Natural Language Processing can sometimes feel like model size is optimized for headlines. 175 billion parameters is certainly an eye-catching number! Why not just train more efficiently with a smaller model? One surprising scaling effect of deep learning is that bigger neural networks are actually compute-efficient. This is something OpenAI in particular has explored in papers like Scaling Laws for Neural Language Models. Research at Hugging Face also leverages this phenomenon, and we've combined it with GPU speed estimations to ensure model size is just right for the compute budget of the experiment (when in doubt, it's bigger than you think!). This blog post will show how this impacts architecture decisions on a standard language modeling benchmark: we replicate the 14-layer state-of-the-art result from Zhang et al.'s Transformer-XL paper without any hyper-parameter optimization and saving 25% of training time. We also estimate that the 18-layer model from the same paper trained for an order of magnitude too many training steps. Wanna play with our demo before reading? Just click here!
Let's look at some loss curves. For our example, the task will be training Transformer-XL, the state-of-the-art in language modeling, on Wikitext-103, a standard, medium-size benchmark. GPT-2 doesn't perform well on this dataset scale. As training progresses, we'll look at the performance of the model (as measured by validation loss) depending on compute cost (as measured by floating point operations). Let's run a few experiments! In the following plot, every line of colour corresponds to a Transformer-XL run of 200000 steps with a different number and size of layers, with all other hyperparameters kept the same. This spans models from a mere thousand to a hundred million parameters (excluding embeddings). Bigger models are on the right as they require more compute for every step. Don't worry, we've already run them so you don't have to. All graphs are interactive, play with them!
""" md2 = """As introduced in Scaling Laws, we plot the validation loss against non-embedding floating-point operations (neFLOs). There seems to be a frontier of performance for a given neFLO budget that no model manages to beat, depicted here in red. In Scaling Laws, it is referred to as the compute frontier. Every run reaches it, or comes close, after an initial phase of quick loss improvement, then tapers away as the end of training is not as efficient. This has a very practical implication: if you have a certain budget in floating-point operations, to reach the best performance, you should choose a model size that reaches the compute frontier after that many operations and stop it at that moment. This is actually way before model convergence, which usually happens around 10 times later! In essence, if you have extra compute budget, you should invest most of it in a bigger model, and only a small part in more training steps. In Scaling Laws, the OpenAI team fitted a power law to the compute frontier on GPT-2 training. This still seems to be a good fit in our task. In addition, we also fitted a power law between the compute budget and the number of parameters of the model that is optimal for that budget. It is pictured in the following plot.
""" md3 = """As good models tend to spend considerable time tangent on the compute frontier, there is a bit of noise in the relationship. However, this also means that there is more tolerance in the estimation even if the model size we predict is a bit off, as the imperfect model will still be very close to optimal. We find that if the compute budget is multiplied by 10, the optimal model size is multiplied by 7.41 and the number of optimal training steps by only 1.35. Extrapolating with this rule to the much-bigger 18-layer SOTA model from Zhang et al., we find that its optimal number of training steps was around 250000. Even if this number is imprecise due to the change of scale, it is much smaller than the 4 million steps from their replication script. Starting from an even bigger model and stopping earlier would have yielded a better loss for that (huge) compute budget.
We now have a rule connecting performance and optimal size with neFLOs. However, neFLOs are a bit hard to picture. Can we translate that into a more immediate resource, like training time? Whether you are constrained by temporal or financial constraints, the main resource is GPU time. In order to establish a connection between neFLOs and GPU time, we benchmarked different Transformer-XL model sizes on 4 different GPUs available on Google Cloud Platform across tens of thousands of runs, taking into account mixed precision training. Here are our findings:
neFLOs per second speed can be modeled as a factorized multivariate function (sounds scary, but this just means the equation can be written simply as below) of model width (the number of neurons per layer), depth (the number of layers) and batch size, by increasing order of importance. In our estimations, the maximum prediction error was 15% of the observed speed.
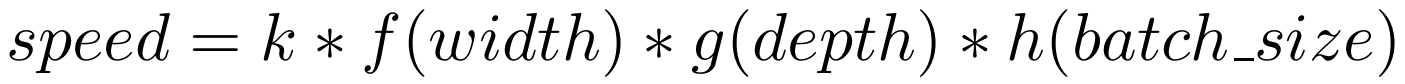
GPUs are optimized for the large feed-forward layers of wide transformers. In all of our experiments, neFLOs per second depended on model width as a power law of exponent around 1.6. This means that a model that's twice as wide, which requires 4 times more operations, also goes through those operations around 3.16 times faster, nearly offsetting the additional compute cost.
neFLOs per second were also positively correlated with depth. Our best results were attained by modeling this connection as proportional to depth * (depth + additive constant). This is coherent with the fact that Transformers must process layers serially. In essence, deeper models aren't actually faster, but they appear to be so as their overhead is smaller relative to the more productive operations. The additive constant, which represents this overhead, was consistently around 5 in our experiments, which essentially means that data loading to the GPU, embeddings, and softmax operations, represent around 5 transformer layers' worth of time.
