在这一章中,我会介绍现阶段模型常见的下载和使用方式,并推荐一些当下使用较为频繁、口碑好的模型,最后会介绍炼制各种模型的方法(鸽了)。
一、模型如何下载
现阶段furry模型的下载方式大概有几种,C站、抱脸HuggingFace、discord上的furry diffusion上的网盘链接、国内镜像网站的个别furry模型、群友在群里发的文件或国内网盘的链接。这里着重讲一下前两个。注意,本文大部分链接打开后有nsfw内容,请不要在公共场合打开。
1.CivitAI
CivitAI,人称C站,是一个专门分享stable diffusion模型的网站,因为只有stable diffusion相关的模型,所以很专业,现在已经是最大的AI绘画模型网站。网址是civitai.com,访问需要魔 法。
详细操作(点击查看)
首先,上C站需要魔 法,需要你注册一个账号,不登陆也可以,但是就只能看到和谐的内容了。打开网页后的界面是这样的:
登陆后右上角的界面:
其中过滤器里的选项,一般来说像我这样设置就行,如果你要查找某一个类型的模型再打开过滤器,点击你想要的模型过滤。模型的类型文章后面会详细讲解,在C站主要是下载checkpoint大模型和LoRA,其次是embedding和poses。
接下来我们以indigo模型为例,看看在模型详情页的功能:


值得注意的是,尽管C站的网页需要魔 法才能登陆,但是它的下载真实链接是不需要魔 法的。我们可以先用浏览器自带的下载获取到真实的下载链接,再把这个链接用像idm或者迅雷这样的下载器下载。
真实链接(点击查看)
真实链接是cloudflarestorageyun云存储的域名,形如https://civitai-delivery-worker-prod-2023-05-19.5ac0637cfd0766c97916cefa3764fbdf.r2.cloudflarestorage.com/4692/model/furry20vixens20v2.P4Fp.safetensors?X-Amz-Expires=86400&response-content-disposition=attachment%3B%20filename%3D%22furryVixens_v20.safetensors%22&X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=2fea663d76bd24a496545da373d610fc/20230524/us-east-1/s3/aws4_request&X-Amz-Date=20230524T081008Z&X-Amz-SignedHeaders=host&X-Amz-Signature=cc030d78219579473223ff75efd06f39367b121c055510bb1f3c703f6db82d58的链接,这个链接会随着你的请求变化。此外几个常用站内链接:
收藏的模型https://civitai.com/?favorites=true 根据tag搜索https://civitai.com/?tag=后面写上想要搜的tag 全文搜索https://civitai.com/?query=后面写上想要搜的词汇
