

stevengrove
commited on
Commit
•
186701e
1
Parent(s):
d912a42
initial commit
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitignore +127 -0
- README.md +141 -11
- app.py +61 -0
- assets/yolo_arch.png +0 -0
- assets/yolo_logo.png +0 -0
- configs/deploy/detection_onnxruntime-fp16_dynamic.py +18 -0
- configs/deploy/detection_onnxruntime-int8_dynamic.py +20 -0
- configs/deploy/detection_onnxruntime_static.py +18 -0
- configs/deploy/detection_tensorrt-fp16_static-640x640.py +38 -0
- configs/deploy/detection_tensorrt-int8_static-640x640.py +30 -0
- configs/finetune_coco/yolo_world_l_t2i_bn_2e-4_100e_4x8gpus_coco_finetune.py +183 -0
- configs/finetune_coco/yolo_world_m_t2i_bn_2e-4_100e_4x8gpus_coco_finetune.py +183 -0
- configs/finetune_coco/yolo_world_s_t2i_bn_2e-4_100e_4x8gpus_coco_finetune.py +183 -0
- configs/pretrain/yolo_world_l_dual_3block_l2norm_2e-4_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py +173 -0
- configs/pretrain/yolo_world_l_t2i_bn_2e-4_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py +182 -0
- configs/pretrain/yolo_world_m_dual_3block_l2norm_2e-4_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py +173 -0
- configs/pretrain/yolo_world_m_t2i_bn_2e-4_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py +171 -0
- configs/pretrain/yolo_world_s_dual_l2norm_3block_2e-4_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py +173 -0
- configs/pretrain/yolo_world_s_t2i_bn_2e-4_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py +172 -0
- configs/scaleup/yolo_world_l_t2i_bn_2e-4_20e_4x8gpus_obj365v1_goldg_train_lvis_minival_s1024.py +216 -0
- configs/scaleup/yolo_world_l_t2i_bn_2e-4_20e_4x8gpus_obj365v1_goldg_train_lvis_minival_s1280.py +216 -0
- configs/scaleup/yolo_world_l_t2i_bn_2e-4_20e_4x8gpus_obj365v1_goldg_train_lvis_minival_s1280_v2.py +216 -0
- deploy/__init__.py +1 -0
- deploy/models/__init__.py +4 -0
- docs/data.md +19 -0
- docs/deploy.md +0 -0
- docs/install.md +0 -0
- docs/training.md +0 -0
- requirements.txt +1 -0
- setup.py +190 -0
- taiji/drun +35 -0
- taiji/erun +23 -0
- taiji/etorchrun +51 -0
- taiji/jizhi_run_vanilla +105 -0
- third_party/mmyolo/.circleci/config.yml +34 -0
- third_party/mmyolo/.circleci/docker/Dockerfile +11 -0
- third_party/mmyolo/.circleci/test.yml +213 -0
- third_party/mmyolo/.dev_scripts/gather_models.py +312 -0
- third_party/mmyolo/.dev_scripts/print_registers.py +448 -0
- third_party/mmyolo/.github/CODE_OF_CONDUCT.md +76 -0
- third_party/mmyolo/.github/CONTRIBUTING.md +1 -0
- third_party/mmyolo/.github/ISSUE_TEMPLATE/1-bug-report.yml +67 -0
- third_party/mmyolo/.github/ISSUE_TEMPLATE/2-feature-request.yml +32 -0
- third_party/mmyolo/.github/ISSUE_TEMPLATE/3-new-model.yml +30 -0
- third_party/mmyolo/.github/ISSUE_TEMPLATE/4-documentation.yml +22 -0
- third_party/mmyolo/.github/ISSUE_TEMPLATE/5-reimplementation.yml +87 -0
- third_party/mmyolo/.github/ISSUE_TEMPLATE/config.yml +9 -0
- third_party/mmyolo/.github/pull_request_template.md +25 -0
- third_party/mmyolo/.github/workflows/deploy.yml +28 -0
- third_party/mmyolo/.gitignore +126 -0
.gitignore
ADDED
|
@@ -0,0 +1,127 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
*$py.class
|
| 5 |
+
|
| 6 |
+
# C extensions
|
| 7 |
+
*.so
|
| 8 |
+
|
| 9 |
+
# Distribution / packaging
|
| 10 |
+
.Python
|
| 11 |
+
build/
|
| 12 |
+
develop-eggs/
|
| 13 |
+
dist/
|
| 14 |
+
downloads/
|
| 15 |
+
eggs/
|
| 16 |
+
.eggs/
|
| 17 |
+
lib/
|
| 18 |
+
lib64/
|
| 19 |
+
parts/
|
| 20 |
+
sdist/
|
| 21 |
+
var/
|
| 22 |
+
wheels/
|
| 23 |
+
*.egg-info/
|
| 24 |
+
.installed.cfg
|
| 25 |
+
*.egg
|
| 26 |
+
MANIFEST
|
| 27 |
+
|
| 28 |
+
# PyInstaller
|
| 29 |
+
# Usually these files are written by a python script from a template
|
| 30 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 31 |
+
*.manifest
|
| 32 |
+
*.spec
|
| 33 |
+
|
| 34 |
+
# Installer logs
|
| 35 |
+
pip-log.txt
|
| 36 |
+
pip-delete-this-directory.txt
|
| 37 |
+
|
| 38 |
+
# Unit test / coverage reports
|
| 39 |
+
htmlcov/
|
| 40 |
+
.tox/
|
| 41 |
+
.coverage
|
| 42 |
+
.coverage.*
|
| 43 |
+
.cache
|
| 44 |
+
nosetests.xml
|
| 45 |
+
coverage.xml
|
| 46 |
+
*.cover
|
| 47 |
+
.hypothesis/
|
| 48 |
+
.pytest_cache/
|
| 49 |
+
|
| 50 |
+
# Translations
|
| 51 |
+
*.mo
|
| 52 |
+
*.pot
|
| 53 |
+
|
| 54 |
+
# Django stuff:
|
| 55 |
+
*.log
|
| 56 |
+
local_settings.py
|
| 57 |
+
db.sqlite3
|
| 58 |
+
|
| 59 |
+
# Flask stuff:
|
| 60 |
+
instance/
|
| 61 |
+
.webassets-cache
|
| 62 |
+
|
| 63 |
+
# Scrapy stuff:
|
| 64 |
+
.scrapy
|
| 65 |
+
|
| 66 |
+
# Sphinx documentation
|
| 67 |
+
docs/en/_build/
|
| 68 |
+
docs/zh_cn/_build/
|
| 69 |
+
|
| 70 |
+
# PyBuilder
|
| 71 |
+
target/
|
| 72 |
+
|
| 73 |
+
# Jupyter Notebook
|
| 74 |
+
.ipynb_checkpoints
|
| 75 |
+
|
| 76 |
+
# pyenv
|
| 77 |
+
.python-version
|
| 78 |
+
|
| 79 |
+
# celery beat schedule file
|
| 80 |
+
celerybeat-schedule
|
| 81 |
+
|
| 82 |
+
# SageMath parsed files
|
| 83 |
+
*.sage.py
|
| 84 |
+
|
| 85 |
+
# Environments
|
| 86 |
+
.env
|
| 87 |
+
.venv
|
| 88 |
+
env/
|
| 89 |
+
venv/
|
| 90 |
+
ENV/
|
| 91 |
+
env.bak/
|
| 92 |
+
venv.bak/
|
| 93 |
+
|
| 94 |
+
# Spyder project settings
|
| 95 |
+
.spyderproject
|
| 96 |
+
.spyproject
|
| 97 |
+
|
| 98 |
+
# Rope project settings
|
| 99 |
+
.ropeproject
|
| 100 |
+
|
| 101 |
+
# mkdocs documentation
|
| 102 |
+
/site
|
| 103 |
+
|
| 104 |
+
# mypy
|
| 105 |
+
.mypy_cache/
|
| 106 |
+
data/
|
| 107 |
+
data
|
| 108 |
+
.vscode
|
| 109 |
+
.idea
|
| 110 |
+
.DS_Store
|
| 111 |
+
|
| 112 |
+
# custom
|
| 113 |
+
*.pkl
|
| 114 |
+
*.pkl.json
|
| 115 |
+
*.log.json
|
| 116 |
+
docs/modelzoo_statistics.md
|
| 117 |
+
mmdet/.mim
|
| 118 |
+
work_dirs
|
| 119 |
+
|
| 120 |
+
# Pytorch
|
| 121 |
+
*.pth
|
| 122 |
+
*.py~
|
| 123 |
+
*.sh~
|
| 124 |
+
|
| 125 |
+
# venus
|
| 126 |
+
venus_run.sh
|
| 127 |
+
|
README.md
CHANGED
|
@@ -1,11 +1,141 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
<center>
|
| 3 |
+
<img width=500px src="./assets/yolo_logo.png">
|
| 4 |
+
</center>
|
| 5 |
+
<br>
|
| 6 |
+
<a href="https://scholar.google.com/citations?hl=zh-CN&user=PH8rJHYAAAAJ">Tianheng Cheng*</a><sup><span>2,3</span></sup>,
|
| 7 |
+
<a href="https://linsong.info/">Lin Song*</a><sup><span>1</span></sup>,
|
| 8 |
+
<a href="">Yixiao Ge</a><sup><span>1,2</span></sup>,
|
| 9 |
+
<a href="">Xinggang Wang</a><sup><span>3</span></sup>,
|
| 10 |
+
<a href="http://eic.hust.edu.cn/professor/liuwenyu/"> Wenyu Liu</a><sup><span>3</span></sup>,
|
| 11 |
+
<a href="">Ying Shan</a><sup><span>1,2</span></sup>
|
| 12 |
+
</br>
|
| 13 |
+
|
| 14 |
+
<sup>1</sup> Tencent AI Lab, <sup>2</sup> ARC Lab, Tencent PCG
|
| 15 |
+
<sup>3</sup> Huazhong University of Science and Technology
|
| 16 |
+
<br>
|
| 17 |
+
<div>
|
| 18 |
+
|
| 19 |
+
[](https://arxiv.org/abs/)
|
| 20 |
+
[](https://huggingface.co/)
|
| 21 |
+
[](LICENSE)
|
| 22 |
+
|
| 23 |
+
</div>
|
| 24 |
+
</div>
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
## Updates
|
| 28 |
+
|
| 29 |
+
`[2024-1-25]:` We are excited to launch **YOLO-World**, a cutting-edge real-time open-vocabulary object detector.
|
| 30 |
+
|
| 31 |
+
## Highlights
|
| 32 |
+
|
| 33 |
+
This repo contains the PyTorch implementation, pre-trained weights, and pre-training/fine-tuning code for YOLO-World.
|
| 34 |
+
|
| 35 |
+
* YOLO-World is pre-trained on large-scale datasets, including detection, grounding, and image-text datasets.
|
| 36 |
+
|
| 37 |
+
* YOLO-World is the next-generation YOLO detector, with a strong open-vocabulary detection capability and grounding ability.
|
| 38 |
+
|
| 39 |
+
* YOLO-World presents a *prompt-then-detect* paradigm for efficient user-vocabulary inference, which re-parameterizes vocabulary embeddings as parameters into the model and achieve superior inference speed. You can try to export your own detection model without extra training or fine-tuning in our [online demo]()!
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
<center>
|
| 43 |
+
<img width=800px src="./assets/yolo_arch.png">
|
| 44 |
+
</center>
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
## Abstract
|
| 48 |
+
|
| 49 |
+
The You Only Look Once (YOLO) series of detectors have established themselves as efficient and practical tools. However, their reliance on predefined and trained object categories limits their applicability in open scenarios. Addressing this limitation, we introduce YOLO-World, an innovative approach that enhances YOLO with open-vocabulary detection capabilities through vision-language modeling and pre-training on large-scale datasets. Specifically, we propose a new Re-parameterizable Vision-Language Path Aggregation Network (RepVL-PAN) and region-text contrastive loss to facilitate the interaction between visual and linguistic information. Our method excels in detecting a wide range of objects in a zero-shot manner with high efficiency. On the challenging LVIS dataset, YOLO-World achieves 35.4 AP with 52.0 FPS on V100, which outperforms many state-of-the-art methods in terms of both accuracy and speed. Furthermore, the fine-tuned YOLO-World achieves remarkable performance on several downstream tasks, including object detection and open-vocabulary instance segmentation.
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
## Demo
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
## Main Results
|
| 56 |
+
|
| 57 |
+
We've pre-trained YOLO-World-S/M/L from scratch and evaluate on the `LVIS val-1.0` and `LVIS minival`. We provide the pre-trained model weights and training logs for applications/research or re-producing the results.
|
| 58 |
+
|
| 59 |
+
### Zero-shot Inference on LVIS dataset
|
| 60 |
+
|
| 61 |
+
| model | Pre-train Data | AP | AP<sub>r</sub> | AP<sub>c</sub> | AP<sub>f</sub> | FPS(V100) | weights | log |
|
| 62 |
+
| :---- | :------------- | :-:| :------------: |:-------------: | :-------: | :-----: | :---: | :---: |
|
| 63 |
+
| [YOLO-World-S](./configs/pretrain/yolo_world_s_t2i_bn_2e-4_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py) | O365+GoldG | 17.6 | 11.9 | 14.5 | 23.2 | - | [wecom](https://drive.weixin.qq.com/s?k=AJEAIQdfAAoREsieRl) | [log]() |
|
| 64 |
+
| [YOLO-World-M](./configs/pretrain/yolo_world_m_t2i_bn_2e-4_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py) | O365+GoldG | 23.5 | 17.2 | 20.4 | 29.6 | - | [wecom](https://drive.weixin.qq.com/s?k=AJEAIQdfAAoj0byBC0) | [log]() |
|
| 65 |
+
| [YOLO-World-L](./configs/pretrain/yolo_world_l_t2i_bn_2e-4_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py) | O365+GoldG | 25.7 | 18.7 | 22.6 | 32.2 | - | [wecom](https://drive.weixin.qq.com/s?k=AJEAIQdfAAoK06oxO2) | [log]() |
|
| 66 |
+
|
| 67 |
+
**NOTE:**
|
| 68 |
+
1. The evaluation results are tested on LVIS minival in a zero-shot manner.
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
## Getting started
|
| 72 |
+
|
| 73 |
+
### 1. Installation
|
| 74 |
+
|
| 75 |
+
YOLO-World is developed based on `torch==1.11.0` `mmyolo==0.6.0` and `mmdetection==3.0.0`.
|
| 76 |
+
|
| 77 |
+
```bash
|
| 78 |
+
# install key dependencies
|
| 79 |
+
pip install mmdetection==3.0.0 mmengine transformers
|
| 80 |
+
|
| 81 |
+
# clone the repo
|
| 82 |
+
git clone https://xxxx.YOLO-World.git
|
| 83 |
+
cd YOLO-World
|
| 84 |
+
|
| 85 |
+
# install mmyolo
|
| 86 |
+
mkdir third_party
|
| 87 |
+
git clone https://github.com/open-mmlab/mmyolo.git
|
| 88 |
+
cd ..
|
| 89 |
+
|
| 90 |
+
```
|
| 91 |
+
|
| 92 |
+
### 2. Preparing Data
|
| 93 |
+
|
| 94 |
+
We provide the details about the pre-training data in [docs/data](./docs/data.md).
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
## Training & Evaluation
|
| 98 |
+
|
| 99 |
+
We adopt the default [training](./tools/train.py) or [evaluation](./tools/test.py) scripts of [mmyolo](https://github.com/open-mmlab/mmyolo).
|
| 100 |
+
We provide the configs for pre-training and fine-tuning in `configs/pretrain` and `configs/finetune_coco`.
|
| 101 |
+
Training YOLO-World is easy:
|
| 102 |
+
|
| 103 |
+
```bash
|
| 104 |
+
chmod +x tools/dist_train.sh
|
| 105 |
+
# sample command for pre-training, use AMP for mixed-precision training
|
| 106 |
+
./tools/dist_train.sh configs/pretrain/yolo_world_l_t2i_bn_2e-4_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py 8 --amp
|
| 107 |
+
```
|
| 108 |
+
**NOTE:** YOLO-World is pre-trained on 4 nodes with 8 GPUs per node (32 GPUs in total). For pre-training, the `node_rank` and `nnodes` for multi-node training should be specified.
|
| 109 |
+
|
| 110 |
+
Evalutating YOLO-World is also easy:
|
| 111 |
+
|
| 112 |
+
```bash
|
| 113 |
+
chmod +x tools/dist_test.sh
|
| 114 |
+
./tools/dist_test.sh path/to/config path/to/weights 8
|
| 115 |
+
```
|
| 116 |
+
|
| 117 |
+
**NOTE:** We mainly evaluate the performance on LVIS-minival for pre-training.
|
| 118 |
+
|
| 119 |
+
## Deployment
|
| 120 |
+
|
| 121 |
+
We provide the details about deployment for downstream applications in [docs/deployment](./docs/deploy.md).
|
| 122 |
+
You can directly download the ONNX model through the online [demo]() in Huggingface Spaces 🤗.
|
| 123 |
+
|
| 124 |
+
## Acknowledgement
|
| 125 |
+
|
| 126 |
+
We sincerely thank [mmyolo](https://github.com/open-mmlab/mmyolo), [mmdetection](https://github.com/open-mmlab/mmdetection), and [transformers](https://github.com/huggingface/transformers) for providing their wonderful code to the community!
|
| 127 |
+
|
| 128 |
+
## Citations
|
| 129 |
+
If you find YOLO-World is useful in your research or applications, please consider giving us a star 🌟 and citing it.
|
| 130 |
+
|
| 131 |
+
```bibtex
|
| 132 |
+
@article{cheng2024yolow,
|
| 133 |
+
title={YOLO-World: Real-Time Open-Vocabulary Object Detection},
|
| 134 |
+
author={Cheng, Tianheng and Song, Lin and Ge, Yixiao and Liu, Wenyu and Wang, Xinggang and Shan, Ying},
|
| 135 |
+
journal={arXiv preprint arXiv:},
|
| 136 |
+
year={2024}
|
| 137 |
+
}
|
| 138 |
+
```
|
| 139 |
+
|
| 140 |
+
## Licence
|
| 141 |
+
YOLO-World is under the GPL-v3 Licence and is supported for comercial usage.
|
app.py
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import os.path as osp
|
| 3 |
+
|
| 4 |
+
from mmengine.config import Config, DictAction
|
| 5 |
+
from mmengine.runner import Runner
|
| 6 |
+
from mmengine.dataset import Compose
|
| 7 |
+
from mmyolo.registry import RUNNERS
|
| 8 |
+
|
| 9 |
+
from tools.demo import demo
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def parse_args():
|
| 13 |
+
parser = argparse.ArgumentParser(
|
| 14 |
+
description='YOLO-World Demo')
|
| 15 |
+
parser.add_argument('--config', default='configs/pretrain/yolo_world_l_t2i_bn_2e-4_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py')
|
| 16 |
+
parser.add_argument('--checkpoint', default='model_zoo/yolow-v8_l_clipv2_frozen_t2iv2_bn_o365_goldg_pretrain.pth')
|
| 17 |
+
parser.add_argument(
|
| 18 |
+
'--work-dir',
|
| 19 |
+
help='the directory to save the file containing evaluation metrics')
|
| 20 |
+
parser.add_argument(
|
| 21 |
+
'--cfg-options',
|
| 22 |
+
nargs='+',
|
| 23 |
+
action=DictAction,
|
| 24 |
+
help='override some settings in the used config, the key-value pair '
|
| 25 |
+
'in xxx=yyy format will be merged into config file. If the value to '
|
| 26 |
+
'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
|
| 27 |
+
'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
|
| 28 |
+
'Note that the quotation marks are necessary and that no white space '
|
| 29 |
+
'is allowed.')
|
| 30 |
+
args = parser.parse_args()
|
| 31 |
+
return args
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
if __name__ == '__main__':
|
| 35 |
+
args = parse_args()
|
| 36 |
+
|
| 37 |
+
# load config
|
| 38 |
+
cfg = Config.fromfile(args.config)
|
| 39 |
+
if args.cfg_options is not None:
|
| 40 |
+
cfg.merge_from_dict(args.cfg_options)
|
| 41 |
+
|
| 42 |
+
if args.work_dir is not None:
|
| 43 |
+
cfg.work_dir = args.work_dir
|
| 44 |
+
elif cfg.get('work_dir', None) is None:
|
| 45 |
+
cfg.work_dir = osp.join('./work_dirs',
|
| 46 |
+
osp.splitext(osp.basename(args.config))[0])
|
| 47 |
+
|
| 48 |
+
cfg.load_from = args.checkpoint
|
| 49 |
+
|
| 50 |
+
if 'runner_type' not in cfg:
|
| 51 |
+
runner = Runner.from_cfg(cfg)
|
| 52 |
+
else:
|
| 53 |
+
runner = RUNNERS.build(cfg)
|
| 54 |
+
|
| 55 |
+
runner.call_hook('before_run')
|
| 56 |
+
runner.load_or_resume()
|
| 57 |
+
pipeline = cfg.test_dataloader.dataset.pipeline
|
| 58 |
+
runner.pipeline = Compose(pipeline)
|
| 59 |
+
runner.model.eval()
|
| 60 |
+
demo(runner, args)
|
| 61 |
+
|
assets/yolo_arch.png
ADDED
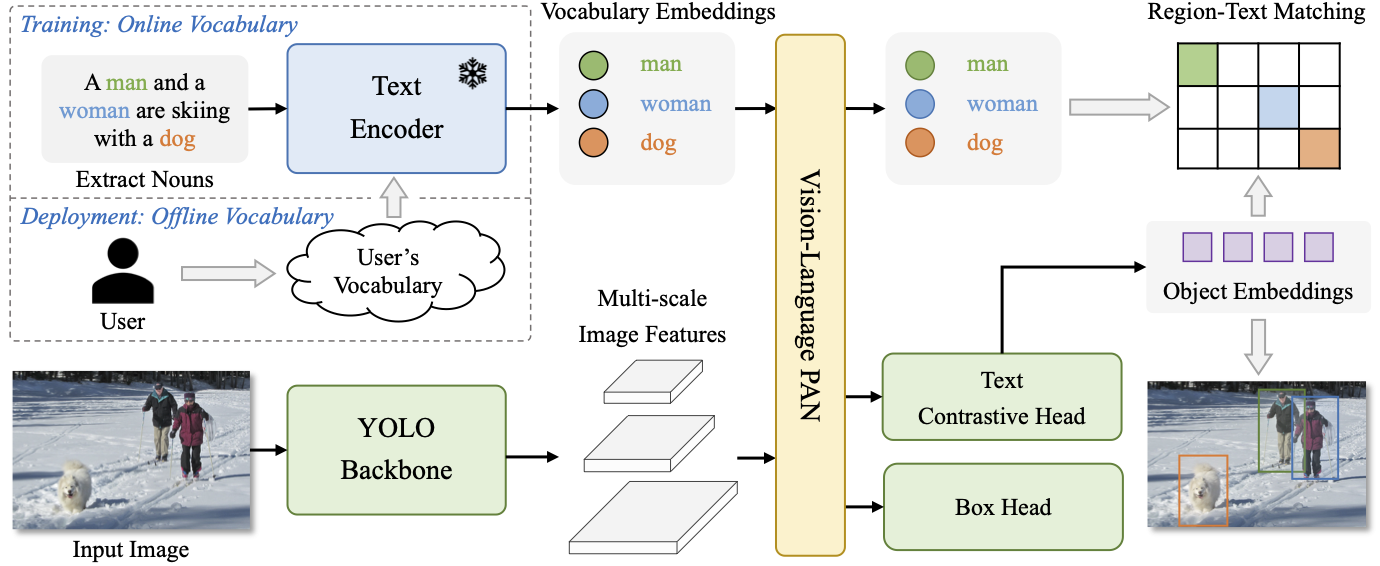
|
assets/yolo_logo.png
ADDED
|
|
configs/deploy/detection_onnxruntime-fp16_dynamic.py
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = (
|
| 2 |
+
'../../third_party/mmdeploy/configs/mmdet/detection/'
|
| 3 |
+
'detection_onnxruntime-fp16_dynamic.py')
|
| 4 |
+
codebase_config = dict(
|
| 5 |
+
type='mmyolo',
|
| 6 |
+
task='ObjectDetection',
|
| 7 |
+
model_type='end2end',
|
| 8 |
+
post_processing=dict(
|
| 9 |
+
score_threshold=0.1,
|
| 10 |
+
confidence_threshold=0.005,
|
| 11 |
+
iou_threshold=0.3,
|
| 12 |
+
max_output_boxes_per_class=100,
|
| 13 |
+
pre_top_k=1000,
|
| 14 |
+
keep_top_k=100,
|
| 15 |
+
background_label_id=-1),
|
| 16 |
+
module=['mmyolo.deploy'])
|
| 17 |
+
backend_config = dict(
|
| 18 |
+
type='onnxruntime')
|
configs/deploy/detection_onnxruntime-int8_dynamic.py
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = (
|
| 2 |
+
'../../third_party/mmdeploy/configs/mmdet/detection/'
|
| 3 |
+
'detection_onnxruntime-fp16_dynamic.py')
|
| 4 |
+
backend_config = dict(
|
| 5 |
+
precision='int8')
|
| 6 |
+
codebase_config = dict(
|
| 7 |
+
type='mmyolo',
|
| 8 |
+
task='ObjectDetection',
|
| 9 |
+
model_type='end2end',
|
| 10 |
+
post_processing=dict(
|
| 11 |
+
score_threshold=0.1,
|
| 12 |
+
confidence_threshold=0.005,
|
| 13 |
+
iou_threshold=0.3,
|
| 14 |
+
max_output_boxes_per_class=100,
|
| 15 |
+
pre_top_k=1000,
|
| 16 |
+
keep_top_k=100,
|
| 17 |
+
background_label_id=-1),
|
| 18 |
+
module=['mmyolo.deploy'])
|
| 19 |
+
backend_config = dict(
|
| 20 |
+
type='onnxruntime')
|
configs/deploy/detection_onnxruntime_static.py
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = (
|
| 2 |
+
'../../third_party/mmyolo/configs/deploy/'
|
| 3 |
+
'detection_onnxruntime_static.py')
|
| 4 |
+
codebase_config = dict(
|
| 5 |
+
type='mmyolo',
|
| 6 |
+
task='ObjectDetection',
|
| 7 |
+
model_type='end2end',
|
| 8 |
+
post_processing=dict(
|
| 9 |
+
score_threshold=0.25,
|
| 10 |
+
confidence_threshold=0.005,
|
| 11 |
+
iou_threshold=0.65,
|
| 12 |
+
max_output_boxes_per_class=200,
|
| 13 |
+
pre_top_k=1000,
|
| 14 |
+
keep_top_k=100,
|
| 15 |
+
background_label_id=-1),
|
| 16 |
+
module=['mmyolo.deploy'])
|
| 17 |
+
backend_config = dict(
|
| 18 |
+
type='onnxruntime')
|
configs/deploy/detection_tensorrt-fp16_static-640x640.py
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = (
|
| 2 |
+
'../../third_party/mmyolo/configs/deploy/'
|
| 3 |
+
'detection_tensorrt-fp16_static-640x640.py')
|
| 4 |
+
onnx_config = dict(
|
| 5 |
+
type='onnx',
|
| 6 |
+
export_params=True,
|
| 7 |
+
keep_initializers_as_inputs=False,
|
| 8 |
+
opset_version=11,
|
| 9 |
+
save_file='end2end.onnx',
|
| 10 |
+
input_names=['input'],
|
| 11 |
+
output_names=['dets', 'labels'],
|
| 12 |
+
input_shape=(640, 640),
|
| 13 |
+
optimize=True)
|
| 14 |
+
backend_config = dict(
|
| 15 |
+
type='tensorrt',
|
| 16 |
+
common_config=dict(fp16_mode=True, max_workspace_size=1 << 34),
|
| 17 |
+
model_inputs=[
|
| 18 |
+
dict(
|
| 19 |
+
input_shapes=dict(
|
| 20 |
+
input=dict(
|
| 21 |
+
min_shape=[1, 3, 640, 640],
|
| 22 |
+
opt_shape=[1, 3, 640, 640],
|
| 23 |
+
max_shape=[1, 3, 640, 640])))
|
| 24 |
+
])
|
| 25 |
+
use_efficientnms = False # whether to replace TRTBatchedNMS plugin with EfficientNMS plugin # noqa E501
|
| 26 |
+
codebase_config = dict(
|
| 27 |
+
type='mmyolo',
|
| 28 |
+
task='ObjectDetection',
|
| 29 |
+
model_type='end2end',
|
| 30 |
+
post_processing=dict(
|
| 31 |
+
score_threshold=0.25,
|
| 32 |
+
confidence_threshold=0.005,
|
| 33 |
+
iou_threshold=0.65,
|
| 34 |
+
max_output_boxes_per_class=100,
|
| 35 |
+
pre_top_k=1,
|
| 36 |
+
keep_top_k=1,
|
| 37 |
+
background_label_id=-1),
|
| 38 |
+
module=['mmyolo.deploy'])
|
configs/deploy/detection_tensorrt-int8_static-640x640.py
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = [
|
| 2 |
+
'../../third_party/mmdeploy/configs/mmdet/_base_/base_static.py',
|
| 3 |
+
'../../third_party/mmdeploy/configs/_base_/backends/tensorrt-int8.py']
|
| 4 |
+
|
| 5 |
+
onnx_config = dict(input_shape=(640, 640))
|
| 6 |
+
|
| 7 |
+
backend_config = dict(
|
| 8 |
+
common_config=dict(max_workspace_size=1 << 30),
|
| 9 |
+
model_inputs=[
|
| 10 |
+
dict(
|
| 11 |
+
input_shapes=dict(
|
| 12 |
+
input=dict(
|
| 13 |
+
min_shape=[1, 3, 640, 640],
|
| 14 |
+
opt_shape=[1, 3, 640, 640],
|
| 15 |
+
max_shape=[1, 3, 640, 640])))
|
| 16 |
+
])
|
| 17 |
+
|
| 18 |
+
codebase_config = dict(
|
| 19 |
+
type='mmyolo',
|
| 20 |
+
task='ObjectDetection',
|
| 21 |
+
model_type='end2end',
|
| 22 |
+
post_processing=dict(
|
| 23 |
+
score_threshold=0.1,
|
| 24 |
+
confidence_threshold=0.005,
|
| 25 |
+
iou_threshold=0.3,
|
| 26 |
+
max_output_boxes_per_class=100,
|
| 27 |
+
pre_top_k=1000,
|
| 28 |
+
keep_top_k=100,
|
| 29 |
+
background_label_id=-1),
|
| 30 |
+
module=['mmyolo.deploy'])
|
configs/finetune_coco/yolo_world_l_t2i_bn_2e-4_100e_4x8gpus_coco_finetune.py
ADDED
|
@@ -0,0 +1,183 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_l_mask-refine_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'],
|
| 4 |
+
allow_failed_imports=False)
|
| 5 |
+
|
| 6 |
+
# hyper-parameters
|
| 7 |
+
num_classes = 80
|
| 8 |
+
num_training_classes = 80
|
| 9 |
+
max_epochs = 80 # Maximum training epochs
|
| 10 |
+
close_mosaic_epochs = 10
|
| 11 |
+
save_epoch_intervals = 5
|
| 12 |
+
text_channels = 512
|
| 13 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 14 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 15 |
+
base_lr = 2e-4
|
| 16 |
+
weight_decay = 0.05
|
| 17 |
+
train_batch_size_per_gpu = 16
|
| 18 |
+
load_from = 'weights/yolow-v8_l_clipv2_frozen_t2iv2_bn_o365_goldg_pretrain.pth'
|
| 19 |
+
persistent_workers = False
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
# model settings
|
| 23 |
+
model = dict(
|
| 24 |
+
type='YOLOWorldDetector',
|
| 25 |
+
mm_neck=True,
|
| 26 |
+
num_train_classes=num_training_classes,
|
| 27 |
+
num_test_classes=num_classes,
|
| 28 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 29 |
+
backbone=dict(
|
| 30 |
+
_delete_=True,
|
| 31 |
+
type='MultiModalYOLOBackbone',
|
| 32 |
+
image_model={{_base_.model.backbone}},
|
| 33 |
+
text_model=dict(
|
| 34 |
+
type='HuggingCLIPLanguageBackbone',
|
| 35 |
+
model_name='pretrained_models/clip-vit-base-patch32-projection',
|
| 36 |
+
frozen_modules=['all'])),
|
| 37 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 38 |
+
guide_channels=text_channels,
|
| 39 |
+
embed_channels=neck_embed_channels,
|
| 40 |
+
num_heads=neck_num_heads,
|
| 41 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv'),
|
| 42 |
+
num_csp_blocks=2),
|
| 43 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 44 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 45 |
+
embed_dims=text_channels,
|
| 46 |
+
use_bn_head=True,
|
| 47 |
+
num_classes=num_training_classes)),
|
| 48 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 49 |
+
|
| 50 |
+
# dataset settings
|
| 51 |
+
text_transform = [
|
| 52 |
+
dict(type='RandomLoadText',
|
| 53 |
+
num_neg_samples=(num_classes, num_classes),
|
| 54 |
+
max_num_samples=num_training_classes,
|
| 55 |
+
padding_to_max=True,
|
| 56 |
+
padding_value=''),
|
| 57 |
+
dict(type='mmdet.PackDetInputs',
|
| 58 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 59 |
+
'flip_direction', 'texts'))
|
| 60 |
+
]
|
| 61 |
+
mosaic_affine_transform = [
|
| 62 |
+
dict(
|
| 63 |
+
type='MultiModalMosaic',
|
| 64 |
+
img_scale=_base_.img_scale,
|
| 65 |
+
pad_val=114.0,
|
| 66 |
+
pre_transform=_base_.pre_transform),
|
| 67 |
+
dict(type='YOLOv5CopyPaste', prob=_base_.copypaste_prob),
|
| 68 |
+
dict(
|
| 69 |
+
type='YOLOv5RandomAffine',
|
| 70 |
+
max_rotate_degree=0.0,
|
| 71 |
+
max_shear_degree=0.0,
|
| 72 |
+
max_aspect_ratio=100.,
|
| 73 |
+
scaling_ratio_range=(1 - _base_.affine_scale,
|
| 74 |
+
1 + _base_.affine_scale),
|
| 75 |
+
# img_scale is (width, height)
|
| 76 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 77 |
+
border_val=(114, 114, 114),
|
| 78 |
+
min_area_ratio=_base_.min_area_ratio,
|
| 79 |
+
use_mask_refine=_base_.use_mask2refine)
|
| 80 |
+
]
|
| 81 |
