|
--- |
|
license: mit |
|
tags: |
|
- vision |
|
- image-classification |
|
datasets: |
|
- imagenet-1k |
|
widget: |
|
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg |
|
example_title: Tiger |
|
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg |
|
example_title: Teapot |
|
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg |
|
example_title: Palace |
|
--- |
|
|
|
# NAT (tiny variant) |
|
|
|
NAT-Tiny trained on ImageNet-1K at 224x224 resolution. |
|
It was introduced in the paper [Neighborhood Attention Transformer](https://arxiv.org/abs/2204.07143) by Hassani et al. and first released in [this repository](https://github.com/SHI-Labs/Neighborhood-Attention-Transformer). |
|
|
|
## Model description |
|
|
|
NAT is a hierarchical vision transformer based on Neighborhood Attention (NA). |
|
Neighborhood Attention is a restricted self attention pattern in which each token's receptive field is limited to its nearest neighboring pixels. |
|
NA is a sliding-window attention patterns, and as a result is highly flexible and maintains translational equivariance. |
|
|
|
NA is implemented in PyTorch implementations through its extension, [NATTEN](https://github.com/SHI-Labs/NATTEN/). |
|
|
|
|
|
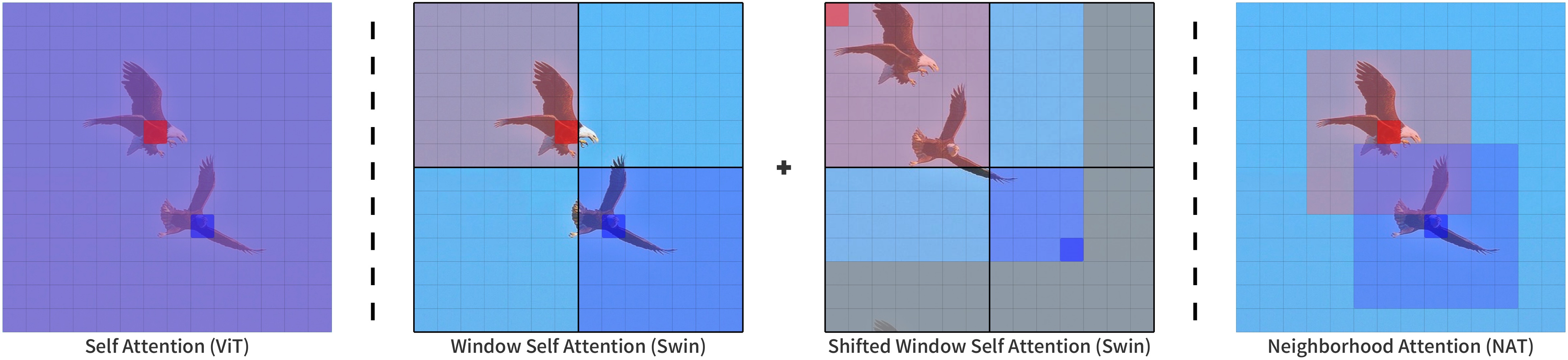 |
|
|
|
[Source](https://paperswithcode.com/paper/neighborhood-attention-transformer) |
|
|
|
|
|
## Intended uses & limitations |
|
|
|
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=nat) to look for |
|
fine-tuned versions on a task that interests you. |
|
|
|
### Example |
|
|
|
Here is how to use this model to classify an image from the COCO 2017 dataset into one of the 1,000 ImageNet classes: |
|
|
|
```python |
|
from transformers import AutoImageProcessor, NatForImageClassification |
|
from PIL import Image |
|
import requests |
|
|
|
url = "http://images.cocodataset.org/val2017/000000039769.jpg" |
|
image = Image.open(requests.get(url, stream=True).raw) |
|
|
|
feature_extractor = AutoImageProcessor.from_pretrained("shi-labs/nat-tiny-in1k-224") |
|
model = NatForImageClassification.from_pretrained("shi-labs/nat-tiny-in1k-224") |
|
|
|
inputs = feature_extractor(images=image, return_tensors="pt") |
|
outputs = model(**inputs) |
|
logits = outputs.logits |
|
# model predicts one of the 1000 ImageNet classes |
|
predicted_class_idx = logits.argmax(-1).item() |
|
print("Predicted class:", model.config.id2label[predicted_class_idx]) |
|
``` |
|
|
|
For more examples, please refer to the [documentation](https://huggingface.co/transformers/model_doc/nat.html#). |
|
|
|
### Requirements |
|
Other than transformers, this model requires the [NATTEN](https://shi-labs.com/natten) package. |
|
|
|
If you're on Linux, you can refer to [shi-labs.com/natten](https://shi-labs.com/natten) for instructions on installing with pre-compiled binaries (just select your torch build to get the correct wheel URL). |
|
|
|
You can alternatively use `pip install natten` to compile on your device, which may take up to a few minutes. |
|
Mac users only have the latter option (no pre-compiled binaries). |
|
|
|
Refer to [NATTEN's GitHub](https://github.com/SHI-Labs/NATTEN/) for more information. |
|
|
|
|
|
### BibTeX entry and citation info |
|
|
|
```bibtex |
|
@article{hassani2022neighborhood, |
|
title = {Neighborhood Attention Transformer}, |
|
author = {Ali Hassani and Steven Walton and Jiachen Li and Shen Li and Humphrey Shi}, |
|
year = 2022, |
|
url = {https://arxiv.org/abs/2204.07143}, |
|
eprint = {2204.07143}, |
|
archiveprefix = {arXiv}, |
|
primaryclass = {cs.CV} |
|
} |
|
``` |

