Spaces:
Running

Running
Commit
•
7088d16
1
Parent(s):
e8bdcf1
Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +30 -0
- .gitignore +15 -0
- .gitmodules +7 -0
- .ipynb_checkpoints/webui-checkpoint.py +1364 -0
- ASR/FunASR.py +54 -0
- ASR/README.md +77 -0
- ASR/Whisper.py +129 -0
- ASR/__init__.py +4 -0
- ASR/requirements_funasr.txt +3 -0
- AutoDL部署.md +234 -0
- FunASR/punc_ct-transformer_zh-cn-common-vocab272727-pytorch/.mdl +0 -0
- FunASR/punc_ct-transformer_zh-cn-common-vocab272727-pytorch/.msc +0 -0
- FunASR/punc_ct-transformer_zh-cn-common-vocab272727-pytorch/README.md +272 -0
- FunASR/punc_ct-transformer_zh-cn-common-vocab272727-pytorch/config.yaml +46 -0
- FunASR/punc_ct-transformer_zh-cn-common-vocab272727-pytorch/configuration.json +13 -0
- FunASR/punc_ct-transformer_zh-cn-common-vocab272727-pytorch/example/punc_example.txt +3 -0
- FunASR/punc_ct-transformer_zh-cn-common-vocab272727-pytorch/fig/struct.png +0 -0
- FunASR/punc_ct-transformer_zh-cn-common-vocab272727-pytorch/model.pt +3 -0
- FunASR/punc_ct-transformer_zh-cn-common-vocab272727-pytorch/tokens.json +0 -0
- FunASR/speech_fsmn_vad_zh-cn-16k-common-pytorch/.mdl +0 -0
- FunASR/speech_fsmn_vad_zh-cn-16k-common-pytorch/.msc +0 -0
- FunASR/speech_fsmn_vad_zh-cn-16k-common-pytorch/README.md +296 -0
- FunASR/speech_fsmn_vad_zh-cn-16k-common-pytorch/am.mvn +8 -0
- FunASR/speech_fsmn_vad_zh-cn-16k-common-pytorch/config.yaml +56 -0
- FunASR/speech_fsmn_vad_zh-cn-16k-common-pytorch/configuration.json +13 -0
- FunASR/speech_fsmn_vad_zh-cn-16k-common-pytorch/fig/struct.png +0 -0
- FunASR/speech_fsmn_vad_zh-cn-16k-common-pytorch/model.pt +3 -0
- FunASR/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/.mdl +0 -0
- FunASR/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/.msc +0 -0
- FunASR/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/README.md +357 -0
- FunASR/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/am.mvn +8 -0
- FunASR/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/config.yaml +159 -0
- FunASR/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/configuration.json +14 -0
- FunASR/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/example/hotword.txt +1 -0
- FunASR/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/fig/res.png +0 -0
- FunASR/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/fig/seaco.png +0 -0
- FunASR/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/model.pt +3 -0
- FunASR/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/seg_dict +0 -0
- FunASR/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/tokens.json +0 -0
- GPT_SoVITS/AR/__init__.py +0 -0
- GPT_SoVITS/AR/data/__init__.py +0 -0
- GPT_SoVITS/AR/data/bucket_sampler.py +162 -0
- GPT_SoVITS/AR/data/data_module.py +74 -0
- GPT_SoVITS/AR/data/dataset.py +320 -0
- GPT_SoVITS/AR/models/__init__.py +0 -0
- GPT_SoVITS/AR/models/t2s_lightning_module.py +140 -0
- GPT_SoVITS/AR/models/t2s_lightning_module_onnx.py +106 -0
- GPT_SoVITS/AR/models/t2s_model.py +327 -0
- GPT_SoVITS/AR/models/t2s_model_onnx.py +337 -0
- GPT_SoVITS/AR/models/utils.py +160 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,33 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
Musetalk/data/video/man_musev.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
Musetalk/data/video/monalisa_musev.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
Musetalk/data/video/seaside4_musev.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
Musetalk/data/video/sit_musev.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
Musetalk/data/video/sun_musev.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
Musetalk/data/video/yongen_musev.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
NeRF/gridencoder/build/lib.linux-x86_64-3.10/_gridencoder.cpython-310-x86_64-linux-gnu.so filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
NeRF/gridencoder/build/temp.linux-x86_64-3.10/root/Linly-Talker/NeRF/gridencoder/src/gridencoder.o filter=lfs diff=lfs merge=lfs -text
|
| 44 |
+
docs/WebUI.png filter=lfs diff=lfs merge=lfs -text
|
| 45 |
+
examples/source_image/art_16.png filter=lfs diff=lfs merge=lfs -text
|
| 46 |
+
examples/source_image/art_17.png filter=lfs diff=lfs merge=lfs -text
|
| 47 |
+
examples/source_image/art_3.png filter=lfs diff=lfs merge=lfs -text
|
| 48 |
+
examples/source_image/art_4.png filter=lfs diff=lfs merge=lfs -text
|
| 49 |
+
examples/source_image/art_5.png filter=lfs diff=lfs merge=lfs -text
|
| 50 |
+
examples/source_image/art_8.png filter=lfs diff=lfs merge=lfs -text
|
| 51 |
+
examples/source_image/art_9.png filter=lfs diff=lfs merge=lfs -text
|
| 52 |
+
inputs/boy.png filter=lfs diff=lfs merge=lfs -text
|
| 53 |
+
pytorch3d/.github/bundle_adjust.gif filter=lfs diff=lfs merge=lfs -text
|
| 54 |
+
pytorch3d/.github/camera_position_teapot.gif filter=lfs diff=lfs merge=lfs -text
|
| 55 |
+
pytorch3d/.github/fit_nerf.gif filter=lfs diff=lfs merge=lfs -text
|
| 56 |
+
pytorch3d/.github/fit_textured_volume.gif filter=lfs diff=lfs merge=lfs -text
|
| 57 |
+
pytorch3d/.github/implicitron_config.gif filter=lfs diff=lfs merge=lfs -text
|
| 58 |
+
pytorch3d/.github/nerf_project_logo.gif filter=lfs diff=lfs merge=lfs -text
|
| 59 |
+
pytorch3d/build/lib.linux-x86_64-3.10/pytorch3d/_C.cpython-310-x86_64-linux-gnu.so filter=lfs diff=lfs merge=lfs -text
|
| 60 |
+
pytorch3d/build/temp.linux-x86_64-3.10/.ninja_deps filter=lfs diff=lfs merge=lfs -text
|
| 61 |
+
pytorch3d/build/temp.linux-x86_64-3.10/root/Linly-Talker/pytorch3d/pytorch3d/csrc/knn/knn.o filter=lfs diff=lfs merge=lfs -text
|
| 62 |
+
pytorch3d/build/temp.linux-x86_64-3.10/root/Linly-Talker/pytorch3d/pytorch3d/csrc/pulsar/cuda/renderer.construct.gpu.o filter=lfs diff=lfs merge=lfs -text
|
| 63 |
+
pytorch3d/build/temp.linux-x86_64-3.10/root/Linly-Talker/pytorch3d/pytorch3d/csrc/pulsar/cuda/renderer.forward.gpu.o filter=lfs diff=lfs merge=lfs -text
|
| 64 |
+
pytorch3d/docs/notes/assets/batch_modes.gif filter=lfs diff=lfs merge=lfs -text
|
| 65 |
+
pytorch3d/docs/notes/assets/meshrcnn.png filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.DS_Store
|
| 2 |
+
checkpoints/
|
| 3 |
+
gfpgan/
|
| 4 |
+
__pycache__/
|
| 5 |
+
*.pyc
|
| 6 |
+
Linly-AI
|
| 7 |
+
Qwen
|
| 8 |
+
checkpoints
|
| 9 |
+
temp
|
| 10 |
+
*.wav
|
| 11 |
+
*.vtt
|
| 12 |
+
*.srt
|
| 13 |
+
results/example_answer.mp4
|
| 14 |
+
request-Linly-api.py
|
| 15 |
+
results
|
.gitmodules
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[submodule "MuseV"]
|
| 2 |
+
path = MuseV
|
| 3 |
+
url = https://github.com/TMElyralab/MuseV.git
|
| 4 |
+
|
| 5 |
+
[submodule "ChatTTS"]
|
| 6 |
+
path = ChatTTS
|
| 7 |
+
url = https://github.com/2noise/ChatTTS.git
|
.ipynb_checkpoints/webui-checkpoint.py
ADDED
|
@@ -0,0 +1,1364 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import random
|
| 3 |
+
import gradio as gr
|
| 4 |
+
import time
|
| 5 |
+
import torch
|
| 6 |
+
import gc
|
| 7 |
+
import warnings
|
| 8 |
+
warnings.filterwarnings('ignore')
|
| 9 |
+
from zhconv import convert
|
| 10 |
+
from LLM import LLM
|
| 11 |
+
from TTS import EdgeTTS
|
| 12 |
+
from src.cost_time import calculate_time
|
| 13 |
+
|
| 14 |
+
from configs import *
|
| 15 |
+
os.environ["GRADIO_TEMP_DIR"]= './temp'
|
| 16 |
+
os.environ["WEBUI"] = "true"
|
| 17 |
+
def get_title(title = 'Linly 智能对话系统 (Linly-Talker)'):
|
| 18 |
+
description = f"""
|
| 19 |
+
<p style="text-align: center; font-weight: bold;">
|
| 20 |
+
<span style="font-size: 28px;">{title}</span>
|
| 21 |
+
<br>
|
| 22 |
+
<span style="font-size: 18px;" id="paper-info">
|
| 23 |
+
[<a href="https://zhuanlan.zhihu.com/p/671006998" target="_blank">知乎</a>]
|
| 24 |
+
[<a href="https://www.bilibili.com/video/BV1rN4y1a76x/" target="_blank">bilibili</a>]
|
| 25 |
+
[<a href="https://github.com/Kedreamix/Linly-Talker" target="_blank">GitHub</a>]
|
| 26 |
+
[<a herf="https://kedreamix.github.io/" target="_blank">个人主页</a>]
|
| 27 |
+
</span>
|
| 28 |
+
<br>
|
| 29 |
+
<span>Linly-Talker是一款创新的数字人对话系统,它融合了最新的人工智能技术,包括大型语言模型(LLM)🤖、自动语音识别(ASR)🎙️、文本到语音转换(TTS)🗣️和语音克隆技术🎤。</span>
|
| 30 |
+
</p>
|
| 31 |
+
"""
|
| 32 |
+
return description
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
# 设置默认system
|
| 36 |
+
default_system = '你是一个很有帮助的助手'
|
| 37 |
+
# 设置默认的prompt
|
| 38 |
+
prefix_prompt = '''请用少于25个字回答以下问题\n\n'''
|
| 39 |
+
|
| 40 |
+
edgetts = EdgeTTS()
|
| 41 |
+
|
| 42 |
+
# 设定默认参数值,可修改
|
| 43 |
+
blink_every = True
|
| 44 |
+
size_of_image = 256
|
| 45 |
+
preprocess_type = 'crop'
|
| 46 |
+
facerender = 'facevid2vid'
|
| 47 |
+
enhancer = False
|
| 48 |
+
is_still_mode = False
|
| 49 |
+
exp_weight = 1
|
| 50 |
+
use_ref_video = False
|
| 51 |
+
ref_video = None
|
| 52 |
+
ref_info = 'pose'
|
| 53 |
+
use_idle_mode = False
|
| 54 |
+
length_of_audio = 5
|
| 55 |
+
|
| 56 |
+
@calculate_time
|
| 57 |
+
def Asr(audio):
|
| 58 |
+
try:
|
| 59 |
+
question = asr.transcribe(audio)
|
| 60 |
+
question = convert(question, 'zh-cn')
|
| 61 |
+
except Exception as e:
|
| 62 |
+
print("ASR Error: ", e)
|
| 63 |
+
question = 'Gradio存在一些bug,麦克风模式有时候可能音频还未传入,请重新点击一下语音识别即可'
|
| 64 |
+
gr.Warning(question)
|
| 65 |
+
return question
|
| 66 |
+
|
| 67 |
+
def clear_memory():
|
| 68 |
+
"""
|
| 69 |
+
清理PyTorch的显存和系统内存缓存。
|
| 70 |
+
"""
|
| 71 |
+
# 1. 清理缓存的变量
|
| 72 |
+
gc.collect() # 触发Python垃圾回收
|
| 73 |
+
torch.cuda.empty_cache() # 清理PyTorch的显存缓存
|
| 74 |
+
torch.cuda.ipc_collect() # 清理PyTorch的跨进程通信缓存
|
| 75 |
+
|
| 76 |
+
# 2. 打印显存使用情况(可选)
|
| 77 |
+
print(f"Memory allocated: {torch.cuda.memory_allocated() / (1024 ** 2):.2f} MB")
|
| 78 |
+
print(f"Max memory allocated: {torch.cuda.max_memory_allocated() / (1024 ** 2):.2f} MB")
|
| 79 |
+
print(f"Cached memory: {torch.cuda.memory_reserved() / (1024 ** 2):.2f} MB")
|
| 80 |
+
print(f"Max cached memory: {torch.cuda.max_memory_reserved() / (1024 ** 2):.2f} MB")
|
| 81 |
+
|
| 82 |
+
@calculate_time
|
| 83 |
+
def TTS_response(text,
|
| 84 |
+
voice, rate, volume, pitch,
|
| 85 |
+
am, voc, lang, male,
|
| 86 |
+
inp_ref, prompt_text, prompt_language, text_language, how_to_cut,
|
| 87 |
+
question_audio, question, use_mic_voice,
|
| 88 |
+
tts_method = 'PaddleTTS', save_path = 'answer.wav'):
|
| 89 |
+
# print(text, voice, rate, volume, pitch, am, voc, lang, male, tts_method, save_path)
|
| 90 |
+
if tts_method == 'Edge-TTS':
|
| 91 |
+
if not edgetts.network:
|
| 92 |
+
gr.Warning("请检查网络或者使用其他模型,例如PaddleTTS")
|
| 93 |
+
return None, None
|
| 94 |
+
try:
|
| 95 |
+
edgetts.predict(text, voice, rate, volume, pitch , 'answer.wav', 'answer.vtt')
|
| 96 |
+
except:
|
| 97 |
+
os.system(f'edge-tts --text "{text}" --voice {voice} --write-media answer.wav --write-subtitles answer.vtt')
|
| 98 |
+
return 'answer.wav', 'answer.vtt'
|
| 99 |
+
elif tts_method == 'PaddleTTS':
|
| 100 |
+
tts.predict(text, am, voc, lang = lang, male=male, save_path = save_path)
|
| 101 |
+
return save_path, None
|
| 102 |
+
elif tts_method == 'GPT-SoVITS克隆声音':
|
| 103 |
+
if use_mic_voice:
|
| 104 |
+
try:
|
| 105 |
+
vits.predict(ref_wav_path = question_audio,
|
| 106 |
+
prompt_text = question,
|
| 107 |
+
prompt_language = "中文",
|
| 108 |
+
text = text, # 回答
|
| 109 |
+
text_language = "中文",
|
| 110 |
+
how_to_cut = "凑四句一切",
|
| 111 |
+
save_path = 'answer.wav')
|
| 112 |
+
return 'answer.wav', None
|
| 113 |
+
except Exception as e:
|
| 114 |
+
gr.Warning("无克隆环境或者无克隆模型权重,无法克隆声音", e)
|
| 115 |
+
return None, None
|
| 116 |
+
else:
|
| 117 |
+
try:
|
| 118 |
+
vits.predict(ref_wav_path = inp_ref,
|
| 119 |
+
prompt_text = prompt_text,
|
| 120 |
+
prompt_language = prompt_language,
|
| 121 |
+
text = text, # 回答
|
| 122 |
+
text_language = text_language,
|
| 123 |
+
how_to_cut = how_to_cut,
|
| 124 |
+
save_path = 'answer.wav')
|
| 125 |
+
return 'answer.wav', None
|
| 126 |
+
except Exception as e:
|
| 127 |
+
gr.Warning("无克隆环境或者无克隆模型权重,无法克隆声音", e)
|
| 128 |
+
return None, None
|
| 129 |
+
return None, None
|
| 130 |
+
@calculate_time
|
| 131 |
+
def LLM_response(question_audio, question,
|
| 132 |
+
voice = 'zh-CN-XiaoxiaoNeural', rate = 0, volume = 0, pitch = 0,
|
| 133 |
+
am='fastspeech2', voc='pwgan',lang='zh', male=False,
|
| 134 |
+
inp_ref = None, prompt_text = "", prompt_language = "", text_language = "", how_to_cut = "", use_mic_voice = False,
|
| 135 |
+
tts_method = 'Edge-TTS'):
|
| 136 |
+
if len(question) == 0:
|
| 137 |
+
gr.Warning("请输入问题")
|
| 138 |
+
return None, None, None
|
| 139 |
+
answer = llm.generate(question, default_system)
|
| 140 |
+
print(answer)
|
| 141 |
+
driven_audio, driven_vtt = TTS_response(answer, voice, rate, volume, pitch,
|
| 142 |
+
am, voc, lang, male,
|
| 143 |
+
inp_ref, prompt_text, prompt_language, text_language, how_to_cut, question_audio, question, use_mic_voice,
|
| 144 |
+
tts_method)
|
| 145 |
+
return driven_audio, driven_vtt, answer
|
| 146 |
+
|
| 147 |
+
@calculate_time
|
| 148 |
+
def Talker_response(question_audio = None, method = 'SadTalker', text = '',
|
| 149 |
+
voice = 'zh-CN-XiaoxiaoNeural', rate = 0, volume = 100, pitch = 0,
|
| 150 |
+
am = 'fastspeech2', voc = 'pwgan', lang = 'zh', male = False,
|
| 151 |
+
inp_ref = None, prompt_text = "", prompt_language = "", text_language = "", how_to_cut = "", use_mic_voice = False,
|
| 152 |
+
tts_method = 'Edge-TTS',batch_size = 2, character = '女性角色',
|
| 153 |
+
progress=gr.Progress(track_tqdm=True)):
|
| 154 |
+
default_voice = None
|
| 155 |
+
if character == '女性角色':
|
| 156 |
+
# 女性角色
|
| 157 |
+
source_image, pic_path = r'inputs/girl.png', r'inputs/girl.png'
|
| 158 |
+
crop_pic_path = "./inputs/first_frame_dir_girl/girl.png"
|
| 159 |
+
first_coeff_path = "./inputs/first_frame_dir_girl/girl.mat"
|
| 160 |
+
crop_info = ((403, 403), (19, 30, 502, 513), [40.05956541381802, 40.17324339233366, 443.7892505041507, 443.9029284826663])
|
| 161 |
+
default_voice = 'zh-CN-XiaoxiaoNeural'
|
| 162 |
+
elif character == '男性角色':
|
| 163 |
+
# 男性角色
|
| 164 |
+
source_image = r'./inputs/boy.png'
|
| 165 |
+
pic_path = "./inputs/boy.png"
|
| 166 |
+
crop_pic_path = "./inputs/first_frame_dir_boy/boy.png"
|
| 167 |
+
first_coeff_path = "./inputs/first_frame_dir_boy/boy.mat"
|
| 168 |
+
crop_info = ((876, 747), (0, 0, 886, 838), [10.382158280494476, 0, 886, 747.7078990925525])
|
| 169 |
+
default_voice = 'zh-CN-YunyangNeural'
|
| 170 |
+
else:
|
| 171 |
+
gr.Warning('未知角色')
|
| 172 |
+
return None
|
| 173 |
+
|
| 174 |
+
voice = default_voice if not voice else voice
|
| 175 |
+
|
| 176 |
+
if not voice:
|
| 177 |
+
gr.Warning('请选择声音')
|
| 178 |
+
|
| 179 |
+
driven_audio, driven_vtt, _ = LLM_response(question_audio, text,
|
| 180 |
+
voice, rate, volume, pitch,
|
| 181 |
+
am, voc, lang, male,
|
| 182 |
+
inp_ref, prompt_text, prompt_language, text_language, how_to_cut, use_mic_voice,
|
| 183 |
+
tts_method)
|
| 184 |
+
if driven_audio is None:
|
| 185 |
+
gr.Warning("音频没有正常生成,请检查TTS是否正确")
|
| 186 |
+
return None
|
| 187 |
+
if method == 'SadTalker':
|
| 188 |
+
pose_style = random.randint(0, 45)
|
| 189 |
+
video = talker.test(pic_path,
|
| 190 |
+
crop_pic_path,
|
| 191 |
+
first_coeff_path,
|
| 192 |
+
crop_info,
|
| 193 |
+
source_image,
|
| 194 |
+
driven_audio,
|
| 195 |
+
preprocess_type,
|
| 196 |
+
is_still_mode,
|
| 197 |
+
enhancer,
|
| 198 |
+
batch_size,
|
| 199 |
+
size_of_image,
|
| 200 |
+
pose_style,
|
| 201 |
+
facerender,
|
| 202 |
+
exp_weight,
|
| 203 |
+
use_ref_video,
|
| 204 |
+
ref_video,
|
| 205 |
+
ref_info,
|
| 206 |
+
use_idle_mode,
|
| 207 |
+
length_of_audio,
|
| 208 |
+
blink_every,
|
| 209 |
+
fps=20)
|
| 210 |
+
elif method == 'Wav2Lip':
|
| 211 |
+
video = talker.predict(crop_pic_path, driven_audio, batch_size, enhancer)
|
| 212 |
+
elif method == 'NeRFTalk':
|
| 213 |
+
video = talker.predict(driven_audio)
|
| 214 |
+
else:
|
| 215 |
+
gr.Warning("不支持的方法:" + method)
|
| 216 |
+
return None
|
| 217 |
+
if driven_vtt:
|
| 218 |
+
return video, driven_vtt
|
| 219 |
+
else:
|
| 220 |
+
return video
|
| 221 |
+
|
| 222 |
+
@calculate_time
|
| 223 |
+
def Talker_response_img(question_audio, method, text, voice, rate, volume, pitch,
|
| 224 |
+
am, voc, lang, male,
|
| 225 |
+
inp_ref , prompt_text, prompt_language, text_language, how_to_cut, use_mic_voice,
|
| 226 |
+
tts_method,
|
| 227 |
+
source_image,
|
| 228 |
+
preprocess_type,
|
| 229 |
+
is_still_mode,
|
| 230 |
+
enhancer,
|
| 231 |
+
batch_size,
|
| 232 |
+
size_of_image,
|
| 233 |
+
pose_style,
|
| 234 |
+
facerender,
|
| 235 |
+
exp_weight,
|
| 236 |
+
blink_every,
|
| 237 |
+
fps, progress=gr.Progress(track_tqdm=True)
|
| 238 |
+
):
|
| 239 |
+
if enhancer:
|
| 240 |
+
gr.Warning("记得请先安装GFPGAN库,pip install gfpgan, 已安装可忽略")
|
| 241 |
+
if not voice:
|
| 242 |
+
gr.Warning("请先选择声音")
|
| 243 |
+
driven_audio, driven_vtt, _ = LLM_response(question_audio, text, voice, rate, volume, pitch,
|
| 244 |
+
am, voc, lang, male,
|
| 245 |
+
inp_ref, prompt_text, prompt_language, text_language, how_to_cut, use_mic_voice,
|
| 246 |
+
tts_method = tts_method)
|
| 247 |
+
if driven_audio is None:
|
| 248 |
+
gr.Warning("音频没有正常生成,请检查TTS是否正确")
|
| 249 |
+
return None
|
| 250 |
+
if method == 'SadTalker':
|
| 251 |
+
video = talker.test2(source_image,
|
| 252 |
+
driven_audio,
|
| 253 |
+
preprocess_type,
|
| 254 |
+
is_still_mode,
|
| 255 |
+
enhancer,
|
| 256 |
+
batch_size,
|
| 257 |
+
size_of_image,
|
| 258 |
+
pose_style,
|
| 259 |
+
facerender,
|
| 260 |
+
exp_weight,
|
| 261 |
+
use_ref_video,
|
| 262 |
+
ref_video,
|
| 263 |
+
ref_info,
|
| 264 |
+
use_idle_mode,
|
| 265 |
+
length_of_audio,
|
| 266 |
+
blink_every,
|
| 267 |
+
fps=fps)
|
| 268 |
+
elif method == 'Wav2Lip':
|
| 269 |
+
video = talker.predict(source_image, driven_audio, batch_size)
|
| 270 |
+
elif method == 'NeRFTalk':
|
| 271 |
+
video = talker.predict(driven_audio)
|
| 272 |
+
else:
|
| 273 |
+
return None
|
| 274 |
+
if driven_vtt:
|
| 275 |
+
return video, driven_vtt
|
| 276 |
+
else:
|
| 277 |
+
return video
|
| 278 |
+
|
| 279 |
+
@calculate_time
|
| 280 |
+
def Talker_Say(preprocess_type,
|
| 281 |
+
is_still_mode,
|
| 282 |
+
enhancer,
|
| 283 |
+
batch_size,
|
| 284 |
+
size_of_image,
|
| 285 |
+
pose_style,
|
| 286 |
+
facerender,
|
| 287 |
+
exp_weight,
|
| 288 |
+
blink_every,
|
| 289 |
+
fps,source_image = None, source_video = None, question_audio = None, method = 'SadTalker', text = '',
|
| 290 |
+
voice = 'zh-CN-XiaoxiaoNeural', rate = 0, volume = 100, pitch = 0,
|
| 291 |
+
am = 'fastspeech2', voc = 'pwgan', lang = 'zh', male = False,
|
| 292 |
+
inp_ref = None, prompt_text = "", prompt_language = "", text_language = "", how_to_cut = "", use_mic_voice = False,
|
| 293 |
+
tts_method = 'Edge-TTS', character = '女性角色',
|
| 294 |
+
progress=gr.Progress(track_tqdm=True)):
|
| 295 |
+
if source_video:
|
| 296 |
+
source_image = source_video
|
| 297 |
+
default_voice = None
|
| 298 |
+
|
| 299 |
+
voice = default_voice if not voice else voice
|
| 300 |
+
|
| 301 |
+
if not voice:
|
| 302 |
+
gr.Warning('请选择声音')
|
| 303 |
+
|
| 304 |
+
driven_audio, driven_vtt = TTS_response(text, voice, rate, volume, pitch,
|
| 305 |
+
am, voc, lang, male,
|
| 306 |
+
inp_ref, prompt_text, prompt_language, text_language, how_to_cut, question_audio, text, use_mic_voice,
|
| 307 |
+
tts_method)
|
| 308 |
+
if driven_audio is None:
|
| 309 |
+
gr.Warning("音频没有正常生成,请检查TTS是否正确")
|
| 310 |
+
return None
|
| 311 |
+
if method == 'SadTalker':
|
| 312 |
+
pose_style = random.randint(0, 45)
|
| 313 |
+
video = talker.test2(source_image,
|
| 314 |
+
driven_audio,
|
| 315 |
+
preprocess_type,
|
| 316 |
+
is_still_mode,
|
| 317 |
+
enhancer,
|
| 318 |
+
batch_size,
|
| 319 |
+
size_of_image,
|
| 320 |
+
pose_style,
|
| 321 |
+
facerender,
|
| 322 |
+
exp_weight,
|
| 323 |
+
use_ref_video,
|
| 324 |
+
ref_video,
|
| 325 |
+
ref_info,
|
| 326 |
+
use_idle_mode,
|
| 327 |
+
length_of_audio,
|
| 328 |
+
blink_every,
|
| 329 |
+
fps=fps)
|
| 330 |
+
elif method == 'Wav2Lip':
|
| 331 |
+
video = talker.predict(source_image, driven_audio, batch_size, enhancer)
|
| 332 |
+
elif method == 'NeRFTalk':
|
| 333 |
+
video = talker.predict(driven_audio)
|
| 334 |
+
else:
|
| 335 |
+
gr.Warning("不支持的方法:" + method)
|
| 336 |
+
return None
|
| 337 |
+
if driven_vtt:
|
| 338 |
+
return video, driven_vtt
|
| 339 |
+
else:
|
| 340 |
+
return video
|
| 341 |
+
|
| 342 |
+
def chat_response(system, message, history):
|
| 343 |
+
# response = llm.generate(message)
|
| 344 |
+
response, history = llm.chat(system, message, history)
|
| 345 |
+
print(history)
|
| 346 |
+
# 流式输出
|
| 347 |
+
for i in range(len(response)):
|
| 348 |
+
time.sleep(0.01)
|
| 349 |
+
yield "", history[:-1] + [(message, response[:i+1])]
|
| 350 |
+
return "", history
|
| 351 |
+
|
| 352 |
+
def modify_system_session(system: str) -> str:
|
| 353 |
+
if system is None or len(system) == 0:
|
| 354 |
+
system = default_system
|
| 355 |
+
llm.clear_history()
|
| 356 |
+
return system, system, []
|
| 357 |
+
|
| 358 |
+
def clear_session():
|
| 359 |
+
# clear history
|
| 360 |
+
llm.clear_history()
|
| 361 |
+
return '', []
|
| 362 |
+
|
| 363 |
+
|
| 364 |
+
def human_response(source_image, history, question_audio, talker_method, voice, rate, volume, pitch,
|
| 365 |
+
am, voc, lang, male,
|
| 366 |
+
inp_ref, prompt_text, prompt_language, text_language, how_to_cut, use_mic_voice,
|
| 367 |
+
tts_method, character,
|
| 368 |
+
preprocess_type, is_still_mode, enhancer, batch_size, size_of_image,
|
| 369 |
+
pose_style, facerender, exp_weight, blink_every, fps = 20, progress=gr.Progress(track_tqdm=True)):
|
| 370 |
+
response = history[-1][1]
|
| 371 |
+
qusetion = history[-1][0]
|
| 372 |
+
# driven_audio, video_vtt = 'answer.wav', 'answer.vtt'
|
| 373 |
+
if character == '女性角色':
|
| 374 |
+
# 女性角色
|
| 375 |
+
source_image, pic_path = r'./inputs/girl.png', r"./inputs/girl.png"
|
| 376 |
+
crop_pic_path = "./inputs/first_frame_dir_girl/girl.png"
|
| 377 |
+
first_coeff_path = "./inputs/first_frame_dir_girl/girl.mat"
|
| 378 |
+
crop_info = ((403, 403), (19, 30, 502, 513), [40.05956541381802, 40.17324339233366, 443.7892505041507, 443.9029284826663])
|
| 379 |
+
default_voice = 'zh-CN-XiaoxiaoNeural'
|
| 380 |
+
elif character == '男性角色':
|
| 381 |
+
# 男性角色
|
| 382 |
+
source_image = r'./inputs/boy.png'
|
| 383 |
+
pic_path = "./inputs/boy.png"
|
| 384 |
+
crop_pic_path = "./inputs/first_frame_dir_boy/boy.png"
|
| 385 |
+
first_coeff_path = "./inputs/first_frame_dir_boy/boy.mat"
|
| 386 |
+
crop_info = ((876, 747), (0, 0, 886, 838), [10.382158280494476, 0, 886, 747.7078990925525])
|
| 387 |
+
default_voice = 'zh-CN-YunyangNeural'
|
| 388 |
+
elif character == '自定义角色':
|
| 389 |
+
if source_image is None:
|
| 390 |
+
gr.Error("自定义角色需要上传正确的图片")
|
| 391 |
+
return None
|
| 392 |
+
default_voice = 'zh-CN-XiaoxiaoNeural'
|
| 393 |
+
voice = default_voice if not voice else voice
|
| 394 |
+
# tts.predict(response, voice, rate, volume, pitch, driven_audio, video_vtt)
|
| 395 |
+
driven_audio, driven_vtt = TTS_response(response, voice, rate, volume, pitch,
|
| 396 |
+
am, voc, lang, male,
|
| 397 |
+
inp_ref, prompt_text, prompt_language, text_language, how_to_cut, question_audio, qusetion, use_mic_voice,
|
| 398 |
+
tts_method)
|
| 399 |
+
if driven_audio is None:
|
| 400 |
+
gr.Warning("音频没有正常生成,请检查TTS是否正确")
|
| 401 |
+
return None
|
| 402 |
+
if talker_method == 'SadTalker':
|
| 403 |
+
pose_style = random.randint(0, 45)
|
| 404 |
+
video = talker.test(pic_path,
|
| 405 |
+
crop_pic_path,
|
| 406 |
+
first_coeff_path,
|
| 407 |
+
crop_info,
|
| 408 |
+
source_image,
|
| 409 |
+
driven_audio,
|
| 410 |
+
preprocess_type,
|
| 411 |
+
is_still_mode,
|
| 412 |
+
enhancer,
|
| 413 |
+
batch_size,
|
| 414 |
+
size_of_image,
|
| 415 |
+
pose_style,
|
| 416 |
+
facerender,
|
| 417 |
+
exp_weight,
|
| 418 |
+
use_ref_video,
|
| 419 |
+
ref_video,
|
| 420 |
+
ref_info,
|
| 421 |
+
use_idle_mode,
|
| 422 |
+
length_of_audio,
|
| 423 |
+
blink_every,
|
| 424 |
+
fps=fps)
|
| 425 |
+
elif talker_method == 'Wav2Lip':
|
| 426 |
+
video = talker.predict(crop_pic_path, driven_audio, batch_size, enhancer)
|
| 427 |
+
elif talker_method == 'NeRFTalk':
|
| 428 |
+
video = talker.predict(driven_audio)
|
| 429 |
+
else:
|
| 430 |
+
gr.Warning("不支持的方法:" + talker_method)
|
| 431 |
+
return None
|
| 432 |
+
if driven_vtt:
|
| 433 |
+
return video, driven_vtt
|
| 434 |
+
else:
|
| 435 |
+
return video
|
| 436 |
+
|
| 437 |
+
|
| 438 |
+
@calculate_time
|
| 439 |
+
def MuseTalker_response(source_video, bbox_shift, question_audio = None, text = '',
|
| 440 |
+
voice = 'zh-CN-XiaoxiaoNeural', rate = 0, volume = 100, pitch = 0,
|
| 441 |
+
am = 'fastspeech2', voc = 'pwgan', lang = 'zh', male = False,
|
| 442 |
+
inp_ref = None, prompt_text = "", prompt_language = "", text_language = "", how_to_cut = "", use_mic_voice = False,
|
| 443 |
+
tts_method = 'Edge-TTS', batch_size = 4,
|
| 444 |
+
progress=gr.Progress(track_tqdm=True)):
|
| 445 |
+
default_voice = None
|
| 446 |
+
voice = default_voice if not voice else voice
|
| 447 |
+
|
| 448 |
+
if not voice:
|
| 449 |
+
gr.Warning('请选择声音')
|
| 450 |
+
|
| 451 |
+
driven_audio, driven_vtt, _ = LLM_response(question_audio, text,
|
| 452 |
+
voice, rate, volume, pitch,
|
| 453 |
+
am, voc, lang, male,
|
| 454 |
+
inp_ref, prompt_text, prompt_language, text_language, how_to_cut, use_mic_voice,
|
| 455 |
+
tts_method)
|
| 456 |
+
print(driven_audio, driven_vtt)
|
| 457 |
+
video = musetalker.inference_noprepare(driven_audio,
|
| 458 |
+
source_video,
|
| 459 |
+
bbox_shift,
|
| 460 |
+
batch_size,
|
| 461 |
+
fps = 25)
|
| 462 |
+
|
| 463 |
+
if driven_vtt:
|
| 464 |
+
return (video, driven_vtt)
|
| 465 |
+
else:
|
| 466 |
+
return video
|
| 467 |
+
GPT_SoVITS_ckpt = "GPT_SoVITS/pretrained_models"
|
| 468 |
+
def load_vits_model(gpt_path, sovits_path, progress=gr.Progress(track_tqdm=True)):
|
| 469 |
+
global vits
|
| 470 |
+
print("模型加载中...", gpt_path, sovits_path)
|
| 471 |
+
all_gpt_path, all_sovits_path = os.path.join(GPT_SoVITS_ckpt, gpt_path), os.path.join(GPT_SoVITS_ckpt, sovits_path)
|
| 472 |
+
vits.load_model(all_gpt_path, all_sovits_path)
|
| 473 |
+
gr.Info("模型加载成功")
|
| 474 |
+
return gpt_path, sovits_path
|
| 475 |
+
|
| 476 |
+
def list_models(dir, endwith = ".pth"):
|
| 477 |
+
list_folder = os.listdir(dir)
|
| 478 |
+
list_folder = [i for i in list_folder if i.endswith(endwith)]
|
| 479 |
+
return list_folder
|
| 480 |
+
|
| 481 |
+
def character_change(character):
|
| 482 |
+
if character == '女性角色':
|
| 483 |
+
# 女性角色
|
| 484 |
+
source_image = r'./inputs/girl.png'
|
| 485 |
+
elif character == '男性角色':
|
| 486 |
+
# 男性角色
|
| 487 |
+
source_image = r'./inputs/boy.png'
|
| 488 |
+
elif character == '自定义角色':
|
| 489 |
+
# gr.Warnings("自定义角色暂未更新,请继续关注后续,可通过自由上传图片模式进行自定义角色")
|
| 490 |
+
source_image = None
|
| 491 |
+
return source_image
|
| 492 |
+
|
| 493 |
+
def webui_setting(talk = False):
|
| 494 |
+
if not talk:
|
| 495 |
+
with gr.Tabs():
|
| 496 |
+
with gr.TabItem('数字人形象设定'):
|
| 497 |
+
source_image = gr.Image(label="Source image", type="filepath")
|
| 498 |
+
else:
|
| 499 |
+
source_image = None
|
| 500 |
+
with gr.Tabs("TTS Method"):
|
| 501 |
+
with gr.Accordion("TTS Method语音方法调节 ", open=True):
|
| 502 |
+
with gr.Tab("Edge-TTS"):
|
| 503 |
+
voice = gr.Dropdown(edgetts.SUPPORTED_VOICE,
|
| 504 |
+
value='zh-CN-XiaoxiaoNeural',
|
| 505 |
+
label="Voice 声音选择")
|
| 506 |
+
rate = gr.Slider(minimum=-100,
|
| 507 |
+
maximum=100,
|
| 508 |
+
value=0,
|
| 509 |
+
step=1.0,
|
| 510 |
+
label='Rate 速率')
|
| 511 |
+
volume = gr.Slider(minimum=0,
|
| 512 |
+
maximum=100,
|
| 513 |
+
value=100,
|
| 514 |
+
step=1,
|
| 515 |
+
label='Volume 音量')
|
| 516 |
+
pitch = gr.Slider(minimum=-100,
|
| 517 |
+
maximum=100,
|
| 518 |
+
value=0,
|
| 519 |
+
step=1,
|
| 520 |
+
label='Pitch 音调')
|
| 521 |
+
with gr.Tab("PaddleTTS"):
|
| 522 |
+
am = gr.Dropdown(["FastSpeech2"], label="声学模型选择", value = 'FastSpeech2')
|
| 523 |
+
voc = gr.Dropdown(["PWGan", "HifiGan"], label="声码器选择", value = 'PWGan')
|
| 524 |
+
lang = gr.Dropdown(["zh", "en", "mix", "canton"], label="语言选择", value = 'zh')
|
| 525 |
+
male = gr.Checkbox(label="男声(Male)", value=False)
|
| 526 |
+
with gr.Tab('GPT-SoVITS'):
|
| 527 |
+
with gr.Row():
|
| 528 |
+
gpt_path = gr.FileExplorer(root = GPT_SoVITS_ckpt, glob = "*.ckpt", value = "s1bert25hz-2kh-longer-epoch=68e-step=50232.ckpt", file_count='single', label="GPT模型路径")
|
| 529 |
+
sovits_path = gr.FileExplorer(root = GPT_SoVITS_ckpt, glob = "*.pth", value = "s2G488k.pth", file_count='single', label="SoVITS模型路径")
|
| 530 |
+
# gpt_path = gr.Dropdown(choices=list_models(GPT_SoVITS_ckpt, 'ckpt'))
|
| 531 |
+
# sovits_path = gr.Dropdown(choices=list_models(GPT_SoVITS_ckpt, 'pth'))
|
| 532 |
+
# gpt_path = gr.Textbox(label="GPT模型路径",
|
| 533 |
+
# value="GPT_SoVITS/pretrained_models/s1bert25hz-2kh-longer-epoch=68e-step=50232.ckpt")
|
| 534 |
+
# sovits_path = gr.Textbox(label="SoVITS模型路径",
|
| 535 |
+
# value="GPT_SoVITS/pretrained_models/s2G488k.pth")
|
| 536 |
+
button = gr.Button("加载模型")
|
| 537 |
+
button.click(fn = load_vits_model,
|
| 538 |
+
inputs=[gpt_path, sovits_path],
|
| 539 |
+
outputs=[gpt_path, sovits_path])
|
| 540 |
+
|
| 541 |
+
with gr.Row():
|
| 542 |
+
inp_ref = gr.Audio(label="请上传3~10秒内参考音频,超过会报错!", sources=["microphone", "upload"], type="filepath")
|
| 543 |
+
use_mic_voice = gr.Checkbox(label="使用语音问答的麦克风")
|
| 544 |
+
prompt_text = gr.Textbox(label="参考音频的文本", value="")
|
| 545 |
+
prompt_language = gr.Dropdown(
|
| 546 |
+
label="参考音频的语种", choices=["中文", "英文", "日文"], value="中文"
|
| 547 |
+
)
|
| 548 |
+
asr_button = gr.Button("语音识别 - 克隆参考音频")
|
| 549 |
+
asr_button.click(fn=Asr,inputs=[inp_ref],outputs=[prompt_text])
|
| 550 |
+
with gr.Row():
|
| 551 |
+
text_language = gr.Dropdown(
|
| 552 |
+
label="需要合成的语种", choices=["中文", "英文", "日文", "中英混合", "日英混合", "多语种混合"], value="中文"
|
| 553 |
+
)
|
| 554 |
+
|
| 555 |
+
how_to_cut = gr.Dropdown(
|
| 556 |
+
label="怎么切",
|
| 557 |
+
choices=["不切", "凑四句一切", "凑50字一切", "按中文句号。切", "按英文句号.切", "按标点符号切" ],
|
| 558 |
+
value="凑四句一切",
|
| 559 |
+
interactive=True,
|
| 560 |
+
)
|
| 561 |
+
|
| 562 |
+
with gr.Column(variant='panel'):
|
| 563 |
+
batch_size = gr.Slider(minimum=1,
|
| 564 |
+
maximum=10,
|
| 565 |
+
value=2,
|
| 566 |
+
step=1,
|
| 567 |
+
label='Talker Batch size')
|
| 568 |
+
|
| 569 |
+
character = gr.Radio(['女性角色',
|
| 570 |
+
'男性角色',
|
| 571 |
+
'自定义角色'],
|
| 572 |
+
label="角色选择", value='自定义角色')
|
| 573 |
+
character.change(fn = character_change, inputs=[character], outputs = [source_image])
|
| 574 |
+
tts_method = gr.Radio(['Edge-TTS', 'PaddleTTS', 'GPT-SoVITS克隆声音', 'Comming Soon!!!'], label="Text To Speech Method",
|
| 575 |
+
value = 'Edge-TTS')
|
| 576 |
+
tts_method.change(fn = tts_model_change, inputs=[tts_method], outputs = [tts_method])
|
| 577 |
+
asr_method = gr.Radio(choices = ['Whisper-tiny', 'Whisper-base', 'FunASR', 'Comming Soon!!!'], value='Whisper-base', label = '语音识别模型选择')
|
| 578 |
+
asr_method.change(fn = asr_model_change, inputs=[asr_method], outputs = [asr_method])
|
| 579 |
+
talker_method = gr.Radio(choices = ['SadTalker', 'Wav2Lip', 'NeRFTalk', 'Comming Soon!!!'],
|
| 580 |
+
value = 'SadTalker', label = '数字人模型选择')
|
| 581 |
+
talker_method.change(fn = talker_model_change, inputs=[talker_method], outputs = [talker_method])
|
| 582 |
+
llm_method = gr.Dropdown(choices = ['Qwen', 'Qwen2', 'Linly', 'Gemini', 'ChatGLM', 'ChatGPT', 'GPT4Free', '直接回复 Direct Reply', 'Comming Soon!!!'], value = '直接回复 Direct Reply', label = 'LLM 模型选择')
|
| 583 |
+
llm_method.change(fn = llm_model_change, inputs=[llm_method], outputs = [llm_method])
|
| 584 |
+
return (source_image, voice, rate, volume, pitch,
|
| 585 |
+
am, voc, lang, male,
|
| 586 |
+
inp_ref, prompt_text, prompt_language, text_language, how_to_cut, use_mic_voice,
|
| 587 |
+
tts_method, batch_size, character, talker_method, asr_method, llm_method)
|
| 588 |
+
|
| 589 |
+
|
| 590 |
+
def exmaple_setting(asr, text, character, talk , tts, voice, llm):
|
| 591 |
+
# 默认text的Example
|
| 592 |
+
examples = [
|
| 593 |
+
['Whisper-base', '应对压力最有效的方法是什么?', '女性角色', 'SadTalker', 'Edge-TTS', 'zh-CN-XiaoxiaoNeural', '直接回复 Direct Reply'],
|
| 594 |
+
['Whisper-tiny', '应对压力最有效的方法是什么?', '女性角色', 'SadTalker', 'PaddleTTS', 'None', '直接回复 Direct Reply'],
|
| 595 |
+
['Whisper-base', '应对压力最有效的方法是什么?', '女性角色', 'SadTalker', 'Edge-TTS', 'zh-CN-XiaoxiaoNeural', 'Qwen'],
|
| 596 |
+
['FunASR', '如何进行时间管理?','男性角色', 'SadTalker', 'Edge-TTS', 'zh-CN-YunyangNeural', 'Qwen'],
|
| 597 |
+
['Whisper-tiny', '为什么有些人选择使用纸质地图或寻求方向,而不是依赖GPS设备或智能手机应用程序?','女性角色', 'Wav2Lip', 'PaddleTTS', 'None', 'Qwen'],
|
| 598 |
+
]
|
| 599 |
+
|
| 600 |
+
with gr.Row(variant='panel'):
|
| 601 |
+
with gr.Column(variant='panel'):
|
| 602 |
+
gr.Markdown("## Test Examples")
|
| 603 |
+
gr.Examples(
|
| 604 |
+
examples = examples,
|
| 605 |
+
inputs = [asr, text, character, talk , tts, voice, llm],
|
| 606 |
+
)
|
| 607 |
+
def app():
|
| 608 |
+
with gr.Blocks(analytics_enabled=False, title = 'Linly-Talker') as inference:
|
| 609 |
+
gr.HTML(get_title("Linly 智能对话系统 (Linly-Talker) 文本/语音对话"))
|
| 610 |
+
with gr.Row(equal_height=False):
|
| 611 |
+
with gr.Column(variant='panel'):
|
| 612 |
+
(source_image, voice, rate, volume, pitch,
|
| 613 |
+
am, voc, lang, male,
|
| 614 |
+
inp_ref, prompt_text, prompt_language, text_language, how_to_cut, use_mic_voice,
|
| 615 |
+
tts_method, batch_size, character, talker_method, asr_method, llm_method)= webui_setting()
|
| 616 |
+
|
| 617 |
+
|
| 618 |
+
with gr.Column(variant='panel'):
|
| 619 |
+
with gr.Tabs():
|
| 620 |
+
with gr.TabItem('对话'):
|
| 621 |
+
with gr.Group():
|
| 622 |
+
question_audio = gr.Audio(sources=['microphone','upload'], type="filepath", label = '语音对话')
|
| 623 |
+
input_text = gr.Textbox(label="输入文字/问题", lines=3)
|
| 624 |
+
asr_text = gr.Button('语音识别(语音对话后点击)')
|
| 625 |
+
asr_text.click(fn=Asr,inputs=[question_audio],outputs=[input_text])
|
| 626 |
+
# with gr.TabItem('SadTalker数字人参数设置'):
|
| 627 |
+
# with gr.Accordion("Advanced Settings",
|
| 628 |
+
# open=False):
|
| 629 |
+
# gr.Markdown("SadTalker: need help? please visit our [[best practice page](https://github.com/OpenTalker/SadTalker/blob/main/docs/best_practice.md)] for more detials")
|
| 630 |
+
# with gr.Column(variant='panel'):
|
| 631 |
+
# # width = gr.Slider(minimum=64, elem_id="img2img_width", maximum=2048, step=8, label="Manually Crop Width", value=512) # img2img_width
|
| 632 |
+
# # height = gr.Slider(minimum=64, elem_id="img2img_height", maximum=2048, step=8, label="Manually Crop Height", value=512) # img2img_width
|
| 633 |
+
# with gr.Row():
|
| 634 |
+
# pose_style = gr.Slider(minimum=0, maximum=45, step=1, label="Pose style", value=0) #
|
| 635 |
+
# exp_weight = gr.Slider(minimum=0, maximum=3, step=0.1, label="expression scale", value=1) #
|
| 636 |
+
# blink_every = gr.Checkbox(label="use eye blink", value=True)
|
| 637 |
+
|
| 638 |
+
# with gr.Row():
|
| 639 |
+
# size_of_image = gr.Radio([256, 512], value=256, label='face model resolution', info="use 256/512 model? 256 is faster") #
|
| 640 |
+
# preprocess_type = gr.Radio(['crop', 'resize','full'], value='full', label='preprocess', info="How to handle input image?")
