
Kandinsky 2.2
Collection
5 items
•
Updated
•
1
Kandinsky inherits best practices from Dall-E 2 and Latent diffusion while introducing some new ideas.
It uses the CLIP model as a text and image encoder, and diffusion image prior (mapping) between latent spaces of CLIP modalities. This approach increases the visual performance of the model and unveils new horizons in blending images and text-guided image manipulation.
The Kandinsky model is created by Arseniy Shakhmatov, Anton Razzhigaev, Aleksandr Nikolich, Igor Pavlov, Andrey Kuznetsov and Denis Dimitrov
Kandinsky 2.2 is available in diffusers!
pip install diffusers transformers accelerate
import torch
import numpy as np
from transformers import pipeline
from diffusers.utils import load_image
from diffusers import KandinskyV22PriorPipeline, KandinskyV22ControlnetPipeline
# let's take an image and extract its depth map.
def make_hint(image, depth_estimator):
image = depth_estimator(image)["depth"]
image = np.array(image)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
detected_map = torch.from_numpy(image).float() / 255.0
hint = detected_map.permute(2, 0, 1)
return hint
img = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/kandinskyv22/cat.png"
).resize((768, 768))
# We can use the `depth-estimation` pipeline from transformers to process the image and retrieve its depth map.
depth_estimator = pipeline("depth-estimation")
hint = make_hint(img, depth_estimator).unsqueeze(0).half().to("cuda")
# Now, we load the prior pipeline and the text-to-image controlnet pipeline
pipe_prior = KandinskyV22PriorPipeline.from_pretrained(
"kandinsky-community/kandinsky-2-2-prior", torch_dtype=torch.float16
)
pipe_prior = pipe_prior.to("cuda")
pipe = KandinskyV22ControlnetPipeline.from_pretrained(
"kandinsky-community/kandinsky-2-2-controlnet-depth", torch_dtype=torch.float16
)
pipe = pipe.to("cuda")
# We pass the prompt and negative prompt through the prior to generate image embeddings
prompt = "A robot, 4k photo"
negative_prior_prompt = "lowres, text, error, cropped, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, out of frame, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck, username, watermark, signature"
generator = torch.Generator(device="cuda").manual_seed(43)
image_emb, zero_image_emb = pipe_prior(
prompt=prompt, negative_prompt=negative_prior_prompt, generator=generator
).to_tuple()
# Now we can pass the image embeddings and the depth image we extracted to the controlnet pipeline. With Kandinsky 2.2, only prior pipelines accept `prompt` input. You do not need to pass the prompt to the controlnet pipeline.
images = pipe(
image_embeds=image_emb,
negative_image_embeds=zero_image_emb,
hint=hint,
num_inference_steps=50,
generator=generator,
height=768,
width=768,
).images
images[0].save("robot_cat.png")


import torch
import numpy as np
from diffusers import KandinskyV22PriorEmb2EmbPipeline, KandinskyV22ControlnetImg2ImgPipeline
from diffusers.utils import load_image
from transformers import pipeline
img = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main" "/kandinskyv22/cat.png"
).resize((768, 768))
def make_hint(image, depth_estimator):
image = depth_estimator(image)["depth"]
image = np.array(image)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
detected_map = torch.from_numpy(image).float() / 255.0
hint = detected_map.permute(2, 0, 1)
return hint
depth_estimator = pipeline("depth-estimation")
hint = make_hint(img, depth_estimator).unsqueeze(0).half().to("cuda")
pipe_prior = KandinskyV22PriorEmb2EmbPipeline.from_pretrained(
"kandinsky-community/kandinsky-2-2-prior", torch_dtype=torch.float16
)
pipe_prior = pipe_prior.to("cuda")
pipe = KandinskyV22ControlnetImg2ImgPipeline.from_pretrained(
"kandinsky-community/kandinsky-2-2-controlnet-depth", torch_dtype=torch.float16
)
pipe = pipe.to("cuda")
prompt = "A robot, 4k photo"
negative_prior_prompt = "lowres, text, error, cropped, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, out of frame, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck, username, watermark, signature"
generator = torch.Generator(device="cuda").manual_seed(43)
# run prior pipeline
img_emb = pipe_prior(prompt=prompt, image=img, strength=0.85, generator=generator)
negative_emb = pipe_prior(prompt=negative_prior_prompt, image=img, strength=1, generator=generator)
# run controlnet img2img pipeline
images = pipe(
image=img,
strength=0.5,
image_embeds=img_emb.image_embeds,
negative_image_embeds=negative_emb.image_embeds,
hint=hint,
num_inference_steps=50,
generator=generator,
height=768,
width=768,
).images
images[0].save("robot_cat.png")
Here is the output. Compared with the output from our text-to-image controlnet example, it kept a lot more cat facial details from the original image and worked into the robot style we asked for.

Kandinsky 2.2 is a text-conditional diffusion model based on unCLIP and latent diffusion, composed of a transformer-based image prior model, a unet diffusion model, and a decoder.
The model architectures are illustrated in the figure below - the chart on the left describes the process to train the image prior model, the figure in the center is the text-to-image generation process, and the figure on the right is image interpolation.
