
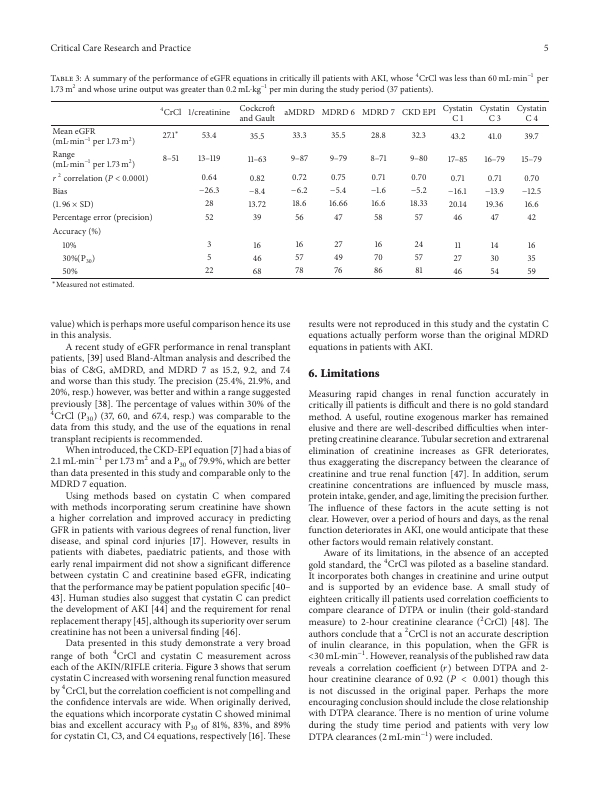
Commit
•
a7d0fb6
1
Parent(s):
8da7a19
first version
Browse files- Base-RCNN-FPN.yml +69 -0
- README.md +5 -5
- app.py +70 -0
- cascade_dit_base.yml +20 -0
- packages.txt +1 -0
- publaynet_example.jpeg +0 -0
- requirements.txt +10 -0
Base-RCNN-FPN.yml
ADDED
|
@@ -0,0 +1,69 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MODEL:
|
| 2 |
+
MASK_ON: True
|
| 3 |
+
META_ARCHITECTURE: "GeneralizedRCNN"
|
| 4 |
+
PIXEL_MEAN: [123.675, 116.280, 103.530]
|
| 5 |
+
PIXEL_STD: [58.395, 57.120, 57.375]
|
| 6 |
+
BACKBONE:
|
| 7 |
+
NAME: "build_vit_fpn_backbone"
|
| 8 |
+
VIT:
|
| 9 |
+
OUT_FEATURES: ["layer3", "layer5", "layer7", "layer11"]
|
| 10 |
+
DROP_PATH: 0.1
|
| 11 |
+
IMG_SIZE: [224,224]
|
| 12 |
+
POS_TYPE: "abs"
|
| 13 |
+
FPN:
|
| 14 |
+
IN_FEATURES: ["layer3", "layer5", "layer7", "layer11"]
|
| 15 |
+
ANCHOR_GENERATOR:
|
| 16 |
+
SIZES: [[32], [64], [128], [256], [512]] # One size for each in feature map
|
| 17 |
+
ASPECT_RATIOS: [[0.5, 1.0, 2.0]] # Three aspect ratios (same for all in feature maps)
|
| 18 |
+
RPN:
|
| 19 |
+
IN_FEATURES: ["p2", "p3", "p4", "p5", "p6"]
