,
+ target_w]).numpy()
+ mixup_gt_bboxes = mixup_gt_bboxes[inside_inds]
+ mixup_gt_bboxes_labels = mixup_gt_bboxes_labels[inside_inds]
+ mixup_gt_ignore_flags = mixup_gt_ignore_flags[inside_inds]
+
+ results['img'] = mixup_img.astype(np.uint8)
+ results['img_shape'] = mixup_img.shape
+ results['gt_bboxes'] = mixup_gt_bboxes
+ results['gt_bboxes_labels'] = mixup_gt_bboxes_labels
+ results['gt_ignore_flags'] = mixup_gt_ignore_flags
+
+ return results
+
+ def __repr__(self) -> str:
+ repr_str = self.__class__.__name__
+ repr_str += f'(img_scale={self.img_scale}, '
+ repr_str += f'ratio_range={self.ratio_range}, '
+ repr_str += f'flip_ratio={self.flip_ratio}, '
+ repr_str += f'pad_val={self.pad_val}, '
+ repr_str += f'max_refetch={self.max_refetch}, '
+ repr_str += f'bbox_clip_border={self.bbox_clip_border})'
+ return repr_str
diff --git a/yolo_world/datasets/transformers/mm_transforms.py b/yolo_world/datasets/transformers/mm_transforms.py
new file mode 100644
index 0000000000000000000000000000000000000000..0008920b82fc29b3ccc0473e894cd718cdb21fa4
--- /dev/null
+++ b/yolo_world/datasets/transformers/mm_transforms.py
@@ -0,0 +1,129 @@
+# Copyright (c) Tencent Inc. All rights reserved.
+import json
+import random
+from typing import Tuple
+
+import numpy as np
+from mmyolo.registry import TRANSFORMS
+
+
+@TRANSFORMS.register_module()
+class RandomLoadText:
+
+ def __init__(self,
+ text_path: str = None,
+ prompt_format: str = '{}',
+ num_neg_samples: Tuple[int, int] = (80, 80),
+ max_num_samples: int = 80,
+ padding_to_max: bool = False,
+ padding_value: str = '') -> None:
+ self.prompt_format = prompt_format
+ self.num_neg_samples = num_neg_samples
+ self.max_num_samples = max_num_samples
+ self.padding_to_max = padding_to_max
+ self.padding_value = padding_value
+ if text_path is not None:
+ with open(text_path, 'r') as f:
+ self.class_texts = json.load(f)
+
+ def __call__(self, results: dict) -> dict:
+ assert 'texts' in results or hasattr(self, 'class_texts'), (
+ 'No texts found in results.')
+ class_texts = results.get(
+ 'texts',
+ getattr(self, 'class_texts', None))
+
+ num_classes = len(class_texts)
+ if 'gt_labels' in results:
+ gt_label_tag = 'gt_labels'
+ elif 'gt_bboxes_labels' in results:
+ gt_label_tag = 'gt_bboxes_labels'
+ else:
+ raise ValueError('No valid labels found in results.')
+ positive_labels = set(results[gt_label_tag])
+
+ if len(positive_labels) > self.max_num_samples:
+ positive_labels = set(random.sample(list(positive_labels),
+ k=self.max_num_samples))
+
+ num_neg_samples = min(
+ min(num_classes, self.max_num_samples) - len(positive_labels),
+ random.randint(*self.num_neg_samples))
+ candidate_neg_labels = []
+ for idx in range(num_classes):
+ if idx not in positive_labels:
+ candidate_neg_labels.append(idx)
+ negative_labels = random.sample(
+ candidate_neg_labels, k=num_neg_samples)
+
+ sampled_labels = list(positive_labels) + list(negative_labels)
+ random.shuffle(sampled_labels)
+
+ label2ids = {label: i for i, label in enumerate(sampled_labels)}
+
+ gt_valid_mask = np.zeros(len(results['gt_bboxes']), dtype=bool)
+ for idx, label in enumerate(results[gt_label_tag]):
+ if label in label2ids:
+ gt_valid_mask[idx] = True
+ results[gt_label_tag][idx] = label2ids[label]
+ results['gt_bboxes'] = results['gt_bboxes'][gt_valid_mask]
+ results[gt_label_tag] = results[gt_label_tag][gt_valid_mask]
+
+ if 'instances' in results:
+ retaged_instances = []
+ for idx, inst in enumerate(results['instances']):
+ label = inst['bbox_label']
+ if label in label2ids:
+ inst['bbox_label'] = label2ids[label]
+ retaged_instances.append(inst)
+ results['instances'] = retaged_instances
+
+ texts = []
+ for label in sampled_labels:
+ cls_caps = class_texts[label]
+ assert len(cls_caps) > 0
+ cap_id = random.randrange(len(cls_caps))
+ sel_cls_cap = self.prompt_format.format(cls_caps[cap_id])
+ texts.append(sel_cls_cap)
+
+ if self.padding_to_max:
+ num_valid_labels = len(positive_labels) + len(negative_labels)
+ num_padding = self.max_num_samples - num_valid_labels
+ if num_padding > 0:
+ texts += [self.padding_value] * num_padding
+
+ results['texts'] = texts
+
+ return results
+
+
+@TRANSFORMS.register_module()
+class LoadText:
+
+ def __init__(self,
+ text_path: str = None,
+ prompt_format: str = '{}',
+ multi_prompt_flag: str = '/') -> None:
+ self.prompt_format = prompt_format
+ self.multi_prompt_flag = multi_prompt_flag
+ if text_path is not None:
+ with open(text_path, 'r') as f:
+ self.class_texts = json.load(f)
+
+ def __call__(self, results: dict) -> dict:
+ assert 'texts' in results or hasattr(self, 'class_texts'), (
+ 'No texts found in results.')
+ class_texts = results.get(
+ 'texts',
+ getattr(self, 'class_texts', None))
+
+ texts = []
+ for idx, cls_caps in enumerate(class_texts):
+ assert len(cls_caps) > 0
+ sel_cls_cap = cls_caps[0]
+ sel_cls_cap = self.prompt_format.format(sel_cls_cap)
+ texts.append(sel_cls_cap)
+
+ results['texts'] = texts
+
+ return results
diff --git a/yolo_world/datasets/utils.py b/yolo_world/datasets/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..fb2acf11ca53dfa3e151e942591de306c5b123a3
--- /dev/null
+++ b/yolo_world/datasets/utils.py
@@ -0,0 +1,91 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import random
+from typing import Any, Sequence
+
+import torch
+from mmengine.dataset import COLLATE_FUNCTIONS
+from mmengine.logging import print_log
+from mmyolo.datasets.yolov5_coco import BatchShapePolicyDataset
+
+
+class RobustBatchShapePolicyDataset(BatchShapePolicyDataset):
+ """Dataset with the batch shape policy that makes paddings with least
+ pixels during batch inference process, which does not require the image
+ scales of all batches to be the same throughout validation."""
+
+ def _prepare_data(self, idx: int) -> Any:
+ if self.test_mode is False:
+ data_info = self.get_data_info(idx)
+ data_info['dataset'] = self
+ return self.pipeline(data_info)
+ else:
+ return super().prepare_data(idx)
+
+ def prepare_data(self, idx: int, timeout=10) -> Any:
+ """Pass the dataset to the pipeline during training to support mixed
+ data augmentation, such as Mosaic and MixUp."""
