
Model Developers
Model Comparison: Quantized vs Basic Model
| Model Type | Meta-Llama-3.1-8B-Instruct | Meta-Llama-3.1-2B-Instruct-AQLM-2Bit-1x16 |
|---|---|---|
| Parameters | 8.03B | 2.04B |
| Peak Memory Usage | 20.15 GB | 4.22 GB |
| MMLU Accuracy | 60.9% | 45.5% |
Model Architecture The Llama 3.1 8B model is a state-of-the-art language model designed for a wide range of conversational and text generation tasks. By applying the Adaptive Quantization Learning Mechanism (AQLM) developed by Yandex Research, the model's size has been significantly reduced without sacrificing its powerful capabilities. This approach dynamically adjusts the precision of model parameters during training, optimizing for both performance and efficiency.
License
- The model operates under the Llama-3 license provided by Meta. For detailed license information, visit: Llama-3 License.
- The quantization technique applied is credited to Yandex Research, detailed in their paper on Adaptive Quantization Learning Mechanism.
Quantization Method Incorporating the innovative AQLM (Adaptive Quantization Learning Mechanism), this model achieves a remarkable balance between size and performance. AQLM fine-tunes the precision of parameters in real-time during training, leading to a streamlined model that maintains the robust capabilities of its full-size counterpart. This quantization method is detailed in the research paper by Yandex Research: Adaptive Quantization Learning Mechanism.
The model was compressed using Vast AI with 8x A100 GPUs, taking approximately 5-6 hours to complete the process.
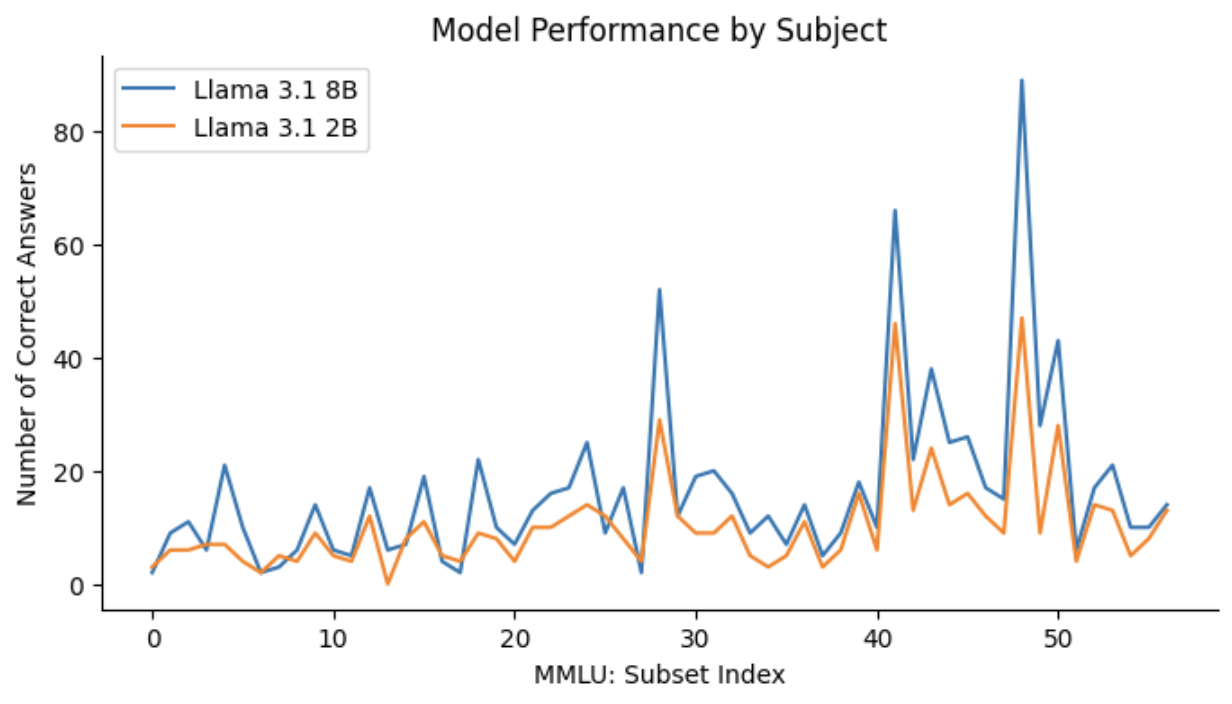
Evaluations The quantized Llama 3.1 8B model was rigorously evaluated using the The MMLU (Massive Multitask Language Understanding) dataset, available on Hugging Face, is designed to evaluate the performance of language models across a wide range of subjects. It includes multiple-choice questions covering diverse topics such as math, history, law, and ethics. Each question is accompanied by four possible answers, making it an ideal benchmark for assessing the accuracy and generalization capabilities of language models.
For the evaluation of our model, we utilized the transformers library from Hugging Face. Below is an example of how to set up and run the evaluation:
dataset = load_dataset("tasksource/mmlu", subset, split="validation")
Colab Notebook with Model Evaluation
How to use To import this model with Python and run it, you can use the following code:
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "azhiboedova/Meta-Llama-3.1-8B-Instruct-AQLM-2Bit-1x16"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Translate English to German!: How are you?"},
]
outputs = pipeline(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1]["content"])
# Output:
# Wie geht es Ihnen?
- Downloads last month
- 751
Model tree for azhiboedova/Meta-Llama-3.1-8B-Instruct-AQLM-2Bit-1x16
Base model
meta-llama/Llama-3.1-8B