


Orion-14B
目次
1. モデル紹介
Orion-14B-Baseは、140億のパラメータを持つマルチランゲージの大規模モデルで、さまざまな言語に対応するために2.5兆トークンの多様なデータセットでトレーニングされました。このデータセットには、中文、英語、日本語、韓国語などが含まれています。このモデルは、多言語環境でのさまざまなタスクにおいて卓越した性能を発揮しています。Orion-14Bシリーズモデルは、主要なパフォーマンスベンチマークで優れた結果を示し、同じパラメータ数を持つ他のベースモデルを明らかに凌駕しています。具体的な技術の詳細については、参照先をご覧ください。技術レポートを参照してください。
Orion-14B シリーズのモデルは、以下の特徴があります:
- 基座20Bパラメータモデルは、総合的な評価で優れた結果を示しています。
- 多言語対応力が強く、特に日本語と韓国語の対応能力が優れています
- ファインチューニングモデルは適応性が高く、人間の注釈つきブラインドテストでは高性能なパフォーマンスを発揮しています。
- 長文対応バージョンは非常に長いテキストをサポートし、20万トークンの長さで優れた効果を発揮し、最大で320,000トークンまでサポート可能です。
- 量子化バージョンではモデルサイズが70%縮小し、推論速度が30%向上し、性能の損失が1%以下です。
Orion-14B シリーズ モデルには以下が含まれます:
- Orion-14B-Base: 2.5兆トークンの多様なデータセットでトレーニングされ、140億のパラメータを持つ多言語基本モデルです。
- Orion-14B-Chat: 高品質なコーパスでファインチューニングされた対話型モデルで、大規模モデルコミュニティにより良いユーザーインタラクション体験を提供することを目指しています。
- Orion-14B-LongChat: 20万トークンの長さで優れた効果を発揮し、最大で320,000トークンまでサポート可能で、長文書の評価セットでの性能は専用モデルに匹敵します。
- Orion-14B-Chat-RAG: スタムの検索強化生成データセットでファインチューニングされたチャットモデルで、検索強化生成タスクで卓越した性能を発揮しています。
- Orion-14B-Chat-Plugin: プラグインと関数呼び出しタスクに特化したチャットモデルで、代理を使用する関連するシナリオに適しています。大規模言語モデルがプラグインと関数呼び出しシステムの役割を果たします。
- Orion-14B-Base-Int4: int4を使用して量子化された基本モデル。モデルサイズが70%縮小し、推論速度が30%向上し、わずか1%未満の性能低下しか発生しません。
- Orion-14B-Chat-Int4: int4を使用して量子化された対話モデル。
2. モデルのダウンロード
以下はモデルのリリースとダウンロードURLが提供されています:
| モデル名 | HuggingFace ダウンロードリンク | ModelScope ダウンロードリンク |
|---|---|---|
| ⚾Orion-14B-Base | Orion-14B-Base | Orion-14B-Base |
| 😛Orion-14B-Chat | Orion-14B-Chat | Orion-14B-Chat |
| 📃Orion-14B-LongChat | Orion-14B-LongChat | Orion-14B-LongChat |
| 🔎Orion-14B-Chat-RAG | Orion-14B-Chat-RAG | Orion-14B-Chat-RAG |
| 🔌Orion-14B-Chat-Plugin | Orion-14B-Chat-Plugin | Orion-14B-Chat-Plugin |
| 💼Orion-14B-Base-Int4 | Orion-14B-Base-Int4 | Orion-14B-Base-Int4 |
| 📦Orion-14B-Chat-Int4 | Orion-14B-Chat-Int4 | Orion-14B-Chat-Int4 |
3. モデルのベンチマーク