以上就是civitai的基本使用方法,作为最专业的模型分享网站,C站还有很多进阶功能和设置,这里不展开讲解了。
2.HuggingFace
HuggingFace,人称抱脸,是服务于人工智能产业和科研团队的模型分享网站,相当于AI界的Github。抱脸不只有AI绘画的模型,而是所有涉及到AI和人工智能等内容的模型都可以在这里开源。抱脸最大的优点是没有被墙,访问方便。大部分朋友在使用谷歌colab、autoDL、阿里云等云端训练或者图片生成的时候都可以直接调用抱脸上的模型,也就是可以把它当成一个不限速的网盘使用。
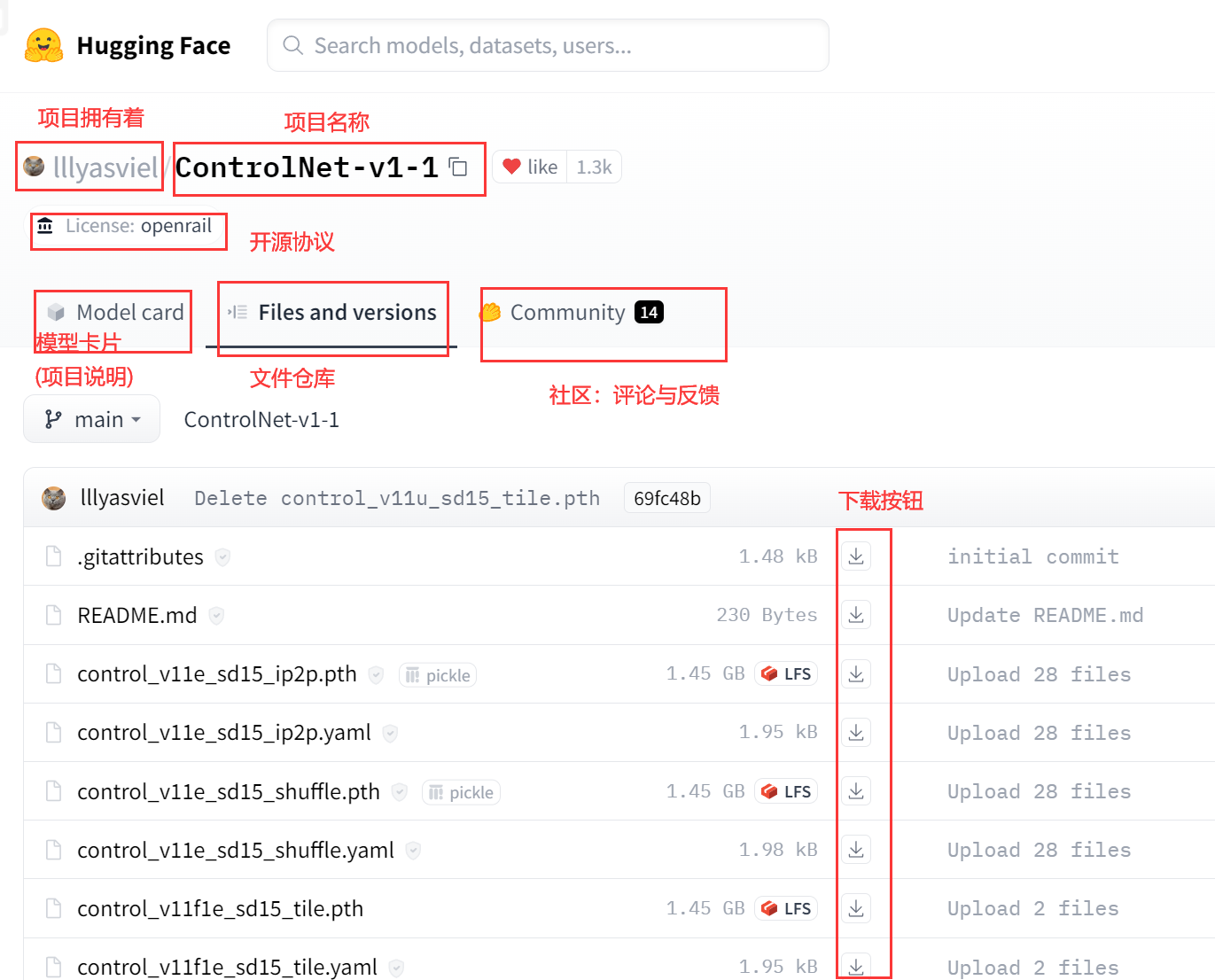 你可以把抱脸当成自己的模型仓库,上传模型方便云端服务调用,但是请记住遵守开源协议和模型制作者的要求。
你可以把抱脸当成自己的模型仓库,上传模型方便云端服务调用,但是请记住遵守开源协议和模型制作者的要求。
二、stable diffusion的checkpoint大模型
SD大模型也就是checkpoint(检查点),是stable diffusion运行的必要模型。没了checkpoint你WebUI(或者naifu、ComfyUI)都是跑不出图的,没有其他模型都可以出图(尽管可能达不到你想要的效果),但是没有大模型是绝对没法运行stable diffusion的。
大小:在2G到8G之间,一般大致有2G、4G、8G三个档位。一般原始模型大概7~8G,pruned剪枝(一种模型压缩技术,在尽可能不影响模型性能的情况下,通过删除模型中不重要的连接和节点来减小模型大小)后大小大概能减半,从fp32换成fp16模型大小也减半(从32位浮点换到16位浮点)。另外,有些模型会内置(烘焙baked)VAE文件,大小大概会增加300M到700M左右。对于图片生成来说,使用fp16和剪枝后的模型和原始模型的体验可能几乎没有差别,使用最小的就行了,但是如果你要融合模型请一定要下载原始8G左右的模型。
格式:.ckpt或者.safetensors,二者几乎等价,safetensors格式没有pickle的风险更安全(其实也从来没有听说谁用ckpt文件被恶意代码攻击的)。
路径:\models\Stable-diffusion
1.现阶段推荐的大模型
因为模型在不断迭代,所以仅推荐当下最合适的大模型:
1.1现在福瑞模型的版本答案
IndigoMix
现在你要问我最推荐的福瑞模型,那我首推的是indigo模型。采用了先进的分层融合技术,在FluffyRock模型上融合进了很多LoRA进去,做到了稳定生成优质图片,各种小众XP都很稳定(有一半的功劳要归功于它的底模FluffyRock),常见画风都能驾驭,相比其他模型更适合中国男同福瑞体质(是针对male特殊优化的,不像很多国外作者制作的female内容居多)。更多介绍请查阅C站的说明,indigo写的很详细了。
推荐指数:★★★★★
