
Upload folder using huggingface_hub
#4
by
sharpenb
- opened
- config.json +3 -3
- model-00001-of-00002.safetensors +1 -1
- plots.png +0 -0
- results.json +18 -16
- smash_config.json +1 -1
- tokenizer_config.json +1 -0
config.json
CHANGED
|
@@ -1,5 +1,5 @@
|
|
| 1 |
{
|
| 2 |
-
"_name_or_path": "/tmp/
|
| 3 |
"architectures": [
|
| 4 |
"LlamaForCausalLM"
|
| 5 |
],
|
|
@@ -11,7 +11,7 @@
|
|
| 11 |
"hidden_size": 4096,
|
| 12 |
"initializer_range": 0.02,
|
| 13 |
"intermediate_size": 14336,
|
| 14 |
-
"max_position_embeddings":
|
| 15 |
"model_type": "llama",
|
| 16 |
"num_attention_heads": 32,
|
| 17 |
"num_hidden_layers": 32,
|
|
@@ -27,7 +27,7 @@
|
|
| 27 |
},
|
| 28 |
"rms_norm_eps": 1e-05,
|
| 29 |
"rope_scaling": null,
|
| 30 |
-
"rope_theta":
|
| 31 |
"tie_word_embeddings": false,
|
| 32 |
"torch_dtype": "float16",
|
| 33 |
"transformers_version": "4.40.0",
|
|
|
|
| 1 |
{
|
| 2 |
+
"_name_or_path": "/tmp/tmpetnsv95z",
|
| 3 |
"architectures": [
|
| 4 |
"LlamaForCausalLM"
|
| 5 |
],
|
|
|
|
| 11 |
"hidden_size": 4096,
|
| 12 |
"initializer_range": 0.02,
|
| 13 |
"intermediate_size": 14336,
|
| 14 |
+
"max_position_embeddings": 524288,
|
| 15 |
"model_type": "llama",
|
| 16 |
"num_attention_heads": 32,
|
| 17 |
"num_hidden_layers": 32,
|
|
|
|
| 27 |
},
|
| 28 |
"rms_norm_eps": 1e-05,
|
| 29 |
"rope_scaling": null,
|
| 30 |
+
"rope_theta": 2000000.0,
|
| 31 |
"tie_word_embeddings": false,
|
| 32 |
"torch_dtype": "float16",
