

QuantFactory/xLAM-7b-fc-r-GGUF
This is quantized version of Salesforce/xLAM-7b-fc-r created using llama.cpp
Original Model Card

[Homepage] | [Paper] | [Dataset] | [Github]
Welcome to the xLAM model family! Large Action Models (LAMs) are advanced large language models designed to enhance decision-making and translate user intentions into executable actions that interact with the world. LAMs autonomously plan and execute tasks to achieve specific goals, serving as the brains of AI agents. They have the potential to automate workflow processes across various domains, making them invaluable for a wide range of applications.
Table of Contents
Model Series
We provide a series of xLAMs in different sizes to cater to various applications, including those optimized for function-calling and general agent applications:
| Model | # Total Params | Context Length | Download Model | Download GGUF files |
|---|---|---|---|---|
| xLAM-1b-fc-r | 1.35B | 16384 | 🤗 Link | 🤗 Link |
| xLAM-7b-fc-r | 6.91B | 4096 | 🤗 Link | 🤗 Link |
The fc series of models are optimized for function-calling capability, providing fast, accurate, and structured responses based on input queries and available APIs. These models are fine-tuned based on the deepseek-coder models and are designed to be small enough for deployment on personal devices like phones or computers.
We also provide their quantized GGUF files for efficient deployment and execution. GGUF is a file format designed to efficiently store and load large language models, making GGUF ideal for running AI models on local devices with limited resources, enabling offline functionality and enhanced privacy.
For more details, check our GitHub and paper.
Repository Overview
This repository is focused on our small xLAM-7b-fc-r model, which is optimized for function-calling and can be easily deployed on personal devices.
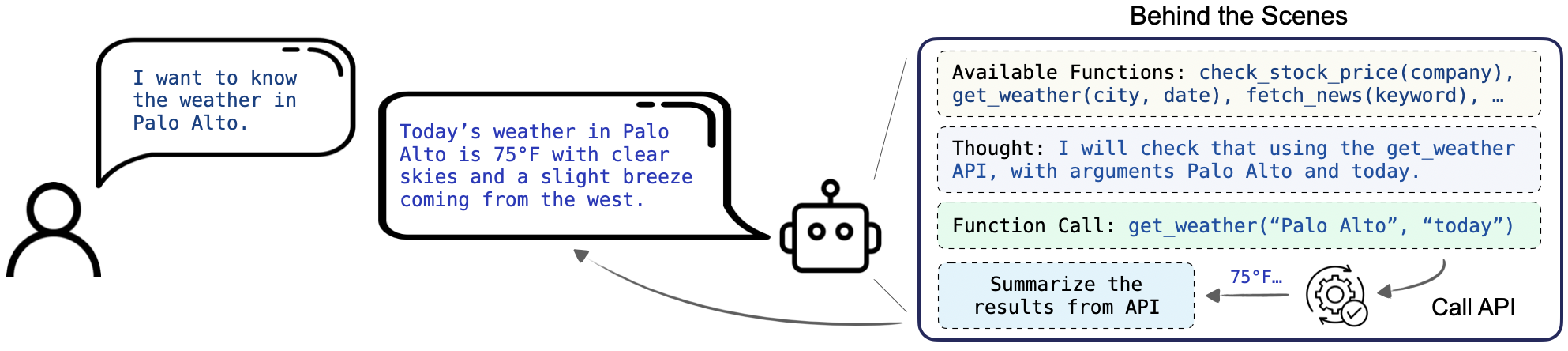
Function-calling, or tool use, is one of the key capabilities for AI agents. It requires the model not only understand and generate human-like text but also to execute functional API calls based on natural language instructions. This extends the utility of LLMs beyond simple conversation tasks to dynamic interactions with a variety of digital services and applications, such as retrieving weather information, managing social media platforms, and handling financial services.
The instructions will guide you through the setup, usage, and integration of xLAM-7b-fc-r with HuggingFace and vLLM.
We will first introduce the basic usage, and then walk through the provided tutorial and example scripts in the examples folder.
Framework Versions
- Transformers 4.41.0
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
Benchmark Results
We mainly test our function-calling models on the Berkeley Function-Calling Leaderboard (BFCL), which offers a comprehensive evaluation framework for assessing LLMs' function-calling capabilities across various programming languages and application domains like Java, JavaScript, and Python.
