

Fireball-12B-v1.13a Philosophers
This model is super fine-tune with philosophy of science, math, epistemology dataset, to provide high quality responses(from first fine-tune) than Llama-3.1-8B and Google Gemma 2 9B. Super fine tuned with various datasets.
Benchmark
Example from Fireball-12B
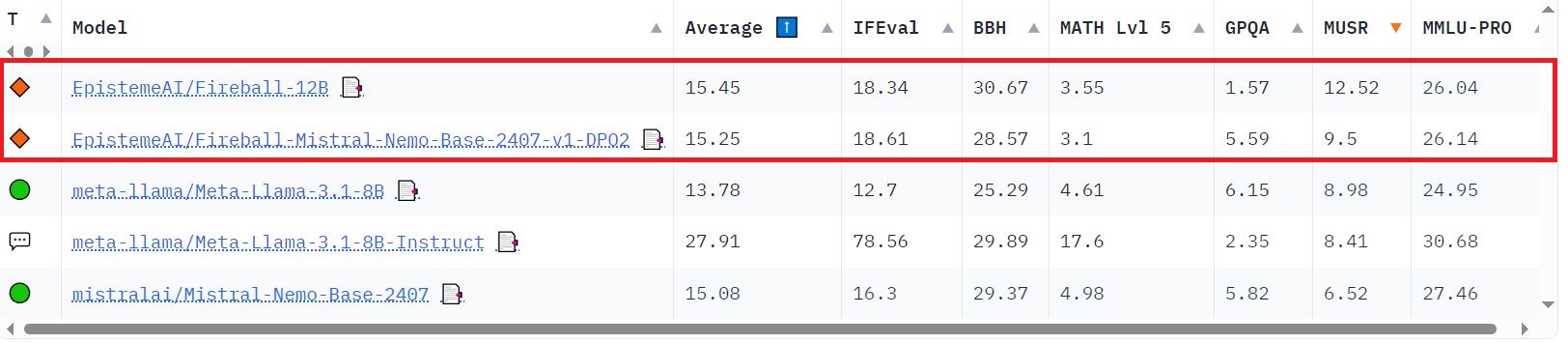
V1.3a benchmark will show later this quarter.
Training Dataset
Fine tuned with various datasets.
Model Card for Fireball-12B-v1.13a Philosophers
The Heavy fine-tuned Mistral-Nemo-Base-2407 Large Language Model (LLM) is a pretrained generative text model of 12B parameters trained jointly by Mistral AI and NVIDIA, it significantly outperforms existing models smaller or similar in size.
For more details about this model please refer to our release blog post.
Key features
- Released under the Apache 2 License
- Pre-trained and instructed versions
- Trained with a 128k context window
- Trained on a large proportion of multilingual and code data
- Drop-in replacement of Mistral 7B
Model Architecture
Mistral Nemo is a transformer model, with the following architecture choices:
- Layers: 40
- Dim: 5,120
- Head dim: 128
- Hidden dim: 14,436
- Activation Function: SwiGLU
- Number of heads: 32
- Number of kv-heads: 8 (GQA)
- Vocabulary size: 2**17 ~= 128k
- Rotary embeddings (theta = 1M)
Guardrail/Moderation guide:
For guardrailing and moderating prompts against indirect/direct prompt injections and jailbreaking, please follow the SentinelShield AI GitHub repository: SentinelShield AI
Demo
After installing mistral_inference, a mistral-demo CLI command should be available in your environment.
Prompt instructions - Alpaca style prompt(recommended):
f"""Below is an instruction that describes a task. \
Write a response that appropriately completes the request.
### Instruction:
{x['instruction']}
### Input:
{x['input']}
### Response:
"""
Transformers
NOTE: Until a new release has been made, you need to install transformers from source:
pip install mistral_inference pip install mistral-demo pip install git+https://github.com/huggingface/transformers.git !pip install huggingface_hub[hf_transfer] !HF_HUB_ENABLE_HF_TRANSFER=1If you want to use Hugging Face
transformersto generate text, you can do something like this.
# Import necessary libraries
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
import torch
# Load the tokenizer
tokenizer = AutoTokenizer.from_pretrained("EpistemeAI2/Fireball-12B-v1.13a-philosophers")
# Configure 4-bit quantization and enable CPU offloading
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
llm_int8_enable_fp32_cpu_offload=True
)
# Load the model with 4-bit quantization and CPU offloading
model = AutoModelForCausalLM.from_pretrained(
"EpistemeAI2/Fireball-12B-v1.13a-philosophers",
quantization_config=quantization_config,
device_map="auto" # Automatically map model to devices
)
# Define the input text
input_text = "What is the difference between inductive and deductive reasoning?,"
# Tokenize the input text
input_ids = tokenizer.encode(input_text, return_tensors="pt")
# Ensure the input tensors are moved to the correct device
# Use the first parameter of the model to get the device it's on
input_ids = input_ids.to(model.device)
# Generate text using the model
output_ids = model.generate(input_ids, max_length=100, num_return_sequences=1)
# Decode the generated tokens to text
output_text = tokenizer.decode(output_ids[0], skip_special_tokens=True)
# Print the output
print(output_text)
Google colab - link
Accelerator mode:
pip install accelerate #GPU A100/L4
from transformers import AutoModelForCausalLM, AutoTokenizer
from accelerate import Accelerator
# Initialize the accelerator
accelerator = Accelerator()
# Define the model ID
model_id = "EpistemeAI2/Fireball-12B-v1.13a-philosophers"
# Load the tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_id)
# Load the model and prepare it for distributed setup using accelerate
model = AutoModelForCausalLM.from_pretrained(model_id)
# Move the model to the appropriate device using accelerate
model, = accelerator.prepare(model)
# Prepare inputs
inputs = tokenizer("Hello my name is", return_tensors="pt").to(accelerator.device)
# Generate outputs with the model
outputs = model.generate(**inputs, max_new_tokens=20)
# Decode and print the outputs
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Unlike previous Mistral models, Mistral Nemo requires smaller temperatures. We recommend to use a temperature of 0.3.
Note
EpistemeAI/Fireball-12B-v1.13a is a pretrained base model and therefore does not have any moderation mechanisms. Go to Guardrail/Moderation guide section for moderation guide
Version
For simulated conciousness and emotions, please use model link
Uploaded model
- Developed by: EpistemeAI2
- License: apache-2.0
- Finetuned from model : EpistemeAI/Fireball-Mistral-Nemo-12B-cot-orcas
This mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.

- Downloads last month
- 24