|
| 641 |
+
|
| 642 |
+
# with gr.Row():
|
| 643 |
+
# is_still_mode = gr.Checkbox(label="Still Mode (fewer head motion, works with preprocess `full`)")
|
| 644 |
+
# facerender = gr.Radio(['facevid2vid'], value='facevid2vid', label='facerender', info="which face render?")
|
| 645 |
+
|
| 646 |
+
# with gr.Row():
|
| 647 |
+
# # batch_size = gr.Slider(label="batch size in generation", step=1, maximum=10, value=1)
|
| 648 |
+
# fps = gr.Slider(label='fps in generation', step=1, maximum=30, value =20)
|
| 649 |
+
# enhancer = gr.Checkbox(label="GFPGAN as Face enhancer(slow)")
|
| 650 |
+
with gr.Tabs():
|
| 651 |
+
with gr.TabItem('数字人问答'):
|
| 652 |
+
gen_video = gr.Video(label="生成视频", format="mp4", autoplay=False)
|
| 653 |
+
video_button = gr.Button("🎬 生成数字人视频", variant='primary')
|
| 654 |
+
video_button.click(fn=Talker_response,inputs=[question_audio, talker_method, input_text, voice, rate, volume, pitch,
|
| 655 |
+
am, voc, lang, male,
|
| 656 |
+
inp_ref, prompt_text, prompt_language, text_language, how_to_cut, use_mic_voice,
|
| 657 |
+
tts_method, batch_size, character],outputs=[gen_video])
|
| 658 |
+
exmaple_setting(asr_method, input_text, character, talker_method, tts_method, voice, llm_method)
|
| 659 |
+
return inference
|
| 660 |
+
|
| 661 |
+
def app_multi():
|
| 662 |
+
with gr.Blocks(analytics_enabled=False, title = 'Linly-Talker') as inference:
|
| 663 |
+
gr.HTML(get_title("Linly 智能对话系统 (Linly-Talker) 多轮GPT对话"))
|
| 664 |
+
with gr.Row():
|
| 665 |
+
with gr.Column():
|
| 666 |
+
(source_image, voice, rate, volume, pitch,
|
| 667 |
+
am, voc, lang, male,
|
| 668 |
+
inp_ref, prompt_text, prompt_language, text_language, how_to_cut, use_mic_voice,
|
| 669 |
+
tts_method, batch_size, character, talker_method, asr_method, llm_method)= webui_setting()
|
| 670 |
+
video = gr.Video(label = '数字人问答', scale = 0.5)
|
| 671 |
+
video_button = gr.Button("🎬 生成数字人视频(对话后)", variant = 'primary')
|
| 672 |
+
|
| 673 |
+
with gr.Column():
|
| 674 |
+
with gr.Tabs(elem_id="sadtalker_checkbox"):
|
| 675 |
+
with gr.TabItem('SadTalker数字人参数设置'):
|
| 676 |
+
with gr.Accordion("Advanced Settings",
|
| 677 |
+
open=False):
|
| 678 |
+
gr.Markdown("SadTalker: need help? please visit our [[best practice page](https://github.com/OpenTalker/SadTalker/blob/main/docs/best_practice.md)] for more detials")
|
| 679 |
+
with gr.Column(variant='panel'):
|
| 680 |
+
# width = gr.Slider(minimum=64, elem_id="img2img_width", maximum=2048, step=8, label="Manually Crop Width", value=512) # img2img_width
|
| 681 |
+
# height = gr.Slider(minimum=64, elem_id="img2img_height", maximum=2048, step=8, label="Manually Crop Height", value=512) # img2img_width
|
| 682 |
+
with gr.Row():
|
| 683 |
+
pose_style = gr.Slider(minimum=0, maximum=45, step=1, label="Pose style", value=0) #
|
| 684 |
+
exp_weight = gr.Slider(minimum=0, maximum=3, step=0.1, label="expression scale", value=1) #
|
| 685 |
+
blink_every = gr.Checkbox(label="use eye blink", value=True)
|
| 686 |
+
|
| 687 |
+
with gr.Row():
|
| 688 |
+
size_of_image = gr.Radio([256, 512], value=256, label='face model resolution', info="use 256/512 model? 256 is faster") #
|
| 689 |
+
preprocess_type = gr.Radio(['crop', 'resize','full', 'extcrop', 'extfull'], value='crop', label='preprocess', info="How to handle input image?")
|
| 690 |
+
|
| 691 |
+
with gr.Row():
|
| 692 |
+
is_still_mode = gr.Checkbox(label="Still Mode (fewer head motion, works with preprocess `full`)")
|
| 693 |
+
facerender = gr.Radio(['facevid2vid'], value='facevid2vid', label='facerender', info="which face render?")
|
| 694 |
+
|
| 695 |
+
with gr.Row():
|
| 696 |
+
fps = gr.Slider(label='fps in generation', step=1, maximum=30, value =20)
|
| 697 |
+
enhancer = gr.Checkbox(label="GFPGAN as Face enhancer(slow)")
|
| 698 |
+
with gr.Row():
|
| 699 |
+
with gr.Column(scale=3):
|
| 700 |
+
system_input = gr.Textbox(value=default_system, lines=1, label='System (设定角色)')
|
| 701 |
+
with gr.Column(scale=1):
|
| 702 |
+
modify_system = gr.Button("🛠️ 设置system并清除历史对话", scale=2)
|
| 703 |
+
system_state = gr.Textbox(value=default_system, visible=False)
|
| 704 |
+
|
| 705 |
+
chatbot = gr.Chatbot(height=400, show_copy_button=True)
|
| 706 |
+
with gr.Group():
|
| 707 |
+
question_audio = gr.Audio(sources=['microphone','upload'], type="filepath", label='语音对话', autoplay=False)
|
| 708 |
+
asr_text = gr.Button('🎤 语音识别(语音对话后点击)')
|
| 709 |
+
|
| 710 |
+
# 创建一个文本框组件,用于输入 prompt。
|
| 711 |
+
msg = gr.Textbox(label="Prompt/问题")
|
| 712 |
+
asr_text.click(fn=Asr,inputs=[question_audio],outputs=[msg])
|
| 713 |
+
|
| 714 |
+
with gr.Row():
|
| 715 |
+
clear_history = gr.Button("🧹 清除历史对话")
|
| 716 |
+
sumbit = gr.Button("🚀 发送", variant = 'primary')
|
| 717 |
+
|
| 718 |
+
# 设置按钮的点击事件。当点击时,调用上面定义的 函数,并传入用户的消息和聊天历史记录,然后更新文本框和聊天机器人组件。
|
| 719 |
+
sumbit.click(chat_response, inputs=[system_input, msg, chatbot],
|
| 720 |
+
outputs=[msg, chatbot])
|
| 721 |
+
|
| 722 |
+
# 点击后清空后端存储的聊天记录
|
| 723 |
+
clear_history.click(fn = clear_session, outputs = [msg, chatbot])
|
| 724 |
+
|
| 725 |
+
# 设置system并清除历史对话
|
| 726 |
+
modify_system.click(fn=modify_system_session,
|
| 727 |
+
inputs=[system_input],
|
| 728 |
+
outputs=[system_state, system_input, chatbot])
|
| 729 |
+
|
| 730 |
+
video_button.click(fn = human_response, inputs = [source_image, chatbot, question_audio, talker_method, voice, rate, volume, pitch,
|
| 731 |
+
am, voc, lang, male,
|
| 732 |
+
inp_ref, prompt_text, prompt_language, text_language, how_to_cut, use_mic_voice,
|
| 733 |
+
tts_method, character,preprocess_type,
|
| 734 |
+
is_still_mode, enhancer, batch_size, size_of_image,
|
| 735 |
+
pose_style, facerender, exp_weight, blink_every, fps], outputs = [video])
|
| 736 |
+
|
| 737 |
+
exmaple_setting(asr_method, msg, character, talker_method, tts_method, voice, llm_method)
|
| 738 |
+
return inference
|
| 739 |
+
|
| 740 |
+
def app_img():
|
| 741 |
+
with gr.Blocks(analytics_enabled=False, title = 'Linly-Talker') as inference:
|
| 742 |
+
gr.HTML(get_title("Linly 智能对话系统 (Linly-Talker) 个性化角色互动"))
|
| 743 |
+
with gr.Row(equal_height=False):
|
| 744 |
+
with gr.Column(variant='panel'):
|
| 745 |
+
(source_image, voice, rate, volume, pitch,
|
| 746 |
+
am, voc, lang, male,
|
| 747 |
+
inp_ref, prompt_text, prompt_language, text_language, how_to_cut, use_mic_voice,
|
| 748 |
+
tts_method, batch_size, character, talker_method, asr_method, llm_method)= webui_setting()
|
| 749 |
+
|
| 750 |
+
# driven_audio = 'answer.wav'
|
| 751 |
+
with gr.Column(variant='panel'):
|
| 752 |
+
with gr.Tabs():
|
| 753 |
+
with gr.TabItem('对话'):
|
| 754 |
+
with gr.Group():
|
| 755 |
+
question_audio = gr.Audio(sources=['microphone','upload'], type="filepath", label = '语音对话')
|
| 756 |
+
input_text = gr.Textbox(label="输入文字/问题", lines=3)
|
| 757 |
+
asr_text = gr.Button('语音识别(语音对话后点击)')
|
| 758 |
+
asr_text.click(fn=Asr,inputs=[question_audio],outputs=[input_text])
|
| 759 |
+
with gr.Tabs(elem_id="text_examples"):
|
| 760 |
+
gr.Markdown("## Text Examples")
|
| 761 |
+
examples = [
|
| 762 |
+
['应对压力最有效���方法是什么?'],
|
| 763 |
+
['如何进行时间管理?'],
|
| 764 |
+
['为什么有些人选择使用纸质地图或寻求方向,而不是依赖GPS设备或智能手机应用程序?'],
|
| 765 |
+
]
|
| 766 |
+
gr.Examples(
|
| 767 |
+
examples = examples,
|
| 768 |
+
inputs = [input_text],
|
| 769 |
+
)
|
| 770 |
+
with gr.Tabs(elem_id="sadtalker_checkbox"):
|
| 771 |
+
with gr.TabItem('SadTalker数字人参数设置'):
|
| 772 |
+
with gr.Accordion("Advanced Settings",
|
| 773 |
+
open=False):
|
| 774 |
+
gr.Markdown("SadTalker: need help? please visit our [[best practice page](https://github.com/OpenTalker/SadTalker/blob/main/docs/best_practice.md)] for more detials")
|
| 775 |
+
with gr.Column(variant='panel'):
|
| 776 |
+
# width = gr.Slider(minimum=64, elem_id="img2img_width", maximum=2048, step=8, label="Manually Crop Width", value=512) # img2img_width
|
| 777 |
+
# height = gr.Slider(minimum=64, elem_id="img2img_height", maximum=2048, step=8, label="Manually Crop Height", value=512) # img2img_width
|
| 778 |
+
with gr.Row():
|
| 779 |
+
pose_style = gr.Slider(minimum=0, maximum=45, step=1, label="Pose style", value=0) #
|
| 780 |
+
exp_weight = gr.Slider(minimum=0, maximum=3, step=0.1, label="expression scale", value=1) #
|
| 781 |
+
blink_every = gr.Checkbox(label="use eye blink", value=True)
|
| 782 |
+
|
| 783 |
+
with gr.Row():
|
| 784 |
+
size_of_image = gr.Radio([256, 512], value=256, label='face model resolution', info="use 256/512 model? 256 is faster") #
|
| 785 |
+
preprocess_type = gr.Radio(['crop', 'resize','full', 'extcrop', 'extfull'], value='crop', label='preprocess', info="How to handle input image?")
|
| 786 |
+
|
| 787 |
+
with gr.Row():
|
| 788 |
+
is_still_mode = gr.Checkbox(label="Still Mode (fewer head motion, works with preprocess `full`)")
|
| 789 |
+
facerender = gr.Radio(['facevid2vid'], value='facevid2vid', label='facerender', info="which face render?")
|
| 790 |
+
|
| 791 |
+
with gr.Row():
|
| 792 |
+
fps = gr.Slider(label='fps in generation', step=1, maximum=30, value =20)
|
| 793 |
+
enhancer = gr.Checkbox(label="GFPGAN as Face enhancer(slow)")
|
| 794 |
+
|
| 795 |
+
with gr.Tabs(elem_id="sadtalker_genearted"):
|
| 796 |
+
gen_video = gr.Video(label="数字人视频", format="mp4")
|
| 797 |
+
|
| 798 |
+
submit = gr.Button('🎬 生成数字人视频', elem_id="sadtalker_generate", variant='primary')
|
| 799 |
+
submit.click(
|
| 800 |
+
fn=Talker_response_img,
|
| 801 |
+
inputs=[question_audio,
|
| 802 |
+
talker_method,
|
| 803 |
+
input_text,
|
| 804 |
+
voice, rate, volume, pitch,
|
| 805 |
+
am, voc, lang, male,
|
| 806 |
+
inp_ref, prompt_text, prompt_language, text_language, how_to_cut, use_mic_voice,
|
| 807 |
+
tts_method,
|
| 808 |
+
source_image,
|
| 809 |
+
preprocess_type,
|
| 810 |
+
is_still_mode,
|
| 811 |
+
enhancer,
|
| 812 |
+
batch_size,
|
| 813 |
+
size_of_image,
|
| 814 |
+
pose_style,
|
| 815 |
+
facerender,
|
| 816 |
+
exp_weight,
|
| 817 |
+
blink_every,
|
| 818 |
+
fps],
|
| 819 |
+
outputs=[gen_video]
|
| 820 |
+
)
|
| 821 |
+
|
| 822 |
+
with gr.Row():
|
| 823 |
+
examples = [
|
| 824 |
+
[
|
| 825 |
+
'examples/source_image/full_body_2.png', 'SadTalker',
|
| 826 |
+
'crop',
|
| 827 |
+
False,
|
| 828 |
+
False
|
| 829 |
+
],
|
| 830 |
+
[
|
| 831 |
+
'examples/source_image/full_body_1.png', 'SadTalker',
|
| 832 |
+
'full',
|
| 833 |
+
True,
|
| 834 |
+
False
|
| 835 |
+
],
|
| 836 |
+
[
|
| 837 |
+
'examples/source_image/full4.jpeg', 'SadTalker',
|
| 838 |
+
'crop',
|
| 839 |
+
False,
|
| 840 |
+
True
|
| 841 |
+
],
|
| 842 |
+
]
|
| 843 |
+
gr.Examples(examples=examples,
|
| 844 |
+
inputs=[
|
| 845 |
+
source_image, talker_method,
|
| 846 |
+
preprocess_type,
|
| 847 |
+
is_still_mode,
|
| 848 |
+
enhancer],
|
| 849 |
+
outputs=[gen_video],
|
| 850 |
+
# cache_examples=True,
|
| 851 |
+
)
|
| 852 |
+
return inference
|
| 853 |
+
|
| 854 |
+
def app_vits():
|
| 855 |
+
with gr.Blocks(analytics_enabled=False, title = 'Linly-Talker') as inference:
|
| 856 |
+
gr.HTML(get_title("Linly 智能对话系统 (Linly-Talker) 语音克隆"))
|
| 857 |
+
with gr.Row(equal_height=False):
|
| 858 |
+
with gr.Column(variant='panel'):
|
| 859 |
+
(source_image, voice, rate, volume, pitch,
|
| 860 |
+
am, voc, lang, male,
|
| 861 |
+
inp_ref, prompt_text, prompt_language, text_language, how_to_cut, use_mic_voice,
|
| 862 |
+
tts_method, batch_size, character, talker_method, asr_method, llm_method)= webui_setting()
|
| 863 |
+
with gr.Column(variant='panel'):
|
| 864 |
+
with gr.Tabs():
|
| 865 |
+
with gr.TabItem('对话'):
|
| 866 |
+
with gr.Group():
|
| 867 |
+
question_audio = gr.Audio(sources=['microphone','upload'], type="filepath", label = '语音对话')
|
| 868 |
+
input_text = gr.Textbox(label="输入文字/问题", lines=3)
|
| 869 |
+
asr_text = gr.Button('语音识别(语音对话后点击)')
|
| 870 |
+
asr_text.click(fn=Asr,inputs=[question_audio],outputs=[input_text])
|
| 871 |
+
with gr.Tabs():
|
| 872 |
+
with gr.TabItem('数字人问答'):
|
| 873 |
+
gen_video = gr.Video(label="数字人视频", format="mp4", autoplay=False)
|
| 874 |
+
video_button = gr.Button("🎬 生成数字人视频", variant='primary')
|
| 875 |
+
video_button.click(fn=Talker_response,inputs=[question_audio, talker_method, input_text, voice, rate, volume, pitch, am, voc, lang, male,
|
| 876 |
+
inp_ref, prompt_text, prompt_language, text_language, how_to_cut, use_mic_voice,
|
| 877 |
+
tts_method, batch_size, character],outputs=[gen_video])
|
| 878 |
+
exmaple_setting(asr_method, input_text, character, talker_method, tts_method, voice, llm_method)
|
| 879 |
+
return inference
|
| 880 |
+
|
| 881 |
+
def app_talk():
|
| 882 |
+
with gr.Blocks(analytics_enabled=False, title = 'Linly-Talker') as inference:
|
| 883 |
+
gr.HTML(get_title("Linly 智能对话系统 (Linly-Talker) 数字人播报"))
|
| 884 |
+
with gr.Row(equal_height=False):
|
| 885 |
+
with gr.Column(variant='panel'):
|
| 886 |
+
with gr.Tabs():
|
| 887 |
+
with gr.Tab("图片人物"):
|
| 888 |
+
source_image = gr.Image(label='Source image', type = 'filepath')
|
| 889 |
+
|
| 890 |
+
with gr.Tab("视频人物"):
|
| 891 |
+
source_video = gr.Video(label="Source video")
|
| 892 |
+
|
| 893 |
+
(_, voice, rate, volume, pitch,
|
| 894 |
+
am, voc, lang, male,
|
| 895 |
+
inp_ref, prompt_text, prompt_language, text_language, how_to_cut, use_mic_voice,
|
| 896 |
+
tts_method, batch_size, character, talker_method, asr_method, llm_method)= webui_setting()
|
| 897 |
+
|
| 898 |
+
with gr.Column(variant='panel'):
|
| 899 |
+
with gr.Tabs():
|
| 900 |
+
with gr.TabItem('对话'):
|
| 901 |
+
with gr.Group():
|
| 902 |
+
question_audio = gr.Audio(sources=['microphone','upload'], type="filepath", label = '语音对话')
|
| 903 |
+
input_text = gr.Textbox(label="输入文字/问题", lines=3)
|
| 904 |
+
asr_text = gr.Button('语音识别(语音对话后点击)')
|
| 905 |
+
asr_text.click(fn=Asr,inputs=[question_audio],outputs=[input_text])
|
| 906 |
+
with gr.Tabs():
|
| 907 |
+
with gr.TabItem('SadTalker数字人参数设置'):
|
| 908 |
+
with gr.Accordion("Advanced Settings",
|
| 909 |
+
open=False):
|
| 910 |
+
gr.Markdown("SadTalker: need help? please visit our [[best practice page](https://github.com/OpenTalker/SadTalker/blob/main/docs/best_practice.md)] for more detials")
|
| 911 |
+
with gr.Column(variant='panel'):
|
| 912 |
+
# width = gr.Slider(minimum=64, elem_id="img2img_width", maximum=2048, step=8, label="Manually Crop Width", value=512) # img2img_width
|
| 913 |
+
# height = gr.Slider(minimum=64, elem_id="img2img_height", maximum=2048, step=8, label="Manually Crop Height", value=512) # img2img_width
|
| 914 |
+
with gr.Row():
|
| 915 |
+
pose_style = gr.Slider(minimum=0, maximum=45, step=1, label="Pose style", value=0) #
|
| 916 |
+
exp_weight = gr.Slider(minimum=0, maximum=3, step=0.1, label="expression scale", value=1) #
|
| 917 |
+
blink_every = gr.Checkbox(label="use eye blink", value=True)
|
| 918 |
+
|
| 919 |
+
with gr.Row():
|
| 920 |
+
size_of_image = gr.Radio([256, 512], value=256, label='face model resolution', info="use 256/512 model? 256 is faster") #
|
| 921 |
+
preprocess_type = gr.Radio(['crop', 'resize','full'], value='full', label='preprocess', info="How to handle input image?")
|
| 922 |
+
|
| 923 |
+
with gr.Row():
|
| 924 |
+
is_still_mode = gr.Checkbox(label="Still Mode (fewer head motion, works with preprocess `full`)")
|
| 925 |
+
facerender = gr.Radio(['facevid2vid'], value='facevid2vid', label='facerender', info="which face render?")
|
| 926 |
+
|
| 927 |
+
with gr.Row():
|
| 928 |
+
# batch_size = gr.Slider(label="batch size in generation", step=1, maximum=10, value=1)
|
| 929 |
+
fps = gr.Slider(label='fps in generation', step=1, maximum=30, value =20)
|
| 930 |
+
enhancer = gr.Checkbox(label="GFPGAN as Face enhancer(slow)")
|
| 931 |
+
|
| 932 |
+
with gr.Tabs():
|
| 933 |
+
gen_video = gr.Video(label="数字人视频", format="mp4")
|
| 934 |
+
|
| 935 |
+
video_button = gr.Button('🎬 生成数字人视频', elem_id="sadtalker_generate", variant='primary')
|
| 936 |
+
|
| 937 |
+
video_button.click(fn=Talker_Say,inputs=[preprocess_type, is_still_mode, enhancer, batch_size, size_of_image,
|
| 938 |
+
pose_style, facerender, exp_weight, blink_every, fps,
|
| 939 |
+
source_image, source_video, question_audio, talker_method, input_text, voice, rate, volume, pitch, am, voc, lang, male,
|
| 940 |
+
inp_ref, prompt_text, prompt_language, text_language, how_to_cut, use_mic_voice,
|
| 941 |
+
tts_method, character],outputs=[gen_video])
|
| 942 |
+
|
| 943 |
+
with gr.Row():
|
| 944 |
+
with gr.Column(variant='panel'):
|
| 945 |
+
gr.Markdown("## Test Examples")
|
| 946 |
+
gr.Examples(
|
| 947 |
+
examples = [
|
| 948 |
+
[
|
| 949 |
+
'examples/source_image/full_body_2.png',
|
| 950 |
+
'应对压力最有效的方法是什么?',
|
| 951 |
+
],
|
| 952 |
+
[
|
| 953 |
+
'examples/source_image/full_body_1.png',
|
| 954 |
+
'如何进行时间管理?',
|
| 955 |
+
],
|
| 956 |
+
[
|
| 957 |
+
'examples/source_image/full3.png',
|
| 958 |
+
'为什么有些人选择使用纸质地图或寻求方向,而不是依赖GPS设备或智能手机应用程序?',
|
| 959 |
+
],
|
| 960 |
+
],
|
| 961 |
+
fn = Talker_Say,
|
| 962 |
+
inputs = [source_image, input_text],
|
| 963 |
+
)
|
| 964 |
+
return inference
|
| 965 |
+
|
| 966 |
+
def load_musetalk_model():
|
| 967 |
+
gr.Warning("若显存不足,可能会导致模型加载失败,可以尝试使用其他摸型或者换其他设备尝试。")
|
| 968 |
+
gr.Info("MuseTalk模型导入中...")
