
datasets:
- louisbrulenaudet/Romulus-cpt-fr
license: llama3
language:
- fr
base_model: meta-llama/Meta-Llama-3.1-8B-Instruct
pipeline_tag: text-generation
library_name: transformers
tags:
- law
- droit
- unsloth
- trl
- transformers
- sft
- llama

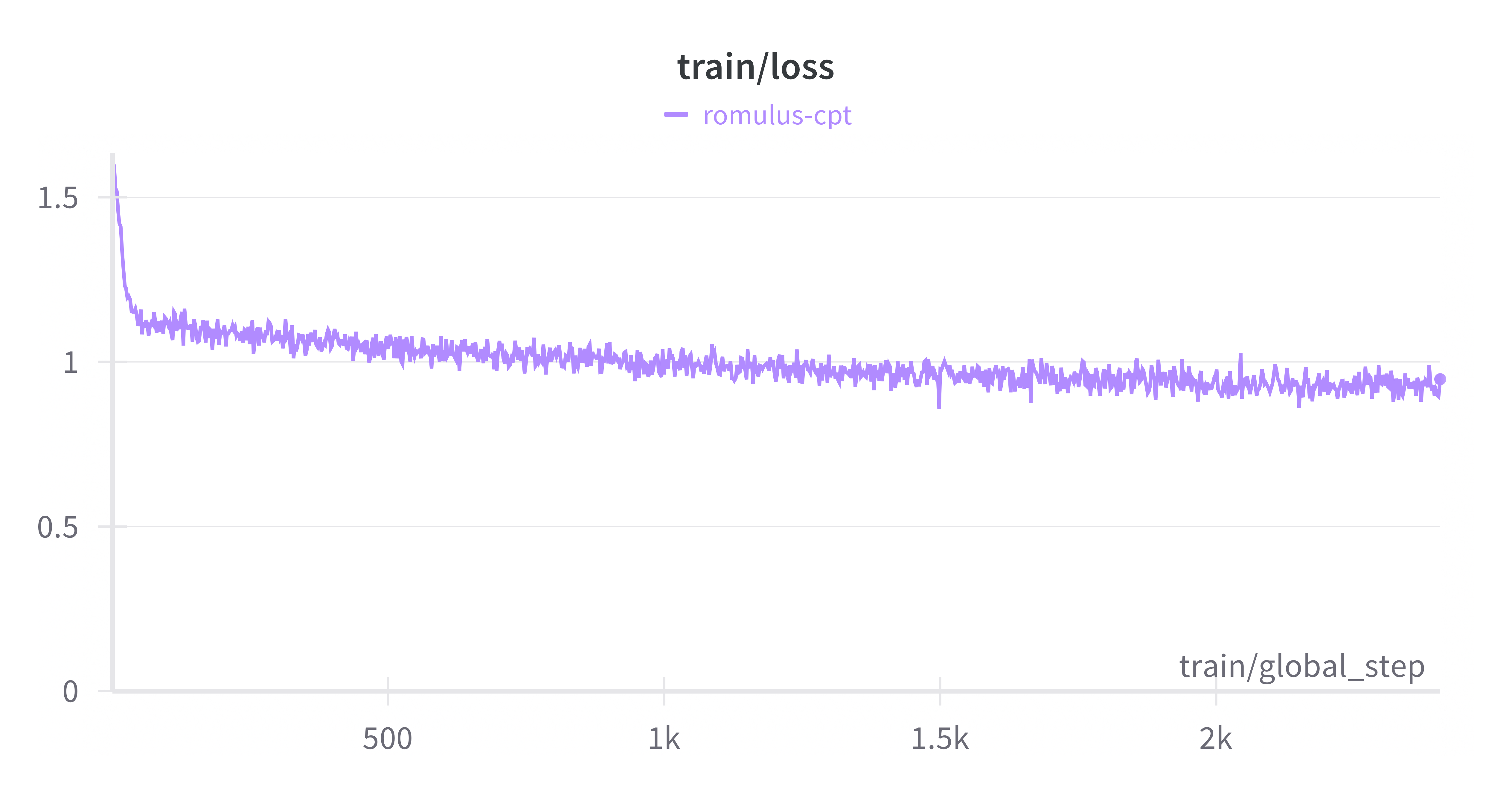
Romulus, continually pre-trained models for French law.
Romulus is a series of continually pre-trained models enriched in French law and intended to serve as the basis for a fine-tuning process on labeled data. Please note that these models have not been aligned for the production of usable text as they stand, and will certainly need to be fine-tuned for the desired tasks in order to produce satisfactory results.
The training corpus is made up of around 34,864,949 tokens (calculated with the meta-llama/Meta-Llama-3.1-8B-Instruct tokenizer).