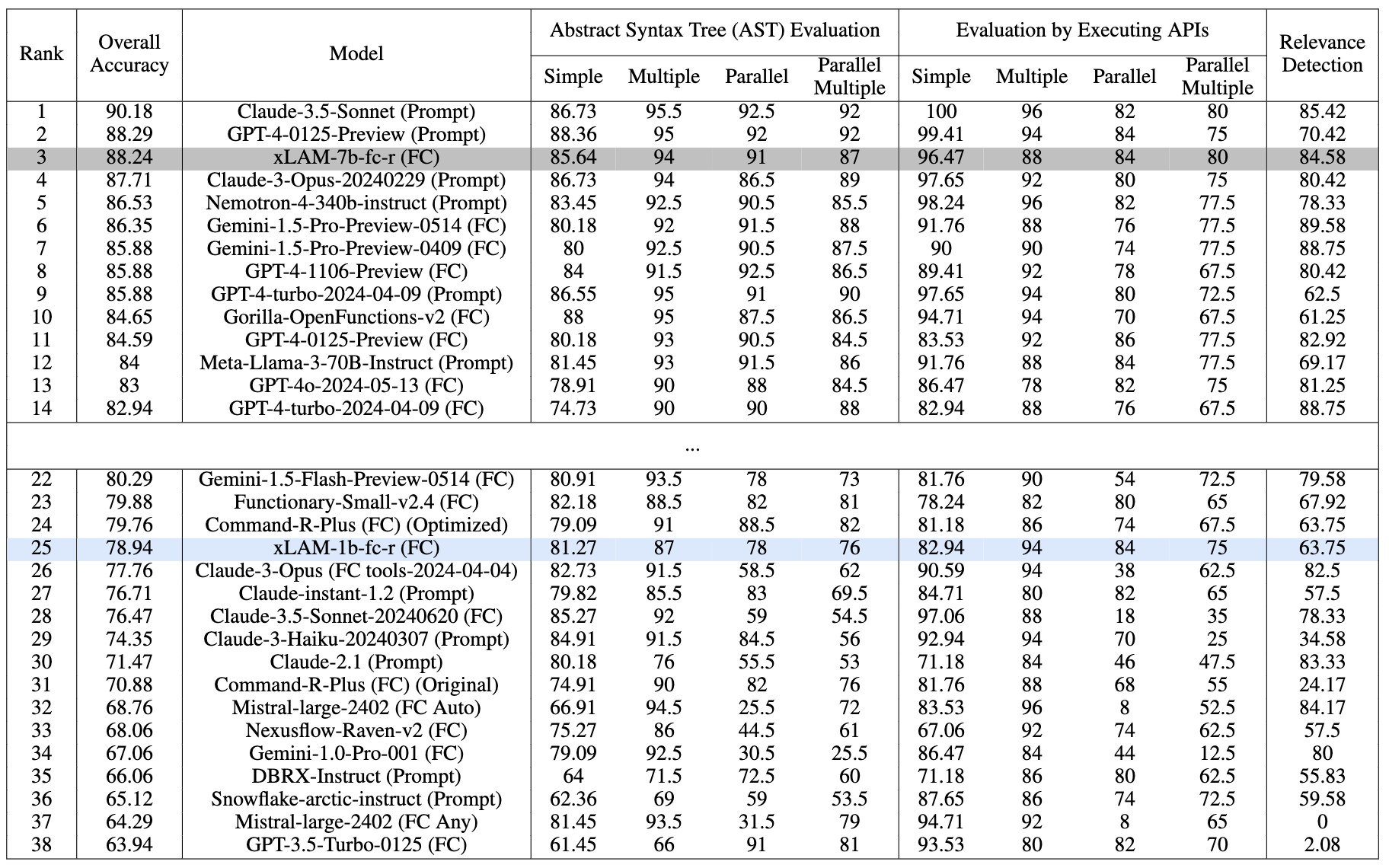
Performance comparison on the BFCL benchmark as of date 07/18/2024. Evaluated with temperature=0.001 and top_p=1
Our xLAM-7b-fc-r secures the 3rd place with an overall accuracy of 88.24% on the leaderboard, outperforming many strong models. Notably, our xLAM-1b-fc-r model is the only tiny model with less than 2B parameters on the leaderboard, but still achieves a competitive overall accuracy of 78.94% and outperforming GPT3-Turbo and many larger models.
Both models exhibit balanced performance across various categories, showing their strong function-calling capabilities despite their small sizes.
See our paper and Github repo for more detailed analysis.
Usage
Basic Usage with Huggingface
To use the xLAM-7b-fc-r model from Huggingface, please first install the transformers library:
pip install transformers>=4.41.0
We use the following example to illustrate how to use our model to perform function-calling tasks. Please note that, our model works best with our provided prompt format. It allows us to extract JSON output that is similar to the function-calling mode of ChatGPT.
import json
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
torch.random.manual_seed(0)
model_name = "Salesforce/xLAM-7b-fc-r"
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", torch_dtype="auto", trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Please use our provided instruction prompt for best performance
task_instruction = """
You are an expert in composing functions. You are given a question and a set of possible functions.
Based on the question, you will need to make one or more function/tool calls to achieve the purpose.
If none of the functions can be used, point it out and refuse to answer.
If the given question lacks the parameters required by the function, also point it out.
""".strip()
format_instruction = """
The output MUST strictly adhere to the following JSON format, and NO other text MUST be included.
The example format is as follows. Please make sure the parameter type is correct. If no function call is needed, please make tool_calls an empty list '[]'.