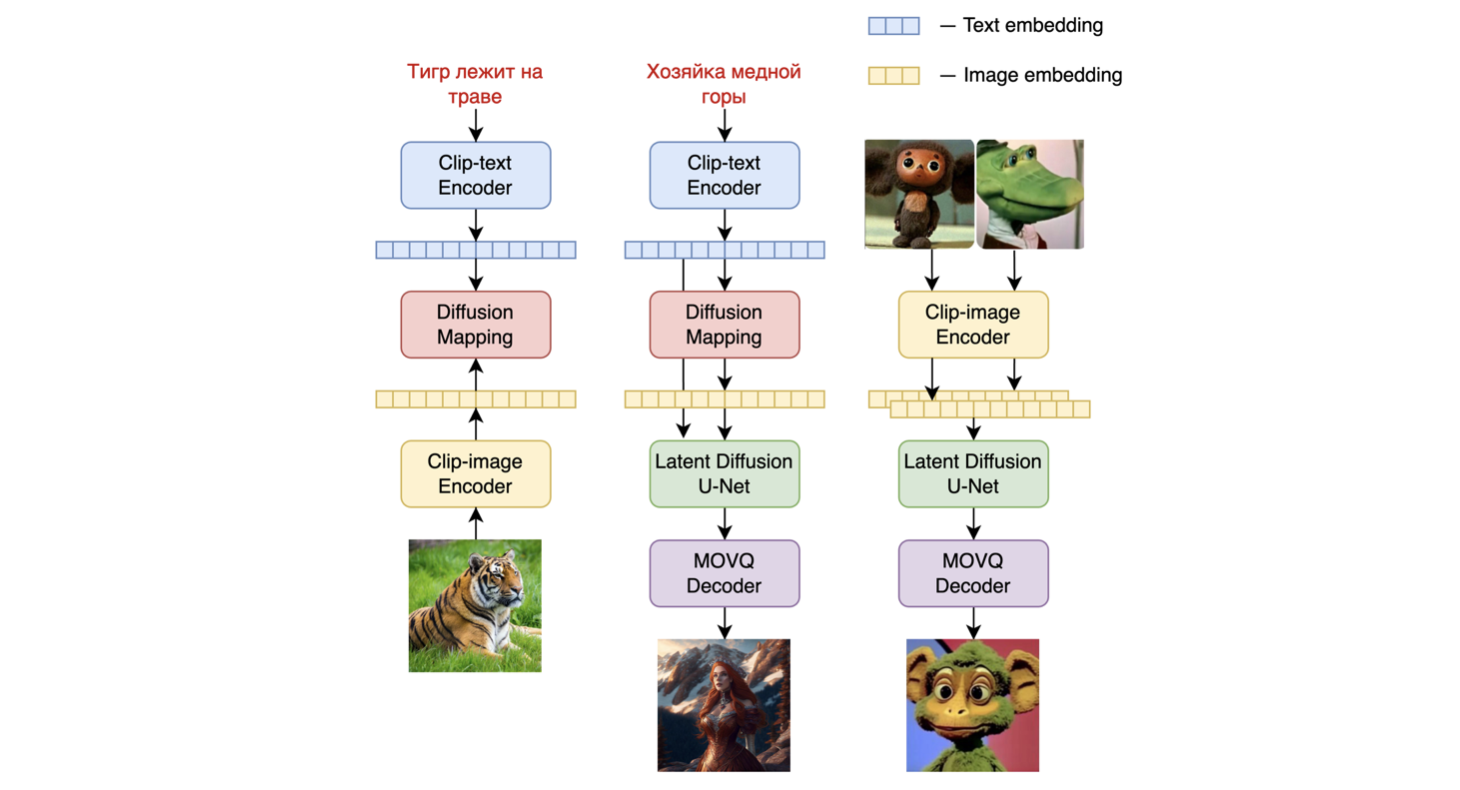
Specifically, the image prior model was trained on CLIP text and image embeddings generated with a pre-trained CLIP-ViT-G model. The trained image prior model is then used to generate CLIP image embeddings for input text prompts. Both the input text prompts and its CLIP image embeddings are used in the diffusion process. A MoVQGAN model acts as the final block of the model, which decodes the latent representation into an actual image.
The image prior training of the model was performed on the LAION Improved Aesthetics dataset, and then fine-tuning was performed on the LAION HighRes data.
The main Text2Image diffusion model was trained on LAION HighRes dataset and then fine-tuned with a dataset of 2M very high-quality high-resolution images with descriptions (COYO, anime, landmarks_russia, and a number of others) was used separately collected from open sources.
The main change in Kandinsky 2.2 is the replacement of CLIP-ViT-G. Its image encoder significantly increases the model's capability to generate more aesthetic pictures and better understand text, thus enhancing its overall performance.
Due to the switch CLIP model, the image prior model was retrained, and the Text2Image diffusion model was fine-tuned for 2000 iterations. Kandinsky 2.2 was trained on data of various resolutions, from 512 x 512 to 1536 x 1536, and also as different aspect ratios. As a result, Kandinsky 2.2 can generate 1024 x 1024 outputs with any aspect ratio.
We quantitatively measure the performance of Kandinsky 2.1 on the COCO_30k dataset, in zero-shot mode. The table below presents FID.
FID metric values for generative models on COCO_30k
| FID (30k) | |
|---|---|
| eDiff-I (2022) | 6.95 |
| Image (2022) | 7.27 |
| Kandinsky 2.1 (2023) | 8.21 |
| Stable Diffusion 2.1 (2022) | 8.59 |
| GigaGAN, 512x512 (2023) | 9.09 |
| DALL-E 2 (2022) | 10.39 |
| GLIDE (2022) | 12.24 |
| Kandinsky 1.0 (2022) | 15.40 |
| DALL-E (2021) | 17.89 |
| Kandinsky 2.0 (2022) | 20.00 |
| GLIGEN (2022) | 21.04 |
For more information, please refer to the upcoming technical report.
If you find this repository useful in your research, please cite:
@misc{kandinsky 2.2,
title = {kandinsky 2.2},
author = {Arseniy Shakhmatov, Anton Razzhigaev, Aleksandr Nikolich, Vladimir Arkhipkin, Igor Pavlov, Andrey Kuznetsov, Denis Dimitrov},
year = {2023},
howpublished = {},
}