|
| 20 |
+
PRE_NMS_TOPK_TRAIN: 2000 # Per FPN level
|
| 21 |
+
PRE_NMS_TOPK_TEST: 1000 # Per FPN level
|
| 22 |
+
# Detectron1 uses 2000 proposals per-batch,
|
| 23 |
+
# (See "modeling/rpn/rpn_outputs.py" for details of this legacy issue)
|
| 24 |
+
# which is approximately 1000 proposals per-image since the default batch size for FPN is 2.
|
| 25 |
+
POST_NMS_TOPK_TRAIN: 1000
|
| 26 |
+
POST_NMS_TOPK_TEST: 1000
|
| 27 |
+
ROI_HEADS:
|
| 28 |
+
NAME: "StandardROIHeads"
|
| 29 |
+
IN_FEATURES: ["p2", "p3", "p4", "p5"]
|
| 30 |
+
NUM_CLASSES: 5
|
| 31 |
+
ROI_BOX_HEAD:
|
| 32 |
+
NAME: "FastRCNNConvFCHead"
|
| 33 |
+
NUM_FC: 2
|
| 34 |
+
POOLER_RESOLUTION: 7
|
| 35 |
+
ROI_MASK_HEAD:
|
| 36 |
+
NAME: "MaskRCNNConvUpsampleHead"
|
| 37 |
+
NUM_CONV: 4
|
| 38 |
+
POOLER_RESOLUTION: 14
|
| 39 |
+
DATASETS:
|
| 40 |
+
TRAIN: ("publaynet_train",)
|
| 41 |
+
TEST: ("publaynet_val",)
|
| 42 |
+
SOLVER:
|
| 43 |
+
LR_SCHEDULER_NAME: "WarmupCosineLR"
|
| 44 |
+
AMP:
|
| 45 |
+
ENABLED: True
|
| 46 |
+
OPTIMIZER: "ADAMW"
|
| 47 |
+
BACKBONE_MULTIPLIER: 1.0
|
| 48 |
+
CLIP_GRADIENTS:
|
| 49 |
+
ENABLED: True
|
| 50 |
+
CLIP_TYPE: "full_model"
|
| 51 |
+
CLIP_VALUE: 1.0
|
| 52 |
+
NORM_TYPE: 2.0
|
| 53 |
+
WARMUP_FACTOR: 0.01
|
| 54 |
+
BASE_LR: 0.0004
|
| 55 |
+
WEIGHT_DECAY: 0.05
|
| 56 |
+
IMS_PER_BATCH: 32
|
| 57 |
+
INPUT:
|
| 58 |
+
CROP:
|
| 59 |
+
ENABLED: True
|
| 60 |
+
TYPE: "absolute_range"
|
| 61 |
+
SIZE: (384, 600)
|
| 62 |
+
MIN_SIZE_TRAIN: (480, 512, 544, 576, 608, 640, 672, 704, 736, 768, 800)
|
| 63 |
+
FORMAT: "RGB"
|
| 64 |
+
DATALOADER:
|
| 65 |
+
FILTER_EMPTY_ANNOTATIONS: False
|
| 66 |
+
VERSION: 2
|
| 67 |
+
AUG:
|
| 68 |
+
DETR: True
|
| 69 |
+
SEED: 42
|
README.md
CHANGED
|
@@ -1,10 +1,10 @@
|
|
| 1 |
---
|
| 2 |
-
title: Document Layout
|
| 3 |
-
emoji:
|
| 4 |
-
colorFrom:
|
| 5 |
-
colorTo:
|
| 6 |
sdk: gradio
|
| 7 |
-
sdk_version:
|
| 8 |
app_file: app.py
|
| 9 |
pinned: false
|
| 10 |
---
|
|
|
|
| 1 |
---
|
| 2 |
+
title: Dit Document Layout Analysis
|
| 3 |
+
emoji: 👀
|
| 4 |
+
colorFrom: purple
|
| 5 |
+
colorTo: red
|
| 6 |
sdk: gradio
|
| 7 |
+
sdk_version: 2.8.9
|
| 8 |
app_file: app.py
|
| 9 |
pinned: false
|
| 10 |
---
|
app.py
ADDED
|
@@ -0,0 +1,70 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
os.system('pip install detectron2 -f https://dl.fbaipublicfiles.com/detectron2/wheels/cu102/torch1.9/index.html')
|
| 3 |
+
os.system("git clone https://github.com/microsoft/unilm.git")
|
| 4 |
+
|
| 5 |
+
import sys
|
| 6 |
+
sys.path.append("unilm")
|
| 7 |
+
|
| 8 |
+
import cv2
|
| 9 |
+
|
| 10 |
+
from unilm.dit.object_detection.ditod import add_vit_config
|
| 11 |
+
|
| 12 |
+
import torch
|
| 13 |
+
|
| 14 |
+
from detectron2.config import CfgNode as CN
|
| 15 |
+
from detectron2.config import get_cfg
|
| 16 |
+
from detectron2.utils.visualizer import ColorMode, Visualizer
|
| 17 |
+
from detectron2.data import MetadataCatalog
|
| 18 |
+
from detectron2.engine import DefaultPredictor
|
| 19 |
+
|
| 20 |
+
import gradio as gr
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
# Step 1: instantiate config
|
| 24 |
+
cfg = get_cfg()
|
| 25 |
+
add_vit_config(cfg)
|
| 26 |
+
cfg.merge_from_file("cascade_dit_base.yml")
|
| 27 |
+
|
| 28 |
+
# Step 2: add model weights URL to config
|
| 29 |
+
cfg.MODEL.WEIGHTS = "https://layoutlm.blob.core.windows.net/dit/dit-fts/publaynet_dit-b_cascade.pth"
|
| 30 |
+
|
| 31 |
+
