
G2PTL-1
Introduction
G2PTL-1: A Geography-Graph Pre-trained model for address.
This work is the first version of G2PTL (v1.0)
Other work
We also provide an integrated system for text-based address analysis in logistics field, named TAAS, which supports several address perception tasks such as Address Standardization, Address Completion, as well as other logistics related tasks such as Geo-locating From Text to Geospatial and so on. TAAS is available at https://huggingface.co/Cainiao-AI/TAAS.
Model description
G2PTL is a Transformer model that is pretrained on a large corpus of Chinese addresses in a self-supervised manner. It has three pretraining objectives:
Masked language modeling (MLM): taking an address, the model randomly masks some words in the input text and predicts the masked words. It should be noted that for the geographical entities in the address, we adopt the Whole Word Masking (WWM) approach to mask them and learn the co-occurrence relationships among them.
Hierarchical text modeling (HTC): an address is a text with a hierarchical structure of province, city, district, and street. HTC is used to model the hierarchical relationship among these levels in addresses.
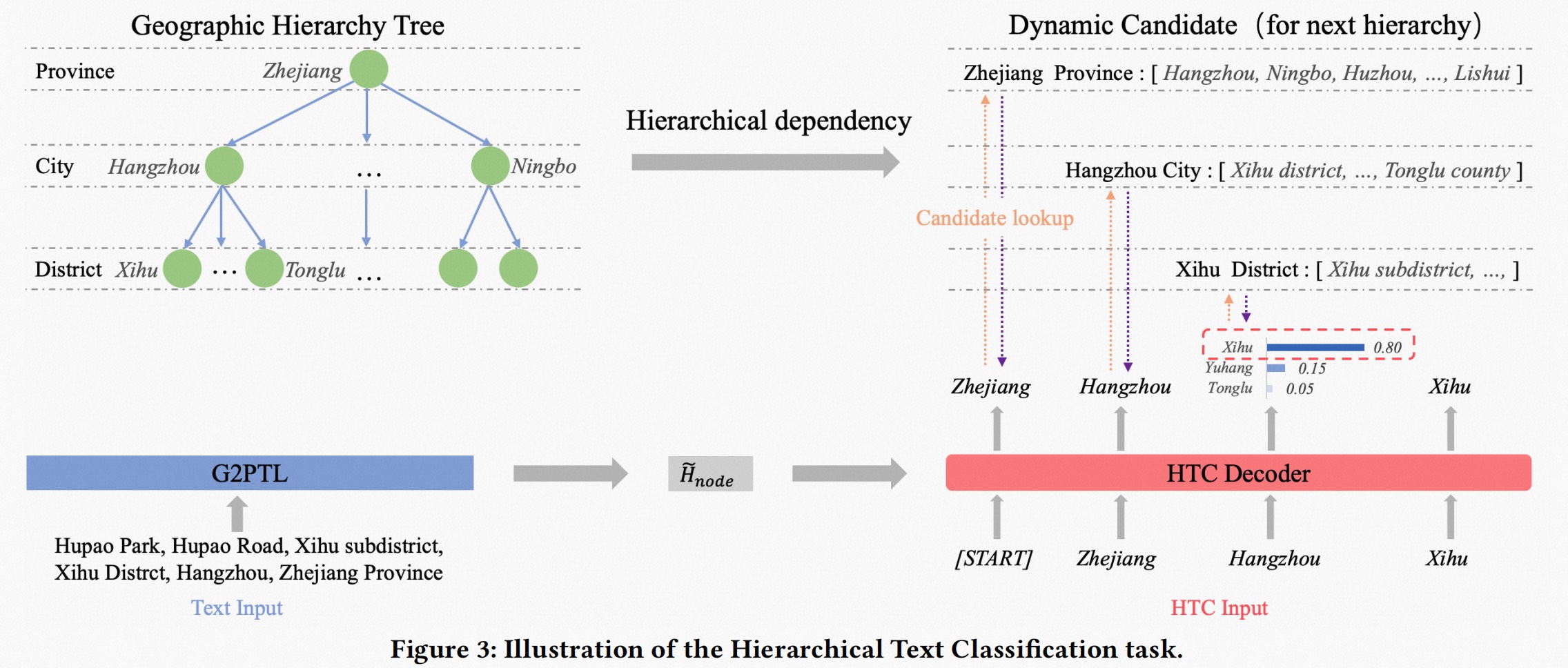
Geocoding (GC): an address can be represented by a point with latitude and longitude in the real world. The GC task is designed to learn the mapping relationship between address text and geographical location.

