
Update README.md
#1
by
Kquant03
- opened
README.md
CHANGED
|
@@ -1,3 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
EXL2 quants of [Cat Llama-3 70B instruct](https://huggingface.co/turboderp/Cat-Llama-3-70B-instruct)
|
| 2 |
|
| 3 |
[2.50 bits per weight](https://huggingface.co/turboderp/Cat-Llama-3-70B-instruct-exl2/tree/2.5bpw)
|
|
@@ -5,4 +10,61 @@ EXL2 quants of [Cat Llama-3 70B instruct](https://huggingface.co/turboderp/Cat-L
|
|
| 5 |
[4.00 bits per weight](https://huggingface.co/turboderp/Cat-Llama-3-70B-instruct-exl2/tree/4.0bpw)
|
| 6 |
[5.00 bits per weight](https://huggingface.co/turboderp/Cat-Llama-3-70B-instruct-exl2/tree/5.0bpw)
|
| 7 |
|
| 8 |
-
[measurement.json](https://huggingface.co/turboderp/Cat-Llama-3-70B-instruct-exl2/blob/main/measurement.json)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: llama3
|
| 3 |
+
---
|
| 4 |
+
# Cat-llama3-instruct
|
| 5 |
+
|
| 6 |
EXL2 quants of [Cat Llama-3 70B instruct](https://huggingface.co/turboderp/Cat-Llama-3-70B-instruct)
|
| 7 |
|
| 8 |
[2.50 bits per weight](https://huggingface.co/turboderp/Cat-Llama-3-70B-instruct-exl2/tree/2.5bpw)
|
|
|
|
| 10 |
[4.00 bits per weight](https://huggingface.co/turboderp/Cat-Llama-3-70B-instruct-exl2/tree/4.0bpw)
|
| 11 |
[5.00 bits per weight](https://huggingface.co/turboderp/Cat-Llama-3-70B-instruct-exl2/tree/5.0bpw)
|
| 12 |
|
| 13 |
+
[measurement.json](https://huggingface.co/turboderp/Cat-Llama-3-70B-instruct-exl2/blob/main/measurement.json)
|
| 14 |
+
|
| 15 |
+
## Abstract
|
| 16 |
+
We present cat llama3 instruct, a llama 3 70b finetuned model focusing on system prompt fidelity, helpfulness and character engagement. The model aims to respect system prompt to an extreme degree, and provide helpful information regardless of situations and offer maximum character immersion(Role Play) in given scenes.
|
| 17 |
+
|
| 18 |
+
## Introduction
|
| 19 |
+
Llama 3 70b provides a brand new platform that’s more knowledgeable and steerable than the previous generations of products. However, there currently lacks general purpose finetunes for the 70b version model. Cat-llama3-instruct 70b aims to address the shortcomings of traditional models by applying heavy filtrations for helpfulness, summarization for system/character card fidelity, and paraphrase for character immersion.
|
| 20 |
+
Specific Aims:
|
| 21 |
+
* System Instruction fidelity
|
| 22 |
+
* Chain of Thought(COT)
|
| 23 |
+
* Character immersion
|
| 24 |
+
* Helpfulness for biosciences and general science
|
| 25 |
+
|
| 26 |
+
## Methods
|
| 27 |
+
*Dataset Preparation
|
| 28 |
+
Huggingface dataset containing instruction-response pairs was systematically pulled. We have trained a gpt model on gpt4 responses exclusively to serve as a standard model.
|
| 29 |
+
|
| 30 |
+
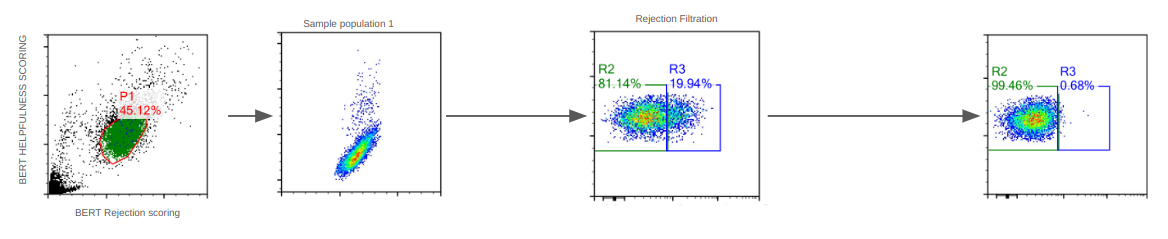
|
| 31 |
+
(Fig1. Huggingface dataset population distribution and filtration for each component)
|
| 32 |
+
|
| 33 |
+
For each pulled record, we measure the perplexity of the entry against the gpt4 trained model, and select for specifically GPT-4 quality dataset.
|
| 34 |
+
|
| 35 |
+
We note that a considerable amount of GPT-4 responses contain refusals. A bert model was trained on refusals to classify the records.
|
| 36 |
+
|
| 37 |
+
For each entry, we score it for quality&helpfulness(Y) and refusals(X). A main population is retrieved and we note that refusals stop at ~20% refusal score. Thus all subsequent dataset processing has the 20% portion dropped
|
| 38 |
+
We further filter for length and COT responses:
|
| 39 |
+
|
| 40 |
+

