|
--- |
|
language: |
|
- uz |
|
license: apache-2.0 |
|
tags: |
|
- whisper-event |
|
- generated_from_trainer |
|
datasets: |
|
- mozilla-foundation/common_voice_11_0 |
|
- google/fleurs |
|
metrics: |
|
- wer |
|
model-index: |
|
- name: Whisper Small Uzbek |
|
results: |
|
- task: |
|
type: automatic-speech-recognition |
|
name: Automatic Speech Recognition |
|
dataset: |
|
name: mozilla-foundation/common_voice_11_0 |
|
type: mozilla-foundation/common_voice_11_0 |
|
config: uz |
|
split: test |
|
args: da |
|
metrics: |
|
- type: wer |
|
value: 23.650914047642605 |
|
name: Wer |
|
- task: |
|
type: automatic-speech-recognition |
|
name: Automatic Speech Recognition |
|
dataset: |
|
name: google/fleurs |
|
type: google/fleurs |
|
config: uz_uz |
|
split: test |
|
metrics: |
|
- type: wer |
|
value: 47.15 |
|
name: WER |
|
--- |
|
|
|
<!-- Disclaimer: I've never written a model card before. I'm probably not correctly following standard practices on how they should be written. |
|
I'm new to this. I'm sorry --> |
|
|
|
# Whisper Small Uzbek |
|
|
|
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) trained and evaluated on the mozilla-foundation/common_voice_11_0 uz and google/fleurs uz_uz datasets. |
|
|
|
It achieves the following results on the common_voice_11_0 evaluation set: |
|
- Loss: 0.3872 |
|
- Wer: 23.6509 |
|
|
|
It achieves the following results on the FLEURS evaluation set: |
|
- Wer: 47.15 |
|
|
|
## Model description |
|
|
|
This model was created as part of the Whisper fine-tune sprint event. |
|
|
|
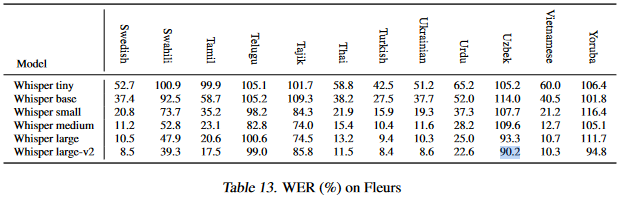
Based on eval, this model achieves a WER of 23.6509 against the Common Voice 11 dataset and 47.15 against the FLEURS dataset. |
|
|
|
This is a significant improvement over the smallest reported WER of 90.2 for the Uzbek language recorded on the [Whisper article](https://cdn.openai.com/papers/whisper.pdf): |
|
|
|
 |
|
|
|
## Intended uses & limitations |
|
|
|
More information needed |
|
|
|
## Training and evaluation data |
|
|
|
Training was performed using the train and evaluation splits from [Mozilla's Common Voice 11](https://huggingface.co/mozilla-foundation/common_voice_11_0) and [Google's FLEURS](https://huggingface.co/google/fleurs) datasets. |
|
|
|
Testing was performed using the test splits from the same datasets. |
|
|
|
## Training procedure |
|
|
|
Training and CV11 testing was performed using a modified version of Hugging Face's [run_speech_recognition_seq2seq_streaming.py](https://github.com/kamfonas/whisper-fine-tuning-event/blob/e0377f55004667f18b37215d11bf0e54f5bda463/run_speech_recognition_seq2seq_streaming.py) script by Michael Kamfonas. |
|
|
|
FLEURS testing was performed using the standard [run_eval_whisper_streaming.py](https://github.com/huggingface/community-events/blob/main/whisper-fine-tuning-event/run_eval_whisper_streaming.py) script. |
|
|
|
### Training hyperparameters |
|
|
|
The following hyperparameters were used during training: |
|
- learning_rate: 1e-05 |
|
- train_batch_size: 64 |
|
- eval_batch_size: 32 |
|
- seed: 42 |
|
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08 |
|
- lr_scheduler_type: linear |
|
- lr_scheduler_warmup_steps: 400 |
|
- training_steps: 5000 |
|
- mixed_precision_training: Native AMP |
|
|
|
### Training results |
|
|
|
| Training Loss | Epoch | Step | Validation Loss | Wer | |
|
|:-------------:|:-----:|:----:|:---------------:|:-------:| |
|
| 0.1542 | 0.2 | 1000 | 0.4711 | 30.8413 | |
|
| 0.0976 | 0.4 | 2000 | 0.4040 | 26.6464 | |
|
| 0.1088 | 1.0 | 3000 | 0.3765 | 24.4952 | |
|
| 0.0527 | 1.21 | 4000 | 0.3872 | 23.6509 | |
|
| 0.0534 | 1.41 | 5000 | 0.3843 | 23.6817 | |
|
|
|
|
|
### Framework versions |
|
|
|
- Transformers 4.26.0.dev0 |
|
- Pytorch 1.13.0+cu117 |
|
- Datasets 2.7.1.dev0 |
|
- Tokenizers 0.13.2 |
|
|