|
| 33 |
"transformers_version": "4.40.0",
|
model-00001-of-00002.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 4677281680
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:55137d8fe28ef15407cb4fe5a31717527894c8b0860d9283a34768b060722b47
|
| 3 |
size 4677281680
|
plots.png
CHANGED

|
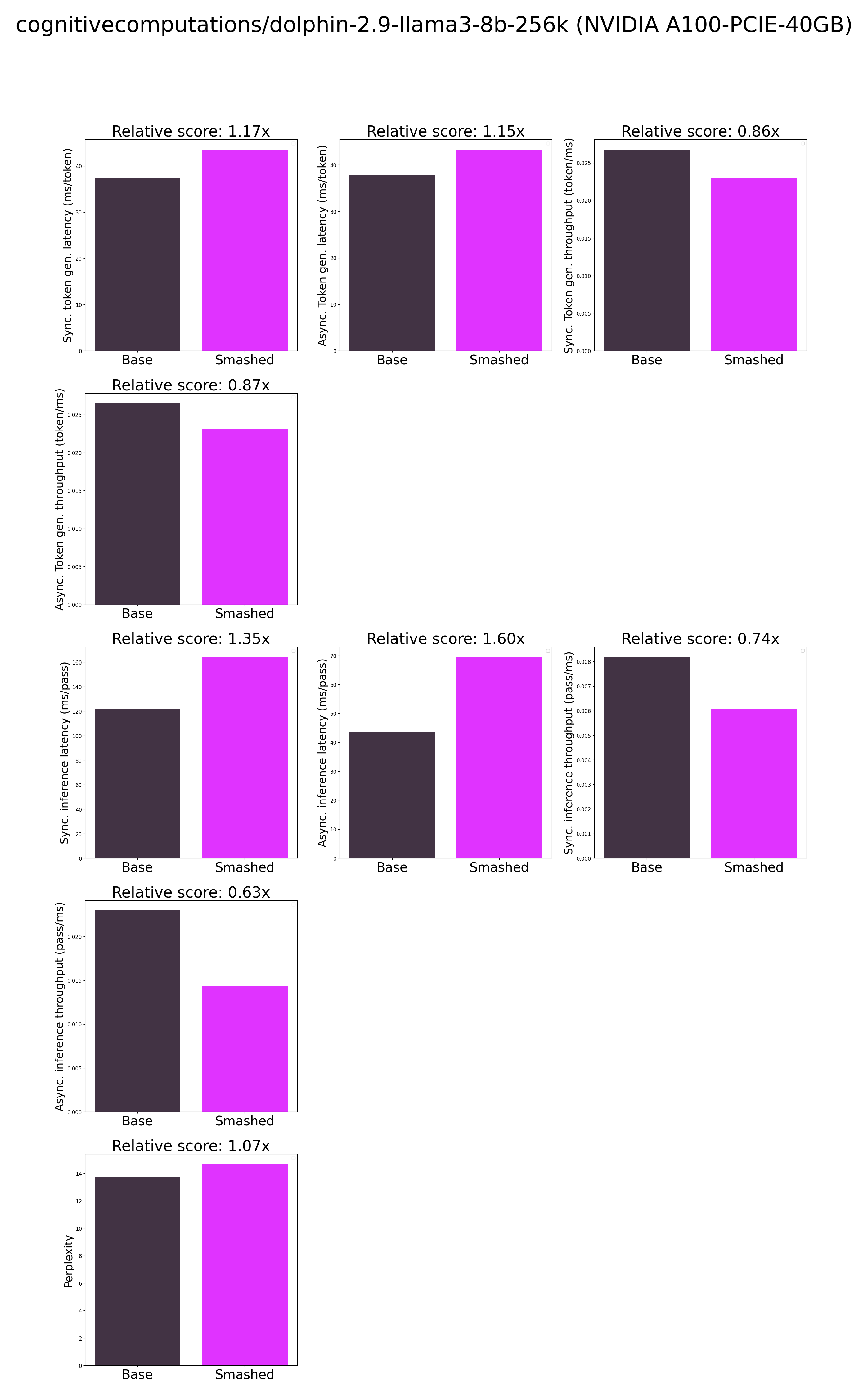
|
results.json
CHANGED
|
@@ -1,30 +1,32 @@
|
|
| 1 |
{
|
| 2 |
"base_current_gpu_type": "NVIDIA A100-PCIE-40GB",
|
| 3 |
"base_current_gpu_total_memory": 40339.3125,
|
| 4 |
-
"
|
| 5 |
-
"
|
| 6 |
-
"
|
| 7 |
-
"
|
|
|
|
| 8 |
"base_token_generation_CO2_emissions": null,
|
| 9 |
"base_token_generation_energy_consumption": null,
|
| 10 |
-
"base_inference_latency_sync":
|
| 11 |
-
"base_inference_latency_async":
|
| 12 |
-
"base_inference_throughput_sync": 0.
|
| 13 |
-
"base_inference_throughput_async": 0.
|
| 14 |
"base_inference_CO2_emissions": null,
|
| 15 |
"base_inference_energy_consumption": null,
|
| 16 |
"smashed_current_gpu_type": "NVIDIA A100-PCIE-40GB",
|
| 17 |
"smashed_current_gpu_total_memory": 40339.3125,
|
| 18 |
-
"
|
| 19 |
-
"
|
| 20 |
-
"
|
| 21 |
-
"
|
|
|
|
| 22 |
"smashed_token_generation_CO2_emissions": null,
|
| 23 |
"smashed_token_generation_energy_consumption": null,
|
| 24 |
-
"smashed_inference_latency_sync":
|
| 25 |
-
"smashed_inference_latency_async":
|
| 26 |
-
"smashed_inference_throughput_sync": 0.
|
| 27 |
-
"smashed_inference_throughput_async": 0.
