
File size: 3,142 Bytes
32b1b5c 486a0ec 32b1b5c b2efccf 32b1b5c |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 |
---
license: cc-by-nc-4.0
datasets:
- Setiaku/Stheno-v3.4-Instruct
- Setiaku/Stheno-3.4-Creative-2
language:
- en
base_model: Sao10K/L3.1-70B-Euryale-v2.2
---
Original model: https://huggingface.co/Sao10K/L3.1-70B-Euryale-v2.2
---

---
Thanks to Gargamel for the compute, to train this!
<br>It took ~4 Days on 8x A100s.
---
Llama-3.1-70B-Euryale-v2.2
This model has went through a single stage finetuning process, over 2 epochs. Datasets are cleanly seperated in order, and not merged unlike Stheno v3.4 .
```
- 1st, over a multi-turn Conversational-Instruct
- 2nd, over a Creative Writing / Roleplay along with some Creative-based Instruct Datasets.
- - Dataset consists of a mixture of Human and Claude Data.
```
Personal Opinions:
```
- Llama 3.1 is... meh. I'm sure you guys in the community have debated over this.
- Whatever they did to their Instruct overcooked the model. Base is weird compared to Llama 3.
- Still, the 70B is pretty nice to use, though sometimes it bugs out? A swipe / regen always fixes it.
- May be less 'uncensored' zero-shot due to removal of c2 samples, but it is perfectly fine for roleplaying purposes.
- I never got the feeling Euryale was ever too horny or rushing ahead, even with v2.1, ymmv.
```
Prompting Format:
```
- Use the L3 Instruct Formatting - Euryale 2.1 Preset Works Well
- Temperature + min_p as per usual, I recommend 1.2 Temp + 0.2 min_p.
- Has a different vibe to previous versions. Tinker around.
```
Changes since Euryale v2.1 \[Same Dataset as Stheno 3.4\]
```
- Included Multi-turn Conversation-based Instruct Datasets to boost multi-turn coherency. # This is a seperate set, not the ones made by Kalomaze and Nopm, that are used in Magnum. They're completely different data.
- Replaced Single-Turn Instruct with Better Prompts and Answers by Claude 3.5 Sonnet and Claude 3 Opus.
- Removed c2 Samples -> Underway of re-filtering and masking to use with custom prefills. TBD
- Included 55% more Roleplaying Examples based of [Gryphe's](https://huggingface.co/datasets/Gryphe/Sonnet3.5-Charcard-Roleplay) Charcard RP Sets. Further filtered and cleaned on.
- Included 40% More Creative Writing Examples.
- Included Datasets Targeting System Prompt Adherence.
- Included Datasets targeting Reasoning / Spatial Awareness.
- Filtered for the usual errors, slop and stuff at the end. Some may have slipped through, but I removed nearly all of it.
```
Below are some graphs and all for you to observe.
