
![]()
NoticIA-7B: A Model for Clickbait Article Summarization in Spanish.
- 📖 Dataset Card en Español: https://huggingface.co/somosnlp/NoticIA-7B/blob/main/README_es.md
Model Details
Model Description
We define a clickbait article as one that seeks to attract the reader's attention through curiosity. To do this, the headline poses a question or an incomplete, sensationalist, exaggerated, or misleading statement. The answer to the question generated by the headline usually does not appear until the end of the article, which is preceded by a large amount of irrelevant content. The goal is for the user to enter the website through the headline and then scroll to the end of the article, viewing as much advertising as possible. Clickbait articles tend to be of low quality and do not provide value to the reader beyond the initial curiosity. This phenomenon undermines public trust in news sources and negatively affects the advertising revenues of legitimate content creators, who could see their web traffic reduced.
We present a 7B parameter model, trained with the dataset NoticIA-it. This model is capable of generating concise and high-quality summaries of articles with clickbait headlines.
- Developed by: Iker García-Ferrero, Begoña Altuna
- Funded by: SomosNLP, HuggingFace, HiTZ Zentroa
- Model type: Language model, instruction tuned
- Language(s): es-ES
- License: apache-2.0
- Fine-tuned from model: openchat/openchat-3.5-0106
- Dataset used: https://huggingface.co/datasets/somosnlp/NoticIA-it
Model Sources
- 💻 Repository: https://github.com/ikergarcia1996/NoticIA
- 📖 Paper: NoticIA: A Clickbait Article Summarization Dataset in Spanish
- 🤖 Dataset and Pre Trained Models https://huggingface.co/collections/Iker/noticia-and-clickbaitfighter-65fdb2f80c34d7c063d3e48e
- 🔌 Demo: https://huggingface.co/spaces/somosnlp/NoticIA-demo
- ▶️ Video presentation (Spanish): https://youtu.be/xc60K_NzUgk?si=QMqk6OzQZfKP1EUS
- 🐱💻 Hackathon #Somos600M: https://somosnlp.org/hackathon
Uses
This model is tailored for scientific research, particularly for evaluating the performance of task-specific models in contrast to using instruction-tuned models in zero-shot settings. It can also be used by individuals to summarize clickbait articles for personal use.
Direct Use
- 📖 Summarization of clickbait articles
- 📈 Evaluation of Language Models in Spanish.
- 📚 Develop new academic resources (ie. synthetic data generation)
- 🎓 Any other academic research purpose.
Out-of-Scope Use
We prohibit the use of this model for any action that may harm the legitimacy or economic viability of legitimate and professional media outlets.
Bias, Risks, and Limitations
The model has been primarily trained with Spanish news from Spain, and the annotators of the data are also from Spain. Therefore, we expect this model to be proficient with Spanish from Spain. However, we cannot assure that it will perform well with news from Latin America or news in other languages.
How to Get Started with the Model
Making a summary of a clickbait article on the Web
The following code shows an example of how to use the template to generate a summary from the URL of a clickbait article.
import torch # pip install torch
from newspaper import Article #pip3 install newspaper3k
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig # pip install transformers
from transformers import BitsAndBytesConfig # pip install bitsandbytes
article_url ="https://www.huffingtonpost.es/virales/le-compra-abrigo-abuela-97nos-reaccion-fantasia.html"
article = Article(article_url)
article.download()
article.parse()
headline=article.title
body = article.text
def prompt(
headline: str,
body: str,
) -> str:
"""
Generate the prompt for the model.
Args:
headline (`str`):
The headline of the article.
body (`str`):
The body of the article.
Returns:
`str`: The formatted prompt.