+ try:
+ return self._prepare_data(idx)
+ except Exception as e:
+ if timeout <= 0:
+ raise e
+ print_log(f'Failed to prepare data, due to {e}.'
+ f'Retrying {timeout} attempts.')
+ if not self.test_mode:
+ idx = random.randrange(len(self))
+ return self.prepare_data(idx, timeout=timeout - 1)
+
+
+@COLLATE_FUNCTIONS.register_module()
+def yolow_collate(data_batch: Sequence,
+ use_ms_training: bool = False) -> dict:
+ """Rewrite collate_fn to get faster training speed.
+
+ Args:
+ data_batch (Sequence): Batch of data.
+ use_ms_training (bool): Whether to use multi-scale training.
+ """
+ batch_imgs = []
+ batch_bboxes_labels = []
+ batch_masks = []
+ for i in range(len(data_batch)):
+ datasamples = data_batch[i]['data_samples']
+ inputs = data_batch[i]['inputs']
+ batch_imgs.append(inputs)
+
+ gt_bboxes = datasamples.gt_instances.bboxes.tensor
+ gt_labels = datasamples.gt_instances.labels
+ if 'masks' in datasamples.gt_instances:
+ masks = datasamples.gt_instances.masks.to_tensor(
+ dtype=torch.bool, device=gt_bboxes.device)
+ batch_masks.append(masks)
+ batch_idx = gt_labels.new_full((len(gt_labels), 1), i)
+ bboxes_labels = torch.cat((batch_idx, gt_labels[:, None], gt_bboxes),
+ dim=1)
+ batch_bboxes_labels.append(bboxes_labels)
+
+ collated_results = {
+ 'data_samples': {
+ 'bboxes_labels': torch.cat(batch_bboxes_labels, 0)
+ }
+ }
+ if len(batch_masks) > 0:
+ collated_results['data_samples']['masks'] = torch.cat(batch_masks, 0)
+
+ if use_ms_training:
+ collated_results['inputs'] = batch_imgs
+ else:
+ collated_results['inputs'] = torch.stack(batch_imgs, 0)
+
+ if hasattr(data_batch[0]['data_samples'], 'texts'):
+ batch_texts = [meta['data_samples'].texts for meta in data_batch]
+ collated_results['data_samples']['texts'] = batch_texts
+
+ if hasattr(data_batch[0]['data_samples'], 'is_detection'):
+ # detection flag
+ batch_detection = [meta['data_samples'].is_detection
+ for meta in data_batch]
+ collated_results['data_samples']['is_detection'] = torch.tensor(
+ batch_detection)
+
+ return collated_results
diff --git a/yolo_world/datasets/yolov5_lvis.py b/yolo_world/datasets/yolov5_lvis.py
new file mode 100644
index 0000000000000000000000000000000000000000..554383952252fe028fb90ae7f3e9bb1eee97e6d1
--- /dev/null
+++ b/yolo_world/datasets/yolov5_lvis.py
@@ -0,0 +1,15 @@
+# Copyright (c) Tencent Inc. All rights reserved.
+from mmdet.datasets import LVISV1Dataset
+from mmyolo.registry import DATASETS
+
+from .utils import RobustBatchShapePolicyDataset
+
+
+@DATASETS.register_module()
+class YOLOv5LVISV1Dataset(RobustBatchShapePolicyDataset, LVISV1Dataset):
+ """Dataset for YOLOv5 LVIS Dataset.
+
+ We only add `BatchShapePolicy` function compared with Objects365V1Dataset.
+ See `mmyolo/datasets/utils.py#BatchShapePolicy` for details
+ """
+ pass
diff --git a/yolo_world/datasets/yolov5_mixed_grounding.py b/yolo_world/datasets/yolov5_mixed_grounding.py
new file mode 100644
index 0000000000000000000000000000000000000000..ad4348cfe8964c148bf21baab85b2d91dbc7ef70
--- /dev/null
+++ b/yolo_world/datasets/yolov5_mixed_grounding.py
@@ -0,0 +1,201 @@
+# Copyright (c) Tencent Inc. All rights reserved.
+import os.path as osp
+from typing import List, Union
+
+from mmengine.fileio import get_local_path, join_path
+from mmengine.utils import is_abs
+from mmdet.datasets.coco import CocoDataset
+from mmyolo.registry import DATASETS
+
+from .utils import RobustBatchShapePolicyDataset
+
+
+@DATASETS.register_module()
+class YOLOv5MixedGroundingDataset(RobustBatchShapePolicyDataset, CocoDataset):
+ """Mixed grounding dataset."""
+
+ METAINFO = {
+ 'classes': ('object',),
+ 'palette': [(220, 20, 60)]}
+
+ def load_data_list(self) -> List[dict]:
+ """Load annotations from an annotation file named as ``self.ann_file``
+
+ Returns:
+ List[dict]: A list of annotation.
+ """ # noqa: E501
+ with get_local_path(
+ self.ann_file, backend_args=self.backend_args) as local_path:
+ self.coco = self.COCOAPI(local_path)
+
+ img_ids = self.coco.get_img_ids()
+ data_list = []
+ total_ann_ids = []
+ for img_id in img_ids:
+ raw_img_info = self.coco.load_imgs([img_id])[0]
+ raw_img_info['img_id'] = img_id
+
+ ann_ids = self.coco.get_ann_ids(img_ids=[img_id])
+ raw_ann_info = self.coco.load_anns(ann_ids)
+ total_ann_ids.extend(ann_ids)
+
+ parsed_data_info = self.parse_data_info({
+ 'raw_ann_info':
+ raw_ann_info,
+ 'raw_img_info':
+ raw_img_info
+ })
+ data_list.append(parsed_data_info)
+ if self.ANN_ID_UNIQUE:
+ assert len(set(total_ann_ids)) == len(
+ total_ann_ids
+ ), f"Annotation ids in '{self.ann_file}' are not unique!"
+
+ del self.coco
+ # print(len(data_list))
+ return data_list
+
+ def parse_data_info(self, raw_data_info: dict) -> Union[dict, List[dict]]:
+ """Parse raw annotation to target format.
+
+ Args:
+ raw_data_info (dict): Raw data information load from ``ann_file``
+
+ Returns:
+ Union[dict, List[dict]]: Parsed annotation.