链接:C站链接 (需要魔 法)如果方便,请给作者一个like。 HuggingFace链接如果方便,请给作者一个like。
版本:最推荐,也是使用最广泛的是v16版本,使用kemono/anime来生成动漫内容,chibi/cute来生成非常“kemono”的内容,并使用realistic来生成逼真的内容,这个版本最擅长生成 bara、yaoi、kemono 和 NSFW 内容,稳定性拉满。v16版本的C站链接(需要魔 法)或HuggingFace链接。
之后有写实风格的v20和复刻niji风格的v25,但是现阶段indigo本人还是更推荐v16。对于clip skip,v16和v20推荐用1,v25可以用2。
tag体系:由于打标是混合使用e621和danbooru体系的tag,所以两个体系的prompt在indigo上都可以很好地运行。
Indigo门🙏!他本人也在我们的QQ群里,加群方式请看目录(AI兽人魔法书全目录——从入门到精通)。
另外,关于模型融合心得,indigo讲了:分层融合的本质就相当于把一些LoRA在大模型中永久调用,可是多个LoRA在模型中也会打架,indigo采用的做法是分步,融合一些角色画风LoRA之后再加几个风景LoRA,这样才能保证indigo模型在人物稳定性、LoRA兼容性、画风泛化性上都如此出色。
CrossKemono
C站累计下载量最高的福瑞模型,足以证明其含金量。主打日系福瑞kemono风格,偏兽太偏可爱。也采用了先进的分层融合技术,但是底模是大量融合而来的,包括但不限于Anything系列、Orange系列、Pastel+(Yohan系列)、Counterfeit系列、7th系列共计50多个模型。更多介绍请参考C站发布页说明。
推荐指数:★★★★★
链接:C站链接 (需要魔 法)如果方便,请给作者一个like。
版本:截止撰稿日,有ABCDEFG、2.0、2.5等多个型号,每个型号在C站模型介绍页有详细说明。
按照上传顺序对模型以英文字母顺序命名型号,并不是越后面上传的模型就越好,请根据你的需要选择A型、B型、C型、D型、E型、F型、G型,这有点类似orange以及7th,你可以从参考图像直观获得对比,每个型号都有较大的差异。
- 如果你只想用简短的prompt,不调整权重,也不使用kemono风格的Hypernetwork或者Lora来简单生成kemono,那么请选择B型号。
- 如果你有一定的prompt基础,可以接受调整权重,但不使用kemono风格的Hypernetwork或者Lora来生成kemono,那么可以选择D型号。
- 如果你想要一个很不一样的风格,同时又能接受使用kemono风格的Hypernetwork或者Lora来生成kemono,那么请选择C型号。
- 如果你想要和目前主流的anime模型接近的画风和构图,想生成好看的人类又想生成kemono风格的兽人,同时又能接受使用kemono风格的Hypernetwork或者Lora来生成kemono,那么可以选择A型号。
- 如果你想要类似AOM2orAOM3的那样更加立体的质感,又能接受不使用kemono风格的Hypernetwork或者Lora来生成kemono时画风较为写实,那么请选择F型号。