"""
return (
f"Ahora eres una Inteligencia Artificial experta en desmontar titulares sensacionalistas o clickbait. "
f"Tu tarea consiste en analizar noticias con titulares sensacionalistas y "
f"generar un resumen de una sola frase que revele la verdad detrás del titular.\n"
f"Este es el titular de la noticia: {headline}\n"
f"El titular plantea una pregunta o proporciona información incompleta. "
f"Debes buscar en el cuerpo de la noticia una frase que responda lo que se sugiere en el título. "
f"Siempre que puedas cita el texto original, especialmente si se trata de una frase que alguien ha dicho. "
f"Si citas una frase que alguien ha dicho, usa comillas para indicar que es una cita. "
f"Usa siempre las mínimas palabras posibles. No es necesario que la respuesta sea una oración completa. "
f"Puede ser sólo el foco de la pregunta. "
f"Recuerda responder siempre en Español.\n"
f"Este es el cuerpo de la noticia:\n"
f"{body}\n"
)
prompt = prompt(headline=headline, body=body)
tokenizer = AutoTokenizer.from_pretrained("somosnlp/NoticIA-7B")
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
)
model = AutoModelForCausalLM.from_pretrained(
"somosnlp/NoticIA-7B", torch_dtype=torch.bfloat16, device_map="auto", quantization_config=quantization_config,
)
formatted_prompt = tokenizer.apply_chat_template(
[{"role": "user", "content": prompt}],
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer(
[formatted_prompt], return_tensors="pt", add_special_tokens=False
)
model_output = model.generate(**model_inputs.to(model.device), generation_config=GenerationConfig(
max_new_tokens=64,
min_new_tokens=1,
do_sample=False,
num_beams=1,
use_cache=True
))
summary = tokenizer.batch_decode(model_output,skip_special_tokens=True)[0]
print(summary.strip().split("\n")[-1]) # Get only the summary, without the prompt.
Performing inference on the NoticIA dataset
The following code shows an example of how to perform an inference on an example of our dataset.
import torch # pip install torch
from datasets import load_dataset # pip install datasets
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig # pip install transformers
from transformers import BitsAndBytesConfig # pip install bitsandbytes
dataset = load_dataset("somosnlp/NoticIA-it",split="test")
tokenizer = AutoTokenizer.from_pretrained("somosnlp/NoticIA-7B")
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_use_double_quant=True,
)
model = AutoModelForCausalLM.from_pretrained(
"somosnlp/NoticIA-7B", torch_dtype=torch.bfloat16, device_map="auto", quantization_config=quantization_config,
)
formatted_prompt = tokenizer.apply_chat_template(
[{"role": "user", "content": dataset[0]["pregunta"]}],
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer(
[formatted_prompt], return_tensors="pt", add_special_tokens=False
)
model_output = model.generate(**model_inputs.to(model.device), generation_config=GenerationConfig(
max_new_tokens=64,
min_new_tokens=1,
do_sample=False,
num_beams=1,
use_cache=True
))
summary = tokenizer.batch_decode(model_output,skip_special_tokens=True)[0]
print(summary.strip().split("\n")[-1]) # Get only the summary, without the prompt.
Training Details
Training Data
We define a clickbait article as one that seeks to attract the reader's attention through curiosity. For this purpose, the headline poses a question or an incomplete, sensationalist, exaggerated, or misleading statement. The answer to the question raised in the headline usually does not appear until the end of the article, preceded by a large amount of irrelevant content. The goal is for the user to enter the website through the headline and then scroll to the end of the article, viewing as much advertising as possible. Clickbait articles tend to be of low quality and provide no value to the reader beyond the initial curiosity. This phenomenon undermines public trust in news sources and negatively affects the advertising revenue of legitimate content creators, who could see their web traffic reduced.
We train the model with NoticIA, a dataset consisting of 850 Spanish news articles with clickbait headlines, each paired with high-quality, single-sentence generative summaries written by humans. This task demands advanced skills in text comprehension and summarization, challenging the ability of models to infer and connect various pieces of information to satisfy the user's informational curiosity generated by the clickbait headline.
Training Procedure
To train the model, we have developed our own training and annotation library: https://github.com/ikergarcia1996/NoticIA. This library utilizes 🤗 Transformers, 🤗 PEFT, Bitsandbytes, and Deepspeed.