+
train_pipeline = [
|
| 82 |
+
*_base_.pre_transform,
|
| 83 |
+
*mosaic_affine_transform,
|
| 84 |
+
dict(
|
| 85 |
+
type='YOLOv5MultiModalMixUp',
|
| 86 |
+
prob=_base_.mixup_prob,
|
| 87 |
+
pre_transform=[*_base_.pre_transform,
|
| 88 |
+
*mosaic_affine_transform]),
|
| 89 |
+
*_base_.last_transform[:-1],
|
| 90 |
+
*text_transform
|
| 91 |
+
]
|
| 92 |
+
train_pipeline_stage2 = [
|
| 93 |
+
*_base_.train_pipeline_stage2[:-1],
|
| 94 |
+
*text_transform
|
| 95 |
+
]
|
| 96 |
+
coco_train_dataset = dict(
|
| 97 |
+
_delete_=True,
|
| 98 |
+
type='MultiModalDataset',
|
| 99 |
+
dataset=dict(
|
| 100 |
+
type='YOLOv5CocoDataset',
|
| 101 |
+
data_root='data/coco',
|
| 102 |
+
ann_file='annotations/instances_train2017.json',
|
| 103 |
+
data_prefix=dict(img='train2017/'),
|
| 104 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 105 |
+
class_text_path='data/captions/coco_class_captions.json',
|
| 106 |
+
pipeline=train_pipeline)
|
| 107 |
+
train_dataloader = dict(
|
| 108 |
+
persistent_workers=persistent_workers,
|
| 109 |
+
batch_size=train_batch_size_per_gpu,
|
| 110 |
+
collate_fn=dict(type='yolow_collate'),
|
| 111 |
+
dataset=coco_train_dataset)
|
| 112 |
+
test_pipeline = [
|
| 113 |
+
*_base_.test_pipeline[:-1],
|
| 114 |
+
dict(type='LoadTextFixed'),
|
| 115 |
+
dict(
|
| 116 |
+
type='mmdet.PackDetInputs',
|
| 117 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 118 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 119 |
+
]
|
| 120 |
+
coco_val_dataset = dict(
|
| 121 |
+
_delete_=True,
|
| 122 |
+
type='MultiModalDataset',
|
| 123 |
+
dataset=dict(
|
| 124 |
+
type='YOLOv5CocoDataset',
|
| 125 |
+
data_root='data/coco',
|
| 126 |
+
ann_file='annotations/instances_val2017.json',
|
| 127 |
+
data_prefix=dict(img='val2017/'),
|
| 128 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 129 |
+
class_text_path='data/captions/coco_class_captions.json',
|
| 130 |
+
pipeline=test_pipeline)
|
| 131 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 132 |
+
test_dataloader = val_dataloader
|
| 133 |
+
# training settings
|
| 134 |
+
default_hooks = dict(
|
| 135 |
+
param_scheduler=dict(
|
| 136 |
+
scheduler_type='linear',
|
| 137 |
+
lr_factor=0.01,
|
| 138 |
+
max_epochs=max_epochs),
|
| 139 |
+
checkpoint=dict(
|
| 140 |
+
max_keep_ckpts=-1,
|
| 141 |
+
save_best=None,
|
| 142 |
+
interval=save_epoch_intervals))
|
| 143 |
+
custom_hooks = [
|
| 144 |
+
dict(
|
| 145 |
+
type='EMAHook',
|
| 146 |
+
ema_type='ExpMomentumEMA',
|
| 147 |
+
momentum=0.0001,
|
| 148 |
+
update_buffers=True,
|
| 149 |
+
strict_load=False,
|
| 150 |
+
priority=49),
|
| 151 |
+
dict(
|
| 152 |
+
type='mmdet.PipelineSwitchHook',
|
| 153 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 154 |
+
switch_pipeline=train_pipeline_stage2)
|
| 155 |
+
]
|
| 156 |
+
train_cfg = dict(
|
| 157 |
+
max_epochs=max_epochs,
|
| 158 |
+
val_interval=5,
|
| 159 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 160 |
+
_base_.val_interval_stage2)])
|
| 161 |
+
optim_wrapper = dict(
|
| 162 |
+
optimizer=dict(
|
| 163 |
+
_delete_=True,
|
| 164 |
+
type='AdamW',
|
| 165 |
+
lr=base_lr,
|
| 166 |
+
weight_decay=weight_decay,
|
| 167 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 168 |
+
paramwise_cfg=dict(
|
| 169 |
+
bias_decay_mult=0.0,
|
| 170 |
+
norm_decay_mult=0.0,
|
| 171 |
+
custom_keys={'backbone.text_model': dict(lr_mult=0.01),
|
| 172 |
+
'logit_scale': dict(weight_decay=0.0)}),
|
| 173 |
+
constructor='YOLOWv5OptimizerConstructor')
|
| 174 |
+
|
| 175 |
+
# evaluation settings
|
| 176 |
+
val_evaluator = dict(
|
| 177 |
+
_delete_=True,
|
| 178 |
+
type='mmdet.CocoMetric',
|
| 179 |
+
proposal_nums=(100, 1, 10),
|
| 180 |
+
ann_file='data/coco/annotations/instances_val2017.json',
|
| 181 |
+
metric='bbox')
|
| 182 |
+
|
| 183 |
+
test_evaluator = val_evaluator
|
configs/finetune_coco/yolo_world_m_t2i_bn_2e-4_100e_4x8gpus_coco_finetune.py
ADDED
|
@@ -0,0 +1,183 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_m_mask-refine_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'],
|
| 4 |
+
allow_failed_imports=False)
|
| 5 |
+
|
| 6 |
+
# hyper-parameters
|
| 7 |
+
num_classes = 80
|
| 8 |
+
num_training_classes = 80
|
| 9 |
+
max_epochs = 80 # Maximum training epochs
|
| 10 |
+
close_mosaic_epochs = 10
|
| 11 |
+
save_epoch_intervals = 5
|
| 12 |
+
text_channels = 512
|
| 13 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 14 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 15 |
+
base_lr = 2e-4
|
| 16 |
+
weight_decay = 0.05
|
| 17 |
+
train_batch_size_per_gpu = 16
|
| 18 |
+
load_from = 'weights/yolow-v8_m_clipv2_frozen_t2iv2_bn_o365_goldg_pretrain.pth'
|
| 19 |
+
persistent_workers = False
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
# model settings
|
| 23 |
+
model = dict(
|
| 24 |
+
type='YOLOWorldDetector',
|
| 25 |
+
mm_neck=True,
|
| 26 |
+
num_train_classes=num_training_classes,
|
| 27 |
+
num_test_classes=num_classes,
|
| 28 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 29 |
+
backbone=dict(
|
| 30 |
+
_delete_=True,
|
| 31 |
+
type='MultiModalYOLOBackbone',
|
| 32 |
+
image_model={{_base_.model.backbone}},
|
| 33 |
+
text_model=dict(
|
| 34 |
+
type='HuggingCLIPLanguageBackbone',
|
| 35 |
+
model_name='pretrained_models/clip-vit-base-patch32-projection',
|
| 36 |
+
frozen_modules=['all'])),
|
| 37 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 38 |
+
guide_channels=text_channels,
|
| 39 |
+
embed_channels=neck_embed_channels,
|
| 40 |
+
num_heads=neck_num_heads,
|
| 41 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv'),
|
| 42 |
+
num_csp_blocks=2),
|
| 43 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 44 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 45 |
+
embed_dims=text_channels,
|
| 46 |
+
use_bn_head=True,
|
| 47 |
+
num_classes=num_training_classes)),
|
| 48 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 49 |
+
|
| 50 |
+
# dataset settings
|
| 51 |
+
text_transform = [
|
| 52 |
+
dict(type='RandomLoadText',
|
| 53 |
+
num_neg_samples=(num_classes, num_classes),
|
| 54 |
+
max_num_samples=num_training_classes,
|
| 55 |
+
padding_to_max=True,
|
| 56 |
+
padding_value=''),
|
| 57 |
+
dict(type='mmdet.PackDetInputs',
|
| 58 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 59 |
+
'flip_direction', 'texts'))
|
| 60 |
+
]
|
| 61 |
+
mosaic_affine_transform = [
|
| 62 |
+
dict(
|
| 63 |
+
type='MultiModalMosaic',
|
| 64 |
+
img_scale=_base_.img_scale,
|
| 65 |
+
pad_val=114.0,
|
| 66 |
+
pre_transform=_base_.pre_transform),
|
| 67 |
+
dict(type='YOLOv5CopyPaste', prob=_base_.copypaste_prob),
|
| 68 |
+
dict(
|
| 69 |
+
type='YOLOv5RandomAffine',
|
| 70 |
+
max_rotate_degree=0.0,
|
| 71 |
+
max_shear_degree=0.0,
|
| 72 |
+
max_aspect_ratio=100.,
|
| 73 |
+
scaling_ratio_range=(1 - _base_.affine_scale,
|
| 74 |
+
1 + _base_.affine_scale),
|
| 75 |
+
# img_scale is (width, height)
|
| 76 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 77 |
+
border_val=(114, 114, 114),
|
| 78 |
+
min_area_ratio=_base_.min_area_ratio,
|
| 79 |
+
use_mask_refine=_base_.use_mask2refine)
|
| 80 |
+
]
|
| 81 |
+
train_pipeline = [
|
| 82 |
+
*_base_.pre_transform,
|
| 83 |
+
*mosaic_affine_transform,
|
| 84 |
+
dict(
|
| 85 |
+
type='YOLOv5MultiModalMixUp',
|
| 86 |
+
prob=_base_.mixup_prob,
|
| 87 |
+
pre_transform=[*_base_.pre_transform,
|
| 88 |
+
*mosaic_affine_transform]),
|
| 89 |
+
*_base_.last_transform[:-1],
|
| 90 |
+
*text_transform
|
| 91 |
+
]
|
| 92 |
+
train_pipeline_stage2 = [
|
| 93 |
+
*_base_.train_pipeline_stage2[:-1],
|
| 94 |
+
*text_transform
|
| 95 |
+
]
|
| 96 |
+
coco_train_dataset = dict(
|
| 97 |
+
_delete_=True,
|
| 98 |
+
type='MultiModalDataset',
|
| 99 |
+
dataset=dict(
|
| 100 |
+
type='YOLOv5CocoDataset',
|
| 101 |
+
data_root='data/coco',
|
| 102 |
+
ann_file='annotations/instances_train2017.json',
|
| 103 |
+
data_prefix=dict(img='train2017/'),
|
| 104 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 105 |
+
class_text_path='data/captions/coco_class_captions.json',
|
| 106 |
+
pipeline=train_pipeline)
|
| 107 |
+
train_dataloader = dict(
|
| 108 |
+
persistent_workers=persistent_workers,
|
| 109 |
+
batch_size=train_batch_size_per_gpu,
|
| 110 |
+
collate_fn=dict(type='yolow_collate'),
|
| 111 |
+
dataset=coco_train_dataset)
|
| 112 |
+
test_pipeline = [
|
| 113 |
+
*_base_.test_pipeline[:-1],
|
| 114 |
+
dict(type='LoadTextFixed'),
|
| 115 |
+
dict(
|
| 116 |
+
type='mmdet.PackDetInputs',
|
| 117 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 118 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 119 |
+
]
|
| 120 |
+
coco_val_dataset = dict(
|
| 121 |
+
_delete_=True,
|
| 122 |
+
type='MultiModalDataset',
|
| 123 |
+
dataset=dict(
|
| 124 |
+
type='YOLOv5CocoDataset',
|
| 125 |
+
data_root='data/coco',
|
| 126 |
+
ann_file='annotations/instances_val2017.json',
|
| 127 |
+
data_prefix=dict(img='val2017/'),
|
| 128 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 129 |
+
class_text_path='data/captions/coco_class_captions.json',
|
| 130 |
+
pipeline=test_pipeline)
|
| 131 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 132 |
+
test_dataloader = val_dataloader
|
| 133 |
+
# training settings
|
| 134 |
+
default_hooks = dict(
|
| 135 |
+
param_scheduler=dict(
|
| 136 |
+
scheduler_type='linear',
|
| 137 |
+
lr_factor=0.01,
|
| 138 |
+
max_epochs=max_epochs),
|
| 139 |
+
checkpoint=dict(
|
| 140 |
+
max_keep_ckpts=-1,
|
| 141 |
+
save_best=None,
|
| 142 |
+
interval=save_epoch_intervals))
|
| 143 |
+
custom_hooks = [
|
| 144 |
+
dict(
|
| 145 |
+
type='EMAHook',
|
| 146 |
+
ema_type='ExpMomentumEMA',
|
| 147 |
+
momentum=0.0001,
|
| 148 |
+
update_buffers=True,
|
| 149 |
+
strict_load=False,
|
| 150 |
+
priority=49),
|
| 151 |
+
dict(
|
| 152 |
+
type='mmdet.PipelineSwitchHook',
|
| 153 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 154 |
+
switch_pipeline=train_pipeline_stage2)
|
| 155 |
+
]
|
| 156 |
+
train_cfg = dict(
|
| 157 |
+
max_epochs=max_epochs,
|
| 158 |
+
val_interval=5,
|
| 159 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 160 |
+
_base_.val_interval_stage2)])
|
| 161 |
+
optim_wrapper = dict(
|
| 162 |
+
optimizer=dict(
|
| 163 |
+
_delete_=True,
|
| 164 |
+
type='AdamW',
|
| 165 |
+
lr=base_lr,
|
| 166 |
+
weight_decay=weight_decay,
|
| 167 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 168 |
+
paramwise_cfg=dict(
|
| 169 |
+
bias_decay_mult=0.0,
|
| 170 |
+
norm_decay_mult=0.0,
|
| 171 |
+
custom_keys={'backbone.text_model': dict(lr_mult=0.01),
|
| 172 |
+
'logit_scale': dict(weight_decay=0.0)}),
|
| 173 |
+
constructor='YOLOWv5OptimizerConstructor')
|
| 174 |
+
|
| 175 |
+
# evaluation settings
|
| 176 |
+
val_evaluator = dict(
|
| 177 |
+
_delete_=True,
|
| 178 |
+
type='mmdet.CocoMetric',
|
| 179 |
+
proposal_nums=(100, 1, 10),
|
| 180 |
+
ann_file='data/coco/annotations/instances_val2017.json',
|
| 181 |
+
metric='bbox')
|
| 182 |
+
|
| 183 |
+
test_evaluator = val_evaluator
|
configs/finetune_coco/yolo_world_s_t2i_bn_2e-4_100e_4x8gpus_coco_finetune.py
ADDED
|
@@ -0,0 +1,183 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_s_mask-refine_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'],
|
| 4 |
+
allow_failed_imports=False)
|
| 5 |
+
|
| 6 |
+
# hyper-parameters
|
| 7 |
+
num_classes = 80
|
| 8 |
+
num_training_classes = 80
|
| 9 |
+
max_epochs = 80 # Maximum training epochs
|
| 10 |
+
close_mosaic_epochs = 10
|
| 11 |
+
save_epoch_intervals = 5
|
| 12 |
+
text_channels = 512
|
| 13 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 14 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 15 |
+
base_lr = 2e-4
|
| 16 |
+
weight_decay = 0.05
|
| 17 |
+
train_batch_size_per_gpu = 16
|
| 18 |
+
load_from = 'weights/yolow-v8_s_clipv2_frozen_t2iv2_bn_o365_goldg_pretrain.pth'
|
| 19 |
+
persistent_workers = False
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
# model settings
|
| 23 |
+
model = dict(
|
| 24 |
+
type='YOLOWorldDetector',
|
| 25 |
+
mm_neck=True,
|
| 26 |
+
num_train_classes=num_training_classes,
|
| 27 |
+
num_test_classes=num_classes,
|
| 28 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 29 |
+
backbone=dict(
|
| 30 |
+
_delete_=True,
|
| 31 |
+
type='MultiModalYOLOBackbone',
|
| 32 |
+
image_model={{_base_.model.backbone}},
|
| 33 |
+
text_model=dict(
|
| 34 |
+
type='HuggingCLIPLanguageBackbone',
|
| 35 |
+
model_name='pretrained_models/clip-vit-base-patch32-projection',
|
| 36 |
+
frozen_modules=['all'])),
|
| 37 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 38 |
+
guide_channels=text_channels,
|
| 39 |
+
embed_channels=neck_embed_channels,
|
| 40 |
+
num_heads=neck_num_heads,
|
| 41 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv'),
|
| 42 |
+
num_csp_blocks=2),
|
| 43 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 44 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 45 |
+
embed_dims=text_channels,
|
| 46 |
+
use_bn_head=True,
|
| 47 |
+
num_classes=num_training_classes)),
|
| 48 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 49 |
+
|
| 50 |
+
# dataset settings
|
| 51 |
+
text_transform = [
|
| 52 |
+
dict(type='RandomLoadText',
|
| 53 |
+
num_neg_samples=(num_classes, num_classes),
|
| 54 |
+
max_num_samples=num_training_classes,
|
| 55 |
+
padding_to_max=True,
|
| 56 |
+
padding_value=''),
|
| 57 |
+
dict(type='mmdet.PackDetInputs',
|
| 58 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 59 |
+
'flip_direction', 'texts'))
|
| 60 |
+
]
|
| 61 |
+
mosaic_affine_transform = [
|
| 62 |
+
dict(
|
| 63 |
+
type='MultiModalMosaic',
|
| 64 |
+
img_scale=_base_.img_scale,
|
| 65 |
+
pad_val=114.0,
|
| 66 |
+
pre_transform=_base_.pre_transform),
|
| 67 |
+
dict(type='YOLOv5CopyPaste', prob=_base_.copypaste_prob),
|
| 68 |
+
dict(
|
| 69 |
+
type='YOLOv5RandomAffine',
|
| 70 |
+
max_rotate_degree=0.0,
|
| 71 |
+
max_shear_degree=0.0,
|
| 72 |
+
max_aspect_ratio=100.,
|
| 73 |
+
scaling_ratio_range=(1 - _base_.affine_scale,
|
| 74 |
+
1 + _base_.affine_scale),
|
| 75 |
+
# img_scale is (width, height)
|
| 76 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 77 |
+
border_val=(114, 114, 114),
|
| 78 |
+
min_area_ratio=_base_.min_area_ratio,
|
| 79 |
+
use_mask_refine=_base_.use_mask2refine)
|
| 80 |
+
]
|
| 81 |
+
train_pipeline = [
|
| 82 |
+
*_base_.pre_transform,
|
| 83 |
+
*mosaic_affine_transform,
|
| 84 |
+
dict(
|
| 85 |
+
type='YOLOv5MultiModalMixUp',
|
| 86 |
+
prob=_base_.mixup_prob,
|
| 87 |
+
pre_transform=[*_base_.pre_transform,
|
| 88 |
+
*mosaic_affine_transform]),
|
| 89 |
+
*_base_.last_transform[:-1],
|
| 90 |
+
*text_transform
|
| 91 |
+
]
|
| 92 |
+
train_pipeline_stage2 = [
|
| 93 |
+
*_base_.train_pipeline_stage2[:-1],
|
| 94 |
+
*text_transform
|
| 95 |
+
]
|
| 96 |
+
coco_train_dataset = dict(
|
| 97 |
+
_delete_=True,
|
| 98 |
+
type='MultiModalDataset',
|
| 99 |
+
dataset=dict(
|
| 100 |
+
type='YOLOv5CocoDataset',
|
| 101 |
+
data_root='data/coco',
|
| 102 |
+
ann_file='annotations/instances_train2017.json',
|
| 103 |
+
data_prefix=dict(img='train2017/'),
|
| 104 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 105 |
+
class_text_path='data/captions/coco_class_captions.json',
|
| 106 |
+
pipeline=train_pipeline)
|
| 107 |
+
train_dataloader = dict(
|
| 108 |
+
persistent_workers=persistent_workers,
|
| 109 |
+
batch_size=train_batch_size_per_gpu,
|
| 110 |
+
collate_fn=dict(type='yolow_collate'),
|
| 111 |
+
dataset=coco_train_dataset)
|
| 112 |
+
test_pipeline = [
|
| 113 |
+
*_base_.test_pipeline[:-1],
|
| 114 |
+
dict(type='LoadTextFixed'),
|
| 115 |
+
dict(
|
| 116 |
+
type='mmdet.PackDetInputs',
|
| 117 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 118 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 119 |
+
]
|
| 120 |
+
coco_val_dataset = dict(
|
| 121 |
+
_delete_=True,
|
| 122 |
+
type='MultiModalDataset',
|
| 123 |
+
dataset=dict(
|
| 124 |
+
type='YOLOv5CocoDataset',
|
| 125 |
+
data_root='data/coco',
|
| 126 |
+
ann_file='annotations/instances_val2017.json',
|
| 127 |
+
data_prefix=dict(img='val2017/'),
|
| 128 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 129 |
+
class_text_path='data/captions/coco_class_captions.json',
|
| 130 |
+
pipeline=test_pipeline)
|
| 131 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 132 |
+
test_dataloader = val_dataloader
|
| 133 |
+
# training settings
|
| 134 |
+
default_hooks = dict(
|
| 135 |
+
param_scheduler=dict(
|
| 136 |
+
scheduler_type='linear',
|
| 137 |
+
lr_factor=0.01,
|
| 138 |
+
max_epochs=max_epochs),
|
| 139 |
+
checkpoint=dict(
|
| 140 |
+
max_keep_ckpts=-1,
|
| 141 |
+
save_best=None,
|
| 142 |
+
interval=save_epoch_intervals))
|
| 143 |
+
custom_hooks = [
|
| 144 |
+
dict(
|
| 145 |
+
type='EMAHook',
|
| 146 |
+
ema_type='ExpMomentumEMA',
|
| 147 |
+
momentum=0.0001,
|
| 148 |
+
update_buffers=True,
|
| 149 |
+
strict_load=False,
|
| 150 |
+
priority=49),
|
| 151 |
+
dict(
|
| 152 |
+
type='mmdet.PipelineSwitchHook',
|
| 153 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 154 |
+
switch_pipeline=train_pipeline_stage2)
|
| 155 |
+
]
|
| 156 |
+
train_cfg = dict(
|
| 157 |
+
max_epochs=max_epochs,
|
| 158 |
+
val_interval=5,
|
| 159 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 160 |
+
_base_.val_interval_stage2)])
|
| 161 |
+
optim_wrapper = dict(
|
| 162 |
+
optimizer=dict(
|
| 163 |
+
_delete_=True,
|
| 164 |
+
type='AdamW',
|
| 165 |
+
lr=base_lr,
|
| 166 |
+
weight_decay=weight_decay,
|
| 167 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 168 |
+
paramwise_cfg=dict(
|
| 169 |
+
bias_decay_mult=0.0,
|
| 170 |
+
norm_decay_mult=0.0,
|
| 171 |
+
custom_keys={'backbone.text_model': dict(lr_mult=0.01),
|
| 172 |
+
'logit_scale': dict(weight_decay=0.0)}),
|
| 173 |
+
constructor='YOLOWv5OptimizerConstructor')
|
| 174 |
+
|
| 175 |
+
# evaluation settings
|
| 176 |
+
val_evaluator = dict(
|
| 177 |
+
_delete_=True,
|
| 178 |
+
type='mmdet.CocoMetric',
|
| 179 |
+
proposal_nums=(100, 1, 10),
|
| 180 |
+
ann_file='data/coco/annotations/instances_val2017.json',
|
| 181 |
+
metric='bbox')
|
| 182 |
+
|
| 183 |
+
test_evaluator = val_evaluator
|
configs/pretrain/yolo_world_l_dual_3block_l2norm_2e-4_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py
ADDED
|
@@ -0,0 +1,173 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_l_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'],
|
| 4 |
+
allow_failed_imports=False)
|
| 5 |
+
|
| 6 |
+
# hyper-parameters
|
| 7 |
+
num_classes = 1203
|
| 8 |
+
num_training_classes = 80
|
| 9 |
+
max_epochs = 100 # Maximum training epochs
|
| 10 |
+
close_mosaic_epochs = 2
|
| 11 |
+
save_epoch_intervals = 2
|
| 12 |
+
text_channels = 512
|
| 13 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 14 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 15 |
+
base_lr = 2e-3
|
| 16 |
+
weight_decay = 0.05 / 2
|
| 17 |
+
train_batch_size_per_gpu = 16
|
| 18 |
+
|
| 19 |
+
# model settings
|
| 20 |
+
model = dict(
|
| 21 |
+
type='YOLOWorldDetector',
|
| 22 |
+
mm_neck=True,
|
| 23 |
+
num_train_classes=num_training_classes,
|
| 24 |
+
num_test_classes=num_classes,
|
| 25 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 26 |
+
backbone=dict(
|
| 27 |
+
_delete_=True,
|
| 28 |
+
type='MultiModalYOLOBackbone',
|
| 29 |
+
image_model={{_base_.model.backbone}},
|
| 30 |
+
text_model=dict(
|
| 31 |
+
type='HuggingCLIPLanguageBackbone',
|
| 32 |
+
model_name='pretrained_models/clip-vit-base-patch32-projection',
|
| 33 |
+
frozen_modules=['all'])),
|
| 34 |
+
neck=dict(type='YOLOWolrdDualPAFPN',
|
| 35 |
+
guide_channels=text_channels,
|
| 36 |
+
embed_channels=neck_embed_channels,
|
| 37 |
+
num_heads=neck_num_heads,
|
| 38 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv'),
|
| 39 |
+
text_enhancder=dict(type='ImagePoolingAttentionModule',
|
| 40 |
+
embed_channels=256,
|
| 41 |
+
num_heads=8)),
|
| 42 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 43 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 44 |
+
embed_dims=text_channels,
|
| 45 |
+
num_classes=num_training_classes)),
|
| 46 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 47 |
+
|
| 48 |
+
# dataset settings
|
| 49 |
+
text_transform = [
|
| 50 |
+
dict(type='RandomLoadText',
|
| 51 |
+
num_neg_samples=(num_classes, num_classes),
|
| 52 |
+
max_num_samples=num_training_classes,
|
| 53 |
+
padding_to_max=True,
|
| 54 |
+
padding_value=''),
|
| 55 |
+
dict(type='mmdet.PackDetInputs',
|
| 56 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 57 |
+
'flip_direction', 'texts'))
|
| 58 |
+
]
|
| 59 |
+
train_pipeline = [
|
| 60 |
+
*_base_.pre_transform,
|
| 61 |
+
dict(type='MultiModalMosaic',
|
| 62 |
+
img_scale=_base_.img_scale,
|
| 63 |
+
pad_val=114.0,
|
| 64 |
+
pre_transform=_base_.pre_transform),
|
| 65 |
+
dict(
|
| 66 |
+
type='YOLOv5RandomAffine',
|
| 67 |
+
max_rotate_degree=0.0,
|
| 68 |
+
max_shear_degree=0.0,
|
| 69 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 70 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 71 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 72 |
+
border_val=(114, 114, 114)),
|
| 73 |
+
*_base_.last_transform[:-1],
|
| 74 |
+
*text_transform,
|
| 75 |
+
]
|
| 76 |
+
train_pipeline_stage2 = [*_base_.train_pipeline_stage2[:-1], *text_transform]
|
| 77 |
+
obj365v1_train_dataset = dict(
|
| 78 |
+
type='MultiModalDataset',
|
| 79 |
+
dataset=dict(
|
| 80 |
+
type='YOLOv5Objects365V1Dataset',
|
| 81 |
+
data_root='data/objects365v1/',
|
| 82 |
+
ann_file='annotations/objects365_train.json',
|
| 83 |
+
data_prefix=dict(img='train/'),
|
| 84 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 85 |
+
class_text_path='data/captions/obj365v1_class_captions.json',
|
| 86 |
+
pipeline=train_pipeline)
|
| 87 |
+
|
| 88 |
+
mg_train_dataset = dict(type='YOLOv5MixedGroundingDataset',
|
| 89 |
+
data_root='data/mixed_grounding/',
|
| 90 |
+
ann_file='annotations/final_mixed_train_no_coco.json',
|
| 91 |
+
data_prefix=dict(img='gqa/images/'),
|
| 92 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 93 |
+
pipeline=train_pipeline)
|
| 94 |
+
|
| 95 |
+
flickr_train_dataset = dict(
|
| 96 |
+
type='YOLOv5MixedGroundingDataset',
|
| 97 |
+
data_root='data/flickr/',
|
| 98 |
+
ann_file='annotations/final_flickr_separateGT_train.json',
|
| 99 |
+
data_prefix=dict(img='full_images/'),
|
| 100 |
+
filter_cfg=dict(filter_empty_gt=True, min_size=32),
|
| 101 |
+
pipeline=train_pipeline)
|
| 102 |
+
|
| 103 |
+
train_dataloader = dict(batch_size=train_batch_size_per_gpu,
|
| 104 |
+
collate_fn=dict(type='yolow_collate'),
|
| 105 |
+
dataset=dict(_delete_=True,
|
| 106 |
+
type='ConcatDataset',
|
| 107 |
+
datasets=[
|
| 108 |
+
obj365v1_train_dataset,
|
| 109 |
+
flickr_train_dataset, mg_train_dataset
|
| 110 |
+
],
|
| 111 |
+
ignore_keys=['classes', 'palette']))
|
| 112 |
+
|
| 113 |
+
test_pipeline = [
|
| 114 |
+
*_base_.test_pipeline[:-1],
|
| 115 |
+
dict(type='LoadText'),
|
| 116 |
+
dict(type='mmdet.PackDetInputs',
|
| 117 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 118 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 119 |
+
]
|
| 120 |
+
coco_val_dataset = dict(
|
| 121 |
+
_delete_=True,
|
| 122 |
+
type='MultiModalDataset',
|
| 123 |
+
dataset=dict(type='YOLOv5LVISV1Dataset',
|
| 124 |
+
data_root='data/coco/',
|
| 125 |
+
test_mode=True,
|
| 126 |
+
ann_file='lvis/lvis_v1_minival_inserted_image_name.json',
|
| 127 |
+
data_prefix=dict(img=''),
|
| 128 |
+
batch_shapes_cfg=None),
|
| 129 |
+
class_text_path='data/captions/lvis_v1_class_captions.json',
|
| 130 |
+
pipeline=test_pipeline)
|
| 131 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 132 |
+
test_dataloader = val_dataloader
|
| 133 |
+
|
| 134 |
+
val_evaluator = dict(type='mmdet.LVISMetric',
|
| 135 |
+
ann_file='data/coco/lvis/\
|
| 136 |
+
lvis_v1_minival_inserted_image_name.json',
|
| 137 |
+
metric='bbox')
|
| 138 |
+
test_evaluator = val_evaluator
|
| 139 |
+
|
| 140 |
+
# training settings
|
| 141 |
+
default_hooks = dict(param_scheduler=dict(max_epochs=max_epochs),
|
| 142 |
+
checkpoint=dict(interval=save_epoch_intervals,
|
| 143 |
+
rule='greater'))
|
| 144 |
+
custom_hooks = [
|
| 145 |
+
dict(type='EMAHook',
|
| 146 |
+
ema_type='ExpMomentumEMA',
|
| 147 |
+
momentum=0.0001,
|
| 148 |
+
update_buffers=True,
|
| 149 |
+
strict_load=False,
|
| 150 |
+
priority=49),
|
| 151 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 152 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 153 |
+
switch_pipeline=train_pipeline_stage2)
|
| 154 |
+
]
|
| 155 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 156 |
+
val_interval=10,
|
| 157 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 158 |
+
_base_.val_interval_stage2)])
