Spaces:
Runtime error

A newer version of the Gradio SDK is available:
5.8.0
Run Table Tasks with TAPEX
TAPEX is a table pre-training approach for table-related tasks. By learning a neural SQL executor over a synthetic corpus based on generative language models (e.g., BART), it achieves state-of-the-art performance on several table-based question answering benchmarks and table-based fact verification benchmark. More details can be found in the original paper TAPEX: Table Pre-training via Learning a Neural SQL Executor.
If you are also familiar with fairseq, you may also find the official implementation useful, which leverages the framework.
Table Question Answering Tasks
What is Table Question Answering

The task of Table Question Answering (TableQA) is to empower machines to answer users' questions over a given table. The resulting answer(s) can be a region in the table, or a number calculated by applying aggregation operators to a specific region.
What Questions Can be Answered
Benefiting from the powerfulness of generative models, TAPEX can deal with almost all kinds of questions over tables (if there is training data). Below are some typical question and their answers taken from WikiTableQuestion.
| Question | Answer |
|---|---|
| What is the years won for each team? | 2004, 2008, 2012 |
| How long did Taiki Tsuchiya last? | 4:27 |
| What is the total amount of matches drawn? | 1 |
| Besides Tiger Woods, what other player won between 2007 and 2009? | Camilo Villegas |
| What was the last Baekje Temple? | Uija |
| What is the difference between White voters and Black voters in 1948? | 0 |
| What is the average number of sailors for each country during the worlds qualification tournament? | 2 |
How to Fine-tune TAPEX on TableQA
We provide a fine-tuning script of tapex for TableQA on the WikiSQL benchmark: WikiSQL.
This script is customized for tapex models, and can be easily adapted to other benchmarks such as WikiTableQuestion
(only some tweaks in the function preprocess_tableqa_function).
TAPEX-Base on WikiSQL
Here is how to run the script on the WikiSQL with tapex-base:
The default hyper-parameter may allow you to reproduce our reported tapex-base results within the memory budget of 16GB and 1 GPU card. If you have more GPU cards, you could reduce
gradient_accumulation_stepsaccordingly.
export EXP_NAME=wikisql_tapex_base
python run_wikisql_with_tapex.py \
--do_train \
--do_eval \
--output_dir $EXP_NAME \
--model_name_or_path microsoft/tapex-base \
--overwrite_output_dir \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 8 \
--per_device_eval_batch_size 4 \
--learning_rate 3e-5 \
--logging_steps 10 \
--eval_steps 1000 \
--save_steps 1000 \
--warmup_steps 1000 \
--evaluation_strategy steps \
--predict_with_generate \
--num_beams 5 \
--weight_decay 1e-2 \
--label_smoothing_factor 0.1 \
--max_steps 20000
TAPEX-Large on WikiSQL
Here is how to run the script on the WikiSQL with tapex-large:
The default hyper-parameter may allow you to reproduce our reported tapex-large results within the memory budget of 16GB and 1 GPU card with fp16. If you have more GPU cards, you could reduce
gradient_accumulation_stepsaccordingly. If you do not install apex or other mixed-precision-training libs, you could disable thepredict_with_generateoption to save GPU memory and manually evaluate the model once the fine-tuning finished. Or just pick up the last checkpoint, which usually performs good enough on the dataset.
export EXP_NAME=wikisql_tapex_large
python run_wikisql_with_tapex.py \
--do_train \
--do_eval \
--output_dir $EXP_NAME \
--model_name_or_path microsoft/tapex-large \
--overwrite_output_dir \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 32 \
--per_device_eval_batch_size 4 \
--learning_rate 3e-5 \
--logging_steps 10 \
--eval_steps 1000 \
--save_steps 1000 \
--warmup_steps 1000 \
--evaluation_strategy steps \
--predict_with_generate \
--num_beams 5 \
--weight_decay 1e-2 \
--label_smoothing_factor 0.1 \
--max_steps 20000 \
--fp16
TAPEX-Base on WikiTableQuestions
Here is how to run the script on the WikiTableQuestions with tapex-base:
The default hyper-parameter may allow you to reproduce our reported tapex-base results within the memory budget of 16GB and 1 GPU card. If you have more GPU cards, you could reduce
gradient_accumulation_stepsaccordingly.
