Marsilia-Embeddings-FR-Large 🚀
Introduction 🌟
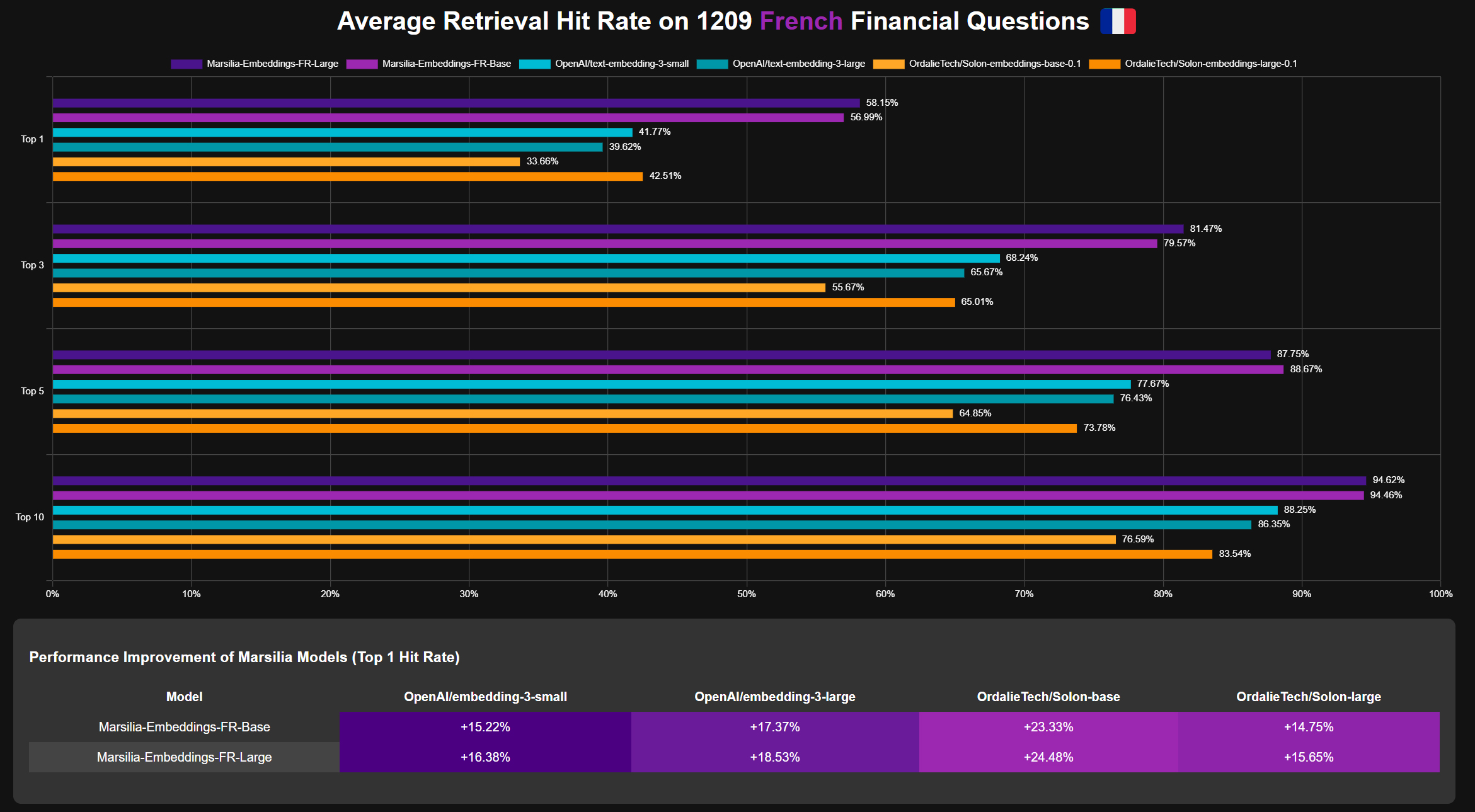
Marsilia-Embeddings-FR-Large is a state-of-the-art French language embedding model specifically designed for financial domain tasks. This model serves as a proof of concept, demonstrating the critical importance of fine-tuning embedding models for specific tasks in Retrieval-Augmented Generation (RAG) applications.