|
| 969 |
+
musetalker.init_model()
|
| 970 |
+
gr.Info("MuseTalk模型导入成功")
|
| 971 |
+
return "MuseTalk模型导入成功"
|
| 972 |
+
def musetalk_prepare_material(source_video, bbox_shift):
|
| 973 |
+
if musetalker.load is False:
|
| 974 |
+
gr.Warning("请先加载MuseTalk模型后重新上传文件")
|
| 975 |
+
return source_video, None
|
| 976 |
+
return musetalker.prepare_material(source_video, bbox_shift)
|
| 977 |
+
def app_muse():
|
| 978 |
+
with gr.Blocks(analytics_enabled=False, title = 'Linly-Talker') as inference:
|
| 979 |
+
gr.HTML(get_title("Linly 智能对话系统 (Linly-Talker) MuseTalker数字人实时对话"))
|
| 980 |
+
with gr.Row(equal_height=False):
|
| 981 |
+
with gr.Column(variant='panel'):
|
| 982 |
+
with gr.TabItem('MuseV Video'):
|
| 983 |
+
gr.Markdown("MuseV: need help? please visit MuseVDemo to generate Video https://huggingface.co/spaces/AnchorFake/MuseVDemo")
|
| 984 |
+
with gr.Row():
|
| 985 |
+
source_video = gr.Video(label="Reference Video",sources=['upload'])
|
| 986 |
+
gr.Markdown("BBox_shift 推荐值下限,在生成初始结果后生成相应的 bbox 范围。如果结果不理想,可以根据该参考值进行调整。\n一般来说,在我们的实验观察中,我们发现正值(向下半部分移动)通常会增加嘴巴的张开度,而负值(向上半部分移动)通常会减少嘴巴的张开度。然而,需要注意的是,这并不是绝对的规则,用户可能需要根据他们的具体需求和期望效果来调整该参数。")
|
| 987 |
+
with gr.Row():
|
| 988 |
+
bbox_shift = gr.Number(label="BBox_shift value, px", value=0)
|
| 989 |
+
bbox_shift_scale = gr.Textbox(label="bbox_shift_scale",
|
| 990 |
+
value="",interactive=False)
|
| 991 |
+
load_musetalk = gr.Button("加载MuseTalk模型(传入视频前先加载)", variant='primary')
|
| 992 |
+
load_musetalk.click(fn=load_musetalk_model, outputs=bbox_shift_scale)
|
| 993 |
+
|
| 994 |
+
# (_, voice, rate, volume, pitch,
|
| 995 |
+
# am, voc, lang, male,
|
| 996 |
+
# inp_ref, prompt_text, prompt_language, text_language, how_to_cut, use_mic_voice,
|
| 997 |
+
# tts_method, batch_size, character, talker_method, asr_method, llm_method)= webui_setting()
|
| 998 |
+
with gr.Tabs("TTS Method"):
|
| 999 |
+
with gr.Accordion("TTS Method语音方法调节 ", open=True):
|
| 1000 |
+
with gr.Tab("Edge-TTS"):
|
| 1001 |
+
voice = gr.Dropdown(edgetts.SUPPORTED_VOICE,
|
| 1002 |
+
value='zh-CN-XiaoxiaoNeural',
|
| 1003 |
+
label="Voice 声音选择")
|
| 1004 |
+
rate = gr.Slider(minimum=-100,
|
| 1005 |
+
maximum=100,
|
| 1006 |
+
value=0,
|
| 1007 |
+
step=1.0,
|
| 1008 |
+
label='Rate 速率')
|
| 1009 |
+
volume = gr.Slider(minimum=0,
|
| 1010 |
+
maximum=100,
|
| 1011 |
+
value=100,
|
| 1012 |
+
step=1,
|
| 1013 |
+
label='Volume 音量')
|
| 1014 |
+
pitch = gr.Slider(minimum=-100,
|
| 1015 |
+
maximum=100,
|
| 1016 |
+
value=0,
|
| 1017 |
+
step=1,
|
| 1018 |
+
label='Pitch 音调')
|
| 1019 |
+
with gr.Tab("PaddleTTS"):
|
| 1020 |
+
am = gr.Dropdown(["FastSpeech2"], label="声学模型选择", value = 'FastSpeech2')
|
| 1021 |
+
voc = gr.Dropdown(["PWGan", "HifiGan"], label="声码器选择", value = 'PWGan')
|
| 1022 |
+
lang = gr.Dropdown(["zh", "en", "mix", "canton"], label="语言选择", value = 'zh')
|
| 1023 |
+
male = gr.Checkbox(label="男声(Male)", value=False)
|
| 1024 |
+
with gr.Tab('GPT-SoVITS'):
|
| 1025 |
+
with gr.Row():
|
| 1026 |
+
gpt_path = gr.FileExplorer(root = GPT_SoVITS_ckpt, glob = "*.ckpt", value = "s1bert25hz-2kh-longer-epoch=68e-step=50232.ckpt", file_count='single', label="GPT模型路径")
|
| 1027 |
+
sovits_path = gr.FileExplorer(root = GPT_SoVITS_ckpt, glob = "*.pth", value = "s2G488k.pth", file_count='single', label="SoVITS模型路径")
|
| 1028 |
+
# gpt_path = gr.Dropdown(choices=list_models(GPT_SoVITS_ckpt, 'ckpt'))
|
| 1029 |
+
# sovits_path = gr.Dropdown(choices=list_models(GPT_SoVITS_ckpt, 'pth'))
|
| 1030 |
+
# gpt_path = gr.Textbox(label="GPT模型路径",
|
| 1031 |
+
# value="GPT_SoVITS/pretrained_models/s1bert25hz-2kh-longer-epoch=68e-step=50232.ckpt")
|
| 1032 |
+
# sovits_path = gr.Textbox(label="SoVITS模型路径",
|
| 1033 |
+
# value="GPT_SoVITS/pretrained_models/s2G488k.pth")
|
| 1034 |
+
button = gr.Button("加载模型")
|
| 1035 |
+
button.click(fn = load_vits_model,
|
| 1036 |
+
inputs=[gpt_path, sovits_path],
|
| 1037 |
+
outputs=[gpt_path, sovits_path])
|
| 1038 |
+
|
| 1039 |
+
with gr.Row():
|
| 1040 |
+
inp_ref = gr.Audio(label="请上传3~10秒内参考音频,超过会报错!", sources=["microphone", "upload"], type="filepath")
|
| 1041 |
+
use_mic_voice = gr.Checkbox(label="使用语音问答的麦克风")
|
| 1042 |
+
prompt_text = gr.Textbox(label="参考音频的文本", value="")
|
| 1043 |
+
prompt_language = gr.Dropdown(
|
| 1044 |
+
label="参考音频的语种", choices=["中文", "英文", "日文"], value="中文"
|
| 1045 |
+
)
|
| 1046 |
+
asr_button = gr.Button("语音识别 - 克隆参考音频")
|
| 1047 |
+
asr_button.click(fn=Asr,inputs=[inp_ref],outputs=[prompt_text])
|
| 1048 |
+
with gr.Row():
|
| 1049 |
+
text_language = gr.Dropdown(
|
| 1050 |
+
label="需要合成的语种", choices=["中文", "英文", "日文", "中英混合", "日英混合", "多语种混合"], value="中文"
|
| 1051 |
+
)
|
| 1052 |
+
|
| 1053 |
+
how_to_cut = gr.Dropdown(
|
| 1054 |
+
label="怎么切",
|
| 1055 |
+
choices=["不切", "凑四句一切", "凑50字一切", "按中文句号。切", "按英文句号.切", "按标点符号切" ],
|
| 1056 |
+
value="凑四句一切",
|
| 1057 |
+
interactive=True,
|
| 1058 |
+
)
|
| 1059 |
+
|
| 1060 |
+
with gr.Column(variant='panel'):
|
| 1061 |
+
batch_size = gr.Slider(minimum=1,
|
| 1062 |
+
maximum=10,
|
| 1063 |
+
value=2,
|
| 1064 |
+
step=1,
|
| 1065 |
+
label='Talker Batch size')
|
| 1066 |
+
|
| 1067 |
+
tts_method = gr.Radio(['Edge-TTS', 'PaddleTTS', 'GPT-SoVITS克隆声音', 'Comming Soon!!!'], label="Text To Speech Method",
|
| 1068 |
+
value = 'Edge-TTS')
|
| 1069 |
+
tts_method.change(fn = tts_model_change, inputs=[tts_method], outputs = [tts_method])
|
| 1070 |
+
asr_method = gr.Radio(choices = ['Whisper-tiny', 'Whisper-base', 'FunASR', 'Comming Soon!!!'], value='Whisper-base', label = '语音识别模型选择')
|
| 1071 |
+
asr_method.change(fn = asr_model_change, inputs=[asr_method], outputs = [asr_method])
|
| 1072 |
+
llm_method = gr.Dropdown(choices = ['Qwen', 'Qwen2', 'Linly', 'Gemini', 'ChatGLM', 'ChatGPT', 'GPT4Free', '直接回复 Direct Reply', 'Comming Soon!!!'], value = '直接回复 Direct Reply', label = 'LLM 模型选择')
|
| 1073 |
+
llm_method.change(fn = llm_model_change, inputs=[llm_method], outputs = [llm_method])
|
| 1074 |
+
|
| 1075 |
+
source_video.change(fn=musetalk_prepare_material, inputs=[source_video, bbox_shift], outputs=[source_video, bbox_shift_scale])
|
| 1076 |
+
|
| 1077 |
+
with gr.Column(variant='panel'):
|
| 1078 |
+
with gr.Tabs():
|
| 1079 |
+
with gr.TabItem('对话'):
|
| 1080 |
+
with gr.Group():
|
| 1081 |
+
question_audio = gr.Audio(sources=['microphone','upload'], type="filepath", label = '语音对话')
|
| 1082 |
+
input_text = gr.Textbox(label="输入文字/问题", lines=3)
|
| 1083 |
+
asr_text = gr.Button('语音识别(语音对话后点击)')
|
| 1084 |
+
asr_text.click(fn=Asr,inputs=[question_audio],outputs=[input_text])
|
| 1085 |
+
|
| 1086 |
+
with gr.TabItem("MuseTalk Video"):
|
| 1087 |
+
gen_video = gr.Video(label="数字人视频", format="mp4")
|
| 1088 |
+
submit = gr.Button('Generate', elem_id="sadtalker_generate", variant='primary')
|
| 1089 |
+
examples = [os.path.join('Musetalk/data/video', video) for video in os.listdir("Musetalk/data/video")]
|
| 1090 |
+
# ['Musetalk/data/video/yongen_musev.mp4', 'Musetalk/data/video/musk_musev.mp4', 'Musetalk/data/video/monalisa_musev.mp4', 'Musetalk/data/video/sun_musev.mp4', 'Musetalk/data/video/seaside4_musev.mp4', 'Musetalk/data/video/sit_musev.mp4', 'Musetalk/data/video/man_musev.mp4']
|
| 1091 |
+
|
| 1092 |
+
gr.Markdown("## MuseV Video Examples")
|
| 1093 |
+
gr.Examples(
|
| 1094 |
+
examples=[
|
| 1095 |
+
['Musetalk/data/video/yongen_musev.mp4', 5],
|
| 1096 |
+
['Musetalk/data/video/musk_musev.mp4', 5],
|
| 1097 |
+
['Musetalk/data/video/monalisa_musev.mp4', 5],
|
| 1098 |
+
['Musetalk/data/video/sun_musev.mp4', 5],
|
| 1099 |
+
['Musetalk/data/video/seaside4_musev.mp4', 5],
|
| 1100 |
+
['Musetalk/data/video/sit_musev.mp4', 5],
|
| 1101 |
+
['Musetalk/data/video/man_musev.mp4', 5]
|
| 1102 |
+
],
|
| 1103 |
+
inputs =[source_video, bbox_shift],
|
| 1104 |
+
)
|
| 1105 |
+
|
| 1106 |
+
submit.click(
|
| 1107 |
+
fn=MuseTalker_response,
|
| 1108 |
+
inputs=[source_video, bbox_shift, question_audio, input_text, voice, rate, volume, pitch, am, voc, lang, male,
|
| 1109 |
+
inp_ref, prompt_text, prompt_language, text_language, how_to_cut, use_mic_voice,
|
| 1110 |
+
tts_method, batch_size],
|
| 1111 |
+
outputs=[gen_video]
|
| 1112 |
+
)
|
| 1113 |
+
return inference
|
| 1114 |
+
def asr_model_change(model_name, progress=gr.Progress(track_tqdm=True)):
|
| 1115 |
+
global asr
|
| 1116 |
+
|
| 1117 |
+
# 清理显存,在加载新的模型之前释放不必要的显存
|
| 1118 |
+
clear_memory()
|
| 1119 |
+
|
| 1120 |
+
if model_name == "Whisper-tiny":
|
| 1121 |
+
try:
|
| 1122 |
+
if os.path.exists('Whisper/tiny.pt'):
|
| 1123 |
+
asr = WhisperASR('Whisper/tiny.pt')
|
| 1124 |
+
else:
|
| 1125 |
+
asr = WhisperASR('tiny')
|
| 1126 |
+
gr.Info("Whisper-tiny模型导入成功")
|
| 1127 |
+
except Exception as e:
|
| 1128 |
+
gr.Warning(f"Whisper-tiny模型下载失败 {e}")
|
| 1129 |
+
elif model_name == "Whisper-base":
|
| 1130 |
+
try:
|
| 1131 |
+
if os.path.exists('Whisper/base.pt'):
|
| 1132 |
+
asr = WhisperASR('Whisper/base.pt')
|
| 1133 |
+
else:
|
| 1134 |
+
asr = WhisperASR('base')
|
| 1135 |
+
gr.Info("Whisper-base模型导入成功")
|
| 1136 |
+
except Exception as e:
|
| 1137 |
+
gr.Warning(f"Whisper-base模型下载失败 {e}")
|
| 1138 |
+
elif model_name == 'FunASR':
|
| 1139 |
+
try:
|
| 1140 |
+
from ASR import FunASR
|
| 1141 |
+
asr = FunASR()
|
| 1142 |
+
gr.Info("FunASR模型导入成功")
|
| 1143 |
+
except Exception as e:
|
| 1144 |
+
gr.Warning(f"FunASR模型下载失败 {e}")
|
| 1145 |
+
else:
|
| 1146 |
+
gr.Warning("未知ASR模型,可提issue和PR 或者 建议更新模型")
|
| 1147 |
+
return model_name
|
| 1148 |
+
|
| 1149 |
+
def llm_model_change(model_name, progress=gr.Progress(track_tqdm=True)):
|
| 1150 |
+
global llm
|
| 1151 |
+
gemini_apikey = ""
|
| 1152 |
+
openai_apikey = ""
|
| 1153 |
+
proxy_url = None
|
| 1154 |
+
|
| 1155 |
+
# 清理显存,在加载新的模型之前释放不必要的显存
|
| 1156 |
+
clear_memory()
|
| 1157 |
+
|
| 1158 |
+
if model_name == 'Linly':
|
| 1159 |
+
try:
|
| 1160 |
+
llm = llm_class.init_model('Linly', 'Linly-AI/Chinese-LLaMA-2-7B-hf', prefix_prompt=prefix_prompt)
|
| 1161 |
+
gr.Info("Linly模型导入成功")
|
| 1162 |
+
except Exception as e:
|
| 1163 |
+
gr.Warning(f"Linly模型下载失败 {e}")
|
| 1164 |
+
elif model_name == 'Qwen':
|
| 1165 |
+
try:
|
| 1166 |
+
llm = llm_class.init_model('Qwen', 'Qwen/Qwen-1_8B-Chat', prefix_prompt=prefix_prompt)
|
| 1167 |
+
gr.Info("Qwen模型导入成功")
|
| 1168 |
+
except Exception as e:
|
| 1169 |
+
gr.Warning(f"Qwen模型下载失败 {e}")
|
| 1170 |
+
elif model_name == 'Qwen2':
|
| 1171 |
+
try:
|
| 1172 |
+
llm = llm_class.init_model('Qwen2', 'Qwen/Qwen1.5-0.5B-Chat', prefix_prompt=prefix_prompt)
|
| 1173 |
+
gr.Info("Qwen2模型导入成功")
|
| 1174 |
+
except Exception as e:
|
| 1175 |
+
gr.Warning(f"Qwen2模型下载失败 {e}")
|
| 1176 |
+
elif model_name == 'Gemini':
|
| 1177 |
+
if gemini_apikey:
|
| 1178 |
+
llm = llm_class.init_model('Gemini', 'gemini-pro', gemini_apikey, proxy_url)
|
| 1179 |
+
gr.Info("Gemini模型导入成功")
|
| 1180 |
+
else:
|
| 1181 |
+
gr.Warning("请填写Gemini的api_key")
|
| 1182 |
+
elif model_name == 'ChatGLM':
|
| 1183 |
+
try:
|
| 1184 |
+
llm = llm_class.init_model('ChatGLM', 'THUDM/chatglm3-6b', prefix_prompt=prefix_prompt)
|
| 1185 |
+
gr.Info("ChatGLM模型导入成功")
|
| 1186 |
+
except Exception as e:
|
| 1187 |
+
gr.Warning(f"ChatGLM模型导入失败 {e}")
|
| 1188 |
+
elif model_name == 'ChatGPT':
|
| 1189 |
+
if openai_apikey:
|
| 1190 |
+
llm = llm_class.init_model('ChatGPT', api_key=openai_apikey, proxy_url=proxy_url, prefix_prompt=prefix_prompt)
|
| 1191 |
+
else:
|
| 1192 |
+
gr.Warning("请填写OpenAI的api_key")
|
| 1193 |
+
elif model_name == '直接回复 Direct Reply':
|
| 1194 |
+
llm =llm_class.init_model(model_name)
|
| 1195 |
+
gr.Info("直接回复,不实用LLM模型")
|
| 1196 |
+
elif model_name == 'GPT4Free':
|
| 1197 |
+
try:
|
| 1198 |
+
llm = llm_class.init_model('GPT4Free', prefix_prompt=prefix_prompt)
|
| 1199 |
+
gr.Info("GPT4Free模型导入成功, 请注意GPT4Free可能不稳定")
|
| 1200 |
+
except Exception as e:
|
| 1201 |
+
gr.Warning(f"GPT4Free模型下载失败 {e}")
|
| 1202 |
+
else:
|
| 1203 |
+
gr.Warning("未知LLM模型,可提issue和PR 或者 建议更新模型")
|
| 1204 |
+
return model_name
|
| 1205 |
+
|
| 1206 |
+
def talker_model_change(model_name, progress=gr.Progress(track_tqdm=True)):
|
| 1207 |
+
global talker
|
| 1208 |
+
|
| 1209 |
+
# 清理显存,在加载新的模型之前释放不必要的显存
|
| 1210 |
+
clear_memory()
|
| 1211 |
+
|
| 1212 |
+
if model_name not in ['SadTalker', 'Wav2Lip', 'NeRFTalk']:
|
| 1213 |
+
gr.Warning("其他模型还未集成,请等待")
|
| 1214 |
+
if model_name == 'SadTalker':
|
| 1215 |
+
try:
|
| 1216 |
+
from TFG import SadTalker
|
| 1217 |
+
talker = SadTalker(lazy_load=True)
|
| 1218 |
+
gr.Info("SadTalker模型导入成功")
|
| 1219 |
+
except Exception as e:
|
| 1220 |
+
gr.Warning("SadTalker模型加载失败", e)
|
| 1221 |
+
elif model_name == 'Wav2Lip':
|
| 1222 |
+
try:
|
| 1223 |
+
from TFG import Wav2Lip
|
| 1224 |
+
clear_memory()
|
| 1225 |
+
talker = Wav2Lip("checkpoints/wav2lip_gan.pth")
|
| 1226 |
+
gr.Info("Wav2Lip模型导入成功")
|
| 1227 |
+
except Exception as e:
|
| 1228 |
+
gr.Warning("Wav2Lip模型加载失败", e)
|
| 1229 |
+
elif model_name == 'NeRFTalk':
|
| 1230 |
+
try:
|
| 1231 |
+
from TFG import ERNeRF
|
| 1232 |
+
talker = ERNeRF()
|
| 1233 |
+
talker.init_model('checkpoints/Obama_ave.pth', 'checkpoints/Obama.json')
|
| 1234 |
+
gr.Info("NeRFTalk模型导入成功")
|
| 1235 |
+
gr.Warning("NeRFTalk模型是针对单个人进行训练的,内置了奥班马Obama的模型,上传图片无效")
|
| 1236 |
+
except Exception as e:
|
| 1237 |
+
gr.Warning("NeRFTalk模型加载失败", e)
|
| 1238 |
+
else:
|
| 1239 |
+
gr.Warning("未知TFG模型,可提issue和PR 或者 建议更新模型")
|
| 1240 |
+
return model_name
|
| 1241 |
+
|
| 1242 |
+
def tts_model_change(model_name, progress=gr.Progress(track_tqdm=True)):
|
| 1243 |
+
global tts
|
| 1244 |
+
|
| 1245 |
+
# 清理显存,在加载新的模型之前释放不必要的显存
|
| 1246 |
+
clear_memory()
|
| 1247 |
+
|
| 1248 |
+
if model_name == 'Edge-TTS':
|
| 1249 |
+
# tts = EdgeTTS()
|
| 1250 |
+
if edgetts.network:
|
| 1251 |
+
gr.Info("EdgeTTS模型导入成功")
|
| 1252 |
+
else:
|
| 1253 |
+
gr.Warning("EdgeTTS模型加载失败,请检查网络是否正常连接,否则无法使用")
|
| 1254 |
+
elif model_name == 'PaddleTTS':
|
| 1255 |
+
try:
|
| 1256 |
+
from TTS import PaddleTTS
|
| 1257 |
+
tts = PaddleTTS()
|
| 1258 |
+
gr.Info("PaddleTTS模型导入成功")
|
| 1259 |
+
except Exception as e:
|
| 1260 |
+
gr.Warning(f"PaddleTTS模型下载失败 {e}")
|
| 1261 |
+
elif model_name == 'GPT-SoVITS克隆声音':
|
| 1262 |
+
try:
|
| 1263 |
+
gpt_path = "GPT_SoVITS/pretrained_models/s1bert25hz-2kh-longer-epoch=68e-step=50232.ckpt"
|
| 1264 |
+
sovits_path = "GPT_SoVITS/pretrained_models/s2G488k.pth"
|
| 1265 |
+
vits.load_model(gpt_path, sovits_path)
|
| 1266 |
+
gr.Info("模型加载成功")
|
| 1267 |
+
except Exception as e:
|
| 1268 |
+
gr.Warning(f"模型加载失败 {e}")
|
| 1269 |
+
gr.Warning("注意注意⚠️:GPT-SoVITS要上传参考音频进行克隆,请点击TTS Method语音方法调节操作")
|
| 1270 |
+
else:
|
| 1271 |
+
gr.Warning("未知TTS模型,可提issue和PR 或者 建议更新模型")
|
| 1272 |
+
return model_name
|
| 1273 |
+
|
| 1274 |
+
def success_print(text):
|
| 1275 |
+
print(f"\033[1;32;40m{text}\033[0m")
|
| 1276 |
+
|
| 1277 |
+
def error_print(text):
|
| 1278 |
+
print(f"\033[1;31;40m{text}\033[0m")
|
| 1279 |
+
|
| 1280 |
+
if __name__ == "__main__":
|
| 1281 |
+
llm_class = LLM(mode='offline')
|
| 1282 |
+
llm = llm_class.init_model('直接回复 Direct Reply')
|
| 1283 |
+
success_print("默认不使用LLM模型,直接回复问题,同时减少显存占用!")
|
| 1284 |
+
|
| 1285 |
+
try:
|
| 1286 |
+
from VITS import *
|
| 1287 |
+
vits = GPT_SoVITS()
|
| 1288 |
+
success_print("Success!!! GPT-SoVITS模块加载成功,语音克隆默认使用GPT-SoVITS模型")
|
| 1289 |
+
# gpt_path = "GPT_SoVITS/pretrained_models/s1bert25hz-2kh-longer-epoch=68e-step=50232.ckpt"
|
| 1290 |
+
# sovits_path = "GPT_SoVITS/pretrained_models/s2G488k.pth"
|
| 1291 |
+
# vits.load_model(gpt_path, sovits_path)
|
| 1292 |
+
except Exception as e:
|
| 1293 |
+
error_print(f"GPT-SoVITS Error: {e}")
|
| 1294 |
+
error_print("如果使用VITS,请先下载GPT-SoVITS模型和安装环境")
|
| 1295 |
+
|
| 1296 |
+
try:
|
| 1297 |
+
from TFG import SadTalker
|
| 1298 |
+
talker = SadTalker(lazy_load=True)
|
| 1299 |
+
success_print("Success!!! SadTalker模块加载成功,默认使用SadTalker模型")
|
| 1300 |
+
except Exception as e:
|
| 1301 |
+
error_print(f"SadTalker Error: {e}")
|
| 1302 |
+
error_print("如果使用SadTalker,请先下载SadTalker模型")
|
| 1303 |
+
|
| 1304 |
+
try:
|
| 1305 |
+
from ASR import WhisperASR
|
| 1306 |
+
if os.path.exists('Whisper/base.pt'):
|
| 1307 |
+
asr = WhisperASR('Whisper/base.pt')
|
| 1308 |
+
else:
|
| 1309 |
+
asr = WhisperASR('base')
|
| 1310 |
+
success_print("Success!!! WhisperASR模块加载成功,默认使用Whisper-base模型")
|
| 1311 |
+
except Exception as e:
|
| 1312 |
+
error_print(f"ASR Error: {e}")
|
| 1313 |
+
error_print("如果使用FunASR,请先下载WhisperASR模型和安装环境")
|
| 1314 |
+
|
| 1315 |
+
# 判断显存是否8g,若小于8g不建议使用MuseTalk功能
|
| 1316 |
+
# Check if GPU is available and has at least 8GB of memory
|
| 1317 |
+
if torch.cuda.is_available():
|
| 1318 |
+
gpu_memory = torch.cuda.get_device_properties(0).total_memory / (1024 ** 3) # Convert bytes to GB
|
| 1319 |
+
if gpu_memory < 8:
|
| 1320 |
+
error_print("警告: 您的显卡显存小于8GB,不建议使用MuseTalk功能")
|
| 1321 |
+
|
| 1322 |
+
try:
|
| 1323 |
+
from TFG import MuseTalk_RealTime
|
| 1324 |
+
musetalker = MuseTalk_RealTime()
|
| 1325 |
+
success_print("Success!!! MuseTalk模块加载成功")
|
| 1326 |
+
except Exception as e:
|
| 1327 |
+
error_print(f"MuseTalk Error: {e}")
|
| 1328 |
+
error_print("如果使用MuseTalk,请先下载MuseTalk模型")
|
| 1329 |
+
|
| 1330 |
+
tts = edgetts
|
| 1331 |
+
if not tts.network:
|
| 1332 |
+
error_print("EdgeTTS模块加载失败,请检查网络是否正常连接,否则无法使用")
|
| 1333 |
+
|
| 1334 |
+
gr.close_all()
|
| 1335 |
+
# demo_app = app()
|
| 1336 |
+
demo_img = app_img()
|
| 1337 |
+
demo_multi = app_multi()
|
| 1338 |
+
# demo_vits = app_vits()
|
| 1339 |
+
# demo_talk = app_talk()
|
| 1340 |
+
demo_muse = app_muse()
|
| 1341 |
+
demo = gr.TabbedInterface(interface_list = [
|
| 1342 |
+
# demo_app,
|
| 1343 |
+
demo_img,
|
| 1344 |
+
demo_multi,
|
| 1345 |
+
# demo_vits,
|
| 1346 |
+
# demo_talk,
|
| 1347 |
+
demo_muse,
|
| 1348 |
+
],
|
| 1349 |
+
tab_names = [
|
| 1350 |
+
"个性化角色互动",
|
| 1351 |
+
"数字人多轮智能对话",
|
| 1352 |
+
"MuseTalk数字人实时对话"
|
| 1353 |
+
],
|
| 1354 |
+
title = "Linly-Talker WebUI")
|
| 1355 |
+
demo.queue()
|
| 1356 |
+
demo.launch(server_name=ip, # 本地端口localhost:127.0.0.1 全局端口转发:"0.0.0.0"
|
| 1357 |
+
server_port=port,
|
| 1358 |
+
# 似乎在Gradio4.0以上版本可以不使用证书也可以进行麦克风对话
|
| 1359 |
+
# ssl_certfile=ssl_certfile,
|
| 1360 |
+
# ssl_keyfile=ssl_keyfile,
|
| 1361 |
+
# ssl_verify=False,
|
| 1362 |
+
# share=True,
|
| 1363 |
+
debug=True,
|
| 1364 |
+
)
|
ASR/FunASR.py
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
'''
|
| 2 |
+
Reference: https://github.com/alibaba-damo-academy/FunASR
|
| 3 |
+
pip install funasr
|
| 4 |
+
pip install modelscope
|
| 5 |
+
pip install -U rotary_embedding_torch
|
| 6 |
+
'''
|
| 7 |
+
try:
|
| 8 |
+
from funasr import AutoModel
|
| 9 |
+
except:
|
| 10 |
+
print("如果想使用FunASR,请先安装funasr,若使用Whisper,请忽略此条信息")
|
| 11 |
+
import os
|
| 12 |
+
import sys
|
| 13 |
+
sys.path.append('./')
|
| 14 |
+
from src.cost_time import calculate_time
|
| 15 |
+
|
| 16 |
+
class FunASR:
|
| 17 |
+
def __init__(self) -> None:
|
| 18 |
+
# 定义模型的自定义路径
|
| 19 |
+
model_path = "FunASR/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch"
|
| 20 |
+
vad_model_path = "FunASR/speech_fsmn_vad_zh-cn-16k-common-pytorch"
|
| 21 |
+
punc_model_path = "FunASR/punc_ct-transformer_zh-cn-common-vocab272727-pytorch"
|
| 22 |
+
|
| 23 |
+
# 检查文件是否存在于 FunASR 目录下
|
| 24 |
+
model_exists = os.path.exists(model_path)
|
| 25 |
+
vad_model_exists = os.path.exists(vad_model_path)
|
| 26 |
+
punc_model_exists = os.path.exists(punc_model_path)
|
| 27 |
+
# Modelscope AutoDownload
|
| 28 |
+
self.model = AutoModel(
|
| 29 |
+
model=model_path if model_exists else "paraformer-zh",
|
| 30 |
+
vad_model=vad_model_path if vad_model_exists else "fsmn-vad",
|
| 31 |
+
punc_model=punc_model_path if punc_model_exists else "ct-punc-c",
|
| 32 |
+
)
|
| 33 |
+
# 自定义路径
|
| 34 |
+
# self.model = AutoModel(model="FunASR/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch", # model_revision="v2.0.4",
|
| 35 |
+
# vad_model="FunASR/speech_fsmn_vad_zh-cn-16k-common-pytorch", # vad_model_revision="v2.0.4",
|
| 36 |
+
# punc_model="FunASR/punc_ct-transformer_zh-cn-common-vocab272727-pytorch", # punc_model_revision="v2.0.4",
|
| 37 |
+
# # spk_model="cam++", spk_model_revision="v2.0.2",
|
| 38 |
+
# )
|
| 39 |
+
@calculate_time
|
| 40 |
+
def transcribe(self, audio_file):
|
| 41 |
+
res = self.model.generate(input=audio_file,
|
| 42 |
+
batch_size_s=300)
|
| 43 |
+
print(res)
|
| 44 |
+
return res[0]['text']
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
if __name__ == "__main__":
|
| 48 |
+
import os
|
| 49 |
+
# 创建ASR对象并进行语音识别
|
| 50 |
+
audio_file = "output.wav" # 音频文件路径
|
| 51 |
+
if not os.path.exists(audio_file):
|
| 52 |
+
os.system('edge-tts --text "hello" --write-media output.wav')
|
| 53 |
+
asr = FunASR()
|
| 54 |
+
print(asr.transcribe(audio_file))
|
ASR/README.md
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## ASR 同数字人沟通的桥梁
|
| 2 |
+
|
| 3 |
+
### Whisper OpenAI
|
| 4 |
+
|
| 5 |
+
Whisper 是一个自动语音识别 (ASR) 系统,它使用从网络上收集的 680,000 小时多语言和多任务监督数据进行训练。使用如此庞大且多样化的数据集可以提高对口音、背景噪音和技术语言的鲁棒性。此外,它还支持多种语言的转录,以及将这些语言翻译成英语。
|
| 6 |
+
|
| 7 |
+
使用方法很简单,我们只要安装以下库,后续模型会自动下载
|
| 8 |
+
|
| 9 |
+
```bash
|
| 10 |
+
pip install -U openai-whisper
|
| 11 |
+
```
|
| 12 |
+
|
| 13 |
+
借鉴OpenAI的Whisper实现了ASR的语音识别,具体使用方法参考 [https://github.com/openai/whisper](https://github.com/openai/whisper)
|
| 14 |
+
|
| 15 |
+
```python
|
| 16 |
+
'''
|
| 17 |
+
https://github.com/openai/whisper
|
| 18 |
+
pip install -U openai-whisper
|
| 19 |
+
'''
|
| 20 |
+
import whisper
|
| 21 |
+
|
| 22 |
+
class WhisperASR:
|
| 23 |
+
def __init__(self, model_path):
|
| 24 |
+
self.LANGUAGES = {
|
| 25 |
+
"en": "english",
|
| 26 |
+
"zh": "chinese",
|
| 27 |
+
}
|
| 28 |
+
self.model = whisper.load_model(model_path)
|
| 29 |
+
|
| 30 |
+
def transcribe(self, audio_file):
|
| 31 |
+
result = self.model.transcribe(audio_file)
|
| 32 |
+
return result["text"]
|
| 33 |
+
```
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
### FunASR Alibaba
|
| 38 |
+
|
| 39 |
+
阿里的`FunASR`的语音识别效果也是相当不错,而且时间也是比whisper更快的,更能达到实时的效果,所以也将FunASR添加进去了,在ASR文件夹下的FunASR文件里可以进行体验,参考 [https://github.com/alibaba-damo-academy/FunASR](https://github.com/alibaba-damo-academy/FunASR)
|
| 40 |
+
|
| 41 |
+
需要注意的是,在第一次运行的时候,需要安装以下库。
|
| 42 |
+
|
| 43 |
+
```bash
|
| 44 |
+
pip install funasr
|
| 45 |
+
pip install modelscope
|
| 46 |
+
pip install -U rotary_embedding_torch
|
| 47 |
+
```
|
| 48 |
+
|
| 49 |
+
```python
|
| 50 |
+
'''
|
| 51 |
+
Reference: https://github.com/alibaba-damo-academy/FunASR
|
| 52 |
+
pip install funasr
|
| 53 |
+
pip install modelscope
|
| 54 |
+
pip install -U rotary_embedding_torch
|
| 55 |
+
'''
|
| 56 |
+
try:
|
| 57 |
+
from funasr import AutoModel
|
| 58 |
+
except:
|
| 59 |
+
print("如果想使用FunASR,请先安装funasr,若使用Whisper,请忽略此条信息")
|
| 60 |
+
|
| 61 |
+
class FunASR:
|
| 62 |
+
def __init__(self) -> None:
|
| 63 |
+
self.model = AutoModel(model="paraformer-zh", model_revision="v2.0.4",
|
| 64 |
+
vad_model="fsmn-vad", vad_model_revision="v2.0.4",
|
| 65 |
+
punc_model="ct-punc-c", punc_model_revision="v2.0.4",
|
| 66 |
+
# spk_model="cam++", spk_model_revision="v2.0.2",
|
| 67 |
+
)
|
| 68 |
+
|
| 69 |
+
def transcribe(self, audio_file):
|
| 70 |
+
res = self.model.generate(input=audio_file,
|
| 71 |
+
batch_size_s=300)
|
| 72 |
+
print(res)
|
| 73 |
+
return res[0]['text']
|
| 74 |
+
```
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
|
ASR/Whisper.py
ADDED
|
@@ -0,0 +1,129 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
'''
|
| 2 |
+
https://github.com/openai/whisper
|
| 3 |
+
pip install -U openai-whisper
|
| 4 |
+
'''
|
| 5 |
+
import whisper
|
| 6 |
+
import sys
|
| 7 |
+
sys.path.append('./')
|
| 8 |
+
from src.cost_time import calculate_time
|
| 9 |
+
|
| 10 |
+
class WhisperASR:
|
| 11 |
+
def __init__(self, model_path):
|
| 12 |
+
self.LANGUAGES = {
|
| 13 |
+
"en": "english",
|
| 14 |
+
"zh": "chinese",
|
| 15 |
+
"de": "german",
|
| 16 |
+
"es": "spanish",
|
| 17 |
+
"ru": "russian",
|
| 18 |
+
"ko": "korean",
|
| 19 |
+
"fr": "french",
|
| 20 |
+
"ja": "japanese",
|
| 21 |
+
"pt": "portuguese",
|
| 22 |
+
"tr": "turkish",
|
| 23 |
+
"pl": "polish",
|
| 24 |
+
"ca": "catalan",
|
| 25 |
+
"nl": "dutch",
|
| 26 |
+
"ar": "arabic",
|
| 27 |
+
"sv": "swedish",
|
| 28 |
+
"it": "italian",
|
| 29 |
+
"id": "indonesian",
|
| 30 |
+
"hi": "hindi",
|
| 31 |
+
"fi": "finnish",
|
| 32 |
+
"vi": "vietnamese",
|
| 33 |
+
"he": "hebrew",
|
| 34 |
+
"uk": "ukrainian",
|
| 35 |
+
"el": "greek",
|
| 36 |
+
"ms": "malay",
|
| 37 |
+
"cs": "czech",
|
| 38 |
+
"ro": "romanian",
|
| 39 |
+
"da": "danish",
|
| 40 |
+
"hu": "hungarian",
|
| 41 |
+
"ta": "tamil",
|
| 42 |
+
"no": "norwegian",
|
| 43 |
+
"th": "thai",
|
| 44 |
+
"ur": "urdu",
|
| 45 |
+
"hr": "croatian",
|
| 46 |
+
"bg": "bulgarian",
|
| 47 |
+
"lt": "lithuanian",
|
| 48 |
+
"la": "latin",
|
| 49 |
+
"mi": "maori",
|
| 50 |
+
"ml": "malayalam",
|
| 51 |
+
"cy": "welsh",
|
| 52 |
+
"sk": "slovak",
|
| 53 |
+
"te": "telugu",
|
| 54 |
+
"fa": "persian",
|
| 55 |
+
"lv": "latvian",
|
| 56 |
+
"bn": "bengali",
|
| 57 |
+
"sr": "serbian",
|
| 58 |
+
"az": "azerbaijani",
|
| 59 |
+
"sl": "slovenian",
|
| 60 |
+
"kn": "kannada",
|
| 61 |
+
"et": "estonian",
|
| 62 |
+
"mk": "macedonian",
|
| 63 |
+
"br": "breton",
|
| 64 |
+
"eu": "basque",
|
| 65 |
+
"is": "icelandic",
|
| 66 |
+
"hy": "armenian",
|
| 67 |
+
"ne": "nepali",
|
| 68 |
+
"mn": "mongolian",
|
| 69 |
+
"bs": "bosnian",
|
| 70 |
+
"kk": "kazakh",
|
| 71 |
+
"sq": "albanian",
|
| 72 |
+
"sw": "swahili",
|
| 73 |
+
"gl": "galician",
|
| 74 |
+
"mr": "marathi",
|
| 75 |
+
"pa": "punjabi",
|
| 76 |
+
"si": "sinhala",
|
| 77 |
+
"km": "khmer",
|
| 78 |
+
"sn": "shona",
|
| 79 |
+
"yo": "yoruba",
|
| 80 |
+
"so": "somali",
|
| 81 |
+
"af": "afrikaans",
|
| 82 |
+
"oc": "occitan",
|
| 83 |
+
"ka": "georgian",
|
| 84 |
+
"be": "belarusian",
|
| 85 |
+
"tg": "tajik",
|
| 86 |
+
"sd": "sindhi",
|
| 87 |
+
"gu": "gujarati",
|
| 88 |
+
"am": "amharic",
|
| 89 |
+
"yi": "yiddish",
|
| 90 |
+
"lo": "lao",
|
| 91 |
+
"uz": "uzbek",
|
| 92 |
+
"fo": "faroese",
|
| 93 |
+
"ht": "haitian creole",
|
| 94 |
+
"ps": "pashto",
|
| 95 |
+
"tk": "turkmen",
|
| 96 |
+
"nn": "nynorsk",
|
| 97 |
+
"mt": "maltese",
|
| 98 |
+
"sa": "sanskrit",
|
| 99 |
+
"lb": "luxembourgish",
|
| 100 |
+
"my": "myanmar",
|
| 101 |
+
"bo": "tibetan",
|
| 102 |
+
"tl": "tagalog",
|
| 103 |
+
"mg": "malagasy",
|
| 104 |
+
"as": "assamese",
|
| 105 |
+
"tt": "tatar",
|
| 106 |
+
"haw": "hawaiian",
|
| 107 |
+
"ln": "lingala",
|
| 108 |
+
"ha": "hausa",
|
| 109 |
+
"ba": "bashkir",
|
| 110 |
+
"jw": "javanese",
|
| 111 |
+
"su": "sundanese",
|
| 112 |
+
}
|
| 113 |
+
self.model = whisper.load_model(model_path)
|
| 114 |
+
|
| 115 |
+
@calculate_time
|
| 116 |
+
def transcribe(self, audio_file):
|
| 117 |
+
result = self.model.transcribe(audio_file)
|
| 118 |
+
return result["text"]
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
if __name__ == "__main__":
|
| 122 |
+
import os
|
| 123 |
+
# 创建ASR对象并进行语音识别
|
| 124 |
+
model_path = "./Whisper/tiny.pt" # 模型路径
|
| 125 |
+
audio_file = "output.wav" # 音频文件路径
|
| 126 |
+
if not os.path.exists(audio_file):
|
| 127 |
+
os.system('edge-tts --text "hello" --write-media output.wav')
|
| 128 |
+
asr = WhisperASR(model_path)
|
| 129 |
+
print(asr.transcribe(audio_file))
|
ASR/__init__.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .Whisper import WhisperASR
|
| 2 |
+
from .FunASR import FunASR
|
| 3 |
+
|
| 4 |
+
__all__ = ['WhisperASR', 'FunASR']
|
ASR/requirements_funasr.txt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
funasr
|
| 2 |
+
modelscope
|
| 3 |
+
# rotary_embedding_torch
|
AutoDL部署.md
ADDED
|
@@ -0,0 +1,234 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 在AutoDL平台部署Linly-Talker (0基础小白超详细教程)
|
| 2 |
+
|
| 3 |
+
<!-- TOC -->
|
| 4 |
+
|
| 5 |
+
- [在AutoDL平台部署Linly-Talker 0基础小白超详细教程](#%E5%9C%A8autodl%E5%B9%B3%E5%8F%B0%E9%83%A8%E7%BD%B2linly-talker-0%E5%9F%BA%E7%A1%80%E5%B0%8F%E7%99%BD%E8%B6%85%E8%AF%A6%E7%BB%86%E6%95%99%E7%A8%8B)
|
| 6 |
+
- [快速上手直接使用镜像以下安装操作全免](#%E5%BF%AB%E9%80%9F%E4%B8%8A%E6%89%8B%E7%9B%B4%E6%8E%A5%E4%BD%BF%E7%94%A8%E9%95%9C%E5%83%8F%E4%BB%A5%E4%B8%8B%E5%AE%89%E8%A3%85%E6%93%8D%E4%BD%9C%E5%85%A8%E5%85%8D)
|
| 7 |
+
- [一、注册AutoDL](#%E4%B8%80%E6%B3%A8%E5%86%8Cautodl)
|
| 8 |
+
- [二、创建实例](#%E4%BA%8C%E5%88%9B%E5%BB%BA%E5%AE%9E%E4%BE%8B)
|
| 9 |
+
- [登录AutoDL,进入算力市场,选择机器](#%E7%99%BB%E5%BD%95autodl%E8%BF%9B%E5%85%A5%E7%AE%97%E5%8A%9B%E5%B8%82%E5%9C%BA%E9%80%89%E6%8B%A9%E6%9C%BA%E5%99%A8)
|
| 10 |
+
- [配置基础镜像](#%E9%85%8D%E7%BD%AE%E5%9F%BA%E7%A1%80%E9%95%9C%E5%83%8F)
|
| 11 |
+
- [无卡模式开机](#%E6%97%A0%E5%8D%A1%E6%A8%A1%E5%BC%8F%E5%BC%80%E6%9C%BA)
|
| 12 |
+
- [三、部署环境](#%E4%B8%89%E9%83%A8%E7%BD%B2%E7%8E%AF%E5%A2%83)
|
| 13 |
+
- [进入终端](#%E8%BF%9B%E5%85%A5%E7%BB%88%E7%AB%AF)
|
| 14 |
+
- [下载代码文件](#%E4%B8%8B%E8%BD%BD%E4%BB%A3%E7%A0%81%E6%96%87%E4%BB%B6)
|
| 15 |
+
- [下载模型文件](#%E4%B8%8B%E8%BD%BD%E6%A8%A1%E5%9E%8B%E6%96%87%E4%BB%B6)
|
| 16 |
+
- [四、Linly-Talker项目](#%E5%9B%9Blinly-talker%E9%A1%B9%E7%9B%AE)
|
| 17 |
+
- [环境安装](#%E7%8E%AF%E5%A2%83%E5%AE%89%E8%A3%85)
|
| 18 |
+
- [端口设置](#%E7%AB%AF%E5%8F%A3%E8%AE%BE%E7%BD%AE)
|
| 19 |
+
- [有卡开机](#%E6%9C%89%E5%8D%A1%E5%BC%80%E6%9C%BA)
|
| 20 |
+
- [运行网页版对话webui](#%E8%BF%90%E8%A1%8C%E7%BD%91%E9%A1%B5%E7%89%88%E5%AF%B9%E8%AF%9Dwebui)
|
| 21 |
+
- [端口映射](#%E7%AB%AF%E5%8F%A3%E6%98%A0%E5%B0%84)
|
| 22 |
+
- [体验Linly-Talker(成功)](#%E4%BD%93%E9%AA%8Clinly-talker%E6%88%90%E5%8A%9F)
|
| 23 |
+
|
| 24 |
+
<!-- /TOC -->
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
## 快速上手直接使用镜像(以下安装操作全免)
|
| 29 |
+
|
| 30 |
+
若使用我设定好的镜像,可以直接运行即可,不需要安装环境,直接运行webui.py或者是app_talk.py即可体验,不需要安装任何环境,可直接跳到4.4即可
|
| 31 |
+
|
| 32 |
+
访问后在自定义设置里面打开端口,默认是6006端口,直接使用运行即可!