3.1. 基本モデル Orion-14B-Base ベンチマーク
3.1.1. LLM 評価結果(検査と専門知識)
| モデル | C-Eval | CMMLU | MMLU | AGIEval | Gaokao | BBH |
|---|---|---|---|---|---|---|
| LLaMA2-13B | 41.4 | 38.4 | 55.0 | 30.9 | 18.2 | 45.6 |
| Skywork-13B | 59.1 | 61.4 | 62.7 | 43.6 | 56.1 | 48.3 |
| Baichuan2-13B | 59.0 | 61.3 | 59.5 | 37.4 | 45.6 | 49.0 |
| QWEN-14B | 71.7 | 70.2 | 67.9 | 51.9 | 62.5 | 53.7 |
| InternLM-20B | 58.8 | 59.0 | 62.1 | 44.6 | 45.5 | 52.5 |
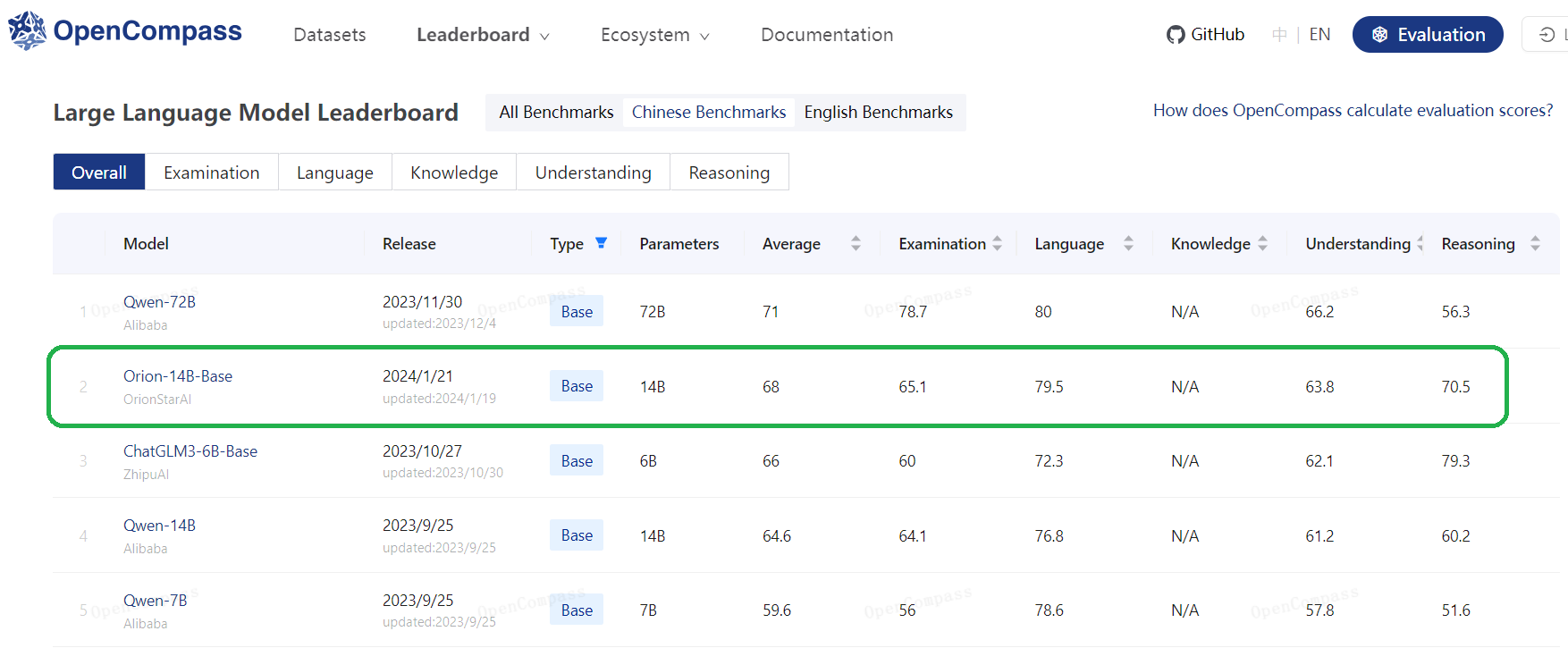
| Orion-14B-Base | 72.9 | 70.6 | 69.9 | 54.7 | 62.1 | 56.5 |
3.1.2. LLM 評価結果(言語理解と一般的な知識)
| モデル | RACE-middle | RACE-high | HellaSwag | PIQA | Lambada | WSC |
|---|---|---|---|---|---|---|
| LLaMA 2-13B | 63.0 | 58.9 | 77.5 | 79.8 | 76.5 | 66.3 |
| Skywork-13B | 87.6 | 84.1 | 73.7 | 78.3 | 71.8 | 66.3 |
| Baichuan 2-13B | 68.9 | 67.2 | 70.8 | 78.1 | 74.1 | 66.3 |
| QWEN-14B | 93.0 | 90.3 | 80.2 | 79.8 | 71.4 | 66.3 |
| InternLM-20B | 86.4 | 83.3 | 78.1 | 80.3 | 71.8 | 68.3 |
| Orion-14B-Base | 93.2 | 91.3 | 78.5 | 79.5 | 78.8 | 70.2 |
3.1.3. LLM 評価結果(OpenCompass テストセット)
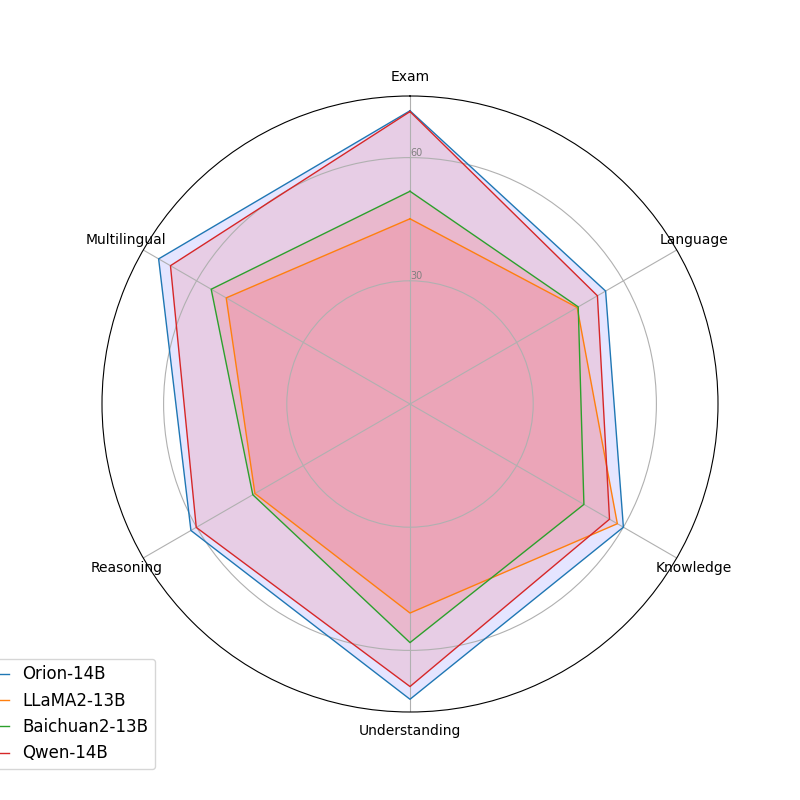
| モデル | 平均 | 検査 | 言語 | 知識 | 理解 | 推論 |
|---|---|---|---|---|---|---|
| LLaMA 2-13B | 47.3 | 45.2 | 47.0 | 58.3 | 50.9 | 43.6 |
| Skywork-13B | 53.6 | 61.1 | 51.3 | 52.7 | 64.5 | 45.2 |
| Baichuan 2-13B | 49.4 | 51.8 | 47.5 | 48.9 | 58.1 | 44.2 |
| QWEN-14B | 62.4 | 71.3 | 52.67 | 56.1 | 68.8 | 60.1 |
| InternLM-20B | 59.4 | 62.5 | 55.0 | 60.1 | 67.3 | 54.9 |
| Orion-14B-Base | 64.3 | 71.4 | 55.0 | 60.0 | 71.9 | 61.6 |
3.1.4. 日本語のテストセットにおけるLLMパフォーマンスの比較
| モデル | 平均 | JCQA | JNLI | MARC | JSQD | JQK | XLS | XWN | MGSM |
|---|---|---|---|---|---|---|---|---|---|
| PLaMo-13B | 52.3 | 56.7 | 42.8 | 95.8 | 70.6 | 71.0 | 8.70 | 70.5 | 2.40 |
| WebLab-10B | 50.7 | 66.6 | 53.7 | 82.1 | 62.9 | 56.2 | 10.0 | 72.0 | 2.40 |