# Step 3: set device
|
| 32 |
+
cfg.MODEL.DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
|
| 33 |
+
|
| 34 |
+
# Step 4: define model
|
| 35 |
+
predictor = DefaultPredictor(cfg)
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def analyze_image(img):
|
| 39 |
+
md = MetadataCatalog.get(cfg.DATASETS.TEST[0])
|
| 40 |
+
if cfg.DATASETS.TEST[0]=='icdar2019_test':
|
| 41 |
+
md.set(thing_classes=["table"])
|
| 42 |
+
else:
|
| 43 |
+
md.set(thing_classes=["text","title","list","table","figure"])
|
| 44 |
+
|
| 45 |
+
output = predictor(img)["instances"]
|
| 46 |
+
v = Visualizer(img[:, :, ::-1],
|
| 47 |
+
md,
|
| 48 |
+
scale=1.0,
|
| 49 |
+
instance_mode=ColorMode.SEGMENTATION)
|
| 50 |
+
result = v.draw_instance_predictions(output.to("cpu"))
|
| 51 |
+
result_image = result.get_image()[:, :, ::-1]
|
| 52 |
+
|
| 53 |
+
return result_image
|
| 54 |
+
|
| 55 |
+
title = "Interactive demo: Document Layout Analysis with DiT"
|
| 56 |
+
description = "Demo for Microsoft's DiT, the Document Image Transformer for state-of-the-art document understanding tasks. This particular model is fine-tuned on PubLayNet, a large dataset for document layout analysis (read more at the links below). To use it, simply upload an image or use the example image below and click 'Submit'. Results will show up in a few seconds. If you want to make the output bigger, right-click on it and select 'Open image in new tab'."
|
| 57 |
+
article = "<p style='text-align: center'><a href='https://arxiv.org/abs/2203.02378' target='_blank'>Paper</a> | <a href='https://github.com/microsoft/unilm/tree/master/dit' target='_blank'>Github Repo</a></p> | <a href='https://huggingface.co/docs/transformers/master/en/model_doc/dit' target='_blank'>HuggingFace doc</a></p>"
|
| 58 |
+
examples =[['publaynet_example.jpeg']]
|
| 59 |
+
css = ".output-image, .input-image, .image-preview {height: 600px !important}"
|
| 60 |
+
|
| 61 |
+
iface = gr.Interface(fn=analyze_image,
|
| 62 |
+
inputs=gr.inputs.Image(type="numpy", label="document image"),
|
| 63 |
+
outputs=gr.outputs.Image(type="numpy", label="annotated document"),
|
| 64 |
+
title=title,
|
| 65 |
+
description=description,
|
| 66 |
+
examples=examples,
|
| 67 |
+
article=article,
|
| 68 |
+
css=css,
|
| 69 |
+
enable_queue=True)
|
| 70 |
+
iface.launch(debug=True, cache_examples=True)
|
cascade_dit_base.yml
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: "Base-RCNN-FPN.yml"
|
| 2 |
+
MODEL:
|
| 3 |
+
PIXEL_MEAN: [ 127.5, 127.5, 127.5 ]
|
| 4 |
+
PIXEL_STD: [ 127.5, 127.5, 127.5 ]
|
| 5 |
+
WEIGHTS: "https://layoutlm.blob.core.windows.net/dit/dit-pts/dit-base-224-p16-500k-62d53a.pth"
|
| 6 |
+
VIT:
|
| 7 |
+
NAME: "dit_base_patch16"
|
| 8 |
+
ROI_HEADS:
|
| 9 |
+
NAME: CascadeROIHeads
|
| 10 |
+
ROI_BOX_HEAD:
|
| 11 |
+
CLS_AGNOSTIC_BBOX_REG: True
|
| 12 |
+
RPN:
|
| 13 |
+
POST_NMS_TOPK_TRAIN: 2000
|
| 14 |
+
SOLVER:
|
| 15 |
+
WARMUP_ITERS: 1000
|
| 16 |
+
IMS_PER_BATCH: 16
|
| 17 |
+
MAX_ITER: 60000
|
| 18 |
+
CHECKPOINT_PERIOD: 2000
|
| 19 |
+
TEST:
|
| 20 |
+
EVAL_PERIOD: 2000
|
packages.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
python3-opencv
|
publaynet_example.jpeg
ADDED
|
requirements.txt
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
pyyaml==5.1
|
| 2 |
+
torch==1.9.0
|
| 3 |
+
torchvision==0.10.0
|
| 4 |
+
|
| 5 |
+
gradio
|
| 6 |
+
numpy
|
| 7 |
+
scipy
|
| 8 |
+
shapely
|
| 9 |
+
timm
|
| 10 |
+
opencv-python
|