Spaces:
Runtime error

Runtime error

| import os | |
| import requests | |
| import gradio as gr | |
| from languages import LANGUAGES | |
| from time import time | |
| GLADIA_API_KEY = os.environ.get("GLADIA_API_KEY") | |
| headers = { | |
| "accept": "application/json", | |
| "x-gladia-key": GLADIA_API_KEY, | |
| } | |
| ACCEPTED_LANGUAGE_BEHAVIOUR = [ | |
| "manual", | |
| "automatic single language", | |
| "automatic multiple languages", | |
| ] | |
| def transcribe( | |
| audio_url: str = None, | |
| audio: str = None, | |
| video: str = None, | |
| language_behaviour: str = ACCEPTED_LANGUAGE_BEHAVIOUR[2], | |
| language: str = "english", | |
| ) -> dict: | |
| """ | |
| This function transcribes audio to text using the Gladia API. | |
| It sends a request to the API with the given audio file or audio URL, and returns the transcribed text. | |
| Find your api key at gladia.io | |
| Parameters: | |
| audio_url (str): The URL of the audio file to transcribe. If audio_url is provided, audio file will be ignored. | |
| audio (str): The path to the audio file to transcribe. | |
| video (str): The path to the video file. If provided, the audio field will be set to the content of this video. | |
| language_behaviour (str): Determines how language detection should be performed. | |
| Must be one of [ | |
| "manual", | |
| "automatic single language", | |
| "automatic multiple languages" | |
| ] | |
| If "manual", the language field must be provided and the API will transcribe the audio in the given language. | |
| If "automatic single language", the language of the audio will be automatically detected by the API | |
| but will force the transcription to be in a single language. | |
| If "automatic multiple languages", the language of the audio will be automatically detected by the API for | |
| each sentence allowing code-switching over 97 languages. | |
| language (str): The language of the audio file. This field is ignored if language_behaviour is set to "automatic*". | |
| Returns: | |
| dict: A dictionary containing the transcribed text and other metadata about the transcription process. If an error occurs, the function returns a string with an error message. | |
| """ | |
| # if video file is there then send the audio field as the content of the video | |
| files = { | |
| "language_behaviour": (None, language_behaviour), | |
| } | |
| # priority given to the video | |
| if video: | |
| audio = video | |
| # priority given to the audio or video | |
| if audio: | |
| files["audio"] = (audio, open(audio, "rb"), "audio/wav") | |
| else: | |
| files["audio_url"] = ((None, audio_url),) | |
| # if language is manual then send the language field | |
| # if it's there for language_behaviour == automatic* | |
| # it will ignored anyways | |
| if language_behaviour == "manual": | |
| files["language"] = (None, language) | |
| start_transfer = time() | |
| response = requests.post( | |
| "https://api.gladia.io/audio/text/audio-transcription/", | |
| headers=headers, | |
| files=files, | |
| ) | |
| end_transfer = time() | |
| if response.status_code != 200: | |
| print(response.content, response.status_code) | |
| return "Sorry, an error occured with your request :/" | |
| # we have 2 outputs: | |
| # prediction and prediction_raw | |
| # prediction_raw has more details about the processing | |
| # and other debugging detailed element you might be | |
| # interested in | |
| output = response.json()["prediction_raw"] | |
| output["metadata"]["client_total_execution_time"] = end_transfer - start_transfer | |
| output["metadata"]["data_transfer_time"] = output["metadata"]["client_total_execution_time"] -output["metadata"]["total_transcription_time"] | |
| output["metadata"]["api_server_transcription_time"] = output["metadata"]["total_transcription_time"] | |
| del output["metadata"]["original_mediainfo"] | |
| return output | |
| iface = gr.Interface( | |
| title="Gladia.io fast audio transcription", | |
| description="""Gladia.io Whisper large-v2 fast audio transcription API | |
| is able to perform fast audio transcription for any audio / video or url format.<br/><br/> | |
| However it's prefered for faster performance to provide <br/> | |
| wav 16KHz with 16b encoding (pcm_u16be) to avoid further the conversion time.<br/> | |
| "automatic single language" language discovery behavior may also<br/> | |
| slow down (just a little bit - talking about ms) the process. | |
| <br/> | |
| Here is a benchmark ran on multiple Speech-To-Text providers | |
| 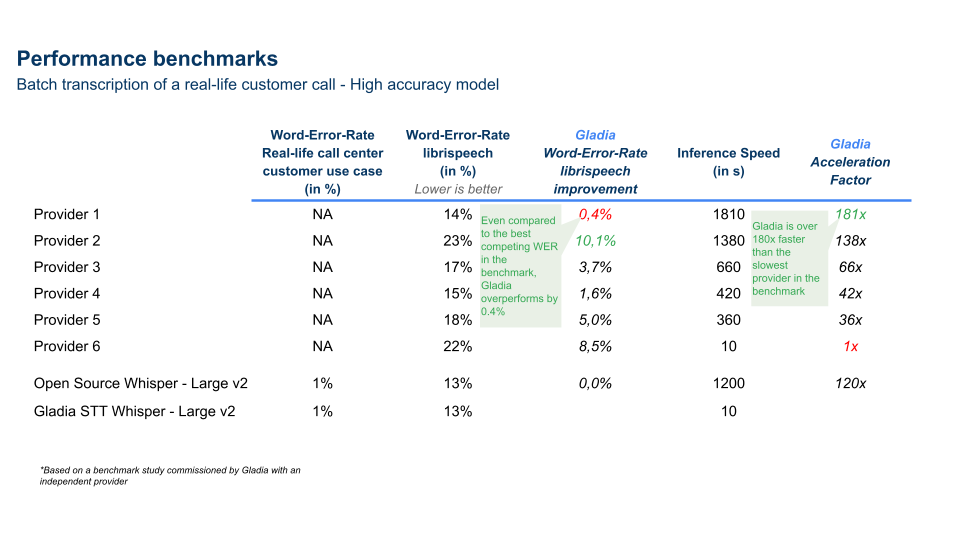<br/> | |
| Join our [Slack](https://gladia-io.slack.com) to discuss with us.<br/><br/> | |
| Get your own API key on [Gladia.io](https://gladia.io/) during free alpha | |
| """, | |
| fn=transcribe, | |
| inputs=[ | |
| gr.Textbox( | |
| lines=1, | |
| label="Audio/Video url to transcribe", | |
| ), | |
| gr.Audio(label="or Audio file to transcribe", source="upload", type="filepath"), | |
| gr.Video(label="or Video file to transcribe", source="upload", type="filepath"), | |
| gr.Dropdown( | |
| label="""Language transcription behaviour:\n | |
| If "manual", the language field must be provided and the API will transcribe the audio in the given language. | |
| If "automatic single language", the language of the audio will be automatically detected by the API | |
| but will force the transcription to be in a single language. | |
| If "automatic multiple languages", the language of the audio will be automatically detected by the API for | |
| each sentence allowing code-switching over 97 languages. | |
| """, | |
| choices=ACCEPTED_LANGUAGE_BEHAVIOUR, | |
| value=ACCEPTED_LANGUAGE_BEHAVIOUR[1] | |
| ), | |
| gr.Dropdown( | |
| choices=sorted([language_name for language_name in LANGUAGES.keys()]), | |
| label="Language (only if language behaviour is set to manual)", | |
| value="english" | |
| ), | |
| ], | |
| outputs="json", | |
| ) | |
| iface.queue() | |
| iface.launch() | |