|
| 159 |
+
optim_wrapper = dict(optimizer=dict(
|
| 160 |
+
_delete_=True,
|
| 161 |
+
type='AdamW',
|
| 162 |
+
lr=base_lr,
|
| 163 |
+
weight_decay=weight_decay,
|
| 164 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 165 |
+
paramwise_cfg=dict(bias_decay_mult=0.0,
|
| 166 |
+
norm_decay_mult=0.0,
|
| 167 |
+
custom_keys={
|
| 168 |
+
'backbone.text_model':
|
| 169 |
+
dict(lr_mult=0.01),
|
| 170 |
+
'logit_scale':
|
| 171 |
+
dict(weight_decay=0.0)
|
| 172 |
+
}),
|
| 173 |
+
constructor='YOLOWv5OptimizerConstructor')
|
configs/pretrain/yolo_world_l_t2i_bn_2e-4_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py
ADDED
|
@@ -0,0 +1,182 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_l_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'],
|
| 4 |
+
allow_failed_imports=False)
|
| 5 |
+
|
| 6 |
+
# hyper-parameters
|
| 7 |
+
num_classes = 1203
|
| 8 |
+
num_training_classes = 80
|
| 9 |
+
max_epochs = 100 # Maximum training epochs
|
| 10 |
+
close_mosaic_epochs = 2
|
| 11 |
+
save_epoch_intervals = 2
|
| 12 |
+
text_channels = 512
|
| 13 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 14 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 15 |
+
base_lr = 2e-3
|
| 16 |
+
weight_decay = 0.05 / 2
|
| 17 |
+
train_batch_size_per_gpu = 16
|
| 18 |
+
|
| 19 |
+
# model settings
|
| 20 |
+
model = dict(
|
| 21 |
+
type='YOLOWorldDetector',
|
| 22 |
+
mm_neck=True,
|
| 23 |
+
num_train_classes=num_training_classes,
|
| 24 |
+
num_test_classes=num_classes,
|
| 25 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 26 |
+
backbone=dict(
|
| 27 |
+
_delete_=True,
|
| 28 |
+
type='MultiModalYOLOBackbone',
|
| 29 |
+
image_model={{_base_.model.backbone}},
|
| 30 |
+
text_model=dict(
|
| 31 |
+
type='HuggingCLIPLanguageBackbone',
|
| 32 |
+
model_name='openai/clip-vit-base-patch32',
|
| 33 |
+
frozen_modules=['all'])),
|
| 34 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 35 |
+
guide_channels=text_channels,
|
| 36 |
+
embed_channels=neck_embed_channels,
|
| 37 |
+
num_heads=neck_num_heads,
|
| 38 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv'),
|
| 39 |
+
num_csp_blocks=2),
|
| 40 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 41 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 42 |
+
embed_dims=text_channels,
|
| 43 |
+
use_bn_head=True,
|
| 44 |
+
num_classes=num_training_classes)),
|
| 45 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 46 |
+
|
| 47 |
+
# dataset settings
|
| 48 |
+
text_transform = [
|
| 49 |
+
dict(type='RandomLoadText',
|
| 50 |
+
num_neg_samples=(num_classes, num_classes),
|
| 51 |
+
max_num_samples=num_training_classes,
|
| 52 |
+
padding_to_max=True,
|
| 53 |
+
padding_value=''),
|
| 54 |
+
dict(type='mmdet.PackDetInputs',
|
| 55 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 56 |
+
'flip_direction', 'texts'))
|
| 57 |
+
]
|
| 58 |
+
train_pipeline = [
|
| 59 |
+
*_base_.pre_transform,
|
| 60 |
+
dict(type='MultiModalMosaic',
|
| 61 |
+
img_scale=_base_.img_scale,
|
| 62 |
+
pad_val=114.0,
|
| 63 |
+
pre_transform=_base_.pre_transform),
|
| 64 |
+
dict(
|
| 65 |
+
type='YOLOv5RandomAffine',
|
| 66 |
+
max_rotate_degree=0.0,
|
| 67 |
+
max_shear_degree=0.0,
|
| 68 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 69 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 70 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 71 |
+
border_val=(114, 114, 114)),
|
| 72 |
+
*_base_.last_transform[:-1],
|
| 73 |
+
*text_transform,
|
| 74 |
+
]
|
| 75 |
+
train_pipeline_stage2 = [*_base_.train_pipeline_stage2[:-1], *text_transform]
|
| 76 |
+
obj365v1_train_dataset = dict(
|
| 77 |
+
type='MultiModalDataset',
|
| 78 |
+
dataset=dict(
|
| 79 |
+
type='YOLOv5Objects365V1Dataset',
|
| 80 |
+
data_root='data/objects365v1/',
|
| 81 |
+
ann_file='annotations/objects365_train.json',
|
| 82 |
+
data_prefix=dict(img='train/'),
|
| 83 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 84 |
+
class_text_path='data/captions/obj365v1_class_captions.json',
|
| 85 |
+
pipeline=train_pipeline)
|
| 86 |
+
|
| 87 |
+
mg_train_dataset = dict(
|
| 88 |
+
type='YOLOv5MixedGroundingDataset',
|
| 89 |
+
data_root='data/mixed_grounding/',
|
| 90 |
+
ann_file='annotations/final_mixed_train_no_coco.json',
|
| 91 |
+
data_prefix=dict(img='gqa/images/'),
|
| 92 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 93 |
+
pipeline=train_pipeline)
|
| 94 |
+
|
| 95 |
+
flickr_train_dataset = dict(
|
| 96 |
+
type='YOLOv5MixedGroundingDataset',
|
| 97 |
+
data_root='data/flickr/',
|
| 98 |
+
ann_file='annotations/final_flickr_separateGT_train.json',
|
| 99 |
+
data_prefix=dict(img='images/'),
|
| 100 |
+
filter_cfg=dict(filter_empty_gt=True, min_size=32),
|
| 101 |
+
pipeline=train_pipeline)
|
| 102 |
+
|
| 103 |
+
train_dataloader = dict(
|
| 104 |
+
batch_size=train_batch_size_per_gpu,
|
| 105 |
+
collate_fn=dict(type='yolow_collate'),
|
| 106 |
+
dataset=dict(
|
| 107 |
+
_delete_=True,
|
| 108 |
+
type='ConcatDataset',
|
| 109 |
+
datasets=[
|
| 110 |
+
obj365v1_train_dataset,
|
| 111 |
+
flickr_train_dataset,
|
| 112 |
+
mg_train_dataset
|
| 113 |
+
],
|
| 114 |
+
ignore_keys=['classes', 'palette']))
|
| 115 |
+
|
| 116 |
+
test_pipeline = [
|
| 117 |
+
*_base_.test_pipeline[:-1],
|
| 118 |
+
dict(type='LoadText'),
|
| 119 |
+
dict(type='mmdet.PackDetInputs',
|
| 120 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 121 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 122 |
+
]
|
| 123 |
+
coco_val_dataset = dict(
|
| 124 |
+
_delete_=True,
|
| 125 |
+
type='MultiModalDataset',
|
| 126 |
+
dataset=dict(
|
| 127 |
+
type='YOLOv5LVISV1Dataset',
|
| 128 |
+
data_root='data/lvis/',
|
| 129 |
+
test_mode=True,
|
| 130 |
+
ann_file='annotations/'
|
| 131 |
+
'lvis_v1_minival_inserted_image_name.json',
|
| 132 |
+
data_prefix=dict(img=''),
|
| 133 |
+
batch_shapes_cfg=None),
|
| 134 |
+
class_text_path='data/captions/lvis_v1_class_captions.json',
|
| 135 |
+
pipeline=test_pipeline)
|
| 136 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 137 |
+
test_dataloader = val_dataloader
|
| 138 |
+
|
| 139 |
+
val_evaluator = dict(
|
| 140 |
+
type='mmdet.LVISMetric',
|
| 141 |
+
ann_file='data/lvis/annotations/'
|
| 142 |
+
'lvis_v1_minival_inserted_image_name.json',
|
| 143 |
+
metric='bbox')
|
| 144 |
+
test_evaluator = val_evaluator
|
| 145 |
+
|
| 146 |
+
# training settings
|
| 147 |
+
default_hooks = dict(
|
| 148 |
+
param_scheduler=dict(max_epochs=max_epochs),
|
| 149 |
+
checkpoint=dict(interval=save_epoch_intervals,
|
| 150 |
+
rule='greater'))
|
| 151 |
+
custom_hooks = [
|
| 152 |
+
dict(type='EMAHook',
|
| 153 |
+
ema_type='ExpMomentumEMA',
|
| 154 |
+
momentum=0.0001,
|
| 155 |
+
update_buffers=True,
|
| 156 |
+
strict_load=False,
|
| 157 |
+
priority=49),
|
| 158 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 159 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 160 |
+
switch_pipeline=train_pipeline_stage2)
|
| 161 |
+
]
|
| 162 |
+
train_cfg = dict(
|
| 163 |
+
max_epochs=max_epochs,
|
| 164 |
+
val_interval=10,
|
| 165 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 166 |
+
_base_.val_interval_stage2)])
|
| 167 |
+
optim_wrapper = dict(optimizer=dict(
|
| 168 |
+
_delete_=True,
|
| 169 |
+
type='AdamW',
|
| 170 |
+
lr=base_lr,
|
| 171 |
+
weight_decay=weight_decay,
|
| 172 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 173 |
+
paramwise_cfg=dict(
|
| 174 |
+
bias_decay_mult=0.0,
|
| 175 |
+
norm_decay_mult=0.0,
|
| 176 |
+
custom_keys={
|
| 177 |
+
'backbone.text_model':
|
| 178 |
+
dict(lr_mult=0.01),
|
| 179 |
+
'logit_scale':
|
| 180 |
+
dict(weight_decay=0.0)
|
| 181 |
+
}),
|
| 182 |
+
constructor='YOLOWv5OptimizerConstructor')
|
configs/pretrain/yolo_world_m_dual_3block_l2norm_2e-4_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py
ADDED
|
@@ -0,0 +1,173 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_m_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'],
|
| 4 |
+
allow_failed_imports=False)
|
| 5 |
+
|
| 6 |
+
# hyper-parameters
|
| 7 |
+
num_classes = 1203
|
| 8 |
+
num_training_classes = 80
|
| 9 |
+
max_epochs = 100 # Maximum training epochs
|
| 10 |
+
close_mosaic_epochs = 2
|
| 11 |
+
save_epoch_intervals = 2
|
| 12 |
+
text_channels = 512
|
| 13 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 14 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 15 |
+
base_lr = 2e-3
|
| 16 |
+
weight_decay = 0.05 / 2
|
| 17 |
+
train_batch_size_per_gpu = 16
|
| 18 |
+
|
| 19 |
+
# model settings
|
| 20 |
+
model = dict(
|
| 21 |
+
type='YOLOWorldDetector',
|
| 22 |
+
mm_neck=True,
|
| 23 |
+
num_train_classes=num_training_classes,
|
| 24 |
+
num_test_classes=num_classes,
|
| 25 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 26 |
+
backbone=dict(
|
| 27 |
+
_delete_=True,
|
| 28 |
+
type='MultiModalYOLOBackbone',
|
| 29 |
+
image_model={{_base_.model.backbone}},
|
| 30 |
+
text_model=dict(
|
| 31 |
+
type='HuggingCLIPLanguageBackbone',
|
| 32 |
+
model_name='pretrained_models/clip-vit-base-patch32-projection',
|
| 33 |
+
frozen_modules=['all'])),
|
| 34 |
+
neck=dict(type='YOLOWolrdDualPAFPN',
|
| 35 |
+
guide_channels=text_channels,
|
| 36 |
+
embed_channels=neck_embed_channels,
|
| 37 |
+
num_heads=neck_num_heads,
|
| 38 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv'),
|
| 39 |
+
text_enhancder=dict(type='ImagePoolingAttentionModule',
|
| 40 |
+
embed_channels=256,
|
| 41 |
+
num_heads=8)),
|
| 42 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 43 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 44 |
+
embed_dims=text_channels,
|
| 45 |
+
num_classes=num_training_classes)),
|
| 46 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 47 |
+
|
| 48 |
+
# dataset settings
|
| 49 |
+
text_transform = [
|
| 50 |
+
dict(type='RandomLoadText',
|
| 51 |
+
num_neg_samples=(num_classes, num_classes),
|
| 52 |
+
max_num_samples=num_training_classes,
|
| 53 |
+
padding_to_max=True,
|
| 54 |
+
padding_value=''),
|
| 55 |
+
dict(type='mmdet.PackDetInputs',
|
| 56 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 57 |
+
'flip_direction', 'texts'))
|
| 58 |
+
]
|
| 59 |
+
train_pipeline = [
|
| 60 |
+
*_base_.pre_transform,
|
| 61 |
+
dict(type='MultiModalMosaic',
|
| 62 |
+
img_scale=_base_.img_scale,
|
| 63 |
+
pad_val=114.0,
|
| 64 |
+
pre_transform=_base_.pre_transform),
|
| 65 |
+
dict(
|
| 66 |
+
type='YOLOv5RandomAffine',
|
| 67 |
+
max_rotate_degree=0.0,
|
| 68 |
+
max_shear_degree=0.0,
|
| 69 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 70 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 71 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 72 |
+
border_val=(114, 114, 114)),
|
| 73 |
+
*_base_.last_transform[:-1],
|
| 74 |
+
*text_transform,
|
| 75 |
+
]
|
| 76 |
+
train_pipeline_stage2 = [*_base_.train_pipeline_stage2[:-1], *text_transform]
|
| 77 |
+
obj365v1_train_dataset = dict(
|
| 78 |
+
type='MultiModalDataset',
|
| 79 |
+
dataset=dict(
|
| 80 |
+
type='YOLOv5Objects365V1Dataset',
|
| 81 |
+
data_root='data/objects365v1/',
|
| 82 |
+
ann_file='annotations/objects365_train.json',
|
| 83 |
+
data_prefix=dict(img='train/'),
|
| 84 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 85 |
+
class_text_path='data/captions/obj365v1_class_captions.json',
|
| 86 |
+
pipeline=train_pipeline)
|
| 87 |
+
|
| 88 |
+
mg_train_dataset = dict(type='YOLOv5MixedGroundingDataset',
|
| 89 |
+
data_root='data/mixed_grounding/',
|
| 90 |
+
ann_file='annotations/final_mixed_train_no_coco.json',
|
| 91 |
+
data_prefix=dict(img='gqa/images/'),
|
| 92 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 93 |
+
pipeline=train_pipeline)
|
| 94 |
+
|
| 95 |
+
flickr_train_dataset = dict(
|
| 96 |
+
type='YOLOv5MixedGroundingDataset',
|
| 97 |
+
data_root='data/flickr/',
|
| 98 |
+
ann_file='annotations/final_flickr_separateGT_train.json',
|
| 99 |
+
data_prefix=dict(img='full_images/'),
|
| 100 |
+
filter_cfg=dict(filter_empty_gt=True, min_size=32),
|
| 101 |
+
pipeline=train_pipeline)
|
| 102 |
+
|
| 103 |
+
train_dataloader = dict(batch_size=train_batch_size_per_gpu,
|
| 104 |
+
collate_fn=dict(type='yolow_collate'),
|
| 105 |
+
dataset=dict(_delete_=True,
|
| 106 |
+
type='ConcatDataset',
|
| 107 |
+
datasets=[
|
| 108 |
+
obj365v1_train_dataset,
|
| 109 |
+
flickr_train_dataset, mg_train_dataset
|
| 110 |
+
],
|
| 111 |
+
ignore_keys=['classes', 'palette']))
|
| 112 |
+
|
| 113 |
+
test_pipeline = [
|
| 114 |
+
*_base_.test_pipeline[:-1],
|
| 115 |
+
dict(type='LoadText'),
|
| 116 |
+
dict(type='mmdet.PackDetInputs',
|
| 117 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 118 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 119 |
+
]
|
| 120 |
+
coco_val_dataset = dict(
|
| 121 |
+
_delete_=True,
|
| 122 |
+
type='MultiModalDataset',
|
| 123 |
+
dataset=dict(type='YOLOv5LVISV1Dataset',
|
| 124 |
+
data_root='data/coco/',
|
| 125 |
+
test_mode=True,
|
| 126 |
+
ann_file='lvis/lvis_v1_minival_inserted_image_name.json',
|
| 127 |
+
data_prefix=dict(img=''),
|
| 128 |
+
batch_shapes_cfg=None),
|
| 129 |
+
class_text_path='data/captions/lvis_v1_class_captions.json',
|
| 130 |
+
pipeline=test_pipeline)
|
| 131 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 132 |
+
test_dataloader = val_dataloader
|
| 133 |
+
|
| 134 |
+
val_evaluator = dict(type='mmdet.LVISMetric',
|
| 135 |
+
ann_file='data/coco/lvis/\
|
| 136 |
+
lvis_v1_minival_inserted_image_name.json',
|
| 137 |
+
metric='bbox')
|
| 138 |
+
test_evaluator = val_evaluator
|
| 139 |
+
|
| 140 |
+
# training settings
|
| 141 |
+
default_hooks = dict(param_scheduler=dict(max_epochs=max_epochs),
|
| 142 |
+
checkpoint=dict(interval=save_epoch_intervals,
|
| 143 |
+
rule='greater'))
|
| 144 |
+
custom_hooks = [
|
| 145 |
+
dict(type='EMAHook',
|
| 146 |
+
ema_type='ExpMomentumEMA',
|
| 147 |
+
momentum=0.0001,
|
| 148 |
+
update_buffers=True,
|
| 149 |
+
strict_load=False,
|
| 150 |
+
priority=49),
|
| 151 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 152 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 153 |
+
switch_pipeline=train_pipeline_stage2)
|
| 154 |
+
]
|
| 155 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 156 |
+
val_interval=10,
|
| 157 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 158 |
+
_base_.val_interval_stage2)])
|
| 159 |
+
optim_wrapper = dict(optimizer=dict(
|
| 160 |
+
_delete_=True,
|
| 161 |
+
type='AdamW',
|
| 162 |
+
lr=base_lr,
|
| 163 |
+
weight_decay=weight_decay,
|
| 164 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 165 |
+
paramwise_cfg=dict(bias_decay_mult=0.0,
|
| 166 |
+
norm_decay_mult=0.0,
|
| 167 |
+
custom_keys={
|
| 168 |
+
'backbone.text_model':
|
| 169 |
+
dict(lr_mult=0.01),
|
| 170 |
+
'logit_scale':
|
| 171 |
+
dict(weight_decay=0.0)
|
| 172 |
+
}),
|
| 173 |
+
constructor='YOLOWv5OptimizerConstructor')
|
configs/pretrain/yolo_world_m_t2i_bn_2e-4_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py
ADDED
|
@@ -0,0 +1,171 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_m_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'],
|
| 4 |
+
allow_failed_imports=False)
|
| 5 |
+
|
| 6 |
+
# hyper-parameters
|
| 7 |
+
num_classes = 1203
|
| 8 |
+
num_training_classes = 80
|
| 9 |
+
max_epochs = 100 # Maximum training epochs
|
| 10 |
+
close_mosaic_epochs = 2
|
| 11 |
+
save_epoch_intervals = 2
|
| 12 |
+
text_channels = 512
|
| 13 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 14 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 15 |
+
base_lr = 2e-3
|
| 16 |
+
weight_decay = 0.05 / 2
|
| 17 |
+
train_batch_size_per_gpu = 16
|
| 18 |
+
|
| 19 |
+
# model settings
|
| 20 |
+
model = dict(
|
| 21 |
+
type='YOLOWorldDetector',
|
| 22 |
+
mm_neck=True,
|
| 23 |
+
num_train_classes=num_training_classes,
|
| 24 |
+
num_test_classes=num_classes,
|
| 25 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 26 |
+
backbone=dict(
|
| 27 |
+
_delete_=True,
|
| 28 |
+
type='MultiModalYOLOBackbone',
|
| 29 |
+
image_model={{_base_.model.backbone}},
|
| 30 |
+
text_model=dict(
|
| 31 |
+
type='HuggingCLIPLanguageBackbone',
|
| 32 |
+
model_name='pretrained_models/clip-vit-base-patch32-projection',
|
| 33 |
+
frozen_modules=['all'])),
|
| 34 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 35 |
+
guide_channels=text_channels,
|
| 36 |
+
embed_channels=neck_embed_channels,
|
| 37 |
+
num_heads=neck_num_heads,
|
| 38 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv'),
|
| 39 |
+
num_csp_blocks=2),
|
| 40 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 41 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 42 |
+
embed_dims=text_channels,
|
| 43 |
+
use_bn_head=True,
|
| 44 |
+
num_classes=num_training_classes)),
|
| 45 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 46 |
+
|
| 47 |
+
# dataset settings
|
| 48 |
+
text_transform = [
|
| 49 |
+
dict(type='RandomLoadText',
|
| 50 |
+
num_neg_samples=(num_classes, num_classes),
|
| 51 |
+
max_num_samples=num_training_classes,
|
| 52 |
+
padding_to_max=True,
|
| 53 |
+
padding_value=''),
|
| 54 |
+
dict(type='mmdet.PackDetInputs',
|
| 55 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 56 |
+
'flip_direction', 'texts'))
|
| 57 |
+
]
|
| 58 |
+
train_pipeline = [
|
| 59 |
+
*_base_.pre_transform,
|
| 60 |
+
dict(type='MultiModalMosaic',
|
| 61 |
+
img_scale=_base_.img_scale,
|
| 62 |
+
pad_val=114.0,
|
| 63 |
+
pre_transform=_base_.pre_transform),
|
| 64 |
+
dict(
|
| 65 |
+
type='YOLOv5RandomAffine',
|
| 66 |
+
max_rotate_degree=0.0,
|
| 67 |
+
max_shear_degree=0.0,
|
| 68 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 69 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 70 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 71 |
+
border_val=(114, 114, 114)),
|
| 72 |
+
*_base_.last_transform[:-1],
|
| 73 |
+
*text_transform,
|
| 74 |
+
]
|
| 75 |
+
train_pipeline_stage2 = [*_base_.train_pipeline_stage2[:-1], *text_transform]
|
| 76 |
+
obj365v1_train_dataset = dict(
|
| 77 |
+
type='MultiModalDataset',
|
| 78 |
+
dataset=dict(
|
| 79 |
+
type='YOLOv5Objects365V1Dataset',
|
| 80 |
+
data_root='data/objects365v1/',
|
| 81 |
+
ann_file='annotations/objects365_train.json',
|
| 82 |
+
data_prefix=dict(img='train/'),
|
| 83 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 84 |
+
class_text_path='data/captions/obj365v1_class_captions.json',
|
| 85 |
+
pipeline=train_pipeline)
|
| 86 |
+
|
| 87 |
+
mg_train_dataset = dict(type='YOLOv5MixedGroundingDataset',
|
| 88 |
+
data_root='data/mixed_grounding/',
|
| 89 |
+
ann_file='annotations/final_mixed_train_no_coco.json',
|
| 90 |
+
data_prefix=dict(img='gqa/images/'),
|
| 91 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 92 |
+
pipeline=train_pipeline)
|
| 93 |
+
|
| 94 |
+
flickr_train_dataset = dict(
|
| 95 |
+
type='YOLOv5MixedGroundingDataset',
|
| 96 |
+
data_root='data/flickr/',
|
| 97 |
+
ann_file='annotations/final_flickr_separateGT_train.json',
|
| 98 |
+
data_prefix=dict(img='full_images/'),
|
| 99 |
+
filter_cfg=dict(filter_empty_gt=True, min_size=32),
|
| 100 |
+
pipeline=train_pipeline)
|
| 101 |
+
|
| 102 |
+
train_dataloader = dict(batch_size=train_batch_size_per_gpu,
|
| 103 |
+
collate_fn=dict(type='yolow_collate'),
|
| 104 |
+
dataset=dict(_delete_=True,
|
| 105 |
+
type='ConcatDataset',
|
| 106 |
+
datasets=[
|
| 107 |
+
obj365v1_train_dataset,
|
| 108 |
+
flickr_train_dataset, mg_train_dataset
|
| 109 |
+
],
|
| 110 |
+
ignore_keys=['classes', 'palette']))
|
| 111 |
+
|
| 112 |
+
test_pipeline = [
|
| 113 |
+
*_base_.test_pipeline[:-1],
|
| 114 |
+
dict(type='LoadText'),
|
| 115 |
+
dict(type='mmdet.PackDetInputs',
|
| 116 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 117 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 118 |
+
]
|
| 119 |
+
coco_val_dataset = dict(
|
| 120 |
+
_delete_=True,
|
| 121 |
+
type='MultiModalDataset',
|
| 122 |
+
dataset=dict(type='YOLOv5LVISV1Dataset',
|
| 123 |
+
data_root='data/coco/',
|
| 124 |
+
test_mode=True,
|
| 125 |
+
ann_file='lvis/lvis_v1_minival_inserted_image_name.json',
|
| 126 |
+
data_prefix=dict(img=''),
|
| 127 |
+
batch_shapes_cfg=None),
|
| 128 |
+
class_text_path='data/captions/lvis_v1_class_captions.json',
|
| 129 |
+
pipeline=test_pipeline)
|
| 130 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 131 |
+
test_dataloader = val_dataloader
|
| 132 |
+
|
| 133 |
+
val_evaluator = dict(type='mmdet.LVISMetric',
|
| 134 |
+
ann_file='data/coco/lvis/lvis_v1_minival_inserted_image_name.json',
|
| 135 |
+
metric='bbox')
|
| 136 |
+
test_evaluator = val_evaluator
|
| 137 |
+
|
| 138 |
+
# training settings
|
| 139 |
+
default_hooks = dict(param_scheduler=dict(max_epochs=max_epochs),
|
| 140 |
+
checkpoint=dict(interval=save_epoch_intervals,
|
| 141 |
+
rule='greater'))
|
| 142 |
+
custom_hooks = [
|
| 143 |
+
dict(type='EMAHook',
|
| 144 |
+
ema_type='ExpMomentumEMA',
|
| 145 |
+
momentum=0.0001,
|
| 146 |
+
update_buffers=True,
|
| 147 |
+
strict_load=False,
|
| 148 |
+
priority=49),
|
| 149 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 150 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 151 |
+
switch_pipeline=train_pipeline_stage2)
|
| 152 |
+
]
|
| 153 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 154 |
+
val_interval=10,
|
| 155 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 156 |
+
_base_.val_interval_stage2)])
|
| 157 |
+
optim_wrapper = dict(optimizer=dict(
|
| 158 |
+
_delete_=True,
|
| 159 |
+
type='AdamW',
|
| 160 |
+
lr=base_lr,
|
| 161 |
+
weight_decay=weight_decay,
|
| 162 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 163 |
+
paramwise_cfg=dict(bias_decay_mult=0.0,
|
| 164 |
+
norm_decay_mult=0.0,
|
| 165 |
+
custom_keys={
|
| 166 |
+
'backbone.text_model':
|
| 167 |
+
dict(lr_mult=0.01),
|
| 168 |
+
'logit_scale':
|
| 169 |
+
dict(weight_decay=0.0)
|
| 170 |
+
}),
|
| 171 |
+
constructor='YOLOWv5OptimizerConstructor')
|
configs/pretrain/yolo_world_s_dual_l2norm_3block_2e-4_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py
ADDED
|
@@ -0,0 +1,173 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_s_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'],
|
| 4 |
+
allow_failed_imports=False)
|
| 5 |
+
|
| 6 |
+
# hyper-parameters
|
| 7 |
+
num_classes = 1203
|
| 8 |
+
num_training_classes = 80
|
| 9 |
+
max_epochs = 100 # Maximum training epochs
|
| 10 |
+
close_mosaic_epochs = 2
|
| 11 |
+
save_epoch_intervals = 2
|
| 12 |
+
text_channels = 512
|
| 13 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 14 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 15 |
+
base_lr = 2e-3
|
| 16 |
+
weight_decay = 0.05 / 2
|
| 17 |
+
train_batch_size_per_gpu = 16
|
| 18 |
+
|
| 19 |
+
# model settings
|
| 20 |
+
model = dict(
|
| 21 |
+
type='YOLOWorldDetector',
|
| 22 |
+
mm_neck=True,
|
| 23 |
+
num_train_classes=num_training_classes,
|
| 24 |
+
num_test_classes=num_classes,
|
| 25 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 26 |
+
backbone=dict(
|
| 27 |
+
_delete_=True,
|
| 28 |
+
type='MultiModalYOLOBackbone',
|
| 29 |
+
image_model={{_base_.model.backbone}},
|
| 30 |
+
text_model=dict(
|
| 31 |
+
type='HuggingCLIPLanguageBackbone',
|
| 32 |
+
model_name='pretrained_models/clip-vit-base-patch32-projection',
|
| 33 |
+
frozen_modules=['all'])),
|
| 34 |
+
neck=dict(type='YOLOWolrdDualPAFPN',
|
| 35 |
+
guide_channels=text_channels,
|
| 36 |
+
embed_channels=neck_embed_channels,
|
| 37 |
+
num_heads=neck_num_heads,
|
| 38 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv'),
|
| 39 |
+
text_enhancder=dict(type='ImagePoolingAttentionModule',
|
| 40 |
+
embed_channels=256,
|
| 41 |
+
num_heads=8)),
|
| 42 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 43 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 44 |
+
embed_dims=text_channels,
|
| 45 |
+
num_classes=num_training_classes)),
|
| 46 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 47 |
+
|
| 48 |
+
# dataset settings
|
| 49 |
+
text_transform = [
|
| 50 |
+
dict(type='RandomLoadText',
|
| 51 |
+
num_neg_samples=(num_classes, num_classes),
|
| 52 |
+
max_num_samples=num_training_classes,
|
| 53 |
+
padding_to_max=True,
|
| 54 |
+
padding_value=''),
|
| 55 |
+
dict(type='mmdet.PackDetInputs',
|
| 56 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 57 |
+
'flip_direction', 'texts'))
|
| 58 |
+
]
|
| 59 |
+
train_pipeline = [
|
| 60 |
+
*_base_.pre_transform,
|
| 61 |
+
dict(type='MultiModalMosaic',
|
| 62 |
+
img_scale=_base_.img_scale,
|
| 63 |
+
pad_val=114.0,
|
| 64 |
+
pre_transform=_base_.pre_transform),
|
| 65 |
+
dict(
|
| 66 |
+
type='YOLOv5RandomAffine',
|
| 67 |
+
max_rotate_degree=0.0,
|
| 68 |
+
max_shear_degree=0.0,
|
