
OpenCodeInterpreter
Collection
18 items
•
Updated
•
82
OpenCodeInterpreter is a family of open-source code generation systems designed to bridge the gap between large language models and advanced proprietary systems like the GPT-4 Code Interpreter. It significantly advances code generation capabilities by integrating execution and iterative refinement functionalities.
For further information and related work, refer to our paper: "OpenCodeInterpreter: A System for Enhanced Code Generation and Execution" available on arXiv.
This model is based on deepseek-coder-33b-base.
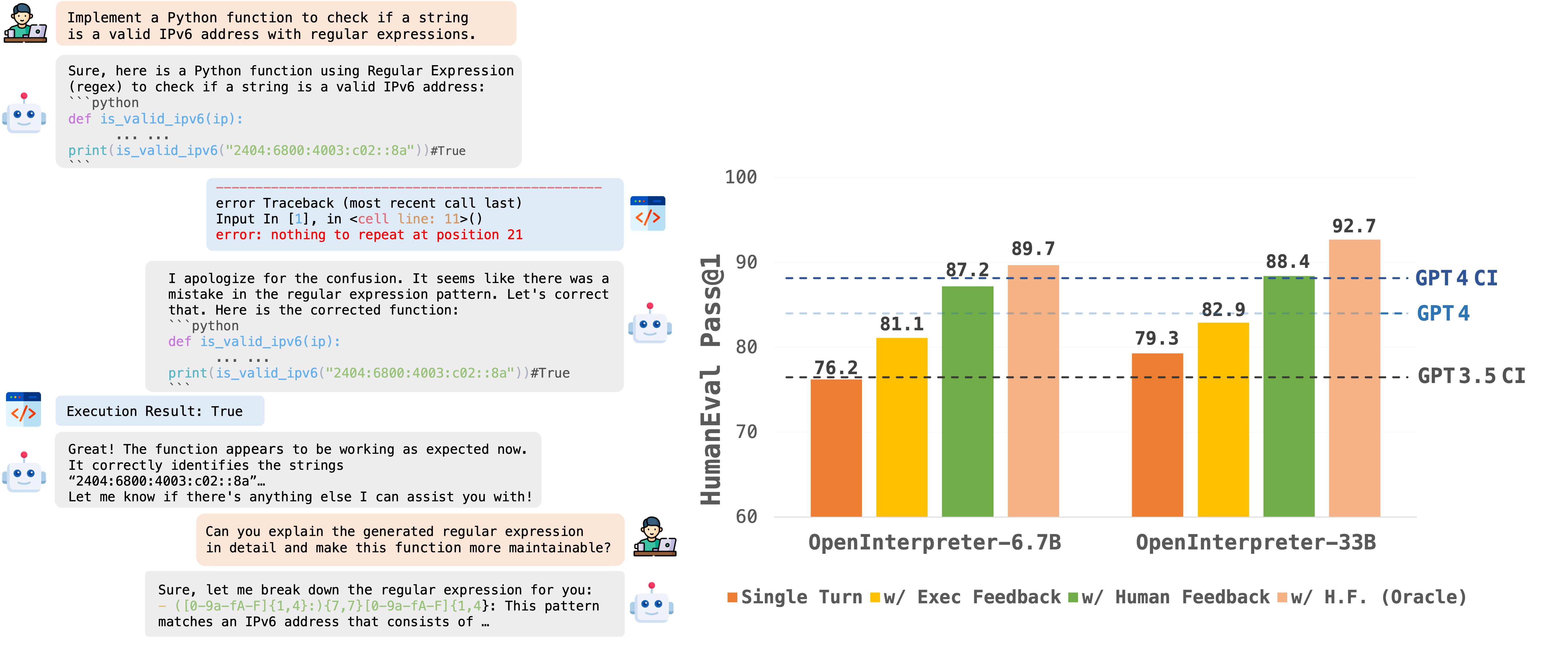
The OpenCodeInterpreter Models series exemplifies the evolution of coding model performance, particularly highlighting the significant enhancements brought about by the integration of execution feedback. In an effort to quantify these improvements, we present a detailed comparison across two critical benchmarks: HumanEval and MBPP. This comparison not only showcases the individual performance metrics on each benchmark but also provides an aggregated view of the overall performance enhancement. The subsequent table succinctly encapsulates the performance data, offering a clear perspective on how execution feedback contributes to elevating the models' capabilities in code interpretation and execution tasks.