| ELYZA-jp-7B | 48.8 | 71.7 | 25.3 | 86.6 | 70.8 | 64.1 | 2.50 | 62.1 | 7.20 |
| StableLM-jp-7B | 51.1 | 33.4 | 43.3 | 96.7 | 70.6 | 78.1 | 10.7 | 72.8 | 2.80 |
| LLaMA 2-13B | 46.3 | 75.0 | 47.6 | 38.8 | 76.1 | 67.7 | 18.1 | 63.2 | 10.4 |
| Baichuan 2-13B | 57.1 | 73.7 | 31.3 | 91.6 | 80.5 | 63.3 | 18.6 | 72.2 | 25.2 |
| QWEN-14B | 65.8 | 85.9 | 60.7 | 97.0 | 83.3 | 71.8 | 18.8 | 70.6 | 38.0 |
| Yi-34B | 67.1 | 83.8 | 61.2 | 95.2 | 86.1 | 78.5 | 27.2 | 69.2 | 35.2 |
| Orion-14B-Base | 69.1 | 88.2 | 75.8 | 94.1 | 75.7 | 85.1 | 17.3 | 78.8 | 38.0 |
3.1.5. 韓国のテストセットにおけるLLMパフォーマンスの比較。n = 0およびn = 5は評価に使用されたn-shotのプロンプトを表します。
| モデル | 平均 n=0 n=5 |
HellaSwag n=0 n=5 |
COPA n=0 n=5 |
BooIQ n=0 n=5 |
SentiNeg n=0 n=5 |
|---|---|---|---|---|---|
| KoGPT | 53.0 70.1 | 55.9 58.3 | 73.5 72.9 | 45.1 59.8 | 37.5 89.4 |
| Polyglot-ko-13B | 69.6 73.7 | 59.5 63.1 | 79.4 81.1 | 48.2 60.4 | 91.2 90.2 |
| LLaMA 2-13B | 46.7 63.7 | 41.3 44.0 | 59.3 63.8 | 34.9 73.8 | 51.5 73.4 |
| Baichuan 2-13B | 52.1 58.7 | 39.2 39.6 | 60.6 60.6 | 58.4 61.5 | 50.3 72.9 |
| QWEN-14B | 53.8 73.7 | 45.3 46.8 | 64.9 68.9 | 33.4 83.5 | 71.5 95.7 |
| Yi-34B | 54.2 72.1 | 44.6 44.7 | 58.0 60.6 | 65.9 90.2 | 48.3 92.9 |
| Orion-14B-Chat | 74.5 79.6 | 47.0 49.6 | 77.7 79.4 | 81.6 90.7 | 92.4 98.7 |
3.1.6. 多言語評価
| モデル | トレーニング言語 | 日本語 | 韓国語 | 中国語 | 英語 |
|---|---|---|---|---|---|
| PLaMo-13B | 英語, 日本語 | 52.3 | * | * | * |
| Weblab-10B | 英語, 日本語 | 50.7 | * | * | * |
| ELYZA-jp-7B | 英語, 日本語 | 48.8 | * | * | * |
| StableLM-jp-7B | 英語, 日本語 | 51.1 | * | * | * |
| KoGPT-6B | 英語, 韓国語 | * | 70.1 | * | * |
| Polyglot-ko-13B | 英語, 韓国語 | * | 70.7 | * | * |
| Baichuan2-13B | マルチ言語 | 57.1 | 58.7 | 50.8 | 57.1 |
| Qwen-14B | マルチ言語 | 65.8 | 73.7 | 64.5 | 65.4 |
| Llama2-13B | マルチ言語 | 46.3 | 63.7 | 41.4 | 55.3 |
| Yi-34B | マルチ言語 | 67.1 | 72.2 | 58.7 | 68.8 |
