
This is the beta version of the yama-no-susume character model (ヤマノススメ, aka encouragement of climb in English). Unlike most of the models out there, this model is capable of generating multi-character scenes beyond images of a single character. Of course, the result is still hit-or-miss, but it is possible to get as many as 5 characters right in one shot, and otherwise, you can always rely on inpainting. Here are two examples:
With inpainting

Without inpainting

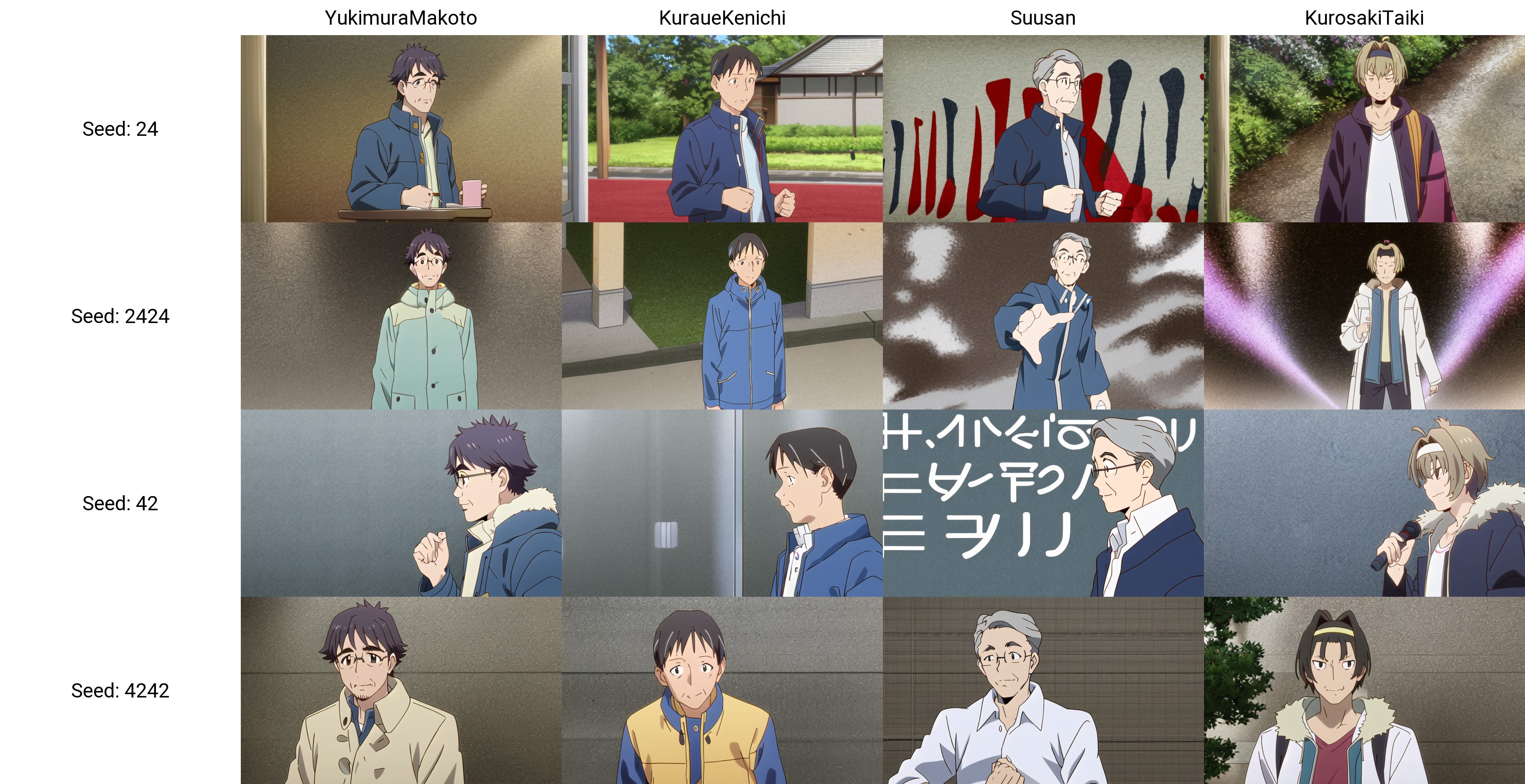
Characters
The model knows 18 characters from yama no susume and for Aoi and Hinata it knows two hair styles for each of them. The ressemblance with a character can be improved by a better description of their appearance.




Dataset description
The dataset contains around 40K images with the following composition
- 11423 anime screenshots from the four seasons of the anime
- 726 fan arts
- ~30K customized regularization images
The model is trained with a specific weighting scheme to balance between different concepts. For example, the above three categories have weights respectively 0.3, 0.2, and 0.5. Each category is itself split into many sub-categories in a hierarchical way. For more detail on the data preparation process please refer to https://github.com/cyber-meow/anime_screenshot_pipeline
Training Details
Trainer
The model was trained using EveryDream1 as
EveryDream seems to be the only trainer out there that supports sample weighting (through the use of multiply.txt).
Note that for future training it makes sense to migrate to EveryDream2.
Hardware and cost
The model was trained on runpod with an A6000 and cost me around 80 dollors. However, I estimate a model of similar quality can be trained with fewer than 20 dollars on runpod.
Hyperparameter specification
- The model was first trained for 18000 steps, at batch size 8, lr 1e-6, resolution 640, and conditional dropping rate of 15%.
- After this, I modified a little the captions and trained the model for another 22000 steps, at batch size 8, lr 1e-6, reslution 704, and conditional dropping rate of 15%.
(Intermediate checkpoints can be found in the branch all)
Note that as a consequence of the weighting scheme which translates into a number of different multiply for each image, the count of repeat and epoch has a quite different meaning here. For example, depending on the weighting, I have 400K~600K images (some images are used multiple times) in an epoch, and therefore I did not even finish an entire epoch with the 40000 steps at batch size 8.
Failures
I tried several things in this model (this is why I trained for so long), but I failed most of them.
- I put the number of people at the beginning of the captions, but at the end of 40000 steps the model still cannot count (it can generate like 3~5 people when we prompt 3people).
- I use some tokens to describe the face position within a 5x5 grid but the model did not learn anything about these tokens. I think this is either due to 1) face position being too abstract to learn, 2) data imbalance as I did not balance my training for this, or 3) captions not enough focused on these concepts (it is much longer and contains other information).
- As mentioned, the model can generate multi-character scenes but the success rate becomes lower and lower as we increase the number of characters in the scene. Character bleeding is always a hard problem to solve.
- The model is trained with 5% weight for hand images, but I doubt it helps in any kind.
Actually, I have a doubt whether the last 22000 steps really improved the model. This is how I get my 20$ estimate taking into account that we can simply train at resolution 512 on 3090 (and also ED2 will be more efficient).
More Example Generations
With inpainting


Without inpainting











Some failure cases