+ """
+ img_info = raw_data_info['raw_img_info']
+ ann_info = raw_data_info['raw_ann_info']
+
+ data_info = {}
+
+ img_path = None
+ img_prefix = self.data_prefix.get('img', None)
+ if isinstance(img_prefix, str):
+ img_path = osp.join(img_prefix, img_info['file_name'])
+ elif isinstance(img_prefix, (list, tuple)):
+ for prefix in img_prefix:
+ candidate_img_path = osp.join(prefix, img_info['file_name'])
+ if osp.exists(candidate_img_path):
+ img_path = candidate_img_path
+ break
+ assert img_path is not None, (
+ f'Image path {img_info["file_name"]} not found in'
+ f'{img_prefix}')
+ if self.data_prefix.get('seg', None):
+ seg_map_path = osp.join(
+ self.data_prefix['seg'],
+ img_info['file_name'].rsplit('.', 1)[0] + self.seg_map_suffix)
+ else:
+ seg_map_path = None
+ data_info['img_path'] = img_path
+ data_info['img_id'] = img_info['img_id']
+ data_info['seg_map_path'] = seg_map_path
+ data_info['height'] = float(img_info['height'])
+ data_info['width'] = float(img_info['width'])
+
+ cat2id = {}
+ texts = []
+ for ann in ann_info:
+ cat_name = ' '.join([img_info['caption'][t[0]:t[1]]
+ for t in ann['tokens_positive']])
+ if cat_name not in cat2id:
+ cat2id[cat_name] = len(cat2id)
+ texts.append([cat_name])
+ data_info['texts'] = texts
+
+ instances = []
+ for i, ann in enumerate(ann_info):
+ instance = {}
+
+ if ann.get('ignore', False):
+ continue
+ x1, y1, w, h = ann['bbox']
+ inter_w = max(0,
+ min(x1 + w, float(img_info['width'])) - max(x1, 0))
+ inter_h = max(0,
+ min(y1 + h, float(img_info['height'])) - max(y1, 0))
+ if inter_w * inter_h == 0:
+ continue
+ if ann['area'] <= 0 or w < 1 or h < 1:
+ continue
+ bbox = [x1, y1, x1 + w, y1 + h]
+
+ if ann.get('iscrowd', False):
+ instance['ignore_flag'] = 1
+ else:
+ instance['ignore_flag'] = 0
+ instance['bbox'] = bbox
+
+ cat_name = ' '.join([img_info['caption'][t[0]:t[1]]
+ for t in ann['tokens_positive']])
+ instance['bbox_label'] = cat2id[cat_name]
+
+ if ann.get('segmentation', None):
+ instance['mask'] = ann['segmentation']
+
+ instances.append(instance)
+ # NOTE: for detection task, we set `is_detection` to 1
+ data_info['is_detection'] = 1
+ data_info['instances'] = instances
+ # print(data_info['texts'])
+ return data_info
+
+ def filter_data(self) -> List[dict]:
+ """Filter annotations according to filter_cfg.
+
+ Returns:
+ List[dict]: Filtered results.
+ """
+ if self.test_mode:
+ return self.data_list
+
+ if self.filter_cfg is None:
+ return self.data_list
+
+ filter_empty_gt = self.filter_cfg.get('filter_empty_gt', False)
+ min_size = self.filter_cfg.get('min_size', 0)
+
+ # obtain images that contain annotation
+ ids_with_ann = set(data_info['img_id'] for data_info in self.data_list)
+
+ valid_data_infos = []
+ for i, data_info in enumerate(self.data_list):
+ img_id = data_info['img_id']
+ width = int(data_info['width'])
+ height = int(data_info['height'])
+ if filter_empty_gt and img_id not in ids_with_ann:
+ continue
+ if min(width, height) >= min_size:
+ valid_data_infos.append(data_info)
+
+ return valid_data_infos
+
+ def _join_prefix(self):
+ """Join ``self.data_root`` with ``self.data_prefix`` and
+ ``self.ann_file``.
+ """
+ # Automatically join annotation file path with `self.root` if
+ # `self.ann_file` is not an absolute path.
+ if self.ann_file and not is_abs(self.ann_file) and self.data_root:
+ self.ann_file = join_path(self.data_root, self.ann_file)
+ # Automatically join data directory with `self.root` if path value in
+ # `self.data_prefix` is not an absolute path.
+ for data_key, prefix in self.data_prefix.items():
+ if isinstance(prefix, (list, tuple)):
+ abs_prefix = []
+ for p in prefix:
+ if not is_abs(p) and self.data_root:
+ abs_prefix.append(join_path(self.data_root, p))
+ else:
+ abs_prefix.append(p)
+ self.data_prefix[data_key] = abs_prefix
+ elif isinstance(prefix, str):
+ if not is_abs(prefix) and self.data_root:
+ self.data_prefix[data_key] = join_path(
+ self.data_root, prefix)
+ else:
+ self.data_prefix[data_key] = prefix
+ else:
+ raise TypeError('prefix should be a string, tuple or list,'
+ f'but got {type(prefix)}')
diff --git a/yolo_world/datasets/yolov5_obj365v1.py b/yolo_world/datasets/yolov5_obj365v1.py
new file mode 100644
index 0000000000000000000000000000000000000000..79eff774d2e0ed8f3ce6f0c8d19016956b73c434
--- /dev/null
+++ b/yolo_world/datasets/yolov5_obj365v1.py
@@ -0,0 +1,16 @@
+# Copyright (c) Tencent Inc. All rights reserved.
+from mmdet.datasets import Objects365V1Dataset
+from mmyolo.registry import DATASETS
+
+from .utils import RobustBatchShapePolicyDataset
+
+
+@DATASETS.register_module()
+class YOLOv5Objects365V1Dataset(RobustBatchShapePolicyDataset,
+ Objects365V1Dataset):
+ """Dataset for YOLOv5 VOC Dataset.
+
+ We only add `BatchShapePolicy` function compared with Objects365V1Dataset.
+ See `mmyolo/datasets/utils.py#BatchShapePolicy` for details
+ """
+ pass
diff --git a/yolo_world/datasets/yolov5_obj365v2.py b/yolo_world/datasets/yolov5_obj365v2.py
new file mode 100644
index 0000000000000000000000000000000000000000..9552f2d1193cacc02dfce0899a46b8a5df16a728
--- /dev/null
+++ b/yolo_world/datasets/yolov5_obj365v2.py
@@ -0,0 +1,16 @@
+# Copyright (c) Tencent Inc. All rights reserved.
+from mmdet.datasets import Objects365V2Dataset
+from mmyolo.registry import DATASETS
+
+from .utils import RobustBatchShapePolicyDataset
+
+
+@DATASETS.register_module()
+class YOLOv5Objects365V2Dataset(RobustBatchShapePolicyDataset,
+ Objects365V2Dataset):
+ """Dataset for YOLOv5 VOC Dataset.
+
+ We only add `BatchShapePolicy` function compared with Objects365V1Dataset.
+ See `mmyolo/datasets/utils.py#BatchShapePolicy` for details
+ """
+ pass
diff --git a/yolo_world/datasets/yolov5_v3det.py b/yolo_world/datasets/yolov5_v3det.py
new file mode 100644
index 0000000000000000000000000000000000000000..d947948a262f7146feaedff48ad8d2f048820ef3
--- /dev/null
+++ b/yolo_world/datasets/yolov5_v3det.py
@@ -0,0 +1,109 @@
+# Copyright (c) Tencent Inc. All rights reserved.