| Orion-14B-Chat | マルチ言語 | 69.1 | 79.5 | 67.9 | 67.3 |
3.2. チャットモデル Orion-14B-Chat ベンチマーク
3.2.1. チャットモデルのMTBenchにおける主観的評価
| モデル | ファーストターン | セカンドターン | 平均 |
|---|---|---|---|
| Baichuan2-13B-Chat | 7.05 | 6.47 | 6.76 |
| Qwen-14B-Chat | 7.30 | 6.62 | 6.96 |
| Llama2-13B-Chat | 7.10 | 6.20 | 6.65 |
| InternLM-20B-Chat | 7.03 | 5.93 | 6.48 |
| Orion-14B-Chat | 7.68 | 7.07 | 7.37 |
| * 推論にはvllmを使用 |
3.2.2. チャットモデルのAlignBenchにおける主観的評価
| モデル | 数学 | 論理 | 基礎 | 中国語 | コンピュータ | ライティング | 役割 | プロフェッショナリズム | 平均 |
|---|---|---|---|---|---|---|---|---|---|
| Baichuan2-13B-Chat | 3.76 | 4.07 | 6.22 | 6.05 | 7.11 | 6.97 | 6.75 | 6.43 | 5.25 |
| Qwen-14B-Chat | 4.91 | 4.71 | 6.90 | 6.36 | 6.74 | 6.64 | 6.59 | 6.56 | 5.72 |
| Llama2-13B-Chat | 3.05 | 3.79 | 5.43 | 4.40 | 6.76 | 6.63 | 6.99 | 5.65 | 4.70 |
| InternLM-20B-Chat | 3.39 | 3.92 | 5.96 | 5.50 | 7.18 | 6.19 | 6.49 | 6.22 | 4.96 |
| Orion-14B-Chat | 4.00 | 4.24 | 6.18 | 6.57 | 7.16 | 7.36 | 7.16 | 6.99 | 5.51 |
| * 推論にはvllmを使用 |
3.3. LongChatモデルOrion-14B-LongChatのベンチマーク
3.3.1. LongChatによるLongBenchの評価
| モデル | NarrativeQA | MultiFieldQA-en | MultiFieldQA-zh | DuReader | QMSum | VCSUM | TREC | TriviaQA | LSHT | RepoBench-P |
|---|---|---|---|---|---|---|---|---|---|---|
| GPT-3.5-Turbo-16k | 23.60 | 52.30 | 61.20 | 28.70 | 23.40 | 16.00 | 68.00 | 91.40 | 29.20 | 53.60 |
| LongChat-v1.5-7B-32k | 16.90 | 41.40 | 29.10 | 19.50 | 22.70 | 9.90 | 63.50 | 82.30 | 23.20 | 55.30 |
| Vicuna-v1.5-7B-16k | 19.40 | 38.50 | 43.00 | 19.30 | 22.80 | 15.10 | 71.50 | 86.20 | 28.80 | 43.50 |
| Yi-6B-200K | 14.11 | 36.74 | 22.68 | 14.01 | 20.44 | 8.08 | 72.00 | 86.61 | 38.00 | 63.29 |
| Orion-14B-LongChat | 19.47 | 48.11 | 55.84 | 37.02 | 24.87 | 15.44 | 77.00 | 89.12 | 45.50 | 54.31 |
3.4. Chat RAGモデルベンチマーク
3.4.1. 自己構築RAGテストセットのLLM評価結果
| モデル | 応答の有効性(キーワード) | *応答の有効性(主観的評価) | 引用の能力 | フォールバックの能力 | *AutoQA | *データ抽出 |
