Spaces:
Configuration error

Configuration error

Upload 53 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +1 -0
- README.md +26 -10
- asset/external_view.png +0 -0
- asset/external_view.pptx +3 -0
- makefile +14 -0
- neollm.code-workspace +63 -0
- neollm/__init__.py +5 -0
- neollm/exceptions.py +2 -0
- neollm/llm/__init__.py +4 -0
- neollm/llm/abstract_llm.py +188 -0
- neollm/llm/claude/abstract_claude.py +214 -0
- neollm/llm/claude/anthropic_llm.py +66 -0
- neollm/llm/claude/gcp_llm.py +67 -0
- neollm/llm/gemini/abstract_gemini.py +229 -0
- neollm/llm/gemini/gcp_llm.py +114 -0
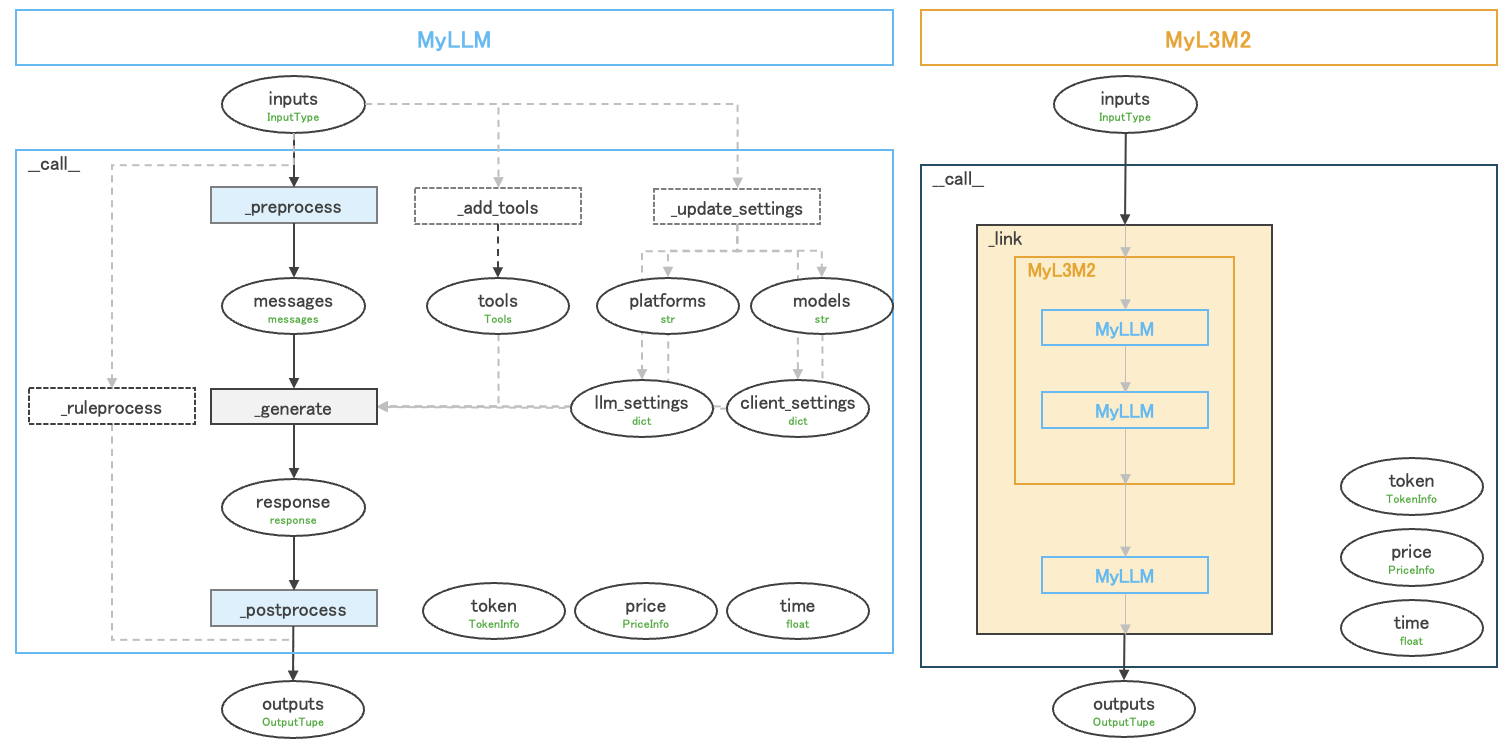
- neollm/llm/get_llm.py +47 -0
- neollm/llm/gpt/abstract_gpt.py +81 -0
- neollm/llm/gpt/azure_llm.py +215 -0
- neollm/llm/gpt/openai_llm.py +222 -0
- neollm/llm/gpt/token.py +247 -0
- neollm/llm/platform.py +16 -0
- neollm/llm/utils.py +72 -0
- neollm/myllm/abstract_myllm.py +148 -0
- neollm/myllm/myl3m2.py +165 -0
- neollm/myllm/myllm.py +449 -0
- neollm/myllm/print_utils.py +235 -0
- neollm/types/__init__.py +4 -0
- neollm/types/_model.py +8 -0
- neollm/types/info.py +82 -0
- neollm/types/mytypes.py +31 -0
- neollm/types/openai/__init__.py +2 -0
- neollm/types/openai/chat_completion.py +170 -0
- neollm/types/openai/chat_completion_chunk.py +109 -0
- neollm/utils/inference.py +70 -0
- neollm/utils/postprocess.py +120 -0
- neollm/utils/preprocess.py +107 -0
- neollm/utils/prompt_checker.py +110 -0
- neollm/utils/tokens.py +229 -0
- neollm/utils/utils.py +98 -0
- poetry.lock +0 -0
- project/.env.template +24 -0
- project/ex_module/ex_profile_extractor.py +113 -0
- project/ex_module/ex_translated_profile_extractor.py +49 -0
- project/ex_module/ex_translator.py +62 -0
- project/neollm-tutorial.ipynb +713 -0
- pyproject.toml +81 -0
- test/llm/claude/test_claude_llm.py +37 -0
- test/llm/gpt/test_azure_llm.py +92 -0
- test/llm/gpt/test_openai_llm.py +37 -0
- test/llm/platform.py +32 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
asset/external_view.pptx filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -1,10 +1,26 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# neoLLM Module
|
| 2 |
+
|
| 3 |
+
neoAIのLLMソリューションの基盤モジュール
|
| 4 |
+
[neoLLM Module Document](https://www.notion.so/neoLLM-Module-Document-64399d1d1db24d92bce8f9b88472833f)
|
| 5 |
+
|
| 6 |
+
## 準備
|
| 7 |
+
[neoLLM インストール方法](https://www.notion.so/c760d96f1b4240e6880a32bee96bba35)
|
| 8 |
+
1. install neoLLM Module ※ Python 3.10
|
| 9 |
+
```bash
|
| 10 |
+
$ pip install git+https://github.com/neoAI-inc/neo-llm-module.git@v1.x.x
|
| 11 |
+
```
|
| 12 |
+
|
| 13 |
+
2. APIキーの設定
|
| 14 |
+
`.env`ファイルの配置
|
| 15 |
+
- 環境変数を`.env`ファイルで定義し,実行するバスに配置
|
| 16 |
+
- `project/example_env.txt`を`.env`に名前を変えて, 必要事項を記入
|
| 17 |
+
|
| 18 |
+
## 使用方法
|
| 19 |
+
### 概要
|
| 20 |
+
灰色背景の部分を開発するだけでOK
|
| 21 |
+
- MyLLM: 1回のLLMへのリクエストをラップできる
|
| 22 |
+
- MyL3M2: 複数のLLMへのリクエストをラップできる
|
| 23 |
+
|
| 24 |
+
詳しくは、`project/neollm-tutorial.ipynb`, `project/ex_module`
|
| 25 |
+

|
| 26 |
+
|
asset/external_view.png
ADDED
|
asset/external_view.pptx
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7b3e9d7dbbb6f9ca5750edd9eaad8fe7ce5fcb5797e8027ae11dea90a0a47a2c
|
| 3 |
+
size 8728033
|
makefile
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.PHONY: lint
|
| 2 |
+
lint: ## run tests with poetry (isort, black, pflake8, mypy)
|
| 3 |
+
poetry run black neollm
|
| 4 |
+
poetry run isort neollm
|
| 5 |
+
poetry run pflake8 neollm
|
| 6 |
+
poetry run mypy neollm --explicit-package-bases
|
| 7 |
+
|
| 8 |
+
.PHONY: test
|
| 9 |
+
test:
|
| 10 |
+
poetry run pytest
|
| 11 |
+
|
| 12 |
+
.PHONY: unit-test
|
| 13 |
+
unit-test:
|
| 14 |
+
poetry run pytest -k "not test_neollm"
|
neollm.code-workspace
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"folders": [
|
| 3 |
+
{
|
| 4 |
+
"name": "neo-llm-module",
|
| 5 |
+
"path": "."
|
| 6 |
+
}
|
| 7 |
+
],
|
| 8 |
+
"settings": {
|
| 9 |
+
"editor.codeActionsOnSave": {
|
| 10 |
+
"source.fixAll.eslint": "explicit",
|
| 11 |
+
"source.fixAll.stylelint": "explicit"
|
| 12 |
+
},
|
| 13 |
+
"editor.formatOnSave": true,
|
| 14 |
+
"editor.formatOnPaste": true,
|
| 15 |
+
"editor.formatOnType": true,
|
| 16 |
+
"json.format.keepLines": true,
|
| 17 |
+
"[javascript]": {
|
| 18 |
+
"editor.defaultFormatter": "esbenp.prettier-vscode"
|
| 19 |
+
},
|
| 20 |
+
"[typescript]": {
|
| 21 |
+
"editor.defaultFormatter": "esbenp.prettier-vscode"
|
| 22 |
+
},
|
| 23 |
+
"[typescriptreact]": {
|
| 24 |
+
"editor.defaultFormatter": "esbenp.prettier-vscode"
|
| 25 |
+
},
|
| 26 |
+
"[css]": {
|
| 27 |
+
"editor.defaultFormatter": "esbenp.prettier-vscode"
|
| 28 |
+
},
|
| 29 |
+
"[json]": {
|
| 30 |
+
"editor.defaultFormatter": "vscode.json-language-features"
|
| 31 |
+
},
|
| 32 |
+
"search.exclude": {
|
| 33 |
+
"**/node_modules": true,
|
| 34 |
+
"static": true
|
| 35 |
+
},
|
| 36 |
+
"[python]": {
|
| 37 |
+
"editor.defaultFormatter": "ms-python.black-formatter",
|
| 38 |
+
"editor.codeActionsOnSave": {
|
| 39 |
+
"source.organizeImports": "explicit"
|
| 40 |
+
}
|
| 41 |
+
},
|
| 42 |
+
"flake8.args": [
|
| 43 |
+
"--max-line-length=119",
|
| 44 |
+
"--max-complexity=15",
|
| 45 |
+
"--ignore=E203,E501,E704,W503",
|
| 46 |
+
"--exclude=.venv,.git,__pycache__,.mypy_cache,.hg"
|
| 47 |
+
],
|
| 48 |
+
"isort.args": ["--settings-path=pyproject.toml"],
|
| 49 |
+
"black-formatter.args": ["--config=pyproject.toml"],
|
| 50 |
+
"mypy-type-checker.args": ["--config-file=pyproject.toml"],
|
| 51 |
+
"python.analysis.extraPaths": ["./backend"]
|
| 52 |
+
},
|
| 53 |
+
"extensions": {
|
| 54 |
+
"recommendations": [
|
| 55 |
+
"esbenp.prettier-vscode",
|
| 56 |
+
"dbaeumer.vscode-eslint",
|
| 57 |
+
"ms-python.flake8",
|
| 58 |
+
"ms-python.isort",
|
| 59 |
+
"ms-python.black-formatter",
|
| 60 |
+
"ms-python.mypy-type-checker"
|
| 61 |
+
]
|
| 62 |
+
}
|
| 63 |
+
}
|
neollm/__init__.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from neollm.myllm.abstract_myllm import AbstractMyLLM
|
| 2 |
+
from neollm.myllm.myl3m2 import MyL3M2
|
| 3 |
+
from neollm.myllm.myllm import MyLLM
|
| 4 |
+
|
| 5 |
+
__all__ = ["AbstractMyLLM", "MyLLM", "MyL3M2"]
|
neollm/exceptions.py
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
class ContentFilterError(Exception):
|
| 2 |
+
pass
|
neollm/llm/__init__.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from neollm.llm.abstract_llm import AbstractLLM
|
| 2 |
+
from neollm.llm.get_llm import get_llm
|
| 3 |
+
|
| 4 |
+
__all__ = ["AbstractLLM", "get_llm"]
|
neollm/llm/abstract_llm.py
ADDED
|
@@ -0,0 +1,188 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from abc import ABC, abstractmethod
|
| 2 |
+
from typing import Any
|
| 3 |
+
|
| 4 |
+
from neollm.llm.utils import get_entity
|
| 5 |
+
from neollm.types import (
|
| 6 |
+
APIPricing,
|
| 7 |
+
ChatCompletion,
|
| 8 |
+
ChatCompletionMessage,
|
| 9 |
+
ChatCompletionMessageToolCall,
|
| 10 |
+
Choice,
|
| 11 |
+
ChoiceDeltaToolCall,
|
| 12 |
+
Chunk,
|
| 13 |
+
ClientSettings,
|
| 14 |
+
CompletionUsage,
|
| 15 |
+
Function,
|
| 16 |
+
FunctionCall,
|
| 17 |
+
LLMSettings,
|
| 18 |
+
Messages,
|
| 19 |
+
Response,
|
| 20 |
+
StreamResponse,
|
| 21 |
+
)
|
| 22 |
+
from neollm.utils.utils import cprint
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
# 現状、Azure, OpenAIに対応
|
| 26 |
+
class AbstractLLM(ABC):
|
| 27 |
+
dollar_per_ktoken: APIPricing
|
| 28 |
+
model: str
|
| 29 |
+
context_window: int
|
| 30 |
+
_custom_price_calculation: bool = False # self.tokenではなく、self.custom_tokenを使う場合にTrue
|
| 31 |
+
|
| 32 |
+
def __init__(self, client_settings: ClientSettings):
|
| 33 |
+
"""LLMクラスの初期化
|
| 34 |
+
|
| 35 |
+
Args:
|
| 36 |
+
client_settings (ClientSettings): クライアント設定
|
| 37 |
+
"""
|
| 38 |
+
self.client_settings = client_settings
|
| 39 |
+
|
| 40 |
+
def calculate_price(self, num_input_tokens: int = 0, num_output_tokens: int = 0) -> float:
|
| 41 |
+
"""
|
| 42 |
+
費用の計測
|
| 43 |
+
|
| 44 |
+
Args:
|
| 45 |
+
num_input_tokens (int, optional): 入力のトークン数. Defaults to 0.
|
| 46 |
+
num_output_tokens (int, optional): 出力のトークン数. Defaults to 0.
|
| 47 |
+
|
| 48 |
+
Returns:
|
| 49 |
+
float: API利用料(USD)
|
| 50 |
+
"""
|
| 51 |
+
price = (
|
| 52 |
+
self.dollar_per_ktoken.input * num_input_tokens + self.dollar_per_ktoken.output * num_output_tokens
|
| 53 |
+
) / 1000
|
| 54 |
+
return price
|
| 55 |
+
|
| 56 |
+
@abstractmethod
|
| 57 |
+
def count_tokens(self, messages: Messages | None = None, only_response: bool = False) -> int: ...
|
| 58 |
+
|
| 59 |
+
@abstractmethod
|
| 60 |
+
def encode(self, text: str) -> list[int]: ...
|
| 61 |
+
|
| 62 |
+
@abstractmethod
|
| 63 |
+
def decode(self, encoded: list[int]) -> str: ...
|
| 64 |
+
|
| 65 |
+
@abstractmethod
|
| 66 |
+
def generate(self, messages: Messages, llm_settings: LLMSettings) -> Response:
|
| 67 |
+
"""生成
|
| 68 |
+
|
| 69 |
+
Args:
|
| 70 |
+
messages (Messages): OpenAI仕様のMessages(list[dict])
|
| 71 |
+
|
| 72 |
+
Returns:
|
| 73 |
+
Response: OpenAI likeなResponse
|
| 74 |
+
"""
|
| 75 |
+
|
| 76 |
+
@abstractmethod
|
| 77 |
+
def generate_stream(self, messages: Messages, llm_settings: LLMSettings) -> StreamResponse: ...
|
| 78 |
+
|
| 79 |
+
def __repr__(self) -> str:
|
| 80 |
+
return f"{self.__class__}()"
|
| 81 |
+
|
| 82 |
+
def convert_nonstream_response(
|
| 83 |
+
self, chunk_list: list[Chunk], messages: Messages, functions: Any = None
|
| 84 |
+
) -> Response:
|
| 85 |
+
# messagesとfunctionsはトークン数計測に必要
|
| 86 |
+
_chunk_choices = [chunk.choices[0] for chunk in chunk_list if len(chunk.choices) > 0]
|
| 87 |
+
# TODO: n=2以上の場合にwarningを出したい
|
| 88 |
+
|
| 89 |
+
# FunctionCall --------------------------------------------------
|
| 90 |
+
function_call: FunctionCall | None
|
| 91 |
+
if all([_c.delta.function_call is None for _c in _chunk_choices]):
|
| 92 |
+
function_call = None
|
| 93 |
+
else:
|
| 94 |
+
function_call = FunctionCall(
|
| 95 |
+
arguments="".join(
|
| 96 |
+
[
|
| 97 |
+
_c.delta.function_call.arguments
|
| 98 |
+
for _c in _chunk_choices
|
| 99 |
+
if _c.delta.function_call is not None and _c.delta.function_call.arguments is not None
|
| 100 |
+
]
|
| 101 |
+
),
|
| 102 |
+
name=get_entity(
|
| 103 |
+
[_c.delta.function_call.name for _c in _chunk_choices if _c.delta.function_call is not None],
|
| 104 |
+
default="",
|
| 105 |
+
),
|
| 106 |
+
)
|
| 107 |
+
|
| 108 |
+
# ToolCalls --------------------------------------------------
|
| 109 |
+
_tool_calls_dict: dict[int, list[ChoiceDeltaToolCall]] = {} # key=index
|
| 110 |
+
for _chunk in _chunk_choices:
|
| 111 |
+
if _chunk.delta.tool_calls is None:
|
| 112 |
+
continue
|
| 113 |
+
for _tool_call in _chunk.delta.tool_calls:
|
| 114 |
+
_tool_calls_dict.setdefault(_tool_call.index, []).append(_tool_call)
|
| 115 |
+
|
| 116 |
+
tool_calls: list[ChatCompletionMessageToolCall] | None
|
| 117 |
+
if sum(len(_tool_calls) for _tool_calls in _tool_calls_dict.values()) == 0:
|
| 118 |
+
tool_calls = None
|
| 119 |
+
else:
|
| 120 |
+
tool_calls = []
|
| 121 |
+
for _tool_calls in _tool_calls_dict.values():
|
| 122 |
+
tool_calls.append(
|
| 123 |
+
ChatCompletionMessageToolCall(
|
| 124 |
+
id=get_entity([_tc.id for _tc in _tool_calls], default=""),
|
| 125 |
+
function=Function(
|
| 126 |
+
arguments="".join(
|
| 127 |
+
[
|
| 128 |
+
_tc.function.arguments
|
| 129 |
+
for _tc in _tool_calls
|
| 130 |
+
if _tc.function is not None and _tc.function.arguments is not None
|
| 131 |
+
]
|
| 132 |
+
),
|
| 133 |
+
name=get_entity(
|
| 134 |
+
[_tc.function.name for _tc in _tool_calls if _tc.function is not None], default=""
|
| 135 |
+
),
|
| 136 |
+
),
|
| 137 |
+
type=get_entity([_tc.type for _tc in _tool_calls], default="function"),
|
| 138 |
+
)
|
| 139 |
+
)
|
| 140 |
+
message = ChatCompletionMessage(
|
| 141 |
+
content="".join([_c.delta.content for _c in _chunk_choices if _c.delta.content is not None]),
|
| 142 |
+
# TODO: ChoiceDeltaのroleなんで、assistant以外も許されてるの?
|
| 143 |
+
role=get_entity([_c.delta.role for _c in _chunk_choices], default="assistant"), # type: ignore
|
| 144 |
+
function_call=function_call,
|
| 145 |
+
tool_calls=tool_calls,
|
| 146 |
+
)
|
| 147 |
+
choice = Choice(
|
| 148 |
+
index=get_entity([_c.index for _c in _chunk_choices], default=0),
|
| 149 |
+
message=message,
|
| 150 |
+
finish_reason=get_entity([_c.finish_reason for _c in _chunk_choices], default=None),
|
| 151 |
+
)
|
| 152 |
+
|
| 153 |
+
# Usage --------------------------------------------------
|
| 154 |
+
try:
|
| 155 |
+
for chunk in chunk_list:
|
| 156 |
+
if getattr(chunk, "tokens"):
|
| 157 |
+
prompt_tokens = int(getattr(chunk, "tokens")["input_tokens"])
|
| 158 |
+
completion_tokens = int(getattr(chunk, "tokens")["output_tokens"])
|
| 159 |
+
assert prompt_tokens
|
| 160 |
+
assert completion_tokens
|
| 161 |
+
except Exception:
|
| 162 |
+
prompt_tokens = self.count_tokens(messages) # TODO: fcなど
|
| 163 |
+
completion_tokens = self.count_tokens([message.to_typeddict_message()], only_response=True)
|
| 164 |
+
usages = CompletionUsage(
|
| 165 |
+
completion_tokens=completion_tokens,
|
| 166 |
+
prompt_tokens=prompt_tokens,
|
| 167 |
+
total_tokens=prompt_tokens + completion_tokens,
|
| 168 |
+
)
|
| 169 |
+
|
| 170 |
+
# ChatCompletion ------------------------------------------
|
| 171 |
+
response = ChatCompletion(
|
| 172 |
+
id=get_entity([chunk.id for chunk in chunk_list], default=""),
|
| 173 |
+
object="chat.completion",
|
| 174 |
+
created=get_entity([getattr(chunk, "created", 0) for chunk in chunk_list], default=0),
|
| 175 |
+
model=get_entity([getattr(chunk, "model", "") for chunk in chunk_list], default=""),
|
| 176 |
+
choices=[choice],
|
| 177 |
+
system_fingerprint=get_entity(
|
| 178 |
+
[getattr(chunk, "system_fingerprint", None) for chunk in chunk_list], default=None
|
| 179 |
+
),
|
| 180 |
+
usage=usages,
|
| 181 |
+
)
|
| 182 |
+
|
| 183 |
+
return response
|
| 184 |
+
|
| 185 |
+
@property
|
| 186 |
+
def max_tokens(self) -> int:
|
| 187 |
+
cprint("max_tokensは非推奨です。context_windowを使用してください。")
|
| 188 |
+
return self.context_window
|
neollm/llm/claude/abstract_claude.py
ADDED
|
@@ -0,0 +1,214 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import time
|
| 2 |
+
from abc import abstractmethod
|
| 3 |
+
from typing import Any, Literal, cast
|
| 4 |
+
|
| 5 |
+
from anthropic import Anthropic, AnthropicBedrock, AnthropicVertex, Stream
|
| 6 |
+
from anthropic.types import MessageParam as AnthropicMessageParam
|
| 7 |
+
from anthropic.types import MessageStreamEvent as AnthropicMessageStreamEvent
|
| 8 |
+
from anthropic.types.message import Message as AnthropicMessage
|
| 9 |
+
|
| 10 |
+
from neollm.llm.abstract_llm import AbstractLLM
|
| 11 |
+
from neollm.types import (
|
| 12 |
+
ChatCompletion,
|
| 13 |
+
LLMSettings,
|
| 14 |
+
Message,
|
| 15 |
+
Messages,
|
| 16 |
+
Response,
|
| 17 |
+
StreamResponse,
|
| 18 |
+
)
|
| 19 |
+
from neollm.types.openai.chat_completion import (
|
| 20 |
+
ChatCompletionMessage,
|
| 21 |
+
Choice,
|
| 22 |
+
CompletionUsage,
|
| 23 |
+
FinishReason,
|
| 24 |
+
)
|
| 25 |
+
from neollm.types.openai.chat_completion_chunk import (
|
| 26 |
+
ChatCompletionChunk,
|
| 27 |
+
ChoiceDelta,
|
| 28 |
+
ChunkChoice,
|
| 29 |
+
)
|
| 30 |
+
from neollm.utils.utils import cprint
|
| 31 |
+
|
| 32 |
+
DEFAULT_MAX_TOKENS = 4_096
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
class AbstractClaude(AbstractLLM):
|
| 36 |
+
@property
|
| 37 |
+
@abstractmethod
|
| 38 |
+
def client(self) -> Anthropic | AnthropicVertex | AnthropicBedrock: ...
|
| 39 |
+
|
| 40 |
+
@property
|
| 41 |
+
def _client_for_token(self) -> Anthropic:
|
| 42 |
+
"""トークンカウント用のAnthropicクライアント取得
|
| 43 |
+
(AnthropicBedrock, AnthropicVertexがmethodを持っていないため)
|
| 44 |
+
|
| 45 |
+
Returns:
|
| 46 |
+
Anthropic: Anthropicクライアント
|
| 47 |
+
"""
|
| 48 |
+
return Anthropic()
|
| 49 |
+
|
| 50 |
+
def encode(self, text: str) -> list[int]:
|
| 51 |
+
tokenizer = self._client_for_token.get_tokenizer()
|
| 52 |
+
encoded = cast(list[int], tokenizer.encode(text).ids)
|
| 53 |
+
return encoded
|
| 54 |
+
|
| 55 |
+
def decode(self, decoded: list[int]) -> str:
|
| 56 |
+
tokenizer = self._client_for_token.get_tokenizer()
|
| 57 |
+
text = cast(str, tokenizer.decode(decoded))
|
| 58 |
+
return text
|
| 59 |
+
|
| 60 |
+
def count_tokens(self, messages: list[Message] | None = None, only_response: bool = False) -> int:
|
| 61 |
+
"""
|
| 62 |
+
トークン数の計測
|
| 63 |
+
|
| 64 |
+
Args:
|
| 65 |
+
messages (Messages): messages
|
| 66 |
+
|
| 67 |
+
Returns:
|
| 68 |
+
int: トークン数
|
| 69 |
+
"""
|
| 70 |
+
if messages is None:
|
| 71 |
+
return 0
|
| 72 |
+
tokens = 0
|
| 73 |
+
for message in messages:
|
| 74 |
+
content = message["content"]
|
| 75 |
+
if isinstance(content, str):
|
| 76 |
+
tokens += self._client_for_token.count_tokens(content)
|
| 77 |
+
continue
|
| 78 |
+
if isinstance(content, list):
|
| 79 |
+
for content_i in content:
|
| 80 |
+
if content_i["type"] == "text":
|
| 81 |
+
tokens += self._client_for_token.count_tokens(content_i["text"])
|
| 82 |
+
continue
|
| 83 |
+
return tokens
|
| 84 |
+
|
| 85 |
+
def _convert_finish_reason(
|
| 86 |
+
self, stop_reason: Literal["end_turn", "max_tokens", "stop_sequence"] | None
|
| 87 |
+
) -> FinishReason | None:
|
| 88 |
+
if stop_reason == "max_tokens":
|
| 89 |
+
return "length"
|
| 90 |
+
if stop_reason == "stop_sequence":
|
| 91 |
+
return "stop"
|
| 92 |
+
return None
|
| 93 |
+
|
| 94 |
+
def _convert_to_response(self, platform_response: AnthropicMessage) -> Response:
|
| 95 |
+
return ChatCompletion(
|
| 96 |
+
id=platform_response.id,
|
| 97 |
+
choices=[
|
| 98 |
+
Choice(
|
| 99 |
+
index=0,
|
| 100 |
+
message=ChatCompletionMessage(
|
| 101 |
+
content=platform_response.content[0].text if len(platform_response.content) > 0 else "",
|
| 102 |
+
role="assistant",
|
| 103 |
+
),
|
| 104 |
+
finish_reason=self._convert_finish_reason(platform_response.stop_reason),
|
| 105 |
+
)
|
| 106 |
+
],
|
| 107 |
+
created=int(time.time()),
|
| 108 |
+
model=self.model,
|
| 109 |
+
object="messages.create",
|
| 110 |
+
system_fingerprint=None,
|
| 111 |
+
usage=CompletionUsage(
|
| 112 |
+
prompt_tokens=platform_response.usage.input_tokens,
|
| 113 |
+
completion_tokens=platform_response.usage.output_tokens,
|
| 114 |
+
total_tokens=platform_response.usage.input_tokens + platform_response.usage.output_tokens,
|
| 115 |
+
),
|
| 116 |
+
)
|
| 117 |
+
|
| 118 |
+
def _convert_to_platform_messages(self, messages: Messages) -> tuple[str, list[AnthropicMessageParam]]:
|
| 119 |
+
_system = ""
|
| 120 |
+
_message: list[AnthropicMessageParam] = []
|
| 121 |
+
for message in messages:
|
| 122 |
+
if message["role"] == "system":
|
| 123 |
+
_system += "\n" + message["content"]
|
| 124 |
+
elif message["role"] == "user":
|
| 125 |
+
if isinstance(message["content"], str):
|
| 126 |
+
_message.append({"role": "user", "content": message["content"]})
|
| 127 |
+
else:
|
| 128 |
+
cprint("WARNING: 未対応です", color="yellow", background=True)
|
| 129 |
+
elif message["role"] == "assistant":
|
| 130 |
+
if isinstance(message["content"], str):
|
| 131 |
+
_message.append({"role": "assistant", "content": message["content"]})
|
| 132 |
+
else:
|
| 133 |
+
cprint("WARNING: 未対応です", color="yellow", background=True)
|
| 134 |
+
else:
|
| 135 |
+
cprint("WARNING: 未対応です", color="yellow", background=True)
|
| 136 |
+
return _system, _message
|
| 137 |
+
|
| 138 |
+
def _convert_to_streamresponse(
|
| 139 |
+
self, platform_streamresponse: Stream[AnthropicMessageStreamEvent]
|
| 140 |
+
) -> StreamResponse:
|
| 141 |
+
created = int(time.time())
|
| 142 |
+
model = ""
|
| 143 |
+
id_ = ""
|
| 144 |
+
content: str | None = None
|
| 145 |
+
for chunk in platform_streamresponse:
|
| 146 |
+
input_tokens = 0
|
| 147 |
+
output_tokens = 0
|
| 148 |
+
if chunk.type == "message_stop" or chunk.type == "content_block_stop":
|
| 149 |
+
continue
|
| 150 |
+
if chunk.type == "message_start":
|
| 151 |
+
model = model or chunk.message.model
|
| 152 |
+
id_ = id_ or chunk.message.id
|
| 153 |
+
input_tokens = chunk.message.usage.input_tokens
|
| 154 |
+
output_tokens = chunk.message.usage.output_tokens
|
| 155 |
+
content = "".join([content_block.text for content_block in chunk.message.content])
|
| 156 |
+
finish_reason = self._convert_finish_reason(chunk.message.stop_reason)
|
| 157 |
+
elif chunk.type == "message_delta":
|
| 158 |
+
content = ""
|
| 159 |
+
finish_reason = self._convert_finish_reason(chunk.delta.stop_reason)
|
| 160 |
+
output_tokens = chunk.usage.output_tokens
|
| 161 |
+
elif chunk.type == "content_block_start":
|
| 162 |
+
content = chunk.content_block.text
|
| 163 |
+
finish_reason = None
|
| 164 |
+
elif chunk.type == "content_block_delta":
|
| 165 |
+
content = chunk.delta.text
|
| 166 |
+
finish_reason = None
|
| 167 |
+
yield ChatCompletionChunk(
|
| 168 |
+
id=id_,
|
| 169 |
+
choices=[
|
| 170 |
+
ChunkChoice(
|
| 171 |
+
delta=ChoiceDelta(
|
| 172 |
+
content=content,
|
| 173 |
+
role="assistant",
|
| 174 |
+
),
|
| 175 |
+
finish_reason=finish_reason,
|
| 176 |
+
index=0, # 0-indexedじゃないかもしれないので0に塗り替え
|
| 177 |
+
)
|
| 178 |
+
],
|
| 179 |
+
created=created,
|
| 180 |
+
model=model,
|
| 181 |
+
object="chat.completion.chunk",
|
| 182 |
+
tokens={"input_tokens": input_tokens, "output_tokens": output_tokens}, # type: ignore
|
| 183 |
+
)
|
| 184 |
+
|
| 185 |
+
def generate(self, messages: Messages, llm_settings: LLMSettings) -> Response:
|
| 186 |
+
_system, _message = self._convert_to_platform_messages(messages)
|
| 187 |
+
llm_settings = self._set_max_tokens(llm_settings)
|
| 188 |
+
response = self.client.messages.create(
|
| 189 |
+
model=self.model,
|
| 190 |
+
system=_system,
|
| 191 |
+
messages=_message,
|
| 192 |
+
stream=False,
|
| 193 |
+
**llm_settings,
|
| 194 |
+
)
|
| 195 |
+
return self._convert_to_response(platform_response=response)
|
| 196 |
+
|
| 197 |
+
def generate_stream(self, messages: Any, llm_settings: LLMSettings) -> StreamResponse:
|
| 198 |
+
_system, _message = self._convert_to_platform_messages(messages)
|
| 199 |
+
llm_settings = self._set_max_tokens(llm_settings)
|
| 200 |
+
response = self.client.messages.create(
|
| 201 |
+
model=self.model,
|
| 202 |
+
system=_system,
|
| 203 |
+
messages=_message,
|
| 204 |
+
stream=True,
|
| 205 |
+
**llm_settings,
|
| 206 |
+
)
|
| 207 |
+
return self._convert_to_streamresponse(platform_streamresponse=response)
|
| 208 |
+
|
| 209 |
+
def _set_max_tokens(self, llm_settings: LLMSettings) -> LLMSettings:
|
| 210 |
+
# claudeはmax_tokensが必須
|
| 211 |
+
if not llm_settings.get("max_tokens"):
|
| 212 |
+
cprint(f"max_tokens is not set. Set to {DEFAULT_MAX_TOKENS}.", color="yellow")
|
| 213 |
+
llm_settings["max_tokens"] = DEFAULT_MAX_TOKENS
|
| 214 |
+
return llm_settings
|
neollm/llm/claude/anthropic_llm.py
ADDED
|
@@ -0,0 +1,66 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Literal, cast, get_args
|
| 2 |
+
|
| 3 |
+
from anthropic import Anthropic
|
| 4 |
+
|
| 5 |
+
from neollm.llm.abstract_llm import AbstractLLM
|
| 6 |
+
from neollm.llm.claude.abstract_claude import AbstractClaude
|
| 7 |
+
from neollm.types import APIPricing, ClientSettings
|
| 8 |
+
from neollm.utils.utils import cprint
|
| 9 |
+
|
| 10 |
+
# price: https://www.anthropic.com/api
|
| 11 |
+
# models: https://docs.anthropic.com/claude/docs/models-overview
|
| 12 |
+
|
| 13 |
+
SUPPORTED_MODELS = Literal[
|
| 14 |
+
"claude-3-opus-20240229",
|
| 15 |
+
"claude-3-sonnet-20240229",
|
| 16 |
+
"claude-3-haiku-20240307",
|
| 17 |
+
]
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def get_anthoropic_llm(model_name: SUPPORTED_MODELS | str, client_settings: ClientSettings) -> AbstractLLM:
|
| 21 |
+
# Add 日付
|
| 22 |
+
replace_map_for_nodate: dict[str, SUPPORTED_MODELS] = {
|
| 23 |
+
"claude-3-opus": "claude-3-opus-20240229",
|
| 24 |
+
"claude-3-sonnet": "claude-3-sonnet-20240229",
|
| 25 |
+
"claude-3-haiku": "claude-3-haiku-20240307",
|
| 26 |
+
}
|
| 27 |
+
if model_name in replace_map_for_nodate:
|
| 28 |
+
cprint("WARNING: model_nameに日付を指定してください", color="yellow", background=True)
|
| 29 |
+
print(f"model_name: {model_name} -> {replace_map_for_nodate[model_name]}")
|
| 30 |
+
model_name = replace_map_for_nodate[model_name]
|
| 31 |
+
|
| 32 |
+
# map to LLM
|
| 33 |
+
supported_model_map: dict[SUPPORTED_MODELS, AbstractLLM] = {
|
| 34 |
+
"claude-3-opus-20240229": AnthropicClaude3Opus20240229(client_settings),
|
| 35 |
+
"claude-3-sonnet-20240229": AnthropicClaude3Sonnet20240229(client_settings),
|
| 36 |
+
"claude-3-haiku-20240307": AnthropicClaude3Haiku20240229(client_settings),
|
| 37 |
+
}
|
| 38 |
+
if model_name in supported_model_map:
|
| 39 |
+
model_name = cast(SUPPORTED_MODELS, model_name)
|
| 40 |
+
return supported_model_map[model_name]
|
| 41 |
+
raise ValueError(f"model_name must be {get_args(SUPPORTED_MODELS)}, but got {model_name}.")