By focusing on the financial domain, Marsilia-Embeddings-FR-Large achieves performance that surpasses even closed-source models like OpenAI's embeddings, while offering a more cost-effective solution. This showcases how targeted fine-tuning can dramatically enhance the capabilities of open-source models, making them competitive with or even superior to proprietary alternatives in specialized domains.
Model Details 📊
- Model Name: Marsilia-Embeddings-FR-Large
- Model Type: Sentence Embedding Model
- Language: French 🇫🇷
- Base Model: OrdalieTech/Solon-embeddings-large-0.1
- Maximum Sequence Length: 512 tokens
- Output Dimensionality: 1024
- Similarity Function: Cosine Similarity
Usage 💻
To use this model with the Sentence Transformers library:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("sujet-ai/Marsilia-Embeddings-FR-Large")
sentences = [
'Quelles mesures à caractère non strictement comptable sont mentionnées dans le rapport financier de Vivendi ?',
"mercredi 8 mars 2023 Rapport financier et États financiers consolidés audités de l'exercice clos le 31 décembre 2022 Vivendi / 6 I- Rapport financier de l'exercice 2022 Notes préliminaires : Le 6 mars 2023, le présent rapport financier et les états financiers consolidés audités de l'exercice clos le 31 décembre 2022 ont été arrêtés par le Directoire. Après avis du Comité d'audit qui s'est réuni le 6 mars 2023, le Conseil de surveillance du 8 mars 2023 a exa miné le rapport financier et les états financiers consolidés audités de l'exercice clos le 31 décembre 2022, tels qu'arrêtés par le Directoire du 6 mars 2023. Les états financiers consolidés de l'exercice clos le 31 décembre 2022 sont audités et certifiés sans réserve par les Commissai res aux comptes. Leur rapport sur la certification des états financiers consolidés est présenté en préambule des états financiers.",
]
embeddings = model.encode(sentences)
print(embeddings.shape)
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
Intended Use 🎯
This model is designed for generating sentence embeddings for French text, particularly in the financial domain. It can be used for various natural language processing tasks such as semantic search, clustering, and information retrieval.
Training Data 📚
The model was fine-tuned on the sujet-ai/Sujet-Financial-RAG-FR-Dataset. This dataset consists of question-context pairs in French, focusing on financial topics.
- Training Set Size: 28,880 samples
Training Procedure 🛠️
Training Hyperparameters
- Loss Function: MultipleNegativesRankingLoss
- Scale: 20.0
- Similarity Function: Cosine Similarity
- Evaluation Strategy: Steps
- Per Device Train Batch Size: 32
- Gradient Accumulation Steps: 16
- Per Device Eval Batch Size: 16
- TF32: True
- BF16: True
- Number of Train Epochs: 5
- Batch Sampler: no_duplicates
- Multi Dataset Batch Sampler: round_robin
- Scheduler: warmupcosine
Framework Versions
- Python: 3.10.13
- Sentence Transformers: 3.0.1
- Transformers: 4.42.3
- PyTorch: 2.5.0.dev20240704+cu124
- Accelerate: 0.32.1
- Datasets: 2.20.0
- Tokenizers: 0.19.1
Evaluation 📈
The model was evaluated using the InformationRetrievalEvaluator on the test split of the sujet-ai/Sujet-Financial-RAG-FR-Dataset. Specific evaluation metrics are not provided in the given information.
Limitations ⚠️
The model is specifically trained on French financial texts and may not perform optimally on other domains or languages. Users should be aware of potential biases present in the training data.
Citation 📄
If you use this model in your research, please cite:
@software{Marsilia-Embeddings-FR-Large,
author = {Sujet AI, Allaa Boutaleb, Hamed Rahimi},
title = {Marsilia-Embeddings-FR-Large: A fine-tuned French embedding model for financial texts},
year = {2024},
url = {https://huggingface.co/sujet-ai/Marsilia-Embeddings-FR-Large}
}
Contact Information 📧
For questions, feedback, or collaborations, please reach out to us on LinkedIn or visit our website https://sujet.ai.