Hyperparameters
The following table outlines the key hyperparameters used for training Romulus.
| Parameter | Description | Value |
|---|---|---|
max_seq_length |
Maximum sequence length for the model | 4096 |
load_in_4bit |
Whether to load the model in 4-bit precision | False |
model_name |
Pre-trained model name from Hugging Face | meta-llama/Meta-Llama-3.1-8B-Instruct |
r |
Rank of the LoRA adapter | 128 |
lora_alpha |
Alpha value for the LoRA module | 32 |
lora_dropout |
Dropout rate for LoRA layers | 0 |
bias |
Bias type for LoRA adapters | none |
use_gradient_checkpointing |
Whether to use gradient checkpointing | unsloth |
train_batch_size |
Per device training batch size | 8 |
gradient_accumulation_steps |
Number of gradient accumulation steps | 8 |
warmup_ratio |
Warmup steps as a fraction of total steps | 0.1 |
num_train_epochs |
Number of training epochs | 1 |
learning_rate |
Learning rate for the model | 5e-5 |
embedding_learning_rate |
Learning rate for embeddings | 1e-5 |
optim |
Optimizer used for training | adamw_8bit |
weight_decay |
Weight decay to prevent overfitting | 0.01 |
lr_scheduler_type |
Type of learning rate scheduler | linear |
Training script
Romulus was trained using Unsloth on a Nvidia H100 Azure EST US instance provided by the Microsoft for Startups program from this script:
# -*- coding: utf-8 -*-
import os
from typing import (
Dict,
)
from datasets import load_dataset
from unsloth import (
FastLanguageModel,
is_bfloat16_supported,
UnslothTrainer,
UnslothTrainingArguments,
)
max_seq_length = 4096
dtype = None
load_in_4bit = False
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="meta-llama/Meta-Llama-3.1-8B-Instruct",
max_seq_length=max_seq_length,
dtype=dtype,
load_in_4bit=load_in_4bit,
token="hf_token",
)
model = FastLanguageModel.get_peft_model(
model,
r=128,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
"embed_tokens",
"lm_head",
],
lora_alpha=32,
lora_dropout=0,
bias="none",
use_gradient_checkpointing="unsloth",
random_state=3407,
use_rslora=True,
loftq_config=None,
)
prompt = """### Référence :
{}
### Contenu :
{}"""
EOS_TOKEN = tokenizer.eos_token
def formatting_prompts_func(examples):
"""
Format input examples into prompts for a language model.
This function takes a dictionary of examples containing titles and texts,
combines them into formatted prompts, and appends an end-of-sequence token.
Parameters
----------
examples : dict
A dictionary containing two keys:
- 'title': A list of titles.
- 'text': A list of corresponding text content.
Returns
-------
dict
A dictionary with a single key 'text', containing a list of formatted prompts.
Notes
-----
- The function assumes the existence of a global `prompt` variable, which is a
formatting string used to combine the title and text.
- The function also assumes the existence of a global `EOS_TOKEN` variable,
which is appended to the end of each formatted prompt.
- The input lists 'title' and 'text' are expected to have the same length.
Examples
--------
>>> examples = {
... 'title': ['Title 1', 'Title 2'],
... 'text': ['Content 1', 'Content 2']
... }
>>> formatting_cpt_prompts_func(examples)
{'text': ['<formatted_prompt_1><EOS>', '<formatted_prompt_2><EOS>']}
"""
refs = examples["ref"]
texts = examples["texte"]
outputs = []
for ref, text in zip(refs, texts):
text = prompt.format(ref, text) + EOS_TOKEN
outputs.append(text)
return {
"text": outputs,
}
cpt_dataset = load_dataset(
"louisbrulenaudet/Romulus-cpt-fr",
split="train",
token="hf_token",
)
cpt_dataset = cpt_dataset.map(
formatting_prompts_func,
batched=True,
)
trainer = UnslothTrainer(
model=model,
tokenizer=tokenizer,
train_dataset=cpt_dataset,
dataset_text_field="text",
max_seq_length=max_seq_length,
dataset_num_proc=2,
args=UnslothTrainingArguments(
per_device_train_batch_size=8,
gradient_accumulation_steps=8,
warmup_ratio=0.1,
num_train_epochs=1,
learning_rate=5e-5,
embedding_learning_rate=1e-5,
fp16=not is_bfloat16_supported(),
bf16=is_bfloat16_supported(),
logging_steps=1,
report_to="wandb",
save_steps=350,
run_name="romulus-cpt",
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs",
),
)
trainer_stats = trainer.train()
Citing & Authors
If you use this code in your research, please use the following BibTeX entry.
@misc{louisbrulenaudet2024,
author = {Louis Brulé Naudet},
title = {Romulus, continually pre-trained models for French law},
year = {2024}
howpublished = {\url{https://huggingface.co/datasets/louisbrulenaudet/Romulus-cpt-fr}},
}
Feedback
If you have any feedback, please reach out at louisbrulenaudet@icloud.com.