| 69 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 70 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 71 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 72 |
+
border_val=(114, 114, 114)),
|
| 73 |
+
*_base_.last_transform[:-1],
|
| 74 |
+
*text_transform,
|
| 75 |
+
]
|
| 76 |
+
train_pipeline_stage2 = [*_base_.train_pipeline_stage2[:-1], *text_transform]
|
| 77 |
+
obj365v1_train_dataset = dict(
|
| 78 |
+
type='MultiModalDataset',
|
| 79 |
+
dataset=dict(
|
| 80 |
+
type='YOLOv5Objects365V1Dataset',
|
| 81 |
+
data_root='data/objects365v1/',
|
| 82 |
+
ann_file='annotations/objects365_train.json',
|
| 83 |
+
data_prefix=dict(img='train/'),
|
| 84 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 85 |
+
class_text_path='data/captions/obj365v1_class_captions.json',
|
| 86 |
+
pipeline=train_pipeline)
|
| 87 |
+
|
| 88 |
+
mg_train_dataset = dict(type='YOLOv5MixedGroundingDataset',
|
| 89 |
+
data_root='data/mixed_grounding/',
|
| 90 |
+
ann_file='annotations/final_mixed_train_no_coco.json',
|
| 91 |
+
data_prefix=dict(img='gqa/images/'),
|
| 92 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 93 |
+
pipeline=train_pipeline)
|
| 94 |
+
|
| 95 |
+
flickr_train_dataset = dict(
|
| 96 |
+
type='YOLOv5MixedGroundingDataset',
|
| 97 |
+
data_root='data/flickr/',
|
| 98 |
+
ann_file='annotations/final_flickr_separateGT_train.json',
|
| 99 |
+
data_prefix=dict(img='full_images/'),
|
| 100 |
+
filter_cfg=dict(filter_empty_gt=True, min_size=32),
|
| 101 |
+
pipeline=train_pipeline)
|
| 102 |
+
|
| 103 |
+
train_dataloader = dict(batch_size=train_batch_size_per_gpu,
|
| 104 |
+
collate_fn=dict(type='yolow_collate'),
|
| 105 |
+
dataset=dict(_delete_=True,
|
| 106 |
+
type='ConcatDataset',
|
| 107 |
+
datasets=[
|
| 108 |
+
obj365v1_train_dataset,
|
| 109 |
+
flickr_train_dataset, mg_train_dataset
|
| 110 |
+
],
|
| 111 |
+
ignore_keys=['classes', 'palette']))
|
| 112 |
+
|
| 113 |
+
test_pipeline = [
|
| 114 |
+
*_base_.test_pipeline[:-1],
|
| 115 |
+
dict(type='LoadText'),
|
| 116 |
+
dict(type='mmdet.PackDetInputs',
|
| 117 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 118 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 119 |
+
]
|
| 120 |
+
coco_val_dataset = dict(
|
| 121 |
+
_delete_=True,
|
| 122 |
+
type='MultiModalDataset',
|
| 123 |
+
dataset=dict(type='YOLOv5LVISV1Dataset',
|
| 124 |
+
data_root='data/coco/',
|
| 125 |
+
test_mode=True,
|
| 126 |
+
ann_file='lvis/lvis_v1_minival_inserted_image_name.json',
|
| 127 |
+
data_prefix=dict(img=''),
|
| 128 |
+
batch_shapes_cfg=None),
|
| 129 |
+
class_text_path='data/captions/lvis_v1_class_captions.json',
|
| 130 |
+
pipeline=test_pipeline)
|
| 131 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 132 |
+
test_dataloader = val_dataloader
|
| 133 |
+
|
| 134 |
+
val_evaluator = dict(type='mmdet.LVISMetric',
|
| 135 |
+
ann_file='data/coco/lvis/\
|
| 136 |
+
lvis_v1_minival_inserted_image_name.json',
|
| 137 |
+
metric='bbox')
|
| 138 |
+
test_evaluator = val_evaluator
|
| 139 |
+
|
| 140 |
+
# training settings
|
| 141 |
+
default_hooks = dict(param_scheduler=dict(max_epochs=max_epochs),
|
| 142 |
+
checkpoint=dict(interval=save_epoch_intervals,
|
| 143 |
+
rule='greater'))
|
| 144 |
+
custom_hooks = [
|
| 145 |
+
dict(type='EMAHook',
|
| 146 |
+
ema_type='ExpMomentumEMA',
|
| 147 |
+
momentum=0.0001,
|
| 148 |
+
update_buffers=True,
|
| 149 |
+
strict_load=False,
|
| 150 |
+
priority=49),
|
| 151 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 152 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 153 |
+
switch_pipeline=train_pipeline_stage2)
|
| 154 |
+
]
|
| 155 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 156 |
+
val_interval=10,
|
| 157 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 158 |
+
_base_.val_interval_stage2)])
|
| 159 |
+
optim_wrapper = dict(optimizer=dict(
|
| 160 |
+
_delete_=True,
|
| 161 |
+
type='AdamW',
|
| 162 |
+
lr=base_lr,
|
| 163 |
+
weight_decay=weight_decay,
|
| 164 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 165 |
+
paramwise_cfg=dict(bias_decay_mult=0.0,
|
| 166 |
+
norm_decay_mult=0.0,
|
| 167 |
+
custom_keys={
|
| 168 |
+
'backbone.text_model':
|
| 169 |
+
dict(lr_mult=0.01),
|
| 170 |
+
'logit_scale':
|
| 171 |
+
dict(weight_decay=0.0)
|
| 172 |
+
}),
|
| 173 |
+
constructor='YOLOWv5OptimizerConstructor')
|
configs/pretrain/yolo_world_s_t2i_bn_2e-4_100e_4x8gpus_obj365v1_goldg_train_lvis_minival.py
ADDED
|
@@ -0,0 +1,172 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_s_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'],
|
| 4 |
+
allow_failed_imports=False)
|
| 5 |
+
|
| 6 |
+
# hyper-parameters
|
| 7 |
+
num_classes = 1203
|
| 8 |
+
num_training_classes = 80
|
| 9 |
+
max_epochs = 100 # Maximum training epochs
|
| 10 |
+
close_mosaic_epochs = 2
|
| 11 |
+
save_epoch_intervals = 2
|
| 12 |
+
text_channels = 512
|
| 13 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 14 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 15 |
+
base_lr = 2e-3
|
| 16 |
+
# for 4 nodes, 8 gpus per node, 32 total gpus
|
| 17 |
+
weight_decay = 0.05 / 2
|
| 18 |
+
train_batch_size_per_gpu = 16
|
| 19 |
+
|
| 20 |
+
# model settings
|
| 21 |
+
model = dict(
|
| 22 |
+
type='YOLOWorldDetector',
|
| 23 |
+
mm_neck=True,
|
| 24 |
+
num_train_classes=num_training_classes,
|
| 25 |
+
num_test_classes=num_classes,
|
| 26 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 27 |
+
backbone=dict(
|
| 28 |
+
_delete_=True,
|
| 29 |
+
type='MultiModalYOLOBackbone',
|
| 30 |
+
image_model={{_base_.model.backbone}},
|
| 31 |
+
text_model=dict(
|
| 32 |
+
type='HuggingCLIPLanguageBackbone',
|
| 33 |
+
model_name='pretrained_models/clip-vit-base-patch32-projection',
|
| 34 |
+
frozen_modules=['all'])),
|
| 35 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 36 |
+
guide_channels=text_channels,
|
| 37 |
+
embed_channels=neck_embed_channels,
|
| 38 |
+
num_heads=neck_num_heads,
|
| 39 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv'),
|
| 40 |
+
num_csp_blocks=2),
|
| 41 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 42 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 43 |
+
embed_dims=text_channels,
|
| 44 |
+
use_bn_head=True,
|
| 45 |
+
num_classes=num_training_classes)),
|
| 46 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 47 |
+
|
| 48 |
+
# dataset settings
|
| 49 |
+
text_transform = [
|
| 50 |
+
dict(type='RandomLoadText',
|
| 51 |
+
num_neg_samples=(num_classes, num_classes),
|
| 52 |
+
max_num_samples=num_training_classes,
|
| 53 |
+
padding_to_max=True,
|
| 54 |
+
padding_value=''),
|
| 55 |
+
dict(type='mmdet.PackDetInputs',
|
| 56 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 57 |
+
'flip_direction', 'texts'))
|
| 58 |
+
]
|
| 59 |
+
train_pipeline = [
|
| 60 |
+
*_base_.pre_transform,
|
| 61 |
+
dict(type='MultiModalMosaic',
|
| 62 |
+
img_scale=_base_.img_scale,
|
| 63 |
+
pad_val=114.0,
|
| 64 |
+
pre_transform=_base_.pre_transform),
|
| 65 |
+
dict(
|
| 66 |
+
type='YOLOv5RandomAffine',
|
| 67 |
+
max_rotate_degree=0.0,
|
| 68 |
+
max_shear_degree=0.0,
|
| 69 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 70 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 71 |
+
border=(-_base_.img_scale[0] // 2, -_base_.img_scale[1] // 2),
|
| 72 |
+
border_val=(114, 114, 114)),
|
| 73 |
+
*_base_.last_transform[:-1],
|
| 74 |
+
*text_transform,
|
| 75 |
+
]
|
| 76 |
+
train_pipeline_stage2 = [*_base_.train_pipeline_stage2[:-1], *text_transform]
|
| 77 |
+
obj365v1_train_dataset = dict(
|
| 78 |
+
type='MultiModalDataset',
|
| 79 |
+
dataset=dict(
|
| 80 |
+
type='YOLOv5Objects365V1Dataset',
|
| 81 |
+
data_root='data/objects365v1/',
|
| 82 |
+
ann_file='annotations/objects365_train.json',
|
| 83 |
+
data_prefix=dict(img='train/'),
|
| 84 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 85 |
+
class_text_path='data/captions/obj365v1_class_captions.json',
|
| 86 |
+
pipeline=train_pipeline)
|
| 87 |
+
|
| 88 |
+
mg_train_dataset = dict(type='YOLOv5MixedGroundingDataset',
|
| 89 |
+
data_root='data/mixed_grounding/',
|
| 90 |
+
ann_file='annotations/final_mixed_train_no_coco.json',
|
| 91 |
+
data_prefix=dict(img='gqa/images/'),
|
| 92 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 93 |
+
pipeline=train_pipeline)
|
| 94 |
+
|
| 95 |
+
flickr_train_dataset = dict(
|
| 96 |
+
type='YOLOv5MixedGroundingDataset',
|
| 97 |
+
data_root='data/flickr/',
|
| 98 |
+
ann_file='annotations/final_flickr_separateGT_train.json',
|
| 99 |
+
data_prefix=dict(img='full_images/'),
|
| 100 |
+
filter_cfg=dict(filter_empty_gt=True, min_size=32),
|
| 101 |
+
pipeline=train_pipeline)
|
| 102 |
+
|
| 103 |
+
train_dataloader = dict(batch_size=train_batch_size_per_gpu,
|
| 104 |
+
collate_fn=dict(type='yolow_collate'),
|
| 105 |
+
dataset=dict(_delete_=True,
|
| 106 |
+
type='ConcatDataset',
|
| 107 |
+
datasets=[
|
| 108 |
+
obj365v1_train_dataset,
|
| 109 |
+
flickr_train_dataset, mg_train_dataset
|
| 110 |
+
],
|
| 111 |
+
ignore_keys=['classes', 'palette']))
|
| 112 |
+
|
| 113 |
+
test_pipeline = [
|
| 114 |
+
*_base_.test_pipeline[:-1],
|
| 115 |
+
dict(type='LoadText'),
|
| 116 |
+
dict(type='mmdet.PackDetInputs',
|
| 117 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 118 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 119 |
+
]
|
| 120 |
+
coco_val_dataset = dict(
|
| 121 |
+
_delete_=True,
|
| 122 |
+
type='MultiModalDataset',
|
| 123 |
+
dataset=dict(type='YOLOv5LVISV1Dataset',
|
| 124 |
+
data_root='data/coco/',
|
| 125 |
+
test_mode=True,
|
| 126 |
+
ann_file='lvis/lvis_v1_minival_inserted_image_name.json',
|
| 127 |
+
data_prefix=dict(img=''),
|
| 128 |
+
batch_shapes_cfg=None),
|
| 129 |
+
class_text_path='data/captions/lvis_v1_class_captions.json',
|
| 130 |
+
pipeline=test_pipeline)
|
| 131 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 132 |
+
test_dataloader = val_dataloader
|
| 133 |
+
|
| 134 |
+
val_evaluator = dict(type='mmdet.LVISMetric',
|
| 135 |
+
ann_file='data/coco/lvis/lvis_v1_minival_inserted_image_name.json',
|
| 136 |
+
metric='bbox')
|
| 137 |
+
test_evaluator = val_evaluator
|
| 138 |
+
|
| 139 |
+
# training settings
|
| 140 |
+
default_hooks = dict(param_scheduler=dict(max_epochs=max_epochs),
|
| 141 |
+
checkpoint=dict(interval=save_epoch_intervals,
|
| 142 |
+
rule='greater'))
|
| 143 |
+
custom_hooks = [
|
| 144 |
+
dict(type='EMAHook',
|
| 145 |
+
ema_type='ExpMomentumEMA',
|
| 146 |
+
momentum=0.0001,
|
| 147 |
+
update_buffers=True,
|
| 148 |
+
strict_load=False,
|
| 149 |
+
priority=49),
|
| 150 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 151 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 152 |
+
switch_pipeline=train_pipeline_stage2)
|
| 153 |
+
]
|
| 154 |
+
train_cfg = dict(max_epochs=max_epochs,
|
| 155 |
+
val_interval=10,
|
| 156 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 157 |
+
_base_.val_interval_stage2)])
|
| 158 |
+
optim_wrapper = dict(optimizer=dict(
|
| 159 |
+
_delete_=True,
|
| 160 |
+
type='AdamW',
|
| 161 |
+
lr=base_lr,
|
| 162 |
+
weight_decay=weight_decay,
|
| 163 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 164 |
+
paramwise_cfg=dict(bias_decay_mult=0.0,
|
| 165 |
+
norm_decay_mult=0.0,
|
| 166 |
+
custom_keys={
|
| 167 |
+
'backbone.text_model':
|
| 168 |
+
dict(lr_mult=0.01),
|
| 169 |
+
'logit_scale':
|
| 170 |
+
dict(weight_decay=0.0)
|
| 171 |
+
}),
|
| 172 |
+
constructor='YOLOWv5OptimizerConstructor')
|
configs/scaleup/yolo_world_l_t2i_bn_2e-4_20e_4x8gpus_obj365v1_goldg_train_lvis_minival_s1024.py
ADDED
|
@@ -0,0 +1,216 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_l_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'],
|
| 4 |
+
allow_failed_imports=False)
|
| 5 |
+
|
| 6 |
+
# hyper-parameters
|
| 7 |
+
num_classes = 1203
|
| 8 |
+
num_training_classes = 80
|
| 9 |
+
max_epochs = 20 # Maximum training epochs
|
| 10 |
+
close_mosaic_epochs = 2
|
| 11 |
+
save_epoch_intervals = 2
|
| 12 |
+
text_channels = 512
|
| 13 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 14 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 15 |
+
base_lr = 2e-4
|
| 16 |
+
weight_decay = 0.05 / 2
|
| 17 |
+
train_batch_size_per_gpu = 8
|
| 18 |
+
img_scale = (1024, 1024)
|
| 19 |
+
load_from = 'work_dirs/model_zoo/yolow-v8_l_clipv2_frozen_t2iv2_bn_o365_goldg_pretrain.pth' # noqa
|
| 20 |
+
|
| 21 |
+
# model settings
|
| 22 |
+
model = dict(
|
| 23 |
+
type='YOLOWorldDetector',
|
| 24 |
+
mm_neck=True,
|
| 25 |
+
num_train_classes=num_training_classes,
|
| 26 |
+
num_test_classes=num_classes,
|
| 27 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 28 |
+
backbone=dict(
|
| 29 |
+
_delete_=True,
|
| 30 |
+
type='MultiModalYOLOBackbone',
|
| 31 |
+
image_model={{_base_.model.backbone}},
|
| 32 |
+
text_model=dict(
|
| 33 |
+
type='HuggingCLIPLanguageBackbone',
|
| 34 |
+
model_name='openai/clip-vit-base-patch32',
|
| 35 |
+
frozen_modules=['all'])),
|
| 36 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 37 |
+
guide_channels=text_channels,
|
| 38 |
+
embed_channels=neck_embed_channels,
|
| 39 |
+
num_heads=neck_num_heads,
|
| 40 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv'),
|
| 41 |
+
num_csp_blocks=2),
|
| 42 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 43 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 44 |
+
embed_dims=text_channels,
|
| 45 |
+
use_bn_head=True,
|
| 46 |
+
num_classes=num_training_classes)),
|
| 47 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 48 |
+
|
| 49 |
+
# dataset settings
|
| 50 |
+
text_transform = [
|
| 51 |
+
dict(type='RandomLoadText',
|
| 52 |
+
num_neg_samples=(num_classes, num_classes),
|
| 53 |
+
max_num_samples=num_training_classes,
|
| 54 |
+
padding_to_max=True,
|
| 55 |
+
padding_value=''),
|
| 56 |
+
dict(type='mmdet.PackDetInputs',
|
| 57 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 58 |
+
'flip_direction', 'texts'))
|
| 59 |
+
]
|
| 60 |
+
mosaic_affine_transform = [
|
| 61 |
+
dict(type='MultiModalMosaic',
|
| 62 |
+
img_scale=img_scale,
|
| 63 |
+
pad_val=114.0,
|
| 64 |
+
pre_transform=_base_.pre_transform),
|
| 65 |
+
dict(
|
| 66 |
+
type='YOLOv5RandomAffine',
|
| 67 |
+
max_rotate_degree=0.0,
|
| 68 |
+
max_shear_degree=0.0,
|
| 69 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 70 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 71 |
+
border=(-img_scale[0] // 2, -img_scale[1] // 2),
|
| 72 |
+
border_val=(114, 114, 114))
|
| 73 |
+
]
|
| 74 |
+
train_pipeline = [
|
| 75 |
+
*_base_.pre_transform,
|
| 76 |
+
*mosaic_affine_transform,
|
| 77 |
+
dict(
|
| 78 |
+
type='YOLOv5MultiModalMixUp',
|
| 79 |
+
prob=_base_.mixup_prob,
|
| 80 |
+
pre_transform=[*_base_.pre_transform,
|
| 81 |
+
*mosaic_affine_transform]),
|
| 82 |
+
*_base_.last_transform[:-1],
|
| 83 |
+
*text_transform,
|
| 84 |
+
]
|
| 85 |
+
train_pipeline_stage2 = [
|
| 86 |
+
*_base_.pre_transform,
|
| 87 |
+
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
|
| 88 |
+
dict(
|
| 89 |
+
type='LetterResize',
|
| 90 |
+
scale=img_scale,
|
| 91 |
+
allow_scale_up=True,
|
| 92 |
+
pad_val=dict(img=114.0)),
|
| 93 |
+
dict(
|
| 94 |
+
type='YOLOv5RandomAffine',
|
| 95 |
+
max_rotate_degree=0.0,
|
| 96 |
+
max_shear_degree=0.0,
|
| 97 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 98 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 99 |
+
border_val=(114, 114, 114)),
|
| 100 |
+
*_base_.last_transform[:-1],
|
| 101 |
+
*text_transform,
|
| 102 |
+
]
|
| 103 |
+
obj365v1_train_dataset = dict(
|
| 104 |
+
type='MultiModalDataset',
|
| 105 |
+
dataset=dict(
|
| 106 |
+
type='YOLOv5Objects365V1Dataset',
|
| 107 |
+
data_root='data/objects365v1/',
|
| 108 |
+
ann_file='annotations/objects365_train.json',
|
| 109 |
+
data_prefix=dict(img='train/'),
|
| 110 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 111 |
+
class_text_path='data/captions/obj365v1_class_captions.json',
|
| 112 |
+
pipeline=train_pipeline)
|
| 113 |
+
|
| 114 |
+
mg_train_dataset = dict(
|
| 115 |
+
type='YOLOv5MixedGroundingDataset',
|
| 116 |
+
data_root='data/mixed_grounding/',
|
| 117 |
+
ann_file='annotations/final_mixed_train_no_coco.json',
|
| 118 |
+
data_prefix=dict(img='gqa/images/'),
|
| 119 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 120 |
+
pipeline=train_pipeline)
|
| 121 |
+
|
| 122 |
+
flickr_train_dataset = dict(
|
| 123 |
+
type='YOLOv5MixedGroundingDataset',
|
| 124 |
+
data_root='data/flickr/',
|
| 125 |
+
ann_file='annotations/final_flickr_separateGT_train.json',
|
| 126 |
+
data_prefix=dict(img='images/'),
|
| 127 |
+
filter_cfg=dict(filter_empty_gt=True, min_size=32),
|
| 128 |
+
pipeline=train_pipeline)
|
| 129 |
+
|
| 130 |
+
train_dataloader = dict(
|
| 131 |
+
batch_size=train_batch_size_per_gpu,
|
| 132 |
+
collate_fn=dict(type='yolow_collate'),
|
| 133 |
+
dataset=dict(
|
| 134 |
+
_delete_=True,
|
| 135 |
+
type='ConcatDataset',
|
| 136 |
+
datasets=[
|
| 137 |
+
obj365v1_train_dataset,
|
| 138 |
+
flickr_train_dataset,
|
| 139 |
+
mg_train_dataset
|
| 140 |
+
],
|
| 141 |
+
ignore_keys=['classes', 'palette']))
|
| 142 |
+
|
| 143 |
+
test_pipeline = [
|
| 144 |
+
dict(type='LoadImageFromFile', backend_args=_base_.backend_args),
|
| 145 |
+
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
|
| 146 |
+
dict(
|
| 147 |
+
type='LetterResize',
|
| 148 |
+
scale=img_scale,
|
| 149 |
+
allow_scale_up=False,
|
| 150 |
+
pad_val=dict(img=114)),
|
| 151 |
+
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
|
| 152 |
+
dict(type='LoadText'),
|
| 153 |
+
dict(type='mmdet.PackDetInputs',
|
| 154 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 155 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 156 |
+
]
|
| 157 |
+
coco_val_dataset = dict(
|
| 158 |
+
_delete_=True,
|
| 159 |
+
type='MultiModalDataset',
|
| 160 |
+
dataset=dict(
|
| 161 |
+
type='YOLOv5LVISV1Dataset',
|
| 162 |
+
data_root='data/lvis/',
|
| 163 |
+
test_mode=True,
|
| 164 |
+
ann_file='annotations/'
|
| 165 |
+
'lvis_v1_minival_inserted_image_name.json',
|
| 166 |
+
data_prefix=dict(img=''),
|
| 167 |
+
batch_shapes_cfg=None),
|
| 168 |
+
class_text_path='data/captions/lvis_v1_class_captions.json',
|
| 169 |
+
pipeline=test_pipeline)
|
| 170 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 171 |
+
test_dataloader = val_dataloader
|
| 172 |
+
|
| 173 |
+
val_evaluator = dict(
|
| 174 |
+
type='mmdet.LVISMetric',
|
| 175 |
+
ann_file='data/lvis/annotations/'
|
| 176 |
+
'lvis_v1_minival_inserted_image_name.json',
|
| 177 |
+
metric='bbox')
|
| 178 |
+
test_evaluator = val_evaluator
|
| 179 |
+
|
| 180 |
+
# training settings
|
| 181 |
+
default_hooks = dict(
|
| 182 |
+
param_scheduler=dict(max_epochs=max_epochs),
|
| 183 |
+
checkpoint=dict(interval=save_epoch_intervals,
|
| 184 |
+
rule='greater'))
|
| 185 |
+
custom_hooks = [
|
| 186 |
+
dict(type='EMAHook',
|
| 187 |
+
ema_type='ExpMomentumEMA',
|
| 188 |
+
momentum=0.0001,
|
| 189 |
+
update_buffers=True,
|
| 190 |
+
strict_load=False,
|
| 191 |
+
priority=49),
|
| 192 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 193 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 194 |
+
switch_pipeline=train_pipeline_stage2)
|
| 195 |
+
]
|
| 196 |
+
train_cfg = dict(
|
| 197 |
+
max_epochs=max_epochs,
|
| 198 |
+
val_interval=10,
|
| 199 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 200 |
+
_base_.val_interval_stage2)])
|
| 201 |
+
optim_wrapper = dict(optimizer=dict(
|
| 202 |
+
_delete_=True,
|
| 203 |
+
type='AdamW',
|
| 204 |
+
lr=base_lr,
|
| 205 |
+
weight_decay=weight_decay,
|
| 206 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 207 |
+
paramwise_cfg=dict(
|
| 208 |
+
bias_decay_mult=0.0,
|
| 209 |
+
norm_decay_mult=0.0,
|
| 210 |
+
custom_keys={
|
| 211 |
+
'backbone.text_model':
|
| 212 |
+
dict(lr_mult=0.0),
|
| 213 |
+
'logit_scale':
|
| 214 |
+
dict(weight_decay=0.0)
|
| 215 |
+
}),
|
| 216 |
+
constructor='YOLOWv5OptimizerConstructor')
|
configs/scaleup/yolo_world_l_t2i_bn_2e-4_20e_4x8gpus_obj365v1_goldg_train_lvis_minival_s1280.py
ADDED
|
@@ -0,0 +1,216 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_l_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'],
|
| 4 |
+
allow_failed_imports=False)
|
| 5 |
+
|
| 6 |
+
# hyper-parameters
|
| 7 |
+
num_classes = 1203
|
| 8 |
+
num_training_classes = 80
|
| 9 |
+
max_epochs = 20 # Maximum training epochs
|
| 10 |
+
close_mosaic_epochs = 2
|
| 11 |
+
save_epoch_intervals = 2
|
| 12 |
+
text_channels = 512
|
| 13 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 14 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 15 |
+
base_lr = 2e-4
|
| 16 |
+
weight_decay = 0.05 / 2
|
| 17 |
+
train_batch_size_per_gpu = 4
|
| 18 |
+
img_scale = (1280, 1280)
|
| 19 |
+
load_from = 'work_dirs/model_zoo/yolow-v8_l_clipv2_frozen_t2iv2_bn_o365_goldg_pretrain.pth' # noqa
|
| 20 |
+
|
| 21 |
+
# model settings
|
| 22 |
+
model = dict(
|
| 23 |
+
type='YOLOWorldDetector',
|
| 24 |
+
mm_neck=True,
|
| 25 |
+
num_train_classes=num_training_classes,
|
| 26 |
+
num_test_classes=num_classes,
|
| 27 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 28 |
+
backbone=dict(
|
| 29 |
+
_delete_=True,
|
| 30 |
+
type='MultiModalYOLOBackbone',
|
| 31 |
+
image_model={{_base_.model.backbone}},
|
| 32 |
+
text_model=dict(
|
| 33 |
+
type='HuggingCLIPLanguageBackbone',
|
| 34 |
+
model_name='openai/clip-vit-base-patch32',
|
| 35 |
+
frozen_modules=['all'])),
|
| 36 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 37 |
+
guide_channels=text_channels,
|
| 38 |
+
embed_channels=neck_embed_channels,
|
| 39 |
+
num_heads=neck_num_heads,
|
| 40 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv'),
|
| 41 |
+
num_csp_blocks=2),
|
| 42 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 43 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 44 |
+
embed_dims=text_channels,
|
| 45 |
+
use_bn_head=True,
|
| 46 |
+
num_classes=num_training_classes)),
|
| 47 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 48 |
+
|
| 49 |
+
# dataset settings
|
| 50 |
+
text_transform = [
|
| 51 |
+
dict(type='RandomLoadText',
|
| 52 |
+
num_neg_samples=(num_classes, num_classes),
|
| 53 |
+
max_num_samples=num_training_classes,
|
| 54 |
+
padding_to_max=True,
|
| 55 |
+
padding_value=''),
|
| 56 |
+
dict(type='mmdet.PackDetInputs',
|
| 57 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 58 |
+
'flip_direction', 'texts'))
|
| 59 |
+
]
|
| 60 |
+
mosaic_affine_transform = [
|
| 61 |
+
dict(type='MultiModalMosaic',
|
| 62 |
+
img_scale=img_scale,
|
| 63 |
+
pad_val=114.0,
|
| 64 |
+
pre_transform=_base_.pre_transform),
|
| 65 |
+
dict(
|
| 66 |
+
type='YOLOv5RandomAffine',
|
| 67 |
+
max_rotate_degree=0.0,
|
| 68 |
+
max_shear_degree=0.0,
|
| 69 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 70 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 71 |
+
border=(-img_scale[0] // 2, -img_scale[1] // 2),
|
| 72 |
+
border_val=(114, 114, 114))
|
| 73 |
+
]
|
| 74 |
+
train_pipeline = [
|
| 75 |
+
*_base_.pre_transform,
|
| 76 |
+
*mosaic_affine_transform,
|
| 77 |
+
dict(
|
| 78 |
+
type='YOLOv5MultiModalMixUp',
|
| 79 |
+
prob=_base_.mixup_prob,
|
| 80 |
+
pre_transform=[*_base_.pre_transform,
|
| 81 |
+
*mosaic_affine_transform]),
|
| 82 |
+
*_base_.last_transform[:-1],
|
| 83 |
+
*text_transform,
|
| 84 |
+
]
|
| 85 |
+
train_pipeline_stage2 = [
|
| 86 |
+
*_base_.pre_transform,
|
| 87 |
+
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
|
| 88 |
+
dict(
|
| 89 |
+
type='LetterResize',
|
| 90 |
+
scale=img_scale,
|
| 91 |
+
allow_scale_up=True,
|
| 92 |
+
pad_val=dict(img=114.0)),
|
| 93 |
+
dict(
|
| 94 |
+
type='YOLOv5RandomAffine',
|
| 95 |
+
max_rotate_degree=0.0,
|
| 96 |
+
max_shear_degree=0.0,
|
| 97 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 98 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 99 |
+
border_val=(114, 114, 114)),
|
| 100 |
+
*_base_.last_transform[:-1],
|
| 101 |
+
*text_transform,
|
| 102 |
+
]
|
| 103 |
+
obj365v1_train_dataset = dict(
|
| 104 |
+
type='MultiModalDataset',
|
| 105 |
+
dataset=dict(
|
| 106 |
+
type='YOLOv5Objects365V1Dataset',
|
| 107 |
+
data_root='data/objects365v1/',
|
| 108 |
+
ann_file='annotations/objects365_train.json',
|
| 109 |
+
data_prefix=dict(img='train/'),
|
| 110 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 111 |
+
class_text_path='data/captions/obj365v1_class_captions.json',
|
| 112 |
+
pipeline=train_pipeline)
|
| 113 |
+
|
| 114 |
+
mg_train_dataset = dict(
|
| 115 |
+
type='YOLOv5MixedGroundingDataset',
|
| 116 |
+
data_root='data/mixed_grounding/',
|
| 117 |
+
ann_file='annotations/final_mixed_train_no_coco.json',
|
| 118 |
+
data_prefix=dict(img='gqa/images/'),
|
| 119 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 120 |
+
pipeline=train_pipeline)
|