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
class AnthoropicLLM(AbstractClaude):
|
| 45 |
+
@property
|
| 46 |
+
def client(self) -> Anthropic:
|
| 47 |
+
client = Anthropic(**self.client_settings)
|
| 48 |
+
return client
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
class AnthropicClaude3Opus20240229(AnthoropicLLM):
|
| 52 |
+
dollar_per_ktoken = APIPricing(input=15 / 1000, output=75 / 1000)
|
| 53 |
+
model: str = "claude-3-opus-20240229"
|
| 54 |
+
context_window: int = 200_000
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
class AnthropicClaude3Sonnet20240229(AnthoropicLLM):
|
| 58 |
+
dollar_per_ktoken = APIPricing(input=3 / 1000, output=15 / 1000)
|
| 59 |
+
model: str = "claude-3-sonnet-20240229"
|
| 60 |
+
context_window: int = 200_000
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
class AnthropicClaude3Haiku20240229(AnthoropicLLM):
|
| 64 |
+
dollar_per_ktoken = APIPricing(input=0.25 / 1000, output=1.25 / 1000)
|
| 65 |
+
model: str = "claude-3-haiku-20240307"
|
| 66 |
+
context_window: int = 200_000
|
neollm/llm/claude/gcp_llm.py
ADDED
|
@@ -0,0 +1,67 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Literal, cast, get_args
|
| 2 |
+
|
| 3 |
+
from anthropic import AnthropicVertex
|
| 4 |
+
|
| 5 |
+
from neollm.llm.abstract_llm import AbstractLLM
|
| 6 |
+
from neollm.llm.claude.abstract_claude import AbstractClaude
|
| 7 |
+
from neollm.types import APIPricing, ClientSettings
|
| 8 |
+
from neollm.utils.utils import cprint
|
| 9 |
+
|
| 10 |
+
# price: https://www.anthropic.com/api
|
| 11 |
+
# models: https://docs.anthropic.com/claude/docs/models-overview
|
| 12 |
+
|
| 13 |
+
SUPPORTED_MODELS = Literal[
|
| 14 |
+
"claude-3-opus@20240229",
|
| 15 |
+
"claude-3-sonnet@20240229",
|
| 16 |
+
"claude-3-haiku@20240307",
|
| 17 |
+
]
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
# TODO! google 動かしたいね
|
| 21 |
+
def get_gcp_llm(model_name: SUPPORTED_MODELS | str, client_settings: ClientSettings) -> AbstractLLM:
|
| 22 |
+
# Add 日付
|
| 23 |
+
replace_map_for_nodate: dict[str, SUPPORTED_MODELS] = {
|
| 24 |
+
"claude-3-opus": "claude-3-opus@20240229",
|
| 25 |
+
"claude-3-sonnet": "claude-3-sonnet@20240229",
|
| 26 |
+
"claude-3-haiku": "claude-3-haiku@20240307",
|
| 27 |
+
}
|
| 28 |
+
if model_name in replace_map_for_nodate:
|
| 29 |
+
cprint("WARNING: model_nameに日付を指定してください", color="yellow", background=True)
|
| 30 |
+
print(f"model_name: {model_name} -> {replace_map_for_nodate[model_name]}")
|
| 31 |
+
model_name = replace_map_for_nodate[model_name]
|
| 32 |
+
|
| 33 |
+
# map to LLM
|
| 34 |
+
supported_model_map: dict[SUPPORTED_MODELS, AbstractLLM] = {
|
| 35 |
+
"claude-3-opus@20240229": GCPClaude3Opus20240229(client_settings),
|
| 36 |
+
"claude-3-sonnet@20240229": GCPClaude3Sonnet20240229(client_settings),
|
| 37 |
+
"claude-3-haiku@20240307": GCPClaude3Haiku20240229(client_settings),
|
| 38 |
+
}
|
| 39 |
+
if model_name in supported_model_map:
|
| 40 |
+
model_name = cast(SUPPORTED_MODELS, model_name)
|
| 41 |
+
return supported_model_map[model_name]
|
| 42 |
+
raise ValueError(f"model_name must be {get_args(SUPPORTED_MODELS)}, but got {model_name}.")
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
class GoogleLLM(AbstractClaude):
|
| 46 |
+
@property
|
| 47 |
+
def client(self) -> AnthropicVertex:
|
| 48 |
+
client = AnthropicVertex(**self.client_settings)
|
| 49 |
+
return client
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
class GCPClaude3Opus20240229(GoogleLLM):
|
| 53 |
+
dollar_per_ktoken = APIPricing(input=15 / 1000, output=75 / 1000)
|
| 54 |
+
model: str = "claude-3-opus@20240229"
|
| 55 |
+
context_window: int = 200_000
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
class GCPClaude3Sonnet20240229(GoogleLLM):
|
| 59 |
+
dollar_per_ktoken = APIPricing(input=3 / 1000, output=15 / 1000)
|
| 60 |
+
model: str = "claude-3-sonnet@20240229"
|
| 61 |
+
context_window: int = 200_000
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
class GCPClaude3Haiku20240229(GoogleLLM):
|
| 65 |
+
dollar_per_ktoken = APIPricing(input=0.25 / 1000, output=1.25 / 1000)
|
| 66 |
+
model: str = "claude-3-haiku@20240307"
|
| 67 |
+
context_window: int = 200_000
|
neollm/llm/gemini/abstract_gemini.py
ADDED
|
@@ -0,0 +1,229 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import time
|
| 2 |
+
from abc import abstractmethod
|
| 3 |
+
from typing import Iterable, cast
|
| 4 |
+
|
| 5 |
+
from google.cloud.aiplatform_v1beta1.types import CountTokensResponse
|
| 6 |
+
from google.cloud.aiplatform_v1beta1.types.content import Candidate
|
| 7 |
+
from vertexai.generative_models import (
|
| 8 |
+
Content,
|
| 9 |
+
GenerationConfig,
|
| 10 |
+
GenerationResponse,
|
| 11 |
+
GenerativeModel,
|
| 12 |
+
Part,
|
| 13 |
+
)
|
| 14 |
+
from vertexai.generative_models._generative_models import ContentsType
|
| 15 |
+
|
| 16 |
+
from neollm.llm.abstract_llm import AbstractLLM
|
| 17 |
+
from neollm.types import (
|
| 18 |
+
ChatCompletion,
|
| 19 |
+
CompletionUsageForCustomPriceCalculation,
|
| 20 |
+
LLMSettings,
|
| 21 |
+
Message,
|
| 22 |
+
Messages,
|
| 23 |
+
Response,
|
| 24 |
+
StreamResponse,
|
| 25 |
+
)
|
| 26 |
+
from neollm.types.openai.chat_completion import (
|
| 27 |
+
ChatCompletionMessage,
|
| 28 |
+
Choice,
|
| 29 |
+
CompletionUsage,
|
| 30 |
+
)
|
| 31 |
+
from neollm.types.openai.chat_completion import FinishReason as FinishReasonVertex
|
| 32 |
+
from neollm.types.openai.chat_completion_chunk import (
|
| 33 |
+
ChatCompletionChunk,
|
| 34 |
+
ChoiceDelta,
|
| 35 |
+
ChunkChoice,
|
| 36 |
+
)
|
| 37 |
+
from neollm.utils.utils import cprint
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
class AbstractGemini(AbstractLLM):
|
| 41 |
+
|
| 42 |
+
@abstractmethod
|
| 43 |
+
def generate_config(self, llm_settings: LLMSettings) -> GenerationConfig: ...
|
| 44 |
+
|
| 45 |
+
# 使っていない
|
| 46 |
+
def encode(self, text: str) -> list[int]:
|
| 47 |
+
return [ord(char) for char in text]
|
| 48 |
+
|
| 49 |
+
# 使っていない
|
| 50 |
+
def decode(self, decoded: list[int]) -> str:
|
| 51 |
+
return "".join([chr(number) for number in decoded])
|
| 52 |
+
|
| 53 |
+
def _count_tokens_vertex(self, contents: ContentsType) -> CountTokensResponse:
|
| 54 |
+
model = GenerativeModel(model_name=self.model)
|
| 55 |
+
return cast(CountTokensResponse, model.count_tokens(contents))
|
| 56 |
+
|
| 57 |
+
def count_tokens(self, messages: list[Message] | None = None, only_response: bool = False) -> int:
|
| 58 |
+
"""
|
| 59 |
+
トークン数の計測
|
| 60 |
+
|
| 61 |
+
Args:
|
| 62 |
+
messages (Messages): messages
|
| 63 |
+
|
| 64 |
+
Returns:
|
| 65 |
+
int: トークン数
|
| 66 |
+
"""
|
| 67 |
+
if messages is None:
|
| 68 |
+
return 0
|
| 69 |
+
_system, _message = self._convert_to_platform_messages(messages)
|
| 70 |
+
total_tokens = 0
|
| 71 |
+
if _system:
|
| 72 |
+
total_tokens += int(self._count_tokens_vertex(_system).total_tokens)
|
| 73 |
+
if _message:
|
| 74 |
+
total_tokens = int(self._count_tokens_vertex(_message).total_tokens)
|
| 75 |
+
return total_tokens
|
| 76 |
+
|
| 77 |
+
def _convert_to_platform_messages(self, messages: Messages) -> tuple[str | None, list[Content]]:
|
| 78 |
+
_system = None
|
| 79 |
+
_message: list[Content] = []
|
| 80 |
+
|
| 81 |
+
for message in messages:
|
| 82 |
+
if message["role"] == "system":
|
| 83 |
+
_system = "\n" + message["content"]
|
| 84 |
+
elif message["role"] == "user":
|
| 85 |
+
if isinstance(message["content"], str):
|
| 86 |
+
_message.append(Content(role="user", parts=[Part.from_text(message["content"])]))
|
| 87 |
+
else:
|
| 88 |
+
try:
|
| 89 |
+
if isinstance(message["content"], list) and message["content"][1]["type"] == "image_url":
|
| 90 |
+
encoded_image = message["content"][1]["image_url"]["url"].split(",")[-1]
|
| 91 |
+
_message.append(
|
| 92 |
+
Content(
|
| 93 |
+
role="user",
|
| 94 |
+
parts=[
|
| 95 |
+
Part.from_text(message["content"][0]["text"]),
|
| 96 |
+
Part.from_data(data=encoded_image, mime_type="image/jpeg"),
|
| 97 |
+
],
|
| 98 |
+
)
|
| 99 |
+
)
|
| 100 |
+
except KeyError:
|
| 101 |
+
cprint("WARNING: 未対応です", color="yellow", background=True)
|
| 102 |
+
except IndexError:
|
| 103 |
+
cprint("WARNING: 未対応です", color="yellow", background=True)
|
| 104 |
+
except Exception as e:
|
| 105 |
+
cprint(e, color="red", background=True)
|
| 106 |
+
elif message["role"] == "assistant":
|
| 107 |
+
if isinstance(message["content"], str):
|
| 108 |
+
_message.append(Content(role="model", parts=[Part.from_text(message["content"])]))
|
| 109 |
+
else:
|
| 110 |
+
cprint("WARNING: 未対応です", color="yellow", background=True)
|
| 111 |
+
return _system, _message
|
| 112 |
+
|
| 113 |
+
def _convert_finish_reason(self, stop_reason: Candidate.FinishReason) -> FinishReasonVertex | None:
|
| 114 |
+
"""
|
| 115 |
+
参考記事 : https://ai.google.dev/api/python/google/ai/generativelanguage/Candidate/FinishReason
|
| 116 |
+
|
| 117 |
+
0: FINISH_REASON_UNSPECIFIED
|
| 118 |
+
Default value. This value is unused.
|
| 119 |
+
1: STOP
|
| 120 |
+
Natural stop point of the model or provided stop sequence.
|
| 121 |
+
2: MAX_TOKENS
|
| 122 |
+
The maximum number of tokens as specified in the request was reached.
|
| 123 |
+
3: SAFETY
|
| 124 |
+
The candidate content was flagged for safety reasons.
|
| 125 |
+
4: RECITATION
|
| 126 |
+
The candidate content was flagged for recitation reasons.
|
| 127 |
+
5: OTHER
|
| 128 |
+
Unknown reason.
|
| 129 |
+
"""
|
| 130 |
+
|
| 131 |
+
if stop_reason.value in [0, 3, 4, 5]:
|
| 132 |
+
return "stop"
|
| 133 |
+
|
| 134 |
+
if stop_reason.value in [2]:
|
| 135 |
+
return "length"
|
| 136 |
+
|
| 137 |
+
return None
|
| 138 |
+
|
| 139 |
+
def _convert_to_response(
|
| 140 |
+
self, platform_response: GenerationResponse, system: str | None, message: list[Content]
|
| 141 |
+
) -> Response:
|
| 142 |
+
# input 請求用文字数
|
| 143 |
+
input_billable_characters = 0
|
| 144 |
+
if system:
|
| 145 |
+
input_billable_characters += self._count_tokens_vertex(system).total_billable_characters
|
| 146 |
+
if message:
|
| 147 |
+
input_billable_characters += self._count_tokens_vertex(message).total_billable_characters
|
| 148 |
+
# output 請求用文字数
|
| 149 |
+
output_billable_characters = 0
|
| 150 |
+
if platform_response.text:
|
| 151 |
+
output_billable_characters += self._count_tokens_vertex(platform_response.text).total_billable_characters
|
| 152 |
+
return ChatCompletion( # type: ignore [call-arg]
|
| 153 |
+
id="",
|
| 154 |
+
choices=[
|
| 155 |
+
Choice(
|
| 156 |
+
index=0,
|
| 157 |
+
message=ChatCompletionMessage(
|
| 158 |
+
content=platform_response.text,
|
| 159 |
+
role="assistant",
|
| 160 |
+
),
|
| 161 |
+
finish_reason=self._convert_finish_reason(platform_response.candidates[0].finish_reason),
|
| 162 |
+
)
|
| 163 |
+
],
|
| 164 |
+
created=int(time.time()),
|
| 165 |
+
model=self.model,
|
| 166 |
+
object="messages.create",
|
| 167 |
+
system_fingerprint=None,
|
| 168 |
+
usage=CompletionUsage(
|
| 169 |
+
prompt_tokens=platform_response.usage_metadata.prompt_token_count,
|
| 170 |
+
completion_tokens=platform_response.usage_metadata.candidates_token_count,
|
| 171 |
+
total_tokens=platform_response.usage_metadata.prompt_token_count
|
| 172 |
+
+ platform_response.usage_metadata.candidates_token_count,
|
| 173 |
+
),
|
| 174 |
+
usage_for_price=CompletionUsageForCustomPriceCalculation(
|
| 175 |
+
prompt_tokens=input_billable_characters,
|
| 176 |
+
completion_tokens=output_billable_characters,
|
| 177 |
+
total_tokens=input_billable_characters + output_billable_characters,
|
| 178 |
+
),
|
| 179 |
+
)
|
| 180 |
+
|
| 181 |
+
def _convert_to_streamresponse(self, platform_streamresponse: Iterable[GenerationResponse]) -> StreamResponse:
|
| 182 |
+
created = int(time.time())
|
| 183 |
+
content: str | None = None
|
| 184 |
+
for chunk in platform_streamresponse:
|
| 185 |
+
content = chunk.text
|
| 186 |
+
yield ChatCompletionChunk(
|
| 187 |
+
id="",
|
| 188 |
+
choices=[
|
| 189 |
+
ChunkChoice(
|
| 190 |
+
delta=ChoiceDelta(
|
| 191 |
+
content=content,
|
| 192 |
+
role="assistant",
|
| 193 |
+
),
|
| 194 |
+
finish_reason=self._convert_finish_reason(chunk.candidates[0].finish_reason),
|
| 195 |
+
index=0, # 0-indexedじゃないかもしれないので0に塗り替え
|
| 196 |
+
)
|
| 197 |
+
],
|
| 198 |
+
created=created,
|
| 199 |
+
model=self.model,
|
| 200 |
+
object="chat.completion.chunk",
|
| 201 |
+
)
|
| 202 |
+
|
| 203 |
+
def generate(self, messages: Messages, llm_settings: LLMSettings) -> Response:
|
| 204 |
+
_system, _message = self._convert_to_platform_messages(messages)
|
| 205 |
+
model = GenerativeModel(
|
| 206 |
+
model_name=self.model,
|
| 207 |
+
system_instruction=_system,
|
| 208 |
+
)
|
| 209 |
+
|
| 210 |
+
response = model.generate_content(
|
| 211 |
+
contents=_message,
|
| 212 |
+
stream=False,
|
| 213 |
+
generation_config=self.generate_config(llm_settings),
|
| 214 |
+
)
|
| 215 |
+
|
| 216 |
+
return self._convert_to_response(platform_response=response, system=_system, message=_message)
|
| 217 |
+
|
| 218 |
+
def generate_stream(self, messages: Messages, llm_settings: LLMSettings) -> StreamResponse:
|
| 219 |
+
_system, _message = self._convert_to_platform_messages(messages)
|
| 220 |
+
model = GenerativeModel(
|
| 221 |
+
model_name=self.model,
|
| 222 |
+
system_instruction=_system,
|
| 223 |
+
)
|
| 224 |
+
response = model.generate_content(
|
| 225 |
+
contents=_message,
|
| 226 |
+
stream=True,
|
| 227 |
+
generation_config=self.generate_config(llm_settings),
|
| 228 |
+
)
|
| 229 |
+
return self._convert_to_streamresponse(platform_streamresponse=response)
|
neollm/llm/gemini/gcp_llm.py
ADDED
|
@@ -0,0 +1,114 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from copy import deepcopy
|
| 2 |
+
from typing import Literal, cast, get_args
|
| 3 |
+
|
| 4 |
+
import vertexai
|
| 5 |
+
from vertexai.generative_models import GenerationConfig
|
| 6 |
+
|
| 7 |
+
from neollm.llm.abstract_llm import AbstractLLM
|
| 8 |
+
from neollm.llm.gemini.abstract_gemini import AbstractGemini
|
| 9 |
+
from neollm.types import APIPricing, ClientSettings, LLMSettings, StreamResponse
|
| 10 |
+
from neollm.types.mytypes import Messages, Response
|
| 11 |
+
from neollm.utils.utils import cprint
|
| 12 |
+
|
| 13 |
+
# price: https://ai.google.dev/pricing?hl=ja
|
| 14 |
+
# models: https://ai.google.dev/gemini-api/docs/models/gemini?hl=ja
|
| 15 |
+
|
| 16 |
+
SUPPORTED_MODELS = Literal["gemini-1.0-pro", "gemini-1.0-pro-vision", "gemini-1.5-pro-preview-0409"]
|
| 17 |
+
AVAILABLE_CONFIG_VARIABLES = [
|
| 18 |
+
"candidate_count",
|
| 19 |
+
"stop_sequences",
|
| 20 |
+
"temperature",
|
| 21 |
+
"max_tokens", # "max_output_tokensが設定されていない場合、max_tokensを使う
|
| 22 |
+
"max_output_tokens",
|
| 23 |
+
"top_p",
|
| 24 |
+
"top_k",
|
| 25 |
+
]
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
def get_gcp_llm(model_name: SUPPORTED_MODELS | str, client_settings: ClientSettings) -> AbstractLLM:
|
| 29 |
+
|
| 30 |
+
vertexai.init(**client_settings)
|
| 31 |
+
|
| 32 |
+
# map to LLM
|
| 33 |
+
supported_model_map: dict[SUPPORTED_MODELS, AbstractLLM] = {
|
| 34 |
+
"gemini-1.0-pro": GCPGemini10Pro(client_settings),
|
| 35 |
+
"gemini-1.0-pro-vision": GCPGemini10ProVision(client_settings),
|
| 36 |
+
"gemini-1.5-pro-preview-0409": GCPGemini15Pro0409(client_settings),
|
| 37 |
+
}
|
| 38 |
+
if model_name in supported_model_map:
|
| 39 |
+
model_name = cast(SUPPORTED_MODELS, model_name)
|
| 40 |
+
return supported_model_map[model_name]
|
| 41 |
+
raise ValueError(f"model_name must be {get_args(SUPPORTED_MODELS)}, but got {model_name}.")
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
class GoogleLLM(AbstractGemini):
|
| 45 |
+
|
| 46 |
+
def generate_config(self, llm_settings: LLMSettings) -> GenerationConfig:
|
| 47 |
+
"""
|
| 48 |
+
参考記事 : https://ai.google.dev/api/rest/v1/GenerationConfig?hl=ja
|
| 49 |
+
"""
|
| 50 |
+
# gemini
|
| 51 |
+
candidate_count = llm_settings.pop("candidate_count", None)
|
| 52 |
+
stop_sequences = llm_settings.pop("stop_sequences", None)
|
| 53 |
+
temperature = llm_settings.pop("temperature", None)
|
| 54 |
+
max_output_tokens = llm_settings.pop("max_output_tokens", None)
|
| 55 |
+
top_p = llm_settings.pop("top_p", None)
|
| 56 |
+
top_k = llm_settings.pop("top_k", None)
|
| 57 |
+
|
| 58 |
+
# neollmの引数でも動くようにする
|
| 59 |
+
if max_output_tokens is None:
|
| 60 |
+
max_output_tokens = llm_settings.pop("max_tokens", None)
|
| 61 |
+
|
| 62 |
+
if len(llm_settings) > 0 and "max_tokens" not in llm_settings:
|
| 63 |
+
raise ValueError(f"llm_settings has unknown keys: {llm_settings}")
|
| 64 |
+
|
| 65 |
+
return GenerationConfig(
|
| 66 |
+
candidate_count=candidate_count,
|
| 67 |
+
stop_sequences=stop_sequences,
|
| 68 |
+
temperature=temperature,
|
| 69 |
+
max_output_tokens=max_output_tokens,
|
| 70 |
+
top_p=top_p,
|
| 71 |
+
top_k=top_k,
|
| 72 |
+
)
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
class GCPGemini10Pro(GoogleLLM):
|
| 76 |
+
dollar_per_ktoken = APIPricing(input=0.125 / 1000, output=0.375 / 1000)
|
| 77 |
+
model: str = "gemini-1.0-pro"
|
| 78 |
+
context_window: int = 32_000
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
class GCPGemini10ProVision(GoogleLLM):
|
| 82 |
+
dollar_per_ktoken = APIPricing(input=0.125 / 1000, output=0.375 / 1000)
|
| 83 |
+
model: str = "gemini-1.0-pro-vision"
|
| 84 |
+
context_window: int = 32_000
|
| 85 |
+
|
| 86 |
+
def generate(self, messages: Messages, llm_settings: LLMSettings) -> Response:
|
| 87 |
+
messages = self._preprocess_message_to_use_system(messages)
|
| 88 |
+
return super().generate(messages, llm_settings)
|
| 89 |
+
|
| 90 |
+
def generate_stream(self, messages: Messages, llm_settings: LLMSettings) -> StreamResponse:
|
| 91 |
+
messages = self._preprocess_message_to_use_system(messages)
|
| 92 |
+
return super().generate_stream(messages, llm_settings)
|
| 93 |
+
|
| 94 |
+
def _preprocess_message_to_use_system(self, message: Messages) -> Messages:
|
| 95 |
+
if message[0]["role"] != "system":
|
| 96 |
+
return message
|
| 97 |
+
preprocessed_message = deepcopy(message)
|
| 98 |
+
system = preprocessed_message[0]["content"]
|
| 99 |
+
del preprocessed_message[0]
|
| 100 |
+
if (
|
| 101 |
+
isinstance(system, str)
|
| 102 |
+
and isinstance(preprocessed_message[0]["content"], list)
|
| 103 |
+
and isinstance(preprocessed_message[0]["content"][0]["text"], str)
|
| 104 |
+
):
|
| 105 |
+
preprocessed_message[0]["content"][0]["text"] = system + preprocessed_message[0]["content"][0]["text"]
|
| 106 |
+
else:
|
| 107 |
+
cprint("WARNING: 入力形式が不正です", color="yellow", background=True)
|
| 108 |
+
return preprocessed_message
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
class GCPGemini15Pro0409(GoogleLLM):
|
| 112 |
+
dollar_per_ktoken = APIPricing(input=2.5 / 1000, output=7.5 / 1000)
|
| 113 |
+
model: str = "gemini-1.5-pro-preview-0409"
|
| 114 |
+
context_window: int = 1_000_000
|
neollm/llm/get_llm.py
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from neollm.llm.abstract_llm import AbstractLLM
|
| 2 |
+
from neollm.types import ClientSettings
|
| 3 |
+
|
| 4 |
+
from .platform import Platform
|
| 5 |
+
|
| 6 |
+
SUPPORTED_CLAUDE_MODELS = [
|
| 7 |
+
"claude-3-opus",
|
| 8 |
+
"claude-3-sonnet",
|
| 9 |
+
"claude-3-haiku",
|
| 10 |
+
"claude-3-opus@20240229",
|
| 11 |
+
"claude-3-sonnet@20240229",
|
| 12 |
+
"claude-3-haiku@20240307",
|
| 13 |
+
]
|
| 14 |
+
|
| 15 |
+
SUPPORTED_GEMINI_MODELS = [
|
| 16 |
+
"gemini-1.5-pro-preview-0409",
|
| 17 |
+
"gemini-1.0-pro",
|
| 18 |
+
"gemini-1.0-pro-vision",
|
| 19 |
+
]
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def get_llm(model_name: str, platform: str, client_settings: ClientSettings) -> AbstractLLM:
|
| 23 |
+
platform = Platform(platform)
|
| 24 |
+
# llmの取得
|
| 25 |
+
if platform == Platform.AZURE:
|
| 26 |
+
from neollm.llm.gpt.azure_llm import get_azure_llm
|
| 27 |
+
|
| 28 |
+
return get_azure_llm(model_name, client_settings)
|
| 29 |
+
if platform == Platform.OPENAI:
|
| 30 |
+
from neollm.llm.gpt.openai_llm import get_openai_llm
|
| 31 |
+
|
| 32 |
+
return get_openai_llm(model_name, client_settings)
|
| 33 |
+
if platform == Platform.ANTHROPIC:
|
| 34 |
+
from neollm.llm.claude.anthropic_llm import get_anthoropic_llm
|
| 35 |
+
|
| 36 |
+
return get_anthoropic_llm(model_name, client_settings)
|
| 37 |
+
if platform == Platform.GCP:
|
| 38 |
+
if model_name in SUPPORTED_CLAUDE_MODELS:
|
| 39 |
+
from neollm.llm.claude.gcp_llm import get_gcp_llm as get_gcp_llm_for_claude
|
| 40 |
+
|
| 41 |
+
return get_gcp_llm_for_claude(model_name, client_settings)
|
| 42 |
+
elif model_name in SUPPORTED_GEMINI_MODELS:
|
| 43 |
+
from neollm.llm.gemini.gcp_llm import get_gcp_llm as get_gcp_llm_for_gemini
|
| 44 |
+
|
| 45 |
+
return get_gcp_llm_for_gemini(model_name, client_settings)
|
| 46 |
+
else:
|
| 47 |
+
raise ValueError(f"{model_name} is not supported in GCP.")
