
新闻 | News
[2024-04-06] 开源puff系列模型,专门针对检索和语义匹配任务,更多的考虑泛化性和私有通用测试集效果,向量维度可变,中英双语。
[2024-02-27] 开源stella-mrl-large-zh-v3.5-1792d模型,支持向量可变维度。
[2024-02-17] 开源stella v3系列、dialogue编码模型和相关训练数据。
[2023-10-19] 开源stella-base-en-v2 使用简单,不需要任何前缀文本。
[2023-10-12] 开源stella-base-zh-v2和stella-large-zh-v2, 效果更好且使用简单,不需要任何前缀文本。
[2023-09-11] 开源stella-base-zh和stella-large-zh
欢迎去本人主页查看最新模型,并提出您的宝贵意见!
1 开源清单
本次开源2个通用向量编码模型和一个针对dialogue进行编码的向量模型,同时开源全量160万对话重写数据集和20万的难负例的检索数据集。
开源模型:
| ModelName | ModelSize | MaxTokens | EmbeddingDimensions | Language | Scenario | C-MTEB Score |
|---|---|---|---|---|---|---|
| infgrad/stella-base-zh-v3-1792d | 0.4GB | 512 | 1792 | zh-CN | 通用文本 | 67.96 |
| infgrad/stella-large-zh-v3-1792d | 1.3GB | 512 | 1792 | zh-CN | 通用文本 | 68.48 |
| infgrad/stella-dialogue-large-zh-v3-1792d | 1.3GB | 512 | 1792 | zh-CN | 对话文本 | 不适用 |
开源数据:
- 全量对话重写数据集 约160万
- 部分带有难负例的检索数据集 约20万
上述数据集均使用LLM构造,欢迎各位贡献数据集。
2 使用方法
2.1 通用编码模型使用方法
直接SentenceTransformer加载即可:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("infgrad/stella-base-zh-v3-1792d")
# model = SentenceTransformer("infgrad/stella-large-zh-v3-1792d")
vectors = model.encode(["text1", "text2"])
2.2 dialogue编码模型使用方法
使用场景: 在一段对话中,需要根据用户语句去检索相关文本,但是对话中的用户语句存在大量的指代和省略,导致直接使用通用编码模型效果不好, 可以使用本项目的专门的dialogue编码模型进行编码
使用要点:
- 对dialogue进行编码时,dialogue中的每个utterance需要是如下格式:
"{ROLE}: {TEXT}",然后使用[SEP]join一下 - 整个对话都要送入模型进行编码,如果长度不够就删掉早期的对话,编码后的向量本质是对话中最后一句话的重写版本的向量!!
- 对话用stella-dialogue-large-zh-v3-1792d编码,被检索文本使用stella-large-zh-v3-1792d进行编码,所以本场景是需要2个编码模型的
如果对使用方法还有疑惑,请到下面章节阅读该模型是如何训练的。
使用示例:
from sentence_transformers import SentenceTransformer
dial_model = SentenceTransformer("infgrad/stella-dialogue-large-zh-v3-1792d")
general_model = SentenceTransformer("infgrad/stella-large-zh-v3-1792d")
# dialogue = ["张三: 吃饭吗", "李四: 等会去"]
dialogue = ["A: 最近去打篮球了吗", "B: 没有"]
corpus = ["B没打篮球是因为受伤了。", "B没有打乒乓球"]
last_utterance_vector = dial_model.encode(["[SEP]".join(dialogue)], normalize_embeddings=True)
corpus_vectors = general_model.encode(corpus, normalize_embeddings=True)
# 计算相似度
sims = (last_utterance_vector * corpus_vectors).sum(axis=1)
print(sims)
3 通用编码模型训练技巧分享
hard negative
难负例挖掘也是个经典的trick了,几乎总能提升效果
dropout-1d
dropout已经是深度学习的标配,我们可以稍微改造下使其更适合句向量的训练。 我们在训练时会尝试让每一个token-embedding都可以表征整个句子,而在推理时使用mean_pooling从而达到类似模型融合的效果。 具体操作是在mean_pooling时加入dropout_1d,torch代码如下:
vector_dropout = nn.Dropout1d(0.3) # 算力有限,试了0.3和0.5 两个参数,其中0.3更优
last_hidden_state = bert_model(...)[0]
last_hidden = last_hidden_state.masked_fill(~attention_mask[..., None].bool(), 0.0)
last_hidden = vector_dropout(last_hidden)
vectors = last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
4 dialogue编码模型细节
4.1 为什么需要一个dialogue编码模型?