Batch size played the least role. It was positively correlated with speed for small values, but quickly saturated (and even seemed to hurt at high values, after 64 on the V100 and P100 and 16 on the K80 and P4). We modeled its contribution as a logarithmic function to keep things simple as it was also the variable for which the factorized independence assumption was the weakest. We ran all our experiments at size 64 on a single GPU. This is another perk of big models: as bigger batch sizes don't seem to help much, if your model is too big to fit on a GPU, you could just use a smaller batch size and gradient accumulation.
Finally, one surprising takeaway was that hyperparameters whose width or batch size were powers of 2 out-performed the others. That was the case on GPUs with and without Tensor Core capability. On Tensor Core GPUs like the V100, NVIDIA recommends tensor shapes that are multiples of 8; however, we kept seeing improvements beyond that, up to multiples of 512. In the end, we only fitted on powers of 2 as fitting on all data points meant a poor fit quality that consistently under-estimated speed for powers of 2 points, and one might as well choose the fastest parameters.
In the end, our final estimation of operation speed was as follows:
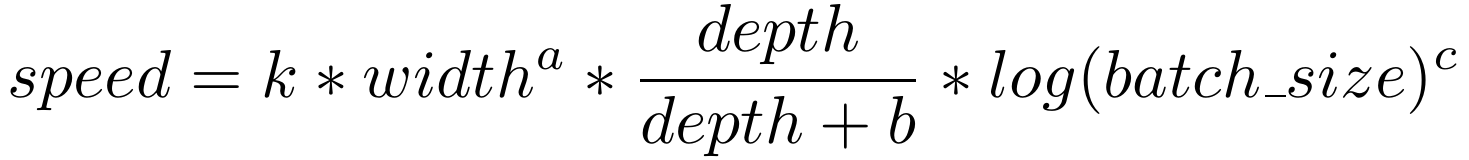
with, for example on a V100 GPU without mixed precision, k=2.21*107, a=1.66, b=5.92, and c=1.33. Different GPUs had close results with a different multiplicative constant.
Now that we have obtained a relation between model size and training speed, we can predict, for a certain GPU time or price budget, the optimal model size on the task and the performance it will achieve.
""" md4 = """Prices are indicated for Google Cloud Platform. The energy consumption was estimated thanks to Peter Henderson's Experiment impact tracker and the CO2 emissions with Electricity map Netherlands data (where Google's European servers are located). Even though huge training costs make headlines, it is still possible to replicate a state-of-the-art result on a medium-size dataset for thirty bucks! A single V100 with properly optimized training is already quite a powerful weapon.
Data shown is for single-GPU training at batch size 60 on Wikitext-103 for a target and memory length of 150, following CMU's Transformer-XL repo. In order to leverage the Tensor Core capability of the V100, we set batch size 64 and sequence length 152 on that GPU. In our model size and speed predictions, we assumed that the inner feed-forward layer dimension was the same as the embedding and attention dimensions, and that the width-to-depth ratio was constant. This is a good way to save memory, as Reformer has shown. Scaling Laws has observed that shape doesn't impact performance significantly in GPT-2. However, for large scales, we found that the final performance of taller models with a bigger feed-forward layer was consistently better, which is why we give two possible model shapes.
In order to replicate the result of the medium-size Transformer-XL pre-trained model (3.15 loss), we tweaked our example model size to add a bigger feed-forward dimension and have high powers of 2 while keeping the same number of parameters. This gave us a model of 14 layers with 768 hidden dimensions and 1024 feed-forward dimensions. In comparison, the CMU pre-trained model was found through aggressive hyper-parameter search with a much more unusual shape of 16 layers of 410 hidden dimensions and 2100 feed-forward dimensions. In our experiment, even though it was 50% bigger, our model was actually 20% faster per batch on an NVIDIA RTX Titan as its shapes were high powers of 2, and it was a shorter, wider model. For that model, the script provided by the CMU team was already very close to optimal stopping time; in the end, we obtained the same performance with 25% less training time. Most importantly, this was the case even though the pre-trained model's hyper-parameter tuning gave it a much more optimized shape, and we had also kept the same random seed it was tuned with. Since we calculated our scaling laws with much smaller-scale trainings, saving on parameter search might actually be the bigger gain here. If you took the shortcut to the demo before reading, you can come back the start here!
I built this tool automatically using the data from our Transformer-XL runs. If you are interested in having this feature available for other NLP tasks as part of the Hugging Face repository, you can contact me on Twitter at @Fluke_Ellington, drop me a mail at teven@huggingface.co, or add a reaction on our Github issue!