- 如果你想要清晰的线条的赛璐璐上色,又能接受使用模型E时,该模型生成的人物会显得非常年轻和娇小,那么请选择E型号。如果你想要非常厚涂的上色风格,以及非常细致且正确的场景,非常丰富多姿的色彩涂抹,又能接受在使用模型G时生成kemono的时候生成的姿态会非常具备肉感,也就是肚脐可能会比较明显,那么请选择G型号。 (这个型号需要使用kemono风格的Hypernetwork或者Lora来生成kemono,否则可能会生成不必要的人类耳朵和不正确的动物鼻子)。
tag体系:danbooru。
toynya门🙏!他本人也在我们的QQ群里,加群方式请看目录(AI兽人魔法书全目录——从入门到精通)。
BB95
主打photorealistic照相写实主义,现阶段厚涂、写实、美系画风SD模型的天花板(AI绘画写实天花板还是Midjourney v5),对于male和female都有很好的支持。详细参数请参考C站发布页说明。
推荐指数:★★★★☆
链接:C站链接如果方便,请给作者一个like。
版本:用最新版即可,现在最新版v7链接。
1.2次推荐的福瑞模型
FluffyRock
目前furry diffusion最热的模型,使用dreambooth大量训练,对于sex有专门的训练,人物结构稳定,各种你想要的都有。可是为什么不把FluffyRock放到首要推荐里呢,因为第一是风格偏向写实和美式,泛化性较差;第二FluffyRock其实很难用,对prompt敏感,咒语写的不好就很难出高质量的图片,不如基于FluffyRock的indigo适合小白。
因为是完全使用e621的图片训练的,要写艺术家用by someone,使用空格 而不是_。clip skip设置为1(其他模型一般都是2),分辨率567到1088都支持。
推荐指数:★★★★☆
链接:FluffyRock没有在C站上发布。HuggingFace链接,文件目录如果方便,请给作者一个like。 FluffyRock 的discord发布页,是furry diffusion评论最多的模型帖子(2W+),有很多技术讨论,建议去翻阅学习。快速上手说明https://discord.com/channels/1019133813105905664/1086767639763898458/1101869673076772915
版本:作者推荐的默认版本fluffyrock-576-704-832-960-1088-lion-low-lr-e27.safetensors,或者用稍微新一点的offset-noise版本fluffyrock-576-704-832-960-1088-lion-low-lr-e18-offset-noise-e3.safetensors,或者选一个最新版本也没问题。另外,由于是db训练的模型,FluffyRock的huggingface发布页把所有文件都发布了,需要自己选择合适的版本。这里稍微讲解一下命名规则:其中576-704-832-960-1088是训练图片大小的梯度(扩散隐藏层),lion是优化器算法,low-lr是较低学习率,e17是第17个epoch,offset-noise是用了噪声偏移技术(能够生成HDR高对比度的图片)
