
Description
It is a ViT model that has been fine-tuned on a Stable Diffusion 2.0 image dataset and applied LORA.
It produces optimal results in a reasonable time. Moreover, its implementation with Pytorch is straightforward.
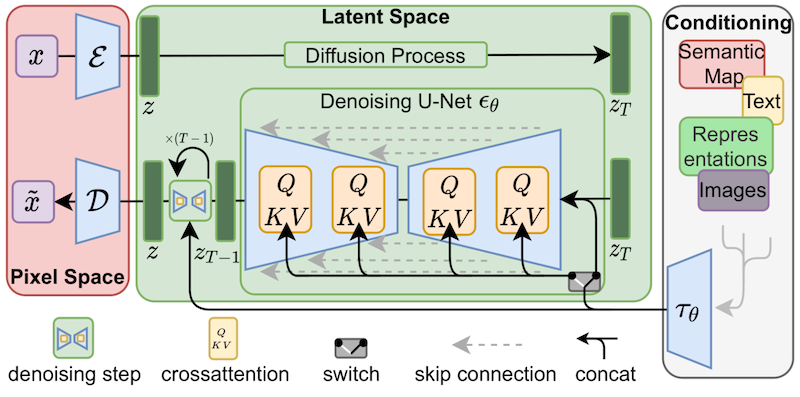
- Reference: https://huggingface.co/blog/lora
Usage
# Libraries
from transformers import ViTFeatureExtractor, AutoTokenizer, VisionEncoderDecoderModel
# Model
model_id = "nttdataspain/vit-gpt2-stablediffusion2-lora"
model = VisionEncoderDecoderModel.from_pretrained(model_id)
tokenizer = AutoTokenizer.from_pretrained(model_id)
feature_extractor = ViTFeatureExtractor.from_pretrained(model_id)
# Predict function
def predict_prompts(list_images, max_length=16):
model.eval()
pixel_values = feature_extractor(images=list_images, return_tensors="pt").pixel_values
with torch.no_grad():
output_ids = model.generate(pixel_values, max_length=max_length, num_beams=4, return_dict_in_generate=True).sequences
preds = tokenizer.batch_decode(output_ids, skip_special_tokens=True)
preds = [pred.strip() for pred in preds]
return preds
# Get an image and predict
img = Image.open(image_path).convert('RGB')
pred_prompts = predict_prompts([img], max_length=16)
- Downloads last month
- 117
This model does not have enough activity to be deployed to Inference API (serverless) yet. Increase its social
visibility and check back later, or deploy to Inference Endpoints (dedicated)
instead.