For the hackathon, we decided to train a model with 7 trillion parameters, since using 4-bit quantization, it is possible to run the model on domestic hardware. After analyzing the performance of a large number of LLMs, we chose openchat-3.5-0106 due to its high performance without the need for pretraining. To minimally disturb the prior knowledge of the model that allows for this performance, we opted to use the Low-Rank Adaptation (LoRA) training technique.
Training Hyperparameters
- Training regime: bfloat16
- Training method: LoRA + Deepspeed Zero3
- Batch size: 64
- Sequence Length: 8192
- Epochs: 3
- Optimizer:: AdamW
- Software: Huggingface, Peft, Pytorch, Deepspeed
The exact training configuration is available at: https://huggingface.co/somosnlp/NoticIA-7B/blob/main/openchat-3.5-0106_LoRA.yaml
Evaluation
Testing Data, Factors & Metrics
Testing Data
We use the Test split of the NoticIA-it dataset: https://huggingface.co/datasets/somosnlp/NoticIA-it
Prompts
The prompt used for training is the same as defined and explained at https://huggingface.co/datasets/somosnlp/NoticIA-it. The prompt is converted into the chat template specific to each model.
Metrics
As is customary in summarization tasks, we use the ROUGE scoring metric to automatically evaluate the summaries produced by the models. Our main metric is ROUGE-1, which considers whole words as basic units. To calculate the ROUGE score, we lowercase both summaries and remove punctuation marks. In addition to the ROUGE score, we also consider the average length of the summaries. For our task, we aim for the summaries to be concise, an aspect that the ROUGE score does not evaluate. Therefore, when evaluating models, we consider both the ROUGE-1 score and the average length of the summaries. Our goal is to find a model that achieves the highest possible ROUGE score with the shortest possible summary length, balancing quality and brevity.
Results
We have evaluated the best language models trained to follow current instructions, and we have also included the performance obtained by a human annotator. The code to reproduce the results is available at the following link: https://github.com/ikergarcia1996/NoticIA
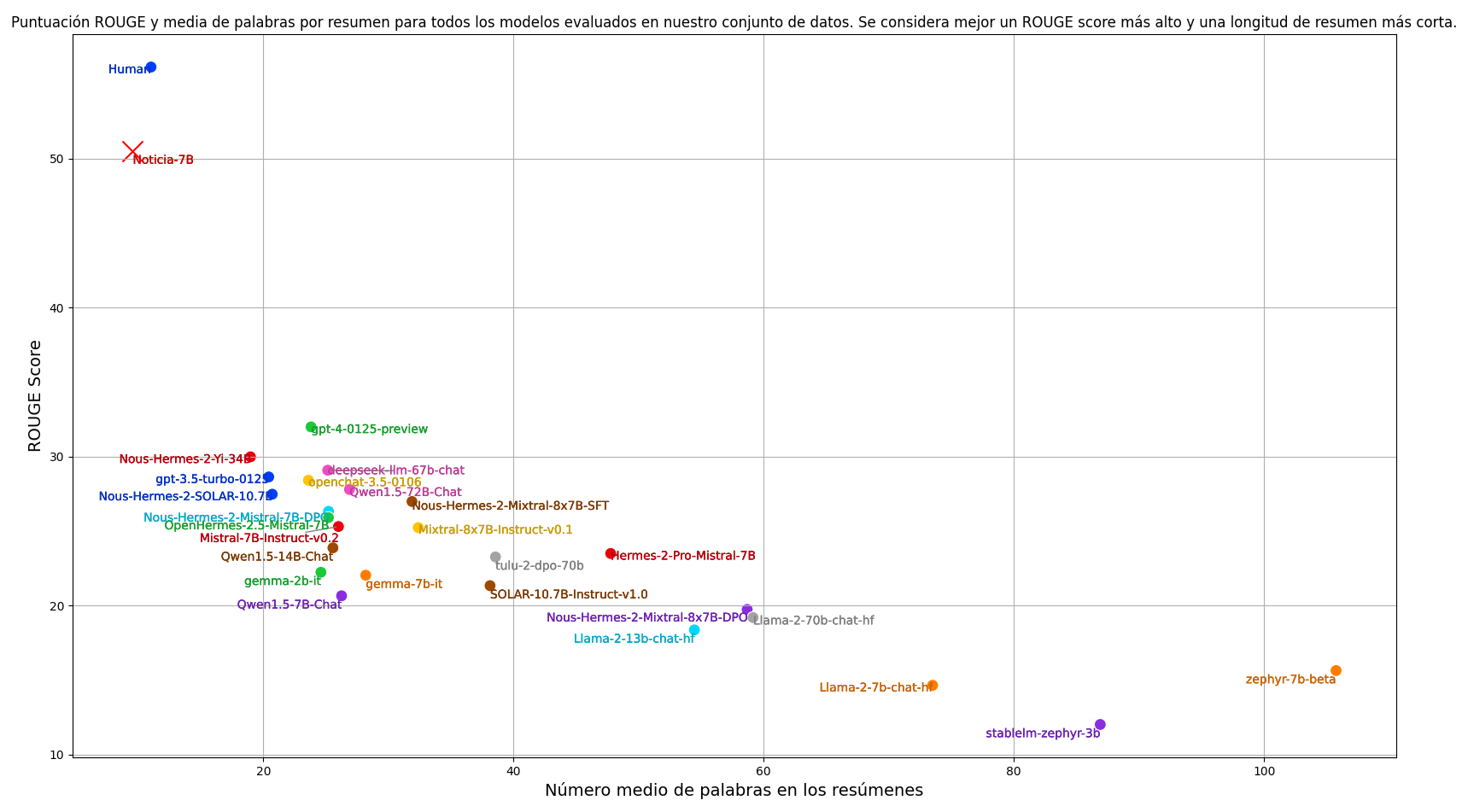
