

title: ControlNet in 🧨 Diffusers
thumbnail: /blog/assets/controlnet/thumbnail.png
authors:
- user: sayakpaul
- user: yiyixu
- user: patrickvonplaten
使用 🧨 Diffusers 实现 ControlNet 高速推理
自从 Stable Diffusion 风靡全球以来,人们一直在寻求如何更好地控制生成过程的方法。ControlNet 提供了一个简单的迁移学习方法,能够允许用户在很大程度上自定义生成过程。通过 ControlNet,用户可以轻松地使用多种空间语义条件信息(例如深度图、分割图、涂鸦图、关键点等)来控制生成过程。
具体来说,我们可以:
将卡通绘图转化为逼真的照片,同时保持极佳的布局连贯性。
| Realistic Lofi Girl |
|---|
 |
进行室内设计。
| Before | After |
|---|---|
 |
 |
将涂鸦草图变成艺术作品。
| Before | After |
|---|---|
 |
 |
甚至拟人化著名的 logo 形象。
| Before | After |
|---|---|
 |
ControlNet,使一切皆有可能 🌠
本文的主要内容:
- 介绍
StableDiffusionControlNetPipeline - 展示多种控制条件样例
让我们开启控制之旅!
ControlNet 简述
ControlNet 在 Adding Conditional Control to Text-to-Image Diffusion Models 一文中提被出,作者是 Lvmin Zhang 和 Maneesh Agrawala。它引入了一个框架,支持在扩散模型(如 Stable Diffusion)上附加额外的多种空间语义条件来控制生成过程。
训练 ControlNet 包括以下步骤:
- 克隆扩散模型的预训练参数(文中称为 可训练副本, trainable copy。如 Stable Diffusion 的 latent UNet 部分),同时保留原本的预训练参数(文中称为 锁定副本, locked copy)。这样可以实现:a) 让锁定副本保留从大型数据集中学到的丰富知识;b) 让可训练副本学习特定任务的知识。
- 可训练副本和锁定副本的参数通过 “零卷积” 层(详见 此处)连接。“零卷积” 层是 ControlNet 框架的一部分,会在特定任务中优化参数。这是一种训练技巧,可以在新任务条件训练时保留已冻结模型已经学到的语义信息。
训练 ControlNet 的过程如图所示:

图表摘录于此处
{kind=link}
ControlNet 训练集中的其中一种样例如下(额外的控制条件是 Canny 边缘图):
| Prompt | Original Image | Conditioning |
|---|---|---|
| "bird" |  |
 |
同样地,如果我们使用的额外控制条件是语义分割图,那么 ControlNet 训练集的样例就是这样:
| Prompt | Original Image | Conditioning |
|---|---|---|
| "big house" |  |
 |
每对 ControlNet 施加一种额外的控制条件,都需要训练一份新的可训练副本参数。论文中提出了 8 种不同的控制条件,对应的控制模型在 Diffusers 中均已支持!
推理阶段需要同时使用扩散模型的预训练权重以及训练过的 ControlNet 权重。如要使用 Stable Diffusion v1-5 以及其 ControlNet 权重推理,其参数量要比仅使用 Stable Diffusion v1-5 多大约 7 亿个,因此推理 ControlNet 需要消耗更多的内存。
由于在训练过程中扩散模型预训练参数为锁定副本,因此在使用不同的控制条件训练时,只需要切换 ControlNet 可训练副本的参数即可。这样在一个应用程序中部署多个 ControlNet 权重就非常简单了,本文会在后面详细介绍。
StableDiffusionControlNetPipeline
在开始之前,我们要向社区贡献者 Takuma Mori 表示巨大的感谢。将 ControlNet 集成到 Diffusers 中,他功不可没 ❤️。
类似 Diffusers 中的 其他 Pipeline,Diffusers 同样为 ControlNet 提供了 StableDiffusionControlNetPipeline 供用户使用。 StableDiffusionControlNetPipeline 的核心是 controlnet 参数,它接收用户指定的训练过的 ControlNetModel 实例作为输入,同时保持扩散模型的预训练权重不变。
本文将介绍 StableDiffusionControlNetPipeline 的多个不同用例。首先要介绍的第一个 ControlNet 模型是 Canny 模型,这是目前最流行的 ControlNet 模型之一,您可能已经在网上见识过一些它生成的精美图片。在阅读到各个部分的代码时,也欢迎您使用此 Colab 笔记本 运行相关代码片段。
运行代码之前,首先确保我们已经安装好所有必要的库:
pip install diffusers==0.14.0 transformers xformers git+https://github.com/huggingface/accelerate.git
为处理不同 ControlNet 对应的多种控制条件,还需要安装一些额外的依赖项:
- OpenCV
- controlnet-aux - ControlNet 预处理模型库
pip install opencv-contrib-python
pip install controlnet_aux
我们将以著名的油画作品《戴珍珠耳环的少女》为例,首先让我们下载这张图像并查看一下:
from diffusers.utils import load_image
image = load_image(
"https://hf.co/datasets/huggingface/documentation-images/resolve/main/diffusers/input_image_vermeer.png"
)
image