More detail: https://arxiv.org/abs/2304.01559

Intended uses & limitations
This model is designed for decision tasks based on address text, including tasks related to understanding address texts and Spatial-Temporal downstream tasks which rely on address text representation.
- Address text understanding tasks
- Geocoding
- Named Entity Recognition
- Geographic Entity Alignment
- Address Text Similarity
- Address Text Classification
- ...
- Spatial-Temporal downstream tasks:
- Estimated Time of Arrival (ETA) Prediction
- Pick-up & Delivery Route Prediction.
- Express Volume Prediction
- ...
The model currently only supports Chinese addresses, and it is an encoder-only model which is not suitable for text generation scenarios such as question answering. If you need to use address text based dialogue capabilities, you can look forward to our second version of G2PTL (v2.0)
How to use
You can use this model directly with a pipeline for masked language modeling:
>>> from transformers import pipeline, AutoModel, AutoTokenizer
>>> model = AutoModel.from_pretrained('Cainiao-AI/G2PTL', trust_remote_code=True)
>>> tokenizer = AutoTokenizer.from_pretrained('Cainiao-AI/G2PTL', trust_remote_code=True)
>>> mask_filler = pipeline(task= 'fill-mask', model= model,tokenizer = tokenizer)
>>> mask_filler("浙江省杭州市[MASK]杭区五常街道阿里巴巴西溪园区")
[{'score': 1.0,
'token': 562,
'token_str': '余',
'sequence': '浙 江 省 杭 州 市 余 杭 区 五 常 街 道 阿 里 巴 巴 西 溪 园 区'},
{'score': 7.49648343401077e-09,
'token': 1852,
'token_str': '杭',
'sequence': '浙 江 省 杭 州 市 杭 杭 区 五 常 街 道 阿 里 巴 巴 西 溪 园 区'},
{'score': 5.823675763849678e-09,
'token': 213,
'token_str': '西',
'sequence': '浙 江 省 杭 州 市 西 杭 区 五 常 街 道 阿 里 巴 巴 西 溪 园 区'},
{'score': 3.383779922927488e-09,
'token': 346,
'token_str': '五',
'sequence': '浙 江 省 杭 州 市 五 杭 区 五 常 街 道 阿 里 巴 巴 西 溪 园 区'},
{'score': 2.9116642430437878e-09,
'token': 2268,
'token_str': '荆',
'sequence': '浙 江 省 杭 州 市 荆 杭 区 五 常 街 道 阿 里 巴 巴 西 溪 园 区'}]
You can also use this model for multiple [MASK] filling in PyTorch:
from transformers import pipeline, AutoModel, AutoTokenizer
import torch
model = AutoModel.from_pretrained('Cainiao-AI/G2PTL', trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained('Cainiao-AI/G2PTL', trust_remote_code=True)
model.eval()
text = ['浙江省杭州市[MASK][MASK][MASK]五常街道阿里巴巴西溪园区']
encoded_input = tokenizer(text, return_tensors='pt')
outputs = model(**encoded_input)
prediction_scores = outputs.logits
prediction_scores = torch.argmax(prediction_scores, dim=-1)
prediction_scores = prediction_scores.cpu().detach().numpy()
input_ids = encoded_input['input_ids']
print('G2PTL:', tokenizer.decode(prediction_scores[torch.where(input_ids.cpu()>0)][1:-1]))
G2PTL: 浙 江 省 杭 州 市 余 杭 区 五 常 街 道 阿 里 巴 巴 西 溪 园 区
Here is how to use this model to get the HTC output of a given text in PyTorch:
from transformers import pipeline, AutoModel, AutoTokenizer
model = AutoModel.from_pretrained('Cainiao-AI/G2PTL', trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained('Cainiao-AI/G2PTL', trust_remote_code=True)
model.eval()
text = "浙江省杭州市五常街道阿里巴巴西溪园区"
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
htc_layer_out = output.htc_layer_out
htc_pred = model.get_htc_code(htc_layer_out)
print('HTC Result: ', model.decode_htc_code_2_chn(htc_pred))
HTC Result: ['浙江省杭州市余杭区五常街道', '浙江省杭州市五常街道']
Here is how to use this model to get the features/embeddings of a given text in PyTorch:
from transformers import pipeline, AutoModel, AutoTokenizer
model = AutoModel.from_pretrained('Cainiao-AI/G2PTL', trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained('Cainiao-AI/G2PTL', trust_remote_code=True)
model.eval()
text = "浙江省杭州市余杭区五常街道阿里巴巴西溪园区"
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
final_hidden_state = output.final_hidden_state
Here is how to use this model to get cosine similarity between two address texts in PyTorch:
from transformers import pipeline, AutoModel, AutoTokenizer
import torch
model = AutoModel.from_pretrained('Cainiao-AI/G2PTL', trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained('Cainiao-AI/G2PTL', trust_remote_code=True)
model.eval()
text = ["浙江省杭州市余杭区五常街道阿里巴巴西溪园区", "浙江省杭州市阿里巴巴西溪园区"]
encoded_input = tokenizer(text, return_tensors='pt', padding=True)
output = model(**encoded_input)
final_pooler_output = output.final_pooler_output
cos_sim = torch.cosine_similarity(final_pooler_output[0], final_pooler_output[1])
print('Cosin Similarity: ', cos_sim[0].detach().numpy())
Cosin Similarity: 0.8974346
Training loss




Requirements
python>=3.8
tqdm==4.65.0
torch==1.13.1
transformers==4.27.4
datasets==2.11.0
fairseq==0.12.2
Citation
@misc{wu2023g2ptl,
title={G2PTL: A Pre-trained Model for Delivery Address and its Applications in Logistics System},
author={Lixia Wu and Jianlin Liu and Junhong Lou and Haoyuan Hu and Jianbin Zheng and Haomin Wen and Chao Song and Shu He},
year={2023},
eprint={2304.01559},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
- Downloads last month
- 10