
hemangjoshi37a/autotrain-ratnakar_1000_sample_curated-1474454086
Token Classification
•
Updated
•
13
Error code: DatasetGenerationError
Exception: ArrowNotImplementedError
Message: Cannot write struct type '_format_kwargs' with no child field to Parquet. Consider adding a dummy child field.
Traceback: Traceback (most recent call last):
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/builder.py", line 2011, in _prepare_split_single
writer.write_table(table)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/arrow_writer.py", line 583, in write_table
self._build_writer(inferred_schema=pa_table.schema)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/arrow_writer.py", line 404, in _build_writer
self.pa_writer = self._WRITER_CLASS(self.stream, schema)
File "/src/services/worker/.venv/lib/python3.9/site-packages/pyarrow/parquet/core.py", line 1010, in __init__
self.writer = _parquet.ParquetWriter(
File "pyarrow/_parquet.pyx", line 2157, in pyarrow._parquet.ParquetWriter.__cinit__
File "pyarrow/error.pxi", line 154, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 91, in pyarrow.lib.check_status
pyarrow.lib.ArrowNotImplementedError: Cannot write struct type '_format_kwargs' with no child field to Parquet. Consider adding a dummy child field.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/builder.py", line 2027, in _prepare_split_single
num_examples, num_bytes = writer.finalize()
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/arrow_writer.py", line 602, in finalize
self._build_writer(self.schema)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/arrow_writer.py", line 404, in _build_writer
self.pa_writer = self._WRITER_CLASS(self.stream, schema)
File "/src/services/worker/.venv/lib/python3.9/site-packages/pyarrow/parquet/core.py", line 1010, in __init__
self.writer = _parquet.ParquetWriter(
File "pyarrow/_parquet.pyx", line 2157, in pyarrow._parquet.ParquetWriter.__cinit__
File "pyarrow/error.pxi", line 154, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 91, in pyarrow.lib.check_status
pyarrow.lib.ArrowNotImplementedError: Cannot write struct type '_format_kwargs' with no child field to Parquet. Consider adding a dummy child field.
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/src/services/worker/src/worker/job_runners/config/parquet_and_info.py", line 1529, in compute_config_parquet_and_info_response
parquet_operations = convert_to_parquet(builder)
File "/src/services/worker/src/worker/job_runners/config/parquet_and_info.py", line 1154, in convert_to_parquet
builder.download_and_prepare(
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/builder.py", line 1027, in download_and_prepare
self._download_and_prepare(
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/builder.py", line 1122, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/builder.py", line 1882, in _prepare_split
for job_id, done, content in self._prepare_split_single(
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/builder.py", line 2038, in _prepare_split_single
raise DatasetGenerationError("An error occurred while generating the dataset") from e
datasets.exceptions.DatasetGenerationError: An error occurred while generating the datasetNeed help to make the dataset viewer work? Make sure to review how to configure the dataset viewer, and open a discussion for direct support.
_data_files
list | _fingerprint
string | _format_columns
sequence | _format_kwargs
dict | _format_type
null | _indexes
dict | _output_all_columns
bool | _split
null |
|---|---|---|---|---|---|---|---|
[
{
"filename": "dataset.arrow"
}
] | aa6a064e24659c49 | [
"tags",
"tokens"
] | {} | null | {} | false | null |
This dataset has been automatically processed by AutoTrain for project ratnakar_1000_sample_curated.
The BCP-47 code for the dataset's language is en.
A sample from this dataset looks as follows:
[
{
"tokens": [
"INTRADAY",
"NAHARINDUS",
" ABOVE ",
"128",
" - 129 SL ",
"126",
" TARGET ",
"140",
" "
],
"tags": [
8,
10,
0,
3,
0,
9,
0,
5,
0
]
},
{
"tokens": [
"INTRADAY",
"ASTRON",
" ABV ",
"39",
" SL ",
"37.50",
" TARGET ",
"45",
" "
],
"tags": [
8,
10,
0,
3,
0,
9,
0,
5,
0
]
}
]
The dataset has the following fields (also called "features"):
{
"tokens": "Sequence(feature=Value(dtype='string', id=None), length=-1, id=None)",
"tags": "Sequence(feature=ClassLabel(num_classes=12, names=['NANA', 'btst', 'delivery', 'enter', 'entry_momentum', 'exit', 'exit2', 'exit3', 'intraday', 'sl', 'symbol', 'touched'], id=None), length=-1, id=None)"
}
This dataset is split into a train and validation split. The split sizes are as follow:
| Split name | Num samples |
|---|---|
| train | 726 |
| valid | 259 |
Label data using LabelStudio NER(Named Entity Recognition or Token Classification) tool.
 convert to
convert to 
Convert LabelStudio CSV or JSON to HuggingFace-autoTrain dataset conversion script