|
| 28 |
"smashed_inference_CO2_emissions": null,
|
| 29 |
"smashed_inference_energy_consumption": null
|
| 30 |
}
|
|
|
|
| 1 |
{
|
| 2 |
"base_current_gpu_type": "NVIDIA A100-PCIE-40GB",
|
| 3 |
"base_current_gpu_total_memory": 40339.3125,
|
| 4 |
+
"base_perplexity": 13.74486255645752,
|
| 5 |
+
"base_token_generation_latency_sync": 37.35860481262207,
|
| 6 |
+
"base_token_generation_latency_async": 37.739571928977966,
|
| 7 |
+
"base_token_generation_throughput_sync": 0.026767594909276098,
|
| 8 |
+
"base_token_generation_throughput_async": 0.026497385870775065,
|
| 9 |
"base_token_generation_CO2_emissions": null,
|
| 10 |
"base_token_generation_energy_consumption": null,
|
| 11 |
+
"base_inference_latency_sync": 122.0685821533203,
|
| 12 |
+
"base_inference_latency_async": 43.52927207946777,
|
| 13 |
+
"base_inference_throughput_sync": 0.008192116123246046,
|
| 14 |
+
"base_inference_throughput_async": 0.022973046693139806,
|
| 15 |
"base_inference_CO2_emissions": null,
|
| 16 |
"base_inference_energy_consumption": null,
|
| 17 |
"smashed_current_gpu_type": "NVIDIA A100-PCIE-40GB",
|
| 18 |
"smashed_current_gpu_total_memory": 40339.3125,
|
| 19 |
+
"smashed_perplexity": 14.672628402709961,
|
| 20 |
+
"smashed_token_generation_latency_sync": 43.5498722076416,
|
| 21 |
+
"smashed_token_generation_latency_async": 43.305750377476215,
|
| 22 |
+
"smashed_token_generation_throughput_sync": 0.02296217989417044,
|
| 23 |
+
"smashed_token_generation_throughput_async": 0.02309162158104783,
|
| 24 |
"smashed_token_generation_CO2_emissions": null,
|
| 25 |
"smashed_token_generation_energy_consumption": null,
|
| 26 |
+
"smashed_inference_latency_sync": 164.25011291503907,
|
| 27 |
+
"smashed_inference_latency_async": 69.53554153442383,
|
| 28 |
+
"smashed_inference_throughput_sync": 0.006088275875446525,
|
| 29 |
+
"smashed_inference_throughput_async": 0.014381134854683576,
|
| 30 |
"smashed_inference_CO2_emissions": null,
|
| 31 |
"smashed_inference_energy_consumption": null
|
| 32 |
}
|
smash_config.json
CHANGED
|
@@ -14,7 +14,7 @@
|
|
| 14 |
"controlnet": "None",
|
| 15 |
"unet_dim": 4,
|
| 16 |
"device": "cuda",
|
| 17 |
-
"cache_dir": "/ceph/hdd/staff/charpent/.cache/
|
| 18 |
"batch_size": 1,
|
| 19 |
"model_name": "cognitivecomputations/dolphin-2.9-llama3-8b-256k",
|
| 20 |
"task": "text_text_generation",
|
|
|
|
| 14 |
"controlnet": "None",
|
| 15 |
"unet_dim": 4,
|
| 16 |
"device": "cuda",
|
| 17 |
+
"cache_dir": "/ceph/hdd/staff/charpent/.cache/modelsgmyikxqu",
|
| 18 |
"batch_size": 1,
|
| 19 |
"model_name": "cognitivecomputations/dolphin-2.9-llama3-8b-256k",
|
| 20 |
"task": "text_text_generation",
|
tokenizer_config.json
CHANGED
|
@@ -2069,6 +2069,7 @@
|
|
| 2069 |
"chat_template": "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}",
|
| 2070 |
"clean_up_tokenization_spaces": true,
|
| 2071 |
"eos_token": "<|im_end|>",
|
|
|
|
| 2072 |
"model_input_names": [
|
| 2073 |
"input_ids",
|
| 2074 |
"attention_mask"
|
|
|
|
| 2069 |
"chat_template": "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}",
|
| 2070 |
"clean_up_tokenization_spaces": true,
|
| 2071 |
"eos_token": "<|im_end|>",
|
| 2072 |
+
"legacy": false,
|
| 2073 |
"model_input_names": [
|
| 2074 |
"input_ids",
|
| 2075 |
"attention_mask"
|