
MathBERTa model
Pretrained model on English language and LaTeX using a masked language modeling (MLM) objective. It was introduced in this paper and first released in this repository. This model is case-sensitive: it makes a difference between english and English.
Model description
MathBERTa is the RoBERTa base transformer model whose tokenizer has been extended with LaTeX math symbols and which has been fine-tuned on a large corpus of English mathematical texts.
Like RoBERTa, MathBERTa has been fine-tuned with the Masked language modeling (MLM) objective. Taking a sentence, the model randomly masks 15% of the words and math symbols in the input then run the entire masked sentence through the model and has to predict the masked words and symbols. This way, the model learns an inner representation of the English language and LaTeX that can then be used to extract features useful for downstream tasks.
Intended uses & limitations
You can use the raw model for masked language modeling, but it's mostly intended to be fine-tuned on a downstream task. See the model hub to look for fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked) to make decisions, such as sequence classification, token classification or question answering. For tasks such as text generation you should look at model like GPT2.
How to use
Due to the large number of added LaTeX tokens, MathBERTa is affected by a software bug in the 🤗 Transformers library that causes it to load for tens of minutes. The bug was fixed in version 4.20.0.
You can use this model directly with a pipeline for masked language modeling:
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='witiko/mathberta')
>>> unmasker(r"If [MATH] \theta = \pi [/MATH] , then [MATH] \sin(\theta) [/MATH] is <mask>.")
[{'sequence': ' If \\theta = \\pi, then\\sin(\\theta ) is zero.'
'score': 0.23291291296482086,
'token': 4276,
'token_str': ' zero'},
{'sequence': ' If \\theta = \\pi, then\\sin(\\theta ) is 0.'
'score': 0.11734672635793686,
'token': 321,
'token_str': ' 0'},
{'sequence': ' If \\theta = \\pi, then\\sin(\\theta ) is real.'
'score': 0.0793389230966568,
'token': 588,
'token_str': ' real'},
{'sequence': ' If \\theta = \\pi, then\\sin(\\theta ) is 1.'
'score': 0.0753420740365982,
'token': 112,
'token_str': ' 1'},
{'sequence': ' If \\theta = \\pi, then\\sin(\\theta ) is even.'
'score': 0.06487451493740082,
'token': 190,
'token_str': ' even'}]
Here is how to use this model to get the features of a given text in PyTorch:
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('witiko/mathberta')
model = AutoModel.from_pretrained('witiko/mathberta')
text = r"Replace me by any text and [MATH] \text{math} [/MATH] you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
Training data
Our model was fine-tuned on two datasets:
- ArXMLiv 2020, a dataset consisting of 1,581,037 ArXiv documents.
- Math StackExchange, a dataset of 2,466,080 questions and answers.
Together theses datasets weight 52GB of text and LaTeX.