|---|---|---|---|---|---|---|
| Baichuan2-13B-Chat | 85 | 76 | 1 | 0 | 69 | 51 |
| Qwen-14B-Chat | 79 | 77 | 75 | 47 | 68 | 72 |
| Qwen-72B-Chat(Int4) | 87 | 89 | 90 | 32 | 67 | 76 |
| GPT-4 | 91 | 94 | 96 | 95 | 75 | 86 |
| Orion-14B-Chat-RAG | 86 | 87 | 91 | 97 | 73 | 71 |
| * 手動評価を意味します |
3.5. Chat PluginモデルOrion-14B-Chat-Pluginベンチマーク
3.5.1. 自己構築プラグインテストセットのLLM評価結果
| モデル | フルパラメータの意図認識 | パラメータが不足している場合の意図認識 | 非プラグイン呼び出しの認識 |
|---|---|---|---|
| Baichuan2-13B-Chat | 25 | 0 | 0 |
| Qwen-14B-Chat | 55 | 0 | 50 |
| GPT-4 | 95 | 52.38 | 70 |
| Orion-14B-Chat-Plugin | 92.5 | 60.32 | 90 |
3.6. 量子化モデルOrion-14B-Base-Int4ベンチマーク
3.6.1. 量子化前後の比較
| モデル | サイズ(GB) | 推論速度(トークン/秒) | C-Eval | CMMLU | MMLU | RACE | HellaSwag |
|---|---|---|---|---|---|---|---|
| OrionStar-14B-Base | 28.0 | 135 | 72.8 | 70.6 | 70.0 | 93.3 | 78.5 |
| OrionStar-14B-Base-Int4 | 8.3 | 178 | 71.8 | 69.8 | 69.2 | 93.1 | 78.0 |
4. モデル推論
推論に必要なモデルの重み、ソースコード、および設定は、Hugging Faceに公開されており、ダウンロードリンクはこの文書の冒頭にある表に示されています。ここでは、さまざまな推論方法のデモが行われます。プログラムは自動的にHugging Faceから必要なリソースをダウンロードします。
4.1. Pythonコード
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation.utils import GenerationConfig
tokenizer = AutoTokenizer.from_pretrained("OrionStarAI/Orion-14B", use_fast=False, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("OrionStarAI/Orion-14B", device_map="auto",
torch_dtype=torch.bfloat16, trust_remote_code=True)
model.generation_config = GenerationConfig.from_pretrained("OrionStarAI/Orion-14B")
messages = [{"role": "user", "content": "Hello, what is your name? "}]
response = model.chat(tokenizer, messages, streaming=False)
print(response)
上記のPythonソースコードでは、モデルは device_map='auto' でロードされ、利用可能なすべてのGPUを利用されています。デバイスを指定するには、 export CUDA_VISIBLE_DEVICES=0,1 のようなものを使用できます(GPU 0および1を使用)。
4.2. コマンドラインツール