export EXP_NAME=wikitablequestions_tapex_base
python run_wikitablequestions_with_tapex.py \
--do_train \
--do_eval \
--output_dir $EXP_NAME \
--model_name_or_path microsoft/tapex-base \
--overwrite_output_dir \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 8 \
--per_device_eval_batch_size 4 \
--learning_rate 3e-5 \
--logging_steps 10 \
--eval_steps 1000 \
--save_steps 1000 \
--warmup_steps 1000 \
--evaluation_strategy steps \
--predict_with_generate \
--num_beams 5 \
--weight_decay 1e-2 \
--label_smoothing_factor 0.1 \
--max_steps 20000
TAPEX-Large on WikiTableQuestions
Here is how to run the script on the WikiTableQuestions with tapex-large:
The default hyper-parameter may allow you to reproduce our reported tapex-large results within the memory budget of 16GB and 1 GPU card with fp16. If you have more GPU cards, you could reduce
gradient_accumulation_stepsaccordingly. If you do not install apex or other mixed-precision-training libs, you could reduce theper_device_train_batch_sizeandper_device_eval_batch_sizeand have another try. Or you could disable thepredict_with_generateoption to save GPU memory and manually evaluate the model once the fine-tuning finished. Or just pick up the last checkpoint, which usually performs good enough on the dataset.
export EXP_NAME=wikitablequestions_tapex_large
python run_wikitablequestions_with_tapex.py \
--do_train \
--do_eval \
--output_dir $EXP_NAME \
--model_name_or_path microsoft/tapex-large \
--overwrite_output_dir \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 12 \
--per_device_eval_batch_size 4 \
--learning_rate 3e-5 \
--logging_steps 10 \
--eval_steps 1000 \
--save_steps 1000 \
--warmup_steps 1000 \
--evaluation_strategy steps \
--predict_with_generate \
--num_beams 5 \
--weight_decay 1e-2 \
--label_smoothing_factor 0.1 \
--max_steps 20000 \
--fp16
How to Evaluate TAPEX Fine-tuned Models on TableQA
We provide fine-tuned model weights to reproduce our results. You can evaluate them using the following command:
You can also replace
microsoft/tapex-base-finetuned-wikisqlwith your local directory to evaluate your fine-tuned models. Notice that if the model has a larger size, you should reduceper_device_eval_batch_sizeto fit the memory requirement.
export EXP_NAME=wikisql_tapex_base_eval
python run_wikisql_with_tapex.py \
--do_eval \
--model_name_or_path microsoft/tapex-base-finetuned-wikisql \
--output_dir $EXP_NAME \
--per_device_eval_batch_size 4 \
--predict_with_generate \
--num_beams 5
Table Fact Verification Tasks
What is Table Fact Verification
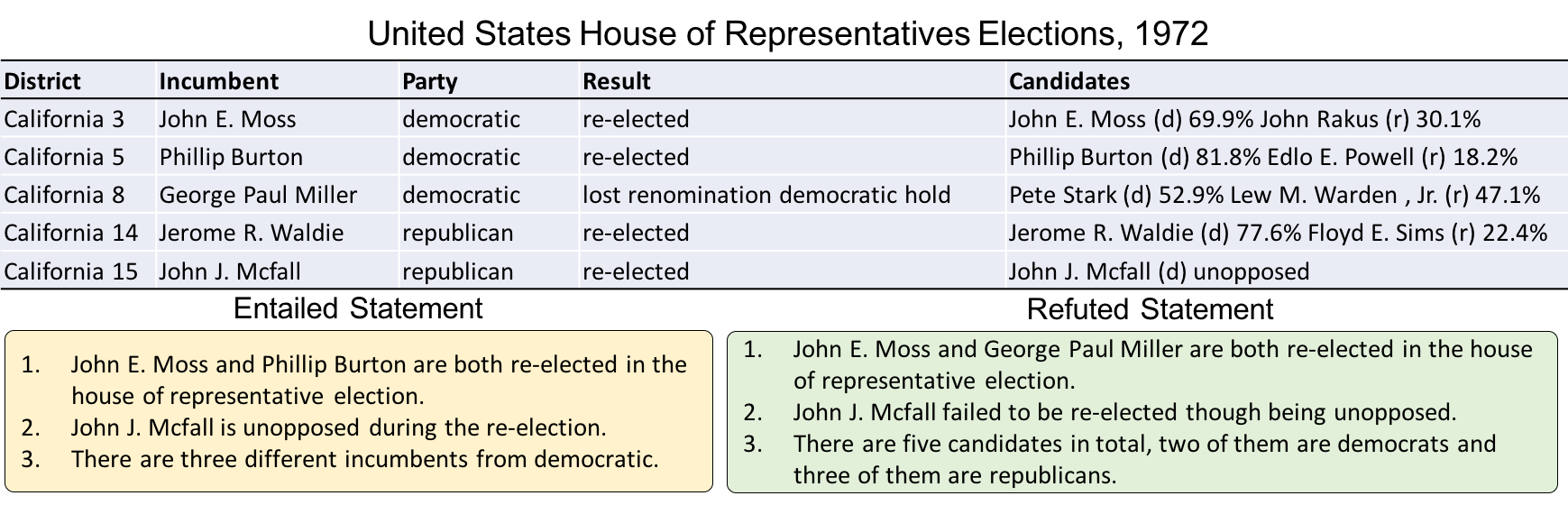
The task of Table Fact Verification (TableFV) is to empower machines to justify if a statement follows facts in a given table. The result is a binary classification belonging to 1 (entailed) or 0 (refused).
