
UniSpeech-Large-Multi-Lingual
The multi-lingual large model pretrained on 16kHz sampled speech audio and phonetic labels. When using the model make sure that your speech input is also sampled at 16kHz and your text in converted into a sequence of phonemes.
Note: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model speech recognition, a tokenizer should be created and the model should be fine-tuned on labeled text data. Check out this blog for more in-detail explanation of how to fine-tune the model.
Paper: UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data
Authors: Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang
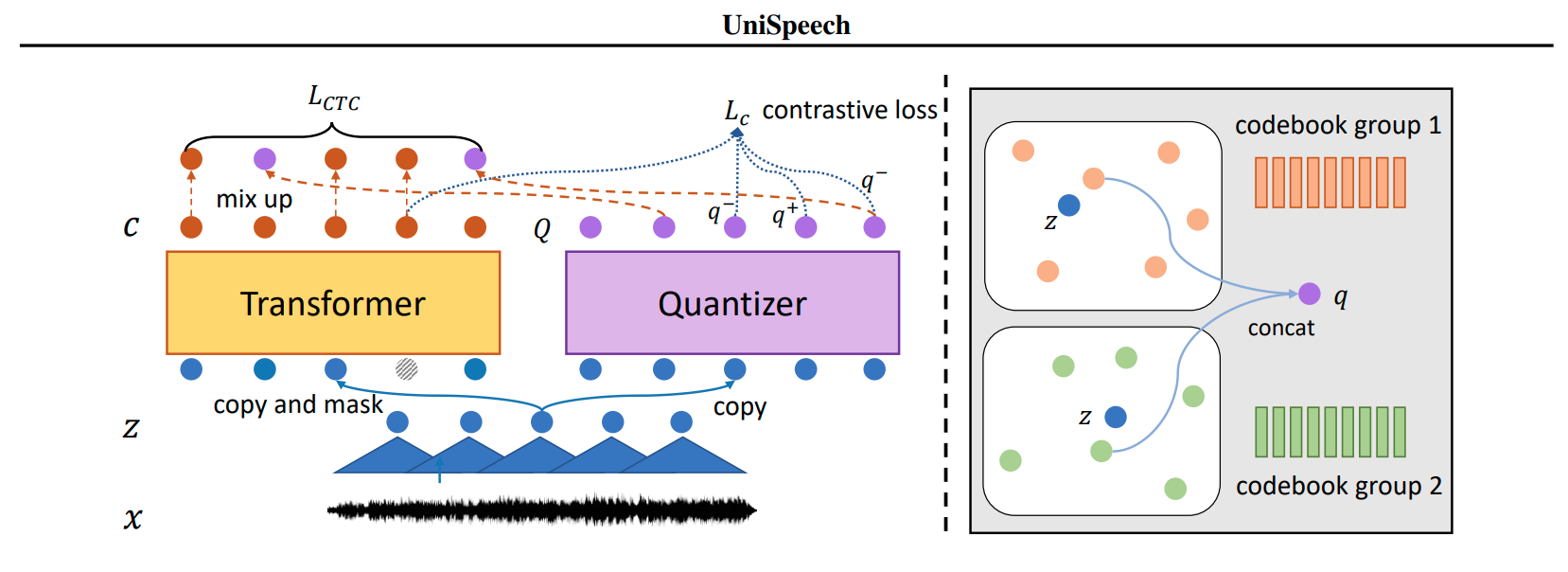
Abstract In this paper, we propose a unified pre-training approach called UniSpeech to learn speech representations with both unlabeled and labeled data, in which supervised phonetic CTC learning and phonetically-aware contrastive self-supervised learning are conducted in a multi-task learning manner. The resultant representations can capture information more correlated with phonetic structures and improve the generalization across languages and domains. We evaluate the effectiveness of UniSpeech for cross-lingual representation learning on public CommonVoice corpus. The results show that UniSpeech outperforms self-supervised pretraining and supervised transfer learning for speech recognition by a maximum of 13.4% and 17.8% relative phone error rate reductions respectively (averaged over all testing languages). The transferability of UniSpeech is also demonstrated on a domain-shift speech recognition task, i.e., a relative word error rate reduction of 6% against the previous approach.
The original model can be found under https://github.com/microsoft/UniSpeech/tree/main/UniSpeech.
Usage
This is a multi-lingually pre-trained speech model that has to be fine-tuned on a downstream task like speech recognition or audio classification before it can be used in inference. The model was pre-trained in English, Spanish, French, and Italian and should therefore perform well only in those or similar languages.
Note: The model was pre-trained on phonemes rather than characters. This means that one should make sure that the input text is converted to a sequence of phonemes before fine-tuning.
Speech Recognition
To fine-tune the model for speech recognition, see the official speech recognition example.
Speech Classification
To fine-tune the model for speech classification, see the official audio classification example.
Contribution
The model was contributed by cywang and patrickvonplaten.
License
The official license can be found here
- Downloads last month
- 8