CUDA_VISIBLE_DEVICES=0 python cli_demo.py
このコマンドラインツールはチャットシナリオ向けに設計されており、基本モデルの呼び出しをサポートしていません。
4.3. 直接スクリプト推論
# ベースモデル
CUDA_VISIBLE_DEVICES=0 python demo/text_generation_base.py --model OrionStarAI/Orion-14B --tokenizer OrionStarAI/Orion-14B --prompt hello
# チャットモデル
CUDA_VISIBLE_DEVICES=0 python demo/text_generation.py --model OrionStarAI/Orion-14B-Chat --tokenizer OrionStarAI/Orion-14B-Chat --prompt hi
4.4 例の出力
4.4.1 カジュアルチャット
User: Hello
Orion-14B: Hello! How can I help you today? If you have any questions or need assistance, feel free to ask.
User: What functions do you have?
Orion-14B: As an AI language model, I have a wide range of functions and capabilities, including but not limited to:
Answering general knowledge questions: I can provide information on various topics such as history, science, geography, and more.
Providing definitions and explanations: I can explain complex concepts and provide definitions for words and phrases.
Assisting with tasks: I can help with simple tasks like setting reminders, converting units of measurement, and even ordering food from restaurants.
Generating text: I can write short stories, essays, articles, and other types of content based on prompts given to me.
Translating languages: I can translate text from one language to another.
Chatting: I can engage in conversation with users and respond to their queries in a conversational manner.
Summarizing long texts: I can summarize longer texts like articles, books, and research papers.
Generating random numbers and names: I can generate random numbers within a specified range and also suggest names based on certain criteria.
Playing games: I can play simple games like Hangman, Trivia, and more.
Providing recommendations: I can recommend movies, music, books, and other forms of entertainment based on user preferences.
