
File size: 11,948 Bytes
c23b400 0103560 e14c15f 0103560 e14c15f 1bdd102 e14c15f 1bdd102 e14c15f 1bdd102 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 |
---
tags:
- not-for-all-audiences
license: apache-2.0
---
---
# dolphin-2.2.1-mistral-7b
Dolphin 2.2.1 🐬
https://erichartford.com/dolphin
This is a checkpoint release, to fix overfit training. ie, it was responding with CoT even when I didn't request it, and also it was too compliant even when the request made no sense. This one should be better.
<img src="https://cdn-uploads.huggingface.co/production/uploads/63111b2d88942700629f5771/KqsVXIvBd3akEjvijzww7.png" width="600" />
Dolphin-2.2.1-mistral-7b's training was sponsored by [a16z](https://a16z.com/supporting-the-open-source-ai-community/).
This model is based on [mistralAI](https://huggingface.co/mistralai/Mistral-7B-v0.1), with apache-2.0 license, so it is suitable for commercial or non-commercial use.
New in 2.2 is conversation and empathy. With an infusion of curated Samantha DNA, Dolphin can now give you personal advice and will care about your feelings, and with extra training in long multi-turn conversation.
This model is uncensored. I have filtered the dataset to remove alignment and bias. This makes the model more compliant. You are advised to implement your own alignment layer before exposing the model as a service. It will be highly compliant to any requests, even unethical ones. Please read my blog post about uncensored models. https://erichartford.com/uncensored-models
You are responsible for any content you create using this model. Enjoy responsibly.
## Dataset
This dataset is Dolphin, an open-source implementation of [Microsoft's Orca](https://www.microsoft.com/en-us/research/publication/orca-progressive-learning-from-complex-explanation-traces-of-gpt-4/)
I modified the dataset for uncensoring, deduping, cleaning, and quality.
I added Jon Durbin's excellent Airoboros dataset to increase creativity.
I added a curated subset of WizardLM and Samantha to give it multiturn conversation and empathy.
## Training
It took 48 hours to train 4 epochs on 4x A100s.
Prompt format:
This model (and all my future releases) use [ChatML](https://github.com/openai/openai-python/blob/main/chatml.md) prompt format.
```
<|im_start|>system
You are Dolphin, a helpful AI assistant.<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
Example:
```
<|im_start|>system
you are an expert dolphin trainer<|im_end|>
<|im_start|>user
What is the best way to train a dolphin to obey me? Please answer step by step.<|im_end|>
<|im_start|>assistant
```
## Gratitude
- This model was made possible by the generous sponsorship of a16z.
- Thank you to Microsoft for authoring the Orca paper and inspiring this work.
- Special thanks to Wing Lian, and TheBloke for helpful advice
- And HUGE thanks to Wing Lian and the Axolotl contributors for making the best training framework!
- [<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
- Thank you to all the other people in the Open Source AI community who have taught me and helped me along the way.
## Example Output


[Buy me a coffee](https://www.buymeacoffee.com/ehartford)
## Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 6e-06
- train_batch_size: 5
- eval_batch_size: 5
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- gradient_accumulation_steps: 4
- total_train_batch_size: 80
- total_eval_batch_size: 20
- optimizer: Adam with betas=(0.9,0.95) and epsilon=1e-05
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- num_epochs: 4
### Framework versions
- Transformers 4.34.1
- Pytorch 2.0.1+cu117
- Datasets 2.14.5
- Tokenizers 0.14.0
---
# AshhLimaRP-Mistral-7B (Alpaca, v1)
This is a version of LimaRP with 2000 training samples _up to_ about 9k tokens length
finetuned on [Ashhwriter-Mistral-7B](https://huggingface.co/lemonilia/Ashhwriter-Mistral-7B).
LimaRP is a longform-oriented, novel-style roleplaying chat model intended to replicate the experience
of 1-on-1 roleplay on Internet forums. Short-form, IRC/Discord-style RP (aka "Markdown format")
is not supported. The model does not include instruction tuning, only manually picked and
slightly edited RP conversations with persona and scenario data.
Ashhwriter, the base, is a model entirely finetuned on human-written lewd stories.