参见本人历史文章:https://www.zhihu.com/pin/1674913544847077376
4.2 训练数据
单条数据示例:
{
"dialogue": [
"A: 最近去打篮球了吗",
"B: 没有"
],
"last_utterance_rewrite": "B: 我最近没有去打篮球"
}
4.3 训练Loss
loss = cosine_loss( dial_model.encode(dialogue), existing_model.encode(last_utterance_rewrite) )
dial_model就是要被训练的模型,本人是以stella-large-zh-v3-1792d作为base-model进行继续训练的
existing_model就是现有训练好的通用编码模型,本人使用的是stella-large-zh-v3-1792d
已开源dialogue-embedding的全量训练数据,理论上可以复现本模型效果。
Loss下降情况:
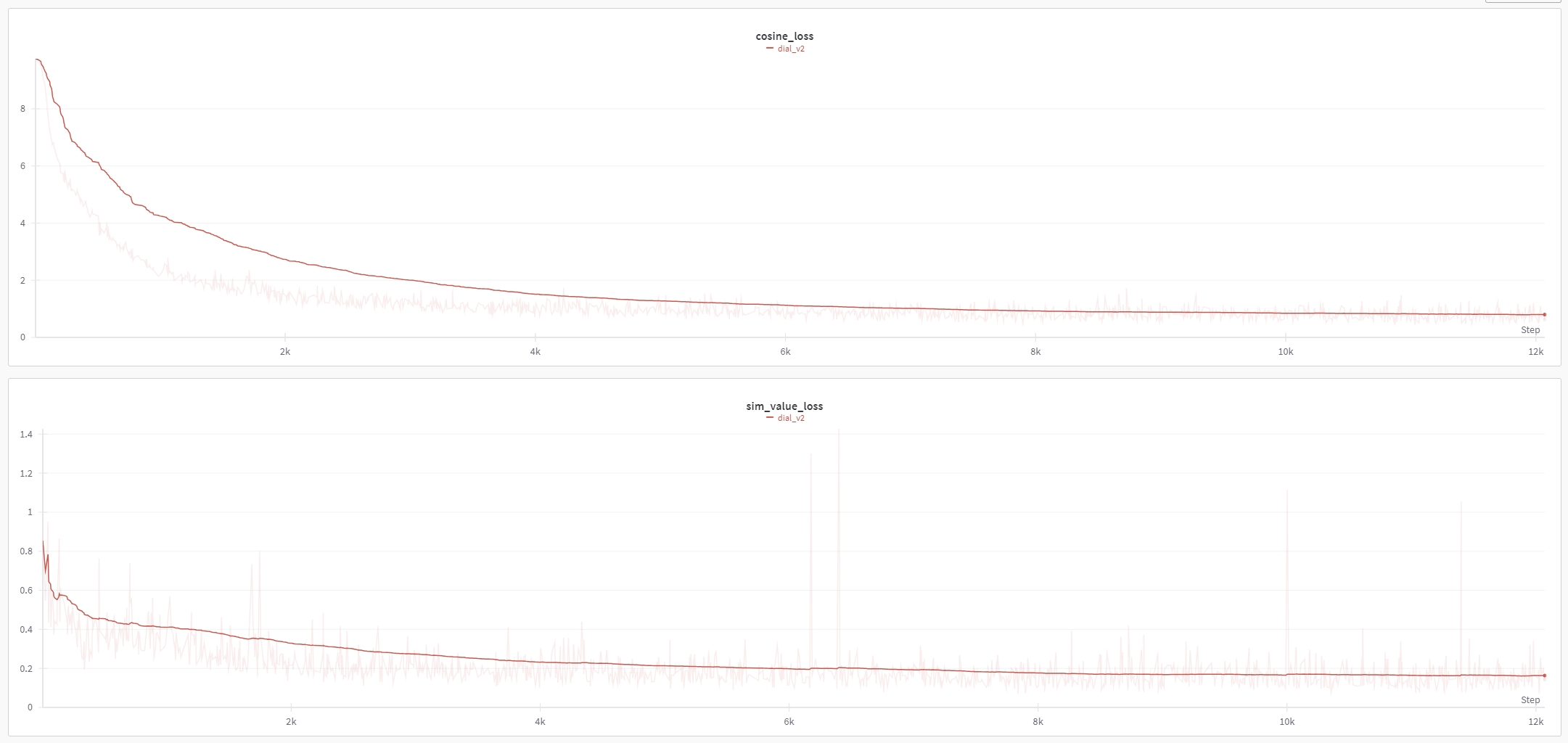
4.4 效果
目前还没有专门测试集,本人简单测试了下是有效果的,部分测试结果见文件dial_retrieval_test.xlsx。
5 后续TODO
- 更多的dial-rewrite数据
- 不同EmbeddingDimensions的编码模型
6 FAQ
Q: 为什么向量维度是1792?
A: 最初考虑发布768、1024,768+768,1024+1024,1024+768维度,但是时间有限,先做了1792就只发布1792维度的模型。理论上维度越高效果越好。
Q: 如何复现CMTEB效果?
A: SentenceTransformer加载后直接用官方评测脚本就行,注意对于Classification任务向量需要先normalize一下
Q: 复现的CMTEB效果和本文不一致?
A: 聚类不一致正常,官方评测代码没有设定seed,其他不一致建议检查代码或联系本人。
Q: 如何选择向量模型?
A: 没有免费的午餐,在自己测试集上试试,本人推荐bge、e5和stella.
Q: 长度为什么只有512,能否更长?
A: 可以但没必要,长了效果普遍不好,这是当前训练方法和数据导致的,几乎无解,建议长文本还是走分块。
Q: 训练资源和算力?
A: 亿级别的数据,单卡A100要一个月起步
- Downloads last month
- 36