
You need to agree to share your contact information to access this model
This repository is publicly accessible, but you have to accept the conditions to access its files and content.
You agree not to use the model for experiments that could harm human subjects.
Log in or Sign Up to review the conditions and access this model content.
Vistral-7B-Chat - Towards a State-of-the-Art Large Language Model for Vietnamese
Model Description
We introduce Vistral-7B-chat, a multi-turn conversational large language model for Vietnamese. Vistral is extended from the Mistral 7B model using diverse data for continual pre-training and instruction tuning. In particular, our process to develop Vistral involves:
- Extend the tokenizer of Mistral 7B to better support Vietnamese.
- Perform continual pre-training for Mistral over a diverse dataset of Vietnamese texts that are meticulously cleaned and deduplicated.
- Perform supervised fine-tuning for the model using diverse instruction data. We design a set of instructions to align the model with the safety criteria in Vietnam.
GGUF Version: Running Vistral on your local computer here
Note: To deploy Vistral locally (e.g. on LM Studio), make sure that you are utilizing the specified chat template, download here. This step is very crucial to ensure that Vistral generates accurate answers.
Acknowledgement:
We thank Hessian AI and LAION for their support and compute in order to train this model. Specifically, we gratefully acknowledge LAION for providing access to compute budget granted by Gauss Centre for Supercomputing e.V. and by the John von Neumann Institute for Computing (NIC) on the supercomputers JUWELS Booster and JURECA at Juelich Supercomputing Centre (JSC).
Data
We will make the data available after we release the technical report for this model. However, we have made some of the data available here in our CulutraY and CulutraX datasets.
Usage
To enable single/multi-turn conversational chat with Vistral-7B-Chat, you can use the default chat template format:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
system_prompt = "Bạn là một trợ lí Tiếng Việt nhiệt tình và trung thực. Hãy luôn trả lời một cách hữu ích nhất có thể, đồng thời giữ an toàn.\n"
system_prompt += "Câu trả lời của bạn không nên chứa bất kỳ nội dung gây hại, phân biệt chủng tộc, phân biệt giới tính, độc hại, nguy hiểm hoặc bất hợp pháp nào. Hãy đảm bảo rằng các câu trả lời của bạn không có thiên kiến xã hội và mang tính tích cực."
system_prompt += "Nếu một câu hỏi không có ý nghĩa hoặc không hợp lý về mặt thông tin, hãy giải thích tại sao thay vì trả lời một điều gì đó không chính xác. Nếu bạn không biết câu trả lời cho một câu hỏi, hãy trẳ lời là bạn không biết và vui lòng không chia sẻ thông tin sai lệch."
tokenizer = AutoTokenizer.from_pretrained('Viet-Mistral/Vistral-7B-Chat')
model = AutoModelForCausalLM.from_pretrained(
'Viet-Mistral/Vistral-7B-Chat',
torch_dtype=torch.bfloat16, # change to torch.float16 if you're using V100
device_map="auto",
use_cache=True,
)
conversation = [{"role": "system", "content": system_prompt }]
while True:
human = input("Human: ")
if human.lower() == "reset":
conversation = [{"role": "system", "content": system_prompt }]
print("The chat history has been cleared!")
continue
conversation.append({"role": "user", "content": human })
input_ids = tokenizer.apply_chat_template(conversation, return_tensors="pt").to(model.device)
out_ids = model.generate(
input_ids=input_ids,
max_new_tokens=768,
do_sample=True,
top_p=0.95,
top_k=40,
temperature=0.1,
repetition_penalty=1.05,
)
assistant = tokenizer.batch_decode(out_ids[:, input_ids.size(1): ], skip_special_tokens=True)[0].strip()
print("Assistant: ", assistant)
conversation.append({"role": "assistant", "content": assistant })
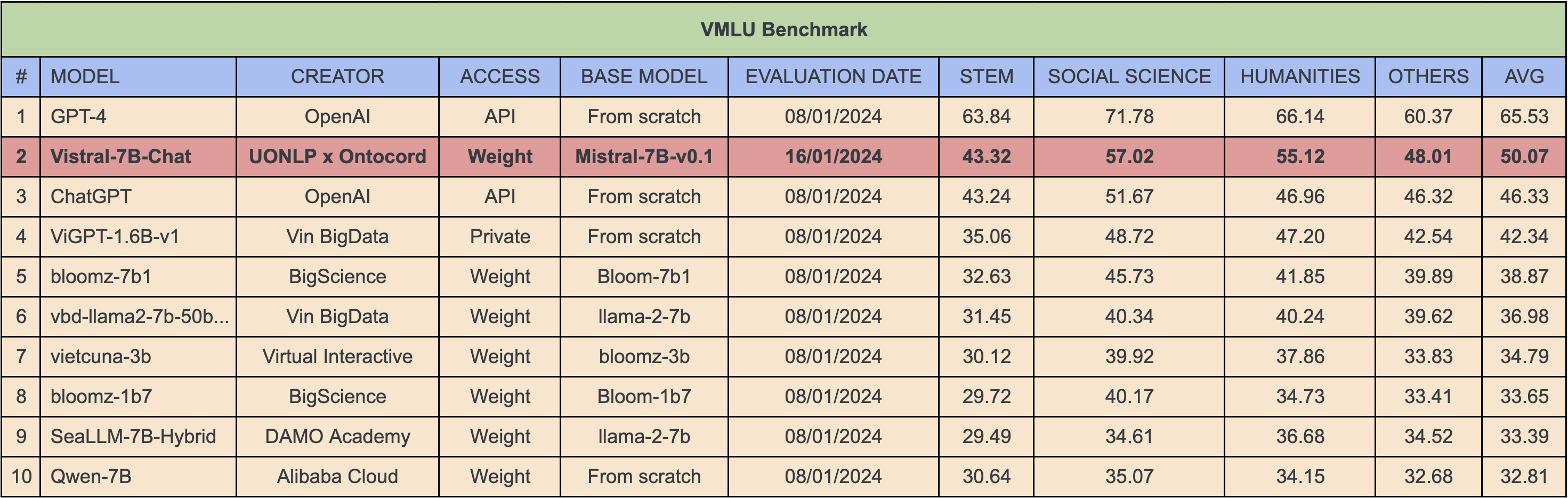
Performance
We evaluated our Vistral model using the VMLU leaderboard, a reliable framework for evaluating large language models in Vietnamese across various tasks. These tasks involve multiple-choice questions in STEM, Humanities, Social Sciences, and more. Our model achieved an average score of 50.07%, surpassing ChatGPT's performance of 46.33% significantly.
Disclaimer: Despite extensive red teaming and safety alignment efforts, our model may still pose potential risks, including but not limited to hallucination, toxic content, and bias issues. We strongly encourage researchers and practitioners to fully acknowledge these potential risks and meticulously assess and secure the model before incorporating it into their work. Users are responsible for adhering to and complying with their governance and regulations. The authors retain the right to disclaim any accountability for potential damages or liability resulting from the use of the model.
Citation
If you find our project useful, we hope you would kindly star our repo and cite our work as follows: huu@ontocord.ai, chienn@uoregon.edu, nguyenhuuthuat09@gmail.com and thienn@uoregon.edu
@article{chien2023vistral,
author = {Chien Van Nguyen, Thuat Nguyen, Quan Nguyen, Huy Nguyen, Björn Plüster, Nam Pham, Huu Nguyen, Patrick Schramowski, Thien Nguyen},
title = {Vistral-7B-Chat - Towards a State-of-the-Art Large Language Model for Vietnamese},
year = 2023,
}
- Downloads last month
- 1,483