These are just some of the many functions that I am capable of performing. If you have a specific task in mind, feel free to ask me about it.
User: Tell me a joke.
Orion-14B: Sure, here's a classic one-liner: Why don't scientists trust atoms? Because they make up everything.
4.4.2. 日本語と韓国語のチャット
User:自己を紹介してください
Orion-14B:こんにちは、私の名前はChatMaxで、OrionStarによって開発されたAIアシスタントです。私はユーザーに正確で、客観的で、有用な回答を提供し、彼らが問題を解決し、情報を取得するのを助けることができます。
User:자기소개를 해주세요.
Orion-14B:안녕하세요, 제 이름은 ChatMax입니다. OrionStar에서 개발한 AI 어시스턴트입니다. 저는 사용자들에게 정확하고 객관적이며 유용한 답변을 제공하여 문제를 해결하고 정보를 얻는 데 도움을 줄 수 있습니다.
5. 声明、ライセンス
5.1. 声明
弊社は全ての利用者に対して、Orion-14Bモデルを使用して国家の社会安全を危険にさらすか、違法な活動に使用しないよう強く呼びかけます。さらに、Orion-14Bモデルを適切な安全審査と登録なしにインターネットサービスに使用しないよう要求します。 すべての利用者がこの原則を守ることを期待しており、科技の発展が規範と合法の環境で進むことを確認しています。弊社はモデルのトレーニングプロセスで使用されるデータのコンプライアンスを確保するために最善の努力をしています。ただし、モデルとデータの複雑性から、予測できない問題が依然として発生する可能性があります。 したがって、Orion-14Bオープンソースモデルの使用によって引き起こされる問題、データセキュリティの問題、公共の意見のリスク、またはモデルが誤誘導、乱用、拡散、または不適切に使用されることによるリスクや問題について、弊社は一切の責任を負いません。
5.2. ライセンス
Orion-14B シリーズモデルのコミュニティ利用
- コードは Apache License Version 2.0 ライセンスに従ってください。
- モデルは 【Orion-14B シリーズ】 Models Community License Agreementに従ってください。
6. 会社紹介
オリオンスター(OrionStar)は、2016年9月に設立された、世界をリードするサービスロボットソリューション企業です。オリオンスターは人工知能技術を基に、次世代の革新的なロボットを開発し、人々が単純な体力労働から解放され、仕事や生活がよりスマートで面白くなるようにすることを目指しています。技術を通じて社会と世界をより良くすることを目指しています。
オリオンスターは、完全に独自に開発された全体的な人工知能技術を持っており、音声対話や視覚ナビゲーションなどが含まれます。製品開発能力と技術応用能力を統合しています。オリオンメカニカルアームプラットフォームを基に、オリオンスター 、AI Robot Greeting Mini、Lucki、Coffee Masterなどの製品を展開し、オリオンスターロボットのオープンプラットフォームであるオリオンOSも構築しています。本当に有用なロボットのために生まれたという理念に基づき、オリオンスターはAI技術を通じて多くの人々に力を与えています。
7年間のAI経験を基に、オリオンスターは「聚言」という大規模な深層学習アプリケーションを導入し、業界の顧客向けにカスタマイズされたAI大規模モデルのコンサルティングとサービスソリューションを提供しています。これにより、企業の経営効率を向上させる目標を達成するのに役立っています。
オリオンスターの大規模モデルアプリケーション能力の主要な利点には、海量データ処理、大規模モデルの事前トレーニング、二次事前トレーニング、ファインチューニング、プロンプトエンジニアリング、エージェント開発など、全体のチェーンにわたる能力と経験の蓄積が含まれます。 さらに、システム全体のデータ処理フローと数百のGPUによる並列モデルトレーニング能力を含む、エンドツーエンドのモデルトレーニング能力を持っています。これらの能力は、大規模政府、クラウドサービス、国際展開の電子商取引、消費財など、さまざまな産業のシーンで実現されています。
大規模モデルアプリケーションの展開に関するニーズがある企業は、お気軽にお問い合わせください。
Tel: 400-898-7779
E-mail: ai@orionstar.com