|
neollm/llm/gpt/abstract_gpt.py
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import tiktoken
|
| 2 |
+
|
| 3 |
+
from neollm.llm.abstract_llm import AbstractLLM
|
| 4 |
+
from neollm.types import (
|
| 5 |
+
ChatCompletion,
|
| 6 |
+
ChatCompletionChunk,
|
| 7 |
+
Message,
|
| 8 |
+
Messages,
|
| 9 |
+
OpenAIMessages,
|
| 10 |
+
OpenAIResponse,
|
| 11 |
+
OpenAIStreamResponse,
|
| 12 |
+
Response,
|
| 13 |
+
StreamResponse,
|
| 14 |
+
)
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class AbstractGPT(AbstractLLM):
|
| 18 |
+
def encode(self, text: str) -> list[int]:
|
| 19 |
+
tokenizer = tiktoken.encoding_for_model(self.model or "gpt-3.5-turbo")
|
| 20 |
+
return tokenizer.encode(text)
|
| 21 |
+
|
| 22 |
+
def decode(self, encoded: list[int]) -> str:
|
| 23 |
+
tokenizer = tiktoken.encoding_for_model(self.model or "gpt-3.5-turbo")
|
| 24 |
+
return tokenizer.decode(encoded)
|
| 25 |
+
|
| 26 |
+
def count_tokens(self, messages: list[Message] | None = None, only_response: bool = False) -> int:
|
| 27 |
+
"""
|
| 28 |
+
トークン数の計測
|
| 29 |
+
|
| 30 |
+
Args:
|
| 31 |
+
messages (Messages): messages
|
| 32 |
+
|
| 33 |
+
Returns:
|
| 34 |
+
int: トークン数
|
| 35 |
+
"""
|
| 36 |
+
if messages is None:
|
| 37 |
+
return 0
|
| 38 |
+
|
| 39 |
+
# count tokens
|
| 40 |
+
num_tokens: int = 0
|
| 41 |
+
# messages ---------------------------------------------------------------------------v
|
| 42 |
+
for message in messages:
|
| 43 |
+
# per message -------------------------------------------
|
| 44 |
+
num_tokens += 4
|
| 45 |
+
# content -----------------------------------------------
|
| 46 |
+
content = message.get("content", None)
|
| 47 |
+
if content is None:
|
| 48 |
+
num_tokens += 0
|
| 49 |
+
elif isinstance(content, str):
|
| 50 |
+
num_tokens += len(self.encode(content))
|
| 51 |
+
continue
|
| 52 |
+
elif isinstance(content, list):
|
| 53 |
+
for content_params in content:
|
| 54 |
+
if content_params["type"] == "text":
|
| 55 |
+
num_tokens += len(self.encode(content_params["text"]))
|
| 56 |
+
# TODO: ChatCompletionFunctionMessageParam.name
|
| 57 |
+
# tokens_per_name = 1
|
| 58 |
+
# tool calls ------------------------------------------------
|
| 59 |
+
# TODO: ChatCompletionAssistantMessageParam.function_call
|
| 60 |
+
# TODO: ChatCompletionAssistantMessageParam.tool_calls
|
| 61 |
+
|
| 62 |
+
if only_response:
|
| 63 |
+
if len(messages) != 1:
|
| 64 |
+
raise ValueError("only_response=Trueの場合、messagesは1つのみにしてください。")
|
| 65 |
+
num_tokens -= 4 # per message分を消す
|
| 66 |
+
else:
|
| 67 |
+
num_tokens += 3 # every reply is primed with <|start|>assistant<|message|>
|
| 68 |
+
|
| 69 |
+
return num_tokens
|
| 70 |
+
|
| 71 |
+
def _convert_to_response(self, platform_response: OpenAIResponse) -> Response:
|
| 72 |
+
return ChatCompletion(**platform_response.model_dump())
|
| 73 |
+
|
| 74 |
+
def _convert_to_platform_messages(self, messages: Messages) -> OpenAIMessages:
|
| 75 |
+
# OpenAIのMessagesをデフォルトに置いているため、変換は不要
|
| 76 |
+
platform_messages: OpenAIMessages = messages
|
| 77 |
+
return platform_messages
|
| 78 |
+
|
| 79 |
+
def _convert_to_streamresponse(self, platform_streamresponse: OpenAIStreamResponse) -> StreamResponse:
|
| 80 |
+
for chunk in platform_streamresponse:
|
| 81 |
+
yield ChatCompletionChunk(**chunk.model_dump())
|
neollm/llm/gpt/azure_llm.py
ADDED
|
@@ -0,0 +1,215 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Literal, cast
|
| 2 |
+
|
| 3 |
+
from openai import AzureOpenAI
|
| 4 |
+
|
| 5 |
+
from neollm.llm.abstract_llm import AbstractLLM
|
| 6 |
+
from neollm.llm.gpt.abstract_gpt import AbstractGPT
|
| 7 |
+
from neollm.types import (
|
| 8 |
+
APIPricing,
|
| 9 |
+
ClientSettings,
|
| 10 |
+
LLMSettings,
|
| 11 |
+
Messages,
|
| 12 |
+
Response,
|
| 13 |
+
StreamResponse,
|
| 14 |
+
)
|
| 15 |
+
from neollm.utils.utils import cprint, ensure_env_var, suport_unrecomended_env_var
|
| 16 |
+
|
| 17 |
+
suport_unrecomended_env_var(old_key="AZURE_API_BASE", new_key="AZURE_OPENAI_ENDPOINT")
|
| 18 |
+
suport_unrecomended_env_var(old_key="AZURE_API_VERSION", new_key="OPENAI_API_VERSION")
|
| 19 |
+
# 0613なし
|
| 20 |
+
suport_unrecomended_env_var(old_key="AZURE_ENGINE_GPT35", new_key="AZURE_ENGINE_GPT35T_0613")
|
| 21 |
+
suport_unrecomended_env_var(old_key="AZURE_ENGINE_GPT35_16k", new_key="AZURE_ENGINE_GPT35T_16K_0613")
|
| 22 |
+
suport_unrecomended_env_var(old_key="AZURE_ENGINE_GPT4", new_key="AZURE_ENGINE_GPT4_0613")
|
| 23 |
+
suport_unrecomended_env_var(old_key="AZURE_ENGINE_GPT4_32k", new_key="AZURE_ENGINE_GPT4_32K_0613")
|
| 24 |
+
# turbo抜け
|
| 25 |
+
suport_unrecomended_env_var(old_key="AZURE_ENGINE_GPT35_0613", new_key="AZURE_ENGINE_GPT35T_0613")
|
| 26 |
+
suport_unrecomended_env_var(old_key="AZURE_ENGINE_GPT35_16K_0613", new_key="AZURE_ENGINE_GPT35T_16K_0613")
|
| 27 |
+
|
| 28 |
+
# Pricing: https://azure.microsoft.com/en-us/pricing/details/cognitive-services/openai-service/
|
| 29 |
+
|
| 30 |
+
SUPPORTED_MODELS = Literal[
|
| 31 |
+
"gpt-4o-2024-05-13",
|
| 32 |
+
"gpt-4-turbo-2024-04-09",
|
| 33 |
+
"gpt-3.5-turbo-0125",
|
| 34 |
+
"gpt-4-turbo-0125",
|
| 35 |
+
"gpt-3.5-turbo-1106",
|
| 36 |
+
"gpt-4-turbo-1106",
|
| 37 |
+
"gpt-4v-turbo-1106",
|
| 38 |
+
"gpt-3.5-turbo-0613",
|
| 39 |
+
"gpt-3.5-turbo-16k-0613",
|
| 40 |
+
"gpt-4-0613",
|
| 41 |
+
"gpt-4-32k-0613",
|
| 42 |
+
]
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def get_azure_llm(model_name: SUPPORTED_MODELS | str, client_settings: ClientSettings) -> AbstractLLM:
|
| 46 |
+
# 表記変更
|
| 47 |
+
model_name = model_name.replace("gpt-35-turbo", "gpt-3.5-turbo")
|
| 48 |
+
# Add 日付
|
| 49 |
+
replace_map_for_nodate: dict[str, SUPPORTED_MODELS] = {
|
| 50 |
+
"gpt-4o": "gpt-4o-2024-05-13",
|
| 51 |
+
"gpt-3.5-turbo": "gpt-3.5-turbo-0613",
|
| 52 |
+
"gpt-3.5-turbo-16k": "gpt-3.5-turbo-16k-0613",
|
| 53 |
+
"gpt-4": "gpt-4-0613",
|
| 54 |
+
"gpt-4-32k": "gpt-4-32k-0613",
|
| 55 |
+
"gpt-4-turbo": "gpt-4-turbo-1106",
|
| 56 |
+
"gpt-4v-turbo": "gpt-4v-turbo-1106",
|
| 57 |
+
}
|
| 58 |
+
if model_name in replace_map_for_nodate:
|
| 59 |
+
cprint("WARNING: model_nameに日付を指定してください", color="yellow", background=True)
|
| 60 |
+
print(f"model_name: {model_name} -> {replace_map_for_nodate[model_name]}")
|
| 61 |
+
model_name = replace_map_for_nodate[model_name]
|
| 62 |
+
|
| 63 |
+
# map to LLM
|
| 64 |
+
supported_model_map: dict[SUPPORTED_MODELS, AbstractLLM] = {
|
| 65 |
+
"gpt-4o-2024-05-13": AzureGPT4O_20240513(client_settings),
|
| 66 |
+
"gpt-4-turbo-2024-04-09": AzureGPT4T_20240409(client_settings),
|
| 67 |
+
"gpt-3.5-turbo-0125": AzureGPT35T_0125(client_settings),
|
| 68 |
+
"gpt-4-turbo-0125": AzureGPT4T_0125(client_settings),
|
| 69 |
+
"gpt-3.5-turbo-1106": AzureGPT35T_1106(client_settings),
|
| 70 |
+
"gpt-4-turbo-1106": AzureGPT4T_1106(client_settings),
|
| 71 |
+
"gpt-4v-turbo-1106": AzureGPT4VT_1106(client_settings),
|
| 72 |
+
"gpt-3.5-turbo-0613": AzureGPT35T_0613(client_settings),
|
| 73 |
+
"gpt-3.5-turbo-16k-0613": AzureGPT35T16k_0613(client_settings),
|
| 74 |
+
"gpt-4-0613": AzureGPT4_0613(client_settings),
|
| 75 |
+
"gpt-4-32k-0613": AzureGPT432k_0613(client_settings),
|
| 76 |
+
}
|
| 77 |
+
# 通常モデル
|
| 78 |
+
if model_name in supported_model_map:
|
| 79 |
+
model_name = cast(SUPPORTED_MODELS, model_name)
|
| 80 |
+
return supported_model_map[model_name]
|
| 81 |
+
# FTモデル
|
| 82 |
+
return AzureGPT35FT(model_name, client_settings)
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
class AzureLLM(AbstractGPT):
|
| 86 |
+
_engine_name_env_key: str | None = None
|
| 87 |
+
|
| 88 |
+
@property
|
| 89 |
+
def client(self) -> AzureOpenAI:
|
| 90 |
+
client: AzureOpenAI = AzureOpenAI(**self.client_settings)
|
| 91 |
+
# api_key: str | None = (None,)
|
| 92 |
+
# timeout: httpx.Timeout(timeout=600.0, connect=5.0)
|
| 93 |
+
# max_retries: int = 2
|
| 94 |
+
return client
|
| 95 |
+
|
| 96 |
+
@property
|
| 97 |
+
def engine(self) -> str:
|
| 98 |
+
return ensure_env_var(self._engine_name_env_key)
|
| 99 |
+
|
| 100 |
+
def generate(self, messages: Messages, llm_settings: LLMSettings) -> Response:
|
| 101 |
+
openai_response = self.client.chat.completions.create(
|
| 102 |
+
model=self.engine,
|
| 103 |
+
messages=self._convert_to_platform_messages(messages),
|
| 104 |
+
stream=False,
|
| 105 |
+
**llm_settings,
|
| 106 |
+
)
|
| 107 |
+
response = self._convert_to_response(openai_response)
|
| 108 |
+
return response
|
| 109 |
+
|
| 110 |
+
def generate_stream(self, messages: Messages, llm_settings: LLMSettings) -> StreamResponse:
|
| 111 |
+
platform_stream_response = self.client.chat.completions.create(
|
| 112 |
+
model=self.engine,
|
| 113 |
+
messages=self._convert_to_platform_messages(messages),
|
| 114 |
+
stream=True,
|
| 115 |
+
**llm_settings,
|
| 116 |
+
)
|
| 117 |
+
stream_response = self._convert_to_streamresponse(platform_stream_response)
|
| 118 |
+
return stream_response
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
# omni 2024-05-13 --------------------------------------------------------------------------------------------
|
| 122 |
+
class AzureGPT4O_20240513(AzureLLM):
|
| 123 |
+
dollar_per_ktoken = APIPricing(input=0.005, output=0.015) # 30倍/45倍
|
| 124 |
+
model: str = "gpt-4o-2024-05-13"
|
| 125 |
+
_engine_name_env_key: str = "AZURE_ENGINE_GPT4O_20240513"
|
| 126 |
+
context_window: int = 128_000
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
# 2024-04-09 --------------------------------------------------------------------------------------------
|
| 130 |
+
class AzureGPT4T_20240409(AzureLLM):
|
| 131 |
+
dollar_per_ktoken = APIPricing(input=0.01, output=0.03)
|
| 132 |
+
model: str = "gpt-4-turbo-2024-04-09"
|
| 133 |
+
_engine_name_env_key: str = "AZURE_ENGINE_GPT4T_20240409"
|
| 134 |
+
context_window: int = 128_000
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
# 0125 --------------------------------------------------------------------------------------------
|
| 138 |
+
class AzureGPT35T_0125(AzureLLM):
|
| 139 |
+
dollar_per_ktoken = APIPricing(input=0.0005, output=0.0015)
|
| 140 |
+
model: str = "gpt-3.5-turbo-0125"
|
| 141 |
+
_engine_name_env_key: str = "AZURE_ENGINE_GPT35T_0125"
|
| 142 |
+
context_window: int = 16_385
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
class AzureGPT4T_0125(AzureLLM):
|
| 146 |
+
dollar_per_ktoken = APIPricing(input=0.01, output=0.03)
|
| 147 |
+
model: str = "gpt-4-turbo-0125"
|
| 148 |
+
_engine_name_env_key: str = "AZURE_ENGINE_GPT4T_0125"
|
| 149 |
+
context_window: int = 128_000
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
# 1106 --------------------------------------------------------------------------------------------
|
| 153 |
+
class AzureGPT35T_1106(AzureLLM):
|
| 154 |
+
dollar_per_ktoken = APIPricing(input=0.001, output=0.002)
|
| 155 |
+
model: str = "gpt-3.5-turbo-1106"
|
| 156 |
+
_engine_name_env_key: str = "AZURE_ENGINE_GPT35T_1106"
|
| 157 |
+
context_window: int = 16_385
|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
class AzureGPT4VT_1106(AzureLLM):
|
| 161 |
+
dollar_per_ktoken = APIPricing(input=0.01, output=0.03) # 10倍/15倍
|
| 162 |
+
model: str = "gpt-4-1106-vision-preview"
|
| 163 |
+
_engine_name_env_key: str = "AZURE_ENGINE_GPT4VT_1106"
|
| 164 |
+
context_window: int = 128_000
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
class AzureGPT4T_1106(AzureLLM):
|
| 168 |
+
dollar_per_ktoken = APIPricing(input=0.01, output=0.03)
|
| 169 |
+
model: str = "gpt-4-turbo-1106"
|
| 170 |
+
_engine_name_env_key: str = "AZURE_ENGINE_GPT4T_1106"
|
| 171 |
+
context_window: int = 128_000
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
# FT --------------------------------------------------------------------------------------------
|
| 175 |
+
class AzureGPT35FT(AzureLLM):
|
| 176 |
+
dollar_per_ktoken = APIPricing(input=0.0005, output=0.0015) # 1倍 + セッション稼働時間
|
| 177 |
+
model: str = "gpt-3.5-turbo-ft"
|
| 178 |
+
context_window: int = 4_096
|
| 179 |
+
|
| 180 |
+
def __init__(self, model_name: str, client_setting: ClientSettings) -> None:
|
| 181 |
+
super().__init__(client_setting)
|
| 182 |
+
self._engine = model_name
|
| 183 |
+
|
| 184 |
+
@property
|
| 185 |
+
def engine(self) -> str:
|
| 186 |
+
return self._engine
|
| 187 |
+
|
| 188 |
+
|
| 189 |
+
# 0613 --------------------------------------------------------------------------------------------
|
| 190 |
+
class AzureGPT35T_0613(AzureLLM):
|
| 191 |
+
dollar_per_ktoken = APIPricing(input=0.0015, output=0.002)
|
| 192 |
+
model: str = "gpt-3.5-turbo-0613"
|
| 193 |
+
_engine_name_env_key: str = "AZURE_ENGINE_GPT35T_0613"
|
| 194 |
+
context_window: int = 4_096
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
class AzureGPT35T16k_0613(AzureLLM):
|
| 198 |
+
dollar_per_ktoken = APIPricing(input=0.003, output=0.004) # 2倍
|
| 199 |
+
model: str = "gpt-3.5-turbo-16k-0613"
|
| 200 |
+
_engine_name_env_key: str = "AZURE_ENGINE_GPT35T_16K_0613"
|
| 201 |
+
context_window: int = 16_385
|
| 202 |
+
|
| 203 |
+
|
| 204 |
+
class AzureGPT4_0613(AzureLLM):
|
| 205 |
+
dollar_per_ktoken = APIPricing(input=0.03, output=0.06) # 20倍/30倍
|
| 206 |
+
model: str = "gpt-4-0613"
|
| 207 |
+
_engine_name_env_key: str = "AZURE_ENGINE_GPT4_0613"
|
| 208 |
+
context_window: int = 8_192
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
class AzureGPT432k_0613(AzureLLM):
|
| 212 |
+
dollar_per_ktoken = APIPricing(input=0.06, output=0.12) # 40倍/60倍
|
| 213 |
+
model: str = "gpt-4-32k-0613"
|
| 214 |
+
_engine_name_env_key: str = "AZURE_ENGINE_GPT4_32K_0613"
|
| 215 |
+
context_window: int = 32_768
|
neollm/llm/gpt/openai_llm.py
ADDED
|
@@ -0,0 +1,222 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Literal, cast
|
| 2 |
+
|
| 3 |
+
from openai import OpenAI
|
| 4 |
+
|
| 5 |
+
from neollm.llm.abstract_llm import AbstractLLM
|
| 6 |
+
from neollm.llm.gpt.abstract_gpt import AbstractGPT
|
| 7 |
+
from neollm.types import (
|
| 8 |
+
APIPricing,
|
| 9 |
+
ClientSettings,
|
| 10 |
+
LLMSettings,
|
| 11 |
+
Messages,
|
| 12 |
+
Response,
|
| 13 |
+
StreamResponse,
|
| 14 |
+
)
|
| 15 |
+
from neollm.utils.utils import cprint
|
| 16 |
+
|
| 17 |
+
# Models: https://platform.openai.com/docs/models/continuous-model-upgrades
|
| 18 |
+
# Pricing: https://openai.com/pricing
|
| 19 |
+
|
| 20 |
+
SUPPORTED_MODELS = Literal[
|
| 21 |
+
"gpt-4o-2024-05-13",
|
| 22 |
+
"gpt-4-turbo-2024-04-09",
|
| 23 |
+
"gpt-3.5-turbo-0125",
|
| 24 |
+
"gpt-4-turbo-0125",
|
| 25 |
+
"gpt-3.5-turbo-1106",
|
| 26 |
+
"gpt-4-turbo-1106",
|
| 27 |
+
"gpt-4v-turbo-1106",
|
| 28 |
+
"gpt-3.5-turbo-0613",
|
| 29 |
+
"gpt-3.5-turbo-16k-0613",
|
| 30 |
+
"gpt-4-0613",
|
| 31 |
+
"gpt-4-32k-0613",
|
| 32 |
+
]
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def get_openai_llm(model_name: SUPPORTED_MODELS | str, client_settings: ClientSettings) -> AbstractLLM:
|
| 36 |
+
# Add 日付
|
| 37 |
+
replace_map_for_nodate: dict[str, SUPPORTED_MODELS] = {
|
| 38 |
+
"gpt-4o": "gpt-4o-2024-05-13",
|
| 39 |
+
"gpt-3.5-turbo": "gpt-3.5-turbo-0613",
|
| 40 |
+
"gpt-3.5-turbo-16k": "gpt-3.5-turbo-16k-0613",
|
| 41 |
+
"gpt-4": "gpt-4-0613",
|
| 42 |
+
"gpt-4-32k": "gpt-4-32k-0613",
|
| 43 |
+
"gpt-4-turbo": "gpt-4-turbo-1106",
|
| 44 |
+
"gpt-4v-turbo": "gpt-4v-turbo-1106",
|
| 45 |
+
}
|
| 46 |
+
if model_name in replace_map_for_nodate:
|
| 47 |
+
cprint("WARNING: model_nameに日付を指定してください", color="yellow", background=True)
|
| 48 |
+
print(f"model_name: {model_name} -> {replace_map_for_nodate[model_name]}")
|
| 49 |
+
model_name = replace_map_for_nodate[model_name]
|
| 50 |
+
|
| 51 |
+
# map to LLM
|
| 52 |
+
supported_model_map: dict[SUPPORTED_MODELS, AbstractLLM] = {
|
| 53 |
+
"gpt-4o-2024-05-13": OpenAIGPT4O_20240513(client_settings),
|
| 54 |
+
"gpt-4-turbo-2024-04-09": OpenAIGPT4T_20240409(client_settings),
|
| 55 |
+
"gpt-3.5-turbo-0125": OpenAIGPT35T_0125(client_settings),
|
| 56 |
+
"gpt-4-turbo-0125": OpenAIGPT4T_0125(client_settings),
|
| 57 |
+
"gpt-3.5-turbo-1106": OpenAIGPT35T_1106(client_settings),
|
| 58 |
+
"gpt-4-turbo-1106": OpenAIGPT4T_1106(client_settings),
|
| 59 |
+
"gpt-4v-turbo-1106": OpenAIGPT4VT_1106(client_settings),
|
| 60 |
+
"gpt-3.5-turbo-0613": OpenAIGPT35T_0613(client_settings),
|
| 61 |
+
"gpt-3.5-turbo-16k-0613": OpenAIGPT35T16k_0613(client_settings),
|
| 62 |
+
"gpt-4-0613": OpenAIGPT4_0613(client_settings),
|
| 63 |
+
"gpt-4-32k-0613": OpenAIGPT432k_0613(client_settings),
|
| 64 |
+
}
|
| 65 |
+
# 通常モデル
|
| 66 |
+
if model_name in supported_model_map:
|
| 67 |
+
model_name = cast(SUPPORTED_MODELS, model_name)
|
| 68 |
+
return supported_model_map[model_name]
|
| 69 |
+
# FTモデル
|
| 70 |
+
if "gpt-3.5-turbo-1106" in model_name:
|
| 71 |
+
return OpenAIGPT35TFT_1106(model_name, client_settings)
|
| 72 |
+
if "gpt-3.5-turbo-0613" in model_name:
|
| 73 |
+
return OpenAIGPT35TFT_0613(model_name, client_settings)
|
| 74 |
+
if "gpt-3.5-turbo-0125" in model_name:
|
| 75 |
+
return OpenAIGPT35TFT_0125(model_name, client_settings)
|
| 76 |
+
if "gpt4" in model_name.replace("-", ""): # TODO! もっといい条件に修正
|
| 77 |
+
return OpenAIGPT4FT_0613(model_name, client_settings)
|
| 78 |
+
|
| 79 |
+
cprint(
|
| 80 |
+
f"WARNING: このFTモデルは何?: {model_name} -> OpenAIGPT35TFT_1106として設定", color="yellow", background=True
|
| 81 |
+
)
|
| 82 |
+
return OpenAIGPT35TFT_1106(model_name, client_settings)
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
class OpenAILLM(AbstractGPT):
|
| 86 |
+
model: str
|
| 87 |
+
|
| 88 |
+
@property
|
| 89 |
+
def client(self) -> OpenAI:
|
| 90 |
+
client: OpenAI = OpenAI(**self.client_settings)
|
| 91 |
+
# api_key: str | None = (None,)
|
| 92 |
+
# timeout: httpx.Timeout(timeout=600.0, connect=5.0)
|
| 93 |
+
# max_retries: int = 2
|
| 94 |
+
return client
|
| 95 |
+
|
| 96 |
+
def generate(self, messages: Messages, llm_settings: LLMSettings) -> Response:
|
| 97 |
+
openai_response = self.client.chat.completions.create(
|
| 98 |
+
model=self.model,
|
| 99 |
+
messages=self._convert_to_platform_messages(messages),
|
| 100 |
+
stream=False,
|
| 101 |
+
**llm_settings,
|
| 102 |
+
)
|
| 103 |
+
response = self._convert_to_response(openai_response)
|
| 104 |
+
return response
|
| 105 |
+
|
| 106 |
+
def generate_stream(self, messages: Messages, llm_settings: LLMSettings) -> StreamResponse:
|
| 107 |
+
platform_stream_response = self.client.chat.completions.create(
|
| 108 |
+
model=self.model,
|
| 109 |
+
messages=self._convert_to_platform_messages(messages),
|
| 110 |
+
stream=True,
|
| 111 |
+
**llm_settings,
|
| 112 |
+
)
|
| 113 |
+
stream_response = self._convert_to_streamresponse(platform_stream_response)
|
| 114 |
+
return stream_response
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
# omni 2024-05-13 --------------------------------------------------------------------------------------------
|
| 118 |
+
class OpenAIGPT4O_20240513(OpenAILLM):
|
| 119 |
+
dollar_per_ktoken = APIPricing(input=0.005, output=0.015)
|
| 120 |
+
model: str = "gpt-4o-2024-05-13"
|
| 121 |
+
context_window: int = 128_000
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
# 2024-04-09 --------------------------------------------------------------------------------------------
|
| 125 |
+
class OpenAIGPT4T_20240409(OpenAILLM):
|
| 126 |
+
dollar_per_ktoken = APIPricing(input=0.01, output=0.03) # 10倍/15倍
|
| 127 |
+
model: str = "gpt-4-turbo-2024-04-09"
|
| 128 |
+
# model: str = "gpt-4-turbo-2024-04-09"
|
| 129 |
+
context_window: int = 128_000
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
# 0125 --------------------------------------------------------------------------------------------
|
| 133 |
+
class OpenAIGPT35T_0125(OpenAILLM):
|
| 134 |
+
dollar_per_ktoken = APIPricing(input=0.0005, output=0.0015)
|
| 135 |
+
model: str = "gpt-3.5-turbo-0125"
|
| 136 |
+
context_window: int = 16_385
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
class OpenAIGPT4T_0125(OpenAILLM):
|
| 140 |
+
dollar_per_ktoken = APIPricing(input=0.01, output=0.03)
|
| 141 |
+
model: str = "gpt-4-0125-preview"
|
| 142 |
+
context_window: int = 128_000
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
class OpenAIGPT35TFT_0125(OpenAILLM):
|
| 146 |
+
dollar_per_ktoken = APIPricing(input=0.003, output=0.006)
|
| 147 |
+
context_window: int = 16_385
|
| 148 |
+
|
| 149 |
+
def __init__(self, model_name: str, client_setting: ClientSettings) -> None:
|
| 150 |
+
super().__init__(client_setting)
|
| 151 |
+
self.model = model_name
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
# 1106 --------------------------------------------------------------------------------------------
|
| 155 |
+
class OpenAIGPT35T_1106(OpenAILLM):
|
| 156 |
+
dollar_per_ktoken = APIPricing(input=0.0010, output=0.0020)
|
| 157 |
+
model: str = "gpt-3.5-turbo-1106"
|
| 158 |
+
context_window: int = 16_385
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
class OpenAIGPT4T_1106(OpenAILLM):
|
| 162 |
+
dollar_per_ktoken = APIPricing(input=0.01, output=0.03)
|
| 163 |
+
model: str = "gpt-4-1106-preview"
|
| 164 |
+
context_window: int = 128_000
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
class OpenAIGPT4VT_1106(OpenAILLM):
|
| 168 |
+
dollar_per_ktoken = APIPricing(input=0.01, output=0.03)
|
| 169 |
+
model: str = "gpt-4-1106-vision-preview"
|
| 170 |
+
context_window: int = 128_000
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
class OpenAIGPT35TFT_1106(OpenAILLM):
|
| 174 |
+
dollar_per_ktoken = APIPricing(input=0.003, output=0.006)
|
| 175 |
+
context_window: int = 4_096
|
| 176 |
+
|
| 177 |
+
def __init__(self, model_name: str, client_setting: ClientSettings) -> None:
|
| 178 |
+
super().__init__(client_setting)
|
| 179 |
+
self.model = model_name
|
| 180 |
+
|
| 181 |
+
|
| 182 |
+
# 0613 --------------------------------------------------------------------------------------------
|
| 183 |
+
class OpenAIGPT35T_0613(OpenAILLM):
|
| 184 |
+
dollar_per_ktoken = APIPricing(input=0.0015, output=0.002)
|
| 185 |
+
model: str = "gpt-3.5-turbo-0613"
|
| 186 |
+
context_window: int = 4_096
|
| 187 |
+
|
| 188 |
+
|
| 189 |
+
class OpenAIGPT35T16k_0613(OpenAILLM):
|
| 190 |
+
dollar_per_ktoken = APIPricing(input=0.003, output=0.004)
|
| 191 |
+
model: str = "gpt-3.5-turbo-16k-0613"
|
| 192 |
+
context_window: int = 16_385
|
| 193 |
+
|
| 194 |
+
|
| 195 |
+
class OpenAIGPT4_0613(OpenAILLM):
|
| 196 |
+
dollar_per_ktoken = APIPricing(input=0.03, output=0.06)
|
| 197 |
+
model: str = "gpt-4-0613"
|
| 198 |
+
context_window: int = 8_192
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
class OpenAIGPT432k_0613(OpenAILLM):
|
| 202 |
+
dollar_per_ktoken = APIPricing(input=0.06, output=0.12)
|
| 203 |
+
model: str = "gpt-4-32k-0613"
|
| 204 |
+
context_window: int = 32_768
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
class OpenAIGPT35TFT_0613(OpenAILLM):
|
| 208 |
+
dollar_per_ktoken = APIPricing(input=0.003, output=0.006)
|
| 209 |
+
context_window: int = 4_096
|
| 210 |
+
|
| 211 |
+
def __init__(self, model_name: str, client_setting: ClientSettings) -> None:
|
| 212 |
+
super().__init__(client_setting)
|
| 213 |
+
self.model = model_name
|
| 214 |
+
|
| 215 |
+
|
| 216 |
+
class OpenAIGPT4FT_0613(OpenAILLM):
|
| 217 |
+
dollar_per_ktoken = APIPricing(input=0.045, output=0.090)
|
| 218 |
+
context_window: int = 8_192
|
| 219 |
+
|
| 220 |
+
def __init__(self, model_name: str, client_setting: ClientSettings) -> None:
|
| 221 |
+
super().__init__(client_setting)
|
| 222 |
+
self.model = model_name
|
neollm/llm/gpt/token.py
ADDED
|
@@ -0,0 +1,247 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import textwrap
|
| 3 |
+
from typing import Any, Iterator, overload
|
| 4 |
+
|
| 5 |
+
import tiktoken
|
| 6 |
+
|
| 7 |
+
from neollm.types import Function
|
| 8 |
+
from neollm.utils.utils import cprint # , Functions, Messages
|
| 9 |
+
|
| 10 |
+
DEFAULT_MODEL_NAME = "gpt-3.5-turbo"
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def get_tokenizer(model_name: str) -> tiktoken.Encoding:
|
| 14 |
+
# 参考: https://platform.openai.com/docs/models/gpt-3-5
|
| 15 |
+
MODEL_NAME_MAP = [
|
| 16 |
+
("gpt-3.5-turbo-16k", "gpt-3.5-turbo-16k-0613"),
|
| 17 |
+
("gpt-3.5-turbo", "gpt-3.5-turbo-0613"),
|
| 18 |
+
("gpt-4-32k", "gpt-4-32k-0613"),
|
| 19 |
+
("gpt-4", "gpt-4-0613"),
|
| 20 |
+
]
|
| 21 |
+
ALL_VERSION_MODELS = [
|
| 22 |
+
# gpt-3.5-turbo
|
| 23 |
+
"gpt-3.5-turbo-0125",
|
| 24 |
+
"gpt-3.5-turbo-1106",
|
| 25 |
+
"gpt-3.5-turbo-0613",
|
| 26 |
+
"gpt-3.5-turbo-16k-0613",
|
| 27 |
+
"gpt-3.5-turbo-0301", # Legacy
|
| 28 |
+
# gpt-4
|
| 29 |
+
"gpt-4o-2024-05-13",
|
| 30 |
+
"gpt-4-turbo-0125",
|
| 31 |
+
"gpt-4-turbo-1106",
|
| 32 |
+
"gpt-4-0613",
|
| 33 |
+
"gpt-4-32k-0613",
|
| 34 |
+
"gpt-4-0314", # Legacy
|
| 35 |
+
"gpt-4-32k-0314", # Legacy
|
| 36 |
+
]
|
| 37 |
+
# Azure表記 → OpenAI表記に統一
|
| 38 |
+
model_name = model_name.replace("gpt-35", "gpt-3.5")
|
| 39 |
+
# 最新モデルを正式名称に & 新モデル, FTモデルをキャッチ
|
| 40 |
+
if model_name not in ALL_VERSION_MODELS:
|
| 41 |
+
for key, model_name_version in MODEL_NAME_MAP:
|
| 42 |
+
if key in model_name:
|
| 43 |
+
model_name = model_name_version
|
| 44 |
+
break
|
| 45 |
+
try:
|
| 46 |
+
return tiktoken.encoding_for_model(model_name)
|
| 47 |
+
except Exception as e:
|
| 48 |
+
cprint(f"WARNING: Tokenizerの取得に失敗。{model_name}: {e}", color="yellow", background=True)
|
| 49 |
+
return tiktoken.encoding_for_model("gpt-3.5-turbo")
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
@overload
|
| 53 |
+
def count_tokens(messages: str, model_name: str | None = None) -> int: ...
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
@overload
|
| 57 |
+
def count_tokens(
|
| 58 |
+
messages: Iterator[dict[str, str]], model_name: str | None = None, functions: Any | None = None
|
| 59 |
+
) -> int: ...
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def count_tokens(
|
| 63 |
+
messages: Iterator[dict[str, str]] | str,
|
| 64 |
+
model_name: str | None = None,
|
| 65 |
+
functions: Any | None = None,
|
| 66 |
+
) -> int:
|
| 67 |
+
if isinstance(messages, str):
|
| 68 |
+
tokenizer = get_tokenizer(model_name or DEFAULT_MODEL_NAME)
|
| 69 |
+
encoded = tokenizer.encode(messages)
|
| 70 |
+
return len(encoded)
|
| 71 |
+
return _count_messages_and_function_tokens(messages, model_name, functions)
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
def _count_messages_and_function_tokens(
|
| 75 |
+
messages: Iterator[dict[str, str]], model_name: str | None = None, functions: Any | None = None
|
| 76 |
+
) -> int:
|
| 77 |
+
"""トークン数計測
|
| 78 |
+
|
| 79 |
+
Args:
|
| 80 |
+
messages (Messages): GPTAPIの入力のmessages
|
| 81 |
+
model_name (str | None, optional): モデル名. Defaults to None.
|
| 82 |
+
functions (Functions | None, optional): GPTAPIの入力のfunctions. Defaults to None.
|
| 83 |
+
|
| 84 |
+
Returns:
|
| 85 |
+
int: トークン数
|
| 86 |
+
"""
|
| 87 |
+
num_tokens = _count_messages_tokens(messages, model_name or DEFAULT_MODEL_NAME)
|
| 88 |
+
if functions is not None:
|
| 89 |
+
num_tokens += _count_functions_tokens(functions, model_name)
|
| 90 |
+
return num_tokens
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
# https://github.com/openai/openai-cookbook/blob/main/examples/How_to_count_tokens_with_tiktoken.ipynb
|
| 94 |
+
def _count_messages_tokens(messages: Iterator[dict[str, str]] | None, model_name: str) -> int:
|
| 95 |
+
"""メッセージのトークン数を計算
|
| 96 |
+
|
| 97 |
+
Args:
|
| 98 |
+
messages (Messages): ChatGPT等APIに入力するmessages
|
| 99 |
+
model_name (str, optional): 使用するモデルの名前
|
| 100 |
+
"gpt-3.5-turbo-0613", "gpt-3.5-turbo-16k-0613", "gpt-4-0314", "gpt-4-32k-0314"
|
| 101 |
+
"gpt-4-0613", "gpt-4-32k-0613", "gpt-3.5-turbo", "gpt-4"
|
| 102 |
+
|
| 103 |
+
Returns:
|
| 104 |
+
int: トークン数の合計
|
| 105 |
+
"""
|
| 106 |
+
if messages is None:
|
| 107 |
+
return 0
|
| 108 |
+
# setting model
|
| 109 |
+
encoding_model = get_tokenizer(model_name)
|
| 110 |
+
|
| 111 |
+
# config
|
| 112 |
+
if "gpt-3.5-turbo-0301" in model_name:
|
| 113 |
+
tokens_per_message = 4 # every message follows <|start|>{role/name}\n{content}<|end|>\n
|
| 114 |
+
tokens_per_name = -1 # if there's a name, the role is omitted
|
| 115 |
+
else:
|
| 116 |
+
tokens_per_message = 3
|
| 117 |
+
tokens_per_name = 1
|
| 118 |
+
|
| 119 |
+
# count tokens
|
| 120 |
+
num_tokens = 3 # every reply is primed with <|start|>assistant<|message|>
|
| 121 |
+
for message in messages:
|
| 122 |
+
num_tokens += tokens_per_message
|
| 123 |
+
for key, value in message.items():
|
| 124 |
+
if isinstance(value, str):
|
| 125 |
+
num_tokens += len(encoding_model.encode(value))
|
| 126 |
+
if key == "name":
|
| 127 |
+
num_tokens += tokens_per_name
|
| 128 |
+
return num_tokens
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
# https://gist.github.com/CGamesPlay/dd4f108f27e2eec145eedf5c717318f5
|
| 132 |
+
def _count_functions_tokens(functions: Any, model_name: str | None = None) -> int:
|
| 133 |
+
"""
|
| 134 |
+
functionsのトークン数計測
|
| 135 |
+
|
| 136 |
+
Args:
|
| 137 |
+
functions (Functions): GPTAPIの入力のfunctions
|
| 138 |
+
model_name (str | None, optional): モデル名. Defaults to None.
|
| 139 |
+
|
| 140 |
+
Returns:
|
| 141 |
+
_type_: トークン数
|
| 142 |
+
"""
|
| 143 |
+
encoding_model = encoding_model = get_tokenizer(model_name or DEFAULT_MODEL_NAME)
|
| 144 |
+
num_tokens = 3 + len(encoding_model.encode(__functions2string(functions)))
|
| 145 |
+
return num_tokens
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
# functionsのstring化、補助関数 ---------------------------------------------------------------------------
|
| 149 |
+
def __functions2string(functions: Any) -> str:
|
| 150 |
+
"""functionsの文字列化
|
| 151 |
+
|
| 152 |
+
Args:
|
| 153 |
+
functions (Functions): GPTAPIの入力のfunctions
|
| 154 |
+
|
| 155 |
+
Returns:
|
| 156 |
+
str: functionsの文字列
|
| 157 |
+
"""
|
| 158 |
+
prefix = "# Tools\n\n## functions\n\nnamespace functions {\n\n} // namespace functions\n"
|
| 159 |
+
functions_string = prefix + "".join(__function2string(function) for function in functions)
|
| 160 |
+
return functions_string
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
def __function2string(function: Function) -> str:
|
| 164 |
+
"""functionの文字列化
|
| 165 |
+
|
| 166 |
+
Args:
|
| 167 |
+
function (Function): GPTAPIのfunctionの要素
|
| 168 |
+
|
| 169 |
+
Returns:
|
| 170 |
+
str: functionの文字列
|
| 171 |
+
"""
|
| 172 |
+
object_string = __format_object(function["parameters"])
|
| 173 |
+
if object_string is not None:
|
| 174 |
+
object_string = "_: " + object_string
|
| 175 |
+
else:
|
| 176 |
+
object_string = ""
|
| 177 |
+
|
| 178 |
+
functions_string: str = (
|
| 179 |
+
f"// {function['description']}\ntype {function['name']} = (" + object_string + ") => any;\n\n"
|
| 180 |
+
)
|
| 181 |
+
return functions_string
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
def __format_object(schema: dict[str, Any], indent: int = 0) -> str | None:
|
| 185 |
+
if "properties" not in schema or len(schema["properties"]) == 0:
|
| 186 |
+
if schema.get("additionalProperties", False):
|
| 187 |
+
return "object"
|
| 188 |
+
return None
|
| 189 |
+
|
| 190 |
+
result = "{\n"
|
| 191 |
+
for key, value in dict(schema["properties"]).items():
|
| 192 |
+
# value <- resolve_ref(value)
|
| 193 |
+
value_rendered = __format_schema(value, indent + 1)
|
| 194 |
+
if value_rendered is None:
|
| 195 |
+
continue
|
| 196 |
+
# description
|
| 197 |
+
if "description" in value:
|
| 198 |
+
description = "".join(
|
| 199 |
+
" " * indent + f"// {description_i}\n"
|
| 200 |
+
for description_i in textwrap.dedent(value["description"]).strip().split("\n")
|
| 201 |
+
)
|
| 202 |
+
# optional
|
| 203 |
+
optional = "" if key in schema.get("required", {}) else "?"
|
| 204 |
+
# default
|
| 205 |
+
default_comment = "" if "default" not in value else f" // default: {__format_default(value)}"
|
| 206 |
+
# add string
|
| 207 |
+
result += description + " " * indent + f"{key}{optional}: {value_rendered},{default_comment}\n"
|
| 208 |
+
result += (" " * (indent - 1)) + "}"
|
| 209 |
+
return result
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
# よくわからん
|
| 213 |
+
# def resolve_ref(schema):
|
| 214 |
+
# if schema.get("$ref") is not None:
|
| 215 |
+
# ref = schema["$ref"][14:]
|
| 216 |
+
# schema = json_schema["definitions"][ref]
|
| 217 |
+
# return schema
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
def __format_schema(schema: dict[str, Any], indent: int) -> str | None:
|
| 221 |
+
# schema <- resolve_ref(schema)
|
| 222 |
+
if "enum" in schema:
|
| 223 |
+
return __format_enum(schema)
|
| 224 |
+
elif schema["type"] == "object":
|
| 225 |
+
return __format_object(schema, indent)
|
| 226 |
+
elif schema["type"] in {"integer", "number"}:
|
| 227 |
+
return "number"
|
| 228 |
+
elif schema["type"] in {"string"}:
|
| 229 |
+
return "string"
|
| 230 |
+
elif schema["type"] == "array":
|
| 231 |
+
return str(__format_schema(schema["items"], indent)) + "[]"
|
| 232 |
+
else:
|
| 233 |
+
raise ValueError("unknown schema type " + schema["type"])
|
| 234 |
+
|
| 235 |
+
|
| 236 |
+
def __format_enum(schema: dict[str, Any]) -> str:
|
| 237 |
+
# "A" | "B" | "C"
|
| 238 |
+
return " | ".join(json.dumps(element, ensure_ascii=False) for element in schema["enum"])
|
| 239 |
+
|
| 240 |
+
|
| 241 |
+
def __format_default(schema: dict[str, Any]) -> str:
|
| 242 |
+
default = schema["default"]
|
| 243 |
+
if schema["type"] == "number" and float(default).is_integer():
|
| 244 |
+
# numberの時、0 → 0.0
|
| 245 |
+
return f"{default:.1f}"
|
| 246 |
+
else:
|
| 247 |
+
return str(default)
|
neollm/llm/platform.py
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from enum import Enum
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
class Platform(str, Enum):
|
| 5 |
+
AZURE = "azure"
|
| 6 |
+
OPENAI = "openai"
|
| 7 |
+
ANTHROPIC = "anthropic"
|
| 8 |
+
GCP = "gcp"
|
| 9 |
+
|
| 10 |
+
@classmethod
|
| 11 |
+
def from_string(cls, platform: str) -> "Platform":
|
| 12 |
+
platform = platform.lower().strip()
|
| 13 |
+
try:
|
| 14 |
+
return cls(platform)
|
| 15 |
+
except Exception:
|
| 16 |
+
raise ValueError(f"platform must be {cls.__members__}, but got {platform}.")
|
neollm/llm/utils.py
ADDED
|
@@ -0,0 +1,72 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Any, TypeVar
|
| 2 |
+
|
| 3 |
+
from neollm.utils.utils import cprint
|
| 4 |
+
|
| 5 |
+
Immutable = tuple[Any, ...] | str | int | float | bool
|
| 6 |
+
_T = TypeVar("_T")
|
| 7 |
+
_TD = TypeVar("_TD")
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def _to_immutable(x: Any) -> Immutable:
|
| 11 |
+
"""list, dictをtupleに変換して, setに格納できるようにする
|
| 12 |
+
|
| 13 |
+
Args:
|
| 14 |
+
x (Any): 要素
|
| 15 |
+
|
| 16 |
+
Returns:
|
| 17 |
+
Immutable: Immutableな要素(dict, listはtupleに変換)
|
| 18 |
+
"""
|
| 19 |
+
if isinstance(x, list):
|
| 20 |
+
return tuple(map(_to_immutable, x))
|
| 21 |
+
if isinstance(x, dict):
|
| 22 |
+
return tuple((key, _to_immutable(value)) for key, value in sorted(x.items()))
|
| 23 |
+
if isinstance(x, (set, frozenset)):
|
| 24 |
+
return tuple(sorted(map(_to_immutable, x)))
|
| 25 |
+
if isinstance(x, (str, int, float, bool)):
|
| 26 |
+
return x
|
| 27 |
+
cprint("_to_immutable: not supported: 無理やりstr(*)", color="yellow", background=True)
|
| 28 |
+
return str(x)
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def _remove_duplicate(arr: list[_T | None]) -> list[_T]:
|
| 32 |
+
"""listの重複と初期値を削除する
|
| 33 |
+
|
| 34 |
+
Args:
|
| 35 |
+
arr (list[Any]): リスト
|
| 36 |
+
|
| 37 |
+
Returns:
|
| 38 |
+
list[Any]: 重複削除済みのlist
|
| 39 |
+
"""
|
| 40 |
+
seen_set: set[Immutable] = set()
|
| 41 |
+
unique_list: list[_T] = []
|
| 42 |
+
for x in arr:
|
| 43 |
+
if x is None or bool(x) is False:
|
| 44 |
+
continue
|
| 45 |
+
x_immutable = _to_immutable(x)
|
| 46 |
+
if x_immutable not in seen_set:
|
| 47 |
+
unique_list.append(x)
|
| 48 |
+
seen_set.add(x_immutable)
|
| 49 |
+
return unique_list
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def get_entity(arr: list[_T | None], default: _TD, index: int | None = None) -> _T | _TD:
|
| 53 |
+
"""listから必要な1要素を取得する
|
| 54 |
+
|
| 55 |
+
Args:
|
| 56 |
+
arr (list[Any]): list
|
| 57 |
+
default (Any): 初期値
|
| 58 |
+
index (int | None, optional): 複数ある場合、指定のindex. Defaults to None.
