

language:
- ar
tags:
- Arabic T5
- MSA
- Twitter
- Arabic Dialect
- Arabic Machine Translation
- Arabic Text Summarization
- Arabic News Title and Question Generation
- Arabic Paraphrasing and Transliteration
- Arabic Code-Switched Translation
AraT5-base
AraT5: Text-to-Text Transformers for Arabic Language Generation
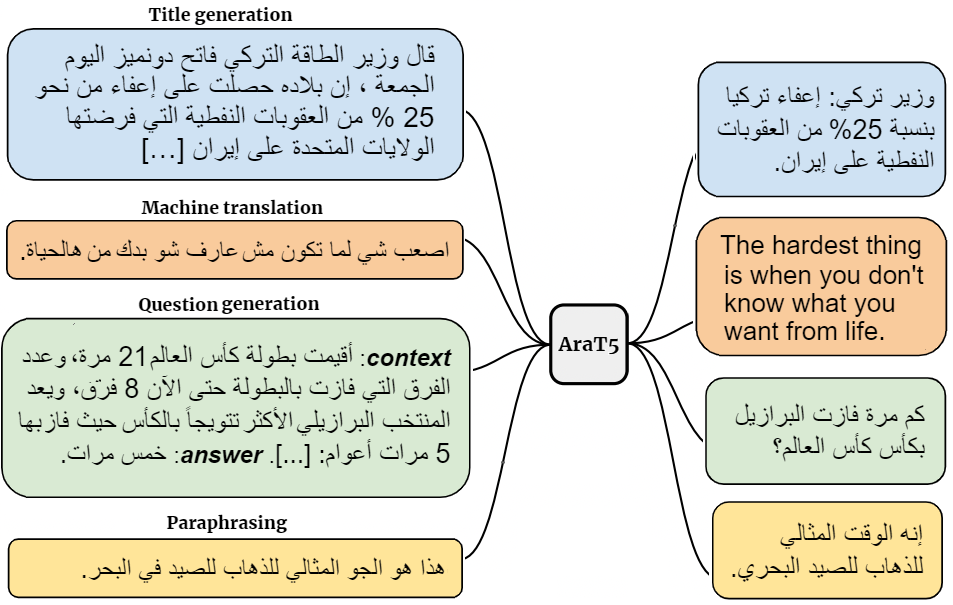
This is the repository accompanying our paper AraT5: Text-to-Text Transformers for Arabic Language Understanding and Generation. In this is the repository we Introduce AraT5MSA, AraT5Tweet, and AraT5: three powerful Arabic-specific text-to-text Transformer based models;
How to use AraT5 models
Below is an example for fine-tuning AraT5-base for News Title Generation on the Aranews dataset
!python run_trainier_seq2seq_huggingface.py \
--learning_rate 5e-5 \
--max_target_length 128 --max_source_length 128 \
--per_device_train_batch_size 8 --per_device_eval_batch_size 8 \
--model_name_or_path "UBC-NLP/AraT5-base" \
--output_dir "/content/AraT5_FT_title_generation" --overwrite_output_dir \
--num_train_epochs 3 \
--train_file "/content/ARGEn_title_genration_sample_train.tsv" \
--validation_file "/content/ARGEn_title_genration_sample_valid.tsv" \
--task "title_generation" --text_column "document" --summary_column "title" \
--load_best_model_at_end --metric_for_best_model "eval_bleu" --greater_is_better True --evaluation_strategy epoch --logging_strategy epoch --predict_with_generate\
--do_train --do_eval
For more details about the fine-tuning example, please read this notebook ![]()
In addition, we release the fine-tuned checkpoint of the News Title Generation (NGT) which is described in the paper. The model available at Huggingface (UBC-NLP/AraT5-base-title-generation).
For more details, please visit our own GitHub.
AraT5 Models Checkpoints
AraT5 Pytorch and TensorFlow checkpoints are available on the Huggingface website for direct download and use exclusively for research. For commercial use, please contact the authors via email @ (muhammad.mageed[at]ubc[dot]ca).
| Model | Link |
|---|---|
| AraT5-base | https://huggingface.co/UBC-NLP/AraT5-base |
| AraT5-msa-base | https://huggingface.co/UBC-NLP/AraT5-msa-base |
| AraT5-tweet-base | https://huggingface.co/UBC-NLP/AraT5-tweet-base |
| AraT5-msa-small | https://huggingface.co/UBC-NLP/AraT5-msa-small |
| AraT5-tweet-small | https://huggingface.co/UBC-NLP/AraT5-tweet-small |
BibTex
If you use our models (Arat5-base, Arat5-msa-base, Arat5-tweet-base, Arat5-msa-small, or Arat5-tweet-small ) for your scientific publication, or if you find the resources in this repository useful, please cite our paper as follows (to be updated):
@inproceedings{nagoudi2022_arat5,
@inproceedings{nagoudi-etal-2022-arat5,
title = "{A}ra{T}5: Text-to-Text Transformers for {A}rabic Language Generation",
author = "Nagoudi, El Moatez Billah and
Elmadany, AbdelRahim and
Abdul-Mageed, Muhammad",
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = may,
year = "2022",
address = "Dublin, Ireland",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.acl-long.47",
pages = "628--647",
abstract = "Transfer learning with a unified Transformer framework (T5) that converts all language problems into a text-to-text format was recently proposed as a simple and effective transfer learning approach. Although a multilingual version of the T5 model (mT5) was also introduced, it is not clear how well it can fare on non-English tasks involving diverse data. To investigate this question, we apply mT5 on a language with a wide variety of dialects{--}Arabic. For evaluation, we introduce a novel benchmark for ARabic language GENeration (ARGEN), covering seven important tasks. For model comparison, we pre-train three powerful Arabic T5-style models and evaluate them on ARGEN. Although pre-trained with {\textasciitilde}49 less data, our new models perform significantly better than mT5 on all ARGEN tasks (in 52 out of 59 test sets) and set several new SOTAs. Our models also establish new SOTA on the recently-proposed, large Arabic language understanding evaluation benchmark ARLUE (Abdul-Mageed et al., 2021). Our new models are publicly available. We also link to ARGEN datasets through our repository: https://github.com/UBC-NLP/araT5.",
}
## Acknowledgments
We gratefully acknowledge support from the Natural Sciences and Engineering Research Council of Canada, the Social Sciences and Humanities Research Council of Canada, Canadian Foundation for Innovation, [ComputeCanada](www.computecanada.ca) and [UBC ARC-Sockeye](https://doi.org/10.14288/SOCKEYE). We also thank the [Google TensorFlow Research Cloud (TFRC)](https://www.tensorflow.org/tfrc) program for providing us with free TPU access.