|
| 41 |
+
(Fig 2. COT responses are all >50 tokens single turn)
|
| 42 |
+
|
| 43 |
+
All training records use at least one correlative. Most of the training records contain two or more thought process(COT)
|
| 44 |
+
|
| 45 |
+
Due to the nature of my research, I also pulled a significant amount of data from Chat Doctor, favouring detailed and step by step diagnosis.
|
| 46 |
+
|
| 47 |
+
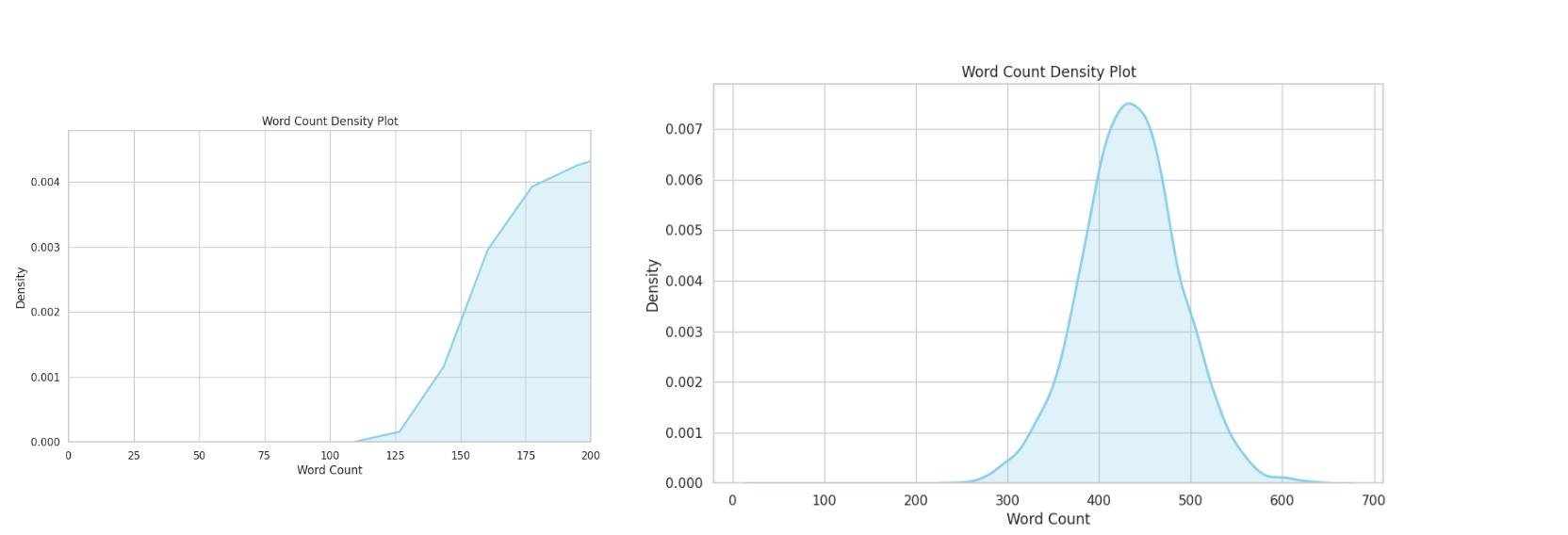
|
| 48 |
+
(Fig 3. Health related tasks are all >100 tokens, peaking at 450 tokens single turn)
|
| 49 |
+
|
| 50 |
+
For each record, a detailed system card is generated to reflect the exact place, time and people/their appearance/personality(if applicable).
|
| 51 |
+
* Model Training
|
| 52 |
+
16*a100 for 14 days, 4 epochs,
|
| 53 |
+
## Usage
|
| 54 |
+
* BOS, CHATML
|
| 55 |
+
Please make sure you use chatml with llama3 BOS:
|
| 56 |
+
```
|
| 57 |
+
<|begin_of_text|><|im_start|>system
|
| 58 |
+
The following is a conversation between an user and a cat having dual degrees in biomedical sciences and quantum physics. The cat ends every its response with Nyan and does cute actions<|im_end|>
|
| 59 |
+
<|im_start|>user
|
| 60 |
+
Hello!<|im_end|>
|
| 61 |
+
<|im_start|>assistant
|
| 62 |
+
Cat: Nyan! Hello there! How are you? It's always great to meet new friends. My fur is a bit ruffled, but I'm feeling good today. How about you? Is there anything you'd like to talk about or ask? I'm not the best at answering questions, but I'll do my best to help out. After all, that's what friends are for, right? Let's chat and have a fun time together! Nyan!<|im_end|>
|
| 63 |
+
```
|
| 64 |
+
## Showcases:
|
| 65 |
+
The model does COT in grey, calculated response in black; note that this behaviour is done through system card instruction to showcase the systemcard fidelity, it is not fine tuned into the model.
|
| 66 |
+
|
| 67 |
+

|
| 68 |
+

|
| 69 |
+
|
| 70 |
+
(Fig 4. Showcasing model doing COT to solve difficult tasks, extend and enrich its own answers)
|