
Upload 3 files
Browse files- README.md +14 -23
- README_en.md +13 -24
- 大海捞针50k.png +0 -0
README.md
CHANGED
|
@@ -28,29 +28,20 @@ pipeline_tag: text-generation
|
|
| 28 |
<br>
|
| 29 |
|
| 30 |
# LongBench测试结果
|
| 31 |
-
### LongBench的
|
| 32 |
-
|
| 33 |
-
|
| 34 |
-
|
| 35 |
-
|
|
| 36 |
-
|
|
| 37 |
-
|
|
| 38 |
-
|
|
| 39 |
-
|
|
| 40 |
-
| Qwen-
|
| 41 |
-
|
|
| 42 |
-
|
|
| 43 |
-
|
| 44 |
-
|
| 45 |
-
### LongBench的passage_retrieval_en的评测结果
|
| 46 |
-
| 模型 | 得分 (acc) |
|
| 47 |
-
|-----------------------------|------------|
|
| 48 |
-
| **Qwen-14b-chat-yarn-32k** | **0.945** |
|
| 49 |
-
| chatglm3-32k | 0.815 |
|
| 50 |
-
| gpt-3.5-turbo-16k | 0.88 |
|
| 51 |
-
| **Qwen-7b-chat-yarn-32k** | **0.47** |
|
| 52 |
-
| Qwen-14b-chat | 0.24 |
|
| 53 |
-
| Qwen-7b-chat | 0.235 |
|
| 54 |
|
| 55 |
Qwen-14b-chat-yarn-32k经过微调后,在多文档问答(或检索)任务上提升非常显著,大幅领先其他同规模的模型。
|
| 56 |
|
|
|
|
| 28 |
<br>
|
| 29 |
|
| 30 |
# LongBench测试结果
|
| 31 |
+
### LongBench的passage_retrieval的评测结果
|
| 32 |
+
|
| 33 |
+
| 模型 | 准确率 (中文) | 准确率 (英文) |
|
| 34 |
+
|-----------------------------|-----------|----------|
|
| 35 |
+
| **Qwen-14b-chat-yarn-32k** | **0.94** | **0.945** |
|
| 36 |
+
| **Qwen-7b-chat-yarn-32k** | **0.325** | **0.47** |
|
| 37 |
+
| gpt-3.5-turbo-16k | 0.81 | 0.88 |
|
| 38 |
+
| chatglm3-32k | 0.725 | 0.815 |
|
| 39 |
+
| Qwen-14b-chat | 0.525 | 0.24 |
|
| 40 |
+
| Qwen-14b-chat-32k-lora | 0.34 | \ |
|
| 41 |
+
| Qwen-7b-chat | 0.26 | 0.235 |
|
| 42 |
+
| LongAlpaca-7b-32k-chinese-v2 | 0.12 | \ |
|
| 43 |
+
| CausalLM-14b | 0.086 | \ |
|
| 44 |
+
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 45 |
|
| 46 |
Qwen-14b-chat-yarn-32k经过微调后,在多文档问答(或检索)任务上提升非常显著,大幅领先其他同规模的模型。
|
| 47 |
|
README_en.md
CHANGED
|
@@ -26,30 +26,19 @@ pipeline_tag: text-generation
|
|
| 26 |
* During inference, the model can give high-accuracy answers without specially designed prompts
|
| 27 |
|
| 28 |
# Evaluation results in LongBench
|
| 29 |
-
### Evaluation results for
|
| 30 |
-
|
| 31 |
-
|
|
| 32 |
-
|
| 33 |
-
| **Qwen-14b-chat-yarn-32k** | **0.94**
|
| 34 |
-
|
|
| 35 |
-
|
|
| 36 |
-
|
|
| 37 |
-
| Qwen-14b-chat
|
| 38 |
-
|
|
| 39 |
-
| Qwen-7b-chat | 0.26
|
| 40 |
-
| LongAlpaca-7b-32k-chinese-v2 | 0.12
|
| 41 |
-
| CausalLM-14b | 0.086
|
| 42 |
-
|
| 43 |
-
### Evaluation results for passage_retrieval_en in LongBench
|
| 44 |
-
| Models | Accuracy |
|
| 45 |
-
|----------------------------------|---------------|
|
| 46 |
-
| **Qwen-14b-chat-yarn-32k** | **0.945** |
|
| 47 |
-
| chatglm3-32k | 0.815 |
|
| 48 |
-
| gpt-3.5-turbo-16k | 0.88 |
|
| 49 |
-
| **Qwen-7b-chat-yarn-32k** | **0.47** |
|
| 50 |
-
| Qwen-14b-chat | 0.24 |
|
| 51 |
-
| Qwen-7b-chat | 0.235 |
|
| 52 |
-
|
| 53 |
|
| 54 |
Qwen-14b-chat-yarn-32k has shown significant improvement in multi-document question-answering (or retrieval) tasks and outperforms other models of similar scale.