tag体系:e621系统。
Furry Vixens
作者想要复刻NovelAI的furry beta3模型而训练的,对美式风格福瑞和female支持得更好,详细参数请参考C站发布页说明。
推荐指数:★★★★
链接:C站链接如果方便,请给作者一个like。
Fluffusion
训练的模型。给了详细的训练tag作为prompt列表,值得表扬!详细信息请参考C站发布页和discord发布页。
推荐指数:★★★★(有待确认)
链接:C站链接如果方便,请给作者一个like。 Fluffusion的discord发布页,1.7W+评论,每个epoch都有网盘链接。
Yiffy Mix
融合模型。因为融合的底模是几个偏写实、厚涂、欧美风格的模型,所以厚涂效果很好。详细信息请参考C站发布页。
推荐指数:★★★☆(有待确认)
链接:C站链接
版本:v1基于 yiffy-e18, v2基于 fluffyrock-832-lion-e16-offset-noise-e1 + yiffy-e18, v2.1基于 fluffyrock-1088-lion-e16-offset-noise-e1 + Fluffusion-e15。
gay621 Solo Male Focus
主打厚涂写实,基于SD1.5重新开炉训练,训练自120,000张male gay focused福瑞图,使用e621tag体系。没有以下内容-animated -human_only -hyper -watersports -scat -cub -comic -diaper -pixel_(artwork) -3d_(artwork) -vore -chibi。更多内容请参考C站发布页和discord发布页。
推荐指数:★★★☆
链接:C站链接如果方便,请给作者一个like。 gay621的discord发布页,可以查看更多的参数设置。
1.3其他福瑞模型
Yiffy epoch18等第一代福瑞模型
大名鼎鼎的ye18模型,去年AI画兽人用的最广泛的模型,首发在furry diffusion上。基于e621的tag体系,训练了大量的e621图片,在画师chunie的支持下有着非常强烈的写实厚涂味道。虽然已经退环境了,但是它仍然存活于某些混合模型里,而且厚涂的风格也影响了后来对AI兽人的评判(“喜欢我ye18吗”)。
推荐指数:★★☆
链接:ye18的discord发布页,。
此外,跟着ye18一起进入历史垃圾桶的早期模型还有Zack3D_Kinky、furry_epoch4等第一代模型,他们的特点都是使用db训练且斥资巨大,但是由于早期对技术的理解尚且浅薄,走了很多弯路(比如图片选取不是一味追求越多越好,而是需要高质量+多内容的图片,ye18就是典型,没有做数据清洗,训练集一股脑地把e621的图片全塞进去,低质图片就拉低了整体质量,而且大量chunie的图片权重导致画风泛化性很差)
fking_scifi