+import copy
+import os.path as osp
+from typing import List
+
+from mmengine.fileio import get_local_path
+from mmdet.datasets.api_wrappers import COCO
+from mmdet.datasets import CocoDataset
+from mmyolo.registry import DATASETS
+
+from .utils import RobustBatchShapePolicyDataset
+
+v3det_ignore_list = [
+ 'a00013820/26_275_28143226914_ff3a247c53_c.jpg',
+ 'n03815615/12_1489_32968099046_be38fa580e_c.jpg',
+ 'n04550184/19_1480_2504784164_ffa3db8844_c.jpg',
+ 'a00008703/2_363_3576131784_dfac6fc6ce_c.jpg',
+ 'n02814533/28_2216_30224383848_a90697f1b3_c.jpg',
+ 'n12026476/29_186_15091304754_5c219872f7_c.jpg',
+ 'n01956764/12_2004_50133201066_72e0d9fea5_c.jpg',
+ 'n03785016/14_2642_518053131_d07abcb5da_c.jpg',
+ 'a00011156/33_250_4548479728_9ce5246596_c.jpg',
+ 'a00009461/19_152_2792869324_db95bebc84_c.jpg',
+]
+
+# # ugly code here
+# import json
+# with open(osp.join("data/v3det/cats.json"), 'r') as f:
+# _classes = json.load(f)['classes']
+
+
+@DATASETS.register_module()
+class V3DetDataset(CocoDataset):
+ """Objects365 v1 dataset for detection."""
+
+ METAINFO = {'classes': 'classes', 'palette': None}
+
+ COCOAPI = COCO
+ # ann_id is unique in coco dataset.
+ ANN_ID_UNIQUE = True
+
+ def load_data_list(self) -> List[dict]:
+ """Load annotations from an annotation file named as ``self.ann_file``
+
+ Returns:
+ List[dict]: A list of annotation.
+ """ # noqa: E501
+ with get_local_path(self.ann_file,
+ backend_args=self.backend_args) as local_path:
+ self.coco = self.COCOAPI(local_path)
+
+ # 'categories' list in objects365_train.json and objects365_val.json
+ # is inconsistent, need sort list(or dict) before get cat_ids.
+ cats = self.coco.cats
+ sorted_cats = {i: cats[i] for i in sorted(cats)}
+ self.coco.cats = sorted_cats
+ categories = self.coco.dataset['categories']
+ sorted_categories = sorted(categories, key=lambda i: i['id'])
+ self.coco.dataset['categories'] = sorted_categories
+ # The order of returned `cat_ids` will not
+ # change with the order of the `classes`
+ self.cat_ids = self.coco.get_cat_ids(
+ cat_names=self.metainfo['classes'])
+ self.cat2label = {cat_id: i for i, cat_id in enumerate(self.cat_ids)}
+ self.cat_img_map = copy.deepcopy(self.coco.cat_img_map)
+
+ img_ids = self.coco.get_img_ids()
+ data_list = []
+ total_ann_ids = []
+ for img_id in img_ids:
+ raw_img_info = self.coco.load_imgs([img_id])[0]
+ raw_img_info['img_id'] = img_id
+
+ ann_ids = self.coco.get_ann_ids(img_ids=[img_id])
+ raw_ann_info = self.coco.load_anns(ann_ids)
+ total_ann_ids.extend(ann_ids)
+
+ file_name = osp.join(
+ osp.split(osp.split(raw_img_info['file_name'])[0])[-1],
+ osp.split(raw_img_info['file_name'])[-1])
+
+ if file_name in v3det_ignore_list:
+ continue
+
+ parsed_data_info = self.parse_data_info({
+ 'raw_ann_info':
+ raw_ann_info,
+ 'raw_img_info':
+ raw_img_info
+ })
+ data_list.append(parsed_data_info)
+ if self.ANN_ID_UNIQUE:
+ assert len(set(total_ann_ids)) == len(
+ total_ann_ids
+ ), f"Annotation ids in '{self.ann_file}' are not unique!"
+
+ del self.coco
+
+ return data_list
+
+
+@DATASETS.register_module()
+class YOLOv5V3DetDataset(RobustBatchShapePolicyDataset, V3DetDataset):
+ """Dataset for YOLOv5 VOC Dataset.
+
+ We only add `BatchShapePolicy` function compared with Objects365V1Dataset.
+ See `mmyolo/datasets/utils.py#BatchShapePolicy` for details
+ """
+ pass
diff --git a/yolo_world/easydeploy/README.md b/yolo_world/easydeploy/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..1816e7ed96ee34209c56af4a22eda5f1eb7e499b
--- /dev/null
+++ b/yolo_world/easydeploy/README.md
@@ -0,0 +1,11 @@
+# MMYOLO Model Easy-Deployment
+
+## Introduction
+
+This project is developed for easily converting your MMYOLO models to other inference backends without the need of MMDeploy, which reduces the cost of both time and effort on getting familiar with MMDeploy.
+
+Currently we support converting to `ONNX` and `TensorRT` formats, other inference backends such `ncnn` will be added to this project as well.
+
+## Supported Backends
+
+- [Model Convert](docs/model_convert.md)
diff --git a/yolo_world/easydeploy/README_zh-CN.md b/yolo_world/easydeploy/README_zh-CN.md
new file mode 100644
index 0000000000000000000000000000000000000000..4c6bc0cf4ef91edeced04bdf15af08ae1f6f0dcd
--- /dev/null
+++ b/yolo_world/easydeploy/README_zh-CN.md
@@ -0,0 +1,11 @@
+# MMYOLO 模型转换
+
+## 介绍
+
+本项目作为 MMYOLO 的部署 project 单独存在,意图剥离 MMDeploy 当前的体系,独自支持用户完成模型训练后的转换和部署功能,使用户的学习和工程成本下降。
+
+当前支持对 ONNX 格式和 TensorRT 格式的转换,后续对其他推理平台也会支持起来。
+
+## 转换教程
+
+- [Model Convert](docs/model_convert.md)
diff --git a/yolo_world/easydeploy/backbone/__init__.py b/yolo_world/easydeploy/backbone/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..dc167f8515c66a30d884ed9655a11d45e21481c0
--- /dev/null
+++ b/yolo_world/easydeploy/backbone/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .common import DeployC2f
+from .focus import DeployFocus, GConvFocus, NcnnFocus
+
+__all__ = ['DeployFocus', 'NcnnFocus', 'GConvFocus', 'DeployC2f']
diff --git a/yolo_world/easydeploy/backbone/common.py b/yolo_world/easydeploy/backbone/common.py
new file mode 100644
index 0000000000000000000000000000000000000000..617875bd979a5b9150e476544090777118087a0b
--- /dev/null
+++ b/yolo_world/easydeploy/backbone/common.py
@@ -0,0 +1,16 @@
+import torch
+import torch.nn as nn
+from torch import Tensor
+
+
+class DeployC2f(nn.Module):
+
+ def __init__(self, *args, **kwargs):
+ super().__init__()
+
+ def forward(self, x: Tensor) -> Tensor:
+ x_main = self.main_conv(x)
+ x_main = [x_main, x_main[:, self.mid_channels:, ...]]