然后将图像输入给 Canny 预处理器:
import cv2
from PIL import Image
import numpy as np
image = np.array(image)
low_threshold = 100
high_threshold = 200
image = cv2.Canny(image, low_threshold, high_threshold)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
canny_image = Image.fromarray(image)
canny_image
如图可见,Canny 本质上是边缘检测器:

接下来,我们加载 runwaylml/stable-diffusion-v1-5 和 Canny 边缘 ControlNet 模型。设置参数 torch.dtype=torch.float16 可以指定模型以半精度模式加载,可实现内存高效和快速的推理。
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel
import torch
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny", torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=torch.float16
)
这里我们不使用 Stable Diffusion 默认的 PNDMScheduler 调度器,而使用改进的 UniPCMultistepScheduler(目前最快的扩散模型调度器之一),可以极大地加快推理速度。经测试,在保证生成图像质量的同时,我们能将推理阶段的采样步数从 50 降到 20。更多关于调度器的信息可以点击 此处 查看。
from diffusers import UniPCMultistepScheduler
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
我们通过调用 enable_model_cpu_offload function 函数来启用智能 CPU 卸载,而不是直接将 pipeline 加载到 GPU 上。
智能 CPU 卸载是一种降低显存占用的方法。扩散模型(如 Stable Diffusion)的推理并不是运行一个单独的模型,而是多个模型组件的串行推理。如在推理 ControlNet Stable Diffusion 时,需要首先运行 CLIP 文本编码器,其次推理扩散模型 UNet 和 ControlNet,然后运行 VAE 解码器,最后运行 safety checker(安全检查器,主要用于审核过滤违规图像)。而在扩散过程中大多数组件仅运行一次,因此不需要一直占用 GPU 内存。通过启用智能模型卸载,可以确保每个组件在不需要参与 GPU 计算时卸载到 CPU 上,从而显著降低显存占用,并且不会显著增加推理时间(仅增加了模型在 GPU-CPU 之间的转移时间)。
注意:启用 enable_model_cpu_offload 后,pipeline 会自动进行 GPU 内存管理,因此请不要再使用 .to("cuda") 手动将 pipeline 转移到 GPU。
pipe.enable_model_cpu_offload()
最后,我们要充分利用 FlashAttention/xformers 进行注意力层加速。运行下列代码以实现加速,如果该代码没有起作用,那么您可能没有正确安装 xformers 库,此时您可以跳过该代码。
pipe.enable_xformers_memory_efficient_attention()
基本条件准备就绪,现在来运行 ControlNet pipeline!
跟运行 Stable Diffusion image-to-image pipeline 相同的是,我们也使用了文本提示语来引导图像生成过程。不过有一些不同的是,ControlNet 允许施加更多种类的控制条件来控制图像生成过程,比如使用刚才我们创建的 Canny 边缘图就能更精确的控制生成图像的构图。
让我们来看一些有趣的,将 17 世纪的名作《戴珍珠耳环的少女》中的少女一角换为现代的名人会是什么样?使用 ControlNet 就能轻松做到,只需要在提示语中写上他们的名字即可!
首先创建一个非常简单的帮助函数来实现生成图像的网格可视化。
def image_grid(imgs, rows, cols):
assert len(imgs) == rows * cols
w, h = imgs[0].size
grid = Image.new("RGB", size=(cols * w, rows * h))
grid_w, grid_h = grid.size
for i, img in enumerate(imgs):
grid.paste(img, box=(i % cols * w, i // cols * h))
return grid
然后输入名字提示语,并设置随机种子以便复现。
prompt = ", best quality, extremely detailed"
prompt = [t + prompt for t in ["Sandra Oh", "Kim Kardashian", "rihanna", "taylor swift"]] # 分别为:吴珊卓、金·卡戴珊、蕾哈娜、泰勒·斯威夫特
generator = [torch.Generator(device="cpu").manual_seed(2) for i in range(len(prompt))]
最后运行 pipeline,并可视化生成的图像!
output = pipe(
prompt,
canny_image,
negative_prompt=["monochrome, lowres, bad anatomy, worst quality, low quality"] * 4,
num_inference_steps=20,
generator=generator,
)
image_grid(output.images, 2, 2)