科幻模型,基于SD2.1,用大量幻想生物的图片训练(写实兽人、外星人、机器人),写实能力很强。需要config文件。详细信息请参考C站发布页。
推荐指数:★★★
链接:C站链接
Kavka Mix
融合模型,对male支持较好。详细信息请参考C站发布页和discord发布页。
推荐指数:★★★(有待确认)
链接:C站链接如果方便,请给作者一个like。 Kavka Mix的discord发布页。
Lawlas's yiffymix
融合的模型,更擅长厚涂和美式风格,C站累计20k下载。详细信息请参考C站发布页和discord发布页。
推荐指数:★★☆
链接:C站链接Lawlas's yiffymix (furry model) C站链接Lawlas's Yiffymix 2.0 (furry model)如果方便,请给作者一个like。 Lawlas's yiffymix的discord发布页
anythingfurry
厚涂、写实、美式风格,主打female女性视角。推荐clip skip 1,不过2也合适(风格很不一样)。需要使用 config文件 (yaml)。
推荐指数:★★☆
链接:C站链接如果方便,请给作者一个like。
YiffAI
YiffAI (YAI)基于SD2.x训练。需要.yaml格式的config文件。详细信息请参考C站发布页。
推荐指数:★★☆
链接:C站链接 如果方便,请给作者一个like。
YMAN
由YiffyMix和anything等模型融合而成。详细信息请参考discord发布页。
推荐指数:★★☆
链接:YMAN的discord发布页。
1.4其他非福瑞模型推荐
再推荐几个非福瑞模型,如果需要融合模型、训练LoRA可能用得到(注意,训练LoRA最好不要使用融合模型,且最好不要使用剪枝过的或者降低精度的模型)。 首先是原版SD模型(runway发行的原版SD1.5,stabilityai开源的2.1)和NovelAI泄露的anime系列(因为是泄露的,所以没有官方发布页,我找了个别人在抱脸上的仓库) 此外C站上还开源有国人用的最多的anything系列(万象熔炉 | Anything V5,是融合出来的)大名鼎鼎的真人写实模型chilloutmix系列,超火的动画风格Counterfeit系列(counterfeit-v3.0,训练的),同样是超火的二次元模型橘子系列(比如深渊橘子abyssorangemix2,融合的),新晋热门模型、擅长幻想世界、半写实、2.5D的rev-animated(融合)等等,就不详细介绍了。
FluffyRock
主打photorealistic照相写实主义,现阶段厚涂、写实、美系画风模型的天花板,对于male和female都有很好的支持。一定要写艺术家
推荐指数:★★★★☆
链接:C站链接 HuggingFace链接,文件目录如果方便,请给作者一个like。 FluffyRock 的discord发布页,是furry diffusion评论最多的模型帖子(2W+),有很多技术讨论,建议去翻阅学习。
2.模型的炼制与融合
待更新……
待更新……二、LoRA