+ x_main.extend(blocks(x_main[-1]) for blocks in self.blocks)
+ x_main.pop(1)
+ return self.final_conv(torch.cat(x_main, 1))
diff --git a/yolo_world/easydeploy/backbone/focus.py b/yolo_world/easydeploy/backbone/focus.py
new file mode 100644
index 0000000000000000000000000000000000000000..2a19afcca1d9c4e27109daeebd83907cd9b7b284
--- /dev/null
+++ b/yolo_world/easydeploy/backbone/focus.py
@@ -0,0 +1,79 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from torch import Tensor
+
+
+class DeployFocus(nn.Module):
+
+ def __init__(self, orin_Focus: nn.Module):
+ super().__init__()
+ self.__dict__.update(orin_Focus.__dict__)
+
+ def forward(self, x: Tensor) -> Tensor:
+ batch_size, channel, height, width = x.shape
+ x = x.reshape(batch_size, channel, -1, 2, width)
+ x = x.reshape(batch_size, channel, x.shape[2], 2, -1, 2)
+ half_h = x.shape[2]
+ half_w = x.shape[4]
+ x = x.permute(0, 5, 3, 1, 2, 4)
+ x = x.reshape(batch_size, channel * 4, half_h, half_w)
+
+ return self.conv(x)
+
+
+class NcnnFocus(nn.Module):
+
+ def __init__(self, orin_Focus: nn.Module):
+ super().__init__()
+ self.__dict__.update(orin_Focus.__dict__)
+
+ def forward(self, x: Tensor) -> Tensor:
+ batch_size, c, h, w = x.shape
+ assert h % 2 == 0 and w % 2 == 0, f'focus for yolox needs even feature\
+ height and width, got {(h, w)}.'
+
+ x = x.reshape(batch_size, c * h, 1, w)
+ _b, _c, _h, _w = x.shape
+ g = _c // 2
+ # fuse to ncnn's shufflechannel
+ x = x.view(_b, g, 2, _h, _w)
+ x = torch.transpose(x, 1, 2).contiguous()
+ x = x.view(_b, -1, _h, _w)
+
+ x = x.reshape(_b, c * h * w, 1, 1)
+
+ _b, _c, _h, _w = x.shape
+ g = _c // 2
+ # fuse to ncnn's shufflechannel
+ x = x.view(_b, g, 2, _h, _w)
+ x = torch.transpose(x, 1, 2).contiguous()
+ x = x.view(_b, -1, _h, _w)
+
+ x = x.reshape(_b, c * 4, h // 2, w // 2)
+
+ return self.conv(x)
+
+
+class GConvFocus(nn.Module):
+
+ def __init__(self, orin_Focus: nn.Module):
+ super().__init__()
+ device = next(orin_Focus.parameters()).device
+ self.weight1 = torch.tensor([[1., 0], [0, 0]]).expand(3, 1, 2,
+ 2).to(device)
+ self.weight2 = torch.tensor([[0, 0], [1., 0]]).expand(3, 1, 2,
+ 2).to(device)
+ self.weight3 = torch.tensor([[0, 1.], [0, 0]]).expand(3, 1, 2,
+ 2).to(device)
+ self.weight4 = torch.tensor([[0, 0], [0, 1.]]).expand(3, 1, 2,
+ 2).to(device)
+ self.__dict__.update(orin_Focus.__dict__)
+
+ def forward(self, x: Tensor) -> Tensor:
+ conv1 = F.conv2d(x, self.weight1, stride=2, groups=3)
+ conv2 = F.conv2d(x, self.weight2, stride=2, groups=3)
+ conv3 = F.conv2d(x, self.weight3, stride=2, groups=3)
+ conv4 = F.conv2d(x, self.weight4, stride=2, groups=3)
+ return self.conv(torch.cat([conv1, conv2, conv3, conv4], dim=1))
diff --git a/yolo_world/easydeploy/bbox_code/__init__.py b/yolo_world/easydeploy/bbox_code/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..b85a815536a5749a15f0ad6aab2b028eb6a3fe0a
--- /dev/null
+++ b/yolo_world/easydeploy/bbox_code/__init__.py
@@ -0,0 +1,5 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from .bbox_coder import (rtmdet_bbox_decoder, yolov5_bbox_decoder,
+ yolox_bbox_decoder)
+
+__all__ = ['yolov5_bbox_decoder', 'rtmdet_bbox_decoder', 'yolox_bbox_decoder']
diff --git a/yolo_world/easydeploy/bbox_code/bbox_coder.py b/yolo_world/easydeploy/bbox_code/bbox_coder.py
new file mode 100644
index 0000000000000000000000000000000000000000..6483cf8b0328aff3d61f1fa0788337ab536d347d
--- /dev/null
+++ b/yolo_world/easydeploy/bbox_code/bbox_coder.py
@@ -0,0 +1,46 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import Optional
+
+import torch
+from torch import Tensor
+
+
+def yolov5_bbox_decoder(priors: Tensor, bbox_preds: Tensor,
+ stride: Tensor) -> Tensor:
+ bbox_preds = bbox_preds.sigmoid()
+
+ x_center = (priors[..., 0] + priors[..., 2]) * 0.5
+ y_center = (priors[..., 1] + priors[..., 3]) * 0.5
+ w = priors[..., 2] - priors[..., 0]
+ h = priors[..., 3] - priors[..., 1]
+
+ x_center_pred = (bbox_preds[..., 0] - 0.5) * 2 * stride + x_center
+ y_center_pred = (bbox_preds[..., 1] - 0.5) * 2 * stride + y_center
+ w_pred = (bbox_preds[..., 2] * 2)**2 * w
+ h_pred = (bbox_preds[..., 3] * 2)**2 * h
+
+ decoded_bboxes = torch.stack(
+ [x_center_pred, y_center_pred, w_pred, h_pred], dim=-1)
+
+ return decoded_bboxes
+
+
+def rtmdet_bbox_decoder(priors: Tensor, bbox_preds: Tensor,
+ stride: Optional[Tensor]) -> Tensor:
+ stride = stride[None, :, None]
+ bbox_preds *= stride
+ tl_x = (priors[..., 0] - bbox_preds[..., 0])
+ tl_y = (priors[..., 1] - bbox_preds[..., 1])
+ br_x = (priors[..., 0] + bbox_preds[..., 2])
+ br_y = (priors[..., 1] + bbox_preds[..., 3])
+ decoded_bboxes = torch.stack([tl_x, tl_y, br_x, br_y], -1)
+ return decoded_bboxes
+
+
+def yolox_bbox_decoder(priors: Tensor, bbox_preds: Tensor,
+ stride: Optional[Tensor]) -> Tensor:
+ stride = stride[None, :, None]
+ xys = (bbox_preds[..., :2] * stride) + priors
+ whs = bbox_preds[..., 2:].exp() * stride
+ decoded_bboxes = torch.cat([xys, whs], -1)
+ return decoded_bboxes
diff --git a/yolo_world/easydeploy/deepstream/CMakeLists.txt b/yolo_world/easydeploy/deepstream/CMakeLists.txt
new file mode 100644
index 0000000000000000000000000000000000000000..f640bea13bacfc0f6cc2f33e598f65cf5ce0922e
--- /dev/null
+++ b/yolo_world/easydeploy/deepstream/CMakeLists.txt
@@ -0,0 +1,35 @@
+cmake_minimum_required(VERSION 2.8.12)
+
+set(CMAKE_CUDA_ARCHITECTURES 60 61 62 70 72 75 86)
+set(CMAKE_CUDA_COMPILER /usr/local/cuda/bin/nvcc)
+
+project(nvdsparsebbox_mmyolo LANGUAGES CXX)
+
+set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++14 -O3 -g -Wall -Werror -shared -fPIC")
+set(CMAKE_CXX_STANDARD 14)
+set(CMAKE_BUILD_TYPE Release)
+option(CUDA_USE_STATIC_CUDA_RUNTIME OFF)
+
+# CUDA
+find_package(CUDA REQUIRED)
+
+# TensorRT
+set(TensorRT_INCLUDE_DIRS "/usr/include/x86_64-linux-gnu" CACHE STRING "TensorRT headers path")
+set(TensorRT_LIBRARIES "/usr/lib/x86_64-linux-gnu" CACHE STRING "TensorRT libs path")
+
+# DeepStream
+set(DEEPSTREAM "/opt/nvidia/deepstream/deepstream" CACHE STRING "DeepStream root path")
+set(DS_LIBRARIES ${DEEPSTREAM}/lib)
+set(DS_INCLUDE_DIRS ${DEEPSTREAM}/sources/includes)
+
+include_directories(
+ ${CUDA_INCLUDE_DIRS}
+ ${TensorRT_INCLUDE_DIRS}
+ ${DS_INCLUDE_DIRS})
+
+add_library(
+ ${PROJECT_NAME}
+ SHARED
+ custom_mmyolo_bbox_parser/nvdsparsebbox_mmyolo.cpp)
+
+target_link_libraries(${PROJECT_NAME} PRIVATE nvinfer nvinfer_plugin)
diff --git a/yolo_world/easydeploy/deepstream/README.md b/yolo_world/easydeploy/deepstream/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..111f3765e41d558b64097d8a25585bd9c14acf4f
--- /dev/null
+++ b/yolo_world/easydeploy/deepstream/README.md
@@ -0,0 +1,48 @@
+# Inference MMYOLO Models with DeepStream
+
+This project demonstrates how to inference MMYOLO models with customized parsers in [DeepStream SDK](https://developer.nvidia.com/deepstream-sdk).
