
Document Processing
Collection
Any model or dataset dealing with documentary-type objects (layout detection, VQA, OCR, etc.)
•
9 items
•
Updated
•
2
paligemma-3b-ft-docvqa-896-lora is a fine-tuned version of the google/paligemma-3b-ft-docvqa-896 model, specifically trained on the doc-vqa dataset published by Crédit Mutuel Arkéa. Optimized using the LoRA (Low-Rank Adaptation) method, this model was designed to enhance performance while reducing the complexity of fine-tuning.
During training, particular attention was given to linguistic balance, with a focus on french. The model was exposed to a predominantly french context, with a 70% likelihood of interacting with french questions/answers for a given image. It operates exclusively in bfloat16 precision, optimizing computational resources. The entire training process took 3 week on a single A100 40GB.
Thanks to its multilingual specialization and emphasis on french, this model excels in francophone environments, while also performing well in english. It is especially suited for tasks that require the analysis and understanding of complex documents, such as extracting information from forms, invoices, reports, and other text-based documents in a visual question-answering context.
Model usage is simple via transformers API
from transformers import AutoProcessor, PaliGemmaForConditionalGeneration
from PIL import Image
import requests
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
model_id = "cmarkea/paligemma-3b-ft-docvqa-896-lora"
url = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/car.jpg?download=true"
image = Image.open(requests.get(url, stream=True).raw)
model = PaliGemmaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map=device,
).eval()
processor = AutoProcessor.from_pretrained("google/paligemma-3b-ft-docvqa-896")
# Instruct the model to create a caption in french
prompt = "caption fr"
model_inputs = processor(text=prompt, images=image, return_tensors="pt").to(model.device)
input_len = model_inputs["input_ids"].shape[-1]
with torch.inference_mode():
generation = model.generate(**model_inputs, max_new_tokens=100, do_sample=False)
generation = generation[0][input_len:]
decoded = processor.decode(generation, skip_special_tokens=True)
print(decoded)
By following the LLM-as-Juries evaluation method, the following results were obtained using three judge models (GPT-4o, Gemini1.5 Pro and Claude 3.5-Sonnet). This metric was adapted to the VQA context, with clear criteria for each score (0 to 5) to ensure the highest possible precision in meeting expectations.
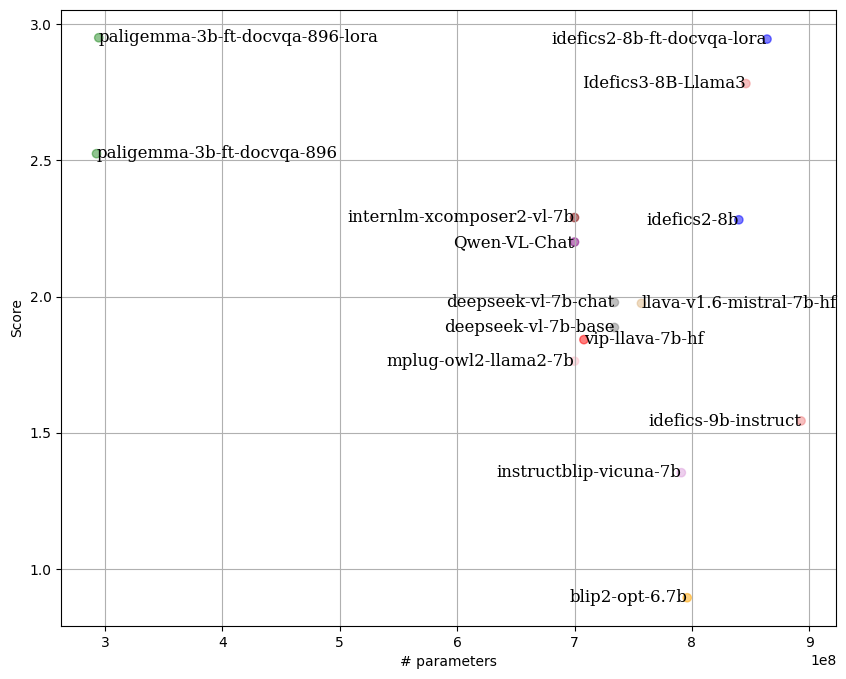
idefics2-8b-ft-docvqa-lora and paligemma-3b-ft-docvqa-896-lora demonstrate equivalent performance despite having different model sizes.
@online{SoSoPaligemma,
AUTHOR = {Loïc SOKOUDJOU SONAGU and Yoann SOLA},
URL = {https://huggingface.co/cmarkea/paligemma-3b-ft-docvqa-896-lora},
YEAR = {2024},
KEYWORDS = {Multimodal ; VQA},
}
Base model
google/paligemma-3b-ft-docvqa-896