可以风格、角色、动作任何画面特征都可以学习,100MB左右,
常见格式: .safetensors,.ckpt,.pt
LoRA的调用直接在prompt最后写<lora:LoRA名字:权重>,也可以直接在UI界面点选LoRA加入到prompt里。
存放路径:对于年初用插件实现LoRA功能的版本的存放路径:\extensions\sd-webui-additional-networks\models\lora2,之后的新版本内置LoRA的存放路径: \models\lora
1.LoRA推荐
太多了……
待更新……2.LoRA的炼制
待更新……
待更新……三、Embedding/Textual Inversion
嵌入式Embedding (简称emb)文件是通过textual inversion(简称T.I.)对提示词打包,把很多prompt提炼成一个词汇快速调用。常见的有角色、动作、风格、负面的embedding。现在最常用的嵌入式文件还是负面文件,比如boring_e621、deformityv6、EasyNegative等,其他的比如 charturnerv2角色三视图也比较常用。常用的负面提示词我打包了一份,抱脸下载链接,他们的原始下载链接:
格式:最主要的格式是.pt,也有少量.safetensors等格式。
大小:一般都是几kb。
路径:\embeddings。
嵌入式文件可以在c站右上角选项卡中选择开启Textual Inversion。
四、Hypernetwork
大小: 几十K
常见格式:pt
存放路径: \models\bypernetworks通过画风训练产出,能指定特定的画风,新版本可在页面上直接加载
五、DreamBooth(简称DB)
大小: 2G-7G
常见格式: .ckpt,.safetensors
可以训练角色,画风,物件等,使用方法和主模型相同
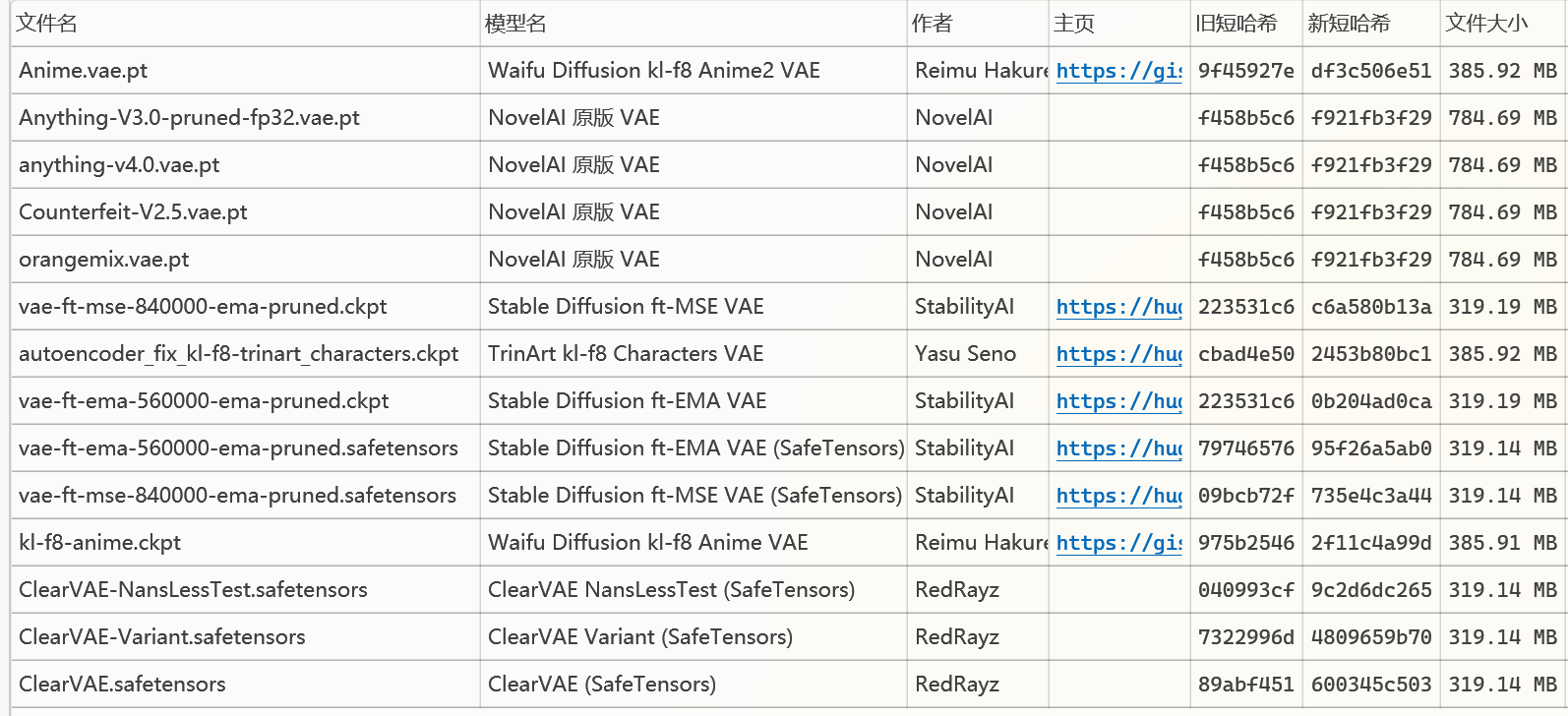
六、VAE
VAE(Variational AutoEncoder变分自动编码器)文件在绝大多数的情况下可以理解为滤镜,如果你生成的图片发灰,那大概率是没有加载vae文件。
大小:fp32的大小约为780MB,fp16的大小为300MB~400MB(有待求证)
存放路径: \models\VAE
常见格式: .vae.pt(也有部分是ckpt,safetensors)
注意:1.有些sd大模型是内置(烘焙baked)了vae文件的,所以不加载vae也能正常使用,请参考这个模型的介绍。
2.绝大多数模型(尤其是融合模型)都没有单独炼一个vea,大部分模型在炼制和融合的时候都是使用的NovelAI原版fp32的VAE。
3.VAE的加载可以在WebUI的settings设置-stable diffusion-sd_vae模型的vae中切换(如果你在快捷显示中把vae切换放在UI的顶部了那直接在那里修改就行)。
常见的VAE:如图是秋叶启动器预设提供的VAE,我们可以看到any3、any4、counterfeit、橘子这些大模型的VAE都是用的NovelAI原版VAE。