| 121 |
+
|
| 122 |
+
flickr_train_dataset = dict(
|
| 123 |
+
type='YOLOv5MixedGroundingDataset',
|
| 124 |
+
data_root='data/flickr/',
|
| 125 |
+
ann_file='annotations/final_flickr_separateGT_train.json',
|
| 126 |
+
data_prefix=dict(img='images/'),
|
| 127 |
+
filter_cfg=dict(filter_empty_gt=True, min_size=32),
|
| 128 |
+
pipeline=train_pipeline)
|
| 129 |
+
|
| 130 |
+
train_dataloader = dict(
|
| 131 |
+
batch_size=train_batch_size_per_gpu,
|
| 132 |
+
collate_fn=dict(type='yolow_collate'),
|
| 133 |
+
dataset=dict(
|
| 134 |
+
_delete_=True,
|
| 135 |
+
type='ConcatDataset',
|
| 136 |
+
datasets=[
|
| 137 |
+
obj365v1_train_dataset,
|
| 138 |
+
flickr_train_dataset,
|
| 139 |
+
mg_train_dataset
|
| 140 |
+
],
|
| 141 |
+
ignore_keys=['classes', 'palette']))
|
| 142 |
+
|
| 143 |
+
test_pipeline = [
|
| 144 |
+
dict(type='LoadImageFromFile', backend_args=_base_.backend_args),
|
| 145 |
+
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
|
| 146 |
+
dict(
|
| 147 |
+
type='LetterResize',
|
| 148 |
+
scale=img_scale,
|
| 149 |
+
allow_scale_up=False,
|
| 150 |
+
pad_val=dict(img=114)),
|
| 151 |
+
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
|
| 152 |
+
dict(type='LoadText'),
|
| 153 |
+
dict(type='mmdet.PackDetInputs',
|
| 154 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 155 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 156 |
+
]
|
| 157 |
+
coco_val_dataset = dict(
|
| 158 |
+
_delete_=True,
|
| 159 |
+
type='MultiModalDataset',
|
| 160 |
+
dataset=dict(
|
| 161 |
+
type='YOLOv5LVISV1Dataset',
|
| 162 |
+
data_root='data/lvis/',
|
| 163 |
+
test_mode=True,
|
| 164 |
+
ann_file='annotations/'
|
| 165 |
+
'lvis_v1_minival_inserted_image_name.json',
|
| 166 |
+
data_prefix=dict(img=''),
|
| 167 |
+
batch_shapes_cfg=None),
|
| 168 |
+
class_text_path='data/captions/lvis_v1_class_captions.json',
|
| 169 |
+
pipeline=test_pipeline)
|
| 170 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 171 |
+
test_dataloader = val_dataloader
|
| 172 |
+
|
| 173 |
+
val_evaluator = dict(
|
| 174 |
+
type='mmdet.LVISMetric',
|
| 175 |
+
ann_file='data/lvis/annotations/'
|
| 176 |
+
'lvis_v1_minival_inserted_image_name.json',
|
| 177 |
+
metric='bbox')
|
| 178 |
+
test_evaluator = val_evaluator
|
| 179 |
+
|
| 180 |
+
# training settings
|
| 181 |
+
default_hooks = dict(
|
| 182 |
+
param_scheduler=dict(max_epochs=max_epochs),
|
| 183 |
+
checkpoint=dict(interval=save_epoch_intervals,
|
| 184 |
+
rule='greater'))
|
| 185 |
+
custom_hooks = [
|
| 186 |
+
dict(type='EMAHook',
|
| 187 |
+
ema_type='ExpMomentumEMA',
|
| 188 |
+
momentum=0.0001,
|
| 189 |
+
update_buffers=True,
|
| 190 |
+
strict_load=False,
|
| 191 |
+
priority=49),
|
| 192 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 193 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 194 |
+
switch_pipeline=train_pipeline_stage2)
|
| 195 |
+
]
|
| 196 |
+
train_cfg = dict(
|
| 197 |
+
max_epochs=max_epochs,
|
| 198 |
+
val_interval=10,
|
| 199 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 200 |
+
_base_.val_interval_stage2)])
|
| 201 |
+
optim_wrapper = dict(optimizer=dict(
|
| 202 |
+
_delete_=True,
|
| 203 |
+
type='AdamW',
|
| 204 |
+
lr=base_lr,
|
| 205 |
+
weight_decay=weight_decay,
|
| 206 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 207 |
+
paramwise_cfg=dict(
|
| 208 |
+
bias_decay_mult=0.0,
|
| 209 |
+
norm_decay_mult=0.0,
|
| 210 |
+
custom_keys={
|
| 211 |
+
'backbone.text_model':
|
| 212 |
+
dict(lr_mult=0.0),
|
| 213 |
+
'logit_scale':
|
| 214 |
+
dict(weight_decay=0.0)
|
| 215 |
+
}),
|
| 216 |
+
constructor='YOLOWv5OptimizerConstructor')
|
configs/scaleup/yolo_world_l_t2i_bn_2e-4_20e_4x8gpus_obj365v1_goldg_train_lvis_minival_s1280_v2.py
ADDED
|
@@ -0,0 +1,216 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_base_ = ('../../third_party/mmyolo/configs/yolov8/'
|
| 2 |
+
'yolov8_l_syncbn_fast_8xb16-500e_coco.py')
|
| 3 |
+
custom_imports = dict(imports=['yolo_world'],
|
| 4 |
+
allow_failed_imports=False)
|
| 5 |
+
|
| 6 |
+
# hyper-parameters
|
| 7 |
+
num_classes = 1203
|
| 8 |
+
num_training_classes = 80
|
| 9 |
+
max_epochs = 20 # Maximum training epochs
|
| 10 |
+
close_mosaic_epochs = 2
|
| 11 |
+
save_epoch_intervals = 2
|
| 12 |
+
text_channels = 512
|
| 13 |
+
neck_embed_channels = [128, 256, _base_.last_stage_out_channels // 2]
|
| 14 |
+
neck_num_heads = [4, 8, _base_.last_stage_out_channels // 2 // 32]
|
| 15 |
+
base_lr = 2e-4
|
| 16 |
+
weight_decay = 0.05 / 2
|
| 17 |
+
train_batch_size_per_gpu = 6
|
| 18 |
+
img_scale = (1280, 1280)
|
| 19 |
+
load_from = 'work_dirs/yolo_world_l_t2i_bn_2e-4_20e_4x8gpus_obj365v1_goldg_train_lvis_minival_s1280/epoch_20.pth' # noqa
|
| 20 |
+
|
| 21 |
+
# model settings
|
| 22 |
+
model = dict(
|
| 23 |
+
type='YOLOWorldDetector',
|
| 24 |
+
mm_neck=True,
|
| 25 |
+
num_train_classes=num_training_classes,
|
| 26 |
+
num_test_classes=num_classes,
|
| 27 |
+
data_preprocessor=dict(type='YOLOWDetDataPreprocessor'),
|
| 28 |
+
backbone=dict(
|
| 29 |
+
_delete_=True,
|
| 30 |
+
type='MultiModalYOLOBackbone',
|
| 31 |
+
image_model={{_base_.model.backbone}},
|
| 32 |
+
text_model=dict(
|
| 33 |
+
type='HuggingCLIPLanguageBackbone',
|
| 34 |
+
model_name='openai/clip-vit-base-patch32',
|
| 35 |
+
frozen_modules=['all'])),
|
| 36 |
+
neck=dict(type='YOLOWorldPAFPN',
|
| 37 |
+
guide_channels=text_channels,
|
| 38 |
+
embed_channels=neck_embed_channels,
|
| 39 |
+
num_heads=neck_num_heads,
|
| 40 |
+
block_cfg=dict(type='MaxSigmoidCSPLayerWithTwoConv'),
|
| 41 |
+
num_csp_blocks=2),
|
| 42 |
+
bbox_head=dict(type='YOLOWorldHead',
|
| 43 |
+
head_module=dict(type='YOLOWorldHeadModule',
|
| 44 |
+
embed_dims=text_channels,
|
| 45 |
+
use_bn_head=True,
|
| 46 |
+
num_classes=num_training_classes)),
|
| 47 |
+
train_cfg=dict(assigner=dict(num_classes=num_training_classes)))
|
| 48 |
+
|
| 49 |
+
# dataset settings
|
| 50 |
+
text_transform = [
|
| 51 |
+
dict(type='RandomLoadText',
|
| 52 |
+
num_neg_samples=(num_classes, num_classes),
|
| 53 |
+
max_num_samples=num_training_classes,
|
| 54 |
+
padding_to_max=True,
|
| 55 |
+
padding_value=''),
|
| 56 |
+
dict(type='mmdet.PackDetInputs',
|
| 57 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape', 'flip',
|
| 58 |
+
'flip_direction', 'texts'))
|
| 59 |
+
]
|
| 60 |
+
mosaic_affine_transform = [
|
| 61 |
+
dict(type='MultiModalMosaic',
|
| 62 |
+
img_scale=img_scale,
|
| 63 |
+
pad_val=114.0,
|
| 64 |
+
pre_transform=_base_.pre_transform),
|
| 65 |
+
dict(
|
| 66 |
+
type='YOLOv5RandomAffine',
|
| 67 |
+
max_rotate_degree=0.0,
|
| 68 |
+
max_shear_degree=0.0,
|
| 69 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 70 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 71 |
+
border=(-img_scale[0] // 2, -img_scale[1] // 2),
|
| 72 |
+
border_val=(114, 114, 114))
|
| 73 |
+
]
|
| 74 |
+
train_pipeline = [
|
| 75 |
+
*_base_.pre_transform,
|
| 76 |
+
*mosaic_affine_transform,
|
| 77 |
+
dict(
|
| 78 |
+
type='YOLOv5MultiModalMixUp',
|
| 79 |
+
prob=_base_.mixup_prob,
|
| 80 |
+
pre_transform=[*_base_.pre_transform,
|
| 81 |
+
*mosaic_affine_transform]),
|
| 82 |
+
*_base_.last_transform[:-1],
|
| 83 |
+
*text_transform,
|
| 84 |
+
]
|
| 85 |
+
train_pipeline_stage2 = [
|
| 86 |
+
*_base_.pre_transform,
|
| 87 |
+
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
|
| 88 |
+
dict(
|
| 89 |
+
type='LetterResize',
|
| 90 |
+
scale=img_scale,
|
| 91 |
+
allow_scale_up=True,
|
| 92 |
+
pad_val=dict(img=114.0)),
|
| 93 |
+
dict(
|
| 94 |
+
type='YOLOv5RandomAffine',
|
| 95 |
+
max_rotate_degree=0.0,
|
| 96 |
+
max_shear_degree=0.0,
|
| 97 |
+
scaling_ratio_range=(1 - _base_.affine_scale, 1 + _base_.affine_scale),
|
| 98 |
+
max_aspect_ratio=_base_.max_aspect_ratio,
|
| 99 |
+
border_val=(114, 114, 114)),
|
| 100 |
+
*_base_.last_transform[:-1],
|
| 101 |
+
*text_transform,
|
| 102 |
+
]
|
| 103 |
+
obj365v1_train_dataset = dict(
|
| 104 |
+
type='MultiModalDataset',
|
| 105 |
+
dataset=dict(
|
| 106 |
+
type='YOLOv5Objects365V1Dataset',
|
| 107 |
+
data_root='data/objects365v1/',
|
| 108 |
+
ann_file='annotations/objects365_train.json',
|
| 109 |
+
data_prefix=dict(img='train/'),
|
| 110 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32)),
|
| 111 |
+
class_text_path='data/captions/obj365v1_class_captions.json',
|
| 112 |
+
pipeline=train_pipeline)
|
| 113 |
+
|
| 114 |
+
mg_train_dataset = dict(
|
| 115 |
+
type='YOLOv5MixedGroundingDataset',
|
| 116 |
+
data_root='data/mixed_grounding/',
|
| 117 |
+
ann_file='annotations/final_mixed_train_no_coco.json',
|
| 118 |
+
data_prefix=dict(img='gqa/images/'),
|
| 119 |
+
filter_cfg=dict(filter_empty_gt=False, min_size=32),
|
| 120 |
+
pipeline=train_pipeline)
|
| 121 |
+
|
| 122 |
+
flickr_train_dataset = dict(
|
| 123 |
+
type='YOLOv5MixedGroundingDataset',
|
| 124 |
+
data_root='data/flickr/',
|
| 125 |
+
ann_file='annotations/final_flickr_separateGT_train.json',
|
| 126 |
+
data_prefix=dict(img='images/'),
|
| 127 |
+
filter_cfg=dict(filter_empty_gt=True, min_size=32),
|
| 128 |
+
pipeline=train_pipeline)
|
| 129 |
+
|
| 130 |
+
train_dataloader = dict(
|
| 131 |
+
batch_size=train_batch_size_per_gpu,
|
| 132 |
+
collate_fn=dict(type='yolow_collate'),
|
| 133 |
+
dataset=dict(
|
| 134 |
+
_delete_=True,
|
| 135 |
+
type='ConcatDataset',
|
| 136 |
+
datasets=[
|
| 137 |
+
obj365v1_train_dataset,
|
| 138 |
+
flickr_train_dataset,
|
| 139 |
+
mg_train_dataset
|
| 140 |
+
],
|
| 141 |
+
ignore_keys=['classes', 'palette']))
|
| 142 |
+
|
| 143 |
+
test_pipeline = [
|
| 144 |
+
dict(type='LoadImageFromFile', backend_args=_base_.backend_args),
|
| 145 |
+
dict(type='YOLOv5KeepRatioResize', scale=img_scale),
|
| 146 |
+
dict(
|
| 147 |
+
type='LetterResize',
|
| 148 |
+
scale=img_scale,
|
| 149 |
+
allow_scale_up=False,
|
| 150 |
+
pad_val=dict(img=114)),
|
| 151 |
+
dict(type='LoadAnnotations', with_bbox=True, _scope_='mmdet'),
|
| 152 |
+
dict(type='LoadText'),
|
| 153 |
+
dict(type='mmdet.PackDetInputs',
|
| 154 |
+
meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
|
| 155 |
+
'scale_factor', 'pad_param', 'texts'))
|
| 156 |
+
]
|
| 157 |
+
coco_val_dataset = dict(
|
| 158 |
+
_delete_=True,
|
| 159 |
+
type='MultiModalDataset',
|
| 160 |
+
dataset=dict(
|
| 161 |
+
type='YOLOv5LVISV1Dataset',
|
| 162 |
+
data_root='data/lvis/',
|
| 163 |
+
test_mode=True,
|
| 164 |
+
ann_file='annotations/'
|
| 165 |
+
'lvis_v1_minival_inserted_image_name.json',
|
| 166 |
+
data_prefix=dict(img=''),
|
| 167 |
+
batch_shapes_cfg=None),
|
| 168 |
+
class_text_path='data/captions/lvis_v1_class_captions.json',
|
| 169 |
+
pipeline=test_pipeline)
|
| 170 |
+
val_dataloader = dict(dataset=coco_val_dataset)
|
| 171 |
+
test_dataloader = val_dataloader
|
| 172 |
+
|
| 173 |
+
val_evaluator = dict(
|
| 174 |
+
type='mmdet.LVISMetric',
|
| 175 |
+
ann_file='data/lvis/annotations/'
|
| 176 |
+
'lvis_v1_minival_inserted_image_name.json',
|
| 177 |
+
metric='bbox')
|
| 178 |
+
test_evaluator = val_evaluator
|
| 179 |
+
|
| 180 |
+
# training settings
|
| 181 |
+
default_hooks = dict(
|
| 182 |
+
param_scheduler=dict(max_epochs=max_epochs),
|
| 183 |
+
checkpoint=dict(interval=save_epoch_intervals,
|
| 184 |
+
rule='greater'))
|
| 185 |
+
custom_hooks = [
|
| 186 |
+
dict(type='EMAHook',
|
| 187 |
+
ema_type='ExpMomentumEMA',
|
| 188 |
+
momentum=0.0001,
|
| 189 |
+
update_buffers=True,
|
| 190 |
+
strict_load=False,
|
| 191 |
+
priority=49),
|
| 192 |
+
dict(type='mmdet.PipelineSwitchHook',
|
| 193 |
+
switch_epoch=max_epochs - close_mosaic_epochs,
|
| 194 |
+
switch_pipeline=train_pipeline_stage2)
|
| 195 |
+
]
|
| 196 |
+
train_cfg = dict(
|
| 197 |
+
max_epochs=max_epochs,
|
| 198 |
+
val_interval=10,
|
| 199 |
+
dynamic_intervals=[((max_epochs - close_mosaic_epochs),
|
| 200 |
+
_base_.val_interval_stage2)])
|
| 201 |
+
optim_wrapper = dict(optimizer=dict(
|
| 202 |
+
_delete_=True,
|
| 203 |
+
type='AdamW',
|
| 204 |
+
lr=base_lr,
|
| 205 |
+
weight_decay=weight_decay,
|
| 206 |
+
batch_size_per_gpu=train_batch_size_per_gpu),
|
| 207 |
+
paramwise_cfg=dict(
|
| 208 |
+
bias_decay_mult=0.0,
|
| 209 |
+
norm_decay_mult=0.0,
|
| 210 |
+
custom_keys={
|
| 211 |
+
'backbone.text_model':
|
| 212 |
+
dict(lr_mult=0.0),
|
| 213 |
+
'logit_scale':
|
| 214 |
+
dict(weight_decay=0.0)
|
| 215 |
+
}),
|
| 216 |
+
constructor='YOLOWv5OptimizerConstructor')
|
deploy/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .models import * # noqa
|
deploy/models/__init__.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .detectors import * # noqa
|
| 2 |
+
from .dense_heads import * # noqa
|
| 3 |
+
from .layers import * # noqa
|
| 4 |
+
from .necks import * # noqa
|
docs/data.md
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Preparing Data for YOLO-World
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
### Overview
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
### Pre-training Data
|
| 9 |
+
|
| 10 |
+
| Data | Samples | Type | Boxes | Annotations |
|
| 11 |
+
| :-- | :-----: | :---:| :---: | :---------: |
|
| 12 |
+
| Objects365v1 | | detection | | |
|
| 13 |
+
| GQA | | ground | | |
|
| 14 |
+
| Flickr | | ground | | |
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
|
docs/deploy.md
ADDED
|
File without changes
|
docs/install.md
ADDED
|
File without changes
|
docs/training.md
ADDED
|
File without changes
|
requirements.txt
CHANGED
|
@@ -15,3 +15,4 @@ regex
|
|
| 15 |
pot
|
| 16 |
sentencepiece
|
| 17 |
tokenizers
|
|
|
|
|
|
| 15 |
pot
|
| 16 |
sentencepiece
|
| 17 |
tokenizers
|
| 18 |
+
|
setup.py
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Tencent Inc. All rights reserved.
|
| 2 |
+
import os
|
| 3 |
+
import os.path as osp
|
| 4 |
+
import shutil
|
| 5 |
+
import sys
|
| 6 |
+
import warnings
|
| 7 |
+
from setuptools import find_packages, setup
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def readme():
|
| 11 |
+
with open('README.md', encoding='utf-8') as f:
|
| 12 |
+
content = f.read()
|
| 13 |
+
return content
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def get_version():
|
| 17 |
+
version_file = 'yolo_world/version.py'
|
| 18 |
+
with open(version_file, 'r', encoding='utf-8') as f:
|
| 19 |
+
exec(compile(f.read(), version_file, 'exec'))
|
| 20 |
+
return locals()['__version__']
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def parse_requirements(fname='requirements.txt', with_version=True):
|
| 24 |
+
"""Parse the package dependencies listed in a requirements file but strips
|
| 25 |
+
specific versioning information.
|
| 26 |
+
|
| 27 |
+
Args:
|
| 28 |
+
fname (str): path to requirements file
|
| 29 |
+
with_version (bool, default=False): if True include version specs
|
| 30 |
+
|
| 31 |
+
Returns:
|
| 32 |
+
List[str]: list of requirements items
|
| 33 |
+
|
| 34 |
+
CommandLine:
|
| 35 |
+
python -c "import setup; print(setup.parse_requirements())"
|
| 36 |
+
"""
|
| 37 |
+
import re
|
| 38 |
+
import sys
|
| 39 |
+
from os.path import exists
|
| 40 |
+
require_fpath = fname
|
| 41 |
+
|
| 42 |
+
def parse_line(line):
|
| 43 |
+
"""Parse information from a line in a requirements text file."""
|
| 44 |
+
if line.startswith('-r '):
|
| 45 |
+
# Allow specifying requirements in other files
|
| 46 |
+
target = line.split(' ')[1]
|
| 47 |
+
for info in parse_require_file(target):
|
| 48 |
+
yield info
|
| 49 |
+
else:
|
| 50 |
+
info = {'line': line}
|
| 51 |
+
if line.startswith('-e '):
|
| 52 |
+
info['package'] = line.split('#egg=')[1]
|
| 53 |
+
else:
|
| 54 |
+
# Remove versioning from the package
|
| 55 |
+
pat = '(' + '|'.join(['>=', '==', '>']) + ')'
|
| 56 |
+
parts = re.split(pat, line, maxsplit=1)
|
| 57 |
+
parts = [p.strip() for p in parts]
|
| 58 |
+
|
| 59 |
+
info['package'] = parts[0]
|
| 60 |
+
if len(parts) > 1:
|
| 61 |
+
op, rest = parts[1:]
|
| 62 |
+
if ';' in rest:
|
| 63 |
+
# Handle platform specific dependencies
|
| 64 |
+
# http://setuptools.readthedocs.io/en/latest/setuptools.html#declaring-platform-specific-dependencies
|
| 65 |
+
version, platform_deps = map(str.strip,
|
| 66 |
+
rest.split(';'))
|
| 67 |
+
info['platform_deps'] = platform_deps
|
| 68 |
+
else:
|
| 69 |
+
version = rest # NOQA
|
| 70 |
+
if '--' in version:
|
| 71 |
+
# the `extras_require` doesn't accept options.
|
| 72 |
+
version = version.split('--')[0].strip()
|
| 73 |
+
info['version'] = (op, version)
|
| 74 |
+
yield info
|
| 75 |
+
|
| 76 |
+
def parse_require_file(fpath):
|
| 77 |
+
with open(fpath, 'r') as f:
|
| 78 |
+
for line in f.readlines():
|
| 79 |
+
line = line.strip()
|
| 80 |
+
if line and not line.startswith('#'):
|
| 81 |
+
for info in parse_line(line):
|
| 82 |
+
yield info
|
| 83 |
+
|
| 84 |
+
def gen_packages_items():
|
| 85 |
+
if exists(require_fpath):
|
| 86 |
+
for info in parse_require_file(require_fpath):
|
| 87 |
+
parts = [info['package']]
|
| 88 |
+
if with_version and 'version' in info:
|
| 89 |
+
parts.extend(info['version'])
|
| 90 |
+
if not sys.version.startswith('3.4'):
|
| 91 |
+
# apparently package_deps are broken in 3.4
|
| 92 |
+
platform_deps = info.get('platform_deps')
|
| 93 |
+
if platform_deps is not None:
|
| 94 |
+
parts.append(';' + platform_deps)
|
| 95 |
+
item = ''.join(parts)
|
| 96 |
+
yield item
|
| 97 |
+
|
| 98 |
+
packages = list(gen_packages_items())
|
| 99 |
+
return packages
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
def add_mim_extension():
|
| 103 |
+
"""Add extra files that are required to support MIM into the package.
|
| 104 |
+
|
| 105 |
+
These files will be added by creating a symlink to the originals if the
|
| 106 |
+
package is installed in `editable` mode (e.g. pip install -e .), or by
|
| 107 |
+
copying from the originals otherwise.
|
| 108 |
+
"""
|
| 109 |
+
|
| 110 |
+
# parse installment mode
|
| 111 |
+
if 'develop' in sys.argv:
|
| 112 |
+
# installed by `pip install -e .`
|
| 113 |
+
mode = 'symlink'
|
| 114 |
+
elif 'sdist' in sys.argv or 'bdist_wheel' in sys.argv:
|
| 115 |
+
# installed by `pip install .`
|
| 116 |
+
# or create source distribution by `python setup.py sdist`
|
| 117 |
+
mode = 'copy'
|
| 118 |
+
else:
|
| 119 |
+
return
|
| 120 |
+
|
| 121 |
+
filenames = ['tools', 'configs', 'model-index.yml', 'dataset-index.yml']
|
| 122 |
+
repo_path = osp.dirname(__file__)
|
| 123 |
+
mim_path = osp.join(repo_path, 'yolo_world', '.mim')
|
| 124 |
+
os.makedirs(mim_path, exist_ok=True)
|
| 125 |
+
|
| 126 |
+
for filename in filenames:
|
| 127 |
+
if osp.exists(filename):
|
| 128 |
+
src_path = osp.join(repo_path, filename)
|
| 129 |
+
tar_path = osp.join(mim_path, filename)
|
| 130 |
+
|
| 131 |
+
if osp.isfile(tar_path) or osp.islink(tar_path):
|
| 132 |
+
os.remove(tar_path)
|
| 133 |
+
elif osp.isdir(tar_path):
|
| 134 |
+
shutil.rmtree(tar_path)
|
| 135 |
+
|
| 136 |
+
if mode == 'symlink':
|
| 137 |
+
src_relpath = osp.relpath(src_path, osp.dirname(tar_path))
|
| 138 |
+
try:
|
| 139 |
+
os.symlink(src_relpath, tar_path)
|
| 140 |
+
except OSError:
|
| 141 |
+
# Creating a symbolic link on windows may raise an
|
| 142 |
+
# `OSError: [WinError 1314]` due to privilege. If
|
| 143 |
+
# the error happens, the src file will be copied
|
| 144 |
+
mode = 'copy'
|
| 145 |
+
warnings.warn(
|
| 146 |
+
f'Failed to create a symbolic link for {src_relpath}, '
|
| 147 |
+
f'and it will be copied to {tar_path}')
|
| 148 |
+
else:
|
| 149 |
+
continue
|
| 150 |
+
|
| 151 |
+
if mode == 'copy':
|
| 152 |
+
if osp.isfile(src_path):
|
| 153 |
+
shutil.copyfile(src_path, tar_path)
|
| 154 |
+
elif osp.isdir(src_path):
|
| 155 |
+
shutil.copytree(src_path, tar_path)
|
| 156 |
+
else:
|
| 157 |
+
warnings.warn(f'Cannot copy file {src_path}.')
|
| 158 |
+
else:
|
| 159 |
+
raise ValueError(f'Invalid mode {mode}')
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
if __name__ == '__main__':
|
| 163 |
+
setup(
|
| 164 |
+
name='yolo_world',
|
| 165 |
+
version=get_version(),
|
| 166 |
+
description='YOLO-World: Real-time Open Vocabulary Object Detection',
|
| 167 |
+
long_description=readme(),
|
| 168 |
+
long_description_content_type='text/markdown',
|
| 169 |
+
keywords='object detection',
|
| 170 |
+
packages=find_packages(exclude=(
|
| 171 |
+
'data', 'third_party', 'tools')),
|
| 172 |
+
include_package_data=True,
|
| 173 |
+
python_requires='>=3.7',
|
| 174 |
+
classifiers=[
|
| 175 |
+
'Development Status :: 4 - Beta',
|
| 176 |
+
'License :: OSI Approved :: Apache Software License',
|
| 177 |
+
'Operating System :: OS Independent',
|
| 178 |
+
'Programming Language :: Python :: 3',
|
| 179 |
+
'Programming Language :: Python :: 3.7',
|
| 180 |
+
'Programming Language :: Python :: 3.8',
|
| 181 |
+
'Programming Language :: Python :: 3.9',
|
| 182 |
+
'Programming Language :: Python :: 3.10',
|
| 183 |
+
'Programming Language :: Python :: 3.11',
|
| 184 |
+
'Topic :: Scientific/Engineering :: Artificial Intelligence',
|
| 185 |
+
],
|
| 186 |
+
author='Tencent AILab',
|
| 187 |
+
author_email='ronnysong@tencent.com',
|
| 188 |
+
license='Apache License 2.0',
|
| 189 |
+
install_requires=parse_requirements('requirements.txt'),
|
| 190 |
+
zip_safe=False)
|
taiji/drun
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
DOCKER_IMAGE="mirrors.tencent.com/ronnysong_rd/fastdet:torch2.0.1-cuda11.7"
|
| 3 |
+
|
| 4 |
+
if [ ! -n "$DEBUG" ]; then
|
| 5 |
+
COMMAND_PREFIX="pip3 install -e ."
|
| 6 |
+
else
|
| 7 |
+
COMMAND_PREFIX="pip3 install -q -e third_party/mmengine;
|
| 8 |
+
pip3 install -q -e third_party/mmdetection;
|
| 9 |
+
pip3 install -q -e third_party/mmcv;
|
| 10 |
+
pip3 install -q -e third_party/mmyolo;
|
| 11 |
+
pip3 install -q -e ."
|
| 12 |
+
fi
|
| 13 |
+
|
| 14 |
+
sudo nvidia-docker run \
|
| 15 |
+
--rm \
|
| 16 |
+
-it \
|
| 17 |
+
-e NVIDIA_VISIBLE_DEVICES=all \
|
| 18 |
+
--env="DISPLAY" \
|
| 19 |
+
--env="QT_X11_NO_MITSHM=1" \
|
| 20 |
+
--volume="$HOME/.Xauthority:/root/.Xauthority:rw" \
|
| 21 |
+
--shm-size=20gb \
|
| 22 |
+
--network=host \
|
| 23 |
+
-v /apdcephfs/:/apdcephfs/ \
|
| 24 |
+
-v /apdcephfs_cq2/:/apdcephfs_cq2/ \
|
| 25 |
+
-v /apdcephfs_cq3/:/apdcephfs_cq3/ \
|
| 26 |
+
-v /data/:/data/ \
|
| 27 |
+
-w $PWD \
|
| 28 |
+
$DOCKER_IMAGE \
|
| 29 |
+
bash -c "export TRANSFORMERS_CACHE=$PWD/work_dirs/.cache/transformers;
|
| 30 |
+
export TORCH_HOME=$PWD/work_dirs/.cache/torch;
|
| 31 |
+
export CLIP_CACHE=$PWD/work_dirs/.cache/clip;
|
| 32 |
+
export HF_HOME=$PWD/work_dirs/.cache/hf;
|
| 33 |
+
export TOKENIZERS_PARALLELISM=false;
|
| 34 |
+
$COMMAND_PREFIX
|
| 35 |
+
$*"
|
taiji/erun
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
export NCCL_IB_GID_INDEX=3
|
| 3 |
+
|
| 4 |
+
export TRANSFORMERS_CACHE=$PWD/work_dirs/.cache/transformers
|
| 5 |
+
export TORCH_HOME=$PWD/work_dirs/.cache/torch
|
| 6 |
+
export CLIP_CACHE=$PWD/work_dirs/.cache/clip
|
| 7 |
+
export HF_HOME=$PWD/work_dirs/.cache/hf
|
| 8 |
+
export TOKENIZERS_PARALLELISM=false
|
| 9 |
+
export MKL_NUM_THREADS=1
|
| 10 |
+
export OMP_NUM_THREADS=1
|
| 11 |
+
export TORCH_DISTRIBUTED_DEBUG=INFO
|
| 12 |
+
export HF_DATASETS_OFFLINE=1
|
| 13 |
+
export TRANSFORMERS_OFFLINE=1
|
| 14 |
+
export http_proxy="http://star-proxy.oa.com:3128"
|
| 15 |
+
export https_proxy="http://star-proxy.oa.com:3128"
|
| 16 |
+
export ftp_proxy="http://star-proxy.oa.com:3128"
|
| 17 |
+
export no_proxy=".woa.com,mirrors.cloud.tencent.com,tlinux-mirror.tencent-cloud.com,tlinux-mirrorlist.tencent-cloud.com,localhost,127.0.0.1,mirrors-tlinux.tencentyun.com,.oa.com,.local,.3gqq.com,.7700.org,.ad.com,.ada_sixjoy.com,.addev.com,.app.local,.apps.local,.aurora.com,.autotest123.com,.bocaiwawa.com,.boss.com,.cdc.com,.cdn.com,.cds.com,.cf.com,.cjgc.local,.cm.com,.code.com,.datamine.com,.dvas.com,.dyndns.tv,.ecc.com,.expochart.cn,.expovideo.cn,.fms.com,.great.com,.hadoop.sec,.heme.com,.home.com,.hotbar.com,.ibg.com,.ied.com,.ieg.local,.ierd.com,.imd.com,.imoss.com,.isd.com,.isoso.com,.itil.com,.kao5.com,.kf.com,.kitty.com,.lpptp.com,.m.com,.matrix.cloud,.matrix.net,.mickey.com,.mig.local,.mqq.com,.oiweb.com,.okbuy.isddev.com,.oss.com,.otaworld.com,.paipaioa.com,.qqbrowser.local,.qqinternal.com,.qqwork.com,.rtpre.com,.sc.oa.com,.sec.com,.server.com,.service.com,.sjkxinternal.com,.sllwrnm5.cn,.sng.local,.soc.com,.t.km,.tcna.com,.teg.local,.tencentvoip.com,.tenpayoa.com,.test.air.tenpay.com,.tr.com,.tr_autotest123.com,.vpn.com,.wb.local,.webdev.com,.webdev2.com,.wizard.com,.wqq.com,.wsd.com,.sng.com,.music.lan,.mnet2.com,.tencentb2.com,.tmeoa.com,.pcg.com,www.wip3.adobe.com,www-mm.wip3.adobe.com,mirrors.tencent.com,csighub.tencentyun.com"
|
| 18 |
+
sed -i 's/np.float/float/g' /usr/local/python/lib/python3.8/site-packages/lvis/eval.py
|
| 19 |
+
touch /tmp/.unhold
|
| 20 |
+
|
| 21 |
+
pip3 install -e .