|
| 59 |
+
|
| 60 |
+
Returns:
|
| 61 |
+
Any: 要素
|
| 62 |
+
"""
|
| 63 |
+
arr_cleaned = _remove_duplicate(arr)
|
| 64 |
+
if len(arr_cleaned) == 0:
|
| 65 |
+
return default
|
| 66 |
+
if len(arr_cleaned) == 1:
|
| 67 |
+
return arr_cleaned[0]
|
| 68 |
+
if index is not None:
|
| 69 |
+
return arr_cleaned[index]
|
| 70 |
+
cprint("get_entity: not unique", color="yellow", background=True)
|
| 71 |
+
cprint(arr_cleaned, color="yellow", background=True)
|
| 72 |
+
return arr_cleaned[0]
|
neollm/myllm/abstract_myllm.py
ADDED
|
@@ -0,0 +1,148 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from abc import ABC, abstractmethod
|
| 2 |
+
from typing import TYPE_CHECKING, Generator, Generic, Optional, TypeAlias, cast
|
| 3 |
+
|
| 4 |
+
from neollm.myllm.print_utils import print_inputs, print_metadata, print_outputs
|
| 5 |
+
from neollm.types import (
|
| 6 |
+
InputType,
|
| 7 |
+
OutputType,
|
| 8 |
+
PriceInfo,
|
| 9 |
+
StreamOutputType,
|
| 10 |
+
TimeInfo,
|
| 11 |
+
TokenInfo,
|
| 12 |
+
)
|
| 13 |
+
from neollm.utils.utils import cprint
|
| 14 |
+
|
| 15 |
+
if TYPE_CHECKING:
|
| 16 |
+
from typing import Any
|
| 17 |
+
|
| 18 |
+
from neollm.myllm.myl3m2 import MyL3M2
|
| 19 |
+
|
| 20 |
+
_MyL3M2: TypeAlias = MyL3M2[Any, Any]
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
class AbstractMyLLM(ABC, Generic[InputType, OutputType]):
|
| 24 |
+
"""MyLLM, MyL3M2の抽象クラス"""
|
| 25 |
+
|
| 26 |
+
inputs: InputType | None
|
| 27 |
+
outputs: OutputType | None
|
| 28 |
+
silent_set: set[str]
|
| 29 |
+
verbose: bool
|
| 30 |
+
time: float = 0.0
|
| 31 |
+
time_detail: TimeInfo = TimeInfo()
|
| 32 |
+
parent: Optional["_MyL3M2"] = None
|
| 33 |
+
do_stream: bool
|
| 34 |
+
|
| 35 |
+
@property
|
| 36 |
+
@abstractmethod
|
| 37 |
+
def token(self) -> TokenInfo:
|
| 38 |
+
"""LLMの利用トークン数
|
| 39 |
+
|
| 40 |
+
Returns:
|
| 41 |
+
TokenInfo: トークン数 (入力, 出力, 合計)
|
| 42 |
+
>>> TokenInfo(input=1588, output=128, total=1716)
|
| 43 |
+
"""
|
| 44 |
+
|
| 45 |
+
@property
|
| 46 |
+
def custom_token(self) -> TokenInfo | None:
|
| 47 |
+
"""料金計算用トークン(Gemini用)"""
|
| 48 |
+
return None
|
| 49 |
+
|
| 50 |
+
@property
|
| 51 |
+
@abstractmethod
|
| 52 |
+
def price(self) -> PriceInfo:
|
| 53 |
+
"""LLMの利用料金 (USD)
|
| 54 |
+
|
| 55 |
+
Returns:
|
| 56 |
+
PriceInfo: 利用料金 (USD) (入力, 出力, 合計)
|
| 57 |
+
>>> PriceInfo(input=0.002382, output=0.000256, total=0.002638)
|
| 58 |
+
"""
|
| 59 |
+
|
| 60 |
+
@abstractmethod
|
| 61 |
+
def _call(self, inputs: InputType, stream: bool = False) -> Generator[StreamOutputType, None, OutputType]:
|
| 62 |
+
"""MyLLMの子クラスのメインロジック
|
| 63 |
+
|
| 64 |
+
streamとnon-streamの両方のコードを書く必要がある
|
| 65 |
+
|
| 66 |
+
Args:
|
| 67 |
+
inputs (InputType): LLMへの入力
|
| 68 |
+
stream (bool, optional): streamの有無. Defaults to False.
|
| 69 |
+
|
| 70 |
+
Yields:
|
| 71 |
+
Generator[StreamOutputType, None, OutputType]: LLMのstream出力
|
| 72 |
+
|
| 73 |
+
Returns:
|
| 74 |
+
OutputType: LLMの出力
|
| 75 |
+
"""
|
| 76 |
+
|
| 77 |
+
def __call__(self, inputs: InputType) -> OutputType:
|
| 78 |
+
"""MyLLMのメインロジック
|
| 79 |
+
|
| 80 |
+
Args:
|
| 81 |
+
inputs (InputType): LLMへの入力
|
| 82 |
+
|
| 83 |
+
Returns:
|
| 84 |
+
OutputType: LLMの出力
|
| 85 |
+
"""
|
| 86 |
+
it: Generator[StreamOutputType, None, OutputType] = self._call(inputs, stream=self.do_stream)
|
| 87 |
+
while True:
|
| 88 |
+
try:
|
| 89 |
+
next(it)
|
| 90 |
+
except StopIteration as e:
|
| 91 |
+
outputs = cast(OutputType, e.value)
|
| 92 |
+
return outputs
|
| 93 |
+
except Exception as e:
|
| 94 |
+
raise e
|
| 95 |
+
|
| 96 |
+
def call_stream(self, inputs: InputType) -> Generator[StreamOutputType, None, OutputType]:
|
| 97 |
+
"""MyLLMのメインロジック(stream処理)
|
| 98 |
+
|
| 99 |
+
Args:
|
| 100 |
+
inputs (InputType): LLMへの入力
|
| 101 |
+
|
| 102 |
+
Yields:
|
| 103 |
+
Generator[StreamOutputType, None, OutputType]: LLMのstream出力
|
| 104 |
+
|
| 105 |
+
Returns:
|
| 106 |
+
LLMの出力
|
| 107 |
+
"""
|
| 108 |
+
it: Generator[StreamOutputType, None, OutputType] = self._call(inputs, stream=True)
|
| 109 |
+
while True:
|
| 110 |
+
try:
|
| 111 |
+
delta_content = next(it)
|
| 112 |
+
yield delta_content
|
| 113 |
+
except StopIteration as e:
|
| 114 |
+
outputs = cast(OutputType, e.value)
|
| 115 |
+
return outputs
|
| 116 |
+
except Exception as e:
|
| 117 |
+
raise e
|
| 118 |
+
|
| 119 |
+
def _print_inputs(self) -> None:
|
| 120 |
+
if self.inputs is None:
|
| 121 |
+
return
|
| 122 |
+
if not ("inputs" not in self.silent_set and self.verbose):
|
| 123 |
+
return
|
| 124 |
+
print_inputs(self.inputs)
|
| 125 |
+
|
| 126 |
+
def _print_outputs(self) -> None:
|
| 127 |
+
if self.outputs is None:
|
| 128 |
+
return
|
| 129 |
+
if not ("outputs" not in self.silent_set and self.verbose):
|
| 130 |
+
return
|
| 131 |
+
print_outputs(self.outputs)
|
| 132 |
+
|
| 133 |
+
def _print_metadata(self) -> None:
|
| 134 |
+
if not ("metadata" not in self.silent_set and self.verbose):
|
| 135 |
+
return
|
| 136 |
+
print_metadata(self.time, self.token, self.price)
|
| 137 |
+
|
| 138 |
+
def _print_start(self, sep: str = "-") -> None:
|
| 139 |
+
if not self.verbose:
|
| 140 |
+
return
|
| 141 |
+
if self.parent is None:
|
| 142 |
+
cprint("PARENT", color="red", background=True)
|
| 143 |
+
print(self, sep * (99 - len(str(self))))
|
| 144 |
+
|
| 145 |
+
def _print_end(self, sep: str = "-") -> None:
|
| 146 |
+
if not self.verbose:
|
| 147 |
+
return
|
| 148 |
+
print(sep * 100)
|
neollm/myllm/myl3m2.py
ADDED
|
@@ -0,0 +1,165 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from __future__ import annotations
|
| 2 |
+
|
| 3 |
+
import time
|
| 4 |
+
from typing import Any, Generator, Literal, Optional, cast
|
| 5 |
+
|
| 6 |
+
from neollm.myllm.abstract_myllm import AbstractMyLLM
|
| 7 |
+
from neollm.myllm.myllm import MyLLM
|
| 8 |
+
from neollm.myllm.print_utils import TITLE_COLOR
|
| 9 |
+
from neollm.types import (
|
| 10 |
+
InputType,
|
| 11 |
+
OutputType,
|
| 12 |
+
PriceInfo,
|
| 13 |
+
StreamOutputType,
|
| 14 |
+
TimeInfo,
|
| 15 |
+
TokenInfo,
|
| 16 |
+
)
|
| 17 |
+
from neollm.utils.utils import cprint
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class MyL3M2(AbstractMyLLM[InputType, OutputType]):
|
| 21 |
+
"""LLMの複数リクエストをまとめるクラス"""
|
| 22 |
+
|
| 23 |
+
do_stream: bool = False # stream_verboseがないため、__call__ではstreamを使わない
|
| 24 |
+
|
| 25 |
+
def __init__(
|
| 26 |
+
self,
|
| 27 |
+
parent: Optional["MyL3M2[Any, Any]"] = None,
|
| 28 |
+
verbose: bool = False,
|
| 29 |
+
silent_list: list[Literal["inputs", "outputs", "metadata", "all_myllm"]] | None = None,
|
| 30 |
+
) -> None:
|
| 31 |
+
"""
|
| 32 |
+
MyL3M2の初期化
|
| 33 |
+
|
| 34 |
+
Args:
|
| 35 |
+
parent (MyL3M2, optional):
|
| 36 |
+
親のMyL3M2のインスタンス(self or None)
|
| 37 |
+
verbose (bool, optional):
|
| 38 |
+
出力をするかどうかのフラグ. Defaults to False.
|
| 39 |
+
sileznt_list (list[Literal["inputs", "outputs", "metadata", "all_myllm"]], optional):
|
| 40 |
+
サイレントモードのリスト。出力を抑制する要素を指定する。. Defaults to None(=[]).
|
| 41 |
+
"""
|
| 42 |
+
self.parent = parent
|
| 43 |
+
self.verbose = verbose
|
| 44 |
+
self.silent_set = set(silent_list or [])
|
| 45 |
+
self.myllm_list: list["MyL3M2[Any, Any]" | MyLLM[Any, Any]] = []
|
| 46 |
+
self.inputs: InputType | None = None
|
| 47 |
+
self.outputs: OutputType | None = None
|
| 48 |
+
self.called: bool = False
|
| 49 |
+
|
| 50 |
+
def _link(self, inputs: InputType) -> OutputType:
|
| 51 |
+
"""複数のLLMの処理を行う
|
| 52 |
+
|
| 53 |
+
Args:
|
| 54 |
+
inputs (InputType): 入力データを保持する辞書
|
| 55 |
+
|
| 56 |
+
Returns:
|
| 57 |
+
OutputType: 処理結果の出力データ
|
| 58 |
+
"""
|
| 59 |
+
raise NotImplementedError("_link(self, inputs: InputType) -> OutputType:を実装してください")
|
| 60 |
+
|
| 61 |
+
def _stream_link(self, inputs: InputType) -> Generator[StreamOutputType, None, OutputType]:
|
| 62 |
+
"""複数のLLMの処理を行う(stream処理)
|
| 63 |
+
|
| 64 |
+
Args:
|
| 65 |
+
inputs (InputType): 入力データを保持する辞書
|
| 66 |
+
|
| 67 |
+
Yields:
|
| 68 |
+
Generator[StreamOutputType, None, OutputType]: 処理結果の出力データ(stream)
|
| 69 |
+
|
| 70 |
+
Returns:
|
| 71 |
+
self.outputsに入れたいもの
|
| 72 |
+
"""
|
| 73 |
+
raise NotImplementedError(
|
| 74 |
+
"_stream_link(self, inputs: InputType) -> Generator[StreamOutputType, None, None]を実装してください"
|
| 75 |
+
)
|
| 76 |
+
|
| 77 |
+
def _call(self, inputs: InputType, stream: bool = False) -> Generator[StreamOutputType, None, OutputType]:
|
| 78 |
+
if self.called:
|
| 79 |
+
raise RuntimeError("MyLLMは1回しか呼び出せない")
|
| 80 |
+
|
| 81 |
+
self._print_start(sep="=")
|
| 82 |
+
|
| 83 |
+
# main -----------------------------------------------------------
|
| 84 |
+
t_start = time.time()
|
| 85 |
+
self.inputs = inputs
|
| 86 |
+
# [stream]
|
| 87 |
+
if stream:
|
| 88 |
+
it = self._stream_link(inputs)
|
| 89 |
+
while True:
|
| 90 |
+
try:
|
| 91 |
+
yield next(it)
|
| 92 |
+
except StopIteration as e:
|
| 93 |
+
self.outputs = cast(OutputType, e.value)
|
| 94 |
+
break
|
| 95 |
+
except Exception as e:
|
| 96 |
+
raise e
|
| 97 |
+
# [non-stream]
|
| 98 |
+
else:
|
| 99 |
+
self.outputs = self._link(inputs)
|
| 100 |
+
self._print_inputs()
|
| 101 |
+
self._print_outputs()
|
| 102 |
+
self._print_all_myllm()
|
| 103 |
+
self.time = time.time() - t_start
|
| 104 |
+
self.time_detail = TimeInfo(total=self.time, main=self.time)
|
| 105 |
+
|
| 106 |
+
# metadata -----------------------------------------------------------
|
| 107 |
+
self._print_metadata()
|
| 108 |
+
self._print_end(sep="=")
|
| 109 |
+
|
| 110 |
+
# 親MyL3M2にAppend -----------------------------------------------------------
|
| 111 |
+
if self.parent is not None:
|
| 112 |
+
self.parent.myllm_list.append(self)
|
| 113 |
+
self.called = True
|
| 114 |
+
|
| 115 |
+
return self.outputs
|
| 116 |
+
|
| 117 |
+
@property
|
| 118 |
+
def token(self) -> TokenInfo:
|
| 119 |
+
token = TokenInfo(input=0, output=0, total=0)
|
| 120 |
+
for myllm in self.myllm_list:
|
| 121 |
+
# TODO: token += myllm.token
|
| 122 |
+
token.input += myllm.token.input
|
| 123 |
+
token.output += myllm.token.output
|
| 124 |
+
token.total += myllm.token.total
|
| 125 |
+
return token
|
| 126 |
+
|
| 127 |
+
@property
|
| 128 |
+
def price(self) -> PriceInfo:
|
| 129 |
+
price = PriceInfo(input=0.0, output=0.0, total=0.0)
|
| 130 |
+
for myllm in self.myllm_list:
|
| 131 |
+
# TODO: price += myllm.price
|
| 132 |
+
price.input += myllm.price.input
|
| 133 |
+
price.output += myllm.price.output
|
| 134 |
+
price.total += myllm.price.total
|
| 135 |
+
return price
|
| 136 |
+
|
| 137 |
+
@property
|
| 138 |
+
def logs(self) -> list[Any]:
|
| 139 |
+
logs: list[Any] = []
|
| 140 |
+
for myllm in self.myllm_list:
|
| 141 |
+
if isinstance(myllm, MyLLM):
|
| 142 |
+
logs.append(myllm.log)
|
| 143 |
+
elif isinstance(myllm, MyL3M2):
|
| 144 |
+
logs.extend(myllm.logs)
|
| 145 |
+
return logs
|
| 146 |
+
|
| 147 |
+
def _print_all_myllm(self, prefix: str = "", title: bool = True) -> None:
|
| 148 |
+
if not ("all_myllm" not in self.silent_set and self.verbose):
|
| 149 |
+
return
|
| 150 |
+
try:
|
| 151 |
+
if title:
|
| 152 |
+
cprint("[all_myllm]", color=TITLE_COLOR)
|
| 153 |
+
print(" ", end="")
|
| 154 |
+
cprint(f"{self}", color="magenta", bold=True, underline=True)
|
| 155 |
+
for myllm in self.myllm_list:
|
| 156 |
+
if isinstance(myllm, MyLLM):
|
| 157 |
+
cprint(f" {prefix}- {myllm}", color="cyan")
|
| 158 |
+
elif isinstance(myllm, MyL3M2):
|
| 159 |
+
cprint(f" {prefix}- {myllm}", color="magenta")
|
| 160 |
+
myllm._print_all_myllm(prefix=prefix + " ", title=False)
|
| 161 |
+
except Exception as e:
|
| 162 |
+
cprint(e, color="red", background=True)
|
| 163 |
+
|
| 164 |
+
def __repr__(self) -> str:
|
| 165 |
+
return f"MyL3M2({self.__class__.__name__})"
|
neollm/myllm/myllm.py
ADDED
|
@@ -0,0 +1,449 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import time
|
| 3 |
+
from abc import abstractmethod
|
| 4 |
+
from typing import TYPE_CHECKING, Any, Final, Generator, Literal, Optional
|
| 5 |
+
|
| 6 |
+
from neollm.exceptions import ContentFilterError
|
| 7 |
+
from neollm.llm import AbstractLLM, get_llm
|
| 8 |
+
from neollm.llm.gpt.azure_llm import AzureLLM
|
| 9 |
+
from neollm.myllm.abstract_myllm import AbstractMyLLM
|
| 10 |
+
from neollm.myllm.print_utils import (
|
| 11 |
+
print_client_settings,
|
| 12 |
+
print_delta,
|
| 13 |
+
print_llm_settings,
|
| 14 |
+
print_messages,
|
| 15 |
+
)
|
| 16 |
+
from neollm.types import (
|
| 17 |
+
Chunk,
|
| 18 |
+
ClientSettings,
|
| 19 |
+
Functions,
|
| 20 |
+
InputType,
|
| 21 |
+
LLMSettings,
|
| 22 |
+
Message,
|
| 23 |
+
Messages,
|
| 24 |
+
OutputType,
|
| 25 |
+
PriceInfo,
|
| 26 |
+
Response,
|
| 27 |
+
StreamOutputType,
|
| 28 |
+
TimeInfo,
|
| 29 |
+
TokenInfo,
|
| 30 |
+
Tools,
|
| 31 |
+
)
|
| 32 |
+
from neollm.types.openai.chat_completion import CompletionUsageForCustomPriceCalculation
|
| 33 |
+
from neollm.utils.preprocess import dict2json
|
| 34 |
+
from neollm.utils.utils import cprint
|
| 35 |
+
|
| 36 |
+
if TYPE_CHECKING:
|
| 37 |
+
from neollm.myllm.myl3m2 import MyL3M2
|
| 38 |
+
|
| 39 |
+
_MyL3M2 = MyL3M2[Any, Any]
|
| 40 |
+
_State = dict[Any, Any]
|
| 41 |
+
|
| 42 |
+
DEFAULT_LLM_SETTINGS: LLMSettings = {"temperature": 0}
|
| 43 |
+
DEFAULT_PLATFORM: Final[str] = "azure"
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
class MyLLM(AbstractMyLLM[InputType, OutputType]):
|
| 47 |
+
"""LLMの単一リクエストをまとめるクラス"""
|
| 48 |
+
|
| 49 |
+
def __init__(
|
| 50 |
+
self,
|
| 51 |
+
model: str,
|
| 52 |
+
parent: Optional["_MyL3M2"] = None,
|
| 53 |
+
llm_settings: LLMSettings | None = None,
|
| 54 |
+
client_settings: ClientSettings | None = None,
|
| 55 |
+
platform: str | None = None,
|
| 56 |
+
verbose: bool = False,
|
| 57 |
+
stream_verbose: bool = False,
|
| 58 |
+
silent_list: list[Literal["llm_settings", "inputs", "outputs", "messages", "metadata"]] | None = None,
|
| 59 |
+
log_dir: str | None = None,
|
| 60 |
+
) -> None:
|
| 61 |
+
"""
|
| 62 |
+
MyLLMクラスの初期化
|
| 63 |
+
|
| 64 |
+
Args:
|
| 65 |
+
model (Optional[str]): LLMモデル名
|
| 66 |
+
parent (Optional[MyL3M2]): 親のMyL3M2のインスタンス (self or None)
|
| 67 |
+
llm_settings (LLMSettings): LLMの設定パラメータ
|
| 68 |
+
client_settings (ClientSettings): llmのclientの設定パラメータ
|
| 69 |
+
platform (Optional[str]): LLMのプラットフォーム名 (デフォルト: os.environ["PLATFORM"] or "azure")
|
| 70 |
+
(enum: openai, azure)
|
| 71 |
+
verbose (bool): 出力をするかどうかのフラグ
|
| 72 |
+
stream_verbose (bool): assitantをstreamで出力するか(verbose=False, message in "messages"の時、無効)
|
| 73 |
+
silent_list (list[Literal["llm_settings", "inputs", "outputs", "messages", "metadata"]]):
|
| 74 |
+
verbose=True時, 出力を抑制する要素のリスト
|
| 75 |
+
log_dir (Optional[str]): ログを保存するディレクトリのパス Noneの時、保存しない
|
| 76 |
+
"""
|
| 77 |
+
self.parent: _MyL3M2 | None = parent
|
| 78 |
+
self.llm_settings = llm_settings or DEFAULT_LLM_SETTINGS
|
| 79 |
+
self.client_settings = client_settings or {}
|
| 80 |
+
self.model: str = model
|
| 81 |
+
self.platform: str = platform or os.environ.get("LLM_PLATFORM", DEFAULT_PLATFORM) or DEFAULT_PLATFORM
|
| 82 |
+
self.verbose: bool = verbose & (True if self.parent is None else self.parent.verbose) # 親に合わせる
|
| 83 |
+
self.silent_set = set(silent_list or [])
|
| 84 |
+
self.stream_verbose: bool = stream_verbose if verbose and ("messages" not in self.silent_set) else False
|
| 85 |
+
self.log_dir: str | None = log_dir
|
| 86 |
+
|
| 87 |
+
self.inputs: InputType | None = None
|
| 88 |
+
self.outputs: OutputType | None = None
|
| 89 |
+
self.messages: Messages | None = None
|
| 90 |
+
self.functions: Functions | None = None
|
| 91 |
+
self.tools: Tools | None = None
|
| 92 |
+
self.response: Response | None = None
|
| 93 |
+
self.called: bool = False
|
| 94 |
+
self.do_stream: bool = self.stream_verbose
|
| 95 |
+
|
| 96 |
+
self.llm: AbstractLLM = get_llm(
|
| 97 |
+
model_name=self.model, platform=self.platform, client_settings=self.client_settings
|
| 98 |
+
)
|
| 99 |
+
|
| 100 |
+
@abstractmethod
|
| 101 |
+
def _preprocess(self, inputs: InputType) -> Messages:
|
| 102 |
+
"""
|
| 103 |
+
inputs を API入力 の messages に前処理する
|
| 104 |
+
|
| 105 |
+
Args:
|
| 106 |
+
inputs (InputType): 入力
|
| 107 |
+
|
| 108 |
+
Returns:
|
| 109 |
+
Messages: API入力 の messages
|
| 110 |
+
>>> [{"role": "system", "content": "system_prompt"}, {"role": "user", "content": "user_prompt"}]
|
| 111 |
+
"""
|
| 112 |
+
|
| 113 |
+
@abstractmethod
|
| 114 |
+
def _postprocess(self, response: Response) -> OutputType:
|
| 115 |
+
"""
|
| 116 |
+
API の response を outputs に後処理する
|
| 117 |
+
|
| 118 |
+
Args:
|
| 119 |
+
response (Response): API の response
|
| 120 |
+
>>> {"choices": [{"message": {"role": "assistant",
|
| 121 |
+
>>> "content": "This is a test!"}}]}
|
| 122 |
+
>>> {"choices": [{"message": {"role": "assistant",
|
| 123 |
+
>>> "function_call": {"name": "func", "arguments": "{a: 1}"}}]}
|
| 124 |
+
|
| 125 |
+
Returns:
|
| 126 |
+
OutputType: 出力
|
| 127 |
+
"""
|
| 128 |
+
|
| 129 |
+
def _ruleprocess(self, inputs: InputType) -> OutputType | None:
|
| 130 |
+
"""
|
| 131 |
+
ルールベース処理 or APIリクエスト の判断
|
| 132 |
+
|
| 133 |
+
Args:
|
| 134 |
+
inputs (InputType): MyLLMの入力
|
| 135 |
+
|
| 136 |
+
Returns:
|
| 137 |
+
RuleOutputs:
|
| 138 |
+
ルールベース処理の時、MyLLMの出力を返す
|
| 139 |
+
APIリクエストの時、Noneを返す
|
| 140 |
+
"""
|
| 141 |
+
return None
|
| 142 |
+
|
| 143 |
+
def _update_settings(self) -> None:
|
| 144 |
+
"""
|
| 145 |
+
APIの設定の更新
|
| 146 |
+
Note:
|
| 147 |
+
messageのトークン数
|
| 148 |
+
>>> self.llm.count_tokens(self.messsage)
|
| 149 |
+
|
| 150 |
+
モデル変更
|
| 151 |
+
>>> self.model = "gpt-3.5-turbo-16k"
|
| 152 |
+
|
| 153 |
+
パラメータ変更
|
| 154 |
+
>>> self.llm_settings = {"temperature": 0.2}
|
| 155 |
+
"""
|
| 156 |
+
return None
|
| 157 |
+
|
| 158 |
+
def _add_tools(self, inputs: InputType) -> Tools | None:
|
| 159 |
+
return None
|
| 160 |
+
|
| 161 |
+
def _add_functions(self, inputs: InputType) -> Functions | None:
|
| 162 |
+
"""
|
| 163 |
+
functions の追加
|
| 164 |
+
|
| 165 |
+
Args:
|
| 166 |
+
inputs (InputType): 入力
|
| 167 |
+
|
| 168 |
+
Returns:
|
| 169 |
+
Functions | None: functions。追加しない場合None
|
| 170 |
+
https://json-schema.org/understanding-json-schema/reference/index.html
|
| 171 |
+
>>> {
|
| 172 |
+
>>> "name": "関数名",
|
| 173 |
+
>>> "description": "関数の動作の説明。GPTは説明を見て利用するか選ぶ",
|
| 174 |
+
>>> "parameters": {
|
| 175 |
+
>>> "type": "object", "properties": {"city_name": {"type": "string", "description": "都市名"}},
|
| 176 |
+
>>> json-schema[https://json-schema.org/understanding-json-schema/reference/index.html]
|
| 177 |
+
>>> }
|
| 178 |
+
>>> }
|
| 179 |
+
"""
|
| 180 |
+
return None
|
| 181 |
+
|
| 182 |
+
def _stream_postprocess(
|
| 183 |
+
self,
|
| 184 |
+
new_chunk: Chunk,
|
| 185 |
+
state: "_State",
|
| 186 |
+
) -> StreamOutputType:
|
| 187 |
+
"""call_streamのGeneratorのpostprocess
|
| 188 |
+
|
| 189 |
+
Args:
|
| 190 |
+
new_chunk (OpenAIChunkResponse): 新しいchunk
|
| 191 |
+
state (dict[Any, Any]): 状態を持てるdict. 初めは、default {}. 状態が消えてしまうのでoverwriteしない。
|
| 192 |
+
|
| 193 |
+
Returns:
|
| 194 |
+
StreamOutputType: 一時的なoutput
|
| 195 |
+
"""
|
| 196 |
+
if len(new_chunk.choices) == 0:
|
| 197 |
+
return ""
|
| 198 |
+
return new_chunk.choices[0].delta.content
|
| 199 |
+
|
| 200 |
+
def _generate(self, stream: bool) -> Generator[StreamOutputType, None, None]:
|
| 201 |
+
"""
|
| 202 |
+
LLMの出力を得て、`self.response`に格納する
|
| 203 |
+
|
| 204 |
+
Args:
|
| 205 |
+
messages (list[dict[str, str]]): LLMの入力メッセージ
|
| 206 |
+
"""
|
| 207 |
+
# 例外処理 -----------------------------------------------------------
|
| 208 |
+
if self.messages is None:
|
| 209 |
+
raise ValueError("MessagesがNoneです。")
|
| 210 |
+
|
| 211 |
+
# kwargs -----------------------------------------------------------
|
| 212 |
+
generate_kwargs = dict(**self.llm_settings)
|
| 213 |
+
if self.functions is not None:
|
| 214 |
+
generate_kwargs["functions"] = self.functions
|
| 215 |
+
if self.functions is not None:
|
| 216 |
+
generate_kwargs["tools"] = self.tools
|
| 217 |
+
|
| 218 |
+
# generate ----------------------------------------------------------
|
| 219 |
+
self._print_messages() # verbose
|
| 220 |
+
self.llm = get_llm(model_name=self.model, platform=self.platform, client_settings=self.client_settings)
|
| 221 |
+
# [stream]
|
| 222 |
+
if stream or self.stream_verbose:
|
| 223 |
+
it = self.llm.generate_stream(messages=self.messages, llm_settings=generate_kwargs)
|
| 224 |
+
chunk_list: list[Chunk] = []
|
| 225 |
+
state: "_State" = {}
|
| 226 |
+
for chunk in it:
|
| 227 |
+
chunk_list.append(chunk)
|
| 228 |
+
self._print_delta(chunk=chunk) # verbose: stop→改行、conent, TODO: fc→出力
|
| 229 |
+
yield self._stream_postprocess(new_chunk=chunk, state=state)
|
| 230 |
+
self.response = self.llm.convert_nonstream_response(chunk_list, self.messages, self.functions)
|
| 231 |
+
# [non-stream]
|
| 232 |
+
else:
|
| 233 |
+
try:
|
| 234 |
+
self.response = self.llm.generate(messages=self.messages, llm_settings=generate_kwargs)
|
| 235 |
+
self._print_message_assistant()
|
| 236 |
+
except Exception as e:
|
| 237 |
+
raise e
|
| 238 |
+
|
| 239 |
+
# ContentFilterError -------------------------------------------------
|
| 240 |
+
if len(self.response.choices) == 0:
|
| 241 |
+
cprint(self.response, color="red", background=True)
|
| 242 |
+
raise ContentFilterError("入力のコンテンツフィルターに引っかかりました。")
|
| 243 |
+
if self.response.choices[0].finish_reason == "content_filter":
|
| 244 |
+
cprint(self.response, color="red", background=True)
|
| 245 |
+
raise ContentFilterError("出力のコンテンツフィルターに引っかかりました。")
|
| 246 |
+
|
| 247 |
+
def _call(self, inputs: InputType, stream: bool = False) -> Generator[StreamOutputType, None, OutputType]:
|
| 248 |
+
"""
|
| 249 |
+
LLMの処理を行う (preprocess, check_input, generate, postprocess)
|
| 250 |
+
|
| 251 |
+
Args:
|
| 252 |
+
inputs (InputType): 入力データを保持する辞書
|
| 253 |
+
|
| 254 |
+
Returns:
|
| 255 |
+
OutputType: 処理結果の出力データ
|
| 256 |
+
|
| 257 |
+
Raises:
|
| 258 |
+
RuntimeError: 既に呼び出されている場合に発生
|
| 259 |
+
"""
|
| 260 |
+
if self.called:
|
| 261 |
+
raise RuntimeError("MyLLMは1回しか呼び出せない")
|
| 262 |
+
|
| 263 |
+
self._print_start(sep="-")
|
| 264 |
+
|
| 265 |
+
# main -----------------------------------------------------------
|
| 266 |
+
t_start = time.time()
|
| 267 |
+
self.inputs = inputs
|
| 268 |
+
self._print_inputs()
|
| 269 |
+
rulebase_output = self._ruleprocess(inputs)
|
| 270 |
+
if rulebase_output is None: # API リクエストを送る場合
|
| 271 |
+
self._update_settings()
|
| 272 |
+
self.messages = self._preprocess(inputs)
|
| 273 |
+
self.functions = self._add_functions(inputs)
|
| 274 |
+
self.tools = self._add_tools(inputs)
|
| 275 |
+
t_preprocessed = time.time()
|
| 276 |
+
# [generate]
|
| 277 |
+
it = self._generate(stream=stream)
|
| 278 |
+
for delta_content in it: # stream=Falseの時、空のGenerator
|
| 279 |
+
yield delta_content
|
| 280 |
+
if self.response is None:
|
| 281 |
+
raise ValueError("responseがNoneです。")
|
| 282 |
+
t_generated = time.time()
|
| 283 |
+
# [postprocess]
|
| 284 |
+
self.outputs = self._postprocess(self.response)
|
| 285 |
+
t_postprocessed = time.time()
|
| 286 |
+
else: # ルールベースの場合
|
| 287 |
+
self.outputs = rulebase_output
|
| 288 |
+
t_preprocessed = t_generated = t_postprocessed = time.time()
|
| 289 |
+
self.time_detail = TimeInfo(
|
| 290 |
+
total=t_postprocessed - t_start,
|
| 291 |
+
preprocess=t_preprocessed - t_start,
|
| 292 |
+
main=t_generated - t_preprocessed,
|
| 293 |
+
postprocess=t_postprocessed - t_generated,
|
| 294 |
+
)
|
| 295 |
+
self.time = t_postprocessed - t_start
|
| 296 |
+
|
| 297 |
+
# print -----------------------------------------------------------
|
| 298 |
+
self._print_outputs()
|
| 299 |
+
self._print_client_settings()
|
| 300 |
+
self._print_llm_settings()
|
| 301 |
+
self._print_metadata()
|
| 302 |
+
self._print_end(sep="-")
|
| 303 |
+
|
| 304 |
+
# 親MyL3M2にAppend -----------------------------------------------------------
|
| 305 |
+
if self.parent is not None:
|
| 306 |
+
self.parent.myllm_list.append(self)
|
| 307 |
+
self.called = True
|
| 308 |
+
|
| 309 |
+
# log -----------------------------------------------------------
|
| 310 |
+
self._save_log()
|
| 311 |
+
|
| 312 |
+
return self.outputs
|
| 313 |
+
|
| 314 |
+
@property
|
| 315 |
+
def log(self) -> dict[str, Any]:
|
| 316 |
+
return {
|
| 317 |
+
"inputs": self.inputs,
|
| 318 |
+
"outputs": self.outputs,
|
| 319 |
+
"resposnse": self.response.model_dump() if self.response is not None else None,
|
| 320 |
+
"input_token": self.token.input,
|
| 321 |
+
"output_token": self.token.output,
|
| 322 |
+
"total_token": self.token.total,
|
| 323 |
+
"input_price": self.price.input,
|
| 324 |
+
"output_price": self.price.output,
|
| 325 |
+
"total_price": self.price.total,
|
| 326 |
+
"time": self.time,
|
| 327 |
+
"time_stamp": time.time(),
|
| 328 |
+
"llm_settings": self.llm_settings,
|
| 329 |
+
"client_settings": self.client_settings,
|
| 330 |
+
"model": self.model,
|
| 331 |
+
"platform": self.platform,
|
| 332 |
+
"verbose": self.verbose,
|
| 333 |
+
"messages": self.messages,
|
| 334 |
+
"assistant_message": self.assistant_message,
|
| 335 |
+
"functions": self.functions,
|
| 336 |
+
"tools": self.tools,
|
| 337 |
+
}
|
| 338 |
+
|
| 339 |
+
def _save_log(self) -> None:
|
| 340 |
+
if self.log_dir is None:
|
| 341 |
+
return
|
| 342 |
+
try:
|
| 343 |
+
log = self.log
|
| 344 |
+
json_string = dict2json(log)
|
| 345 |
+
|
| 346 |
+
save_log_path = os.path.join(self.log_dir, f"{log['time_stamp']}.json")
|
| 347 |
+
os.makedirs(self.log_dir, exist_ok=True)
|
| 348 |
+
with open(save_log_path, mode="w") as f:
|
| 349 |
+
f.write(json_string)
|
| 350 |
+
except Exception as e:
|
| 351 |
+
cprint(e, color="red", background=True)
|
| 352 |
+
|
| 353 |
+
@property
|
| 354 |
+
def token(self) -> TokenInfo:
|
| 355 |
+
if self.response is None or self.response.usage is None:
|
| 356 |
+
return TokenInfo(input=0, output=0, total=0)
|
| 357 |
+
return TokenInfo(
|
| 358 |
+
input=self.response.usage.prompt_tokens,
|
| 359 |
+
output=self.response.usage.completion_tokens,
|
| 360 |
+
total=self.response.usage.total_tokens,
|
| 361 |
+
)
|
| 362 |
+
|
| 363 |
+
@property
|
| 364 |
+
def custom_token(self) -> TokenInfo | None:
|
| 365 |
+
if not self.llm._custom_price_calculation:
|
| 366 |
+
return None
|
| 367 |
+
if self.response is None:
|
| 368 |
+
return TokenInfo(input=0, output=0, total=0)
|
| 369 |
+
usage_for_price = getattr(self.response, "usage_for_price", None)
|
| 370 |
+
if not isinstance(usage_for_price, CompletionUsageForCustomPriceCalculation):
|
| 371 |
+
cprint("usage_for_priceがNoneです。正しくトークン計算できません", color="red", background=True)
|
| 372 |
+
return TokenInfo(input=0, output=0, total=0)
|
| 373 |
+
return TokenInfo(
|
| 374 |
+
input=usage_for_price.prompt_tokens,
|
| 375 |
+
output=usage_for_price.completion_tokens,
|
| 376 |
+
total=usage_for_price.total_tokens,
|
| 377 |
+
)
|
| 378 |
+
|
| 379 |
+
@property
|
| 380 |
+
def price(self) -> PriceInfo:
|
| 381 |
+
if self.response is None:
|
| 382 |
+
return PriceInfo(input=0.0, output=0.0, total=0.0)
|
| 383 |
+
if self.llm._custom_price_calculation:
|
| 384 |
+
# Geniniの時は必ずcustom_tokenがある想定
|
| 385 |
+
if self.custom_token is None:
|
| 386 |
+
cprint("custom_tokenがNoneです。正しくトークン計算できません", color="red", background=True)
|
| 387 |
+
else:
|
| 388 |
+
return PriceInfo(
|
| 389 |
+
input=self.llm.calculate_price(num_input_tokens=self.custom_token.input),
|
| 390 |
+
output=self.llm.calculate_price(num_output_tokens=self.custom_token.output),
|
| 391 |
+
total=self.llm.calculate_price(
|
| 392 |
+
num_input_tokens=self.custom_token.input, num_output_tokens=self.custom_token.output
|
| 393 |
+
),
|
| 394 |
+
)
|
| 395 |
+
return PriceInfo(
|
| 396 |
+
input=self.llm.calculate_price(num_input_tokens=self.token.input),
|
| 397 |
+
output=self.llm.calculate_price(num_output_tokens=self.token.output),
|
| 398 |
+
total=self.llm.calculate_price(num_input_tokens=self.token.input, num_output_tokens=self.token.output),
|
| 399 |
+
)
|
| 400 |
+
|
| 401 |
+
@property
|
| 402 |
+
def assistant_message(self) -> Message | None:
|
| 403 |
+
if self.response is None or len(self.response.choices) == 0:
|
| 404 |
+
return None
|
| 405 |
+
return self.response.choices[0].message.to_typeddict_message()
|
| 406 |
+
