Datasets:

license: cc-by-sa-3.0
task_categories:
- question-answering
- summarization
language:
- ja
size_categories:
- 10K<n<100K
日本語はこちら
Summary
databricks-dolly-15k-ja-scored is a version of databricks-dolly-15k-ja, which is a machine-translated version of databricks-dolly-15k, with added translation quality scores provided by BERTScore.
This dataset can be used for any purpose, whether academic or commercial, under the terms of the Creative Commons Attribution-ShareAlike 3.0 Unported License.
Languages: Japanese
Translation Quality Score
When examining the data contained in databricks-dolly-15k-ja, I found the following data of poor quality.
- Data where
inputandoutputare exactly the same - Data where
outputis copied toinstruction - Data in which the consistency of expression is not maintained due to notation.
- Data that has failed to translate proper nouns, etc.
Note that in databricks-dolly-15k
- Data corresponding to
1.has been removed. - Data corresponding to
2.has its instruction removed and its category changed to open-qa.
Therefore, I back-translated these data from Japanese to English and examined the similarity with the original text by BertScore. Below is a histogram of f1 score, the harmonic mean of precision and recall.
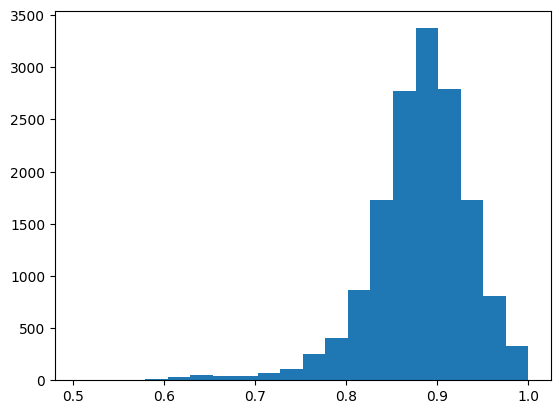
You can filter out low-quality data by filtering with f1 score.
Notes
The derived score varies depending on the service used for Japanese-English translation and the model used in BertScore. Even with data that is OK to use for learning, the score may drop depending on the accuracy of the Japanese-English translation.
Description of each field
I will explain only the added parts and the items that need attention.
1. index
A unique identifier for the data.
Originally a field indicating which lines of databricks-dolly-15k have been translated, but the index does not correspond to the actual line because databricks-dolly-15k-ja does not reflect a change in the element deletion of databricks-dolly-15k.
| Field | Description |
|---|---|
| Index | The unique identifier for the data |
2. bertscore
Evaluation score provided by the BERT model. It consists of three indices: recall, precision, and f1.
| Field | Description |
|---|---|
| recall | A measure of how much information contained in a correct answer text is reflected in the generated text |
| precision | A measure of how well each part of the generated text matches the correct text |
| f1 | Harmonic mean of precision and recall. |
3. translator
Information of the translation services used. There are two fields, "en_ja" and "ja_en", which represent the services used to translate English to Japanese and Japanese to English, respectively.
| Field | Description |
|---|---|
| en_ja | Service used to translate from English to Japanese |
| ja_en | Service used to translate from Japanese to English |
Acknowledgments
This dataset, databricks-dolly-15k-ja-scored, builds upon the work done by kun1em0n, who created the databricks-dolly-15k-ja dataset. I want to express my deep appreciation for his valuable work and contribution to the community.
License/Credits
databricks-dolly-15k-ja-scored
Copyright (2023) Sakusakumura. This dataset is licensed under CC BY-SA 3.0.databricks-dolly-15k-ja
Developed by kun1em0n. Available at https://github.com/kunishou/databricks-dolly-15k-ja. This dataset is licensed under CC BY-SA 3.0.databricks-dolly-15k
Developed by Databricks, Inc. Available at https://huggingface.co/datasets/databricks-dolly-15k. This dataset is licensed under CC BY-SA 3.0.