我们还能轻松地将 ControlNet 与微调结合使用!例如使用 DreamBooth 对模型进行微调,然后使用 ControlNet 增加控制信息,将其渲染到不同的场景中。
本文将以我们最爱的土豆先生为例,来介绍怎样结合使用 ControlNet 和 DreamBooth。
相较于上文,pipeline 中使用的 ControlNet 部分保持不变,但是不使用 Stable Diffusion 1.5,而是重新加载一个 土豆先生 模型(使用 Dreambooth 微调的 Stable Diffusion 模型)🥔。
虽然 ControlNet 没变,但仍然需要重新加载 pipeline。
model_id = "sd-dreambooth-library/mr-potato-head"
pipe = StableDiffusionControlNetPipeline.from_pretrained(
model_id,
controlnet=controlnet,
torch_dtype=torch.float16,
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
pipe.enable_xformers_memory_efficient_attention()
现在来让土豆先生摆一个《戴珍珠耳环的少女》的姿势吧!
generator = torch.manual_seed(2)
prompt = "a photo of sks mr potato head, best quality, extremely detailed"
output = pipe(
prompt,
canny_image,
negative_prompt="monochrome, lowres, bad anatomy, worst quality, low quality",
num_inference_steps=20,
generator=generator,
)
output.images[0]
看得出来土豆先生尽力了,这场景着实不太适合他,不过他仍然抓住了精髓🍟。

ControlNet 还有另一个独特应用:从图像提取人体姿态,用姿态信息控制生成具有相同姿态的新图像。因此在下一个示例中,我们将使用 Open Pose ControlNet 来教超级英雄如何做瑜伽!
首先,我们需要收集一些瑜伽动作图像集:
urls = "yoga1.jpeg", "yoga2.jpeg", "yoga3.jpeg", "yoga4.jpeg"
imgs = [
load_image("https://huggingface.co/datasets/YiYiXu/controlnet-testing/resolve/main/" + url)
for url in urls
]
image_grid(imgs, 2, 2)