+
+## Pre-requisites
+
+### 1. Install Nvidia Driver and CUDA
+
+First, please follow the official documents and instructions to install dedicated Nvidia graphic driver and CUDA matched to your gpu and target Nvidia AIoT devices.
+
+### 2. Install DeepStream SDK
+
+Second, please follow the official instruction to download and install DeepStream SDK. Currently stable version of DeepStream is v6.2.
+
+### 3. Generate TensorRT Engine
+
+As DeepStream builds on top of several NVIDIA libraries, you need to first convert your trained MMYOLO models to TensorRT engine files. We strongly recommend you to try the supported TensorRT deployment solution in [EasyDeploy](../../easydeploy/).
+
+## Build and Run
+
+Please make sure that your converted TensorRT engine is already located in the `deepstream` folder as the config shows. Create your own model config files and change the `config-file` parameter in [deepstream_app_config.txt](deepstream_app_config.txt) to the model you want to run with.
+
+```bash
+mkdir build && cd build
+cmake ..
+make -j$(nproc) && make install
+```
+
+Then you can run the inference with this command.
+
+```bash
+deepstream-app -c deepstream_app_config.txt
+```
+
+## Code Structure
+
+```bash
+├── deepstream
+│ ├── configs # config file for MMYOLO models
+│ │ └── config_infer_rtmdet.txt
+│ ├── custom_mmyolo_bbox_parser # customized parser for MMYOLO models to DeepStream formats
+│ │ └── nvdsparsebbox_mmyolo.cpp
+| ├── CMakeLists.txt
+│ ├── coco_labels.txt # labels for coco detection
+│ ├── deepstream_app_config.txt # deepStream reference app configs for MMYOLO models
+│ ├── README_zh-CN.md
+│ └── README.md
+```
diff --git a/yolo_world/easydeploy/deepstream/README_zh-CN.md b/yolo_world/easydeploy/deepstream/README_zh-CN.md
new file mode 100644
index 0000000000000000000000000000000000000000..13a85d5bc90159c3ff9f1a32e93d01e82ed2faa4
--- /dev/null
+++ b/yolo_world/easydeploy/deepstream/README_zh-CN.md
@@ -0,0 +1,48 @@
+# 使用 DeepStream SDK 推理 MMYOLO 模型
+
+本项目演示了如何使用 [DeepStream SDK](https://developer.nvidia.com/deepstream-sdk) 配合改写的 parser 来推理 MMYOLO 的模型。
+
+## 预先准备
+
+### 1. 安装 Nidia 驱动和 CUDA
+
+首先请根据当前的显卡驱动和目标使用设备的驱动完成显卡驱动和 CUDA 的安装。
+
+### 2. 安装 DeepStream SDK
+
+目前 DeepStream SDK 稳定版本已经更新到 v6.2,官方推荐使用这个版本。
+
+### 3. 将 MMYOLO 模型转换为 TensorRT Engine
+
+推荐使用 EasyDeploy 中的 TensorRT 方案完成目标模型的转换部署,具体可参考 [此文档](../../easydeploy/docs/model_convert.md) 。
+
+## 编译使用
+
+当前项目使用的是 MMYOLO 的 rtmdet 模型,若想使用其他的模型,请参照目录下的配置文件进行改写。然后将转换完的 TensorRT engine 放在当前目录下并执行如下命令:
+
+```bash
+mkdir build && cd build
+cmake ..