After training, our model acquires the ability to perform summaries with a capacity close to that of humans, significantly surpassing any model in a zero-shot setting. At the same time, the model produces more concise and shorter summaries.
Environmental Impact
For the carbon footprint estimation, we estimated the values considering a 400W consumption per GPU with a 0.083 kg/kWh carbon intensity: https://app.electricitymaps.com/map
- Hardware Type: 4 X Nvidia A100 80Gb
- Hours used: 2 hours
- Compute Region: Donostia, Basque Country, Spain
- Carbon Emitted: 0.3984 kg Co2
Model Architecture and Objective
Decoder-only model. Pretrained for instruction. We employ the standard Next Token Prediction (NTP) loss for training our models. To prevent the loss associated with the article body tokens from overshadowing the loss of the summary output tokens, we compute the loss exclusively over the summary tokens.
Compute Infrastructure
We conducted all our experiments on a machine equipped with four NVIDIA A100 GPUs, each with 80GB of memory, interconnected via NVLink. The machine features two AMD EPYC 7513 32-Core Processors and 1TB (1024GB) of RAM.
Software
- Huggingface Transformers: https://github.com/huggingface/transformers
- PEFT: https://github.com/huggingface/peft
- Deepspeed: https://github.com/microsoft/DeepSpeed
- Pytorch: https://pytorch.org/
Our code is available at https://github.com/ikergarcia1996/NoticIA
License
We release our model under the Apache 2.0 license.
Citation
If you use this dataset, please cite our paper: NoticIA: A Clickbait Article Summarization Dataset in Spanish
BibTeX:
@misc{garcíaferrero2024noticia,
title={NoticIA: A Clickbait Article Summarization Dataset in Spanish},
author={Iker García-Ferrero and Begoña Altuna},
year={2024},
eprint={2404.07611},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
More Information
This project was developed during the Hackathon #Somos600M organized by SomosNLP. Demo endpoints were sponsored by HuggingFace.
Team:
Contact: {iker.garciaf,begona.altuna}@ehu.eus
This dataset was created by Iker García-Ferrero and Begoña Altuna. We are researchers in NLP at the University of the Basque Country, within the IXA research group, and we are part of HiTZ, the Basque Language Technology Center.
- Downloads last month
- 7