How to Fine-tune TAPEX on TableFV
TAPEX-Base on TabFact
We provide a fine-tuning script of tapex for TableFV on the TabFact benchmark: TabFact.
Here is how to run the script on the TabFact:
The default hyper-parameter may allow you to reproduce our reported tapex-base results within the memory budget of 16GB and 1 GPU card. If you have more GPU cards, you could reduce
gradient_accumulation_stepsaccordingly. Note that theeval_accumulation_stepsis necessary, otherwise GPU memory leaks will occur during the evaluation.
export EXP_NAME=tabfact_tapex_base
python run_tabfact_with_tapex.py \
--do_train \
--do_eval \
--output_dir $EXP_NAME \
--model_name_or_path microsoft/tapex-base \
--overwrite_output_dir \
--per_device_train_batch_size 3 \
--gradient_accumulation_steps 16 \
--per_device_eval_batch_size 12 \
--eval_accumulation_steps 6 \
--warm_steps 1000 \
--logging_steps 10 \
--learning_rate 3e-5 \
--eval_steps 1000 \
--save_steps 1000 \
--evaluation_strategy steps \
--weight_decay 1e-2 \
--max_steps 30000 \
--max_grad_norm 0.1
TAPEX-Large on TabFact
Here is how to run the script on the TabFact:
The default hyper-parameter may allow you to reproduce our reported tapex-base results within the memory budget of 24GB and 1 GPU card. Sorry we cannot reduce the memory consumption since the model input in TabFact usually contains nearly ~1000 tokens. If you have more GPU cards, you could reduce
gradient_accumulation_stepsaccordingly. Note that theeval_accumulation_stepsis necessary, otherwise GPU memory leaks will occur during the evaluation.
export EXP_NAME=tabfact_tapex_large
python run_tabfact_with_tapex.py \
--do_train \
--do_eval \
--output_dir $EXP_NAME \
--model_name_or_path microsoft/tapex-large \
--overwrite_output_dir \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 18 \
--per_device_eval_batch_size 4 \
--eval_accumulation_steps 12 \
--warm_steps 1000 \
--logging_steps 10 \
--learning_rate 3e-5 \
--eval_steps 1000 \
--save_steps 1000 \
--evaluation_strategy steps \
--weight_decay 1e-2 \
--max_steps 30000 \
--max_grad_norm 0.1
How to Evaluate TAPEX Fine-tuned Models on TableFV
We provide fine-tuned model weights to reproduce our results. You can evaluate them using the following command:
You can also replace
microsoft/tapex-base-finetuned-tabfactwith your local directory to evaluate your fine-tuned models. Notice that if the model has a larger size, you should reduceper_device_eval_batch_sizeto fit the memory requirement.
export EXP_NAME=tabfact_tapex_base_eval
python run_tabfact_with_tapex.py \
--do_eval \
--model_name_or_path microsoft/tapex-base-finetuned-tabfact \
--output_dir $EXP_NAME \
--per_device_eval_batch_size 12 \
--eval_accumulation_steps 6
Reproduced Results
We get the following results on the dev set of the benchmark with the previous commands:
| Task | Model Size | Metric | Result |
|---|---|---|---|
| WikiSQL (Weak) | Base | Denotation Accuracy | 88.1 |
| WikiSQL (Weak) | Large | Denotation Accuracy | 89.5 |
| WikiTableQuestion | Base | Denotation Accuracy | 47.1 |
| WikiTableQuestion | Large | Denotation Accuracy | 57.2 |
| TabFact | Base | Accuracy | 78.7 |
| TabFact | Large | Accuracy | 83.6 |