Intrinsic evaluation results
Our model achieves the following intrinsic evaluation results:
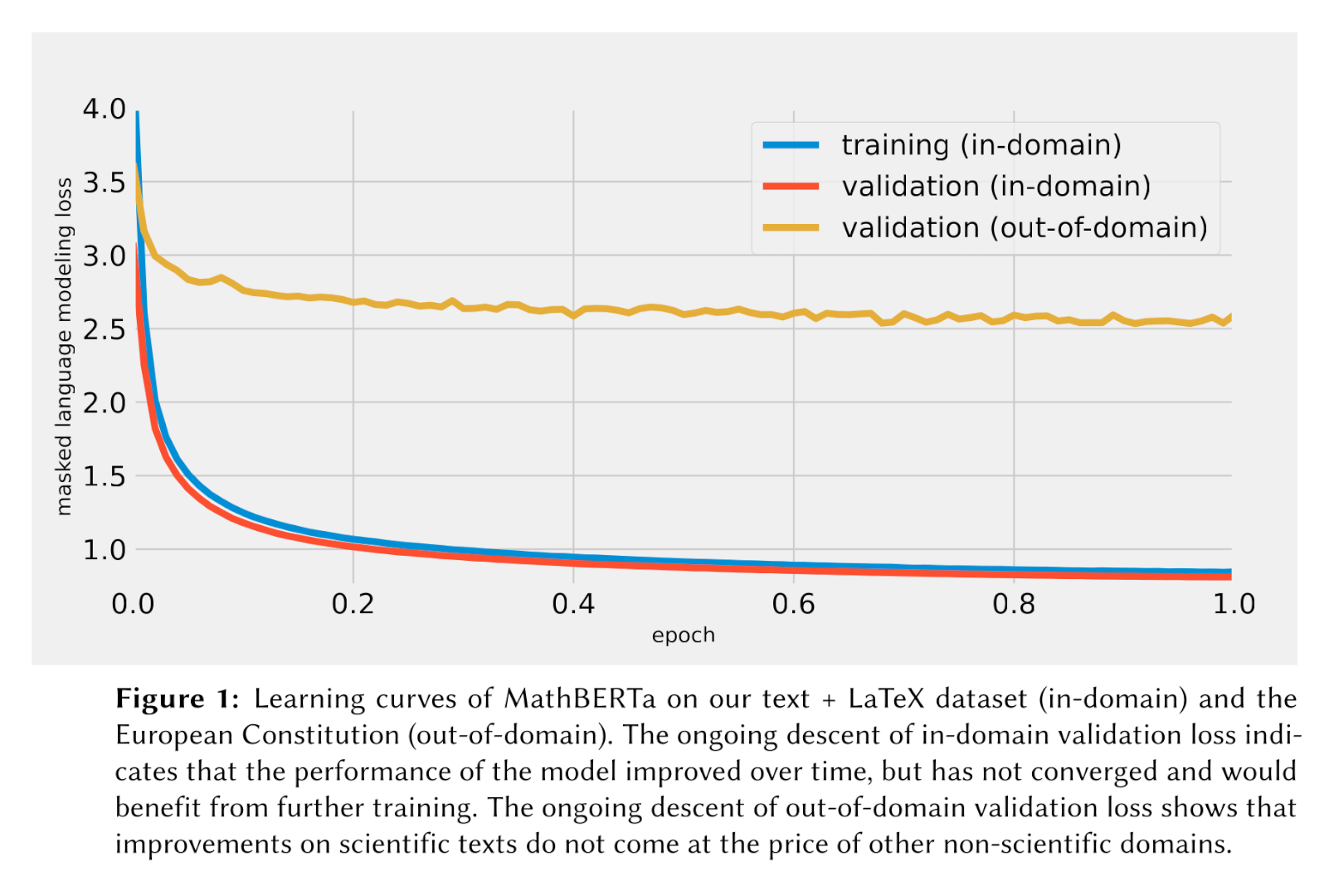
Citing
Text
Vít Novotný and Michal Štefánik. “Combining Sparse and Dense Information Retrieval. Soft Vector Space Model and MathBERTa at ARQMath-3”. In: Proceedings of the Working Notes of CLEF 2022. To Appear. CEUR-WS, 2022.
Bib(La)TeX
@inproceedings{novotny2022combining,
booktitle = {Proceedings of the Working Notes of {CLEF} 2022},
editor = {Faggioli, Guglielmo and Ferro, Nicola and Hanbury, Allan and Potthast, Martin},
issn = {1613-0073},
title = {Combining Sparse and Dense Information Retrieval},
subtitle = {Soft Vector Space Model and MathBERTa at ARQMath-3 Task 1 (Answer Retrieval)},
author = {Novotný, Vít and Štefánik, Michal},
publisher = {{CEUR-WS}},
year = {2022},
pages = {104-118},
numpages = {15},
url = {http://ceur-ws.org/Vol-3180/paper-06.pdf},
urldate = {2022-08-12},
}
- Downloads last month
- 220