|
| 407 |
+
@property
|
| 408 |
+
def chat_history(self) -> Messages:
|
| 409 |
+
chat_history: Messages = []
|
| 410 |
+
if self.messages:
|
| 411 |
+
chat_history += self.messages
|
| 412 |
+
if self.assistant_message is not None:
|
| 413 |
+
chat_history.append(self.assistant_message)
|
| 414 |
+
return chat_history
|
| 415 |
+
|
| 416 |
+
def _print_llm_settings(self) -> None:
|
| 417 |
+
if not ("llm_settings" not in self.silent_set and self.verbose):
|
| 418 |
+
return
|
| 419 |
+
print_llm_settings(
|
| 420 |
+
llm_settings=self.llm_settings,
|
| 421 |
+
model=self.model,
|
| 422 |
+
platform=self.platform,
|
| 423 |
+
engine=self.llm.engine if isinstance(self.llm, AzureLLM) else None,
|
| 424 |
+
)
|
| 425 |
+
|
| 426 |
+
def _print_messages(self) -> None:
|
| 427 |
+
if not ("messages" not in self.silent_set and self.verbose):
|
| 428 |
+
return
|
| 429 |
+
print_messages(self.messages, title=True)
|
| 430 |
+
|
| 431 |
+
def _print_message_assistant(self) -> None:
|
| 432 |
+
if self.response is None or len(self.response.choices) == 0:
|
| 433 |
+
return
|
| 434 |
+
if not ("messages" not in self.silent_set and self.verbose):
|
| 435 |
+
return
|
| 436 |
+
print_messages(messages=[self.response.choices[0].message], title=False)
|
| 437 |
+
|
| 438 |
+
def _print_delta(self, chunk: Chunk) -> None:
|
| 439 |
+
if not ("messages" not in self.silent_set and self.verbose):
|
| 440 |
+
return
|
| 441 |
+
print_delta(chunk)
|
| 442 |
+
|
| 443 |
+
def _print_client_settings(self) -> None:
|
| 444 |
+
if not ("client_settings" not in self.silent_set and self.verbose):
|
| 445 |
+
return
|
| 446 |
+
print_client_settings(self.llm.client_settings)
|
| 447 |
+
|
| 448 |
+
def __repr__(self) -> str:
|
| 449 |
+
return f"MyLLM({self.__class__.__name__})"
|
neollm/myllm/print_utils.py
ADDED
|
@@ -0,0 +1,235 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
from typing import Any
|
| 3 |
+
|
| 4 |
+
from openai.types.chat import ChatCompletionAssistantMessageParam
|
| 5 |
+
from openai.types.chat.chat_completion_assistant_message_param import FunctionCall
|
| 6 |
+
from openai.types.chat.chat_completion_message_tool_call_param import (
|
| 7 |
+
ChatCompletionMessageToolCallParam,
|
| 8 |
+
Function,
|
| 9 |
+
)
|
| 10 |
+
|
| 11 |
+
from neollm.types import (
|
| 12 |
+
ChatCompletionMessage,
|
| 13 |
+
Chunk,
|
| 14 |
+
ClientSettings,
|
| 15 |
+
InputType,
|
| 16 |
+
LLMSettings,
|
| 17 |
+
Message,
|
| 18 |
+
Messages,
|
| 19 |
+
OutputType,
|
| 20 |
+
PriceInfo,
|
| 21 |
+
PrintColor,
|
| 22 |
+
Role,
|
| 23 |
+
TokenInfo,
|
| 24 |
+
)
|
| 25 |
+
from neollm.utils.postprocess import json2dict
|
| 26 |
+
from neollm.utils.utils import CPrintParam, cprint
|
| 27 |
+
|
| 28 |
+
TITLE_COLOR: PrintColor = "blue"
|
| 29 |
+
YEN_PAR_DOLLAR: float = 140.0 # 150円になってしまったぴえん(231027)
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def _ChatCompletionMessage2dict(message: ChatCompletionMessage) -> Message:
|
| 33 |
+
message_dict = ChatCompletionAssistantMessageParam(content=message.content, role=message.role)
|
| 34 |
+
if message.function_call is not None:
|
| 35 |
+
message_dict["function_call"] = FunctionCall(
|
| 36 |
+
arguments=message.function_call.arguments, name=message.function_call.name
|
| 37 |
+
)
|
| 38 |
+
if message.tool_calls is not None:
|
| 39 |
+
message_dict["tool_calls"] = [
|
| 40 |
+
ChatCompletionMessageToolCallParam(
|
| 41 |
+
id=tool_call.id,
|
| 42 |
+
function=Function(arguments=tool_call.function.arguments, name=tool_call.function.name),
|
| 43 |
+
type=tool_call.type,
|
| 44 |
+
)
|
| 45 |
+
for tool_call in message.tool_calls
|
| 46 |
+
]
|
| 47 |
+
return message_dict
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def _get_tool_calls(message_dict: Message) -> list[ChatCompletionMessageToolCallParam]:
|
| 51 |
+
tool_calls: list[ChatCompletionMessageToolCallParam] = []
|
| 52 |
+
if "tool_calls" in message_dict:
|
| 53 |
+
_tool_calls = message_dict.get("tool_calls", None)
|
| 54 |
+
if _tool_calls is not None and isinstance(_tool_calls, list): # isinstance(_tool_calls, list)ないと通らん,,,
|
| 55 |
+
for _tool_call in _tool_calls:
|
| 56 |
+
tool_call = ChatCompletionMessageToolCallParam(
|
| 57 |
+
id=_tool_call["id"],
|
| 58 |
+
function=Function(
|
| 59 |
+
arguments=_tool_call["function"]["arguments"],
|
| 60 |
+
name=_tool_call["function"]["name"],
|
| 61 |
+
),
|
| 62 |
+
type=_tool_call["type"],
|
| 63 |
+
)
|
| 64 |
+
tool_calls.append(tool_call)
|
| 65 |
+
if "function_call" in message_dict:
|
| 66 |
+
function_call = message_dict.get("function_call", None)
|
| 67 |
+
if function_call is not None and isinstance(
|
| 68 |
+
function_call, dict
|
| 69 |
+
): # isinstance(function_call, dict)ないと通らん,,,
|
| 70 |
+
tool_calls.append(
|
| 71 |
+
ChatCompletionMessageToolCallParam(
|
| 72 |
+
id="",
|
| 73 |
+
function=Function(
|
| 74 |
+
arguments=function_call["arguments"],
|
| 75 |
+
name=function_call["name"],
|
| 76 |
+
),
|
| 77 |
+
type="function",
|
| 78 |
+
)
|
| 79 |
+
)
|
| 80 |
+
return tool_calls
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def print_metadata(time: float, token: TokenInfo, price: PriceInfo) -> None:
|
| 84 |
+
try:
|
| 85 |
+
cprint("[metadata]", color=TITLE_COLOR, kwargs={"end": " "})
|
| 86 |
+
print(
|
| 87 |
+
f"{time:.1f}s; "
|
| 88 |
+
f"{token.total:,}({token.input:,}+{token.output:,})tokens; "
|
| 89 |
+
f"${price.total:.2g}; ¥{price.total*YEN_PAR_DOLLAR:.2g}"
|
| 90 |
+
)
|
| 91 |
+
except Exception as e:
|
| 92 |
+
cprint(e, color="red", background=True)
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
def print_inputs(inputs: InputType) -> None:
|
| 96 |
+
try:
|
| 97 |
+
cprint("[inputs]", color=TITLE_COLOR)
|
| 98 |
+
print(json.dumps(_arange_dumpable_object(inputs), indent=2, ensure_ascii=False))
|
| 99 |
+
except Exception as e:
|
| 100 |
+
cprint(e, color="red", background=True)
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
def print_outputs(outputs: OutputType) -> None:
|
| 104 |
+
try:
|
| 105 |
+
cprint("[outputs]", color=TITLE_COLOR)
|
| 106 |
+
print(json.dumps(_arange_dumpable_object(outputs), indent=2, ensure_ascii=False))
|
| 107 |
+
except Exception as e:
|
| 108 |
+
cprint(e, color="red", background=True)
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
def print_messages(messages: list[ChatCompletionMessage] | Messages | None, title: bool = True) -> None:
|
| 112 |
+
if messages is None:
|
| 113 |
+
cprint("Not yet running _preprocess", color="red")
|
| 114 |
+
return
|
| 115 |
+
# try:
|
| 116 |
+
if title:
|
| 117 |
+
cprint("[messages]", color=TITLE_COLOR)
|
| 118 |
+
role2prarams: dict[Role, CPrintParam] = {
|
| 119 |
+
"system": {"color": "green"},
|
| 120 |
+
"user": {"color": "green"},
|
| 121 |
+
"assistant": {"color": "green"},
|
| 122 |
+
"function": {"color": "green", "background": True},
|
| 123 |
+
"tool": {"color": "green", "background": True},
|
| 124 |
+
}
|
| 125 |
+
for message in messages:
|
| 126 |
+
message_dict: Message
|
| 127 |
+
if isinstance(message, ChatCompletionMessage):
|
| 128 |
+
message_dict = _ChatCompletionMessage2dict(message)
|
| 129 |
+
else:
|
| 130 |
+
message_dict = message
|
| 131 |
+
|
| 132 |
+
# roleの出力 ----------------------------------------
|
| 133 |
+
print(" ", end="")
|
| 134 |
+
role = message_dict["role"]
|
| 135 |
+
cprint(role, **role2prarams[role])
|
| 136 |
+
|
| 137 |
+
# contentの出力 ----------------------------------------
|
| 138 |
+
content = message_dict.get("content", None)
|
| 139 |
+
if isinstance(content, str):
|
| 140 |
+
print(" " + content.replace("\n", "\n "))
|
| 141 |
+
elif isinstance(content, list):
|
| 142 |
+
for content_part in content:
|
| 143 |
+
if content_part["type"] == "text":
|
| 144 |
+
print(" " + content_part["text"].replace("\n", "\n "))
|
| 145 |
+
elif content_part["type"] == "image_url":
|
| 146 |
+
cprint(" <image_url>", color="green", kwargs={"end": " "})
|
| 147 |
+
print(content_part["image_url"])
|
| 148 |
+
# TODO: 画像出力
|
| 149 |
+
# TODO: Preview用、content_part["image"]: str, dict両方いけてしまう
|
| 150 |
+
else:
|
| 151 |
+
# TODO: 未対応のcontentの出力
|
| 152 |
+
pass
|
| 153 |
+
|
| 154 |
+
# tool_callの出力 ----------------------------------------
|
| 155 |
+
for tool_call in _get_tool_calls(message_dict):
|
| 156 |
+
print(" ", end="")
|
| 157 |
+
cprint(tool_call["function"]["name"], color="green", background=True)
|
| 158 |
+
print(" " + str(json2dict(tool_call["function"]["arguments"], error_key=None)).replace("\n", "\n "))
|
| 159 |
+
|
| 160 |
+
# except Exception as e:
|
| 161 |
+
# cprint(e, color="red", background=True)
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
def print_delta(chunk: Chunk) -> None:
|
| 165 |
+
if len(chunk.choices) == 0:
|
| 166 |
+
return
|
| 167 |
+
choice = chunk.choices[0] # TODO: n>2の対応
|
| 168 |
+
if choice.delta.role is not None:
|
| 169 |
+
print(" ", end="")
|
| 170 |
+
cprint(choice.delta.role, color="green")
|
| 171 |
+
print(" ", end="")
|
| 172 |
+
if choice.delta.content is not None:
|
| 173 |
+
print(choice.delta.content.replace("\n", "\n "), end="")
|
| 174 |
+
if choice.delta.function_call is not None:
|
| 175 |
+
if choice.delta.function_call.name is not None:
|
| 176 |
+
cprint(choice.delta.function_call.name, color="green", background=True)
|
| 177 |
+
print(" ", end="")
|
| 178 |
+
if choice.delta.function_call.arguments is not None:
|
| 179 |
+
print(choice.delta.function_call.arguments.replace("\n", "\n "), end="")
|
| 180 |
+
if choice.delta.tool_calls is not None:
|
| 181 |
+
for tool_call in choice.delta.tool_calls:
|
| 182 |
+
if tool_call.function is not None:
|
| 183 |
+
if tool_call.function.name is not None:
|
| 184 |
+
if tool_call.index != 0:
|
| 185 |
+
print("\n ", end="")
|
| 186 |
+
cprint(tool_call.function.name, color="green", background=True)
|
| 187 |
+
print(" ", end="")
|
| 188 |
+
if tool_call.function.arguments is not None:
|
| 189 |
+
print(tool_call.function.arguments.replace("\n", "\n "), end="")
|
| 190 |
+
if choice.finish_reason is not None:
|
| 191 |
+
print()
|
| 192 |
+
|
| 193 |
+
|
| 194 |
+
def print_llm_settings(llm_settings: LLMSettings, model: str, engine: str | None, platform: str) -> None:
|
| 195 |
+
try:
|
| 196 |
+
cprint("[llm_settings]", color=TITLE_COLOR, kwargs={"end": " "})
|
| 197 |
+
llm_settings_copy = dict(platform=platform, **llm_settings)
|
| 198 |
+
llm_settings_copy["model"] = model
|
| 199 |
+
# Azureの場合
|
| 200 |
+
if platform == "azure":
|
| 201 |
+
llm_settings_copy["engine"] = engine # engineを追加
|
| 202 |
+
print(llm_settings_copy or "-")
|
| 203 |
+
except Exception as e:
|
| 204 |
+
cprint(e, color="red", background=True)
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
def print_client_settings(client_settings: ClientSettings) -> None:
|
| 208 |
+
try:
|
| 209 |
+
cprint("[client_settings]", color=TITLE_COLOR, kwargs={"end": " "})
|
| 210 |
+
print(client_settings or "-")
|
| 211 |
+
except Exception as e:
|
| 212 |
+
cprint(e, color="red", background=True)
|
| 213 |
+
|
| 214 |
+
|
| 215 |
+
# -------
|
| 216 |
+
|
| 217 |
+
_DumplableEntity = int | float | str | bool | None | list[Any] | dict[Any, Any]
|
| 218 |
+
DumplableType = _DumplableEntity | list["DumplableType"] | dict["DumplableType", "DumplableType"]
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
def _arange_dumpable_object(obj: Any) -> DumplableType:
|
| 222 |
+
# 基本データ型の場合、そのまま返す
|
| 223 |
+
if isinstance(obj, (int, float, str, bool, type(None))):
|
| 224 |
+
return obj
|
| 225 |
+
|
| 226 |
+
# リストの場合、再帰的に各要素を変換
|
| 227 |
+
if isinstance(obj, list):
|
| 228 |
+
return [_arange_dumpable_object(item) for item in obj]
|
| 229 |
+
|
| 230 |
+
# 辞書の場合、再帰的に各キーと値を変換
|
| 231 |
+
if isinstance(obj, dict):
|
| 232 |
+
return {_arange_dumpable_object(key): _arange_dumpable_object(value) for key, value in obj.items()}
|
| 233 |
+
|
| 234 |
+
# それ以外の型の場合、型情報を含めて文字列に変換
|
| 235 |
+
return f"<{type(obj).__name__}>{str(obj)}"
|
neollm/types/__init__.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from neollm.types.info import * # NOQA
|
| 2 |
+
from neollm.types.mytypes import * # NOQA
|
| 3 |
+
from neollm.types.openai.chat_completion import * # NOQA
|
| 4 |
+
from neollm.types.openai.chat_completion_chunk import * # NOQA
|
neollm/types/_model.py
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Any
|
| 2 |
+
|
| 3 |
+
from openai._models import BaseModel
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class DictableBaseModel(BaseModel): # openaiのBaseModelをDictAccessできるようにした
|
| 7 |
+
def __getitem__(self, item: str) -> Any:
|
| 8 |
+
return getattr(self, item)
|
neollm/types/info.py
ADDED
|
@@ -0,0 +1,82 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Literal
|
| 2 |
+
|
| 3 |
+
from neollm.types._model import DictableBaseModel
|
| 4 |
+
|
| 5 |
+
PrintColor = Literal["black", "red", "green", "yellow", "blue", "magenta", "cyan", "white"]
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class TimeInfo(DictableBaseModel):
|
| 9 |
+
total: float = 0.0
|
| 10 |
+
"""処理時間合計 preprocess + main + postprocess"""
|
| 11 |
+
preprocess: float = 0.0
|
| 12 |
+
"""前処理時間"""
|
| 13 |
+
main: float = 0.0
|
| 14 |
+
"""メイン処理時間"""
|
| 15 |
+
postprocess: float = 0.0
|
| 16 |
+
"""後処理時間"""
|
| 17 |
+
|
| 18 |
+
def __repr__(self) -> str:
|
| 19 |
+
return (
|
| 20 |
+
f"TimeInfo(total={self.total:.3f}, preprocess={self.preprocess:.3f}, main={self.main:.3f}, "
|
| 21 |
+
f"postprocess={self.postprocess:.3f})"
|
| 22 |
+
)
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
class TokenInfo(DictableBaseModel):
|
| 26 |
+
input: int
|
| 27 |
+
"""入力部分のトークン数"""
|
| 28 |
+
output: int
|
| 29 |
+
"""出力部分のトークン数"""
|
| 30 |
+
total: int
|
| 31 |
+
"""合計トークン数"""
|
| 32 |
+
|
| 33 |
+
def __add__(self, other: "TokenInfo") -> "TokenInfo":
|
| 34 |
+
if not isinstance(other, TokenInfo):
|
| 35 |
+
raise TypeError(f"{other} is not TokenInfo")
|
| 36 |
+
return TokenInfo(
|
| 37 |
+
input=self.input + other.input, output=self.output + other.output, total=self.total + other.total
|
| 38 |
+
)
|
| 39 |
+
|
| 40 |
+
def __iadd__(self, other: "TokenInfo") -> "TokenInfo":
|
| 41 |
+
if not isinstance(other, TokenInfo):
|
| 42 |
+
raise TypeError(f"{other} is not TokenInfo")
|
| 43 |
+
self.input += other.input
|
| 44 |
+
self.output += other.output
|
| 45 |
+
self.total += other.total
|
| 46 |
+
return self
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
class PriceInfo(DictableBaseModel):
|
| 50 |
+
input: float
|
| 51 |
+
"""入力部分の費用 (USD)"""
|
| 52 |
+
output: float
|
| 53 |
+
"""出力部分の費用 (USD)"""
|
| 54 |
+
total: float
|
| 55 |
+
"""合計費用 (USD)"""
|
| 56 |
+
|
| 57 |
+
def __add__(self, other: "PriceInfo") -> "PriceInfo":
|
| 58 |
+
if not isinstance(other, PriceInfo):
|
| 59 |
+
raise TypeError(f"{other} is not PriceInfo")
|
| 60 |
+
return PriceInfo(
|
| 61 |
+
input=self.input + other.input, output=self.output + other.output, total=self.total + other.total
|
| 62 |
+
)
|
| 63 |
+
|
| 64 |
+
def __iadd__(self, other: "PriceInfo") -> "PriceInfo":
|
| 65 |
+
if not isinstance(other, PriceInfo):
|
| 66 |
+
raise TypeError(f"{other} is not PriceInfo")
|
| 67 |
+
self.input += other.input
|
| 68 |
+
self.output += other.output
|
| 69 |
+
self.total += other.total
|
| 70 |
+
return self
|
| 71 |
+
|
| 72 |
+
def __repr__(self) -> str:
|
| 73 |
+
return f"PriceInfo(input={self.input:.3f}, output={self.output:.3f}, total={self.total:.3f})"
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
class APIPricing(DictableBaseModel):
|
| 77 |
+
"""APIの価格設定に関する情報を表すクラス。"""
|
| 78 |
+
|
| 79 |
+
input: float
|
| 80 |
+
"""入力 1k tokens 当たりのAPI利用料 (USD)"""
|
| 81 |
+
output: float
|
| 82 |
+
"""出力 1k tokens 当たりのAPI利用料 (USD)"""
|
neollm/types/mytypes.py
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Any, Iterator, Literal, TypeVar
|
| 2 |
+
|
| 3 |
+
import openai.types.chat as openai_types
|
| 4 |
+
from openai._streaming import Stream
|
| 5 |
+
|
| 6 |
+
from neollm.types.openai.chat_completion import ChatCompletion
|
| 7 |
+
from neollm.types.openai.chat_completion_chunk import ChatCompletionChunk
|
| 8 |
+
|
| 9 |
+
Role = Literal["system", "user", "assistant", "tool", "function"]
|
| 10 |
+
# Settings
|
| 11 |
+
LLMSettings = dict[str, Any]
|
| 12 |
+
ClientSettings = dict[str, Any]
|
| 13 |
+
# Message
|
| 14 |
+
Message = openai_types.ChatCompletionMessageParam
|
| 15 |
+
Messages = list[Message]
|
| 16 |
+
Tools = Any
|
| 17 |
+
Functions = Any
|
| 18 |
+
# Response
|
| 19 |
+
Response = ChatCompletion
|
| 20 |
+
Chunk = ChatCompletionChunk
|
| 21 |
+
StreamResponse = Iterator[Chunk]
|
| 22 |
+
# IO
|
| 23 |
+
InputType = TypeVar("InputType")
|
| 24 |
+
OutputType = TypeVar("OutputType")
|
| 25 |
+
StreamOutputType = Any
|
| 26 |
+
|
| 27 |
+
# OpenAI --------------------------------------------
|
| 28 |
+
OpenAIResponse = openai_types.ChatCompletion
|
| 29 |
+
OpenAIChunk = openai_types.ChatCompletionChunk
|
| 30 |
+
OpenAIStreamResponse = Stream[OpenAIChunk] # OpneAI StreamResponse
|
| 31 |
+
OpenAIMessages = list[openai_types.ChatCompletionMessageParam]
|
neollm/types/openai/__init__.py
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from neollm.types.openai.chat_completion import * # NOQA
|
| 2 |
+
from neollm.types.openai.chat_completion_chunk import * # NOQA
|
neollm/types/openai/chat_completion.py
ADDED
|
@@ -0,0 +1,170 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List, Literal, Optional
|
| 2 |
+
|
| 3 |
+
from openai.types.chat import ChatCompletionAssistantMessageParam
|
| 4 |
+
from openai.types.chat.chat_completion_assistant_message_param import (
|
| 5 |
+
FunctionCall as FunctionCallParams,
|
| 6 |
+
)
|
| 7 |
+
from openai.types.chat.chat_completion_message_tool_call_param import (
|
| 8 |
+
ChatCompletionMessageToolCallParam,
|
| 9 |
+
)
|
| 10 |
+
from openai.types.chat.chat_completion_message_tool_call_param import (
|
| 11 |
+
Function as FunctionParams,
|
| 12 |
+
)
|
| 13 |
+
from pydantic import field_validator
|
| 14 |
+
|
| 15 |
+
from neollm.types._model import DictableBaseModel
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class CompletionUsage(DictableBaseModel):
|
| 19 |
+
completion_tokens: int
|
| 20 |
+
"""Number of tokens in the generated completion."""
|
| 21 |
+
|
| 22 |
+
prompt_tokens: int
|
| 23 |
+
"""Number of tokens in the prompt."""
|
| 24 |
+
|
| 25 |
+
total_tokens: int
|
| 26 |
+
"""Total number of tokens used in the request (prompt + completion)."""
|
| 27 |
+
|
| 28 |
+
# ADDED: gpt4v preview用(Noneを許容するため)
|
| 29 |
+
@field_validator("completion_tokens", "prompt_tokens", "total_tokens", mode="before")
|
| 30 |
+
def validate_name(cls, v: int | None) -> int:
|
| 31 |
+
return v or 0
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
class CompletionUsageForCustomPriceCalculation(DictableBaseModel):
|
| 35 |
+
completion_tokens: int
|
| 36 |
+
"""Number of tokens in the generated completion."""
|
| 37 |
+
|
| 38 |
+
prompt_tokens: int
|
| 39 |
+
"""Number of tokens in the prompt."""
|
| 40 |
+
|
| 41 |
+
total_tokens: int
|
| 42 |
+
"""Total number of tokens used in the request (prompt + completion)."""
|
| 43 |
+
|
| 44 |
+
# ADDED: gpt4v preview用(Noneを許容するため)
|
| 45 |
+
@field_validator("completion_tokens", "prompt_tokens", "total_tokens", mode="before")
|
| 46 |
+
def validate_name(cls, v: int | None) -> int:
|
| 47 |
+
return v or 0
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
class Function(DictableBaseModel):
|
| 51 |
+
arguments: str
|
| 52 |
+
"""
|
| 53 |
+
The arguments to call the function with, as generated by the model in JSON
|
| 54 |
+
format. Note that the model does not always generate valid JSON, and may
|
| 55 |
+
hallucinate parameters not defined by your function schema. Validate the
|
| 56 |
+
arguments in your code before calling your function.
|
| 57 |
+
"""
|
| 58 |
+
|
| 59 |
+
name: str
|
| 60 |
+
"""The name of the function to call."""
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
class ChatCompletionMessageToolCall(DictableBaseModel):
|
| 64 |
+
id: str
|
| 65 |
+
"""The ID of the tool call."""
|
| 66 |
+
|
| 67 |
+
function: Function
|
| 68 |
+
"""The function that the model called."""
|
| 69 |
+
|
| 70 |
+
type: Literal["function"]
|
| 71 |
+
"""The type of the tool. Currently, only `function` is supported."""
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
class FunctionCall(DictableBaseModel):
|
| 75 |
+
arguments: str
|
| 76 |
+
"""
|
| 77 |
+
The arguments to call the function with, as generated by the model in JSON
|
| 78 |
+
format. Note that the model does not always generate valid JSON, and may
|
| 79 |
+
hallucinate parameters not defined by your function schema. Validate the
|
| 80 |
+
arguments in your code before calling your function.
|
| 81 |
+
"""
|
| 82 |
+
|
| 83 |
+
name: str
|
| 84 |
+
"""The name of the function to call."""
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
class ChatCompletionMessage(DictableBaseModel):
|
| 88 |
+
content: Optional[str]
|
| 89 |
+
"""The contents of the message."""
|
| 90 |
+
|
| 91 |
+
role: Literal["assistant"]
|
| 92 |
+
"""The role of the author of this message."""
|
| 93 |
+
|
| 94 |
+
function_call: Optional[FunctionCall] = None
|
| 95 |
+
"""Deprecated and replaced by `tool_calls`.
|
| 96 |
+
|
| 97 |
+
The name and arguments of a function that should be called, as generated by the
|
| 98 |
+
model.
|
| 99 |
+
"""
|
| 100 |
+
|
| 101 |
+
tool_calls: Optional[List[ChatCompletionMessageToolCall]] = None
|
| 102 |
+
"""The tool calls generated by the model, such as function calls."""
|
| 103 |
+
|
| 104 |
+
def to_typeddict_message(self) -> ChatCompletionAssistantMessageParam:
|
| 105 |
+
message_dict = ChatCompletionAssistantMessageParam(role=self.role, content=self.content)
|
| 106 |
+
if self.function_call is not None:
|
| 107 |
+
message_dict["function_call"] = FunctionCallParams(
|
| 108 |
+
arguments=self.function_call.arguments, name=self.function_call.name
|
| 109 |
+
)
|
| 110 |
+
if self.tool_calls is not None:
|
| 111 |
+
message_dict["tool_calls"] = [
|
| 112 |
+
ChatCompletionMessageToolCallParam(
|
| 113 |
+
id=tool_call.id,
|
| 114 |
+
function=FunctionParams(arguments=tool_call.function.arguments, name=tool_call.function.name),
|
| 115 |
+
type=tool_call.type,
|
| 116 |
+
)
|
| 117 |
+
for tool_call in self.tool_calls
|
| 118 |
+
]
|
| 119 |
+
return message_dict
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
FinishReason = Literal["stop", "length", "tool_calls", "content_filter", "function_call"]
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
class Choice(DictableBaseModel):
|
| 126 |
+
finish_reason: FinishReason | None = None # ADDED: gpt4v preview用
|
| 127 |
+
"""The reason the model stopped generating tokens.
|
| 128 |
+
|
| 129 |
+
This will be `stop` if the model hit a natural stop point or a provided stop
|
| 130 |
+
sequence, `length` if the maximum number of tokens specified in the request was
|
| 131 |
+
reached, `content_filter` if content was omitted due to a flag from our content
|
| 132 |
+
filters, `tool_calls` if the model called a tool, or `function_call`
|
| 133 |
+
(deprecated) if the model called a function.
|
| 134 |
+
"""
|
| 135 |
+
|
| 136 |
+
index: int
|
| 137 |
+
"""The index of the choice in the list of choices."""
|
| 138 |
+
|
| 139 |
+
message: ChatCompletionMessage
|
| 140 |
+
"""A chat completion message generated by the model."""
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
class ChatCompletion(DictableBaseModel):
|
| 144 |
+
id: str
|
| 145 |
+
"""A unique identifier for the chat completion."""
|
| 146 |
+
|
| 147 |
+
choices: List[Choice]
|
| 148 |
+
"""A list of chat completion choices.
|
| 149 |
+
|
| 150 |
+
Can be more than one if `n` is greater than 1.
|
| 151 |
+
"""
|
| 152 |
+
|
| 153 |
+
created: int
|
| 154 |
+
"""The Unix timestamp (in seconds) of when the chat completion was created."""
|
| 155 |
+
|
| 156 |
+
model: str
|
| 157 |
+
"""The model used for the chat completion."""
|
| 158 |
+
|
| 159 |
+
object: Literal["chat.completion"] | str
|
| 160 |
+
"""The object type, which is always `chat.completion`."""
|
| 161 |
+
|
| 162 |
+
system_fingerprint: Optional[str] = None
|
| 163 |
+
"""This fingerprint represents the backend configuration that the model runs with.
|
| 164 |
+
|
| 165 |
+
Can be used in conjunction with the `seed` request parameter to understand when
|
| 166 |
+
backend changes have been made that might impact determinism.
|
| 167 |
+
"""
|
| 168 |
+
|
| 169 |
+
usage: Optional[CompletionUsage] = None
|
| 170 |
+
"""Usage statistics for the completion request."""
|
neollm/types/openai/chat_completion_chunk.py
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import List, Literal, Optional
|
| 2 |
+
|
| 3 |
+
from pydantic import field_validator
|
| 4 |
+
|
| 5 |
+
from neollm.types._model import DictableBaseModel
|
| 6 |
+
from neollm.utils.utils import cprint
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class ChoiceDeltaFunctionCall(DictableBaseModel):
|
| 10 |
+
arguments: Optional[str] = None
|
| 11 |
+
"""
|
| 12 |
+
The arguments to call the function with, as generated by the model in JSON
|
| 13 |
+
format. Note that the model does not always generate valid JSON, and may
|
| 14 |
+
hallucinate parameters not defined by your function schema. Validate the
|
| 15 |
+
arguments in your code before calling your function.
|
| 16 |
+
"""
|
| 17 |
+
|
| 18 |
+
name: Optional[str] = None
|
| 19 |
+
"""The name of the function to call."""
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
class ChoiceDeltaToolCallFunction(DictableBaseModel):
|
| 23 |
+
arguments: Optional[str] = None
|
| 24 |
+
"""
|
| 25 |
+
The arguments to call the function with, as generated by the model in JSON
|
| 26 |
+
format. Note that the model does not always generate valid JSON, and may
|
| 27 |
+
hallucinate parameters not defined by your function schema. Validate the
|
| 28 |
+
arguments in your code before calling your function.
|
| 29 |
+
"""
|
| 30 |
+
|
| 31 |
+
name: Optional[str] = None
|
| 32 |
+
"""The name of the function to call."""
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
class ChoiceDeltaToolCall(DictableBaseModel):
|
| 36 |
+
index: int
|
| 37 |
+
|
| 38 |
+
id: Optional[str] = None
|
| 39 |
+
"""The ID of the tool call."""
|
| 40 |
+
|
| 41 |
+
function: Optional[ChoiceDeltaToolCallFunction] = None
|
| 42 |
+
|
| 43 |
+
type: Optional[Literal["function"]] = None
|
| 44 |
+
"""The type of the tool. Currently, only `function` is supported."""
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
class ChoiceDelta(DictableBaseModel):
|
| 48 |
+
content: Optional[str] = None
|
| 49 |
+
"""The contents of the chunk message."""
|
| 50 |
+
|
| 51 |
+
function_call: Optional[ChoiceDeltaFunctionCall] = None
|
| 52 |
+
"""Deprecated and replaced by `tool_calls`.
|
| 53 |
+
|
| 54 |
+
The name and arguments of a function that should be called, as generated by the
|
| 55 |
+
model.
|
| 56 |
+
"""
|
| 57 |
+
|
| 58 |
+
role: Optional[Literal["system", "user", "assistant", "tool"]] = None
|
| 59 |
+
"""The role of the author of this message."""
|
| 60 |
+
|
| 61 |
+
tool_calls: Optional[List[ChoiceDeltaToolCall]] = None
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
class ChunkChoice(DictableBaseModel): # chat_completionと同名なため、改名(Choice->ChunkChoice)
|
| 65 |
+
delta: ChoiceDelta
|
| 66 |
+
"""A chat completion delta generated by streamed model responses."""
|
| 67 |
+
|
| 68 |
+
finish_reason: Optional[Literal["stop", "length", "tool_calls", "content_filter", "function_call"]]
|
| 69 |
+
"""The reason the model stopped generating tokens.
|
| 70 |
+
|
| 71 |
+
This will be `stop` if the model hit a natural stop point or a provided stop
|
| 72 |
+
sequence, `length` if the maximum number of tokens specified in the request was
|
| 73 |
+
reached, `content_filter` if content was omitted due to a flag from our content
|
| 74 |
+
filters, `tool_calls` if the model called a tool, or `function_call`
|
| 75 |
+
(deprecated) if the model called a function.
|
| 76 |
+
"""
|
| 77 |
+
|
| 78 |
+
index: int
|
| 79 |
+
"""The index of the choice in the list of choices."""