|
| 33 |
+
|
| 34 |
+
```bash
|
| 35 |
+
python webui.py
|
| 36 |
+
python app_talk.py
|
| 37 |
+
```
|
| 38 |
+
|
| 39 |
+
环境模型都安装好了,直接使用即可,镜像地址在:[https://www.codewithgpu.com/i/Kedreamix/Linly-Talker/Kedreamix-Linly-Talker](https://www.codewithgpu.com/i/Kedreamix/Linly-Talker/Kedreamix-Linly-Talker),感谢大家的支持
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
## 一、注册AutoDL
|
| 44 |
+
|
| 45 |
+
[AutoDL官网](https://www.autodl.com/home) 注册账户好并充值,自己选择机器,我觉得如果正常跑一下,5元已经够了
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
## 二、创建实例
|
| 50 |
+
|
| 51 |
+
### 2.1 登录AutoDL,进入算力市场,选择机器
|
| 52 |
+
|
| 53 |
+
这一部分实际上我觉得12g都OK的,无非是速度问题而已
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
### 2.2 配置基础镜像
|
| 60 |
+
|
| 61 |
+
选择镜像,最好选择2.0以上可以体验克隆声音功能,其他无所谓
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
### 2.3 无卡模式开机
|
| 68 |
+
|
| 69 |
+
创建成功后为了省钱先关机,然后使用无卡模式开机。
|
| 70 |
+
无卡模式一个小时只需要0.1元,比较适合部署环境。
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
## 三、部署环境
|
| 75 |
+
|
| 76 |
+
### 3.1 进入终端
|
| 77 |
+
|
| 78 |
+
打开jupyterLab,进入数据盘(autodl-tmp),打开终端,将Linly-Talker模型下载到数据盘中。
|
| 79 |
+
|
| 80 |
+
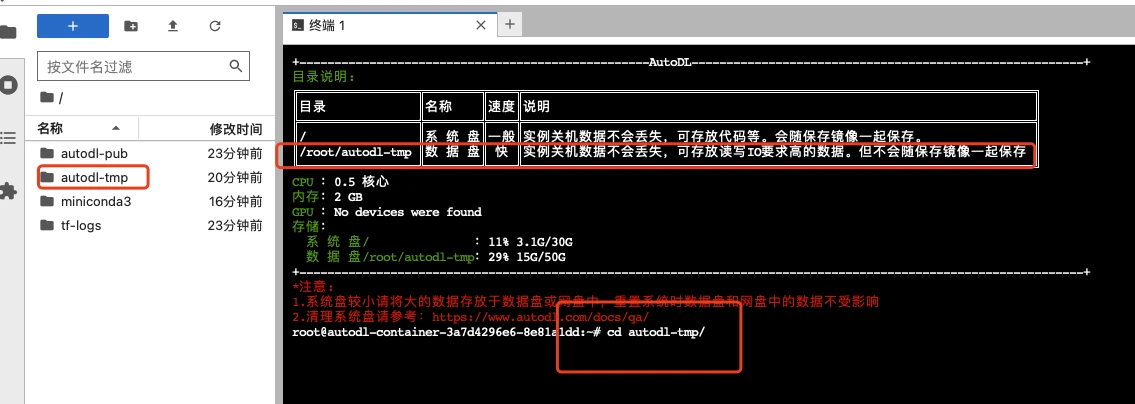
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
### 3.2 下载代码文件
|
| 85 |
+
|
| 86 |
+
根据Github上的说明,使用命令行下载模型文件和代码文件,利用学术加速会快一点
|
| 87 |
+
|
| 88 |
+
```bash
|
| 89 |
+
# 开启学术镜像,更快的clone代码 参考 https://www.autodl.com/docs/network_turbo/
|
| 90 |
+
source /etc/network_turbo
|
| 91 |
+
|
| 92 |
+
cd /root/autodl-tmp/
|
| 93 |
+
# 下载代码
|
| 94 |
+
git clone https://github.com/Kedreamix/Linly-Talker.git
|
| 95 |
+
|
| 96 |
+
# 取消学术加速
|
| 97 |
+
unset http_proxy && unset https_proxy
|
| 98 |
+
```
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
### 3.3 下载模型文件
|
| 103 |
+
|
| 104 |
+
安装git lfs
|
| 105 |
+
|
| 106 |
+
```sh
|
| 107 |
+
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
|
| 108 |
+
sudo apt-get install git-lfs
|
| 109 |
+
```
|
| 110 |
+
|
| 111 |
+
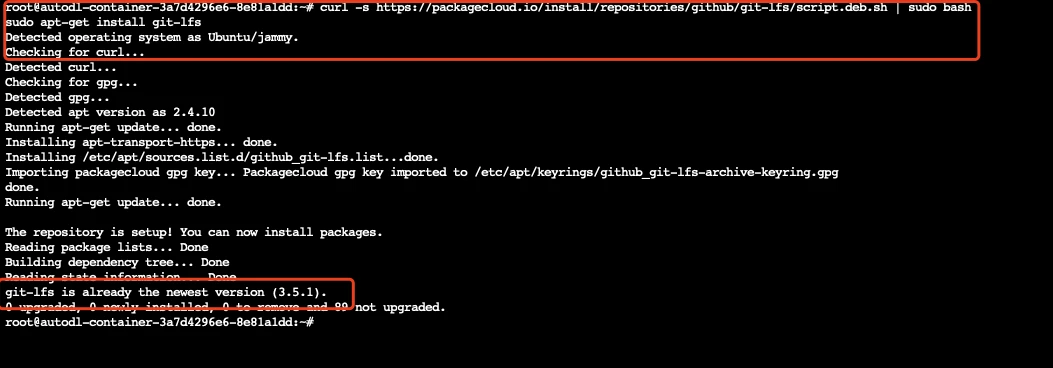
|
| 112 |
+
|
| 113 |
+
根据 [https://www.modelscope.cn/Kedreamix/Linly-Talker](https://www.modelscope.cn/Kedreamix/Linly-Talker) 下载模型文件,走modelscope还是很快的,不过文件有点多,还是得等一下,记住是在Linly-Talker代码路径下执行这个文件
|
| 114 |
+
|
| 115 |
+
```bash
|
| 116 |
+
cd /root/autodl-tmp/Linly-Talker/
|
| 117 |
+
git lfs install
|
| 118 |
+
git lfs clone https://www.modelscope.cn/Kedreamix/Linly-Talker.git
|
| 119 |
+
```
|
| 120 |
+
|
| 121 |
+
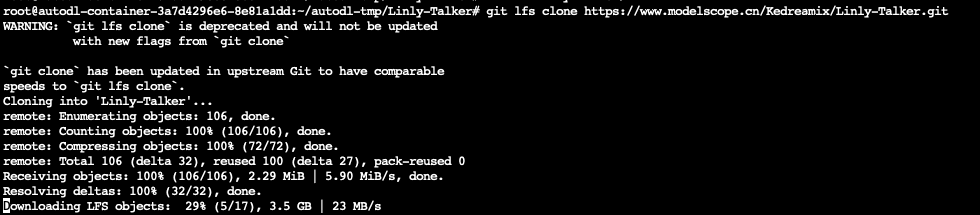
|
| 122 |
+
|
| 123 |
+
等待一段时间下载完以后,利用命令将模型移动到指定目���,直接复制即可
|
| 124 |
+
|
| 125 |
+
```bash
|
| 126 |
+
# 移动所有模型到当前目录
|
| 127 |
+
# checkpoint中含有SadTalker和Wav2Lip
|
| 128 |
+
mv Linly-Talker/checkpoints/* ./checkpoints
|
| 129 |
+
|
| 130 |
+
# SadTalker的增强GFPGAN
|
| 131 |
+
# pip install gfpgan
|
| 132 |
+
# mv Linly-Talker/gfpan ./
|
| 133 |
+
|
| 134 |
+
# 语音克隆模型
|
| 135 |
+
mv Linly-Talker/GPT_SoVITS/pretrained_models/* ./GPT_SoVITS/pretrained_models/
|
| 136 |
+
|
| 137 |
+
# Qwen大模型
|
| 138 |
+
mv Linly-Talker/Qwen ./
|
| 139 |
+
```
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
## 四、Linly-Talker项目
|
| 144 |
+
|
| 145 |
+
### 4.1 环境安装
|
| 146 |
+
|
| 147 |
+
进入代码路径,进行安装环境,由于选了镜像是含有pytorch的,所以只需要进行安装其他依赖即可
|
| 148 |
+
|
| 149 |
+
```bash
|
| 150 |
+
cd /root/autodl-tmp/Linly-Talker
|
| 151 |
+
|
| 152 |
+
conda install -q ffmpeg # ffmpeg==4.2.2
|
| 153 |
+
|
| 154 |
+
# 安装Linly-Talker对应依赖
|
| 155 |
+
pip install -r requirements_app.txt
|
| 156 |
+
|
| 157 |
+
# 安装语音克隆对应的依赖
|
| 158 |
+
pip install -r VITS/requirements_gptsovits.txt
|
| 159 |
+
```
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
### 4.2 端口设置
|
| 164 |
+
|
| 165 |
+
由于似乎autodl开放的是6006端口,所以这里面的端口映射也可以改一下成6006,这里吗只需要修改configs.py文件里面的port为6006即可
|
| 166 |
+
|
| 167 |
+
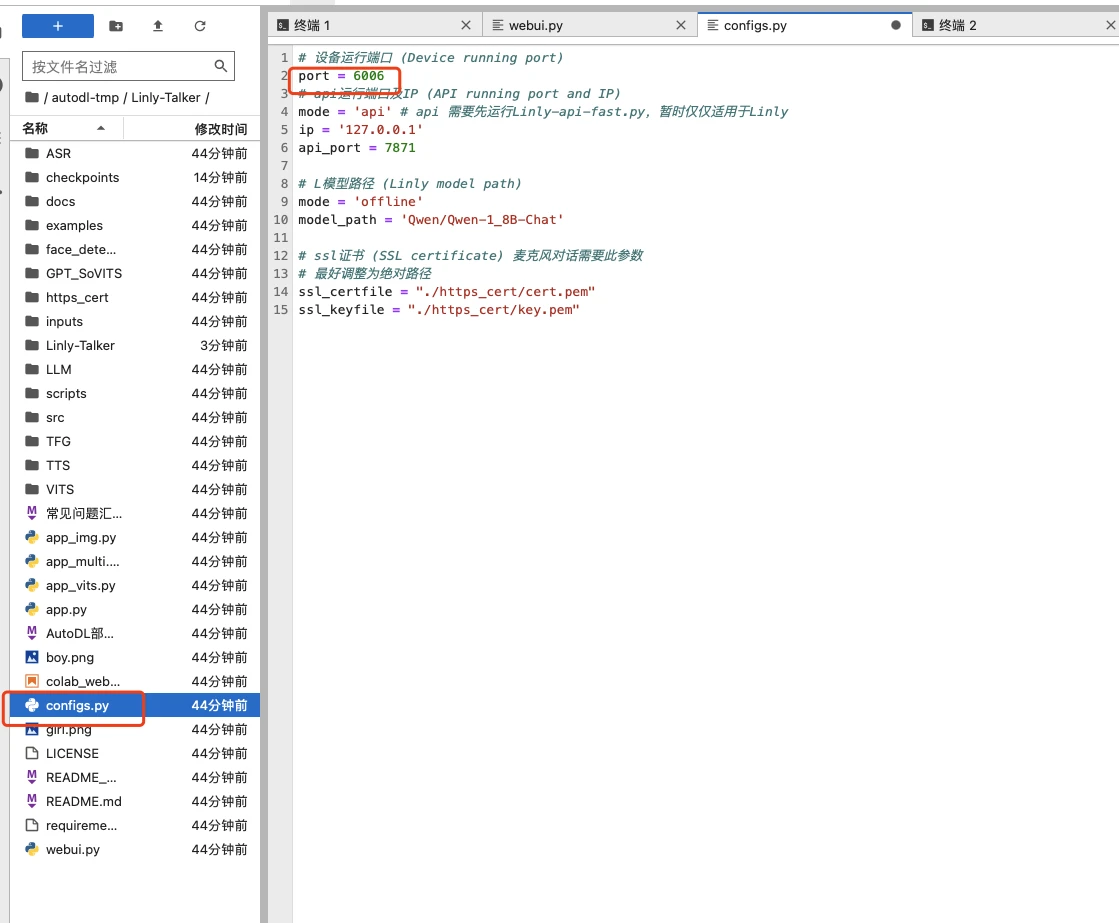
|
| 168 |
+
|
| 169 |
+
除此之外,我发现其实对于autodl来说,不是很支持https的端口映射,所以需要注释掉几行代码即可,在webui.py的最后几行注释掉代码ssl相关代码
|
| 170 |
+
|
| 171 |
+
```bash
|
| 172 |
+
demo.launch(server_name="127.0.0.1", # 本地端口localhost:127.0.0.1 全局端口转发:"0.0.0.0"
|
| 173 |
+
server_port=port,
|
| 174 |
+
# 似乎在Gradio4.0以上版本可以不使用证书也可以进行麦克风对话
|
| 175 |
+
# ssl_certfile=ssl_certfile,
|
| 176 |
+
# ssl_keyfile=ssl_keyfile,
|
| 177 |
+
# ssl_verify=False,
|
| 178 |
+
debug=True,
|
| 179 |
+
)
|
| 180 |
+
```
|
| 181 |
+
|
| 182 |
+
如果使用app.py同理
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
### 4.3 有卡开机
|
| 187 |
+
|
| 188 |
+
进入autodl容器实例界面,执行关机操作,然后进行有卡开机,开机后打开jupyterLab。
|
| 189 |
+
|
| 190 |
+
查看配置
|
| 191 |
+
|
| 192 |
+
```bash
|
| 193 |
+
nvidia-smi
|
| 194 |
+
```
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
### 4.4 运行网页版对话webui
|
| 201 |
+
|
| 202 |
+
需要有卡模式开机,执行下边命令,这里面就跟代码是一模一样的了
|
| 203 |
+
|
| 204 |
+
```bash
|
| 205 |
+
python webui.py
|
| 206 |
+
```
|
| 207 |
+
|
| 208 |
+

|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
### 4.4 端口映射
|
| 213 |
+
|
| 214 |
+
这可以直接打开autodl的自定义服务,默认是6006端口,我们已经设置了,所以直接使用即可
|
| 215 |
+
|
| 216 |
+
|
| 217 |
+
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
### 4.5 体验Linly-Talker(成功)
|
| 221 |
+
|
| 222 |
+
点开网页,即可正确执行Linly-Talker,这一部分就跟视频一模一样了
|
| 223 |
+
|
| 224 |
+
|
| 225 |
+
|
| 226 |
+
|
| 227 |
+
|
| 228 |
+
|
| 229 |
+
|
| 230 |
+
ssh端口映射工具:windows:[https://autodl-public.ks3-cn-beijing.ksyuncs.com/tool/AutoDL-SSH-Tools.zip](https://autodl-public.ks3-cn-beijing.ksyuncs.com/tool/AutoDL-SSH-Tools.zip)
|
| 231 |
+
|
| 232 |
+
**!!!注意:不用了,一定要去控制台=》容器实例,把镜像实例关机,它是按时收费的,不关机会一直扣费的。**
|
| 233 |
+
|
| 234 |
+
**建议选北京区的,稍微便宜一些。可以晚上部署,网速快,便宜的GPU也充足。白天部署,北京区的GPU容易没有。**
|
FunASR/punc_ct-transformer_zh-cn-common-vocab272727-pytorch/.mdl
ADDED
|
Binary file (79 Bytes). View file
|
|
|
FunASR/punc_ct-transformer_zh-cn-common-vocab272727-pytorch/.msc
ADDED
|
Binary file (566 Bytes). View file
|
|
|
FunASR/punc_ct-transformer_zh-cn-common-vocab272727-pytorch/README.md
ADDED
|
@@ -0,0 +1,272 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
tasks:
|
| 3 |
+
- punctuation
|
| 4 |
+
domain:
|
| 5 |
+
- audio
|
| 6 |
+
model-type:
|
| 7 |
+
- Classification
|
| 8 |
+
frameworks:
|
| 9 |
+
- pytorch
|
| 10 |
+
metrics:
|
| 11 |
+
- f1_score
|
| 12 |
+
license: Apache License 2.0
|
| 13 |
+
language:
|
| 14 |
+
- cn
|
| 15 |
+
tags:
|
| 16 |
+
- FunASR
|
| 17 |
+
- CT-Transformer
|
| 18 |
+
- Alibaba
|
| 19 |
+
- ICASSP 2020
|
| 20 |
+
datasets:
|
| 21 |
+
train:
|
| 22 |
+
- 33M-samples online data
|
| 23 |
+
test:
|
| 24 |
+
- wikipedia data test
|
| 25 |
+
- 10000 industrial Mandarin sentences test
|
| 26 |
+
widgets:
|
| 27 |
+
- task: punctuation
|
| 28 |
+
model_revision: v2.0.4
|
| 29 |
+
inputs:
|
| 30 |
+
- type: text
|
| 31 |
+
name: input
|
| 32 |
+
title: 文本
|
| 33 |
+
examples:
|
| 34 |
+
- name: 1
|
| 35 |
+
title: 示例1
|
| 36 |
+
inputs:
|
| 37 |
+
- name: input
|
| 38 |
+
data: 我们都是木头人不会讲话不会动
|
| 39 |
+
inferencespec:
|
| 40 |
+
cpu: 1 #CPU数量
|
| 41 |
+
memory: 4096
|
| 42 |
+
---
|
| 43 |
+
|
| 44 |
+
# Controllable Time-delay Transformer模型介绍
|
| 45 |
+
|
| 46 |
+
[//]: # (Controllable Time-delay Transformer 模型是一种端到端标点分类模型。)
|
| 47 |
+
|
| 48 |
+
[//]: # (常规的Transformer会依赖很远的未来信息,导致长时间结果不固定。Controllable Time-delay Transformer 在效果无损的情况下,有效控制标点的延时。)
|
| 49 |
+
|
| 50 |
+
# Highlights
|
| 51 |
+
- 中文标点通用模型:可用于语音识别模型输出文本的标点预测。
|
| 52 |
+
- 基于[Paraformer-large长音频模型](https://www.modelscope.cn/models/damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch/summary)场景的使用
|
| 53 |
+
- 基于[FunASR框架](https://github.com/alibaba-damo-academy/FunASR),可进行ASR,VAD,标点的自由组合
|
| 54 |
+
- 基于纯文本输入的标点预测
|
| 55 |
+
|
| 56 |
+
## <strong>[FunASR开源项目介绍](https://github.com/alibaba-damo-academy/FunASR)</strong>
|
| 57 |
+
<strong>[FunASR](https://github.com/alibaba-damo-academy/FunASR)</strong>希望在语音识别的学术研究和工业应用之间架起一座桥梁。通过发布工业级语音识别模型的训练和微调,研究人员和开发人员可以更方便地进行语音识别模型的研究和生产,并推动语音识别生态的发展。让语音识别更有趣!
|
| 58 |
+
|
| 59 |
+
[**github仓库**](https://github.com/alibaba-damo-academy/FunASR)
|
| 60 |
+
| [**最新动态**](https://github.com/alibaba-damo-academy/FunASR#whats-new)
|
| 61 |
+
| [**环境安装**](https://github.com/alibaba-damo-academy/FunASR#installation)
|
| 62 |
+
| [**服务部署**](https://www.funasr.com)
|
| 63 |
+
| [**模型库**](https://github.com/alibaba-damo-academy/FunASR/tree/main/model_zoo)
|
| 64 |
+
| [**联系我们**](https://github.com/alibaba-damo-academy/FunASR#contact)
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
## 模型原理介绍
|
| 68 |
+
|
| 69 |
+
Controllable Time-delay Transformer是达摩院语音团队提出的高效后处理框架中的标点模块。本项目为中文通用标点模型,模型可以被应用于文本类输入的标点预测,也可应用于语音识别结果的后处理步骤,协助语音识别模块输出具有可读性的文本结果。
|
| 70 |
+
|
| 71 |
+
<p align="center">
|
| 72 |
+
<img src="fig/struct.png" alt="Controllable Time-delay Transformer模型结构" width="500" />
|
| 73 |
+
|
| 74 |
+
Controllable Time-delay Transformer 模型结构如上图所示,由 Embedding、Encoder 和 Predictor 三部分组成。Embedding 是词向量叠加位置向量。Encoder可以采用不同的网络结构,例如self-attention,conformer,SAN-M等。Predictor 预测每个token后的标点类型。
|
| 75 |
+
|
| 76 |
+
在模型的选择上采用了性能优越的Transformer模型。Transformer模型在获得良好性能的同时,由于模型自身序列化输入等特性,会给系统带来较大时延。常规的Transformer可以看到未来的全部信息,导致标点会依赖很远的未来信息。这会给用户带来一种标点一直在变化刷新,长时间结果不固定的不良感受。基于这一问题,我们创新性的提出了可控时延的Transformer模型(Controllable Time-Delay Transformer, CT-Transformer),在模型性能无损失的情况下,有效控制标点的延时。
|
| 77 |
+
|
| 78 |
+
更详细的细节见:
|
| 79 |
+
- 论文: [CONTROLLABLE TIME-DELAY TRANSFORMER FOR REAL-TIME PUNCTUATION PREDICTION AND DISFLUENCY DETECTION](https://arxiv.org/pdf/2003.01309.pdf)
|
| 80 |
+
|
| 81 |
+
## 基于ModelScope进行推理
|
| 82 |
+
|
| 83 |
+
以下为三种支持格式及api调用方式参考如下范例:
|
| 84 |
+
- text.scp文件路径,例如example/punc_example.txt,格式为: key + "\t" + value
|
| 85 |
+
```sh
|
| 86 |
+
cat example/punc_example.txt
|
| 87 |
+
1 跨境河流是养育沿岸人民的生命之源
|
| 88 |
+
2 从存储上来说仅仅是全景图片它就会是图片的四倍的容量
|
| 89 |
+
3 那今天的会就到这里吧happy new year明年见
|
| 90 |
+
```
|
| 91 |
+
```python
|
| 92 |
+
from modelscope.pipelines import pipeline
|
| 93 |
+
from modelscope.utils.constant import Tasks
|
| 94 |
+
|
| 95 |
+
inference_pipline = pipeline(
|
| 96 |
+
task=Tasks.punctuation,
|
| 97 |
+
model='damo/punc_ct-transformer_zh-cn-common-vocab272727-pytorch',
|
| 98 |
+
model_revision="v2.0.4")
|
| 99 |
+
|
| 100 |
+
rec_result = inference_pipline(input='example/punc_example.txt')
|
| 101 |
+
print(rec_result)
|
| 102 |
+
```
|
| 103 |
+
- text二进制数据,例如:用户直接从文件里读出bytes数据
|
| 104 |
+
```python
|
| 105 |
+
rec_result = inference_pipline(input='我们都是木头人不会讲话不会动')
|
| 106 |
+
```
|
| 107 |
+
- text文件url,例如:https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_text/punc_example.txt
|
| 108 |
+
```python
|
| 109 |
+
rec_result = inference_pipline(input='https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_text/punc_example.txt')
|
| 110 |
+
```
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
## 基于FunASR进行推理
|
| 114 |
+
|
| 115 |
+
下面为快速上手教程,测试音频([中文](https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/vad_example.wav),[英文](https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_en.wav))
|
| 116 |
+
|
| 117 |
+
### 可执行命令行
|
| 118 |
+
在命令行终端执行:
|
| 119 |
+
|
| 120 |
+
```shell
|
| 121 |
+
funasr ++model=paraformer-zh ++vad_model="fsmn-vad" ++punc_model="ct-punc" ++input=vad_example.wav
|
| 122 |
+
```
|
| 123 |
+
|
| 124 |
+
注:支持单条音频文件识别,也支持文件列表,列表为kaldi风格wav.scp:`wav_id wav_path`
|
| 125 |
+
|
| 126 |
+
### python示例
|
| 127 |
+
#### 非实时语音识别
|
| 128 |
+
```python
|
| 129 |
+
from funasr import AutoModel
|
| 130 |
+
# paraformer-zh is a multi-functional asr model
|
| 131 |
+
# use vad, punc, spk or not as you need
|
| 132 |
+
model = AutoModel(model="paraformer-zh", model_revision="v2.0.4",
|
| 133 |
+
vad_model="fsmn-vad", vad_model_revision="v2.0.4",
|
| 134 |
+
punc_model="ct-punc-c", punc_model_revision="v2.0.4",
|
| 135 |
+
# spk_model="cam++", spk_model_revision="v2.0.2",
|
| 136 |
+
)
|
| 137 |
+
res = model.generate(input=f"{model.model_path}/example/asr_example.wav",
|
| 138 |
+
batch_size_s=300,
|
| 139 |
+
hotword='魔搭')
|
| 140 |
+
print(res)
|
| 141 |
+
```
|
| 142 |
+
注:`model_hub`:表示模型仓库,`ms`为选择modelscope下载,`hf`为选择huggingface下载。
|
| 143 |
+
|
| 144 |
+
#### 实时语音识别
|
| 145 |
+
|
| 146 |
+
```python
|
| 147 |
+
from funasr import AutoModel
|
| 148 |
+
|
| 149 |
+
chunk_size = [0, 10, 5] #[0, 10, 5] 600ms, [0, 8, 4] 480ms
|
| 150 |
+
encoder_chunk_look_back = 4 #number of chunks to lookback for encoder self-attention
|
| 151 |
+
decoder_chunk_look_back = 1 #number of encoder chunks to lookback for decoder cross-attention
|
| 152 |
+
|
| 153 |
+
model = AutoModel(model="paraformer-zh-streaming", model_revision="v2.0.4")
|
| 154 |
+
|
| 155 |
+
import soundfile
|
| 156 |
+
import os
|
| 157 |
+
|
| 158 |
+
wav_file = os.path.join(model.model_path, "example/asr_example.wav")
|
| 159 |
+
speech, sample_rate = soundfile.read(wav_file)
|
| 160 |
+
chunk_stride = chunk_size[1] * 960 # 600ms
|
| 161 |
+
|
| 162 |
+
cache = {}
|
| 163 |
+
total_chunk_num = int(len((speech)-1)/chunk_stride+1)
|
| 164 |
+
for i in range(total_chunk_num):
|
| 165 |
+
speech_chunk = speech[i*chunk_stride:(i+1)*chunk_stride]
|
| 166 |
+
is_final = i == total_chunk_num - 1
|
| 167 |
+
res = model.generate(input=speech_chunk, cache=cache, is_final=is_final, chunk_size=chunk_size, encoder_chunk_look_back=encoder_chunk_look_back, decoder_chunk_look_back=decoder_chunk_look_back)
|
| 168 |
+
print(res)
|
| 169 |
+
```
|
| 170 |
+
|
| 171 |
+
注:`chunk_size`为流式延时配置,`[0,10,5]`表示上屏实时出字粒度为`10*60=600ms`,未来信息为`5*60=300ms`。每次推理输入为`600ms`(采样点数为`16000*0.6=960`),输出为对应文字,最后一个语音片段输入需要设置`is_final=True`来强制输出最后一个字。
|
| 172 |
+
|
| 173 |
+
#### 语音端点检测(非实时)
|
| 174 |
+
```python
|
| 175 |
+
from funasr import AutoModel
|
| 176 |
+
|
| 177 |
+
model = AutoModel(model="fsmn-vad", model_revision="v2.0.4")
|
| 178 |
+
|
| 179 |
+
wav_file = f"{model.model_path}/example/asr_example.wav"
|
| 180 |
+
res = model.generate(input=wav_file)
|
| 181 |
+
print(res)
|
| 182 |
+
```
|
| 183 |
+
|
| 184 |
+
#### 语音端点检测(实时)
|
| 185 |
+
```python
|
| 186 |
+
from funasr import AutoModel
|
| 187 |
+
|
| 188 |
+
chunk_size = 200 # ms
|
| 189 |
+
model = AutoModel(model="fsmn-vad", model_revision="v2.0.4")
|
| 190 |
+
|
| 191 |
+
import soundfile
|
| 192 |
+
|
| 193 |
+
wav_file = f"{model.model_path}/example/vad_example.wav"
|
| 194 |
+
speech, sample_rate = soundfile.read(wav_file)
|
| 195 |
+
chunk_stride = int(chunk_size * sample_rate / 1000)
|
| 196 |
+
|
| 197 |
+
cache = {}
|
| 198 |
+
total_chunk_num = int(len((speech)-1)/chunk_stride+1)
|
| 199 |
+
for i in range(total_chunk_num):
|
| 200 |
+
speech_chunk = speech[i*chunk_stride:(i+1)*chunk_stride]
|
| 201 |
+
is_final = i == total_chunk_num - 1
|
| 202 |
+
res = model.generate(input=speech_chunk, cache=cache, is_final=is_final, chunk_size=chunk_size)
|
| 203 |
+
if len(res[0]["value"]):
|
| 204 |
+
print(res)
|
| 205 |
+
```
|
| 206 |
+
|
| 207 |
+
#### 标点恢复
|
| 208 |
+
```python
|
| 209 |
+
from funasr import AutoModel
|
| 210 |
+
|
| 211 |
+
model = AutoModel(model="ct-punc", model_revision="v2.0.4")
|
| 212 |
+
|
| 213 |
+
res = model.generate(input="那今天的会就到这里吧 happy new year 明年见")
|
| 214 |
+
print(res)
|
| 215 |
+
```
|
| 216 |
+
|
| 217 |
+
#### 时间戳预测
|
| 218 |
+
```python
|
| 219 |
+
from funasr import AutoModel
|
| 220 |
+
|
| 221 |
+
model = AutoModel(model="fa-zh", model_revision="v2.0.4")
|
| 222 |
+
|
| 223 |
+
wav_file = f"{model.model_path}/example/asr_example.wav"
|
| 224 |
+
text_file = f"{model.model_path}/example/text.txt"
|
| 225 |
+
res = model.generate(input=(wav_file, text_file), data_type=("sound", "text"))
|
| 226 |
+
print(res)
|
| 227 |
+
```
|
| 228 |
+
|
| 229 |
+
更多详细用法([示例](https://github.com/alibaba-damo-academy/FunASR/tree/main/examples/industrial_data_pretraining))
|
| 230 |
+
|
| 231 |
+
|
| 232 |
+
## 微调
|
| 233 |
+
|
| 234 |
+
详细用法([示例](https://github.com/alibaba-damo-academy/FunASR/tree/main/examples/industrial_data_pretraining))
|
| 235 |
+
|
| 236 |
+
|
| 237 |
+
|
| 238 |
+
|
| 239 |
+
|
| 240 |
+
## Benchmark
|
| 241 |
+
中文标点预测通用模型在自采集的通用领域业务场景数据上有良好效果。训练数据大约33M个sample,每个sample可能包含1句或多句。
|
| 242 |
+
|
| 243 |
+
### 自采集数据(20000+ samples)
|
| 244 |
+
|
| 245 |
+
| precision | recall | f1_score |
|
| 246 |
+
|:------------------------------------:|:-------------------------------------:|:-------------------------------------:|
|
| 247 |
+
| <div style="width: 150pt">53.8</div> | <div style="width: 150pt">60.0</div> | <div style="width: 150pt">56.5</div> |
|
| 248 |
+
|
| 249 |
+
## 使用方式以及适用范围
|
| 250 |
+
|
| 251 |
+
运行范围
|
| 252 |
+
- 支持Linux-x86_64、Mac和Windows运行。
|
| 253 |
+
|
| 254 |
+
使用方式
|
| 255 |
+
- 直接推理:可以直接对输入文本进行计算,输出带有标点的目标文字。
|
| 256 |
+
|
| 257 |
+
使用范围与目标场景
|
| 258 |
+
- 适合对文本数据进行标点预测,文本长度不限。
|
| 259 |
+
|
| 260 |
+
## 相关论文以及引用信息
|
| 261 |
+
|
| 262 |
+
```BibTeX
|
| 263 |
+
@inproceedings{chen2020controllable,
|
| 264 |
+
title={Controllable Time-Delay Transformer for Real-Time Punctuation Prediction and Disfluency Detection},
|
| 265 |
+
author={Chen, Qian and Chen, Mengzhe and Li, Bo and Wang, Wen},
|
| 266 |
+
booktitle={ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
|
| 267 |
+
pages={8069--8073},
|
| 268 |
+
year={2020},
|
| 269 |
+
organization={IEEE}
|
| 270 |
+
}
|
| 271 |
+
```
|
| 272 |
+
|
FunASR/punc_ct-transformer_zh-cn-common-vocab272727-pytorch/config.yaml
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model: CTTransformer
|
| 2 |
+
model_conf:
|
| 3 |
+
ignore_id: 0
|
| 4 |
+
embed_unit: 256
|
| 5 |
+
att_unit: 256
|
| 6 |
+
dropout_rate: 0.1
|
| 7 |
+
punc_list:
|
| 8 |
+
- <unk>
|
| 9 |
+
- _
|
| 10 |
+
- ,
|
| 11 |
+
- 。
|
| 12 |
+
- ?