|
| 22 |
+
$*
|
| 23 |
+
rm /tmp/.unhold
|
taiji/etorchrun
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
if [ ! -n "$SH" ]; then
|
| 3 |
+
#export NCCL_IB_GID_INDEX=3
|
| 4 |
+
export NCCL_IB_DISABLE=1
|
| 5 |
+
export NCCL_P2P_DISABLE=1
|
| 6 |
+
export NCCL_SOCKET_IFNAME=eth1
|
| 7 |
+
else
|
| 8 |
+
export NCCL_IB_GID_INDEX=3
|
| 9 |
+
export NCCL_IB_SL=3
|
| 10 |
+
export NCCL_CHECKS_DISABLE=1
|
| 11 |
+
export NCCL_P2P_DISABLE=0
|
| 12 |
+
export NCCL_IB_DISABLE=0
|
| 13 |
+
export NCCL_LL_THRESHOLD=16384
|
| 14 |
+
export NCCL_IB_CUDA_SUPPORT=1
|
| 15 |
+
export NCCL_SOCKET_IFNAME=bond1
|
| 16 |
+
export UCX_NET_DEVICES=bond1
|
| 17 |
+
export NCCL_IB_HCA=mlx5_bond_1,mlx5_bond_5,mlx5_bond_3,mlx5_bond_7,mlx5_bond_4,mlx5_bond_8,mlx5_bond_2,mlx5_bond_6
|
| 18 |
+
export NCCL_COLLNET_ENABLE=0
|
| 19 |
+
export SHARP_COLL_ENABLE_SAT=0
|
| 20 |
+
export NCCL_NET_GDR_LEVEL=2
|
| 21 |
+
export NCCL_IB_QPS_PER_CONNECTION=4
|
| 22 |
+
export NCCL_IB_TC=160
|
| 23 |
+
export NCCL_PXN_DISABLE=1
|
| 24 |
+
export GLOO_SOCKET_IFNAME=bond1
|
| 25 |
+
export NCCL_DEBUG=info
|
| 26 |
+
fi
|
| 27 |
+
|
| 28 |
+
export TRANSFORMERS_CACHE=$PWD/work_dirs/.cache/transformers
|
| 29 |
+
export TORCH_HOME=$PWD/work_dirs/.cache/torch
|
| 30 |
+
export CLIP_CACHE=$PWD/work_dirs/.cache/clip
|
| 31 |
+
export HF_HOME=$PWD/work_dirs/.cache/hf
|
| 32 |
+
export TOKENIZERS_PARALLELISM=false
|
| 33 |
+
export MKL_NUM_THREADS=1
|
| 34 |
+
export OMP_NUM_THREADS=1
|
| 35 |
+
export TORCH_DISTRIBUTED_DEBUG=INFO
|
| 36 |
+
export HF_DATASETS_OFFLINE=1
|
| 37 |
+
export TRANSFORMERS_OFFLINE=1
|
| 38 |
+
|
| 39 |
+
export http_proxy="http://star-proxy.oa.com:3128"
|
| 40 |
+
export https_proxy="http://star-proxy.oa.com:3128"
|
| 41 |
+
export ftp_proxy="http://star-proxy.oa.com:3128"
|
| 42 |
+
export no_proxy=".woa.com,mirrors.cloud.tencent.com,tlinux-mirror.tencent-cloud.com,tlinux-mirrorlist.tencent-cloud.com,localhost,127.0.0.1,mirrors-tlinux.tencentyun.com,.oa.com,.local,.3gqq.com,.7700.org,.ad.com,.ada_sixjoy.com,.addev.com,.app.local,.apps.local,.aurora.com,.autotest123.com,.bocaiwawa.com,.boss.com,.cdc.com,.cdn.com,.cds.com,.cf.com,.cjgc.local,.cm.com,.code.com,.datamine.com,.dvas.com,.dyndns.tv,.ecc.com,.expochart.cn,.expovideo.cn,.fms.com,.great.com,.hadoop.sec,.heme.com,.home.com,.hotbar.com,.ibg.com,.ied.com,.ieg.local,.ierd.com,.imd.com,.imoss.com,.isd.com,.isoso.com,.itil.com,.kao5.com,.kf.com,.kitty.com,.lpptp.com,.m.com,.matrix.cloud,.matrix.net,.mickey.com,.mig.local,.mqq.com,.oiweb.com,.okbuy.isddev.com,.oss.com,.otaworld.com,.paipaioa.com,.qqbrowser.local,.qqinternal.com,.qqwork.com,.rtpre.com,.sc.oa.com,.sec.com,.server.com,.service.com,.sjkxinternal.com,.sllwrnm5.cn,.sng.local,.soc.com,.t.km,.tcna.com,.teg.local,.tencentvoip.com,.tenpayoa.com,.test.air.tenpay.com,.tr.com,.tr_autotest123.com,.vpn.com,.wb.local,.webdev.com,.webdev2.com,.wizard.com,.wqq.com,.wsd.com,.sng.com,.music.lan,.mnet2.com,.tencentb2.com,.tmeoa.com,.pcg.com,www.wip3.adobe.com,www-mm.wip3.adobe.com,mirrors.tencent.com,csighub.tencentyun.com"
|
| 43 |
+
|
| 44 |
+
sed -i 's/np.float/float/g' /usr/local/python/lib/python3.8/site-packages/lvis/eval.py
|
| 45 |
+
|
| 46 |
+
touch /tmp/.unhold
|
| 47 |
+
|
| 48 |
+
pip3 install -e .
|
| 49 |
+
torchrun --nnodes=$1 --nproc_per_node=$2 --node_rank=$INDEX --master_addr=$CHIEF_IP ${@:3}
|
| 50 |
+
|
| 51 |
+
rm /tmp/.unhold
|
taiji/jizhi_run_vanilla
ADDED
|
@@ -0,0 +1,105 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
if [[ $1 = "--help" ]] || [[ $1 = "-h" ]]
|
| 3 |
+
then
|
| 4 |
+
echo "Usage: jizhi_run NUM_MECHINES NUM_GPUS TASK_NAME <CMDS>"
|
| 5 |
+
fi
|
| 6 |
+
|
| 7 |
+
# user configuration
|
| 8 |
+
TOKEN=$TOKEN
|
| 9 |
+
if [ ! -n "$IMAGE_FULL_NAME" ]; then
|
| 10 |
+
IMAGE_FULL_NAME="mirrors.tencent.com/ronnysong_rd/fastdet:torch2.0.1-cuda11.7"
|
| 11 |
+
fi
|
| 12 |
+
if [ ! -n "$BUSINESS_FLAG" ]; then
|
| 13 |
+
BUSINESS_FLAG="TEG_AILab_CVC_chongqing"
|
| 14 |
+
fi
|
| 15 |
+
if [ ! -n "$CEPH_BUSINESS_FLAG" ]; then
|
| 16 |
+
CEPH_BUSINESS_FLAG="TEG_AILab_CVC_chongqing"
|
| 17 |
+
fi
|
| 18 |
+
if [ ! -n "$GPU_NAME" ]; then
|
| 19 |
+
GPU_NAME="V100"
|
| 20 |
+
fi
|
| 21 |
+
if [ ! -n "$PRIORITY_LEVEL" ]; then
|
| 22 |
+
PRIORITY_LEVEL="HIGH"
|
| 23 |
+
fi
|
| 24 |
+
if [ ! -n "$ELASTIC_LEVEL" ]; then
|
| 25 |
+
ELASTIC_LEVEL=1
|
| 26 |
+
fi
|
| 27 |
+
if [ ! -n "$RDMA" ]; then
|
| 28 |
+
RDMA="false"
|
| 29 |
+
fi
|
| 30 |
+
if [ ! -n "$CUDA" ]; then
|
| 31 |
+
CUDA="11.0"
|
| 32 |
+
fi
|
| 33 |
+
|
| 34 |
+
CMD_PATH="start.sh"
|
| 35 |
+
CONF_PATH="jizhi_conf.json"
|
| 36 |
+
ROOT_PATH=$PWD
|
| 37 |
+
UUID=$(date +%s)
|
| 38 |
+
|
| 39 |
+
rm -f $CMD_PATH
|
| 40 |
+
|
| 41 |
+
echo 'cd '$ROOT_PATH >> $CMD_PATH
|
| 42 |
+
echo 'export HF_HOME="'$ROOT_PATH'/work_dirs/.cache/hf"' >> $CMD_PATH
|
| 43 |
+
echo 'export TORCH_HOME="'$ROOT_PATH'/work_dirs/.cache/torch"' >> $CMD_PATH
|
| 44 |
+
echo 'export CLIP_CACHE="'$ROOT_PATH'/work_dirs/.cache/clip"' >> $CMD_PATH
|
| 45 |
+
echo 'export TRANSFORMERS_CACHE="'$ROOT_PATH'/work_dirs/.cache/transformers"' >> $CMD_PATH
|
| 46 |
+
echo 'export MKL_NUM_THREADS=1' >> $CMD_PATH
|
| 47 |
+
echo 'export OMP_NUM_THREADS=1' >> $CMD_PATH
|
| 48 |
+
echo 'export TOKENIZERS_PARALLELISM=false' >> $CMD_PATH
|
| 49 |
+
echo 'export TORCH_DISTRIBUTED_DEBUG=INFO' >> $CMD_PATH
|
| 50 |
+
echo 'export NCCL_IB_GID_INDEX=3' >> $CMD_PATH
|
| 51 |
+
if [ $BUSINESS_FLAG = "TaiJi_HYAide_BUFFER_SH_A800H" ]; then
|
| 52 |
+
echo 'export NCCL_IB_GID_INDEX=3' >> $CMD_PATH
|
| 53 |
+
echo 'export NCCL_IB_SL=3' >> $CMD_PATH
|
| 54 |
+
echo 'export NCCL_CHECKS_DISABLE=1' >> $CMD_PATH
|
| 55 |
+
echo 'export NCCL_P2P_DISABLE=0' >> $CMD_PATH
|
| 56 |
+
echo 'export NCCL_IB_DISABLE=0' >> $CMD_PATH
|
| 57 |
+
echo 'export NCCL_LL_THRESHOLD=16384' >> $CMD_PATH
|
| 58 |
+
echo 'export NCCL_IB_CUDA_SUPPORT=1' >> $CMD_PATH
|
| 59 |
+
echo 'export NCCL_SOCKET_IFNAME=bond1' >> $CMD_PATH
|
| 60 |
+
echo 'export UCX_NET_DEVICES=bond1' >> $CMD_PATH
|
| 61 |
+
echo 'export NCCL_IB_HCA=mlx5_bond_1,mlx5_bond_5,mlx5_bond_3,mlx5_bond_7,mlx5_bond_4,mlx5_bond_8,mlx5_bond_2,mlx5_bond_6' >> $CMD_PATH
|
| 62 |
+
echo 'export NCCL_COLLNET_ENABLE=0' >> $CMD_PATH
|
| 63 |
+
echo 'export SHARP_COLL_ENABLE_SAT=0' >> $CMD_PATH
|
| 64 |
+
echo 'export NCCL_NET_GDR_LEVEL=2' >> $CMD_PATH
|
| 65 |
+
echo 'export NCCL_IB_QPS_PER_CONNECTION=4' >> $CMD_PATH
|
| 66 |
+
echo 'export NCCL_IB_TC=160' >> $CMD_PATH
|
| 67 |
+
echo 'export NCCL_PXN_DISABLE=1' >> $CMD_PATH
|
| 68 |
+
fi
|
| 69 |
+
echo ${@:4} >> $CMD_PATH
|
| 70 |
+
|
| 71 |
+
chmod +x $CMD_PATH
|
| 72 |
+
|
| 73 |
+
rm -f $CONF_PATH
|
| 74 |
+
|
| 75 |
+
#INIT_CMD="jizhi_client mount -bf TEG_AILab_CVC_chongqing -tk $TOKEN"
|
| 76 |
+
INIT_CMD=""
|
| 77 |
+
|
| 78 |
+
echo '{' > $CONF_PATH
|
| 79 |
+
echo '"Token": "'$TOKEN'",' >> $CONF_PATH
|
| 80 |
+
echo '"business_flag": "'$BUSINESS_FLAG'",' >> $CONF_PATH
|
| 81 |
+
echo '"model_local_file_path": "'$ROOT_PATH'/'$CMD_PATH'",' >> $CONF_PATH
|
| 82 |
+
echo '"host_num": '$1',' >> $CONF_PATH
|
| 83 |
+
echo '"host_gpu_num": '$2',' >> $CONF_PATH
|
| 84 |
+
echo '"task_flag": "'$3'_'$UUID'",' >> $CONF_PATH
|
| 85 |
+
echo '"priority_level": "'$PRIORITY_LEVEL'",' >> $CONF_PATH
|
| 86 |
+
echo '"elastic_level": '$ELASTIC_LEVEL',' >> $CONF_PATH
|
| 87 |
+
echo '"cuda_version": "'$CUDA'",' >> $CONF_PATH
|
| 88 |
+
echo '"image_full_name": "'$IMAGE_FULL_NAME'",' >> $CONF_PATH
|
| 89 |
+
echo '"GPUName": "'$GPU_NAME'",' >> $CONF_PATH
|
| 90 |
+
echo '"mount_ceph_business_flag": "'$CEPH_BUSINESS_FLAG'",' >> $CONF_PATH
|
| 91 |
+
echo '"exec_start_in_all_mpi_pods": true,' >> $CONF_PATH
|
| 92 |
+
echo '"enable_rdma": '$RDMA',' >> $CONF_PATH
|
| 93 |
+
echo '"init_cmd": "'$INIT_CMD'",' >> $CONF_PATH
|
| 94 |
+
echo '"envs": {' >> $CONF_PATH
|
| 95 |
+
echo ' "HUNYUAN_TASK_CATEGORY": "LLM",' >> $CONF_PATH
|
| 96 |
+
echo ' "HUNYUAN_TASK_MODEL_TYPE": "SFT",' >> $CONF_PATH
|
| 97 |
+
echo ' "HUNYUAN_TASK_DOMAIN": "NLP",' >> $CONF_PATH
|
| 98 |
+
echo ' "HUNYUAN_TASK_START_MODEL_TYPE": "7B冷启"}' >> $CONF_PATH
|
| 99 |
+
echo '}' >> $CONF_PATH
|
| 100 |
+
|
| 101 |
+
jizhi_client start -scfg $CONF_PATH
|
| 102 |
+
|
| 103 |
+
rm -f $CMD_PATH
|
| 104 |
+
rm -f $CONF_PATH
|
| 105 |
+
|
third_party/mmyolo/.circleci/config.yml
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version: 2.1
|
| 2 |
+
|
| 3 |
+
# this allows you to use CircleCI's dynamic configuration feature
|
| 4 |
+
setup: true
|
| 5 |
+
|
| 6 |
+
# the path-filtering orb is required to continue a pipeline based on
|
| 7 |
+
# the path of an updated fileset
|
| 8 |
+
orbs:
|
| 9 |
+
path-filtering: circleci/path-filtering@0.1.2
|
| 10 |
+
|
| 11 |
+
workflows:
|
| 12 |
+
# the always-run workflow is always triggered, regardless of the pipeline parameters.
|
| 13 |
+
always-run:
|
| 14 |
+
jobs:
|
| 15 |
+
# the path-filtering/filter job determines which pipeline
|
| 16 |
+
# parameters to update.
|
| 17 |
+
- path-filtering/filter:
|
| 18 |
+
name: check-updated-files
|
| 19 |
+
# 3-column, whitespace-delimited mapping. One mapping per
|
| 20 |
+
# line:
|
| 21 |
+
# <regex path-to-test> <parameter-to-set> <value-of-pipeline-parameter>
|
| 22 |
+
mapping: |
|
| 23 |
+
mmyolo/.* lint_only false
|
| 24 |
+
requirements/.* lint_only false
|
| 25 |
+
tests/.* lint_only false
|
| 26 |
+
tools/.* lint_only false
|
| 27 |
+
configs/.* lint_only false
|
| 28 |
+
.circleci/.* lint_only false
|
| 29 |
+
base-revision: main
|
| 30 |
+
# this is the path of the configuration we should trigger once
|
| 31 |
+
# path filtering and pipeline parameter value updates are
|
| 32 |
+
# complete. In this case, we are using the parent dynamic
|
| 33 |
+
# configuration itself.
|
| 34 |
+
config-path: .circleci/test.yml
|
third_party/mmyolo/.circleci/docker/Dockerfile
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
ARG PYTORCH="1.8.1"
|
| 2 |
+
ARG CUDA="10.2"
|
| 3 |
+
ARG CUDNN="7"
|
| 4 |
+
|
| 5 |
+
FROM pytorch/pytorch:${PYTORCH}-cuda${CUDA}-cudnn${CUDNN}-devel
|
| 6 |
+
|
| 7 |
+
# To fix GPG key error when running apt-get update
|
| 8 |
+
RUN apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/3bf863cc.pub
|
| 9 |
+
RUN apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64/7fa2af80.pub
|
| 10 |
+
|
| 11 |
+
RUN apt-get update && apt-get install -y ninja-build libglib2.0-0 libsm6 libxrender-dev libxext6 libgl1-mesa-glx
|
third_party/mmyolo/.circleci/test.yml
ADDED
|
@@ -0,0 +1,213 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version: 2.1
|
| 2 |
+
|
| 3 |
+
# the default pipeline parameters, which will be updated according to
|
| 4 |
+
# the results of the path-filtering orb
|
| 5 |
+
parameters:
|
| 6 |
+
lint_only:
|
| 7 |
+
type: boolean
|
| 8 |
+
default: true
|
| 9 |
+
|
| 10 |
+
jobs:
|
| 11 |
+
lint:
|
| 12 |
+
docker:
|
| 13 |
+
- image: cimg/python:3.7.4
|
| 14 |
+
steps:
|
| 15 |
+
- checkout
|
| 16 |
+
- run:
|
| 17 |
+
name: Install pre-commit hook
|
| 18 |
+
command: |
|
| 19 |
+
pip install pre-commit
|
| 20 |
+
pre-commit install
|
| 21 |
+
- run:
|
| 22 |
+
name: Linting
|
| 23 |
+
command: pre-commit run --all-files
|
| 24 |
+
- run:
|
| 25 |
+
name: Check docstring coverage
|
| 26 |
+
command: |
|
| 27 |
+
pip install interrogate
|
| 28 |
+
interrogate -v --ignore-init-method --ignore-module --ignore-nested-functions --ignore-magic --ignore-regex "__repr__" --fail-under 90 mmyolo
|
| 29 |
+
build_cpu:
|
| 30 |
+
parameters:
|
| 31 |
+
# The python version must match available image tags in
|
| 32 |
+
# https://circleci.com/developer/images/image/cimg/python
|
| 33 |
+
python:
|
| 34 |
+
type: string
|
| 35 |
+
torch:
|
| 36 |
+
type: string
|
| 37 |
+
torchvision:
|
| 38 |
+
type: string
|
| 39 |
+
docker:
|
| 40 |
+
- image: cimg/python:<< parameters.python >>
|
| 41 |
+
resource_class: large
|
| 42 |
+
steps:
|
| 43 |
+
- checkout
|
| 44 |
+
- run:
|
| 45 |
+
name: Install Libraries
|
| 46 |
+
command: |
|
| 47 |
+
sudo apt-get update
|
| 48 |
+
sudo apt-get install -y ninja-build libglib2.0-0 libsm6 libxrender-dev libxext6 libgl1-mesa-glx libjpeg-dev zlib1g-dev libtinfo-dev libncurses5
|
| 49 |
+
- run:
|
| 50 |
+
name: Configure Python & pip
|
| 51 |
+
command: |
|
| 52 |
+
pip install --upgrade pip
|
| 53 |
+
pip install wheel
|
| 54 |
+
- run:
|
| 55 |
+
name: Install PyTorch
|
| 56 |
+
command: |
|
| 57 |
+
python -V
|
| 58 |
+
pip install torch==<< parameters.torch >>+cpu torchvision==<< parameters.torchvision >>+cpu -f https://download.pytorch.org/whl/torch_stable.html
|
| 59 |
+
- run:
|
| 60 |
+
name: Install ONNXRuntime
|
| 61 |
+
command: |
|
| 62 |
+
pip install onnxruntime==1.8.1
|
| 63 |
+
wget https://github.com/microsoft/onnxruntime/releases/download/v1.8.1/onnxruntime-linux-x64-1.8.1.tgz
|
| 64 |
+
tar xvf onnxruntime-linux-x64-1.8.1.tgz
|
| 65 |
+
- run:
|
| 66 |
+
name: Install mmyolo dependencies
|
| 67 |
+
command: |
|
| 68 |
+
pip install -U openmim
|
| 69 |
+
mim install git+https://github.com/open-mmlab/mmengine.git@main
|
| 70 |
+
mim install 'mmcv >= 2.0.0'
|
| 71 |
+
mim install git+https://github.com/open-mmlab/mmdetection.git@dev-3.x
|
| 72 |
+
pip install -r requirements/albu.txt
|
| 73 |
+
pip install -r requirements/tests.txt
|
| 74 |
+
- run:
|
| 75 |
+
name: Install mmdeploy
|
| 76 |
+
command: |
|
| 77 |
+
pip install setuptools
|
| 78 |
+
git clone -b dev-1.x --depth 1 https://github.com/open-mmlab/mmdeploy.git mmdeploy --recurse-submodules
|
| 79 |
+
wget https://github.com/Kitware/CMake/releases/download/v3.20.0/cmake-3.20.0-linux-x86_64.tar.gz
|
| 80 |
+
tar -xzvf cmake-3.20.0-linux-x86_64.tar.gz
|
| 81 |
+
sudo ln -sf $(pwd)/cmake-3.20.0-linux-x86_64/bin/* /usr/bin/
|
| 82 |
+
cd mmdeploy && mkdir build && cd build && cmake .. -DMMDEPLOY_TARGET_BACKENDS=ort -DONNXRUNTIME_DIR=/home/circleci/project/onnxruntime-linux-x64-1.8.1 && make -j8 && make install
|
| 83 |
+
export LD_LIBRARY_PATH=/home/circleci/project/onnxruntime-linux-x64-1.8.1/lib:${LD_LIBRARY_PATH}
|
| 84 |
+
cd /home/circleci/project/mmdeploy && python -m pip install -v -e .
|
| 85 |
+
- run:
|
| 86 |
+
name: Build and install
|
| 87 |
+
command: |
|
| 88 |
+
pip install -e .
|
| 89 |
+
- run:
|
| 90 |
+
name: Run unittests
|
| 91 |
+
command: |
|
| 92 |
+
export LD_LIBRARY_PATH=/home/circleci/project/onnxruntime-linux-x64-1.8.1/lib:${LD_LIBRARY_PATH}
|
| 93 |
+
pytest tests/
|
| 94 |
+
# coverage run --branch --source mmyolo -m pytest tests/
|
| 95 |
+
# coverage xml
|
| 96 |
+
# coverage report -m
|
| 97 |
+
build_cuda:
|
| 98 |
+
parameters:
|
| 99 |
+
torch:
|
| 100 |
+
type: string
|
| 101 |
+
cuda:
|
| 102 |
+
type: enum
|
| 103 |
+
enum: ["10.1", "10.2", "11.0", "11.7"]
|
| 104 |
+
cudnn:
|
| 105 |
+
type: integer
|
| 106 |
+
default: 7
|
| 107 |
+
machine:
|
| 108 |
+
image: ubuntu-2004-cuda-11.4:202110-01
|
| 109 |
+
# docker_layer_caching: true
|
| 110 |
+
resource_class: gpu.nvidia.small
|
| 111 |
+
steps:
|
| 112 |
+
- checkout
|
| 113 |
+
- run:
|
| 114 |
+
# Cloning repos in VM since Docker doesn't have access to the private key
|
| 115 |
+
name: Clone Repos
|
| 116 |
+
command: |
|
| 117 |
+
git clone -b main --depth 1 https://github.com/open-mmlab/mmengine.git /home/circleci/mmengine
|
| 118 |
+
git clone -b dev-3.x --depth 1 https://github.com/open-mmlab/mmdetection.git /home/circleci/mmdetection
|
| 119 |
+
- run:
|
| 120 |
+
name: Build Docker image
|
| 121 |
+
command: |
|
| 122 |
+
docker build .circleci/docker -t mmyolo:gpu --build-arg PYTORCH=<< parameters.torch >> --build-arg CUDA=<< parameters.cuda >> --build-arg CUDNN=<< parameters.cudnn >>
|
| 123 |
+
docker run --gpus all -t -d -v /home/circleci/project:/mmyolo -v /home/circleci/mmengine:/mmengine -v /home/circleci/mmdetection:/mmdetection -w /mmyolo --name mmyolo mmyolo:gpu
|
| 124 |
+
- run:
|
| 125 |
+
name: Install mmyolo dependencies
|
| 126 |
+
command: |
|
| 127 |
+
docker exec mmyolo pip install -U openmim
|
| 128 |
+
docker exec mmyolo mim install -e /mmengine
|
| 129 |
+
docker exec mmyolo mim install 'mmcv >= 2.0.0'
|
| 130 |
+
docker exec mmyolo pip install -e /mmdetection
|
| 131 |
+
docker exec mmyolo pip install -r requirements/albu.txt
|
| 132 |
+
docker exec mmyolo pip install -r requirements/tests.txt
|
| 133 |
+
- run:
|
| 134 |
+
name: Build and install
|
| 135 |
+
command: |
|
| 136 |
+
docker exec mmyolo pip install -e .
|
| 137 |
+
- run:
|
| 138 |
+
name: Run unittests
|
| 139 |
+
command: |
|
| 140 |
+
docker exec mmyolo pytest tests/
|
| 141 |
+
|
| 142 |
+
workflows:
|
| 143 |
+
pr_stage_lint:
|
| 144 |
+
when: << pipeline.parameters.lint_only >>
|
| 145 |
+
jobs:
|
| 146 |
+
- lint:
|
| 147 |
+
name: lint
|
| 148 |
+
filters:
|
| 149 |
+
branches:
|
| 150 |
+
ignore:
|
| 151 |
+
- main
|
| 152 |
+
|
| 153 |
+
pr_stage_test:
|
| 154 |
+
when:
|
| 155 |
+
not: << pipeline.parameters.lint_only >>
|
| 156 |
+
jobs:
|
| 157 |
+
- lint:
|
| 158 |
+
name: lint
|
| 159 |
+
filters:
|
| 160 |
+
branches:
|
| 161 |
+
ignore:
|
| 162 |
+
- main
|
| 163 |
+
- build_cpu:
|
| 164 |
+
name: minimum_version_cpu
|
| 165 |
+
torch: 1.8.0
|
| 166 |
+
torchvision: 0.9.0
|
| 167 |
+
python: 3.8.0 # The lowest python 3.7.x version available on CircleCI images
|
| 168 |
+
requires:
|
| 169 |
+
- lint
|
| 170 |
+
- build_cpu:
|
| 171 |
+
name: maximum_version_cpu
|
| 172 |
+
# mmdeploy not supported
|
| 173 |
+
# torch: 2.0.0
|
| 174 |
+
# torchvision: 0.15.1
|
| 175 |
+
torch: 1.12.1
|
| 176 |
+
torchvision: 0.13.1
|
| 177 |
+
python: 3.9.0
|
| 178 |
+
requires:
|
| 179 |
+
- minimum_version_cpu
|
| 180 |
+
- hold:
|
| 181 |
+
type: approval
|
| 182 |
+
requires:
|
| 183 |
+
- maximum_version_cpu
|
| 184 |
+
- build_cuda:
|
| 185 |
+
name: mainstream_version_gpu
|
| 186 |
+
torch: 1.8.1
|
| 187 |
+
# Use double quotation mark to explicitly specify its type
|
| 188 |
+
# as string instead of number
|
| 189 |
+
cuda: "10.2"
|
| 190 |
+
requires:
|
| 191 |
+
- hold
|
| 192 |
+
- build_cuda:
|
| 193 |
+
name: maximum_version_gpu
|
| 194 |
+
torch: 2.0.0
|
| 195 |
+
cuda: "11.7"
|
| 196 |
+
cudnn: 8
|
| 197 |
+
requires:
|
| 198 |
+
- hold
|
| 199 |
+
merge_stage_test:
|
| 200 |
+
when:
|
| 201 |
+
not: << pipeline.parameters.lint_only >>
|
| 202 |
+
jobs:
|
| 203 |
+
- build_cuda:
|
| 204 |
+
name: minimum_version_gpu
|
| 205 |
+
torch: 1.7.0
|
| 206 |
+
# Use double quotation mark to explicitly specify its type
|
| 207 |
+
# as string instead of number
|
| 208 |
+
cuda: "11.0"
|
| 209 |
+
cudnn: 8
|
| 210 |
+
filters:
|
| 211 |
+
branches:
|
| 212 |
+
only:
|
| 213 |
+
- main
|
third_party/mmyolo/.dev_scripts/gather_models.py
ADDED
|
@@ -0,0 +1,312 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) OpenMMLab. All rights reserved.