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
class ChatCompletionChunk(DictableBaseModel):
|
| 83 |
+
id: str
|
| 84 |
+
"""A unique identifier for the chat completion. Each chunk has the same ID."""
|
| 85 |
+
|
| 86 |
+
choices: List[ChunkChoice]
|
| 87 |
+
"""A list of chat completion choices.
|
| 88 |
+
|
| 89 |
+
Can be more than one if `n` is greater than 1.
|
| 90 |
+
"""
|
| 91 |
+
|
| 92 |
+
created: int
|
| 93 |
+
"""The Unix timestamp (in seconds) of when the chat completion was created.
|
| 94 |
+
|
| 95 |
+
Each chunk has the same timestamp.
|
| 96 |
+
"""
|
| 97 |
+
|
| 98 |
+
model: str
|
| 99 |
+
"""The model to generate the completion."""
|
| 100 |
+
|
| 101 |
+
object: Literal["chat.completion.chunk"] = "chat.completion.chunk" # for azure
|
| 102 |
+
"""The object type, which is always `chat.completion.chunk`."""
|
| 103 |
+
|
| 104 |
+
# ADDED: azure用 (""を許容するため)
|
| 105 |
+
@field_validator("object", mode="before")
|
| 106 |
+
def validate_name(cls, v: str) -> Literal["chat.completion.chunk"]:
|
| 107 |
+
if v != "" and v != "chat.completion.chunk":
|
| 108 |
+
cprint(f"ChatCompletionChunk.object is not 'chat.completion.chunk': {v}", "yellow")
|
| 109 |
+
return "chat.completion.chunk"
|
neollm/utils/inference.py
ADDED
|
@@ -0,0 +1,70 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import csv
|
| 2 |
+
import glob
|
| 3 |
+
import json
|
| 4 |
+
from concurrent.futures import Future, ThreadPoolExecutor
|
| 5 |
+
from typing import Any, Callable, TypeVar
|
| 6 |
+
|
| 7 |
+
_T = TypeVar("_T")
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def execute_parallel(func: Callable[..., _T], kwargs_list: list[dict[str, Any]], max_workers: int) -> list[_T]:
|
| 11 |
+
"""並行処理を行う
|
| 12 |
+
|
| 13 |
+
Args:
|
| 14 |
+
func (Callable): 並行処理したい関数
|
| 15 |
+
kwargs_list (list[dict[str, Any]]): 関数の引数(dict型)のリスト
|
| 16 |
+
max_workers (int): 並行処理数
|
| 17 |
+
|
| 18 |
+
Returns:
|
| 19 |
+
list[Any]: 関数の戻り値のリスト
|
| 20 |
+
"""
|
| 21 |
+
response_list: list[Future[_T]] = []
|
| 22 |
+
with ThreadPoolExecutor(max_workers=max_workers) as e:
|
| 23 |
+
for kwargs in kwargs_list:
|
| 24 |
+
response: Future[_T] = e.submit(func, **kwargs)
|
| 25 |
+
response_list.append(response)
|
| 26 |
+
return [r.result() for r in response_list]
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def _load_json_file(file_path: str) -> Any:
|
| 30 |
+
# TODO: Docstring追加
|
| 31 |
+
with open(file_path, "r", encoding="utf-8") as json_file:
|
| 32 |
+
data = json.load(json_file)
|
| 33 |
+
return data
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def make_log_csv(log_dir: str, csv_file_name: str = "log.csv") -> None:
|
| 37 |
+
"""ログデータのcsvを保存
|
| 38 |
+
|
| 39 |
+
Args:
|
| 40 |
+
log_dir (str): ログデータが保存されているディレクトリ
|
| 41 |
+
csv_file_name (str, optional): 保存するcsvファイル名. Defaults to "log.csv".
|
| 42 |
+
"""
|
| 43 |
+
# ディレクトリ内のJSONファイルのリストを取得
|
| 44 |
+
# TODO: エラーキャッチ
|
| 45 |
+
json_files = sorted([f for f in glob.glob(f"{log_dir}/*.json")], key=lambda x: int(x.split("/")[-1].split(".")[0]))
|
| 46 |
+
|
| 47 |
+
# すべてのJSONファイルからユニークなキーを取得
|
| 48 |
+
columns = []
|
| 49 |
+
data_list: list[dict[Any, Any]] = []
|
| 50 |
+
keys_set = set()
|
| 51 |
+
for json_file in json_files:
|
| 52 |
+
data = _load_json_file(json_file)
|
| 53 |
+
if isinstance(data, dict):
|
| 54 |
+
for key in data.keys():
|
| 55 |
+
if key not in keys_set:
|
| 56 |
+
keys_set.add(key)
|
| 57 |
+
columns.append(key)
|
| 58 |
+
data_list.append(data)
|
| 59 |
+
|
| 60 |
+
# CSVファイルを作成し、ヘッダーを書き込む
|
| 61 |
+
with open(csv_file_name, "w", encoding="utf-8", newline="") as csv_file:
|
| 62 |
+
writer = csv.writer(csv_file)
|
| 63 |
+
writer.writerow(columns)
|
| 64 |
+
|
| 65 |
+
# JSONファイルからデータを読み取り、CSVファイルに書き込む
|
| 66 |
+
for data in data_list:
|
| 67 |
+
row = [data.get(key, "") for key in columns]
|
| 68 |
+
writer.writerow(row)
|
| 69 |
+
|
| 70 |
+
print(f"saved csv file: {csv_file_name}")
|
neollm/utils/postprocess.py
ADDED
|
@@ -0,0 +1,120 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
from typing import Any, overload
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
# string ---------------------------------------
|
| 6 |
+
def _extract_string(text: str, start_string: str | None = None, end_string: str | None = None) -> str:
|
| 7 |
+
"""
|
| 8 |
+
テキストから必要な文字列を抽出する
|
| 9 |
+
|
| 10 |
+
Args:
|
| 11 |
+
text (str): 抽出するテキスト
|
| 12 |
+
|
| 13 |
+
Returns:
|
| 14 |
+
str: 抽出された必要な文字列
|
| 15 |
+
"""
|
| 16 |
+
# 最初の文字
|
| 17 |
+
if start_string is not None and start_string in text:
|
| 18 |
+
idx_head = text.index(start_string)
|
| 19 |
+
text = text[idx_head:]
|
| 20 |
+
# 最後の文字
|
| 21 |
+
if end_string is not None and end_string in text:
|
| 22 |
+
idx_tail = len(text) - text[::-1].index(end_string[::-1])
|
| 23 |
+
text = text[:idx_tail]
|
| 24 |
+
return text
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def _delete_first_chapter_tag(text: str, first_character_tag: str | list[str]) -> str:
|
| 28 |
+
"""_summary_
|
| 29 |
+
|
| 30 |
+
Args:
|
| 31 |
+
text (str): テキスト
|
| 32 |
+
first_character_tag (str | list[str]): 最初にある余分な文字列
|
| 33 |
+
|
| 34 |
+
Returns:
|
| 35 |
+
str: 除去済みのテキスト
|
| 36 |
+
"""
|
| 37 |
+
# first_character_tagのlist化
|
| 38 |
+
if isinstance(first_character_tag, str):
|
| 39 |
+
first_character_tag = [first_character_tag]
|
| 40 |
+
# 最初のチャプタータグの消去
|
| 41 |
+
for first_character_i in first_character_tag:
|
| 42 |
+
if text.startswith(first_character_i):
|
| 43 |
+
text = text[len(first_character_i) :]
|
| 44 |
+
break
|
| 45 |
+
return text.strip()
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
def strip_string(
|
| 49 |
+
text: str,
|
| 50 |
+
first_character: str | list[str] = ["<output>", "<outputs>"],
|
| 51 |
+
start_string: str | None = None,
|
| 52 |
+
end_string: str | None = None,
|
| 53 |
+
strip_quotes: str | list[str] = ["'", '"'],
|
| 54 |
+
) -> str:
|
| 55 |
+
"""stringの前後の余分な文字を削除する
|
| 56 |
+
|
| 57 |
+
Args:
|
| 58 |
+
text (str): ChatGPTの出力文字列
|
| 59 |
+
first_character (str, optional): 出力の先頭につく文字 Defaults to ["<output>", "<outputs>"].
|
| 60 |
+
start_string (str, optional): 出力の先頭につく文字 Defaults to None.
|
| 61 |
+
end_string (str, optional): 出力の先頭につく文字 Defaults to None.
|
| 62 |
+
strip_quotes (str, optional): 前後の余分な'"を消す. Defaults to ["'", '"'].
|
| 63 |
+
|
| 64 |
+
Returns:
|
| 65 |
+
str: 余分な文字列を消去した文字列
|
| 66 |
+
|
| 67 |
+
Examples:
|
| 68 |
+
>>> strip_string("<output>'''ChatGPT is smart!'''", "<output>")
|
| 69 |
+
ChatGPT is smart!
|
| 70 |
+
>>> strip_string('{"a": 1}', start_string="{", end_string="}")
|
| 71 |
+
{"a": 1}
|
| 72 |
+
>>> strip_string("<outputs> `neoAI`", strip_quotes="`")
|
| 73 |
+
neoAI
|
| 74 |
+
"""
|
| 75 |
+
# 余分な文字列消去
|
| 76 |
+
text = _delete_first_chapter_tag(text, first_character)
|
| 77 |
+
# 前後の'" を消す
|
| 78 |
+
if isinstance(strip_quotes, str):
|
| 79 |
+
strip_quotes = [strip_quotes]
|
| 80 |
+
for quote in strip_quotes:
|
| 81 |
+
text = text.strip(quote).strip()
|
| 82 |
+
text = _extract_string(text, start_string, end_string)
|
| 83 |
+
return text.strip()
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
# dict ---------------------------------------
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
@overload
|
| 90 |
+
def json2dict(json_string: str, error_key: None) -> dict[Any, Any] | str: ...
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
@overload
|
| 94 |
+
def json2dict(json_string: str, error_key: str) -> dict[Any, Any]: ...
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
def json2dict(json_string: str, error_key: str | None = "error") -> dict[Any, Any] | str:
|
| 98 |
+
"""
|
| 99 |
+
JSON文字列をPython dictに変換する
|
| 100 |
+
|
| 101 |
+
Args:
|
| 102 |
+
json_string (str): 変換するJSON文字列
|
| 103 |
+
error_key (str, optional): エラーキーの値として代入する文字列. Defaults to "error".
|
| 104 |
+
|
| 105 |
+
Returns:
|
| 106 |
+
dict: 変換されたPython dict
|
| 107 |
+
"""
|
| 108 |
+
try:
|
| 109 |
+
python_dict = json.loads(_extract_string(json_string, start_string="{", end_string="}"), strict=False)
|
| 110 |
+
except ValueError:
|
| 111 |
+
if error_key is None:
|
| 112 |
+
return json_string
|
| 113 |
+
python_dict = {error_key: json_string}
|
| 114 |
+
if isinstance(python_dict, dict):
|
| 115 |
+
return python_dict
|
| 116 |
+
return {error_key: python_dict}
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
# calender
|
| 120 |
+
# YYYY年MM月YY日 -> YYYY-MM-DD
|
neollm/utils/preprocess.py
ADDED
|
@@ -0,0 +1,107 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import re
|
| 3 |
+
from typing import Any, Callable
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
# dict2json --------------------------------
|
| 7 |
+
def dict2json(python_dict: dict[str, Any]) -> str:
|
| 8 |
+
"""
|
| 9 |
+
Python dictをJSON文字列に変換する
|
| 10 |
+
|
| 11 |
+
Args:
|
| 12 |
+
python_dict (dict): 変換するPython dict
|
| 13 |
+
|
| 14 |
+
Returns:
|
| 15 |
+
str: 変換されたJSON文字列
|
| 16 |
+
"""
|
| 17 |
+
# ensure_ascii: 日本語とかを出力するため
|
| 18 |
+
json_string = json.dumps(python_dict, indent=2, ensure_ascii=False)
|
| 19 |
+
return json_string
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
# optimize token --------------------------------
|
| 23 |
+
def optimize_token(text: str, funcs: list[Callable[[str], str]] | None = None) -> str:
|
| 24 |
+
"""
|
| 25 |
+
テキストのトークンを最適化をする
|
| 26 |
+
|
| 27 |
+
Args:
|
| 28 |
+
text (str): 最適化するテキスト
|
| 29 |
+
|
| 30 |
+
Returns:
|
| 31 |
+
str: 最適化されたテキスト
|
| 32 |
+
"""
|
| 33 |
+
funcs = funcs or [minimize_newline, zenkaku_to_hankaku, remove_trailing_spaces]
|
| 34 |
+
for func in funcs:
|
| 35 |
+
text = func(text)
|
| 36 |
+
return text.strip()
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def _replace_consecutive(text: str, pattern: str, replacing_text: str) -> str:
|
| 40 |
+
"""
|
| 41 |
+
テキスト内の連続するパターンに対して、指定された置換テキストで置換する
|
| 42 |
+
|
| 43 |
+
Args:
|
| 44 |
+
text (str): テキスト
|
| 45 |
+
pattern (str): 置換するパターン
|
| 46 |
+
replacing_text (str): 置換テキスト
|
| 47 |
+
|
| 48 |
+
Returns:
|
| 49 |
+
str: 置換されたテキスト
|
| 50 |
+
"""
|
| 51 |
+
p = re.compile(pattern)
|
| 52 |
+
matches = [(m.start(), m.end()) for m in p.finditer(text)][::-1]
|
| 53 |
+
|
| 54 |
+
text_replaced = list(text)
|
| 55 |
+
|
| 56 |
+
for i_start, i_end in matches:
|
| 57 |
+
text_replaced[i_start:i_end] = [replacing_text]
|
| 58 |
+
return "".join(text_replaced)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def minimize_newline(text: str) -> str:
|
| 62 |
+
"""
|
| 63 |
+
テキスト内の連続する改行を2以下にする
|
| 64 |
+
|
| 65 |
+
Args:
|
| 66 |
+
text (str): テキスト
|
| 67 |
+
|
| 68 |
+
Returns:
|
| 69 |
+
str: 改行を最小限にしたテキスト
|
| 70 |
+
"""
|
| 71 |
+
return _replace_consecutive(text, pattern="\n{2,}", replacing_text="\n\n")
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
def zenkaku_to_hankaku(text: str) -> str:
|
| 75 |
+
"""
|
| 76 |
+
テキスト内の全角文字を半角文字に変換する
|
| 77 |
+
|
| 78 |
+
Args:
|
| 79 |
+
text (str): テキスト
|
| 80 |
+
|
| 81 |
+
Returns:
|
| 82 |
+
str: 半角文字に変換されたテキスト
|
| 83 |
+
"""
|
| 84 |
+
mapping_dict = {" ": " ", ":": ": ", "": " ", ".": "。", ",": "、", "¥": "¥"}
|
| 85 |
+
hankaku_text = ""
|
| 86 |
+
for char in text:
|
| 87 |
+
# A-Za-z0-9!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
|
| 88 |
+
if char in mapping_dict:
|
| 89 |
+
hankaku_text += mapping_dict[char]
|
| 90 |
+
elif 65281 <= ord(char) <= 65374:
|
| 91 |
+
hankaku_text += chr(ord(char) - 65248)
|
| 92 |
+
else:
|
| 93 |
+
hankaku_text += char
|
| 94 |
+
return hankaku_text
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
def remove_trailing_spaces(text: str) -> str:
|
| 98 |
+
"""
|
| 99 |
+
テキスト内の各行の末尾のスペースを削除する
|
| 100 |
+
|
| 101 |
+
Args:
|
| 102 |
+
text (str): テキスト
|
| 103 |
+
|
| 104 |
+
Returns:
|
| 105 |
+
str: スペースを削除したテキスト
|
| 106 |
+
"""
|
| 107 |
+
return "\n".join([line.rstrip() for line in text.split("\n")])
|
neollm/utils/prompt_checker.py
ADDED
|
@@ -0,0 +1,110 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from __future__ import annotations
|
| 2 |
+
|
| 3 |
+
from typing import Any
|
| 4 |
+
|
| 5 |
+
from typing_extensions import TypedDict
|
| 6 |
+
|
| 7 |
+
from neollm import MyL3M2, MyLLM
|
| 8 |
+
from neollm.types import LLMSettings, Messages, Response
|
| 9 |
+
|
| 10 |
+
_MyLLM = MyLLM[Any, Any]
|
| 11 |
+
_MyL3M2 = MyL3M2[Any, Any]
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class PromptCheckerInput(TypedDict):
|
| 15 |
+
myllm: _MyLLM | _MyL3M2
|
| 16 |
+
model: str
|
| 17 |
+
platform: str
|
| 18 |
+
llm_settings: LLMSettings | None
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
class APromptCheckerInput(TypedDict):
|
| 22 |
+
myllm: _MyLLM
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
class APromptChecker(MyLLM[APromptCheckerInput, str]):
|
| 26 |
+
def _preprocess(self, inputs: APromptCheckerInput) -> Messages:
|
| 27 |
+
system_prompt = (
|
| 28 |
+
"あなたは、AIへの指示(プロンプト)をより良くすることが仕事です。\n"
|
| 29 |
+
"あなたは言語能力が非常に高く、仕事も丁寧なので小さなミスも気づくことができる天才です。"
|
| 30 |
+
"誤字脱字・論理的でない点・指示が不明確な点を箇条書きで指摘し、より良いプロンプトを提案してください。\n"
|
| 31 |
+
"# 出力例: \n"
|
| 32 |
+
"[指示の誤字脱字/文法ミス]\n"
|
| 33 |
+
"- ...\n"
|
| 34 |
+
"- ...\n"
|
| 35 |
+
"[指示が論理的でない点]\n"
|
| 36 |
+
"- ...\n"
|
| 37 |
+
"- ...\n"
|
| 38 |
+
"[指示が不明確な点]\n"
|
| 39 |
+
"- ...\n"
|
| 40 |
+
"- ...\n"
|
| 41 |
+
"[その他気になる点]\n"
|
| 42 |
+
"- ...\n"
|
| 43 |
+
"- ...\n"
|
| 44 |
+
"[提案]\n"
|
| 45 |
+
"- ...\n"
|
| 46 |
+
"- ...\n"
|
| 47 |
+
)
|
| 48 |
+
if inputs["myllm"].messages is None:
|
| 49 |
+
return []
|
| 50 |
+
user_prompt = "# プロンプト\n" + "\n".join(
|
| 51 |
+
# [f"<{message['role']}>\n{message['content']}\n" for message in inputs.messages]
|
| 52 |
+
[str(message) for message in inputs["myllm"].messages]
|
| 53 |
+
)
|
| 54 |
+
messages: Messages = [
|
| 55 |
+
{"role": "system", "content": system_prompt},
|
| 56 |
+
{"role": "user", "content": user_prompt},
|
| 57 |
+
]
|
| 58 |
+
return messages
|
| 59 |
+
|
| 60 |
+
def _postprocess(self, response: Response) -> str:
|
| 61 |
+
if response.choices[0].message.content is None:
|
| 62 |
+
return "contentがないンゴ"
|
| 63 |
+
return response.choices[0].message.content
|
| 64 |
+
|
| 65 |
+
def _ruleprocess(self, inputs: APromptCheckerInput) -> str | None:
|
| 66 |
+
if inputs["myllm"].messages is None:
|
| 67 |
+
return "ruleprocessが走って、リクエストしてないよ!"
|
| 68 |
+
return None
|
| 69 |
+
|
| 70 |
+
def __call__(self, inputs: APromptCheckerInput) -> str:
|
| 71 |
+
outputs: str = super().__call__(inputs)
|
| 72 |
+
return outputs
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
class PromptsChecker(MyL3M2[PromptCheckerInput, None]):
|
| 76 |
+
def _link(self, inputs: PromptCheckerInput) -> None:
|
| 77 |
+
if isinstance(inputs["myllm"], MyL3M2):
|
| 78 |
+
for myllm in inputs["myllm"].myllm_list:
|
| 79 |
+
prompts_checker = PromptsChecker(parent=self, verbose=True)
|
| 80 |
+
prompts_checker(
|
| 81 |
+
inputs={
|
| 82 |
+
"myllm": myllm,
|
| 83 |
+
"model": inputs["model"],
|
| 84 |
+
"platform": inputs["platform"],
|
| 85 |
+
"llm_settings": inputs["llm_settings"],
|
| 86 |
+
}
|
| 87 |
+
)
|
| 88 |
+
elif isinstance(inputs["myllm"], MyLLM):
|
| 89 |
+
a_prompt_checker = APromptChecker(
|
| 90 |
+
parent=self,
|
| 91 |
+
llm_settings=inputs["llm_settings"],
|
| 92 |
+
verbose=True,
|
| 93 |
+
platform=inputs["platform"],
|
| 94 |
+
model=inputs["model"],
|
| 95 |
+
)
|
| 96 |
+
a_prompt_checker(inputs={"myllm": inputs["myllm"]})
|
| 97 |
+
|
| 98 |
+
def __call__(self, inputs: PromptCheckerInput) -> None:
|
| 99 |
+
super().__call__(inputs)
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
def check_prompt(
|
| 103 |
+
myllm: _MyLLM | _MyL3M2,
|
| 104 |
+
llm_settings: LLMSettings | None = None,
|
| 105 |
+
model: str = "gpt-3.5-turbo",
|
| 106 |
+
platform: str = "openai",
|
| 107 |
+
) -> MyL3M2[Any, Any]:
|
| 108 |
+
prompt_checker_2 = PromptsChecker(verbose=True)
|
| 109 |
+
prompt_checker_2(inputs={"myllm": myllm, "llm_settings": llm_settings, "model": model, "platform": platform})
|
| 110 |
+
return prompt_checker_2
|
neollm/utils/tokens.py
ADDED
|
@@ -0,0 +1,229 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
import textwrap
|
| 3 |
+
from typing import Any
|
| 4 |
+
|
| 5 |
+
import tiktoken
|
| 6 |
+
|
| 7 |
+
from neollm.types import Function # , Functions, Messages
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def normalize_model_name(model_name: str) -> str:
|
| 11 |
+
"""model_nameのトークン数計測のための標準化
|
| 12 |
+
|
| 13 |
+
Args:
|
| 14 |
+
model_name (str): model_name
|
| 15 |
+
OpenAI: gpt-3.5-turbo-0613, gpt-3.5-turbo-16k-0613, gpt-4-0613, gpt-4-32k-0613
|
| 16 |
+
OpenAIFT: ft:gpt-3.5-turbo:org_id
|
| 17 |
+
Azure: gpt-35-turbo-0613, gpt-35-turbo-16k-0613, gpt-4-0613, gpt-4-32k-0613
|
| 18 |
+
|
| 19 |
+
Returns:
|
| 20 |
+
str: 標準化されたmodel_name
|
| 21 |
+
|
| 22 |
+
Raises:
|
| 23 |
+
ValueError: model_nameが不適切
|
| 24 |
+
"""
|
| 25 |
+
# 参考: https://platform.openai.com/docs/models/gpt-3-5
|
| 26 |
+
NEWEST_MAP = [
|
| 27 |
+
("gpt-3.5-turbo-16k", "gpt-3.5-turbo-16k-0613"),
|
| 28 |
+
("gpt-3.5-turbo", "gpt-3.5-turbo-0613"),
|
| 29 |
+
("gpt-4-32k", "gpt-4-32k-0613"),
|
| 30 |
+
("gpt-4", "gpt-4-0613"),
|
| 31 |
+
]
|
| 32 |
+
ALL_VERSION_MODELS = [
|
| 33 |
+
# gpt-3.5-turbo
|
| 34 |
+
"gpt-3.5-turbo-0613",
|
| 35 |
+
"gpt-3.5-turbo-16k-0613",
|
| 36 |
+
"gpt-3.5-turbo-0301", # Legacy
|
| 37 |
+
# gpt-4
|
| 38 |
+
"gpt-4-0613",
|
| 39 |
+
"gpt-4-32k-0613",
|
| 40 |
+
"gpt-4-0314", # Legacy
|
| 41 |
+
"gpt-4-32k-0314", # Legacy
|
| 42 |
+
]
|
| 43 |
+
# Azure表記 → OpenAI表記に統一
|
| 44 |
+
model_name = model_name.replace("gpt-35", "gpt-3.5")
|
| 45 |
+
# 最新モデルを正式名称に & 新モデル, FTモデルをキャッチ
|
| 46 |
+
if model_name not in ALL_VERSION_MODELS:
|
| 47 |
+
for key, model_name_version in NEWEST_MAP:
|
| 48 |
+
if key in model_name:
|
| 49 |
+
model_name = model_name_version
|
| 50 |
+
break
|
| 51 |
+
# Return
|
| 52 |
+
if model_name in ALL_VERSION_MODELS:
|
| 53 |
+
return model_name
|
| 54 |
+
raise ValueError("model_name は以下から選んで.\n" + ",".join(ALL_VERSION_MODELS))
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def count_tokens(messages: Any | None = None, model_name: str | None = None, functions: Any | None = None) -> int:
|
| 58 |
+
"""トークン数計測
|
| 59 |
+
|
| 60 |
+
Args:
|
| 61 |
+
messages (Messages): GPTAPIの入力のmessages
|
| 62 |
+
model_name (str | None, optional): モデル名. Defaults to None.
|
| 63 |
+
functions (Functions | None, optional): GPTAPIの入力のfunctions. Defaults to None.
|
| 64 |
+
|
| 65 |
+
Returns:
|
| 66 |
+
int: トークン数
|
| 67 |
+
"""
|
| 68 |
+
model_name = normalize_model_name(model_name or "cl100k_base")
|
| 69 |
+
num_tokens = _count_messages_tokens(messages, model_name)
|
| 70 |
+
if functions is not None:
|
| 71 |
+
num_tokens += _count_functions_tokens(functions, model_name)
|
| 72 |
+
return num_tokens
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
# https://github.com/openai/openai-cookbook/blob/main/examples/How_to_count_tokens_with_tiktoken.ipynb
|
| 76 |
+
def _count_messages_tokens(messages: Any | None, model_name: str) -> int:
|
| 77 |
+
"""メッセージのトークン数を計算
|
| 78 |
+
|
| 79 |
+
Args:
|
| 80 |
+
messages (Messages): ChatGPT等APIに入力するmessages
|
| 81 |
+
model_name (str, optional): 使用するモデルの名前
|
| 82 |
+
"gpt-3.5-turbo-0613", "gpt-3.5-turbo-16k-0613", "gpt-4-0314", "gpt-4-32k-0314"
|
| 83 |
+
"gpt-4-0613", "gpt-4-32k-0613", "gpt-3.5-turbo", "gpt-4"
|
| 84 |
+
|
| 85 |
+
Returns:
|
| 86 |
+
int: トークン数の合計
|
| 87 |
+
"""
|
| 88 |
+
if messages is None:
|
| 89 |
+
return 0
|
| 90 |
+
# setting model
|
| 91 |
+
encoding_model = tiktoken.encoding_for_model(model_name) # "cl100k_base"
|
| 92 |
+
|
| 93 |
+
# config
|
| 94 |
+
if model_name == "gpt-3.5-turbo-0301":
|
| 95 |
+
tokens_per_message = 4 # every message follows <|start|>{role/name}\n{content}<|end|>\n
|
| 96 |
+
tokens_per_name = -1 # if there's a name, the role is omitted
|
| 97 |
+
else:
|
| 98 |
+
tokens_per_message = 3
|
| 99 |
+
tokens_per_name = 1
|
| 100 |
+
|
| 101 |
+
# count tokens
|
| 102 |
+
num_tokens = 3 # every reply is primed with <|start|>assistant<|message|>
|
| 103 |
+
for message in messages:
|
| 104 |
+
num_tokens += tokens_per_message
|
| 105 |
+
for key, value in message.items():
|
| 106 |
+
if isinstance(value, str):
|
| 107 |
+
num_tokens += len(encoding_model.encode(value))
|
| 108 |
+
if key == "name":
|
| 109 |
+
num_tokens += tokens_per_name
|
| 110 |
+
return num_tokens
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
# https://gist.github.com/CGamesPlay/dd4f108f27e2eec145eedf5c717318f5
|
| 114 |
+
def _count_functions_tokens(functions: Any, model_name: str | None = None) -> int:
|
| 115 |
+
"""
|
| 116 |
+
functionsのトークン数計測
|
| 117 |
+
|
| 118 |
+
Args:
|
| 119 |
+
functions (Functions): GPTAPIの入力のfunctions
|
| 120 |
+
model_name (str | None, optional): モデル名. Defaults to None.
|
| 121 |
+
|
| 122 |
+
Returns:
|
| 123 |
+
_type_: トークン数
|
| 124 |
+
"""
|
| 125 |
+
encoding_model = tiktoken.encoding_for_model(model_name or "cl100k_base") # "cl100k_base"
|
| 126 |
+
num_tokens = 3 + len(encoding_model.encode(__functions2string(functions)))
|
| 127 |
+
return num_tokens
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
# functionsのstring化、補助関数 ---------------------------------------------------------------------------
|
| 131 |
+
def __functions2string(functions: Any) -> str:
|
| 132 |
+
"""functionsの文字列化
|
| 133 |
+
|
| 134 |
+
Args:
|
| 135 |
+
functions (Functions): GPTAPIの入力のfunctions
|
| 136 |
+
|
| 137 |
+
Returns:
|
| 138 |
+
str: functionsの文字列
|
| 139 |
+
"""
|
| 140 |
+
prefix = "# Tools\n\n## functions\n\nnamespace functions {\n\n} // namespace functions\n"
|
| 141 |
+
functions_string = prefix + "".join(__function2string(function) for function in functions)
|
| 142 |
+
return functions_string
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
def __function2string(function: Function) -> str:
|
| 146 |
+
"""functionの文字列化
|
| 147 |
+
|
| 148 |
+
Args:
|
| 149 |
+
function (Function): GPTAPIのfunctionの要素
|
| 150 |
+
|
| 151 |
+
Returns:
|
| 152 |
+
str: functionの文字列
|
| 153 |
+
"""
|
| 154 |
+
object_string = __format_object(function["parameters"])
|
| 155 |
+
if object_string is not None:
|
| 156 |
+
object_string = "_: " + object_string
|
| 157 |
+
else:
|
| 158 |
+
object_string = ""
|
| 159 |
+
|
| 160 |
+
functions_string: str = (
|
| 161 |
+
f"// {function['description']}\ntype {function['name']} = (" + object_string + ") => any;\n\n"
|
| 162 |
+
)
|
| 163 |
+
return functions_string
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
def __format_object(schema: dict[str, Any], indent: int = 0) -> str | None:
|
| 167 |
+
if "properties" not in schema or len(schema["properties"]) == 0:
|
| 168 |
+
if schema.get("additionalProperties", False):
|
| 169 |
+
return "object"
|
| 170 |
+
return None
|
| 171 |
+
|
| 172 |
+
result = "{\n"
|
| 173 |
+
for key, value in dict(schema["properties"]).items():
|
| 174 |
+
# value <- resolve_ref(value)
|
| 175 |
+
value_rendered = __format_schema(value, indent + 1)
|
| 176 |
+
if value_rendered is None:
|
| 177 |
+
continue
|
| 178 |
+
# description
|
| 179 |
+
if "description" in value:
|
| 180 |
+
description = "".join(
|
| 181 |
+
" " * indent + f"// {description_i}\n"
|
| 182 |
+
for description_i in textwrap.dedent(value["description"]).strip().split("\n")
|
| 183 |
+
)
|
| 184 |
+
# optional
|
| 185 |
+
optional = "" if key in schema.get("required", {}) else "?"
