
LEVER (for Codex on MBPP)
This is one of the models produced by the paper "LEVER: Learning to Verify Language-to-Code Generation with Execution".
Authors: Ansong Ni, Srini Iyer, Dragomir Radev, Ves Stoyanov, Wen-tau Yih, Sida I. Wang*, Xi Victoria Lin*
Note: This specific model is for Codex on the MBPP dataset, for the models pretrained on other datasets, please see:
Model Details
Model Description
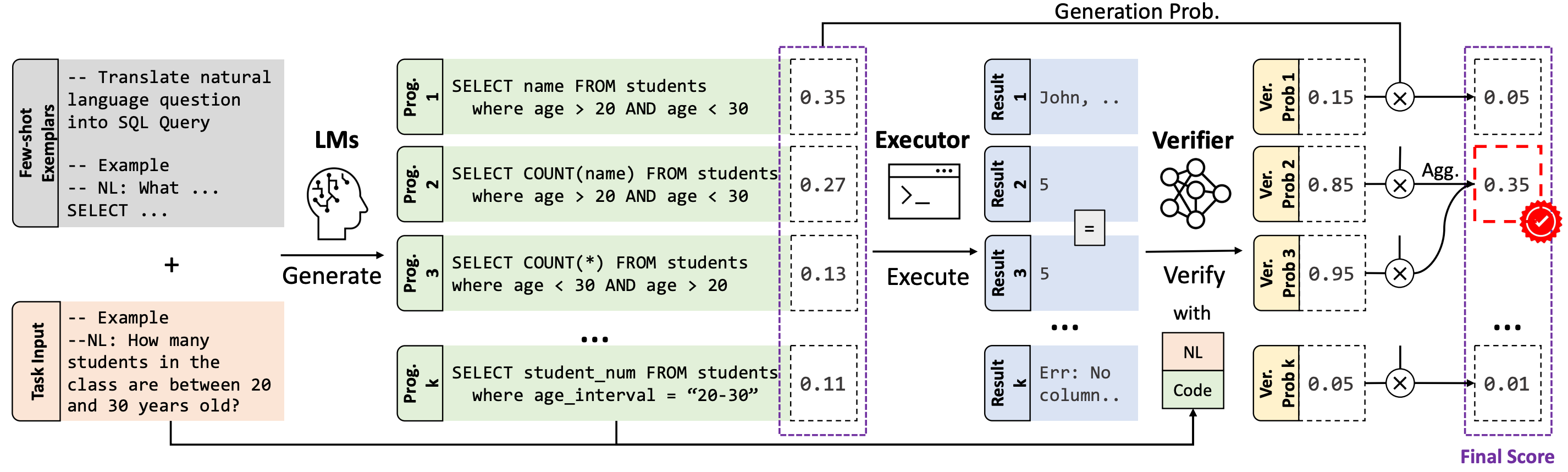
The advent of pre-trained code language models (Code LLMs) has led to significant progress in language-to-code generation. State-of-the-art approaches in this area combine CodeLM decoding with sample pruning and reranking using test cases or heuristics based on the execution results. However, it is challenging to obtain test cases for many real-world language-to-code applications, and heuristics cannot well capture the semantic features of the execution results, such as data type and value range, which often indicates the correctness of the program. In this work, we propose LEVER, a simple approach to improve language-to-code generation by learning to verify the generated programs with their execution results. Specifically, we train verifiers to determine whether a program sampled from the CodeLM is correct or not based on the natural language input, the program itself and its execution results. The sampled programs are reranked by combining the verification score with the CodeLM generation probability, and marginalizing over programs with the same execution results. On four datasets across the domains of table QA, math QA and basic Python programming, LEVER consistently improves over the base Code LLMs (4.6% to 10.9% with code-davinci-002) and achieves new state-of-the-art results on all of them.
Developed by: Yale University and Meta AI
Shared by: Ansong Ni
Model type: Text Classification
Language(s) (NLP): More information needed
License: Apache-2.0
Parent Model: T5-large
Resources for more information:
Uses
Direct Use
This model is not intended to be directly used. LEVER is used to verify and rerank the programs generated by code LLMs (e.g., Codex). We recommend checking out our Github Repo for more details.
Downstream Use
LEVER is learned to verify and rerank the programs sampled from code LLMs for different tasks.
More specifically, for lever-mbpp-codex, it was trained on the outputs of code-davinci-002 on the MBPP dataset. It can be used to rerank the SQL programs generated by Codex out-of-box.
Moreover, it may also be applied to other model's outputs on the MBPP dataset, as studied in the Original Paper.
Out-of-Scope Use
The model should not be used to intentionally create hostile or alienating environments for people.
Bias, Risks, and Limitations
Significant research has explored bias and fairness issues with language models (see, e.g., Sheng et al. (2021) and Bender et al. (2021)). Predictions generated by the model may include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups.
Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
Training Details
Training Data
The model is trained with the outputs from code-davinci-002 model on the MBPP dataset.
Training Procedure
20 program samples are drawn from the Codex model on the training examples of the MBPP dataset, those programs are later executed to obtain the execution information. And for each example and its program sample, the natural language description and execution information are also part of the inputs that used to train the T5-based model to predict "yes" or "no" as the verification labels.
Preprocessing
Please follow the instructions in the Github Repo to reproduce the results.
Speeds, Sizes, Times
More information needed
Evaluation
Testing Data, Factors & Metrics
Testing Data
Dev set of the MBPP dataset.
Factors
More information needed
Metrics
Execution accuracy (i.e., pass@1)
Results
MBPP Python Program Generation
| Exec. Acc. (Dev) | Exec. Acc. (Test) | |
|---|---|---|
| Codex | 61.1 | 62.0 |
| Codex+LEVER | 75.4 | 68.9 |
Model Examination
More information needed
Environmental Impact
Carbon emissions can be estimated using the Machine Learning Impact calculator presented in Lacoste et al. (2019).
- Hardware Type: More information needed
- Hours used: More information needed
- Cloud Provider: More information needed
- Compute Region: More information needed
- Carbon Emitted: More information needed
Technical Specifications [optional]
Model Architecture and Objective
lever-mbpp-codex is based on T5-large.
Compute Infrastructure
More information needed
Hardware
More information needed
Software
More information needed.
Citation
BibTeX:
@inproceedings{ni2023lever,
title={Lever: Learning to verify language-to-code generation with execution},
author={Ni, Ansong and Iyer, Srini and Radev, Dragomir and Stoyanov, Ves and Yih, Wen-tau and Wang, Sida I and Lin, Xi Victoria},
booktitle={Proceedings of the 40th International Conference on Machine Learning (ICML'23)},
year={2023}
}
Glossary [optional]
More information needed
More Information [optional]
More information needed
Model Card Author and Contact
Ansong Ni, contact info on personal website
How to Get Started with the Model
This model is not intended to be directly used, please follow the instructions in the Github Repo.
- Downloads last month
- 14
Dataset used to train niansong1996/lever-mbpp-codex
Evaluation results
- accuracy on mbpp (Python code generation)self-reported68.900