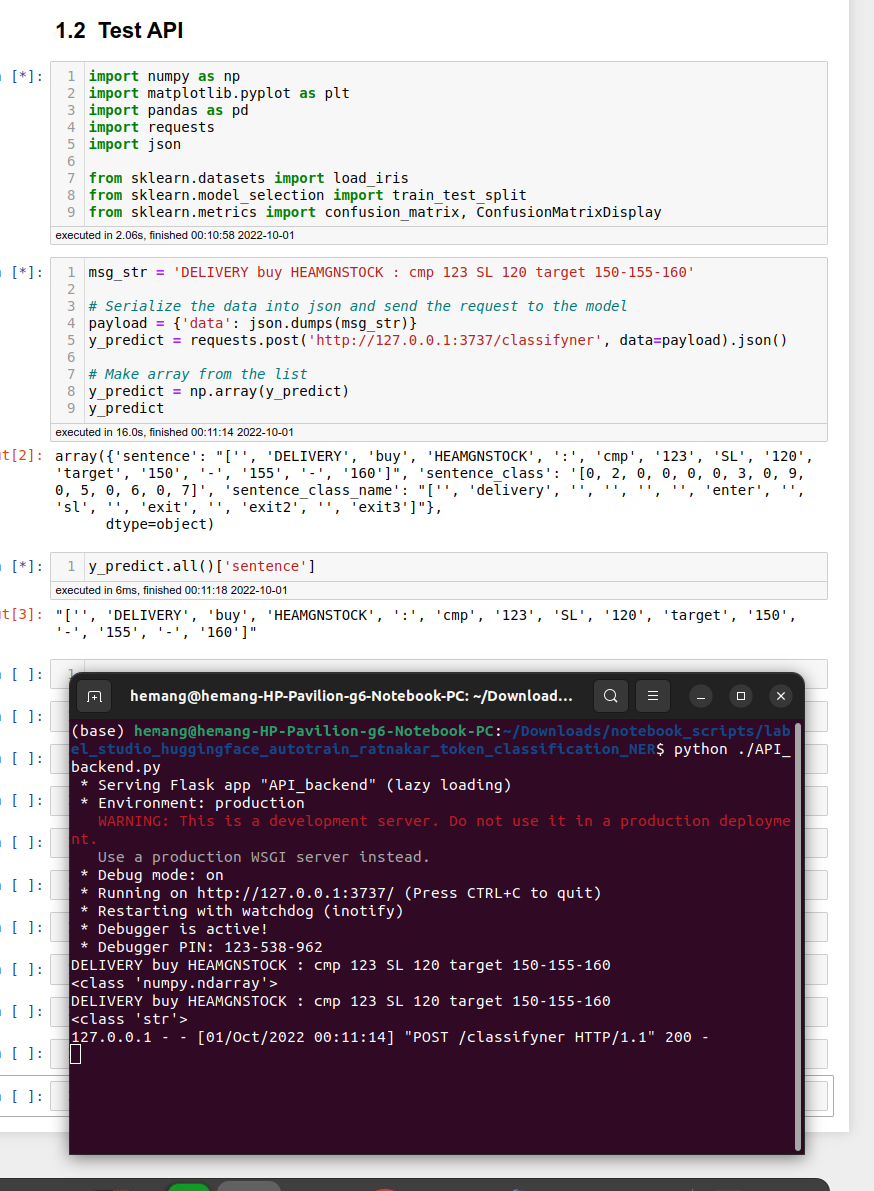
Train NER model on Hugginface-autoTrain.

Use Hugginface-autoTrain model to predict labels on new data in LabelStudio using LabelStudio-ML-Backend.



Define python function to predict labels using Hugginface-autoTrain model.


Only label new data from newly predicted-labels-dataset that has falsified labels.

Backtest Truely labelled dataset against real historical data of the stock using zerodha kiteconnect and jugaad_trader.
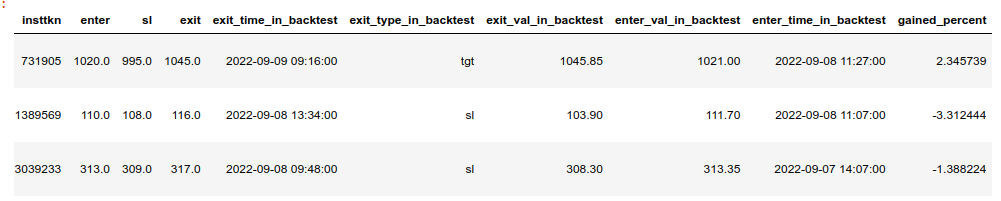
Evaluate total gained percentage since inception summation-wise and compounded and plot.

Listen to telegram channel for new LIVE messages using telegram API for algotrading.

Serve the app as flask web API for web request and respond to it as labelled tokens.
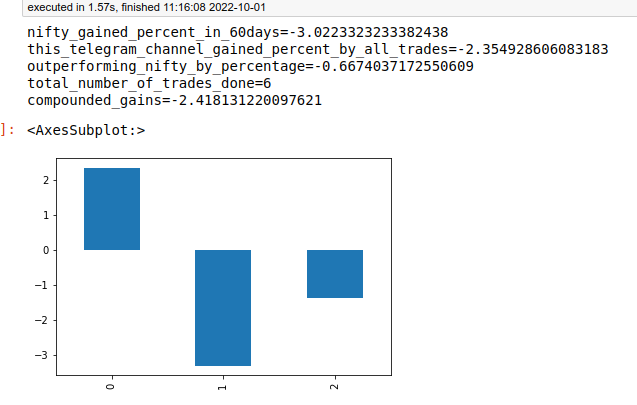
Outperforming or underperforming results of the telegram channel tips against exchange index by percentage.
Place a custom order on hjLabs.in : https://hjLabs.in
Mobile : +917016525813 Whatsapp & Telegram : +919409077371
Email : hemangjoshi37a@gmail.com
Place a custom order on hjLabs.in : https://hjLabs.in
Please contribute your suggestions and corections to support our efforts.
Thank you.
Buy us a coffee for $5 on PayPal ?