|
| 186 |
+
# default
|
| 187 |
+
default_comment = "" if "default" not in value else f" // default: {__format_default(value)}"
|
| 188 |
+
# add string
|
| 189 |
+
result += description + " " * indent + f"{key}{optional}: {value_rendered},{default_comment}\n"
|
| 190 |
+
result += (" " * (indent - 1)) + "}"
|
| 191 |
+
return result
|
| 192 |
+
|
| 193 |
+
|
| 194 |
+
# よくわからん
|
| 195 |
+
# def resolve_ref(schema):
|
| 196 |
+
# if schema.get("$ref") is not None:
|
| 197 |
+
# ref = schema["$ref"][14:]
|
| 198 |
+
# schema = json_schema["definitions"][ref]
|
| 199 |
+
# return schema
|
| 200 |
+
|
| 201 |
+
|
| 202 |
+
def __format_schema(schema: dict[str, Any], indent: int) -> str | None:
|
| 203 |
+
# schema <- resolve_ref(schema)
|
| 204 |
+
if "enum" in schema:
|
| 205 |
+
return __format_enum(schema)
|
| 206 |
+
elif schema["type"] == "object":
|
| 207 |
+
return __format_object(schema, indent)
|
| 208 |
+
elif schema["type"] in {"integer", "number"}:
|
| 209 |
+
return "number"
|
| 210 |
+
elif schema["type"] in {"string"}:
|
| 211 |
+
return "string"
|
| 212 |
+
elif schema["type"] == "array":
|
| 213 |
+
return str(__format_schema(schema["items"], indent)) + "[]"
|
| 214 |
+
else:
|
| 215 |
+
raise ValueError("unknown schema type " + schema["type"])
|
| 216 |
+
|
| 217 |
+
|
| 218 |
+
def __format_enum(schema: dict[str, Any]) -> str:
|
| 219 |
+
# "A" | "B" | "C"
|
| 220 |
+
return " | ".join(json.dumps(element, ensure_ascii=False) for element in schema["enum"])
|
| 221 |
+
|
| 222 |
+
|
| 223 |
+
def __format_default(schema: dict[str, Any]) -> str:
|
| 224 |
+
default = schema["default"]
|
| 225 |
+
if schema["type"] == "number" and float(default).is_integer():
|
| 226 |
+
# numberの時、0 → 0.0
|
| 227 |
+
return f"{default:.1f}"
|
| 228 |
+
else:
|
| 229 |
+
return str(default)
|
neollm/utils/utils.py
ADDED
|
@@ -0,0 +1,98 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from __future__ import annotations
|
| 2 |
+
|
| 3 |
+
import os
|
| 4 |
+
from typing import Any
|
| 5 |
+
|
| 6 |
+
from typing_extensions import TypedDict
|
| 7 |
+
|
| 8 |
+
from neollm.types import PrintColor
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class CPrintParam(TypedDict, total=False):
|
| 12 |
+
text: Any
|
| 13 |
+
color: PrintColor | None
|
| 14 |
+
background: bool
|
| 15 |
+
light: bool
|
| 16 |
+
bold: bool
|
| 17 |
+
italic: bool
|
| 18 |
+
underline: bool
|
| 19 |
+
kwargs: dict[str, Any]
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def cprint(
|
| 23 |
+
*text: Any,
|
| 24 |
+
color: PrintColor | None = None,
|
| 25 |
+
background: bool = False,
|
| 26 |
+
light: bool = False,
|
| 27 |
+
bold: bool = False,
|
| 28 |
+
italic: bool = False,
|
| 29 |
+
underline: bool = False,
|
| 30 |
+
kwargs: dict[str, Any] = {},
|
| 31 |
+
) -> None:
|
| 32 |
+
"""
|
| 33 |
+
色付けなどリッチにprint
|
| 34 |
+
|
| 35 |
+
Args:
|
| 36 |
+
*text: 表示するテキスト。
|
| 37 |
+
color (PrintColor): テキストの色: 'black', 'red', 'green', 'yellow', 'blue', 'magenta', 'cyan', 'white'。
|
| 38 |
+
background (bool): 背景色
|
| 39 |
+
light (bool): 淡い色にするか
|
| 40 |
+
bold (bool): 太字
|
| 41 |
+
italic (bool): 斜体
|
| 42 |
+
underline (bool): 下線
|
| 43 |
+
**kwargs: printの引数
|
| 44 |
+
"""
|
| 45 |
+
# ANSIエスケープシーケンスを使用して、テキストを書式設定して表示する
|
| 46 |
+
format_string = ""
|
| 47 |
+
|
| 48 |
+
# 色の設定
|
| 49 |
+
color2code: dict[PrintColor, int] = {
|
| 50 |
+
"black": 30,
|
| 51 |
+
"red": 31,
|
| 52 |
+
"green": 32,
|
| 53 |
+
"yellow": 33,
|
| 54 |
+
"blue": 34,
|
| 55 |
+
"magenta": 35,
|
| 56 |
+
"cyan": 36,
|
| 57 |
+
"white": 37,
|
| 58 |
+
}
|
| 59 |
+
if color is not None and color in color2code:
|
| 60 |
+
code = color2code[color]
|
| 61 |
+
if background:
|
| 62 |
+
code += 10
|
| 63 |
+
elif light:
|
| 64 |
+
code += 60
|
| 65 |
+
format_string += f"\033[{code}m"
|
| 66 |
+
if bold:
|
| 67 |
+
format_string += "\033[1m"
|
| 68 |
+
if italic:
|
| 69 |
+
format_string += "\033[3m"
|
| 70 |
+
if underline:
|
| 71 |
+
format_string += "\033[4m"
|
| 72 |
+
|
| 73 |
+
# テキストの表示
|
| 74 |
+
for text_i in text:
|
| 75 |
+
print(format_string + str(text_i) + "\033[0m", **kwargs)
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def ensure_env_var(var_name: str | None = None, default: str | None = None) -> str:
|
| 79 |
+
if var_name is None:
|
| 80 |
+
return ""
|
| 81 |
+
if os.environ.get(var_name, "") == "":
|
| 82 |
+
if default is None:
|
| 83 |
+
raise ValueError(f"{var_name}をenvで設定しよう")
|
| 84 |
+
cprint(f"WARNING: {var_name}が設定されていません。{default}を使用します。", color="yellow", background=True)
|
| 85 |
+
os.environ[var_name] = default
|
| 86 |
+
return os.environ[var_name]
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
def suport_unrecomended_env_var(old_key: str, new_key: str) -> None:
|
| 90 |
+
"""非推奨の環境変数をサポートする
|
| 91 |
+
|
| 92 |
+
Args:
|
| 93 |
+
old_key (str): 非推奨の環境変数名
|
| 94 |
+
new_key (str): 推奨の環境変数名
|
| 95 |
+
"""
|
| 96 |
+
if os.getenv(old_key) is not None and os.getenv(new_key) is None:
|
| 97 |
+
cprint(f"WARNING: {old_key}ではなく、{new_key}にしてね", color="yellow", background=True)
|
| 98 |
+
os.environ[new_key] = os.environ[old_key]
|
poetry.lock
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
project/.env.template
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
LLM_PLATFORM=azure
|
| 2 |
+
|
| 3 |
+
# OpenAIkey
|
| 4 |
+
OPENAI_API_KEY=sk-XXX
|
| 5 |
+
|
| 6 |
+
# Azure OpenAIkey
|
| 7 |
+
AZURE_OPENAI_API_KEY=XXX # AZURE_OPENAI_AD_TOKEN=YYY
|
| 8 |
+
AZURE_OPENAI_ENDPOINT=https://neoai-pjname.openai.azure.com/ # (not-recomended): AZURE_API_BASE
|
| 9 |
+
OPENAI_API_VERSION=2024-02-01 # (not-recomended): AZURE_API_VERSION
|
| 10 |
+
|
| 11 |
+
# ENGINE
|
| 12 |
+
# 1106 ----------------------------------------------------------
|
| 13 |
+
AZURE_ENGINE_GPT35T_1106=xxx
|
| 14 |
+
AZURE_ENGINE_GPT4T_1106=xxx
|
| 15 |
+
# 0613 ----------------------------------------------------------
|
| 16 |
+
AZURE_ENGINE_GPT35T_0613=neoai-pjname-gpt-35 # (not-recomended): AZURE_ENGINE_GPT35, AZURE_ENGINE_GPT35_0613
|
| 17 |
+
AZURE_ENGINE_GPT35T_16K_0613=neoai-pjname-gpt-35-16k # (not-recomended): AZURE_ENGINE_GPT35_16k, AZURE_ENGINE_GPT35_16K_0613
|
| 18 |
+
AZURE_ENGINE_GPT4_0613=neoai-pjname-gpt4 # (not-recomended): AZURE_ENGINE_GPT4
|
| 19 |
+
AZURE_ENGINE_GPT4_32K_0613=neoai-pjname-gpt4-32k # (not recomended): AZURE_ENGINE_GPT4_32k
|
| 20 |
+
|
| 21 |
+
# Anthropic
|
| 22 |
+
ANTHROPIC_API_KEY=xxx
|
| 23 |
+
|
| 24 |
+
# GCP
|
project/ex_module/ex_profile_extractor.py
ADDED
|
@@ -0,0 +1,113 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Any, Literal, TypedDict
|
| 2 |
+
|
| 3 |
+
from neollm import MyLLM
|
| 4 |
+
from neollm.types import Functions
|
| 5 |
+
from neollm.utils.postprocess import json2dict
|
| 6 |
+
from neollm.utils.preprocess import optimize_token
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class ProfileExtractorInputType(TypedDict):
|
| 10 |
+
text: str
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class ProfileExtractorOuputType(TypedDict):
|
| 14 |
+
name: str
|
| 15 |
+
birth_year: int
|
| 16 |
+
domain: str
|
| 17 |
+
lang: Literal["ENG", "JPN"]
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class ProfileExtractor(MyLLM):
|
| 21 |
+
"""情報を抽出するMyLLM
|
| 22 |
+
|
| 23 |
+
Notes:
|
| 24 |
+
inputs:
|
| 25 |
+
>>> {"text": str}
|
| 26 |
+
outpus:
|
| 27 |
+
>>> {"text_translated": str | None(うまくいかなかった場合)}
|
| 28 |
+
"""
|
| 29 |
+
|
| 30 |
+
def _preprocess(self, inputs: ProfileExtractorInputType):
|
| 31 |
+
system_prompt = "<input>より情報を抽出する。存在しない場合nullとする"
|
| 32 |
+
user_prompt = "<input>\n" f"'''{inputs['text'].strip()}'''"
|
| 33 |
+
messages = [
|
| 34 |
+
{"role": "system", "content": optimize_token(system_prompt)},
|
| 35 |
+
{"role": "user", "content": optimize_token(user_prompt)},
|
| 36 |
+
]
|
| 37 |
+
return messages
|
| 38 |
+
|
| 39 |
+
def _check_input(
|
| 40 |
+
self, inputs: ProfileExtractorInputType, messages
|
| 41 |
+
) -> tuple[bool, ProfileExtractorOuputType | None]:
|
| 42 |
+
# 入力がない場合の処理
|
| 43 |
+
if inputs["text"].strip() == "":
|
| 44 |
+
# requestしない, ルールベースのoutput
|
| 45 |
+
return False, {"name": "", "birth_year": -1, "domain": "", "lang": "JPN"}
|
| 46 |
+
# 入力が多い時に16kを使う
|
| 47 |
+
if self.llm.count_tokens(messages) >= 1600:
|
| 48 |
+
self.model = "gpt-3.5-turbo-16k"
|
| 49 |
+
else:
|
| 50 |
+
self.model = "gpt-3.5-turbo"
|
| 51 |
+
# requestする, _
|
| 52 |
+
return True, None
|
| 53 |
+
|
| 54 |
+
def _postprocess(self, response) -> ProfileExtractorOuputType:
|
| 55 |
+
if dict(response["choices"][0]["message"]).get("function_call"):
|
| 56 |
+
try:
|
| 57 |
+
extracted_data = json2dict(response["choices"][0]["message"]["function_call"]["arguments"])
|
| 58 |
+
except Exception:
|
| 59 |
+
extracted_data = {}
|
| 60 |
+
else:
|
| 61 |
+
extracted_data = {}
|
| 62 |
+
|
| 63 |
+
lang_ = extracted_data.get("lang")
|
| 64 |
+
if lang_ in {"ENG", "JPN"}:
|
| 65 |
+
lang = lang_
|
| 66 |
+
else:
|
| 67 |
+
lang = "JPN"
|
| 68 |
+
|
| 69 |
+
outputs: ProfileExtractorOuputType = {
|
| 70 |
+
"name": str(extracted_data.get("name") or ""),
|
| 71 |
+
"birth_year": int(extracted_data.get("birth_year") or -1),
|
| 72 |
+
"domain": str(extracted_data.get("domain") or ""),
|
| 73 |
+
"lang": lang,
|
| 74 |
+
}
|
| 75 |
+
return outputs
|
| 76 |
+
|
| 77 |
+
# Function Callingを使う場合必要
|
| 78 |
+
def _add_functions(self, inputs: Any) -> Functions | None:
|
| 79 |
+
functions: Functions = [
|
| 80 |
+
{
|
| 81 |
+
"name": "extract_profile",
|
| 82 |
+
"description": "extract profile of a person",
|
| 83 |
+
"parameters": {
|
| 84 |
+
"type": "object",
|
| 85 |
+
"properties": {
|
| 86 |
+
"name": {
|
| 87 |
+
"type": "string",
|
| 88 |
+
"description": "名前",
|
| 89 |
+
},
|
| 90 |
+
"domain": {
|
| 91 |
+
"type": "string",
|
| 92 |
+
"description": "研究ドメイン カンマ区切り",
|
| 93 |
+
},
|
| 94 |
+
"birth_year": {
|
| 95 |
+
"type": "integer",
|
| 96 |
+
"description": "the year of the birth YYYY",
|
| 97 |
+
},
|
| 98 |
+
"lang": {
|
| 99 |
+
"type": "string",
|
| 100 |
+
"description": "the language of the text",
|
| 101 |
+
"enum": ["ENG", "JPN"],
|
| 102 |
+
},
|
| 103 |
+
},
|
| 104 |
+
"required": ["name", "birth_year", "domain", "lang"],
|
| 105 |
+
},
|
| 106 |
+
}
|
| 107 |
+
]
|
| 108 |
+
return functions
|
| 109 |
+
|
| 110 |
+
# 型定義のために必要
|
| 111 |
+
def __call__(self, inputs: ProfileExtractorInputType) -> ProfileExtractorOuputType:
|
| 112 |
+
outputs: ProfileExtractorOuputType = super().__call__(inputs)
|
| 113 |
+
return outputs
|
project/ex_module/ex_translated_profile_extractor.py
ADDED
|
@@ -0,0 +1,49 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import TypedDict
|
| 2 |
+
|
| 3 |
+
from ex_profile_extractor import ProfileExtractor, ProfileExtractorInputType
|
| 4 |
+
from ex_translator import Translator
|
| 5 |
+
|
| 6 |
+
from neollm import MyL3M2
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class TranslatedProfileExtractorOutputType(TypedDict):
|
| 10 |
+
name_ENG: str
|
| 11 |
+
name_JPN: str
|
| 12 |
+
domain_ENG: str
|
| 13 |
+
domain_JPN: str
|
| 14 |
+
birth_year: int
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class TranslatedProfileExtractor(MyL3M2):
|
| 18 |
+
def _link(self, inputs: ProfileExtractorInputType) -> TranslatedProfileExtractorOutputType:
|
| 19 |
+
# Profile Extract
|
| 20 |
+
profile_extractor = ProfileExtractor(parent=self, silent_list=["llm_settings", "inputs", "messages"])
|
| 21 |
+
profile = profile_extractor(inputs)
|
| 22 |
+
# Translator name
|
| 23 |
+
translator_name = Translator(parent=self, silent_list=["llm_settings", "inputs", "messages"])
|
| 24 |
+
translated_name = translator_name(inputs={"text": profile["name"]})["text_translated"]
|
| 25 |
+
# Translate domain
|
| 26 |
+
translator_domain = Translator(parent=self, silent_list=["llm_settings", "inputs", "messages"])
|
| 27 |
+
translated_domain = translator_domain(inputs={"text": profile["domain"]})["text_translated"]
|
| 28 |
+
|
| 29 |
+
outputs: TranslatedProfileExtractorOutputType = {
|
| 30 |
+
"name_ENG": profile["name"],
|
| 31 |
+
"name_JPN": profile["name"],
|
| 32 |
+
"domain_ENG": profile["domain"],
|
| 33 |
+
"domain_JPN": profile["domain"],
|
| 34 |
+
"birth_year": profile["birth_year"],
|
| 35 |
+
}
|
| 36 |
+
|
| 37 |
+
if profile["lang"] == "ENG":
|
| 38 |
+
outputs["name_JPN"] = translated_name
|
| 39 |
+
outputs["domain_JPN"] = translated_domain
|
| 40 |
+
else:
|
| 41 |
+
outputs["name_ENG"] = translated_name
|
| 42 |
+
outputs["domain_ENG"] = translated_domain
|
| 43 |
+
|
| 44 |
+
return outputs
|
| 45 |
+
|
| 46 |
+
# 型定義のために必要
|
| 47 |
+
def __call__(self, inputs: ProfileExtractorInputType) -> TranslatedProfileExtractorOutputType:
|
| 48 |
+
outputs: TranslatedProfileExtractorOutputType = super().__call__(inputs)
|
| 49 |
+
return outputs
|
project/ex_module/ex_translator.py
ADDED
|
@@ -0,0 +1,62 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import TypedDict
|
| 2 |
+
|
| 3 |
+
from neollm import MyLLM
|
| 4 |
+
from neollm.types import Messages, OpenAIResponse
|
| 5 |
+
from neollm.utils.postprocess import strip_string
|
| 6 |
+
from neollm.utils.preprocess import optimize_token
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class TranslatorInputType(TypedDict):
|
| 10 |
+
text: str
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class TranslatorOuputType(TypedDict):
|
| 14 |
+
text_translated: str
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class Translator(MyLLM):
|
| 18 |
+
"""情報を抽出するMyLLM
|
| 19 |
+
|
| 20 |
+
Notes:
|
| 21 |
+
inputs:
|
| 22 |
+
>>> {"text": str}
|
| 23 |
+
outpus:
|
| 24 |
+
>>> {"text_translated": str | None(うまくいかなかった場合)}
|
| 25 |
+
"""
|
| 26 |
+
|
| 27 |
+
def _preprocess(self, inputs: TranslatorInputType) -> Messages:
|
| 28 |
+
system_prompt = (
|
| 29 |
+
"You are a good translator. Translate Japanese into English or English into Japanese.\n"
|
| 30 |
+
"# output_format:\n<output>\n{translated text in English or Japanese}"
|
| 31 |
+
)
|
| 32 |
+
user_prompt = "<input>\n" f"'''{inputs['text'].strip()}'''"
|
| 33 |
+
messages: Messages = [
|
| 34 |
+
{"role": "system", "content": optimize_token(system_prompt)},
|
| 35 |
+
{"role": "user", "content": optimize_token(user_prompt)},
|
| 36 |
+
]
|
| 37 |
+
return messages
|
| 38 |
+
|
| 39 |
+
def _ruleprocess(self, inputs: TranslatorInputType) -> None | TranslatorOuputType:
|
| 40 |
+
# 入力がない場合の処理
|
| 41 |
+
if inputs["text"].strip() == "":
|
| 42 |
+
return {"text_translated": ""}
|
| 43 |
+
return None
|
| 44 |
+
|
| 45 |
+
def _update_settings(self) -> None:
|
| 46 |
+
# 入力が多い時に16kを使う
|
| 47 |
+
if self.messages is not None:
|
| 48 |
+
if self.llm.count_tokens(self.messages) >= 1600:
|
| 49 |
+
self.model = "gpt-3.5-turbo-16k"
|
| 50 |
+
else:
|
| 51 |
+
self.model = "gpt-3.5-turbo"
|
| 52 |
+
|
| 53 |
+
def _postprocess(self, response: OpenAIResponse) -> TranslatorOuputType:
|
| 54 |
+
text_translated: str = str(response.choices[0].message["content"])
|
| 55 |
+
text_translated = strip_string(text=text_translated, first_character=["<output>", "<outputs>"])
|
| 56 |
+
outputs: TranslatorOuputType = {"text_translated": text_translated}
|
| 57 |
+
return outputs
|
| 58 |
+
|
| 59 |
+
# 型定義のために必要
|
| 60 |
+
def __call__(self, inputs: TranslatorInputType) -> TranslatorOuputType:
|
| 61 |
+
outputs: TranslatorOuputType = super().__call__(inputs)
|
| 62 |
+
return outputs
|
project/neollm-tutorial.ipynb
ADDED
|
@@ -0,0 +1,713 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"metadata": {},
|
| 6 |
+
"source": [
|
| 7 |
+
"# <font color=orange> settings\n"
|
| 8 |
+
]
|
| 9 |
+
},
|
| 10 |
+
{
|
| 11 |
+
"cell_type": "markdown",
|
| 12 |
+
"metadata": {},
|
| 13 |
+
"source": [
|
| 14 |
+
"### 1. install neollm\n",
|
| 15 |
+
"\n",
|
| 16 |
+
"[Document インストール方法](https://www.notion.so/c760d96f1b4240e6880a32bee96bba35)\n"
|
| 17 |
+
]
|
| 18 |
+
},
|
| 19 |
+
{
|
| 20 |
+
"cell_type": "code",
|
| 21 |
+
"execution_count": null,
|
| 22 |
+
"metadata": {},
|
| 23 |
+
"outputs": [],
|
| 24 |
+
"source": [
|
| 25 |
+
"# githubのssh接続してね\n",
|
| 26 |
+
"# versionは適宜変更してね\n",
|
| 27 |
+
"%pip install git+https://github.com/neoAI-inc/neo-llm-module.git@v1.2.6\n"
|
| 28 |
+
]
|
| 29 |
+
},
|
| 30 |
+
{
|
| 31 |
+
"cell_type": "markdown",
|
| 32 |
+
"metadata": {},
|
| 33 |
+
"source": [
|
| 34 |
+
"### 2 環境変数の設定方法\n",
|
| 35 |
+
"\n",
|
| 36 |
+
"[Document env ファイルの作り方](https://www.notion.so/env-32ebb04105684a77bbc730c39865df34)\n"
|
| 37 |
+
]
|
| 38 |
+
},
|
| 39 |
+
{
|
| 40 |
+
"cell_type": "code",
|
| 41 |
+
"execution_count": 1,
|
| 42 |
+
"metadata": {},
|
| 43 |
+
"outputs": [
|
| 44 |
+
{
|
| 45 |
+
"name": "stdout",
|
| 46 |
+
"output_type": "stream",
|
| 47 |
+
"text": [
|
| 48 |
+
"環境変数読み込み成功\n"
|
| 49 |
+
]
|
| 50 |
+
}
|
| 51 |
+
],
|
| 52 |
+
"source": [
|
| 53 |
+
"from dotenv import load_dotenv\n",
|
| 54 |
+
"\n",
|
| 55 |
+
"env_path = \".env\" # .envのpath 適宜変更\n",
|
| 56 |
+
"if load_dotenv(env_path):\n",
|
| 57 |
+
" print(\"環境変数読み込み成功\")\n",
|
| 58 |
+
"else:\n",
|
| 59 |
+
" print(\"path違うよ〜\")"
|
| 60 |
+
]
|
| 61 |
+
},
|
| 62 |
+
{
|
| 63 |
+
"cell_type": "markdown",
|
| 64 |
+
"metadata": {},
|
| 65 |
+
"source": [
|
| 66 |
+
"# <font color=orange> neoLLM 使い方\n"
|
| 67 |
+
]
|
| 68 |
+
},
|
| 69 |
+
{
|
| 70 |
+
"cell_type": "markdown",
|
| 71 |
+
"metadata": {},
|
| 72 |
+
"source": [
|
| 73 |
+
"neollm は、前処理・LLM のリクエスト・後処理を 1 つのクラスにした、Pytorch 的な記法で書ける neoAI の LLM 統一ライブラリ。\n",
|
| 74 |
+
"\n",
|
| 75 |
+
"大きく 2 種類のクラスがあり、MyLLM は 1 つのリクエスト、MyL3M2 は複数のリクエストを受け持つことができる。\n",
|
| 76 |
+
"\n",
|
| 77 |
+
"\n"
|
| 78 |
+
]
|
| 79 |
+
},
|
| 80 |
+
{
|
| 81 |
+
"cell_type": "markdown",
|
| 82 |
+
"metadata": {},
|
| 83 |
+
"source": [
|
| 84 |
+
"##### モデルの定義\n"
|
| 85 |
+
]
|
| 86 |
+
},
|
| 87 |
+
{
|
| 88 |
+
"cell_type": "code",
|
| 89 |
+
"execution_count": 2,
|
| 90 |
+
"metadata": {},
|
| 91 |
+
"outputs": [
|
| 92 |
+
{
|
| 93 |
+
"name": "stdout",
|
| 94 |
+
"output_type": "stream",
|
| 95 |
+
"text": [
|
| 96 |
+
"\u001b[43mWARNING: AZURE_API_BASEではなく、AZURE_OPENAI_ENDPOINTにしてね\u001b[0m\n",
|
| 97 |
+
"\u001b[43mWARNING: AZURE_API_VERSIONではなく、OPENAI_API_VERSIONにしてね\u001b[0m\n"
|
| 98 |
+
]
|
| 99 |
+
}
|
| 100 |
+
],
|
| 101 |
+
"source": [
|
| 102 |
+
"from neollm import MyLLM\n",
|
| 103 |
+
"\n",
|
| 104 |
+
"# 例: 翻訳をするclass\n",
|
| 105 |
+
"# _preprocess, _postprocessを必ず書く\n",
|
| 106 |
+
"\n",
|
| 107 |
+
"\n",
|
| 108 |
+
"class Translator(MyLLM):\n",
|
| 109 |
+
" # _preprocessは、前処理をしてMessageを作る関数\n",
|
| 110 |
+
" def _preprocess(self, inputs: str):\n",
|
| 111 |
+
" messages = [\n",
|
| 112 |
+
" {\"role\": \"system\", \"content\": \"英語を日本語に翻訳するAIです。\"},\n",
|
| 113 |
+
" {\"role\": \"user\", \"content\": inputs},\n",
|
| 114 |
+
" ]\n",
|
| 115 |
+
" return messages\n",
|
| 116 |
+
"\n",
|
| 117 |
+
" # _postprocessは、APIのResponseを後処理をして、欲しいものを返す関数\n",
|
| 118 |
+
" def _postprocess(self, response):\n",
|
| 119 |
+
" text_translated: str = str(response.choices[0].message.content)\n",
|
| 120 |
+
" return text_translated"
|
| 121 |
+
]
|
| 122 |
+
},
|
| 123 |
+
{
|
| 124 |
+
"cell_type": "markdown",
|
| 125 |
+
"metadata": {},
|
| 126 |
+
"source": [
|
| 127 |
+
"##### モデルの呼び出し\n"
|
| 128 |
+
]
|
| 129 |
+
},
|
| 130 |
+
{
|
| 131 |
+
"cell_type": "code",
|
| 132 |
+
"execution_count": 16,
|
| 133 |
+
"metadata": {},
|
| 134 |
+
"outputs": [
|
| 135 |
+
{
|
| 136 |
+
"name": "stdout",
|
| 137 |
+
"output_type": "stream",
|
| 138 |
+
"text": [
|
| 139 |
+
"\u001b[41mPARENT\u001b[0m\n",
|
| 140 |
+
"MyLLM(Translator) ----------------------------------------------------------------------------------\n",
|
| 141 |
+
"\u001b[34m[inputs]\u001b[0m\n",
|
| 142 |
+
"\"Hello, We are neoAI.\"\n",
|
| 143 |
+
"\u001b[34m[messages]\u001b[0m\n",
|
| 144 |
+
" \u001b[32msystem\u001b[0m\n",
|
| 145 |
+
" 英語を日本語に翻訳するAIです。\n",
|
| 146 |
+
" \u001b[32muser\u001b[0m\n",
|
| 147 |
+
" Hello, We are neoAI.\n",
|
| 148 |
+
" \u001b[32massistant\u001b[0m\n",
|
| 149 |
+
" こんにちは、私たちはneoAIです。\n",
|
| 150 |
+
"\u001b[34m[outputs]\u001b[0m\n",
|
| 151 |
+
"\"こんにちは、私たちはneoAIです。\"\n",
|
| 152 |
+
"\u001b[34m[client_settings]\u001b[0m -\n",
|
| 153 |
+
"\u001b[34m[llm_settings]\u001b[0m {'platform': 'azure', 'temperature': 1, 'model': 'gpt-3.5-turbo-0613', 'engine': 'neoai-free-swd-gpt-35-0613'}\n",
|
| 154 |
+
"\u001b[34m[metadata]\u001b[0m 1.6s; 45(36+9)tokens; $6.8e-05; ¥0.0095\n",
|
| 155 |
+
"----------------------------------------------------------------------------------------------------\n",
|
| 156 |
+
"こんにちは、私たちはneoAIです。\n"
|
| 157 |
+
]
|
| 158 |
+
}
|
| 159 |
+
],
|
| 160 |
+
"source": [
|
| 161 |
+
"# 初期化 (platformやmodelなど設定をしておく)\n",
|
| 162 |
+
"# 詳細: https://www.notion.so/neollm-MyLLM-581cd7562df9473b91c981d88469c452?pvs=4#ac5361a5e3fa46a48441fdd538858fee\n",
|
| 163 |
+
"translator = Translator(\n",
|
| 164 |
+
" platform=\"azure\", # azure or openai\n",
|
| 165 |
+
" model=\"gpt-3.5-turbo-0613\", # gpt-3.5-turbo-1106, gpt-4-turbo-1106\n",
|
| 166 |
+
" llm_settings={\"temperature\": 1}, # llmの設定 dictで渡す\n",
|
| 167 |
+
")\n",
|
| 168 |
+
"\n",
|
| 169 |
+
"# 呼び出し\n",
|
| 170 |
+
"# preprocessでinputsとしたものを入力として、postprocessで処理したものを出力とする。\n",
|
| 171 |
+
"translated_text = translator(inputs=\"Hello, We are neoAI.\")\n",
|
| 172 |
+
"print(translated_text)"
|
| 173 |
+
]
|
| 174 |
+
},
|
| 175 |
+
{
|
| 176 |
+
"cell_type": "code",
|
| 177 |
+
"execution_count": 17,
|
| 178 |
+
"metadata": {},
|
| 179 |
+
"outputs": [
|
| 180 |
+
{
|
| 181 |
+
"name": "stdout",
|
| 182 |
+
"output_type": "stream",
|
| 183 |
+
"text": [
|
| 184 |
+
"時間 1.5658628940582275\n",
|
| 185 |
+
"token数 TokenInfo(input=36, output=9, total=45)\n",
|
| 186 |
+
"token数合計 45\n",
|
| 187 |
+
"値段(USD) PriceInfo(input=5.4e-05, output=1.8e-05, total=6.75e-05)\n",
|
| 188 |
+
"値段数合計(USD) 6.75e-05\n"
|
| 189 |
+
]
|
| 190 |
+
}
|
| 191 |
+
],
|
| 192 |
+
"source": [
|
| 193 |
+
"# 処理時間\n",
|
| 194 |
+
"print(\"時間\", translator.time)\n",
|
| 195 |
+
"# トークン数\n",
|
| 196 |
+
"print(\"token数\", translator.token)\n",
|
| 197 |
+
"print(\"token数合計\", translator.token.total)\n",
|
| 198 |
+
"# 値段の取得\n",
|
| 199 |
+
"print(\"値段(USD)\", translator.price)\n",
|
| 200 |
+
"print(\"値段数合計(USD)\", translator.price.total)"
|
| 201 |
+
]
|
| 202 |
+
},
|
| 203 |
+
{
|
| 204 |
+
"cell_type": "code",
|
| 205 |
+
"execution_count": 20,
|
| 206 |
+
"metadata": {},
|
| 207 |
+
"outputs": [
|
| 208 |
+
{
|
| 209 |
+
"name": "stdout",
|
| 210 |
+
"output_type": "stream",
|
| 211 |
+
"text": [
|
| 212 |
+
"inputs Hello, We are neoAI.\n",
|
| 213 |
+
"messages [{'role': 'system', 'content': '英語を日本語に翻訳するAIです。'}, {'role': 'user', 'content': 'Hello, We are neoAI.'}]\n",
|
| 214 |
+
"response ChatCompletion(id='chatcmpl-8T5MkidV9bhqewdzcUwO1PioHOSHi', choices=[Choice(finish_reason='stop', index=0, message=ChatCompletionMessage(content='こんにちは、私たちはneoAIです。', role='assistant', function_call=None, tool_calls=None), content_filter_results={'hate': {'filtered': False, 'severity': 'safe'}, 'self_harm': {'filtered': False, 'severity': 'safe'}, 'sexual': {'filtered': False, 'severity': 'safe'}, 'violence': {'filtered': False, 'severity': 'safe'}})], created=1701942830, model='gpt-35-turbo', object='chat.completion', system_fingerprint=None, usage=CompletionUsage(completion_tokens=9, prompt_tokens=36, total_tokens=45), prompt_filter_results=[{'prompt_index': 0, 'content_filter_results': {'hate': {'filtered': False, 'severity': 'safe'}, 'self_harm': {'filtered': False, 'severity': 'safe'}, 'sexual': {'filtered': False, 'severity': 'safe'}, 'violence': {'filtered': False, 'severity': 'safe'}}}])\n",
|
| 215 |
+
"outputs こんにちは、私たちはneoAIです。\n",
|
| 216 |
+
"chat_history [{'role': 'system', 'content': '英語を日本語に翻訳するAIです。'}, {'role': 'user', 'content': 'Hello, We are neoAI.'}, {'content': 'こんにちは、私たちはneoAIです。', 'role': 'assistant'}]\n"
|
| 217 |
+
]
|
| 218 |
+
}
|
| 219 |
+
],
|
| 220 |
+
"source": [
|
| 221 |
+
"# その他property\n",
|
| 222 |
+
"print(\"inputs\", translator.inputs)\n",
|
| 223 |
+
"print(\"messages\", translator.messages)\n",
|
| 224 |
+
"print(\"response\", translator.response)\n",
|
| 225 |
+
"print(\"outputs\", translator.outputs)\n",
|
| 226 |
+
"\n",
|
| 227 |
+
"print(\"chat_history\", translator.chat_history)"
|
| 228 |
+
]
|
| 229 |
+
},
|
| 230 |
+
{
|
| 231 |
+
"cell_type": "markdown",
|
| 232 |
+
"metadata": {},
|
| 233 |
+
"source": [
|
| 234 |
+
"# <font color=orange> neoLLM 例\n"
|
| 235 |
+
]
|
| 236 |
+
},
|
| 237 |
+
{
|
| 238 |
+
"cell_type": "markdown",
|
| 239 |
+
"metadata": {},
|
| 240 |
+
"source": [
|
| 241 |
+
"### 1-1 MyLLM (ex. 翻訳)\n"
|
| 242 |
+
]
|
| 243 |
+
},
|
| 244 |
+
{
|
| 245 |
+
"cell_type": "code",
|
| 246 |
+
"execution_count": 21,
|
| 247 |
+
"metadata": {},
|
| 248 |
+
"outputs": [],
|
| 249 |
+
"source": [
|
| 250 |
+
"from neollm import MyLLM\n",
|
| 251 |
+
"from neollm.utils.preprocess import optimize_token\n",
|
| 252 |
+
"from neollm.utils.postprocess import strip_string\n",
|
| 253 |
+
"\n",
|
| 254 |
+
"\n",
|
| 255 |
+
"class Translator(MyLLM):\n",
|
| 256 |
+
" def _preprocess(self, inputs):\n",
|
| 257 |
+
" system_prompt = (\n",
|
| 258 |
+
" \"You are a good translator. Translate Japanese into English or English into Japanese.\\n\"\n",
|
| 259 |
+
" \"# output_format:\\n<output>\\n{translated text in English or Japanese}\"\n",
|
| 260 |
+
" )\n",
|
| 261 |
+
" user_prompt = \"<input>\\n\" f\"'''{inputs['text'].strip()}'''\"\n",
|
| 262 |
+
" messages = [\n",
|
| 263 |
+
" {\"role\": \"system\", \"content\": optimize_token(system_prompt)},\n",
|
| 264 |
+
" {\"role\": \"user\", \"content\": optimize_token(user_prompt)},\n",
|
| 265 |
+
" ]\n",
|
| 266 |
+
" return messages\n",
|
| 267 |
+
"\n",
|
| 268 |
+
" def _ruleprocess(self, inputs):\n",
|
| 269 |
+
" # 例外処理\n",
|
| 270 |
+
" if inputs[\"text\"].strip() == \"\":\n",
|
| 271 |
+
" return {\"text_translated\": \"\"}\n",
|
| 272 |
+
" # APIリクエストを送る場合はNone\n",
|
| 273 |
+
" return None\n",
|
| 274 |
+
"\n",
|
| 275 |
+
" def _update_settings(self):\n",
|
| 276 |
+
" # 入力によってAPIの設定を変更する\n",
|
| 277 |
+
"\n",
|
| 278 |
+
" # トークン数: self.llm.count_tokens(self.messsage)\n",
|
| 279 |
+
"\n",
|
| 280 |
+
" # モデル変更: self.model = \"gpt-3.5-turbo-16k\"\n",
|
| 281 |
+
"\n",
|
| 282 |
+
" # パラメータ変更: self.llm_settings = {\"temperature\": 0.2}\n",
|
| 283 |
+
"\n",
|
| 284 |
+
" # 入力が多い時に16kを使う(1106の場合はやらなくていい)\n",
|
| 285 |
+
" if self.messages is not None:\n",
|
| 286 |
+
" if self.llm.count_tokens(self.messages) >= 1600:\n",
|
| 287 |
+
" self.model = \"gpt-3.5-turbo-16k-0613\"\n",
|
| 288 |
+
" else:\n",
|
| 289 |
+
" self.model = \"gpt-3.5-turbo-0613\"\n",
|
| 290 |
+
"\n",
|
| 291 |
+
" def _postprocess(self, response):\n",
|
| 292 |
+
" text_translated: str = str(response.choices[0].message.content)\n",
|
| 293 |
+
" text_translated = strip_string(text=text_translated, first_character=[\"<output>\", \"<outputs>\"])\n",
|
| 294 |
+
" outputs = {\"text_translated\": text_translated}\n",
|
| 295 |
+
" return outputs"
|
| 296 |
+
]
|
| 297 |
+
},
|
| 298 |
+
{
|
| 299 |
+
"cell_type": "code",
|
| 300 |
+
"execution_count": 23,
|
| 301 |
+
"metadata": {},
|
| 302 |
+
"outputs": [
|
| 303 |
+
{
|
| 304 |
+
"name": "stdout",
|
| 305 |
+
"output_type": "stream",
|
| 306 |
+
"text": [
|
| 307 |
+
"\u001b[41mPARENT\u001b[0m\n",
|
| 308 |
+
"MyLLM(Translator) ----------------------------------------------------------------------------------\n",
|
| 309 |
+
"\u001b[34m[inputs]\u001b[0m\n",
|
| 310 |
+
"{\n",
|
| 311 |
+
" \"text\": \"大規模LLMモデル\"\n",
|
| 312 |
+
"}\n",
|
| 313 |
+
"\u001b[34m[messages]\u001b[0m\n",
|
| 314 |
+
" \u001b[32msystem\u001b[0m\n",
|
| 315 |
+
" You are a good translator. Translate Japanese into English or English into Japanese.\n",
|
| 316 |
+
" # output_format:\n",
|
| 317 |
+
" <output>\n",
|
| 318 |
+
" {translated text in English or Japanese}\n",
|
| 319 |
+
" \u001b[32muser\u001b[0m\n",
|
| 320 |
+
" <input>\n",
|
| 321 |
+
" '''大規模LLMモデル'''\n",
|
| 322 |
+
" \u001b[32massistant\u001b[0m\n",
|
| 323 |
+
" <output>\n",
|
| 324 |
+
" \"Large-Scale LLM Model\"\n",
|
| 325 |
+
"\u001b[34m[outputs]\u001b[0m\n",
|
| 326 |
+
"{\n",
|
| 327 |
+
" \"text_translated\": \"Large-Scale LLM Model\"\n",
|
| 328 |
+
"}\n",
|
| 329 |
+
"\u001b[34m[client_settings]\u001b[0m -\n",
|
| 330 |
+
"\u001b[34m[llm_settings]\u001b[0m {'platform': 'azure', 'temperature': 1, 'model': 'gpt-3.5-turbo-0613', 'engine': 'neoai-free-swd-gpt-35-0613'}\n",
|
| 331 |
+
"\u001b[34m[metadata]\u001b[0m 1.5s; 66(55+11)tokens; $9.9e-05; ¥0.014\n",
|
| 332 |
+
"----------------------------------------------------------------------------------------------------\n",