|
| 2 |
+
import argparse
|
| 3 |
+
import glob
|
| 4 |
+
import os
|
| 5 |
+
import os.path as osp
|
| 6 |
+
import shutil
|
| 7 |
+
import subprocess
|
| 8 |
+
import time
|
| 9 |
+
from collections import OrderedDict
|
| 10 |
+
|
| 11 |
+
import torch
|
| 12 |
+
import yaml
|
| 13 |
+
from mmengine.config import Config
|
| 14 |
+
from mmengine.fileio import dump
|
| 15 |
+
from mmengine.utils import mkdir_or_exist, scandir
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def ordered_yaml_dump(data, stream=None, Dumper=yaml.SafeDumper, **kwds):
|
| 19 |
+
|
| 20 |
+
class OrderedDumper(Dumper):
|
| 21 |
+
pass
|
| 22 |
+
|
| 23 |
+
def _dict_representer(dumper, data):
|
| 24 |
+
return dumper.represent_mapping(
|
| 25 |
+
yaml.resolver.BaseResolver.DEFAULT_MAPPING_TAG, data.items())
|
| 26 |
+
|
| 27 |
+
OrderedDumper.add_representer(OrderedDict, _dict_representer)
|
| 28 |
+
return yaml.dump(data, stream, OrderedDumper, **kwds)
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def process_checkpoint(in_file, out_file):
|
| 32 |
+
checkpoint = torch.load(in_file, map_location='cpu')
|
| 33 |
+
# remove optimizer for smaller file size
|
| 34 |
+
if 'optimizer' in checkpoint:
|
| 35 |
+
del checkpoint['optimizer']
|
| 36 |
+
if 'message_hub' in checkpoint:
|
| 37 |
+
del checkpoint['message_hub']
|
| 38 |
+
if 'ema_state_dict' in checkpoint:
|
| 39 |
+
del checkpoint['ema_state_dict']
|
| 40 |
+
|
| 41 |
+
for key in list(checkpoint['state_dict']):
|
| 42 |
+
if key.startswith('data_preprocessor'):
|
| 43 |
+
checkpoint['state_dict'].pop(key)
|
| 44 |
+
elif 'priors_base_sizes' in key:
|
| 45 |
+
checkpoint['state_dict'].pop(key)
|
| 46 |
+
elif 'grid_offset' in key:
|
| 47 |
+
checkpoint['state_dict'].pop(key)
|
| 48 |
+
elif 'prior_inds' in key:
|
| 49 |
+
checkpoint['state_dict'].pop(key)
|
| 50 |
+
|
| 51 |
+
# if it is necessary to remove some sensitive data in checkpoint['meta'],
|
| 52 |
+
# add the code here.
|
| 53 |
+
if torch.__version__ >= '1.6':
|
| 54 |
+
torch.save(checkpoint, out_file, _use_new_zipfile_serialization=False)
|
| 55 |
+
else:
|
| 56 |
+
torch.save(checkpoint, out_file)
|
| 57 |
+
sha = subprocess.check_output(['sha256sum', out_file]).decode()
|
| 58 |
+
final_file = out_file.rstrip('.pth') + f'-{sha[:8]}.pth'
|
| 59 |
+
subprocess.Popen(['mv', out_file, final_file])
|
| 60 |
+
return final_file
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
def is_by_epoch(config):
|
| 64 |
+
cfg = Config.fromfile('./configs/' + config)
|
| 65 |
+
return cfg.train_cfg.type == 'EpochBasedTrainLoop'
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def get_final_epoch_or_iter(config):
|
| 69 |
+
cfg = Config.fromfile('./configs/' + config)
|
| 70 |
+
if cfg.train_cfg.type == 'EpochBasedTrainLoop':
|
| 71 |
+
return cfg.train_cfg.max_epochs
|
| 72 |
+
else:
|
| 73 |
+
return cfg.train_cfg.max_iters
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
def get_best_epoch_or_iter(exp_dir):
|
| 77 |
+
best_epoch_iter_full_path = list(
|
| 78 |
+
sorted(glob.glob(osp.join(exp_dir, 'best_*.pth'))))[-1]
|
| 79 |
+
best_epoch_or_iter_model_path = best_epoch_iter_full_path.split('/')[-1]
|
| 80 |
+
best_epoch_or_iter = best_epoch_or_iter_model_path. \
|
| 81 |
+
split('_')[-1].split('.')[0]
|
| 82 |
+
return best_epoch_or_iter_model_path, int(best_epoch_or_iter)
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
def get_real_epoch_or_iter(config):
|
| 86 |
+
cfg = Config.fromfile('./configs/' + config)
|
| 87 |
+
if cfg.train_cfg.type == 'EpochBasedTrainLoop':
|
| 88 |
+
epoch = cfg.train_cfg.max_epochs
|
| 89 |
+
return epoch
|
| 90 |
+
else:
|
| 91 |
+
return cfg.runner.max_iters
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
def get_final_results(log_json_path,
|
| 95 |
+
epoch_or_iter,
|
| 96 |
+
results_lut='coco/bbox_mAP',
|
| 97 |
+
by_epoch=True):
|
| 98 |
+
result_dict = dict()
|
| 99 |
+
with open(log_json_path) as f:
|
| 100 |
+
r = f.readlines()[-1]
|
| 101 |
+
last_metric = r.split(',')[0].split(': ')[-1].strip()
|
| 102 |
+
result_dict[results_lut] = last_metric
|
| 103 |
+
return result_dict
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
def get_dataset_name(config):
|
| 107 |
+
# If there are more dataset, add here.
|
| 108 |
+
name_map = dict(
|
| 109 |
+
CityscapesDataset='Cityscapes',
|
| 110 |
+
CocoDataset='COCO',
|
| 111 |
+
PoseCocoDataset='COCO Person',
|
| 112 |
+
YOLOv5CocoDataset='COCO',
|
| 113 |
+
CocoPanopticDataset='COCO',
|
| 114 |
+
YOLOv5DOTADataset='DOTA 1.0',
|
| 115 |
+
DeepFashionDataset='Deep Fashion',
|
| 116 |
+
LVISV05Dataset='LVIS v0.5',
|
| 117 |
+
LVISV1Dataset='LVIS v1',
|
| 118 |
+
VOCDataset='Pascal VOC',
|
| 119 |
+
YOLOv5VOCDataset='Pascal VOC',
|
| 120 |
+
WIDERFaceDataset='WIDER Face',
|
| 121 |
+
OpenImagesDataset='OpenImagesDataset',
|
| 122 |
+
OpenImagesChallengeDataset='OpenImagesChallengeDataset')
|
| 123 |
+
cfg = Config.fromfile('./configs/' + config)
|
| 124 |
+
return name_map[cfg.dataset_type]
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
def find_last_dir(model_dir):
|
| 128 |
+
dst_times = []
|
| 129 |
+
for time_stamp in os.scandir(model_dir):
|
| 130 |
+
if osp.isdir(time_stamp):
|
| 131 |
+
dst_time = time.mktime(
|
| 132 |
+
time.strptime(time_stamp.name, '%Y%m%d_%H%M%S'))
|
| 133 |
+
dst_times.append([dst_time, time_stamp.name])
|
| 134 |
+
return max(dst_times, key=lambda x: x[0])[1]
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
def convert_model_info_to_pwc(model_infos):
|
| 138 |
+
pwc_files = {}
|
| 139 |
+
for model in model_infos:
|
| 140 |
+
cfg_folder_name = osp.split(model['config'])[-2]
|
| 141 |
+
pwc_model_info = OrderedDict()
|
| 142 |
+
pwc_model_info['Name'] = osp.split(model['config'])[-1].split('.')[0]
|
| 143 |
+
pwc_model_info['In Collection'] = 'Please fill in Collection name'
|
| 144 |
+
pwc_model_info['Config'] = osp.join('configs', model['config'])
|
| 145 |
+
|
| 146 |
+
# get metadata
|
| 147 |
+
meta_data = OrderedDict()
|
| 148 |
+
if 'epochs' in model:
|
| 149 |
+
meta_data['Epochs'] = get_real_epoch_or_iter(model['config'])
|
| 150 |
+
else:
|
| 151 |
+
meta_data['Iterations'] = get_real_epoch_or_iter(model['config'])
|
| 152 |
+
pwc_model_info['Metadata'] = meta_data
|
| 153 |
+
|
| 154 |
+
# get dataset name
|
| 155 |
+
dataset_name = get_dataset_name(model['config'])
|
| 156 |
+
|
| 157 |
+
# get results
|
| 158 |
+
results = []
|
| 159 |
+
# if there are more metrics, add here.
|
| 160 |
+
if 'bbox_mAP' in model['results']:
|
| 161 |
+
metric = round(model['results']['bbox_mAP'] * 100, 1)
|
| 162 |
+
results.append(
|
| 163 |
+
OrderedDict(
|
| 164 |
+
Task='Object Detection',
|
| 165 |
+
Dataset=dataset_name,
|
| 166 |
+
Metrics={'box AP': metric}))
|
| 167 |
+
if 'segm_mAP' in model['results']:
|
| 168 |
+
metric = round(model['results']['segm_mAP'] * 100, 1)
|
| 169 |
+
results.append(
|
| 170 |
+
OrderedDict(
|
| 171 |
+
Task='Instance Segmentation',
|
| 172 |
+
Dataset=dataset_name,
|
| 173 |
+
Metrics={'mask AP': metric}))
|
| 174 |
+
if 'PQ' in model['results']:
|
| 175 |
+
metric = round(model['results']['PQ'], 1)
|
| 176 |
+
results.append(
|
| 177 |
+
OrderedDict(
|
| 178 |
+
Task='Panoptic Segmentation',
|
| 179 |
+
Dataset=dataset_name,
|
| 180 |
+
Metrics={'PQ': metric}))
|
| 181 |
+
pwc_model_info['Results'] = results
|
| 182 |
+
|
| 183 |
+
link_string = 'https://download.openmmlab.com/mmyolo/v0/'
|
| 184 |
+
link_string += '{}/{}'.format(model['config'].rstrip('.py'),
|
| 185 |
+
osp.split(model['model_path'])[-1])
|
| 186 |
+
pwc_model_info['Weights'] = link_string
|
| 187 |
+
if cfg_folder_name in pwc_files:
|
| 188 |
+
pwc_files[cfg_folder_name].append(pwc_model_info)
|
| 189 |
+
else:
|
| 190 |
+
pwc_files[cfg_folder_name] = [pwc_model_info]
|
| 191 |
+
return pwc_files
|
| 192 |
+
|
| 193 |
+
|
| 194 |
+
def parse_args():
|
| 195 |
+
parser = argparse.ArgumentParser(description='Gather benchmarked models')
|
| 196 |
+
parser.add_argument(
|
| 197 |
+
'root',
|
| 198 |
+
type=str,
|
| 199 |
+
help='root path of benchmarked models to be gathered')
|
| 200 |
+
parser.add_argument(
|
| 201 |
+
'out', type=str, help='output path of gathered models to be stored')
|
| 202 |
+
parser.add_argument(
|
| 203 |
+
'--best',
|
| 204 |
+
action='store_true',
|
| 205 |
+
help='whether to gather the best model.')
|
| 206 |
+
|
| 207 |
+
args = parser.parse_args()
|
| 208 |
+
return args
|
| 209 |
+
|
| 210 |
+
|
| 211 |
+
# TODO: Refine
|
| 212 |
+
def main():
|
| 213 |
+
args = parse_args()
|
| 214 |
+
models_root = args.root
|
| 215 |
+
models_out = args.out
|
| 216 |
+
mkdir_or_exist(models_out)
|
| 217 |
+
|
| 218 |
+
# find all models in the root directory to be gathered
|
| 219 |
+
raw_configs = list(scandir('./configs', '.py', recursive=True))
|
| 220 |
+
|
| 221 |
+
# filter configs that is not trained in the experiments dir
|
| 222 |
+
used_configs = []
|
| 223 |
+
for raw_config in raw_configs:
|
| 224 |
+
if osp.exists(osp.join(models_root, raw_config)):
|
| 225 |
+
used_configs.append(raw_config)
|
| 226 |
+
print(f'Find {len(used_configs)} models to be gathered')
|
| 227 |
+
|
| 228 |
+
# find final_ckpt and log file for trained each config
|
| 229 |
+
# and parse the best performance
|
| 230 |
+
model_infos = []
|
| 231 |
+
for used_config in used_configs:
|
| 232 |
+
exp_dir = osp.join(models_root, used_config)
|
| 233 |
+
by_epoch = is_by_epoch(used_config)
|
| 234 |
+
# check whether the exps is finished
|
| 235 |
+
if args.best is True:
|
| 236 |
+
final_model, final_epoch_or_iter = get_best_epoch_or_iter(exp_dir)
|
| 237 |
+
else:
|
| 238 |
+
final_epoch_or_iter = get_final_epoch_or_iter(used_config)
|
| 239 |
+
final_model = '{}_{}.pth'.format('epoch' if by_epoch else 'iter',
|
| 240 |
+
final_epoch_or_iter)
|
| 241 |
+
|
| 242 |
+
model_path = osp.join(exp_dir, final_model)
|
| 243 |
+
# skip if the model is still training
|
| 244 |
+
if not osp.exists(model_path):
|
| 245 |
+
continue
|
| 246 |
+
|
| 247 |
+
# get the latest logs
|
| 248 |
+
latest_exp_name = find_last_dir(exp_dir)
|
| 249 |
+
latest_exp_json = osp.join(exp_dir, latest_exp_name, 'vis_data',
|
| 250 |
+
latest_exp_name + '.json')
|
| 251 |
+
|
| 252 |
+
model_performance = get_final_results(
|
| 253 |
+
latest_exp_json, final_epoch_or_iter, by_epoch=by_epoch)
|
| 254 |
+
|
| 255 |
+
if model_performance is None:
|
| 256 |
+
continue
|
| 257 |
+
|
| 258 |
+
model_info = dict(
|
| 259 |
+
config=used_config,
|
| 260 |
+
results=model_performance,
|
| 261 |
+
final_model=final_model,
|
| 262 |
+
latest_exp_json=latest_exp_json,
|
| 263 |
+
latest_exp_name=latest_exp_name)
|
| 264 |
+
model_info['epochs' if by_epoch else 'iterations'] = \
|
| 265 |
+
final_epoch_or_iter
|
| 266 |
+
model_infos.append(model_info)
|
| 267 |
+
|
| 268 |
+
# publish model for each checkpoint
|
| 269 |
+
publish_model_infos = []
|
| 270 |
+
for model in model_infos:
|
| 271 |
+
model_publish_dir = osp.join(models_out, model['config'].rstrip('.py'))
|
| 272 |
+
mkdir_or_exist(model_publish_dir)
|
| 273 |
+
|
| 274 |
+
model_name = osp.split(model['config'])[-1].split('.')[0]
|
| 275 |
+
|
| 276 |
+
model_name += '_' + model['latest_exp_name']
|
| 277 |
+
publish_model_path = osp.join(model_publish_dir, model_name)
|
| 278 |
+
trained_model_path = osp.join(models_root, model['config'],
|
| 279 |
+
model['final_model'])
|
| 280 |
+
|
| 281 |
+
# convert model
|
| 282 |
+
final_model_path = process_checkpoint(trained_model_path,
|
| 283 |
+
publish_model_path)
|
| 284 |
+
|
| 285 |
+
# copy log
|
| 286 |
+
shutil.copy(model['latest_exp_json'],
|
| 287 |
+
osp.join(model_publish_dir, f'{model_name}.log.json'))
|
| 288 |
+
|
| 289 |
+
# copy config to guarantee reproducibility
|
| 290 |
+
config_path = model['config']
|
| 291 |
+
config_path = osp.join(
|
| 292 |
+
'configs',
|
| 293 |
+
config_path) if 'configs' not in config_path else config_path
|
| 294 |
+
target_config_path = osp.split(config_path)[-1]
|
| 295 |
+
shutil.copy(config_path, osp.join(model_publish_dir,
|
| 296 |
+
target_config_path))
|
| 297 |
+
|
| 298 |
+
model['model_path'] = final_model_path
|
| 299 |
+
publish_model_infos.append(model)
|
| 300 |
+
|
| 301 |
+
models = dict(models=publish_model_infos)
|
| 302 |
+
print(f'Totally gathered {len(publish_model_infos)} models')
|
| 303 |
+
dump(models, osp.join(models_out, 'model_info.json'))
|
| 304 |
+
|
| 305 |
+
pwc_files = convert_model_info_to_pwc(publish_model_infos)
|
| 306 |
+
for name in pwc_files:
|
| 307 |
+
with open(osp.join(models_out, name + '_metafile.yml'), 'w') as f:
|
| 308 |
+
ordered_yaml_dump(pwc_files[name], f, encoding='utf-8')
|
| 309 |
+
|
| 310 |
+
|
| 311 |
+
if __name__ == '__main__':
|
| 312 |
+
main()
|
third_party/mmyolo/.dev_scripts/print_registers.py
ADDED
|
@@ -0,0 +1,448 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) OpenMMLab. All rights reserved.
|
| 2 |
+
import argparse
|
| 3 |
+
import importlib
|
| 4 |
+
import os
|
| 5 |
+
import os.path as osp
|
| 6 |
+
import pkgutil
|
| 7 |
+
import sys
|
| 8 |
+
import tempfile
|
| 9 |
+
from multiprocessing import Pool
|
| 10 |
+
from pathlib import Path
|
| 11 |
+
|
| 12 |
+
import numpy as np
|
| 13 |
+
import pandas as pd
|
| 14 |
+
|
| 15 |
+
# host_addr = 'https://gitee.com/open-mmlab'
|
| 16 |
+
host_addr = 'https://github.com/open-mmlab'
|
| 17 |
+
tools_list = ['tools', '.dev_scripts']
|
| 18 |
+
proxy_names = {
|
| 19 |
+
'mmdet': 'mmdetection',
|
| 20 |
+
'mmseg': 'mmsegmentation',
|
| 21 |
+
'mmcls': 'mmclassification'
|
| 22 |
+
}
|
| 23 |
+
merge_module_keys = {'mmcv': ['mmengine']}
|
| 24 |
+
# exclude_prefix = {'mmcv': ['<class \'mmengine.model.']}
|
| 25 |
+
exclude_prefix = {}
|
| 26 |
+
markdown_title = '# MM 系列开源库注册表\n'
|
| 27 |
+
markdown_title += '(注意:本文档是通过 .dev_scripts/print_registers.py 脚本自动生成)'
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def capitalize(repo_name):
|
| 31 |
+
lower = repo_name.lower()
|
| 32 |
+
if lower == 'mmcv':
|
| 33 |
+
return repo_name.upper()
|
| 34 |
+
elif lower.startswith('mm'):
|
| 35 |
+
return 'MM' + repo_name[2:]
|
| 36 |
+
return repo_name.capitalize()
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def mkdir_or_exist(dir_name, mode=0o777):
|
| 40 |
+
if dir_name == '':
|
| 41 |
+
return
|
| 42 |
+
dir_name = osp.expanduser(dir_name)
|
| 43 |
+
os.makedirs(dir_name, mode=mode, exist_ok=True)
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def parse_repo_name(repo_name):
|
| 47 |
+
proxy_names_rev = dict(zip(proxy_names.values(), proxy_names.keys()))
|
| 48 |
+
repo_name = proxy_names.get(repo_name, repo_name)
|
| 49 |
+
module_name = proxy_names_rev.get(repo_name, repo_name)
|
| 50 |
+
return repo_name, module_name
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def git_pull_branch(repo_name, branch_name='', pulldir='.'):
|
| 54 |
+
mkdir_or_exist(pulldir)
|
| 55 |
+
exec_str = f'cd {pulldir};git init;git pull '
|
| 56 |
+
exec_str += f'{host_addr}/{repo_name}.git'
|
| 57 |
+
if branch_name:
|
| 58 |
+
exec_str += f' {branch_name}'
|
| 59 |
+
returncode = os.system(exec_str)
|
| 60 |
+
if returncode:
|
| 61 |
+
raise RuntimeError(
|
| 62 |
+
f'failed to get the remote repo, code: {returncode}')
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
def load_modules_from_dir(module_name, module_root, throw_error=False):
|
| 66 |
+
print(f'loading the {module_name} modules...')
|
| 67 |
+
# # install the dependencies
|
| 68 |
+
# if osp.exists(osp.join(pkg_dir, 'requirements.txt')):
|
| 69 |
+
# os.system('pip install -r requirements.txt')
|
| 70 |
+
# get all module list
|
| 71 |
+
module_list = []
|
| 72 |
+
error_dict = {}
|
| 73 |
+
module_root = osp.join(module_root, module_name)
|
| 74 |
+
assert osp.exists(module_root), \
|
| 75 |
+
f'cannot find the module root: {module_root}'
|
| 76 |
+
for _root, _dirs, _files in os.walk(module_root):
|
| 77 |
+
if (('__init__.py' not in _files)
|
| 78 |
+
and (osp.split(_root)[1] != '__pycache__')):
|
| 79 |
+
# add __init__.py file to the package
|
| 80 |
+
with open(osp.join(_root, '__init__.py'), 'w') as _:
|
| 81 |
+
pass
|
| 82 |
+
|
| 83 |
+
def _onerror(*args, **kwargs):
|
| 84 |
+
pass
|
| 85 |
+
|
| 86 |
+
for _finder, _name, _ispkg in pkgutil.walk_packages([module_root],
|
| 87 |
+
prefix=module_name +
|
| 88 |
+
'.',
|
| 89 |
+
onerror=_onerror):
|
| 90 |
+
try:
|
| 91 |
+
module = importlib.import_module(_name)
|
| 92 |
+
module_list.append(module)
|
| 93 |
+
except Exception as e:
|
| 94 |
+
if throw_error:
|
| 95 |
+
raise e
|
| 96 |
+
_error_msg = f'{type(e)}: {e}.'
|
| 97 |
+
print(f'cannot import the module: {_name} ({_error_msg})')
|
| 98 |
+
assert (_name not in error_dict), \
|
| 99 |
+
f'duplicate error name was found: {_name}'
|
| 100 |
+
error_dict[_name] = _error_msg
|
| 101 |
+
for module in module_list:
|
| 102 |
+
assert module.__file__.startswith(module_root), \
|
| 103 |
+
f'the importing path of package was wrong: {module.__file__}'
|
| 104 |
+
print('modules were loaded...')
|
| 105 |
+
return module_list, error_dict
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
def get_registries_from_modules(module_list):
|
| 109 |
+
registries = {}
|
| 110 |
+
objects_set = set()
|
| 111 |
+
# import the Registry class,
|
| 112 |
+
# import at the beginning is not allowed
|
| 113 |
+
# because it is not the temp package
|
| 114 |
+
from mmengine.registry import Registry
|
| 115 |
+
|
| 116 |
+
# only get the specific registries in module list
|
| 117 |
+
for module in module_list:
|
| 118 |
+
for obj_name in dir(module):
|
| 119 |
+
_obj = getattr(module, obj_name)
|
| 120 |
+
if isinstance(_obj, Registry):
|
| 121 |
+
objects_set.add(_obj)
|
| 122 |
+
for _obj in objects_set:
|
| 123 |
+
if _obj.scope not in registries:
|
| 124 |
+
registries[_obj.scope] = {}
|
| 125 |
+
registries_scope = registries[_obj.scope]
|
| 126 |
+
assert _obj.name not in registries_scope, \
|
| 127 |
+
f'multiple definition of {_obj.name} in registries'
|
| 128 |
+
registries_scope[_obj.name] = {
|
| 129 |
+
key: str(val)
|
| 130 |
+
for key, val in _obj.module_dict.items()
|
| 131 |
+
}
|
| 132 |
+
print('registries got...')
|
| 133 |
+
return registries
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
def merge_registries(src_dict, dst_dict):
|
| 137 |
+
assert type(src_dict) == type(dst_dict), \
|
| 138 |
+
(f'merge type is not supported: '
|
| 139 |
+
f'{type(dst_dict)} and {type(src_dict)}')
|
| 140 |
+
if isinstance(src_dict, str):
|
| 141 |
+
return
|
| 142 |
+
for _k, _v in dst_dict.items():
|
| 143 |
+
if (_k not in src_dict):
|
| 144 |
+
src_dict.update({_k: _v})
|
| 145 |
+
else:
|
| 146 |
+
assert isinstance(_v, (dict, str)) and \
|
| 147 |
+
isinstance(src_dict[_k], (dict, str)), \
|
| 148 |
+
'merge type is not supported: ' \
|
| 149 |
+
f'{type(_v)} and {type(src_dict[_k])}'
|
| 150 |
+
merge_registries(src_dict[_k], _v)
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
def exclude_registries(registries, exclude_key):
|
| 154 |
+
for _k in list(registries.keys()):
|
| 155 |
+
_v = registries[_k]
|
| 156 |
+
if isinstance(_v, str) and _v.startswith(exclude_key):
|
| 157 |
+
registries.pop(_k)
|
| 158 |
+
elif isinstance(_v, dict):
|
| 159 |
+
exclude_registries(_v, exclude_key)
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
def get_scripts_from_dir(root):
|
| 163 |
+
|
| 164 |
+
def _recurse(_dict, _chain):
|
| 165 |
+
if len(_chain) <= 1:
|
| 166 |
+
_dict[_chain[0]] = None
|
| 167 |
+
return
|
| 168 |
+
_key, *_chain = _chain
|
| 169 |
+
if _key not in _dict:
|
| 170 |
+
_dict[_key] = {}
|
| 171 |
+
_recurse(_dict[_key], _chain)
|
| 172 |
+
|
| 173 |
+
# find all scripts in the root directory. (not just ('.py', '.sh'))
|
| 174 |
+
# can not use the scandir function in mmengine to scan the dir,
|
| 175 |
+
# because mmengine import is not allowed before git pull
|
| 176 |
+
scripts = {}
|
| 177 |
+
for _subroot, _dirs, _files in os.walk(root):
|
| 178 |
+
for _file in _files:
|
| 179 |
+
_script = osp.join(osp.relpath(_subroot, root), _file)
|
| 180 |
+
_recurse(scripts, Path(_script).parts)
|
| 181 |
+
return scripts
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
def get_version_from_module_name(module_name, branch):
|
| 185 |
+
branch_str = str(branch) if branch is not None else ''
|
| 186 |
+
version_str = ''
|
| 187 |
+
try:
|
| 188 |
+
exec(f'import {module_name}')
|
| 189 |
+
_module = eval(f'{module_name}')
|
| 190 |
+
if hasattr(_module, '__version__'):
|
| 191 |
+
version_str = str(_module.__version__)
|
| 192 |
+
else:
|
| 193 |
+
version_str = branch_str
|
| 194 |
+
version_str = f' ({version_str})' if version_str else version_str
|
| 195 |
+
except (ImportError, AttributeError) as e:
|
| 196 |
+
print(f'can not get the version of module {module_name}: {e}')
|
| 197 |
+
return version_str
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
def print_tree(print_dict):
|
| 201 |
+
# recursive print the dict tree
|
| 202 |
+
def _recurse(_dict, _connector='', n=0):
|
| 203 |
+
assert isinstance(_dict, dict), 'recursive type must be dict'
|
| 204 |
+
tree = ''
|
| 205 |
+
for idx, (_key, _val) in enumerate(_dict.items()):
|
| 206 |
+
sub_tree = ''
|
| 207 |
+
_last = (idx == (len(_dict) - 1))
|
| 208 |
+
if isinstance(_val, str):
|
| 209 |
+
_key += f' ({_val})'
|
| 210 |
+
elif isinstance(_val, dict):
|
| 211 |
+
sub_tree = _recurse(_val,
|
| 212 |
+
_connector + (' ' if _last else '│ '),
|
| 213 |
+
n + 1)
|
| 214 |
+
else:
|
| 215 |
+
assert (_val is None), f'unknown print type {_val}'
|
| 216 |
+
tree += ' ' + _connector + \
|
| 217 |
+
('└─' if _last else '├─') + f'({n}) {_key}' + '\n'
|
| 218 |
+
tree += sub_tree
|
| 219 |
+
return tree
|
| 220 |
+
|
| 221 |
+
for _pname, _pdict in print_dict.items():
|
| 222 |
+
print('-' * 100)
|
| 223 |
+
print(f'{_pname}\n' + _recurse(_pdict))
|
| 224 |
+
|
| 225 |
+
|
| 226 |
+
def divide_list_into_groups(_array, _maxsize_per_group):
|
| 227 |
+
if not _array:
|
| 228 |
+
return _array
|
| 229 |
+
_groups = np.asarray(len(_array) / _maxsize_per_group)
|
| 230 |
+
if len(_array) % _maxsize_per_group:
|
| 231 |
+
_groups = np.floor(_groups) + 1
|
| 232 |
+
_groups = _groups.astype(int)
|
| 233 |
+
return np.array_split(_array, _groups)
|
| 234 |
+
|
| 235 |
+
|
| 236 |
+
def registries_to_html(registries, title=''):
|
| 237 |
+
max_col_per_row = 5
|
| 238 |
+
max_size_per_cell = 20
|
| 239 |
+
html = ''
|
| 240 |
+
table_data = []
|
| 241 |
+
# save repository registries
|
| 242 |
+
for registry_name, registry_dict in registries.items():
|
| 243 |
+
# filter the empty registries
|
| 244 |
+
if not registry_dict:
|
| 245 |
+
continue
|
| 246 |
+
registry_strings = []
|
| 247 |
+
if isinstance(registry_dict, dict):
|
| 248 |
+
registry_dict = list(registry_dict.keys())
|
| 249 |
+
elif isinstance(registry_dict, list):
|
| 250 |
+
pass
|
| 251 |
+
else:
|
| 252 |
+
raise TypeError(
|
| 253 |
+
f'unknown type of registry_dict {type(registry_dict)}')
|
| 254 |
+
for _k in registry_dict:
|
| 255 |
+
registry_strings.append(f'<li>{_k}</li>')
|
| 256 |
+
table_data.append((registry_name, registry_strings))
|
| 257 |
+
|
| 258 |
+
# sort the data list
|
| 259 |
+
table_data = sorted(table_data, key=lambda x: len(x[1]))
|
| 260 |
+
# split multi parts
|
| 261 |
+
table_data_multi_parts = []
|
| 262 |
+
for (registry_name, registry_strings) in table_data:
|
| 263 |
+
multi_parts = False
|
| 264 |
+
if len(registry_strings) > max_size_per_cell:
|
| 265 |
+
multi_parts = True
|
| 266 |
+
for cell_idx, registry_cell in enumerate(
|
| 267 |
+
divide_list_into_groups(registry_strings, max_size_per_cell)):
|
| 268 |
+
registry_str = ''.join(registry_cell.tolist())
|
| 269 |
+
registry_str = f'<ul>{registry_str}</ul>'
|
| 270 |
+
table_data_multi_parts.append([
|
| 271 |
+
registry_name if not multi_parts else
|
| 272 |
+
f'{registry_name} (part {cell_idx + 1})', registry_str
|
| 273 |
+
])
|
| 274 |
+
|
| 275 |
+
for table_data in divide_list_into_groups(table_data_multi_parts,
|
| 276 |
+
max_col_per_row):
|
| 277 |
+
table_data = list(zip(*table_data.tolist()))
|
| 278 |
+
html += dataframe_to_html(
|
| 279 |
+
pd.DataFrame([table_data[1]], columns=table_data[0]))
|
| 280 |
+
if html:
|
| 281 |
+
html = f'<div align=\'center\'><b>{title}</b></div>\n{html}'
|
| 282 |
+
html = f'<details open>{html}</details>\n'
|
| 283 |
+
return html
|
| 284 |
+
|
| 285 |
+
|
| 286 |
+
def tools_to_html(tools_dict, repo_name=''):
|
| 287 |
+
|
| 288 |
+
def _recurse(_dict, _connector, _result):
|
| 289 |
+
assert isinstance(_dict, dict), \
|
| 290 |
+
f'unknown recurse type: {_dict} ({type(_dict)})'
|
| 291 |
+
for _k, _v in _dict.items():
|
| 292 |
+
if _v is None:
|
| 293 |
+
if _connector not in _result:
|
| 294 |
+
_result[_connector] = []
|
| 295 |
+
_result[_connector].append(_k)
|
| 296 |
+
else:
|
| 297 |
+
_recurse(_v, osp.join(_connector, _k), _result)
|
| 298 |
+
|
| 299 |
+
table_data = {}
|
| 300 |
+
title = f'{capitalize(repo_name)} Tools'
|
| 301 |
+
_recurse(tools_dict, '', table_data)
|
| 302 |
+
return registries_to_html(table_data, title)
|
| 303 |
+
|
| 304 |
+
|
| 305 |
+
def dataframe_to_html(dataframe):
|
| 306 |
+
styler = dataframe.style
|
| 307 |
+
styler = styler.hide(axis='index')
|
| 308 |
+
styler = styler.format(na_rep='-')
|
| 309 |
+
styler = styler.set_properties(**{
|
| 310 |
+
'text-align': 'left',
|
| 311 |
+
'align': 'center',
|
| 312 |
+
'vertical-align': 'top'
|
| 313 |
+
})
|
| 314 |
+
styler = styler.set_table_styles([{
|
| 315 |
+
'selector':
|
| 316 |
+
'thead th',
|
| 317 |
+
'props':
|
| 318 |
+
'align:center;text-align:center;vertical-align:bottom'
|
| 319 |
+
}])
|
| 320 |
+
html = styler.to_html()
|
| 321 |
+
html = f'<div align=\'center\'>\n{html}</div>'
|
| 322 |
+
return html
|
| 323 |
+
|
| 324 |
+
|
| 325 |
+
def generate_markdown_by_repository(repo_name,
|
| 326 |
+
module_name,
|
| 327 |
+
branch,
|
| 328 |
+
pulldir,
|
| 329 |
+
throw_error=False):
|
| 330 |
+
# add the pull dir to the system path so that it can be found
|
| 331 |
+
if pulldir not in sys.path:
|
| 332 |
+
sys.path.insert(0, pulldir)
|
| 333 |
+
module_list, error_dict = load_modules_from_dir(
|
| 334 |
+
module_name, pulldir, throw_error=throw_error)
|
| 335 |
+
registries_tree = get_registries_from_modules(module_list)
|
| 336 |
+
if error_dict:
|
| 337 |
+
error_dict_name = 'error_modules'
|
| 338 |
+
assert (error_dict_name not in registries_tree), \
|
| 339 |
+
f'duplicate module name was found: {error_dict_name}'
|
| 340 |
+
registries_tree.update({error_dict_name: error_dict})
|
| 341 |
+
# get the tools files
|
| 342 |
+
for tools_name in tools_list:
|
| 343 |
+
assert (tools_name not in registries_tree), \
|
| 344 |
+
f'duplicate tools name was found: {tools_name}'
|
| 345 |
+
tools_tree = osp.join(pulldir, tools_name)
|
| 346 |
+
tools_tree = get_scripts_from_dir(tools_tree)
|
| 347 |
+
registries_tree.update({tools_name: tools_tree})
|
| 348 |
+
# print_tree(registries_tree)
|
| 349 |
+
# get registries markdown string
|
| 350 |
+
module_registries = registries_tree.get(module_name, {})
|
| 351 |
+
for merge_key in merge_module_keys.get(module_name, []):
|
| 352 |
+
merge_dict = registries_tree.get(merge_key, {})
|
| 353 |
+
merge_registries(module_registries, merge_dict)
|
| 354 |
+
for exclude_key in exclude_prefix.get(module_name, []):
|
| 355 |
+
exclude_registries(module_registries, exclude_key)
|
| 356 |
+
markdown_str = registries_to_html(
|
| 357 |
+
module_registries, title=f'{capitalize(repo_name)} Module Components')
|
| 358 |
+
# get tools markdown string
|
| 359 |
+
tools_registries = {}
|
| 360 |
+
for tools_name in tools_list:
|
| 361 |
+
tools_registries.update(
|
| 362 |
+
{tools_name: registries_tree.get(tools_name, {})})
|
| 363 |
+
markdown_str += tools_to_html(tools_registries, repo_name=repo_name)
|
| 364 |
+
version_str = get_version_from_module_name(module_name, branch)
|
| 365 |
+
title_str = f'\n\n## {capitalize(repo_name)}{version_str}\n'
|
| 366 |
+
# remove the pull dir from system path
|
| 367 |
+
if pulldir in sys.path:
|
| 368 |
+
sys.path.remove(pulldir)
|
| 369 |
+
return f'{title_str}{markdown_str}'
|
| 370 |
+
|
| 371 |
+
|
| 372 |
+
def parse_args():
|
| 373 |
+
parser = argparse.ArgumentParser(
|
| 374 |
+
description='print registries in openmmlab repositories')
|
| 375 |
+
parser.add_argument(
|
| 376 |
+
'-r',
|
| 377 |
+
'--repositories',
|
| 378 |
+
nargs='+',
|
| 379 |
+
default=['mmdet', 'mmcls', 'mmseg', 'mmengine', 'mmcv'],
|
| 380 |
+
type=str,
|
| 381 |
+
help='git repositories name in OpenMMLab')
|
| 382 |
+
parser.add_argument(
|
| 383 |
+
'-b',
|
| 384 |
+
'--branches',
|
| 385 |
+
nargs='+',
|
| 386 |
+
default=['3.x', '1.x', '1.x', 'main', '2.x'],
|
| 387 |
+
type=str,
|
| 388 |
+
help='the branch names of git repositories, the length of branches '
|
| 389 |
+
'must be same as the length of repositories')
|
| 390 |
+
parser.add_argument(
|
| 391 |
+
'-o', '--out', type=str, default='.', help='output path of the file')
|
| 392 |
+
parser.add_argument(
|
| 393 |
+
'--throw-error',
|
| 394 |
+
action='store_true',
|
| 395 |
+
default=False,
|
| 396 |
+
help='whether to throw error when trying to import modules')
|
| 397 |
+
args = parser.parse_args()
|
| 398 |
+
return args
|
| 399 |
+
|
| 400 |
+
|
| 401 |
+
# TODO: Refine
|
| 402 |
+
def main():
|
| 403 |
+
args = parse_args()
|
| 404 |
+
repositories = args.repositories
|
| 405 |
+
branches = args.branches
|
| 406 |
+
assert isinstance(repositories, list), \
|
| 407 |
+
'Type of repositories must be list'
|
| 408 |
+
if branches is None:
|
| 409 |
+
branches = [None] * len(repositories)
|
| 410 |
+
assert isinstance(branches, list) and \
|
| 411 |
+
len(branches) == len(repositories), \
|
| 412 |
+
'The length of branches must be same as ' \
|
| 413 |
+
'that of repositories'
|
| 414 |
+
assert isinstance(args.out, str), \
|
| 415 |
+
'The type of output path must be string'
|
| 416 |
+
# save path of file
|
| 417 |
+
mkdir_or_exist(args.out)
|
| 418 |
+
save_path = osp.join(args.out, 'registries_info.md')
|
| 419 |
+
with tempfile.TemporaryDirectory() as tmpdir:
|
| 420 |
+
# multi process init
|
| 421 |
+
pool = Pool(processes=len(repositories))
|
| 422 |
+
multi_proc_input_list = []
|
| 423 |
+
multi_proc_output_list = []
|
| 424 |
+
# get the git repositories
|
| 425 |
+
for branch, repository in zip(branches, repositories):
|
| 426 |
+
repo_name, module_name = parse_repo_name(repository)
|
| 427 |
+
pulldir = osp.join(tmpdir, f'tmp_{repo_name}')
|
| 428 |
+
git_pull_branch(
|
| 429 |
+
repo_name=repo_name, branch_name=branch, pulldir=pulldir)
|
| 430 |
+
multi_proc_input_list.append(
|
| 431 |
+
(repo_name, module_name, branch, pulldir, args.throw_error))
|
| 432 |
+
print('starting the multi process to get the registries')
|
| 433 |
+
for multi_proc_input in multi_proc_input_list:
|
| 434 |
+
multi_proc_output_list.append(
|
| 435 |
+
pool.apply_async(generate_markdown_by_repository,
|
| 436 |
+
multi_proc_input))
|
| 437 |
+
pool.close()
|
| 438 |
+
pool.join()
|
| 439 |
+
with open(save_path, 'w', encoding='utf-8') as fw:
|
| 440 |
+
fw.write(f'{markdown_title}\n')
|
| 441 |
+
for multi_proc_output in multi_proc_output_list:
|
| 442 |
+
markdown_str = multi_proc_output.get()
|
| 443 |
+
fw.write(f'{markdown_str}\n')
|
| 444 |
+
print(f'saved registries to the path: {save_path}')
|
| 445 |
+
|
| 446 |
+
|
| 447 |
+
if __name__ == '__main__':
|
| 448 |
+
main()
|
third_party/mmyolo/.github/CODE_OF_CONDUCT.md
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Contributor Covenant Code of Conduct
|
| 2 |
+
|
| 3 |
+
## Our Pledge
|
| 4 |
+
|
| 5 |
+
In the interest of fostering an open and welcoming environment, we as
|
| 6 |
+
contributors and maintainers pledge to making participation in our project and
|
| 7 |
+
our community a harassment-free experience for everyone, regardless of age, body
|
| 8 |
+
size, disability, ethnicity, sex characteristics, gender identity and expression,
|
| 9 |
+
level of experience, education, socio-economic status, nationality, personal
|
| 10 |
+
appearance, race, religion, or sexual identity and orientation.