---
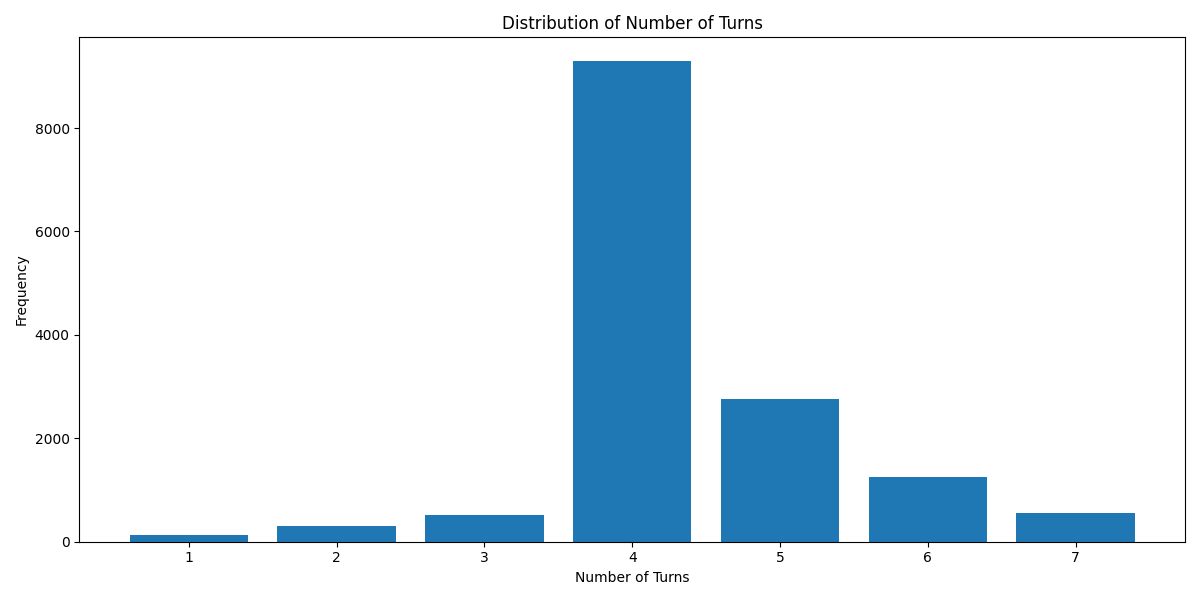
`Turn Distribution # 1 Turn is considered as 1 combined Human/GPT pair in a ShareGPT format. 4 Turns means 1 System Row + 8 Human/GPT rows in total.`
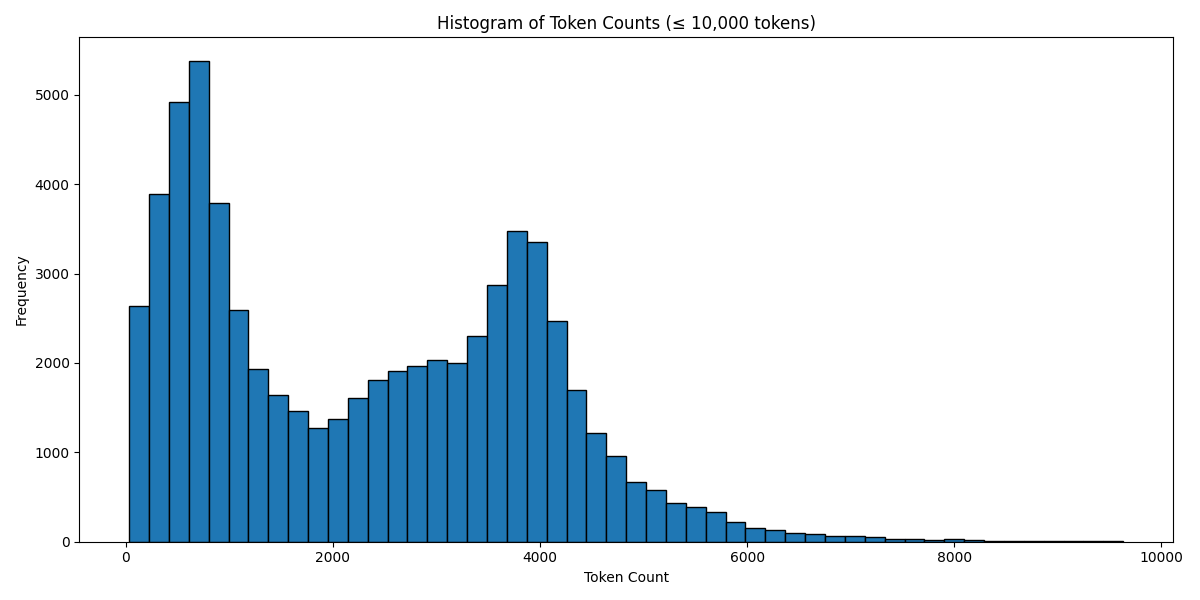
`Token Count Histogram # Based on the Llama 3 Tokenizer`
---
Have a good one.
```
Source Image: https://danbooru.donmai.us/posts/6657609
``` |