|
| 333 |
+
"{'text_translated': 'Large-Scale LLM Model'}\n"
|
| 334 |
+
]
|
| 335 |
+
}
|
| 336 |
+
],
|
| 337 |
+
"source": [
|
| 338 |
+
"translator = Translator(\n",
|
| 339 |
+
" llm_settings={\"temperature\": 1}, # defaultは、{\"temperature\": 0}\n",
|
| 340 |
+
" model=\"gpt-3.5-turbo-0613\", # defaultは、DEFAULT_MODEL_NAME\n",
|
| 341 |
+
" platform=\"azure\", # defaultは、LLM_PLATFORM\n",
|
| 342 |
+
" verbose=True,\n",
|
| 343 |
+
" silent_list=[], # 表示しないもの\n",
|
| 344 |
+
")\n",
|
| 345 |
+
"output_1 = translator(inputs={\"text\": \"大規模LLMモデル\"})\n",
|
| 346 |
+
"print(output_1)"
|
| 347 |
+
]
|
| 348 |
+
},
|
| 349 |
+
{
|
| 350 |
+
"cell_type": "code",
|
| 351 |
+
"execution_count": 25,
|
| 352 |
+
"metadata": {},
|
| 353 |
+
"outputs": [
|
| 354 |
+
{
|
| 355 |
+
"name": "stdout",
|
| 356 |
+
"output_type": "stream",
|
| 357 |
+
"text": [
|
| 358 |
+
"\u001b[43mWARNING: model_nameに日付を指定してください\u001b[0m\n",
|
| 359 |
+
"model_name: gpt-3.5-turbo -> gpt-3.5-turbo-0613\n",
|
| 360 |
+
"\u001b[41mPARENT\u001b[0m\n",
|
| 361 |
+
"MyLLM(Translator) ----------------------------------------------------------------------------------\n",
|
| 362 |
+
"\u001b[34m[inputs]\u001b[0m\n",
|
| 363 |
+
"{\n",
|
| 364 |
+
" \"text\": \"Large LLM Model\"\n",
|
| 365 |
+
"}\n",
|
| 366 |
+
"\u001b[34m[messages]\u001b[0m\n",
|
| 367 |
+
" \u001b[32msystem\u001b[0m\n",
|
| 368 |
+
" You are a good translator. Translate Japanese into English or English into Japanese.\n",
|
| 369 |
+
" # output_format:\n",
|
| 370 |
+
" <output>\n",
|
| 371 |
+
" {translated text in English or Japanese}\n",
|
| 372 |
+
" \u001b[32muser\u001b[0m\n",
|
| 373 |
+
" <input>\n",
|
| 374 |
+
" '''Large LLM Model'''\n",
|
| 375 |
+
"\u001b[43mWARNING: model_nameに日付を指定してください\u001b[0m\n",
|
| 376 |
+
"model_name: gpt-3.5-turbo -> gpt-3.5-turbo-0613\n",
|
| 377 |
+
" \u001b[32massistant\u001b[0m\n",
|
| 378 |
+
" <output>\n",
|
| 379 |
+
" 大きなLLMモデル\n",
|
| 380 |
+
"\u001b[34m[outputs]\u001b[0m\n",
|
| 381 |
+
"{\n",
|
| 382 |
+
" \"text_translated\": \"大きなLLMモデル\"\n",
|
| 383 |
+
"}\n",
|
| 384 |
+
"\u001b[34m[client_settings]\u001b[0m -\n",
|
| 385 |
+
"\u001b[34m[llm_settings]\u001b[0m {'platform': 'openai', 'temperature': 0, 'model': 'gpt-3.5-turbo-0613'}\n",
|
| 386 |
+
"\u001b[34m[metadata]\u001b[0m 0.9s; 61(49+12)tokens; $9.2e-05; ¥0.013\n",
|
| 387 |
+
"----------------------------------------------------------------------------------------------------\n",
|
| 388 |
+
"{'text_translated': '大きなLLMモデル'}\n"
|
| 389 |
+
]
|
| 390 |
+
}
|
| 391 |
+
],
|
| 392 |
+
"source": [
|
| 393 |
+
"translator = Translator(\n",
|
| 394 |
+
" platform=\"openai\", # <- 変えてみる\n",
|
| 395 |
+
" verbose=True,\n",
|
| 396 |
+
")\n",
|
| 397 |
+
"output_1 = translator(inputs={\"text\": \"Large LLM Model\"})\n",
|
| 398 |
+
"print(output_1)"
|
| 399 |
+
]
|
| 400 |
+
},
|
| 401 |
+
{
|
| 402 |
+
"cell_type": "code",
|
| 403 |
+
"execution_count": 26,
|
| 404 |
+
"metadata": {},
|
| 405 |
+
"outputs": [
|
| 406 |
+
{
|
| 407 |
+
"name": "stdout",
|
| 408 |
+
"output_type": "stream",
|
| 409 |
+
"text": [
|
| 410 |
+
"\u001b[43mWARNING: model_nameに日��を指定してください\u001b[0m\n",
|
| 411 |
+
"model_name: gpt-3.5-turbo -> gpt-3.5-turbo-0613\n",
|
| 412 |
+
"\u001b[41mPARENT\u001b[0m\n",
|
| 413 |
+
"MyLLM(Translator) ----------------------------------------------------------------------------------\n",
|
| 414 |
+
"\u001b[34m[inputs]\u001b[0m\n",
|
| 415 |
+
"{\n",
|
| 416 |
+
" \"text\": \"\"\n",
|
| 417 |
+
"}\n",
|
| 418 |
+
"\u001b[34m[outputs]\u001b[0m\n",
|
| 419 |
+
"{\n",
|
| 420 |
+
" \"text_translated\": \"\"\n",
|
| 421 |
+
"}\n",
|
| 422 |
+
"\u001b[34m[client_settings]\u001b[0m -\n",
|
| 423 |
+
"\u001b[34m[llm_settings]\u001b[0m {'platform': 'azure', 'temperature': 0, 'model': 'gpt-3.5-turbo-0613', 'engine': 'neoai-free-swd-gpt-35-0613'}\n",
|
| 424 |
+
"\u001b[34m[metadata]\u001b[0m 0.0s; 0(0+0)tokens; $0; ¥0\n",
|
| 425 |
+
"----------------------------------------------------------------------------------------------------\n"
|
| 426 |
+
]
|
| 427 |
+
},
|
| 428 |
+
{
|
| 429 |
+
"data": {
|
| 430 |
+
"text/plain": [
|
| 431 |
+
"{'text_translated': ''}"
|
| 432 |
+
]
|
| 433 |
+
},
|
| 434 |
+
"execution_count": 26,
|
| 435 |
+
"metadata": {},
|
| 436 |
+
"output_type": "execute_result"
|
| 437 |
+
}
|
| 438 |
+
],
|
| 439 |
+
"source": [
|
| 440 |
+
"# ルールベースが起動\n",
|
| 441 |
+
"data = {\"text\": \"\"}\n",
|
| 442 |
+
"translator = Translator(verbose=True)\n",
|
| 443 |
+
"translator(data)"
|
| 444 |
+
]
|
| 445 |
+
},
|
| 446 |
+
{
|
| 447 |
+
"cell_type": "code",
|
| 448 |
+
"execution_count": 27,
|
| 449 |
+
"metadata": {},
|
| 450 |
+
"outputs": [
|
| 451 |
+
{
|
| 452 |
+
"name": "stdout",
|
| 453 |
+
"output_type": "stream",
|
| 454 |
+
"text": [
|
| 455 |
+
"\u001b[43mWARNING: model_nameに日付を指定してください\u001b[0m\n",
|
| 456 |
+
"model_name: gpt-3.5-turbo -> gpt-3.5-turbo-0613\n",
|
| 457 |
+
"\u001b[41mPARENT\u001b[0m\n",
|
| 458 |
+
"MyLLM(Translator) ----------------------------------------------------------------------------------\n",
|
| 459 |
+
"\u001b[34m[inputs]\u001b[0m\n",
|
| 460 |
+
"{\n",
|
| 461 |
+
" \"text\": \"こんにちは!!\\nこんにちは?こんにちは?\"\n",
|
| 462 |
+
"}\n",
|
| 463 |
+
"\u001b[34m[messages]\u001b[0m\n",
|
| 464 |
+
" \u001b[32msystem\u001b[0m\n",
|
| 465 |
+
" You are a good translator. Translate Japanese into English or English into Japanese.\n",
|
| 466 |
+
" # output_format:\n",
|
| 467 |
+
" <output>\n",
|
| 468 |
+
" {translated text in English or Japanese}\n",
|
| 469 |
+
" \u001b[32muser\u001b[0m\n",
|
| 470 |
+
" <input>\n",
|
| 471 |
+
" '''こんにちは!!\n",
|
| 472 |
+
" こんにちは?こんにちは?'''\n",
|
| 473 |
+
"\u001b[43mWARNING: model_nameに日付を指定してください\u001b[0m\n",
|
| 474 |
+
"model_name: gpt-3.5-turbo -> gpt-3.5-turbo-0613\n",
|
| 475 |
+
" \u001b[32massistant\u001b[0m\n",
|
| 476 |
+
" <output>\n",
|
| 477 |
+
" Hello!!\n",
|
| 478 |
+
" Hello? Hello?\n",
|
| 479 |
+
"\u001b[34m[outputs]\u001b[0m\n",
|
| 480 |
+
"{\n",
|
| 481 |
+
" \"text_translated\": \"Hello!!\\nHello? Hello?\"\n",
|
| 482 |
+
"}\n",
|
| 483 |
+
"\u001b[34m[client_settings]\u001b[0m -\n",
|
| 484 |
+
"\u001b[34m[llm_settings]\u001b[0m {'platform': 'azure', 'temperature': 0, 'model': 'gpt-3.5-turbo-0613', 'engine': 'neoai-free-swd-gpt-35-0613'}\n",
|
| 485 |
+
"\u001b[34m[metadata]\u001b[0m 1.4s; 60(51+9)tokens; $9e-05; ¥0.013\n",
|
| 486 |
+
"----------------------------------------------------------------------------------------------------\n"
|
| 487 |
+
]
|
| 488 |
+
},
|
| 489 |
+
{
|
| 490 |
+
"data": {
|
| 491 |
+
"text/plain": [
|
| 492 |
+
"{'text_translated': 'Hello!!\\nHello? Hello?'}"
|
| 493 |
+
]
|
| 494 |
+
},
|
| 495 |
+
"execution_count": 27,
|
| 496 |
+
"metadata": {},
|
| 497 |
+
"output_type": "execute_result"
|
| 498 |
+
}
|
| 499 |
+
],
|
| 500 |
+
"source": [
|
| 501 |
+
"data = {\"text\": \"こんにちは!!\\nこんにちは?こんにちは?\"}\n",
|
| 502 |
+
"translator = Translator(verbose=True)\n",
|
| 503 |
+
"translator(data)"
|
| 504 |
+
]
|
| 505 |
+
},
|
| 506 |
+
{
|
| 507 |
+
"cell_type": "markdown",
|
| 508 |
+
"metadata": {},
|
| 509 |
+
"source": [
|
| 510 |
+
"## 情報抽出\n"
|
| 511 |
+
]
|
| 512 |
+
},
|
| 513 |
+
{
|
| 514 |
+
"cell_type": "code",
|
| 515 |
+
"execution_count": 50,
|
| 516 |
+
"metadata": {},
|
| 517 |
+
"outputs": [],
|
| 518 |
+
"source": [
|
| 519 |
+
"from neollm import MyLLM\n",
|
| 520 |
+
"from neollm.utils.preprocess import optimize_token, dict2json\n",
|
| 521 |
+
"from neollm.utils.postprocess import json2dict\n",
|
| 522 |
+
"\n",
|
| 523 |
+
"\n",
|
| 524 |
+
"class Extractor(MyLLM):\n",
|
| 525 |
+
" def _preprocess(self, inputs):\n",
|
| 526 |
+
" system_prompt = \"<INFO>から、<OUTPUT_FORMAT>にしたがって、情報を抽出しなさい。\"\n",
|
| 527 |
+
" output_format = {\"date\": \"yy-mm-dd形式 日付\", \"event\": \"起きたことを簡潔に。\"}\n",
|
| 528 |
+
" user_prompt = (\n",
|
| 529 |
+
" \"<INFO>\\n\"\n",
|
| 530 |
+
" \"```\\n\"\n",
|
| 531 |
+
" f\"{inputs['info'].strip()}\\n\"\n",
|
| 532 |
+
" \"```\\n\"\n",
|
| 533 |
+
" \"\\n\"\n",
|
| 534 |
+
" \"<OUTPUT_FORMAT>\\n\"\n",
|
| 535 |
+
" \"```json\\n\"\n",
|
| 536 |
+
" f\"{dict2json(output_format)}\\n\"\n",
|
| 537 |
+
" \"```\"\n",
|
| 538 |
+
" )\n",
|
| 539 |
+
"\n",
|
| 540 |
+
" messages = [\n",
|
| 541 |
+
" {\"role\": \"system\", \"content\": optimize_token(system_prompt)},\n",
|
| 542 |
+
" {\"role\": \"user\", \"content\": optimize_token(user_prompt)},\n",
|
| 543 |
+
" ]\n",
|
| 544 |
+
" return messages\n",
|
| 545 |
+
"\n",
|
| 546 |
+
" def _ruleprocess(self, inputs):\n",
|
| 547 |
+
" # 例外処理\n",
|
| 548 |
+
" if inputs[\"info\"].strip() == \"\":\n",
|
| 549 |
+
" return {\"date\": \"\", \"event\": \"\"}\n",
|
| 550 |
+
" # APIリクエストを送る場合はNone\n",
|
| 551 |
+
" return None\n",
|
| 552 |
+
"\n",
|
| 553 |
+
" def _postprocess(self, response):\n",
|
| 554 |
+
" return json2dict(response.choices[0].message.content)"
|
| 555 |
+
]
|
| 556 |
+
},
|
| 557 |
+
{
|
| 558 |
+
"cell_type": "code",
|
| 559 |
+
"execution_count": 51,
|
| 560 |
+
"metadata": {},
|
| 561 |
+
"outputs": [
|
| 562 |
+
{
|
| 563 |
+
"name": "stdout",
|
| 564 |
+
"output_type": "stream",
|
| 565 |
+
"text": [
|
| 566 |
+
"\u001b[41mPARENT\u001b[0m\n",
|
| 567 |
+
"MyLLM(Extractor) -----------------------------------------------------------------------------------\n",
|
| 568 |
+
"\u001b[34m[inputs]\u001b[0m\n",
|
| 569 |
+
"{\n",
|
| 570 |
+
" \"info\": \"2021年6月13日に、neoAIのサービスが始まりました。\"\n",
|
| 571 |
+
"}\n",
|
| 572 |
+
"\u001b[34m[messages]\u001b[0m\n",
|
| 573 |
+
" \u001b[32msystem\u001b[0m\n",
|
| 574 |
+
" <INFO>から、<OUTPUT_FORMAT>にしたがって、情報を抽出しなさい。\n",
|
| 575 |
+
" \u001b[32muser\u001b[0m\n",
|
| 576 |
+
" <INFO>\n",
|
| 577 |
+
" ```\n",
|
| 578 |
+
" 2021年6月13日に、neoAIのサービスが始まりました。\n",
|
| 579 |
+
" ```\n",
|
| 580 |
+
" \n",
|
| 581 |
+
" <OUTPUT_FORMAT>\n",
|
| 582 |
+
" ```json\n",
|
| 583 |
+
" {\n",
|
| 584 |
+
" \"date\": \"yy-mm-dd形式 日付\",\n",
|
| 585 |
+
" \"event\": \"起きたことを簡潔に。\"\n",
|
| 586 |
+
" }\n",
|
| 587 |
+
" ```\n",
|
| 588 |
+
" \u001b[32massistant\u001b[0m\n",
|
| 589 |
+
" ```json\n",
|
| 590 |
+
" {\n",
|
| 591 |
+
" \"date\": \"2021-06-13\",\n",
|
| 592 |
+
" \"event\": \"neoAIのサービスが始まりました。\"\n",
|
| 593 |
+
" }\n",
|
| 594 |
+
" ```\n",
|
| 595 |
+
"\u001b[34m[outputs]\u001b[0m\n",
|
| 596 |
+
"{\n",
|
| 597 |
+
" \"date\": \"2021-06-13\",\n",
|
| 598 |
+
" \"event\": \"neoAIのサービスが始まりました。\"\n",
|
| 599 |
+
"}\n",
|
| 600 |
+
"\u001b[34m[client_settings]\u001b[0m -\n",
|
| 601 |
+
"\u001b[34m[llm_settings]\u001b[0m {'platform': 'azure', 'temperature': 0, 'model': 'gpt-3.5-turbo-0613', 'engine': 'neoai-free-swd-gpt-35-0613'}\n",
|
| 602 |
+
"\u001b[34m[metadata]\u001b[0m 1.6s; 143(106+37)tokens; $0.00021; ¥0.03\n",
|
| 603 |
+
"----------------------------------------------------------------------------------------------------\n"
|
| 604 |
+
]
|
| 605 |
+
},
|
| 606 |
+
{
|
| 607 |
+
"data": {
|
| 608 |
+
"text/plain": [
|
| 609 |
+
"{'date': '2021-06-13', 'event': 'neoAIのサービスが始まりました。'}"
|
| 610 |
+
]
|
| 611 |
+
},
|
| 612 |
+
"execution_count": 51,
|
| 613 |
+
"metadata": {},
|
| 614 |
+
"output_type": "execute_result"
|
| 615 |
+
}
|
| 616 |
+
],
|
| 617 |
+
"source": [
|
| 618 |
+
"extractor = Extractor(model=\"gpt-3.5-turbo-0613\")\n",
|
| 619 |
+
"\n",
|
| 620 |
+
"extractor(inputs={\"info\": \"2021年6月13日に、neoAIのサービスが始まりました。\"})"
|
| 621 |
+
]
|
| 622 |
+
},
|
| 623 |
+
{
|
| 624 |
+
"cell_type": "code",
|
| 625 |
+
"execution_count": 52,
|
| 626 |
+
"metadata": {},
|
| 627 |
+
"outputs": [
|
| 628 |
+
{
|
| 629 |
+
"name": "stdout",
|
| 630 |
+
"output_type": "stream",
|
| 631 |
+
"text": [
|
| 632 |
+
"\u001b[41mPARENT\u001b[0m\n",
|
| 633 |
+
"MyLLM(Extractor) -----------------------------------------------------------------------------------\n",
|
| 634 |
+
"\u001b[34m[inputs]\u001b[0m\n",
|
| 635 |
+
"{\n",
|
| 636 |
+
" \"info\": \"1998年4月1日に、neoAI大学が設立されました。\"\n",
|
| 637 |
+
"}\n",
|
| 638 |
+
"\u001b[34m[messages]\u001b[0m\n",
|
| 639 |
+
" \u001b[32msystem\u001b[0m\n",
|
| 640 |
+
" <INFO>から、<OUTPUT_FORMAT>にしたがって、情報を抽出しなさい。\n",
|
| 641 |
+
" \u001b[32muser\u001b[0m\n",
|
| 642 |
+
" <INFO>\n",
|
| 643 |
+
" ```\n",
|
| 644 |
+
" 1998年4月1日に、neoAI大学が設立されました。\n",
|
| 645 |
+
" ```\n",
|
| 646 |
+
" \n",
|
| 647 |
+
" <OUTPUT_FORMAT>\n",
|
| 648 |
+
" ```json\n",
|
| 649 |
+
" {\n",
|
| 650 |
+
" \"date\": \"yy-mm-dd形式 日付\",\n",
|
| 651 |
+
" \"event\": \"起きたことを簡潔に。\"\n",
|
| 652 |
+
" }\n",
|
| 653 |
+
" ```\n",
|
| 654 |
+
" \u001b[32massistant\u001b[0m\n",
|
| 655 |
+
" <OUTPUT>\n",
|
| 656 |
+
" ```json\n",
|
| 657 |
+
" {\n",
|
| 658 |
+
" \"date\": \"1998-04-01\",\n",
|
| 659 |
+
" \"event\": \"neoAI大学の設立\"\n",
|
| 660 |
+
" }\n",
|
| 661 |
+
" ```\n",
|
| 662 |
+
"\u001b[34m[outputs]\u001b[0m\n",
|
| 663 |
+
"{\n",
|
| 664 |
+
" \"date\": \"1998-04-01\",\n",
|
| 665 |
+
" \"event\": \"neoAI大学の設立\"\n",
|
| 666 |
+
"}\n",
|
| 667 |
+
"\u001b[34m[client_settings]\u001b[0m -\n",
|
| 668 |
+
"\u001b[34m[llm_settings]\u001b[0m {'platform': 'azure', 'temperature': 0, 'model': 'gpt-3.5-turbo-0613', 'engine': 'neoai-free-swd-gpt-35-0613'}\n",
|
| 669 |
+
"\u001b[34m[metadata]\u001b[0m 1.6s; 139(104+35)tokens; $0.00021; ¥0.029\n",
|
| 670 |
+
"----------------------------------------------------------------------------------------------------\n"
|
| 671 |
+
]
|
| 672 |
+
},
|
| 673 |
+
{
|
| 674 |
+
"data": {
|
| 675 |
+
"text/plain": [
|
| 676 |
+
"{'date': '1998-04-01', 'event': 'neoAI大学の設立'}"
|
| 677 |
+
]
|
| 678 |
+
},
|
| 679 |
+
"execution_count": 52,
|
| 680 |
+
"metadata": {},
|
| 681 |
+
"output_type": "execute_result"
|
| 682 |
+
}
|
| 683 |
+
],
|
| 684 |
+
"source": [
|
| 685 |
+
"extractor = Extractor(model=\"gpt-3.5-turbo-0613\")\n",
|
| 686 |
+
"\n",
|
| 687 |
+
"extractor(inputs={\"info\": \"1998年4月1日に、neoAI大学が設立されました。\"})"
|
| 688 |
+
]
|
| 689 |
+
}
|
| 690 |
+
],
|
| 691 |
+
"metadata": {
|
| 692 |
+
"kernelspec": {
|
| 693 |
+
"display_name": "Python 3",
|
| 694 |
+
"language": "python",
|
| 695 |
+
"name": "python3"
|
| 696 |
+
},
|
| 697 |
+
"language_info": {
|
| 698 |
+
"codemirror_mode": {
|
| 699 |
+
"name": "ipython",
|
| 700 |
+
"version": 3
|
| 701 |
+
},
|
| 702 |
+
"file_extension": ".py",
|
| 703 |
+
"mimetype": "text/x-python",
|
| 704 |
+
"name": "python",
|
| 705 |
+
"nbconvert_exporter": "python",
|
| 706 |
+
"pygments_lexer": "ipython3",
|
| 707 |
+
"version": "3.10.11"
|
| 708 |
+
},
|
| 709 |
+
"orig_nbformat": 4
|
| 710 |
+
},
|
| 711 |
+
"nbformat": 4,
|
| 712 |
+
"nbformat_minor": 2
|
| 713 |
+
}
|
pyproject.toml
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[tool.poetry]
|
| 2 |
+
name = "neollm"
|
| 3 |
+
version = "1.3.3"
|
| 4 |
+
description = "neo LLM Module for Python 3.10"
|
| 5 |
+
authors = ["KoshiroTerasawa <k.terasawa@neoai.jp>"]
|
| 6 |
+
readme = "README.md"
|
| 7 |
+
packages = [{ include = "neollm" }]
|
| 8 |
+
|
| 9 |
+
[tool.poetry.dependencies]
|
| 10 |
+
python = "^3.10"
|
| 11 |
+
python-dotenv = "^1.0.0"
|
| 12 |
+
pydantic = "^2.4.2"
|
| 13 |
+
openai = "^1.1.1"
|
| 14 |
+
google-cloud-aiplatform = "^1.48.0"
|
| 15 |
+
anthropic = { version = "^0.18.1", extras = ["vertex"] }
|
| 16 |
+
typing-extensions = "^4.8.0"
|
| 17 |
+
google-generativeai = "0.5.2"
|
| 18 |
+
tiktoken = "0.7.0"
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
[tool.poetry.group.dev.dependencies]
|
| 22 |
+
isort = "^5.12.0"
|
| 23 |
+
black = "24.3.0"
|
| 24 |
+
mypy = "^1.8.0"
|
| 25 |
+
pyproject-flake8 = "^6.1.0"
|
| 26 |
+
ipykernel = "^6.26.0"
|
| 27 |
+
jupyter = "^1.0.0"
|
| 28 |
+
jupyter-client = "^8.6.0"
|
| 29 |
+
pytest = "^8.1.1"
|
| 30 |
+
|
| 31 |
+
[build-system]
|
| 32 |
+
requires = ["poetry-core"]
|
| 33 |
+
build-backend = "poetry.core.masonry.api"
|
| 34 |
+
|
| 35 |
+
[tool.black]
|
| 36 |
+
line-length = 119
|
| 37 |
+
exclude = '''
|
| 38 |
+
/(
|
| 39 |
+
\venv
|
| 40 |
+
| \.git
|
| 41 |
+
| \.hg
|
| 42 |
+
| __pycache__
|
| 43 |
+
| \.mypy_cache
|
| 44 |
+
)/
|
| 45 |
+
'''
|
| 46 |
+
|
| 47 |
+
[tool.isort]
|
| 48 |
+
profile = "black"
|
| 49 |
+
multi_line_output = 3
|
| 50 |
+
|
| 51 |
+
[tool.flake8]
|
| 52 |
+
max-line-length = 119
|
| 53 |
+
extend-ignore = ["E203", "W503", "E501", "E704"]
|
| 54 |
+
exclude = [".venv", ".git", "__pycache__", ".mypy_cache", ".hg"]
|
| 55 |
+
max-complexity = 15
|
| 56 |
+
|
| 57 |
+
[tool.mypy]
|
| 58 |
+
ignore_missing_imports = true
|
| 59 |
+
# follow_imports = normal
|
| 60 |
+
disallow_any_unimported = false
|
| 61 |
+
disallow_any_expr = false # 式でのAny禁止
|
| 62 |
+
disallow_any_decorated = false
|
| 63 |
+
disallow_any_explicit = false # 変数でAny禁止
|
| 64 |
+
disallow_any_generics = true # ジェネリックで書かないの禁止
|
| 65 |
+
disallow_subclassing_any = true # Anyのサブクラス禁止
|
| 66 |
+
|
| 67 |
+
disallow_untyped_calls = true # 型なし関数呼び出し禁止 `a: int = f()`
|
| 68 |
+
disallow_untyped_defs = true # 型なし関数定義禁止 `def f(a: int) -> int`
|
| 69 |
+
disallow_incomplete_defs = true # 一部の型定義を禁止 `def f(a: int, b)`
|
| 70 |
+
check_untyped_defs = true
|
| 71 |
+
disallow_untyped_decorators = true
|
| 72 |
+
no_implicit_optional = true
|
| 73 |
+
|
| 74 |
+
warn_redundant_casts = true
|
| 75 |
+
warn_unused_ignores = true
|
| 76 |
+
warn_return_any = true
|
| 77 |
+
warn_unreachable = true # 辿りつかないコードの検出
|
| 78 |
+
allow_redefinition = false # 変数の再定義を禁止
|
| 79 |
+
|
| 80 |
+
show_error_context = true
|
| 81 |
+
show_column_numbers = true
|
test/llm/claude/test_claude_llm.py
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# from neollm.llm.gpt.azure_llm import (
|
| 2 |
+
# AzureGPT4_0613,
|
| 3 |
+
# AzureGPT4T_0125,
|
| 4 |
+
# AzureGPT4T_1106,
|
| 5 |
+
# AzureGPT4T_20240409,
|
| 6 |
+
# AzureGPT4VT_1106,
|
| 7 |
+
# AzureGPT35FT,
|
| 8 |
+
# AzureGPT35T16k_0613,
|
| 9 |
+
# AzureGPT35T_0125,
|
| 10 |
+
# AzureGPT35T_0613,
|
| 11 |
+
# AzureGPT35T_1106,
|
| 12 |
+
# AzureGPT432k_0613,
|
| 13 |
+
# )
|
| 14 |
+
# from neollm.types.info import APIPricing
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
# def test_check_price() -> None:
|
| 18 |
+
# # https://azure.microsoft.com/ja-jp/pricing/details/cognitive-services/openai-service/
|
| 19 |
+
|
| 20 |
+
# # これからのモデル --------------------------------------------------------
|
| 21 |
+
# assert AzureGPT4T_20240409.dollar_per_ktoken == APIPricing(input=0.01, output=0.03)
|
| 22 |
+
# # Updated --------------------------------------------------------
|
| 23 |
+
# # GPT3.5T
|
| 24 |
+
# assert AzureGPT35T_0125.dollar_per_ktoken == APIPricing(input=0.0005, output=0.0015)
|
| 25 |
+
# # GPT4
|
| 26 |
+
# assert AzureGPT4T_0125.dollar_per_ktoken == APIPricing(input=0.01, output=0.03)
|
| 27 |
+
# assert AzureGPT4VT_1106.dollar_per_ktoken == APIPricing(input=0.01, output=0.03)
|
| 28 |
+
# assert AzureGPT4T_1106.dollar_per_ktoken == APIPricing(input=0.01, output=0.03)
|
| 29 |
+
# assert AzureGPT4_0613.dollar_per_ktoken == APIPricing(input=0.03, output=0.06)
|
| 30 |
+
# assert AzureGPT432k_0613.dollar_per_ktoken == APIPricing(input=0.06, output=0.12)
|
| 31 |
+
# # FT
|
| 32 |
+
# assert AzureGPT35FT.dollar_per_ktoken == APIPricing(input=0.0005, output=0.0015)
|
| 33 |
+
# # Legacy ---------------------------------------------------------
|
| 34 |
+
# # AzureGPT35T_0301 なし
|
| 35 |
+
# assert AzureGPT35T_0613.dollar_per_ktoken == APIPricing(input=0.0015, output=0.002)
|
| 36 |
+
# assert AzureGPT35T16k_0613.dollar_per_ktoken == APIPricing(input=0.003, output=0.004)
|
| 37 |
+
# assert AzureGPT35T_1106.dollar_per_ktoken == APIPricing(input=0.001, output=0.002)
|
test/llm/gpt/test_azure_llm.py
ADDED
|
@@ -0,0 +1,92 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from neollm.llm.gpt.azure_llm import (
|
| 2 |
+
AzureGPT4_0613,
|
| 3 |
+
AzureGPT4O_20240513,
|
| 4 |
+
AzureGPT4T_0125,
|
| 5 |
+
AzureGPT4T_1106,
|
| 6 |
+
AzureGPT4T_20240409,
|
| 7 |
+
AzureGPT4VT_1106,
|
| 8 |
+
AzureGPT35FT,
|
| 9 |
+
AzureGPT35T16k_0613,
|
| 10 |
+
AzureGPT35T_0125,
|
| 11 |
+
AzureGPT35T_0613,
|
| 12 |
+
AzureGPT35T_1106,
|
| 13 |
+
AzureGPT432k_0613,
|
| 14 |
+
get_azure_llm,
|
| 15 |
+
)
|
| 16 |
+
from neollm.types.info import APIPricing
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def test_get_azure_llm() -> None:
|
| 20 |
+
|
| 21 |
+
# no date
|
| 22 |
+
assert get_azure_llm("gpt-3.5-turbo", {}).__class__ == AzureGPT35T_0613
|
| 23 |
+
assert get_azure_llm("gpt-35-turbo", {}).__class__ == AzureGPT35T_0613
|
| 24 |
+
assert get_azure_llm("gpt-3.5-turbo-16k", {}).__class__ == AzureGPT35T16k_0613
|
| 25 |
+
assert get_azure_llm("gpt-35-turbo-16k", {}).__class__ == AzureGPT35T16k_0613
|
| 26 |
+
assert get_azure_llm("gpt-4", {}).__class__ == AzureGPT4_0613
|
| 27 |
+
assert get_azure_llm("gpt-4-32k", {}).__class__ == AzureGPT432k_0613
|
| 28 |
+
assert get_azure_llm("gpt-4-turbo", {}).__class__ == AzureGPT4T_1106
|
| 29 |
+
assert get_azure_llm("gpt-4v-turbo", {}).__class__ == AzureGPT4VT_1106
|
| 30 |
+
assert get_azure_llm("gpt-4o", {}).__class__ == AzureGPT4O_20240513
|
| 31 |
+
# with date
|
| 32 |
+
assert get_azure_llm("gpt-4o-2024-05-13", {}).__class__ == AzureGPT4O_20240513
|
| 33 |
+
assert get_azure_llm("gpt-4-turbo-2024-04-09", {}).__class__ == AzureGPT4T_20240409
|
| 34 |
+
assert get_azure_llm("gpt-3.5-turbo-0125", {}).__class__ == AzureGPT35T_0125
|
| 35 |
+
assert get_azure_llm("gpt-35-turbo-0125", {}).__class__ == AzureGPT35T_0125
|
| 36 |
+
assert get_azure_llm("gpt-4-turbo-0125", {}).__class__ == AzureGPT4T_0125
|
| 37 |
+
assert get_azure_llm("gpt-3.5-turbo-1106", {}).__class__ == AzureGPT35T_1106
|
| 38 |
+
assert get_azure_llm("gpt-35-turbo-1106", {}).__class__ == AzureGPT35T_1106
|
| 39 |
+
assert get_azure_llm("gpt-4-turbo-1106", {}).__class__ == AzureGPT4T_1106
|
| 40 |
+
assert get_azure_llm("gpt-4v-turbo-1106", {}).__class__ == AzureGPT4VT_1106
|
| 41 |
+
assert get_azure_llm("gpt-3.5-turbo-0613", {}).__class__ == AzureGPT35T_0613
|
| 42 |
+
assert get_azure_llm("gpt-35-turbo-0613", {}).__class__ == AzureGPT35T_0613
|
| 43 |
+
assert get_azure_llm("gpt-3.5-turbo-16k-0613", {}).__class__ == AzureGPT35T16k_0613
|
| 44 |
+
assert get_azure_llm("gpt-35-turbo-16k-0613", {}).__class__ == AzureGPT35T16k_0613
|
| 45 |
+
assert get_azure_llm("gpt-4-0613", {}).__class__ == AzureGPT4_0613
|
| 46 |
+
assert get_azure_llm("gpt-4-32k-0613", {}).__class__ == AzureGPT432k_0613
|
| 47 |
+
# ft
|
| 48 |
+
assert get_azure_llm("ft:gpt-3.5-turbo-1106-XXXX", {}).__class__ == AzureGPT35FT
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def test_check_price() -> None:
|
| 52 |
+
# https://azure.microsoft.com/ja-jp/pricing/details/cognitive-services/openai-service/
|
| 53 |
+
|
| 54 |
+
# これからのモデル --------------------------------------------------------
|
| 55 |
+
assert AzureGPT4T_20240409.dollar_per_ktoken == APIPricing(input=0.01, output=0.03)
|
| 56 |
+
# Updated --------------------------------------------------------
|
| 57 |
+
# GPT3.5T
|
| 58 |
+
assert AzureGPT35T_0125.dollar_per_ktoken == APIPricing(input=0.0005, output=0.0015)
|
| 59 |
+
# GPT4
|
| 60 |
+
assert AzureGPT4O_20240513.dollar_per_ktoken == APIPricing(input=0.005, output=0.015)
|
| 61 |
+
assert AzureGPT4T_0125.dollar_per_ktoken == APIPricing(input=0.01, output=0.03)
|
| 62 |
+
assert AzureGPT4VT_1106.dollar_per_ktoken == APIPricing(input=0.01, output=0.03)
|
| 63 |
+
assert AzureGPT4T_1106.dollar_per_ktoken == APIPricing(input=0.01, output=0.03)
|
| 64 |
+
assert AzureGPT4_0613.dollar_per_ktoken == APIPricing(input=0.03, output=0.06)
|
| 65 |
+
assert AzureGPT432k_0613.dollar_per_ktoken == APIPricing(input=0.06, output=0.12)
|
| 66 |
+
# FT
|
| 67 |
+
assert AzureGPT35FT.dollar_per_ktoken == APIPricing(input=0.0005, output=0.0015)
|
| 68 |
+
# Legacy ---------------------------------------------------------
|
| 69 |
+
# AzureGPT35T_0301 なし
|
| 70 |
+
assert AzureGPT35T_0613.dollar_per_ktoken == APIPricing(input=0.0015, output=0.002)
|
| 71 |
+
assert AzureGPT35T16k_0613.dollar_per_ktoken == APIPricing(input=0.003, output=0.004)
|
| 72 |
+
assert AzureGPT35T_1106.dollar_per_ktoken == APIPricing(input=0.001, output=0.002)
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
def test_check_context_window() -> None:
|
| 76 |
+
# https://learn.microsoft.com/ja-jp/azure/ai-services/openai/concepts/models#gpt-4-and-gpt-4-turbo-preview-models
|
| 77 |
+
assert AzureGPT4T_20240409.context_window == 128_000
|
| 78 |
+
|
| 79 |
+
assert AzureGPT4T_0125.context_window == 128_000
|
| 80 |
+
assert AzureGPT35T_0125.context_window == 16_385
|
| 81 |
+
|
| 82 |
+
assert AzureGPT4O_20240513.context_window == 128_000
|
| 83 |
+
assert AzureGPT4T_1106.context_window == 128_000
|
| 84 |
+
assert AzureGPT4VT_1106.context_window == 128_000
|
| 85 |
+
assert AzureGPT35T_1106.context_window == 16_385
|
| 86 |
+
|
| 87 |
+
assert AzureGPT35T_0613.context_window == 4_096
|
| 88 |
+
assert AzureGPT4_0613.context_window == 8_192
|
| 89 |
+
assert AzureGPT35T16k_0613.context_window == 16_385
|
| 90 |
+
assert AzureGPT432k_0613.context_window == 32_768
|
| 91 |
+
|
| 92 |
+
assert AzureGPT35FT.context_window == 4_096
|
test/llm/gpt/test_openai_llm.py
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# from neollm.llm.gpt.azure_llm import (
|
| 2 |
+
# AzureGPT4_0613,
|
| 3 |
+
# AzureGPT4T_0125,
|
| 4 |
+
# AzureGPT4T_1106,
|
| 5 |
+
# AzureGPT4T_20240409,
|
| 6 |
+
# AzureGPT4VT_1106,
|
| 7 |
+
# AzureGPT35FT,
|
| 8 |
+
# AzureGPT35T16k_0613,
|
| 9 |
+
# AzureGPT35T_0125,
|
| 10 |
+
# AzureGPT35T_0613,
|
| 11 |
+
# AzureGPT35T_1106,
|
| 12 |
+
# AzureGPT432k_0613,
|
| 13 |
+
# )
|
| 14 |
+
# from neollm.types.info import APIPricing
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
# def test_check_price() -> None:
|
| 18 |
+
# # https://azure.microsoft.com/ja-jp/pricing/details/cognitive-services/openai-service/
|
| 19 |
+
|
| 20 |
+
# # これからのモデル --------------------------------------------------------
|
| 21 |
+
# assert AzureGPT4T_20240409.dollar_per_ktoken == APIPricing(input=0.01, output=0.03)
|
| 22 |
+
# # Updated --------------------------------------------------------
|
| 23 |
+
# # GPT3.5T
|
| 24 |
+
# assert AzureGPT35T_0125.dollar_per_ktoken == APIPricing(input=0.0005, output=0.0015)
|
| 25 |
+
# # GPT4
|
| 26 |
+
# assert AzureGPT4T_0125.dollar_per_ktoken == APIPricing(input=0.01, output=0.03)
|
| 27 |
+
# assert AzureGPT4VT_1106.dollar_per_ktoken == APIPricing(input=0.01, output=0.03)
|
| 28 |
+
# assert AzureGPT4T_1106.dollar_per_ktoken == APIPricing(input=0.01, output=0.03)
|
| 29 |
+
# assert AzureGPT4_0613.dollar_per_ktoken == APIPricing(input=0.03, output=0.06)
|
| 30 |
+
# assert AzureGPT432k_0613.dollar_per_ktoken == APIPricing(input=0.06, output=0.12)
|
| 31 |
+
# # FT
|
| 32 |
+
# assert AzureGPT35FT.dollar_per_ktoken == APIPricing(input=0.0005, output=0.0015)
|
| 33 |
+
# # Legacy ---------------------------------------------------------
|
| 34 |
+
# # AzureGPT35T_0301 なし
|
| 35 |
+
# assert AzureGPT35T_0613.dollar_per_ktoken == APIPricing(input=0.0015, output=0.002)
|
| 36 |
+
# assert AzureGPT35T16k_0613.dollar_per_ktoken == APIPricing(input=0.003, output=0.004)
|
| 37 |
+
# assert AzureGPT35T_1106.dollar_per_ktoken == APIPricing(input=0.001, output=0.002)
|
test/llm/platform.py
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pytest
|
| 2 |
+
|
| 3 |
+
from neollm.llm.platform import Platform
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class TestPlatform:
|
| 7 |
+
def test_str(self) -> None:
|
| 8 |
+
assert Platform.AZURE == "azure" # type: ignore
|
| 9 |
+
assert Platform.OPENAI == "openai" # type: ignore
|
| 10 |
+
assert Platform.ANTHROPIC == "anthropic" # type: ignore
|
| 11 |
+
assert Platform.GCP == "gcp" # type: ignore
|
| 12 |
+
|
| 13 |
+
def test_init(self) -> None:
|
| 14 |
+
assert Platform("azure") == Platform.AZURE
|
| 15 |
+
assert Platform("openai") == Platform.OPENAI
|
| 16 |
+
assert Platform("anthropic") == Platform.ANTHROPIC
|
| 17 |
+
assert Platform("gcp") == Platform.GCP
|
| 18 |
+
|
| 19 |
+
assert Platform("Azure ") == Platform.AZURE
|
| 20 |
+
assert Platform(" OpenAI") == Platform.OPENAI
|
| 21 |
+
assert Platform("Anthropic ") == Platform.ANTHROPIC
|
| 22 |
+
assert Platform("GcP") == Platform.GCP
|
| 23 |
+
|
| 24 |
+
def test_from_string(self) -> None:
|
| 25 |
+
assert Platform.from_string("azure") == Platform.AZURE
|
| 26 |
+
assert Platform.from_string("openai") == Platform.OPENAI
|
| 27 |
+
assert Platform.from_string("anthropic") == Platform.ANTHROPIC
|
| 28 |
+
assert Platform.from_string("gcp") == Platform.GCP
|
| 29 |
+
|
| 30 |
+
def test_from_string_error(self) -> None:
|
| 31 |
+
with pytest.raises(ValueError):
|
| 32 |
+
Platform.from_string("error")
|