|
| 13 |
+
- 、
|
| 14 |
+
punc_weight:
|
| 15 |
+
- 1.0
|
| 16 |
+
- 1.0
|
| 17 |
+
- 1.0
|
| 18 |
+
- 1.0
|
| 19 |
+
- 1.0
|
| 20 |
+
- 1.0
|
| 21 |
+
sentence_end_id: 3
|
| 22 |
+
|
| 23 |
+
encoder: SANMEncoder
|
| 24 |
+
encoder_conf:
|
| 25 |
+
input_size: 256
|
| 26 |
+
output_size: 256
|
| 27 |
+
attention_heads: 8
|
| 28 |
+
linear_units: 1024
|
| 29 |
+
num_blocks: 4
|
| 30 |
+
dropout_rate: 0.1
|
| 31 |
+
positional_dropout_rate: 0.1
|
| 32 |
+
attention_dropout_rate: 0.0
|
| 33 |
+
input_layer: pe
|
| 34 |
+
pos_enc_class: SinusoidalPositionEncoder
|
| 35 |
+
normalize_before: true
|
| 36 |
+
kernel_size: 11
|
| 37 |
+
sanm_shfit: 0
|
| 38 |
+
selfattention_layer_type: sanm
|
| 39 |
+
padding_idx: 0
|
| 40 |
+
|
| 41 |
+
tokenizer: CharTokenizer
|
| 42 |
+
tokenizer_conf:
|
| 43 |
+
unk_symbol: <unk>
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
|
FunASR/punc_ct-transformer_zh-cn-common-vocab272727-pytorch/configuration.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"framework": "pytorch",
|
| 3 |
+
"task" : "punctuation",
|
| 4 |
+
"model": {"type" : "funasr"},
|
| 5 |
+
"pipeline": {"type":"funasr-pipeline"},
|
| 6 |
+
"model_name_in_hub": {
|
| 7 |
+
"ms":"iic/punc_ct-transformer_zh-cn-common-vocab272727-pytorch",
|
| 8 |
+
"hf":""},
|
| 9 |
+
"file_path_metas": {
|
| 10 |
+
"init_param":"model.pt",
|
| 11 |
+
"config":"config.yaml",
|
| 12 |
+
"tokenizer_conf": {"token_list": "tokens.json"}}
|
| 13 |
+
}
|
FunASR/punc_ct-transformer_zh-cn-common-vocab272727-pytorch/example/punc_example.txt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
1 跨境河流是养育沿岸人民的生命之源长期以来为帮助下游地区防灾减灾中方技术人员在上游地区极为恶劣的自然条件下克服巨大困难甚至冒着生命危险向印方提供汛期水文资料处理紧急事件中方重视印方在跨境河流问题上的关切愿意进一步完善双方联合工作机制凡是中方能做的我们都会去做而且会做得更好我请印度朋友们放心中国在上游的任何开发利用都会经过科学规划和论证兼顾上下游的利益
|
| 2 |
+
2 从存储上来说仅仅是全景图片它就会是图片的四倍的容量然后全景的视频会是普通视频八倍的这个存储的容要求而三d的模型会是图片的十倍这都对我们今天运行在的云计算的平台存储的平台提出了更高的要求
|
| 3 |
+
3 那今天的会就到这里吧 happy new year 明年见
|
FunASR/punc_ct-transformer_zh-cn-common-vocab272727-pytorch/fig/struct.png
ADDED

|
FunASR/punc_ct-transformer_zh-cn-common-vocab272727-pytorch/model.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a5818bb9d933805a916eebe41eb41648f7f9caad30b4bd59d56f3ca135421916
|
| 3 |
+
size 291979892
|
FunASR/punc_ct-transformer_zh-cn-common-vocab272727-pytorch/tokens.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
FunASR/speech_fsmn_vad_zh-cn-16k-common-pytorch/.mdl
ADDED
|
Binary file (67 Bytes). View file
|
|
|
FunASR/speech_fsmn_vad_zh-cn-16k-common-pytorch/.msc
ADDED
|
Binary file (497 Bytes). View file
|
|
|
FunASR/speech_fsmn_vad_zh-cn-16k-common-pytorch/README.md
ADDED
|
@@ -0,0 +1,296 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
tasks:
|
| 3 |
+
- voice-activity-detection
|
| 4 |
+
domain:
|
| 5 |
+
- audio
|
| 6 |
+
model-type:
|
| 7 |
+
- VAD model
|
| 8 |
+
frameworks:
|
| 9 |
+
- pytorch
|
| 10 |
+
backbone:
|
| 11 |
+
- fsmn
|
| 12 |
+
metrics:
|
| 13 |
+
- f1_score
|
| 14 |
+
license: Apache License 2.0
|
| 15 |
+
language:
|
| 16 |
+
- cn
|
| 17 |
+
tags:
|
| 18 |
+
- FunASR
|
| 19 |
+
- FSMN
|
| 20 |
+
- Alibaba
|
| 21 |
+
- Online
|
| 22 |
+
datasets:
|
| 23 |
+
train:
|
| 24 |
+
- 20,000 hour industrial Mandarin task
|
| 25 |
+
test:
|
| 26 |
+
- 20,000 hour industrial Mandarin task
|
| 27 |
+
widgets:
|
| 28 |
+
- task: voice-activity-detection
|
| 29 |
+
model_revision: v2.0.4
|
| 30 |
+
inputs:
|
| 31 |
+
- type: audio
|
| 32 |
+
name: input
|
| 33 |
+
title: 音频
|
| 34 |
+
examples:
|
| 35 |
+
- name: 1
|
| 36 |
+
title: 示例1
|
| 37 |
+
inputs:
|
| 38 |
+
- name: input
|
| 39 |
+
data: git://example/vad_example.wav
|
| 40 |
+
inferencespec:
|
| 41 |
+
cpu: 1 #CPU数量
|
| 42 |
+
memory: 4096
|
| 43 |
+
---
|
| 44 |
+
|
| 45 |
+
# FSMN-Monophone VAD 模型介绍
|
| 46 |
+
|
| 47 |
+
[//]: # (FSMN-Monophone VAD 模型)
|
| 48 |
+
|
| 49 |
+
## Highlight
|
| 50 |
+
- 16k中文通用VAD模型:可用于检测长语音片段中有效语音的起止时间点。
|
| 51 |
+
- 基于[Paraformer-large长音频模型](https://www.modelscope.cn/models/damo/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch/summary)场景的使用
|
| 52 |
+
- 基于[FunASR框架](https://github.com/alibaba-damo-academy/FunASR),可进行ASR,VAD,[中文标点](https://www.modelscope.cn/models/damo/punc_ct-transformer_zh-cn-common-vocab272727-pytorch/summary)的自由组合
|
| 53 |
+
- 基于音频数据的有效语音片段起止时间点检测
|
| 54 |
+
|
| 55 |
+
## <strong>[FunASR开源项目介绍](https://github.com/alibaba-damo-academy/FunASR)</strong>
|
| 56 |
+
<strong>[FunASR](https://github.com/alibaba-damo-academy/FunASR)</strong>希望在语音识别的学术研究和工业应用之间架起一座桥梁。通过发布工业级语音识别模型的训练和微调,研究人员和开发人员可以更方便地进行语音识别模型的研究和生产,并推动语音识别生态的发展。让语音识别更有趣!
|
| 57 |
+
|
| 58 |
+
[**github仓库**](https://github.com/alibaba-damo-academy/FunASR)
|
| 59 |
+
| [**最新动态**](https://github.com/alibaba-damo-academy/FunASR#whats-new)
|
| 60 |
+
| [**环境安装**](https://github.com/alibaba-damo-academy/FunASR#installation)
|
| 61 |
+
| [**服务部署**](https://www.funasr.com)
|
| 62 |
+
| [**模型库**](https://github.com/alibaba-damo-academy/FunASR/tree/main/model_zoo)
|
| 63 |
+
| [**联系我们**](https://github.com/alibaba-damo-academy/FunASR#contact)
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
## 模型原理介绍
|
| 67 |
+
|
| 68 |
+
FSMN-Monophone VAD是达摩院语音团队提出的高效语音端点检测模型,用于检测输入音频中有效语音的起止时间点信息,并将检测出来的有效音频片段输入识别引擎进行识别,减少无效语音带来的识别错误。
|
| 69 |
+
|
| 70 |
+
<p align="center">
|
| 71 |
+
<img src="fig/struct.png" alt="VAD模型结构" width="500" />
|
| 72 |
+
|
| 73 |
+
FSMN-Monophone VAD模型结构如上图所示:模型结构层面,FSMN模型结构建模时可考虑上下文信息,训练和推理速度快,且时延可控;同时根据VAD模型size以及低时延的要求,对FSMN的网络结构、右看帧数进行了适配。在建模单元层面,speech信息比较丰富,仅用单类来表征学习能力有限,我们将单一speech类升级为Monophone。建模单元细分,可以避免参数平均,抽象学习能力增强,区分性更好。
|
| 74 |
+
|
| 75 |
+
## 基于ModelScope进行推理
|
| 76 |
+
|
| 77 |
+
- 推理支持音频格式如下:
|
| 78 |
+
- wav文件路径,例如:data/test/audios/vad_example.wav
|
| 79 |
+
- wav文件url,例如:https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/vad_example.wav
|
| 80 |
+
- wav二进制数据,格式bytes,例如:用户直接从文件里读出bytes数据或者是麦克风录出bytes数据。
|
| 81 |
+
- 已解析的audio音频,例如:audio, rate = soundfile.read("vad_example_zh.wav"),类型为numpy.ndarray或者torch.Tensor。
|
| 82 |
+
- wav.scp文件,需符合如下要求:
|
| 83 |
+
|
| 84 |
+
```sh
|
| 85 |
+
cat wav.scp
|
| 86 |
+
vad_example1 data/test/audios/vad_example1.wav
|
| 87 |
+
vad_example2 data/test/audios/vad_example2.wav
|
| 88 |
+
...
|
| 89 |
+
```
|
| 90 |
+
|
| 91 |
+
- 若输入格式wav文件url,api调用方式可参考如下范例:
|
| 92 |
+
|
| 93 |
+
```python
|
| 94 |
+
from modelscope.pipelines import pipeline
|
| 95 |
+
from modelscope.utils.constant import Tasks
|
| 96 |
+
|
| 97 |
+
inference_pipeline = pipeline(
|
| 98 |
+
task=Tasks.voice_activity_detection,
|
| 99 |
+
model='iic/speech_fsmn_vad_zh-cn-16k-common-pytorch',
|
| 100 |
+
model_revision="v2.0.4",
|
| 101 |
+
)
|
| 102 |
+
|
| 103 |
+
segments_result = inference_pipeline(input='https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/vad_example.wav')
|
| 104 |
+
print(segments_result)
|
| 105 |
+
```
|
| 106 |
+
|
| 107 |
+
- 输入音频为pcm格式,调用api时需要传入音频采样率参数fs,例如:
|
| 108 |
+
|
| 109 |
+
```python
|
| 110 |
+
segments_result = inference_pipeline(input='https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/vad_example.pcm', fs=16000)
|
| 111 |
+
```
|
| 112 |
+
|
| 113 |
+
- 若输入格式为文件wav.scp(注:文件名需要以.scp结尾),可添加 output_dir 参数将识别结果写入文件中,参考示例如下:
|
| 114 |
+
|
| 115 |
+
```python
|
| 116 |
+
inference_pipeline(input="wav.scp", output_dir='./output_dir')
|
| 117 |
+
```
|
| 118 |
+
识别结果输出路径结构如下:
|
| 119 |
+
|
| 120 |
+
```sh
|
| 121 |
+
tree output_dir/
|
| 122 |
+
output_dir/
|
| 123 |
+
└── 1best_recog
|
| 124 |
+
└── text
|
| 125 |
+
|
| 126 |
+
1 directory, 1 files
|
| 127 |
+
```
|
| 128 |
+
text:VAD检测语音起止时间点结果文件(单位:ms)
|
| 129 |
+
|
| 130 |
+
- 若输入音频为已解析的audio音频,api调用方式可参考如下范例:
|
| 131 |
+
|
| 132 |
+
```python
|
| 133 |
+
import soundfile
|
| 134 |
+
|
| 135 |
+
waveform, sample_rate = soundfile.read("vad_example_zh.wav")
|
| 136 |
+
segments_result = inference_pipeline(input=waveform)
|
| 137 |
+
print(segments_result)
|
| 138 |
+
```
|
| 139 |
+
|
| 140 |
+
- VAD常用参数调整说明(参考:vad.yaml文件):
|
| 141 |
+
- max_end_silence_time:尾部连续检测到多长时间静音进行尾点判停,参数范围500ms~6000ms,默认值800ms(该值过低容易出现语音提前截断的情况)。
|
| 142 |
+
- speech_noise_thres:speech的得分减去noise的得分大于此值则判断为speech,参数范围:(-1,1)
|
| 143 |
+
- 取值越趋于-1,噪音被误判定为语音的概率越大,FA越高
|
| 144 |
+
- 取值越趋于+1,语音被误判定为噪音的概率越大,Pmiss越高
|
| 145 |
+
- 通常情况下,该值会根据当前模型在长语音测试集上的效果取balance
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
## 基于FunASR进行推理
|
| 151 |
+
|
| 152 |
+
下面为快速上手教程,测试音频([中文](https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/vad_example.wav),[英文](https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_en.wav))
|
| 153 |
+
|
| 154 |
+
### 可执行命令行
|
| 155 |
+
在命令行终端执行:
|
| 156 |
+
|
| 157 |
+
```shell
|
| 158 |
+
funasr ++model=paraformer-zh ++vad_model="fsmn-vad" ++punc_model="ct-punc" ++input=vad_example.wav
|
| 159 |
+
```
|
| 160 |
+
|
| 161 |
+
注:支持单条音频文件识别,也支持文件列表,列表为kaldi风格wav.scp:`wav_id wav_path`
|
| 162 |
+
|
| 163 |
+
### python示例
|
| 164 |
+
#### 非实时语音识别
|
| 165 |
+
```python
|
| 166 |
+
from funasr import AutoModel
|
| 167 |
+
# paraformer-zh is a multi-functional asr model
|
| 168 |
+
# use vad, punc, spk or not as you need
|
| 169 |
+
model = AutoModel(model="paraformer-zh", model_revision="v2.0.4",
|
| 170 |
+
vad_model="fsmn-vad", vad_model_revision="v2.0.4",
|
| 171 |
+
punc_model="ct-punc-c", punc_model_revision="v2.0.4",
|
| 172 |
+
# spk_model="cam++", spk_model_revision="v2.0.2",
|
| 173 |
+
)
|
| 174 |
+
res = model.generate(input=f"{model.model_path}/example/asr_example.wav",
|
| 175 |
+
batch_size_s=300,
|
| 176 |
+
hotword='魔搭')
|
| 177 |
+
print(res)
|
| 178 |
+
```
|
| 179 |
+
注:`model_hub`:表示模型仓库,`ms`为选择modelscope下载,`hf`为选择huggingface下载。
|
| 180 |
+
|
| 181 |
+
#### 实时语音识别
|
| 182 |
+
|
| 183 |
+
```python
|
| 184 |
+
from funasr import AutoModel
|
| 185 |
+
|
| 186 |
+
chunk_size = [0, 10, 5] #[0, 10, 5] 600ms, [0, 8, 4] 480ms
|
| 187 |
+
encoder_chunk_look_back = 4 #number of chunks to lookback for encoder self-attention
|
| 188 |
+
decoder_chunk_look_back = 1 #number of encoder chunks to lookback for decoder cross-attention
|
| 189 |
+
|
| 190 |
+
model = AutoModel(model="paraformer-zh-streaming", model_revision="v2.0.4")
|
| 191 |
+
|
| 192 |
+
import soundfile
|
| 193 |
+
import os
|
| 194 |
+
|
| 195 |
+
wav_file = os.path.join(model.model_path, "example/asr_example.wav")
|
| 196 |
+
speech, sample_rate = soundfile.read(wav_file)
|
| 197 |
+
chunk_stride = chunk_size[1] * 960 # 600ms
|
| 198 |
+
|
| 199 |
+
cache = {}
|
| 200 |
+
total_chunk_num = int(len((speech)-1)/chunk_stride+1)
|
| 201 |
+
for i in range(total_chunk_num):
|
| 202 |
+
speech_chunk = speech[i*chunk_stride:(i+1)*chunk_stride]
|
| 203 |
+
is_final = i == total_chunk_num - 1
|
| 204 |
+
res = model.generate(input=speech_chunk, cache=cache, is_final=is_final, chunk_size=chunk_size, encoder_chunk_look_back=encoder_chunk_look_back, decoder_chunk_look_back=decoder_chunk_look_back)
|
| 205 |
+
print(res)
|
| 206 |
+
```
|
| 207 |
+
|
| 208 |
+
注:`chunk_size`为流式延时配置,`[0,10,5]`表示上屏实时出字粒度为`10*60=600ms`,未来信息为`5*60=300ms`。每次推理输入为`600ms`(采样点数为`16000*0.6=960`),输出为对应文字,最后一个语音片段输入需要设置`is_final=True`来强制输出最后一个字。
|
| 209 |
+
|
| 210 |
+
#### 语音端点检测(非实时)
|
| 211 |
+
```python
|
| 212 |
+
from funasr import AutoModel
|
| 213 |
+
|
| 214 |
+
model = AutoModel(model="fsmn-vad", model_revision="v2.0.4")
|
| 215 |
+
|
| 216 |
+
wav_file = f"{model.model_path}/example/asr_example.wav"
|
| 217 |
+
res = model.generate(input=wav_file)
|
| 218 |
+
print(res)
|
| 219 |
+
```
|
| 220 |
+
|
| 221 |
+
#### 语音端点检测(实时)
|
| 222 |
+
```python
|
| 223 |
+
from funasr import AutoModel
|
| 224 |
+
|
| 225 |
+
chunk_size = 200 # ms
|
| 226 |
+
model = AutoModel(model="fsmn-vad", model_revision="v2.0.4")
|
| 227 |
+
|
| 228 |
+
import soundfile
|
| 229 |
+
|
| 230 |
+
wav_file = f"{model.model_path}/example/vad_example.wav"
|
| 231 |
+
speech, sample_rate = soundfile.read(wav_file)
|
| 232 |
+
chunk_stride = int(chunk_size * sample_rate / 1000)
|
| 233 |
+
|
| 234 |
+
cache = {}
|
| 235 |
+
total_chunk_num = int(len((speech)-1)/chunk_stride+1)
|
| 236 |
+
for i in range(total_chunk_num):
|
| 237 |
+
speech_chunk = speech[i*chunk_stride:(i+1)*chunk_stride]
|
| 238 |
+
is_final = i == total_chunk_num - 1
|
| 239 |
+
res = model.generate(input=speech_chunk, cache=cache, is_final=is_final, chunk_size=chunk_size)
|
| 240 |
+
if len(res[0]["value"]):
|
| 241 |
+
print(res)
|
| 242 |
+
```
|
| 243 |
+
|
| 244 |
+
#### 标点恢复
|
| 245 |
+
```python
|
| 246 |
+
from funasr import AutoModel
|
| 247 |
+
|
| 248 |
+
model = AutoModel(model="ct-punc", model_revision="v2.0.4")
|
| 249 |
+
|
| 250 |
+
res = model.generate(input="那今天的会就到这里吧 happy new year 明年见")
|
| 251 |
+
print(res)
|
| 252 |
+
```
|
| 253 |
+
|
| 254 |
+
#### 时间戳预测
|
| 255 |
+
```python
|
| 256 |
+
from funasr import AutoModel
|
| 257 |
+
|
| 258 |
+
model = AutoModel(model="fa-zh", model_revision="v2.0.4")
|
| 259 |
+
|
| 260 |
+
wav_file = f"{model.model_path}/example/asr_example.wav"
|
| 261 |
+
text_file = f"{model.model_path}/example/text.txt"
|
| 262 |
+
res = model.generate(input=(wav_file, text_file), data_type=("sound", "text"))
|
| 263 |
+
print(res)
|
| 264 |
+
```
|
| 265 |
+
|
| 266 |
+
更多详细用法��[示例](https://github.com/alibaba-damo-academy/FunASR/tree/main/examples/industrial_data_pretraining))
|
| 267 |
+
|
| 268 |
+
|
| 269 |
+
## 微调
|
| 270 |
+
|
| 271 |
+
详细用法([示例](https://github.com/alibaba-damo-academy/FunASR/tree/main/examples/industrial_data_pretraining))
|
| 272 |
+
|
| 273 |
+
|
| 274 |
+
|
| 275 |
+
|
| 276 |
+
|
| 277 |
+
## 使用方式以及适用范围
|
| 278 |
+
|
| 279 |
+
运行范围
|
| 280 |
+
- 支持Linux-x86_64、Mac和Windows运行。
|
| 281 |
+
|
| 282 |
+
使用方式
|
| 283 |
+
- 直接推理:可以直接对长语音数据进行计算,有效语音片段的起止时间点信息(单位:ms)。
|
| 284 |
+
|
| 285 |
+
## 相关论文以及引用信息
|
| 286 |
+
|
| 287 |
+
```BibTeX
|
| 288 |
+
@inproceedings{zhang2018deep,
|
| 289 |
+
title={Deep-FSMN for large vocabulary continuous speech recognition},
|
| 290 |
+
author={Zhang, Shiliang and Lei, Ming and Yan, Zhijie and Dai, Lirong},
|
| 291 |
+
booktitle={2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
|
| 292 |
+
pages={5869--5873},
|
| 293 |
+
year={2018},
|
| 294 |
+
organization={IEEE}
|
| 295 |
+
}
|
| 296 |
+
```
|
FunASR/speech_fsmn_vad_zh-cn-16k-common-pytorch/am.mvn
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<Nnet>
|
| 2 |
+
<Splice> 400 400
|
| 3 |
+
[ 0 ]
|
| 4 |
+
<AddShift> 400 400
|
| 5 |
+
<LearnRateCoef> 0 [ -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 ]
|
| 6 |
+
<Rescale> 400 400
|
| 7 |
+
<LearnRateCoef> 0 [ 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 ]
|
| 8 |
+
</Nnet>
|
FunASR/speech_fsmn_vad_zh-cn-16k-common-pytorch/config.yaml
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
frontend: WavFrontendOnline
|
| 2 |
+
frontend_conf:
|
| 3 |
+
fs: 16000
|
| 4 |
+
window: hamming
|
| 5 |
+
n_mels: 80
|
| 6 |
+
frame_length: 25
|
| 7 |
+
frame_shift: 10
|
| 8 |
+
dither: 0.0
|
| 9 |
+
lfr_m: 5
|
| 10 |
+
lfr_n: 1
|
| 11 |
+
|
| 12 |
+
model: FsmnVADStreaming
|
| 13 |
+
model_conf:
|
| 14 |
+
sample_rate: 16000
|
| 15 |
+
detect_mode: 1
|
| 16 |
+
snr_mode: 0
|
| 17 |
+
max_end_silence_time: 800
|
| 18 |
+
max_start_silence_time: 3000
|
| 19 |
+
do_start_point_detection: True
|
| 20 |
+
do_end_point_detection: True
|
| 21 |
+
window_size_ms: 200
|
| 22 |
+
sil_to_speech_time_thres: 150
|
| 23 |
+
speech_to_sil_time_thres: 150
|
| 24 |
+
speech_2_noise_ratio: 1.0
|
| 25 |
+
do_extend: 1
|
| 26 |
+
lookback_time_start_point: 200
|
| 27 |
+
lookahead_time_end_point: 100
|
| 28 |
+
max_single_segment_time: 60000
|
| 29 |
+
snr_thres: -100.0
|
| 30 |
+
noise_frame_num_used_for_snr: 100
|
| 31 |
+
decibel_thres: -100.0
|
| 32 |
+
speech_noise_thres: 0.6
|
| 33 |
+
fe_prior_thres: 0.0001
|
| 34 |
+
silence_pdf_num: 1
|
| 35 |
+
sil_pdf_ids: [0]
|
| 36 |
+
speech_noise_thresh_low: -0.1
|
| 37 |
+
speech_noise_thresh_high: 0.3
|
| 38 |
+
output_frame_probs: False
|
| 39 |
+
frame_in_ms: 10
|
| 40 |
+
frame_length_ms: 25
|
| 41 |
+
|
| 42 |
+
encoder: FSMN
|
| 43 |
+
encoder_conf:
|
| 44 |
+
input_dim: 400
|
| 45 |
+
input_affine_dim: 140
|
| 46 |
+
fsmn_layers: 4
|
| 47 |
+
linear_dim: 250
|
| 48 |
+
proj_dim: 128
|
| 49 |
+
lorder: 20
|
| 50 |
+
rorder: 0
|
| 51 |
+
lstride: 1
|
| 52 |
+
rstride: 0
|
| 53 |
+
output_affine_dim: 140
|
| 54 |
+
output_dim: 248
|
| 55 |
+
|
| 56 |
+
|
FunASR/speech_fsmn_vad_zh-cn-16k-common-pytorch/configuration.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"framework": "pytorch",
|
| 3 |
+
"task" : "voice-activity-detection",
|
| 4 |
+
"pipeline": {"type":"funasr-pipeline"},
|
| 5 |
+
"model": {"type" : "funasr"},
|
| 6 |
+
"file_path_metas": {
|
| 7 |
+
"init_param":"model.pt",
|
| 8 |
+
"config":"config.yaml",
|
| 9 |
+
"frontend_conf":{"cmvn_file": "am.mvn"}},
|
| 10 |
+
"model_name_in_hub": {
|
| 11 |
+
"ms":"iic/speech_fsmn_vad_zh-cn-16k-common-pytorch",
|
| 12 |
+
"hf":""}
|
| 13 |
+
}
|
FunASR/speech_fsmn_vad_zh-cn-16k-common-pytorch/fig/struct.png
ADDED
|
FunASR/speech_fsmn_vad_zh-cn-16k-common-pytorch/model.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b3be75be477f0780277f3bae0fe489f48718f585f3a6e45d7dd1fbb1a4255fc5
|
| 3 |
+
size 1721366
|
FunASR/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/.mdl
ADDED
|
Binary file (99 Bytes). View file
|
|
|
FunASR/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/.msc
ADDED
|
Binary file (838 Bytes). View file
|
|
|
FunASR/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/README.md
ADDED
|
@@ -0,0 +1,357 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
tasks:
|
| 3 |
+
- auto-speech-recognition
|
| 4 |
+
domain:
|
| 5 |
+
- audio
|
| 6 |
+
model-type:
|
| 7 |
+
- Non-autoregressive
|
| 8 |
+
frameworks:
|
| 9 |
+
- pytorch
|
| 10 |
+
backbone:
|
| 11 |
+
- transformer/conformer
|
| 12 |
+
metrics:
|
| 13 |
+
- CER
|
| 14 |
+
license: Apache License 2.0
|
| 15 |
+
language:
|
| 16 |
+
- cn
|
| 17 |
+
tags:
|
| 18 |
+
- FunASR
|
| 19 |
+
- Paraformer
|
| 20 |
+
- Alibaba
|
| 21 |
+
- ICASSP2024
|
| 22 |
+
- Hotword
|
| 23 |
+
datasets:
|
| 24 |
+
train:
|
| 25 |
+
- 50,000 hour industrial Mandarin task
|
| 26 |
+
test:
|
| 27 |
+
- AISHELL-1-hotword dev/test
|
| 28 |
+
indexing:
|
| 29 |
+
results:
|
| 30 |
+
- task:
|
| 31 |
+
name: Automatic Speech Recognition
|
| 32 |
+
dataset:
|
| 33 |
+
name: 50,000 hour industrial Mandarin task
|
| 34 |
+
type: audio # optional
|
| 35 |
+
args: 16k sampling rate, 8404 characters # optional
|
| 36 |
+
metrics:
|
| 37 |
+
- type: CER
|
| 38 |
+
value: 8.53% # float
|
| 39 |
+
description: greedy search, withou lm, avg.
|
| 40 |
+
args: default
|
| 41 |
+
- type: RTF
|
| 42 |
+
value: 0.0251 # float
|
| 43 |
+
description: GPU inference on V100
|
| 44 |
+
args: batch_size=1
|
| 45 |
+
widgets:
|
| 46 |
+
- task: auto-speech-recognition
|
| 47 |
+
inputs:
|
| 48 |
+
- type: audio
|
| 49 |
+
name: input
|
| 50 |
+
title: 音频
|
| 51 |
+
parameters:
|
| 52 |
+
- name: hotword
|
| 53 |
+
title: 热词
|
| 54 |
+
type: string
|
| 55 |
+
examples:
|
| 56 |
+
- name: 1
|
| 57 |
+
title: 示例1
|
| 58 |
+
inputs:
|
| 59 |
+
- name: input
|
| 60 |
+
data: git://example/asr_example.wav
|
| 61 |
+
parameters:
|
| 62 |
+
- name: hotword
|
| 63 |
+
value: 魔搭
|
| 64 |
+
model_revision: v2.0.4
|
| 65 |
+
inferencespec:
|
| 66 |
+
cpu: 8 #CPU数量
|
| 67 |
+
memory: 4096
|
| 68 |
+
---
|
| 69 |
+
|
| 70 |
+
# Paraformer-large模型介绍
|
| 71 |
+
|
| 72 |
+
## Highlights
|
| 73 |
+
Paraformer-large热词版模型支持热词定制功能:实现热词定制化功能,基于提供的热词列表进行激励增强,提升热词的召回率和准确率。
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
## <strong>[FunASR开源项目介绍](https://github.com/alibaba-damo-academy/FunASR)</strong>
|
| 77 |
+
<strong>[FunASR](https://github.com/alibaba-damo-academy/FunASR)</strong>希望在语音识别的学术研究和工业应用之间架起一座桥梁。通过发布工业级语音识别模型的训练和微调,研究人员和开发人员可以更方便地进行语音识别模型的研究和生产,并推动语音识别生态的发展。让语音识别更有趣!
|
| 78 |
+
|
| 79 |
+
[**github仓库**](https://github.com/alibaba-damo-academy/FunASR)
|
| 80 |
+
| [**最新动态**](https://github.com/alibaba-damo-academy/FunASR#whats-new)
|
| 81 |
+
| [**环境安装**](https://github.com/alibaba-damo-academy/FunASR#installation)
|
| 82 |
+
| [**服务部署**](https://www.funasr.com)
|
| 83 |
+
| [**模型库**](https://github.com/alibaba-damo-academy/FunASR/tree/main/model_zoo)
|
| 84 |
+
| [**联系我们**](https://github.com/alibaba-damo-academy/FunASR#contact)
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
## 模型原理介绍
|
| 88 |
+
|
| 89 |
+
SeACoParaformer是阿里巴巴语音实验室提出的新一代热词定制化非自回归语音识别模型。相比于上一代基于CLAS的热词定制化方案,SeACoParaformer解耦了热词模块与ASR模型,通过后验概率融合的方式进行热词激励,使激励过程可见可控,并且热词召回率显著提升。
|
| 90 |
+
|
| 91 |
+
<p align="center">
|
| 92 |
+
<img src="fig/seaco.png" alt="SeACoParaformer模型结构" width="380" />
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
SeACoParaformer的模型结构与训练流程如上图所示,通过引入bias encoder进行热词embedding提取,bias decoder进行注意力建模,SeACoParaformer能够捕捉到Predictor输出和Decoder输出的信息与热词的相关性,并且预测与ASR结果同步的热词输出。通过后验概率的融合,实现热词激励。与ContextualParaformer相比,SeACoParaformer有明显的效果提升,如下图所示:
|
| 96 |
+
|
| 97 |
+
<p align="center">
|
| 98 |
+
<img src="fig/res.png" alt="SeACoParaformer模型结构" width="700" />
|
| 99 |
+
|
| 100 |
+
更详细的细节见:
|
| 101 |
+
- 论文: [SeACo-Paraformer: A Non-Autoregressive ASR System with Flexible and Effective Hotword Customization Ability](https://arxiv.org/abs/2308.03266)
|
| 102 |
+
|
| 103 |
+
## 复现论文中的结果
|
| 104 |
+
```python
|
| 105 |
+
from funasr import AutoModel
|
| 106 |
+
|
| 107 |
+
model = AutoModel(model="iic/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch",
|
| 108 |
+
model_revision="v2.0.4",
|
| 109 |
+
# vad_model="damo/speech_fsmn_vad_zh-cn-16k-common-pytorch",
|
| 110 |
+
# vad_model_revision="v2.0.4",
|
| 111 |
+
# punc_model="damo/punc_ct-transformer_zh-cn-common-vocab272727-pytorch",
|
| 112 |
+
# punc_model_revision="v2.0.4",
|
| 113 |
+
# spk_model="damo/speech_campplus_sv_zh-cn_16k-common",
|
| 114 |
+
# spk_model_revision="v2.0.2",
|
| 115 |
+
device="cuda:0"
|
| 116 |
+
)
|
| 117 |
+
|
| 118 |
+
res = model.generate(input="YOUR_PATH/aishell1_hotword_dev.scp",
|
| 119 |
+
hotword='./data/dev/hotword.txt',
|
| 120 |
+
batch_size_s=300,
|
| 121 |
+
)
|
| 122 |
+
fout1 = open("dev.output", 'w')
|
| 123 |
+
for resi in res:
|
| 124 |
+
fout1.write("{}\t{}\n".format(resi['key'], resi['text']))
|
| 125 |
+
|
| 126 |
+
res = model.generate(input="YOUR_PATH/aishell1_hotword_test.scp",
|
| 127 |
+
hotword='./data/test/hotword.txt',
|
| 128 |
+
batch_size_s=300,
|
| 129 |
+
)
|
| 130 |
+
fout2 = open("test.output", 'w')
|
| 131 |
+
for resi in res:
|
| 132 |
+
fout2.write("{}\t{}\n".format(resi['key'], resi['text']))
|
| 133 |
+
```
|
| 134 |
+
|
| 135 |
+
## 基于ModelScope进行推理
|
| 136 |
+
|
| 137 |
+
- 推理支��音频格式如下:
|
| 138 |
+
- wav文件路径,例如:data/test/audios/asr_example.wav
|
| 139 |
+
- pcm文件路径,例如:data/test/audios/asr_example.pcm
|
| 140 |
+
- wav文件url,例如:https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_zh.wav
|
| 141 |
+
- wav二进制数据,格式bytes,例如:用户直接从文件里读出bytes数据或者是麦克风录出bytes数据。
|
| 142 |
+
- 已解析的audio音频,例如:audio, rate = soundfile.read("asr_example_zh.wav"),类型为numpy.ndarray或者torch.Tensor。
|
| 143 |
+
- wav.scp文件,需符合如下要求:
|
| 144 |
+
|
| 145 |
+
```sh
|
| 146 |
+
cat wav.scp
|
| 147 |
+
asr_example1 data/test/audios/asr_example1.wav
|
| 148 |
+
asr_example2 data/test/audios/asr_example2.wav
|
| 149 |
+
...