+make -j$(nproc) && make install
+```
+
+完成编译后可使用如下命令进行推理:
+
+```bash
+deepstream-app -c deepstream_app_config.txt
+```
+
+## 项目代码结构
+
+```bash
+├── deepstream
+│ ├── configs # MMYOLO 模型对应的 DeepStream 配置
+│ │ └── config_infer_rtmdet.txt
+│ ├── custom_mmyolo_bbox_parser # 适配 DeepStream formats 的 parser
+│ │ └── nvdsparsebbox_mmyolo.cpp
+| ├── CMakeLists.txt
+│ ├── coco_labels.txt # coco labels
+│ ├── deepstream_app_config.txt # DeepStream app 配置
+│ ├── README_zh-CN.md
+│ └── README.md
+```
diff --git a/yolo_world/easydeploy/deepstream/coco_labels.txt b/yolo_world/easydeploy/deepstream/coco_labels.txt
new file mode 100644
index 0000000000000000000000000000000000000000..ca76c80b5b2cd0b25047f75736656cfebc9da7aa
--- /dev/null
+++ b/yolo_world/easydeploy/deepstream/coco_labels.txt
@@ -0,0 +1,80 @@
+person
+bicycle
+car
+motorbike
+aeroplane
+bus
+train
+truck
+boat
+traffic light
+fire hydrant
+stop sign
+parking meter
+bench
+bird
+cat
+dog
+horse
+sheep
+cow
+elephant
+bear
+zebra
+giraffe
+backpack
+umbrella
+handbag
+tie
+suitcase
+frisbee
+skis
+snowboard
+sports ball
+kite
+baseball bat
+baseball glove
+skateboard
+surfboard
+tennis racket
+bottle
+wine glass
+cup
+fork
+knife
+spoon
+bowl
+banana
+apple
+sandwich
+orange
+broccoli
+carrot
+hot dog
+pizza
+donut
+cake
+chair
+sofa
+pottedplant
+bed
+diningtable
+toilet
+tvmonitor
+laptop
+mouse
+remote
+keyboard
+cell phone
+microwave
+oven
+toaster
+sink
+refrigerator
+book
+clock
+vase
+scissors
+teddy bear
+hair drier
+toothbrush
diff --git a/yolo_world/easydeploy/deepstream/configs/config_infer_rtmdet.txt b/yolo_world/easydeploy/deepstream/configs/config_infer_rtmdet.txt
new file mode 100644
index 0000000000000000000000000000000000000000..a1e5efd2a3810730144e037ee96dfbd36124b0e6
--- /dev/null
+++ b/yolo_world/easydeploy/deepstream/configs/config_infer_rtmdet.txt
@@ -0,0 +1,22 @@
+[property]
+gpu-id=0
+net-scale-factor=0.01735207357279195
+offsets=57.375;57.12;58.395
+model-color-format=1
+model-engine-file=../end2end.engine
+labelfile-path=../coco_labels.txt
+batch-size=1
+network-mode=0
+num-detected-classes=80
+interval=0
+gie-unique-id=1
+process-mode=1
+network-type=0
+cluster-mode=2
+maintain-aspect-ratio=1
+parse-bbox-func-name=NvDsInferParseCustomMMYOLO
+custom-lib-path=../build/libnvdsparsebbox_mmyolo.so
+
+[class-attrs-all]
+pre-cluster-threshold=0.45
+topk=100
diff --git a/yolo_world/easydeploy/deepstream/configs/config_infer_yolov5.txt b/yolo_world/easydeploy/deepstream/configs/config_infer_yolov5.txt
new file mode 100644
index 0000000000000000000000000000000000000000..6ad7d6429cacd0a6050821e5b2a41317478f5119
--- /dev/null
+++ b/yolo_world/easydeploy/deepstream/configs/config_infer_yolov5.txt
@@ -0,0 +1,21 @@
+[property]
+gpu-id=0
+net-scale-factor=0.0039215697906911373
+model-color-format=0
+model-engine-file=../end2end.engine
+labelfile-path=../coco_labels.txt
+batch-size=1
+network-mode=0
+num-detected-classes=80
+interval=0
+gie-unique-id=1
+process-mode=1
+network-type=0
+cluster-mode=2
+maintain-aspect-ratio=1
+parse-bbox-func-name=NvDsInferParseCustomMMYOLO
+custom-lib-path=../build/libnvdsparsebbox_mmyolo.so
+
+[class-attrs-all]
+pre-cluster-threshold=0.45
+topk=100
diff --git a/yolo_world/easydeploy/deepstream/configs/config_infer_yolov8.txt b/yolo_world/easydeploy/deepstream/configs/config_infer_yolov8.txt
new file mode 100644
index 0000000000000000000000000000000000000000..6ad7d6429cacd0a6050821e5b2a41317478f5119
--- /dev/null
+++ b/yolo_world/easydeploy/deepstream/configs/config_infer_yolov8.txt
@@ -0,0 +1,21 @@
+[property]
+gpu-id=0
+net-scale-factor=0.0039215697906911373
+model-color-format=0
+model-engine-file=../end2end.engine
+labelfile-path=../coco_labels.txt
+batch-size=1
+network-mode=0
+num-detected-classes=80
+interval=0
+gie-unique-id=1
+process-mode=1
+network-type=0
+cluster-mode=2
+maintain-aspect-ratio=1
+parse-bbox-func-name=NvDsInferParseCustomMMYOLO
+custom-lib-path=../build/libnvdsparsebbox_mmyolo.so
+
+[class-attrs-all]
+pre-cluster-threshold=0.45
+topk=100
diff --git a/yolo_world/easydeploy/deepstream/custom_mmyolo_bbox_parser/nvdsparsebbox_mmyolo.cpp b/yolo_world/easydeploy/deepstream/custom_mmyolo_bbox_parser/nvdsparsebbox_mmyolo.cpp
new file mode 100644
index 0000000000000000000000000000000000000000..eb780856cbd2b289cdf9dc8518438f946a2ab548
--- /dev/null
+++ b/yolo_world/easydeploy/deepstream/custom_mmyolo_bbox_parser/nvdsparsebbox_mmyolo.cpp
@@ -0,0 +1,118 @@
+#include "nvdsinfer_custom_impl.h"
+#include
+#include
+
+/**
+ * Function expected by DeepStream for decoding the MMYOLO output.
+ *
+ * C-linkage [extern "C"] was written to prevent name-mangling. This function must return true after
+ * adding all bounding boxes to the objectList vector.
+ *
+ * @param [outputLayersInfo] std::vector of NvDsInferLayerInfo objects with information about the output layer.
+ * @param [networkInfo] NvDsInferNetworkInfo object with information about the MMYOLO network.
+ * @param [detectionParams] NvDsInferParseDetectionParams with information about some config params.
+ * @param [objectList] std::vector of NvDsInferParseObjectInfo objects to which bounding box information must
+ * be stored.
+ *
+ * @return true
+ */
+
+// This is just the function prototype. The definition is written at the end of the file.
+extern "C" bool NvDsInferParseCustomMMYOLO(
+ std::vector const& outputLayersInfo,
+ NvDsInferNetworkInfo const& networkInfo,
+ NvDsInferParseDetectionParams const& detectionParams,
+ std::vector& objectList);
+
+static __inline__ float clamp(float& val, float min, float max)
+{
+ return val > min ? (val < max ? val : max) : min;
+}
+
+static std::vector decodeMMYoloTensor(
+ const int* num_dets,
+ const float* bboxes,
+ const float* scores,
+ const int* labels,
+ const float& conf_thres,
+ const unsigned int& img_w,
+ const unsigned int& img_h
+)
+{
+ std::vector bboxInfo;
+ size_t nums = num_dets[0];
+ for (size_t i = 0; i < nums; i++)
+ {
+ float score = scores[i];
+ if (score < conf_thres)continue;
+ float x0 = (bboxes[i * 4]);
+ float y0 = (bboxes[i * 4 + 1]);
+ float x1 = (bboxes[i * 4 + 2]);
+ float y1 = (bboxes[i * 4 + 3]);
+ x0 = clamp(x0, 0.f, img_w);
+ y0 = clamp(y0, 0.f, img_h);
+ x1 = clamp(x1, 0.f, img_w);
+ y1 = clamp(y1, 0.f, img_h);
+ NvDsInferParseObjectInfo obj;
+ obj.left = x0;
+ obj.top = y0;
+ obj.width = x1 - x0;
+ obj.height = y1 - y0;
+ obj.detectionConfidence = score;
+ obj.classId = labels[i];
+ bboxInfo.push_back(obj);
+ }
+
+ return bboxInfo;
+}
+
+/* C-linkage to prevent name-mangling */
+extern "C" bool NvDsInferParseCustomMMYOLO(
+ std::vector const& outputLayersInfo,
+ NvDsInferNetworkInfo const& networkInfo,
+ NvDsInferParseDetectionParams const& detectionParams,
+ std::vector& objectList)
+{
+
+// Some assertions and error checking.
