
i2b2 QueryBuilder - 34b
Model Description
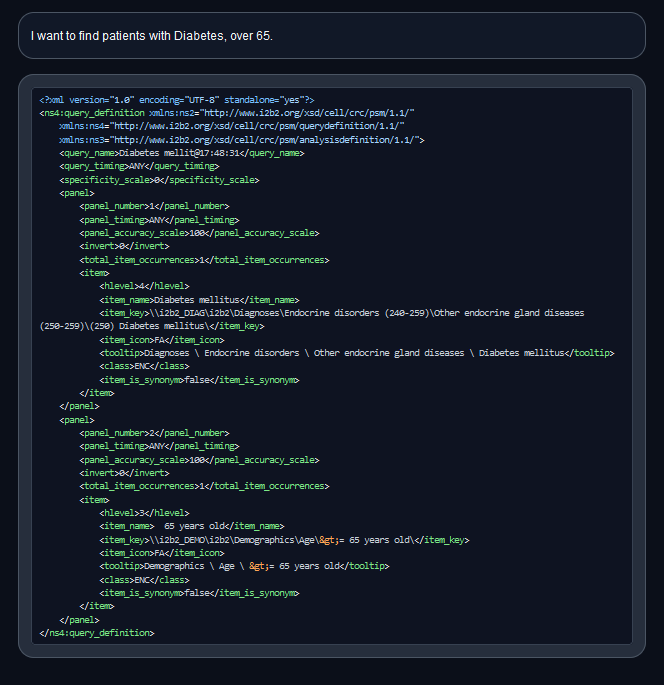
This model will generate queries for your i2b2 query builder trained on this dataset for 10 epochs . For evaluation use.
- Do not use as a final research query builder.
- Results may be incorrect or mal-formatted.
- The onus of research accuracy is on the researcher, not the AI model.
Prompt Format
If you are using text-generation-webui, you can download the instruction template i2b2.yaml
Below is an instruction that describes a task.
### Instruction:
{input}
### Response:
```xml
Architecture
nmitchko/i2b2-querybuilder-codellama-34b is a large language model LoRa specifically fine-tuned for generating queries in the i2b2 query builder.
It is based on codellama-34b-hf at 34 billion parameters.
The primary goal of this model is to improve research accuracy with the i2b2 tool. It was trained using LoRA, specifically QLora Multi GPU, to reduce memory footprint.
See Training Parameters for more info This Lora supports 4-bit and 8-bit modes.
Requirements
bitsandbytes>=0.41.0
peft@main
transformers@main
Steps to load this model:
- Load base model (codellama-34b-hf) using transformers
- Apply LoRA using peft
# Sample Code Coming
Training Parameters
The model was trained for or 10 epochs on i2b2-query-data-1.0
i2b2-query-data-1.0 contains only tasks and outputs for i2b2 queries xsd schemas.
| Item | Amount | Units |
|---|---|---|
| LoRA Rank | 64 | ~ |
| LoRA Alpha | 16 | ~ |
| Learning Rate | 1e-4 | SI |
| Dropout | 5 | % |
Training procedure
The following bitsandbytes quantization config was used during training:
- quant_method: QuantizationMethod.BITS_AND_BYTES
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
Framework versions
- PEFT 0.6.0.dev0
- Downloads last month
- 7