|
| 150 |
+
```
|
| 151 |
+
|
| 152 |
+
- 若输入格式wav文件url,api调用方式可参考如下范例:
|
| 153 |
+
|
| 154 |
+
```python
|
| 155 |
+
from modelscope.pipelines import pipeline
|
| 156 |
+
from modelscope.utils.constant import Tasks
|
| 157 |
+
|
| 158 |
+
inference_pipeline = pipeline(
|
| 159 |
+
task=Tasks.auto_speech_recognition,
|
| 160 |
+
model='iic/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch', model_revision="v2.0.4")
|
| 161 |
+
|
| 162 |
+
rec_result = inference_pipeline('https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_zh.wav', hotword='达摩院 魔搭')
|
| 163 |
+
print(rec_result)
|
| 164 |
+
```
|
| 165 |
+
|
| 166 |
+
- 输入音频为pcm格式,调用api时需要传入音频采样率参数audio_fs,例如:
|
| 167 |
+
|
| 168 |
+
```python
|
| 169 |
+
rec_result = inference_pipeline('https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_zh.pcm', fs=16000, hotword='达摩院 魔搭')
|
| 170 |
+
```
|
| 171 |
+
|
| 172 |
+
- 输入音频为wav格式,api调用方式可参考如下范例:
|
| 173 |
+
|
| 174 |
+
```python
|
| 175 |
+
rec_result = inference_pipeline('asr_example_zh.wav', hotword='达摩院 魔搭')
|
| 176 |
+
```
|
| 177 |
+
|
| 178 |
+
- 若输入格式为文件wav.scp(注:文件名需要以.scp结尾),可添加 output_dir 参数将识别结果写入文件中,api调用方式可参考如下范例:
|
| 179 |
+
|
| 180 |
+
```python
|
| 181 |
+
inference_pipeline("wav.scp", output_dir='./output_dir', hotword='达摩院 魔搭')
|
| 182 |
+
```
|
| 183 |
+
识别结果输出路径结构如下:
|
| 184 |
+
|
| 185 |
+
```sh
|
| 186 |
+
tree output_dir/
|
| 187 |
+
output_dir/
|
| 188 |
+
└── 1best_recog
|
| 189 |
+
├── score
|
| 190 |
+
└── text
|
| 191 |
+
|
| 192 |
+
1 directory, 3 files
|
| 193 |
+
```
|
| 194 |
+
|
| 195 |
+
score:识别路径得分
|
| 196 |
+
|
| 197 |
+
text:语音识别结果文件
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
- 若输入音频为已解析的audio音频,api调用方式可参考如下范例:
|
| 201 |
+
|
| 202 |
+
```python
|
| 203 |
+
import soundfile
|
| 204 |
+
|
| 205 |
+
waveform, sample_rate = soundfile.read("asr_example_zh.wav")
|
| 206 |
+
rec_result = inference_pipeline(waveform, hotword='达摩院 魔搭')
|
| 207 |
+
```
|
| 208 |
+
|
| 209 |
+
- ASR、VAD、PUNC模型自由组合
|
| 210 |
+
|
| 211 |
+
可根据使用需求对VAD和PUNC标点模型进行自由组合,使用方式如下:
|
| 212 |
+
```python
|
| 213 |
+
inference_pipeline = pipeline(
|
| 214 |
+
task=Tasks.auto_speech_recognition,
|
| 215 |
+
model='iic/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch', model_revision="v2.0.4",
|
| 216 |
+
vad_model='iic/speech_fsmn_vad_zh-cn-16k-common-pytorch', vad_model_revision="v2.0.4",
|
| 217 |
+
punc_model='iic/punc_ct-transformer_zh-cn-common-vocab272727-pytorch', punc_model_revision="v2.0.3",
|
| 218 |
+
# spk_model="iic/speech_campplus_sv_zh-cn_16k-common",
|
| 219 |
+
# spk_model_revision="v2.0.2",
|
| 220 |
+
)
|
| 221 |
+
```
|
| 222 |
+
若不使用PUNC模型,可配置punc_model=None,或不传入punc_model参数,如需加入LM模型,可增加配置lm_model='iic/speech_transformer_lm_zh-cn-common-vocab8404-pytorch',并设置lm_weight和beam_size参数。
|
| 223 |
+
|
| 224 |
+
## 基于FunASR进行推理
|
| 225 |
+
|
| 226 |
+
下面为快速上手教程,测试音频([中文](https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/vad_example.wav),[英文](https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_en.wav))
|
| 227 |
+
|
| 228 |
+
### 可执行命令行
|
| 229 |
+
在命令行终端执行:
|
| 230 |
+
|
| 231 |
+
```shell
|
| 232 |
+
funasr +model=paraformer-zh +vad_model="fsmn-vad" +punc_model="ct-punc" +input=vad_example.wav
|
| 233 |
+
```
|
| 234 |
+
|
| 235 |
+
注:支持单条音频文件识别,也支持文件列表,列表为kaldi风格wav.scp:`wav_id wav_path`
|
| 236 |
+
|
| 237 |
+
### python示例
|
| 238 |
+
#### 非实时语音识别
|
| 239 |
+
```python
|
| 240 |
+
from funasr import AutoModel
|
| 241 |
+
# paraformer-zh is a multi-functional asr model
|
| 242 |
+
# use vad, punc, spk or not as you need
|
| 243 |
+
model = AutoModel(model="paraformer-zh", model_revision="v2.0.4",
|
| 244 |
+
vad_model="fsmn-vad", vad_model_revision="v2.0.4",
|
| 245 |
+
punc_model="ct-punc-c", punc_model_revision="v2.0.4",
|
| 246 |
+
# spk_model="cam++", spk_model_revision="v2.0.2",
|
| 247 |
+
)
|
| 248 |
+
res = model.generate(input=f"{model.model_path}/example/asr_example.wav",
|
| 249 |
+
batch_size_s=300,
|
| 250 |
+
hotword='魔搭')
|
| 251 |
+
print(res)
|
| 252 |
+
```
|
| 253 |
+
注:`model_hub`:表示模型仓库,`ms`为选择modelscope下载,`hf`为选择huggingface下载。
|
| 254 |
+
|
| 255 |
+
#### 实时语音识别
|
| 256 |
+
|
| 257 |
+
```python
|
| 258 |
+
from funasr import AutoModel
|
| 259 |
+
|
| 260 |
+
chunk_size = [0, 10, 5] #[0, 10, 5] 600ms, [0, 8, 4] 480ms
|
| 261 |
+
encoder_chunk_look_back = 4 #number of chunks to lookback for encoder self-attention
|
| 262 |
+
decoder_chunk_look_back = 1 #number of encoder chunks to lookback for decoder cross-attention
|
| 263 |
+
|
| 264 |
+
model = AutoModel(model="paraformer-zh-streaming", model_revision="v2.0.4")
|
| 265 |
+
|
| 266 |
+
import soundfile
|
| 267 |
+
import os
|
| 268 |
+
|
| 269 |
+
wav_file = os.path.join(model.model_path, "example/asr_example.wav")
|
| 270 |
+
speech, sample_rate = soundfile.read(wav_file)
|
| 271 |
+
chunk_stride = chunk_size[1] * 960 # 600ms
|
| 272 |
+
|
| 273 |
+
cache = {}
|
| 274 |
+
total_chunk_num = int(len((speech)-1)/chunk_stride+1)
|
| 275 |
+
for i in range(total_chunk_num):
|
| 276 |
+
speech_chunk = speech[i*chunk_stride:(i+1)*chunk_stride]
|
| 277 |
+
is_final = i == total_chunk_num - 1
|
| 278 |
+
res = model.generate(input=speech_chunk, cache=cache, is_final=is_final, chunk_size=chunk_size, encoder_chunk_look_back=encoder_chunk_look_back, decoder_chunk_look_back=decoder_chunk_look_back)
|
| 279 |
+
print(res)
|
| 280 |
+
```
|
| 281 |
+
|
| 282 |
+
注:`chunk_size`为流式延时配置,`[0,10,5]`表示上屏实时出字粒度为`10*60=600ms`,未来信息为`5*60=300ms`。每次推理输入为`600ms`(采样点数为`16000*0.6=960`),输出为对应文字,最后一个语音片段输入需要设置`is_final=True`来强制输出最后一个字。
|
| 283 |
+
|
| 284 |
+
#### 语音端点检测(非实时)
|
| 285 |
+
```python
|
| 286 |
+
from funasr import AutoModel
|
| 287 |
+
|
| 288 |
+
model = AutoModel(model="fsmn-vad", model_revision="v2.0.4")
|
| 289 |
+
|
| 290 |
+
wav_file = f"{model.model_path}/example/asr_example.wav"
|
| 291 |
+
res = model.generate(input=wav_file)
|
| 292 |
+
print(res)
|
| 293 |
+
```
|
| 294 |
+
|
| 295 |
+
#### 语音端点检测(实时)
|
| 296 |
+
```python
|
| 297 |
+
from funasr import AutoModel
|
| 298 |
+
|
| 299 |
+
chunk_size = 200 # ms
|
| 300 |
+
model = AutoModel(model="fsmn-vad", model_revision="v2.0.4")
|
| 301 |
+
|
| 302 |
+
import soundfile
|
| 303 |
+
|
| 304 |
+
wav_file = f"{model.model_path}/example/vad_example.wav"
|
| 305 |
+
speech, sample_rate = soundfile.read(wav_file)
|
| 306 |
+
chunk_stride = int(chunk_size * sample_rate / 1000)
|
| 307 |
+
|
| 308 |
+
cache = {}
|
| 309 |
+
total_chunk_num = int(len((speech)-1)/chunk_stride+1)
|
| 310 |
+
for i in range(total_chunk_num):
|
| 311 |
+
speech_chunk = speech[i*chunk_stride:(i+1)*chunk_stride]
|
| 312 |
+
is_final = i == total_chunk_num - 1
|
| 313 |
+
res = model.generate(input=speech_chunk, cache=cache, is_final=is_final, chunk_size=chunk_size)
|
| 314 |
+
if len(res[0]["value"]):
|
| 315 |
+
print(res)
|
| 316 |
+
```
|
| 317 |
+
|
| 318 |
+
#### 标点恢复
|
| 319 |
+
```python
|
| 320 |
+
from funasr import AutoModel
|
| 321 |
+
|
| 322 |
+
model = AutoModel(model="ct-punc", model_revision="v2.0.4")
|
| 323 |
+
|
| 324 |
+
res = model.generate(input="那今天的会就到这里吧 happy new year 明年见")
|
| 325 |
+
print(res)
|
| 326 |
+
```
|
| 327 |
+
|
| 328 |
+
#### 时间戳预测
|
| 329 |
+
```python
|
| 330 |
+
from funasr import AutoModel
|
| 331 |
+
|
| 332 |
+
model = AutoModel(model="fa-zh", model_revision="v2.0.4")
|
| 333 |
+
|
| 334 |
+
wav_file = f"{model.model_path}/example/asr_example.wav"
|
| 335 |
+
text_file = f"{model.model_path}/example/text.txt"
|
| 336 |
+
res = model.generate(input=(wav_file, text_file), data_type=("sound", "text"))
|
| 337 |
+
print(res)
|
| 338 |
+
```
|
| 339 |
+
|
| 340 |
+
更多详细用法([示例](https://github.com/alibaba-damo-academy/FunASR/tree/main/examples/industrial_data_pretraining))
|
| 341 |
+
|
| 342 |
+
|
| 343 |
+
## 微调
|
| 344 |
+
|
| 345 |
+
详细用法([示例](https://github.com/alibaba-damo-academy/FunASR/tree/main/examples/industrial_data_pretraining))
|
| 346 |
+
|
| 347 |
+
|
| 348 |
+
## 相关论文以及引用信息
|
| 349 |
+
|
| 350 |
+
```BibTeX
|
| 351 |
+
@article{shi2023seaco,
|
| 352 |
+
title={SeACo-Paraformer: A Non-Autoregressive ASR System with Flexible and Effective Hotword Customization Ability},
|
| 353 |
+
author={Shi, Xian and Yang, Yexin and Li, Zerui and Zhang, Shiliang},
|
| 354 |
+
journal={arXiv preprint arXiv:2308.03266 (accepted by ICASSP2024)},
|
| 355 |
+
year={2023}
|
| 356 |
+
}
|
| 357 |
+
```
|
FunASR/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/am.mvn
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<Nnet>
|
| 2 |
+
<Splice> 560 560
|
| 3 |
+
[ 0 ]
|
| 4 |
+
<AddShift> 560 560
|
| 5 |
+
<LearnRateCoef> 0 [ -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 -8.311879 -8.600912 -9.615928 -10.43595 -11.21292 -11.88333 -12.36243 -12.63706 -12.8818 -12.83066 -12.89103 -12.95666 -13.19763 -13.40598 -13.49113 -13.5546 -13.55639 -13.51915 -13.68284 -13.53289 -13.42107 -13.65519 -13.50713 -13.75251 -13.76715 -13.87408 -13.73109 -13.70412 -13.56073 -13.53488 -13.54895 -13.56228 -13.59408 -13.62047 -13.64198 -13.66109 -13.62669 -13.58297 -13.57387 -13.4739 -13.53063 -13.48348 -13.61047 -13.64716 -13.71546 -13.79184 -13.90614 -14.03098 -14.18205 -14.35881 -14.48419 -14.60172 -14.70591 -14.83362 -14.92122 -15.00622 -15.05122 -15.03119 -14.99028 -14.92302 -14.86927 -14.82691 -14.7972 -14.76909 -14.71356 -14.61277 -14.51696 -14.42252 -14.36405 -14.30451 -14.23161 -14.19851 -14.16633 -14.15649 -14.10504 -13.99518 -13.79562 -13.3996 -12.7767 -11.71208 ]
|
| 6 |
+
<Rescale> 560 560
|
| 7 |
+
<LearnRateCoef> 0 [ 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 0.155775 0.154484 0.1527379 0.1518718 0.1506028 0.1489256 0.147067 0.1447061 0.1436307 0.1443568 0.1451849 0.1455157 0.1452821 0.1445717 0.1439195 0.1435867 0.1436018 0.1438781 0.1442086 0.1448844 0.1454756 0.145663 0.146268 0.1467386 0.1472724 0.147664 0.1480913 0.1483739 0.1488841 0.1493636 0.1497088 0.1500379 0.1502916 0.1505389 0.1506787 0.1507102 0.1505992 0.1505445 0.1505938 0.1508133 0.1509569 0.1512396 0.1514625 0.1516195 0.1516156 0.1515561 0.1514966 0.1513976 0.1512612 0.151076 0.1510596 0.1510431 0.151077 0.1511168 0.1511917 0.151023 0.1508045 0.1505885 0.1503493 0.1502373 0.1501726 0.1500762 0.1500065 0.1499782 0.150057 0.1502658 0.150469 0.1505335 0.1505505 0.1505328 0.1504275 0.1502438 0.1499674 0.1497118 0.1494661 0.1493102 0.1493681 0.1495501 0.1499738 0.1509654 ]
|
| 8 |
+
</Nnet>
|
FunASR/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/config.yaml
ADDED
|
@@ -0,0 +1,159 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This is an example that demonstrates how to configure a model file.
|
| 2 |
+
# You can modify the configuration according to your own requirements.
|
| 3 |
+
|
| 4 |
+
# to print the register_table:
|
| 5 |
+
# from funasr.utils.register import registry_tables
|
| 6 |
+
# registry_tables.print()
|
| 7 |
+
|
| 8 |
+
# network architecture
|
| 9 |
+
model: SeacoParaformer
|
| 10 |
+
model_conf:
|
| 11 |
+
ctc_weight: 0.0
|
| 12 |
+
lsm_weight: 0.1
|
| 13 |
+
length_normalized_loss: true
|
| 14 |
+
predictor_weight: 1.0
|
| 15 |
+
predictor_bias: 1
|
| 16 |
+
sampling_ratio: 0.75
|
| 17 |
+
inner_dim: 512
|
| 18 |
+
bias_encoder_type: lstm
|
| 19 |
+
bias_encoder_bid: false
|
| 20 |
+
seaco_lsm_weight: 0.1
|
| 21 |
+
seaco_length_normal: true
|
| 22 |
+
train_decoder: true
|
| 23 |
+
NO_BIAS: 8377
|
| 24 |
+
|
| 25 |
+
# encoder
|
| 26 |
+
encoder: SANMEncoder
|
| 27 |
+
encoder_conf:
|
| 28 |
+
output_size: 512
|
| 29 |
+
attention_heads: 4
|
| 30 |
+
linear_units: 2048
|
| 31 |
+
num_blocks: 50
|
| 32 |
+
dropout_rate: 0.1
|
| 33 |
+
positional_dropout_rate: 0.1
|
| 34 |
+
attention_dropout_rate: 0.1
|
| 35 |
+
input_layer: pe
|
| 36 |
+
pos_enc_class: SinusoidalPositionEncoder
|
| 37 |
+
normalize_before: true
|
| 38 |
+
kernel_size: 11
|
| 39 |
+
sanm_shfit: 0
|
| 40 |
+
selfattention_layer_type: sanm
|
| 41 |
+
|
| 42 |
+
# decoder
|
| 43 |
+
decoder: ParaformerSANMDecoder
|
| 44 |
+
decoder_conf:
|
| 45 |
+
attention_heads: 4
|
| 46 |
+
linear_units: 2048
|
| 47 |
+
num_blocks: 16
|
| 48 |
+
dropout_rate: 0.1
|
| 49 |
+
positional_dropout_rate: 0.1
|
| 50 |
+
self_attention_dropout_rate: 0.1
|
| 51 |
+
src_attention_dropout_rate: 0.1
|
| 52 |
+
att_layer_num: 16
|
| 53 |
+
kernel_size: 11
|
| 54 |
+
sanm_shfit: 0
|
| 55 |
+
|
| 56 |
+
# seaco decoder
|
| 57 |
+
seaco_decoder: ParaformerSANMDecoder
|
| 58 |
+
seaco_decoder_conf:
|
| 59 |
+
attention_heads: 4
|
| 60 |
+
linear_units: 1024
|
| 61 |
+
num_blocks: 4
|
| 62 |
+
dropout_rate: 0.1
|
| 63 |
+
positional_dropout_rate: 0.1
|
| 64 |
+
self_attention_dropout_rate: 0.1
|
| 65 |
+
src_attention_dropout_rate: 0.1
|
| 66 |
+
kernel_size: 21
|
| 67 |
+
sanm_shfit: 0
|
| 68 |
+
use_output_layer: false
|
| 69 |
+
wo_input_layer: true
|
| 70 |
+
|
| 71 |
+
predictor: CifPredictorV3
|
| 72 |
+
predictor_conf:
|
| 73 |
+
idim: 512
|
| 74 |
+
threshold: 1.0
|
| 75 |
+
l_order: 1
|
| 76 |
+
r_order: 1
|
| 77 |
+
tail_threshold: 0.45
|
| 78 |
+
smooth_factor2: 0.25
|
| 79 |
+
noise_threshold2: 0.01
|
| 80 |
+
upsample_times: 3
|
| 81 |
+
use_cif1_cnn: false
|
| 82 |
+
upsample_type: cnn_blstm
|
| 83 |
+
|
| 84 |
+
# frontend related
|
| 85 |
+
frontend: WavFrontend
|
| 86 |
+
frontend_conf:
|
| 87 |
+
fs: 16000
|
| 88 |
+
window: hamming
|
| 89 |
+
n_mels: 80
|
| 90 |
+
frame_length: 25
|
| 91 |
+
frame_shift: 10
|
| 92 |
+
lfr_m: 7
|
| 93 |
+
lfr_n: 6
|
| 94 |
+
dither: 0.0
|
| 95 |
+
|
| 96 |
+
specaug: SpecAugLFR
|
| 97 |
+
specaug_conf:
|
| 98 |
+
apply_time_warp: false
|
| 99 |
+
time_warp_window: 5
|
| 100 |
+
time_warp_mode: bicubic
|
| 101 |
+
apply_freq_mask: true
|
| 102 |
+
freq_mask_width_range:
|
| 103 |
+
- 0
|
| 104 |
+
- 30
|
| 105 |
+
lfr_rate: 6
|
| 106 |
+
num_freq_mask: 1
|
| 107 |
+
apply_time_mask: true
|
| 108 |
+
time_mask_width_range:
|
| 109 |
+
- 0
|
| 110 |
+
- 12
|
| 111 |
+
num_time_mask: 1
|
| 112 |
+
|
| 113 |
+
train_conf:
|
| 114 |
+
accum_grad: 1
|
| 115 |
+
grad_clip: 5
|
| 116 |
+
max_epoch: 150
|
| 117 |
+
val_scheduler_criterion:
|
| 118 |
+
- valid
|
| 119 |
+
- acc
|
| 120 |
+
best_model_criterion:
|
| 121 |
+
- - valid
|
| 122 |
+
- acc
|
| 123 |
+
- max
|
| 124 |
+
keep_nbest_models: 10
|
| 125 |
+
log_interval: 50
|
| 126 |
+
|
| 127 |
+
optim: adam
|
| 128 |
+
optim_conf:
|
| 129 |
+
lr: 0.0005
|
| 130 |
+
scheduler: warmuplr
|
| 131 |
+
scheduler_conf:
|
| 132 |
+
warmup_steps: 30000
|
| 133 |
+
|
| 134 |
+
dataset: AudioDatasetHotword
|
| 135 |
+
dataset_conf:
|
| 136 |
+
seaco_id: 8377
|
| 137 |
+
index_ds: IndexDSJsonl
|
| 138 |
+
batch_sampler: DynamicBatchLocalShuffleSampler
|
| 139 |
+
batch_type: example # example or length
|
| 140 |
+
batch_size: 1 # if batch_type is example, batch_size is the numbers of samples; if length, batch_size is source_token_len+target_token_len;
|
| 141 |
+
max_token_length: 2048 # filter samples if source_token_len+target_token_len > max_token_length,
|
| 142 |
+
buffer_size: 500
|
| 143 |
+
shuffle: True
|
| 144 |
+
num_workers: 0
|
| 145 |
+
|
| 146 |
+
tokenizer: CharTokenizer
|
| 147 |
+
tokenizer_conf:
|
| 148 |
+
unk_symbol: <unk>
|
| 149 |
+
split_with_space: true
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
ctc_conf:
|
| 153 |
+
dropout_rate: 0.0
|
| 154 |
+
ctc_type: builtin
|
| 155 |
+
reduce: true
|
| 156 |
+
ignore_nan_grad: true
|
| 157 |
+
|
| 158 |
+
normalize: null
|
| 159 |
+
unused_parameters: true
|
FunASR/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/configuration.json
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"framework": "pytorch",
|
| 3 |
+
"task" : "auto-speech-recognition",
|
| 4 |
+
"model": {"type" : "funasr"},
|
| 5 |
+
"pipeline": {"type":"funasr-pipeline"},
|
| 6 |
+
"model_name_in_hub": {
|
| 7 |
+
"ms":"iic/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch",
|
| 8 |
+
"hf":""},
|
| 9 |
+
"file_path_metas": {
|
| 10 |
+
"init_param":"model.pt",
|
| 11 |
+
"config":"config.yaml",
|
| 12 |
+
"tokenizer_conf": {"token_list": "tokens.json", "seg_dict_file": "seg_dict"},
|
| 13 |
+
"frontend_conf":{"cmvn_file": "am.mvn"}}
|
| 14 |
+
}
|
FunASR/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/example/hotword.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
魔搭
|
FunASR/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/fig/res.png
ADDED

|
FunASR/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/fig/seaco.png
ADDED

|
FunASR/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/model.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3d491689244ec5dfbf9170ef3827c358aa10f1f20e42a7c59e15e688647946d1
|
| 3 |
+
size 989763045
|
FunASR/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/seg_dict
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
FunASR/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch/tokens.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
GPT_SoVITS/AR/__init__.py
ADDED
|
File without changes
|
GPT_SoVITS/AR/data/__init__.py
ADDED
|
File without changes
|
GPT_SoVITS/AR/data/bucket_sampler.py
ADDED
|
@@ -0,0 +1,162 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/feng-yufei/shared_debugging_code/blob/main/bucketsampler.py
|
| 2 |
+
import itertools
|
| 3 |
+
import math
|
| 4 |
+
import random
|
| 5 |
+
from random import shuffle
|
| 6 |
+
from typing import Iterator
|
| 7 |
+
from typing import Optional
|
| 8 |
+
from typing import TypeVar
|
| 9 |
+
|
| 10 |
+
import torch
|
| 11 |
+
import torch.distributed as dist
|
| 12 |
+
from torch.utils.data import Dataset
|
| 13 |
+
from torch.utils.data import Sampler
|
| 14 |
+
|
| 15 |
+
__all__ = [
|
| 16 |
+
"DistributedBucketSampler",
|
| 17 |
+
]
|
| 18 |
+
|
| 19 |
+
T_co = TypeVar("T_co", covariant=True)
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
class DistributedBucketSampler(Sampler[T_co]):
|
| 23 |
+
r"""
|
| 24 |
+
sort the dataset wrt. input length
|
| 25 |
+
divide samples into buckets
|
| 26 |
+
sort within buckets
|
| 27 |
+
divide buckets into batches
|
| 28 |
+
sort batches
|
| 29 |
+
"""
|
| 30 |
+
|
| 31 |
+
def __init__(
|
| 32 |
+
self,
|
| 33 |
+
dataset: Dataset,
|
| 34 |
+
num_replicas: Optional[int] = None,
|
| 35 |
+
rank: Optional[int] = None,
|
| 36 |
+
shuffle: bool = True,
|
| 37 |
+
seed: int = 0,
|
| 38 |
+
drop_last: bool = False,
|
| 39 |
+
batch_size: int = 32,
|
| 40 |
+
) -> None:
|
| 41 |
+
if num_replicas is None:
|
| 42 |
+
if not dist.is_available():
|
| 43 |
+
raise RuntimeError("Requires distributed package to be available")
|
| 44 |
+
num_replicas = dist.get_world_size() if torch.cuda.is_available() else 1
|
| 45 |
+
if rank is None:
|
| 46 |
+
if not dist.is_available():
|
| 47 |
+
raise RuntimeError("Requires distributed package to be available")
|
| 48 |
+
rank = dist.get_rank() if torch.cuda.is_available() else 0
|
| 49 |
+
if torch.cuda.is_available():
|
| 50 |
+
torch.cuda.set_device(rank)
|
| 51 |
+
if rank >= num_replicas or rank < 0:
|
| 52 |
+
raise ValueError(
|
| 53 |
+
"Invalid rank {}, rank should be in the interval"
|
| 54 |
+
" [0, {}]".format(rank, num_replicas - 1)
|
| 55 |
+
)
|
| 56 |
+
self.dataset = dataset
|
| 57 |
+
self.num_replicas = num_replicas
|
| 58 |
+
self.rank = rank
|
| 59 |
+
self.epoch = 0
|
| 60 |
+
self.drop_last = drop_last
|
| 61 |
+
# If the dataset length is evenly divisible by # of replicas, then there
|
| 62 |
+
# is no need to drop any data, since the dataset will be split equally.
|
| 63 |
+
if (
|
| 64 |
+
self.drop_last and len(self.dataset) % self.num_replicas != 0
|
| 65 |
+
): # type: ignore[arg-type]
|
| 66 |
+
# Split to nearest available length that is evenly divisible.
|
| 67 |
+
# This is to ensure each rank receives the same amount of data when
|
| 68 |
+
# using this Sampler.
|
| 69 |
+
self.num_samples = math.ceil(
|
| 70 |
+
(len(self.dataset) - self.num_replicas)
|
| 71 |
+
/ self.num_replicas # type: ignore[arg-type]
|
| 72 |
+
)
|
| 73 |
+
else:
|
| 74 |
+
self.num_samples = math.ceil(
|
| 75 |
+
len(self.dataset) / self.num_replicas
|
| 76 |
+
) # type: ignore[arg-type]
|
| 77 |
+
self.total_size = self.num_samples * self.num_replicas
|
| 78 |
+
self.shuffle = shuffle
|
| 79 |
+
self.seed = seed
|
| 80 |
+
self.batch_size = batch_size
|
| 81 |
+
self.id_with_length = self._get_sample_lengths()
|
| 82 |
+
self.id_buckets = self.make_buckets(bucket_width=2.0)
|
| 83 |
+
|
| 84 |
+
def _get_sample_lengths(self):
|
| 85 |
+
id_with_lengths = []
|
| 86 |
+
for i in range(len(self.dataset)):
|
| 87 |
+
id_with_lengths.append((i, self.dataset.get_sample_length(i)))
|
| 88 |
+
id_with_lengths.sort(key=lambda x: x[1])
|
| 89 |
+
return id_with_lengths
|
| 90 |
+
|
| 91 |
+
def make_buckets(self, bucket_width: float = 2.0):
|
| 92 |
+
buckets = []
|
| 93 |
+
cur = []
|
| 94 |
+
max_sec = bucket_width
|
| 95 |
+
for id, sec in self.id_with_length:
|
| 96 |
+
if sec < max_sec:
|
| 97 |
+
cur.append(id)
|
| 98 |
+
else:
|
| 99 |
+
buckets.append(cur)
|
| 100 |
+
cur = [id]
|
| 101 |
+
max_sec += bucket_width
|
| 102 |
+
if len(cur) > 0:
|
| 103 |
+
buckets.append(cur)
|
| 104 |
+
return buckets
|
| 105 |
+
|
| 106 |
+
def __iter__(self) -> Iterator[T_co]:
|
| 107 |
+
if self.shuffle:
|
| 108 |
+
# deterministically shuffle based on epoch and seed
|
| 109 |
+
g = torch.Generator()
|
| 110 |
+
g.manual_seed(self.seed + self.epoch)
|
| 111 |
+
random.seed(self.epoch + self.seed)
|
| 112 |
+
shuffled_bucket = []
|
| 113 |
+
for buc in self.id_buckets:
|
| 114 |
+
buc_copy = buc.copy()
|
| 115 |
+
shuffle(buc_copy)
|
| 116 |
+
shuffled_bucket.append(buc_copy)
|
| 117 |
+
grouped_batch_size = self.batch_size * self.num_replicas
|
| 118 |
+
shuffled_bucket = list(itertools.chain(*shuffled_bucket))
|
| 119 |
+
n_batch = int(math.ceil(len(shuffled_bucket) / grouped_batch_size))
|
| 120 |
+
batches = [
|
| 121 |
+
shuffled_bucket[b * grouped_batch_size : (b + 1) * grouped_batch_size]
|
| 122 |
+
for b in range(n_batch)
|
| 123 |
+
]
|
| 124 |
+
shuffle(batches)
|
| 125 |
+
indices = list(itertools.chain(*batches))
|
| 126 |
+
else:
|
| 127 |
+
# type: ignore[arg-type]
|
| 128 |
+
indices = list(range(len(self.dataset)))
|
| 129 |
+
|
| 130 |
+
if not self.drop_last:
|
| 131 |
+
# add extra samples to make it evenly divisible
|
| 132 |
+
padding_size = self.total_size - len(indices)
|
| 133 |
+
if padding_size <= len(indices):
|
| 134 |
+
indices += indices[:padding_size]
|
| 135 |
+
else:
|
| 136 |
+
indices += (indices * math.ceil(padding_size / len(indices)))[
|
| 137 |
+
:padding_size
|
| 138 |
+
]
|
| 139 |
+
else:
|
| 140 |
+
# remove tail of data to make it evenly divisible.
|
| 141 |
+
indices = indices[: self.total_size]
|
| 142 |
+
assert len(indices) == self.total_size
|
| 143 |
+
|
| 144 |
+
# subsample
|
| 145 |
+
indices = indices[self.rank : self.total_size : self.num_replicas]
|
| 146 |
+
assert len(indices) == self.num_samples
|
| 147 |
+
|
| 148 |
+
return iter(indices)
|
| 149 |
+
|
| 150 |
+
def __len__(self) -> int:
|
| 151 |
+
return self.num_samples
|
| 152 |
+
|
| 153 |
+
def set_epoch(self, epoch: int) -> None:
|
| 154 |
+
r"""
|
| 155 |
+
Sets the epoch for this sampler. When :attr:`shuffle=True`, this ensures all replicas
|
| 156 |
+
use a different random ordering for each epoch. Otherwise, the next iteration of this
|
| 157 |
+
sampler will yield the same ordering.
|
| 158 |
+
|
| 159 |
+
Args:
|
| 160 |
+
epoch (int): Epoch number.
|
| 161 |
+
"""
|
| 162 |
+
self.epoch = epoch
|
GPT_SoVITS/AR/data/data_module.py
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/feng-yufei/shared_debugging_code/blob/main/data_module.py
|
| 2 |
+
from pytorch_lightning import LightningDataModule
|
| 3 |
+
from AR.data.bucket_sampler import DistributedBucketSampler
|
| 4 |
+
from AR.data.dataset import Text2SemanticDataset
|
| 5 |
+
from torch.utils.data import DataLoader
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class Text2SemanticDataModule(LightningDataModule):
|
| 9 |
+
def __init__(
|
| 10 |
+
self,
|
| 11 |
+
config,
|
| 12 |
+
train_semantic_path,
|
| 13 |
+
train_phoneme_path,
|
| 14 |
+
dev_semantic_path=None,
|
| 15 |
+
dev_phoneme_path=None,
|
| 16 |
+
):
|
| 17 |
+
super().__init__()
|
| 18 |
+
self.config = config
|
| 19 |
+
self.train_semantic_path = train_semantic_path
|
| 20 |
+
self.train_phoneme_path = train_phoneme_path
|
| 21 |
+
self.dev_semantic_path = dev_semantic_path
|
| 22 |
+
self.dev_phoneme_path = dev_phoneme_path
|
| 23 |
+
self.num_workers = self.config["data"]["num_workers"]
|
| 24 |
+
|
| 25 |
+
def prepare_data(self):
|
| 26 |
+
pass
|
| 27 |
+
|
| 28 |
+
def setup(self, stage=None, output_logs=False):
|
| 29 |
+
self._train_dataset = Text2SemanticDataset(
|
| 30 |
+
phoneme_path=self.train_phoneme_path,
|
| 31 |
+
semantic_path=self.train_semantic_path,
|
| 32 |
+
max_sec=self.config["data"]["max_sec"],
|
| 33 |
+
pad_val=self.config["data"]["pad_val"],
|
| 34 |
+
)
|
| 35 |
+
self._dev_dataset = self._train_dataset
|
| 36 |
+
# self._dev_dataset = Text2SemanticDataset(
|
| 37 |
+
# phoneme_path=self.dev_phoneme_path,
|
| 38 |
+
# semantic_path=self.dev_semantic_path,
|
| 39 |
+
# max_sample=self.config['data']['max_eval_sample'],
|
| 40 |
+
# max_sec=self.config['data']['max_sec'],
|
| 41 |
+
# pad_val=self.config['data']['pad_val'])
|
| 42 |
+
|
| 43 |
+
def train_dataloader(self):
|
| 44 |
+
batch_size = max(min(self.config["train"]["batch_size"],len(self._train_dataset)//4),1)#防止不保存
|
| 45 |
+
sampler = DistributedBucketSampler(self._train_dataset, batch_size=batch_size)
|
| 46 |
+
return DataLoader(
|
| 47 |
+
self._train_dataset,
|
| 48 |
+
batch_size=batch_size,
|
| 49 |
+
sampler=sampler,
|
| 50 |
+
collate_fn=self._train_dataset.collate,
|
| 51 |
+
num_workers=self.num_workers,
|
| 52 |
+
persistent_workers=True,
|
| 53 |
+
prefetch_factor=16,
|
| 54 |
+
)
|
| 55 |
+
|
| 56 |
+
def val_dataloader(self):
|
| 57 |
+
return DataLoader(
|
| 58 |
+
self._dev_dataset,
|
| 59 |
+
batch_size=1,
|
| 60 |
+
shuffle=False,
|
| 61 |
+
collate_fn=self._train_dataset.collate,
|
| 62 |
+
num_workers=max(self.num_workers, 12),
|
| 63 |
+
persistent_workers=True,
|
| 64 |
+
prefetch_factor=16,
|
| 65 |
+
)
|
| 66 |
+
|
| 67 |
+
# 这个会使用到嘛?
|
| 68 |
+
def test_dataloader(self):
|
| 69 |
+
return DataLoader(
|
| 70 |
+
self._dev_dataset,
|
| 71 |
+
batch_size=1,
|
| 72 |
+
shuffle=False,
|
| 73 |
+
collate_fn=self._train_dataset.collate,
|
| 74 |
+
)
|
GPT_SoVITS/AR/data/dataset.py
ADDED
|
@@ -0,0 +1,320 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/feng-yufei/shared_debugging_code/blob/main/t2s_dataset.py
|
| 2 |
+
import pdb
|
| 3 |
+
import sys
|
| 4 |
+
|
| 5 |
+
# sys.path.append("/data/docker/liujing04/gpt-vits/mq-vits-s1bert_no_bert")
|
| 6 |
+
import traceback, os
|
| 7 |
+
from typing import Dict
|
| 8 |
+
from typing import List
|
| 9 |
+
|
| 10 |
+
import numpy as np
|
| 11 |
+
import pandas as pd
|
| 12 |
+
import torch, json
|
| 13 |
+
from torch.utils.data import DataLoader
|
| 14 |
+
from torch.utils.data import Dataset
|
| 15 |
+
from transformers import AutoTokenizer
|
| 16 |
+
|
| 17 |
+
from text import cleaned_text_to_sequence
|
| 18 |
+
|
| 19 |
+
# from config import exp_dir
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def batch_sequences(sequences: List[np.array], axis: int = 0, pad_value: int = 0):
|
| 23 |
+
seq = sequences[0]
|
| 24 |
+
ndim = seq.ndim
|
| 25 |
+
if axis < 0:
|
| 26 |
+
axis += ndim
|
| 27 |
+
dtype = seq.dtype
|
| 28 |
+
pad_value = dtype.type(pad_value)
|
| 29 |
+
seq_lengths = [seq.shape[axis] for seq in sequences]
|
| 30 |
+
max_length = np.max(seq_lengths)
|
| 31 |
+
|
| 32 |
+
padded_sequences = []
|
| 33 |
+
for seq, length in zip(sequences, seq_lengths):
|
| 34 |
+
padding = (
|
| 35 |
+
[(0, 0)] * axis + [(0, max_length - length)] + [(0, 0)] * (ndim - axis - 1)
|
| 36 |
+
)
|
| 37 |
+
padded_seq = np.pad(seq, padding, mode="constant", constant_values=pad_value)
|
| 38 |
+
padded_sequences.append(padded_seq)
|
| 39 |
+
batch = np.stack(padded_sequences)
|
| 40 |
+
return batch
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
class Text2SemanticDataset(Dataset):
|
| 44 |
+
"""dataset class for text tokens to semantic model training."""
