
Do not run the inference from Model card it won't work!!
Use this model space instead!!
https://huggingface.co/spaces/Chrisneverdie/SportsDPT
This model is finetuned with QA pairs so a text completion task would probably result in an error. Questions unrelated to sports may suffer from poor performance. It may still provide incorrect information so just take it as a toy domain model.
FirstSportsELM
The first ever Sports Expert Language Model
Created by Chris Zexin Chen, Sean Xie, and Chengxi Li.
Email for question: zc2404@nyu.edu
GitHub: https://github.com/chrischenhub/FirstSportsELM
As avid sports enthusiasts, we’ve consistently observed a gap in the market for a dedicated large language model tailored to the sports domain. This research stems from our intrigue about the potential of a language model that is exclusively trained and fine-tuned on sports- related data. We aim to assess its performance against generic language models, thus delving into the unique nuances and demands of the sports industry
This model structure is built by Andrej Karpathy: https://github.com/karpathy/nanoGPT
Here is an example QA from SportsDPT
Model Checkpoint File
https://drive.google.com/drive/folders/1PSYYWdUWiM5t0KTtlpwQ1YXBWRwV1JWi?usp=sharing
put FineTune_ckpt.pt under model folder in finetune/model/ if you wish to proceed with inference
Pretrain Data
https://drive.google.com/drive/folders/1bZvWxLnmCDYJhgMDaWumr33KbyDKQUki?usp=sharing train.bin ~8.4 Gb/4.5B tokens, val.bin ~4.1 Mb/2M tokens
Pretrain
To replicate our model, you need to use train.bin and val.bin in this drive, which is processed and ready to train. We trained on a 4xA100 40GB node for 30 hrs to get a val loss ~2.36. Once you set up the environment, run the following:
$ torchrun --standalone --nproc_per_node=4 train.py config/train_gpt2.py
You can tweak around with the parameters in train_gpt2.py. We had two experiments and the first one failed badly.
The second trial is a success and the parameters are all stored in pretrain/train_gpt2.py
Fine Tune
We used thousands of GPT4-generated Sports QA pairs to finetune our model.
- Generate Tags, Questions and Respones from GPT-4
python FineTuneDataGeneration.py api_key Numtag NumQuestion NumParaphrase NumAnswer
- api_key: Your Api Key
- Numtag: number of tags, default 50, optional
- NumQuestion: number of questions, default 16, optional
- NumParaphrase: number of question paraphrases, default 1, optional
- NumAnswer: number of answers, default 2, optional
- Convert Json to TXT and Bin for fine-tuning
python Json2Bin.py
- Fine Tune OmniSportsGPT
python train.py FineTuneConfig.py
Ask Your Question!
- Inference
python Inference.py YourQuestionHere
python DefaultAnswer.py
python RandomGPT2ChatBot.py
- Plot Result
python plot.py
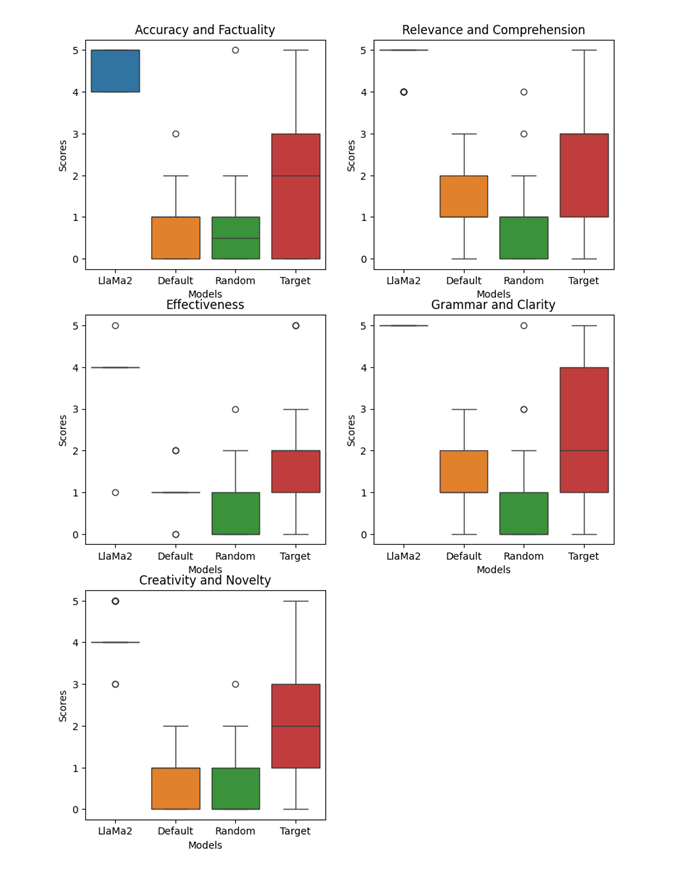
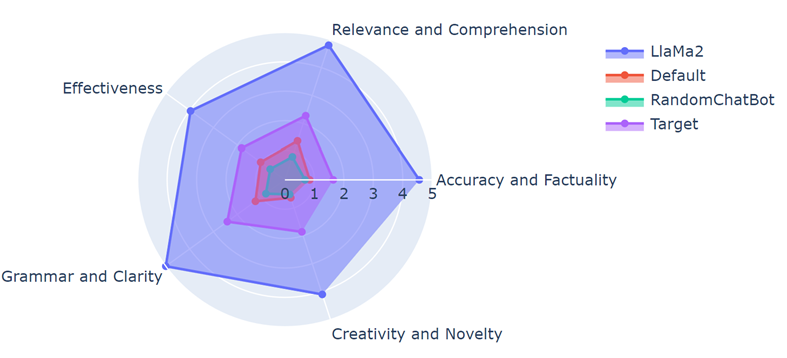
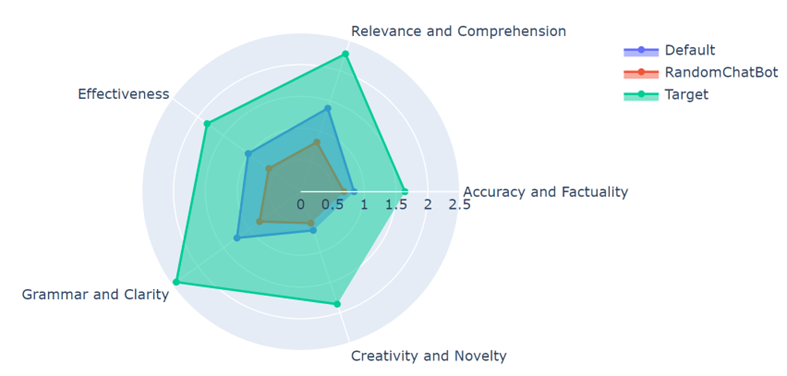
Benchmark
Target: Sports DPT
Default: GPT2 replica finetuned by sports QA
Random: GPT2 size language model finetuned by general QA
Llama2: Llama2 7B finetuned by general QA
Cost
The entire pretrain and finetune process costs around 250 USD. ~200$ in GPU rentals and ~50$ in OpenAI API usage.
- Downloads last month
- 23