
📷 EasyAnimate | An End-to-End Solution for High-Resolution and Long Video Generation
😊 EasyAnimate is an end-to-end solution for generating high-resolution and long videos. We can train transformer based diffusion generators, train VAEs for processing long videos, and preprocess metadata.
😊 Based on Sora like structure and DIT, we use transformer as a diffuser for video generation. We built easyanimate based on motion module, u-vit and slice-vae. In the future, we will try more training programs to improve the effect.
😊 Welcome!
The model trained with size 768*768*144 for EasyAnimate. We give a simple usage here, for more details, you can refer to EasyAnimate.
Table of Contents
Result Gallery
These are our generated results GALLERY:
Our UI interface is as follows:

How to use
# clone code
git clone https://github.com/aigc-apps/EasyAnimate.git
# enter EasyAnimate's dir
cd EasyAnimate
# download weights
mkdir models/Diffusion_Transformer
mkdir models/Motion_Module
mkdir models/Personalized_Model
cd models/Diffusion_Transformer/
git lfs install
git clone https://huggingface.co/alibaba-pai/EasyAnimateV2-XL-2-768x768
cd ../../
Model zoo
EasyAnimateV2:
| Name | Type | Storage Space | Url | Hugging Face | Model Scope | Description |
|---|---|---|---|---|---|---|
| EasyAnimateV2-XL-2-512x512.tar | EasyAnimateV2 | 16.2GB | - | 🤗Link | 😄Link | EasyAnimateV2 official weights for 512x512 resolution. Training with 144 frames and fps 24 |
| EasyAnimateV2-XL-2-768x768.tar | EasyAnimateV2 | 16.2GB | - | 🤗Link | 😄Link | EasyAnimateV2 official weights for 768x768 resolution. Training with 144 frames and fps 24 |
| easyanimatev2_minimalism_lora.safetensors | Lora of Pixart | 485.1MB | Download | - | - | A lora training with a specifial type images. Images can be downloaded from Url. |
Algorithm Detailed
1. Data Preprocessing
Video Cut
For long video cut, EasyAnimate utilizes PySceneDetect to identify scene changes within the video and performs scene cutting based on certain threshold values to ensure consistency in the themes of the video segments. After cutting, we only keep segments with lengths ranging from 3 to 10 seconds for model training.
Video Cleaning and Description
Following SVD's data preparation process, EasyAnimate provides a simple yet effective data processing pipeline for high-quality data filtering and labeling. It also supports distributed processing to accelerate the speed of data preprocessing. The overall process is as follows:
- Duration filtering: Analyze the basic information of the video to filter out low-quality videos that are short in duration or low in resolution.
- Aesthetic filtering: Filter out videos with poor content (blurry, dim, etc.) by calculating the average aesthetic score of uniformly distributed 4 frames.
- Text filtering: Use easyocr to calculate the text proportion of middle frames to filter out videos with a large proportion of text.
- Motion filtering: Calculate interframe optical flow differences to filter out videos that move too slowly or too quickly.
- Text description: Recaption video frames using videochat2 and vila. PAI is also developing a higher quality video recaption model, which will be released for use as soon as possible.
2. Model Architecture
We have adopted PixArt-alpha as the base model and modified the VAE and DiT model structures on this basis to better support video generation. The overall structure of EasyAnimate is as follows:
The diagram below outlines the pipeline of EasyAnimate. It includes the Text Encoder, Video VAE (video encoder and decoder), and Diffusion Transformer (DiT). The T5 Encoder is used as the text encoder. Other components are detailed in the sections below.