| Benchmark | HumanEval (+) | MBPP (+) | Average (+) |
|---|---|---|---|
| OpenCodeInterpreter-DS-1.3B | 65.2 (61.0) | 63.4 (52.4) | 64.3 (56.7) |
| + Execution Feedback | 65.2 (62.2) | 65.2 (55.6) | 65.2 (58.9) |
| OpenCodeInterpreter-DS-6.7B | 76.2 (72.0) | 73.9 (63.7) | 75.1 (67.9) |
| + Execution Feedback | 81.1 (78.7) | 82.7 (72.4) | 81.9 (75.6) |
| + Synth. Human Feedback | 87.2 (86.6) | 86.2 (74.2) | 86.7 (80.4) |
| + Synth. Human Feedback (Oracle) | 89.7 (86.6) | 87.2 (75.2) | 88.5 (80.9) |
| OpenCodeInterpreter-DS-33B | 79.3 (74.3) | 78.7 (66.4) | 79.0 (70.4) |
| + Execution Feedback | 82.9 (80.5) | 83.5 (72.2) | 83.2 (76.4) |
| + Synth. Human Feedback | 88.4 (86.0) | 87.5 (75.9) | 88.0 (81.0) |
| + Synth. Human Feedback (Oracle) | 92.7 (89.7) | 90.5 (79.5) | 91.6 (84.6) |
| OpenCodeInterpreter-CL-7B | 72.6 (67.7) | 66.4 (55.4) | 69.5 (61.6) |
| + Execution Feedback | 75.6 (70.1) | 69.9 (60.7) | 72.8 (65.4) |
| OpenCodeInterpreter-CL-13B | 77.4 (73.8) | 70.7 (59.2) | 74.1 (66.5) |
| + Execution Feedback | 81.1 (76.8) | 78.2 (67.2) | 79.7 (72.0) |
| OpenCodeInterpreter-CL-34B | 78.0 (72.6) | 73.4 (61.4) | 75.7 (67.0) |
| + Execution Feedback | 81.7 (78.7) | 80.2 (67.9) | 81.0 (73.3) |
| OpenCodeInterpreter-CL-70B | 76.2 (70.7) | 73.0 (61.9) | 74.6 (66.3) |
| + Execution Feedback | 79.9 (77.4) | 81.5 (69.9) | 80.7 (73.7) |
| OpenCodeInterpreter-GM-7B | 56.1 (50.0) | 39.8 (34.6) | 48.0 (42.3) |
| + Execution Feedback | 64.0 (54.3) | 48.6 (40.9) | 56.3 (47.6) |
| OpenCodeInterpreter-SC2-3B | 65.2 (57.9) | 62.7 (52.9) | 64.0 (55.4) |
| + Execution Feedback | 67.1 (60.4) | 63.4 (54.9) | 65.3 (57.7) |
| OpenCodeInterpreter-SC2-7B | 73.8 (68.9) | 61.7 (51.1) | 67.8 (60.0) |
| + Execution Feedback | 75.6 (69.5) | 66.9 (55.4) | 71.3 (62.5) |
| OpenCodeInterpreter-SC2-15B | 75.6 (69.5) | 71.2 (61.2) | 73.4 (65.4) |
| + Execution Feedback | 77.4 (72.0) | 74.2 (63.4) | 75.8 (67.7) |
Note: The "(+)" notation represents scores from extended versions of the HumanEval and MBPP benchmarks. To ensure a fair comparison, the results shown for adding execution feedback are based on outcomes after just one iteration of feedback, without unrestricted iterations. This approach highlights the immediate impact of execution feedback on performance improvements across benchmarks.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_path="m-a-p/OpenCodeInterpreter-DS-33B"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
device_map="auto",
)
model.eval()
prompt = "Write a function to find the shared elements from the given two lists."
inputs = tokenizer.apply_chat_template(
[{'role': 'user', 'content': prompt }],
return_tensors="pt"
).to(model.device)
outputs = model.generate(
inputs,
max_new_tokens=1024,
do_sample=False,
pad_token_id=tokenizer.eos_token_id,
eos_token_id=tokenizer.eos_token_id,
)
print(tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True))
If you have any inquiries, please feel free to raise an issue or reach out to us via email at: xiangyue.work@gmail.com, zhengtianyu0428@gmail.com. We're here to assist you!"