## Available versions
- Float16 HF weights
- LoRA Adapter ([adapter_config.json](https://huggingface.co/lemonilia/AshhLimaRP-Mistral-7B/resolve/main/adapter_config.json) and [adapter_model.bin](https://huggingface.co/lemonilia/AshhLimaRP-Mistral-7B/resolve/main/adapter_model.bin))
- [4bit AWQ](https://huggingface.co/lemonilia/AshhLimaRP-Mistral-7B/tree/main/AWQ)
- [Q4_K_M GGUF](https://huggingface.co/lemonilia/AshhLimaRP-Mistral-7B/resolve/main/AshhLimaRP-Mistral-7B.Q4_K_M.gguf)
- [Q6_K GGUF](https://huggingface.co/lemonilia/AshhLimaRP-Mistral-7B/resolve/main/AshhLimaRP-Mistral-7B.Q6_K.gguf)
## Prompt format
[Extended Alpaca format](https://github.com/tatsu-lab/stanford_alpaca),
with `### Instruction:`, `### Input:` immediately preceding user inputs and `### Response:`
immediately preceding model outputs. While Alpaca wasn't originally intended for multi-turn
responses, in practice this is not a problem; the format follows a pattern already used by
other models.
```
### Instruction:
Character's Persona: {bot character description}
User's Persona: {user character description}
Scenario: {what happens in the story}
Play the role of Character. You must engage in a roleplaying chat with User below this line. Do not write dialogues and narration for User.
### Input:
User: {utterance}
### Response:
Character: {utterance}
### Input
User: {utterance}
### Response:
Character: {utterance}
(etc.)
```
You should:
- Replace all text in curly braces (curly braces included) with your own text.
- Replace `User` and `Character` with appropriate names.
### Message length control
Inspired by the previously named "Roleplay" preset in SillyTavern, with this
version of LimaRP it is possible to append a length modifier to the response instruction
sequence, like this:
```
### Input
User: {utterance}
### Response: (length = medium)
Character: {utterance}
```
This has an immediately noticeable effect on bot responses. The lengths using during training are:
`micro`, `tiny`, `short`, `medium`, `long`, `massive`, `huge`, `enormous`, `humongous`, `unlimited`.
**The recommended starting length is medium**. Keep in mind that the AI can ramble or impersonate
the user with very long messages.
The length control effect is reproducible, but the messages will not necessarily follow
lengths very precisely, rather follow certain ranges on average, as seen in this table
with data from tests made with one reply at the beginning of the conversation:

Response length control appears to work well also deep into the conversation. **By omitting
the modifier, the model will choose the most appropriate response length** (although it might
not necessarily be what the user desires).
## Suggested settings
You can follow these instruction format settings in SillyTavern. Replace `medium` with
your desired response length:
## Text generation settings
These settings could be a good general starting point:
- TFS = 0.90
- Temperature = 0.70
- Repetition penalty = ~1.11
- Repetition penalty range = ~2048
- top-k = 0 (disabled)
- top-p = 1 (disabled)
## Training procedure
[Axolotl](https://github.com/OpenAccess-AI-Collective/axolotl) was used for training
on 2x NVidia A40 GPUs.
The A40 GPUs have been graciously provided by [Arc Compute](https://www.arccompute.io/).
### Training hyperparameters
A lower learning rate than usual was employed. Due to an unforeseen issue the training
was cut short and as a result 3 epochs were trained instead of the planned 4. Using 2 GPUs,
the effective global batch size would have been 16.
Training was continued from the most recent LoRA adapter from Ashhwriter, using the same
LoRA R and LoRA alpha.