|
| 45 |
+
|
| 46 |
+
def __init__(
|
| 47 |
+
self,
|
| 48 |
+
phoneme_path: str,
|
| 49 |
+
semantic_path: str,
|
| 50 |
+
max_sample: int = None,
|
| 51 |
+
max_sec: int = 100,
|
| 52 |
+
pad_val: int = 1024,
|
| 53 |
+
# min value of phoneme/sec
|
| 54 |
+
min_ps_ratio: int = 3,
|
| 55 |
+
# max value of phoneme/sec
|
| 56 |
+
max_ps_ratio: int = 25,
|
| 57 |
+
) -> None:
|
| 58 |
+
super().__init__()
|
| 59 |
+
|
| 60 |
+
self.semantic_data = pd.read_csv(
|
| 61 |
+
semantic_path, delimiter="\t", encoding="utf-8"
|
| 62 |
+
)
|
| 63 |
+
# get dict
|
| 64 |
+
self.path2 = phoneme_path # "%s/2-name2text.txt"%exp_dir#phoneme_path
|
| 65 |
+
self.path3 = "%s/3-bert" % (
|
| 66 |
+
os.path.basename(phoneme_path)
|
| 67 |
+
) # "%s/3-bert"%exp_dir#bert_dir
|
| 68 |
+
self.path6 = semantic_path # "%s/6-name2semantic.tsv"%exp_dir#semantic_path
|
| 69 |
+
assert os.path.exists(self.path2)
|
| 70 |
+
assert os.path.exists(self.path6)
|
| 71 |
+
self.phoneme_data = {}
|
| 72 |
+
with open(self.path2, "r", encoding="utf8") as f:
|
| 73 |
+
lines = f.read().strip("\n").split("\n")
|
| 74 |
+
|
| 75 |
+
for line in lines:
|
| 76 |
+
tmp = line.split("\t")
|
| 77 |
+
if len(tmp) != 4:
|
| 78 |
+
continue
|
| 79 |
+
self.phoneme_data[tmp[0]] = [tmp[1], tmp[2], tmp[3]]
|
| 80 |
+
|
| 81 |
+
# self.phoneme_data = np.load(phoneme_path, allow_pickle=True).item()
|
| 82 |
+
# pad for semantic tokens
|
| 83 |
+
self.PAD: int = pad_val
|
| 84 |
+
# self.hz = 25
|
| 85 |
+
# with open("/data/docker/liujing04/gpt-vits/mq-vits-s1bert_no_bert/configs/s2.json", "r") as f:data = f.read()
|
| 86 |
+
# data=json.loads(data)["model"]["semantic_frame_rate"]#50hz
|
| 87 |
+
# self.hz=int(data[:-2])#
|
| 88 |
+
self.hz = int(os.environ.get("hz", "25hz")[:-2])
|
| 89 |
+
|
| 90 |
+
# max seconds of semantic token
|
| 91 |
+
self.max_sec = max_sec
|
| 92 |
+
self.min_ps_ratio = min_ps_ratio
|
| 93 |
+
self.max_ps_ratio = max_ps_ratio
|
| 94 |
+
|
| 95 |
+
if max_sample is not None:
|
| 96 |
+
self.semantic_data = self.semantic_data[:max_sample]
|
| 97 |
+
|
| 98 |
+
# {idx: (semantic, phoneme)}
|
| 99 |
+
# semantic list, phoneme list
|
| 100 |
+
self.semantic_phoneme = []
|
| 101 |
+
self.item_names = []
|
| 102 |
+
|
| 103 |
+
self.inited = False
|
| 104 |
+
|
| 105 |
+
if not self.inited:
|
| 106 |
+
# 调用初始化函数
|
| 107 |
+
self.init_batch()
|
| 108 |
+
self.inited = True
|
| 109 |
+
del self.semantic_data
|
| 110 |
+
del self.phoneme_data
|
| 111 |
+
# self.tokenizer = AutoTokenizer.from_pretrained("hfl/chinese-roberta-wwm-ext-large")
|
| 112 |
+
# self.tokenizer = AutoTokenizer.from_pretrained("/data/docker/liujing04/bert-vits2/Bert-VITS2-master20231106/bert/chinese-roberta-wwm-ext-large")
|
| 113 |
+
|
| 114 |
+
def init_batch(self):
|
| 115 |
+
semantic_data_len = len(self.semantic_data)
|
| 116 |
+
phoneme_data_len = len(self.phoneme_data.keys())
|
| 117 |
+
print("semantic_data_len:", semantic_data_len)
|
| 118 |
+
print("phoneme_data_len:", phoneme_data_len)
|
| 119 |
+
print(self.semantic_data)
|
| 120 |
+
idx = 0
|
| 121 |
+
num_not_in = 0
|
| 122 |
+
num_deleted_bigger = 0
|
| 123 |
+
num_deleted_ps = 0
|
| 124 |
+
for i in range(semantic_data_len):
|
| 125 |
+
# 先依次遍历
|
| 126 |
+
# get str
|
| 127 |
+
item_name = self.semantic_data.iloc[i,0]
|
| 128 |
+
# print(self.phoneme_data)
|
| 129 |
+
try:
|
| 130 |
+
phoneme, word2ph, text = self.phoneme_data[item_name]
|
| 131 |
+
except Exception:
|
| 132 |
+
traceback.print_exc()
|
| 133 |
+
# print(f"{item_name} not in self.phoneme_data !")
|
| 134 |
+
num_not_in += 1
|
| 135 |
+
continue
|
| 136 |
+
|
| 137 |
+
semantic_str = self.semantic_data.iloc[i,1]
|
| 138 |
+
# get token list
|
| 139 |
+
semantic_ids = [int(idx) for idx in semantic_str.split(" ")]
|
| 140 |
+
# (T), 是否需要变成 (1, T) -> 不需要,因为需要求 len
|
| 141 |
+
# 过滤掉太长的样本
|
| 142 |
+
if (
|
| 143 |
+
len(semantic_ids) > self.max_sec * self.hz
|
| 144 |
+
): #########1###根据token个数推测总时长过滤时长60s(config里)#40*25=1k
|
| 145 |
+
num_deleted_bigger += 1
|
| 146 |
+
continue
|
| 147 |
+
# (T, ), 这个速度不会很慢,所以可以在一开始就处理,无需在 __getitem__ 里面单个处理####
|
| 148 |
+
phoneme = phoneme.split(" ")
|
| 149 |
+
|
| 150 |
+
try:
|
| 151 |
+
phoneme_ids = cleaned_text_to_sequence(phoneme)
|
| 152 |
+
except:
|
| 153 |
+
traceback.print_exc()
|
| 154 |
+
# print(f"{item_name} not in self.phoneme_data !")
|
| 155 |
+
num_not_in += 1
|
| 156 |
+
continue
|
| 157 |
+
# if len(phoneme_ids) >400:###########2:改为恒定限制为semantic/2.5就行
|
| 158 |
+
if (
|
| 159 |
+
len(phoneme_ids) > self.max_sec * self.hz / 2.5
|
| 160 |
+
): ###########2:改为恒定限制为semantic/2.5就行
|
| 161 |
+
num_deleted_ps += 1
|
| 162 |
+
continue
|
| 163 |
+
# if len(semantic_ids) > 1000:###########3
|
| 164 |
+
# num_deleted_bigger += 1
|
| 165 |
+
# continue
|
| 166 |
+
|
| 167 |
+
ps_ratio = len(phoneme_ids) / (len(semantic_ids) / self.hz)
|
| 168 |
+
|
| 169 |
+
if (
|
| 170 |
+
ps_ratio > self.max_ps_ratio or ps_ratio < self.min_ps_ratio
|
| 171 |
+
): ##########4#3~25#每秒多少个phone
|
| 172 |
+
num_deleted_ps += 1
|
| 173 |
+
# print(item_name)
|
| 174 |
+
continue
|
| 175 |
+
|
| 176 |
+
self.semantic_phoneme.append((semantic_ids, phoneme_ids))
|
| 177 |
+
idx += 1
|
| 178 |
+
self.item_names.append(item_name)
|
| 179 |
+
|
| 180 |
+
min_num = 100 # 20直接不补#30补了也不存ckpt
|
| 181 |
+
leng = len(self.semantic_phoneme)
|
| 182 |
+
if leng < min_num:
|
| 183 |
+
tmp1 = self.semantic_phoneme
|
| 184 |
+
tmp2 = self.item_names
|
| 185 |
+
self.semantic_phoneme = []
|
| 186 |
+
self.item_names = []
|
| 187 |
+
for _ in range(max(2, int(min_num / leng))):
|
| 188 |
+
self.semantic_phoneme += tmp1
|
| 189 |
+
self.item_names += tmp2
|
| 190 |
+
if num_not_in > 0:
|
| 191 |
+
print(f"there are {num_not_in} semantic datas not in phoneme datas")
|
| 192 |
+
if num_deleted_bigger > 0:
|
| 193 |
+
print(
|
| 194 |
+
f"deleted {num_deleted_bigger} audios who's duration are bigger than {self.max_sec} seconds"
|
| 195 |
+
)
|
| 196 |
+
if num_deleted_ps > 0:
|
| 197 |
+
# 4702 for LibriTTS, LirbriTTS 是标注数据, 是否需要筛?=> 需要,有值为 100 的极端值
|
| 198 |
+
print(
|
| 199 |
+
f"deleted {num_deleted_ps} audios who's phoneme/sec are bigger than {self.max_ps_ratio} or smaller than {self.min_ps_ratio}"
|
| 200 |
+
)
|
| 201 |
+
"""
|
| 202 |
+
there are 31 semantic datas not in phoneme datas
|
| 203 |
+
deleted 34 audios who's duration are bigger than 54 seconds
|
| 204 |
+
deleted 3190 audios who's phoneme/sec are bigger than 25 or smaller than 3
|
| 205 |
+
dataset.__len__(): 366463
|
| 206 |
+
|
| 207 |
+
"""
|
| 208 |
+
# 345410 for LibriTTS
|
| 209 |
+
print("dataset.__len__():", self.__len__())
|
| 210 |
+
|
| 211 |
+
def __get_item_names__(self) -> List[str]:
|
| 212 |
+
return self.item_names
|
| 213 |
+
|
| 214 |
+
def __len__(self) -> int:
|
| 215 |
+
return len(self.semantic_phoneme)
|
| 216 |
+
|
| 217 |
+
def __getitem__(self, idx: int) -> Dict:
|
| 218 |
+
semantic_ids, phoneme_ids = self.semantic_phoneme[idx]
|
| 219 |
+
item_name = self.item_names[idx]
|
| 220 |
+
phoneme_ids_len = len(phoneme_ids)
|
| 221 |
+
# semantic tokens target
|
| 222 |
+
semantic_ids_len = len(semantic_ids)
|
| 223 |
+
|
| 224 |
+
flag = 0
|
| 225 |
+
path_bert = "%s/%s.pt" % (self.path3, item_name)
|
| 226 |
+
if os.path.exists(path_bert) == True:
|
| 227 |
+
bert_feature = torch.load(path_bert, map_location="cpu")
|
| 228 |
+
else:
|
| 229 |
+
flag = 1
|
| 230 |
+
if flag == 1:
|
| 231 |
+
# bert_feature=torch.zeros_like(phoneme_ids,dtype=torch.float32)
|
| 232 |
+
bert_feature = None
|
| 233 |
+
else:
|
| 234 |
+
assert bert_feature.shape[-1] == len(phoneme_ids)
|
| 235 |
+
return {
|
| 236 |
+
"idx": idx,
|
| 237 |
+
"phoneme_ids": phoneme_ids,
|
| 238 |
+
"phoneme_ids_len": phoneme_ids_len,
|
| 239 |
+
"semantic_ids": semantic_ids,
|
| 240 |
+
"semantic_ids_len": semantic_ids_len,
|
| 241 |
+
"bert_feature": bert_feature,
|
| 242 |
+
}
|
| 243 |
+
|
| 244 |
+
def get_sample_length(self, idx: int):
|
| 245 |
+
semantic_ids = self.semantic_phoneme[idx][0]
|
| 246 |
+
sec = 1.0 * len(semantic_ids) / self.hz
|
| 247 |
+
return sec
|
| 248 |
+
|
| 249 |
+
def collate(self, examples: List[Dict]) -> Dict:
|
| 250 |
+
sample_index: List[int] = []
|
| 251 |
+
phoneme_ids: List[torch.Tensor] = []
|
| 252 |
+
phoneme_ids_lens: List[int] = []
|
| 253 |
+
semantic_ids: List[torch.Tensor] = []
|
| 254 |
+
semantic_ids_lens: List[int] = []
|
| 255 |
+
# return
|
| 256 |
+
|
| 257 |
+
for item in examples:
|
| 258 |
+
sample_index.append(item["idx"])
|
| 259 |
+
phoneme_ids.append(np.array(item["phoneme_ids"], dtype=np.int64))
|
| 260 |
+
semantic_ids.append(np.array(item["semantic_ids"], dtype=np.int64))
|
| 261 |
+
phoneme_ids_lens.append(item["phoneme_ids_len"])
|
| 262 |
+
semantic_ids_lens.append(item["semantic_ids_len"])
|
| 263 |
+
|
| 264 |
+
# pad 0
|
| 265 |
+
phoneme_ids = batch_sequences(phoneme_ids)
|
| 266 |
+
semantic_ids = batch_sequences(semantic_ids, pad_value=self.PAD)
|
| 267 |
+
|
| 268 |
+
# # convert each batch to torch.tensor
|
| 269 |
+
phoneme_ids = torch.tensor(phoneme_ids)
|
| 270 |
+
semantic_ids = torch.tensor(semantic_ids)
|
| 271 |
+
phoneme_ids_lens = torch.tensor(phoneme_ids_lens)
|
| 272 |
+
semantic_ids_lens = torch.tensor(semantic_ids_lens)
|
| 273 |
+
bert_padded = torch.FloatTensor(len(examples), 1024, max(phoneme_ids_lens))
|
| 274 |
+
bert_padded.zero_()
|
| 275 |
+
|
| 276 |
+
for idx, item in enumerate(examples):
|
| 277 |
+
bert = item["bert_feature"]
|
| 278 |
+
if bert != None:
|
| 279 |
+
bert_padded[idx, :, : bert.shape[-1]] = bert
|
| 280 |
+
|
| 281 |
+
return {
|
| 282 |
+
# List[int]
|
| 283 |
+
"ids": sample_index,
|
| 284 |
+
# torch.Tensor (B, max_phoneme_length)
|
| 285 |
+
"phoneme_ids": phoneme_ids,
|
| 286 |
+
# torch.Tensor (B)
|
| 287 |
+
"phoneme_ids_len": phoneme_ids_lens,
|
| 288 |
+
# torch.Tensor (B, max_semantic_ids_length)
|
| 289 |
+
"semantic_ids": semantic_ids,
|
| 290 |
+
# torch.Tensor (B)
|
| 291 |
+
"semantic_ids_len": semantic_ids_lens,
|
| 292 |
+
# torch.Tensor (B, 1024, max_phoneme_length)
|
| 293 |
+
"bert_feature": bert_padded,
|
| 294 |
+
}
|
| 295 |
+
|
| 296 |
+
|
| 297 |
+
if __name__ == "__main__":
|
| 298 |
+
root_dir = "/data/docker/liujing04/gpt-vits/prepare/dump_mix/"
|
| 299 |
+
dataset = Text2SemanticDataset(
|
| 300 |
+
phoneme_path=root_dir + "phoneme_train.npy",
|
| 301 |
+
semantic_path=root_dir + "semantic_train.tsv",
|
| 302 |
+
)
|
| 303 |
+
|
| 304 |
+
batch_size = 12
|
| 305 |
+
dataloader = DataLoader(
|
| 306 |
+
dataset, batch_size=batch_size, collate_fn=dataset.collate, shuffle=False
|
| 307 |
+
)
|
| 308 |
+
for i, batch in enumerate(dataloader):
|
| 309 |
+
if i % 1000 == 0:
|
| 310 |
+
print(i)
|
| 311 |
+
# if i == 0:
|
| 312 |
+
# print('batch["ids"]:', batch["ids"])
|
| 313 |
+
# print('batch["phoneme_ids"]:', batch["phoneme_ids"],
|
| 314 |
+
# batch["phoneme_ids"].shape)
|
| 315 |
+
# print('batch["phoneme_ids_len"]:', batch["phoneme_ids_len"],
|
| 316 |
+
# batch["phoneme_ids_len"].shape)
|
| 317 |
+
# print('batch["semantic_ids"]:', batch["semantic_ids"],
|
| 318 |
+
# batch["semantic_ids"].shape)
|
| 319 |
+
# print('batch["semantic_ids_len"]:', batch["semantic_ids_len"],
|
| 320 |
+
# batch["semantic_ids_len"].shape)
|
GPT_SoVITS/AR/models/__init__.py
ADDED
|
File without changes
|
GPT_SoVITS/AR/models/t2s_lightning_module.py
ADDED
|
@@ -0,0 +1,140 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/feng-yufei/shared_debugging_code/blob/main/model/t2s_lightning_module.py
|
| 2 |
+
import os, sys
|
| 3 |
+
|
| 4 |
+
now_dir = os.getcwd()
|
| 5 |
+
sys.path.append(now_dir)
|
| 6 |
+
from typing import Dict
|
| 7 |
+
|
| 8 |
+
import torch
|
| 9 |
+
from pytorch_lightning import LightningModule
|
| 10 |
+
from AR.models.t2s_model import Text2SemanticDecoder
|
| 11 |
+
from AR.modules.lr_schedulers import WarmupCosineLRSchedule
|
| 12 |
+
from AR.modules.optim import ScaledAdam
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class Text2SemanticLightningModule(LightningModule):
|
| 16 |
+
def __init__(self, config, output_dir, is_train=True):
|
| 17 |
+
super().__init__()
|
| 18 |
+
self.config = config
|
| 19 |
+
self.top_k = 3
|
| 20 |
+
self.model = Text2SemanticDecoder(config=config, top_k=self.top_k)
|
| 21 |
+
pretrained_s1 = config.get("pretrained_s1")
|
| 22 |
+
if pretrained_s1 and is_train:
|
| 23 |
+
# print(self.load_state_dict(torch.load(pretrained_s1,map_location="cpu")["state_dict"]))
|
| 24 |
+
print(
|
| 25 |
+
self.load_state_dict(
|
| 26 |
+
torch.load(pretrained_s1, map_location="cpu")["weight"]
|
| 27 |
+
)
|
| 28 |
+
)
|
| 29 |
+
if is_train:
|
| 30 |
+
self.automatic_optimization = False
|
| 31 |
+
self.save_hyperparameters()
|
| 32 |
+
self.eval_dir = output_dir / "eval"
|
| 33 |
+
self.eval_dir.mkdir(parents=True, exist_ok=True)
|
| 34 |
+
|
| 35 |
+
def training_step(self, batch: Dict, batch_idx: int):
|
| 36 |
+
opt = self.optimizers()
|
| 37 |
+
scheduler = self.lr_schedulers()
|
| 38 |
+
loss, acc = self.model.forward(
|
| 39 |
+
batch["phoneme_ids"],
|
| 40 |
+
batch["phoneme_ids_len"],
|
| 41 |
+
batch["semantic_ids"],
|
| 42 |
+
batch["semantic_ids_len"],
|
| 43 |
+
batch["bert_feature"],
|
| 44 |
+
)
|
| 45 |
+
self.manual_backward(loss)
|
| 46 |
+
if batch_idx > 0 and batch_idx % 4 == 0:
|
| 47 |
+
opt.step()
|
| 48 |
+
opt.zero_grad()
|
| 49 |
+
scheduler.step()
|
| 50 |
+
|
| 51 |
+
self.log(
|
| 52 |
+
"total_loss",
|
| 53 |
+
loss,
|
| 54 |
+
on_step=True,
|
| 55 |
+
on_epoch=True,
|
| 56 |
+
prog_bar=True,
|
| 57 |
+
sync_dist=True,
|
| 58 |
+
)
|
| 59 |
+
self.log(
|
| 60 |
+
"lr",
|
| 61 |
+
scheduler.get_last_lr()[0],
|
| 62 |
+
on_epoch=True,
|
| 63 |
+
prog_bar=True,
|
| 64 |
+
sync_dist=True,
|
| 65 |
+
)
|
| 66 |
+
self.log(
|
| 67 |
+
f"top_{self.top_k}_acc",
|
| 68 |
+
acc,
|
| 69 |
+
on_step=True,
|
| 70 |
+
on_epoch=True,
|
| 71 |
+
prog_bar=True,
|
| 72 |
+
sync_dist=True,
|
| 73 |
+
)
|
| 74 |
+
|
| 75 |
+
def validation_step(self, batch: Dict, batch_idx: int):
|
| 76 |
+
return
|
| 77 |
+
|
| 78 |
+
# # get loss
|
| 79 |
+
# loss, acc = self.model.forward(
|
| 80 |
+
# batch['phoneme_ids'], batch['phoneme_ids_len'],
|
| 81 |
+
# batch['semantic_ids'], batch['semantic_ids_len'],
|
| 82 |
+
# batch['bert_feature']
|
| 83 |
+
# )
|
| 84 |
+
#
|
| 85 |
+
# self.log(
|
| 86 |
+
# "val_total_loss",
|
| 87 |
+
# loss,
|
| 88 |
+
# on_step=True,
|
| 89 |
+
# on_epoch=True,
|
| 90 |
+
# prog_bar=True,
|
| 91 |
+
# sync_dist=True)
|
| 92 |
+
# self.log(
|
| 93 |
+
# f"val_top_{self.top_k}_acc",
|
| 94 |
+
# acc,
|
| 95 |
+
# on_step=True,
|
| 96 |
+
# on_epoch=True,
|
| 97 |
+
# prog_bar=True,
|
| 98 |
+
# sync_dist=True)
|
| 99 |
+
#
|
| 100 |
+
# # get infer output
|
| 101 |
+
# semantic_len = batch['semantic_ids'].size(1)
|
| 102 |
+
# prompt_len = min(int(semantic_len * 0.5), 150)
|
| 103 |
+
# prompt = batch['semantic_ids'][:, :prompt_len]
|
| 104 |
+
# pred_semantic = self.model.infer(batch['phoneme_ids'],
|
| 105 |
+
# batch['phoneme_ids_len'], prompt,
|
| 106 |
+
# batch['bert_feature']
|
| 107 |
+
# )
|
| 108 |
+
# save_name = f'semantic_toks_{batch_idx}.pt'
|
| 109 |
+
# save_path = os.path.join(self.eval_dir, save_name)
|
| 110 |
+
# torch.save(pred_semantic.detach().cpu(), save_path)
|
| 111 |
+
|
| 112 |
+
def configure_optimizers(self):
|
| 113 |
+
model_parameters = self.model.parameters()
|
| 114 |
+
parameters_names = []
|
| 115 |
+
parameters_names.append(
|
| 116 |
+
[name_param_pair[0] for name_param_pair in self.model.named_parameters()]
|
| 117 |
+
)
|
| 118 |
+
lm_opt = ScaledAdam(
|
| 119 |
+
model_parameters,
|
| 120 |
+
lr=0.01,
|
| 121 |
+
betas=(0.9, 0.95),
|
| 122 |
+
clipping_scale=2.0,
|
| 123 |
+
parameters_names=parameters_names,
|
| 124 |
+
show_dominant_parameters=False,
|
| 125 |
+
clipping_update_period=1000,
|
| 126 |
+
)
|
| 127 |
+
|
| 128 |
+
return {
|
| 129 |
+
"optimizer": lm_opt,
|
| 130 |
+
"lr_scheduler": {
|
| 131 |
+
"scheduler": WarmupCosineLRSchedule(
|
| 132 |
+
lm_opt,
|
| 133 |
+
init_lr=self.config["optimizer"]["lr_init"],
|
| 134 |
+
peak_lr=self.config["optimizer"]["lr"],
|
| 135 |
+
end_lr=self.config["optimizer"]["lr_end"],
|
| 136 |
+
warmup_steps=self.config["optimizer"]["warmup_steps"],
|
| 137 |
+
total_steps=self.config["optimizer"]["decay_steps"],
|
| 138 |
+
)
|
| 139 |
+
},
|
| 140 |
+
}
|
GPT_SoVITS/AR/models/t2s_lightning_module_onnx.py
ADDED
|
@@ -0,0 +1,106 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/feng-yufei/shared_debugging_code/blob/main/model/t2s_lightning_module.py
|
| 2 |
+
import os, sys
|
| 3 |
+
|
| 4 |
+
now_dir = os.getcwd()
|
| 5 |
+
sys.path.append(now_dir)
|
| 6 |
+
from typing import Dict
|
| 7 |
+
|
| 8 |
+
import torch
|
| 9 |
+
from pytorch_lightning import LightningModule
|
| 10 |
+
from AR.models.t2s_model_onnx import Text2SemanticDecoder
|
| 11 |
+
from AR.modules.lr_schedulers import WarmupCosineLRSchedule
|
| 12 |
+
from AR.modules.optim import ScaledAdam
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class Text2SemanticLightningModule(LightningModule):
|
| 16 |
+
def __init__(self, config, output_dir, is_train=True):
|
| 17 |
+
super().__init__()
|
| 18 |
+
self.config = config
|
| 19 |
+
self.top_k = 3
|
| 20 |
+
self.model = Text2SemanticDecoder(config=config, top_k=self.top_k)
|
| 21 |
+
pretrained_s1 = config.get("pretrained_s1")
|
| 22 |
+
if pretrained_s1 and is_train:
|
| 23 |
+
# print(self.load_state_dict(torch.load(pretrained_s1,map_location="cpu")["state_dict"]))
|
| 24 |
+
print(
|
| 25 |
+
self.load_state_dict(
|
| 26 |
+
torch.load(pretrained_s1, map_location="cpu")["weight"]
|
| 27 |
+
)
|
| 28 |
+
)
|
| 29 |
+
if is_train:
|
| 30 |
+
self.automatic_optimization = False
|
| 31 |
+
self.save_hyperparameters()
|
| 32 |
+
self.eval_dir = output_dir / "eval"
|
| 33 |
+
self.eval_dir.mkdir(parents=True, exist_ok=True)
|
| 34 |
+
|
| 35 |
+
def training_step(self, batch: Dict, batch_idx: int):
|
| 36 |
+
opt = self.optimizers()
|
| 37 |
+
scheduler = self.lr_schedulers()
|
| 38 |
+
loss, acc = self.model.forward(
|
| 39 |
+
batch["phoneme_ids"],
|
| 40 |
+
batch["phoneme_ids_len"],
|
| 41 |
+
batch["semantic_ids"],
|
| 42 |
+
batch["semantic_ids_len"],
|
| 43 |
+
batch["bert_feature"],
|
| 44 |
+
)
|
| 45 |
+
self.manual_backward(loss)
|
| 46 |
+
if batch_idx > 0 and batch_idx % 4 == 0:
|
| 47 |
+
opt.step()
|
| 48 |
+
opt.zero_grad()
|
| 49 |
+
scheduler.step()
|
| 50 |
+
|
| 51 |
+
self.log(
|
| 52 |
+
"total_loss",
|
| 53 |
+
loss,
|
| 54 |
+
on_step=True,
|
| 55 |
+
on_epoch=True,
|
| 56 |
+
prog_bar=True,
|
| 57 |
+
sync_dist=True,
|
| 58 |
+
)
|
| 59 |
+
self.log(
|
| 60 |
+
"lr",
|
| 61 |
+
scheduler.get_last_lr()[0],
|
| 62 |
+
on_epoch=True,
|
| 63 |
+
prog_bar=True,
|
| 64 |
+
sync_dist=True,
|
| 65 |
+
)
|
| 66 |
+
self.log(
|
| 67 |
+
f"top_{self.top_k}_acc",
|
| 68 |
+
acc,
|
| 69 |
+
on_step=True,
|
| 70 |
+
on_epoch=True,
|
| 71 |
+
prog_bar=True,
|
| 72 |
+
sync_dist=True,
|
| 73 |
+
)
|
| 74 |
+
|
| 75 |
+
def validation_step(self, batch: Dict, batch_idx: int):
|
| 76 |
+
return
|
| 77 |
+
|
| 78 |
+
def configure_optimizers(self):
|
| 79 |
+
model_parameters = self.model.parameters()
|
| 80 |
+
parameters_names = []
|
| 81 |
+
parameters_names.append(
|
| 82 |
+
[name_param_pair[0] for name_param_pair in self.model.named_parameters()]
|
| 83 |
+
)
|
| 84 |
+
lm_opt = ScaledAdam(
|
| 85 |
+
model_parameters,
|
| 86 |
+
lr=0.01,
|
| 87 |
+
betas=(0.9, 0.95),
|
| 88 |
+
clipping_scale=2.0,
|
| 89 |
+
parameters_names=parameters_names,
|
| 90 |
+
show_dominant_parameters=False,
|
| 91 |
+
clipping_update_period=1000,
|
| 92 |
+
)
|
| 93 |
+
|
| 94 |
+
return {
|
| 95 |
+
"optimizer": lm_opt,
|
| 96 |
+
"lr_scheduler": {
|
| 97 |
+
"scheduler": WarmupCosineLRSchedule(
|
| 98 |
+
lm_opt,
|
| 99 |
+
init_lr=self.config["optimizer"]["lr_init"],
|
| 100 |
+
peak_lr=self.config["optimizer"]["lr"],
|
| 101 |
+
end_lr=self.config["optimizer"]["lr_end"],
|
| 102 |
+
warmup_steps=self.config["optimizer"]["warmup_steps"],
|
| 103 |
+
total_steps=self.config["optimizer"]["decay_steps"],
|
| 104 |
+
)
|
| 105 |
+
},
|
| 106 |
+
}
|
GPT_SoVITS/AR/models/t2s_model.py
ADDED
|
@@ -0,0 +1,327 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/feng-yufei/shared_debugging_code/blob/main/model/t2s_model.py
|
| 2 |
+
import torch
|
| 3 |
+
from tqdm import tqdm
|
| 4 |
+
|
| 5 |
+
from AR.models.utils import make_pad_mask
|
| 6 |
+
from AR.models.utils import (
|
| 7 |
+
topk_sampling,
|
| 8 |
+
sample,
|
| 9 |
+
logits_to_probs,
|
| 10 |
+
multinomial_sample_one_no_sync,
|
| 11 |
+
)
|
| 12 |
+
from AR.modules.embedding import SinePositionalEmbedding
|
| 13 |
+
from AR.modules.embedding import TokenEmbedding
|
| 14 |
+
from AR.modules.transformer import LayerNorm
|
| 15 |
+
from AR.modules.transformer import TransformerEncoder
|
| 16 |
+
from AR.modules.transformer import TransformerEncoderLayer
|
| 17 |
+
from torch import nn
|
| 18 |
+
from torch.nn import functional as F
|
| 19 |
+
from torchmetrics.classification import MulticlassAccuracy
|
| 20 |
+
|
| 21 |
+
default_config = {
|
| 22 |
+
"embedding_dim": 512,
|
| 23 |
+
"hidden_dim": 512,
|
| 24 |
+
"num_head": 8,
|
| 25 |
+
"num_layers": 12,
|
| 26 |
+
"num_codebook": 8,
|
| 27 |
+
"p_dropout": 0.0,
|
| 28 |
+
"vocab_size": 1024 + 1,
|
| 29 |
+
"phoneme_vocab_size": 512,
|
| 30 |
+
"EOS": 1024,
|
| 31 |
+
}
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
class Text2SemanticDecoder(nn.Module):
|
| 35 |
+
def __init__(self, config, norm_first=False, top_k=3):
|
| 36 |
+
super(Text2SemanticDecoder, self).__init__()
|
| 37 |
+
self.model_dim = config["model"]["hidden_dim"]
|
| 38 |
+
self.embedding_dim = config["model"]["embedding_dim"]
|
| 39 |
+
self.num_head = config["model"]["head"]
|
| 40 |
+
self.num_layers = config["model"]["n_layer"]
|
| 41 |
+
self.norm_first = norm_first
|
| 42 |
+
self.vocab_size = config["model"]["vocab_size"]
|
| 43 |
+
self.phoneme_vocab_size = config["model"]["phoneme_vocab_size"]
|
| 44 |
+
self.p_dropout = config["model"]["dropout"]
|
| 45 |
+
self.EOS = config["model"]["EOS"]
|
| 46 |
+
self.norm_first = norm_first
|
| 47 |
+
assert self.EOS == self.vocab_size - 1
|
| 48 |
+
# should be same as num of kmeans bin
|
| 49 |
+
# assert self.EOS == 1024
|
| 50 |
+
self.bert_proj = nn.Linear(1024, self.embedding_dim)
|
| 51 |
+
self.ar_text_embedding = TokenEmbedding(
|
| 52 |
+
self.embedding_dim, self.phoneme_vocab_size, self.p_dropout
|
| 53 |
+
)
|
| 54 |
+
self.ar_text_position = SinePositionalEmbedding(
|
| 55 |
+
self.embedding_dim, dropout=0.1, scale=False, alpha=True
|
| 56 |
+
)
|
| 57 |
+
self.ar_audio_embedding = TokenEmbedding(
|
| 58 |
+
self.embedding_dim, self.vocab_size, self.p_dropout
|
| 59 |
+
)
|
| 60 |
+
self.ar_audio_position = SinePositionalEmbedding(
|
| 61 |
+
self.embedding_dim, dropout=0.1, scale=False, alpha=True
|
| 62 |
+
)
|
| 63 |
+
|
| 64 |
+
self.h = TransformerEncoder(
|
| 65 |
+
TransformerEncoderLayer(
|
| 66 |
+
d_model=self.model_dim,
|
| 67 |
+
nhead=self.num_head,
|
| 68 |
+
dim_feedforward=self.model_dim * 4,
|
| 69 |
+
dropout=0.1,
|
| 70 |
+
batch_first=True,
|
| 71 |
+
norm_first=norm_first,
|
| 72 |
+
),
|
| 73 |
+
num_layers=self.num_layers,
|
| 74 |
+
norm=LayerNorm(self.model_dim) if norm_first else None,
|
| 75 |
+
)
|
| 76 |
+
|
| 77 |
+
self.ar_predict_layer = nn.Linear(self.model_dim, self.vocab_size, bias=False)
|
| 78 |
+
self.loss_fct = nn.CrossEntropyLoss(reduction="sum")
|
| 79 |
+
|
| 80 |
+
self.ar_accuracy_metric = MulticlassAccuracy(
|
| 81 |
+
self.vocab_size,
|
| 82 |
+
top_k=top_k,
|
| 83 |
+
average="micro",
|
| 84 |
+
multidim_average="global",
|
| 85 |
+
ignore_index=self.EOS,
|
| 86 |
+
)
|
| 87 |
+
|
| 88 |
+
def forward(self, x, x_lens, y, y_lens, bert_feature):
|
| 89 |
+
"""
|
| 90 |
+
x: phoneme_ids
|
| 91 |
+
y: semantic_ids
|
| 92 |
+
"""
|
| 93 |
+
x = self.ar_text_embedding(x)
|
| 94 |
+
x = x + self.bert_proj(bert_feature.transpose(1, 2))
|
| 95 |
+
x = self.ar_text_position(x)
|
| 96 |
+
x_mask = make_pad_mask(x_lens)
|
| 97 |
+
|
| 98 |
+
y_mask = make_pad_mask(y_lens)
|
| 99 |
+
y_mask_int = y_mask.type(torch.int64)
|
| 100 |
+
codes = y.type(torch.int64) * (1 - y_mask_int)
|
| 101 |
+
|
| 102 |
+
# Training
|
| 103 |
+
# AR Decoder
|
| 104 |
+
y, targets = self.pad_y_eos(codes, y_mask_int, eos_id=self.EOS)
|
| 105 |
+
x_len = x_lens.max()
|
| 106 |
+
y_len = y_lens.max()
|
| 107 |
+
y_emb = self.ar_audio_embedding(y)
|
| 108 |
+
y_pos = self.ar_audio_position(y_emb)
|
| 109 |
+
|
| 110 |
+
xy_padding_mask = torch.concat([x_mask, y_mask], dim=1)
|
| 111 |
+
ar_xy_padding_mask = xy_padding_mask
|
| 112 |
+
|
| 113 |
+
x_attn_mask = F.pad(
|
| 114 |
+
torch.zeros((x_len, x_len), dtype=torch.bool, device=x.device),
|
| 115 |
+
(0, y_len),
|
| 116 |
+
value=True,
|
| 117 |
+
)
|
| 118 |
+
y_attn_mask = F.pad(
|
| 119 |
+
torch.triu(
|
| 120 |
+
torch.ones(y_len, y_len, dtype=torch.bool, device=x.device),
|
| 121 |
+
diagonal=1,
|
| 122 |
+
),
|
| 123 |
+
(x_len, 0),
|
| 124 |
+
value=False,
|
| 125 |
+
)
|
| 126 |
+
xy_attn_mask = torch.concat([x_attn_mask, y_attn_mask], dim=0)
|
| 127 |
+
bsz, src_len = x.shape[0], x_len + y_len
|
| 128 |
+
_xy_padding_mask = (
|
| 129 |
+
ar_xy_padding_mask.view(bsz, 1, 1, src_len)
|
| 130 |
+
.expand(-1, self.num_head, -1, -1)
|
| 131 |
+
.reshape(bsz * self.num_head, 1, src_len)
|
| 132 |
+
)
|
| 133 |
+
xy_attn_mask = xy_attn_mask.logical_or(_xy_padding_mask)
|
| 134 |
+
new_attn_mask = torch.zeros_like(xy_attn_mask, dtype=x.dtype)
|
| 135 |
+
new_attn_mask.masked_fill_(xy_attn_mask, float("-inf"))
|
| 136 |
+
xy_attn_mask = new_attn_mask
|
| 137 |
+
# x 和完整的 y 一次性输入模型
|
| 138 |
+
xy_pos = torch.concat([x, y_pos], dim=1)
|
| 139 |
+
xy_dec, _ = self.h(
|
| 140 |
+
(xy_pos, None),
|
| 141 |
+
mask=xy_attn_mask,
|
| 142 |
+
)
|
| 143 |
+
logits = self.ar_predict_layer(xy_dec[:, x_len:]).permute(0, 2, 1)
|
| 144 |
+
# loss
|
| 145 |
+
# from feiteng: 每次 duration 越多, 梯度更新也应该更多, 所以用 sum
|
| 146 |
+
loss = F.cross_entropy(logits, targets, reduction="sum")
|
| 147 |
+
acc = self.ar_accuracy_metric(logits.detach(), targets).item()
|
| 148 |
+
return loss, acc
|
| 149 |
+
|
| 150 |
+
# 需要看下这个函数和 forward 的区别以及没有 semantic 的时候 prompts 输入什么
|
| 151 |
+
def infer(
|
| 152 |
+
self,
|
| 153 |
+
x,
|
| 154 |
+
x_lens,
|
| 155 |
+
prompts,
|
| 156 |
+
bert_feature,
|
| 157 |
+
top_k: int = -100,
|
| 158 |
+
early_stop_num: int = -1,
|
| 159 |
+
temperature: float = 1.0,
|
| 160 |
+
):
|
| 161 |
+
x = self.ar_text_embedding(x)
|
| 162 |
+
x = x + self.bert_proj(bert_feature.transpose(1, 2))
|
| 163 |
+
x = self.ar_text_position(x)
|
| 164 |
+
|
| 165 |
+
# AR Decoder
|
| 166 |
+
y = prompts
|
| 167 |
+
prefix_len = y.shape[1]
|
| 168 |
+
x_len = x.shape[1]
|
| 169 |
+
x_attn_mask = torch.zeros((x_len, x_len), dtype=torch.bool)
|
| 170 |
+
stop = False
|
| 171 |
+
for _ in tqdm(range(1500)):
|
| 172 |
+
y_emb = self.ar_audio_embedding(y)
|
| 173 |
+
y_pos = self.ar_audio_position(y_emb)
|
| 174 |
+
# x 和逐渐增长的 y 一起输入给模型
|
| 175 |
+
xy_pos = torch.concat([x, y_pos], dim=1)
|
| 176 |
+
y_len = y.shape[1]
|
| 177 |
+
x_attn_mask_pad = F.pad(
|
| 178 |
+
x_attn_mask,
|
| 179 |
+
(0, y_len),
|
| 180 |
+
value=True,
|
| 181 |
+
)
|
| 182 |
+
y_attn_mask = F.pad(
|
| 183 |
+
torch.triu(torch.ones(y_len, y_len, dtype=torch.bool), diagonal=1),
|
| 184 |
+
(x_len, 0),
|
| 185 |
+
value=False,
|
| 186 |
+
)
|
| 187 |
+
xy_attn_mask = torch.concat([x_attn_mask_pad, y_attn_mask], dim=0).to(
|
| 188 |
+
y.device
|
| 189 |
+
)
|
| 190 |
+
|
| 191 |
+
xy_dec, _ = self.h(
|
| 192 |
+
(xy_pos, None),
|
| 193 |
+
mask=xy_attn_mask,
|
| 194 |
+
)
|
| 195 |
+
logits = self.ar_predict_layer(xy_dec[:, -1])
|
| 196 |
+
samples = topk_sampling(
|
| 197 |
+
logits, top_k=top_k, top_p=1.0, temperature=temperature
|
| 198 |
+
)
|
| 199 |
+
|
| 200 |
+
if early_stop_num != -1 and (y.shape[1] - prefix_len) > early_stop_num:
|
| 201 |
+
print("use early stop num:", early_stop_num)
|
| 202 |
+
stop = True
|
| 203 |