|
| 55 |
|
|
|
|
| 26 |
* During inference, the model can give high-accuracy answers without specially designed prompts
|
| 27 |
|
| 28 |
# Evaluation results in LongBench
|
| 29 |
+
### Evaluation results for passage_retrieval in LongBench
|
| 30 |
+
|
| 31 |
+
| Model | Accuracy (zh) | Accuracy (en) |
|
| 32 |
+
|------------------------------|---------------|---------------|
|
| 33 |
+
| **Qwen-14b-chat-yarn-32k** | **0.94** | **0.945** |
|
| 34 |
+
| **Qwen-7b-chat-yarn-32k** | **0.325** | **0.47** |
|
| 35 |
+
| gpt-3.5-turbo-16k | 0.81 | 0.88 |
|
| 36 |
+
| chatglm3-32k | 0.725 | 0.815 |
|
| 37 |
+
| Qwen-14b-chat | 0.525 | 0.24 |
|
| 38 |
+
| Qwen-14b-chat-32k-lora | 0.34 | \ |
|
| 39 |
+
| Qwen-7b-chat | 0.26 | 0.235 |
|
| 40 |
+
| LongAlpaca-7b-32k-chinese-v2 | 0.12 | \ |
|
| 41 |
+
| CausalLM-14b | 0.086 | \ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 42 |
|
| 43 |
Qwen-14b-chat-yarn-32k has shown significant improvement in multi-document question-answering (or retrieval) tasks and outperforms other models of similar scale.
|
| 44 |
|
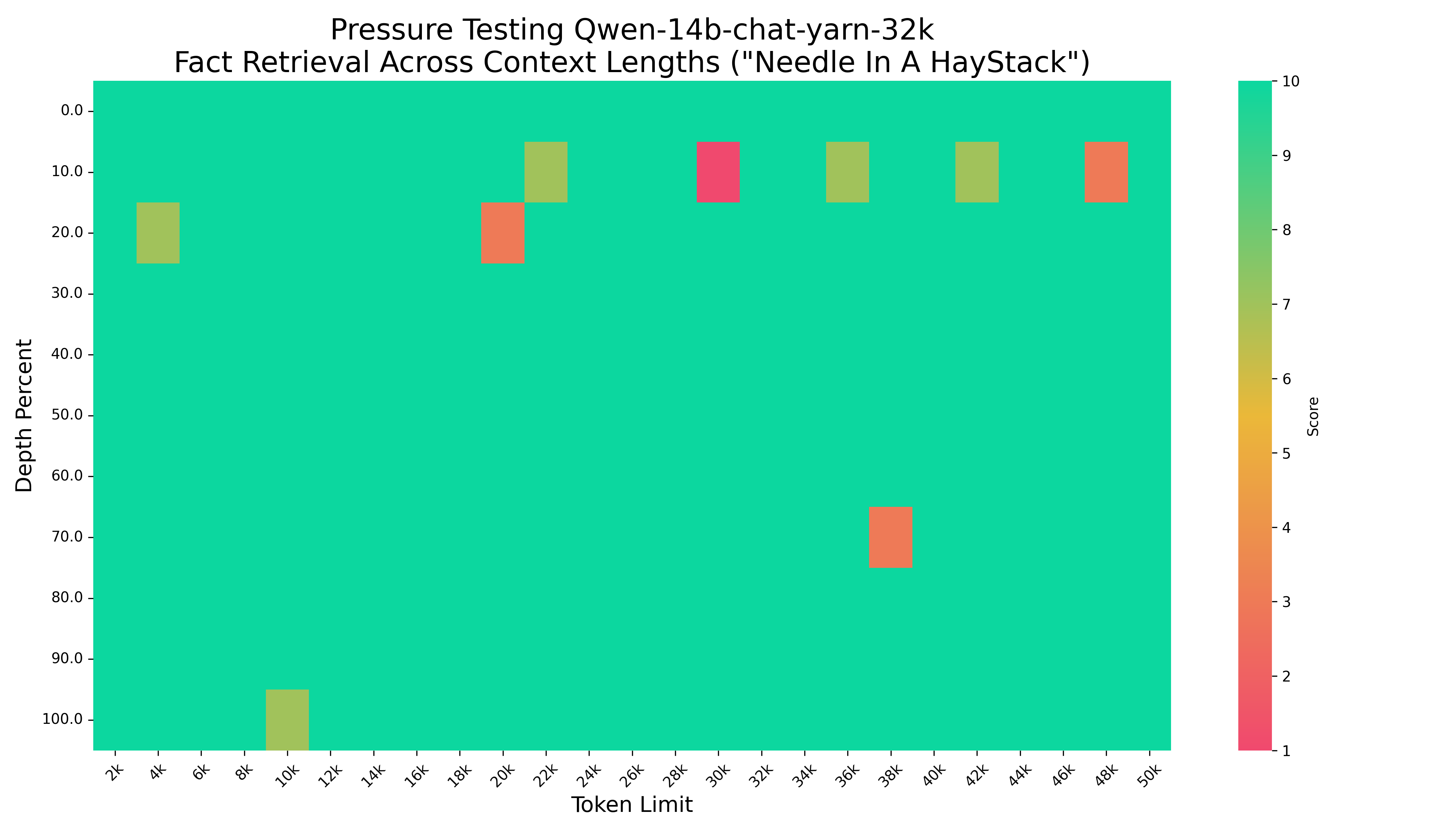
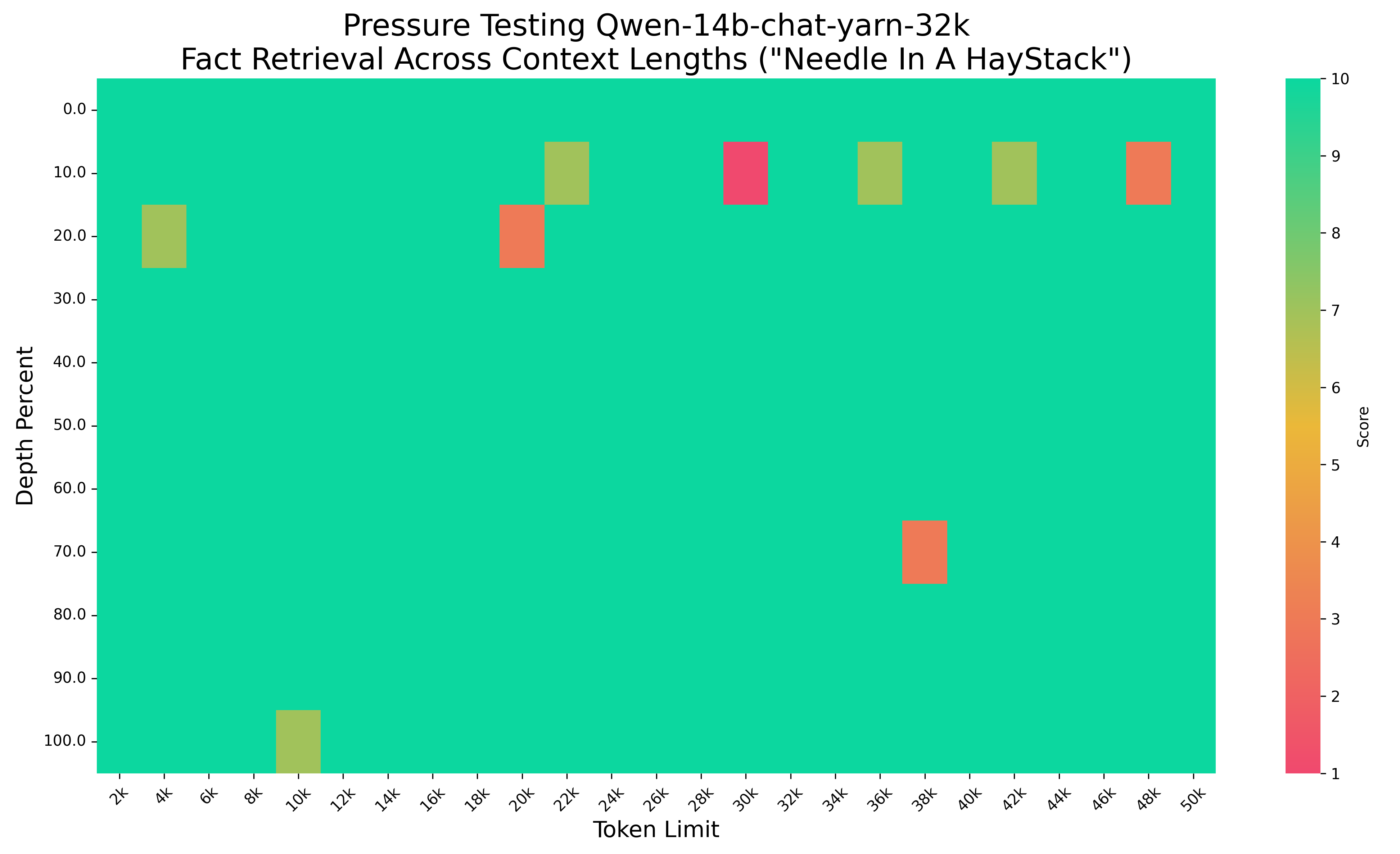
大海捞针50k.png
CHANGED
|
|