```
{
"tool_calls": [
{"name": "func_name1", "arguments": {"argument1": "value1", "argument2": "value2"}},
... (more tool calls as required)
]
}
```
""".strip()
# Define the input query and available tools
query = "What's the weather like in New York in fahrenheit?"
get_weather_api = {
"name": "get_weather",
"description": "Get the current weather for a location",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, New York"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The unit of temperature to return"
}
},
"required": ["location"]
}
}
search_api = {
"name": "search",
"description": "Search for information on the internet",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "The search query, e.g. 'latest news on AI'"
}
},
"required": ["query"]
}
}
openai_format_tools = [get_weather_api, search_api]
# Helper function to convert openai format tools to our more concise xLAM format
def convert_to_xlam_tool(tools):
''''''
if isinstance(tools, dict):
return {
"name": tools["name"],
"description": tools["description"],
"parameters": {k: v for k, v in tools["parameters"].get("properties", {}).items()}
}
elif isinstance(tools, list):
return [convert_to_xlam_tool(tool) for tool in tools]
else:
return tools
# Helper function to build the input prompt for our model
def build_prompt(task_instruction: str, format_instruction: str, tools: list, query: str):
prompt = f"[BEGIN OF TASK INSTRUCTION]\n{task_instruction}\n[END OF TASK INSTRUCTION]\n\n"
prompt += f"[BEGIN OF AVAILABLE TOOLS]\n{json.dumps(xlam_format_tools)}\n[END OF AVAILABLE TOOLS]\n\n"
prompt += f"[BEGIN OF FORMAT INSTRUCTION]\n{format_instruction}\n[END OF FORMAT INSTRUCTION]\n\n"
prompt += f"[BEGIN OF QUERY]\n{query}\n[END OF QUERY]\n\n"
return prompt
# Build the input and start the inference
xlam_format_tools = convert_to_xlam_tool(openai_format_tools)
content = build_prompt(task_instruction, format_instruction, xlam_format_tools, query)
messages=[
{ 'role': 'user', 'content': content}
]
inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(model.device)
# tokenizer.eos_token_id is the id of <|EOT|> token
outputs = model.generate(inputs, max_new_tokens=512, do_sample=False, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id)
print(tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True))
Then you should be able to see the following output string in JSON format:
{"tool_calls": [{"name": "get_weather", "arguments": {"location": "New York", "unit": "fahrenheit"}}]}
We highly recommend to use our provided prompt format and helper functions to yield the best function-calling performance of our model.
Usage with vLLM
We provide example scripts to deploy our model with vllm and run inferences. First, install the required packages:
pip install vllm openai argparse jinja2
The example scripts are located in the examples folder.
1. Test Prompt Template
To build prompts using the chat template and output formatted prompts ready for various test cases, run:
python test_prompt_template.py --model
2. Test xLAM Model with a Manually Served Endpoint
a. Serve the model with vLLM:
python -m vllm.entrypoints.openai.api_server --model Salesforce/xLAM-7b-fc-r --served-model-name xLAM-7b-fc-r --dtype bfloat16 --port 8001
b. Run the test script:
python test_xlam_model_with_endpoint.py --model_name xLAM-7b-fc-r --port 8001 [OPTIONS]
Options:
--temperature: Default 0.3--top_p: Default 1.0--max_tokens: Default 512
This test script provides a handler implementation that can be easily applied to your customized function-calling applications.
3. Test xLAM Model by Directly Using vLLM Library
To test the xLAM model directly with the vLLM library, run:
python test_xlam_model_with_vllm.py --model Salesforce/xLAM-7b-fc-r [OPTIONS]
Options are the same as for the endpoint test. This test script also provides a handler implementation that can be easily applied to your customized function-calling applications.
Customization
These examples are designed to be flexible and easily integrated into your own projects. Feel free to modify the scripts to suit your specific needs and applications. You can adjust test queries or API definitions in each script to test different scenarios or model capabilities.
Additional customization tips:
- Modify the
--dtypeparameter when serving the model based on your GPU capacity. - Refer to the vLLM documentation for more detailed configuration options.
- Explore the
demo.ipynbfile for a comprehensive description of the entire workflow, including how to execute APIs.
These resources provide a robust foundation for integrating xLAM models into your applications, allowing for tailored and efficient deployment.
License
xLAM-7b-fc-r is distributed under the CC-BY-NC-4.0 license, with additional terms specified in the Deepseek license.
Citation
If you find this repo helpful, please cite our paper:
@article{liu2024apigen,
title={APIGen: Automated Pipeline for Generating Verifiable and Diverse Function-Calling Datasets},
author={Liu, Zuxin and Hoang, Thai and Zhang, Jianguo and Zhu, Ming and Lan, Tian and Kokane, Shirley and Tan, Juntao and Yao, Weiran and Liu, Zhiwei and Feng, Yihao and others},
journal={arXiv preprint arXiv:2406.18518},
year={2024}
}
- Downloads last month
- 206