|
| 11 |
+
|
| 12 |
+
## Our Standards
|
| 13 |
+
|
| 14 |
+
Examples of behavior that contributes to creating a positive environment
|
| 15 |
+
include:
|
| 16 |
+
|
| 17 |
+
- Using welcoming and inclusive language
|
| 18 |
+
- Being respectful of differing viewpoints and experiences
|
| 19 |
+
- Gracefully accepting constructive criticism
|
| 20 |
+
- Focusing on what is best for the community
|
| 21 |
+
- Showing empathy towards other community members
|
| 22 |
+
|
| 23 |
+
Examples of unacceptable behavior by participants include:
|
| 24 |
+
|
| 25 |
+
- The use of sexualized language or imagery and unwelcome sexual attention or
|
| 26 |
+
advances
|
| 27 |
+
- Trolling, insulting/derogatory comments, and personal or political attacks
|
| 28 |
+
- Public or private harassment
|
| 29 |
+
- Publishing others' private information, such as a physical or electronic
|
| 30 |
+
address, without explicit permission
|
| 31 |
+
- Other conduct which could reasonably be considered inappropriate in a
|
| 32 |
+
professional setting
|
| 33 |
+
|
| 34 |
+
## Our Responsibilities
|
| 35 |
+
|
| 36 |
+
Project maintainers are responsible for clarifying the standards of acceptable
|
| 37 |
+
behavior and are expected to take appropriate and fair corrective action in
|
| 38 |
+
response to any instances of unacceptable behavior.
|
| 39 |
+
|
| 40 |
+
Project maintainers have the right and responsibility to remove, edit, or
|
| 41 |
+
reject comments, commits, code, wiki edits, issues, and other contributions
|
| 42 |
+
that are not aligned to this Code of Conduct, or to ban temporarily or
|
| 43 |
+
permanently any contributor for other behaviors that they deem inappropriate,
|
| 44 |
+
threatening, offensive, or harmful.
|
| 45 |
+
|
| 46 |
+
## Scope
|
| 47 |
+
|
| 48 |
+
This Code of Conduct applies both within project spaces and in public spaces
|
| 49 |
+
when an individual is representing the project or its community. Examples of
|
| 50 |
+
representing a project or community include using an official project e-mail
|
| 51 |
+
address, posting via an official social media account, or acting as an appointed
|
| 52 |
+
representative at an online or offline event. Representation of a project may be
|
| 53 |
+
further defined and clarified by project maintainers.
|
| 54 |
+
|
| 55 |
+
## Enforcement
|
| 56 |
+
|
| 57 |
+
Instances of abusive, harassing, or otherwise unacceptable behavior may be
|
| 58 |
+
reported by contacting the project team at chenkaidev@gmail.com. All
|
| 59 |
+
complaints will be reviewed and investigated and will result in a response that
|
| 60 |
+
is deemed necessary and appropriate to the circumstances. The project team is
|
| 61 |
+
obligated to maintain confidentiality with regard to the reporter of an incident.
|
| 62 |
+
Further details of specific enforcement policies may be posted separately.
|
| 63 |
+
|
| 64 |
+
Project maintainers who do not follow or enforce the Code of Conduct in good
|
| 65 |
+
faith may face temporary or permanent repercussions as determined by other
|
| 66 |
+
members of the project's leadership.
|
| 67 |
+
|
| 68 |
+
## Attribution
|
| 69 |
+
|
| 70 |
+
This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 1.4,
|
| 71 |
+
available at https://www.contributor-covenant.org/version/1/4/code-of-conduct.html
|
| 72 |
+
|
| 73 |
+
For answers to common questions about this code of conduct, see
|
| 74 |
+
https://www.contributor-covenant.org/faq
|
| 75 |
+
|
| 76 |
+
[homepage]: https://www.contributor-covenant.org
|
third_party/mmyolo/.github/CONTRIBUTING.md
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
We appreciate all contributions to improve MMYOLO. Please refer to [CONTRIBUTING.md](https://github.com/open-mmlab/mmcv/blob/master/CONTRIBUTING.md) in MMCV for more details about the contributing guideline.
|
third_party/mmyolo/.github/ISSUE_TEMPLATE/1-bug-report.yml
ADDED
|
@@ -0,0 +1,67 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: "🐞 Bug report"
|
| 2 |
+
description: "Create a report to help us reproduce and fix the bug"
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
body:
|
| 6 |
+
- type: markdown
|
| 7 |
+
attributes:
|
| 8 |
+
value: |
|
| 9 |
+
Thank you for reporting this issue to help us improve!
|
| 10 |
+
If you have already identified the reason, we strongly appreciate you creating a new PR to fix it [here](https://github.com/open-mmlab/mmyolo/pulls)!
|
| 11 |
+
If this issue is about installing MMCV, please file an issue at [MMCV](https://github.com/open-mmlab/mmcv/issues/new/choose).
|
| 12 |
+
If you need our help, please fill in as much of the following form as you're able.
|
| 13 |
+
|
| 14 |
+
- type: checkboxes
|
| 15 |
+
attributes:
|
| 16 |
+
label: Prerequisite
|
| 17 |
+
description: Please check the following items before creating a new issue.
|
| 18 |
+
options:
|
| 19 |
+
- label: I have searched [the existing and past issues](https://github.com/open-mmlab/mmyolo/issues) but cannot get the expected help.
|
| 20 |
+
required: true
|
| 21 |
+
- label: I have read the [FAQ documentation](https://mmyolo.readthedocs.io/en/latest/faq.html) but cannot get the expected help.
|
| 22 |
+
required: true
|
| 23 |
+
- label: The bug has not been fixed in the [latest version](https://github.com/open-mmlab/mmyolo).
|
| 24 |
+
required: true
|
| 25 |
+
|
| 26 |
+
- type: textarea
|
| 27 |
+
attributes:
|
| 28 |
+
label: 🐞 Describe the bug
|
| 29 |
+
description: |
|
| 30 |
+
Please provide a clear and concise description of what the bug is.
|
| 31 |
+
Preferably a simple and minimal code snippet that we can reproduce the error by running the code.
|
| 32 |
+
placeholder: |
|
| 33 |
+
A clear and concise description of what the bug is.
|
| 34 |
+
|
| 35 |
+
```python
|
| 36 |
+
# Sample code to reproduce the problem
|
| 37 |
+
```
|
| 38 |
+
|
| 39 |
+
```shell
|
| 40 |
+
The command or script you run.
|
| 41 |
+
```
|
| 42 |
+
|
| 43 |
+
```
|
| 44 |
+
The error message or logs you got, with the full traceback.
|
| 45 |
+
```
|
| 46 |
+
validations:
|
| 47 |
+
required: true
|
| 48 |
+
|
| 49 |
+
- type: textarea
|
| 50 |
+
attributes:
|
| 51 |
+
label: Environment
|
| 52 |
+
description: |
|
| 53 |
+
Please run `python mmyolo/utils/collect_env.py` to collect necessary environment information and paste it here.
|
| 54 |
+
You may add addition that may be helpful for locating the problem, such as
|
| 55 |
+
- How you installed PyTorch \[e.g., pip, conda, source\]
|
| 56 |
+
- Other environment variables that may be related (such as `$PATH`, `$LD_LIBRARY_PATH`, `$PYTHONPATH`, etc.)
|
| 57 |
+
validations:
|
| 58 |
+
required: true
|
| 59 |
+
|
| 60 |
+
- type: textarea
|
| 61 |
+
attributes:
|
| 62 |
+
label: Additional information
|
| 63 |
+
description: Tell us anything else you think we should know.
|
| 64 |
+
placeholder: |
|
| 65 |
+
1. Did you make any modifications on the code or config? Did you understand what you have modified?
|
| 66 |
+
2. What dataset did you use?
|
| 67 |
+
3. What do you think might be the reason?
|
third_party/mmyolo/.github/ISSUE_TEMPLATE/2-feature-request.yml
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: 🚀 Feature request
|
| 2 |
+
description: Suggest an idea for this project
|
| 3 |
+
labels: [feature request]
|
| 4 |
+
|
| 5 |
+
body:
|
| 6 |
+
- type: markdown
|
| 7 |
+
attributes:
|
| 8 |
+
value: |
|
| 9 |
+
Thank you for suggesting an idea to make MMYOLO better.
|
| 10 |
+
We strongly appreciate you creating a PR to implete this feature [here](https://github.com/open-mmlab/mmyolo/pulls)!
|
| 11 |
+
|
| 12 |
+
If you need our help, please fill in as much of the following form as you're able.
|
| 13 |
+
|
| 14 |
+
- type: textarea
|
| 15 |
+
attributes:
|
| 16 |
+
label: What is the problem this feature will solve?
|
| 17 |
+
placeholder: |
|
| 18 |
+
E.g., It is inconvenient when \[....\].
|
| 19 |
+
validations:
|
| 20 |
+
required: true
|
| 21 |
+
|
| 22 |
+
- type: textarea
|
| 23 |
+
attributes:
|
| 24 |
+
label: What is the feature you are proposing to solve the problem?
|
| 25 |
+
validations:
|
| 26 |
+
required: true
|
| 27 |
+
|
| 28 |
+
- type: textarea
|
| 29 |
+
attributes:
|
| 30 |
+
label: What alternatives have you considered?
|
| 31 |
+
description: |
|
| 32 |
+
Add any other context or screenshots about the feature request here.
|
third_party/mmyolo/.github/ISSUE_TEMPLATE/3-new-model.yml
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: "\U0001F31F New model/dataset addition"
|
| 2 |
+
description: Submit a proposal/request to implement a new model / dataset
|
| 3 |
+
labels: [ "New model/dataset" ]
|
| 4 |
+
|
| 5 |
+
body:
|
| 6 |
+
- type: textarea
|
| 7 |
+
id: description-request
|
| 8 |
+
validations:
|
| 9 |
+
required: true
|
| 10 |
+
attributes:
|
| 11 |
+
label: Model/Dataset description
|
| 12 |
+
description: |
|
| 13 |
+
Put any and all important information relative to the model/dataset
|
| 14 |
+
|
| 15 |
+
- type: checkboxes
|
| 16 |
+
attributes:
|
| 17 |
+
label: Open source status
|
| 18 |
+
description: |
|
| 19 |
+
Please provide the open-source status, which would be very helpful
|
| 20 |
+
options:
|
| 21 |
+
- label: "The model implementation is available"
|
| 22 |
+
- label: "The model weights are available."
|
| 23 |
+
|
| 24 |
+
- type: textarea
|
| 25 |
+
id: additional-info
|
| 26 |
+
attributes:
|
| 27 |
+
label: Provide useful links for the implementation
|
| 28 |
+
description: |
|
| 29 |
+
Please provide information regarding the implementation, the weights, and the authors.
|
| 30 |
+
Please mention the authors by @gh-username if you're aware of their usernames.
|
third_party/mmyolo/.github/ISSUE_TEMPLATE/4-documentation.yml
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: 📚 Documentation
|
| 2 |
+
description: Report an issue related to https://mmyolo.readthedocs.io/en/latest/.
|
| 3 |
+
|
| 4 |
+
body:
|
| 5 |
+
- type: textarea
|
| 6 |
+
attributes:
|
| 7 |
+
label: 📚 The doc issue
|
| 8 |
+
description: >
|
| 9 |
+
A clear and concise description of what content in https://mmyolo.readthedocs.io/en/latest/ is an issue.
|
| 10 |
+
validations:
|
| 11 |
+
required: true
|
| 12 |
+
|
| 13 |
+
- type: textarea
|
| 14 |
+
attributes:
|
| 15 |
+
label: Suggest a potential alternative/fix
|
| 16 |
+
description: >
|
| 17 |
+
Tell us how we could improve the documentation in this regard.
|
| 18 |
+
|
| 19 |
+
- type: markdown
|
| 20 |
+
attributes:
|
| 21 |
+
value: >
|
| 22 |
+
Thanks for contributing 🎉!
|
third_party/mmyolo/.github/ISSUE_TEMPLATE/5-reimplementation.yml
ADDED
|
@@ -0,0 +1,87 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: "💥 Reimplementation Questions"
|
| 2 |
+
description: "Ask about questions during model reimplementation"
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
body:
|
| 6 |
+
- type: markdown
|
| 7 |
+
attributes:
|
| 8 |
+
value: |
|
| 9 |
+
If you have already identified the reason, we strongly appreciate you creating a new PR to fix it [here](https://github.com/open-mmlab/mmyolo/pulls)!
|
| 10 |
+
|
| 11 |
+
- type: checkboxes
|
| 12 |
+
attributes:
|
| 13 |
+
label: Prerequisite
|
| 14 |
+
description: Please check the following items before creating a new issue.
|
| 15 |
+
options:
|
| 16 |
+
- label: I have searched [the existing and past issues](https://github.com/open-mmlab/mmyolo/issues) but cannot get the expected help.
|
| 17 |
+
required: true
|
| 18 |
+
- label: I have read the [FAQ documentation](https://mmyolo.readthedocs.io/en/latest/faq.html) but cannot get the expected help.
|
| 19 |
+
required: true
|
| 20 |
+
- label: The bug has not been fixed in the [latest version](https://github.com/open-mmlab/mmyolo).
|
| 21 |
+
required: true
|
| 22 |
+
validations:
|
| 23 |
+
required: true
|
| 24 |
+
|
| 25 |
+
- type: textarea
|
| 26 |
+
attributes:
|
| 27 |
+
label: 💬 Describe the reimplementation questions
|
| 28 |
+
description: |
|
| 29 |
+
A clear and concise description of what the problem you meet and what have you done.
|
| 30 |
+
There are several common situations in the reimplementation issues as below
|
| 31 |
+
|
| 32 |
+
1. Reimplement a model in the model zoo using the provided configs
|
| 33 |
+
2. Reimplement a model in the model zoo on other dataset (e.g., custom datasets)
|
| 34 |
+
3. Reimplement a custom model but all the components are implemented in MMDetection
|
| 35 |
+
4. Reimplement a custom model with new modules implemented by yourself
|
| 36 |
+
|
| 37 |
+
There are several things to do for different cases as below.
|
| 38 |
+
|
| 39 |
+
- For case 1 & 3, please follow the steps in the following sections thus we could help to quick identify the issue.
|
| 40 |
+
- For case 2 & 4, please understand that we are not able to do much help here because we usually do not know the full code and the users should be responsible to the code they write.
|
| 41 |
+
- One suggestion for case 2 & 4 is that the users should first check whether the bug lies in the self-implemented code or the original code. For example, users can first make sure that the same model runs well on supported datasets. If you still need help, please describe what you have done and what you obtain in the issue, and follow the steps in the following sections and try as clear as possible so that we can better help you.
|
| 42 |
+
placeholder: |
|
| 43 |
+
A clear and concise description of what the bug is.
|
| 44 |
+
What config dir you run?
|
| 45 |
+
|
| 46 |
+
```none
|
| 47 |
+
A placeholder for the config.
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |
+
```shell
|
| 51 |
+
The command or script you run.
|
| 52 |
+
```
|
| 53 |
+
|
| 54 |
+
```
|
| 55 |
+
The error message or logs you got, with the full traceback.
|
| 56 |
+
```
|
| 57 |
+
validations:
|
| 58 |
+
required: true
|
| 59 |
+
|
| 60 |
+
- type: textarea
|
| 61 |
+
attributes:
|
| 62 |
+
label: Environment
|
| 63 |
+
description: |
|
| 64 |
+
Please run `python mmyolo/utils/collect_env.py` to collect necessary environment information and paste it here.
|
| 65 |
+
You may add addition that may be helpful for locating the problem, such as
|
| 66 |
+
- How you installed PyTorch \[e.g., pip, conda, source\]
|
| 67 |
+
- Other environment variables that may be related (such as `$PATH`, `$LD_LIBRARY_PATH`, `$PYTHONPATH`, etc.)
|
| 68 |
+
validations:
|
| 69 |
+
required: true
|
| 70 |
+
|
| 71 |
+
- type: textarea
|
| 72 |
+
attributes:
|
| 73 |
+
label: Expected results
|
| 74 |
+
description: If applicable, paste the related results here, e.g., what you expect and what you get.
|
| 75 |
+
placeholder: |
|
| 76 |
+
```none
|
| 77 |
+
A placeholder for results comparison
|
| 78 |
+
```
|
| 79 |
+
|
| 80 |
+
- type: textarea
|
| 81 |
+
attributes:
|
| 82 |
+
label: Additional information
|
| 83 |
+
description: Tell us anything else you think we should know.
|
| 84 |
+
placeholder: |
|
| 85 |
+
1. Did you make any modifications on the code or config? Did you understand what you have modified?
|
| 86 |
+
2. What dataset did you use?
|
| 87 |
+
3. What do you think might be the reason?
|
third_party/mmyolo/.github/ISSUE_TEMPLATE/config.yml
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
blank_issues_enabled: true
|
| 2 |
+
|
| 3 |
+
contact_links:
|
| 4 |
+
- name: 💬 Forum
|
| 5 |
+
url: https://github.com/open-mmlab/mmyolo/discussions
|
| 6 |
+
about: Ask general usage questions and discuss with other MMYOLO community members
|
| 7 |
+
- name: 🌐 Explore OpenMMLab
|
| 8 |
+
url: https://openmmlab.com/
|
| 9 |
+
about: Get know more about OpenMMLab
|
third_party/mmyolo/.github/pull_request_template.md
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Thanks for your contribution and we appreciate it a lot. The following instructions would make your pull request more healthy and more easily get feedback. If you do not understand some items, don't worry, just make the pull request and seek help from maintainers.
|
| 2 |
+
|
| 3 |
+
## Motivation
|
| 4 |
+
|
| 5 |
+
Please describe the motivation for this PR and the goal you want to achieve through this PR.
|
| 6 |
+
|
| 7 |
+
## Modification
|
| 8 |
+
|
| 9 |
+
Please briefly describe what modification is made in this PR.
|
| 10 |
+
|
| 11 |
+
## BC-breaking (Optional)
|
| 12 |
+
|
| 13 |
+
Does the modification introduce changes that break the backward compatibility of the downstream repos?
|
| 14 |
+
If so, please describe how it breaks the compatibility and how the downstream projects should modify their code to keep compatibility with this PR.
|
| 15 |
+
|
| 16 |
+
## Use cases (Optional)
|
| 17 |
+
|
| 18 |
+
If this PR introduces a new feature, it is better to list some use cases here and update the documentation.
|
| 19 |
+
|
| 20 |
+
## Checklist
|
| 21 |
+
|
| 22 |
+
1. Pre-commit or other linting tools are used to fix potential lint issues.
|
| 23 |
+
2. The modification is covered by complete unit tests. If not, please add more unit tests to ensure the correctness.
|
| 24 |
+
3. If the modification has a potential influence on downstream projects, this PR should be tested with downstream projects, like MMDetection or MMClassification.
|
| 25 |
+
4. The documentation has been modified accordingly, like docstring or example tutorials.
|
third_party/mmyolo/.github/workflows/deploy.yml
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: deploy
|
| 2 |
+
|
| 3 |
+
on: push
|
| 4 |
+
|
| 5 |
+
concurrency:
|
| 6 |
+
group: ${{ github.workflow }}-${{ github.ref }}
|
| 7 |
+
cancel-in-progress: true
|
| 8 |
+
|
| 9 |
+
jobs:
|
| 10 |
+
build-n-publish:
|
| 11 |
+
runs-on: ubuntu-latest
|
| 12 |
+
if: startsWith(github.event.ref, 'refs/tags')
|
| 13 |
+
steps:
|
| 14 |
+
- uses: actions/checkout@v2
|
| 15 |
+
- name: Set up Python 3.7
|
| 16 |
+
uses: actions/setup-python@v2
|
| 17 |
+
with:
|
| 18 |
+
python-version: 3.7
|
| 19 |
+
- name: Install torch
|
| 20 |
+
run: pip install torch
|
| 21 |
+
- name: Install wheel
|
| 22 |
+
run: pip install wheel
|
| 23 |
+
- name: Build MMYOLO
|
| 24 |
+
run: python setup.py sdist bdist_wheel
|
| 25 |
+
- name: Publish distribution to PyPI
|
| 26 |
+
run: |
|
| 27 |
+
pip install twine
|
| 28 |
+
twine upload dist/* -u __token__ -p ${{ secrets.pypi_password }}
|
third_party/mmyolo/.gitignore
ADDED
|
@@ -0,0 +1,126 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
*$py.class
|
| 5 |
+
|
| 6 |
+
# C extensions
|
| 7 |
+
*.so
|
| 8 |
+
|
| 9 |
+
# Distribution / packaging
|
| 10 |
+
.Python
|
| 11 |
+
build/
|
| 12 |
+
develop-eggs/
|
| 13 |
+
dist/
|
| 14 |
+
downloads/
|
| 15 |
+
eggs/
|
| 16 |
+
.eggs/
|
| 17 |
+
lib/
|
| 18 |
+
lib64/
|
| 19 |
+
parts/
|
| 20 |
+
sdist/
|
| 21 |
+
var/
|
| 22 |
+
wheels/
|
| 23 |
+
*.egg-info/
|
| 24 |
+
.installed.cfg
|
| 25 |
+
*.egg
|
| 26 |
+
MANIFEST
|
| 27 |
+
|
| 28 |
+
# PyInstaller
|
| 29 |
+
# Usually these files are written by a python script from a template
|
| 30 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 31 |
+
*.manifest
|
| 32 |
+
*.spec
|
| 33 |
+
|
| 34 |
+
# Installer logs
|
| 35 |
+
pip-log.txt
|
| 36 |
+
pip-delete-this-directory.txt
|
| 37 |
+
|
| 38 |
+
# Unit test / coverage reports
|
| 39 |
+
htmlcov/
|
| 40 |
+
.tox/
|
| 41 |
+
.coverage
|
| 42 |
+
.coverage.*
|
| 43 |
+
.cache
|
| 44 |
+
nosetests.xml
|
| 45 |
+
coverage.xml
|
| 46 |
+
*.cover
|
| 47 |
+
.hypothesis/
|
| 48 |
+
.pytest_cache/
|
| 49 |
+
|
| 50 |
+
# Translations
|
| 51 |
+
*.mo
|
| 52 |
+
*.pot
|
| 53 |
+
|
| 54 |
+
# Django stuff:
|
| 55 |
+
*.log
|
| 56 |
+
local_settings.py
|
| 57 |
+
db.sqlite3
|
| 58 |
+
|
| 59 |
+
# Flask stuff:
|
| 60 |
+
instance/
|
| 61 |
+
.webassets-cache
|
| 62 |
+
|
| 63 |
+
# Scrapy stuff:
|
| 64 |
+
.scrapy
|
| 65 |
+
|
| 66 |
+
# Sphinx documentation
|
| 67 |
+
docs/en/_build/
|
| 68 |
+
docs/zh_cn/_build/
|
| 69 |
+
|
| 70 |
+
# PyBuilder
|
| 71 |
+
target/
|
| 72 |
+
|
| 73 |
+
# Jupyter Notebook
|
| 74 |
+
.ipynb_checkpoints
|
| 75 |
+
|
| 76 |
+
# pyenv
|
| 77 |
+
.python-version
|
| 78 |
+
|
| 79 |
+
# celery beat schedule file
|
| 80 |
+
celerybeat-schedule
|
| 81 |
+
|
| 82 |
+
# SageMath parsed files
|
| 83 |
+
*.sage.py
|
| 84 |
+
|
| 85 |
+
# Environments
|
| 86 |
+
.env
|
| 87 |
+
.venv
|
| 88 |
+
env/
|
| 89 |
+
venv/
|
| 90 |
+
ENV/
|
| 91 |
+
env.bak/
|
| 92 |
+
venv.bak/
|
| 93 |
+
|
| 94 |
+
# Spyder project settings
|
| 95 |
+
.spyderproject
|
| 96 |
+
.spyproject
|
| 97 |
+
|
| 98 |
+
# Rope project settings
|
| 99 |
+
.ropeproject
|
| 100 |
+
|
| 101 |
+
# mkdocs documentation
|
| 102 |
+
/site
|
| 103 |
+
|
| 104 |
+
# mypy
|
| 105 |
+
.mypy_cache/
|
| 106 |
+
data/
|
| 107 |
+
data
|
| 108 |
+
.vscode
|
| 109 |
+
.idea
|
| 110 |
+
.DS_Store
|
| 111 |
+
|
| 112 |
+
# custom
|
| 113 |
+
*.pkl
|
| 114 |
+
*.pkl.json
|
| 115 |
+
*.log.json
|
| 116 |
+
docs/modelzoo_statistics.md
|
| 117 |
+
mmyolo/.mim
|
| 118 |
+
output/
|
| 119 |
+
work_dirs
|
| 120 |
+
yolov5-6.1/
|
| 121 |
+
|
| 122 |
+
# Pytorch
|
| 123 |
+
*.pth
|
| 124 |
+
*.pt
|
| 125 |
+
*.py~
|
| 126 |
+
*.sh~
|