+ if (outputLayersInfo.empty() || outputLayersInfo.size() != 4)
+ {
+ std::cerr << "Could not find output layer in bbox parsing" << std::endl;
+ return false;
+ }
+
+// Score threshold of bboxes.
+ const float conf_thres = detectionParams.perClassThreshold[0];
+
+// Obtaining the output layer.
+ const NvDsInferLayerInfo& num_dets = outputLayersInfo[0];
+ const NvDsInferLayerInfo& bboxes = outputLayersInfo[1];
+ const NvDsInferLayerInfo& scores = outputLayersInfo[2];
+ const NvDsInferLayerInfo& labels = outputLayersInfo[3];
+
+// num_dets(int) bboxes(float) scores(float) labels(int)
+ assert (num_dets.dims.numDims == 2);
+ assert (bboxes.dims.numDims == 3);
+ assert (scores.dims.numDims == 2);
+ assert (labels.dims.numDims == 2);
+
+
+// Decoding the output tensor of MMYOLO to the NvDsInferParseObjectInfo format.
+ std::vector objects =
+ decodeMMYoloTensor(
+ (const int*)(num_dets.buffer),
+ (const float*)(bboxes.buffer),
+ (const float*)(scores.buffer),
+ (const int*)(labels.buffer),
+ conf_thres,
+ networkInfo.width,
+ networkInfo.height
+ );
+
+ objectList.clear();
+ objectList = objects;
+ return true;
+}
+
+/* Check that the custom function has been defined correctly */
+CHECK_CUSTOM_PARSE_FUNC_PROTOTYPE(NvDsInferParseCustomMMYOLO);
diff --git a/yolo_world/easydeploy/deepstream/deepstream_app_config.txt b/yolo_world/easydeploy/deepstream/deepstream_app_config.txt
new file mode 100644
index 0000000000000000000000000000000000000000..331776897a5e9109b9007ed1b7974f128287c4fc
--- /dev/null
+++ b/yolo_world/easydeploy/deepstream/deepstream_app_config.txt
@@ -0,0 +1,62 @@
+[application]
+enable-perf-measurement=1
+perf-measurement-interval-sec=5
+
+[tiled-display]
+enable=1
+rows=1
+columns=1
+width=1280
+height=720
+gpu-id=0
+nvbuf-memory-type=0
+
+[source0]
+enable=1
+type=3
+uri=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4
+num-sources=1
+gpu-id=0
+cudadec-memtype=0
+
+[sink0]
+enable=1
+type=2
+sync=0
+gpu-id=0
+nvbuf-memory-type=0
+
+[osd]
+enable=1
+gpu-id=0
+border-width=5
+text-size=15
+text-color=1;1;1;1;
+text-bg-color=0.3;0.3;0.3;1
+font=Serif
+show-clock=0
+clock-x-offset=800
+clock-y-offset=820
+clock-text-size=12
+clock-color=1;0;0;0
+nvbuf-memory-type=0
+
+[streammux]
+gpu-id=0
+live-source=0
+batch-size=1
+batched-push-timeout=40000
+width=1920
+height=1080
+enable-padding=0
+nvbuf-memory-type=0
+
+[primary-gie]
+enable=1
+gpu-id=0
+gie-unique-id=1
+nvbuf-memory-type=0
+config-file=configs/config_infer_rtmdet.txt
+
+[tests]
+file-loop=0
diff --git a/yolo_world/easydeploy/docs/model_convert.md b/yolo_world/easydeploy/docs/model_convert.md
new file mode 100644
index 0000000000000000000000000000000000000000..9af62599dd1b56648680fc315ca88c35c7b31cb9
--- /dev/null
+++ b/yolo_world/easydeploy/docs/model_convert.md
@@ -0,0 +1,156 @@
+# MMYOLO 模型 ONNX 转换
+
+## 1. 导出后端支持的 ONNX
+
+## 环境依赖
+
+- [onnx](https://github.com/onnx/onnx)
+
+ ```shell
+ pip install onnx
+ ```
+
+ [onnx-simplifier](https://github.com/daquexian/onnx-simplifier) (可选,用于简化模型)
+
+ ```shell
+ pip install onnx-simplifier
+ ```
+
+\*\*\* 请确保您在 `MMYOLO` 根目录下运行相关脚本,避免无法找到相关依赖包。\*\*\*
+
+## 使用方法
+
+[模型导出脚本](./projects/easydeploy/tools/export_onnx.py)用于将 `MMYOLO` 模型转换为 `onnx` 。
+
+### 参数介绍:
+
+- `config` : 构建模型使用的配置文件,如 [`yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py`](./configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py) 。
+- `checkpoint` : 训练得到的权重文件,如 `yolov5s.pth` 。
+- `--work-dir` : 转换后的模型保存路径。
+- `--img-size`: 转换模型时输入的尺寸,如 `640 640`。
+- `--batch-size`: 转换后的模型输入 `batch size` 。
+- `--device`: 转换模型使用的设备,默认为 `cuda:0`。
+- `--simplify`: 是否简化导出的 `onnx` 模型,需要安装 [onnx-simplifier](https://github.com/daquexian/onnx-simplifier),默认关闭。
+- `--opset`: 指定导出 `onnx` 的 `opset`,默认为 `11` 。
+- `--backend`: 指定导出 `onnx` 用于的后端名称,`ONNXRuntime`: `onnxruntime`, `TensorRT8`: `tensorrt8`, `TensorRT7`: `tensorrt7`,默认为`onnxruntime`即 `ONNXRuntime`。
+- `--pre-topk`: 指定导出 `onnx` 的后处理筛选候选框个数阈值,默认为 `1000`。
+- `--keep-topk`: 指定导出 `onnx` 的非极大值抑制输出的候选框个数阈值,默认为 `100`。
+- `--iou-threshold`: 非极大值抑制中过滤重复候选框的 `iou` 阈值,默认为 `0.65`。
+- `--score-threshold`: 非极大值抑制中过滤候选框得分的阈值,默认为 `0.25`。
+- `--model-only`: 指定仅导出模型 backbone + neck, 不包含后处理,默认关闭。
+
+例子:
+
+```shell
+python ./projects/easydeploy/tools/export.py \
+ configs/yolov5/yolov5_s-v61_syncbn_fast_8xb16-300e_coco.py \
+ yolov5s.pth \
+ --work-dir work_dir \
+ --img-size 640 640 \
+ --batch 1 \
+ --device cpu \
+ --simplify \
+ --opset 11 \
+ --backend 1 \
+ --pre-topk 1000 \
+ --keep-topk 100 \
+ --iou-threshold 0.65 \
+ --score-threshold 0.25
+```
+
+然后利用后端支持的工具如 `TensorRT` 读取 `onnx` 再次转换为后端支持的模型格式如 `.engine/.plan` 等。
+
+`MMYOLO` 目前支持 `TensorRT8`, `TensorRT7`, `ONNXRuntime` 后端的端到端模型转换,目前仅支持静态 shape 模型的导出和转换,动态 batch 或动态长宽的模型端到端转换会在未来继续支持。
+
+端到端转换得到的 `onnx` 模型输入输出如图:
+
+
+
+
+
+
 +
+