+
|
| 204 |
+
if torch.argmax(logits, dim=-1)[0] == self.EOS or samples[0, 0] == self.EOS:
|
| 205 |
+
# print(torch.argmax(logits, dim=-1)[0] == self.EOS, samples[0, 0] == self.EOS)
|
| 206 |
+
stop = True
|
| 207 |
+
if stop:
|
| 208 |
+
if prompts.shape[1] == y.shape[1]:
|
| 209 |
+
y = torch.concat([y, torch.zeros_like(samples)], dim=1)
|
| 210 |
+
print("bad zero prediction")
|
| 211 |
+
print(f"T2S Decoding EOS [{prefix_len} -> {y.shape[1]}]")
|
| 212 |
+
break
|
| 213 |
+
# 本次生成的 semantic_ids 和之前的 y 构成新的 y
|
| 214 |
+
# print(samples.shape)#[1,1]#第一个1是bs
|
| 215 |
+
# import os
|
| 216 |
+
# os._exit(2333)
|
| 217 |
+
y = torch.concat([y, samples], dim=1)
|
| 218 |
+
return y
|
| 219 |
+
|
| 220 |
+
def pad_y_eos(self, y, y_mask_int, eos_id):
|
| 221 |
+
targets = F.pad(y, (0, 1), value=0) + eos_id * F.pad(
|
| 222 |
+
y_mask_int, (0, 1), value=1
|
| 223 |
+
)
|
| 224 |
+
# 错位
|
| 225 |
+
return targets[:, :-1], targets[:, 1:]
|
| 226 |
+
|
| 227 |
+
def infer_panel(
|
| 228 |
+
self,
|
| 229 |
+
x, #####全部文本token
|
| 230 |
+
x_lens,
|
| 231 |
+
prompts, ####参考音频token
|
| 232 |
+
bert_feature,
|
| 233 |
+
top_k: int = -100,
|
| 234 |
+
early_stop_num: int = -1,
|
| 235 |
+
temperature: float = 1.0,
|
| 236 |
+
):
|
| 237 |
+
x = self.ar_text_embedding(x)
|
| 238 |
+
x = x + self.bert_proj(bert_feature.transpose(1, 2))
|
| 239 |
+
x = self.ar_text_position(x)
|
| 240 |
+
|
| 241 |
+
# AR Decoder
|
| 242 |
+
y = prompts
|
| 243 |
+
prefix_len = y.shape[1]
|
| 244 |
+
x_len = x.shape[1]
|
| 245 |
+
x_attn_mask = torch.zeros((x_len, x_len), dtype=torch.bool)
|
| 246 |
+
stop = False
|
| 247 |
+
# print(1111111,self.num_layers)
|
| 248 |
+
cache = {
|
| 249 |
+
"all_stage": self.num_layers,
|
| 250 |
+
"k": [None] * self.num_layers, ###根据配置自己手写
|
| 251 |
+
"v": [None] * self.num_layers,
|
| 252 |
+
# "xy_pos":None,##y_pos位置编码每次都不一样的没法缓存,每次都要重新拼xy_pos.主要还是写法原因,其实是可以历史统一一样的,但也没啥计算量就不管了
|
| 253 |
+
"y_emb": None, ##只需要对最新的samples求emb,再拼历史的就行
|
| 254 |
+
# "logits":None,###原版就已经只对结尾求再拼接了,不用管
|
| 255 |
+
# "xy_dec":None,###不需要,本来只需要最后一个做logits
|
| 256 |
+
"first_infer": 1,
|
| 257 |
+
"stage": 0,
|
| 258 |
+
}
|
| 259 |
+
for idx in tqdm(range(1500)):
|
| 260 |
+
if cache["first_infer"] == 1:
|
| 261 |
+
y_emb = self.ar_audio_embedding(y)
|
| 262 |
+
else:
|
| 263 |
+
y_emb = torch.cat(
|
| 264 |
+
[cache["y_emb"], self.ar_audio_embedding(y[:, -1:])], 1
|
| 265 |
+
)
|
| 266 |
+
cache["y_emb"] = y_emb
|
| 267 |
+
y_pos = self.ar_audio_position(y_emb)
|
| 268 |
+
# x 和逐渐增长的 y 一起输入给模型
|
| 269 |
+
if cache["first_infer"] == 1:
|
| 270 |
+
xy_pos = torch.concat([x, y_pos], dim=1)
|
| 271 |
+
else:
|
| 272 |
+
xy_pos = y_pos[:, -1:]
|
| 273 |
+
y_len = y_pos.shape[1]
|
| 274 |
+
###以下3个不做缓存
|
| 275 |
+
if cache["first_infer"] == 1:
|
| 276 |
+
x_attn_mask_pad = F.pad(
|
| 277 |
+
x_attn_mask,
|
| 278 |
+
(0, y_len), ###xx的纯0扩展到xx纯0+xy纯1,(x,x+y)
|
| 279 |
+
value=True,
|
| 280 |
+
)
|
| 281 |
+
y_attn_mask = F.pad( ###yy的右上1扩展到左边xy的0,(y,x+y)
|
| 282 |
+
torch.triu(torch.ones(y_len, y_len, dtype=torch.bool), diagonal=1),
|
| 283 |
+
(x_len, 0),
|
| 284 |
+
value=False,
|
| 285 |
+
)
|
| 286 |
+
xy_attn_mask = torch.concat([x_attn_mask_pad, y_attn_mask], dim=0).to(
|
| 287 |
+
y.device
|
| 288 |
+
)
|
| 289 |
+
else:
|
| 290 |
+
###最右边一列(是错的)
|
| 291 |
+
# xy_attn_mask=torch.ones((1, x_len+y_len), dtype=torch.bool,device=xy_pos.device)
|
| 292 |
+
# xy_attn_mask[:,-1]=False
|
| 293 |
+
###最下面一行(是对的)
|
| 294 |
+
xy_attn_mask = torch.zeros(
|
| 295 |
+
(1, x_len + y_len), dtype=torch.bool, device=xy_pos.device
|
| 296 |
+
)
|
| 297 |
+
# pdb.set_trace()
|
| 298 |
+
###缓存重头戏
|
| 299 |
+
# print(1111,xy_pos.shape,xy_attn_mask.shape,x_len,y_len)
|
| 300 |
+
xy_dec, _ = self.h((xy_pos, None), mask=xy_attn_mask, cache=cache)
|
| 301 |
+
logits = self.ar_predict_layer(
|
| 302 |
+
xy_dec[:, -1]
|
| 303 |
+
) ##不用改,如果用了cache的默认就是只有一帧,取最后一帧一样的
|
| 304 |
+
# samples = topk_sampling(logits, top_k=top_k, top_p=1.0, temperature=temperature)
|
| 305 |
+
if(idx==0):###第一次跑不能EOS否则没有了
|
| 306 |
+
logits = logits[:, :-1] ###刨除1024终止符号的概率
|
| 307 |
+
samples = sample(
|
| 308 |
+
logits[0], y, top_k=top_k, top_p=1.0, repetition_penalty=1.35
|
| 309 |
+
)[0].unsqueeze(0)
|
| 310 |
+
if early_stop_num != -1 and (y.shape[1] - prefix_len) > early_stop_num:
|
| 311 |
+
print("use early stop num:", early_stop_num)
|
| 312 |
+
stop = True
|
| 313 |
+
|
| 314 |
+
if torch.argmax(logits, dim=-1)[0] == self.EOS or samples[0, 0] == self.EOS:
|
| 315 |
+
# print(torch.argmax(logits, dim=-1)[0] == self.EOS, samples[0, 0] == self.EOS)
|
| 316 |
+
stop = True
|
| 317 |
+
if stop:
|
| 318 |
+
if prompts.shape[1] == y.shape[1]:
|
| 319 |
+
y = torch.concat([y, torch.zeros_like(samples)], dim=1)
|
| 320 |
+
print("bad zero prediction")
|
| 321 |
+
print(f"T2S Decoding EOS [{prefix_len} -> {y.shape[1]}]")
|
| 322 |
+
break
|
| 323 |
+
# 本次生成的 semantic_ids 和之前的 y 构成新的 y
|
| 324 |
+
# print(samples.shape)#[1,1]#第一个1是bs
|
| 325 |
+
y = torch.concat([y, samples], dim=1)
|
| 326 |
+
cache["first_infer"] = 0
|
| 327 |
+
return y, idx
|
GPT_SoVITS/AR/models/t2s_model_onnx.py
ADDED
|
@@ -0,0 +1,337 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/feng-yufei/shared_debugging_code/blob/main/model/t2s_model.py
|
| 2 |
+
import torch
|
| 3 |
+
from tqdm import tqdm
|
| 4 |
+
|
| 5 |
+
from AR.modules.embedding_onnx import SinePositionalEmbedding
|
| 6 |
+
from AR.modules.embedding_onnx import TokenEmbedding
|
| 7 |
+
from AR.modules.transformer_onnx import LayerNorm
|
| 8 |
+
from AR.modules.transformer_onnx import TransformerEncoder
|
| 9 |
+
from AR.modules.transformer_onnx import TransformerEncoderLayer
|
| 10 |
+
from torch import nn
|
| 11 |
+
from torch.nn import functional as F
|
| 12 |
+
from torchmetrics.classification import MulticlassAccuracy
|
| 13 |
+
|
| 14 |
+
default_config = {
|
| 15 |
+
"embedding_dim": 512,
|
| 16 |
+
"hidden_dim": 512,
|
| 17 |
+
"num_head": 8,
|
| 18 |
+
"num_layers": 12,
|
| 19 |
+
"num_codebook": 8,
|
| 20 |
+
"p_dropout": 0.0,
|
| 21 |
+
"vocab_size": 1024 + 1,
|
| 22 |
+
"phoneme_vocab_size": 512,
|
| 23 |
+
"EOS": 1024,
|
| 24 |
+
}
|
| 25 |
+
|
| 26 |
+
inf_tensor_value = torch.FloatTensor([-float("Inf")]).float()
|
| 27 |
+
|
| 28 |
+
def logits_to_probs(
|
| 29 |
+
logits,
|
| 30 |
+
previous_tokens = None,
|
| 31 |
+
temperature: float = 1.0,
|
| 32 |
+
top_k = None,
|
| 33 |
+
top_p = None,
|
| 34 |
+
repetition_penalty: float = 1.0,
|
| 35 |
+
):
|
| 36 |
+
previous_tokens = previous_tokens.squeeze()
|
| 37 |
+
if previous_tokens is not None and repetition_penalty != 1.0:
|
| 38 |
+
previous_tokens = previous_tokens.long()
|
| 39 |
+
score = torch.gather(logits, dim=0, index=previous_tokens)
|
| 40 |
+
score = torch.where(
|
| 41 |
+
score < 0, score * repetition_penalty, score / repetition_penalty
|
| 42 |
+
)
|
| 43 |
+
logits.scatter_(dim=0, index=previous_tokens, src=score)
|
| 44 |
+
|
| 45 |
+
if top_p is not None and top_p < 1.0:
|
| 46 |
+
sorted_logits, sorted_indices = torch.sort(logits, descending=True)
|
| 47 |
+
cum_probs = torch.cumsum(
|
| 48 |
+
torch.nn.functional.softmax(sorted_logits, dim=-1), dim=-1
|
| 49 |
+
)
|
| 50 |
+
sorted_indices_to_remove = cum_probs > top_p
|
| 51 |
+
sorted_indices_to_remove[0] = False # keep at least one option
|
| 52 |
+
indices_to_remove = sorted_indices_to_remove.scatter(
|
| 53 |
+
dim=0, index=sorted_indices, src=sorted_indices_to_remove
|
| 54 |
+
)
|
| 55 |
+
logits = logits.masked_fill(indices_to_remove, -float("Inf"))
|
| 56 |
+
|
| 57 |
+
logits = logits / max(temperature, 1e-5)
|
| 58 |
+
|
| 59 |
+
if top_k is not None:
|
| 60 |
+
v, _ = torch.topk(logits, min(top_k, logits.size(-1)))
|
| 61 |
+
pivot = v.select(-1, -1).unsqueeze(-1)
|
| 62 |
+
logits = torch.where(logits < pivot, inf_tensor_value, logits)
|
| 63 |
+
|
| 64 |
+
probs = torch.nn.functional.softmax(logits, dim=-1)
|
| 65 |
+
return probs
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def multinomial_sample_one_no_sync(
|
| 69 |
+
probs_sort
|
| 70 |
+
): # Does multinomial sampling without a cuda synchronization
|
| 71 |
+
q = torch.randn_like(probs_sort)
|
| 72 |
+
return torch.argmax(probs_sort / q, dim=-1, keepdim=True).to(dtype=torch.int)
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
def sample(
|
| 76 |
+
logits,
|
| 77 |
+
previous_tokens,
|
| 78 |
+
**sampling_kwargs,
|
| 79 |
+
):
|
| 80 |
+
probs = logits_to_probs(
|
| 81 |
+
logits=logits, previous_tokens=previous_tokens, **sampling_kwargs
|
| 82 |
+
)
|
| 83 |
+
idx_next = multinomial_sample_one_no_sync(probs)
|
| 84 |
+
return idx_next, probs
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
class OnnxEncoder(nn.Module):
|
| 88 |
+
def __init__(self, ar_text_embedding, bert_proj, ar_text_position):
|
| 89 |
+
super().__init__()
|
| 90 |
+
self.ar_text_embedding = ar_text_embedding
|
| 91 |
+
self.bert_proj = bert_proj
|
| 92 |
+
self.ar_text_position = ar_text_position
|
| 93 |
+
|
| 94 |
+
def forward(self, x, bert_feature):
|
| 95 |
+
x = self.ar_text_embedding(x)
|
| 96 |
+
x = x + self.bert_proj(bert_feature.transpose(1, 2))
|
| 97 |
+
return self.ar_text_position(x)
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
class T2SFirstStageDecoder(nn.Module):
|
| 101 |
+
def __init__(self, ar_audio_embedding, ar_audio_position, h, ar_predict_layer, loss_fct, ar_accuracy_metric,
|
| 102 |
+
top_k, early_stop_num, num_layers):
|
| 103 |
+
super().__init__()
|
| 104 |
+
self.ar_audio_embedding = ar_audio_embedding
|
| 105 |
+
self.ar_audio_position = ar_audio_position
|
| 106 |
+
self.h = h
|
| 107 |
+
self.ar_predict_layer = ar_predict_layer
|
| 108 |
+
self.loss_fct = loss_fct
|
| 109 |
+
self.ar_accuracy_metric = ar_accuracy_metric
|
| 110 |
+
self.top_k = top_k
|
| 111 |
+
self.early_stop_num = early_stop_num
|
| 112 |
+
self.num_layers = num_layers
|
| 113 |
+
|
| 114 |
+
def forward(self, x, prompt):
|
| 115 |
+
y = prompt
|
| 116 |
+
x_example = x[:,:,0] * 0.0
|
| 117 |
+
#N, 1, 512
|
| 118 |
+
cache = {
|
| 119 |
+
"all_stage": self.num_layers,
|
| 120 |
+
"k": None,
|
| 121 |
+
"v": None,
|
| 122 |
+
"y_emb": None,
|
| 123 |
+
"first_infer": 1,
|
| 124 |
+
"stage": 0,
|
| 125 |
+
}
|
| 126 |
+
|
| 127 |
+
y_emb = self.ar_audio_embedding(y)
|
| 128 |
+
|
| 129 |
+
cache["y_emb"] = y_emb
|
| 130 |
+
y_pos = self.ar_audio_position(y_emb)
|
| 131 |
+
|
| 132 |
+
xy_pos = torch.concat([x, y_pos], dim=1)
|
| 133 |
+
|
| 134 |
+
y_example = y_pos[:,:,0] * 0.0
|
| 135 |
+
x_attn_mask = torch.matmul(x_example.transpose(0, 1) , x_example).bool()
|
| 136 |
+
y_attn_mask = torch.ones_like(torch.matmul(y_example.transpose(0, 1), y_example), dtype=torch.int64)
|
| 137 |
+
y_attn_mask = torch.cumsum(y_attn_mask, dim=1) - torch.cumsum(
|
| 138 |
+
torch.ones_like(y_example.transpose(0, 1), dtype=torch.int64), dim=0
|
| 139 |
+
)
|
| 140 |
+
y_attn_mask = y_attn_mask > 0
|
| 141 |
+
|
| 142 |
+
x_y_pad = torch.matmul(x_example.transpose(0, 1), y_example).bool()
|
| 143 |
+
y_x_pad = torch.matmul(y_example.transpose(0, 1), x_example).bool()
|
| 144 |
+
x_attn_mask_pad = torch.cat([x_attn_mask, torch.ones_like(x_y_pad)], dim=1)
|
| 145 |
+
y_attn_mask = torch.cat([y_x_pad, y_attn_mask], dim=1)
|
| 146 |
+
xy_attn_mask = torch.concat([x_attn_mask_pad, y_attn_mask], dim=0)
|
| 147 |
+
cache["k"] = torch.matmul(x_attn_mask_pad[0].float().unsqueeze(-1), torch.zeros((1, 512)))\
|
| 148 |
+
.unsqueeze(1).repeat(self.num_layers, 1, 1, 1)
|
| 149 |
+
cache["v"] = torch.matmul(x_attn_mask_pad[0].float().unsqueeze(-1), torch.zeros((1, 512)))\
|
| 150 |
+
.unsqueeze(1).repeat(self.num_layers, 1, 1, 1)
|
| 151 |
+
|
| 152 |
+
xy_dec = self.h(xy_pos, mask=xy_attn_mask, cache=cache)
|
| 153 |
+
logits = self.ar_predict_layer(xy_dec[:, -1])
|
| 154 |
+
samples = sample(logits[0], y, top_k=self.top_k, top_p=1.0, repetition_penalty=1.35)[0].unsqueeze(0)
|
| 155 |
+
|
| 156 |
+
y = torch.concat([y, samples], dim=1)
|
| 157 |
+
|
| 158 |
+
return y, cache["k"], cache["v"], cache["y_emb"], x_example
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
class T2SStageDecoder(nn.Module):
|
| 162 |
+
def __init__(self, ar_audio_embedding, ar_audio_position, h, ar_predict_layer, loss_fct, ar_accuracy_metric,
|
| 163 |
+
top_k, early_stop_num, num_layers):
|
| 164 |
+
super().__init__()
|
| 165 |
+
self.ar_audio_embedding = ar_audio_embedding
|
| 166 |
+
self.ar_audio_position = ar_audio_position
|
| 167 |
+
self.h = h
|
| 168 |
+
self.ar_predict_layer = ar_predict_layer
|
| 169 |
+
self.loss_fct = loss_fct
|
| 170 |
+
self.ar_accuracy_metric = ar_accuracy_metric
|
| 171 |
+
self.top_k = top_k
|
| 172 |
+
self.early_stop_num = early_stop_num
|
| 173 |
+
self.num_layers = num_layers
|
| 174 |
+
|
| 175 |
+
def forward(self, y, k, v, y_emb, x_example):
|
| 176 |
+
cache = {
|
| 177 |
+
"all_stage": self.num_layers,
|
| 178 |
+
"k": torch.nn.functional.pad(k, (0, 0, 0, 0, 0, 1)),
|
| 179 |
+
"v": torch.nn.functional.pad(v, (0, 0, 0, 0, 0, 1)),
|
| 180 |
+
"y_emb": y_emb,
|
| 181 |
+
"first_infer": 0,
|
| 182 |
+
"stage": 0,
|
| 183 |
+
}
|
| 184 |
+
|
| 185 |
+
y_emb = torch.cat(
|
| 186 |
+
[cache["y_emb"], self.ar_audio_embedding(y[:, -1:])], 1
|
| 187 |
+
)
|
| 188 |
+
cache["y_emb"] = y_emb
|
| 189 |
+
y_pos = self.ar_audio_position(y_emb)
|
| 190 |
+
|
| 191 |
+
xy_pos = y_pos[:, -1:]
|
| 192 |
+
|
| 193 |
+
y_example = y_pos[:,:,0] * 0.0
|
| 194 |
+
|
| 195 |
+
xy_attn_mask = torch.cat([x_example, y_example], dim=1)
|
| 196 |
+
xy_attn_mask = torch.zeros_like(xy_attn_mask, dtype=torch.bool)
|
| 197 |
+
|
| 198 |
+
xy_dec = self.h(xy_pos, mask=xy_attn_mask, cache=cache)
|
| 199 |
+
logits = self.ar_predict_layer(xy_dec[:, -1])
|
| 200 |
+
samples = sample(logits[0], y, top_k=self.top_k, top_p=1.0, repetition_penalty=1.35)[0].unsqueeze(0)
|
| 201 |
+
|
| 202 |
+
y = torch.concat([y, samples], dim=1)
|
| 203 |
+
|
| 204 |
+
return y, cache["k"], cache["v"], cache["y_emb"], logits, samples
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
class Text2SemanticDecoder(nn.Module):
|
| 208 |
+
def __init__(self, config, norm_first=False, top_k=3):
|
| 209 |
+
super(Text2SemanticDecoder, self).__init__()
|
| 210 |
+
self.model_dim = config["model"]["hidden_dim"]
|
| 211 |
+
self.embedding_dim = config["model"]["embedding_dim"]
|
| 212 |
+
self.num_head = config["model"]["head"]
|
| 213 |
+
self.num_layers = config["model"]["n_layer"]
|
| 214 |
+
self.norm_first = norm_first
|
| 215 |
+
self.vocab_size = config["model"]["vocab_size"]
|
| 216 |
+
self.phoneme_vocab_size = config["model"]["phoneme_vocab_size"]
|
| 217 |
+
self.p_dropout = float(config["model"]["dropout"])
|
| 218 |
+
self.EOS = config["model"]["EOS"]
|
| 219 |
+
self.norm_first = norm_first
|
| 220 |
+
assert self.EOS == self.vocab_size - 1
|
| 221 |
+
self.bert_proj = nn.Linear(1024, self.embedding_dim)
|
| 222 |
+
self.ar_text_embedding = TokenEmbedding(self.embedding_dim, self.phoneme_vocab_size, self.p_dropout)
|
| 223 |
+
self.ar_text_position = SinePositionalEmbedding(self.embedding_dim, dropout=0.1, scale=False, alpha=True)
|
| 224 |
+
self.ar_audio_embedding = TokenEmbedding(self.embedding_dim, self.vocab_size, self.p_dropout)
|
| 225 |
+
self.ar_audio_position = SinePositionalEmbedding(self.embedding_dim, dropout=0.1, scale=False, alpha=True)
|
| 226 |
+
self.h = TransformerEncoder(
|
| 227 |
+
TransformerEncoderLayer(
|
| 228 |
+
d_model=self.model_dim,
|
| 229 |
+
nhead=self.num_head,
|
| 230 |
+
dim_feedforward=self.model_dim * 4,
|
| 231 |
+
dropout=0.1,
|
| 232 |
+
batch_first=True,
|
| 233 |
+
norm_first=norm_first,
|
| 234 |
+
),
|
| 235 |
+
num_layers=self.num_layers,
|
| 236 |
+
norm=LayerNorm(self.model_dim) if norm_first else None,
|
| 237 |
+
)
|
| 238 |
+
self.ar_predict_layer = nn.Linear(self.model_dim, self.vocab_size, bias=False)
|
| 239 |
+
self.loss_fct = nn.CrossEntropyLoss(reduction="sum")
|
| 240 |
+
self.ar_accuracy_metric = MulticlassAccuracy(
|
| 241 |
+
self.vocab_size,
|
| 242 |
+
top_k=top_k,
|
| 243 |
+
average="micro",
|
| 244 |
+
multidim_average="global",
|
| 245 |
+
ignore_index=self.EOS,
|
| 246 |
+
)
|
| 247 |
+
self.top_k = torch.LongTensor([1])
|
| 248 |
+
self.early_stop_num = torch.LongTensor([-1])
|
| 249 |
+
|
| 250 |
+
def init_onnx(self):
|
| 251 |
+
self.onnx_encoder = OnnxEncoder(self.ar_text_embedding, self.bert_proj, self.ar_text_position)
|
| 252 |
+
self.first_stage_decoder = T2SFirstStageDecoder(self.ar_audio_embedding, self.ar_audio_position, self.h,
|
| 253 |
+
self.ar_predict_layer, self.loss_fct, self.ar_accuracy_metric, self.top_k, self.early_stop_num,
|
| 254 |
+
self.num_layers)
|
| 255 |
+
self.stage_decoder = T2SStageDecoder(self.ar_audio_embedding, self.ar_audio_position, self.h,
|
| 256 |
+
self.ar_predict_layer, self.loss_fct, self.ar_accuracy_metric, self.top_k, self.early_stop_num,
|
| 257 |
+
self.num_layers)
|
| 258 |
+
|
| 259 |
+
def forward(self, x, prompts, bert_feature):
|
| 260 |
+
early_stop_num = self.early_stop_num
|
| 261 |
+
prefix_len = prompts.shape[1]
|
| 262 |
+
|
| 263 |
+
x = self.onnx_encoder(x, bert_feature)
|
| 264 |
+
y, k, v, y_emb, stage, x_example = self.first_stage_decoder(x, prompts)
|
| 265 |
+
|
| 266 |
+
stop = False
|
| 267 |
+
for idx in range(1, 1500):
|
| 268 |
+
enco = self.stage_decoder(y, k, v, y_emb, stage, x_example)
|
| 269 |
+
y, k, v, y_emb, stage, logits, samples = enco
|
| 270 |
+
if early_stop_num != -1 and (y.shape[1] - prefix_len) > early_stop_num:
|
| 271 |
+
stop = True
|
| 272 |
+
if torch.argmax(logits, dim=-1)[0] == self.EOS or samples[0, 0] == self.EOS:
|
| 273 |
+
stop = True
|
| 274 |
+
if stop:
|
| 275 |
+
break
|
| 276 |
+
y[0, -1] = 0
|
| 277 |
+
return y, idx
|
| 278 |
+
|
| 279 |
+
def infer(self, x, prompts, bert_feature):
|
| 280 |
+
top_k = self.top_k
|
| 281 |
+
early_stop_num = self.early_stop_num
|
| 282 |
+
|
| 283 |
+
x = self.onnx_encoder(x, bert_feature)
|
| 284 |
+
|
| 285 |
+
y = prompts
|
| 286 |
+
prefix_len = y.shape[1]
|
| 287 |
+
x_len = x.shape[1]
|
| 288 |
+
x_example = x[:,:,0] * 0.0
|
| 289 |
+
x_attn_mask = torch.matmul(x_example.transpose(0, 1), x_example)
|
| 290 |
+
x_attn_mask = torch.zeros_like(x_attn_mask, dtype=torch.bool)
|
| 291 |
+
|
| 292 |
+
stop = False
|
| 293 |
+
cache = {
|
| 294 |
+
"all_stage": self.num_layers,
|
| 295 |
+
"k": [None] * self.num_layers,
|
| 296 |
+
"v": [None] * self.num_layers,
|
| 297 |
+
"y_emb": None,
|
| 298 |
+
"first_infer": 1,
|
| 299 |
+
"stage": 0,
|
| 300 |
+
}
|
| 301 |
+
for idx in range(1500):
|
| 302 |
+
if cache["first_infer"] == 1:
|
| 303 |
+
y_emb = self.ar_audio_embedding(y)
|
| 304 |
+
else:
|
| 305 |
+
y_emb = torch.cat(
|
| 306 |
+
[cache["y_emb"], self.ar_audio_embedding(y[:, -1:])], 1
|
| 307 |
+
)
|
| 308 |
+
cache["y_emb"] = y_emb
|
| 309 |
+
y_pos = self.ar_audio_position(y_emb)
|
| 310 |
+
if cache["first_infer"] == 1:
|
| 311 |
+
xy_pos = torch.concat([x, y_pos], dim=1)
|
| 312 |
+
else:
|
| 313 |
+
xy_pos = y_pos[:, -1:]
|
| 314 |
+
y_len = y_pos.shape[1]
|
| 315 |
+
if cache["first_infer"] == 1:
|
| 316 |
+
x_attn_mask_pad = F.pad(x_attn_mask, (0, y_len), value=True)
|
| 317 |
+
y_attn_mask = F.pad(
|
| 318 |
+
torch.triu(torch.ones(y_len, y_len, dtype=torch.bool), diagonal=1),
|
| 319 |
+
(x_len, 0), value=False
|
| 320 |
+
)
|
| 321 |
+
xy_attn_mask = torch.concat([x_attn_mask_pad, y_attn_mask], dim=0)
|
| 322 |
+
else:
|
| 323 |
+
xy_attn_mask = torch.zeros((1, x_len + y_len), dtype=torch.bool)
|
| 324 |
+
xy_dec = self.h(xy_pos, mask=xy_attn_mask, cache=cache)
|
| 325 |
+
logits = self.ar_predict_layer(xy_dec[:, -1])
|
| 326 |
+
samples = sample(logits[0], y, top_k=top_k, top_p=1.0, repetition_penalty=1.35)[0].unsqueeze(0)
|
| 327 |
+
if early_stop_num != -1 and (y.shape[1] - prefix_len) > early_stop_num:
|
| 328 |
+
stop = True
|
| 329 |
+
if torch.argmax(logits, dim=-1)[0] == self.EOS or samples[0, 0] == self.EOS:
|
| 330 |
+
stop = True
|
| 331 |
+
if stop:
|
| 332 |
+
if prompts.shape[1] == y.shape[1]:
|
| 333 |
+
y = torch.concat([y, torch.zeros_like(samples)], dim=1)
|
| 334 |
+
break
|
| 335 |
+
y = torch.concat([y, samples], dim=1)
|
| 336 |
+
cache["first_infer"] = 0
|
| 337 |
+
return y, idx
|
GPT_SoVITS/AR/models/utils.py
ADDED
|
@@ -0,0 +1,160 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/feng-yufei/shared_debugging_code/blob/main/model/utils.py\
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def sequence_mask(length, max_length=None):
|
| 7 |
+
if max_length is None:
|
| 8 |
+
max_length = length.max()
|
| 9 |
+
x = torch.arange(max_length, dtype=length.dtype, device=length.device)
|
| 10 |
+
return x.unsqueeze(0) < length.unsqueeze(1)
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def make_pad_mask(lengths: torch.Tensor, max_len: int = 0) -> torch.Tensor:
|
| 14 |
+
"""
|
| 15 |
+
Args:
|
| 16 |
+
lengths:
|
| 17 |
+
A 1-D tensor containing sentence lengths.
|
| 18 |
+
max_len:
|
| 19 |
+
The length of masks.
|
| 20 |
+
Returns:
|
| 21 |
+
Return a 2-D bool tensor, where masked positions
|
| 22 |
+
are filled with `True` and non-masked positions are
|
| 23 |
+
filled with `False`.
|
| 24 |
+
|
| 25 |
+
#>>> lengths = torch.tensor([1, 3, 2, 5])
|
| 26 |
+
#>>> make_pad_mask(lengths)
|
| 27 |
+
tensor([[False, True, True, True, True],
|
| 28 |
+
[False, False, False, True, True],
|
| 29 |
+
[False, False, True, True, True],
|
| 30 |
+
[False, False, False, False, False]])
|
| 31 |
+
"""
|
| 32 |
+
assert lengths.ndim == 1, lengths.ndim
|
| 33 |
+
max_len = max(max_len, lengths.max())
|
| 34 |
+
n = lengths.size(0)
|
| 35 |
+
seq_range = torch.arange(0, max_len, device=lengths.device)
|
| 36 |
+
expaned_lengths = seq_range.unsqueeze(0).expand(n, max_len)
|
| 37 |
+
|
| 38 |
+
return expaned_lengths >= lengths.unsqueeze(-1)
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
# https://github.com/microsoft/unilm/blob/master/xtune/src/transformers/modeling_utils.py
|
| 42 |
+
def top_k_top_p_filtering(
|
| 43 |
+
logits, top_k=0, top_p=1.0, filter_value=-float("Inf"), min_tokens_to_keep=1
|
| 44 |
+
):
|
| 45 |
+
"""Filter a distribution of logits using top-k and/or nucleus (top-p) filtering
|
| 46 |
+
Args:
|
| 47 |
+
logits: logits distribution shape (batch size, vocabulary size)
|
| 48 |
+
if top_k > 0: keep only top k tokens with highest probability (top-k filtering).
|
| 49 |
+
if top_p < 1.0: keep the top tokens with cumulative probability >= top_p (nucleus filtering).
|
| 50 |
+
Nucleus filtering is described in Holtzman et al. (http://arxiv.org/abs/1904.09751)
|
| 51 |
+
Make sure we keep at least min_tokens_to_keep per batch example in the output
|
| 52 |
+
From: https://gist.github.com/thomwolf/1a5a29f6962089e871b94cbd09daf317
|
| 53 |
+
"""
|
| 54 |
+
if top_k > 0:
|
| 55 |
+
top_k = min(max(top_k, min_tokens_to_keep), logits.size(-1)) # Safety check
|
| 56 |
+
# Remove all tokens with a probability less than the last token of the top-k
|
| 57 |
+
indices_to_remove = logits < torch.topk(logits, top_k)[0][..., -1, None]
|
| 58 |
+
logits[indices_to_remove] = filter_value
|
| 59 |
+
|
| 60 |
+
if top_p < 1.0:
|
| 61 |
+
sorted_logits, sorted_indices = torch.sort(logits, descending=True)
|
| 62 |
+
cumulative_probs = torch.cumsum(F.softmax(sorted_logits, dim=-1), dim=-1)
|
| 63 |
+
|
| 64 |
+
# Remove tokens with cumulative probability above the threshold (token with 0 are kept)
|
| 65 |
+
sorted_indices_to_remove = cumulative_probs > top_p
|
| 66 |
+
if min_tokens_to_keep > 1:
|
| 67 |
+
# Keep at least min_tokens_to_keep (set to min_tokens_to_keep-1 because we add the first one below)
|
| 68 |
+
sorted_indices_to_remove[..., :min_tokens_to_keep] = 0
|
| 69 |
+
# Shift the indices to the right to keep also the first token above the threshold
|
| 70 |
+
sorted_indices_to_remove[..., 1:] = sorted_indices_to_remove[..., :-1].clone()
|
| 71 |
+
sorted_indices_to_remove[..., 0] = 0
|
| 72 |
+
|
| 73 |
+
# scatter sorted tensors to original indexing
|
| 74 |
+
indices_to_remove = sorted_indices_to_remove.scatter(
|
| 75 |
+
1, sorted_indices, sorted_indices_to_remove
|
| 76 |
+
)
|
| 77 |
+
logits[indices_to_remove] = filter_value
|
| 78 |
+
return logits
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
def topk_sampling(logits, top_k=10, top_p=1.0, temperature=1.0):
|
| 82 |
+
# temperature: (`optional`) float
|
| 83 |
+
# The value used to module the next token probabilities. Must be strictly positive. Default to 1.0.
|
| 84 |
+
# top_k: (`optional`) int
|
| 85 |
+
# The number of highest probability vocabulary tokens to keep for top-k-filtering. Between 1 and infinity. Default to 50.
|
| 86 |
+
# top_p: (`optional`) float
|
| 87 |
+
# The cumulative probability of parameter highest probability vocabulary tokens to keep for nucleus sampling. Must be between 0 and 1. Default to 1.
|
| 88 |
+
|
| 89 |
+
# Temperature (higher temperature => more likely to sample low probability tokens)
|
| 90 |
+
if temperature != 1.0:
|
| 91 |
+
logits = logits / temperature
|
| 92 |
+
# Top-p/top-k filtering
|
| 93 |
+
logits = top_k_top_p_filtering(logits, top_k=top_k, top_p=top_p)
|
| 94 |
+
# Sample
|
| 95 |
+
token = torch.multinomial(F.softmax(logits, dim=-1), num_samples=1)
|
| 96 |
+
return token
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
from typing import Optional, Tuple
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
def multinomial_sample_one_no_sync(
|
| 103 |
+
probs_sort,
|
| 104 |
+
): # Does multinomial sampling without a cuda synchronization
|
| 105 |
+
q = torch.empty_like(probs_sort).exponential_(1)
|
| 106 |
+
return torch.argmax(probs_sort / q, dim=-1, keepdim=True).to(dtype=torch.int)
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
def logits_to_probs(
|
| 110 |
+
logits,
|
| 111 |
+
previous_tokens: Optional[torch.Tensor] = None,
|
| 112 |
+
temperature: float = 1.0,
|
| 113 |
+
top_k: Optional[int] = None,
|
| 114 |
+
top_p: Optional[int] = None,
|
| 115 |
+
repetition_penalty: float = 1.0,
|
| 116 |
+
):
|
| 117 |
+
previous_tokens = previous_tokens.squeeze()
|
| 118 |
+
# print(logits.shape,previous_tokens.shape)
|
| 119 |
+
# pdb.set_trace()
|
| 120 |
+
if previous_tokens is not None and repetition_penalty != 1.0:
|
| 121 |
+
previous_tokens = previous_tokens.long()
|
| 122 |
+
score = torch.gather(logits, dim=0, index=previous_tokens)
|
| 123 |
+
score = torch.where(
|
| 124 |
+
score < 0, score * repetition_penalty, score / repetition_penalty
|
| 125 |
+
)
|
| 126 |
+
logits.scatter_(dim=0, index=previous_tokens, src=score)
|
| 127 |
+
|
| 128 |
+
if top_p is not None and top_p < 1.0:
|
| 129 |
+
sorted_logits, sorted_indices = torch.sort(logits, descending=True)
|
| 130 |
+
cum_probs = torch.cumsum(
|
| 131 |
+
torch.nn.functional.softmax(sorted_logits, dim=-1), dim=-1
|
| 132 |
+
)
|
| 133 |
+
sorted_indices_to_remove = cum_probs > top_p
|
| 134 |
+
sorted_indices_to_remove[0] = False # keep at least one option
|
| 135 |
+
indices_to_remove = sorted_indices_to_remove.scatter(
|
| 136 |
+
dim=0, index=sorted_indices, src=sorted_indices_to_remove
|
| 137 |
+
)
|
| 138 |
+
logits = logits.masked_fill(indices_to_remove, -float("Inf"))
|
| 139 |
+
|
| 140 |
+
logits = logits / max(temperature, 1e-5)
|
| 141 |
+
|
| 142 |
+
if top_k is not None:
|
| 143 |
+
v, _ = torch.topk(logits, min(top_k, logits.size(-1)))
|
| 144 |
+
pivot = v.select(-1, -1).unsqueeze(-1)
|
| 145 |
+
logits = torch.where(logits < pivot, -float("Inf"), logits)
|
| 146 |
+
|
| 147 |
+
probs = torch.nn.functional.softmax(logits, dim=-1)
|
| 148 |
+
return probs
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
def sample(
|
| 152 |
+
logits,
|
| 153 |
+
previous_tokens: Optional[torch.Tensor] = None,
|
| 154 |
+
**sampling_kwargs,
|
| 155 |
+
) -> Tuple[torch.Tensor, torch.Tensor]:
|
| 156 |
+
probs = logits_to_probs(
|
| 157 |
+
logits=logits, previous_tokens=previous_tokens, **sampling_kwargs
|
| 158 |
+
)
|
| 159 |
+
idx_next = multinomial_sample_one_no_sync(probs)
|
| 160 |
+
return idx_next, probs
|