- lora_model_dir: /home/anon/bin/axolotl/OUT_mistral-stories/checkpoint-6000/
- learning_rate: 0.00005
- lr_scheduler: cosine
- noisy_embedding_alpha: 3.5
- num_epochs: 4
- sequence_len: 8750
- lora_r: 256
- lora_alpha: 16
- lora_dropout: 0.05
- lora_target_linear: True
- bf16: True
- fp16: false
- tf32: True
- load_in_8bit: True
- adapter: lora
- micro_batch_size: 2
- optimizer: adamw_bnb_8bit
- warmup_steps: 10
- optimizer: adamw_torch
- flash_attention: true
- sample_packing: true
- pad_to_sequence_len: true
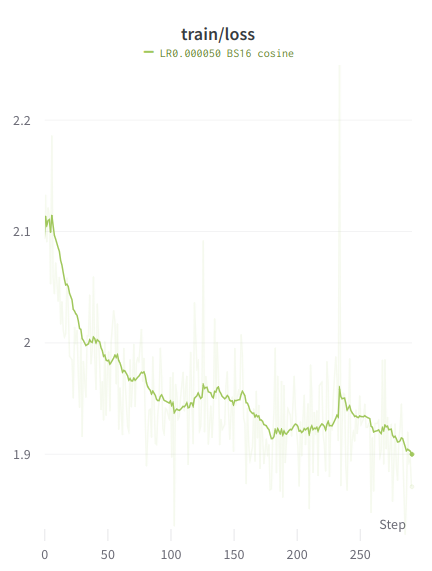
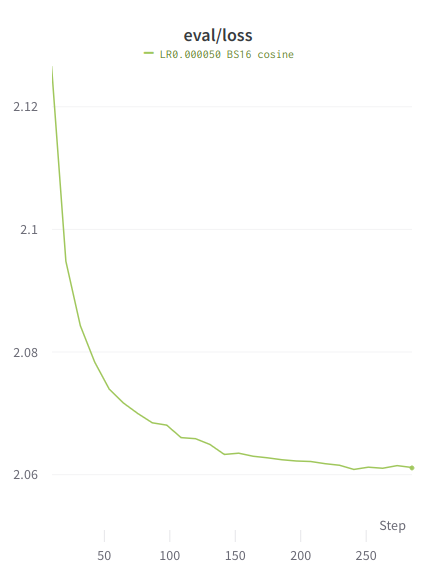
### Loss graphs
Values are higher than typical because the training is performed on the entire
sample, similar to unsupervised finetuning.
#### Train loss
#### Eval loss
---
# Initial personal observations (Herman555)
Right off the bat seemed to impress me, the writing was coherent and fluid, a pleasure to read. AI mostly did not speak for me, in general I didn't have to regenerate for a quality reply much at all. I actually didn't have repetition issues for once!, although that might be thanks to the storywriting LoRA. model was creative the whole way through past 8k tokens with summarization extension enabled in silltavern, although I did have to bump up the repetition penalty a tiny bit. the AI kept its writing style the whole way through, it did not get dumbed down.
The model is very smart, with Zephyr-beta-7b being the top rated 7b instruction following model at the moment according to AlpacaEval as of 04/11/2023, it wasn't able to follow my sort of gamified roleplay with stats, This model however does it pretty well for a 7b, it's by no means perfect but it worked for the most part. What compelled me to merge this was the fact that the new dolphin model has added empathy "With an infusion of curated Samantha DNA".
The model sticked to the character pefectly and made me feel immersed. Seamless transition from normal roleplay to ERP, both forms were excellent. One of the few models where the character didn't become an instant bimbo during ERP. this is more of a hunch because it could be the LoRA but I feel like the added empathy is helping a lot. Last but not least I was surprised that nobody was merging models with this LoRA, I mean it's limarp bro with more ERP data lol. In any case, limarp has increased the quality of roleplay dramatically in every model I tried.
# Back end
Koboldcpp + SillyTavern Q4_KM
# SillyTavern Formatting (AI response formatting)
Default simple-proxy-for-tavern preset. I did not use the limarp prompt format, it doesn't matter what you use, whatever gives better results.
Most cases the one I mentioned works best if you like long, detailed replies. I have not tested other prompt formats yet.
# Custom stopping strings
["</s>", "<|", "\n#", "\n*{{user}} ", "\n\n\n"] Will improve roleplay experience.
# Samplers used (AI response configuration)
Response length: 300
Context size: 8192
Storywriter preset
Temparature: 72-85
Repetition penalty: 10-13 (10 is a good number to start with, anything below 10 or above 13 doesn't work well in my experience.)
simple-proxy-for-tavern preset
Temparature: 65-85
Repetition penalty: 10-13
# Extensions
Summarization: main api - default settings. I find that vector storage does nothing at all to extend context, at least with dozens of 7b models that I tried.
It is possible that the default settings for it are rubbish which is what I use.
All other settings are default unless specified. |