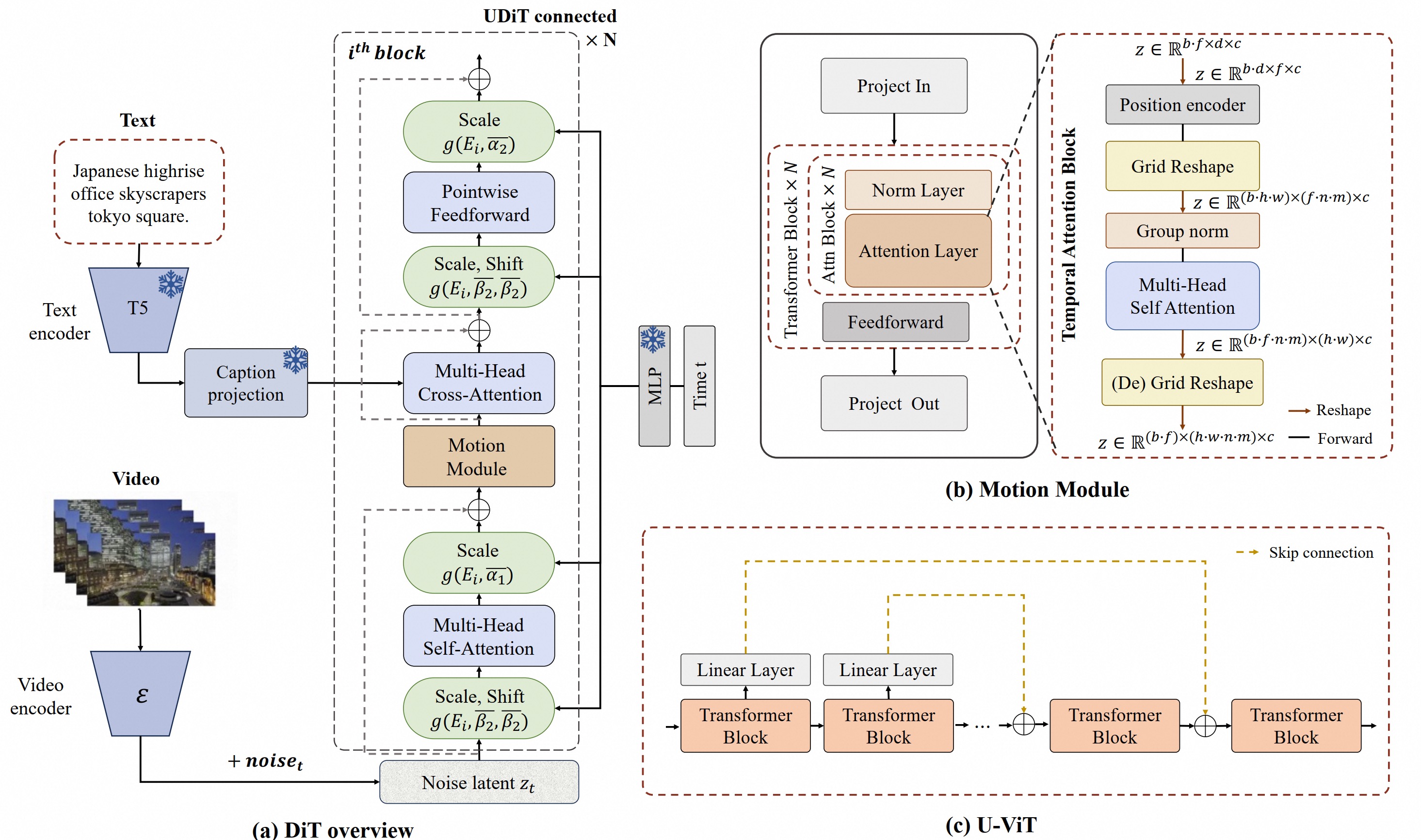
To introduce feature information along the temporal axis, EasyAnimate incorporates the Motion Module to achieve the expansion from 2D images to 3D videos. For better generation effects, it jointly finetunes the Backbone together with the Motion Module, thereby achieving image generation and video generation within a single Pipeline.
Additionally, referencing U-ViT, it introduces a skip connection structure into EasyAnimate to further optimize deeper features by incorporating shallow features. A fully connected layer is also zero-initialized for each skip connection structure, allowing it to be applied as a plug-in module to previously trained and well-performing DiTs.
Moreover, it proposes Slice VAE, which addresses the memory difficulties encountered by MagViT when dealing with long and large videos, while also achieving greater compression in the temporal dimension during video encoding and decoding stages compared to MagViT.
For more details, please refer to arxiv.
TODO List
- Support model with larger resolution.
- Support video inpaint model.
Contact Us
- Use Dingding to search group 77450006752 or Scan to join
- You need to scan the image to join the WeChat group or if it is expired, add this student as a friend first to invite you.


Reference
- magvit: https://github.com/google-research/magvit
- PixArt: https://github.com/PixArt-alpha/PixArt-alpha
- Open-Sora-Plan: https://github.com/PKU-YuanGroup/Open-Sora-Plan
- Open-Sora: https://github.com/hpcaitech/Open-Sora
- Animatediff: https://github.com/guoyww/AnimateDiff
License
This project is licensed under the Apache License (Version 2.0).
- Downloads last month
- 14