通过 controlnet_aux 提供的 OpenPose 预处理器,我们可以很方便地提取瑜伽姿态。
from controlnet_aux import OpenposeDetector
model = OpenposeDetector.from_pretrained("lllyasviel/ControlNet")
poses = [model(img) for img in imgs]
image_grid(poses, 2, 2)
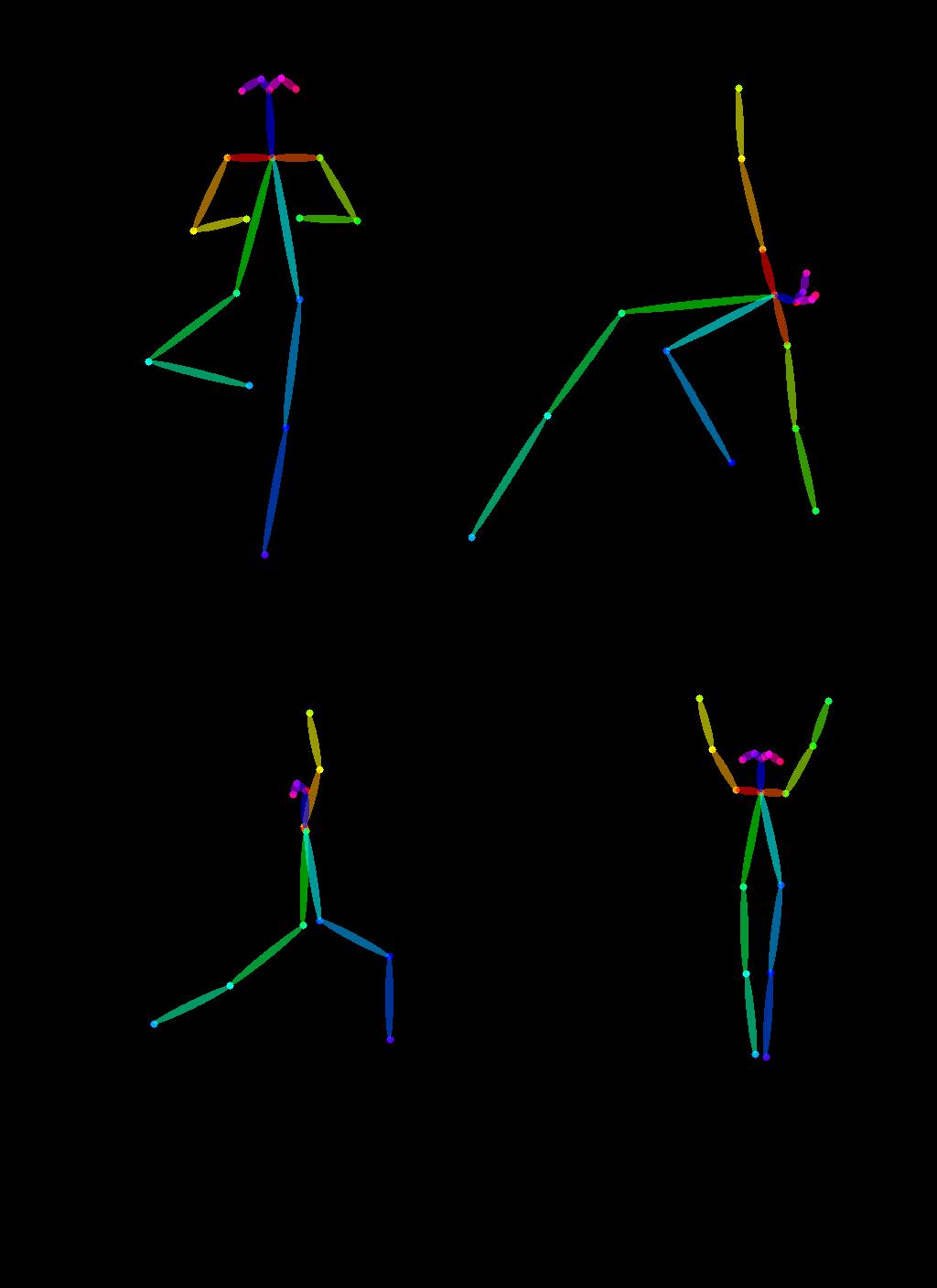
瑜伽姿态提取完成后,我们接着创建一个 Open Pose ControlNet pipeline 来生成一些相同姿态的超级英雄图像。Let's go 🚀
controlnet = ControlNetModel.from_pretrained(
"fusing/stable-diffusion-v1-5-controlnet-openpose", torch_dtype=torch.float16
)
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionControlNetPipeline.from_pretrained(
model_id,
controlnet=controlnet,
torch_dtype=torch.float16,
)
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
超级英雄的瑜伽时间!
generator = [torch.Generator(device="cpu").manual_seed(2) for i in range(4)]
prompt = "super-hero character, best quality, extremely detailed"
output = pipe(
[prompt] * 4,
poses,
negative_prompt=["monochrome, lowres, bad anatomy, worst quality, low quality"] * 4,
generator=generator,
num_inference_steps=20,
)
image_grid(output.images, 2, 2)

通过以上示例,我们对 StableDiffusionControlNetPipeline 的多种用法有了直观的认识,也学会了如何使用 Diffusers 玩转 ControlNet。不过,还有一些 ControlNet 支持的其他类型的控制条件示例,由于篇幅原因本文不再展开,如想了解更多信息,可以点击以下链接查看相应的模型文档页面:
- lllyasviel/sd-controlnet-depth
- lllyasviel/sd-controlnet-hed
- lllyasviel/sd-controlnet-normal
- lllyasviel/sd-controlnet-scribble
- lllyasviel/sd-controlnet-seg
- lllyasviel/sd-controlnet-openpose
- lllyasviel/sd-controlnet-mlsd
- lllyasviel/sd-controlnet-mlsd
我们非常欢迎您尝试组合不同的控制组件来生成精美的图像,并在 twitter 上与 @diffuserslib 分享您的作品。如果您还没有运行上述代码段,这里再次建议您查看此 Colab 笔记本,亲自运行代码体验示例的效果!
在上文中,我们介绍了加速生成过程、减少显存占用的一些技巧,它们包括:快速调度器、智能模型卸载、xformers。如果结合使用这些技巧,单张图像的生成过程仅需要:V100 GPU 上约 3 秒的推理时间以及约 4 GB 的 VRAM 占用;免费 GPU 服务(如 Google Colab 的 T4)上约 5 秒的推理时间。如果没有实现这些技巧,同样的生成过程可达 17 秒!现已集成至 Diffusers 工具箱,来使用 Diffusers 吧,它真的非常强力!💪
结语
本文介绍了 StableDiffusionControlNetPipeline 的多个用例,非常有趣!我们也非常期待看到社区在此 pipeline 的基础上能构建出什么好玩的应用。如果您想了解更多 Diffusers 支持的关于控制模型的其他 pipeline 和技术细节,请查看我们的 官方文档。
如果您想直接尝试 ControlNet 的控制效果,我们也能满足!只需点击以下 HuggingFace Spaces 即可尝试控制生成图像: